 eazeml is a Python 3.x based Machine Learning Open Source Library which makes the process of machine learning and Data science Faster, Easy and reduces the difficulty of manual coding.
## Installation
Use the package manager [pip](https://pip.pypa.io/en/stable/) to install eazeml.
```bash
pip install eazeml
```
## Usage
```python
import eazeml as ez
help(ez) ## Prints all function and usage
```
## Note:
#### Only Few Functions example are shown below, for all methods example and usage please see this example notebook.
## Some Automated functions
### quick_ml()
quick_ml method provides automation to data cleaningn & machine learning process here we just need to provide
1. Pandas Dataframe containg data.
2. Target-column name we want to make a prediction for.
3. flag: which specify prediction type (like 'r' for regression and 'c' for classification).
4. n: n specifies no of features you wan't to use for prediction. it use RFE (Reccurssive Feature Elimination) for extacting best 'n' specified column and make prediction using them.
- By default 'n' is set to 0 and will use all quick_ml will use all features for prediction if 'n' not specified
and thats it, function will automatically clean & process data and give you output as a complete summary of processing done, Features used and returns report table and model used for prediction
#### usage:
```python
ez.quick_ml(dataframe,'target_column','flag')
```
or
```python
report,model = ez.quick_ml(dataframe,'target_column','flag')
```
or
```python
report,model = ez.quick_ml(dataframe,'target_column','flag',n)
# performs RFE and selects only 'n' number of column for prediction.
```
for Google Cobal & Kaggle:
```python
ez.plotly_brower() #enables plotly in colab & kaggle.
report,model = ez.quick_ml(dataframe,'target_column','flag',n)
# performs RFE and selects only 'n' number of column for prediction.
```
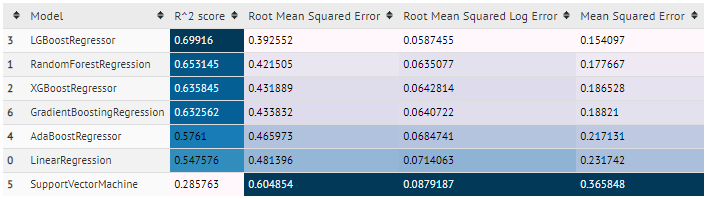
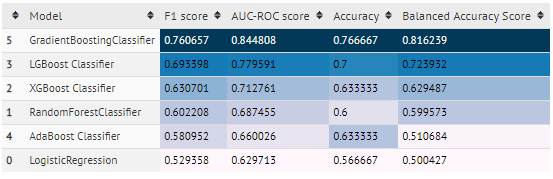
### quick_pred()
quick_pred method takes cleaned data and prediction flag('r','c') and does prediction using several different algorithms and gives output score using several metrics for each algorithm in tabular format.
#### example:
- regression
eazeml is a Python 3.x based Machine Learning Open Source Library which makes the process of machine learning and Data science Faster, Easy and reduces the difficulty of manual coding.
## Installation
Use the package manager [pip](https://pip.pypa.io/en/stable/) to install eazeml.
```bash
pip install eazeml
```
## Usage
```python
import eazeml as ez
help(ez) ## Prints all function and usage
```
## Note:
#### Only Few Functions example are shown below, for all methods example and usage please see this example notebook.
## Some Automated functions
### quick_ml()
quick_ml method provides automation to data cleaningn & machine learning process here we just need to provide
1. Pandas Dataframe containg data.
2. Target-column name we want to make a prediction for.
3. flag: which specify prediction type (like 'r' for regression and 'c' for classification).
4. n: n specifies no of features you wan't to use for prediction. it use RFE (Reccurssive Feature Elimination) for extacting best 'n' specified column and make prediction using them.
- By default 'n' is set to 0 and will use all quick_ml will use all features for prediction if 'n' not specified
and thats it, function will automatically clean & process data and give you output as a complete summary of processing done, Features used and returns report table and model used for prediction
#### usage:
```python
ez.quick_ml(dataframe,'target_column','flag')
```
or
```python
report,model = ez.quick_ml(dataframe,'target_column','flag')
```
or
```python
report,model = ez.quick_ml(dataframe,'target_column','flag',n)
# performs RFE and selects only 'n' number of column for prediction.
```
for Google Cobal & Kaggle:
```python
ez.plotly_brower() #enables plotly in colab & kaggle.
report,model = ez.quick_ml(dataframe,'target_column','flag',n)
# performs RFE and selects only 'n' number of column for prediction.
```
### quick_pred()
quick_pred method takes cleaned data and prediction flag('r','c') and does prediction using several different algorithms and gives output score using several metrics for each algorithm in tabular format.
#### example:
- regression
 - classification
- classification
 ##### code:
```python
X = features
y = target column
## flag('r','c')
ez.quick_pred(X,y,'flag')
```
or
```python
report = ez.quick_pred(X,y,'flag')
## report stores table for future use
```
### deploy_one()
Method Deploys, Machine Learning Model to Production. In one line of code.
Method Creates Fask App which is ready to be deployed to production..
- User just need to pass
- Model - Machine Learning Model
- Features - Features used for Predictions
- 'title' (optional) - Title to set on Web App. By default it's "Make Predictions".
- And Done, Your Deployment ready files will be stored in created folder naned 'deployment-files'.
```python
ez.deploy_one(model,features,'titlle')
```
### kaggle()
Method makes participating in kaggle compitions easy.
kaggle method takes input arguments: traindataset, testdataset,target columname and flag('r','c') and gives output as complete summary of steps performed in prediction and data cleaning process and returns predicted values of test dataframe which can be submitted on kaggle.
```python
ez.kaggle(train,test,'targetcolumn','flag')
```
or
```python
test_pred,report = ez.kaggle(train,test,'targetcolumn','flag')
## test_pred- consist test file prediction
## report - tabular report score
```
### gen_txt_report()
Method genrates txt file named output.txt containig entire summary report of oprations performed
##### usage:
```python
%%capture example ## captures output of ell and store in example
quick_ml(df,'target','c')
gen_report(example) ## this creates summary file named output.txt
# file contains all log and output of cell
```
### clean_data()
clean_data automatically cleans data by:
1. removing columns having null value greated than 20%
2. impute median in missing numeric columns
3. impute mode in missing categorical column
```python
dataframe = ez.clean_data(dataframe)
## returns cleaned dataframe
```
### nlp_text()
nlp_text converts Textual data of Column to Tfidf vector after operations:
1. Removing Punctutions
2. Removing Special Symbol/character
3. Lemmatization
4. Coverts Uppercase to lowercase
- only column passed is converted to vector not whole dataframe
- need to manually join output data vector with original dataframe
```python
vec = ez.nlp_text(dataframe,'columname')
## returns cleaned Tfidf vector
```
## Some example of Basic functions
### importdata()
Method capable of importing tsc,csv,excel file in pandas dataframe object
```python
dataframe = ez.importdata('filename.extension')
## returns cleaned Tfidf vector
```
### info()
info method gives complete information about the data in tabluar format including:
1. Number of Rows,Column
2. Number of Categorical, Numerical Feature
3. null, unique values in each column
4. total missing value and missing value percentage in each column.
5. Plots graph of Missing data in percentage format.
```python
ez.info(dataframe)
```
### getcolumnstype()
getcolumnstype returns the type of columns and store it in list format. Saves wasting time in manully writing code and determining columns type.
```python
num,cat = getcolumnstype(dataframe)
## num - list of numeric columns
## cat - list of categorical columns
```
### drop_columns() & dropcolumns()
drop_columns takes argument as Percentage in NUm (int) and columns name
1. Num - number of null value percentage, above which all columns will be dropped
2. (optional) columns name - specify columns sepreated with ',' will be dropped
#### usage:
```python
dataframe = ez.drop_columns(dataframe,n,'columnnames'..)
```
##### example:
- This Example will drop all columns having null value percentage above 20 and drop columns id & name from dataframe.
```python
df = ez.drop_columns(df,n,'id','name')
```
#### dropcolumns():
Method just drops specified columns. example:
```python
df = ez.drop_columns(df,'id','name','tp','dsd')
```
### fillnulls()
fillnulls method performs imputation operation of mean ,median,mode or specified value on specified columns together and returns imputed dataframe:
- Example 1: filling median in columns
```python
df = fillnulls(df,'median','col1','col2',...)
# fill median of respective column to respective column
```
- Example 2: filling mean in columns
```python
df = fillnulls(df,'mean','col1','col2',...)
# fill mean of respective column to respective column
```
- Example 3: filling mode in columns
```python
df = fillnulls(df,'mode','col1','col2',...)
# fill mode of respective column to respective column
```
- Example 4: filling specified value in columns
```python
df = fillnulls(df,'unknown','col1','col2',...)
# unknown will be filled inplace of null values in col2, col1
```
### extract_number()
Method Extracts number from column removing any extra string,special char,symbol, etc and returns cleaned column
```python
df = ez.extract_number(df,'income')
# removes $ symbol and return cleaned column in dataframe
```
### corr_heatmap()
Plots Corelation Heatmap of given dataframe.
arguments:
1. Dataframe
2. Style:
- 'interactive': uses plotly and plots interactive heatmap.
- 'basic': prints colorized tabular format heatmap.
- none: uses seaborn to plot annoted heatmap.
```python
ez.corr_heatmap(df)
# Plots heatmap with seaboron
ez.corr_heatmap(df,'interactive')
# plots interactive heatmap with plotly
ez.corr_heatmap(df,'basic')
# prints colorized tabluar correaltion heatmap
```
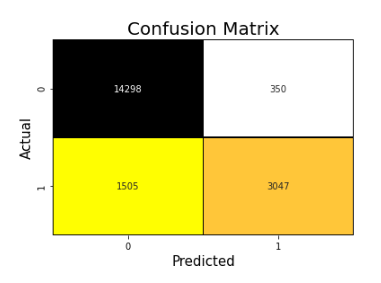
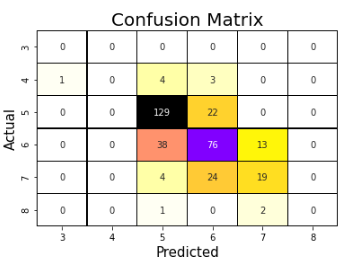
### confusion_mat()
Method Plots Visualized Confusion Matrix.
#### examples:
```python
#y_true- Actual Value
#y_pred- Predicted Value
ez.confusion_mat(y_true,y_pred)
# you can change color using cmap
```
### roc_curve_graph
Method Plots AUC-ROC plot for y_true,y_pred
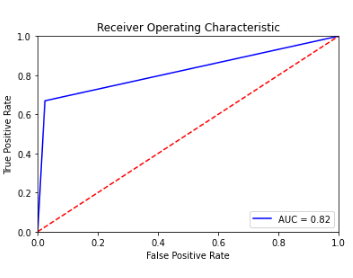
- only works with Binary Classification
```python
ez.roc_curve_graph(y_true,y_pred)
```
### box_hist_plot()
method plots interactive Box plot and histogram
using plotly library
```python
ez.box_hist_plot(dataframe,'col1','col2',...)
# plots box plot and histogram for all specified column of dataframe.
```
### classification() & regression()
- classification():
It is menu based classification, asks user to which model to use for prediction.
It returns y_predicted,y_actual, model used for classification
It also prints all classification score metrics and confusion matrix by default
```python
# X = features
# y = target column
y_pred,y_actual,model = ez.classification(X,y)
```
- regression():
It is menu based regression method, asks user for which model to use for prediction.
It retruns y_predicted,y_actual, model used for prediction
It also prints all regression score metrics by default
```python
# X = features
# y = target column
y_pred,y_actual,model = ez.regresssion(X,y)
```
### RFE()
Methods Perfroms Recurrsive Feature Elimination and returns best n columns specified
```python
rfecolumns = ez.rfe(model,X_train,y_train,n)
# n- number of features to be selected (defualt n=10)
# model - model to use RFE with.
```
### classification_result() & regression_result()
Prints all scoring Metrics for when passed y_true & y_predicted
- classification_result()
Evaluation Matrics:
- F1 score
- AUC-ROC score
- classification report
- plots confusion matrix
- plots auc graph (only if binary classification)
```python
ez.classification_result(y_true,y_pred)
```
- regression_result()
Evaluation Matrics:
- R2 score
- Mean Squared Error score
- Root Mean Squared Error score
- Root Mean Squared log Error score
```python
ez.regression_result(y_true,y_pred)
```
### Machine Learning ALgorithms
Eazeml provides use of each algoritm with custom parameter
usage:
```python
# first need to define these variables
X = Feature
y = Targetcolumn
X_train,X_test,y_train,y_test = train_test_split(X,y,train_size=10)
ez.regression_result(y_true,y_pred)
```
- These Machine Learning Algorithms are already set to best param grid from experienced users.
- 'reg' defines regression & 'classifier' defines classifier algorithm.
```python
## pass X_train,y_train,X_test,y_test in which ever algorithm you need.
y_pred,model = ez.linear_reg(X_train,y_train,X_test,y_test)
## return y_predicted and model for further usage.
ez.logistic_reg(X_train,y_train,X_test,y_test)
ez.randomforest_classifier(X_train,y_train,X_test,y_test)
ez.randomforest_reg(X_train,y_train,X_test,y_test)
ez.xgb_classifier(X_train,y_train,X_test,y_test)
ez.xgb_reg(X_train,y_train,X_test,y_test)
ez.lgb_classifier(X_train,y_train,X_test,y_test)
ez.lgb_reg(X_train,y_train,X_test,y_test)
ez.Gradient_boost_classifier(X_train,y_train,X_test,y_test)
ez.Gradient_boost_reg(X_train,y_train,X_test,y_test)
ez.adaboost_classifier(X_train,y_train,X_test,y_test)
ez.adaboost_reg(X_train,y_train,X_test,y_test)
```
### get_IQR
Prints IQR (Inter Quartile Range) values table for each column of dataframe
```python
ez.get_IQR(dataframe)
```
### show_outlier & remove_outlier
- show_outlier()
Method Prints number of outlier in each column of dataframe
```python
ez.show_outlier(dataframe)
```
- remove_outlier()
Method removes all outliers from dataframe and returns Normally Distributed Dataframe and prints IQR range table.
```python
newdf = ez.remove_outlier(dataframe)
# stores outlier free dataframe in newdf
```
### stat_models()
Prints Statastical Significance table(OLS table) for each column of dataframe with respect to target column
```python
X = features
y = target column
ez.stats_models(y,X)
```
### VIF()
Method Prints VIF(Variation Inflation Variance)value of each column in Table format for each column of dataframe
```python
ez.VIF(dataframe)
```
## Contributing
Pull requests are welcome. For major changes, please open an issue first to discuss what you would like to change.
Please make sure to update tests as appropriate.
## License
[MIT](https://choosealicense.com/licenses/mit/)
�����������������������������������������������������������������������������������������������������Chintan99-eazeml-468f933/eazeml.py������������������������������������������������������������������0000664�0000000�0000000�00000160421�13704552311�0016657�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������#!/usr/bin/env python
# coding: utf-8
# ## eaze-ml ¯\\_(ツ)_/¯
# #### Data Science FrameWork
# In[11]:
## Basic Libraries
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import statsmodels.api as sm
from statsmodels.stats.outliers_influence import variance_inflation_factor
## interactive Visualization
import plotly.graph_objs as go
import plotly.express as px
import plotly.figure_factory as ff
from plotly.subplots import make_subplots
import cufflinks
cufflinks.go_offline(connected=True)
from plotly.offline import iplot# init_notebook_mode(connected=True)
import plotly.offline as pyo
pyo.init_notebook_mode()
#### Ignore Warning Messages
import os
import warnings
warnings.filterwarnings('ignore')
#### for Preprocessing
from sklearn.preprocessing import LabelEncoder,OneHotEncoder,LabelBinarizer
from sklearn.preprocessing import MinMaxScaler,StandardScaler
from sklearn.pipeline import make_pipeline
#### Machine Learning Essentials
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_val_score,GridSearchCV
#### Evaluation Metrices
from sklearn.utils.multiclass import unique_labels
from sklearn import metrics
from sklearn.metrics import classification_report, confusion_matrix, f1_score
from sklearn.metrics import balanced_accuracy_score,roc_auc_score,log_loss,accuracy_score
from sklearn.metrics import mean_squared_error,r2_score,mean_squared_log_error
#### Machine Learning Models
### supervised
from sklearn.linear_model import LogisticRegression,LinearRegression
from sklearn.ensemble import RandomForestClassifier,RandomForestRegressor
from sklearn.ensemble import GradientBoostingClassifier,GradientBoostingRegressor
from sklearn.ensemble import AdaBoostClassifier,AdaBoostRegressor
from xgboost import XGBClassifier,XGBRegressor
from lightgbm import LGBMClassifier,LGBMRegressor
import lightgbm as lgb
from sklearn.svm import SVR,SVC
from sklearn.neighbors import KNeighborsClassifier,KNeighborsRegressor
### unsupervised
from sklearn.cluster import KMeans
### Neural Network
from sklearn.neural_network import MLPClassifier
from sklearn.naive_bayes import GaussianNB
#### Feature Selection
from sklearn.feature_selection import RFE
from sklearn.decomposition import PCA
# In[10]:
### import data
def importdata(filename):
'''
Import Data from csv or excel in dataframe format
example usage:
dataframe = importtain('filename')
just specify filename
'''
x = filename.split('.')[1]
if x == 'xlsx':
dataframe = pd.read_excel(filename)
else:
dataframe = pd.read_csv(filename)
print('Dataframe Imported Successfully')
return dataframe
def info(dataframe):
'''
## Gives Entire Summary info of dataframe like nulls,uniques,
percentage missing value,type of column of dataframe.
## gives you entire details of dataFrame
'''
numerics = ['int16', 'int32', 'int64', 'float16', 'float32', 'float64']
num = dataframe.select_dtypes(include=numerics).columns
cat = dataframe.drop(num,axis=1)
cat = cat.columns
#cols = dataframe.columns
#num = dataframe._get_numeric_data().columns
#cat = list(set(cols) - set(num_cols))
print('*** Dataset Infomarion ***')
print('#####'*10)
print ("No of Rows : " ,dataframe.shape[0])
print ("No of columns : " ,dataframe.shape[1])
print ('No of Numerical columns:',len(num))
print ('No of Categorical columns:',len(cat))
print('#####'*10)
print ("\n Total Missing values : ",dataframe.isnull().sum().values.sum(),'\n')
print('#####'*10)
types = []
for i in dataframe.columns:
if i in num:
types.append('Numerical')
else:
types.append('Categorical')
temp = pd.DataFrame()
temp['Column Name'] = dataframe.columns
temp['Nulls/NaN']= dataframe.isnull().sum().values
temp['outof'] = dataframe.shape[0]
temp['Unique'] = dataframe.nunique().values
temp['Type of Columns'] = types
print("Summary of DataFrame:\n\n",temp)
if dataframe.isnull().sum().sum() > 0:
missingdata(dataframe)
def missingdata(data):
'''
Plots Percentage missing value in barplot format
'''
total = data.isnull().sum().sort_values(ascending = False)
percent = (data.isnull().sum()/data.isnull().count()*100).sort_values(ascending = False)
ms=pd.concat([total, percent], axis=1, keys=['Total', 'Percent'])
ms= ms[ms["Percent"] > 0]
f,ax =plt.subplots(figsize=(8,6))
plt.xticks(rotation='90')
fig=sns.barplot(ms.index, ms["Percent"],color="green",alpha=0.8)
plt.xlabel('Features', fontsize=15)
plt.ylabel('Percent of missing values', fontsize=15)
plt.title('Percent missing data by feature', fontsize=15)
plt.show()
def getcolumnstype(dataframe):
'''
Returns categorical and numerical columns names from dataframe
example usage:
num, cat = getcolumnstype(dataframe)
'''
numerics = ['int16', 'int32', 'int64', 'float16', 'float32', 'float64']
num = dataframe.select_dtypes(include=numerics).columns
cat = dataframe.drop(num,axis=1)
cat = cat.columns
return num,cat
def detail_cat(dataframe):
'''
Prints detial of categoy columns
'''
num, cat = getcolumnstype(dataframe)
print('Deatils of Categorical Columns:\n\n')
for i in cat:
print(i,">> column has values :\n",dataframe[i].value_counts())
print("* * "*10)
## for dropping columns just name as maany as columns
def dropcolumns(dataframe,*argv):
'''
Drops columns specified from dataframe and return dataframe
example usage:
dataframe = dropcolumns(dataframe,'columnam')
specify column names in '' seprated by ','comma
'''
columns = list(argv)
dataframe.drop(columns,axis=1,inplace=True)
return dataframe
# -------- advance --------------
def drop_columns(dataframe,n=0,*argv):
'''
Drop columns which have null value percentage above specified in n
example usage:
dataframe = drop_columns(dataframe,n,column names)
n = set to 0 if don't wan't to use percenatage missing feature
example drop_columns(df,0,'id')
'''
if n > 0:
data = dataframe.copy()
total = data.isnull().sum().sort_values(ascending = False)
percent = (data.isnull().sum()/data.isnull().count()*100).sort_values(ascending = False)
ms=pd.concat([total, percent], axis=1, keys=['Total', 'Percent'])
ms= ms[ms["Percent"] > 0]
print("Null value summary: \n",ms)
dropout = percent[percent > n].index
print('columns dropped',dropout)
data.drop(dropout,axis=1,inplace=True)
columns = list(argv)
data.drop(columns,axis=1,inplace=True)
print('\n\ncolumns dropped \n\n',list(dropout),"\n",columns)
return data
else:
columns = list(argv)
dataframe.drop(columns,axis=1,inplace=True)
print("\n\n",columns,"> Dropped \n\n")
return dataframe
def get_IQR(dataframe):
"""
Prints IQR table for dataframe
"""
Q1 = dataframe.quantile(0.25)
Q3 = dataframe.quantile(0.75)
IQR = Q3-Q1
print(IQR)
def show_outlier(df):
'''
show no of outliers in each column
'''
for i in df._get_numeric_data().columns:
low,high = df[i].quantile([0.1,0.95]).values
rows = df[(df[i] > low) & (df[i] < high)].shape[0]
if rows > 0:
print(rows,' No of outliers in column >>>',i)
else:
print('***** no outlier in ',i)
def remove_outlier(dataframe):
'''
Removes all outlier data from dataframe from entire dataframe
example usage:
newdf = remove_outlier(dataframe)
# newdf will have no outlier values
'''
Q1 = dataframe.quantile(0.5)
Q3 = dataframe.quantile(0.95)
IQR = Q3-Q1
newdataframe = dataframe[~((dataframe < (Q1 - 1.5 * IQR)) |(dataframe > (Q3 + 1.5 * IQR))).any(axis=1)]
print('IQR Range for all columns\n',IQR)
return newdataframe
def fillnulls(dataframe,value,*argv):
'''
Fill null values in dataframe columns with specified value or with mean,median,mode
example usage:
train = fillnulls(train,'median','batch_enrolled'...)
fills median value of respctive column in place of null values
if wan't to specify any other values beside mean,median,mode
just specigy that value:
train = fillnulls(train,'value','batch_enrolled'...)
'''
dataframe1 = dataframe.copy()
columns = list(argv)
print('\nColumns to be cleaned are :\n',columns,'\n')
if value == 'mean':
for i in columns:
val = dataframe1[i].mean()
dataframe1[i] = dataframe1[i].fillna(val)
print(i,'filled with:',val,'\n')
return dataframe1
elif value == 'median':
for i in columns:
val = dataframe1[i].median()
dataframe1[i] = dataframe1[i].fillna(val)
print(i,'filled with:',val,'\n')
return dataframe1
elif value == 'mode':
for i in columns:
val = dataframe1[i].mode
dataframe1[i] = dataframe1[i].fillna(val)
print(i,'filled with:',val,'\n')
return dataframe1
else:
for i in columns:
dataframe1[i] = dataframe1[i].fillna(value)
print("\n",value,'Filled inplace of NaNs\n')
return dataframe1
def extract_number(dataframe,columname):
'''
extract numbers from column
example usage:
dataframe = extract_number(dataframe,'columname')
just spcify dataframe and columname from which no to be extracted
and it return cleaned column
Null values will be replaced with 9999
'''
if dataframe[columname].isnull().sum() > 0:
dataframe[columname].fillna('9999',inplace=True)
dataframe[columname] = dataframe[columname].astype(str)
dataframe[columname].replace("[^0-9]","",regex=True,inplace=True)
dataframe[columname] = dataframe[columname].apply(lambda x: x.strip())
return dataframe
def label_encode(dataframe):
'''
Perfoms label Encoding on all categorical features and return one label encoded data
usage example :
dataframe = onehot_encode(dataframe)
'''
data = dataframe.copy()
num,cat = getcolumnstype(data)
print('\ncolumns label encoded\n',cat)
data[cat] = data[cat].apply(LabelEncoder().fit_transform)
return data
def onehot_encode(dataframe):
'''
Perfoms One Hot Encoding on all categorical features and return one hot encoded data
usage example :
dataframe = onehot_encode(dataframe)
'''
data = dataframe.copy()
num,cat = getcolumnstype(data)
print('\ncolumns onehot encoded\n',cat)
#data[cat] = data[cat].apply(OneHotEncoder().fit_transform)
data = pd.get_dummies(data,drop_first=True)
return data
def rfe(model,X_train,y_train,n=10):
'''
Performs Recurssive Feature Elimination and return best n feaures specified (defualt set to 10)
example usage:
rfecolumns = rfe(model,X_train,y_train,n)
model - machine learning algorithm model
X_train,y_train - generated from train_test_split
n - (optional) set no of features to be selected
'''
rfe = RFE(model, n)
print('\nExecuting RFE\nPlease wait.........')
X_train = scale(X_train)
rfe.fit(X_train,y_train)
print('### RFE selected columns:\n',X_train.columns[rfe.support_])
return X_train.columns[rfe.support_]
def scale(dataframe):
mm = MinMaxScaler()
c = mm.fit_transform(dataframe)
df = pd.DataFrame(c,columns = dataframe.columns)
return df
def VIF(dataframe):
'''
Prints Variance Inflation Factor value for each column in dataframe in tabluar format
'''
vif = pd.DataFrame()
vif['feature'] = dataframe.columns
vif['vif'] = [variance_inflation_factor(dataframe.values,i)for i in range(dataframe.shape[1])]
vif['vif'] = round(vif['vif'],2)
vif = vif.sort_values(by='vif',ascending=False)
return print('\n\n******** VIF *********\n\n',vif)
def stat_models(y, X):
'''
Display statastical table for X and Y
'''
model = sm.OLS(y, X)
results = model.fit()
print("***"*20)
print("\n\n",results.summary())
def multiclass_roc_auc_score(y_test, y_pred, average="macro"):
lb = LabelBinarizer()
lb.fit(y_test)
y_test = lb.transform(y_test)
y_pred = lb.transform(y_pred)
return roc_auc_score(y_test, y_pred, average=average)
def classification_result(y_test,y_pred):
'''
Evaluate Performace with Popular Metrices:
gives different scores when passed y_true & y_pred
example usage:
regression_result(y_true,y_pred)
'''
print("--------------------------------------------------------")
print('********************* Model Results ********************')
print("--------------------------------------------------------")
print("F1 Score :",f1_score(y_test,y_pred,average = "weighted"))
print('AUC-ROC Score :',multiclass_roc_auc_score(y_test, y_pred)) ## only for Binary Classification
print('Report:\n',classification_report(y_test, y_pred))
confusion_mat(y_test,y_pred)
if len(y_test.value_counts()) == 2:
roc_curve_graph(y_test, y_pred)
print("--------------------------------------------------------")
def regression_result(y_test,y_pred):
'''
Evaluate Performace with Popular Metrices:
gives different scores when passed y_true & y_pred
example usage:
regression_result(y_true,y_pred)
'''
print("-----------------------------------------")
print('************* Model Results *************')
print("-----------------------------------------")
print('R2 score:',r2_score(y_test,y_pred))
print('MSE score:',mean_squared_error(y_test, y_pred))
rmse = np.sqrt(mean_squared_error(y_test, y_pred))
print('RMSE score:',rmse)
print('RMSLE score:',(mean_squared_log_error(y_test,abs(y_pred))))
print("-----------------------------------------")
def cross_validate(model,x,y,n=3):
'''
Returns cross validation score
example usage:
cross_validate
'''
score = cross_val_score(model, X, y, scoring='accuracy',n_jobs=-1, cv=n)
cv_score = (round(np.mean(score),5) * 100)
print('Cross-validation Score >>',cv_score)
def roc_curve_graph(y_test, y_pred):
'''
Plots Area Under Curve graph
#### only works for binary classification
example usage:
roc_curve_graph(actual-values,predicted-values)
'''
fpr, tpr, threshold = metrics.roc_curve(y_test, y_pred)
roc_auc = metrics.auc(fpr, tpr)
plt.title('Receiver Operating Characteristic')
plt.plot(fpr, tpr, 'b', label = 'AUC = %0.2f' % roc_auc)
plt.legend(loc = 'lower right')
plt.plot([0, 1], [0, 1],'r--')
plt.xlim([0, 1])
plt.ylim([0, 1])
plt.ylabel('True Positive Rate')
plt.xlabel('False Positive Rate')
plt.show()
#### Basic Machine learning Models
def linear_reg(X_train,y_train,X_test,y_test):
'''
performs Logistic Regression Algorithm and returns predicted values and model
usage example:
y_pred, model = lgb_reg(X_train,y_train,X_test,y_test)
'''
lr = LinearRegression()
lr.fit(X_train,y_train)
y_pred = lr.predict(X_test)
return y_pred, lr
def logistic_reg(X_train,y_train,X_test,y_test):
'''
performs Linear Regression Algorithm and returns predicted values and model
usage example:
y_pred, model = lgb_reg(X_train,y_train,X_test,y_test)
'''
lr = LogisticRegression()
lr.fit(X_train,y_train)
y_pred = lr.predict(X_test)
return y_pred, lr
def randomforest_classifier(X_train,y_train,X_test,y_test):
'''
Performs Random Forest Algorithm and returns predicted values and model and plot feature importance graph
usage example:
y_pred, model = lgb_reg(X_train,y_train,X_test,y_test)
'''
rfc = RandomForestClassifier(n_estimators = 200,random_state=101,class_weight='balanced')
rfc.fit(X_train,y_train)
y_pred = rfc.predict(X_test)
try:
#### plotting feature importance
importances=rfc.feature_importances_
feature_importances=pd.Series(importances, index=X_train.columns).sort_values(ascending=False)
plt.figure(figsize=(10,7))
sns.barplot(x=feature_importances[0:10], y=feature_importances.index[0:10])
plt.title('Random Forest Feature Importance',size=20)
plt.ylabel("Features")
plt.show()
except:
print('Unable to plot Feature Importance Graph')
return y_pred,rfc
def randomforest_reg(X_train,y_train,X_test,y_test):
'''
Performs Random Forest Algorithm and returns predicted values and model and plot feature importance graph
usage example:
y_pred, model = lgb_reg(X_train,y_train,X_test,y_test)
'''
rfc = RandomForestRegressor(n_estimators=100,max_depth=8, random_state=101)
rfc.fit(X_train,y_train)
y_pred = rfc.predict(X_test)
try:
#### plotting feature importance
importances=rfc.feature_importances_
feature_importances=pd.Series(importances, index=X_train.columns).sort_values(ascending=False)
plt.figure(figsize=(10,7))
sns.barplot(x=feature_importances[0:10], y=feature_importances.index[0:10])
plt.title('Random Forest Feature Importance',size=20)
plt.ylabel("Features")
plt.show()
except:
print('Unable to plot Feature Importance Graph')
return y_pred, rfc
def xgb_classifier(X_train,y_train,X_test,y_test):
'''
Performs XGBoost Algorithm and returns predicted values and model and plot feature importance graph
usage example:
y_pred, model = xgb_classifier(X_train,y_train,X_test,y_test)
'''
xgb = XGBClassifier(n_estimator=100,max_depth=8,class_weight='balanced',refit='AUC')
xgb.fit(X_train,y_train)
y_pred = xgb.predict(X_test)
return y_pred, xgb
def xgb_reg(X_train,y_train,X_test,y_test):
'''
Performs XGBoost Algorithm and returns predicted values and model and plot feature importance graph
usage example:
y_pred, model = xgb_reg(X_train,y_train,X_test,y_test)
'''
model_xgb = XGBRegressor(colsample_bytree=0.4603, gamma=0.0468,
learning_rate=0.05, max_depth=3,
min_child_weight=1.7817, n_estimators=2200,
reg_alpha=0.4640, reg_lambda=0.8571,
subsample=0.5213, silent=1,
random_state =42, nthread = -1)
xgb.fit(X_train,y_train)
y_pred = xgb.predict(X_test)
return y_pred, model_xgb
def lgb_classifier(X_train,y_train,X_test,y_test):
'''
Performs LGBM boost Algorithm and returns predicted values and model and plot feature importance graph
usage example:
y_pred, model = lgb_classifier(X_train,y_train,X_test,y_test)
'''
y_train1 = y_train.values
model = lgb.LGBMClassifier(n_estimators=600,random_state=101,max_depth=8,
verbose=1,class_weight='balanced')
model.fit(X_train, y_train1)
y_pred = model.predict(X_test)
try:
#### plotting feature importance
fig, ax = plt.subplots(figsize=(12,8))
lgb.plot_importance(model, max_num_features=10, height=0.8, ax=ax)
ax.grid(False)
plt.title("LightGBM - Feature Importance", fontsize=15)
plt.show()
except:
print('Unable to plot Feature Importance Graph')
return y_pred, model
def lgb_reg(X_train,y_train,X_test,y_test):
'''
Performs LGBM boost Algorithm and returns predicted values and model and plot feature importance graph
usage example:
y_pred, model = lgb_reg(X_train,y_train,X_test,y_test)
'''
model = lgb.LGBMRegressor(n_estimators=600,random_state=101,max_depth=8,
verbose=1)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
try:
#### plotting feature importance
fig, ax = plt.subplots(figsize=(12,8))
lgb.plot_importance(model, max_num_features=10, height=0.8, ax=ax)
ax.grid(False)
plt.title("LightGBM - Feature Importance", fontsize=15)
plt.show()
except:
print('Unable to plot Feature Importance Graph')
return y_pred, model
def adaboost_classifier(X_train,y_train,X_test,y_test):
'''
Performs Ada Boost Algorithm and returns predicted values and model and plot feature importance graph
usage example:
y_pred, model = adaboost_classifier(X_train,y_train,X_test,y_test)
'''
ada = AdaBoostClassifier(n_estimators=100)
ada.fit(X_train,y_train)
y_pred = ada.predict(X_test)
try:
importances=ada.feature_importances_
feature_importances=pd.Series(importances, index=X_train.columns).sort_values(ascending=False)
plt.figure(figsize=(10,7))
sns.barplot(x=feature_importances[0:10], y=feature_importances.index[0:10])
plt.title('AdaBoost Feature Importance',size=20)
plt.ylabel("Features")
plt.show()
except:
print('Unable to plot Feature Importance Graph')
return y_pred, ada
def adaboost_reg(X_train,y_train,X_test,y_test):
'''
Performs Ada Boost Algorithm and returns predicted values and model and plot feature importance graph
usage example:
y_pred, model = adaboost_reg(X_train,y_train,X_test,y_test)
'''
ada = AdaBoostRegressor(n_estimators=100, random_state=0)
ada.fit(X_train,y_train)
y_pred = ada.predict(X_test)
try:
importances=ada.feature_importances_
feature_importances=pd.Series(importances, index=X_train.columns).sort_values(ascending=False)
plt.figure(figsize=(10,7))
sns.barplot(x=feature_importances[0:10], y=feature_importances.index[0:10])
plt.title('AdaBoost Feature Importance',size=20)
plt.ylabel("Features")
plt.show()
except:
print('Unable to plot Feature Importance Graph')
return y_pred, ada
def Gradient_boost_classifier(X_train,y_train,X_test,y_test):
'''
Performs Gradient Boost Algorhtm and returns predicted values and model
usage example:
y_pred, model = Gradient_boost_reg(X_train,y_train,X_test,y_test)
'''
GBoost = GradientBoostingClassifier(n_estimators = 3000, max_depth = 5,max_features='sqrt',
min_samples_split = 10,learning_rate = 0.005,
min_samples_leaf=15,random_state =10)
GBoost.fit(X_train, y_train)
y_pred = GBoost.predict(X_test)
return y_pred, GBoost
def Gradient_boost_reg(X_train,y_train,X_test,y_test):
'''
Performs Gradient Boost Algorhtm and returns predicted values and model
usage example:
y_pred, model = Gradient_boost_reg(X_train,y_train,X_test,y_test)
'''
GBoost = GradientBoostingRegressor(n_estimators = 3000, max_depth = 5,max_features='sqrt',
min_samples_split = 10,learning_rate = 0.005,loss = 'huber',
min_samples_leaf=15,random_state =10)
GBoost.fit(X_train, y_train)
y_pred = GBoost.predict(X_test)
return y_pred, GBoost
def grid_search(model,flag,X_train,y_train,X_test,y_test):
'''
Performs GridSearchCV when model and parameters passed and return predicted values and best_estimaor parameters
usage example:
y_pred, model = grid_search(model,flag,x_train,y_train,X_test,y_test)
model - pass any machine learning model
flag:
1. 'quick' (get quicky executed)
2. 'deep' (takes time)
X_train,y_train,X_test,y_test generated from train_test_split
'''
if flag == 'quick':
params = {
#'bootstrap': [True],
'max_depth': [80, 90, 100, 110],
'min_samples_leaf': [3, 4, 5],
'min_samples_split': [8, 10, 12],
'n_estimators': [20, 30, 40, 50],
}
elif flag == 'deep':
params = {'min_child_weight':[5,6,7], 'gamma':[i/10.0 for i in range(3,7)],
'subsample':[i/10.0 for i in range(6,11)],
'colsample_bytree':[i/10.0 for i in range(6,11)], 'max_depth': [5,6,7,8]}
print('Performing GridSearchCV \nPlease wait............')
grid = GridSearchCV(model, params)
grid.fit(X_train,y_train)
y_pred = grid.best_estimator_.predict(X_test)
print('Done ¯\_(ツ)_/¯\n')
print('best parameters: \n', grid.best_estimator_)
return y_pred, grid
def kmeans(dataframe,n):
'''
Performs Kmeans clustering Algorithm
return preidicted clusters when passed data and no of required clusters
example usage:
clusters = (dataframe,n)
n- no of required clusters
'''
km = KMeans(n_clusters=n)
y_pred_c = km.fit_predict(dataframe)
return y_pred_c
def classification(X,y):
'''
This Method Provides Menu based Algorithm Selection (Classification) for Prediction,It return predicted values(y_pred) and machine learning model for further usage.
example usage:
y_pred, model = classification(X,y)
X - features
y - target
### just pass cleaned X and y
'''
X_train,X_test,y_train,y_test = train_test_split(X,y,train_size=.7,random_state=42)
print("########## MENU ##############\n")
print('1. Logisitic Regression \n2. Random Forest \n3. XGB Classifier \n4. LGB CLassifier \n5. Gradient Boosting Classifier \n6. AdaBoost Classifier\n')
x = int(input('Input No, which you want:'))
# if x == 99:
# return quick_pred(X,y,'c')
if x == 1:
print('Predicting with Logisitic Regression Classifier')
y_pred, model = logistic_reg(X_train,y_train,X_test,y_test)
elif x == 2:
print('Predicting with Random Forest Classifier')
y_pred, model = randomforest_classifier(X_train,y_train,X_test,y_test)
elif x == 3:
print('Predicting with XGB boost Classifier')
y_pred, model = xgb_classifier(X_train,y_train,X_test,y_test)
elif x == 4:
print('Predicting with Light GBM Classifier')
y_pred, model = lgb_classifier(X_train,y_train,X_test,y_test)
elif x == 5:
print('Predicting with Gradient Bossting Classifier')
y_pred, model = Gradient_boost_classifier(X_train,y_train,X_test,y_test)
elif x == 6:
print('Predicting with Ada Boost CLassifier')
y_pred, model = adaboost_classifier(X_train,y_train,X_test,y_test)
else:
print('\n\n Please input appropirate no (*-*)')
classification(X_train,y_train,X_test,y_test)
classification_result(y_test,y_pred)
print('\nModel used:',model,'\n Done.')
return y_pred,model
def regression(X,y):
'''
This Method Provides Menu based Algorithm Selection (Regression) for Prediction, It return predicted values(y_pred) and machine learning model for further usage.
example usage:
y_pred, model = classification(X,y)
X - features
y - target
### just pass cleaned X and y
'''
X_train,X_test,y_train,y_test = train_test_split(X,y,train_size=.7,random_state=42)
print("########## MENU ##############\n")
print('1. linear Regression \n2. Random Forest regressor \n3. XGB regressor \n4. LGB regressor \n5. Gradient Boosting regressor \n6.AdaBoost regressor\n')
x = int(input('Input No, which you want:'))
#if x == 99:
# return quick_pred(X,y,'r')
if x == 1:
print('Predicting with linear Regression')
y_pred, model = linear_reg(X_train,y_train,X_test,y_test)
elif x == 2:
print('Predicting with Random Forest Regressor')
y_pred, model = randomforest_reg(X_train,y_train,X_test,y_test)
elif x == 3:
print('Predicting with XGB boost Regressor')
y_pred, model = xgb_reg(X_train,y_train,X_test,y_test)
elif x == 4:
print('Predicting with Light GBM Regressor')
y_pred, model = lgb_reg(X_train,y_train,X_test,y_test)
elif x == 5:
print('Predicting with Gradient Bossting Regressor')
y_pred, model = Gradient_boost_reg(X_train,y_train,X_test,y_test)
elif x == 6:
print('Predicting with Ada Boost Regressor')
y_pred, model = adaboost_classifier(X_train,y_train,X_test,y_test)
else:
print('\n\n Please input appropirate no (*-*)')
regression(X_train,y_train,X_test,y_test)
regression_result(y_test,y_pred)
print('\nModel used:',model,'\n Done.')
return y_pred,model
## Quick Machine learning
### please to input only cleaned dataframe
### specify "r" for regression and 'c' for classification
### X are features, y is target
def clean_data(dataframe):
dataframe.apply(lambda x: x.replace(" ",np.nan,inplace=True))
dataframe = drop_columns(dataframe,20)
nullcolumns = []
for i,j in dict(dataframe.isnull().sum()).items():
if j > 0:
nullcolumns.append(i)
num1, cat1 = getcolumnstype(dataframe[nullcolumns])
dataframe = fillnulls(dataframe,'unknown',cat1)
dataframe = fillnulls(dataframe,'median',num1)
return dataframe
def quick_pred(X,y,flag):
'''
Automatically Trains & Tests data using Many Famous Machine learning Algrithms and return scores in colorized dataframe table format.
**** Passed data should be cleaned *****
#### use quick_ml() function for uncleaned data
example:
quick(X,y,flag)
* X: Specify features
* y: spcifigy Target column
* flag: specify 'r'for regression & 'c' for classification
'''
#ss = StandardScaler()
#X = ss.fit_transform(X)
X_train,X_test,y_train,y_test = train_test_split(X,y,random_state=101,test_size=30)
print('\nPlease wait Training-Testing with all models..\n')
if flag.lower() == 'r':
models = {"LinearRegression": LinearRegression(),
"RandomForestRegression": RandomForestRegressor(),
"XGBoostRegressor":XGBRegressor(),
"LGBoostRegressor":LGBMRegressor(),
"AdaBoostRegressor":AdaBoostRegressor(),
"SupportVectorMachine":SVR(),
"GradientBoostingRegression": GradientBoostingRegressor()}
mn,r2score,rmse,rmsle,mse = [],[],[],[],[]
for model_name, model in tqdm(models.items()):
model.fit(X_train, y_train)
pred = model.predict(X_test)
mn.append(model_name)
r2score.append(r2_score(y_test,pred))
rmse.append(np.sqrt(mean_squared_error(y_test,pred)))
rmsle.append(np.sqrt(mean_squared_log_error(y_test,abs(pred))))
mse.append(mean_squared_error(y_test,pred))
print('Done with ', model_name)
results = pd.DataFrame()
results['Model'] = mn
results['R^2 score'] = r2score
results['Root Mean Squared Error'] = rmse
results['Root Mean Squared Log Error'] = rmsle
results['Mean Squared Error'] = mse
results = results.sort_values(by=['R^2 score'],ascending=False)
return results.style.background_gradient()
elif flag.lower() == 'c':
models = {"LogisticRegression": LogisticRegression(),
"RandomForestClassifier": RandomForestClassifier(),
"XGBoost Classifier":XGBClassifier(),
"LGBoost Classifier":LGBMClassifier(),
"AdaBoost Classifier":AdaBoostClassifier(),
#"SupportVectorMachine":SVC(),
"GradientBoostingClassifier": GradientBoostingClassifier()}
f1,auc,mn,acc,ll = [],[],[],[],[]
for model_name, model in tqdm(models.items()):
model.fit(X_train, y_train)
pred = model.predict(X_test)
mn.append(model_name)
f1.append(f1_score(y_test,pred,average = "weighted"))
if len(pd.Series(pred).value_counts()) == 2:
auc.append(roc_auc_score(y_test,pred))
else:
auc.append(multiclass_roc_auc_score(y_test, pred))
acc.append(accuracy_score(y_test, pred))
ll.append(balanced_accuracy_score(y_test,pred))
print('Done with ', model_name)
results = pd.DataFrame()
results['Model'] = mn
results['F1 score'] = f1
results['AUC-ROC score'] = auc
results['Accuracy'] = acc
results['Balanced Accuracy Score'] = ll
results = results.sort_values(by=['F1 score'],ascending=False)
print(results)
print('\nCheck returned table\n')
return results.style.background_gradient()
### pass Dataframe,Target column-name & flag (r for regression and c for classification)
def quick_ml(df1,target,flag,n=0):
'''
quick_ml: No hazzle Machine learning.
This methods Automatically takes dataframe and target column and flag as input and gives you the Preidiction using famous Machine learning Algorithm.
example usage:-
result, model = quick_ml(dataframe,'target-column-name','flag')
parameters:
* dataframe: the dataframe you wan't to get prediction from
* 'target-column-name' : specify target column name
* 'flag': specify flag 'r'for regression and 'c'for classification
optional:
'n'= no of features you wan't to be used for prediction using RFE
(by default set to 0 and predicts using all features )
(Rfe May Take Time in Execution so wait)
'''
info(df1)
if df1.isnull().sum().sum() > 0:
df1 = clean_data(df1)
num,cat = getcolumnstype(df1)
if len(cat) > 0:
df1=label_encode(df1)
corr_heatmap(df1,'interactive')
X = df1.drop(target,axis=1)
y = df1[target]
X_train,X_test,y_train,y_test = train_test_split(X,y,train_size=.7,random_state=42)
if flag == 'c':
showbias(df1,target)
print('Detailed Executing with RandomForest ..')
y_pred, model = randomforest_classifier(X_train,y_train,X_test,y_test)
classification_result(y_test,y_pred)
if n>0:
print('\n please wait while performing prediction using RFE...')
rfecols = rfe(model,X_train,y_train,n)
X_train = X_train[rfecols]
X_test = X_test[rfecols]
print('RFE Selected Features',rfecols)
y_pred, model = randomforest_classifier(X_train,y_train,X_test,y_test)
print('Features used for prediction\n',X_train.columns)
X = scale(X)
return quick_pred(X,y,'c'),model
elif flag == 'r':
box_hist_plot(df1,target)
print('Detailed Executing with RandomForest ..')
y_pred, model = randomforest_reg(X_train,y_train,X_test,y_test)
regression_result(y_test,y_pred)
if n>0:
print('\n please wait while performing prediction using RFE...')
rfecols = rfe(model,X_train,y_train,n)
X_train = X_train[rfecols]
X_test = X_test[rfecols]
y_pred, model = randomforest_reg(X_train,y_train,X_test,y_test)
print(' RFE Selected Features',rfecols)
print('Features used for prediction:\n',X_train.columns)
X = scale(X)
return quick_pred(X,y,'r'),model
### Visualization
def showbias(dataframe,target):
'''
Plots interactive Pie Graph for Column and show percentage of each class in column
example usage:-
showbias(dataframe,'columname')
'''
data = dataframe.copy()
labels = list(data[target].value_counts().index)
fig = px.pie(names = labels,values = data[target].value_counts().values,title='Percentage data of '+target)
fig.update_traces(hole=.4, hoverinfo="label+percent+name")
fig.show()
def corr_heatmap(dataframe,style=None):
'''
Plot interactive corealtion heatmap for dataframe passed.
example usage:-
corr_heatmap(dataframe,style)
optional style:
1. 'basic' - return basic tabular highlighted corelation table
2. interactive - plots interactive(zoomable) heatmap with plotly
if columns names are not passed it will plot histrogram and boxplot for all numeric columns
'''
if style == 'basic':
return dataframe.corr().style.background_gradient()
elif style =='interactive':
corrs = dataframe.corr()
figure = ff.create_annotated_heatmap(
z=corrs.values,
x=list(corrs.columns),
y=list(corrs.index),
annotation_text=corrs.round(2).values,
showscale=True)
figure.show()
else:
plt.figure(figsize=(20,20))
sns.heatmap(dataframe.corr(),square=True,annot=True,linewidths=0.2,cmap='Greens')
def box_hist_plot(dataframe,*argv):
'''
Plot interactive Boxplot & Histogram for n no of column passed after dataframe name.
example usage:-
box_hist_plot(dataframe,'columname1','columname2')
if columns names are not passed it will plot histrogram and boxplot for all numeric columns
'''
columns = list(argv)
if len(columns) > 0:
for i in columns:
dataframe[i].iplot(kind='hist', title= i+' Distribution')
dataframe[i].iplot(kind='box', title= i+' Box plot')
else:
for i in dataframe._get_numeric_data().columns:
dataframe[i].iplot(kind='hist', title= i+' Distribution')
dataframe[i].iplot(kind='box', title= i+' Box plot')
def confusion_mat(y_test,y_pred,cmap=None):
'''
plots confusion matrix
'''
if cmap != None:
clr = cmap
else:
clr = 'gnuplot2_r'
y_pred_temp = pd.Series(y_pred)
labels = unique_labels(y_test,y_pred)
sns.heatmap(confusion_matrix(y_test,y_pred),annot=True,
fmt='d',cmap=clr,
cbar=False,
xticklabels = labels,
yticklabels = labels,
linewidth=0.2,
linecolor='black'
)
plt.ylabel('Actual',size=15)
plt.xlabel('Predicted',size=15)
plt.title('Confusion Matrix',size=20)
plt.show()
from wordcloud import WordCloud
def wordcloud(df1,columname,bgcolor=None):
'''
df : dataframe
columname : columne for which word cloud needed
bgcolor : black or white background
'''
if bgcolor != None:
bgcolor = bgcolor
from wordcloud import WordCloud
x2011 = df1[columname]
plt.subplots(figsize=(8,8))
wordcloud = WordCloud(
background_color=bgcolor,
width=512,
height=384
).generate(" ".join(x2011))
plt.imshow(wordcloud)
plt.axis('off')
plt.show()
### Visualization
def showbias(dataframe,target):
'''
Plots interactive Pie Graph for Column and show percentage of each class in column
example usage:-
showbias(dataframe,'columname')
'''
data = dataframe.copy()
labels = list(data[target].value_counts().index)
fig = px.pie(names = labels,values = data[target].value_counts().values,title='Percentage data of '+target)
fig.update_traces(hole=.4, hoverinfo="label+percent+name")
fig.show()
def corr_heatmap(dataframe,style=None):
'''
Plot interactive corealtion heatmap for dataframe passed.
example usage:-
corr_heatmap(dataframe,style)
optional style:
1. 'basic' - return basic tabular highlighted corelation table
2. interactive - plots interactive(zoomable) heatmap with plotly
if columns names are not passed it will plot histrogram and boxplot for all numeric columns
'''
if style == 'basic':
return dataframe.corr().style.background_gradient()
elif style =='interactive':
corrs = dataframe.corr()
figure = ff.create_annotated_heatmap(
z=corrs.values,
x=list(corrs.columns),
y=list(corrs.index),
annotation_text=corrs.round(2).values,
showscale=True)
figure.show()
else:
plt.figure(figsize=(20,20))
sns.heatmap(dataframe.corr(),square=True,annot=True,linewidths=0.2,cmap='Greens')
def box_hist_plot(dataframe,*argv):
'''
Plot interactive Boxplot & Histogram for n no of column passed after dataframe name.
example usage:-
box_hist_plot(dataframe,'columname1','columname2')
if columns names are not passed it will plot histrogram and boxplot for all numeric columns
'''
columns = list(argv)
if len(columns) > 0:
for i in columns:
dataframe[i].iplot(kind='hist', title= i+' Distribution')
dataframe[i].iplot(kind='box', title= i+' Box plot')
else:
for i in dataframe._get_numeric_data().columns:
dataframe[i].iplot(kind='hist', title= i+' Distribution')
dataframe[i].iplot(kind='box', title= i+' Box plot')
def confusion_mat(y_test,y_pred,cmap=None):
'''
plots confusion matrix
'''
if cmap != None:
clr = cmap
else:
clr = 'gnuplot2_r'
y_pred_temp = pd.Series(y_pred)
labels = unique_labels(y_test,y_pred)
sns.heatmap(confusion_matrix(y_test,y_pred),annot=True,
fmt='d',cmap=clr,
cbar=False,
xticklabels = labels,
yticklabels = labels,
linewidth=0.2,
linecolor='black'
)
plt.ylabel('Actual',size=15)
plt.xlabel('Predicted',size=15)
plt.title('Confusion Matrix',size=20)
plt.show()
from wordcloud import WordCloud
def wordcloud(df1,columname,bgcolor=None):
'''
df : dataframe
columname : columne for which word cloud needed
bgcolor : black or white background
'''
if bgcolor != None:
bgcolor = bgcolor
from wordcloud import WordCloud
x2011 = df1[columname]
plt.subplots(figsize=(8,8))
wordcloud = WordCloud(
background_color=bgcolor,
width=512,
height=384
).generate(" ".join(x2011))
plt.imshow(wordcloud)
plt.axis('off')
plt.show()
### NLP processing
from textblob import TextBlob ### For Sentiment Polarity
stop_words = ['has', 'no', 'doing', "weren't", 'have', 'while', 'an', 'some', 'above', 'than', "mightn't", 'all',
'theirs', 'am', 'are', 'won', 'does', 'until', 'again', "wasn't", 'will', 'was', 'not', 'into', 'so',
'that', 'my', 'before', 'itself', 'whom', 'for', 'we', 'do', 'just', "doesn't", 'were', 'during', 'them',
'be', 'from', 'there', 'after', 'any', 'did', 'once', "needn't", 'needn', 't', "wouldn't", 'your', 'in', 'they', 'his', 'had',
'wasn', 'hers', 'd', 'why', 'being', 'yourselves', 'i', 'few', 'our', 'me', 'himself', 'shan', 'which', "hasn't", 'by',
'at', 'wouldn', "that'll", "shan't", 'm', "you've", 'if', 'ain', 'further', 'hasn', 're', 'its', 'herself', 'haven', 'here',
'themselves', 'yourself', 'didn', 'been', 'where', 'each', 'because', 'hadn', 'on', "couldn't", 'mightn', 'having', 'isn', 'don', 'their',
'he', "hadn't", 'more', 'such', "shouldn't", 'she', 'can', 'as', "won't", 'who', 'now', "you'll", 'between', 'other', 'very', 'ours', 'and', 'her', 'it', 'weren',
'most', "aren't", "didn't", "isn't", 'when', 'shouldn', 'you', 'under', 'below', 'how', 'is',
"should've", 'through', 've', 'doesn', 'same', 'should', "it's", "she's", "don't", 'couldn', 'or', 'to', 'those', 'this', 'with', 'both', 'too', 'of', 'him', "mustn't", 'what',
'nor', 'own', 'o', 's', 'up', 'myself', 'll', 'about', 'y', 'yours', 'the', 'aren', 'a', 'over',
'against', "you're", 'ourselves', 'then', 'down', 'mustn', 'off', 'only', 'ma', "you'd", 'but', 'these', 'out', "haven't"]
import string
import nltk
from nltk.stem import PorterStemmer,WordNetLemmatizer
from sklearn.feature_extraction.text import TfidfVectorizer
from tqdm.notebook import tqdm as tqdm
def text_process(mess):
'''
Method removes Punctuations and Special Characters from column
and return lower cased
'''
nopunc = [char for char in mess if char not in string.punctuation]
nopunc = ''.join(nopunc)
nopunc = ' '.join([word for word in nopunc.split() if word.lower() not in stop_words])
return str(TextBlob(nopunc)).lower()
def nlp_text(dataframe,columname):
'''
Method converts Textual data of Column to Tfidf vector after:
Removing Punctutions, Speical Symbol/character, Coverts Uppercase to lowercase and Lemmetization
### only column passed is converted to vector not whole dataframe
### need to manually join output data vector with original dataframe
example usage:
data = nlp_text(dataframe,'columname')
## after this execute this :
dataframe.drop('columname',axis=1)
newdf = pd.concat([dataframe,pd.DataFrame(data)],axis=1)
'''
joined = dataframe[columname]
joined.replace("[^a-zA-Z]"," ",regex=True,inplace=True)
joined = joined.apply(text_process)
story = []
for i in joined:
story.append(i)
stemmer = PorterStemmer()
lemmatizer = WordNetLemmatizer()
new_sentence = []
for i in tqdm(range(len(story))):
words = nltk.word_tokenize(story[i])
words = [lemmatizer.lemmatize(word) for word in words]
new_sentence.append(' '.join(words))
## just checking result with both, Using Lemmatization as it is good.
#for word in words:
#print(word,"---to setm-------->",stemmer.stem(word))
#print(word,'---to lematize---->',lemmatizer.lemmatize(word))
print('Processed Text looks like >>\n',new_sentence[2])
tfid = TfidfVectorizer()
data = tfid.fit_transform(new_sentence).toarray()
print('\nshape before Text Processing:',dataframe[columname].shape)
print('\nshape before Text Processing:',data.shape)
return data
### Deep Learning
from sklearn.neural_network import MLPClassifier, MLPRegressor
def neural_network(X_train,y_train,X_test,y_test,flag,solver=None):
'''
example usage:
y_pred,model = neural_network(X_train,y_train,X_test,y_test,flag)
flag: 'r' for regresssion ,'c' for classification
optional solver: 'adam','lbfgs','sgd'
Neural Netowrks needs to be hardcoded for every dataset
try optimizing them:
solver = 'adam','lbfgs','sgd'
hidden_layer_sizes=(100, 100),
solver='adam',tol=1e-2,
max_iter=500, random_state=1
'''
print('Please wait, Building Neural Netowrk....')
if solver != None:
bp = solver
else:
bp = 'lbfgs'
if flag == 'c':
mlp = make_pipeline(StandardScaler(),
MLPClassifier(solver = bp))
mlp.fit(X_train, y_train)
y_pred = mlp.predict(X_test)
classification_result(y_test,y_pred)
elif flag =='r':
#hidden_layer_sizes=(100, 100),solver='adam',tol=1e-2, max_iter=500, random_state=1
mlp = make_pipeline(StandardScaler(),
MLPRegressor(solver = bp))
mlp.fit(X_train, y_train)
y_pred = mlp.predict(X_test)
regression_result(y_test,y_pred)
else:
print('Please Specify Flag (r) or (c)')
return y_pred, mlp
from sklearn.neural_network import MLPClassifier, MLPRegressor
def neural_network(X_train,y_train,X_test,y_test,flag,solver=None):
'''
example usage:
y_pred,model = neural_network(X_train,y_train,X_test,y_test,flag)
flag: 'r' for regresssion ,'c' for classification
optional solver: 'adam','lbfgs','sgd'
Neural Netowrks needs to be hardcoded for every dataset
try optimizing them:
solver = 'adam','lbfgs','sgd'
hidden_layer_sizes=(100, 100),
solver='adam',tol=1e-2,
max_iter=500, random_state=1
'''
print('Please wait, Building Neural Netowrk....')
if solver != None:
bp = solver
else:
bp = 'lbfgs'
if flag == 'c':
mlp = make_pipeline(StandardScaler(),
MLPClassifier(solver = bp))
mlp.fit(X_train, y_train)
y_pred = mlp.predict(X_test)
classification_result(y_test,y_pred)
elif flag =='r':
#hidden_layer_sizes=(100, 100),solver='adam',tol=1e-2, max_iter=500, random_state=1
mlp = make_pipeline(StandardScaler(),
MLPRegressor(solver = bp))
mlp.fit(X_train, y_train)
y_pred = mlp.predict(X_test)
regression_result(y_test,y_pred)
else:
print('Please Specify Flag (r) or (c)')
return y_pred, mlp
# In[14]:
### Deployment
import pickle as pickle
app_py = ['import numpy as np\n',
'from flask import Flask, request, jsonify, render_template\n',
'import pickle\n',
'\n',
'app = Flask(__name__)\n',
"model = pickle.load(open('model.pkl', 'rb'))\n",
'\n',
"@app.route('/')\n",
'def home():\n',
" return render_template('index.html')\n",
'\n',
"@app.route('/predict',methods=['POST'])\n",
'def predict():\n',
" '''\n",
' For rendering results on HTML GUI\n',
" '''\n",
' int_features = [int(x) for x in request.form.values()]\n',
' final_features = [np.array(int_features)]\n',
' prediction = model.predict(final_features)\n',
'\n',
' output = round(prediction[0], 2)\n',
'\n',
" return render_template('index.html', prediction_text='Prediction: {}'.format(output))\n",
'\n',
"@app.route('/predict_api',methods=['POST'])\n",
'def predict_api():\n',
" '''\n",
' For direct API calls trought request\n',
" '''\n",
' data = request.get_json(force=True)\n',
' prediction = model.predict([np.array(list(data.values()))])\n',
'\n',
' output = prediction[0]\n',
' return jsonify(output)\n',
'\n',
'if __name__ == "__main__":\n',
' app.run(debug=True)']
### Makes Html file for deployment
def index_file(title):
htm = ['\n',
'\n',
'\n',
' \n',
'
##### code:
```python
X = features
y = target column
## flag('r','c')
ez.quick_pred(X,y,'flag')
```
or
```python
report = ez.quick_pred(X,y,'flag')
## report stores table for future use
```
### deploy_one()
Method Deploys, Machine Learning Model to Production. In one line of code.
Method Creates Fask App which is ready to be deployed to production..
- User just need to pass
- Model - Machine Learning Model
- Features - Features used for Predictions
- 'title' (optional) - Title to set on Web App. By default it's "Make Predictions".
- And Done, Your Deployment ready files will be stored in created folder naned 'deployment-files'.
```python
ez.deploy_one(model,features,'titlle')
```
### kaggle()
Method makes participating in kaggle compitions easy.
kaggle method takes input arguments: traindataset, testdataset,target columname and flag('r','c') and gives output as complete summary of steps performed in prediction and data cleaning process and returns predicted values of test dataframe which can be submitted on kaggle.
```python
ez.kaggle(train,test,'targetcolumn','flag')
```
or
```python
test_pred,report = ez.kaggle(train,test,'targetcolumn','flag')
## test_pred- consist test file prediction
## report - tabular report score
```
### gen_txt_report()
Method genrates txt file named output.txt containig entire summary report of oprations performed
##### usage:
```python
%%capture example ## captures output of ell and store in example
quick_ml(df,'target','c')
gen_report(example) ## this creates summary file named output.txt
# file contains all log and output of cell
```
### clean_data()
clean_data automatically cleans data by:
1. removing columns having null value greated than 20%
2. impute median in missing numeric columns
3. impute mode in missing categorical column
```python
dataframe = ez.clean_data(dataframe)
## returns cleaned dataframe
```
### nlp_text()
nlp_text converts Textual data of Column to Tfidf vector after operations:
1. Removing Punctutions
2. Removing Special Symbol/character
3. Lemmatization
4. Coverts Uppercase to lowercase
- only column passed is converted to vector not whole dataframe
- need to manually join output data vector with original dataframe
```python
vec = ez.nlp_text(dataframe,'columname')
## returns cleaned Tfidf vector
```
## Some example of Basic functions
### importdata()
Method capable of importing tsc,csv,excel file in pandas dataframe object
```python
dataframe = ez.importdata('filename.extension')
## returns cleaned Tfidf vector
```
### info()
info method gives complete information about the data in tabluar format including:
1. Number of Rows,Column
2. Number of Categorical, Numerical Feature
3. null, unique values in each column
4. total missing value and missing value percentage in each column.
5. Plots graph of Missing data in percentage format.
```python
ez.info(dataframe)
```
### getcolumnstype()
getcolumnstype returns the type of columns and store it in list format. Saves wasting time in manully writing code and determining columns type.
```python
num,cat = getcolumnstype(dataframe)
## num - list of numeric columns
## cat - list of categorical columns
```
### drop_columns() & dropcolumns()
drop_columns takes argument as Percentage in NUm (int) and columns name
1. Num - number of null value percentage, above which all columns will be dropped
2. (optional) columns name - specify columns sepreated with ',' will be dropped
#### usage:
```python
dataframe = ez.drop_columns(dataframe,n,'columnnames'..)
```
##### example:
- This Example will drop all columns having null value percentage above 20 and drop columns id & name from dataframe.
```python
df = ez.drop_columns(df,n,'id','name')
```
#### dropcolumns():
Method just drops specified columns. example:
```python
df = ez.drop_columns(df,'id','name','tp','dsd')
```
### fillnulls()
fillnulls method performs imputation operation of mean ,median,mode or specified value on specified columns together and returns imputed dataframe:
- Example 1: filling median in columns
```python
df = fillnulls(df,'median','col1','col2',...)
# fill median of respective column to respective column
```
- Example 2: filling mean in columns
```python
df = fillnulls(df,'mean','col1','col2',...)
# fill mean of respective column to respective column
```
- Example 3: filling mode in columns
```python
df = fillnulls(df,'mode','col1','col2',...)
# fill mode of respective column to respective column
```
- Example 4: filling specified value in columns
```python
df = fillnulls(df,'unknown','col1','col2',...)
# unknown will be filled inplace of null values in col2, col1
```
### extract_number()
Method Extracts number from column removing any extra string,special char,symbol, etc and returns cleaned column
```python
df = ez.extract_number(df,'income')
# removes $ symbol and return cleaned column in dataframe
```
### corr_heatmap()
Plots Corelation Heatmap of given dataframe.
arguments:
1. Dataframe
2. Style:
- 'interactive': uses plotly and plots interactive heatmap.
- 'basic': prints colorized tabular format heatmap.
- none: uses seaborn to plot annoted heatmap.
```python
ez.corr_heatmap(df)
# Plots heatmap with seaboron
ez.corr_heatmap(df,'interactive')
# plots interactive heatmap with plotly
ez.corr_heatmap(df,'basic')
# prints colorized tabluar correaltion heatmap
```
### confusion_mat()
Method Plots Visualized Confusion Matrix.
#### examples:


```python
#y_true- Actual Value
#y_pred- Predicted Value
ez.confusion_mat(y_true,y_pred)
# you can change color using cmap
```
### roc_curve_graph
Method Plots AUC-ROC plot for y_true,y_pred

- only works with Binary Classification
```python
ez.roc_curve_graph(y_true,y_pred)
```
### box_hist_plot()
method plots interactive Box plot and histogram
using plotly library
```python
ez.box_hist_plot(dataframe,'col1','col2',...)
# plots box plot and histogram for all specified column of dataframe.
```
### classification() & regression()
- classification():
It is menu based classification, asks user to which model to use for prediction.
It returns y_predicted,y_actual, model used for classification
It also prints all classification score metrics and confusion matrix by default
```python
# X = features
# y = target column
y_pred,y_actual,model = ez.classification(X,y)
```
- regression():
It is menu based regression method, asks user for which model to use for prediction.
It retruns y_predicted,y_actual, model used for prediction
It also prints all regression score metrics by default
```python
# X = features
# y = target column
y_pred,y_actual,model = ez.regresssion(X,y)
```
### RFE()
Methods Perfroms Recurrsive Feature Elimination and returns best n columns specified
```python
rfecolumns = ez.rfe(model,X_train,y_train,n)
# n- number of features to be selected (defualt n=10)
# model - model to use RFE with.
```
### classification_result() & regression_result()
Prints all scoring Metrics for when passed y_true & y_predicted
- classification_result()
Evaluation Matrics:
- F1 score
- AUC-ROC score
- classification report
- plots confusion matrix
- plots auc graph (only if binary classification)
```python
ez.classification_result(y_true,y_pred)
```
- regression_result()
Evaluation Matrics:
- R2 score
- Mean Squared Error score
- Root Mean Squared Error score
- Root Mean Squared log Error score
```python
ez.regression_result(y_true,y_pred)
```
### Machine Learning ALgorithms
Eazeml provides use of each algoritm with custom parameter
usage:
```python
# first need to define these variables
X = Feature
y = Targetcolumn
X_train,X_test,y_train,y_test = train_test_split(X,y,train_size=10)
ez.regression_result(y_true,y_pred)
```
- These Machine Learning Algorithms are already set to best param grid from experienced users.
- 'reg' defines regression & 'classifier' defines classifier algorithm.
```python
## pass X_train,y_train,X_test,y_test in which ever algorithm you need.
y_pred,model = ez.linear_reg(X_train,y_train,X_test,y_test)
## return y_predicted and model for further usage.
ez.logistic_reg(X_train,y_train,X_test,y_test)
ez.randomforest_classifier(X_train,y_train,X_test,y_test)
ez.randomforest_reg(X_train,y_train,X_test,y_test)
ez.xgb_classifier(X_train,y_train,X_test,y_test)
ez.xgb_reg(X_train,y_train,X_test,y_test)
ez.lgb_classifier(X_train,y_train,X_test,y_test)
ez.lgb_reg(X_train,y_train,X_test,y_test)
ez.Gradient_boost_classifier(X_train,y_train,X_test,y_test)
ez.Gradient_boost_reg(X_train,y_train,X_test,y_test)
ez.adaboost_classifier(X_train,y_train,X_test,y_test)
ez.adaboost_reg(X_train,y_train,X_test,y_test)
```
### get_IQR
Prints IQR (Inter Quartile Range) values table for each column of dataframe
```python
ez.get_IQR(dataframe)
```
### show_outlier & remove_outlier
- show_outlier()
Method Prints number of outlier in each column of dataframe
```python
ez.show_outlier(dataframe)
```
- remove_outlier()
Method removes all outliers from dataframe and returns Normally Distributed Dataframe and prints IQR range table.
```python
newdf = ez.remove_outlier(dataframe)
# stores outlier free dataframe in newdf
```
### stat_models()
Prints Statastical Significance table(OLS table) for each column of dataframe with respect to target column
```python
X = features
y = target column
ez.stats_models(y,X)
```
### VIF()
Method Prints VIF(Variation Inflation Variance)value of each column in Table format for each column of dataframe
```python
ez.VIF(dataframe)
```
## Contributing
Pull requests are welcome. For major changes, please open an issue first to discuss what you would like to change.
Please make sure to update tests as appropriate.
## License
[MIT](https://choosealicense.com/licenses/mit/)
�����������������������������������������������������������������������������������������������������Chintan99-eazeml-468f933/eazeml.py������������������������������������������������������������������0000664�0000000�0000000�00000160421�13704552311�0016657�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������#!/usr/bin/env python
# coding: utf-8
# ## eaze-ml ¯\\_(ツ)_/¯
# #### Data Science FrameWork
# In[11]:
## Basic Libraries
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import statsmodels.api as sm
from statsmodels.stats.outliers_influence import variance_inflation_factor
## interactive Visualization
import plotly.graph_objs as go
import plotly.express as px
import plotly.figure_factory as ff
from plotly.subplots import make_subplots
import cufflinks
cufflinks.go_offline(connected=True)
from plotly.offline import iplot# init_notebook_mode(connected=True)
import plotly.offline as pyo
pyo.init_notebook_mode()
#### Ignore Warning Messages
import os
import warnings
warnings.filterwarnings('ignore')
#### for Preprocessing
from sklearn.preprocessing import LabelEncoder,OneHotEncoder,LabelBinarizer
from sklearn.preprocessing import MinMaxScaler,StandardScaler
from sklearn.pipeline import make_pipeline
#### Machine Learning Essentials
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_val_score,GridSearchCV
#### Evaluation Metrices
from sklearn.utils.multiclass import unique_labels
from sklearn import metrics
from sklearn.metrics import classification_report, confusion_matrix, f1_score
from sklearn.metrics import balanced_accuracy_score,roc_auc_score,log_loss,accuracy_score
from sklearn.metrics import mean_squared_error,r2_score,mean_squared_log_error
#### Machine Learning Models
### supervised
from sklearn.linear_model import LogisticRegression,LinearRegression
from sklearn.ensemble import RandomForestClassifier,RandomForestRegressor
from sklearn.ensemble import GradientBoostingClassifier,GradientBoostingRegressor
from sklearn.ensemble import AdaBoostClassifier,AdaBoostRegressor
from xgboost import XGBClassifier,XGBRegressor
from lightgbm import LGBMClassifier,LGBMRegressor
import lightgbm as lgb
from sklearn.svm import SVR,SVC
from sklearn.neighbors import KNeighborsClassifier,KNeighborsRegressor
### unsupervised
from sklearn.cluster import KMeans
### Neural Network
from sklearn.neural_network import MLPClassifier
from sklearn.naive_bayes import GaussianNB
#### Feature Selection
from sklearn.feature_selection import RFE
from sklearn.decomposition import PCA
# In[10]:
### import data
def importdata(filename):
'''
Import Data from csv or excel in dataframe format
example usage:
dataframe = importtain('filename')
just specify filename
'''
x = filename.split('.')[1]
if x == 'xlsx':
dataframe = pd.read_excel(filename)
else:
dataframe = pd.read_csv(filename)
print('Dataframe Imported Successfully')
return dataframe
def info(dataframe):
'''
## Gives Entire Summary info of dataframe like nulls,uniques,
percentage missing value,type of column of dataframe.
## gives you entire details of dataFrame
'''
numerics = ['int16', 'int32', 'int64', 'float16', 'float32', 'float64']
num = dataframe.select_dtypes(include=numerics).columns
cat = dataframe.drop(num,axis=1)
cat = cat.columns
#cols = dataframe.columns
#num = dataframe._get_numeric_data().columns
#cat = list(set(cols) - set(num_cols))
print('*** Dataset Infomarion ***')
print('#####'*10)
print ("No of Rows : " ,dataframe.shape[0])
print ("No of columns : " ,dataframe.shape[1])
print ('No of Numerical columns:',len(num))
print ('No of Categorical columns:',len(cat))
print('#####'*10)
print ("\n Total Missing values : ",dataframe.isnull().sum().values.sum(),'\n')
print('#####'*10)
types = []
for i in dataframe.columns:
if i in num:
types.append('Numerical')
else:
types.append('Categorical')
temp = pd.DataFrame()
temp['Column Name'] = dataframe.columns
temp['Nulls/NaN']= dataframe.isnull().sum().values
temp['outof'] = dataframe.shape[0]
temp['Unique'] = dataframe.nunique().values
temp['Type of Columns'] = types
print("Summary of DataFrame:\n\n",temp)
if dataframe.isnull().sum().sum() > 0:
missingdata(dataframe)
def missingdata(data):
'''
Plots Percentage missing value in barplot format
'''
total = data.isnull().sum().sort_values(ascending = False)
percent = (data.isnull().sum()/data.isnull().count()*100).sort_values(ascending = False)
ms=pd.concat([total, percent], axis=1, keys=['Total', 'Percent'])
ms= ms[ms["Percent"] > 0]
f,ax =plt.subplots(figsize=(8,6))
plt.xticks(rotation='90')
fig=sns.barplot(ms.index, ms["Percent"],color="green",alpha=0.8)
plt.xlabel('Features', fontsize=15)
plt.ylabel('Percent of missing values', fontsize=15)
plt.title('Percent missing data by feature', fontsize=15)
plt.show()
def getcolumnstype(dataframe):
'''
Returns categorical and numerical columns names from dataframe
example usage:
num, cat = getcolumnstype(dataframe)
'''
numerics = ['int16', 'int32', 'int64', 'float16', 'float32', 'float64']
num = dataframe.select_dtypes(include=numerics).columns
cat = dataframe.drop(num,axis=1)
cat = cat.columns
return num,cat
def detail_cat(dataframe):
'''
Prints detial of categoy columns
'''
num, cat = getcolumnstype(dataframe)
print('Deatils of Categorical Columns:\n\n')
for i in cat:
print(i,">> column has values :\n",dataframe[i].value_counts())
print("* * "*10)
## for dropping columns just name as maany as columns
def dropcolumns(dataframe,*argv):
'''
Drops columns specified from dataframe and return dataframe
example usage:
dataframe = dropcolumns(dataframe,'columnam')
specify column names in '' seprated by ','comma
'''
columns = list(argv)
dataframe.drop(columns,axis=1,inplace=True)
return dataframe
# -------- advance --------------
def drop_columns(dataframe,n=0,*argv):
'''
Drop columns which have null value percentage above specified in n
example usage:
dataframe = drop_columns(dataframe,n,column names)
n = set to 0 if don't wan't to use percenatage missing feature
example drop_columns(df,0,'id')
'''
if n > 0:
data = dataframe.copy()
total = data.isnull().sum().sort_values(ascending = False)
percent = (data.isnull().sum()/data.isnull().count()*100).sort_values(ascending = False)
ms=pd.concat([total, percent], axis=1, keys=['Total', 'Percent'])
ms= ms[ms["Percent"] > 0]
print("Null value summary: \n",ms)
dropout = percent[percent > n].index
print('columns dropped',dropout)
data.drop(dropout,axis=1,inplace=True)
columns = list(argv)
data.drop(columns,axis=1,inplace=True)
print('\n\ncolumns dropped \n\n',list(dropout),"\n",columns)
return data
else:
columns = list(argv)
dataframe.drop(columns,axis=1,inplace=True)
print("\n\n",columns,"> Dropped \n\n")
return dataframe
def get_IQR(dataframe):
"""
Prints IQR table for dataframe
"""
Q1 = dataframe.quantile(0.25)
Q3 = dataframe.quantile(0.75)
IQR = Q3-Q1
print(IQR)
def show_outlier(df):
'''
show no of outliers in each column
'''
for i in df._get_numeric_data().columns:
low,high = df[i].quantile([0.1,0.95]).values
rows = df[(df[i] > low) & (df[i] < high)].shape[0]
if rows > 0:
print(rows,' No of outliers in column >>>',i)
else:
print('***** no outlier in ',i)
def remove_outlier(dataframe):
'''
Removes all outlier data from dataframe from entire dataframe
example usage:
newdf = remove_outlier(dataframe)
# newdf will have no outlier values
'''
Q1 = dataframe.quantile(0.5)
Q3 = dataframe.quantile(0.95)
IQR = Q3-Q1
newdataframe = dataframe[~((dataframe < (Q1 - 1.5 * IQR)) |(dataframe > (Q3 + 1.5 * IQR))).any(axis=1)]
print('IQR Range for all columns\n',IQR)
return newdataframe
def fillnulls(dataframe,value,*argv):
'''
Fill null values in dataframe columns with specified value or with mean,median,mode
example usage:
train = fillnulls(train,'median','batch_enrolled'...)
fills median value of respctive column in place of null values
if wan't to specify any other values beside mean,median,mode
just specigy that value:
train = fillnulls(train,'value','batch_enrolled'...)
'''
dataframe1 = dataframe.copy()
columns = list(argv)
print('\nColumns to be cleaned are :\n',columns,'\n')
if value == 'mean':
for i in columns:
val = dataframe1[i].mean()
dataframe1[i] = dataframe1[i].fillna(val)
print(i,'filled with:',val,'\n')
return dataframe1
elif value == 'median':
for i in columns:
val = dataframe1[i].median()
dataframe1[i] = dataframe1[i].fillna(val)
print(i,'filled with:',val,'\n')
return dataframe1
elif value == 'mode':
for i in columns:
val = dataframe1[i].mode
dataframe1[i] = dataframe1[i].fillna(val)
print(i,'filled with:',val,'\n')
return dataframe1
else:
for i in columns:
dataframe1[i] = dataframe1[i].fillna(value)
print("\n",value,'Filled inplace of NaNs\n')
return dataframe1
def extract_number(dataframe,columname):
'''
extract numbers from column
example usage:
dataframe = extract_number(dataframe,'columname')
just spcify dataframe and columname from which no to be extracted
and it return cleaned column
Null values will be replaced with 9999
'''
if dataframe[columname].isnull().sum() > 0:
dataframe[columname].fillna('9999',inplace=True)
dataframe[columname] = dataframe[columname].astype(str)
dataframe[columname].replace("[^0-9]","",regex=True,inplace=True)
dataframe[columname] = dataframe[columname].apply(lambda x: x.strip())
return dataframe
def label_encode(dataframe):
'''
Perfoms label Encoding on all categorical features and return one label encoded data
usage example :
dataframe = onehot_encode(dataframe)
'''
data = dataframe.copy()
num,cat = getcolumnstype(data)
print('\ncolumns label encoded\n',cat)
data[cat] = data[cat].apply(LabelEncoder().fit_transform)
return data
def onehot_encode(dataframe):
'''
Perfoms One Hot Encoding on all categorical features and return one hot encoded data
usage example :
dataframe = onehot_encode(dataframe)
'''
data = dataframe.copy()
num,cat = getcolumnstype(data)
print('\ncolumns onehot encoded\n',cat)
#data[cat] = data[cat].apply(OneHotEncoder().fit_transform)
data = pd.get_dummies(data,drop_first=True)
return data
def rfe(model,X_train,y_train,n=10):
'''
Performs Recurssive Feature Elimination and return best n feaures specified (defualt set to 10)
example usage:
rfecolumns = rfe(model,X_train,y_train,n)
model - machine learning algorithm model
X_train,y_train - generated from train_test_split
n - (optional) set no of features to be selected
'''
rfe = RFE(model, n)
print('\nExecuting RFE\nPlease wait.........')
X_train = scale(X_train)
rfe.fit(X_train,y_train)
print('### RFE selected columns:\n',X_train.columns[rfe.support_])
return X_train.columns[rfe.support_]
def scale(dataframe):
mm = MinMaxScaler()
c = mm.fit_transform(dataframe)
df = pd.DataFrame(c,columns = dataframe.columns)
return df
def VIF(dataframe):
'''
Prints Variance Inflation Factor value for each column in dataframe in tabluar format
'''
vif = pd.DataFrame()
vif['feature'] = dataframe.columns
vif['vif'] = [variance_inflation_factor(dataframe.values,i)for i in range(dataframe.shape[1])]
vif['vif'] = round(vif['vif'],2)
vif = vif.sort_values(by='vif',ascending=False)
return print('\n\n******** VIF *********\n\n',vif)
def stat_models(y, X):
'''
Display statastical table for X and Y
'''
model = sm.OLS(y, X)
results = model.fit()
print("***"*20)
print("\n\n",results.summary())
def multiclass_roc_auc_score(y_test, y_pred, average="macro"):
lb = LabelBinarizer()
lb.fit(y_test)
y_test = lb.transform(y_test)
y_pred = lb.transform(y_pred)
return roc_auc_score(y_test, y_pred, average=average)
def classification_result(y_test,y_pred):
'''
Evaluate Performace with Popular Metrices:
gives different scores when passed y_true & y_pred
example usage:
regression_result(y_true,y_pred)
'''
print("--------------------------------------------------------")
print('********************* Model Results ********************')
print("--------------------------------------------------------")
print("F1 Score :",f1_score(y_test,y_pred,average = "weighted"))
print('AUC-ROC Score :',multiclass_roc_auc_score(y_test, y_pred)) ## only for Binary Classification
print('Report:\n',classification_report(y_test, y_pred))
confusion_mat(y_test,y_pred)
if len(y_test.value_counts()) == 2:
roc_curve_graph(y_test, y_pred)
print("--------------------------------------------------------")
def regression_result(y_test,y_pred):
'''
Evaluate Performace with Popular Metrices:
gives different scores when passed y_true & y_pred
example usage:
regression_result(y_true,y_pred)
'''
print("-----------------------------------------")
print('************* Model Results *************')
print("-----------------------------------------")
print('R2 score:',r2_score(y_test,y_pred))
print('MSE score:',mean_squared_error(y_test, y_pred))
rmse = np.sqrt(mean_squared_error(y_test, y_pred))
print('RMSE score:',rmse)
print('RMSLE score:',(mean_squared_log_error(y_test,abs(y_pred))))
print("-----------------------------------------")
def cross_validate(model,x,y,n=3):
'''
Returns cross validation score
example usage:
cross_validate
'''
score = cross_val_score(model, X, y, scoring='accuracy',n_jobs=-1, cv=n)
cv_score = (round(np.mean(score),5) * 100)
print('Cross-validation Score >>',cv_score)
def roc_curve_graph(y_test, y_pred):
'''
Plots Area Under Curve graph
#### only works for binary classification
example usage:
roc_curve_graph(actual-values,predicted-values)
'''
fpr, tpr, threshold = metrics.roc_curve(y_test, y_pred)
roc_auc = metrics.auc(fpr, tpr)
plt.title('Receiver Operating Characteristic')
plt.plot(fpr, tpr, 'b', label = 'AUC = %0.2f' % roc_auc)
plt.legend(loc = 'lower right')
plt.plot([0, 1], [0, 1],'r--')
plt.xlim([0, 1])
plt.ylim([0, 1])
plt.ylabel('True Positive Rate')
plt.xlabel('False Positive Rate')
plt.show()
#### Basic Machine learning Models
def linear_reg(X_train,y_train,X_test,y_test):
'''
performs Logistic Regression Algorithm and returns predicted values and model
usage example:
y_pred, model = lgb_reg(X_train,y_train,X_test,y_test)
'''
lr = LinearRegression()
lr.fit(X_train,y_train)
y_pred = lr.predict(X_test)
return y_pred, lr
def logistic_reg(X_train,y_train,X_test,y_test):
'''
performs Linear Regression Algorithm and returns predicted values and model
usage example:
y_pred, model = lgb_reg(X_train,y_train,X_test,y_test)
'''
lr = LogisticRegression()
lr.fit(X_train,y_train)
y_pred = lr.predict(X_test)
return y_pred, lr
def randomforest_classifier(X_train,y_train,X_test,y_test):
'''
Performs Random Forest Algorithm and returns predicted values and model and plot feature importance graph
usage example:
y_pred, model = lgb_reg(X_train,y_train,X_test,y_test)
'''
rfc = RandomForestClassifier(n_estimators = 200,random_state=101,class_weight='balanced')
rfc.fit(X_train,y_train)
y_pred = rfc.predict(X_test)
try:
#### plotting feature importance
importances=rfc.feature_importances_
feature_importances=pd.Series(importances, index=X_train.columns).sort_values(ascending=False)
plt.figure(figsize=(10,7))
sns.barplot(x=feature_importances[0:10], y=feature_importances.index[0:10])
plt.title('Random Forest Feature Importance',size=20)
plt.ylabel("Features")
plt.show()
except:
print('Unable to plot Feature Importance Graph')
return y_pred,rfc
def randomforest_reg(X_train,y_train,X_test,y_test):
'''
Performs Random Forest Algorithm and returns predicted values and model and plot feature importance graph
usage example:
y_pred, model = lgb_reg(X_train,y_train,X_test,y_test)
'''
rfc = RandomForestRegressor(n_estimators=100,max_depth=8, random_state=101)
rfc.fit(X_train,y_train)
y_pred = rfc.predict(X_test)
try:
#### plotting feature importance
importances=rfc.feature_importances_
feature_importances=pd.Series(importances, index=X_train.columns).sort_values(ascending=False)
plt.figure(figsize=(10,7))
sns.barplot(x=feature_importances[0:10], y=feature_importances.index[0:10])
plt.title('Random Forest Feature Importance',size=20)
plt.ylabel("Features")
plt.show()
except:
print('Unable to plot Feature Importance Graph')
return y_pred, rfc
def xgb_classifier(X_train,y_train,X_test,y_test):
'''
Performs XGBoost Algorithm and returns predicted values and model and plot feature importance graph
usage example:
y_pred, model = xgb_classifier(X_train,y_train,X_test,y_test)
'''
xgb = XGBClassifier(n_estimator=100,max_depth=8,class_weight='balanced',refit='AUC')
xgb.fit(X_train,y_train)
y_pred = xgb.predict(X_test)
return y_pred, xgb
def xgb_reg(X_train,y_train,X_test,y_test):
'''
Performs XGBoost Algorithm and returns predicted values and model and plot feature importance graph
usage example:
y_pred, model = xgb_reg(X_train,y_train,X_test,y_test)
'''
model_xgb = XGBRegressor(colsample_bytree=0.4603, gamma=0.0468,
learning_rate=0.05, max_depth=3,
min_child_weight=1.7817, n_estimators=2200,
reg_alpha=0.4640, reg_lambda=0.8571,
subsample=0.5213, silent=1,
random_state =42, nthread = -1)
xgb.fit(X_train,y_train)
y_pred = xgb.predict(X_test)
return y_pred, model_xgb
def lgb_classifier(X_train,y_train,X_test,y_test):
'''
Performs LGBM boost Algorithm and returns predicted values and model and plot feature importance graph
usage example:
y_pred, model = lgb_classifier(X_train,y_train,X_test,y_test)
'''
y_train1 = y_train.values
model = lgb.LGBMClassifier(n_estimators=600,random_state=101,max_depth=8,
verbose=1,class_weight='balanced')
model.fit(X_train, y_train1)
y_pred = model.predict(X_test)
try:
#### plotting feature importance
fig, ax = plt.subplots(figsize=(12,8))
lgb.plot_importance(model, max_num_features=10, height=0.8, ax=ax)
ax.grid(False)
plt.title("LightGBM - Feature Importance", fontsize=15)
plt.show()
except:
print('Unable to plot Feature Importance Graph')
return y_pred, model
def lgb_reg(X_train,y_train,X_test,y_test):
'''
Performs LGBM boost Algorithm and returns predicted values and model and plot feature importance graph
usage example:
y_pred, model = lgb_reg(X_train,y_train,X_test,y_test)
'''
model = lgb.LGBMRegressor(n_estimators=600,random_state=101,max_depth=8,
verbose=1)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
try:
#### plotting feature importance
fig, ax = plt.subplots(figsize=(12,8))
lgb.plot_importance(model, max_num_features=10, height=0.8, ax=ax)
ax.grid(False)
plt.title("LightGBM - Feature Importance", fontsize=15)
plt.show()
except:
print('Unable to plot Feature Importance Graph')
return y_pred, model
def adaboost_classifier(X_train,y_train,X_test,y_test):
'''
Performs Ada Boost Algorithm and returns predicted values and model and plot feature importance graph
usage example:
y_pred, model = adaboost_classifier(X_train,y_train,X_test,y_test)
'''
ada = AdaBoostClassifier(n_estimators=100)
ada.fit(X_train,y_train)
y_pred = ada.predict(X_test)
try:
importances=ada.feature_importances_
feature_importances=pd.Series(importances, index=X_train.columns).sort_values(ascending=False)
plt.figure(figsize=(10,7))
sns.barplot(x=feature_importances[0:10], y=feature_importances.index[0:10])
plt.title('AdaBoost Feature Importance',size=20)
plt.ylabel("Features")
plt.show()
except:
print('Unable to plot Feature Importance Graph')
return y_pred, ada
def adaboost_reg(X_train,y_train,X_test,y_test):
'''
Performs Ada Boost Algorithm and returns predicted values and model and plot feature importance graph
usage example:
y_pred, model = adaboost_reg(X_train,y_train,X_test,y_test)
'''
ada = AdaBoostRegressor(n_estimators=100, random_state=0)
ada.fit(X_train,y_train)
y_pred = ada.predict(X_test)
try:
importances=ada.feature_importances_
feature_importances=pd.Series(importances, index=X_train.columns).sort_values(ascending=False)
plt.figure(figsize=(10,7))
sns.barplot(x=feature_importances[0:10], y=feature_importances.index[0:10])
plt.title('AdaBoost Feature Importance',size=20)
plt.ylabel("Features")
plt.show()
except:
print('Unable to plot Feature Importance Graph')
return y_pred, ada
def Gradient_boost_classifier(X_train,y_train,X_test,y_test):
'''
Performs Gradient Boost Algorhtm and returns predicted values and model
usage example:
y_pred, model = Gradient_boost_reg(X_train,y_train,X_test,y_test)
'''
GBoost = GradientBoostingClassifier(n_estimators = 3000, max_depth = 5,max_features='sqrt',
min_samples_split = 10,learning_rate = 0.005,
min_samples_leaf=15,random_state =10)
GBoost.fit(X_train, y_train)
y_pred = GBoost.predict(X_test)
return y_pred, GBoost
def Gradient_boost_reg(X_train,y_train,X_test,y_test):
'''
Performs Gradient Boost Algorhtm and returns predicted values and model
usage example:
y_pred, model = Gradient_boost_reg(X_train,y_train,X_test,y_test)
'''
GBoost = GradientBoostingRegressor(n_estimators = 3000, max_depth = 5,max_features='sqrt',
min_samples_split = 10,learning_rate = 0.005,loss = 'huber',
min_samples_leaf=15,random_state =10)
GBoost.fit(X_train, y_train)
y_pred = GBoost.predict(X_test)
return y_pred, GBoost
def grid_search(model,flag,X_train,y_train,X_test,y_test):
'''
Performs GridSearchCV when model and parameters passed and return predicted values and best_estimaor parameters
usage example:
y_pred, model = grid_search(model,flag,x_train,y_train,X_test,y_test)
model - pass any machine learning model
flag:
1. 'quick' (get quicky executed)
2. 'deep' (takes time)
X_train,y_train,X_test,y_test generated from train_test_split
'''
if flag == 'quick':
params = {
#'bootstrap': [True],
'max_depth': [80, 90, 100, 110],
'min_samples_leaf': [3, 4, 5],
'min_samples_split': [8, 10, 12],
'n_estimators': [20, 30, 40, 50],
}
elif flag == 'deep':
params = {'min_child_weight':[5,6,7], 'gamma':[i/10.0 for i in range(3,7)],
'subsample':[i/10.0 for i in range(6,11)],
'colsample_bytree':[i/10.0 for i in range(6,11)], 'max_depth': [5,6,7,8]}
print('Performing GridSearchCV \nPlease wait............')
grid = GridSearchCV(model, params)
grid.fit(X_train,y_train)
y_pred = grid.best_estimator_.predict(X_test)
print('Done ¯\_(ツ)_/¯\n')
print('best parameters: \n', grid.best_estimator_)
return y_pred, grid
def kmeans(dataframe,n):
'''
Performs Kmeans clustering Algorithm
return preidicted clusters when passed data and no of required clusters
example usage:
clusters = (dataframe,n)
n- no of required clusters
'''
km = KMeans(n_clusters=n)
y_pred_c = km.fit_predict(dataframe)
return y_pred_c
def classification(X,y):
'''
This Method Provides Menu based Algorithm Selection (Classification) for Prediction,It return predicted values(y_pred) and machine learning model for further usage.
example usage:
y_pred, model = classification(X,y)
X - features
y - target
### just pass cleaned X and y
'''
X_train,X_test,y_train,y_test = train_test_split(X,y,train_size=.7,random_state=42)
print("########## MENU ##############\n")
print('1. Logisitic Regression \n2. Random Forest \n3. XGB Classifier \n4. LGB CLassifier \n5. Gradient Boosting Classifier \n6. AdaBoost Classifier\n')
x = int(input('Input No, which you want:'))
# if x == 99:
# return quick_pred(X,y,'c')
if x == 1:
print('Predicting with Logisitic Regression Classifier')
y_pred, model = logistic_reg(X_train,y_train,X_test,y_test)
elif x == 2:
print('Predicting with Random Forest Classifier')
y_pred, model = randomforest_classifier(X_train,y_train,X_test,y_test)
elif x == 3:
print('Predicting with XGB boost Classifier')
y_pred, model = xgb_classifier(X_train,y_train,X_test,y_test)
elif x == 4:
print('Predicting with Light GBM Classifier')
y_pred, model = lgb_classifier(X_train,y_train,X_test,y_test)
elif x == 5:
print('Predicting with Gradient Bossting Classifier')
y_pred, model = Gradient_boost_classifier(X_train,y_train,X_test,y_test)
elif x == 6:
print('Predicting with Ada Boost CLassifier')
y_pred, model = adaboost_classifier(X_train,y_train,X_test,y_test)
else:
print('\n\n Please input appropirate no (*-*)')
classification(X_train,y_train,X_test,y_test)
classification_result(y_test,y_pred)
print('\nModel used:',model,'\n Done.')
return y_pred,model
def regression(X,y):
'''
This Method Provides Menu based Algorithm Selection (Regression) for Prediction, It return predicted values(y_pred) and machine learning model for further usage.
example usage:
y_pred, model = classification(X,y)
X - features
y - target
### just pass cleaned X and y
'''
X_train,X_test,y_train,y_test = train_test_split(X,y,train_size=.7,random_state=42)
print("########## MENU ##############\n")
print('1. linear Regression \n2. Random Forest regressor \n3. XGB regressor \n4. LGB regressor \n5. Gradient Boosting regressor \n6.AdaBoost regressor\n')
x = int(input('Input No, which you want:'))
#if x == 99:
# return quick_pred(X,y,'r')
if x == 1:
print('Predicting with linear Regression')
y_pred, model = linear_reg(X_train,y_train,X_test,y_test)
elif x == 2:
print('Predicting with Random Forest Regressor')
y_pred, model = randomforest_reg(X_train,y_train,X_test,y_test)
elif x == 3:
print('Predicting with XGB boost Regressor')
y_pred, model = xgb_reg(X_train,y_train,X_test,y_test)
elif x == 4:
print('Predicting with Light GBM Regressor')
y_pred, model = lgb_reg(X_train,y_train,X_test,y_test)
elif x == 5:
print('Predicting with Gradient Bossting Regressor')
y_pred, model = Gradient_boost_reg(X_train,y_train,X_test,y_test)
elif x == 6:
print('Predicting with Ada Boost Regressor')
y_pred, model = adaboost_classifier(X_train,y_train,X_test,y_test)
else:
print('\n\n Please input appropirate no (*-*)')
regression(X_train,y_train,X_test,y_test)
regression_result(y_test,y_pred)
print('\nModel used:',model,'\n Done.')
return y_pred,model
## Quick Machine learning
### please to input only cleaned dataframe
### specify "r" for regression and 'c' for classification
### X are features, y is target
def clean_data(dataframe):
dataframe.apply(lambda x: x.replace(" ",np.nan,inplace=True))
dataframe = drop_columns(dataframe,20)
nullcolumns = []
for i,j in dict(dataframe.isnull().sum()).items():
if j > 0:
nullcolumns.append(i)
num1, cat1 = getcolumnstype(dataframe[nullcolumns])
dataframe = fillnulls(dataframe,'unknown',cat1)
dataframe = fillnulls(dataframe,'median',num1)
return dataframe
def quick_pred(X,y,flag):
'''
Automatically Trains & Tests data using Many Famous Machine learning Algrithms and return scores in colorized dataframe table format.
**** Passed data should be cleaned *****
#### use quick_ml() function for uncleaned data
example:
quick(X,y,flag)
* X: Specify features
* y: spcifigy Target column
* flag: specify 'r'for regression & 'c' for classification
'''
#ss = StandardScaler()
#X = ss.fit_transform(X)
X_train,X_test,y_train,y_test = train_test_split(X,y,random_state=101,test_size=30)
print('\nPlease wait Training-Testing with all models..\n')
if flag.lower() == 'r':
models = {"LinearRegression": LinearRegression(),
"RandomForestRegression": RandomForestRegressor(),
"XGBoostRegressor":XGBRegressor(),
"LGBoostRegressor":LGBMRegressor(),
"AdaBoostRegressor":AdaBoostRegressor(),
"SupportVectorMachine":SVR(),
"GradientBoostingRegression": GradientBoostingRegressor()}
mn,r2score,rmse,rmsle,mse = [],[],[],[],[]
for model_name, model in tqdm(models.items()):
model.fit(X_train, y_train)
pred = model.predict(X_test)
mn.append(model_name)
r2score.append(r2_score(y_test,pred))
rmse.append(np.sqrt(mean_squared_error(y_test,pred)))
rmsle.append(np.sqrt(mean_squared_log_error(y_test,abs(pred))))
mse.append(mean_squared_error(y_test,pred))
print('Done with ', model_name)
results = pd.DataFrame()
results['Model'] = mn
results['R^2 score'] = r2score
results['Root Mean Squared Error'] = rmse
results['Root Mean Squared Log Error'] = rmsle
results['Mean Squared Error'] = mse
results = results.sort_values(by=['R^2 score'],ascending=False)
return results.style.background_gradient()
elif flag.lower() == 'c':
models = {"LogisticRegression": LogisticRegression(),
"RandomForestClassifier": RandomForestClassifier(),
"XGBoost Classifier":XGBClassifier(),
"LGBoost Classifier":LGBMClassifier(),
"AdaBoost Classifier":AdaBoostClassifier(),
#"SupportVectorMachine":SVC(),
"GradientBoostingClassifier": GradientBoostingClassifier()}
f1,auc,mn,acc,ll = [],[],[],[],[]
for model_name, model in tqdm(models.items()):
model.fit(X_train, y_train)
pred = model.predict(X_test)
mn.append(model_name)
f1.append(f1_score(y_test,pred,average = "weighted"))
if len(pd.Series(pred).value_counts()) == 2:
auc.append(roc_auc_score(y_test,pred))
else:
auc.append(multiclass_roc_auc_score(y_test, pred))
acc.append(accuracy_score(y_test, pred))
ll.append(balanced_accuracy_score(y_test,pred))
print('Done with ', model_name)
results = pd.DataFrame()
results['Model'] = mn
results['F1 score'] = f1
results['AUC-ROC score'] = auc
results['Accuracy'] = acc
results['Balanced Accuracy Score'] = ll
results = results.sort_values(by=['F1 score'],ascending=False)
print(results)
print('\nCheck returned table\n')
return results.style.background_gradient()
### pass Dataframe,Target column-name & flag (r for regression and c for classification)
def quick_ml(df1,target,flag,n=0):
'''
quick_ml: No hazzle Machine learning.
This methods Automatically takes dataframe and target column and flag as input and gives you the Preidiction using famous Machine learning Algorithm.
example usage:-
result, model = quick_ml(dataframe,'target-column-name','flag')
parameters:
* dataframe: the dataframe you wan't to get prediction from
* 'target-column-name' : specify target column name
* 'flag': specify flag 'r'for regression and 'c'for classification
optional:
'n'= no of features you wan't to be used for prediction using RFE
(by default set to 0 and predicts using all features )
(Rfe May Take Time in Execution so wait)
'''
info(df1)
if df1.isnull().sum().sum() > 0:
df1 = clean_data(df1)
num,cat = getcolumnstype(df1)
if len(cat) > 0:
df1=label_encode(df1)
corr_heatmap(df1,'interactive')
X = df1.drop(target,axis=1)
y = df1[target]
X_train,X_test,y_train,y_test = train_test_split(X,y,train_size=.7,random_state=42)
if flag == 'c':
showbias(df1,target)
print('Detailed Executing with RandomForest ..')
y_pred, model = randomforest_classifier(X_train,y_train,X_test,y_test)
classification_result(y_test,y_pred)
if n>0:
print('\n please wait while performing prediction using RFE...')
rfecols = rfe(model,X_train,y_train,n)
X_train = X_train[rfecols]
X_test = X_test[rfecols]
print('RFE Selected Features',rfecols)
y_pred, model = randomforest_classifier(X_train,y_train,X_test,y_test)
print('Features used for prediction\n',X_train.columns)
X = scale(X)
return quick_pred(X,y,'c'),model
elif flag == 'r':
box_hist_plot(df1,target)
print('Detailed Executing with RandomForest ..')
y_pred, model = randomforest_reg(X_train,y_train,X_test,y_test)
regression_result(y_test,y_pred)
if n>0:
print('\n please wait while performing prediction using RFE...')
rfecols = rfe(model,X_train,y_train,n)
X_train = X_train[rfecols]
X_test = X_test[rfecols]
y_pred, model = randomforest_reg(X_train,y_train,X_test,y_test)
print(' RFE Selected Features',rfecols)
print('Features used for prediction:\n',X_train.columns)
X = scale(X)
return quick_pred(X,y,'r'),model
### Visualization
def showbias(dataframe,target):
'''
Plots interactive Pie Graph for Column and show percentage of each class in column
example usage:-
showbias(dataframe,'columname')
'''
data = dataframe.copy()
labels = list(data[target].value_counts().index)
fig = px.pie(names = labels,values = data[target].value_counts().values,title='Percentage data of '+target)
fig.update_traces(hole=.4, hoverinfo="label+percent+name")
fig.show()
def corr_heatmap(dataframe,style=None):
'''
Plot interactive corealtion heatmap for dataframe passed.
example usage:-
corr_heatmap(dataframe,style)
optional style:
1. 'basic' - return basic tabular highlighted corelation table
2. interactive - plots interactive(zoomable) heatmap with plotly
if columns names are not passed it will plot histrogram and boxplot for all numeric columns
'''
if style == 'basic':
return dataframe.corr().style.background_gradient()
elif style =='interactive':
corrs = dataframe.corr()
figure = ff.create_annotated_heatmap(
z=corrs.values,
x=list(corrs.columns),
y=list(corrs.index),
annotation_text=corrs.round(2).values,
showscale=True)
figure.show()
else:
plt.figure(figsize=(20,20))
sns.heatmap(dataframe.corr(),square=True,annot=True,linewidths=0.2,cmap='Greens')
def box_hist_plot(dataframe,*argv):
'''
Plot interactive Boxplot & Histogram for n no of column passed after dataframe name.
example usage:-
box_hist_plot(dataframe,'columname1','columname2')
if columns names are not passed it will plot histrogram and boxplot for all numeric columns
'''
columns = list(argv)
if len(columns) > 0:
for i in columns:
dataframe[i].iplot(kind='hist', title= i+' Distribution')
dataframe[i].iplot(kind='box', title= i+' Box plot')
else:
for i in dataframe._get_numeric_data().columns:
dataframe[i].iplot(kind='hist', title= i+' Distribution')
dataframe[i].iplot(kind='box', title= i+' Box plot')
def confusion_mat(y_test,y_pred,cmap=None):
'''
plots confusion matrix
'''
if cmap != None:
clr = cmap
else:
clr = 'gnuplot2_r'
y_pred_temp = pd.Series(y_pred)
labels = unique_labels(y_test,y_pred)
sns.heatmap(confusion_matrix(y_test,y_pred),annot=True,
fmt='d',cmap=clr,
cbar=False,
xticklabels = labels,
yticklabels = labels,
linewidth=0.2,
linecolor='black'
)
plt.ylabel('Actual',size=15)
plt.xlabel('Predicted',size=15)
plt.title('Confusion Matrix',size=20)
plt.show()
from wordcloud import WordCloud
def wordcloud(df1,columname,bgcolor=None):
'''
df : dataframe
columname : columne for which word cloud needed
bgcolor : black or white background
'''
if bgcolor != None:
bgcolor = bgcolor
from wordcloud import WordCloud
x2011 = df1[columname]
plt.subplots(figsize=(8,8))
wordcloud = WordCloud(
background_color=bgcolor,
width=512,
height=384
).generate(" ".join(x2011))
plt.imshow(wordcloud)
plt.axis('off')
plt.show()
### Visualization
def showbias(dataframe,target):
'''
Plots interactive Pie Graph for Column and show percentage of each class in column
example usage:-
showbias(dataframe,'columname')
'''
data = dataframe.copy()
labels = list(data[target].value_counts().index)
fig = px.pie(names = labels,values = data[target].value_counts().values,title='Percentage data of '+target)
fig.update_traces(hole=.4, hoverinfo="label+percent+name")
fig.show()
def corr_heatmap(dataframe,style=None):
'''
Plot interactive corealtion heatmap for dataframe passed.
example usage:-
corr_heatmap(dataframe,style)
optional style:
1. 'basic' - return basic tabular highlighted corelation table
2. interactive - plots interactive(zoomable) heatmap with plotly
if columns names are not passed it will plot histrogram and boxplot for all numeric columns
'''
if style == 'basic':
return dataframe.corr().style.background_gradient()
elif style =='interactive':
corrs = dataframe.corr()
figure = ff.create_annotated_heatmap(
z=corrs.values,
x=list(corrs.columns),
y=list(corrs.index),
annotation_text=corrs.round(2).values,
showscale=True)
figure.show()
else:
plt.figure(figsize=(20,20))
sns.heatmap(dataframe.corr(),square=True,annot=True,linewidths=0.2,cmap='Greens')
def box_hist_plot(dataframe,*argv):
'''
Plot interactive Boxplot & Histogram for n no of column passed after dataframe name.
example usage:-
box_hist_plot(dataframe,'columname1','columname2')
if columns names are not passed it will plot histrogram and boxplot for all numeric columns
'''
columns = list(argv)
if len(columns) > 0:
for i in columns:
dataframe[i].iplot(kind='hist', title= i+' Distribution')
dataframe[i].iplot(kind='box', title= i+' Box plot')
else:
for i in dataframe._get_numeric_data().columns:
dataframe[i].iplot(kind='hist', title= i+' Distribution')
dataframe[i].iplot(kind='box', title= i+' Box plot')
def confusion_mat(y_test,y_pred,cmap=None):
'''
plots confusion matrix
'''
if cmap != None:
clr = cmap
else:
clr = 'gnuplot2_r'
y_pred_temp = pd.Series(y_pred)
labels = unique_labels(y_test,y_pred)
sns.heatmap(confusion_matrix(y_test,y_pred),annot=True,
fmt='d',cmap=clr,
cbar=False,
xticklabels = labels,
yticklabels = labels,
linewidth=0.2,
linecolor='black'
)
plt.ylabel('Actual',size=15)
plt.xlabel('Predicted',size=15)
plt.title('Confusion Matrix',size=20)
plt.show()
from wordcloud import WordCloud
def wordcloud(df1,columname,bgcolor=None):
'''
df : dataframe
columname : columne for which word cloud needed
bgcolor : black or white background
'''
if bgcolor != None:
bgcolor = bgcolor
from wordcloud import WordCloud
x2011 = df1[columname]
plt.subplots(figsize=(8,8))
wordcloud = WordCloud(
background_color=bgcolor,
width=512,
height=384
).generate(" ".join(x2011))
plt.imshow(wordcloud)
plt.axis('off')
plt.show()
### NLP processing
from textblob import TextBlob ### For Sentiment Polarity
stop_words = ['has', 'no', 'doing', "weren't", 'have', 'while', 'an', 'some', 'above', 'than', "mightn't", 'all',
'theirs', 'am', 'are', 'won', 'does', 'until', 'again', "wasn't", 'will', 'was', 'not', 'into', 'so',
'that', 'my', 'before', 'itself', 'whom', 'for', 'we', 'do', 'just', "doesn't", 'were', 'during', 'them',
'be', 'from', 'there', 'after', 'any', 'did', 'once', "needn't", 'needn', 't', "wouldn't", 'your', 'in', 'they', 'his', 'had',
'wasn', 'hers', 'd', 'why', 'being', 'yourselves', 'i', 'few', 'our', 'me', 'himself', 'shan', 'which', "hasn't", 'by',
'at', 'wouldn', "that'll", "shan't", 'm', "you've", 'if', 'ain', 'further', 'hasn', 're', 'its', 'herself', 'haven', 'here',
'themselves', 'yourself', 'didn', 'been', 'where', 'each', 'because', 'hadn', 'on', "couldn't", 'mightn', 'having', 'isn', 'don', 'their',
'he', "hadn't", 'more', 'such', "shouldn't", 'she', 'can', 'as', "won't", 'who', 'now', "you'll", 'between', 'other', 'very', 'ours', 'and', 'her', 'it', 'weren',
'most', "aren't", "didn't", "isn't", 'when', 'shouldn', 'you', 'under', 'below', 'how', 'is',
"should've", 'through', 've', 'doesn', 'same', 'should', "it's", "she's", "don't", 'couldn', 'or', 'to', 'those', 'this', 'with', 'both', 'too', 'of', 'him', "mustn't", 'what',
'nor', 'own', 'o', 's', 'up', 'myself', 'll', 'about', 'y', 'yours', 'the', 'aren', 'a', 'over',
'against', "you're", 'ourselves', 'then', 'down', 'mustn', 'off', 'only', 'ma', "you'd", 'but', 'these', 'out', "haven't"]
import string
import nltk
from nltk.stem import PorterStemmer,WordNetLemmatizer
from sklearn.feature_extraction.text import TfidfVectorizer
from tqdm.notebook import tqdm as tqdm
def text_process(mess):
'''
Method removes Punctuations and Special Characters from column
and return lower cased
'''
nopunc = [char for char in mess if char not in string.punctuation]
nopunc = ''.join(nopunc)
nopunc = ' '.join([word for word in nopunc.split() if word.lower() not in stop_words])
return str(TextBlob(nopunc)).lower()
def nlp_text(dataframe,columname):
'''
Method converts Textual data of Column to Tfidf vector after:
Removing Punctutions, Speical Symbol/character, Coverts Uppercase to lowercase and Lemmetization
### only column passed is converted to vector not whole dataframe
### need to manually join output data vector with original dataframe
example usage:
data = nlp_text(dataframe,'columname')
## after this execute this :
dataframe.drop('columname',axis=1)
newdf = pd.concat([dataframe,pd.DataFrame(data)],axis=1)
'''
joined = dataframe[columname]
joined.replace("[^a-zA-Z]"," ",regex=True,inplace=True)
joined = joined.apply(text_process)
story = []
for i in joined:
story.append(i)
stemmer = PorterStemmer()
lemmatizer = WordNetLemmatizer()
new_sentence = []
for i in tqdm(range(len(story))):
words = nltk.word_tokenize(story[i])
words = [lemmatizer.lemmatize(word) for word in words]
new_sentence.append(' '.join(words))
## just checking result with both, Using Lemmatization as it is good.
#for word in words:
#print(word,"---to setm-------->",stemmer.stem(word))
#print(word,'---to lematize---->',lemmatizer.lemmatize(word))
print('Processed Text looks like >>\n',new_sentence[2])
tfid = TfidfVectorizer()
data = tfid.fit_transform(new_sentence).toarray()
print('\nshape before Text Processing:',dataframe[columname].shape)
print('\nshape before Text Processing:',data.shape)
return data
### Deep Learning
from sklearn.neural_network import MLPClassifier, MLPRegressor
def neural_network(X_train,y_train,X_test,y_test,flag,solver=None):
'''
example usage:
y_pred,model = neural_network(X_train,y_train,X_test,y_test,flag)
flag: 'r' for regresssion ,'c' for classification
optional solver: 'adam','lbfgs','sgd'
Neural Netowrks needs to be hardcoded for every dataset
try optimizing them:
solver = 'adam','lbfgs','sgd'
hidden_layer_sizes=(100, 100),
solver='adam',tol=1e-2,
max_iter=500, random_state=1
'''
print('Please wait, Building Neural Netowrk....')
if solver != None:
bp = solver
else:
bp = 'lbfgs'
if flag == 'c':
mlp = make_pipeline(StandardScaler(),
MLPClassifier(solver = bp))
mlp.fit(X_train, y_train)
y_pred = mlp.predict(X_test)
classification_result(y_test,y_pred)
elif flag =='r':
#hidden_layer_sizes=(100, 100),solver='adam',tol=1e-2, max_iter=500, random_state=1
mlp = make_pipeline(StandardScaler(),
MLPRegressor(solver = bp))
mlp.fit(X_train, y_train)
y_pred = mlp.predict(X_test)
regression_result(y_test,y_pred)
else:
print('Please Specify Flag (r) or (c)')
return y_pred, mlp
from sklearn.neural_network import MLPClassifier, MLPRegressor
def neural_network(X_train,y_train,X_test,y_test,flag,solver=None):
'''
example usage:
y_pred,model = neural_network(X_train,y_train,X_test,y_test,flag)
flag: 'r' for regresssion ,'c' for classification
optional solver: 'adam','lbfgs','sgd'
Neural Netowrks needs to be hardcoded for every dataset
try optimizing them:
solver = 'adam','lbfgs','sgd'
hidden_layer_sizes=(100, 100),
solver='adam',tol=1e-2,
max_iter=500, random_state=1
'''
print('Please wait, Building Neural Netowrk....')
if solver != None:
bp = solver
else:
bp = 'lbfgs'
if flag == 'c':
mlp = make_pipeline(StandardScaler(),
MLPClassifier(solver = bp))
mlp.fit(X_train, y_train)
y_pred = mlp.predict(X_test)
classification_result(y_test,y_pred)
elif flag =='r':
#hidden_layer_sizes=(100, 100),solver='adam',tol=1e-2, max_iter=500, random_state=1
mlp = make_pipeline(StandardScaler(),
MLPRegressor(solver = bp))
mlp.fit(X_train, y_train)
y_pred = mlp.predict(X_test)
regression_result(y_test,y_pred)
else:
print('Please Specify Flag (r) or (c)')
return y_pred, mlp
# In[14]:
### Deployment
import pickle as pickle
app_py = ['import numpy as np\n',
'from flask import Flask, request, jsonify, render_template\n',
'import pickle\n',
'\n',
'app = Flask(__name__)\n',
"model = pickle.load(open('model.pkl', 'rb'))\n",
'\n',
"@app.route('/')\n",
'def home():\n',
" return render_template('index.html')\n",
'\n',
"@app.route('/predict',methods=['POST'])\n",
'def predict():\n',
" '''\n",
' For rendering results on HTML GUI\n',
" '''\n",
' int_features = [int(x) for x in request.form.values()]\n',
' final_features = [np.array(int_features)]\n',
' prediction = model.predict(final_features)\n',
'\n',
' output = round(prediction[0], 2)\n',
'\n',
" return render_template('index.html', prediction_text='Prediction: {}'.format(output))\n",
'\n',
"@app.route('/predict_api',methods=['POST'])\n",
'def predict_api():\n',
" '''\n",
' For direct API calls trought request\n',
" '''\n",
' data = request.get_json(force=True)\n',
' prediction = model.predict([np.array(list(data.values()))])\n',
'\n',
' output = prediction[0]\n',
' return jsonify(output)\n',
'\n',
'if __name__ == "__main__":\n',
' app.run(debug=True)']
### Makes Html file for deployment
def index_file(title):
htm = ['\n',
'\n',
'\n',
' \n',
' In [1]:
import easeml as es ## import just one package
In [2]:
### just in case you are not able to view plots
import plotly.graph_objs as go
import plotly.express as px
import plotly.figure_factory as ff
from plotly.subplots import make_subplots
import cufflinks
cufflinks.go_offline(connected=True)
from plotly.offline import iplot, init_notebook_mode
In [3]:
# es.help() prints all function available and usage
Example for quick_ml method¶
Advance house price prediction ¶
In [5]:
df = es.importdata('adv-housing.csv')
es.quick_ml(df,'SalePrice','r')



Out[5]:
Loan Risk Prediction dataset ¶
In [6]:
df1 = es.importdata('train_split.csv')
df1 = es.dropcolumns(df1,'batch_enrolled','member_id')
## no hazzle to clean data or do anything just pass target and dataframe use quick_ml fucntion in easeml
## just pass dataframe, targetcolumn and flag(r-regression/c=classification)
es.quick_ml(df1,'loan_status','c')




Out[6]:
house Price Prediction dataset ¶
In [7]:
df = es.importdata('Housing.csv')
es.quick_ml(df,'price','r')


Out[7]:
car popularity dataset ¶
In [8]:
df = es.importdata('TrainDataset.csv')
es.quick_ml(df,'popularity','c')


Out[8]:
We all know we cannot depend on automation for final decisions so we can use methods in easeml to short the hazzle of writing and remebering codes and manually use easeml to quicky get to the decision
Using EaseMl methods example ¶
credit risk loan dataset¶
In [10]:
df1 = es.importdata('train_split.csv')
es.info(df1)
es.box_hist_plot(df1,'emp_length')
df1 = es.drop_columns(df1,20,'member_id','pymnt_plan','batch_enrolled')
es.missingdata(df1)
es.extract_number(df1,'emp_length')
df1 = es.fillnulls(df1,'unknown','emp_title','title')
es.box_hist_plot(df1,'revol_util','tot_cur_bal','total_rev_hi_lim')
df1 = es.dropcolumns(df1,'tot_coll_amt')
df1 = es.fillnulls(df1,'mean','revol_util','tot_cur_bal','total_rev_hi_lim')
df2 = es.label_encode(df1)
es.corr_heatmap(df2,'interactive')
es.dropcolumns(df2,'funded_amnt_inv','funded_amnt','collections_12_mths_ex_med')
es.showbias(df1,'loan_status')
X = df2.drop('loan_status',axis=1)
y = df2['loan_status']
es.stat_models(y,X)
es.VIF(df2)
X_train,X_test,y_train,y_test = train_test_split(X,y,train_size=.7,random_state=101)
print('\n *************** Random Forest ***************\n')
y_pred, rfc = es.randomforest_classifier(X_train,y_train,X_test,y_test)
es.classification_result(y_test,y_pred)
es.roc_curve_graph(y_test, y_pred)





menu based classification available and All models results¶
In [11]:
y_pred, model = es.classification(X,y)
es.classification_result(y_test,y_pred)
es.roc_curve_graph(y_test, y_pred)
es.quick_pred(X,y,'c')



Out[11]:
In [6]:
## car popularity dataset
df = es.importdata('TrainDataset.csv')
es.info(df)
X = df.drop('popularity',axis=1)
y = df['popularity']
X_train,X_test,y_train,y_test = train_test_split(X,y,train_size=0.7,random_state=42)
es.stat_models(y,X)
es.VIF(df)
y_pred , model = es.classification(X,y)
print('\n\n*** Start Hypertuning ***\n')
y_pred,grid = es.grid_search(model,'quick',X_train,y_train,X_test,y_test)
print('\n\n*** Grid Search CV Result ***\n')
es.classification_result(y_test,y_pred)

In [13]:
es.quick_pred(X,y,'c') ## use quick pred instantly on clean data to get immidate result
Out[13]:
thank you¶
"
]
},
"metadata": {
"needs_background": "light"
},
"output_type": "display_data"
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"Null value summary: \n",
" Total Percent\n",
"PoolQC 1453 99.520548\n",
"MiscFeature 1406 96.301370\n",
"Alley 1369 93.767123\n",
"Fence 1179 80.753425\n",
"FireplaceQu 690 47.260274\n",
"LotFrontage 259 17.739726\n",
"GarageCond 81 5.547945\n",
"GarageType 81 5.547945\n",
"GarageYrBlt 81 5.547945\n",
"GarageFinish 81 5.547945\n",
"GarageQual 81 5.547945\n",
"BsmtExposure 38 2.602740\n",
"BsmtFinType2 38 2.602740\n",
"BsmtFinType1 37 2.534247\n",
"BsmtCond 37 2.534247\n",
"BsmtQual 37 2.534247\n",
"MasVnrArea 8 0.547945\n",
"MasVnrType 8 0.547945\n",
"Electrical 1 0.068493\n",
"columns dropped Index(['PoolQC', 'MiscFeature', 'Alley', 'Fence', 'FireplaceQu',\n",
" 'LotFrontage'],\n",
" dtype='object')\n",
"\n",
"\n",
"columns dropped \n",
"\n",
" ['PoolQC', 'MiscFeature', 'Alley', 'Fence', 'FireplaceQu', 'LotFrontage'] \n",
" []\n",
"Dropped null values from columns:\n",
" ['MasVnrType', 'MasVnrArea', 'BsmtQual', 'BsmtCond', 'BsmtExposure', 'BsmtFinType1', 'BsmtFinType2', 'Electrical', 'GarageType', 'GarageYrBlt', 'GarageFinish', 'GarageQual', 'GarageCond']\n",
"\n",
"columns label encoded\n",
" Index(['MSZoning', 'Street', 'LotShape', 'LandContour', 'Utilities',\n",
" 'LotConfig', 'LandSlope', 'Neighborhood', 'Condition1', 'Condition2',\n",
" 'BldgType', 'HouseStyle', 'RoofStyle', 'RoofMatl', 'Exterior1st',\n",
" 'Exterior2nd', 'MasVnrType', 'ExterQual', 'ExterCond', 'Foundation',\n",
" 'BsmtQual', 'BsmtCond', 'BsmtExposure', 'BsmtFinType1', 'BsmtFinType2',\n",
" 'Heating', 'HeatingQC', 'CentralAir', 'Electrical', 'KitchenQual',\n",
" 'Functional', 'GarageType', 'GarageFinish', 'GarageQual', 'GarageCond',\n",
" 'PavedDrive', 'SaleType', 'SaleCondition'],\n",
" dtype='object')\n"
]
},
{
"data": {
"application/vnd.plotly.v1+json": {
"config": {
"plotlyServerURL": "https://plot.ly"
},
"data": [
{
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"reversescale": false,
"showscale": true,
"type": "heatmap",
"x": [
"Id",
"MSSubClass",
"MSZoning",
"LotArea",
"Street",
"LotShape",
"LandContour",
"Utilities",
"LotConfig",
"LandSlope",
"Neighborhood",
"Condition1",
"Condition2",
"BldgType",
"HouseStyle",
"OverallQual",
"OverallCond",
"YearBuilt",
"YearRemodAdd",
"RoofStyle",
"RoofMatl",
"Exterior1st",
"Exterior2nd",
"MasVnrType",
"MasVnrArea",
"ExterQual",
"ExterCond",
"Foundation",
"BsmtQual",
"BsmtCond",
"BsmtExposure",
"BsmtFinType1",
"BsmtFinSF1",
"BsmtFinType2",
"BsmtFinSF2",
"BsmtUnfSF",
"TotalBsmtSF",
"Heating",
"HeatingQC",
"CentralAir",
"Electrical",
"1stFlrSF",
"2ndFlrSF",
"LowQualFinSF",
"GrLivArea",
"BsmtFullBath",
"BsmtHalfBath",
"FullBath",
"HalfBath",
"BedroomAbvGr",
"KitchenAbvGr",
"KitchenQual",
"TotRmsAbvGrd",
"Functional",
"Fireplaces",
"GarageType",
"GarageYrBlt",
"GarageFinish",
"GarageCars",
"GarageArea",
"GarageQual",
"GarageCond",
"PavedDrive",
"WoodDeckSF",
"OpenPorchSF",
"EnclosedPorch",
"3SsnPorch",
"ScreenPorch",
"PoolArea",
"MiscVal",
"MoSold",
"YrSold",
"SaleType",
"SaleCondition",
"SalePrice"
],
"y": [
"Id",
"MSSubClass",
"MSZoning",
"LotArea",
"Street",
"LotShape",
"LandContour",
"Utilities",
"LotConfig",
"LandSlope",
"Neighborhood",
"Condition1",
"Condition2",
"BldgType",
"HouseStyle",
"OverallQual",
"OverallCond",
"YearBuilt",
"YearRemodAdd",
"RoofStyle",
"RoofMatl",
"Exterior1st",
"Exterior2nd",
"MasVnrType",
"MasVnrArea",
"ExterQual",
"ExterCond",
"Foundation",
"BsmtQual",
"BsmtCond",
"BsmtExposure",
"BsmtFinType1",
"BsmtFinSF1",
"BsmtFinType2",
"BsmtFinSF2",
"BsmtUnfSF",
"TotalBsmtSF",
"Heating",
"HeatingQC",
"CentralAir",
"Electrical",
"1stFlrSF",
"2ndFlrSF",
"LowQualFinSF",
"GrLivArea",
"BsmtFullBath",
"BsmtHalfBath",
"FullBath",
"HalfBath",
"BedroomAbvGr",
"KitchenAbvGr",
"KitchenQual",
"TotRmsAbvGrd",
"Functional",
"Fireplaces",
"GarageType",
"GarageYrBlt",
"GarageFinish",
"GarageCars",
"GarageArea",
"GarageQual",
"GarageCond",
"PavedDrive",
"WoodDeckSF",
"OpenPorchSF",
"EnclosedPorch",
"3SsnPorch",
"ScreenPorch",
"PoolArea",
"MiscVal",
"MoSold",
"YrSold",
"SaleType",
"SaleCondition",
"SalePrice"
],
"z": [
[
1,
0.016724850721380448,
-0.0073936564408228185,
-0.036083306444502694,
0.0060179408844522305,
0.03382313775655192,
-0.015138415604763675,
0.013866293371153629,
0.062310977965240086,
0.005724212964376406,
-0.012844303706595363,
-0.016067338025940146,
-0.0023582839304543495,
0.016535750263915423,
0.005108807699847791,
-0.044455007597614934,
0.011849992159687933,
-0.023595056229011417,
-0.028433768510356117,
0.04048229691512185,
-0.030305240131385008,
-0.029797424686465433,
-0.03990251998263351,
0.050935697302656305,
-0.05103796659352416,
0.00256655498710262,
0.015349128652156058,
-0.006207854482020908,
0.06381576206670506,
0.010862171443242825,
-0.02015108144956258,
0.00498025184150966,
-0.0049187427810349965,
0.049617528021505465,
-0.004908029104022174,
-0.010196265502941127,
-0.018636787861170893,
0.03922350440638393,
0.009264673863445818,
0.010435115106807726,
0.023090626928982547,
0.009749715502245541,
-0.0028655731545146044,
-0.04795771853773425,
0.001066880432408302,
0.010209829055903352,
-0.028332957022560418,
-0.00033388479198054343,
-0.01319734878660714,
0.04129014393845963,
0.013833911015233234,
-0.0014295264091029106,
0.022852408645722053,
0.000367998951150668,
-0.017839045941519204,
0.0005026949894766652,
-0.003114479119402124,
-0.010019746028836839,
0.009797334242141055,
0.01365805935604715,
-0.002989817698019096,
-0.01010875732119869,
-0.018114560024225512,
-0.03280084930244921,
-0.00533240932506013,
0.005106053070483421,
-0.04376579864957937,
0.0009041955482458529,
0.05945450086800625,
-0.0022057006514021506,
0.02093883801772228,
0.0022407468273066837,
0.014868155412809163,
-0.0008387004712326996,
-0.03047303628015024
],
[
0.016724850721380448,
1,
0.019851742369612436,
-0.13415814649982225,
-0.020590600137966864,
0.10159022823651404,
0.004685322708555751,
-0.023965469316717444,
0.06306588333766479,
-0.012477065826100092,
-0.02036718031822959,
-0.02966188799783152,
-0.04545011357356848,
0.7544037813018366,
0.4007366795888637,
0.051690158029714973,
-0.09815330642840471,
0.056456213110010596,
0.03851305887948726,
-0.12329584279336962,
-0.031849878512887016,
-0.08218960402128231,
-0.1366804705829697,
-0.03636183252992421,
0.03133321870928325,
-0.029121790830118323,
0.004914130762263025,
0.07561623033615099,
-0.055933884443635576,
-0.00179753739300854,
-0.044427564451478226,
0.013230526675087766,
-0.06905344343420232,
0.05505901383447219,
-0.07932907728553659,
-0.14102532562967923,
-0.2636134027659649,
0.06872760531149968,
0.006384227655262995,
-0.0982424713576209,
0.05573175881216029,
-0.25878702788544344,
0.3067085314571813,
0.019989949493411662,
0.06878207746290756,
-0.011316890355120702,
-0.0001513823799178705,
0.1177198737926676,
0.19752035361248924,
-0.06569914153410501,
0.23917660866612175,
0.00815098980794901,
0.014514149327814578,
-0.02554213220012112,
-0.02475160161154742,
0.11795260866229235,
0.08203997778664511,
-0.009521763312374714,
0.006871699740459917,
-0.07027845838794604,
0.004023312861598408,
-0.008049373143581758,
-0.011233765337528,
-0.010175195750555642,
-0.00035905639738251645,
-0.022598287475612964,
-0.04139136779739513,
-0.022748025272168983,
0.01019895236429125,
-0.021511829276601772,
-0.016283496913698726,
-0.02159082620119275,
0.011011556592627803,
-0.011691566560833646,
-0.07959851790075388
],
[
-0.0073936564408228185,
0.019851742369612436,
1,
-0.02612262971723523,
0.10047217103306191,
0.05747158289314555,
-0.024759814594990465,
-0.0010479475985960061,
-0.020601647962157358,
-0.02165809011707972,
-0.2626235601234107,
-0.032014498897729504,
0.03421805066206291,
-0.00030302315701037473,
-0.11825036317848527,
-0.1727745249396502,
0.18990164894432962,
-0.3254882695069772,
-0.17855862187732507,
0.013325143054307886,
0.007029387755874145,
0.006036296884285464,
0.022058869266053816,
-0.03405719710614271,
-0.06187782423524834,
0.1959374830543725,
-0.09638050426332337,
-0.25349790825750174,
0.12879124424611044,
-0.01549569986878101,
0.04565875513050261,
0.02741912958173165,
-0.04097784960012804,
-0.02938652432080022,
0.025796408467497707,
-0.03606286907469771,
-0.07490715795156963,
0.04639416055872486,
0.1493694321201849,
-0.06051140338844939,
-0.09103335832025274,
-0.035350440769571514,
-0.05731632696132807,
0.05504720560483714,
-0.07043058095001202,
-0.020998724674517417,
0.01022399845502744,
-0.20654841344924196,
-0.13516682277738565,
-0.0010351358781264554,
0.06886673863477615,
0.1351650498762633,
-0.03144034274548059,
-0.10150433363081748,
-0.006977590918863724,
0.13401570466292576,
-0.27397387020377517,
0.16116146892567643,
-0.15653812439904954,
-0.19554639010608096,
-0.1615519537409934,
-0.09210904003589121,
-0.11791285567643743,
-0.008916459385232268,
-0.1421073802406923,
0.14406759034539635,
0.00151594682245454,
0.022452990246766526,
-0.0027501200521137296,
0.002839143360859719,
-0.011368518019475088,
-0.023208822431282774,
0.09245649841146167,
-0.0031167788893623296,
-0.16380931577091148
],
[
-0.036083306444502694,
-0.13415814649982225,
-0.02612262971723523,
1,
-0.21509481722715126,
-0.16259529019908164,
-0.16910247464972192,
0.009710261052852394,
-0.12020891696483707,
0.45815170513115294,
0.04457239254177544,
0.01901163830101622,
0.02126327713090433,
-0.20418569939146586,
-0.035476946118567235,
0.09045061138732781,
0.0014153279674146842,
-0.005021980687721198,
0.0016814729908463675,
0.06947890829588298,
0.15427874529127975,
-0.0025575701000400326,
-0.007625256391013138,
-0.001761143569173118,
0.09672702623529465,
-0.05033606274961689,
0.00918122571492824,
-0.020026423872781852,
-0.05723325383932298,
0.010486268321722165,
-0.14351619397986629,
-0.05579315513486682,
0.21014764940939437,
-0.06660894559868079,
0.11049314513683212,
-0.01458897721797496,
0.26718806266776374,
0.08782135737606003,
0.00535149748506627,
0.0340593549121656,
0.03953881778494272,
0.2885018187291621,
0.04777323181247231,
0.009729125446327775,
0.2554451577452976,
0.16068746262292583,
0.04641987193391543,
0.11572667076515877,
0.006052389656955813,
0.12036857257786046,
-0.012611273893924992,
-0.056815269341822947,
0.18565386358760266,
-0.00988592625244942,
0.2630610990857339,
-0.1300418844835832,
-0.025700275640004013,
-0.10251906661574786,
0.13822820411647535,
0.16863025291502634,
0.021880743238163122,
0.03078490327846076,
-0.015528452155783568,
0.16782204895494518,
0.08494198120724036,
-0.01796814374447305,
0.0193256932899186,
0.0384892692888955,
0.07705022824516986,
0.040823885173202144,
0.0001175202505775026,
-0.012066376168532754,
0.014409771403381169,
0.03146507687279525,
0.2547573502139699
],
[
0.0060179408844522305,
-0.020590600137966864,
0.10047217103306191,
-0.21509481722715126,
1,
-0.004162446475095465,
0.1415194719850622,
0.0016749591661448498,
0.022596914629629507,
-0.20611649596428924,
-0.02254499184969635,
-0.0792478864162515,
0.0022114763385724335,
-0.006154049677768274,
0.047828500297799136,
0.07492598920505604,
0.04525867162577222,
0.03612035446824632,
0.08171140493989407,
-0.027194043615256912,
0.007697692438898529,
-0.01051275253688075,
-0.007685344954104669,
-0.004799263276489851,
0.02150927191979548,
0.06295591390129314,
-0.020923221055723685,
0.03487911202250895,
-0.03907255091908936,
-0.017089415745357144,
0.0556932699809924,
-0.023604855853853923,
-0.005096651871932288,
0.07071758526411866,
-0.04518934567238191,
0.026806947754550677,
0.004796176560964124,
0.0069253207869607175,
-0.046278024446122425,
0.10405695449724181,
0.03323125134350933,
-0.0020248072942370453,
0.04504607971744589,
0.006353536479903294,
0.037094596680458176,
-0.04292835398132114,
0.015346570801680193,
0.04201327230710782,
0.02464880133386127,
0.03665948655370173,
0.010484543025237018,
-0.020403691316523545,
0.04445388006099216,
-0.015036186173145292,
-0.014360271885975839,
-0.00497805737094708,
0.027689784249408402,
-0.0018361185820532837,
-0.05105492411298621,
-0.08429325644928268,
-0.013825538735983644,
-0.011664930084399228,
0.04424275876853673,
-0.026813132105382442,
-0.008265100288747282,
0.021411949145583982,
0.007269014514968439,
-0.03816944779540477,
0.004395581225108923,
-0.026514354076164665,
-0.0015470268585642205,
-0.036572154661852804,
0.01938037831579925,
0.011845726829113742,
0.042106016066563355
],
[
0.03382313775655192,
0.10159022823651404,
0.05747158289314555,
-0.16259529019908164,
-0.004162446475095465,
1,
0.0832837465233896,
-0.036698833959207346,
0.22079014468128189,
-0.096192845218598,
-0.048163397796844885,
-0.11837453422306088,
-0.04845407851988838,
0.10907949852665139,
-0.11167425883963582,
-0.19086988665645155,
0.00827989678605748,
-0.22944657834649157,
-0.1590437508370721,
0.010524219475265295,
-0.06963464572088618,
-0.0008174207060273792,
-0.016329205224042066,
0.0014959642510510146,
-0.0985282311931722,
0.1431086351779486,
-0.042484767523804694,
-0.16672819107008033,
0.15626490161668055,
-0.011557185325724749,
0.1397638442928494,
0.07283444050181676,
-0.1168542725348184,
0.01886384633853748,
-0.031727785316206715,
-0.009939803028428817,
-0.15597887782779843,
0.06507658890626067,
0.09361199638454391,
-0.10072855825021224,
-0.09352766095760935,
-0.1655382975590517,
-0.06888093982249427,
0.029951178846677366,
-0.1788681058560465,
-0.06583214095839227,
-0.015680706997172632,
-0.17591334179785742,
-0.10770607055019246,
-0.06545097662244599,
0.05085482776077683,
0.11542062744284054,
-0.1343468394537626,
-0.0512990710756872,
-0.18726548843260596,
0.18090004058535558,
-0.19298250910121809,
0.22667337015724842,
-0.18246065416176238,
-0.148814526623833,
-0.10299251014191207,
-0.0800763240171814,
-0.1247199561717356,
-0.1569586766781947,
-0.08473952333645134,
0.07471274190288142,
-0.038387686712762416,
-0.047455707886364586,
-0.018836145425574116,
-0.04244734647114658,
-0.04396760150371732,
0.03165912354375219,
-0.007835725350096029,
-0.032899485530652375,
-0.25309204131214885
],
[
-0.015138415604763675,
0.004685322708555751,
-0.024759814594990465,
-0.16910247464972192,
0.1415194719850622,
0.0832837465233896,
1,
0.008448169441444584,
-0.015729611384442004,
-0.382911495008291,
0.03100550755217965,
0.018493079426928637,
-0.017142269876602247,
0.05285778558409131,
0.07441098755055303,
0.011833148976895764,
-0.03695798364691597,
0.15448404624114595,
0.09912469630061865,
-0.004157296005580165,
-0.027526981089108088,
-0.003946627505597646,
-0.033104947189651575,
-0.07538875101757556,
0.04167834038293154,
-0.005746254687495589,
-0.011776342060096328,
0.060989097684453736,
0.010355079658370058,
0.008955331562487045,
0.05455576560749247,
-0.06303857877145162,
-0.03530566213848387,
-0.0397485076782317,
0.011051399963209528,
0.02886907708416442,
-0.004093900617630184,
0.028347397409779367,
-0.0677172805391479,
0.12541880073254466,
0.06845924224510988,
-0.04763358309669704,
-0.032480499861109714,
-0.07098418327241365,
-0.06840300706371609,
-0.009295821458376107,
0.0143746614274504,
0.05651081766049946,
0.024617132444208684,
-0.007591257422062977,
-0.03431744081264898,
0.005122918756194039,
-0.038290640210961895,
0.034279293216391844,
-0.07377919976696438,
-0.10494946040708829,
0.1298497620129026,
-0.07243254090602405,
0.009421164403590301,
0.011330637394811017,
0.012838980569483658,
0.01046197240335421,
0.13751146317497312,
-0.016676821148531917,
0.04994571947655422,
-0.07055209324177596,
-0.02655380325011126,
-0.00012518297309117553,
-0.015170502376441122,
0.01878471170823421,
-0.019250584722489673,
0.018654366228497855,
-0.027535457035299814,
0.00574973731068094,
0.0015173935763670237
],
[
0.013866293371153629,
-0.023965469316717444,
-0.0010479475985960061,
0.009710261052852394,
0.0016749591661448498,
-0.036698833959207346,
0.008448169441444584,
1,
-0.03357655375141616,
-0.0062437423628820725,
0.04806477231558159,
-0.0016372508023809816,
-0.0009875217415635878,
-0.010803163278580476,
0.055790981807245656,
-0.004538843335186787,
0.010241550713568208,
-0.013908316849733838,
-0.03729652158019512,
-0.013780535538770986,
-0.00343735924761877,
-0.032377955742055674,
-0.03409060059564063,
-0.03240444423569835,
0.06347775149456443,
0.01882748517783975,
0.009343141201956196,
-0.015575062164531653,
0.023686236640640883,
0.0076311780075621225,
0.01777910843771242,
-0.010527113137245105,
-0.021064140785699337,
-0.02007510142913887,
0.05017224493602903,
-0.014209181672910152,
-0.018682940504383044,
-0.0030924612328614488,
0.008049684918958633,
0.005977282268454327,
-0.10427559773826277,
0.011871875951457698,
-0.022190308720397584,
-0.0028371343162421053,
-0.010173756971870994,
-0.023277699667795027,
0.10634717922345817,
-0.02875358314737922,
-0.021859443188251934,
0.00476517225091826,
-0.004681810972693491,
-0.010668272564702094,
0.007765838523659378,
0.006714320428028173,
0.014890674873585075,
-0.00393498653254095,
-0.022745559833628293,
-0.005910379357123157,
0.005544829530676808,
0.0034498542101277395,
0.006173712941204807,
0.005208905865843047,
0.006664433714960577,
-0.021319678400363095,
0.029390899247553965,
-0.009561379853680062,
-0.0032459356440167775,
0.10206394380661554,
-0.0019628209223371304,
-0.0023119232224790755,
-0.054038152091504865,
0.02455501172582275,
-0.12981290787131344,
-0.09821136084010303,
-0.017078650564686607
],
[
0.062310977965240086,
0.06306588333766479,
-0.020601647962157358,
-0.12020891696483707,
0.022596914629629507,
0.22079014468128189,
-0.015729611384442004,
-0.03357655375141616,
1,
-0.008447089927049428,
-0.043809783215461424,
0.010289380727279569,
0.030635134226934604,
0.10413223244619264,
-0.03525076905482092,
-0.02542965188486932,
-0.051128561036420606,
0.021593260073328225,
-0.016954699100246967,
-0.002634847469880711,
-0.05680427963508923,
0.024512366119302055,
0.006981600462715749,
0.0018092312754269522,
-0.027204494186775847,
-0.00461455525013374,
0.053002320870454624,
0.00016012031254417758,
0.023278647627322555,
0.03248280028252951,
0.018866432045552717,
0.028152320182605547,
-0.027391210170418144,
-0.000673045922017702,
-0.0134068897314506,
0.002009829174242677,
-0.034300780078473356,
0.024866395023751726,
-0.016648208649101767,
-0.01078857357463228,
-0.029732685353952685,
-0.06129149624419643,
-0.050691509090022506,
0.005007810857881887,
-0.08800743101122101,
-0.028352953992485067,
-0.0021273498145420316,
-0.0018015610760747426,
-0.02620242764803231,
-0.05534637105677964,
-0.031659694684004674,
-0.010304661020708705,
-0.055581803464847736,
-0.0303879697344421,
-0.052085700417345775,
0.017932669962502795,
-0.002465714744599853,
0.0201096548745226,
-0.06199704444066005,
-0.056526223233211964,
0.021681127831878696,
0.015221103876701007,
-0.04849521350731529,
-0.04005838181102943,
-0.05631891273663907,
-0.07025489718785788,
-0.033491059452548606,
-0.001784411761206332,
-0.04787187842954997,
-0.02397730531170623,
0.016536948986703624,
-0.0074483236605016705,
0.0075437435538039666,
0.0594466310346893,
-0.06573503174195633
],
[
0.005724212964376406,
-0.012477065826100092,
-0.02165809011707972,
0.45815170513115294,
-0.20611649596428924,
-0.096192845218598,
-0.382911495008291,
-0.0062437423628820725,
-0.008447089927049428,
1,
-0.07900072235489447,
-0.019727967003594103,
-0.028207685115269613,
-0.04803931764977174,
-0.032366925381443895,
-0.052090426372970906,
0.04063540016168354,
-0.07802371556371811,
-0.05756791072044208,
-0.025928513829492506,
0.19272098116483874,
-0.060502706059177486,
-0.04275005394728947,
0.03909599446296835,
-0.02415585396438889,
0.041919564168097445,
0.021870187651766626,
-0.022090051577431394,
0.023111232797587603,
0.004964003213805874,
-0.17037626674469414,
-0.06275470097653332,
0.11698967589563214,
-0.06873100971748537,
0.0907370155808782,
-0.12468115677389954,
0.03427559079548718,
0.006693808907272821,
0.04396709426019784,
0.011269075309143832,
0.007877651999064964,
0.08211397340626231,
-0.002495808327890459,
0.029377239755394417,
0.061174122796999866,
0.12354741596754584,
0.07620173272618024,
-0.03393815260733667,
-0.006615724605275096,
-0.03287044110318166,
-0.023702819028113227,
0.017782462843909635,
-0.018233518034407682,
-0.09726711166786804,
0.13679530069899445,
0.0034374295801951516,
-0.07664689463520605,
0.026674021183174846,
0.003925896925215691,
0.011995132910763257,
0.016831131398870904,
-0.018742016933083156,
-0.035183906936079326,
0.10397520170204337,
-0.029043267313532902,
-0.013841099887284002,
0.009618286115884844,
0.0538798909791917,
-0.016385400467922924,
-0.0020904987061326537,
0.021692637546267587,
-0.0009748849025312992,
0.05524556658150756,
-0.05936709342638509,
0.06162913272815378
],
[
-0.012844303706595363,
-0.02036718031822959,
-0.2626235601234107,
0.04457239254177544,
-0.02254499184969635,
-0.048163397796844885,
0.03100550755217965,
0.04806477231558159,
-0.043809783215461424,
-0.07900072235489447,
1,
-0.038573784520407044,
0.021194088597530823,
-0.00037173082788493185,
0.038517263405479674,
0.17412587189203,
-0.0551499719665956,
0.08916703910969971,
0.0856415598870842,
0.11966097428539996,
-0.001873614318484352,
-0.08692776114099206,
-0.10133449702221821,
0.08765654968084284,
0.11695140238315857,
-0.15946026956681675,
0.026324629667579723,
0.06610096085367631,
-0.15926551945954037,
0.032150740018952025,
0.052578558034144136,
-0.04200098772499464,
0.11752293864948343,
-0.03259248565641787,
0.0410541166682348,
-0.010301017685363928,
0.1385997647077993,
-0.018973036651658684,
-0.02674819050468072,
0.028351685024030328,
0.06743597921177182,
0.15563920865511718,
0.014616034586072519,
0.03466623295528151,
0.13067020130768697,
0.07535640388347087,
-0.02728760633470674,
0.13136904135594896,
0.05007994828293328,
0.01938917884024398,
0.05806212376510432,
-0.14411146576407582,
0.08241985872108805,
0.004820206645700774,
0.05748105746764286,
-0.06360591222585198,
0.10676516197543212,
-0.04958640010754587,
0.17847558274121678,
0.20394636574799854,
-0.017367198978466163,
0.004158885441727495,
0.006732393970521492,
0.06281538327454438,
0.14139560803873602,
0.03895443890956474,
-0.024015503385765403,
0.00850922344186706,
-0.012304935224082018,
0.0022877204122000636,
0.0059439814450761375,
0.037856641298543374,
-0.03407180234018274,
0.015368995477880662,
0.19967722625129594
],
[
-0.016067338025940146,
-0.02966188799783152,
-0.032014498897729504,
0.01901163830101622,
-0.0792478864162515,
-0.11837453422306088,
0.018493079426928637,
-0.0016372508023809816,
0.010289380727279569,
-0.019727967003594103,
-0.038573784520407044,
1,
-0.08050243598045302,
-0.02921881424223972,
0.08468625387457666,
0.08559307259328972,
-0.03313000264747504,
0.14054544185562726,
0.1350876780661982,
0.002803832341189609,
0.007767518838432563,
0.01675296427578575,
0.00490939808651431,
0.007620342599243688,
0.01160428666900426,
-0.06853344385285168,
0.07771497852109396,
0.07508118788227025,
-0.10298696537272337,
0.004850254373989393,
-0.011486004635706155,
-0.018868282259844476,
0.013385056763329753,
-0.028871328385822754,
0.022907451534498496,
0.017232088998516918,
0.043223222167349855,
-0.006769411006774106,
-0.07621312729359682,
-0.023295546534257593,
0.06471583878228135,
0.04386351168835183,
0.013162236800188583,
-0.04416630152957403,
0.04025727301431323,
0.012843585658688853,
-0.06735223712913062,
0.09264302448038639,
0.04918331022271554,
0.025635493364451124,
-0.08750201974994211,
-0.0507948059642043,
0.05903951532853358,
-0.015270515920455202,
-0.005305967127884751,
-0.052280300281721134,
0.14537377670451695,
-0.12913885552069282,
0.07198110949872359,
0.03944688015989324,
0.07888608486617085,
0.02279733509548903,
0.06753618843636407,
0.03514335640255836,
0.09214694231584714,
-0.077561586520586,
0.08052481073717128,
0.004448698251411438,
0.007201623402851556,
-0.013694102549178825,
-0.009549327002071136,
-0.01851141058121313,
-0.0018677249909708525,
0.050811544029446105,
0.07503192231642285
],
[
-0.0023582839304543495,
-0.04545011357356848,
0.03421805066206291,
0.02126327713090433,
0.0022114763385724335,
-0.04845407851988838,
-0.017142269876602247,
-0.0009875217415635878,
0.030635134226934604,
-0.028207685115269613,
0.021194088597530823,
-0.08050243598045302,
1,
0.00867473474412566,
-0.033712522047953684,
0.0065948033752818045,
0.005790227894077778,
0.023461522277419537,
0.0062022510866259145,
0.04762787393275533,
-0.004538402366416239,
-0.007786825869800208,
-0.017222680359770332,
-0.003310754356622403,
0.03563501192753698,
-0.03473383884461161,
-0.038450064259071784,
-0.008162578330911524,
0.012264979779632616,
0.023092416924468406,
0.006629279314947595,
0.019724690734134624,
0.009502196606841658,
-0.011901492850842493,
0.053804339513675414,
0.019348845346864388,
0.053788507963794946,
-0.004083027803099829,
-0.013395588393594074,
-0.0453709887069188,
0.021282878010818594,
0.03964169801485141,
-0.003305625524563051,
-0.014392829656124907,
0.02552103653628539,
-0.003789887370853636,
-0.009048024949757922,
0.01785551669830549,
0.020738843095562304,
-0.0187516111720734,
0.04153474087757888,
-0.04421830128148692,
0.020771384232572822,
0.008865028507145723,
-0.019087646642344695,
0.04952834385419031,
-0.006141162226570326,
-0.004385837239088038,
0.0160824729996424,
0.05405384828278298,
-0.02325337589067172,
0.05513947209442576,
-0.024742943430320286,
0.008496800048682456,
0.03412907068476666,
0.020348390377908608,
-0.00428566261098433,
-0.01022609849102695,
-0.002591544984702289,
0.12984779288405893,
0.00791159729291587,
-0.019782461186570434,
-0.0026368328163665477,
0.03810576009982164,
0.0018914223017047222
],
[
0.016535750263915423,
0.7544037813018366,
-0.00030302315701037473,
-0.20418569939146586,
-0.006154049677768274,
0.10907949852665139,
0.05285778558409131,
-0.010803163278580476,
0.10413223244619264,
-0.04803931764977174,
-0.00037173082788493185,
-0.02921881424223972,
0.00867473474412566,
1,
0.052315201618659435,
0.07103331443515178,
-0.1773688342502928,
0.22905728323622135,
0.12140856828795692,
-0.05277806449033029,
-0.04354294389969534,
-0.0973369080552566,
-0.13214547526940498,
-0.028496681379501527,
0.04647839988244959,
-0.10766529857991093,
0.0865853565872056,
0.15716691016782963,
-0.11828351408012855,
0.03212592225977051,
-0.0314211970709489,
-0.05220385080766569,
0.00783098951698722,
0.03260997880090551,
-0.024084127661394433,
-0.03575506151950359,
-0.039798256222469276,
-0.025990600253092064,
-0.03142637417948327,
0.036033298179129605,
0.07896990103903755,
-0.08309170761446666,
-0.08740846731484941,
-0.027633134159873916,
-0.1378081272292663,
0.04217774359732086,
-0.007011254685324479,
0.0582852421422606,
-0.013247724004056771,
-0.3215099243849895,
0.13383597771592143,
-0.0365409387973652,
-0.22673002077020515,
-0.010709588207720224,
-0.07862801730441539,
-0.009584889154066072,
0.20597441753054338,
-0.07169819666895963,
0.027521715784369065,
-0.05588879836068081,
0.06723966420335346,
0.059745726851186995,
0.06942748387657853,
-0.009074244416722653,
-0.024105592350611996,
-0.10907958735873159,
-0.02065344555876409,
-0.025610890144336297,
-0.02835065035550131,
-0.010909781668084682,
-0.03508206980883779,
0.00016923319988008272,
-0.04374989459584764,
0.006898912816087958,
-0.08187986195308612
],
[
0.005108807699847791,
0.4007366795888637,
-0.11825036317848527,
-0.035476946118567235,
0.047828500297799136,
-0.11167425883963582,
0.07441098755055303,
0.055790981807245656,
-0.03525076905482092,
-0.032366925381443895,
0.038517263405479674,
0.08468625387457666,
-0.033712522047953684,
0.052315201618659435,
1,
0.19907991660003127,
-0.05207485966936504,
0.2593572257762402,
0.1999992520334135,
-0.038863404983405785,
0.04011494273535409,
-0.036147211458462454,
-0.07229867346085267,
-0.12656676168082734,
0.1585417255383038,
-0.08481098179326435,
0.05365293132636732,
0.20941720641147912,
-0.127611114248357,
0.01871500780407587,
-0.17443786695527191,
-0.03433937826753578,
-0.008456781831141173,
0.016975315743483065,
-0.03900605254038184,
-0.16413221036429035,
-0.2036043145038347,
-0.059951542037792065,
-0.05969661166579692,
0.031426026313619376,
0.1640571594160559,
-0.18544976928819318,
0.478887774264597,
-0.06509319710040079,
0.2622323252224905,
0.02521117161271464,
0.02959263410221105,
0.24031707932177052,
0.41587218250401187,
0.20476316080935997,
0.02504751430572349,
-0.08193486006956507,
0.26295334550789723,
0.03109604767188451,
0.08691015993125557,
-0.10185829365431776,
0.2064878337208006,
-0.2052822459648225,
0.18924485748285055,
0.13522982159507746,
0.061643198013823806,
0.007182768663123965,
0.08186230857094262,
0.07027445477174898,
0.13713025767680034,
-0.0672904426794365,
-0.029546092674310107,
-0.03485921338462889,
0.07779321600697005,
-0.04924440342355729,
0.0289168443143115,
-0.017118131443216132,
0.048060173838034174,
0.012076671414924843,
0.1610077737062108
],
[
-0.044455007597614934,
0.051690158029714973,
-0.1727745249396502,
0.09045061138732781,
0.07492598920505604,
-0.19086988665645155,
0.011833148976895764,
-0.004538843335186787,
-0.02542965188486932,
-0.052090426372970906,
0.17412587189203,
0.08559307259328972,
0.0065948033752818045,
0.07103331443515178,
0.19907991660003127,
1,
-0.16307960287997786,
0.570668179325408,
0.5494601248697408,
0.17188060189498985,
0.0843098158266863,
0.15696978117717292,
0.15762167113762118,
0.03600240782723811,
0.4011747375868,
-0.675389466513745,
0.11420313157723185,
0.48685201373144665,
-0.6063521456608485,
0.0542456605130827,
-0.2368955694139229,
0.07775617950906802,
0.19744149384950824,
0.10849363418332508,
-0.08601364866269622,
0.2929400179124754,
0.5058965803730809,
-0.04951264501196124,
-0.44167112771707995,
0.19052593542854807,
0.20658634986135016,
0.4819779103629154,
0.28114459380333623,
-0.01670375066283301,
0.59447019806393,
0.08325367684549462,
-0.0649520486452631,
0.580425194333127,
0.24928297909040176,
0.08199436386128246,
-0.13508393883200037,
-0.6090939011647342,
0.44294061659027856,
0.13011812029108893,
0.37735900883048845,
-0.3495856794547723,
0.545834564443336,
-0.5165278399741617,
0.591877791157789,
0.5300918839150316,
0.11952499445216692,
0.15911977480621992,
0.16314629342609765,
0.21856953420394784,
0.3076147309600645,
-0.11693095622879052,
0.02646990748560078,
0.045256702232239425,
0.06456987460203505,
-0.029350832456647227,
0.06264144983858497,
-0.013949153887412302,
-0.05287466148895335,
0.18878877871731548,
0.7835456113843237
],
[
0.011849992159687933,
-0.09815330642840471,
0.18990164894432962,
0.0014153279674146842,
0.04525867162577222,
0.00827989678605748,
-0.03695798364691597,
0.010241550713568208,
-0.051128561036420606,
0.04063540016168354,
-0.0551499719665956,
-0.03313000264747504,
0.005790227894077778,
-0.1773688342502928,
-0.05207485966936504,
-0.16307960287997786,
1,
-0.4173297870299569,
0.03507649819677994,
-0.016728781147281418,
0.04249414662732977,
-0.0692044082135262,
-0.054722784137850915,
0.007886258765726495,
-0.14107956690186194,
0.17267877932570774,
-0.2529217907182825,
-0.3316771022887584,
0.2688954603159834,
-0.018911792956274143,
0.10081451396976993,
-0.07946237962876346,
-0.06006752616812258,
-0.09337866359840867,
0.035697505771196514,
-0.1610376778167363,
-0.22801953476382458,
-0.029001570178530084,
0.08011365010270782,
0.057784627271707675,
0.03168530466322039,
-0.1440657147406244,
0.011684568880857909,
0.04186481529450761,
-0.09384310502971577,
-0.07008911339799866,
0.11967078669644289,
-0.2118823745012079,
-0.07356826122792803,
0.023179716993687045,
-0.07091037093534514,
0.06917534608414315,
-0.06388282788414294,
0.05146567468083967,
-0.0319101709219359,
0.19168225723276208,
-0.33654128329423727,
0.223433364546768,
-0.24983180899078664,
-0.2049048044564097,
-0.09797779542478702,
-0.04053174516928885,
-0.10632988251865728,
-0.012946977008197757,
-0.060429082023547194,
0.07147329718568772,
0.023788760166174528,
0.05375911480852094,
-0.003543836941888403,
0.0773135478366433,
-0.011772274303491013,
0.05634002174155075,
0.09524007224848526,
0.003052436153181428,
-0.1086270972695443
],
[
-0.023595056229011417,
0.056456213110010596,
-0.3254882695069772,
-0.005021980687721198,
0.03612035446824632,
-0.22944657834649157,
0.15448404624114595,
-0.013908316849733838,
0.021593260073328225,
-0.07802371556371811,
0.08916703910969971,
0.14054544185562726,
0.023461522277419537,
0.22905728323622135,
0.2593572257762402,
0.570668179325408,
-0.4173297870299569,
1,
0.6171563222221312,
0.045740195794162726,
-0.027977021716830766,
0.11392177894127772,
0.09557122266093863,
-0.037268959472492605,
0.29941018690066906,
-0.5145253726304001,
0.264965953108123,
0.7241661803117199,
-0.5334170831926786,
0.13933705402516516,
-0.3037582976523181,
-0.10787843940456322,
0.22426386105322857,
0.0760526723449593,
-0.07040251867550996,
0.1477616118068355,
0.38514607943667567,
-0.18698667275110634,
-0.41666501697556985,
0.3595706175365072,
0.3233619242940471,
0.26358543221916664,
0.006989088940665577,
-0.1602893977674938,
0.1891459809489941,
0.17510831159773813,
-0.05520397086692119,
0.48677731596173274,
0.2276264316617981,
-0.08064434451492349,
-0.17612391687364642,
-0.384457858727966,
0.09941461593878198,
0.15026857976219882,
0.11080715280971148,
-0.5159558366376603,
0.8251723703726819,
-0.5832188734251933,
0.5240758310844763,
0.4438540209512734,
0.33840764418609415,
0.2749273642303913,
0.38913857073365976,
0.21229564671312867,
0.21679333902671258,
-0.38541458488430597,
0.028982135268052656,
-0.07080877581034056,
0.0010060347394037416,
-0.03349316362455502,
0.004396082441172591,
-0.007898124743179068,
-0.04229481406709492,
0.1977912291854145,
0.504297175093091
],
[
-0.028433768510356117,
0.03851305887948726,
-0.17855862187732507,
0.0016814729908463675,
0.08171140493989407,
-0.1590437508370721,
0.09912469630061865,
-0.03729652158019512,
-0.016954699100246967,
-0.05756791072044208,
0.0856415598870842,
0.1350876780661982,
0.0062022510866259145,
0.12140856828795692,
0.1999992520334135,
0.5494601248697408,
0.03507649819677994,
0.6171563222221312,
1,
0.025507327891157477,
-0.031049004710119118,
0.24466776137162163,
0.23142367543706796,
0.08186549893560781,
0.16831050298973319,
-0.5088226075615108,
0.09054812067320005,
0.532201099763918,
-0.4787415140739781,
0.028246664892720815,
-0.21868936443360137,
0.01467305448443999,
0.09968054964037755,
0.08832811801792068,
-0.08526822669167149,
0.17188068811725313,
0.26428114913317813,
-0.13637242754938658,
-0.5159572213202074,
0.2560299434469796,
0.30962893653775686,
0.24188878126511085,
0.12054456886890334,
-0.06439501767177201,
0.2765802979625044,
0.0992936540083092,
-0.023966253410943165,
0.4601196002562738,
0.16945613439289786,
-0.074393280883922,
-0.15414668453880773,
-0.4863317532914487,
0.17466047616562724,
0.06939113747117548,
0.08995214529827836,
-0.29490246493511696,
0.6415853437752634,
-0.4528689785920439,
0.4594486613200945,
0.38621255311930736,
0.14762310636584136,
0.15704986280426197,
0.15883603912217042,
0.2010572140928977,
0.23112929320769734,
-0.2184516657997792,
0.03942222190264912,
-0.0525132610404103,
0.003354446094102964,
-0.001379347959197944,
0.014552383148361442,
0.03450324490695675,
0.03724337871298398,
0.22982974944604675,
0.5014353821077956
],
[
0.04048229691512185,
-0.12329584279336962,
0.013325143054307886,
0.06947890829588298,
-0.027194043615256912,
0.010524219475265295,
-0.004157296005580165,
-0.013780535538770986,
-0.002634847469880711,
-0.025928513829492506,
0.11966097428539996,
0.002803832341189609,
0.04762787393275533,
-0.05277806449033029,
-0.038863404983405785,
0.17188060189498985,
-0.016728781147281418,
0.045740195794162726,
0.025507327891157477,
1,
0.0023701171305096124,
-0.04492562842035764,
-0.084392235218181,
-0.08664471207764157,
0.25627274482374424,
-0.186360375258556,
0.04260927699559769,
0.0293457168865586,
-0.1362905805126434,
-0.0018848013674438518,
-0.013838557119797241,
-0.04436394344597931,
0.20129415590450517,
0.02030588202280404,
0.01450840833479855,
0.0421098326378459,
0.27934529680731607,
0.0019746785602996857,
-0.01815074232915911,
-0.0002506607055838844,
0.017280259304823648,
0.2986090001233989,
-0.08396983108130977,
-0.04705070773613428,
0.14707843651165375,
0.09856872406627099,
0.0020299911364910802,
0.01706619079202472,
-0.024978647078815006,
0.007952805453499337,
-0.010195097891000454,
-0.12290434630798018,
0.13413990063446055,
-0.007911727335835558,
0.11650032675952587,
-0.06950950441489676,
0.01761655819928833,
-0.1328686342721223,
0.12869830904653998,
0.14115534220406384,
0.04079954583684342,
-0.004899028011692639,
-0.03762087767931008,
0.07667176757398075,
0.005675561048217082,
-0.01096546449127881,
0.013001922496996499,
0.06407751797198656,
0.019318600150528012,
0.09264115505408192,
0.009905661010279471,
0.009698509820609994,
-0.03334715722000794,
0.06852960163142395,
0.2253702403125615
],
[
-0.030305240131385008,
-0.031849878512887016,
0.007029387755874145,
0.15427874529127975,
0.007697692438898529,
-0.06963464572088618,
-0.027526981089108088,
-0.00343735924761877,
-0.05680427963508923,
0.19272098116483874,
-0.001873614318484352,
0.007767518838432563,
-0.004538402366416239,
-0.04354294389969534,
0.04011494273535409,
0.0843098158266863,
0.04249414662732977,
-0.027977021716830766,
-0.031049004710119118,
0.0023701171305096124,
1,
0.0015301695964780302,
-0.003106744668733247,
-0.01272142606361989,
0.03094426024171083,
-0.020983521881012553,
-0.043963491129333,
-0.03856915109209296,
-0.019039717085674195,
-0.011126383123276087,
-0.07949184107034267,
-0.02125897254105701,
0.0402297394624921,
-0.02099356737492749,
0.06896914076784544,
0.003949338949375922,
0.07805869245301594,
-0.014212176589699355,
0.06399372984931179,
0.02747009088522906,
0.01944816649401931,
0.1626675623510933,
0.017820434007623433,
0.09087376114905868,
0.14299650604752065,
0.060366347070452665,
0.0399110853603839,
0.005178762826096544,
0.03889926101100143,
-0.020952953276857738,
-0.00034805989004358295,
-0.037146188718245994,
0.06524190531101359,
-0.014265193520379974,
0.09517352738279419,
-0.045829510589232354,
-0.03298116845541073,
-0.030195044744168932,
0.0449170862257143,
0.05053931638018961,
-0.035316551137936504,
-0.016503281257261332,
0.030628066674169317,
0.1298801023003024,
0.058881953985485305,
-0.026315672595815652,
-0.004313614846049807,
0.10412699589098141,
0.06359864996591898,
-0.010625019563881842,
0.028838321106423623,
-0.027956696051350923,
0.010138089633966887,
-0.04315007530393975,
0.14381445916813645
],
[
-0.029797424686465433,
-0.08218960402128231,
0.006036296884285464,
-0.0025575701000400326,
-0.01051275253688075,
-0.0008174207060273792,
-0.003946627505597646,
-0.032377955742055674,
0.024512366119302055,
-0.060502706059177486,
-0.08692776114099206,
0.01675296427578575,
-0.007786825869800208,
-0.0973369080552566,
-0.036147211458462454,
0.15696978117717292,
-0.0692044082135262,
0.11392177894127772,
0.24466776137162163,
-0.04492562842035764,
0.0015301695964780302,
1,
0.8549143011660274,
0.038533413998002905,
0.01895179011368495,
-0.13859419292778663,
0.039649062010761287,
0.1640267410580117,
-0.16511749746283305,
-0.049102304689910954,
-0.06962564431940792,
0.1812548460468096,
-0.09498440833333649,
0.05020774653974614,
-0.05858331678928654,
0.13692882276791704,
0.017081391653671424,
-0.055040768244519006,
-0.2578204172894949,
-0.022251534883055347,
0.004816407233495779,
0.006449890932516569,
0.06863930682534586,
0.030847814741459388,
0.06526052988116966,
-0.025369964853549167,
-0.014099083633000706,
0.13331577767977473,
-0.014424864893117752,
-0.01462210845452165,
-0.06178040861304181,
-0.1320975078079644,
0.06702040255472218,
0.02878274364829709,
-0.011951206295161165,
-0.0031924531356895295,
0.18354813581078439,
-0.08222195094298555,
0.14872508248747318,
0.10973874848453537,
0.0023167324322512614,
0.024308216001897465,
-0.0721234060490155,
0.03494817432207492,
0.05873891386229862,
-0.0345276607892722,
-0.047015569590430385,
-0.052842041612664994,
-0.0024806054868633963,
-0.022387861482622076,
0.0012815558849344118,
-0.03776932448308001,
0.0025952656266980674,
0.06019165287212961,
0.09794217667224688
],
[
-0.03990251998263351,
-0.1366804705829697,
0.022058869266053816,
-0.007625256391013138,
-0.007685344954104669,
-0.016329205224042066,
-0.033104947189651575,
-0.03409060059564063,
0.006981600462715749,
-0.04275005394728947,
-0.10133449702221821,
0.00490939808651431,
-0.017222680359770332,
-0.13214547526940498,
-0.07229867346085267,
0.15762167113762118,
-0.054722784137850915,
0.09557122266093863,
0.23142367543706796,
-0.084392235218181,
-0.003106744668733247,
0.8549143011660274,
1,
0.05989913704293461,
0.0002314399650268745,
-0.11382634510893846,
0.04808455527664005,
0.1364505978894803,
-0.14357346141487592,
-0.05096627559784722,
-0.054148525911914484,
0.1686948949063883,
-0.09479226677729606,
0.029391920019766878,
-0.03476166382952144,
0.1389514346277066,
0.02925504622065212,
-0.033645787208428056,
-0.23939331063131628,
-0.018413680267114884,
-0.022714855772262975,
0.02232335798800095,
0.06139720060958015,
0.015699113107989215,
0.0697397040788631,
-0.022339055695671167,
-0.054151009367887595,
0.12881000897379238,
-0.01804484411262108,
-0.0021081012324330704,
-0.049469846704989745,
-0.11878941098477398,
0.06732042280753076,
0.005315111479683734,
0.006511223018773587,
0.0001855034694746642,
0.15878580416705376,
-0.07224301302352999,
0.14592137254860746,
0.104592878050649,
-0.030535666443641984,
0.010579010700678192,
-0.04657350484715869,
0.019972323897372114,
0.05905541828270895,
-0.027703827285138084,
-0.024188879788889072,
-0.023099522098105146,
-0.018981834948314836,
-0.02151592516954578,
-0.010313827644718351,
-0.034873176906859434,
0.011154131571145845,
0.06698266702360248,
0.10441577346940069
],
[
0.050935697302656305,
-0.03636183252992421,
-0.03405719710614271,
-0.001761143569173118,
-0.004799263276489851,
0.0014959642510510146,
-0.07538875101757556,
-0.03240444423569835,
0.0018092312754269522,
0.03909599446296835,
0.08765654968084284,
0.007620342599243688,
-0.003310754356622403,
-0.028496681379501527,
-0.12656676168082734,
0.03600240782723811,
0.007886258765726495,
-0.037268959472492605,
0.08186549893560781,
-0.08664471207764157,
-0.01272142606361989,
0.038533413998002905,
0.05989913704293461,
1,
-0.33272347467935093,
-0.0958080909620945,
0.013302519829572135,
0.026009635030992337,
-0.12332541550356443,
-0.04177583623130568,
-0.033356669678544705,
0.06730728502800136,
0.005994093668753843,
0.018802246468273335,
-0.019286974919292005,
0.035840965682409374,
0.037757858988230475,
0.030286972176307457,
-0.09288221608902439,
-0.06351904496260784,
-0.05652225515780245,
0.0011271364287756174,
-0.050448558254105574,
0.04089108510405193,
-0.03863606952683531,
0.024111000064000496,
-0.06731421411125378,
-0.012478686185821822,
-0.12281911558391756,
-0.09300036474324878,
-0.0068589229709324516,
-0.1279031751709701,
-0.01584603392902108,
-0.05482778744552837,
-0.028032213246705417,
0.12513890003070843,
0.013067051760033829,
0.034360595106043945,
0.009426173322028907,
0.03466177147905239,
-0.06801262109429888,
-0.06140455268411041,
-0.07610125813745654,
-0.034328438368517504,
0.02558250810304121,
0.03958555405045165,
-0.024580512288238248,
-0.025603491319675726,
0.008960905654058354,
0.001764956996893076,
0.008674368063861675,
0.05952863085857922,
-0.027635072665767677,
0.09561914136007107,
0.04125674705752859
],
[
-0.05103796659352416,
0.03133321870928325,
-0.06187782423524834,
0.09672702623529465,
0.02150927191979548,
-0.0985282311931722,
0.04167834038293154,
0.06347775149456443,
-0.027204494186775847,
-0.02415585396438889,
0.11695140238315857,
0.01160428666900426,
0.03563501192753698,
0.04647839988244959,
0.1585417255383038,
0.4011747375868,
-0.14107956690186194,
0.29941018690066906,
0.16831050298973319,
0.25627274482374424,
0.03094426024171083,
0.01895179011368495,
0.0002314399650268745,
-0.33272347467935093,
1,
-0.35663332452216645,
0.060427643921515194,
0.19980905329945423,
-0.3104110853067701,
0.06580268924689431,
-0.11908405986277103,
-0.05722660043983494,
0.253014938336386,
0.056026801157131705,
-0.08330302295770645,
0.10466152120125237,
0.365629214741211,
-0.05897120655987269,
-0.13826449567367557,
0.11142602740621055,
0.10204292891710032,
0.3410010656127989,
0.169730324283825,
-0.06170656142162997,
0.39200625385060844,
0.07887533891834693,
0.015803586942269614,
0.2722714245728211,
0.19326818577693275,
0.10882909665809933,
-0.007298646101964353,
-0.2633446718740683,
0.2897583455381086,
0.08212752581510128,
0.22936505678447705,
-0.18099818628346412,
0.24974950065249285,
-0.2531233660153511,
0.3639161112014302,
0.36723738587201804,
0.11676700253895504,
0.07320129478038383,
0.12244564396616399,
0.1491815633645443,
0.12901469114172806,
-0.11222460622066968,
0.015220832966882045,
0.05247422946785528,
0.00933432031672865,
-0.028974930528621913,
-0.0134606390479068,
-0.001521241139994098,
-0.04983837398202528,
0.08023098212895718,
0.46581143360024846
],
[
0.00256655498710262,
-0.029121790830118323,
0.1959374830543725,
-0.05033606274961689,
0.06295591390129314,
0.1431086351779486,
-0.005746254687495589,
0.01882748517783975,
-0.00461455525013374,
0.041919564168097445,
-0.15946026956681675,
-0.06853344385285168,
-0.03473383884461161,
-0.10766529857991093,
-0.08481098179326435,
-0.675389466513745,
0.17267877932570774,
-0.5145253726304001,
-0.5088226075615108,
-0.186360375258556,
-0.020983521881012553,
-0.13859419292778663,
-0.11382634510893846,
-0.0958080909620945,
-0.35663332452216645,
1,
-0.076032552750028,
-0.4750014086117038,
0.5949788287755896,
-0.016756302049118963,
0.22667807256556763,
-0.05028478246409307,
-0.18032287591405655,
-0.07469802265961566,
0.07781548031426128,
-0.268996309762481,
-0.46391594804508757,
0.051967253818878595,
0.4408765971347626,
-0.08896590518866765,
-0.16962878083111835,
-0.39735002794569463,
-0.14682284273538915,
0.02316576175065051,
-0.41749593208009306,
-0.09429756206836867,
0.0618863938375439,
-0.43626803371891637,
-0.1454403095591264,
0.038389863628287065,
0.09948809654039628,
0.6460896590991358,
-0.31085147858484613,
-0.07575825764341372,
-0.20913783018621257,
0.2410642184089191,
-0.5204067379728421,
0.45130871691899854,
-0.49363323752260463,
-0.4734445138577729,
-0.09152161058831157,
-0.10635485009563528,
-0.1135415357763584,
-0.1756479932389436,
-0.27856058454408583,
0.12399613071473216,
-0.03628877227974044,
-0.0067855936035387835,
-0.033290118372013455,
0.02216558429454408,
-0.02547094540759063,
-0.037884832343612035,
0.07509611122607979,
-0.19635749027716293,
-0.6480234752256352
],
[
0.015349128652156058,
0.004914130762263025,
-0.09638050426332337,
0.00918122571492824,
-0.020923221055723685,
-0.042484767523804694,
-0.011776342060096328,
0.009343141201956196,
0.053002320870454624,
0.021870187651766626,
0.026324629667579723,
0.07771497852109396,
-0.038450064259071784,
0.0865853565872056,
0.05365293132636732,
0.11420313157723185,
-0.2529217907182825,
0.264965953108123,
0.09054812067320005,
0.04260927699559769,
-0.043963491129333,
0.039649062010761287,
0.04808455527664005,
0.013302519829572135,
0.060427643921515194,
-0.076032552750028,
1,
0.1916548716154317,
-0.13779372913509044,
0.1913309089032248,
-0.0749502845382389,
0.00582367678886752,
0.0315334646874124,
0.01675098049317889,
-0.022065418379650953,
0.06599184636254783,
0.09821928116521869,
-0.04406949725747411,
-0.048775326806299445,
0.06571386112048085,
0.02576547304824495,
0.043810903535241336,
-0.016885908913784088,
-0.010800198557301936,
0.017411870862019237,
0.014297680854709192,
-0.051761691902098825,
0.07029599542398986,
0.08326659053879434,
-0.03689546317507298,
-0.019767643266256397,
-0.06439842376969733,
0.012644799003395117,
0.01915072879361577,
0.025804083504971632,
-0.13216408058664186,
0.20475075249745556,
-0.14475933650038042,
0.14934040883620073,
0.09194302805349801,
0.017474399164500876,
0.05176748852926625,
0.11005998680578676,
0.014567682778698373,
-0.008158546498538078,
-0.08290129235042414,
0.00862853400307156,
-0.02381814970659313,
-0.033656840711237514,
-0.05887600669107351,
0.004392619345990163,
-0.024957862949332225,
0.01420825445665947,
0.06054959536506916,
0.0944427112499175
],
[
-0.006207854482020908,
0.07561623033615099,
-0.25349790825750174,
-0.020026423872781852,
0.03487911202250895,
-0.16672819107008033,
0.060989097684453736,
-0.015575062164531653,
0.00016012031254417758,
-0.022090051577431394,
0.06610096085367631,
0.07508118788227025,
-0.008162578330911524,
0.15716691016782963,
0.20941720641147912,
0.48685201373144665,
-0.3316771022887584,
0.7241661803117199,
0.532201099763918,
0.0293457168865586,
-0.03856915109209296,
0.1640267410580117,
0.1364505978894803,
0.026009635030992337,
0.19980905329945423,
-0.4750014086117038,
0.1916548716154317,
1,
-0.46334062650945806,
0.08419527793524308,
-0.22820292801599407,
0.0005077473383559313,
0.13700191996803976,
0.11181318653049076,
-0.0976415381199476,
0.15755095770426153,
0.285886108937905,
-0.17883240902595293,
-0.4185824778143702,
0.24178248859964246,
0.24753081674344257,
0.19677157412653526,
0.11786351943886754,
-0.07545135704192084,
0.23993845189856922,
0.10439959198170985,
-0.06443575943467772,
0.4233940482636476,
0.17379031522785282,
-0.03400941061460791,
-0.09112392768541977,
-0.37768365318094105,
0.15329067879947347,
0.13742209589908033,
0.07560293417506558,
-0.38561463719447137,
0.6615441527804113,
-0.47619058612712933,
0.441766975468218,
0.37518431990387924,
0.2686955736257913,
0.19651433122125775,
0.2328045544180641,
0.16918042033911349,
0.1963766070076527,
-0.2299935461672655,
0.04399392824368729,
-0.06993062161368865,
0.00014963369603380398,
-0.028081284501108972,
-0.004493604321707122,
0.012118040928127275,
0.0077435576363617566,
0.16678616063552565,
0.4445163366279452
],
[
0.06381576206670506,
-0.055933884443635576,
0.12879124424611044,
-0.05723325383932298,
-0.03907255091908936,
0.15626490161668055,
0.010355079658370058,
0.023686236640640883,
0.023278647627322555,
0.023111232797587603,
-0.15926551945954037,
-0.10298696537272337,
0.012264979779632616,
-0.11828351408012855,
-0.127611114248357,
-0.6063521456608485,
0.2688954603159834,
-0.5334170831926786,
-0.4787415140739781,
-0.1362905805126434,
-0.019039717085674195,
-0.16511749746283305,
-0.14357346141487592,
-0.12332541550356443,
-0.3104110853067701,
0.5949788287755896,
-0.13779372913509044,
-0.46334062650945806,
1,
0.003351965416637321,
0.2663277055757402,
-0.06578752458628839,
-0.2260716978298814,
-0.1154329813599367,
0.10745356590848298,
-0.1854866720087544,
-0.4129322987485257,
0.0515038219087089,
0.3870138265022745,
-0.09529939112499444,
-0.14667133115597336,
-0.36117623345641386,
-0.12431426682845598,
0.05465873854571272,
-0.36912742504633367,
-0.13770823015089784,
0.05118585899098077,
-0.4443269744738073,
-0.12975307568396782,
0.08625535997981719,
0.07992642338664543,
0.5258868434770011,
-0.26583842027847077,
-0.054718477301931544,
-0.18880388069067888,
0.2498564034965103,
-0.5266614312287718,
0.4546443628041613,
-0.518435100809879,
-0.46090730060531543,
-0.0592015343831046,
-0.051401845525401266,
-0.10811137549989384,
-0.21322300554257656,
-0.24617815106135668,
0.14873463497367434,
-0.014436578455732613,
0.009374714285629733,
-0.0264879623145721,
0.03137039538409655,
0.0022580872309592125,
0.01830959387711647,
0.06366084303419912,
-0.1835870142850241,
-0.6118334877813076
],
[
0.010862171443242825,
-0.00179753739300854,
-0.01549569986878101,
0.010486268321722165,
-0.017089415745357144,
-0.011557185325724749,
0.008955331562487045,
0.0076311780075621225,
0.03248280028252951,
0.004964003213805874,
0.032150740018952025,
0.004850254373989393,
0.023092416924468406,
0.03212592225977051,
0.01871500780407587,
0.0542456605130827,
-0.018911792956274143,
0.13933705402516516,
0.028246664892720815,
-0.0018848013674438518,
-0.011126383123276087,
-0.049102304689910954,
-0.05096627559784722,
-0.04177583623130568,
0.06580268924689431,
-0.016756302049118963,
0.1913309089032248,
0.08419527793524308,
0.003351965416637321,
1,
-0.03675650210174938,
-0.08595953292396662,
0.08208345080556599,
0.04276761830558865,
-0.025445393243768523,
-0.020376929324515198,
0.060326024567941276,
-0.03203784830894228,
-0.055875495158213134,
0.1405063962780845,
0.12372213704375704,
0.0333488190950258,
-0.04589345387367548,
-0.012448804534143362,
-0.015023067195898625,
0.049498218117814595,
-0.050892947349111754,
0.022483744266259455,
0.05392518496499453,
-0.01703934779260162,
-0.025772723358806742,
-0.013588145712000272,
-0.01954993457034272,
0.035861157180677845,
0.01818048668175917,
-0.08603441547641663,
0.10237607906425784,
-0.06755237019509383,
0.03733658874685138,
0.04575502822638484,
0.042612782084012125,
0.16774606639578793,
0.10682808260873516,
-0.00021070185869706494,
0.01972739236233947,
-0.06889236544647445,
0.033117908080680485,
0.014642267808199712,
0.020026436138565754,
0.004369931590688738,
-0.03577705939022553,
0.09176983844959984,
0.02105845793339862,
0.005927004062525821,
0.06161323257110658
],
[
-0.02015108144956258,
-0.044427564451478226,
0.04565875513050261,
-0.14351619397986629,
0.0556932699809924,
0.1397638442928494,
0.05455576560749247,
0.01777910843771242,
0.018866432045552717,
-0.17037626674469414,
0.052578558034144136,
-0.011486004635706155,
0.006629279314947595,
-0.0314211970709489,
-0.17443786695527191,
-0.2368955694139229,
0.10081451396976993,
-0.3037582976523181,
-0.21868936443360137,
-0.013838557119797241,
-0.07949184107034267,
-0.06962564431940792,
-0.054148525911914484,
-0.033356669678544705,
-0.11908405986277103,
0.22667807256556763,
-0.0749502845382389,
-0.22820292801599407,
0.2663277055757402,
-0.03675650210174938,
1,
0.15403962987477607,
-0.254282921303002,
0.05028279897213652,
-0.04302758882354223,
0.03825329374054904,
-0.2637982702435195,
0.04216127797464939,
0.1282454870677622,
-0.08000170446376843,
-0.12250655405073613,
-0.25364362506474314,
0.13550956042893494,
0.05834001742719262,
-0.06920473598555979,
-0.2544230689599653,
-0.046150971266015944,
-0.09606973984093074,
0.08922678536383113,
0.11774548379929106,
0.05567259868852402,
0.2130062373982784,
-0.021546261773949405,
-0.07173470522606179,
-0.10606086805366352,
0.21163074394481532,
-0.26256792101505605,
0.2281339877322006,
-0.2523094346455051,
-0.24663493415799975,
-0.08713993875193107,
-0.06131537948431773,
-0.08804508659922156,
-0.20164958263842908,
-0.05798717867643989,
0.10138068519680658,
0.01590811779724749,
0.0008922809768403907,
-0.054715370337986076,
0.012102402361201694,
-0.022276071960971495,
0.05495813976909885,
-0.002048963833124546,
-0.08057390805007991,
-0.2903027403705881
],
[
0.00498025184150966,
0.013230526675087766,
0.02741912958173165,
-0.05579315513486682,
-0.023604855853853923,
0.07283444050181676,
-0.06303857877145162,
-0.010527113137245105,
0.028152320182605547,
-0.06275470097653332,
-0.04200098772499464,
-0.018868282259844476,
0.019724690734134624,
-0.05220385080766569,
-0.03433937826753578,
0.07775617950906802,
-0.07946237962876346,
-0.10787843940456322,
0.01467305448443999,
-0.04436394344597931,
-0.02125897254105701,
0.1812548460468096,
0.1686948949063883,
0.06730728502800136,
-0.05722660043983494,
-0.05028478246409307,
0.00582367678886752,
0.0005077473383559313,
-0.06578752458628839,
-0.08595953292396662,
0.15403962987477607,
1,
-0.5533902909554538,
0.14902901916656072,
-0.13857164933778035,
0.5262503191551753,
-0.11193885721572844,
0.023671240788846252,
-0.0975076919876227,
-0.11893486165997019,
-0.11480173701376256,
-0.10399690503865344,
0.19575982825409552,
0.06637092142727341,
0.09353071295753039,
-0.4552843011143294,
-0.11177298751360934,
0.10394092854207128,
0.04156662474570601,
0.11209217828826244,
0.09894858181407948,
-0.03663581567935554,
0.1451194610293689,
-0.00293954449697474,
-0.08746326045383049,
0.16546049308697316,
-0.024431720785107053,
0.03471575690702997,
0.0280994573724849,
-0.012734621469982874,
-0.12964915267148436,
-0.10850066286744733,
-0.21509472932619042,
-0.09816562040344941,
-0.0031875152919912946,
0.08835310722626896,
-0.044882664982565414,
-0.022489386023292375,
-0.03500877718626529,
-0.04197978008829885,
0.05416324481520814,
-0.04981092422610047,
-0.05725905086428903,
0.03903947823362395,
-0.04815347459005512
],
[
-0.0049187427810349965,
-0.06905344343420232,
-0.04097784960012804,
0.21014764940939437,
-0.005096651871932288,
-0.1168542725348184,
-0.03530566213848387,
-0.021064140785699337,
-0.027391210170418144,
0.11698967589563214,
0.11752293864948343,
0.013385056763329753,
0.009502196606841658,
0.00783098951698722,
-0.008456781831141173,
0.19744149384950824,
-0.06006752616812258,
0.22426386105322857,
0.09968054964037755,
0.20129415590450517,
0.0402297394624921,
-0.09498440833333649,
-0.09479226677729606,
0.005994093668753843,
0.253014938336386,
-0.18032287591405655,
0.0315334646874124,
0.13700191996803976,
-0.2260716978298814,
0.08208345080556599,
-0.254282921303002,
-0.5533902909554538,
1,
0.025382291750486535,
-0.0648552513374527,
-0.5528094511777646,
0.5049997521887187,
-0.023204565994201086,
-0.04078560456191758,
0.12461061164132925,
0.12547410477222745,
0.4503658087820488,
-0.15187624562251498,
-0.051908518094097994,
0.20197363969343446,
0.6380944444826607,
0.05722722940915904,
0.04509408210661268,
-0.025251368780084424,
-0.11910029616945528,
-0.035623116643607886,
-0.19177836400963275,
0.04628374801959108,
0.032395801911628,
0.2453230504806542,
-0.2508836843721934,
0.1446105777327811,
-0.22094809688495207,
0.19755890777731325,
0.2840954904105337,
0.13807630133482635,
0.10351574267454199,
0.16940668235135584,
0.1871781847073771,
0.10756072875012912,
-0.10566890118260427,
0.026810593362810588,
0.05190592883783905,
0.14270779613070145,
0.007869425742333215,
-0.021241787261421213,
0.023958277288284917,
0.009937200282198435,
0.0222667360927309,
0.35967663312618064
],
[
0.049617528021505465,
0.05505901383447219,
-0.02938652432080022,
-0.06660894559868079,
0.07071758526411866,
0.01886384633853748,
-0.0397485076782317,
-0.02007510142913887,
-0.000673045922017702,
-0.06873100971748537,
-0.03259248565641787,
-0.028871328385822754,
-0.011901492850842493,
0.03260997880090551,
0.016975315743483065,
0.10849363418332508,
-0.09337866359840867,
0.0760526723449593,
0.08832811801792068,
0.02030588202280404,
-0.02099356737492749,
0.05020774653974614,
0.029391920019766878,
0.018802246468273335,
0.056026801157131705,
-0.07469802265961566,
0.01675098049317889,
0.11181318653049076,
-0.1154329813599367,
0.04276761830558865,
0.05028279897213652,
0.14902901916656072,
0.025382291750486535,
1,
-0.7359491407273431,
0.22895936389631424,
-0.0245003788053046,
0.016877854743415008,
-0.10206513574780504,
-0.0430212193250119,
-0.0013650257717674524,
-0.026577422624611203,
0.08365011671154071,
-0.019858032143718576,
0.04946162459600221,
-0.1429601200573724,
-0.09285015541472078,
0.10265567967847725,
0.061980813918768814,
-0.00572109265674136,
0.03635310401630078,
-0.07887396560635264,
0.04425905085413,
0.10488118742016261,
-0.013294473622214396,
0.022237068970247426,
0.08190813393470699,
-0.04259182162834297,
0.07569304575805098,
0.03217794696015472,
-0.037401219119548884,
0.0032523254986387604,
-0.05079860994478311,
-0.0638618175091105,
0.035269049202661114,
-0.05642172307683878,
0.011412188067371947,
-0.030534353432311003,
-0.04012943150066245,
-0.009463156194938649,
0.03496827210890537,
-0.033975755379038595,
-0.015419155495378558,
0.05132371532586345,
0.05323329280512587
],
[
-0.004908029104022174,
-0.07932907728553659,
0.025796408467497707,
0.11049314513683212,
-0.04518934567238191,
-0.031727785316206715,
0.011051399963209528,
0.05017224493602903,
-0.0134068897314506,
0.0907370155808782,
0.0410541166682348,
0.022907451534498496,
0.053804339513675414,
-0.024084127661394433,
-0.03900605254038184,
-0.08601364866269622,
0.035697505771196514,
-0.07040251867550996,
-0.08526822669167149,
0.01450840833479855,
0.06896914076784544,
-0.05858331678928654,
-0.03476166382952144,
-0.019286974919292005,
-0.08330302295770645,
0.07781548031426128,
-0.022065418379650953,
-0.0976415381199476,
0.10745356590848298,
-0.025445393243768523,
-0.04302758882354223,
-0.13857164933778035,
-0.0648552513374527,
-0.7359491407273431,
1,
-0.23344881053320699,
0.08318380019485543,
0.016349900717922777,
0.1102151296866814,
0.019395030997441467,
-0.001395017692673585,
0.0940652281972692,
-0.10925362509714337,
0.0070716220143146455,
-0.021993442411915635,
0.15497975067462855,
0.07281305924353752,
-0.0904479876212113,
-0.0384944768609957,
-0.008178744565367433,
-0.02827842135322798,
0.07404369620331201,
-0.042206652430106247,
-0.1100599475725225,
0.035643216123719616,
-0.037682926492934345,
-0.09259482219148328,
0.039759605071627076,
-0.08026438846727484,
-0.05341110930975736,
0.04920571690167427,
0.0028557476395959275,
0.04718146940878057,
0.06120600766837853,
0.004211169347973952,
0.0456680512976618,
-0.031475178970346046,
0.0858648487208668,
0.041147946590913524,
0.0062460065640478355,
-0.022039483584164698,
0.03285493244483844,
-0.03165717775692895,
-0.07667596726267506,
-0.031225787844299704
],
[
-0.010196265502941127,
-0.14102532562967923,
-0.03606286907469771,
-0.01458897721797496,
0.026806947754550677,
-0.009939803028428817,
0.02886907708416442,
-0.014209181672910152,
0.002009829174242677,
-0.12468115677389954,
-0.010301017685363928,
0.017232088998516918,
0.019348845346864388,
-0.03575506151950359,
-0.16413221036429035,
0.2929400179124754,
-0.1610376778167363,
0.1477616118068355,
0.17188068811725313,
0.0421098326378459,
0.003949338949375922,
0.13692882276791704,
0.1389514346277066,
0.035840965682409374,
0.10466152120125237,
-0.268996309762481,
0.06599184636254783,
0.15755095770426153,
-0.1854866720087544,
-0.020376929324515198,
0.03825329374054904,
0.5262503191551753,
-0.5528094511777646,
0.22895936389631424,
-0.23344881053320699,
1,
0.36376706631136896,
-0.005434079261670887,
-0.20619681003174742,
-0.0025811280170771516,
-0.02817303277548877,
0.31809692139724394,
-0.01611714982677274,
-0.0023842150017208664,
0.22243792764169706,
-0.4639860530066823,
-0.10535883202773243,
0.30580161197507827,
-0.07415709371606137,
0.15493533157738432,
0.08179497575551697,
-0.20662389058043465,
0.24201992852946788,
0.033838735257075626,
0.03315748933517243,
-0.05802902487328299,
0.18053915699617665,
-0.09703527888023089,
0.2422782578987996,
0.19540122229273182,
-0.05152887380380284,
0.000417693118964614,
-0.05247198180745228,
-0.02071121160913865,
0.12217145266659353,
-0.0033724263795620085,
0.02370054406208866,
-0.02306519576370083,
-0.039315391523727594,
-0.018566233149059638,
0.03120222002712654,
-0.039076475316944186,
-0.08828747556806149,
0.1108391437154425,
0.1916888789020209
],
[
-0.018636787861170893,
-0.2636134027659649,
-0.07490715795156963,
0.26718806266776374,
0.004796176560964124,
-0.15597887782779843,
-0.004093900617630184,
-0.018682940504383044,
-0.034300780078473356,
0.03427559079548718,
0.1385997647077993,
0.043223222167349855,
0.053788507963794946,
-0.039798256222469276,
-0.2036043145038347,
0.5058965803730809,
-0.22801953476382458,
0.38514607943667567,
0.26428114913317813,
0.27934529680731607,
0.07805869245301594,
0.017081391653671424,
0.02925504622065212,
0.037757858988230475,
0.365629214741211,
-0.46391594804508757,
0.09821928116521869,
0.285886108937905,
-0.4129322987485257,
0.060326024567941276,
-0.2637982702435195,
-0.11193885721572844,
0.5049997521887187,
-0.0245003788053046,
0.08318380019485543,
0.36376706631136896,
1,
-0.025445430980833742,
-0.2246582351086547,
0.14611657099236866,
0.11081121675606598,
0.8931098180724768,
-0.2340696834511818,
-0.05841112767215653,
0.460777660443253,
0.2820314140527415,
-0.019716152180024336,
0.3456854248366318,
-0.12478778517751932,
0.029989287103836873,
0.03684425207612298,
-0.4107585216896487,
0.2976094360235673,
0.02825448194452008,
0.3281034069510372,
-0.3622108252881274,
0.32149960649383375,
-0.33892398140022434,
0.4534269481632856,
0.5114750740641821,
0.12046724954396822,
0.11872787913942985,
0.15405780183413817,
0.214363956683255,
0.25593931469238296,
-0.10448392104040116,
0.04314216576739562,
0.06888581119100474,
0.13565398713633098,
-0.008678801006624515,
0.0007865166013506799,
-0.0018233369244867465,
-0.0975068220940425,
0.11400754549935195,
0.6020422814414277
],
[
0.03922350440638393,
0.06872760531149968,
0.04639416055872486,
0.08782135737606003,
0.0069253207869607175,
0.06507658890626067,
0.028347397409779367,
-0.0030924612328614488,
0.024866395023751726,
0.006693808907272821,
-0.018973036651658684,
-0.006769411006774106,
-0.004083027803099829,
-0.025990600253092064,
-0.059951542037792065,
-0.04951264501196124,
-0.029001570178530084,
-0.18698667275110634,
-0.13637242754938658,
0.0019746785602996857,
-0.014212176589699355,
-0.055040768244519006,
-0.033645787208428056,
0.030286972176307457,
-0.05897120655987269,
0.051967253818878595,
-0.04406949725747411,
-0.17883240902595293,
0.0515038219087089,
-0.03203784830894228,
0.04216127797464939,
0.023671240788846252,
-0.023204565994201086,
0.016877854743415008,
0.016349900717922777,
-0.005434079261670887,
-0.025445430980833742,
1,
0.04632246470530805,
-0.38726921607732184,
-0.07059918181391239,
-0.02139866157769127,
0.05563842480542549,
-0.011730474182779572,
0.03025034116834572,
-0.017268256104220208,
0.009108929662656265,
-0.044515544275137535,
-0.009611522414188368,
0.03135367864150854,
0.032443190804087196,
-0.0004930457726763403,
0.012126671037724133,
-0.020952855335018894,
-0.0015300127057494757,
0.1314019007235736,
-0.1818950752437004,
0.09800243727585885,
-0.03414339778109316,
-0.052991006606748624,
-0.16441995025019757,
-0.11817856882605732,
-0.1472289211048567,
-0.06863602830632431,
0.023497556609328233,
0.10272960707820476,
-0.0134207126018398,
0.030564974707938664,
-0.008115519953737146,
0.0006829230278733183,
0.01123713219417093,
-0.0072834177390089135,
0.001431272351737689,
0.016548953754172344,
-0.05063854507223604
],
[
0.009264673863445818,
0.006384227655262995,
0.1493694321201849,
0.00535149748506627,
-0.046278024446122425,
0.09361199638454391,
-0.0677172805391479,
0.008049684918958633,
-0.016648208649101767,
0.04396709426019784,
-0.02674819050468072,
-0.07621312729359682,
-0.013395588393594074,
-0.03142637417948327,
-0.05969661166579692,
-0.44167112771707995,
0.08011365010270782,
-0.41666501697556985,
-0.5159572213202074,
-0.01815074232915911,
0.06399372984931179,
-0.2578204172894949,
-0.23939331063131628,
-0.09288221608902439,
-0.13826449567367557,
0.4408765971347626,
-0.048775326806299445,
-0.4185824778143702,
0.3870138265022745,
-0.055875495158213134,
0.1282454870677622,
-0.0975076919876227,
-0.04078560456191758,
-0.10206513574780504,
0.1102151296866814,
-0.20619681003174742,
-0.2246582351086547,
0.04632246470530805,
1,
-0.16556158301683385,
-0.1271748090978041,
-0.18012157655148492,
-0.1466609991957639,
0.0296238038402101,
-0.2555141283649034,
-0.04879193426889702,
0.04164639420234484,
-0.351096492190212,
-0.0990673279317911,
0.036970891151074596,
0.1293553699849977,
0.4025972267140891,
-0.18394004090989827,
-0.06808514546583712,
-0.11082944802822921,
0.18717289019466773,
-0.4242502469267758,
0.37752708333700175,
-0.32407193695186554,
-0.26065140195528225,
-0.03512116810541757,
-0.0527325168743707,
-0.08213368223780368,
-0.10006952678250002,
-0.17459027377587144,
0.09500336894892442,
-0.050389959272691125,
0.0666181553995323,
0.030864412956388795,
0.02181696753687386,
-0.010117865596457316,
0.013373458233184289,
-0.018955314947644398,
-0.1574977604244828,
-0.4056509232234902
],
[
0.010435115106807726,
-0.0982424713576209,
-0.06051140338844939,
0.0340593549121656,
0.10405695449724181,
-0.10072855825021224,
0.12541880073254466,
0.005977282268454327,
-0.01078857357463228,
0.011269075309143832,
0.028351685024030328,
-0.023295546534257593,
-0.0453709887069188,
0.036033298179129605,
0.031426026313619376,
0.19052593542854807,
0.057784627271707675,
0.3595706175365072,
0.2560299434469796,
-0.0002506607055838844,
0.02747009088522906,
-0.022251534883055347,
-0.018413680267114884,
-0.06351904496260784,
0.11142602740621055,
-0.08896590518866765,
0.06571386112048085,
0.24178248859964246,
-0.09529939112499444,
0.1405063962780845,
-0.08000170446376843,
-0.11893486165997019,
0.12461061164132925,
-0.0430212193250119,
0.019395030997441467,
-0.0025811280170771516,
0.14611657099236866,
-0.38726921607732184,
-0.16556158301683385,
1,
0.22916947916738553,
0.12185265856731746,
-0.048623817422079156,
-0.019672922004505326,
0.04783606312677156,
0.08870906650839988,
0.025105232123433182,
0.11196350311766491,
0.1107110218518369,
-0.019621910952432972,
-0.22930662252891915,
-0.06590274023259854,
0.0035152849688586934,
0.05439089709927144,
0.14202051986708047,
-0.2549490522002923,
0.31820784863911233,
-0.20847011328828033,
0.12521619177744256,
0.12243249999669405,
0.2110846646309416,
0.2281454662269352,
0.2582657167336859,
0.11934234232155215,
0.01062372777567423,
-0.16558877720888887,
0.02594030496245603,
0.037014202296273814,
0.01568613148753237,
0.010899075862725977,
0.0003215272099970834,
0.011168765196826405,
0.012471670893499341,
0.05106493977055598,
0.19975935469806486
],
[
0.023090626928982547,
0.05573175881216029,
-0.09103335832025274,
0.03953881778494272,
0.03323125134350933,
-0.09352766095760935,
0.06845924224510988,
-0.10427559773826277,
-0.029732685353952685,
0.007877651999064964,
0.06743597921177182,
0.06471583878228135,
0.021282878010818594,
0.07896990103903755,
0.1640571594160559,
0.20658634986135016,
0.03168530466322039,
0.3233619242940471,
0.30962893653775686,
0.017280259304823648,
0.01944816649401931,
0.004816407233495779,
-0.022714855772262975,
-0.05652225515780245,
0.10204292891710032,
-0.16962878083111835,
0.02576547304824495,
0.24753081674344257,
-0.14667133115597336,
0.12372213704375704,
-0.12250655405073613,
-0.11480173701376256,
0.12547410477222745,
-0.0013650257717674524,
-0.001395017692673585,
-0.02817303277548877,
0.11081121675606598,
-0.07059918181391239,
-0.1271748090978041,
0.22916947916738553,
1,
0.10648166433512148,
0.03762523729752427,
-0.04571905311083527,
0.10733524490788494,
0.10363488142262013,
0.008832212572246857,
0.21792551553321832,
0.12430212375168591,
0.027841265918916794,
-0.12350323858971594,
-0.11001745525088487,
0.060750627822321324,
0.02298164118030185,
0.10127321706252275,
-0.1745499071747452,
0.31411825129974935,
-0.21312343992291727,
0.23577348843398419,
0.20978712019064275,
0.13408322821136018,
0.13637546576028675,
0.1820294371393392,
0.14340410328976833,
0.11158737569312428,
-0.14613711845797409,
-0.0001278731989842695,
-0.007945601392267894,
0.019734344165714235,
0.019309992678907255,
-0.013172609568095874,
0.025864499625263916,
0.02706974474908458,
0.0885048320943334,
0.2111885885892675
],
[
0.009749715502245541,
-0.25878702788544344,
-0.035350440769571514,
0.2885018187291621,
-0.0020248072942370453,
-0.1655382975590517,
-0.04763358309669704,
0.011871875951457698,
-0.06129149624419643,
0.08211397340626231,
0.15563920865511718,
0.04386351168835183,
0.03964169801485141,
-0.08309170761446666,
-0.18544976928819318,
0.4819779103629154,
-0.1440657147406244,
0.26358543221916664,
0.24188878126511085,
0.2986090001233989,
0.1626675623510933,
0.006449890932516569,
0.02232335798800095,
0.0011271364287756174,
0.3410010656127989,
-0.39735002794569463,
0.043810903535241336,
0.19677157412653526,
-0.36117623345641386,
0.0333488190950258,
-0.25364362506474314,
-0.10399690503865344,
0.4503658087820488,
-0.026577422624611203,
0.0940652281972692,
0.31809692139724394,
0.8931098180724768,
-0.02139866157769127,
-0.18012157655148492,
0.12185265856731746,
0.10648166433512148,
1,
-0.22027938146553527,
-0.019859960588525412,
0.5548463943776133,
0.2515968247872321,
-6.387038018079811e-05,
0.36749800275346506,
-0.14649426493741485,
0.10064332192204008,
0.059242471577874524,
-0.3782828248558993,
0.3937859743270962,
-0.0782460712404498,
0.40192875830142466,
-0.3599704921953107,
0.23792763270239456,
-0.31373307878662765,
0.4402371994707011,
0.5000711260901144,
0.09678792531246175,
0.10709342179082486,
0.12326784904047197,
0.23319963959811235,
0.22661515067354668,
-0.05600310127985605,
0.05315893459190707,
0.08305389720639884,
0.1348794299714107,
-0.014226372342032103,
0.02410923916990364,
-0.011257980305426712,
-0.12060646860622755,
0.07053433889257732,
0.6047144846292783
],
[
-0.0028655731545146044,
0.3067085314571813,
-0.05731632696132807,
0.04777323181247231,
0.04504607971744589,
-0.06888093982249427,
-0.032480499861109714,
-0.022190308720397584,
-0.050691509090022506,
-0.002495808327890459,
0.014616034586072519,
0.013162236800188583,
-0.003305625524563051,
-0.08740846731484941,
0.478887774264597,
0.28114459380333623,
0.011684568880857909,
0.006989088940665577,
0.12054456886890334,
-0.08396983108130977,
0.017820434007623433,
0.06863930682534586,
0.06139720060958015,
-0.050448558254105574,
0.169730324283825,
-0.14682284273538915,
-0.016885908913784088,
0.11786351943886754,
-0.12431426682845598,
-0.04589345387367548,
0.13550956042893494,
0.19575982825409552,
-0.15187624562251498,
0.08365011671154071,
-0.10925362509714337,
-0.01611714982677274,
-0.2340696834511818,
0.05563842480542549,
-0.1466609991957639,
-0.048623817422079156,
0.03762523729752427,
-0.22027938146553527,
1,
0.04450439729158129,
0.6857101599320978,
-0.18411212226393348,
-0.023955282585928474,
0.4195227007841692,
0.6194498692060798,
0.5092162062619568,
0.06846435681000373,
-0.14158914742167863,
0.6192749810587656,
0.005566900235483681,
0.18851430777515962,
0.08730918579216244,
0.06041369673023831,
-0.12536717491026647,
0.18720806790858244,
0.12456374351799851,
-0.050286838389303916,
-0.017729334726246073,
-0.05304547150922476,
0.0812907022579819,
0.20279146984595758,
0.05965353466567714,
-0.024786492440264627,
0.03566378776318002,
0.0827529257922385,
0.013755187398007027,
0.042201350462982026,
-0.034825604239672306,
0.061813798881866736,
0.041397028672044374,
0.31135402669959245
],
[
-0.04795771853773425,
0.019989949493411662,
0.05504720560483714,
0.009729125446327775,
0.006353536479903294,
0.029951178846677366,
-0.07098418327241365,
-0.0028371343162421053,
0.005007810857881887,
0.029377239755394417,
0.03466623295528151,
-0.04416630152957403,
-0.014392829656124907,
-0.027633134159873916,
-0.06509319710040079,
-0.01670375066283301,
0.04186481529450761,
-0.1602893977674938,
-0.06439501767177201,
-0.04705070773613428,
0.09087376114905868,
0.030847814741459388,
0.015699113107989215,
0.04089108510405193,
-0.06170656142162997,
0.02316576175065051,
-0.010800198557301936,
-0.07545135704192084,
0.05465873854571272,
-0.012448804534143362,
0.05834001742719262,
0.06637092142727341,
-0.051908518094097994,
-0.019858032143718576,
0.0070716220143146455,
-0.0023842150017208664,
-0.05841112767215653,
-0.011730474182779572,
0.0296238038402101,
-0.019672922004505326,
-0.04571905311083527,
-0.019859960588525412,
0.04450439729158129,
1,
0.10109985832701955,
-0.029154755336075,
0.003802172223933461,
-0.023549639482157433,
0.0009239224460590203,
0.059138002342186725,
-0.01775927282781638,
0.023306832556394503,
0.09224140345400696,
-0.060232084488389556,
0.0017456878735635495,
0.13835717298736736,
-0.037214416695816474,
0.06450963002316729,
-0.017604797315670582,
0.013996145095664672,
-0.057262256334189715,
-0.02966456312260254,
0.005587016236790502,
-0.008739723505597442,
0.01832647105928302,
0.05008096617512517,
-5.897496422105555e-05,
0.04483736773772634,
0.08042503026037283,
-0.00017815955331289013,
-0.027212373023109453,
-0.020533075032865757,
0.03282750857029285,
-0.013624260733549562,
-0.00999239700593434
],
[
0.001066880432408302,
0.06878207746290756,
-0.07043058095001202,
0.2554451577452976,
0.037094596680458176,
-0.1788681058560465,
-0.06840300706371609,
-0.010173756971870994,
-0.08800743101122101,
0.061174122796999866,
0.13067020130768697,
0.04025727301431323,
0.02552103653628539,
-0.1378081272292663,
0.2622323252224905,
0.59447019806393,
-0.09384310502971577,
0.1891459809489941,
0.2765802979625044,
0.14707843651165375,
0.14299650604752065,
0.06526052988116966,
0.0697397040788631,
-0.03863606952683531,
0.39200625385060844,
-0.41749593208009306,
0.017411870862019237,
0.23993845189856922,
-0.36912742504633367,
-0.015023067195898625,
-0.06920473598555979,
0.09353071295753039,
0.20197363969343446,
0.04946162459600221,
-0.021993442411915635,
0.22243792764169706,
0.460777660443253,
0.03025034116834572,
-0.2555141283649034,
0.04783606312677156,
0.10733524490788494,
0.5548463943776133,
0.6857101599320978,
0.10109985832701955,
1,
0.028857254890950326,
-0.020012308996407567,
0.6259534291265201,
0.41522073801987364,
0.5100878896008458,
0.10052123299368086,
-0.3988964672462648,
0.8234912342064489,
-0.05811677738897634,
0.4581090100282428,
-0.18268748956287065,
0.2249031610110193,
-0.3340106398481078,
0.48394323911411047,
0.47786769444438604,
0.024873606930151643,
0.06222432117783091,
0.047122661285661116,
0.2412770146337058,
0.3412730025715972,
0.012779142507472193,
0.018512281201446133,
0.09535804948235475,
0.17646275383372328,
0.001054484930020002,
0.05147361078398953,
-0.03942408109707644,
-0.034725160754620975,
0.08633680587578428,
0.7117061511024302
],
[
0.010209829055903352,
-0.011316890355120702,
-0.020998724674517417,
0.16068746262292583,
-0.04292835398132114,
-0.06583214095839227,
-0.009295821458376107,
-0.023277699667795027,
-0.028352953992485067,
0.12354741596754584,
0.07535640388347087,
0.012843585658688853,
-0.003789887370853636,
0.04217774359732086,
0.02521117161271464,
0.08325367684549462,
-0.07008911339799866,
0.17510831159773813,
0.0992936540083092,
0.09856872406627099,
0.060366347070452665,
-0.025369964853549167,
-0.022339055695671167,
0.024111000064000496,
0.07887533891834693,
-0.09429756206836867,
0.014297680854709192,
0.10439959198170985,
-0.13770823015089784,
0.049498218117814595,
-0.2544230689599653,
-0.4552843011143294,
0.6380944444826607,
-0.1429601200573724,
0.15497975067462855,
-0.4639860530066823,
0.2820314140527415,
-0.017268256104220208,
-0.04879193426889702,
0.08870906650839988,
0.10363488142262013,
0.2515968247872321,
-0.18411212226393348,
-0.029154755336075,
0.028857254890950326,
1,
-0.15926251915021566,
-0.08426682697428857,
-0.05888388310779742,
-0.16172258270229162,
-0.012858105993494361,
-0.12577873682802335,
-0.05206511498367661,
0.010631787619964526,
0.13304452428274474,
-0.1706226827890917,
0.11575090542031488,
-0.14647687357797226,
0.13140336690168164,
0.18655758164329636,
0.09845845083401691,
0.06693408571491415,
0.10935576453018662,
0.1619818934984059,
0.07280529300410707,
-0.04677156539770777,
0.00048221590615306413,
0.017068861544105883,
0.06923582245481744,
-0.020703654190529615,
-0.022992776271535845,
0.0720160588826401,
0.028906834460317384,
-0.0006781183969891244,
0.20969465592752243
],
[
-0.028332957022560418,
-0.0001513823799178705,
0.01022399845502744,
0.04641987193391543,
0.015346570801680193,
-0.015680706997172632,
0.0143746614274504,
0.10634717922345817,
-0.0021273498145420316,
0.07620173272618024,
-0.02728760633470674,
-0.06735223712913062,
-0.009048024949757922,
-0.007011254685324479,
0.02959263410221105,
-0.0649520486452631,
0.11967078669644289,
-0.05520397086692119,
-0.023966253410943165,
0.0020299911364910802,
0.0399110853603839,
-0.014099083633000706,
-0.054151009367887595,
-0.06731421411125378,
0.015803586942269614,
0.0618863938375439,
-0.051761691902098825,
-0.06443575943467772,
0.05118585899098077,
-0.050892947349111754,
-0.046150971266015944,
-0.11177298751360934,
0.05722722940915904,
-0.09285015541472078,
0.07281305924353752,
-0.10535883202773243,
-0.019716152180024336,
0.009108929662656265,
0.04164639420234484,
0.025105232123433182,
0.008832212572246857,
-6.387038018079811e-05,
-0.023955282585928474,
0.003802172223933461,
-0.020012308996407567,
-0.15926251915021566,
1,
-0.0656408756989068,
-0.01614327710094017,
0.0476447412003851,
0.010247476927151923,
0.03276610581829281,
-0.01670488884169751,
-0.028439925873615213,
0.026147095509744138,
-0.018639871681424156,
-0.07936197107329102,
0.044815977382571856,
-0.041898828988608784,
-0.04497916977953163,
0.04157565877409055,
0.029808566909286426,
0.023704417273768794,
0.0393051866329195,
-0.03481797523291756,
-0.003070591955767723,
0.03630118587817062,
0.029737499232828857,
0.019776581830163283,
-0.006685469117956385,
0.026506577029215984,
-0.04246630701750443,
0.000978923431768766,
-0.05897644330874224,
-0.03017500037561527
],
[
-0.00033388479198054343,
0.1177198737926676,
-0.20654841344924196,
0.11572667076515877,
0.04201327230710782,
-0.17591334179785742,
0.05651081766049946,
-0.02875358314737922,
-0.0018015610760747426,
-0.03393815260733667,
0.13136904135594896,
0.09264302448038639,
0.01785551669830549,
0.0582852421422606,
0.24031707932177052,
0.580425194333127,
-0.2118823745012079,
0.48677731596173274,
0.4601196002562738,
0.01706619079202472,
0.005178762826096544,
0.13331577767977473,
0.12881000897379238,
-0.012478686185821822,
0.2722714245728211,
-0.43626803371891637,
0.07029599542398986,
0.4233940482636476,
-0.4443269744738073,
0.022483744266259455,
-0.09606973984093074,
0.10394092854207128,
0.04509408210661268,
0.10265567967847725,
-0.0904479876212113,
0.30580161197507827,
0.3456854248366318,
-0.044515544275137535,
-0.351096492190212,
0.11196350311766491,
0.21792551553321832,
0.36749800275346506,
0.4195227007841692,
-0.023549639482157433,
0.6259534291265201,
-0.08426682697428857,
-0.0656408756989068,
1,
0.13495318484448424,
0.35554151592898753,
0.07803652289357443,
-0.3591042653745018,
0.5475917008779602,
0.022828184549702136,
0.23805326082640837,
-0.29500484558801104,
0.4860134740883423,
-0.42378812094127033,
0.5125018909335458,
0.4246925728304788,
0.1050134883553162,
0.11852978524656121,
0.12759202363834948,
0.18953234223067322,
0.28495103011347567,
-0.1308854200855007,
0.03998737857006402,
-0.013937949753827752,
0.05077954083431393,
-0.01849237525946881,
0.058435816538785795,
-0.025019202310181878,
-0.031109409680964647,
0.14588166385214468,
0.5693126295659892
],
[
-0.01319734878660714,
0.19752035361248924,
-0.13516682277738565,
0.006052389656955813,
0.02464880133386127,
-0.10770607055019246,
0.024617132444208684,
-0.021859443188251934,
-0.02620242764803231,
-0.006615724605275096,
0.05007994828293328,
0.04918331022271554,
0.020738843095562304,
-0.013247724004056771,
0.41587218250401187,
0.24928297909040176,
-0.07356826122792803,
0.2276264316617981,
0.16945613439289786,
-0.024978647078815006,
0.03889926101100143,
-0.014424864893117752,
-0.01804484411262108,
-0.12281911558391756,
0.19326818577693275,
-0.1454403095591264,
0.08326659053879434,
0.17379031522785282,
-0.12975307568396782,
0.05392518496499453,
0.08922678536383113,
0.04156662474570601,
-0.025251368780084424,
0.061980813918768814,
-0.0384944768609957,
-0.07415709371606137,
-0.12478778517751932,
-0.009611522414188368,
-0.0990673279317911,
0.1107110218518369,
0.12430212375168591,
-0.14649426493741485,
0.6194498692060798,
0.0009239224460590203,
0.41522073801987364,
-0.05888388310779742,
-0.01614327710094017,
0.13495318484448424,
1,
0.24813841544565785,
-0.060406172929690714,
-0.1366175438047737,
0.357991064250617,
0.06846289274916156,
0.1915494538197657,
-0.09246603801117939,
0.18751839010335036,
-0.21105535301461237,
0.19713597165670285,
0.12628334461925658,
0.041511514997245744,
0.07493681988005246,
0.07658509562663816,
0.0848708946277089,
0.2023626733211742,
-0.08724203896010073,
-0.006568405844062428,
0.06449781523703381,
0.02048225431729566,
0.003618490831398004,
-0.010914555467920991,
-0.011439726603573166,
0.03519408025847396,
0.0631786173612733,
0.2581749248797554
],
[
0.04129014393845963,
-0.06569914153410501,
-0.0010351358781264554,
0.12036857257786046,
0.03665948655370173,
-0.06545097662244599,
-0.007591257422062977,
0.00476517225091826,
-0.05534637105677964,
-0.03287044110318166,
0.01938917884024398,
0.025635493364451124,
-0.0187516111720734,
-0.3215099243849895,
0.20476316080935997,
0.08199436386128246,
0.023179716993687045,
-0.08064434451492349,
-0.074393280883922,
0.007952805453499337,
-0.020952953276857738,
-0.01462210845452165,
-0.0021081012324330704,
-0.09300036474324878,
0.10882909665809933,
0.038389863628287065,
-0.03689546317507298,
-0.03400941061460791,
0.08625535997981719,
-0.01703934779260162,
0.11774548379929106,
0.11209217828826244,
-0.11910029616945528,
-0.00572109265674136,
-0.008178744565367433,
0.15493533157738432,
0.029989287103836873,
0.03135367864150854,
0.036970891151074596,
-0.019621910952432972,
0.027841265918916794,
0.10064332192204008,
0.5092162062619568,
0.059138002342186725,
0.5100878896008458,
-0.16172258270229162,
0.0476447412003851,
0.35554151592898753,
0.24813841544565785,
1,
0.1731506171779945,
0.02851560959918949,
0.6589226103462142,
-0.0324092969494877,
0.11701218166686403,
-0.010152389395102011,
-0.07156520330628793,
0.010411736803143942,
0.11953662595100333,
0.08903643362896353,
0.01975188446491984,
-0.007167269187074307,
-0.023859596119000962,
0.04954569012433562,
0.09332985274766831,
0.043569017891241305,
-0.02771775862118473,
0.049394624948630124,
0.07775146197401044,
0.008296128633417143,
0.049966355911371614,
-0.04644038459965603,
0.04112366610709155,
0.02243452930764989,
0.16926554693331156
],
[
0.013833911015233234,
0.23917660866612175,
0.06886673863477615,
-0.012611273893924992,
0.010484543025237018,
0.05085482776077683,
-0.03431744081264898,
-0.004681810972693491,
-0.031659694684004674,
-0.023702819028113227,
0.05806212376510432,
-0.08750201974994211,
0.04153474087757888,
0.13383597771592143,
0.02504751430572349,
-0.13508393883200037,
-0.07091037093534514,
-0.17612391687364642,
-0.15414668453880773,
-0.010195097891000454,
-0.00034805989004358295,
-0.06178040861304181,
-0.049469846704989745,
-0.0068589229709324516,
-0.007298646101964353,
0.09948809654039628,
-0.019767643266256397,
-0.09112392768541977,
0.07992642338664543,
-0.025772723358806742,
0.05567259868852402,
0.09894858181407948,
-0.035623116643607886,
0.03635310401630078,
-0.02827842135322798,
0.08179497575551697,
0.03684425207612298,
0.032443190804087196,
0.1293553699849977,
-0.22930662252891915,
-0.12350323858971594,
0.059242471577874524,
0.06846435681000373,
-0.01775927282781638,
0.10052123299368086,
-0.012858105993494361,
0.010247476927151923,
0.07803652289357443,
-0.060406172929690714,
0.1731506171779945,
1,
0.11893741902200274,
0.23498362441598303,
-0.03633082684700585,
-0.0925351088533467,
0.13677971501398387,
-0.12561428165478578,
0.1367847189792986,
0.048208229747693336,
0.035486693761196855,
-0.1203467005124265,
-0.0913326466568612,
-0.15467575067222986,
-0.07363132105846126,
-0.03735567467731495,
0.03753666338436048,
-0.020318197962507546,
-0.04118027890101714,
-0.012286437082789578,
0.06052813555372696,
0.0360446266934577,
0.005703787625589249,
-0.01354290744632157,
-0.06946412051573217,
-0.1114081974082277
],
[
-0.0014295264091029106,
0.00815098980794901,
0.1351650498762633,
-0.056815269341822947,
-0.020403691316523545,
0.11542062744284054,
0.005122918756194039,
-0.010668272564702094,
-0.010304661020708705,
0.017782462843909635,
-0.14411146576407582,
-0.0507948059642043,
-0.04421830128148692,
-0.0365409387973652,
-0.08193486006956507,
-0.6090939011647342,
0.06917534608414315,
-0.384457858727966,
-0.4863317532914487,
-0.12290434630798018,
-0.037146188718245994,
-0.1320975078079644,
-0.11878941098477398,
-0.1279031751709701,
-0.2633446718740683,
0.6460896590991358,
-0.06439842376969733,
-0.37768365318094105,
0.5258868434770011,
-0.013588145712000272,
0.2130062373982784,
-0.03663581567935554,
-0.19177836400963275,
-0.07887396560635264,
0.07404369620331201,
-0.20662389058043465,
-0.4107585216896487,
-0.0004930457726763403,
0.4025972267140891,
-0.06590274023259854,
-0.11001745525088487,
-0.3782828248558993,
-0.14158914742167863,
0.023306832556394503,
-0.3988964672462648,
-0.12577873682802335,
0.03276610581829281,
-0.3591042653745018,
-0.1366175438047737,
0.02851560959918949,
0.11893741902200274,
1,
-0.2866640552843544,
-0.10216702781917929,
-0.2344555728801771,
0.19033379202962594,
-0.39060301491791644,
0.3823818562894975,
-0.42816101167006687,
-0.4152080238432143,
-0.019620182653907633,
-0.08049765336225426,
-0.05507364564996238,
-0.16023516735480514,
-0.2369465380290241,
0.06835435241827154,
-0.01251494391730379,
-0.02240232019660663,
-0.06008413266129773,
0.04797638500851867,
-0.046969106442759014,
-0.014804616396404822,
0.02879291313706437,
-0.14244925289377533,
-0.6168669685619569
],
[
0.022852408645722053,
0.014514149327814578,
-0.03144034274548059,
0.18565386358760266,
0.04445388006099216,
-0.1343468394537626,
-0.038290640210961895,
0.007765838523659378,
-0.055581803464847736,
-0.018233518034407682,
0.08241985872108805,
0.05903951532853358,
0.020771384232572822,
-0.22673002077020515,
0.26295334550789723,
0.44294061659027856,
-0.06388282788414294,
0.09941461593878198,
0.17466047616562724,
0.13413990063446055,
0.06524190531101359,
0.06702040255472218,
0.06732042280753076,
-0.01584603392902108,
0.2897583455381086,
-0.31085147858484613,
0.012644799003395117,
0.15329067879947347,
-0.26583842027847077,
-0.01954993457034272,
-0.021546261773949405,
0.1451194610293689,
0.04628374801959108,
0.04425905085413,
-0.042206652430106247,
0.24201992852946788,
0.2976094360235673,
0.012126671037724133,
-0.18394004090989827,
0.0035152849688586934,
0.060750627822321324,
0.3937859743270962,
0.6192749810587656,
0.09224140345400696,
0.8234912342064489,
-0.05206511498367661,
-0.01670488884169751,
0.5475917008779602,
0.357991064250617,
0.6589226103462142,
0.23498362441598303,
-0.2866640552843544,
1,
-0.04024907863738935,
0.332325265495532,
-0.10677220434186767,
0.14862510460379677,
-0.24856619411808012,
0.4044164898500434,
0.3684345076957485,
0.0021819942312685525,
0.009661884475797695,
-0.01907049634688575,
0.1660516659163675,
0.24939602261372912,
-0.003320665504676853,
-0.011026121982751222,
0.058056436137498925,
0.0882788766059013,
0.026110978052444958,
0.041562150632203955,
-0.04644613987333911,
-0.039703750032482533,
0.09151593283428885,
0.5518206950104778
],
[
0.000367998951150668,
-0.02554213220012112,
-0.10150433363081748,
-0.00988592625244942,
-0.015036186173145292,
-0.0512990710756872,
0.034279293216391844,
0.006714320428028173,
-0.0303879697344421,
-0.09726711166786804,
0.004820206645700774,
-0.015270515920455202,
0.008865028507145723,
-0.010709588207720224,
0.03109604767188451,
0.13011812029108893,
0.05146567468083967,
0.15026857976219882,
0.06939113747117548,
-0.007911727335835558,
-0.014265193520379974,
0.02878274364829709,
0.005315111479683734,
-0.05482778744552837,
0.08212752581510128,
-0.07575825764341372,
0.01915072879361577,
0.13742209589908033,
-0.054718477301931544,
0.035861157180677845,
-0.07173470522606179,
-0.00293954449697474,
0.032395801911628,
0.10488118742016261,
-0.1100599475725225,
0.033838735257075626,
0.02825448194452008,
-0.020952855335018894,
-0.06808514546583712,
0.05439089709927144,
0.02298164118030185,
-0.0782460712404498,
0.005566900235483681,
-0.060232084488389556,
-0.05811677738897634,
0.010631787619964526,
-0.028439925873615213,
0.022828184549702136,
0.06846289274916156,
-0.0324092969494877,
-0.03633082684700585,
-0.10216702781917929,
-0.04024907863738935,
1,
-0.012648468269712039,
-0.08293803605293794,
0.13215877214866237,
-0.11333964443102118,
0.08733510904675533,
0.06784457119975974,
0.02908825839016259,
0.012292947877342985,
0.01404897616568443,
-0.03228018925282518,
0.057701502418067784,
-0.043204982036662426,
0.017949208401847373,
-0.020384657735502812,
0.01762033451880248,
-0.014400184663510422,
0.013188188092155752,
0.0022586323287378538,
-0.005349085568597863,
0.03684938702398462,
0.10693029962567567
],
[
-0.017839045941519204,
-0.02475160161154742,
-0.006977590918863724,
0.2630610990857339,
-0.014360271885975839,
-0.18726548843260596,
-0.07377919976696438,
0.014890674873585075,
-0.052085700417345775,
0.13679530069899445,
0.05748105746764286,
-0.005305967127884751,
-0.019087646642344695,
-0.07862801730441539,
0.08691015993125557,
0.37735900883048845,
-0.0319101709219359,
0.11080715280971148,
0.08995214529827836,
0.11650032675952587,
0.09517352738279419,
-0.011951206295161165,
0.006511223018773587,
-0.028032213246705417,
0.22936505678447705,
-0.20913783018621257,
0.025804083504971632,
0.07560293417506558,
-0.18880388069067888,
0.01818048668175917,
-0.10606086805366352,
-0.08746326045383049,
0.2453230504806542,
-0.013294473622214396,
0.035643216123719616,
0.03315748933517243,
0.3281034069510372,
-0.0015300127057494757,
-0.11082944802822921,
0.14202051986708047,
0.10127321706252275,
0.40192875830142466,
0.18851430777515962,
0.0017456878735635495,
0.4581090100282428,
0.13304452428274474,
0.026147095509744138,
0.23805326082640837,
0.1915494538197657,
0.11701218166686403,
-0.0925351088533467,
-0.2344555728801771,
0.332325265495532,
-0.012648468269712039,
1,
-0.25749591677937145,
0.039870579744270156,
-0.2743295926443679,
0.24589463147156596,
0.20376331821459212,
0.051105640841695,
0.09982188412363036,
0.09394950602574059,
0.18377847286299043,
0.17164291193231457,
-0.021637445317799892,
0.0026608405761710213,
0.1775146596548751,
0.09525287722116253,
0.005279204745316234,
0.055794953166773666,
-0.018576558956638407,
0.024194602173261682,
0.09219024279264115,
0.4454344326389212
],
[
0.0005026949894766652,
0.11795260866229235,
0.13401570466292576,
-0.1300418844835832,
-0.00497805737094708,
0.18090004058535558,
-0.10494946040708829,
-0.00393498653254095,
0.017932669962502795,
0.0034374295801951516,
-0.06360591222585198,
-0.052280300281721134,
0.04952834385419031,
-0.009584889154066072,
-0.10185829365431776,
-0.3495856794547723,
0.19168225723276208,
-0.5159558366376603,
-0.29490246493511696,
-0.06950950441489676,
-0.045829510589232354,
-0.0031924531356895295,
0.0001855034694746642,
0.12513890003070843,
-0.18099818628346412,
0.2410642184089191,
-0.13216408058664186,
-0.38561463719447137,
0.2498564034965103,
-0.08603441547641663,
0.21163074394481532,
0.16546049308697316,
-0.2508836843721934,
0.022237068970247426,
-0.037682926492934345,
-0.05802902487328299,
-0.3622108252881274,
0.1314019007235736,
0.18717289019466773,
-0.2549490522002923,
-0.1745499071747452,
-0.3599704921953107,
0.08730918579216244,
0.13835717298736736,
-0.18268748956287065,
-0.1706226827890917,
-0.018639871681424156,
-0.29500484558801104,
-0.09246603801117939,
-0.010152389395102011,
0.13677971501398387,
0.19033379202962594,
-0.10677220434186767,
-0.08293803605293794,
-0.25749591677937145,
1,
-0.35497307764789104,
0.48087968140390863,
-0.26212047960847423,
-0.22927501929946686,
-0.22166434173126506,
-0.21463909120578864,
-0.26875019065312866,
-0.21403096003212727,
-0.12775307011316672,
0.1983479262708385,
-0.05386604589721306,
-0.033135645565357294,
-0.0301857210127286,
-0.0051301984404425625,
0.00912244249223009,
0.0014097741961951044,
0.03141862493917326,
-0.10017472560029807,
-0.34840092738222384
],
[
-0.003114479119402124,
0.08203997778664511,
-0.27397387020377517,
-0.025700275640004013,
0.027689784249408402,
-0.19298250910121809,
0.1298497620129026,
-0.022745559833628293,
-0.002465714744599853,
-0.07664689463520605,
0.10676516197543212,
0.14537377670451695,
-0.006141162226570326,
0.20597441753054338,
0.2064878337208006,
0.545834564443336,
-0.33654128329423727,
0.8251723703726819,
0.6415853437752634,
0.01761655819928833,
-0.03298116845541073,
0.18354813581078439,
0.15878580416705376,
0.013067051760033829,
0.24974950065249285,
-0.5204067379728421,
0.20475075249745556,
0.6615441527804113,
-0.5266614312287718,
0.10237607906425784,
-0.26256792101505605,
-0.024431720785107053,
0.1446105777327811,
0.08190813393470699,
-0.09259482219148328,
0.18053915699617665,
0.32149960649383375,
-0.1818950752437004,
-0.4242502469267758,
0.31820784863911233,
0.31411825129974935,
0.23792763270239456,
0.06041369673023831,
-0.037214416695816474,
0.2249031610110193,
0.11575090542031488,
-0.07936197107329102,
0.4860134740883423,
0.18751839010335036,
-0.07156520330628793,
-0.12561428165478578,
-0.39060301491791644,
0.14862510460379677,
0.13215877214866237,
0.039870579744270156,
-0.35497307764789104,
1,
-0.5192280222420828,
0.590300743374351,
0.5638604268863069,
0.3147316344592751,
0.25850663040403987,
0.3119324549587349,
0.2240746780326318,
0.2208794308775354,
-0.3035252331521662,
0.027561686698380303,
-0.07742848087681298,
-0.014934086165700543,
-0.031451242624292934,
0.002462674442372394,
-0.0029479384245078765,
-0.033024172969691325,
0.20609784904471212,
0.48172978591824045
],
[
-0.010019746028836839,
-0.009521763312374714,
0.16116146892567643,
-0.10251906661574786,
-0.0018361185820532837,
0.22667337015724842,
-0.07243254090602405,
-0.005910379357123157,
0.0201096548745226,
0.026674021183174846,
-0.04958640010754587,
-0.12913885552069282,
-0.004385837239088038,
-0.07169819666895963,
-0.2052822459648225,
-0.5165278399741617,
0.223433364546768,
-0.5832188734251933,
-0.4528689785920439,
-0.1328686342721223,
-0.030195044744168932,
-0.08222195094298555,
-0.07224301302352999,
0.034360595106043945,
-0.2531233660153511,
0.45130871691899854,
-0.14475933650038042,
-0.47619058612712933,
0.4546443628041613,
-0.06755237019509383,
0.2281339877322006,
0.03471575690702997,
-0.22094809688495207,
-0.04259182162834297,
0.039759605071627076,
-0.09703527888023089,
-0.33892398140022434,
0.09800243727585885,
0.37752708333700175,
-0.20847011328828033,
-0.21312343992291727,
-0.31373307878662765,
-0.12536717491026647,
0.06450963002316729,
-0.3340106398481078,
-0.14647687357797226,
0.044815977382571856,
-0.42378812094127033,
-0.21105535301461237,
0.010411736803143942,
0.1367847189792986,
0.3823818562894975,
-0.24856619411808012,
-0.11333964443102118,
-0.2743295926443679,
0.48087968140390863,
-0.5192280222420828,
1,
-0.4348234629314139,
-0.3564776606641135,
-0.17550777820133345,
-0.14348474012425305,
-0.20053975768162585,
-0.22842953563079496,
-0.20798380857882767,
0.19338759910962922,
-0.022849671899608435,
-0.009429975933363035,
-0.023425240080253557,
0.0016746148558864629,
0.015001410190233338,
-0.011293094304657062,
0.03870411685694867,
-0.1459534150397722,
-0.5082316799671449
],
[
0.009797334242141055,
0.006871699740459917,
-0.15653812439904954,
0.13822820411647535,
-0.05105492411298621,
-0.18246065416176238,
0.009421164403590301,
0.005544829530676808,
-0.06199704444066005,
0.003925896925215691,
0.17847558274121678,
0.07198110949872359,
0.0160824729996424,
0.027521715784369065,
0.18924485748285055,
0.591877791157789,
-0.24983180899078664,
0.5240758310844763,
0.4594486613200945,
0.12869830904653998,
0.0449170862257143,
0.14872508248747318,
0.14592137254860746,
0.009426173322028907,
0.3639161112014302,
-0.49363323752260463,
0.14934040883620073,
0.441766975468218,
-0.518435100809879,
0.03733658874685138,
-0.2523094346455051,
0.0280994573724849,
0.19755890777731325,
0.07569304575805098,
-0.08026438846727484,
0.2422782578987996,
0.4534269481632856,
-0.03414339778109316,
-0.32407193695186554,
0.12521619177744256,
0.23577348843398419,
0.4402371994707011,
0.18720806790858244,
-0.017604797315670582,
0.48394323911411047,
0.13140336690168164,
-0.041898828988608784,
0.5125018909335458,
0.19713597165670285,
0.11953662595100333,
0.048208229747693336,
-0.42816101167006687,
0.4044164898500434,
0.08733510904675533,
0.24589463147156596,
-0.26212047960847423,
0.590300743374351,
-0.4348234629314139,
1,
0.8321655011873562,
0.15224079876598437,
0.1252363304831474,
0.1413379359078871,
0.20867365324957826,
0.24280541320899193,
-0.14794522406180866,
0.030461930760418317,
0.01575652840138003,
0.013961105699982547,
-0.048289823111657096,
0.03279571709804125,
-0.03759345312349018,
-0.05968122945750201,
0.14623836043702887,
0.6401543580531925
],
[
0.01365805935604715,
-0.07027845838794604,
-0.19554639010608096,
0.16863025291502634,
-0.08429325644928268,
-0.148814526623833,
0.011330637394811017,
0.0034498542101277395,
-0.056526223233211964,
0.011995132910763257,
0.20394636574799854,
0.03944688015989324,
0.05405384828278298,
-0.05588879836068081,
0.13522982159507746,
0.5300918839150316,
-0.2049048044564097,
0.4438540209512734,
0.38621255311930736,
0.14115534220406384,
0.05053931638018961,
0.10973874848453537,
0.104592878050649,
0.03466177147905239,
0.36723738587201804,
-0.4734445138577729,
0.09194302805349801,
0.37518431990387924,
-0.46090730060531543,
0.04575502822638484,
-0.24663493415799975,
-0.012734621469982874,
0.2840954904105337,
0.03217794696015472,
-0.05341110930975736,
0.19540122229273182,
0.5114750740641821,
-0.052991006606748624,
-0.26065140195528225,
0.12243249999669405,
0.20978712019064275,
0.5000711260901144,
0.12456374351799851,
0.013996145095664672,
0.47786769444438604,
0.18655758164329636,
-0.04497916977953163,
0.4246925728304788,
0.12628334461925658,
0.08903643362896353,
0.035486693761196855,
-0.4152080238432143,
0.3684345076957485,
0.06784457119975974,
0.20376331821459212,
-0.22927501929946686,
0.5638604268863069,
-0.3564776606641135,
0.8321655011873562,
1,
0.15582823747640462,
0.13201103129657835,
0.16081743855005923,
0.20403266864571615,
0.26949835181418086,
-0.11111912294758075,
0.029687703285159423,
0.018501208761241634,
0.06207681666968013,
-0.028575418467782384,
0.016794327464828188,
-0.02203004907742357,
-0.08423758106212033,
0.14229307726965407,
0.6075353838509889
],
[
-0.002989817698019096,
0.004023312861598408,
-0.1615519537409934,
0.021880743238163122,
-0.013825538735983644,
-0.10299251014191207,
0.012838980569483658,
0.006173712941204807,
0.021681127831878696,
0.016831131398870904,
-0.017367198978466163,
0.07888608486617085,
-0.02325337589067172,
0.06723966420335346,
0.061643198013823806,
0.11952499445216692,
-0.09797779542478702,
0.33840764418609415,
0.14762310636584136,
0.04079954583684342,
-0.035316551137936504,
0.0023167324322512614,
-0.030535666443641984,
-0.06801262109429888,
0.11676700253895504,
-0.09152161058831157,
0.017474399164500876,
0.2686955736257913,
-0.0592015343831046,
0.042612782084012125,
-0.08713993875193107,
-0.12964915267148436,
0.13807630133482635,
-0.037401219119548884,
0.04920571690167427,
-0.05152887380380284,
0.12046724954396822,
-0.16441995025019757,
-0.03512116810541757,
0.2110846646309416,
0.13408322821136018,
0.09678792531246175,
-0.050286838389303916,
-0.057262256334189715,
0.024873606930151643,
0.09845845083401691,
0.04157565877409055,
0.1050134883553162,
0.041511514997245744,
0.01975188446491984,
-0.1203467005124265,
-0.019620182653907633,
0.0021819942312685525,
0.02908825839016259,
0.051105640841695,
-0.22166434173126506,
0.3147316344592751,
-0.17550777820133345,
0.15224079876598437,
0.15582823747640462,
1,
0.5233364922543896,
0.2336304085808705,
0.0593314892431202,
0.009872179509993665,
-0.11304719131336448,
-0.013162302362455755,
-0.03739899126747119,
-0.026276950323627212,
-0.0023093989549759207,
0.012102865110194753,
0.0405317782353117,
-0.031705962726084926,
0.057561902049014804,
0.12079187995952888
],
[
-0.01010875732119869,
-0.008049373143581758,
-0.09210904003589121,
0.03078490327846076,
-0.011664930084399228,
-0.0800763240171814,
0.01046197240335421,
0.005208905865843047,
0.015221103876701007,
-0.018742016933083156,
0.004158885441727495,
0.02279733509548903,
0.05513947209442576,
0.059745726851186995,
0.007182768663123965,
0.15911977480621992,
-0.04053174516928885,
0.2749273642303913,
0.15704986280426197,
-0.004899028011692639,
-0.016503281257261332,
0.024308216001897465,
0.010579010700678192,
-0.06140455268411041,
0.07320129478038383,
-0.10635485009563528,
0.05176748852926625,
0.19651433122125775,
-0.051401845525401266,
0.16774606639578793,
-0.06131537948431773,
-0.10850066286744733,
0.10351574267454199,
0.0032523254986387604,
0.0028557476395959275,
0.000417693118964614,
0.11872787913942985,
-0.11817856882605732,
-0.0527325168743707,
0.2281454662269352,
0.13637546576028675,
0.10709342179082486,
-0.017729334726246073,
-0.02966456312260254,
0.06222432117783091,
0.06693408571491415,
0.029808566909286426,
0.11852978524656121,
0.07493681988005246,
-0.007167269187074307,
-0.0913326466568612,
-0.08049765336225426,
0.009661884475797695,
0.012292947877342985,
0.09982188412363036,
-0.21463909120578864,
0.25850663040403987,
-0.14348474012425305,
0.1252363304831474,
0.13201103129657835,
0.5233364922543896,
1,
0.26374240989803216,
0.07727614780330934,
0.05764485768283967,
-0.119595516629384,
0.0025476270551330893,
0.04846958444192215,
-0.0371038789664036,
0.0037420926126844594,
0.0036375435417093376,
0.03183671555443971,
-0.016437399299890867,
0.028940136547431744,
0.14792531402015788
],
[
-0.018114560024225512,
-0.011233765337528,
-0.11791285567643743,
-0.015528452155783568,
0.04424275876853673,
-0.1247199561717356,
0.13751146317497312,
0.006664433714960577,
-0.04849521350731529,
-0.035183906936079326,
0.006732393970521492,
0.06753618843636407,
-0.024742943430320286,
0.06942748387657853,
0.08186230857094262,
0.16314629342609765,
-0.10632988251865728,
0.38913857073365976,
0.15883603912217042,
-0.03762087767931008,
0.030628066674169317,
-0.0721234060490155,
-0.04657350484715869,
-0.07610125813745654,
0.12244564396616399,
-0.1135415357763584,
0.11005998680578676,
0.2328045544180641,
-0.10811137549989384,
0.10682808260873516,
-0.08804508659922156,
-0.21509472932619042,
0.16940668235135584,
-0.05079860994478311,
0.04718146940878057,
-0.05247198180745228,
0.15405780183413817,
-0.1472289211048567,
-0.08213368223780368,
0.2582657167336859,
0.1820294371393392,
0.12326784904047197,
-0.05304547150922476,
0.005587016236790502,
0.047122661285661116,
0.10935576453018662,
0.023704417273768794,
0.12759202363834948,
0.07658509562663816,
-0.023859596119000962,
-0.15467575067222986,
-0.05507364564996238,
-0.01907049634688575,
0.01404897616568443,
0.09394950602574059,
-0.26875019065312866,
0.3119324549587349,
-0.20053975768162585,
0.1413379359078871,
0.16081743855005923,
0.2336304085808705,
0.26374240989803216,
1,
0.09656129259342244,
0.057453491732392704,
-0.18155396680183533,
0.012194004483015216,
0.034235860553098886,
0.01748941723808593,
-0.044115411032668916,
-0.011506894325790454,
0.0010405707723082028,
-0.047409524912486845,
0.021578057832832908,
0.1766089143291643
],
[
-0.03280084930244921,
-0.010175195750555642,
-0.008916459385232268,
0.16782204895494518,
-0.026813132105382442,
-0.1569586766781947,
-0.016676821148531917,
-0.021319678400363095,
-0.04005838181102943,
0.10397520170204337,
0.06281538327454438,
0.03514335640255836,
0.008496800048682456,
-0.009074244416722653,
0.07027445477174898,
0.21856953420394784,
-0.012946977008197757,
0.21229564671312867,
0.2010572140928977,
0.07667176757398075,
0.1298801023003024,
0.03494817432207492,
0.019972323897372114,
-0.034328438368517504,
0.1491815633645443,
-0.1756479932389436,
0.014567682778698373,
0.16918042033911349,
-0.21322300554257656,
-0.00021070185869706494,
-0.20164958263842908,
-0.09816562040344941,
0.1871781847073771,
-0.0638618175091105,
0.06120600766837853,
-0.02071121160913865,
0.214363956683255,
-0.06863602830632431,
-0.10006952678250002,
0.11934234232155215,
0.14340410328976833,
0.23319963959811235,
0.0812907022579819,
-0.008739723505597442,
0.2412770146337058,
0.1619818934984059,
0.0393051866329195,
0.18953234223067322,
0.0848708946277089,
0.04954569012433562,
-0.07363132105846126,
-0.16023516735480514,
0.1660516659163675,
-0.03228018925282518,
0.18377847286299043,
-0.21403096003212727,
0.2240746780326318,
-0.22842953563079496,
0.20867365324957826,
0.20403266864571615,
0.0593314892431202,
0.07727614780330934,
0.09656129259342244,
1,
0.0582672816468396,
-0.1311012607435605,
-0.039634876856794565,
-0.08782982225338849,
0.07245417907910393,
-0.009820780294822374,
0.031197269345638108,
0.02183320859552377,
0.06189467318665239,
0.0482657464256531,
0.30598288316822747
],
[
-0.00533240932506013,
-0.00035905639738251645,
-0.1421073802406923,
0.08494198120724036,
-0.008265100288747282,
-0.08473952333645134,
0.04994571947655422,
0.029390899247553965,
-0.05631891273663907,
-0.029043267313532902,
0.14139560803873602,
0.09214694231584714,
0.03412907068476666,
-0.024105592350611996,
0.13713025767680034,
0.3076147309600645,
-0.060429082023547194,
0.21679333902671258,
0.23112929320769734,
0.005675561048217082,
0.058881953985485305,
0.05873891386229862,
0.05905541828270895,
0.02558250810304121,
0.12901469114172806,
-0.27856058454408583,
-0.008158546498538078,
0.1963766070076527,
-0.24617815106135668,
0.01972739236233947,
-0.05798717867643989,
-0.0031875152919912946,
0.10756072875012912,
0.035269049202661114,
0.004211169347973952,
0.12217145266659353,
0.25593931469238296,
0.023497556609328233,
-0.17459027377587144,
0.01062372777567423,
0.11158737569312428,
0.22661515067354668,
0.20279146984595758,
0.01832647105928302,
0.3412730025715972,
0.07280529300410707,
-0.03481797523291756,
0.28495103011347567,
0.2023626733211742,
0.09332985274766831,
-0.03735567467731495,
-0.2369465380290241,
0.24939602261372912,
0.057701502418067784,
0.17164291193231457,
-0.12775307011316672,
0.2208794308775354,
-0.20798380857882767,
0.24280541320899193,
0.26949835181418086,
0.009872179509993665,
0.05764485768283967,
0.057453491732392704,
0.0582672816468396,
1,
-0.10376939076119406,
-0.005127541707407689,
0.07408001974096541,
0.06312261761096662,
-0.015167683623210889,
0.06091300064690735,
-0.06284828161531644,
-0.012600086219363751,
0.08831275276053487,
0.3227857346419753
],
[
0.005106053070483421,
-0.022598287475612964,
0.14406759034539635,
-0.01796814374447305,
0.021411949145583982,
0.07471274190288142,
-0.07055209324177596,
-0.009561379853680062,
-0.07025489718785788,
-0.013841099887284002,
0.03895443890956474,
-0.077561586520586,
0.020348390377908608,
-0.10907958735873159,
-0.0672904426794365,
-0.11693095622879052,
0.07147329718568772,
-0.38541458488430597,
-0.2184516657997792,
-0.01096546449127881,
-0.026315672595815652,
-0.0345276607892722,
-0.027703827285138084,
0.03958555405045165,
-0.11222460622066968,
0.12399613071473216,
-0.08290129235042414,
-0.2299935461672655,
0.14873463497367434,
-0.06889236544647445,
0.10138068519680658,
0.08835310722626896,
-0.10566890118260427,
-0.05642172307683878,
0.0456680512976618,
-0.0033724263795620085,
-0.10448392104040116,
0.10272960707820476,
0.09500336894892442,
-0.16558877720888887,
-0.14613711845797409,
-0.05600310127985605,
0.05965353466567714,
0.05008096617512517,
0.012779142507472193,
-0.04677156539770777,
-0.003070591955767723,
-0.1308854200855007,
-0.08724203896010073,
0.043569017891241305,
0.03753666338436048,
0.06835435241827154,
-0.003320665504676853,
-0.043204982036662426,
-0.021637445317799892,
0.1983479262708385,
-0.3035252331521662,
0.19338759910962922,
-0.14794522406180866,
-0.11111912294758075,
-0.11304719131336448,
-0.119595516629384,
-0.18155396680183533,
-0.1311012607435605,
-0.10376939076119406,
1,
-0.03671166013491978,
-0.08403058854014495,
0.057704429148285864,
0.023827035888405304,
-0.0221687350455888,
-0.006165430939960744,
-0.014235764404831987,
-0.11552561460039934,
-0.12738527654209783
],
[
-0.04376579864957937,
-0.04139136779739513,
0.00151594682245454,
0.0193256932899186,
0.007269014514968439,
-0.038387686712762416,
-0.02655380325011126,
-0.0032459356440167775,
-0.033491059452548606,
0.009618286115884844,
-0.024015503385765403,
0.08052481073717128,
-0.00428566261098433,
-0.02065344555876409,
-0.029546092674310107,
0.02646990748560078,
0.023788760166174528,
0.028982135268052656,
0.03942222190264912,
0.013001922496996499,
-0.004313614846049807,
-0.047015569590430385,
-0.024188879788889072,
-0.024580512288238248,
0.015220832966882045,
-0.03628877227974044,
0.00862853400307156,
0.04399392824368729,
-0.014436578455732613,
0.033117908080680485,
0.01590811779724749,
-0.044882664982565414,
0.026810593362810588,
0.011412188067371947,
-0.031475178970346046,
0.02370054406208866,
0.04314216576739562,
-0.0134207126018398,
-0.050389959272691125,
0.02594030496245603,
-0.0001278731989842695,
0.05315893459190707,
-0.024786492440264627,
-5.897496422105555e-05,
0.018512281201446133,
0.00048221590615306413,
0.03630118587817062,
0.03998737857006402,
-0.006568405844062428,
-0.02771775862118473,
-0.020318197962507546,
-0.01251494391730379,
-0.011026121982751222,
0.017949208401847373,
0.0026608405761710213,
-0.05386604589721306,
0.027561686698380303,
-0.022849671899608435,
0.030461930760418317,
0.029687703285159423,
-0.013162302362455755,
0.0025476270551330893,
0.012194004483015216,
-0.039634876856794565,
-0.005127541707407689,
-0.03671166013491978,
1,
-0.033612685365988944,
-0.008518281557628498,
0.0008771606355775407,
0.03134102245387141,
0.023326424478975837,
-0.009784704197603482,
-1.5704069541035621e-06,
0.04215866955782426
],
[
0.0009041955482458529,
-0.022748025272168983,
0.022452990246766526,
0.0384892692888955,
-0.03816944779540477,
-0.047455707886364586,
-0.00012518297309117553,
0.10206394380661554,
-0.001784411761206332,
0.0538798909791917,
0.00850922344186706,
0.004448698251411438,
-0.01022609849102695,
-0.025610890144336297,
-0.03485921338462889,
0.045256702232239425,
0.05375911480852094,
-0.07080877581034056,
-0.0525132610404103,
0.06407751797198656,
0.10412699589098141,
-0.052842041612664994,
-0.023099522098105146,
-0.025603491319675726,
0.05247422946785528,
-0.0067855936035387835,
-0.02381814970659313,
-0.06993062161368865,
0.009374714285629733,
0.014642267808199712,
0.0008922809768403907,
-0.022489386023292375,
0.05190592883783905,
-0.030534353432311003,
0.0858648487208668,
-0.02306519576370083,
0.06888581119100474,
0.030564974707938664,
0.0666181553995323,
0.037014202296273814,
-0.007945601392267894,
0.08305389720639884,
0.03566378776318002,
0.04483736773772634,
0.09535804948235475,
0.017068861544105883,
0.029737499232828857,
-0.013937949753827752,
0.06449781523703381,
0.049394624948630124,
-0.04118027890101714,
-0.02240232019660663,
0.058056436137498925,
-0.020384657735502812,
0.1775146596548751,
-0.033135645565357294,
-0.07742848087681298,
-0.009429975933363035,
0.01575652840138003,
0.018501208761241634,
-0.03739899126747119,
0.04846958444192215,
0.034235860553098886,
-0.08782982225338849,
0.07408001974096541,
-0.08403058854014495,
-0.033612685365988944,
1,
0.04979167246876981,
0.03300686098363106,
0.023330844000420597,
0.013331519833355116,
0.0069976906665835704,
-0.03106537873575294,
0.0966239807980718
],
[
0.05945450086800625,
0.01019895236429125,
-0.0027501200521137296,
0.07705022824516986,
0.004395581225108923,
-0.018836145425574116,
-0.015170502376441122,
-0.0019628209223371304,
-0.04787187842954997,
-0.016385400467922924,
-0.012304935224082018,
0.007201623402851556,
-0.002591544984702289,
-0.02835065035550131,
0.07779321600697005,
0.06456987460203505,
-0.003543836941888403,
0.0010060347394037416,
0.003354446094102964,
0.019318600150528012,
0.06359864996591898,
-0.0024806054868633963,
-0.018981834948314836,
0.008960905654058354,
0.00933432031672865,
-0.033290118372013455,
-0.033656840711237514,
0.00014963369603380398,
-0.0264879623145721,
0.020026436138565754,
-0.054715370337986076,
-0.03500877718626529,
0.14270779613070145,
-0.04012943150066245,
0.041147946590913524,
-0.039315391523727594,
0.13565398713633098,
-0.008115519953737146,
0.030864412956388795,
0.01568613148753237,
0.019734344165714235,
0.1348794299714107,
0.0827529257922385,
0.08042503026037283,
0.17646275383372328,
0.06923582245481744,
0.019776581830163283,
0.05077954083431393,
0.02048225431729566,
0.07775146197401044,
-0.012286437082789578,
-0.06008413266129773,
0.0882788766059013,
0.01762033451880248,
0.09525287722116253,
-0.0301857210127286,
-0.014934086165700543,
-0.023425240080253557,
0.013961105699982547,
0.06207681666968013,
-0.026276950323627212,
-0.0371038789664036,
0.01748941723808593,
0.07245417907910393,
0.06312261761096662,
0.057704429148285864,
-0.008518281557628498,
0.04979167246876981,
1,
0.03034989459632135,
-0.03556841693875225,
-0.061701027580798457,
0.011885565505007786,
-0.07530911638558206,
0.091881076190269
],
[
-0.0022057006514021506,
-0.021511829276601772,
0.002839143360859719,
0.040823885173202144,
-0.026514354076164665,
-0.04244734647114658,
0.01878471170823421,
-0.0023119232224790755,
-0.02397730531170623,
-0.0020904987061326537,
0.0022877204122000636,
-0.013694102549178825,
0.12984779288405893,
-0.010909781668084682,
-0.04924440342355729,
-0.029350832456647227,
0.0773135478366433,
-0.03349316362455502,
-0.001379347959197944,
0.09264115505408192,
-0.010625019563881842,
-0.022387861482622076,
-0.02151592516954578,
0.001764956996893076,
-0.028974930528621913,
0.02216558429454408,
-0.05887600669107351,
-0.028081284501108972,
0.03137039538409655,
0.004369931590688738,
0.012102402361201694,
-0.04197978008829885,
0.007869425742333215,
-0.009463156194938649,
0.0062460065640478355,
-0.018566233149059638,
-0.008678801006624515,
0.0006829230278733183,
0.02181696753687386,
0.010899075862725977,
0.019309992678907255,
-0.014226372342032103,
0.013755187398007027,
-0.00017815955331289013,
0.001054484930020002,
-0.020703654190529615,
-0.006685469117956385,
-0.01849237525946881,
0.003618490831398004,
0.008296128633417143,
0.06052813555372696,
0.04797638500851867,
0.026110978052444958,
-0.014400184663510422,
0.005279204745316234,
-0.0051301984404425625,
-0.031451242624292934,
0.0016746148558864629,
-0.048289823111657096,
-0.028575418467782384,
-0.0023093989549759207,
0.0037420926126844594,
-0.044115411032668916,
-0.009820780294822374,
-0.015167683623210889,
0.023827035888405304,
0.0008771606355775407,
0.03300686098363106,
0.03034989459632135,
1,
-0.008497879888354229,
-0.002566090111890573,
0.014456542430295332,
0.009746615608799076,
-0.016989857604916444
],
[
0.02093883801772228,
-0.016283496913698726,
-0.011368518019475088,
0.0001175202505775026,
-0.0015470268585642205,
-0.04396760150371732,
-0.019250584722489673,
-0.054038152091504865,
0.016536948986703624,
0.021692637546267587,
0.0059439814450761375,
-0.009549327002071136,
0.00791159729291587,
-0.03508206980883779,
0.0289168443143115,
0.06264144983858497,
-0.011772274303491013,
0.004396082441172591,
0.014552383148361442,
0.009905661010279471,
0.028838321106423623,
0.0012815558849344118,
-0.010313827644718351,
0.008674368063861675,
-0.0134606390479068,
-0.02547094540759063,
0.004392619345990163,
-0.004493604321707122,
0.0022580872309592125,
-0.03577705939022553,
-0.022276071960971495,
0.05416324481520814,
-0.021241787261421213,
0.03496827210890537,
-0.022039483584164698,
0.03120222002712654,
0.0007865166013506799,
0.01123713219417093,
-0.010117865596457316,
0.0003215272099970834,
-0.013172609568095874,
0.02410923916990364,
0.042201350462982026,
-0.027212373023109453,
0.05147361078398953,
-0.022992776271535845,
0.026506577029215984,
0.058435816538785795,
-0.010914555467920991,
0.049966355911371614,
0.0360446266934577,
-0.046969106442759014,
0.041562150632203955,
0.013188188092155752,
0.055794953166773666,
0.00912244249223009,
0.002462674442372394,
0.015001410190233338,
0.03279571709804125,
0.016794327464828188,
0.012102865110194753,
0.0036375435417093376,
-0.011506894325790454,
0.031197269345638108,
0.06091300064690735,
-0.0221687350455888,
0.03134102245387141,
0.023330844000420597,
-0.03556841693875225,
-0.008497879888354229,
1,
-0.14486183954703294,
-0.03838835669005236,
0.026561305262562517,
0.041309605129427975
],
[
0.0022407468273066837,
-0.02159082620119275,
-0.023208822431282774,
-0.012066376168532754,
-0.036572154661852804,
0.03165912354375219,
0.018654366228497855,
0.02455501172582275,
-0.0074483236605016705,
-0.0009748849025312992,
0.037856641298543374,
-0.01851141058121313,
-0.019782461186570434,
0.00016923319988008272,
-0.017118131443216132,
-0.013949153887412302,
0.05634002174155075,
-0.007898124743179068,
0.03450324490695675,
0.009698509820609994,
-0.027956696051350923,
-0.03776932448308001,
-0.034873176906859434,
0.05952863085857922,
-0.001521241139994098,
-0.037884832343612035,
-0.024957862949332225,
0.012118040928127275,
0.01830959387711647,
0.09176983844959984,
0.05495813976909885,
-0.04981092422610047,
0.023958277288284917,
-0.033975755379038595,
0.03285493244483844,
-0.039076475316944186,
-0.0018233369244867465,
-0.0072834177390089135,
0.013373458233184289,
0.011168765196826405,
0.025864499625263916,
-0.011257980305426712,
-0.034825604239672306,
-0.020533075032865757,
-0.03942408109707644,
0.0720160588826401,
-0.04246630701750443,
-0.025019202310181878,
-0.011439726603573166,
-0.04644038459965603,
0.005703787625589249,
-0.014804616396404822,
-0.04644613987333911,
0.0022586323287378538,
-0.018576558956638407,
0.0014097741961951044,
-0.0029479384245078765,
-0.011293094304657062,
-0.03759345312349018,
-0.02203004907742357,
0.0405317782353117,
0.03183671555443971,
0.0010405707723082028,
0.02183320859552377,
-0.06284828161531644,
-0.006165430939960744,
0.023326424478975837,
0.013331519833355116,
-0.061701027580798457,
-0.002566090111890573,
-0.14486183954703294,
1,
0.005333872770962497,
-0.006213611128850575,
-0.02045101634599536
],
[
0.014868155412809163,
0.011011556592627803,
0.09245649841146167,
0.014409771403381169,
0.01938037831579925,
-0.007835725350096029,
-0.027535457035299814,
-0.12981290787131344,
0.0075437435538039666,
0.05524556658150756,
-0.03407180234018274,
-0.0018677249909708525,
-0.0026368328163665477,
-0.04374989459584764,
0.048060173838034174,
-0.05287466148895335,
0.09524007224848526,
-0.04229481406709492,
0.03724337871298398,
-0.03334715722000794,
0.010138089633966887,
0.0025952656266980674,
0.011154131571145845,
-0.027635072665767677,
-0.04983837398202528,
0.07509611122607979,
0.01420825445665947,
0.0077435576363617566,
0.06366084303419912,
0.02105845793339862,
-0.002048963833124546,
-0.05725905086428903,
0.009937200282198435,
-0.015419155495378558,
-0.03165717775692895,
-0.08828747556806149,
-0.0975068220940425,
0.001431272351737689,
-0.018955314947644398,
0.012471670893499341,
0.02706974474908458,
-0.12060646860622755,
0.061813798881866736,
0.03282750857029285,
-0.034725160754620975,
0.028906834460317384,
0.000978923431768766,
-0.031109409680964647,
0.03519408025847396,
0.04112366610709155,
-0.01354290744632157,
0.02879291313706437,
-0.039703750032482533,
-0.005349085568597863,
0.024194602173261682,
0.03141862493917326,
-0.033024172969691325,
0.03870411685694867,
-0.05968122945750201,
-0.08423758106212033,
-0.031705962726084926,
-0.016437399299890867,
-0.047409524912486845,
0.06189467318665239,
-0.012600086219363751,
-0.014235764404831987,
-0.009784704197603482,
0.0069976906665835704,
0.011885565505007786,
0.014456542430295332,
-0.03838835669005236,
0.005333872770962497,
1,
0.20245287357378822,
-0.04585609495197025
],
[
-0.0008387004712326996,
-0.011691566560833646,
-0.0031167788893623296,
0.03146507687279525,
0.011845726829113742,
-0.032899485530652375,
0.00574973731068094,
-0.09821136084010303,
0.0594466310346893,
-0.05936709342638509,
0.015368995477880662,
0.050811544029446105,
0.03810576009982164,
0.006898912816087958,
0.012076671414924843,
0.18878877871731548,
0.003052436153181428,
0.1977912291854145,
0.22982974944604675,
0.06852960163142395,
-0.04315007530393975,
0.06019165287212961,
0.06698266702360248,
0.09561914136007107,
0.08023098212895718,
-0.19635749027716293,
0.06054959536506916,
0.16678616063552565,
-0.1835870142850241,
0.005927004062525821,
-0.08057390805007991,
0.03903947823362395,
0.0222667360927309,
0.05132371532586345,
-0.07667596726267506,
0.1108391437154425,
0.11400754549935195,
0.016548953754172344,
-0.1574977604244828,
0.05106493977055598,
0.0885048320943334,
0.07053433889257732,
0.041397028672044374,
-0.013624260733549562,
0.08633680587578428,
-0.0006781183969891244,
-0.05897644330874224,
0.14588166385214468,
0.0631786173612733,
0.02243452930764989,
-0.06946412051573217,
-0.14244925289377533,
0.09151593283428885,
0.03684938702398462,
0.09219024279264115,
-0.10017472560029807,
0.20609784904471212,
-0.1459534150397722,
0.14623836043702887,
0.14229307726965407,
0.057561902049014804,
0.028940136547431744,
0.021578057832832908,
0.0482657464256531,
0.08831275276053487,
-0.11552561460039934,
-1.5704069541035621e-06,
-0.03106537873575294,
-0.07530911638558206,
0.009746615608799076,
0.026561305262562517,
-0.006213611128850575,
0.20245287357378822,
1,
0.202301267755556
],
[
-0.03047303628015024,
-0.07959851790075388,
-0.16380931577091148,
0.2547573502139699,
0.042106016066563355,
-0.25309204131214885,
0.0015173935763670237,
-0.017078650564686607,
-0.06573503174195633,
0.06162913272815378,
0.19967722625129594,
0.07503192231642285,
0.0018914223017047222,
-0.08187986195308612,
0.1610077737062108,
0.7835456113843237,
-0.1086270972695443,
0.504297175093091,
0.5014353821077956,
0.2253702403125615,
0.14381445916813645,
0.09794217667224688,
0.10441577346940069,
0.04125674705752859,
0.46581143360024846,
-0.6480234752256352,
0.0944427112499175,
0.4445163366279452,
-0.6118334877813076,
0.06161323257110658,
-0.2903027403705881,
-0.04815347459005512,
0.35967663312618064,
0.05323329280512587,
-0.031225787844299704,
0.1916888789020209,
0.6020422814414277,
-0.05063854507223604,
-0.4056509232234902,
0.19975935469806486,
0.2111885885892675,
0.6047144846292783,
0.31135402669959245,
-0.00999239700593434,
0.7117061511024302,
0.20969465592752243,
-0.03017500037561527,
0.5693126295659892,
0.2581749248797554,
0.16926554693331156,
-0.1114081974082277,
-0.6168669685619569,
0.5518206950104778,
0.10693029962567567,
0.4454344326389212,
-0.34840092738222384,
0.48172978591824045,
-0.5082316799671449,
0.6401543580531925,
0.6075353838509889,
0.12079187995952888,
0.14792531402015788,
0.1766089143291643,
0.30598288316822747,
0.3227857346419753,
-0.12738527654209783,
0.04215866955782426,
0.0966239807980718,
0.091881076190269,
-0.016989857604916444,
0.041309605129427975,
-0.02045101634599536,
-0.04585609495197025,
0.202301267755556,
1
]
]
}
],
"layout": {
"annotations": [
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "Id",
"xref": "x",
"y": "Id",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "MSSubClass",
"xref": "x",
"y": "Id",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "MSZoning",
"xref": "x",
"y": "Id",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "LotArea",
"xref": "x",
"y": "Id",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Street",
"xref": "x",
"y": "Id",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "LotShape",
"xref": "x",
"y": "Id",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "LandContour",
"xref": "x",
"y": "Id",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Utilities",
"xref": "x",
"y": "Id",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "LotConfig",
"xref": "x",
"y": "Id",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "LandSlope",
"xref": "x",
"y": "Id",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "Neighborhood",
"xref": "x",
"y": "Id",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "Condition1",
"xref": "x",
"y": "Id",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "Condition2",
"xref": "x",
"y": "Id",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "BldgType",
"xref": "x",
"y": "Id",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "HouseStyle",
"xref": "x",
"y": "Id",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "OverallQual",
"xref": "x",
"y": "Id",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "OverallCond",
"xref": "x",
"y": "Id",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "YearBuilt",
"xref": "x",
"y": "Id",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "YearRemodAdd",
"xref": "x",
"y": "Id",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "RoofStyle",
"xref": "x",
"y": "Id",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "RoofMatl",
"xref": "x",
"y": "Id",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "Exterior1st",
"xref": "x",
"y": "Id",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "Exterior2nd",
"xref": "x",
"y": "Id",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "MasVnrType",
"xref": "x",
"y": "Id",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "MasVnrArea",
"xref": "x",
"y": "Id",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "ExterQual",
"xref": "x",
"y": "Id",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "ExterCond",
"xref": "x",
"y": "Id",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "Foundation",
"xref": "x",
"y": "Id",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "BsmtQual",
"xref": "x",
"y": "Id",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "BsmtCond",
"xref": "x",
"y": "Id",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "BsmtExposure",
"xref": "x",
"y": "Id",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "BsmtFinType1",
"xref": "x",
"y": "Id",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "BsmtFinSF1",
"xref": "x",
"y": "Id",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "BsmtFinType2",
"xref": "x",
"y": "Id",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "BsmtFinSF2",
"xref": "x",
"y": "Id",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "BsmtUnfSF",
"xref": "x",
"y": "Id",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "TotalBsmtSF",
"xref": "x",
"y": "Id",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "Heating",
"xref": "x",
"y": "Id",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "HeatingQC",
"xref": "x",
"y": "Id",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "CentralAir",
"xref": "x",
"y": "Id",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "Electrical",
"xref": "x",
"y": "Id",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "1stFlrSF",
"xref": "x",
"y": "Id",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "2ndFlrSF",
"xref": "x",
"y": "Id",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "LowQualFinSF",
"xref": "x",
"y": "Id",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "GrLivArea",
"xref": "x",
"y": "Id",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "BsmtFullBath",
"xref": "x",
"y": "Id",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "BsmtHalfBath",
"xref": "x",
"y": "Id",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "FullBath",
"xref": "x",
"y": "Id",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "HalfBath",
"xref": "x",
"y": "Id",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "BedroomAbvGr",
"xref": "x",
"y": "Id",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "KitchenAbvGr",
"xref": "x",
"y": "Id",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "KitchenQual",
"xref": "x",
"y": "Id",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "TotRmsAbvGrd",
"xref": "x",
"y": "Id",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "Functional",
"xref": "x",
"y": "Id",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "Fireplaces",
"xref": "x",
"y": "Id",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "GarageType",
"xref": "x",
"y": "Id",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "GarageYrBlt",
"xref": "x",
"y": "Id",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "GarageFinish",
"xref": "x",
"y": "Id",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "GarageCars",
"xref": "x",
"y": "Id",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "GarageArea",
"xref": "x",
"y": "Id",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "GarageQual",
"xref": "x",
"y": "Id",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "GarageCond",
"xref": "x",
"y": "Id",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "PavedDrive",
"xref": "x",
"y": "Id",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "WoodDeckSF",
"xref": "x",
"y": "Id",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "OpenPorchSF",
"xref": "x",
"y": "Id",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "EnclosedPorch",
"xref": "x",
"y": "Id",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "3SsnPorch",
"xref": "x",
"y": "Id",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "ScreenPorch",
"xref": "x",
"y": "Id",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "PoolArea",
"xref": "x",
"y": "Id",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "MiscVal",
"xref": "x",
"y": "Id",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "MoSold",
"xref": "x",
"y": "Id",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "YrSold",
"xref": "x",
"y": "Id",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "SaleType",
"xref": "x",
"y": "Id",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "SaleCondition",
"xref": "x",
"y": "Id",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "SalePrice",
"xref": "x",
"y": "Id",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "Id",
"xref": "x",
"y": "MSSubClass",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "MSSubClass",
"xref": "x",
"y": "MSSubClass",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "MSZoning",
"xref": "x",
"y": "MSSubClass",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.13",
"x": "LotArea",
"xref": "x",
"y": "MSSubClass",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "Street",
"xref": "x",
"y": "MSSubClass",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "LotShape",
"xref": "x",
"y": "MSSubClass",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "LandContour",
"xref": "x",
"y": "MSSubClass",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "Utilities",
"xref": "x",
"y": "MSSubClass",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "LotConfig",
"xref": "x",
"y": "MSSubClass",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "LandSlope",
"xref": "x",
"y": "MSSubClass",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "Neighborhood",
"xref": "x",
"y": "MSSubClass",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "Condition1",
"xref": "x",
"y": "MSSubClass",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "Condition2",
"xref": "x",
"y": "MSSubClass",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.75",
"x": "BldgType",
"xref": "x",
"y": "MSSubClass",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.4",
"x": "HouseStyle",
"xref": "x",
"y": "MSSubClass",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "OverallQual",
"xref": "x",
"y": "MSSubClass",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "OverallCond",
"xref": "x",
"y": "MSSubClass",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "YearBuilt",
"xref": "x",
"y": "MSSubClass",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "YearRemodAdd",
"xref": "x",
"y": "MSSubClass",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.12",
"x": "RoofStyle",
"xref": "x",
"y": "MSSubClass",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "RoofMatl",
"xref": "x",
"y": "MSSubClass",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "Exterior1st",
"xref": "x",
"y": "MSSubClass",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.14",
"x": "Exterior2nd",
"xref": "x",
"y": "MSSubClass",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "MasVnrType",
"xref": "x",
"y": "MSSubClass",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "MasVnrArea",
"xref": "x",
"y": "MSSubClass",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "ExterQual",
"xref": "x",
"y": "MSSubClass",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "ExterCond",
"xref": "x",
"y": "MSSubClass",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "Foundation",
"xref": "x",
"y": "MSSubClass",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "BsmtQual",
"xref": "x",
"y": "MSSubClass",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "BsmtCond",
"xref": "x",
"y": "MSSubClass",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "BsmtExposure",
"xref": "x",
"y": "MSSubClass",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "BsmtFinType1",
"xref": "x",
"y": "MSSubClass",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "BsmtFinSF1",
"xref": "x",
"y": "MSSubClass",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "BsmtFinType2",
"xref": "x",
"y": "MSSubClass",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "BsmtFinSF2",
"xref": "x",
"y": "MSSubClass",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.14",
"x": "BsmtUnfSF",
"xref": "x",
"y": "MSSubClass",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.26",
"x": "TotalBsmtSF",
"xref": "x",
"y": "MSSubClass",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "Heating",
"xref": "x",
"y": "MSSubClass",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "HeatingQC",
"xref": "x",
"y": "MSSubClass",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "CentralAir",
"xref": "x",
"y": "MSSubClass",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "Electrical",
"xref": "x",
"y": "MSSubClass",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.26",
"x": "1stFlrSF",
"xref": "x",
"y": "MSSubClass",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.31",
"x": "2ndFlrSF",
"xref": "x",
"y": "MSSubClass",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "LowQualFinSF",
"xref": "x",
"y": "MSSubClass",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "GrLivArea",
"xref": "x",
"y": "MSSubClass",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "BsmtFullBath",
"xref": "x",
"y": "MSSubClass",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "BsmtHalfBath",
"xref": "x",
"y": "MSSubClass",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "FullBath",
"xref": "x",
"y": "MSSubClass",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.2",
"x": "HalfBath",
"xref": "x",
"y": "MSSubClass",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "BedroomAbvGr",
"xref": "x",
"y": "MSSubClass",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.24",
"x": "KitchenAbvGr",
"xref": "x",
"y": "MSSubClass",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "KitchenQual",
"xref": "x",
"y": "MSSubClass",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "TotRmsAbvGrd",
"xref": "x",
"y": "MSSubClass",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "Functional",
"xref": "x",
"y": "MSSubClass",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "Fireplaces",
"xref": "x",
"y": "MSSubClass",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "GarageType",
"xref": "x",
"y": "MSSubClass",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "GarageYrBlt",
"xref": "x",
"y": "MSSubClass",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "GarageFinish",
"xref": "x",
"y": "MSSubClass",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "GarageCars",
"xref": "x",
"y": "MSSubClass",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "GarageArea",
"xref": "x",
"y": "MSSubClass",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "GarageQual",
"xref": "x",
"y": "MSSubClass",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "GarageCond",
"xref": "x",
"y": "MSSubClass",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "PavedDrive",
"xref": "x",
"y": "MSSubClass",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "WoodDeckSF",
"xref": "x",
"y": "MSSubClass",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "OpenPorchSF",
"xref": "x",
"y": "MSSubClass",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "EnclosedPorch",
"xref": "x",
"y": "MSSubClass",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "3SsnPorch",
"xref": "x",
"y": "MSSubClass",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "ScreenPorch",
"xref": "x",
"y": "MSSubClass",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "PoolArea",
"xref": "x",
"y": "MSSubClass",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "MiscVal",
"xref": "x",
"y": "MSSubClass",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "MoSold",
"xref": "x",
"y": "MSSubClass",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "YrSold",
"xref": "x",
"y": "MSSubClass",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "SaleType",
"xref": "x",
"y": "MSSubClass",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "SaleCondition",
"xref": "x",
"y": "MSSubClass",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "SalePrice",
"xref": "x",
"y": "MSSubClass",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "Id",
"xref": "x",
"y": "MSZoning",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "MSSubClass",
"xref": "x",
"y": "MSZoning",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "MSZoning",
"xref": "x",
"y": "MSZoning",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "LotArea",
"xref": "x",
"y": "MSZoning",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "Street",
"xref": "x",
"y": "MSZoning",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "LotShape",
"xref": "x",
"y": "MSZoning",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "LandContour",
"xref": "x",
"y": "MSZoning",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "Utilities",
"xref": "x",
"y": "MSZoning",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "LotConfig",
"xref": "x",
"y": "MSZoning",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "LandSlope",
"xref": "x",
"y": "MSZoning",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.26",
"x": "Neighborhood",
"xref": "x",
"y": "MSZoning",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "Condition1",
"xref": "x",
"y": "MSZoning",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "Condition2",
"xref": "x",
"y": "MSZoning",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "BldgType",
"xref": "x",
"y": "MSZoning",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.12",
"x": "HouseStyle",
"xref": "x",
"y": "MSZoning",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.17",
"x": "OverallQual",
"xref": "x",
"y": "MSZoning",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.19",
"x": "OverallCond",
"xref": "x",
"y": "MSZoning",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.33",
"x": "YearBuilt",
"xref": "x",
"y": "MSZoning",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.18",
"x": "YearRemodAdd",
"xref": "x",
"y": "MSZoning",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "RoofStyle",
"xref": "x",
"y": "MSZoning",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "RoofMatl",
"xref": "x",
"y": "MSZoning",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Exterior1st",
"xref": "x",
"y": "MSZoning",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "Exterior2nd",
"xref": "x",
"y": "MSZoning",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "MasVnrType",
"xref": "x",
"y": "MSZoning",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "MasVnrArea",
"xref": "x",
"y": "MSZoning",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.2",
"x": "ExterQual",
"xref": "x",
"y": "MSZoning",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "ExterCond",
"xref": "x",
"y": "MSZoning",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.25",
"x": "Foundation",
"xref": "x",
"y": "MSZoning",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.13",
"x": "BsmtQual",
"xref": "x",
"y": "MSZoning",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "BsmtCond",
"xref": "x",
"y": "MSZoning",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "BsmtExposure",
"xref": "x",
"y": "MSZoning",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "BsmtFinType1",
"xref": "x",
"y": "MSZoning",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "BsmtFinSF1",
"xref": "x",
"y": "MSZoning",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "BsmtFinType2",
"xref": "x",
"y": "MSZoning",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "BsmtFinSF2",
"xref": "x",
"y": "MSZoning",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "BsmtUnfSF",
"xref": "x",
"y": "MSZoning",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "TotalBsmtSF",
"xref": "x",
"y": "MSZoning",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "Heating",
"xref": "x",
"y": "MSZoning",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.15",
"x": "HeatingQC",
"xref": "x",
"y": "MSZoning",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "CentralAir",
"xref": "x",
"y": "MSZoning",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.09",
"x": "Electrical",
"xref": "x",
"y": "MSZoning",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "1stFlrSF",
"xref": "x",
"y": "MSZoning",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "2ndFlrSF",
"xref": "x",
"y": "MSZoning",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "LowQualFinSF",
"xref": "x",
"y": "MSZoning",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "GrLivArea",
"xref": "x",
"y": "MSZoning",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "BsmtFullBath",
"xref": "x",
"y": "MSZoning",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "BsmtHalfBath",
"xref": "x",
"y": "MSZoning",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.21",
"x": "FullBath",
"xref": "x",
"y": "MSZoning",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.14",
"x": "HalfBath",
"xref": "x",
"y": "MSZoning",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "BedroomAbvGr",
"xref": "x",
"y": "MSZoning",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "KitchenAbvGr",
"xref": "x",
"y": "MSZoning",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "KitchenQual",
"xref": "x",
"y": "MSZoning",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "TotRmsAbvGrd",
"xref": "x",
"y": "MSZoning",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "Functional",
"xref": "x",
"y": "MSZoning",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "Fireplaces",
"xref": "x",
"y": "MSZoning",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.13",
"x": "GarageType",
"xref": "x",
"y": "MSZoning",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.27",
"x": "GarageYrBlt",
"xref": "x",
"y": "MSZoning",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.16",
"x": "GarageFinish",
"xref": "x",
"y": "MSZoning",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.16",
"x": "GarageCars",
"xref": "x",
"y": "MSZoning",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.2",
"x": "GarageArea",
"xref": "x",
"y": "MSZoning",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.16",
"x": "GarageQual",
"xref": "x",
"y": "MSZoning",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.09",
"x": "GarageCond",
"xref": "x",
"y": "MSZoning",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.12",
"x": "PavedDrive",
"xref": "x",
"y": "MSZoning",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "WoodDeckSF",
"xref": "x",
"y": "MSZoning",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.14",
"x": "OpenPorchSF",
"xref": "x",
"y": "MSZoning",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "EnclosedPorch",
"xref": "x",
"y": "MSZoning",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "3SsnPorch",
"xref": "x",
"y": "MSZoning",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "ScreenPorch",
"xref": "x",
"y": "MSZoning",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "PoolArea",
"xref": "x",
"y": "MSZoning",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "MiscVal",
"xref": "x",
"y": "MSZoning",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "MoSold",
"xref": "x",
"y": "MSZoning",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "YrSold",
"xref": "x",
"y": "MSZoning",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "SaleType",
"xref": "x",
"y": "MSZoning",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "SaleCondition",
"xref": "x",
"y": "MSZoning",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.16",
"x": "SalePrice",
"xref": "x",
"y": "MSZoning",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "Id",
"xref": "x",
"y": "LotArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.13",
"x": "MSSubClass",
"xref": "x",
"y": "LotArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "MSZoning",
"xref": "x",
"y": "LotArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "LotArea",
"xref": "x",
"y": "LotArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.22",
"x": "Street",
"xref": "x",
"y": "LotArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.16",
"x": "LotShape",
"xref": "x",
"y": "LotArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.17",
"x": "LandContour",
"xref": "x",
"y": "LotArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Utilities",
"xref": "x",
"y": "LotArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.12",
"x": "LotConfig",
"xref": "x",
"y": "LotArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.46",
"x": "LandSlope",
"xref": "x",
"y": "LotArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "Neighborhood",
"xref": "x",
"y": "LotArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "Condition1",
"xref": "x",
"y": "LotArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "Condition2",
"xref": "x",
"y": "LotArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.2",
"x": "BldgType",
"xref": "x",
"y": "LotArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "HouseStyle",
"xref": "x",
"y": "LotArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "OverallQual",
"xref": "x",
"y": "LotArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "OverallCond",
"xref": "x",
"y": "LotArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "YearBuilt",
"xref": "x",
"y": "LotArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "YearRemodAdd",
"xref": "x",
"y": "LotArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "RoofStyle",
"xref": "x",
"y": "LotArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.15",
"x": "RoofMatl",
"xref": "x",
"y": "LotArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "Exterior1st",
"xref": "x",
"y": "LotArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "Exterior2nd",
"xref": "x",
"y": "LotArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "MasVnrType",
"xref": "x",
"y": "LotArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "MasVnrArea",
"xref": "x",
"y": "LotArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "ExterQual",
"xref": "x",
"y": "LotArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "ExterCond",
"xref": "x",
"y": "LotArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "Foundation",
"xref": "x",
"y": "LotArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "BsmtQual",
"xref": "x",
"y": "LotArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "BsmtCond",
"xref": "x",
"y": "LotArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.14",
"x": "BsmtExposure",
"xref": "x",
"y": "LotArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "BsmtFinType1",
"xref": "x",
"y": "LotArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.21",
"x": "BsmtFinSF1",
"xref": "x",
"y": "LotArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "BsmtFinType2",
"xref": "x",
"y": "LotArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.11",
"x": "BsmtFinSF2",
"xref": "x",
"y": "LotArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "BsmtUnfSF",
"xref": "x",
"y": "LotArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.27",
"x": "TotalBsmtSF",
"xref": "x",
"y": "LotArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "Heating",
"xref": "x",
"y": "LotArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "HeatingQC",
"xref": "x",
"y": "LotArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "CentralAir",
"xref": "x",
"y": "LotArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "Electrical",
"xref": "x",
"y": "LotArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.29",
"x": "1stFlrSF",
"xref": "x",
"y": "LotArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "2ndFlrSF",
"xref": "x",
"y": "LotArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "LowQualFinSF",
"xref": "x",
"y": "LotArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.26",
"x": "GrLivArea",
"xref": "x",
"y": "LotArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.16",
"x": "BsmtFullBath",
"xref": "x",
"y": "LotArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "BsmtHalfBath",
"xref": "x",
"y": "LotArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "FullBath",
"xref": "x",
"y": "LotArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "HalfBath",
"xref": "x",
"y": "LotArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "BedroomAbvGr",
"xref": "x",
"y": "LotArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "KitchenAbvGr",
"xref": "x",
"y": "LotArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "KitchenQual",
"xref": "x",
"y": "LotArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.19",
"x": "TotRmsAbvGrd",
"xref": "x",
"y": "LotArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "Functional",
"xref": "x",
"y": "LotArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.26",
"x": "Fireplaces",
"xref": "x",
"y": "LotArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.13",
"x": "GarageType",
"xref": "x",
"y": "LotArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "GarageYrBlt",
"xref": "x",
"y": "LotArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "GarageFinish",
"xref": "x",
"y": "LotArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "GarageCars",
"xref": "x",
"y": "LotArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.17",
"x": "GarageArea",
"xref": "x",
"y": "LotArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "GarageQual",
"xref": "x",
"y": "LotArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "GarageCond",
"xref": "x",
"y": "LotArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "PavedDrive",
"xref": "x",
"y": "LotArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.17",
"x": "WoodDeckSF",
"xref": "x",
"y": "LotArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "OpenPorchSF",
"xref": "x",
"y": "LotArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "EnclosedPorch",
"xref": "x",
"y": "LotArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "3SsnPorch",
"xref": "x",
"y": "LotArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "ScreenPorch",
"xref": "x",
"y": "LotArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "PoolArea",
"xref": "x",
"y": "LotArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "MiscVal",
"xref": "x",
"y": "LotArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "MoSold",
"xref": "x",
"y": "LotArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "YrSold",
"xref": "x",
"y": "LotArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "SaleType",
"xref": "x",
"y": "LotArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "SaleCondition",
"xref": "x",
"y": "LotArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.25",
"x": "SalePrice",
"xref": "x",
"y": "LotArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Id",
"xref": "x",
"y": "Street",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "MSSubClass",
"xref": "x",
"y": "Street",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "MSZoning",
"xref": "x",
"y": "Street",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.22",
"x": "LotArea",
"xref": "x",
"y": "Street",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "Street",
"xref": "x",
"y": "Street",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "LotShape",
"xref": "x",
"y": "Street",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "LandContour",
"xref": "x",
"y": "Street",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "Utilities",
"xref": "x",
"y": "Street",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "LotConfig",
"xref": "x",
"y": "Street",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.21",
"x": "LandSlope",
"xref": "x",
"y": "Street",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "Neighborhood",
"xref": "x",
"y": "Street",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "Condition1",
"xref": "x",
"y": "Street",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "Condition2",
"xref": "x",
"y": "Street",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "BldgType",
"xref": "x",
"y": "Street",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "HouseStyle",
"xref": "x",
"y": "Street",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "OverallQual",
"xref": "x",
"y": "Street",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "OverallCond",
"xref": "x",
"y": "Street",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "YearBuilt",
"xref": "x",
"y": "Street",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "YearRemodAdd",
"xref": "x",
"y": "Street",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "RoofStyle",
"xref": "x",
"y": "Street",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "RoofMatl",
"xref": "x",
"y": "Street",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "Exterior1st",
"xref": "x",
"y": "Street",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "Exterior2nd",
"xref": "x",
"y": "Street",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "MasVnrType",
"xref": "x",
"y": "Street",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "MasVnrArea",
"xref": "x",
"y": "Street",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "ExterQual",
"xref": "x",
"y": "Street",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "ExterCond",
"xref": "x",
"y": "Street",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "Foundation",
"xref": "x",
"y": "Street",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "BsmtQual",
"xref": "x",
"y": "Street",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "BsmtCond",
"xref": "x",
"y": "Street",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "BsmtExposure",
"xref": "x",
"y": "Street",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "BsmtFinType1",
"xref": "x",
"y": "Street",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "BsmtFinSF1",
"xref": "x",
"y": "Street",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "BsmtFinType2",
"xref": "x",
"y": "Street",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "BsmtFinSF2",
"xref": "x",
"y": "Street",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "BsmtUnfSF",
"xref": "x",
"y": "Street",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "TotalBsmtSF",
"xref": "x",
"y": "Street",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Heating",
"xref": "x",
"y": "Street",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "HeatingQC",
"xref": "x",
"y": "Street",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "CentralAir",
"xref": "x",
"y": "Street",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "Electrical",
"xref": "x",
"y": "Street",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "1stFlrSF",
"xref": "x",
"y": "Street",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "2ndFlrSF",
"xref": "x",
"y": "Street",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "LowQualFinSF",
"xref": "x",
"y": "Street",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "GrLivArea",
"xref": "x",
"y": "Street",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "BsmtFullBath",
"xref": "x",
"y": "Street",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "BsmtHalfBath",
"xref": "x",
"y": "Street",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "FullBath",
"xref": "x",
"y": "Street",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "HalfBath",
"xref": "x",
"y": "Street",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "BedroomAbvGr",
"xref": "x",
"y": "Street",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "KitchenAbvGr",
"xref": "x",
"y": "Street",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "KitchenQual",
"xref": "x",
"y": "Street",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "TotRmsAbvGrd",
"xref": "x",
"y": "Street",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "Functional",
"xref": "x",
"y": "Street",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "Fireplaces",
"xref": "x",
"y": "Street",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "GarageType",
"xref": "x",
"y": "Street",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "GarageYrBlt",
"xref": "x",
"y": "Street",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "GarageFinish",
"xref": "x",
"y": "Street",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "GarageCars",
"xref": "x",
"y": "Street",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "GarageArea",
"xref": "x",
"y": "Street",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "GarageQual",
"xref": "x",
"y": "Street",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "GarageCond",
"xref": "x",
"y": "Street",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "PavedDrive",
"xref": "x",
"y": "Street",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "WoodDeckSF",
"xref": "x",
"y": "Street",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "OpenPorchSF",
"xref": "x",
"y": "Street",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "EnclosedPorch",
"xref": "x",
"y": "Street",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "3SsnPorch",
"xref": "x",
"y": "Street",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "ScreenPorch",
"xref": "x",
"y": "Street",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "PoolArea",
"xref": "x",
"y": "Street",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "MiscVal",
"xref": "x",
"y": "Street",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "MoSold",
"xref": "x",
"y": "Street",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "YrSold",
"xref": "x",
"y": "Street",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "SaleType",
"xref": "x",
"y": "Street",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "SaleCondition",
"xref": "x",
"y": "Street",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "SalePrice",
"xref": "x",
"y": "Street",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "Id",
"xref": "x",
"y": "LotShape",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "MSSubClass",
"xref": "x",
"y": "LotShape",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "MSZoning",
"xref": "x",
"y": "LotShape",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.16",
"x": "LotArea",
"xref": "x",
"y": "LotShape",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "Street",
"xref": "x",
"y": "LotShape",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "LotShape",
"xref": "x",
"y": "LotShape",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "LandContour",
"xref": "x",
"y": "LotShape",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "Utilities",
"xref": "x",
"y": "LotShape",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.22",
"x": "LotConfig",
"xref": "x",
"y": "LotShape",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "LandSlope",
"xref": "x",
"y": "LotShape",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "Neighborhood",
"xref": "x",
"y": "LotShape",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.12",
"x": "Condition1",
"xref": "x",
"y": "LotShape",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "Condition2",
"xref": "x",
"y": "LotShape",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.11",
"x": "BldgType",
"xref": "x",
"y": "LotShape",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.11",
"x": "HouseStyle",
"xref": "x",
"y": "LotShape",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.19",
"x": "OverallQual",
"xref": "x",
"y": "LotShape",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "OverallCond",
"xref": "x",
"y": "LotShape",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.23",
"x": "YearBuilt",
"xref": "x",
"y": "LotShape",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.16",
"x": "YearRemodAdd",
"xref": "x",
"y": "LotShape",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "RoofStyle",
"xref": "x",
"y": "LotShape",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "RoofMatl",
"xref": "x",
"y": "LotShape",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "Exterior1st",
"xref": "x",
"y": "LotShape",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "Exterior2nd",
"xref": "x",
"y": "LotShape",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "MasVnrType",
"xref": "x",
"y": "LotShape",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "MasVnrArea",
"xref": "x",
"y": "LotShape",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "ExterQual",
"xref": "x",
"y": "LotShape",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "ExterCond",
"xref": "x",
"y": "LotShape",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.17",
"x": "Foundation",
"xref": "x",
"y": "LotShape",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.16",
"x": "BsmtQual",
"xref": "x",
"y": "LotShape",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "BsmtCond",
"xref": "x",
"y": "LotShape",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "BsmtExposure",
"xref": "x",
"y": "LotShape",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "BsmtFinType1",
"xref": "x",
"y": "LotShape",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.12",
"x": "BsmtFinSF1",
"xref": "x",
"y": "LotShape",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "BsmtFinType2",
"xref": "x",
"y": "LotShape",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "BsmtFinSF2",
"xref": "x",
"y": "LotShape",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "BsmtUnfSF",
"xref": "x",
"y": "LotShape",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.16",
"x": "TotalBsmtSF",
"xref": "x",
"y": "LotShape",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "Heating",
"xref": "x",
"y": "LotShape",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "HeatingQC",
"xref": "x",
"y": "LotShape",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "CentralAir",
"xref": "x",
"y": "LotShape",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.09",
"x": "Electrical",
"xref": "x",
"y": "LotShape",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.17",
"x": "1stFlrSF",
"xref": "x",
"y": "LotShape",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "2ndFlrSF",
"xref": "x",
"y": "LotShape",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "LowQualFinSF",
"xref": "x",
"y": "LotShape",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.18",
"x": "GrLivArea",
"xref": "x",
"y": "LotShape",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "BsmtFullBath",
"xref": "x",
"y": "LotShape",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "BsmtHalfBath",
"xref": "x",
"y": "LotShape",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.18",
"x": "FullBath",
"xref": "x",
"y": "LotShape",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.11",
"x": "HalfBath",
"xref": "x",
"y": "LotShape",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "BedroomAbvGr",
"xref": "x",
"y": "LotShape",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "KitchenAbvGr",
"xref": "x",
"y": "LotShape",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "KitchenQual",
"xref": "x",
"y": "LotShape",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.13",
"x": "TotRmsAbvGrd",
"xref": "x",
"y": "LotShape",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "Functional",
"xref": "x",
"y": "LotShape",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.19",
"x": "Fireplaces",
"xref": "x",
"y": "LotShape",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.18",
"x": "GarageType",
"xref": "x",
"y": "LotShape",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.19",
"x": "GarageYrBlt",
"xref": "x",
"y": "LotShape",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.23",
"x": "GarageFinish",
"xref": "x",
"y": "LotShape",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.18",
"x": "GarageCars",
"xref": "x",
"y": "LotShape",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.15",
"x": "GarageArea",
"xref": "x",
"y": "LotShape",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "GarageQual",
"xref": "x",
"y": "LotShape",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "GarageCond",
"xref": "x",
"y": "LotShape",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.12",
"x": "PavedDrive",
"xref": "x",
"y": "LotShape",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.16",
"x": "WoodDeckSF",
"xref": "x",
"y": "LotShape",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "OpenPorchSF",
"xref": "x",
"y": "LotShape",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "EnclosedPorch",
"xref": "x",
"y": "LotShape",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "3SsnPorch",
"xref": "x",
"y": "LotShape",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "ScreenPorch",
"xref": "x",
"y": "LotShape",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "PoolArea",
"xref": "x",
"y": "LotShape",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "MiscVal",
"xref": "x",
"y": "LotShape",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "MoSold",
"xref": "x",
"y": "LotShape",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "YrSold",
"xref": "x",
"y": "LotShape",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "SaleType",
"xref": "x",
"y": "LotShape",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "SaleCondition",
"xref": "x",
"y": "LotShape",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.25",
"x": "SalePrice",
"xref": "x",
"y": "LotShape",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "Id",
"xref": "x",
"y": "LandContour",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "MSSubClass",
"xref": "x",
"y": "LandContour",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "MSZoning",
"xref": "x",
"y": "LandContour",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.17",
"x": "LotArea",
"xref": "x",
"y": "LandContour",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "Street",
"xref": "x",
"y": "LandContour",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "LotShape",
"xref": "x",
"y": "LandContour",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "LandContour",
"xref": "x",
"y": "LandContour",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Utilities",
"xref": "x",
"y": "LandContour",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "LotConfig",
"xref": "x",
"y": "LandContour",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.38",
"x": "LandSlope",
"xref": "x",
"y": "LandContour",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "Neighborhood",
"xref": "x",
"y": "LandContour",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "Condition1",
"xref": "x",
"y": "LandContour",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "Condition2",
"xref": "x",
"y": "LandContour",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "BldgType",
"xref": "x",
"y": "LandContour",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "HouseStyle",
"xref": "x",
"y": "LandContour",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "OverallQual",
"xref": "x",
"y": "LandContour",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "OverallCond",
"xref": "x",
"y": "LandContour",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.15",
"x": "YearBuilt",
"xref": "x",
"y": "LandContour",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "YearRemodAdd",
"xref": "x",
"y": "LandContour",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "RoofStyle",
"xref": "x",
"y": "LandContour",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "RoofMatl",
"xref": "x",
"y": "LandContour",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "Exterior1st",
"xref": "x",
"y": "LandContour",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "Exterior2nd",
"xref": "x",
"y": "LandContour",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "MasVnrType",
"xref": "x",
"y": "LandContour",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "MasVnrArea",
"xref": "x",
"y": "LandContour",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "ExterQual",
"xref": "x",
"y": "LandContour",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "ExterCond",
"xref": "x",
"y": "LandContour",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "Foundation",
"xref": "x",
"y": "LandContour",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "BsmtQual",
"xref": "x",
"y": "LandContour",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "BsmtCond",
"xref": "x",
"y": "LandContour",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "BsmtExposure",
"xref": "x",
"y": "LandContour",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "BsmtFinType1",
"xref": "x",
"y": "LandContour",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "BsmtFinSF1",
"xref": "x",
"y": "LandContour",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "BsmtFinType2",
"xref": "x",
"y": "LandContour",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "BsmtFinSF2",
"xref": "x",
"y": "LandContour",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "BsmtUnfSF",
"xref": "x",
"y": "LandContour",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "TotalBsmtSF",
"xref": "x",
"y": "LandContour",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "Heating",
"xref": "x",
"y": "LandContour",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "HeatingQC",
"xref": "x",
"y": "LandContour",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.13",
"x": "CentralAir",
"xref": "x",
"y": "LandContour",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "Electrical",
"xref": "x",
"y": "LandContour",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "1stFlrSF",
"xref": "x",
"y": "LandContour",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "2ndFlrSF",
"xref": "x",
"y": "LandContour",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "LowQualFinSF",
"xref": "x",
"y": "LandContour",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "GrLivArea",
"xref": "x",
"y": "LandContour",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "BsmtFullBath",
"xref": "x",
"y": "LandContour",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "BsmtHalfBath",
"xref": "x",
"y": "LandContour",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "FullBath",
"xref": "x",
"y": "LandContour",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "HalfBath",
"xref": "x",
"y": "LandContour",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "BedroomAbvGr",
"xref": "x",
"y": "LandContour",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "KitchenAbvGr",
"xref": "x",
"y": "LandContour",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "KitchenQual",
"xref": "x",
"y": "LandContour",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "TotRmsAbvGrd",
"xref": "x",
"y": "LandContour",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "Functional",
"xref": "x",
"y": "LandContour",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "Fireplaces",
"xref": "x",
"y": "LandContour",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "GarageType",
"xref": "x",
"y": "LandContour",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.13",
"x": "GarageYrBlt",
"xref": "x",
"y": "LandContour",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "GarageFinish",
"xref": "x",
"y": "LandContour",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "GarageCars",
"xref": "x",
"y": "LandContour",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "GarageArea",
"xref": "x",
"y": "LandContour",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "GarageQual",
"xref": "x",
"y": "LandContour",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "GarageCond",
"xref": "x",
"y": "LandContour",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "PavedDrive",
"xref": "x",
"y": "LandContour",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "WoodDeckSF",
"xref": "x",
"y": "LandContour",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "OpenPorchSF",
"xref": "x",
"y": "LandContour",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "EnclosedPorch",
"xref": "x",
"y": "LandContour",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "3SsnPorch",
"xref": "x",
"y": "LandContour",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "ScreenPorch",
"xref": "x",
"y": "LandContour",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "PoolArea",
"xref": "x",
"y": "LandContour",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "MiscVal",
"xref": "x",
"y": "LandContour",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "MoSold",
"xref": "x",
"y": "LandContour",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "YrSold",
"xref": "x",
"y": "LandContour",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "SaleType",
"xref": "x",
"y": "LandContour",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "SaleCondition",
"xref": "x",
"y": "LandContour",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "SalePrice",
"xref": "x",
"y": "LandContour",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Id",
"xref": "x",
"y": "Utilities",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "MSSubClass",
"xref": "x",
"y": "Utilities",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "MSZoning",
"xref": "x",
"y": "Utilities",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "LotArea",
"xref": "x",
"y": "Utilities",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "Street",
"xref": "x",
"y": "Utilities",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "LotShape",
"xref": "x",
"y": "Utilities",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "LandContour",
"xref": "x",
"y": "Utilities",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "Utilities",
"xref": "x",
"y": "Utilities",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "LotConfig",
"xref": "x",
"y": "Utilities",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "LandSlope",
"xref": "x",
"y": "Utilities",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "Neighborhood",
"xref": "x",
"y": "Utilities",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "Condition1",
"xref": "x",
"y": "Utilities",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "Condition2",
"xref": "x",
"y": "Utilities",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "BldgType",
"xref": "x",
"y": "Utilities",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "HouseStyle",
"xref": "x",
"y": "Utilities",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "OverallQual",
"xref": "x",
"y": "Utilities",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "OverallCond",
"xref": "x",
"y": "Utilities",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "YearBuilt",
"xref": "x",
"y": "Utilities",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "YearRemodAdd",
"xref": "x",
"y": "Utilities",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "RoofStyle",
"xref": "x",
"y": "Utilities",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "RoofMatl",
"xref": "x",
"y": "Utilities",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "Exterior1st",
"xref": "x",
"y": "Utilities",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "Exterior2nd",
"xref": "x",
"y": "Utilities",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "MasVnrType",
"xref": "x",
"y": "Utilities",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "MasVnrArea",
"xref": "x",
"y": "Utilities",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "ExterQual",
"xref": "x",
"y": "Utilities",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "ExterCond",
"xref": "x",
"y": "Utilities",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "Foundation",
"xref": "x",
"y": "Utilities",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "BsmtQual",
"xref": "x",
"y": "Utilities",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "BsmtCond",
"xref": "x",
"y": "Utilities",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "BsmtExposure",
"xref": "x",
"y": "Utilities",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "BsmtFinType1",
"xref": "x",
"y": "Utilities",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "BsmtFinSF1",
"xref": "x",
"y": "Utilities",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "BsmtFinType2",
"xref": "x",
"y": "Utilities",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "BsmtFinSF2",
"xref": "x",
"y": "Utilities",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "BsmtUnfSF",
"xref": "x",
"y": "Utilities",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "TotalBsmtSF",
"xref": "x",
"y": "Utilities",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "Heating",
"xref": "x",
"y": "Utilities",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "HeatingQC",
"xref": "x",
"y": "Utilities",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "CentralAir",
"xref": "x",
"y": "Utilities",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "Electrical",
"xref": "x",
"y": "Utilities",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "1stFlrSF",
"xref": "x",
"y": "Utilities",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "2ndFlrSF",
"xref": "x",
"y": "Utilities",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "LowQualFinSF",
"xref": "x",
"y": "Utilities",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "GrLivArea",
"xref": "x",
"y": "Utilities",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "BsmtFullBath",
"xref": "x",
"y": "Utilities",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.11",
"x": "BsmtHalfBath",
"xref": "x",
"y": "Utilities",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "FullBath",
"xref": "x",
"y": "Utilities",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "HalfBath",
"xref": "x",
"y": "Utilities",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "BedroomAbvGr",
"xref": "x",
"y": "Utilities",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "KitchenAbvGr",
"xref": "x",
"y": "Utilities",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "KitchenQual",
"xref": "x",
"y": "Utilities",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "TotRmsAbvGrd",
"xref": "x",
"y": "Utilities",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Functional",
"xref": "x",
"y": "Utilities",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Fireplaces",
"xref": "x",
"y": "Utilities",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "GarageType",
"xref": "x",
"y": "Utilities",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "GarageYrBlt",
"xref": "x",
"y": "Utilities",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "GarageFinish",
"xref": "x",
"y": "Utilities",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "GarageCars",
"xref": "x",
"y": "Utilities",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "GarageArea",
"xref": "x",
"y": "Utilities",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "GarageQual",
"xref": "x",
"y": "Utilities",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "GarageCond",
"xref": "x",
"y": "Utilities",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "PavedDrive",
"xref": "x",
"y": "Utilities",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "WoodDeckSF",
"xref": "x",
"y": "Utilities",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "OpenPorchSF",
"xref": "x",
"y": "Utilities",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "EnclosedPorch",
"xref": "x",
"y": "Utilities",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "3SsnPorch",
"xref": "x",
"y": "Utilities",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "ScreenPorch",
"xref": "x",
"y": "Utilities",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "PoolArea",
"xref": "x",
"y": "Utilities",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "MiscVal",
"xref": "x",
"y": "Utilities",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "MoSold",
"xref": "x",
"y": "Utilities",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "YrSold",
"xref": "x",
"y": "Utilities",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.13",
"x": "SaleType",
"xref": "x",
"y": "Utilities",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "SaleCondition",
"xref": "x",
"y": "Utilities",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "SalePrice",
"xref": "x",
"y": "Utilities",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "Id",
"xref": "x",
"y": "LotConfig",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "MSSubClass",
"xref": "x",
"y": "LotConfig",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "MSZoning",
"xref": "x",
"y": "LotConfig",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.12",
"x": "LotArea",
"xref": "x",
"y": "LotConfig",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "Street",
"xref": "x",
"y": "LotConfig",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.22",
"x": "LotShape",
"xref": "x",
"y": "LotConfig",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "LandContour",
"xref": "x",
"y": "LotConfig",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "Utilities",
"xref": "x",
"y": "LotConfig",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "LotConfig",
"xref": "x",
"y": "LotConfig",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "LandSlope",
"xref": "x",
"y": "LotConfig",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "Neighborhood",
"xref": "x",
"y": "LotConfig",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Condition1",
"xref": "x",
"y": "LotConfig",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "Condition2",
"xref": "x",
"y": "LotConfig",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "BldgType",
"xref": "x",
"y": "LotConfig",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "HouseStyle",
"xref": "x",
"y": "LotConfig",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "OverallQual",
"xref": "x",
"y": "LotConfig",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "OverallCond",
"xref": "x",
"y": "LotConfig",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "YearBuilt",
"xref": "x",
"y": "LotConfig",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "YearRemodAdd",
"xref": "x",
"y": "LotConfig",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "RoofStyle",
"xref": "x",
"y": "LotConfig",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "RoofMatl",
"xref": "x",
"y": "LotConfig",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "Exterior1st",
"xref": "x",
"y": "LotConfig",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Exterior2nd",
"xref": "x",
"y": "LotConfig",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "MasVnrType",
"xref": "x",
"y": "LotConfig",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "MasVnrArea",
"xref": "x",
"y": "LotConfig",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "ExterQual",
"xref": "x",
"y": "LotConfig",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "ExterCond",
"xref": "x",
"y": "LotConfig",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "Foundation",
"xref": "x",
"y": "LotConfig",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "BsmtQual",
"xref": "x",
"y": "LotConfig",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "BsmtCond",
"xref": "x",
"y": "LotConfig",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "BsmtExposure",
"xref": "x",
"y": "LotConfig",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "BsmtFinType1",
"xref": "x",
"y": "LotConfig",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "BsmtFinSF1",
"xref": "x",
"y": "LotConfig",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "BsmtFinType2",
"xref": "x",
"y": "LotConfig",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "BsmtFinSF2",
"xref": "x",
"y": "LotConfig",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "BsmtUnfSF",
"xref": "x",
"y": "LotConfig",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "TotalBsmtSF",
"xref": "x",
"y": "LotConfig",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "Heating",
"xref": "x",
"y": "LotConfig",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "HeatingQC",
"xref": "x",
"y": "LotConfig",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "CentralAir",
"xref": "x",
"y": "LotConfig",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "Electrical",
"xref": "x",
"y": "LotConfig",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "1stFlrSF",
"xref": "x",
"y": "LotConfig",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "2ndFlrSF",
"xref": "x",
"y": "LotConfig",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "LowQualFinSF",
"xref": "x",
"y": "LotConfig",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.09",
"x": "GrLivArea",
"xref": "x",
"y": "LotConfig",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "BsmtFullBath",
"xref": "x",
"y": "LotConfig",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "BsmtHalfBath",
"xref": "x",
"y": "LotConfig",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "FullBath",
"xref": "x",
"y": "LotConfig",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "HalfBath",
"xref": "x",
"y": "LotConfig",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "BedroomAbvGr",
"xref": "x",
"y": "LotConfig",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "KitchenAbvGr",
"xref": "x",
"y": "LotConfig",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "KitchenQual",
"xref": "x",
"y": "LotConfig",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "TotRmsAbvGrd",
"xref": "x",
"y": "LotConfig",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "Functional",
"xref": "x",
"y": "LotConfig",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "Fireplaces",
"xref": "x",
"y": "LotConfig",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "GarageType",
"xref": "x",
"y": "LotConfig",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "GarageYrBlt",
"xref": "x",
"y": "LotConfig",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "GarageFinish",
"xref": "x",
"y": "LotConfig",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "GarageCars",
"xref": "x",
"y": "LotConfig",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "GarageArea",
"xref": "x",
"y": "LotConfig",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "GarageQual",
"xref": "x",
"y": "LotConfig",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "GarageCond",
"xref": "x",
"y": "LotConfig",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "PavedDrive",
"xref": "x",
"y": "LotConfig",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "WoodDeckSF",
"xref": "x",
"y": "LotConfig",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "OpenPorchSF",
"xref": "x",
"y": "LotConfig",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "EnclosedPorch",
"xref": "x",
"y": "LotConfig",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "3SsnPorch",
"xref": "x",
"y": "LotConfig",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "ScreenPorch",
"xref": "x",
"y": "LotConfig",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "PoolArea",
"xref": "x",
"y": "LotConfig",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "MiscVal",
"xref": "x",
"y": "LotConfig",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "MoSold",
"xref": "x",
"y": "LotConfig",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "YrSold",
"xref": "x",
"y": "LotConfig",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "SaleType",
"xref": "x",
"y": "LotConfig",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "SaleCondition",
"xref": "x",
"y": "LotConfig",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "SalePrice",
"xref": "x",
"y": "LotConfig",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Id",
"xref": "x",
"y": "LandSlope",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "MSSubClass",
"xref": "x",
"y": "LandSlope",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "MSZoning",
"xref": "x",
"y": "LandSlope",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.46",
"x": "LotArea",
"xref": "x",
"y": "LandSlope",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.21",
"x": "Street",
"xref": "x",
"y": "LandSlope",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "LotShape",
"xref": "x",
"y": "LandSlope",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.38",
"x": "LandContour",
"xref": "x",
"y": "LandSlope",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "Utilities",
"xref": "x",
"y": "LandSlope",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "LotConfig",
"xref": "x",
"y": "LandSlope",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "LandSlope",
"xref": "x",
"y": "LandSlope",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "Neighborhood",
"xref": "x",
"y": "LandSlope",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "Condition1",
"xref": "x",
"y": "LandSlope",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "Condition2",
"xref": "x",
"y": "LandSlope",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "BldgType",
"xref": "x",
"y": "LandSlope",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "HouseStyle",
"xref": "x",
"y": "LandSlope",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "OverallQual",
"xref": "x",
"y": "LandSlope",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "OverallCond",
"xref": "x",
"y": "LandSlope",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "YearBuilt",
"xref": "x",
"y": "LandSlope",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "YearRemodAdd",
"xref": "x",
"y": "LandSlope",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "RoofStyle",
"xref": "x",
"y": "LandSlope",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.19",
"x": "RoofMatl",
"xref": "x",
"y": "LandSlope",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "Exterior1st",
"xref": "x",
"y": "LandSlope",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "Exterior2nd",
"xref": "x",
"y": "LandSlope",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "MasVnrType",
"xref": "x",
"y": "LandSlope",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "MasVnrArea",
"xref": "x",
"y": "LandSlope",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "ExterQual",
"xref": "x",
"y": "LandSlope",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "ExterCond",
"xref": "x",
"y": "LandSlope",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "Foundation",
"xref": "x",
"y": "LandSlope",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "BsmtQual",
"xref": "x",
"y": "LandSlope",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "BsmtCond",
"xref": "x",
"y": "LandSlope",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.17",
"x": "BsmtExposure",
"xref": "x",
"y": "LandSlope",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "BsmtFinType1",
"xref": "x",
"y": "LandSlope",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "BsmtFinSF1",
"xref": "x",
"y": "LandSlope",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "BsmtFinType2",
"xref": "x",
"y": "LandSlope",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "BsmtFinSF2",
"xref": "x",
"y": "LandSlope",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.12",
"x": "BsmtUnfSF",
"xref": "x",
"y": "LandSlope",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "TotalBsmtSF",
"xref": "x",
"y": "LandSlope",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Heating",
"xref": "x",
"y": "LandSlope",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "HeatingQC",
"xref": "x",
"y": "LandSlope",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "CentralAir",
"xref": "x",
"y": "LandSlope",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Electrical",
"xref": "x",
"y": "LandSlope",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "1stFlrSF",
"xref": "x",
"y": "LandSlope",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "2ndFlrSF",
"xref": "x",
"y": "LandSlope",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "LowQualFinSF",
"xref": "x",
"y": "LandSlope",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "GrLivArea",
"xref": "x",
"y": "LandSlope",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "BsmtFullBath",
"xref": "x",
"y": "LandSlope",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "BsmtHalfBath",
"xref": "x",
"y": "LandSlope",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "FullBath",
"xref": "x",
"y": "LandSlope",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "HalfBath",
"xref": "x",
"y": "LandSlope",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "BedroomAbvGr",
"xref": "x",
"y": "LandSlope",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "KitchenAbvGr",
"xref": "x",
"y": "LandSlope",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "KitchenQual",
"xref": "x",
"y": "LandSlope",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "TotRmsAbvGrd",
"xref": "x",
"y": "LandSlope",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "Functional",
"xref": "x",
"y": "LandSlope",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "Fireplaces",
"xref": "x",
"y": "LandSlope",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "GarageType",
"xref": "x",
"y": "LandSlope",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "GarageYrBlt",
"xref": "x",
"y": "LandSlope",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "GarageFinish",
"xref": "x",
"y": "LandSlope",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "GarageCars",
"xref": "x",
"y": "LandSlope",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "GarageArea",
"xref": "x",
"y": "LandSlope",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "GarageQual",
"xref": "x",
"y": "LandSlope",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "GarageCond",
"xref": "x",
"y": "LandSlope",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "PavedDrive",
"xref": "x",
"y": "LandSlope",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "WoodDeckSF",
"xref": "x",
"y": "LandSlope",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "OpenPorchSF",
"xref": "x",
"y": "LandSlope",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "EnclosedPorch",
"xref": "x",
"y": "LandSlope",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "3SsnPorch",
"xref": "x",
"y": "LandSlope",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "ScreenPorch",
"xref": "x",
"y": "LandSlope",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "PoolArea",
"xref": "x",
"y": "LandSlope",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "MiscVal",
"xref": "x",
"y": "LandSlope",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "MoSold",
"xref": "x",
"y": "LandSlope",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "YrSold",
"xref": "x",
"y": "LandSlope",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "SaleType",
"xref": "x",
"y": "LandSlope",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "SaleCondition",
"xref": "x",
"y": "LandSlope",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "SalePrice",
"xref": "x",
"y": "LandSlope",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "Id",
"xref": "x",
"y": "Neighborhood",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "MSSubClass",
"xref": "x",
"y": "Neighborhood",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.26",
"x": "MSZoning",
"xref": "x",
"y": "Neighborhood",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "LotArea",
"xref": "x",
"y": "Neighborhood",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "Street",
"xref": "x",
"y": "Neighborhood",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "LotShape",
"xref": "x",
"y": "Neighborhood",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "LandContour",
"xref": "x",
"y": "Neighborhood",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "Utilities",
"xref": "x",
"y": "Neighborhood",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "LotConfig",
"xref": "x",
"y": "Neighborhood",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "LandSlope",
"xref": "x",
"y": "Neighborhood",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "Neighborhood",
"xref": "x",
"y": "Neighborhood",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "Condition1",
"xref": "x",
"y": "Neighborhood",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "Condition2",
"xref": "x",
"y": "Neighborhood",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "BldgType",
"xref": "x",
"y": "Neighborhood",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "HouseStyle",
"xref": "x",
"y": "Neighborhood",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.17",
"x": "OverallQual",
"xref": "x",
"y": "Neighborhood",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "OverallCond",
"xref": "x",
"y": "Neighborhood",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "YearBuilt",
"xref": "x",
"y": "Neighborhood",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "YearRemodAdd",
"xref": "x",
"y": "Neighborhood",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "RoofStyle",
"xref": "x",
"y": "Neighborhood",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "RoofMatl",
"xref": "x",
"y": "Neighborhood",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.09",
"x": "Exterior1st",
"xref": "x",
"y": "Neighborhood",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "Exterior2nd",
"xref": "x",
"y": "Neighborhood",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "MasVnrType",
"xref": "x",
"y": "Neighborhood",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "MasVnrArea",
"xref": "x",
"y": "Neighborhood",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.16",
"x": "ExterQual",
"xref": "x",
"y": "Neighborhood",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "ExterCond",
"xref": "x",
"y": "Neighborhood",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "Foundation",
"xref": "x",
"y": "Neighborhood",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.16",
"x": "BsmtQual",
"xref": "x",
"y": "Neighborhood",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "BsmtCond",
"xref": "x",
"y": "Neighborhood",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "BsmtExposure",
"xref": "x",
"y": "Neighborhood",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "BsmtFinType1",
"xref": "x",
"y": "Neighborhood",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "BsmtFinSF1",
"xref": "x",
"y": "Neighborhood",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "BsmtFinType2",
"xref": "x",
"y": "Neighborhood",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "BsmtFinSF2",
"xref": "x",
"y": "Neighborhood",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "BsmtUnfSF",
"xref": "x",
"y": "Neighborhood",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "TotalBsmtSF",
"xref": "x",
"y": "Neighborhood",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "Heating",
"xref": "x",
"y": "Neighborhood",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "HeatingQC",
"xref": "x",
"y": "Neighborhood",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "CentralAir",
"xref": "x",
"y": "Neighborhood",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "Electrical",
"xref": "x",
"y": "Neighborhood",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.16",
"x": "1stFlrSF",
"xref": "x",
"y": "Neighborhood",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "2ndFlrSF",
"xref": "x",
"y": "Neighborhood",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "LowQualFinSF",
"xref": "x",
"y": "Neighborhood",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.13",
"x": "GrLivArea",
"xref": "x",
"y": "Neighborhood",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "BsmtFullBath",
"xref": "x",
"y": "Neighborhood",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "BsmtHalfBath",
"xref": "x",
"y": "Neighborhood",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.13",
"x": "FullBath",
"xref": "x",
"y": "Neighborhood",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "HalfBath",
"xref": "x",
"y": "Neighborhood",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "BedroomAbvGr",
"xref": "x",
"y": "Neighborhood",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "KitchenAbvGr",
"xref": "x",
"y": "Neighborhood",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.14",
"x": "KitchenQual",
"xref": "x",
"y": "Neighborhood",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "TotRmsAbvGrd",
"xref": "x",
"y": "Neighborhood",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "Functional",
"xref": "x",
"y": "Neighborhood",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "Fireplaces",
"xref": "x",
"y": "Neighborhood",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "GarageType",
"xref": "x",
"y": "Neighborhood",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.11",
"x": "GarageYrBlt",
"xref": "x",
"y": "Neighborhood",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "GarageFinish",
"xref": "x",
"y": "Neighborhood",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.18",
"x": "GarageCars",
"xref": "x",
"y": "Neighborhood",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.2",
"x": "GarageArea",
"xref": "x",
"y": "Neighborhood",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "GarageQual",
"xref": "x",
"y": "Neighborhood",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "GarageCond",
"xref": "x",
"y": "Neighborhood",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "PavedDrive",
"xref": "x",
"y": "Neighborhood",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "WoodDeckSF",
"xref": "x",
"y": "Neighborhood",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "OpenPorchSF",
"xref": "x",
"y": "Neighborhood",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "EnclosedPorch",
"xref": "x",
"y": "Neighborhood",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "3SsnPorch",
"xref": "x",
"y": "Neighborhood",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "ScreenPorch",
"xref": "x",
"y": "Neighborhood",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "PoolArea",
"xref": "x",
"y": "Neighborhood",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "MiscVal",
"xref": "x",
"y": "Neighborhood",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "MoSold",
"xref": "x",
"y": "Neighborhood",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "YrSold",
"xref": "x",
"y": "Neighborhood",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "SaleType",
"xref": "x",
"y": "Neighborhood",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "SaleCondition",
"xref": "x",
"y": "Neighborhood",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.2",
"x": "SalePrice",
"xref": "x",
"y": "Neighborhood",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "Id",
"xref": "x",
"y": "Condition1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "MSSubClass",
"xref": "x",
"y": "Condition1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "MSZoning",
"xref": "x",
"y": "Condition1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "LotArea",
"xref": "x",
"y": "Condition1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "Street",
"xref": "x",
"y": "Condition1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.12",
"x": "LotShape",
"xref": "x",
"y": "Condition1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "LandContour",
"xref": "x",
"y": "Condition1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "Utilities",
"xref": "x",
"y": "Condition1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "LotConfig",
"xref": "x",
"y": "Condition1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "LandSlope",
"xref": "x",
"y": "Condition1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "Neighborhood",
"xref": "x",
"y": "Condition1",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "Condition1",
"xref": "x",
"y": "Condition1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "Condition2",
"xref": "x",
"y": "Condition1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "BldgType",
"xref": "x",
"y": "Condition1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "HouseStyle",
"xref": "x",
"y": "Condition1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "OverallQual",
"xref": "x",
"y": "Condition1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "OverallCond",
"xref": "x",
"y": "Condition1",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "YearBuilt",
"xref": "x",
"y": "Condition1",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "YearRemodAdd",
"xref": "x",
"y": "Condition1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "RoofStyle",
"xref": "x",
"y": "Condition1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "RoofMatl",
"xref": "x",
"y": "Condition1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "Exterior1st",
"xref": "x",
"y": "Condition1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "Exterior2nd",
"xref": "x",
"y": "Condition1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "MasVnrType",
"xref": "x",
"y": "Condition1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "MasVnrArea",
"xref": "x",
"y": "Condition1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "ExterQual",
"xref": "x",
"y": "Condition1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "ExterCond",
"xref": "x",
"y": "Condition1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "Foundation",
"xref": "x",
"y": "Condition1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "BsmtQual",
"xref": "x",
"y": "Condition1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "BsmtCond",
"xref": "x",
"y": "Condition1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "BsmtExposure",
"xref": "x",
"y": "Condition1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "BsmtFinType1",
"xref": "x",
"y": "Condition1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "BsmtFinSF1",
"xref": "x",
"y": "Condition1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "BsmtFinType2",
"xref": "x",
"y": "Condition1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "BsmtFinSF2",
"xref": "x",
"y": "Condition1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "BsmtUnfSF",
"xref": "x",
"y": "Condition1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "TotalBsmtSF",
"xref": "x",
"y": "Condition1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "Heating",
"xref": "x",
"y": "Condition1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "HeatingQC",
"xref": "x",
"y": "Condition1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "CentralAir",
"xref": "x",
"y": "Condition1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "Electrical",
"xref": "x",
"y": "Condition1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "1stFlrSF",
"xref": "x",
"y": "Condition1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "2ndFlrSF",
"xref": "x",
"y": "Condition1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "LowQualFinSF",
"xref": "x",
"y": "Condition1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "GrLivArea",
"xref": "x",
"y": "Condition1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "BsmtFullBath",
"xref": "x",
"y": "Condition1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "BsmtHalfBath",
"xref": "x",
"y": "Condition1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "FullBath",
"xref": "x",
"y": "Condition1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "HalfBath",
"xref": "x",
"y": "Condition1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "BedroomAbvGr",
"xref": "x",
"y": "Condition1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.09",
"x": "KitchenAbvGr",
"xref": "x",
"y": "Condition1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "KitchenQual",
"xref": "x",
"y": "Condition1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "TotRmsAbvGrd",
"xref": "x",
"y": "Condition1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "Functional",
"xref": "x",
"y": "Condition1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "Fireplaces",
"xref": "x",
"y": "Condition1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "GarageType",
"xref": "x",
"y": "Condition1",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.15",
"x": "GarageYrBlt",
"xref": "x",
"y": "Condition1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.13",
"x": "GarageFinish",
"xref": "x",
"y": "Condition1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "GarageCars",
"xref": "x",
"y": "Condition1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "GarageArea",
"xref": "x",
"y": "Condition1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "GarageQual",
"xref": "x",
"y": "Condition1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "GarageCond",
"xref": "x",
"y": "Condition1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "PavedDrive",
"xref": "x",
"y": "Condition1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "WoodDeckSF",
"xref": "x",
"y": "Condition1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "OpenPorchSF",
"xref": "x",
"y": "Condition1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "EnclosedPorch",
"xref": "x",
"y": "Condition1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "3SsnPorch",
"xref": "x",
"y": "Condition1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "ScreenPorch",
"xref": "x",
"y": "Condition1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "PoolArea",
"xref": "x",
"y": "Condition1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "MiscVal",
"xref": "x",
"y": "Condition1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "MoSold",
"xref": "x",
"y": "Condition1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "YrSold",
"xref": "x",
"y": "Condition1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "SaleType",
"xref": "x",
"y": "Condition1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "SaleCondition",
"xref": "x",
"y": "Condition1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "SalePrice",
"xref": "x",
"y": "Condition1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "Id",
"xref": "x",
"y": "Condition2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "MSSubClass",
"xref": "x",
"y": "Condition2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "MSZoning",
"xref": "x",
"y": "Condition2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "LotArea",
"xref": "x",
"y": "Condition2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "Street",
"xref": "x",
"y": "Condition2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "LotShape",
"xref": "x",
"y": "Condition2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "LandContour",
"xref": "x",
"y": "Condition2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "Utilities",
"xref": "x",
"y": "Condition2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "LotConfig",
"xref": "x",
"y": "Condition2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "LandSlope",
"xref": "x",
"y": "Condition2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "Neighborhood",
"xref": "x",
"y": "Condition2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "Condition1",
"xref": "x",
"y": "Condition2",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "Condition2",
"xref": "x",
"y": "Condition2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "BldgType",
"xref": "x",
"y": "Condition2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "HouseStyle",
"xref": "x",
"y": "Condition2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "OverallQual",
"xref": "x",
"y": "Condition2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "OverallCond",
"xref": "x",
"y": "Condition2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "YearBuilt",
"xref": "x",
"y": "Condition2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "YearRemodAdd",
"xref": "x",
"y": "Condition2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "RoofStyle",
"xref": "x",
"y": "Condition2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "RoofMatl",
"xref": "x",
"y": "Condition2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "Exterior1st",
"xref": "x",
"y": "Condition2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "Exterior2nd",
"xref": "x",
"y": "Condition2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "MasVnrType",
"xref": "x",
"y": "Condition2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "MasVnrArea",
"xref": "x",
"y": "Condition2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "ExterQual",
"xref": "x",
"y": "Condition2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "ExterCond",
"xref": "x",
"y": "Condition2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "Foundation",
"xref": "x",
"y": "Condition2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "BsmtQual",
"xref": "x",
"y": "Condition2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "BsmtCond",
"xref": "x",
"y": "Condition2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "BsmtExposure",
"xref": "x",
"y": "Condition2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "BsmtFinType1",
"xref": "x",
"y": "Condition2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "BsmtFinSF1",
"xref": "x",
"y": "Condition2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "BsmtFinType2",
"xref": "x",
"y": "Condition2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "BsmtFinSF2",
"xref": "x",
"y": "Condition2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "BsmtUnfSF",
"xref": "x",
"y": "Condition2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "TotalBsmtSF",
"xref": "x",
"y": "Condition2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "Heating",
"xref": "x",
"y": "Condition2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "HeatingQC",
"xref": "x",
"y": "Condition2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "CentralAir",
"xref": "x",
"y": "Condition2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "Electrical",
"xref": "x",
"y": "Condition2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "1stFlrSF",
"xref": "x",
"y": "Condition2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "2ndFlrSF",
"xref": "x",
"y": "Condition2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "LowQualFinSF",
"xref": "x",
"y": "Condition2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "GrLivArea",
"xref": "x",
"y": "Condition2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "BsmtFullBath",
"xref": "x",
"y": "Condition2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "BsmtHalfBath",
"xref": "x",
"y": "Condition2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "FullBath",
"xref": "x",
"y": "Condition2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "HalfBath",
"xref": "x",
"y": "Condition2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "BedroomAbvGr",
"xref": "x",
"y": "Condition2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "KitchenAbvGr",
"xref": "x",
"y": "Condition2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "KitchenQual",
"xref": "x",
"y": "Condition2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "TotRmsAbvGrd",
"xref": "x",
"y": "Condition2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Functional",
"xref": "x",
"y": "Condition2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "Fireplaces",
"xref": "x",
"y": "Condition2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "GarageType",
"xref": "x",
"y": "Condition2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "GarageYrBlt",
"xref": "x",
"y": "Condition2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "GarageFinish",
"xref": "x",
"y": "Condition2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "GarageCars",
"xref": "x",
"y": "Condition2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "GarageArea",
"xref": "x",
"y": "Condition2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "GarageQual",
"xref": "x",
"y": "Condition2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "GarageCond",
"xref": "x",
"y": "Condition2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "PavedDrive",
"xref": "x",
"y": "Condition2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "WoodDeckSF",
"xref": "x",
"y": "Condition2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "OpenPorchSF",
"xref": "x",
"y": "Condition2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "EnclosedPorch",
"xref": "x",
"y": "Condition2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "3SsnPorch",
"xref": "x",
"y": "Condition2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "ScreenPorch",
"xref": "x",
"y": "Condition2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "PoolArea",
"xref": "x",
"y": "Condition2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.13",
"x": "MiscVal",
"xref": "x",
"y": "Condition2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "MoSold",
"xref": "x",
"y": "Condition2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "YrSold",
"xref": "x",
"y": "Condition2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "SaleType",
"xref": "x",
"y": "Condition2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "SaleCondition",
"xref": "x",
"y": "Condition2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "SalePrice",
"xref": "x",
"y": "Condition2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "Id",
"xref": "x",
"y": "BldgType",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.75",
"x": "MSSubClass",
"xref": "x",
"y": "BldgType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "MSZoning",
"xref": "x",
"y": "BldgType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.2",
"x": "LotArea",
"xref": "x",
"y": "BldgType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "Street",
"xref": "x",
"y": "BldgType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.11",
"x": "LotShape",
"xref": "x",
"y": "BldgType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "LandContour",
"xref": "x",
"y": "BldgType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "Utilities",
"xref": "x",
"y": "BldgType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "LotConfig",
"xref": "x",
"y": "BldgType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "LandSlope",
"xref": "x",
"y": "BldgType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "Neighborhood",
"xref": "x",
"y": "BldgType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "Condition1",
"xref": "x",
"y": "BldgType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Condition2",
"xref": "x",
"y": "BldgType",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "BldgType",
"xref": "x",
"y": "BldgType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "HouseStyle",
"xref": "x",
"y": "BldgType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "OverallQual",
"xref": "x",
"y": "BldgType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.18",
"x": "OverallCond",
"xref": "x",
"y": "BldgType",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.23",
"x": "YearBuilt",
"xref": "x",
"y": "BldgType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "YearRemodAdd",
"xref": "x",
"y": "BldgType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "RoofStyle",
"xref": "x",
"y": "BldgType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "RoofMatl",
"xref": "x",
"y": "BldgType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "Exterior1st",
"xref": "x",
"y": "BldgType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.13",
"x": "Exterior2nd",
"xref": "x",
"y": "BldgType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "MasVnrType",
"xref": "x",
"y": "BldgType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "MasVnrArea",
"xref": "x",
"y": "BldgType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.11",
"x": "ExterQual",
"xref": "x",
"y": "BldgType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "ExterCond",
"xref": "x",
"y": "BldgType",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.16",
"x": "Foundation",
"xref": "x",
"y": "BldgType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.12",
"x": "BsmtQual",
"xref": "x",
"y": "BldgType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "BsmtCond",
"xref": "x",
"y": "BldgType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "BsmtExposure",
"xref": "x",
"y": "BldgType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "BsmtFinType1",
"xref": "x",
"y": "BldgType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "BsmtFinSF1",
"xref": "x",
"y": "BldgType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "BsmtFinType2",
"xref": "x",
"y": "BldgType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "BsmtFinSF2",
"xref": "x",
"y": "BldgType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "BsmtUnfSF",
"xref": "x",
"y": "BldgType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "TotalBsmtSF",
"xref": "x",
"y": "BldgType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "Heating",
"xref": "x",
"y": "BldgType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "HeatingQC",
"xref": "x",
"y": "BldgType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "CentralAir",
"xref": "x",
"y": "BldgType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "Electrical",
"xref": "x",
"y": "BldgType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "1stFlrSF",
"xref": "x",
"y": "BldgType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.09",
"x": "2ndFlrSF",
"xref": "x",
"y": "BldgType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "LowQualFinSF",
"xref": "x",
"y": "BldgType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.14",
"x": "GrLivArea",
"xref": "x",
"y": "BldgType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "BsmtFullBath",
"xref": "x",
"y": "BldgType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "BsmtHalfBath",
"xref": "x",
"y": "BldgType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "FullBath",
"xref": "x",
"y": "BldgType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "HalfBath",
"xref": "x",
"y": "BldgType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.32",
"x": "BedroomAbvGr",
"xref": "x",
"y": "BldgType",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.13",
"x": "KitchenAbvGr",
"xref": "x",
"y": "BldgType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "KitchenQual",
"xref": "x",
"y": "BldgType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.23",
"x": "TotRmsAbvGrd",
"xref": "x",
"y": "BldgType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "Functional",
"xref": "x",
"y": "BldgType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "Fireplaces",
"xref": "x",
"y": "BldgType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "GarageType",
"xref": "x",
"y": "BldgType",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.21",
"x": "GarageYrBlt",
"xref": "x",
"y": "BldgType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "GarageFinish",
"xref": "x",
"y": "BldgType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "GarageCars",
"xref": "x",
"y": "BldgType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "GarageArea",
"xref": "x",
"y": "BldgType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "GarageQual",
"xref": "x",
"y": "BldgType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "GarageCond",
"xref": "x",
"y": "BldgType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "PavedDrive",
"xref": "x",
"y": "BldgType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "WoodDeckSF",
"xref": "x",
"y": "BldgType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "OpenPorchSF",
"xref": "x",
"y": "BldgType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.11",
"x": "EnclosedPorch",
"xref": "x",
"y": "BldgType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "3SsnPorch",
"xref": "x",
"y": "BldgType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "ScreenPorch",
"xref": "x",
"y": "BldgType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "PoolArea",
"xref": "x",
"y": "BldgType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "MiscVal",
"xref": "x",
"y": "BldgType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "MoSold",
"xref": "x",
"y": "BldgType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "YrSold",
"xref": "x",
"y": "BldgType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "SaleType",
"xref": "x",
"y": "BldgType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "SaleCondition",
"xref": "x",
"y": "BldgType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "SalePrice",
"xref": "x",
"y": "BldgType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Id",
"xref": "x",
"y": "HouseStyle",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.4",
"x": "MSSubClass",
"xref": "x",
"y": "HouseStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.12",
"x": "MSZoning",
"xref": "x",
"y": "HouseStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "LotArea",
"xref": "x",
"y": "HouseStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "Street",
"xref": "x",
"y": "HouseStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.11",
"x": "LotShape",
"xref": "x",
"y": "HouseStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "LandContour",
"xref": "x",
"y": "HouseStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "Utilities",
"xref": "x",
"y": "HouseStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "LotConfig",
"xref": "x",
"y": "HouseStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "LandSlope",
"xref": "x",
"y": "HouseStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "Neighborhood",
"xref": "x",
"y": "HouseStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "Condition1",
"xref": "x",
"y": "HouseStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "Condition2",
"xref": "x",
"y": "HouseStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "BldgType",
"xref": "x",
"y": "HouseStyle",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "HouseStyle",
"xref": "x",
"y": "HouseStyle",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.2",
"x": "OverallQual",
"xref": "x",
"y": "HouseStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "OverallCond",
"xref": "x",
"y": "HouseStyle",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.26",
"x": "YearBuilt",
"xref": "x",
"y": "HouseStyle",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.2",
"x": "YearRemodAdd",
"xref": "x",
"y": "HouseStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "RoofStyle",
"xref": "x",
"y": "HouseStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "RoofMatl",
"xref": "x",
"y": "HouseStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "Exterior1st",
"xref": "x",
"y": "HouseStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "Exterior2nd",
"xref": "x",
"y": "HouseStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.13",
"x": "MasVnrType",
"xref": "x",
"y": "HouseStyle",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.16",
"x": "MasVnrArea",
"xref": "x",
"y": "HouseStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "ExterQual",
"xref": "x",
"y": "HouseStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "ExterCond",
"xref": "x",
"y": "HouseStyle",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.21",
"x": "Foundation",
"xref": "x",
"y": "HouseStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.13",
"x": "BsmtQual",
"xref": "x",
"y": "HouseStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "BsmtCond",
"xref": "x",
"y": "HouseStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.17",
"x": "BsmtExposure",
"xref": "x",
"y": "HouseStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "BsmtFinType1",
"xref": "x",
"y": "HouseStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "BsmtFinSF1",
"xref": "x",
"y": "HouseStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "BsmtFinType2",
"xref": "x",
"y": "HouseStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "BsmtFinSF2",
"xref": "x",
"y": "HouseStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.16",
"x": "BsmtUnfSF",
"xref": "x",
"y": "HouseStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.2",
"x": "TotalBsmtSF",
"xref": "x",
"y": "HouseStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "Heating",
"xref": "x",
"y": "HouseStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "HeatingQC",
"xref": "x",
"y": "HouseStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "CentralAir",
"xref": "x",
"y": "HouseStyle",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.16",
"x": "Electrical",
"xref": "x",
"y": "HouseStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.19",
"x": "1stFlrSF",
"xref": "x",
"y": "HouseStyle",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.48",
"x": "2ndFlrSF",
"xref": "x",
"y": "HouseStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "LowQualFinSF",
"xref": "x",
"y": "HouseStyle",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.26",
"x": "GrLivArea",
"xref": "x",
"y": "HouseStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "BsmtFullBath",
"xref": "x",
"y": "HouseStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "BsmtHalfBath",
"xref": "x",
"y": "HouseStyle",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.24",
"x": "FullBath",
"xref": "x",
"y": "HouseStyle",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.42",
"x": "HalfBath",
"xref": "x",
"y": "HouseStyle",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.2",
"x": "BedroomAbvGr",
"xref": "x",
"y": "HouseStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "KitchenAbvGr",
"xref": "x",
"y": "HouseStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "KitchenQual",
"xref": "x",
"y": "HouseStyle",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.26",
"x": "TotRmsAbvGrd",
"xref": "x",
"y": "HouseStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "Functional",
"xref": "x",
"y": "HouseStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "Fireplaces",
"xref": "x",
"y": "HouseStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "GarageType",
"xref": "x",
"y": "HouseStyle",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.21",
"x": "GarageYrBlt",
"xref": "x",
"y": "HouseStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.21",
"x": "GarageFinish",
"xref": "x",
"y": "HouseStyle",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.19",
"x": "GarageCars",
"xref": "x",
"y": "HouseStyle",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "GarageArea",
"xref": "x",
"y": "HouseStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "GarageQual",
"xref": "x",
"y": "HouseStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "GarageCond",
"xref": "x",
"y": "HouseStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "PavedDrive",
"xref": "x",
"y": "HouseStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "WoodDeckSF",
"xref": "x",
"y": "HouseStyle",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "OpenPorchSF",
"xref": "x",
"y": "HouseStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "EnclosedPorch",
"xref": "x",
"y": "HouseStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "3SsnPorch",
"xref": "x",
"y": "HouseStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "ScreenPorch",
"xref": "x",
"y": "HouseStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "PoolArea",
"xref": "x",
"y": "HouseStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "MiscVal",
"xref": "x",
"y": "HouseStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "MoSold",
"xref": "x",
"y": "HouseStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "YrSold",
"xref": "x",
"y": "HouseStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "SaleType",
"xref": "x",
"y": "HouseStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "SaleCondition",
"xref": "x",
"y": "HouseStyle",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.16",
"x": "SalePrice",
"xref": "x",
"y": "HouseStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "Id",
"xref": "x",
"y": "OverallQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "MSSubClass",
"xref": "x",
"y": "OverallQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.17",
"x": "MSZoning",
"xref": "x",
"y": "OverallQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "LotArea",
"xref": "x",
"y": "OverallQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "Street",
"xref": "x",
"y": "OverallQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.19",
"x": "LotShape",
"xref": "x",
"y": "OverallQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "LandContour",
"xref": "x",
"y": "OverallQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "Utilities",
"xref": "x",
"y": "OverallQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "LotConfig",
"xref": "x",
"y": "OverallQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "LandSlope",
"xref": "x",
"y": "OverallQual",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.17",
"x": "Neighborhood",
"xref": "x",
"y": "OverallQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "Condition1",
"xref": "x",
"y": "OverallQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Condition2",
"xref": "x",
"y": "OverallQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "BldgType",
"xref": "x",
"y": "OverallQual",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.2",
"x": "HouseStyle",
"xref": "x",
"y": "OverallQual",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "OverallQual",
"xref": "x",
"y": "OverallQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.16",
"x": "OverallCond",
"xref": "x",
"y": "OverallQual",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.57",
"x": "YearBuilt",
"xref": "x",
"y": "OverallQual",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.55",
"x": "YearRemodAdd",
"xref": "x",
"y": "OverallQual",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.17",
"x": "RoofStyle",
"xref": "x",
"y": "OverallQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "RoofMatl",
"xref": "x",
"y": "OverallQual",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.16",
"x": "Exterior1st",
"xref": "x",
"y": "OverallQual",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.16",
"x": "Exterior2nd",
"xref": "x",
"y": "OverallQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "MasVnrType",
"xref": "x",
"y": "OverallQual",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.4",
"x": "MasVnrArea",
"xref": "x",
"y": "OverallQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.68",
"x": "ExterQual",
"xref": "x",
"y": "OverallQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.11",
"x": "ExterCond",
"xref": "x",
"y": "OverallQual",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.49",
"x": "Foundation",
"xref": "x",
"y": "OverallQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.61",
"x": "BsmtQual",
"xref": "x",
"y": "OverallQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "BsmtCond",
"xref": "x",
"y": "OverallQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.24",
"x": "BsmtExposure",
"xref": "x",
"y": "OverallQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "BsmtFinType1",
"xref": "x",
"y": "OverallQual",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.2",
"x": "BsmtFinSF1",
"xref": "x",
"y": "OverallQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.11",
"x": "BsmtFinType2",
"xref": "x",
"y": "OverallQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.09",
"x": "BsmtFinSF2",
"xref": "x",
"y": "OverallQual",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.29",
"x": "BsmtUnfSF",
"xref": "x",
"y": "OverallQual",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.51",
"x": "TotalBsmtSF",
"xref": "x",
"y": "OverallQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "Heating",
"xref": "x",
"y": "OverallQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.44",
"x": "HeatingQC",
"xref": "x",
"y": "OverallQual",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.19",
"x": "CentralAir",
"xref": "x",
"y": "OverallQual",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.21",
"x": "Electrical",
"xref": "x",
"y": "OverallQual",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.48",
"x": "1stFlrSF",
"xref": "x",
"y": "OverallQual",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.28",
"x": "2ndFlrSF",
"xref": "x",
"y": "OverallQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "LowQualFinSF",
"xref": "x",
"y": "OverallQual",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.59",
"x": "GrLivArea",
"xref": "x",
"y": "OverallQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "BsmtFullBath",
"xref": "x",
"y": "OverallQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "BsmtHalfBath",
"xref": "x",
"y": "OverallQual",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.58",
"x": "FullBath",
"xref": "x",
"y": "OverallQual",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.25",
"x": "HalfBath",
"xref": "x",
"y": "OverallQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "BedroomAbvGr",
"xref": "x",
"y": "OverallQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.14",
"x": "KitchenAbvGr",
"xref": "x",
"y": "OverallQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.61",
"x": "KitchenQual",
"xref": "x",
"y": "OverallQual",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.44",
"x": "TotRmsAbvGrd",
"xref": "x",
"y": "OverallQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.13",
"x": "Functional",
"xref": "x",
"y": "OverallQual",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.38",
"x": "Fireplaces",
"xref": "x",
"y": "OverallQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.35",
"x": "GarageType",
"xref": "x",
"y": "OverallQual",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.55",
"x": "GarageYrBlt",
"xref": "x",
"y": "OverallQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.52",
"x": "GarageFinish",
"xref": "x",
"y": "OverallQual",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.59",
"x": "GarageCars",
"xref": "x",
"y": "OverallQual",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.53",
"x": "GarageArea",
"xref": "x",
"y": "OverallQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "GarageQual",
"xref": "x",
"y": "OverallQual",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.16",
"x": "GarageCond",
"xref": "x",
"y": "OverallQual",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.16",
"x": "PavedDrive",
"xref": "x",
"y": "OverallQual",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.22",
"x": "WoodDeckSF",
"xref": "x",
"y": "OverallQual",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.31",
"x": "OpenPorchSF",
"xref": "x",
"y": "OverallQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.12",
"x": "EnclosedPorch",
"xref": "x",
"y": "OverallQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "3SsnPorch",
"xref": "x",
"y": "OverallQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "ScreenPorch",
"xref": "x",
"y": "OverallQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "PoolArea",
"xref": "x",
"y": "OverallQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "MiscVal",
"xref": "x",
"y": "OverallQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "MoSold",
"xref": "x",
"y": "OverallQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "YrSold",
"xref": "x",
"y": "OverallQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "SaleType",
"xref": "x",
"y": "OverallQual",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.19",
"x": "SaleCondition",
"xref": "x",
"y": "OverallQual",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.78",
"x": "SalePrice",
"xref": "x",
"y": "OverallQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Id",
"xref": "x",
"y": "OverallCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "MSSubClass",
"xref": "x",
"y": "OverallCond",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.19",
"x": "MSZoning",
"xref": "x",
"y": "OverallCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "LotArea",
"xref": "x",
"y": "OverallCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "Street",
"xref": "x",
"y": "OverallCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "LotShape",
"xref": "x",
"y": "OverallCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "LandContour",
"xref": "x",
"y": "OverallCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Utilities",
"xref": "x",
"y": "OverallCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "LotConfig",
"xref": "x",
"y": "OverallCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "LandSlope",
"xref": "x",
"y": "OverallCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "Neighborhood",
"xref": "x",
"y": "OverallCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "Condition1",
"xref": "x",
"y": "OverallCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Condition2",
"xref": "x",
"y": "OverallCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.18",
"x": "BldgType",
"xref": "x",
"y": "OverallCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "HouseStyle",
"xref": "x",
"y": "OverallCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.16",
"x": "OverallQual",
"xref": "x",
"y": "OverallCond",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "OverallCond",
"xref": "x",
"y": "OverallCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.42",
"x": "YearBuilt",
"xref": "x",
"y": "OverallCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "YearRemodAdd",
"xref": "x",
"y": "OverallCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "RoofStyle",
"xref": "x",
"y": "OverallCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "RoofMatl",
"xref": "x",
"y": "OverallCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "Exterior1st",
"xref": "x",
"y": "OverallCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "Exterior2nd",
"xref": "x",
"y": "OverallCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "MasVnrType",
"xref": "x",
"y": "OverallCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.14",
"x": "MasVnrArea",
"xref": "x",
"y": "OverallCond",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.17",
"x": "ExterQual",
"xref": "x",
"y": "OverallCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.25",
"x": "ExterCond",
"xref": "x",
"y": "OverallCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.33",
"x": "Foundation",
"xref": "x",
"y": "OverallCond",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.27",
"x": "BsmtQual",
"xref": "x",
"y": "OverallCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "BsmtCond",
"xref": "x",
"y": "OverallCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "BsmtExposure",
"xref": "x",
"y": "OverallCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "BsmtFinType1",
"xref": "x",
"y": "OverallCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "BsmtFinSF1",
"xref": "x",
"y": "OverallCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.09",
"x": "BsmtFinType2",
"xref": "x",
"y": "OverallCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "BsmtFinSF2",
"xref": "x",
"y": "OverallCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.16",
"x": "BsmtUnfSF",
"xref": "x",
"y": "OverallCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.23",
"x": "TotalBsmtSF",
"xref": "x",
"y": "OverallCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "Heating",
"xref": "x",
"y": "OverallCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "HeatingQC",
"xref": "x",
"y": "OverallCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "CentralAir",
"xref": "x",
"y": "OverallCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "Electrical",
"xref": "x",
"y": "OverallCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.14",
"x": "1stFlrSF",
"xref": "x",
"y": "OverallCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "2ndFlrSF",
"xref": "x",
"y": "OverallCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "LowQualFinSF",
"xref": "x",
"y": "OverallCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.09",
"x": "GrLivArea",
"xref": "x",
"y": "OverallCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "BsmtFullBath",
"xref": "x",
"y": "OverallCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "BsmtHalfBath",
"xref": "x",
"y": "OverallCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.21",
"x": "FullBath",
"xref": "x",
"y": "OverallCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "HalfBath",
"xref": "x",
"y": "OverallCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "BedroomAbvGr",
"xref": "x",
"y": "OverallCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "KitchenAbvGr",
"xref": "x",
"y": "OverallCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "KitchenQual",
"xref": "x",
"y": "OverallCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "TotRmsAbvGrd",
"xref": "x",
"y": "OverallCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "Functional",
"xref": "x",
"y": "OverallCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "Fireplaces",
"xref": "x",
"y": "OverallCond",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.19",
"x": "GarageType",
"xref": "x",
"y": "OverallCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.34",
"x": "GarageYrBlt",
"xref": "x",
"y": "OverallCond",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.22",
"x": "GarageFinish",
"xref": "x",
"y": "OverallCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.25",
"x": "GarageCars",
"xref": "x",
"y": "OverallCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.2",
"x": "GarageArea",
"xref": "x",
"y": "OverallCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "GarageQual",
"xref": "x",
"y": "OverallCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "GarageCond",
"xref": "x",
"y": "OverallCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.11",
"x": "PavedDrive",
"xref": "x",
"y": "OverallCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "WoodDeckSF",
"xref": "x",
"y": "OverallCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "OpenPorchSF",
"xref": "x",
"y": "OverallCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "EnclosedPorch",
"xref": "x",
"y": "OverallCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "3SsnPorch",
"xref": "x",
"y": "OverallCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "ScreenPorch",
"xref": "x",
"y": "OverallCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "PoolArea",
"xref": "x",
"y": "OverallCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "MiscVal",
"xref": "x",
"y": "OverallCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "MoSold",
"xref": "x",
"y": "OverallCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "YrSold",
"xref": "x",
"y": "OverallCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "SaleType",
"xref": "x",
"y": "OverallCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "SaleCondition",
"xref": "x",
"y": "OverallCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.11",
"x": "SalePrice",
"xref": "x",
"y": "OverallCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "Id",
"xref": "x",
"y": "YearBuilt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "MSSubClass",
"xref": "x",
"y": "YearBuilt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.33",
"x": "MSZoning",
"xref": "x",
"y": "YearBuilt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "LotArea",
"xref": "x",
"y": "YearBuilt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "Street",
"xref": "x",
"y": "YearBuilt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.23",
"x": "LotShape",
"xref": "x",
"y": "YearBuilt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.15",
"x": "LandContour",
"xref": "x",
"y": "YearBuilt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "Utilities",
"xref": "x",
"y": "YearBuilt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "LotConfig",
"xref": "x",
"y": "YearBuilt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "LandSlope",
"xref": "x",
"y": "YearBuilt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "Neighborhood",
"xref": "x",
"y": "YearBuilt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "Condition1",
"xref": "x",
"y": "YearBuilt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "Condition2",
"xref": "x",
"y": "YearBuilt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.23",
"x": "BldgType",
"xref": "x",
"y": "YearBuilt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.26",
"x": "HouseStyle",
"xref": "x",
"y": "YearBuilt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.57",
"x": "OverallQual",
"xref": "x",
"y": "YearBuilt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.42",
"x": "OverallCond",
"xref": "x",
"y": "YearBuilt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "YearBuilt",
"xref": "x",
"y": "YearBuilt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.62",
"x": "YearRemodAdd",
"xref": "x",
"y": "YearBuilt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "RoofStyle",
"xref": "x",
"y": "YearBuilt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "RoofMatl",
"xref": "x",
"y": "YearBuilt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.11",
"x": "Exterior1st",
"xref": "x",
"y": "YearBuilt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "Exterior2nd",
"xref": "x",
"y": "YearBuilt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "MasVnrType",
"xref": "x",
"y": "YearBuilt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.3",
"x": "MasVnrArea",
"xref": "x",
"y": "YearBuilt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.51",
"x": "ExterQual",
"xref": "x",
"y": "YearBuilt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.26",
"x": "ExterCond",
"xref": "x",
"y": "YearBuilt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.72",
"x": "Foundation",
"xref": "x",
"y": "YearBuilt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.53",
"x": "BsmtQual",
"xref": "x",
"y": "YearBuilt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "BsmtCond",
"xref": "x",
"y": "YearBuilt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.3",
"x": "BsmtExposure",
"xref": "x",
"y": "YearBuilt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.11",
"x": "BsmtFinType1",
"xref": "x",
"y": "YearBuilt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.22",
"x": "BsmtFinSF1",
"xref": "x",
"y": "YearBuilt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "BsmtFinType2",
"xref": "x",
"y": "YearBuilt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "BsmtFinSF2",
"xref": "x",
"y": "YearBuilt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.15",
"x": "BsmtUnfSF",
"xref": "x",
"y": "YearBuilt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.39",
"x": "TotalBsmtSF",
"xref": "x",
"y": "YearBuilt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.19",
"x": "Heating",
"xref": "x",
"y": "YearBuilt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.42",
"x": "HeatingQC",
"xref": "x",
"y": "YearBuilt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.36",
"x": "CentralAir",
"xref": "x",
"y": "YearBuilt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.32",
"x": "Electrical",
"xref": "x",
"y": "YearBuilt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.26",
"x": "1stFlrSF",
"xref": "x",
"y": "YearBuilt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "2ndFlrSF",
"xref": "x",
"y": "YearBuilt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.16",
"x": "LowQualFinSF",
"xref": "x",
"y": "YearBuilt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.19",
"x": "GrLivArea",
"xref": "x",
"y": "YearBuilt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.18",
"x": "BsmtFullBath",
"xref": "x",
"y": "YearBuilt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "BsmtHalfBath",
"xref": "x",
"y": "YearBuilt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.49",
"x": "FullBath",
"xref": "x",
"y": "YearBuilt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.23",
"x": "HalfBath",
"xref": "x",
"y": "YearBuilt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "BedroomAbvGr",
"xref": "x",
"y": "YearBuilt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.18",
"x": "KitchenAbvGr",
"xref": "x",
"y": "YearBuilt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.38",
"x": "KitchenQual",
"xref": "x",
"y": "YearBuilt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "TotRmsAbvGrd",
"xref": "x",
"y": "YearBuilt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.15",
"x": "Functional",
"xref": "x",
"y": "YearBuilt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.11",
"x": "Fireplaces",
"xref": "x",
"y": "YearBuilt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.52",
"x": "GarageType",
"xref": "x",
"y": "YearBuilt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.83",
"x": "GarageYrBlt",
"xref": "x",
"y": "YearBuilt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.58",
"x": "GarageFinish",
"xref": "x",
"y": "YearBuilt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.52",
"x": "GarageCars",
"xref": "x",
"y": "YearBuilt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.44",
"x": "GarageArea",
"xref": "x",
"y": "YearBuilt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.34",
"x": "GarageQual",
"xref": "x",
"y": "YearBuilt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.27",
"x": "GarageCond",
"xref": "x",
"y": "YearBuilt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.39",
"x": "PavedDrive",
"xref": "x",
"y": "YearBuilt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.21",
"x": "WoodDeckSF",
"xref": "x",
"y": "YearBuilt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.22",
"x": "OpenPorchSF",
"xref": "x",
"y": "YearBuilt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.39",
"x": "EnclosedPorch",
"xref": "x",
"y": "YearBuilt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "3SsnPorch",
"xref": "x",
"y": "YearBuilt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "ScreenPorch",
"xref": "x",
"y": "YearBuilt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "PoolArea",
"xref": "x",
"y": "YearBuilt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "MiscVal",
"xref": "x",
"y": "YearBuilt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "MoSold",
"xref": "x",
"y": "YearBuilt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "YrSold",
"xref": "x",
"y": "YearBuilt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "SaleType",
"xref": "x",
"y": "YearBuilt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.2",
"x": "SaleCondition",
"xref": "x",
"y": "YearBuilt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.5",
"x": "SalePrice",
"xref": "x",
"y": "YearBuilt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "Id",
"xref": "x",
"y": "YearRemodAdd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "MSSubClass",
"xref": "x",
"y": "YearRemodAdd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.18",
"x": "MSZoning",
"xref": "x",
"y": "YearRemodAdd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "LotArea",
"xref": "x",
"y": "YearRemodAdd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "Street",
"xref": "x",
"y": "YearRemodAdd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.16",
"x": "LotShape",
"xref": "x",
"y": "YearRemodAdd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "LandContour",
"xref": "x",
"y": "YearRemodAdd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "Utilities",
"xref": "x",
"y": "YearRemodAdd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "LotConfig",
"xref": "x",
"y": "YearRemodAdd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "LandSlope",
"xref": "x",
"y": "YearRemodAdd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "Neighborhood",
"xref": "x",
"y": "YearRemodAdd",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "Condition1",
"xref": "x",
"y": "YearRemodAdd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Condition2",
"xref": "x",
"y": "YearRemodAdd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "BldgType",
"xref": "x",
"y": "YearRemodAdd",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.2",
"x": "HouseStyle",
"xref": "x",
"y": "YearRemodAdd",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.55",
"x": "OverallQual",
"xref": "x",
"y": "YearRemodAdd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "OverallCond",
"xref": "x",
"y": "YearRemodAdd",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.62",
"x": "YearBuilt",
"xref": "x",
"y": "YearRemodAdd",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "YearRemodAdd",
"xref": "x",
"y": "YearRemodAdd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "RoofStyle",
"xref": "x",
"y": "YearRemodAdd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "RoofMatl",
"xref": "x",
"y": "YearRemodAdd",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.24",
"x": "Exterior1st",
"xref": "x",
"y": "YearRemodAdd",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.23",
"x": "Exterior2nd",
"xref": "x",
"y": "YearRemodAdd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "MasVnrType",
"xref": "x",
"y": "YearRemodAdd",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.17",
"x": "MasVnrArea",
"xref": "x",
"y": "YearRemodAdd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.51",
"x": "ExterQual",
"xref": "x",
"y": "YearRemodAdd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "ExterCond",
"xref": "x",
"y": "YearRemodAdd",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.53",
"x": "Foundation",
"xref": "x",
"y": "YearRemodAdd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.48",
"x": "BsmtQual",
"xref": "x",
"y": "YearRemodAdd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "BsmtCond",
"xref": "x",
"y": "YearRemodAdd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.22",
"x": "BsmtExposure",
"xref": "x",
"y": "YearRemodAdd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "BsmtFinType1",
"xref": "x",
"y": "YearRemodAdd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "BsmtFinSF1",
"xref": "x",
"y": "YearRemodAdd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "BsmtFinType2",
"xref": "x",
"y": "YearRemodAdd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.09",
"x": "BsmtFinSF2",
"xref": "x",
"y": "YearRemodAdd",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.17",
"x": "BsmtUnfSF",
"xref": "x",
"y": "YearRemodAdd",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.26",
"x": "TotalBsmtSF",
"xref": "x",
"y": "YearRemodAdd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.14",
"x": "Heating",
"xref": "x",
"y": "YearRemodAdd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.52",
"x": "HeatingQC",
"xref": "x",
"y": "YearRemodAdd",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.26",
"x": "CentralAir",
"xref": "x",
"y": "YearRemodAdd",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.31",
"x": "Electrical",
"xref": "x",
"y": "YearRemodAdd",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.24",
"x": "1stFlrSF",
"xref": "x",
"y": "YearRemodAdd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "2ndFlrSF",
"xref": "x",
"y": "YearRemodAdd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "LowQualFinSF",
"xref": "x",
"y": "YearRemodAdd",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.28",
"x": "GrLivArea",
"xref": "x",
"y": "YearRemodAdd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "BsmtFullBath",
"xref": "x",
"y": "YearRemodAdd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "BsmtHalfBath",
"xref": "x",
"y": "YearRemodAdd",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.46",
"x": "FullBath",
"xref": "x",
"y": "YearRemodAdd",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.17",
"x": "HalfBath",
"xref": "x",
"y": "YearRemodAdd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "BedroomAbvGr",
"xref": "x",
"y": "YearRemodAdd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.15",
"x": "KitchenAbvGr",
"xref": "x",
"y": "YearRemodAdd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.49",
"x": "KitchenQual",
"xref": "x",
"y": "YearRemodAdd",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.17",
"x": "TotRmsAbvGrd",
"xref": "x",
"y": "YearRemodAdd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "Functional",
"xref": "x",
"y": "YearRemodAdd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "Fireplaces",
"xref": "x",
"y": "YearRemodAdd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.29",
"x": "GarageType",
"xref": "x",
"y": "YearRemodAdd",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.64",
"x": "GarageYrBlt",
"xref": "x",
"y": "YearRemodAdd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.45",
"x": "GarageFinish",
"xref": "x",
"y": "YearRemodAdd",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.46",
"x": "GarageCars",
"xref": "x",
"y": "YearRemodAdd",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.39",
"x": "GarageArea",
"xref": "x",
"y": "YearRemodAdd",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.15",
"x": "GarageQual",
"xref": "x",
"y": "YearRemodAdd",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.16",
"x": "GarageCond",
"xref": "x",
"y": "YearRemodAdd",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.16",
"x": "PavedDrive",
"xref": "x",
"y": "YearRemodAdd",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.2",
"x": "WoodDeckSF",
"xref": "x",
"y": "YearRemodAdd",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.23",
"x": "OpenPorchSF",
"xref": "x",
"y": "YearRemodAdd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.22",
"x": "EnclosedPorch",
"xref": "x",
"y": "YearRemodAdd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "3SsnPorch",
"xref": "x",
"y": "YearRemodAdd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "ScreenPorch",
"xref": "x",
"y": "YearRemodAdd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "PoolArea",
"xref": "x",
"y": "YearRemodAdd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "MiscVal",
"xref": "x",
"y": "YearRemodAdd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "MoSold",
"xref": "x",
"y": "YearRemodAdd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "YrSold",
"xref": "x",
"y": "YearRemodAdd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "SaleType",
"xref": "x",
"y": "YearRemodAdd",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.23",
"x": "SaleCondition",
"xref": "x",
"y": "YearRemodAdd",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.5",
"x": "SalePrice",
"xref": "x",
"y": "YearRemodAdd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "Id",
"xref": "x",
"y": "RoofStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.12",
"x": "MSSubClass",
"xref": "x",
"y": "RoofStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "MSZoning",
"xref": "x",
"y": "RoofStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "LotArea",
"xref": "x",
"y": "RoofStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "Street",
"xref": "x",
"y": "RoofStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "LotShape",
"xref": "x",
"y": "RoofStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "LandContour",
"xref": "x",
"y": "RoofStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "Utilities",
"xref": "x",
"y": "RoofStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "LotConfig",
"xref": "x",
"y": "RoofStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "LandSlope",
"xref": "x",
"y": "RoofStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "Neighborhood",
"xref": "x",
"y": "RoofStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "Condition1",
"xref": "x",
"y": "RoofStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "Condition2",
"xref": "x",
"y": "RoofStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "BldgType",
"xref": "x",
"y": "RoofStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "HouseStyle",
"xref": "x",
"y": "RoofStyle",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.17",
"x": "OverallQual",
"xref": "x",
"y": "RoofStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "OverallCond",
"xref": "x",
"y": "RoofStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "YearBuilt",
"xref": "x",
"y": "RoofStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "YearRemodAdd",
"xref": "x",
"y": "RoofStyle",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "RoofStyle",
"xref": "x",
"y": "RoofStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "RoofMatl",
"xref": "x",
"y": "RoofStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "Exterior1st",
"xref": "x",
"y": "RoofStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "Exterior2nd",
"xref": "x",
"y": "RoofStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.09",
"x": "MasVnrType",
"xref": "x",
"y": "RoofStyle",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.26",
"x": "MasVnrArea",
"xref": "x",
"y": "RoofStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.19",
"x": "ExterQual",
"xref": "x",
"y": "RoofStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "ExterCond",
"xref": "x",
"y": "RoofStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "Foundation",
"xref": "x",
"y": "RoofStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.14",
"x": "BsmtQual",
"xref": "x",
"y": "RoofStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "BsmtCond",
"xref": "x",
"y": "RoofStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "BsmtExposure",
"xref": "x",
"y": "RoofStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "BsmtFinType1",
"xref": "x",
"y": "RoofStyle",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.2",
"x": "BsmtFinSF1",
"xref": "x",
"y": "RoofStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "BsmtFinType2",
"xref": "x",
"y": "RoofStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "BsmtFinSF2",
"xref": "x",
"y": "RoofStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "BsmtUnfSF",
"xref": "x",
"y": "RoofStyle",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.28",
"x": "TotalBsmtSF",
"xref": "x",
"y": "RoofStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "Heating",
"xref": "x",
"y": "RoofStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "HeatingQC",
"xref": "x",
"y": "RoofStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "CentralAir",
"xref": "x",
"y": "RoofStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "Electrical",
"xref": "x",
"y": "RoofStyle",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.3",
"x": "1stFlrSF",
"xref": "x",
"y": "RoofStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "2ndFlrSF",
"xref": "x",
"y": "RoofStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "LowQualFinSF",
"xref": "x",
"y": "RoofStyle",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.15",
"x": "GrLivArea",
"xref": "x",
"y": "RoofStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "BsmtFullBath",
"xref": "x",
"y": "RoofStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "BsmtHalfBath",
"xref": "x",
"y": "RoofStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "FullBath",
"xref": "x",
"y": "RoofStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "HalfBath",
"xref": "x",
"y": "RoofStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "BedroomAbvGr",
"xref": "x",
"y": "RoofStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "KitchenAbvGr",
"xref": "x",
"y": "RoofStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.12",
"x": "KitchenQual",
"xref": "x",
"y": "RoofStyle",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.13",
"x": "TotRmsAbvGrd",
"xref": "x",
"y": "RoofStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "Functional",
"xref": "x",
"y": "RoofStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "Fireplaces",
"xref": "x",
"y": "RoofStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "GarageType",
"xref": "x",
"y": "RoofStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "GarageYrBlt",
"xref": "x",
"y": "RoofStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.13",
"x": "GarageFinish",
"xref": "x",
"y": "RoofStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.13",
"x": "GarageCars",
"xref": "x",
"y": "RoofStyle",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "GarageArea",
"xref": "x",
"y": "RoofStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "GarageQual",
"xref": "x",
"y": "RoofStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "GarageCond",
"xref": "x",
"y": "RoofStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "PavedDrive",
"xref": "x",
"y": "RoofStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "WoodDeckSF",
"xref": "x",
"y": "RoofStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "OpenPorchSF",
"xref": "x",
"y": "RoofStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "EnclosedPorch",
"xref": "x",
"y": "RoofStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "3SsnPorch",
"xref": "x",
"y": "RoofStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "ScreenPorch",
"xref": "x",
"y": "RoofStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "PoolArea",
"xref": "x",
"y": "RoofStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "MiscVal",
"xref": "x",
"y": "RoofStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "MoSold",
"xref": "x",
"y": "RoofStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "YrSold",
"xref": "x",
"y": "RoofStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "SaleType",
"xref": "x",
"y": "RoofStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "SaleCondition",
"xref": "x",
"y": "RoofStyle",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.23",
"x": "SalePrice",
"xref": "x",
"y": "RoofStyle",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "Id",
"xref": "x",
"y": "RoofMatl",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "MSSubClass",
"xref": "x",
"y": "RoofMatl",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "MSZoning",
"xref": "x",
"y": "RoofMatl",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.15",
"x": "LotArea",
"xref": "x",
"y": "RoofMatl",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Street",
"xref": "x",
"y": "RoofMatl",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "LotShape",
"xref": "x",
"y": "RoofMatl",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "LandContour",
"xref": "x",
"y": "RoofMatl",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "Utilities",
"xref": "x",
"y": "RoofMatl",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "LotConfig",
"xref": "x",
"y": "RoofMatl",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.19",
"x": "LandSlope",
"xref": "x",
"y": "RoofMatl",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "Neighborhood",
"xref": "x",
"y": "RoofMatl",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Condition1",
"xref": "x",
"y": "RoofMatl",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "Condition2",
"xref": "x",
"y": "RoofMatl",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "BldgType",
"xref": "x",
"y": "RoofMatl",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "HouseStyle",
"xref": "x",
"y": "RoofMatl",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "OverallQual",
"xref": "x",
"y": "RoofMatl",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "OverallCond",
"xref": "x",
"y": "RoofMatl",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "YearBuilt",
"xref": "x",
"y": "RoofMatl",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "YearRemodAdd",
"xref": "x",
"y": "RoofMatl",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "RoofStyle",
"xref": "x",
"y": "RoofMatl",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "RoofMatl",
"xref": "x",
"y": "RoofMatl",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "Exterior1st",
"xref": "x",
"y": "RoofMatl",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "Exterior2nd",
"xref": "x",
"y": "RoofMatl",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "MasVnrType",
"xref": "x",
"y": "RoofMatl",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "MasVnrArea",
"xref": "x",
"y": "RoofMatl",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "ExterQual",
"xref": "x",
"y": "RoofMatl",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "ExterCond",
"xref": "x",
"y": "RoofMatl",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "Foundation",
"xref": "x",
"y": "RoofMatl",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "BsmtQual",
"xref": "x",
"y": "RoofMatl",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "BsmtCond",
"xref": "x",
"y": "RoofMatl",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "BsmtExposure",
"xref": "x",
"y": "RoofMatl",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "BsmtFinType1",
"xref": "x",
"y": "RoofMatl",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "BsmtFinSF1",
"xref": "x",
"y": "RoofMatl",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "BsmtFinType2",
"xref": "x",
"y": "RoofMatl",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "BsmtFinSF2",
"xref": "x",
"y": "RoofMatl",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "BsmtUnfSF",
"xref": "x",
"y": "RoofMatl",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "TotalBsmtSF",
"xref": "x",
"y": "RoofMatl",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "Heating",
"xref": "x",
"y": "RoofMatl",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "HeatingQC",
"xref": "x",
"y": "RoofMatl",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "CentralAir",
"xref": "x",
"y": "RoofMatl",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "Electrical",
"xref": "x",
"y": "RoofMatl",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.16",
"x": "1stFlrSF",
"xref": "x",
"y": "RoofMatl",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "2ndFlrSF",
"xref": "x",
"y": "RoofMatl",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "LowQualFinSF",
"xref": "x",
"y": "RoofMatl",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "GrLivArea",
"xref": "x",
"y": "RoofMatl",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "BsmtFullBath",
"xref": "x",
"y": "RoofMatl",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "BsmtHalfBath",
"xref": "x",
"y": "RoofMatl",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "FullBath",
"xref": "x",
"y": "RoofMatl",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "HalfBath",
"xref": "x",
"y": "RoofMatl",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "BedroomAbvGr",
"xref": "x",
"y": "RoofMatl",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "KitchenAbvGr",
"xref": "x",
"y": "RoofMatl",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "KitchenQual",
"xref": "x",
"y": "RoofMatl",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "TotRmsAbvGrd",
"xref": "x",
"y": "RoofMatl",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "Functional",
"xref": "x",
"y": "RoofMatl",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "Fireplaces",
"xref": "x",
"y": "RoofMatl",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "GarageType",
"xref": "x",
"y": "RoofMatl",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "GarageYrBlt",
"xref": "x",
"y": "RoofMatl",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "GarageFinish",
"xref": "x",
"y": "RoofMatl",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "GarageCars",
"xref": "x",
"y": "RoofMatl",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "GarageArea",
"xref": "x",
"y": "RoofMatl",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "GarageQual",
"xref": "x",
"y": "RoofMatl",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "GarageCond",
"xref": "x",
"y": "RoofMatl",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "PavedDrive",
"xref": "x",
"y": "RoofMatl",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.13",
"x": "WoodDeckSF",
"xref": "x",
"y": "RoofMatl",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "OpenPorchSF",
"xref": "x",
"y": "RoofMatl",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "EnclosedPorch",
"xref": "x",
"y": "RoofMatl",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "3SsnPorch",
"xref": "x",
"y": "RoofMatl",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "ScreenPorch",
"xref": "x",
"y": "RoofMatl",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "PoolArea",
"xref": "x",
"y": "RoofMatl",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "MiscVal",
"xref": "x",
"y": "RoofMatl",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "MoSold",
"xref": "x",
"y": "RoofMatl",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "YrSold",
"xref": "x",
"y": "RoofMatl",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "SaleType",
"xref": "x",
"y": "RoofMatl",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "SaleCondition",
"xref": "x",
"y": "RoofMatl",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "SalePrice",
"xref": "x",
"y": "RoofMatl",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "Id",
"xref": "x",
"y": "Exterior1st",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "MSSubClass",
"xref": "x",
"y": "Exterior1st",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "MSZoning",
"xref": "x",
"y": "Exterior1st",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "LotArea",
"xref": "x",
"y": "Exterior1st",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "Street",
"xref": "x",
"y": "Exterior1st",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "LotShape",
"xref": "x",
"y": "Exterior1st",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "LandContour",
"xref": "x",
"y": "Exterior1st",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "Utilities",
"xref": "x",
"y": "Exterior1st",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "LotConfig",
"xref": "x",
"y": "Exterior1st",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "LandSlope",
"xref": "x",
"y": "Exterior1st",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.09",
"x": "Neighborhood",
"xref": "x",
"y": "Exterior1st",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "Condition1",
"xref": "x",
"y": "Exterior1st",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "Condition2",
"xref": "x",
"y": "Exterior1st",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "BldgType",
"xref": "x",
"y": "Exterior1st",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "HouseStyle",
"xref": "x",
"y": "Exterior1st",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.16",
"x": "OverallQual",
"xref": "x",
"y": "Exterior1st",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "OverallCond",
"xref": "x",
"y": "Exterior1st",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.11",
"x": "YearBuilt",
"xref": "x",
"y": "Exterior1st",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.24",
"x": "YearRemodAdd",
"xref": "x",
"y": "Exterior1st",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "RoofStyle",
"xref": "x",
"y": "Exterior1st",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "RoofMatl",
"xref": "x",
"y": "Exterior1st",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "Exterior1st",
"xref": "x",
"y": "Exterior1st",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.85",
"x": "Exterior2nd",
"xref": "x",
"y": "Exterior1st",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "MasVnrType",
"xref": "x",
"y": "Exterior1st",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "MasVnrArea",
"xref": "x",
"y": "Exterior1st",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.14",
"x": "ExterQual",
"xref": "x",
"y": "Exterior1st",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "ExterCond",
"xref": "x",
"y": "Exterior1st",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.16",
"x": "Foundation",
"xref": "x",
"y": "Exterior1st",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.17",
"x": "BsmtQual",
"xref": "x",
"y": "Exterior1st",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "BsmtCond",
"xref": "x",
"y": "Exterior1st",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "BsmtExposure",
"xref": "x",
"y": "Exterior1st",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.18",
"x": "BsmtFinType1",
"xref": "x",
"y": "Exterior1st",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.09",
"x": "BsmtFinSF1",
"xref": "x",
"y": "Exterior1st",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "BsmtFinType2",
"xref": "x",
"y": "Exterior1st",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "BsmtFinSF2",
"xref": "x",
"y": "Exterior1st",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "BsmtUnfSF",
"xref": "x",
"y": "Exterior1st",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "TotalBsmtSF",
"xref": "x",
"y": "Exterior1st",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "Heating",
"xref": "x",
"y": "Exterior1st",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.26",
"x": "HeatingQC",
"xref": "x",
"y": "Exterior1st",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "CentralAir",
"xref": "x",
"y": "Exterior1st",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "Electrical",
"xref": "x",
"y": "Exterior1st",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "1stFlrSF",
"xref": "x",
"y": "Exterior1st",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "2ndFlrSF",
"xref": "x",
"y": "Exterior1st",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "LowQualFinSF",
"xref": "x",
"y": "Exterior1st",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "GrLivArea",
"xref": "x",
"y": "Exterior1st",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "BsmtFullBath",
"xref": "x",
"y": "Exterior1st",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "BsmtHalfBath",
"xref": "x",
"y": "Exterior1st",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.13",
"x": "FullBath",
"xref": "x",
"y": "Exterior1st",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "HalfBath",
"xref": "x",
"y": "Exterior1st",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "BedroomAbvGr",
"xref": "x",
"y": "Exterior1st",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "KitchenAbvGr",
"xref": "x",
"y": "Exterior1st",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.13",
"x": "KitchenQual",
"xref": "x",
"y": "Exterior1st",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "TotRmsAbvGrd",
"xref": "x",
"y": "Exterior1st",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "Functional",
"xref": "x",
"y": "Exterior1st",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "Fireplaces",
"xref": "x",
"y": "Exterior1st",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "GarageType",
"xref": "x",
"y": "Exterior1st",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.18",
"x": "GarageYrBlt",
"xref": "x",
"y": "Exterior1st",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "GarageFinish",
"xref": "x",
"y": "Exterior1st",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.15",
"x": "GarageCars",
"xref": "x",
"y": "Exterior1st",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.11",
"x": "GarageArea",
"xref": "x",
"y": "Exterior1st",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "GarageQual",
"xref": "x",
"y": "Exterior1st",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "GarageCond",
"xref": "x",
"y": "Exterior1st",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "PavedDrive",
"xref": "x",
"y": "Exterior1st",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "WoodDeckSF",
"xref": "x",
"y": "Exterior1st",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "OpenPorchSF",
"xref": "x",
"y": "Exterior1st",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "EnclosedPorch",
"xref": "x",
"y": "Exterior1st",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "3SsnPorch",
"xref": "x",
"y": "Exterior1st",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "ScreenPorch",
"xref": "x",
"y": "Exterior1st",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "PoolArea",
"xref": "x",
"y": "Exterior1st",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "MiscVal",
"xref": "x",
"y": "Exterior1st",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "MoSold",
"xref": "x",
"y": "Exterior1st",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "YrSold",
"xref": "x",
"y": "Exterior1st",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "SaleType",
"xref": "x",
"y": "Exterior1st",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "SaleCondition",
"xref": "x",
"y": "Exterior1st",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "SalePrice",
"xref": "x",
"y": "Exterior1st",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "Id",
"xref": "x",
"y": "Exterior2nd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.14",
"x": "MSSubClass",
"xref": "x",
"y": "Exterior2nd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "MSZoning",
"xref": "x",
"y": "Exterior2nd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "LotArea",
"xref": "x",
"y": "Exterior2nd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "Street",
"xref": "x",
"y": "Exterior2nd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "LotShape",
"xref": "x",
"y": "Exterior2nd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "LandContour",
"xref": "x",
"y": "Exterior2nd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "Utilities",
"xref": "x",
"y": "Exterior2nd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "LotConfig",
"xref": "x",
"y": "Exterior2nd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "LandSlope",
"xref": "x",
"y": "Exterior2nd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "Neighborhood",
"xref": "x",
"y": "Exterior2nd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "Condition1",
"xref": "x",
"y": "Exterior2nd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "Condition2",
"xref": "x",
"y": "Exterior2nd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.13",
"x": "BldgType",
"xref": "x",
"y": "Exterior2nd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "HouseStyle",
"xref": "x",
"y": "Exterior2nd",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.16",
"x": "OverallQual",
"xref": "x",
"y": "Exterior2nd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "OverallCond",
"xref": "x",
"y": "Exterior2nd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "YearBuilt",
"xref": "x",
"y": "Exterior2nd",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.23",
"x": "YearRemodAdd",
"xref": "x",
"y": "Exterior2nd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "RoofStyle",
"xref": "x",
"y": "Exterior2nd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "RoofMatl",
"xref": "x",
"y": "Exterior2nd",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.85",
"x": "Exterior1st",
"xref": "x",
"y": "Exterior2nd",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "Exterior2nd",
"xref": "x",
"y": "Exterior2nd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "MasVnrType",
"xref": "x",
"y": "Exterior2nd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "MasVnrArea",
"xref": "x",
"y": "Exterior2nd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.11",
"x": "ExterQual",
"xref": "x",
"y": "Exterior2nd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "ExterCond",
"xref": "x",
"y": "Exterior2nd",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "Foundation",
"xref": "x",
"y": "Exterior2nd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.14",
"x": "BsmtQual",
"xref": "x",
"y": "Exterior2nd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "BsmtCond",
"xref": "x",
"y": "Exterior2nd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "BsmtExposure",
"xref": "x",
"y": "Exterior2nd",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.17",
"x": "BsmtFinType1",
"xref": "x",
"y": "Exterior2nd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.09",
"x": "BsmtFinSF1",
"xref": "x",
"y": "Exterior2nd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "BsmtFinType2",
"xref": "x",
"y": "Exterior2nd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "BsmtFinSF2",
"xref": "x",
"y": "Exterior2nd",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "BsmtUnfSF",
"xref": "x",
"y": "Exterior2nd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "TotalBsmtSF",
"xref": "x",
"y": "Exterior2nd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "Heating",
"xref": "x",
"y": "Exterior2nd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.24",
"x": "HeatingQC",
"xref": "x",
"y": "Exterior2nd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "CentralAir",
"xref": "x",
"y": "Exterior2nd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "Electrical",
"xref": "x",
"y": "Exterior2nd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "1stFlrSF",
"xref": "x",
"y": "Exterior2nd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "2ndFlrSF",
"xref": "x",
"y": "Exterior2nd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "LowQualFinSF",
"xref": "x",
"y": "Exterior2nd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "GrLivArea",
"xref": "x",
"y": "Exterior2nd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "BsmtFullBath",
"xref": "x",
"y": "Exterior2nd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "BsmtHalfBath",
"xref": "x",
"y": "Exterior2nd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.13",
"x": "FullBath",
"xref": "x",
"y": "Exterior2nd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "HalfBath",
"xref": "x",
"y": "Exterior2nd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "BedroomAbvGr",
"xref": "x",
"y": "Exterior2nd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "KitchenAbvGr",
"xref": "x",
"y": "Exterior2nd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.12",
"x": "KitchenQual",
"xref": "x",
"y": "Exterior2nd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "TotRmsAbvGrd",
"xref": "x",
"y": "Exterior2nd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Functional",
"xref": "x",
"y": "Exterior2nd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Fireplaces",
"xref": "x",
"y": "Exterior2nd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "GarageType",
"xref": "x",
"y": "Exterior2nd",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.16",
"x": "GarageYrBlt",
"xref": "x",
"y": "Exterior2nd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "GarageFinish",
"xref": "x",
"y": "Exterior2nd",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.15",
"x": "GarageCars",
"xref": "x",
"y": "Exterior2nd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "GarageArea",
"xref": "x",
"y": "Exterior2nd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "GarageQual",
"xref": "x",
"y": "Exterior2nd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "GarageCond",
"xref": "x",
"y": "Exterior2nd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "PavedDrive",
"xref": "x",
"y": "Exterior2nd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "WoodDeckSF",
"xref": "x",
"y": "Exterior2nd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "OpenPorchSF",
"xref": "x",
"y": "Exterior2nd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "EnclosedPorch",
"xref": "x",
"y": "Exterior2nd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "3SsnPorch",
"xref": "x",
"y": "Exterior2nd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "ScreenPorch",
"xref": "x",
"y": "Exterior2nd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "PoolArea",
"xref": "x",
"y": "Exterior2nd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "MiscVal",
"xref": "x",
"y": "Exterior2nd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "MoSold",
"xref": "x",
"y": "Exterior2nd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "YrSold",
"xref": "x",
"y": "Exterior2nd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "SaleType",
"xref": "x",
"y": "Exterior2nd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "SaleCondition",
"xref": "x",
"y": "Exterior2nd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "SalePrice",
"xref": "x",
"y": "Exterior2nd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "Id",
"xref": "x",
"y": "MasVnrType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "MSSubClass",
"xref": "x",
"y": "MasVnrType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "MSZoning",
"xref": "x",
"y": "MasVnrType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "LotArea",
"xref": "x",
"y": "MasVnrType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "Street",
"xref": "x",
"y": "MasVnrType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "LotShape",
"xref": "x",
"y": "MasVnrType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "LandContour",
"xref": "x",
"y": "MasVnrType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "Utilities",
"xref": "x",
"y": "MasVnrType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "LotConfig",
"xref": "x",
"y": "MasVnrType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "LandSlope",
"xref": "x",
"y": "MasVnrType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "Neighborhood",
"xref": "x",
"y": "MasVnrType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Condition1",
"xref": "x",
"y": "MasVnrType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "Condition2",
"xref": "x",
"y": "MasVnrType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "BldgType",
"xref": "x",
"y": "MasVnrType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.13",
"x": "HouseStyle",
"xref": "x",
"y": "MasVnrType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "OverallQual",
"xref": "x",
"y": "MasVnrType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "OverallCond",
"xref": "x",
"y": "MasVnrType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "YearBuilt",
"xref": "x",
"y": "MasVnrType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "YearRemodAdd",
"xref": "x",
"y": "MasVnrType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.09",
"x": "RoofStyle",
"xref": "x",
"y": "MasVnrType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "RoofMatl",
"xref": "x",
"y": "MasVnrType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "Exterior1st",
"xref": "x",
"y": "MasVnrType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "Exterior2nd",
"xref": "x",
"y": "MasVnrType",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "MasVnrType",
"xref": "x",
"y": "MasVnrType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.33",
"x": "MasVnrArea",
"xref": "x",
"y": "MasVnrType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "ExterQual",
"xref": "x",
"y": "MasVnrType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "ExterCond",
"xref": "x",
"y": "MasVnrType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "Foundation",
"xref": "x",
"y": "MasVnrType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.12",
"x": "BsmtQual",
"xref": "x",
"y": "MasVnrType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "BsmtCond",
"xref": "x",
"y": "MasVnrType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "BsmtExposure",
"xref": "x",
"y": "MasVnrType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "BsmtFinType1",
"xref": "x",
"y": "MasVnrType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "BsmtFinSF1",
"xref": "x",
"y": "MasVnrType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "BsmtFinType2",
"xref": "x",
"y": "MasVnrType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "BsmtFinSF2",
"xref": "x",
"y": "MasVnrType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "BsmtUnfSF",
"xref": "x",
"y": "MasVnrType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "TotalBsmtSF",
"xref": "x",
"y": "MasVnrType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "Heating",
"xref": "x",
"y": "MasVnrType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.09",
"x": "HeatingQC",
"xref": "x",
"y": "MasVnrType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "CentralAir",
"xref": "x",
"y": "MasVnrType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "Electrical",
"xref": "x",
"y": "MasVnrType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "1stFlrSF",
"xref": "x",
"y": "MasVnrType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "2ndFlrSF",
"xref": "x",
"y": "MasVnrType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "LowQualFinSF",
"xref": "x",
"y": "MasVnrType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "GrLivArea",
"xref": "x",
"y": "MasVnrType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "BsmtFullBath",
"xref": "x",
"y": "MasVnrType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "BsmtHalfBath",
"xref": "x",
"y": "MasVnrType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "FullBath",
"xref": "x",
"y": "MasVnrType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.12",
"x": "HalfBath",
"xref": "x",
"y": "MasVnrType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.09",
"x": "BedroomAbvGr",
"xref": "x",
"y": "MasVnrType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "KitchenAbvGr",
"xref": "x",
"y": "MasVnrType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.13",
"x": "KitchenQual",
"xref": "x",
"y": "MasVnrType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "TotRmsAbvGrd",
"xref": "x",
"y": "MasVnrType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "Functional",
"xref": "x",
"y": "MasVnrType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "Fireplaces",
"xref": "x",
"y": "MasVnrType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.13",
"x": "GarageType",
"xref": "x",
"y": "MasVnrType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "GarageYrBlt",
"xref": "x",
"y": "MasVnrType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "GarageFinish",
"xref": "x",
"y": "MasVnrType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "GarageCars",
"xref": "x",
"y": "MasVnrType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "GarageArea",
"xref": "x",
"y": "MasVnrType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "GarageQual",
"xref": "x",
"y": "MasVnrType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "GarageCond",
"xref": "x",
"y": "MasVnrType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "PavedDrive",
"xref": "x",
"y": "MasVnrType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "WoodDeckSF",
"xref": "x",
"y": "MasVnrType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "OpenPorchSF",
"xref": "x",
"y": "MasVnrType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "EnclosedPorch",
"xref": "x",
"y": "MasVnrType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "3SsnPorch",
"xref": "x",
"y": "MasVnrType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "ScreenPorch",
"xref": "x",
"y": "MasVnrType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "PoolArea",
"xref": "x",
"y": "MasVnrType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "MiscVal",
"xref": "x",
"y": "MasVnrType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "MoSold",
"xref": "x",
"y": "MasVnrType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "YrSold",
"xref": "x",
"y": "MasVnrType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "SaleType",
"xref": "x",
"y": "MasVnrType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "SaleCondition",
"xref": "x",
"y": "MasVnrType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "SalePrice",
"xref": "x",
"y": "MasVnrType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "Id",
"xref": "x",
"y": "MasVnrArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "MSSubClass",
"xref": "x",
"y": "MasVnrArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "MSZoning",
"xref": "x",
"y": "MasVnrArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "LotArea",
"xref": "x",
"y": "MasVnrArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "Street",
"xref": "x",
"y": "MasVnrArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "LotShape",
"xref": "x",
"y": "MasVnrArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "LandContour",
"xref": "x",
"y": "MasVnrArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "Utilities",
"xref": "x",
"y": "MasVnrArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "LotConfig",
"xref": "x",
"y": "MasVnrArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "LandSlope",
"xref": "x",
"y": "MasVnrArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "Neighborhood",
"xref": "x",
"y": "MasVnrArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Condition1",
"xref": "x",
"y": "MasVnrArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "Condition2",
"xref": "x",
"y": "MasVnrArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "BldgType",
"xref": "x",
"y": "MasVnrArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.16",
"x": "HouseStyle",
"xref": "x",
"y": "MasVnrArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.4",
"x": "OverallQual",
"xref": "x",
"y": "MasVnrArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.14",
"x": "OverallCond",
"xref": "x",
"y": "MasVnrArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.3",
"x": "YearBuilt",
"xref": "x",
"y": "MasVnrArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.17",
"x": "YearRemodAdd",
"xref": "x",
"y": "MasVnrArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.26",
"x": "RoofStyle",
"xref": "x",
"y": "MasVnrArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "RoofMatl",
"xref": "x",
"y": "MasVnrArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "Exterior1st",
"xref": "x",
"y": "MasVnrArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "Exterior2nd",
"xref": "x",
"y": "MasVnrArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.33",
"x": "MasVnrType",
"xref": "x",
"y": "MasVnrArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "MasVnrArea",
"xref": "x",
"y": "MasVnrArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.36",
"x": "ExterQual",
"xref": "x",
"y": "MasVnrArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "ExterCond",
"xref": "x",
"y": "MasVnrArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.2",
"x": "Foundation",
"xref": "x",
"y": "MasVnrArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.31",
"x": "BsmtQual",
"xref": "x",
"y": "MasVnrArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "BsmtCond",
"xref": "x",
"y": "MasVnrArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.12",
"x": "BsmtExposure",
"xref": "x",
"y": "MasVnrArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "BsmtFinType1",
"xref": "x",
"y": "MasVnrArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.25",
"x": "BsmtFinSF1",
"xref": "x",
"y": "MasVnrArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "BsmtFinType2",
"xref": "x",
"y": "MasVnrArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "BsmtFinSF2",
"xref": "x",
"y": "MasVnrArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "BsmtUnfSF",
"xref": "x",
"y": "MasVnrArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.37",
"x": "TotalBsmtSF",
"xref": "x",
"y": "MasVnrArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "Heating",
"xref": "x",
"y": "MasVnrArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.14",
"x": "HeatingQC",
"xref": "x",
"y": "MasVnrArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.11",
"x": "CentralAir",
"xref": "x",
"y": "MasVnrArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "Electrical",
"xref": "x",
"y": "MasVnrArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.34",
"x": "1stFlrSF",
"xref": "x",
"y": "MasVnrArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.17",
"x": "2ndFlrSF",
"xref": "x",
"y": "MasVnrArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "LowQualFinSF",
"xref": "x",
"y": "MasVnrArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.39",
"x": "GrLivArea",
"xref": "x",
"y": "MasVnrArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "BsmtFullBath",
"xref": "x",
"y": "MasVnrArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "BsmtHalfBath",
"xref": "x",
"y": "MasVnrArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.27",
"x": "FullBath",
"xref": "x",
"y": "MasVnrArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.19",
"x": "HalfBath",
"xref": "x",
"y": "MasVnrArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.11",
"x": "BedroomAbvGr",
"xref": "x",
"y": "MasVnrArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "KitchenAbvGr",
"xref": "x",
"y": "MasVnrArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.26",
"x": "KitchenQual",
"xref": "x",
"y": "MasVnrArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.29",
"x": "TotRmsAbvGrd",
"xref": "x",
"y": "MasVnrArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "Functional",
"xref": "x",
"y": "MasVnrArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.23",
"x": "Fireplaces",
"xref": "x",
"y": "MasVnrArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.18",
"x": "GarageType",
"xref": "x",
"y": "MasVnrArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.25",
"x": "GarageYrBlt",
"xref": "x",
"y": "MasVnrArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.25",
"x": "GarageFinish",
"xref": "x",
"y": "MasVnrArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.36",
"x": "GarageCars",
"xref": "x",
"y": "MasVnrArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.37",
"x": "GarageArea",
"xref": "x",
"y": "MasVnrArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "GarageQual",
"xref": "x",
"y": "MasVnrArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "GarageCond",
"xref": "x",
"y": "MasVnrArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "PavedDrive",
"xref": "x",
"y": "MasVnrArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.15",
"x": "WoodDeckSF",
"xref": "x",
"y": "MasVnrArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.13",
"x": "OpenPorchSF",
"xref": "x",
"y": "MasVnrArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.11",
"x": "EnclosedPorch",
"xref": "x",
"y": "MasVnrArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "3SsnPorch",
"xref": "x",
"y": "MasVnrArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "ScreenPorch",
"xref": "x",
"y": "MasVnrArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "PoolArea",
"xref": "x",
"y": "MasVnrArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "MiscVal",
"xref": "x",
"y": "MasVnrArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "MoSold",
"xref": "x",
"y": "MasVnrArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "YrSold",
"xref": "x",
"y": "MasVnrArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "SaleType",
"xref": "x",
"y": "MasVnrArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "SaleCondition",
"xref": "x",
"y": "MasVnrArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.47",
"x": "SalePrice",
"xref": "x",
"y": "MasVnrArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "Id",
"xref": "x",
"y": "ExterQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "MSSubClass",
"xref": "x",
"y": "ExterQual",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.2",
"x": "MSZoning",
"xref": "x",
"y": "ExterQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "LotArea",
"xref": "x",
"y": "ExterQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "Street",
"xref": "x",
"y": "ExterQual",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "LotShape",
"xref": "x",
"y": "ExterQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "LandContour",
"xref": "x",
"y": "ExterQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "Utilities",
"xref": "x",
"y": "ExterQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "LotConfig",
"xref": "x",
"y": "ExterQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "LandSlope",
"xref": "x",
"y": "ExterQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.16",
"x": "Neighborhood",
"xref": "x",
"y": "ExterQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "Condition1",
"xref": "x",
"y": "ExterQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "Condition2",
"xref": "x",
"y": "ExterQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.11",
"x": "BldgType",
"xref": "x",
"y": "ExterQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "HouseStyle",
"xref": "x",
"y": "ExterQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.68",
"x": "OverallQual",
"xref": "x",
"y": "ExterQual",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.17",
"x": "OverallCond",
"xref": "x",
"y": "ExterQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.51",
"x": "YearBuilt",
"xref": "x",
"y": "ExterQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.51",
"x": "YearRemodAdd",
"xref": "x",
"y": "ExterQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.19",
"x": "RoofStyle",
"xref": "x",
"y": "ExterQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "RoofMatl",
"xref": "x",
"y": "ExterQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.14",
"x": "Exterior1st",
"xref": "x",
"y": "ExterQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.11",
"x": "Exterior2nd",
"xref": "x",
"y": "ExterQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "MasVnrType",
"xref": "x",
"y": "ExterQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.36",
"x": "MasVnrArea",
"xref": "x",
"y": "ExterQual",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "ExterQual",
"xref": "x",
"y": "ExterQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "ExterCond",
"xref": "x",
"y": "ExterQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.48",
"x": "Foundation",
"xref": "x",
"y": "ExterQual",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.59",
"x": "BsmtQual",
"xref": "x",
"y": "ExterQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "BsmtCond",
"xref": "x",
"y": "ExterQual",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.23",
"x": "BsmtExposure",
"xref": "x",
"y": "ExterQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "BsmtFinType1",
"xref": "x",
"y": "ExterQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.18",
"x": "BsmtFinSF1",
"xref": "x",
"y": "ExterQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "BsmtFinType2",
"xref": "x",
"y": "ExterQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "BsmtFinSF2",
"xref": "x",
"y": "ExterQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.27",
"x": "BsmtUnfSF",
"xref": "x",
"y": "ExterQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.46",
"x": "TotalBsmtSF",
"xref": "x",
"y": "ExterQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "Heating",
"xref": "x",
"y": "ExterQual",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.44",
"x": "HeatingQC",
"xref": "x",
"y": "ExterQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.09",
"x": "CentralAir",
"xref": "x",
"y": "ExterQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.17",
"x": "Electrical",
"xref": "x",
"y": "ExterQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.4",
"x": "1stFlrSF",
"xref": "x",
"y": "ExterQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.15",
"x": "2ndFlrSF",
"xref": "x",
"y": "ExterQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "LowQualFinSF",
"xref": "x",
"y": "ExterQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.42",
"x": "GrLivArea",
"xref": "x",
"y": "ExterQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.09",
"x": "BsmtFullBath",
"xref": "x",
"y": "ExterQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "BsmtHalfBath",
"xref": "x",
"y": "ExterQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.44",
"x": "FullBath",
"xref": "x",
"y": "ExterQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.15",
"x": "HalfBath",
"xref": "x",
"y": "ExterQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "BedroomAbvGr",
"xref": "x",
"y": "ExterQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "KitchenAbvGr",
"xref": "x",
"y": "ExterQual",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.65",
"x": "KitchenQual",
"xref": "x",
"y": "ExterQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.31",
"x": "TotRmsAbvGrd",
"xref": "x",
"y": "ExterQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "Functional",
"xref": "x",
"y": "ExterQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.21",
"x": "Fireplaces",
"xref": "x",
"y": "ExterQual",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.24",
"x": "GarageType",
"xref": "x",
"y": "ExterQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.52",
"x": "GarageYrBlt",
"xref": "x",
"y": "ExterQual",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.45",
"x": "GarageFinish",
"xref": "x",
"y": "ExterQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.49",
"x": "GarageCars",
"xref": "x",
"y": "ExterQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.47",
"x": "GarageArea",
"xref": "x",
"y": "ExterQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.09",
"x": "GarageQual",
"xref": "x",
"y": "ExterQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.11",
"x": "GarageCond",
"xref": "x",
"y": "ExterQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.11",
"x": "PavedDrive",
"xref": "x",
"y": "ExterQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.18",
"x": "WoodDeckSF",
"xref": "x",
"y": "ExterQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.28",
"x": "OpenPorchSF",
"xref": "x",
"y": "ExterQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "EnclosedPorch",
"xref": "x",
"y": "ExterQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "3SsnPorch",
"xref": "x",
"y": "ExterQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "ScreenPorch",
"xref": "x",
"y": "ExterQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "PoolArea",
"xref": "x",
"y": "ExterQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "MiscVal",
"xref": "x",
"y": "ExterQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "MoSold",
"xref": "x",
"y": "ExterQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "YrSold",
"xref": "x",
"y": "ExterQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "SaleType",
"xref": "x",
"y": "ExterQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.2",
"x": "SaleCondition",
"xref": "x",
"y": "ExterQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.65",
"x": "SalePrice",
"xref": "x",
"y": "ExterQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "Id",
"xref": "x",
"y": "ExterCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "MSSubClass",
"xref": "x",
"y": "ExterCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "MSZoning",
"xref": "x",
"y": "ExterCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "LotArea",
"xref": "x",
"y": "ExterCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "Street",
"xref": "x",
"y": "ExterCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "LotShape",
"xref": "x",
"y": "ExterCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "LandContour",
"xref": "x",
"y": "ExterCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Utilities",
"xref": "x",
"y": "ExterCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "LotConfig",
"xref": "x",
"y": "ExterCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "LandSlope",
"xref": "x",
"y": "ExterCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "Neighborhood",
"xref": "x",
"y": "ExterCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "Condition1",
"xref": "x",
"y": "ExterCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "Condition2",
"xref": "x",
"y": "ExterCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "BldgType",
"xref": "x",
"y": "ExterCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "HouseStyle",
"xref": "x",
"y": "ExterCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.11",
"x": "OverallQual",
"xref": "x",
"y": "ExterCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.25",
"x": "OverallCond",
"xref": "x",
"y": "ExterCond",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.26",
"x": "YearBuilt",
"xref": "x",
"y": "ExterCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "YearRemodAdd",
"xref": "x",
"y": "ExterCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "RoofStyle",
"xref": "x",
"y": "ExterCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "RoofMatl",
"xref": "x",
"y": "ExterCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "Exterior1st",
"xref": "x",
"y": "ExterCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "Exterior2nd",
"xref": "x",
"y": "ExterCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "MasVnrType",
"xref": "x",
"y": "ExterCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "MasVnrArea",
"xref": "x",
"y": "ExterCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "ExterQual",
"xref": "x",
"y": "ExterCond",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "ExterCond",
"xref": "x",
"y": "ExterCond",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.19",
"x": "Foundation",
"xref": "x",
"y": "ExterCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.14",
"x": "BsmtQual",
"xref": "x",
"y": "ExterCond",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.19",
"x": "BsmtCond",
"xref": "x",
"y": "ExterCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "BsmtExposure",
"xref": "x",
"y": "ExterCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "BsmtFinType1",
"xref": "x",
"y": "ExterCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "BsmtFinSF1",
"xref": "x",
"y": "ExterCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "BsmtFinType2",
"xref": "x",
"y": "ExterCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "BsmtFinSF2",
"xref": "x",
"y": "ExterCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "BsmtUnfSF",
"xref": "x",
"y": "ExterCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "TotalBsmtSF",
"xref": "x",
"y": "ExterCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "Heating",
"xref": "x",
"y": "ExterCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "HeatingQC",
"xref": "x",
"y": "ExterCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "CentralAir",
"xref": "x",
"y": "ExterCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "Electrical",
"xref": "x",
"y": "ExterCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "1stFlrSF",
"xref": "x",
"y": "ExterCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "2ndFlrSF",
"xref": "x",
"y": "ExterCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "LowQualFinSF",
"xref": "x",
"y": "ExterCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "GrLivArea",
"xref": "x",
"y": "ExterCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "BsmtFullBath",
"xref": "x",
"y": "ExterCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "BsmtHalfBath",
"xref": "x",
"y": "ExterCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "FullBath",
"xref": "x",
"y": "ExterCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "HalfBath",
"xref": "x",
"y": "ExterCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "BedroomAbvGr",
"xref": "x",
"y": "ExterCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "KitchenAbvGr",
"xref": "x",
"y": "ExterCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "KitchenQual",
"xref": "x",
"y": "ExterCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "TotRmsAbvGrd",
"xref": "x",
"y": "ExterCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "Functional",
"xref": "x",
"y": "ExterCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "Fireplaces",
"xref": "x",
"y": "ExterCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.13",
"x": "GarageType",
"xref": "x",
"y": "ExterCond",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.2",
"x": "GarageYrBlt",
"xref": "x",
"y": "ExterCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.14",
"x": "GarageFinish",
"xref": "x",
"y": "ExterCond",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.15",
"x": "GarageCars",
"xref": "x",
"y": "ExterCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "GarageArea",
"xref": "x",
"y": "ExterCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "GarageQual",
"xref": "x",
"y": "ExterCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "GarageCond",
"xref": "x",
"y": "ExterCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.11",
"x": "PavedDrive",
"xref": "x",
"y": "ExterCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "WoodDeckSF",
"xref": "x",
"y": "ExterCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "OpenPorchSF",
"xref": "x",
"y": "ExterCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "EnclosedPorch",
"xref": "x",
"y": "ExterCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "3SsnPorch",
"xref": "x",
"y": "ExterCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "ScreenPorch",
"xref": "x",
"y": "ExterCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "PoolArea",
"xref": "x",
"y": "ExterCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "MiscVal",
"xref": "x",
"y": "ExterCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "MoSold",
"xref": "x",
"y": "ExterCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "YrSold",
"xref": "x",
"y": "ExterCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "SaleType",
"xref": "x",
"y": "ExterCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "SaleCondition",
"xref": "x",
"y": "ExterCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "SalePrice",
"xref": "x",
"y": "ExterCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "Id",
"xref": "x",
"y": "Foundation",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "MSSubClass",
"xref": "x",
"y": "Foundation",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.25",
"x": "MSZoning",
"xref": "x",
"y": "Foundation",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "LotArea",
"xref": "x",
"y": "Foundation",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "Street",
"xref": "x",
"y": "Foundation",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.17",
"x": "LotShape",
"xref": "x",
"y": "Foundation",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "LandContour",
"xref": "x",
"y": "Foundation",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "Utilities",
"xref": "x",
"y": "Foundation",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "LotConfig",
"xref": "x",
"y": "Foundation",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "LandSlope",
"xref": "x",
"y": "Foundation",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "Neighborhood",
"xref": "x",
"y": "Foundation",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "Condition1",
"xref": "x",
"y": "Foundation",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "Condition2",
"xref": "x",
"y": "Foundation",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.16",
"x": "BldgType",
"xref": "x",
"y": "Foundation",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.21",
"x": "HouseStyle",
"xref": "x",
"y": "Foundation",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.49",
"x": "OverallQual",
"xref": "x",
"y": "Foundation",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.33",
"x": "OverallCond",
"xref": "x",
"y": "Foundation",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.72",
"x": "YearBuilt",
"xref": "x",
"y": "Foundation",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.53",
"x": "YearRemodAdd",
"xref": "x",
"y": "Foundation",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "RoofStyle",
"xref": "x",
"y": "Foundation",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "RoofMatl",
"xref": "x",
"y": "Foundation",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.16",
"x": "Exterior1st",
"xref": "x",
"y": "Foundation",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "Exterior2nd",
"xref": "x",
"y": "Foundation",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "MasVnrType",
"xref": "x",
"y": "Foundation",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.2",
"x": "MasVnrArea",
"xref": "x",
"y": "Foundation",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.48",
"x": "ExterQual",
"xref": "x",
"y": "Foundation",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.19",
"x": "ExterCond",
"xref": "x",
"y": "Foundation",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "Foundation",
"xref": "x",
"y": "Foundation",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.46",
"x": "BsmtQual",
"xref": "x",
"y": "Foundation",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "BsmtCond",
"xref": "x",
"y": "Foundation",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.23",
"x": "BsmtExposure",
"xref": "x",
"y": "Foundation",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "BsmtFinType1",
"xref": "x",
"y": "Foundation",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "BsmtFinSF1",
"xref": "x",
"y": "Foundation",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.11",
"x": "BsmtFinType2",
"xref": "x",
"y": "Foundation",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "BsmtFinSF2",
"xref": "x",
"y": "Foundation",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.16",
"x": "BsmtUnfSF",
"xref": "x",
"y": "Foundation",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.29",
"x": "TotalBsmtSF",
"xref": "x",
"y": "Foundation",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.18",
"x": "Heating",
"xref": "x",
"y": "Foundation",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.42",
"x": "HeatingQC",
"xref": "x",
"y": "Foundation",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.24",
"x": "CentralAir",
"xref": "x",
"y": "Foundation",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.25",
"x": "Electrical",
"xref": "x",
"y": "Foundation",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.2",
"x": "1stFlrSF",
"xref": "x",
"y": "Foundation",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "2ndFlrSF",
"xref": "x",
"y": "Foundation",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "LowQualFinSF",
"xref": "x",
"y": "Foundation",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.24",
"x": "GrLivArea",
"xref": "x",
"y": "Foundation",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "BsmtFullBath",
"xref": "x",
"y": "Foundation",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "BsmtHalfBath",
"xref": "x",
"y": "Foundation",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.42",
"x": "FullBath",
"xref": "x",
"y": "Foundation",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.17",
"x": "HalfBath",
"xref": "x",
"y": "Foundation",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "BedroomAbvGr",
"xref": "x",
"y": "Foundation",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.09",
"x": "KitchenAbvGr",
"xref": "x",
"y": "Foundation",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.38",
"x": "KitchenQual",
"xref": "x",
"y": "Foundation",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.15",
"x": "TotRmsAbvGrd",
"xref": "x",
"y": "Foundation",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "Functional",
"xref": "x",
"y": "Foundation",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "Fireplaces",
"xref": "x",
"y": "Foundation",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.39",
"x": "GarageType",
"xref": "x",
"y": "Foundation",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.66",
"x": "GarageYrBlt",
"xref": "x",
"y": "Foundation",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.48",
"x": "GarageFinish",
"xref": "x",
"y": "Foundation",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.44",
"x": "GarageCars",
"xref": "x",
"y": "Foundation",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.38",
"x": "GarageArea",
"xref": "x",
"y": "Foundation",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.27",
"x": "GarageQual",
"xref": "x",
"y": "Foundation",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.2",
"x": "GarageCond",
"xref": "x",
"y": "Foundation",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.23",
"x": "PavedDrive",
"xref": "x",
"y": "Foundation",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.17",
"x": "WoodDeckSF",
"xref": "x",
"y": "Foundation",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.2",
"x": "OpenPorchSF",
"xref": "x",
"y": "Foundation",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.23",
"x": "EnclosedPorch",
"xref": "x",
"y": "Foundation",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "3SsnPorch",
"xref": "x",
"y": "Foundation",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "ScreenPorch",
"xref": "x",
"y": "Foundation",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "PoolArea",
"xref": "x",
"y": "Foundation",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "MiscVal",
"xref": "x",
"y": "Foundation",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "MoSold",
"xref": "x",
"y": "Foundation",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "YrSold",
"xref": "x",
"y": "Foundation",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "SaleType",
"xref": "x",
"y": "Foundation",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.17",
"x": "SaleCondition",
"xref": "x",
"y": "Foundation",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.44",
"x": "SalePrice",
"xref": "x",
"y": "Foundation",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "Id",
"xref": "x",
"y": "BsmtQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "MSSubClass",
"xref": "x",
"y": "BsmtQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.13",
"x": "MSZoning",
"xref": "x",
"y": "BsmtQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "LotArea",
"xref": "x",
"y": "BsmtQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "Street",
"xref": "x",
"y": "BsmtQual",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.16",
"x": "LotShape",
"xref": "x",
"y": "BsmtQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "LandContour",
"xref": "x",
"y": "BsmtQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "Utilities",
"xref": "x",
"y": "BsmtQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "LotConfig",
"xref": "x",
"y": "BsmtQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "LandSlope",
"xref": "x",
"y": "BsmtQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.16",
"x": "Neighborhood",
"xref": "x",
"y": "BsmtQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "Condition1",
"xref": "x",
"y": "BsmtQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Condition2",
"xref": "x",
"y": "BsmtQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.12",
"x": "BldgType",
"xref": "x",
"y": "BsmtQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.13",
"x": "HouseStyle",
"xref": "x",
"y": "BsmtQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.61",
"x": "OverallQual",
"xref": "x",
"y": "BsmtQual",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.27",
"x": "OverallCond",
"xref": "x",
"y": "BsmtQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.53",
"x": "YearBuilt",
"xref": "x",
"y": "BsmtQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.48",
"x": "YearRemodAdd",
"xref": "x",
"y": "BsmtQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.14",
"x": "RoofStyle",
"xref": "x",
"y": "BsmtQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "RoofMatl",
"xref": "x",
"y": "BsmtQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.17",
"x": "Exterior1st",
"xref": "x",
"y": "BsmtQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.14",
"x": "Exterior2nd",
"xref": "x",
"y": "BsmtQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.12",
"x": "MasVnrType",
"xref": "x",
"y": "BsmtQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.31",
"x": "MasVnrArea",
"xref": "x",
"y": "BsmtQual",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.59",
"x": "ExterQual",
"xref": "x",
"y": "BsmtQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.14",
"x": "ExterCond",
"xref": "x",
"y": "BsmtQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.46",
"x": "Foundation",
"xref": "x",
"y": "BsmtQual",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "BsmtQual",
"xref": "x",
"y": "BsmtQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "BsmtCond",
"xref": "x",
"y": "BsmtQual",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.27",
"x": "BsmtExposure",
"xref": "x",
"y": "BsmtQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "BsmtFinType1",
"xref": "x",
"y": "BsmtQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.23",
"x": "BsmtFinSF1",
"xref": "x",
"y": "BsmtQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.12",
"x": "BsmtFinType2",
"xref": "x",
"y": "BsmtQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.11",
"x": "BsmtFinSF2",
"xref": "x",
"y": "BsmtQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.19",
"x": "BsmtUnfSF",
"xref": "x",
"y": "BsmtQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.41",
"x": "TotalBsmtSF",
"xref": "x",
"y": "BsmtQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "Heating",
"xref": "x",
"y": "BsmtQual",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.39",
"x": "HeatingQC",
"xref": "x",
"y": "BsmtQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "CentralAir",
"xref": "x",
"y": "BsmtQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.15",
"x": "Electrical",
"xref": "x",
"y": "BsmtQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.36",
"x": "1stFlrSF",
"xref": "x",
"y": "BsmtQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.12",
"x": "2ndFlrSF",
"xref": "x",
"y": "BsmtQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "LowQualFinSF",
"xref": "x",
"y": "BsmtQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.37",
"x": "GrLivArea",
"xref": "x",
"y": "BsmtQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.14",
"x": "BsmtFullBath",
"xref": "x",
"y": "BsmtQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "BsmtHalfBath",
"xref": "x",
"y": "BsmtQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.44",
"x": "FullBath",
"xref": "x",
"y": "BsmtQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.13",
"x": "HalfBath",
"xref": "x",
"y": "BsmtQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "BedroomAbvGr",
"xref": "x",
"y": "BsmtQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "KitchenAbvGr",
"xref": "x",
"y": "BsmtQual",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.53",
"x": "KitchenQual",
"xref": "x",
"y": "BsmtQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.27",
"x": "TotRmsAbvGrd",
"xref": "x",
"y": "BsmtQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "Functional",
"xref": "x",
"y": "BsmtQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.19",
"x": "Fireplaces",
"xref": "x",
"y": "BsmtQual",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.25",
"x": "GarageType",
"xref": "x",
"y": "BsmtQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.53",
"x": "GarageYrBlt",
"xref": "x",
"y": "BsmtQual",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.45",
"x": "GarageFinish",
"xref": "x",
"y": "BsmtQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.52",
"x": "GarageCars",
"xref": "x",
"y": "BsmtQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.46",
"x": "GarageArea",
"xref": "x",
"y": "BsmtQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "GarageQual",
"xref": "x",
"y": "BsmtQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "GarageCond",
"xref": "x",
"y": "BsmtQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.11",
"x": "PavedDrive",
"xref": "x",
"y": "BsmtQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.21",
"x": "WoodDeckSF",
"xref": "x",
"y": "BsmtQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.25",
"x": "OpenPorchSF",
"xref": "x",
"y": "BsmtQual",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.15",
"x": "EnclosedPorch",
"xref": "x",
"y": "BsmtQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "3SsnPorch",
"xref": "x",
"y": "BsmtQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "ScreenPorch",
"xref": "x",
"y": "BsmtQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "PoolArea",
"xref": "x",
"y": "BsmtQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "MiscVal",
"xref": "x",
"y": "BsmtQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "MoSold",
"xref": "x",
"y": "BsmtQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "YrSold",
"xref": "x",
"y": "BsmtQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "SaleType",
"xref": "x",
"y": "BsmtQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.18",
"x": "SaleCondition",
"xref": "x",
"y": "BsmtQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.61",
"x": "SalePrice",
"xref": "x",
"y": "BsmtQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Id",
"xref": "x",
"y": "BsmtCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "MSSubClass",
"xref": "x",
"y": "BsmtCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "MSZoning",
"xref": "x",
"y": "BsmtCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "LotArea",
"xref": "x",
"y": "BsmtCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "Street",
"xref": "x",
"y": "BsmtCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "LotShape",
"xref": "x",
"y": "BsmtCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "LandContour",
"xref": "x",
"y": "BsmtCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Utilities",
"xref": "x",
"y": "BsmtCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "LotConfig",
"xref": "x",
"y": "BsmtCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "LandSlope",
"xref": "x",
"y": "BsmtCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "Neighborhood",
"xref": "x",
"y": "BsmtCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "Condition1",
"xref": "x",
"y": "BsmtCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "Condition2",
"xref": "x",
"y": "BsmtCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "BldgType",
"xref": "x",
"y": "BsmtCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "HouseStyle",
"xref": "x",
"y": "BsmtCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "OverallQual",
"xref": "x",
"y": "BsmtCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "OverallCond",
"xref": "x",
"y": "BsmtCond",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "YearBuilt",
"xref": "x",
"y": "BsmtCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "YearRemodAdd",
"xref": "x",
"y": "BsmtCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "RoofStyle",
"xref": "x",
"y": "BsmtCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "RoofMatl",
"xref": "x",
"y": "BsmtCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "Exterior1st",
"xref": "x",
"y": "BsmtCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "Exterior2nd",
"xref": "x",
"y": "BsmtCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "MasVnrType",
"xref": "x",
"y": "BsmtCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "MasVnrArea",
"xref": "x",
"y": "BsmtCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "ExterQual",
"xref": "x",
"y": "BsmtCond",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.19",
"x": "ExterCond",
"xref": "x",
"y": "BsmtCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "Foundation",
"xref": "x",
"y": "BsmtCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "BsmtQual",
"xref": "x",
"y": "BsmtCond",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "BsmtCond",
"xref": "x",
"y": "BsmtCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "BsmtExposure",
"xref": "x",
"y": "BsmtCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.09",
"x": "BsmtFinType1",
"xref": "x",
"y": "BsmtCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "BsmtFinSF1",
"xref": "x",
"y": "BsmtCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "BsmtFinType2",
"xref": "x",
"y": "BsmtCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "BsmtFinSF2",
"xref": "x",
"y": "BsmtCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "BsmtUnfSF",
"xref": "x",
"y": "BsmtCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "TotalBsmtSF",
"xref": "x",
"y": "BsmtCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "Heating",
"xref": "x",
"y": "BsmtCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "HeatingQC",
"xref": "x",
"y": "BsmtCond",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "CentralAir",
"xref": "x",
"y": "BsmtCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "Electrical",
"xref": "x",
"y": "BsmtCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "1stFlrSF",
"xref": "x",
"y": "BsmtCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "2ndFlrSF",
"xref": "x",
"y": "BsmtCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "LowQualFinSF",
"xref": "x",
"y": "BsmtCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "GrLivArea",
"xref": "x",
"y": "BsmtCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "BsmtFullBath",
"xref": "x",
"y": "BsmtCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "BsmtHalfBath",
"xref": "x",
"y": "BsmtCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "FullBath",
"xref": "x",
"y": "BsmtCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "HalfBath",
"xref": "x",
"y": "BsmtCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "BedroomAbvGr",
"xref": "x",
"y": "BsmtCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "KitchenAbvGr",
"xref": "x",
"y": "BsmtCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "KitchenQual",
"xref": "x",
"y": "BsmtCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "TotRmsAbvGrd",
"xref": "x",
"y": "BsmtCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "Functional",
"xref": "x",
"y": "BsmtCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "Fireplaces",
"xref": "x",
"y": "BsmtCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.09",
"x": "GarageType",
"xref": "x",
"y": "BsmtCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "GarageYrBlt",
"xref": "x",
"y": "BsmtCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "GarageFinish",
"xref": "x",
"y": "BsmtCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "GarageCars",
"xref": "x",
"y": "BsmtCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "GarageArea",
"xref": "x",
"y": "BsmtCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "GarageQual",
"xref": "x",
"y": "BsmtCond",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.17",
"x": "GarageCond",
"xref": "x",
"y": "BsmtCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.11",
"x": "PavedDrive",
"xref": "x",
"y": "BsmtCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "WoodDeckSF",
"xref": "x",
"y": "BsmtCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "OpenPorchSF",
"xref": "x",
"y": "BsmtCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "EnclosedPorch",
"xref": "x",
"y": "BsmtCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "3SsnPorch",
"xref": "x",
"y": "BsmtCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "ScreenPorch",
"xref": "x",
"y": "BsmtCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "PoolArea",
"xref": "x",
"y": "BsmtCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "MiscVal",
"xref": "x",
"y": "BsmtCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "MoSold",
"xref": "x",
"y": "BsmtCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "YrSold",
"xref": "x",
"y": "BsmtCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "SaleType",
"xref": "x",
"y": "BsmtCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "SaleCondition",
"xref": "x",
"y": "BsmtCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "SalePrice",
"xref": "x",
"y": "BsmtCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "Id",
"xref": "x",
"y": "BsmtExposure",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "MSSubClass",
"xref": "x",
"y": "BsmtExposure",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "MSZoning",
"xref": "x",
"y": "BsmtExposure",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.14",
"x": "LotArea",
"xref": "x",
"y": "BsmtExposure",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "Street",
"xref": "x",
"y": "BsmtExposure",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "LotShape",
"xref": "x",
"y": "BsmtExposure",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "LandContour",
"xref": "x",
"y": "BsmtExposure",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "Utilities",
"xref": "x",
"y": "BsmtExposure",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "LotConfig",
"xref": "x",
"y": "BsmtExposure",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.17",
"x": "LandSlope",
"xref": "x",
"y": "BsmtExposure",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "Neighborhood",
"xref": "x",
"y": "BsmtExposure",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "Condition1",
"xref": "x",
"y": "BsmtExposure",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Condition2",
"xref": "x",
"y": "BsmtExposure",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "BldgType",
"xref": "x",
"y": "BsmtExposure",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.17",
"x": "HouseStyle",
"xref": "x",
"y": "BsmtExposure",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.24",
"x": "OverallQual",
"xref": "x",
"y": "BsmtExposure",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "OverallCond",
"xref": "x",
"y": "BsmtExposure",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.3",
"x": "YearBuilt",
"xref": "x",
"y": "BsmtExposure",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.22",
"x": "YearRemodAdd",
"xref": "x",
"y": "BsmtExposure",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "RoofStyle",
"xref": "x",
"y": "BsmtExposure",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "RoofMatl",
"xref": "x",
"y": "BsmtExposure",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "Exterior1st",
"xref": "x",
"y": "BsmtExposure",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "Exterior2nd",
"xref": "x",
"y": "BsmtExposure",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "MasVnrType",
"xref": "x",
"y": "BsmtExposure",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.12",
"x": "MasVnrArea",
"xref": "x",
"y": "BsmtExposure",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.23",
"x": "ExterQual",
"xref": "x",
"y": "BsmtExposure",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "ExterCond",
"xref": "x",
"y": "BsmtExposure",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.23",
"x": "Foundation",
"xref": "x",
"y": "BsmtExposure",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.27",
"x": "BsmtQual",
"xref": "x",
"y": "BsmtExposure",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "BsmtCond",
"xref": "x",
"y": "BsmtExposure",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "BsmtExposure",
"xref": "x",
"y": "BsmtExposure",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.15",
"x": "BsmtFinType1",
"xref": "x",
"y": "BsmtExposure",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.25",
"x": "BsmtFinSF1",
"xref": "x",
"y": "BsmtExposure",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "BsmtFinType2",
"xref": "x",
"y": "BsmtExposure",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "BsmtFinSF2",
"xref": "x",
"y": "BsmtExposure",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "BsmtUnfSF",
"xref": "x",
"y": "BsmtExposure",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.26",
"x": "TotalBsmtSF",
"xref": "x",
"y": "BsmtExposure",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "Heating",
"xref": "x",
"y": "BsmtExposure",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.13",
"x": "HeatingQC",
"xref": "x",
"y": "BsmtExposure",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "CentralAir",
"xref": "x",
"y": "BsmtExposure",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.12",
"x": "Electrical",
"xref": "x",
"y": "BsmtExposure",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.25",
"x": "1stFlrSF",
"xref": "x",
"y": "BsmtExposure",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "2ndFlrSF",
"xref": "x",
"y": "BsmtExposure",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "LowQualFinSF",
"xref": "x",
"y": "BsmtExposure",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "GrLivArea",
"xref": "x",
"y": "BsmtExposure",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.25",
"x": "BsmtFullBath",
"xref": "x",
"y": "BsmtExposure",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "BsmtHalfBath",
"xref": "x",
"y": "BsmtExposure",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "FullBath",
"xref": "x",
"y": "BsmtExposure",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "HalfBath",
"xref": "x",
"y": "BsmtExposure",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "BedroomAbvGr",
"xref": "x",
"y": "BsmtExposure",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "KitchenAbvGr",
"xref": "x",
"y": "BsmtExposure",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.21",
"x": "KitchenQual",
"xref": "x",
"y": "BsmtExposure",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "TotRmsAbvGrd",
"xref": "x",
"y": "BsmtExposure",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "Functional",
"xref": "x",
"y": "BsmtExposure",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.11",
"x": "Fireplaces",
"xref": "x",
"y": "BsmtExposure",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.21",
"x": "GarageType",
"xref": "x",
"y": "BsmtExposure",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.26",
"x": "GarageYrBlt",
"xref": "x",
"y": "BsmtExposure",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.23",
"x": "GarageFinish",
"xref": "x",
"y": "BsmtExposure",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.25",
"x": "GarageCars",
"xref": "x",
"y": "BsmtExposure",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.25",
"x": "GarageArea",
"xref": "x",
"y": "BsmtExposure",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.09",
"x": "GarageQual",
"xref": "x",
"y": "BsmtExposure",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "GarageCond",
"xref": "x",
"y": "BsmtExposure",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.09",
"x": "PavedDrive",
"xref": "x",
"y": "BsmtExposure",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.2",
"x": "WoodDeckSF",
"xref": "x",
"y": "BsmtExposure",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "OpenPorchSF",
"xref": "x",
"y": "BsmtExposure",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "EnclosedPorch",
"xref": "x",
"y": "BsmtExposure",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "3SsnPorch",
"xref": "x",
"y": "BsmtExposure",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "ScreenPorch",
"xref": "x",
"y": "BsmtExposure",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "PoolArea",
"xref": "x",
"y": "BsmtExposure",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "MiscVal",
"xref": "x",
"y": "BsmtExposure",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "MoSold",
"xref": "x",
"y": "BsmtExposure",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "YrSold",
"xref": "x",
"y": "BsmtExposure",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "SaleType",
"xref": "x",
"y": "BsmtExposure",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "SaleCondition",
"xref": "x",
"y": "BsmtExposure",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.29",
"x": "SalePrice",
"xref": "x",
"y": "BsmtExposure",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "Id",
"xref": "x",
"y": "BsmtFinType1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "MSSubClass",
"xref": "x",
"y": "BsmtFinType1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "MSZoning",
"xref": "x",
"y": "BsmtFinType1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "LotArea",
"xref": "x",
"y": "BsmtFinType1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "Street",
"xref": "x",
"y": "BsmtFinType1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "LotShape",
"xref": "x",
"y": "BsmtFinType1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "LandContour",
"xref": "x",
"y": "BsmtFinType1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "Utilities",
"xref": "x",
"y": "BsmtFinType1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "LotConfig",
"xref": "x",
"y": "BsmtFinType1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "LandSlope",
"xref": "x",
"y": "BsmtFinType1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "Neighborhood",
"xref": "x",
"y": "BsmtFinType1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "Condition1",
"xref": "x",
"y": "BsmtFinType1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "Condition2",
"xref": "x",
"y": "BsmtFinType1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "BldgType",
"xref": "x",
"y": "BsmtFinType1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "HouseStyle",
"xref": "x",
"y": "BsmtFinType1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "OverallQual",
"xref": "x",
"y": "BsmtFinType1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "OverallCond",
"xref": "x",
"y": "BsmtFinType1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.11",
"x": "YearBuilt",
"xref": "x",
"y": "BsmtFinType1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "YearRemodAdd",
"xref": "x",
"y": "BsmtFinType1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "RoofStyle",
"xref": "x",
"y": "BsmtFinType1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "RoofMatl",
"xref": "x",
"y": "BsmtFinType1",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.18",
"x": "Exterior1st",
"xref": "x",
"y": "BsmtFinType1",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.17",
"x": "Exterior2nd",
"xref": "x",
"y": "BsmtFinType1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "MasVnrType",
"xref": "x",
"y": "BsmtFinType1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "MasVnrArea",
"xref": "x",
"y": "BsmtFinType1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "ExterQual",
"xref": "x",
"y": "BsmtFinType1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "ExterCond",
"xref": "x",
"y": "BsmtFinType1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "Foundation",
"xref": "x",
"y": "BsmtFinType1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "BsmtQual",
"xref": "x",
"y": "BsmtFinType1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.09",
"x": "BsmtCond",
"xref": "x",
"y": "BsmtFinType1",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.15",
"x": "BsmtExposure",
"xref": "x",
"y": "BsmtFinType1",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "BsmtFinType1",
"xref": "x",
"y": "BsmtFinType1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.55",
"x": "BsmtFinSF1",
"xref": "x",
"y": "BsmtFinType1",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.15",
"x": "BsmtFinType2",
"xref": "x",
"y": "BsmtFinType1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.14",
"x": "BsmtFinSF2",
"xref": "x",
"y": "BsmtFinType1",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.53",
"x": "BsmtUnfSF",
"xref": "x",
"y": "BsmtFinType1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.11",
"x": "TotalBsmtSF",
"xref": "x",
"y": "BsmtFinType1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "Heating",
"xref": "x",
"y": "BsmtFinType1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "HeatingQC",
"xref": "x",
"y": "BsmtFinType1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.12",
"x": "CentralAir",
"xref": "x",
"y": "BsmtFinType1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.11",
"x": "Electrical",
"xref": "x",
"y": "BsmtFinType1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "1stFlrSF",
"xref": "x",
"y": "BsmtFinType1",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.2",
"x": "2ndFlrSF",
"xref": "x",
"y": "BsmtFinType1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "LowQualFinSF",
"xref": "x",
"y": "BsmtFinType1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "GrLivArea",
"xref": "x",
"y": "BsmtFinType1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.46",
"x": "BsmtFullBath",
"xref": "x",
"y": "BsmtFinType1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.11",
"x": "BsmtHalfBath",
"xref": "x",
"y": "BsmtFinType1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "FullBath",
"xref": "x",
"y": "BsmtFinType1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "HalfBath",
"xref": "x",
"y": "BsmtFinType1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.11",
"x": "BedroomAbvGr",
"xref": "x",
"y": "BsmtFinType1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "KitchenAbvGr",
"xref": "x",
"y": "BsmtFinType1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "KitchenQual",
"xref": "x",
"y": "BsmtFinType1",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.15",
"x": "TotRmsAbvGrd",
"xref": "x",
"y": "BsmtFinType1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "Functional",
"xref": "x",
"y": "BsmtFinType1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.09",
"x": "Fireplaces",
"xref": "x",
"y": "BsmtFinType1",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.17",
"x": "GarageType",
"xref": "x",
"y": "BsmtFinType1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "GarageYrBlt",
"xref": "x",
"y": "BsmtFinType1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "GarageFinish",
"xref": "x",
"y": "BsmtFinType1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "GarageCars",
"xref": "x",
"y": "BsmtFinType1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "GarageArea",
"xref": "x",
"y": "BsmtFinType1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.13",
"x": "GarageQual",
"xref": "x",
"y": "BsmtFinType1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.11",
"x": "GarageCond",
"xref": "x",
"y": "BsmtFinType1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.22",
"x": "PavedDrive",
"xref": "x",
"y": "BsmtFinType1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "WoodDeckSF",
"xref": "x",
"y": "BsmtFinType1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "OpenPorchSF",
"xref": "x",
"y": "BsmtFinType1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "EnclosedPorch",
"xref": "x",
"y": "BsmtFinType1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "3SsnPorch",
"xref": "x",
"y": "BsmtFinType1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "ScreenPorch",
"xref": "x",
"y": "BsmtFinType1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "PoolArea",
"xref": "x",
"y": "BsmtFinType1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "MiscVal",
"xref": "x",
"y": "BsmtFinType1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "MoSold",
"xref": "x",
"y": "BsmtFinType1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "YrSold",
"xref": "x",
"y": "BsmtFinType1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "SaleType",
"xref": "x",
"y": "BsmtFinType1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "SaleCondition",
"xref": "x",
"y": "BsmtFinType1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "SalePrice",
"xref": "x",
"y": "BsmtFinType1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "Id",
"xref": "x",
"y": "BsmtFinSF1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "MSSubClass",
"xref": "x",
"y": "BsmtFinSF1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "MSZoning",
"xref": "x",
"y": "BsmtFinSF1",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.21",
"x": "LotArea",
"xref": "x",
"y": "BsmtFinSF1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "Street",
"xref": "x",
"y": "BsmtFinSF1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.12",
"x": "LotShape",
"xref": "x",
"y": "BsmtFinSF1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "LandContour",
"xref": "x",
"y": "BsmtFinSF1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "Utilities",
"xref": "x",
"y": "BsmtFinSF1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "LotConfig",
"xref": "x",
"y": "BsmtFinSF1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "LandSlope",
"xref": "x",
"y": "BsmtFinSF1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "Neighborhood",
"xref": "x",
"y": "BsmtFinSF1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Condition1",
"xref": "x",
"y": "BsmtFinSF1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Condition2",
"xref": "x",
"y": "BsmtFinSF1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "BldgType",
"xref": "x",
"y": "BsmtFinSF1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "HouseStyle",
"xref": "x",
"y": "BsmtFinSF1",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.2",
"x": "OverallQual",
"xref": "x",
"y": "BsmtFinSF1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "OverallCond",
"xref": "x",
"y": "BsmtFinSF1",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.22",
"x": "YearBuilt",
"xref": "x",
"y": "BsmtFinSF1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "YearRemodAdd",
"xref": "x",
"y": "BsmtFinSF1",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.2",
"x": "RoofStyle",
"xref": "x",
"y": "BsmtFinSF1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "RoofMatl",
"xref": "x",
"y": "BsmtFinSF1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.09",
"x": "Exterior1st",
"xref": "x",
"y": "BsmtFinSF1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.09",
"x": "Exterior2nd",
"xref": "x",
"y": "BsmtFinSF1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "MasVnrType",
"xref": "x",
"y": "BsmtFinSF1",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.25",
"x": "MasVnrArea",
"xref": "x",
"y": "BsmtFinSF1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.18",
"x": "ExterQual",
"xref": "x",
"y": "BsmtFinSF1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "ExterCond",
"xref": "x",
"y": "BsmtFinSF1",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "Foundation",
"xref": "x",
"y": "BsmtFinSF1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.23",
"x": "BsmtQual",
"xref": "x",
"y": "BsmtFinSF1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "BsmtCond",
"xref": "x",
"y": "BsmtFinSF1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.25",
"x": "BsmtExposure",
"xref": "x",
"y": "BsmtFinSF1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.55",
"x": "BsmtFinType1",
"xref": "x",
"y": "BsmtFinSF1",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "BsmtFinSF1",
"xref": "x",
"y": "BsmtFinSF1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "BsmtFinType2",
"xref": "x",
"y": "BsmtFinSF1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "BsmtFinSF2",
"xref": "x",
"y": "BsmtFinSF1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.55",
"x": "BsmtUnfSF",
"xref": "x",
"y": "BsmtFinSF1",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.5",
"x": "TotalBsmtSF",
"xref": "x",
"y": "BsmtFinSF1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "Heating",
"xref": "x",
"y": "BsmtFinSF1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "HeatingQC",
"xref": "x",
"y": "BsmtFinSF1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "CentralAir",
"xref": "x",
"y": "BsmtFinSF1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.13",
"x": "Electrical",
"xref": "x",
"y": "BsmtFinSF1",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.45",
"x": "1stFlrSF",
"xref": "x",
"y": "BsmtFinSF1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.15",
"x": "2ndFlrSF",
"xref": "x",
"y": "BsmtFinSF1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "LowQualFinSF",
"xref": "x",
"y": "BsmtFinSF1",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.2",
"x": "GrLivArea",
"xref": "x",
"y": "BsmtFinSF1",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.64",
"x": "BsmtFullBath",
"xref": "x",
"y": "BsmtFinSF1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "BsmtHalfBath",
"xref": "x",
"y": "BsmtFinSF1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "FullBath",
"xref": "x",
"y": "BsmtFinSF1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "HalfBath",
"xref": "x",
"y": "BsmtFinSF1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.12",
"x": "BedroomAbvGr",
"xref": "x",
"y": "BsmtFinSF1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "KitchenAbvGr",
"xref": "x",
"y": "BsmtFinSF1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.19",
"x": "KitchenQual",
"xref": "x",
"y": "BsmtFinSF1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "TotRmsAbvGrd",
"xref": "x",
"y": "BsmtFinSF1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "Functional",
"xref": "x",
"y": "BsmtFinSF1",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.25",
"x": "Fireplaces",
"xref": "x",
"y": "BsmtFinSF1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.25",
"x": "GarageType",
"xref": "x",
"y": "BsmtFinSF1",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "GarageYrBlt",
"xref": "x",
"y": "BsmtFinSF1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.22",
"x": "GarageFinish",
"xref": "x",
"y": "BsmtFinSF1",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.2",
"x": "GarageCars",
"xref": "x",
"y": "BsmtFinSF1",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.28",
"x": "GarageArea",
"xref": "x",
"y": "BsmtFinSF1",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "GarageQual",
"xref": "x",
"y": "BsmtFinSF1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "GarageCond",
"xref": "x",
"y": "BsmtFinSF1",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.17",
"x": "PavedDrive",
"xref": "x",
"y": "BsmtFinSF1",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.19",
"x": "WoodDeckSF",
"xref": "x",
"y": "BsmtFinSF1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.11",
"x": "OpenPorchSF",
"xref": "x",
"y": "BsmtFinSF1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.11",
"x": "EnclosedPorch",
"xref": "x",
"y": "BsmtFinSF1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "3SsnPorch",
"xref": "x",
"y": "BsmtFinSF1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "ScreenPorch",
"xref": "x",
"y": "BsmtFinSF1",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "PoolArea",
"xref": "x",
"y": "BsmtFinSF1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "MiscVal",
"xref": "x",
"y": "BsmtFinSF1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "MoSold",
"xref": "x",
"y": "BsmtFinSF1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "YrSold",
"xref": "x",
"y": "BsmtFinSF1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "SaleType",
"xref": "x",
"y": "BsmtFinSF1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "SaleCondition",
"xref": "x",
"y": "BsmtFinSF1",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.36",
"x": "SalePrice",
"xref": "x",
"y": "BsmtFinSF1",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "Id",
"xref": "x",
"y": "BsmtFinType2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "MSSubClass",
"xref": "x",
"y": "BsmtFinType2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "MSZoning",
"xref": "x",
"y": "BsmtFinType2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "LotArea",
"xref": "x",
"y": "BsmtFinType2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "Street",
"xref": "x",
"y": "BsmtFinType2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "LotShape",
"xref": "x",
"y": "BsmtFinType2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "LandContour",
"xref": "x",
"y": "BsmtFinType2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "Utilities",
"xref": "x",
"y": "BsmtFinType2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "LotConfig",
"xref": "x",
"y": "BsmtFinType2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "LandSlope",
"xref": "x",
"y": "BsmtFinType2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "Neighborhood",
"xref": "x",
"y": "BsmtFinType2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "Condition1",
"xref": "x",
"y": "BsmtFinType2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "Condition2",
"xref": "x",
"y": "BsmtFinType2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "BldgType",
"xref": "x",
"y": "BsmtFinType2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "HouseStyle",
"xref": "x",
"y": "BsmtFinType2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.11",
"x": "OverallQual",
"xref": "x",
"y": "BsmtFinType2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.09",
"x": "OverallCond",
"xref": "x",
"y": "BsmtFinType2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "YearBuilt",
"xref": "x",
"y": "BsmtFinType2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "YearRemodAdd",
"xref": "x",
"y": "BsmtFinType2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "RoofStyle",
"xref": "x",
"y": "BsmtFinType2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "RoofMatl",
"xref": "x",
"y": "BsmtFinType2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "Exterior1st",
"xref": "x",
"y": "BsmtFinType2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "Exterior2nd",
"xref": "x",
"y": "BsmtFinType2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "MasVnrType",
"xref": "x",
"y": "BsmtFinType2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "MasVnrArea",
"xref": "x",
"y": "BsmtFinType2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "ExterQual",
"xref": "x",
"y": "BsmtFinType2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "ExterCond",
"xref": "x",
"y": "BsmtFinType2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.11",
"x": "Foundation",
"xref": "x",
"y": "BsmtFinType2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.12",
"x": "BsmtQual",
"xref": "x",
"y": "BsmtFinType2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "BsmtCond",
"xref": "x",
"y": "BsmtFinType2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "BsmtExposure",
"xref": "x",
"y": "BsmtFinType2",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.15",
"x": "BsmtFinType1",
"xref": "x",
"y": "BsmtFinType2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "BsmtFinSF1",
"xref": "x",
"y": "BsmtFinType2",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "BsmtFinType2",
"xref": "x",
"y": "BsmtFinType2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.74",
"x": "BsmtFinSF2",
"xref": "x",
"y": "BsmtFinType2",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.23",
"x": "BsmtUnfSF",
"xref": "x",
"y": "BsmtFinType2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "TotalBsmtSF",
"xref": "x",
"y": "BsmtFinType2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "Heating",
"xref": "x",
"y": "BsmtFinType2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "HeatingQC",
"xref": "x",
"y": "BsmtFinType2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "CentralAir",
"xref": "x",
"y": "BsmtFinType2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "Electrical",
"xref": "x",
"y": "BsmtFinType2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "1stFlrSF",
"xref": "x",
"y": "BsmtFinType2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "2ndFlrSF",
"xref": "x",
"y": "BsmtFinType2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "LowQualFinSF",
"xref": "x",
"y": "BsmtFinType2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "GrLivArea",
"xref": "x",
"y": "BsmtFinType2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.14",
"x": "BsmtFullBath",
"xref": "x",
"y": "BsmtFinType2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.09",
"x": "BsmtHalfBath",
"xref": "x",
"y": "BsmtFinType2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "FullBath",
"xref": "x",
"y": "BsmtFinType2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "HalfBath",
"xref": "x",
"y": "BsmtFinType2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "BedroomAbvGr",
"xref": "x",
"y": "BsmtFinType2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "KitchenAbvGr",
"xref": "x",
"y": "BsmtFinType2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "KitchenQual",
"xref": "x",
"y": "BsmtFinType2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "TotRmsAbvGrd",
"xref": "x",
"y": "BsmtFinType2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "Functional",
"xref": "x",
"y": "BsmtFinType2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "Fireplaces",
"xref": "x",
"y": "BsmtFinType2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "GarageType",
"xref": "x",
"y": "BsmtFinType2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "GarageYrBlt",
"xref": "x",
"y": "BsmtFinType2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "GarageFinish",
"xref": "x",
"y": "BsmtFinType2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "GarageCars",
"xref": "x",
"y": "BsmtFinType2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "GarageArea",
"xref": "x",
"y": "BsmtFinType2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "GarageQual",
"xref": "x",
"y": "BsmtFinType2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "GarageCond",
"xref": "x",
"y": "BsmtFinType2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "PavedDrive",
"xref": "x",
"y": "BsmtFinType2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "WoodDeckSF",
"xref": "x",
"y": "BsmtFinType2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "OpenPorchSF",
"xref": "x",
"y": "BsmtFinType2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "EnclosedPorch",
"xref": "x",
"y": "BsmtFinType2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "3SsnPorch",
"xref": "x",
"y": "BsmtFinType2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "ScreenPorch",
"xref": "x",
"y": "BsmtFinType2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "PoolArea",
"xref": "x",
"y": "BsmtFinType2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "MiscVal",
"xref": "x",
"y": "BsmtFinType2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "MoSold",
"xref": "x",
"y": "BsmtFinType2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "YrSold",
"xref": "x",
"y": "BsmtFinType2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "SaleType",
"xref": "x",
"y": "BsmtFinType2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "SaleCondition",
"xref": "x",
"y": "BsmtFinType2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "SalePrice",
"xref": "x",
"y": "BsmtFinType2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "Id",
"xref": "x",
"y": "BsmtFinSF2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "MSSubClass",
"xref": "x",
"y": "BsmtFinSF2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "MSZoning",
"xref": "x",
"y": "BsmtFinSF2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.11",
"x": "LotArea",
"xref": "x",
"y": "BsmtFinSF2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "Street",
"xref": "x",
"y": "BsmtFinSF2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "LotShape",
"xref": "x",
"y": "BsmtFinSF2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "LandContour",
"xref": "x",
"y": "BsmtFinSF2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "Utilities",
"xref": "x",
"y": "BsmtFinSF2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "LotConfig",
"xref": "x",
"y": "BsmtFinSF2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "LandSlope",
"xref": "x",
"y": "BsmtFinSF2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "Neighborhood",
"xref": "x",
"y": "BsmtFinSF2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "Condition1",
"xref": "x",
"y": "BsmtFinSF2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "Condition2",
"xref": "x",
"y": "BsmtFinSF2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "BldgType",
"xref": "x",
"y": "BsmtFinSF2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "HouseStyle",
"xref": "x",
"y": "BsmtFinSF2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.09",
"x": "OverallQual",
"xref": "x",
"y": "BsmtFinSF2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "OverallCond",
"xref": "x",
"y": "BsmtFinSF2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "YearBuilt",
"xref": "x",
"y": "BsmtFinSF2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.09",
"x": "YearRemodAdd",
"xref": "x",
"y": "BsmtFinSF2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "RoofStyle",
"xref": "x",
"y": "BsmtFinSF2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "RoofMatl",
"xref": "x",
"y": "BsmtFinSF2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "Exterior1st",
"xref": "x",
"y": "BsmtFinSF2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "Exterior2nd",
"xref": "x",
"y": "BsmtFinSF2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "MasVnrType",
"xref": "x",
"y": "BsmtFinSF2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "MasVnrArea",
"xref": "x",
"y": "BsmtFinSF2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "ExterQual",
"xref": "x",
"y": "BsmtFinSF2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "ExterCond",
"xref": "x",
"y": "BsmtFinSF2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "Foundation",
"xref": "x",
"y": "BsmtFinSF2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.11",
"x": "BsmtQual",
"xref": "x",
"y": "BsmtFinSF2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "BsmtCond",
"xref": "x",
"y": "BsmtFinSF2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "BsmtExposure",
"xref": "x",
"y": "BsmtFinSF2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.14",
"x": "BsmtFinType1",
"xref": "x",
"y": "BsmtFinSF2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "BsmtFinSF1",
"xref": "x",
"y": "BsmtFinSF2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.74",
"x": "BsmtFinType2",
"xref": "x",
"y": "BsmtFinSF2",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "BsmtFinSF2",
"xref": "x",
"y": "BsmtFinSF2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.23",
"x": "BsmtUnfSF",
"xref": "x",
"y": "BsmtFinSF2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "TotalBsmtSF",
"xref": "x",
"y": "BsmtFinSF2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "Heating",
"xref": "x",
"y": "BsmtFinSF2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.11",
"x": "HeatingQC",
"xref": "x",
"y": "BsmtFinSF2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "CentralAir",
"xref": "x",
"y": "BsmtFinSF2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "Electrical",
"xref": "x",
"y": "BsmtFinSF2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "1stFlrSF",
"xref": "x",
"y": "BsmtFinSF2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.11",
"x": "2ndFlrSF",
"xref": "x",
"y": "BsmtFinSF2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "LowQualFinSF",
"xref": "x",
"y": "BsmtFinSF2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "GrLivArea",
"xref": "x",
"y": "BsmtFinSF2",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.15",
"x": "BsmtFullBath",
"xref": "x",
"y": "BsmtFinSF2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "BsmtHalfBath",
"xref": "x",
"y": "BsmtFinSF2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.09",
"x": "FullBath",
"xref": "x",
"y": "BsmtFinSF2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "HalfBath",
"xref": "x",
"y": "BsmtFinSF2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "BedroomAbvGr",
"xref": "x",
"y": "BsmtFinSF2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "KitchenAbvGr",
"xref": "x",
"y": "BsmtFinSF2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "KitchenQual",
"xref": "x",
"y": "BsmtFinSF2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "TotRmsAbvGrd",
"xref": "x",
"y": "BsmtFinSF2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.11",
"x": "Functional",
"xref": "x",
"y": "BsmtFinSF2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "Fireplaces",
"xref": "x",
"y": "BsmtFinSF2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "GarageType",
"xref": "x",
"y": "BsmtFinSF2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.09",
"x": "GarageYrBlt",
"xref": "x",
"y": "BsmtFinSF2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "GarageFinish",
"xref": "x",
"y": "BsmtFinSF2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "GarageCars",
"xref": "x",
"y": "BsmtFinSF2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "GarageArea",
"xref": "x",
"y": "BsmtFinSF2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "GarageQual",
"xref": "x",
"y": "BsmtFinSF2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "GarageCond",
"xref": "x",
"y": "BsmtFinSF2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "PavedDrive",
"xref": "x",
"y": "BsmtFinSF2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "WoodDeckSF",
"xref": "x",
"y": "BsmtFinSF2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "OpenPorchSF",
"xref": "x",
"y": "BsmtFinSF2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "EnclosedPorch",
"xref": "x",
"y": "BsmtFinSF2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "3SsnPorch",
"xref": "x",
"y": "BsmtFinSF2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "ScreenPorch",
"xref": "x",
"y": "BsmtFinSF2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "PoolArea",
"xref": "x",
"y": "BsmtFinSF2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "MiscVal",
"xref": "x",
"y": "BsmtFinSF2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "MoSold",
"xref": "x",
"y": "BsmtFinSF2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "YrSold",
"xref": "x",
"y": "BsmtFinSF2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "SaleType",
"xref": "x",
"y": "BsmtFinSF2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "SaleCondition",
"xref": "x",
"y": "BsmtFinSF2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "SalePrice",
"xref": "x",
"y": "BsmtFinSF2",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "Id",
"xref": "x",
"y": "BsmtUnfSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.14",
"x": "MSSubClass",
"xref": "x",
"y": "BsmtUnfSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "MSZoning",
"xref": "x",
"y": "BsmtUnfSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "LotArea",
"xref": "x",
"y": "BsmtUnfSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "Street",
"xref": "x",
"y": "BsmtUnfSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "LotShape",
"xref": "x",
"y": "BsmtUnfSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "LandContour",
"xref": "x",
"y": "BsmtUnfSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "Utilities",
"xref": "x",
"y": "BsmtUnfSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "LotConfig",
"xref": "x",
"y": "BsmtUnfSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.12",
"x": "LandSlope",
"xref": "x",
"y": "BsmtUnfSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "Neighborhood",
"xref": "x",
"y": "BsmtUnfSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "Condition1",
"xref": "x",
"y": "BsmtUnfSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "Condition2",
"xref": "x",
"y": "BsmtUnfSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "BldgType",
"xref": "x",
"y": "BsmtUnfSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.16",
"x": "HouseStyle",
"xref": "x",
"y": "BsmtUnfSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.29",
"x": "OverallQual",
"xref": "x",
"y": "BsmtUnfSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.16",
"x": "OverallCond",
"xref": "x",
"y": "BsmtUnfSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.15",
"x": "YearBuilt",
"xref": "x",
"y": "BsmtUnfSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.17",
"x": "YearRemodAdd",
"xref": "x",
"y": "BsmtUnfSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "RoofStyle",
"xref": "x",
"y": "BsmtUnfSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "RoofMatl",
"xref": "x",
"y": "BsmtUnfSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "Exterior1st",
"xref": "x",
"y": "BsmtUnfSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "Exterior2nd",
"xref": "x",
"y": "BsmtUnfSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "MasVnrType",
"xref": "x",
"y": "BsmtUnfSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "MasVnrArea",
"xref": "x",
"y": "BsmtUnfSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.27",
"x": "ExterQual",
"xref": "x",
"y": "BsmtUnfSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "ExterCond",
"xref": "x",
"y": "BsmtUnfSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.16",
"x": "Foundation",
"xref": "x",
"y": "BsmtUnfSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.19",
"x": "BsmtQual",
"xref": "x",
"y": "BsmtUnfSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "BsmtCond",
"xref": "x",
"y": "BsmtUnfSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "BsmtExposure",
"xref": "x",
"y": "BsmtUnfSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.53",
"x": "BsmtFinType1",
"xref": "x",
"y": "BsmtUnfSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.55",
"x": "BsmtFinSF1",
"xref": "x",
"y": "BsmtUnfSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.23",
"x": "BsmtFinType2",
"xref": "x",
"y": "BsmtUnfSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.23",
"x": "BsmtFinSF2",
"xref": "x",
"y": "BsmtUnfSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "BsmtUnfSF",
"xref": "x",
"y": "BsmtUnfSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.36",
"x": "TotalBsmtSF",
"xref": "x",
"y": "BsmtUnfSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "Heating",
"xref": "x",
"y": "BsmtUnfSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.21",
"x": "HeatingQC",
"xref": "x",
"y": "BsmtUnfSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "CentralAir",
"xref": "x",
"y": "BsmtUnfSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "Electrical",
"xref": "x",
"y": "BsmtUnfSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.32",
"x": "1stFlrSF",
"xref": "x",
"y": "BsmtUnfSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "2ndFlrSF",
"xref": "x",
"y": "BsmtUnfSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "LowQualFinSF",
"xref": "x",
"y": "BsmtUnfSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.22",
"x": "GrLivArea",
"xref": "x",
"y": "BsmtUnfSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.46",
"x": "BsmtFullBath",
"xref": "x",
"y": "BsmtUnfSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.11",
"x": "BsmtHalfBath",
"xref": "x",
"y": "BsmtUnfSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.31",
"x": "FullBath",
"xref": "x",
"y": "BsmtUnfSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "HalfBath",
"xref": "x",
"y": "BsmtUnfSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.15",
"x": "BedroomAbvGr",
"xref": "x",
"y": "BsmtUnfSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "KitchenAbvGr",
"xref": "x",
"y": "BsmtUnfSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.21",
"x": "KitchenQual",
"xref": "x",
"y": "BsmtUnfSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.24",
"x": "TotRmsAbvGrd",
"xref": "x",
"y": "BsmtUnfSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "Functional",
"xref": "x",
"y": "BsmtUnfSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "Fireplaces",
"xref": "x",
"y": "BsmtUnfSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "GarageType",
"xref": "x",
"y": "BsmtUnfSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.18",
"x": "GarageYrBlt",
"xref": "x",
"y": "BsmtUnfSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "GarageFinish",
"xref": "x",
"y": "BsmtUnfSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.24",
"x": "GarageCars",
"xref": "x",
"y": "BsmtUnfSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.2",
"x": "GarageArea",
"xref": "x",
"y": "BsmtUnfSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "GarageQual",
"xref": "x",
"y": "BsmtUnfSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "GarageCond",
"xref": "x",
"y": "BsmtUnfSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "PavedDrive",
"xref": "x",
"y": "BsmtUnfSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "WoodDeckSF",
"xref": "x",
"y": "BsmtUnfSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "OpenPorchSF",
"xref": "x",
"y": "BsmtUnfSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "EnclosedPorch",
"xref": "x",
"y": "BsmtUnfSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "3SsnPorch",
"xref": "x",
"y": "BsmtUnfSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "ScreenPorch",
"xref": "x",
"y": "BsmtUnfSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "PoolArea",
"xref": "x",
"y": "BsmtUnfSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "MiscVal",
"xref": "x",
"y": "BsmtUnfSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "MoSold",
"xref": "x",
"y": "BsmtUnfSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "YrSold",
"xref": "x",
"y": "BsmtUnfSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.09",
"x": "SaleType",
"xref": "x",
"y": "BsmtUnfSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.11",
"x": "SaleCondition",
"xref": "x",
"y": "BsmtUnfSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.19",
"x": "SalePrice",
"xref": "x",
"y": "BsmtUnfSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "Id",
"xref": "x",
"y": "TotalBsmtSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.26",
"x": "MSSubClass",
"xref": "x",
"y": "TotalBsmtSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "MSZoning",
"xref": "x",
"y": "TotalBsmtSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.27",
"x": "LotArea",
"xref": "x",
"y": "TotalBsmtSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "Street",
"xref": "x",
"y": "TotalBsmtSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.16",
"x": "LotShape",
"xref": "x",
"y": "TotalBsmtSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "LandContour",
"xref": "x",
"y": "TotalBsmtSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "Utilities",
"xref": "x",
"y": "TotalBsmtSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "LotConfig",
"xref": "x",
"y": "TotalBsmtSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "LandSlope",
"xref": "x",
"y": "TotalBsmtSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "Neighborhood",
"xref": "x",
"y": "TotalBsmtSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "Condition1",
"xref": "x",
"y": "TotalBsmtSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "Condition2",
"xref": "x",
"y": "TotalBsmtSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "BldgType",
"xref": "x",
"y": "TotalBsmtSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.2",
"x": "HouseStyle",
"xref": "x",
"y": "TotalBsmtSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.51",
"x": "OverallQual",
"xref": "x",
"y": "TotalBsmtSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.23",
"x": "OverallCond",
"xref": "x",
"y": "TotalBsmtSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.39",
"x": "YearBuilt",
"xref": "x",
"y": "TotalBsmtSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.26",
"x": "YearRemodAdd",
"xref": "x",
"y": "TotalBsmtSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.28",
"x": "RoofStyle",
"xref": "x",
"y": "TotalBsmtSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "RoofMatl",
"xref": "x",
"y": "TotalBsmtSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "Exterior1st",
"xref": "x",
"y": "TotalBsmtSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "Exterior2nd",
"xref": "x",
"y": "TotalBsmtSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "MasVnrType",
"xref": "x",
"y": "TotalBsmtSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.37",
"x": "MasVnrArea",
"xref": "x",
"y": "TotalBsmtSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.46",
"x": "ExterQual",
"xref": "x",
"y": "TotalBsmtSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "ExterCond",
"xref": "x",
"y": "TotalBsmtSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.29",
"x": "Foundation",
"xref": "x",
"y": "TotalBsmtSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.41",
"x": "BsmtQual",
"xref": "x",
"y": "TotalBsmtSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "BsmtCond",
"xref": "x",
"y": "TotalBsmtSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.26",
"x": "BsmtExposure",
"xref": "x",
"y": "TotalBsmtSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.11",
"x": "BsmtFinType1",
"xref": "x",
"y": "TotalBsmtSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.5",
"x": "BsmtFinSF1",
"xref": "x",
"y": "TotalBsmtSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "BsmtFinType2",
"xref": "x",
"y": "TotalBsmtSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "BsmtFinSF2",
"xref": "x",
"y": "TotalBsmtSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.36",
"x": "BsmtUnfSF",
"xref": "x",
"y": "TotalBsmtSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "TotalBsmtSF",
"xref": "x",
"y": "TotalBsmtSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "Heating",
"xref": "x",
"y": "TotalBsmtSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.22",
"x": "HeatingQC",
"xref": "x",
"y": "TotalBsmtSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.15",
"x": "CentralAir",
"xref": "x",
"y": "TotalBsmtSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.11",
"x": "Electrical",
"xref": "x",
"y": "TotalBsmtSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.89",
"x": "1stFlrSF",
"xref": "x",
"y": "TotalBsmtSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.23",
"x": "2ndFlrSF",
"xref": "x",
"y": "TotalBsmtSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "LowQualFinSF",
"xref": "x",
"y": "TotalBsmtSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.46",
"x": "GrLivArea",
"xref": "x",
"y": "TotalBsmtSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.28",
"x": "BsmtFullBath",
"xref": "x",
"y": "TotalBsmtSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "BsmtHalfBath",
"xref": "x",
"y": "TotalBsmtSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.35",
"x": "FullBath",
"xref": "x",
"y": "TotalBsmtSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.12",
"x": "HalfBath",
"xref": "x",
"y": "TotalBsmtSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "BedroomAbvGr",
"xref": "x",
"y": "TotalBsmtSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "KitchenAbvGr",
"xref": "x",
"y": "TotalBsmtSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.41",
"x": "KitchenQual",
"xref": "x",
"y": "TotalBsmtSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.3",
"x": "TotRmsAbvGrd",
"xref": "x",
"y": "TotalBsmtSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "Functional",
"xref": "x",
"y": "TotalBsmtSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.33",
"x": "Fireplaces",
"xref": "x",
"y": "TotalBsmtSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.36",
"x": "GarageType",
"xref": "x",
"y": "TotalBsmtSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.32",
"x": "GarageYrBlt",
"xref": "x",
"y": "TotalBsmtSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.34",
"x": "GarageFinish",
"xref": "x",
"y": "TotalBsmtSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.45",
"x": "GarageCars",
"xref": "x",
"y": "TotalBsmtSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.51",
"x": "GarageArea",
"xref": "x",
"y": "TotalBsmtSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "GarageQual",
"xref": "x",
"y": "TotalBsmtSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "GarageCond",
"xref": "x",
"y": "TotalBsmtSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.15",
"x": "PavedDrive",
"xref": "x",
"y": "TotalBsmtSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.21",
"x": "WoodDeckSF",
"xref": "x",
"y": "TotalBsmtSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.26",
"x": "OpenPorchSF",
"xref": "x",
"y": "TotalBsmtSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "EnclosedPorch",
"xref": "x",
"y": "TotalBsmtSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "3SsnPorch",
"xref": "x",
"y": "TotalBsmtSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "ScreenPorch",
"xref": "x",
"y": "TotalBsmtSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "PoolArea",
"xref": "x",
"y": "TotalBsmtSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "MiscVal",
"xref": "x",
"y": "TotalBsmtSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "MoSold",
"xref": "x",
"y": "TotalBsmtSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "YrSold",
"xref": "x",
"y": "TotalBsmtSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "SaleType",
"xref": "x",
"y": "TotalBsmtSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.11",
"x": "SaleCondition",
"xref": "x",
"y": "TotalBsmtSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.6",
"x": "SalePrice",
"xref": "x",
"y": "TotalBsmtSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "Id",
"xref": "x",
"y": "Heating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "MSSubClass",
"xref": "x",
"y": "Heating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "MSZoning",
"xref": "x",
"y": "Heating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "LotArea",
"xref": "x",
"y": "Heating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Street",
"xref": "x",
"y": "Heating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "LotShape",
"xref": "x",
"y": "Heating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "LandContour",
"xref": "x",
"y": "Heating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "Utilities",
"xref": "x",
"y": "Heating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "LotConfig",
"xref": "x",
"y": "Heating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "LandSlope",
"xref": "x",
"y": "Heating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "Neighborhood",
"xref": "x",
"y": "Heating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "Condition1",
"xref": "x",
"y": "Heating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "Condition2",
"xref": "x",
"y": "Heating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "BldgType",
"xref": "x",
"y": "Heating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "HouseStyle",
"xref": "x",
"y": "Heating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "OverallQual",
"xref": "x",
"y": "Heating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "OverallCond",
"xref": "x",
"y": "Heating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.19",
"x": "YearBuilt",
"xref": "x",
"y": "Heating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.14",
"x": "YearRemodAdd",
"xref": "x",
"y": "Heating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "RoofStyle",
"xref": "x",
"y": "Heating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "RoofMatl",
"xref": "x",
"y": "Heating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "Exterior1st",
"xref": "x",
"y": "Heating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "Exterior2nd",
"xref": "x",
"y": "Heating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "MasVnrType",
"xref": "x",
"y": "Heating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "MasVnrArea",
"xref": "x",
"y": "Heating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "ExterQual",
"xref": "x",
"y": "Heating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "ExterCond",
"xref": "x",
"y": "Heating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.18",
"x": "Foundation",
"xref": "x",
"y": "Heating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "BsmtQual",
"xref": "x",
"y": "Heating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "BsmtCond",
"xref": "x",
"y": "Heating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "BsmtExposure",
"xref": "x",
"y": "Heating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "BsmtFinType1",
"xref": "x",
"y": "Heating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "BsmtFinSF1",
"xref": "x",
"y": "Heating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "BsmtFinType2",
"xref": "x",
"y": "Heating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "BsmtFinSF2",
"xref": "x",
"y": "Heating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "BsmtUnfSF",
"xref": "x",
"y": "Heating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "TotalBsmtSF",
"xref": "x",
"y": "Heating",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "Heating",
"xref": "x",
"y": "Heating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "HeatingQC",
"xref": "x",
"y": "Heating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.39",
"x": "CentralAir",
"xref": "x",
"y": "Heating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "Electrical",
"xref": "x",
"y": "Heating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "1stFlrSF",
"xref": "x",
"y": "Heating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "2ndFlrSF",
"xref": "x",
"y": "Heating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "LowQualFinSF",
"xref": "x",
"y": "Heating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "GrLivArea",
"xref": "x",
"y": "Heating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "BsmtFullBath",
"xref": "x",
"y": "Heating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "BsmtHalfBath",
"xref": "x",
"y": "Heating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "FullBath",
"xref": "x",
"y": "Heating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "HalfBath",
"xref": "x",
"y": "Heating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "BedroomAbvGr",
"xref": "x",
"y": "Heating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "KitchenAbvGr",
"xref": "x",
"y": "Heating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "KitchenQual",
"xref": "x",
"y": "Heating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "TotRmsAbvGrd",
"xref": "x",
"y": "Heating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "Functional",
"xref": "x",
"y": "Heating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "Fireplaces",
"xref": "x",
"y": "Heating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.13",
"x": "GarageType",
"xref": "x",
"y": "Heating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.18",
"x": "GarageYrBlt",
"xref": "x",
"y": "Heating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "GarageFinish",
"xref": "x",
"y": "Heating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "GarageCars",
"xref": "x",
"y": "Heating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "GarageArea",
"xref": "x",
"y": "Heating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.16",
"x": "GarageQual",
"xref": "x",
"y": "Heating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.12",
"x": "GarageCond",
"xref": "x",
"y": "Heating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.15",
"x": "PavedDrive",
"xref": "x",
"y": "Heating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "WoodDeckSF",
"xref": "x",
"y": "Heating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "OpenPorchSF",
"xref": "x",
"y": "Heating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "EnclosedPorch",
"xref": "x",
"y": "Heating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "3SsnPorch",
"xref": "x",
"y": "Heating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "ScreenPorch",
"xref": "x",
"y": "Heating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "PoolArea",
"xref": "x",
"y": "Heating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "MiscVal",
"xref": "x",
"y": "Heating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "MoSold",
"xref": "x",
"y": "Heating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "YrSold",
"xref": "x",
"y": "Heating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "SaleType",
"xref": "x",
"y": "Heating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "SaleCondition",
"xref": "x",
"y": "Heating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "SalePrice",
"xref": "x",
"y": "Heating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Id",
"xref": "x",
"y": "HeatingQC",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "MSSubClass",
"xref": "x",
"y": "HeatingQC",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.15",
"x": "MSZoning",
"xref": "x",
"y": "HeatingQC",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "LotArea",
"xref": "x",
"y": "HeatingQC",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "Street",
"xref": "x",
"y": "HeatingQC",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "LotShape",
"xref": "x",
"y": "HeatingQC",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "LandContour",
"xref": "x",
"y": "HeatingQC",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Utilities",
"xref": "x",
"y": "HeatingQC",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "LotConfig",
"xref": "x",
"y": "HeatingQC",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "LandSlope",
"xref": "x",
"y": "HeatingQC",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "Neighborhood",
"xref": "x",
"y": "HeatingQC",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "Condition1",
"xref": "x",
"y": "HeatingQC",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "Condition2",
"xref": "x",
"y": "HeatingQC",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "BldgType",
"xref": "x",
"y": "HeatingQC",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "HouseStyle",
"xref": "x",
"y": "HeatingQC",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.44",
"x": "OverallQual",
"xref": "x",
"y": "HeatingQC",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "OverallCond",
"xref": "x",
"y": "HeatingQC",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.42",
"x": "YearBuilt",
"xref": "x",
"y": "HeatingQC",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.52",
"x": "YearRemodAdd",
"xref": "x",
"y": "HeatingQC",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "RoofStyle",
"xref": "x",
"y": "HeatingQC",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "RoofMatl",
"xref": "x",
"y": "HeatingQC",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.26",
"x": "Exterior1st",
"xref": "x",
"y": "HeatingQC",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.24",
"x": "Exterior2nd",
"xref": "x",
"y": "HeatingQC",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.09",
"x": "MasVnrType",
"xref": "x",
"y": "HeatingQC",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.14",
"x": "MasVnrArea",
"xref": "x",
"y": "HeatingQC",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.44",
"x": "ExterQual",
"xref": "x",
"y": "HeatingQC",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "ExterCond",
"xref": "x",
"y": "HeatingQC",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.42",
"x": "Foundation",
"xref": "x",
"y": "HeatingQC",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.39",
"x": "BsmtQual",
"xref": "x",
"y": "HeatingQC",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "BsmtCond",
"xref": "x",
"y": "HeatingQC",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.13",
"x": "BsmtExposure",
"xref": "x",
"y": "HeatingQC",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "BsmtFinType1",
"xref": "x",
"y": "HeatingQC",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "BsmtFinSF1",
"xref": "x",
"y": "HeatingQC",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "BsmtFinType2",
"xref": "x",
"y": "HeatingQC",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.11",
"x": "BsmtFinSF2",
"xref": "x",
"y": "HeatingQC",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.21",
"x": "BsmtUnfSF",
"xref": "x",
"y": "HeatingQC",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.22",
"x": "TotalBsmtSF",
"xref": "x",
"y": "HeatingQC",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "Heating",
"xref": "x",
"y": "HeatingQC",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "HeatingQC",
"xref": "x",
"y": "HeatingQC",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.17",
"x": "CentralAir",
"xref": "x",
"y": "HeatingQC",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.13",
"x": "Electrical",
"xref": "x",
"y": "HeatingQC",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.18",
"x": "1stFlrSF",
"xref": "x",
"y": "HeatingQC",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.15",
"x": "2ndFlrSF",
"xref": "x",
"y": "HeatingQC",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "LowQualFinSF",
"xref": "x",
"y": "HeatingQC",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.26",
"x": "GrLivArea",
"xref": "x",
"y": "HeatingQC",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "BsmtFullBath",
"xref": "x",
"y": "HeatingQC",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "BsmtHalfBath",
"xref": "x",
"y": "HeatingQC",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.35",
"x": "FullBath",
"xref": "x",
"y": "HeatingQC",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "HalfBath",
"xref": "x",
"y": "HeatingQC",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "BedroomAbvGr",
"xref": "x",
"y": "HeatingQC",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.13",
"x": "KitchenAbvGr",
"xref": "x",
"y": "HeatingQC",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.4",
"x": "KitchenQual",
"xref": "x",
"y": "HeatingQC",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.18",
"x": "TotRmsAbvGrd",
"xref": "x",
"y": "HeatingQC",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "Functional",
"xref": "x",
"y": "HeatingQC",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.11",
"x": "Fireplaces",
"xref": "x",
"y": "HeatingQC",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.19",
"x": "GarageType",
"xref": "x",
"y": "HeatingQC",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.42",
"x": "GarageYrBlt",
"xref": "x",
"y": "HeatingQC",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.38",
"x": "GarageFinish",
"xref": "x",
"y": "HeatingQC",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.32",
"x": "GarageCars",
"xref": "x",
"y": "HeatingQC",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.26",
"x": "GarageArea",
"xref": "x",
"y": "HeatingQC",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "GarageQual",
"xref": "x",
"y": "HeatingQC",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "GarageCond",
"xref": "x",
"y": "HeatingQC",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "PavedDrive",
"xref": "x",
"y": "HeatingQC",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "WoodDeckSF",
"xref": "x",
"y": "HeatingQC",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.17",
"x": "OpenPorchSF",
"xref": "x",
"y": "HeatingQC",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "EnclosedPorch",
"xref": "x",
"y": "HeatingQC",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "3SsnPorch",
"xref": "x",
"y": "HeatingQC",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "ScreenPorch",
"xref": "x",
"y": "HeatingQC",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "PoolArea",
"xref": "x",
"y": "HeatingQC",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "MiscVal",
"xref": "x",
"y": "HeatingQC",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "MoSold",
"xref": "x",
"y": "HeatingQC",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "YrSold",
"xref": "x",
"y": "HeatingQC",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "SaleType",
"xref": "x",
"y": "HeatingQC",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.16",
"x": "SaleCondition",
"xref": "x",
"y": "HeatingQC",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.41",
"x": "SalePrice",
"xref": "x",
"y": "HeatingQC",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Id",
"xref": "x",
"y": "CentralAir",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "MSSubClass",
"xref": "x",
"y": "CentralAir",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "MSZoning",
"xref": "x",
"y": "CentralAir",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "LotArea",
"xref": "x",
"y": "CentralAir",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "Street",
"xref": "x",
"y": "CentralAir",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "LotShape",
"xref": "x",
"y": "CentralAir",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.13",
"x": "LandContour",
"xref": "x",
"y": "CentralAir",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Utilities",
"xref": "x",
"y": "CentralAir",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "LotConfig",
"xref": "x",
"y": "CentralAir",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "LandSlope",
"xref": "x",
"y": "CentralAir",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "Neighborhood",
"xref": "x",
"y": "CentralAir",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "Condition1",
"xref": "x",
"y": "CentralAir",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "Condition2",
"xref": "x",
"y": "CentralAir",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "BldgType",
"xref": "x",
"y": "CentralAir",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "HouseStyle",
"xref": "x",
"y": "CentralAir",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.19",
"x": "OverallQual",
"xref": "x",
"y": "CentralAir",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "OverallCond",
"xref": "x",
"y": "CentralAir",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.36",
"x": "YearBuilt",
"xref": "x",
"y": "CentralAir",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.26",
"x": "YearRemodAdd",
"xref": "x",
"y": "CentralAir",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "RoofStyle",
"xref": "x",
"y": "CentralAir",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "RoofMatl",
"xref": "x",
"y": "CentralAir",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "Exterior1st",
"xref": "x",
"y": "CentralAir",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "Exterior2nd",
"xref": "x",
"y": "CentralAir",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "MasVnrType",
"xref": "x",
"y": "CentralAir",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.11",
"x": "MasVnrArea",
"xref": "x",
"y": "CentralAir",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.09",
"x": "ExterQual",
"xref": "x",
"y": "CentralAir",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "ExterCond",
"xref": "x",
"y": "CentralAir",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.24",
"x": "Foundation",
"xref": "x",
"y": "CentralAir",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "BsmtQual",
"xref": "x",
"y": "CentralAir",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "BsmtCond",
"xref": "x",
"y": "CentralAir",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "BsmtExposure",
"xref": "x",
"y": "CentralAir",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.12",
"x": "BsmtFinType1",
"xref": "x",
"y": "CentralAir",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "BsmtFinSF1",
"xref": "x",
"y": "CentralAir",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "BsmtFinType2",
"xref": "x",
"y": "CentralAir",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "BsmtFinSF2",
"xref": "x",
"y": "CentralAir",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "BsmtUnfSF",
"xref": "x",
"y": "CentralAir",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.15",
"x": "TotalBsmtSF",
"xref": "x",
"y": "CentralAir",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.39",
"x": "Heating",
"xref": "x",
"y": "CentralAir",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.17",
"x": "HeatingQC",
"xref": "x",
"y": "CentralAir",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "CentralAir",
"xref": "x",
"y": "CentralAir",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.23",
"x": "Electrical",
"xref": "x",
"y": "CentralAir",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "1stFlrSF",
"xref": "x",
"y": "CentralAir",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "2ndFlrSF",
"xref": "x",
"y": "CentralAir",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "LowQualFinSF",
"xref": "x",
"y": "CentralAir",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "GrLivArea",
"xref": "x",
"y": "CentralAir",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "BsmtFullBath",
"xref": "x",
"y": "CentralAir",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "BsmtHalfBath",
"xref": "x",
"y": "CentralAir",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.11",
"x": "FullBath",
"xref": "x",
"y": "CentralAir",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.11",
"x": "HalfBath",
"xref": "x",
"y": "CentralAir",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "BedroomAbvGr",
"xref": "x",
"y": "CentralAir",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.23",
"x": "KitchenAbvGr",
"xref": "x",
"y": "CentralAir",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "KitchenQual",
"xref": "x",
"y": "CentralAir",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "TotRmsAbvGrd",
"xref": "x",
"y": "CentralAir",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "Functional",
"xref": "x",
"y": "CentralAir",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "Fireplaces",
"xref": "x",
"y": "CentralAir",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.25",
"x": "GarageType",
"xref": "x",
"y": "CentralAir",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.32",
"x": "GarageYrBlt",
"xref": "x",
"y": "CentralAir",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.21",
"x": "GarageFinish",
"xref": "x",
"y": "CentralAir",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.13",
"x": "GarageCars",
"xref": "x",
"y": "CentralAir",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "GarageArea",
"xref": "x",
"y": "CentralAir",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.21",
"x": "GarageQual",
"xref": "x",
"y": "CentralAir",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.23",
"x": "GarageCond",
"xref": "x",
"y": "CentralAir",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.26",
"x": "PavedDrive",
"xref": "x",
"y": "CentralAir",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "WoodDeckSF",
"xref": "x",
"y": "CentralAir",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "OpenPorchSF",
"xref": "x",
"y": "CentralAir",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.17",
"x": "EnclosedPorch",
"xref": "x",
"y": "CentralAir",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "3SsnPorch",
"xref": "x",
"y": "CentralAir",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "ScreenPorch",
"xref": "x",
"y": "CentralAir",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "PoolArea",
"xref": "x",
"y": "CentralAir",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "MiscVal",
"xref": "x",
"y": "CentralAir",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "MoSold",
"xref": "x",
"y": "CentralAir",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "YrSold",
"xref": "x",
"y": "CentralAir",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "SaleType",
"xref": "x",
"y": "CentralAir",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "SaleCondition",
"xref": "x",
"y": "CentralAir",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.2",
"x": "SalePrice",
"xref": "x",
"y": "CentralAir",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "Id",
"xref": "x",
"y": "Electrical",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "MSSubClass",
"xref": "x",
"y": "Electrical",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.09",
"x": "MSZoning",
"xref": "x",
"y": "Electrical",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "LotArea",
"xref": "x",
"y": "Electrical",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "Street",
"xref": "x",
"y": "Electrical",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.09",
"x": "LotShape",
"xref": "x",
"y": "Electrical",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "LandContour",
"xref": "x",
"y": "Electrical",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "Utilities",
"xref": "x",
"y": "Electrical",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "LotConfig",
"xref": "x",
"y": "Electrical",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "LandSlope",
"xref": "x",
"y": "Electrical",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "Neighborhood",
"xref": "x",
"y": "Electrical",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "Condition1",
"xref": "x",
"y": "Electrical",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "Condition2",
"xref": "x",
"y": "Electrical",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "BldgType",
"xref": "x",
"y": "Electrical",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.16",
"x": "HouseStyle",
"xref": "x",
"y": "Electrical",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.21",
"x": "OverallQual",
"xref": "x",
"y": "Electrical",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "OverallCond",
"xref": "x",
"y": "Electrical",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.32",
"x": "YearBuilt",
"xref": "x",
"y": "Electrical",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.31",
"x": "YearRemodAdd",
"xref": "x",
"y": "Electrical",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "RoofStyle",
"xref": "x",
"y": "Electrical",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "RoofMatl",
"xref": "x",
"y": "Electrical",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "Exterior1st",
"xref": "x",
"y": "Electrical",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "Exterior2nd",
"xref": "x",
"y": "Electrical",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "MasVnrType",
"xref": "x",
"y": "Electrical",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "MasVnrArea",
"xref": "x",
"y": "Electrical",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.17",
"x": "ExterQual",
"xref": "x",
"y": "Electrical",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "ExterCond",
"xref": "x",
"y": "Electrical",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.25",
"x": "Foundation",
"xref": "x",
"y": "Electrical",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.15",
"x": "BsmtQual",
"xref": "x",
"y": "Electrical",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "BsmtCond",
"xref": "x",
"y": "Electrical",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.12",
"x": "BsmtExposure",
"xref": "x",
"y": "Electrical",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.11",
"x": "BsmtFinType1",
"xref": "x",
"y": "Electrical",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.13",
"x": "BsmtFinSF1",
"xref": "x",
"y": "Electrical",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "BsmtFinType2",
"xref": "x",
"y": "Electrical",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "BsmtFinSF2",
"xref": "x",
"y": "Electrical",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "BsmtUnfSF",
"xref": "x",
"y": "Electrical",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.11",
"x": "TotalBsmtSF",
"xref": "x",
"y": "Electrical",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "Heating",
"xref": "x",
"y": "Electrical",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.13",
"x": "HeatingQC",
"xref": "x",
"y": "Electrical",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.23",
"x": "CentralAir",
"xref": "x",
"y": "Electrical",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "Electrical",
"xref": "x",
"y": "Electrical",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.11",
"x": "1stFlrSF",
"xref": "x",
"y": "Electrical",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "2ndFlrSF",
"xref": "x",
"y": "Electrical",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "LowQualFinSF",
"xref": "x",
"y": "Electrical",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.11",
"x": "GrLivArea",
"xref": "x",
"y": "Electrical",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "BsmtFullBath",
"xref": "x",
"y": "Electrical",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "BsmtHalfBath",
"xref": "x",
"y": "Electrical",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.22",
"x": "FullBath",
"xref": "x",
"y": "Electrical",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "HalfBath",
"xref": "x",
"y": "Electrical",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "BedroomAbvGr",
"xref": "x",
"y": "Electrical",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.12",
"x": "KitchenAbvGr",
"xref": "x",
"y": "Electrical",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.11",
"x": "KitchenQual",
"xref": "x",
"y": "Electrical",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "TotRmsAbvGrd",
"xref": "x",
"y": "Electrical",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "Functional",
"xref": "x",
"y": "Electrical",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "Fireplaces",
"xref": "x",
"y": "Electrical",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.17",
"x": "GarageType",
"xref": "x",
"y": "Electrical",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.31",
"x": "GarageYrBlt",
"xref": "x",
"y": "Electrical",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.21",
"x": "GarageFinish",
"xref": "x",
"y": "Electrical",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.24",
"x": "GarageCars",
"xref": "x",
"y": "Electrical",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.21",
"x": "GarageArea",
"xref": "x",
"y": "Electrical",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.13",
"x": "GarageQual",
"xref": "x",
"y": "Electrical",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "GarageCond",
"xref": "x",
"y": "Electrical",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.18",
"x": "PavedDrive",
"xref": "x",
"y": "Electrical",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "WoodDeckSF",
"xref": "x",
"y": "Electrical",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.11",
"x": "OpenPorchSF",
"xref": "x",
"y": "Electrical",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.15",
"x": "EnclosedPorch",
"xref": "x",
"y": "Electrical",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "3SsnPorch",
"xref": "x",
"y": "Electrical",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "ScreenPorch",
"xref": "x",
"y": "Electrical",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "PoolArea",
"xref": "x",
"y": "Electrical",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "MiscVal",
"xref": "x",
"y": "Electrical",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "MoSold",
"xref": "x",
"y": "Electrical",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "YrSold",
"xref": "x",
"y": "Electrical",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "SaleType",
"xref": "x",
"y": "Electrical",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "SaleCondition",
"xref": "x",
"y": "Electrical",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.21",
"x": "SalePrice",
"xref": "x",
"y": "Electrical",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Id",
"xref": "x",
"y": "1stFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.26",
"x": "MSSubClass",
"xref": "x",
"y": "1stFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "MSZoning",
"xref": "x",
"y": "1stFlrSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.29",
"x": "LotArea",
"xref": "x",
"y": "1stFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "Street",
"xref": "x",
"y": "1stFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.17",
"x": "LotShape",
"xref": "x",
"y": "1stFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "LandContour",
"xref": "x",
"y": "1stFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Utilities",
"xref": "x",
"y": "1stFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "LotConfig",
"xref": "x",
"y": "1stFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "LandSlope",
"xref": "x",
"y": "1stFlrSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.16",
"x": "Neighborhood",
"xref": "x",
"y": "1stFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "Condition1",
"xref": "x",
"y": "1stFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "Condition2",
"xref": "x",
"y": "1stFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "BldgType",
"xref": "x",
"y": "1stFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.19",
"x": "HouseStyle",
"xref": "x",
"y": "1stFlrSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.48",
"x": "OverallQual",
"xref": "x",
"y": "1stFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.14",
"x": "OverallCond",
"xref": "x",
"y": "1stFlrSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.26",
"x": "YearBuilt",
"xref": "x",
"y": "1stFlrSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.24",
"x": "YearRemodAdd",
"xref": "x",
"y": "1stFlrSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.3",
"x": "RoofStyle",
"xref": "x",
"y": "1stFlrSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.16",
"x": "RoofMatl",
"xref": "x",
"y": "1stFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Exterior1st",
"xref": "x",
"y": "1stFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "Exterior2nd",
"xref": "x",
"y": "1stFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "MasVnrType",
"xref": "x",
"y": "1stFlrSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.34",
"x": "MasVnrArea",
"xref": "x",
"y": "1stFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.4",
"x": "ExterQual",
"xref": "x",
"y": "1stFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "ExterCond",
"xref": "x",
"y": "1stFlrSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.2",
"x": "Foundation",
"xref": "x",
"y": "1stFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.36",
"x": "BsmtQual",
"xref": "x",
"y": "1stFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "BsmtCond",
"xref": "x",
"y": "1stFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.25",
"x": "BsmtExposure",
"xref": "x",
"y": "1stFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "BsmtFinType1",
"xref": "x",
"y": "1stFlrSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.45",
"x": "BsmtFinSF1",
"xref": "x",
"y": "1stFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "BsmtFinType2",
"xref": "x",
"y": "1stFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "BsmtFinSF2",
"xref": "x",
"y": "1stFlrSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.32",
"x": "BsmtUnfSF",
"xref": "x",
"y": "1stFlrSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.89",
"x": "TotalBsmtSF",
"xref": "x",
"y": "1stFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "Heating",
"xref": "x",
"y": "1stFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.18",
"x": "HeatingQC",
"xref": "x",
"y": "1stFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "CentralAir",
"xref": "x",
"y": "1stFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.11",
"x": "Electrical",
"xref": "x",
"y": "1stFlrSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "1stFlrSF",
"xref": "x",
"y": "1stFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.22",
"x": "2ndFlrSF",
"xref": "x",
"y": "1stFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "LowQualFinSF",
"xref": "x",
"y": "1stFlrSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.55",
"x": "GrLivArea",
"xref": "x",
"y": "1stFlrSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.25",
"x": "BsmtFullBath",
"xref": "x",
"y": "1stFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "BsmtHalfBath",
"xref": "x",
"y": "1stFlrSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.37",
"x": "FullBath",
"xref": "x",
"y": "1stFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.15",
"x": "HalfBath",
"xref": "x",
"y": "1stFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "BedroomAbvGr",
"xref": "x",
"y": "1stFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "KitchenAbvGr",
"xref": "x",
"y": "1stFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.38",
"x": "KitchenQual",
"xref": "x",
"y": "1stFlrSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.39",
"x": "TotRmsAbvGrd",
"xref": "x",
"y": "1stFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "Functional",
"xref": "x",
"y": "1stFlrSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.4",
"x": "Fireplaces",
"xref": "x",
"y": "1stFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.36",
"x": "GarageType",
"xref": "x",
"y": "1stFlrSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.24",
"x": "GarageYrBlt",
"xref": "x",
"y": "1stFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.31",
"x": "GarageFinish",
"xref": "x",
"y": "1stFlrSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.44",
"x": "GarageCars",
"xref": "x",
"y": "1stFlrSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.5",
"x": "GarageArea",
"xref": "x",
"y": "1stFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "GarageQual",
"xref": "x",
"y": "1stFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.11",
"x": "GarageCond",
"xref": "x",
"y": "1stFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "PavedDrive",
"xref": "x",
"y": "1stFlrSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.23",
"x": "WoodDeckSF",
"xref": "x",
"y": "1stFlrSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.23",
"x": "OpenPorchSF",
"xref": "x",
"y": "1stFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "EnclosedPorch",
"xref": "x",
"y": "1stFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "3SsnPorch",
"xref": "x",
"y": "1stFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "ScreenPorch",
"xref": "x",
"y": "1stFlrSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.13",
"x": "PoolArea",
"xref": "x",
"y": "1stFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "MiscVal",
"xref": "x",
"y": "1stFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "MoSold",
"xref": "x",
"y": "1stFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "YrSold",
"xref": "x",
"y": "1stFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.12",
"x": "SaleType",
"xref": "x",
"y": "1stFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "SaleCondition",
"xref": "x",
"y": "1stFlrSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.6",
"x": "SalePrice",
"xref": "x",
"y": "1stFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "Id",
"xref": "x",
"y": "2ndFlrSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.31",
"x": "MSSubClass",
"xref": "x",
"y": "2ndFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "MSZoning",
"xref": "x",
"y": "2ndFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "LotArea",
"xref": "x",
"y": "2ndFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "Street",
"xref": "x",
"y": "2ndFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "LotShape",
"xref": "x",
"y": "2ndFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "LandContour",
"xref": "x",
"y": "2ndFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "Utilities",
"xref": "x",
"y": "2ndFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "LotConfig",
"xref": "x",
"y": "2ndFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "LandSlope",
"xref": "x",
"y": "2ndFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Neighborhood",
"xref": "x",
"y": "2ndFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Condition1",
"xref": "x",
"y": "2ndFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "Condition2",
"xref": "x",
"y": "2ndFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.09",
"x": "BldgType",
"xref": "x",
"y": "2ndFlrSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.48",
"x": "HouseStyle",
"xref": "x",
"y": "2ndFlrSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.28",
"x": "OverallQual",
"xref": "x",
"y": "2ndFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "OverallCond",
"xref": "x",
"y": "2ndFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "YearBuilt",
"xref": "x",
"y": "2ndFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "YearRemodAdd",
"xref": "x",
"y": "2ndFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "RoofStyle",
"xref": "x",
"y": "2ndFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "RoofMatl",
"xref": "x",
"y": "2ndFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "Exterior1st",
"xref": "x",
"y": "2ndFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "Exterior2nd",
"xref": "x",
"y": "2ndFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "MasVnrType",
"xref": "x",
"y": "2ndFlrSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.17",
"x": "MasVnrArea",
"xref": "x",
"y": "2ndFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.15",
"x": "ExterQual",
"xref": "x",
"y": "2ndFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "ExterCond",
"xref": "x",
"y": "2ndFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "Foundation",
"xref": "x",
"y": "2ndFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.12",
"x": "BsmtQual",
"xref": "x",
"y": "2ndFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "BsmtCond",
"xref": "x",
"y": "2ndFlrSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "BsmtExposure",
"xref": "x",
"y": "2ndFlrSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.2",
"x": "BsmtFinType1",
"xref": "x",
"y": "2ndFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.15",
"x": "BsmtFinSF1",
"xref": "x",
"y": "2ndFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "BsmtFinType2",
"xref": "x",
"y": "2ndFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.11",
"x": "BsmtFinSF2",
"xref": "x",
"y": "2ndFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "BsmtUnfSF",
"xref": "x",
"y": "2ndFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.23",
"x": "TotalBsmtSF",
"xref": "x",
"y": "2ndFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "Heating",
"xref": "x",
"y": "2ndFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.15",
"x": "HeatingQC",
"xref": "x",
"y": "2ndFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "CentralAir",
"xref": "x",
"y": "2ndFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "Electrical",
"xref": "x",
"y": "2ndFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.22",
"x": "1stFlrSF",
"xref": "x",
"y": "2ndFlrSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "2ndFlrSF",
"xref": "x",
"y": "2ndFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "LowQualFinSF",
"xref": "x",
"y": "2ndFlrSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.69",
"x": "GrLivArea",
"xref": "x",
"y": "2ndFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.18",
"x": "BsmtFullBath",
"xref": "x",
"y": "2ndFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "BsmtHalfBath",
"xref": "x",
"y": "2ndFlrSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.42",
"x": "FullBath",
"xref": "x",
"y": "2ndFlrSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.62",
"x": "HalfBath",
"xref": "x",
"y": "2ndFlrSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.51",
"x": "BedroomAbvGr",
"xref": "x",
"y": "2ndFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "KitchenAbvGr",
"xref": "x",
"y": "2ndFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.14",
"x": "KitchenQual",
"xref": "x",
"y": "2ndFlrSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.62",
"x": "TotRmsAbvGrd",
"xref": "x",
"y": "2ndFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Functional",
"xref": "x",
"y": "2ndFlrSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.19",
"x": "Fireplaces",
"xref": "x",
"y": "2ndFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "GarageType",
"xref": "x",
"y": "2ndFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "GarageYrBlt",
"xref": "x",
"y": "2ndFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.13",
"x": "GarageFinish",
"xref": "x",
"y": "2ndFlrSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.19",
"x": "GarageCars",
"xref": "x",
"y": "2ndFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "GarageArea",
"xref": "x",
"y": "2ndFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "GarageQual",
"xref": "x",
"y": "2ndFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "GarageCond",
"xref": "x",
"y": "2ndFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "PavedDrive",
"xref": "x",
"y": "2ndFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "WoodDeckSF",
"xref": "x",
"y": "2ndFlrSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.2",
"x": "OpenPorchSF",
"xref": "x",
"y": "2ndFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "EnclosedPorch",
"xref": "x",
"y": "2ndFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "3SsnPorch",
"xref": "x",
"y": "2ndFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "ScreenPorch",
"xref": "x",
"y": "2ndFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "PoolArea",
"xref": "x",
"y": "2ndFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "MiscVal",
"xref": "x",
"y": "2ndFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "MoSold",
"xref": "x",
"y": "2ndFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "YrSold",
"xref": "x",
"y": "2ndFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "SaleType",
"xref": "x",
"y": "2ndFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "SaleCondition",
"xref": "x",
"y": "2ndFlrSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.31",
"x": "SalePrice",
"xref": "x",
"y": "2ndFlrSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "Id",
"xref": "x",
"y": "LowQualFinSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "MSSubClass",
"xref": "x",
"y": "LowQualFinSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "MSZoning",
"xref": "x",
"y": "LowQualFinSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "LotArea",
"xref": "x",
"y": "LowQualFinSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Street",
"xref": "x",
"y": "LowQualFinSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "LotShape",
"xref": "x",
"y": "LowQualFinSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "LandContour",
"xref": "x",
"y": "LowQualFinSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "Utilities",
"xref": "x",
"y": "LowQualFinSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "LotConfig",
"xref": "x",
"y": "LowQualFinSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "LandSlope",
"xref": "x",
"y": "LowQualFinSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "Neighborhood",
"xref": "x",
"y": "LowQualFinSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "Condition1",
"xref": "x",
"y": "LowQualFinSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "Condition2",
"xref": "x",
"y": "LowQualFinSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "BldgType",
"xref": "x",
"y": "LowQualFinSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "HouseStyle",
"xref": "x",
"y": "LowQualFinSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "OverallQual",
"xref": "x",
"y": "LowQualFinSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "OverallCond",
"xref": "x",
"y": "LowQualFinSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.16",
"x": "YearBuilt",
"xref": "x",
"y": "LowQualFinSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "YearRemodAdd",
"xref": "x",
"y": "LowQualFinSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "RoofStyle",
"xref": "x",
"y": "LowQualFinSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "RoofMatl",
"xref": "x",
"y": "LowQualFinSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "Exterior1st",
"xref": "x",
"y": "LowQualFinSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "Exterior2nd",
"xref": "x",
"y": "LowQualFinSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "MasVnrType",
"xref": "x",
"y": "LowQualFinSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "MasVnrArea",
"xref": "x",
"y": "LowQualFinSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "ExterQual",
"xref": "x",
"y": "LowQualFinSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "ExterCond",
"xref": "x",
"y": "LowQualFinSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "Foundation",
"xref": "x",
"y": "LowQualFinSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "BsmtQual",
"xref": "x",
"y": "LowQualFinSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "BsmtCond",
"xref": "x",
"y": "LowQualFinSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "BsmtExposure",
"xref": "x",
"y": "LowQualFinSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "BsmtFinType1",
"xref": "x",
"y": "LowQualFinSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "BsmtFinSF1",
"xref": "x",
"y": "LowQualFinSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "BsmtFinType2",
"xref": "x",
"y": "LowQualFinSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "BsmtFinSF2",
"xref": "x",
"y": "LowQualFinSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "BsmtUnfSF",
"xref": "x",
"y": "LowQualFinSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "TotalBsmtSF",
"xref": "x",
"y": "LowQualFinSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "Heating",
"xref": "x",
"y": "LowQualFinSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "HeatingQC",
"xref": "x",
"y": "LowQualFinSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "CentralAir",
"xref": "x",
"y": "LowQualFinSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "Electrical",
"xref": "x",
"y": "LowQualFinSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "1stFlrSF",
"xref": "x",
"y": "LowQualFinSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "2ndFlrSF",
"xref": "x",
"y": "LowQualFinSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "LowQualFinSF",
"xref": "x",
"y": "LowQualFinSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "GrLivArea",
"xref": "x",
"y": "LowQualFinSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "BsmtFullBath",
"xref": "x",
"y": "LowQualFinSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "BsmtHalfBath",
"xref": "x",
"y": "LowQualFinSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "FullBath",
"xref": "x",
"y": "LowQualFinSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "HalfBath",
"xref": "x",
"y": "LowQualFinSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "BedroomAbvGr",
"xref": "x",
"y": "LowQualFinSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "KitchenAbvGr",
"xref": "x",
"y": "LowQualFinSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "KitchenQual",
"xref": "x",
"y": "LowQualFinSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "TotRmsAbvGrd",
"xref": "x",
"y": "LowQualFinSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "Functional",
"xref": "x",
"y": "LowQualFinSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "Fireplaces",
"xref": "x",
"y": "LowQualFinSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "GarageType",
"xref": "x",
"y": "LowQualFinSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "GarageYrBlt",
"xref": "x",
"y": "LowQualFinSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "GarageFinish",
"xref": "x",
"y": "LowQualFinSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "GarageCars",
"xref": "x",
"y": "LowQualFinSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "GarageArea",
"xref": "x",
"y": "LowQualFinSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "GarageQual",
"xref": "x",
"y": "LowQualFinSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "GarageCond",
"xref": "x",
"y": "LowQualFinSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "PavedDrive",
"xref": "x",
"y": "LowQualFinSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "WoodDeckSF",
"xref": "x",
"y": "LowQualFinSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "OpenPorchSF",
"xref": "x",
"y": "LowQualFinSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "EnclosedPorch",
"xref": "x",
"y": "LowQualFinSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "3SsnPorch",
"xref": "x",
"y": "LowQualFinSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "ScreenPorch",
"xref": "x",
"y": "LowQualFinSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "PoolArea",
"xref": "x",
"y": "LowQualFinSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "MiscVal",
"xref": "x",
"y": "LowQualFinSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "MoSold",
"xref": "x",
"y": "LowQualFinSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "YrSold",
"xref": "x",
"y": "LowQualFinSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "SaleType",
"xref": "x",
"y": "LowQualFinSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "SaleCondition",
"xref": "x",
"y": "LowQualFinSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "SalePrice",
"xref": "x",
"y": "LowQualFinSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "Id",
"xref": "x",
"y": "GrLivArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "MSSubClass",
"xref": "x",
"y": "GrLivArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "MSZoning",
"xref": "x",
"y": "GrLivArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.26",
"x": "LotArea",
"xref": "x",
"y": "GrLivArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "Street",
"xref": "x",
"y": "GrLivArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.18",
"x": "LotShape",
"xref": "x",
"y": "GrLivArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "LandContour",
"xref": "x",
"y": "GrLivArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "Utilities",
"xref": "x",
"y": "GrLivArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.09",
"x": "LotConfig",
"xref": "x",
"y": "GrLivArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "LandSlope",
"xref": "x",
"y": "GrLivArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.13",
"x": "Neighborhood",
"xref": "x",
"y": "GrLivArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "Condition1",
"xref": "x",
"y": "GrLivArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "Condition2",
"xref": "x",
"y": "GrLivArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.14",
"x": "BldgType",
"xref": "x",
"y": "GrLivArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.26",
"x": "HouseStyle",
"xref": "x",
"y": "GrLivArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.59",
"x": "OverallQual",
"xref": "x",
"y": "GrLivArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.09",
"x": "OverallCond",
"xref": "x",
"y": "GrLivArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.19",
"x": "YearBuilt",
"xref": "x",
"y": "GrLivArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.28",
"x": "YearRemodAdd",
"xref": "x",
"y": "GrLivArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.15",
"x": "RoofStyle",
"xref": "x",
"y": "GrLivArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "RoofMatl",
"xref": "x",
"y": "GrLivArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "Exterior1st",
"xref": "x",
"y": "GrLivArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "Exterior2nd",
"xref": "x",
"y": "GrLivArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "MasVnrType",
"xref": "x",
"y": "GrLivArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.39",
"x": "MasVnrArea",
"xref": "x",
"y": "GrLivArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.42",
"x": "ExterQual",
"xref": "x",
"y": "GrLivArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "ExterCond",
"xref": "x",
"y": "GrLivArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.24",
"x": "Foundation",
"xref": "x",
"y": "GrLivArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.37",
"x": "BsmtQual",
"xref": "x",
"y": "GrLivArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "BsmtCond",
"xref": "x",
"y": "GrLivArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "BsmtExposure",
"xref": "x",
"y": "GrLivArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "BsmtFinType1",
"xref": "x",
"y": "GrLivArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.2",
"x": "BsmtFinSF1",
"xref": "x",
"y": "GrLivArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "BsmtFinType2",
"xref": "x",
"y": "GrLivArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "BsmtFinSF2",
"xref": "x",
"y": "GrLivArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.22",
"x": "BsmtUnfSF",
"xref": "x",
"y": "GrLivArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.46",
"x": "TotalBsmtSF",
"xref": "x",
"y": "GrLivArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "Heating",
"xref": "x",
"y": "GrLivArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.26",
"x": "HeatingQC",
"xref": "x",
"y": "GrLivArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "CentralAir",
"xref": "x",
"y": "GrLivArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.11",
"x": "Electrical",
"xref": "x",
"y": "GrLivArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.55",
"x": "1stFlrSF",
"xref": "x",
"y": "GrLivArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.69",
"x": "2ndFlrSF",
"xref": "x",
"y": "GrLivArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "LowQualFinSF",
"xref": "x",
"y": "GrLivArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "GrLivArea",
"xref": "x",
"y": "GrLivArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "BsmtFullBath",
"xref": "x",
"y": "GrLivArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "BsmtHalfBath",
"xref": "x",
"y": "GrLivArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.63",
"x": "FullBath",
"xref": "x",
"y": "GrLivArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.42",
"x": "HalfBath",
"xref": "x",
"y": "GrLivArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.51",
"x": "BedroomAbvGr",
"xref": "x",
"y": "GrLivArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "KitchenAbvGr",
"xref": "x",
"y": "GrLivArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.4",
"x": "KitchenQual",
"xref": "x",
"y": "GrLivArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.82",
"x": "TotRmsAbvGrd",
"xref": "x",
"y": "GrLivArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "Functional",
"xref": "x",
"y": "GrLivArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.46",
"x": "Fireplaces",
"xref": "x",
"y": "GrLivArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.18",
"x": "GarageType",
"xref": "x",
"y": "GrLivArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.22",
"x": "GarageYrBlt",
"xref": "x",
"y": "GrLivArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.33",
"x": "GarageFinish",
"xref": "x",
"y": "GrLivArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.48",
"x": "GarageCars",
"xref": "x",
"y": "GrLivArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.48",
"x": "GarageArea",
"xref": "x",
"y": "GrLivArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "GarageQual",
"xref": "x",
"y": "GrLivArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "GarageCond",
"xref": "x",
"y": "GrLivArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "PavedDrive",
"xref": "x",
"y": "GrLivArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.24",
"x": "WoodDeckSF",
"xref": "x",
"y": "GrLivArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.34",
"x": "OpenPorchSF",
"xref": "x",
"y": "GrLivArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "EnclosedPorch",
"xref": "x",
"y": "GrLivArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "3SsnPorch",
"xref": "x",
"y": "GrLivArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "ScreenPorch",
"xref": "x",
"y": "GrLivArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.18",
"x": "PoolArea",
"xref": "x",
"y": "GrLivArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "MiscVal",
"xref": "x",
"y": "GrLivArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "MoSold",
"xref": "x",
"y": "GrLivArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "YrSold",
"xref": "x",
"y": "GrLivArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "SaleType",
"xref": "x",
"y": "GrLivArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "SaleCondition",
"xref": "x",
"y": "GrLivArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.71",
"x": "SalePrice",
"xref": "x",
"y": "GrLivArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Id",
"xref": "x",
"y": "BsmtFullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "MSSubClass",
"xref": "x",
"y": "BsmtFullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "MSZoning",
"xref": "x",
"y": "BsmtFullBath",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.16",
"x": "LotArea",
"xref": "x",
"y": "BsmtFullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "Street",
"xref": "x",
"y": "BsmtFullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "LotShape",
"xref": "x",
"y": "BsmtFullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "LandContour",
"xref": "x",
"y": "BsmtFullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "Utilities",
"xref": "x",
"y": "BsmtFullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "LotConfig",
"xref": "x",
"y": "BsmtFullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "LandSlope",
"xref": "x",
"y": "BsmtFullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "Neighborhood",
"xref": "x",
"y": "BsmtFullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Condition1",
"xref": "x",
"y": "BsmtFullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "Condition2",
"xref": "x",
"y": "BsmtFullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "BldgType",
"xref": "x",
"y": "BsmtFullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "HouseStyle",
"xref": "x",
"y": "BsmtFullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "OverallQual",
"xref": "x",
"y": "BsmtFullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "OverallCond",
"xref": "x",
"y": "BsmtFullBath",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.18",
"x": "YearBuilt",
"xref": "x",
"y": "BsmtFullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "YearRemodAdd",
"xref": "x",
"y": "BsmtFullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "RoofStyle",
"xref": "x",
"y": "BsmtFullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "RoofMatl",
"xref": "x",
"y": "BsmtFullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "Exterior1st",
"xref": "x",
"y": "BsmtFullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "Exterior2nd",
"xref": "x",
"y": "BsmtFullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "MasVnrType",
"xref": "x",
"y": "BsmtFullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "MasVnrArea",
"xref": "x",
"y": "BsmtFullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.09",
"x": "ExterQual",
"xref": "x",
"y": "BsmtFullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "ExterCond",
"xref": "x",
"y": "BsmtFullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "Foundation",
"xref": "x",
"y": "BsmtFullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.14",
"x": "BsmtQual",
"xref": "x",
"y": "BsmtFullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "BsmtCond",
"xref": "x",
"y": "BsmtFullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.25",
"x": "BsmtExposure",
"xref": "x",
"y": "BsmtFullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.46",
"x": "BsmtFinType1",
"xref": "x",
"y": "BsmtFullBath",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.64",
"x": "BsmtFinSF1",
"xref": "x",
"y": "BsmtFullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.14",
"x": "BsmtFinType2",
"xref": "x",
"y": "BsmtFullBath",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.15",
"x": "BsmtFinSF2",
"xref": "x",
"y": "BsmtFullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.46",
"x": "BsmtUnfSF",
"xref": "x",
"y": "BsmtFullBath",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.28",
"x": "TotalBsmtSF",
"xref": "x",
"y": "BsmtFullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "Heating",
"xref": "x",
"y": "BsmtFullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "HeatingQC",
"xref": "x",
"y": "BsmtFullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "CentralAir",
"xref": "x",
"y": "BsmtFullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "Electrical",
"xref": "x",
"y": "BsmtFullBath",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.25",
"x": "1stFlrSF",
"xref": "x",
"y": "BsmtFullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.18",
"x": "2ndFlrSF",
"xref": "x",
"y": "BsmtFullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "LowQualFinSF",
"xref": "x",
"y": "BsmtFullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "GrLivArea",
"xref": "x",
"y": "BsmtFullBath",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "BsmtFullBath",
"xref": "x",
"y": "BsmtFullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.16",
"x": "BsmtHalfBath",
"xref": "x",
"y": "BsmtFullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "FullBath",
"xref": "x",
"y": "BsmtFullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "HalfBath",
"xref": "x",
"y": "BsmtFullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.16",
"x": "BedroomAbvGr",
"xref": "x",
"y": "BsmtFullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "KitchenAbvGr",
"xref": "x",
"y": "BsmtFullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.13",
"x": "KitchenQual",
"xref": "x",
"y": "BsmtFullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "TotRmsAbvGrd",
"xref": "x",
"y": "BsmtFullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Functional",
"xref": "x",
"y": "BsmtFullBath",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.13",
"x": "Fireplaces",
"xref": "x",
"y": "BsmtFullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.17",
"x": "GarageType",
"xref": "x",
"y": "BsmtFullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "GarageYrBlt",
"xref": "x",
"y": "BsmtFullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.15",
"x": "GarageFinish",
"xref": "x",
"y": "BsmtFullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.13",
"x": "GarageCars",
"xref": "x",
"y": "BsmtFullBath",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.19",
"x": "GarageArea",
"xref": "x",
"y": "BsmtFullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "GarageQual",
"xref": "x",
"y": "BsmtFullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "GarageCond",
"xref": "x",
"y": "BsmtFullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.11",
"x": "PavedDrive",
"xref": "x",
"y": "BsmtFullBath",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.16",
"x": "WoodDeckSF",
"xref": "x",
"y": "BsmtFullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "OpenPorchSF",
"xref": "x",
"y": "BsmtFullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "EnclosedPorch",
"xref": "x",
"y": "BsmtFullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "3SsnPorch",
"xref": "x",
"y": "BsmtFullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "ScreenPorch",
"xref": "x",
"y": "BsmtFullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "PoolArea",
"xref": "x",
"y": "BsmtFullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "MiscVal",
"xref": "x",
"y": "BsmtFullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "MoSold",
"xref": "x",
"y": "BsmtFullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "YrSold",
"xref": "x",
"y": "BsmtFullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "SaleType",
"xref": "x",
"y": "BsmtFullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "SaleCondition",
"xref": "x",
"y": "BsmtFullBath",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.21",
"x": "SalePrice",
"xref": "x",
"y": "BsmtFullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "Id",
"xref": "x",
"y": "BsmtHalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "MSSubClass",
"xref": "x",
"y": "BsmtHalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "MSZoning",
"xref": "x",
"y": "BsmtHalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "LotArea",
"xref": "x",
"y": "BsmtHalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "Street",
"xref": "x",
"y": "BsmtHalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "LotShape",
"xref": "x",
"y": "BsmtHalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "LandContour",
"xref": "x",
"y": "BsmtHalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.11",
"x": "Utilities",
"xref": "x",
"y": "BsmtHalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "LotConfig",
"xref": "x",
"y": "BsmtHalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "LandSlope",
"xref": "x",
"y": "BsmtHalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "Neighborhood",
"xref": "x",
"y": "BsmtHalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "Condition1",
"xref": "x",
"y": "BsmtHalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "Condition2",
"xref": "x",
"y": "BsmtHalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "BldgType",
"xref": "x",
"y": "BsmtHalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "HouseStyle",
"xref": "x",
"y": "BsmtHalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "OverallQual",
"xref": "x",
"y": "BsmtHalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "OverallCond",
"xref": "x",
"y": "BsmtHalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "YearBuilt",
"xref": "x",
"y": "BsmtHalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "YearRemodAdd",
"xref": "x",
"y": "BsmtHalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "RoofStyle",
"xref": "x",
"y": "BsmtHalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "RoofMatl",
"xref": "x",
"y": "BsmtHalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "Exterior1st",
"xref": "x",
"y": "BsmtHalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "Exterior2nd",
"xref": "x",
"y": "BsmtHalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "MasVnrType",
"xref": "x",
"y": "BsmtHalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "MasVnrArea",
"xref": "x",
"y": "BsmtHalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "ExterQual",
"xref": "x",
"y": "BsmtHalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "ExterCond",
"xref": "x",
"y": "BsmtHalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "Foundation",
"xref": "x",
"y": "BsmtHalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "BsmtQual",
"xref": "x",
"y": "BsmtHalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "BsmtCond",
"xref": "x",
"y": "BsmtHalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "BsmtExposure",
"xref": "x",
"y": "BsmtHalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.11",
"x": "BsmtFinType1",
"xref": "x",
"y": "BsmtHalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "BsmtFinSF1",
"xref": "x",
"y": "BsmtHalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.09",
"x": "BsmtFinType2",
"xref": "x",
"y": "BsmtHalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "BsmtFinSF2",
"xref": "x",
"y": "BsmtHalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.11",
"x": "BsmtUnfSF",
"xref": "x",
"y": "BsmtHalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "TotalBsmtSF",
"xref": "x",
"y": "BsmtHalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Heating",
"xref": "x",
"y": "BsmtHalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "HeatingQC",
"xref": "x",
"y": "BsmtHalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "CentralAir",
"xref": "x",
"y": "BsmtHalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Electrical",
"xref": "x",
"y": "BsmtHalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "1stFlrSF",
"xref": "x",
"y": "BsmtHalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "2ndFlrSF",
"xref": "x",
"y": "BsmtHalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "LowQualFinSF",
"xref": "x",
"y": "BsmtHalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "GrLivArea",
"xref": "x",
"y": "BsmtHalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.16",
"x": "BsmtFullBath",
"xref": "x",
"y": "BsmtHalfBath",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "BsmtHalfBath",
"xref": "x",
"y": "BsmtHalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "FullBath",
"xref": "x",
"y": "BsmtHalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "HalfBath",
"xref": "x",
"y": "BsmtHalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "BedroomAbvGr",
"xref": "x",
"y": "BsmtHalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "KitchenAbvGr",
"xref": "x",
"y": "BsmtHalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "KitchenQual",
"xref": "x",
"y": "BsmtHalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "TotRmsAbvGrd",
"xref": "x",
"y": "BsmtHalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "Functional",
"xref": "x",
"y": "BsmtHalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "Fireplaces",
"xref": "x",
"y": "BsmtHalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "GarageType",
"xref": "x",
"y": "BsmtHalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "GarageYrBlt",
"xref": "x",
"y": "BsmtHalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "GarageFinish",
"xref": "x",
"y": "BsmtHalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "GarageCars",
"xref": "x",
"y": "BsmtHalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "GarageArea",
"xref": "x",
"y": "BsmtHalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "GarageQual",
"xref": "x",
"y": "BsmtHalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "GarageCond",
"xref": "x",
"y": "BsmtHalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "PavedDrive",
"xref": "x",
"y": "BsmtHalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "WoodDeckSF",
"xref": "x",
"y": "BsmtHalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "OpenPorchSF",
"xref": "x",
"y": "BsmtHalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "EnclosedPorch",
"xref": "x",
"y": "BsmtHalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "3SsnPorch",
"xref": "x",
"y": "BsmtHalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "ScreenPorch",
"xref": "x",
"y": "BsmtHalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "PoolArea",
"xref": "x",
"y": "BsmtHalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "MiscVal",
"xref": "x",
"y": "BsmtHalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "MoSold",
"xref": "x",
"y": "BsmtHalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "YrSold",
"xref": "x",
"y": "BsmtHalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "SaleType",
"xref": "x",
"y": "BsmtHalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "SaleCondition",
"xref": "x",
"y": "BsmtHalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "SalePrice",
"xref": "x",
"y": "BsmtHalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "Id",
"xref": "x",
"y": "FullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "MSSubClass",
"xref": "x",
"y": "FullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.21",
"x": "MSZoning",
"xref": "x",
"y": "FullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "LotArea",
"xref": "x",
"y": "FullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "Street",
"xref": "x",
"y": "FullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.18",
"x": "LotShape",
"xref": "x",
"y": "FullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "LandContour",
"xref": "x",
"y": "FullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "Utilities",
"xref": "x",
"y": "FullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "LotConfig",
"xref": "x",
"y": "FullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "LandSlope",
"xref": "x",
"y": "FullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.13",
"x": "Neighborhood",
"xref": "x",
"y": "FullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "Condition1",
"xref": "x",
"y": "FullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "Condition2",
"xref": "x",
"y": "FullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "BldgType",
"xref": "x",
"y": "FullBath",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.24",
"x": "HouseStyle",
"xref": "x",
"y": "FullBath",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.58",
"x": "OverallQual",
"xref": "x",
"y": "FullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.21",
"x": "OverallCond",
"xref": "x",
"y": "FullBath",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.49",
"x": "YearBuilt",
"xref": "x",
"y": "FullBath",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.46",
"x": "YearRemodAdd",
"xref": "x",
"y": "FullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "RoofStyle",
"xref": "x",
"y": "FullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "RoofMatl",
"xref": "x",
"y": "FullBath",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.13",
"x": "Exterior1st",
"xref": "x",
"y": "FullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.13",
"x": "Exterior2nd",
"xref": "x",
"y": "FullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "MasVnrType",
"xref": "x",
"y": "FullBath",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.27",
"x": "MasVnrArea",
"xref": "x",
"y": "FullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.44",
"x": "ExterQual",
"xref": "x",
"y": "FullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "ExterCond",
"xref": "x",
"y": "FullBath",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.42",
"x": "Foundation",
"xref": "x",
"y": "FullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.44",
"x": "BsmtQual",
"xref": "x",
"y": "FullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "BsmtCond",
"xref": "x",
"y": "FullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "BsmtExposure",
"xref": "x",
"y": "FullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "BsmtFinType1",
"xref": "x",
"y": "FullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "BsmtFinSF1",
"xref": "x",
"y": "FullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "BsmtFinType2",
"xref": "x",
"y": "FullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.09",
"x": "BsmtFinSF2",
"xref": "x",
"y": "FullBath",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.31",
"x": "BsmtUnfSF",
"xref": "x",
"y": "FullBath",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.35",
"x": "TotalBsmtSF",
"xref": "x",
"y": "FullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "Heating",
"xref": "x",
"y": "FullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.35",
"x": "HeatingQC",
"xref": "x",
"y": "FullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.11",
"x": "CentralAir",
"xref": "x",
"y": "FullBath",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.22",
"x": "Electrical",
"xref": "x",
"y": "FullBath",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.37",
"x": "1stFlrSF",
"xref": "x",
"y": "FullBath",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.42",
"x": "2ndFlrSF",
"xref": "x",
"y": "FullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "LowQualFinSF",
"xref": "x",
"y": "FullBath",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.63",
"x": "GrLivArea",
"xref": "x",
"y": "FullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "BsmtFullBath",
"xref": "x",
"y": "FullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "BsmtHalfBath",
"xref": "x",
"y": "FullBath",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "FullBath",
"xref": "x",
"y": "FullBath",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.13",
"x": "HalfBath",
"xref": "x",
"y": "FullBath",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.36",
"x": "BedroomAbvGr",
"xref": "x",
"y": "FullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "KitchenAbvGr",
"xref": "x",
"y": "FullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.36",
"x": "KitchenQual",
"xref": "x",
"y": "FullBath",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.55",
"x": "TotRmsAbvGrd",
"xref": "x",
"y": "FullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "Functional",
"xref": "x",
"y": "FullBath",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.24",
"x": "Fireplaces",
"xref": "x",
"y": "FullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.3",
"x": "GarageType",
"xref": "x",
"y": "FullBath",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.49",
"x": "GarageYrBlt",
"xref": "x",
"y": "FullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.42",
"x": "GarageFinish",
"xref": "x",
"y": "FullBath",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.51",
"x": "GarageCars",
"xref": "x",
"y": "FullBath",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.42",
"x": "GarageArea",
"xref": "x",
"y": "FullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.11",
"x": "GarageQual",
"xref": "x",
"y": "FullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "GarageCond",
"xref": "x",
"y": "FullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.13",
"x": "PavedDrive",
"xref": "x",
"y": "FullBath",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.19",
"x": "WoodDeckSF",
"xref": "x",
"y": "FullBath",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.28",
"x": "OpenPorchSF",
"xref": "x",
"y": "FullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.13",
"x": "EnclosedPorch",
"xref": "x",
"y": "FullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "3SsnPorch",
"xref": "x",
"y": "FullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "ScreenPorch",
"xref": "x",
"y": "FullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "PoolArea",
"xref": "x",
"y": "FullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "MiscVal",
"xref": "x",
"y": "FullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "MoSold",
"xref": "x",
"y": "FullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "YrSold",
"xref": "x",
"y": "FullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "SaleType",
"xref": "x",
"y": "FullBath",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.15",
"x": "SaleCondition",
"xref": "x",
"y": "FullBath",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.57",
"x": "SalePrice",
"xref": "x",
"y": "FullBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "Id",
"xref": "x",
"y": "HalfBath",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.2",
"x": "MSSubClass",
"xref": "x",
"y": "HalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.14",
"x": "MSZoning",
"xref": "x",
"y": "HalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "LotArea",
"xref": "x",
"y": "HalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "Street",
"xref": "x",
"y": "HalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.11",
"x": "LotShape",
"xref": "x",
"y": "HalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "LandContour",
"xref": "x",
"y": "HalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "Utilities",
"xref": "x",
"y": "HalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "LotConfig",
"xref": "x",
"y": "HalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "LandSlope",
"xref": "x",
"y": "HalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "Neighborhood",
"xref": "x",
"y": "HalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "Condition1",
"xref": "x",
"y": "HalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "Condition2",
"xref": "x",
"y": "HalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "BldgType",
"xref": "x",
"y": "HalfBath",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.42",
"x": "HouseStyle",
"xref": "x",
"y": "HalfBath",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.25",
"x": "OverallQual",
"xref": "x",
"y": "HalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "OverallCond",
"xref": "x",
"y": "HalfBath",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.23",
"x": "YearBuilt",
"xref": "x",
"y": "HalfBath",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.17",
"x": "YearRemodAdd",
"xref": "x",
"y": "HalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "RoofStyle",
"xref": "x",
"y": "HalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "RoofMatl",
"xref": "x",
"y": "HalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "Exterior1st",
"xref": "x",
"y": "HalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "Exterior2nd",
"xref": "x",
"y": "HalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.12",
"x": "MasVnrType",
"xref": "x",
"y": "HalfBath",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.19",
"x": "MasVnrArea",
"xref": "x",
"y": "HalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.15",
"x": "ExterQual",
"xref": "x",
"y": "HalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "ExterCond",
"xref": "x",
"y": "HalfBath",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.17",
"x": "Foundation",
"xref": "x",
"y": "HalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.13",
"x": "BsmtQual",
"xref": "x",
"y": "HalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "BsmtCond",
"xref": "x",
"y": "HalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "BsmtExposure",
"xref": "x",
"y": "HalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "BsmtFinType1",
"xref": "x",
"y": "HalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "BsmtFinSF1",
"xref": "x",
"y": "HalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "BsmtFinType2",
"xref": "x",
"y": "HalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "BsmtFinSF2",
"xref": "x",
"y": "HalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "BsmtUnfSF",
"xref": "x",
"y": "HalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.12",
"x": "TotalBsmtSF",
"xref": "x",
"y": "HalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "Heating",
"xref": "x",
"y": "HalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "HeatingQC",
"xref": "x",
"y": "HalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.11",
"x": "CentralAir",
"xref": "x",
"y": "HalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "Electrical",
"xref": "x",
"y": "HalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.15",
"x": "1stFlrSF",
"xref": "x",
"y": "HalfBath",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.62",
"x": "2ndFlrSF",
"xref": "x",
"y": "HalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "LowQualFinSF",
"xref": "x",
"y": "HalfBath",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.42",
"x": "GrLivArea",
"xref": "x",
"y": "HalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "BsmtFullBath",
"xref": "x",
"y": "HalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "BsmtHalfBath",
"xref": "x",
"y": "HalfBath",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.13",
"x": "FullBath",
"xref": "x",
"y": "HalfBath",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "HalfBath",
"xref": "x",
"y": "HalfBath",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.25",
"x": "BedroomAbvGr",
"xref": "x",
"y": "HalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "KitchenAbvGr",
"xref": "x",
"y": "HalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.14",
"x": "KitchenQual",
"xref": "x",
"y": "HalfBath",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.36",
"x": "TotRmsAbvGrd",
"xref": "x",
"y": "HalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "Functional",
"xref": "x",
"y": "HalfBath",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.19",
"x": "Fireplaces",
"xref": "x",
"y": "HalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.09",
"x": "GarageType",
"xref": "x",
"y": "HalfBath",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.19",
"x": "GarageYrBlt",
"xref": "x",
"y": "HalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.21",
"x": "GarageFinish",
"xref": "x",
"y": "HalfBath",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.2",
"x": "GarageCars",
"xref": "x",
"y": "HalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.13",
"x": "GarageArea",
"xref": "x",
"y": "HalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "GarageQual",
"xref": "x",
"y": "HalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "GarageCond",
"xref": "x",
"y": "HalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "PavedDrive",
"xref": "x",
"y": "HalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "WoodDeckSF",
"xref": "x",
"y": "HalfBath",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.2",
"x": "OpenPorchSF",
"xref": "x",
"y": "HalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.09",
"x": "EnclosedPorch",
"xref": "x",
"y": "HalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "3SsnPorch",
"xref": "x",
"y": "HalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "ScreenPorch",
"xref": "x",
"y": "HalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "PoolArea",
"xref": "x",
"y": "HalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "MiscVal",
"xref": "x",
"y": "HalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "MoSold",
"xref": "x",
"y": "HalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "YrSold",
"xref": "x",
"y": "HalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "SaleType",
"xref": "x",
"y": "HalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "SaleCondition",
"xref": "x",
"y": "HalfBath",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.26",
"x": "SalePrice",
"xref": "x",
"y": "HalfBath",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "Id",
"xref": "x",
"y": "BedroomAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "MSSubClass",
"xref": "x",
"y": "BedroomAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "MSZoning",
"xref": "x",
"y": "BedroomAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "LotArea",
"xref": "x",
"y": "BedroomAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "Street",
"xref": "x",
"y": "BedroomAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "LotShape",
"xref": "x",
"y": "BedroomAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "LandContour",
"xref": "x",
"y": "BedroomAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "Utilities",
"xref": "x",
"y": "BedroomAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "LotConfig",
"xref": "x",
"y": "BedroomAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "LandSlope",
"xref": "x",
"y": "BedroomAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "Neighborhood",
"xref": "x",
"y": "BedroomAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "Condition1",
"xref": "x",
"y": "BedroomAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "Condition2",
"xref": "x",
"y": "BedroomAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.32",
"x": "BldgType",
"xref": "x",
"y": "BedroomAbvGr",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.2",
"x": "HouseStyle",
"xref": "x",
"y": "BedroomAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "OverallQual",
"xref": "x",
"y": "BedroomAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "OverallCond",
"xref": "x",
"y": "BedroomAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "YearBuilt",
"xref": "x",
"y": "BedroomAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "YearRemodAdd",
"xref": "x",
"y": "BedroomAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "RoofStyle",
"xref": "x",
"y": "BedroomAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "RoofMatl",
"xref": "x",
"y": "BedroomAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "Exterior1st",
"xref": "x",
"y": "BedroomAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "Exterior2nd",
"xref": "x",
"y": "BedroomAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.09",
"x": "MasVnrType",
"xref": "x",
"y": "BedroomAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.11",
"x": "MasVnrArea",
"xref": "x",
"y": "BedroomAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "ExterQual",
"xref": "x",
"y": "BedroomAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "ExterCond",
"xref": "x",
"y": "BedroomAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "Foundation",
"xref": "x",
"y": "BedroomAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "BsmtQual",
"xref": "x",
"y": "BedroomAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "BsmtCond",
"xref": "x",
"y": "BedroomAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "BsmtExposure",
"xref": "x",
"y": "BedroomAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.11",
"x": "BsmtFinType1",
"xref": "x",
"y": "BedroomAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.12",
"x": "BsmtFinSF1",
"xref": "x",
"y": "BedroomAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "BsmtFinType2",
"xref": "x",
"y": "BedroomAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "BsmtFinSF2",
"xref": "x",
"y": "BedroomAbvGr",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.15",
"x": "BsmtUnfSF",
"xref": "x",
"y": "BedroomAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "TotalBsmtSF",
"xref": "x",
"y": "BedroomAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "Heating",
"xref": "x",
"y": "BedroomAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "HeatingQC",
"xref": "x",
"y": "BedroomAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "CentralAir",
"xref": "x",
"y": "BedroomAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "Electrical",
"xref": "x",
"y": "BedroomAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "1stFlrSF",
"xref": "x",
"y": "BedroomAbvGr",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.51",
"x": "2ndFlrSF",
"xref": "x",
"y": "BedroomAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "LowQualFinSF",
"xref": "x",
"y": "BedroomAbvGr",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.51",
"x": "GrLivArea",
"xref": "x",
"y": "BedroomAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.16",
"x": "BsmtFullBath",
"xref": "x",
"y": "BedroomAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "BsmtHalfBath",
"xref": "x",
"y": "BedroomAbvGr",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.36",
"x": "FullBath",
"xref": "x",
"y": "BedroomAbvGr",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.25",
"x": "HalfBath",
"xref": "x",
"y": "BedroomAbvGr",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "BedroomAbvGr",
"xref": "x",
"y": "BedroomAbvGr",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.17",
"x": "KitchenAbvGr",
"xref": "x",
"y": "BedroomAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "KitchenQual",
"xref": "x",
"y": "BedroomAbvGr",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.66",
"x": "TotRmsAbvGrd",
"xref": "x",
"y": "BedroomAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "Functional",
"xref": "x",
"y": "BedroomAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "Fireplaces",
"xref": "x",
"y": "BedroomAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "GarageType",
"xref": "x",
"y": "BedroomAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "GarageYrBlt",
"xref": "x",
"y": "BedroomAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "GarageFinish",
"xref": "x",
"y": "BedroomAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "GarageCars",
"xref": "x",
"y": "BedroomAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "GarageArea",
"xref": "x",
"y": "BedroomAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "GarageQual",
"xref": "x",
"y": "BedroomAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "GarageCond",
"xref": "x",
"y": "BedroomAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "PavedDrive",
"xref": "x",
"y": "BedroomAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "WoodDeckSF",
"xref": "x",
"y": "BedroomAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "OpenPorchSF",
"xref": "x",
"y": "BedroomAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "EnclosedPorch",
"xref": "x",
"y": "BedroomAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "3SsnPorch",
"xref": "x",
"y": "BedroomAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "ScreenPorch",
"xref": "x",
"y": "BedroomAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "PoolArea",
"xref": "x",
"y": "BedroomAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "MiscVal",
"xref": "x",
"y": "BedroomAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "MoSold",
"xref": "x",
"y": "BedroomAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "YrSold",
"xref": "x",
"y": "BedroomAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "SaleType",
"xref": "x",
"y": "BedroomAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "SaleCondition",
"xref": "x",
"y": "BedroomAbvGr",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.17",
"x": "SalePrice",
"xref": "x",
"y": "BedroomAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Id",
"xref": "x",
"y": "KitchenAbvGr",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.24",
"x": "MSSubClass",
"xref": "x",
"y": "KitchenAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "MSZoning",
"xref": "x",
"y": "KitchenAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "LotArea",
"xref": "x",
"y": "KitchenAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Street",
"xref": "x",
"y": "KitchenAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "LotShape",
"xref": "x",
"y": "KitchenAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "LandContour",
"xref": "x",
"y": "KitchenAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "Utilities",
"xref": "x",
"y": "KitchenAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "LotConfig",
"xref": "x",
"y": "KitchenAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "LandSlope",
"xref": "x",
"y": "KitchenAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "Neighborhood",
"xref": "x",
"y": "KitchenAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.09",
"x": "Condition1",
"xref": "x",
"y": "KitchenAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "Condition2",
"xref": "x",
"y": "KitchenAbvGr",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.13",
"x": "BldgType",
"xref": "x",
"y": "KitchenAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "HouseStyle",
"xref": "x",
"y": "KitchenAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.14",
"x": "OverallQual",
"xref": "x",
"y": "KitchenAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "OverallCond",
"xref": "x",
"y": "KitchenAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.18",
"x": "YearBuilt",
"xref": "x",
"y": "KitchenAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.15",
"x": "YearRemodAdd",
"xref": "x",
"y": "KitchenAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "RoofStyle",
"xref": "x",
"y": "KitchenAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "RoofMatl",
"xref": "x",
"y": "KitchenAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "Exterior1st",
"xref": "x",
"y": "KitchenAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "Exterior2nd",
"xref": "x",
"y": "KitchenAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "MasVnrType",
"xref": "x",
"y": "KitchenAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "MasVnrArea",
"xref": "x",
"y": "KitchenAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "ExterQual",
"xref": "x",
"y": "KitchenAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "ExterCond",
"xref": "x",
"y": "KitchenAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.09",
"x": "Foundation",
"xref": "x",
"y": "KitchenAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "BsmtQual",
"xref": "x",
"y": "KitchenAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "BsmtCond",
"xref": "x",
"y": "KitchenAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "BsmtExposure",
"xref": "x",
"y": "KitchenAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "BsmtFinType1",
"xref": "x",
"y": "KitchenAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "BsmtFinSF1",
"xref": "x",
"y": "KitchenAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "BsmtFinType2",
"xref": "x",
"y": "KitchenAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "BsmtFinSF2",
"xref": "x",
"y": "KitchenAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "BsmtUnfSF",
"xref": "x",
"y": "KitchenAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "TotalBsmtSF",
"xref": "x",
"y": "KitchenAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "Heating",
"xref": "x",
"y": "KitchenAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.13",
"x": "HeatingQC",
"xref": "x",
"y": "KitchenAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.23",
"x": "CentralAir",
"xref": "x",
"y": "KitchenAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.12",
"x": "Electrical",
"xref": "x",
"y": "KitchenAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "1stFlrSF",
"xref": "x",
"y": "KitchenAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "2ndFlrSF",
"xref": "x",
"y": "KitchenAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "LowQualFinSF",
"xref": "x",
"y": "KitchenAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "GrLivArea",
"xref": "x",
"y": "KitchenAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "BsmtFullBath",
"xref": "x",
"y": "KitchenAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "BsmtHalfBath",
"xref": "x",
"y": "KitchenAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "FullBath",
"xref": "x",
"y": "KitchenAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "HalfBath",
"xref": "x",
"y": "KitchenAbvGr",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.17",
"x": "BedroomAbvGr",
"xref": "x",
"y": "KitchenAbvGr",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "KitchenAbvGr",
"xref": "x",
"y": "KitchenAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "KitchenQual",
"xref": "x",
"y": "KitchenAbvGr",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.23",
"x": "TotRmsAbvGrd",
"xref": "x",
"y": "KitchenAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "Functional",
"xref": "x",
"y": "KitchenAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.09",
"x": "Fireplaces",
"xref": "x",
"y": "KitchenAbvGr",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "GarageType",
"xref": "x",
"y": "KitchenAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.13",
"x": "GarageYrBlt",
"xref": "x",
"y": "KitchenAbvGr",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "GarageFinish",
"xref": "x",
"y": "KitchenAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "GarageCars",
"xref": "x",
"y": "KitchenAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "GarageArea",
"xref": "x",
"y": "KitchenAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.12",
"x": "GarageQual",
"xref": "x",
"y": "KitchenAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.09",
"x": "GarageCond",
"xref": "x",
"y": "KitchenAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.15",
"x": "PavedDrive",
"xref": "x",
"y": "KitchenAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "WoodDeckSF",
"xref": "x",
"y": "KitchenAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "OpenPorchSF",
"xref": "x",
"y": "KitchenAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "EnclosedPorch",
"xref": "x",
"y": "KitchenAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "3SsnPorch",
"xref": "x",
"y": "KitchenAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "ScreenPorch",
"xref": "x",
"y": "KitchenAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "PoolArea",
"xref": "x",
"y": "KitchenAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "MiscVal",
"xref": "x",
"y": "KitchenAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "MoSold",
"xref": "x",
"y": "KitchenAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "YrSold",
"xref": "x",
"y": "KitchenAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "SaleType",
"xref": "x",
"y": "KitchenAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "SaleCondition",
"xref": "x",
"y": "KitchenAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.11",
"x": "SalePrice",
"xref": "x",
"y": "KitchenAbvGr",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "Id",
"xref": "x",
"y": "KitchenQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "MSSubClass",
"xref": "x",
"y": "KitchenQual",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "MSZoning",
"xref": "x",
"y": "KitchenQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "LotArea",
"xref": "x",
"y": "KitchenQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "Street",
"xref": "x",
"y": "KitchenQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "LotShape",
"xref": "x",
"y": "KitchenQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "LandContour",
"xref": "x",
"y": "KitchenQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "Utilities",
"xref": "x",
"y": "KitchenQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "LotConfig",
"xref": "x",
"y": "KitchenQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "LandSlope",
"xref": "x",
"y": "KitchenQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.14",
"x": "Neighborhood",
"xref": "x",
"y": "KitchenQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "Condition1",
"xref": "x",
"y": "KitchenQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "Condition2",
"xref": "x",
"y": "KitchenQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "BldgType",
"xref": "x",
"y": "KitchenQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "HouseStyle",
"xref": "x",
"y": "KitchenQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.61",
"x": "OverallQual",
"xref": "x",
"y": "KitchenQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "OverallCond",
"xref": "x",
"y": "KitchenQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.38",
"x": "YearBuilt",
"xref": "x",
"y": "KitchenQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.49",
"x": "YearRemodAdd",
"xref": "x",
"y": "KitchenQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.12",
"x": "RoofStyle",
"xref": "x",
"y": "KitchenQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "RoofMatl",
"xref": "x",
"y": "KitchenQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.13",
"x": "Exterior1st",
"xref": "x",
"y": "KitchenQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.12",
"x": "Exterior2nd",
"xref": "x",
"y": "KitchenQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.13",
"x": "MasVnrType",
"xref": "x",
"y": "KitchenQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.26",
"x": "MasVnrArea",
"xref": "x",
"y": "KitchenQual",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.65",
"x": "ExterQual",
"xref": "x",
"y": "KitchenQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "ExterCond",
"xref": "x",
"y": "KitchenQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.38",
"x": "Foundation",
"xref": "x",
"y": "KitchenQual",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.53",
"x": "BsmtQual",
"xref": "x",
"y": "KitchenQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "BsmtCond",
"xref": "x",
"y": "KitchenQual",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.21",
"x": "BsmtExposure",
"xref": "x",
"y": "KitchenQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "BsmtFinType1",
"xref": "x",
"y": "KitchenQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.19",
"x": "BsmtFinSF1",
"xref": "x",
"y": "KitchenQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "BsmtFinType2",
"xref": "x",
"y": "KitchenQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "BsmtFinSF2",
"xref": "x",
"y": "KitchenQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.21",
"x": "BsmtUnfSF",
"xref": "x",
"y": "KitchenQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.41",
"x": "TotalBsmtSF",
"xref": "x",
"y": "KitchenQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "Heating",
"xref": "x",
"y": "KitchenQual",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.4",
"x": "HeatingQC",
"xref": "x",
"y": "KitchenQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "CentralAir",
"xref": "x",
"y": "KitchenQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.11",
"x": "Electrical",
"xref": "x",
"y": "KitchenQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.38",
"x": "1stFlrSF",
"xref": "x",
"y": "KitchenQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.14",
"x": "2ndFlrSF",
"xref": "x",
"y": "KitchenQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "LowQualFinSF",
"xref": "x",
"y": "KitchenQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.4",
"x": "GrLivArea",
"xref": "x",
"y": "KitchenQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.13",
"x": "BsmtFullBath",
"xref": "x",
"y": "KitchenQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "BsmtHalfBath",
"xref": "x",
"y": "KitchenQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.36",
"x": "FullBath",
"xref": "x",
"y": "KitchenQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.14",
"x": "HalfBath",
"xref": "x",
"y": "KitchenQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "BedroomAbvGr",
"xref": "x",
"y": "KitchenQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "KitchenAbvGr",
"xref": "x",
"y": "KitchenQual",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "KitchenQual",
"xref": "x",
"y": "KitchenQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.29",
"x": "TotRmsAbvGrd",
"xref": "x",
"y": "KitchenQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "Functional",
"xref": "x",
"y": "KitchenQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.23",
"x": "Fireplaces",
"xref": "x",
"y": "KitchenQual",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.19",
"x": "GarageType",
"xref": "x",
"y": "KitchenQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.39",
"x": "GarageYrBlt",
"xref": "x",
"y": "KitchenQual",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.38",
"x": "GarageFinish",
"xref": "x",
"y": "KitchenQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.43",
"x": "GarageCars",
"xref": "x",
"y": "KitchenQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.42",
"x": "GarageArea",
"xref": "x",
"y": "KitchenQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "GarageQual",
"xref": "x",
"y": "KitchenQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "GarageCond",
"xref": "x",
"y": "KitchenQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "PavedDrive",
"xref": "x",
"y": "KitchenQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.16",
"x": "WoodDeckSF",
"xref": "x",
"y": "KitchenQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.24",
"x": "OpenPorchSF",
"xref": "x",
"y": "KitchenQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "EnclosedPorch",
"xref": "x",
"y": "KitchenQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "3SsnPorch",
"xref": "x",
"y": "KitchenQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "ScreenPorch",
"xref": "x",
"y": "KitchenQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "PoolArea",
"xref": "x",
"y": "KitchenQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "MiscVal",
"xref": "x",
"y": "KitchenQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "MoSold",
"xref": "x",
"y": "KitchenQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "YrSold",
"xref": "x",
"y": "KitchenQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "SaleType",
"xref": "x",
"y": "KitchenQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.14",
"x": "SaleCondition",
"xref": "x",
"y": "KitchenQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.62",
"x": "SalePrice",
"xref": "x",
"y": "KitchenQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "Id",
"xref": "x",
"y": "TotRmsAbvGrd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "MSSubClass",
"xref": "x",
"y": "TotRmsAbvGrd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "MSZoning",
"xref": "x",
"y": "TotRmsAbvGrd",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.19",
"x": "LotArea",
"xref": "x",
"y": "TotRmsAbvGrd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "Street",
"xref": "x",
"y": "TotRmsAbvGrd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.13",
"x": "LotShape",
"xref": "x",
"y": "TotRmsAbvGrd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "LandContour",
"xref": "x",
"y": "TotRmsAbvGrd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Utilities",
"xref": "x",
"y": "TotRmsAbvGrd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "LotConfig",
"xref": "x",
"y": "TotRmsAbvGrd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "LandSlope",
"xref": "x",
"y": "TotRmsAbvGrd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "Neighborhood",
"xref": "x",
"y": "TotRmsAbvGrd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "Condition1",
"xref": "x",
"y": "TotRmsAbvGrd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "Condition2",
"xref": "x",
"y": "TotRmsAbvGrd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.23",
"x": "BldgType",
"xref": "x",
"y": "TotRmsAbvGrd",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.26",
"x": "HouseStyle",
"xref": "x",
"y": "TotRmsAbvGrd",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.44",
"x": "OverallQual",
"xref": "x",
"y": "TotRmsAbvGrd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "OverallCond",
"xref": "x",
"y": "TotRmsAbvGrd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "YearBuilt",
"xref": "x",
"y": "TotRmsAbvGrd",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.17",
"x": "YearRemodAdd",
"xref": "x",
"y": "TotRmsAbvGrd",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.13",
"x": "RoofStyle",
"xref": "x",
"y": "TotRmsAbvGrd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "RoofMatl",
"xref": "x",
"y": "TotRmsAbvGrd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "Exterior1st",
"xref": "x",
"y": "TotRmsAbvGrd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "Exterior2nd",
"xref": "x",
"y": "TotRmsAbvGrd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "MasVnrType",
"xref": "x",
"y": "TotRmsAbvGrd",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.29",
"x": "MasVnrArea",
"xref": "x",
"y": "TotRmsAbvGrd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.31",
"x": "ExterQual",
"xref": "x",
"y": "TotRmsAbvGrd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "ExterCond",
"xref": "x",
"y": "TotRmsAbvGrd",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.15",
"x": "Foundation",
"xref": "x",
"y": "TotRmsAbvGrd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.27",
"x": "BsmtQual",
"xref": "x",
"y": "TotRmsAbvGrd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "BsmtCond",
"xref": "x",
"y": "TotRmsAbvGrd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "BsmtExposure",
"xref": "x",
"y": "TotRmsAbvGrd",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.15",
"x": "BsmtFinType1",
"xref": "x",
"y": "TotRmsAbvGrd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "BsmtFinSF1",
"xref": "x",
"y": "TotRmsAbvGrd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "BsmtFinType2",
"xref": "x",
"y": "TotRmsAbvGrd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "BsmtFinSF2",
"xref": "x",
"y": "TotRmsAbvGrd",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.24",
"x": "BsmtUnfSF",
"xref": "x",
"y": "TotRmsAbvGrd",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.3",
"x": "TotalBsmtSF",
"xref": "x",
"y": "TotRmsAbvGrd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Heating",
"xref": "x",
"y": "TotRmsAbvGrd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.18",
"x": "HeatingQC",
"xref": "x",
"y": "TotRmsAbvGrd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "CentralAir",
"xref": "x",
"y": "TotRmsAbvGrd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "Electrical",
"xref": "x",
"y": "TotRmsAbvGrd",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.39",
"x": "1stFlrSF",
"xref": "x",
"y": "TotRmsAbvGrd",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.62",
"x": "2ndFlrSF",
"xref": "x",
"y": "TotRmsAbvGrd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "LowQualFinSF",
"xref": "x",
"y": "TotRmsAbvGrd",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.82",
"x": "GrLivArea",
"xref": "x",
"y": "TotRmsAbvGrd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "BsmtFullBath",
"xref": "x",
"y": "TotRmsAbvGrd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "BsmtHalfBath",
"xref": "x",
"y": "TotRmsAbvGrd",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.55",
"x": "FullBath",
"xref": "x",
"y": "TotRmsAbvGrd",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.36",
"x": "HalfBath",
"xref": "x",
"y": "TotRmsAbvGrd",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.66",
"x": "BedroomAbvGr",
"xref": "x",
"y": "TotRmsAbvGrd",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.23",
"x": "KitchenAbvGr",
"xref": "x",
"y": "TotRmsAbvGrd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.29",
"x": "KitchenQual",
"xref": "x",
"y": "TotRmsAbvGrd",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "TotRmsAbvGrd",
"xref": "x",
"y": "TotRmsAbvGrd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "Functional",
"xref": "x",
"y": "TotRmsAbvGrd",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.33",
"x": "Fireplaces",
"xref": "x",
"y": "TotRmsAbvGrd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.11",
"x": "GarageType",
"xref": "x",
"y": "TotRmsAbvGrd",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.15",
"x": "GarageYrBlt",
"xref": "x",
"y": "TotRmsAbvGrd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.25",
"x": "GarageFinish",
"xref": "x",
"y": "TotRmsAbvGrd",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.4",
"x": "GarageCars",
"xref": "x",
"y": "TotRmsAbvGrd",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.37",
"x": "GarageArea",
"xref": "x",
"y": "TotRmsAbvGrd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "GarageQual",
"xref": "x",
"y": "TotRmsAbvGrd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "GarageCond",
"xref": "x",
"y": "TotRmsAbvGrd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "PavedDrive",
"xref": "x",
"y": "TotRmsAbvGrd",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.17",
"x": "WoodDeckSF",
"xref": "x",
"y": "TotRmsAbvGrd",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.25",
"x": "OpenPorchSF",
"xref": "x",
"y": "TotRmsAbvGrd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "EnclosedPorch",
"xref": "x",
"y": "TotRmsAbvGrd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "3SsnPorch",
"xref": "x",
"y": "TotRmsAbvGrd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "ScreenPorch",
"xref": "x",
"y": "TotRmsAbvGrd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "PoolArea",
"xref": "x",
"y": "TotRmsAbvGrd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "MiscVal",
"xref": "x",
"y": "TotRmsAbvGrd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "MoSold",
"xref": "x",
"y": "TotRmsAbvGrd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "YrSold",
"xref": "x",
"y": "TotRmsAbvGrd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "SaleType",
"xref": "x",
"y": "TotRmsAbvGrd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "SaleCondition",
"xref": "x",
"y": "TotRmsAbvGrd",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.55",
"x": "SalePrice",
"xref": "x",
"y": "TotRmsAbvGrd",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "Id",
"xref": "x",
"y": "Functional",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "MSSubClass",
"xref": "x",
"y": "Functional",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "MSZoning",
"xref": "x",
"y": "Functional",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "LotArea",
"xref": "x",
"y": "Functional",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "Street",
"xref": "x",
"y": "Functional",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "LotShape",
"xref": "x",
"y": "Functional",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "LandContour",
"xref": "x",
"y": "Functional",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Utilities",
"xref": "x",
"y": "Functional",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "LotConfig",
"xref": "x",
"y": "Functional",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "LandSlope",
"xref": "x",
"y": "Functional",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "Neighborhood",
"xref": "x",
"y": "Functional",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "Condition1",
"xref": "x",
"y": "Functional",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Condition2",
"xref": "x",
"y": "Functional",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "BldgType",
"xref": "x",
"y": "Functional",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "HouseStyle",
"xref": "x",
"y": "Functional",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.13",
"x": "OverallQual",
"xref": "x",
"y": "Functional",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "OverallCond",
"xref": "x",
"y": "Functional",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.15",
"x": "YearBuilt",
"xref": "x",
"y": "Functional",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "YearRemodAdd",
"xref": "x",
"y": "Functional",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "RoofStyle",
"xref": "x",
"y": "Functional",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "RoofMatl",
"xref": "x",
"y": "Functional",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "Exterior1st",
"xref": "x",
"y": "Functional",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Exterior2nd",
"xref": "x",
"y": "Functional",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "MasVnrType",
"xref": "x",
"y": "Functional",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "MasVnrArea",
"xref": "x",
"y": "Functional",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "ExterQual",
"xref": "x",
"y": "Functional",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "ExterCond",
"xref": "x",
"y": "Functional",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "Foundation",
"xref": "x",
"y": "Functional",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "BsmtQual",
"xref": "x",
"y": "Functional",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "BsmtCond",
"xref": "x",
"y": "Functional",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "BsmtExposure",
"xref": "x",
"y": "Functional",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "BsmtFinType1",
"xref": "x",
"y": "Functional",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "BsmtFinSF1",
"xref": "x",
"y": "Functional",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "BsmtFinType2",
"xref": "x",
"y": "Functional",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.11",
"x": "BsmtFinSF2",
"xref": "x",
"y": "Functional",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "BsmtUnfSF",
"xref": "x",
"y": "Functional",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "TotalBsmtSF",
"xref": "x",
"y": "Functional",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "Heating",
"xref": "x",
"y": "Functional",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "HeatingQC",
"xref": "x",
"y": "Functional",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "CentralAir",
"xref": "x",
"y": "Functional",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "Electrical",
"xref": "x",
"y": "Functional",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "1stFlrSF",
"xref": "x",
"y": "Functional",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "2ndFlrSF",
"xref": "x",
"y": "Functional",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "LowQualFinSF",
"xref": "x",
"y": "Functional",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "GrLivArea",
"xref": "x",
"y": "Functional",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "BsmtFullBath",
"xref": "x",
"y": "Functional",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "BsmtHalfBath",
"xref": "x",
"y": "Functional",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "FullBath",
"xref": "x",
"y": "Functional",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "HalfBath",
"xref": "x",
"y": "Functional",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "BedroomAbvGr",
"xref": "x",
"y": "Functional",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "KitchenAbvGr",
"xref": "x",
"y": "Functional",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "KitchenQual",
"xref": "x",
"y": "Functional",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "TotRmsAbvGrd",
"xref": "x",
"y": "Functional",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "Functional",
"xref": "x",
"y": "Functional",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "Fireplaces",
"xref": "x",
"y": "Functional",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "GarageType",
"xref": "x",
"y": "Functional",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.13",
"x": "GarageYrBlt",
"xref": "x",
"y": "Functional",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.11",
"x": "GarageFinish",
"xref": "x",
"y": "Functional",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "GarageCars",
"xref": "x",
"y": "Functional",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "GarageArea",
"xref": "x",
"y": "Functional",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "GarageQual",
"xref": "x",
"y": "Functional",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "GarageCond",
"xref": "x",
"y": "Functional",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "PavedDrive",
"xref": "x",
"y": "Functional",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "WoodDeckSF",
"xref": "x",
"y": "Functional",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "OpenPorchSF",
"xref": "x",
"y": "Functional",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "EnclosedPorch",
"xref": "x",
"y": "Functional",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "3SsnPorch",
"xref": "x",
"y": "Functional",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "ScreenPorch",
"xref": "x",
"y": "Functional",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "PoolArea",
"xref": "x",
"y": "Functional",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "MiscVal",
"xref": "x",
"y": "Functional",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "MoSold",
"xref": "x",
"y": "Functional",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "YrSold",
"xref": "x",
"y": "Functional",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "SaleType",
"xref": "x",
"y": "Functional",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "SaleCondition",
"xref": "x",
"y": "Functional",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.11",
"x": "SalePrice",
"xref": "x",
"y": "Functional",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "Id",
"xref": "x",
"y": "Fireplaces",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "MSSubClass",
"xref": "x",
"y": "Fireplaces",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "MSZoning",
"xref": "x",
"y": "Fireplaces",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.26",
"x": "LotArea",
"xref": "x",
"y": "Fireplaces",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "Street",
"xref": "x",
"y": "Fireplaces",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.19",
"x": "LotShape",
"xref": "x",
"y": "Fireplaces",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "LandContour",
"xref": "x",
"y": "Fireplaces",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Utilities",
"xref": "x",
"y": "Fireplaces",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "LotConfig",
"xref": "x",
"y": "Fireplaces",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "LandSlope",
"xref": "x",
"y": "Fireplaces",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "Neighborhood",
"xref": "x",
"y": "Fireplaces",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "Condition1",
"xref": "x",
"y": "Fireplaces",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "Condition2",
"xref": "x",
"y": "Fireplaces",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "BldgType",
"xref": "x",
"y": "Fireplaces",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "HouseStyle",
"xref": "x",
"y": "Fireplaces",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.38",
"x": "OverallQual",
"xref": "x",
"y": "Fireplaces",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "OverallCond",
"xref": "x",
"y": "Fireplaces",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.11",
"x": "YearBuilt",
"xref": "x",
"y": "Fireplaces",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "YearRemodAdd",
"xref": "x",
"y": "Fireplaces",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "RoofStyle",
"xref": "x",
"y": "Fireplaces",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "RoofMatl",
"xref": "x",
"y": "Fireplaces",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "Exterior1st",
"xref": "x",
"y": "Fireplaces",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Exterior2nd",
"xref": "x",
"y": "Fireplaces",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "MasVnrType",
"xref": "x",
"y": "Fireplaces",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.23",
"x": "MasVnrArea",
"xref": "x",
"y": "Fireplaces",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.21",
"x": "ExterQual",
"xref": "x",
"y": "Fireplaces",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "ExterCond",
"xref": "x",
"y": "Fireplaces",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "Foundation",
"xref": "x",
"y": "Fireplaces",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.19",
"x": "BsmtQual",
"xref": "x",
"y": "Fireplaces",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "BsmtCond",
"xref": "x",
"y": "Fireplaces",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.11",
"x": "BsmtExposure",
"xref": "x",
"y": "Fireplaces",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.09",
"x": "BsmtFinType1",
"xref": "x",
"y": "Fireplaces",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.25",
"x": "BsmtFinSF1",
"xref": "x",
"y": "Fireplaces",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "BsmtFinType2",
"xref": "x",
"y": "Fireplaces",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "BsmtFinSF2",
"xref": "x",
"y": "Fireplaces",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "BsmtUnfSF",
"xref": "x",
"y": "Fireplaces",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.33",
"x": "TotalBsmtSF",
"xref": "x",
"y": "Fireplaces",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "Heating",
"xref": "x",
"y": "Fireplaces",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.11",
"x": "HeatingQC",
"xref": "x",
"y": "Fireplaces",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "CentralAir",
"xref": "x",
"y": "Fireplaces",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "Electrical",
"xref": "x",
"y": "Fireplaces",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.4",
"x": "1stFlrSF",
"xref": "x",
"y": "Fireplaces",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.19",
"x": "2ndFlrSF",
"xref": "x",
"y": "Fireplaces",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "LowQualFinSF",
"xref": "x",
"y": "Fireplaces",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.46",
"x": "GrLivArea",
"xref": "x",
"y": "Fireplaces",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.13",
"x": "BsmtFullBath",
"xref": "x",
"y": "Fireplaces",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "BsmtHalfBath",
"xref": "x",
"y": "Fireplaces",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.24",
"x": "FullBath",
"xref": "x",
"y": "Fireplaces",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.19",
"x": "HalfBath",
"xref": "x",
"y": "Fireplaces",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "BedroomAbvGr",
"xref": "x",
"y": "Fireplaces",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.09",
"x": "KitchenAbvGr",
"xref": "x",
"y": "Fireplaces",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.23",
"x": "KitchenQual",
"xref": "x",
"y": "Fireplaces",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.33",
"x": "TotRmsAbvGrd",
"xref": "x",
"y": "Fireplaces",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "Functional",
"xref": "x",
"y": "Fireplaces",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "Fireplaces",
"xref": "x",
"y": "Fireplaces",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.26",
"x": "GarageType",
"xref": "x",
"y": "Fireplaces",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "GarageYrBlt",
"xref": "x",
"y": "Fireplaces",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.27",
"x": "GarageFinish",
"xref": "x",
"y": "Fireplaces",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.25",
"x": "GarageCars",
"xref": "x",
"y": "Fireplaces",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.2",
"x": "GarageArea",
"xref": "x",
"y": "Fireplaces",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "GarageQual",
"xref": "x",
"y": "Fireplaces",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "GarageCond",
"xref": "x",
"y": "Fireplaces",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "PavedDrive",
"xref": "x",
"y": "Fireplaces",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.18",
"x": "WoodDeckSF",
"xref": "x",
"y": "Fireplaces",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.17",
"x": "OpenPorchSF",
"xref": "x",
"y": "Fireplaces",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "EnclosedPorch",
"xref": "x",
"y": "Fireplaces",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "3SsnPorch",
"xref": "x",
"y": "Fireplaces",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.18",
"x": "ScreenPorch",
"xref": "x",
"y": "Fireplaces",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "PoolArea",
"xref": "x",
"y": "Fireplaces",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "MiscVal",
"xref": "x",
"y": "Fireplaces",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "MoSold",
"xref": "x",
"y": "Fireplaces",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "YrSold",
"xref": "x",
"y": "Fireplaces",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "SaleType",
"xref": "x",
"y": "Fireplaces",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "SaleCondition",
"xref": "x",
"y": "Fireplaces",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.45",
"x": "SalePrice",
"xref": "x",
"y": "Fireplaces",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "Id",
"xref": "x",
"y": "GarageType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "MSSubClass",
"xref": "x",
"y": "GarageType",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.13",
"x": "MSZoning",
"xref": "x",
"y": "GarageType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.13",
"x": "LotArea",
"xref": "x",
"y": "GarageType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "Street",
"xref": "x",
"y": "GarageType",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.18",
"x": "LotShape",
"xref": "x",
"y": "GarageType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "LandContour",
"xref": "x",
"y": "GarageType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "Utilities",
"xref": "x",
"y": "GarageType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "LotConfig",
"xref": "x",
"y": "GarageType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "LandSlope",
"xref": "x",
"y": "GarageType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "Neighborhood",
"xref": "x",
"y": "GarageType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "Condition1",
"xref": "x",
"y": "GarageType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "Condition2",
"xref": "x",
"y": "GarageType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "BldgType",
"xref": "x",
"y": "GarageType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "HouseStyle",
"xref": "x",
"y": "GarageType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.35",
"x": "OverallQual",
"xref": "x",
"y": "GarageType",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.19",
"x": "OverallCond",
"xref": "x",
"y": "GarageType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.52",
"x": "YearBuilt",
"xref": "x",
"y": "GarageType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.29",
"x": "YearRemodAdd",
"xref": "x",
"y": "GarageType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "RoofStyle",
"xref": "x",
"y": "GarageType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "RoofMatl",
"xref": "x",
"y": "GarageType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "Exterior1st",
"xref": "x",
"y": "GarageType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "Exterior2nd",
"xref": "x",
"y": "GarageType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.13",
"x": "MasVnrType",
"xref": "x",
"y": "GarageType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.18",
"x": "MasVnrArea",
"xref": "x",
"y": "GarageType",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.24",
"x": "ExterQual",
"xref": "x",
"y": "GarageType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.13",
"x": "ExterCond",
"xref": "x",
"y": "GarageType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.39",
"x": "Foundation",
"xref": "x",
"y": "GarageType",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.25",
"x": "BsmtQual",
"xref": "x",
"y": "GarageType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.09",
"x": "BsmtCond",
"xref": "x",
"y": "GarageType",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.21",
"x": "BsmtExposure",
"xref": "x",
"y": "GarageType",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.17",
"x": "BsmtFinType1",
"xref": "x",
"y": "GarageType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.25",
"x": "BsmtFinSF1",
"xref": "x",
"y": "GarageType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "BsmtFinType2",
"xref": "x",
"y": "GarageType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "BsmtFinSF2",
"xref": "x",
"y": "GarageType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "BsmtUnfSF",
"xref": "x",
"y": "GarageType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.36",
"x": "TotalBsmtSF",
"xref": "x",
"y": "GarageType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.13",
"x": "Heating",
"xref": "x",
"y": "GarageType",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.19",
"x": "HeatingQC",
"xref": "x",
"y": "GarageType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.25",
"x": "CentralAir",
"xref": "x",
"y": "GarageType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.17",
"x": "Electrical",
"xref": "x",
"y": "GarageType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.36",
"x": "1stFlrSF",
"xref": "x",
"y": "GarageType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "2ndFlrSF",
"xref": "x",
"y": "GarageType",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "LowQualFinSF",
"xref": "x",
"y": "GarageType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.18",
"x": "GrLivArea",
"xref": "x",
"y": "GarageType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.17",
"x": "BsmtFullBath",
"xref": "x",
"y": "GarageType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "BsmtHalfBath",
"xref": "x",
"y": "GarageType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.3",
"x": "FullBath",
"xref": "x",
"y": "GarageType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.09",
"x": "HalfBath",
"xref": "x",
"y": "GarageType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "BedroomAbvGr",
"xref": "x",
"y": "GarageType",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "KitchenAbvGr",
"xref": "x",
"y": "GarageType",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.19",
"x": "KitchenQual",
"xref": "x",
"y": "GarageType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.11",
"x": "TotRmsAbvGrd",
"xref": "x",
"y": "GarageType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "Functional",
"xref": "x",
"y": "GarageType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.26",
"x": "Fireplaces",
"xref": "x",
"y": "GarageType",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "GarageType",
"xref": "x",
"y": "GarageType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.35",
"x": "GarageYrBlt",
"xref": "x",
"y": "GarageType",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.48",
"x": "GarageFinish",
"xref": "x",
"y": "GarageType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.26",
"x": "GarageCars",
"xref": "x",
"y": "GarageType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.23",
"x": "GarageArea",
"xref": "x",
"y": "GarageType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.22",
"x": "GarageQual",
"xref": "x",
"y": "GarageType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.21",
"x": "GarageCond",
"xref": "x",
"y": "GarageType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.27",
"x": "PavedDrive",
"xref": "x",
"y": "GarageType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.21",
"x": "WoodDeckSF",
"xref": "x",
"y": "GarageType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.13",
"x": "OpenPorchSF",
"xref": "x",
"y": "GarageType",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.2",
"x": "EnclosedPorch",
"xref": "x",
"y": "GarageType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "3SsnPorch",
"xref": "x",
"y": "GarageType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "ScreenPorch",
"xref": "x",
"y": "GarageType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "PoolArea",
"xref": "x",
"y": "GarageType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "MiscVal",
"xref": "x",
"y": "GarageType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "MoSold",
"xref": "x",
"y": "GarageType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "YrSold",
"xref": "x",
"y": "GarageType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "SaleType",
"xref": "x",
"y": "GarageType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "SaleCondition",
"xref": "x",
"y": "GarageType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.35",
"x": "SalePrice",
"xref": "x",
"y": "GarageType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "Id",
"xref": "x",
"y": "GarageYrBlt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "MSSubClass",
"xref": "x",
"y": "GarageYrBlt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.27",
"x": "MSZoning",
"xref": "x",
"y": "GarageYrBlt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "LotArea",
"xref": "x",
"y": "GarageYrBlt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "Street",
"xref": "x",
"y": "GarageYrBlt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.19",
"x": "LotShape",
"xref": "x",
"y": "GarageYrBlt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.13",
"x": "LandContour",
"xref": "x",
"y": "GarageYrBlt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "Utilities",
"xref": "x",
"y": "GarageYrBlt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "LotConfig",
"xref": "x",
"y": "GarageYrBlt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "LandSlope",
"xref": "x",
"y": "GarageYrBlt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.11",
"x": "Neighborhood",
"xref": "x",
"y": "GarageYrBlt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.15",
"x": "Condition1",
"xref": "x",
"y": "GarageYrBlt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "Condition2",
"xref": "x",
"y": "GarageYrBlt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.21",
"x": "BldgType",
"xref": "x",
"y": "GarageYrBlt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.21",
"x": "HouseStyle",
"xref": "x",
"y": "GarageYrBlt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.55",
"x": "OverallQual",
"xref": "x",
"y": "GarageYrBlt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.34",
"x": "OverallCond",
"xref": "x",
"y": "GarageYrBlt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.83",
"x": "YearBuilt",
"xref": "x",
"y": "GarageYrBlt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.64",
"x": "YearRemodAdd",
"xref": "x",
"y": "GarageYrBlt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "RoofStyle",
"xref": "x",
"y": "GarageYrBlt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "RoofMatl",
"xref": "x",
"y": "GarageYrBlt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.18",
"x": "Exterior1st",
"xref": "x",
"y": "GarageYrBlt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.16",
"x": "Exterior2nd",
"xref": "x",
"y": "GarageYrBlt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "MasVnrType",
"xref": "x",
"y": "GarageYrBlt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.25",
"x": "MasVnrArea",
"xref": "x",
"y": "GarageYrBlt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.52",
"x": "ExterQual",
"xref": "x",
"y": "GarageYrBlt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.2",
"x": "ExterCond",
"xref": "x",
"y": "GarageYrBlt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.66",
"x": "Foundation",
"xref": "x",
"y": "GarageYrBlt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.53",
"x": "BsmtQual",
"xref": "x",
"y": "GarageYrBlt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "BsmtCond",
"xref": "x",
"y": "GarageYrBlt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.26",
"x": "BsmtExposure",
"xref": "x",
"y": "GarageYrBlt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "BsmtFinType1",
"xref": "x",
"y": "GarageYrBlt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "BsmtFinSF1",
"xref": "x",
"y": "GarageYrBlt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "BsmtFinType2",
"xref": "x",
"y": "GarageYrBlt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.09",
"x": "BsmtFinSF2",
"xref": "x",
"y": "GarageYrBlt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.18",
"x": "BsmtUnfSF",
"xref": "x",
"y": "GarageYrBlt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.32",
"x": "TotalBsmtSF",
"xref": "x",
"y": "GarageYrBlt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.18",
"x": "Heating",
"xref": "x",
"y": "GarageYrBlt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.42",
"x": "HeatingQC",
"xref": "x",
"y": "GarageYrBlt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.32",
"x": "CentralAir",
"xref": "x",
"y": "GarageYrBlt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.31",
"x": "Electrical",
"xref": "x",
"y": "GarageYrBlt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.24",
"x": "1stFlrSF",
"xref": "x",
"y": "GarageYrBlt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "2ndFlrSF",
"xref": "x",
"y": "GarageYrBlt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "LowQualFinSF",
"xref": "x",
"y": "GarageYrBlt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.22",
"x": "GrLivArea",
"xref": "x",
"y": "GarageYrBlt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "BsmtFullBath",
"xref": "x",
"y": "GarageYrBlt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "BsmtHalfBath",
"xref": "x",
"y": "GarageYrBlt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.49",
"x": "FullBath",
"xref": "x",
"y": "GarageYrBlt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.19",
"x": "HalfBath",
"xref": "x",
"y": "GarageYrBlt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "BedroomAbvGr",
"xref": "x",
"y": "GarageYrBlt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.13",
"x": "KitchenAbvGr",
"xref": "x",
"y": "GarageYrBlt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.39",
"x": "KitchenQual",
"xref": "x",
"y": "GarageYrBlt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.15",
"x": "TotRmsAbvGrd",
"xref": "x",
"y": "GarageYrBlt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.13",
"x": "Functional",
"xref": "x",
"y": "GarageYrBlt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "Fireplaces",
"xref": "x",
"y": "GarageYrBlt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.35",
"x": "GarageType",
"xref": "x",
"y": "GarageYrBlt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "GarageYrBlt",
"xref": "x",
"y": "GarageYrBlt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.52",
"x": "GarageFinish",
"xref": "x",
"y": "GarageYrBlt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.59",
"x": "GarageCars",
"xref": "x",
"y": "GarageYrBlt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.56",
"x": "GarageArea",
"xref": "x",
"y": "GarageYrBlt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.31",
"x": "GarageQual",
"xref": "x",
"y": "GarageYrBlt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.26",
"x": "GarageCond",
"xref": "x",
"y": "GarageYrBlt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.31",
"x": "PavedDrive",
"xref": "x",
"y": "GarageYrBlt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.22",
"x": "WoodDeckSF",
"xref": "x",
"y": "GarageYrBlt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.22",
"x": "OpenPorchSF",
"xref": "x",
"y": "GarageYrBlt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.3",
"x": "EnclosedPorch",
"xref": "x",
"y": "GarageYrBlt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "3SsnPorch",
"xref": "x",
"y": "GarageYrBlt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "ScreenPorch",
"xref": "x",
"y": "GarageYrBlt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "PoolArea",
"xref": "x",
"y": "GarageYrBlt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "MiscVal",
"xref": "x",
"y": "GarageYrBlt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "MoSold",
"xref": "x",
"y": "GarageYrBlt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "YrSold",
"xref": "x",
"y": "GarageYrBlt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "SaleType",
"xref": "x",
"y": "GarageYrBlt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.21",
"x": "SaleCondition",
"xref": "x",
"y": "GarageYrBlt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.48",
"x": "SalePrice",
"xref": "x",
"y": "GarageYrBlt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "Id",
"xref": "x",
"y": "GarageFinish",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "MSSubClass",
"xref": "x",
"y": "GarageFinish",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.16",
"x": "MSZoning",
"xref": "x",
"y": "GarageFinish",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "LotArea",
"xref": "x",
"y": "GarageFinish",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "Street",
"xref": "x",
"y": "GarageFinish",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.23",
"x": "LotShape",
"xref": "x",
"y": "GarageFinish",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "LandContour",
"xref": "x",
"y": "GarageFinish",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "Utilities",
"xref": "x",
"y": "GarageFinish",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "LotConfig",
"xref": "x",
"y": "GarageFinish",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "LandSlope",
"xref": "x",
"y": "GarageFinish",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "Neighborhood",
"xref": "x",
"y": "GarageFinish",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.13",
"x": "Condition1",
"xref": "x",
"y": "GarageFinish",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "Condition2",
"xref": "x",
"y": "GarageFinish",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "BldgType",
"xref": "x",
"y": "GarageFinish",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.21",
"x": "HouseStyle",
"xref": "x",
"y": "GarageFinish",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.52",
"x": "OverallQual",
"xref": "x",
"y": "GarageFinish",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.22",
"x": "OverallCond",
"xref": "x",
"y": "GarageFinish",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.58",
"x": "YearBuilt",
"xref": "x",
"y": "GarageFinish",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.45",
"x": "YearRemodAdd",
"xref": "x",
"y": "GarageFinish",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.13",
"x": "RoofStyle",
"xref": "x",
"y": "GarageFinish",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "RoofMatl",
"xref": "x",
"y": "GarageFinish",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "Exterior1st",
"xref": "x",
"y": "GarageFinish",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "Exterior2nd",
"xref": "x",
"y": "GarageFinish",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "MasVnrType",
"xref": "x",
"y": "GarageFinish",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.25",
"x": "MasVnrArea",
"xref": "x",
"y": "GarageFinish",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.45",
"x": "ExterQual",
"xref": "x",
"y": "GarageFinish",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.14",
"x": "ExterCond",
"xref": "x",
"y": "GarageFinish",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.48",
"x": "Foundation",
"xref": "x",
"y": "GarageFinish",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.45",
"x": "BsmtQual",
"xref": "x",
"y": "GarageFinish",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "BsmtCond",
"xref": "x",
"y": "GarageFinish",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.23",
"x": "BsmtExposure",
"xref": "x",
"y": "GarageFinish",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "BsmtFinType1",
"xref": "x",
"y": "GarageFinish",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.22",
"x": "BsmtFinSF1",
"xref": "x",
"y": "GarageFinish",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "BsmtFinType2",
"xref": "x",
"y": "GarageFinish",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "BsmtFinSF2",
"xref": "x",
"y": "GarageFinish",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "BsmtUnfSF",
"xref": "x",
"y": "GarageFinish",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.34",
"x": "TotalBsmtSF",
"xref": "x",
"y": "GarageFinish",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "Heating",
"xref": "x",
"y": "GarageFinish",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.38",
"x": "HeatingQC",
"xref": "x",
"y": "GarageFinish",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.21",
"x": "CentralAir",
"xref": "x",
"y": "GarageFinish",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.21",
"x": "Electrical",
"xref": "x",
"y": "GarageFinish",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.31",
"x": "1stFlrSF",
"xref": "x",
"y": "GarageFinish",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.13",
"x": "2ndFlrSF",
"xref": "x",
"y": "GarageFinish",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "LowQualFinSF",
"xref": "x",
"y": "GarageFinish",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.33",
"x": "GrLivArea",
"xref": "x",
"y": "GarageFinish",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.15",
"x": "BsmtFullBath",
"xref": "x",
"y": "GarageFinish",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "BsmtHalfBath",
"xref": "x",
"y": "GarageFinish",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.42",
"x": "FullBath",
"xref": "x",
"y": "GarageFinish",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.21",
"x": "HalfBath",
"xref": "x",
"y": "GarageFinish",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "BedroomAbvGr",
"xref": "x",
"y": "GarageFinish",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "KitchenAbvGr",
"xref": "x",
"y": "GarageFinish",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.38",
"x": "KitchenQual",
"xref": "x",
"y": "GarageFinish",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.25",
"x": "TotRmsAbvGrd",
"xref": "x",
"y": "GarageFinish",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.11",
"x": "Functional",
"xref": "x",
"y": "GarageFinish",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.27",
"x": "Fireplaces",
"xref": "x",
"y": "GarageFinish",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.48",
"x": "GarageType",
"xref": "x",
"y": "GarageFinish",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.52",
"x": "GarageYrBlt",
"xref": "x",
"y": "GarageFinish",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "GarageFinish",
"xref": "x",
"y": "GarageFinish",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.43",
"x": "GarageCars",
"xref": "x",
"y": "GarageFinish",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.36",
"x": "GarageArea",
"xref": "x",
"y": "GarageFinish",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.18",
"x": "GarageQual",
"xref": "x",
"y": "GarageFinish",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.14",
"x": "GarageCond",
"xref": "x",
"y": "GarageFinish",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.2",
"x": "PavedDrive",
"xref": "x",
"y": "GarageFinish",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.23",
"x": "WoodDeckSF",
"xref": "x",
"y": "GarageFinish",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.21",
"x": "OpenPorchSF",
"xref": "x",
"y": "GarageFinish",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.19",
"x": "EnclosedPorch",
"xref": "x",
"y": "GarageFinish",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "3SsnPorch",
"xref": "x",
"y": "GarageFinish",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "ScreenPorch",
"xref": "x",
"y": "GarageFinish",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "PoolArea",
"xref": "x",
"y": "GarageFinish",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "MiscVal",
"xref": "x",
"y": "GarageFinish",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "MoSold",
"xref": "x",
"y": "GarageFinish",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "YrSold",
"xref": "x",
"y": "GarageFinish",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "SaleType",
"xref": "x",
"y": "GarageFinish",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.15",
"x": "SaleCondition",
"xref": "x",
"y": "GarageFinish",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.51",
"x": "SalePrice",
"xref": "x",
"y": "GarageFinish",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Id",
"xref": "x",
"y": "GarageCars",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "MSSubClass",
"xref": "x",
"y": "GarageCars",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.16",
"x": "MSZoning",
"xref": "x",
"y": "GarageCars",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "LotArea",
"xref": "x",
"y": "GarageCars",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "Street",
"xref": "x",
"y": "GarageCars",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.18",
"x": "LotShape",
"xref": "x",
"y": "GarageCars",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "LandContour",
"xref": "x",
"y": "GarageCars",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Utilities",
"xref": "x",
"y": "GarageCars",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "LotConfig",
"xref": "x",
"y": "GarageCars",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "LandSlope",
"xref": "x",
"y": "GarageCars",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.18",
"x": "Neighborhood",
"xref": "x",
"y": "GarageCars",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "Condition1",
"xref": "x",
"y": "GarageCars",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "Condition2",
"xref": "x",
"y": "GarageCars",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "BldgType",
"xref": "x",
"y": "GarageCars",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.19",
"x": "HouseStyle",
"xref": "x",
"y": "GarageCars",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.59",
"x": "OverallQual",
"xref": "x",
"y": "GarageCars",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.25",
"x": "OverallCond",
"xref": "x",
"y": "GarageCars",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.52",
"x": "YearBuilt",
"xref": "x",
"y": "GarageCars",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.46",
"x": "YearRemodAdd",
"xref": "x",
"y": "GarageCars",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.13",
"x": "RoofStyle",
"xref": "x",
"y": "GarageCars",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "RoofMatl",
"xref": "x",
"y": "GarageCars",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.15",
"x": "Exterior1st",
"xref": "x",
"y": "GarageCars",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.15",
"x": "Exterior2nd",
"xref": "x",
"y": "GarageCars",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "MasVnrType",
"xref": "x",
"y": "GarageCars",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.36",
"x": "MasVnrArea",
"xref": "x",
"y": "GarageCars",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.49",
"x": "ExterQual",
"xref": "x",
"y": "GarageCars",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.15",
"x": "ExterCond",
"xref": "x",
"y": "GarageCars",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.44",
"x": "Foundation",
"xref": "x",
"y": "GarageCars",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.52",
"x": "BsmtQual",
"xref": "x",
"y": "GarageCars",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "BsmtCond",
"xref": "x",
"y": "GarageCars",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.25",
"x": "BsmtExposure",
"xref": "x",
"y": "GarageCars",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "BsmtFinType1",
"xref": "x",
"y": "GarageCars",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.2",
"x": "BsmtFinSF1",
"xref": "x",
"y": "GarageCars",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "BsmtFinType2",
"xref": "x",
"y": "GarageCars",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "BsmtFinSF2",
"xref": "x",
"y": "GarageCars",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.24",
"x": "BsmtUnfSF",
"xref": "x",
"y": "GarageCars",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.45",
"x": "TotalBsmtSF",
"xref": "x",
"y": "GarageCars",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "Heating",
"xref": "x",
"y": "GarageCars",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.32",
"x": "HeatingQC",
"xref": "x",
"y": "GarageCars",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.13",
"x": "CentralAir",
"xref": "x",
"y": "GarageCars",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.24",
"x": "Electrical",
"xref": "x",
"y": "GarageCars",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.44",
"x": "1stFlrSF",
"xref": "x",
"y": "GarageCars",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.19",
"x": "2ndFlrSF",
"xref": "x",
"y": "GarageCars",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "LowQualFinSF",
"xref": "x",
"y": "GarageCars",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.48",
"x": "GrLivArea",
"xref": "x",
"y": "GarageCars",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.13",
"x": "BsmtFullBath",
"xref": "x",
"y": "GarageCars",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "BsmtHalfBath",
"xref": "x",
"y": "GarageCars",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.51",
"x": "FullBath",
"xref": "x",
"y": "GarageCars",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.2",
"x": "HalfBath",
"xref": "x",
"y": "GarageCars",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "BedroomAbvGr",
"xref": "x",
"y": "GarageCars",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "KitchenAbvGr",
"xref": "x",
"y": "GarageCars",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.43",
"x": "KitchenQual",
"xref": "x",
"y": "GarageCars",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.4",
"x": "TotRmsAbvGrd",
"xref": "x",
"y": "GarageCars",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "Functional",
"xref": "x",
"y": "GarageCars",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.25",
"x": "Fireplaces",
"xref": "x",
"y": "GarageCars",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.26",
"x": "GarageType",
"xref": "x",
"y": "GarageCars",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.59",
"x": "GarageYrBlt",
"xref": "x",
"y": "GarageCars",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.43",
"x": "GarageFinish",
"xref": "x",
"y": "GarageCars",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "GarageCars",
"xref": "x",
"y": "GarageCars",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.83",
"x": "GarageArea",
"xref": "x",
"y": "GarageCars",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.15",
"x": "GarageQual",
"xref": "x",
"y": "GarageCars",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.13",
"x": "GarageCond",
"xref": "x",
"y": "GarageCars",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "PavedDrive",
"xref": "x",
"y": "GarageCars",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.21",
"x": "WoodDeckSF",
"xref": "x",
"y": "GarageCars",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.24",
"x": "OpenPorchSF",
"xref": "x",
"y": "GarageCars",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.15",
"x": "EnclosedPorch",
"xref": "x",
"y": "GarageCars",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "3SsnPorch",
"xref": "x",
"y": "GarageCars",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "ScreenPorch",
"xref": "x",
"y": "GarageCars",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "PoolArea",
"xref": "x",
"y": "GarageCars",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "MiscVal",
"xref": "x",
"y": "GarageCars",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "MoSold",
"xref": "x",
"y": "GarageCars",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "YrSold",
"xref": "x",
"y": "GarageCars",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "SaleType",
"xref": "x",
"y": "GarageCars",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.15",
"x": "SaleCondition",
"xref": "x",
"y": "GarageCars",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.64",
"x": "SalePrice",
"xref": "x",
"y": "GarageCars",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Id",
"xref": "x",
"y": "GarageArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "MSSubClass",
"xref": "x",
"y": "GarageArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.2",
"x": "MSZoning",
"xref": "x",
"y": "GarageArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.17",
"x": "LotArea",
"xref": "x",
"y": "GarageArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "Street",
"xref": "x",
"y": "GarageArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.15",
"x": "LotShape",
"xref": "x",
"y": "GarageArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "LandContour",
"xref": "x",
"y": "GarageArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "Utilities",
"xref": "x",
"y": "GarageArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "LotConfig",
"xref": "x",
"y": "GarageArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "LandSlope",
"xref": "x",
"y": "GarageArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.2",
"x": "Neighborhood",
"xref": "x",
"y": "GarageArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "Condition1",
"xref": "x",
"y": "GarageArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "Condition2",
"xref": "x",
"y": "GarageArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "BldgType",
"xref": "x",
"y": "GarageArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "HouseStyle",
"xref": "x",
"y": "GarageArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.53",
"x": "OverallQual",
"xref": "x",
"y": "GarageArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.2",
"x": "OverallCond",
"xref": "x",
"y": "GarageArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.44",
"x": "YearBuilt",
"xref": "x",
"y": "GarageArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.39",
"x": "YearRemodAdd",
"xref": "x",
"y": "GarageArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "RoofStyle",
"xref": "x",
"y": "GarageArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "RoofMatl",
"xref": "x",
"y": "GarageArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.11",
"x": "Exterior1st",
"xref": "x",
"y": "GarageArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "Exterior2nd",
"xref": "x",
"y": "GarageArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "MasVnrType",
"xref": "x",
"y": "GarageArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.37",
"x": "MasVnrArea",
"xref": "x",
"y": "GarageArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.47",
"x": "ExterQual",
"xref": "x",
"y": "GarageArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "ExterCond",
"xref": "x",
"y": "GarageArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.38",
"x": "Foundation",
"xref": "x",
"y": "GarageArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.46",
"x": "BsmtQual",
"xref": "x",
"y": "GarageArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "BsmtCond",
"xref": "x",
"y": "GarageArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.25",
"x": "BsmtExposure",
"xref": "x",
"y": "GarageArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "BsmtFinType1",
"xref": "x",
"y": "GarageArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.28",
"x": "BsmtFinSF1",
"xref": "x",
"y": "GarageArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "BsmtFinType2",
"xref": "x",
"y": "GarageArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "BsmtFinSF2",
"xref": "x",
"y": "GarageArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.2",
"x": "BsmtUnfSF",
"xref": "x",
"y": "GarageArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.51",
"x": "TotalBsmtSF",
"xref": "x",
"y": "GarageArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "Heating",
"xref": "x",
"y": "GarageArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.26",
"x": "HeatingQC",
"xref": "x",
"y": "GarageArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "CentralAir",
"xref": "x",
"y": "GarageArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.21",
"x": "Electrical",
"xref": "x",
"y": "GarageArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.5",
"x": "1stFlrSF",
"xref": "x",
"y": "GarageArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "2ndFlrSF",
"xref": "x",
"y": "GarageArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "LowQualFinSF",
"xref": "x",
"y": "GarageArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.48",
"x": "GrLivArea",
"xref": "x",
"y": "GarageArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.19",
"x": "BsmtFullBath",
"xref": "x",
"y": "GarageArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "BsmtHalfBath",
"xref": "x",
"y": "GarageArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.42",
"x": "FullBath",
"xref": "x",
"y": "GarageArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.13",
"x": "HalfBath",
"xref": "x",
"y": "GarageArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "BedroomAbvGr",
"xref": "x",
"y": "GarageArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "KitchenAbvGr",
"xref": "x",
"y": "GarageArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.42",
"x": "KitchenQual",
"xref": "x",
"y": "GarageArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.37",
"x": "TotRmsAbvGrd",
"xref": "x",
"y": "GarageArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "Functional",
"xref": "x",
"y": "GarageArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.2",
"x": "Fireplaces",
"xref": "x",
"y": "GarageArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.23",
"x": "GarageType",
"xref": "x",
"y": "GarageArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.56",
"x": "GarageYrBlt",
"xref": "x",
"y": "GarageArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.36",
"x": "GarageFinish",
"xref": "x",
"y": "GarageArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.83",
"x": "GarageCars",
"xref": "x",
"y": "GarageArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "GarageArea",
"xref": "x",
"y": "GarageArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.16",
"x": "GarageQual",
"xref": "x",
"y": "GarageArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.13",
"x": "GarageCond",
"xref": "x",
"y": "GarageArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.16",
"x": "PavedDrive",
"xref": "x",
"y": "GarageArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.2",
"x": "WoodDeckSF",
"xref": "x",
"y": "GarageArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.27",
"x": "OpenPorchSF",
"xref": "x",
"y": "GarageArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.11",
"x": "EnclosedPorch",
"xref": "x",
"y": "GarageArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "3SsnPorch",
"xref": "x",
"y": "GarageArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "ScreenPorch",
"xref": "x",
"y": "GarageArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "PoolArea",
"xref": "x",
"y": "GarageArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "MiscVal",
"xref": "x",
"y": "GarageArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "MoSold",
"xref": "x",
"y": "GarageArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "YrSold",
"xref": "x",
"y": "GarageArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "SaleType",
"xref": "x",
"y": "GarageArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "SaleCondition",
"xref": "x",
"y": "GarageArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.61",
"x": "SalePrice",
"xref": "x",
"y": "GarageArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "Id",
"xref": "x",
"y": "GarageQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "MSSubClass",
"xref": "x",
"y": "GarageQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.16",
"x": "MSZoning",
"xref": "x",
"y": "GarageQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "LotArea",
"xref": "x",
"y": "GarageQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "Street",
"xref": "x",
"y": "GarageQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "LotShape",
"xref": "x",
"y": "GarageQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "LandContour",
"xref": "x",
"y": "GarageQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Utilities",
"xref": "x",
"y": "GarageQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "LotConfig",
"xref": "x",
"y": "GarageQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "LandSlope",
"xref": "x",
"y": "GarageQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "Neighborhood",
"xref": "x",
"y": "GarageQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "Condition1",
"xref": "x",
"y": "GarageQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "Condition2",
"xref": "x",
"y": "GarageQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "BldgType",
"xref": "x",
"y": "GarageQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "HouseStyle",
"xref": "x",
"y": "GarageQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "OverallQual",
"xref": "x",
"y": "GarageQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "OverallCond",
"xref": "x",
"y": "GarageQual",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.34",
"x": "YearBuilt",
"xref": "x",
"y": "GarageQual",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.15",
"x": "YearRemodAdd",
"xref": "x",
"y": "GarageQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "RoofStyle",
"xref": "x",
"y": "GarageQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "RoofMatl",
"xref": "x",
"y": "GarageQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "Exterior1st",
"xref": "x",
"y": "GarageQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "Exterior2nd",
"xref": "x",
"y": "GarageQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "MasVnrType",
"xref": "x",
"y": "GarageQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "MasVnrArea",
"xref": "x",
"y": "GarageQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.09",
"x": "ExterQual",
"xref": "x",
"y": "GarageQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "ExterCond",
"xref": "x",
"y": "GarageQual",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.27",
"x": "Foundation",
"xref": "x",
"y": "GarageQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "BsmtQual",
"xref": "x",
"y": "GarageQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "BsmtCond",
"xref": "x",
"y": "GarageQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.09",
"x": "BsmtExposure",
"xref": "x",
"y": "GarageQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.13",
"x": "BsmtFinType1",
"xref": "x",
"y": "GarageQual",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "BsmtFinSF1",
"xref": "x",
"y": "GarageQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "BsmtFinType2",
"xref": "x",
"y": "GarageQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "BsmtFinSF2",
"xref": "x",
"y": "GarageQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "BsmtUnfSF",
"xref": "x",
"y": "GarageQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "TotalBsmtSF",
"xref": "x",
"y": "GarageQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.16",
"x": "Heating",
"xref": "x",
"y": "GarageQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "HeatingQC",
"xref": "x",
"y": "GarageQual",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.21",
"x": "CentralAir",
"xref": "x",
"y": "GarageQual",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.13",
"x": "Electrical",
"xref": "x",
"y": "GarageQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "1stFlrSF",
"xref": "x",
"y": "GarageQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "2ndFlrSF",
"xref": "x",
"y": "GarageQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "LowQualFinSF",
"xref": "x",
"y": "GarageQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "GrLivArea",
"xref": "x",
"y": "GarageQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "BsmtFullBath",
"xref": "x",
"y": "GarageQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "BsmtHalfBath",
"xref": "x",
"y": "GarageQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.11",
"x": "FullBath",
"xref": "x",
"y": "GarageQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "HalfBath",
"xref": "x",
"y": "GarageQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "BedroomAbvGr",
"xref": "x",
"y": "GarageQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.12",
"x": "KitchenAbvGr",
"xref": "x",
"y": "GarageQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "KitchenQual",
"xref": "x",
"y": "GarageQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "TotRmsAbvGrd",
"xref": "x",
"y": "GarageQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "Functional",
"xref": "x",
"y": "GarageQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "Fireplaces",
"xref": "x",
"y": "GarageQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.22",
"x": "GarageType",
"xref": "x",
"y": "GarageQual",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.31",
"x": "GarageYrBlt",
"xref": "x",
"y": "GarageQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.18",
"x": "GarageFinish",
"xref": "x",
"y": "GarageQual",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.15",
"x": "GarageCars",
"xref": "x",
"y": "GarageQual",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.16",
"x": "GarageArea",
"xref": "x",
"y": "GarageQual",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "GarageQual",
"xref": "x",
"y": "GarageQual",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.52",
"x": "GarageCond",
"xref": "x",
"y": "GarageQual",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.23",
"x": "PavedDrive",
"xref": "x",
"y": "GarageQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "WoodDeckSF",
"xref": "x",
"y": "GarageQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "OpenPorchSF",
"xref": "x",
"y": "GarageQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.11",
"x": "EnclosedPorch",
"xref": "x",
"y": "GarageQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "3SsnPorch",
"xref": "x",
"y": "GarageQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "ScreenPorch",
"xref": "x",
"y": "GarageQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "PoolArea",
"xref": "x",
"y": "GarageQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "MiscVal",
"xref": "x",
"y": "GarageQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "MoSold",
"xref": "x",
"y": "GarageQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "YrSold",
"xref": "x",
"y": "GarageQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "SaleType",
"xref": "x",
"y": "GarageQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "SaleCondition",
"xref": "x",
"y": "GarageQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "SalePrice",
"xref": "x",
"y": "GarageQual",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "Id",
"xref": "x",
"y": "GarageCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "MSSubClass",
"xref": "x",
"y": "GarageCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.09",
"x": "MSZoning",
"xref": "x",
"y": "GarageCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "LotArea",
"xref": "x",
"y": "GarageCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "Street",
"xref": "x",
"y": "GarageCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "LotShape",
"xref": "x",
"y": "GarageCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "LandContour",
"xref": "x",
"y": "GarageCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Utilities",
"xref": "x",
"y": "GarageCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "LotConfig",
"xref": "x",
"y": "GarageCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "LandSlope",
"xref": "x",
"y": "GarageCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "Neighborhood",
"xref": "x",
"y": "GarageCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "Condition1",
"xref": "x",
"y": "GarageCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "Condition2",
"xref": "x",
"y": "GarageCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "BldgType",
"xref": "x",
"y": "GarageCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "HouseStyle",
"xref": "x",
"y": "GarageCond",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.16",
"x": "OverallQual",
"xref": "x",
"y": "GarageCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "OverallCond",
"xref": "x",
"y": "GarageCond",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.27",
"x": "YearBuilt",
"xref": "x",
"y": "GarageCond",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.16",
"x": "YearRemodAdd",
"xref": "x",
"y": "GarageCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "RoofStyle",
"xref": "x",
"y": "GarageCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "RoofMatl",
"xref": "x",
"y": "GarageCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "Exterior1st",
"xref": "x",
"y": "GarageCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Exterior2nd",
"xref": "x",
"y": "GarageCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "MasVnrType",
"xref": "x",
"y": "GarageCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "MasVnrArea",
"xref": "x",
"y": "GarageCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.11",
"x": "ExterQual",
"xref": "x",
"y": "GarageCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "ExterCond",
"xref": "x",
"y": "GarageCond",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.2",
"x": "Foundation",
"xref": "x",
"y": "GarageCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "BsmtQual",
"xref": "x",
"y": "GarageCond",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.17",
"x": "BsmtCond",
"xref": "x",
"y": "GarageCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "BsmtExposure",
"xref": "x",
"y": "GarageCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.11",
"x": "BsmtFinType1",
"xref": "x",
"y": "GarageCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "BsmtFinSF1",
"xref": "x",
"y": "GarageCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "BsmtFinType2",
"xref": "x",
"y": "GarageCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "BsmtFinSF2",
"xref": "x",
"y": "GarageCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "BsmtUnfSF",
"xref": "x",
"y": "GarageCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "TotalBsmtSF",
"xref": "x",
"y": "GarageCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.12",
"x": "Heating",
"xref": "x",
"y": "GarageCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "HeatingQC",
"xref": "x",
"y": "GarageCond",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.23",
"x": "CentralAir",
"xref": "x",
"y": "GarageCond",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "Electrical",
"xref": "x",
"y": "GarageCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.11",
"x": "1stFlrSF",
"xref": "x",
"y": "GarageCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "2ndFlrSF",
"xref": "x",
"y": "GarageCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "LowQualFinSF",
"xref": "x",
"y": "GarageCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "GrLivArea",
"xref": "x",
"y": "GarageCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "BsmtFullBath",
"xref": "x",
"y": "GarageCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "BsmtHalfBath",
"xref": "x",
"y": "GarageCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "FullBath",
"xref": "x",
"y": "GarageCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "HalfBath",
"xref": "x",
"y": "GarageCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "BedroomAbvGr",
"xref": "x",
"y": "GarageCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.09",
"x": "KitchenAbvGr",
"xref": "x",
"y": "GarageCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "KitchenQual",
"xref": "x",
"y": "GarageCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "TotRmsAbvGrd",
"xref": "x",
"y": "GarageCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Functional",
"xref": "x",
"y": "GarageCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "Fireplaces",
"xref": "x",
"y": "GarageCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.21",
"x": "GarageType",
"xref": "x",
"y": "GarageCond",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.26",
"x": "GarageYrBlt",
"xref": "x",
"y": "GarageCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.14",
"x": "GarageFinish",
"xref": "x",
"y": "GarageCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.13",
"x": "GarageCars",
"xref": "x",
"y": "GarageCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.13",
"x": "GarageArea",
"xref": "x",
"y": "GarageCond",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.52",
"x": "GarageQual",
"xref": "x",
"y": "GarageCond",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "GarageCond",
"xref": "x",
"y": "GarageCond",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.26",
"x": "PavedDrive",
"xref": "x",
"y": "GarageCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "WoodDeckSF",
"xref": "x",
"y": "GarageCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "OpenPorchSF",
"xref": "x",
"y": "GarageCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.12",
"x": "EnclosedPorch",
"xref": "x",
"y": "GarageCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "3SsnPorch",
"xref": "x",
"y": "GarageCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "ScreenPorch",
"xref": "x",
"y": "GarageCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "PoolArea",
"xref": "x",
"y": "GarageCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "MiscVal",
"xref": "x",
"y": "GarageCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "MoSold",
"xref": "x",
"y": "GarageCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "YrSold",
"xref": "x",
"y": "GarageCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "SaleType",
"xref": "x",
"y": "GarageCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "SaleCondition",
"xref": "x",
"y": "GarageCond",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.15",
"x": "SalePrice",
"xref": "x",
"y": "GarageCond",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "Id",
"xref": "x",
"y": "PavedDrive",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "MSSubClass",
"xref": "x",
"y": "PavedDrive",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.12",
"x": "MSZoning",
"xref": "x",
"y": "PavedDrive",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "LotArea",
"xref": "x",
"y": "PavedDrive",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "Street",
"xref": "x",
"y": "PavedDrive",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.12",
"x": "LotShape",
"xref": "x",
"y": "PavedDrive",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "LandContour",
"xref": "x",
"y": "PavedDrive",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Utilities",
"xref": "x",
"y": "PavedDrive",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "LotConfig",
"xref": "x",
"y": "PavedDrive",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "LandSlope",
"xref": "x",
"y": "PavedDrive",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Neighborhood",
"xref": "x",
"y": "PavedDrive",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "Condition1",
"xref": "x",
"y": "PavedDrive",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "Condition2",
"xref": "x",
"y": "PavedDrive",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "BldgType",
"xref": "x",
"y": "PavedDrive",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "HouseStyle",
"xref": "x",
"y": "PavedDrive",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.16",
"x": "OverallQual",
"xref": "x",
"y": "PavedDrive",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.11",
"x": "OverallCond",
"xref": "x",
"y": "PavedDrive",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.39",
"x": "YearBuilt",
"xref": "x",
"y": "PavedDrive",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.16",
"x": "YearRemodAdd",
"xref": "x",
"y": "PavedDrive",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "RoofStyle",
"xref": "x",
"y": "PavedDrive",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "RoofMatl",
"xref": "x",
"y": "PavedDrive",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "Exterior1st",
"xref": "x",
"y": "PavedDrive",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "Exterior2nd",
"xref": "x",
"y": "PavedDrive",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "MasVnrType",
"xref": "x",
"y": "PavedDrive",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "MasVnrArea",
"xref": "x",
"y": "PavedDrive",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.11",
"x": "ExterQual",
"xref": "x",
"y": "PavedDrive",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.11",
"x": "ExterCond",
"xref": "x",
"y": "PavedDrive",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.23",
"x": "Foundation",
"xref": "x",
"y": "PavedDrive",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.11",
"x": "BsmtQual",
"xref": "x",
"y": "PavedDrive",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.11",
"x": "BsmtCond",
"xref": "x",
"y": "PavedDrive",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.09",
"x": "BsmtExposure",
"xref": "x",
"y": "PavedDrive",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.22",
"x": "BsmtFinType1",
"xref": "x",
"y": "PavedDrive",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.17",
"x": "BsmtFinSF1",
"xref": "x",
"y": "PavedDrive",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "BsmtFinType2",
"xref": "x",
"y": "PavedDrive",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "BsmtFinSF2",
"xref": "x",
"y": "PavedDrive",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "BsmtUnfSF",
"xref": "x",
"y": "PavedDrive",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.15",
"x": "TotalBsmtSF",
"xref": "x",
"y": "PavedDrive",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.15",
"x": "Heating",
"xref": "x",
"y": "PavedDrive",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "HeatingQC",
"xref": "x",
"y": "PavedDrive",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.26",
"x": "CentralAir",
"xref": "x",
"y": "PavedDrive",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.18",
"x": "Electrical",
"xref": "x",
"y": "PavedDrive",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "1stFlrSF",
"xref": "x",
"y": "PavedDrive",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "2ndFlrSF",
"xref": "x",
"y": "PavedDrive",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "LowQualFinSF",
"xref": "x",
"y": "PavedDrive",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "GrLivArea",
"xref": "x",
"y": "PavedDrive",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.11",
"x": "BsmtFullBath",
"xref": "x",
"y": "PavedDrive",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "BsmtHalfBath",
"xref": "x",
"y": "PavedDrive",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.13",
"x": "FullBath",
"xref": "x",
"y": "PavedDrive",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "HalfBath",
"xref": "x",
"y": "PavedDrive",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "BedroomAbvGr",
"xref": "x",
"y": "PavedDrive",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.15",
"x": "KitchenAbvGr",
"xref": "x",
"y": "PavedDrive",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "KitchenQual",
"xref": "x",
"y": "PavedDrive",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "TotRmsAbvGrd",
"xref": "x",
"y": "PavedDrive",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Functional",
"xref": "x",
"y": "PavedDrive",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "Fireplaces",
"xref": "x",
"y": "PavedDrive",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.27",
"x": "GarageType",
"xref": "x",
"y": "PavedDrive",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.31",
"x": "GarageYrBlt",
"xref": "x",
"y": "PavedDrive",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.2",
"x": "GarageFinish",
"xref": "x",
"y": "PavedDrive",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "GarageCars",
"xref": "x",
"y": "PavedDrive",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.16",
"x": "GarageArea",
"xref": "x",
"y": "PavedDrive",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.23",
"x": "GarageQual",
"xref": "x",
"y": "PavedDrive",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.26",
"x": "GarageCond",
"xref": "x",
"y": "PavedDrive",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "PavedDrive",
"xref": "x",
"y": "PavedDrive",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "WoodDeckSF",
"xref": "x",
"y": "PavedDrive",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "OpenPorchSF",
"xref": "x",
"y": "PavedDrive",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.18",
"x": "EnclosedPorch",
"xref": "x",
"y": "PavedDrive",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "3SsnPorch",
"xref": "x",
"y": "PavedDrive",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "ScreenPorch",
"xref": "x",
"y": "PavedDrive",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "PoolArea",
"xref": "x",
"y": "PavedDrive",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "MiscVal",
"xref": "x",
"y": "PavedDrive",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "MoSold",
"xref": "x",
"y": "PavedDrive",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "YrSold",
"xref": "x",
"y": "PavedDrive",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "SaleType",
"xref": "x",
"y": "PavedDrive",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "SaleCondition",
"xref": "x",
"y": "PavedDrive",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.18",
"x": "SalePrice",
"xref": "x",
"y": "PavedDrive",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "Id",
"xref": "x",
"y": "WoodDeckSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "MSSubClass",
"xref": "x",
"y": "WoodDeckSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "MSZoning",
"xref": "x",
"y": "WoodDeckSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.17",
"x": "LotArea",
"xref": "x",
"y": "WoodDeckSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "Street",
"xref": "x",
"y": "WoodDeckSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.16",
"x": "LotShape",
"xref": "x",
"y": "WoodDeckSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "LandContour",
"xref": "x",
"y": "WoodDeckSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "Utilities",
"xref": "x",
"y": "WoodDeckSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "LotConfig",
"xref": "x",
"y": "WoodDeckSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "LandSlope",
"xref": "x",
"y": "WoodDeckSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "Neighborhood",
"xref": "x",
"y": "WoodDeckSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "Condition1",
"xref": "x",
"y": "WoodDeckSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Condition2",
"xref": "x",
"y": "WoodDeckSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "BldgType",
"xref": "x",
"y": "WoodDeckSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "HouseStyle",
"xref": "x",
"y": "WoodDeckSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.22",
"x": "OverallQual",
"xref": "x",
"y": "WoodDeckSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "OverallCond",
"xref": "x",
"y": "WoodDeckSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.21",
"x": "YearBuilt",
"xref": "x",
"y": "WoodDeckSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.2",
"x": "YearRemodAdd",
"xref": "x",
"y": "WoodDeckSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "RoofStyle",
"xref": "x",
"y": "WoodDeckSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.13",
"x": "RoofMatl",
"xref": "x",
"y": "WoodDeckSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "Exterior1st",
"xref": "x",
"y": "WoodDeckSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "Exterior2nd",
"xref": "x",
"y": "WoodDeckSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "MasVnrType",
"xref": "x",
"y": "WoodDeckSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.15",
"x": "MasVnrArea",
"xref": "x",
"y": "WoodDeckSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.18",
"x": "ExterQual",
"xref": "x",
"y": "WoodDeckSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "ExterCond",
"xref": "x",
"y": "WoodDeckSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.17",
"x": "Foundation",
"xref": "x",
"y": "WoodDeckSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.21",
"x": "BsmtQual",
"xref": "x",
"y": "WoodDeckSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "BsmtCond",
"xref": "x",
"y": "WoodDeckSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.2",
"x": "BsmtExposure",
"xref": "x",
"y": "WoodDeckSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "BsmtFinType1",
"xref": "x",
"y": "WoodDeckSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.19",
"x": "BsmtFinSF1",
"xref": "x",
"y": "WoodDeckSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "BsmtFinType2",
"xref": "x",
"y": "WoodDeckSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "BsmtFinSF2",
"xref": "x",
"y": "WoodDeckSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "BsmtUnfSF",
"xref": "x",
"y": "WoodDeckSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.21",
"x": "TotalBsmtSF",
"xref": "x",
"y": "WoodDeckSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "Heating",
"xref": "x",
"y": "WoodDeckSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "HeatingQC",
"xref": "x",
"y": "WoodDeckSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "CentralAir",
"xref": "x",
"y": "WoodDeckSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "Electrical",
"xref": "x",
"y": "WoodDeckSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.23",
"x": "1stFlrSF",
"xref": "x",
"y": "WoodDeckSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "2ndFlrSF",
"xref": "x",
"y": "WoodDeckSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "LowQualFinSF",
"xref": "x",
"y": "WoodDeckSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.24",
"x": "GrLivArea",
"xref": "x",
"y": "WoodDeckSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.16",
"x": "BsmtFullBath",
"xref": "x",
"y": "WoodDeckSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "BsmtHalfBath",
"xref": "x",
"y": "WoodDeckSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.19",
"x": "FullBath",
"xref": "x",
"y": "WoodDeckSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "HalfBath",
"xref": "x",
"y": "WoodDeckSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "BedroomAbvGr",
"xref": "x",
"y": "WoodDeckSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "KitchenAbvGr",
"xref": "x",
"y": "WoodDeckSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.16",
"x": "KitchenQual",
"xref": "x",
"y": "WoodDeckSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.17",
"x": "TotRmsAbvGrd",
"xref": "x",
"y": "WoodDeckSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "Functional",
"xref": "x",
"y": "WoodDeckSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.18",
"x": "Fireplaces",
"xref": "x",
"y": "WoodDeckSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.21",
"x": "GarageType",
"xref": "x",
"y": "WoodDeckSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.22",
"x": "GarageYrBlt",
"xref": "x",
"y": "WoodDeckSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.23",
"x": "GarageFinish",
"xref": "x",
"y": "WoodDeckSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.21",
"x": "GarageCars",
"xref": "x",
"y": "WoodDeckSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.2",
"x": "GarageArea",
"xref": "x",
"y": "WoodDeckSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "GarageQual",
"xref": "x",
"y": "WoodDeckSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "GarageCond",
"xref": "x",
"y": "WoodDeckSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "PavedDrive",
"xref": "x",
"y": "WoodDeckSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "WoodDeckSF",
"xref": "x",
"y": "WoodDeckSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "OpenPorchSF",
"xref": "x",
"y": "WoodDeckSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.13",
"x": "EnclosedPorch",
"xref": "x",
"y": "WoodDeckSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "3SsnPorch",
"xref": "x",
"y": "WoodDeckSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.09",
"x": "ScreenPorch",
"xref": "x",
"y": "WoodDeckSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "PoolArea",
"xref": "x",
"y": "WoodDeckSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "MiscVal",
"xref": "x",
"y": "WoodDeckSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "MoSold",
"xref": "x",
"y": "WoodDeckSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "YrSold",
"xref": "x",
"y": "WoodDeckSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "SaleType",
"xref": "x",
"y": "WoodDeckSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "SaleCondition",
"xref": "x",
"y": "WoodDeckSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.31",
"x": "SalePrice",
"xref": "x",
"y": "WoodDeckSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "Id",
"xref": "x",
"y": "OpenPorchSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "MSSubClass",
"xref": "x",
"y": "OpenPorchSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.14",
"x": "MSZoning",
"xref": "x",
"y": "OpenPorchSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "LotArea",
"xref": "x",
"y": "OpenPorchSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "Street",
"xref": "x",
"y": "OpenPorchSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "LotShape",
"xref": "x",
"y": "OpenPorchSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "LandContour",
"xref": "x",
"y": "OpenPorchSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "Utilities",
"xref": "x",
"y": "OpenPorchSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "LotConfig",
"xref": "x",
"y": "OpenPorchSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "LandSlope",
"xref": "x",
"y": "OpenPorchSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "Neighborhood",
"xref": "x",
"y": "OpenPorchSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "Condition1",
"xref": "x",
"y": "OpenPorchSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "Condition2",
"xref": "x",
"y": "OpenPorchSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "BldgType",
"xref": "x",
"y": "OpenPorchSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "HouseStyle",
"xref": "x",
"y": "OpenPorchSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.31",
"x": "OverallQual",
"xref": "x",
"y": "OpenPorchSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "OverallCond",
"xref": "x",
"y": "OpenPorchSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.22",
"x": "YearBuilt",
"xref": "x",
"y": "OpenPorchSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.23",
"x": "YearRemodAdd",
"xref": "x",
"y": "OpenPorchSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "RoofStyle",
"xref": "x",
"y": "OpenPorchSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "RoofMatl",
"xref": "x",
"y": "OpenPorchSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "Exterior1st",
"xref": "x",
"y": "OpenPorchSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "Exterior2nd",
"xref": "x",
"y": "OpenPorchSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "MasVnrType",
"xref": "x",
"y": "OpenPorchSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.13",
"x": "MasVnrArea",
"xref": "x",
"y": "OpenPorchSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.28",
"x": "ExterQual",
"xref": "x",
"y": "OpenPorchSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "ExterCond",
"xref": "x",
"y": "OpenPorchSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.2",
"x": "Foundation",
"xref": "x",
"y": "OpenPorchSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.25",
"x": "BsmtQual",
"xref": "x",
"y": "OpenPorchSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "BsmtCond",
"xref": "x",
"y": "OpenPorchSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "BsmtExposure",
"xref": "x",
"y": "OpenPorchSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "BsmtFinType1",
"xref": "x",
"y": "OpenPorchSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.11",
"x": "BsmtFinSF1",
"xref": "x",
"y": "OpenPorchSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "BsmtFinType2",
"xref": "x",
"y": "OpenPorchSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "BsmtFinSF2",
"xref": "x",
"y": "OpenPorchSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "BsmtUnfSF",
"xref": "x",
"y": "OpenPorchSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.26",
"x": "TotalBsmtSF",
"xref": "x",
"y": "OpenPorchSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "Heating",
"xref": "x",
"y": "OpenPorchSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.17",
"x": "HeatingQC",
"xref": "x",
"y": "OpenPorchSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "CentralAir",
"xref": "x",
"y": "OpenPorchSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.11",
"x": "Electrical",
"xref": "x",
"y": "OpenPorchSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.23",
"x": "1stFlrSF",
"xref": "x",
"y": "OpenPorchSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.2",
"x": "2ndFlrSF",
"xref": "x",
"y": "OpenPorchSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "LowQualFinSF",
"xref": "x",
"y": "OpenPorchSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.34",
"x": "GrLivArea",
"xref": "x",
"y": "OpenPorchSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "BsmtFullBath",
"xref": "x",
"y": "OpenPorchSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "BsmtHalfBath",
"xref": "x",
"y": "OpenPorchSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.28",
"x": "FullBath",
"xref": "x",
"y": "OpenPorchSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.2",
"x": "HalfBath",
"xref": "x",
"y": "OpenPorchSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "BedroomAbvGr",
"xref": "x",
"y": "OpenPorchSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "KitchenAbvGr",
"xref": "x",
"y": "OpenPorchSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.24",
"x": "KitchenQual",
"xref": "x",
"y": "OpenPorchSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.25",
"x": "TotRmsAbvGrd",
"xref": "x",
"y": "OpenPorchSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "Functional",
"xref": "x",
"y": "OpenPorchSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.17",
"x": "Fireplaces",
"xref": "x",
"y": "OpenPorchSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.13",
"x": "GarageType",
"xref": "x",
"y": "OpenPorchSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.22",
"x": "GarageYrBlt",
"xref": "x",
"y": "OpenPorchSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.21",
"x": "GarageFinish",
"xref": "x",
"y": "OpenPorchSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.24",
"x": "GarageCars",
"xref": "x",
"y": "OpenPorchSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.27",
"x": "GarageArea",
"xref": "x",
"y": "OpenPorchSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "GarageQual",
"xref": "x",
"y": "OpenPorchSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "GarageCond",
"xref": "x",
"y": "OpenPorchSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "PavedDrive",
"xref": "x",
"y": "OpenPorchSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "WoodDeckSF",
"xref": "x",
"y": "OpenPorchSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "OpenPorchSF",
"xref": "x",
"y": "OpenPorchSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "EnclosedPorch",
"xref": "x",
"y": "OpenPorchSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "3SsnPorch",
"xref": "x",
"y": "OpenPorchSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "ScreenPorch",
"xref": "x",
"y": "OpenPorchSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "PoolArea",
"xref": "x",
"y": "OpenPorchSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "MiscVal",
"xref": "x",
"y": "OpenPorchSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "MoSold",
"xref": "x",
"y": "OpenPorchSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "YrSold",
"xref": "x",
"y": "OpenPorchSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "SaleType",
"xref": "x",
"y": "OpenPorchSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "SaleCondition",
"xref": "x",
"y": "OpenPorchSF",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.32",
"x": "SalePrice",
"xref": "x",
"y": "OpenPorchSF",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Id",
"xref": "x",
"y": "EnclosedPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "MSSubClass",
"xref": "x",
"y": "EnclosedPorch",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "MSZoning",
"xref": "x",
"y": "EnclosedPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "LotArea",
"xref": "x",
"y": "EnclosedPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "Street",
"xref": "x",
"y": "EnclosedPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "LotShape",
"xref": "x",
"y": "EnclosedPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "LandContour",
"xref": "x",
"y": "EnclosedPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "Utilities",
"xref": "x",
"y": "EnclosedPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "LotConfig",
"xref": "x",
"y": "EnclosedPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "LandSlope",
"xref": "x",
"y": "EnclosedPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "Neighborhood",
"xref": "x",
"y": "EnclosedPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "Condition1",
"xref": "x",
"y": "EnclosedPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "Condition2",
"xref": "x",
"y": "EnclosedPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.11",
"x": "BldgType",
"xref": "x",
"y": "EnclosedPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "HouseStyle",
"xref": "x",
"y": "EnclosedPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.12",
"x": "OverallQual",
"xref": "x",
"y": "EnclosedPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "OverallCond",
"xref": "x",
"y": "EnclosedPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.39",
"x": "YearBuilt",
"xref": "x",
"y": "EnclosedPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.22",
"x": "YearRemodAdd",
"xref": "x",
"y": "EnclosedPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "RoofStyle",
"xref": "x",
"y": "EnclosedPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "RoofMatl",
"xref": "x",
"y": "EnclosedPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "Exterior1st",
"xref": "x",
"y": "EnclosedPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "Exterior2nd",
"xref": "x",
"y": "EnclosedPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "MasVnrType",
"xref": "x",
"y": "EnclosedPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.11",
"x": "MasVnrArea",
"xref": "x",
"y": "EnclosedPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "ExterQual",
"xref": "x",
"y": "EnclosedPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "ExterCond",
"xref": "x",
"y": "EnclosedPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.23",
"x": "Foundation",
"xref": "x",
"y": "EnclosedPorch",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.15",
"x": "BsmtQual",
"xref": "x",
"y": "EnclosedPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "BsmtCond",
"xref": "x",
"y": "EnclosedPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "BsmtExposure",
"xref": "x",
"y": "EnclosedPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "BsmtFinType1",
"xref": "x",
"y": "EnclosedPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.11",
"x": "BsmtFinSF1",
"xref": "x",
"y": "EnclosedPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "BsmtFinType2",
"xref": "x",
"y": "EnclosedPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "BsmtFinSF2",
"xref": "x",
"y": "EnclosedPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "BsmtUnfSF",
"xref": "x",
"y": "EnclosedPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "TotalBsmtSF",
"xref": "x",
"y": "EnclosedPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "Heating",
"xref": "x",
"y": "EnclosedPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "HeatingQC",
"xref": "x",
"y": "EnclosedPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.17",
"x": "CentralAir",
"xref": "x",
"y": "EnclosedPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.15",
"x": "Electrical",
"xref": "x",
"y": "EnclosedPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "1stFlrSF",
"xref": "x",
"y": "EnclosedPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "2ndFlrSF",
"xref": "x",
"y": "EnclosedPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "LowQualFinSF",
"xref": "x",
"y": "EnclosedPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "GrLivArea",
"xref": "x",
"y": "EnclosedPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "BsmtFullBath",
"xref": "x",
"y": "EnclosedPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "BsmtHalfBath",
"xref": "x",
"y": "EnclosedPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.13",
"x": "FullBath",
"xref": "x",
"y": "EnclosedPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.09",
"x": "HalfBath",
"xref": "x",
"y": "EnclosedPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "BedroomAbvGr",
"xref": "x",
"y": "EnclosedPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "KitchenAbvGr",
"xref": "x",
"y": "EnclosedPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "KitchenQual",
"xref": "x",
"y": "EnclosedPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "TotRmsAbvGrd",
"xref": "x",
"y": "EnclosedPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "Functional",
"xref": "x",
"y": "EnclosedPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "Fireplaces",
"xref": "x",
"y": "EnclosedPorch",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.2",
"x": "GarageType",
"xref": "x",
"y": "EnclosedPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.3",
"x": "GarageYrBlt",
"xref": "x",
"y": "EnclosedPorch",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.19",
"x": "GarageFinish",
"xref": "x",
"y": "EnclosedPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.15",
"x": "GarageCars",
"xref": "x",
"y": "EnclosedPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.11",
"x": "GarageArea",
"xref": "x",
"y": "EnclosedPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.11",
"x": "GarageQual",
"xref": "x",
"y": "EnclosedPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.12",
"x": "GarageCond",
"xref": "x",
"y": "EnclosedPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.18",
"x": "PavedDrive",
"xref": "x",
"y": "EnclosedPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.13",
"x": "WoodDeckSF",
"xref": "x",
"y": "EnclosedPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "OpenPorchSF",
"xref": "x",
"y": "EnclosedPorch",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "EnclosedPorch",
"xref": "x",
"y": "EnclosedPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "3SsnPorch",
"xref": "x",
"y": "EnclosedPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "ScreenPorch",
"xref": "x",
"y": "EnclosedPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "PoolArea",
"xref": "x",
"y": "EnclosedPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "MiscVal",
"xref": "x",
"y": "EnclosedPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "MoSold",
"xref": "x",
"y": "EnclosedPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "YrSold",
"xref": "x",
"y": "EnclosedPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "SaleType",
"xref": "x",
"y": "EnclosedPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.12",
"x": "SaleCondition",
"xref": "x",
"y": "EnclosedPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.13",
"x": "SalePrice",
"xref": "x",
"y": "EnclosedPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "Id",
"xref": "x",
"y": "3SsnPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "MSSubClass",
"xref": "x",
"y": "3SsnPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "MSZoning",
"xref": "x",
"y": "3SsnPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "LotArea",
"xref": "x",
"y": "3SsnPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Street",
"xref": "x",
"y": "3SsnPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "LotShape",
"xref": "x",
"y": "3SsnPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "LandContour",
"xref": "x",
"y": "3SsnPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "Utilities",
"xref": "x",
"y": "3SsnPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "LotConfig",
"xref": "x",
"y": "3SsnPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "LandSlope",
"xref": "x",
"y": "3SsnPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "Neighborhood",
"xref": "x",
"y": "3SsnPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "Condition1",
"xref": "x",
"y": "3SsnPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "Condition2",
"xref": "x",
"y": "3SsnPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "BldgType",
"xref": "x",
"y": "3SsnPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "HouseStyle",
"xref": "x",
"y": "3SsnPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "OverallQual",
"xref": "x",
"y": "3SsnPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "OverallCond",
"xref": "x",
"y": "3SsnPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "YearBuilt",
"xref": "x",
"y": "3SsnPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "YearRemodAdd",
"xref": "x",
"y": "3SsnPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "RoofStyle",
"xref": "x",
"y": "3SsnPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "RoofMatl",
"xref": "x",
"y": "3SsnPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "Exterior1st",
"xref": "x",
"y": "3SsnPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "Exterior2nd",
"xref": "x",
"y": "3SsnPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "MasVnrType",
"xref": "x",
"y": "3SsnPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "MasVnrArea",
"xref": "x",
"y": "3SsnPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "ExterQual",
"xref": "x",
"y": "3SsnPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "ExterCond",
"xref": "x",
"y": "3SsnPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "Foundation",
"xref": "x",
"y": "3SsnPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "BsmtQual",
"xref": "x",
"y": "3SsnPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "BsmtCond",
"xref": "x",
"y": "3SsnPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "BsmtExposure",
"xref": "x",
"y": "3SsnPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "BsmtFinType1",
"xref": "x",
"y": "3SsnPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "BsmtFinSF1",
"xref": "x",
"y": "3SsnPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "BsmtFinType2",
"xref": "x",
"y": "3SsnPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "BsmtFinSF2",
"xref": "x",
"y": "3SsnPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "BsmtUnfSF",
"xref": "x",
"y": "3SsnPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "TotalBsmtSF",
"xref": "x",
"y": "3SsnPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "Heating",
"xref": "x",
"y": "3SsnPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "HeatingQC",
"xref": "x",
"y": "3SsnPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "CentralAir",
"xref": "x",
"y": "3SsnPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "Electrical",
"xref": "x",
"y": "3SsnPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "1stFlrSF",
"xref": "x",
"y": "3SsnPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "2ndFlrSF",
"xref": "x",
"y": "3SsnPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "LowQualFinSF",
"xref": "x",
"y": "3SsnPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "GrLivArea",
"xref": "x",
"y": "3SsnPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "BsmtFullBath",
"xref": "x",
"y": "3SsnPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "BsmtHalfBath",
"xref": "x",
"y": "3SsnPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "FullBath",
"xref": "x",
"y": "3SsnPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "HalfBath",
"xref": "x",
"y": "3SsnPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "BedroomAbvGr",
"xref": "x",
"y": "3SsnPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "KitchenAbvGr",
"xref": "x",
"y": "3SsnPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "KitchenQual",
"xref": "x",
"y": "3SsnPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "TotRmsAbvGrd",
"xref": "x",
"y": "3SsnPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "Functional",
"xref": "x",
"y": "3SsnPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "Fireplaces",
"xref": "x",
"y": "3SsnPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "GarageType",
"xref": "x",
"y": "3SsnPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "GarageYrBlt",
"xref": "x",
"y": "3SsnPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "GarageFinish",
"xref": "x",
"y": "3SsnPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "GarageCars",
"xref": "x",
"y": "3SsnPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "GarageArea",
"xref": "x",
"y": "3SsnPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "GarageQual",
"xref": "x",
"y": "3SsnPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "GarageCond",
"xref": "x",
"y": "3SsnPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "PavedDrive",
"xref": "x",
"y": "3SsnPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "WoodDeckSF",
"xref": "x",
"y": "3SsnPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "OpenPorchSF",
"xref": "x",
"y": "3SsnPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "EnclosedPorch",
"xref": "x",
"y": "3SsnPorch",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "3SsnPorch",
"xref": "x",
"y": "3SsnPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "ScreenPorch",
"xref": "x",
"y": "3SsnPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "PoolArea",
"xref": "x",
"y": "3SsnPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "MiscVal",
"xref": "x",
"y": "3SsnPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "MoSold",
"xref": "x",
"y": "3SsnPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "YrSold",
"xref": "x",
"y": "3SsnPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "SaleType",
"xref": "x",
"y": "3SsnPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "SaleCondition",
"xref": "x",
"y": "3SsnPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "SalePrice",
"xref": "x",
"y": "3SsnPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "Id",
"xref": "x",
"y": "ScreenPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "MSSubClass",
"xref": "x",
"y": "ScreenPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "MSZoning",
"xref": "x",
"y": "ScreenPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "LotArea",
"xref": "x",
"y": "ScreenPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "Street",
"xref": "x",
"y": "ScreenPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "LotShape",
"xref": "x",
"y": "ScreenPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "LandContour",
"xref": "x",
"y": "ScreenPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "Utilities",
"xref": "x",
"y": "ScreenPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "LotConfig",
"xref": "x",
"y": "ScreenPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "LandSlope",
"xref": "x",
"y": "ScreenPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Neighborhood",
"xref": "x",
"y": "ScreenPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "Condition1",
"xref": "x",
"y": "ScreenPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "Condition2",
"xref": "x",
"y": "ScreenPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "BldgType",
"xref": "x",
"y": "ScreenPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "HouseStyle",
"xref": "x",
"y": "ScreenPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "OverallQual",
"xref": "x",
"y": "ScreenPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "OverallCond",
"xref": "x",
"y": "ScreenPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "YearBuilt",
"xref": "x",
"y": "ScreenPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "YearRemodAdd",
"xref": "x",
"y": "ScreenPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "RoofStyle",
"xref": "x",
"y": "ScreenPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "RoofMatl",
"xref": "x",
"y": "ScreenPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "Exterior1st",
"xref": "x",
"y": "ScreenPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "Exterior2nd",
"xref": "x",
"y": "ScreenPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "MasVnrType",
"xref": "x",
"y": "ScreenPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "MasVnrArea",
"xref": "x",
"y": "ScreenPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "ExterQual",
"xref": "x",
"y": "ScreenPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "ExterCond",
"xref": "x",
"y": "ScreenPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "Foundation",
"xref": "x",
"y": "ScreenPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "BsmtQual",
"xref": "x",
"y": "ScreenPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "BsmtCond",
"xref": "x",
"y": "ScreenPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "BsmtExposure",
"xref": "x",
"y": "ScreenPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "BsmtFinType1",
"xref": "x",
"y": "ScreenPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "BsmtFinSF1",
"xref": "x",
"y": "ScreenPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "BsmtFinType2",
"xref": "x",
"y": "ScreenPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "BsmtFinSF2",
"xref": "x",
"y": "ScreenPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "BsmtUnfSF",
"xref": "x",
"y": "ScreenPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "TotalBsmtSF",
"xref": "x",
"y": "ScreenPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "Heating",
"xref": "x",
"y": "ScreenPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "HeatingQC",
"xref": "x",
"y": "ScreenPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "CentralAir",
"xref": "x",
"y": "ScreenPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "Electrical",
"xref": "x",
"y": "ScreenPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "1stFlrSF",
"xref": "x",
"y": "ScreenPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "2ndFlrSF",
"xref": "x",
"y": "ScreenPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "LowQualFinSF",
"xref": "x",
"y": "ScreenPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "GrLivArea",
"xref": "x",
"y": "ScreenPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "BsmtFullBath",
"xref": "x",
"y": "ScreenPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "BsmtHalfBath",
"xref": "x",
"y": "ScreenPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "FullBath",
"xref": "x",
"y": "ScreenPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "HalfBath",
"xref": "x",
"y": "ScreenPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "BedroomAbvGr",
"xref": "x",
"y": "ScreenPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "KitchenAbvGr",
"xref": "x",
"y": "ScreenPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "KitchenQual",
"xref": "x",
"y": "ScreenPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "TotRmsAbvGrd",
"xref": "x",
"y": "ScreenPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "Functional",
"xref": "x",
"y": "ScreenPorch",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.18",
"x": "Fireplaces",
"xref": "x",
"y": "ScreenPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "GarageType",
"xref": "x",
"y": "ScreenPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "GarageYrBlt",
"xref": "x",
"y": "ScreenPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "GarageFinish",
"xref": "x",
"y": "ScreenPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "GarageCars",
"xref": "x",
"y": "ScreenPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "GarageArea",
"xref": "x",
"y": "ScreenPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "GarageQual",
"xref": "x",
"y": "ScreenPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "GarageCond",
"xref": "x",
"y": "ScreenPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "PavedDrive",
"xref": "x",
"y": "ScreenPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.09",
"x": "WoodDeckSF",
"xref": "x",
"y": "ScreenPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "OpenPorchSF",
"xref": "x",
"y": "ScreenPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "EnclosedPorch",
"xref": "x",
"y": "ScreenPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "3SsnPorch",
"xref": "x",
"y": "ScreenPorch",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "ScreenPorch",
"xref": "x",
"y": "ScreenPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "PoolArea",
"xref": "x",
"y": "ScreenPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "MiscVal",
"xref": "x",
"y": "ScreenPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "MoSold",
"xref": "x",
"y": "ScreenPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "YrSold",
"xref": "x",
"y": "ScreenPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "SaleType",
"xref": "x",
"y": "ScreenPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "SaleCondition",
"xref": "x",
"y": "ScreenPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "SalePrice",
"xref": "x",
"y": "ScreenPorch",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "Id",
"xref": "x",
"y": "PoolArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "MSSubClass",
"xref": "x",
"y": "PoolArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "MSZoning",
"xref": "x",
"y": "PoolArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "LotArea",
"xref": "x",
"y": "PoolArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "Street",
"xref": "x",
"y": "PoolArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "LotShape",
"xref": "x",
"y": "PoolArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "LandContour",
"xref": "x",
"y": "PoolArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "Utilities",
"xref": "x",
"y": "PoolArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "LotConfig",
"xref": "x",
"y": "PoolArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "LandSlope",
"xref": "x",
"y": "PoolArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "Neighborhood",
"xref": "x",
"y": "PoolArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Condition1",
"xref": "x",
"y": "PoolArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "Condition2",
"xref": "x",
"y": "PoolArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "BldgType",
"xref": "x",
"y": "PoolArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "HouseStyle",
"xref": "x",
"y": "PoolArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "OverallQual",
"xref": "x",
"y": "PoolArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "OverallCond",
"xref": "x",
"y": "PoolArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "YearBuilt",
"xref": "x",
"y": "PoolArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "YearRemodAdd",
"xref": "x",
"y": "PoolArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "RoofStyle",
"xref": "x",
"y": "PoolArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "RoofMatl",
"xref": "x",
"y": "PoolArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "Exterior1st",
"xref": "x",
"y": "PoolArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "Exterior2nd",
"xref": "x",
"y": "PoolArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "MasVnrType",
"xref": "x",
"y": "PoolArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "MasVnrArea",
"xref": "x",
"y": "PoolArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "ExterQual",
"xref": "x",
"y": "PoolArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "ExterCond",
"xref": "x",
"y": "PoolArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "Foundation",
"xref": "x",
"y": "PoolArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "BsmtQual",
"xref": "x",
"y": "PoolArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "BsmtCond",
"xref": "x",
"y": "PoolArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "BsmtExposure",
"xref": "x",
"y": "PoolArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "BsmtFinType1",
"xref": "x",
"y": "PoolArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "BsmtFinSF1",
"xref": "x",
"y": "PoolArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "BsmtFinType2",
"xref": "x",
"y": "PoolArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "BsmtFinSF2",
"xref": "x",
"y": "PoolArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "BsmtUnfSF",
"xref": "x",
"y": "PoolArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "TotalBsmtSF",
"xref": "x",
"y": "PoolArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "Heating",
"xref": "x",
"y": "PoolArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "HeatingQC",
"xref": "x",
"y": "PoolArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "CentralAir",
"xref": "x",
"y": "PoolArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "Electrical",
"xref": "x",
"y": "PoolArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.13",
"x": "1stFlrSF",
"xref": "x",
"y": "PoolArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "2ndFlrSF",
"xref": "x",
"y": "PoolArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "LowQualFinSF",
"xref": "x",
"y": "PoolArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.18",
"x": "GrLivArea",
"xref": "x",
"y": "PoolArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "BsmtFullBath",
"xref": "x",
"y": "PoolArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "BsmtHalfBath",
"xref": "x",
"y": "PoolArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "FullBath",
"xref": "x",
"y": "PoolArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "HalfBath",
"xref": "x",
"y": "PoolArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "BedroomAbvGr",
"xref": "x",
"y": "PoolArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "KitchenAbvGr",
"xref": "x",
"y": "PoolArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "KitchenQual",
"xref": "x",
"y": "PoolArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "TotRmsAbvGrd",
"xref": "x",
"y": "PoolArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "Functional",
"xref": "x",
"y": "PoolArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "Fireplaces",
"xref": "x",
"y": "PoolArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "GarageType",
"xref": "x",
"y": "PoolArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "GarageYrBlt",
"xref": "x",
"y": "PoolArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "GarageFinish",
"xref": "x",
"y": "PoolArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "GarageCars",
"xref": "x",
"y": "PoolArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "GarageArea",
"xref": "x",
"y": "PoolArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "GarageQual",
"xref": "x",
"y": "PoolArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "GarageCond",
"xref": "x",
"y": "PoolArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "PavedDrive",
"xref": "x",
"y": "PoolArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "WoodDeckSF",
"xref": "x",
"y": "PoolArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "OpenPorchSF",
"xref": "x",
"y": "PoolArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "EnclosedPorch",
"xref": "x",
"y": "PoolArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "3SsnPorch",
"xref": "x",
"y": "PoolArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "ScreenPorch",
"xref": "x",
"y": "PoolArea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "PoolArea",
"xref": "x",
"y": "PoolArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "MiscVal",
"xref": "x",
"y": "PoolArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "MoSold",
"xref": "x",
"y": "PoolArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "YrSold",
"xref": "x",
"y": "PoolArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "SaleType",
"xref": "x",
"y": "PoolArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "SaleCondition",
"xref": "x",
"y": "PoolArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "SalePrice",
"xref": "x",
"y": "PoolArea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "Id",
"xref": "x",
"y": "MiscVal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "MSSubClass",
"xref": "x",
"y": "MiscVal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "MSZoning",
"xref": "x",
"y": "MiscVal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "LotArea",
"xref": "x",
"y": "MiscVal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "Street",
"xref": "x",
"y": "MiscVal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "LotShape",
"xref": "x",
"y": "MiscVal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "LandContour",
"xref": "x",
"y": "MiscVal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "Utilities",
"xref": "x",
"y": "MiscVal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "LotConfig",
"xref": "x",
"y": "MiscVal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "LandSlope",
"xref": "x",
"y": "MiscVal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "Neighborhood",
"xref": "x",
"y": "MiscVal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "Condition1",
"xref": "x",
"y": "MiscVal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.13",
"x": "Condition2",
"xref": "x",
"y": "MiscVal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "BldgType",
"xref": "x",
"y": "MiscVal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "HouseStyle",
"xref": "x",
"y": "MiscVal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "OverallQual",
"xref": "x",
"y": "MiscVal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "OverallCond",
"xref": "x",
"y": "MiscVal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "YearBuilt",
"xref": "x",
"y": "MiscVal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "YearRemodAdd",
"xref": "x",
"y": "MiscVal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "RoofStyle",
"xref": "x",
"y": "MiscVal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "RoofMatl",
"xref": "x",
"y": "MiscVal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "Exterior1st",
"xref": "x",
"y": "MiscVal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "Exterior2nd",
"xref": "x",
"y": "MiscVal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "MasVnrType",
"xref": "x",
"y": "MiscVal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "MasVnrArea",
"xref": "x",
"y": "MiscVal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "ExterQual",
"xref": "x",
"y": "MiscVal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "ExterCond",
"xref": "x",
"y": "MiscVal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "Foundation",
"xref": "x",
"y": "MiscVal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "BsmtQual",
"xref": "x",
"y": "MiscVal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "BsmtCond",
"xref": "x",
"y": "MiscVal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "BsmtExposure",
"xref": "x",
"y": "MiscVal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "BsmtFinType1",
"xref": "x",
"y": "MiscVal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "BsmtFinSF1",
"xref": "x",
"y": "MiscVal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "BsmtFinType2",
"xref": "x",
"y": "MiscVal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "BsmtFinSF2",
"xref": "x",
"y": "MiscVal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "BsmtUnfSF",
"xref": "x",
"y": "MiscVal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "TotalBsmtSF",
"xref": "x",
"y": "MiscVal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "Heating",
"xref": "x",
"y": "MiscVal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "HeatingQC",
"xref": "x",
"y": "MiscVal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "CentralAir",
"xref": "x",
"y": "MiscVal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "Electrical",
"xref": "x",
"y": "MiscVal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "1stFlrSF",
"xref": "x",
"y": "MiscVal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "2ndFlrSF",
"xref": "x",
"y": "MiscVal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "LowQualFinSF",
"xref": "x",
"y": "MiscVal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "GrLivArea",
"xref": "x",
"y": "MiscVal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "BsmtFullBath",
"xref": "x",
"y": "MiscVal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "BsmtHalfBath",
"xref": "x",
"y": "MiscVal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "FullBath",
"xref": "x",
"y": "MiscVal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "HalfBath",
"xref": "x",
"y": "MiscVal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "BedroomAbvGr",
"xref": "x",
"y": "MiscVal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "KitchenAbvGr",
"xref": "x",
"y": "MiscVal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "KitchenQual",
"xref": "x",
"y": "MiscVal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "TotRmsAbvGrd",
"xref": "x",
"y": "MiscVal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "Functional",
"xref": "x",
"y": "MiscVal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Fireplaces",
"xref": "x",
"y": "MiscVal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "GarageType",
"xref": "x",
"y": "MiscVal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "GarageYrBlt",
"xref": "x",
"y": "MiscVal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "GarageFinish",
"xref": "x",
"y": "MiscVal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "GarageCars",
"xref": "x",
"y": "MiscVal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "GarageArea",
"xref": "x",
"y": "MiscVal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "GarageQual",
"xref": "x",
"y": "MiscVal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "GarageCond",
"xref": "x",
"y": "MiscVal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "PavedDrive",
"xref": "x",
"y": "MiscVal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "WoodDeckSF",
"xref": "x",
"y": "MiscVal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "OpenPorchSF",
"xref": "x",
"y": "MiscVal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "EnclosedPorch",
"xref": "x",
"y": "MiscVal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "3SsnPorch",
"xref": "x",
"y": "MiscVal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "ScreenPorch",
"xref": "x",
"y": "MiscVal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "PoolArea",
"xref": "x",
"y": "MiscVal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "MiscVal",
"xref": "x",
"y": "MiscVal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "MoSold",
"xref": "x",
"y": "MiscVal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "YrSold",
"xref": "x",
"y": "MiscVal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "SaleType",
"xref": "x",
"y": "MiscVal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "SaleCondition",
"xref": "x",
"y": "MiscVal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "SalePrice",
"xref": "x",
"y": "MiscVal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "Id",
"xref": "x",
"y": "MoSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "MSSubClass",
"xref": "x",
"y": "MoSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "MSZoning",
"xref": "x",
"y": "MoSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "LotArea",
"xref": "x",
"y": "MoSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "Street",
"xref": "x",
"y": "MoSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "LotShape",
"xref": "x",
"y": "MoSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "LandContour",
"xref": "x",
"y": "MoSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "Utilities",
"xref": "x",
"y": "MoSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "LotConfig",
"xref": "x",
"y": "MoSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "LandSlope",
"xref": "x",
"y": "MoSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Neighborhood",
"xref": "x",
"y": "MoSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "Condition1",
"xref": "x",
"y": "MoSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Condition2",
"xref": "x",
"y": "MoSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "BldgType",
"xref": "x",
"y": "MoSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "HouseStyle",
"xref": "x",
"y": "MoSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "OverallQual",
"xref": "x",
"y": "MoSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "OverallCond",
"xref": "x",
"y": "MoSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "YearBuilt",
"xref": "x",
"y": "MoSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "YearRemodAdd",
"xref": "x",
"y": "MoSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "RoofStyle",
"xref": "x",
"y": "MoSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "RoofMatl",
"xref": "x",
"y": "MoSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "Exterior1st",
"xref": "x",
"y": "MoSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "Exterior2nd",
"xref": "x",
"y": "MoSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "MasVnrType",
"xref": "x",
"y": "MoSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "MasVnrArea",
"xref": "x",
"y": "MoSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "ExterQual",
"xref": "x",
"y": "MoSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "ExterCond",
"xref": "x",
"y": "MoSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "Foundation",
"xref": "x",
"y": "MoSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "BsmtQual",
"xref": "x",
"y": "MoSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "BsmtCond",
"xref": "x",
"y": "MoSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "BsmtExposure",
"xref": "x",
"y": "MoSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "BsmtFinType1",
"xref": "x",
"y": "MoSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "BsmtFinSF1",
"xref": "x",
"y": "MoSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "BsmtFinType2",
"xref": "x",
"y": "MoSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "BsmtFinSF2",
"xref": "x",
"y": "MoSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "BsmtUnfSF",
"xref": "x",
"y": "MoSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "TotalBsmtSF",
"xref": "x",
"y": "MoSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Heating",
"xref": "x",
"y": "MoSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "HeatingQC",
"xref": "x",
"y": "MoSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "CentralAir",
"xref": "x",
"y": "MoSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "Electrical",
"xref": "x",
"y": "MoSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "1stFlrSF",
"xref": "x",
"y": "MoSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "2ndFlrSF",
"xref": "x",
"y": "MoSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "LowQualFinSF",
"xref": "x",
"y": "MoSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "GrLivArea",
"xref": "x",
"y": "MoSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "BsmtFullBath",
"xref": "x",
"y": "MoSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "BsmtHalfBath",
"xref": "x",
"y": "MoSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "FullBath",
"xref": "x",
"y": "MoSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "HalfBath",
"xref": "x",
"y": "MoSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "BedroomAbvGr",
"xref": "x",
"y": "MoSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "KitchenAbvGr",
"xref": "x",
"y": "MoSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "KitchenQual",
"xref": "x",
"y": "MoSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "TotRmsAbvGrd",
"xref": "x",
"y": "MoSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Functional",
"xref": "x",
"y": "MoSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "Fireplaces",
"xref": "x",
"y": "MoSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "GarageType",
"xref": "x",
"y": "MoSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "GarageYrBlt",
"xref": "x",
"y": "MoSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "GarageFinish",
"xref": "x",
"y": "MoSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "GarageCars",
"xref": "x",
"y": "MoSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "GarageArea",
"xref": "x",
"y": "MoSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "GarageQual",
"xref": "x",
"y": "MoSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "GarageCond",
"xref": "x",
"y": "MoSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "PavedDrive",
"xref": "x",
"y": "MoSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "WoodDeckSF",
"xref": "x",
"y": "MoSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "OpenPorchSF",
"xref": "x",
"y": "MoSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "EnclosedPorch",
"xref": "x",
"y": "MoSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "3SsnPorch",
"xref": "x",
"y": "MoSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "ScreenPorch",
"xref": "x",
"y": "MoSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "PoolArea",
"xref": "x",
"y": "MoSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "MiscVal",
"xref": "x",
"y": "MoSold",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "MoSold",
"xref": "x",
"y": "MoSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.14",
"x": "YrSold",
"xref": "x",
"y": "MoSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "SaleType",
"xref": "x",
"y": "MoSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "SaleCondition",
"xref": "x",
"y": "MoSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "SalePrice",
"xref": "x",
"y": "MoSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "Id",
"xref": "x",
"y": "YrSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "MSSubClass",
"xref": "x",
"y": "YrSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "MSZoning",
"xref": "x",
"y": "YrSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "LotArea",
"xref": "x",
"y": "YrSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "Street",
"xref": "x",
"y": "YrSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "LotShape",
"xref": "x",
"y": "YrSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "LandContour",
"xref": "x",
"y": "YrSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "Utilities",
"xref": "x",
"y": "YrSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "LotConfig",
"xref": "x",
"y": "YrSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "LandSlope",
"xref": "x",
"y": "YrSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "Neighborhood",
"xref": "x",
"y": "YrSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "Condition1",
"xref": "x",
"y": "YrSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "Condition2",
"xref": "x",
"y": "YrSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "BldgType",
"xref": "x",
"y": "YrSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "HouseStyle",
"xref": "x",
"y": "YrSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "OverallQual",
"xref": "x",
"y": "YrSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "OverallCond",
"xref": "x",
"y": "YrSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "YearBuilt",
"xref": "x",
"y": "YrSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "YearRemodAdd",
"xref": "x",
"y": "YrSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "RoofStyle",
"xref": "x",
"y": "YrSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "RoofMatl",
"xref": "x",
"y": "YrSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "Exterior1st",
"xref": "x",
"y": "YrSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "Exterior2nd",
"xref": "x",
"y": "YrSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "MasVnrType",
"xref": "x",
"y": "YrSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "MasVnrArea",
"xref": "x",
"y": "YrSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "ExterQual",
"xref": "x",
"y": "YrSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "ExterCond",
"xref": "x",
"y": "YrSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Foundation",
"xref": "x",
"y": "YrSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "BsmtQual",
"xref": "x",
"y": "YrSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "BsmtCond",
"xref": "x",
"y": "YrSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "BsmtExposure",
"xref": "x",
"y": "YrSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "BsmtFinType1",
"xref": "x",
"y": "YrSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "BsmtFinSF1",
"xref": "x",
"y": "YrSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "BsmtFinType2",
"xref": "x",
"y": "YrSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "BsmtFinSF2",
"xref": "x",
"y": "YrSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "BsmtUnfSF",
"xref": "x",
"y": "YrSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "TotalBsmtSF",
"xref": "x",
"y": "YrSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "Heating",
"xref": "x",
"y": "YrSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "HeatingQC",
"xref": "x",
"y": "YrSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "CentralAir",
"xref": "x",
"y": "YrSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "Electrical",
"xref": "x",
"y": "YrSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "1stFlrSF",
"xref": "x",
"y": "YrSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "2ndFlrSF",
"xref": "x",
"y": "YrSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "LowQualFinSF",
"xref": "x",
"y": "YrSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "GrLivArea",
"xref": "x",
"y": "YrSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "BsmtFullBath",
"xref": "x",
"y": "YrSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "BsmtHalfBath",
"xref": "x",
"y": "YrSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "FullBath",
"xref": "x",
"y": "YrSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "HalfBath",
"xref": "x",
"y": "YrSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "BedroomAbvGr",
"xref": "x",
"y": "YrSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "KitchenAbvGr",
"xref": "x",
"y": "YrSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "KitchenQual",
"xref": "x",
"y": "YrSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "TotRmsAbvGrd",
"xref": "x",
"y": "YrSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "Functional",
"xref": "x",
"y": "YrSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "Fireplaces",
"xref": "x",
"y": "YrSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "GarageType",
"xref": "x",
"y": "YrSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "GarageYrBlt",
"xref": "x",
"y": "YrSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "GarageFinish",
"xref": "x",
"y": "YrSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "GarageCars",
"xref": "x",
"y": "YrSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "GarageArea",
"xref": "x",
"y": "YrSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "GarageQual",
"xref": "x",
"y": "YrSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "GarageCond",
"xref": "x",
"y": "YrSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "PavedDrive",
"xref": "x",
"y": "YrSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "WoodDeckSF",
"xref": "x",
"y": "YrSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "OpenPorchSF",
"xref": "x",
"y": "YrSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "EnclosedPorch",
"xref": "x",
"y": "YrSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "3SsnPorch",
"xref": "x",
"y": "YrSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "ScreenPorch",
"xref": "x",
"y": "YrSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "PoolArea",
"xref": "x",
"y": "YrSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "MiscVal",
"xref": "x",
"y": "YrSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.14",
"x": "MoSold",
"xref": "x",
"y": "YrSold",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "YrSold",
"xref": "x",
"y": "YrSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "SaleType",
"xref": "x",
"y": "YrSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "SaleCondition",
"xref": "x",
"y": "YrSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "SalePrice",
"xref": "x",
"y": "YrSold",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Id",
"xref": "x",
"y": "SaleType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "MSSubClass",
"xref": "x",
"y": "SaleType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "MSZoning",
"xref": "x",
"y": "SaleType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "LotArea",
"xref": "x",
"y": "SaleType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "Street",
"xref": "x",
"y": "SaleType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "LotShape",
"xref": "x",
"y": "SaleType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "LandContour",
"xref": "x",
"y": "SaleType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.13",
"x": "Utilities",
"xref": "x",
"y": "SaleType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "LotConfig",
"xref": "x",
"y": "SaleType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "LandSlope",
"xref": "x",
"y": "SaleType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "Neighborhood",
"xref": "x",
"y": "SaleType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "Condition1",
"xref": "x",
"y": "SaleType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "Condition2",
"xref": "x",
"y": "SaleType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "BldgType",
"xref": "x",
"y": "SaleType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "HouseStyle",
"xref": "x",
"y": "SaleType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "OverallQual",
"xref": "x",
"y": "SaleType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "OverallCond",
"xref": "x",
"y": "SaleType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "YearBuilt",
"xref": "x",
"y": "SaleType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "YearRemodAdd",
"xref": "x",
"y": "SaleType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "RoofStyle",
"xref": "x",
"y": "SaleType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "RoofMatl",
"xref": "x",
"y": "SaleType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "Exterior1st",
"xref": "x",
"y": "SaleType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Exterior2nd",
"xref": "x",
"y": "SaleType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "MasVnrType",
"xref": "x",
"y": "SaleType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "MasVnrArea",
"xref": "x",
"y": "SaleType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "ExterQual",
"xref": "x",
"y": "SaleType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "ExterCond",
"xref": "x",
"y": "SaleType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Foundation",
"xref": "x",
"y": "SaleType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "BsmtQual",
"xref": "x",
"y": "SaleType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "BsmtCond",
"xref": "x",
"y": "SaleType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "BsmtExposure",
"xref": "x",
"y": "SaleType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "BsmtFinType1",
"xref": "x",
"y": "SaleType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "BsmtFinSF1",
"xref": "x",
"y": "SaleType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "BsmtFinType2",
"xref": "x",
"y": "SaleType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "BsmtFinSF2",
"xref": "x",
"y": "SaleType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.09",
"x": "BsmtUnfSF",
"xref": "x",
"y": "SaleType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "TotalBsmtSF",
"xref": "x",
"y": "SaleType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "Heating",
"xref": "x",
"y": "SaleType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "HeatingQC",
"xref": "x",
"y": "SaleType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "CentralAir",
"xref": "x",
"y": "SaleType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "Electrical",
"xref": "x",
"y": "SaleType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.12",
"x": "1stFlrSF",
"xref": "x",
"y": "SaleType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "2ndFlrSF",
"xref": "x",
"y": "SaleType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "LowQualFinSF",
"xref": "x",
"y": "SaleType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "GrLivArea",
"xref": "x",
"y": "SaleType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "BsmtFullBath",
"xref": "x",
"y": "SaleType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "BsmtHalfBath",
"xref": "x",
"y": "SaleType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "FullBath",
"xref": "x",
"y": "SaleType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "HalfBath",
"xref": "x",
"y": "SaleType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "BedroomAbvGr",
"xref": "x",
"y": "SaleType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "KitchenAbvGr",
"xref": "x",
"y": "SaleType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "KitchenQual",
"xref": "x",
"y": "SaleType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "TotRmsAbvGrd",
"xref": "x",
"y": "SaleType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "Functional",
"xref": "x",
"y": "SaleType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "Fireplaces",
"xref": "x",
"y": "SaleType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "GarageType",
"xref": "x",
"y": "SaleType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "GarageYrBlt",
"xref": "x",
"y": "SaleType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "GarageFinish",
"xref": "x",
"y": "SaleType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "GarageCars",
"xref": "x",
"y": "SaleType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "GarageArea",
"xref": "x",
"y": "SaleType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "GarageQual",
"xref": "x",
"y": "SaleType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "GarageCond",
"xref": "x",
"y": "SaleType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "PavedDrive",
"xref": "x",
"y": "SaleType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "WoodDeckSF",
"xref": "x",
"y": "SaleType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "OpenPorchSF",
"xref": "x",
"y": "SaleType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "EnclosedPorch",
"xref": "x",
"y": "SaleType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "3SsnPorch",
"xref": "x",
"y": "SaleType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "ScreenPorch",
"xref": "x",
"y": "SaleType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "PoolArea",
"xref": "x",
"y": "SaleType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "MiscVal",
"xref": "x",
"y": "SaleType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "MoSold",
"xref": "x",
"y": "SaleType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "YrSold",
"xref": "x",
"y": "SaleType",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "SaleType",
"xref": "x",
"y": "SaleType",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.2",
"x": "SaleCondition",
"xref": "x",
"y": "SaleType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "SalePrice",
"xref": "x",
"y": "SaleType",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "Id",
"xref": "x",
"y": "SaleCondition",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "MSSubClass",
"xref": "x",
"y": "SaleCondition",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "MSZoning",
"xref": "x",
"y": "SaleCondition",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "LotArea",
"xref": "x",
"y": "SaleCondition",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "Street",
"xref": "x",
"y": "SaleCondition",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "LotShape",
"xref": "x",
"y": "SaleCondition",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "LandContour",
"xref": "x",
"y": "SaleCondition",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "Utilities",
"xref": "x",
"y": "SaleCondition",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "LotConfig",
"xref": "x",
"y": "SaleCondition",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "LandSlope",
"xref": "x",
"y": "SaleCondition",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "Neighborhood",
"xref": "x",
"y": "SaleCondition",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "Condition1",
"xref": "x",
"y": "SaleCondition",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "Condition2",
"xref": "x",
"y": "SaleCondition",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "BldgType",
"xref": "x",
"y": "SaleCondition",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "HouseStyle",
"xref": "x",
"y": "SaleCondition",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.19",
"x": "OverallQual",
"xref": "x",
"y": "SaleCondition",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "OverallCond",
"xref": "x",
"y": "SaleCondition",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.2",
"x": "YearBuilt",
"xref": "x",
"y": "SaleCondition",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.23",
"x": "YearRemodAdd",
"xref": "x",
"y": "SaleCondition",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "RoofStyle",
"xref": "x",
"y": "SaleCondition",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "RoofMatl",
"xref": "x",
"y": "SaleCondition",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "Exterior1st",
"xref": "x",
"y": "SaleCondition",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "Exterior2nd",
"xref": "x",
"y": "SaleCondition",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "MasVnrType",
"xref": "x",
"y": "SaleCondition",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "MasVnrArea",
"xref": "x",
"y": "SaleCondition",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.2",
"x": "ExterQual",
"xref": "x",
"y": "SaleCondition",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "ExterCond",
"xref": "x",
"y": "SaleCondition",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.17",
"x": "Foundation",
"xref": "x",
"y": "SaleCondition",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.18",
"x": "BsmtQual",
"xref": "x",
"y": "SaleCondition",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "BsmtCond",
"xref": "x",
"y": "SaleCondition",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "BsmtExposure",
"xref": "x",
"y": "SaleCondition",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "BsmtFinType1",
"xref": "x",
"y": "SaleCondition",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "BsmtFinSF1",
"xref": "x",
"y": "SaleCondition",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "BsmtFinType2",
"xref": "x",
"y": "SaleCondition",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "BsmtFinSF2",
"xref": "x",
"y": "SaleCondition",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.11",
"x": "BsmtUnfSF",
"xref": "x",
"y": "SaleCondition",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.11",
"x": "TotalBsmtSF",
"xref": "x",
"y": "SaleCondition",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "Heating",
"xref": "x",
"y": "SaleCondition",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.16",
"x": "HeatingQC",
"xref": "x",
"y": "SaleCondition",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "CentralAir",
"xref": "x",
"y": "SaleCondition",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "Electrical",
"xref": "x",
"y": "SaleCondition",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "1stFlrSF",
"xref": "x",
"y": "SaleCondition",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "2ndFlrSF",
"xref": "x",
"y": "SaleCondition",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "LowQualFinSF",
"xref": "x",
"y": "SaleCondition",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "GrLivArea",
"xref": "x",
"y": "SaleCondition",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "BsmtFullBath",
"xref": "x",
"y": "SaleCondition",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "BsmtHalfBath",
"xref": "x",
"y": "SaleCondition",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.15",
"x": "FullBath",
"xref": "x",
"y": "SaleCondition",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "HalfBath",
"xref": "x",
"y": "SaleCondition",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "BedroomAbvGr",
"xref": "x",
"y": "SaleCondition",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "KitchenAbvGr",
"xref": "x",
"y": "SaleCondition",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.14",
"x": "KitchenQual",
"xref": "x",
"y": "SaleCondition",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "TotRmsAbvGrd",
"xref": "x",
"y": "SaleCondition",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "Functional",
"xref": "x",
"y": "SaleCondition",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "Fireplaces",
"xref": "x",
"y": "SaleCondition",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "GarageType",
"xref": "x",
"y": "SaleCondition",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.21",
"x": "GarageYrBlt",
"xref": "x",
"y": "SaleCondition",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.15",
"x": "GarageFinish",
"xref": "x",
"y": "SaleCondition",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.15",
"x": "GarageCars",
"xref": "x",
"y": "SaleCondition",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "GarageArea",
"xref": "x",
"y": "SaleCondition",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "GarageQual",
"xref": "x",
"y": "SaleCondition",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "GarageCond",
"xref": "x",
"y": "SaleCondition",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "PavedDrive",
"xref": "x",
"y": "SaleCondition",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "WoodDeckSF",
"xref": "x",
"y": "SaleCondition",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "OpenPorchSF",
"xref": "x",
"y": "SaleCondition",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.12",
"x": "EnclosedPorch",
"xref": "x",
"y": "SaleCondition",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "3SsnPorch",
"xref": "x",
"y": "SaleCondition",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "ScreenPorch",
"xref": "x",
"y": "SaleCondition",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "PoolArea",
"xref": "x",
"y": "SaleCondition",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "MiscVal",
"xref": "x",
"y": "SaleCondition",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "MoSold",
"xref": "x",
"y": "SaleCondition",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "YrSold",
"xref": "x",
"y": "SaleCondition",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.2",
"x": "SaleType",
"xref": "x",
"y": "SaleCondition",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "SaleCondition",
"xref": "x",
"y": "SaleCondition",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.2",
"x": "SalePrice",
"xref": "x",
"y": "SaleCondition",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "Id",
"xref": "x",
"y": "SalePrice",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "MSSubClass",
"xref": "x",
"y": "SalePrice",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.16",
"x": "MSZoning",
"xref": "x",
"y": "SalePrice",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.25",
"x": "LotArea",
"xref": "x",
"y": "SalePrice",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "Street",
"xref": "x",
"y": "SalePrice",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.25",
"x": "LotShape",
"xref": "x",
"y": "SalePrice",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "LandContour",
"xref": "x",
"y": "SalePrice",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "Utilities",
"xref": "x",
"y": "SalePrice",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "LotConfig",
"xref": "x",
"y": "SalePrice",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "LandSlope",
"xref": "x",
"y": "SalePrice",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.2",
"x": "Neighborhood",
"xref": "x",
"y": "SalePrice",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "Condition1",
"xref": "x",
"y": "SalePrice",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "Condition2",
"xref": "x",
"y": "SalePrice",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "BldgType",
"xref": "x",
"y": "SalePrice",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.16",
"x": "HouseStyle",
"xref": "x",
"y": "SalePrice",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.78",
"x": "OverallQual",
"xref": "x",
"y": "SalePrice",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.11",
"x": "OverallCond",
"xref": "x",
"y": "SalePrice",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.5",
"x": "YearBuilt",
"xref": "x",
"y": "SalePrice",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.5",
"x": "YearRemodAdd",
"xref": "x",
"y": "SalePrice",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.23",
"x": "RoofStyle",
"xref": "x",
"y": "SalePrice",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "RoofMatl",
"xref": "x",
"y": "SalePrice",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "Exterior1st",
"xref": "x",
"y": "SalePrice",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "Exterior2nd",
"xref": "x",
"y": "SalePrice",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "MasVnrType",
"xref": "x",
"y": "SalePrice",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.47",
"x": "MasVnrArea",
"xref": "x",
"y": "SalePrice",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.65",
"x": "ExterQual",
"xref": "x",
"y": "SalePrice",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "ExterCond",
"xref": "x",
"y": "SalePrice",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.44",
"x": "Foundation",
"xref": "x",
"y": "SalePrice",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.61",
"x": "BsmtQual",
"xref": "x",
"y": "SalePrice",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "BsmtCond",
"xref": "x",
"y": "SalePrice",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.29",
"x": "BsmtExposure",
"xref": "x",
"y": "SalePrice",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "BsmtFinType1",
"xref": "x",
"y": "SalePrice",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.36",
"x": "BsmtFinSF1",
"xref": "x",
"y": "SalePrice",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "BsmtFinType2",
"xref": "x",
"y": "SalePrice",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "BsmtFinSF2",
"xref": "x",
"y": "SalePrice",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.19",
"x": "BsmtUnfSF",
"xref": "x",
"y": "SalePrice",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.6",
"x": "TotalBsmtSF",
"xref": "x",
"y": "SalePrice",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "Heating",
"xref": "x",
"y": "SalePrice",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.41",
"x": "HeatingQC",
"xref": "x",
"y": "SalePrice",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.2",
"x": "CentralAir",
"xref": "x",
"y": "SalePrice",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.21",
"x": "Electrical",
"xref": "x",
"y": "SalePrice",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.6",
"x": "1stFlrSF",
"xref": "x",
"y": "SalePrice",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.31",
"x": "2ndFlrSF",
"xref": "x",
"y": "SalePrice",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "LowQualFinSF",
"xref": "x",
"y": "SalePrice",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.71",
"x": "GrLivArea",
"xref": "x",
"y": "SalePrice",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.21",
"x": "BsmtFullBath",
"xref": "x",
"y": "SalePrice",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "BsmtHalfBath",
"xref": "x",
"y": "SalePrice",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.57",
"x": "FullBath",
"xref": "x",
"y": "SalePrice",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.26",
"x": "HalfBath",
"xref": "x",
"y": "SalePrice",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.17",
"x": "BedroomAbvGr",
"xref": "x",
"y": "SalePrice",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.11",
"x": "KitchenAbvGr",
"xref": "x",
"y": "SalePrice",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.62",
"x": "KitchenQual",
"xref": "x",
"y": "SalePrice",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.55",
"x": "TotRmsAbvGrd",
"xref": "x",
"y": "SalePrice",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.11",
"x": "Functional",
"xref": "x",
"y": "SalePrice",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.45",
"x": "Fireplaces",
"xref": "x",
"y": "SalePrice",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.35",
"x": "GarageType",
"xref": "x",
"y": "SalePrice",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.48",
"x": "GarageYrBlt",
"xref": "x",
"y": "SalePrice",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.51",
"x": "GarageFinish",
"xref": "x",
"y": "SalePrice",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.64",
"x": "GarageCars",
"xref": "x",
"y": "SalePrice",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.61",
"x": "GarageArea",
"xref": "x",
"y": "SalePrice",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "GarageQual",
"xref": "x",
"y": "SalePrice",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.15",
"x": "GarageCond",
"xref": "x",
"y": "SalePrice",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.18",
"x": "PavedDrive",
"xref": "x",
"y": "SalePrice",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.31",
"x": "WoodDeckSF",
"xref": "x",
"y": "SalePrice",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.32",
"x": "OpenPorchSF",
"xref": "x",
"y": "SalePrice",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.13",
"x": "EnclosedPorch",
"xref": "x",
"y": "SalePrice",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "3SsnPorch",
"xref": "x",
"y": "SalePrice",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "ScreenPorch",
"xref": "x",
"y": "SalePrice",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "PoolArea",
"xref": "x",
"y": "SalePrice",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "MiscVal",
"xref": "x",
"y": "SalePrice",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "MoSold",
"xref": "x",
"y": "SalePrice",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "YrSold",
"xref": "x",
"y": "SalePrice",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "SaleType",
"xref": "x",
"y": "SalePrice",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.2",
"x": "SaleCondition",
"xref": "x",
"y": "SalePrice",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "SalePrice",
"xref": "x",
"y": "SalePrice",
"yref": "y"
}
],
"template": {
"data": {
"bar": [
{
"error_x": {
"color": "#2a3f5f"
},
"error_y": {
"color": "#2a3f5f"
},
"marker": {
"line": {
"color": "#E5ECF6",
"width": 0.5
}
},
"type": "bar"
}
],
"barpolar": [
{
"marker": {
"line": {
"color": "#E5ECF6",
"width": 0.5
}
},
"type": "barpolar"
}
],
"carpet": [
{
"aaxis": {
"endlinecolor": "#2a3f5f",
"gridcolor": "white",
"linecolor": "white",
"minorgridcolor": "white",
"startlinecolor": "#2a3f5f"
},
"baxis": {
"endlinecolor": "#2a3f5f",
"gridcolor": "white",
"linecolor": "white",
"minorgridcolor": "white",
"startlinecolor": "#2a3f5f"
},
"type": "carpet"
}
],
"choropleth": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "choropleth"
}
],
"contour": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "contour"
}
],
"contourcarpet": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "contourcarpet"
}
],
"heatmap": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "heatmap"
}
],
"heatmapgl": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "heatmapgl"
}
],
"histogram": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "histogram"
}
],
"histogram2d": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "histogram2d"
}
],
"histogram2dcontour": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "histogram2dcontour"
}
],
"mesh3d": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "mesh3d"
}
],
"parcoords": [
{
"line": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "parcoords"
}
],
"pie": [
{
"automargin": true,
"type": "pie"
}
],
"scatter": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatter"
}
],
"scatter3d": [
{
"line": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatter3d"
}
],
"scattercarpet": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattercarpet"
}
],
"scattergeo": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattergeo"
}
],
"scattergl": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattergl"
}
],
"scattermapbox": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattermapbox"
}
],
"scatterpolar": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterpolar"
}
],
"scatterpolargl": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterpolargl"
}
],
"scatterternary": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterternary"
}
],
"surface": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "surface"
}
],
"table": [
{
"cells": {
"fill": {
"color": "#EBF0F8"
},
"line": {
"color": "white"
}
},
"header": {
"fill": {
"color": "#C8D4E3"
},
"line": {
"color": "white"
}
},
"type": "table"
}
]
},
"layout": {
"annotationdefaults": {
"arrowcolor": "#2a3f5f",
"arrowhead": 0,
"arrowwidth": 1
},
"coloraxis": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"colorscale": {
"diverging": [
[
0,
"#8e0152"
],
[
0.1,
"#c51b7d"
],
[
0.2,
"#de77ae"
],
[
0.3,
"#f1b6da"
],
[
0.4,
"#fde0ef"
],
[
0.5,
"#f7f7f7"
],
[
0.6,
"#e6f5d0"
],
[
0.7,
"#b8e186"
],
[
0.8,
"#7fbc41"
],
[
0.9,
"#4d9221"
],
[
1,
"#276419"
]
],
"sequential": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"sequentialminus": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
]
},
"colorway": [
"#636efa",
"#EF553B",
"#00cc96",
"#ab63fa",
"#FFA15A",
"#19d3f3",
"#FF6692",
"#B6E880",
"#FF97FF",
"#FECB52"
],
"font": {
"color": "#2a3f5f"
},
"geo": {
"bgcolor": "white",
"lakecolor": "white",
"landcolor": "#E5ECF6",
"showlakes": true,
"showland": true,
"subunitcolor": "white"
},
"hoverlabel": {
"align": "left"
},
"hovermode": "closest",
"mapbox": {
"style": "light"
},
"paper_bgcolor": "white",
"plot_bgcolor": "#E5ECF6",
"polar": {
"angularaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"bgcolor": "#E5ECF6",
"radialaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
}
},
"scene": {
"xaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
},
"yaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
},
"zaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
}
},
"shapedefaults": {
"line": {
"color": "#2a3f5f"
}
},
"ternary": {
"aaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"baxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"bgcolor": "#E5ECF6",
"caxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
}
},
"title": {
"x": 0.05
},
"xaxis": {
"automargin": true,
"gridcolor": "white",
"linecolor": "white",
"ticks": "",
"title": {
"standoff": 15
},
"zerolinecolor": "white",
"zerolinewidth": 2
},
"yaxis": {
"automargin": true,
"gridcolor": "white",
"linecolor": "white",
"ticks": "",
"title": {
"standoff": 15
},
"zerolinecolor": "white",
"zerolinewidth": 2
}
}
},
"xaxis": {
"dtick": 1,
"gridcolor": "rgb(0, 0, 0)",
"side": "top",
"ticks": ""
},
"yaxis": {
"dtick": 1,
"ticks": "",
"ticksuffix": " "
}
}
},
"text/html": [
"
\n",
" \n",
" \n",
" \n",
" \n",
"
"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"application/vnd.plotly.v1+json": {
"config": {
"linkText": "Export to plot.ly",
"plotlyServerURL": "https://plot.ly",
"showLink": true
},
"data": [
{
"histfunc": "count",
"histnorm": "",
"marker": {
"color": "rgba(255, 153, 51, 1.0)",
"line": {
"color": "#4D5663",
"width": 1.3
}
},
"name": "SalePrice",
"opacity": 0.8,
"orientation": "v",
"type": "histogram",
"x": [
208500,
181500,
223500,
140000,
250000,
143000,
307000,
200000,
129900,
118000,
129500,
345000,
144000,
279500,
157000,
132000,
149000,
159000,
139000,
325300,
139400,
230000,
129900,
154000,
256300,
134800,
306000,
207500,
68500,
40000,
149350,
179900,
165500,
277500,
309000,
145000,
153000,
109000,
160000,
170000,
144000,
130250,
141000,
319900,
239686,
249700,
127000,
177000,
114500,
110000,
385000,
130000,
180500,
172500,
196500,
438780,
124900,
158000,
101000,
202500,
140000,
219500,
317000,
180000,
226000,
80000,
225000,
244000,
129500,
185000,
144900,
107400,
91000,
135750,
127000,
110000,
193500,
153500,
245000,
126500,
168500,
260000,
174000,
164500,
98600,
163500,
133900,
204750,
185000,
214000,
94750,
83000,
205000,
178000,
198900,
169500,
250000,
100000,
115000,
190000,
136900,
180000,
383970,
217000,
259500,
176000,
139000,
155000,
320000,
163990,
180000,
100000,
136000,
153900,
181000,
128000,
155000,
150000,
226000,
244000,
150750,
220000,
180000,
174000,
143000,
171000,
230000,
231500,
260000,
166000,
204000,
125000,
130000,
105000,
222500,
115000,
122000,
372402,
190000,
235000,
125000,
269500,
254900,
320000,
162500,
412500,
220000,
152000,
190000,
325624,
183500,
228000,
128500,
215000,
239000,
163000,
184000,
243000,
211000,
172500,
501837,
100000,
177000,
200100,
200000,
127000,
475000,
173000,
135000,
153337,
286000,
315000,
184000,
192000,
130000,
127000,
148500,
311872,
235000,
274900,
140000,
171500,
112000,
149000,
110000,
180500,
143900,
141000,
277000,
145000,
186000,
252678,
156000,
161750,
134450,
210000,
107000,
311500,
167240,
204900,
200000,
179900,
97000,
386250,
112000,
290000,
106000,
125000,
192500,
148000,
403000,
94500,
128200,
89500,
185500,
194500,
318000,
113000,
262500,
79000,
120000,
205000,
241500,
137000,
140000,
180000,
277000,
235000,
173000,
158000,
145000,
230000,
207500,
220000,
231500,
176000,
276000,
151000,
130000,
73000,
175500,
185000,
179500,
120500,
148000,
266000,
241500,
290000,
139000,
124500,
205000,
201000,
141000,
415298,
192000,
228500,
185000,
207500,
244600,
179200,
164700,
159000,
122000,
153575,
233230,
131000,
235000,
167000,
142500,
152000,
239000,
175000,
158500,
157000,
267000,
205000,
149900,
295000,
305900,
225000,
82500,
360000,
165600,
132000,
119900,
375000,
178000,
188500,
260000,
270000,
260000,
187500,
342643,
354000,
301000,
126175,
242000,
87000,
324000,
145250,
214500,
78000,
119000,
139000,
207000,
192000,
228950,
377426,
214000,
202500,
155000,
202900,
82000,
266000,
85000,
140200,
151500,
157500,
154000,
437154,
318061,
190000,
95000,
105900,
140000,
177500,
173000,
134000,
130000,
280000,
156000,
145000,
118000,
190000,
147000,
159000,
165000,
132000,
162000,
172400,
125000,
123000,
219500,
148000,
340000,
394432,
179000,
127000,
187750,
213500,
76000,
240000,
192000,
125000,
191000,
426000,
119000,
215000,
109000,
129000,
123000,
169500,
67000,
241000,
245500,
164990,
108000,
258000,
168000,
150000,
115000,
177000,
280000,
339750,
60000,
145000,
222000,
115000,
228000,
181134,
149500,
239000,
126000,
142000,
206300,
215000,
113000,
315000,
139000,
135000,
275000,
109008,
195400,
175000,
85400,
122500,
181000,
212000,
116000,
119000,
90350,
110000,
555000,
162900,
172500,
210000,
127500,
190000,
199900,
119500,
120000,
110000,
280000,
204000,
210000,
188000,
175500,
98000,
256000,
161000,
110000,
263435,
155000,
62383,
188700,
178740,
167000,
146500,
250000,
187000,
212000,
190000,
148000,
440000,
251000,
132500,
208900,
380000,
297000,
89471,
326000,
374000,
155000,
164000,
132500,
147000,
156000,
175000,
160000,
86000,
115000,
133000,
172785,
155000,
91300,
430000,
184000,
130000,
120000,
113000,
226700,
140000,
289000,
147000,
124500,
215000,
208300,
161000,
124500,
164900,
202665,
129900,
134000,
96500,
402861,
158000,
265000,
211000,
234000,
150000,
159000,
184750,
315750,
176000,
132000,
446261,
175000,
128000,
178000,
188000,
111250,
158000,
272000,
315000,
248000,
213250,
133000,
179665,
229000,
210000,
129500,
125000,
263000,
140000,
112500,
255500,
284000,
113000,
141000,
108000,
175000,
234000,
121500,
170000,
185000,
268000,
128000,
325000,
214000,
316600,
135960,
142600,
120000,
224500,
170000,
139000,
118500,
145000,
164500,
146000,
131500,
181900,
253293,
325000,
133000,
369900,
130000,
137000,
143000,
79500,
185900,
451950,
138000,
140000,
110000,
319000,
114504,
194201,
217500,
151000,
275000,
141000,
220000,
151000,
221000,
205000,
152000,
225000,
359100,
118500,
313000,
148000,
261500,
137500,
183200,
105500,
314813,
305000,
240000,
135000,
168500,
165150,
160000,
139900,
153000,
135000,
168500,
124000,
209500,
82500,
139400,
144000,
93000,
264561,
274000,
226000,
345000,
152000,
370878,
143250,
155000,
155000,
108000,
191000,
135000,
350000,
88000,
145500,
149000,
97500,
167000,
197900,
402000,
110000,
137500,
423000,
230500,
129000,
193500,
168000,
137500,
173500,
103600,
165000,
257500,
140000,
148500,
87000,
109500,
372500,
128500,
143000,
159434,
173000,
285000,
221000,
207500,
227875,
148800,
392000,
194700,
141000,
755000,
335000,
108480,
141500,
176000,
89000,
123500,
138500,
196000,
312500,
140000,
361919,
140000,
213000,
302000,
254000,
179540,
109900,
102776,
189000,
129000,
130500,
165000,
159500,
157000,
341000,
128500,
275000,
143000,
124500,
135000,
320000,
120500,
222000,
194500,
110000,
103000,
236500,
187500,
222500,
131400,
108000,
163000,
239900,
190000,
132000,
142000,
179000,
175000,
180000,
299800,
236000,
265979,
260400,
162000,
217000,
275500,
156000,
172500,
212000,
158900,
179400,
290000,
127500,
100000,
215200,
337000,
270000,
264132,
196500,
160000,
216837,
538000,
134900,
102000,
107000,
114500,
395000,
162000,
221500,
142500,
135000,
176000,
175900,
187100,
165500,
161500,
139000,
233000,
107900,
187500,
160200,
146800,
269790,
225000,
194500,
171000,
143500,
110000,
485000,
175000,
200000,
109900,
189000,
582933,
118000,
227680,
135500,
223500,
159950,
106000,
181000,
144500,
55993,
157900,
116000,
224900,
137000,
271000,
155000,
224000,
183000,
93000,
225000,
139500,
232600,
385000,
189000,
185000,
147400,
166000,
151000,
237000,
167000,
139950,
128000,
153500,
100000,
144000,
130500,
140000,
157500,
174900,
153900,
171000,
213000,
133500,
240000,
187000,
131500,
215000,
164000,
158000,
170000,
127000,
147000,
174000,
152000,
250000,
189950,
131500,
152000,
132500,
250580,
148500,
248900,
129000,
236000,
109500,
200500,
116000,
133000,
66500,
303477,
132250,
350000,
148000,
136500,
157000,
187500,
178000,
118500,
100000,
328900,
145000,
135500,
268000,
149500,
122900,
172500,
154500,
165000,
140000,
106500,
611657,
135000,
110000,
153000,
180000,
240000,
125500,
128000,
255000,
250000,
131000,
174000,
154300,
143500,
88000,
145000,
173733,
75000,
35311,
135000,
238000,
176500,
201000,
169990,
193000,
207500,
175000,
285000,
176000,
236500,
222000,
201000,
117500,
320000,
190000,
242000,
79900,
253000,
239799,
244400,
150900,
214000,
143000,
137500,
124900,
143000,
270000,
197500,
129000,
119900,
133900,
172000,
145000,
124000,
132000,
185000,
155000,
272000,
155000,
239000,
214900,
178900,
160000,
135000,
140000,
173000,
99500,
167500,
165000,
110000,
139000,
178400,
336000,
159895,
255900,
125000,
117000,
395192,
195000,
197000,
348000,
168000,
187000,
173900,
337500,
121600,
136500,
185000,
91000,
206000,
86000,
232000,
136905,
181000,
149900,
163500,
88000,
240000,
135000,
165000,
85000,
119200,
227000,
203000,
187500,
160000,
213490,
176000,
194000,
87000,
191000,
287000,
112500,
167500,
293077,
105000,
118000,
197000,
310000,
230000,
119750,
315500,
287000,
80000,
155000,
173000,
196000,
262280,
278000,
556581,
145000,
176485,
200141,
165000,
144500,
255000,
180000,
185850,
248000,
335000,
220000,
213500,
81000,
90000,
110500,
154000,
328000,
178000,
167900,
151400,
135000,
135000,
154000,
91500,
159500,
194000,
219500,
170000,
138800,
155900,
126000,
145000,
133000,
192000,
160000,
187500,
147000,
83500,
252000,
137500,
197000,
160000,
136500,
146000,
129000,
176432,
170000,
128000,
157000,
60000,
119500,
135000,
159500,
106000,
325000,
179900,
274725,
181000,
280000,
188000,
205000,
129900,
134500,
117000,
318000,
184100,
130000,
140000,
133700,
118400,
212900,
112000,
163900,
115000,
174000,
259000,
215000,
140000,
135000,
117500,
239500,
169000,
102000,
119000,
196000,
144000,
139000,
197500,
424870,
80000,
149000,
180000,
174500,
116900,
143000,
124000,
149900,
230000,
120500,
201800,
218000,
179900,
230000,
235128,
185000,
146000,
224000,
129000,
108959,
194000,
233170,
245350,
173000,
235000,
625000,
171000,
163000,
171900,
239000,
285000,
119500,
115000,
154900,
250000,
392500,
745000,
120000,
186700,
104900,
95000,
262000,
195000,
189000,
168000,
174000,
125000,
165000,
158000,
176000,
219210,
144000,
178000,
148000,
116050,
197900,
117000,
213000,
153500,
271900,
107000,
200000,
140000,
290000,
189000,
164000,
113000,
145000,
134500,
125000,
229456,
115000,
134000,
143000,
137900,
184000,
145000,
214000,
147000,
367294,
127000,
190000,
132500,
142000,
138887,
175500,
195000,
142500,
265900,
224900,
248328,
170000,
230000,
178000,
186500,
169900,
129500,
119000,
244000,
171750,
130000,
294000,
165400,
127500,
301500,
190000,
151000,
181000,
128900,
161500,
180500,
181000,
183900,
122000,
378500,
381000,
144000,
260000,
185750,
137000,
177000,
139000,
137000,
162000,
197900,
68400,
227000,
180000,
150500,
169000,
132500,
143000,
190000,
278000,
281000,
180500,
119500,
107500,
162900,
115000,
138500,
155000,
140000,
160000,
154000,
225000,
177500,
290000,
232000,
130000,
325000,
202500,
138000,
147000,
179200,
335000,
203000,
302000,
333168,
119000,
206900,
295493,
208900,
275000,
111000,
156500,
190000,
147000,
130500,
256000,
176500,
227000,
132500,
100000,
125500,
125000,
167900,
135000,
200000,
128500,
123000,
155000,
228500,
177000,
155835,
108500,
262500,
283463,
215000,
200000,
171000,
134900,
410000,
235000,
170000,
110000,
149900,
177500,
315000,
189000,
260000,
104900,
156932,
144152,
216000,
193000,
127000,
144000,
232000,
105000,
165500,
274300,
466500,
250000,
239000,
91000,
117000,
83000,
58500,
237500,
157000,
112000,
105000,
125500,
250000,
136000,
377500,
131000,
235000,
124000,
123000,
163000,
246578,
281213,
160000,
137500,
138000,
137450,
120000,
193000,
193879,
282922,
105000,
275000,
133000,
125500,
215000,
230000,
140000,
257000,
207000,
175900,
122500,
340000,
124000,
223000,
179900,
127500,
136500,
274970,
144000,
142000,
271000,
140000,
119000,
182900,
192140,
143750,
64500,
186500,
160000,
174000,
120500,
394617,
149700,
197000,
191000,
149300,
310000,
121000,
179600,
129000,
157900,
240000,
112000,
287090,
145000,
185000,
175000,
210000,
266500,
142125,
147500
]
}
],
"layout": {
"barmode": "overlay",
"legend": {
"bgcolor": "#F5F6F9",
"font": {
"color": "#4D5663"
}
},
"paper_bgcolor": "#F5F6F9",
"plot_bgcolor": "#F5F6F9",
"template": {
"data": {
"bar": [
{
"error_x": {
"color": "#2a3f5f"
},
"error_y": {
"color": "#2a3f5f"
},
"marker": {
"line": {
"color": "#E5ECF6",
"width": 0.5
}
},
"type": "bar"
}
],
"barpolar": [
{
"marker": {
"line": {
"color": "#E5ECF6",
"width": 0.5
}
},
"type": "barpolar"
}
],
"carpet": [
{
"aaxis": {
"endlinecolor": "#2a3f5f",
"gridcolor": "white",
"linecolor": "white",
"minorgridcolor": "white",
"startlinecolor": "#2a3f5f"
},
"baxis": {
"endlinecolor": "#2a3f5f",
"gridcolor": "white",
"linecolor": "white",
"minorgridcolor": "white",
"startlinecolor": "#2a3f5f"
},
"type": "carpet"
}
],
"choropleth": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "choropleth"
}
],
"contour": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "contour"
}
],
"contourcarpet": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "contourcarpet"
}
],
"heatmap": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "heatmap"
}
],
"heatmapgl": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "heatmapgl"
}
],
"histogram": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "histogram"
}
],
"histogram2d": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "histogram2d"
}
],
"histogram2dcontour": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "histogram2dcontour"
}
],
"mesh3d": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "mesh3d"
}
],
"parcoords": [
{
"line": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "parcoords"
}
],
"pie": [
{
"automargin": true,
"type": "pie"
}
],
"scatter": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatter"
}
],
"scatter3d": [
{
"line": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatter3d"
}
],
"scattercarpet": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattercarpet"
}
],
"scattergeo": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattergeo"
}
],
"scattergl": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattergl"
}
],
"scattermapbox": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattermapbox"
}
],
"scatterpolar": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterpolar"
}
],
"scatterpolargl": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterpolargl"
}
],
"scatterternary": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterternary"
}
],
"surface": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "surface"
}
],
"table": [
{
"cells": {
"fill": {
"color": "#EBF0F8"
},
"line": {
"color": "white"
}
},
"header": {
"fill": {
"color": "#C8D4E3"
},
"line": {
"color": "white"
}
},
"type": "table"
}
]
},
"layout": {
"annotationdefaults": {
"arrowcolor": "#2a3f5f",
"arrowhead": 0,
"arrowwidth": 1
},
"coloraxis": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"colorscale": {
"diverging": [
[
0,
"#8e0152"
],
[
0.1,
"#c51b7d"
],
[
0.2,
"#de77ae"
],
[
0.3,
"#f1b6da"
],
[
0.4,
"#fde0ef"
],
[
0.5,
"#f7f7f7"
],
[
0.6,
"#e6f5d0"
],
[
0.7,
"#b8e186"
],
[
0.8,
"#7fbc41"
],
[
0.9,
"#4d9221"
],
[
1,
"#276419"
]
],
"sequential": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"sequentialminus": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
]
},
"colorway": [
"#636efa",
"#EF553B",
"#00cc96",
"#ab63fa",
"#FFA15A",
"#19d3f3",
"#FF6692",
"#B6E880",
"#FF97FF",
"#FECB52"
],
"font": {
"color": "#2a3f5f"
},
"geo": {
"bgcolor": "white",
"lakecolor": "white",
"landcolor": "#E5ECF6",
"showlakes": true,
"showland": true,
"subunitcolor": "white"
},
"hoverlabel": {
"align": "left"
},
"hovermode": "closest",
"mapbox": {
"style": "light"
},
"paper_bgcolor": "white",
"plot_bgcolor": "#E5ECF6",
"polar": {
"angularaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"bgcolor": "#E5ECF6",
"radialaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
}
},
"scene": {
"xaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
},
"yaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
},
"zaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
}
},
"shapedefaults": {
"line": {
"color": "#2a3f5f"
}
},
"ternary": {
"aaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"baxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"bgcolor": "#E5ECF6",
"caxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
}
},
"title": {
"x": 0.05
},
"xaxis": {
"automargin": true,
"gridcolor": "white",
"linecolor": "white",
"ticks": "",
"title": {
"standoff": 15
},
"zerolinecolor": "white",
"zerolinewidth": 2
},
"yaxis": {
"automargin": true,
"gridcolor": "white",
"linecolor": "white",
"ticks": "",
"title": {
"standoff": 15
},
"zerolinecolor": "white",
"zerolinewidth": 2
}
}
},
"title": {
"font": {
"color": "#4D5663"
},
"text": "SalePrice Distribution"
},
"xaxis": {
"gridcolor": "#E1E5ED",
"showgrid": true,
"tickfont": {
"color": "#4D5663"
},
"title": {
"font": {
"color": "#4D5663"
},
"text": ""
},
"zerolinecolor": "#E1E5ED"
},
"yaxis": {
"gridcolor": "#E1E5ED",
"showgrid": true,
"tickfont": {
"color": "#4D5663"
},
"title": {
"font": {
"color": "#4D5663"
},
"text": ""
},
"zerolinecolor": "#E1E5ED"
}
}
},
"text/html": [
"\n",
" \n",
" \n",
" \n",
" \n",
"
"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"application/vnd.plotly.v1+json": {
"config": {
"linkText": "Export to plot.ly",
"plotlyServerURL": "https://plot.ly",
"showLink": true
},
"data": [
{
"boxpoints": false,
"line": {
"width": 1.3
},
"marker": {
"color": "rgba(255, 153, 51, 1.0)"
},
"name": "SalePrice",
"orientation": "v",
"type": "box",
"y": [
208500,
181500,
223500,
140000,
250000,
143000,
307000,
200000,
129900,
118000,
129500,
345000,
144000,
279500,
157000,
132000,
149000,
159000,
139000,
325300,
139400,
230000,
129900,
154000,
256300,
134800,
306000,
207500,
68500,
40000,
149350,
179900,
165500,
277500,
309000,
145000,
153000,
109000,
160000,
170000,
144000,
130250,
141000,
319900,
239686,
249700,
127000,
177000,
114500,
110000,
385000,
130000,
180500,
172500,
196500,
438780,
124900,
158000,
101000,
202500,
140000,
219500,
317000,
180000,
226000,
80000,
225000,
244000,
129500,
185000,
144900,
107400,
91000,
135750,
127000,
110000,
193500,
153500,
245000,
126500,
168500,
260000,
174000,
164500,
98600,
163500,
133900,
204750,
185000,
214000,
94750,
83000,
205000,
178000,
198900,
169500,
250000,
100000,
115000,
190000,
136900,
180000,
383970,
217000,
259500,
176000,
139000,
155000,
320000,
163990,
180000,
100000,
136000,
153900,
181000,
128000,
155000,
150000,
226000,
244000,
150750,
220000,
180000,
174000,
143000,
171000,
230000,
231500,
260000,
166000,
204000,
125000,
130000,
105000,
222500,
115000,
122000,
372402,
190000,
235000,
125000,
269500,
254900,
320000,
162500,
412500,
220000,
152000,
190000,
325624,
183500,
228000,
128500,
215000,
239000,
163000,
184000,
243000,
211000,
172500,
501837,
100000,
177000,
200100,
200000,
127000,
475000,
173000,
135000,
153337,
286000,
315000,
184000,
192000,
130000,
127000,
148500,
311872,
235000,
274900,
140000,
171500,
112000,
149000,
110000,
180500,
143900,
141000,
277000,
145000,
186000,
252678,
156000,
161750,
134450,
210000,
107000,
311500,
167240,
204900,
200000,
179900,
97000,
386250,
112000,
290000,
106000,
125000,
192500,
148000,
403000,
94500,
128200,
89500,
185500,
194500,
318000,
113000,
262500,
79000,
120000,
205000,
241500,
137000,
140000,
180000,
277000,
235000,
173000,
158000,
145000,
230000,
207500,
220000,
231500,
176000,
276000,
151000,
130000,
73000,
175500,
185000,
179500,
120500,
148000,
266000,
241500,
290000,
139000,
124500,
205000,
201000,
141000,
415298,
192000,
228500,
185000,
207500,
244600,
179200,
164700,
159000,
122000,
153575,
233230,
131000,
235000,
167000,
142500,
152000,
239000,
175000,
158500,
157000,
267000,
205000,
149900,
295000,
305900,
225000,
82500,
360000,
165600,
132000,
119900,
375000,
178000,
188500,
260000,
270000,
260000,
187500,
342643,
354000,
301000,
126175,
242000,
87000,
324000,
145250,
214500,
78000,
119000,
139000,
207000,
192000,
228950,
377426,
214000,
202500,
155000,
202900,
82000,
266000,
85000,
140200,
151500,
157500,
154000,
437154,
318061,
190000,
95000,
105900,
140000,
177500,
173000,
134000,
130000,
280000,
156000,
145000,
118000,
190000,
147000,
159000,
165000,
132000,
162000,
172400,
125000,
123000,
219500,
148000,
340000,
394432,
179000,
127000,
187750,
213500,
76000,
240000,
192000,
125000,
191000,
426000,
119000,
215000,
109000,
129000,
123000,
169500,
67000,
241000,
245500,
164990,
108000,
258000,
168000,
150000,
115000,
177000,
280000,
339750,
60000,
145000,
222000,
115000,
228000,
181134,
149500,
239000,
126000,
142000,
206300,
215000,
113000,
315000,
139000,
135000,
275000,
109008,
195400,
175000,
85400,
122500,
181000,
212000,
116000,
119000,
90350,
110000,
555000,
162900,
172500,
210000,
127500,
190000,
199900,
119500,
120000,
110000,
280000,
204000,
210000,
188000,
175500,
98000,
256000,
161000,
110000,
263435,
155000,
62383,
188700,
178740,
167000,
146500,
250000,
187000,
212000,
190000,
148000,
440000,
251000,
132500,
208900,
380000,
297000,
89471,
326000,
374000,
155000,
164000,
132500,
147000,
156000,
175000,
160000,
86000,
115000,
133000,
172785,
155000,
91300,
430000,
184000,
130000,
120000,
113000,
226700,
140000,
289000,
147000,
124500,
215000,
208300,
161000,
124500,
164900,
202665,
129900,
134000,
96500,
402861,
158000,
265000,
211000,
234000,
150000,
159000,
184750,
315750,
176000,
132000,
446261,
175000,
128000,
178000,
188000,
111250,
158000,
272000,
315000,
248000,
213250,
133000,
179665,
229000,
210000,
129500,
125000,
263000,
140000,
112500,
255500,
284000,
113000,
141000,
108000,
175000,
234000,
121500,
170000,
185000,
268000,
128000,
325000,
214000,
316600,
135960,
142600,
120000,
224500,
170000,
139000,
118500,
145000,
164500,
146000,
131500,
181900,
253293,
325000,
133000,
369900,
130000,
137000,
143000,
79500,
185900,
451950,
138000,
140000,
110000,
319000,
114504,
194201,
217500,
151000,
275000,
141000,
220000,
151000,
221000,
205000,
152000,
225000,
359100,
118500,
313000,
148000,
261500,
137500,
183200,
105500,
314813,
305000,
240000,
135000,
168500,
165150,
160000,
139900,
153000,
135000,
168500,
124000,
209500,
82500,
139400,
144000,
93000,
264561,
274000,
226000,
345000,
152000,
370878,
143250,
155000,
155000,
108000,
191000,
135000,
350000,
88000,
145500,
149000,
97500,
167000,
197900,
402000,
110000,
137500,
423000,
230500,
129000,
193500,
168000,
137500,
173500,
103600,
165000,
257500,
140000,
148500,
87000,
109500,
372500,
128500,
143000,
159434,
173000,
285000,
221000,
207500,
227875,
148800,
392000,
194700,
141000,
755000,
335000,
108480,
141500,
176000,
89000,
123500,
138500,
196000,
312500,
140000,
361919,
140000,
213000,
302000,
254000,
179540,
109900,
102776,
189000,
129000,
130500,
165000,
159500,
157000,
341000,
128500,
275000,
143000,
124500,
135000,
320000,
120500,
222000,
194500,
110000,
103000,
236500,
187500,
222500,
131400,
108000,
163000,
239900,
190000,
132000,
142000,
179000,
175000,
180000,
299800,
236000,
265979,
260400,
162000,
217000,
275500,
156000,
172500,
212000,
158900,
179400,
290000,
127500,
100000,
215200,
337000,
270000,
264132,
196500,
160000,
216837,
538000,
134900,
102000,
107000,
114500,
395000,
162000,
221500,
142500,
135000,
176000,
175900,
187100,
165500,
161500,
139000,
233000,
107900,
187500,
160200,
146800,
269790,
225000,
194500,
171000,
143500,
110000,
485000,
175000,
200000,
109900,
189000,
582933,
118000,
227680,
135500,
223500,
159950,
106000,
181000,
144500,
55993,
157900,
116000,
224900,
137000,
271000,
155000,
224000,
183000,
93000,
225000,
139500,
232600,
385000,
189000,
185000,
147400,
166000,
151000,
237000,
167000,
139950,
128000,
153500,
100000,
144000,
130500,
140000,
157500,
174900,
153900,
171000,
213000,
133500,
240000,
187000,
131500,
215000,
164000,
158000,
170000,
127000,
147000,
174000,
152000,
250000,
189950,
131500,
152000,
132500,
250580,
148500,
248900,
129000,
236000,
109500,
200500,
116000,
133000,
66500,
303477,
132250,
350000,
148000,
136500,
157000,
187500,
178000,
118500,
100000,
328900,
145000,
135500,
268000,
149500,
122900,
172500,
154500,
165000,
140000,
106500,
611657,
135000,
110000,
153000,
180000,
240000,
125500,
128000,
255000,
250000,
131000,
174000,
154300,
143500,
88000,
145000,
173733,
75000,
35311,
135000,
238000,
176500,
201000,
169990,
193000,
207500,
175000,
285000,
176000,
236500,
222000,
201000,
117500,
320000,
190000,
242000,
79900,
253000,
239799,
244400,
150900,
214000,
143000,
137500,
124900,
143000,
270000,
197500,
129000,
119900,
133900,
172000,
145000,
124000,
132000,
185000,
155000,
272000,
155000,
239000,
214900,
178900,
160000,
135000,
140000,
173000,
99500,
167500,
165000,
110000,
139000,
178400,
336000,
159895,
255900,
125000,
117000,
395192,
195000,
197000,
348000,
168000,
187000,
173900,
337500,
121600,
136500,
185000,
91000,
206000,
86000,
232000,
136905,
181000,
149900,
163500,
88000,
240000,
135000,
165000,
85000,
119200,
227000,
203000,
187500,
160000,
213490,
176000,
194000,
87000,
191000,
287000,
112500,
167500,
293077,
105000,
118000,
197000,
310000,
230000,
119750,
315500,
287000,
80000,
155000,
173000,
196000,
262280,
278000,
556581,
145000,
176485,
200141,
165000,
144500,
255000,
180000,
185850,
248000,
335000,
220000,
213500,
81000,
90000,
110500,
154000,
328000,
178000,
167900,
151400,
135000,
135000,
154000,
91500,
159500,
194000,
219500,
170000,
138800,
155900,
126000,
145000,
133000,
192000,
160000,
187500,
147000,
83500,
252000,
137500,
197000,
160000,
136500,
146000,
129000,
176432,
170000,
128000,
157000,
60000,
119500,
135000,
159500,
106000,
325000,
179900,
274725,
181000,
280000,
188000,
205000,
129900,
134500,
117000,
318000,
184100,
130000,
140000,
133700,
118400,
212900,
112000,
163900,
115000,
174000,
259000,
215000,
140000,
135000,
117500,
239500,
169000,
102000,
119000,
196000,
144000,
139000,
197500,
424870,
80000,
149000,
180000,
174500,
116900,
143000,
124000,
149900,
230000,
120500,
201800,
218000,
179900,
230000,
235128,
185000,
146000,
224000,
129000,
108959,
194000,
233170,
245350,
173000,
235000,
625000,
171000,
163000,
171900,
239000,
285000,
119500,
115000,
154900,
250000,
392500,
745000,
120000,
186700,
104900,
95000,
262000,
195000,
189000,
168000,
174000,
125000,
165000,
158000,
176000,
219210,
144000,
178000,
148000,
116050,
197900,
117000,
213000,
153500,
271900,
107000,
200000,
140000,
290000,
189000,
164000,
113000,
145000,
134500,
125000,
229456,
115000,
134000,
143000,
137900,
184000,
145000,
214000,
147000,
367294,
127000,
190000,
132500,
142000,
138887,
175500,
195000,
142500,
265900,
224900,
248328,
170000,
230000,
178000,
186500,
169900,
129500,
119000,
244000,
171750,
130000,
294000,
165400,
127500,
301500,
190000,
151000,
181000,
128900,
161500,
180500,
181000,
183900,
122000,
378500,
381000,
144000,
260000,
185750,
137000,
177000,
139000,
137000,
162000,
197900,
68400,
227000,
180000,
150500,
169000,
132500,
143000,
190000,
278000,
281000,
180500,
119500,
107500,
162900,
115000,
138500,
155000,
140000,
160000,
154000,
225000,
177500,
290000,
232000,
130000,
325000,
202500,
138000,
147000,
179200,
335000,
203000,
302000,
333168,
119000,
206900,
295493,
208900,
275000,
111000,
156500,
190000,
147000,
130500,
256000,
176500,
227000,
132500,
100000,
125500,
125000,
167900,
135000,
200000,
128500,
123000,
155000,
228500,
177000,
155835,
108500,
262500,
283463,
215000,
200000,
171000,
134900,
410000,
235000,
170000,
110000,
149900,
177500,
315000,
189000,
260000,
104900,
156932,
144152,
216000,
193000,
127000,
144000,
232000,
105000,
165500,
274300,
466500,
250000,
239000,
91000,
117000,
83000,
58500,
237500,
157000,
112000,
105000,
125500,
250000,
136000,
377500,
131000,
235000,
124000,
123000,
163000,
246578,
281213,
160000,
137500,
138000,
137450,
120000,
193000,
193879,
282922,
105000,
275000,
133000,
125500,
215000,
230000,
140000,
257000,
207000,
175900,
122500,
340000,
124000,
223000,
179900,
127500,
136500,
274970,
144000,
142000,
271000,
140000,
119000,
182900,
192140,
143750,
64500,
186500,
160000,
174000,
120500,
394617,
149700,
197000,
191000,
149300,
310000,
121000,
179600,
129000,
157900,
240000,
112000,
287090,
145000,
185000,
175000,
210000,
266500,
142125,
147500
]
}
],
"layout": {
"legend": {
"bgcolor": "#F5F6F9",
"font": {
"color": "#4D5663"
}
},
"paper_bgcolor": "#F5F6F9",
"plot_bgcolor": "#F5F6F9",
"template": {
"data": {
"bar": [
{
"error_x": {
"color": "#2a3f5f"
},
"error_y": {
"color": "#2a3f5f"
},
"marker": {
"line": {
"color": "#E5ECF6",
"width": 0.5
}
},
"type": "bar"
}
],
"barpolar": [
{
"marker": {
"line": {
"color": "#E5ECF6",
"width": 0.5
}
},
"type": "barpolar"
}
],
"carpet": [
{
"aaxis": {
"endlinecolor": "#2a3f5f",
"gridcolor": "white",
"linecolor": "white",
"minorgridcolor": "white",
"startlinecolor": "#2a3f5f"
},
"baxis": {
"endlinecolor": "#2a3f5f",
"gridcolor": "white",
"linecolor": "white",
"minorgridcolor": "white",
"startlinecolor": "#2a3f5f"
},
"type": "carpet"
}
],
"choropleth": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "choropleth"
}
],
"contour": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "contour"
}
],
"contourcarpet": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "contourcarpet"
}
],
"heatmap": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "heatmap"
}
],
"heatmapgl": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "heatmapgl"
}
],
"histogram": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "histogram"
}
],
"histogram2d": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "histogram2d"
}
],
"histogram2dcontour": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "histogram2dcontour"
}
],
"mesh3d": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "mesh3d"
}
],
"parcoords": [
{
"line": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "parcoords"
}
],
"pie": [
{
"automargin": true,
"type": "pie"
}
],
"scatter": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatter"
}
],
"scatter3d": [
{
"line": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatter3d"
}
],
"scattercarpet": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattercarpet"
}
],
"scattergeo": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattergeo"
}
],
"scattergl": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattergl"
}
],
"scattermapbox": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattermapbox"
}
],
"scatterpolar": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterpolar"
}
],
"scatterpolargl": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterpolargl"
}
],
"scatterternary": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterternary"
}
],
"surface": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "surface"
}
],
"table": [
{
"cells": {
"fill": {
"color": "#EBF0F8"
},
"line": {
"color": "white"
}
},
"header": {
"fill": {
"color": "#C8D4E3"
},
"line": {
"color": "white"
}
},
"type": "table"
}
]
},
"layout": {
"annotationdefaults": {
"arrowcolor": "#2a3f5f",
"arrowhead": 0,
"arrowwidth": 1
},
"coloraxis": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"colorscale": {
"diverging": [
[
0,
"#8e0152"
],
[
0.1,
"#c51b7d"
],
[
0.2,
"#de77ae"
],
[
0.3,
"#f1b6da"
],
[
0.4,
"#fde0ef"
],
[
0.5,
"#f7f7f7"
],
[
0.6,
"#e6f5d0"
],
[
0.7,
"#b8e186"
],
[
0.8,
"#7fbc41"
],
[
0.9,
"#4d9221"
],
[
1,
"#276419"
]
],
"sequential": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"sequentialminus": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
]
},
"colorway": [
"#636efa",
"#EF553B",
"#00cc96",
"#ab63fa",
"#FFA15A",
"#19d3f3",
"#FF6692",
"#B6E880",
"#FF97FF",
"#FECB52"
],
"font": {
"color": "#2a3f5f"
},
"geo": {
"bgcolor": "white",
"lakecolor": "white",
"landcolor": "#E5ECF6",
"showlakes": true,
"showland": true,
"subunitcolor": "white"
},
"hoverlabel": {
"align": "left"
},
"hovermode": "closest",
"mapbox": {
"style": "light"
},
"paper_bgcolor": "white",
"plot_bgcolor": "#E5ECF6",
"polar": {
"angularaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"bgcolor": "#E5ECF6",
"radialaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
}
},
"scene": {
"xaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
},
"yaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
},
"zaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
}
},
"shapedefaults": {
"line": {
"color": "#2a3f5f"
}
},
"ternary": {
"aaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"baxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"bgcolor": "#E5ECF6",
"caxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
}
},
"title": {
"x": 0.05
},
"xaxis": {
"automargin": true,
"gridcolor": "white",
"linecolor": "white",
"ticks": "",
"title": {
"standoff": 15
},
"zerolinecolor": "white",
"zerolinewidth": 2
},
"yaxis": {
"automargin": true,
"gridcolor": "white",
"linecolor": "white",
"ticks": "",
"title": {
"standoff": 15
},
"zerolinecolor": "white",
"zerolinewidth": 2
}
}
},
"title": {
"font": {
"color": "#4D5663"
},
"text": "SalePrice Box plot"
},
"xaxis": {
"gridcolor": "#E1E5ED",
"showgrid": true,
"tickfont": {
"color": "#4D5663"
},
"title": {
"font": {
"color": "#4D5663"
},
"text": ""
},
"zerolinecolor": "#E1E5ED"
},
"yaxis": {
"gridcolor": "#E1E5ED",
"showgrid": true,
"tickfont": {
"color": "#4D5663"
},
"title": {
"font": {
"color": "#4D5663"
},
"text": ""
},
"zerolinecolor": "#E1E5ED"
}
}
},
"text/html": [
"\n",
" \n",
" \n",
" \n",
" \n",
"
"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"Detailed Executing with RandomForest ..\n"
]
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAApoAAAGwCAYAAAAJ08UyAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADt0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjByYzEsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy/xvVyzAAAgAElEQVR4nO3debgkZX3+//cNw74vgizCoBIQFFlORERlEfcFiSCiUUdNcDeY4PKNCaIman5JNCpuGBWJEhQQRI0rMuACwgwMDItolCGCKGGRTUAYPr8/qk5omj4zfc6cmrPM+3VdfZ3uqqee+lR1zTn3PFVdnapCkiRJmmyrTXUBkiRJmp0MmpIkSeqEQVOSJEmdMGhKkiSpEwZNSZIkdcKgKUmSpE4YNKVVQJJ5SSrJvKmuRZK06jBoSuPUBrbex9IkNyeZ3wa6THWNM12SYwfs597HkqmucSLa2udPYLkTlrM/xt3nRPXUMndlrXOyJNl/Ze+vqeJ/LjVdzJnqAqQZ7D3tzzWARwOHAPsBI8CbpqqoWeYcYP6A6b9fyXVMF18DFg2YvmQl1yFJQzFoShNUVcf2vk6yL3Au8IYk/1pVV09JYbPL/P79vIo7o6pOmOoiJGlYnjqXJklV/Rj4GRBgr955SfZK8pEkl7Sn2e9O8osk/5pkk/6+ek97JTmgPS1/e5LbknwzyWMG1ZDk0UlOSXJLkjuT/CTJc5dVd1vbaUluSHJPkmuSfCLJVgPajp423SHJm5Jc0W7LkiR/O3rZQJLDklzQ1nBDkuOSrD2O3TkuE9yGRyZ5c5JLk9zVezo1yaZJPpDkynberUnOSvKMAf2tmeQtSS5q9/sf2v3xtSQHtW3mJRn9vt/9+k57H9vB/jgiydltPXe32/F3SdYa0PaFSb6Y5Oft+3VHkoXtNq3W17aAV7Yvrx50KUO77UsYIA9cErF/f7/tMf7wJP+e5Lo0l6TM62mzd5JTk/w2yR+T/DrJp5NsPdH91NN377+3pyf5Ybsf/jfJ55Ns3LbbI8k32v16R5IzM+ASgnZbKslaSf4hydXtcfnLJO9OsuYYdTwtybfzwO+Inyf5YJKNlrGONZMck+Sqdh0ntMfy59umn+873ua2y2/dLvfjnn36myQnZcDvlyRz2+VPaJ+fnOTGts4FSZ63jP17ePvvZ3S7liT5zyQjA9oOfexqZnBEU5pco9dn3ts3/S9pTq2fA3wfWB3YE/hr4NlJ9q6q2wf09zzgYOBbwKeAXYDnAH+aZJequvH/VpzsCJwHbNa2X0RzSv+M9vVDi23+OJzW1n0qcA1NSH49cHCSfatqyYBF/wXYH/g68F3gBcA/AmsmuRn4YLveHwJPB97YbvPrB9WxIlZgGz4CPAX4JvBfwNK2v+1pTtfPbev/NrAezXvx7SSvrarP9PRzAnAEcBlwInAXsDXwZOBZNO/3IppLLd7d1ndCz/LzJ7rtgyT5LPBq4FrgqzSXGTwReB/wtCRPr6r7ehb5IHA/8FPgOmAj4ECa/fOnwMt72r4HeCHw+Hb+6CUMk3Epw6bA+cAdbd33A79rt+lVwGeAe4AzgV8DOwJ/ATw/yROr6n8moYYX0LzP36D59/YkYB6wQ5J3AmfRHBOfBR4HPB94VJLHVdX9A/r7Cs0+PJXmd8LBwLHASJIXVNXofz5I8lrgk8CdwCnADTT/xt7RbuO+VTVoP5/WruNbNP/mbqA5pn7frq//covRPp4KvBM4u+3jDpp9eijwgnZ9lwxY3/bABcCvgP+ged8OB76W5KCqOrtnm0ITeF8J3Ejzvv4vsC1wAHAVsKCn/XiPXc0EVeXDh49xPIBq/uk8ZPpTacLKPcBWffO2B1YfsMxr2v7e0Td9Xjv9PuBpffM+0M57e9/077bT/6pv+sGjNQPzeqavT/PLfynwlL5l3tG2/27f9BPa6UuAbXqmb9z2dSfNH5LH9MxbC7ii3S9bDLmPj23XM7993v+YOwnbcB2ww4B1z6cJOS/pm74xzR/su4At22kbtW0XjPH+bjbg2Jk/gWNutOYzxtgfG/cdN18F1hljn/YfH48asL7VgC+07fceo5a5Y9S6BFiynPd1/0H/pmiC+py+eX8C/BH4795jrp13YPvenz7kftx/0HvAg/+97de3H77XzrsZeFnfcp9t5x084Bgq4OfAJj3T16b5z2ABL++Zvj3Nv4/bgJ37+vpE2/74MdZxKbD5gG0d3aZ5Y+yLLYANBkx/PE3o/Fbf9Lk979O7++Y9s53+X33Tj2ynXwBs1DdvdXp+T07k2PUxMx5TXoAPHzPt0fPL9tj28Y/Al9s/hvcDbx5HXwFuBX7QN330l+4XByyzQzvv1J5p27bTfsXgwDP6R2lez7SXtdNOGtB+DnB1O3+7nukntNNeM2CZz7Xz3jtg3rvbefsNuV9G/7CM9dh/ErbhIX+02j+yBZwyRl2jof0N7esN29c/BjLksTN/AsfcaM1jPea27S6mGTnbeEAfq9OE8guGXOeebd/HjFHL3DGWW8LEgubA/4gAH27nP3eMPk+nCYgPCU0D2u4/6D3ggX9v/zFgmVe0884dMG8/Bgev+fSFyQE1nN0z7V3ttPcPaL8JTQC9C1hrwDoO7l+mb5vmDZq/nP10JnA3sEbPtLk88J/MQb9jrgFu7Ju2uF1mjyHWOWnHro/p9fDUuTRx7+57PRrAPt/fMMkawGuBl9Cc/t6IB18jvc0Y61gwYNqv25+913bu0f78UVUtHbDMfJo/ir32bH/+oL9xVd2X5FyaPy57AP2nJQfV9Zv258IB865rf247YN6yvKeW/WGgFdmGCwb0t0/7c6MMvnbyYe3Px7TruC3J12lOoS5KchrNqdWfVtUfllH3RL2qxvgwUJJ1aYLyjcBRGXyXrXtGa+9ZbjPgbTSXZDyS5jKBXmMdm5NtSVXdMGD66HuyX5I/HTB/C5og8icMPvbGY7KP63MGTPshTTDeo2faso7jW5JcTHPGZGeg/3T2oON4KGmu334dzZ0yNuehl9NtDlzfN23RGL9jfs0D7xVJ1gMeC/yuqi5eTh0TOnY1Mxg0pQmqqtEPvqxH8wv2s8CnklxTVf1/ML5Mc43mr2iumfotzS9OgKNoTi8P8pBrstoABc0f11GjHxb43Rj9/HbAtNFl+v+Q0Dd94wHzbh0w7b4h5q0xxromakW2YdA+2az9+fT2MZb1e54fTnOa/qU8cMuru5OcChxdVWO9J5NtE5oR8ofx0P8EDdR+yOVCmlHyC2hOXd9M835tDPwVYx+bk23Q+wEPvCdvW87y6y9n/jAm+7h+yHtfVUuT3EQTkEdN9nG8XEneQnOd7S00lwf8D/AHmv8wj16HO+i9H+t63Pt48H+eR2u9bkDbfuM+djVzGDSlFVRVdwLfT/J84CLgC0l2Gh3Raj9ZeQjNh0KeU1X/90GhNJ/qffsklDH6R3DLMeY/fBnLDJoHsFVfu+loRbahltHfX1XVR4cpoKruor2MIskjaEae5gF/TjOa+pRh+pkEo7VfXFV7LrPlA/6CJmQ+ZOQ4yT40QXO87gcGfqqawUFp1KD3Ax7Yro2q6rYJ1DOVtqRvJD3J6jThuXdbeo/jywf0M+ZxXFVj7bcxJZlD85+i3wJ7VtX1ffP3Gbjg+IwG0mFGxCdy7GqG8PZG0iSpqktpPhm7LfDWnlmPbn+e2RsyW08A1pmE1Y+emnpy+4es3/7LWOYh89o/RE9uX160osV1aLK34fz254TCYVX9uqq+RPPhiF/QvB+b9TS5nwePRE+aqrqDJqTsmmTTIRcbPTZPGzCv/1KLUaOnTcfajluALdvLRfo95HY2Q1ih92SKDdqHT6EZ5Ok9nbys43hjYHeaayavHMe6l/U+bU4T+n8yIGSuzwOn8ies/Q/4ZTTHwh7LaTuRY1czhEFTmlz/QPMH4eg8cH/MJe3P/XsbJtkC+PhkrLSqrqU5/bUDfd9KlORgBv/BO4PmNOkRSZ7YN+8omuv1vl+Tc9uYrkzqNlTVAppr6P4syasHtUnyuPa9I8nDkuw9oNl6wAY0pxP/2DP9JuARw9QyQR+iGU38XBtQHiTJJkl6Q8SS9uf+fe32AP7fGOu4qf253RjzL6AJUq/q63MesO/YpY/pOJoPiXw4yZ/0z2zvIzldQ+jf9/weIM29ZD/Qvuy9lvuLNNv45iSP5sHeR/Ohsy9W1T0Mb1nv0w00p8n3aoPlaH1r0JxO33wc61mW0bMCn07fvUCTrJYH3+d2vMeuZghPnUuTqKquS/JpmlOOb6f5Y30hzaeS/yzJT4Af0ZxSezbNfeR+M0Z34/VGmlun/FuaG4tfwgNfjTn6gZXeWu9ow9QpwDlJTqE5zbcX8Aya02qvnaTaOtHRNryU5kMZn22vY/spzWnAbYHdaD7gsA/NH+ttgPOTXEkzavprmlDwPJrToB+tB98f9SzgJe0HiBbSBNFzq+rc8W77IFX1uSR7AW8AfpnkOzT7Y1Oa/4Q8lSbgvK5d5ESaax//LckBNKOwO7b1f5Xm+tN+Z7XLfKa9DvUO4PdVdVw7/2M0IfOTSZ5Gs08eT3NPym+0fY9nm37WvsefAy5P8m2a2watQROinkJzS62dx9PvSnIlTc2999F8FM29W/9jtFFVLUlyFM1/PC9K8hWabdqP5lj7Gc11wONxHk2YPKodJRy9XvRjVXVrko/S3EdzcZKv0YS8A2iOlbPb5yvq32nOKrwC+EW7nv+luc/sgTTv6bEwoWNXM8VUf+zdh4+Z9mCM+2j2zN+S5n6Sd/LA/RY3pbkf3hKaEc9fAu8H1mXA7WBY/j3wBt4mhyZYnkoTjO6k+WPz3GX1R3Oz59Np/gD8keaX+yeBrQe0PYExbm3DGLeuGWZ7ltHXsUO2n5Rt6GmzAfC3NGHwDppby1xNExCOBNZr220MHEMTTK+j+YDX9TSf8j+Cvlse0XwA5CSaP/pLh93GnpqH3X+jNx2/od0fv6UZafwHHnqfxl1obmdzQ3vMLKS5dnNuu84TBvT/1zQh6p62Tf/x+2Sar2P9A821iN+kCekDj5Gxjue+No9r98M17Xpvpjk1+2ngwCH3y/6D1rWs47NnmYe8T2PtIx649dBa7T6/uq35VzQfdllrjPqeQXM/3Fva9v8N/H8MvuXPfJbxe6ht8yya3wF38NBbYc1p38craI7v39KE3+0Z8G9kWcfD8uqhuQ3ZOTTXYt7d7o8v0VwfOuFj18fMeKR9YyVJ0iRI8xWQ+1V7ZwppVeY1mpIkSeqEQVOSJEmdMGhKkiSpE16jKUmSpE54e6NpaPPNN6+5c+dOdRmSJEnLtXDhwhur6mGD5hk0p6G5c+eyYMGCqS5DkiRpuZJcM9Y8r9GUJElSJwyakiRJ6oSnzqehK6+9ib3eduJUlyFJkmawhf/8iqkuwRFNSZIkdcOgKUmSpE4YNCVJktQJg6YkSZI6YdCUJElSJwyakiRJ6oRBU5IkSZ0waEqSJKkTBk1JkiR1wqApSZKkThg0JUmS1IlpGTSTbJvka0l+keSXST6SZM2O13lH+3Nukst6pj85yQVJfpbkqiRvnIz1SJIkzXbTLmgmCfBV4Iyq2hH4E2B94B9XsN85E1jm4cBJwOuqamdgX+DVSQ5ZkVokSZJWBdMuaAIHAndX1ecBqmop8FaagHdhkl1HGyaZn2SvJOsl+Vw7/+IkB7fz5yU5JcnXge8mWT/JWUkuSrJ4tN0yvBE4oaouamu5EXg78La2/xOSHNpTz+io6HjXI0mSNOuMe5RvJdgVWNg7oapuS/I/wDeAFwPvTrIVsHVVLUzyfuAHVfXqJBsDFyT5frv4PsBuVXVzO6p5SNvf5sD5Sc6sqlpGLV/om7YA2GU523D3ONdDkiOBIwHW3GCz5XQvSZI0/U3HEc0AgwJZgPnAYe3rFwOntM+fAbwzyaK2zdrAdu2871XVzT19vD/JpcD3gW2ALSdQyzDbMJ71UFXHV9VIVY3MWXeDCaxSkiRpepmOI5qXAy/qnZBkQ+ARwIXATUl2Aw4HXjvaBHhRVV3Vt9zewJ09k14GPAzYq6ruTbKEJpQuq5YR4MyeaXvRjGoC3Ecb1ttrS0c/sDTe9UiSJM0603FE8yxg3SSvAEiyOvCvNNdK/gE4meY6yY2qanG7zHeAN7dhjyR7jNH3RsANbfg7ANh+ObV8HJiXZPe2381oPpT0vnb+EprgCXAwsMYE1yNJkjTrTLug2V7HeAhwWJJfAD+nuebxb9smpwIvAb7Ss9j7aELepe2tid7HYF8CRpIsoBl1/Nlyarke+HPg+CRXAb8BPlpV57RNPgPsl+QCoHf0dFzrkSRJmo2yjM+nqE97D83XAU+tqlu6Ws96D9+hdn75e7rqXpIkrQIW/vMrVsp6kiysqpFB86bdiOZ0VlUfr6rHdRkyJUmSZguDpiRJkjph0JQkSVInDJqSJEnqhEFTkiRJnTBoSpIkqRMGTUmSJHXCoClJkqROGDQlSZLUCYOmJEmSOjFnqgvQQz1m281YsJK+NkqSJKkrjmhKkiSpEwZNSZIkdcKgKUmSpE4YNCVJktQJg6YkSZI6YdCUJElSJ7y90TT0x+sv53/e+7ipLkMzxHbHLJ7qEiRJGsgRTUmSJHXCoClJkqROGDQlSZLUCYOmJEmSOmHQlCRJUicMmpIkSeqEQVOSJEmdMGhKkiSpEwZNSZIkdcKgKUmSpE4YNCVJktSJGR00k2yZ5KQkv0qyMMl5SQ4Z0G5ukssGTH9vkoOGWM8eSSrJMyerdkmSpNluxgbNJAHOAM6tqkdW1V7AS4Bt+9rNGauPqjqmqr4/xOqOAH7U/hxYS5IZuy8lSZK6MJPD0YHAH6vqU6MTquqaqvpYknlJTknydeC7Y3WQ5IQkhyZ5dpKv9Ezfv112NNAeCswDnpFk7Xb63CRXJvkEcBHwiCRvS3JhkkuTvKenvzPaEdfLkxw5ubtBkiRpeprJQXNXmoA3ln2AV1bVgUP09T3giUnWa18fDny5fb4vcHVV/RKYDzynZ7mdgBOrao/2+Y7AE4Ddgb2SPLVt9+p2xHUEeEuSzfoLSHJkkgVJFtx859IhSpYkSZreZnLQfJAkH09ySZIL20nfq6qbh1m2qu4Dvg08vz3V/lzga+3sI4CT2+cn8+DT59dU1fnt82e0j4tpAvDONMETmnB5CXA+8Iie6b01HF9VI1U1sul6qw9TtiRJ0rQ25vWLM8DlwItGX1TVG5NsDixoJ905zv6+DLwRuBm4sKpuT7J6u44XJHkXEGCzJBsMWEeAD1TVp3s7TbI/cBCwT1X9Icl8YO1x1iZJkjTjzOQRzR8Aayd5fc+0dVegv/nAnsBf8sBp84OAS6rqEVU1t6q2B04DXjhg+e8Ar06yPkCSbZJsAWwE3NKGzJ2BJ65AjZIkSTPGjA2aVVU0gW+/JFcnuQD4AvCOMRbZKcm1PY/D+vpbCnwDeHb7E5rT5Kf39XMa8NIB9XwXOAk4L8li4FRgA5pT8nOSXAq8j+b0uSRJ0qyXJq9pOtltm3XqG6999FSXoRliu2MWT3UJkqRVWJKFVTUyaN6MHdGUJEnS9GbQlCRJUicMmpIkSeqEQVOSJEmdMGhKkiSpEwZNSZIkdcKgKUmSpE4YNCVJktQJg6YkSZI6YdCUJElSJ+ZMdQF6qDW32pXtjlkw1WVIkiStEEc0JUmS1AmDpiRJkjph0JQkSVInDJqSJEnqhEFTkiRJnTBoSpIkqRPe3mga+tkNP2Pfj+071WVMih+/+cdTXYIkSZoijmhKkiSpEwZNSZIkdcKgKUmSpE4YNCVJktQJg6YkSZI6YdCUJElSJwyakiRJ6oRBU5IkSZ0waEqSJKkTBk1JkiR1wqApSZKkTkyLoJlksySL2sdvk1zX83rNvrZHJVl3iD7nJxlpny9Jsrjtb3GSgyeh5rlJXtrzet0kX2r7vyzJj5Ks385b2rM9i5LMXdH1S5IkTXdzproAgKq6CdgdIMmxwB1V9S9jND8K+CLwh3Gu5oCqujHJTsB3ga9NsNxRc4GXAie1r/8K+F1VPQ6gXc+97by7qmr3FVyfJEnSjDItRjQHSfK0JBe3I4SfS7JWkrcAWwNnJzm7bffJJAuSXJ7kPUN0vSFwS7vsekm+meSSdhTy8Hb6kiTvT3Je2/eeSb6T5JdJXtf280HgKe0I5VuBrYDrRldSVVdV1T2Tt0ckSZJmlmkxojnA2sAJwNOq6udJTgReX1X/luSvaUcn27bvqqqbk6wOnJVkt6q6dECfZycJ8Ejgxe20ZwG/qarnAiTZqKf9r6tqnyQfbmvZt63rcuBTwDuBo6vqee2yuwPfTXIocBbwhar6RdvXOkkWtc+vrqpD+otLciRwJMCam6zZP1uSJGnGma4jmqvTBLKft6+/ADx1jLYvTnIRcDGwK7DLGO0OqKrHAo8Djmuvn1wMHJTkn5I8papu7Wl/ZvtzMfDTqrq9qv4XuDvJxv2dV9UimhD7z8CmwIVJHtPOvquqdm8fDwmZ7fLHV9VIVY2ssf4aY2yCJEnSzDFdg+adwzRKsgNwNM3I527AN2lGHcdUVb8Efgfs0gbZvWjC5AeSHNPTdPS09/09z0dfDxwJrqo7quqrVfUGmutInzPMdkiSJM1G0zVorg3MTfLo9vXLgXPa57cDG7TPN6QJpbcm2RJ49vI6TrIFsANwTZKtgT9U1ReBfwH2HEeNvXWQZN8km7TP16QZWb1mHP1JkiTNKtP1Gs27gVcBpySZA1xIc10kwPHAt5JcX1UHJLmY5rrJXwE/XkafZydZCqwBvLOqfpfkmcA/J7mf5hPirx9HjZcC9yW5hOYazpuAT7bXga5GM7p62jj6kyRJmlVSVVNdg/qsv9369fi3PX6qy5gUP37zsrK/JEma6ZIsrKqRQfOm66lzSZIkzXAGTUmSJHXCoClJkqROGDQlSZLUCYOmJEmSOmHQlCRJUicMmpIkSeqEQVOSJEmdMGhKkiSpEwZNSZIkdWK6ftf5Km3nLXb2qxslSdKM54imJEmSOmHQlCRJUicMmpIkSeqEQVOSJEmdMGhKkiSpEwZNSZIkdcLbG01Dt191Fec8db9O17Hfued02r8kSZIjmpIkSeqEQVOSJEmdMGhKkiSpEwZNSZIkdcKgKUmSpE4YNCVJktQJg6YkSZI6YdCUJElSJwyakiRJ6oRBU5IkSZ0waEqSJKkTszpoJvlckhuSXLacdvsneVLP62OTXJdkUfv4YDt9fpKRMfp4XpKLk1yS5Iokr11WX5IkSbPdnKkuoGMnAMcBJy6n3f7AHcBPeqZ9uKr+ZZiVJFkLOB54QlVd276eO5G+JEmSZotZPaJZVecCN/dOS/KWdsTx0iQnJ5kLvA54azvi+JRh+k5yR5L3JvkpsDdNaL+pXe89VXXVZG6LJEnSTDOrg+YY3gnsUVW7Aa+rqiXAp2hGHXevqh+27d7ac7r7mQP6WQ+4rKr2bgPtmcA1Sf4zycuS9O7b5fVFkiOTLEiy4NZ77520jZUkSZoqq2LQvBT4UpI/B+5bRrvR4Ll7VX1nwPylwGmjL6rqL4CnARcARwOfG0dfVNXxVTVSVSMbrbHGeLdJkiRp2lkVg+ZzgY8DewELk0z0OtW7q2pp74SqWlxVHwaeDrxoxcqUJEma2VapoNmezn5EVZ0NvB3YGFgfuB3YYAX6XT/J/j2TdgeuWYFSJUmSZrxZ/anzJP9J84nyzZNcC7wPeHmSjYDQnNL+fZKvA6cmORh480RWBbw9yaeBu4A7gXmTsAmSJEkzVqpqqmtQn5022KCO32PPTtex37nndNq/JElaNSRZWFUD7zO+Sp06lyRJ0spj0JQkSVInDJqSJEnqhEFTkiRJnTBoSpIkqRMGTUmSJHXCoClJkqROGDQlSZLUCYOmJEmSOmHQlCRJUidm9Xedz1Qb7LSTXxEpSZJmPEc0JUmS1AmDpiRJkjph0JQkSVInDJqSJEnqhEFTkiRJnTBoSpIkqRPe3mgauuHaWznub74+af296V+fP2l9SZIkDcsRTUmSJHXCoClJkqROGDQlSZLUCYOmJEmSOmHQlCRJUicMmpIkSeqEQVOSJEmdMGhKkiSpEwZNSZIkdcKgKUmSpE4YNCVJktSJaRk0kyxNsijJJUkuSvKkSehz9yTP6Xk9L8n/tutZlOTEJC9I8s7l9LNako8muSzJ4iQXJtmhnbeknTba55Pa6d9O8vsk31jR7ZAkSZop5kx1AWO4q6p2B0jyTOADwH4r2OfuwAjwXz3TvlxVb+prd+Zy+jkc2BrYraruT7ItcGfP/AOq6sa+Zf4ZWBd47fjLliRJmpmm5Yhmnw2BWwCSbJXk3Ha08LIkT2mn35Hkn5IsTPL9JE9IMj/Jr9pRyjWB9wKHt8sePmhF7Sjnce3zE9qRy5+0/RzaNtsKuL6q7geoqmur6pZlbUBVnQXcPhk7Q5IkaaaYriOa6yRZBKxNE+wObKe/FPhOVf1jktVpRgkB1gPmV9U7kpwO/APwdGAX4AtVdWaSY4CR0RHMJPNogueT2z4+AlRfHVsBTwZ2phnpPBX4CvCjNuSeBXyxqi7uWebsJEuBe6pq78nYGZIkSTPRUEEzyaOAa6vqniT7A7sBJ1bV7zuqq/fU+T7AiUkeC1wIfC7JGsAZVbWobf9H4Nvt88U0Ie/eJIuBuctYz4NOnbfhs9cZ7cjlFUm2hGYEM8lONOH3QOCsJIe1o5Yw+NT5ciU5EjgSYJMNHjbexSVJkqadYU+dnwYsTfJo4LPADsBJnVXVo6rOAzYHHlZV5wJPBa4D/iPJK9pm91bV6Gjk/cA97bL3s2Kjtvf0PE9PTfdU1beq6m3A+4EXrsA6Rvs8vqpGqmpk/XU3WtHuJEmSptywQfP+qroPOAT4t6p6K81p5c4l2RlYHbgpyfbADVX1GZrAu+c4urod2GAS6tkzydbt89VoRnevWdF+JUmSZpthR/vuTXIE8Erg+e20NbopCXjgGk1oRhJfWVVL29P2b0tyL3AH8IqxOhjgbOCdbb8fWIHatgA+k2St9vUFwHHLWiDJD2mu81w/ybXAa6rqOytQgyRJ0rSXB844L6NRsgvwOuC8qvrP9r6Rh1fVB1l9VeEAABe1SURBVLsucFW03cN3rLe/7EOT1t+b/vX5y28kSZI0AUkWVtXIoHlDjWhW1RVJ3gFs176+GjBkSpIkaUxDXaOZ5PnAItpPdrffsrO8G5tLkiRpFTbsh4GOBZ4A/B6gva3QDh3VJEmSpFlg2KB5X1Xd2jdt+Rd3SpIkaZU17KfOL0vyUmD1JDsCbwF+0l1ZkiRJmumGHdF8M7ArzQ3MTwJuBY7qqihJkiTNfMsd0Wy/U/zMqjoIeFf3JUmSJGk2WO6IZlUtBf6QxO9FlCRJ0tCGvUbzbmBxku8Bd45OrKq3dFKVJEmSZrxhg+Y324ckSZI0lKG+glIr18jISC1YsGCqy5AkSVquFf4KyiRXM+C+mVX1yBWsTZIkSbPUsKfOe1Pq2sBhwKaTX44kSZJmi6Huo1lVN/U8rquqfwMO7Lg2SZIkzWDDnjrfs+flajQjnBt0UpEkSZJmhWFPnf9rz/P7gKuBF09+OZIkSZothg2ar6mqX/VOSLJDB/VIkiRplhjq9kZJLqqqPfumLayqvTqrbBW2zWab1Bue/bQJLfuuL546ydVIkiSNbcK3N0qyM7ArsFGSP+uZtSHNp88lSZKkgZZ36nwn4HnAxsDze6bfDvxlV0VJkiRp5ltm0KyqrwFfS7JPVZ23kmqSJEnSLDDsh4EuTvJGmtPo/3fKvKpe3UlVkiRJmvGGumE78B/Aw4FnAucA29KcPpckSZIGGjZoPrqq/h64s6q+ADwXeFx3ZUmSJGmmGzZo3tv+/H2SxwIbAXM7qUiSJEmzwrDXaB6fZBPg74EzgfWBYzqrSpIkSTPeUEGzqv69fXoO8MjuypEkSdJsMdSp8yRbJvlskm+1r3dJ8ppuS5MkSdJMNuw1micA3wG2bl//HDiqi4IkSZI0OwwbNDevqq8A9wNU1X3A0s6qmqAkj0hydpIrk1ye5K/Gufz8JCPt8yVJFidZ1D6elGRuksvGWHa1JB9Nclm73IVJdhirrxXfWkmSpOlt2A8D3ZlkM6AAkjwRuLWzqibuPuBvquqiJBsAC5N8r6qumGB/B1TVjaMvkswd1CjJHOAwmhHf3arq/iTbAneO1ZckSdJsN2zQ/GuaT5s/KsmPgYcBh3ZW1QRV1fXA9e3z25NcCWyT5BPAT4EDaL63/TVV9cMk6wCfB3YBrgTWGXZdSebR3E90bWA94BvA9VU1Oup77WRtlyRJ0ky0zKCZZLuq+p92hHA/YCcgwFVVde+ylp1q7ejjHjQBE2BOVT0hyXOAdwMHAa8H/lBVuyXZDbior5uzkywF7qmqvQesZh+aEcyb2xHMHyV5CnAW8MWqungcfUmSJM0qyxvRPAPYs33+5ap6Ucf1TIok6wOnAUdV1W1JAL7azl7IAzebfyrwUYCqujTJpX1dLe909/eq6uZ2+WuT7AQc2D7OSnJYVZ01TF9JjgSOBNho3aEHViVJkqat5QXN9DyfEffPTLIGTcj8UlV9tWfWPe3PpTx4u2sFVtd7DSZVdQ/wLeBbSX4HvJBmdHO5qup44HiAbTbbZEVqkiRJmhaW96nzGuP5tJRm6PKzwJVV9aEhFjkXeFm77GOB3VZg3Xsm2bp9vlrb1zUT7U+SJGmmW96I5uOT3EYzsrlO+5z2dVXVhp1WN377Ai8HFidZ1E7722W0/yTw+faU+SLgghVY9xbAZ5Ks1b6+ADhuBfqTJEma0VI17QcqVznbbLZJveHZT5vQsu/64qmTXI0kSdLYkiysqpFB84a9YbskSZI0LgZNSZIkdcKgKUmSpE4YNCVJktQJg6YkSZI6YdCUJElSJwyakiRJ6oRBU5IkSZ0waEqSJKkTBk1JkiR1Ynnfda4psNUOj/KrJCVJ0ozniKYkSZI6YdCUJElSJwyakiRJ6oRBU5IkSZ0waEqSJKkTBk1JkiR1wtsbTUN3X387V/7jDya07GPedeAkVyNJkjQxjmhKkiSpEwZNSZIkdcKgKUmSpE4YNCVJktQJg6YkSZI6YdCUJElSJwyakiRJ6oRBU5IkSZ0waEqSJKkTBk1JkiR1wqApSZKkThg0JUmS1IlZHTSTLE2yqOcxdxlt5yU5rn1+bJKj2+cnJLm6Xf5nSd49xHrnJdm65/WSJJuv+BZJkiTNHHOmuoCO3VVVu09CP2+rqlOTrA1ckeTEqrp6Ge3nAZcBv5mEdUuSJM1Is3pEc5De0cUkI0nmj2Pxtdufd7bLH5PkwiSXJTk+jUOBEeBL7SjoOu0yb05yUZLFSXaerO2RJEmarmZ70Fyn57T56SvQzz8nWQRcC5xcVTe004+rqj+tqscC6wDPq6pTgQXAy6pq96q6q217Y1XtCXwSOLp/BUmOTLIgyYKb7/z9CpQqSZI0Pcz2oHlXG/Z2r6pDVqCft7Wn4B8OPC3Jk9rpByT5aZLFwIHArsvo46vtz4XA3P6ZVXV8VY1U1cim6228AqVKkiRND7M9aA5yHw9s99rLativqu4A5gNPbq/X/ARwaFU9DvjMcvq7p/25lNl/bawkSdIqGTSXAHu1z180ngWTzAH2Bn7JA6HyxiTrA4f2NL0d2GDFypQkSZrZVsWg+R7gI0l+SDO6OIzRazQvBRYDX62q39OMYi4GzgAu7Gl/AvCpvg8DSZIkrVJSVVNdg/o8dpud6pQ3fHJCyz7mXQdOcjWSJEljS7KwqkYGzVsVRzQlSZK0Ehg0JUmS1AmDpiRJkjph0JQkSVInDJqSJEnqhEFTkiRJnTBoSpIkqRMGTUmSJHXCoClJkqROzJnqAvRQa2+1gd/wI0mSZjxHNCVJktQJg6YkSZI6YdCUJElSJwyakiRJ6oRBU5IkSZ0waEqSJKkT3t5oGvrNb37DscceO+7lJrKMJElSVxzRlCRJUicMmpIkSeqEQVOSJEmdMGhKkiSpEwZNSZIkdcKgKUmSpE4YNCVJktQJg6YkSZI6YdCUJElSJwyakiRJ6oRBU5IkSZ0waEqSJKkT0y5oJtkyyUlJfpVkYZLzkhwyxTV9Lcl5U1mDJEnSTDOtgmaSAGcA51bVI6tqL+AlwLZDLr96BzVtDOwJbJxkhzHazJns9UqSJM100ypoAgcCf6yqT41OqKprqupjSeYm+WGSi9rHkwCS7J/k7CQnAYvbaWe0o6GXJzlytK8kr0ny8yTzk3wmyXHt9IclOS3Jhe1j356aXgR8HTiZJvSO9nVCkg8lORv4pySPSvLtdr0/TLJz2+75SX6a5OIk30+yZWd7T5IkaRqZbiNxuwIXjTHvBuDpVXV3kh2B/wRG2nlPAB5bVVe3r19dVTcnWQe4MMlpwFrA39OMTt4O/AC4pG3/EeDDVfWjJNsB3wEe0847AngP8DvgVOADPTX9CXBQVS1Nchbwuqr6RZK9gU/QBOcfAU+sqkryF8Dbgb/p37g2EB8JsNFGGw2zryRJkqa16RY0HyTJx4EnA38EDgKOS7I7sJQm5I26oCdkAryl57rORwA7Ag8Hzqmqm9u+T+np4yBgl+bMPQAbJtkAWBd4NPCjNijel+SxVXVZ2+6UNmSuDzwJOKWnj7Xan9sCX06yFbAm0Fvn/6mq44HjAbbeeusabg9JkiRNX9MtaF5Oc6oagKp6Y5LNgQXAW2lGFR9Pc8r/7p7l7hx9kmR/muC4T1X9Icl8YG0gjG21tv1dvROTvArYBLi6DZAb0pw+/7u+9a4G/L6qdh/Q98eAD1XVmW1txy6jDkmSpFljul2j+QNg7SSv75m2bvtzI+D6qrofeDkw1gd/NgJuaUPmzsAT2+kXAPsl2aT98M6Lepb5LvCm0RftqCk0p82fVVVzq2ouMPrhpAepqttowuhh7fJJ8vieeq5rn79ymVsvSZI0i0yroFlVBbyQJhBeneQC4AvAO2iueXxlkvNpTnnfOUY33wbmJLkUeB9wftv3dcD7gZ8C3weuAG5tl3kLMJLk0iRXAK9LMhfYbnT5to+rgdvaazD7vQx4TZJLaEZmD26nH0tzSv2HwI3j2iGSJEkzWJpst2pIsn5V3dGOaJ4OfK6qTp/quvptvfXWdeSRRy6/YZ9jjz128ouRJElahiQLq2pk0LxpNaK5EhybZBFwGc2Hcs6Y4nokSZJmren2YaBOVdXRU12DJEnSqmJVG9GUJEnSSmLQlCRJUicMmpIkSeqEQVOSJEmdMGhKkiSpEwZNSZIkdcKgKUmSpE6sUt8MNFOMjIzUggULproMSZKk5fKbgSRJkrTSGTQlSZLUCYOmJEmSOmHQlCRJUicMmpIkSeqEQVOSJEmdMGhKkiSpE3OmugA91C23XMlXTnnCuJd78WEXdFCNJEnSxDiiKUmSpE4YNCVJktQJg6YkSZI6YdCUJElSJwyakiRJ6oRBU5IkSZ0waEqSJKkTBk1JkiR1wqApSZKkThg0JUmS1AmDpiRJkjqxSgTNJHeMo+28JFv3TXtYknuTvHbyq5MkSZqdVomgOU7zgK37ph0GnA8cMdZCSVbvsCZJkqQZZ5UNmkl2T3J+kkuTnJ5kkySHAiPAl5IsSrJO2/wI4G+AbZNs09PHHUnem+SnwD5J/jzJBe2ynx4Nn0k+mWRBksuTvGdlb6skSdJUWGWDJnAi8I6q2g1YDLy7qk4FFgAvq6rdq+quJI8AHl5VFwBfAQ7v6WM94LKq2hu4qZ23b1XtDiwFXta2e1dVjQC7Afsl2a2/mCRHtmF0wW233dfNFkuSJK1Eq2TQTLIRsHFVndNO+gLw1DGav4QmYAKczINPny8FTmufPw3YC7gwyaL29SPbeS9OchFwMbArsEv/Sqrq+KoaqaqRDTecM7ENkyRJmkZMNMt3BLBlktHRya2T7FhVvwDurqql7fQAX6iq/9e7cJIdgKOBP62qW5KcAKy9kmqXJEmaMqvkiGZV3QrckuQp7aSXA6Ojm7cDGwAk2QlYr6q2qaq5VTUX+ADNKGe/s4BDk2zRLrtpku2BDYE7gVuTbAk8u6PNkiRJmlZWlRHNdZNc2/P6Q8ArgU8lWRf4FfCqdt4J7fS7gO8Ap/f1dRrNKfT39U6sqiuS/B3w3SSrAfcCb6yq85NcDFzerufHk7plkiRJ09QqETSraqyR2ycOaHsaD1x3OaivS2mvsayq9fvmfRn48oBl5o2jXEmSpFlhlTx1LkmSpO4ZNCVJktQJg6YkSZI6YdCUJElSJwyakiRJ6oRBU5IkSZ0waEqSJKkTBk1JkiR1wqApSZKkTqwS3ww002yyyWN48WEXTHUZkiRJK8QRTUmSJHXCoClJkqROGDQlSZLUCYOmJEmSOmHQlCRJUicMmpIkSeqEQVOSJEmd8D6a09AVt9zG40/9zriXu+TQZ3ZQjSRJ0sQ4oilJkqROGDQlSZLUCYOmJEmSOmHQlCRJUicMmpIkSeqEQVOSJEmdMGhKkiSpEwZNSZIkdcKgKUmSpE4YNCVJktQJg6YkSZI60UnQTLJZkkXt47dJrut5vWZf26OSrNvzekmSxUkuTXJOku0nsa63Jrk7yUY90+YlOW6c/eyY5BtJfplkYZKzkzx1yGWXJNl8vLVLkiTNNJ0Ezaq6qap2r6rdgU8BHx59XVV/7Gt+FLBu37QDqmo3YD7wd5NY2hHAhcAhE+0gydrAN4Hjq+pRVbUX8GbgkQPazpnoeiRJkma6lXbqPMnTklzcjlZ+LslaSd4CbA2cneTsAYudB2zTLj83yc+S/HuSy5J8KclBSX6c5BdJntC2269n9PTiJBu00x8FrE8TXI/oW88jknw7yVVJ3t22/6ckb+ip/9gkfwO8DDivqs4cnVdVl1XVCT3tjk/yXeDEdnT3u20tnwYyCbtTkiRp2ltZQXNt4ATg8Kp6HDAHeH1VfRT4Dc0I5gEDlnsWcEbP60cDHwF2A3YGXgo8GTga+Nu2zdHAG9vR1KcAd7XTjwD+E/ghsFOSLXr6fQJNgNwdOCzJCHAycHhPmxcDpwC7AhctZ3v3Ag6uqpcC7wZ+VFV7AGcC2w1aIMmRSRYkWXDfbbcup3tJkqTpb2UFzdWBq6vq5+3rLwDLuqbx7CQ3AAcBJ/VMv7qqFlfV/cDlwFlVVcBiYG7b5sfAh9rR0o2r6r52+kuAk9tlvwoc1tPv99rT/Xe1855cVRcDWyTZOsnjgVuq6n/6C01yejvC+tWeyWe2fdFu5xcBquqbwC2DNriqjq+qkaoambPhRoOaSJIkzSgrK2jeOc72BwDb04TJ9/ZMv6fn+f09r++nGSWlqj4I/AWwDnB+kp2T7AbsCHwvyRKa0Nl7+rz61j/6+lTgUJqRzZPbaZcDe/5fw6pDgHnApj3L929vf/+SJEmz3so8dT43yaPb1y8Hzmmf3w5s0L9AOyJ4FPCKJJv2zx9Lkke1o57/BCygOcV+BHBsVc1tH1sD2/R8ov3pSTZNsg7wQppRUWjC5Utowuap7bSTgH2TvKBntf0fZup1Ls1peZI8G9hk2G2RJEmayVZW0LwbeBVwSpLFNCOQn2rnHQ98a9CHgarqeprrKt84jnUd1Z7KvoTm+sxv0YTF0/vand5OB/gR8B/AIuC0qlrQrv9ymhB8XVvLaAB+HvC6JL9Kch7NB4z+YYx63gM8NclFwDOAh5x+lyRJmo3SXOKo6WTdR/1J7fhPHxv3cpcc+swOqpEkSRpbkoVVNTJont8MJEmSpE4YNCVJktQJg6YkSZI6YdCUJElSJwyakiRJ6oRBU5IkSZ0waEqSJKkTBk1JkiR1wqApSZKkTsyZ6gL0ULtssiEL/JYfSZI0wzmiKUmSpE4YNCVJktQJg6YkSZI6kaqa6hrUJ8ntwFVTXccqaHPgxqkuYhXkfp8a7vep4X6fGu73bm1fVQ8bNMMPA01PV1XVyFQXsapJssD9vvK536eG+31quN+nhvt96njqXJIkSZ0waEqSJKkTBs3p6fipLmAV5X6fGu73qeF+nxru96nhfp8ifhhIkiRJnXBEU5IkSZ0waEqSJKkTBs0plORZSa5K8t9J3jlgfpJ8tJ1/aZI9p6LO2WaI/b5zkvOS3JPk6KmocTYaYr+/rD3OL03ykySPn4o6Z5Mh9vnB7f5elGRBkidPRZ2zzfL2e0+7P02yNMmhK7O+2WqI433/JLe2x/uiJMdMRZ2rGq/RnCJJVgd+DjwduBa4EDiiqq7oafMc4M3Ac4C9gY9U1d5TUO6sMeR+3wLYHnghcEtV/ctU1DqbDLnfnwRcWVW3JHk2cKzH+8QNuc/XB+6sqkqyG/CVqtp5SgqeJYbZ7z3tvgfcDXyuqk5d2bXOJkMe7/sDR1fV86akyFWUI5pT5wnAf1fVr6rqj8DJwMF9bQ4GTqzG+cDGSbZa2YXOMsvd71V1Q1VdCNw7FQXOUsPs959U1S3ty/OBbVdyjbPNMPv8jnpgtGE9wJGHFTfM73ZoBhFOA25YmcXNYsPud61kBs2psw3w657X17bTxttG4+M+nRrj3e+vAb7VaUWz31D7PMkhSX4GfBN49UqqbTZb7n5Psg1wCPCplVjXbDfs75h9klyS5FtJdl05pa3aDJpTJwOm9Y8mDNNG4+M+nRpD7/ckB9AEzXd0WtHsN9Q+r6rT29PlLwTe13lVs98w+/3fgHdU1dKVUM+qYpj9fhHNd3I/HvgYcEbnVcmgOYWuBR7R83pb4DcTaKPxcZ9OjaH2e3ud4L8DB1fVTSupttlqXMd6VZ0LPCrJ5l0XNssNs99HgJOTLAEOBT6R5IUrp7xZa7n7vapuq6o72uf/Bazh8d49g+bUuRDYMckOSdYEXgKc2dfmTOAV7afPnwjcWlXXr+xCZ5lh9rsm33L3e5LtgK8CL6+qn09BjbPNMPv80UnSPt8TWBMw4K+Y5e73qtqhquZW1VzgVOANVeXo2ooZ5nh/eM/x/gSaDOTx3rE5U13Aqqqq7kvyJuA7wOo0nzq8PMnr2vmfAv6L5hPn/w38AXjVVNU7Wwyz35M8HFgAbAjcn+QoYJequm3KCp/hhjzejwE2oxndAbivqkamquaZbsh9/iKa/8zeC9wFHN7z4SBNwJD7XZNsyP1+KPD6JPfRHO8v8Xjvnrc3kiRJUic8dS5JkqROGDQlSZLUCYOmJEmSOmHQlCRJUicMmpIkSeqEQVOSJEmdMGhKkiSpE/8/Ojpoa+ERZfQAAAAASUVORK5CYII=\n",
"text/plain": [
""
]
},
"metadata": {
"needs_background": "light"
},
"output_type": "display_data"
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"-----------------------------------------\n",
"************* Model Results *************\n",
"-----------------------------------------\n",
"R2 score 0.6273971463490331\n",
"MSE score: 1607856695.0580575\n",
"RMSE score score: 40098.088421495326\n",
"-----------------------------------------\n",
"\n",
"Executing RFE\n",
"Please wait.........\n",
"### RFE selected columns:\n",
" Index(['LotArea', 'OverallQual', 'YearBuilt', 'BsmtFinSF1', 'TotalBsmtSF',\n",
" '1stFlrSF', '2ndFlrSF', 'GrLivArea', 'TotRmsAbvGrd', 'GarageArea'],\n",
" dtype='object')\n"
]
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAApoAAAGwCAYAAAAJ08UyAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADt0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjByYzEsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy/xvVyzAAAgAElEQVR4nOzdeZxkVX3//9cbhn0ZEARZxEFEEZR1giKyihpXJIKIRkVNENdg4vaNiaLGJb8kapS4YFQkigsgiBpERQZcQJiBYReNMiiIEhbZBITh8/vj3g5FUT1TPd23t3k9H496dNW555577q3bXe8+d6lUFZIkSdJEW2WqOyBJkqTZyaApSZKkThg0JUmS1AmDpiRJkjph0JQkSVInDJqSJEnqhEFTWgkkOTxJJTl8qvsiSVp5GDSlMWoDW+9jaZKbkyxoA12muo8zXZKjB2zn3seSqe7jimj7vmAF5jtuOdtjzG2uqJ6+zJusZU6UJPtO9vaaKv5zqelizlR3QJrB3tP+XA14DHAQsA8wH3jDVHVqljkbWDCg/A+T3I/p4hvA4gHlSya5H5I0FIOmtIKq6uje10n2BM4BXpfk36rq6inp2OyyoH87r+ROrarjproTkjQsD51LE6Sqfgz8DAiwW++0JLsl+fckF7eH2e9O8osk/5Zkw/62eg97JdmvPSx/e5Lbknw7yeMH9SHJY5KcmOSWJHcm+UmS5yyr323fTk5yQ5J7klyT5BNJNhtQd+Sw6dZJ3pDkinZdliT5+5HTBpIckuT8tg83JDkmyZpj2JxjsoLr8Ogkb0xySZK7eg+nJnlYkg8mubKddmuSM5M8Y0B7qyd5U5IL2+3+x3Z7fCPJAW2dw5OMfN/vPn2HvY/uYHscluSstj93t+vxD0nWGFD3BUm+mOTn7ft1R5JF7Tqt0le3gFe0L68edCpDu+5LGCAPnBKxb3+77T7+iCT/meS6NKekHN5T50lJTkryuyR/SvKbJJ9OsvmKbqeetnt/356e5IftdvjfJJ9PskFbb5ck32q36x1JTsuAUwjadakkayT5pyRXt/vlL5O8O8nqo/TjaUm+kwf+Rvw8yYeSzF3GMlZP8q4kV7XLOK7dlz/fVv183/42r51/83a+H/ds098mOSED/r4kmdfOf1z7/CtJbmz7uTDJc5exfQ9tf39G1mtJki8nmT+g7tD7rmYGRzSliTVyfua9feV/TXNo/Wzg+8CqwK7A3wLPSvKkqrp9QHvPBQ4ETgc+BWwPPBv4syTbV9WN/7fgZFvgXGCjtv5imkP6p7avH9rZ5sPh5LbfJwHX0ITk1wIHJtmzqpYMmPVfgX2BbwLfBZ4PvB9YPcnNwIfa5f4QeDrw+nadXzuoH+MxjnX4d2Av4NvAfwNL2/YeRXO4fl7b/+8A69C8F99J8pqq+kxPO8cBhwGXAccDdwGbA08F/pzm/V5Mc6rFu9v+Hdcz/4IVXfdBknwWeBVwLfB1mtMMngy8D3hakqdX1X09s3wIuB/4KXAdMBfYn2b7/Bnwsp667wFeAOzUTh85hWEiTmV4GHAecEfb7/uB37fr9ErgM8A9wGnAb4Btgb8CnpfkyVX16wnow/Np3udv0fy+PQU4HNg6yTuAM2n2ic8CTwSeB2yT5IlVdf+A9r5Gsw1PovmbcCBwNDA/yfOrauSfD5K8BvgkcCdwInADze/Y29t13LOqBm3nk9tlnE7zO3cDzT71h3Z5/adbjLSxN/AO4Ky2jTtotunBwPPb5V08YHmPAs4HfgX8F837dijwjSQHVNVZPesUmsD7CuBGmvf1f4Etgf2Aq4CFPfXHuu9qJqgqHz58jOEBVPOr85DyvWnCyj3AZn3THgWsOmCeV7ftvb2v/PC2/D7gaX3TPthOe1tf+Xfb8r/pKz9wpM/A4T3l69L88V8K7NU3z9vb+t/tKz+uLV8CbNFTvkHb1p00HySP75m2BnBFu102GXIbH90uZ0H7vP8xbwLW4Tpg6wHLXkATcl7cV74BzQf2XcCmbdnctu7CUd7fjQbsOwtWYJ8b6fOpo2yPDfr2m68Da42yTfv3j20GLG8V4Att/SeN0pd5o/R1CbBkOe/rvoN+p2iC+py+aY8F/gT8T+8+107bv33vTxlyO+476D3gwb9v+/Rth++1024GXto332fbaQcO2IcK+DmwYU/5mjT/DBbwsp7yR9H8ftwGbNfX1ifa+seOsoxLgI0HrOvIOh0+yrbYBFhvQPlONKHz9L7yeT3v07v7pj2zLf/vvvIj2vLzgbl901al5+/kiuy7PmbGY8o74MPHTHv0/LE9un28H/hq+2F4P/DGMbQV4FbgB33lI390vzhgnq3baSf1lG3Zlv2KwYFn5EPp8J6yl7ZlJwyoPwe4up2+VU/5cW3ZqwfM87l22nsHTHt3O22fIbfLyAfLaI99J2AdHvKh1X7IFnDiKP0aCe2va1+v377+MZAh950FK7DPjfR5tMe8tt5FNCNnGwxoY1WaUH7+kMvctW37XaP0Zd4o8y1hxYLmwH9EgI+0058zSpun0ATEh4SmAXX3HfQe8MDv238NmOfl7bRzBkzbh8HBawF9YXJAH87qKXtnW/aBAfU3pAmgdwFrDFjGgf3z9K3T4YOmL2c7nQbcDazWUzaPB/7JHPQ35hrgxr6yS9t5dhlimRO27/qYXg8PnUsr7t19r0cC2Of7KyZZDXgN8GKaw99zefA50luMsoyFA8p+0/7sPbdzl/bnj6pq6YB5FtB8KPbatf35g/7KVXVfknNoPlx2AfoPSw7q12/bn4sGTLuu/bnlgGnL8p5a9sVA41mH8we0t0f7c24Gnzv58Pbn49tl3JbkmzSHUBcnOZnm0OpPq+qPy+j3inpljXIxUJK1aYLyjcBRGXyXrXtG+t4z30bAW2lOyXg0zWkCvUbbNyfakqq6YUD5yHuyT5I/GzB9E5og8lgG73tjMdH79dkDyn5IE4x36Slb1n58S5KLaI6YbAf0H84etB8PJc3520fS3CljYx56Ot3GwPV9ZYtH+RvzGx54r0iyDvAE4PdVddFy+rFC+65mBoOmtIKqauTCl3Vo/sB+FvhUkmuqqv8D46s052j+iuacqd/R/OEEOIrm8PIgDzknqw1Q0Hy4jhi5WOD3o7TzuwFlI/P0f5DQV77BgGm3Dii7b4hpq42yrBU1nnUYtE02an8+vX2MZt2e54fSHKZ/CQ/c8uruJCcBb6mq0d6TibYhzQj5w3noP0EDtRe5XEAzSn4+zaHrm2nerw2Av2H0fXOiDXo/4IH35K3LmX/d5UwfxkTv1w9576tqaZKbaALyiInej5cryZtozrO9heb0gF8Df6T5h3nkPNxB7/1o5+Pex4P/eR7p63UD6vYb876rmcOgKY1TVd0JfD/J84ALgS8kedzIiFZ7ZeVBNBeFPLuq/u9CoTRX9b5tArox8iG46SjTH7GMeQZNA9isr950NJ51qGW09zdV9bFhOlBVd9GeRpHkkTQjT4cDf0kzmrrXMO1MgJG+X1RVuy6z5gP+iiZkPmTkOMkeNEFzrO4HBl5VzeCgNGLQ+wEPrNfcqrptBfozlTalbyQ9yao04bl3XXr348sHtDPqflxVo223USWZQ/NP0e+AXavq+r7pewyccWxGAukwI+Irsu9qhvD2RtIEqapLaK6M3RJ4c8+kx7Q/T+sNma3dgbUmYPEjh6ae2n6Q9dt3GfM8ZFr7QfTU9uWF4+1chyZ6Hc5rf65QOKyq31TVl2gujvgFzfuxUU+V+3nwSPSEqao7aELKDkkeNuRsI/vmyQOm9Z9qMWLksOlo63ELsGl7uki/h9zOZgjjek+m2KBtuBfNIE/v4eRl7ccbADvTnDN55RiWvaz3aWOa0P+TASFzXR44lL/C2n/AL6PZF3ZZTt0V2Xc1Qxg0pYn1TzQfCG/JA/fHXNL+3Le3YpJNgP+YiIVW1bU0h7+2pu9biZIcyOAPvFNpDpMeluTJfdOOojlf7/s1MbeN6cqErkNVLaQ5h+4vkrxqUJ0kT2zfO5I8PMmTBlRbB1iP5nDin3rKbwIeOUxfVtCHaUYTP9cGlAdJsmGS3hCxpP25b1+9XYD/N8oybmp/bjXK9PNpgtQr+9o8HNhz9K6P6hiai0Q+kuSx/RPb+0hO1xD6jz1/B0hzL9kPti97z+X+Is06vjHJY3iw99FcdPbFqrqH4S3rfbqB5jD5bm2wHOnfajSH0zcew3KWZeSowKfTdy/QJKvkwfe5Heu+qxnCQ+fSBKqq65J8muaQ49toPqwvoLkq+S+S/AT4Ec0htWfR3Efut6M0N1avp7l1ykfT3Fj8Yh74asyRC1Z6+3pHG6ZOBM5OciLNYb7dgGfQHFZ7zQT1rRMdrcNLaC7K+Gx7HttPaQ4DbgnsSHOBwx40H9ZbAOcluZJm1PQ3NKHguTSHQT9WD74/6pnAi9sLiBbRBNFzquqcsa77IFX1uSS7Aa8DfpnkDJrt8TCaf0L2pgk4R7azHE9z7uNHk+xHMwq7bdv/r9Ocf9rvzHaez7Tnod4B/KGqjmmnf5wmZH4yydNotslONPek/Fbb9ljW6Wfte/w54PIk36G5bdBqNCFqL5pbam03lnYnyZU0fe69j+Y2NPdu/a+RSlW1JMlRNP94XpjkazTrtA/NvvYzmvOAx+JcmjB5VDtKOHK+6Mer6tYkH6O5j+alSb5BE/L2o9lXzmqfj9d/0hxVeDnwi3Y5/0tzn9n9ad7To2GF9l3NFFN92bsPHzPtwSj30eyZvinN/STv5IH7LT6M5n54S2hGPH8JfABYmwG3g2H598AbeJscmmB5Ek0wupPmw+Y5y2qP5mbPp9B8APyJ5o/7J4HNB9Q9jlFubcMot64ZZn2W0dbRQ9afkHXoqbMe8Pc0YfAOmlvLXE0TEI4A1mnrbQC8iyaYXkdzgdf1NFf5H0bfLY9oLgA5geZDf+mw69jT52G338hNx29ot8fvaEYa/4mH3qdxe5rb2dzQ7jOLaM7dnNcu87gB7f8tTYi6p63Tv/8+lebrWP9Icy7it2lC+sB9ZLT9ua/OE9vtcE273JtpDs1+Gth/yO2y76BlLWv/7JnnIe/TaNuIB249tEa7za9u+/wrmotd1hilf8+guR/uLW39/wH+Pwbf8mcBy/g71Nb5c5q/AXfw0FthzWnfxyto9u/f0YTfRzHgd2RZ+8Py+kNzG7Kzac7FvLvdHl+iOT90hfddHzPjkfaNlSRJEyDNV0DuU+2dKaSVmedoSpIkqRMGTUmSJHXCoClJkqROeI6mJEmSOuHtjaahjTfeuObNmzfV3ZAkSVquRYsW3VhVDx80zaA5Dc2bN4+FCxdOdTckSZKWK8k1o03zHE1JkiR1wqApSZKkTnjofBq68tqb2O2tx091NyRJ0gy26F9ePtVdcERTkiRJ3TBoSpIkqRMGTUmSJHXCoClJkqROGDQlSZLUCYOmJEmSOmHQlCRJUicMmpIkSeqEQVOSJEmdMGhKkiSpEwZNSZIkdWJaBs0kWyb5RpJfJPllkn9PsnrHy7yj/TkvyWU95U9Ncn6SnyW5KsnrJ2I5kiRJs920C5pJAnwdOLWqtgUeC6wLvH+c7c5ZgXkeAZwAHFlV2wF7Aq9KctB4+iJJkrQymHZBE9gfuLuqPg9QVUuBN9MEvAuS7DBSMcmCJLslWSfJ59rpFyU5sJ1+eJITk3wT+G6SdZOcmeTCJJeO1FuG1wPHVdWFbV9uBN4GvLVt/7gkB/f0Z2RUdKzLkSRJmnXGPMo3CXYAFvUWVNVtSX4NfAt4EfDuJJsBm1fVoiQfAH5QVa9KsgFwfpLvt7PvAexYVTe3o5oHte1tDJyX5LSqqmX05Qt9ZQuB7ZezDnePcTkkOQI4AmD19TZaTvOSJEnT33Qc0QwwKJAFWAAc0r5+EXBi+/wZwDuSLG7rrAls1U77XlXd3NPGB5JcAnwf2ALYdAX6Msw6jGU5VNWxVTW/qubPWXu9FVikJEnS9DIdRzQvB17YW5BkfeCRwAXATUl2BA4FXjNSBXhhVV3VN9+TgDt7il4KPBzYraruTbKEJpQuqy/zgdN6ynajGdUEuI82rLfnlo5csDTW5UiSJM0603FE80xg7SQvB0iyKvBvNOdK/hH4Cs15knOr6tJ2njOAN7ZhjyS7jNL2XOCGNvztBzxqOX35D+DwJDu37W5Ec1HS+9rpS2iCJ8CBwGoruBxJkqRZZ9oFzfY8xoOAQ5L8Avg5zTmPf99WOQl4MfC1ntneRxPyLmlvTfQ+BvsSMD/JQppRx58tpy/XA38JHJvkKuC3wMeq6uy2ymeAfZKcD/SOno5pOZIkSbNRlnF9ivq099A8Eti7qm7pajnrPGLr2u5l7+mqeUmStBJY9C8vn5TlJFlUVfMHTZt2I5rTWVX9R1U9scuQKUmSNFsYNCVJktQJg6YkSZI6YdCUJElSJwyakiRJ6oRBU5IkSZ0waEqSJKkTBk1JkiR1wqApSZKkThg0JUmS1Ik5U90BPdTjt9yIhZP0tVGSJEldcURTkiRJnTBoSpIkqRMGTUmSJHXCoClJkqROGDQlSZLUCYOmJEmSOuHtjaahP11/Ob9+7xOnuhuaZbZ616VT3QVJ0krGEU1JkiR1wqApSZKkThg0JUmS1AmDpiRJkjph0JQkSVInDJqSJEnqhEFTkiRJnTBoSpIkqRMGTUmSJHXCoClJkqROGDQlSZLUiRkdNJNsmuSEJL9KsijJuUkOGlBvXpLLBpS/N8kBQyxnlySV5JkT1XdJkqTZbsYGzSQBTgXOqapHV9VuwIuBLfvqzRmtjap6V1V9f4jFHQb8qP05sC9JZuy2lCRJ6sJMDkf7A3+qqk+NFFTVNVX18SSHJzkxyTeB747WQJLjkhyc5FlJvtZTvm8770igPRg4HHhGkjXb8nlJrkzyCeBC4JFJ3prkgiSXJHlPT3untiOulyc5YmI3gyRJ0vQ0k4PmDjQBbzR7AK+oqv2HaOt7wJOTrNO+PhT4avt8T+DqqvolsAB4ds98jwOOr6pd2ufbArsDOwO7Jdm7rfeqdsR1PvCmJBv1dyDJEUkWJll4851Lh+iyJEnS9DaTg+aDJPmPJBcnuaAt+l5V3TzMvFV1H/Ad4HntofbnAN9oJx8GfKV9/hUefPj8mqo6r33+jPZxEU0A3o4meEITLi8GzgMe2VPe24djq2p+Vc1/2DqrDtNtSZKkaW3U8xdngMuBF468qKrXJ9kYWNgW3TnG9r4KvB64Gbigqm5Psmq7jOcneScQYKMk6w1YRoAPVtWnextNsi9wALBHVf0xyQJgzTH2TZIkacaZySOaPwDWTPLanrK1x9HeAmBX4K954LD5AcDFVfXIqppXVY8CTgZeMGD+M4BXJVkXIMkWSTYB5gK3tCFzO+DJ4+ijJEnSjDFjg2ZVFU3g2yfJ1UnOB74AvH2UWR6X5NqexyF97S0FvgU8q/0JzWHyU/raORl4yYD+fBc4ATg3yaXAScB6NIfk5yS5BHgfzeFzSZKkWS9NXtN0suMWa9W3XvOYqe6GZpmt3nXpVHdBkjQLJVlUVfMHTZuxI5qSJEma3gyakiRJ6oRBU5IkSZ0waEqSJKkTBk1JkiR1wqApSZKkThg0JUmS1AmDpiRJkjph0JQkSVInDJqSJEnqxJyp7oAeavXNdmCrdy2c6m5IkiSNiyOakiRJ6oRBU5IkSZ0waEqSJKkTBk1JkiR1wqApSZKkThg0JUmS1AlvbzQN/eyGn7Hnx/ec6m507sdv/PFUd0GSJHXIEU1JkiR1wqApSZKkThg0JUmS1AmDpiRJkjph0JQkSVInDJqSJEnqhEFTkiRJnTBoSpIkqRMGTUmSJHXCoClJkqROGDQlSZLUiWkRNJNslGRx+/hdkut6Xq/eV/eoJGsP0eaCJPPb50uSXNq2d2mSAyegz/OSvKTn9dpJvtS2f1mSHyVZt522tGd9FieZN97lS5IkTXdzproDAFV1E7AzQJKjgTuq6l9HqX4U8EXgj2NczH5VdWOSxwHfBb6xgt0dMQ94CXBC+/pvgN9X1RMB2uXc2067q6p2HufyJEmSZpRpMaI5SJKnJbmoHSH8XJI1krwJ2Bw4K8lZbb1PJlmY5PIk7xmi6fWBW9p510ny7SQXt6OQh7blS5J8IMm5bdu7JjkjyS+THNm28yFgr3aE8s3AZsB1Iwupqquq6p6J2yKSJEkzy7QY0RxgTeA44GlV9fMkxwOvraqPJvlb2tHJtu47q+rmJKsCZybZsaouGdDmWUkCPBp4UVv258Bvq+o5AEnm9tT/TVXtkeQjbV/2bPt1OfAp4B3AW6rque28OwPfTXIwcCbwhar6RdvWWkkWt8+vrqqD+juX5AjgCIDVN1y9f7IkSdKMM11HNFelCWQ/b19/Adh7lLovSnIhcBGwA7D9KPX2q6onAE8EjmnPn7wUOCDJPyfZq6pu7al/WvvzUuCnVXV7Vf0vcHeSDfobr6rFNCH2X4CHARckeXw7+a6q2rl9PCRktvMfW1Xzq2r+auuuNsoqSJIkzRzTNWjeOUylJFsDb6EZ+dwR+DbNqOOoquqXwO+B7dsguxtNmPxgknf1VB057H1/z/OR1wNHgqvqjqr6elW9juY80mcPsx6SJEmz0XQNmmsC85I8pn39MuDs9vntwHrt8/VpQumtSTYFnrW8hpNsAmwNXJNkc+CPVfVF4F+BXcfQx95+kGTPJBu2z1enGVm9ZgztSZIkzSrT9RzNu4FXAicmmQNcQHNeJMCxwOlJrq+q/ZJcRHPe5K+AHy+jzbOSLAVWA95RVb9P8kzgX5LcT3OF+GvH0MdLgPuSXExzDudNwCfb80BXoRldPXkM7UmSJM0qqaqp7oP6rLvVurXTW3ea6m507sdvXNb/BZIkaSZIsqiq5g+aNl0PnUuSJGmGM2hKkiSpEwZNSZIkdcKgKUmSpE4YNCVJktQJg6YkSZI6YdCUJElSJwyakiRJ6oRBU5IkSZ0waEqSJKkT0/W7zldq222ynV/PKEmSZjxHNCVJktQJg6YkSZI6YdCUJElSJwyakiRJ6oRBU5IkSZ0waEqSJKkT3t5oGrr9qqs4e+99JnWZ+5xz9qQuT5IkzX6OaEqSJKkTBk1JkiR1wqApSZKkThg0JUmS1AmDpiRJkjph0JQkSVInDJqSJEnqhEFTkiRJnTBoSpIkqRMGTUmSJHXCoClJkqROzOqgmeRzSW5Ictly6u2b5Ck9r49Ocl2Sxe3jQ235giTzR2njuUkuSnJxkiuSvGZZbUmSJM12c6a6Ax07DjgGOH459fYF7gB+0lP2kar612EWkmQN4Fhg96q6tn09b0XakiRJmi1m9YhmVZ0D3NxbluRN7YjjJUm+kmQecCTw5nbEca9h2k5yR5L3Jvkp8CSa0H5Tu9x7quqqiVwXSZKkmWZWB81RvAPYpap2BI6sqiXAp2hGHXeuqh+29d7cc7j7mQPaWQe4rKqe1Aba04Brknw5yUuT9G7b5bVFkiOSLEyy8NZ7752wlZUkSZoqK2PQvAT4UpK/BO5bRr2R4LlzVZ0xYPpS4OSRF1X1V8DTgPOBtwCfG0NbVNWxVTW/qubPXW21sa6TJEnStLMyBs3nAP8B7AYsSrKi56neXVVLewuq6tKq+gjwdOCF4+umJEnSzLZSBc32cPYjq+os4G3ABsC6wO3AeuNod90k+/YU7QxcM46uSpIkzXiz+qrzJF+muaJ84yTXAu8DXpZkLhCaQ9p/SPJN4KQkBwJvXJFFAW9L8mngLuBO4PAJWAVJkqQZK1U11X1Qn8ett14du8uuk7rMfc45e1KXJ0mSZocki6pq4H3GV6pD55IkSZo8Bk1JkiR1wqApSZKkThg0JUmS1AmDpiRJkjph0JQkSVInDJqSJEnqhEFTkiRJnTBoSpIkqRMGTUmSJHViVn/X+Uy13uMe51dCSpKkGc8RTUmSJHXCoClJkqROGDQlSZLUCYOmJEmSOmHQlCRJUicMmpIkSeqEtzeahm649laO+btvTuoy3/Bvz5vU5UmSpNnPEU1JkiR1wqApSZKkThg0JUmS1AmDpiRJkjph0JQkSVInDJqSJEnqhEFTkiRJnTBoSpIkqRMGTUmSJHXCoClJkqROGDQlSZLUiWkZNJMsTbI4ycVJLkzylAloc+ckz+55fXiS/22XszjJ8Umen+Qdy2lnlSQfS3JZkkuTXJBk63bakrZspM2ntOXfSfKHJN8a73pIkiTNFHOmugOjuKuqdgZI8kzgg8A+42xzZ2A+8N89ZV+tqjf01TttOe0cCmwO7FhV9yfZErizZ/p+VXVj3zz/AqwNvGbs3ZYkSZqZpuWIZp/1gVsAkmyW5Jx2tPCyJHu15Xck+ecki5J8P8nuSRYk+VU7Srk68F7g0HbeQwctqB3lPKZ9flw7cvmTtp2D22qbAddX1f0AVXVtVd2yrBWoqjOB2ydiY0iSJM0U03VEc60ki4E1aYLd/m35S4Azqur9SValGSUEWAdYUFVvT3IK8E/A04HtgS9U1WlJ3gXMHxnBTHI4TfB8atvGvwPV14/NgKcC29GMdJ4EfA34URtyzwS+WFUX9cxzVpKlwD1V9aSJ2BiSJEkz0VBBM8k2wLVVdU+SfYEdgeOr6g8d9av30PkewPFJngBcAHwuyWrAqVW1uK3/J+A77fNLaULevUkuBeYtYzkPOnTehs9ep7Yjl1ck2RSaEcwkj6MJv/sDZyY5pB21hMGHzpcryRHAEQAbrvfwsc4uSZI07Qx76PxkYGmSxwCfBbYGTuisVz2q6lxgY+DhVXUOsDdwHfBfSV7eVru3qkZGI+8H7mnnvZ/xjdre0/M8PX26p6pOr6q3Ah8AXjCOZYy0eWxVza+q+euuPXe8zUmSJE25YYPm/VV1H3AQ8NGqejPNYeXOJdkOWBW4KcmjgBuq6jM0gXfXMTR1O7DeBPRn1ySbt89XoRndvWa87UqSJM02w4723ZvkMOAVwPPastW66RLwwDma0IwkvqKqlraH7d+a5F7gDuDlozUwwFnAO9p2PziOvm0CfCbJGu3r84FjljVDkh/SnOe5bpJrgVdX1Rnj6IMkSdK0lweOOC+jUrI9cCRwblV9ub1v5KFV9VOzqGsAABiwSURBVKGuO7gy2uoR29bbXvrhSV3mG/7tecuvJEmS1CfJoqqaP2jaUCOaVXVFkrcDW7WvrwYMmZIkSRrVUOdoJnkesJj2yu72W3aWd2NzSZIkrcSGvRjoaGB34A8A7W2Ftu6oT5IkSZoFhg2a91XVrX1lyz+5U5IkSSutYa86vyzJS4BVk2wLvAn4SXfdkiRJ0kw37IjmG4EdaG5gfgJwK3BUV52SJEnSzLfcEc32O8VPq6oDgHd23yVJkiTNBssd0ayqpcAfk/i9iJIkSRrasOdo3g1cmuR7wJ0jhVX1pk56JUmSpBlv2KD57fYhSZIkDWWor6DU5Jo/f34tXLhwqrshSZK0XOP+CsokVzPgvplV9ehx9k2SJEmz1LCHzntT6prAIcDDJr47kiRJmi2Guo9mVd3U87iuqj4K7N9x3yRJkjSDDXvofNeel6vQjHCu10mPJEmSNCsMe+j833qe3wdcDbxo4rsjSZKk2WLYoPnqqvpVb0GSrTvojyRJkmaJoW5vlOTCqtq1r2xRVe3WWc9WYltstGG97llPm7TlvfOLJ03asiRJ0uyywrc3SrIdsAMwN8lf9Exan+bqc0mSJGmg5R06fxzwXGAD4Hk95bcDf91VpyRJkjTzLTNoVtU3gG8k2aOqzp2kPkmSJGkWGPZioIuSvJ7mMPr/HTKvqld10itJkiTNeEPdsB34L+ARwDOBs4EtaQ6fS5IkSQMNGzQfU1X/CNxZVV8AngM8sbtuSZIkaaYbNmje2/78Q5InAHOBeZ30SJIkSbPCsOdoHptkQ+AfgdOAdYF3ddYrSZIkzXhDBc2q+s/26dnAo7vrjiRJkmaLoQ6dJ9k0yWeTnN6+3j7Jq7vtmiRJkmayYc/RPA44A9i8ff1z4KguOiRJkqTZYdiguXFVfQ24H6Cq7gOWdtarFZDGj5I8q6fsRUm+M852lyZZnOTiJBcmecoQ8/xnku3b50uSbJxkgySvG09fJEmSZpJhg+adSTYCCiDJk4FbO+vVCqiqAo4EPpxkzSTrAO8HXr8i7SVZtX16V1XtXFU7Af8P+OAQffmrqrqir3gDwKApSZJWGsMGzb+ludp8myQ/Bo4H3thZr1ZQVV0GfBN4O/Bu4IvAO5NckOSiJAcCJJmX5IftCOX/jVIm2TfJWUlOAC4dsIj1gVt66n5rZEKSY5Ic3j5fkGR+37wfotl+i5P8y4SuuCRJ0jS0zKvOk2xVVb+uqguT7AM8DghwVVXdu6x5p9B7gAuBPwHfAn5QVa9KsgFwfpLvAzcAT6+qu5NsC3wZGAmGuwNPqKqr29drJVlM89WbmwH7r2C/3tG2u/MKzi9JkjSjLO/2RqcCu7bPv1pVL+y4P+NWVXcm+SpwB/Ai4HlJ3tJOXhPYCvgtcEySnWnONX1sTxPn94RMaA+dAyTZAzi+vWn9hEpyBHAEwNy115ro5iVJkibd8oJmep7PpPtn3t8+Arywqq7qnZjkaOD3wE40pw/c3TP5ztEarapzk2wMPBy4jweferDmeDpcVccCxwJssdGGNZ62JEmSpoPlnaNZozyfKc4A3pgkAEl2acvnAtdX1f3Ay4BVR5n/QZJs19a9CbgG2D7JGknmAk9bzuy3A+uNfRUkSZJmpuWNaO6U5DaakcG12ue0r6uq1u+0d+P3PuCjwCVt2FwCPBf4BHBykkOAs1jGKCYPnKMJzXq/oqqWAr9J8jXgEuAXwEXL6khV3ZTkx0kuA06vqreOY70kSZKmvTR3BdJ0ssVGG9brnrW8AdKJ884vnjRpy5IkSbNLkkVV1X+3HWD42xtJkiRJY2LQlCRJUicMmpIkSeqEQVOSJEmdMGhKkiSpEwZNSZIkdcKgKUmSpE4YNCVJktQJg6YkSZI6YdCUJElSJ5b3XeeaApttvY1fCylJkmY8RzQlSZLUCYOmJEmSOmHQlCRJUicMmpIkSeqEQVOSJEmdMGhKkiSpE97eaBq6+/rbufL9P5jwdh//zv0nvE1JkqTROKIpSZKkThg0JUmS1AmDpiRJkjph0JQkSVInDJqSJEnqhEFTkiRJnTBoSpIkqRMGTUmSJHXCoClJkqROGDQlSZLUCYOmJEmSOmHQlCRJUidWiqCZ5I4x1D08yeZ9ZQ9Pcm+S10x87yRJkmanlSJojtHhwOZ9ZYcA5wGHjTZTklU77JMkSdKMs9IGzSQ7JzkvySVJTkmyYZKDgfnAl5IsTrJWW/0w4O+ALZNs0dPGHUnem+SnwB5J/jLJ+e28nx4Jn0k+mWRhksuTvGey11WSJGkqrLRBEzgeeHtV7QhcCry7qk4CFgIvraqdq+quJI8EHlFV5wNfAw7taWMd4LKqehJwUzttz6raGVgKvLSt986qmg/sCOyTZMf+ziQ5og2jC2++8w/drLEkSdIkWimDZpK5wAZVdXZb9AVg71Gqv5gmYAJ8hQcfPl8KnNw+fxqwG3BBksXt60e3016U5ELgImAHYPv+hVTVsVU1v6rmP2ydDVZsxSRJkqaROVPdgRngMGDTJCOjk5sn2baqfgHcXVVL2/IAX6iq/9c7c5KtgbcAf1ZVtyQ5DlhzkvouSZI0ZVbKEc2quhW4JclebdHLgJHRzduB9QCSPA5Yp6q2qKp5VTUP+CDNKGe/M4GDk2zSzvuwJI8C1gfuBG5NsinwrI5WS5IkaVpZWUY0105ybc/rDwOvAD6VZG3gV8Ar22nHteV3AWcAp/S1dTLNIfT39RZW1RVJ/gH4bpJVgHuB11fVeUkuAi5vl/PjCV0zSZKkaWqlCJpVNdrI7ZMH1D2ZB867HNTWJbTnWFbVun3Tvgp8dcA8h4+hu5IkSbPCSnnoXJIkSd0zaEqSJKkTBk1JkiR1wqApSZKkThg0JUmS1AmDpiRJkjph0JQkSVInDJqSJEnqhEFTkiRJnVgpvhlopllzs/V4/Dv3n+puSJIkjYsjmpIkSeqEQVOSJEmdMGhKkiSpEwZNSZIkdcKgKUmSpE4YNCVJktQJb280Df32t7/l6KOPnvB2u2hTkiRpNI5oSpIkqRMGTUmSJHXCoClJkqROGDQlSZLUCYOmJEmSOmHQlCRJUicMmpIkSeqEQVOSJEmdMGhKkiSpEwZNSZIkdcKgKUmSpE4YNCVJktSJaRc0k2ya5IQkv0qyKMm5SQ6a4j59I8m5U9kHSZKkmWZaBc0kAU4FzqmqR1fVbsCLgS2HnH/VDvq0AbArsEGSrUepM2eilytJkjTTTaugCewP/KmqPjVSUFXXVNXHk8xL8sMkF7aPpwAk2TfJWUlOAC5ty05tR0MvT3LESFtJXp3k50kWJPlMkmPa8ocnOTnJBe1jz54+vRD4JvAVmtA70tZxST6c5Czgn5Nsk+Q77XJ/mGS7tt7zkvw0yUVJvp9k0862niRJ0jQy3UbidgAuHGXaDcDTq+ruJNsCXwbmt9N2B55QVVe3r19VVTcnWQu4IMnJwBrAP9KMTt4O/AC4uK3/78BHqupHSbYCzgAe3047DHgP8HvgJOCDPX16LHBAVS1NciZwZFX9IsmTgE/QBOcfAU+uqkryV8DbgL/rX7k2EB8BMHfu3GG2lSRJ0rQ23YLmgyT5D+CpwJ+AA4BjkuwMLKUJeSPO7wmZAG/qOa/zkcC2wCOAs6vq5rbtE3vaOADYvjlyD8D6SdYD1gYeA/yoDYr3JXlCVV3W1juxDZnrAk8BTuxpY43255bAV5NsBqwO9Pbz/1TVscCxAJtvvnkNt4UkSZKmr+kWNC+nOVQNQFW9PsnGwELgzTSjijvRHPK/u2e+O0eeJNmXJjjuUVV/TLIAWBMIo1ulrX9Xb2GSVwIbAle3AXJ9msPn/9C33FWAP1TVzgPa/jjw4ao6re3b0cvohyRJ0qwx3c7R/AGwZpLX9pSt3f6cC1xfVfcDLwNGu/BnLnBLGzK3A57clp8P7JNkw/binRf2zPNd4A0jL9pRU2gOm/95Vc2rqnnAyMVJD1JVt9GE0UPa+ZNkp57+XNc+f8Uy116SJGkWmVZBs6oKeAFNILw6yfnAF4C305zz+Iok59Ec8r5zlGa+A8xJcgnwPuC8tu3rgA8APwW+D1wB3NrO8yZgfpJLklwBHJlkHrDVyPxtG1cDt7XnYPZ7KfDqJBfTjMwe2JYfTXNI/YfAjWPaIJIkSTNYmmy3ckiyblXd0Y5ongJ8rqpOmep+9dt8883riCOOWH7FMTr66KMnvE1JkrRyS7KoquYPmjatRjQnwdFJFgOX0VyUc+oU90eSJGnWmm4XA3Wqqt4y1X2QJElaWaxsI5qSJEmaJAZNSZIkdcKgKUmSpE4YNCVJktQJg6YkSZI6YdCUJElSJwyakiRJ6sRK9c1AM8X8+fNr4cKFU90NSZKk5fKbgSRJkjTpDJqSJEnqhEFTkiRJnTBoSpIkqRMGTUmSJHXCoClJkqROGDQlSZLUiTlT3QE91C23XMnXTtx9wtp70SHnT1hbkiRJw3JEU5IkSZ0waEqSJKkTBk1JkiR1wqApSZKkThg0JUmS1AmDpiRJkjph0JQkSVInDJqSJEnqhEFTkiRJnTBoSpIkqRMGTUmSJHViVgXNJI9MclaSK5NcnuRvxjj/giTz2+dLklyaZHH7eEqSeUkuG2XeVZJ8LMll7XwXJNl6tLbGv7aSJEnT25yp7sAEuw/4u6q6MMl6wKIk36uqK1awvf2q6saRF0nmDaqUZA5wCLA5sGNV3Z9kS+DO0dqSJEma7WZV0Kyq64Hr2+e3J7kS2CLJJ4CfAvsBGwCvrqofJlkL+DywPXAlsNawy0pyOPAcYE1gHeBbwPVVdX+7/Gsnar0kSZJmolkVNHu1o4+70ARMgDlVtXuSZwPvBg4AXgv8sap2TLIjcGFfM2clWQrcU1VPGrCYPWhGMG9uRzB/lGQv4Ezgi1V10bBtJTkCOAJg441XX7GVliRJmkZmZdBMsi5wMnBUVd2WBODr7eRFwLz2+d7AxwCq6pIkl/Q1tbzD3d+rqpvb+a9N8jhg//ZxZpJDqurMYdqqqmOBYwG22WadGm5NJUmSpq9ZFzSTrEYTMr9UVV/vmXRP+3MpD17v8YS63nMwqap7gNOB05P8HngBzeimJEnSSme2XXUe4LPAlVX14SFmOQd4aTvvE4Adx7HsXZNs3j5fpW3rmhVtT5IkaaabbSOaewIvAy5Nsrgt+/tl1P8k8Pn2kPli4PxxLHsT4DNJ1mhfnw8cM472JEmSZrRUeTrgdLPNNuvUBz+0w4S196JDxpOfJUmSRpdkUVXNHzRtVh06lyRJ0vRh0JQkSVInDJqSJEnqhEFTkiRJnTBoSpIkqRMGTUmSJHXCoClJkqROGDQlSZLUCYOmJEmSOjHbvoJyVthww8f7bT6SJGnGc0RTkiRJnTBoSpIkqRMGTUmSJHXCoClJkqROGDQlSZLUCYOmJEmSOmHQlCRJUie8j+Y0dMUtt7HTSWeMq42LD37mBPVGkiRpxTiiKUmSpE4YNCVJktQJg6YkSZI6YdCUJElSJwyakiRJ6oRBU5IkSZ0waEqSJKkTBk1JkiR1wqApSZKkThg0JUmS1AmDpiRJkjrRSdBMslGSxe3jd0mu63m9el/do5Ks3fN6SZJLk1yS5Owkj5rAfr05yd1J5vaUHZ7kmDG2s22SbyX5ZZJFSc5KsveQ8y5JsvFY+y5JkjTTdBI0q+qmqtq5qnYGPgV8ZOR1Vf2pr/pRwNp9ZftV1Y7AAuAfJrBrhwEXAAetaANJ1gS+DRxbVdtU1W7AG4FHD6g7Z0WXI0mSNNNN2qHzJE9LclE7Wvm5JGskeROwOXBWkrMGzHYusEU7/7wkP0vyn0kuS/KlJAck+XGSXyTZva23T8/o6UVJ1mvLtwHWpQmuh/Ut55FJvpPkqiTvbuv/c5LX9fT/6CR/B7wUOLeqThuZVlWXVdVxPfWOTfJd4Ph2dPe7bV8+DWQCNqckSdK0N1lBc03gOODQqnoiMAd4bVV9DPgtzQjmfgPm+3Pg1J7XjwH+HdgR2A54CfBU4C3A37d13gK8vh1N3Qu4qy0/DPgy8EPgcUk26Wl3d5oAuTNwSJL5wFeAQ3vqvAg4EdgBuHA567sbcGBVvQR4N/CjqtoFOA3YatAMSY5IsjDJwvtuu3U5zUuSJE1/kxU0VwWurqqft6+/ACzrnMazktwAHACc0FN+dVVdWlX3A5cDZ1ZVAZcC89o6PwY+3I6WblBV97XlLwa+0s77deCQnna/1x7uv6ud9tSqugjYJMnmSXYCbqmqX/d3NMkp7Qjr13uKT2vbol3PLwJU1beBWwatcFUdW1Xzq2r+nPXnDqoiSZI0o0xW0LxzjPX3Ax5FEybf21N+T8/z+3te308zSkpVfQj4K2At4Lwk2yXZEdgW+F6SJTShs/fwefUtf+T1ScDBNCObX2nLLgd2/b+KVQcBhwMP65m/f33725ckSZr1JvPQ+bwkj2lfvww4u31+O7Be/wztiOBRwMuTPKx/+miSbNOOev4zsJDmEPthwNFVNa99bA5s0XNF+9OTPCzJWsALaEZFoQmXL6YJmye1ZScAeyZ5fs9i+y9m6nUOzWF5kjwL2HDYdZEkSZrJJito3g28EjgxyaU0I5CfaqcdC5w+6GKgqrqe5rzK149hWUe1h7Ivpjk/83SasHhKX71T2nKAHwH/BSwGTq6qhe3yL6cJwde1fRkJwM8FjkzyqyTn0lxg9E+j9Oc9wN5JLgSeATzk8LskSdJslOYUR00na2/z2Nr2nz8+rjYuPviZE9QbSZKk0SVZVFXzB03zm4EkSZLUCYOmJEmSOmHQlCRJUicMmpIkSeqEQVOSJEmdMGhKkiSpEwZNSZIkdcKgKUmSpE4YNCVJktSJOVPdAT3U9huuz0K/2UeSJM1wjmhKkiSpEwZNSZIkdcKgKUmSpE6kqqa6D+qT5Hbgqqnux0piY+DGqe7ESsDtPDnczpPHbT053M6TZzzb+lFV9fBBE7wYaHq6qqrmT3UnVgZJFrqtu+d2nhxu58njtp4cbufJ09W29tC5JEmSOmHQlCRJUicMmtPTsVPdgZWI23pyuJ0nh9t58ritJ4fbefJ0sq29GEiSJEmdcERTkiRJnTBoSpIkqRMGzSmU5M+TXJXkf5K8Y8D0JPlYO/2SJLtORT9nuiG283ZJzk1yT5K3TEUfZ4shtvVL2335kiQ/SbLTVPRzphtiOx/YbuPFSRYmeepU9HOmW9527qn3Z0mWJjl4Mvs3mwyxT++b5NZ2n16c5F1T0c+Zbph9ut3Wi5NcnuTscS+0qnxMwQNYFfgl8GhgdeBiYPu+Os8GTgcCPBn46VT3e6Y9htzOmwB/BrwfeMtU93mmPobc1k8BNmyfP8t9urPtvC4PnIO/I/Czqe73THsMs5176v0A+G/g4Knu90x8DLlP7wt8a6r7OpMfQ27nDYArgK3a15uMd7mOaE6d3YH/qapfVdWfgK8AB/bVORA4vhrnARsk2WyyOzrDLXc7V9UNVXUBcO9UdHAWGWZb/6SqbmlfngdsOcl9nA2G2c53VPspAawDeNXn2A3zNxrgjcDJwA2T2blZZthtrfEZZju/BPh6Vf0ams/H8S7UoDl1tgB+0/P62rZsrHW0bG7DyTPWbf1qmhF7jc1Q2znJQUl+BnwbeNUk9W02We52TrIFcBDwqUns12w07N+OPZJcnOT0JDtMTtdmlWG282OBDZMsSLIoycvHu1C/gnLqZEBZ/6jDMHW0bG7DyTP0tk6yH03Q9NzBsRtqO1fVKcApSfYG3gcc0HXHZplhtvNHgbdX1dJkUHUNaZhtfSHN92nfkeTZwKnAtp33bHYZZjvPAXYDngasBZyb5Lyq+vmKLtSgOXWuBR7Z83pL4LcrUEfL5jacPENt6yQ7Av8JPKuqbpqkvs0mY9qnq+qcJNsk2biqbuy8d7PHMNt5PvCVNmRuDDw7yX1VderkdHHWWO62rqrbep7/d5JPuE+P2bC548aquhO4M8k5wE7ACgdND51PnQuAbZNsnWR14MXAaX11TgNe3l59/mTg1qq6frI7OsMNs501MZa7rZNsBXwdeNl4/kNeyQ2znR+TNv20d6tYHTDUj81yt3NVbV1V86pqHnAS8DpD5goZZp9+RM8+vTtNfnGfHpthPg+/AeyVZE6StYEnAVeOZ6GOaE6RqrovyRuAM2iuBPtcVV2e5Mh2+qdormJ8NvA/wB+BV05Vf2eqYbZzkkcAC4H1gfuTHEVzJd5tozashxhyn34XsBHwifYz477/v707OEEoBoIAOunJThS0BXuyEOsQwVI8KK6Hf/EY0UWE9xpIGPYwIYRU1epXe/5HkzmvsxxSb0muSbYvj4OYMJkzXzCZ9SbJfoxxzzLTOzP9npmcq+oyxjgmOSV5JDlU1fmTdX1BCQBAC1fnAAC0UDQBAGihaAIA0ELRBACghaIJAEALRRMAgBaKJgAALZ7UgojV+ICrWgAAAABJRU5ErkJggg==\n",
"text/plain": [
"
"
]
},
"metadata": {
"needs_background": "light"
},
"output_type": "display_data"
},
{
"name": "stdout",
"output_type": "stream",
"text": [
" RFE Selected Features\n",
"\n",
"Please wait Training-Testing with all models..\n",
"\n",
"Done with LinearRegression\n",
"Done with RandomForestRegression\n",
"[15:36:16] WARNING: C:/Jenkins/workspace/xgboost-win64_release_0.90/src/objective/regression_obj.cu:152: reg:linear is now deprecated in favor of reg:squarederror.\n",
"Done with XGBoostRegressor\n",
"Done with LGBoostRegressor\n",
"Done with AdaBoostRegressor\n",
"Done with SupportVectorMachine\n",
"Done with GradientBoostingRegression\n"
]
},
{
"data": {
"text/html": [
"
"
],
"text/plain": [
""
]
},
"execution_count": 5,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"df = es.importdata('adv-housing.csv')\n",
"es.quick_ml(df,'SalePrice','r')"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Loan Risk Prediction dataset "
]
},
{
"cell_type": "code",
"execution_count": 6,
"metadata": {
"ExecuteTime": {
"end_time": "2020-03-17T10:18:24.220603Z",
"start_time": "2020-03-17T10:15:47.861093Z"
}
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Dataframe Imported Successfully\n",
"*** Dataset Infomarion ***\n",
"##################################################\n",
"No of Rows : 63999\n",
"No of columns : 43\n",
"No of Numerical columns: 26\n",
"No of Categorical columns: 17\n",
"##################################################\n",
"\n",
" Total Missing values : 276727 \n",
"\n",
"##################################################\n",
"Summary of DataFrame:\n",
"\n",
" Column Name Nulls/NaN outof Unique Type of Columns\n",
"0 loan_amnt 0 63999 1273 Numerical\n",
"1 funded_amnt 0 63999 1275 Numerical\n",
"2 funded_amnt_inv 0 63999 1965 Numerical\n",
"3 term 0 63999 2 Categorical\n",
"4 int_rate 0 63999 459 Numerical\n",
"5 grade 0 63999 7 Categorical\n",
"6 sub_grade 0 63999 35 Categorical\n",
"7 emp_title 3826 63999 31609 Categorical\n",
"8 emp_length 3324 63999 11 Categorical\n",
"9 home_ownership 0 63999 6 Categorical\n",
"10 annual_inc 0 63999 6368 Numerical\n",
"11 verification_status 0 63999 3 Categorical\n",
"12 pymnt_plan 0 63999 1 Categorical\n",
"13 desc 54849 63999 8757 Categorical\n",
"14 purpose 0 63999 14 Categorical\n",
"15 title 13 63999 6409 Categorical\n",
"16 zip_code 0 63999 866 Categorical\n",
"17 addr_state 0 63999 51 Categorical\n",
"18 dti 0 63999 3943 Numerical\n",
"19 delinq_2yrs 0 63999 19 Numerical\n",
"20 inq_last_6mths 0 63999 15 Numerical\n",
"21 mths_since_last_delinq 32831 63999 103 Numerical\n",
"22 mths_since_last_record 54349 63999 121 Numerical\n",
"23 open_acc 0 63999 54 Numerical\n",
"24 pub_rec 0 63999 14 Numerical\n",
"25 revol_bal 0 63999 30608 Numerical\n",
"26 revol_util 29 63999 1090 Numerical\n",
"27 total_acc 0 63999 101 Numerical\n",
"28 initial_list_status 0 63999 2 Categorical\n",
"29 total_rec_int 0 63999 50744 Numerical\n",
"30 total_rec_late_fee 0 63999 600 Numerical\n",
"31 recoveries 0 63999 1754 Numerical\n",
"32 collection_recovery_fee 0 63999 1653 Numerical\n",
"33 collections_12_mths_ex_med 8 63999 5 Numerical\n",
"34 mths_since_last_major_derog 48155 63999 148 Numerical\n",
"35 application_type 0 63999 2 Categorical\n",
"36 verification_status_joint 63971 63999 3 Categorical\n",
"37 last_week_pay 0 63999 87 Categorical\n",
"38 acc_now_delinq 0 63999 5 Numerical\n",
"39 tot_coll_amt 5124 63999 2579 Numerical\n",
"40 tot_cur_bal 5124 63999 52207 Numerical\n",
"41 total_rev_hi_lim 5124 63999 3617 Numerical\n",
"42 loan_status 0 63999 2 Numerical\n"
]
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAfkAAAITCAYAAAAEgWWdAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADt0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjByYzEsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy/xvVyzAAAgAElEQVR4nOzdd5gkZbn+8e+95BxkCQrLAgdBRARdyQIrgmICUYLHABgQVARFBDw/JCiCIIpiRCQpogQRDoKAyy4cUETCEiRIFFBgySDIkp7fH+/bbm1vz0ztTHdVTc/9ua6+uququ99nunv66XqjIgIzMzPrP+PqDsDMzMx6w0nezMysTznJm5mZ9SkneTMzsz7lJG9mZtannOTNzMz6lJO8VUrSIZKicPmnpLMlrVZ3bHNL0pclbdHjMk6WdE1Tn28EcTwq6ZC5fMzWkvbpYgw9fS0kbSvpVkkvSLq3y8/d1dfC+peTvNXhKWCjfPkSsC4wRdIitUY1974MbNHjMr4G7Nrg56vS1sCoSGyS5gFOBW4A3ga8v8tFjJrXwuo1b90B2Jj0UkRclW9fJek+4P+AdwFnDucJJS0UEf/uVoBNERF3Nfn5bEArAIsDv4yIK+oOZij9+v9jPpO3Zrg2X08EkLSgpKMk3S9ppqQbJL2r+ABJ90o6RtJBkh4Ans7755F0oKS/5cc+IOnktsduK+kaSc9LeiiXNV/h+CG5Onk9SVdJek7S9ZLeWiwfeBVwcKHpYYtOf5ykLfLxLSWdK+lZSXfkKtd5JB2dy/uHpC+2PXa2KmVJS0o6ITdzPC/pPkk/LRxfUdIZkmZI+rekuyR9bZDn2zXH9gZJl+TYbpO0fVsckvS1/LxPSzpR0s75sRM7/d2Fx26W38PnJV0raeMO93l3Lr/1/FdJ2rr4ngD7AisXXu+T87GNJJ2XX5NnJU2X9OHBYmore7v8Nz8v6QpJaxWOnSlpaofHHCrp4eLnpnBsV+D+vHlujvWQfGycpAMk3Zk/n3+TtEsXX4tpks5qe77W52/tvD0xb39Y0qmSngT+Nx9bWtJP8t/2vKQ/Stqg7GtpzeMzeWuCifn6oXx9FrA+cDBwF7AjcJ6kSRExvfC4/wb+CnyGWZ/lnwAfA44CLgOWBj7YeoCkHYHT8/2+AqwGHEH6wfulwnMvDJwCfCfHdTBwjqQJEfEcqfp1ao71hPyYW4b4O3+SLz8gVfWfBZwGKP8t7waOkfTHQk1Hu28DGwNfyHGtBGxWOH4qsBCwO/AksCqw5hBxAfwSOB44GtgL+JWkVSPigXx8H9LrdThwBbAt6TUelKRXAxcCV5Peh1fnv3nhtruuQko03wJeAbYBLpS0WURcSXqNV2f2qu9H8vXKwJXAj4HngU2AkyS9EhGnDxHiyqTX9CDg38ChwEWSVo+I53O5F0paJSLuyX+TSJ+xX0TEix2e83fA9sBvSJ+pK4HW63gcsAtwGHAdsBVwoqTHIuL8LrwWc+NbOcYdgJclLQD8AVgS2A+YAewJ/CG/Hg8N+EzWXBHhiy+VXYBDgEdJSXle4LWkZPk0qYpzSyCAzdsedzlwZmH7XuBBYMHCvjXzYz8/QNkC/g6c1Lb/46Qv+FcVYgzgbYX7rJv3vbOw71HgkBJ/8xb5sQcX9q2V911a2DeOlLi/Wdh3MnBNYftmYK9ByvoX8N5Bjrc/3645jo8X9r0KeAnYI2/Pk1/rH7Q91wX5sRMHKe8o4DFg4cK+D+fHdXzt8uswL3ARcGJh/7eAe4d4rZUf+5PiazvIaxHAxoV9K7f97ePyZ+bQwn3elh+39iDPPTHf5z2Fff9FStq7tN33VOAv3XgtgGnAWQN8/tZui+2ctvt9AngBWL2wb17SD+2jh/qc+9LMi6vrrQ6vAl7Ml9tJZ5s7RcSDwNtJie5KSfO2LsAUYFLb80yJdLbVMjlfnzxAua8FJgBntD33pcCCwNqF+75I+sJsaZ2lr1j6r5zTlMLtO/P1pa0dEfEKcDfwmkGeYzqwn6TPSHrtAMePyNXwE+YitosLcTxGOotr/a0rAcsD57U9pn27k/WBSyLVfrT8pv1OuZnhFEn/ICXZF0mdyzr9je2PXUrS9yT9nVmfq93LPBaYERF/bG1ExN9JzUfr5+1XSJ+nj+UzeEg/jK6JiJtLPH/RlqQkf06Hz/a6Sp31RvRazKXftW2/nfS331OIDVKNWPv/no0Srq63OjxF+kIJUkL/Z+TTBmAZUkLpVA36ctv2w23brwKejYinByh3mXx9wQDHVyrcfjp/wQMQES/k7/gFB3hsGU92eL4n2+7zwhBlfI5U1ftV4AeS7gQOiohf5eM7karUvwMsKekGYN+ImNLx2TrE1iGO5fN1e5VwmSri5YEbizsi4t+S/tXaljSO9INhMdLfdSfwLOnvXLZEGScDG5JGDtxCqhXak9SkMJQZA+xbobB9Eqk6f7KkvwAfYPamnbKWIdWKPDXA8RUk/ZORvRZzo/3/ZxnS69jpf88dNkcpJ3mrw0sRMdD45MeBfwDblXie9nWSHwMWkbT4AIn+8Xy9O3B9h+P3lCizVhHxJPB54POS1iG17Z8m6caIuCUi/gHsmhPn+qSmh/NyX4LHhllsqy12fNv+9u2BHjtbcpK0ELBoYdd/AesB20TE79vuNyhJC5L6MnwuIn5c2F+2lrJT4lyW1NcDgIi4V9IfSGfwq5Cq0Idq6+/kcdKZ+SakM/p2MxjBa5E9D8zftm/pAe7b/v/zOHAN6QdSu5kly7eGcZK3pplC6jn8r4i4bS4f26r6/hjw/Q7Hbyf9gJgYET/tcHxuDXXW3VMRcaOk/Uht3GtS6PiXayGuknQo8EdSW/Nwk/z9pGS9LaltuOV9JR77F+DjkhYuVNlv33afVgL7TyKRtDIpGRZrATq93guQzo6Lj10sx9aexDpZVtLGrSr73MTxJtLZe9HPgBOB1wO/zT+25talOdYlIuKSTncoJPPhvBaQOvht1rZvq5LxTSE1C9wXEZ1qOGwUcpK3prmElEgukfRN0hnV4qSObwtGxIEDPTAibpd0PKmH+rKkznpLAh+MiJ0j4hVJ+wI/l7Q4qdf3C6Q+Advl+z030PN3cBvwbkm/J3V4uz0inpnbP3huSLoCOIfUAS+AT5Gqc6+WtATptTsV+BspAe5LStC3DrfMiHhZ0tHA0ZIeIfUWfx/whnyXTmelLccCnwXOl/RtUu/6A0kdHVtuIyWnYyQdRKqqPpT0g4y2+y2Xh6jdDDyaz7L/AnxV0tM5lgNIVeKLl/jzHiV9Hlq96w8jnVGf3Ha/3wI/JP0AGPAzOJj8+fwxaeTCUaSz5gVJPxxeGxGfZISvBemz8QlJ3yG1uU8G3lEyxFOBPYBpkr5F6h/yKlKN0EMR8Z3h/N1Ws7p7/vkyti7k3vVD3GcB0hfbnaQk/BDwe+DdhfvcC3yrw2PnIQ31ujs/9gHm7E2/DWnynWdJ7bfTga8D8w4WIympfq6w/Wbgqvw8AWwxwN+zBR16Y7c/X943jULvaObsDX80cBPwDKkdfSrw1sLr9lNSjcVzpAR2PvCGQZ5v1xzHom1xzPb6knqtf43UDv8MaRjcnvmxSw7xfm5BOgudmV/rTWgbmQC8hTTM7t/AHTmu9lgXJJ1hz8jlnpz3/xfpLPlZ4D5SE0aZz9nJpES7PelH0UzSD5iOveaBX+TnH1ficz6Rtt71hddxH9KP15n59bwM+Fg3Xot87EBS7cszOeZWrUZ77/r3dIh7CeC7+fGt/5/fAJvU/d3hy/Auym+smdlckXQCsFVErFx3LL2We5r/nTSM7aC64zEry9X1ZjakPFvaTqT2/dYELbsB+9cZV69Jmh94I2myoleRxt+bjRpO8mZWxrPApqQhfIuQzmr3B46pM6gKvJpUdT4D+HTMmgHQbFRwdb2ZmVmf8ox3ZmZmfcpJ3szMrE/1XZv8MsssExMnTqw7DDMzs8pce+21j0bEHLNQ9l2SnzhxItdcM9CMqWZmZv0nL9A0B1fXm5mZ9SkneTMzsz7lJG9mZtannOTNzMz6lJO8mZlZn3KSNzMz61NO8mZmZn3KSd7MzKxPOcmbmZn1KSd5MzOzPlVpkpd0oqQZkm4u7Fta0iWS7sjXSxWOHSjpTkm3S3pHlbGamZmNdlWfyZ8MvLNt3wHAlIhYHZiSt5G0FrAz8Pr8mB9Kmqe6UM3MzEa3SpN8RFwOPN62e1vglHz7FGC7wv5fRcTMiLgHuBNYv5JAzczM+kATVqFbLiIeBIiIByUtm/e/BriqcL8H8r45SNod2B1gwoQJsx2bfMzkbsc7oKn7Tq2sLDMzs6E0ueOdOuyLTneMiOMjYlJETBo/fo7ldM3MzMakJiT5hyWtAJCvZ+T9DwArFe63IvDPimMzMzMbtZqQ5M8Ddsm3dwHOLezfWdICklYBVgeuriE+MzOzUanSNnlJpwNbAMtIegA4GDgSOEPSJ4D7gB0AIuKvks4AbgFeAj4bES9XGa+ZmdloVmmSj4gPDXBoywHufzhweO8iMjMz619NqK43MzOzHnCSNzMz61NO8mZmZn3KSd7MzKxPOcmbmZn1KSd5MzOzPuUkb2Zm1qec5M3MzPqUk7yZmVmfcpI3MzPrU07yZmZmfcpJ3szMrE85yZuZmfUpJ3kzM7M+5SRvZmbWp5zkzczM+pSTvJmZWZ9ykjczM+tTTvJmZmZ9yknezMysTznJm5mZ9SkneTMzsz7lJG9mZtannOTNzMz6lJO8mZlZn3KSNzMz61NO8mZmZn3KSd7MzKxPOcmbmZn1KSd5MzOzPuUkb2Zm1qec5M3MzPqUk7yZmVmfcpI3MzPrU07yZmZmfcpJ3szMrE85yZuZmfUpJ3kzM7M+5SRvZmbWp+atO4CxYvIxkystb+q+Uystz8zMmsdn8mZmZn3KZ/JjjGsUzMzGDp/Jm5mZ9SkneTMzsz7lJG9mZtannOTNzMz6lJO8mZlZn3KSNzMz61Olkrykt0ratrC9jKRfSpou6RhJ8/UuRDMzMxuOsmfyRwFrF7a/C2wJXAXsChza3bDMzMxspMom+TWAawEkLQy8H9g7IvYAvgzs1JvwzMzMbLjKJvn5gefz7U1IM+X9Lm//DVihy3GZmZnZCJVN8rcB78y3Pwz8KSKeyduvBh7vdmBmZmY2MmWT/GHAFyQ9Avw3cGTh2DuB60caiKQvSPqrpJslnS5pQUlLS7pE0h35eqmRlmNmZjZWlEryEXEe8DpgD2DtiLiwcPhPwOEjCULSa4DPA5MiYm1gHmBn4ABgSkSsDkzJ22ZmZlZC6VXoIuJu4O4O+4/vYiwLSXoRWBj4J3AgsEU+fgowDdi/S+WZmZn1tdKT4UhaR9KvJd0laaakN+X9h0vaZiRBRMQ/gG8B9wEPAk9FxMXAchHxYL7Pg8CyA8S2u6RrJF3zyCOPjCQUMzOzvlF2MpxtSEPolgdOBYqT38wE9hpJELmtfVtgFVJHvkUkfaTs4yPi+IiYFBGTxo8fP5JQzMzM+kbZM/kjgJMjYnPmbH+fDqw7wjjeDtwTEY9ExIvAb4CNgYclrQCQr2eMsBwzM7Mxo2ySXxP4db4dbceeBpYeYRz3ARtKWliSSLPp3QqcB+yS77MLcO4IyzEzMxszyna8mwGsOsCx15OS9LBFxJ8lnQVcB7xEGpJ3PLAocIakT+QydhhJOWZmZmNJ2ST/K+AwSbeQhswBhKTXknq7/2ykgUTEwcDBbbtnks7qzczMbC6VTfIHAWsBlwEP5X3nkjriXQx8o/uhmZmZ2UiUSvIRMRN4j6QtSWfWy5Cmsp0SEZf0MD4zMzMbptKT4QBExBTSzHNmZmbWcKWSvKS1hrpPRNwy8nDMzMysW8qeyd/MnEPn2s0zwljMzMysi8om+ckd9i0NbJ0ve3ctIjMzM+uKsh3vLhvg0DmSvg7sCJzftajMzMxsxEovUDOIqaR5583MzKxBupHk3w082YXnMTMzsy4q27v+jA675yfNab868JVuBmVjw+RjOnX16I2p+06trCwzs6Yo2/Gu0/qtzwP/B3wxIi7oXkhmZmbWDWU73lV3ymVmZmZd0Y02eTMzM2ugAc/kJR01F88TEbF/F+IxMzOzLhmsun5u1m4P0pKzZmZm1hADJvmIWKXKQMzMzKy73CZvZmbWp0ovNStJwCbAa4EF249HxA+7GJeZmZmNUNnJcJYjrSO/Fqn9XflQcWU6J3kzM7MGKVtdfwzwFLASKcFvAEwEDgLuIJ3dm5mZWYOUra7fnLSc7IN5WxFxH/ANSeNIZ/Hv6EF8ZmZmNkxlz+SXBB6JiFeAp4FlC8f+CGzc7cDMzMxsZMom+XuAFfLtvwIfLhx7L/B4N4MyMzOzkStbXf87YGvgDODrwLmSHgBeBCbgiXDMzMwap+wCNQcWbl8oaWPg/cBCwCURcWGP4jMzM7NhKj1OvigirgGu6XIsZmZm1kWl2uQl3Svpm5LW63VAZmZm1h1lO96dBewEXCPpb5IOk7R2D+MyMzOzESqV5CPiSxExEdgUuAD4OHCDpJslHSRp9R7GaGZmZsMwVwvURMSfImIf0sx3WwDTgL2AW7semZmZmY3IcFehW4Q0dG5lYAlgZtciMjMzs64oneQlLSRpR0lnAzOAn5EWqPk4sFyP4jMzM7NhKrsK3a+BdwMLAJcCnwXOiYgnexibmZmZjUDZcfLLAV8CzoqIR3sYj5mZmXVJ2RnvtuhxHGZmZtZlw+14Z2ZmZg3nJG9mZtannOTNzMz6lJO8mZlZn3KSNzMz61Nlx8l/dZDDrwBPAzdExGVdicrMzMxGrOw4+b2ABUnT2QL8C1g03342P88CkqYD20TEw12N0szMzOZa2er6dwEPkpabXSgiFgcWAnbO+98ObAaMB47pQZxmZmY2l8qeyX8fODIizmztiIiZwBmSFgOOi4g3Sfo68PUexGlmZmZzqeyZ/DrAQwMcexB4Xb59G7DYSIMyMzOzkSub5P8G7C1p/uJOSQsAXwBuz7uWB9web2Zm1gBlq+v3Bn4HPCDpEuARUvv7VqTOeO/K91sP+E23gzQzM7O5V3aBmmmSViedtU8C3kSqvj8ZODYi/pnvd0CP4jQzM7O5VPZMnpzI9+thLGZmZtZFnvHOzMysT5Wd8W4+Urv89sCKpIlxZhMRy3Y3NDMzMxuJstX13wE+DZwPTAVe6FlEZmZm1hVlk/wOwAER4dnszMzMRomybfICbuxlIJKWlHSWpNsk3SppI0lLS7pE0h35eqlexmBmZtZPyib5nwIf6mUgwHeB30fEmsAbgVuBA4ApEbE6MCVvm5mZWQllq+sfBj4saSpwCfBk2/GIiB8NNwhJi5MWuNk1P9kLwAuStgW2yHc7BZgG7D/ccszMzMaSskn+2Hw9Adi8w/EAhp3kgVVJs+idJOmNwLWk3vzLRcSDABHxoKSOPfgl7Q7sDjBhwoQRhGFmZtY/SlXXR8S4IS7zjDCOeUmz6P0oItYjrVFfumo+Io6PiEkRMWn8+PEjDMXMzKw/NGUynAeAByLiz3n7LFLSf1jSCgD5ekZN8ZmZmY06A1bXS1oLuCsiZubbg4qIW4YbREQ8JOl+SWtExO3AlsAt+bILcGS+Pne4ZZiZmY01g7XJ3wxsCFydb8cA91M+NtIq+72A0/JytncDu5FqGs6Q9AngPtJ4fTMzMythsCQ/mXQm3brdUxExnbTCXbste122mZlZPxowyUfEZZ1um5mZ2ehQquOdpGUlrVLYlqTdJR0r6b29C8/MzMyGq2zv+pOBLxS2DwV+CLwTOEfSrt0Ny8zMzEaqbJJ/E3ApgKRxwJ7AV/IUtIcD+/QmPDMzMxuuskl+CeCxfPvNwNLAaXn7UuC/uhyXmZmZjVDZJP8A0Bor/27gtoj4R95eAni+24GZmZnZyJSdu/5E4ChJbycl+QMLxzYkrRhnZmZmDVIqyUfEEZL+AbyFNGnNiYXDSwMn9CA2MzMzG4GyZ/JExKnAqR3279HViMzMzKwryo6Tf52kDQvbC0v6hqTfStqrd+GZmZnZcJXtePdDoDjpzdGk9d4XBL4pab9uB2ZmZmYjUzbJrw38CUDSfMBHgH0i4p3AV4CP9yY8MzMzG66ySX4R4Ol8e8O8/Zu8fR2wcpfjMjMzsxEqm+TvJiV3gPcD10dEa3KcZYBnuh2YmZmZjUzZ3vXfAX4kaQdgPdJa7y1bADd2OS4zMzMbobLj5H8m6Q7SOPkDImJK4fDjwLG9CM7MzMyGb27GyV8OXN5h/yHdDMjMzMy6Y8AkL2kt4K6ImJlvDyoibulqZGZmZjYig53J30zqbHd1vh0D3E/52DzdDc3MzMxGYrAkPxm4pXDbzMzMRpEBk3xEXNbptpmZmY0OpTvetUiaF5i/fX9EPNeViMzMzKwrSiV5SUsAR5AmwhlPaodv5zZ5G5UmH1Nta9TUfadWWp6ZjV1lz+RPBjYHfgrcCbzQq4DMzMysO8om+S2BT0fE6b0MxszMzLqn7Nz19wFuczczMxtFyib5LwP/T9KEXgZjZmZm3VN27voLJL0duFPSvcCTHe6zfpdjMzMzsxEo27v+W8A+wF9wxzszM7NRoWzHu08C/xMRR/QyGDMzM+uesm3yzwHX9jIQMzMz666ySf67wO6SOk2CY2ZmZg1Utrp+GWAD4HZJ05iz411ExP7dDMzMzMxGpmyS/yDwEjAfsFWH4wE4yZuZmTVI2SF0q/Q6EDMzM+uusm3yZmZmNso4yZuZmfUpJ3kzM7M+5SRvZmbWpwZM8pI2k7RolcGYmZlZ9wx2Jj8VWAtA0t2S3lhNSGZmZtYNgyX5Z4Cl8u2JwPw9j8bMzMy6ZrBx8n8ETpD057x9hKTHB7hvRMRO3Q3NzMzMRmKwJP9x4H+ANUkz2i0FzFNFUGZmZjZyAyb5iHgI2AtA0ivAnhFxdVWBmZmZ2ciUndbWQ+3MzMxGmbIL1CBpSeDTwKbA0sDjwP8Bx0dE+6p0ZmZmVrNSZ+iSVgNuAg4DFgHuy9eHATfm42ZmZtYgZc/kv0NaQ37DiPhHa6ek1wAXAt8Gtu1+eGZmZjZcZdvatwC+WkzwAHn7UGByl+MyMzOzESqb5IOBh8+Ny8fNzMysQcom+anA1yStXNyZtw8DpnQ7MDMzMxuZsm3y+wCXAndIug54GFgWeDNwP/DF3oRnZmZmw1XqTD4i7iXNfPd54K/AfMAtwOeA1+XjIyZpHknXSzo/by8t6RJJd+TrpYZ6DjMzM0tKj5OPiBeAH+dLr+wN3AosnrcPAKZExJGSDsjb+/ewfDMzs77RmJnsJK0IvBs4obB7W+CUfPsUYLuq4zIzMxutGpPkgWOBLwOvFPYtFxEPAuTrZesIzMzMbDRqRJKX9B5gRkRcO8zH7y7pGknXPPLII12OzszMbHRqRJIHNgHeJ+le4FfA2yT9AnhY0goA+XpGpwdHxPERMSkiJo0fP76qmM3MzBqt7Nz1m0ladIBji0rabCRBRMSBEbFiREwEdgYujYiPAOcBu+S77QKcO5JyzMzMxpK5mQxnrQGOrZGP98KRwFaS7gC2yttmZmZWQtkhdBrk2KLAc12IBYCImAZMy7cfA7bs1nObmZmNJQMm+VwFv0Vh1yclvbPtbguShr3d1P3QzMzMbCQGO5PfANgr3w5gB+Cltvu8ANwG7Nf90MzMzGwkBkzyEXE0cDSApHuA7SLihqoCMzMzs5Ep1SYfEav0OhAzMzPrrtJz10taENgMWJHUFl8UEfGjbgZmZmZmI1MqyUvaFPgNsMwAdwnASd7MzKxByo6T/x5wF7AesEBEjGu7zNO7EM3MzGw4ylbXrwFs7453ZmZmo0fZM/kbgeV7GYiZmZl1V9kkvyfwBUmb9zIYMzMz656y1fWXAAsDl0p6EXi6/Q4R4bXezczMGqRskv8BqQe9mZmZjRJlJ8M5pMdxmJmZWZeVngwHQNJSwNrASsCFEfFEniTnhYh4pRcBmpmZ2fCU6ngnaV5JRwEPAJcBPwdaU92eDRzcm/DMzMxsuMr2rj8c+BTwOWBVZl9f/lzgvV2Oy8zMzEaobHX9x4ADIuIkSe2z291FSvxmZmbWIGXP5JckJfNO5gc8ra2ZmVnDlE3yNwPbDnBsG+C67oRjZmZm3VK2uv7rwNmSFgLOJI2ZX1fS+4FPA+/rUXxmZmY2TKXO5CPiXOC/gbcDF5I63p0A7Ap8NCIu6lWAZmZmNjylx8lHxBnAGZJeS1pX/nHg9ojwTHhmZmYNNFeT4QBExN+Av/UgFjMzM+uispPhnCjp1wMcO13SCd0Ny8zMzEaqbO/6rYCzBjh2NrB1d8IxMzOzbimb5MeT2uA7eQLwMrNmZmYNUzbJ/x3YbIBjm5HmtDczM7MGKZvkTwb2l/RZSYsCSFpU0meAL5OG05mZmVmDlO1d/01gNeA44HuSngUWIY2XPz4fNzMzswYpleTzWvGflHQ0MBl4FfAYcGkeUmdmZmYNM2SSl7Qg8BSwU0T8Fri951GZmZnZiA3ZJh8RzwMzgJd6H46ZmZl1S9mOdz8BPi9pvl4GY2ZmZt1TtuPdksDawL2SpgAPk1aia4mI2L/bwZmZmdnwlU3yHwBm5ttv7XA8ACd5MzOzBinbu36VXgdiZmZm3VW2Td7MzMxGmdJJXtI6kn4t6S5JMyW9Ke8/XNI2vQvRzMzMhqPsUrPbANcCywOnAsVe9jOBvbofmpmZmY1E2TP5I4CTI2Jz4PC2Y9OBdbsalZmZmY1Y2SS/JvDrfDvajj0NLN21iMzMzKwryib5GcCqAxx7PXBfd8IxMzOzbimb5H8FHCZp08K+kPRa0vj407oemZmZmY1I2clwDgLWAi4HHsz7ziV1xLsY+Eb3QzMzM7ORKDsZzkzgPZK2BLYElgEeB6ZExCU9jM/MzMyGadAkL2kh4F3ARNIZ/JSImFJBXGZmZjZCAyZ5SasCfyAl+JanJe0YERf3OjAzMzMbmcE63h0FvEJakGZhUi/660nLzpqZmVnDDZbkNwL+X0RcGRHPR8StwKeBCZJWqCY8MzMzG67BkvwKwN1t++4CROpVb2ZmZg021Dj59tntzMzMbJQYagjdRZJe6rB/Svv+iFi2e2GZmZnZSHxKVGQAACAASURBVA2W5A+tLAozMzPrugGTfERUluQlrURawnZ5Uo/+4yPiu5KWJi2MMxG4F9gxIp6oKi4zM7PRrOzc9b32ErBvRLwO2BD4rKS1gANIE/CsDkzJ22ZmZlZCI5J8RDwYEdfl288AtwKvAbYFTsl3OwXYrp4IzczMRp9GJPkiSROB9YA/A8tFxIOQfggA7txnZmZWUqOSvKRFgbOBfSLi6bl43O6SrpF0zSOPPNK7AM3MzEaRxiR5SfOREvxpEfGbvPvh1ux6+XpGp8dGxPERMSkiJo0fP76agM3MzBquEUlekoCfAbdGxLcLh84Ddsm3dyGtYW9mZmYllFpPvgKbAB8FbpI0Pe/7CnAkcIakTwD3ATvUFJ+Zmdmo04gkHxFXkObE72TLKmMxMzPrF42orjczM7Puc5I3MzPrU07yZmZmfcpJ3szMrE85yZuZmfUpJ3kzM7M+5SRvZmbWp5zkzczM+pSTvJmZWZ9ykjczM+tTTvJmZmZ9yknezMysTznJm5mZ9SkneTMzsz7lJG9mZtannOTNzMz6lJO8mZlZn3KSNzMz61NO8mZmZn3KSd7MzKxPOcmbmZn1KSd5MzOzPuUkb2Zm1qec5M3MzPqUk7yZmVmfcpI3MzPrU07yZmZmfcpJ3szMrE85yZuZmfUpJ3kzM7M+5SRvZmbWp5zkzczM+tS8dQdgZsnkYyZXWt7UfacOeKzKWJoSBwwei9lo5DN5MzOzPuUkb2Zm1qec5M3MzPqUk7yZmVmfcpI3MzPrU+5db2Y2BPfyt9HKZ/JmZmZ9yknezMysT7m63sxsFGnKREU2OvhM3szMrE85yZuZmfUpJ3kzM7M+5SRvZmbWp5zkzczM+pSTvJmZWZ9ykjczM+tTTvJmZmZ9yknezMysTznJm5mZ9SkneTMzsz41KpK8pHdKul3SnZIOqDseMzOz0aDxSV7SPMAPgG2AtYAPSVqr3qjMzMyar/FJHlgfuDMi7o6IF4BfAdvWHJOZmVnjjYYk/xrg/sL2A3mfmZmZDUIRUXcMg5K0A/COiPhk3v4osH5E7FW4z+7A7nlzDeD2ERa7DPDoCJ+jW5oSS1PigObE4jjm1JRYHMecmhKL45hTN2JZOSLGt++cd4RPWoUHgJUK2ysC/yzeISKOB47vVoGSromISd16vpFoSixNiQOaE4vjmFNTYnEcc2pKLI5jTr2MZTRU1/8FWF3SKpLmB3YGzqs5JjMzs8Zr/Jl8RLwk6XPARcA8wIkR8deawzIzM2u8xid5gIi4ALigwiK7VvXfBU2JpSlxQHNicRxzakosjmNOTYnFccypZ7E0vuOdmZmZDc9oaJM3MzOzYXCSNzMz61NO8mZmZn1qVHS8q4Kkn0fER4faZ1YnSUsPdjwiHq8qFkiTVUXEmUPtG4skLRIRz9YcwzzAchS+6yPivvoiql/d74ukNw12PCKu62p57niXSLouIt5U2J4HuCkiKl0MR9JngdMi4sm8vRTwoYj4YYUxbD/Y8Yj4TVWxtEh6Bmj/sD4FXAPsGxF3VxTHFwc7HhHf7nH595BeB3UuPlbtZfkd4pnt/2agfRXFMg/wbmAisye1nr4nHeLYGDgBWDQiJkh6I/DpiPhMxXHsBRwMPAy8kndHRKxTYQw3Mef/LaTPb9WxNOV9mZpvLghMAm4gvR7rAH+OiE27Wd6YP5OXdCDwFWAhSU+3dgMvUM8Qi09FxA9aGxHxhKRPAZUleeC9+XpZYGPg0rw9GZgGVJ7kgW+TZjr8Jen92RlYnjSF8YnAFhXFMQl4C7MmZHovcDmzr6/QMxGxShXlDEXSNsC7gNdI+l7h0OLAS/VExf8CzwM3MSup1eE7wDvIn5GIuEHSZjXEsTewRkQ8VkPZLe+psex2jXhfImIygKRfAbtHxE15e23gS90ub8wn+Yg4AjhC0hERcWDd8QDjJClyFUs+O5m/ygAiYrdc9vnAWhHxYN5egbTsbx3eGREbFLaPl3RVRBwm6SsVxrEM8KaIeAZA0iHAma21FaqUa3lWJ50RABARl1dU/D9JtSjvA64t7H8G+EJFMbRbscozw8FExP3SbJUtL9cQxv2k2q7aRMTf6yy/XUPel5Y1WwkeICJulrRutwsZ80m+JSIOlPQaYGVmr+qr6kuz5SLgDEk/JlVz7QH8vuIYWia2Enz2MPDammJ5RdKOwFl5+4OFY1W2OU0g1fK0vECqHq6UpE+SztRWBKYDGwJ/At5WRfkRcQNwg6RfRsSLVZRZwoWSto6Ii2uO4/5cNRx5Ku7PA7dWVXihSeluYJqk3wEzW8erbL6QdEVEbNqhua1VXb94VbFQ8/vSwa2STgB+QXptPtKLeJzkM0lHkqqAb2HWr7sgVcVWaX/Sinp7kv4RLia1I9VhmqSLgNNJr8XOwNTBH9IzHwa+y6xmiz8BH5G0EPC5CuP4OXC1pHNIr8n7gVMrLL9lb1KzwVURMVnSmsChNcTxDklfY9aP4zq+vFuuAs6RNA54scZY9iB9Vl9DWmDrYuCzFZa/WL6+L1/mZ1ZtYKWdsFrtyxGx2FD3rUDd70u73Ujf83vn7cuBH3W7EHe8yyTdDqwTETOHvHNFck/qFSPixhpjeD/Qare6PCLOqSuWppD0ZqDVOebyiLi+hhj+EhFvkTQd2CAiZkqaHhFdr+4bIo47ge1JnVRr/TKRdDewXRNiaYImjXzw6KXO8knKhIgY6fLoA/KZ/Cx3A/NRqNaqg6RppHbOeUnVsI9IuiwiBu3V3YM4xgE3RsTaQO2JXdKKwHHAJqSzkSuAvSPigRrCmQ48SP7/kTShhmFJD0haEvgtcImkJ2hbgrki9wM3NySp3kGNsUg6jkHOlCPi8xWGA3Ag0J7QO+2rwuuLG5LmBd5cRcENfF8AkPQ+4GhSLcsquT3+sIh4XzfLcZKf5TlguqQpzN5+VfUHYImIeDq3uZ4UEQdLqvxMPiJekXRDTQmsk5NIPet3yNsfyfu2qjKItmFJL5OrhEnDXyoTEe/PNw/JQ3KWoJ6+G18GLpB0GTW1+xY8SGpiurCmWK6pqJxBNWnkQ0NGLzXifengYGB90oglImK6pIndLsRJfpbzaMY69fPmXuw7Av9TcywrAH+VdDXwn8kjuv1Ls6TxEXFSYftkSfvUEEcThiUB/5lUY1PSj4wrI+KFIR7SC4cD/yL18K90FEgH9+RLsQ26MhFxCgxcTV5hKI0Z+dCE0UsNel/avRQRT7X19u86t8k3TP7QHUT60t5T0qrA0RHxgRpi2bzT/oi4rIZY/gCcTOoECPAhYLeI2LLiOKYCW0VEXWPBW3F8lVSr0ZqzYDvSUL6vVxzHNRExqcoym64pEwRJmq8pIx8GGo9e5eilprwvhbJ/BkwBDgA+QOrtP19E7NHVcsZ6kpd0RkTsONDMTE0Zd1sXScuRenEDXB0RM2qKYwLwfWAj0vv0R1KbfKXjcPM/5hpAbcOSchy3AutFxPN5eyHguoh4XcVxHAlcWuewNUnHRsQ+kv6Xzv/DldQ8FarJdwR+XTi0OGm+ifWriKMQT6fvtNYskV+vsjYqvzctC5Kqqa+NiJ4P+Wza+1KIa2FSbe3WpCaMi4Cvtf6nu8XV9bOGLzRiZiZJryUNo1guItaWtA7wvqrP0HIsO5I6hkwjfQiPk7RfRJw16AO7H8c8wDdqaiZo12lYUh3uJX1Ztr4QFgDuqiGOzwJfljST+oat/Txff6vCMjtpTDV5diGp38gv8/bOpPfnKVKt2Hs7P6z7ImK2siStBBxVUfFNe18AiIjnSEm+p82yY/5MvqgJZ625A9N+wE8iYr287+bcy73qWG4gVU3PyNvjgT9ExBtriOUi4L01tTs3RqGn8ATSZ/WSvL0VcEVE7FxjeEbqOV53c06O48qI2KTTPkk3RcQbaoxNpNE7lcXQpOYLAEmTSJ0SJzL7BGxdrT32mXzWlLNWYOGIuLqtM0ZdXxjj2n7oPEZ9yxPfC1wp6Txm7wRYSTV5U6qEmdVT+FpmH9o4raLy56B6p9cdbBGUViyVNLm1mv6A6yU1oelvUUkbRMSfc3zrA4vmY1X3si8OYxsHrEtamKWKslvvy3UNeV9aTiOd0PV0rQUn+Vn+B3hL+1krs6ZRrcqjklYj/0NI+iBpaFAdfl+Y8Q5gJ1IVYB3+mS/jmDWjV5UaUSXc6ik8FElnV9FZUzVPr5s1oqmNhjX9AZ8ETpS0KOnE5Wngk5IWAY6oOJbiMLaXgNMj4sqKym69L7eSkmqLqK7JoJNHIqLnI7pcXZ+1V1/lyWBuqLpKK/emP560+tsTpCFBH666g1khnu1Jw7REA2a8UwPW6B4NJF3fau7pcTk3MWt63XWVp9eNiJ16XfbckvSniNiognK+GRH7D7WvKpKWIH3XP1lH+WVU8aN0gN71N9Z1Ji9pS9Ioofa5Wbq6yqfP5GfpdNZ6QVWFa/Z1yi8gzRE/jlQ1/QHSUquVkrQKcEHrQydpIUkTI+LeGmLZCPgZqbqx8rWgB6kSrnxd7JKq+vX+fEQ8LwlJC0TEbZLWqKjsubXg0Hfpiq1Ia1AUbdNhX09JWoD03TGRNP8GABFxWJVxlLRqr55Y0p7AZ4BV2yYWWwyoqjahk92ANUkzrbaq64MuL+XtJJ9FxH6SPkCaNlXA8RWftbaqoNcgnRmdm+P4KNUvktNyJqlGoeXlvO8tne/eU8dS71rQTamCbZqmTK9bRk9/+DQwmZxL6kl/LTVP111CL9+bX5KaGY8gjUlveSYiHu9huUN5YxU1xU7yBRFxNnB2TWUfCiDpYjqsV15HTMC8xd7sEfGC0hKNtYga14IuNpdIWhlYPSL+kMenN/H/qLfTaGVDTa8raamIeKKKWBqgVDKp8DVZMSLeWUE5jRYRT5F+7Hyo7ljaXCVprYi4pZeF1NVTujEkXZGvn5H0dIfLPZIqqRLOGrFeefaI0iIKAEjaFni0plhmWwta0peoYS1oSZ8idcb8Sd61IukstsoY5pH0iyHuVnn7b0RcFhHntQ1znFJ1HIPo6Q+fiHgqIu6NiA9FxN8Ll/azxapekz9Kqm2Y3Fyq5Edpw2xKWi/ldkk3SrpJPVinpIlnIJWKIdY7lvQq0j/LLyvquNJpvfJSPap7YA/gNEk/yLE8AHysxliasBb0Z0mzdf0ZICLukLRslQFExMuSxkuaf6B5A+qcga5Nk768m7KsaVWvyabArpLuIVXXN7X/CNTwo7QBBq1l6VaNj3vXlyDp1cD5Vc1xrLTwyFvzZi3rlbfFsyjps/JMnXE0gaQ/R8QGrd7rSktmXlf1F6eknwBvIvVRqHzegLI69WjuQRlXRMSmkp5h9rbdOmbfG1IVr0kuZ+VO+6scqTMKO6w2Rrc+J2P+TL6MiPin1OOlgmYv7zrguqrKG4jSDIDfAF4dEdtIWgvYKCJ+VmEMTVsL+jJJraUztyJ1tPrfIR7TC3XPG9AYQ9XGjVUR8XdJm5L6j5yU5/5YdKjHdZk7rA5fV3KOk3x5Y7HK42TSmu2tuZX/RlrgobIkz6xJNDYB1mLWAhM7MPs81FU5APgEaZaqT5OGO55QdRCtjpqjQKXV9UrrHCzH7NOE3ldlDCVU8ppIOhiYRBqxcxJpqNYvSP9LlWjrsFr7tOGjTFdyjqvrS6qqiq1JJP0lIt5SnFhF0vSIWLeGWKYCW7fmnpY0H3BxREyuOpYmyK9Hpyk6K5lpTtLSgx1vdTaTtHRVw5Qk7QUcDDxMYdxxHVXCucltU9J7dGWunWsdq+Q1kTQdWI/UnNT6/61l8hfNOW34W4E6pg0fNVxdX70mdSCqyrO542Frit0NSUNR6vBqUrV068tx0byvEoO0LQK1zH/9pcLtBUmTnlQ5H/m1pNej0/9FkCc3qXgc8t7AGlHhEqqdSPoqqaapNanJSZLOjLySZIWvyQsREcrztStNZ1uXpkwbPpq4ur6blOaLfyAiZkraAlgHOLXQo37L2oKrzxdJHbtWk3QlMB74YE2xHEla+GNq3t4cOKTC8ltti60e/a257D8MPFdhHABERHtTxZVKKxhWVf4qVZU1F+6nvh+hRR8C1ou8LrikI0l9bKpeLvqM3EFzyTz08+PATyuOoaVJi101gqS3R8Qf2vbtErPWp+hKznF1fZartiaRxqRfREpua0TEu+qMqy65bfPzwHGkNj0Bt0eNSzVKWh7YIG/+OSIeKhx7fUT8tYIYBly+s9dlt5VZrC4fB7wZ+F5EVDKlbK6OHlCxerqCWFpTQr+e9Fn9HbPPBV7piANJFwIfap0g5BkBfxERlXdCy51Dtyb9/14UEZdUHUOO42jSiVNx2vAbo6b5/JtA0uXAX0m1couS+vbMjIiunkg5yWet9g9J+5Hm4z5OFS3y0VSSpkXEFnXHUUaFw5KmA5+LiNYkShsDP6y6n0Ie+9yqLn+JtJDRYa24Kih/6iCHo6q+ATmWgwc7XnUnRUm/JXUwu4T0Hm0FXAHMyPFUPSKkEdSwxa7qlkds7UvqwAvw1Yg4fZCHDIur62d5UdKHgF2A9+Z989UYTxNcKen7pB7txbHYtQ/v66CqPhOfIC3fuQTpC/wpUjVopequLm9Sh8eySVzScRGxV6/jAc7Jl5ZpFZT5Hx3mC/jPIWqaN0DSF4Azo8srrI1yS5FqJu8izZy5siRFl8+8fSaf5THgewB/iojTlVZg2ykijqw5tNoMcLZW6VlaWVWPfpC0OOn/56m2/cU2tV6W/1ngtEKV8FKkKuIf9rrstjjmA/YEWosFTQN+UmezzkDG4giZwXRrRrWSZR0M7EjqOPsr4KyIeLiKsptK0t+AIyPiRKU1ML4JTIqIjYd46NyV4yRvw1VVQiujKV/gVTYbtDcR1NG8JOkEUo1X63PwUeDliPhklXGUUeF78x7ga8DKpNrSMT3zXluZ65Da4z9A6uj89irLbxJJE9rncJC0WUR0ddVRV9dnhTbO2UREz9Y57gN7U8G8+rntasWIuH+Qu3Wcw70GVTUbjCtW7eWOknWsEPiWiHhjYftSSTfUEEeTHAtsD9zU7arXLqtjWPAM4CFS7/pK13xooEclHQRMiIhPSVod6PoPQSf5WSYVbi9IGuc66IQfVtlyppE7M715kPtsWEUsJVT1pX4RaYjUj3OZe1BY4rVCL0taLSLuApC0KhUuATyXqkpq9wM3NzzBQ4WzeErak3QGP540Nv5T0eMlVkeBk0jzTWyUtx8gLSt+fjcLcZLPOkygcazSMrRfrSOeUaLKL7GrJL0lIv5SYZnDUVUi2R/YndQeLtKqfJVPrwvsB0yVdHeOY2VgtxriQNJ6MfhiTt+tKJQvAxfkeQtqG8rXMCsD+0TE9LoDaZDVImKn3OGbiPh3rrXsKif5rG3c7zjSmb0XvBhcldV9k4FPS/o7qad/LatYSVolIu4ZZN+VVcQREa8AP86XOUg6OyI+UEEcU3I1Y2suhdsiYuYQD+uVb0tagXQ29Kv2eRMi4uSK4jgc+BepRrCOJpSyqlx06wBJm0raLQqL5bT/L40xL+QOd60mt9Uo/CjsFne8y9p6krfGHR8TEbfXFFLthkpokr4fEZ+rKJbal83McczRWUnStRExYFNCHarqhNeUXv6FeJYn9eLeidS++evI08lWGMM1ETFp6Hv2nhowh34u6z+L5UTEa5WW7z6z6kmkmiRPVPT/SAtvXUxaOGjXiJjW1XKc5BNJq0bE3W375khyY0nTEpqkN5IWtgD4v4iorIOXpDVJM6odRaqiblmctNDG66uKpYyx1su/naQ3kKrNd4qISs+m8zS2l0bExVWW2yGO9jn0tyMl1qqn123UYjlNorQ2yIakWpWrIuLRwrGuzOLp6vpZzgLavxTPYpDOXv2qkNCWyLNUtSxOqoKsI6a9gU8x6wvrF5KOj4jjKgphDdL89Usya7IkgGdyXGNVU3r5I+l1pDP4HYBHSeOx960hlM8C+0l6AXiR+obQNWUOfWjWYjmNkfuC/W6Awz9nzpw018Z8km9iQmuAJia0TwAbRMSzAJK+CfyJNLd+z0XEucC5kjaKiD9VUeYIVdXe2pRe/pB6K58ObBUR/6wpBoAlSAsXrRIRh0maAKxQQxz3kr7Dns/bC5BmV6tU7kx2vpqzWM5o4VXouqSJCa1WDU1oYvahWS9Tzzjf90v6K/BvUjJ7I6nX8C+qDELS3hHx3UH2VbXwR1N6+RMRG+aOTBPqKL/gB6T17N8GHEb6LjmbNJ99lWYCf5U02xz6kr4H1c2hn8/gtyN9Vp4mfed+NWpaLGcU6Upbutvks4YltEaQdBSpaq/WhJZj+SJpXYHWnODbASdHxLEVxzE9ItaV9P4cwxeAqW0TwlQRR6f+ErW3hberqpd/Luu9wLeA+SNiFUnrkhbteV8V5RfiaC129Z/3Q9INNXxGdhnseJWzVUr6Aen/telDYBujW/1qfCY/y/W5p/DrKVTTR0Tli480yNYR8eWc0B4gtXVOBSpP8hHxbUnTmLWK1W5DjInuldaiRe8CTo+Ix3swtHVAeUztfwOrSDqvcGgx0ixiTVPljJGHAOuTF4SJiOmSJlZYfsuLuW9Cq/15POnMvlJVJvES2ofAAjDWO94NoSuzeDrJz/Jz4DbgHaQqtg8Dt9YaUf1qTWiQFoKJiKeV1k+/N19ax5YCno6IKmdY+19Jt5FqNz6Tv8CfH+Ix3fRH4EFgGeCYwv5ngBsrjKOsKqsKX4qIp6r+jHbwPVKN07KSDgc+SBoqVSk1aw79bWoos9EkbQJMj4hnJX2E1Mnuu61hwd2axdPV9Vmraq01rENpda2LooErrlUl98bdjpTQ1if1Wzg/IjaoMIbzI+I9mnNtgdY3+aLATyPiKxXG9J8fF5IWBhaPiIeqKr8Qx3LMaue9OiJmVB3DUKoaypfL+hkwBTiAtADK54H5ImKPKspvi2VNYEvS53RKRFR+wiDpTkbHHPpjkqQbSU2g65BOMn8GbB8Rm3e1HL/3iaSrI2J9SZcDnyEtonB1jPEFapqS0AaSq0VvjojXVVjm2qQJLIrNOqdWVX6OYQdS+/M0UiJ5K2m8/llVxjGUKvsJ5M/n/wBb510XAV9vDSEba/IEX1tGmh3RGqbQd+OrwD8i4me9+FHsJJ9J+iSpB+wbgJNJZ4gHRcRP6oyrbk1IaIVYlgJWb4ulq8sylojhYGAL0mtyAaka8oqI+GDFcdxAGio2I2+PB/5QQ+euQXv5S9q6iklh8o+9i2IML13aTtJbSNX1nkO/gZTWNvg9aa2HzYBHSNX3b+hmOeO6+WSj3JSIeCIiLo+IVSNiWdJwoDErJ7Tj8mUyaba3SnsqF2L5JHA56ezs0Hx9SA2hfJBUDftQROxGqm5boIY4xrVVzz9GPf/PnXpw79q6UdWsb7lfxnOSlqiivFHicOA50o/ixQoXa4adSD++PpFrR18DHN3tQtzxbpaz8Yx37T5ISmLXR8RuuQ24ljHQpLXr30Ka+nFybvM8tIY4/h0Rr0h6SdLipPWx62jSuVDSRaTJXyB9YVxQVeEN7eX/PHBTHhde7MFdyXjwBlo6IrYe+m5Wh5zYv13Yvg/oei3pmE/ynvFuUE1JaADPR8TzkpC0QETcJmmNGuK4RtKSpNm6riWtNnZ1DXEE8BNmDSk8njQHdlWa2Mv/dww8RehY9Ieqmkts7uV8801gWdL/cE9GP4z5NnlJ25J6kL8PKJ6RPENarvKPtQTWAJJ+CHwF2Jk0B/i/SG1Gla8XLukcUtvVPqSZxJ4g9Zx+V9WxFGKaSOqIWHlSG2AynFoW/BgNvfyh2ol5mkDSM8DCpPHWdc6hbx3k0Q/v7fXIizGf5Fs8493g6kxo7SRtTpof/PcR0ZUJI0qUOWiP1ygs4dnjOPYkjf5YldnnIV+MtJToR6qIoxDPqOjlD82cEbCXJI2jwxz6EfHnmkMzQNKVUcFSu07yWZOmcK1bUxJau9y7fiUKzUwVJtepgxyOquZTyB3LlgKOII0Hb3kmKlobvC2eRvTyL6PKMftNIOlH5Dn0I+J1+f/n4oioeg59Kyg0C28OLA/8ltlHP/ym0+OGa8y3yRc0ZgrXBjhmkGNBqi6vlKSvkXpt382sKUIriyUiJpe5n6StoocLb0TEU8BTpGVEm6ApvfxtThvkcdjXA0TEE5JqWQbYZlNcCO05Zs3rAOk7zUm+R2qfwrUpmpLQ2uwIrFZV9fwIfBMYS6tr1drLfy6NtX/oRsyhb7Nr9WmStElEXFk8lqe67Sr/4p6lNSf5JGBKDXOSj0bfrLCsm0nT6jbdWEskrV7+65CauI6vN5xBVbX8blO0z6F/BfCNekOyguNK7hsRt8kXtE3hugiwWGsK14rPWkeFiqcsnQScS0r2xfarWibnGcgYbPetvZe/pJvovBBOqzf5mF3prAlz6NvsJG0EbEwaKfSdwqHFgfd3uz+Lq+sLIuKJwu1nKUyowdirhi2jyl+Ip5Deg5twlWPtir3880IbLYsBV3Z+VM+8p+LyRo2IuI20uqY1x/ykadPnZfYZCJ8mTUDWVT6TL2msDb8po+IVxi7r9upMvSDpNxGx/dD3HN2a1svfbLSRtHLkZWV7yWfy5fnX0JzurbCsayUdQZqwqFhdX+lwvrzS2b7AhIj4lKTVgTUi4vwcT98neGhkL38kbUhq03wd6WxpHuBZT/5iDTVe0rHAysw+LLirzUtO8jaghiW0Vi1KcerWOobznUSaznajvP0AcCZwfsVx2Jy+T5qd8UxSB9qPAf9Va0RmAzsN2I8eN0E6yZd3b90B1KAxCW2oYX2SdomIUyoIZbWI2Ckv0EJE/FtjdaxlA0XEnZLmyavSnSRpzE5LbY33SEScN/TdRsZJvkDSxsBEZq86OTVfj4lq2DajKaHtTeqc12svSFqIWWOPV6PQfGC1ei5P9jI9z2D5ILBIzTGZDeRgSScAU/CMd70n6efAasB0te3sWgAAFBFJREFU4OW8O+jB0n+jyGhKaFX9+DiYNO3xSpJOAzahsH661eqjpLk/Pgd8gTQF8lj8cW6jw27AmqSJ2IqzeHY1ybt3fSbpVmCt8AvyH5K2Av4fsBZwMTmhRcS0OuPqpOKe/q8i9Q0QaX37R6so1wYnae+I+O5Q+8yaQNJNEfGGXpfjGe9muZm0WIBlefKf7UlnqqcDk5qY4LNKzuTz2gYvRcTvcgfElyRtV0XZNqRdOuzbteogzEq6StJavS7EZ/JZXmVsXeBqGjyjWpVyQrs0D5dC0pLAFhHx/9u78yi7qiqP498fkyAQBERowQbJAmyQQSYTwzLMCjI4IYrQEhxabCUsRARbBFq6FWyRNCqjBifQdgiiIIIgUxQF7BAEpFsIKNoICiSRwRDy6z/OfVSlUpXx1rtv+H3WqlX17n31ziZUvV33nHP3vqyBWF5ue9ZIxyR93vYH2xDHDNs7DDmWGgoNqvaMHAbsBtw06NQYyh9kezcSWMRiVLPHY4FZlJwzKhUak+QrVY/yRdi+od2xdIpOSmgjlE+93fZObY5jkZKt7Zp2i+FJ2hR4OcMU5gFm2p7fSGARi1H93C6iVSBH0rqDq7Aur2y8q9i+QdKGQKvX8i+HtNDsR8Mt57T1Z6aqvb0NsM6gPsxQrtJWb2csldsknQV8gbJJ5kOU2wyjIdWb4oPA+CG/w/ckwUenWopqd9cCK7zPKGvyFUlvo0zVH0Jpa/oLSbXXEe4yt0k6S9JYSZtL+hztT2hbUWqTv4jSh7n1sSPw3jbHAiWpzwO+RakZ8Azwzw3EEUNIOoT8DkfvqGWfUabrK5LuAPZpXb1XrWZ/UndHoG5SdeI7Gdib8gN3NXB61byn3bGMt/3zdo8b3SO/w9FL6rpjKNP1A1YaMj3/F/p8pqNK5icu8Ynt8SZJdwFPU+5T3x441vbX2xmEpC2B41m0aFK7y+vGovI7HDFEkvyAqyT9mHKrGMChwJUNxtO4Dkto+9o+odrx/xBlSvanQFuTPGWK/jzgIgaKJkVn+FF+h6OH1DJdnyRfsf0RSW+hFHwRcIHtaQ2H1bROSmirVp/3By61/VhDFXbn2z63iYFjiQycT7mVTsAFLNzQKKKb7FXHi2RNPkbUxC1qI5H0aeCNlOn6XSkb8X5o+9VtjuNU4BFgGgvXU0gP9YaNcJvlIrc8RjRJ0rbAhcDGwI+Aj7ZulZP0S9u71jpevyd5STfb3k3SXBbuGd8qTNC3vag7LaFJWheYY/u5qg3uGNsPtzmGWcMctu3N2xlHDJB0NPABYHPgvkGn1gam2z68kcAihiHpZuB04BbgPZQa9gfZvm806pD0fZKPkXVaQpP0Skod/efvj291CYz+JWkdYF2GKYaTGZboNEOLjEnag7K0dATwxbp7cCTJVyR9zfYRSzoWzZB0CrA7JclfCewH3Gy7LfdBS9rT9nVDCvI8r+72kBHRm6pbPV/bKhdeHdsO+C6wnu316xwvG+8GbDP4gaRVgI5Yj263Dk1ob6XcNvfftidVlc0uauP4E4HrKIV4hqq9PWRE9KwzgH+gTNcDYHumpL0odUlq1fdJXtJJwMeANSTNaR2mVDW7oLHAmtWJCe1p2wskzZc0hrJXoG3LBrZPqT5PateYEdF7bF8ywvHfMQpVPDNdX5H0KdsnNR1HDE/SFyl/jL0d+DDwV2BGu5OupMnAVErzkwsp5XVPtH11O+OIiN4j6QLb76v1NZPkB1S7t7dg4Y1dNzYXUbM6NaFJ2oyys35mA2PfYXt7Sa+j1Kw/GZha92aZiOhNktYb6RRwh+1N6hyv76frWyS9B5gMbALMoBTR+DnQz+VKj7I9pUpoL6Hc6jGVUsO+LSSNmDwl7Wj7V+2KpTVs9Xl/SnK/Qw1V5YmIrvQopWvi4PcNV49fUvdgSfIDJlNaVN5ie4+qxelpDcfUtE5IaJ9dzDnT/j/Cbpd0NaV/+UmS1gYWtDmGiOhe9wN7VWvwC5H0+7oHS5If8IztZyQh6QW2fyNpq6aDaljjCc32HkvzPEn72L5mtOMB3g3sANxv+ylJ61NmOFpxbGP7rjbEERHd6WxKXYdFkjxwZt2DZU2+Imka5c36WMrV4ePAqrb3bzSwBklaiYGE9kSV0DZurYV3UkKrqy1jr8QREd2trguXJPlhSJoIrANcZXte0/F0qk5KaKNRDrKb44iI7lbX+2t6LVckjaumo7F9A6WNad6sF6+TNpx1yl+rnRJHRHS3Wt5fk+QHnEu597rlyepYjCwJLSJidNTy/pokP0AetHZhewHZmNhNHmg6gEqWdyKiYyTJD7hf0jGSVq0+JlNudYiRtS2hSXqhpJMlXVg93kLSAa3ztoetsz8KcUyQtGb19eGSzpK06aA4xrUjjojoeQ/U8SJJ8gPeD7wG+APwEPBqoNbygt2mwxLaVEpP+/HV44coPZnb7VzgKUnbAydQilqk3W1ELBNJh7T2gUn6uKTvDS7+VdeFS5J8xfYjtt9u+yW2N7R9mO1Hmo6rYZ2U0MbaPhN4FsD20zSz8W9+taxzMDDF9hRg7QbiiIjudrLtuZJ2A14HfIVR2AfW92vOkk6wfaakcxhmo4PtYxoIq1PMt21JrYT2JUnvaiiWeZLWoPp/JGks5cq+3eZWnQsPB14raWVg1QbiiIju9lz1+Q3Auba/L+nUugfp+yQP3F19vq3RKDpTJyW0U4CrgJdJ+gYwATiygTgOBQ4D3m37YUl/D3ymgTgiorv9QdL5wN7AGZJewCjMrvd9MRxJX7N9hKTJ1dRrVCRtRElot9q+qUpou9tuZMq+qrg3jjJNf4vtPzcRR0TEipL0QuD1wJ22/1fS3wHb1t3lM0leuhvYD7gc2J0h67y2H2sgrBhC0puA62zPrh6/iPIHx2VtjuPNwBmUblGqPmx7TDvjiIjuV82ObsigWfXhGtes0BhJ8joGOBrYnLKzfqH2f7Y3bySwDtBJCU3SDNs7DDnW9hKykn4LHGj7nnaOGxG9RdKHKMuQf2Kg8Zdtb1frOP2e5FsknWv76Kbj6CSdlNAkzRz6wy/pTtvbtjmO6bYntHPMiOg91fvrq23/ZVTH6fckL2mM7TmS1hvufD9P13dSQpP0ZeAJ4AuUHfYfAta1fWSbxm/dszoR2Ai4jEG7+21/rx1xRERvkPRTYB/b80d1nCR5/dD2AZJmUZJH30/Xd2JCq4rynEzZiSrgauB020+2afypizlt20e1I46I6A2SvgRsBVzBwu+vZ9U6Tr8neQBJAl5W94aHbpWENjJJE2xPX9KxiIjFkXTKcMdtn1brOEnyhaTbbe/UdBydpJMSmqQtgeOBzVh4J+qebY5jkR7PdfV9joj+U5W2te2/LvHJyyHFcAbcImkX27c2HUgHOQcYmryGO9YO3wbOAy5ioFJU20gaT+ltsIGk4wadGgOs3O54IqK7SXol8DVgverxn4F/tH1XneMkyQ/YA3i/pAcoveRbt4vVejtDN+jQhDbfdu11nZfBasBalN+ZtQYdnw28pZGIIqKbXQAcZ/unAJJ2By6kvPfWJkl+wH5NB9BBOjGh/UDSB4BpLLxJpS13P9i+AbhB0pXAx1h42WAS0Hd/DEbEClmzleABbF/f6vpZp6zJD1J1A9rC9lRJGwBr2Z7VdFxNkbQLiya0RmY3qrsfhmr73Q+S7qXsDfg1AwUssP1gO+OIiO4maRrwK8qUPZQeITvbfmOt4yTJF9VOx52BrWxvKemlwLc75T7xJiShLUrSzbZ3azqOiOhuktYFTgN2oywP3wicavvxWsdJki8kzQBeBfyqVSp1uCpr/aQTEpqkPW1fN+je/YW0+559SXsB7wCuJcVwIqLDZU1+wLyqd3qrX3ntayNd6BRJF9FsQpsIXAccOMw5A+1OrpOAV1Ba7j5fb7qBOCKiC0k62/axkn5Aee9YiO2Dah0vV/KFpOOBLYB9gE8BRwGX2D6n0cAaJOnrlIR2Fws3UOjnYjhtr5cfEb1D0k62b5c0cbjz1Sbf2uRKfsAC4CZgDrAl8Anb1zQbUuO275SEJmkyMBWYS7nNZEfgxLp7Ly+FWyRtbfvuNo8bET3A9u3VlzvYnjL4XPU+V2uSX6nOF+tyawMnAeOAB4CZjUbTGW6RtHXTQVSOsj0H2JfS+nYS8OkG4tgNmCHpXkkzJd0pKT8rEbGs3jXMsSPrHiTT9UNI2g44lHI/+EO29244pMZIugcYC8yirMk3ViCotQlS0hTgetvTGuonv+lwx/v5joOIWHqS3gEcRrlguGnQqbWB5+rOOZmuX9QjwMPAXyhXjP3s9U0HMMjtkq4GXg6cVNV7XrCE76ldknlErKCfAf8HvBj47KDjcxmFGeRcyVckHU25gt8A+A7wray7dg5JKwE7APfbfkLS+sDGtmdW57epu+ZzRMRokbQ58Efbz1SP1wA2tP1AreMkyReSPg180/aMpmOJZZdOcBHRTSTdBrzG9rzq8WrAdNu71DlOpusrtk9sOoZYIWo6gIiIZbBKK8ED2J5XJfpaZXd99IpMSUVEN3lU0vOFbyQdDPy57kEyXR89IdP1EdFNJI0FvgFsTLlIeYjST/63dY6T6froFfOW/JSIiM5g+z5gnKS1KBfcc0djnEzXR1eQNKHVT0DS4ZLOGnzPuu1xzUUXEbFsJG0o6UuUbqdzJW0t6d11j5MkH93iXOApSdsDJwAPAl9tNqSIiOV2MfBj4KXV4/8Bjq17kCT56BbzXTaQHAxMqWo+r91wTBERy+vFtv+LqqiX7fnAc3UPkjX56BZzJZ0EHA68VtLKlHavERHd6MmqqFervfk4YHbdg2R3fXQFSRtR6j3favsmSX8P7G47U/YR0XUk7QicA7wS+DWl2upbW1U8axsnST4iIqL9JK0CbEUp5nWv7WdrHyNJPrqBpDcDZ1CaBomBjnhjGg0sImIZVO9lI7L9vVrHS5KPbiDpt8CBtu9pOpaIiOUlaepiTtv2UbWOlyQf3UDSdNsTmo4jIqKbJMlHRxs0tTUR2Ai4DPhb63zdU1sREaNJ0nGLO2/7rDrHyy100ekOHPT1U8C+gx4bSJKPiG7S1voeuZKPriBpgu3pSzoWEREDUvEuusU5S3ksIqLjSdpE0jRJj0j6k6TvStqk7nEyXR8dTdJ44DXABkPWssYAKzcTVUTECpsKXAIcUj0+vDq2T52D5Eo+Ot1qwFqUP0jXGvQxG3hLg3FFRKyIDWxPtT2/+riYUvWuVlmTj64gaRfgY8BmDMxA2fZ2jQUVEbGcJP2E0onu0urQO4BJtveqdZwk+egGku4FjqfUeF7QOm77wcaCiohYTlX/jc8D4yl3Cv0MOMb27+ocJ2vy0S0etf2DpoOIiKjJJ4F32X4cQNJ6wH8AtVa8S5KPbnGKpIuAa0kxnIjoftu1EjyA7cckvaruQZLko1tMAl5B6SHfmq5PMZyI6FYrSVp3yJV87Tk5ST66xfa2t206iIiImnwW+Jmk71AuWN4G/Fvdg2TjXXQFSRcCn7N9d9OxRETUQdLWwJ6U1tnXjsb7W5J8dAVJ9wBjgVmUNflWP/ncQhcRMYIk+egKkjYd7nhuoYuIGFmSfERERI9KWduIiIgelSQfERHRo5LkI3qMpFMleZiPn9Q4xq6STq3r9SJidOQ++YjeNBt4/TDH6rIrcApwao2vGRE1S5KP6E3zbd/SdBBLS9Iatp9uOo6IXpPp+og+I+k9ku6S9DdJD0o6Ycj58ZIul/RHSU9KmiHpnYPOHwmcU33dWgq4vnp8saTbhrzeZtVzDhh0zJKOk3S2pEeBO6vjq0s6U9Lvq/jukLT/kNc7SNLtVWyPS/qFpIn1/itF9IZcyUf0KElDf7+fo7Tr/XfgTOB6YCfgk5Kesv356nmbAtOB84BngAnAVEkLbF8KXEEpyflhSptMgDnLEeJHgBuBIxi44PgOA0sB91FKfV4uaWfbMySNrZ4zpfr+1av/hvWWY/yInpckH9Gb1geeHXLsYEryPN32adWxayS9EPi4pHNtP2f7m61vkCRKIt4EeC9wqe1HJT0AsIJLAg/bPnTQWHsBbwB2t31DdfhqSVsC/wIcArwKmGv7I4Ne58oViCGip2W6PqI3zQZ2GfIhYE3g25JWaX0A1wEbUhI5ktaV9J+SHqT8ofAs8D5gy5pjvGLI472Bh4HpQ+K7Fti5es6dwDqSviJpX0lr1hxTRE/JlXxEb5pve+ja+FbVl3eN8D0vAx4ELgbGAZ8E7qZMxR9NmQmo05+GPH4xsBGLzkBAWWrA9r2SDgZOpFzBPytpGjDZ9qM1xxfR9ZLkI/rHY9XnA1g0wQLcK2l1ypT5B22f1zohaWln/Z4BVhtybKT18qE1tR8D/gC8cXED2L4CuELSOlWsZ1M2Ar59KWOM6BtJ8hH94+fA08BLq0S5iCpxrkzp9Nc6tjZwEAsn5XnVudVtPzPo+EPAZkOO77OU8V1L2cz3V9u/WdKTbc8GLql21o9f0vMj+lGSfESfsP1EVaVuStXV70bKvpwtgT1sv8n2bEm3Ap+QNAdYQJkanw2MGfRyrSQ8WdJ1wBzb9wKXAf8KXCTpYspGuUlLGeI1wI8pmwHPoCwrjAF2AFa3fZKkf6Ik9KuAPwJbUDbkfXWZ/0Ei+kA23kX0EdtnUjbR7Qd8H7gUeCdw06CnHQbMoiTOKcB3WTSJ3gR8BpgM/AI4v3r9XwNHURLx5cDE6vHSxGbgzcCXgWMpCf/86rVurp42E9gAOAu4Gvg4cCHw0aUZI6LfpNVsREREj8qVfERERI9Kko+IiOhRSfIRERE9Kkk+IiKiRyXJR0RE9Kgk+YiIiB6VJB8REdGjkuQjIiJ6VJJ8REREj/p/9kr4HSV2EhIAAAAASUVORK5CYII=\n",
"text/plain": [
"
| Model | R^2 score | Root Mean Squared Error | Root Mean Squared Log Error | Mean Squared Error | |
|---|---|---|---|---|---|
| 1 | \n", "RandomForestRegression | \n", "0.88781 | \n", "16097.1 | \n", "0.106443 | \n", "2.59116e+08 | \n", "
| 2 | \n", "XGBoostRegressor | \n", "0.886151 | \n", "16215.7 | \n", "0.0977401 | \n", "2.62949e+08 | \n", "
| 6 | \n", "GradientBoostingRegression | \n", "0.883387 | \n", "16411.4 | \n", "0.0990406 | \n", "2.69333e+08 | \n", "
| 4 | \n", "AdaBoostRegressor | \n", "0.837192 | \n", "19391.4 | \n", "0.108653 | \n", "3.76025e+08 | \n", "
| 0 | \n", "LinearRegression | \n", "0.759426 | \n", "23571.9 | \n", "0.191409 | \n", "5.55637e+08 | \n", "
| 3 | \n", "LGBoostRegressor | \n", "0.244415 | \n", "41774.7 | \n", "0.24101 | \n", "1.74512e+09 | \n", "
| 5 | \n", "SupportVectorMachine | \n", "-0.0113428 | \n", "48330.4 | \n", "0.263462 | \n", "2.33583e+09 | \n", "
"
]
},
"metadata": {
"needs_background": "light"
},
"output_type": "display_data"
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"Null value summary: \n",
" Total Percent\n",
"verification_status_joint 63971 99.956249\n",
"desc 54849 85.702902\n",
"mths_since_last_record 54349 84.921639\n",
"mths_since_last_major_derog 48155 75.243363\n",
"mths_since_last_delinq 32831 51.299239\n",
"tot_cur_bal 5124 8.006375\n",
"tot_coll_amt 5124 8.006375\n",
"total_rev_hi_lim 5124 8.006375\n",
"emp_title 3826 5.978218\n",
"emp_length 3324 5.193831\n",
"revol_util 29 0.045313\n",
"title 13 0.020313\n",
"collections_12_mths_ex_med 8 0.012500\n",
"columns dropped Index(['verification_status_joint', 'desc', 'mths_since_last_record',\n",
" 'mths_since_last_major_derog', 'mths_since_last_delinq'],\n",
" dtype='object')\n",
"\n",
"\n",
"columns dropped \n",
"\n",
" ['verification_status_joint', 'desc', 'mths_since_last_record', 'mths_since_last_major_derog', 'mths_since_last_delinq'] \n",
" []\n",
"Dropped null values from columns:\n",
" ['emp_title', 'emp_length', 'title', 'revol_util', 'collections_12_mths_ex_med', 'tot_coll_amt', 'tot_cur_bal', 'total_rev_hi_lim']\n",
"\n",
"columns label encoded\n",
" Index(['term', 'grade', 'sub_grade', 'emp_title', 'emp_length',\n",
" 'home_ownership', 'verification_status', 'pymnt_plan', 'purpose',\n",
" 'title', 'zip_code', 'addr_state', 'initial_list_status',\n",
" 'application_type', 'last_week_pay'],\n",
" dtype='object')\n"
]
},
{
"data": {
"application/vnd.plotly.v1+json": {
"config": {
"plotlyServerURL": "https://plot.ly"
},
"data": [
{
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"reversescale": false,
"showscale": true,
"type": "heatmap",
"x": [
"loan_amnt",
"funded_amnt",
"funded_amnt_inv",
"term",
"int_rate",
"grade",
"sub_grade",
"emp_title",
"emp_length",
"home_ownership",
"annual_inc",
"verification_status",
"pymnt_plan",
"purpose",
"title",
"zip_code",
"addr_state",
"dti",
"delinq_2yrs",
"inq_last_6mths",
"open_acc",
"pub_rec",
"revol_bal",
"revol_util",
"total_acc",
"initial_list_status",
"total_rec_int",
"total_rec_late_fee",
"recoveries",
"collection_recovery_fee",
"collections_12_mths_ex_med",
"application_type",
"last_week_pay",
"acc_now_delinq",
"tot_coll_amt",
"tot_cur_bal",
"total_rev_hi_lim",
"loan_status"
],
"y": [
"loan_amnt",
"funded_amnt",
"funded_amnt_inv",
"term",
"int_rate",
"grade",
"sub_grade",
"emp_title",
"emp_length",
"home_ownership",
"annual_inc",
"verification_status",
"pymnt_plan",
"purpose",
"title",
"zip_code",
"addr_state",
"dti",
"delinq_2yrs",
"inq_last_6mths",
"open_acc",
"pub_rec",
"revol_bal",
"revol_util",
"total_acc",
"initial_list_status",
"total_rec_int",
"total_rec_late_fee",
"recoveries",
"collection_recovery_fee",
"collections_12_mths_ex_med",
"application_type",
"last_week_pay",
"acc_now_delinq",
"tot_coll_amt",
"tot_cur_bal",
"total_rev_hi_lim",
"loan_status"
],
"z": [
[
1,
1,
0.999994495733883,
0.411643847850033,
0.13341174067816444,
0.14365139723032622,
0.148040310874597,
-0.03345736902279111,
-0.05214432290641173,
-0.20190893423386652,
0.3943849779103391,
0.29699348070097814,
null,
-0.15640846128328392,
-0.12152921559291331,
-0.005003788445499,
0.014867813197747423,
0.031097803171138645,
-0.0051990961637801685,
-0.02679527879693172,
0.17776809368576413,
-0.0869249130313525,
0.3403890509680704,
0.12494989154703962,
0.21184271082705258,
0.05798371707079072,
0.5290896823671647,
0.03271861708995069,
0.07136278639469175,
0.05965868117069199,
-0.02033050434071409,
0.004827445463749915,
0.0015675606918417006,
-0.0021701721748424454,
-0.022538808108693024,
0.3282165872243522,
0.3594553697754661,
-0.06430272957407543
],
[
1,
1,
0.999994495733883,
0.411643847850033,
0.13341174067816444,
0.14365139723032622,
0.148040310874597,
-0.03345736902279111,
-0.05214432290641173,
-0.20190893423386652,
0.3943849779103391,
0.29699348070097814,
null,
-0.15640846128328392,
-0.12152921559291331,
-0.005003788445499,
0.014867813197747423,
0.031097803171138645,
-0.0051990961637801685,
-0.02679527879693172,
0.17776809368576413,
-0.0869249130313525,
0.3403890509680704,
0.12494989154703962,
0.21184271082705258,
0.05798371707079072,
0.5290896823671647,
0.03271861708995069,
0.07136278639469175,
0.05965868117069199,
-0.02033050434071409,
0.004827445463749915,
0.0015675606918417006,
-0.0021701721748424454,
-0.022538808108693024,
0.3282165872243522,
0.3594553697754661,
-0.06430272957407543
],
[
0.999994495733883,
0.999994495733883,
1,
0.4116211981363267,
0.13330321442743942,
0.14356391630716778,
0.1479551448770509,
-0.0334535694970512,
-0.052142218469309824,
-0.20191314255862555,
0.3944353627655065,
0.29689239937439876,
null,
-0.15638961961855535,
-0.12160268147659396,
-0.005015654065783122,
0.014847459817229196,
0.03103086216931911,
-0.00522672842553775,
-0.026779496506202444,
0.17782352342882665,
-0.0869326232147233,
0.34040123474747214,
0.12488210723020533,
0.2119023033076363,
0.05862360578882378,
0.529047743588068,
0.032718140016315296,
0.0713633584841391,
0.059652507483449996,
-0.02034069056316485,
0.004838075684853557,
0.0016427430674703558,
-0.0022036163051467827,
-0.022515537412302975,
0.328227581053997,
0.35951763072496024,
-0.06436720911612873
],
[
0.411643847850033,
0.411643847850033,
0.4116211981363267,
1,
0.43242054507915517,
0.4487692455624989,
0.4583107977540626,
-0.006525116970180671,
-0.0259507384000173,
-0.10253217459922696,
0.06693503234344986,
0.17703917409790568,
null,
-0.054471759896246974,
-0.0532091384347456,
-0.029949213840562823,
0.02208375681397544,
0.10920225283911296,
-0.0034607987059967274,
-0.0003018919435005439,
0.08105874803339941,
-0.02465585056112282,
0.09290080327686923,
0.09029401171731229,
0.10146062194674152,
0.12400292757101573,
0.38221963694398137,
0.008985323298450322,
0.0595640048056376,
0.046509396326972034,
-0.003075339529337968,
0.009418383603054905,
0.013761818670810323,
0.003992750724320375,
-0.013134849722798613,
0.10886346076007944,
0.07633799177605005,
-0.10687809277597168
],
[
0.13341174067816444,
0.13341174067816444,
0.13330321442743942,
0.43242054507915517,
1,
0.9568120349006187,
0.9808942419465159,
0.019290932132249982,
0.0009832040656923193,
0.06666876420140866,
-0.0872888111722311,
0.25540293980548257,
null,
0.1900905277462646,
0.1250962917659113,
0.002210193808871197,
0.00761362589292576,
0.15361477983671495,
0.048771490662113996,
0.2503070387855911,
-0.015074903511783507,
0.054261397532826,
-0.04361724679128139,
0.2509006231656625,
-0.03548640260476882,
-0.13733360458346447,
0.45332252220313235,
0.049632406728605805,
0.11169060160739858,
0.08249911413989408,
0.013090363196429216,
0.006606480372419443,
-0.038143196690063524,
0.02586770056314991,
0.0018599053430908637,
-0.08903928597899048,
-0.185996856469334,
0.04592716912266617
],
[
0.14365139723032622,
0.14365139723032622,
0.14356391630716778,
0.4487692455624989,
0.9568120349006187,
1,
0.9761781172966195,
0.020836871908368703,
-0.0008381745386867137,
0.06683960393126964,
-0.07744330335530084,
0.2362435166109863,
null,
0.18930433854921652,
0.07837523386678563,
-0.0009762168691404375,
0.00896590480117838,
0.16558562657842,
0.05462433505685077,
0.23024604567599788,
-0.0018921002366307767,
0.06451300071782581,
-0.0371376106587789,
0.22756160604279693,
-0.02811518641506502,
-0.09104695906248507,
0.3742195238975501,
0.04093847308098334,
0.09024311546711916,
0.0699149788354491,
0.02139619382062605,
0.010375738233339586,
0.008405122400321974,
0.027252919385799556,
0.006907891718743711,
-0.081364800368034,
-0.1680639352395392,
-0.024173488321323728
],
[
0.148040310874597,
0.148040310874597,
0.1479551448770509,
0.4583107977540626,
0.9808942419465159,
0.9761781172966195,
1,
0.021192228823886945,
3.765885501821178e-05,
0.06967314272157825,
-0.08071547907729802,
0.24831527927597943,
null,
0.19406006332547251,
0.07973516178480118,
-0.0003448816611944948,
0.008873805380029631,
0.17224520859071138,
0.055940761217560024,
0.23677277907075353,
-0.002643004699713159,
0.06559666934059569,
-0.03789496731071385,
0.23795724331412396,
-0.030358662215885814,
-0.08525476864388916,
0.38561050955520737,
0.04186107500035107,
0.09206652788407618,
0.07065030451290114,
0.02131753585290153,
0.010455774604816668,
0.009118118057806096,
0.028793320575960832,
0.006992363279745647,
-0.0851815247220811,
-0.17558717071192803,
-0.023619393344547476
],
[
-0.03345736902279111,
-0.03345736902279111,
-0.0334535694970512,
-0.006525116970180671,
0.019290932132249982,
0.020836871908368703,
0.021192228823886945,
1,
-0.02679628963359327,
-0.011060660341041804,
-0.03154681505590142,
-0.00827889714159167,
null,
0.016179319443497552,
0.07863102542717455,
-0.009885524392084738,
0.013183445731949744,
0.003774854407921696,
0.002093277995515338,
0.0044429315521822355,
-0.03453741173748368,
0.025776098986780176,
-0.028236373323319405,
-0.018395381420226953,
-0.02987420649528939,
0.00018768869689582247,
-0.0147287080035628,
0.006862437232011302,
-0.0002977651383586123,
0.002300148096544028,
0.016102732314310413,
-0.006050578553942374,
0.008986675815959726,
0.0028126645252870173,
0.01353894239092688,
-0.029722870499016566,
-0.028090922839431855,
-0.022643872138407205
],
[
-0.05214432290641173,
-0.05214432290641173,
-0.052142218469309824,
-0.0259507384000173,
0.0009832040656923193,
-0.0008381745386867137,
3.765885501821178e-05,
-0.02679628963359327,
1,
0.0777952848041867,
-0.04038277916220209,
-0.02450140291997443,
null,
-0.001105283666290456,
-0.009894853398877131,
0.009510531416396989,
-0.011732276866312109,
-0.007266243723978409,
-0.0254463429211081,
-0.000624256237605875,
-0.013204511471286248,
-0.004814782787200738,
-0.04182447401915748,
-0.009135701094754207,
-0.05225682995496444,
-0.0029429832813062523,
-0.02753904000840772,
-0.005148153380314195,
0.0037319343549299406,
0.005600858780428672,
-0.004299741328166502,
-0.002979099061422837,
0.008701473085459795,
-0.00811937468596631,
-0.011874848209115545,
-0.03671545190839008,
-0.048851765252982425,
0.002334709453603825
],
[
-0.20190893423386652,
-0.20190893423386652,
-0.20191314255862555,
-0.10253217459922696,
0.06666876420140866,
0.06683960393126964,
0.06967314272157825,
-0.011060660341041804,
0.0777952848041867,
1,
-0.17874006561271882,
-0.03422793629456061,
null,
0.04297122735833981,
-0.008599218722325587,
0.019430156464053668,
-0.06978060400418964,
0.015409031231796214,
-0.0503492351422965,
-0.03202615172285241,
-0.12288005667338896,
0.01155886610890551,
-0.16383573110237895,
-0.02696025527335592,
-0.2040309721615895,
-0.015415227745475366,
-0.11018187171940627,
-0.007885565065526906,
-0.00788710372595157,
-0.006658508799305959,
0.005477301742834623,
0.00089219401158786,
0.013462849884493944,
-0.016543840411658482,
-0.013396847689041359,
-0.5157690267179609,
-0.18111350959052855,
-0.023420293544534128
],
[
0.3943849779103391,
0.3943849779103391,
0.3944353627655065,
0.06693503234344986,
-0.0872888111722311,
-0.07744330335530084,
-0.08071547907729802,
-0.03154681505590142,
-0.04038277916220209,
-0.17874006561271882,
1,
0.1070676026605617,
null,
-4.787326308137939e-05,
-0.027100367014102116,
-0.018505342579039106,
-0.0018361495759812052,
-0.21683113050688405,
0.055431662102665875,
0.043208027684253345,
0.14347713143534285,
-0.007278630914388226,
0.35331405447987435,
0.04239382604383482,
0.20792354084130998,
0.04020712907084762,
0.1492311078350909,
0.014456482958179738,
0.002486191677443967,
0.002780819996663449,
-0.0063913228961272155,
-0.005973941158552865,
0.01717272900569184,
0.021957231030312076,
0.0033550174094531177,
0.4894022262353208,
0.3550412917859109,
-0.0010650854191582516
],
[
0.29699348070097814,
0.29699348070097814,
0.29689239937439876,
0.17703917409790568,
0.25540293980548257,
0.2362435166109863,
0.24831527927597943,
-0.00827889714159167,
-0.02450140291997443,
-0.03422793629456061,
0.1070676026605617,
1,
null,
0.01859331060070948,
0.01679759228498351,
0.00016138503919858115,
-0.00042429793960168695,
0.08568383755629155,
0.0010093328534758396,
0.09489780275005717,
0.0580559156327676,
0.031070009407150125,
0.09979264485824219,
0.08994937434256821,
0.06916799940756982,
-0.04296843857197572,
0.2801353097421754,
0.016546223631548465,
0.05115437279800124,
0.03682432534728316,
0.01323404250982127,
0.005409199687627417,
-0.05881425810185473,
0.008722765128821305,
-0.006454292049226884,
0.08340227608820469,
0.06873991191015719,
-0.0017472909426664131
],
[
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null
],
[
-0.15640846128328392,
-0.15640846128328392,
-0.15638961961855535,
-0.054471759896246974,
0.1900905277462646,
0.18930433854921652,
0.19406006332547251,
0.016179319443497552,
-0.001105283666290456,
0.04297122735833981,
-4.787326308137939e-05,
0.01859331060070948,
null,
1,
0.42437422621832327,
-0.004660136512439664,
-0.0030225937189394705,
-0.0597443900456897,
0.022682088289025078,
0.03526598753512214,
-0.06094187529997616,
0.031825329793904886,
-0.0749805820291455,
-0.09158503786001469,
-0.04941690683082344,
-0.03962410001727894,
-0.03835968939288057,
0.0054597127693265905,
0.011836182922146825,
0.0067143230694241135,
0.012791492265833208,
0.0018680229958332722,
0.00501993082734048,
0.012375560885476807,
0.012696152529661409,
-0.038629148765286885,
-0.06699246028706989,
0.016815725631719233
],
[
-0.12152921559291331,
-0.12152921559291331,
-0.12160268147659396,
-0.0532091384347456,
0.1250962917659113,
0.07837523386678563,
0.07973516178480118,
0.07863102542717455,
-0.009894853398877131,
-0.008599218722325587,
-0.027100367014102116,
0.01679759228498351,
null,
0.42437422621832327,
1,
0.001159888132459448,
-0.004110217208918749,
-0.05067201925926505,
-0.005398788354380876,
0.03785459540691737,
-0.05555053341392243,
-0.002822204117035821,
-0.06400080050450789,
-0.04326396957268407,
-0.04290074146865703,
-0.10497703536706231,
0.0645863299575317,
0.02176587534319986,
0.04204130564480481,
0.023882615969059984,
-0.01131783273608649,
-0.003696948961644592,
-0.13883957955447754,
0.005223778130661524,
-0.004823491896660796,
-0.030836765966353034,
-0.06304284152595521,
0.1134495117856535
],
[
-0.005003788445499,
-0.005003788445499,
-0.005015654065783122,
-0.029949213840562823,
0.002210193808871197,
-0.0009762168691404375,
-0.0003448816611944948,
-0.009885524392084738,
0.009510531416396989,
0.019430156464053668,
-0.018505342579039106,
0.00016138503919858115,
null,
-0.004660136512439664,
0.001159888132459448,
1,
-0.2542894057355472,
0.003407314429469929,
-0.03387487542936775,
0.0020611973496215577,
-0.05833241793410183,
-0.0027088074762154635,
-0.030075489736417316,
0.01726980668789022,
-0.025253510910513498,
-0.014190433969258938,
-0.005220417146414958,
-0.0008349115051341253,
0.0029303001518226845,
0.00772985291281308,
-0.0010806014569760855,
0.0010963671729656268,
-0.011009554560477426,
-0.0019614215867220456,
0.012076374765780985,
-0.007047376120552391,
-0.038803723692928775,
0.025920985210723568
],
[
0.014867813197747423,
0.014867813197747423,
0.014847459817229196,
0.02208375681397544,
0.00761362589292576,
0.00896590480117838,
0.008873805380029631,
0.013183445731949744,
-0.011732276866312109,
-0.06978060400418964,
-0.0018361495759812052,
-0.00042429793960168695,
null,
-0.0030225937189394705,
-0.004110217208918749,
-0.2542894057355472,
1,
0.03842034111796081,
0.018922652658377698,
0.0032800524834388726,
0.035297007622749794,
-0.012891158725024724,
-0.005912299215423409,
0.004618914072314268,
0.04714559820598085,
0.011871601539986147,
0.013183947671637618,
0.0015047398260846353,
-0.005578006863996218,
-0.004196590204390526,
0.008365811756044401,
0.002561042941319928,
0.00874741181671812,
0.009038265727623602,
0.0023241776025089704,
-0.004653840902100008,
-0.00018421064645880825,
-0.015787877821600772
],
[
0.031097803171138645,
0.031097803171138645,
0.03103086216931911,
0.10920225283911296,
0.15361477983671495,
0.16558562657842,
0.17224520859071138,
0.003774854407921696,
-0.007266243723978409,
0.015409031231796214,
-0.21683113050688405,
0.08568383755629155,
null,
-0.0597443900456897,
-0.05067201925926505,
0.003407314429469929,
0.03842034111796081,
1,
-0.012878835782459132,
-0.0013417753367401287,
0.2950813181707151,
-0.05798279320199415,
0.1347037317957068,
0.16118662179296042,
0.22076781458622582,
0.015416807536295405,
0.026204192606914405,
0.0033603788896303393,
0.007279283327616287,
0.012927782540382021,
-0.0014531807066610332,
0.022122299822703945,
0.009797667927093275,
0.011162230988940942,
-0.029304937341284105,
-0.014719060356981221,
0.08840318772760983,
-0.09197154859665731
],
[
-0.0051990961637801685,
-0.0051990961637801685,
-0.00522672842553775,
-0.0034607987059967274,
0.048771490662113996,
0.05462433505685077,
0.055940761217560024,
0.002093277995515338,
-0.0254463429211081,
-0.0503492351422965,
0.055431662102665875,
0.0010093328534758396,
null,
0.022682088289025078,
-0.005398788354380876,
-0.03387487542936775,
0.018922652658377698,
-0.012878835782459132,
1,
0.024972500111194083,
0.04884854345276507,
-0.013845736003051837,
-0.03442477607485866,
-0.01272289026673626,
0.12063820754532421,
-0.002385223078926241,
0.0006809991538338856,
0.017194268473996143,
-0.005395798377591259,
-0.005310247213717818,
0.06429355516619162,
-0.00034673886056677206,
0.01677286466210006,
0.13308397716784076,
0.005737580516261322,
0.06481589664845744,
-0.04702042397865263,
-0.024065250441369482
],
[
-0.02679527879693172,
-0.02679527879693172,
-0.026779496506202444,
-0.0003018919435005439,
0.2503070387855911,
0.23024604567599788,
0.23677277907075353,
0.0044429315521822355,
-0.000624256237605875,
-0.03202615172285241,
0.043208027684253345,
0.09489780275005717,
null,
0.03526598753512214,
0.03785459540691737,
0.0020611973496215577,
0.0032800524834388726,
-0.0013417753367401287,
0.024972500111194083,
1,
0.12978560366989778,
0.06142798195890451,
-0.024631446585513646,
-0.09238698187763053,
0.1495452898957319,
-0.07076809248191095,
0.09514652150091438,
0.016788496767471406,
0.04305593266324206,
0.032435948627276126,
0.007972517580294401,
-0.006109805669505345,
0.004360026350886059,
-0.004630765391207512,
0.018684709618392106,
0.031140336309666523,
0.003259794658264172,
0.07527113045364453
],
[
0.17776809368576413,
0.17776809368576413,
0.17782352342882665,
0.08105874803339941,
-0.015074903511783507,
-0.0018921002366307767,
-0.002643004699713159,
-0.03453741173748368,
-0.013204511471286248,
-0.12288005667338896,
0.14347713143534285,
0.0580559156327676,
null,
-0.06094187529997616,
-0.05555053341392243,
-0.05833241793410183,
0.035297007622749794,
0.2950813181707151,
0.04884854345276507,
0.12978560366989778,
1,
-0.04053975984354845,
0.2105778140244576,
-0.1611865395562159,
0.7001869564233922,
0.03797227061567175,
0.06394267617241056,
0.0019133570387316213,
0.0024884786264883323,
0.005280577929058326,
0.0070187576913303875,
-0.0035572486238639213,
0.017378892178661766,
0.016180177637332104,
0.004249236973014104,
0.24045262822239255,
0.36534325483701396,
-0.036866795446310406
],
[
-0.0869249130313525,
-0.0869249130313525,
-0.0869326232147233,
-0.02465585056112282,
0.054261397532826,
0.06451300071782581,
0.06559666934059569,
0.025776098986780176,
-0.004814782787200738,
0.01155886610890551,
-0.007278630914388226,
0.031070009407150125,
null,
0.031825329793904886,
-0.002822204117035821,
-0.0027088074762154635,
-0.012891158725024724,
-0.05798279320199415,
-0.013845736003051837,
0.06142798195890451,
-0.04053975984354845,
1,
-0.10510329152191356,
-0.08537739548569803,
0.00546887502219134,
0.0034311062878890418,
-0.051270295161779035,
-0.010642052254048044,
-0.013413426506514281,
-0.006349590242665383,
0.02656290325561187,
0.003223390873465645,
0.041023996699775835,
0.006895335479530639,
0.04807670765083582,
-0.07521187217683446,
-0.11650036282252389,
-0.022056012848177653
],
[
0.3403890509680704,
0.3403890509680704,
0.34040123474747214,
0.09290080327686923,
-0.04361724679128139,
-0.0371376106587789,
-0.03789496731071385,
-0.028236373323319405,
-0.04182447401915748,
-0.16383573110237895,
0.35331405447987435,
0.09979264485824219,
null,
-0.0749805820291455,
-0.06400080050450789,
-0.030075489736417316,
-0.005912299215423409,
0.1347037317957068,
-0.03442477607485866,
-0.024631446585513646,
0.2105778140244576,
-0.10510329152191356,
1,
0.2152985198748145,
0.17148199037987857,
0.033949972474484516,
0.14282180325181157,
0.002710802330655974,
0.010202925669417625,
0.008608576910214586,
-0.02851448432708907,
-0.0013598593331021374,
5.1702264607155354e-05,
-0.0009488154792403558,
-0.03235111441657712,
0.4513125972206511,
0.8478668817136357,
-0.03495434066957358
],
[
0.12494989154703962,
0.12494989154703962,
0.12488210723020533,
0.09029401171731229,
0.2509006231656625,
0.22756160604279693,
0.23795724331412396,
-0.018395381420226953,
-0.009135701094754207,
-0.02696025527335592,
0.04239382604383482,
0.08994937434256821,
null,
-0.09158503786001469,
-0.04326396957268407,
0.01726980668789022,
0.004618914072314268,
0.16118662179296042,
-0.01272289026673626,
-0.09238698187763053,
-0.1611865395562159,
-0.08537739548569803,
0.2152985198748145,
1,
-0.12296636670402021,
-0.04739518968174796,
0.18578139348205852,
0.01918713210588612,
0.026698665677940863,
0.019405962923863863,
-0.04121443265274518,
0.00937879982283195,
-0.026424049231996594,
-0.03150196147336829,
-0.04517890426365494,
0.08286205323670082,
-0.13597087127963567,
-0.03074386681652146
],
[
0.21184271082705258,
0.21184271082705258,
0.2119023033076363,
0.10146062194674152,
-0.03548640260476882,
-0.02811518641506502,
-0.030358662215885814,
-0.02987420649528939,
-0.05225682995496444,
-0.2040309721615895,
0.20792354084130998,
0.06916799940756982,
null,
-0.04941690683082344,
-0.04290074146865703,
-0.025253510910513498,
0.04714559820598085,
0.22076781458622582,
0.12063820754532421,
0.1495452898957319,
0.7001869564233922,
0.00546887502219134,
0.17148199037987857,
-0.12296636670402021,
1,
0.03015390728006784,
0.0954919121466136,
0.0027944220046931963,
0.012055566276777358,
0.0117283858446742,
0.0072598408821065875,
-0.0052535429298472954,
0.017331146498846563,
0.023252288092782878,
0.03528048484896114,
0.3093230627988265,
0.28721452960793153,
0.025092731309658813
],
[
0.05798371707079072,
0.05798371707079072,
0.05862360578882378,
0.12400292757101573,
-0.13733360458346447,
-0.09104695906248507,
-0.08525476864388916,
0.00018768869689582247,
-0.0029429832813062523,
-0.015415227745475366,
0.04020712907084762,
-0.04296843857197572,
null,
-0.03962410001727894,
-0.10497703536706231,
-0.014190433969258938,
0.011871601539986147,
0.015416807536295405,
-0.002385223078926241,
-0.07076809248191095,
0.03797227061567175,
0.0034311062878890418,
0.033949972474484516,
-0.04739518968174796,
0.03015390728006784,
1,
-0.15278907552427376,
-0.020276205219848204,
-0.06230213079596386,
-0.05340730184364182,
0.017373680500846454,
0.011444564743778925,
0.13055972121332204,
7.244017235525579e-05,
0.00623492679075896,
0.029733436834442344,
0.06669892628770463,
-0.1414373413511235
],
[
0.5290896823671647,
0.5290896823671647,
0.529047743588068,
0.38221963694398137,
0.45332252220313235,
0.3742195238975501,
0.38561050955520737,
-0.0147287080035628,
-0.02753904000840772,
-0.11018187171940627,
0.1492311078350909,
0.2801353097421754,
null,
-0.03835968939288057,
0.0645863299575317,
-0.005220417146414958,
0.013183947671637618,
0.026204192606914405,
0.0006809991538338856,
0.09514652150091438,
0.06394267617241056,
-0.051270295161779035,
0.14282180325181157,
0.18578139348205852,
0.0954919121466136,
-0.15278907552427376,
1,
0.0784775529366447,
0.06351610101169157,
0.0640325463863722,
-0.028292917885403206,
-0.01541770441940767,
-0.15119488189848246,
0.0012468157529322366,
-0.02207732476943483,
0.13673973882889998,
0.0869422146635074,
0.029738316514548422
],
[
0.03271861708995069,
0.03271861708995069,
0.032718140016315296,
0.008985323298450322,
0.049632406728605805,
0.04093847308098334,
0.04186107500035107,
0.006862437232011302,
-0.005148153380314195,
-0.007885565065526906,
0.014456482958179738,
0.016546223631548465,
null,
0.0054597127693265905,
0.02176587534319986,
-0.0008349115051341253,
0.0015047398260846353,
0.0033603788896303393,
0.017194268473996143,
0.016788496767471406,
0.0019133570387316213,
-0.010642052254048044,
0.002710802330655974,
0.01918713210588612,
0.0027944220046931963,
-0.020276205219848204,
0.0784775529366447,
1,
0.0751062338791593,
0.07379992652837061,
-0.004378036861908481,
0.001661949203492916,
-0.01394821938485686,
0.006259431485720145,
-0.0050841052011687295,
0.00815600931299343,
-0.0040455961592433184,
-0.01187460709920478
],
[
0.07136278639469175,
0.07136278639469175,
0.0713633584841391,
0.0595640048056376,
0.11169060160739858,
0.09024311546711916,
0.09206652788407618,
-0.0002977651383586123,
0.0037319343549299406,
-0.00788710372595157,
0.002486191677443967,
0.05115437279800124,
null,
0.011836182922146825,
0.04204130564480481,
0.0029303001518226845,
-0.005578006863996218,
0.007279283327616287,
-0.005395798377591259,
0.04305593266324206,
0.0024884786264883323,
-0.013413426506514281,
0.010202925669417625,
0.026698665677940863,
0.012055566276777358,
-0.06230213079596386,
0.06351610101169157,
0.0751062338791593,
1,
0.8231990601943079,
0.00043677943966006756,
-0.00234419889215663,
0.009542031734390612,
0.0010728309442243182,
-0.008770362414212293,
-0.0032046349168055304,
0.0024114944810843574,
-0.05369938378729858
],
[
0.05965868117069199,
0.05965868117069199,
0.059652507483449996,
0.046509396326972034,
0.08249911413989408,
0.0699149788354491,
0.07065030451290114,
0.002300148096544028,
0.005600858780428672,
-0.006658508799305959,
0.002780819996663449,
0.03682432534728316,
null,
0.0067143230694241135,
0.023882615969059984,
0.00772985291281308,
-0.004196590204390526,
0.012927782540382021,
-0.005310247213717818,
0.032435948627276126,
0.005280577929058326,
-0.006349590242665383,
0.008608576910214586,
0.019405962923863863,
0.0117283858446742,
-0.05340730184364182,
0.0640325463863722,
0.07379992652837061,
0.8231990601943079,
1,
0.005484028071252457,
-0.001747856338522723,
0.005138940810677774,
-0.0018449833858160002,
-0.006098508323899788,
0.001340961068254494,
0.0038503747515918688,
-0.04003875637059248
],
[
-0.02033050434071409,
-0.02033050434071409,
-0.02034069056316485,
-0.003075339529337968,
0.013090363196429216,
0.02139619382062605,
0.02131753585290153,
0.016102732314310413,
-0.004299741328166502,
0.005477301742834623,
-0.0063913228961272155,
0.01323404250982127,
null,
0.012791492265833208,
-0.01131783273608649,
-0.0010806014569760855,
0.008365811756044401,
-0.0014531807066610332,
0.06429355516619162,
0.007972517580294401,
0.0070187576913303875,
0.02656290325561187,
-0.02851448432708907,
-0.04121443265274518,
0.0072598408821065875,
0.017373680500846454,
-0.028292917885403206,
-0.004378036861908481,
0.00043677943966006756,
0.005484028071252457,
1,
-0.0025185157904696926,
0.011344640678366642,
0.017946641993161316,
0.05833379111590448,
-0.015545602934903128,
-0.023471281335192558,
-0.026714847482287616
],
[
0.004827445463749915,
0.004827445463749915,
0.004838075684853557,
0.009418383603054905,
0.006606480372419443,
0.010375738233339586,
0.010455774604816668,
-0.006050578553942374,
-0.002979099061422837,
0.00089219401158786,
-0.005973941158552865,
0.005409199687627417,
null,
0.0018680229958332722,
-0.003696948961644592,
0.0010963671729656268,
0.002561042941319928,
0.022122299822703945,
-0.00034673886056677206,
-0.006109805669505345,
-0.0035572486238639213,
0.003223390873465645,
-0.0013598593331021374,
0.00937879982283195,
-0.0052535429298472954,
0.011444564743778925,
-0.01541770441940767,
0.001661949203492916,
-0.00234419889215663,
-0.001747856338522723,
-0.0025185157904696926,
1,
0.017957341023761498,
-0.0015117447027497807,
-0.00046506782646470033,
-0.0004993348989062701,
-0.004906502053026574,
-0.010356319260756655
],
[
0.0015675606918417006,
0.0015675606918417006,
0.0016427430674703558,
0.013761818670810323,
-0.038143196690063524,
0.008405122400321974,
0.009118118057806096,
0.008986675815959726,
0.008701473085459795,
0.013462849884493944,
0.01717272900569184,
-0.05881425810185473,
null,
0.00501993082734048,
-0.13883957955447754,
-0.011009554560477426,
0.00874741181671812,
0.009797667927093275,
0.01677286466210006,
0.004360026350886059,
0.017378892178661766,
0.041023996699775835,
5.1702264607155354e-05,
-0.026424049231996594,
0.017331146498846563,
0.13055972121332204,
-0.15119488189848246,
-0.01394821938485686,
0.009542031734390612,
0.005138940810677774,
0.011344640678366642,
0.017957341023761498,
1,
0.002122710850834316,
0.015937045070166425,
-0.0020915339335350015,
0.006510234283615116,
-0.034957948941779914
],
[
-0.0021701721748424454,
-0.0021701721748424454,
-0.0022036163051467827,
0.003992750724320375,
0.02586770056314991,
0.027252919385799556,
0.028793320575960832,
0.0028126645252870173,
-0.00811937468596631,
-0.016543840411658482,
0.021957231030312076,
0.008722765128821305,
null,
0.012375560885476807,
0.005223778130661524,
-0.0019614215867220456,
0.009038265727623602,
0.011162230988940942,
0.13308397716784076,
-0.004630765391207512,
0.016180177637332104,
0.006895335479530639,
-0.0009488154792403558,
-0.03150196147336829,
0.023252288092782878,
7.244017235525579e-05,
0.0012468157529322366,
0.006259431485720145,
0.0010728309442243182,
-0.0018449833858160002,
0.017946641993161316,
-0.0015117447027497807,
0.002122710850834316,
1,
-0.00022548688489349255,
0.0257905990600058,
0.009361531040761187,
-0.008280657174122753
],
[
-0.022538808108693024,
-0.022538808108693024,
-0.022515537412302975,
-0.013134849722798613,
0.0018599053430908637,
0.006907891718743711,
0.006992363279745647,
0.01353894239092688,
-0.011874848209115545,
-0.013396847689041359,
0.0033550174094531177,
-0.006454292049226884,
null,
0.012696152529661409,
-0.004823491896660796,
0.012076374765780985,
0.0023241776025089704,
-0.029304937341284105,
0.005737580516261322,
0.018684709618392106,
0.004249236973014104,
0.04807670765083582,
-0.03235111441657712,
-0.04517890426365494,
0.03528048484896114,
0.00623492679075896,
-0.02207732476943483,
-0.0050841052011687295,
-0.008770362414212293,
-0.006098508323899788,
0.05833379111590448,
-0.00046506782646470033,
0.015937045070166425,
-0.00022548688489349255,
1,
4.848115046660499e-05,
-0.03232423106336386,
-0.009107495424103456
],
[
0.3282165872243522,
0.3282165872243522,
0.328227581053997,
0.10886346076007944,
-0.08903928597899048,
-0.081364800368034,
-0.0851815247220811,
-0.029722870499016566,
-0.03671545190839008,
-0.5157690267179609,
0.4894022262353208,
0.08340227608820469,
null,
-0.038629148765286885,
-0.030836765966353034,
-0.007047376120552391,
-0.004653840902100008,
-0.014719060356981221,
0.06481589664845744,
0.031140336309666523,
0.24045262822239255,
-0.07521187217683446,
0.4513125972206511,
0.08286205323670082,
0.3093230627988265,
0.029733436834442344,
0.13673973882889998,
0.00815600931299343,
-0.0032046349168055304,
0.001340961068254494,
-0.015545602934903128,
-0.0004993348989062701,
-0.0020915339335350015,
0.0257905990600058,
4.848115046660499e-05,
1,
0.42908397283846533,
0.014130323091986497
],
[
0.3594553697754661,
0.3594553697754661,
0.35951763072496024,
0.07633799177605005,
-0.185996856469334,
-0.1680639352395392,
-0.17558717071192803,
-0.028090922839431855,
-0.048851765252982425,
-0.18111350959052855,
0.3550412917859109,
0.06873991191015719,
null,
-0.06699246028706989,
-0.06304284152595521,
-0.038803723692928775,
-0.00018421064645880825,
0.08840318772760983,
-0.04702042397865263,
0.003259794658264172,
0.36534325483701396,
-0.11650036282252389,
0.8478668817136357,
-0.13597087127963567,
0.28721452960793153,
0.06669892628770463,
0.0869422146635074,
-0.0040455961592433184,
0.0024114944810843574,
0.0038503747515918688,
-0.023471281335192558,
-0.004906502053026574,
0.006510234283615116,
0.009361531040761187,
-0.03232423106336386,
0.42908397283846533,
1,
-0.03021030227171473
],
[
-0.06430272957407543,
-0.06430272957407543,
-0.06436720911612873,
-0.10687809277597168,
0.04592716912266617,
-0.024173488321323728,
-0.023619393344547476,
-0.022643872138407205,
0.002334709453603825,
-0.023420293544534128,
-0.0010650854191582516,
-0.0017472909426664131,
null,
0.016815725631719233,
0.1134495117856535,
0.025920985210723568,
-0.015787877821600772,
-0.09197154859665731,
-0.024065250441369482,
0.07527113045364453,
-0.036866795446310406,
-0.022056012848177653,
-0.03495434066957358,
-0.03074386681652146,
0.025092731309658813,
-0.1414373413511235,
0.029738316514548422,
-0.01187460709920478,
-0.05369938378729858,
-0.04003875637059248,
-0.026714847482287616,
-0.010356319260756655,
-0.034957948941779914,
-0.008280657174122753,
-0.009107495424103456,
0.014130323091986497,
-0.03021030227171473,
1
]
]
}
],
"layout": {
"annotations": [
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "loan_amnt",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "funded_amnt",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "funded_amnt_inv",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.41",
"x": "term",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.13",
"x": "int_rate",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "grade",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.15",
"x": "sub_grade",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.03",
"x": "emp_title",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.05",
"x": "emp_length",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.2",
"x": "home_ownership",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.39",
"x": "annual_inc",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.3",
"x": "verification_status",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "nan",
"x": "pymnt_plan",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.16",
"x": "purpose",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.12",
"x": "title",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "zip_code",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "addr_state",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.03",
"x": "dti",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "delinq_2yrs",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.03",
"x": "inq_last_6mths",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.18",
"x": "open_acc",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.09",
"x": "pub_rec",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.34",
"x": "revol_bal",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.12",
"x": "revol_util",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.21",
"x": "total_acc",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.06",
"x": "initial_list_status",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.53",
"x": "total_rec_int",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.03",
"x": "total_rec_late_fee",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.07",
"x": "recoveries",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.06",
"x": "collection_recovery_fee",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.02",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "application_type",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "last_week_pay",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "acc_now_delinq",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.02",
"x": "tot_coll_amt",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.33",
"x": "tot_cur_bal",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.36",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.06",
"x": "loan_status",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "loan_amnt",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "funded_amnt",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "funded_amnt_inv",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.41",
"x": "term",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.13",
"x": "int_rate",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "grade",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.15",
"x": "sub_grade",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.03",
"x": "emp_title",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.05",
"x": "emp_length",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.2",
"x": "home_ownership",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.39",
"x": "annual_inc",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.3",
"x": "verification_status",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "nan",
"x": "pymnt_plan",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.16",
"x": "purpose",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.12",
"x": "title",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "zip_code",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "addr_state",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.03",
"x": "dti",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "delinq_2yrs",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.03",
"x": "inq_last_6mths",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.18",
"x": "open_acc",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.09",
"x": "pub_rec",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.34",
"x": "revol_bal",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.12",
"x": "revol_util",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.21",
"x": "total_acc",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.06",
"x": "initial_list_status",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.53",
"x": "total_rec_int",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.03",
"x": "total_rec_late_fee",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.07",
"x": "recoveries",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.06",
"x": "collection_recovery_fee",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.02",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "application_type",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "last_week_pay",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "acc_now_delinq",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.02",
"x": "tot_coll_amt",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.33",
"x": "tot_cur_bal",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.36",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.06",
"x": "loan_status",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "loan_amnt",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "funded_amnt",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "funded_amnt_inv",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.41",
"x": "term",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.13",
"x": "int_rate",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "grade",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.15",
"x": "sub_grade",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.03",
"x": "emp_title",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.05",
"x": "emp_length",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.2",
"x": "home_ownership",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.39",
"x": "annual_inc",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.3",
"x": "verification_status",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "nan",
"x": "pymnt_plan",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.16",
"x": "purpose",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.12",
"x": "title",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "zip_code",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "addr_state",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.03",
"x": "dti",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "delinq_2yrs",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.03",
"x": "inq_last_6mths",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.18",
"x": "open_acc",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.09",
"x": "pub_rec",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.34",
"x": "revol_bal",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.12",
"x": "revol_util",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.21",
"x": "total_acc",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.06",
"x": "initial_list_status",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.53",
"x": "total_rec_int",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.03",
"x": "total_rec_late_fee",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.07",
"x": "recoveries",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.06",
"x": "collection_recovery_fee",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.02",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "application_type",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "last_week_pay",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "acc_now_delinq",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.02",
"x": "tot_coll_amt",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.33",
"x": "tot_cur_bal",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.36",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.06",
"x": "loan_status",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.41",
"x": "loan_amnt",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.41",
"x": "funded_amnt",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.41",
"x": "funded_amnt_inv",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "term",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.43",
"x": "int_rate",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.45",
"x": "grade",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.46",
"x": "sub_grade",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "emp_title",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.03",
"x": "emp_length",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.1",
"x": "home_ownership",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.07",
"x": "annual_inc",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.18",
"x": "verification_status",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "nan",
"x": "pymnt_plan",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.05",
"x": "purpose",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.05",
"x": "title",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.03",
"x": "zip_code",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.02",
"x": "addr_state",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.11",
"x": "dti",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "delinq_2yrs",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "inq_last_6mths",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.08",
"x": "open_acc",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.02",
"x": "pub_rec",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.09",
"x": "revol_bal",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.09",
"x": "revol_util",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.1",
"x": "total_acc",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.12",
"x": "initial_list_status",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.38",
"x": "total_rec_int",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "total_rec_late_fee",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.06",
"x": "recoveries",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.05",
"x": "collection_recovery_fee",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "application_type",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "last_week_pay",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "acc_now_delinq",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "tot_coll_amt",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.11",
"x": "tot_cur_bal",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.08",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.11",
"x": "loan_status",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.13",
"x": "loan_amnt",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.13",
"x": "funded_amnt",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.13",
"x": "funded_amnt_inv",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.43",
"x": "term",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "int_rate",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.96",
"x": "grade",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.98",
"x": "sub_grade",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.02",
"x": "emp_title",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "emp_length",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.07",
"x": "home_ownership",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.09",
"x": "annual_inc",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.26",
"x": "verification_status",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "nan",
"x": "pymnt_plan",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.19",
"x": "purpose",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.13",
"x": "title",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "zip_code",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "addr_state",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.15",
"x": "dti",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.05",
"x": "delinq_2yrs",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.25",
"x": "inq_last_6mths",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.02",
"x": "open_acc",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.05",
"x": "pub_rec",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.04",
"x": "revol_bal",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.25",
"x": "revol_util",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.04",
"x": "total_acc",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.14",
"x": "initial_list_status",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.45",
"x": "total_rec_int",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.05",
"x": "total_rec_late_fee",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.11",
"x": "recoveries",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.08",
"x": "collection_recovery_fee",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "application_type",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.04",
"x": "last_week_pay",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.03",
"x": "acc_now_delinq",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "tot_coll_amt",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.09",
"x": "tot_cur_bal",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.19",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.05",
"x": "loan_status",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "loan_amnt",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "funded_amnt",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "funded_amnt_inv",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.45",
"x": "term",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.96",
"x": "int_rate",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "grade",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.98",
"x": "sub_grade",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.02",
"x": "emp_title",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "emp_length",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.07",
"x": "home_ownership",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.08",
"x": "annual_inc",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.24",
"x": "verification_status",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "nan",
"x": "pymnt_plan",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.19",
"x": "purpose",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.08",
"x": "title",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "zip_code",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "addr_state",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.17",
"x": "dti",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.05",
"x": "delinq_2yrs",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.23",
"x": "inq_last_6mths",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "open_acc",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.06",
"x": "pub_rec",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.04",
"x": "revol_bal",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.23",
"x": "revol_util",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.03",
"x": "total_acc",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.09",
"x": "initial_list_status",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.37",
"x": "total_rec_int",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.04",
"x": "total_rec_late_fee",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.09",
"x": "recoveries",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.07",
"x": "collection_recovery_fee",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.02",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "application_type",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "last_week_pay",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.03",
"x": "acc_now_delinq",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "tot_coll_amt",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.08",
"x": "tot_cur_bal",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.17",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.02",
"x": "loan_status",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.15",
"x": "loan_amnt",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.15",
"x": "funded_amnt",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.15",
"x": "funded_amnt_inv",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.46",
"x": "term",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.98",
"x": "int_rate",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.98",
"x": "grade",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "sub_grade",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.02",
"x": "emp_title",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "emp_length",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.07",
"x": "home_ownership",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.08",
"x": "annual_inc",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.25",
"x": "verification_status",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "nan",
"x": "pymnt_plan",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.19",
"x": "purpose",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.08",
"x": "title",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "zip_code",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "addr_state",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.17",
"x": "dti",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.06",
"x": "delinq_2yrs",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.24",
"x": "inq_last_6mths",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "open_acc",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.07",
"x": "pub_rec",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.04",
"x": "revol_bal",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.24",
"x": "revol_util",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.03",
"x": "total_acc",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.09",
"x": "initial_list_status",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.39",
"x": "total_rec_int",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.04",
"x": "total_rec_late_fee",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.09",
"x": "recoveries",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.07",
"x": "collection_recovery_fee",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.02",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "application_type",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "last_week_pay",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.03",
"x": "acc_now_delinq",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "tot_coll_amt",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.09",
"x": "tot_cur_bal",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.18",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.02",
"x": "loan_status",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.03",
"x": "loan_amnt",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.03",
"x": "funded_amnt",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.03",
"x": "funded_amnt_inv",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "term",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.02",
"x": "int_rate",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.02",
"x": "grade",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.02",
"x": "sub_grade",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "emp_title",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.03",
"x": "emp_length",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "home_ownership",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.03",
"x": "annual_inc",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "verification_status",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "nan",
"x": "pymnt_plan",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.02",
"x": "purpose",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.08",
"x": "title",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "zip_code",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "addr_state",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "dti",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "delinq_2yrs",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "inq_last_6mths",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.03",
"x": "open_acc",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.03",
"x": "pub_rec",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.03",
"x": "revol_bal",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.02",
"x": "revol_util",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.03",
"x": "total_acc",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "initial_list_status",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "total_rec_int",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "total_rec_late_fee",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "recoveries",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "collection_recovery_fee",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.02",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "application_type",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "last_week_pay",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "acc_now_delinq",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "tot_coll_amt",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.03",
"x": "tot_cur_bal",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.03",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.02",
"x": "loan_status",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.05",
"x": "loan_amnt",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.05",
"x": "funded_amnt",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.05",
"x": "funded_amnt_inv",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.03",
"x": "term",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "int_rate",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "grade",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "sub_grade",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.03",
"x": "emp_title",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "emp_length",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.08",
"x": "home_ownership",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.04",
"x": "annual_inc",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.02",
"x": "verification_status",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "nan",
"x": "pymnt_plan",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "purpose",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "title",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "zip_code",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "addr_state",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "dti",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.03",
"x": "delinq_2yrs",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "inq_last_6mths",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "open_acc",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "pub_rec",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.04",
"x": "revol_bal",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "revol_util",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.05",
"x": "total_acc",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "initial_list_status",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.03",
"x": "total_rec_int",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "total_rec_late_fee",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "recoveries",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "collection_recovery_fee",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "application_type",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "last_week_pay",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "acc_now_delinq",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "tot_coll_amt",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.04",
"x": "tot_cur_bal",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.05",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "loan_status",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.2",
"x": "loan_amnt",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.2",
"x": "funded_amnt",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.2",
"x": "funded_amnt_inv",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.1",
"x": "term",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.07",
"x": "int_rate",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.07",
"x": "grade",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.07",
"x": "sub_grade",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "emp_title",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.08",
"x": "emp_length",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "home_ownership",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.18",
"x": "annual_inc",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.03",
"x": "verification_status",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "nan",
"x": "pymnt_plan",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.04",
"x": "purpose",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "title",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.02",
"x": "zip_code",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.07",
"x": "addr_state",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.02",
"x": "dti",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.05",
"x": "delinq_2yrs",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.03",
"x": "inq_last_6mths",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.12",
"x": "open_acc",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "pub_rec",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.16",
"x": "revol_bal",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.03",
"x": "revol_util",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.2",
"x": "total_acc",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.02",
"x": "initial_list_status",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.11",
"x": "total_rec_int",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "total_rec_late_fee",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "recoveries",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "collection_recovery_fee",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "application_type",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "last_week_pay",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.02",
"x": "acc_now_delinq",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "tot_coll_amt",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.52",
"x": "tot_cur_bal",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.18",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.02",
"x": "loan_status",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.39",
"x": "loan_amnt",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.39",
"x": "funded_amnt",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.39",
"x": "funded_amnt_inv",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.07",
"x": "term",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.09",
"x": "int_rate",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.08",
"x": "grade",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.08",
"x": "sub_grade",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.03",
"x": "emp_title",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.04",
"x": "emp_length",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.18",
"x": "home_ownership",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "annual_inc",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.11",
"x": "verification_status",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "nan",
"x": "pymnt_plan",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "purpose",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.03",
"x": "title",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.02",
"x": "zip_code",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "addr_state",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.22",
"x": "dti",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.06",
"x": "delinq_2yrs",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.04",
"x": "inq_last_6mths",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "open_acc",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "pub_rec",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.35",
"x": "revol_bal",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.04",
"x": "revol_util",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.21",
"x": "total_acc",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.04",
"x": "initial_list_status",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.15",
"x": "total_rec_int",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "total_rec_late_fee",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "recoveries",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "collection_recovery_fee",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "application_type",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.02",
"x": "last_week_pay",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.02",
"x": "acc_now_delinq",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "tot_coll_amt",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.49",
"x": "tot_cur_bal",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.36",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "loan_status",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.3",
"x": "loan_amnt",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.3",
"x": "funded_amnt",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.3",
"x": "funded_amnt_inv",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.18",
"x": "term",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.26",
"x": "int_rate",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.24",
"x": "grade",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.25",
"x": "sub_grade",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "emp_title",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.02",
"x": "emp_length",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.03",
"x": "home_ownership",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.11",
"x": "annual_inc",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "verification_status",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "nan",
"x": "pymnt_plan",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.02",
"x": "purpose",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.02",
"x": "title",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "zip_code",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "addr_state",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.09",
"x": "dti",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "delinq_2yrs",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.09",
"x": "inq_last_6mths",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.06",
"x": "open_acc",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.03",
"x": "pub_rec",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.1",
"x": "revol_bal",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.09",
"x": "revol_util",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.07",
"x": "total_acc",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.04",
"x": "initial_list_status",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.28",
"x": "total_rec_int",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.02",
"x": "total_rec_late_fee",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.05",
"x": "recoveries",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.04",
"x": "collection_recovery_fee",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "application_type",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.06",
"x": "last_week_pay",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "acc_now_delinq",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "tot_coll_amt",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.08",
"x": "tot_cur_bal",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.07",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "loan_status",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "nan",
"x": "loan_amnt",
"xref": "x",
"y": "pymnt_plan",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "nan",
"x": "funded_amnt",
"xref": "x",
"y": "pymnt_plan",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "nan",
"x": "funded_amnt_inv",
"xref": "x",
"y": "pymnt_plan",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "nan",
"x": "term",
"xref": "x",
"y": "pymnt_plan",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "nan",
"x": "int_rate",
"xref": "x",
"y": "pymnt_plan",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "nan",
"x": "grade",
"xref": "x",
"y": "pymnt_plan",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "nan",
"x": "sub_grade",
"xref": "x",
"y": "pymnt_plan",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "nan",
"x": "emp_title",
"xref": "x",
"y": "pymnt_plan",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "nan",
"x": "emp_length",
"xref": "x",
"y": "pymnt_plan",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "nan",
"x": "home_ownership",
"xref": "x",
"y": "pymnt_plan",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "nan",
"x": "annual_inc",
"xref": "x",
"y": "pymnt_plan",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "nan",
"x": "verification_status",
"xref": "x",
"y": "pymnt_plan",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "nan",
"x": "pymnt_plan",
"xref": "x",
"y": "pymnt_plan",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "nan",
"x": "purpose",
"xref": "x",
"y": "pymnt_plan",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "nan",
"x": "title",
"xref": "x",
"y": "pymnt_plan",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "nan",
"x": "zip_code",
"xref": "x",
"y": "pymnt_plan",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "nan",
"x": "addr_state",
"xref": "x",
"y": "pymnt_plan",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "nan",
"x": "dti",
"xref": "x",
"y": "pymnt_plan",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "nan",
"x": "delinq_2yrs",
"xref": "x",
"y": "pymnt_plan",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "nan",
"x": "inq_last_6mths",
"xref": "x",
"y": "pymnt_plan",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "nan",
"x": "open_acc",
"xref": "x",
"y": "pymnt_plan",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "nan",
"x": "pub_rec",
"xref": "x",
"y": "pymnt_plan",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "nan",
"x": "revol_bal",
"xref": "x",
"y": "pymnt_plan",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "nan",
"x": "revol_util",
"xref": "x",
"y": "pymnt_plan",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "nan",
"x": "total_acc",
"xref": "x",
"y": "pymnt_plan",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "nan",
"x": "initial_list_status",
"xref": "x",
"y": "pymnt_plan",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "nan",
"x": "total_rec_int",
"xref": "x",
"y": "pymnt_plan",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "nan",
"x": "total_rec_late_fee",
"xref": "x",
"y": "pymnt_plan",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "nan",
"x": "recoveries",
"xref": "x",
"y": "pymnt_plan",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "nan",
"x": "collection_recovery_fee",
"xref": "x",
"y": "pymnt_plan",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "nan",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "pymnt_plan",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "nan",
"x": "application_type",
"xref": "x",
"y": "pymnt_plan",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "nan",
"x": "last_week_pay",
"xref": "x",
"y": "pymnt_plan",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "nan",
"x": "acc_now_delinq",
"xref": "x",
"y": "pymnt_plan",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "nan",
"x": "tot_coll_amt",
"xref": "x",
"y": "pymnt_plan",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "nan",
"x": "tot_cur_bal",
"xref": "x",
"y": "pymnt_plan",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "nan",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "pymnt_plan",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "nan",
"x": "loan_status",
"xref": "x",
"y": "pymnt_plan",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.16",
"x": "loan_amnt",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.16",
"x": "funded_amnt",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.16",
"x": "funded_amnt_inv",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.05",
"x": "term",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.19",
"x": "int_rate",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.19",
"x": "grade",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.19",
"x": "sub_grade",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.02",
"x": "emp_title",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "emp_length",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.04",
"x": "home_ownership",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "annual_inc",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.02",
"x": "verification_status",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "nan",
"x": "pymnt_plan",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "purpose",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.42",
"x": "title",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "zip_code",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "addr_state",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.06",
"x": "dti",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.02",
"x": "delinq_2yrs",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.04",
"x": "inq_last_6mths",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.06",
"x": "open_acc",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.03",
"x": "pub_rec",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.07",
"x": "revol_bal",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.09",
"x": "revol_util",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.05",
"x": "total_acc",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.04",
"x": "initial_list_status",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.04",
"x": "total_rec_int",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "total_rec_late_fee",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "recoveries",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "collection_recovery_fee",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "application_type",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "last_week_pay",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "acc_now_delinq",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "tot_coll_amt",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.04",
"x": "tot_cur_bal",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.07",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.02",
"x": "loan_status",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.12",
"x": "loan_amnt",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.12",
"x": "funded_amnt",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.12",
"x": "funded_amnt_inv",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.05",
"x": "term",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.13",
"x": "int_rate",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.08",
"x": "grade",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.08",
"x": "sub_grade",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.08",
"x": "emp_title",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "emp_length",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "home_ownership",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.03",
"x": "annual_inc",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.02",
"x": "verification_status",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "nan",
"x": "pymnt_plan",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.42",
"x": "purpose",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "title",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "zip_code",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "addr_state",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.05",
"x": "dti",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "delinq_2yrs",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.04",
"x": "inq_last_6mths",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.06",
"x": "open_acc",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "pub_rec",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.06",
"x": "revol_bal",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.04",
"x": "revol_util",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.04",
"x": "total_acc",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.1",
"x": "initial_list_status",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.06",
"x": "total_rec_int",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.02",
"x": "total_rec_late_fee",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.04",
"x": "recoveries",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.02",
"x": "collection_recovery_fee",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "application_type",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.14",
"x": "last_week_pay",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "acc_now_delinq",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "tot_coll_amt",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.03",
"x": "tot_cur_bal",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.06",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.11",
"x": "loan_status",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "loan_amnt",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "funded_amnt",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "funded_amnt_inv",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.03",
"x": "term",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "int_rate",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "grade",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "sub_grade",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "emp_title",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "emp_length",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.02",
"x": "home_ownership",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.02",
"x": "annual_inc",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "verification_status",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "nan",
"x": "pymnt_plan",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "purpose",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "title",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "zip_code",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.25",
"x": "addr_state",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "dti",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.03",
"x": "delinq_2yrs",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "inq_last_6mths",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.06",
"x": "open_acc",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "pub_rec",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.03",
"x": "revol_bal",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.02",
"x": "revol_util",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.03",
"x": "total_acc",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "initial_list_status",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "total_rec_int",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "total_rec_late_fee",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "recoveries",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "collection_recovery_fee",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "application_type",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "last_week_pay",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "acc_now_delinq",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "tot_coll_amt",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "tot_cur_bal",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.04",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.03",
"x": "loan_status",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "loan_amnt",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "funded_amnt",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "funded_amnt_inv",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.02",
"x": "term",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "int_rate",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "grade",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "sub_grade",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "emp_title",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "emp_length",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.07",
"x": "home_ownership",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "annual_inc",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "verification_status",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "nan",
"x": "pymnt_plan",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "purpose",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "title",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.25",
"x": "zip_code",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "addr_state",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.04",
"x": "dti",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.02",
"x": "delinq_2yrs",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "inq_last_6mths",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.04",
"x": "open_acc",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "pub_rec",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "revol_bal",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "revol_util",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.05",
"x": "total_acc",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "initial_list_status",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "total_rec_int",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "total_rec_late_fee",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "recoveries",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "collection_recovery_fee",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "application_type",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "last_week_pay",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "acc_now_delinq",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "tot_coll_amt",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "tot_cur_bal",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.02",
"x": "loan_status",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.03",
"x": "loan_amnt",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.03",
"x": "funded_amnt",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.03",
"x": "funded_amnt_inv",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.11",
"x": "term",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.15",
"x": "int_rate",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.17",
"x": "grade",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.17",
"x": "sub_grade",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "emp_title",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "emp_length",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.02",
"x": "home_ownership",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.22",
"x": "annual_inc",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.09",
"x": "verification_status",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "nan",
"x": "pymnt_plan",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.06",
"x": "purpose",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.05",
"x": "title",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "zip_code",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.04",
"x": "addr_state",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "dti",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "delinq_2yrs",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "inq_last_6mths",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.3",
"x": "open_acc",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.06",
"x": "pub_rec",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.13",
"x": "revol_bal",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.16",
"x": "revol_util",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.22",
"x": "total_acc",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.02",
"x": "initial_list_status",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.03",
"x": "total_rec_int",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "total_rec_late_fee",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "recoveries",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "collection_recovery_fee",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.02",
"x": "application_type",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "last_week_pay",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "acc_now_delinq",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.03",
"x": "tot_coll_amt",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "tot_cur_bal",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.09",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.09",
"x": "loan_status",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "loan_amnt",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "funded_amnt",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "funded_amnt_inv",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "term",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.05",
"x": "int_rate",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.05",
"x": "grade",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.06",
"x": "sub_grade",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "emp_title",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.03",
"x": "emp_length",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.05",
"x": "home_ownership",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.06",
"x": "annual_inc",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "verification_status",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "nan",
"x": "pymnt_plan",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.02",
"x": "purpose",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "title",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.03",
"x": "zip_code",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.02",
"x": "addr_state",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "dti",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "delinq_2yrs",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.02",
"x": "inq_last_6mths",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.05",
"x": "open_acc",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "pub_rec",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.03",
"x": "revol_bal",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "revol_util",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.12",
"x": "total_acc",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "initial_list_status",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "total_rec_int",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.02",
"x": "total_rec_late_fee",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "recoveries",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "collection_recovery_fee",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.06",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "application_type",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.02",
"x": "last_week_pay",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.13",
"x": "acc_now_delinq",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "tot_coll_amt",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.06",
"x": "tot_cur_bal",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.05",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.02",
"x": "loan_status",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.03",
"x": "loan_amnt",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.03",
"x": "funded_amnt",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.03",
"x": "funded_amnt_inv",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "term",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.25",
"x": "int_rate",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.23",
"x": "grade",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.24",
"x": "sub_grade",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "emp_title",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "emp_length",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.03",
"x": "home_ownership",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.04",
"x": "annual_inc",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.09",
"x": "verification_status",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "nan",
"x": "pymnt_plan",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.04",
"x": "purpose",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.04",
"x": "title",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "zip_code",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "addr_state",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "dti",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.02",
"x": "delinq_2yrs",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "inq_last_6mths",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.13",
"x": "open_acc",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.06",
"x": "pub_rec",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.02",
"x": "revol_bal",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.09",
"x": "revol_util",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.15",
"x": "total_acc",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.07",
"x": "initial_list_status",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.1",
"x": "total_rec_int",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.02",
"x": "total_rec_late_fee",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.04",
"x": "recoveries",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.03",
"x": "collection_recovery_fee",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "application_type",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "last_week_pay",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "acc_now_delinq",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.02",
"x": "tot_coll_amt",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.03",
"x": "tot_cur_bal",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.08",
"x": "loan_status",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.18",
"x": "loan_amnt",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.18",
"x": "funded_amnt",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.18",
"x": "funded_amnt_inv",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.08",
"x": "term",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.02",
"x": "int_rate",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "grade",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "sub_grade",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.03",
"x": "emp_title",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "emp_length",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.12",
"x": "home_ownership",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "annual_inc",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.06",
"x": "verification_status",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "nan",
"x": "pymnt_plan",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.06",
"x": "purpose",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.06",
"x": "title",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.06",
"x": "zip_code",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.04",
"x": "addr_state",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.3",
"x": "dti",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.05",
"x": "delinq_2yrs",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.13",
"x": "inq_last_6mths",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "open_acc",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.04",
"x": "pub_rec",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.21",
"x": "revol_bal",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.16",
"x": "revol_util",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.7",
"x": "total_acc",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.04",
"x": "initial_list_status",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.06",
"x": "total_rec_int",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "total_rec_late_fee",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "recoveries",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "collection_recovery_fee",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "application_type",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.02",
"x": "last_week_pay",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.02",
"x": "acc_now_delinq",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "tot_coll_amt",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.24",
"x": "tot_cur_bal",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.37",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.04",
"x": "loan_status",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.09",
"x": "loan_amnt",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.09",
"x": "funded_amnt",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.09",
"x": "funded_amnt_inv",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.02",
"x": "term",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.05",
"x": "int_rate",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.06",
"x": "grade",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.07",
"x": "sub_grade",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.03",
"x": "emp_title",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "emp_length",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "home_ownership",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "annual_inc",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.03",
"x": "verification_status",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "nan",
"x": "pymnt_plan",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.03",
"x": "purpose",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "title",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "zip_code",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "addr_state",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.06",
"x": "dti",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "delinq_2yrs",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.06",
"x": "inq_last_6mths",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.04",
"x": "open_acc",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "pub_rec",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.11",
"x": "revol_bal",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.09",
"x": "revol_util",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "total_acc",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "initial_list_status",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.05",
"x": "total_rec_int",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "total_rec_late_fee",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "recoveries",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "collection_recovery_fee",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.03",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "application_type",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.04",
"x": "last_week_pay",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "acc_now_delinq",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.05",
"x": "tot_coll_amt",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.08",
"x": "tot_cur_bal",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.12",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.02",
"x": "loan_status",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.34",
"x": "loan_amnt",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.34",
"x": "funded_amnt",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.34",
"x": "funded_amnt_inv",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.09",
"x": "term",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.04",
"x": "int_rate",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.04",
"x": "grade",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.04",
"x": "sub_grade",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.03",
"x": "emp_title",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.04",
"x": "emp_length",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.16",
"x": "home_ownership",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.35",
"x": "annual_inc",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.1",
"x": "verification_status",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "nan",
"x": "pymnt_plan",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.07",
"x": "purpose",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.06",
"x": "title",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.03",
"x": "zip_code",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "addr_state",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.13",
"x": "dti",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.03",
"x": "delinq_2yrs",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.02",
"x": "inq_last_6mths",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.21",
"x": "open_acc",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.11",
"x": "pub_rec",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "revol_bal",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.22",
"x": "revol_util",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.17",
"x": "total_acc",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.03",
"x": "initial_list_status",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "total_rec_int",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "total_rec_late_fee",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "recoveries",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "collection_recovery_fee",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.03",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "application_type",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "last_week_pay",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "acc_now_delinq",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.03",
"x": "tot_coll_amt",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.45",
"x": "tot_cur_bal",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.85",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.03",
"x": "loan_status",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.12",
"x": "loan_amnt",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.12",
"x": "funded_amnt",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.12",
"x": "funded_amnt_inv",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.09",
"x": "term",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.25",
"x": "int_rate",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.23",
"x": "grade",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.24",
"x": "sub_grade",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.02",
"x": "emp_title",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "emp_length",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.03",
"x": "home_ownership",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.04",
"x": "annual_inc",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.09",
"x": "verification_status",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "nan",
"x": "pymnt_plan",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.09",
"x": "purpose",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.04",
"x": "title",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.02",
"x": "zip_code",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "addr_state",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.16",
"x": "dti",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "delinq_2yrs",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.09",
"x": "inq_last_6mths",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.16",
"x": "open_acc",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.09",
"x": "pub_rec",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.22",
"x": "revol_bal",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "revol_util",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.12",
"x": "total_acc",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.05",
"x": "initial_list_status",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.19",
"x": "total_rec_int",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.02",
"x": "total_rec_late_fee",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.03",
"x": "recoveries",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.02",
"x": "collection_recovery_fee",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.04",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "application_type",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.03",
"x": "last_week_pay",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.03",
"x": "acc_now_delinq",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.05",
"x": "tot_coll_amt",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.08",
"x": "tot_cur_bal",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.14",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.03",
"x": "loan_status",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.21",
"x": "loan_amnt",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.21",
"x": "funded_amnt",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.21",
"x": "funded_amnt_inv",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.1",
"x": "term",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.04",
"x": "int_rate",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.03",
"x": "grade",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.03",
"x": "sub_grade",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.03",
"x": "emp_title",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.05",
"x": "emp_length",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.2",
"x": "home_ownership",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.21",
"x": "annual_inc",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.07",
"x": "verification_status",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "nan",
"x": "pymnt_plan",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.05",
"x": "purpose",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.04",
"x": "title",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.03",
"x": "zip_code",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.05",
"x": "addr_state",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.22",
"x": "dti",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.12",
"x": "delinq_2yrs",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.15",
"x": "inq_last_6mths",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.7",
"x": "open_acc",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "pub_rec",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.17",
"x": "revol_bal",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.12",
"x": "revol_util",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "total_acc",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.03",
"x": "initial_list_status",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.1",
"x": "total_rec_int",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "total_rec_late_fee",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "recoveries",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "collection_recovery_fee",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "application_type",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.02",
"x": "last_week_pay",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.02",
"x": "acc_now_delinq",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.04",
"x": "tot_coll_amt",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.31",
"x": "tot_cur_bal",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.29",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.03",
"x": "loan_status",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.06",
"x": "loan_amnt",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.06",
"x": "funded_amnt",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.06",
"x": "funded_amnt_inv",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.12",
"x": "term",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.14",
"x": "int_rate",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.09",
"x": "grade",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.09",
"x": "sub_grade",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "emp_title",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "emp_length",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.02",
"x": "home_ownership",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.04",
"x": "annual_inc",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.04",
"x": "verification_status",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "nan",
"x": "pymnt_plan",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.04",
"x": "purpose",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.1",
"x": "title",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "zip_code",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "addr_state",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.02",
"x": "dti",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "delinq_2yrs",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.07",
"x": "inq_last_6mths",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.04",
"x": "open_acc",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "pub_rec",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.03",
"x": "revol_bal",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.05",
"x": "revol_util",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.03",
"x": "total_acc",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "initial_list_status",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.15",
"x": "total_rec_int",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.02",
"x": "total_rec_late_fee",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.06",
"x": "recoveries",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.05",
"x": "collection_recovery_fee",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.02",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "application_type",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.13",
"x": "last_week_pay",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "acc_now_delinq",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "tot_coll_amt",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.03",
"x": "tot_cur_bal",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.07",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.14",
"x": "loan_status",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.53",
"x": "loan_amnt",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.53",
"x": "funded_amnt",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.53",
"x": "funded_amnt_inv",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.38",
"x": "term",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.45",
"x": "int_rate",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.37",
"x": "grade",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.39",
"x": "sub_grade",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "emp_title",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.03",
"x": "emp_length",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.11",
"x": "home_ownership",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.15",
"x": "annual_inc",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.28",
"x": "verification_status",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "nan",
"x": "pymnt_plan",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.04",
"x": "purpose",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.06",
"x": "title",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "zip_code",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "addr_state",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.03",
"x": "dti",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "delinq_2yrs",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.1",
"x": "inq_last_6mths",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.06",
"x": "open_acc",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.05",
"x": "pub_rec",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "revol_bal",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.19",
"x": "revol_util",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.1",
"x": "total_acc",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.15",
"x": "initial_list_status",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "total_rec_int",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.08",
"x": "total_rec_late_fee",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.06",
"x": "recoveries",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.06",
"x": "collection_recovery_fee",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.03",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.02",
"x": "application_type",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.15",
"x": "last_week_pay",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "acc_now_delinq",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.02",
"x": "tot_coll_amt",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "tot_cur_bal",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.09",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.03",
"x": "loan_status",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.03",
"x": "loan_amnt",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.03",
"x": "funded_amnt",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.03",
"x": "funded_amnt_inv",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "term",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.05",
"x": "int_rate",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.04",
"x": "grade",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.04",
"x": "sub_grade",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "emp_title",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "emp_length",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "home_ownership",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "annual_inc",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.02",
"x": "verification_status",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "nan",
"x": "pymnt_plan",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "purpose",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.02",
"x": "title",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "zip_code",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "addr_state",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "dti",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.02",
"x": "delinq_2yrs",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.02",
"x": "inq_last_6mths",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "open_acc",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "pub_rec",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "revol_bal",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.02",
"x": "revol_util",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "total_acc",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.02",
"x": "initial_list_status",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.08",
"x": "total_rec_int",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "total_rec_late_fee",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.08",
"x": "recoveries",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.07",
"x": "collection_recovery_fee",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "application_type",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "last_week_pay",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "acc_now_delinq",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "tot_coll_amt",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "tot_cur_bal",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "loan_status",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.07",
"x": "loan_amnt",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.07",
"x": "funded_amnt",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.07",
"x": "funded_amnt_inv",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.06",
"x": "term",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.11",
"x": "int_rate",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.09",
"x": "grade",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.09",
"x": "sub_grade",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "emp_title",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "emp_length",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "home_ownership",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "annual_inc",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.05",
"x": "verification_status",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "nan",
"x": "pymnt_plan",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "purpose",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.04",
"x": "title",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "zip_code",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "addr_state",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "dti",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "delinq_2yrs",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.04",
"x": "inq_last_6mths",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "open_acc",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "pub_rec",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "revol_bal",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.03",
"x": "revol_util",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "total_acc",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.06",
"x": "initial_list_status",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.06",
"x": "total_rec_int",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.08",
"x": "total_rec_late_fee",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "recoveries",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.82",
"x": "collection_recovery_fee",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "application_type",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "last_week_pay",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "acc_now_delinq",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "tot_coll_amt",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "tot_cur_bal",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.05",
"x": "loan_status",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.06",
"x": "loan_amnt",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.06",
"x": "funded_amnt",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.06",
"x": "funded_amnt_inv",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.05",
"x": "term",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.08",
"x": "int_rate",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.07",
"x": "grade",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.07",
"x": "sub_grade",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "emp_title",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "emp_length",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "home_ownership",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "annual_inc",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.04",
"x": "verification_status",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "nan",
"x": "pymnt_plan",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "purpose",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.02",
"x": "title",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "zip_code",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "addr_state",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "dti",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "delinq_2yrs",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.03",
"x": "inq_last_6mths",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "open_acc",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "pub_rec",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "revol_bal",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.02",
"x": "revol_util",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "total_acc",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.05",
"x": "initial_list_status",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.06",
"x": "total_rec_int",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.07",
"x": "total_rec_late_fee",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.82",
"x": "recoveries",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "collection_recovery_fee",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "application_type",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "last_week_pay",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "acc_now_delinq",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "tot_coll_amt",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "tot_cur_bal",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.04",
"x": "loan_status",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.02",
"x": "loan_amnt",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.02",
"x": "funded_amnt",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.02",
"x": "funded_amnt_inv",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "term",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "int_rate",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.02",
"x": "grade",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.02",
"x": "sub_grade",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.02",
"x": "emp_title",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "emp_length",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "home_ownership",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "annual_inc",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "verification_status",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "nan",
"x": "pymnt_plan",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "purpose",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "title",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "zip_code",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "addr_state",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "dti",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.06",
"x": "delinq_2yrs",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "inq_last_6mths",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "open_acc",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.03",
"x": "pub_rec",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.03",
"x": "revol_bal",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.04",
"x": "revol_util",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "total_acc",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.02",
"x": "initial_list_status",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.03",
"x": "total_rec_int",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "total_rec_late_fee",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "recoveries",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "collection_recovery_fee",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "application_type",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "last_week_pay",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.02",
"x": "acc_now_delinq",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.06",
"x": "tot_coll_amt",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.02",
"x": "tot_cur_bal",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.02",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.03",
"x": "loan_status",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "loan_amnt",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "funded_amnt",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "funded_amnt_inv",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "term",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "int_rate",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "grade",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "sub_grade",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "emp_title",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "emp_length",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "home_ownership",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "annual_inc",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "verification_status",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "nan",
"x": "pymnt_plan",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "purpose",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "title",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "zip_code",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "addr_state",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.02",
"x": "dti",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "delinq_2yrs",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "inq_last_6mths",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "open_acc",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "pub_rec",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "revol_bal",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "revol_util",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "total_acc",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "initial_list_status",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.02",
"x": "total_rec_int",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "total_rec_late_fee",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "recoveries",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "collection_recovery_fee",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "application_type",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.02",
"x": "last_week_pay",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "acc_now_delinq",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "tot_coll_amt",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "tot_cur_bal",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "loan_status",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "loan_amnt",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "funded_amnt",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "funded_amnt_inv",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "term",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.04",
"x": "int_rate",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "grade",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "sub_grade",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "emp_title",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "emp_length",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "home_ownership",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.02",
"x": "annual_inc",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.06",
"x": "verification_status",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "nan",
"x": "pymnt_plan",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "purpose",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.14",
"x": "title",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "zip_code",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "addr_state",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "dti",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.02",
"x": "delinq_2yrs",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "inq_last_6mths",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.02",
"x": "open_acc",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.04",
"x": "pub_rec",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "revol_bal",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.03",
"x": "revol_util",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.02",
"x": "total_acc",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.13",
"x": "initial_list_status",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.15",
"x": "total_rec_int",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "total_rec_late_fee",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "recoveries",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "collection_recovery_fee",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.02",
"x": "application_type",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "last_week_pay",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "acc_now_delinq",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.02",
"x": "tot_coll_amt",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "tot_cur_bal",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.03",
"x": "loan_status",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "loan_amnt",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "funded_amnt",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "funded_amnt_inv",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "term",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.03",
"x": "int_rate",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.03",
"x": "grade",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.03",
"x": "sub_grade",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "emp_title",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "emp_length",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.02",
"x": "home_ownership",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.02",
"x": "annual_inc",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "verification_status",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "nan",
"x": "pymnt_plan",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "purpose",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "title",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "zip_code",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "addr_state",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "dti",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.13",
"x": "delinq_2yrs",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "inq_last_6mths",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.02",
"x": "open_acc",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "pub_rec",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "revol_bal",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.03",
"x": "revol_util",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.02",
"x": "total_acc",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "initial_list_status",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "total_rec_int",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "total_rec_late_fee",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "recoveries",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "collection_recovery_fee",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.02",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "application_type",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "last_week_pay",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "acc_now_delinq",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "tot_coll_amt",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.03",
"x": "tot_cur_bal",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "loan_status",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.02",
"x": "loan_amnt",
"xref": "x",
"y": "tot_coll_amt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.02",
"x": "funded_amnt",
"xref": "x",
"y": "tot_coll_amt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.02",
"x": "funded_amnt_inv",
"xref": "x",
"y": "tot_coll_amt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "term",
"xref": "x",
"y": "tot_coll_amt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "int_rate",
"xref": "x",
"y": "tot_coll_amt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "grade",
"xref": "x",
"y": "tot_coll_amt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "sub_grade",
"xref": "x",
"y": "tot_coll_amt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "emp_title",
"xref": "x",
"y": "tot_coll_amt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "emp_length",
"xref": "x",
"y": "tot_coll_amt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "home_ownership",
"xref": "x",
"y": "tot_coll_amt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "annual_inc",
"xref": "x",
"y": "tot_coll_amt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "verification_status",
"xref": "x",
"y": "tot_coll_amt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "nan",
"x": "pymnt_plan",
"xref": "x",
"y": "tot_coll_amt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "purpose",
"xref": "x",
"y": "tot_coll_amt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "title",
"xref": "x",
"y": "tot_coll_amt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "zip_code",
"xref": "x",
"y": "tot_coll_amt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "addr_state",
"xref": "x",
"y": "tot_coll_amt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.03",
"x": "dti",
"xref": "x",
"y": "tot_coll_amt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "delinq_2yrs",
"xref": "x",
"y": "tot_coll_amt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.02",
"x": "inq_last_6mths",
"xref": "x",
"y": "tot_coll_amt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "open_acc",
"xref": "x",
"y": "tot_coll_amt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.05",
"x": "pub_rec",
"xref": "x",
"y": "tot_coll_amt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.03",
"x": "revol_bal",
"xref": "x",
"y": "tot_coll_amt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.05",
"x": "revol_util",
"xref": "x",
"y": "tot_coll_amt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.04",
"x": "total_acc",
"xref": "x",
"y": "tot_coll_amt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "initial_list_status",
"xref": "x",
"y": "tot_coll_amt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.02",
"x": "total_rec_int",
"xref": "x",
"y": "tot_coll_amt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "total_rec_late_fee",
"xref": "x",
"y": "tot_coll_amt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "recoveries",
"xref": "x",
"y": "tot_coll_amt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "collection_recovery_fee",
"xref": "x",
"y": "tot_coll_amt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.06",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "tot_coll_amt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "application_type",
"xref": "x",
"y": "tot_coll_amt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.02",
"x": "last_week_pay",
"xref": "x",
"y": "tot_coll_amt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "acc_now_delinq",
"xref": "x",
"y": "tot_coll_amt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "tot_coll_amt",
"xref": "x",
"y": "tot_coll_amt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "tot_cur_bal",
"xref": "x",
"y": "tot_coll_amt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.03",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "tot_coll_amt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "loan_status",
"xref": "x",
"y": "tot_coll_amt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.33",
"x": "loan_amnt",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.33",
"x": "funded_amnt",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.33",
"x": "funded_amnt_inv",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.11",
"x": "term",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.09",
"x": "int_rate",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.08",
"x": "grade",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.09",
"x": "sub_grade",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.03",
"x": "emp_title",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.04",
"x": "emp_length",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.52",
"x": "home_ownership",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.49",
"x": "annual_inc",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.08",
"x": "verification_status",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "nan",
"x": "pymnt_plan",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.04",
"x": "purpose",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.03",
"x": "title",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "zip_code",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "addr_state",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "dti",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.06",
"x": "delinq_2yrs",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.03",
"x": "inq_last_6mths",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.24",
"x": "open_acc",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.08",
"x": "pub_rec",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.45",
"x": "revol_bal",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.08",
"x": "revol_util",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.31",
"x": "total_acc",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.03",
"x": "initial_list_status",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.14",
"x": "total_rec_int",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "total_rec_late_fee",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "recoveries",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "collection_recovery_fee",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.02",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "application_type",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "last_week_pay",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.03",
"x": "acc_now_delinq",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "tot_coll_amt",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "tot_cur_bal",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.43",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "loan_status",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.36",
"x": "loan_amnt",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.36",
"x": "funded_amnt",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.36",
"x": "funded_amnt_inv",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.08",
"x": "term",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.19",
"x": "int_rate",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.17",
"x": "grade",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.18",
"x": "sub_grade",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.03",
"x": "emp_title",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.05",
"x": "emp_length",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.18",
"x": "home_ownership",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.36",
"x": "annual_inc",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.07",
"x": "verification_status",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "nan",
"x": "pymnt_plan",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.07",
"x": "purpose",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.06",
"x": "title",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.04",
"x": "zip_code",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "addr_state",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.09",
"x": "dti",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.05",
"x": "delinq_2yrs",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "inq_last_6mths",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.37",
"x": "open_acc",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.12",
"x": "pub_rec",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.85",
"x": "revol_bal",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.14",
"x": "revol_util",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.29",
"x": "total_acc",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.07",
"x": "initial_list_status",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.09",
"x": "total_rec_int",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "total_rec_late_fee",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "recoveries",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "collection_recovery_fee",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.02",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "application_type",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "last_week_pay",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "acc_now_delinq",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.03",
"x": "tot_coll_amt",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.43",
"x": "tot_cur_bal",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.03",
"x": "loan_status",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.06",
"x": "loan_amnt",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.06",
"x": "funded_amnt",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.06",
"x": "funded_amnt_inv",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.11",
"x": "term",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.05",
"x": "int_rate",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.02",
"x": "grade",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.02",
"x": "sub_grade",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.02",
"x": "emp_title",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.0",
"x": "emp_length",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.02",
"x": "home_ownership",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "annual_inc",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.0",
"x": "verification_status",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "nan",
"x": "pymnt_plan",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.02",
"x": "purpose",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.11",
"x": "title",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.03",
"x": "zip_code",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.02",
"x": "addr_state",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.09",
"x": "dti",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.02",
"x": "delinq_2yrs",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.08",
"x": "inq_last_6mths",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.04",
"x": "open_acc",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.02",
"x": "pub_rec",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.03",
"x": "revol_bal",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.03",
"x": "revol_util",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.03",
"x": "total_acc",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.14",
"x": "initial_list_status",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.03",
"x": "total_rec_int",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "total_rec_late_fee",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.05",
"x": "recoveries",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.04",
"x": "collection_recovery_fee",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.03",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "application_type",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.03",
"x": "last_week_pay",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "acc_now_delinq",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.01",
"x": "tot_coll_amt",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.01",
"x": "tot_cur_bal",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "-0.03",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "loan_status",
"xref": "x",
"y": "loan_status",
"yref": "y"
}
],
"template": {
"data": {
"bar": [
{
"error_x": {
"color": "#2a3f5f"
},
"error_y": {
"color": "#2a3f5f"
},
"marker": {
"line": {
"color": "#E5ECF6",
"width": 0.5
}
},
"type": "bar"
}
],
"barpolar": [
{
"marker": {
"line": {
"color": "#E5ECF6",
"width": 0.5
}
},
"type": "barpolar"
}
],
"carpet": [
{
"aaxis": {
"endlinecolor": "#2a3f5f",
"gridcolor": "white",
"linecolor": "white",
"minorgridcolor": "white",
"startlinecolor": "#2a3f5f"
},
"baxis": {
"endlinecolor": "#2a3f5f",
"gridcolor": "white",
"linecolor": "white",
"minorgridcolor": "white",
"startlinecolor": "#2a3f5f"
},
"type": "carpet"
}
],
"choropleth": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "choropleth"
}
],
"contour": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "contour"
}
],
"contourcarpet": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "contourcarpet"
}
],
"heatmap": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "heatmap"
}
],
"heatmapgl": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "heatmapgl"
}
],
"histogram": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "histogram"
}
],
"histogram2d": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "histogram2d"
}
],
"histogram2dcontour": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "histogram2dcontour"
}
],
"mesh3d": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "mesh3d"
}
],
"parcoords": [
{
"line": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "parcoords"
}
],
"pie": [
{
"automargin": true,
"type": "pie"
}
],
"scatter": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatter"
}
],
"scatter3d": [
{
"line": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatter3d"
}
],
"scattercarpet": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattercarpet"
}
],
"scattergeo": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattergeo"
}
],
"scattergl": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattergl"
}
],
"scattermapbox": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattermapbox"
}
],
"scatterpolar": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterpolar"
}
],
"scatterpolargl": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterpolargl"
}
],
"scatterternary": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterternary"
}
],
"surface": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "surface"
}
],
"table": [
{
"cells": {
"fill": {
"color": "#EBF0F8"
},
"line": {
"color": "white"
}
},
"header": {
"fill": {
"color": "#C8D4E3"
},
"line": {
"color": "white"
}
},
"type": "table"
}
]
},
"layout": {
"annotationdefaults": {
"arrowcolor": "#2a3f5f",
"arrowhead": 0,
"arrowwidth": 1
},
"coloraxis": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"colorscale": {
"diverging": [
[
0,
"#8e0152"
],
[
0.1,
"#c51b7d"
],
[
0.2,
"#de77ae"
],
[
0.3,
"#f1b6da"
],
[
0.4,
"#fde0ef"
],
[
0.5,
"#f7f7f7"
],
[
0.6,
"#e6f5d0"
],
[
0.7,
"#b8e186"
],
[
0.8,
"#7fbc41"
],
[
0.9,
"#4d9221"
],
[
1,
"#276419"
]
],
"sequential": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"sequentialminus": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
]
},
"colorway": [
"#636efa",
"#EF553B",
"#00cc96",
"#ab63fa",
"#FFA15A",
"#19d3f3",
"#FF6692",
"#B6E880",
"#FF97FF",
"#FECB52"
],
"font": {
"color": "#2a3f5f"
},
"geo": {
"bgcolor": "white",
"lakecolor": "white",
"landcolor": "#E5ECF6",
"showlakes": true,
"showland": true,
"subunitcolor": "white"
},
"hoverlabel": {
"align": "left"
},
"hovermode": "closest",
"mapbox": {
"style": "light"
},
"paper_bgcolor": "white",
"plot_bgcolor": "#E5ECF6",
"polar": {
"angularaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"bgcolor": "#E5ECF6",
"radialaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
}
},
"scene": {
"xaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
},
"yaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
},
"zaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
}
},
"shapedefaults": {
"line": {
"color": "#2a3f5f"
}
},
"ternary": {
"aaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"baxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"bgcolor": "#E5ECF6",
"caxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
}
},
"title": {
"x": 0.05
},
"xaxis": {
"automargin": true,
"gridcolor": "white",
"linecolor": "white",
"ticks": "",
"title": {
"standoff": 15
},
"zerolinecolor": "white",
"zerolinewidth": 2
},
"yaxis": {
"automargin": true,
"gridcolor": "white",
"linecolor": "white",
"ticks": "",
"title": {
"standoff": 15
},
"zerolinecolor": "white",
"zerolinewidth": 2
}
}
},
"xaxis": {
"dtick": 1,
"gridcolor": "rgb(0, 0, 0)",
"side": "top",
"ticks": ""
},
"yaxis": {
"dtick": 1,
"ticks": "",
"ticksuffix": " "
}
}
},
"text/html": [
"
value=%{value}", "labels": [ 0, 1 ], "legendgroup": "", "name": "", "showlegend": true, "type": "pie", "values": [ 44715, 10608 ] } ], "layout": { "legend": { "tracegroupgap": 0 }, "template": { "data": { "bar": [ { "error_x": { "color": "#2a3f5f" }, "error_y": { "color": "#2a3f5f" }, "marker": { "line": { "color": "#E5ECF6", "width": 0.5 } }, "type": "bar" } ], "barpolar": [ { "marker": { "line": { "color": "#E5ECF6", "width": 0.5 } }, "type": "barpolar" } ], "carpet": [ { "aaxis": { "endlinecolor": "#2a3f5f", "gridcolor": "white", "linecolor": "white", "minorgridcolor": "white", "startlinecolor": "#2a3f5f" }, "baxis": { "endlinecolor": "#2a3f5f", "gridcolor": "white", "linecolor": "white", "minorgridcolor": "white", "startlinecolor": "#2a3f5f" }, "type": "carpet" } ], "choropleth": [ { "colorbar": { "outlinewidth": 0, "ticks": "" }, "type": "choropleth" } ], "contour": [ { "colorbar": { "outlinewidth": 0, "ticks": "" }, "colorscale": [ [ 0, "#0d0887" ], [ 0.1111111111111111, "#46039f" ], [ 0.2222222222222222, "#7201a8" ], [ 0.3333333333333333, "#9c179e" ], [ 0.4444444444444444, "#bd3786" ], [ 0.5555555555555556, "#d8576b" ], [ 0.6666666666666666, "#ed7953" ], [ 0.7777777777777778, "#fb9f3a" ], [ 0.8888888888888888, "#fdca26" ], [ 1, "#f0f921" ] ], "type": "contour" } ], "contourcarpet": [ { "colorbar": { "outlinewidth": 0, "ticks": "" }, "type": "contourcarpet" } ], "heatmap": [ { "colorbar": { "outlinewidth": 0, "ticks": "" }, "colorscale": [ [ 0, "#0d0887" ], [ 0.1111111111111111, "#46039f" ], [ 0.2222222222222222, "#7201a8" ], [ 0.3333333333333333, "#9c179e" ], [ 0.4444444444444444, "#bd3786" ], [ 0.5555555555555556, "#d8576b" ], [ 0.6666666666666666, "#ed7953" ], [ 0.7777777777777778, "#fb9f3a" ], [ 0.8888888888888888, "#fdca26" ], [ 1, "#f0f921" ] ], "type": "heatmap" } ], "heatmapgl": [ { "colorbar": { "outlinewidth": 0, "ticks": "" }, "colorscale": [ [ 0, "#0d0887" ], [ 0.1111111111111111, "#46039f" ], [ 0.2222222222222222, "#7201a8" ], [ 0.3333333333333333, "#9c179e" ], [ 0.4444444444444444, "#bd3786" ], [ 0.5555555555555556, "#d8576b" ], [ 0.6666666666666666, "#ed7953" ], [ 0.7777777777777778, "#fb9f3a" ], [ 0.8888888888888888, "#fdca26" ], [ 1, "#f0f921" ] ], "type": "heatmapgl" } ], "histogram": [ { "marker": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "histogram" } ], "histogram2d": [ { "colorbar": { "outlinewidth": 0, "ticks": "" }, "colorscale": [ [ 0, "#0d0887" ], [ 0.1111111111111111, "#46039f" ], [ 0.2222222222222222, "#7201a8" ], [ 0.3333333333333333, "#9c179e" ], [ 0.4444444444444444, "#bd3786" ], [ 0.5555555555555556, "#d8576b" ], [ 0.6666666666666666, "#ed7953" ], [ 0.7777777777777778, "#fb9f3a" ], [ 0.8888888888888888, "#fdca26" ], [ 1, "#f0f921" ] ], "type": "histogram2d" } ], "histogram2dcontour": [ { "colorbar": { "outlinewidth": 0, "ticks": "" }, "colorscale": [ [ 0, "#0d0887" ], [ 0.1111111111111111, "#46039f" ], [ 0.2222222222222222, "#7201a8" ], [ 0.3333333333333333, "#9c179e" ], [ 0.4444444444444444, "#bd3786" ], [ 0.5555555555555556, "#d8576b" ], [ 0.6666666666666666, "#ed7953" ], [ 0.7777777777777778, "#fb9f3a" ], [ 0.8888888888888888, "#fdca26" ], [ 1, "#f0f921" ] ], "type": "histogram2dcontour" } ], "mesh3d": [ { "colorbar": { "outlinewidth": 0, "ticks": "" }, "type": "mesh3d" } ], "parcoords": [ { "line": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "parcoords" } ], "pie": [ { "automargin": true, "type": "pie" } ], "scatter": [ { "marker": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "scatter" } ], "scatter3d": [ { "line": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "marker": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "scatter3d" } ], "scattercarpet": [ { "marker": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "scattercarpet" } ], "scattergeo": [ { "marker": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "scattergeo" } ], "scattergl": [ { "marker": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "scattergl" } ], "scattermapbox": [ { "marker": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "scattermapbox" } ], "scatterpolar": [ { "marker": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "scatterpolar" } ], "scatterpolargl": [ { "marker": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "scatterpolargl" } ], "scatterternary": [ { "marker": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "scatterternary" } ], "surface": [ { "colorbar": { "outlinewidth": 0, "ticks": "" }, "colorscale": [ [ 0, "#0d0887" ], [ 0.1111111111111111, "#46039f" ], [ 0.2222222222222222, "#7201a8" ], [ 0.3333333333333333, "#9c179e" ], [ 0.4444444444444444, "#bd3786" ], [ 0.5555555555555556, "#d8576b" ], [ 0.6666666666666666, "#ed7953" ], [ 0.7777777777777778, "#fb9f3a" ], [ 0.8888888888888888, "#fdca26" ], [ 1, "#f0f921" ] ], "type": "surface" } ], "table": [ { "cells": { "fill": { "color": "#EBF0F8" }, "line": { "color": "white" } }, "header": { "fill": { "color": "#C8D4E3" }, "line": { "color": "white" } }, "type": "table" } ] }, "layout": { "annotationdefaults": { "arrowcolor": "#2a3f5f", "arrowhead": 0, "arrowwidth": 1 }, "coloraxis": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "colorscale": { "diverging": [ [ 0, "#8e0152" ], [ 0.1, "#c51b7d" ], [ 0.2, "#de77ae" ], [ 0.3, "#f1b6da" ], [ 0.4, "#fde0ef" ], [ 0.5, "#f7f7f7" ], [ 0.6, "#e6f5d0" ], [ 0.7, "#b8e186" ], [ 0.8, "#7fbc41" ], [ 0.9, "#4d9221" ], [ 1, "#276419" ] ], "sequential": [ [ 0, "#0d0887" ], [ 0.1111111111111111, "#46039f" ], [ 0.2222222222222222, "#7201a8" ], [ 0.3333333333333333, "#9c179e" ], [ 0.4444444444444444, "#bd3786" ], [ 0.5555555555555556, "#d8576b" ], [ 0.6666666666666666, "#ed7953" ], [ 0.7777777777777778, "#fb9f3a" ], [ 0.8888888888888888, "#fdca26" ], [ 1, "#f0f921" ] ], "sequentialminus": [ [ 0, "#0d0887" ], [ 0.1111111111111111, "#46039f" ], [ 0.2222222222222222, "#7201a8" ], [ 0.3333333333333333, "#9c179e" ], [ 0.4444444444444444, "#bd3786" ], [ 0.5555555555555556, "#d8576b" ], [ 0.6666666666666666, "#ed7953" ], [ 0.7777777777777778, "#fb9f3a" ], [ 0.8888888888888888, "#fdca26" ], [ 1, "#f0f921" ] ] }, "colorway": [ "#636efa", "#EF553B", "#00cc96", "#ab63fa", "#FFA15A", "#19d3f3", "#FF6692", "#B6E880", "#FF97FF", "#FECB52" ], "font": { "color": "#2a3f5f" }, "geo": { "bgcolor": "white", "lakecolor": "white", "landcolor": "#E5ECF6", "showlakes": true, "showland": true, "subunitcolor": "white" }, "hoverlabel": { "align": "left" }, "hovermode": "closest", "mapbox": { "style": "light" }, "paper_bgcolor": "white", "plot_bgcolor": "#E5ECF6", "polar": { "angularaxis": { "gridcolor": "white", "linecolor": "white", "ticks": "" }, "bgcolor": "#E5ECF6", "radialaxis": { "gridcolor": "white", "linecolor": "white", "ticks": "" } }, "scene": { "xaxis": { "backgroundcolor": "#E5ECF6", "gridcolor": "white", "gridwidth": 2, "linecolor": "white", "showbackground": true, "ticks": "", "zerolinecolor": "white" }, "yaxis": { "backgroundcolor": "#E5ECF6", "gridcolor": "white", "gridwidth": 2, "linecolor": "white", "showbackground": true, "ticks": "", "zerolinecolor": "white" }, "zaxis": { "backgroundcolor": "#E5ECF6", "gridcolor": "white", "gridwidth": 2, "linecolor": "white", "showbackground": true, "ticks": "", "zerolinecolor": "white" } }, "shapedefaults": { "line": { "color": "#2a3f5f" } }, "ternary": { "aaxis": { "gridcolor": "white", "linecolor": "white", "ticks": "" }, "baxis": { "gridcolor": "white", "linecolor": "white", "ticks": "" }, "bgcolor": "#E5ECF6", "caxis": { "gridcolor": "white", "linecolor": "white", "ticks": "" } }, "title": { "x": 0.05 }, "xaxis": { "automargin": true, "gridcolor": "white", "linecolor": "white", "ticks": "", "title": { "standoff": 15 }, "zerolinecolor": "white", "zerolinewidth": 2 }, "yaxis": { "automargin": true, "gridcolor": "white", "linecolor": "white", "ticks": "", "title": { "standoff": 15 }, "zerolinecolor": "white", "zerolinewidth": 2 } } }, "title": { "text": "Percentage data of loan_status" } } }, "text/html": [ "
\n",
" \n",
" \n",
" \n",
" \n",
"
"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"application/vnd.plotly.v1+json": {
"config": {
"plotlyServerURL": "https://plot.ly"
},
"data": [
{
"domain": {
"x": [
0,
1
],
"y": [
0,
1
]
},
"hole": 0.4,
"hoverinfo": "label+percent+name",
"hoverlabel": {
"namelength": 0
},
"hovertemplate": "label=%{label}value=%{value}", "labels": [ 0, 1 ], "legendgroup": "", "name": "", "showlegend": true, "type": "pie", "values": [ 44715, 10608 ] } ], "layout": { "legend": { "tracegroupgap": 0 }, "template": { "data": { "bar": [ { "error_x": { "color": "#2a3f5f" }, "error_y": { "color": "#2a3f5f" }, "marker": { "line": { "color": "#E5ECF6", "width": 0.5 } }, "type": "bar" } ], "barpolar": [ { "marker": { "line": { "color": "#E5ECF6", "width": 0.5 } }, "type": "barpolar" } ], "carpet": [ { "aaxis": { "endlinecolor": "#2a3f5f", "gridcolor": "white", "linecolor": "white", "minorgridcolor": "white", "startlinecolor": "#2a3f5f" }, "baxis": { "endlinecolor": "#2a3f5f", "gridcolor": "white", "linecolor": "white", "minorgridcolor": "white", "startlinecolor": "#2a3f5f" }, "type": "carpet" } ], "choropleth": [ { "colorbar": { "outlinewidth": 0, "ticks": "" }, "type": "choropleth" } ], "contour": [ { "colorbar": { "outlinewidth": 0, "ticks": "" }, "colorscale": [ [ 0, "#0d0887" ], [ 0.1111111111111111, "#46039f" ], [ 0.2222222222222222, "#7201a8" ], [ 0.3333333333333333, "#9c179e" ], [ 0.4444444444444444, "#bd3786" ], [ 0.5555555555555556, "#d8576b" ], [ 0.6666666666666666, "#ed7953" ], [ 0.7777777777777778, "#fb9f3a" ], [ 0.8888888888888888, "#fdca26" ], [ 1, "#f0f921" ] ], "type": "contour" } ], "contourcarpet": [ { "colorbar": { "outlinewidth": 0, "ticks": "" }, "type": "contourcarpet" } ], "heatmap": [ { "colorbar": { "outlinewidth": 0, "ticks": "" }, "colorscale": [ [ 0, "#0d0887" ], [ 0.1111111111111111, "#46039f" ], [ 0.2222222222222222, "#7201a8" ], [ 0.3333333333333333, "#9c179e" ], [ 0.4444444444444444, "#bd3786" ], [ 0.5555555555555556, "#d8576b" ], [ 0.6666666666666666, "#ed7953" ], [ 0.7777777777777778, "#fb9f3a" ], [ 0.8888888888888888, "#fdca26" ], [ 1, "#f0f921" ] ], "type": "heatmap" } ], "heatmapgl": [ { "colorbar": { "outlinewidth": 0, "ticks": "" }, "colorscale": [ [ 0, "#0d0887" ], [ 0.1111111111111111, "#46039f" ], [ 0.2222222222222222, "#7201a8" ], [ 0.3333333333333333, "#9c179e" ], [ 0.4444444444444444, "#bd3786" ], [ 0.5555555555555556, "#d8576b" ], [ 0.6666666666666666, "#ed7953" ], [ 0.7777777777777778, "#fb9f3a" ], [ 0.8888888888888888, "#fdca26" ], [ 1, "#f0f921" ] ], "type": "heatmapgl" } ], "histogram": [ { "marker": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "histogram" } ], "histogram2d": [ { "colorbar": { "outlinewidth": 0, "ticks": "" }, "colorscale": [ [ 0, "#0d0887" ], [ 0.1111111111111111, "#46039f" ], [ 0.2222222222222222, "#7201a8" ], [ 0.3333333333333333, "#9c179e" ], [ 0.4444444444444444, "#bd3786" ], [ 0.5555555555555556, "#d8576b" ], [ 0.6666666666666666, "#ed7953" ], [ 0.7777777777777778, "#fb9f3a" ], [ 0.8888888888888888, "#fdca26" ], [ 1, "#f0f921" ] ], "type": "histogram2d" } ], "histogram2dcontour": [ { "colorbar": { "outlinewidth": 0, "ticks": "" }, "colorscale": [ [ 0, "#0d0887" ], [ 0.1111111111111111, "#46039f" ], [ 0.2222222222222222, "#7201a8" ], [ 0.3333333333333333, "#9c179e" ], [ 0.4444444444444444, "#bd3786" ], [ 0.5555555555555556, "#d8576b" ], [ 0.6666666666666666, "#ed7953" ], [ 0.7777777777777778, "#fb9f3a" ], [ 0.8888888888888888, "#fdca26" ], [ 1, "#f0f921" ] ], "type": "histogram2dcontour" } ], "mesh3d": [ { "colorbar": { "outlinewidth": 0, "ticks": "" }, "type": "mesh3d" } ], "parcoords": [ { "line": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "parcoords" } ], "pie": [ { "automargin": true, "type": "pie" } ], "scatter": [ { "marker": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "scatter" } ], "scatter3d": [ { "line": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "marker": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "scatter3d" } ], "scattercarpet": [ { "marker": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "scattercarpet" } ], "scattergeo": [ { "marker": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "scattergeo" } ], "scattergl": [ { "marker": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "scattergl" } ], "scattermapbox": [ { "marker": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "scattermapbox" } ], "scatterpolar": [ { "marker": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "scatterpolar" } ], "scatterpolargl": [ { "marker": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "scatterpolargl" } ], "scatterternary": [ { "marker": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "scatterternary" } ], "surface": [ { "colorbar": { "outlinewidth": 0, "ticks": "" }, "colorscale": [ [ 0, "#0d0887" ], [ 0.1111111111111111, "#46039f" ], [ 0.2222222222222222, "#7201a8" ], [ 0.3333333333333333, "#9c179e" ], [ 0.4444444444444444, "#bd3786" ], [ 0.5555555555555556, "#d8576b" ], [ 0.6666666666666666, "#ed7953" ], [ 0.7777777777777778, "#fb9f3a" ], [ 0.8888888888888888, "#fdca26" ], [ 1, "#f0f921" ] ], "type": "surface" } ], "table": [ { "cells": { "fill": { "color": "#EBF0F8" }, "line": { "color": "white" } }, "header": { "fill": { "color": "#C8D4E3" }, "line": { "color": "white" } }, "type": "table" } ] }, "layout": { "annotationdefaults": { "arrowcolor": "#2a3f5f", "arrowhead": 0, "arrowwidth": 1 }, "coloraxis": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "colorscale": { "diverging": [ [ 0, "#8e0152" ], [ 0.1, "#c51b7d" ], [ 0.2, "#de77ae" ], [ 0.3, "#f1b6da" ], [ 0.4, "#fde0ef" ], [ 0.5, "#f7f7f7" ], [ 0.6, "#e6f5d0" ], [ 0.7, "#b8e186" ], [ 0.8, "#7fbc41" ], [ 0.9, "#4d9221" ], [ 1, "#276419" ] ], "sequential": [ [ 0, "#0d0887" ], [ 0.1111111111111111, "#46039f" ], [ 0.2222222222222222, "#7201a8" ], [ 0.3333333333333333, "#9c179e" ], [ 0.4444444444444444, "#bd3786" ], [ 0.5555555555555556, "#d8576b" ], [ 0.6666666666666666, "#ed7953" ], [ 0.7777777777777778, "#fb9f3a" ], [ 0.8888888888888888, "#fdca26" ], [ 1, "#f0f921" ] ], "sequentialminus": [ [ 0, "#0d0887" ], [ 0.1111111111111111, "#46039f" ], [ 0.2222222222222222, "#7201a8" ], [ 0.3333333333333333, "#9c179e" ], [ 0.4444444444444444, "#bd3786" ], [ 0.5555555555555556, "#d8576b" ], [ 0.6666666666666666, "#ed7953" ], [ 0.7777777777777778, "#fb9f3a" ], [ 0.8888888888888888, "#fdca26" ], [ 1, "#f0f921" ] ] }, "colorway": [ "#636efa", "#EF553B", "#00cc96", "#ab63fa", "#FFA15A", "#19d3f3", "#FF6692", "#B6E880", "#FF97FF", "#FECB52" ], "font": { "color": "#2a3f5f" }, "geo": { "bgcolor": "white", "lakecolor": "white", "landcolor": "#E5ECF6", "showlakes": true, "showland": true, "subunitcolor": "white" }, "hoverlabel": { "align": "left" }, "hovermode": "closest", "mapbox": { "style": "light" }, "paper_bgcolor": "white", "plot_bgcolor": "#E5ECF6", "polar": { "angularaxis": { "gridcolor": "white", "linecolor": "white", "ticks": "" }, "bgcolor": "#E5ECF6", "radialaxis": { "gridcolor": "white", "linecolor": "white", "ticks": "" } }, "scene": { "xaxis": { "backgroundcolor": "#E5ECF6", "gridcolor": "white", "gridwidth": 2, "linecolor": "white", "showbackground": true, "ticks": "", "zerolinecolor": "white" }, "yaxis": { "backgroundcolor": "#E5ECF6", "gridcolor": "white", "gridwidth": 2, "linecolor": "white", "showbackground": true, "ticks": "", "zerolinecolor": "white" }, "zaxis": { "backgroundcolor": "#E5ECF6", "gridcolor": "white", "gridwidth": 2, "linecolor": "white", "showbackground": true, "ticks": "", "zerolinecolor": "white" } }, "shapedefaults": { "line": { "color": "#2a3f5f" } }, "ternary": { "aaxis": { "gridcolor": "white", "linecolor": "white", "ticks": "" }, "baxis": { "gridcolor": "white", "linecolor": "white", "ticks": "" }, "bgcolor": "#E5ECF6", "caxis": { "gridcolor": "white", "linecolor": "white", "ticks": "" } }, "title": { "x": 0.05 }, "xaxis": { "automargin": true, "gridcolor": "white", "linecolor": "white", "ticks": "", "title": { "standoff": 15 }, "zerolinecolor": "white", "zerolinewidth": 2 }, "yaxis": { "automargin": true, "gridcolor": "white", "linecolor": "white", "ticks": "", "title": { "standoff": 15 }, "zerolinecolor": "white", "zerolinewidth": 2 } } }, "title": { "text": "Percentage data of loan_status" } } }, "text/html": [ "
\n",
" \n",
" \n",
" \n",
" \n",
"
"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"Detailed Executing with RandomForest ..\n"
]
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAsYAAAGwCAYAAACq+6P0AAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADt0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjByYzEsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy/xvVyzAAAgAElEQVR4nOzdeZgkZZm2/fNikbWl2QUcbEQEWWTpVkRkFXVeN1xQVFzaZdBxFHE+VD4dEcdhwHFXXtQeVEZFBwEXxGFRZJet2UHADRAFZQBlExCa+/0joiRJsqqyq6sqq6rP33HkUZlPPBFxR2RU5VWRT0amqpAkSZKWdssMugBJkiRpKjAYS5IkSRiMJUmSJMBgLEmSJAEGY0mSJAkwGEuSJEmAwVjSFJRkfpJKMn/QtUiSlh4GY2mGawNm521RkjuSnNEG0Ay6xukuycE99nPn7YZB1zgWbe1njGG+o0bZH4u9zLHqqGXOZK1zvCTZdbL316D4z7CmiuUGXYCkSfPR9ufywFOAlwO7APOAdw2qqBnmTOCMHu1/nuQ6poofAJf1aL9hkuuQpL4YjKWlRFUd3Pk4yY7AWcA7k3yqqq4fSGEzyxnd+3kp9/2qOmrQRUhSvxxKIS2lqupc4FogwNzOaUnmJvlcksvbYRf3J/llkk8lWb17WZ1vgybZrR2mcXeSu5L8KMnTetWQ5ClJjk3ypyT3JvlZkheNVHdb2/FJbk3yQJIbkxyRZL0efYfeRt8oybuS/LzdlhuSfHBoGEmSVyW5sK3h1iSHJ1lxMXbnYhnjNjw5ybuTXJHkvs6315OskeTQJNe00+5MclqS5/dY3uOS7Jfkkna//6XdHz9IskfbZ36SamfZpWsYxMETsD9em+T0tp772+34lyQr9Oj7siTfTPKL9vm6J8nF7TYt09W3gDe1D6/vNbSl3fYb6CGPDJHZtXu57TH+hCRHJvl9miFK8zv6bJ/kuCR/SPLXJDcl+XKS9ce6nzqW3fn79rwkZ7f74X+TfC3J7LbftklObPfrPUlOSI8hJe22VJIVkvxbkuvb4/LXST6S5HHD1PHcJCfnkb8Rv0hyWJLVRljH45IclOS6dh1Htcfy19quX+s63ua086/fznduxz69Ocm30uPvS5I57fxHtff/O8ltbZ0Lk7x4hP27d/v7M7RdNyT5dpJ5Pfr2fexqevCMsbR0Gxpf/GBX+z/QDLU4E/gJsCywHfDPwP9Jsn1V3d1jeS8G9gROAr4EbA68EHhGks2r6ra/rTjZBDgPWLPtfxnNEI/vt48fW2zzYnZ8W/dxwI00of4fgT2T7FhVN/SY9ZPArsAPgVOBlwKHAI9LcgdwWLves4HnAf/UbvM/9qpjSSzBNnwO2An4EfA/wKJ2eU+iGb4xp63/ZGAVmufi5CRvr6r/7FjOUcBrgauArwP3AesDzwH+nub5voxm6M1H2vqO6pj/jLFuey9JvgK8Bfgd8F2aYSfPAj4GPDfJ86rqoY5ZDgMeBi4Afg+sBuxOs3+eAbyho+9HgZcBW7fTh4a0jMfQljWA84F72rofBv7YbtObgf8EHgBOAG4CNgHeBrwkybOq6rfjUMNLaZ7nE2l+354NzAc2SnIgcBrNMfEVYCvgJcDGSbaqqod7LO87NPvwOJq/CXsCBwPzkry0qob+WSLJ24EvAvcCxwK30vyOfaDdxh2rqtd+Pr5dx0k0v3O30hxTf27X1z38ZmgZOwMHAqe3y7iHZp/uBby0Xd/lPdb3JOBC4DfAN2iet72BHyTZo6pO79im0AT0NwG30Tyv/ws8EdgNuA5Y2NF/cY9dTQdV5c2btxl8A6r5VX9M+8404eoBYL2uaU8Clu0xz1vb5X2gq31+2/4Q8NyuaYe2097f1X5q2/6ervY9h2oG5ne0r0rzYrUI2Klrng+0/U/taj+qbb8B2KCjfXa7rHtpXvie1jFtBeDn7X5Zp899fHC7njPa+923OeOwDb8HNuqx7jNoQtlrutpn0wSM+4B127bV2r4Lh3l+1+xx7JwxhmNuqObvD7M/ZncdN98FVhpmn3YfHxv3WN8ywH+1/bcfppY5w9R6A3DDKM/rrr1+p2j+sViua9pTgb8Cv+o85tppu7fP/ff63I+79noOePTv2y5d++HH7bQ7gH265vtKO23PHsdQAb8AVu9oX5Hmn9cC3tDR/iSa34+7gM26lnVE23/BMOu4Alirx7YObdP8YfbFOsCsHu1b04Tkk7ra53Q8Tx/pmvaCtv1/utr3bdsvBFbrmrYsHX8nx3Lsepset4EX4M2bt4m9dbw4HNzeDgGOaV+8HwbevRjLCnAn8NOu9qEXiW/2mGejdtpxHW1PbNt+Q++ANvQiOr+jbZ+27Vs9+i8HXN9O37Cj/ai27a095vlqO+1fe0z7SDttlz73y9AL4XC3XcdhGx7zItuGggKOHaauoX8y3tk+fnz7+FwgfR47Z4zhmBuqebjbnLbfpTRnJmf3WMayNP9EXNjnOrdrl33QMLXMGWa+GxhbMO75jxPwmXb6i4ZZ5vdoAu1jQl6Pvrv2eg545PftGz3meWM77awe03ahd1A8g67w26OG0zvaPtS2/XuP/qvTBOb7gBV6rGPP7nm6tml+r+mj7KcTgPuB5Tva5vDIP8W9/sbcCNzW1XZlO8+2faxz3I5db1Pr5lAKaenxka7HQ4Hxa90dkywPvB14Dc1wiNV49GcSNhhmHQt7tN3U/uwcm7xt+/OcqlrUY54zaF7EO23X/vxpd+eqeijJWTQvhtsC3W9T96rr5vbnxT2m/b79+cQe00by0Rr5w3dLsg0X9ljeDu3P1dJ77O/a7c+nteu4K8kPad5SvyzJ8TRvtV9QVX8Zoe6xenMN8+G7JCvTBPvbgP3T+6qBDwzV3jHfmsD7aIboPJlm2Ein4Y7N8XZDVd3ao33oOdklyTN6TF+HJjg9ld7H3uIY7+P6zB5tZ9ME+W072kY6jv+U5FKad6Q2A7qHN/Q6jvuS5vMH76C5ks5aPHY46FrALV1tlw3zN+YmHnmuSLIKsCXwx6q6dJQ6xnTsanowGEtLiaoa+qDZKjQvCF8BvpTkxqrqfoE7hmaM8W9oxvz9geYPPcD+NMMNennMmMI28EETBoYMfTjnj8Ms5w892obm6X7ho6t9do9pd/Zoe6iPacsPs66xWpJt6LVP1mx/Pq+9DWfVjvt70wzbeB2PXMLv/iTHAQdU1XDPyXhbneYdiLV57D9tPbUfKruI5l2IC2mGMtxB83zNBt7D8MfmeOv1fMAjz8n7Rpl/1VGm92O8j+vHPPdVtSjJ7TSBfsh4H8ejSrIfzTjxP9EMF/kt8Beaf/CHxpH3eu6HG0/+EI/+Z3+o1t/36NttsY9dTR8GY2kpU1X3Aj9J8hLgEuC/kmw6dMaw/eT1y2k+hPXCqvrbB/PSfOr//eNQxtCL9rrDTH/CCPP0mgawXle/qWhJtqFGWN57qurz/RRQVffRDqtJ8nc0Z/bmA6+nOVu9Uz/LGQdDtV9aVduN2PMRb6MJxY85M59kB5pgvLgeBnpedYHewW5Ir+cDHtmu1arqrjHUM0jr0vVORZJlacJ+57Z0HsdX91jOsMdxVQ2334aVZDmaf+L+AGxXVbd0Td+h54yLZyhA9/OOw1iOXU0TXq5NWkpV1RU0n5x/IvDejklPaX+e0BmKW88EVhqH1Q+9Vfmc9oW3264jzPOYae0L53Pah5csaXETaLy34fz255jCbFXdVFVH03wY6Zc0z8eaHV0e5tFn+sdNVd1DE6q2SLJGn7MNHZvH95jWPfRmyNDb6MNtx5+AddvhQ90ec3muPizRczJgvfbhTjQn0TqHF4x0HM8GtqEZ83vNYqx7pOdpLZp/Un7WIxSvyiNDO8asPWFwFc2xsO0ofcdy7GqaMBhLS7d/o3kBOyCPXJ/4hvbnrp0dk6wD/N/xWGlV/Y7m7dCN6PrWvSR70vsF+vs0b5u/NsmzuqbtTzPe9Cc1PpfBmijjug1VtZBmDOgrkrylV58kW7XPHUnWTrJ9j26rALNo3l7+a0f77cDf9VPLGH2a5mztV9tA9ShJVk/SGXpuaH/u2tVvW+D/H2Ydt7c/Nxxm+oU0we/NXcucD+w4fOnDOpzmQ1mfSfLU7ontdXynamj+cMffAdJcy/vQ9mHnZxG+SbON707yFB7tYzQf8vxmVT1A/0Z6nm6lGTYxtw3CQ/UtTzO8Yq3FWM9Iht51+XK6rsWcZJk8+jrji3vsappwKIW0FKuq3yf5Ms1b0O+nCRcX0Vy14BVJfgacQ/MW6/+huY7nzcMsbnH9E82loD6b5osoLueRr6oe+oBYZ633tOHvWODMJMfSvO07F3g+zdusbx+n2ibEBG3D62g+BPWVdhzmBTRvCz8ReDrNB4p2oAkXGwDnJ7mG5qz0TTQh5sU0b4t/vh59ferTgNe0H9i7mCY4n1VVZy3utvdSVV9NMhd4J/DrJKfQ7I81aP5p2pkmkL2jneXrNGN3P5tkN5qz3Ju09X+XZvx0t9Paef6zHUd9D/Dnqjq8nf4FmlD8xSTPpdknW9NcE/jEdtmLs03Xts/xV4Grk5xMcxm05WlC3040lwjcbHGWO0muoam58zrGG9NcO/sbQ52q6oYk+9P8o3xJku/QbNMuNMfatTTj2BfHeTThd//2LOzQeOcvVNWdST5Pcx3jK5P8gCaU7kZzrJze3l9SR9K8a/NG4Jftev6X5jrfu9M8pwfDmI5dTReDviyGN2/eJvbGMNcx7pi+Ls31fO/lkevdrkFzPdIbaM4o/xr4d2BlelzeitGvQdrzsl80Qfg4miB3L82L44tGWh7NlwN8j+YF6680L0ZfBNbv0fcohrlUF8Nciquf7RlhWQf32X9ctqGjzyzggzTh9R6aS2VdTxNo9gVWafvNBg6iCdK/p/lA5S00VwF5LV2XcKP5wNW3aELKon63saPmfvff0JdU3Nrujz/QnMn9Nx57ndzNaS7PdWt7zFxMM/Z4TrvOo3os/59pQt8DbZ/u4/c5NF+P/heasbQ/ovmnoucxMtzx3NVnq3Y/3Niu9w6at+q/DOze537Ztde6Rjo+O+Z5zPM03D7ikUuprdDu8+vbmn9D8+GyFYap7/k01yP/U9v/V8B/0PsSZmcwwt+hts/f0/wNuIfHXtpvufZ5/DnN8f0HmrD+JHr8jox0PIxWD81lFc+kGUt8f7s/jqYZ3zzmY9fb9LilfWIlSdJSKM1XMu9S7ZVrpKWZY4wlSZIkDMaSJEkSYDCWJEmSABxjLEmSJIGXa9M4WWuttWrOnDmDLkOSJGlUF1988W1VtXZ3u8FY42LOnDksXLhw0GVIkiSNKsmNvdodYyxJkiRhMJYkSZIAh1JonFzzu9uZ+76vD7oMSZI0TV38iTcOugTPGEuSJElgMJYkSZIAg7EkSZIEGIwlSZIkwGAsSZIkAQZjSZIkCTAYS5IkSYDBWJIkSQIMxpIkSRJgMJYkSZIAg7EkSZIEGIxntCSzk7yzvb9+kuPa+9skeWFHv/lJDh9UnZIkSVOBwXhmmw28E6Cqbq6qvdr2bYAXDjuXJEnSUmi5QRegCXUYsHGSy4BfAk8DtgP+FVgpyXOAQztnSLI28CVgw7Zp/6o6d/JKliRJGgzPGM9sBwK/rqptgPcBVNVfgYOAY6pqm6o6pmuezwGfqapnAK8Ejhxu4Un2TbIwycKH/nL3xGyBJEnSJPGMsbrtAWyeZOjx45PMqqrHJN+qWgAsAFjlCRvV5JUoSZI0/gzG6rYMsENV3TfoQiRJkiaTQylmtruBWYvRDnAq8K6hB0m2mYC6JEmSphyD8QxWVbcD5ya5CvhEx6TTaYZLXJZk767Z9gPmJbkiyc+Bd0xSuZIkSQPlUIoZrqpe16PtDuAZXc1HtdNuA7rDsiRJ0oznGWNJkiQJg7EkSZIEGIwlSZIkwGAsSZIkAQZjSZIkCTAYS5IkSYDBWJIkSQIMxpIkSRJgMJYkSZIAg7EkSZIE+JXQGidPe+KaLPzEGwddhiRJ0ph5xliSJEnCYCxJkiQBBmNJkiQJMBhLkiRJgMFYkiRJAgzGkiRJEuDl2jRO/nrL1fz2X7cadBmSJA3MhgddOegStIQ8YyxJkiRhMJYkSZIAg7EkSZIEGIwlSZIkwGAsSZIkAQZjSZIkCTAYS5IkSYDBWJIkSQIMxpIkSRJgMJYkSZIAg7EkSZIEGIwlSZIkYCkIxkl+1kefI5Ns3t7/4Bjmv2eEaXOSXNXen5fk86P0fd1o6+sx3+wk7xyvfpIkSUujGR+Mq+rZffR5W1X9vH34wa5po86/GLUsrKr9RugyB1jsYAzMBvoJvP32kyRJWurM+GA8dDY3ya5JzkhyXJJrkxydJO20M9qzuYcBKyW5LMnRXfOvmuS0JJckuTLJnmOoZdckJ7b3d2nXc1mSS5PMAg4Ddmrb3jvMMrZIcmHb54okm7Tzbdy2fWKEWrv7/a2edtmHJ5nf3j8syc/bdXxymFr2TbIwycI77l20uLtDkiRpSllu0AVMsm2BLYCbgXOBHYFzhiZW1YFJ3lVV2/SY937g5VV1V5K1gPOTnFBVNcZaDgD+qarOTbJqu/wDgQOq6sUjzPcO4HNVdXSSxwHLtvNtOVR3kuV61dqj3669VpBkDeDlwGZVVUlm9+pXVQuABQBP32Clse4HSZKkKWHGnzHucmFV/a6qHgYuoxm60K8A/57kCuAnwAbAuktQy7nAp5PsB8yuqof6nO884INJPgA8qarum4Ba76IJ6kcmeQXwl8WYV5IkaVpa2oLxAx33F7F4Z8z3AdYG5rZnXP8IrDjWQqrqMOBtwEo0Z3Q363O+bwEvBe4DTkmy+xLU+hCPPgZWbNfxEPBM4HjgZcDJ/dQmSZI0nS1tQyn68WCS5avqwa721YBbq+rBJLsBT1qSlSTZuKquBK5MsgOwGXATMGuU+Z4M/KaqPt/efzpwedd8w9V6d1e/G4HNk6xAE4qfC5zTDu1Yuar+J8n5wK+WZFslSZKmA4PxYy0ArkhySVXt09F+NPDDJAtphmFcu4Tr2b8NrYuAnwMnAQ8DDyW5HDiqqj7TY769gdcneRD4A/CvVXVHknPby8KdBHy8V61VdXtnv6p6X5LvAFcAvwQubdcxC/hBkhVphmX0/CCgJEnSTJKxf3ZMesTTN1ipTnz7UwZdhiRJA7PhQVcOugT1KcnFVTWvu31pG2MsSZIk9eRQinGSZCvgG13ND1TV9mNc3gtohkR0ur6qXj6W5UmSJGlkBuNx0n6Qrtf1j8e6vFOAU8ZreZIkSRqZQykkSZIkDMaSJEkSYDCWJEmSAIOxJEmSBBiMJUmSJMBgLEmSJAFerk3j5HHrbcGGBy0cdBmSJElj5hljSZIkCYOxJEmSBBiMJUmSJMBgLEmSJAEGY0mSJAkwGEuSJEmAl2vTOLn21mvZ8Qs7DroMSZp057773EGXIGmceMZYkiRJwmAsSZIkAQZjSZIkCTAYS5IkSYDBWJIkSQIMxpIkSRJgMJYkSZIAg7EkSZIEGIwlSZIkwGAsSZIkAQZjSZIkCTAYS5IkSYDB+FGS3DPG+fZPsvJ41zPKOo9KstdkrlOSJGkmMxiPj/2BSQ3GkiRJGl8G4x6SrJrktCSXJLkyyZ5t+ypJfpTk8iRXJdk7yX7A+sDpSU4fZnmvTvLp9v57kvymvb9xknPa+3OTnJnk4iSnJFmvo8/JbfvZSTbrsfyPtWeQez6fSW5I8vEkF7a3p7TtL0lyQZJLk/wkybpJlknyyyRrt32WSfKrJGv1WO6+SRYmWfjgPQ8u/o6WJEmaQgzGvd0PvLyqtgN2Az6VJMDfAzdX1dZVtSVwclV9HrgZ2K2qdhtmeWcBO7X3dwJuT7IB8Bzg7CTLA18A9qqqucBXgUPa/guAd7ftBwBHdC44yX8A6wBvrqqHR9imu6rqmcDhwGfbtnOAZ1XVtsB/A+9vl/FNYJ+2zx7A5VV1W/cCq2pBVc2rqnnLr7r8CKuWJEma+pYbdAFTVIB/T7Iz8DCwAbAucCXwySQfB06sqrP7WVhV/aE9Cz0L+DvgW8DONCH5u8CmwJbAj5v8zbLALUlWBZ4NHNu2A6zQsegPAxdU1b59lPHtjp+fae8/ETimPTv9OOD6tv2rwA9oAvRbgK/1s52SJEnTmWeMe9sHWBuYW1XbAH8EVqyqXwBzaQLyoUkOWoxlnge8GbgOOJsmFO8AnEsTxK+uqm3a21ZV9Xya5+fPHe3bVNXTOpZ5ETA3yRp9rL963P8CcHhVbQW8HVgRoKpuAv6YZHdge+CkxdhOSZKkaclg3NtqwK1V9WCS3YAnASRZH/hLVX0T+CSwXdv/bmDWKMs8i2YoxFnApTRDNB6oqjtpwvLaSXZo17N8ki2q6i7g+iSvatuTZOuOZZ4MHAb8qD0bPZK9O36e17Gdv2/vv6mr/5E0Qyq+U1WLRlm2JEnStOdQit6OBn6YZCFwGXBt274V8IkkDwMPAv/Yti8ATkpyywjjjM+mGUZxVlUtSnLT0HKr6q/tpdc+n2Q1mufls8DVNGevv5jkX4DlacYCXz600Ko6tg3FJyR5YVXdN8z6V0hyAc0/Q69t2w6mGabxe+B8YKOO/ifQDKFwGIUkSVoqpKpG76VpLckNwLxeH6AbYZ55wGeqaqdROwOrbrhqbf2+rUfvKEkzzLnvPnfQJUhaTEkurqp53e2eMdZjJDmQ5mz4PqP1lSRJmikMxuOsHa6wQlfzG6rqyklY9/d49HAIgA9U1ZzFWU5VHUYzdlmSJGmpYTAeZ1W1/QDX/fJBrVuSJGm686oUkiRJEgZjSZIkCTAYS5IkSYDBWJIkSQIMxpIkSRJgMJYkSZIAL9emcbLZOpv57U+SJGla84yxJEmShMFYkiRJAgzGkiRJEmAwliRJkgCDsSRJkgQYjCVJkiTAy7VpnNx93XWcufMugy5DkibMLmedOegSJE0wzxhLkiRJGIwlSZIkwGAsSZIkAQZjSZIkCTAYS5IkSYDBWJIkSQIMxpIkSRJgMJYkSZIAg7EkSZIEGIwlSZIkwGAsSZIkAQZjSZIkCTAYj0mS2UneOUqfOUle18ey5iS5avyqG12SI5NsPkqfl43WR5IkaSYxGI/NbGDEYAzMAUYNxosjyXLjsZyqeltV/XyUbi8DDMaSJGmpYTAem8OAjZNcluQT7e2qJFcm2bujz05tn/e2Z4bPTnJJe3t2PytKMj/JsUl+CJyaZJUkX01yUZJLk+zZ9ls2ySfbGq5I8u4RlnlGknnt/XuSHJLk8iTnJ1m3re2lwCfa+jceZjn7JlmYZOGdDz7Y/96TJEmagsblDORS6EBgy6raJskrgXcAWwNrARclOavtc0BVvRggycrA86rq/iSbAN8G5vW5vh2Ap1fVHUn+HfhpVb0lyWzgwiQ/Ad4IbARsW1UPJVmjz2WvApxfVR9K8h/AP1TVvyU5ATixqo4bbsaqWgAsANh01qzqc32SJElTksF4yT0H+HZVLQL+mORM4BnAXV39lgcOT7INsAh46mKs48dVdUd7//nAS5Mc0D5eEdgQ2AP4UlU9BNDRfzR/BU5s718MPG8x6pIkSZoxDMZLLn32ey/wR5ozy8sA9y/GOu7tWt8rq+q6RxWRBBjLWdsHq2povkV4TEiSpKWUY4zH5m5gVnv/LGDvdozv2sDOwIVdfQBWA26pqoeBNwDLjnHdpwDvboMwSbZt208F3jH0Ab3FGEoxnO76JUmSZjSD8RhU1e3Aue1l1nYArgAuB34KvL+q/tC2PdR+qO29wBHAm5KcTzOM4t7eSx/Vx2iGZVzRrv9jbfuRwG/b9stZ8iti/DfwvvYDfj0/fCdJkjST5JF30aWx23TWrFqw7XaDLkOSJswuZ5056BIkjZMkF1fVYy6C4BljSZIkCT9oNWUkeQHw8a7m66vq5UuwzO/RXMKt0weq6pSxLlOSJGmmMhhPEW1YHdfAuiShWpIkaWnjUApJkiQJg7EkSZIEGIwlSZIkwGAsSZIkAQZjSZIkCTAYS5IkSYCXa9M4mbXppn4rlCRJmtY8YyxJkiRhMJYkSZIAg7EkSZIEGIwlSZIkwGAsSZIkAQZjSZIkCfBybRont/7uTg7//3446DIkDcC7PvWSQZcgSePCM8aSJEkSBmNJkiQJMBhLkiRJgMFYkiRJAgzGkiRJEmAwliRJkgCDsSRJkgQYjCVJkiTAYCxJkiQBBmNJkiQJMBhLkiRJgMFYkiRJAgzGU1KSn/XRZ/8kK4/T+uYnWX88liVJkjRdGYynoKp6dh/d9gf6DsZJlh1h8nzAYCxJkpZqBuMpKMk97c9dk5yR5Lgk1yY5Oo39aILs6UlOH2k5Sf41yQXADkkOSnJRkquSLGiXtRcwDzg6yWVJVkoyN8mZSS5OckqS9SZlwyVJkgaor2CcZOMkK7T3d02yX5LZE1uaWtvSnB3eHHgysGNVfR64GditqnYbYd5VgKuqavuqOgc4vKqeUVVbAisBL66q44CFwD5VtQ3wEPAFYK+qmgt8FTik18KT7JtkYZKF9/zlzvHZWkmSpAHp94zx8cCiJE8BvgJsBHxrwqpSpwur6ndV9TBwGTBnMeZdRPPcDdktyQVJrgR2B7boMc+mwJbAj5NcBvwL8MReC6+qBVU1r6rmrbryaotRliRJ0tSzXJ/9Hq6qh5K8HPhsVX0hyaUTWZj+5oGO+4vo/zkDuL+qFgEkWRE4AphXVTclORhYscc8Aa6uqh3GWK8kSdK01O8Z4weTvBZ4E3Bi27b8xJSkPt0NzFqM/kMh+LYkqwJ7DbOs64C1k+wAkGT5JL3OLEuSJM0o/QbjNwM7AIdU1fVJNgK+OXFlqQ8LgJNG+vBdp6r6M/CfwJXA94GLOiYfBXypHTqxLE1o/niSy2mGb/RzlQxJkqRpLVXVX8dkJWDDqrpuYkvSdLThEzap9+/z6UGXIWkA3vWplwy6BElaLEkurqp53e39XpXiJTRnDk9uH2+T5ITxLVGSJEkanH4/yHUw8EzgDICquqwdTqEpoL1O8QpdzW+oqisHUY8kSdJ01G8wfqiq7kzS2dbfGAxNuKraftA1SJIkTXf9BuOrkrwOWDbJJgSbxaMAABdaSURBVMB+wM8mrixJkiRpcvV7VYp303wZxAM0X+xxJ823sUmSJEkzwqhnjJMsC5xQVXsAH5r4kiRJkqTJN+oZ4/ab0/6SxO/8lSRJ0ozV7xjj+4Erk/wYuHeosar2m5CqJEmSpEnWbzD+UXuTJEmSZqS+v/lOGsm8efNq4cKFgy5DkiRpVMN9811fZ4yTXE+P6xZX1ZPHoTZJkiRp4PodStGZqFcEXgWsMf7lSJIkSYPR13WMq+r2jtvvq+qzwO4TXJskSZI0afodSrFdx8NlaM4gz5qQiiRJkqQB6Hcoxac67j8EXA+8evzLkSRJkgaj32D81qr6TWdDko0moB5JkiRpIPq6XFuSS6pqu662i6tq7oRVpmllgzVXr3f+n+cOugxJrQ9987hBlyBJU9aYLteWZDNgC2C1JK/omPR4mqtTSJIkSTPCaEMpNgVeDMwGXtLRfjfwDxNVlCRJkjTZRgzGVfUD4AdJdqiq8yapJkmSJGnS9fvhu0uT/BPNsIq/DaGoqrdMSFWSJEnSJOvrCz6AbwBPAF4AnAk8kWY4hSRJkjQj9BuMn1JVHwburar/Al4EbDVxZUmSJEmTq99g/GD7889JtgRWA+ZMSEWSJEnSAPQ7xnhBktWBDwMnAKsCB01YVZIkSdIk6ysYV9WR7d0zgSdPXDmSJEnSYPQ1lCLJukm+kuSk9vHmSd46saVJkiRJk6ffMcZHAacA67ePfwHsPxEFSZIkSYPQbzBeq6q+AzwMUFUPAYsmrCqNSZLZSd456DokSZKmo36D8b1J1gQKIMmzgDsnrCqN1Wyg72CcRr/HgCRJ0ozWbyj6Z5qrUWyc5Fzg68C7J6wqjdVhNM/RZUk+keR9SS5KckWSjwIkmZPkmiRHAJcAOyW5NsmRSa5KcnSSPZKcm+SXSZ450C2SJEmaJCMG4yQbAlTVJcAuwLOBtwNbVNUVE1+eFtOBwK+rahvgx8AmwDOBbYC5SXZu+20KfL2qtgVuBJ4CfA54OrAZ8DrgOcABwAcndQskSZIGZLTLtX0f2K69f0xVvXKC69H4eX57u7R9vCpNUP4tcGNVnd/R9/qquhIgydXAaVVVSa5khC9ySbIvsC/AaiuvNO4bIEmSNJlGC8bpuO/1i6eXAIdW1Zcf1ZjMAe7t6vtAx/2HOx4/zAjHSFUtABYAbLDm6rVk5UqSJA3WaGOMa5j7mpruBma1908B3pJkVYAkGyRZZ2CVSZIkTXGjnTHeOsldNGcfV2rv0z6uqnr8hFanxVJVt7cfmrsKOAn4FnBeEoB7gNfjZfYkSZJ6GjEYV9Wyk1WIxkdVva6r6XM9um3Z0f+Grsfzh5smSZI0k3kNW0mSJAmDsSRJkgQYjCVJkiTAYCxJkiQBBmNJkiQJMBhLkiRJgMFYkiRJAgzGkiRJEmAwliRJkgCDsSRJkgSM8pXQUr/W22hjPvTN4wZdhiRJ0ph5xliSJEnCYCxJkiQBBmNJkiQJMBhLkiRJgMFYkiRJAgzGkiRJEuDl2jRO7r/lbq455KeDLkOasZ72od0HXYIkzXieMZYkSZIwGEuSJEmAwViSJEkCDMaSJEkSYDCWJEmSAIOxJEmSBBiMJUmSJMBgLEmSJAEGY0mSJAkwGEuSJEmAwViSJEkCDMaSJEkSAMsNugBNDUkOBu4BbgNOraqb2/YjgU9X1c8HWJ4kSdKEMxir23zgKuBmgKp620CrkSRJmiQOpViKJflQkuuS/ATYtG2eBxyd5LIkKyU5I8m8AZYpSZI0KTxjvJRKMhd4DbAtzXFwCXAxsBA4oKoWtv1GWsa+wL4A6622zgRXLEmSNLE8Y7z02gn4XlX9paruAk5Y3AVU1YKqmldV89ZYZfb4VyhJkjSJDMZLtxp0AZIkSVOFwXjpdRbw8nYc8SzgJW373cCswZUlSZI0GI4xXkpV1SVJjgEuA24Ezm4nHQV8Kcl9wA4DKk+SJGnSGYyXYlV1CHBIj0nHd9zfdXKqkSRJGiyHUkiSJEkYjCVJkiTAYCxJkiQBBmNJkiQJMBhLkiRJgMFYkiRJAgzGkiRJEmAwliRJkgCDsSRJkgT4zXcaJyuuN4unfWj3QZchSZI0Zp4xliRJkjAYS5IkSYDBWJIkSQIMxpIkSRJgMJYkSZIAg7EkSZIEeLk2jZObb76Zgw8+eNBlaIbwWJIkDYJnjCVJkiQMxpIkSRJgMJYkSZIAg7EkSZIEGIwlSZIkwGAsSZIkAQZjSZIkCTAYS5IkSYDBWJIkSQIMxpIkSRJgMJYkSZIAg7EkSZIEGIyXSklemuTAQdchSZI0lSw36AKWJkkCpKoeHmANy1XVCcAJg6pBkiRpKvKM8QRLMifJNUmOAC4BPpzkoiRXJPloR783tm2XJ/lG2/akJKe17acl2TDJakluSLJM22flJDclWT7JxklOTnJxkrOTbNb2OSrJp5OcDnw8yfwkh7fT1k5yfFvTRUl2bNt3SXJZe7s0yaxJ3nWSJEmTyjPGk2NT4M3A94G9gGcCAU5IsjNwO/AhYMequi3JGu18hwNfr6r/SvIW4PNV9bIklwO7AKcDLwFOqaoHkywA3lFVv0yyPXAEsHu7rKcCe1TVoiTzO2r7HPCZqjonyYbAKcDTgAOAf6qqc5OsCtzfvVFJ9gX2BVhttdXGYz9JkiQNjMF4ctxYVecn+STwfODStn1VYBNga+C4qroNoKruaKfvALyivf8N4D/a+8cAe9ME49cAR7Th9dnAsc2IDQBW6Kjh2Kpa1KO2PYDNO+Z5fHt2+Fzg00mOBr5bVb/rnrGqFgALANZff/3qZ0dIkiRNVQbjyXFv+zPAoVX15c6JSfYD+gmWQ31OAA5tzyzPBX4KrAL8uaq2GaWGbssAO1TVfV3thyX5EfBC4Pwke1TVtX3UKEmSNC05xnhynQK8pT27S5INkqwDnAa8OsmabfvQUIqf0ZwRBtgHOAegqu4BLqQZBnFiVS2qqruA65O8ql1GkmzdR02nAu8aepBkm/bnxlV1ZVV9HFgIbLYE2y1JkjTlGYwnUVWdCnwLOC/JlcBxwKyquho4BDizHT/86XaW/YA3J7kCeAPwno7FHQO8vv05ZB/gre0yrgb27KOs/YB57Qf8fg68o23fP8lV7bLuA05a/C2WJEmaPlLl0FAtufXXX7/23XffQZehGeLggw8edAmSpBksycVVNa+73TPGkiRJEgZjSZIkCTAYS5IkSYDBWJIkSQIMxpIkSRJgMJYkSZIAg7EkSZIEGIwlSZIkwGAsSZIkAX7zncbJvHnzauHChYMuQ5IkaVR+850kSZI0AoOxJEmShMFYkiRJAgzGkiRJEmAwliRJkgCDsSRJkgQYjCVJkiQAlht0AZoZ/vSna/jOsc8cdBkag1e/6sJBlyBJ0pTgGWNJkiQJg7EkSZIEGIwlSZIkwGAsSZIkAQZjSZIkCTAYS5IkSYDBWJIkSQIMxpIkSRJgMJYkSZIAg7EkSZIEGIwlSZIkwGAsSZIkAQbjKSPJwUkOGOD67xnUuiVJkqYCg/EMlmTZQdcgSZI0XRiMJ1CSVZL8KMnlSa5KsneSG5Ks1U6fl+SMjlm2TvLTJL9M8g8jLHeZJEckuTrJiUn+J8le7bQbkhyU5BzgVUn+IclFbQ3HJ1m57bdRkvPaaR/rWv772vYrknx0hDr2TbIwycK77npoCfaUJEnS4BmMJ9bfAzdX1dZVtSVw8ij9nw68CNgBOCjJ+sP0ewUwB9gKeFvbv9P9VfWcqvpv4LtV9Yyq2hq4Bnhr2+dzwBer6hnAH4ZmTPJ8YBPgmcA2wNwkO/cqoqoWVNW8qpr3+McvN8qmSZIkTW0G44l1JbBHko8n2amq7hyl/w+q6r6qug04nSac9vIc4Niqeriq/tD27XRMx/0tk5yd5EpgH2CLtn1H4Nvt/W909H9+e7sUuATYjCYoS5IkzWie5ptAVfWLJHOBFwKHJjkVeIhH/iFZsXuWUR4PySirvrfj/lHAy6rq8iTzgV1HWX6AQ6vqy6OsQ5IkaUbxjPEEaodC/KWqvgl8EtgOuAGY23Z5ZdcseyZZMcmaNAH2omEWfQ7wynas8bo8Oux2mwXckmR5mjPGQ84FXtPe72w/BXhLklXbbdggyTojLF+SJGlG8IzxxNoK+ESSh4EHgX8EVgK+kuSDwAVd/S8EfgRsCHysqm4eZrnHA88FrgJ+0S5nuGEaH26n30gztGNW2/4e4FtJ3tMuD4CqOjXJ04DzkgDcA7weuLXPbZYkSZqWUjXcu/WaypKsWlX3tGeXLwR2bMcbD8TGG69Shx62xegdNeW8+lUXDroESZImVZKLq2ped7tnjKevE5PMBh5Hc3Z5YKFYkiRpJjAYT2FJtuLRV4wAeKCqtq+qXQdQkiRJ0oxlMJ7CqupKmmsJS5IkaYJ5VQpJkiQJg7EkSZIEGIwlSZIkwGAsSZIkAQZjSZIkCfCqFBonq6/+NL8oQpIkTWueMZYkSZIwGEuSJEmAwViSJEkCDMaSJEkSYDCWJEmSAIOxJEmSBBiMJUmSJMDrGGuc/PxPd7H1cacMugyN4PK9XjDoEiRJmtI8YyxJkiRhMJYkSZIAg7EkSZIEGIwlSZIkwGAsSZIkAQZjSZIkCTAYS5IkSYDBWJIkSQIMxpIkSRJgMJYkSZIAg7EkSZIEGIwlSZIkYIoE4yQHJzmgvX9Ukr3GsIw5SV7X8Xheks+PZ53TXZK1k1yQ5NIkOw26HkmSpKlkSgTjcTIH+FswrqqFVbXfRKwojYHvuyTLLeYszwWuraptq+rsiahJkiRpuprQcJfkjUmuSHJ5km8keVKS09q205JsOMr8c5OcmeTiJKckWa9tf0qSn7TLvSTJxsBhwE5JLkvy3iS7Jjmx7b9Gku+36z0/ydPb9oOTfDXJGUl+k2TYIN2ekb4myRHAJcDfJXlfkova5X50uO1u2x6z7UlWS3LDUMhOsnKSm5Isn2TjJCe32352ks3aPkcl+XSS04FPJPllkrXbacsk+VWStXrUvw3wH8AL2320UpLnJzmv3YfHJll1pP3eY5n7JlmYZOFDd9050lMpSZI05U1YME6yBfAhYPeq2hp4D3A48PWqejpwNDDsUIckywNfAPaqqrnAV4FD2slHA/+3Xe6zgVuAA4Gzq2qbqvpM1+I+ClzarveDwNc7pm0GvAB4JvCRdr3D2bStf9v2/ibtfNsAc5PsPMx202vbq+pO4HJgl7bPS4BTqupBYAHw7nbbDwCO6KjjqcAeVfVe4JvAPm37HsDlVXVbd+FVdRlwEHBMVW0DrAL8S7uc7YCFwD+Pst+7l7mgquZV1bzlHr/aCLtNkiRp6lvct+IXx+7AcUMhraruSLID8Ip2+jdozmAOZ1NgS+DHSQCWBW5JMgvYoKq+1y73foC2z3CeA7yy7f/TJGsmGUpyP6qqB4AHktwKrAv8bpjl3FhV57f3n9/eLm0fr0oTlLfu3u52+nDbfgywN3A68BrgiPbM7bOBYzu2a4WOOo6tqkXt/a8CPwA+C7wF+NpIO6LDs4DNgXPbdTwOOI9h9nufy5QkSZq2JjIYB6hR+ow0PcDVVbXDoxqTx4+xluHW/UBH2yJG3if3di3z0Kr6cld9+zH6dneu/wTg0CRrAHOBn9Kczf1ze2Z3xDqq6qYkf0yyO7A9j5w9Hk2AH1fVa7vq34oe+12SJGmmm8gxxqcBr06yJjTjfIGf0ZwVhSbAnTPC/NcBa7dnmWnH3W5RVXcBv0vysrZ9hSQrA3cDs4ZZ1lnt+kiyK3Bbu5wlcQrwlo5xuRskWYfe2w3DbHtV3QNcCHwOOLGqFrW1XZ/kVe0ykmTrEWo5kmZIxXc6ziSP5nxgxyRPadexcpKnMsx+73OZkiRJ09aEBeOquppmbOqZSS4HPg3sB7w5yRXAG3hk/G2v+f8K7AV8vJ3/MprhBbTz7tcu52fAE4ArgIfaD7y9t2txBwPz2v6HAW8ah+07FfgWcF6SK4HjgFnDbDeMvO3HAK9vfw7ZB3hru4yrgT1HKOcEmqEc/Q6joKr+F5gPfLut6Xxgs1H2uyRJ0oyVqn7e9ddUlmQe8JmqGti1iVfe+Km1yce/MKjVqw+X7/WCQZcgSdKUkOTiqprX3T6RY4w1CZIcCPwj/Y8tliRJUg8G4y7t2ODTekx6blXdPtn1jKaqDqMZHvI3ST4EvKqr67FV1fOya5IkSTIYP0Ybfoe7GsS00AZgQ7AkSdJiGPjXGkuSJElTgcFYkiRJwmAsSZIkAQZjSZIkCTAYS5IkSYBXpdA42Xz1x7PQL5CQJEnTmGeMJUmSJAzGkiRJEmAwliRJkgBIVQ26Bs0ASe4Grht0HdPAWsBtgy5imnBf9cf91B/3U//cV/1xP/VvKu6rJ1XV2t2NfvhO4+W6qpo36CKmuiQL3U/9cV/1x/3UH/dT/9xX/XE/9W867SuHUkiSJEkYjCVJkiTAYKzxs2DQBUwT7qf+ua/6437qj/upf+6r/rif+jdt9pUfvpMkSZLwjLEkSZIEGIwlSZIkwGCsUST5+yTXJflVkgN7TE+Sz7fTr0iyXb/zziRj3U9J/i7J6UmuSXJ1kvdMfvWTa0mOqXb6skkuTXLi5FU9+Zbwd292kuOSXNseWztMbvWTawn31Xvb372rknw7yYqTW/3k6WM/bZbkvCQPJDlgceadaca6r5a2v+lLcky106fe3/Oq8uat5w1YFvg18GTgccDlwOZdfV4InAQEeBZwQb/zzpTbEu6n9YDt2vuzgF/M1P20pPuqY/o/A98CThz09kzV/QT8F/C29v7jgNmD3qapuK+ADYDrgZXax98B5g96mwa4n9YBngEcAhywOPPOpNsS7qul5m/6kuynjulT7u+5Z4w1kmcCv6qq31TVX4H/Bvbs6rMn8PVqnA/MTrJen/POFGPeT1V1S1VdAlBVdwPX0LxYz1RLckyR5InAi4AjJ7PoARjzfkryeGBn4CsAVfXXqvrzZBY/yZbomKL5oquVkiwHrAzcPFmFT7JR91NV3VpVFwEPLu68M8yY99VS9jd9SY6pKfv33GCskWwA3NTx+Hc89hd8uD79zDtTLMl++pskc4BtgQvGvcKpY0n31WeB9wMPT1SBU8SS7KcnA/8LfK19i/LIJKtMZLEDNuZ9VVW/Bz4J/Ba4Bbizqk6dwFoHaUn+Ji9Nf89hnLZ3KfibvqT7aUr+PTcYayTp0dZ9fb/h+vQz70yxJPupmZisChwP7F9Vd41jbVPNmPdVkhcDt1bVxeNf1pSzJMfUcsB2wBeralvgXmAmjwldkmNqdZozXBv9v/bu3kemMAzD+HUnKEjUIiuhEJ16Q2fVagUSnYJEyx+hVqlst9lii000eiFIBI0gbEKiU2hsPIpzJEKsMe/OhznXr5uZ8ybv+2TOPc+cjxngMHAgyYVdnt+8aMnkIeU57MJ6B5LpY9dpnvPcxlg72QKO/PR4id9PM/5pm1HGLoqWOpFkL12ArlbV+gTnOQ9aanUaOJfkLd0puzNJ7k5uqjPVuu9tVdWPo1RrdI3yomqp1VngTVV9qqqvwDpwaoJznaWWTB5SnkPjegeU6S11mts8tzHWTh4Cx5McS7IPOA9s/LLNBnCpv+t7me5U5IcRxy6KseuUJHTXgr6sqlvTnfZMjF2rqrpRVUtVdbQfd7+qFvXoXkudPgLvk5zot1sBXkxt5tPXklPvgOUk+/t9cYXumtBF1JLJQ8pzaFjvwDJ97DrNc57vmfUENL+qajvJVeAe3d2nd6rqeZIr/eu3gU26O75fAV+AyzuNncEyJq6lTnTfmi8Cz5I87Z+7WVWb01zDtDTWajB2oU7XgNX+w+o1C1zDxpx6kGQNeAxsA0/4j/669l+MUqckh4BHwEHgW5LrdL8y8HkoeQ5ttQJOMpBMb31PzWzif+FfQkuSJEl4KYUkSZIE2BhLkiRJgI2xJEmSBNgYS5IkSYCNsSRJkgTYGEuSJEmAjbEkSZIEwHeD0Vdt2Fs/GgAAAABJRU5ErkJggg==\n",
"text/plain": [
""
]
},
"metadata": {
"needs_background": "light"
},
"output_type": "display_data"
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"-----------------------------------------\n",
"************* Model Results *************\n",
"-----------------------------------------\n",
"F1 Score : 0.7112312634261447\n",
"Report:\n",
" precision recall f1-score support\n",
"\n",
" 0 0.89 0.68 0.77 13359\n",
" 1 0.34 0.67 0.45 3238\n",
"\n",
" accuracy 0.68 16597\n",
" macro avg 0.62 0.68 0.61 16597\n",
"weighted avg 0.79 0.68 0.71 16597\n",
"\n"
]
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAWcAAAENCAYAAADT16SxAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADt0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjByYzEsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy/xvVyzAAAgAElEQVR4nO3dd3wUdf7H8deHIJ0klAQ4UEFFBPVEUYoV9CSRU4oiRFFQkdxx9vJTsQL2Xu6EM6iHqCdyqIBKUUHFBohKBwWlRSAJJaETEr6/P2YSlmSTbDTAMr6fj8c8dvc73zI7u/nsN9/5zow55xARkehS6WBvgIiIFKfgLCIShRScRUSikIKziEgUUnAWEYlCCs4iIlFIwTlAzOxGM1tkZjvMzJnZzQegzRVmtmJ/t/NH4H9mnx3s7ZDooOD8G5jZcWb2TzNbYGY5ZpZrZmvM7EMz629m1Q7CNqUAzwM7geeAIcCMA70d0cD/wXD+0qmUfP8JyTf4d7bZsSLqESlQ+WBvwKHGzO4HHsD7YZsBvAZsBRoAHYGXgYHAqQd40y4seHTOrTmA7Z53ANsqrzxgAPBp0RVmFgv08vNEy99BS2D7wd4IiQ7R8qU8JJjZ3Xg90tXApc65mWHyXAjcdqC3DfgTwAEOzDjnfj6Q7ZXTB8DFZlbPObehyLo+QA3gPaDHAd+yMJxzSw72Nkj00LBGhMysKTAY2A10CReYAZxzHwDJYcr3MrPp/jDIDjObb2aDzKxqmLwr/KWGmT1pZqvMbJeZLTOzO83MQvIONjMHdPJfF/yb7gq22389soT39VlB3pA0M7N+Zva1mWWZ2U4zW21mU8ysd7htDVNvVTO7y8zmmdl2M9tsZl+YWa8weQu30X8+2szW++3O9n/wfosRQFXgyjDrBuD9yE4OV9DMjjWzx/z2s/z9v9LM0sysSZG8I9nbO38g9DMws45+nqv811eZWbK/33NC933RMWcza2Zm2Wa20cyOLNJmTTNbbGb5ZnZOeXeMRD/1nCN3NXAYMNo5t6C0jM65XaGvzewRYBCwHvgv3jDIBcAjQJKZne+c212kmsOAj/B6xJPw/v3uDjwGVMPrwQN85j9eBRwZkv57POxv73JgDJADNAJOAy4F3i6tsJlVAaYA5wBLgBfxeqk9gbfNrLVz7u4wRY8EZgG/AK8DdYHewHgz+4tzrtjwRBk+BlYA1+KNwxdsXxvgZLx9taeEshcDf8cLul8DucDxfl0Xmdmpzrlf/bzj/Md+wOfs/Uzw2w/VE+/HexLwb6BpSRvvnFtuZtcC/wPeMrOznXN5/uphwHHAYOfc5yXVIYcw55yWCBZgKuCAa8tZroNfbhXQMCS9MvC+v+7uImVW+OkTgeoh6YlAtr8cVqTMZ97HWaz9pn5dI0vYvmLlgA1AOlAjTP76YbZ1RZG0QSHbX7nI9he8t9PDbKMDHihSV1JBXeXY5wVtVAbu9Z93CFn/byAfOAIv2Dq8IBdaR2Ogapi6O/tlhxdJ7xiunpD1V/nr9wDJJeRxwGdh0of56x71X/f1X38KVDrYfxta9s+iYY3INfIf08tZ7hr/8SHn3LqCROf1gG7D+2O9toSyNzrndoSUyQTGA3FAi3JuR3ntxgtC+3DOrY+g7DV4weNWt7enV7D9D/ovw73nlcBDRdqbgvfD1jayzS7mVbz3MQC84QDgcmCKc25VSYWcc7+6Iv8B+ekfAQvxfjR+i/HOubBDKaW4FZgL3Glm1+MF6yygj3OupJ6/HOIUnCNXMM5b3musnuI/Tiu6wjn3E16wb2Zm8UVW5zjnloWpb7X/WKec21Eeb+L1Zhea2aP+GGlcJAXNrDZwDLDGhT/AVbAfTg6zbo5zrtgPAt57/k3v13kHSCcCvfwZGilAbbzx6BL54+5XmNkn/phzXshY/ol4PevfYlZ5CzjnduIN72wD/ok3RNTXHeCDv3JgKThHruAPoUmpuYorCGprS1i/tki+Atkl5C/oicaUczvK4xbgZrxgcBfe+Oh6MxtvZseUUTbS91v0xwhKf8+/57s6AqgJXIbXg16HN6RUmmfwxr1b4Y2fP403Rj0Er4df5Tduy7qys4T1EzDPf74I73iEBJiCc+S+9B/LO683x39sWML6RkXyVbSCf3tLOvhbLEg65/Kdc887507Cm799Cd6Us67A5HAzTEIc7PcbzkTgV7zx53bAf0KHW4oys0TgRmAB0MI5d4Vz7k7n3GDn3GCg2HBHOfzWu1vcBZyOd1D5eLxxfQkwBefI/QdvHPYSM2tVWsYiwesH/7FjmHzH4PXElzvnSuo1/l6b/MfDw7QfCxxbWmHnXKZz7l3nXC+8IYmjgRNKyb8F+BlobGbNw2QpOGPv+wi2vUL4QyWv4u1rB7xSRpGj8P42PvLfTyF/Gt1RYcoUDMdU+H80ZnY6MBT4EW/f/wgMMbMzK7otiR4KzhFyzq3Am+dcBfjQzMKeAWhmBdOkCrzqP95rZgkh+WKAp/A+g7KCxW/mB5clwBmhPyp++88A1UPz+/OTzwudS+2nH4Y3tQ3KPovtVbwx+if9dgrqqA/cF5LnQHoB72STJFf2iTMr/Mczi2x/LbwhknD/hRSc5HLE79zOfZhZHeAtvOCf4pzLwBt/zsObXlevItuT6KF5zuXgnHvEzCrjnb79rZl9Dcxm7+nbZwPN/bSCMl+b2RPAHcACMxuLN5Z7AV4v6Evgyf286U/i/QB8ZWb/w7v+Rie8udRzgZNC8lYHPgFWmNlMvPHVasD5eKcXT3DOLS6jvafw3l83YK6ZTcQ7iHUp3nS6J5xzX5ZSvsL5s0zGlZnRy7vOzEbjHTycY2Yf4Y2ln4+37+YArYsU+xFv6CTFzHLxZpg44HXn3Mrfsemv4gX8G51zc/ztm2tmtwH/wvuPruvvqF+i1cGey3coLnhB6p94Y5Kb8U5QWIvXY+5P+PmxKXiBeAveH/hC4B6gWpi8Kygydzhk3WC8P/qORdI/I8w855D1/f02d+EdlHoJqFe0HF7AvsN/L6v8bc3Cu47I34EqkWwrXkC/299HO/z3/SVwWZi8TSnnXOwyPp8Vfn2VI8hb0jznGngn4yzz98FqvJNpiu2zkDKn4c2Hz8Eb6y/8nNg7z/mqUrZln3nOwA1+2vgS8r/rr7/lYP9NaKn4xfwPWUREoojGnEVEopCCs4hIFFJwFhGJQgrOIiJRaL9Ppeto9+uIoxQzaPIVB3sTJAolJR1rZecqXXlizmdu6O9ub39Rz1lEpARmdpN59wpdaP4Nk82srpl9bGZL/cc6IfkHmXdTjB/NLCkkvY15N9hYZmYvFD3JKxwFZxEJFDOLeCmjnhPwLpTVFu9ErQv9SxLcBUx1zjXHm9d+l5+/Fd75DMfj3VBhWMgZpsOBVLyT1JoT5m5JRSk4i0igWIxFvJShJTDDObfdeRfK+hzvEgDd8G7sjP/Y3X/eDe9OSbucc8vxTmBqa2aNgFjn3DfOO7FkVEiZEik4i0igmJVnsVTz7hNZsKSGVLUAONvM6plZDaAL3gXEGjjn1gL4j4l+/sbsvd46eNdqb+wv6WHSS6Vra4hIsJQ9nFvIOZcGpJWwbrGZPY53L8qteNehKfFSs+y9Icc+1ZSSXir1nEUkUMrTcy6Lc+4V59wpzrmzgY3AUiDDH6rAf8z0s6ez76V5m+DdpCOdfW/SUZBeKgVnEQkUq2QRL2XW5d14ATM7Au+O7G8BE/DutI7/ON5/PgHvqoRVzawZ3oG/Wf7QxxYza+/P0ugbUqZEGtYQkWApx7BGBN7xr5m9G7jOObfJzB4DxphZf7wrN14K4JxbaGZj8G4jlufnL7gJw0BgJN4leSex7zXfw1JwFpFAqRRBjzhSzrmzwqRtoITb1TnnHsa71GzR9NmUcgehcBScRSRYovacv/JRcBaRQIlkLPlQoOAsIoFSsUPOB4+Cs4gES0Cis4KziARKpbJPyz4kKDiLSLCo5ywiEn0CEpsVnEUkWCK4VPIhQcFZRIIlGLFZwVlEgkXznEVEopCCs4hIFNKYs4hINArIhZAVnEUkUNRzFhGJQgGJzQrOIhIsOiAoIhKFFJxFRKJRQMY1FJxFJFACEpsVnEUkWDRbQ0QkGmmes4hI9KlUKRjRWcFZRALFghGbFZxFJGA05iwiEn0CEpsVnEUkWHQSiohINApI11nBWUQCpVKMgrOISPRRz1lEJPoEJDYrOItIsATlgGBApmuLiPisHEtp1Zi1MLM5IctmM7vZzAab2a8h6V1Cygwys2Vm9qOZJYWktzGz+f66FyyCC4Co5ywigVIppmL6nM65H4HWAGYWA/wKvAdcDTzrnHsqNL+ZtQJSgOOBPwGfmNmxzrl8YDiQCswAJgLJwKRS30eFvAsRkShhFvlSDucBPzvnVpaSpxsw2jm3yzm3HFgGtDWzRkCsc+4b55wDRgHdy2pQwVlEgqUc0dnMUs1sdsiSWkKtKcBbIa+vN7N5ZvaqmdXx0xoDq0PypPtpjf3nRdNLpeAsIoFilSzixTmX5pw7NWRJK1afWRWgK/A/P2k4cDTekMda4OmCrGE2x5WSXiqNOYtIoOyHqXQXAN875zIACh69tmwE8IH/Mh04PKRcE2CNn94kTHqp1HMWkWCp+EHnywgZ0vDHkAv0ABb4zycAKWZW1cyaAc2BWc65tcAWM2vvz9LoC4wvq1H1nEUkUCry9G0zqwGcD/wtJPkJM2uNNzSxomCdc26hmY0BFgF5wHX+TA2AgcBIoDreLI1SZ2qAgrOIBE0Fjms457YD9YqkXVlK/oeBh8OkzwZOKE/bCs4iEig6ffsQdMmN7blwQBsw48MR3zH2+W84p+fxXDW4E0e2rM/Atmn8+J03Tt/mL0eT+tj5HFYlht25+fz7/6bww6fLAXju06up26g2uTt2A3B751FkZ20r1t7ld53FX/ufQn6+4583TuTbj5YBcOwpjbhr5MVUrV6ZGROX8s+bJgJwWJUYBo26mBZt/kTOhh0M7T2GdSuzAUjq25or7z0HgNcf+pwpo+YA0LBpPPeP7kVs3er89P0aHrnyXfJ2e/9J3fB8F9p3ac7O7bt57Kr3WPrD2v21aw95e/bk8+STtxIfX5e//e0Bxo17lQULZlG58mHUr9+Qyy+/iRo1arFy5U+MHv0vAJxzXHDB5Zx0Uod96kpLe5ANG9YxaNCLYdv66KP/MWPGx1SqVIlLLkmlZctTAFi1ahlvvvkcu3fn0qpVGy65JBUzY/fu3bzxxjOsXv0zNWvW5qqr7qBevQYAzJw5lY8+ehuAzp17067deQBs2LCOkSOfZPv2LTRpcjRXXnkrlSsfhnOOd95JY9Gi76hSpSp9+tzE4Ycfs1/26cGi07cPMc2OT+TCAW34e9s0rj1pGB0uPJbGx9Rl+YIM7r/4LeZN33duec76bdx90Ztc8+cXeazfu9z9+iX7rH+4z1iuPXk41548PGxgPrJlAuemnMhVx/+LO5JHcfOwC6nkf2luGX4RT6VOoE/z52nSvB5tk5sD0KX/KWzdtJM+zZ9n7LNfk/r4+QDUrlOdfg90ZGC7NP7e9iX6PdCRWvHVAPjb450Z++zXXHHs82zdtJMu/b0/9HYXNKdJ83r0af48T6dO4JbhF1XsDg2Yzz57n4YN9x5Qb9GiNYMGvchdd/2ThITGfPzxWAAaNTqC229/ljvvfIGBA4fw9tsvkp+fX1hu7tyvqVq1WontrF27iu+/n86gQS8ycOBgxowZzp49XvkxY4aRknI99933EllZa1i8+DsAZsz4iBo1anH//Wl07NiNCRNGArBt2xYmT36LW299mttue4bJk99i+/atAIwfP5KOHbtx331p1KhRi2+++RiARYu+IytrDffd9xK9e1/HmDHDK24nRov9dBbKgVZmcDaz48zsTv988Of95y0PxMZVpCNaJrBoRjq7duwmP38Pcz5fwVk9WrFqyXpW/7ShWP5lc9axYe0WAJYvzKRKtcocViUm4vbO6HYc00bPZ3duPutWZPPrso0c17YJdRvWomZsVRbN8OaqTxk1hzO7H+eXacnk17we8edjF9HmvKMAOC3pGGZ//DNbNu1ga/ZOZn/8c2FAP+XcZnw+dhEAk1+bw5ndWxa2X9C7XjQznVrx1ajbsFa599sfwaZN61m06Fs6dOhcmNay5SnExHifd9OmLcjOXg9AlSrVCtPz8nIJvUTCrl07+PTTcXTu3LvEtubPn8kpp5zNYYcdRr16DUlIaMTKlUvJydnIzp3badbsOMyMtm3PZd68GYVl2rb1esStW5/BTz/NxTnHkiXf06JFa2rWrE2NGrVo0aI1ixd/h3OOpUvn0br1GQC0bXse8+cX1DWDtm3Pxcxo1uw4duzYRk7OxoralVEhILG59OBsZncCo/EmUc8CvvWfv2Vmd+3/zas4yxdk8OezjyS2bnWqVj+M9l2OJfHw2IjKnnNJK5b9sJbduXt7SHf+pwcv/zCwcKihqITGsWStzil8nZWeQ0Lj2l56+uaQ9M0kNI71y9QuLJOfv4etObuIq1fDr6t4mbh6NdiavZP8/D37tBG+/b3tyL7efXcEXbtejZVw2+YZMz6mVas2ha9XrPiRRx75B48+egO9ev2jMFh/+OEbdOrUgypVqpbYVk7OBurUqV/4Oj6+PtnZG8jJ2UB8/L7pOTkbCssUrIuJiaFatZps27aZ7OwN1KmTUKyubds2U716rcLtio+vF7auouuCwmIqRbxEs7LGnPsDxzvndocmmtkzwELgsXCF/FMgUwGa81f+xCkVsKm/z6ol63nr8S956uN+7Niay89z15Gft6fMck1bJZD6eGf+r/NrhWkP9RnL+jVbqF6rCkPfSaHzlSfx0etz9y0Y5lfZlXCukCs4VyjMT7lzroQyJaWXUZfsY8GCWdSuHccRRxzD0qXzi62fMuVtYmJiOPXUjoVpTZu24O67h7Fu3WreeONZWrVqQ0ZGOllZa7n44gFs2JBRrJ4C4T4Ds5I+GyulTPhun5kR/mMuqKvkdUER7T3iSJX107EH7+pKRTXy14UVekpkNATmAhNf/Z7UNv/mpnNeZfPGHaQvLb3HkNA4lgffu4xH+77Lml82FaavX+MNd+zYmsvU/86jZdsmxcpmpW8m4fC4vXU1iWP9mi1eepPYkPRY1q/ZXKxMTEwlasVVZfPGHX560TJbyFm/nVrx1YjxewAFbXh15RRpP7Zwnez1yy+LmT9/FoMH92fkyCf46ad5jBrlnY07c+ZUFi78lr59bwsbDBs2PJwqVaqxdu1Kli9fwurVPzN4cH+ee+5OMjPX8MILg4qViY+vz6ZN6wtfZ2evJy6unt/rLZpet7BMwbr8/Hx27txGjRq1iY+vx6ZNWcXK1KoVy44dWwvHwrOzN4TUVa9IO3vXBUV5Tt+OZmUF55uBqWY2yczS/GUyMBW4af9vXsWKT6gJQOLhcZx9cUumvlW8p1SgVlw1Hv3wCkYM+oQFX68qTI+JqURcvRre88qV6HBhC5YvKN5T+nrCEs5NOZHDqsTQsGk8TZrXZcmsdDau28r2Lbm0aucF9KS+rflq/JLCMsn9WgNwTs9WfD/Nmx3y7ZRlnNb5GGrFV6NWfDVO63wM307xZn788OlyzunZCoDkfq35avxiv64fSerr1dWqXRO25exk47qtv3HPBVfXrv148MGRDB78CldddQfHHvtn+va9jUWLvuOTT95hwID7qFJl7wG+DRvWFQa9jRszycz8lbp1EznrrC489NBrDB78Cjff/DiJiX/ixhsfLdbeiSe25fvvp7N79242bFhHVtYajjyyOXFxdalWrTrLly/BOcesWdM48cT2AJxwQjtmzZoKwJw5X9G8+Z8xM4477hSWLPmB7du3sn37VpYs+YHjjjsFM6N58z8zZ85XAMyaNZUTT2znt9+OWbOm4Zxj+fIlVKtWI3jB2bugUURLNCt1WMM5N9nMjgXa4l1FyfDOE/825MyXQ8bQd1KIrVedvN17eO66D9mavZMzu7fkpn92IS6hJo9+eAXL5qzjjuRR9Li+HY2PqUvf+86h733euPLtnUexc1suT0zpS+XDKlEpphLfffIzH4zwjqqfflELWpzamP88MI0Vi7L4bMwCRi66gfw8r709e7z/KZ8d+D53jexBleqHMWvSUmZOWgrAxFe+5+7XL+bNpTexeeMOhqZ411nZsmkHox78jJe+9U5Sem3oZ2zZtAOAl+78mPtHX0r/h85j6Q9rmfjK9wDMmPgT7bo0581lN7Nr+24ev/q9A7ejA2Ds2JfIy9vNsGH3Ad5QRu/e1/Hzz4v45JOxxMRUxszo1evv1KoVV2pd8+fPZNWqpfz1r1fQqNGRnHzymTzyiDdWfemlf6dSJW9suFevf/Dmm8+Rm+tNpSsY5+7Q4Xxef/0Zhg5NpUaNWlx11R0A1KxZm6SkFJ566lYAkpMvo2ZN75hD165XMXLkE3z44Rs0aXIU7dt7BztbtTqVhQtnM3RoauFUusCJ7pgbMdvf45Ad7X4NdEoxgyZfcbA3QaJQUtKxvzu03nTZ6IhjzvNvpURtKP9DnYQiIn8AUT6WHCkFZxEJlCgfSo6YgrOIBEq0H+iLlIKziASLhjVERKJPQDrOCs4iEizRflp2pBScRSRQNOYsIhKFSrh+1SFHwVlEAkU9ZxGRaKTgLCISfTSsISIShTRbQ0QkCmnMWUQkCgUkNis4i0jA6PRtEZHoo2ENEZEoZDEKziIiUUc9ZxGRKBTtd9WOlIKziARLMGKzgrOIBIuGNUREolBQhjWCcZ6jiIjPKlnES5l1mcWb2VgzW2Jmi82sg5nVNbOPzWyp/1gnJP8gM1tmZj+aWVJIehszm++ve8Ei6N4rOItIoJhZxEsEngcmO+eOA04CFgN3AVOdc82Bqf5rzKwVkAIcDyQDw8wsxq9nOJAKNPeX5LIaVnAWkUAxi3wpvR6LBc4GXgFwzuU657KBbsBrfrbXgO7+827AaOfcLufccmAZ0NbMGgGxzrlvnHMOGBVSpkQKziISKOUJzmaWamazQ5bUkKqOArKA/5jZD2b2spnVBBo459YC+I+Jfv7GwOqQ8ul+WmP/edH0UumAoIgESnlmazjn0oC0ElZXBk4BbnDOzTSz5/GHMEpqOlwTpaSXSj1nEQmUSpUs4qUM6UC6c26m/3osXrDO8Icq8B8zQ/IfHlK+CbDGT28SJr3091FWBhGRQ0lFjTk759YBq82shZ90HrAImAD089P6AeP95xOAFDOrambN8A78zfKHPraYWXt/lkbfkDIl0rCGiARKBZ+EcgPwpplVAX4Brsbr1I4xs/7AKuBSAOfcQjMbgxfA84DrnHP5fj0DgZFAdWCSv5RKwVlEAqUiY7Nzbg5waphV55WQ/2Hg4TDps4ETytO2grOIBIoF5OIaCs4iEigBubSGgrOIBEsEszAOCQrOIhIo6jmLiESjgERnBWcRCZSAxGYFZxEJFl1sX0QkCgUkNis4i0iwaLaGiEgUCkZoVnAWkYDRmLOISBQKSGxWcBaRYFHPWUQkCumAoIhIFApIx1nBWUSCRcFZRCQKacxZRCQKBSQ27//gPHX34P3dhByCNufsONibIAGlnrOISBQyzdYQEYk+6jmLiEShgMRmBWcRCRb1nEVEolBAYrOCs4gEi3rOIiJRSNfWEBGJQuo5i4hEIc1zFhGJQgHpOCs4i0iwaFhDRCQKBeWAYKWDvQEiIhXJzCJeIqwvxsx+MLMP/NeDzexXM5vjL11C8g4ys2Vm9qOZJYWktzGz+f66FyyCxhWcRSRQzCJfInQTsLhI2rPOudb+MtFr11oBKcDxQDIwzMxi/PzDgVSgub8kl9WogrOIBEsFRmczawL8FXg5gpa7AaOdc7ucc8uBZUBbM2sExDrnvnHOOWAU0L2syhScRSRQyjOsYWapZjY7ZEktUt1zwB3AniLp15vZPDN71czq+GmNgdUhedL9tMb+86LppVJwFpFAKU/H2TmX5pw7NWRJ21uPXQhkOue+K9LEcOBooDWwFni6oEiYzXGlpJdKszVEJFAqxVTYbI0zgK7+Ab9qQKyZveGcu6Igg5mNAD7wX6YDh4eUbwKs8dObhEkvlXrOIhIoFTVbwzk3yDnXxDnXFO9A3zTn3BX+GHKBHsAC//kEIMXMqppZM7wDf7Occ2uBLWbW3p+l0RcYX9b7UM9ZRALlAJyE8oSZtcYbmlgB/A3AObfQzMYAi4A84DrnXL5fZiAwEqgOTPKXUpl38HD/yc/bs38bkEOSbvAq4dSpV/N3R9aJE5dEHHO6dDkuas9YUc9ZRAJFp2+LiEQhBWcRkSgUlGtrKDiLSKCo5ywiEoUCEpsVnEUkWHQnFBGRKKSes4hIFNKYs4hIFFJwFhGJQgGJzQrOIhIs6jmLiEShgMRmBWcRCRb1nEVEopBO3xYRiUIB6TgrOItIsCg4i4hEIQt7P9VDj4KziASKes4iIlFIBwRFRKKQptKJiEShgMRmBWcRCRb1nEVEolEwYrOCs4gEi3rOIiJRSLM1RESiUDBCs4KziASMhjVERKJQQGIzlQ72BhxI99x7D2eedQZdu11UmJadnU3/a68h+YIk+l97DTk5OQC8/8H79Li4R+Fy/AmtWLx4MQCpqQPo0aM7F3W9kMFDBpOfnx+2vbQRaSQlJ9Hlrxfw5ZdfFqYvXLiQbt27kpScxMOPPIxzDoDc3Fxuve0WkpKT6J3Sm19//bWwzLhx40i+IInkC5IYN25cYXp6ejq9U3qTfEESt952C7m5uQA453j4kYdJSk6ie49uLFq0sIL2YrBkZKzjH9en0vuyi7msT0/efvu/AEyd9jGX9elJhzPasHjxon3KLF32E9cO6MdlfXrS54pe7Nq1C4CB1w2gV0oPruyXwpX9Uti4cWPYNl8b9So9L+1Kr5QezJjxdWH6kiWL6HNFL3pe2pWnn3lin+/FPffdSc9Lu3LNtX1Zs3ZNYZkPJ75Pz17d6NmrGx9OfL8wfc2aX7nm2r707NWNe+67k927dwPe9+LpZ56g56Vd6XNlL5b8uLgC9mJ0MbOIl2j2hwrOPbp3J+2ltH3SXn55BO3bdWDypCm0b9eBlxfl/hkAAA6oSURBVF8eAcBFF17Ee+++x3vvvsfjjz1O48aNadmyJQDPPPMs7703jgnj32fTxo1MmTK5WFvLli1j0sSJvD/hfdJeGsGDDw0tDOJDhw5hyOAhTJ40mZUrV/LFl18A8M47Y4mNjWPK5Cn069uXp595CvB+QIYNf5HRb73N26PHMGz4i4U/Ik8/8zT9+vZl8qQpxMbG8e677wAw/YvprFy5ksmTJjNk8BCGDB26H/booS8mJoYbb7iFt996l5fTXmPsu2NYvvwXjjrqaB575Clatz5ln/x5eXkMHnIvd95xD2+9OZZhL6ZRufLef0CHPPAwr782mtdfG03dunWLtbd8+S98/MkU/vvmWJ575l88+dRjhd+LJ558lLvuvIf/jRnP6vRVfOMH7gnvjyO2dixj/zeBy3r34cVhzwOQszmHV15N45WXR/Hqy6/zyqtpbN68GYAXh73AZb37MHbMeGJrxzLhfe8H/ZtvvmJ1+ir+N2Y8g+68lyeefLTid+pBZhb5Es3+UMH51FNPIy4ufp+0aZ9Oo3v3bgB0796NqdOmFiv34cQP6dLlr4Wva9WqBXh/qLt37w77Czzt02lc0KULVapUoUmTJhxx+BHMnz+PrKxMtm7bSuvWJ2NmdOvajalTvTanTZtG927etnTunMSMGTNwzvHVV1/RocPpxMfHExcXR4cOp/Pll1/inGPmzBl07pzkbX+3fevq1rUbZsZJJ7Vmy5bNZGVl/t5dGDj16ydwXAvvR7dmzZo0PbIZmVmZNGt6FEce2bRY/lmzZnDM0c1p3vxYAOLi4omJiYm4velffMb5f0miSpUq/OlPjWnSpAmLFi1g/fostm3bxoknnoSZ0SX5QqZP/xSAL774jC4XXAhAp07nMXv2t95nP+Mb2p7WjrjYOGJjY2l7WjtmzPga5xyzv/uWTp3OA6DLBXvrmv7FZ3RJvhAz44QT/szWrVtYvz7rN++/aFSpkkW8RLM/VHAOZ8OGDSQkJAKQkJAY9l/RyZMn8dcuXfZJGzDgWs46+0xq1qxZGBxDZWZk0LBhw8LXDRo2ICMjk4yMTBo0aLBPemZmBgAZmRk0bNgIgMqVK1O7dm2ys7PJyMygUUhdDRs0ICMzg+zsbGrXji3suTVo0JAMv67MzCLtN2hIRoaCc2nWrF3DT0t/5ITjTygxz6rVKzEzbrr5H/S96nJef2PkPusfengwV/ZL4dX/jCgclgiVlZVJYuLezz8xsQFZWVlkZWWRkJgYkp5Y+GOalZVFgwbeZ1m5cmVq1axFTk42WeszSUxsuG9d6zPJycmmdq1ahd+LgjYK2w/5/iUmJBauC4o/fM/ZzK4uZV2qmc02s9kjRqSVlO2QMHfeXKpVq1bYUyowYsTLfP7ZdHJzc5k5c0axcuH+MM0sfLo/+Sd8mXLWZaXVFeXfxoNo+/btDLr7dm6+6TZq1qxVYr78/HzmzpvDkMEPk/bvV/j880/5dvZMAIYMfpg33xjDv4e9wpw5PzBp8ofFyof7XCjhsyyIHo7IP38wwldV8L0osZnAqKgxZzOrZmazzGyumS00syF+el0z+9jMlvqPdULKDDKzZWb2o5klhaS3MbP5/roXLII/xt/Tcx5S0grnXJpz7lTn3KkDBqT+jib2v3r16oX0UDKLjRNOmjhxnyGNUFWrVqVTp3OZNm1asXUNGjZk3bp1ha8z1mWQmJhAw4YNyMjI2Ce9oMfUsEFD1q1bC3hDJlu2bCEuLp6GDRqyNqSudRkZJCYkUqdOHbZs2UxeXp5XV8Y6Ev3/Aho0KNJ+xjoSExMi3zF/IHl5uxl09+0kde5Cp47nlZo3MaEBJ5/chvj4OlSrVp3TTz+TH39c4q/z9r3331QyixYtKF4+ce9/SuD9h5NQv77XU87MDEnPJKF+QmG9GRnr/G3NY+u2rcTGxpGY0IDMzHVF6kogPj6eLVu3Fn4vMjMzqF+/vt9+Ipkh37/MrEzq19f3ogS7gHOdcycBrYFkM2sP3AVMdc41B6b6rzGzVkAKcDyQDAwzs4Ixr+FAKtDcX5LLarzU4Gxm80pY5gMNSit7qOjU6VzGjRsPwLhx4zm307mF6/bs2cOUj6bQ5YK9Qxrbtm0rDOZ5eXlM/+JzmjU7Kky9nZg0cSK5ubmkp6ezctVKTjzxzyQkJFKzRk3mzp2Dc47xE8Zz7rnnFpYZN97blo8+mkK7du0xM8444wy+/vorcnJyyMnJ4euvv+KMM87AzGjbth0ffTTF2/7xe+s6t1Mnxk8Yj3OOuXPnULtW7cLhG9nLm9UylKZNm3H5ZVeUmb9duw4sW7aUnTt3kJeXx/c/fEezpkeRl5dHdvYmwAv2X331BUcddUyx8medeQ4ffzKF3Nxc1qz5ldXpq2nV6gTq10+gRo0aLFgwD+ccEyd/wNlndfTKnHUOEyd9AMCnn07l1DanYWa0a9+BmbNmsHnzZjZv3szMWTNo174DZkabU07l00+94w8TJ33AWQV1nXkOEyd/gHOOBQvmUatmrcAF54rqOTvPVv/lYf7igG7Aa376a0B3/3k3YLRzbpdzbjmwDGhrZo2AWOfcN877d2dUSJkSlTXPuQGQBGwq+v6Br4tnj263334bs76dRXZ2Np3O7cj1113PgGuv5ZZbb+Wdd8fSqNGfePaZZwvzz549mwYNGnD44YcXpu3YsYPrrruO3N255Ofn065de3r37g14B+EWLlzADTfcSPNjmpOUnMxFXS8kJiaGe++9r/DA0f33P8Dd9wxi165dnHXmWZx91tkAXHJJT+68606SkpOIj4vjqaeeBiA+Pp6//30gvXr3AmDgwH8QH+8d2Lzt1tu4/fbbeP6FF2jZsiWXXNITgLPPPofp06eTfEES1apV4+GHHtm/O/cQNXfeHCZN/pCjjz6GK/ulADDwb9eTuzuXp595guzsTdx6+40c2/xYnn9uGLGxsVyW0oer+1+JYXQ4/QzOOOMsduzYwU23XEdeXh579uzhtFPb0a1rDwCmf/E5S5YsInXAQI466mjOO/d8Lru8JzGVY7j9trsKvxd3/N/dPPjQA+zatYsOHU6nQ4czALjowu4MGXofPS/tSmxsHA8O9WZYxMXGcc3V13JNf+9Hpf/VA4iLjQPgun/cyH33D+KltBc59tjj6HqRFwtOP/1Mvv7mS3pe2o1q1apx7z2DD9i+PlDKM0xjZql4PdoCac65tJD1McB3wDHAi865mWbWwDm3FsA5t9bMCno9jYHQMc50P223/7xoeunbFn7cqnDDXgH+45z7Msy6/zrnLi+rgfy8PSU3IH9Ym3N2HOxNkChUp17N3z0C/ssvGyKOOUcdVS+i9swsHngPuAH40jkXH7Juk3Oujpm9CHzjnHvDT38FmAisAh51zv3FTz8LuMM5d1HRdkKV2nN2zvUvZV2ZgVlE5EDbHzd4dc5lm9lneGPFGWbWyO81NwIKDhakA4eHFGsCrPHTm4RJL9UffiqdiASMlWMprRqzBL/HjJlVB/4CLAEmAP38bP2A8f7zCUCKmVU1s2Z4B/5m+UMgW8ysvT9Lo29ImRLp2hoiEigVODWwEfCaP+5cCRjjnPvAzL4BxphZf7whi0sBnHMLzWwMsAjIA65zzhVc22EgMBKoDkzyl9LfR2ljzhVBY84SjsacJZyKGHNeuWJTxDHnyKZ1onaWt3rOIhIoQTmpRsFZRAIlKGfCKjiLSLAEIzYrOItIsAQkNis4i0iwBGVYQ/OcRUSikHrOIhIo0X4R/Uip5ywiEoXUcxaRQAnIkLOCs4gEy/648NHBoOAsIsESjNis4CwiwRKQ44EKziISMAEZdFZwFpFACUZoVnAWkYAJSMdZwVlEAiYg0VnBWUQCJRihWcFZRAImKBc+UnAWkUAJSGzWtTVERKKRes4iEihB6TkrOItIwAQjOis4i0igqOcsIhKNFJxFRKJPUC4ZqtkaIiJRSD1nEQmUoIw5q+csIhKF1HMWkUDR6dsiItEoGLFZwVlEgiUgsVljziISMGaRL2VWZa+aWaaZLQhJG2xmv5rZHH/pErJukJktM7MfzSwpJL2Nmc33171gEYy9KDiLiJRsJJAcJv1Z51xrf5kIYGatgBTgeL/MMDOL8fMPB1KB5v4Srs59KDiLSKBYOZayOOemAxsjbLobMNo5t8s5txxYBrQ1s0ZArHPuG+ecA0YB3cuqTMFZRALFzMqzpJrZ7JAlNcJmrjezef6wRx0/rTGwOiRPup/W2H9eNL1UCs4iEizl6Do759Kcc6eGLGkRtDAcOBpoDawFng5puShXSnqpFJxFJFAqclgjHOdchnMu3zm3BxgBtPVXpQOHh2RtAqzx05uESS+VgrOIBMt+js7+GHKBHkDBTI4JQIqZVTWzZngH/mY559YCW8ysvT9Loy8wvqx2NM9ZRAKm4mY6m9lbQEegvpmlAw8AHc2sNd7QxArgbwDOuYVmNgZYBOQB1znn8v2qBuLN/KgOTPKX0tv2Dh7uP/l5e/ZvA3JI2pyz42BvgkShOvVq/u7ImrszL+KYU6Va5ag9Z0U9ZxEJlIBcWkPBWUQCJiDRWQcERUSikHrOIhIoAek4q+csIhKN1HMWkUAJysX29/tUOtnLzFIjPD1U/kD0vZBwNKxxYEV6URX5Y9H3QopRcBYRiUIKziIiUUjB+cDSuKKEo++FFKMDgiIiUUg9ZxGRKKTgLCIShRScDxAzS/Zvl77MzO462NsjB59//7lMM1tQdm75o1FwPgD826O/CFwAtAIu82+jLn9sI4Hkg70REp0UnA+MtsAy59wvzrlcYDTebdTlD8w5Nx3YeLC3Q6KTgvOBUdIt00VEwlJwPjB+063RReSPS8H5wCjplukiImEpOB8Y3wLNzayZmVUBUvBuoy4iEpaC8wHgnMsDrgemAIuBMc65hQd3q+RgM7O3gG+AFmaWbmb9D/Y2SfTQ6dsiIlFIPWcRkSik4CwiEoUUnEVEopCCs4hIFFJwFhGJQgrOIiJRSMFZRCQK/T8n4V7O0MqS2gAAAABJRU5ErkJggg==\n",
"text/plain": [
"
"
]
},
"metadata": {
"needs_background": "light"
},
"output_type": "display_data"
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"-----------------------------------------\n",
"\n",
"Executing RFE\n",
"Please wait.........\n",
"### RFE selected columns:\n",
" Index(['funded_amnt_inv', 'term', 'int_rate', 'sub_grade', 'title', 'dti',\n",
" 'initial_list_status', 'total_rec_int', 'recoveries', 'last_week_pay'],\n",
" dtype='object')\n",
" RFE Selected Features\n"
]
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAqcAAAGwCAYAAACU3sy6AAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADt0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjByYzEsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy/xvVyzAAAgAElEQVR4nO3deZQldX3//+eLRUAYGVlE0eAgoogg26AiIqBGE6MiLnEhmnFD44IkP1x++pVgjBHjrnyNIipR0SjgghjFjUVRhAEGBtyVMSgqwYVNQBje3z+qWi6X2923t7nV3c/HOff0vZ/6VNW7qu7t++raOlWFJEmS1AXrjboASZIkaYzhVJIkSZ1hOJUkSVJnGE4lSZLUGYZTSZIkdYbhVJIkSZ1hOJU0UJIVSSrJilHXIklaPAyn0jrQhrzex9okv0tyRhsCM+oa57skRw1Yz72PNaOucTra2s+YxnjHT7I+pjzN6eqpZdm6mudsSXLAul5fo+IfpOqKDUZdgLTIvKH9uSFwX+BgYH9gOfCyURW1wJwJnDGg/Q/ruI6u+DywakD7mnVchyQNxXAqrUNVdVTv6yT7AmcBL0ny9qq6bCSFLSxn9K/nRe5zVXX8qIuQpGF5WF8aoao6G/gBEGCv3mFJ9kry7iQXtacA3Jjkx0nenuSu/dPqPSSX5MD2lIFrk1yT5ItJHjCohiT3TXJikt8nuT7Jt5P8zUR1t7WdnOTKJDcl+XmS9yW5x4C+Y4d0t0/ysiTfa5dlTZLXjp3SkORpSc5ta7gyyTFJNp7C6pySaS7DfZK8PMnFSW7oPdSbZIskb07y/XbY1Um+nuQxA6Z3pySHJbmgXe9/bNfH55M8uu2zIsnY/5fev++Q/FFzsD6emeT0tp4b2+X4P0k2GtD3SUk+nuRH7fa6Lsn57TKt19e3gL9vX1426DSLdtnXMEBuO13jgP7ptu/xuyc5Lskv05wus6Knz0OSnJTk10n+lOTyJB9Isu1011PPtHs/b3+Z5JvtevjfJB9JsrTtt0eSU9v1el2SUzLg9IZ2WSrJRkn+Ncll7fvyp0n+OcmdxqnjUUm+nNt+R/woydFJNp9gHndKcmSSH7bzOL59L3+k7fqRvvfbsnb8bdvxzu5Zp1ck+UQG/H5Jsqwd//j2+X8luaqtc2WSx0+wfp/efn7GlmtNkk8mWT6g79DvXc0P7jmVRm/sfNOb+9pfSHPY/0zga8D6wJ7APwF/neQhVXXtgOk9HjgI+BLwfmBn4HHA3kl2rqqr/jzjZEfgO8CWbf9VNKcbfK59fcdimy+Uk9u6TwJ+ThOs/wE4KMm+VbVmwKhvAw4AvgB8BXgi8CbgTkl+BxzdzvebwF8CL22X+R8G1TETM1iGdwP7AV8E/htY207v3jSnEixr6/8ysCnNtvhykhdV1Qd7pnM88EzgEuCjwA3AtsDDgb+i2d6raE4D+ee2vuN7xj9juss+SJIPAc8DfgF8huYUiIcCbwQeleQvq+qWnlGOBm4Fvgv8EtgceCTN+tkbeHZP3zcATwJ2a4ePnV4xG6dZbAGcA1zX1n0r8Jt2mZ4LfBC4CTgFuBzYEXgB8IQkD62q/5mFGp5Is51Ppfm8PQxYAWyf5DXA12neEx8CdgWeAOyQZNequnXA9D5Nsw5PovmdcBBwFLA8yROrauwPFpK8CPgP4HrgROBKms/Yq9tl3LeqBq3nk9t5fInmM3clzXvqD+38+k8FGZvGI4DXAKe307iOZp0+FXhiO7+LBszv3sC5wM+Aj9Fst6cDn0/y6Ko6vWeZQhOS/x64ima7/i9wL+BA4IfAyp7+U33vaj6oKh8+fMzxA6jm43aH9kfQBJybgHv0Dbs3sP6AcZ7fTu/Vfe0r2vZbgEf1DXtzO+xVfe1fadtf0dd+0FjNwIqe9s1ovjDWAvv1jfPqtv9X+tqPb9vXAPfsaV/aTut6mi+fB/QM2wj4Xrte7jbkOj6qnc8Z7fP+x7JZWIZfAtsPmPcZNMHoGX3tS2m+5G8AtmnbNm/7rhxn+2454L1zxjTec2M1f26c9bG0733zGWCTcdZp//tjhwHzWw/4z7b/Q8apZdk4ta4B1kyyXQ8Y9JmiCfcb9A27H/An4Ce977l22CPbbf/ZIdfjAYO2Abf/vO3ftx6+2g77HXBI33gfaocdNOA9VMCPgLv2tG9M8wdkAc/uab83zefjGmCnvmm9r+1/7DjzuBjYasCyji3TinHWxd2AJQPad6MJql/qa1/Ws53+uW/YY9v2/+5rP7RtPxfYvG/Y+vT8npzOe9fH/HiMvAAfPhbDo+cX9FHt403Ap9ov0FuBl09hWgGuBr7R1z72i/rjA8bZvh12Uk/bvdq2nzE4JI19ka3oaTukbfvEgP4bAJe1w7fraT++bXv+gHE+3A77lwHD/rkdtv+Q62Xsy2i8xwGzsAx3+KJrv5gLOHGcusaC/kva13dpX58NZMj3zhnTeM+N1TzeY1nb70KaPXRLB0xjfZogf+6Q89yznfaR49SybJzx1jC9cDrwjxfgne3wvxlnmp+lCZV3CFoD+h4waBtw2+ftYwPGeU477KwBw/ZncFg7g74AOqCG03vaXte2/duA/nelCa03ABsNmMdB/eP0LdOKQcMnWU+nADcCG/a0LeO2P0wH/Y75OXBVX9vqdpw9hpjnrL13fXTr4WF9ad36577XY6HtI/0dk2wIvAh4Bs2h+c25/Xni9xxnHisHtF3e/uw9V3WP9ue3qmrtgHHOoPki7bVn+/Mb/Z2r6pYkZ9F8Ie0B9B8yHVTXFe3P8wcM+2X7814Dhk3kDTXxBVEzWYZzB0xvn/bn5hl8LujW7c8HtPO4JskXaA7vrkpyMs1h3+9W1R8nqHu6nlvjXBCV5M404foq4PAMvqPZTWO194y3JfBKmtNF7kNzCkOv8d6bs21NVV05oH1sm+yfZO8Bw+9GE17ux+D33lTM9vv6zAFt36QJ03v0tE30Pv59kgtpjszsBPQfah/0Ph5KmvPRX0xzh5GtuOPpgVsBv+prWzXO75jLuW1bkWRTYBfgN1V14SR1TOu9q/nBcCqtQ1U1dvHPpjS/lD8EvD/Jz6uq/0vmUzTnnP6M5hywX9P8sgU4nObQ9yB3OMesDV3QfCGPGbtg4jfjTOfXA9rGxun/8qGvfemAYVcPaLtliGEbjjOv6ZrJMgxaJ1u2P/+yfYxns57nT6c5heBZ3HZ7sRuTnAQcUVXjbZPZdleaPfFbc8c/nAZqL/Q5j2Zv/Lk0h9V/R7O9lgKvYPz35mwbtD3gtm3yyknG32yS4cOY7ff1HbZ9Va1N8luaUD1mtt/Hk0pyGM15w7+nOXXhf4A/0vyRPXZe8aBtP975xbdw+z+4x2r95YC+/ab83tX8YTiVRqCqrge+luQJwAXAfya5/9ies/aK1INpLox5XFX9+WKpNFdDv2oWyhj74txmnOF3n2CcQcMA7tHXr4tmsgw1wfReUVXvGaaAqrqB9hSPJH9Bs4drBfB3NHtt9xtmOrNgrPYLq2rPCXve5gU0wfQOe6iT7EMTTqfqVmDg1egMDldjBm0PuG25Nq+qa6ZRzyhtQ98e+yTr0wTu3mXpfR9fOmA6476Pq2q89TauJBvQ/CH1a2DPqvpV3/B9Bo44NWMhdpg979N572qe8FZS0ghV1cU0VxTfC/jHnkH3bX+e0htMWw8GNpmF2Y8dNnt4++XX74AJxrnDsPbL6+HtywtmWtwcmu1lOKf9Oa1AWVWXV9UJNBeI/Jhme2zZ0+VWbr/He9ZU1XU0weaBSbYYcrSx9+bJA4b1nwYyZuyQ7njL8Xtgm/ZUln53uHXQEGa0TUZs0Drcj2ZnUu+h7onex0uB3WnOAf3+FOY90XbaiuYPhW8PCKabcdtpBtPW/tF+Cc17YY9J+k7nvat5wnAqjd6/0nyJHJHb7l+6pv15QG/HJHcD/u9szLSqfkFzaG57+v47VZKDGPwl+TmaQ7jPTPLQvmGH05x/+LWanVv0zJVZXYaqWklzTuCTkzxvUJ8ku7bbjiRbJ3nIgG6bAktoDnX+qaf9t8BfDFPLNL2DZq/lh9tQcztJ7pqkN3isaX8e0NdvD+D/H2cev21/bjfO8HNpwtdz+6a5Ath3/NLHdQzNhTLvTHK//oHtfT67Glxf3/N7gDT3+n1z+7L33PSP0yzjy5Pcl9t7I82Fdx+vqpsY3kTb6UqaQ/h7tWF0rL4NaQ71bzWF+Uxk7OjDB9J3r9Yk6+X29yGe6ntX84SH9aURq6pfJvkAzeHQV9F8wZ9HczX3k5N8G/gWzeG+v6a5z98V40xuql5Kc5uad6W5WfxF3PZvVccu2umt9bo2gJ0InJnkRJpDkHsBj6E55PeiWaptTszRMjyL5sKUD7Xn5X2X5hDlvYAH0VzksQ/NF/w9gXOSfJ9m7+zlNEHi8TSHaN9Tt79/7deBZ7QXUZ1PE17Pqqqzprrsg1TVh5PsBbwE+GmS02jWxxY0f7g8giYUvbgd5aM053K+K8mBNHt7d2zr/wzN+bT9vt6O88H2vNrrgD9U1THt8PfSBNP/SPIomnWyG809Q09tpz2VZfpBu40/DFya5Ms0t2jakCZ47Udz+7KdpjLddeT7NDX33ud0B5p7635srFNVrUlyOM0fqxck+TTNMu1P8177Ac15zVPxHZoAeni7N3Ls/Nf3VtXVSd5Dc5/T1Uk+TxMMD6R5r5zePp+p42iOXjwH+HE7n/+luQ/wI2m26VEwrfeu5otR3y7Ah4/F8GCc+5z2DN+G5n6f13Pb/TC3oLlf4RqaPas/Bf4NuDMDbr3D5PcoHHhLIpowehJNmLqe5gvqbyaaHs0NvD9L86XxJ5ovhP8Ath3Q93jGuY0Q49wmaJjlmWBaRw3Zf1aWoafPEuC1NAHyOprb+FxGEyoOBTZt+y0FjqQJs7+kucjtVzR3R3gmfbeXorkI5hM0QWHtsMvYU/Ow62/sRvJXtuvj1zR7NP+VO95Hc2eaWwdd2b5nzqc5F3VZO8/jB0z/n2iC101tn/7378Np/pXvH2nOrfwiTbAf+B4Z7/3c12fXdj38vJ3v72gOG38AeOSQ6+WAQfOa6P3ZM84dttN464jbbvO0UbvOL2tr/hnNBT8bjVPfY2juV/z7tv9PgH9n8O2VzmCC30Ntn7+i+R1wHXe87dgG7Xb8Hs37+9c0gfneDPiMTPR+mKwemlu+nUlzbumN7fo4geZ812m/d33Mj0faDStJkkYkzb8P3b/aO3pIi5nnnEqSJKkzDKeSJEnqDMOpJEmSOsNzTiVJktQZ3kpqAdlqq61q2bJloy5DkiRpUueff/5VVbV1f7vhdAFZtmwZK1euHHUZkiRJk0ry80HtnnMqSZKkzjCcSpIkqTM8rL+AfP8Xv2WvV3501GVIkqR56vy3PmfUJbjnVJIkSd1hOJUkSVJnGE4lSZLUGYZTSZIkdYbhVJIkSZ1hOJUkSVJnGE4lSZLUGYZTSZIkdYbhVJIkSZ1hOJUkSVJnGE4lSZLUGYbTOZZkaZKXtM+3TXJS+3z3JI/r6bciyTGjqlOSJKkLDKdzbynwEoCquqKqntq27w48btyxJEmSFqENRl3AInA0sEOSVcCPgQcAewL/AmyS5OHAm3tHSLI18H5gu7bp8Ko6e92VLEmSNBruOZ17rwF+WlW7A68EqKo/AUcCn6qq3avqU33jvBt4Z1XtDTwFOG68iSc5NMnKJCtv+eO1c7MEkiRJ64h7Trvp0cDOScZe3yXJkqq6Q/qsqmOBYwE2vfv2te5KlCRJmn2G025aD9inqm4YdSGSJEnrkof15961wJIptAN8BXjZ2Isku89BXZIkSZ1jOJ1jVfVb4OwklwBv7Rl0Os2h+1VJnt432mHA8iQXJ/ke8OJ1VK4kSdJIeVh/HaiqZw1o+x2wd1/z8e2wq4D+wCpJkrTguedUkiRJnWE4lSRJUmcYTiVJktQZhlNJkiR1huFUkiRJnWE4lSRJUmcYTiVJktQZhlNJkiR1huFUkiRJnWE4lSRJUmf470sXkAfca0tWvvU5oy5DkiRp2txzKkmSpM4wnEqSJKkzDKeSJEnqDMOpJEmSOsNwKkmSpM4wnEqSJKkzvJXUAvKnX13K//zLrqMuQ5IWne2OXD3qEqQFwz2nkiRJ6gzDqSRJkjrDcCpJkqTOMJxKkiSpMwynkiRJ6gzDqSRJkjrDcCpJkqTOMJxKkiSpMwynkiRJ6gzDqSRJkjrDcCpJkqTOMJxKkiSpMzoXTpNcN83xDk9y59muZ5J5Hp/kqetynpIkSQtZ58LpDBwOrNNwKkmSpNnV2XCaZLMkX09yQZLVSQ5q2zdN8sUkFyW5JMnTkxwGbAucnuT0cab3t0ne0T5/RZKftc93SPKt9vleSc5Mcn6S05Lco6fPl9v2bybZacD039juSR24TpOsSfKWJOe2j/u27U9I8t0kFyb5WpJtkqyX5MdJtm77rJfkJ0m2GjDdQ5OsTLLyd9evnfqKliRJ6pDOhlPgRuDgqtoTOBB4e5IAfwVcUVW7VdUuwJer6j3AFcCBVXXgONM7C9ivfb4f8Nsk9wQeDnwzyYbAe4GnVtVewIeBN7X9jwVe3rYfAbyvd8JJ/h24G/Dcqrp1gmW6pqoeDBwDvKtt+xbw0KraA/gv4FXtND4OHNL2eTRwUVVd1T/Bqjq2qpZX1fItNl1/gllLkiR13wajLmACAf4tySOAW4F7AtsAq4G3JXkLcGpVfXOYiVXVr9u9sUuAvwA+ATyCJqh+Brg/sAvw1SYDsz7wqySbAQ8DTmzbATbqmfTrge9W1aFDlPHJnp/vbJ/fC/hUu5f2TsBlbfuHgc/ThNjnAR8ZZjklSZLmsy7vOT0E2BrYq6p2B34DbFxVPwL2ogmpb05y5BSm+R3gucAPgW/SBNN9gLNpwvClVbV7+9i1qh5Ds47+0NO+e1U9oGea5wF7JdliiPnXgOfvBY6pql2BFwEbA1TV5cBvkjwSeAjwpSkspyRJ0rzU5XC6OXBlVd2c5EDg3gBJtgX+WFUfB94G7Nn2vxZYMsk0z6I5LH8WcCHN6QI3VdXVNIF16yT7tPPZMMkDq+oa4LIkT2vbk2S3nml+GTga+GK7V3YiT+/5+Z2e5fxl+/zv+/ofR3N4/9NV5QmlkiRpwevyYf0TgC8kWQmsAn7Qtu8KvDXJrcDNwD+07ccCX0ryqwnOO/0mzSH9s6pqbZLLx6ZbVX9qbwv1niSb06ybdwGX0uzF/Y8k/wfYkObc0IvGJlpVJ7bB9JQkj6uqG8aZ/0ZJvkvzR8Ez27ajaE4Z+CVwDrB9T/9TaA7ne0hfkiQtCqmqyXtpxpKsAZYPuqhpgnGWA++sqv0m7Qw86J6b1Kkvuu80K5QkTdd2R64edQnSvJPk/Kpa3t/e5T2ni1qS19DsFT5ksr6SJEkLxYIMp+2h8436mp9dVXP+p22Sz3L7Q/MAr66qZVOZTlUdTXMuqyRJ0qKxIMNpVT1khPM+eFTzliRJmu+6fLW+JEmSFhnDqSRJkjrDcCpJkqTOMJxKkiSpMwynkiRJ6gzDqSRJkjpjQd5KarG60z0eyHZHrhx1GZIkSdPmnlNJkiR1huFUkiRJnWE4lSRJUmcYTiVJktQZhlNJkiR1huFUkiRJneGtpBaQH1z5A/Z9776jLkOS1qmzX372qEuQNIvccypJkqTOMJxKkiSpMwynkiRJ6gzDqSRJkjrDcCpJkqTOMJxKkiSpMwynkiRJ6gzDqSRJkjrDcCpJkqTOMJxKkiSpMwynkiRJ6gzDqSRJkjpjnYTTJN8eos9xSXZun792GuNfN8GwZUkuaZ8vT/KeSfo+a7L5DRhvaZKXzFY/SZKkxWidhNOqetgQfV5QVd9rX762b9ik40+hlpVVddgEXZYBUw6nwFJgmNA5bD9JkqRFZ13tOb2u/XlAkjOSnJTkB0lOSJJ22BntXs2jgU2SrEpyQt/4myX5epILkqxOctA0ajkgyant8/3b+axKcmGSJcDRwH5t2z+OM40HJjm37XNxkh3b8XZo2946Qa39/f5cTzvtY5KsaJ8fneR77TzeNk4thyZZmWTlzdfdPNXVIUmS1CkbjGCeewAPBK4Azgb2Bb41NrCqXpPkZVW1+4BxbwQOrqprkmwFnJPklKqqadZyBPDSqjo7yWbt9F8DHFFVj59gvBcD766qE5LcCVi/HW+XsbqTbDCo1gH9Dhg0gyRbAAcDO1VVJVk6qF9VHQscC7DZdptNdz1IkiR1wiguiDq3qn5RVbcCq2gOow8rwL8luRj4GnBPYJsZ1HI28I4khwFLq+qWIcf7DvDaJK8G7l1VN8xBrdfQhOXjkjwZ+OMUxpUkSZqXRhFOb+p5vpap7b09BNga2Kvd8/gbYOPpFlJVRwMvADah2bO505DjfQJ4InADcFqSR86g1lu4/XbYuJ3HLcCDgZOBJwFfHqY2SZKk+WwUh/WHcXOSDauq/yTKzYErq+rmJAcC957JTJLsUFWrgdVJ9gF2Ai4Hlkwy3n2An1XVe9rnDwIu6htvvFqv7ev3c2DnJBvRBNNHAd9qTzO4c1X9d5JzgJ/MZFklSZLmg66G02OBi5NcUFWH9LSfAHwhyUqaUwJ+MMP5HN4Gx7XA94AvAbcCtyS5CDi+qt45YLynA3+X5Gbg18C/VNXvkpzd3rLqS8BbBtVaVb/t7VdVr0zyaeBi4MfAhe08lgCfT7IxzSkCAy/OkiRJWkgy/WuJ1DWbbbdZ7fbK3UZdhiStU2e//OxRlyBpGpKcX1XL+9v9D1GSJEnqjK4e1p+WJLsCH+trvqmqHjLN6T2W5vB8r8uq6uDpTE+SJEkTW1DhtL24adD9Uac7vdOA02ZrepIkSZqYh/UlSZLUGYZTSZIkdYbhVJIkSZ1hOJUkSVJnGE4lSZLUGYZTSZIkdcaCupXUYrfT3XbyP6VIkqR5zT2nkiRJ6gzDqSRJkjrDcCpJkqTOMJxKkiSpMwynkiRJ6gzDqSRJkjrDW0ktINf+8Iec+Yj9R12GpFm2/1lnjroESVpn3HMqSZKkzjCcSpIkqTMMp5IkSeoMw6kkSZI6w3AqSZKkzjCcSpIkqTMMp5IkSeoMw6kkSZI6w3AqSZKkzjCcSpIkqTMMp5IkSeoMw6kkSZI6w3A6jiTfHqLP4UnuPEvzW5Fk29mYliRJ0nxlOB1HVT1siG6HA0OH0yTrTzB4BWA4lSRJi5rhdBxJrmt/HpDkjCQnJflBkhPSOIwmTJ6e5PSJppPkX5J8F9gnyZFJzktySZJj22k9FVgOnJBkVZJNkuyV5Mwk5yc5Lck9xpn+oUlWJll59c03z8GakCRJWncMp8PZg2Yv6c7AfYB9q+o9wBXAgVV14ATjbgpcUlUPqapvAcdU1d5VtQuwCfD4qjoJWAkcUlW7A7cA7wWeWlV7AR8G3jRo4lV1bFUtr6rlm2+44ewsrSRJ0ohsMOoC5olzq+oXAElWAcuAbw057lrg5J7XByZ5Fc3pAFsAlwJf6Bvn/sAuwFeTAKwP/Gq6xUuSJM0XhtPh3NTzfC1TW283VtVagCQbA+8DllfV5UmOAjYeME6AS6tqn2nWK0mSNC95WH9mrgWWTKH/WBC9KslmwFPHmdYPga2T7AOQZMMkD5xpsZIkSV1nOJ2ZY4EvTXRBVK+q+gPwQWA18DngvJ7BxwPvb08bWJ8muL4lyUXAKmCYuwdIkiTNa6mqUdegWXL/JUvq2D32HHUZkmbZ/medOeoSJGnWJTm/qpb3t7vnVJIkSZ3hBVGzpL2P6UZ9zc+uqtWjqEeSJGk+MpzOkqp6yKhrkCRJmu88rC9JkqTOMJxKkiSpMwynkiRJ6gzDqSRJkjrDcCpJkqTOMJxKkiSpM7yV1AKy5P739z/JSJKkec09p5IkSeoMw6kkSZI6w3AqSZKkzjCcSpIkqTMMp5IkSeoMw6kkSZI6w1tJLSBX/uJqjvn/vjDqMqR572Vvf8KoS5CkRcs9p5IkSeoMw6kkSZI6w3AqSZKkzjCcSpIkqTMMp5IkSeoMw6kkSZI6w3AqSZKkzjCcSpIkqTMMp5IkSeoMw6kkSZI6w3AqSZKkzjCcSpIkqTPmbThNsjTJSybpsyzJs4aY1rIkl8xedZNLclySnSfp86TJ+kiSJC0k8zacAkuBCcMpsAyYNJxORZINZmM6VfWCqvreJN2eBBhOJUnSojGfw+nRwA5JViV5a/u4JMnqJE/v6bNf2+cf2z2k30xyQft42DAzSrIiyYlJvgB8JcmmST6c5LwkFyY5qO23fpK3tTVcnOTlE0zzjCTL2+fXJXlTkouSnJNkm7a2JwJvbevfYSYrS5IkaT4Yai9gG4x+UVU3JTkAeBDw0ar6w1wWN4nXALtU1e5JngK8GNgN2Ao4L8lZbZ8jqurxAEnuDPxlVd2YZEfgk8DyIee3D/Cgqvpdkn8DvlFVz0uyFDg3ydeA5wDbA3tU1S1Jthhy2psC51TV65L8O/DCqvrXJKcAp1bVSeONmORQ4FCAuy7ZesjZSZIkddOwe05PBtYmuS/wIZoA9ok5q2rqHg58sqrWVtVvgDOBvQf02xD4YJLVwIlM7ZD5V6vqd+3zxwCvSbIKOAPYGNgOeDTw/qq6BaCn/2T+BJzaPj+f5nSEoVTVsVW1vKqWb3bnzYcdTZIkqZOGPX/y1nZP4MHAu6rqvUkunMvCpihD9vtH4Dc0e1jXA26cwjyu75vfU6rqh7crIglQU5jmmJuramy8tQy/XSRJkhaUYfec3pzkmcDfc9sevg3npqShXQssaZ+fBTy9Pedza+ARwLl9fQA2B35VVbcCzwbWn+a8TwNe3oZRkuzRtn8FePHYRVNTOKw/nv76JUmSFrRhw+lzac65fFNVXZZke+Djc1fW5Krqt8DZ7S2g9gEuBi4CvgG8qqp+3bbd0l5o9I/A+4C/T3IOcD9uvzd0Kt5IE84vbuf/xrb9OOB/2vaLmPmdAv4LeGV70ZUXREmSpAUvtx1NnqRjsgmwXf+hbHXHdnffsV51yDtGXYY0773s7U8YdQmStOAlOb+q7nBh+lB7TpM8AVgFfLl9vXt7JbkkSZI0a4a98OYo4ME0V6ZTVavaQ/sLSpLHAm/pa76sql3MG2QAABTpSURBVA6ewTQ/S3N3g16vrqrTpjtNSZKkhWrYcHpLVV3dXv8zZjpXpXdaGxhnNTTOJNhKkiQtNsOG00va/1G/fnvz+sOAb89dWZIkSVqMhr1a/+XAA4GbaG6+fzVw+FwVJUmSpMVp0j2nSdYHTqmqRwOvm/uSJEmStFhNuue0qtYCf0zi/8aUJEnSnBr2nNMbgdVJvkrPjeur6rA5qUqSJEmL0rDh9IvtQ5IkSZozQ/+HKHXf8uXLa+XKlaMuQ5IkaVLj/YeoofacJrmMAfc1rar7zEJtkiRJEjD8Yf3eVLsx8DRgi9kvR5IkSYvZUPc5rarf9jx+WVXvAh45x7VJkiRpkRn2sP6ePS/Xo9mTumROKpIkSdKiNexh/bf3PL8FuAz429kvR5IkSYvZsOH0+VX1s96GJNvPQT2SJElaxIa6lVSSC6pqz76286tqrzmrTFN2zy3vWi/560eNugxp1r3u4yeNugRJ0iyb1q2kkuwEPBDYPMmTewbdheaqfUmSJGnWTHZY//7A44GlwBN62q8FXjhXRUmSJGlxmjCcVtXngc8n2aeqvrOOapIkSdIiNewFURcmeSnNIf4/H86vqufNSVWSJElalIa6CT/wMeDuwGOBM4F70RzalyRJkmbNsOH0vlX1euD6qvpP4G+AXeeuLEmSJC1Gw4bTm9uff0iyC7A5sGxOKpIkSdKiNew5p8cmuSvweuAUYDPgyDmrSpIkSYvSUOG0qo5rn54J3GfuypEkSdJiNtRh/STbJPlQki+1r3dO8vy5LU2SJEmLzbDnnB4PnAZs277+EXD4XBQkSZKkxWvYcLpVVX0auBWgqm4B1s5ZVYtUkqOSHJFkRZJte9qPS7LzKGuTJElaF4a9IOr6JFsCBZDkocDVc1aVVgCXAFcAVNULRlqNJEnSOjLsntN/orlKf4ckZwMfBV4+Z1UtIklel+SHSb4G3L9tXg6ckGRVkk2SnJFk+QjLlCRJWicm3HOaZLuq+p+quiDJ/jThKcAPq+rmicbV5JLsBTwD2INmW1wAnA+sBI6oqpVtv5HVKEmStC5Ntuf0cz3PP1VVl1bVJQbTWbMf8Nmq+mNVXUOzd3pKkhyaZGWSldffeNPsVyhJkrQOTRZOe3fZeX/TuVEzGrnq2KpaXlXLN914o9mqSZIkaSQmC6c1znPNjrOAg9vzSpcAT2jbrwWWjK4sSZKk0Zjsav3dklxDswd1k/Y57euqqrvMaXULXHsu76eAVcDPgW+2g44H3p/kBmCfEZUnSZK0zk0YTqtq/XVVyGJVVW8C3jRg0Mk9zw9YN9VIkiSN1rC3kpIkSZLmnOFUkiRJnWE4lSRJUmcYTiVJktQZhlNJkiR1huFUkiRJnWE4lSRJUmcYTiVJktQZhlNJkiR1huFUkiRJnTHhvy/V/HKP7XfgdR8/adRlSJIkTZt7TiVJktQZhlNJkiR1huFUkiRJnWE4lSRJUmcYTiVJktQZhlNJkiR1hreSWkBu/NW1fP9N3xh1GdKUPOB1jxx1CZKkDnHPqSRJkjrDcCpJkqTOMJxKkiSpMwynkiRJ6gzDqSRJkjrDcCpJkqTOMJxKkiSpMwynkiRJ6gzDqSRJkjrDcCpJkqTOMJxKkiSpMwynkiRJ6gzD6SxLsjTJS0ZdhyRJ0nxkOJ19S4Ghw2kabgdJkiQMp3PhaGCHJKuSvDXJK5Ocl+TiJG8ASLIsyfeTvA+4ANgvyQ+SHJfkkiQnJHl0krOT/DjJg0e6RJIkSeuI4XT2vQb4aVXtDnwV2BF4MLA7sFeSR7T97g98tKr2AH4O3Bd4N/AgYCfgWcDDgSOA1443sySHJlmZZOXvrv/DHC2SJEnSumE4nVuPaR8X0uwh3YkmrAL8vKrO6el7WVWtrqpbgUuBr1dVAauBZePNoKqOrarlVbV8i02XzsUySJIkrTMbjLqABS7Am6vqA7drTJYB1/f1vann+a09r2/F7SRJkhYJ95zOvmuBJe3z04DnJdkMIMk9k9xtZJVJkiR1nHvkZllV/ba9kOkS4EvAJ4DvJAG4Dvg7YO0IS5QkSeosw+kcqKpn9TW9e0C3XXr6r+l7vWK8YZIkSQuZh/UlSZLUGYZTSZIkdYbhVJIkSZ1hOJUkSVJnGE4lSZLUGYZTSZIkdYbhVJIkSZ1hOJUkSVJnGE4lSZLUGf6HqAVk43ss4QGve+Soy5AkSZo295xKkiSpMwynkiRJ6gzDqSRJkjrDcCpJkqTOMJxKkiSpMwynkiRJ6gxvJbWAXHHFFRx11FGjLkO6A9+XkqRhuedUkiRJnWE4lSRJUmcYTiVJktQZhlNJkiR1huFUkiRJnWE4lSRJUmcYTiVJktQZhlNJkiR1huFUkiRJnWE4lSRJUmcYTiVJktQZhlNJkiR1huF0RJI8MclrRl2HJElSl2ww6gLWtSQBUlW3jrCGDarqFOCUUdUgSZLURYtiz2mSZUm+n+R9wAXA65Ocl+TiJG/o6fectu2iJB9r2+6d5Ott+9eTbJdk8yRrkqzX9rlzksuTbJhkhyRfTnJ+km8m2antc3ySdyQ5HXhLkhVJjmmHbZ3k5Lam85Ls27bvn2RV+7gwyZJ1vOokSZLWqcW05/T+wHOBzwFPBR4MBDglySOA3wKvA/atqquSbNGOdwzw0ar6zyTPA95TVU9KchGwP3A68ATgtKq6OcmxwIur6sdJHgK8D3hkO637AY+uqrVJVvTU9m7gnVX1rSTbAacBDwCOAF5aVWcn2Qy4sX+hkhwKHAqw+eabz8Z6kiRJGpnFFE5/XlXnJHkb8BjgwrZ9M2BHYDfgpKq6CqCqftcO3wd4cvv8Y8C/t88/BTydJpw+A3hfGyAfBpzYnD0AwEY9NZxYVWsH1PZoYOeece7S7iU9G3hHkhOAz1TVL/pHrKpjgWMBtt122xpmRUiSJHXVYgqn17c/A7y5qj7QOzDJYcAw4W6szynAm9s9rHsB3wA2Bf5QVbtPUkO/9YB9quqGvvajk3wReBxwTpJHV9UPhqhRkiRpXloU55z2OQ14XruXkyT3THI34OvA3ybZsm0fO6z/bZo9owCHAN8CqKrrgHNpDsmfWlVrq+oa4LIkT2unkSS7DVHTV4CXjb1Isnv7c4eqWl1VbwFWAjvNYLklSZI6b9GF06r6CvAJ4DtJVgMnAUuq6lLgTcCZ7fmk72hHOQx4bpKLgWcDr+iZ3KeAv2t/jjkEeH47jUuBg4Yo6zBgeXvR1feAF7fthye5pJ3WDcCXpr7EkiRJ80eqPE1xodh2223r0EMPHXUZ0h0cddRRoy5BktQxSc6vquX97Ytuz6kkSZK6y3AqSZKkzjCcSpIkqTMMp5IkSeoMw6kkSZI6w3AqSZKkzjCcSpIkqTMMp5IkSeoMw6kkSZI6w/8QtYAsX768Vq5cOeoyJEmSJuV/iJIkSVLnGU4lSZLUGYZTSZIkdYbhVJIkSZ1hOJUkSVJnGE4lSZLUGYZTSZIkdcYGoy5As+f3v/8+nz7xwaMuQx31t087d9QlSJI0KfecSpIkqTMMp5IkSeoMw6kkSZI6w3AqSZKkzjCcSpIkqTMMp5IkSeoMw6kkSZI6w3AqSZKkzjCcSpIkqTMMp5IkSeoMw6kkSZI6w3AqSZKkzjCc9khyVJIjRjj/60Y1b0mSpC4wnM6xJOuPugZJkqT5YsGH0ySbJvlikouSXJLk6UnWJNmqHb48yRk9o+yW5BtJfpzkhRNMd70k70tyaZJTk/x3kqe2w9YkOTLJt4CnJXlhkvPaGk5Ocue23/ZJvtMOe2Pf9F/Ztl+c5A0T1HFokpVJVl5zzS0zWFOSJEmjt+DDKfBXwBVVtVtV7QJ8eZL+DwL+BtgHODLJtuP0ezKwDNgVeEHbv9eNVfXwqvov4DNVtXdV7QZ8H3h+2+fdwH9U1d7Ar8dGTPIYYEfgwcDuwF5JHjGoiKo6tqqWV9Xyu9xlg0kWTZIkqdsWQzhdDTw6yVuS7FdVV0/S//NVdUNVXQWcThMQB3k4cGJV3VpVv2779vpUz/NdknwzyWrgEOCBbfu+wCfb5x/r6f+Y9nEhcAGwE01YlSRJWtAW/K62qvpRkr2AxwFvTvIV4BZuC+Yb948yyesxmWTW1/c8Px54UlVdlGQFcMAk0w/w5qr6wCTzkCRJWlAW/J7T9rD8H6vq48DbgD2BNcBebZen9I1yUJKNk2xJEyLPG2fS3wKe0p57ug23D5z9lgC/SrIhzZ7TMWcDz2if97afBjwvyWbtMtwzyd0mmL4kSdKCsOD3nNKcE/rWJLcCNwP/AGwCfCjJa4Hv9vU/F/gisB3wxqq6Ypzpngw8CrgE+FE7nfFOGXh9O/znNKcZLGnbXwF8Iskr2ukBUFVfSfIA4DtJAK4D/g64cshlliRJmpdSNd5Ra00myWZVdV27l/VcYN/2/NOR2GGHTevNRz9w8o5alP72aeeOugRJkv4syflVtby/fTHsOZ1LpyZZCtyJZi/ryIKpJEnSQmA4nUSSXbn9lfQAN1XVQ6rqgBGUJEmStGAZTidRVatp7jUqSZKkObbgr9aXJEnS/GE4lSRJUmcYTiVJktQZhlNJkiR1huFUkiRJneHV+gvIXe/6AG+0LkmS5jX3nEqSJKkzDKeSJEnqDMOpJEmSOsNwKkmSpM4wnEqSJKkzDKeSJEnqDMOpJEmSOsP7nC4g3/v9Nex20mmjLmNBueipjx11CZIkLSruOZUkSVJnGE4lSZLUGYZTSZIkdYbhVJIkSZ1hOJUkSVJnGE4lSZLUGYZTSZIkdYbhVJIkSZ1hOJUkSVJnGE4lSZLUGYZTSZIkdYbhVJIkSZ0xZ+E0yWFJvp/khBlOZ1mSS6Y4zvFJnjqT+U5HkhVJtp2kz3FJdl5XNUmSJM0nG8zhtF8C/HVVXTaH8+iaFcAlwBXjdaiqF6yzaiRJkuaZOdlzmuT9wH2AU5JcneSInmGXtHtDl7V7Vj+Y5NIkX0mySdtnryQXJfkO8NKecddP8tYk5yW5OMmL2vYkOSbJ95J8EbjbJPUd2U7jkiTHJknbfkaSdyY5q61t7ySfSfLjJP/a9hlYd7undjlwQpJVY8syYN5nJFnePr8uyZvaZT0nyTZJNk+yJsl6bZ87J7k8yYbjTO/QJCuTrLzlmquH20CSJEkdNSfhtKpeTLP38EDgnRN03RH4v1X1QOAPwFPa9o8Ah1XVPn39nw9cXVV7A3sDL0yyPXAwcH9gV+CFwMMmKfGYqtq7qnYBNgEe3zPsT1X1COD9wOdpwvEuwIokW45Xd1WdBKwEDqmq3avqhklqANgUOKeqdgPOAl5YVVcDFwH7t32eAJxWVTcPmkBVHVtVy6tq+QZ32XyIWUqSJHXXqC+IuqyqVrXPzweWJdkcWFpVZ7btH+vp/xjgOUlWAd8FtqQJio8APllVa6vqCuAbk8z3wCTfTbIaeCTwwJ5hp7Q/VwOXVtWvquom4GfAX4xX9/CLfDt/Ak4dMJ1PAU9vnz+jfS1JkrTgzeU5p2Nu4fYheOOe5zf1PF9LsxczQI0zrQAvr6rTbteYPG6CcW4/gWRj4H3A8qq6PMlR49R0a199t3Lb+hpU93TcXFVjda/tmf4pwJuTbAHsxeRhW5IkaUFYF3tO1wB7AiTZE9h+os5V9Qfg6iQPb5sO6Rl8GvAPY+dfJrlfkk1pDok/oz0n9R40pxOMZyyIXpVkM2A2r+q/Flgy04lU1XXAucC7gVOrau1MpylJkjQfrIs9pydz26H484AfDTHOc4EPJ/kjTSAdcxzNoe8L2ouY/hd4EvBZmsPzq9vpn8k4quoPST7Y9l3T1jRbjgfen+QGYJ8hzzsdz6eAE4EDZqEuSZKkeSG3HVXWfHfnHe5XO77lvaMuY0G56KmPHXUJkiQtSEnOr6rl/e2jviBKkiRJ+rN1cVh/ZJJ8ljue4/rq/guqFtq8JUmS5qsFHU6r6uDFOG9JkqT5ysP6kiRJ6gzDqSRJkjrDcCpJkqTOMJxKkiSpMwynkiRJ6owFfbX+YrPzXe/CSm8aL0mS5jH3nEqSJKkzDKeSJEnqDMOpJEmSOiNVNeoaNEuSXAv8cNR1aM5sBVw16iI0Z9y+C5/beGFz+07dvatq6/5GL4haWH5YVctHXYTmRpKVbt+Fy+278LmNFza37+zxsL4kSZI6w3AqSZKkzjCcLizHjroAzSm378Lm9l343MYLm9t3lnhBlCRJkjrDPaeSJEnqDMOpJEmSOsNwOg8k+askP0zykySvGTA8Sd7TDr84yZ7DjqvRm+H2XZNkdZJVSVau28o1rCG28U5JvpPkpiRHTGVcjd4Mt6+f4XlgiG18SPv7+eIk306y27DjaoCq8tHhB7A+8FPgPsCdgIuAnfv6PA74EhDgocB3hx3Xx/zdvu2wNcBWo14OHzPexncD9gbeBBwxlXF9zN/t2w7zM9zxx5Db+GHAXdvnf+338Mwe7jntvgcDP6mqn1XVn4D/Ag7q63MQ8NFqnAMsTXKPIcfVaM1k+2p+mHQbV9WVVXUecPNUx9XIzWT7an4YZht/u6p+3748B7jXsOPqjgyn3XdP4PKe179o24bpM8y4Gq2ZbF+AAr6S5Pwkh85ZlZqJmXwO/Qx330y3kZ/h7pvqNn4+zdGu6Ywr/Pel80EGtPXf/2u8PsOMq9GayfYF2LeqrkhyN+CrSX5QVWfNaoWaqZl8Dv0Md99Mt5Gf4e4behsnOZAmnD58quPqNu457b5fAH/R8/pewBVD9hlmXI3WTLYvVTX280rgszSHkNQtM/kc+hnuvhltIz/D88JQ2zjJg4DjgIOq6rdTGVe3ZzjtvvOAHZNsn+ROwDOAU/r6nAI8p72q+6HA1VX1qyHH1WhNe/sm2TTJEoAkmwKPAS5Zl8VrKDP5HPoZ7r5pbyM/w/PGpNs4yXbAZ4BnV9WPpjKu7sjD+h1XVbckeRlwGs1Vfx+uqkuTvLgd/n7gv2mu6P4J8EfguRONO4LF0Dhmsn2BbYDPJoHms/yJqvryOl4ETWKYbZzk7sBK4C7ArUkOp7mi9xo/w902k+0LbIWf4c4b8vf0kcCWwPva7XlLVS33e3h6/PelkiRJ6gwP60uSJKkzDKeSJEnqDMOpJEmSOsNwKkmSpM4wnEqSJKkzDKeSJEnqDMOpJEmSOuP/Af4s0T13G00pAAAAAElFTkSuQmCC\n",
"text/plain": [
"
"
]
},
"metadata": {
"needs_background": "light"
},
"output_type": "display_data"
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"\n",
"Please wait Training-Testing with all models..\n",
"\n",
"Done with LogisticRegression\n",
"Done with RandomForestClassifier\n",
"Done with XGBoost Classifier\n",
"Done with LGBoost Classifier\n",
"Done with AdaBoost Classifier\n",
"Done with GradientBoostingClassifier\n"
]
},
{
"data": {
"text/html": [
"
"
],
"text/plain": [
""
]
},
"execution_count": 6,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"df1 = es.importdata('train_split.csv')\n",
"df1 = es.dropcolumns(df1,'batch_enrolled','member_id')\n",
"## no hazzle to clean data or do anything just pass target and dataframe use quick_ml fucntion in easeml\n",
"## just pass dataframe, targetcolumn and flag(r-regression/c=classification)\n",
"es.quick_ml(df1,'loan_status','c')"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## house Price Prediction dataset "
]
},
{
"cell_type": "code",
"execution_count": 7,
"metadata": {
"ExecuteTime": {
"end_time": "2020-03-17T10:18:34.287387Z",
"start_time": "2020-03-17T10:18:31.053593Z"
},
"scrolled": true
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Dataframe Imported Successfully\n",
"*** Dataset Infomarion ***\n",
"##################################################\n",
"No of Rows : 545\n",
"No of columns : 13\n",
"No of Numerical columns: 6\n",
"No of Categorical columns: 7\n",
"##################################################\n",
"\n",
" Total Missing values : 0 \n",
"\n",
"##################################################\n",
"Summary of DataFrame:\n",
"\n",
" Column Name Nulls/NaN outof Unique Type of Columns\n",
"0 price 0 545 219 Numerical\n",
"1 area 0 545 284 Numerical\n",
"2 bedrooms 0 545 6 Numerical\n",
"3 bathrooms 0 545 4 Numerical\n",
"4 stories 0 545 4 Numerical\n",
"5 mainroad 0 545 2 Categorical\n",
"6 guestroom 0 545 2 Categorical\n",
"7 basement 0 545 2 Categorical\n",
"8 hotwaterheating 0 545 2 Categorical\n",
"9 airconditioning 0 545 2 Categorical\n",
"10 parking 0 545 4 Numerical\n",
"11 prefarea 0 545 2 Categorical\n",
"12 furnishingstatus 0 545 3 Categorical\n",
"Null value summary: \n",
" Empty DataFrame\n",
"Columns: [Total, Percent]\n",
"Index: []\n",
"columns dropped Index([], dtype='object')\n",
"\n",
"\n",
"columns dropped \n",
"\n",
" [] \n",
" []\n",
"\n",
"columns label encoded\n",
" Index(['mainroad', 'guestroom', 'basement', 'hotwaterheating',\n",
" 'airconditioning', 'prefarea', 'furnishingstatus'],\n",
" dtype='object')\n"
]
},
{
"data": {
"application/vnd.plotly.v1+json": {
"config": {
"plotlyServerURL": "https://plot.ly"
},
"data": [
{
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"reversescale": false,
"showscale": true,
"type": "heatmap",
"x": [
"price",
"area",
"bedrooms",
"bathrooms",
"stories",
"mainroad",
"guestroom",
"basement",
"hotwaterheating",
"airconditioning",
"parking",
"prefarea",
"furnishingstatus"
],
"y": [
"price",
"area",
"bedrooms",
"bathrooms",
"stories",
"mainroad",
"guestroom",
"basement",
"hotwaterheating",
"airconditioning",
"parking",
"prefarea",
"furnishingstatus"
],
"z": [
[
1,
0.5359973457780788,
0.36649402577386786,
0.5175453394550077,
0.42071236618861413,
0.2968984892639757,
0.25551728993500045,
0.18705659793805243,
0.09307284392139714,
0.4529540842560462,
0.3843936486357239,
0.32977704986811035,
-0.3047214615374341
],
[
0.5359973457780788,
1,
0.15185848557453643,
0.1938195310520514,
0.08399605092891933,
0.28887411412506786,
0.14029659048177065,
0.047416988564942884,
-0.009229236053235295,
0.22239310353898015,
0.3529804812116809,
0.23477879839351296,
-0.17144536095782656
],
[
0.36649402577386786,
0.15185848557453643,
1,
0.373930235972153,
0.40856423753814824,
-0.012033244762023821,
0.08054870420223764,
0.09731242409811487,
0.046048886983068096,
0.16060325689743865,
0.13926989686561128,
0.07902306408232272,
-0.12324399876430843
],
[
0.5175453394550077,
0.1938195310520514,
0.373930235972153,
1,
0.3261647061329375,
0.04239762400552751,
0.126468844805267,
0.10210570644531275,
0.06715909647508744,
0.1869150278323909,
0.17749582102283126,
0.06347174021699521,
-0.14355949825183148
],
[
0.42071236618861413,
0.08399605092891933,
0.40856423753814824,
0.3261647061329375,
1,
0.12170613053945556,
0.04353767150057466,
-0.17239361748659449,
0.018846510680018545,
0.2936020003739396,
0.045547091916846104,
0.04442487225791428,
-0.1046723332858143
],
[
0.2968984892639757,
0.28887411412506786,
-0.012033244762023821,
0.04239762400552751,
0.12170613053945556,
1,
0.09233691908079647,
0.044002081101454774,
-0.011781489896788079,
0.10542299807285278,
0.20443254752943632,
0.19987577692801145,
-0.15672586313241518
],
[
0.25551728993500045,
0.14029659048177065,
0.08054870420223764,
0.126468844805267,
0.04353767150057466,
0.09233691908079647,
1,
0.3720657075225606,
-0.010307884273308216,
0.1381787666091448,
0.03746574580371576,
0.16089693624045273,
-0.11832756557090868
],
[
0.18705659793805243,
0.047416988564942884,
0.09731242409811487,
0.10210570644531275,
-0.17239361748659449,
0.044002081101454774,
0.3720657075225606,
1,
0.004384836068968946,
0.04734118851852897,
0.05149717539519657,
0.22808285272641954,
-0.11283073245662545
],
[
0.09307284392139714,
-0.009229236053235295,
0.046048886983068096,
0.06715909647508744,
0.018846510680018545,
-0.011781489896788079,
-0.010307884273308216,
0.004384836068968946,
1,
-0.13002283342067628,
0.06786388846517284,
-0.05941138180401223,
-0.03162820403853522
],
[
0.4529540842560462,
0.22239310353898015,
0.16060325689743865,
0.1869150278323909,
0.2936020003739396,
0.10542299807285278,
0.1381787666091448,
0.04734118851852897,
-0.13002283342067628,
1,
0.15917268297096374,
0.11738209724461225,
-0.15047728577374692
],
[
0.3843936486357239,
0.3529804812116809,
0.13926989686561128,
0.17749582102283126,
0.045547091916846104,
0.20443254752943632,
0.03746574580371576,
0.05149717539519657,
0.06786388846517284,
0.15917268297096374,
1,
0.09162706193381073,
-0.17753860680724298
],
[
0.32977704986811035,
0.23477879839351296,
0.07902306408232272,
0.06347174021699521,
0.04442487225791428,
0.19987577692801145,
0.16089693624045273,
0.22808285272641954,
-0.05941138180401223,
0.11738209724461225,
0.09162706193381073,
1,
-0.10768597141348296
],
[
-0.3047214615374341,
-0.17144536095782656,
-0.12324399876430843,
-0.14355949825183148,
-0.1046723332858143,
-0.15672586313241518,
-0.11832756557090868,
-0.11283073245662545,
-0.03162820403853522,
-0.15047728577374692,
-0.17753860680724298,
-0.10768597141348296,
1
]
]
}
],
"layout": {
"annotations": [
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "price",
"xref": "x",
"y": "price",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.54",
"x": "area",
"xref": "x",
"y": "price",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.37",
"x": "bedrooms",
"xref": "x",
"y": "price",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.52",
"x": "bathrooms",
"xref": "x",
"y": "price",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.42",
"x": "stories",
"xref": "x",
"y": "price",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.3",
"x": "mainroad",
"xref": "x",
"y": "price",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.26",
"x": "guestroom",
"xref": "x",
"y": "price",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.19",
"x": "basement",
"xref": "x",
"y": "price",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "hotwaterheating",
"xref": "x",
"y": "price",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.45",
"x": "airconditioning",
"xref": "x",
"y": "price",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.38",
"x": "parking",
"xref": "x",
"y": "price",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.33",
"x": "prefarea",
"xref": "x",
"y": "price",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.3",
"x": "furnishingstatus",
"xref": "x",
"y": "price",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.54",
"x": "price",
"xref": "x",
"y": "area",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "area",
"xref": "x",
"y": "area",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.15",
"x": "bedrooms",
"xref": "x",
"y": "area",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.19",
"x": "bathrooms",
"xref": "x",
"y": "area",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "stories",
"xref": "x",
"y": "area",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.29",
"x": "mainroad",
"xref": "x",
"y": "area",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.14",
"x": "guestroom",
"xref": "x",
"y": "area",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "basement",
"xref": "x",
"y": "area",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "hotwaterheating",
"xref": "x",
"y": "area",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.22",
"x": "airconditioning",
"xref": "x",
"y": "area",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.35",
"x": "parking",
"xref": "x",
"y": "area",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.23",
"x": "prefarea",
"xref": "x",
"y": "area",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.17",
"x": "furnishingstatus",
"xref": "x",
"y": "area",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.37",
"x": "price",
"xref": "x",
"y": "bedrooms",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.15",
"x": "area",
"xref": "x",
"y": "bedrooms",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "bedrooms",
"xref": "x",
"y": "bedrooms",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.37",
"x": "bathrooms",
"xref": "x",
"y": "bedrooms",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.41",
"x": "stories",
"xref": "x",
"y": "bedrooms",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "mainroad",
"xref": "x",
"y": "bedrooms",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "guestroom",
"xref": "x",
"y": "bedrooms",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "basement",
"xref": "x",
"y": "bedrooms",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "hotwaterheating",
"xref": "x",
"y": "bedrooms",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.16",
"x": "airconditioning",
"xref": "x",
"y": "bedrooms",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.14",
"x": "parking",
"xref": "x",
"y": "bedrooms",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "prefarea",
"xref": "x",
"y": "bedrooms",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.12",
"x": "furnishingstatus",
"xref": "x",
"y": "bedrooms",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.52",
"x": "price",
"xref": "x",
"y": "bathrooms",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.19",
"x": "area",
"xref": "x",
"y": "bathrooms",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.37",
"x": "bedrooms",
"xref": "x",
"y": "bathrooms",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "bathrooms",
"xref": "x",
"y": "bathrooms",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.33",
"x": "stories",
"xref": "x",
"y": "bathrooms",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "mainroad",
"xref": "x",
"y": "bathrooms",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.13",
"x": "guestroom",
"xref": "x",
"y": "bathrooms",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "basement",
"xref": "x",
"y": "bathrooms",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "hotwaterheating",
"xref": "x",
"y": "bathrooms",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.19",
"x": "airconditioning",
"xref": "x",
"y": "bathrooms",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.18",
"x": "parking",
"xref": "x",
"y": "bathrooms",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "prefarea",
"xref": "x",
"y": "bathrooms",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.14",
"x": "furnishingstatus",
"xref": "x",
"y": "bathrooms",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.42",
"x": "price",
"xref": "x",
"y": "stories",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "area",
"xref": "x",
"y": "stories",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.41",
"x": "bedrooms",
"xref": "x",
"y": "stories",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.33",
"x": "bathrooms",
"xref": "x",
"y": "stories",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "stories",
"xref": "x",
"y": "stories",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "mainroad",
"xref": "x",
"y": "stories",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "guestroom",
"xref": "x",
"y": "stories",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.17",
"x": "basement",
"xref": "x",
"y": "stories",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "hotwaterheating",
"xref": "x",
"y": "stories",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.29",
"x": "airconditioning",
"xref": "x",
"y": "stories",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "parking",
"xref": "x",
"y": "stories",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "prefarea",
"xref": "x",
"y": "stories",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "furnishingstatus",
"xref": "x",
"y": "stories",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.3",
"x": "price",
"xref": "x",
"y": "mainroad",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.29",
"x": "area",
"xref": "x",
"y": "mainroad",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "bedrooms",
"xref": "x",
"y": "mainroad",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "bathrooms",
"xref": "x",
"y": "mainroad",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "stories",
"xref": "x",
"y": "mainroad",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "mainroad",
"xref": "x",
"y": "mainroad",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "guestroom",
"xref": "x",
"y": "mainroad",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "basement",
"xref": "x",
"y": "mainroad",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "hotwaterheating",
"xref": "x",
"y": "mainroad",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.11",
"x": "airconditioning",
"xref": "x",
"y": "mainroad",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.2",
"x": "parking",
"xref": "x",
"y": "mainroad",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.2",
"x": "prefarea",
"xref": "x",
"y": "mainroad",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.16",
"x": "furnishingstatus",
"xref": "x",
"y": "mainroad",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.26",
"x": "price",
"xref": "x",
"y": "guestroom",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.14",
"x": "area",
"xref": "x",
"y": "guestroom",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "bedrooms",
"xref": "x",
"y": "guestroom",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.13",
"x": "bathrooms",
"xref": "x",
"y": "guestroom",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "stories",
"xref": "x",
"y": "guestroom",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "mainroad",
"xref": "x",
"y": "guestroom",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "guestroom",
"xref": "x",
"y": "guestroom",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.37",
"x": "basement",
"xref": "x",
"y": "guestroom",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "hotwaterheating",
"xref": "x",
"y": "guestroom",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.14",
"x": "airconditioning",
"xref": "x",
"y": "guestroom",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "parking",
"xref": "x",
"y": "guestroom",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.16",
"x": "prefarea",
"xref": "x",
"y": "guestroom",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.12",
"x": "furnishingstatus",
"xref": "x",
"y": "guestroom",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.19",
"x": "price",
"xref": "x",
"y": "basement",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "area",
"xref": "x",
"y": "basement",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "bedrooms",
"xref": "x",
"y": "basement",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "bathrooms",
"xref": "x",
"y": "basement",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.17",
"x": "stories",
"xref": "x",
"y": "basement",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "mainroad",
"xref": "x",
"y": "basement",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.37",
"x": "guestroom",
"xref": "x",
"y": "basement",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "basement",
"xref": "x",
"y": "basement",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "hotwaterheating",
"xref": "x",
"y": "basement",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "airconditioning",
"xref": "x",
"y": "basement",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "parking",
"xref": "x",
"y": "basement",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.23",
"x": "prefarea",
"xref": "x",
"y": "basement",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.11",
"x": "furnishingstatus",
"xref": "x",
"y": "basement",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "price",
"xref": "x",
"y": "hotwaterheating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "area",
"xref": "x",
"y": "hotwaterheating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "bedrooms",
"xref": "x",
"y": "hotwaterheating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "bathrooms",
"xref": "x",
"y": "hotwaterheating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "stories",
"xref": "x",
"y": "hotwaterheating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "mainroad",
"xref": "x",
"y": "hotwaterheating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "guestroom",
"xref": "x",
"y": "hotwaterheating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "basement",
"xref": "x",
"y": "hotwaterheating",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "hotwaterheating",
"xref": "x",
"y": "hotwaterheating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.13",
"x": "airconditioning",
"xref": "x",
"y": "hotwaterheating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "parking",
"xref": "x",
"y": "hotwaterheating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "prefarea",
"xref": "x",
"y": "hotwaterheating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "furnishingstatus",
"xref": "x",
"y": "hotwaterheating",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.45",
"x": "price",
"xref": "x",
"y": "airconditioning",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.22",
"x": "area",
"xref": "x",
"y": "airconditioning",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.16",
"x": "bedrooms",
"xref": "x",
"y": "airconditioning",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.19",
"x": "bathrooms",
"xref": "x",
"y": "airconditioning",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.29",
"x": "stories",
"xref": "x",
"y": "airconditioning",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.11",
"x": "mainroad",
"xref": "x",
"y": "airconditioning",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.14",
"x": "guestroom",
"xref": "x",
"y": "airconditioning",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "basement",
"xref": "x",
"y": "airconditioning",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.13",
"x": "hotwaterheating",
"xref": "x",
"y": "airconditioning",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "airconditioning",
"xref": "x",
"y": "airconditioning",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.16",
"x": "parking",
"xref": "x",
"y": "airconditioning",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "prefarea",
"xref": "x",
"y": "airconditioning",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.15",
"x": "furnishingstatus",
"xref": "x",
"y": "airconditioning",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.38",
"x": "price",
"xref": "x",
"y": "parking",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.35",
"x": "area",
"xref": "x",
"y": "parking",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.14",
"x": "bedrooms",
"xref": "x",
"y": "parking",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.18",
"x": "bathrooms",
"xref": "x",
"y": "parking",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "stories",
"xref": "x",
"y": "parking",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.2",
"x": "mainroad",
"xref": "x",
"y": "parking",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "guestroom",
"xref": "x",
"y": "parking",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "basement",
"xref": "x",
"y": "parking",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "hotwaterheating",
"xref": "x",
"y": "parking",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.16",
"x": "airconditioning",
"xref": "x",
"y": "parking",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "parking",
"xref": "x",
"y": "parking",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "prefarea",
"xref": "x",
"y": "parking",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.18",
"x": "furnishingstatus",
"xref": "x",
"y": "parking",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.33",
"x": "price",
"xref": "x",
"y": "prefarea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.23",
"x": "area",
"xref": "x",
"y": "prefarea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "bedrooms",
"xref": "x",
"y": "prefarea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "bathrooms",
"xref": "x",
"y": "prefarea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "stories",
"xref": "x",
"y": "prefarea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.2",
"x": "mainroad",
"xref": "x",
"y": "prefarea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.16",
"x": "guestroom",
"xref": "x",
"y": "prefarea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.23",
"x": "basement",
"xref": "x",
"y": "prefarea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "hotwaterheating",
"xref": "x",
"y": "prefarea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "airconditioning",
"xref": "x",
"y": "prefarea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "parking",
"xref": "x",
"y": "prefarea",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "prefarea",
"xref": "x",
"y": "prefarea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.11",
"x": "furnishingstatus",
"xref": "x",
"y": "prefarea",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.3",
"x": "price",
"xref": "x",
"y": "furnishingstatus",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.17",
"x": "area",
"xref": "x",
"y": "furnishingstatus",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.12",
"x": "bedrooms",
"xref": "x",
"y": "furnishingstatus",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.14",
"x": "bathrooms",
"xref": "x",
"y": "furnishingstatus",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "stories",
"xref": "x",
"y": "furnishingstatus",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.16",
"x": "mainroad",
"xref": "x",
"y": "furnishingstatus",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.12",
"x": "guestroom",
"xref": "x",
"y": "furnishingstatus",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.11",
"x": "basement",
"xref": "x",
"y": "furnishingstatus",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "hotwaterheating",
"xref": "x",
"y": "furnishingstatus",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.15",
"x": "airconditioning",
"xref": "x",
"y": "furnishingstatus",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.18",
"x": "parking",
"xref": "x",
"y": "furnishingstatus",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.11",
"x": "prefarea",
"xref": "x",
"y": "furnishingstatus",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "furnishingstatus",
"xref": "x",
"y": "furnishingstatus",
"yref": "y"
}
],
"template": {
"data": {
"bar": [
{
"error_x": {
"color": "#2a3f5f"
},
"error_y": {
"color": "#2a3f5f"
},
"marker": {
"line": {
"color": "#E5ECF6",
"width": 0.5
}
},
"type": "bar"
}
],
"barpolar": [
{
"marker": {
"line": {
"color": "#E5ECF6",
"width": 0.5
}
},
"type": "barpolar"
}
],
"carpet": [
{
"aaxis": {
"endlinecolor": "#2a3f5f",
"gridcolor": "white",
"linecolor": "white",
"minorgridcolor": "white",
"startlinecolor": "#2a3f5f"
},
"baxis": {
"endlinecolor": "#2a3f5f",
"gridcolor": "white",
"linecolor": "white",
"minorgridcolor": "white",
"startlinecolor": "#2a3f5f"
},
"type": "carpet"
}
],
"choropleth": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "choropleth"
}
],
"contour": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "contour"
}
],
"contourcarpet": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "contourcarpet"
}
],
"heatmap": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "heatmap"
}
],
"heatmapgl": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "heatmapgl"
}
],
"histogram": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "histogram"
}
],
"histogram2d": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "histogram2d"
}
],
"histogram2dcontour": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "histogram2dcontour"
}
],
"mesh3d": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "mesh3d"
}
],
"parcoords": [
{
"line": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "parcoords"
}
],
"pie": [
{
"automargin": true,
"type": "pie"
}
],
"scatter": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatter"
}
],
"scatter3d": [
{
"line": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatter3d"
}
],
"scattercarpet": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattercarpet"
}
],
"scattergeo": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattergeo"
}
],
"scattergl": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattergl"
}
],
"scattermapbox": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattermapbox"
}
],
"scatterpolar": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterpolar"
}
],
"scatterpolargl": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterpolargl"
}
],
"scatterternary": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterternary"
}
],
"surface": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "surface"
}
],
"table": [
{
"cells": {
"fill": {
"color": "#EBF0F8"
},
"line": {
"color": "white"
}
},
"header": {
"fill": {
"color": "#C8D4E3"
},
"line": {
"color": "white"
}
},
"type": "table"
}
]
},
"layout": {
"annotationdefaults": {
"arrowcolor": "#2a3f5f",
"arrowhead": 0,
"arrowwidth": 1
},
"coloraxis": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"colorscale": {
"diverging": [
[
0,
"#8e0152"
],
[
0.1,
"#c51b7d"
],
[
0.2,
"#de77ae"
],
[
0.3,
"#f1b6da"
],
[
0.4,
"#fde0ef"
],
[
0.5,
"#f7f7f7"
],
[
0.6,
"#e6f5d0"
],
[
0.7,
"#b8e186"
],
[
0.8,
"#7fbc41"
],
[
0.9,
"#4d9221"
],
[
1,
"#276419"
]
],
"sequential": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"sequentialminus": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
]
},
"colorway": [
"#636efa",
"#EF553B",
"#00cc96",
"#ab63fa",
"#FFA15A",
"#19d3f3",
"#FF6692",
"#B6E880",
"#FF97FF",
"#FECB52"
],
"font": {
"color": "#2a3f5f"
},
"geo": {
"bgcolor": "white",
"lakecolor": "white",
"landcolor": "#E5ECF6",
"showlakes": true,
"showland": true,
"subunitcolor": "white"
},
"hoverlabel": {
"align": "left"
},
"hovermode": "closest",
"mapbox": {
"style": "light"
},
"paper_bgcolor": "white",
"plot_bgcolor": "#E5ECF6",
"polar": {
"angularaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"bgcolor": "#E5ECF6",
"radialaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
}
},
"scene": {
"xaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
},
"yaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
},
"zaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
}
},
"shapedefaults": {
"line": {
"color": "#2a3f5f"
}
},
"ternary": {
"aaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"baxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"bgcolor": "#E5ECF6",
"caxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
}
},
"title": {
"x": 0.05
},
"xaxis": {
"automargin": true,
"gridcolor": "white",
"linecolor": "white",
"ticks": "",
"title": {
"standoff": 15
},
"zerolinecolor": "white",
"zerolinewidth": 2
},
"yaxis": {
"automargin": true,
"gridcolor": "white",
"linecolor": "white",
"ticks": "",
"title": {
"standoff": 15
},
"zerolinecolor": "white",
"zerolinewidth": 2
}
}
},
"xaxis": {
"dtick": 1,
"gridcolor": "rgb(0, 0, 0)",
"side": "top",
"ticks": ""
},
"yaxis": {
"dtick": 1,
"ticks": "",
"ticksuffix": " "
}
}
},
"text/html": [
"
| Model | F1 score | AUC-ROC score | Accuracy | Confustion-Matrix | |
|---|---|---|---|---|---|
| 3 | \n", "LGBoost Classifier | \n", "0.923457 | \n", "0.75 | \n", "0.933333 | \n", "[[26 0]\n", " [ 2 2]] | \n", "
| 0 | \n", "LogisticRegression | \n", "0.872727 | \n", "0.625 | \n", "0.9 | \n", "[[26 0]\n", " [ 3 1]] | \n", "
| 1 | \n", "RandomForestClassifier | \n", "0.872727 | \n", "0.625 | \n", "0.9 | \n", "[[26 0]\n", " [ 3 1]] | \n", "
| 2 | \n", "XGBoost Classifier | \n", "0.804762 | \n", "0.5 | \n", "0.866667 | \n", "[[26 0]\n", " [ 4 0]] | \n", "
| 4 | \n", "AdaBoost Classifier | \n", "0.804762 | \n", "0.5 | \n", "0.866667 | \n", "[[26 0]\n", " [ 4 0]] | \n", "
| 5 | \n", "GradientBoostingClassifier | \n", "0.804762 | \n", "0.5 | \n", "0.866667 | \n", "[[26 0]\n", " [ 4 0]] | \n", "
\n",
" \n",
" \n",
" \n",
" \n",
"
"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"application/vnd.plotly.v1+json": {
"config": {
"linkText": "Export to plot.ly",
"plotlyServerURL": "https://plot.ly",
"showLink": true
},
"data": [
{
"histfunc": "count",
"histnorm": "",
"marker": {
"color": "rgba(255, 153, 51, 1.0)",
"line": {
"color": "#4D5663",
"width": 1.3
}
},
"name": "price",
"opacity": 0.8,
"orientation": "v",
"type": "histogram",
"x": [
13300000,
12250000,
12250000,
12215000,
11410000,
10850000,
10150000,
10150000,
9870000,
9800000,
9800000,
9681000,
9310000,
9240000,
9240000,
9100000,
9100000,
8960000,
8890000,
8855000,
8750000,
8680000,
8645000,
8645000,
8575000,
8540000,
8463000,
8400000,
8400000,
8400000,
8400000,
8400000,
8295000,
8190000,
8120000,
8080940,
8043000,
7980000,
7962500,
7910000,
7875000,
7840000,
7700000,
7700000,
7560000,
7560000,
7525000,
7490000,
7455000,
7420000,
7420000,
7420000,
7350000,
7350000,
7350000,
7350000,
7343000,
7245000,
7210000,
7210000,
7140000,
7070000,
7070000,
7035000,
7000000,
6930000,
6930000,
6895000,
6860000,
6790000,
6790000,
6755000,
6720000,
6685000,
6650000,
6650000,
6650000,
6650000,
6650000,
6650000,
6629000,
6615000,
6615000,
6580000,
6510000,
6510000,
6510000,
6475000,
6475000,
6440000,
6440000,
6419000,
6405000,
6300000,
6300000,
6300000,
6300000,
6300000,
6293000,
6265000,
6230000,
6230000,
6195000,
6195000,
6195000,
6160000,
6160000,
6125000,
6107500,
6090000,
6090000,
6090000,
6083000,
6083000,
6020000,
6020000,
6020000,
5950000,
5950000,
5950000,
5950000,
5950000,
5950000,
5950000,
5950000,
5943000,
5880000,
5880000,
5873000,
5873000,
5866000,
5810000,
5810000,
5810000,
5803000,
5775000,
5740000,
5740000,
5740000,
5740000,
5740000,
5652500,
5600000,
5600000,
5600000,
5600000,
5600000,
5600000,
5600000,
5600000,
5600000,
5565000,
5565000,
5530000,
5530000,
5530000,
5523000,
5495000,
5495000,
5460000,
5460000,
5460000,
5460000,
5425000,
5390000,
5383000,
5320000,
5285000,
5250000,
5250000,
5250000,
5250000,
5250000,
5250000,
5250000,
5250000,
5250000,
5243000,
5229000,
5215000,
5215000,
5215000,
5145000,
5145000,
5110000,
5110000,
5110000,
5110000,
5075000,
5040000,
5040000,
5040000,
5040000,
5033000,
5005000,
4970000,
4970000,
4956000,
4935000,
4907000,
4900000,
4900000,
4900000,
4900000,
4900000,
4900000,
4900000,
4900000,
4900000,
4900000,
4900000,
4900000,
4893000,
4893000,
4865000,
4830000,
4830000,
4830000,
4830000,
4795000,
4795000,
4767000,
4760000,
4760000,
4760000,
4753000,
4690000,
4690000,
4690000,
4690000,
4690000,
4690000,
4655000,
4620000,
4620000,
4620000,
4620000,
4620000,
4613000,
4585000,
4585000,
4550000,
4550000,
4550000,
4550000,
4550000,
4550000,
4550000,
4543000,
4543000,
4515000,
4515000,
4515000,
4515000,
4480000,
4480000,
4480000,
4480000,
4480000,
4473000,
4473000,
4473000,
4445000,
4410000,
4410000,
4403000,
4403000,
4403000,
4382000,
4375000,
4340000,
4340000,
4340000,
4340000,
4340000,
4319000,
4305000,
4305000,
4277000,
4270000,
4270000,
4270000,
4270000,
4270000,
4270000,
4235000,
4235000,
4200000,
4200000,
4200000,
4200000,
4200000,
4200000,
4200000,
4200000,
4200000,
4200000,
4200000,
4200000,
4200000,
4200000,
4200000,
4200000,
4200000,
4193000,
4193000,
4165000,
4165000,
4165000,
4130000,
4130000,
4123000,
4098500,
4095000,
4095000,
4095000,
4060000,
4060000,
4060000,
4060000,
4060000,
4025000,
4025000,
4025000,
4007500,
4007500,
3990000,
3990000,
3990000,
3990000,
3990000,
3920000,
3920000,
3920000,
3920000,
3920000,
3920000,
3920000,
3885000,
3885000,
3850000,
3850000,
3850000,
3850000,
3850000,
3850000,
3850000,
3836000,
3815000,
3780000,
3780000,
3780000,
3780000,
3780000,
3780000,
3773000,
3773000,
3773000,
3745000,
3710000,
3710000,
3710000,
3710000,
3710000,
3703000,
3703000,
3675000,
3675000,
3675000,
3675000,
3640000,
3640000,
3640000,
3640000,
3640000,
3640000,
3640000,
3640000,
3640000,
3633000,
3605000,
3605000,
3570000,
3570000,
3570000,
3570000,
3535000,
3500000,
3500000,
3500000,
3500000,
3500000,
3500000,
3500000,
3500000,
3500000,
3500000,
3500000,
3500000,
3500000,
3500000,
3500000,
3500000,
3500000,
3493000,
3465000,
3465000,
3465000,
3430000,
3430000,
3430000,
3430000,
3430000,
3430000,
3423000,
3395000,
3395000,
3395000,
3360000,
3360000,
3360000,
3360000,
3360000,
3360000,
3360000,
3360000,
3353000,
3332000,
3325000,
3325000,
3290000,
3290000,
3290000,
3290000,
3290000,
3290000,
3290000,
3290000,
3255000,
3255000,
3234000,
3220000,
3220000,
3220000,
3220000,
3150000,
3150000,
3150000,
3150000,
3150000,
3150000,
3150000,
3150000,
3150000,
3143000,
3129000,
3118850,
3115000,
3115000,
3115000,
3087000,
3080000,
3080000,
3080000,
3080000,
3045000,
3010000,
3010000,
3010000,
3010000,
3010000,
3010000,
3010000,
3003000,
2975000,
2961000,
2940000,
2940000,
2940000,
2940000,
2940000,
2940000,
2940000,
2940000,
2870000,
2870000,
2870000,
2870000,
2852500,
2835000,
2835000,
2835000,
2800000,
2800000,
2730000,
2730000,
2695000,
2660000,
2660000,
2660000,
2660000,
2660000,
2660000,
2660000,
2653000,
2653000,
2604000,
2590000,
2590000,
2590000,
2520000,
2520000,
2520000,
2485000,
2485000,
2450000,
2450000,
2450000,
2450000,
2450000,
2450000,
2408000,
2380000,
2380000,
2380000,
2345000,
2310000,
2275000,
2275000,
2275000,
2240000,
2233000,
2135000,
2100000,
2100000,
2100000,
1960000,
1890000,
1890000,
1855000,
1820000,
1767150,
1750000,
1750000,
1750000
]
}
],
"layout": {
"barmode": "overlay",
"legend": {
"bgcolor": "#F5F6F9",
"font": {
"color": "#4D5663"
}
},
"paper_bgcolor": "#F5F6F9",
"plot_bgcolor": "#F5F6F9",
"template": {
"data": {
"bar": [
{
"error_x": {
"color": "#2a3f5f"
},
"error_y": {
"color": "#2a3f5f"
},
"marker": {
"line": {
"color": "#E5ECF6",
"width": 0.5
}
},
"type": "bar"
}
],
"barpolar": [
{
"marker": {
"line": {
"color": "#E5ECF6",
"width": 0.5
}
},
"type": "barpolar"
}
],
"carpet": [
{
"aaxis": {
"endlinecolor": "#2a3f5f",
"gridcolor": "white",
"linecolor": "white",
"minorgridcolor": "white",
"startlinecolor": "#2a3f5f"
},
"baxis": {
"endlinecolor": "#2a3f5f",
"gridcolor": "white",
"linecolor": "white",
"minorgridcolor": "white",
"startlinecolor": "#2a3f5f"
},
"type": "carpet"
}
],
"choropleth": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "choropleth"
}
],
"contour": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "contour"
}
],
"contourcarpet": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "contourcarpet"
}
],
"heatmap": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "heatmap"
}
],
"heatmapgl": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "heatmapgl"
}
],
"histogram": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "histogram"
}
],
"histogram2d": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "histogram2d"
}
],
"histogram2dcontour": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "histogram2dcontour"
}
],
"mesh3d": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "mesh3d"
}
],
"parcoords": [
{
"line": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "parcoords"
}
],
"pie": [
{
"automargin": true,
"type": "pie"
}
],
"scatter": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatter"
}
],
"scatter3d": [
{
"line": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatter3d"
}
],
"scattercarpet": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattercarpet"
}
],
"scattergeo": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattergeo"
}
],
"scattergl": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattergl"
}
],
"scattermapbox": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattermapbox"
}
],
"scatterpolar": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterpolar"
}
],
"scatterpolargl": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterpolargl"
}
],
"scatterternary": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterternary"
}
],
"surface": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "surface"
}
],
"table": [
{
"cells": {
"fill": {
"color": "#EBF0F8"
},
"line": {
"color": "white"
}
},
"header": {
"fill": {
"color": "#C8D4E3"
},
"line": {
"color": "white"
}
},
"type": "table"
}
]
},
"layout": {
"annotationdefaults": {
"arrowcolor": "#2a3f5f",
"arrowhead": 0,
"arrowwidth": 1
},
"coloraxis": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"colorscale": {
"diverging": [
[
0,
"#8e0152"
],
[
0.1,
"#c51b7d"
],
[
0.2,
"#de77ae"
],
[
0.3,
"#f1b6da"
],
[
0.4,
"#fde0ef"
],
[
0.5,
"#f7f7f7"
],
[
0.6,
"#e6f5d0"
],
[
0.7,
"#b8e186"
],
[
0.8,
"#7fbc41"
],
[
0.9,
"#4d9221"
],
[
1,
"#276419"
]
],
"sequential": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"sequentialminus": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
]
},
"colorway": [
"#636efa",
"#EF553B",
"#00cc96",
"#ab63fa",
"#FFA15A",
"#19d3f3",
"#FF6692",
"#B6E880",
"#FF97FF",
"#FECB52"
],
"font": {
"color": "#2a3f5f"
},
"geo": {
"bgcolor": "white",
"lakecolor": "white",
"landcolor": "#E5ECF6",
"showlakes": true,
"showland": true,
"subunitcolor": "white"
},
"hoverlabel": {
"align": "left"
},
"hovermode": "closest",
"mapbox": {
"style": "light"
},
"paper_bgcolor": "white",
"plot_bgcolor": "#E5ECF6",
"polar": {
"angularaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"bgcolor": "#E5ECF6",
"radialaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
}
},
"scene": {
"xaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
},
"yaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
},
"zaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
}
},
"shapedefaults": {
"line": {
"color": "#2a3f5f"
}
},
"ternary": {
"aaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"baxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"bgcolor": "#E5ECF6",
"caxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
}
},
"title": {
"x": 0.05
},
"xaxis": {
"automargin": true,
"gridcolor": "white",
"linecolor": "white",
"ticks": "",
"title": {
"standoff": 15
},
"zerolinecolor": "white",
"zerolinewidth": 2
},
"yaxis": {
"automargin": true,
"gridcolor": "white",
"linecolor": "white",
"ticks": "",
"title": {
"standoff": 15
},
"zerolinecolor": "white",
"zerolinewidth": 2
}
}
},
"title": {
"font": {
"color": "#4D5663"
},
"text": "price Distribution"
},
"xaxis": {
"gridcolor": "#E1E5ED",
"showgrid": true,
"tickfont": {
"color": "#4D5663"
},
"title": {
"font": {
"color": "#4D5663"
},
"text": ""
},
"zerolinecolor": "#E1E5ED"
},
"yaxis": {
"gridcolor": "#E1E5ED",
"showgrid": true,
"tickfont": {
"color": "#4D5663"
},
"title": {
"font": {
"color": "#4D5663"
},
"text": ""
},
"zerolinecolor": "#E1E5ED"
}
}
},
"text/html": [
"\n",
" \n",
" \n",
" \n",
" \n",
"
"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"application/vnd.plotly.v1+json": {
"config": {
"linkText": "Export to plot.ly",
"plotlyServerURL": "https://plot.ly",
"showLink": true
},
"data": [
{
"boxpoints": false,
"line": {
"width": 1.3
},
"marker": {
"color": "rgba(255, 153, 51, 1.0)"
},
"name": "price",
"orientation": "v",
"type": "box",
"y": [
13300000,
12250000,
12250000,
12215000,
11410000,
10850000,
10150000,
10150000,
9870000,
9800000,
9800000,
9681000,
9310000,
9240000,
9240000,
9100000,
9100000,
8960000,
8890000,
8855000,
8750000,
8680000,
8645000,
8645000,
8575000,
8540000,
8463000,
8400000,
8400000,
8400000,
8400000,
8400000,
8295000,
8190000,
8120000,
8080940,
8043000,
7980000,
7962500,
7910000,
7875000,
7840000,
7700000,
7700000,
7560000,
7560000,
7525000,
7490000,
7455000,
7420000,
7420000,
7420000,
7350000,
7350000,
7350000,
7350000,
7343000,
7245000,
7210000,
7210000,
7140000,
7070000,
7070000,
7035000,
7000000,
6930000,
6930000,
6895000,
6860000,
6790000,
6790000,
6755000,
6720000,
6685000,
6650000,
6650000,
6650000,
6650000,
6650000,
6650000,
6629000,
6615000,
6615000,
6580000,
6510000,
6510000,
6510000,
6475000,
6475000,
6440000,
6440000,
6419000,
6405000,
6300000,
6300000,
6300000,
6300000,
6300000,
6293000,
6265000,
6230000,
6230000,
6195000,
6195000,
6195000,
6160000,
6160000,
6125000,
6107500,
6090000,
6090000,
6090000,
6083000,
6083000,
6020000,
6020000,
6020000,
5950000,
5950000,
5950000,
5950000,
5950000,
5950000,
5950000,
5950000,
5943000,
5880000,
5880000,
5873000,
5873000,
5866000,
5810000,
5810000,
5810000,
5803000,
5775000,
5740000,
5740000,
5740000,
5740000,
5740000,
5652500,
5600000,
5600000,
5600000,
5600000,
5600000,
5600000,
5600000,
5600000,
5600000,
5565000,
5565000,
5530000,
5530000,
5530000,
5523000,
5495000,
5495000,
5460000,
5460000,
5460000,
5460000,
5425000,
5390000,
5383000,
5320000,
5285000,
5250000,
5250000,
5250000,
5250000,
5250000,
5250000,
5250000,
5250000,
5250000,
5243000,
5229000,
5215000,
5215000,
5215000,
5145000,
5145000,
5110000,
5110000,
5110000,
5110000,
5075000,
5040000,
5040000,
5040000,
5040000,
5033000,
5005000,
4970000,
4970000,
4956000,
4935000,
4907000,
4900000,
4900000,
4900000,
4900000,
4900000,
4900000,
4900000,
4900000,
4900000,
4900000,
4900000,
4900000,
4893000,
4893000,
4865000,
4830000,
4830000,
4830000,
4830000,
4795000,
4795000,
4767000,
4760000,
4760000,
4760000,
4753000,
4690000,
4690000,
4690000,
4690000,
4690000,
4690000,
4655000,
4620000,
4620000,
4620000,
4620000,
4620000,
4613000,
4585000,
4585000,
4550000,
4550000,
4550000,
4550000,
4550000,
4550000,
4550000,
4543000,
4543000,
4515000,
4515000,
4515000,
4515000,
4480000,
4480000,
4480000,
4480000,
4480000,
4473000,
4473000,
4473000,
4445000,
4410000,
4410000,
4403000,
4403000,
4403000,
4382000,
4375000,
4340000,
4340000,
4340000,
4340000,
4340000,
4319000,
4305000,
4305000,
4277000,
4270000,
4270000,
4270000,
4270000,
4270000,
4270000,
4235000,
4235000,
4200000,
4200000,
4200000,
4200000,
4200000,
4200000,
4200000,
4200000,
4200000,
4200000,
4200000,
4200000,
4200000,
4200000,
4200000,
4200000,
4200000,
4193000,
4193000,
4165000,
4165000,
4165000,
4130000,
4130000,
4123000,
4098500,
4095000,
4095000,
4095000,
4060000,
4060000,
4060000,
4060000,
4060000,
4025000,
4025000,
4025000,
4007500,
4007500,
3990000,
3990000,
3990000,
3990000,
3990000,
3920000,
3920000,
3920000,
3920000,
3920000,
3920000,
3920000,
3885000,
3885000,
3850000,
3850000,
3850000,
3850000,
3850000,
3850000,
3850000,
3836000,
3815000,
3780000,
3780000,
3780000,
3780000,
3780000,
3780000,
3773000,
3773000,
3773000,
3745000,
3710000,
3710000,
3710000,
3710000,
3710000,
3703000,
3703000,
3675000,
3675000,
3675000,
3675000,
3640000,
3640000,
3640000,
3640000,
3640000,
3640000,
3640000,
3640000,
3640000,
3633000,
3605000,
3605000,
3570000,
3570000,
3570000,
3570000,
3535000,
3500000,
3500000,
3500000,
3500000,
3500000,
3500000,
3500000,
3500000,
3500000,
3500000,
3500000,
3500000,
3500000,
3500000,
3500000,
3500000,
3500000,
3493000,
3465000,
3465000,
3465000,
3430000,
3430000,
3430000,
3430000,
3430000,
3430000,
3423000,
3395000,
3395000,
3395000,
3360000,
3360000,
3360000,
3360000,
3360000,
3360000,
3360000,
3360000,
3353000,
3332000,
3325000,
3325000,
3290000,
3290000,
3290000,
3290000,
3290000,
3290000,
3290000,
3290000,
3255000,
3255000,
3234000,
3220000,
3220000,
3220000,
3220000,
3150000,
3150000,
3150000,
3150000,
3150000,
3150000,
3150000,
3150000,
3150000,
3143000,
3129000,
3118850,
3115000,
3115000,
3115000,
3087000,
3080000,
3080000,
3080000,
3080000,
3045000,
3010000,
3010000,
3010000,
3010000,
3010000,
3010000,
3010000,
3003000,
2975000,
2961000,
2940000,
2940000,
2940000,
2940000,
2940000,
2940000,
2940000,
2940000,
2870000,
2870000,
2870000,
2870000,
2852500,
2835000,
2835000,
2835000,
2800000,
2800000,
2730000,
2730000,
2695000,
2660000,
2660000,
2660000,
2660000,
2660000,
2660000,
2660000,
2653000,
2653000,
2604000,
2590000,
2590000,
2590000,
2520000,
2520000,
2520000,
2485000,
2485000,
2450000,
2450000,
2450000,
2450000,
2450000,
2450000,
2408000,
2380000,
2380000,
2380000,
2345000,
2310000,
2275000,
2275000,
2275000,
2240000,
2233000,
2135000,
2100000,
2100000,
2100000,
1960000,
1890000,
1890000,
1855000,
1820000,
1767150,
1750000,
1750000,
1750000
]
}
],
"layout": {
"legend": {
"bgcolor": "#F5F6F9",
"font": {
"color": "#4D5663"
}
},
"paper_bgcolor": "#F5F6F9",
"plot_bgcolor": "#F5F6F9",
"template": {
"data": {
"bar": [
{
"error_x": {
"color": "#2a3f5f"
},
"error_y": {
"color": "#2a3f5f"
},
"marker": {
"line": {
"color": "#E5ECF6",
"width": 0.5
}
},
"type": "bar"
}
],
"barpolar": [
{
"marker": {
"line": {
"color": "#E5ECF6",
"width": 0.5
}
},
"type": "barpolar"
}
],
"carpet": [
{
"aaxis": {
"endlinecolor": "#2a3f5f",
"gridcolor": "white",
"linecolor": "white",
"minorgridcolor": "white",
"startlinecolor": "#2a3f5f"
},
"baxis": {
"endlinecolor": "#2a3f5f",
"gridcolor": "white",
"linecolor": "white",
"minorgridcolor": "white",
"startlinecolor": "#2a3f5f"
},
"type": "carpet"
}
],
"choropleth": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "choropleth"
}
],
"contour": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "contour"
}
],
"contourcarpet": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "contourcarpet"
}
],
"heatmap": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "heatmap"
}
],
"heatmapgl": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "heatmapgl"
}
],
"histogram": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "histogram"
}
],
"histogram2d": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "histogram2d"
}
],
"histogram2dcontour": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "histogram2dcontour"
}
],
"mesh3d": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "mesh3d"
}
],
"parcoords": [
{
"line": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "parcoords"
}
],
"pie": [
{
"automargin": true,
"type": "pie"
}
],
"scatter": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatter"
}
],
"scatter3d": [
{
"line": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatter3d"
}
],
"scattercarpet": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattercarpet"
}
],
"scattergeo": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattergeo"
}
],
"scattergl": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattergl"
}
],
"scattermapbox": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattermapbox"
}
],
"scatterpolar": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterpolar"
}
],
"scatterpolargl": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterpolargl"
}
],
"scatterternary": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterternary"
}
],
"surface": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "surface"
}
],
"table": [
{
"cells": {
"fill": {
"color": "#EBF0F8"
},
"line": {
"color": "white"
}
},
"header": {
"fill": {
"color": "#C8D4E3"
},
"line": {
"color": "white"
}
},
"type": "table"
}
]
},
"layout": {
"annotationdefaults": {
"arrowcolor": "#2a3f5f",
"arrowhead": 0,
"arrowwidth": 1
},
"coloraxis": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"colorscale": {
"diverging": [
[
0,
"#8e0152"
],
[
0.1,
"#c51b7d"
],
[
0.2,
"#de77ae"
],
[
0.3,
"#f1b6da"
],
[
0.4,
"#fde0ef"
],
[
0.5,
"#f7f7f7"
],
[
0.6,
"#e6f5d0"
],
[
0.7,
"#b8e186"
],
[
0.8,
"#7fbc41"
],
[
0.9,
"#4d9221"
],
[
1,
"#276419"
]
],
"sequential": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"sequentialminus": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
]
},
"colorway": [
"#636efa",
"#EF553B",
"#00cc96",
"#ab63fa",
"#FFA15A",
"#19d3f3",
"#FF6692",
"#B6E880",
"#FF97FF",
"#FECB52"
],
"font": {
"color": "#2a3f5f"
},
"geo": {
"bgcolor": "white",
"lakecolor": "white",
"landcolor": "#E5ECF6",
"showlakes": true,
"showland": true,
"subunitcolor": "white"
},
"hoverlabel": {
"align": "left"
},
"hovermode": "closest",
"mapbox": {
"style": "light"
},
"paper_bgcolor": "white",
"plot_bgcolor": "#E5ECF6",
"polar": {
"angularaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"bgcolor": "#E5ECF6",
"radialaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
}
},
"scene": {
"xaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
},
"yaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
},
"zaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
}
},
"shapedefaults": {
"line": {
"color": "#2a3f5f"
}
},
"ternary": {
"aaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"baxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"bgcolor": "#E5ECF6",
"caxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
}
},
"title": {
"x": 0.05
},
"xaxis": {
"automargin": true,
"gridcolor": "white",
"linecolor": "white",
"ticks": "",
"title": {
"standoff": 15
},
"zerolinecolor": "white",
"zerolinewidth": 2
},
"yaxis": {
"automargin": true,
"gridcolor": "white",
"linecolor": "white",
"ticks": "",
"title": {
"standoff": 15
},
"zerolinecolor": "white",
"zerolinewidth": 2
}
}
},
"title": {
"font": {
"color": "#4D5663"
},
"text": "price Box plot"
},
"xaxis": {
"gridcolor": "#E1E5ED",
"showgrid": true,
"tickfont": {
"color": "#4D5663"
},
"title": {
"font": {
"color": "#4D5663"
},
"text": ""
},
"zerolinecolor": "#E1E5ED"
},
"yaxis": {
"gridcolor": "#E1E5ED",
"showgrid": true,
"tickfont": {
"color": "#4D5663"
},
"title": {
"font": {
"color": "#4D5663"
},
"text": ""
},
"zerolinecolor": "#E1E5ED"
}
}
},
"text/html": [
"\n",
" \n",
" \n",
" \n",
" \n",
"
"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"Detailed Executing with RandomForest ..\n"
]
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAqQAAAGwCAYAAAB/6Xe5AAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADt0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjByYzEsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy/xvVyzAAAgAElEQVR4nO3dd5wkdZ3/8ddbFiUsEhUBhUVUkBwWFCUq55kx4CnH73TVExWVQ38Y7jwR9Tzx1DOeYU2o6KmAIibEQFCCsAvLLsF0sP4wHaLkJOHz+6NqpOnt2endnZma2Xk9H49+dPe3vlX1qaqe6fdUmlQVkiRJUlfu13UBkiRJmtkMpJIkSeqUgVSSJEmdMpBKkiSpUwZSSZIkdcpAKkmSpE4ZSCUBkGRekkoyr+taJEkzi4FUmgBtsOt93J3kz0nObINfuq5xukty7ID13PtY2nWNK6Ot/cyVGO/4MdbHCk9zZfXUMmey5jlekhww2eurK/4RqqlkVtcFSKu5t7XPawKPAJ4N7A/MBV7dVVGrmbOAMwe0Xz/JdUwV3wAWDWhfOsl1SNLQDKTSBKqqY3vfJ3k8cDZwRJL3VdVVnRS2ejmzfz3PcKdU1fFdFyFJK8JD9tIkqqpzgJ8BAfboHZZkjyQfTHJJe3j/9iS/TPK+JBv2T6v3cFuSA9vTAW5KcmOSbyd59KAakjwiyYlJrktyS5JzkzxteXW3tZ2c5JokdyT5dZKPJtlsQN+Rw7VbJ3l1ksvbZVma5F9GTldI8rwkF7Q1XJPkI0nWWoHVuUJWchkenuQ1SRYnua33MG6SjZK8K8kV7bAbkvwwyZMGTO/+SY5MclG73m9t18c3khzU9pmXZOR/Oe/fd7j92AlYH4cmOaOt5/Z2Of41yQMG9H1WkhOS/KLdXjcnWdgu0/36+hbwovbtVYNOoWiXfSkD5N5TMQ7on277GX9Ikk8l+W2aU2Hm9fR5TJKTkvwhyV+SXJ3kE0k2X9n11DPt3p+3v0ny43Y9/DHJZ5Ns0PbbLcm32vV6c5JTM+DUhXZZKskDkvxbkqvaz+X/JHlrkvuPUscTk5yWe39H/CLJcUnWX8487p/kmCQ/b+dxfPtZ/mzb9bN9n7c57fibt+Od07NOf5fkSxnw+yXJnHb849vXX05ybVvngiRPX876fX778zOyXEuT/HeSuQP6Dv3Z1fThHlJp8o2cP3pnX/vLaA7pnwX8AFgD2B14HfCUJI+pqpsGTO/pwMHAd4GPA9sDTwX2TLJ9VV371xknjwTOAzZu+y+iOZXglPb9ssU2XyInt3WfBPyaJky/Ejg4yeOraumAUd8LHAB8EzgdeCbwTuD+Sf4MHNfO98fA3wCvapf5lYPqWBWrsAwfBPYFvg18B7i7nd5WNKcJzGnrPw1Yl2ZbnJbk5VX1yZ7pHA8cClwKfB64Ddgc2Ad4Ms32XkRzisdb2/qO7xn/zJVd9kGSfBp4CfAb4Gs0pzc8FngH8MQkf1NVd/WMchxwD/BT4LfA+sATaNbPnsA/9PR9G/AsYJd2+MipE+NxCsVGwPnAzW3d9wD/2y7Ti4FPAncApwJXA48E/hF4RpLHVtX/G4cankmznb9F8/P2OGAesHWSNwE/pPlMfBrYCXgGsE2SnarqngHT+yrNOjyJ5nfCwcCxwNwkz6yqkT9SSPJy4GPALcCJwDU0P2NvbJfx8VU1aD2f3M7juzQ/c9fQfKaub+fXf5rHyDT2A94EnNFO42aadXoI8Mx2fpcMmN9WwAXAlcAXaLbb84FvJDmoqs7oWabQBOMXAdfSbNc/Ag8FDgR+Dizo6b+in11NF1Xlw4ePcX4A1fx4LdO+H02ouQPYrG/YVsAaA8Z5aTu9N/a1z2vb7wKe2DfsXe2wN/S1n962/1Nf+8EjNQPzetpn03xJ3A3s2zfOG9v+p/e1H9+2LwW26GnfoJ3WLTRfOI/uGfYA4PJ2vTx4yHV8bDufM9vX/Y8547AMvwW2HjDvM2nC0Av62jeg+WK/Ddi0bVu/7btglO278YDPzpkr8ZkbqfmUUdbHBn2fm68Ba4+yTvs/H9sMmN/9gM+1/R8zSi1zRql1KbB0jO16wKCfKZpAP6tv2KOAvwC/6v3MtcOe0G77rw+5Hg8YtA2478/b/n3r4fvtsD8Dh/WN9+l22MEDPkMF/ALYsKd9LZo/Ggv4h572rWh+Pm4Etuub1kfb/vNHmcdiYJMByzqyTPNGWRcPBtYb0L4LTTj9bl/7nJ7t9Na+YX/btn+nr/3wtv0CYP2+YWvQ83tyZT67PqbPo/MCfPhYHR89v5SPbR/vBL7SfmneA7xmBaYV4AbgR33tI7+cTxgwztbtsJN62h7atl3J4GA08uU1r6ftsLbtSwP6zwKuaodv2dN+fNv20gHjfKYd9vYBw97aDtt/yPUy8gU02uOAcViGZb7c2i/jAk4cpa6RcH9E+/6B7ftzgAz52TlzJT5zIzWP9pjT9ruYZk/cBgOmsQZNeL9gyHnu3k77mFFqmTPKeEtZuUA68A8W4P3t8KeNMs2v0wTJZcLVgL4HDNoG3Pvz9oUB47ywHXb2gGH7MzignUlf6BxQwxk9bW9u2/59QP8NaYLqbcADBszj4P5x+pZp3qDhY6ynU4HbgTV72uZw7x+jg37H/Bq4tq9tSTvObkPMc9w+uz6m3sND9tLEemvf+5Gg9tn+jknWBF4OvIDmsPv63Pc87y1GmceCAW1Xt8+9557u1j7/pKruHjDOmTRfnr12b59/1N+5qu5KcjbNl9BuQP/h0EF1/a59Xjhg2G/b54cOGLY8b6vlX9S0KstwwYDp7d0+r5/B53Y+qH1+dDuPG5N8k+bQ7aIkJ9Mc0v1pVd26nLpX1otrlIuakqxDE6ivBY7K4LuP3TFSe894GwOvpzkV5OE0pyf0Gu2zOd6WVtU1A9pHtsn+SfYcMPzBNIHlUQz+7K2I8f5cnzWg7cc0AXq3nrblfY6vS3IxzRGY7YD+w+iDPsdDSXN++Sto7gyyCcue6rcJ8Pu+tkWj/I65mnu3FUnWBXYE/reqLh6jjpX67Gr6MJBKE6iqRi7gWZfmF/GngY8n+XVV9X+xfIXmHNIrac7p+gPNL1iAo2gOaw+yzDljbdCC5kt4xMhFD/87ynT+MKBtZJz+Lxz62jcYMOyGAW13DTFszVHmtbJWZRkGrZON2+e/aR+jmd3z+vk0pwf8PffeCuz2JCcBR1fVaNtkvG1Is8f9QSz7x9JA7cU6F9Lsdb+A5pD5n2m21wbAPzH6Z3O8DdoecO82ef0Y488eY/gwxvtzvcy2r6q7k/yJJkiPGO/P8ZiSHElzHvB1NKcl/D/gVpo/rEfOEx607Uc7X/gu7vtH9kitvx3Qt98Kf3Y1vRhIpUlQVbcAP0jyDOAi4HNJth3ZQ9ZeSfpsmotbnlpVf73gKc1VzG8YhzJGviw3HWX4Q5YzzqBhAJv19ZuKVmUZajnT+6eq+tAwBVTVbbSnbyR5GM2erHnA/6HZO7vvMNMZByO1X1xVuy+3573+kSaMLrMnOsneNIF0Rd0DDLyKnMGBasSg7QH3Ltf6VXXjStTTpU3p2zOfZA2akN27LL2f48sGTGfUz3FVjbbeRpVkFs0fT38Adq+q3/cN33vgiCtmJLgOs4d9ZT67mka87ZM0iapqMc2VwA8FXtsz6BHt86m9YbS1F7D2OMx+5JDYPu0XXr8DljPOMsPaL6x92rcXrWpxE2i8l+H89nmlQmRVXV1VX6S5yOOXNNtj454u93DfPdvjpqpupgkzOyTZaMjRRj6bJw8Y1n+Kx4iRw7WjLcd1wKbtaSr9lrnNzxBWaZt0bNA63Jdmh1HvYezlfY43AHalOafzihWY9/K20yY0fxycOyCMzubeUwhWWvuH+qU0n4Xdxui7Mp9dTSMGUmny/RvNF8fRuff+okvb5wN6OyZ5MPBf4zHTqvoNzWG3ren7L1FJDmbwF+MpNIdnD03y2L5hR9GcT/iDGp/b6UyUcV2GqlpAc47fc5K8ZFCfJDu1244kD0rymAHd1gXWozmM+Zee9j8BDxumlpX0nzR7Jz/TBpn7SLJhkt6wsbR9PqCv327AP48yjz+1z1uOMvwCmsD14r5pzgMeP3rpo/oIzcUu70/yqP6B7X04p2pYfUvP7wHS3Iv3Xe3b3nPNT6BZxtckeQT39Q6ai+dOqKo7GN7yttM1NIfn92gD6Eh9a9Icxt9kBeazPCNHGT6RvnupJrlf7nuf4BX97Goa8ZC9NMmq6rdJPkFzqPMNNF/qF9Jchf2cJOcCP6E5lPcUmvvw/W6Uya2oV9HcUuYDaW7gfgn3/kvTkQtvemu9uQ1dJwJnJTmR5vDiHsCTaA7nvXycapsQE7QMf09zccmn2/Psfkpz+PGhwM40F2rsTfOlvgVwfpIraPbCXk0THp5Oc/j1Q3Xf+8v+EHhBeyHUQprAenZVnb2iyz5IVX0myR7AEcD/JPkezfrYiOaPlf1ogtAr2lE+T3Nu5geSHEizV/eRbf1fozk/tt8P23E+2Z4nezNwfVV9pB3+YZow+rEkT6RZJ7vQ3NPzW+20V2SZftZu488AlyU5jeZ2SmvShK19aW41tt2KTHeSXEFTc+99SLehufftF0Y6VdXSJEfR/IF6UZKv0izT/jSftZ/RnKe8Is6jCZ1HtXsdR85n/XBV3ZDkQzT3IV2S5Bs0YfBAms/KGe3rVfUpmqMULwR+2c7njzT36X0CzTY9Flbqs6vppOvL/H34WB0fjHIf0p7hm9Lcj/MW7r1f5UY09xNcSrMH9X+AfwfWYcBtchj7HoIDbx9EE0BPoglQt9B8KT1tedOjuan212m+KP5C8yXwMWDzAX2PZ5Rb/jDKLX2GWZ7lTOvYIfuPyzL09FkP+Bea0HgzzS13rqIJEocD67b9NgCOoQmwv6W5UO33NHc1OJS+W0HRXMjyJZpwcPewy9hT87Drb+Tm7te06+MPNHsu/41l73O5Pc1tfq5pPzMLac4tndPO8/gB038dTdi6o+3T//ndh+bf6N5Kc67kt2nC/MDPyGif574+O7Xr4dftfP9Mc0j4E8AThlwvBwya1/I+nz3jLLOdRltH3HtLpge06/yqtuYraS7aecAo9T2J5n7C17X9fwX8B4NvhXQmy/k91PZ5Ms3vgJtZ9hZhs9rteDnN5/sPNCF5Kwb8jCzv8zBWPTS3ZzuL5lzR29v18UWa81dX+rPrY/o80m5cSZI0SdL86879q70ThzTTeQ6pJEmSOmUglSRJUqcMpJIkSeqU55BKkiSpU972aRrbZJNNas6cOV2XIUmSNKaFCxdeW1UPGjTMQDqNzZkzhwULFnRdhiRJ0piS/Hq0YZ5DKkmSpE4ZSCVJktQpD9lPY1f85k/s8frPd12GJEmapha+54VdlwC4h1SSJEkdM5BKkiSpUwZSSZIkdcpAKkmSpE4ZSCVJktQpA6kkSZI6ZSCVJElSpwykkiRJ6pSBVJIkSZ0ykEqSJKlTBlJJkiR1ykAqSZKkThlIJ1GSNbquQZIkaaoxkI6jJKckWZjksiSHt203J3l7kp8Ceyf5P0kuSLIoySdGQmqSjyVZ0I77tk4XRJIkaRIZSMfXS6pqD2AucGSSjYF1gUur6jHAn4DnA4+vql2Bu4HD2nHfXFVzgZ2B/ZPsPGgGSQ5vg+uCu269aaKXR5IkacLN6rqA1cyRSZ7dvn4Y8Eia0Hly2/ZEYA/gwiQAawPXtMP+rt2rOgvYDNgeWNw/g6qaD8wHWPchW9fELIYkSdLkMZCOkyQHAAcBe1fVrUnOBNYCbq+qu0e6AZ+rqn/uG3dr4Ghgz6q6Lsnx7biSJEmrPQ/Zj5/1gevaMLod8NgBfX4IHJLkwQBJNkqyFfBA4BbghiSbAk+ZrKIlSZK65h7S8XMa8Ioki4GfA+f3d6iqy5P8K3B6kvsBdwKvqqrzk1wMXAZcCZwziXVLkiR1ykA6TqrqDgbv2Zzd1+8rwFcGjD9vYiqTJEma2jxkL0mSpE4ZSCVJktQpA6kkSZI6ZSCVJElSpwykkiRJ6pSBVJIkSZ0ykEqSJKlTBlJJkiR1ykAqSZKkThlIJUmS1Cn/deg09uiHbsyC97yw6zIkSZJWiXtIJUmS1CkDqSRJkjplIJUkSVKnDKSSJEnqlIFUkiRJnTKQSpIkqVPe9mka+8vvL+P/vX2nrsuQxrTlMUu6LkGSNIW5h1SSJEmdMpBKkiSpUwZSSZIkdcpAKkmSpE4ZSCVJktQpA6kkSZI6ZSCVJElSpwykkiRJ6pSBVJIkSZ0ykEqSJKlTBlJJkiR1arUKpEnmJLl0BfrPS7J5z/ulSTaZmOokSZI0yGoVSFfCPGDzsTr1SjJrYkqRJEmamVbHQDoryeeSLE5yUpJ1khyT5MIklyaZn8YhwFzgi0kWJVm7Hf81SS5KsiTJdgBJjm3HOx34fJKtkvywnccPk2zZ9hut/fgkH0tyRpIrk+yf5DNJrkhyfNtnjbbfpe28Xzvpa06SJKkDq2Mg3RaYX1U7AzcCRwAfqao9q2pHYG3g6VV1ErAAOKyqdq2q29rxr62q3YGPAUf3THcP4OCq+nvgI8Dn23l8EfhQ22e0doANgScArwW+Cbwf2AHYKcmuwK7AFlW1Y1XtBHx20MIlOTzJgiQL/nzL3Su9kiRJkqaK1TGQXl1V57SvTwD2AQ5M8tMkS2hC4Q7LGf9r7fNCYE5P+6k9oXVv4Evt6y+081heO8A3q6qAJcD/VtWSqroHuKydz5XAw5N8OMmTacL0MqpqflXNraq5G627xnIWQ5IkaXpYHQNpDXj/UeCQds/jJ4G1ljP+He3z3UDv+aK3rMA8B7WPTPeentcj72dV1XXALsCZwKuATy1nfpIkSauN1TGQbplk7/b1ocBP2tfXJpkNHNLT9yZgvZWYx7nAC9rXh/XMY7T2MbVX99+vqk4G3gLsvhJ1SZIkTTur4xXjVwAvSvIJ4Jc054JuSHOofClwYU/f44GPJ7mN5nD7sI4EPpPk9cAfgReP0T6MLYDPJhn5I+GfV2BcSZKkaSvNaY2ajnbeYu361ssf0XUZ0pi2PGZJ1yVIkjqWZGFVzR00bHU8ZC9JkqRpxEAqSZKkThlIJUmS1CkDqSRJkjplIJUkSVKnDKSSJEnqlIFUkiRJnTKQSpIkqVMGUkmSJHXKQCpJkqROrY7/y37GuP9mO7DlMQu6LkOSJGmVuIdUkiRJnTKQSpIkqVMGUkmSJHXKQCpJkqROGUglSZLUKQOpJEmSOuVtn6axn13zMx7/4cd3XcaUds5rzum6BEmSNAb3kEqSJKlTBlJJkiR1ykAqSZKkThlIJUmS1CkDqSRJkjplIJUkSVKnDKSSJEnqlIFUkiRJnTKQSpIkqVMGUkmSJHXKQCpJkqROGUjHUZLjkxwyoP1TSbbvoiZJkqSpblbXBawukoy6LqvqHyezFkmSpOnEPaQ9ksxJ8rMkn0uyOMlJSdZJckySC5NcmmR+krT9z0zy70nOAv6pb1rvaPeY3q/tN7dtvznJO5NckuT8JJu27du07y9M8vYkN0/6CpAkSeqAgXRZ2wLzq2pn4EbgCOAjVbVnVe0IrA08vaf/BlW1f1W9b6QhyX8ADwZeXFX39E1/XeD8qtoFOBt4Wdv+QeCDVbUn8LvRiktyeJIFSRbcefOdq7akkiRJU4CBdFlXV9U57esTgH2AA5P8NMkS4AnADj39v9I3/ltoQurLq6oGTP8vwLfa1wuBOe3rvYET29dfGq24qppfVXOrau6as9ccdpkkSZKmLAPpsvpDZAEfBQ6pqp2ATwJr9Qy/pa//hcAeSTYaZfp39gTVu/E8XkmSNMMZSJe1ZZK929eHAj9pX1+bZDawzFX0fU4DjgO+nWS9FZjv+cBz29cvWIHxJEmSpjUD6bKuAF6UZDGwEfAxmr2iS4BTaPaALldVndiOc2qStYec71HA65JcAGwG3LAStUuSJE07GXya48yUZA7wrfbipcme9zrAbVVVSV4AHFpVBy9vnNlbzq5dXr/L5BQ4TZ3zmnPG7iRJkiZckoVVNXfQMM9fnDr2AD7S3lLqeuAlHdcjSZI0KQykPapqKTDpe0fbef8YcHenJEmacTyHVJIkSZ0ykEqSJKlTBlJJkiR1ykAqSZKkThlIJUmS1CkDqSRJkjplIJUkSVKnDKSSJEnqlDfGn8a2e/B2/mtMSZI07bmHVJIkSZ0ykEqSJKlTBlJJkiR1ykAqSZKkThlIJUmS1CkDqSRJkjrlbZ+msZt+/nPO2m//rsuYEPuffVbXJUiSpEniHlJJkiR1ykAqSZKkThlIJUmS1CkDqSRJkjplIJUkSVKnDKSSJEnqlIFUkiRJnTKQSpIkqVMGUkmSJHXKQCpJkqROGUglSZLUqQkPpEmOTHJFki+Ow7TenuSg5Qw/PskhA9o3T3LSqs6/b5q7JnnqePWTJEmaqWZNwjyOAJ5SVVeN1TFJgFTVPYOGV9UxK1NAVf0OWCaorqJdgbnAd8apnyRJ0ow0oXtIk3wceDhwapIbkhzdM+zSJHPaxxVJPgpcBOzbvv9kksuSnJ5k7Xacv+4BTXJcksuTLE7y3p7Z7pfk3CRX9vSdk+TS9vW8JF9LclqSXyb5j56aXprkF0nObOf/kbb9eW29lyQ5O8n9gbcDz0+yKMnzk+zVzvfi9nnbUfodO8p6WDfJt9t5XJrk+ROyUSRJkqaYCd1DWlWvSPJk4EDg1cvpui3w4qo6Iskc4JHAoVX1siRfBZ4LnDDSOclGwLOB7aqqkmzQM63NgH2A7YBTgUGH6ncFdgPuAH6e5MPA3cBbgN2Bm4AfAZe0/Y8B/raqfptkg6r6S5JjgLlV9eq2pgcC+1XVXe1pBf9eVc8d0O/YUdbBk4HfVdXT2n7rD+qU5HDgcIBNH/CAUSYlSZI0fUyVi5p+XVXn97y/qqoWta8XAnP6+t8I3A58KslzgFt7hp1SVfdU1eXApqPM74dVdUNV3Q5cDmwF7AWcVVV/rqo7gRN7+p8DHJ/kZcAao0xzfeDEdk/s+4EdlrO8gywBDkry7iT7VtUNgzpV1fyqmltVc9dfc80VnIUkSdLUM5mB9K6++a3V8/qWvr539Ly+m749uVV1F02APBl4FnDaKONmlFoGTX+0vlTVK4B/BR4GLEqy8YBu7wDOqKodgWdw3+XrNXA9VNUvgD1ogum72j2rkiRJq73JDKRLaQ6Hk2R3YOuVnVCS2cD6VfUd4CiaQ/Cr6gJg/yQbJplFc5rAyPy2qaqfthdVXUsTTG8C1usZf33gt+3reT3t/f2WMmA9JNkcuLWqTgDeO9JHkiRpdTeZgfRkYKMki4BXAr9YhWmtB3wryWLgLOC1q1pcVf0W+Hfgp8APaA7ljxw2f0+SJe3h+LNpzi09A9h+5GIl4D9o9myew30P6/f3G2097ARc0La/Gfi3VV0mSZKk6SBV1XUNU0aS2VV1c7uH9OvAZ6rq613XNZpt11uv5u+2eu5I3f/ss7ouQZIkjaMkC6tq7qBhU+Wipqni2HYP5aXAVcApHdcjSZK02puMG+NPG1V19Ni9JEmSNJ7cQypJkqROGUglSZLUKQOpJEmSOmUglSRJUqcMpJIkSeqUgVSSJEmdMpBKkiSpUwZSSZIkdcob409j6227rf9iU5IkTXvuIZUkSVKnDKSSJEnqlIFUkiRJnTKQSpIkqVMGUkmSJHXKQCpJkqROedunaeya39zAR/7vN7suY1y9+n3P6LoESZI0ydxDKkmSpE4ZSCVJktQpA6kkSZI6ZSCVJElSpwykkiRJ6pSBVJIkSZ0ykEqSJKlTBlJJkiR1ykAqSZKkThlIJUmS1CkDqSRJkjplIF1BSY5Kss5KjPepJNtPRE2SJEnTmYF0xR0FrFAgTbJGVf1jVV0+QTVJkiRNWwbS5UiybpJvJ7kkyaVJ3gpsDpyR5Iy2z6FJlrTD390z7s1J3p7kp8DeSc5MMrcd9qQk5yW5KMmJSWa37ccluTzJ4iTv7WCRJUmSJt2srguY4p4M/K6qngaQZH3gxcCBVXVtks2BdwN7ANcBpyd5VlWdAqwLXFpVx7Tj0j5vAvwrcFBV3ZLkjcDrknwEeDawXVVVkg0mdUklSZI6MtQe0iTbJHlA+/qAJEfOkMC0BDgoybuT7FtVN/QN3xM4s6r+WFV3AV8E9muH3Q2cPGCajwW2B85Jsgh4EbAVcCNwO/CpJM8Bbh1UUJLDkyxIsuDmW/vLkSRJmn6GPWR/MnB3kkcAnwa2Br40YVVNEVX1C5q9n0uAdyU5pq9LljP67VV194D2AN+vql3bx/ZV9dI20O5Fs66fBZw2Sk3zq2puVc2dvc76K7xMkiRJU82wgfSeNjA9G/hAVb0W2Gziypoa2kPyt1bVCcB7gd2Bm4D12i4/BfZPskmSNYBDgbPGmOz5wOPbcE+SdZI8qj2PdP2q+g7NhVO7jv8SSZIkTT3DnkN6Z5JDaQ4vP6NtW3NiSppSdgLek+Qe4E7glcDewHeT/L6qDkzyz8AZNHs+v1NV31jeBKvqj0nmAf89choEzTmlNwHfSLJWO63XTsgSSZIkTTHDBtIXA68A3llVVyXZGjhh4sqaGqrqe8D3+poXAB/u6fMlBpy+UFWz+94f0PP6RzTnn/bbaxXKlSRJmpaGCqRVdXl7NfiW7furgOMmsjBJkiTNDMNeZf8MYBHthTZJdk1y6kQWJkmSpJlh2IuajqU5nHw9QFUtornSXpIkSVolwwbSuwbcg7PGuxhJkiTNPMNe1HRpkr8H1kjySOBI4NyJK0uSJEkzxbB7SF8D7ADcQXNF+Q0098qUJEmSVsmYe0jbG76fWlUHAW+e+JIkSZI0k4y5h7T995e3JvH/VEqSJGncDXsO6e3AkiTfB24ZaayqIyekKkmSJM0YwwbSb7cPSZIkaVylyrs3TVdz586tBQsWdF2GJEnSmJIsrKq5g4YNtYc0yVUMuO9oVT18FWuTJEnSDDfsIfveNLsW8Dxgo/EvR5IkSTPNUPchrao/9Tx+W1UfAJ4wwbVJkiRpBhj2kP3uPW/vR7PHdL0JqUiSJEkzyrCH7N/X8/ou4Crg78a/HEmSJM00wwbSl1bVlb0NSdad0ukAABdXSURBVLaegHokSZI0wwx126ckF1XV7n1tC6tqjwmrTGPaYuMN64inPLHrMlbZm084qesSJEnSBFvp2z4l2Q7YAVg/yXN6Bj2Q5mp7SZIkaZWMdch+W+DpwAbAM3rabwJeNlFFSZIkaeZYbiCtqm8A30iyd1WdN0k1SZIkaQYZ9qKmi5O8iubw/V8P1VfVSyakKkmSJM0YQ90YH/gC8BDgb4GzgIfSHLaXJEmSVsmwgfQRVfUW4Jaq+hzwNGCniStLkiRJM8WwgfTO9vn6JDsC6wNzJqQiSZIkzSjDnkM6P8mGwFuAU4HZwDETVpUkSZJmjKECaVV9qn15FvDwiStHkiRJM81Qh+yTbJrk00m+277fPslLJ7Y0SZIkzQTDnkN6PPA9YPP2/S+AoyaiIEmSJM0swwbSTarqq8A9AFV1F3D3hFU1TpLMSXLpZI8rSZKk4Q0bSG9JsjFQAEkeC9wwYVVNYUmGvRBMkiRJQxg2XL2O5ur6bZKcAzwIOGTCqhpfs5J8DtiN5lSDFwKPBv6T5m4B1wLzqur3SfYAPgPcCvxkZAJJ5tHce3UtYN0kh7T9Ht72PbyqFifZaJT2Y4Gtgc2AR9Gsz8cCTwF+Czyjqu5MchzwTOAu4PSqOnrC1ookSdIUsdw9pEm2BKiqi4D9gccBLwd2qKrFE1/euNgWmF9VOwM3Aq8CPgwcUlUjAfSdbd/PAkdW1d4DprM38KKqegLwNuDidpr/Any+7TNaO8A2NKH2YOAE4Iyq2gm4DXhaG2afTbNudwb+bVyWXpIkaYob65D9KT2vv1JVl1XVpVV156hjTD1XV9U57esTaP796Y7A95MsAv4VeGiS9YENquqstu8X+qbz/ar6c/t6n5HhVfUjYON2/NHaAb7brrclwBrAaW37Epp/MnAjcDvwqSTPodnDuowkhydZkGTBLbffseJrQ5IkaYoZ65B9el5P1/uPVt/7m4DL+veCJtlgQN9et/R2H2U+o7UD3AFQVfckubOqRtrvAWZV1V1J9gKeCLwAeDXwhGUmVjUfmA+wxcYbLq9eSZKkaWGsPaQ1yuvpZMskI+HzUOB84EEjbUnWTLJDVV0P3JBkn7bvYcuZ5tkjw5McAFxbVTcup31MSWYD61fVd2huqbXr8IsoSZI0fY21h3SXJDfS7Plbu31N+76q6oETWt34uAJ4UZJPAL+kOX/0e8CH2sPps4APAJcBLwY+k+TWts9ojgU+m2QxzaH1F43RPoz1gG8kWYtm/b52BcaVJEmatnLvkWNNN1tsvGEd8ZQndl3GKnvzCSd1XYIkSZpgSRZW1dxBw4a9D6kkSZI0IQykkiRJ6pSBVJIkSZ0ykEqSJKlTBlJJkiR1ykAqSZKkThlIJUmS1CkDqSRJkjplIJUkSVKnDKSSJEnq1Fj/y15T2GZbb+O/3ZQkSdOee0glSZLUKQOpJEmSOmUglSRJUqcMpJIkSeqUgVSSJEmdMpBKkiSpU972aRq7/fc3ccU7f9R1GUN59Juf0HUJkiRpinIPqSRJkjplIJUkSVKnDKSSJEnqlIFUkiRJnTKQSpIkqVMGUkmSJHXKQCpJkqROGUglSZLUKQOpJEmSOmUglSRJUqcMpJIkSeqUgVSSJEmdmnKBNMl3kmwwifM7M8nc3nm3jyN6+mye5KRVmMekLpMkSdJ0MuUCaVU9taqu721LY8Jr7Zn3BsARPe2/q6pDxmG6kiRJ6tNpIE1ySpKFSS5LcnjbtjTJJknmJLkiyUeBi4CHJXlDkiVJLklyXNt/1yTnJ1mc5OtJNmzbz0zy7iQXJPlFkn3b9rWTfLnt/xVg7Z56libZBDgO2CbJoiTvaWu5tO2zVpLPtnVcnOTAtn1ekq8lOS3JL5P8R/90e5bpk+0yn55k7bbPnm1N57XzvHQSNoEkSVLnut5D+pKq2gOYCxyZZOO+4dsCn6+q3YDtgWcBj6mqXYCRwPd54I1VtTOwBHhrz/izqmov4Kie9lcCt7b93wnsMaCuNwH/U1W7VtXr+4a9CqCqdgIOBT6XZK122K7A84GdgOcnediAaT8S+K+q2gG4Hnhu2/5Z4BVVtTdw94DxAEhyeJIFSRb8+RZ3ukqSpOmv60B6ZJJLgPOBh9GEtV6/rqrz29cHAZ+tqlsBqurPSdYHNqiqs9o+nwP26xn/a+3zQmBO+3o/4IR2GouBxStY8z7AF9rxfwb8GnhUO+yHVXVDVd0OXA5sNWD8q6pqUW9d7fml61XVuW37l0abeVXNr6q5VTV3o3U9LVWSJE1/s7qacZIDaELm3lV1a5IzgbX6ut3SOwpQKzibO9rnu7nvsq7odHpliPkNmudofdYeY5qSJEmrtS73kK4PXNeG0e2Ax47R/3TgJUnWAUiyUVXdAFw3cn4o8A/AWaNNoHU2cFg7jR2BnQf0uQlYb4jxHwVsCfx8jHkuV1VdB9yUZGQdvGBVpidJkjSddBlITwNmJVkMvIPmsP2oquo04FRgQZJFwNHtoBcB72mnsyvw9jHm+zFgdtv/DcAFA+b1J+CcJJcmeU/f4I8CayRZAnwFmFdVd/RPYyW8FJif5DyaPaY3jMM0JUmSprxUrcrRa42XJLOr6ub29ZuAzarqn5Y3zo5bbFsnHvGxSalvVT36zU/ougRJktShJAurau6gYZ2dQ6plPC3JP9Nsk18D87otR5IkaXIYSKeIqvoKzSkAkiRJM0rXt32SJEnSDGcglSRJUqcMpJIkSeqUgVSSJEmdMpBKkiSpUwZSSZIkdcpAKkmSpE55H9JpbK3N1vM/IEmSpGnPPaSSJEnqlIFUkiRJnTKQSpIkqVMGUkmSJHXKQCpJkqROGUglSZLUKW/7NI397ne/49hjj+26jPuYavVIkqSpzz2kkiRJ6pSBVJIkSZ0ykEqSJKlTBlJJkiR1ykAqSZKkThlIJUmS1CkDqSRJkjplIJUkSVKnDKSSJEnqlIFUkiRJnTKQSpIkqVMGUkmSJHVqtQ6kSeYkubTrOlZEW/Pfd12HJEnSZFmtA+k0NQcwkEqSpBljJgTSWUk+l2RxkpOSrJPkmCQXJrk0yfwkAUhyZJLL275fbtvWTfKZtv/FSQ5u2+clOSXJN5NcleTVSV7X9jk/yUZtv22SnJZkYZIfJ9mubT8+yYeSnJvkyiSHtPUeB+ybZFGS107+6pIkSZpcMyGQbgvMr6qdgRuBI4CPVNWeVbUjsDbw9Lbvm4Dd2r6vaNveDPyoqvYEDgTek2TddtiONHsz9wLeCdxaVbsB5wEvbPvMB15TVXsARwMf7altM2Cfdv7H9dTw46ratare378wSQ5PsiDJgltvvXXl14okSdIUMavrAibB1VV1Tvv6BOBI4KokbwDWATYCLgO+CSwGvpjkFOCUdpwnAc9McnT7fi1gy/b1GVV1E3BTkhvaaQAsAXZOMht4HHBiuxMW4AE9tZ1SVfcAlyfZdJiFqar5NCGXzTffvIYZR5IkaSqbCYG0P7QVzV7KuVV1dZJjaUImwNOA/YBnAm9JsgMQ4LlV9fPeiSR5DHBHT9M9Pe/voVm39wOur6pdR6mtd/yM0keSJGm1NhMO2W+ZZO/29aHAT9rX17Z7MA8BSHI/4GFVdQbwBmADYDbwPeA1PeeZ7jbsjKvqRpq9sc9rx02SXcYY7SZgvWHnIUmSNN3NhEB6BfCiJItpDs9/DPgkzWH1U4AL235rACckWQJcDLy/qq4H3gGsCSxubyH1jhWc/2HAS5NcQnNqwMFj9F8M3JXkEi9qkiRJM0GqPA1xutp8883r8MMP77qM+zj22GO7LkGSJE1BSRZW1dxBw2bCHlJJkiRNYQZSSZIkdcpAKkmSpE4ZSCVJktQpA6kkSZI6ZSCVJElSpwykkiRJ6pSBVJIkSZ0ykEqSJKlT/qemaWzu3Lm1YMGCrsuQJEkak/+pSZIkSVOWgVSSJEmdMpBKkiSpUwZSSZIkdcpAKkmSpE4ZSCVJktQpA6kkSZI6NavrArTyrrvuCr564l6TMq+/e94FkzIfSZI087iHVJIkSZ0ykEqSJKlTBlJJkiR1ykAqSZKkThlIJUmS1CkDqSRJkjplIJUkSVKnDKSSJEnqlIFUkiRJnTKQSpIkqVMGUkmSJHXKQLoKkuyb5LIki5Ks3XU9kiRJ05GBdAxJ1ljO4MOA91bVrlV12xDTShLXuSRJUo8ZHY6SzEnysySfS7I4yUlJ1kmyNMkxSX4CPC/Jk5Kcl+SiJCcmmZ3kH4G/A45J8sW27YdtnyVJDu6ZxxVJPgpcBDwsyeuTXNjO82099ZySZGG71/XwTlaKJEnSJJvRgbS1LTC/qnYGbgSOaNtvr6p9gB8A/wocVFW7AwuA11XVp4BTgddX1WHA7cCz2z4HAu9Lkp55fL6qdmtfPxLYC9gV2CPJfm2/l1TVHsBc4MgkG/cXm+TwJAuSLLjxxrvGeVVIkiRNvlldFzAFXF1V57SvTwCObF9/pX1+LLA9cE6bL+8PnDdgOgH+vQ2X9wBbAJu2w35dVee3r5/UPi5u38+mCahn04TQZ7ftD2vb/9Q7k6qaD8wH2GabdWtFF1aSJGmqMZBCf6gbeX9L+xzg+1V16BjTOQx4ELBHVd2ZZCmwVt+0Rqb3rqr6RO/ISQ4ADgL2rqpbk5zZM74kSdJqy0P2sGWSvdvXhwI/6Rt+PvD4JI8AaM8xfdSA6awPXNOG0QOBrUaZ3/eAlySZ3U5viyQPbse/rg2j29HsmZUkSVrtGUjhCuBFSRYDGwEf6x1YVX8E5gH/3fY5H9huwHS+CMxNsoBmb+nPBs2sqk4HvgScl2QJcBKwHnAaMKudxzva+UiSJK32PGQP91TVK/ra5vS+qaofAXv2j1hV83peXwvs3d+ntWPfeB8EPjig31PGLleSJGn14h5SSZIkdWpG7yGtqqX07b2UJEnS5HIPqSRJkjplIJUkSVKnDKSSJEnqlIFUkiRJnTKQSpIkqVMGUkmSJHXKQCpJkqROzej7kE53G274aP7ueRd0XYYkSdIqcQ+pJEmSOmUglSRJUqcMpJIkSeqUgVSSJEmdMpBKkiSpUwZSSZIkdcpAKkmSpE55H9Jp7PLrbmSXk743YdO/5JC/nbBpS5IkjXAPqSRJkjplIJUkSVKnDKSSJEnqlIFUkiRJnTKQSpIkqVMGUkmSJHXKQCpJkqROGUglSZLUKQOpJEmSOmUglSRJUqcMpJIkSerUhAXSJHOSXLoC/ecl2Xwc5vusJNuvxHjHJzlkVeffTutf+t6fOx7TlSRJWh1NpT2k84BVDqTAs4AVCqRJZo3DfHvdJ5BW1ePGefqSJEmrjYkOpGsk+WSSy5KcnmTtJLsmOT/J4iRfT7Jhu2dyLvDFJIuS7J/kawBJDk5yW5L7J1kryZVt+8uSXJjkkiQnJ1knyeOAZwLvaaezTfs4LcnCJD9Osl07/vFJ/jPJGcC723r3S3Jukit795YmeX07r8VJ3tbTfko73cuSHN62HQes3c7/i23bze3zAUnOTHJSkp8l+WKStMOe2rb9JMmHknxrQreMJEnSFDHRgfSRwH9V1Q7A9cBzgc8Db6yqnYElwFur6iRgAXBYVe0KnAPs1k5jX+BSYE/gMcBP2/avVdWeVbULcAXw0qo6FzgVeH1V7VpV/wPMB15TVXsARwMf7anvUcBBVfV/2/ebAfsATweOA0jypHY59gJ2BfZIsl/b/yXtdOcCRybZuKreBNzWzv+wAetkN+Aomr24Dwcen2Qt4BPAU6pqH+BBo63QJIcnWZBkwV033jBaN0mSpGljvA9V97uqqha1rxcC2wAbVNVZbdvngBP7R6qqu5L8KsmjaYLgfwL7AWsAP2677Zjk34ANgNnA9/qnk2Q28DjgxHZHJMADerqcWFV397w/paruAS5Psmnb9qT2cXH7fjZNQD2bJoQ+u21/WNv+p+WsD4ALquo3bX2LgDnAzcCVVXVV2+e/gcMHjVxV82lCNuts86gaY16SJElT3kQH0jt6Xt9NEx6H9WPgKcCdwA+A42kC6dHt8OOBZ1XVJUnmAQcMmMb9gOvbva6D3LKcetPz/K6q+kRvxyQHAAcBe1fVrUnOBNYaY5n653E3zTbIKH0lSZJWe5N9UdMNwHVJ9m3f/wMwsrf0JmC9nr5n0xzaPq+q/ghsDGwHXNYOXw/4fZI1gd5D43+dTlXdCFyV5HkAaeyygjV/D3hJu7eVJFskeTCwPnBdG0a3Ax7bM86dbV3D+hnw8CRz2vfPX8EaJUmSpq0urrJ/Ec1FR4tpzsl8e9t+PPDx9mKgtWnOFd2UJpgCLAYWV9XIYeq3tH2+TxPoRnwZeH2Si5NsQxNWX5rkEpowe/CKFFtVpwNfAs5LsgQ4iSbwngbMapfjHcD5PaPNBxaPXNQ0xDxuA44ATkvyE+B/acK7JEnSai/35jt1Kcnsqrq5ver+v4BfVtX7lzfOOts8qh757g9PWE2XHPK3EzZtSZI0syRZWFVzBw2bSvchnele1l7kdBnN6QCfGKO/JEnSamGiL2rSkNq9ocvdIypJkrQ6cg+pJEmSOmUglSRJUqcMpJIkSeqUgVSSJEmdMpBKkiSpUwZSSZIkdcpAKkmSpE55H9JpbPsNH8gC/5uSJEma5txDKkmSpE4ZSCVJktQpA6kkSZI6larqugatpCQ3AT/vug6tkE2Aa7suQkNze00/brPpx202vazK9tqqqh40aIAXNU1vP6+quV0XoeElWeA2mz7cXtOP22z6cZtNLxO1vTxkL0mSpE4ZSCVJktQpA+n0Nr/rArTC3GbTi9tr+nGbTT9us+llQraXFzVJkiSpU+4hlSRJUqcMpJIkSeqUgXSKS/LkJD9P8qskbxowPEk+1A5fnGT3LurUvYbYZtslOS/JHUmO7qJG3dcQ2+yw9udrcZJzk+zSRZ261xDb7OB2ey1KsiDJPl3UqcZY26un355J7k5yyGTWp2UN8TN2QJIb2p+xRUmOWaX5eQ7p1JVkDeAXwN8AvwEuBA6tqst7+jwVeA3wVOAxwAer6jEdlCuG3mYPBrYCngVcV1Xv7aJWNYbcZo8Drqiq65I8BTjWn7PuDLnNZgO3VFUl2Rn4alVt10nBM9ww26un3/eB24HPVNVJk12rGkP+jB0AHF1VTx+PebqHdGrbC/hVVV1ZVX8Bvgwc3NfnYODz1Tgf2CDJZpNdqP5qzG1WVddU1YXAnV0UqGUMs83Orarr2rfnAw+d5Bp1X8Nss5vr3j0u6wLufenOMN9l0OxcORm4ZjKL00DDbrNxYyCd2rYAru55/5u2bUX7aPK4PaafFd1mLwW+O6EVaSxDbbMkz07yM+DbwEsmqTYta8ztlWQL4NnAxyexLo1u2N+Leye5JMl3k+ywKjM0kE5tGdDW/1f+MH00edwe08/Q2yzJgTSB9I0TWpHGMtQ2q6qvt4fpnwW8Y8Kr0miG2V4fAN5YVXdPQj0a2zDb7CKa/02/C/Bh4JRVmaGBdGr7DfCwnvcPBX63En00edwe089Q26w9D/FTwMFV9adJqk2DrdDPWVWdDWyTZJOJLkwDDbO95gJfTrIUOAT4aJJnTU55GmDMbVZVN1bVze3r7wBrrsrPmIF0arsQeGSSrZPcH3gBcGpfn1OBF7ZX2z8WuKGqfj/ZheqvhtlmmlrG3GZJtgS+BvxDVf2igxp1X8Nss0ckSft6d+D+gH9IdGPM7VVVW1fVnKqaA5wEHFFVq7THTatkmJ+xh/T8jO1FkylX+mds1ioUqwlWVXcleTXwPWANmqsOL0vyinb4x4Hv0Fxh/yvgVuDFXdWr4bZZkocAC4AHAvckOQrYvqpu7KzwGWzIn7NjgI1p9toA3FVVc7uqeaYbcps9l+aP9TuB24Dn91zkpEk05PbSFDLkNjsEeGWSu2h+xl6wKj9j3vZJkiRJnfKQvSRJkjplIJUkSVKnDKSSJEnqlIFUkiRJnTKQSpIkqVMGUkmSJHXKQCpJkqRO/X94zU0MfZPB+AAAAABJRU5ErkJggg==\n",
"text/plain": [
""
]
},
"metadata": {
"needs_background": "light"
},
"output_type": "display_data"
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"-----------------------------------------\n",
"************* Model Results *************\n",
"-----------------------------------------\n",
"R2 score 0.5499416877756778\n",
"MSE score: 1938127160645.6133\n",
"RMSE score score: 1392166.3552340337\n",
"-----------------------------------------\n",
"\n",
"Executing RFE\n",
"Please wait.........\n",
"### RFE selected columns:\n",
" Index(['area', 'bedrooms', 'bathrooms', 'stories', 'basement',\n",
" 'hotwaterheating', 'airconditioning', 'parking', 'prefarea',\n",
" 'furnishingstatus'],\n",
" dtype='object')\n"
]
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAqQAAAGwCAYAAAB/6Xe5AAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADt0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjByYzEsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy/xvVyzAAAgAElEQVR4nO3deZwkdX3/8ddbFuVY5FQCKCyigtzHgqKcSow3Hhgl/KKrRjSoBP3hkRgRNUaMJsYjHuuFikYDKOKFGOVQDmEXll0OjwTWHx4JotyXHJ/fH1UjTW/PTO/uzNTMzuv5ePSju7/1rapPVfVMv6euSVUhSZIkdeVBXRcgSZKk2c1AKkmSpE4ZSCVJktQpA6kkSZI6ZSCVJElSpwykkiRJ6pSBVBIASRYkqSQLuq5FkjS7GEilSdAGu97HvUl+n+TsNvil6xpnuiTHD1jPvY/lXde4Ktraz16F8U4cZ32s9DRXVU8t86ZqnhMlyUFTvb664h+hmk7mdF2AtIZ7R/u8NvBo4HnAgcB84LVdFbWGOQc4e0D7jVNcx3TxdWDJgPblU1yHJA3NQCpNoqo6vvd9kicB5wJHJfnnqrqmk8LWLGf3r+dZ7rSqOrHrIiRpZXjIXppCVXUe8BMgwF69w5LsleSDSS5rD+/fmeTnSf45ycb90+o93Jbk4PZ0gFuS3JzkW0keN6iGJI9OcnKSG5LcluT8JM8cq+62tlOTXJfkriS/SPLRJFsM6DtyuHbbJK9NcmW7LMuT/N3I6QpJXpjkoraG65J8JMk6K7E6V8oqLsOjkrwuydIkd/Qexk2ySZL3JLmqHXZTku8neeqA6T04ydFJLmnX++3t+vh6kkPaPguSjPwv5wP7DrcfPwnr4/AkZ7X13Nkux98neciAvs9NclKSn7Xb69Yki9tlelBf3wJe2r69ZtApFO2yL2eA3H8qxkH9020/43+S5FNJfpXmVJgFPX0en+SUJP+T5A9Jrk3yiSRbrup66pl278/bnyb5Ybsefpvks0k2avvtkeSb7Xq9NcnpGXDqQrssleQhSf4hyTXt5/K/k7w9yYNHqeMpSc7I/b8jfpbkhCQbjjGPByc5LslP23mc2H6WP9t2/Wzf521eO/6W7Xjn9azTXyf5Ugb8fkkyrx3/xPb1l5Nc39a5KMmzxli/L2p/fkaWa3mSf08yf0DfoT+7mjncQypNvZHzR+/ua38lzSH9c4D/BNYC9gTeADw9yeOr6pYB03sWcCjwHeDjwI7AM4C9k+xYVdf/ccbJY4ALgE3b/ktoTiU4rX2/YrHNl8ipbd2nAL+gCdN/DRya5ElVtXzAqO8HDgK+AZwJPAd4N/DgJL8HTmjn+0PgT4HXtMv814PqWB2rsQwfBPYHvgV8G7i3nd42NKcJzGvrPwNYn2ZbnJHkVVX1yZ7pnAgcDlwOfB64A9gS2A94Gs32XkJzisfb2/pO7Bn/7FVd9kGSfBp4OfBL4Ks0pzc8AXgX8JQkf1pV9/SMcgJwH/Bj4FfAhsCTadbP3sBf9vR9B/BcYLd2+MipExNxCsUmwIXArW3d9wH/2y7Ty4BPAncBpwPXAo8B/gp4dpInVNX/m4AankOznb9J8/P2RGABsG2StwDfp/lMfBrYBXg2sF2SXarqvgHT+w+adXgKze+EQ4HjgflJnlNVI3+kkORVwMeA24CTgetofsbe3C7jk6pq0Ho+tZ3Hd2h+5q6j+Uzd2M6v/zSPkWkcALwFOKudxq006/Qw4Dnt/C4bML9tgIuAq4Ev0Gy3FwFfT3JIVZ3Vs0yhCcYvBa6n2a6/BR4BHAz8FFjU039lP7uaKarKhw8fE/wAqvnxWqH9AJpQcxewRd+wbYC1BozzinZ6b+5rX9C23wM8pW/Ye9phb+prP7Nt/5u+9kNHagYW9LTPpfmSuBfYv2+cN7f9z+xrP7FtXw5s1dO+UTut22i+cB7XM+whwJXtenn4kOv4+HY+Z7ev+x/zJmAZfgVsO2DeZ9OEoRf3tW9E88V+B7B527Zh23fRKNt30wGfnbNX4TM3UvNpo6yPjfo+N18F1h1lnfZ/PrYbML8HAZ9r+z9+lFrmjVLrcmD5ONv1oEE/UzSBfk7fsMcCfwD+q/cz1w57crvtvzbkejxo0DbggT9vB/ath++1w34PHNE33qfbYYcO+AwV8DNg4572dWj+aCzgL3vat6H5+bgZ2KFvWh9t+y8cZR5Lgc0GLOvIMi0YZV08HNhgQPtuNOH0O33t83q209v7hv1Z2/7tvvYj2/aLgA37hq1Fz+/JVfns+pg5j84L8OFjTXz0/FI+vn28G/hK+6V5H/C6lZhWgJuAH/S1j/xyPmnAONu2w07paXtE23Y1g4PRyJfXgp62I9q2Lw3oPwe4ph2+dU/7iW3bKwaM85l22DsHDHt7O+zAIdfLyBfQaI+DJmAZVvhya7+MCzh5lLpGwv1R7fuHtu/PAzLkZ+fsVfjMjdQ82mNe2+9Smj1xGw2Yxlo04f2iIee5Zzvt40apZd4o4y1n1QLpwD9YgA+0w585yjS/RhMkVwhXA/oeNGgbcP/P2xcGjPOSdti5A4YdyOCAdjZ9oXNADWf1tL21bfvHAf03pgmqdwAPGTCPQ/vH6VumBYOGj7OeTgfuBNbuaZvH/X+MDvod8wvg+r62Ze04ewwxzwn77PqYfg8P2UuT6+1970eC2mf7OyZZG3gV8GKaw+4b8sDzvLcaZR6LBrRd2z73nnu6R/v8o6q6d8A4Z9N8efbas33+QX/nqronybk0X0J7AP2HQwfV9ev2efGAYb9qnx8xYNhY3lFjX9S0Ostw0YDp7ds+b5jB53Y+rH1+XDuPm5N8g+bQ7ZIkp9Ic0v1xVd0+Rt2r6mU1ykVNSdajCdTXA8dk8N3H7hqpvWe8TYE30pwK8iia0xN6jfbZnGjLq+q6Ae0j2+TAJHsPGP5wmsDyWAZ/9lbGRH+uzxnQ9kOaAL1HT9tYn+MbklxKcwRmB6D/MPqgz/FQ0pxf/mqaO4Nsxoqn+m0G/Kavbckov2Ou5f5tRZL1gZ2B/62qS8epY5U+u5o5DKTSJKqqkQt41qf5Rfxp4ONJflFV/V8sX6E5h/RqmnO6/ofmFyzAMTSHtQdZ4ZyxNmhB8yU8YuSih/8dZTr/M6BtZJz+Lxz62jcaMOymAW33DDFs7VHmtapWZxkGrZNN2+c/bR+jmdvz+kU0pwf8BfffCuzOJKcAx1bVaNtkom1Ms8f9Yaz4x9JA7cU6F9Psdb+I5pD572m210bA3zD6Z3OiDdoecP82eeM4488dZ/gwJvpzvcK2r6p7k/yOJkiPmOjP8biSHE1zHvANNKcl/D/gdpo/rEfOEx607Uc7X/geHvhH9kitvxrQt99Kf3Y1sxhIpSlQVbcB/5nk2cAlwOeSbD+yh6y9kvR5NBe3PKOq/njBU5qrmN80AWWMfFluPsrwPxljnEHDALbo6zcdrc4y1BjT+5uq+tAwBVTVHbSnbyR5JM2erAXA/6HZO7v/MNOZACO1X1pVe47Z835/RRNGV9gTnWRfmkC6su4DBl5FzuBANWLQ9oD7l2vDqrp5Ferp0ub07ZlPshZNyO5dlt7P8RUDpjPq57iqRltvo0oyh+aPp/8B9qyq3/QN33fgiCtnJLgOs4d9VT67mkG87ZM0hapqKc2VwI8AXt8z6NHt8+m9YbS1D7DuBMx+5JDYfu0XXr+DxhhnhWHtF9Z+7dtLVre4STTRy3Bh+7xKIbKqrq2qL9Jc5PFzmu2xaU+X+3jgnu0JU1W30oSZnZJsMuRoI5/NUwcM6z/FY8TI4drRluMGYPP2NJV+K9zmZwirtU06Nmgd7k+zw6j3MPZYn+ONgN1pzum8aiXmPdZ22ozmj4PzB4TRudx/CsEqa/9Qv5zms7DHOH1X5bOrGcRAKk29f6D54jg2999fdHn7fFBvxyQPB/5tImZaVb+kOey2LX3/JSrJoQz+YjyN5vDs4Ume0DfsGJrzCf+zJuZ2OpNlQpehqhbRnOP3/CQvH9QnyS7ttiPJw5I8fkC39YENaA5j/qGn/XfAI4epZRX9C83eyc+0QeYBkmycpDdsLG+fD+rrtwfwt6PM43ft89ajDL+IJnC9rG+aC4AnjV76qD5Cc7HLB5I8tn9gex/O6RpW39bze4A09+J9T/u291zzk2iW8XVJHs0DvYvm4rmTquouhjfWdrqO5vD8Xm0AHalvbZrD+JutxHzGMnKU4RPpu5dqkgflgfcJXtnPrmYQD9lLU6yqfpXkEzSHOt9E86V+Mc1V2M9Pcj7wI5pDeU+nuQ/fr0eZ3Mp6Dc0tZf41zQ3cL+P+f2k6cuFNb623tqHrZOCcJCfTHF7cC3gqzeG8V01QbZNikpbhL2guLvl0e57dj2kOPz4C2JXmQo19ab7UtwIuTHIVzV7Ya2nCw7NoDr9+qB54f9nvAy9uL4RaTBNYz62qc1d22Qepqs8k2Qs4CvjvJN+lWR+b0PyxcgBNEHp1O8rnac7N/NckB9Ps1X1MW/9Xac6P7ff9dpxPtufJ3grcWFUfaYd/mCaMfizJU2jWyW409/T8ZjvtlVmmn7Tb+DPAFUnOoLmd0to0YWt/mluN7bAy050iV9HU3Hsf0u1o7n37hZFOVbU8yTE0f6BekuQ/aJbpQJrP2k9ozlNeGRfQhM5j2r2OI+ezfriqbkryIZr7kC5L8nWaMHgwzWflrPb16voUzVGKlwA/b+fzW5r79D6ZZpseD6v02dVM0vVl/j58rIkPRrkPac/wzWnux3kb99+vchOa+wkup9mD+t/APwLrMeA2OYx/D8GBtw+iCaCn0ASo22i+lJ451vRobqr9NZovij/QfAl8DNhyQN8TGeWWP4xyS59hlmeMaR0/ZP8JWYaePhsAf0cTGm+lueXONTRB4khg/bbfRsBxNAH2VzQXqv2G5q4Gh9N3KyiaC1m+RBMO7h12GXtqHnb9jdzc/bp2ffwPzZ7Lf2DF+1zuSHObn+vaz8ximnNL57XzPHHA9N9AE7buavv0f373o/k3urfTnCv5LZowP/AzMtrnua/PLu16+EU739/THBL+BPDkIdfLQYPmNdbns2ecFbbTaOuI+2/J9JB2nV/T1nw1zUU7DxmlvqfS3E/4hrb/fwH/xOBbIZ3NGL+H2j5Po/kdcCsr3iJsTrsdr6T5fP8PTUjehgE/I2N9Hsarh+b2bOfQnCt6Z7s+vkhz/uoqf3Z9zJxH2o0rSZKmSJp/3XlgtXfikGY7zyGVJElSpwykkiRJ6pSBVJIkSZ3yHFJJkiR1yts+zWCbbbZZzZs3r+syJEmSxrV48eLrq+phg4YZSGewefPmsWjRoq7LkCRJGleSX4w2zHNIJUmS1CkDqSRJkjrlIfsZ7Kpf/o693vj5rsuQJEkz1OL3vaTrEgD3kEqSJKljBlJJkiR1ykAqSZKkThlIJUmS1CkDqSRJkjplIJUkSVKnDKSSJEnqlIFUkiRJnTKQSpIkqVMGUkmSJHXKQCpJkqROGUglSZLUKQPpFEqyVtc1SJIkTTcG0gmU5LQki5NckeTItu3WJO9M8mNg3yT/J8lFSZYk+cRISE3ysSSL2nHf0emCSJIkTSED6cR6eVXtBcwHjk6yKbA+cHlVPR74HfAi4ElVtTtwL3BEO+5bq2o+sCtwYJJdB80gyZFtcF10z+23TPbySJIkTbo5XRewhjk6yfPa148EHkMTOk9t254C7AVcnARgXeC6dtift3tV5wBbADsCS/tnUFULgYUA6//JtjU5iyFJkjR1DKQTJMlBwCHAvlV1e5KzgXWAO6vq3pFuwOeq6m/7xt0WOBbYu6puSHJiO64kSdIaz0P2E2dD4IY2jO4APGFAn+8DhyV5OECSTZJsAzwUuA24KcnmwNOnqmhJkqSuuYd04pwBvDrJUuCnwIX9HarqyiR/D5yZ5EHA3cBrqurCJJcCVwBXA+dNYd2SJEmdMpBOkKq6i8F7Nuf29fsK8JUB4y+YnMokSZKmNw/ZS5IkqVMGUkmSJHXKQCpJkqROGUglSZLUKQOpJEmSOmUglSRJUqcMpJIkSeqUgVSSJEmdMpBKkiSpUwZSSZIkdcp/HTqDPe4Rm7LofS/pugxJkqTV4h5SSZIkdcpAKkmSpE4ZSCVJktQpA6kkSZI6ZSCVJElSpwykkiRJ6pS3fZrB/vCbK/h/79yl6zKkUW193LKuS5AkzQDuIZUkSVKnDKSSJEnqlIFUkiRJnTKQSpIkqVMGUkmSJHXKQCpJkqROGUglSZLUKQOpJEmSOmUglSRJUqcMpJIkSeqUgVSSJEmdWqMCaZJ5SS5fif4LkmzZ8355ks0mpzpJkiQNskYF0lWwANhyvE69ksyZnFIkSZJmpzUxkM5J8rkkS5OckmS9JMcluTjJ5UkWpnEYMB/4YpIlSdZtx39dkkuSLEuyA0CS49vxzgQ+n2SbJN9v5/H9JFu3/UZrPzHJx5KcleTqJAcm+UySq5Kc2PZZq+13eTvv10/5mpMkSerAmhhItwcWVtWuwM3AUcBHqmrvqtoZWBd4VlWdAiwCjqiq3avqjnb866tqT+BjwLE9090LOLSq/gL4CPD5dh5fBD7U9hmtHWBj4MnA64FvAB8AdgJ2SbI7sDuwVVXtXFW7AJ8dtHBJjkyyKMmi39927yqvJEmSpOliTQyk11bVee3rk4D9gIOT/DjJMppQuNMY43+1fV4MzOtpP70ntO4LfKl9/YV2HmO1A3yjqgpYBvxvVS2rqvuAK9r5XA08KsmHkzyNJkyvoKoWVtX8qpq/yfprjbEYkiRJM8OaGEhrwPuPAoe1ex4/Cawzxvh3tc/3Ar3ni962EvMc1D4y3ft6Xo+8n1NVNwC7AWcDrwE+Ncb8JEmS1hhrYiDdOsm+7evDgR+1r69PMhc4rKfvLcAGqzCP84EXt6+P6JnHaO3jaq/uf1BVnQq8DdhzFeqSJEmacdbEK8avAl6a5BPAz2nOBd2Y5lD5cuDinr4nAh9PcgfN4fZhHQ18Jskbgd8CLxunfRhbAZ9NMvJHwt+uxLiSJEkzVprTGjUT7brVuvXNVz266zKkUW193LKuS5AkTRNJFlfV/EHD1sRD9pIkSZpBDKSSJEnqlIFUkiRJnTKQSpIkqVMGUkmSJHXKQCpJkqROGUglSZLUKQOpJEmSOmUglSRJUqcMpJIkSerUmvi/7GeNB2+xE1sft6jrMiRJklaLe0glSZLUKQOpJEmSOmUglSRJUqcMpJIkSeqUgVSSJEmdMpBKkiSpU972aQb7yXU/4UkfflLXZcwI573uvK5LkCRJo3APqSRJkjplIJUkSVKnDKSSJEnqlIFUkiRJnTKQSpIkqVMGUkmSJHXKQCpJkqROGUglSZLUKQOpJEmSOmUglSRJUqcMpJIkSeqUgXQCJTkxyWED2j+VZMcuapIkSZru5nRdwJoiyajrsqr+aiprkSRJmkncQ9ojybwkP0nyuSRLk5ySZL0kxyW5OMnlSRYmSdv/7CT/mOQc4G/6pvWudo/pg9p+89v2W5O8O8llSS5Msnnbvl37/uIk70xy65SvAEmSpA4YSFe0PbCwqnYFbgaOAj5SVXtX1c7AusCzevpvVFUHVtU/jzQk+Sfg4cDLquq+vumvD1xYVbsB5wKvbNs/CHywqvYGfj1acUmOTLIoyaK7b7179ZZUkiRpGjCQrujaqjqvfX0SsB9wcJIfJ1kGPBnYqaf/V/rGfxtNSH1VVdWA6f8B+Gb7ejEwr329L3By+/pLoxVXVQuran5VzV977trDLpMkSdK0ZSBdUX+ILOCjwGFVtQvwSWCdnuG39fW/GNgrySajTP/unqB6L57HK0mSZjkD6Yq2TrJv+/pw4Eft6+uTzAVWuIq+zxnACcC3kmywEvO9EHhB+/rFKzGeJEnSjGYgXdFVwEuTLAU2AT5Gs1d0GXAazR7QMVXVye04pydZd8j5HgO8IclFwBbATatQuyRJ0oyTwac5zk5J5gHfbC9emup5rwfcUVWV5MXA4VV16FjjzN16bu32xt2mpsAZ7rzXnTd+J0mSNGmSLK6q+YOGef7i9LEX8JH2llI3Ai/vuB5JkqQpYSDtUVXLgSnfO9rO+4eAuzslSdKs4zmkkiRJ6pSBVJIkSZ0ykEqSJKlTBlJJkiR1ykAqSZKkThlIJUmS1CkDqSRJkjplIJUkSVKnvDH+DLbDw3fwX2JKkqQZzz2kkiRJ6pSBVJIkSZ0ykEqSJKlTBlJJkiR1ykAqSZKkThlIJUmS1Clv+zSD3fLTn3LOAQd2XcakOfDcc7ouQZIkTQH3kEqSJKlTBlJJkiR1ykAqSZKkThlIJUmS1CkDqSRJkjplIJUkSVKnDKSSJEnqlIFUkiRJnTKQSpIkqVMGUkmSJHXKQCpJkqROTXogTXJ0kquSfHECpvXOJIeMMfzEJIcNaN8yySmrO/++ae6e5BkT1U+SJGm2mjMF8zgKeHpVXTNexyQBUlX3DRpeVcetSgFV9WtghaC6mnYH5gPfnqB+kiRJs9Kk7iFN8nHgUcDpSW5KcmzPsMuTzGsfVyX5KHAJsH/7/pNJrkhyZpJ123H+uAc0yQlJrkyyNMn7e2Z7QJLzk1zd03deksvb1wuSfDXJGUl+nuSfemp6RZKfJTm7nf9H2vYXtvVeluTcJA8G3gm8KMmSJC9Ksk8730vb5+1H6Xf8KOth/STfaudxeZIXTcpGkSRJmmYmdQ9pVb06ydOAg4HXjtF1e+BlVXVUknnAY4DDq+qVSf4DeAFw0kjnJJsAzwN2qKpKslHPtLYA9gN2AE4HBh2q3x3YA7gL+GmSDwP3Am8D9gRuAX4AXNb2Pw74s6r6VZKNquoPSY4D5lfVa9uaHgocUFX3tKcV/GNVvWBAv+NHWQdPA35dVc9s+204qFOSI4EjATZ/yENGmZQkSdLMMV0uavpFVV3Y8/6aqlrSvl4MzOvrfzNwJ/CpJM8Hbu8ZdlpV3VdVVwKbjzK/71fVTVV1J3AlsA2wD3BOVf2+qu4GTu7pfx5wYpJXAmuNMs0NgZPbPbEfAHYaY3kHWQYckuS9SfavqpsGdaqqhVU1v6rmb7j22is5C0mSpOlnKgPpPX3zW6fn9W19fe/qeX0vfXtyq+oemgB5KvBc4IxRxs0otQya/mh9qapXA38PPBJYkmTTAd3eBZxVVTsDz+aBy9dr4Hqoqp8Be9EE0/e0e1YlSZLWeFMZSJfTHA4nyZ7Atqs6oSRzgQ2r6tvAMTSH4FfXRcCBSTZOMofmNIGR+W1XVT9uL6q6niaY3gJs0DP+hsCv2tcLetr7+y1nwHpIsiVwe1WdBLx/pI8kSdKabioD6anAJkmWAH8N/Gw1prUB8M0kS4FzgNevbnFV9SvgH4EfA/9Jcyh/5LD5+5Isaw/Hn0tzbulZwI4jFysB/0SzZ/M8HnhYv7/faOthF+Citv2twD+s7jJJkiTNBKmqrmuYNpLMrapb2z2kXwM+U1Vf67qu0Wy/wQa1cI81d0fqgeee03UJkiRpgiRZXFXzBw2bLhc1TRfHt3soLweuAU7ruB5JkqQ13lTcGH/GqKpjx+8lSZKkieQeUkmSJHXKQCpJkqROGUglSZLUKQOpJEmSOmUglSRJUqcMpJIkSeqUgVSSJEmdMpBKkiSpU94YfwbbYPvt/feakiRpxnMPqSRJkjplIJUkSVKnDKSSJEnqlIFUkiRJnTKQSpIkqVMGUkmSJHXK2z7NYNf98iY+8n+/0XUZE+61//zsrkuQJElTyD2kkiRJ6pSBVJIkSZ0ykEqSJKlTBlJJkiR1ykAqSZKkThlIJUmS1CkDqSRJkjplIJUkSVKnDKSSJEnqlIFUkiRJnTKQSpIkqVMG0pWU5Jgk663CeJ9KsuNk1CRJkjSTGUhX3jHASgXSJGtV1V9V1ZWTVJMkSdKMZSAdQ5L1k3wryWVJLk/ydmBL4KwkZ7V9Dk+yrB3+3p5xb03yziQ/BvZNcnaS+e2wpya5IMklSU5OMrdtPyHJlUmWJnl/B4ssSZI05eZ0XcA09zTg11X1TIAkGwIvAw6uquuTbAm8F9gLuAE4M8lzq+o0YH3g8qo6rh2X9nkz4O+BQ6rqtiRvBt6Q5CPA84AdqqqSbDSlSypJktSRofaQJtkuyUPa1wclOXqWBKZlwCFJ3ptk/6q6qW/43sDZVfXbqroH+CJwQDvsXuDUAdN8ArAjcF6SJcBLgW2Am4E7gU8leT5w+6CCkhyZZFGSRbfe3l+OJEnSzDPsIftTgXuTPBr4NLAt8KVJq2qaqKqf0ez9XAa8J8lxfV0yxuh3VtW9A9oDfK+qdm8fO1bVK9pAuw/Nun4ucMYoNS2sqvlVNX/uehuu9DJJkiRNN8MG0vvawPQ84F+r6vXAFpNX1vTQHpK/vapOAt4P7AncAmzQdvkxcGCSzZKsBRwOnDPOZC8EntSGe5Ksl+Sx7XmkG1bVt2kunNp94pdIkiRp+hn2HNK7kxxOc3j52W3b2pNT0rSyC/C+JPcBdwN/DewLfCfJb6rq4CR/C5xFs+fz21X19bEmWFW/TbIA+PeR0yBozim9Bfh6knXaab1+UpZIkiRpmhk2kL4MeDXw7qq6Jsm2wEmTV9b0UFXfBb7b17wI+HBPny8x4PSFqprb9/6gntc/oDn/tN8+q1GuJEnSjDRUIK2qK9urwbdu318DnDCZhUmSJGl2GPYq+2cDS2gvtEmye5LTJ7MwSZIkzQ7DXtR0PM3h5BsBqmoJzZX2kiRJ0moZNpDeM+AenDXRxUiSJGn2GfaipsuT/AWwVpLHAEcD509eWZIkSZotht1D+jpgJ+AumivKb6K5V6YkSZK0WsbdQ9re8P30qjoEeOvklyRJkqTZZNw9pO2/v7w9if+nUpIkSRNu2HNI7wSWJfkecNtIY1UdPSlVSZIkadYYNpB+q31IkiRJEypV3r1pppo/f34tWrSo6zIkSZLGlWRxVc0fNGyoPaRJrmHAfUer6lGrWZskSZJmuWEP2fem2XWAFwKbTHw5kiRJmm2Gug9pVf2u5/GrqvpX4MmTXJskSZJmgWEP2e/Z8/ZBNHtMN5iUiiRJkjSrDHvI/p97Xt8DXAP8+cSXI0mSpNlm2ED6iqq6umhzOy0AABdXSURBVLchybaTUI8kSZJmmaFu+5Tkkqras69tcVXtNWmVaVxbbbpxHfX0p3RdxoR460mndF2CJEmaRKt826ckOwA7ARsmeX7PoIfSXG0vSZIkrZbxDtlvDzwL2Ah4dk/7LcArJ6soSZIkzR5jBtKq+jrw9ST7VtUFU1STJEmSZpFhL2q6NMlraA7f//FQfVW9fFKqkiRJ0qwx1I3xgS8AfwL8GXAO8Aiaw/aSJEnSahk2kD66qt4G3FZVnwOeCewyeWVJkiRpthg2kN7dPt+YZGdgQ2DepFQkSZKkWWXYc0gXJtkYeBtwOjAXOG7SqpIkSdKsMVQgrapPtS/PAR41eeVIkiRpthnqkH2SzZN8Osl32vc7JnnF5JYmSZKk2WDYc0hPBL4LbNm+/xlwzGQUJEmSpNll2EC6WVX9B3AfQFXdA9w7aVVNkCTzklw+1eNKkiRpeMMG0tuSbAoUQJInADdNWlXTWJJhLwSTJEnSEIYNV2+gubp+uyTnAQ8DDpu0qibWnCSfA/agOdXgJcDjgH+huVvA9cCCqvpNkr2AzwC3Az8amUCSBTT3Xl0HWD/JYW2/R7V9j6yqpUk2GaX9eGBbYAvgsTTr8wnA04FfAc+uqruTnAA8B7gHOLOqjp20tSJJkjRNjLmHNMnWAFV1CXAg8ETgVcBOVbV08subENsDC6tqV+Bm4DXAh4HDqmokgL677ftZ4Oiq2nfAdPYFXlpVTwbeAVzaTvPvgM+3fUZrB9iOJtQeCpwEnFVVuwB3AM9sw+zzaNbtrsA/TMjSS5IkTXPjHbI/ref1V6rqiqq6vKruHnWM6efaqjqvfX0Szb8/3Rn4XpIlwN8Dj0iyIbBRVZ3T9v1C33S+V1W/b1/vNzK8qn4AbNqOP1o7wHfa9bYMWAs4o21fRvNPBm4G7gQ+leT5NHtYV5DkyCSLkiy67c67Vn5tSJIkTTPjHbJPz+uZev/R6nt/C3BF/17QJBsN6Nvrtt7uo8xntHaAuwCq6r4kd1fVSPt9wJyquifJPsBTgBcDrwWevMLEqhYCCwG22nTjseqVJEmaEcbbQ1qjvJ5Jtk4yEj4PBy4EHjbSlmTtJDtV1Y3ATUn2a/seMcY0zx0ZnuQg4PqqunmM9nElmQtsWFXfprml1u7DL6IkSdLMNd4e0t2S3Eyz52/d9jXt+6qqh05qdRPjKuClST4B/Jzm/NHvAh9qD6fPAf4VuAJ4GfCZJLe3fUZzPPDZJEtpDq2/dJz2YWwAfD3JOjTr9/UrMa4kSdKMlfuPHGum2WrTjeuopz+l6zImxFtPOqXrEiRJ0iRKsriq5g8aNux9SCVJkqRJYSCVJElSpwykkiRJ6pSBVJIkSZ0ykEqSJKlTBlJJkiR1ykAqSZKkThlIJUmS1CkDqSRJkjplIJUkSVKnxvtf9prGtth2O//lpiRJmvHcQypJkqROGUglSZLUKQOpJEmSOmUglSRJUqcMpJIkSeqUgVSSJEmd8rZPM9idv7mFq979g67LGMrj3vrkrkuQJEnTlHtIJUmS1CkDqSRJkjplIJUkSVKnDKSSJEnqlIFUkiRJnTKQSpIkqVMGUkmSJHXKQCpJkqROGUglSZLUKQOpJEmSOmUglSRJUqcMpJIkSerUtAukSb6dZKMpnN/ZSeb3zrt9HNXTZ8skp6zGPKZ0mSRJkmaSaRdIq+oZVXVjb1sak15rz7w3Ao7qaf91VR02AdOVJElSn04DaZLTkixOckWSI9u25Uk2SzIvyVVJPgpcAjwyyZuSLEtyWZIT2v67J7kwydIkX0uycdt+dpL3Jrkoyc+S7N+2r5vky23/rwDr9tSzPMlmwAnAdkmWJHlfW8vlbZ91kny2rePSJAe37QuSfDXJGUl+nuSf+qfbs0yfbJf5zCTrtn32bmu6oJ3n5VOwCSRJkjrX9R7Sl1fVXsB84Ogkm/YN3x74fFXtAewIPBd4fFXtBowEvs8Db66qXYFlwNt7xp9TVfsAx/S0/zVwe9v/3cBeA+p6C/DfVbV7Vb2xb9hrAKpqF+Bw4HNJ1mmH7Q68CNgFeFGSRw6Y9mOAf6uqnYAbgRe07Z8FXl1V+wL3DhgPgCRHJlmUZNHvb3OnqyRJmvm6DqRHJ7kMuBB4JE1Y6/WLqrqwfX0I8Nmquh2gqn6fZENgo6o6p+3zOeCAnvG/2j4vBua1rw8ATmqnsRRYupI17wd8oR3/J8AvgMe2w75fVTdV1Z3AlcA2A8a/pqqW9NbVnl+6QVWd37Z/abSZV9XCqppfVfM3Wd/TUiVJ0sw3p6sZJzmIJmTuW1W3JzkbWKev2229owC1krO5q32+lwcu68pOp1eGmN+geY7WZ91xpilJkrRG63IP6YbADW0Y3QF4wjj9zwRenmQ9gCSbVNVNwA0j54cCfwmcM9oEWucCR7TT2BnYdUCfW4ANhhj/scDWwE/HmeeYquoG4JYkI+vgxaszPUmSpJmky0B6BjAnyVLgXTSH7UdVVWcApwOLkiwBjm0HvRR4Xzud3YF3jjPfjwFz2/5vAi4aMK/fAecluTzJ+/oGfxRYK8ky4CvAgqq6q38aq+AVwMIkF9DsMb1pAqYpSZI07aVqdY5ea6IkmVtVt7av3wJsUVV/M9Y4O2+1fZ181MempL7V9bi3PrnrEiRJUoeSLK6q+YOGdXYOqVbwzCR/S7NNfgEs6LYcSZKkqWEgnSaq6is0pwBIkiTNKl3f9kmSJEmznIFUkiRJnTKQSpIkqVMGUkmSJHXKQCpJkqROGUglSZLUKQOpJEmSOuV9SGewdbbYwP+AJEmSZjz3kEqSJKlTBlJJkiR1ykAqSZKkThlIJUmS1CkDqSRJkjplIJUkSVKnvO3TDPbrX/+a448/vusyxjTd65MkSd1zD6kkSZI6ZSCVJElSpwykkiRJ6pSBVJIkSZ0ykEqSJKlTBlJJkiR1ykAqSZKkThlIJUmS1CkDqSRJkjplIJUkSVKnDKSSJEnqlIFUkiRJnVqjA2mSeUku77qOldHW/Bdd1yFJkjRV1uhAOkPNAwykkiRp1pgNgXROks8lWZrklCTrJTkuycVJLk+yMEkAkhyd5Mq275fbtvWTfKbtf2mSQ9v2BUlOS/KNJNckeW2SN7R9LkyySdtvuyRnJFmc5IdJdmjbT0zyoSTnJ7k6yWFtvScA+ydZkuT1U7+6JEmSptZsCKTbAwuralfgZuAo4CNVtXdV7QysCzyr7fsWYI+276vbtrcCP6iqvYGDgfclWb8dtjPN3sx9gHcDt1fVHsAFwEvaPguB11XVXsCxwEd7atsC2K+d/wk9Nfywqnavqg/0L0ySI5MsSrLo9ttvX/W1IkmSNE3M6bqAKXBtVZ3Xvj4JOBq4JsmbgPWATYArgG8AS4EvJjkNOK0d56nAc5Ic275fB9i6fX1WVd0C3JLkpnYaAMuAXZPMBZ4InNzuhAV4SE9tp1XVfcCVSTYfZmGqaiFNyGXLLbesYcaRJEmazmZDIO0PbUWzl3J+VV2b5HiakAnwTOAA4DnA25LsBAR4QVX9tHciSR4P3NXTdF/P+/to1u2DgBuravdRausdP6P0kSRJWqPNhkP2WyfZt319OPCj9vX17R7MwwCSPAh4ZFWdBbwJ2AiYC3wXeF3PeaZ7DDvjqrqZZm/sC9txk2S3cUa7Bdhg2HlIkiTNdLMhkF4FvDTJUprD8x8DPklzWP004OK231rASUmWAZcCH6iqG4F3AWsDS9tbSL1rJed/BPCKJJfRnBpw6Dj9lwL3JLnMi5okSdJskCpPQ5ypttxyyzryyCO7LmNMxx9/fNclSJKkaSDJ4qqaP2jYbNhDKkmSpGnMQCpJkqROGUglSZLUKQOpJEmSOmUglSRJUqcMpJIkSeqUgVSSJEmdMpBKkiSpUwZSSZIkdcr/1DSDzZ8/vxYtWtR1GZIkSePyPzVJkiRp2jKQSpIkqVMGUkmSJHXKQCpJkqROGUglSZLUKQOpJEmSOmUglSRJUqfmdF2AVt0NN1zFf5y8z5TN789feNGUzUuSJM0e7iGVJElSpwykkiRJ6pSBVJIkSZ0ykEqSJKlTBlJJkiR1ykAqSZKkThlIJUmS1CkDqSRJkjplIJUkSVKnDKSSJEnqlIFUkiRJnTKQroYk+ye5IsmSJOt2XY8kSdJMZCAdR5K1xhh8BPD+qtq9qu4YYlpJ4jqXJEnqMavDUZJ5SX6S5HNJliY5Jcl6SZYnOS7Jj4AXJnlqkguSXJLk5CRzk/wV8OfAcUm+2LZ9v+2zLMmhPfO4KslHgUuARyZ5Y5KL23m+o6ee05Isbve6HtnJSpEkSZpiszqQtrYHFlbVrsDNwFFt+51VtR/wn8DfA4dU1Z7AIuANVfUp4HTgjVV1BHAn8Ly2z8HAPydJzzw+X1V7tK8fA+wD7A7sleSAtt/Lq2ovYD5wdJJN+4tNcmSSRUkW3XzzPRO8KiRJkqbenK4LmAaurarz2tcnAUe3r7/SPj8B2BE4r82XDwYuGDCdAP/Yhsv7gK2Azdthv6iqC9vXT20fl7bv59IE1HNpQujz2vZHtu2/651JVS0EFgJst936tbILK0mSNN0YSKE/1I28v619DvC9qjp8nOkcATwM2Kuq7k6yHFinb1oj03tPVX2id+QkBwGHAPtW1e1Jzu4ZX5IkaY3lIXvYOsm+7evDgR/1Db8QeFKSRwO055g+dsB0NgSua8PowcA2o8zvu8DLk8xtp7dVkoe349/QhtEdaPbMSpIkrfEMpHAV8NIkS4FNgI/1Dqyq3wILgH9v+1wI7DBgOl8E5idZRLO39CeDZlZVZwJfAi5Isgw4BdgAOAOY087jXe18JEmS1ngesof7qurVfW3zet9U1Q+AvftHrKoFPa+vB/bt79PauW+8DwIfHNDv6eOXK0mStGZxD6kkSZI6Nav3kFbVcvr2XkqSJGlquYdUkiRJnTKQSpIkqVMGUkmSJHXKQCpJkqROGUglSZLUKQOpJEmSOmUglSRJUqdm9X1IZ7qNN34cf/7Ci7ouQ5IkabW4h1SSJEmdMpBKkiSpUwZSSZIkdcpAKkmSpE4ZSCVJktQpA6kkSZI6ZSCVJElSp7wP6Qx25Q03s9sp352UaV922J9NynQlSZL6uYdUkiRJnTKQSpIkqVMGUkmSJHXKQCpJkqROGUglSZLUKQOpJEmSOmUglSRJUqcMpJIkSeqUgVSSJEmdMpBKkiSpUwZSSZIkdWrSAmmSeUkuX4n+C5JsOQHzfW6SHVdhvBOTHLa682+n9Xd978+fiOlKkiStiabTHtIFwGoHUuC5wEoF0iRzJmC+vR4QSKvqiRM8fUmSpDXGZAfStZJ8MskVSc5Msm6S3ZNcmGRpkq8l2bjdMzkf+GKSJUkOTPJVgCSHJrkjyYOTrJPk6rb9lUkuTnJZklOTrJfkicBzgPe109mufZyRZHGSHybZoR3/xCT/kuQs4L1tvQckOT/J1b17S5O8sZ3X0iTv6Gk/rZ3uFUmObNtOANZt5//Ftu3W9vmgJGcnOSXJT5J8MUnaYc9o236U5ENJvjmpW0aSJGmamOxA+hjg36pqJ+BG4AXA54E3V9WuwDLg7VV1CrAIOKKqdgfOA/Zop7E/cDmwN/B44Mdt+1erau+q2g24CnhFVZ0PnA68sap2r6r/BhYCr6uqvYBjgY/21PdY4JCq+r/t+y2A/YBnAScAJHlquxz7ALsDeyU5oO3/8na684Gjk2xaVW8B7mjnf8SAdbIHcAzNXtxHAU9Ksg7wCeDpVbUf8LDRVmiSI5MsSrLonptvGq2bJEnSjDHRh6r7XVNVS9rXi4HtgI2q6py27XPAyf0jVdU9Sf4ryeNoguC/AAcAawE/bLvtnOQfgI2AucB3+6eTZC7wRODkdkckwEN6upxcVff2vD+tqu4Drkyyedv21PZxaft+Lk1APZcmhD6vbX9k2/67MdYHwEVV9cu2viXAPOBW4Oqquqbt8+/AkYNGrqqFNCGb9bZ7bI0zL0mSpGlvsgPpXT2v76UJj8P6IfB04G7gP4ETaQLpse3wE4HnVtVlSRYABw2YxoOAG9u9roPcNka96Xl+T1V9ordjkoOAQ4B9q+r2JGcD64yzTP3zuJdmG2SUvpIkSWu8qb6o6SbghiT7t+//EhjZW3oLsEFP33NpDm1fUFW/BTYFdgCuaIdvAPwmydpA76HxP06nqm4GrknyQoA0dlvJmr8LvLzd20qSrZI8HNgQuKENozsAT+gZ5+62rmH9BHhUknnt+xetZI2SJEkzVhdX2b+U5qKjpTTnZL6zbT8R+Hh7MdC6NOeKbk4TTAGWAkurauQw9dvaPt+jCXQjvgy8McmlSbajCauvSHIZTZg9dGWKraozgS8BFyRZBpxCE3jPAOa0y/Eu4MKe0RYCS0cuahpiHncARwFnJPkR8L804V2SJGmNl/vznbqUZG5V3dpedf9vwM+r6gNjjbPedo+tx7z3w5NSz2WH/dmkTFeSJM1OSRZX1fxBw6bTfUhnu1e2FzldQXM6wCfG6S9JkrRGmOyLmjSkdm/omHtEJUmS1kTuIZUkSVKnDKSSJEnqlIFUkiRJnTKQSpIkqVMGUkmSJHXKQCpJkqROGUglSZLUKe9DOoPtuPFDWeR/VJIkSTOce0glSZLUKQOpJEmSOmUglSRJUqdSVV3XoFWU5Bbgp13XoaFsBlzfdREamttr5nBbzRxuq5llMrbXNlX1sEEDvKhpZvtpVc3vugiNL8kit9XM4faaOdxWM4fbamaZ6u3lIXtJkiR1ykAqSZKkThlIZ7aFXRegobmtZha318zhtpo53FYzy5RuLy9qkiRJUqfcQypJkqROGUglSZLUKQPpNJfkaUl+muS/krxlwPAk+VA7fGmSPbuoU40httcOSS5IcleSY7uoUY0httUR7c/U0iTnJ9mtizrVGGJ7HdpuqyVJFiXZr4s6Nf626um3d5J7kxw2lfXpgYb42TooyU3tz9aSJMdNSh2eQzp9JVkL+Bnwp8AvgYuBw6vqyp4+zwBeBzwDeDzwwap6fAflznpDbq+HA9sAzwVuqKr3d1HrbDfktnoicFVV3ZDk6cDx/mx1Y8jtNRe4raoqya7Af1TVDp0UPIsNs616+n0PuBP4TFWdMtW1auifrYOAY6vqWZNZi3tIp7d9gP+qqqur6g/Al4FD+/ocCny+GhcCGyXZYqoLFTDE9qqq66rqYuDuLgrUHw2zrc6vqhvatxcCj5jiGnW/YbbXrXX/Hpb1Afe2dGOY7y1odqScClw3lcVpBcNur0lnIJ3etgKu7Xn/y7ZtZftoargtZo6V3VavAL4zqRVpLENtryTPS/IT4FvAy6eoNj3QuNsqyVbA84CPT2FdGmzY34X7JrksyXeS7DQZhRhIp7cMaOv/q3+YPpoabouZY+htleRgmkD65kmtSGMZantV1dfaw/TPBd416VVpkGG21b8Cb66qe6egHo1tmO11Cc3/oN8N+DBw2mQUYiCd3n4JPLLn/SOAX69CH00Nt8XMMdS2as9F/BRwaFX9bopq04pW6merqs4Ftkuy2WQXphUMs63mA19Oshw4DPhokudOTXnqM+72qqqbq+rW9vW3gbUn42fLQDq9XQw8Jsm2SR4MvBg4va/P6cBL2qvtnwDcVFW/mepCBQy3vTQ9jLutkmwNfBX4y6r6WQc16n7DbK9HJ0n7ek/gwYB/REy9cbdVVW1bVfOqah5wCnBUVU3KXjeNa5ifrT/p+dnahyY7TvjP1pyJnqAmTlXdk+S1wHeBtWiuRLwiyavb4R8Hvk1zhf1/AbcDL+uq3tlumO2V5E+ARcBDgfuSHAPsWFU3d1b4LDTkz9ZxwKY0e28A7qmq+V3VPJsNub1eQPPH+d3AHcCLei5y0hQZcltpmhhyex0G/HWSe2h+tl48GT9b3vZJkiRJnfKQvSRJkjplIJUkSVKnDKSSJEnqlIFUkiRJnTKQSpIkqVMGUkmSJHXKQCpJkqRO/X9yCU0MNfRZhAAAAABJRU5ErkJggg==\n",
"text/plain": [
"
"
]
},
"metadata": {
"needs_background": "light"
},
"output_type": "display_data"
},
{
"name": "stdout",
"output_type": "stream",
"text": [
" RFE Selected Features\n",
"\n",
"Please wait Training-Testing with all models..\n",
"\n",
"Done with LinearRegression\n",
"Done with RandomForestRegression\n",
"[15:48:34] WARNING: C:/Jenkins/workspace/xgboost-win64_release_0.90/src/objective/regression_obj.cu:152: reg:linear is now deprecated in favor of reg:squarederror.\n",
"Done with XGBoostRegressor\n",
"Done with LGBoostRegressor\n",
"Done with AdaBoostRegressor\n",
"Done with SupportVectorMachine\n",
"Done with GradientBoostingRegression\n"
]
},
{
"data": {
"text/html": [
"
"
],
"text/plain": [
""
]
},
"execution_count": 7,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"df = es.importdata('Housing.csv')\n",
"es.quick_ml(df,'price','r')"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## car popularity dataset "
]
},
{
"cell_type": "code",
"execution_count": 8,
"metadata": {
"ExecuteTime": {
"end_time": "2020-03-17T10:18:48.592887Z",
"start_time": "2020-03-17T10:18:45.584417Z"
}
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Dataframe Imported Successfully\n",
"*** Dataset Infomarion ***\n",
"##################################################\n",
"No of Rows : 1302\n",
"No of columns : 7\n",
"No of Numerical columns: 7\n",
"No of Categorical columns: 0\n",
"##################################################\n",
"\n",
" Total Missing values : 0 \n",
"\n",
"##################################################\n",
"Summary of DataFrame:\n",
"\n",
" Column Name Nulls/NaN outof Unique Type of Columns\n",
"0 buying_price 0 1302 4 Numerical\n",
"1 maintainence_cost 0 1302 4 Numerical\n",
"2 number_of_doors 0 1302 4 Numerical\n",
"3 number_of_seats 0 1302 3 Numerical\n",
"4 luggage_boot_size 0 1302 3 Numerical\n",
"5 safety_rating 0 1302 3 Numerical\n",
"6 popularity 0 1302 4 Numerical\n",
"Null value summary: \n",
" Empty DataFrame\n",
"Columns: [Total, Percent]\n",
"Index: []\n",
"columns dropped Index([], dtype='object')\n",
"\n",
"\n",
"columns dropped \n",
"\n",
" [] \n",
" []\n"
]
},
{
"data": {
"application/vnd.plotly.v1+json": {
"config": {
"plotlyServerURL": "https://plot.ly"
},
"data": [
{
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"reversescale": false,
"showscale": true,
"type": "heatmap",
"x": [
"buying_price",
"maintainence_cost",
"number_of_doors",
"number_of_seats",
"luggage_boot_size",
"safety_rating",
"popularity"
],
"y": [
"buying_price",
"maintainence_cost",
"number_of_doors",
"number_of_seats",
"luggage_boot_size",
"safety_rating",
"popularity"
],
"z": [
[
1,
-0.00601914794363575,
0.01431989962017954,
0.022869684564446633,
0.016355250728557667,
0.04381300694020507,
-0.2148840997128597
],
[
-0.00601914794363575,
1,
0.015885336815707744,
0.003790665852549147,
0.026792686209264383,
0.0004764712883163013,
-0.19645299365239596
],
[
0.01431989962017954,
0.015885336815707744,
1,
-0.025651392354451002,
0.01158000083312545,
-0.010466524889640786,
0.047387829407119234
],
[
0.022869684564446633,
0.003790665852549147,
-0.025651392354451002,
1,
-0.013527576547962002,
-0.03534956734726059,
0.36157273687024777
],
[
0.016355250728557667,
0.026792686209264383,
0.01158000083312545,
-0.013527576547962002,
1,
-0.011534135355788986,
0.12351538896214398
],
[
0.04381300694020507,
0.0004764712883163013,
-0.010466524889640786,
-0.03534956734726059,
-0.011534135355788986,
1,
0.42076893798445325
],
[
-0.2148840997128597,
-0.19645299365239596,
0.047387829407119234,
0.36157273687024777,
0.12351538896214398,
0.42076893798445325,
1
]
]
}
],
"layout": {
"annotations": [
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "buying_price",
"xref": "x",
"y": "buying_price",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "maintainence_cost",
"xref": "x",
"y": "buying_price",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "number_of_doors",
"xref": "x",
"y": "buying_price",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "number_of_seats",
"xref": "x",
"y": "buying_price",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "luggage_boot_size",
"xref": "x",
"y": "buying_price",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "safety_rating",
"xref": "x",
"y": "buying_price",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.21",
"x": "popularity",
"xref": "x",
"y": "buying_price",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "buying_price",
"xref": "x",
"y": "maintainence_cost",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "maintainence_cost",
"xref": "x",
"y": "maintainence_cost",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "number_of_doors",
"xref": "x",
"y": "maintainence_cost",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "number_of_seats",
"xref": "x",
"y": "maintainence_cost",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "luggage_boot_size",
"xref": "x",
"y": "maintainence_cost",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "safety_rating",
"xref": "x",
"y": "maintainence_cost",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.2",
"x": "popularity",
"xref": "x",
"y": "maintainence_cost",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "buying_price",
"xref": "x",
"y": "number_of_doors",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "maintainence_cost",
"xref": "x",
"y": "number_of_doors",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "number_of_doors",
"xref": "x",
"y": "number_of_doors",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "number_of_seats",
"xref": "x",
"y": "number_of_doors",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "luggage_boot_size",
"xref": "x",
"y": "number_of_doors",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "safety_rating",
"xref": "x",
"y": "number_of_doors",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "popularity",
"xref": "x",
"y": "number_of_doors",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "buying_price",
"xref": "x",
"y": "number_of_seats",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "maintainence_cost",
"xref": "x",
"y": "number_of_seats",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "number_of_doors",
"xref": "x",
"y": "number_of_seats",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "number_of_seats",
"xref": "x",
"y": "number_of_seats",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "luggage_boot_size",
"xref": "x",
"y": "number_of_seats",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "safety_rating",
"xref": "x",
"y": "number_of_seats",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.36",
"x": "popularity",
"xref": "x",
"y": "number_of_seats",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "buying_price",
"xref": "x",
"y": "luggage_boot_size",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "maintainence_cost",
"xref": "x",
"y": "luggage_boot_size",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "number_of_doors",
"xref": "x",
"y": "luggage_boot_size",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "number_of_seats",
"xref": "x",
"y": "luggage_boot_size",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "luggage_boot_size",
"xref": "x",
"y": "luggage_boot_size",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "safety_rating",
"xref": "x",
"y": "luggage_boot_size",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "popularity",
"xref": "x",
"y": "luggage_boot_size",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "buying_price",
"xref": "x",
"y": "safety_rating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "maintainence_cost",
"xref": "x",
"y": "safety_rating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "number_of_doors",
"xref": "x",
"y": "safety_rating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "number_of_seats",
"xref": "x",
"y": "safety_rating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "luggage_boot_size",
"xref": "x",
"y": "safety_rating",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "safety_rating",
"xref": "x",
"y": "safety_rating",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.42",
"x": "popularity",
"xref": "x",
"y": "safety_rating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.21",
"x": "buying_price",
"xref": "x",
"y": "popularity",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.2",
"x": "maintainence_cost",
"xref": "x",
"y": "popularity",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "number_of_doors",
"xref": "x",
"y": "popularity",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.36",
"x": "number_of_seats",
"xref": "x",
"y": "popularity",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "luggage_boot_size",
"xref": "x",
"y": "popularity",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.42",
"x": "safety_rating",
"xref": "x",
"y": "popularity",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "popularity",
"xref": "x",
"y": "popularity",
"yref": "y"
}
],
"template": {
"data": {
"bar": [
{
"error_x": {
"color": "#2a3f5f"
},
"error_y": {
"color": "#2a3f5f"
},
"marker": {
"line": {
"color": "#E5ECF6",
"width": 0.5
}
},
"type": "bar"
}
],
"barpolar": [
{
"marker": {
"line": {
"color": "#E5ECF6",
"width": 0.5
}
},
"type": "barpolar"
}
],
"carpet": [
{
"aaxis": {
"endlinecolor": "#2a3f5f",
"gridcolor": "white",
"linecolor": "white",
"minorgridcolor": "white",
"startlinecolor": "#2a3f5f"
},
"baxis": {
"endlinecolor": "#2a3f5f",
"gridcolor": "white",
"linecolor": "white",
"minorgridcolor": "white",
"startlinecolor": "#2a3f5f"
},
"type": "carpet"
}
],
"choropleth": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "choropleth"
}
],
"contour": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "contour"
}
],
"contourcarpet": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "contourcarpet"
}
],
"heatmap": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "heatmap"
}
],
"heatmapgl": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "heatmapgl"
}
],
"histogram": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "histogram"
}
],
"histogram2d": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "histogram2d"
}
],
"histogram2dcontour": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "histogram2dcontour"
}
],
"mesh3d": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "mesh3d"
}
],
"parcoords": [
{
"line": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "parcoords"
}
],
"pie": [
{
"automargin": true,
"type": "pie"
}
],
"scatter": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatter"
}
],
"scatter3d": [
{
"line": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatter3d"
}
],
"scattercarpet": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattercarpet"
}
],
"scattergeo": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattergeo"
}
],
"scattergl": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattergl"
}
],
"scattermapbox": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattermapbox"
}
],
"scatterpolar": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterpolar"
}
],
"scatterpolargl": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterpolargl"
}
],
"scatterternary": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterternary"
}
],
"surface": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "surface"
}
],
"table": [
{
"cells": {
"fill": {
"color": "#EBF0F8"
},
"line": {
"color": "white"
}
},
"header": {
"fill": {
"color": "#C8D4E3"
},
"line": {
"color": "white"
}
},
"type": "table"
}
]
},
"layout": {
"annotationdefaults": {
"arrowcolor": "#2a3f5f",
"arrowhead": 0,
"arrowwidth": 1
},
"coloraxis": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"colorscale": {
"diverging": [
[
0,
"#8e0152"
],
[
0.1,
"#c51b7d"
],
[
0.2,
"#de77ae"
],
[
0.3,
"#f1b6da"
],
[
0.4,
"#fde0ef"
],
[
0.5,
"#f7f7f7"
],
[
0.6,
"#e6f5d0"
],
[
0.7,
"#b8e186"
],
[
0.8,
"#7fbc41"
],
[
0.9,
"#4d9221"
],
[
1,
"#276419"
]
],
"sequential": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"sequentialminus": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
]
},
"colorway": [
"#636efa",
"#EF553B",
"#00cc96",
"#ab63fa",
"#FFA15A",
"#19d3f3",
"#FF6692",
"#B6E880",
"#FF97FF",
"#FECB52"
],
"font": {
"color": "#2a3f5f"
},
"geo": {
"bgcolor": "white",
"lakecolor": "white",
"landcolor": "#E5ECF6",
"showlakes": true,
"showland": true,
"subunitcolor": "white"
},
"hoverlabel": {
"align": "left"
},
"hovermode": "closest",
"mapbox": {
"style": "light"
},
"paper_bgcolor": "white",
"plot_bgcolor": "#E5ECF6",
"polar": {
"angularaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"bgcolor": "#E5ECF6",
"radialaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
}
},
"scene": {
"xaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
},
"yaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
},
"zaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
}
},
"shapedefaults": {
"line": {
"color": "#2a3f5f"
}
},
"ternary": {
"aaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"baxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"bgcolor": "#E5ECF6",
"caxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
}
},
"title": {
"x": 0.05
},
"xaxis": {
"automargin": true,
"gridcolor": "white",
"linecolor": "white",
"ticks": "",
"title": {
"standoff": 15
},
"zerolinecolor": "white",
"zerolinewidth": 2
},
"yaxis": {
"automargin": true,
"gridcolor": "white",
"linecolor": "white",
"ticks": "",
"title": {
"standoff": 15
},
"zerolinecolor": "white",
"zerolinewidth": 2
}
}
},
"xaxis": {
"dtick": 1,
"gridcolor": "rgb(0, 0, 0)",
"side": "top",
"ticks": ""
},
"yaxis": {
"dtick": 1,
"ticks": "",
"ticksuffix": " "
}
}
},
"text/html": [
"
value=%{value}", "labels": [ 1, 2, 3, 4 ], "legendgroup": "", "name": "", "showlegend": true, "type": "pie", "values": [ 941, 294, 36, 31 ] } ], "layout": { "legend": { "tracegroupgap": 0 }, "template": { "data": { "bar": [ { "error_x": { "color": "#2a3f5f" }, "error_y": { "color": "#2a3f5f" }, "marker": { "line": { "color": "#E5ECF6", "width": 0.5 } }, "type": "bar" } ], "barpolar": [ { "marker": { "line": { "color": "#E5ECF6", "width": 0.5 } }, "type": "barpolar" } ], "carpet": [ { "aaxis": { "endlinecolor": "#2a3f5f", "gridcolor": "white", "linecolor": "white", "minorgridcolor": "white", "startlinecolor": "#2a3f5f" }, "baxis": { "endlinecolor": "#2a3f5f", "gridcolor": "white", "linecolor": "white", "minorgridcolor": "white", "startlinecolor": "#2a3f5f" }, "type": "carpet" } ], "choropleth": [ { "colorbar": { "outlinewidth": 0, "ticks": "" }, "type": "choropleth" } ], "contour": [ { "colorbar": { "outlinewidth": 0, "ticks": "" }, "colorscale": [ [ 0, "#0d0887" ], [ 0.1111111111111111, "#46039f" ], [ 0.2222222222222222, "#7201a8" ], [ 0.3333333333333333, "#9c179e" ], [ 0.4444444444444444, "#bd3786" ], [ 0.5555555555555556, "#d8576b" ], [ 0.6666666666666666, "#ed7953" ], [ 0.7777777777777778, "#fb9f3a" ], [ 0.8888888888888888, "#fdca26" ], [ 1, "#f0f921" ] ], "type": "contour" } ], "contourcarpet": [ { "colorbar": { "outlinewidth": 0, "ticks": "" }, "type": "contourcarpet" } ], "heatmap": [ { "colorbar": { "outlinewidth": 0, "ticks": "" }, "colorscale": [ [ 0, "#0d0887" ], [ 0.1111111111111111, "#46039f" ], [ 0.2222222222222222, "#7201a8" ], [ 0.3333333333333333, "#9c179e" ], [ 0.4444444444444444, "#bd3786" ], [ 0.5555555555555556, "#d8576b" ], [ 0.6666666666666666, "#ed7953" ], [ 0.7777777777777778, "#fb9f3a" ], [ 0.8888888888888888, "#fdca26" ], [ 1, "#f0f921" ] ], "type": "heatmap" } ], "heatmapgl": [ { "colorbar": { "outlinewidth": 0, "ticks": "" }, "colorscale": [ [ 0, "#0d0887" ], [ 0.1111111111111111, "#46039f" ], [ 0.2222222222222222, "#7201a8" ], [ 0.3333333333333333, "#9c179e" ], [ 0.4444444444444444, "#bd3786" ], [ 0.5555555555555556, "#d8576b" ], [ 0.6666666666666666, "#ed7953" ], [ 0.7777777777777778, "#fb9f3a" ], [ 0.8888888888888888, "#fdca26" ], [ 1, "#f0f921" ] ], "type": "heatmapgl" } ], "histogram": [ { "marker": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "histogram" } ], "histogram2d": [ { "colorbar": { "outlinewidth": 0, "ticks": "" }, "colorscale": [ [ 0, "#0d0887" ], [ 0.1111111111111111, "#46039f" ], [ 0.2222222222222222, "#7201a8" ], [ 0.3333333333333333, "#9c179e" ], [ 0.4444444444444444, "#bd3786" ], [ 0.5555555555555556, "#d8576b" ], [ 0.6666666666666666, "#ed7953" ], [ 0.7777777777777778, "#fb9f3a" ], [ 0.8888888888888888, "#fdca26" ], [ 1, "#f0f921" ] ], "type": "histogram2d" } ], "histogram2dcontour": [ { "colorbar": { "outlinewidth": 0, "ticks": "" }, "colorscale": [ [ 0, "#0d0887" ], [ 0.1111111111111111, "#46039f" ], [ 0.2222222222222222, "#7201a8" ], [ 0.3333333333333333, "#9c179e" ], [ 0.4444444444444444, "#bd3786" ], [ 0.5555555555555556, "#d8576b" ], [ 0.6666666666666666, "#ed7953" ], [ 0.7777777777777778, "#fb9f3a" ], [ 0.8888888888888888, "#fdca26" ], [ 1, "#f0f921" ] ], "type": "histogram2dcontour" } ], "mesh3d": [ { "colorbar": { "outlinewidth": 0, "ticks": "" }, "type": "mesh3d" } ], "parcoords": [ { "line": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "parcoords" } ], "pie": [ { "automargin": true, "type": "pie" } ], "scatter": [ { "marker": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "scatter" } ], "scatter3d": [ { "line": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "marker": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "scatter3d" } ], "scattercarpet": [ { "marker": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "scattercarpet" } ], "scattergeo": [ { "marker": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "scattergeo" } ], "scattergl": [ { "marker": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "scattergl" } ], "scattermapbox": [ { "marker": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "scattermapbox" } ], "scatterpolar": [ { "marker": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "scatterpolar" } ], "scatterpolargl": [ { "marker": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "scatterpolargl" } ], "scatterternary": [ { "marker": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "scatterternary" } ], "surface": [ { "colorbar": { "outlinewidth": 0, "ticks": "" }, "colorscale": [ [ 0, "#0d0887" ], [ 0.1111111111111111, "#46039f" ], [ 0.2222222222222222, "#7201a8" ], [ 0.3333333333333333, "#9c179e" ], [ 0.4444444444444444, "#bd3786" ], [ 0.5555555555555556, "#d8576b" ], [ 0.6666666666666666, "#ed7953" ], [ 0.7777777777777778, "#fb9f3a" ], [ 0.8888888888888888, "#fdca26" ], [ 1, "#f0f921" ] ], "type": "surface" } ], "table": [ { "cells": { "fill": { "color": "#EBF0F8" }, "line": { "color": "white" } }, "header": { "fill": { "color": "#C8D4E3" }, "line": { "color": "white" } }, "type": "table" } ] }, "layout": { "annotationdefaults": { "arrowcolor": "#2a3f5f", "arrowhead": 0, "arrowwidth": 1 }, "coloraxis": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "colorscale": { "diverging": [ [ 0, "#8e0152" ], [ 0.1, "#c51b7d" ], [ 0.2, "#de77ae" ], [ 0.3, "#f1b6da" ], [ 0.4, "#fde0ef" ], [ 0.5, "#f7f7f7" ], [ 0.6, "#e6f5d0" ], [ 0.7, "#b8e186" ], [ 0.8, "#7fbc41" ], [ 0.9, "#4d9221" ], [ 1, "#276419" ] ], "sequential": [ [ 0, "#0d0887" ], [ 0.1111111111111111, "#46039f" ], [ 0.2222222222222222, "#7201a8" ], [ 0.3333333333333333, "#9c179e" ], [ 0.4444444444444444, "#bd3786" ], [ 0.5555555555555556, "#d8576b" ], [ 0.6666666666666666, "#ed7953" ], [ 0.7777777777777778, "#fb9f3a" ], [ 0.8888888888888888, "#fdca26" ], [ 1, "#f0f921" ] ], "sequentialminus": [ [ 0, "#0d0887" ], [ 0.1111111111111111, "#46039f" ], [ 0.2222222222222222, "#7201a8" ], [ 0.3333333333333333, "#9c179e" ], [ 0.4444444444444444, "#bd3786" ], [ 0.5555555555555556, "#d8576b" ], [ 0.6666666666666666, "#ed7953" ], [ 0.7777777777777778, "#fb9f3a" ], [ 0.8888888888888888, "#fdca26" ], [ 1, "#f0f921" ] ] }, "colorway": [ "#636efa", "#EF553B", "#00cc96", "#ab63fa", "#FFA15A", "#19d3f3", "#FF6692", "#B6E880", "#FF97FF", "#FECB52" ], "font": { "color": "#2a3f5f" }, "geo": { "bgcolor": "white", "lakecolor": "white", "landcolor": "#E5ECF6", "showlakes": true, "showland": true, "subunitcolor": "white" }, "hoverlabel": { "align": "left" }, "hovermode": "closest", "mapbox": { "style": "light" }, "paper_bgcolor": "white", "plot_bgcolor": "#E5ECF6", "polar": { "angularaxis": { "gridcolor": "white", "linecolor": "white", "ticks": "" }, "bgcolor": "#E5ECF6", "radialaxis": { "gridcolor": "white", "linecolor": "white", "ticks": "" } }, "scene": { "xaxis": { "backgroundcolor": "#E5ECF6", "gridcolor": "white", "gridwidth": 2, "linecolor": "white", "showbackground": true, "ticks": "", "zerolinecolor": "white" }, "yaxis": { "backgroundcolor": "#E5ECF6", "gridcolor": "white", "gridwidth": 2, "linecolor": "white", "showbackground": true, "ticks": "", "zerolinecolor": "white" }, "zaxis": { "backgroundcolor": "#E5ECF6", "gridcolor": "white", "gridwidth": 2, "linecolor": "white", "showbackground": true, "ticks": "", "zerolinecolor": "white" } }, "shapedefaults": { "line": { "color": "#2a3f5f" } }, "ternary": { "aaxis": { "gridcolor": "white", "linecolor": "white", "ticks": "" }, "baxis": { "gridcolor": "white", "linecolor": "white", "ticks": "" }, "bgcolor": "#E5ECF6", "caxis": { "gridcolor": "white", "linecolor": "white", "ticks": "" } }, "title": { "x": 0.05 }, "xaxis": { "automargin": true, "gridcolor": "white", "linecolor": "white", "ticks": "", "title": { "standoff": 15 }, "zerolinecolor": "white", "zerolinewidth": 2 }, "yaxis": { "automargin": true, "gridcolor": "white", "linecolor": "white", "ticks": "", "title": { "standoff": 15 }, "zerolinecolor": "white", "zerolinewidth": 2 } } }, "title": { "text": "Percentage data of popularity" } } }, "text/html": [ "
| Model | R^2 score | Root Mean Squared Error | Root Mean Squared Log Error | Mean Squared Error | |
|---|---|---|---|---|---|
| 0 | \n", "LinearRegression | \n", "0.536614 | \n", "1.19452e+06 | \n", "0.223221 | \n", "1.42688e+12 | \n", "
| 2 | \n", "XGBoostRegressor | \n", "0.498153 | \n", "1.24311e+06 | \n", "0.224521 | \n", "1.54531e+12 | \n", "
| 6 | \n", "GradientBoostingRegression | \n", "0.485068 | \n", "1.25921e+06 | \n", "0.229515 | \n", "1.5856e+12 | \n", "
| 4 | \n", "AdaBoostRegressor | \n", "0.4731 | \n", "1.27376e+06 | \n", "0.240908 | \n", "1.62246e+12 | \n", "
| 1 | \n", "RandomForestRegression | \n", "0.437476 | \n", "1.31611e+06 | \n", "0.246043 | \n", "1.73215e+12 | \n", "
| 3 | \n", "LGBoostRegressor | \n", "-0.0563305 | \n", "1.80353e+06 | \n", "0.318165 | \n", "3.2527e+12 | \n", "
| 5 | \n", "SupportVectorMachine | \n", "-0.230739 | \n", "1.94673e+06 | \n", "0.341145 | \n", "3.78975e+12 | \n", "
\n",
" \n",
" \n",
" \n",
" \n",
"
"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"application/vnd.plotly.v1+json": {
"config": {
"plotlyServerURL": "https://plot.ly"
},
"data": [
{
"domain": {
"x": [
0,
1
],
"y": [
0,
1
]
},
"hole": 0.4,
"hoverinfo": "label+percent+name",
"hoverlabel": {
"namelength": 0
},
"hovertemplate": "label=%{label}value=%{value}", "labels": [ 1, 2, 3, 4 ], "legendgroup": "", "name": "", "showlegend": true, "type": "pie", "values": [ 941, 294, 36, 31 ] } ], "layout": { "legend": { "tracegroupgap": 0 }, "template": { "data": { "bar": [ { "error_x": { "color": "#2a3f5f" }, "error_y": { "color": "#2a3f5f" }, "marker": { "line": { "color": "#E5ECF6", "width": 0.5 } }, "type": "bar" } ], "barpolar": [ { "marker": { "line": { "color": "#E5ECF6", "width": 0.5 } }, "type": "barpolar" } ], "carpet": [ { "aaxis": { "endlinecolor": "#2a3f5f", "gridcolor": "white", "linecolor": "white", "minorgridcolor": "white", "startlinecolor": "#2a3f5f" }, "baxis": { "endlinecolor": "#2a3f5f", "gridcolor": "white", "linecolor": "white", "minorgridcolor": "white", "startlinecolor": "#2a3f5f" }, "type": "carpet" } ], "choropleth": [ { "colorbar": { "outlinewidth": 0, "ticks": "" }, "type": "choropleth" } ], "contour": [ { "colorbar": { "outlinewidth": 0, "ticks": "" }, "colorscale": [ [ 0, "#0d0887" ], [ 0.1111111111111111, "#46039f" ], [ 0.2222222222222222, "#7201a8" ], [ 0.3333333333333333, "#9c179e" ], [ 0.4444444444444444, "#bd3786" ], [ 0.5555555555555556, "#d8576b" ], [ 0.6666666666666666, "#ed7953" ], [ 0.7777777777777778, "#fb9f3a" ], [ 0.8888888888888888, "#fdca26" ], [ 1, "#f0f921" ] ], "type": "contour" } ], "contourcarpet": [ { "colorbar": { "outlinewidth": 0, "ticks": "" }, "type": "contourcarpet" } ], "heatmap": [ { "colorbar": { "outlinewidth": 0, "ticks": "" }, "colorscale": [ [ 0, "#0d0887" ], [ 0.1111111111111111, "#46039f" ], [ 0.2222222222222222, "#7201a8" ], [ 0.3333333333333333, "#9c179e" ], [ 0.4444444444444444, "#bd3786" ], [ 0.5555555555555556, "#d8576b" ], [ 0.6666666666666666, "#ed7953" ], [ 0.7777777777777778, "#fb9f3a" ], [ 0.8888888888888888, "#fdca26" ], [ 1, "#f0f921" ] ], "type": "heatmap" } ], "heatmapgl": [ { "colorbar": { "outlinewidth": 0, "ticks": "" }, "colorscale": [ [ 0, "#0d0887" ], [ 0.1111111111111111, "#46039f" ], [ 0.2222222222222222, "#7201a8" ], [ 0.3333333333333333, "#9c179e" ], [ 0.4444444444444444, "#bd3786" ], [ 0.5555555555555556, "#d8576b" ], [ 0.6666666666666666, "#ed7953" ], [ 0.7777777777777778, "#fb9f3a" ], [ 0.8888888888888888, "#fdca26" ], [ 1, "#f0f921" ] ], "type": "heatmapgl" } ], "histogram": [ { "marker": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "histogram" } ], "histogram2d": [ { "colorbar": { "outlinewidth": 0, "ticks": "" }, "colorscale": [ [ 0, "#0d0887" ], [ 0.1111111111111111, "#46039f" ], [ 0.2222222222222222, "#7201a8" ], [ 0.3333333333333333, "#9c179e" ], [ 0.4444444444444444, "#bd3786" ], [ 0.5555555555555556, "#d8576b" ], [ 0.6666666666666666, "#ed7953" ], [ 0.7777777777777778, "#fb9f3a" ], [ 0.8888888888888888, "#fdca26" ], [ 1, "#f0f921" ] ], "type": "histogram2d" } ], "histogram2dcontour": [ { "colorbar": { "outlinewidth": 0, "ticks": "" }, "colorscale": [ [ 0, "#0d0887" ], [ 0.1111111111111111, "#46039f" ], [ 0.2222222222222222, "#7201a8" ], [ 0.3333333333333333, "#9c179e" ], [ 0.4444444444444444, "#bd3786" ], [ 0.5555555555555556, "#d8576b" ], [ 0.6666666666666666, "#ed7953" ], [ 0.7777777777777778, "#fb9f3a" ], [ 0.8888888888888888, "#fdca26" ], [ 1, "#f0f921" ] ], "type": "histogram2dcontour" } ], "mesh3d": [ { "colorbar": { "outlinewidth": 0, "ticks": "" }, "type": "mesh3d" } ], "parcoords": [ { "line": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "parcoords" } ], "pie": [ { "automargin": true, "type": "pie" } ], "scatter": [ { "marker": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "scatter" } ], "scatter3d": [ { "line": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "marker": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "scatter3d" } ], "scattercarpet": [ { "marker": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "scattercarpet" } ], "scattergeo": [ { "marker": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "scattergeo" } ], "scattergl": [ { "marker": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "scattergl" } ], "scattermapbox": [ { "marker": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "scattermapbox" } ], "scatterpolar": [ { "marker": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "scatterpolar" } ], "scatterpolargl": [ { "marker": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "scatterpolargl" } ], "scatterternary": [ { "marker": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "scatterternary" } ], "surface": [ { "colorbar": { "outlinewidth": 0, "ticks": "" }, "colorscale": [ [ 0, "#0d0887" ], [ 0.1111111111111111, "#46039f" ], [ 0.2222222222222222, "#7201a8" ], [ 0.3333333333333333, "#9c179e" ], [ 0.4444444444444444, "#bd3786" ], [ 0.5555555555555556, "#d8576b" ], [ 0.6666666666666666, "#ed7953" ], [ 0.7777777777777778, "#fb9f3a" ], [ 0.8888888888888888, "#fdca26" ], [ 1, "#f0f921" ] ], "type": "surface" } ], "table": [ { "cells": { "fill": { "color": "#EBF0F8" }, "line": { "color": "white" } }, "header": { "fill": { "color": "#C8D4E3" }, "line": { "color": "white" } }, "type": "table" } ] }, "layout": { "annotationdefaults": { "arrowcolor": "#2a3f5f", "arrowhead": 0, "arrowwidth": 1 }, "coloraxis": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "colorscale": { "diverging": [ [ 0, "#8e0152" ], [ 0.1, "#c51b7d" ], [ 0.2, "#de77ae" ], [ 0.3, "#f1b6da" ], [ 0.4, "#fde0ef" ], [ 0.5, "#f7f7f7" ], [ 0.6, "#e6f5d0" ], [ 0.7, "#b8e186" ], [ 0.8, "#7fbc41" ], [ 0.9, "#4d9221" ], [ 1, "#276419" ] ], "sequential": [ [ 0, "#0d0887" ], [ 0.1111111111111111, "#46039f" ], [ 0.2222222222222222, "#7201a8" ], [ 0.3333333333333333, "#9c179e" ], [ 0.4444444444444444, "#bd3786" ], [ 0.5555555555555556, "#d8576b" ], [ 0.6666666666666666, "#ed7953" ], [ 0.7777777777777778, "#fb9f3a" ], [ 0.8888888888888888, "#fdca26" ], [ 1, "#f0f921" ] ], "sequentialminus": [ [ 0, "#0d0887" ], [ 0.1111111111111111, "#46039f" ], [ 0.2222222222222222, "#7201a8" ], [ 0.3333333333333333, "#9c179e" ], [ 0.4444444444444444, "#bd3786" ], [ 0.5555555555555556, "#d8576b" ], [ 0.6666666666666666, "#ed7953" ], [ 0.7777777777777778, "#fb9f3a" ], [ 0.8888888888888888, "#fdca26" ], [ 1, "#f0f921" ] ] }, "colorway": [ "#636efa", "#EF553B", "#00cc96", "#ab63fa", "#FFA15A", "#19d3f3", "#FF6692", "#B6E880", "#FF97FF", "#FECB52" ], "font": { "color": "#2a3f5f" }, "geo": { "bgcolor": "white", "lakecolor": "white", "landcolor": "#E5ECF6", "showlakes": true, "showland": true, "subunitcolor": "white" }, "hoverlabel": { "align": "left" }, "hovermode": "closest", "mapbox": { "style": "light" }, "paper_bgcolor": "white", "plot_bgcolor": "#E5ECF6", "polar": { "angularaxis": { "gridcolor": "white", "linecolor": "white", "ticks": "" }, "bgcolor": "#E5ECF6", "radialaxis": { "gridcolor": "white", "linecolor": "white", "ticks": "" } }, "scene": { "xaxis": { "backgroundcolor": "#E5ECF6", "gridcolor": "white", "gridwidth": 2, "linecolor": "white", "showbackground": true, "ticks": "", "zerolinecolor": "white" }, "yaxis": { "backgroundcolor": "#E5ECF6", "gridcolor": "white", "gridwidth": 2, "linecolor": "white", "showbackground": true, "ticks": "", "zerolinecolor": "white" }, "zaxis": { "backgroundcolor": "#E5ECF6", "gridcolor": "white", "gridwidth": 2, "linecolor": "white", "showbackground": true, "ticks": "", "zerolinecolor": "white" } }, "shapedefaults": { "line": { "color": "#2a3f5f" } }, "ternary": { "aaxis": { "gridcolor": "white", "linecolor": "white", "ticks": "" }, "baxis": { "gridcolor": "white", "linecolor": "white", "ticks": "" }, "bgcolor": "#E5ECF6", "caxis": { "gridcolor": "white", "linecolor": "white", "ticks": "" } }, "title": { "x": 0.05 }, "xaxis": { "automargin": true, "gridcolor": "white", "linecolor": "white", "ticks": "", "title": { "standoff": 15 }, "zerolinecolor": "white", "zerolinewidth": 2 }, "yaxis": { "automargin": true, "gridcolor": "white", "linecolor": "white", "ticks": "", "title": { "standoff": 15 }, "zerolinecolor": "white", "zerolinewidth": 2 } } }, "title": { "text": "Percentage data of popularity" } } }, "text/html": [ "
\n",
" \n",
" \n",
" \n",
" \n",
"
"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"Detailed Executing with RandomForest ..\n"
]
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAq8AAAGwCAYAAACHCYxOAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADt0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjByYzEsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy/xvVyzAAAgAElEQVR4nO3deZgkZZmu8fuRRkBAFhtFUWhEFBdkFUVWlXFm3HAd3AdxxA3RmXGb8QyiDooHPS7jBiqioo6KgqijoEiDgtJ0Q7MprrQDKCKCrIos7/kjouwkO6sqq7uqs6L6/l1XXpX5xRcRb0RkVj4V+WVUqgpJkiSpC+426gIkSZKkYRleJUmS1BmGV0mSJHWG4VWSJEmdYXiVJElSZxheJUmS1BmGV0krJcmBSSrJgaOuRZK05jC8SrNAGwJ7b3ckuTbJwjYkZtQ1dl2Swwfs597bslHXuDLa2heuxHzHTbI/przMldVTy4LVtc7pkmTf1b2/RsU/WDVbzBt1AZLu4m3tz7WBBwHPAPYBdgUOGVVRc8wZwMIB7X9czXXMFl8Dlg5oX7aa65CkoRhepVmkqg7vfZxkD+BM4FVJ3ltVl42ksLllYf9+XsOdVFXHjboISRqWwwakWayqzgIuBQLs0jstyS5JPpDkgnaIwZ+T/DzJe5Ns0r+s3o/8kjyuHZJwY5IbknwzyUMH1ZDkQUm+nOS6JDcnOTvJkyequ63tK0muTnJrkl8n+UiS+w7oO/aR8dZJDkny43ZbliX597EhE0mek2RRW8PVST6UZN0p7M4pWclteGCS1yS5MMmfej9KTrJpkncl+Uk77fokpyV54oDl3T3JoUnOa/f7Le3++FqS/do+ByYZ+//e+/R95H/4DOyP5yU5va3nz+12/J8k6wzo+/Qkxyf5WXu8bkqypN2mu/X1LeAf24eXDRrG0W77MgbI8uEg+/Yvt32Ob57kE0muTDMc58CePo9OckKSq5L8JcnlSY5Ocr+V3U89y+59vf1Nku+3++H3ST6VZOO2305JvtHu15uSnJwBwyfabakk6yT5zySXtc/LXyZ5a5K7j1PHE5J8O8t/R/wsyZFJNppgHXdPcliSn7brOK59Ln+q7fqpvufbgnb++7XzndWzT3+T5PMZ8PslyYJ2/uPa+/+d5Jq2zsVJnjLB/j2gff2MbdeyJF9IsuuAvkM/d9UNnnmVZr+x8a639bW/jGZYwRnAd4G1gJ2BfwH+Psmjq+rGAct7CrA/8C3gY8DDgCcBj0rysKq65q8rTrYFfgjcq+2/lGY4w0nt4xWLbd5wvtLWfQLwa5rg/Upg/yR7VNWyAbO+B9gX+DpwKvA04Ajg7kmuBY5s1/t94G+AV7fb/MpBdayKVdiGDwB7Ad8E/ge4o13eVjRDFRa09X8bWJ/mWHw7ycur6uM9yzkOeB5wMfAZ4E/A/YA9gb+jOd5LaYaZvLWt77ie+Reu7LYPkuSTwEHAFcBXaYZYPAZ4B/CEJH9TVbf3zHIkcCdwDnAlsBHweJr98yjgRT193wY8HdihnT42fGM6hnFsCvwIuKmt+07gd+02vQT4OHArcDJwObAt8E/AU5M8pqr+dxpqeBrNcf4GzevtscCBwNZJ3gycRvOc+CSwPfBUYJsk21fVnQOW9yWafXgCze+E/YHDgV2TPK2qxv6gIcnLgY8CNwNfBq6meY29qd3GPapq0H7+SruOb9G85q6meU79sV1f/1CTsWXsDbwZOL1dxk00+/TZwNPa9V0wYH1bAYuAXwGfpTluBwBfS7JfVZ3es02hCdH/CFxDc1x/D9wfeBzwU2BxT/+pPnfVBVXlzZu3Ed+Aal6OK7TvTROAbgXu2zdtK2CtAfO8tF3em/raD2zbbwee0DftXe20N/a1n9q2v7avff+xmoEDe9o3oHlDuQPYq2+eN7X9T+1rP65tXwZs0dO+cbusm2nenB7aM20d4Mftfrn3kPv48HY9C9v7/bcF07ANVwJbD1j3Qprg9Ny+9o1pQsCfgPu0bRu1fRePc3zvNeC5s3AlnnNjNZ80zv7YuO9581VgvXH2af/zY5sB67sb8Om2/6PHqWXBOLUuA5ZNclz3HfSaogn/8/qmPRj4C/CL3udcO+3x7bE/ccj9uO+gY8BdX2/79O2H77TTrgVe0DffJ9tp+w94DhXwM2CTnvZ1af7ALOBFPe1b0bw+bgC261vWR9r+x4yzjguB+QO2dWybDhxnX9wb2HBA+w40QfZbfe0Leo7TW/um/W3b/j997Qe37YuAjfqmrUXP78mVee5668Zt5AV48+btLm+0h7e3I4Avtm+wdwKvmcKyAlwPfK+vfewX+fED5tm6nXZCT9v927ZfMThEjb3RHdjT9oK27fMD+s8DLmunb9nTflzb9tIB8xzbTnv7gGlvbaftM+R+GXuzGu+27zRswwpvhO0bdwFfHqeusT8EXtU+vmf7+CwgQz53Fq7Ec26s5vFuC9p+59Oc4dt4wDLWogn6i4Zc587tsg8bp5YF48y3jJULrwP/uAHe105/8jjLPJEmdK4QxAb03XfQMWD56+2zA+Z5cTvtzAHT9mFwmFtIX0AdUMPpPW1vadveOaD/JjSh9k/AOgPWsX//PH3bdOCg6ZPsp5OBPwNr97QtYPkfroN+x/wauKav7aJ2np2GWOe0PXe9za6bwwak2eWtfY/HQt2n+jsmWRt4OfBcmo/+N+Ku49i3GGcdiwe0Xd7+7B0ru1P78wdVdceAeRbSvNH22rn9+b3+zlV1e5Izad6wdgL6P5IdVNdv2p9LBky7sv15/wHTJvK2mvgLW6uyDYsGLG/39udGGTwWdbP250PbddyQ5Os0Hx8vTfIVmo+Vz6mqWyaoe2W9pMb5wlaSe9CE72uA12XwFdtuHau9Z757AW+gGY7yQJohEr3Ge25Ot2VVdfWA9rFjsk+SRw2Yfm+acPNgBj/3pmK6n9dnDGj7Pk3Y3qmnbaLn8XVJzqf5ZGc7oP+j/EHP46GkGQ//CporpMxnxeGJ84Hf9rUtHed3zOUsP1YkWR94BPC7qjp/kjpW6rmrbjC8SrNIVY19OWl9ml/anwQ+luTXVdX/JvRFmjGvv6IZg3YVzS9jgNfRfLQ+yApj3NpQBs0b9pixL3T8bpzlXDWgbWye/jcn+to3HjDt+gFttw8xbe1x1rWyVmUbBu2Te7U//6a9jWeDnvsH0AxReD7LL5/25yQnAK+vqvGOyXTbhOZM/mas+IfVQO0Xkc6lOZu/iOZj+2tpjtfGwGsZ/7k53QYdD1h+TN4wyfwbTDJ9GNP9vF7h2FfVHUn+QBO6x0z383hSSQ6lGbd8Hc3QiP8FbqH5I3xsXPOgYz/e+Obbuesf5GO1Xjmgb78pP3fVHYZXaRaqqpuB7yZ5KnAe8OkkDxk789Z+o/YZNF/ceVJV/fXLXGm+zf3GaShj7I31PuNM33yCeQZNA7hvX7/ZaFW2oSZY3mur6oPDFFBVf6IdQpLkATRnyA4EXkhz1nevYZYzDcZqP7+qdp6w53L/RBNcVzjDnWR3mvA6VXcCA79Nz+DwNWbQ8YDl27VRVd2wEvWM0n3oO+OfZC2aQN67Lb3P40sGLGfc53FVjbffxpVkHs0fWlcBO1fVb/um7z5wxqkZC7nDnLlfmeeuOsJLZUmzWFVdSPON6PsD/9wz6UHtz5N7g2trN2C9aVj92Mdye7Zvjv32nWCeFaa1b257tg/PW9XiZtB0b8OP2p8rFTir6vKq+hzNF1h+TnM87tXT5U7uesZ82lTVTTTB5+FJNh1ytrHn5lcGTOsfZjJm7CPj8bbjOuA+7VCZfitcGmkIq3RMRmzQPtyL5mRU70fpEz2PNwZ2pBmD+pMprHui4zSf5g+JswcE1w1YPoxhpbV/1F9M81zYaZK+K/PcVUcYXqXZ7z9p3mRen+XXb13W/ty3t2OSewMfno6VVtUVNB/9bU3ff/dKsj+D30RPovmI+HlJHtM37XU04x+/W9NzCaKZMq3bUFWLacYkPjPJQYP6JNm+PXYk2SzJowd0Wx/YkOaj1L/0tP8BeMAwtayk/0dz1vPYNvTcRZJNkvQGk2Xtz337+u0E/Ns46/hD+3PLcaYvoglnL+lb5oHAHuOXPq4P0XyR531JHtw/sb3O6WwNtv/R83uANNc6flf7sHds/PE02/iaJA/irt5B88XA46vqVoY30XG6mmaIwC5tWB2rb22aoQTzp7CeiYx9enF0+q5Vm+Ruuet1mKf63FVHOGxAmuWq6sokR9N83PpGmgBwLs230Z+Z5GzgBzQfJ/49zXUOfzPO4qbq1TSX4Xl/movpX8Dyf1s79qWi3lpvagPal4EzknyZ5iPOXYAn0nyk+PJpqm1GzNA2PJ/mizOfbMcFnkPzEej9gUfSfAlld5oAsAXwoyQ/oTm7ezlN0HgKzUfAH6y7Xr/3NOC57Ze8ltCE2zOr6sypbvsgVXVskl2AVwG/THIKzf7YlOYPm71pQtMr2lk+QzOW9P1JHkdztnjbtv6v0ozn7XdaO8/H23G9NwF/rKoPtdP/iya4fjTJE2j2yQ4010z9RrvsqWzTpe0xPha4JMm3aS5BtTZNMNuL5vJs201luavJT2hq7r3O6zY01xb+7FinqlqW5HU0f8yel+RLNNu0D81z7VKacdVT8UOagPq69mzm2Pjb/6qq65N8kOY6rxcl+RpNcHwczXPl9Pb+qvoEzacfLwZ+3q7n9zTXQX48zTE9HFbquauuGPXlDrx587b8UlkTTL8PzfVOb2b59UA3pble4zKaM7O/BN4J3IMBlxZi8ms0DrzkEk1YPYEmbN1M8wb25ImWR3OB8xNp3lT+QvOG8VHgfgP6Hsc4l0linMsgDbM9Eyzr8CH7T8s29PTZEPh3moB5E81lii6jCR0HA+u3/TYGDqMJu1fSfAnvtzRXd3gefZfPovmSzudpgsQdw25jT83D7r+xC+1f3e6Pq2jOiP4nK15H9GE0l0a6un3OLKEZC7ugXedxA5b/LzTB7Na2T//zd0+af5V8C83Yzm/SBP+Bz5Hxns99fbZv98Ov2/VeS/Ox9NHA44fcL/sOWtdEz8+eeVY4TuPtI5Zfxmqddp9f1tb8K5ovJK0zTn1PpLle83Vt/18A/5fBl49ayAS/h9o+f0fzO+AmVrys2rz2OP6Y5vl9FU2g3ooBr5GJng+T1UNzSbszaMa2/rndH5+jGW+70s9db924pT2wkiRplkrz71n3qfaKJNKazDGvkiRJ6gzDqyRJkjrD8CpJkqTOcMyrJEmSOsNLZa0h5s+fXwsWLBh1GZIkSZNasmTJNVW12aBphtc1xIIFC1i8ePGoy5AkSZpUkl+PN80xr5IkSeoMw6skSZI6w/AqSZKkzjC8SpIkqTMMr5IkSeoMrzawhvjJFX9glzd8ZtRlSJKkDlty1ItHXYJnXiVJktQdhldJkiR1huFVkiRJnWF4lSRJUmcYXiVJktQZhldJkiR1huFVkiRJnWF4lSRJUmcYXiVJktQZhldJkiR1huFVkiRJnWF4lSRJUmcYXiVJktQZhldJkiR1huFVkiRJnWF4lSRJUmcYXiVJktQZhldJkiR1huFVkiRJnWF4lSRJUmcYXiVJktQZhldJkiR1xhoZXpNsl2RpkvOTbDNBv39fDbX8e9/js2d6nZIkSV21RoZX4OnA16pqp6r65QT9Vjm8Jllrki53WUdVPXZV1ylJkjRXzZnwmmT9JN9MckGSi5MckOSwJOe2j49J40nA64B/SnJ6O+8Lkyxqz8YenWStJEcC67Vtn0vyjiSv7VnfEUkOHaeWfZOcnuTzwEVt20lJliS5JMnBbdtd1tG23dSzjIVJTkhyaVtD2mlPatt+kOSDSb4xTh0HJ1mcZPHtt9w4TXtakiRpdOaNuoBp9HfAb6rqyQBJNgK+U1Vvbx9/FnhKVX09yceAm6rqPUkeChwA7FFVtyX5CPCCqnpzkkOqasd2/gXAV4EPJLkb8Fxgtwnq2Q14RFVd1j4+qKquTbIecG6Sr/SvY4CdgIcDvwHOAvZIshg4Gti7qi5L8oXxCqiqY4BjANbffOuaoFZJkqROmDNnXmnOcO6X5N1J9qqq64HHJTknyUXA42mCYL8nALvQBMql7eMH9neqqmXAH5LsBDwROL+q/jBBPYt6givAoUkuAH4EPADYdohtWlRVV1TVncBSYAGwHfCrnmWPG14lSZLmmjlz5rWqfpZkF+BJwLuSnAq8Gti1qi5Pcjiw7oBZA3y6qv5tiNV8AjgQ2Bw4dpK+N/91Bcm+wH7A7lV1S5KF49TS79ae+3fQHK8MMZ8kSdKcNGfOvCa5H3BLVR0PvAfYuZ10TZINgGePM+tpwLOT3LtdzqZJtmqn3ZZk7Z6+J9IMT3gUcMoUytsIuK4NrtsBj+mZ1r+OyVwKPLAdxgDNkAdJkqQ1wpw58wpsDxyV5E7gNuCVNFcVuAhYBpw7aKaq+nGS/wOc2o5lvY3mjO2vacaLXpjkvKp6QVX9pf2S1x+r6o4p1PZt4BVJLgR+SjN0YMxd1jHZgqrqT0leBXw7yTXAoinUIUmS1Gmp8ns8w2rD7XnAc6rq5yOsY4Oquqm9+sCHgZ9X1fsmmmf9zbeu7V70ttVToCRJmpOWHPXi1bKeJEuqatdB0+bMsIGZluRhwC+A00YZXFsva79cdgnNkISjR1yPJEnSajGXhg3MqKr6MX1XIUiyPfDZvq63VtWjZ7iW9wETnmmVJEmaiwyvq6CqLgLGu0arJEmSppnDBiRJktQZhldJkiR1huFVkiRJnWF4lSRJUmcYXiVJktQZhldJkiR1huFVkiRJnWF4lSRJUmcYXiVJktQZhldJkiR1huFVkiRJnWF4lSRJUmcYXiVJktQZhldJkiR1huFVkiRJnTFv1AVo9Xjo/e/F4qNePOoyJEmSVolnXiVJktQZhldJkiR1huFVkiRJnWF4lSRJUmcYXiVJktQZhldJkiR1huFVkiRJnWF4lSRJUmcYXiVJktQZhldJkiR1huFVkiRJnWF4lSRJUmfMG3UBWj3+8ttL+N+3bz/qMiRJI7DlYReNugRp2njmVZIkSZ1heJUkSVJnGF4lSZLUGYZXSZIkdYbhVZIkSZ1heJUkSVJnGF4lSZLUGYZXSZIkdYbhVZIkSZ1heJUkSVJnGF4lSZLUGYZXSZIkdYbhVZIkSZ1heJUkSVJnGF4lSZLUGYZXSZIkdYbhVZIkSZ1heJUkSVJnGF4lSZLUGYZXSZIkdYbhVZIkSZ1heJUkSVJnzLnwmmRBkounYTmvSPLi6aipS+uWJEmazeaNuoDZqqo+Nor1Jpk3qnVLkiTNdnPuzGtrXpJPJ7kwyQlJ7pFkWZL5AEl2TbIwyd2S/DzJZm373ZL8Isn8JIcneX3bvjDJu5MsSvKzJHu17fdI8qV2PV9Mck6SXccrKslNSd6b5Lwkp/Wsd2GSdyY5A3ht37oflOS7SS5o59umbX9DknPbdb9tnPUdnGRxksXX3nzHNO5eSZKk0Zir4fUhwDFV9UjgBuBVgzpV1Z3A8cAL2qb9gAuq6poB3edV1W7A64C3tm2vAq5r1/MOYJdJ6lofOK+qdgbO6FkOwMZVtU9Vvbdvns8BH66qHYDHAr9N8kRgW2A3YEdglyR7D9i+Y6pq16raddP115qkNEmSpNlvrobXy6vqrPb+8cCeE/Q9FhgbX3oQ8Klx+n21/bkEWNDe3xP4b4Cquhi4cJK67gS+OE5dX+zvnGRDYIuqOrFdx5+r6hbgie3tfOA8YDuaMCtJkjSnzdUxrzXg8e0sD+vr/nVC1eVJfpfk8cCjWX4Wtt+t7c87WL7fMo113jxg+njLD/Cuqjp6FdcvSZLUKXP1zOuWSXZv7z8P+AGwjOUf6z+rr/8naM6EfqmqpjI49AfAPwAkeRiw/ST97wY8u73//Hb+cVXVDcAVSZ7ermOdJPcATgEOSrJB275FkntPoW5JkqROmqvh9SfAPya5ENgU+CjwNuADSb5Pc/a018nABow/ZGA8HwE2a9fzJpphA9dP0P9m4OFJlgCPB94+xDpeBBzaruNsYPOqOhX4PPDDJBcBJwAbTrF2SZKkzklV/yfsa572CgHvq6q9pjjfWsDaVfXn9ioApwEPrqq/jNP/pqraYNUrnrpHbrFefePlDxrFqiVJI7blYReNugRpSpIsqaqBV3Caq2Neh5bkzcArGX+s60TuAZyeZG2acaivHC+4SpIkadWt8eG1qo4EjlzJeW8EVvirIMk5wDp9zS8a1VlXSZKkuWKND68zoaoePeoaJEmS5qK5+oUtSZIkzUGGV0mSJHWG4VWSJEmdYXiVJElSZxheJUmS1BmGV0mSJHWG4VWSJEmdYXiVJElSZxheJUmS1BmGV0mSJHWG4VWSJEmdYXiVJElSZxheJUmS1BmGV0mSJHWG4VWSJEmdYXiVJElSZ8wbdQFaPe5+34ez5WGLR12GJEnSKvHMqyRJkjrD8CpJkqTOMLxKkiSpMwyvkiRJ6gzDqyRJkjrD8CpJkqTOMLxKkiSpMwyvkiRJ6gzDqyRJkjrD8CpJkqTOMLxKkiSpM+aNugCtHpdefSl7/Nceoy5DktYYZ73mrFGXIM1JnnmVJElSZxheJUmS1BmGV0mSJHWG4VWSJEmdYXiVJElSZxheJUmS1BmGV0mSJHWG4VWSJEmdYXiVJElSZxheJUmS1BmGV0mSJHWG4VWSJEmdYXiVJElSZxheJUmS1BmGV0mSJHWG4VWSJEmdYXiVJElSZxheJUmS1BmGV0mSJHWG4VWSJEmdYXiVJElSZxheJUmS1BmGV0mSJHXGrAyvSXZN8sFJ+myc5FVDLu/s6als9kny76OuQZIkaXWZleG1qhZX1aGTdNsYGCq8VtVjV72qWcvwKkmS1hgzFl6TLEhyaZJPJLk4yeeS7JfkrCQ/T7Jbezs7yfntz4e08+6b5Bvt/cOTHJtkYZJfJRkLtUcC2yRZmuSoJBskOS3JeUkuSrJ/Ty039Sx3YZIT2to+lyTttF2SnJFkSZJTkty3bV+Y5N1JFiX5WZK92va1krynXdeFSV4z0XLG2UcPSvLdJBe0dW+TxlHtPrsoyQFt3/smObPd3ouT7JXkSGC9tu1zA5Z/cJLFSRbfdtNtq3xMJUmSRm3eDC//QcBzgIOBc4HnA3sCT6M5Y/hiYO+quj3JfsA7gWcNWM52wOOADYGfJvko8GbgEVW1I0CSecAzquqGJPOBHyU5uaqqb1k7AQ8HfgOcBeyR5Bzgv4D9q+r3bWA8AjionWdeVe2W5EnAW4H92m3aGtiprX/TJGtPspx+nwOOrKoTk6xL88fEM4EdgR2A+cC5Sc5s990pVXVEkrWAe1TV95McMrYP+lXVMcAxABtsuUH/fpAkSeqcmQ6vl1XVRQBJLgFOq6pKchGwANgI+HSSbYEC1h5nOd+sqluBW5NcDdxnQJ8A70yyN3AnsEXb76q+fouq6oq2pqVtHX8EHgF8pz0Ruxbw2555vtr+XNL2hybAfqyqbgeoqmuTPGKS5SwvNtkQ2KKqTmzn/3Pbvifwhaq6A/hdkjOAR9GE/2PbgHxSVS0dZ19JkiTNWTMdXm/tuX9nz+M723W/Azi9qp6RZAGwcIjl3MHgul8AbAbsUlW3JVkGrDvksgJcUlW7T7L+3nWHJnD3mmw5/X2Hbq+qM9tg/mTgs0mOqqrPDLEeSZKkOWPUX9jaCLiyvX/gFOe9kWYYQe+yrm6D6+OAraawrJ8CmyXZHSDJ2kkePsk8pwKvaIcrkGTTqSynqm4Arkjy9LbvOknuAZwJHNCOqd0M2BtYlGSrdvs+DnwS2Lld1G3t2VhJkqQ5b9Th9f8C70pyFs1H7EOrqj8AZ7VfXjqKZvzorkkW05yFvXQKy/oL8Gzg3UkuAJYCk12h4BPA/wIXtvM8fyWW8yLg0CQXAmcDmwMnAhcCFwDfA95YVVcB+wJLk5xPMy74A+0yjmlrWOELW5IkSXNNVvw+k+aiDbbcoHZ4ww6jLkOS1hhnveasUZcgdVaSJVW166Bpoz7zKkmSJA1tpr+wJSDJh4E9+po/UFWfGkU9kiRJXWV4XQ2q6tWjrkGSJGkucNiAJEmSOsPwKkmSpM4wvEqSJKkzhgqvSbZJsk57f98khybZeGZLkyRJku5q2DOvXwHuSPIgmv/utDXw+RmrSpIkSRpg2PB6Z1XdDjwDeH9V/TNw35krS5IkSVrRsOH1tiTPA/4R+EbbtvbMlCRJkiQNNmx4fQmwO3BEVV2WZGvg+JkrS5IkSVrRUP+koKp+nORNwJbt48uAI2eyMEmSJKnfsFcbeCqwFPh2+3jHJCfPZGGSJElSv2GHDRwO7Ab8EaCqltJccUCSJElabYYNr7dX1fV9bTXdxUiSJEkTGWrMK3BxkucDayXZFjgUOHvmypIkSZJWNOyZ19cADwdupfnnBNcDr5upoiRJkqRBJj3zmmQt4OSq2g94y8yXJEmSJA02aXitqjuS3JJkowHjXtUR2917O856zVmjLkOSJGmVDDvm9c/ARUm+A9w81lhVh85IVZIkSdIAw4bXb7Y3SZIkaWSG/Q9bn57pQiRJkqTJDBVek1zGgOu6VtUDp70iSZIkaRzDDhvYtef+usBzgE2nvxxJkiRpfENd57Wq/tBzu7Kq3g88foZrkyRJku5i2GEDO/c8vBvNmdgNZ6QiSZIkaRzDDht4b8/924HLgH+Y/nIkSZKk8Q0bXl9aVb/qbUiy9QzUI0mSJI1rqDGvwAlDtkmSJEkzZsIzr0m2Ax4ObJTkmT2T7klz1QFJkiRptZls2MBDgKcAGwNP7Wm/EXjZTBUlSZIkDZKqFf73wIqdkt2r6oeroR7NkIdsuGEds9POk3eUpDlsnzPPGHUJkoaQZElV7Tpo2rBf2Do/yatphhD8dbhAVR00DfVJkiRJQxn2C1ufBTYH/hY4A7g/zdABSZIkabUZNrw+qKr+A7i5qj4NPBnYfubKkiRJklY0bHi9rf35xySPADYCFsxIRZIkSdI4hh3zekySTYD/AE4GNgAOm7GqJEmSpAGGCq9V9Yn27hnAA2euHEmSJGl8Qw0bSHKfJJ9M8q328cOSvHRmSxg8/jwAABNXSURBVJMkSZLuatgxr8cBpwD3ax//DHjdTBQkSZIkjWfY8Dq/qr4E3AlQVbcDd8xYVZIkSdIAw4bXm5PcCyiAJI8Brp+xqiRJkqQBhr3awL/QXGVgmyRnAZsBz56xqiRJkqQBJgyvSbasqv+tqvOS7AM8BAjw06q6baJ5JUmSpOk22bCBk3ruf7GqLqmqiw2ukiRJGoXJwmt67nt9V0mSJI3UZOG1xrkvSZIkrXaTfWFrhyQ30JyBXa+9T/u4quqeM1qdJEmS1GPC8FpVa62uQiRJkqTJDHudV0mSJGnkDK+SJEnqDMOrJEmSOsPwKkmSpM4wvEqSJKkz5mR4TbIwya6rcX1HJbkkyVEzuI6Nk7xqppYvSZLUBZNd53WNk2ReVd0+xdleDmxWVbfORE2tjYFXAR+ZwXVIkiTNaiM985pkQZKfJPl4e+by1CTr9Z45TTI/ybL2/oFJTkry9SSXJTkkyb8kOT/Jj5Js2rP4FyY5O8nFSXZr518/ybFJzm3n2b9nuV9O8nXg1HFqTXuG9eIkFyU5oG0/GVgfOGesbcC8z2nnuyDJmW3bWu3yzk1yYZKXt+0bJDktyXntevZvF3MksE2Spe18901yZvv44iR7DVjvwUkWJ1l8/W23TfHoSJIkzT6z4czrtsDzquplSb4EPGuS/o8AdgLWBX4BvKmqdkryPuDFwPvbfutX1WOT7A0c2873FuB7VXVQko2BRUm+2/bfHXhkVV07znqfCewI7ADMB85NcmZVPS3JTVW14wQ1Hwb8bVVd2a4X4KXA9VX1qCTrAGclORW4HHhGVd2QZD7wozYgvxl4xNh6kvwrcEpVHZFkLeAe/SutqmOAYwAesuGG/ntfSZLUebMhvF5WVUvb+0uABZP0P72qbgRuTHI98PW2/SLgkT39vgBQVWcmuWcbGp8IPC3J69s+6wJbtve/M0FwBdgT+EJV3QH8LskZwKOAkyfdQjgLOK4N519t254IPDLJs9vHG9EE+SuAd7ah+05gC+A+A5Z5LnBskrWBk3r2oSRJ0pw1G8Jr7zjRO4D1gNtZPqRh3Qn639nz+E7uuj39ZxoLCPCsqvpp74QkjwZunqTOTDJ9XFX1inYdTwaWJtmxXd5rquqUvloOBDYDdqmq29ohE/37YCyU790u87NJjqqqz6xsjZIkSV0wW682sAzYpb3/7An6TWRsTOqeNB/PXw+cArwmSdppO01heWcCB7RjVTcD9gYWDTNjkm2q6pyqOgy4BnhAW8sr2zOnJHlwkvVpzsBe3QbXxwFbtYu5EdiwZ5lbtf0+DnwS2HkK2yJJktRJs+HM6yDvAb6U5EXA91ZyGdclORu4J3BQ2/YOmjGxF7YBdhnwlCGXdyLNuNgLaM7ivrGqrhpy3qOSbEtztvW0dhkX0gyROK+t5ffA04HPAV9PshhYClwKUFV/SHJWkouBbwEXA29IchtwE814X0mSpDktVX6PZ03wkA03rGN28uSspDXbPmeeMeoSJA0hyZKqGnjN/tk6bECSJElawWwdNjAySbYHPtvXfGtVPXqIed8CPKev+ctVdcR01SdJkrQmM7z2qaqLaK7nujLzHgEYVCVJkmaIwwYkSZLUGYZXSZIkdYbhVZIkSZ1heJUkSVJnGF4lSZLUGYZXSZIkdYbhVZIkSZ1heJUkSVJnGF4lSZLUGYZXSZIkdYbhVZIkSZ1heJUkSVJnGF4lSZLUGYZXSZIkdYbhVZIkSZ1heJUkSVJnzBt1AVo9NnzIQ9jnzDNGXYYkSdIq8cyrJEmSOsPwKkmSpM4wvEqSJKkzDK+SJEnqDMOrJEmSOsPwKkmSpM4wvEqSJKkzDK+SJEnqDMOrJEmSOsPwKkmSpM4wvEqSJKkz5o26AK0eV19xPR/616+PugxJM+iQ9z511CVI0ozzzKskSZI6w/AqSZKkzjC8SpIkqTMMr5IkSeoMw6skSZI6w/AqSZKkzjC8SpIkqTMMr5IkSeoMw6skSZI6w/AqSZKkzjC8SpIkqTMMr5IkSeoMw6skSZI6w/AqSZKkzjC8SpIkqTMMr5IkSeoMw6skSZI6w/AqSZKkzjC8SpIkqTMMr5IkSeoMw6skSZI6w/AqSZKkzpjx8Jrkpplex3RLcniS10/DchYkef5Kznv2qq5fkiRprvHM68xaAKxUeK2qx05vKZIkSd232sJrkn2TfKPn8YeSHNjef1KSS5P8IMkHx/ol2SzJd5Kcl+ToJL9OMr+ddlKSJUkuSXJwz3JfmuRnSRYm+XiSD/Us6ytJzm1ve0xS8g5Jvpfk50le1i4jSY5KcnGSi5IcMFE7cCSwV5KlSf55nP3y8CSL2j4XJtm2bb+p/fn2dtrSJFcm+VTb/sKe+Y5OstbUjogkSVL3zBt1AUnWBY4G9q6qy5J8oWfyW4HvVdW7kvwdcHDPtIOq6tok6wHnJvkKsA7wH8DOwI3A94AL2v4fAN5XVT9IsiVwCvDQCUp7JPAYYH3g/CTfBHYHdgR2AOa36z0TeOw47W8GXl9VT5lgPa8APlBVn0tyd+AuIbSqDgMOS7IR8H3gQ0keChwA7FFVtyX5CPAC4DO987ah/mCATTbcbIISJEmSumHk4RXYDvhVVV3WPv4Cy0PqnsAzAKrq20mu65nv0CTPaO8/ANgW2Bw4o6quBUjyZeDBbZ/9gIclGZv/nkk2rKobx6nra1X1J+BPSU4Hdmvr+UJV3QH8LskZwKMmaL9hiO3/IfCWJPcHvlpVP+/vkKboz9GE7yVJDgF2oQnJAOsBV/fPV1XHAMcAbLn5tjVELZIkSbPa6gyvt3PXYQrrtj8zoC8TTUuyL00Y3b2qbkmysF3eRMu6W9v/T0PW2x/2aoLlT7TeiVdS9fkk5wBPBk5J8k9V9b2+bocDV1TVp3rW9+mq+reVXa8kSVIXrc4vbP2a5sznOu1H4E9o2y8FHphkQfv4gJ55fgD8A0CSJwKbtO0bAde1wXU7mo/3ARYB+yTZJMk84Fk9yzoVOGTsQZIdJ6l3/yTrJrkXsC9wLnAmcECStZJsBuzdrnO89huBDSdaSZIH0px5/iBwMs1whd7pTwH+Bji0p/k04NlJ7t322TTJVpNsjyRJUuettjOvVXV5ki8BFwI/B85v2/+U5FXAt5NcQxP6xrwN+EL7BagzgN/SBMJvA69IciHwU+BH7bKuTPJO4BzgN8CPgevbZR0KfLidZx5N4HzFBCUvAr4JbAm8o6p+k+REmnGvF9CciX1jVV01QfsfgNuTXAAcV1XvG7CeA4AXJrkNuAp4e9/0fwXuByxqhwicXFWHJfk/wKlJ7gbcBrya5g8ESZKkOStVox8KmWSDqrqpHdv5YeDnVfW+JOsAd1TV7Ul2Bz5aVROeMe1Z1jzgRODYqjpx5rdidtty823rjS/4f6MuQ9IMOuS9Tx11CZI0LZIsqapdB02bDV/YAnhZkn8E7k5zRvbotn1L4Evt2cW/AC8bYlmHJ9mPZgzsqcBJM1CvJEmSRmBWhNf24/QVPlJvv3m/0xSXNfR/xkryEuC1fc1nVdWrp7LOIdf1t8C7+5ovq6pnDOovSZKkFc2K8Doq7bf3PzVpx+lZ1yk015aVJEnSSvLfw0qSJKkzDK+SJEnqDMOrJEmSOsPwKkmSpM4wvEqSJKkzDK+SJEnqDMOrJEmSOsPwKkmSpM4wvEqSJKkzDK+SJEnqDMOrJEmSOsPwKkmSpM4wvEqSJKkzDK+SJEnqDMOrJEmSOsPwKkmSpM6YN+oCtHrc+/4bcch7nzrqMiRJklaJZ14lSZLUGYZXSZIkdYbhVZIkSZ1heJUkSVJnGF4lSZLUGYZXSZIkdYbhVZIkSZ1heJUkSVJnGF4lSZLUGYZXSZIkdYbhVZIkSZ1heJUkSVJnzBt1AVo9fnvZLznihc8edRmaYW85/oRRlyBJ0ozyzKskSZI6w/AqSZKkzjC8SpIkqTMMr5IkSeoMw6skSZI6w/AqSZKkzjC8SpIkqTMMr5IkSeoMw6skSZI6w/AqSZKkzjC8SpIkqTMMr5IkSeoMw6skSZI6w/AqSZKkzjC8SpIkqTMMr5IkSeoMw6skSZI6w/AqSZKkzjC8SpIkqTMMr5IkSeoMw6skSZI6w/AqSZKkzphz4TXJwiS7rsb1HZXkkiRHDdn/ppmuSZIkaa6aN+oCZpMk86rq9inO9nJgs6q6dSZqGiTJWlV1x+panyRJ0mwxsjOvSRYk+UmSj7dnLk9Nsl7vmdMk85Msa+8fmOSkJF9PclmSQ5L8S5Lzk/woyaY9i39hkrOTXJxkt3b+9ZMcm+Tcdp79e5b75SRfB04dp9a0Z1gvTnJRkgPa9pOB9YFzxtoGzLt1kh+2633HEMscr33fJKcn+TxwUbs930xyQdt3hfUnOTjJ4iSLb/7zasvWkiRJM2bUZ163BZ5XVS9L8iXgWZP0fwSwE7Au8AvgTVW1U5L3AS8G3t/2W7+qHptkb+DYdr63AN+rqoOSbAwsSvLdtv/uwCOr6tpx1vtMYEdgB2A+cG6SM6vqaUluqqodJ6j5A8BHq+ozSV492TKBx47TDrAb8IiquizJs4DfVNWTAZJs1L/iqjoGOAZgi3ttUhPUKEmS1AmjHvN6WVUtbe8vARZM0v/0qrqxqn4PXA98vW2/qG/eLwBU1ZnAPduw+kTgzUmWAgtpAvCWbf/vTBBcAfYEvlBVd1TV74AzgEdNvnkA7DFWD/DZIZY50boWVdVlPdu8X5J3J9mrqq4fsh5JkqTOGnV47f0s+w6aM8G3s7yudSfof2fP4zu561nk/rOMBQR4VlXt2N62rKqftNNvnqTOTDJ9MoPOeo63zInW9dc6q+pnwC40IfZdSQ5b+fIkSZK6YdThdZBlNKEM4NkruYyxcaJ7Ate3ZyVPAV6TJO20naawvDOBA5KslWQzYG9g0ZDzngU8t73/giGWOdS6ktwPuKWqjgfeA+w8he2RJEnqpFGPeR3kPcCXkrwI+N5KLuO6JGcD9wQOatveQTMm9sI2wC4DnjLk8k6kGRd7Ac1Z1DdW1VVDzvta4PNJXgt8ZbJlJhmvfbu+5W4PHJXkTuA24JVD1iNJktRZqfJ7PGuCLe61Sb3q758w6jI0w95y/AmjLkGSpFWWZElVDbxu/2wcNiBJkiQNNBuHDYxMku256xUBAG6tqkcPMe9bgOf0NX+5qo6YrvokSZLWdIbXHlV1Ec01Vldm3iMAg6okSdIMctiAJEmSOsPwKkmSpM4wvEqSJKkzDK+SJEnqDMOrJEmSOsPwKkmSpM4wvEqSJKkzDK+SJEnqDMOrJEmSOsPwKkmSpM4wvEqSJKkzDK+SJEnqDMOrJEmSOsPwKkmSpM4wvEqSJKkz5o26AK0e9916G95y/AmjLkOSJGmVeOZVkiRJnWF4lSRJUmcYXiVJktQZhldJkiR1huFVkiRJnWF4lSRJUmekqkZdg1aDJDcCPx11HWI+cM2oi5DHYZbwOMwOHofZweNwV1tV1WaDJnid1zXHT6tq11EXsaZLstjjMHoeh9nB4zA7eBxmB4/D8Bw2IEmSpM4wvEqSJKkzDK9rjmNGXYAAj8Ns4XGYHTwOs4PHYXbwOAzJL2xJkiSpMzzzKkmSpM4wvEqSJKkzDK9zQJK/S/LTJL9I8uYB05Pkg+30C5PsPOy8Gt4qHodlSS5KsjTJ4tVb+dwyxHHYLskPk9ya5PVTmVfDW8Xj4OthmgxxHF7Q/j66MMnZSXYYdl4NbxWPg6+HflXlrcM3YC3gl8ADgbsDFwAP6+vzJOBbQIDHAOcMO6+3mT8O7bRlwPxRb0fXb0Meh3sDjwKOAF4/lXm9zfxxaKf5elh9x+GxwCbt/b/3/WF2HYf2sa+HvptnXrtvN+AXVfWrqvoL8N/A/n199gc+U40fARsnue+Q82o4q3IcNH0mPQ5VdXVVnQvcNtV5NbRVOQ6aPsMch7Or6rr24Y+A+w87r4a2KsdBAxheu28L4PKex1e0bcP0GWZeDWdVjgNAAacmWZLk4Bmrcu5blee0r4fps6r70tfD9JjqcXgpzadDKzOvxrcqxwF8PazAfw/bfRnQ1n/9s/H6DDOvhrMqxwFgj6r6TZJ7A99JcmlVnTmtFa4ZVuU57eth+qzqvvT1MD2GPg5JHkcTmvac6rya1KocB/D1sALPvHbfFcADeh7fH/jNkH2GmVfDWZXjQFWN/bwaOJHmYyZN3ao8p309TJ9V2pe+HqbNUMchySOBTwD7V9UfpjKvhrIqx8HXwwCG1+47F9g2ydZJ7g48Fzi5r8/JwIvbb7s/Bri+qn475LwazkofhyTrJ9kQIMn6wBOBi1dn8XPIqjynfT1Mn5Xel74eptWkxyHJlsBXgRdV1c+mMq+GttLHwdfDYA4b6Liquj3JIcApNN9oPLaqLknyinb6x4D/ofmm+y+AW4CXTDTvCDaj81blOAD3AU5MAs1r8vNV9e3VvAlzwjDHIcnmwGLgnsCdSV5H883fG3w9TI9VOQ7AfHw9TIshfy8dBtwL+Ei7z2+vql19f5g+q3Ic8P1hIP89rCRJkjrDYQOSJEnqDMOrJEmSOsPwKkmSpM4wvEqSJKkzDK+SJEnqDMOrJEmSOsPwKkmSpM74/4QI6ITfB8mVAAAAAElFTkSuQmCC\n",
"text/plain": [
""
]
},
"metadata": {
"needs_background": "light"
},
"output_type": "display_data"
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"-----------------------------------------\n",
"************* Model Results *************\n",
"-----------------------------------------\n",
"F1 Score : 0.9623893476106086\n",
"Report:\n",
" precision recall f1-score support\n",
"\n",
" 1 1.00 0.96 0.98 277\n",
" 2 0.90 0.96 0.93 94\n",
" 3 0.86 1.00 0.92 12\n",
" 4 0.80 1.00 0.89 8\n",
"\n",
" accuracy 0.96 391\n",
" macro avg 0.89 0.98 0.93 391\n",
"weighted avg 0.96 0.96 0.96 391\n",
"\n"
]
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAWAAAAENCAYAAAAxC7/IAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADt0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjByYzEsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy/xvVyzAAAgAElEQVR4nO3deXxU1dnA8d9DAi4sQXAygxKqttpWQaFFUQElQUkISwK2lbYqCor2dddWUNwriHV7WxUV0NatWt+qJCqbkqgsBUVlxwUVaJDMRCAkYcnG8/5xL5NtMplAYMjk+X4+95PMufcs92TyzJkz594RVcUYY8yh1yraDTDGmJbKArAxxkSJBWBjjIkSC8DGGBMlFoCNMSZKLAAbY0yUWACOISJyg4isFZHdIqIictMhqHODiGw42PW0BO7f7INot8McOhaA94OI/ExEnhCR1SKyQ0TKROR7EXlXRMaKyJFRaNMo4K/AHuB/gfuAJYe6HYcD90VB3S05zHF/r3bcvQdY54CmKMe0LPHRbkBzIyJ3A/fgvHgtAV4ASgAvMACYAfwB6H2ImzZ0309V/f4Q1jvwENbVWBXAVUBu7R0i0gH4jXvM4fJ/8HNgV7QbYQ6dw+WJ1yyIyB04I8v/Ar9W1aUhjhkK3Hqo2wYcB3CIgy+q+s2hrK+R3gFGikhnVd1aa9/vgaOBt4ARh7xlIajqF9Fugzm0bAoiQiJyAnAvUA6khwq+AKr6DpAWIv9vROQjd8pit4isEpHbReSIEMducLejReRhEdkkIqUisl5ExouIVDv2XhFRINl9vO8tte5rt/v4H/Wc1wf7jq2WJiIyWkQWi0iBiOwRkf+KyFwRuThUW0OUe4SITBCRlSKyS0SKRGSBiPwmxLHBNrq/vyYiP7j1LnNf1PbHdOAI4NIQ+67CeSGdEyqjiJwiIlPc+gvc/t8oItNEpGutY/9B1Sj7nup/AxEZ4B5zufv4chFJc/t9R/W+rz0HLCInikihiGwTkR/VqrOtiKwTkUoROb+xHWMODzYCjtwVQGvgNVVdHe5AVS2t/lhEJgO3Az8A/8SZshgMTAZSReRCVS2vVUxrYB7OyHY2zlvlTGAKcCTOSBzgA/fn5cCPqqUfiElue78DXgd2AF2AM4FfA/8Kl1lE2gBzgfOBL4CncEabvwL+JSI9VfWOEFl/BHwMfAu8BHQCLgayROQCVa0zldCA94ANwJU48+L72vdLoBdOX+2tJ+9I4BqcwLoYKANOc8saJiK9VXWze+xM9+do4EOq/ia49Vf3K5wX6NnAM8AJ9TVeVb8TkSuB/wNeFZHzVLXC3T0V+Blwr6p+WF8Z5jCnqrZFsAHzAQWubGS+c9x8mwBftfR44G133x218mxw02cBR1VLTwQK3a11rTwfOH/OOvWf4Jb1j3raVycfsBXIA44OcfyxIdq6oVba7dXaH1+r/fvO7dwQbVTgnlplpe4rqxF9vq+OeOBO9/dzqu1/BqgEuuEEVMUJZNXLOB44IkTZg9y8T9dKHxCqnGr7L3f37wXS6jlGgQ9CpE919z3oPr7MfZwLtIr2/4Zt+7/ZFETkurg/8xqZb4z78wFVzd+XqM5I5lacf8gr68l7g6rurpYnAGQBCcBPG9mOxirHCTQ1qOoPEeQdgxMgbtGqEdu+9v/ZfRjqnDcCD9Sqby7Oi9dZkTW7judxzuMqcN66A78D5qrqpvoyqepmrfVOxk2fB6zBeWHYH1mqGnLaI4xbgBXAeBG5DicgFwC/V9X6RvCmGbAAHLl9866NvX/nL9yfObV3qOpXOAH9RBHpWGv3DlVdH6K8/7o/j2lkOxrjFZxR6RoRedCds0yIJKOItAd+AnyvoT9U2tcPvULsW66qdYI+zjnv1/mq86HkLOA37sqHUUB7nPnhernz4JeIyPvuHHBFtbn1Hjgj5P3xcWMzqOoenKmYncATONM5l+kh/sDVND0LwJHb92TvGvaouvYFri317N9S67h9Cus5ft+IMq6R7WiMm4GbcP7hJ+DMV/4gIlki8pMG8kZ6vrVfcCD8OR/Ic3U60Bb4Lc5IOB9n+iecx3DmoU/Fmc9+FGfO+D6ckXqb/WxLfsOHhPQVsNL9fS3O5wOmmbMAHLmF7s/Grnvd4f701bO/S63jmtq+t6j1feBaJxCqaqWq/lVVz8BZ33wRznKt4cCcUCs3qon2+YYyC9iMMx/cB/h79amR2kQkEbgBWA38VFUvUdXxqnqvqt4L1JmaaIT9/QaECcC5OB/knoYzz26aOQvAkfs7zrzoRSJyargDawWoz92fA0Ic9xOcEfV3qlrf6O9AbXd/JoWovwNwSrjMqhpQ1TdV9Tc40wc/BrqHOb4Y+AY4XkRODnHIvivTPoug7U3CndZ4HqevFXiugSwn4fxvzHPPJ8hdgnZSiDz7pk6a/J2JiJwL3A98idP3XwL3iUi/pq7LHFoWgCOkqhtw1gG3Ad4VkZBXuonIviVG+zzv/rxTRDzVjosDHsH5GzQUEPabG0C+APpWf+Fw638MOKr68e763YHV1xq76a1xloVBw1drPY8zZ/6wW8++Mo4F7qp2zKH0N5wLLlK14YtHNrg/+9Vqfzuc6YxQ7yb2XejR7QDbWYOIHAO8ihPgR6mqH2c+uAJnaVrnpqzPHFq2DrgRVHWyiMTjXIr8iYgsBpZRdSnyecDJbtq+PItF5C/AbcBqEfk3ztzqYJzRzELg4YPc9IdxgvwiEfk/nPtFJOOsNV4BnFHt2KOA94ENIrIUZ77zSOBCnEtls1V1XQP1PYJzfhnAChGZhfPB0a9xlqL9RVUXhsnf5NzVGzMbPNA5Nl9EXsP5wG65iMzDmdu+EKfvlgM9a2X7EmeaY5SIlOGs3FDgJVXdeABNfx4nqN+gqsvd9q0QkVuBJ3HemQ0/gPJNNEV7HVxz3HAC0RM4c4RFOIv0t+CMfMcSev3oKJxgW4zzT7wGmAgcGeLYDdRaW1tt3704/9gDaqV/QIh1wNX2j3XrLMX5IOhZoHPtfDhB+Tb3XDa5bS3Aue/FNUCbSNqKE7TvcPtot3veC4Hfhjj2BBq5VrmBv88Gt7z4CI6tbx3w0TgXpKx3++C/OBeU1OmzannOxFkvvgNn7j34d6JqHfDlYdpSYx0wcL2bllXP8W+6+2+O9v+Ebfu3ifuHNMYYc4jZHLAxxkSJBWBjjIkSC8DGGBMlFoCNMSZKDvoytAFyt33K55q7++5oN+GwER9vr/2mrrj4VtLwUeE1JuZ8oPcfcH0Hwv4LjDEmSuxCDGNMTKl1EedhzQKwMSamSJwFYGOMiYpmNAC2AGyMiTHNKAJbADbGxJRmFH8tABtjYosc+Eq2Q8YCsDEmtjSjIbAFYGNMTGnVjEbAdiGGMSa2SCO2cMWIJIlIroisE5E1InKjm36viGwWkeXull4tz+0isl5EvhSR1IaaaiNgY0xMacI54ArgVlX9TETaA5+KyHvuvsdV9ZEa9Tpf+TUK50tTjwPeF5FT1PlOwpBsBGyMiSkikW/hqOoWVf3M/b0YWAccHyZLBvCaqpaq6nc436ZyVrg6LAAbY2JLIyKwiIwTkWXVtnGhi5QTgF7AUjfpOhFZKSLPu1+cCk5w/m+1bHmED9gWgI0xsaVVnES8qeo0Ve1dbZtWuzz327DfAG5S1SLgaeDHOF/MugV4dN+hIZoT9s5sNgdsjIktTbgMTURa4wTfV1T1TQBV9VfbPx14x32YByRVy94V+D5c+TYCNsbElKaaAxbntmrPAetU9bFq6V2qHTYC55u/AbKBUSJyhIicCJwMfByuDhsBG2NiShPejrIvcCmwSkSWu2l3AL8VkZ440wsbgKsBVHWNiLwOrMVZQXFtuBUQYAHYGBNrmij+qurCekqbFSbPJGBSpHVYADbGxBS7F4QxxkSJBWBjjIkS+0oiY4yJlma0tuuQN9XTtQOP51zBC2uv5++rr+OiG84O7htxXR9e/OIG/r76Oq5+aFAw/aQeXp5afBV/X30dz6+8ljZH1H3daH/MUTwybzQvf3Ujj8wbTbuORwb3/W5Cf175+kZe/OIGzhz0k2D6Kb/owvMrr+WVr2/k+r8G76dB6zZx3P3ar3nl6xuZumQcvh91DO5LvawnL391Iy9/dSOpl/UMpvtO6MjUJeN4+asbufu1XxPfOq7RfXP33Xdy/oD+jBiZEUzbsaOQcVdfydBhgxl39ZUUFe0ImXfhogUMGz6EIUPTeO656RHln/HcdIYMTWPY8CEsWrQwmL527RpGXpTJkKFpTJkyGVVnLXlZWRl/+tOtDBmaxu9+P4rNmzcH82Rlz2TosMEMHTaYrOyZjT73cCbeOZF+/fsyPGNYyP2qyqTJk0hNSyVzRAZr164J7luwYAHpQwaTmpbK9OlV/VJYWMjYK8eQNjiVsVeOYceOqn6ZNn0aqWmppA8ZzMKFVf2yZs0aMjKHk5qWyqTJk2r0yy233kxqWioXj7q4Rr80tfrOZ5+W1Bf1EecKt4i2aDvkAbiyYi9Tb53D6FOf4H/OnkbmtWfxo5976DngRPpl/Iyxpz/FFd2f5F+PLAIgLq4VE1++iMeuyeaK7k9y04DnqSivu7LjdxP689n8b7nklL/y2fxv+d2E/gD86OceUkb14PLTnuS2tBe5aerQ4O3qbn56GI+My+b3J/+Vrid35qy0kwFIH/sLSrbv4fcn/5V/P76YcQ9dCDhBfvQ9A/hDn2lcc9azjL5nQDDQX/3QIP79+GIuOeWvlGzfQ/rYXzS6b4ZnZPL008/WSHvu+Rn0OasP77w9mz5n9eG552bU7dPKSiZPnsTTU59h5lvZzJ4zi2++WR82/zffrGfOnFm89WY2T099lkmTH6Cy0unXBx64n3vuvpd33p7Nxk0bWegG5zffeoMOHTrw7jtzuPSSy/jf/3WWRu7YUcgzzzzNKy+/yj9feY1nnnm63heK/TEiM5Npz9a5QCnoowUfsXHjRubMnsN9997HffffH+yXByb9mWefmcbb2W8za9a7rF/v9MuMGdM5u885zJk9l7P7nMOMGU5AWr9+PbNnzeLt7LeZ9ux0/vzA/cF+uf/++7jv3vuYM3sOGzduZMHCBQC88ca/6dAhgblz5jL6sst49LFHQrTywIU7n5bWF+E01TrgQ+GQB+Bt+SV8/fkWAHaXlLFxXQHHHt+BjD+cyT+nLKC8zPkDFxbsBKD3oB/z7Uo/36x0Lj4p2rabvXvrXt3XN+NnzHnhcwDmvPA5/TJ/HkzPeW0V5WWV5G8oZPP6bfzsrK508rWjbYcjWLvEuXR77ovL6Zf5MzfPz5nzgrPs78N/r+WXA08C4MzUn7DsvW8o3r6bksI9LHvvm2DQ/kXKiXz477Vu/cuD9TdG71/2JqFDQo203Nxchg/PBGD48ExycnPq5Fu9ehXdkpLo2jWJ1q3bkJaWTu4HuWHz536QS1paOm3atKFr1650S0pi9epVFBQUULJzJ2ec0RMRYdiw4eTmzAfgg9wchg93RucXXjiIpR8vQVVZtHgR55x9DgkJHenQIYFzzj4nGLSbQu/eZ5KQ0LHe/Tk5OWQMz0BEOOOMnhQXF1FQEGDVqpV0S+pGUlISbdq0YXB6evD8c3JzyMx0ziUzM4P57jnm5OYwOL16v3Rj1aqVFBQEKNlZQs+evRARMoZnMH/+/GD9mRlOWYMGpbJkyZLgiLAphTufltYX4UgriXiLtgYDsIj8TETGi8jfROSv7u+Njy4h+H7UkZN7dWHd0jySTulMj/4/YuqScfzvB2P4ae/jAEg65VhUlb/MuYxpn17DqD/1C1lWJ29btuWXAE6QPyaxLQCe4ztQ8N+q0VhB3g48x7d30vOKqqUX4Tm+g5unfTBPZeVeSnaUktD5aLesunkSOh9NSeEeKiv31qijKWzbthWPx+O0y+Nh27ZtdY7xB/x4fVUX53gTvQT8/rD5A34/Pq+vKo/Xhz/gJxDw4/V6a6QHAgG3ngBen5MnPj6edu3aU1hYSCAQwOerXpY3mOdQCAT8ter34fcH8PsD+LpUpfu8Vf2ydetWPJ5EADyexJr9Ur0snzdYVo1+8XkJBJyy/AE/Prf/4+Pjad/e6ZemFu589mkpfRFOzARgERkPvIazGPlj4BP391dFZMKBVHxU2zbc98YonrxpNruKS4mLb0X7Y47if86exjN/msu9r18MQFx8K3r0+xGTfv9vru/3HP1H/JxfpJwUeUUh+lg1TDqEfG+iqvXkqS898iYesBB1NTS/pSEyiUjo0cq+okLsqy+PNNVq+AiErF8k5Dk29L6z3rLCnGPoPGGr2S+RnE9L6YuwmtEcREMj4LHAmao6RVVfdrcpOPe4HFtfpuq3ePuez+rsj4tvxX1vjOL9V1ay4K11gDOaXPCm8xb+i082s3evknDs0RTk7WDFhxvYsXUXpbvLWTLrK07+RZc6ZW7z76STrx0AnXzt2B7YGSzXk1T1tt7TNYEfvi920rt2qJbegR++L6qTJy6uFe0SjqBo2243vXaeYnb8sIt2HY8kLq5VjTqaQqdOnSkoKHDaVVBAp06d6hzj9Xrx528JPvYH/HgSE8Pm93p95Pvzq/L480n0JLojJn+d9Kp6nDwVFRWUlBSTkJCA1+slP796WX48iZ4mOf9IeL2+WvXnk5jowef1kr+lKj3f7yfR7ZfOnTtTUOCM0gsKAlX94qtVVr7fKcvnrdkv+VV97PP6yHf7v6KiguLi4rBTJvsr3Pns01L6IpxmFH8bDMB7ce7sXlsXd19I1W/xdhx1P4y67blMNq0r4P8eXxxMWzhzHb3ckW3XkzvTuk0cO37Yxcdz13PS6V6OOKo1cXGt6Hn+CWxcW1CnzMXZX5A2uhcAaaN7sSjri2B6yqgetG4Th++EjnQ9uRNffJzHtvwSdhWXcWqfroCzuqF6nrTRzgqH8391Kp/lfAfAJ3PXc+agn9Cu45G063gkZw76CZ/MdT7I+Dz3O87/1alu/T1ZlLWu3k5tjAEDksl2VxVkZ88kOTm5zjGnndadjZs2kZeXR3l5GXPmzGLA+clh8w84P5k5c2ZRVlZGXl4eGzdtonv3Hng8Htq2PZoVK1egqrz9djbJySnVysoC4L335nHWWX0QEfqe25fF/1lMUdEOiop2sPg/i+l7bt8mOf9IpCQnk5WdhaqyYsVy2rdrj8eTSPfuPdi4aSN5eXmUlZUxe9as4PknJ6cwc6ZzLjNnZpHinmNycjKzZ1Xvl4306HE6Hk8ibY9uy4oVy1FVsrKzSEmpyjMzyylr3ry59Olz9kH5hD3c+bS0vginOa2CkHAT5CKSBjwJfE3VjYa7AT8BrlPVOQ1VMEDurlFBj77deGLhlXyzMh91P0ybfsf7fPr+t4x/PpOf9PRRXlbJ03+cy+e5TuC78Pen87vbzwNVlsz6mmfHzwPgT9MzyH7mE7789Hs6dDqKe16/GG+3BPybdnDvr/9F8fbdAFxyx3kMHvMLKiv28uRNs/l4ztcA/PSXxzHhHyNoc1RrPp79NX+9/l0A2hwRzx0vjeTkXl0o2rab+0f9H1u+2w7A4Ct6cckd5wHw0qSPmPMP54O/Licew92v/ZoOnY7i68+3MOmSN4IfKO4zd/fdYfvqtvF/ZNmyTygsLKRTp878zx+uJSVlIH/80y3k52/B5+vCo488RkJCRwKBAPfedzdTn3oGgAULPuIvf5lC5d69ZGaOYNxVVwPOEqNQ+QGmTX+WmTPfIi4ujttum0D/fs7KkTVrVnPnXRMpLS2lX99+3H77RESE0tJS7pg4gS++WEdChwT+8pdH6NrVufveW2+9yYznnJUKV115NZmZI8Kea3x85J///vGPt/LxJx9TWFhI586due7a6yivqABg1MWjUFUeeODPLFy0kCOPPJJJD0yme/fuAHz40YdMmfIge/fuZcSIkVxz9TVuv2zn5ltuYcuW7+nS5Tgef+xxOnZ0+uWZZ5/hrbfeJC4ujgkTbue8/s7fe/Xq1dwx8XZKS0vp368/EyfeGeyX8RPGs27dOjomJPDII4+SlJQU4kwOXKjzee1fr8VMX8TFH/jE7G9O+2vEE4Cvr7kxqlE4bAAGEJFWOFMOx+PMBuYBnzR0l599agfglqyhANySNCYAm5ajKQLwqB5PRBxzXlt1fVQDcINXwqnqXmDJIWiLMcYcMGlGr+12KbIxJrYcBnO7kbIAbIyJKc0o/loANsbElsPhAotIWQA2xsSWZjQEtgBsjIkpreIsABtjTHTYCNgYY6KjGcVfC8DGmNhiH8IZY0y0NJ/4awHYGBNbWsU1n0vhLAAbY2KKzQEbY0y0NKMIbAHYGBNT7EM4Y4yJkmY0ALYAbIyJMc0oAlsANsbEFLsU2RhjosVGwMYYEx3NKP42+K3IxhjTrEgriXgLW45Ikojkisg6EVkjIje66Z1E5D0R+dr9eUy1PLeLyHoR+VJEUhtqqwVgY0xsEYl8C68CuFVVfw6cDVwrIqcCE4D5qnoyMN99jLtvFHAakAZMFZG4cBVYADbGxJSmir+qukVVP3N/LwbW4Xw7fAbwgnvYC0Cm+3sG8Jqqlqrqd8B6nG+Ur9dBnwOeX37vwa6i2Vj6SV60m3DY6HNm12g3wcQoacS9IERkHDCuWtI0VZ0W4rgTgF7AUsCrqlvACdIikugedjw1v0E+z02rl30IZ4yJKY35EM4NtnUCbs3ypB3wBnCTqhZJ/RWE2qHhyrYAbIyJKU15KbKItMYJvq+o6ptusl9Eurij3y5AwE3PA5KqZe8KfB+ufJsDNsbEFBGJeGugHAGeA9ap6mPVdmUDo93fRwNZ1dJHicgRInIicDLwcbg6bARsjIktTTcA7gtcCqwSkeVu2h3AFOB1ERkLbAJ+DaCqa0TkdWAtzgqKa1W1MlwFFoCNMTGlqW7IrqoLqT+cD6wnzyRgUqR1WAA2xsQWux2lMcZER3O6FNkCsDEmpjT04drhxAKwMSa22BSEMcZERzMaAFsANsbElsZcihxtFoCNMTHF5oCNMSZKpPkMgC0AG2Nii42AjTEmWiwAG2NMdNgUhDHGRImtgjDGmCixOWBjjImSZhR/LQAbY2KMXYpsjDHRYVMQxhgTJRJnAdgYY6KiOY2AD6v1GhPvnEi//n0ZnjEs5H5VZdLkSaSmpZI5IoO1a9cE9y1YsID0IYNJTUtl+vTpwfTCwkLGXjmGtMGpjL1yDDt27AjumzZ9GqlpqaQPGczChQuD6WvWrCEjczipaalMmjwJVeebpcvKyrjl1ptJTUvl4lEXs3nz5iY9/3nz3uTOiVcx8Y4rmTfX+QLWkpIiHn54POPHj+bhh8ezc2dxyLyrVn7C7ROuYPxto3n3ndeC6eHyv/POq4y/bTS3T7iCVas+CaZv2PAVd955FeNvG80rLz8VPP/y8jKmTn2A8beN5s/3X88PBfnBPAsXzmP8+NGMHz+ahQvnNWm/tPTnxT5btmzh8stHM3TYEIYNH8pLL71Y55iW0hfhSCuJeIu2wyoAj8jMZNqz0+rd/9GCj9i4cSNzZs/hvnvv47777wegsrKSByb9mWefmcbb2W8za9a7rF+/HoAZM6Zzdp9zmDN7Lmf3OYcZM5wn3vr165k9axZvZ7/NtGen8+cH7qey0vn+vPvvv4/77r2PObPnsHHjRhYsXADAG2/8mw4dEpg7Zy6jL7uMRx97pMnOPS/vOz76cDZ33f0E9//5WVasWEJ+fh6z3v0Xp/68Fw899AKn/rwX7777Wp28e/dW8tJLT3DzLZOZNHkGS5fmsnnzRoB682/evJGPl37AA5Omc8utk3npxSfYu9c5/xdf+BuXX34zUx76B37/5mBwXvDRHNoe3Y6H/vICgwaN5PX/mwE4QT476yXuuusJ7r77SbKzXqr3hWJ/tOTnRXXx8XHcdtttvPP2u7z26r/456v/DJ5PS+uLsKQRW5QdVgG4d+8zSUjoWO/+nJwcMoZnICKccUZPiouLKCgIsGrVSroldSMpKYk2bdowOD2dnNwcJ09uDpmZGQBkZmYwP2d+MH1wejpt2rSha9eudEvqxqpVKykoCFCys4SePXshImQMz2D+/PnB+jMznLIGDUplyZIlwVf+A7Xl+02c9OOfccQRRxIXF8dPf3o6n322iM8/X0zffhcC0LffhXz+2eI6eb/99ksSvceRmNiF+PjWnNVnAJ9/7hxXX/7PP1/MWX0G0Lp1GzyeLiR6j+Pbb7+ksHAru3fv4ic/ORUR4dy+F/CZm+ezzxfTt98gAHqfeR7r1n6OqrJ69TJOPe2XtGvXgbZt23Pqab+sMaI+UC35eVGdx5PIqaeeBkDbtm056aQfEwj4W2RfhNNUX0t/KOx3ABaRK5qyIZEIBPz4fL7gY6/Xh98fwO8P4OtSle7zegn4nSfm1q1b8XgSAecJvG3bNqcsf62yfN5gWV6vt0b6vie5P+DH5+sCQHx8PO3bt6ewsLBJzu34rifw1ZerKCkporR0DytXfsy2rQXs2LGdjh07A9CxY2eKiurWt337D3Tq5Ak+7nTMsWzf/gNAvfnr5vGwffsPbvqxNdIL3bIKt28N5omLi+Ooo9pSUlLE9mrpVfVvbZJ+iUQsPy/qs3nzZtatW8fpp59RI70l9kVtLWUK4r76dojIOBFZJiLLpk+v/61jY4V6JRURlBCvsA28utVbVqh0971K6Dxhq4nYccf9iPT0i3n44fE89ugdJCWdRFxcXGSZw7S5sXlCD1bCnb/UU9ahE8vPi1B27tzJjTfdwO0TJtCuXbsa+1paX4TSnAJw2FUQIrKyvl2At559qOo0YBpAZcXeJnv/4fX6yM+v+uDH788nMdFDeXkZ+Vuq0vP9fhITnVf0zp07U1AQwONJpKAgQKdOnZyyfLXKyveTmOjB5/Pi9/trpHvcsnxeH/n5W/D5fFRUVFBcXBz2rXFjnXf+YM47fzAA//73c3Q6xkNCwjEUFm6lY8fOFBZupUOHuvUd08nDtm0Fwcfbtv9Ax2OcUW99+evmKaDjMZ3p1OlYtm37oU66k+dYtm0roFMnD5WVlezevZO2bdtzTKdj+eKLlTXq/9nPTm+yfmlIrD8vqisvL+emm25k6JBhXHjhoDr7WwFnNgAAABwmSURBVFJf1OdwmFqIVEMjYC9wGTAsxHbo3mO6UpKTycrOQlVZsWI57du1x+NJpHv3HmzctJG8vDzKysqYPWsWycnJACQnpzBzZhYAM2dmkZKc4qYnM3vWLMrKysjLy2Pjpo306HE6Hk8ibY9uy4oVy1FVsrKzSEmpyjMzyylr3ry59OlzdpP+sYuKtgOwdWuAT5ctos/ZyfTseQ6LFr4HwKKF79Gr17l18p144k8J+DdTULCFiopyPl76Ab16nQNQb/5evc7h46UfUF5eRkHBFgL+zZx00k/p2LEzRx51FN+sX4uqsnjR+8GyevU8h0XuCodln3zEz3/eExGhe/ferFn9KTt3FrNzZzFrVn9K9+69m6xfGhLrz4t9VJW77r6Tk046icsvv7xF90U4IpFv0SbhJshF5Dng76q6MMS+f6rq7xqqoDEj4D/+8VY+/uRjCgsL6dy5M9ddex3lFRUAjLp4FKrKAw/8mYWLFnLkkUcy6YHJdO/eHYAPP/qQKVMeZO/evYwYMZJrrr4GgMLC7dx8yy1s2fI9Xbocx+OPPU7Hjs4r8jPPPsNbb71JXFwcEybcznn9zwNg9erV3DHxdkpLS+nfrz8TJ96JiFBaWsr4CeNZt24dHRMSeOSRR0lKSor09Fj6SV7Y/ZMn38zOkiLi4uIZ9durOfXUX1BSUsTUp/7M1m0BOndK5H+uvYt27TqwffsP/P3vj3HLLZMBWLFiKa/+82n27t1L//6pDBv+e4B68wO8nf0KCxbMJS4ujt/+7g+cfvpZAHz33Zc8N+MRyspK6XH6mVxyyXWICOVlZUybNoVNm76hbdv2XPOHiSQmOvN9H300h3ffeRWAocN+S//+aWHPtc+ZXSPut1h/XkTq008/5dLLLuGUU05B3Hsu3nTTTWzZsiVm+iIu/sDnBR647/2IY86d91wQ1TAcNgA3haacgmjuGgrALUljArBpOZoiAE+6f37EMWfi3QOjGoDtSjhjTExpdRh8uBYpC8DGmJhyOMztRsoCsDEmpjSnVRAWgI0xMaUZxV8LwMaY2NLgRUiHkcPqXhDGGHOgmnIdsIg8LyIBEVldLe1eEdksIsvdLb3avttFZL2IfCkiqQ2VbyNgY0xMaeJVEP8AngRq3/vzcVWtcas3ETkVGAWcBhwHvC8ip6hqZb1tbcqWGmNMtDXlCFhVPwK2RVh1BvCaqpaq6nfAeuCscBksABtjYksjInD1G4e527gIa7lORFa6UxTHuGnHA/+tdkyem1YvC8DGmJjSmBGwqk5T1d7Vtkhu3/g08GOgJ7AFeHRf1SGODXtVns0BG2NiysFeB6yqwVvBich04B33YR5Q/cYXXYHvw5VlI2BjTEw52HdDE5Eu1R6OAPatkMgGRonIESJyInAy8HG4smwEbIyJKU25CkJEXgUGAMeKSB5wDzBARHriTC9sAK4GUNU1IvI6sBaoAK4NtwICLAAbY2JMU05AqOpvQyQ/F+b4ScCkSMu3AGyMiSl2LwhjjImSZhR/LQAbY2KLjYCNMSZK7IbsxhgTJc1oAGwB2BgTWywAG2NMlNgcsDHGREkzir8WgA8l+yr2KhXlYS8QalHiW8dFuwkxxUbAxhgTJWKrIIwxJjpsBGyMMVHSjOKvBWBjTGyxEbAxxkRJM4q/FoCNMbHFRsDGGBMldi8IY4yJEhsBG2NMlNg6YGOMiZJmNAC2AGyMiS02BWGMMVFiH8IZY0yU2AjYGGOipBnFXwvAxpgY04wisAVgY0xMsSkIY4yJkmYUfy0AG2NiS6u45hOBLQAbY2KKTUEYY0yUWAA2xpgoaUbx1wKwMSa2NKcRcKtoN6C6BQsWkD5kMKlpqUyfPr3OflVl0uRJpKalkjkig7Vr1zSYt7CwkLFXjiFtcCpjrxzDjh07gvumTZ9Galoq6UMGs3DhwmD6mjVryMgcTmpaKpMmT0JVASgrK+OWW28mNS2Vi0ddzObNmw9GN4Q9n31ivS/uvudOzk8+jxEXZQbTHn3sEYZnDuOiX4/gpptvoKioKGTehYsWMixjKEOGDea552cE03fs2MG4q69k6LB0xl19JUVFVec/47npDBk2mGEZQ1m0eFEwfe3aNYz81QiGDBvMlIcm1zj/P912K0OGDeZ3l/y2xvlnZWcxdFg6Q4elk5Wd1WR9Ava8iISIRLxFnaoe1K2ivFIj2Ur3lOnAgQP1u2836K6du3XY0GH6xbovaxwzf36OjhkzVsvLKvTTZZ/qRRf9qsG8Ux6cok9PfUYryiv16anP6ENTHtKK8kr9Yt2XOmzoMN21c7du+G6jDhw4UEv3lGlFeaVeNPIiXfbJMi0vq9AxY8ZqTk6uVpRX6ksvvqR33nmXVpRXanZWtt5www0RnVtjt5bQF3t2lYXdFi5YrJ99ulwHD04PpuW8n6slRbt0z64yfXDyFH1w8pQ6+XYW79aUlBRd/9U3Wrxjpw4dOlTXrFqne3aV6eRJD+pTT07VPbvK9Kknpwbzr1m1TocOHapFhSW6/utvNSUlRXcW79Y9u8p05IiRuvQ/H+vunaV6xRVj9L1583XPrjL9x99f1Il3TNQ9u8r0rTdn6vXXXa97dpWpf0uBJienqH9LgQbynd8D+QVhz9WeF1VbU8ScuXO/0ki3hsoCngcCwOpqaZ2A94Cv3Z/HVNt3O7Ae+BJIbaj8BkfAIvIzERkoIu1qpac14esAq1atpFtSN5KSkmjTpg2D09PJyc2pcUxOTg4ZwzMQEc44oyfFxUUUFATC5s3JzSEzMwOAzMwM5ufMD6YPTk+nTZs2dO3alW5J3Vi1aiUFBQFKdpbQs2cvRISM4RnMnz8/WH9mhlPWoEGpLFmyJPjKb33RtH3R+5e9SeiQUCPt3HP7Eh/vzJqdfvrp+P3+OvlWr15Ft6RudO2aROvWrUlLHUzuB875536Qy/BhTpuHD8sI9kvuBzmkpQ52zv945/xXr15FQUEBJTt3csYZPRERhg0dTq6b54MPcoJlXXjBIJZ+vBRVZdHiRZxz9jkkJCTQoUMC55x9DgsXLarTzv1hz4vINPEI+B9A7Vg3AZivqicD893HiMipwCjgNDfPVBGJC1d42AAsIjcAWcD1wGoRyai2e3IkrY+U3x/A18UXfOzzegnU+gcLBPz4fFXHeL0+/P5A2Lxbt27F40kEwONJZNu2bU5Z/lpl+bzBsrxeb430QMApyx/w4/N1ASA+Pp727dtTWFjYJOdfnfVFw96a+Rb9+vWrk+4PBPDW6BcvgUAAgG1bt+LxeADweDxV5x8I1OpLL/5AgEDAX/P8vdXPv6qe+Ph42rVrR2FhYYi/S1WeA2XPi8iIRL41RFU/ArbVSs4AXnB/fwHIrJb+mqqWqup3OCPhs8KV39AI+Crgl6qaCQwA7hKRG/edZ32ZRGSciCwTkWXTp09roAqHEuJVslYPhXolFZGI8tapr76yQqW7pxo6T9hq9ov1RXjTpj9LfFwcQ9KH1t1Zz7mE05jzD55kY/qsiTrGnheRkVYS+VYtVrnbuAiq8KrqFgD3Z6Kbfjzw32rH5blp9WpoFUScqpa4FW0QkQHAv0XkR4QJwKo6DZgGUFmxN6L3Hz6vl/wt+cHH+X4/iYmJNY7xen3k51cd4/fnk5jooby8rN68nTt3pqAggMeTSEFBgE6dOjll+WqVle8nMdGDz+et8dbWn+/H45bl8/rIz9+Cz+ejoqKC4uJiEhI6RnJ6jWJ9Ub+s7Cw+WvAR05+dETKweb1e/DX6xR8c9Xbq3JmCggI8Hg8FBQVV5+/11upLP4kejzt69NdKT6xRj8/rnH9JSQkJCQl4vT6WLfukRp7evc9sknO350VkGhPwq8eqpqg6VBXhMjQ0As4XkZ7BkpxgPBQ4FujR6OaF0b17DzZu2kheXh5lZWXMnjWL5OTkGsekJCeTlZ2FqrJixXLat2uPx5MYNm9ycgozZzqfRM+cmUVKcoqbnszsWbMoKysjLy+PjZs20qPH6Xg8ibQ9ui0rVixHVcnKziIlpSrPzCynrHnz5tKnz9kH5ZNU64vQFi5ayN//8Rx/+98nOOqoo0Iec9pp3dm4aRN5m/MoLy9nztzZDDjfOf8B5w8g+22nzdlvZ5E8YF96MnPmznbOf3MeGzdtonv3Hng8HtoefTQrVq5AVXn7newaefaV9d778zjrzD6ICH3P7cvi/yymqGgHRUU7WPyfxfQ9t2+TnL89LyJzCFZB+EWki1tXF5wP6cAZ8SZVO64r8H3YtoabIBeRrkCFquaH2NdXVRv8dCHSETDAhx99yJQpD7J3715GjBjJNVdfw2v/eg2AURePQlV54IE/s3DRQo488kgmPTCZ7t2715sXoLBwOzffcgtbtnxPly7H8fhjj9Oxo/OK/Myzz/DWW28SFxfHhAm3c17/8wBYvXo1d0y8ndLSUvr368/EiXciIpSWljJ+wnjWrVtHx4QEHnnkUZKSkkKcyYGL9b6oKK8Mu/+2CX9i2bJPKCwspFOnzvzPH/6H556fQVlZGR3dEdXpp5/OXXfeQyAQ4N777mHqU08DsGDBR/zl4Yeo3FtJZsYIxl11tXv+hfzxtlvJ37IFX5cuPPrwYyQkOB/0TZv+LDOz3iIuLp7b/jSe/v36A7BmzWruvPtOSkv30K9vf26fcEfw/O+YeDtffLmOhA4J/OWhh+na1Tn/t2a+yYznnGVeV40dR2bmiLDnGt867Oc0NcT68yIu/sC/zuKDD7+LOOYMOP/EBusTkROAd1S1u/v4YWCrqk4RkQlAJ1W9TUROA/6JM+97HM4HdCerar1P9rABuCk0JgCblqOhANySNCYAx7qmCMAffhR5AD7/vPABWERexfn861jAD9wDzAReB7oBm4Bfq+o29/iJwBigArhJVWeHLd8CsIkGC8BVLABXaYoA/NGCDRHHnPP6nxDVqzHsUmRjTEw5HC5wi5QFYGNMTDksLjGOkAVgY0xMsa+lN8aYKGlGA2ALwMaY2GIB2BhjokTqv0j3sGMB2BgTU2wEbIwxUWIfwhljTJTYMjRjjImSZhR/LQAbY2KLjYCNMSZamk/8tQBsjIktNgI2xpgosVUQxhgTJc0n/FoANsbEGJuCMMaYKGlG8dcCsDEmttgI2BhjoqQZxV8LwMaY2GKrIIwxJkpsBGxMA+ybgKtUVu6NdhMOG3HxrQ64jOY0B3zgZ2uMMWa/2AjYGBNTmtMI2AKwMSamNKP4awHYGBNbLAAbY0yU2JdyGmNMtDSf+GsB2BgTW2wKwhhjosSmIIwxJkpsBGyMMVFi64CNMSZamjD+isgGoBioBCpUtbeIdAL+BZwAbAB+o6rb96d8uxTZGBNTpBFbhJJVtaeq9nYfTwDmq+rJwHz38X6xAGyMiSkiEvG2nzKAF9zfXwAy97cgC8DGmBZLRMaJyLJq27hahygwT0Q+rbbPq6pbANyfiftbv80BG2NiSmNuyK6q04BpYQ7pq6rfi0gi8J6IfHGg7avORsDGGFMPVf3e/RkA3gLOAvwi0gXA/RnY3/ItABtjYopI5Fv4cqStiLTf9zswCFgNZAOj3cNGA1n721abgjDGxJQmvBLOC7zlflgXD/xTVeeIyCfA6yIyFtgE/Hp/KxBVbZKW1qeyYu/BrcCYZs6+kqhKmyPiDzh6+vOLI445Xl/7qF61YSNgY0xMaUZfimwB2BgTY+xSZGOMiY7mE34Ps1UQCxYsIH3IYFLTUpk+fXqd/arKpMmTSE1LJXNEBmvXrmkwb2FhIWOvHEPa4FTGXjmGHTt2BPdNmz6N1LRU0ocMZuHChcH0NWvWkJE5nNS0VCZNnsS+efKysjJuufVmUtNSuXjUxWzevPlgdEPY89nH+qJKS+qLF196gcwRwxkxIoPbbvsjpaWlNfarKg9OmUz6kDRGXjSCtWvXBvctXLiAYcOGkD4kjRnPVfXFjh2FXDXuSoYMHcxV465kR1FVX8yYMZ30IWkMGzaERYuq9cXaNYwYmUn6kDQenDK5Rl/88U+3kj4kjd/9btRB7Yv6NNUqiENCVQ/qVlFeqZFspXvKdODAgfrdtxt0187dOmzoMP1i3Zc1jpk/P0fHjBmr5WUV+umyT/Wii37VYN4pD07Rp6c+oxXllfr01Gf0oSkPaUV5pX6x7ksdNnSY7tq5Wzd8t1EHDhyopXvKtKK8Ui8aeZEu+2SZlpdV6JgxYzUnJ1cryiv1pRdf0jvvvEsryis1Oytbb7jhhojOrbGb9UXL6ovSPeURbZs25mnygGTdUVispXvK9brrrtd//ev1Gse89958veKKMbpnd5l+vHSZXjTyIi3dU667du7RlJSBun79t1pSvFOHDh2qa9es09I95frg5Af1qaemaumecn3qqan64INTtHRPua5ds06HDh2qxUU79Zv132lKykDdtXOPlu4p15EjR+rSpZ/ont1lesUVY/T993K0dE+5vvCPF3XixDu1dE+5znwrS6+//oaIz690T7k2Rcz5oaBEI90OdvxraDtsRsCrVq2kW1I3kpKSaNOmDYPT08nJzalxTE5ODhnDMxARzjijJ8XFRRQUBMLmzcnNITMzA4DMzAzm58wPpg9OT6dNmzZ07dqVbkndWLVqJQUFAUp2ltCzZy9EhIzhGcyfPz9Yf2aGU9agQaksWbIk+MpvfWF9cbD7AqCispLS0j1UVFSwZ88eEj01r4LNzc1h+LDhbl+cQXFxMQUFBaxavYpu3ZJI6ppE69ZtGJyWTm5urpsnl4zhzu0MMoZnkpuTE0wfnFatL7olsWr1KgoKCigp2UnPM3oiIgwfNpycXKcvcj/IYfhwpy8uvHAQS5cevL6oz0G4Gc9B02AAFpGzRORM9/dTReQWEUlv6ob4/QF8XXzBxz6vl4DfX+OYQMCPz1d1jNfrw+8PhM27detWPO6T1ONJZNu2bU5Z/lpl+bzBsrxeb430QMApyx/w4/N1ASA+Pp727dtTWFjYJOdfnfVFFeuLKl6vl8tHX86Fgy4gZeAA2rVrx7nn9q1xTCAQqNUXTjsDfj8+b5ca6X63/Vu3bcXj8QDg8XjY6vaFP+DHW6tfA34/gYC/Zl94fQQCzsVgAX8An9fJEx8fT7t2B6cvwjkEN+NpMmEDsIjcA/wNeFpEHgSeBNoBE0RkYlM2RAnxKlmrg0K9kopIRHnr1FdfWaHS3dfK0HnCVrNfrC+qtc36ImhH0Q5yc3OYM3se89/PZffu3bz9zts1jgk52hQJ1RMNBqDG9YWbJ0RNhzrQNac54IZGwL8C+gLnAdcCmap6P5AKXFxfpup3GJo+Pdx9Lqr4vF7yt+QHH+f7/SQm1nx75fX6yM+vOsbvzycx0RM2b+fOnSkocF6dCwoCdOrUySnLV6usfL9Tls+Lv9oIy5/vx+OW5fP6yM/fAkBFRQXFxcUkJHSM6Pwaw/qiivVFlSVLlnB816506tSJ1q1bc8HAC1ix/PMax3i93lp94SfRk+ik+7fUSQfo3KkzBQUFABQUFNDZ7Quf14e/Vr96EhPddxj+OunB+v1OnoqKCkpKiklISGjKbogpDQXgClWtVNVdwDeqWgSgqruBei/fUdVpqtpbVXtfdVXtu7uF1r17DzZu2kheXh5lZWXMnjWL5OTkGsekJCeTlZ2FqrJixXLat2uPx5MYNm9ycgozZzqXas+cmUVKcoqbnszsWbMoKysjLy+PjZs20qPH6Xg8ibQ9ui0rVixHVcnKziIlpSrPzCynrHnz5tKnz9kH5dXd+sL6IpQuvi6sXLmC3bt3o6osXbqEE0/6cY1jkgckk/12ttsXK2jXvh0ej4fup3Vn48ZN5OXlUV5exuw5sxgwwOmLAQOSycqeCUBW9sxgHw0YkMzsOdX6YuMmenTvgcfjoW3bo1mxYgWqSvbb2SS7/TdgQDLZ2U5fvPfePM46q4+NgMMJ9wkdsBQ42v29VbX0BOCzplwFse/T7AsvvFAHDhyoTz75lFaUV+rLL7+iL7/8ilaUV2p5WYXec/c9OnDgQB0yZIgu/3xF2LwV5ZX6Q8EPeumll+kFF1ygl156mf5QsDW478knn9KBAwfqoEGDgp9oV5RX6vLPV2h6eroOHDhQ773nXi0vq9CK8krdWbJLr7vueh048AK9aORF+t23Gw7KJ//WFy2rLxqzSuCxRx/XQYNSNX1wut5yy61aXLRTX3rxZX3pxZe1dE+57tldpnfddbempAzU9PQh+tmnn9dYIXHhhRdqSspAfeJvTwbT/fkFeukllzp9ccmlGvAXBPc98bcnNSVloA66cFBwpUPpnnL97NPPNX1wuqakDNS7775H9+wu09I95Vq0o0SvvfY6HThwoI4cOVLXr//2kK+CKNy2SyPdor0KIuy9IETkCFUtDZF+LNBFVVc1FODtXhDGhGf3gqjSFPeCKCrcHXHM6dDxqMP3XhChgq+b/gPww0FpkTHGHIjDYWohQnYpsjEmpjTh7SgPusPmQgxjjGlpbARsjIkph8XqhgjZCNgYY6LERsDGmJhyOFxiHCkLwMaY2NJ84q8FYGNMbGlG8dcCsDEmxjSjKQj7EM4YY6LERsDGmJjSfMa/FoCNMTHGVkEYY0y0NJ/4awHYGBNbmlH8tQBsjIkxzSgCWwA2xsSY5hOBLQAbY2JK8wm/FoCNMTGmGS2CsABsjIkxzSgC25VwxhgTJRaAjTExpSm/ll5E0kTkSxFZLyITmrqtFoCNMSYEEYkDngIGA6cCvxWRU5uyDgvAxpiYIiIRbw04C1ivqt+qahnwGpDRlG096B/CxcW3OixmxEVknKpOi3Y7DgfWF1UOh76Iiz88xkGHQ180hcbEHBEZB4yrljStWh8cD/y32r48oM+Bt7DK4fGXPzTGNXxIi2F9UcX6okqL6wtVnaaqvatt1V+AQgVybcr6W1IANsaYxsgDkqo97gp835QVWAA2xpjQPgFOFpETRaQNMArIbsoKWtKFGM1+bqsJWV9Usb6oYn1RjapWiMh1wFwgDnheVdc0ZR2i2qRTGsYYYyJkUxDGGBMlFoCNMSZKYj4AH+xLCZsTEXleRAIisjrabYkmEUkSkVwRWScia0Tkxmi3KVpE5EgR+VhEVrh9cV+029SSxPQcsHsp4VfAhThLSj4Bfquqa6PasCgRkfOAEuBFVe0e7fZEi4h0Abqo6mci0h74FMhsic8LcS4Ha6uqJSLSGlgI3KiqS6LctBYh1kfAB/1SwuZEVT8CtkW7HdGmqltU9TP392JgHc5VTy2OOkrch63dLXZHZYeZWA/AoS4lbJH/aCY0ETkB6AUsjW5LokdE4kRkORAA3lPVFtsXh1qsB+CDfimhab5EpB3wBnCTqhZFuz3RoqqVqtoT50qvs0SkxU5PHWqxHoAP+qWEpnly5zvfAF5R1Tej3Z7DgaoWAh8AaVFuSosR6wH4oF9KaJof94On54B1qvpYtNsTTSLiEZGO7u9HARcAX0S3VS1HTAdgVa0A9l1KuA54vakvJWxORORV4D/AT0UkT0TGRrtNUdIXuBRIEZHl7pYe7UZFSRcgV0RW4gxY3lPVd6LcphYjppehGWPM4SymR8DGGHM4swBsjDFRYgHYGGOixAKwMcZEiQVgY4yJEgvAxhgTJRaAjTEmSv4fIebOnK5tfTgAAAAASUVORK5CYII=\n",
"text/plain": [
"
"
]
},
"metadata": {
"needs_background": "light"
},
"output_type": "display_data"
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"-----------------------------------------\n",
"\n",
"Executing RFE\n",
"Please wait.........\n",
"### RFE selected columns:\n",
" Index(['buying_price', 'maintainence_cost', 'number_of_doors',\n",
" 'number_of_seats', 'luggage_boot_size', 'safety_rating'],\n",
" dtype='object')\n",
" RFE Selected Features\n"
]
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAq8AAAGwCAYAAACHCYxOAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADt0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjByYzEsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy/xvVyzAAAgAElEQVR4nO3deZgkZZmu8fuRRkBAFhtFUWhEFBdkFUVWlXFm3HAd3AdxxA3RmXGb8QyiDooHPS7jBiqioo6KgqijoEiDgtJ0Q7MprrQDKCKCrIos7/kjouwkO6sqq7uqs6L6/l1XXpX5xRcRb0RkVj4V+WVUqgpJkiSpC+426gIkSZKkYRleJUmS1BmGV0mSJHWG4VWSJEmdYXiVJElSZxheJUmS1BmGV0krJcmBSSrJgaOuRZK05jC8SrNAGwJ7b3ckuTbJwjYkZtQ1dl2Swwfs597bslHXuDLa2heuxHzHTbI/przMldVTy4LVtc7pkmTf1b2/RsU/WDVbzBt1AZLu4m3tz7WBBwHPAPYBdgUOGVVRc8wZwMIB7X9czXXMFl8Dlg5oX7aa65CkoRhepVmkqg7vfZxkD+BM4FVJ3ltVl42ksLllYf9+XsOdVFXHjboISRqWwwakWayqzgIuBQLs0jstyS5JPpDkgnaIwZ+T/DzJe5Ns0r+s3o/8kjyuHZJwY5IbknwzyUMH1ZDkQUm+nOS6JDcnOTvJkyequ63tK0muTnJrkl8n+UiS+w7oO/aR8dZJDkny43ZbliX597EhE0mek2RRW8PVST6UZN0p7M4pWclteGCS1yS5MMmfej9KTrJpkncl+Uk77fokpyV54oDl3T3JoUnOa/f7Le3++FqS/do+ByYZ+//e+/R95H/4DOyP5yU5va3nz+12/J8k6wzo+/Qkxyf5WXu8bkqypN2mu/X1LeAf24eXDRrG0W77MgbI8uEg+/Yvt32Ob57kE0muTDMc58CePo9OckKSq5L8JcnlSY5Ocr+V3U89y+59vf1Nku+3++H3ST6VZOO2305JvtHu15uSnJwBwyfabakk6yT5zySXtc/LXyZ5a5K7j1PHE5J8O8t/R/wsyZFJNppgHXdPcliSn7brOK59Ln+q7fqpvufbgnb++7XzndWzT3+T5PMZ8PslyYJ2/uPa+/+d5Jq2zsVJnjLB/j2gff2MbdeyJF9IsuuAvkM/d9UNnnmVZr+x8a639bW/jGZYwRnAd4G1gJ2BfwH+Psmjq+rGAct7CrA/8C3gY8DDgCcBj0rysKq65q8rTrYFfgjcq+2/lGY4w0nt4xWLbd5wvtLWfQLwa5rg/Upg/yR7VNWyAbO+B9gX+DpwKvA04Ajg7kmuBY5s1/t94G+AV7fb/MpBdayKVdiGDwB7Ad8E/ge4o13eVjRDFRa09X8bWJ/mWHw7ycur6uM9yzkOeB5wMfAZ4E/A/YA9gb+jOd5LaYaZvLWt77ie+Reu7LYPkuSTwEHAFcBXaYZYPAZ4B/CEJH9TVbf3zHIkcCdwDnAlsBHweJr98yjgRT193wY8HdihnT42fGM6hnFsCvwIuKmt+07gd+02vQT4OHArcDJwObAt8E/AU5M8pqr+dxpqeBrNcf4GzevtscCBwNZJ3gycRvOc+CSwPfBUYJsk21fVnQOW9yWafXgCze+E/YHDgV2TPK2qxv6gIcnLgY8CNwNfBq6meY29qd3GPapq0H7+SruOb9G85q6meU79sV1f/1CTsWXsDbwZOL1dxk00+/TZwNPa9V0wYH1bAYuAXwGfpTluBwBfS7JfVZ3es02hCdH/CFxDc1x/D9wfeBzwU2BxT/+pPnfVBVXlzZu3Ed+Aal6OK7TvTROAbgXu2zdtK2CtAfO8tF3em/raD2zbbwee0DftXe20N/a1n9q2v7avff+xmoEDe9o3oHlDuQPYq2+eN7X9T+1rP65tXwZs0dO+cbusm2nenB7aM20d4Mftfrn3kPv48HY9C9v7/bcF07ANVwJbD1j3Qprg9Ny+9o1pQsCfgPu0bRu1fRePc3zvNeC5s3AlnnNjNZ80zv7YuO9581VgvXH2af/zY5sB67sb8Om2/6PHqWXBOLUuA5ZNclz3HfSaogn/8/qmPRj4C/CL3udcO+3x7bE/ccj9uO+gY8BdX2/79O2H77TTrgVe0DffJ9tp+w94DhXwM2CTnvZ1af7ALOBFPe1b0bw+bgC261vWR9r+x4yzjguB+QO2dWybDhxnX9wb2HBA+w40QfZbfe0Leo7TW/um/W3b/j997Qe37YuAjfqmrUXP78mVee5668Zt5AV48+btLm+0h7e3I4Avtm+wdwKvmcKyAlwPfK+vfewX+fED5tm6nXZCT9v927ZfMThEjb3RHdjT9oK27fMD+s8DLmunb9nTflzb9tIB8xzbTnv7gGlvbaftM+R+GXuzGu+27zRswwpvhO0bdwFfHqeusT8EXtU+vmf7+CwgQz53Fq7Ec26s5vFuC9p+59Oc4dt4wDLWogn6i4Zc587tsg8bp5YF48y3jJULrwP/uAHe105/8jjLPJEmdK4QxAb03XfQMWD56+2zA+Z5cTvtzAHT9mFwmFtIX0AdUMPpPW1vadveOaD/JjSh9k/AOgPWsX//PH3bdOCg6ZPsp5OBPwNr97QtYPkfroN+x/wauKav7aJ2np2GWOe0PXe9za6bwwak2eWtfY/HQt2n+jsmWRt4OfBcmo/+N+Ku49i3GGcdiwe0Xd7+7B0ru1P78wdVdceAeRbSvNH22rn9+b3+zlV1e5Izad6wdgL6P5IdVNdv2p9LBky7sv15/wHTJvK2mvgLW6uyDYsGLG/39udGGTwWdbP250PbddyQ5Os0Hx8vTfIVmo+Vz6mqWyaoe2W9pMb5wlaSe9CE72uA12XwFdtuHau9Z757AW+gGY7yQJohEr3Ge25Ot2VVdfWA9rFjsk+SRw2Yfm+acPNgBj/3pmK6n9dnDGj7Pk3Y3qmnbaLn8XVJzqf5ZGc7oP+j/EHP46GkGQ//CporpMxnxeGJ84Hf9rUtHed3zOUsP1YkWR94BPC7qjp/kjpW6rmrbjC8SrNIVY19OWl9ml/anwQ+luTXVdX/JvRFmjGvv6IZg3YVzS9jgNfRfLQ+yApj3NpQBs0b9pixL3T8bpzlXDWgbWye/jcn+to3HjDt+gFttw8xbe1x1rWyVmUbBu2Te7U//6a9jWeDnvsH0AxReD7LL5/25yQnAK+vqvGOyXTbhOZM/mas+IfVQO0Xkc6lOZu/iOZj+2tpjtfGwGsZ/7k53QYdD1h+TN4wyfwbTDJ9GNP9vF7h2FfVHUn+QBO6x0z383hSSQ6lGbd8Hc3QiP8FbqH5I3xsXPOgYz/e+Obbuesf5GO1Xjmgb78pP3fVHYZXaRaqqpuB7yZ5KnAe8OkkDxk789Z+o/YZNF/ceVJV/fXLXGm+zf3GaShj7I31PuNM33yCeQZNA7hvX7/ZaFW2oSZY3mur6oPDFFBVf6IdQpLkATRnyA4EXkhz1nevYZYzDcZqP7+qdp6w53L/RBNcVzjDnWR3mvA6VXcCA79Nz+DwNWbQ8YDl27VRVd2wEvWM0n3oO+OfZC2aQN67Lb3P40sGLGfc53FVjbffxpVkHs0fWlcBO1fVb/um7z5wxqkZC7nDnLlfmeeuOsJLZUmzWFVdSPON6PsD/9wz6UHtz5N7g2trN2C9aVj92Mdye7Zvjv32nWCeFaa1b257tg/PW9XiZtB0b8OP2p8rFTir6vKq+hzNF1h+TnM87tXT5U7uesZ82lTVTTTB5+FJNh1ytrHn5lcGTOsfZjJm7CPj8bbjOuA+7VCZfitcGmkIq3RMRmzQPtyL5mRU70fpEz2PNwZ2pBmD+pMprHui4zSf5g+JswcE1w1YPoxhpbV/1F9M81zYaZK+K/PcVUcYXqXZ7z9p3mRen+XXb13W/ty3t2OSewMfno6VVtUVNB/9bU3ff/dKsj+D30RPovmI+HlJHtM37XU04x+/W9NzCaKZMq3bUFWLacYkPjPJQYP6JNm+PXYk2SzJowd0Wx/YkOaj1L/0tP8BeMAwtayk/0dz1vPYNvTcRZJNkvQGk2Xtz337+u0E/Ns46/hD+3PLcaYvoglnL+lb5oHAHuOXPq4P0XyR531JHtw/sb3O6WwNtv/R83uANNc6flf7sHds/PE02/iaJA/irt5B88XA46vqVoY30XG6mmaIwC5tWB2rb22aoQTzp7CeiYx9enF0+q5Vm+Ruuet1mKf63FVHOGxAmuWq6sokR9N83PpGmgBwLs230Z+Z5GzgBzQfJ/49zXUOfzPO4qbq1TSX4Xl/movpX8Dyf1s79qWi3lpvagPal4EzknyZ5iPOXYAn0nyk+PJpqm1GzNA2PJ/mizOfbMcFnkPzEej9gUfSfAlld5oAsAXwoyQ/oTm7ezlN0HgKzUfAH6y7Xr/3NOC57Ze8ltCE2zOr6sypbvsgVXVskl2AVwG/THIKzf7YlOYPm71pQtMr2lk+QzOW9P1JHkdztnjbtv6v0ozn7XdaO8/H23G9NwF/rKoPtdP/iya4fjTJE2j2yQ4010z9RrvsqWzTpe0xPha4JMm3aS5BtTZNMNuL5vJs201luavJT2hq7r3O6zY01xb+7FinqlqW5HU0f8yel+RLNNu0D81z7VKacdVT8UOagPq69mzm2Pjb/6qq65N8kOY6rxcl+RpNcHwczXPl9Pb+qvoEzacfLwZ+3q7n9zTXQX48zTE9HFbquauuGPXlDrx587b8UlkTTL8PzfVOb2b59UA3pble4zKaM7O/BN4J3IMBlxZi8ms0DrzkEk1YPYEmbN1M8wb25ImWR3OB8xNp3lT+QvOG8VHgfgP6Hsc4l0linMsgDbM9Eyzr8CH7T8s29PTZEPh3moB5E81lii6jCR0HA+u3/TYGDqMJu1fSfAnvtzRXd3gefZfPovmSzudpgsQdw25jT83D7r+xC+1f3e6Pq2jOiP4nK15H9GE0l0a6un3OLKEZC7ugXedxA5b/LzTB7Na2T//zd0+af5V8C83Yzm/SBP+Bz5Hxns99fbZv98Ov2/VeS/Ox9NHA44fcL/sOWtdEz8+eeVY4TuPtI5Zfxmqddp9f1tb8K5ovJK0zTn1PpLle83Vt/18A/5fBl49ayAS/h9o+f0fzO+AmVrys2rz2OP6Y5vl9FU2g3ooBr5GJng+T1UNzSbszaMa2/rndH5+jGW+70s9db924pT2wkiRplkrz71n3qfaKJNKazDGvkiRJ6gzDqyRJkjrD8CpJkqTOcMyrJEmSOsNLZa0h5s+fXwsWLBh1GZIkSZNasmTJNVW12aBphtc1xIIFC1i8ePGoy5AkSZpUkl+PN80xr5IkSeoMw6skSZI6w/AqSZKkzjC8SpIkqTMMr5IkSeoMrzawhvjJFX9glzd8ZtRlSJKkDlty1ItHXYJnXiVJktQdhldJkiR1huFVkiRJnWF4lSRJUmcYXiVJktQZhldJkiR1huFVkiRJnWF4lSRJUmcYXiVJktQZhldJkiR1huFVkiRJnWF4lSRJUmcYXiVJktQZhldJkiR1huFVkiRJnWF4lSRJUmcYXiVJktQZhldJkiR1huFVkiRJnWF4lSRJUmcYXiVJktQZhldJkiR1xhoZXpNsl2RpkvOTbDNBv39fDbX8e9/js2d6nZIkSV21RoZX4OnA16pqp6r65QT9Vjm8Jllrki53WUdVPXZV1ylJkjRXzZnwmmT9JN9MckGSi5MckOSwJOe2j49J40nA64B/SnJ6O+8Lkyxqz8YenWStJEcC67Vtn0vyjiSv7VnfEUkOHaeWfZOcnuTzwEVt20lJliS5JMnBbdtd1tG23dSzjIVJTkhyaVtD2mlPatt+kOSDSb4xTh0HJ1mcZPHtt9w4TXtakiRpdOaNuoBp9HfAb6rqyQBJNgK+U1Vvbx9/FnhKVX09yceAm6rqPUkeChwA7FFVtyX5CPCCqnpzkkOqasd2/gXAV4EPJLkb8Fxgtwnq2Q14RFVd1j4+qKquTbIecG6Sr/SvY4CdgIcDvwHOAvZIshg4Gti7qi5L8oXxCqiqY4BjANbffOuaoFZJkqROmDNnXmnOcO6X5N1J9qqq64HHJTknyUXA42mCYL8nALvQBMql7eMH9neqqmXAH5LsBDwROL+q/jBBPYt6givAoUkuAH4EPADYdohtWlRVV1TVncBSYAGwHfCrnmWPG14lSZLmmjlz5rWqfpZkF+BJwLuSnAq8Gti1qi5Pcjiw7oBZA3y6qv5tiNV8AjgQ2Bw4dpK+N/91Bcm+wH7A7lV1S5KF49TS79ae+3fQHK8MMZ8kSdKcNGfOvCa5H3BLVR0PvAfYuZ10TZINgGePM+tpwLOT3LtdzqZJtmqn3ZZk7Z6+J9IMT3gUcMoUytsIuK4NrtsBj+mZ1r+OyVwKPLAdxgDNkAdJkqQ1wpw58wpsDxyV5E7gNuCVNFcVuAhYBpw7aKaq+nGS/wOc2o5lvY3mjO2vacaLXpjkvKp6QVX9pf2S1x+r6o4p1PZt4BVJLgR+SjN0YMxd1jHZgqrqT0leBXw7yTXAoinUIUmS1Gmp8ns8w2rD7XnAc6rq5yOsY4Oquqm9+sCHgZ9X1fsmmmf9zbeu7V70ttVToCRJmpOWHPXi1bKeJEuqatdB0+bMsIGZluRhwC+A00YZXFsva79cdgnNkISjR1yPJEnSajGXhg3MqKr6MX1XIUiyPfDZvq63VtWjZ7iW9wETnmmVJEmaiwyvq6CqLgLGu0arJEmSppnDBiRJktQZhldJkiR1huFVkiRJnWF4lSRJUmcYXiVJktQZhldJkiR1huFVkiRJnWF4lSRJUmcYXiVJktQZhldJkiR1huFVkiRJnWF4lSRJUmcYXiVJktQZhldJkiR1huFVkiRJnTFv1AVo9Xjo/e/F4qNePOoyJEmSVolnXiVJktQZhldJkiR1huFVkiRJnWF4lSRJUmcYXiVJktQZhldJkiR1huFVkiRJnWF4lSRJUmcYXiVJktQZhldJkiR1huFVkiRJnWF4lSRJUmfMG3UBWj3+8ttL+N+3bz/qMiRJI7DlYReNugRp2njmVZIkSZ1heJUkSVJnGF4lSZLUGYZXSZIkdYbhVZIkSZ1heJUkSVJnGF4lSZLUGYZXSZIkdYbhVZIkSZ1heJUkSVJnGF4lSZLUGYZXSZIkdYbhVZIkSZ1heJUkSVJnGF4lSZLUGYZXSZIkdYbhVZIkSZ1heJUkSVJnGF4lSZLUGYZXSZIkdYbhVZIkSZ1heJUkSVJnzLnwmmRBkounYTmvSPLi6aipS+uWJEmazeaNuoDZqqo+Nor1Jpk3qnVLkiTNdnPuzGtrXpJPJ7kwyQlJ7pFkWZL5AEl2TbIwyd2S/DzJZm373ZL8Isn8JIcneX3bvjDJu5MsSvKzJHu17fdI8qV2PV9Mck6SXccrKslNSd6b5Lwkp/Wsd2GSdyY5A3ht37oflOS7SS5o59umbX9DknPbdb9tnPUdnGRxksXX3nzHNO5eSZKk0Zir4fUhwDFV9UjgBuBVgzpV1Z3A8cAL2qb9gAuq6poB3edV1W7A64C3tm2vAq5r1/MOYJdJ6lofOK+qdgbO6FkOwMZVtU9Vvbdvns8BH66qHYDHAr9N8kRgW2A3YEdglyR7D9i+Y6pq16raddP115qkNEmSpNlvrobXy6vqrPb+8cCeE/Q9FhgbX3oQ8Klx+n21/bkEWNDe3xP4b4Cquhi4cJK67gS+OE5dX+zvnGRDYIuqOrFdx5+r6hbgie3tfOA8YDuaMCtJkjSnzdUxrzXg8e0sD+vr/nVC1eVJfpfk8cCjWX4Wtt+t7c87WL7fMo113jxg+njLD/Cuqjp6FdcvSZLUKXP1zOuWSXZv7z8P+AGwjOUf6z+rr/8naM6EfqmqpjI49AfAPwAkeRiw/ST97wY8u73//Hb+cVXVDcAVSZ7ermOdJPcATgEOSrJB275FkntPoW5JkqROmqvh9SfAPya5ENgU+CjwNuADSb5Pc/a018nABow/ZGA8HwE2a9fzJpphA9dP0P9m4OFJlgCPB94+xDpeBBzaruNsYPOqOhX4PPDDJBcBJwAbTrF2SZKkzklV/yfsa572CgHvq6q9pjjfWsDaVfXn9ioApwEPrqq/jNP/pqraYNUrnrpHbrFefePlDxrFqiVJI7blYReNugRpSpIsqaqBV3Caq2Neh5bkzcArGX+s60TuAZyeZG2acaivHC+4SpIkadWt8eG1qo4EjlzJeW8EVvirIMk5wDp9zS8a1VlXSZKkuWKND68zoaoePeoaJEmS5qK5+oUtSZIkzUGGV0mSJHWG4VWSJEmdYXiVJElSZxheJUmS1BmGV0mSJHWG4VWSJEmdYXiVJElSZxheJUmS1BmGV0mSJHWG4VWSJEmdYXiVJElSZxheJUmS1BmGV0mSJHWG4VWSJEmdYXiVJElSZ8wbdQFaPe5+34ez5WGLR12GJEnSKvHMqyRJkjrD8CpJkqTOMLxKkiSpMwyvkiRJ6gzDqyRJkjrD8CpJkqTOMLxKkiSpMwyvkiRJ6gzDqyRJkjrD8CpJkqTOMLxKkiSpM+aNugCtHpdefSl7/Nceoy5DktYYZ73mrFGXIM1JnnmVJElSZxheJUmS1BmGV0mSJHWG4VWSJEmdYXiVJElSZxheJUmS1BmGV0mSJHWG4VWSJEmdYXiVJElSZxheJUmS1BmGV0mSJHWG4VWSJEmdYXiVJElSZxheJUmS1BmGV0mSJHWG4VWSJEmdYXiVJElSZxheJUmS1BmGV0mSJHWG4VWSJEmdYXiVJElSZxheJUmS1BmGV0mSJHXGrAyvSXZN8sFJ+myc5FVDLu/s6als9kny76OuQZIkaXWZleG1qhZX1aGTdNsYGCq8VtVjV72qWcvwKkmS1hgzFl6TLEhyaZJPJLk4yeeS7JfkrCQ/T7Jbezs7yfntz4e08+6b5Bvt/cOTHJtkYZJfJRkLtUcC2yRZmuSoJBskOS3JeUkuSrJ/Ty039Sx3YZIT2to+lyTttF2SnJFkSZJTkty3bV+Y5N1JFiX5WZK92va1krynXdeFSV4z0XLG2UcPSvLdJBe0dW+TxlHtPrsoyQFt3/smObPd3ouT7JXkSGC9tu1zA5Z/cJLFSRbfdtNtq3xMJUmSRm3eDC//QcBzgIOBc4HnA3sCT6M5Y/hiYO+quj3JfsA7gWcNWM52wOOADYGfJvko8GbgEVW1I0CSecAzquqGJPOBHyU5uaqqb1k7AQ8HfgOcBeyR5Bzgv4D9q+r3bWA8AjionWdeVe2W5EnAW4H92m3aGtiprX/TJGtPspx+nwOOrKoTk6xL88fEM4EdgR2A+cC5Sc5s990pVXVEkrWAe1TV95McMrYP+lXVMcAxABtsuUH/fpAkSeqcmQ6vl1XVRQBJLgFOq6pKchGwANgI+HSSbYEC1h5nOd+sqluBW5NcDdxnQJ8A70yyN3AnsEXb76q+fouq6oq2pqVtHX8EHgF8pz0Ruxbw2555vtr+XNL2hybAfqyqbgeoqmuTPGKS5SwvNtkQ2KKqTmzn/3Pbvifwhaq6A/hdkjOAR9GE/2PbgHxSVS0dZ19JkiTNWTMdXm/tuX9nz+M723W/Azi9qp6RZAGwcIjl3MHgul8AbAbsUlW3JVkGrDvksgJcUlW7T7L+3nWHJnD3mmw5/X2Hbq+qM9tg/mTgs0mOqqrPDLEeSZKkOWPUX9jaCLiyvX/gFOe9kWYYQe+yrm6D6+OAraawrJ8CmyXZHSDJ2kkePsk8pwKvaIcrkGTTqSynqm4Arkjy9LbvOknuAZwJHNCOqd0M2BtYlGSrdvs+DnwS2Lld1G3t2VhJkqQ5b9Th9f8C70pyFs1H7EOrqj8AZ7VfXjqKZvzorkkW05yFvXQKy/oL8Gzg3UkuAJYCk12h4BPA/wIXtvM8fyWW8yLg0CQXAmcDmwMnAhcCFwDfA95YVVcB+wJLk5xPMy74A+0yjmlrWOELW5IkSXNNVvw+k+aiDbbcoHZ4ww6jLkOS1hhnveasUZcgdVaSJVW166Bpoz7zKkmSJA1tpr+wJSDJh4E9+po/UFWfGkU9kiRJXWV4XQ2q6tWjrkGSJGkucNiAJEmSOsPwKkmSpM4wvEqSJKkzhgqvSbZJsk57f98khybZeGZLkyRJku5q2DOvXwHuSPIgmv/utDXw+RmrSpIkSRpg2PB6Z1XdDjwDeH9V/TNw35krS5IkSVrRsOH1tiTPA/4R+EbbtvbMlCRJkiQNNmx4fQmwO3BEVV2WZGvg+JkrS5IkSVrRUP+koKp+nORNwJbt48uAI2eyMEmSJKnfsFcbeCqwFPh2+3jHJCfPZGGSJElSv2GHDRwO7Ab8EaCqltJccUCSJElabYYNr7dX1fV9bTXdxUiSJEkTGWrMK3BxkucDayXZFjgUOHvmypIkSZJWNOyZ19cADwdupfnnBNcDr5upoiRJkqRBJj3zmmQt4OSq2g94y8yXJEmSJA02aXitqjuS3JJkowHjXtUR2917O856zVmjLkOSJGmVDDvm9c/ARUm+A9w81lhVh85IVZIkSdIAw4bXb7Y3SZIkaWSG/Q9bn57pQiRJkqTJDBVek1zGgOu6VtUDp70iSZIkaRzDDhvYtef+usBzgE2nvxxJkiRpfENd57Wq/tBzu7Kq3g88foZrkyRJku5i2GEDO/c8vBvNmdgNZ6QiSZIkaRzDDht4b8/924HLgH+Y/nIkSZKk8Q0bXl9aVb/qbUiy9QzUI0mSJI1rqDGvwAlDtkmSJEkzZsIzr0m2Ax4ObJTkmT2T7klz1QFJkiRptZls2MBDgKcAGwNP7Wm/EXjZTBUlSZIkDZKqFf73wIqdkt2r6oeroR7NkIdsuGEds9POk3eUpDlsnzPPGHUJkoaQZElV7Tpo2rBf2Do/yatphhD8dbhAVR00DfVJkiRJQxn2C1ufBTYH/hY4A7g/zdABSZIkabUZNrw+qKr+A7i5qj4NPBnYfubKkiRJklY0bHi9rf35xySPADYCFsxIRZIkSdI4hh3zekySTYD/AE4GNgAOm7GqJEmSpAGGCq9V9Yn27hnAA2euHEmSJGl8Qw0bSHKfJJ9M8q328cOSvHRmSxg8/jwAABNXSURBVJMkSZLuatgxr8cBpwD3ax//DHjdTBQkSZIkjWfY8Dq/qr4E3AlQVbcDd8xYVZIkSdIAw4bXm5PcCyiAJI8Brp+xqiRJkqQBhr3awL/QXGVgmyRnAZsBz56xqiRJkqQBJgyvSbasqv+tqvOS7AM8BAjw06q6baJ5JUmSpOk22bCBk3ruf7GqLqmqiw2ukiRJGoXJwmt67nt9V0mSJI3UZOG1xrkvSZIkrXaTfWFrhyQ30JyBXa+9T/u4quqeM1qdJEmS1GPC8FpVa62uQiRJkqTJDHudV0mSJGnkDK+SJEnqDMOrJEmSOsPwKkmSpM4wvEqSJKkz5mR4TbIwya6rcX1HJbkkyVEzuI6Nk7xqppYvSZLUBZNd53WNk2ReVd0+xdleDmxWVbfORE2tjYFXAR+ZwXVIkiTNaiM985pkQZKfJPl4e+by1CTr9Z45TTI/ybL2/oFJTkry9SSXJTkkyb8kOT/Jj5Js2rP4FyY5O8nFSXZr518/ybFJzm3n2b9nuV9O8nXg1HFqTXuG9eIkFyU5oG0/GVgfOGesbcC8z2nnuyDJmW3bWu3yzk1yYZKXt+0bJDktyXntevZvF3MksE2Spe18901yZvv44iR7DVjvwUkWJ1l8/W23TfHoSJIkzT6z4czrtsDzquplSb4EPGuS/o8AdgLWBX4BvKmqdkryPuDFwPvbfutX1WOT7A0c2873FuB7VXVQko2BRUm+2/bfHXhkVV07znqfCewI7ADMB85NcmZVPS3JTVW14wQ1Hwb8bVVd2a4X4KXA9VX1qCTrAGclORW4HHhGVd2QZD7wozYgvxl4xNh6kvwrcEpVHZFkLeAe/SutqmOAYwAesuGG/ntfSZLUebMhvF5WVUvb+0uABZP0P72qbgRuTHI98PW2/SLgkT39vgBQVWcmuWcbGp8IPC3J69s+6wJbtve/M0FwBdgT+EJV3QH8LskZwKOAkyfdQjgLOK4N519t254IPDLJs9vHG9EE+SuAd7ah+05gC+A+A5Z5LnBskrWBk3r2oSRJ0pw1G8Jr7zjRO4D1gNtZPqRh3Qn639nz+E7uuj39ZxoLCPCsqvpp74QkjwZunqTOTDJ9XFX1inYdTwaWJtmxXd5rquqUvloOBDYDdqmq29ohE/37YCyU790u87NJjqqqz6xsjZIkSV0wW682sAzYpb3/7An6TWRsTOqeNB/PXw+cArwmSdppO01heWcCB7RjVTcD9gYWDTNjkm2q6pyqOgy4BnhAW8sr2zOnJHlwkvVpzsBe3QbXxwFbtYu5EdiwZ5lbtf0+DnwS2HkK2yJJktRJs+HM6yDvAb6U5EXA91ZyGdclORu4J3BQ2/YOmjGxF7YBdhnwlCGXdyLNuNgLaM7ivrGqrhpy3qOSbEtztvW0dhkX0gyROK+t5ffA04HPAV9PshhYClwKUFV/SHJWkouBbwEXA29IchtwE814X0mSpDktVX6PZ03wkA03rGN28uSspDXbPmeeMeoSJA0hyZKqGnjN/tk6bECSJElawWwdNjAySbYHPtvXfGtVPXqIed8CPKev+ctVdcR01SdJkrQmM7z2qaqLaK7nujLzHgEYVCVJkmaIwwYkSZLUGYZXSZIkdYbhVZIkSZ1heJUkSVJnGF4lSZLUGYZXSZIkdYbhVZIkSZ1heJUkSVJnGF4lSZLUGYZXSZIkdYbhVZIkSZ1heJUkSVJnGF4lSZLUGYZXSZIkdYbhVZIkSZ1heJUkSVJnzBt1AVo9NnzIQ9jnzDNGXYYkSdIq8cyrJEmSOsPwKkmSpM4wvEqSJKkzDK+SJEnqDMOrJEmSOsPwKkmSpM4wvEqSJKkzDK+SJEnqDMOrJEmSOsPwKkmSpM4wvEqSJKkz5o26AK0eV19xPR/616+PugxJM+iQ9z511CVI0ozzzKskSZI6w/AqSZKkzjC8SpIkqTMMr5IkSeoMw6skSZI6w/AqSZKkzjC8SpIkqTMMr5IkSeoMw6skSZI6w/AqSZKkzjC8SpIkqTMMr5IkSeoMw6skSZI6w/AqSZKkzjC8SpIkqTMMr5IkSeoMw6skSZI6w/AqSZKkzjC8SpIkqTMMr5IkSeoMw6skSZI6w/AqSZKkzpjx8Jrkpplex3RLcniS10/DchYkef5Kznv2qq5fkiRprvHM68xaAKxUeK2qx05vKZIkSd232sJrkn2TfKPn8YeSHNjef1KSS5P8IMkHx/ol2SzJd5Kcl+ToJL9OMr+ddlKSJUkuSXJwz3JfmuRnSRYm+XiSD/Us6ytJzm1ve0xS8g5Jvpfk50le1i4jSY5KcnGSi5IcMFE7cCSwV5KlSf55nP3y8CSL2j4XJtm2bb+p/fn2dtrSJFcm+VTb/sKe+Y5OstbUjogkSVL3zBt1AUnWBY4G9q6qy5J8oWfyW4HvVdW7kvwdcHDPtIOq6tok6wHnJvkKsA7wH8DOwI3A94AL2v4fAN5XVT9IsiVwCvDQCUp7JPAYYH3g/CTfBHYHdgR2AOa36z0TeOw47W8GXl9VT5lgPa8APlBVn0tyd+AuIbSqDgMOS7IR8H3gQ0keChwA7FFVtyX5CPAC4DO987ah/mCATTbcbIISJEmSumHk4RXYDvhVVV3WPv4Cy0PqnsAzAKrq20mu65nv0CTPaO8/ANgW2Bw4o6quBUjyZeDBbZ/9gIclGZv/nkk2rKobx6nra1X1J+BPSU4Hdmvr+UJV3QH8LskZwKMmaL9hiO3/IfCWJPcHvlpVP+/vkKboz9GE7yVJDgF2oQnJAOsBV/fPV1XHAMcAbLn5tjVELZIkSbPa6gyvt3PXYQrrtj8zoC8TTUuyL00Y3b2qbkmysF3eRMu6W9v/T0PW2x/2aoLlT7TeiVdS9fkk5wBPBk5J8k9V9b2+bocDV1TVp3rW9+mq+reVXa8kSVIXrc4vbP2a5sznOu1H4E9o2y8FHphkQfv4gJ55fgD8A0CSJwKbtO0bAde1wXU7mo/3ARYB+yTZJMk84Fk9yzoVOGTsQZIdJ6l3/yTrJrkXsC9wLnAmcECStZJsBuzdrnO89huBDSdaSZIH0px5/iBwMs1whd7pTwH+Bji0p/k04NlJ7t322TTJVpNsjyRJUuettjOvVXV5ki8BFwI/B85v2/+U5FXAt5NcQxP6xrwN+EL7BagzgN/SBMJvA69IciHwU+BH7bKuTPJO4BzgN8CPgevbZR0KfLidZx5N4HzFBCUvAr4JbAm8o6p+k+REmnGvF9CciX1jVV01QfsfgNuTXAAcV1XvG7CeA4AXJrkNuAp4e9/0fwXuByxqhwicXFWHJfk/wKlJ7gbcBrya5g8ESZKkOStVox8KmWSDqrqpHdv5YeDnVfW+JOsAd1TV7Ul2Bz5aVROeMe1Z1jzgRODYqjpx5rdidtty823rjS/4f6MuQ9IMOuS9Tx11CZI0LZIsqapdB02bDV/YAnhZkn8E7k5zRvbotn1L4Evt2cW/AC8bYlmHJ9mPZgzsqcBJM1CvJEmSRmBWhNf24/QVPlJvv3m/0xSXNfR/xkryEuC1fc1nVdWrp7LOIdf1t8C7+5ovq6pnDOovSZKkFc2K8Doq7bf3PzVpx+lZ1yk015aVJEnSSvLfw0qSJKkzDK+SJEnqDMOrJEmSOsPwKkmSpM4wvEqSJKkzDK+SJEnqDMOrJEmSOsPwKkmSpM4wvEqSJKkzDK+SJEnqDMOrJEmSOsPwKkmSpM4wvEqSJKkzDK+SJEnqDMOrJEmSOsPwKkmSpM6YN+oCtHrc+/4bcch7nzrqMiRJklaJZ14lSZLUGYZXSZIkdYbhVZIkSZ1heJUkSVJnGF4lSZLUGYZXSZIkdYbhVZIkSZ1heJUkSVJnGF4lSZLUGYZXSZIkdYbhVZIkSZ1heJUkSVJnzBt1AVo9fnvZLznihc8edRmaYW85/oRRlyBJ0ozyzKskSZI6w/AqSZKkzjC8SpIkqTMMr5IkSeoMw6skSZI6w/AqSZKkzjC8SpIkqTMMr5IkSeoMw6skSZI6w/AqSZKkzjC8SpIkqTMMr5IkSeoMw6skSZI6w/AqSZKkzjC8SpIkqTMMr5IkSeoMw6skSZI6w/AqSZKkzjC8SpIkqTMMr5IkSeoMw6skSZI6w/AqSZKkzphz4TXJwiS7rsb1HZXkkiRHDdn/ppmuSZIkaa6aN+oCZpMk86rq9inO9nJgs6q6dSZqGiTJWlV1x+panyRJ0mwxsjOvSRYk+UmSj7dnLk9Nsl7vmdMk85Msa+8fmOSkJF9PclmSQ5L8S5Lzk/woyaY9i39hkrOTXJxkt3b+9ZMcm+Tcdp79e5b75SRfB04dp9a0Z1gvTnJRkgPa9pOB9YFzxtoGzLt1kh+2633HEMscr33fJKcn+TxwUbs930xyQdt3hfUnOTjJ4iSLb/7zasvWkiRJM2bUZ163BZ5XVS9L8iXgWZP0fwSwE7Au8AvgTVW1U5L3AS8G3t/2W7+qHptkb+DYdr63AN+rqoOSbAwsSvLdtv/uwCOr6tpx1vtMYEdgB2A+cG6SM6vqaUluqqodJ6j5A8BHq+ozSV492TKBx47TDrAb8IiquizJs4DfVNWTAZJs1L/iqjoGOAZgi3ttUhPUKEmS1AmjHvN6WVUtbe8vARZM0v/0qrqxqn4PXA98vW2/qG/eLwBU1ZnAPduw+kTgzUmWAgtpAvCWbf/vTBBcAfYEvlBVd1TV74AzgEdNvnkA7DFWD/DZIZY50boWVdVlPdu8X5J3J9mrqq4fsh5JkqTOGnV47f0s+w6aM8G3s7yudSfof2fP4zu561nk/rOMBQR4VlXt2N62rKqftNNvnqTOTDJ9MoPOeo63zInW9dc6q+pnwC40IfZdSQ5b+fIkSZK6YdThdZBlNKEM4NkruYyxcaJ7Ate3ZyVPAV6TJO20naawvDOBA5KslWQzYG9g0ZDzngU8t73/giGWOdS6ktwPuKWqjgfeA+w8he2RJEnqpFGPeR3kPcCXkrwI+N5KLuO6JGcD9wQOatveQTMm9sI2wC4DnjLk8k6kGRd7Ac1Z1DdW1VVDzvta4PNJXgt8ZbJlJhmvfbu+5W4PHJXkTuA24JVD1iNJktRZqfJ7PGuCLe61Sb3q758w6jI0w95y/AmjLkGSpFWWZElVDbxu/2wcNiBJkiQNNBuHDYxMku256xUBAG6tqkcPMe9bgOf0NX+5qo6YrvokSZLWdIbXHlV1Ec01Vldm3iMAg6okSdIMctiAJEmSOsPwKkmSpM4wvEqSJKkzDK+SJEnqDMOrJEmSOsPwKkmSpM4wvEqSJKkzDK+SJEnqDMOrJEmSOsPwKkmSpM4wvEqSJKkzDK+SJEnqDMOrJEmSOsPwKkmSpM4wvEqSJKkz5o26AK0e9916G95y/AmjLkOSJGmVeOZVkiRJnWF4lSRJUmcYXiVJktQZhldJkiR1huFVkiRJnWF4lSRJUmekqkZdg1aDJDcCPx11HWI+cM2oi5DHYZbwOMwOHofZweNwV1tV1WaDJnid1zXHT6tq11EXsaZLstjjMHoeh9nB4zA7eBxmB4/D8Bw2IEmSpM4wvEqSJKkzDK9rjmNGXYAAj8Ns4XGYHTwOs4PHYXbwOAzJL2xJkiSpMzzzKkmSpM4wvEqSJKkzDK9zQJK/S/LTJL9I8uYB05Pkg+30C5PsPOy8Gt4qHodlSS5KsjTJ4tVb+dwyxHHYLskPk9ya5PVTmVfDW8Xj4OthmgxxHF7Q/j66MMnZSXYYdl4NbxWPg6+HflXlrcM3YC3gl8ADgbsDFwAP6+vzJOBbQIDHAOcMO6+3mT8O7bRlwPxRb0fXb0Meh3sDjwKOAF4/lXm9zfxxaKf5elh9x+GxwCbt/b/3/WF2HYf2sa+HvptnXrtvN+AXVfWrqvoL8N/A/n199gc+U40fARsnue+Q82o4q3IcNH0mPQ5VdXVVnQvcNtV5NbRVOQ6aPsMch7Or6rr24Y+A+w87r4a2KsdBAxheu28L4PKex1e0bcP0GWZeDWdVjgNAAacmWZLk4Bmrcu5blee0r4fps6r70tfD9JjqcXgpzadDKzOvxrcqxwF8PazAfw/bfRnQ1n/9s/H6DDOvhrMqxwFgj6r6TZJ7A99JcmlVnTmtFa4ZVuU57eth+qzqvvT1MD2GPg5JHkcTmvac6rya1KocB/D1sALPvHbfFcADeh7fH/jNkH2GmVfDWZXjQFWN/bwaOJHmYyZN3ao8p309TJ9V2pe+HqbNUMchySOBTwD7V9UfpjKvhrIqx8HXwwCG1+47F9g2ydZJ7g48Fzi5r8/JwIvbb7s/Bri+qn475LwazkofhyTrJ9kQIMn6wBOBi1dn8XPIqjynfT1Mn5Xel74eptWkxyHJlsBXgRdV1c+mMq+GttLHwdfDYA4b6Liquj3JIcApNN9oPLaqLknyinb6x4D/ofmm+y+AW4CXTDTvCDaj81blOAD3AU5MAs1r8vNV9e3VvAlzwjDHIcnmwGLgnsCdSV5H883fG3w9TI9VOQ7AfHw9TIshfy8dBtwL+Ei7z2+vql19f5g+q3Ic8P1hIP89rCRJkjrDYQOSJEnqDMOrJEmSOsPwKkmSpM4wvEqSJKkzDK+SJEnqDMOrJEmSOsPwKkmSpM74/4QI6ITfB8mVAAAAAElFTkSuQmCC\n",
"text/plain": [
"
"
]
},
"metadata": {
"needs_background": "light"
},
"output_type": "display_data"
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"\n",
"Please wait Training-Testing with all models..\n",
"\n",
"Done with LogisticRegression\n",
"Done with RandomForestClassifier\n",
"Done with XGBoost Classifier\n",
"Done with LGBoost Classifier\n",
"Done with AdaBoost Classifier\n",
"Done with GradientBoostingClassifier\n"
]
},
{
"data": {
"text/html": [
"
"
],
"text/plain": [
""
]
},
"execution_count": 8,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"df = es.importdata('TrainDataset.csv')\n",
"es.quick_ml(df,'popularity','c')"
]
},
{
"cell_type": "raw",
"metadata": {},
"source": []
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" We all know we cannot depend on automation for final decisions so we can use methods in easeml to short the hazzle of writing and remebering codes and manually use easeml to quicky get to the decision
| Model | F1 score | AUC-ROC score | Accuracy | Confustion-Matrix | |
|---|---|---|---|---|---|
| 1 | \n", "RandomForestClassifier | \n", "1 | \n", "1 | \n", "1 | \n", "[[21 0]\n", " [ 0 9]] | \n", "
| 3 | \n", "LGBoost Classifier | \n", "1 | \n", "1 | \n", "1 | \n", "[[21 0]\n", " [ 0 9]] | \n", "
| 2 | \n", "XGBoost Classifier | \n", "0.967137 | \n", "0.97619 | \n", "0.966667 | \n", "[[20 1]\n", " [ 0 9]] | \n", "
| 5 | \n", "GradientBoostingClassifier | \n", "0.967137 | \n", "0.97619 | \n", "0.966667 | \n", "[[20 1]\n", " [ 0 9]] | \n", "
| 4 | \n", "AdaBoost Classifier | \n", "0.898222 | \n", "0.865079 | \n", "0.9 | \n", "[[20 1]\n", " [ 2 7]] | \n", "
| 0 | \n", "LogisticRegression | \n", "0.822222 | \n", "0.753968 | \n", "0.833333 | \n", "[[20 1]\n", " [ 4 5]] | \n", "
We all know we cannot depend on automation for final decisions so we can use methods in easeml to short the hazzle of writing and remebering codes and manually use easeml to quicky get to the decision "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Using EaseMl methods example "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### credit risk loan dataset"
]
},
{
"cell_type": "code",
"execution_count": 10,
"metadata": {
"ExecuteTime": {
"end_time": "2020-03-17T10:22:45.899929Z",
"start_time": "2020-03-17T10:22:05.809077Z"
}
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Dataframe Imported Successfully\n",
"*** Dataset Infomarion ***\n",
"##################################################\n",
"No of Rows : 63999\n",
"No of columns : 45\n",
"No of Numerical columns: 27\n",
"No of Categorical columns: 18\n",
"##################################################\n",
"\n",
" Total Missing values : 286991 \n",
"\n",
"##################################################\n",
"Summary of DataFrame:\n",
"\n",
" Column Name Nulls/NaN outof Unique Type of Columns\n",
"0 member_id 0 63999 63999 Numerical\n",
"1 loan_amnt 0 63999 1273 Numerical\n",
"2 funded_amnt 0 63999 1275 Numerical\n",
"3 funded_amnt_inv 0 63999 1965 Numerical\n",
"4 term 0 63999 2 Categorical\n",
"5 batch_enrolled 10264 63999 102 Categorical\n",
"6 int_rate 0 63999 459 Numerical\n",
"7 grade 0 63999 7 Categorical\n",
"8 sub_grade 0 63999 35 Categorical\n",
"9 emp_title 3826 63999 31609 Categorical\n",
"10 emp_length 3324 63999 11 Categorical\n",
"11 home_ownership 0 63999 6 Categorical\n",
"12 annual_inc 0 63999 6368 Numerical\n",
"13 verification_status 0 63999 3 Categorical\n",
"14 pymnt_plan 0 63999 1 Categorical\n",
"15 desc 54849 63999 8757 Categorical\n",
"16 purpose 0 63999 14 Categorical\n",
"17 title 13 63999 6409 Categorical\n",
"18 zip_code 0 63999 866 Categorical\n",
"19 addr_state 0 63999 51 Categorical\n",
"20 dti 0 63999 3943 Numerical\n",
"21 delinq_2yrs 0 63999 19 Numerical\n",
"22 inq_last_6mths 0 63999 15 Numerical\n",
"23 mths_since_last_delinq 32831 63999 103 Numerical\n",
"24 mths_since_last_record 54349 63999 121 Numerical\n",
"25 open_acc 0 63999 54 Numerical\n",
"26 pub_rec 0 63999 14 Numerical\n",
"27 revol_bal 0 63999 30608 Numerical\n",
"28 revol_util 29 63999 1090 Numerical\n",
"29 total_acc 0 63999 101 Numerical\n",
"30 initial_list_status 0 63999 2 Categorical\n",
"31 total_rec_int 0 63999 50744 Numerical\n",
"32 total_rec_late_fee 0 63999 600 Numerical\n",
"33 recoveries 0 63999 1754 Numerical\n",
"34 collection_recovery_fee 0 63999 1653 Numerical\n",
"35 collections_12_mths_ex_med 8 63999 5 Numerical\n",
"36 mths_since_last_major_derog 48155 63999 148 Numerical\n",
"37 application_type 0 63999 2 Categorical\n",
"38 verification_status_joint 63971 63999 3 Categorical\n",
"39 last_week_pay 0 63999 87 Categorical\n",
"40 acc_now_delinq 0 63999 5 Numerical\n",
"41 tot_coll_amt 5124 63999 2579 Numerical\n",
"42 tot_cur_bal 5124 63999 52207 Numerical\n",
"43 total_rev_hi_lim 5124 63999 3617 Numerical\n",
"44 loan_status 0 63999 2 Numerical\n"
]
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAfkAAAITCAYAAAAEgWWdAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADt0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjByYzEsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy/xvVyzAAAgAElEQVR4nOzdedzlc/3/8cdzxk62DCmNoa9IEpokhEmUNlKWUtGmVZSEvr+ylGwp1bdNYmgXiURoDLIly1iyZA2FsRQiY3v9/ni/T3PmzLmu6zPX+SznOtfzfrtdt+t8Pp9zzvt1Pte5zut83qsiAjMzMxs8E5oOwMzMzKrhJG9mZjagnOTNzMwGlJO8mZnZgHKSNzMzG1BO8mZmZgPKSd5qJelASdH28w9Jp0h6SdOxLShJn5e0RcVlTJd0Rb8+Xw9xPCjpwAV8zNaS9ioxhkrPhaRtJd0o6SlJd5b83KWeCxtcTvLWhEeA1+afzwHrATMkLdloVAvu88AWFZfxZWC3Pn6+Om0NjInEJmkicCJwDfB64B0lFzFmzoU1a6GmA7Bx6ZmIuCzfvkzSXcAfgTcDvxrNE0paPCL+U1aA/SIibuvn57MhrQwsDfwsIi5qOpiRDOr/j/lK3vrDlfn3FABJi0k6QtLdkuZIukbSm9sfIOlOSUdJ+qKke4BH8/6JkvaX9Nf82HskTe947LaSrpD0pKT7clkLtx0/MFcnry/pMklPSLpa0uvayweeDxzQ1vSwRbcXJ2mLfHxLSadJelzSLbnKdaKkI3N5f5f02Y7HzlOlLGlZScfmZo4nJd0l6Ydtx1eRdJKk2ZL+I+k2SV8e5vl2y7G9QtK5ObabJG3fEYckfTk/76OSjpO0c37slG6vu+2xm+W/4ZOSrpS0cZf7vCWX33r+yyRt3f43AfYGVm0739PzsddKOj2fk8clzZK0y3AxdZS9XX7NT0q6SNLabcd+JWlml8ccJOn+9vdN27HdgLvz5mk51gPzsQmS9pN0a35//lXSriWei/MlndzxfK333zp5e0re3kXSiZL+Bfw2H1te0g/ya3tS0iWSXlP0XFr/8ZW89YMp+fd9+ffJwIbAAcBtwI7A6ZKmRsSstse9B/gL8Anmvpd/ALwfOAK4AFgeeFfrAZJ2BH6e7/cF4CXAoaQvvJ9re+4lgBOAb+S4DgBOlTQ5Ip4gVb/OzLEemx9zwwiv8wf55zukqv6TgZ8Cyq/lLcBRki5pq+no9HVgY+AzOa4XA5u1HT8RWBzYHfgXsDqw1ghxAfwMOAY4EtgD+IWk1SPinnx8L9L5OgS4CNiWdI6HJemFwFnA5aS/wwvza16i466rkRLN14DngG2AsyRtFhEXk87xGsxb9f1A/r0qcDHwfeBJYBPgeEnPRcTPRwhxVdI5/SLwH+Ag4GxJa0TEk7ncsyStFhF35Nck0nvsJxHxdJfn/B2wPfBr0nvqYqB1Hr8N7AocDFwFbAUcJ+mhiDijhHOxIL6WY9wBeFbSosAfgGWBfYDZwMeBP+Tzcd+Qz2T9KyL845/afoADgQdJSXkh4KWkZPkoqYpzSyCAzTsedyHwq7btO4F7gcXa9q2VH/vpIcoW8Dfg+I79HyR9wD+/LcYAXt92n/Xyvje17XsQOLDAa94iP/aAtn1r533nte2bQErch7ftmw5c0bZ9PbDHMGX9G3jbMMc7n2+3HMcH2/Y9H3gG+FjenpjP9Xc6nuvM/Ngpw5R3BPAQsETbvl3y47qeu3weFgLOBo5r2/814M4RzrXyY3/Qfm6HORcBbNy2b9WO1z4hv2cOarvP6/Pj1hnmuafk+7y1bd//kJL2rh33PRH4cxnnAjgfOHmI9986HbGd2nG/DwFPAWu07VuI9EX7yJHe5/7pzx9X11sTng88nX9uJl1t7hQR9wJvICW6iyUt1PoBZgBTO55nRqSrrZZp+ff0Icp9KTAZOKnjuc8DFgPWabvv06QPzJbWVfoqhV/l/Ga03b41/z6vtSMingNuB140zHPMAvaR9AlJLx3i+KG5Gn7yAsR2TlscD5Gu4lqv9cXAC4DTOx7Tud3NhsC5kWo/Wn7deafczHCCpL+TkuzTpM5l3V5j52OXk/QtSX9j7vtq9yKPBWZHxCWtjYj4G6n5aMO8/Rzp/fT+fAUP6YvRFRFxfYHnb7clKcmf2uW9vZ5SZ72ezsUC+l3H9htIr/2Ottgg1Yh1/u/ZGOHqemvCI6QPlCAl9H9EvmwAViAllG7VoM92bN/fsf184PGIeHSIclfIv88c4viL224/mj/gAYiIp/Jn/GJDPLaIf3V5vn913OepEcr4FKmq90vAdyTdCnwxIn6Rj+9EqlL/BrCspGuAvSNiRtdn6xJblzhekH93VgkXqSJ+AXBt+46I+I+kf7e2JU0gfWF4Hul13Qo8TnqdKxYoYzqwEWnkwA2kWqGPk5oURjJ7iH0rt20fT6rOnybpz8A7mbdpp6gVSLUijwxxfGVJ/6C3c7EgOv9/ViCdx27/e+6wOUY5yVsTnomIocYnPwz8HdiuwPN0rpP8ELCkpKWHSPQP59+7A1d3OX5HgTIbFRH/Aj4NfFrSuqS2/Z9KujYiboiIvwO75cS5Ianp4fTcl+ChURbbaoud1LG/c3uox86TnCQtDizVtut/gPWBbSLi9x33G5akxUh9GT4VEd9v21+0lrJb4lyR1NcDgIi4U9IfSFfwq5Gq0Edq6+/mYdKV+SakK/pOs+nhXGRPAot07Ft+iPt2/v88DFxB+oLUaU7B8q3POMlbv5lB6jn874i4aQEf26r6fj/wf12O30z6AjElIn7Y5fiCGumqu1IRca2kfUht3GvR1vEv10JcJukg4BJSW/Nok/zdpGS9LaltuOXtBR77Z+CDkpZoq7LfvuM+rQT230QiaVVSMmyvBeh2vhclXR23P/Z5ObbOJNbNipI2blXZ5yaODUhX7+1+BBwHvBz4Tf6ytaDOy7EuExHndrtDWzIfzbmA1MFvs459WxWMbwapWeCuiOhWw2FjkJO89ZtzSYnkXEmHk66oliZ1fFssIvYf6oERcbOkY0g91FckddZbFnhXROwcEc9J2hv4saSlSb2+nyL1Cdgu3++JoZ6/i5uAt0j6PanD280R8diCvuAFIeki4FRSB7wAPkKqzr1c0jKkc3ci8FdSAtyblKBvHG2ZEfGspCOBIyU9QOot/nbgFfku3a5KW44GPgmcIenrpN71+5M6OrbcREpOR0n6Iqmq+iDSFzI67rdSHqJ2PfBgvsr+M/AlSY/mWPYjVYkvXeDlPUh6P7R61x9MuqKe3nG/3wDfJX0BGPI9OJz8/vw+aeTCEaSr5sVIXxxeGhEfpsdzQXpvfEjSN0ht7tOANxYM8UTgY8D5kr5G6h/yfFKN0H0R8Y3RvG5rWNM9//wzvn7IvetHuM+ipA+2W0lJ+D7g98Bb2u5zJ/C1Lo+dSBrqdXt+7D3M35t+G9LkO4+T2m9nAV8BFhouRlJS/VTb9quAy/LzBLDFEK9nC7r0xu58vrzvfNp6RzN/b/gjgeuAx0jt6DOB17Wdtx+SaiyeICWwM4BXDPN8u+U4luqIY57zS+q1/mVSO/xjpGFwH8+PXXaEv+cWpKvQOflcb0LHyATg1aRhdv8Bbslxdca6GOkKe3Yud3re/z+kq+THgbtITRhF3mfTSYl2e9KXojmkLzBde80DP8nPP6HA+3wKHb3r287jXqQvr3Py+bwAeH8Z5yIf259U+/JYjrlVq9HZu/6tXeJeBvhmfnzr/+fXwCZNf3b4Z3Q/yn9YM7MFIulYYKuIWLXpWKqWe5r/jTSM7YtNx2NWlKvrzWxEeba0nUjt+60JWj4A7NtkXFWTtAjwStJkRc8njb83GzOc5M2siMeBTUlD+JYkXdXuCxzVZFA1eCGp6nw28NGYOwOg2Zjg6nozM7MB5RnvzMzMBpSTvJmZ2YAauDb5FVZYIaZMmdJ0GGZmZrW58sorH4yI+WahHLgkP2XKFK64YqgZU83MzAZPXqBpPq6uNzMzG1BO8mZmZgPKSd7MzGxAOcmbmZkNKCd5MzOzAeUkb2ZmNqCc5M3MzAaUk7yZmdmAcpI3MzMbUE7yZmZmA6rWJC/pOEmzJV3ftm95SedKuiX/Xq7t2P6SbpV0s6Q31hmrmZnZWFf3lfx04E0d+/YDZkTEGsCMvI2ktYGdgZfnx3xX0sT6QjUzMxvbak3yEXEh8HDH7m2BE/LtE4Dt2vb/IiLmRMQdwK3AhrUEamZmNgD6YRW6lSLiXoCIuFfSinn/i4DL2u53T943H0m7A7sDTJ48eZ5j046aVna885m598zKyzAzM1tQ/dzxTl32Rbc7RsQxETE1IqZOmjTfcrpmZmbjUj8k+fslrQyQf8/O++8BXtx2v1WAf9Qcm5mZ2ZjVD0n+dGDXfHtX4LS2/TtLWlTSasAawOUNxGdmZjYm1domL+nnwBbACpLuAQ4ADgNOkvQh4C5gB4CI+Iukk4AbgGeAT0bEs3XGa2ZmNpbVmuQj4t1DHNpyiPsfAhxSXURmZmaDqx+q683MzKwCTvJmZmYDyknezMxsQDnJm5mZDSgneTMzswHlJG9mZjagnOTNzMwGlJO8mZnZgHKSNzMzG1BO8mZmZgPKSd7MzGxAOcmbmZkNKCd5MzOzAeUkb2ZmNqCc5M3MzAaUk7yZmdmAcpI3MzMbUE7yZmZmA8pJ3szMbEA5yZuZmQ0oJ3kzM7MB5SRvZmY2oJzkzczMBpSTvJmZ2YBykjczMxtQTvJmZmYDyknezMxsQDnJm5mZDSgneTMzswHlJG9mZjagnOTNzMwGlJO8mZnZgHKSNzMzG1BO8mZmZgPKSd7MzGxAOcmbmZkNKCd5MzOzAeUkb2ZmNqCc5M3MzAbUQk0HMMimHTWtlnJm7j2zlnLMzGxs8ZW8mZnZgPKV/ABzTYKZ2fjmK3kzM7MB5SRvZmY2oJzkzczMBpSTvJmZ2YBykjczMxtQTvJmZmYDqlCSl/Q6Sdu2ba8g6WeSZkk6StLC1YVoZmZmo1H0Sv4IYJ227W8CWwKXAbsBB5UblpmZmfWqaJJfE7gSQNISwDuAPSPiY8DngZ2qCc/MzMxGq2iSXwR4Mt/ehDRT3u/y9l+BlUuOy8zMzHpUNMnfBLwp394FuDQiHsvbLwQeLjswMzMz603RJH8w8BlJDwDvAQ5rO/Ym4OpeA5H0GUl/kXS9pJ9LWkzS8pLOlXRL/r1cr+WYmZmNF4WSfEScDrwM+BiwTkSc1Xb4UuCQXoKQ9CLg08DUiFgHmAjsDOwHzIiINYAZedvMzMwKKLwKXUTcDtzeZf8xJcayuKSngSWAfwD7A1vk4ycA5wP7llSemZnZQCs8GY6kdSX9UtJtkuZI2iDvP0TSNr0EERF/B74G3AXcCzwSEecAK0XEvfk+9wIrDhHb7pKukHTFAw880EsoZmZmA6PoZDjbkIbQvQA4EWif/GYOsEcvQeS29m2B1Ugd+ZaU9N6ij4+IYyJiakRMnTRpUi+hmJmZDYyiV/KHAtMjYnPmb3+fBazXYxxvAO6IiAci4mng18DGwP2SVgbIv2f3WI6Zmdm4UTTJrwX8Mt+OjmOPAsv3GMddwEaSlpAk0mx6NwKnA7vm++wKnNZjOWZmZuNG0Y53s4HVhzj2clKSHrWI+JOkk4GrgGdIQ/KOAZYCTpL0oVzGDr2UY2ZmNp4UTfK/AA6WdANpyBxASHopqbf7j3oNJCIOAA7o2D2HdFVvZmZmC6hokv8isDZwAXBf3ncaqSPeOcBXyw/NzMzMelEoyUfEHOCtkrYkXVmvQJrKdkZEnFthfGZmZjZKhSfDAYiIGaSZ58zMzKzPFUryktYe6T4RcUPv4ZiZmVlZil7JX8/8Q+c6TewxFjMzMytR0SQ/rcu+5YGt88+epUVkZmZmpSja8e6CIQ6dKukrwI7AGaVFZWZmZj0rvEDNMGaS5p03MzOzPlJGkn8L8K8SnsfMzMxKVLR3/Ulddi9CmtN+DeALZQZlg2HaUd26cpRv5t4zaynHzGysKdrxrtv6rU8CfwQ+GxFnlheSmZmZlaFox7t6LsnMzMysNGW0yZuZmVkfGvJKXtIRC/A8ERH7lhCPmZmZlWS46voFWbs9SEvOmpmZWZ8YMslHxGp1BmJmZmblcpu8mZnZgCq81KwkAZsALwUW6zweEd8tMS4zMzPrUdHJcFYirSO/Nqn9XflQ+8p0TvJmZmZ9pGh1/VHAI8CLSQn+NcAU4IvALaSrezMzM+sjRavrNyctJ3tv3lZE3AV8VdIE0lX8GyuIz8zMzEap6JX8ssADEfEc8CiwYtuxS4CNyw7MzMzMelM0yd8BrJxv/wXYpe3Y24CHywzKzMzMele0uv53wNbAScBXgNMk3QM8DUzGE+GYmZn1naIL1OzfdvssSRsD7wAWB86NiLMqis/MzMxGqfA4+XYRcQVwRcmxmJmZWYkKtclLulPS4ZLWrzogMzMzK0fRjncnAzsBV0j6q6SDJa1TYVxmZmbWo0JJPiI+FxFTgE2BM4EPAtdIul7SFyWtUWGMZmZmNgoLtEBNRFwaEXuRZr7bAjgf2AO4sfTIzMzMrCejXYVuSdLQuVWBZYA5pUVkZmZmpSic5CUtLmlHSacAs4EfkRao+SCwUkXxmZmZ2SgVXYXul8BbgEWB84BPAqdGxL8qjM3MzMx6UHSc/ErA54CTI+LBCuMxMzOzkhSd8W6LiuMwMzOzko22452ZmZn1OSd5MzOzAeUkb2ZmNqCc5M3MzAaUk7yZmdmAKjpO/kvDHH4OeBS4JiIuKCUqMzMz61nRcfJ7AIuRprMF+DewVL79eH6eRSXNAraJiPtLjdLMzMwWWNHq+jcD95KWm108IpYGFgd2zvvfAGwGTAKOqiBOMzMzW0BFr+T/DzgsIn7V2hERc4CTJD0P+HZEbCDpK8BXKojTzMzMFlDRK/l1gfuGOHYv8LJ8+ybgeb0GZWZmZr0rmuT/CuwpaZH2nZIWBT4D3Jx3vQBwe7yZmVkfKFpdvyfwO+AeSecCD5Da37cidcZ7c77f+sCvyw7SzMzMFlzRBWrOl7QG6ap9KrABqfp+OnB0RPwj32+/iuI0MzOzBVT0Sp6cyPepMBYzMzMrkWe8MzMzG1BFZ7xbmNQuvz2wCmlinHlExIrlhmZmZma9KFpd/w3go8AZwEzgqcoiMjMzs1IUTfI7APtFhGezMzMzGyOKtskLuLbKQCQtK+lkSTdJulHSayUtL+lcSbfk38tVGYOZmdkgKZrkfwi8u8pAgG8Cv4+ItYBXAjcC+wEzImINYEbeNjMzswKKVtffD+wiaSZwLvCvjuMREd8bbRCSliYtcLNbfrKngKckbQtske92AnA+sO9oyzEzMxtPiib5o/PvycDmXY4HMOokD6xOmkXveEmvBK4k9eZfKSLuBYiIeyV17cEvaXdgd4DJkyf3EIaZmdngKFRdHxETRviZ2GMcC5Fm0fteRKxPWqO+cNV8RBwTEVMjYuqkSZN6DMXMzGww9MtkOPcA90TEn/L2yaSkf7+klQHy79kNxWdmZjbmDFldL2lt4LaImJNvDysibhhtEBFxn6S7Ja0ZETcDWwI35J9dgcPy79NGW4aZmdl4M1yb/PXARsDl+XYMcT/lY71W2e8B/DQvZ3s78AFSTcNJkj4E3EUar29mZmYFDJfkp5GupFu3KxURs0gr3HXasuqyzczMBtGQST4iLuh228zMzMaGQh3vJK0oabW2bUnaXdLRkt5WXXhmZmY2WkV7108HPtO2fRDwXeBNwKmSdis3LDMzM+tV0SS/AXAegKQJwMeBL+QpaA8B9qomPDMzMxutokl+GeChfPtVwPLAT/P2ecD/lByXmZmZ9ahokr8HaI2VfwtwU0T8PW8vAzxZdmBmZmbWm6Jz1x8HHCHpDaQkv3/bsY1IK8aZmZlZHymU5CPiUEl/B15NmrTmuLbDywPHVhCbmZmZ9aDolTwRcSJwYpf9Hys1IjMzMytF0XHyL5O0Udv2EpK+Kuk3kvaoLjwzMzMbraId774LtE96cyRpvffFgMMl7VN2YGZmZtabokl+HeBSAEkLA+8F9oqINwFfAD5YTXhmZmY2WkWT/JLAo/n2Rnn713n7KmDVkuMyMzOzHhVN8reTkjvAO4CrI6I1Oc4KwGNlB2ZmZma9Kdq7/hvA9yTtAKxPWuu9ZQvg2pLjMjMzsx4VHSf/I0m3kMbJ7xcRM9oOPwwcXUVwZmZmNnoLMk7+QuDCLvsPLDMgMzMzK8eQSV7S2sBtETEn3x5WRNxQamRmZmbWk+Gu5K8ndba7PN+OIe6nfGxiuaGZmZlZL4ZL8tOAG9pum5mZ2RgyZJKPiAu63TYzM7OxoXDHuxZJCwGLdO6PiCdKicjMzMxKUSjJS1oGOJQ0Ec4kUjt8J7fJW1+ZdlQ9rUwz955ZSzlmZguq6JX8dGBz4IfArcBTVQVkZmZm5Sia5LcEPhoRP68yGDMzMytP0bnr7wLc5m5mZjaGFE3ynwf+n6TJVQZjZmZm5Sk6d/2Zkt4A3CrpTuBfXe6zYcmxmZmZWQ+K9q7/GrAX8Gfc8c7MzGxMKNrx7sPA/0bEoVUGY2ZmZuUp2ib/BHBllYGYmZlZuYom+W8Cu0vqNgmOmZmZ9aGi1fUrAK8BbpZ0PvN3vIuI2LfMwMzMzKw3RZP8u4BngIWBrbocD8BJ3szMrI8UHUK3WtWBmJmZWbmKtsmbmZnZGOMkb2ZmNqCc5M3MzAaUk7yZmdmAGjLJS9pM0lJ1BmNmZmblGe5KfiawNoCk2yW9sp6QzMzMrAzDJfnHgOXy7SnAIpVHY2ZmZqUZbpz8JcCxkv6Utw+V9PAQ942I2Knc0MzMzKwXwyX5DwL/C6xFmtFuOWBiHUGZmZlZ74ZM8hFxH7AHgKTngI9HxOV1BWZmZma9KTqtrYfamZmZjTFFF6hB0rLAR4FNgeWBh4E/AsdEROeqdGZmZtawQlfokl4CXAccDCwJ3JV/Hwxcm4+bmZlZHyl6Jf8N0hryG0XE31s7Jb0IOAv4OrBt+eGZmZnZaBVta98C+FJ7ggfI2wcB00qOy8zMzHpUNMkHQw+fm5CPm5mZWR8pmuRnAl+WtGr7zrx9MDCj7MDMzMysN0Xb5PcCzgNukXQVcD+wIvAq4G7gs9WEZ2ZmZqNV6Eo+Iu4kzXz3aeAvwMLADcCngJfl4z2TNFHS1ZLOyNvLSzpX0i3593IjPYeZmZklhcfJR8RTwPfzT1X2BG4Els7b+wEzIuIwSfvl7X0rLN/MzGxg9M1MdpJWAd4CHNu2e1vghHz7BGC7uuMyMzMbq/omyQNHA58Hnmvbt1JE3AuQf6/YRGBmZmZjUV8keUlvBWZHxJWjfPzukq6QdMUDDzxQcnRmZmZjU18keWAT4O2S7gR+Abxe0k+A+yWtDJB/z+724Ig4JiKmRsTUSZMm1RWzmZlZXys6d/1mkpYa4thSkjbrJYiI2D8iVomIKcDOwHkR8V7gdGDXfLddgdN6KcfMzGw8WZDJcNYe4tia+XgVDgO2knQLsFXeNjMzswKKDqHTMMeWAp4oIRYAIuJ84Px8+yFgy7Ke28zMbDwZMsnnKvgt2nZ9WNKbOu62GGnY23Xlh2ZmZma9GO5K/jXAHvl2ADsAz3Tc5yngJmCf8kMzMzOzXgyZ5CPiSOBIAEl3ANtFxDV1BWZmZma9KdQmHxGrVR2ImZmZlavw3PWSFgM2A1YhtcW3i4j4XpmBmZmZWW8KJXlJmwK/BlYY4i4BOMmbmZn1kaLj5L8F3AasDywaERM6fiZWF6KZmZmNRtHq+jWB7d3xzszMbOwoeiV/LfCCKgMxMzOzchVN8h8HPiNp8yqDMTMzs/IUra4/F1gCOE/S08CjnXeICK/1bmZm1keKJvnvkHrQm5mZ2RhRdDKcAyuOw8zMzEpWeDIcAEnLAesALwbOioh/5klynoqI56oI0MzMzEanUMc7SQtJOgK4B7gA+DHQmur2FOCAasIzMzOz0Srau/4Q4CPAp4DVmXd9+dOAt5Ucl5mZmfWoaHX9+4H9IuJ4SZ2z291GSvxmZmbWR4peyS9LSubdLAJ4WlszM7M+UzTJXw9sO8SxbYCrygnHzMzMylK0uv4rwCmSFgd+RRozv56kdwAfBd5eUXxmZmY2SoWu5CPiNOA9wBuAs0gd744FdgPeFxFnVxWgmZmZjU7hcfIRcRJwkqSXktaVfxi4OSI8E56ZmVkfWqDJcAAi4q/AXyuIxczMzEpUdDKc4yT9cohjP5d0bLlhmZmZWa+K9q7fCjh5iGOnAFuXE46ZmZmVpWiSn0Rqg+/mn4CXmTUzM+szRZP834DNhji2GWlOezMzM+sjRZP8dGBfSZ+UtBSApKUkfQL4PGk4nZmZmfWRor3rDwdeAnwb+Jakx4ElSePlj8nHzczMrI8USvJ5rfgPSzoSmAY8H3gIOC8PqTMzM7M+M2KSl7QY8AiwU0T8Bri58qjMzMysZyO2yUfEk8Bs4JnqwzEzM7OyFO149wPg05IWrjIYMzMzK0/RjnfLAusAd0qaAdxPWomuJSJi37KDMzMzs9ErmuTfCczJt1/X5XgATvJmZmZ9pGjv+tWqDsTMzMzKVbRN3szMzMaYwkle0rqSfinpNklzJG2Q9x8iaZvqQjQzM7PRKLrU7DbAlcALgBOB9l72c4A9yg/NzMzMelH0Sv5QYHpEbA4c0nFsFrBeqVGZmZlZz4om+bWAX+bb0XHsUWD50iIyMzOzUhRN8rOB1Yc49nLgrnLCMTMzs7IUTfK/AA6WtGnbvpD0UtL4+J+WHpmZmZn1pOhkOF8E1gYuBO7N+04jdcQ7B/hq+aGZmZlZL4pOhjMHeKukLYEtgRWAh4EZEXFuhfGZmZnZKA2b5CUtDrwZmEK6gp8RETNqiMvMzMx6NGSSl7Q68AdSgm95VNKOEXFO1YGZmZlZb4breHcE8BxpQZolSL3oryYtO2tmZmZ9brgk/1rg/0XExRHxZETcCHwUmCxp5XrCMzMzs9EaLsmvDNzese82QKRe9WZmZtbHRhon3zm7nZmZmY0RIw2hO1vSM132z+jcHxErlheWmZmZ9Wq4JH9QbVGYmZlZ6WNgYC8AACAASURBVIZM8hFRW5KX9GLSErYvIPXoPyYivilpedLCOFOAO4EdI+KfdcVlZmY2lhWdu75qzwB7R8TLgI2AT0paG9iPNAHPGsCMvG1mZmYF9EWSj4h7I+KqfPsx4EbgRcC2wAn5bicA2zUToZmZ2djTF0m+naQpwPrAn4CVIuJeSF8EAHfuMzMzK6ivkrykpYBTgL0i4tEFeNzukq6QdMUDDzxQXYBmZmZjSN8keUkLkxL8TyPi13n3/a3Z9fLv2d0eGxHHRMTUiJg6adKkegI2MzPrc32R5CUJ+BFwY0R8ve3Q6cCu+faupDXszczMrIBC68nXYBPgfcB1kmblfV8ADgNOkvQh4C5gh4biMzMzG3P6IslHxEWkOfG72bLOWMzMzAZFX1TXm5mZWfmc5M3MzAaUk7yZmdmAcpI3MzMbUE7yZmZmA8pJ3szMbEA5yZuZmQ2ovhgnbzaIph01rfIyZu49s/IyzGzs8pW8mZnZgHKSNzMzG1BO8mZmZgPKSd7MzGxAOcmbmZkNKCd5MzOzAeUkb2ZmNqCc5M3MzAaUk7yZmdmAcpI3MzMbUE7yZmZmA8pJ3szMbEA5yZuZmQ0oJ3kzM7MB5SRvZmY2oJzkzczMBpSTvJmZ2YBykjczMxtQTvJmZmYDyknezMxsQDnJm5mZDSgneTMzswHlJG9mZjagnOTNzMwG1EJNB2Bm1Zh21LTKy5i590yXb9bHfCVvZmY2oJzkzczMBpSTvJmZ2YBykjczMxtQTvJmZmYDyr3rzcxKVkfPfnDvfhuZr+TNzMwGlJO8mZnZgHJ1vZnZgHFzgbX4St7MzGxAOcmbmZkNKCd5MzOzAeUkb2ZmNqCc5M3MzAaUk7yZmdmAcpI3MzMbUE7yZmZmA8pJ3szMbEA5yZuZmQ0oJ3kzM7MBNSaSvKQ3SbpZ0q2S9ms6HjMzs7Gg75O8pInAd4BtgLWBd0tau9mozMzM+l/fJ3lgQ+DWiLg9Ip4CfgFs23BMZmZmfW8sJPkXAXe3bd+T95mZmdkwFBFNxzAsSTsAb4yID+ft9wEbRsQebffZHdg9b64J3NxDkSsAD/bw+F65fJc/Xssfz6/d5bv8XstfNSImde5cqIcnrMs9wIvbtlcB/tF+h4g4BjimjMIkXRERU8t4Lpfv8l3+2Cjb5bv8QS1/LFTX/xlYQ9JqkhYBdgZObzgmMzOzvtf3V/IR8YykTwFnAxOB4yLiLw2HZWZm1vf6PskDRMSZwJk1FVdKtb/Ld/kuf0yV7fJd/kCW3/cd78zMzGx0xkKbvJmZmY2Ck7yZmdmAcpI3MzMbUGOi413VJP04It430j6zQSFp+eGOR8TDNcWxQ0T8aqR9g07SkhHxeENlTwRWoi0fRMRdTcTShCbOvaQNhjseEVeVVpY73oGkqyJig7bticB1EVHLQjiSPgn8NCL+lbeXA94dEd+tuNzthzseEb+usvy2OB4DOt+IjwBXAHtHxO0Vl//Z4Y5HxNcrKvc65n/d7eWuW0W5uew7ctnqXnSsXlXZHXHM87831L4Ky58IvAWYwrxJrpK/eZfyNwaOBZaKiMmSXgl8NCI+UVP5ewAHAPcDz+XdUeV7L5c71HtfdZSfY2js3EuamW8uBkwFriG99nWBP0XEpmWVNa6v5CXtD3wBWFzSo63dwFPUO5ziIxHxndZGRPxT0keASpM88Lb8e0VgY+C8vD0NOB+oJckDXyfNYvgz0vnfGXgBaXri44AtKi5/KvBq5k6y9DbgQuZdM6EKb82/P5l//zj/3gV4osqCI2K1Kp9/JJK2Ad4MvEjSt9oOLQ08U2MovwWeBK5jbpKr0zeAN5LfexFxjaTNaix/T2DNiHioxjJh7nu/SY2d+4iYBiDpF8DuEXFd3l4H+FyZZY3rJB8RhwKHSjo0IvZvMJQJkhS5WiVfXSxSdaER8YFc3hnA2hFxb95embS8b13eFBGvads+RtJlEXGwpC/UUP4KwAYR8RiApAOBX7XWS6hKRPwtl7dJRGzSdmg/SRcDB1dZfkuuOVqDdFXRiu3Ciov9B6mm5u3AlW37HwM+U3HZ7Vap46pxOBFxtzRPhcqzNRZ/N6nWrFat937TGj73AGu1EnyO53pJ65VZwLhO8i0Rsb+kFwGrMm+VXdUfdC1nAydJ+j6pCutjwO9rKhtgSivBZ/cDL62x/Ock7QicnLff1XasjvakyaTam5anSNW3dVlS0qYRcRH8txpxyToKlvRh0tXcKsAsYCPgUuD1VZYbEdcA10j6WUQ8XWVZIzhL0tYRcU5D5d+d/96Rp+3+NHBj1YW2NVHdDpwv6XfAnNbxqpsrJF0UEZt2aaprVdcvXWX5WSPnvsONko4FfkI6D+8tOwYneUDSYaQq4huY+00uSFW2ddiXtIrex0lv8nNIbUV1OV/S2cDPSa97Z2Dm8A8p1S7AN5nbPHEp8F5JiwOfqqH8HwOXSzqV9PrfAZxYQ7ktHwKOk7RMLv8R4IM1lb0nqanisoiYJmkt4KCaygZ4o6QvM/cLdp0f8gCXAadKmgA83UD5HyO9919EWozrHOY231Tpefn3XflnEebWHlb+xbrV5hwRzxvpvhVq6ty3+wDpc3/PvH0h8L0yC3DHO0DSzcC6ETFnxDtXH8vypCrEa2su9x1Aqz3qwog4tc7ymybpVUCrs8uFEXF1AzEsTfqfrK36VNKfI+LVkmYBr4mIOZJmRUSpVYbDlH8rsD2po2vtH0aSbge2a6r8pjU9usEjmyBfzEyOiF6WSB+Sr+ST24GFaauuqpOk80ltkwuRqkwfkHRBRAzb67uksicA10bEOkAjiV3SKsC3gU1IVxEXAXtGxD01hjELuJf8PyFpcl3DiCStBHwVeGFEbCNpbeC1EfGjGoq/R9KywG+AcyX9k46lnCt2N3B9gwn2libKl/Rthh9Z8emaQtkf6Ezo3fZV5eXtG5IWAl5VZYF9dO6R9HbgSFItymq5Pf7giHh7WWU4ySdPALMkzWDedqm6/tjLRMSjuX30+Ig4QFItV/IR8Zyka+pMal0cT+pZv0Pefm/et1UdhXcMI3qWXGVLGs5Sh+mk1/u/efuvwC+BypN8RLwj3zwwD+tZhnr7g3weOFPSBdTYJtzmXlJz1Vk1l39Fxc8/rKZHNzQ8sqnRc9/hAGBD0mgmImKWpCllFuAkn5xOs2vUL5R7tO/I3A/6Oq0M/EXS5cB/J4Uo89vkCCZFxPFt29Ml7VVT2dDcMKKWFSLipPzB11peubZevnlijk1JX2wujoinRnhImQ4B/k3q2V/5iJIu7sg/7W3SlYuIE2Do6vIaQmh0dEOTI5v64Ny3eyYiHuno4V8qJ3nm/tEbdDCph/3FEfFnSauTqhHrUmdHq24elPReUsc/gHcDdSbcRoYRtXlc0vPJVYiSNqorHklfItWgtOZEOF7SryLiK3WUDywfEVvXVNZ8IqLp934j1eV9NrphvrHpNY1sarqpAuB6Se8BJkpag9TD/5IyCxjXHe8knRQROw41+1LT42frlNuFX503L4+I2TWWPRn4P+C1pL/DJaQ2+VrG0kr6EbAmUOsworbyNyD1SVgHuB6YBLyrjs6Xkm4E1o+IJ/P24sBVEfGyqsvO5R0GnFf3EDZJR0fEXpJ+S/f//Uprsdqqy3ckNc20LE2as2LDKstvi6PbZ19rtsmvVF27lc9/y2KkqusrI6KyIZz9cu5zLEuQam+3JjVXnA18ufX/WIbxfiXfGrbQ6OxLkl5KGjaxUkSsI2ld4O11XU3lMepHktqFBHxb0j4RcfKwDyyn7InAV2tsGuim2zCi2kTEVZI2J33REHBzjVdXd5I+XFsfKosCt9VUNqQhS5+XNId6h7C1Zhf8WsXlDKVfJgM6i9QP5Wd5e2fS3+ARUl+Rt3V/WDkiYp7nl/Ri4Igqy6R/zj0R8QQpyVfWTDuur+TbNXwlewGwD/CDiFg/77s+93ivo/xrgK1ar1nSJOAPEfHKmso/G3hbzW3BjVODawe09TCeTHrfn5u3twIuioidqyrb5pK0UETUOY1vZ/kXd8y2+N99kq6LiFfUHI9Io30qL1fSwg03VSBpKqkD4hTmnYittFrk8X4lDzR7JZstERGXd3S+qPMff0LHl5qHqHcZ4juBiyWdzrwd/6qedavRKluGv0oKql07oNXD+ErmHTp5foVldqUGptUdqomurfyqF2g5KSJ2BK6W1GRT4VKSXhMRf8pxbQgslY/V0cu+fTjbBGA90mItVZbZOvdXNXzuAX5KusCrbO0EJ/nkf4FXd17JMnea1ao9KOklzO149S7S0J66/F5zZ7wD2IlUjVeXf+SfCcydiasOjVbZRl47oKGyC3U2lXRKRLyzqjjU0LS6NL9ASl80FQIfJs22uBTpAudR4MOSlgQOraH89uFszwA/j4iLKy6zde5vJCXYFlF9U0GnByKi0pFdrq4nfatvrx7KE8RcU1dVVe5NfwxpJbh/kob07FJXx7Mcw/akYVSioRnv1OCa2k1QQ0vcLghJV7eakCp6/uuYO63uesrT6kbETlWVuSAkXRoRr63w+Q+PiH1H2lc1pSmVFXm5635R5ZdMdV/m+No6r+QlbUkaTdQ5R0tptXi+kk+6XcmeWXWhHR/yZ5Lmi59AqrJ+J2kJ1spJWg04s/XGkrS4pCkRcWdN5b+WNPHLUkBt6zoPU2Vb15rWTc7bXVTVVwFPRsSTkpC0aETcJGnNistcEIuNfJeebEVau6LdNl32VULSoqTPmimk+ToAiIhaVkAsYPWyn1DSx4FPAKt3TDr2PKDqWoROHwDWIs242qquL7WpzkkeiIh9JL2TNK2qgGNqupJtfcivSbqaOS2X/z7qWxwH0rjQjdu2n837Xt397qU7mmbWdW60qrQPxmj3g6an1R1JJV9y+ijRnEbqSX8lDU3rPYIqzv/PSM2RhwL7te1/LCIerqC84byy6hpjJ/ksIk4BTqm5zIMAJJ1Dl/XMawxlofae7RHxlNLSi7WJBtZ1bm8OkbQqsEZE/CGPFa/tf0P9MXf/UKqbiouRp9WVtFxE/LPKGBpSKNHU8PpXiYg3Vfj8fSfSAlCPkKrJm3aZpLUj4oaqCqizB3XfkdRav/sxSY92+blDUqVVxlnT65k/oLRQAgCStgUerLH8edZ1lvQ5alzXWdJHSJ0sf5B3rUK6sqzL8aRajBeSlr38bd5XKUkTJf1khLvV1jYcERdExOkdQyln1FX+ECr5khMRj0TEnRHx7oj4W9tP55Vk1a//Ekm1DpNbQJV+yewDm5LWTblZ0rWSrlPJ65aM6yv5GGFNY6WpRi9Rmvqxyg4p3dYzr3Oq3Y8BP5X0nVz+PcD7ay6/yXWdP0maaetPABFxi6QVayy/kbn7I+JZSZMkLTLUHAV1z0TXRdMf8k0veVr1698U2E3SHaTq+rr6oxRVawfEBgxbi1JGTc64TvIjiYiHJE0DzgM2GOn+PZRziNIqWK/Luz4QNa5nHhG3ARu1htG0mg1qLP9BYJc6y+wwJzdRAP9d7rLOYSdNzt1/Jw3MUbAAqmoTvygiNpX0WEcZ88y4FxHXV1H+Aqj6fbhNxc/fVdFOr33wJbNSBUZQzaDH3OMkP4KI+IdU4RJBc8u5Criq6nK6UUPrmat/1nW+QFJr2cutSB2ifjvCY8r0QdLc/d9g7tz9H6yp7KbmKGjUSLV440VE/E3SpqT+KMfnOUKWGulxJWh6foCxoufc4yRfzKBPJjCdZtYzb02EsQmwNnMXi9iBeeeUrtp+wIdIs059lDSc8dg6ClbDc/ePgR7+lX/Bzn+DlZh3WtG7qi63oEpfv6QDgKmkET7Hk4Zy/YT0P1mZjk6vjU0pPgb0nHuc5A0aWs885q7rvBswrTWPtKTvk9rlaxERzwE/zD+1KtIuXqXco73b1J6Vzjgnafnhjrd1QNuy4jj2AA4A7mfeccp1ToiyAaltPEjLTbfX6FX6+kn9f9Yn1yLmmsvaajfU/JTiA89JvpimO/9UrbH1zLMXkqqKWx/sS+V9lRqmXRCodQ7rO2muXfxzbbcXI02MUse6CVeSzn23/60gT4JSw7jlPYE1o+IlVYci6UukmqvW5CfHS/pV5BUoa3j9T0VEKM/hnqezrVPTU4r3O1fXl0Fp3vh7ImKOpC1I3+JPbOtRX/W36aZ9ljSE6yWSLiavZ15j+YeRFuqYmbc3Bw6sodxWu2CrJ39rLvtdgCdqKL+lsXbxiOhsFrlYaVXEqstdreoyCrqber/Qdno3sH7k9cMlHUa6qq5lmWngJEk/AJbNQ0k/SL01Wk0vjtUoSW+IiD907Ns15q4t0XPu8dz1gKRZpHapKcDZpIS3ZkS8ucm46pDbIz9NmoylifXMW3G8AHhN3vxTRNzXduzlEfGXCssecrnNqsrsFx3V5hOAVwHfiohKp5bNVdRD6qiyrqL81pTSLye973/HvHOH1zWl9FnAu1sXFHn2v59ERG0d03Jn061J//tnR8S5NZZ9JOmiqn1K8Wuj5rn7myLpQuAvpBq1pUh9geZERGkXWU7yzF2oQNI+pLm0v62KF+boJ5LOj4gtmo5jKOqykETJzz8L+FREtCZH2hj4bkSsV1WZHeW/lPRPPoV5O39VvRIbeXx0q9r8GdLiSAe3zkWF5c4c5nDU0CfggOGO19UhUdJvSJ3OziX9HbYizXg4O8dR1wiTxqgPFsdqSh65tTepwy/AlyLi58M8ZIG5uj55WtK7gV2Zu8b3wg3GU7eLJf0fqXd7e5twI0P6uqi6T8SHSMttLkP6oH2E+oawQZrC+Pukb/GVd3hs11S1eURMa6LctvILJXFJ346IPSoM5dT803J+hWX9V5f5Af57iLZ5AmqI4zPAr6LEVdfGmOVINZi3kWbaXFWSosSrb1/JA3lc+MeASyPi50qrsu0UEYc1HFothriqqvxqqqiqr+Tbylma9D/xSMf+9jayKsq9MiJeVdXzj1D2J4GftlUXL0eqPv5uTeUvDHwcaC1IdD7wg7qbi4ZS13uvX5Ux49oIz38AsCOp0+0vgJMj4v6qyus3kv4KHBYRxymtmXE4MDUiNh7hocXLcJK3kVSd5AqU3+gHbQ3NBQeSqmdPZd524cpXxJI0q7NZos6mKknHkmrNWu+v9wHPRsSH6yh/JDX87d8KfBlYlVSzWuuV9Ehq/IK9Lqk9/p2kTtBvqLrMfiBpcuecDJI2i4jSViF1dT3ztEvOIyJKX8t4jNqTiubSz21Sq0TE3cPcrfbx4x2qbi7YNf/ep23ff4eRVWxCe/Vg7ohZ5wqEr46IV7ZtnyfpmhrLb9rRwPbAdWVW0ZaoruHDs4H7SL3r61w3omkPSvoiMDkiPiJpDaDUL3hO8snUttuLkcatDjtZxzhT2T96HqP7G1Kv7qHus1FV5RdU6Ydvw8PJziYNo/o+6XV+jLalXmvwrKSXRFo/AUmrU3O/hBFUneTuBq7v0wQPFb/3JX2cdAU/iTQ2/iNR4bKrfeh40pwRr83b95D66JxRVgFO8qSFaDp2Ha20DO2XmoinD1X9AXSZpFdHxJ8rLme0qp5adAnSXAWTI2L3/G1+zYgo7R99GPsCu5PaxUWaabCWKX2zfYCZkm7P5a8KfKCuwiWtH8MvBvXNikP4PHBmnpug9iF8fWBVYK+ImNV0IA15SUTslDt+ExH/ybWbpXGSZ74xuxNIV/bjeuGKDlVfzUwDPirpb6Te/bUudylptYi4Y5h9F1ccQuvbfKuzTenf5ocSaUrf7+ef+Ug6JSLeWWH5M1pfakh/95siYs4IDyvT1yWtTDrfv+icjyEipldc/iHAv0k1iHU2kxRV6f9+ROwnaVNJH4i2BXI6/x8H2FO5w12ruewltH3ZK4OTfHJU2+3WWOEdG4qldn2Q5BpZ7rLNKcy/nOPJ5CaEiPhUxeVX/m2+B5X2C2jr3X9t3l5O0ofq6t0fEdPyREw7AsfkERa/jDytbA2Wj4itayqrKzU4d74aWiCnjxxAah57saSfkl73bmUW4N71pHbAiLi9Y998iW9QdetBW/ewLkmvBF6XN/8YEZV3vpK0FmnGsyOYt9Pb0sA+EfHyqmPIcVxC+jC9OE/K9BLg5xGxYR3lD6eOiYia7N3fUe4rSNXnO0VELVfVStPYnhcNrZuu+efO3440br2WLzl5Iqr1gataf3NJ19ZVi9cPlNYN2YhUa3JZRDzYdqzn2T59JZ+czDBXcoOqLcktk2edalmaVH1YVxx7Ah9h7gfNTyQdExHfrrjoNUnz1y/L3EmQAB7L8dSl8m/zfazR3v2SXkbq+LUD8CBprPbedZVPWjdhH0lPAU9T/xC6pufOb3qBnMblPmG/G+Lwj5k/Ny2QcZ3k+yXJNahfktyHgNdExOMAkg4HLiXNp1+ZiDgNOE3SayPi0irLGiGOcyVdxdxv83uW/W2+B1U3GzTdu/940rzpW0XEP2ost2UZ0oJIq0XEwZImAyvXWP6dpM+6J/P2oqTZ1yqXm6TOULML5PQ7r0LXo35Jco3olyRHeiO3D5t6lvrG5wK8Q9JfgP+QEswrST1+f1JXAFV/mx+KpD0j4pvD7Kt6oZBGe/dHxEa549Pkusrs8B3SOvavBw4mffacQprPvg5zgL9ImmfufEnfgmrnzs9X8NuR3gOPkj6PvxQ1LpAzBvTcnu42eaAPklyjJB1Bqp5rJMkprQi2K3Pn8N4OmB4RR9dU/qyIWE/SO3LZnwFmdkzS0pgq26iH6I/RN4szVd27X9LbgK8Bi0TEapLWIy3Q8/aqyuwov7U41n/PuaRr6nrvSdp1uONVz3Qp6Tuk//V+HT7bqDL6xIz3K/mWq3Mv35fTVk0fEXUuUtKkrSPi8znJ3UNqn5xJ6uVauYj4uqTzmbsS1QdGGLtcttZiRG8mdXh7uH86twMVzFOQe/K/B1hN0ulth55HmnWsX1Q969+BwIbkhWEiYpakKRWX2e7p3A+h1SY9iXRlX4uqk3gBncNnARhPHe9G0PNsn07yyY+Bm4A3kqrMdgFubDSiejWS5CQtHRGPKq1pfmf+aR1bDng0IuqY/ey3km4i1WR8In/QPjnCY8a6S4B7gRWYdwjpY8C1jUTUXdVVjc9ExCMNfqn7FqkGa0VJhwDvAv5fXYWr+bnzmx4+2yhJmwCzIuJxSe8lNct9MyL+BuXM9unqeuZWT7aGbiitjHV29MkqbFXLPWq3IyW5DUl9FM6IiNdUXO4ZEfFWzb92QOsTdynghxHxhSrjyLH890uF0gx0S0fEfVWXW4Sky8r4Zx/m+Vdibhvw5RExu6qyFlQNQ/h+BMwA9iMtjvJpYOGI+FhVZXaJYS3SEEoBMyKitgsMSbfS33PnDzRJ15KaR9clXWz+CNg+IjYvrQz/XUHS5RGxoaQLgU+QFkq4PMbRAjX9mORyNeb1EfGyGspaB1ibeZtrTqy63LbyX8Tcq6lW+aWtRDVMuTuQ2qTPJyWZ15HmCDi56rKLqLp/QH6v/y/QmpDmbOArrSFlg05pmektI818aDVr65PxJeDvEfGjsr/YOskDkj5M6tH6CmA66QryixHxgybjqlMfJLnlgDU6yq88yeWyDwC2IL3+M0lViBdFxLtqKv9w0ljtG5g7yiDq6PyltOLbVq2r99xU8YcaO34N27tf0tZVTRSTv0SeHeNkWdNuJL2aVF0/XufOb5TSmgW/J63XsBnwAKn6/hWlleEkX2ha14HWB0nuw6TlbFcBZpHGi19aV3OJpOtIVWZXR8Qrc/X1sRHxthEeWlb5NwPrRr1ztrfKvq79A0XSBOCaMj9kRii/0d79udPh+yLikTrK6zeSziHNnX8dbR3+IuKgxoIaR5SmVH4P8OeI+GOeJ2GLMi+w3PEuGXbu8nHgXcxNch9oJbkay9+T1CZ8WaS5xNcC6vyQ+U9EPCfpGaW5y2dTz1ruLbeTOj/WnuSBsySdTZoQBlKNwplVF9pHvfufBK7L48Tbe3dXNj68zzQ+d/54lptEv962fRdQag3quE7y8ox3LU0nuScj4klJSFo0Im6StGaN5V8haVnSTFtXkq5sLq+6UEnfJnU4fAKYJWkG81aZ1pFoAvgBc4cvHkOqSalav/Tu/x1DT0I0HvyhyiYRG17OO4cDK5L+/0of3TCuq+slbUvqVf52oP1q4jHSspOXNBJYzSR9F/gCsDNp3u5/k9qFalnXW9KppDapvUgzf/2T1MP5zXWU3xHLFFKnw8oTTdMTkeQYulWX17pASJ/37q90Mp6mSXoMWII0HruJufPHtTy64W1VjqgY10m+ReN8xrt2dSa5IcrfnDSf9+8joueJIEYoa9gerDHvkptVxrEkqTbj2bw9EVg0Ip6osMyPk0aSrM68c5U/j7Qa3nurKrsjjnHdu79puQ/GfHPnR8SfGg5tXJB0cURUuqyukzzNT+valH5JcjmW5YAXM+8QskrLz8OHhhI1dvy7DHhDRPw7by8FnBMRG1dY5jLAcsChpDHiLY9FxMNVldsljkZ794+k6nH6TZP0PfLc+RHxsvx/eE5E1DV3/rjU1jy8OfAC4DfM21T3626PG41x3SbfptFpXRt01DDHglR1XjlJXyYtrXo7c3v4Vl5+REwrcj9JW0W1i2Ys1krwABHx7zx+uzK5N/kjpKVGmzSho3r+IWBCU8GMQ6/J47SvBoiIf0qqbanfcax95M4TzJ2nAdJnn5N8yfp97vJK9FGS2xF4SdXV8z04HKjy9T8uaYNWzYWkV5FqlcaDRnr3L4BB/yBodO788arV30nSJhFxcfsxpaluS+NvzElr7vKpwAyNj7nLF8ThFT//9aSpdPtV1R/0ewG/kvRHSX8EfgnsUXGZ/aLVu39dUjPZMc2GM5+ql9ptWufc+RcBX202pHHl2wX3jZrb5LOOaV2XBJ7Xmta1hivZvlbD1KJTgdNIyb69XaqW5T5HUnW7rKRFSVdPa5K++drDFgAAFplJREFUUNxEqsZuYtx8rZrq3Z8nQOr24dfqXT5uVkFTg3Pnj1eSXgtsTPqC/422Q0sD7yizT4qr67OI+Gfb7cdpmxiD6qtr+13V3wRPIJ3jeWbdGkcuzYnu+tYOSVcx/wRNA6O9d7/SIh0tzwMu7v6oUr21hjLGhIi4ifTF0uqzCGn69IVI7/mWR0mTk5XGSb6YQW+Xa9qDEfGtpoMYxp1VPGme0vJFwOKS1mfu+2xp0tjlQfYz4Cwa6t0feSlPsyZExAXABZKmV/1edJIvZry3adxZ8fNfKelQ0oRE7dX1dY1TX4I0CdDkiPiIpDWANSPijBzH9sM+wei9kTSqYBXaprYkTcZU+fK6TeqX3v2SNiK1gb6MdHU1EXjck8FYTSZJOpr5V6AsrbnIbfIFjIOxssMmuRrK7zZevc5x6r8kTWf7/ohYR9LipCr09Woq/50RcUodZdm8JF1Bmunx/7d393GXjfUexz9fUgojShwpMgcd5aGiZoxXCD176EFKlNHDSacapwdRaSjnFJ3UHBWhRo86qUgpESmUipoIOUehVKLUmEJj+J4/rrXNvvfcYyaz9lp79vq+X6/7dc9ea9/7dxlz799e13Wt3+90ysbbVwD/bPudrQ4sOqFqTvU2lmwQVNvVfa7kl88NbQ9gyOZSktz06vFNlDe9RpL8sm7lk/TKIZd4nWp736ppCrbvVIP3UNr+sqTnUfoo9LfafU9TY+gy29dJWrWqODhXUifKWcdIuNX2Wct+2gOXJF+RtAOwCROnTD5dfR/WdO2oaDXJLYdZlM15w7Kwunrv3Ss8lQY7wkk6kbIGvwul+9+LaaBBTgBwR1X8ZV5V+fL3wBotjym6Y7akU4DB5lQphlMnSZ8BplJ6md9THTY1t/wbYa0mueUw7A8csynljB8j6XPADMpaeVN2sL11devYUZI+SI0Vr+J+HUCpF/IG4N8ppZXH/UN9jI6ZwOMpBdn6q30myddsO2BLd3eDQttJblmG+v/F9nnVLWvTKB8oZtn+4zBjDuhVt7tD0oaU0q6PazB+l+1tew6l+NVRAJJmAXNaHVV0xTa2txpmgFS8K35OaRLQSVWhnxdSEvtpwHa2L2xzTAOGeiVf9SxYZPvsarPhIkl7DzPmgK9X/eyPpeyNuAH4QoPxu2yydr8HNj2I6KxLJW05zADZXc99u7u3payDjlzFtWGrktwF1W1NVAlnZ9tnNhT/cbavX9oxSR+x/YYhxp83uJO+yRaj1VLJwZQ2qwYuAk6wndLKQ1LtP9kP2JHy990zhfKBb7dWBhadIukaylLx9ZTcU3vFxSR57uthvoSqYMHYG4EkN1lp08ttP6Wh+EuUUZV05bCn0fpifZFyb3yv6+HLgIfbfkkT8btI0saUJZElivEAV9he1MrAolOqf4dL6N1CJ2md/mqsD0TW5CnJXNL6QK+H8o8G2l+Ou8mWbYb+b6Oqmf0EYO2+/spQrqZWn/ynhuIySccBH6VcSb+RMm3elC0GalV/p+qzHkNSvYneCEwf+N2/Jgk+mrIc98OfzwqWt86aPCDpJZSp+n0obU9/KKnW+sEj7jJJx0maKmlTSR+imSS3BaWG+MMp/ZV7X08GXtNA/J43Agsp3d9Op2zC+rcG4/+0qrwGgKSn0Uz99s6TtA/d/t2P0bbC+5EyXQ9UV027967eq1az366zE9Aoq7ruHQHsRvlHdS5wdNWop4n4023/oIlYo6SvE9pqlA88v64ebwxcbfuJLQ6vE7r+ux+jrY5qq5muL1YZmJ7/Ex2a5aiS+WHLfOLwvEDSVZRbyc6h9BU/xPZn7//H6iFpc+CtLFkMadhlddMJrX2d/t2P8ZckX5wj6VuU28cA9gW+0eJ4GtVikut5pu1Dq13+N1GmTr/D4o1ow3Y6cCKl2tw9y3hubdIJbSR8s8u/+zHyVni6PkkesP02SS+iFIERcJLtM1oeVpNaSXJ9Vqu+Pxc4zfZtDVfVXWT7hCYDxsgw8HHKrXQCTqIURYoYBbuu6AtkTT4avV1tKfHfD+xNma5/KmUj3tdtP62h+EcCtwBnMLFOwtD7mke7lnL75hK3VEbUSdJWwMnAo4FvAm/v3Son6Ue2n1pbrC4neUkX295R0gImlk7tFSToRE/pUUhyktYBbrd9T9X6dortmxuKff0kh2170ybiR/MkHQy8HtgU+GXfqbWAS2zv38rAohMkXQwcDVwKvJpSw35P27+su0ZJp5N8FKOQ5CQ9EdiSia1Wu9IgKBomaW1gHSYphpMZnBi2wQJkknahLBUdAHxsRXfUT4iVJF+60Nk+YFnHYjgkzQZ2piT5bwDPAS62PdT7lSU9w/YFA4V47lNnu8eIiJ7q1s2n90qJV8e2Br4MrGv7EXXFysa74gn9DyQ9CGhtjbopI5TkXky5be6ntmdWFchOaSDuTsAFlAI8g2pt9xgR0ecY4F8o0/UA2L5C0q6UmiW16XSSl3Q48A7goZJu7x2mVD87qbWBNWdUktydtu+VtEjSFMr+gKEvFdieXX2fOexYERE9tj+/lOO/puZqn5muByS9z/bhbY+jqyR9jPJh66XAW4C/AvOaSr5V//C5lOYkJ1PK6h5m+9wm4kdE9Eg6yfZra3u9JPmi2t29GRM3fn2vvRE1Z5SSnKRNKDvrr2gw5s9sbyPpWZSa9UcAc+vc/BIR0SNp3aWdAn5me6O6YnV6ur5H0quBWcBGwDxKMYwfAE1VfGvbQbbnVEnuUZTbOeZSatgPjaSlJlFJT7b9k2HG7w9XfX8uJbn/TA1X44mITrmV0gWx/33G1eNH1RkoSb6YRWk1eantXaoWqEe1PKYmtZXkPng/50xzH7Iul3Qupb/44ZLWAu5tKHZEdM+vgF2rNfgJJP2mzkBJ8sVdtu+ShKSH2P6FpC3aHlSDWklytndZnudJ2t32eUMcyquAbYFf2b5D0iMosxm9+E+wfdUQ40dEt3yYUqdhiSQPHFtnoKzJA5LOoLypH0K5evwzsJrt57Y6sIZIWoXFSe4vVZJ7dG9dvO0kV0e7xZU5fkR0Ux0XOEnyAyTtBKwNnGN7YdvjGQVtJ7m6yzyubPEjopvqeO9N32RA0rRqihrb36W0Oc2b+mJtb0Jr+5No2/EjoptW+L03Sb44gXJvds/fqmNRJMlFRDRvhd97k+QLuW/dwva9ZFPiKLmh5fhZtomIlVKSfPErSW+StFr1NYtyi0MUQ01ykh4m6QhJJ1ePN5P0/N5525PW1q8x/gxJa1R/3l/ScZI27os/bZjxIyKW4oYVfYEk+eJ1wA7Ab4GbgKcBtZUVHHUjkOTmUvrYT68e30TptdyUE4A7JG0DHEopUpE2txExVJL26e0Hk/QuSV/pLxJWxwVOkjxg+xbbL7X9KNvr297P9i1tj6tBbSe5qbaPBe4GsH0nzW72W1Qt1+wFzLE9B1irwfgR0U1H2F4gaUfgWcCnqHk/WKfXnSUdavtYScczyQYH229qYVhtWGTbknpJ7hOSXtlg/IWSHkr1/0DSVMqVfVMWVB0J9weeLmlVYLUG40dEN91TfX8ecILtr0o6ss4AnU7ywNXV98taHUX72k5ys4FzgMdI+hwwAziwwfj7AvsBr7J9s6THAh9oMH5EdNNvJX0c2A04RtJDqHmGvdPFcCR9xvYBkmZVU7SdJGkDSpL7se2LqiS3s+3GpuyrKnvTKNP0l9r+Y1OxIyLaIOlhwLOBK23/n6R/AraqswNo15P81cBzgLOAnRlYB7Z9WwvD6hxJLwAusD2/evxwyoeMMxuK/0LgGEr3J1Vftj2lifgR0V3VzOn69M2sT9a45gG/fseT/JuAg4FNKTvrJ7T9s71pKwNrWNtJTtI829sOHGuslKyk64A9bF/TRLyICABJb6QsV/6BxU3BbHvr2mJ0Ocn3SDrB9sFtj6MtbSc5SVcM/qOWdKXtrRqKf4ntGU3Eiojoqd57n2b7T0OL0eUkL2mK7dslrTvZ+a5M17ed5CR9EvgL8FHKDvs3AuvYPnDIcXv3oO4EbACcSd+ufttfGWb8iOg2Sd8Bdre9aGgxOp7kv277+ZKupySXTk3Xj0qSqwrxHEHZYSrgXOBo238bcty593Patg8aZvyI6DZJnwC2AM5m4nvvcbXF6HKSB5Ak4DF1bnRYWSTJFZJm2L5kWcciIuokafZkx20fVVuMrid5AEmX235K2+NoS9tJTtLmwFuBTZi4w/QZDcVfomdzHX2cIyKWR1Xa1rb/uswn/4O6Xgyn51JJ29v+cdsDacnxwGBCm+zYsJwOnAicwuIKUEMnaTqlZ8F6kt7cd2oKsGpT44iIbpL0ROAzwLrV4z8Cr7B9VV0xkuSLXYDXSbqB0ku+dwtZbbcxjKIRSnKLbNdar3k5PRhYk/J7sGbf8fnAi1oYT0R0y0nAm21/B0DSzsDJlPflWiTJF89pewAtGZUk9zVJrwfOYOLmk6He3WD7u8B3JX0DeAcTlwtmAmP9IS8iWrdGL8ED2L6w1xG0LlmTr1RdgDazPVfSesCatq9ve1xNkLQ9Sya5xmYyqrsbBjV2d4Okayl7An7O4oIU2L6xifgR0U2SzgB+Qpmyh9I/ZDvbe9cWI0n+vh2O2wFb2N5c0obA6V0pkNL1JCfpYts7tj2OiOgWSesARwE7UpaJvwccafvPtcVIki9lVYEnAT/plVKdrArbuGoryUl6hu0L+u7Xn6DB+/R3BV4GnE+K4UTEGMmafLGw6qfe62de65rISmC2pFNoPsntBFwA7DHJOQNNJdmZwOMp7XXvqx/dYPyI6BBJH7Z9iKSvUd5rJrC9Z22xciUPkt4KbAbsDrwPOAj4vO3jWx1YQyR9lpLkrmJik4SuFMNprE5+RISkp9i+XNJOk52vNgXXIlfyxb3ARcDtwObAu22f1+6QGrVNm0lO0ixgLrCAcvvIk4HD6uypvAyXStrS9tUNxYuIDrN9efXHbW3P6T9XvR/WluRXqeuFVnJrAYcD04AbgCtaHU3zLpW0ZYvxD7J9O/BMSrvbmcD7G4y/IzBP0rWSrpB0paSu/RuIiOa9cpJjB9YZINP1fSRtDexLuUf8Jtu7tTykRki6BpgKXE9Zk2+0GFBvk6OkOcCFts9ouJ/8xpMd78rdBRHRLEkvA/ajXGBc1HdqLeCeOnNPpusnugW4GfgT5YqyK57dcvzLJZ0LPA44vKrjfO8yfqY2SeYR0bDvA78HHgl8sO/4AmqeSc6VPCDpYMoV/HrAl4D/yfpscyStAmwL/Mr2XyQ9Ani07Suq80+os5ZzRMQokLQp8Dvbd1WPHwqsb/uG2mIkyYOk9wNfsD2v7bHEktIRLiLGkaTLgB1sL6wePxi4xPb2dcXIdD1g+7C2xxD3S20PICJiCB7US/AAthdWib422V0fK4NMN0XEOLpV0n2FbyTtBfyxzgCZro+Rl+n6iBhHkqYCnwMeTbmYuYnST/66umJkuj5WBguX/ZSIiJWL7V8C0yStSbnoXlB3jEzXR+skzej1C5C0v6Tj+u9dtz2tvdFFRAyHpPUlfYLS9XSBpC0lvarOGEnyMQpOAO6QtA1wKHAj8Ol2hxQRMXSnAt8CNqwe/y9wSJ0BkuRjFCxy2RyyFzCnquW8VstjiogYtkfa/iJV8S/bi4B76gyQNfkYBQskHQ7sDzxd0qqUtq8REePsb1Xxr16b82nA/DoDZHd9tE7SBpQ6zj+2fZGkxwI7286UfUSMLUlPBo4Hngj8nFJ19cW9ap+1xEiSj4iIaIekBwFbUIp+XWv77lpfP0k+2ibphcAxlKZAYnEXvCmtDiwiYgiq97ylsv2V2mIlyUfbJF0H7GH7mrbHEhExbJLm3s9p2z6otlhJ8tE2SZfYntH2OCIixk2SfLSmb8pqJ2AD4Ezg773zdU5ZRUSMCklvvr/zto+rK1ZuoYs27dH35zuAZ/Y9NpAkHxHjqLE6ILmSj9ZJmmH7kmUdi4iIf0wq3sUoOH45j0VEjA1JG0k6Q9Itkv4g6cuSNqozRqbrozWSpgM7AOsNrFFNAVZtZ1QREY2ZC3we2Kd6vH91bPe6AuRKPtr0YGBNyofNNfu+5gMvanFcERFNWM/2XNuLqq9TKVXvapM1+WidpO2BdwCbsHh2yba3bm1QERFDJunblE50p1WHXgbMtL1rbTGS5KNtkq4F3kqp3Xxv77jtG1sbVETEkFV9Oj4CTKfcUfR94E22f11XjKzJxyi41fbX2h5ERETD3gu80vafASStC/wXUFvFuyT5GAWzJZ0CnE+K4UREd2zdS/AAtm+T9KQ6AyTJxyiYCTye0kO+N12fYjgRMe5WkbTOwJV8rXk5ST5GwTa2t2p7EBERDfsg8H1JX6Jc2LwE+I86A2TjXbRO0snAh2xf3fZYIiKaJGlL4BmUFtvn1/0+mCQfrZN0DTAVuJ6yJt/rJ59b6CIiVkCSfLRO0saTHc8tdBERKyZJPiIiYkylrG1ERMSYSpKPiIgYU0nyEWNG0pGSPMnXt2uM8VRJR9b1ehExHLlPPmI8zQeePcmxujwVmA0cWeNrRkTNkuQjxtMi25e2PYjlJemhtu9sexwR4ybT9REdI+nVkq6S9HdJN0o6dOD8dElnSfqdpL9Jmifp5X3nDwSOr/7cWwq4sHp8qqTLBl5vk+o5z+87ZklvlvRhSbcCV1bHV5d0rKTfVOP7maTnDrzenpIur8b2Z0k/lLRTvX9LEeMhV/IRY0rS4O/3PZSWvv8JHAtcCDwFeK+kO2x/pHrexsAlwInAXcAMYK6ke22fBpxNKcf5FkqLTIDbH8AQ3wZ8DziAxRccX2LxUsAvKWU+z5K0ne15kqZWz5lT/fzq1X/Dug8gfsTYS5KPGE+PAO4eOLYXJXkebfuo6th5kh4GvEvSCbbvsf2F3g9IEiURbwS8BjjN9q2SbgBYwSWBm23v2xdrV+B5wM62v1sdPlfS5sA7gX2AJwELbL+t73W+sQJjiBhrma6PGE/zge0HvgSsAZwu6UG9L+ACYH1KIkfSOpL+W9KNlA8KdwOvBTaveYxnDzzeDbgZuGRgfOcD21XPuRJYW9KnJD1T0ho1jylirORKPmI8LbI9uDa+RfXHq5byM48BbgROBaYB7wWupkzFH0yZCajTHwYePxLYgCVnIKAsNWD7Wkl7AYdRruDvlnQGMMv2rTWPL2KllyQf0R23Vd+fz5IJFuBaSatTpszfYPvE3glJyzvrdxfw4IFjS1svH6ypfRvwW2Dv+wtg+2zgbElrV2P9MGUj4EuXc4wRnZEkH9EdPwDuBDasEuUSqsS5KqUbYO/YWsCeTEzKC6tzq9u+q+/4TcAmA8d3X87xnU/ZzPdX279Y1pNtzwc+X+2sn76s50d0UZJ8REfY/ktVpW5O1fnve5R9OZsDu9h+ge35kn4MvFvS7cC9lKnx+cCUvpfrJeFZki4Abrd9LXAm8B7gFEmnUjbKzVzOIZ4HfIuyGfAYyrLCFGBbYHXbh0v6V0pCPwf4HbAZZUPep//hv5CIDsjGu4gOsX0sZRPdc4CvAqcBLwcu6nvafsD1lMQ5B/gySybRi4APALOAHwIfr17/58BBlER8FrBT9Xh5xmbghcAngUMoCf/j1WtdXD3tCmA94DjgXOBdwMnA25cnRkTXpNVsRETEmMqVfERExJhKko+IiBhTSfIRERFjKkk+IiJiTCXJR0REjKkk+YiIiDGVJB8RETGmkuQjIiLGVJJ8RETEmPp/huc617dpjPIAAAAASUVORK5CYII=\n",
"text/plain": [
""
]
},
"metadata": {
"needs_background": "light"
},
"output_type": "display_data"
},
{
"data": {
"application/vnd.plotly.v1+json": {
"config": {
"linkText": "Export to plot.ly",
"plotlyServerURL": "https://plot.ly",
"showLink": true
},
"data": [
{
"histfunc": "count",
"histnorm": "",
"marker": {
"color": "rgba(255, 153, 51, 1.0)",
"line": {
"color": "#4D5663",
"width": 1.3
}
},
"name": "emp_length",
"opacity": 0.8,
"orientation": "v",
"type": "histogram",
"x": [
"9 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"8 years",
"7 years",
"2 years",
"10+ years",
"4 years",
"7 years",
"10+ years",
"10+ years",
"4 years",
"9 years",
null,
"7 years",
"7 years",
"9 years",
"2 years",
"10+ years",
"7 years",
"< 1 year",
"4 years",
"2 years",
"1 year",
"3 years",
"2 years",
"10+ years",
"8 years",
"2 years",
"9 years",
"10+ years",
null,
null,
"10+ years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"3 years",
"10+ years",
"9 years",
"4 years",
"7 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"6 years",
"2 years",
"10+ years",
"2 years",
"< 1 year",
"4 years",
"1 year",
"9 years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"< 1 year",
"2 years",
"9 years",
"8 years",
"3 years",
"3 years",
"8 years",
"2 years",
"7 years",
"10+ years",
"7 years",
"1 year",
"10+ years",
null,
"10+ years",
"8 years",
"5 years",
"6 years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"4 years",
null,
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"1 year",
"10+ years",
"5 years",
"8 years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"8 years",
"2 years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"4 years",
"1 year",
"3 years",
"8 years",
"3 years",
"2 years",
null,
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"1 year",
"2 years",
"8 years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"3 years",
"9 years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"3 years",
"4 years",
"4 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
null,
"4 years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"< 1 year",
"10+ years",
"2 years",
"4 years",
"2 years",
"< 1 year",
"4 years",
"2 years",
"1 year",
"5 years",
"4 years",
"3 years",
"9 years",
"5 years",
null,
"10+ years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"6 years",
"10+ years",
"1 year",
"7 years",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"5 years",
"10+ years",
"3 years",
null,
"10+ years",
null,
"10+ years",
"8 years",
"2 years",
"7 years",
"7 years",
"10+ years",
"8 years",
"6 years",
"9 years",
"3 years",
"4 years",
"5 years",
"< 1 year",
"< 1 year",
"7 years",
"7 years",
"< 1 year",
"1 year",
"< 1 year",
null,
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"6 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"8 years",
"1 year",
"< 1 year",
"4 years",
"1 year",
"7 years",
"< 1 year",
"3 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"6 years",
null,
"< 1 year",
"2 years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"9 years",
"4 years",
"3 years",
"10+ years",
"7 years",
null,
null,
"10+ years",
"2 years",
null,
"5 years",
"< 1 year",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"< 1 year",
"10+ years",
"2 years",
null,
"7 years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"5 years",
"< 1 year",
"< 1 year",
"4 years",
"3 years",
"3 years",
"8 years",
"2 years",
"1 year",
"10+ years",
"3 years",
"3 years",
"4 years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"1 year",
null,
"5 years",
"< 1 year",
"4 years",
"3 years",
"2 years",
"3 years",
"1 year",
"9 years",
"7 years",
"1 year",
"10+ years",
"10+ years",
"2 years",
null,
"3 years",
"3 years",
"< 1 year",
"2 years",
"1 year",
"10+ years",
"10+ years",
null,
"10+ years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
null,
null,
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
null,
"4 years",
"10+ years",
"7 years",
"2 years",
"6 years",
"10+ years",
"2 years",
"2 years",
"4 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"6 years",
"6 years",
"8 years",
"1 year",
"3 years",
"5 years",
"6 years",
"9 years",
"3 years",
null,
"7 years",
"5 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"9 years",
"3 years",
"2 years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"6 years",
"< 1 year",
"8 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"6 years",
"2 years",
"9 years",
"3 years",
"8 years",
"8 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"4 years",
"7 years",
"3 years",
"8 years",
"2 years",
"9 years",
"6 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"7 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"< 1 year",
"2 years",
"9 years",
"8 years",
"3 years",
"10+ years",
"8 years",
"10+ years",
"6 years",
"7 years",
"10+ years",
"5 years",
"10+ years",
"1 year",
"1 year",
null,
"3 years",
"10+ years",
"3 years",
"4 years",
"4 years",
"2 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"7 years",
"10+ years",
null,
"2 years",
"< 1 year",
"2 years",
"1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"8 years",
"7 years",
"5 years",
"2 years",
"10+ years",
"1 year",
"7 years",
"10+ years",
null,
"10+ years",
"8 years",
"10+ years",
"4 years",
"8 years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"7 years",
"3 years",
"5 years",
"1 year",
"10+ years",
"6 years",
"10+ years",
null,
"9 years",
"5 years",
"7 years",
"6 years",
"3 years",
"8 years",
"10+ years",
"7 years",
"5 years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"10+ years",
"6 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"1 year",
"8 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"7 years",
"5 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"4 years",
"3 years",
"8 years",
"1 year",
null,
"5 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"4 years",
"10+ years",
"5 years",
"< 1 year",
"2 years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"6 years",
null,
"10+ years",
"5 years",
"4 years",
"9 years",
"6 years",
"4 years",
"4 years",
"< 1 year",
"4 years",
"8 years",
"10+ years",
null,
"1 year",
"7 years",
"9 years",
"1 year",
"8 years",
"8 years",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"9 years",
"10+ years",
"6 years",
"10+ years",
"6 years",
"5 years",
null,
"2 years",
"3 years",
null,
"10+ years",
"3 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"6 years",
"< 1 year",
"10+ years",
null,
"9 years",
"3 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"7 years",
"7 years",
"1 year",
"10+ years",
"7 years",
"10+ years",
"< 1 year",
"8 years",
"2 years",
"8 years",
"4 years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"7 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"8 years",
"3 years",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"8 years",
"5 years",
"10+ years",
"5 years",
"5 years",
"3 years",
"< 1 year",
"10+ years",
"1 year",
"4 years",
"10+ years",
"3 years",
null,
"5 years",
"6 years",
"2 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"3 years",
null,
"< 1 year",
"9 years",
"10+ years",
"10+ years",
"7 years",
"1 year",
"7 years",
"5 years",
"8 years",
"10+ years",
"5 years",
"4 years",
"4 years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"9 years",
"2 years",
"3 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"4 years",
"4 years",
"5 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"1 year",
"2 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"9 years",
"2 years",
"10+ years",
null,
"6 years",
"3 years",
"3 years",
null,
null,
"7 years",
"2 years",
"4 years",
"1 year",
"< 1 year",
"6 years",
"9 years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"2 years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"5 years",
"< 1 year",
"9 years",
"8 years",
"10+ years",
"7 years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"6 years",
"8 years",
"10+ years",
"7 years",
"10+ years",
"5 years",
"3 years",
null,
"6 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
null,
"2 years",
"3 years",
"4 years",
"2 years",
"10+ years",
"5 years",
"9 years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"7 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"7 years",
"3 years",
"5 years",
null,
"10+ years",
"10+ years",
"2 years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"8 years",
"1 year",
"6 years",
"7 years",
"10+ years",
null,
"5 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"3 years",
"< 1 year",
"< 1 year",
"3 years",
"9 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"1 year",
"10+ years",
"4 years",
"6 years",
"10+ years",
"3 years",
"< 1 year",
null,
"10+ years",
"1 year",
"5 years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"8 years",
"10+ years",
"< 1 year",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"4 years",
"< 1 year",
"1 year",
"8 years",
"9 years",
"< 1 year",
"6 years",
"8 years",
"10+ years",
"10+ years",
"9 years",
"6 years",
null,
"< 1 year",
"10+ years",
"5 years",
"5 years",
"10+ years",
"8 years",
"5 years",
"1 year",
"2 years",
"5 years",
"7 years",
"4 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"4 years",
"10+ years",
"3 years",
"7 years",
"4 years",
"9 years",
"3 years",
"9 years",
"7 years",
"10+ years",
"1 year",
"5 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"< 1 year",
"1 year",
"8 years",
"8 years",
"10+ years",
"7 years",
"4 years",
"6 years",
"8 years",
"< 1 year",
"4 years",
"4 years",
"7 years",
"1 year",
"1 year",
"10+ years",
"5 years",
"8 years",
"5 years",
"10+ years",
"7 years",
"8 years",
"5 years",
"2 years",
"10+ years",
"4 years",
null,
null,
"8 years",
"2 years",
"5 years",
"10+ years",
"5 years",
null,
"3 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"3 years",
"3 years",
"9 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"4 years",
"10+ years",
"< 1 year",
"5 years",
null,
"2 years",
"10+ years",
"4 years",
"< 1 year",
"8 years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"4 years",
null,
"9 years",
null,
"7 years",
"7 years",
"2 years",
"1 year",
"1 year",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"6 years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
null,
"5 years",
"< 1 year",
"6 years",
"3 years",
"7 years",
"< 1 year",
"10+ years",
"5 years",
"8 years",
"10+ years",
"7 years",
"1 year",
"4 years",
"10+ years",
"10+ years",
"5 years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"6 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"9 years",
"7 years",
"10+ years",
"6 years",
"8 years",
"2 years",
"3 years",
"3 years",
"10+ years",
"2 years",
"8 years",
"9 years",
"2 years",
"10+ years",
"4 years",
"1 year",
"2 years",
"7 years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
null,
"10+ years",
"6 years",
null,
"10+ years",
"7 years",
null,
"10+ years",
"6 years",
"3 years",
"4 years",
"5 years",
"7 years",
"3 years",
"10+ years",
"6 years",
null,
"< 1 year",
"8 years",
"3 years",
"7 years",
"2 years",
"9 years",
"10+ years",
"2 years",
"7 years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"5 years",
null,
"2 years",
"4 years",
"6 years",
"6 years",
"6 years",
"6 years",
"1 year",
"10+ years",
"3 years",
null,
"10+ years",
"7 years",
"2 years",
"< 1 year",
"4 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
null,
"6 years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
"8 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"1 year",
"10+ years",
"7 years",
"7 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"1 year",
"7 years",
"< 1 year",
"3 years",
"5 years",
"2 years",
"3 years",
"10+ years",
null,
"2 years",
null,
"< 1 year",
"10+ years",
null,
"2 years",
"7 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"5 years",
"1 year",
"1 year",
"3 years",
"4 years",
"6 years",
"3 years",
"2 years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"9 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"1 year",
"< 1 year",
"< 1 year",
"7 years",
"8 years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"8 years",
"3 years",
"4 years",
"< 1 year",
"< 1 year",
"2 years",
"9 years",
"5 years",
"6 years",
"5 years",
"< 1 year",
"10+ years",
"< 1 year",
"1 year",
"7 years",
"1 year",
"10+ years",
"5 years",
"10+ years",
"1 year",
"10+ years",
"2 years",
"2 years",
"2 years",
"3 years",
"7 years",
"7 years",
"8 years",
"10+ years",
null,
null,
null,
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"9 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"6 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"1 year",
"< 1 year",
"10+ years",
"2 years",
"5 years",
"4 years",
"9 years",
"10+ years",
"10+ years",
"3 years",
"9 years",
null,
"8 years",
"1 year",
"10+ years",
"4 years",
"10+ years",
"7 years",
"10+ years",
"1 year",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"3 years",
null,
"5 years",
"1 year",
"1 year",
"10+ years",
"10+ years",
null,
"4 years",
"9 years",
null,
"10+ years",
"10+ years",
"7 years",
"5 years",
null,
"< 1 year",
"2 years",
"2 years",
"1 year",
"10+ years",
"4 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"4 years",
"2 years",
"2 years",
"3 years",
"1 year",
"9 years",
"2 years",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"6 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"4 years",
"6 years",
"9 years",
"1 year",
"2 years",
"2 years",
"6 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"7 years",
"5 years",
"1 year",
"3 years",
"6 years",
"4 years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
null,
"10+ years",
"7 years",
"2 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"3 years",
null,
"10+ years",
"8 years",
"5 years",
"1 year",
"3 years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"7 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"< 1 year",
"6 years",
"8 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"1 year",
"< 1 year",
"< 1 year",
"6 years",
"9 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"8 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"7 years",
"4 years",
"7 years",
"9 years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"8 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"5 years",
"6 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"9 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"8 years",
"6 years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"3 years",
"3 years",
"7 years",
"10+ years",
"6 years",
"7 years",
"4 years",
"4 years",
"2 years",
"< 1 year",
"1 year",
"10+ years",
"2 years",
"10+ years",
"8 years",
null,
"10+ years",
"10+ years",
"2 years",
"3 years",
"1 year",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"3 years",
"7 years",
"6 years",
null,
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
null,
null,
"4 years",
"4 years",
"7 years",
"3 years",
"1 year",
null,
"8 years",
"6 years",
"2 years",
"10+ years",
"2 years",
"< 1 year",
"2 years",
"9 years",
"5 years",
"8 years",
"5 years",
"6 years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
null,
"2 years",
"6 years",
null,
"10+ years",
"3 years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"1 year",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"8 years",
"2 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"5 years",
"7 years",
null,
"1 year",
"10+ years",
"2 years",
"3 years",
"< 1 year",
null,
"10+ years",
"10+ years",
"2 years",
"< 1 year",
null,
"3 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"2 years",
"4 years",
"10+ years",
"< 1 year",
"6 years",
"8 years",
"4 years",
"10+ years",
"1 year",
"5 years",
"9 years",
"10+ years",
null,
"1 year",
"10+ years",
"4 years",
"3 years",
"9 years",
"< 1 year",
"3 years",
"7 years",
"5 years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"8 years",
"< 1 year",
"10+ years",
"7 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"1 year",
"6 years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"7 years",
"10+ years",
"3 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"< 1 year",
"4 years",
"3 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"9 years",
null,
"< 1 year",
"6 years",
"4 years",
"8 years",
"3 years",
"5 years",
"1 year",
"8 years",
"5 years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"2 years",
"3 years",
"< 1 year",
"5 years",
"10+ years",
"5 years",
"9 years",
"2 years",
"4 years",
"5 years",
"6 years",
null,
"7 years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"6 years",
"8 years",
"2 years",
null,
"7 years",
"7 years",
"10+ years",
"7 years",
"< 1 year",
"6 years",
"8 years",
"1 year",
"6 years",
"2 years",
"3 years",
"4 years",
"6 years",
"10+ years",
"8 years",
"6 years",
null,
"5 years",
"7 years",
"3 years",
"2 years",
"10+ years",
"9 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"4 years",
"1 year",
"10+ years",
"5 years",
null,
"10+ years",
"10+ years",
"6 years",
"10+ years",
null,
"6 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"7 years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"2 years",
null,
"10+ years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"10+ years",
"4 years",
"10+ years",
"8 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
null,
"1 year",
"10+ years",
"1 year",
"2 years",
"10+ years",
"< 1 year",
"1 year",
"3 years",
"2 years",
null,
"10+ years",
"10+ years",
"4 years",
null,
"3 years",
"3 years",
"< 1 year",
"9 years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
null,
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"3 years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
null,
"< 1 year",
null,
"3 years",
"3 years",
"4 years",
"2 years",
"10+ years",
"2 years",
"< 1 year",
null,
"10+ years",
"4 years",
"7 years",
"< 1 year",
"9 years",
"2 years",
"4 years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"< 1 year",
"8 years",
"8 years",
"5 years",
"10+ years",
null,
"9 years",
"1 year",
"10+ years",
"5 years",
null,
"7 years",
null,
"6 years",
null,
"5 years",
"5 years",
"3 years",
"9 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"4 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"4 years",
"10+ years",
"8 years",
"7 years",
"< 1 year",
null,
"6 years",
"1 year",
"10+ years",
"5 years",
"5 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"10+ years",
null,
"2 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
null,
"< 1 year",
"< 1 year",
"10+ years",
"2 years",
"4 years",
"1 year",
"2 years",
"10+ years",
"2 years",
"7 years",
"2 years",
"3 years",
"2 years",
"10+ years",
"6 years",
"10+ years",
"7 years",
"3 years",
"4 years",
"7 years",
"2 years",
"1 year",
"6 years",
"1 year",
"10+ years",
"< 1 year",
"4 years",
"5 years",
"5 years",
"7 years",
"< 1 year",
null,
"10+ years",
"9 years",
"4 years",
"3 years",
"9 years",
null,
"10+ years",
"10+ years",
"7 years",
"4 years",
"2 years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"4 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"4 years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"3 years",
"8 years",
"10+ years",
"1 year",
"4 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"8 years",
"1 year",
"8 years",
"6 years",
"4 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
null,
"1 year",
"10+ years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"6 years",
"1 year",
"9 years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"7 years",
"3 years",
"3 years",
"10+ years",
"5 years",
"1 year",
"1 year",
null,
"5 years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"3 years",
"< 1 year",
"7 years",
"3 years",
"5 years",
"10+ years",
null,
"10+ years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"8 years",
"9 years",
"4 years",
"10+ years",
"5 years",
"7 years",
"10+ years",
"10+ years",
"9 years",
"1 year",
"10+ years",
"1 year",
"1 year",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"9 years",
"2 years",
"2 years",
"< 1 year",
"2 years",
"3 years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"4 years",
"9 years",
"3 years",
"3 years",
"10+ years",
"1 year",
"6 years",
"10+ years",
"7 years",
"1 year",
"6 years",
"9 years",
"8 years",
"4 years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"10+ years",
null,
"5 years",
"10+ years",
"10+ years",
"8 years",
"1 year",
"6 years",
null,
null,
"6 years",
"3 years",
"1 year",
"< 1 year",
"7 years",
"2 years",
null,
"2 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"4 years",
"10+ years",
null,
"4 years",
"4 years",
"6 years",
"4 years",
"10+ years",
"10+ years",
"4 years",
null,
"10+ years",
"4 years",
"3 years",
"2 years",
"3 years",
"4 years",
"8 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
null,
"4 years",
"2 years",
"7 years",
"4 years",
"10+ years",
"2 years",
"9 years",
"2 years",
"2 years",
"< 1 year",
"10+ years",
"4 years",
"9 years",
"1 year",
"10+ years",
"3 years",
"3 years",
"10+ years",
"5 years",
"6 years",
"7 years",
"3 years",
"10+ years",
"3 years",
null,
"1 year",
"2 years",
"10+ years",
"7 years",
"8 years",
"10+ years",
"8 years",
"3 years",
"9 years",
"< 1 year",
"9 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
null,
"6 years",
"10+ years",
"3 years",
"8 years",
"6 years",
"5 years",
"< 1 year",
"2 years",
"10+ years",
"2 years",
"10+ years",
null,
"10+ years",
"5 years",
"7 years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"3 years",
"2 years",
"1 year",
"2 years",
"< 1 year",
"2 years",
"3 years",
"3 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"3 years",
null,
"< 1 year",
"3 years",
"< 1 year",
"< 1 year",
"10+ years",
"3 years",
"7 years",
"10+ years",
"2 years",
"4 years",
"2 years",
"10+ years",
"6 years",
"6 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"< 1 year",
"8 years",
"10+ years",
"5 years",
"3 years",
"1 year",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"8 years",
"4 years",
"2 years",
"2 years",
"9 years",
"10+ years",
"7 years",
"10+ years",
"< 1 year",
"9 years",
"2 years",
"< 1 year",
null,
"6 years",
"2 years",
"2 years",
"10+ years",
"4 years",
null,
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"7 years",
"10+ years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"2 years",
"10+ years",
"9 years",
"6 years",
null,
null,
"3 years",
"5 years",
"10+ years",
"8 years",
"5 years",
"6 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"5 years",
"6 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"1 year",
"2 years",
"10+ years",
"6 years",
"9 years",
"9 years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"9 years",
"2 years",
null,
"10+ years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"< 1 year",
null,
"4 years",
null,
"10+ years",
null,
"10+ years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"6 years",
"8 years",
"8 years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"3 years",
"10+ years",
"5 years",
null,
"< 1 year",
"10+ years",
"< 1 year",
"2 years",
"1 year",
"10+ years",
"9 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"3 years",
"9 years",
"5 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"3 years",
"1 year",
"7 years",
"7 years",
"8 years",
"2 years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"< 1 year",
"3 years",
"5 years",
"3 years",
"2 years",
"10+ years",
"3 years",
"8 years",
"5 years",
"7 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
null,
"3 years",
"5 years",
"7 years",
"10+ years",
"2 years",
"2 years",
null,
"3 years",
"4 years",
"8 years",
"10+ years",
"1 year",
"1 year",
"9 years",
"8 years",
"5 years",
"2 years",
"8 years",
"< 1 year",
"6 years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"7 years",
null,
"7 years",
"5 years",
"1 year",
"10+ years",
"10+ years",
"8 years",
"4 years",
"10+ years",
"10+ years",
null,
"10+ years",
"8 years",
"8 years",
"10+ years",
"5 years",
"7 years",
"9 years",
"8 years",
"10+ years",
"4 years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"6 years",
"10+ years",
"10+ years",
null,
"10+ years",
"1 year",
"< 1 year",
null,
"2 years",
"8 years",
"7 years",
"4 years",
"10+ years",
"2 years",
"4 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"7 years",
"10+ years",
"4 years",
"< 1 year",
"2 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"4 years",
"3 years",
"10+ years",
"8 years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"8 years",
"9 years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"2 years",
"9 years",
"10+ years",
"2 years",
"10+ years",
"9 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
null,
"10+ years",
"10+ years",
"1 year",
"3 years",
"5 years",
"8 years",
"7 years",
"6 years",
"2 years",
"5 years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"2 years",
"10+ years",
"1 year",
"3 years",
"2 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"8 years",
"10+ years",
"4 years",
"2 years",
"< 1 year",
"6 years",
"4 years",
"3 years",
"< 1 year",
"10+ years",
"1 year",
"4 years",
"7 years",
"3 years",
"1 year",
"5 years",
"3 years",
"7 years",
"10+ years",
"2 years",
"1 year",
"4 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"1 year",
"2 years",
null,
"7 years",
"10+ years",
null,
"10+ years",
"10+ years",
"3 years",
"5 years",
"1 year",
"10+ years",
"10+ years",
"8 years",
"1 year",
"10+ years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"10+ years",
null,
"10+ years",
"< 1 year",
null,
"2 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"3 years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"2 years",
"3 years",
"2 years",
"10+ years",
"3 years",
"1 year",
"9 years",
"1 year",
"9 years",
"10+ years",
null,
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
null,
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
null,
"7 years",
"3 years",
"1 year",
"4 years",
"9 years",
"1 year",
"5 years",
"10+ years",
"2 years",
"10+ years",
null,
null,
"10+ years",
"2 years",
"10+ years",
"7 years",
"2 years",
"2 years",
null,
"2 years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"9 years",
"3 years",
"2 years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"1 year",
"2 years",
"10+ years",
"1 year",
"2 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"6 years",
"2 years",
"2 years",
"6 years",
"5 years",
"< 1 year",
"3 years",
"7 years",
"8 years",
"8 years",
"4 years",
"9 years",
"7 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"3 years",
null,
"1 year",
"10+ years",
"1 year",
"10+ years",
"5 years",
"5 years",
"2 years",
"9 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"1 year",
"1 year",
"2 years",
"< 1 year",
"10+ years",
null,
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"4 years",
"9 years",
"10+ years",
"9 years",
"3 years",
"6 years",
"6 years",
"3 years",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"2 years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"5 years",
"10+ years",
"3 years",
"6 years",
"10+ years",
"7 years",
"< 1 year",
"9 years",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"6 years",
"< 1 year",
"1 year",
"2 years",
"9 years",
"1 year",
"1 year",
"6 years",
"6 years",
"8 years",
"7 years",
"6 years",
"4 years",
"4 years",
"10+ years",
null,
"9 years",
"4 years",
null,
"3 years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"2 years",
"6 years",
"6 years",
"5 years",
"5 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"3 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"6 years",
"10+ years",
"4 years",
"3 years",
"9 years",
"10+ years",
"10+ years",
"6 years",
"5 years",
"5 years",
"10+ years",
"10+ years",
"4 years",
null,
"< 1 year",
"5 years",
"6 years",
"1 year",
"< 1 year",
"2 years",
"10+ years",
null,
"10+ years",
"< 1 year",
"1 year",
"8 years",
"< 1 year",
"10+ years",
"2 years",
"9 years",
"10+ years",
"1 year",
"< 1 year",
"< 1 year",
"4 years",
"5 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"3 years",
"7 years",
"2 years",
"< 1 year",
"9 years",
"1 year",
"3 years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"8 years",
"7 years",
"7 years",
null,
"10+ years",
"5 years",
"6 years",
"1 year",
"7 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
null,
"2 years",
"5 years",
"9 years",
"3 years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"6 years",
null,
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"5 years",
"10+ years",
"7 years",
"1 year",
null,
"2 years",
"10+ years",
"4 years",
"10+ years",
null,
null,
"10+ years",
"3 years",
"< 1 year",
"6 years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
null,
"2 years",
"2 years",
"2 years",
"8 years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"1 year",
"3 years",
"7 years",
"7 years",
"5 years",
"< 1 year",
"8 years",
"7 years",
"7 years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"1 year",
"4 years",
null,
"10+ years",
"8 years",
"9 years",
"1 year",
null,
"< 1 year",
"1 year",
"1 year",
null,
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"9 years",
null,
"2 years",
"10+ years",
"6 years",
"2 years",
"10+ years",
null,
"10+ years",
"8 years",
"3 years",
"5 years",
null,
"3 years",
"4 years",
"5 years",
"2 years",
"9 years",
"2 years",
"1 year",
"5 years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"3 years",
"5 years",
"1 year",
"7 years",
"10+ years",
"8 years",
"1 year",
"2 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"6 years",
"7 years",
"10+ years",
"8 years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"5 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"4 years",
"8 years",
"10+ years",
"6 years",
"1 year",
"6 years",
"3 years",
"9 years",
"5 years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"1 year",
"6 years",
"2 years",
"1 year",
"1 year",
"10+ years",
"1 year",
"10+ years",
"8 years",
"10+ years",
null,
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"3 years",
null,
"10+ years",
"9 years",
"10+ years",
"6 years",
"9 years",
"1 year",
"< 1 year",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"5 years",
"4 years",
"8 years",
null,
"10+ years",
"4 years",
null,
"2 years",
"10+ years",
"6 years",
"< 1 year",
"10+ years",
null,
"2 years",
null,
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"6 years",
"< 1 year",
"4 years",
"9 years",
"7 years",
"3 years",
"9 years",
"4 years",
"10+ years",
"2 years",
"3 years",
null,
"3 years",
null,
"4 years",
"4 years",
"< 1 year",
"5 years",
"2 years",
"3 years",
"10+ years",
"2 years",
"8 years",
"2 years",
"10+ years",
"9 years",
"1 year",
"7 years",
"7 years",
"9 years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"8 years",
"2 years",
"2 years",
null,
"5 years",
"6 years",
"< 1 year",
"4 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"6 years",
"4 years",
"7 years",
null,
"1 year",
"3 years",
"8 years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"7 years",
"3 years",
"7 years",
"< 1 year",
"8 years",
"2 years",
"2 years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"9 years",
"4 years",
"< 1 year",
"2 years",
"< 1 year",
"8 years",
"7 years",
"10+ years",
"< 1 year",
"< 1 year",
"9 years",
"4 years",
"3 years",
"< 1 year",
"4 years",
"< 1 year",
"9 years",
"10+ years",
"6 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"6 years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"2 years",
"10+ years",
"7 years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
null,
"10+ years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"1 year",
"6 years",
"4 years",
"5 years",
"3 years",
"10+ years",
"9 years",
"8 years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"1 year",
"10+ years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"8 years",
null,
"10+ years",
"10+ years",
"10+ years",
"8 years",
"2 years",
"6 years",
"10+ years",
null,
"7 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"9 years",
"5 years",
"6 years",
"5 years",
"1 year",
"5 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"7 years",
"2 years",
"5 years",
"6 years",
"10+ years",
"< 1 year",
"3 years",
"4 years",
"2 years",
"8 years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"1 year",
"7 years",
"7 years",
"10+ years",
"10+ years",
"7 years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"6 years",
"5 years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"7 years",
"10+ years",
null,
"7 years",
"5 years",
"5 years",
"3 years",
"10+ years",
"9 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"1 year",
"1 year",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"3 years",
null,
"3 years",
"6 years",
"8 years",
"7 years",
"2 years",
"7 years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"< 1 year",
"1 year",
"3 years",
"9 years",
"10+ years",
"2 years",
"10+ years",
"4 years",
"2 years",
"4 years",
"10+ years",
"6 years",
"10+ years",
null,
"9 years",
"7 years",
"7 years",
"1 year",
"1 year",
"5 years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"2 years",
"9 years",
"5 years",
"6 years",
"2 years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"7 years",
"10+ years",
"6 years",
"6 years",
"6 years",
"10+ years",
"6 years",
null,
"10+ years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"2 years",
null,
"10+ years",
"10+ years",
null,
"8 years",
"1 year",
"4 years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"8 years",
"10+ years",
"6 years",
"7 years",
"1 year",
"2 years",
"8 years",
"10+ years",
"1 year",
"3 years",
"< 1 year",
"< 1 year",
null,
"10+ years",
"10+ years",
"3 years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"6 years",
"10+ years",
"10+ years",
"6 years",
"6 years",
"< 1 year",
"5 years",
"5 years",
"1 year",
"4 years",
"8 years",
"10+ years",
"8 years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"3 years",
"7 years",
"4 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"8 years",
"4 years",
"3 years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"8 years",
"9 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"9 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"2 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"3 years",
"4 years",
"9 years",
"10+ years",
"9 years",
"4 years",
"10+ years",
"1 year",
"6 years",
"< 1 year",
null,
"10+ years",
"2 years",
"10+ years",
"9 years",
"4 years",
"< 1 year",
"10+ years",
"1 year",
"2 years",
"10+ years",
"2 years",
null,
"< 1 year",
"10+ years",
"1 year",
"3 years",
"2 years",
"8 years",
null,
"9 years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"9 years",
"6 years",
"< 1 year",
"2 years",
"5 years",
"9 years",
"1 year",
"4 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"4 years",
"3 years",
"10+ years",
"10+ years",
null,
"1 year",
null,
"< 1 year",
"3 years",
"5 years",
"3 years",
"7 years",
null,
"10+ years",
"9 years",
"2 years",
null,
"10+ years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"7 years",
"< 1 year",
null,
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"1 year",
"10+ years",
"2 years",
"9 years",
"3 years",
"3 years",
"< 1 year",
"1 year",
"2 years",
"2 years",
"6 years",
"7 years",
"10+ years",
"< 1 year",
"1 year",
"3 years",
"2 years",
"10+ years",
"5 years",
"2 years",
"7 years",
"3 years",
"1 year",
"8 years",
"2 years",
"6 years",
"2 years",
"4 years",
"3 years",
"8 years",
"1 year",
"10+ years",
"5 years",
"< 1 year",
"4 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"2 years",
"2 years",
"3 years",
"10+ years",
"7 years",
"10+ years",
null,
"2 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"< 1 year",
"3 years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"2 years",
"9 years",
"3 years",
"1 year",
"6 years",
"1 year",
"1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"3 years",
null,
"7 years",
"1 year",
"8 years",
"< 1 year",
"4 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"7 years",
"10+ years",
"< 1 year",
null,
"4 years",
"9 years",
"10+ years",
"2 years",
null,
"7 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"4 years",
"6 years",
"10+ years",
"8 years",
"< 1 year",
"2 years",
"6 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"6 years",
"7 years",
"1 year",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"5 years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"4 years",
"< 1 year",
"10+ years",
null,
"7 years",
"3 years",
"9 years",
"6 years",
null,
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"< 1 year",
"10+ years",
"8 years",
null,
"1 year",
null,
"5 years",
null,
"10+ years",
null,
"10+ years",
"5 years",
"< 1 year",
"4 years",
"5 years",
"10+ years",
"1 year",
"1 year",
"8 years",
"7 years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"4 years",
"4 years",
"2 years",
"7 years",
null,
"10+ years",
"5 years",
null,
"10+ years",
"10+ years",
"10+ years",
"1 year",
"7 years",
"8 years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"6 years",
"10+ years",
"9 years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"6 years",
"6 years",
"2 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
null,
"2 years",
"10+ years",
"3 years",
"8 years",
"< 1 year",
"6 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"4 years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
null,
"10+ years",
null,
"9 years",
"4 years",
"5 years",
"4 years",
"10+ years",
null,
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"10+ years",
"1 year",
"10+ years",
"8 years",
"10+ years",
null,
"3 years",
"8 years",
"3 years",
"3 years",
"2 years",
"2 years",
"6 years",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"9 years",
"< 1 year",
"< 1 year",
"4 years",
"< 1 year",
"1 year",
"3 years",
null,
"3 years",
"6 years",
"8 years",
"6 years",
"7 years",
"10+ years",
"8 years",
null,
"10+ years",
"9 years",
"7 years",
"2 years",
"10+ years",
"2 years",
"2 years",
null,
"10+ years",
"7 years",
"2 years",
"2 years",
"10+ years",
"9 years",
"< 1 year",
"8 years",
"8 years",
"< 1 year",
"10+ years",
"8 years",
"3 years",
"4 years",
null,
"10+ years",
"6 years",
"4 years",
"7 years",
"5 years",
"2 years",
"3 years",
"1 year",
"< 1 year",
"5 years",
"1 year",
null,
"10+ years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"4 years",
"8 years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"1 year",
"2 years",
null,
"10+ years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"7 years",
"3 years",
"10+ years",
"4 years",
"1 year",
"7 years",
"10+ years",
"3 years",
"2 years",
"9 years",
"10+ years",
"8 years",
null,
"2 years",
"2 years",
"7 years",
"10+ years",
"3 years",
null,
"4 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"1 year",
"< 1 year",
"2 years",
"< 1 year",
"10+ years",
"9 years",
"6 years",
"8 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"9 years",
"10+ years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"4 years",
"< 1 year",
"3 years",
"3 years",
"8 years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"6 years",
"< 1 year",
"7 years",
"5 years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"7 years",
"5 years",
"10+ years",
"10+ years",
null,
null,
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"1 year",
"10+ years",
"10+ years",
"8 years",
"9 years",
"10+ years",
"1 year",
"3 years",
"5 years",
"5 years",
"2 years",
"8 years",
"10+ years",
"3 years",
"3 years",
"4 years",
null,
"10+ years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"5 years",
"< 1 year",
"3 years",
"8 years",
"6 years",
"6 years",
"5 years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"6 years",
"10+ years",
"2 years",
"3 years",
"6 years",
"10+ years",
"8 years",
"7 years",
null,
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"8 years",
"3 years",
"< 1 year",
"4 years",
"< 1 year",
"10+ years",
"6 years",
"3 years",
"8 years",
"< 1 year",
"1 year",
"10+ years",
"4 years",
"9 years",
"1 year",
"3 years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
null,
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"6 years",
"3 years",
"10+ years",
"< 1 year",
null,
"10+ years",
"4 years",
"10+ years",
"3 years",
"1 year",
"10+ years",
"2 years",
null,
"< 1 year",
"3 years",
"2 years",
"3 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"6 years",
"9 years",
"5 years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"< 1 year",
"7 years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
null,
"2 years",
"5 years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"2 years",
"10+ years",
"9 years",
"2 years",
"5 years",
"6 years",
"3 years",
"10+ years",
"5 years",
"2 years",
"8 years",
"10+ years",
"< 1 year",
"6 years",
"< 1 year",
"5 years",
"5 years",
"10+ years",
"10+ years",
null,
"1 year",
"2 years",
"2 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"6 years",
"5 years",
"9 years",
"1 year",
"2 years",
"10+ years",
"3 years",
"< 1 year",
"8 years",
"7 years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"8 years",
null,
null,
"10+ years",
"5 years",
"2 years",
"2 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"9 years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"2 years",
"8 years",
"< 1 year",
"8 years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"8 years",
null,
"3 years",
"10+ years",
"2 years",
"10+ years",
"6 years",
"1 year",
"10+ years",
"7 years",
"10+ years",
"7 years",
"3 years",
"1 year",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"2 years",
"10+ years",
"5 years",
"4 years",
"6 years",
"5 years",
"9 years",
"1 year",
"8 years",
"< 1 year",
"10+ years",
"9 years",
"< 1 year",
"7 years",
null,
null,
"10+ years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"2 years",
"2 years",
"4 years",
"< 1 year",
"9 years",
"9 years",
"7 years",
null,
"2 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
null,
"10+ years",
"3 years",
"< 1 year",
"7 years",
"8 years",
"3 years",
"3 years",
"10+ years",
"3 years",
"9 years",
"5 years",
"7 years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"3 years",
"3 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
null,
"3 years",
"3 years",
"1 year",
"< 1 year",
"2 years",
null,
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"7 years",
"10+ years",
"1 year",
"1 year",
"5 years",
"< 1 year",
"3 years",
"3 years",
"4 years",
"8 years",
"< 1 year",
"7 years",
"2 years",
"10+ years",
null,
"4 years",
"5 years",
"1 year",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"6 years",
"5 years",
"8 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"8 years",
null,
"< 1 year",
"6 years",
"10+ years",
"7 years",
"3 years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"8 years",
"2 years",
"< 1 year",
"4 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"4 years",
"3 years",
"10+ years",
"5 years",
"< 1 year",
"9 years",
"4 years",
null,
"3 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"7 years",
"1 year",
"3 years",
"10+ years",
"5 years",
"2 years",
"1 year",
"5 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"7 years",
"5 years",
"7 years",
"5 years",
"2 years",
"10+ years",
"4 years",
"8 years",
"10+ years",
"2 years",
"5 years",
null,
null,
"10+ years",
"10+ years",
"8 years",
"5 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"8 years",
"2 years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"4 years",
"5 years",
"5 years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"1 year",
"8 years",
"10+ years",
"5 years",
"8 years",
null,
"10+ years",
"< 1 year",
"8 years",
"4 years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"2 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"4 years",
"< 1 year",
"8 years",
null,
"10+ years",
"9 years",
"1 year",
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"9 years",
"5 years",
"2 years",
"6 years",
"< 1 year",
"10+ years",
"9 years",
"6 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"4 years",
"7 years",
"5 years",
"10+ years",
"3 years",
"4 years",
null,
"10+ years",
"7 years",
"9 years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"< 1 year",
"10+ years",
"7 years",
"7 years",
"3 years",
"10+ years",
"3 years",
"< 1 year",
"6 years",
"< 1 year",
"10+ years",
"2 years",
"7 years",
"10+ years",
"< 1 year",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"2 years",
"1 year",
"8 years",
null,
"1 year",
"2 years",
"10+ years",
"5 years",
"10+ years",
null,
"1 year",
"2 years",
"10+ years",
"5 years",
"2 years",
"1 year",
"3 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"1 year",
null,
"10+ years",
"7 years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"8 years",
"2 years",
"2 years",
"8 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
null,
"10+ years",
"2 years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"4 years",
"5 years",
"8 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"3 years",
"2 years",
null,
"3 years",
"2 years",
"10+ years",
"3 years",
null,
"8 years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"10+ years",
"8 years",
"2 years",
"6 years",
"4 years",
"6 years",
"7 years",
"9 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"3 years",
"9 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"4 years",
"8 years",
"< 1 year",
"10+ years",
"6 years",
"9 years",
"2 years",
"3 years",
"10+ years",
"4 years",
"10+ years",
"8 years",
"7 years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"1 year",
"5 years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"3 years",
"3 years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"1 year",
"8 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"6 years",
"< 1 year",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"8 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"5 years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"2 years",
"7 years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"4 years",
"8 years",
null,
"5 years",
"2 years",
null,
"10+ years",
"10+ years",
"1 year",
"4 years",
null,
"9 years",
"1 year",
"2 years",
"9 years",
"6 years",
"3 years",
"4 years",
"1 year",
"4 years",
"10+ years",
"3 years",
"6 years",
"10+ years",
"4 years",
"2 years",
"3 years",
"2 years",
"10+ years",
"6 years",
"8 years",
"8 years",
"2 years",
"9 years",
"4 years",
"3 years",
"9 years",
"4 years",
"7 years",
"5 years",
"5 years",
"7 years",
"6 years",
"1 year",
"9 years",
"< 1 year",
"< 1 year",
"< 1 year",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"8 years",
"8 years",
"< 1 year",
"9 years",
"3 years",
"9 years",
"9 years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"7 years",
"5 years",
"6 years",
"10+ years",
null,
"10+ years",
"3 years",
"9 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"5 years",
null,
"3 years",
"10+ years",
"8 years",
"7 years",
"8 years",
"1 year",
"2 years",
"3 years",
"10+ years",
"8 years",
"1 year",
"1 year",
"10+ years",
"4 years",
null,
"3 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
null,
"3 years",
"9 years",
"2 years",
"2 years",
"6 years",
"4 years",
"3 years",
"1 year",
"< 1 year",
"6 years",
"2 years",
"9 years",
"4 years",
"2 years",
"10+ years",
"4 years",
"2 years",
"7 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"10+ years",
null,
"2 years",
"1 year",
"4 years",
"2 years",
"4 years",
"2 years",
"4 years",
"10+ years",
"6 years",
"1 year",
null,
"10+ years",
"4 years",
"10+ years",
"1 year",
"2 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"8 years",
"3 years",
"10+ years",
"8 years",
"5 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"4 years",
"< 1 year",
"2 years",
"10+ years",
"1 year",
"9 years",
"1 year",
"3 years",
"1 year",
"6 years",
"6 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
null,
"1 year",
"10+ years",
null,
"7 years",
"10+ years",
"6 years",
"10+ years",
null,
"10+ years",
"5 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"9 years",
"< 1 year",
"7 years",
"5 years",
"10+ years",
"2 years",
"9 years",
"10+ years",
"3 years",
"9 years",
"5 years",
"10+ years",
"10+ years",
"9 years",
"7 years",
"10+ years",
"5 years",
"1 year",
"5 years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"3 years",
"10+ years",
null,
"5 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"3 years",
"3 years",
"2 years",
"6 years",
"10+ years",
"3 years",
"7 years",
"8 years",
"5 years",
null,
"10+ years",
"10+ years",
"5 years",
"1 year",
"3 years",
"10+ years",
"4 years",
"6 years",
"5 years",
"1 year",
"10+ years",
"6 years",
null,
"2 years",
"7 years",
"10+ years",
"1 year",
"< 1 year",
"9 years",
"10+ years",
"7 years",
"4 years",
"7 years",
"3 years",
"1 year",
"8 years",
"3 years",
"2 years",
"8 years",
"10+ years",
"5 years",
"7 years",
null,
"10+ years",
"4 years",
"7 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"8 years",
"10+ years",
"7 years",
"9 years",
"8 years",
"3 years",
"7 years",
"2 years",
"5 years",
"10+ years",
"5 years",
"4 years",
"9 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"9 years",
"2 years",
"4 years",
"1 year",
"2 years",
"2 years",
"< 1 year",
"4 years",
"10+ years",
"3 years",
"8 years",
"8 years",
"< 1 year",
"3 years",
"4 years",
"4 years",
"5 years",
"10+ years",
"5 years",
"4 years",
"7 years",
"2 years",
"3 years",
null,
"8 years",
"2 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
null,
"3 years",
"4 years",
"10+ years",
"6 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"3 years",
null,
"5 years",
"5 years",
"2 years",
"4 years",
"2 years",
"< 1 year",
"< 1 year",
"< 1 year",
null,
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"< 1 year",
"1 year",
"6 years",
null,
null,
"10+ years",
"5 years",
"10+ years",
"6 years",
"10+ years",
"7 years",
"6 years",
"10+ years",
"5 years",
"7 years",
"3 years",
"10+ years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"5 years",
"< 1 year",
"7 years",
"5 years",
"5 years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"1 year",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"3 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"2 years",
"10+ years",
"2 years",
"2 years",
"3 years",
"< 1 year",
"8 years",
"10+ years",
"5 years",
"3 years",
"4 years",
"2 years",
"9 years",
"9 years",
"6 years",
"4 years",
"2 years",
"10+ years",
"1 year",
"8 years",
"5 years",
"5 years",
"5 years",
"3 years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"1 year",
"3 years",
null,
null,
"2 years",
"10+ years",
"9 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"7 years",
"2 years",
"5 years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"8 years",
"5 years",
"< 1 year",
"3 years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"10+ years",
null,
"4 years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"3 years",
"10+ years",
"6 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
null,
"3 years",
"8 years",
"2 years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"7 years",
"4 years",
null,
"10+ years",
"10+ years",
"2 years",
"5 years",
"9 years",
"1 year",
"10+ years",
"10+ years",
"4 years",
null,
"10+ years",
"10+ years",
"7 years",
"3 years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"< 1 year",
"6 years",
"2 years",
"6 years",
"9 years",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"4 years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"4 years",
"3 years",
"4 years",
"1 year",
"10+ years",
"5 years",
"3 years",
"3 years",
"< 1 year",
"10+ years",
"< 1 year",
"1 year",
"1 year",
"5 years",
"1 year",
"10+ years",
"2 years",
"8 years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"1 year",
"3 years",
"6 years",
"1 year",
"7 years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"8 years",
"5 years",
"< 1 year",
"10+ years",
"3 years",
"1 year",
"6 years",
"10+ years",
"< 1 year",
"1 year",
"3 years",
"5 years",
"3 years",
"8 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"7 years",
"10+ years",
"10+ years",
"10+ years",
null,
"6 years",
"3 years",
"10+ years",
"5 years",
"6 years",
null,
"2 years",
"2 years",
"10+ years",
"< 1 year",
null,
"9 years",
"6 years",
"2 years",
"< 1 year",
"< 1 year",
"10+ years",
"6 years",
"5 years",
"6 years",
"< 1 year",
"4 years",
"6 years",
"1 year",
"3 years",
"10+ years",
"9 years",
"2 years",
"8 years",
"8 years",
"7 years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"3 years",
"9 years",
"2 years",
"< 1 year",
"3 years",
"4 years",
"3 years",
"8 years",
"3 years",
"2 years",
"3 years",
"10+ years",
"2 years",
"9 years",
"10+ years",
"6 years",
"3 years",
"6 years",
"9 years",
"7 years",
"1 year",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"4 years",
"7 years",
"10+ years",
"1 year",
"3 years",
"1 year",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"< 1 year",
"< 1 year",
"3 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"1 year",
"4 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"5 years",
"2 years",
"10+ years",
"4 years",
"7 years",
"7 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"8 years",
"4 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
null,
null,
"9 years",
null,
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"5 years",
"8 years",
"6 years",
"7 years",
"1 year",
"2 years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"8 years",
"1 year",
"1 year",
"10+ years",
"2 years",
"3 years",
"10+ years",
"4 years",
"8 years",
"10+ years",
"1 year",
"4 years",
"10+ years",
"8 years",
"2 years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
"9 years",
"6 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
null,
"4 years",
null,
"7 years",
"2 years",
"2 years",
"6 years",
"6 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"8 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
null,
"10+ years",
"5 years",
"3 years",
"6 years",
"3 years",
"9 years",
"5 years",
"1 year",
"4 years",
"10+ years",
"< 1 year",
"1 year",
"< 1 year",
"6 years",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"2 years",
"1 year",
"10+ years",
"5 years",
"10+ years",
"2 years",
"10+ years",
null,
"9 years",
"10+ years",
"6 years",
"3 years",
"< 1 year",
"10+ years",
"7 years",
"5 years",
"10+ years",
"5 years",
"2 years",
"6 years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"3 years",
"< 1 year",
"1 year",
"< 1 year",
"5 years",
"3 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"2 years",
"8 years",
"2 years",
null,
"10+ years",
"8 years",
"< 1 year",
"< 1 year",
"5 years",
"10+ years",
"1 year",
"8 years",
null,
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"9 years",
"10+ years",
"3 years",
null,
"5 years",
"1 year",
"1 year",
"3 years",
"4 years",
null,
"5 years",
"10+ years",
"8 years",
"4 years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
null,
"10+ years",
"5 years",
null,
"1 year",
"4 years",
"2 years",
"10+ years",
"4 years",
"3 years",
"2 years",
"10+ years",
"3 years",
"3 years",
"8 years",
"4 years",
"8 years",
"5 years",
"2 years",
"10+ years",
"7 years",
"4 years",
"2 years",
"3 years",
"6 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
null,
"4 years",
"10+ years",
"9 years",
null,
"8 years",
"9 years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"6 years",
"8 years",
"10+ years",
"10+ years",
"6 years",
"9 years",
"< 1 year",
"3 years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"1 year",
"9 years",
null,
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"6 years",
"5 years",
null,
"3 years",
"2 years",
"6 years",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"2 years",
"< 1 year",
"< 1 year",
"7 years",
"10+ years",
"1 year",
"2 years",
"4 years",
"6 years",
"4 years",
"10+ years",
"1 year",
"< 1 year",
"2 years",
"8 years",
"10+ years",
"< 1 year",
"9 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"4 years",
"5 years",
"4 years",
null,
"10+ years",
"10+ years",
"4 years",
"3 years",
"< 1 year",
"10+ years",
"1 year",
"7 years",
null,
"4 years",
"5 years",
"6 years",
"3 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"3 years",
null,
"1 year",
"1 year",
"5 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"9 years",
"10+ years",
"5 years",
"2 years",
"5 years",
"10+ years",
"< 1 year",
"1 year",
"4 years",
"< 1 year",
"< 1 year",
"8 years",
"4 years",
"2 years",
"4 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"7 years",
"6 years",
"< 1 year",
"8 years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"8 years",
"3 years",
"2 years",
"10+ years",
"9 years",
"10+ years",
"2 years",
"4 years",
"7 years",
"9 years",
"3 years",
"< 1 year",
"2 years",
"6 years",
"< 1 year",
"5 years",
"2 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
null,
"6 years",
"4 years",
"1 year",
"3 years",
"4 years",
"1 year",
"1 year",
"< 1 year",
"1 year",
"10+ years",
"7 years",
"8 years",
"9 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"5 years",
"9 years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"8 years",
"8 years",
"8 years",
"8 years",
"6 years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"< 1 year",
"< 1 year",
"7 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"2 years",
"8 years",
"1 year",
"1 year",
null,
"10+ years",
"10+ years",
"2 years",
"5 years",
"< 1 year",
"5 years",
"2 years",
"10+ years",
null,
"10+ years",
"7 years",
"6 years",
"6 years",
"5 years",
"5 years",
"4 years",
"10+ years",
"1 year",
"5 years",
"9 years",
"2 years",
"9 years",
"5 years",
"8 years",
"2 years",
"10+ years",
"< 1 year",
"< 1 year",
"2 years",
null,
"7 years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"7 years",
"7 years",
null,
"2 years",
"8 years",
"5 years",
"9 years",
"10+ years",
"9 years",
"8 years",
"9 years",
"10+ years",
null,
"10+ years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"5 years",
"7 years",
"10+ years",
"6 years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"8 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"4 years",
"10+ years",
"1 year",
"8 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"6 years",
"8 years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"7 years",
"3 years",
"5 years",
"1 year",
"< 1 year",
"2 years",
"4 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"9 years",
"9 years",
"7 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"< 1 year",
"10+ years",
null,
"8 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"< 1 year",
"4 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"7 years",
"10+ years",
"5 years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
null,
"2 years",
"8 years",
"9 years",
null,
"< 1 year",
"10+ years",
"< 1 year",
"< 1 year",
"1 year",
"2 years",
"1 year",
"3 years",
"2 years",
"1 year",
"4 years",
"< 1 year",
"1 year",
"10+ years",
"< 1 year",
"3 years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"9 years",
"< 1 year",
null,
"2 years",
"3 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"6 years",
"9 years",
"2 years",
"3 years",
"4 years",
"10+ years",
"1 year",
"5 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"4 years",
"8 years",
"2 years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"5 years",
"1 year",
"9 years",
"7 years",
"1 year",
"8 years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"3 years",
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"6 years",
"4 years",
"10+ years",
"10+ years",
"7 years",
"7 years",
"3 years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"< 1 year",
"3 years",
"2 years",
"2 years",
"10+ years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"6 years",
"10+ years",
"3 years",
"10+ years",
null,
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"8 years",
"7 years",
"9 years",
"3 years",
"3 years",
"2 years",
"4 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"6 years",
"5 years",
"10+ years",
"8 years",
"9 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"9 years",
null,
"6 years",
"9 years",
"5 years",
"4 years",
"10+ years",
"10+ years",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"9 years",
"3 years",
"3 years",
"2 years",
"2 years",
"5 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"2 years",
"8 years",
"8 years",
"3 years",
null,
"3 years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"3 years",
"8 years",
"4 years",
"4 years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"1 year",
"4 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"7 years",
"< 1 year",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"3 years",
null,
"3 years",
"10+ years",
"7 years",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
null,
"8 years",
"10+ years",
"< 1 year",
"8 years",
"3 years",
"10+ years",
"10+ years",
null,
"1 year",
"7 years",
"< 1 year",
"3 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"8 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"5 years",
"10+ years",
null,
"1 year",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"9 years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
null,
"3 years",
"2 years",
"8 years",
"2 years",
"10+ years",
"< 1 year",
"3 years",
"< 1 year",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"5 years",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"5 years",
null,
"2 years",
"8 years",
"1 year",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"5 years",
"3 years",
"10+ years",
"5 years",
"4 years",
"8 years",
"5 years",
null,
"5 years",
"10+ years",
"2 years",
"2 years",
"< 1 year",
"10+ years",
"7 years",
"3 years",
"2 years",
"< 1 year",
"1 year",
"7 years",
"2 years",
"10+ years",
"4 years",
"3 years",
"8 years",
"3 years",
"8 years",
"< 1 year",
"2 years",
"1 year",
"2 years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"2 years",
"5 years",
"< 1 year",
"< 1 year",
"6 years",
"10+ years",
"3 years",
"7 years",
null,
"3 years",
null,
"5 years",
"2 years",
"10+ years",
"7 years",
"3 years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"1 year",
"8 years",
"7 years",
"6 years",
"10+ years",
"7 years",
"10+ years",
"9 years",
"< 1 year",
"3 years",
"5 years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"8 years",
"5 years",
"3 years",
"9 years",
"1 year",
"10+ years",
null,
"3 years",
"5 years",
"8 years",
"3 years",
"7 years",
"3 years",
"7 years",
"3 years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"4 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"8 years",
"8 years",
"1 year",
"4 years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"< 1 year",
"1 year",
"7 years",
"6 years",
"3 years",
"< 1 year",
"3 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"< 1 year",
"9 years",
"2 years",
"9 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
null,
"2 years",
"< 1 year",
"< 1 year",
"4 years",
"7 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"1 year",
"1 year",
"10+ years",
"4 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"7 years",
"< 1 year",
"2 years",
"10+ years",
"5 years",
"8 years",
"2 years",
"3 years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"1 year",
"6 years",
"6 years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"6 years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"3 years",
"8 years",
null,
"7 years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"4 years",
"3 years",
"10+ years",
"3 years",
"7 years",
"9 years",
"10+ years",
"10+ years",
"8 years",
"3 years",
"2 years",
"10+ years",
"9 years",
"8 years",
"< 1 year",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"< 1 year",
"5 years",
"10+ years",
"5 years",
"8 years",
"10+ years",
"9 years",
"10+ years",
"5 years",
"10+ years",
"3 years",
"1 year",
"3 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"6 years",
"3 years",
"10+ years",
"8 years",
"5 years",
"7 years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"1 year",
"8 years",
"10+ years",
"2 years",
"7 years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
null,
"10+ years",
"9 years",
"9 years",
"< 1 year",
"2 years",
"4 years",
"< 1 year",
"5 years",
"5 years",
"3 years",
"10+ years",
"< 1 year",
null,
"10+ years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"7 years",
"10+ years",
"< 1 year",
"9 years",
"9 years",
"2 years",
"9 years",
"8 years",
null,
null,
"10+ years",
"5 years",
"6 years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"9 years",
"4 years",
"2 years",
"3 years",
"1 year",
"10+ years",
"6 years",
"< 1 year",
"8 years",
"3 years",
"5 years",
"10+ years",
"10+ years",
null,
"< 1 year",
null,
"10+ years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"4 years",
"1 year",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
null,
"1 year",
"5 years",
"4 years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"8 years",
"8 years",
"6 years",
"8 years",
"3 years",
"2 years",
"10+ years",
"8 years",
"1 year",
"10+ years",
null,
"4 years",
"4 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"1 year",
"5 years",
"6 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"3 years",
"5 years",
"3 years",
"2 years",
"6 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"7 years",
"2 years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"3 years",
"9 years",
"< 1 year",
"10+ years",
"9 years",
"< 1 year",
"3 years",
"< 1 year",
"4 years",
"2 years",
"5 years",
"7 years",
"10+ years",
"< 1 year",
"2 years",
"4 years",
"1 year",
"6 years",
"1 year",
"10+ years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"3 years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"1 year",
"8 years",
"< 1 year",
"< 1 year",
"4 years",
"10+ years",
null,
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"8 years",
null,
"2 years",
"9 years",
"2 years",
"10+ years",
"8 years",
"3 years",
"8 years",
"10+ years",
"9 years",
"8 years",
"10+ years",
"4 years",
null,
"2 years",
"< 1 year",
"8 years",
"4 years",
"4 years",
"10+ years",
"3 years",
"3 years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"5 years",
"9 years",
"9 years",
"2 years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"2 years",
"6 years",
"5 years",
null,
"5 years",
"< 1 year",
"2 years",
null,
"3 years",
"3 years",
"5 years",
"8 years",
"8 years",
"5 years",
"2 years",
"10+ years",
"7 years",
"8 years",
"2 years",
"5 years",
"10+ years",
"7 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
null,
"7 years",
"3 years",
"7 years",
"6 years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"1 year",
"4 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"3 years",
"7 years",
"2 years",
"7 years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"8 years",
"2 years",
"4 years",
"1 year",
"4 years",
null,
"4 years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"9 years",
"7 years",
"< 1 year",
null,
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"< 1 year",
"4 years",
"5 years",
"< 1 year",
"6 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
null,
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"7 years",
null,
"4 years",
"10+ years",
"9 years",
null,
"9 years",
"10+ years",
"< 1 year",
null,
"3 years",
"8 years",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"7 years",
"9 years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"7 years",
"4 years",
"8 years",
"7 years",
"6 years",
"3 years",
"1 year",
"< 1 year",
"10+ years",
"4 years",
"3 years",
"< 1 year",
"3 years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"9 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
null,
"2 years",
"< 1 year",
"< 1 year",
"4 years",
"8 years",
"4 years",
null,
"10+ years",
"1 year",
"< 1 year",
"1 year",
"< 1 year",
"< 1 year",
"5 years",
"2 years",
"8 years",
"10+ years",
"6 years",
"6 years",
"7 years",
"10+ years",
"4 years",
"2 years",
null,
"< 1 year",
"3 years",
"3 years",
"10+ years",
null,
"2 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"1 year",
"10+ years",
"4 years",
"7 years",
"1 year",
null,
"10+ years",
"4 years",
"2 years",
"2 years",
"5 years",
"9 years",
"2 years",
"5 years",
"10+ years",
"9 years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"3 years",
"1 year",
"8 years",
"5 years",
"4 years",
"9 years",
"2 years",
"10+ years",
"10+ years",
null,
"5 years",
"2 years",
"7 years",
"10+ years",
"1 year",
"8 years",
"5 years",
"9 years",
"7 years",
"6 years",
"7 years",
"4 years",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
null,
"10+ years",
"5 years",
"10+ years",
"9 years",
"8 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"7 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"4 years",
"8 years",
"10+ years",
"10+ years",
"6 years",
"4 years",
"2 years",
"9 years",
"6 years",
"3 years",
"10+ years",
"5 years",
"7 years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"7 years",
null,
"< 1 year",
"10+ years",
"2 years",
"5 years",
"2 years",
"2 years",
"2 years",
null,
"10+ years",
"10+ years",
"8 years",
"2 years",
"3 years",
"3 years",
"4 years",
"6 years",
"8 years",
"10+ years",
"2 years",
null,
"2 years",
"1 year",
"10+ years",
null,
"10+ years",
null,
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"6 years",
"5 years",
"10+ years",
null,
"10+ years",
"10+ years",
"3 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"< 1 year",
"9 years",
null,
"10+ years",
"8 years",
"10+ years",
"10+ years",
"6 years",
null,
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"6 years",
"7 years",
"1 year",
"8 years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"6 years",
"10+ years",
null,
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"3 years",
null,
"10+ years",
"4 years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"< 1 year",
"4 years",
"5 years",
"3 years",
null,
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"9 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"8 years",
null,
"1 year",
"6 years",
"2 years",
"< 1 year",
"6 years",
"9 years",
"10+ years",
"5 years",
"2 years",
"4 years",
"3 years",
"6 years",
"2 years",
"2 years",
"3 years",
null,
"3 years",
null,
"9 years",
"< 1 year",
"1 year",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"9 years",
"2 years",
"5 years",
"4 years",
"7 years",
"9 years",
"10+ years",
"3 years",
"1 year",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"1 year",
"3 years",
"6 years",
"10+ years",
"7 years",
"10+ years",
"7 years",
"3 years",
"6 years",
"10+ years",
"3 years",
"4 years",
null,
"2 years",
"< 1 year",
"3 years",
"10+ years",
"5 years",
null,
"< 1 year",
"6 years",
"1 year",
"4 years",
"3 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
null,
"10+ years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"5 years",
"5 years",
"4 years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"7 years",
"10+ years",
"2 years",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"8 years",
"7 years",
"10+ years",
null,
"< 1 year",
"8 years",
"7 years",
"6 years",
"10+ years",
"9 years",
"2 years",
"5 years",
"1 year",
"5 years",
"10+ years",
"2 years",
"10+ years",
"6 years",
"9 years",
"1 year",
"9 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"5 years",
"5 years",
"10+ years",
"9 years",
"10+ years",
"3 years",
"2 years",
"1 year",
"9 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"5 years",
null,
"5 years",
"10+ years",
"10+ years",
"2 years",
"7 years",
null,
"5 years",
"8 years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"7 years",
"4 years",
"5 years",
"4 years",
"< 1 year",
"5 years",
"10+ years",
"3 years",
"6 years",
"4 years",
null,
null,
"10+ years",
null,
null,
"5 years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"7 years",
"2 years",
"7 years",
"1 year",
"< 1 year",
"3 years",
"1 year",
"10+ years",
"8 years",
"5 years",
"2 years",
"7 years",
"5 years",
"9 years",
"8 years",
"10+ years",
"2 years",
"< 1 year",
"8 years",
"2 years",
"2 years",
"1 year",
"< 1 year",
"5 years",
"2 years",
"5 years",
"10+ years",
"8 years",
"6 years",
"4 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"4 years",
"5 years",
"2 years",
"5 years",
"10+ years",
"1 year",
"4 years",
"6 years",
"3 years",
"8 years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"7 years",
"1 year",
"10+ years",
"6 years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"5 years",
"10+ years",
null,
"3 years",
"8 years",
"8 years",
"10+ years",
"3 years",
"5 years",
"< 1 year",
"10+ years",
"2 years",
"3 years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
null,
"< 1 year",
"6 years",
"3 years",
"5 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"3 years",
"10+ years",
"< 1 year",
"2 years",
"2 years",
"6 years",
"9 years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"4 years",
"2 years",
"2 years",
null,
"10+ years",
"< 1 year",
null,
"1 year",
null,
"10+ years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"9 years",
"1 year",
"7 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"6 years",
"5 years",
"2 years",
"4 years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"4 years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"8 years",
"< 1 year",
"4 years",
"1 year",
null,
"10+ years",
"10+ years",
"10+ years",
"3 years",
null,
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"1 year",
"2 years",
null,
"7 years",
"2 years",
"10+ years",
null,
null,
"2 years",
"1 year",
"7 years",
"10+ years",
"< 1 year",
"5 years",
"5 years",
null,
"10+ years",
"6 years",
null,
"10+ years",
"2 years",
"6 years",
"9 years",
"< 1 year",
"9 years",
"10+ years",
"2 years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"2 years",
"6 years",
"10+ years",
"4 years",
"4 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"5 years",
"5 years",
null,
"4 years",
"5 years",
"2 years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"3 years",
"5 years",
"4 years",
"7 years",
"10+ years",
"7 years",
"10+ years",
"< 1 year",
"2 years",
"9 years",
"1 year",
"3 years",
"10+ years",
"2 years",
"7 years",
"9 years",
"10+ years",
null,
"9 years",
"4 years",
"2 years",
"6 years",
null,
"10+ years",
"1 year",
"3 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"9 years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"8 years",
"8 years",
"1 year",
"10+ years",
"10+ years",
"9 years",
"4 years",
"3 years",
"4 years",
"10+ years",
"2 years",
"1 year",
"7 years",
null,
"1 year",
"10+ years",
"7 years",
"7 years",
"7 years",
"2 years",
"< 1 year",
"9 years",
"4 years",
"2 years",
"10+ years",
"2 years",
"4 years",
"10+ years",
"2 years",
"8 years",
"1 year",
"8 years",
"10+ years",
"3 years",
"9 years",
"8 years",
null,
"10+ years",
"3 years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"1 year",
"2 years",
"5 years",
"2 years",
"5 years",
"5 years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"3 years",
null,
"8 years",
null,
"10+ years",
"5 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"9 years",
"2 years",
"3 years",
"10+ years",
"4 years",
"< 1 year",
"1 year",
"5 years",
"4 years",
"10+ years",
"10+ years",
null,
"4 years",
"10+ years",
"10+ years",
null,
"3 years",
"1 year",
"2 years",
"7 years",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
null,
"10+ years",
"1 year",
"3 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"7 years",
"6 years",
"2 years",
"10+ years",
"6 years",
"4 years",
"10+ years",
"9 years",
"3 years",
"2 years",
"10+ years",
"2 years",
"1 year",
"8 years",
"< 1 year",
"3 years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"4 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"1 year",
"4 years",
"8 years",
"10+ years",
"6 years",
"10+ years",
"5 years",
"10+ years",
"8 years",
"1 year",
"1 year",
"7 years",
"7 years",
"< 1 year",
"8 years",
"10+ years",
null,
"< 1 year",
"8 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
null,
"2 years",
"3 years",
"10+ years",
"3 years",
"4 years",
"8 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"8 years",
"< 1 year",
"4 years",
"5 years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"9 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"3 years",
"5 years",
"1 year",
"8 years",
"10+ years",
"< 1 year",
"8 years",
"2 years",
"1 year",
null,
"10+ years",
"10+ years",
"2 years",
"5 years",
null,
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"8 years",
"10+ years",
"6 years",
"6 years",
"3 years",
"8 years",
"7 years",
null,
null,
"10+ years",
"2 years",
"10+ years",
"2 years",
"1 year",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"9 years",
"4 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"8 years",
"2 years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"6 years",
"7 years",
"5 years",
"8 years",
"10+ years",
"< 1 year",
"< 1 year",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"9 years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"7 years",
"10+ years",
"8 years",
null,
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"5 years",
null,
"10+ years",
null,
"1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"< 1 year",
"1 year",
"5 years",
"4 years",
"2 years",
"10+ years",
"2 years",
"2 years",
"3 years",
null,
"10+ years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"6 years",
"6 years",
"10+ years",
"2 years",
"< 1 year",
"8 years",
"10+ years",
"5 years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
null,
"5 years",
"1 year",
"1 year",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"8 years",
"8 years",
"10+ years",
"4 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"< 1 year",
"8 years",
"1 year",
"4 years",
"8 years",
"2 years",
"10+ years",
"< 1 year",
"2 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
null,
"1 year",
"4 years",
"3 years",
"< 1 year",
"9 years",
"6 years",
"6 years",
null,
"10+ years",
"7 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"8 years",
"8 years",
"8 years",
"4 years",
"4 years",
"< 1 year",
"1 year",
"1 year",
"7 years",
"7 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"4 years",
"3 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"7 years",
"< 1 year",
"5 years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"2 years",
"7 years",
null,
"10+ years",
"10+ years",
"9 years",
"5 years",
"2 years",
"10+ years",
"6 years",
"7 years",
"10+ years",
"4 years",
"3 years",
null,
"10+ years",
"9 years",
"2 years",
"5 years",
"< 1 year",
"7 years",
"4 years",
"2 years",
"2 years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"1 year",
"9 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"4 years",
"10+ years",
null,
"2 years",
"10+ years",
"8 years",
"3 years",
"< 1 year",
"4 years",
"10+ years",
"8 years",
"1 year",
"3 years",
"10+ years",
"1 year",
"10+ years",
"2 years",
"6 years",
"10+ years",
"3 years",
"3 years",
"9 years",
"7 years",
"10+ years",
"3 years",
"1 year",
null,
"2 years",
"6 years",
"6 years",
"< 1 year",
"8 years",
"10+ years",
"2 years",
"6 years",
"5 years",
"6 years",
"3 years",
"6 years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"8 years",
"3 years",
"5 years",
"9 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
null,
"< 1 year",
"10+ years",
"7 years",
"2 years",
"1 year",
"1 year",
"3 years",
"4 years",
"10+ years",
"7 years",
"2 years",
"< 1 year",
"1 year",
"10+ years",
"3 years",
"< 1 year",
"2 years",
"9 years",
"8 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"6 years",
"< 1 year",
"4 years",
"6 years",
"6 years",
"6 years",
"2 years",
"5 years",
"8 years",
null,
"< 1 year",
"6 years",
"6 years",
"4 years",
"7 years",
"7 years",
"7 years",
"7 years",
"10+ years",
null,
"6 years",
"8 years",
"3 years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"4 years",
"9 years",
"9 years",
"8 years",
"3 years",
"1 year",
"9 years",
null,
"< 1 year",
null,
"1 year",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"2 years",
"8 years",
"2 years",
"5 years",
"1 year",
"10+ years",
"7 years",
"2 years",
"8 years",
null,
"6 years",
"< 1 year",
"10+ years",
"7 years",
"9 years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"7 years",
"10+ years",
null,
"10+ years",
"9 years",
"< 1 year",
null,
"10+ years",
"10+ years",
"7 years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"3 years",
"< 1 year",
null,
"5 years",
"10+ years",
"10+ years",
"1 year",
"8 years",
"10+ years",
"6 years",
"8 years",
"2 years",
"10+ years",
"6 years",
"10+ years",
"7 years",
"5 years",
"4 years",
"10+ years",
"1 year",
"7 years",
"1 year",
"< 1 year",
"3 years",
"5 years",
"7 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"2 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"4 years",
"2 years",
"5 years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"< 1 year",
"< 1 year",
"2 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"4 years",
"1 year",
"10+ years",
"10+ years",
"1 year",
"4 years",
"5 years",
"3 years",
"7 years",
"3 years",
"3 years",
"1 year",
"10+ years",
null,
"10+ years",
"3 years",
"9 years",
"< 1 year",
"10+ years",
"7 years",
"1 year",
"2 years",
"< 1 year",
"2 years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"4 years",
null,
"4 years",
"3 years",
"< 1 year",
"5 years",
"5 years",
"5 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"1 year",
"3 years",
"9 years",
"3 years",
"10+ years",
"3 years",
null,
null,
"6 years",
"< 1 year",
"6 years",
"10+ years",
"4 years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"5 years",
"6 years",
"4 years",
"10+ years",
"< 1 year",
null,
"10+ years",
"8 years",
"5 years",
null,
"3 years",
"< 1 year",
"7 years",
"9 years",
"2 years",
"4 years",
"10+ years",
"5 years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"1 year",
"7 years",
"7 years",
"< 1 year",
"6 years",
"5 years",
"7 years",
"10+ years",
"2 years",
null,
"2 years",
"3 years",
"9 years",
"10+ years",
"10+ years",
"8 years",
"6 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"7 years",
"9 years",
"1 year",
null,
"10+ years",
"1 year",
"1 year",
"3 years",
"10+ years",
"5 years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
null,
"< 1 year",
"7 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"6 years",
"10+ years",
null,
"4 years",
"2 years",
"8 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"1 year",
"< 1 year",
"4 years",
"1 year",
"< 1 year",
"8 years",
"10+ years",
"3 years",
"3 years",
"4 years",
"10+ years",
"< 1 year",
"2 years",
"4 years",
"5 years",
"5 years",
"10+ years",
"9 years",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"1 year",
"5 years",
"10+ years",
"5 years",
"5 years",
null,
"6 years",
"10+ years",
"< 1 year",
"6 years",
"7 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"1 year",
"3 years",
"3 years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"< 1 year",
"8 years",
"6 years",
"< 1 year",
"< 1 year",
"1 year",
"1 year",
"7 years",
"4 years",
"1 year",
"2 years",
"6 years",
"< 1 year",
"7 years",
"1 year",
"2 years",
"10+ years",
"6 years",
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"3 years",
"5 years",
"10+ years",
"6 years",
"3 years",
"4 years",
"4 years",
null,
"7 years",
"7 years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"7 years",
"10+ years",
"8 years",
"< 1 year",
"6 years",
"< 1 year",
"9 years",
"1 year",
"10+ years",
"2 years",
"5 years",
null,
"1 year",
"2 years",
"2 years",
"10+ years",
"< 1 year",
"5 years",
"< 1 year",
"9 years",
"10+ years",
"3 years",
"1 year",
"2 years",
"10+ years",
"7 years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"5 years",
null,
"1 year",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
null,
"10+ years",
"9 years",
"7 years",
"1 year",
null,
"10+ years",
"< 1 year",
null,
"10+ years",
null,
"10+ years",
"2 years",
"7 years",
"< 1 year",
null,
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"8 years",
"7 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"8 years",
"10+ years",
null,
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"9 years",
"< 1 year",
"10+ years",
"2 years",
"4 years",
"6 years",
"4 years",
"5 years",
null,
"10+ years",
"5 years",
"8 years",
"8 years",
"3 years",
"8 years",
"1 year",
"2 years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"6 years",
"8 years",
"8 years",
"10+ years",
"6 years",
"1 year",
"10+ years",
"6 years",
"< 1 year",
"9 years",
"7 years",
"< 1 year",
"8 years",
"4 years",
null,
null,
"3 years",
"10+ years",
"3 years",
"5 years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"9 years",
"< 1 year",
"< 1 year",
"3 years",
"8 years",
"4 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"8 years",
"7 years",
"10+ years",
"5 years",
"2 years",
"8 years",
"7 years",
"10+ years",
"2 years",
null,
"8 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"7 years",
"7 years",
"7 years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"6 years",
"7 years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"6 years",
"3 years",
"10+ years",
"5 years",
"2 years",
"4 years",
"5 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
null,
"9 years",
"10+ years",
"7 years",
"2 years",
"2 years",
"1 year",
"8 years",
"8 years",
null,
"10+ years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"6 years",
"10+ years",
"6 years",
"9 years",
null,
"3 years",
"10+ years",
"1 year",
"3 years",
"1 year",
"5 years",
"10+ years",
"7 years",
"< 1 year",
"5 years",
null,
"10+ years",
"10+ years",
"9 years",
null,
"10+ years",
"2 years",
"3 years",
"1 year",
"10+ years",
"5 years",
"6 years",
"4 years",
"3 years",
"3 years",
"2 years",
"10+ years",
"4 years",
"2 years",
"3 years",
null,
null,
"10+ years",
"10+ years",
"10+ years",
"4 years",
"9 years",
null,
"9 years",
"3 years",
"1 year",
"10+ years",
"3 years",
"4 years",
"10+ years",
"5 years",
null,
"2 years",
"9 years",
"10+ years",
"5 years",
"8 years",
"2 years",
"2 years",
"10+ years",
"2 years",
"8 years",
"6 years",
"< 1 year",
"4 years",
"3 years",
"10+ years",
"2 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"2 years",
null,
"4 years",
"3 years",
"10+ years",
"4 years",
"2 years",
"5 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"5 years",
"7 years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"5 years",
"8 years",
"10+ years",
"10+ years",
"8 years",
null,
"7 years",
"5 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"2 years",
"4 years",
"6 years",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"< 1 year",
"5 years",
"3 years",
"2 years",
"6 years",
"8 years",
"4 years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"< 1 year",
"2 years",
"2 years",
"4 years",
"< 1 year",
null,
"6 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"6 years",
"8 years",
"5 years",
"5 years",
"4 years",
"4 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
null,
"2 years",
"10+ years",
"4 years",
null,
"10+ years",
"1 year",
"10+ years",
"10+ years",
"7 years",
"9 years",
"5 years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"6 years",
"3 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"4 years",
"4 years",
"10+ years",
"9 years",
"2 years",
"10+ years",
null,
null,
"1 year",
"< 1 year",
"3 years",
"5 years",
null,
"1 year",
"7 years",
"10+ years",
"1 year",
"4 years",
"10+ years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"4 years",
"2 years",
"3 years",
"6 years",
"2 years",
"6 years",
"3 years",
"9 years",
"3 years",
"3 years",
"8 years",
"1 year",
"9 years",
"1 year",
null,
"4 years",
"2 years",
"< 1 year",
"8 years",
"3 years",
"10+ years",
"7 years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"4 years",
"3 years",
"6 years",
"2 years",
"3 years",
"10+ years",
null,
"10+ years",
"10+ years",
"8 years",
"7 years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
null,
"3 years",
"9 years",
null,
"5 years",
"10+ years",
null,
"2 years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"8 years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"9 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"3 years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"5 years",
"3 years",
null,
"9 years",
"< 1 year",
"< 1 year",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"2 years",
"10+ years",
null,
"7 years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"8 years",
"9 years",
"7 years",
"9 years",
"1 year",
"10+ years",
"1 year",
"9 years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"1 year",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"8 years",
"2 years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"8 years",
"3 years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"4 years",
"10+ years",
"8 years",
null,
"< 1 year",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"8 years",
"< 1 year",
"4 years",
"2 years",
"6 years",
"4 years",
"1 year",
"< 1 year",
"10+ years",
"9 years",
"9 years",
"3 years",
null,
null,
"10+ years",
"< 1 year",
"5 years",
"9 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"5 years",
null,
"< 1 year",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"3 years",
null,
"6 years",
"2 years",
"5 years",
"10+ years",
"8 years",
"9 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"5 years",
"2 years",
"4 years",
"10+ years",
"2 years",
"5 years",
"1 year",
"8 years",
"< 1 year",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"8 years",
"2 years",
"10+ years",
"1 year",
null,
"10+ years",
"5 years",
"2 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
null,
null,
"9 years",
"7 years",
null,
"5 years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"2 years",
"< 1 year",
"2 years",
"5 years",
"7 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"1 year",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"7 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"8 years",
"8 years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"3 years",
"1 year",
"8 years",
"10+ years",
"8 years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"4 years",
"6 years",
"10+ years",
"4 years",
"10+ years",
"1 year",
"10+ years",
"6 years",
"9 years",
"10+ years",
"3 years",
"5 years",
null,
"10+ years",
null,
"6 years",
"9 years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"7 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
null,
"1 year",
"3 years",
"< 1 year",
"5 years",
"7 years",
"5 years",
"1 year",
"7 years",
"2 years",
"10+ years",
null,
"3 years",
"4 years",
"10+ years",
"8 years",
"< 1 year",
null,
"3 years",
"3 years",
"1 year",
"5 years",
"6 years",
"9 years",
"5 years",
"6 years",
"5 years",
"3 years",
"8 years",
"3 years",
"3 years",
"2 years",
"10+ years",
"< 1 year",
"4 years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"5 years",
"5 years",
"10+ years",
"4 years",
"5 years",
"1 year",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"4 years",
"9 years",
"3 years",
"6 years",
"4 years",
"9 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"1 year",
null,
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"7 years",
"2 years",
"1 year",
"9 years",
"4 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"4 years",
"< 1 year",
"10+ years",
"9 years",
null,
"7 years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"3 years",
"3 years",
"4 years",
"1 year",
"1 year",
null,
"4 years",
"2 years",
"4 years",
"4 years",
"10+ years",
"3 years",
"< 1 year",
"9 years",
"1 year",
"1 year",
"< 1 year",
"3 years",
"2 years",
"5 years",
"3 years",
"10+ years",
"3 years",
"5 years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
null,
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"2 years",
"< 1 year",
"2 years",
"6 years",
"10+ years",
null,
"6 years",
"2 years",
"1 year",
null,
"10+ years",
null,
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"6 years",
"7 years",
"9 years",
"6 years",
"2 years",
null,
"2 years",
"10+ years",
"5 years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"< 1 year",
"4 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"7 years",
"10+ years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"3 years",
"8 years",
"5 years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"1 year",
"1 year",
"4 years",
"5 years",
null,
"< 1 year",
"1 year",
"10+ years",
null,
"10+ years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"3 years",
"8 years",
null,
"10+ years",
"< 1 year",
"6 years",
"10+ years",
null,
"8 years",
"2 years",
"10+ years",
"6 years",
"7 years",
"2 years",
"6 years",
"4 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"5 years",
"5 years",
"10+ years",
"7 years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"1 year",
"10+ years",
null,
"1 year",
"5 years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"8 years",
"8 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"3 years",
"9 years",
"5 years",
"10+ years",
"1 year",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"7 years",
"4 years",
"4 years",
"8 years",
"4 years",
"10+ years",
"3 years",
"3 years",
"6 years",
"3 years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"1 year",
"3 years",
"10+ years",
null,
"2 years",
"10+ years",
"8 years",
"10+ years",
"7 years",
"5 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"7 years",
"5 years",
"4 years",
"7 years",
"7 years",
"< 1 year",
"3 years",
"10+ years",
"< 1 year",
"2 years",
"7 years",
"8 years",
"10+ years",
null,
"10+ years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"2 years",
"7 years",
"8 years",
"8 years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"3 years",
"5 years",
"5 years",
"9 years",
"2 years",
"10+ years",
"1 year",
"6 years",
"4 years",
"10+ years",
"< 1 year",
"8 years",
"5 years",
"10+ years",
null,
"4 years",
"3 years",
"1 year",
"4 years",
"10+ years",
"3 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"9 years",
"4 years",
"8 years",
"5 years",
"3 years",
"10+ years",
"7 years",
"4 years",
null,
null,
"10+ years",
"4 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"4 years",
"10+ years",
"7 years",
"8 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
null,
"7 years",
"6 years",
"1 year",
"4 years",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"4 years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"4 years",
"3 years",
"7 years",
null,
"5 years",
"< 1 year",
"1 year",
"10+ years",
"6 years",
"4 years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"6 years",
"5 years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"1 year",
"3 years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"10+ years",
"2 years",
null,
"10+ years",
"9 years",
"10+ years",
"10+ years",
"9 years",
"8 years",
"5 years",
"10+ years",
"< 1 year",
"7 years",
"2 years",
"3 years",
"5 years",
"10+ years",
null,
"3 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"2 years",
"8 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"4 years",
"1 year",
"5 years",
"3 years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"5 years",
"2 years",
null,
"6 years",
"1 year",
"1 year",
"7 years",
"5 years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"5 years",
"2 years",
"10+ years",
"1 year",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"5 years",
"2 years",
"3 years",
"2 years",
"< 1 year",
"6 years",
"3 years",
"2 years",
"7 years",
"5 years",
"7 years",
"4 years",
"10+ years",
"< 1 year",
"< 1 year",
"4 years",
"8 years",
null,
"10+ years",
"10+ years",
"6 years",
"2 years",
"10+ years",
null,
"1 year",
"1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"4 years",
"< 1 year",
"3 years",
"8 years",
"10+ years",
"8 years",
"2 years",
"9 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"5 years",
"2 years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"6 years",
"8 years",
"4 years",
"7 years",
"5 years",
"4 years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"5 years",
"5 years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"3 years",
"10+ years",
"6 years",
"4 years",
"10+ years",
"1 year",
"6 years",
"10+ years",
"5 years",
"4 years",
"5 years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"6 years",
"< 1 year",
"10+ years",
"2 years",
"1 year",
"10+ years",
"2 years",
"8 years",
"4 years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"6 years",
"3 years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"7 years",
"7 years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
null,
"6 years",
"< 1 year",
"< 1 year",
"10+ years",
"4 years",
"9 years",
"< 1 year",
null,
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
"5 years",
"6 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"1 year",
"9 years",
"4 years",
"3 years",
"2 years",
"9 years",
"10+ years",
"2 years",
"4 years",
"1 year",
"3 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
null,
"10+ years",
"< 1 year",
"3 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"8 years",
"9 years",
"10+ years",
"1 year",
"10+ years",
"4 years",
"2 years",
"5 years",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"6 years",
"10+ years",
null,
"10+ years",
"< 1 year",
"8 years",
"6 years",
"5 years",
"1 year",
"3 years",
"1 year",
"7 years",
"9 years",
"2 years",
"8 years",
"9 years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
null,
"10+ years",
"10+ years",
"9 years",
"8 years",
"5 years",
"10+ years",
"4 years",
"8 years",
"10+ years",
"5 years",
"1 year",
"7 years",
"10+ years",
"1 year",
"8 years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"1 year",
"< 1 year",
"9 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"4 years",
"8 years",
"4 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"8 years",
null,
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"3 years",
"10+ years",
"7 years",
"6 years",
"8 years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"7 years",
"10+ years",
"6 years",
"5 years",
"3 years",
"1 year",
"10+ years",
"4 years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"4 years",
"2 years",
null,
"10+ years",
"1 year",
"6 years",
"10+ years",
"6 years",
"5 years",
"10+ years",
"2 years",
"5 years",
"7 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"1 year",
"2 years",
"8 years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"5 years",
"5 years",
"3 years",
"9 years",
"2 years",
"2 years",
"2 years",
"< 1 year",
"2 years",
"10+ years",
"9 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"9 years",
"1 year",
"7 years",
"5 years",
"10+ years",
"10+ years",
"6 years",
"9 years",
"< 1 year",
"5 years",
"6 years",
null,
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"7 years",
null,
"1 year",
"10+ years",
"10+ years",
"8 years",
"2 years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"9 years",
null,
"10+ years",
"3 years",
"10+ years",
"4 years",
"10+ years",
"9 years",
"5 years",
"10+ years",
null,
"< 1 year",
"6 years",
"6 years",
"4 years",
"4 years",
"1 year",
"10+ years",
"< 1 year",
"< 1 year",
"8 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"5 years",
"< 1 year",
"6 years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"10+ years",
"6 years",
null,
"6 years",
"6 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"< 1 year",
"< 1 year",
"7 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"8 years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"< 1 year",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"3 years",
null,
"10+ years",
"1 year",
"8 years",
"7 years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"1 year",
null,
"< 1 year",
"4 years",
"4 years",
"4 years",
"5 years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"5 years",
"10+ years",
"4 years",
"10+ years",
"4 years",
"3 years",
"9 years",
"< 1 year",
"1 year",
"5 years",
"9 years",
"6 years",
null,
"2 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"7 years",
"6 years",
"5 years",
"5 years",
"8 years",
null,
"< 1 year",
"6 years",
"6 years",
"3 years",
"4 years",
"10+ years",
"8 years",
"< 1 year",
"< 1 year",
"6 years",
"10+ years",
"10+ years",
null,
"< 1 year",
"2 years",
"9 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"4 years",
"4 years",
"< 1 year",
"9 years",
"10+ years",
"10+ years",
"1 year",
"6 years",
"8 years",
"9 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"3 years",
"2 years",
"< 1 year",
"3 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"6 years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"1 year",
null,
"3 years",
"2 years",
"4 years",
"10+ years",
"4 years",
"8 years",
"5 years",
"2 years",
"4 years",
"3 years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"2 years",
"< 1 year",
"5 years",
"8 years",
"9 years",
"10+ years",
"10+ years",
"3 years",
null,
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"4 years",
"1 year",
"5 years",
"2 years",
"6 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"6 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"9 years",
"6 years",
"8 years",
"1 year",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"6 years",
null,
"6 years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"2 years",
"1 year",
"10+ years",
"7 years",
"3 years",
"< 1 year",
"10+ years",
"4 years",
"3 years",
"< 1 year",
"5 years",
"7 years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"5 years",
"9 years",
"1 year",
"3 years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"6 years",
null,
"8 years",
"10+ years",
"5 years",
"< 1 year",
"2 years",
"6 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"10+ years",
"7 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"6 years",
null,
"< 1 year",
"< 1 year",
"10+ years",
"3 years",
"7 years",
"< 1 year",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"4 years",
"3 years",
"10+ years",
"9 years",
"10+ years",
"4 years",
"8 years",
"10+ years",
"6 years",
"< 1 year",
null,
"10+ years",
"8 years",
"7 years",
"4 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"3 years",
"< 1 year",
"4 years",
"9 years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"8 years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"9 years",
"2 years",
"6 years",
"10+ years",
"< 1 year",
"3 years",
"9 years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"5 years",
"9 years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"6 years",
"10+ years",
"3 years",
null,
null,
"10+ years",
null,
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"4 years",
"5 years",
"4 years",
"1 year",
null,
"6 years",
"10+ years",
"6 years",
"4 years",
"10+ years",
"< 1 year",
"2 years",
"9 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"8 years",
"3 years",
"5 years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"7 years",
"4 years",
"10+ years",
null,
"7 years",
"2 years",
"6 years",
"9 years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"8 years",
"< 1 year",
"3 years",
"1 year",
"2 years",
"9 years",
"9 years",
"2 years",
"8 years",
"10+ years",
"7 years",
"6 years",
"9 years",
"5 years",
null,
null,
"2 years",
"7 years",
"9 years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"6 years",
"9 years",
"10+ years",
"10+ years",
"2 years",
null,
"3 years",
"5 years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"3 years",
"7 years",
"6 years",
null,
"< 1 year",
"4 years",
"6 years",
"7 years",
"< 1 year",
"< 1 year",
"3 years",
"2 years",
"3 years",
"1 year",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"9 years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"7 years",
"3 years",
"3 years",
"8 years",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"8 years",
"6 years",
"6 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"1 year",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"5 years",
"2 years",
"1 year",
"2 years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"4 years",
"10+ years",
"1 year",
"< 1 year",
"6 years",
"10+ years",
"2 years",
"4 years",
"4 years",
"1 year",
"9 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"7 years",
"5 years",
"6 years",
"3 years",
"10+ years",
null,
null,
"10+ years",
"< 1 year",
"1 year",
"8 years",
"7 years",
"< 1 year",
"10+ years",
null,
"5 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"3 years",
"6 years",
"2 years",
"2 years",
null,
null,
"10+ years",
"7 years",
"10+ years",
"7 years",
"5 years",
"7 years",
"10+ years",
null,
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
null,
"< 1 year",
"3 years",
"4 years",
"10+ years",
"6 years",
"9 years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"9 years",
"10+ years",
"7 years",
"4 years",
"5 years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"7 years",
"9 years",
"8 years",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
"2 years",
"2 years",
"4 years",
"< 1 year",
"1 year",
"4 years",
"10+ years",
"2 years",
"< 1 year",
"6 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"2 years",
"4 years",
"8 years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"3 years",
"< 1 year",
"< 1 year",
"6 years",
"2 years",
"5 years",
"7 years",
"< 1 year",
"6 years",
"2 years",
"2 years",
"9 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"8 years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"7 years",
"5 years",
"10+ years",
"4 years",
"1 year",
null,
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"6 years",
"7 years",
"5 years",
"8 years",
"4 years",
"8 years",
"4 years",
null,
"7 years",
"1 year",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
null,
"7 years",
"< 1 year",
"10+ years",
"8 years",
"5 years",
"10+ years",
"5 years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
null,
"5 years",
"2 years",
null,
"3 years",
"7 years",
"2 years",
"1 year",
"10+ years",
"4 years",
"7 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"1 year",
"2 years",
"1 year",
"8 years",
"5 years",
"8 years",
"9 years",
"< 1 year",
"9 years",
"10+ years",
"1 year",
"9 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"7 years",
"4 years",
"10+ years",
"< 1 year",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"2 years",
"10+ years",
"8 years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
null,
"< 1 year",
"10+ years",
"3 years",
null,
"1 year",
"6 years",
"5 years",
"8 years",
"2 years",
"2 years",
"4 years",
null,
"5 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"3 years",
null,
"10+ years",
"8 years",
"< 1 year",
"1 year",
"10+ years",
"2 years",
"4 years",
"1 year",
"< 1 year",
"2 years",
"10+ years",
"< 1 year",
"2 years",
"6 years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"10+ years",
null,
"10+ years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"5 years",
"5 years",
"2 years",
"1 year",
"< 1 year",
"3 years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"1 year",
"1 year",
"10+ years",
"1 year",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
null,
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
null,
"3 years",
"3 years",
"< 1 year",
"< 1 year",
"10+ years",
"1 year",
"7 years",
"2 years",
"9 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
null,
"10+ years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"4 years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"8 years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"7 years",
"10+ years",
null,
"10+ years",
"10+ years",
"3 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"9 years",
"10+ years",
"10+ years",
"5 years",
"8 years",
"10+ years",
"10+ years",
null,
"1 year",
"< 1 year",
"4 years",
"10+ years",
"7 years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"5 years",
"3 years",
"5 years",
"5 years",
"8 years",
"8 years",
"4 years",
"3 years",
"3 years",
"8 years",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
null,
"10+ years",
"4 years",
"5 years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"6 years",
"2 years",
"1 year",
"1 year",
"9 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"1 year",
"< 1 year",
"1 year",
"3 years",
"4 years",
"2 years",
"7 years",
"5 years",
"1 year",
"10+ years",
"< 1 year",
"4 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
null,
"3 years",
"10+ years",
"2 years",
null,
"3 years",
"4 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
null,
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"4 years",
"2 years",
"5 years",
"2 years",
"8 years",
"4 years",
"2 years",
"10+ years",
"5 years",
null,
"2 years",
"< 1 year",
"9 years",
"5 years",
"3 years",
"10+ years",
"10+ years",
null,
"2 years",
"6 years",
"10+ years",
"2 years",
"9 years",
"6 years",
"2 years",
"< 1 year",
"6 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
null,
"7 years",
"1 year",
"10+ years",
"1 year",
"5 years",
null,
"2 years",
null,
"10+ years",
"1 year",
"5 years",
"10+ years",
"10+ years",
"5 years",
null,
"10+ years",
"10+ years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"2 years",
"1 year",
"3 years",
"8 years",
"< 1 year",
"10+ years",
"6 years",
"2 years",
"9 years",
"2 years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"6 years",
"3 years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"8 years",
"10+ years",
"4 years",
"1 year",
"1 year",
"10+ years",
"6 years",
"2 years",
"1 year",
"7 years",
"8 years",
"5 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"8 years",
"4 years",
"1 year",
"2 years",
"2 years",
"8 years",
"10+ years",
"< 1 year",
"1 year",
"8 years",
"3 years",
"5 years",
"5 years",
"1 year",
"10+ years",
"3 years",
"4 years",
"2 years",
"9 years",
"< 1 year",
"8 years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
null,
"6 years",
null,
"6 years",
"5 years",
"9 years",
null,
"< 1 year",
"5 years",
"8 years",
"4 years",
"9 years",
null,
"1 year",
"10+ years",
"3 years",
"< 1 year",
"5 years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"1 year",
"1 year",
"10+ years",
"8 years",
null,
"3 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"9 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"8 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"1 year",
"4 years",
"8 years",
"3 years",
"6 years",
"10+ years",
"10+ years",
"8 years",
"7 years",
"10+ years",
"2 years",
"5 years",
"6 years",
null,
"< 1 year",
"7 years",
"5 years",
"5 years",
"10+ years",
"< 1 year",
"8 years",
"< 1 year",
"10+ years",
"7 years",
"9 years",
"1 year",
"3 years",
"2 years",
"3 years",
"< 1 year",
"8 years",
null,
"10+ years",
"8 years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
null,
"< 1 year",
"9 years",
"7 years",
"10+ years",
"3 years",
"7 years",
null,
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"6 years",
"7 years",
"6 years",
"10+ years",
null,
"4 years",
"2 years",
"< 1 year",
"6 years",
"10+ years",
"10+ years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"6 years",
"10+ years",
"2 years",
"4 years",
"5 years",
"6 years",
null,
"2 years",
"7 years",
"1 year",
"2 years",
"8 years",
"7 years",
"8 years",
"10+ years",
"< 1 year",
null,
"10+ years",
"3 years",
"4 years",
"10+ years",
"6 years",
"7 years",
"2 years",
"4 years",
"3 years",
"7 years",
"8 years",
"4 years",
"4 years",
"5 years",
"4 years",
"5 years",
"< 1 year",
null,
"3 years",
"4 years",
"10+ years",
"8 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"1 year",
"6 years",
"1 year",
"3 years",
"< 1 year",
"< 1 year",
"2 years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"6 years",
"1 year",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
null,
"3 years",
"6 years",
"< 1 year",
"< 1 year",
"10+ years",
"8 years",
"< 1 year",
"2 years",
"10+ years",
"< 1 year",
"6 years",
null,
"< 1 year",
"4 years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
null,
"< 1 year",
"6 years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"5 years",
"6 years",
"2 years",
"2 years",
"10+ years",
"6 years",
"7 years",
"4 years",
"7 years",
"< 1 year",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
null,
"5 years",
"< 1 year",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"8 years",
"< 1 year",
"1 year",
"5 years",
"2 years",
"1 year",
"7 years",
"7 years",
"4 years",
"3 years",
"2 years",
"7 years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"1 year",
"3 years",
"10+ years",
"4 years",
"3 years",
"10+ years",
"9 years",
"1 year",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
null,
"4 years",
"3 years",
null,
"< 1 year",
"5 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"3 years",
"6 years",
"< 1 year",
"2 years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"5 years",
"4 years",
"10+ years",
"10+ years",
null,
"1 year",
"10+ years",
"5 years",
"5 years",
"1 year",
"3 years",
"2 years",
"9 years",
"9 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"7 years",
"10+ years",
"6 years",
"2 years",
null,
"7 years",
"2 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
null,
null,
"2 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"6 years",
"2 years",
null,
"4 years",
"8 years",
"3 years",
"< 1 year",
"2 years",
"3 years",
"2 years",
"2 years",
"9 years",
"6 years",
"9 years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"5 years",
"10+ years",
"< 1 year",
"4 years",
"2 years",
null,
"8 years",
"8 years",
"< 1 year",
"4 years",
"< 1 year",
null,
"10+ years",
"2 years",
null,
null,
"8 years",
"8 years",
"4 years",
"4 years",
"10+ years",
"5 years",
"2 years",
"1 year",
"3 years",
"10+ years",
"2 years",
"2 years",
"8 years",
"6 years",
"4 years",
"5 years",
"5 years",
"10+ years",
"2 years",
"2 years",
"5 years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"< 1 year",
"8 years",
"10+ years",
"7 years",
"7 years",
"5 years",
"10+ years",
"10+ years",
null,
"2 years",
"2 years",
"4 years",
"5 years",
"10+ years",
null,
"3 years",
"2 years",
"10+ years",
"10+ years",
null,
"2 years",
"8 years",
"10+ years",
"5 years",
"3 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"9 years",
"6 years",
"8 years",
"8 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
null,
"10+ years",
"5 years",
"10+ years",
"4 years",
"7 years",
"10+ years",
"6 years",
"6 years",
null,
"8 years",
"3 years",
"10+ years",
"6 years",
"10+ years",
"6 years",
"< 1 year",
"1 year",
"6 years",
null,
"3 years",
"5 years",
"2 years",
"9 years",
"10+ years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"4 years",
"5 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
null,
"10+ years",
"10+ years",
"8 years",
"7 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"9 years",
null,
"< 1 year",
"2 years",
"10+ years",
"6 years",
"< 1 year",
"9 years",
"9 years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"4 years",
"4 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"1 year",
"4 years",
"7 years",
"5 years",
"10+ years",
"3 years",
"2 years",
null,
"3 years",
"10+ years",
"9 years",
"< 1 year",
"1 year",
"5 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"2 years",
"4 years",
"9 years",
"1 year",
"10+ years",
"10+ years",
"4 years",
"9 years",
"7 years",
"7 years",
"< 1 year",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"1 year",
"7 years",
null,
"4 years",
"6 years",
"< 1 year",
"1 year",
"7 years",
"5 years",
"2 years",
"8 years",
"5 years",
"10+ years",
"6 years",
"10+ years",
null,
"10+ years",
"6 years",
"4 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"2 years",
"3 years",
"4 years",
"5 years",
"6 years",
"10+ years",
"7 years",
"5 years",
"2 years",
"< 1 year",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"7 years",
"9 years",
"10+ years",
"10+ years",
"5 years",
"5 years",
"5 years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"3 years",
"8 years",
"4 years",
"2 years",
"1 year",
"< 1 year",
"6 years",
"7 years",
"3 years",
"6 years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"5 years",
"7 years",
"10+ years",
"7 years",
"10+ years",
"7 years",
"4 years",
"6 years",
"2 years",
"10+ years",
"8 years",
"9 years",
"8 years",
"10+ years",
"5 years",
"9 years",
"5 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"5 years",
"9 years",
"9 years",
"2 years",
"3 years",
"4 years",
"10+ years",
"7 years",
"< 1 year",
"2 years",
"2 years",
"3 years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"9 years",
"4 years",
"6 years",
"8 years",
"5 years",
"6 years",
"2 years",
"10+ years",
"3 years",
"3 years",
"8 years",
"4 years",
null,
"5 years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"< 1 year",
"7 years",
"10+ years",
"7 years",
"10+ years",
"4 years",
"7 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"9 years",
"4 years",
"< 1 year",
"3 years",
"3 years",
"6 years",
"8 years",
"9 years",
"2 years",
"10+ years",
"2 years",
"5 years",
"9 years",
"5 years",
"10+ years",
"8 years",
null,
"2 years",
"6 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"5 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"4 years",
"10+ years",
"7 years",
"10+ years",
"< 1 year",
null,
"1 year",
"10+ years",
"8 years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"8 years",
"< 1 year",
"2 years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"1 year",
"6 years",
"6 years",
"7 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"4 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
null,
"< 1 year",
"1 year",
"9 years",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"3 years",
"3 years",
"5 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
null,
"2 years",
"10+ years",
"2 years",
"2 years",
"7 years",
"7 years",
"9 years",
"5 years",
"< 1 year",
"10+ years",
"5 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"4 years",
"8 years",
"3 years",
"10+ years",
"5 years",
"9 years",
"10+ years",
"7 years",
"8 years",
"5 years",
"4 years",
"8 years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
null,
"< 1 year",
null,
"2 years",
null,
"10+ years",
null,
"2 years",
"3 years",
"10+ years",
"1 year",
"7 years",
"5 years",
"< 1 year",
"< 1 year",
"10+ years",
"5 years",
"2 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"6 years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"8 years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"4 years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"2 years",
null,
"10+ years",
"10+ years",
"6 years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
null,
"10+ years",
"6 years",
"10+ years",
"1 year",
"2 years",
"4 years",
null,
"2 years",
"8 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"1 year",
null,
"1 year",
null,
"5 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"4 years",
"< 1 year",
"5 years",
"2 years",
"3 years",
"6 years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"9 years",
"3 years",
"5 years",
"1 year",
"< 1 year",
"10+ years",
"1 year",
"2 years",
"1 year",
"4 years",
"9 years",
"3 years",
null,
"2 years",
"8 years",
"10+ years",
null,
"10+ years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"4 years",
"4 years",
null,
"10+ years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"5 years",
"8 years",
"< 1 year",
"2 years",
"4 years",
"2 years",
"7 years",
"6 years",
"3 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"9 years",
"3 years",
"7 years",
"8 years",
null,
"1 year",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
null,
"8 years",
"1 year",
"10+ years",
"5 years",
"< 1 year",
null,
"9 years",
"10+ years",
"7 years",
"10+ years",
"1 year",
"2 years",
"2 years",
"1 year",
"5 years",
"2 years",
"10+ years",
"10+ years",
"8 years",
null,
"1 year",
"10+ years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"6 years",
"7 years",
"10+ years",
"9 years",
"9 years",
"10+ years",
"8 years",
"2 years",
"5 years",
null,
"< 1 year",
"10+ years",
"1 year",
"9 years",
"3 years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"< 1 year",
null,
"4 years",
"2 years",
"8 years",
"6 years",
"3 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"5 years",
"1 year",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"< 1 year",
"1 year",
"9 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"7 years",
"6 years",
"1 year",
"1 year",
null,
null,
"6 years",
"4 years",
"3 years",
"< 1 year",
"7 years",
null,
"5 years",
"6 years",
"1 year",
"6 years",
"7 years",
"3 years",
"10+ years",
"9 years",
"3 years",
"5 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"6 years",
"1 year",
"10+ years",
"1 year",
"2 years",
"3 years",
"1 year",
"10+ years",
"2 years",
"4 years",
"8 years",
"< 1 year",
"6 years",
"8 years",
"10+ years",
"2 years",
"10+ years",
null,
"6 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"< 1 year",
"4 years",
"8 years",
"4 years",
"10+ years",
null,
"2 years",
"5 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"3 years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"< 1 year",
"5 years",
"5 years",
"< 1 year",
"< 1 year",
"10+ years",
"1 year",
"6 years",
"10+ years",
"7 years",
"3 years",
"< 1 year",
"2 years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"7 years",
"3 years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"8 years",
"10+ years",
"6 years",
"10+ years",
"1 year",
"6 years",
"10+ years",
"2 years",
"9 years",
"5 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"1 year",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"< 1 year",
"6 years",
"10+ years",
"6 years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"9 years",
"3 years",
"5 years",
"4 years",
"10+ years",
"5 years",
"3 years",
null,
"10+ years",
"7 years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"8 years",
"6 years",
"2 years",
"< 1 year",
"3 years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"9 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"8 years",
"1 year",
"3 years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"1 year",
"6 years",
null,
"10+ years",
"1 year",
"2 years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"7 years",
"2 years",
"1 year",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"4 years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"4 years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"7 years",
"< 1 year",
"< 1 year",
"6 years",
"8 years",
"2 years",
"10+ years",
"1 year",
"7 years",
"10+ years",
"2 years",
"3 years",
"4 years",
"1 year",
"5 years",
"2 years",
"1 year",
"< 1 year",
"4 years",
"10+ years",
"6 years",
"8 years",
"10+ years",
"< 1 year",
"9 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"3 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"6 years",
null,
"8 years",
"3 years",
"5 years",
"1 year",
"3 years",
"2 years",
"10+ years",
null,
"6 years",
"7 years",
"10+ years",
"10+ years",
"8 years",
"6 years",
"4 years",
"3 years",
"7 years",
"< 1 year",
"6 years",
"5 years",
"8 years",
"7 years",
"4 years",
"5 years",
null,
"< 1 year",
null,
"8 years",
"5 years",
"6 years",
"10+ years",
null,
"3 years",
"4 years",
"4 years",
"5 years",
"1 year",
null,
"1 year",
"7 years",
"5 years",
null,
"8 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"1 year",
"< 1 year",
"8 years",
"< 1 year",
"10+ years",
"6 years",
"9 years",
"3 years",
"5 years",
"2 years",
"8 years",
"3 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"9 years",
null,
"7 years",
"3 years",
null,
"6 years",
"10+ years",
"2 years",
"4 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"10+ years",
"5 years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"7 years",
"10+ years",
"10+ years",
null,
"10+ years",
"5 years",
"10+ years",
"9 years",
"< 1 year",
null,
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
null,
"1 year",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"6 years",
null,
"10+ years",
"10+ years",
"9 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"1 year",
null,
"< 1 year",
"< 1 year",
"4 years",
"6 years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"5 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"4 years",
"< 1 year",
"2 years",
"3 years",
"7 years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"7 years",
"10+ years",
"9 years",
"10+ years",
"5 years",
"1 year",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"3 years",
"< 1 year",
"2 years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"8 years",
"8 years",
"6 years",
"< 1 year",
"3 years",
"1 year",
"10+ years",
"5 years",
"10+ years",
"9 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"3 years",
"8 years",
null,
"10+ years",
null,
"2 years",
"8 years",
"5 years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"6 years",
"10+ years",
null,
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"7 years",
"8 years",
"7 years",
null,
"8 years",
"8 years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"7 years",
"1 year",
"7 years",
"10+ years",
null,
"7 years",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"5 years",
"2 years",
"9 years",
"< 1 year",
null,
"3 years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"4 years",
"3 years",
"10+ years",
"1 year",
"3 years",
"1 year",
"5 years",
"10+ years",
null,
"8 years",
"3 years",
null,
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"1 year",
"6 years",
"5 years",
null,
"< 1 year",
"2 years",
"2 years",
"9 years",
"10+ years",
"3 years",
"2 years",
"< 1 year",
"2 years",
"< 1 year",
"3 years",
"1 year",
"10+ years",
"3 years",
"6 years",
"7 years",
"10+ years",
"7 years",
"10+ years",
null,
"8 years",
"2 years",
"2 years",
"5 years",
"10+ years",
"5 years",
"5 years",
"10+ years",
"3 years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"1 year",
"10+ years",
"6 years",
"6 years",
"7 years",
"4 years",
"1 year",
"10+ years",
"7 years",
"2 years",
"4 years",
"8 years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"8 years",
"10+ years",
"3 years",
"6 years",
"10+ years",
"5 years",
"< 1 year",
"1 year",
"7 years",
"6 years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"2 years",
"5 years",
null,
"10+ years",
"7 years",
"4 years",
"3 years",
"6 years",
"9 years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"4 years",
"2 years",
"5 years",
"3 years",
null,
"10+ years",
"5 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
null,
"10+ years",
"4 years",
"1 year",
"10+ years",
"6 years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"6 years",
null,
"3 years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"8 years",
"7 years",
"7 years",
null,
"< 1 year",
"10+ years",
"2 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"2 years",
"3 years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"< 1 year",
"7 years",
"7 years",
"9 years",
"9 years",
"9 years",
"8 years",
"2 years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"< 1 year",
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
null,
"10+ years",
"5 years",
"8 years",
"7 years",
"10+ years",
"4 years",
"9 years",
"3 years",
"7 years",
"4 years",
"5 years",
"4 years",
"4 years",
"10+ years",
"2 years",
"< 1 year",
"2 years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"8 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"9 years",
"1 year",
"3 years",
null,
"10+ years",
"6 years",
"< 1 year",
"5 years",
"2 years",
"10+ years",
"9 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"5 years",
"< 1 year",
"3 years",
"6 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"6 years",
"5 years",
"10+ years",
"10+ years",
null,
"10+ years",
"1 year",
"5 years",
"4 years",
"2 years",
"4 years",
"1 year",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"7 years",
"8 years",
"10+ years",
"1 year",
"6 years",
"7 years",
"10+ years",
"3 years",
"4 years",
"4 years",
"4 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"7 years",
"3 years",
"2 years",
"2 years",
"10+ years",
"3 years",
"3 years",
"< 1 year",
"3 years",
"10+ years",
"3 years",
"6 years",
"7 years",
"5 years",
"5 years",
"< 1 year",
"10+ years",
"3 years",
"5 years",
"8 years",
null,
"1 year",
null,
null,
"1 year",
"4 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"< 1 year",
"2 years",
"1 year",
"10+ years",
"9 years",
"10+ years",
"8 years",
"2 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"2 years",
"5 years",
"2 years",
"4 years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"9 years",
"10+ years",
"3 years",
null,
"< 1 year",
"10+ years",
"10+ years",
"4 years",
null,
"< 1 year",
"2 years",
"10+ years",
"7 years",
"9 years",
"3 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"3 years",
null,
"10+ years",
"7 years",
"3 years",
"10+ years",
"7 years",
"1 year",
"2 years",
"10+ years",
"8 years",
"1 year",
"10+ years",
"3 years",
"7 years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
null,
"10+ years",
"10+ years",
"4 years",
"7 years",
"2 years",
"1 year",
"8 years",
"7 years",
"5 years",
"6 years",
null,
"10+ years",
"3 years",
"< 1 year",
"2 years",
"10+ years",
"3 years",
"1 year",
"5 years",
"10+ years",
"9 years",
"10+ years",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"4 years",
null,
"10+ years",
"9 years",
"3 years",
"1 year",
"4 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"6 years",
"5 years",
null,
"3 years",
"7 years",
"5 years",
"6 years",
"7 years",
"10+ years",
"10+ years",
"9 years",
"4 years",
"5 years",
"1 year",
"3 years",
"9 years",
"7 years",
"10+ years",
"10+ years",
"4 years",
"6 years",
"8 years",
"8 years",
"4 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"7 years",
"< 1 year",
"10+ years",
"9 years",
"5 years",
"10+ years",
"7 years",
"< 1 year",
"2 years",
"2 years",
"5 years",
"7 years",
"3 years",
"2 years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"8 years",
"7 years",
"3 years",
null,
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"1 year",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"< 1 year",
"6 years",
"10+ years",
null,
"5 years",
"5 years",
"7 years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"7 years",
"< 1 year",
"1 year",
"< 1 year",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
null,
"10+ years",
"< 1 year",
"10+ years",
"9 years",
"1 year",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"9 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"1 year",
"10+ years",
"4 years",
"7 years",
"< 1 year",
"7 years",
"5 years",
"6 years",
"< 1 year",
"< 1 year",
"10+ years",
"2 years",
"< 1 year",
"6 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"5 years",
"4 years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"1 year",
"8 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"6 years",
"10+ years",
"7 years",
"2 years",
"4 years",
"7 years",
"7 years",
"4 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"5 years",
"7 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"5 years",
"9 years",
"2 years",
"10+ years",
"3 years",
"4 years",
"1 year",
"8 years",
"4 years",
"10+ years",
"4 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"2 years",
"1 year",
"1 year",
"10+ years",
"< 1 year",
"8 years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"7 years",
"5 years",
"10+ years",
"5 years",
"10+ years",
null,
"2 years",
"3 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"8 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"7 years",
"< 1 year",
"3 years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"7 years",
"10+ years",
"8 years",
"7 years",
"9 years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"4 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"2 years",
"10+ years",
"8 years",
"< 1 year",
"1 year",
"8 years",
"10+ years",
"4 years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"1 year",
"9 years",
"3 years",
"7 years",
"9 years",
"10+ years",
"10+ years",
"5 years",
"7 years",
"< 1 year",
"5 years",
"8 years",
"10+ years",
"< 1 year",
"5 years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"3 years",
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"8 years",
"6 years",
"7 years",
"3 years",
"2 years",
"2 years",
"5 years",
"2 years",
"2 years",
"10+ years",
"6 years",
"10+ years",
"2 years",
null,
"10+ years",
"6 years",
"3 years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"5 years",
"7 years",
"6 years",
null,
"8 years",
null,
"10+ years",
"4 years",
"10+ years",
"5 years",
"2 years",
"8 years",
"5 years",
"7 years",
null,
"1 year",
"10+ years",
"10+ years",
"1 year",
"2 years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"7 years",
"< 1 year",
null,
null,
"6 years",
"10+ years",
"2 years",
"10+ years",
"7 years",
"9 years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"10+ years",
"7 years",
"4 years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"1 year",
"5 years",
null,
"10+ years",
"< 1 year",
"3 years",
null,
"10+ years",
"10+ years",
"6 years",
"5 years",
"2 years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
null,
"6 years",
"1 year",
"5 years",
"9 years",
null,
"10+ years",
"10+ years",
"2 years",
"6 years",
"4 years",
"1 year",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"6 years",
null,
"6 years",
"2 years",
"8 years",
"1 year",
"10+ years",
"< 1 year",
null,
"10+ years",
"10+ years",
"10+ years",
"4 years",
"8 years",
"10+ years",
"6 years",
"3 years",
"6 years",
"< 1 year",
"10+ years",
null,
null,
"10+ years",
"2 years",
"10+ years",
"5 years",
"5 years",
"3 years",
"8 years",
"10+ years",
"5 years",
"6 years",
"8 years",
"10+ years",
"2 years",
"1 year",
"7 years",
"3 years",
"3 years",
"10+ years",
"4 years",
"6 years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"4 years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"< 1 year",
"9 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"8 years",
"10+ years",
null,
"< 1 year",
"< 1 year",
"10+ years",
"1 year",
"2 years",
"7 years",
"9 years",
"10+ years",
"4 years",
"4 years",
"7 years",
"10+ years",
"< 1 year",
null,
"4 years",
"3 years",
"3 years",
null,
"1 year",
"8 years",
"3 years",
"2 years",
"< 1 year",
"< 1 year",
"2 years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"8 years",
"1 year",
"7 years",
"2 years",
"7 years",
"2 years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"9 years",
"5 years",
"10+ years",
"9 years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"3 years",
"6 years",
"< 1 year",
"2 years",
"7 years",
null,
"< 1 year",
"< 1 year",
"7 years",
"7 years",
"6 years",
"2 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"6 years",
"< 1 year",
"8 years",
"10+ years",
"6 years",
"10+ years",
"8 years",
"9 years",
"1 year",
"10+ years",
null,
"10+ years",
"3 years",
"2 years",
"5 years",
"4 years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"1 year",
"1 year",
"10+ years",
"8 years",
"10+ years",
"8 years",
"4 years",
"< 1 year",
"8 years",
"10+ years",
"< 1 year",
"1 year",
"7 years",
null,
"3 years",
"< 1 year",
"6 years",
"10+ years",
"8 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"9 years",
"5 years",
"10+ years",
"7 years",
"< 1 year",
"6 years",
"10+ years",
"5 years",
"< 1 year",
"< 1 year",
"< 1 year",
"3 years",
"6 years",
"10+ years",
"9 years",
"7 years",
"2 years",
null,
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
null,
"10+ years",
"< 1 year",
null,
"< 1 year",
"< 1 year",
"< 1 year",
"10+ years",
"9 years",
"5 years",
"< 1 year",
"10+ years",
"< 1 year",
"8 years",
null,
"5 years",
"10+ years",
"10+ years",
"6 years",
null,
"3 years",
"10+ years",
"7 years",
"10+ years",
"5 years",
"1 year",
"2 years",
"< 1 year",
"10+ years",
"4 years",
"1 year",
"4 years",
"5 years",
"10+ years",
"9 years",
"3 years",
"5 years",
"2 years",
"10+ years",
"1 year",
"5 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
null,
"4 years",
"10+ years",
"9 years",
"1 year",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"4 years",
"< 1 year",
"8 years",
"3 years",
"3 years",
"7 years",
"4 years",
"10+ years",
"5 years",
"10+ years",
"6 years",
"4 years",
"8 years",
"3 years",
"9 years",
"3 years",
"4 years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"10+ years",
null,
"10+ years",
"1 year",
"10+ years",
"10+ years",
null,
"10+ years",
"6 years",
"9 years",
"8 years",
"< 1 year",
"7 years",
"2 years",
"6 years",
"3 years",
"7 years",
null,
"3 years",
"7 years",
"3 years",
"3 years",
"5 years",
"10+ years",
"8 years",
"< 1 year",
"1 year",
"10+ years",
"4 years",
"2 years",
"10+ years",
"1 year",
"8 years",
"10+ years",
"8 years",
"3 years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"9 years",
"< 1 year",
"2 years",
"5 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"6 years",
"6 years",
"8 years",
"10+ years",
"7 years",
"8 years",
"3 years",
"10+ years",
"4 years",
"7 years",
"8 years",
"< 1 year",
"2 years",
"4 years",
"8 years",
"9 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"4 years",
"9 years",
"1 year",
"2 years",
"6 years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"4 years",
"8 years",
"10+ years",
"5 years",
"7 years",
"5 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"8 years",
"4 years",
"8 years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"9 years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"4 years",
"8 years",
"4 years",
"8 years",
"10+ years",
"9 years",
"3 years",
"10+ years",
"3 years",
"2 years",
"6 years",
"3 years",
null,
"10+ years",
"7 years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"9 years",
null,
"4 years",
"4 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"9 years",
"3 years",
"4 years",
"4 years",
"7 years",
"5 years",
"10+ years",
"< 1 year",
"< 1 year",
"4 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"6 years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"6 years",
"4 years",
"8 years",
"< 1 year",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"< 1 year",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"6 years",
"8 years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
null,
"10+ years",
"3 years",
"7 years",
null,
"10+ years",
"5 years",
"10+ years",
"3 years",
"3 years",
"6 years",
"5 years",
"5 years",
"< 1 year",
"< 1 year",
"4 years",
"3 years",
"< 1 year",
"10+ years",
null,
"10+ years",
"10+ years",
"7 years",
"3 years",
"5 years",
"6 years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
null,
"10+ years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"6 years",
"10+ years",
"< 1 year",
"4 years",
"6 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"< 1 year",
"9 years",
"< 1 year",
"6 years",
"< 1 year",
"< 1 year",
"4 years",
"1 year",
"6 years",
"10+ years",
"10+ years",
null,
"10+ years",
"1 year",
null,
"10+ years",
"8 years",
"6 years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"10+ years",
"1 year",
"7 years",
"1 year",
"2 years",
"9 years",
"9 years",
"8 years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"6 years",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"5 years",
"2 years",
"9 years",
"10+ years",
"< 1 year",
"5 years",
"4 years",
"7 years",
"8 years",
"< 1 year",
"1 year",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"1 year",
"9 years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"8 years",
"3 years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"10+ years",
null,
"5 years",
"2 years",
"6 years",
"10+ years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"2 years",
"1 year",
"2 years",
"10+ years",
null,
"10+ years",
"10+ years",
"9 years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"9 years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"7 years",
"7 years",
"10+ years",
null,
"4 years",
"10+ years",
null,
null,
"4 years",
"5 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"6 years",
"< 1 year",
"10+ years",
"2 years",
"2 years",
"5 years",
"6 years",
"4 years",
"6 years",
"4 years",
"< 1 year",
"10+ years",
"8 years",
"4 years",
"9 years",
"10+ years",
"5 years",
"< 1 year",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"3 years",
"2 years",
"1 year",
"4 years",
"3 years",
"10+ years",
"8 years",
"7 years",
"6 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"4 years",
"2 years",
"6 years",
"10+ years",
null,
"4 years",
"10+ years",
null,
"3 years",
"3 years",
"10+ years",
"10+ years",
"6 years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"9 years",
"5 years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"9 years",
"< 1 year",
"2 years",
"10+ years",
"3 years",
"4 years",
"8 years",
"4 years",
"2 years",
"6 years",
"< 1 year",
"10+ years",
"7 years",
"3 years",
"8 years",
"4 years",
"9 years",
"1 year",
"8 years",
"9 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"5 years",
"4 years",
"4 years",
"7 years",
"10+ years",
"10+ years",
"5 years",
"1 year",
"2 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
null,
"10+ years",
"3 years",
"< 1 year",
"1 year",
"< 1 year",
"< 1 year",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"2 years",
"< 1 year",
"5 years",
"9 years",
"2 years",
"10+ years",
"3 years",
null,
"4 years",
null,
null,
"5 years",
"4 years",
"3 years",
"9 years",
"10+ years",
"2 years",
"5 years",
"9 years",
"8 years",
"4 years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"9 years",
"2 years",
"10+ years",
"4 years",
null,
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
null,
"1 year",
"10+ years",
"10+ years",
null,
"5 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"< 1 year",
"5 years",
"< 1 year",
"5 years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"6 years",
null,
"10+ years",
"4 years",
"4 years",
"5 years",
"10+ years",
null,
"2 years",
null,
"8 years",
"1 year",
"10+ years",
"6 years",
"7 years",
"4 years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"2 years",
"4 years",
"4 years",
"7 years",
"1 year",
"3 years",
"2 years",
"2 years",
"8 years",
"9 years",
"10+ years",
"9 years",
"7 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"6 years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"4 years",
null,
"4 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"3 years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"4 years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"9 years",
"3 years",
null,
"7 years",
"2 years",
"6 years",
"10+ years",
"1 year",
"10+ years",
"8 years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"3 years",
"9 years",
"10+ years",
"10+ years",
"2 years",
"7 years",
"< 1 year",
"1 year",
"3 years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"8 years",
"1 year",
"8 years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"8 years",
"2 years",
"3 years",
"3 years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"3 years",
null,
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"< 1 year",
"4 years",
"1 year",
"2 years",
"6 years",
"8 years",
null,
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"1 year",
"1 year",
"4 years",
"6 years",
"7 years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"3 years",
null,
"10+ years",
"6 years",
"< 1 year",
"6 years",
"10+ years",
null,
"1 year",
"10+ years",
"9 years",
"2 years",
"4 years",
"2 years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"7 years",
"9 years",
"8 years",
null,
"< 1 year",
"4 years",
"< 1 year",
"< 1 year",
"8 years",
"2 years",
"3 years",
"10+ years",
"4 years",
"10+ years",
"9 years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
null,
"3 years",
null,
"1 year",
"1 year",
"10+ years",
"8 years",
"6 years",
"10+ years",
"1 year",
"10+ years",
"2 years",
"1 year",
"5 years",
"5 years",
"5 years",
"4 years",
"10+ years",
"10+ years",
"6 years",
"1 year",
"< 1 year",
null,
"4 years",
"10+ years",
"3 years",
null,
"10+ years",
"10+ years",
null,
"1 year",
"2 years",
"6 years",
"10+ years",
"< 1 year",
null,
"2 years",
"7 years",
"3 years",
"10+ years",
"3 years",
null,
"3 years",
null,
"8 years",
"7 years",
"1 year",
"3 years",
null,
"10+ years",
"5 years",
"3 years",
"5 years",
"2 years",
"9 years",
"7 years",
"5 years",
"10+ years",
"2 years",
"9 years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"6 years",
"< 1 year",
"4 years",
null,
"3 years",
"10+ years",
"2 years",
"7 years",
"5 years",
"10+ years",
"9 years",
"8 years",
"10+ years",
"10+ years",
"6 years",
"5 years",
"10+ years",
"5 years",
"7 years",
"8 years",
"5 years",
"2 years",
"< 1 year",
"2 years",
"6 years",
"6 years",
"10+ years",
null,
"7 years",
"8 years",
"10+ years",
null,
"10+ years",
"3 years",
"7 years",
"8 years",
"5 years",
"7 years",
"10+ years",
"8 years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"1 year",
"4 years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"8 years",
"2 years",
"10+ years",
"7 years",
null,
"9 years",
"10+ years",
"5 years",
"< 1 year",
"9 years",
"10+ years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"3 years",
"8 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"7 years",
"3 years",
"9 years",
"< 1 year",
"10+ years",
"2 years",
"1 year",
"9 years",
"7 years",
"5 years",
"10+ years",
"< 1 year",
"6 years",
"3 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"4 years",
"< 1 year",
"10+ years",
"< 1 year",
"5 years",
"3 years",
"< 1 year",
"3 years",
"10+ years",
"2 years",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"2 years",
"1 year",
"2 years",
"7 years",
"6 years",
"9 years",
"5 years",
"7 years",
"10+ years",
"2 years",
"3 years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
null,
"2 years",
"3 years",
"9 years",
"7 years",
"10+ years",
"9 years",
"2 years",
"5 years",
"7 years",
"9 years",
"< 1 year",
"< 1 year",
"3 years",
"10+ years",
null,
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"5 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"8 years",
"10+ years",
"8 years",
"5 years",
"7 years",
"1 year",
"10+ years",
null,
"10+ years",
"10+ years",
"5 years",
"10+ years",
null,
"10+ years",
"4 years",
"2 years",
null,
null,
"10+ years",
"3 years",
"10+ years",
null,
"6 years",
"2 years",
"5 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
null,
"2 years",
"1 year",
"10+ years",
"< 1 year",
"8 years",
"8 years",
"1 year",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"6 years",
"6 years",
"3 years",
"5 years",
"10+ years",
"9 years",
"1 year",
"< 1 year",
null,
"10+ years",
"1 year",
"4 years",
"2 years",
"8 years",
"8 years",
"5 years",
"3 years",
"5 years",
"< 1 year",
"8 years",
"9 years",
"4 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"8 years",
"6 years",
"< 1 year",
"10+ years",
"7 years",
"9 years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"10+ years",
"4 years",
"9 years",
"10+ years",
"10+ years",
null,
"10+ years",
"5 years",
null,
"9 years",
"8 years",
"4 years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"7 years",
"< 1 year",
"3 years",
"2 years",
"10+ years",
"4 years",
"1 year",
"1 year",
"10+ years",
"5 years",
"3 years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"9 years",
"4 years",
"5 years",
"8 years",
"10+ years",
"< 1 year",
"3 years",
"4 years",
"10+ years",
"9 years",
"10+ years",
"8 years",
"8 years",
null,
"2 years",
"4 years",
"6 years",
"2 years",
"7 years",
"5 years",
"4 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"10+ years",
"6 years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"7 years",
"10+ years",
"4 years",
"8 years",
"2 years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"6 years",
"3 years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"4 years",
"10+ years",
"4 years",
null,
"9 years",
"4 years",
"5 years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"< 1 year",
"4 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"3 years",
"5 years",
"10+ years",
null,
"< 1 year",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"1 year",
"2 years",
null,
null,
"10+ years",
null,
"3 years",
"1 year",
"2 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"4 years",
"3 years",
"2 years",
"< 1 year",
"5 years",
"3 years",
"9 years",
"< 1 year",
"10+ years",
"5 years",
null,
"8 years",
null,
"10+ years",
"9 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"6 years",
"< 1 year",
"1 year",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
null,
"10+ years",
"7 years",
"< 1 year",
"6 years",
"< 1 year",
"< 1 year",
"10+ years",
null,
"10+ years",
"10+ years",
null,
"4 years",
"4 years",
"10+ years",
"3 years",
"7 years",
"8 years",
"2 years",
null,
"10+ years",
"< 1 year",
"8 years",
"2 years",
"< 1 year",
"4 years",
"3 years",
"5 years",
"10+ years",
"4 years",
"< 1 year",
"9 years",
"10+ years",
"9 years",
"3 years",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"8 years",
"4 years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"7 years",
"< 1 year",
"1 year",
"8 years",
"8 years",
"10+ years",
"7 years",
"3 years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"9 years",
"4 years",
"4 years",
"8 years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"9 years",
null,
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"6 years",
"2 years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"3 years",
"2 years",
"< 1 year",
"< 1 year",
"< 1 year",
"10+ years",
"7 years",
"< 1 year",
null,
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"3 years",
"3 years",
"3 years",
"4 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"8 years",
"7 years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"6 years",
"10+ years",
null,
"6 years",
"9 years",
"2 years",
"1 year",
"6 years",
"1 year",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"9 years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"2 years",
"5 years",
"3 years",
"2 years",
"10+ years",
"9 years",
"6 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"2 years",
"6 years",
"5 years",
null,
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"1 year",
"9 years",
"10+ years",
"1 year",
"9 years",
"3 years",
"3 years",
"3 years",
"< 1 year",
"< 1 year",
"4 years",
"9 years",
"5 years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
null,
"5 years",
"4 years",
"5 years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"8 years",
"7 years",
"7 years",
"10+ years",
"6 years",
"10+ years",
"9 years",
"2 years",
"10+ years",
"2 years",
"9 years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
null,
"10+ years",
"8 years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"1 year",
"3 years",
"2 years",
"< 1 year",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"6 years",
null,
"< 1 year",
"2 years",
"1 year",
"10+ years",
null,
"6 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"8 years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"9 years",
"9 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"4 years",
"10+ years",
"7 years",
"9 years",
"3 years",
"10+ years",
"8 years",
"3 years",
"3 years",
"3 years",
"< 1 year",
"< 1 year",
"10+ years",
"4 years",
"3 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"6 years",
"8 years",
"1 year",
"4 years",
"9 years",
null,
"1 year",
"4 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"3 years",
"2 years",
"1 year",
"5 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"1 year",
"2 years",
"10+ years",
"7 years",
"4 years",
"7 years",
"6 years",
null,
"< 1 year",
"1 year",
"3 years",
"2 years",
"10+ years",
"1 year",
"2 years",
"5 years",
"4 years",
"6 years",
"< 1 year",
"10+ years",
null,
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"2 years",
"10+ years",
"4 years",
"4 years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"1 year",
"7 years",
"9 years",
"4 years",
"4 years",
"1 year",
"10+ years",
"2 years",
"< 1 year",
"6 years",
"1 year",
null,
"7 years",
"10+ years",
null,
"< 1 year",
"3 years",
"10+ years",
"3 years",
"1 year",
"< 1 year",
"10+ years",
"8 years",
"< 1 year",
"3 years",
null,
"2 years",
"10+ years",
"8 years",
null,
"4 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
null,
"7 years",
"< 1 year",
"3 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"8 years",
"9 years",
"6 years",
null,
"10+ years",
"< 1 year",
null,
"10+ years",
"5 years",
"6 years",
"2 years",
"10+ years",
"6 years",
null,
"7 years",
"10+ years",
"4 years",
null,
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"5 years",
"3 years",
"8 years",
"8 years",
"1 year",
null,
"10+ years",
"7 years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"10+ years",
null,
"2 years",
"5 years",
"10+ years",
"6 years",
"< 1 year",
"5 years",
"5 years",
"4 years",
"3 years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
null,
"1 year",
"8 years",
"6 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"7 years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"9 years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"10+ years",
"4 years",
"3 years",
"10+ years",
null,
"10+ years",
"7 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"6 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"2 years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"5 years",
"5 years",
"10+ years",
"5 years",
"7 years",
"2 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"4 years",
"8 years",
"5 years",
"3 years",
null,
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"3 years",
"5 years",
null,
"9 years",
"10+ years",
"10+ years",
"7 years",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"9 years",
"1 year",
"1 year",
"5 years",
"2 years",
"2 years",
"7 years",
null,
"8 years",
"5 years",
"7 years",
null,
"1 year",
"8 years",
"3 years",
"10+ years",
"8 years",
"10+ years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"2 years",
"3 years",
"4 years",
"2 years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"2 years",
"3 years",
"10+ years",
"9 years",
"< 1 year",
null,
"10+ years",
"8 years",
"4 years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"4 years",
"3 years",
"10+ years",
null,
"7 years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"4 years",
"5 years",
"10+ years",
"3 years",
"8 years",
"3 years",
null,
"3 years",
"7 years",
"2 years",
"< 1 year",
"5 years",
"3 years",
"< 1 year",
"1 year",
"5 years",
"5 years",
"7 years",
"< 1 year",
"5 years",
"< 1 year",
"1 year",
"4 years",
"5 years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"7 years",
"2 years",
"10+ years",
"1 year",
"7 years",
"2 years",
"2 years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"8 years",
"1 year",
"2 years",
"< 1 year",
"< 1 year",
"5 years",
"8 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"2 years",
"10+ years",
"9 years",
"< 1 year",
"6 years",
"1 year",
"< 1 year",
"< 1 year",
"9 years",
"< 1 year",
"6 years",
"< 1 year",
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"2 years",
"4 years",
"< 1 year",
"8 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"4 years",
"7 years",
"5 years",
"5 years",
"7 years",
"5 years",
"4 years",
"3 years",
"10+ years",
"7 years",
"10+ years",
"5 years",
"9 years",
"3 years",
"4 years",
"10+ years",
null,
"9 years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"2 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"1 year",
"6 years",
"9 years",
"10+ years",
"9 years",
"< 1 year",
null,
"8 years",
"2 years",
"6 years",
"2 years",
"10+ years",
"9 years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"8 years",
"6 years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
null,
"1 year",
"10+ years",
"5 years",
"2 years",
"6 years",
"3 years",
"10+ years",
"5 years",
"3 years",
"1 year",
"3 years",
"8 years",
"8 years",
"1 year",
"5 years",
"8 years",
"5 years",
"1 year",
"8 years",
"< 1 year",
"2 years",
"< 1 year",
null,
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"2 years",
null,
"3 years",
"< 1 year",
"2 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"5 years",
"10+ years",
null,
"8 years",
"5 years",
"3 years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"4 years",
"10+ years",
"1 year",
"4 years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"7 years",
"< 1 year",
"< 1 year",
"1 year",
"1 year",
"8 years",
"4 years",
"3 years",
"3 years",
"6 years",
"4 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"6 years",
"3 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
null,
"5 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"6 years",
"6 years",
"5 years",
null,
"5 years",
"7 years",
"7 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"< 1 year",
"3 years",
"10+ years",
"9 years",
"5 years",
"10+ years",
"7 years",
"3 years",
"8 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"1 year",
"< 1 year",
"1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"7 years",
"10+ years",
"7 years",
"2 years",
"< 1 year",
"10+ years",
null,
"5 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"< 1 year",
"1 year",
"4 years",
"1 year",
"4 years",
null,
"3 years",
"3 years",
"5 years",
"5 years",
"10+ years",
null,
null,
"< 1 year",
"2 years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"5 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"2 years",
"5 years",
"9 years",
"7 years",
"1 year",
"5 years",
"2 years",
"10+ years",
"1 year",
"4 years",
"2 years",
"2 years",
"< 1 year",
"6 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"< 1 year",
"< 1 year",
"10+ years",
"1 year",
"< 1 year",
"7 years",
null,
"10+ years",
"10+ years",
"4 years",
"1 year",
"< 1 year",
"2 years",
"5 years",
"1 year",
"3 years",
"1 year",
"10+ years",
"5 years",
"4 years",
"8 years",
"1 year",
"10+ years",
"9 years",
"10+ years",
"2 years",
"3 years",
"5 years",
"4 years",
"3 years",
"2 years",
"1 year",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"8 years",
"7 years",
null,
"4 years",
"< 1 year",
"10+ years",
"2 years",
null,
"10+ years",
"7 years",
"4 years",
"6 years",
"10+ years",
"5 years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"4 years",
null,
null,
"< 1 year",
"10+ years",
"2 years",
"1 year",
"10+ years",
null,
"1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"6 years",
"4 years",
"2 years",
"2 years",
"10+ years",
"5 years",
"7 years",
"3 years",
"10+ years",
null,
"7 years",
"10+ years",
"10+ years",
null,
"1 year",
"10+ years",
"8 years",
null,
"< 1 year",
"< 1 year",
"1 year",
"10+ years",
"2 years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"7 years",
null,
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"1 year",
null,
"8 years",
"6 years",
"10+ years",
"2 years",
"8 years",
"< 1 year",
"3 years",
"5 years",
"4 years",
"3 years",
"8 years",
"9 years",
"4 years",
"4 years",
"3 years",
"3 years",
"5 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"3 years",
"6 years",
"1 year",
"6 years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"10+ years",
null,
"2 years",
"10+ years",
"6 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"< 1 year",
"4 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"3 years",
"9 years",
"1 year",
"7 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"6 years",
"2 years",
"1 year",
"8 years",
"< 1 year",
"7 years",
"3 years",
"9 years",
"8 years",
"1 year",
"10+ years",
"6 years",
"4 years",
"10+ years",
null,
"5 years",
"6 years",
"7 years",
"5 years",
"< 1 year",
"6 years",
"10+ years",
"8 years",
"< 1 year",
"3 years",
"3 years",
"10+ years",
"1 year",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"8 years",
"7 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"8 years",
"8 years",
"1 year",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"3 years",
"8 years",
"9 years",
"6 years",
"7 years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"9 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
null,
"10+ years",
"8 years",
"10+ years",
"9 years",
"3 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"8 years",
"10+ years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"2 years",
"2 years",
"5 years",
"6 years",
"8 years",
"10+ years",
"3 years",
"7 years",
null,
"2 years",
"5 years",
"10+ years",
"8 years",
"10+ years",
"4 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"1 year",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"5 years",
"1 year",
"4 years",
"< 1 year",
"4 years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"2 years",
"10+ years",
"5 years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"2 years",
null,
"5 years",
"1 year",
"10+ years",
"2 years",
"6 years",
"3 years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"1 year",
"9 years",
"6 years",
"1 year",
"8 years",
"8 years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"1 year",
null,
null,
"7 years",
"6 years",
"4 years",
"2 years",
"3 years",
"8 years",
null,
"10+ years",
"6 years",
"2 years",
"10+ years",
"< 1 year",
"< 1 year",
"1 year",
"1 year",
"5 years",
"2 years",
"2 years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"2 years",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"9 years",
null,
"10+ years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"9 years",
"10+ years",
"5 years",
"1 year",
null,
"10+ years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"3 years",
"4 years",
null,
"7 years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"< 1 year",
null,
"5 years",
"1 year",
"1 year",
"10+ years",
"4 years",
"10+ years",
"2 years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"8 years",
"4 years",
"5 years",
"2 years",
null,
"10+ years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"7 years",
"1 year",
"3 years",
"5 years",
"5 years",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"10+ years",
"8 years",
"2 years",
"8 years",
"10+ years",
null,
"10+ years",
"< 1 year",
"10+ years",
null,
"3 years",
"< 1 year",
"< 1 year",
"6 years",
null,
"10+ years",
"10+ years",
"2 years",
"6 years",
"< 1 year",
"7 years",
"< 1 year",
"7 years",
"3 years",
"7 years",
"3 years",
"1 year",
"10+ years",
"2 years",
"7 years",
"3 years",
"1 year",
"10+ years",
"2 years",
"5 years",
"4 years",
"10+ years",
"1 year",
"10+ years",
"6 years",
"3 years",
"10+ years",
null,
"10+ years",
"10+ years",
null,
"6 years",
"8 years",
"7 years",
"9 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"6 years",
"4 years",
"2 years",
"6 years",
"5 years",
null,
"3 years",
"3 years",
"5 years",
"8 years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"6 years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"3 years",
"1 year",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"7 years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"6 years",
"4 years",
null,
null,
"1 year",
"< 1 year",
"7 years",
"10+ years",
null,
"6 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"1 year",
"5 years",
"5 years",
"1 year",
"8 years",
"10+ years",
null,
"1 year",
null,
"1 year",
"3 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"1 year",
"< 1 year",
"1 year",
"< 1 year",
"2 years",
"3 years",
"6 years",
"1 year",
"10+ years",
"8 years",
"9 years",
"10+ years",
"7 years",
"10+ years",
"3 years",
null,
"5 years",
"6 years",
"5 years",
"3 years",
"10+ years",
null,
"9 years",
"8 years",
"10+ years",
"6 years",
"7 years",
"8 years",
"6 years",
"4 years",
"4 years",
"3 years",
"6 years",
"7 years",
"10+ years",
"4 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"1 year",
"9 years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
null,
"10+ years",
"2 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"< 1 year",
"5 years",
"10+ years",
null,
"1 year",
"3 years",
"1 year",
"10+ years",
"2 years",
"8 years",
"6 years",
"< 1 year",
"7 years",
"2 years",
"6 years",
"< 1 year",
"2 years",
"4 years",
"8 years",
"8 years",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"3 years",
null,
"10+ years",
"2 years",
"7 years",
"4 years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"1 year",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
null,
"3 years",
"8 years",
"4 years",
"4 years",
"6 years",
"1 year",
"10+ years",
"2 years",
"4 years",
null,
"7 years",
"9 years",
"5 years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"3 years",
"6 years",
"9 years",
"< 1 year",
"10+ years",
"4 years",
"1 year",
"< 1 year",
"10+ years",
"4 years",
"3 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"9 years",
"4 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"1 year",
"5 years",
"3 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"1 year",
null,
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"6 years",
"1 year",
"10+ years",
"6 years",
"10+ years",
"8 years",
"10+ years",
"8 years",
"10+ years",
null,
"2 years",
null,
"1 year",
"2 years",
"10+ years",
"5 years",
"1 year",
"3 years",
"3 years",
"< 1 year",
"2 years",
"10+ years",
"6 years",
"7 years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"5 years",
"1 year",
"5 years",
"10+ years",
"9 years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"5 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
null,
"6 years",
"10+ years",
"1 year",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"8 years",
"3 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"10+ years",
"4 years",
"< 1 year",
"3 years",
"10+ years",
null,
null,
"10+ years",
"5 years",
"9 years",
null,
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"4 years",
"3 years",
"4 years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"1 year",
null,
"9 years",
"< 1 year",
"5 years",
null,
"< 1 year",
"5 years",
"4 years",
"3 years",
"3 years",
"1 year",
"5 years",
"10+ years",
null,
"10+ years",
"1 year",
"2 years",
null,
"8 years",
"3 years",
"3 years",
"10+ years",
"1 year",
"5 years",
"5 years",
"10+ years",
"4 years",
"6 years",
"3 years",
"2 years",
"5 years",
"6 years",
"< 1 year",
"3 years",
"2 years",
"6 years",
"9 years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"4 years",
"2 years",
"< 1 year",
"9 years",
"10+ years",
"9 years",
"10+ years",
"6 years",
"3 years",
"2 years",
"8 years",
"10+ years",
null,
"10+ years",
"6 years",
"4 years",
"10+ years",
null,
"10+ years",
"5 years",
null,
"10+ years",
"10+ years",
"4 years",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"< 1 year",
"4 years",
"< 1 year",
"4 years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"8 years",
"2 years",
"10+ years",
"< 1 year",
"5 years",
"6 years",
"6 years",
"10+ years",
"2 years",
"4 years",
"10+ years",
"6 years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"2 years",
"4 years",
null,
null,
"2 years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"9 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"6 years",
"7 years",
"10+ years",
null,
"10+ years",
"10+ years",
"7 years",
"2 years",
"< 1 year",
"5 years",
"10+ years",
"5 years",
"7 years",
"3 years",
"10+ years",
"5 years",
null,
"< 1 year",
"3 years",
"4 years",
"10+ years",
"5 years",
"< 1 year",
"4 years",
"3 years",
"2 years",
"4 years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"3 years",
"5 years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"2 years",
"10+ years",
"8 years",
"< 1 year",
"8 years",
null,
"7 years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"7 years",
"4 years",
"10+ years",
"10+ years",
"9 years",
"1 year",
"10+ years",
"3 years",
"9 years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"1 year",
null,
"10+ years",
"3 years",
"6 years",
"9 years",
"4 years",
"10+ years",
"9 years",
"10+ years",
"8 years",
"10+ years",
"9 years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"< 1 year",
null,
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"< 1 year",
"3 years",
"5 years",
"10+ years",
"7 years",
"8 years",
"3 years",
"2 years",
"2 years",
"1 year",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"7 years",
"3 years",
"4 years",
"6 years",
null,
"2 years",
"< 1 year",
"7 years",
"1 year",
null,
"< 1 year",
"8 years",
"10+ years",
"7 years",
"2 years",
null,
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"6 years",
"1 year",
"3 years",
"10+ years",
"3 years",
"2 years",
"1 year",
"9 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"3 years",
null,
"4 years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
null,
"10+ years",
"10+ years",
"5 years",
"3 years",
"1 year",
"10+ years",
null,
"10+ years",
"9 years",
"4 years",
"4 years",
"6 years",
"10+ years",
"3 years",
"5 years",
"2 years",
"10+ years",
"8 years",
"4 years",
null,
"10+ years",
"3 years",
"< 1 year",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"7 years",
"6 years",
"10+ years",
"< 1 year",
"9 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"6 years",
"8 years",
"8 years",
"10+ years",
"< 1 year",
"2 years",
"< 1 year",
"4 years",
"6 years",
"3 years",
"< 1 year",
"8 years",
"10+ years",
"1 year",
"< 1 year",
"8 years",
"4 years",
"1 year",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"< 1 year",
"2 years",
"1 year",
"9 years",
"7 years",
"10+ years",
"1 year",
"10+ years",
null,
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"5 years",
"6 years",
"10+ years",
"1 year",
"3 years",
"5 years",
"7 years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"8 years",
"3 years",
"10+ years",
"10+ years",
null,
"< 1 year",
"8 years",
"1 year",
null,
"10+ years",
"10+ years",
"3 years",
"6 years",
"2 years",
"7 years",
"10+ years",
"1 year",
"9 years",
"3 years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"< 1 year",
"10+ years",
"6 years",
"4 years",
null,
"7 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"4 years",
"9 years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"3 years",
"2 years",
"1 year",
"4 years",
"9 years",
"10+ years",
"7 years",
"2 years",
"< 1 year",
"5 years",
"9 years",
"10+ years",
"9 years",
"4 years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"3 years",
"< 1 year",
"8 years",
"10+ years",
"1 year",
"2 years",
"3 years",
"3 years",
"2 years",
"5 years",
"6 years",
"6 years",
"5 years",
null,
"4 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"1 year",
"4 years",
"4 years",
"3 years",
"10+ years",
"6 years",
"1 year",
"3 years",
"2 years",
"1 year",
null,
null,
"1 year",
"< 1 year",
null,
"1 year",
"10+ years",
"10+ years",
null,
"10+ years",
"5 years",
null,
null,
"2 years",
"8 years",
"5 years",
"10+ years",
"5 years",
"1 year",
"10+ years",
null,
"10+ years",
"7 years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"10+ years",
null,
"< 1 year",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"5 years",
"9 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
null,
"10+ years",
"1 year",
"2 years",
"4 years",
"10+ years",
"1 year",
null,
"10+ years",
"9 years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"8 years",
"< 1 year",
null,
"7 years",
"5 years",
"4 years",
"7 years",
"10+ years",
"7 years",
"3 years",
"6 years",
"10+ years",
"< 1 year",
null,
"5 years",
"6 years",
"3 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"9 years",
"10+ years",
"7 years",
"9 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"4 years",
"8 years",
"8 years",
"7 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"3 years",
"< 1 year",
"2 years",
"< 1 year",
"5 years",
"2 years",
"1 year",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"6 years",
"5 years",
"10+ years",
"8 years",
"10+ years",
"6 years",
"3 years",
"6 years",
"2 years",
"< 1 year",
"10+ years",
"2 years",
"2 years",
"< 1 year",
"10+ years",
"8 years",
"1 year",
"7 years",
"6 years",
"6 years",
"1 year",
"< 1 year",
"1 year",
"10+ years",
"2 years",
"9 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"1 year",
"10+ years",
"3 years",
"3 years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"5 years",
"6 years",
"4 years",
null,
"10+ years",
"1 year",
"8 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"4 years",
"1 year",
"7 years",
"5 years",
"4 years",
"2 years",
"3 years",
"6 years",
"4 years",
"10+ years",
"9 years",
"6 years",
"4 years",
"10+ years",
"< 1 year",
"4 years",
"3 years",
null,
"10+ years",
"10+ years",
"8 years",
"10+ years",
"1 year",
"4 years",
"7 years",
"4 years",
"2 years",
"7 years",
"10+ years",
"4 years",
"8 years",
"2 years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"9 years",
"10+ years",
"1 year",
"10+ years",
"7 years",
"1 year",
"4 years",
"1 year",
"8 years",
"3 years",
"6 years",
"7 years",
"2 years",
"8 years",
"9 years",
"2 years",
"< 1 year",
null,
"10+ years",
"2 years",
"3 years",
"10+ years",
"6 years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"7 years",
"< 1 year",
"< 1 year",
"3 years",
"9 years",
"< 1 year",
"6 years",
"5 years",
"3 years",
"10+ years",
"6 years",
"6 years",
"9 years",
"4 years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"9 years",
"4 years",
"3 years",
"6 years",
"10+ years",
"10+ years",
"7 years",
"6 years",
"1 year",
"< 1 year",
"10+ years",
"9 years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"6 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"7 years",
"4 years",
"10+ years",
"10+ years",
"1 year",
null,
"10+ years",
"10+ years",
"2 years",
"10+ years",
"6 years",
"< 1 year",
"5 years",
"5 years",
"10+ years",
"10+ years",
null,
"3 years",
"3 years",
"6 years",
"8 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"2 years",
"3 years",
"7 years",
"8 years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
null,
"< 1 year",
"< 1 year",
"5 years",
"5 years",
"8 years",
"9 years",
"7 years",
null,
"4 years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"6 years",
"< 1 year",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"4 years",
"10+ years",
"2 years",
null,
"1 year",
"8 years",
"8 years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"5 years",
"10+ years",
"5 years",
"8 years",
"1 year",
"9 years",
null,
null,
"10+ years",
"5 years",
"8 years",
"10+ years",
"9 years",
"5 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"6 years",
null,
"3 years",
"< 1 year",
"10+ years",
"7 years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"< 1 year",
"10+ years",
null,
"5 years",
"6 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"2 years",
"4 years",
"2 years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"7 years",
"10+ years",
"7 years",
"< 1 year",
"2 years",
"3 years",
"1 year",
"1 year",
"5 years",
"10+ years",
"10+ years",
"10+ years",
null,
"3 years",
"5 years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"7 years",
"3 years",
"10+ years",
"4 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"3 years",
"3 years",
"10+ years",
null,
"7 years",
"2 years",
"10+ years",
"9 years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"9 years",
"10+ years",
"2 years",
"9 years",
"7 years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"4 years",
"1 year",
"3 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"5 years",
"< 1 year",
"3 years",
"< 1 year",
"< 1 year",
"2 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"4 years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"9 years",
"8 years",
"4 years",
"4 years",
"7 years",
null,
"10+ years",
"2 years",
"9 years",
"10+ years",
"2 years",
"10+ years",
"6 years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"5 years",
"2 years",
"8 years",
"4 years",
"10+ years",
"< 1 year",
"5 years",
null,
"4 years",
"1 year",
"1 year",
"5 years",
null,
"2 years",
"9 years",
"9 years",
"5 years",
"8 years",
"3 years",
"8 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"5 years",
"10+ years",
"5 years",
"3 years",
"5 years",
"9 years",
"4 years",
"1 year",
"8 years",
"8 years",
"1 year",
"7 years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"3 years",
"8 years",
"10+ years",
"5 years",
"< 1 year",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"7 years",
"10+ years",
null,
"1 year",
null,
"9 years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"7 years",
"6 years",
"10+ years",
"1 year",
null,
"10+ years",
"4 years",
"< 1 year",
"7 years",
"8 years",
"10+ years",
"3 years",
"7 years",
"5 years",
null,
null,
"7 years",
"< 1 year",
"6 years",
"10+ years",
"4 years",
"< 1 year",
"4 years",
"10+ years",
"9 years",
"4 years",
"< 1 year",
"8 years",
"10+ years",
"< 1 year",
"< 1 year",
null,
"8 years",
"< 1 year",
"1 year",
"2 years",
"8 years",
"8 years",
"6 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"8 years",
"9 years",
"< 1 year",
"7 years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"3 years",
"3 years",
"7 years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"6 years",
"5 years",
"3 years",
"1 year",
"3 years",
"7 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"7 years",
null,
"10+ years",
"9 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"4 years",
"8 years",
"8 years",
"4 years",
"3 years",
"1 year",
"2 years",
"9 years",
"9 years",
"10+ years",
"1 year",
"2 years",
"10+ years",
"7 years",
"3 years",
"9 years",
null,
"5 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
null,
"1 year",
"2 years",
"5 years",
"6 years",
"3 years",
"7 years",
"10+ years",
"8 years",
"8 years",
"5 years",
"1 year",
null,
"10+ years",
null,
"4 years",
"8 years",
"1 year",
"10+ years",
"6 years",
"8 years",
"8 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"8 years",
"2 years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"8 years",
"7 years",
"10+ years",
"5 years",
"8 years",
"< 1 year",
"10+ years",
"3 years",
"8 years",
"7 years",
"4 years",
"5 years",
"9 years",
"3 years",
"1 year",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"7 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
null,
"5 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"8 years",
"6 years",
"3 years",
"5 years",
"6 years",
"< 1 year",
"7 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"3 years",
"4 years",
"7 years",
"2 years",
"2 years",
"10+ years",
"6 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
null,
"6 years",
"1 year",
"10+ years",
"6 years",
"10+ years",
"3 years",
"2 years",
null,
"10+ years",
"9 years",
"< 1 year",
"1 year",
null,
"5 years",
"5 years",
"5 years",
"5 years",
"10+ years",
null,
"2 years",
"10+ years",
"8 years",
"10+ years",
"6 years",
"3 years",
"< 1 year",
"4 years",
"4 years",
"3 years",
"4 years",
"10+ years",
"9 years",
"7 years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"4 years",
"8 years",
"4 years",
"10+ years",
"1 year",
"10+ years",
"8 years",
"3 years",
"2 years",
null,
"< 1 year",
"8 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"3 years",
null,
"10+ years",
"4 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
null,
"10+ years",
"9 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
null,
"4 years",
"7 years",
"8 years",
"8 years",
"9 years",
"2 years",
"1 year",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"5 years",
"3 years",
"5 years",
"10+ years",
"< 1 year",
"5 years",
"6 years",
"4 years",
"3 years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
null,
"1 year",
"10+ years",
"10+ years",
"2 years",
"9 years",
"2 years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"4 years",
"10+ years",
"7 years",
"1 year",
"2 years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"1 year",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"6 years",
null,
"9 years",
"4 years",
"2 years",
null,
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"3 years",
"1 year",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
null,
"4 years",
"10+ years",
"10+ years",
"9 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"9 years",
"9 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"8 years",
"3 years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"4 years",
"2 years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
null,
"10+ years",
"6 years",
"10+ years",
"7 years",
"7 years",
"1 year",
"5 years",
"8 years",
null,
"6 years",
null,
"10+ years",
"4 years",
"6 years",
null,
"10+ years",
"7 years",
"9 years",
"4 years",
"5 years",
"2 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"6 years",
"10+ years",
null,
"8 years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"4 years",
"4 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"2 years",
"2 years",
"9 years",
"3 years",
null,
"2 years",
"9 years",
"8 years",
"10+ years",
"4 years",
"10+ years",
"6 years",
"4 years",
"10+ years",
"1 year",
"2 years",
"< 1 year",
"5 years",
"2 years",
"10+ years",
"4 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"3 years",
"10+ years",
null,
"10+ years",
"8 years",
"< 1 year",
"8 years",
"1 year",
"10+ years",
"2 years",
"5 years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"3 years",
"< 1 year",
"6 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
null,
"8 years",
"2 years",
"9 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
null,
"8 years",
"10+ years",
"4 years",
"10+ years",
"6 years",
"6 years",
"1 year",
"2 years",
"6 years",
"10+ years",
"< 1 year",
"< 1 year",
"2 years",
"2 years",
"< 1 year",
"5 years",
"7 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"10+ years",
"7 years",
"< 1 year",
"4 years",
"6 years",
"6 years",
"10+ years",
"3 years",
"10+ years",
null,
"4 years",
"7 years",
"5 years",
"2 years",
"4 years",
null,
"10+ years",
"< 1 year",
"7 years",
"4 years",
null,
"1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"7 years",
null,
null,
"1 year",
"< 1 year",
"5 years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"7 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"2 years",
"< 1 year",
"4 years",
"6 years",
"10+ years",
"7 years",
"2 years",
"1 year",
"4 years",
"10+ years",
"7 years",
"< 1 year",
"1 year",
"10+ years",
"3 years",
"6 years",
"9 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"1 year",
"6 years",
"1 year",
"9 years",
"9 years",
"10+ years",
"8 years",
"9 years",
"6 years",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"< 1 year",
"8 years",
"10+ years",
"4 years",
"10+ years",
null,
"2 years",
"2 years",
"< 1 year",
null,
"9 years",
"8 years",
"3 years",
"< 1 year",
"5 years",
"10+ years",
"6 years",
"6 years",
"10+ years",
"5 years",
"7 years",
"3 years",
"2 years",
"1 year",
"10+ years",
"2 years",
"9 years",
"10+ years",
"4 years",
"< 1 year",
"8 years",
"9 years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"3 years",
"< 1 year",
"4 years",
"1 year",
"< 1 year",
"2 years",
"3 years",
"8 years",
"10+ years",
null,
"10+ years",
"5 years",
null,
"9 years",
"5 years",
"5 years",
"10+ years",
"3 years",
"3 years",
null,
"< 1 year",
"7 years",
"5 years",
"10+ years",
"8 years",
"3 years",
"2 years",
null,
"6 years",
"< 1 year",
"< 1 year",
"5 years",
"< 1 year",
"10+ years",
"3 years",
"5 years",
"2 years",
"2 years",
"7 years",
"9 years",
"7 years",
"9 years",
null,
"9 years",
"< 1 year",
"10+ years",
"9 years",
"9 years",
"2 years",
"8 years",
"3 years",
"4 years",
"8 years",
"5 years",
"10+ years",
"3 years",
"4 years",
"8 years",
"3 years",
"3 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"3 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"7 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"2 years",
"< 1 year",
"10+ years",
"9 years",
"9 years",
"4 years",
"4 years",
"3 years",
null,
"3 years",
"5 years",
"7 years",
null,
null,
"6 years",
null,
"10+ years",
"10+ years",
"6 years",
"1 year",
"5 years",
"3 years",
null,
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"2 years",
"4 years",
"10+ years",
"9 years",
"6 years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"9 years",
"10+ years",
"10+ years",
"9 years",
"4 years",
"5 years",
"1 year",
"4 years",
"7 years",
"9 years",
"10+ years",
"9 years",
"8 years",
null,
"4 years",
"< 1 year",
"1 year",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"9 years",
"10+ years",
"3 years",
null,
null,
"10+ years",
"3 years",
"1 year",
"7 years",
"4 years",
"10+ years",
"3 years",
"1 year",
"7 years",
"10+ years",
"3 years",
"10+ years",
null,
"2 years",
"10+ years",
"10+ years",
"5 years",
"9 years",
"5 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"5 years",
"5 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"7 years",
"3 years",
"10+ years",
"10+ years",
null,
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"9 years",
"2 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"2 years",
"< 1 year",
"10+ years",
null,
null,
"9 years",
"10+ years",
null,
"10+ years",
"4 years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"4 years",
"2 years",
"10+ years",
"3 years",
"< 1 year",
"1 year",
"3 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"4 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"8 years",
"5 years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"2 years",
"3 years",
"10+ years",
"6 years",
"1 year",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"1 year",
"9 years",
"4 years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"6 years",
"< 1 year",
"1 year",
"3 years",
"2 years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"6 years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"10+ years",
"2 years",
"6 years",
"3 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"5 years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"3 years",
"8 years",
"10+ years",
"6 years",
"3 years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"5 years",
null,
"2 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"8 years",
"9 years",
"3 years",
null,
"2 years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"6 years",
"3 years",
"2 years",
"< 1 year",
"4 years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"2 years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"6 years",
"2 years",
"< 1 year",
"5 years",
"3 years",
"< 1 year",
"< 1 year",
"< 1 year",
"4 years",
"4 years",
"3 years",
"10+ years",
null,
"4 years",
"3 years",
"< 1 year",
"2 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"6 years",
"10+ years",
"< 1 year",
"2 years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
null,
"7 years",
"7 years",
"5 years",
"10+ years",
"6 years",
null,
"2 years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
null,
"10+ years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"6 years",
"3 years",
null,
"8 years",
"5 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"4 years",
"< 1 year",
"9 years",
"1 year",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"4 years",
"10+ years",
"1 year",
"10+ years",
"5 years",
"3 years",
"2 years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"8 years",
"< 1 year",
"9 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"4 years",
"3 years",
"10+ years",
"< 1 year",
"7 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"1 year",
"< 1 year",
"3 years",
"10+ years",
"1 year",
"4 years",
"2 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"7 years",
"4 years",
"3 years",
"1 year",
"4 years",
"2 years",
"7 years",
"1 year",
"8 years",
"10+ years",
null,
"5 years",
"4 years",
"10+ years",
"7 years",
"8 years",
"3 years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
"8 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"7 years",
null,
"4 years",
"< 1 year",
"10+ years",
"5 years",
"1 year",
"2 years",
"7 years",
"7 years",
"6 years",
"4 years",
"10+ years",
"6 years",
"10+ years",
"8 years",
"< 1 year",
"5 years",
"2 years",
"4 years",
"9 years",
"4 years",
null,
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"8 years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"1 year",
"3 years",
"3 years",
"10+ years",
"10+ years",
null,
"9 years",
"10+ years",
"10+ years",
"9 years",
"3 years",
null,
"10+ years",
"10+ years",
"4 years",
"4 years",
"8 years",
"1 year",
"2 years",
"8 years",
"10+ years",
"10+ years",
"6 years",
"< 1 year",
"10+ years",
null,
"4 years",
"4 years",
"9 years",
"4 years",
"10+ years",
"4 years",
"2 years",
"< 1 year",
"10+ years",
null,
"3 years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"< 1 year",
"7 years",
"4 years",
"10+ years",
null,
"10+ years",
"6 years",
"9 years",
"9 years",
"< 1 year",
"2 years",
"8 years",
"< 1 year",
"1 year",
"4 years",
"2 years",
null,
"6 years",
"2 years",
"3 years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"8 years",
"1 year",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"7 years",
"6 years",
"3 years",
"5 years",
"10+ years",
"7 years",
"10+ years",
"1 year",
"10+ years",
"5 years",
"3 years",
"7 years",
"8 years",
"10+ years",
"10+ years",
"5 years",
"4 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"2 years",
null,
"7 years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"2 years",
"10+ years",
"7 years",
"5 years",
"5 years",
"10+ years",
"7 years",
"< 1 year",
"5 years",
"2 years",
"10+ years",
"8 years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"2 years",
"4 years",
"10+ years",
"1 year",
"6 years",
"4 years",
"7 years",
"9 years",
"3 years",
"8 years",
"10+ years",
"< 1 year",
"5 years",
"< 1 year",
"8 years",
"10+ years",
"1 year",
"10+ years",
"7 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"2 years",
"9 years",
"3 years",
"10+ years",
"2 years",
"1 year",
"8 years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"8 years",
"3 years",
"7 years",
"9 years",
"3 years",
"2 years",
"10+ years",
"1 year",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"8 years",
"3 years",
null,
"10+ years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"1 year",
"10+ years",
"5 years",
"3 years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"8 years",
"8 years",
"1 year",
"10+ years",
"3 years",
null,
"10+ years",
"8 years",
"1 year",
"3 years",
"2 years",
null,
"1 year",
"3 years",
"10+ years",
"6 years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"2 years",
"< 1 year",
"10+ years",
null,
"6 years",
"< 1 year",
"10+ years",
"2 years",
"3 years",
"5 years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"7 years",
"1 year",
"3 years",
"1 year",
"< 1 year",
"9 years",
"3 years",
"7 years",
"2 years",
"< 1 year",
"2 years",
"7 years",
"8 years",
"10+ years",
"< 1 year",
"3 years",
"2 years",
"2 years",
"1 year",
"10+ years",
"5 years",
"< 1 year",
"3 years",
"2 years",
"10+ years",
"1 year",
"2 years",
"5 years",
"5 years",
"4 years",
"5 years",
"8 years",
"7 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"9 years",
"< 1 year",
"5 years",
"2 years",
"3 years",
"9 years",
"7 years",
"10+ years",
"6 years",
"2 years",
null,
"2 years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"3 years",
null,
"3 years",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"1 year",
null,
"9 years",
"8 years",
"3 years",
null,
"4 years",
"10+ years",
"2 years",
"5 years",
"5 years",
"3 years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"4 years",
"1 year",
"10+ years",
null,
"3 years",
"2 years",
"10+ years",
null,
"10+ years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"8 years",
"8 years",
"10+ years",
"1 year",
"8 years",
null,
"10+ years",
"4 years",
"< 1 year",
"5 years",
"5 years",
"10+ years",
"6 years",
"10+ years",
"9 years",
"2 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"< 1 year",
"3 years",
"4 years",
"4 years",
"9 years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"2 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"1 year",
"4 years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"3 years",
"1 year",
"9 years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"1 year",
"10+ years",
"9 years",
null,
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"9 years",
"7 years",
"10+ years",
"8 years",
"3 years",
"7 years",
"10+ years",
"5 years",
"< 1 year",
"< 1 year",
"3 years",
"10+ years",
"5 years",
"7 years",
"1 year",
"10+ years",
"3 years",
"6 years",
"1 year",
"10+ years",
"2 years",
"2 years",
"5 years",
"6 years",
"7 years",
"4 years",
"10+ years",
"< 1 year",
"5 years",
"< 1 year",
"6 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"9 years",
"10+ years",
"10+ years",
"4 years",
"6 years",
"4 years",
"10+ years",
"1 year",
"10+ years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"5 years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"2 years",
"< 1 year",
"< 1 year",
"4 years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
null,
"1 year",
"10+ years",
"2 years",
"5 years",
"8 years",
"2 years",
"< 1 year",
"10+ years",
"1 year",
"9 years",
"< 1 year",
"7 years",
"4 years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"2 years",
"3 years",
"9 years",
"1 year",
"3 years",
"5 years",
"3 years",
"5 years",
"10+ years",
"1 year",
"< 1 year",
"1 year",
null,
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"5 years",
"4 years",
"8 years",
"4 years",
"5 years",
"6 years",
"10+ years",
"6 years",
"1 year",
"1 year",
null,
"3 years",
"2 years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"8 years",
"9 years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"9 years",
"10+ years",
"< 1 year",
"3 years",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"7 years",
"6 years",
"10+ years",
"9 years",
"2 years",
"7 years",
"5 years",
"1 year",
"7 years",
"10+ years",
"< 1 year",
null,
"10+ years",
"9 years",
"5 years",
"7 years",
"< 1 year",
"10+ years",
"2 years",
"4 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"6 years",
null,
"< 1 year",
"1 year",
"2 years",
"9 years",
"7 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
null,
"10+ years",
null,
"7 years",
"3 years",
"2 years",
"< 1 year",
"3 years",
"5 years",
"2 years",
"4 years",
"10+ years",
null,
"< 1 year",
"< 1 year",
"4 years",
"4 years",
"2 years",
"10+ years",
"3 years",
"9 years",
"10+ years",
"< 1 year",
"9 years",
"4 years",
"7 years",
null,
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"4 years",
"5 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"8 years",
"< 1 year",
null,
"5 years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"7 years",
"3 years",
"2 years",
"10+ years",
"2 years",
"6 years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"6 years",
"7 years",
"10+ years",
null,
"2 years",
"3 years",
"2 years",
null,
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"6 years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"10+ years",
null,
"2 years",
"10+ years",
"7 years",
"10+ years",
"9 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"1 year",
"10+ years",
"5 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"3 years",
null,
"2 years",
"8 years",
"< 1 year",
"10+ years",
"1 year",
null,
"7 years",
"1 year",
"4 years",
null,
"5 years",
"10+ years",
null,
"8 years",
"1 year",
"< 1 year",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"3 years",
"3 years",
"< 1 year",
"10+ years",
"< 1 year",
"2 years",
"8 years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"1 year",
"8 years",
"4 years",
"10+ years",
"1 year",
"9 years",
"5 years",
"7 years",
"1 year",
"6 years",
"3 years",
"7 years",
"2 years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"1 year",
"3 years",
"9 years",
"< 1 year",
"2 years",
"10+ years",
"8 years",
"7 years",
"2 years",
"6 years",
"< 1 year",
"< 1 year",
"1 year",
"10+ years",
"5 years",
"10+ years",
"4 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"8 years",
"1 year",
"10+ years",
null,
"3 years",
"4 years",
"6 years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"1 year",
"5 years",
"2 years",
"6 years",
"6 years",
"7 years",
"3 years",
"8 years",
"10+ years",
"10+ years",
"4 years",
"7 years",
"9 years",
"10+ years",
"4 years",
"9 years",
"< 1 year",
"3 years",
"9 years",
"< 1 year",
"10+ years",
"2 years",
"1 year",
"3 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"7 years",
null,
"10+ years",
"10+ years",
null,
"7 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"5 years",
"< 1 year",
"6 years",
"3 years",
"< 1 year",
"2 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"9 years",
"10+ years",
"6 years",
"1 year",
"< 1 year",
"2 years",
"9 years",
"10+ years",
"< 1 year",
null,
"10+ years",
"< 1 year",
"5 years",
"9 years",
"6 years",
"10+ years",
"1 year",
"4 years",
"3 years",
"3 years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"6 years",
"3 years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"2 years",
"7 years",
"8 years",
"10+ years",
"10+ years",
null,
"1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"7 years",
"10+ years",
"10+ years",
null,
"6 years",
"5 years",
"< 1 year",
"5 years",
"7 years",
"1 year",
"3 years",
"8 years",
"7 years",
null,
null,
"10+ years",
"2 years",
"< 1 year",
null,
"10+ years",
"5 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"8 years",
"5 years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"2 years",
null,
"10+ years",
"8 years",
"6 years",
"9 years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
null,
"4 years",
"7 years",
null,
"8 years",
"10+ years",
"7 years",
"7 years",
"1 year",
"1 year",
"10+ years",
"5 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"3 years",
"3 years",
"9 years",
"4 years",
"1 year",
null,
"3 years",
"2 years",
"3 years",
"4 years",
"10+ years",
"9 years",
"10+ years",
"8 years",
"1 year",
"7 years",
"1 year",
"< 1 year",
"10+ years",
"1 year",
"8 years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"1 year",
null,
"< 1 year",
"2 years",
"2 years",
"10+ years",
null,
"4 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"5 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"7 years",
"2 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"< 1 year",
"8 years",
"6 years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"1 year",
"2 years",
"8 years",
"2 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"10+ years",
"6 years",
"5 years",
"< 1 year",
"3 years",
"4 years",
"1 year",
"8 years",
"6 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"6 years",
"4 years",
"10+ years",
"5 years",
"10+ years",
"6 years",
"4 years",
"10+ years",
"7 years",
"10+ years",
null,
"< 1 year",
"4 years",
"< 1 year",
"4 years",
"2 years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"4 years",
"< 1 year",
"1 year",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"4 years",
"9 years",
"< 1 year",
"10+ years",
"9 years",
"5 years",
"2 years",
"3 years",
"4 years",
"10+ years",
"7 years",
"4 years",
"< 1 year",
"10+ years",
"< 1 year",
"4 years",
"3 years",
"2 years",
"8 years",
"7 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
null,
"10+ years",
"8 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"9 years",
"4 years",
"9 years",
"5 years",
"1 year",
"10+ years",
null,
"3 years",
"10+ years",
"< 1 year",
"4 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"9 years",
"9 years",
"7 years",
"10+ years",
"4 years",
"5 years",
"5 years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
null,
"4 years",
"< 1 year",
"8 years",
"4 years",
"10+ years",
"3 years",
"5 years",
null,
"6 years",
"10+ years",
"10+ years",
"1 year",
"9 years",
"5 years",
"10+ years",
"< 1 year",
null,
"10+ years",
"2 years",
"10+ years",
null,
"5 years",
"4 years",
"5 years",
"9 years",
"< 1 year",
null,
"1 year",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"1 year",
"9 years",
"7 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
null,
"10+ years",
"2 years",
"6 years",
"6 years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"4 years",
null,
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
null,
"6 years",
null,
"10+ years",
"4 years",
"10+ years",
"1 year",
"2 years",
"2 years",
"7 years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"7 years",
"4 years",
"8 years",
"9 years",
"10+ years",
"10+ years",
"8 years",
"1 year",
"3 years",
"6 years",
"3 years",
"1 year",
"1 year",
"4 years",
"5 years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"4 years",
"6 years",
"3 years",
"10+ years",
null,
"10+ years",
"10+ years",
"1 year",
"9 years",
"2 years",
"6 years",
"10+ years",
"9 years",
"10+ years",
"4 years",
"7 years",
"10+ years",
"1 year",
"10+ years",
"5 years",
null,
"10+ years",
"7 years",
"10+ years",
"6 years",
"8 years",
"1 year",
"4 years",
"5 years",
"7 years",
"4 years",
"10+ years",
"1 year",
"< 1 year",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"5 years",
"7 years",
"2 years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"4 years",
null,
"3 years",
"2 years",
"7 years",
"7 years",
"5 years",
"10+ years",
"1 year",
null,
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"6 years",
"10+ years",
"4 years",
"9 years",
"10+ years",
"< 1 year",
"8 years",
"2 years",
"10+ years",
"8 years",
"1 year",
"10+ years",
"3 years",
"6 years",
"10+ years",
"3 years",
"9 years",
"8 years",
"4 years",
"3 years",
"10+ years",
"4 years",
"5 years",
"2 years",
"2 years",
"8 years",
"10+ years",
"10+ years",
null,
"3 years",
"7 years",
"8 years",
"4 years",
"10+ years",
"< 1 year",
"9 years",
"3 years",
"10+ years",
"5 years",
"3 years",
"8 years",
"10+ years",
"3 years",
"5 years",
"8 years",
"1 year",
"1 year",
"10+ years",
"8 years",
"< 1 year",
"2 years",
"2 years",
"3 years",
"2 years",
"8 years",
"10+ years",
"< 1 year",
"8 years",
"3 years",
"4 years",
null,
"10+ years",
"10+ years",
"8 years",
null,
"10+ years",
"6 years",
"9 years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"5 years",
"3 years",
"10+ years",
"7 years",
"10+ years",
"7 years",
"7 years",
"4 years",
"8 years",
"10+ years",
null,
"10+ years",
"10+ years",
"2 years",
"9 years",
"1 year",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"8 years",
"< 1 year",
"< 1 year",
"10+ years",
null,
"10+ years",
"7 years",
"6 years",
"9 years",
"10+ years",
"10+ years",
"9 years",
"4 years",
"2 years",
"2 years",
"10+ years",
"2 years",
"1 year",
"5 years",
null,
"2 years",
"4 years",
"10+ years",
"9 years",
"3 years",
"< 1 year",
"1 year",
"10+ years",
"7 years",
"6 years",
"4 years",
"4 years",
"3 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
null,
"10+ years",
"9 years",
"< 1 year",
"3 years",
"3 years",
"4 years",
"4 years",
"4 years",
"9 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"< 1 year",
"4 years",
"5 years",
"< 1 year",
"2 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"4 years",
"< 1 year",
"10+ years",
"6 years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"8 years",
"3 years",
null,
"5 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"8 years",
"9 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"8 years",
"4 years",
"4 years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"7 years",
"5 years",
"3 years",
"4 years",
"5 years",
"9 years",
"3 years",
"9 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"9 years",
"10+ years",
"4 years",
"7 years",
"6 years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"6 years",
"4 years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"1 year",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"< 1 year",
"< 1 year",
"5 years",
"8 years",
"2 years",
"10+ years",
"5 years",
null,
null,
"1 year",
null,
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"3 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"7 years",
"9 years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"8 years",
"9 years",
"1 year",
"8 years",
"2 years",
"10+ years",
"6 years",
"3 years",
"10+ years",
"2 years",
"6 years",
"9 years",
"2 years",
"10+ years",
null,
null,
"2 years",
"9 years",
"3 years",
"10+ years",
"3 years",
"4 years",
"1 year",
"1 year",
"< 1 year",
"6 years",
"1 year",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"2 years",
"9 years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"8 years",
"4 years",
"6 years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"7 years",
"10+ years",
"2 years",
"< 1 year",
"7 years",
"10+ years",
"2 years",
"3 years",
"1 year",
"4 years",
"3 years",
"3 years",
"9 years",
"1 year",
"4 years",
"2 years",
"7 years",
"3 years",
"9 years",
"1 year",
"10+ years",
null,
"7 years",
"5 years",
"6 years",
"< 1 year",
"10+ years",
"< 1 year",
"7 years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"1 year",
"5 years",
"1 year",
"3 years",
"4 years",
"< 1 year",
"6 years",
"10+ years",
"3 years",
"10+ years",
null,
"10+ years",
"9 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"9 years",
"5 years",
"2 years",
"< 1 year",
"10+ years",
"1 year",
"7 years",
"10+ years",
"10+ years",
"9 years",
"7 years",
"7 years",
"8 years",
"10+ years",
"5 years",
"10+ years",
"1 year",
"4 years",
"10+ years",
"6 years",
"10+ years",
"9 years",
"1 year",
"6 years",
"< 1 year",
"10+ years",
null,
null,
"10+ years",
"< 1 year",
"3 years",
"3 years",
"1 year",
"4 years",
null,
"5 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
null,
"7 years",
"1 year",
"7 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
null,
"5 years",
"6 years",
"8 years",
null,
"4 years",
"1 year",
"2 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"8 years",
"6 years",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"3 years",
"9 years",
"5 years",
"9 years",
"2 years",
null,
"10+ years",
"5 years",
"9 years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"2 years",
"< 1 year",
"3 years",
"7 years",
"10+ years",
"5 years",
"2 years",
"2 years",
"3 years",
"< 1 year",
"10+ years",
"2 years",
"3 years",
"2 years",
"4 years",
"10+ years",
"4 years",
"5 years",
"6 years",
"10+ years",
"7 years",
"3 years",
"2 years",
"5 years",
"4 years",
"< 1 year",
"3 years",
null,
"10+ years",
null,
"10+ years",
"9 years",
"2 years",
"< 1 year",
"3 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"10+ years",
null,
"1 year",
null,
"2 years",
"4 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"7 years",
"3 years",
"4 years",
"4 years",
null,
"10+ years",
"2 years",
"2 years",
"8 years",
"9 years",
"1 year",
"4 years",
"< 1 year",
"4 years",
"10+ years",
"< 1 year",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"8 years",
"10+ years",
"10+ years",
null,
"5 years",
"2 years",
"7 years",
"10+ years",
"7 years",
"5 years",
"5 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"6 years",
"5 years",
"< 1 year",
"10+ years",
"4 years",
"4 years",
"7 years",
"8 years",
"2 years",
"7 years",
"8 years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"2 years",
null,
"4 years",
"2 years",
"< 1 year",
"2 years",
"9 years",
"2 years",
"10+ years",
"9 years",
null,
"1 year",
"7 years",
"4 years",
"9 years",
"5 years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"< 1 year",
"3 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"6 years",
"10+ years",
"< 1 year",
"< 1 year",
"9 years",
"5 years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
null,
"3 years",
"10+ years",
"< 1 year",
"2 years",
null,
"6 years",
"8 years",
"1 year",
"< 1 year",
"3 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
null,
"10+ years",
"5 years",
"4 years",
"8 years",
"2 years",
"10+ years",
"9 years",
null,
"5 years",
"9 years",
"2 years",
"7 years",
"10+ years",
"5 years",
"2 years",
"7 years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"4 years",
"5 years",
"10+ years",
"< 1 year",
"1 year",
"2 years",
"10+ years",
null,
"10+ years",
"10+ years",
"6 years",
null,
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"2 years",
null,
"3 years",
"10+ years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"8 years",
"9 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"2 years",
"3 years",
"8 years",
"10+ years",
"8 years",
"6 years",
"3 years",
"1 year",
"10+ years",
"4 years",
"2 years",
"3 years",
"5 years",
"5 years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"3 years",
"8 years",
null,
"10+ years",
"< 1 year",
"3 years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"2 years",
"2 years",
"6 years",
"9 years",
"10+ years",
"3 years",
"8 years",
null,
"2 years",
"10+ years",
"10+ years",
"4 years",
"9 years",
"2 years",
"1 year",
"10+ years",
"6 years",
"3 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"6 years",
"7 years",
"4 years",
"10+ years",
"10+ years",
"3 years",
null,
"2 years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"4 years",
"4 years",
"< 1 year",
"10+ years",
null,
"8 years",
"10+ years",
"8 years",
"3 years",
"< 1 year",
"10+ years",
"1 year",
"5 years",
"3 years",
"10+ years",
"1 year",
"2 years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"9 years",
"10+ years",
"1 year",
"4 years",
"3 years",
"1 year",
"10+ years",
"< 1 year",
"8 years",
"4 years",
"5 years",
"8 years",
"10+ years",
null,
"10+ years",
"10+ years",
"2 years",
"4 years",
"3 years",
null,
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"3 years",
"10+ years",
"< 1 year",
"6 years",
"5 years",
"3 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"1 year",
"2 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"6 years",
"6 years",
"10+ years",
"6 years",
"7 years",
"1 year",
"10+ years",
"10+ years",
"9 years",
null,
"4 years",
"9 years",
"3 years",
"6 years",
"< 1 year",
null,
"2 years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"4 years",
"2 years",
"< 1 year",
"5 years",
"2 years",
"2 years",
null,
"8 years",
"< 1 year",
null,
"3 years",
"1 year",
"1 year",
"9 years",
"< 1 year",
"8 years",
"1 year",
"< 1 year",
"10+ years",
"8 years",
"7 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
null,
"< 1 year",
"5 years",
"3 years",
"10+ years",
"3 years",
"4 years",
"2 years",
"4 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"1 year",
"2 years",
"7 years",
"7 years",
"2 years",
"5 years",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"5 years",
"4 years",
"4 years",
"< 1 year",
"10+ years",
"1 year",
"6 years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"6 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"< 1 year",
"4 years",
"7 years",
"2 years",
"3 years",
"3 years",
"7 years",
"10+ years",
"2 years",
"5 years",
"8 years",
"1 year",
"4 years",
"1 year",
"10+ years",
"6 years",
"4 years",
"< 1 year",
"3 years",
"8 years",
"3 years",
"< 1 year",
"1 year",
"1 year",
"10+ years",
"3 years",
"10+ years",
"5 years",
"6 years",
null,
"10+ years",
"7 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"2 years",
"1 year",
"4 years",
"10+ years",
"7 years",
"10+ years",
"7 years",
"7 years",
"10+ years",
"8 years",
null,
"10+ years",
"4 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"5 years",
"10+ years",
"2 years",
"< 1 year",
null,
"7 years",
null,
"6 years",
"< 1 year",
"10+ years",
"3 years",
null,
"5 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"8 years",
"6 years",
"< 1 year",
"10+ years",
"7 years",
"6 years",
null,
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"4 years",
"8 years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"3 years",
"5 years",
"6 years",
"< 1 year",
"1 year",
"10+ years",
"< 1 year",
"5 years",
"8 years",
"10+ years",
"2 years",
"< 1 year",
null,
"8 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"3 years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"4 years",
"3 years",
"10+ years",
"9 years",
"6 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
null,
"2 years",
"8 years",
"9 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"3 years",
null,
"10+ years",
"8 years",
null,
"5 years",
null,
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"3 years",
"10+ years",
"9 years",
"5 years",
"5 years",
"2 years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"5 years",
"6 years",
"8 years",
"2 years",
"9 years",
"5 years",
null,
"7 years",
"7 years",
"3 years",
"5 years",
"9 years",
"6 years",
"2 years",
"7 years",
"10+ years",
null,
"3 years",
"10+ years",
"7 years",
"4 years",
"7 years",
"5 years",
"2 years",
"< 1 year",
"2 years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"8 years",
"< 1 year",
"5 years",
null,
"10+ years",
"5 years",
"4 years",
"2 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"6 years",
"3 years",
"10+ years",
"6 years",
"4 years",
"10+ years",
"8 years",
"5 years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"10+ years",
"< 1 year",
"8 years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"7 years",
"< 1 year",
"8 years",
"1 year",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"< 1 year",
"5 years",
"4 years",
"1 year",
"10+ years",
"3 years",
"8 years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
null,
"< 1 year",
"10+ years",
null,
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"5 years",
"2 years",
"5 years",
"10+ years",
"3 years",
"3 years",
"1 year",
"4 years",
"1 year",
"4 years",
null,
null,
"3 years",
"< 1 year",
"3 years",
"< 1 year",
"5 years",
"10+ years",
"4 years",
"2 years",
"5 years",
"7 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"1 year",
"5 years",
"5 years",
"10+ years",
null,
"< 1 year",
"4 years",
"2 years",
null,
"10+ years",
"10+ years",
"4 years",
"6 years",
"3 years",
null,
"10+ years",
"10+ years",
"4 years",
"1 year",
"4 years",
null,
"1 year",
"9 years",
"5 years",
"9 years",
"4 years",
"< 1 year",
"2 years",
"8 years",
"3 years",
"1 year",
"2 years",
"3 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"< 1 year",
"5 years",
"< 1 year",
null,
"3 years",
"10+ years",
"8 years",
"7 years",
"8 years",
"8 years",
"7 years",
"9 years",
"5 years",
"6 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"9 years",
"10+ years",
null,
"2 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
null,
"8 years",
"4 years",
"10+ years",
"10+ years",
"9 years",
null,
"< 1 year",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"4 years",
"8 years",
"10+ years",
null,
"< 1 year",
"3 years",
"< 1 year",
"6 years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"1 year",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"6 years",
"1 year",
"4 years",
"10+ years",
"3 years",
"7 years",
"4 years",
null,
"10+ years",
"6 years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"7 years",
"1 year",
"< 1 year",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"2 years",
"2 years",
"4 years",
"< 1 year",
"1 year",
"4 years",
"7 years",
"1 year",
"2 years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"2 years",
"7 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"8 years",
"< 1 year",
"3 years",
"10+ years",
"< 1 year",
"1 year",
"5 years",
"< 1 year",
"1 year",
"8 years",
"4 years",
null,
"10+ years",
"7 years",
"4 years",
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"2 years",
"8 years",
"< 1 year",
"2 years",
"9 years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"7 years",
null,
"10+ years",
"2 years",
"3 years",
"7 years",
"10+ years",
null,
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"4 years",
"3 years",
"10+ years",
"9 years",
"10+ years",
"9 years",
"8 years",
"10+ years",
"9 years",
"4 years",
"6 years",
"5 years",
"8 years",
null,
"9 years",
"3 years",
"2 years",
"1 year",
"8 years",
"7 years",
"2 years",
"10+ years",
"4 years",
"< 1 year",
null,
"6 years",
"7 years",
"10+ years",
"8 years",
"3 years",
"7 years",
"10+ years",
null,
"3 years",
"7 years",
"10+ years",
"7 years",
"10+ years",
"5 years",
"10+ years",
"1 year",
"9 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"5 years",
"10+ years",
"4 years",
"2 years",
"4 years",
"5 years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"2 years",
"7 years",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
"9 years",
"4 years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"8 years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"4 years",
"6 years",
"2 years",
"< 1 year",
"10+ years",
"5 years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"5 years",
"10+ years",
"8 years",
"6 years",
"< 1 year",
"3 years",
"4 years",
"10+ years",
"1 year",
"7 years",
"2 years",
"6 years",
"4 years",
"7 years",
"10+ years",
null,
"< 1 year",
"3 years",
"< 1 year",
"9 years",
"5 years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"6 years",
"10+ years",
"2 years",
"7 years",
"1 year",
"10+ years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
null,
"7 years",
"10+ years",
"2 years",
"4 years",
"2 years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"9 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"< 1 year",
"3 years",
"5 years",
"9 years",
"5 years",
"< 1 year",
"1 year",
"8 years",
"10+ years",
"5 years",
null,
"2 years",
null,
"8 years",
"6 years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"4 years",
"5 years",
"3 years",
"10+ years",
"1 year",
"1 year",
"6 years",
"10+ years",
"4 years",
"1 year",
"9 years",
"< 1 year",
"10+ years",
"9 years",
"10+ years",
"10+ years",
null,
"10+ years",
"6 years",
"10+ years",
"7 years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
null,
"6 years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"3 years",
"10+ years",
null,
null,
"10+ years",
"9 years",
"2 years",
"10+ years",
"2 years",
"7 years",
null,
"2 years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
null,
"10+ years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"5 years",
"6 years",
"4 years",
"< 1 year",
"1 year",
"10+ years",
"1 year",
"8 years",
"3 years",
"9 years",
"6 years",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"7 years",
"10+ years",
"6 years",
"3 years",
"8 years",
"1 year",
"10+ years",
"7 years",
"3 years",
"4 years",
"6 years",
"2 years",
"< 1 year",
"10+ years",
"3 years",
"4 years",
"10+ years",
"1 year",
"9 years",
null,
"7 years",
"8 years",
"6 years",
"10+ years",
"10+ years",
"9 years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"6 years",
"5 years",
"6 years",
"< 1 year",
"10+ years",
"5 years",
"8 years",
"3 years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"< 1 year",
"< 1 year",
null,
"4 years",
"10+ years",
"9 years",
"3 years",
"2 years",
"< 1 year",
"10+ years",
"5 years",
"3 years",
"9 years",
"4 years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"2 years",
"10+ years",
"9 years",
"7 years",
"10+ years",
null,
"10+ years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"1 year",
"8 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"4 years",
"6 years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"3 years",
"6 years",
"< 1 year",
"2 years",
"6 years",
"2 years",
"3 years",
"10+ years",
null,
"10+ years",
"10+ years",
"6 years",
"7 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"4 years",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"6 years",
"4 years",
"10+ years",
"7 years",
"9 years",
"5 years",
"10+ years",
"7 years",
"10+ years",
null,
"10+ years",
"1 year",
null,
"< 1 year",
"1 year",
"3 years",
"10+ years",
"6 years",
"9 years",
"10+ years",
"2 years",
"5 years",
"7 years",
"10+ years",
"2 years",
"3 years",
null,
"3 years",
"6 years",
"2 years",
"2 years",
"6 years",
"1 year",
"3 years",
"< 1 year",
null,
"4 years",
"5 years",
"< 1 year",
"6 years",
"5 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"5 years",
"4 years",
null,
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"2 years",
"10+ years",
null,
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"9 years",
"8 years",
null,
"< 1 year",
"6 years",
"1 year",
"2 years",
null,
"2 years",
"8 years",
"10+ years",
"2 years",
"10+ years",
"9 years",
"2 years",
"2 years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"9 years",
"4 years",
"< 1 year",
"2 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"1 year",
"< 1 year",
"10+ years",
"7 years",
"1 year",
"5 years",
"1 year",
"10+ years",
"6 years",
"10+ years",
"3 years",
"< 1 year",
"2 years",
"< 1 year",
"4 years",
"2 years",
"2 years",
"2 years",
"8 years",
"4 years",
"10+ years",
"8 years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
null,
"9 years",
"2 years",
"3 years",
"< 1 year",
"3 years",
"2 years",
"8 years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"5 years",
"6 years",
"1 year",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"< 1 year",
"2 years",
"10+ years",
"2 years",
"5 years",
"4 years",
"10+ years",
"2 years",
"< 1 year",
"< 1 year",
"5 years",
"< 1 year",
"10+ years",
"4 years",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"5 years",
"9 years",
"2 years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"1 year",
"2 years",
null,
"10+ years",
"10+ years",
"7 years",
"10+ years",
"5 years",
"< 1 year",
"8 years",
"2 years",
"10+ years",
"10+ years",
"1 year",
"9 years",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"9 years",
"3 years",
null,
"7 years",
"7 years",
"10+ years",
null,
"7 years",
"2 years",
"4 years",
"2 years",
"4 years",
"8 years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"6 years",
"8 years",
"7 years",
"8 years",
"1 year",
"10+ years",
"2 years",
"1 year",
"1 year",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"6 years",
null,
"6 years",
"10+ years",
"10+ years",
"8 years",
"6 years",
"1 year",
"4 years",
"3 years",
"10+ years",
"< 1 year",
"4 years",
"2 years",
"10+ years",
"5 years",
"2 years",
"9 years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"1 year",
"6 years",
"8 years",
"6 years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"10+ years",
null,
"5 years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"4 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"1 year",
"2 years",
"1 year",
"10+ years",
"4 years",
"< 1 year",
null,
"10+ years",
"7 years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"3 years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"4 years",
"7 years",
"8 years",
"10+ years",
"3 years",
"5 years",
"4 years",
"1 year",
"4 years",
"9 years",
"3 years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"4 years",
"4 years",
"10+ years",
"1 year",
"9 years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"3 years",
"7 years",
"4 years",
"2 years",
"1 year",
"1 year",
"< 1 year",
"< 1 year",
"2 years",
"8 years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"5 years",
"3 years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"9 years",
"4 years",
"10+ years",
"4 years",
"2 years",
"2 years",
"10+ years",
"4 years",
"7 years",
"3 years",
"10+ years",
"9 years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
null,
"10+ years",
"6 years",
"8 years",
"2 years",
"10+ years",
"2 years",
"6 years",
"< 1 year",
"9 years",
"1 year",
"4 years",
null,
"2 years",
null,
"10+ years",
null,
"5 years",
"4 years",
"10+ years",
"7 years",
"6 years",
"1 year",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"9 years",
"10+ years",
null,
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"1 year",
"10+ years",
null,
"9 years",
"3 years",
"3 years",
"4 years",
"4 years",
"8 years",
"4 years",
"9 years",
"5 years",
"9 years",
"1 year",
"2 years",
"4 years",
"4 years",
"10+ years",
null,
"< 1 year",
"5 years",
"5 years",
"2 years",
"< 1 year",
"5 years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"3 years",
"5 years",
"8 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
null,
"< 1 year",
"1 year",
"8 years",
"7 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"2 years",
"4 years",
"8 years",
"2 years",
"7 years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"2 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"7 years",
"3 years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"9 years",
"6 years",
"10+ years",
"4 years",
"1 year",
"9 years",
"7 years",
"8 years",
"1 year",
"8 years",
"10+ years",
"4 years",
"3 years",
"5 years",
"3 years",
"< 1 year",
"4 years",
"10+ years",
null,
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"4 years",
null,
"7 years",
null,
"10+ years",
"6 years",
null,
"5 years",
"8 years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"2 years",
null,
"10+ years",
"10+ years",
"5 years",
"2 years",
"7 years",
"< 1 year",
"3 years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"6 years",
"6 years",
"10+ years",
"1 year",
"7 years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"4 years",
"1 year",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"2 years",
"5 years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"6 years",
"10+ years",
"5 years",
"10+ years",
"1 year",
"3 years",
"8 years",
"3 years",
"10+ years",
"8 years",
"7 years",
"10+ years",
"1 year",
"5 years",
"8 years",
"3 years",
"7 years",
"5 years",
"2 years",
"< 1 year",
"10+ years",
"< 1 year",
"7 years",
"1 year",
"5 years",
"5 years",
"10+ years",
"3 years",
"6 years",
"10+ years",
"6 years",
"8 years",
"8 years",
"< 1 year",
"3 years",
"4 years",
"4 years",
"3 years",
"3 years",
"< 1 year",
"9 years",
"10+ years",
"3 years",
null,
"3 years",
"1 year",
"5 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
null,
"10+ years",
"10+ years",
"2 years",
"2 years",
"2 years",
"8 years",
"2 years",
"6 years",
"10+ years",
"1 year",
"6 years",
"2 years",
"7 years",
"< 1 year",
"10+ years",
"< 1 year",
"2 years",
"9 years",
"10+ years",
"7 years",
"3 years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"2 years",
"4 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"3 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"4 years",
null,
"6 years",
"2 years",
"8 years",
"< 1 year",
"3 years",
"< 1 year",
null,
"< 1 year",
"6 years",
"4 years",
"1 year",
"10+ years",
"1 year",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"< 1 year",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"9 years",
"5 years",
null,
"9 years",
"10+ years",
"2 years",
"8 years",
"3 years",
null,
"2 years",
"10+ years",
"1 year",
"10+ years",
"7 years",
"3 years",
"2 years",
"8 years",
"9 years",
"6 years",
"10+ years",
"10+ years",
"1 year",
"7 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"2 years",
"< 1 year",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
"9 years",
"6 years",
"10+ years",
"10+ years",
"7 years",
"9 years",
"1 year",
"2 years",
"7 years",
"10+ years",
null,
"10+ years",
"1 year",
"10+ years",
"< 1 year",
null,
"2 years",
"10+ years",
"9 years",
"10+ years",
"3 years",
"3 years",
"< 1 year",
"9 years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
null,
"3 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"7 years",
"6 years",
"4 years",
"5 years",
"4 years",
"5 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"< 1 year",
"10+ years",
"5 years",
"5 years",
"< 1 year",
"3 years",
"10+ years",
"7 years",
"10+ years",
"< 1 year",
"8 years",
"5 years",
"10+ years",
"< 1 year",
"9 years",
"9 years",
"4 years",
"5 years",
"10+ years",
"< 1 year",
"2 years",
null,
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"1 year",
"< 1 year",
"4 years",
"< 1 year",
"1 year",
"8 years",
"8 years",
"3 years",
"7 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"3 years",
"< 1 year",
null,
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"1 year",
"1 year",
"1 year",
"8 years",
"7 years",
"10+ years",
"2 years",
"1 year",
"3 years",
"4 years",
"7 years",
"< 1 year",
null,
"9 years",
"5 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"8 years",
"10+ years",
"10+ years",
"3 years",
null,
"10+ years",
"< 1 year",
"1 year",
"1 year",
"2 years",
"10+ years",
"10+ years",
"1 year",
"8 years",
null,
null,
"< 1 year",
"1 year",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"3 years",
"10+ years",
"6 years",
"< 1 year",
null,
"2 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"5 years",
"2 years",
"2 years",
"3 years",
"3 years",
"10+ years",
"3 years",
"1 year",
"6 years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"2 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"1 year",
"3 years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"3 years",
"2 years",
"9 years",
"10+ years",
"< 1 year",
null,
"8 years",
"10+ years",
"5 years",
"9 years",
null,
"5 years",
"2 years",
"10+ years",
"2 years",
"1 year",
"6 years",
"4 years",
"3 years",
"7 years",
"6 years",
"1 year",
"4 years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"8 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"1 year",
null,
"2 years",
"5 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"2 years",
"9 years",
"10+ years",
"10+ years",
"4 years",
"7 years",
"7 years",
null,
"7 years",
"1 year",
"9 years",
"4 years",
"10+ years",
null,
"10+ years",
"5 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
null,
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"3 years",
"4 years",
"1 year",
"10+ years",
"4 years",
"10+ years",
"7 years",
"10+ years",
"9 years",
"5 years",
"< 1 year",
"10+ years",
"1 year",
"8 years",
"9 years",
"1 year",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"2 years",
"1 year",
"10+ years",
"5 years",
"8 years",
"< 1 year",
"1 year",
"< 1 year",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"2 years",
"< 1 year",
"< 1 year",
"3 years",
"7 years",
"10+ years",
"2 years",
"< 1 year",
"9 years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"7 years",
"5 years",
"10+ years",
"2 years",
"< 1 year",
"9 years",
"< 1 year",
"7 years",
"5 years",
null,
"1 year",
"10+ years",
"1 year",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"9 years",
"6 years",
"10+ years",
null,
"1 year",
"8 years",
"7 years",
"10+ years",
"8 years",
"4 years",
"10+ years",
"5 years",
"6 years",
"6 years",
"6 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"10+ years",
null,
"3 years",
"10+ years",
"2 years",
"6 years",
"8 years",
"6 years",
"3 years",
"5 years",
"7 years",
"7 years",
"10+ years",
null,
"10+ years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"3 years",
null,
"5 years",
"10+ years",
"< 1 year",
"6 years",
"1 year",
"4 years",
"10+ years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"2 years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"8 years",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"2 years",
null,
"3 years",
"7 years",
"7 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"10+ years",
"1 year",
"< 1 year",
"5 years",
"< 1 year",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"5 years",
"8 years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
null,
"< 1 year",
"2 years",
"10+ years",
"9 years",
"3 years",
"4 years",
"2 years",
"2 years",
"10+ years",
"1 year",
"< 1 year",
"< 1 year",
"9 years",
"< 1 year",
"8 years",
"10+ years",
null,
"3 years",
"8 years",
"6 years",
"9 years",
"7 years",
"6 years",
"2 years",
"4 years",
"9 years",
"3 years",
null,
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"6 years",
"10+ years",
"8 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"3 years",
"< 1 year",
"2 years",
"2 years",
"10+ years",
"8 years",
"3 years",
"2 years",
"10+ years",
"1 year",
"5 years",
"4 years",
"1 year",
"9 years",
"10+ years",
"7 years",
"7 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"1 year",
"9 years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"1 year",
"6 years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"3 years",
null,
null,
"10+ years",
"4 years",
"7 years",
"8 years",
null,
"10+ years",
"3 years",
"7 years",
"1 year",
"6 years",
"10+ years",
"< 1 year",
"< 1 year",
"7 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"3 years",
"9 years",
"8 years",
"1 year",
"< 1 year",
"7 years",
null,
"1 year",
"10+ years",
"5 years",
"8 years",
"8 years",
"< 1 year",
"6 years",
"< 1 year",
"2 years",
"1 year",
"10+ years",
"5 years",
"4 years",
"3 years",
"4 years",
"10+ years",
"3 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"7 years",
"7 years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"3 years",
"9 years",
"< 1 year",
"2 years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"8 years",
"2 years",
"9 years",
null,
"4 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"6 years",
"5 years",
"2 years",
"7 years",
"2 years",
"10+ years",
"5 years",
"4 years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"9 years",
"5 years",
"6 years",
"3 years",
"10+ years",
"3 years",
"3 years",
"2 years",
"10+ years",
null,
"10+ years",
"3 years",
"2 years",
"2 years",
"1 year",
"7 years",
"2 years",
"2 years",
"4 years",
"8 years",
"8 years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"9 years",
"4 years",
"< 1 year",
"10+ years",
"1 year",
"2 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"1 year",
"< 1 year",
"4 years",
"3 years",
"3 years",
"4 years",
null,
"10+ years",
"1 year",
"8 years",
"2 years",
"2 years",
"9 years",
"3 years",
"1 year",
"< 1 year",
"10+ years",
"8 years",
"6 years",
"< 1 year",
"10+ years",
"7 years",
"2 years",
"2 years",
null,
"9 years",
"2 years",
"6 years",
"10+ years",
"7 years",
"3 years",
"5 years",
"5 years",
"1 year",
"10+ years",
null,
"2 years",
"5 years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"8 years",
"4 years",
"< 1 year",
"8 years",
"2 years",
"10+ years",
"4 years",
"< 1 year",
"5 years",
"1 year",
"5 years",
"3 years",
"4 years",
"10+ years",
"10+ years",
null,
"< 1 year",
"< 1 year",
"8 years",
"4 years",
"10+ years",
null,
"< 1 year",
"9 years",
"< 1 year",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"2 years",
"9 years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"5 years",
"5 years",
"10+ years",
"6 years",
"4 years",
"3 years",
"1 year",
"5 years",
"2 years",
"5 years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"1 year",
"2 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"6 years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"7 years",
"4 years",
"6 years",
"10+ years",
"10+ years",
"5 years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
null,
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"< 1 year",
"6 years",
"4 years",
"10+ years",
"5 years",
"4 years",
"10+ years",
"6 years",
"1 year",
"10+ years",
"10+ years",
"9 years",
"2 years",
"5 years",
"5 years",
"9 years",
"2 years",
"10+ years",
"2 years",
"2 years",
"< 1 year",
"4 years",
"7 years",
"< 1 year",
"< 1 year",
"5 years",
"< 1 year",
"8 years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"2 years",
"5 years",
"5 years",
"4 years",
"4 years",
"7 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"4 years",
"< 1 year",
"4 years",
"3 years",
"5 years",
null,
null,
"3 years",
"5 years",
"4 years",
"1 year",
"10+ years",
"5 years",
"10+ years",
"9 years",
"10+ years",
"7 years",
"7 years",
"10+ years",
"8 years",
"9 years",
"1 year",
"2 years",
"1 year",
"8 years",
"10+ years",
"10+ years",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"4 years",
null,
"< 1 year",
"10+ years",
"< 1 year",
"2 years",
null,
"2 years",
"4 years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"1 year",
"4 years",
"4 years",
"7 years",
"3 years",
"6 years",
"10+ years",
"7 years",
"4 years",
"4 years",
"10+ years",
null,
"6 years",
"< 1 year",
"< 1 year",
"10+ years",
"3 years",
"< 1 year",
"3 years",
null,
"8 years",
"2 years",
"1 year",
"10+ years",
"10+ years",
null,
"5 years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"< 1 year",
"9 years",
"8 years",
"10+ years",
"6 years",
"2 years",
"1 year",
"6 years",
"< 1 year",
"7 years",
"7 years",
"3 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"< 1 year",
"1 year",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"5 years",
"2 years",
null,
"8 years",
"10+ years",
"< 1 year",
null,
"2 years",
"8 years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"6 years",
"< 1 year",
null,
"3 years",
null,
"< 1 year",
"4 years",
"6 years",
"6 years",
"1 year",
"2 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"8 years",
"< 1 year",
"10+ years",
"8 years",
"6 years",
"2 years",
"3 years",
"4 years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"7 years",
"1 year",
"7 years",
null,
"10+ years",
"2 years",
"1 year",
"10+ years",
"8 years",
"6 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"8 years",
"7 years",
"< 1 year",
"2 years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"8 years",
null,
"9 years",
null,
"2 years",
"< 1 year",
"9 years",
"< 1 year",
"10+ years",
"7 years",
"3 years",
"1 year",
"3 years",
"8 years",
"3 years",
"10+ years",
"5 years",
"7 years",
"10+ years",
"9 years",
"4 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"4 years",
null,
"10+ years",
"3 years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"1 year",
"2 years",
"7 years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"8 years",
"8 years",
"3 years",
"5 years",
"10+ years",
"3 years",
"8 years",
"4 years",
"< 1 year",
"8 years",
"4 years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"5 years",
"8 years",
"4 years",
"10+ years",
"5 years",
"8 years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"6 years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"8 years",
"2 years",
"3 years",
"4 years",
"< 1 year",
"< 1 year",
"4 years",
null,
"1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"5 years",
"9 years",
"< 1 year",
"2 years",
"2 years",
"6 years",
"1 year",
"3 years",
"3 years",
"10+ years",
"< 1 year",
null,
"3 years",
"10+ years",
"5 years",
"10+ years",
"1 year",
"< 1 year",
null,
"9 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
null,
"10+ years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
null,
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"4 years",
"10+ years",
"3 years",
"< 1 year",
"3 years",
null,
"5 years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"2 years",
null,
"< 1 year",
"4 years",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"4 years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"7 years",
"6 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"8 years",
"8 years",
"4 years",
"10+ years",
"9 years",
null,
"6 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"7 years",
"9 years",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
null,
"4 years",
"3 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"5 years",
null,
"10+ years",
"7 years",
null,
"10+ years",
"4 years",
"4 years",
"5 years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"7 years",
null,
"8 years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"3 years",
null,
"< 1 year",
null,
"3 years",
"2 years",
null,
"10+ years",
"6 years",
"10+ years",
"< 1 year",
null,
"10+ years",
null,
"4 years",
"2 years",
"5 years",
"10+ years",
"8 years",
"5 years",
"3 years",
"7 years",
"7 years",
"10+ years",
"5 years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"4 years",
"6 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"1 year",
"9 years",
"2 years",
"< 1 year",
"10+ years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"7 years",
"5 years",
"10+ years",
null,
"10+ years",
"10+ years",
"9 years",
"8 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"< 1 year",
"5 years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"10+ years",
null,
"10+ years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"3 years",
"8 years",
"10+ years",
"6 years",
"4 years",
"< 1 year",
"5 years",
"6 years",
"4 years",
"2 years",
"10+ years",
"8 years",
"5 years",
"3 years",
"5 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"3 years",
"5 years",
"9 years",
"2 years",
"2 years",
"5 years",
"2 years",
"7 years",
"10+ years",
"< 1 year",
"5 years",
"7 years",
"8 years",
"2 years",
"10+ years",
"5 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"8 years",
"8 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"5 years",
"2 years",
"< 1 year",
"6 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"6 years",
"4 years",
"6 years",
"10+ years",
"2 years",
"10+ years",
"6 years",
"2 years",
"1 year",
null,
"7 years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"8 years",
"9 years",
"7 years",
"10+ years",
"3 years",
"8 years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"8 years",
"7 years",
"6 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
null,
"3 years",
"6 years",
"< 1 year",
"2 years",
null,
"4 years",
"3 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"5 years",
"< 1 year",
"6 years",
"2 years",
"< 1 year",
"< 1 year",
null,
"10+ years",
"1 year",
"5 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"9 years",
"10+ years",
"9 years",
"2 years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"5 years",
"10+ years",
null,
"2 years",
"5 years",
"8 years",
"10+ years",
"1 year",
"2 years",
"10+ years",
"8 years",
"< 1 year",
"2 years",
"3 years",
null,
"10+ years",
null,
"10+ years",
"10+ years",
"8 years",
"1 year",
"6 years",
"4 years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"5 years",
"1 year",
"< 1 year",
"4 years",
null,
"1 year",
null,
"10+ years",
"9 years",
"9 years",
null,
"10+ years",
"10+ years",
"5 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"< 1 year",
"9 years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"5 years",
"< 1 year",
"3 years",
"4 years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"3 years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"3 years",
"< 1 year",
"10+ years",
"2 years",
"7 years",
"10+ years",
"8 years",
"6 years",
"8 years",
"10+ years",
"2 years",
"5 years",
null,
"10+ years",
"4 years",
"5 years",
null,
"4 years",
"10+ years",
null,
"10+ years",
"3 years",
"9 years",
"5 years",
"8 years",
"3 years",
"2 years",
"3 years",
"6 years",
"< 1 year",
"1 year",
"3 years",
"3 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"6 years",
"7 years",
"10+ years",
"2 years",
null,
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"4 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
null,
"10+ years",
"10+ years",
"6 years",
"8 years",
"5 years",
"2 years",
"4 years",
"2 years",
"1 year",
"6 years",
"9 years",
"3 years",
"1 year",
"9 years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"5 years",
"10+ years",
"9 years",
"10+ years",
"7 years",
"3 years",
null,
"6 years",
"1 year",
"2 years",
"< 1 year",
"1 year",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
null,
"10+ years",
"6 years",
"3 years",
"3 years",
"10+ years",
"1 year",
"3 years",
"1 year",
"10+ years",
"10+ years",
"9 years",
"7 years",
"6 years",
"6 years",
"8 years",
"10+ years",
"8 years",
"3 years",
"9 years",
"10+ years",
"7 years",
null,
null,
"6 years",
"4 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"8 years",
"5 years",
"5 years",
"2 years",
"9 years",
"< 1 year",
"4 years",
"5 years",
"10+ years",
"9 years",
"10+ years",
"2 years",
"2 years",
"9 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"3 years",
"4 years",
"6 years",
"10+ years",
"9 years",
"8 years",
"7 years",
"4 years",
"10+ years",
"< 1 year",
"5 years",
"4 years",
"10+ years",
"7 years",
"7 years",
"3 years",
"< 1 year",
"10+ years",
"3 years",
"3 years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"4 years",
"< 1 year",
"6 years",
"10+ years",
"5 years",
null,
"1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
null,
"5 years",
"5 years",
"2 years",
"8 years",
"1 year",
"5 years",
"10+ years",
"1 year",
"10+ years",
"9 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"6 years",
null,
null,
"2 years",
"7 years",
"5 years",
"10+ years",
"5 years",
"1 year",
"3 years",
"5 years",
"10+ years",
"2 years",
"6 years",
"7 years",
"< 1 year",
"7 years",
"7 years",
"10+ years",
"< 1 year",
"9 years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"3 years",
"1 year",
"7 years",
"5 years",
null,
"10+ years",
"9 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"9 years",
"2 years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"9 years",
"3 years",
null,
"6 years",
"2 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"5 years",
"10+ years",
"1 year",
"6 years",
"1 year",
"5 years",
"1 year",
"6 years",
"< 1 year",
"2 years",
"3 years",
"10+ years",
"1 year",
"2 years",
"4 years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"5 years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"6 years",
"5 years",
"10+ years",
"4 years",
"9 years",
"1 year",
"1 year",
"10+ years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"8 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"3 years",
"10+ years",
"3 years",
"1 year",
"< 1 year",
"4 years",
"10+ years",
null,
"8 years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"4 years",
"4 years",
"3 years",
"5 years",
"2 years",
"< 1 year",
"1 year",
"< 1 year",
"2 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
null,
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"5 years",
null,
"10+ years",
"2 years",
"10+ years",
"5 years",
"2 years",
"8 years",
"7 years",
"8 years",
"10+ years",
"1 year",
"5 years",
"10+ years",
"8 years",
"10+ years",
"1 year",
"2 years",
"9 years",
"7 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"9 years",
"9 years",
"< 1 year",
"8 years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"7 years",
"10+ years",
"5 years",
"8 years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"8 years",
"10+ years",
null,
"4 years",
"2 years",
"10+ years",
"1 year",
null,
"1 year",
"3 years",
"10+ years",
"1 year",
"6 years",
"5 years",
"4 years",
"< 1 year",
"2 years",
"1 year",
"1 year",
"5 years",
"5 years",
"< 1 year",
"< 1 year",
"10+ years",
"6 years",
"1 year",
"4 years",
"10+ years",
"10+ years",
"4 years",
"7 years",
null,
"10+ years",
"2 years",
"6 years",
"1 year",
"10+ years",
"< 1 year",
"1 year",
"1 year",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"1 year",
"2 years",
"7 years",
"1 year",
"10+ years",
"< 1 year",
"2 years",
"3 years",
"5 years",
"10+ years",
"8 years",
"2 years",
"3 years",
"10+ years",
null,
"8 years",
"< 1 year",
"2 years",
"4 years",
null,
"4 years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
null,
"2 years",
"3 years",
"7 years",
"10+ years",
"< 1 year",
"1 year",
"2 years",
"1 year",
"10+ years",
"7 years",
"< 1 year",
"8 years",
"2 years",
"10+ years",
"5 years",
"1 year",
null,
"< 1 year",
"2 years",
"10+ years",
"9 years",
"< 1 year",
"8 years",
"10+ years",
"1 year",
"4 years",
"3 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"3 years",
null,
"10+ years",
"10+ years",
"6 years",
"2 years",
"4 years",
"10+ years",
"10+ years",
"7 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"1 year",
"< 1 year",
"10+ years",
"1 year",
"7 years",
null,
"< 1 year",
"2 years",
"10+ years",
"2 years",
"9 years",
"6 years",
"7 years",
"3 years",
"10+ years",
"4 years",
"10+ years",
"9 years",
"10+ years",
"3 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
null,
null,
"10+ years",
"4 years",
"10+ years",
"< 1 year",
null,
"2 years",
"4 years",
"< 1 year",
"5 years",
"2 years",
"10+ years",
null,
"9 years",
"< 1 year",
"3 years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"5 years",
"10+ years",
null,
"5 years",
"2 years",
"10+ years",
"7 years",
"9 years",
"1 year",
"5 years",
"2 years",
"3 years",
"3 years",
"8 years",
null,
"8 years",
"2 years",
"7 years",
"1 year",
"3 years",
"1 year",
"3 years",
"5 years",
"1 year",
"5 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"8 years",
"8 years",
"10+ years",
"6 years",
"4 years",
"6 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"1 year",
"3 years",
"2 years",
"< 1 year",
"4 years",
"6 years",
"4 years",
"1 year",
"8 years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"6 years",
"1 year",
null,
"8 years",
"10+ years",
"9 years",
"5 years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"9 years",
"7 years",
"10+ years",
"2 years",
"3 years",
"7 years",
"3 years",
"2 years",
"3 years",
"7 years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"2 years",
"8 years",
"2 years",
"3 years",
"8 years",
null,
"10+ years",
"10+ years",
"10+ years",
"7 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"< 1 year",
"6 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"2 years",
null,
"10+ years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
null,
"3 years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"7 years",
"7 years",
null,
"2 years",
"10+ years",
"4 years",
null,
"3 years",
"3 years",
"8 years",
"5 years",
"10+ years",
"10+ years",
"6 years",
"< 1 year",
"1 year",
"1 year",
"4 years",
"7 years",
"4 years",
"10+ years",
"10+ years",
"8 years",
null,
"10+ years",
null,
"3 years",
"< 1 year",
"2 years",
"10+ years",
null,
"10+ years",
"8 years",
"10+ years",
"8 years",
"5 years",
"9 years",
"10+ years",
null,
"10+ years",
"3 years",
"6 years",
"5 years",
null,
"< 1 year",
"10+ years",
null,
"< 1 year",
"3 years",
"< 1 year",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"2 years",
"6 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"4 years",
"7 years",
"3 years",
"10+ years",
"1 year",
"5 years",
"10+ years",
"< 1 year",
null,
"10+ years",
null,
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"9 years",
null,
"3 years",
"< 1 year",
"6 years",
"2 years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
null,
"< 1 year",
"7 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
null,
"5 years",
null,
"10+ years",
"7 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
null,
"10+ years",
"9 years",
"7 years",
"4 years",
null,
"1 year",
"10+ years",
"10+ years",
"1 year",
"8 years",
"2 years",
"10+ years",
"7 years",
"7 years",
"2 years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"5 years",
"8 years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"7 years",
"4 years",
null,
"10+ years",
"7 years",
"2 years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
null,
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"8 years",
"3 years",
"< 1 year",
"2 years",
"1 year",
"10+ years",
"7 years",
"4 years",
"7 years",
"10+ years",
"10+ years",
null,
"5 years",
"10+ years",
"6 years",
"10+ years",
"9 years",
"1 year",
null,
"< 1 year",
"10+ years",
"5 years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"3 years",
"9 years",
"1 year",
"6 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"3 years",
"2 years",
null,
"10+ years",
"10+ years",
"10+ years",
"1 year",
"7 years",
"10+ years",
null,
"2 years",
null,
"10+ years",
null,
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"9 years",
"2 years",
"4 years",
null,
"7 years",
"3 years",
"1 year",
"1 year",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"8 years",
"< 1 year",
"6 years",
"8 years",
"10+ years",
"< 1 year",
"1 year",
"1 year",
"< 1 year",
"5 years",
"4 years",
"9 years",
"5 years",
"< 1 year",
"3 years",
"10+ years",
"6 years",
"5 years",
"2 years",
"8 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"5 years",
"4 years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
null,
"10+ years",
"4 years",
"3 years",
"< 1 year",
"10+ years",
null,
"2 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"1 year",
"2 years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"6 years",
"9 years",
"10+ years",
"< 1 year",
"3 years",
"2 years",
"10+ years",
"2 years",
"1 year",
"4 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"10+ years",
"3 years",
"3 years",
"7 years",
"4 years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"4 years",
"7 years",
"9 years",
"3 years",
"1 year",
"1 year",
"8 years",
"3 years",
"< 1 year",
"10+ years",
"7 years",
"1 year",
"10+ years",
"8 years",
"2 years",
"10+ years",
"1 year",
null,
"7 years",
"10+ years",
"7 years",
"3 years",
"10+ years",
"10+ years",
"6 years",
"< 1 year",
"< 1 year",
"5 years",
"6 years",
"4 years",
"10+ years",
"7 years",
"10+ years",
"1 year",
null,
"6 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"3 years",
"6 years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"4 years",
"7 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
null,
"2 years",
"10+ years",
"8 years",
"1 year",
"1 year",
null,
"5 years",
"10+ years",
"8 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"7 years",
null,
"< 1 year",
"2 years",
"9 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"2 years",
"1 year",
"10+ years",
"4 years",
"2 years",
"3 years",
"5 years",
"4 years",
null,
"10+ years",
"4 years",
"10+ years",
"1 year",
"6 years",
"< 1 year",
"< 1 year",
"10+ years",
"1 year",
"< 1 year",
"1 year",
"4 years",
"5 years",
"4 years",
"< 1 year",
null,
"10+ years",
"2 years",
"3 years",
"1 year",
"1 year",
"7 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"6 years",
"1 year",
"< 1 year",
"10+ years",
"7 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"4 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"8 years",
null,
"< 1 year",
null,
"10+ years",
"2 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"4 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
null,
"< 1 year",
"2 years",
"6 years",
"8 years",
"1 year",
"10+ years",
"3 years",
"2 years",
"10+ years",
"2 years",
null,
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"3 years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"7 years",
null,
"5 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"4 years",
"2 years",
"2 years",
"3 years",
"9 years",
"6 years",
null,
"10+ years",
"10+ years",
"2 years",
"10+ years",
null,
"3 years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"2 years",
"3 years",
"7 years",
"2 years",
"< 1 year",
"10+ years",
"9 years",
"10+ years",
"4 years",
"5 years",
"3 years",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
"9 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
null,
"5 years",
"10+ years",
"< 1 year",
"4 years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"8 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"8 years",
"5 years",
null,
"3 years",
"4 years",
"7 years",
"2 years",
"3 years",
"10+ years",
"10+ years",
null,
"10+ years",
"6 years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"4 years",
"9 years",
"2 years",
"4 years",
"2 years",
"2 years",
"2 years",
"1 year",
"2 years",
"6 years",
"10+ years",
"< 1 year",
"5 years",
"< 1 year",
null,
"2 years",
"7 years",
null,
"1 year",
"3 years",
"2 years",
"5 years",
"1 year",
"10+ years",
"8 years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"7 years",
"< 1 year",
"6 years",
"7 years",
"2 years",
"9 years",
"< 1 year",
"8 years",
"10+ years",
"3 years",
"< 1 year",
"3 years",
"10+ years",
"7 years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"8 years",
"2 years",
"< 1 year",
"5 years",
"7 years",
"10+ years",
"10+ years",
"6 years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"8 years",
"2 years",
"3 years",
"5 years",
null,
"10+ years",
"6 years",
"10+ years",
"2 years",
"2 years",
"4 years",
"10+ years",
"1 year",
"2 years",
"1 year",
"4 years",
"< 1 year",
"7 years",
"7 years",
"10+ years",
null,
"8 years",
"3 years",
"2 years",
"< 1 year",
"1 year",
"2 years",
"3 years",
"10+ years",
"5 years",
null,
"6 years",
"10+ years",
"3 years",
"7 years",
"< 1 year",
"3 years",
"4 years",
"3 years",
"10+ years",
"8 years",
"5 years",
"9 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"8 years",
"8 years",
"9 years",
"3 years",
"< 1 year",
"9 years",
"5 years",
"10+ years",
"2 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
null,
"6 years",
"10+ years",
null,
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"7 years",
"5 years",
"2 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"10+ years",
"1 year",
"5 years",
"7 years",
"1 year",
"8 years",
"10+ years",
"4 years",
"10+ years",
null,
"5 years",
"1 year",
"8 years",
"< 1 year",
"4 years",
"7 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
null,
"3 years",
"1 year",
"4 years",
"2 years",
"7 years",
"1 year",
"8 years",
"8 years",
null,
"1 year",
"10+ years",
"1 year",
"10+ years",
"8 years",
"5 years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"3 years",
"7 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"4 years",
null,
"10+ years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"5 years",
null,
"1 year",
"10+ years",
"7 years",
"4 years",
"6 years",
"10+ years",
"< 1 year",
"1 year",
"9 years",
"10+ years",
"2 years",
"3 years",
"5 years",
"3 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
null,
"1 year",
null,
"9 years",
"3 years",
null,
"1 year",
"1 year",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"2 years",
"6 years",
"5 years",
"5 years",
"10+ years",
"< 1 year",
"4 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"3 years",
"9 years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"5 years",
"7 years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"2 years",
"4 years",
"4 years",
"< 1 year",
"4 years",
"5 years",
null,
"7 years",
"2 years",
"1 year",
"2 years",
"2 years",
"5 years",
null,
"3 years",
"2 years",
"10+ years",
"2 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"6 years",
"3 years",
"4 years",
"9 years",
"10+ years",
"2 years",
"2 years",
"1 year",
"6 years",
"7 years",
null,
"10+ years",
"6 years",
"5 years",
"4 years",
"10+ years",
"3 years",
"3 years",
"8 years",
"10+ years",
"3 years",
"2 years",
"7 years",
"3 years",
"4 years",
null,
"3 years",
"10+ years",
"7 years",
"6 years",
"1 year",
"9 years",
"4 years",
"2 years",
"2 years",
"6 years",
"< 1 year",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"9 years",
"6 years",
"3 years",
"10+ years",
"4 years",
"8 years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"8 years",
"7 years",
null,
"< 1 year",
"< 1 year",
"10+ years",
"5 years",
"9 years",
null,
"10+ years",
"7 years",
"6 years",
"10+ years",
"< 1 year",
null,
"10+ years",
"6 years",
"10+ years",
"8 years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"2 years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"9 years",
"3 years",
"6 years",
"1 year",
null,
"5 years",
"7 years",
"10+ years",
"2 years",
"5 years",
"10+ years",
null,
"10+ years",
null,
"6 years",
"7 years",
"10+ years",
null,
"3 years",
"5 years",
"< 1 year",
"< 1 year",
"3 years",
"10+ years",
"2 years",
"3 years",
"7 years",
"5 years",
"9 years",
"4 years",
"1 year",
"2 years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"4 years",
null,
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"4 years",
"2 years",
"< 1 year",
"8 years",
null,
"10+ years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"7 years",
"2 years",
"10+ years",
"2 years",
"9 years",
"10+ years",
"7 years",
"6 years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"1 year",
"7 years",
"2 years",
"4 years",
null,
"2 years",
"8 years",
"3 years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"4 years",
"2 years",
"3 years",
"< 1 year",
"2 years",
"6 years",
"10+ years",
"5 years",
"7 years",
"3 years",
"8 years",
"3 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"1 year",
"10+ years",
null,
"6 years",
"3 years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"1 year",
"6 years",
null,
"10+ years",
null,
"< 1 year",
"7 years",
"3 years",
"10+ years",
"5 years",
"7 years",
null,
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
null,
"6 years",
"1 year",
"< 1 year",
"< 1 year",
"10+ years",
"2 years",
"1 year",
null,
"10+ years",
"7 years",
"1 year",
"8 years",
"3 years",
"5 years",
"1 year",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"3 years",
null,
"10+ years",
"6 years",
"8 years",
"10+ years",
"10+ years",
"1 year",
"6 years",
"6 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"2 years",
"8 years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"3 years",
"2 years",
null,
"10+ years",
"< 1 year",
"6 years",
"8 years",
"< 1 year",
"< 1 year",
"3 years",
"4 years",
"< 1 year",
"2 years",
"10+ years",
"6 years",
"8 years",
"6 years",
"10+ years",
"2 years",
"6 years",
"5 years",
"8 years",
"3 years",
"10+ years",
"4 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"< 1 year",
"7 years",
"2 years",
"4 years",
"10+ years",
"5 years",
"10+ years",
"3 years",
null,
null,
"1 year",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"1 year",
"4 years",
null,
"10+ years",
"3 years",
"2 years",
"10+ years",
null,
"10+ years",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"7 years",
"2 years",
"8 years",
"8 years",
"4 years",
"3 years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"7 years",
"7 years",
"10+ years",
"10+ years",
"1 year",
"4 years",
"7 years",
"6 years",
null,
"3 years",
"1 year",
"10+ years",
"3 years",
"6 years",
"7 years",
"3 years",
"< 1 year",
"< 1 year",
"10+ years",
"< 1 year",
null,
"10+ years",
"6 years",
"1 year",
"4 years",
"6 years",
"< 1 year",
"4 years",
"3 years",
"10+ years",
"1 year",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"< 1 year",
"8 years",
"5 years",
"7 years",
"2 years",
"3 years",
"1 year",
"5 years",
"5 years",
"2 years",
"2 years",
"5 years",
"10+ years",
null,
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"5 years",
"5 years",
"2 years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"4 years",
"2 years",
"10+ years",
null,
"< 1 year",
null,
"4 years",
"2 years",
"6 years",
"8 years",
"3 years",
null,
"1 year",
null,
"2 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"4 years",
"5 years",
"5 years",
"9 years",
"2 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"9 years",
"10+ years",
"2 years",
"7 years",
"3 years",
"3 years",
"7 years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"3 years",
"6 years",
"8 years",
"10+ years",
"8 years",
null,
"10+ years",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
null,
"8 years",
"< 1 year",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"6 years",
"5 years",
"4 years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"3 years",
"10+ years",
null,
"9 years",
"10+ years",
"9 years",
"10+ years",
"2 years",
null,
"10+ years",
"10+ years",
"9 years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"1 year",
"7 years",
"10+ years",
"8 years",
"2 years",
"< 1 year",
"7 years",
"5 years",
"7 years",
"5 years",
null,
"< 1 year",
"< 1 year",
"4 years",
"8 years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"9 years",
"6 years",
"7 years",
"7 years",
"8 years",
"10+ years",
"10+ years",
"2 years",
null,
"10+ years",
"7 years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"4 years",
"10+ years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"8 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"6 years",
"< 1 year",
"5 years",
"10+ years",
null,
"9 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"8 years",
"8 years",
"4 years",
"2 years",
"8 years",
"10+ years",
"4 years",
"4 years",
"< 1 year",
"7 years",
"10+ years",
"9 years",
"8 years",
"9 years",
"< 1 year",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"7 years",
"8 years",
"8 years",
"< 1 year",
"6 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
null,
"1 year",
"2 years",
"2 years",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"9 years",
"8 years",
"10+ years",
"6 years",
"3 years",
"10+ years",
"10+ years",
"9 years",
"1 year",
"10+ years",
"2 years",
"4 years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"< 1 year",
"10+ years",
"4 years",
"2 years",
"5 years",
"1 year",
"10+ years",
"3 years",
"6 years",
"2 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"2 years",
"4 years",
"10+ years",
"10+ years",
"1 year",
"9 years",
"3 years",
null,
"1 year",
"7 years",
"10+ years",
"3 years",
"2 years",
"< 1 year",
"4 years",
"1 year",
"10+ years",
"1 year",
"2 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"< 1 year",
"1 year",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"5 years",
"4 years",
"2 years",
"< 1 year",
"1 year",
"7 years",
"7 years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"< 1 year",
"8 years",
"3 years",
"3 years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"7 years",
"1 year",
"10+ years",
"4 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"2 years",
"8 years",
"9 years",
"6 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"6 years",
"2 years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"9 years",
"10+ years",
"1 year",
"6 years",
"3 years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
null,
"2 years",
"5 years",
"4 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
null,
"9 years",
"10+ years",
"9 years",
"2 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
null,
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"6 years",
"2 years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"9 years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"7 years",
"4 years",
"9 years",
"7 years",
null,
"10+ years",
"5 years",
"10+ years",
"3 years",
"7 years",
"6 years",
"6 years",
"10+ years",
"10+ years",
"8 years",
"6 years",
"8 years",
"< 1 year",
"3 years",
"9 years",
"9 years",
"7 years",
"2 years",
"5 years",
"10+ years",
"< 1 year",
"4 years",
"5 years",
"7 years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"4 years",
"10+ years",
null,
"1 year",
"2 years",
"9 years",
"3 years",
"8 years",
"10+ years",
"5 years",
"6 years",
"6 years",
"3 years",
"1 year",
null,
"2 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"4 years",
"8 years",
"5 years",
"6 years",
"8 years",
"5 years",
"10+ years",
"10+ years",
"7 years",
"6 years",
"10+ years",
"2 years",
"2 years",
"4 years",
"3 years",
"10+ years",
"8 years",
"5 years",
"10+ years",
null,
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"9 years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"6 years",
"10+ years",
"7 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"7 years",
"5 years",
"6 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"4 years",
"10+ years",
"9 years",
"3 years",
"7 years",
"1 year",
"1 year",
"10+ years",
"5 years",
"9 years",
"2 years",
"10+ years",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"2 years",
"< 1 year",
"3 years",
"5 years",
"1 year",
"6 years",
"5 years",
"3 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"5 years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"4 years",
"7 years",
"8 years",
"1 year",
"10+ years",
"3 years",
"7 years",
"3 years",
"10+ years",
"9 years",
"1 year",
"< 1 year",
"< 1 year",
"8 years",
"2 years",
"9 years",
null,
"10+ years",
"< 1 year",
"7 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"2 years",
"7 years",
"5 years",
"9 years",
"3 years",
"< 1 year",
"3 years",
"9 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"8 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"4 years",
"4 years",
"9 years",
"4 years",
"10+ years",
null,
"10+ years",
"10+ years",
"2 years",
"3 years",
"2 years",
"10+ years",
"2 years",
"8 years",
"6 years",
"5 years",
"10+ years",
"6 years",
"10+ years",
"4 years",
"8 years",
null,
"3 years",
"2 years",
"10+ years",
"10+ years",
"9 years",
"7 years",
"3 years",
"2 years",
"< 1 year",
"< 1 year",
"10+ years",
"2 years",
"8 years",
"1 year",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"8 years",
"10+ years",
null,
"2 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"7 years",
null,
"10+ years",
"9 years",
"5 years",
"1 year",
"2 years",
"10+ years",
"< 1 year",
"4 years",
"5 years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"4 years",
"10+ years",
null,
"9 years",
"5 years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"8 years",
"1 year",
"10+ years",
"6 years",
"3 years",
"10+ years",
"1 year",
"5 years",
"8 years",
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"2 years",
"2 years",
"7 years",
"10+ years",
"8 years",
"< 1 year",
"4 years",
"10+ years",
null,
"2 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"8 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"3 years",
"3 years",
null,
null,
"10+ years",
"5 years",
"3 years",
"4 years",
"8 years",
"2 years",
null,
"3 years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"10+ years",
"9 years",
"1 year",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"1 year",
"6 years",
"6 years",
"10+ years",
"10+ years",
"8 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"5 years",
"6 years",
"1 year",
"8 years",
"2 years",
"8 years",
"3 years",
"2 years",
"1 year",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"2 years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"9 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"1 year",
"4 years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"5 years",
"10+ years",
"1 year",
"8 years",
"7 years",
"10+ years",
"10+ years",
"3 years",
null,
"2 years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"4 years",
"5 years",
"8 years",
"10+ years",
"10+ years",
null,
"3 years",
"< 1 year",
"10+ years",
"7 years",
"6 years",
"3 years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
null,
"8 years",
"< 1 year",
"7 years",
"10+ years",
null,
"2 years",
"5 years",
"1 year",
null,
"9 years",
"4 years",
"6 years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"6 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"5 years",
"6 years",
"10+ years",
"1 year",
"10+ years",
"2 years",
null,
"10+ years",
"5 years",
"9 years",
"6 years",
"10+ years",
"3 years",
"< 1 year",
"1 year",
"2 years",
"< 1 year",
null,
"10+ years",
"4 years",
"3 years",
"5 years",
"10+ years",
"4 years",
"8 years",
"< 1 year",
"10+ years",
"1 year",
"4 years",
"2 years",
null,
"3 years",
"3 years",
"10+ years",
"8 years",
"5 years",
"8 years",
"6 years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"1 year",
"7 years",
"4 years",
"7 years",
"7 years",
"7 years",
"6 years",
"10+ years",
"7 years",
"8 years",
null,
"1 year",
"3 years",
"4 years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"3 years",
"9 years",
"7 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"1 year",
"1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"< 1 year",
"< 1 year",
"10+ years",
"2 years",
"2 years",
"5 years",
"3 years",
"3 years",
"8 years",
"5 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"< 1 year",
"< 1 year",
"10+ years",
"1 year",
"1 year",
"4 years",
"1 year",
"9 years",
"4 years",
"10+ years",
"7 years",
"5 years",
"8 years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"2 years",
null,
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"9 years",
"< 1 year",
"8 years",
"3 years",
"2 years",
"2 years",
"6 years",
"10+ years",
"1 year",
"4 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"4 years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"6 years",
"7 years",
"4 years",
"2 years",
null,
"7 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"5 years",
"10+ years",
"2 years",
"4 years",
"10+ years",
null,
null,
"7 years",
"3 years",
"4 years",
"< 1 year",
"9 years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"5 years",
"3 years",
"3 years",
"2 years",
"10+ years",
"8 years",
"9 years",
null,
null,
"3 years",
"2 years",
"4 years",
"1 year",
"7 years",
"10+ years",
"8 years",
"8 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"7 years",
"7 years",
"2 years",
"2 years",
"10+ years",
"9 years",
"3 years",
"2 years",
"4 years",
"3 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"9 years",
null,
null,
"6 years",
"7 years",
"10+ years",
null,
"7 years",
"5 years",
"10+ years",
"< 1 year",
"1 year",
"9 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"2 years",
"10+ years",
null,
"10+ years",
"7 years",
"3 years",
"10+ years",
null,
"4 years",
"7 years",
"10+ years",
"6 years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"2 years",
"1 year",
"3 years",
null,
"9 years",
"10+ years",
"2 years",
"5 years",
"7 years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"3 years",
"< 1 year",
"8 years",
"4 years",
"8 years",
"10+ years",
"5 years",
"7 years",
"10+ years",
"10+ years",
"3 years",
null,
"2 years",
"10+ years",
null,
"4 years",
"10+ years",
"6 years",
"6 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"10+ years",
null,
"5 years",
"3 years",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"9 years",
"1 year",
null,
"1 year",
"10+ years",
"7 years",
"10+ years",
"9 years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"2 years",
"1 year",
"2 years",
"9 years",
"1 year",
"< 1 year",
"9 years",
"5 years",
"10+ years",
"9 years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
null,
"7 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"8 years",
"9 years",
"9 years",
"10+ years",
"1 year",
"2 years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"1 year",
"10+ years",
"9 years",
"5 years",
"7 years",
"2 years",
"2 years",
"10+ years",
"6 years",
"3 years",
"1 year",
"5 years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"9 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"9 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"7 years",
"9 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"7 years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"3 years",
"< 1 year",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"4 years",
"10+ years",
"8 years",
"1 year",
"4 years",
"10+ years",
"2 years",
"2 years",
"4 years",
"5 years",
"< 1 year",
"10+ years",
"7 years",
"3 years",
"6 years",
"8 years",
"3 years",
"< 1 year",
"1 year",
"1 year",
"1 year",
"8 years",
"10+ years",
"6 years",
"4 years",
"10+ years",
"6 years",
"2 years",
"3 years",
null,
"8 years",
"10+ years",
"8 years",
"< 1 year",
"4 years",
"< 1 year",
"6 years",
"10+ years",
"6 years",
"10+ years",
"7 years",
"5 years",
"5 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"9 years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"8 years",
"3 years",
"4 years",
"10+ years",
"4 years",
"10+ years",
"4 years",
"8 years",
"6 years",
"10+ years",
"< 1 year",
"1 year",
"7 years",
"5 years",
"6 years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"5 years",
"5 years",
"2 years",
"7 years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"3 years",
"2 years",
"7 years",
"10+ years",
"6 years",
"5 years",
null,
"< 1 year",
"10+ years",
"7 years",
"8 years",
null,
"< 1 year",
"3 years",
"4 years",
"4 years",
null,
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"9 years",
null,
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"1 year",
"2 years",
"1 year",
"7 years",
"10+ years",
"10+ years",
"5 years",
"8 years",
"2 years",
null,
"7 years",
"2 years",
"< 1 year",
"10+ years",
"3 years",
"9 years",
null,
"< 1 year",
null,
"< 1 year",
"4 years",
"10+ years",
"2 years",
"8 years",
"< 1 year",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"3 years",
"6 years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"9 years",
"6 years",
"10+ years",
"6 years",
"3 years",
"10+ years",
"9 years",
"8 years",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"< 1 year",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"3 years",
"2 years",
"1 year",
"6 years",
"5 years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
null,
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"2 years",
"8 years",
"6 years",
"2 years",
"1 year",
"2 years",
"< 1 year",
"1 year",
"1 year",
"1 year",
"8 years",
"4 years",
"10+ years",
"1 year",
"6 years",
null,
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"8 years",
"1 year",
"10+ years",
"7 years",
"5 years",
"2 years",
"9 years",
"5 years",
"9 years",
"8 years",
"3 years",
"5 years",
"3 years",
"10+ years",
"8 years",
"< 1 year",
"3 years",
null,
"6 years",
"2 years",
"3 years",
"9 years",
"8 years",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"1 year",
"4 years",
"1 year",
null,
"4 years",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
null,
"2 years",
"5 years",
"2 years",
"10+ years",
"7 years",
"7 years",
"4 years",
"7 years",
"7 years",
"4 years",
"5 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"1 year",
"3 years",
"9 years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"6 years",
"2 years",
"2 years",
"1 year",
"5 years",
null,
"10+ years",
"1 year",
"8 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"3 years",
"7 years",
"3 years",
"6 years",
"9 years",
"3 years",
null,
"2 years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"2 years",
"8 years",
null,
"10+ years",
"8 years",
"4 years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"< 1 year",
"6 years",
"8 years",
"7 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
null,
"4 years",
"8 years",
"10+ years",
"4 years",
"7 years",
"6 years",
"10+ years",
"1 year",
"9 years",
"10+ years",
"6 years",
"7 years",
"9 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"8 years",
null,
"8 years",
"4 years",
"7 years",
"8 years",
"< 1 year",
"8 years",
null,
"10+ years",
"3 years",
"2 years",
"1 year",
"1 year",
"10+ years",
"5 years",
null,
"3 years",
"10+ years",
"1 year",
"6 years",
"2 years",
"7 years",
"4 years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"2 years",
"4 years",
"10+ years",
"9 years",
"6 years",
"10+ years",
"8 years",
null,
"10+ years",
"10+ years",
"2 years",
"10+ years",
"9 years",
"4 years",
"3 years",
"10+ years",
"7 years",
"2 years",
"8 years",
"< 1 year",
"6 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"6 years",
"2 years",
"5 years",
"5 years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"6 years",
"2 years",
"9 years",
"3 years",
"6 years",
"9 years",
"10+ years",
"< 1 year",
"4 years",
"< 1 year",
"4 years",
"10+ years",
null,
"10+ years",
"7 years",
null,
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"< 1 year",
"9 years",
"2 years",
"2 years",
"3 years",
"4 years",
"6 years",
"9 years",
"9 years",
"4 years",
"6 years",
null,
"10+ years",
"2 years",
"< 1 year",
null,
"10+ years",
"3 years",
"3 years",
"10+ years",
"5 years",
"9 years",
"9 years",
"10+ years",
"3 years",
"< 1 year",
"1 year",
"3 years",
"10+ years",
"1 year",
"10+ years",
"2 years",
"4 years",
"9 years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"3 years",
"1 year",
"7 years",
null,
"10+ years",
"10+ years",
"6 years",
"2 years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"1 year",
"4 years",
"< 1 year",
"9 years",
"10+ years",
"2 years",
"6 years",
"2 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
null,
null,
"7 years",
"10+ years",
"2 years",
"5 years",
"6 years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"5 years",
"1 year",
"2 years",
"5 years",
"8 years",
"10+ years",
"2 years",
"2 years",
"5 years",
"1 year",
"10+ years",
"2 years",
"2 years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
null,
"2 years",
"10+ years",
"1 year",
"10+ years",
"9 years",
"10+ years",
"7 years",
"8 years",
"4 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"5 years",
"1 year",
"1 year",
"8 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"7 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"3 years",
"7 years",
"6 years",
null,
"10+ years",
"9 years",
"1 year",
"10+ years",
"9 years",
"9 years",
"10+ years",
"1 year",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"6 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"6 years",
"< 1 year",
"6 years",
"10+ years",
"1 year",
"< 1 year",
"4 years",
"8 years",
"< 1 year",
null,
"10+ years",
"7 years",
"6 years",
"10+ years",
"3 years",
"3 years",
"4 years",
"3 years",
"< 1 year",
"10+ years",
"8 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"6 years",
"7 years",
"7 years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"7 years",
"4 years",
"9 years",
"4 years",
"< 1 year",
"10+ years",
"9 years",
"2 years",
"8 years",
"5 years",
"3 years",
"2 years",
"9 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"3 years",
"< 1 year",
"8 years",
"< 1 year",
"3 years",
"8 years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"5 years",
"< 1 year",
"3 years",
"7 years",
"10+ years",
"6 years",
"6 years",
"4 years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"5 years",
"2 years",
"2 years",
"8 years",
"7 years",
"6 years",
"3 years",
"7 years",
"6 years",
"4 years",
"8 years",
"7 years",
"10+ years",
"1 year",
"4 years",
null,
"7 years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"1 year",
"< 1 year",
"10+ years",
"7 years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
null,
"4 years",
"6 years",
"< 1 year",
"10+ years",
"5 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"6 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"5 years",
"< 1 year",
"3 years",
"10+ years",
"6 years",
"5 years",
"1 year",
"10+ years",
"7 years",
"8 years",
"8 years",
null,
"3 years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"2 years",
"3 years",
"< 1 year",
"5 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"9 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"7 years",
null,
"10+ years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
null,
"10+ years",
"7 years",
null,
"2 years",
"3 years",
"5 years",
"5 years",
"10+ years",
"5 years",
"9 years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"7 years",
"6 years",
"7 years",
"10+ years",
"4 years",
"7 years",
null,
"< 1 year",
"< 1 year",
"1 year",
"7 years",
"3 years",
"1 year",
"< 1 year",
"2 years",
"3 years",
"10+ years",
"5 years",
null,
"10+ years",
"10+ years",
"9 years",
"4 years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"3 years",
"3 years",
null,
"1 year",
null,
"1 year",
"10+ years",
"3 years",
"8 years",
"5 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"7 years",
"2 years",
"4 years",
"10+ years",
"3 years",
"2 years",
"2 years",
"5 years",
"10+ years",
"9 years",
"6 years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"6 years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
null,
"3 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"7 years",
"6 years",
"1 year",
"< 1 year",
"< 1 year",
"10+ years",
"2 years",
"5 years",
"2 years",
"1 year",
"9 years",
"10+ years",
"10+ years",
"5 years",
"1 year",
"1 year",
"< 1 year",
"10+ years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"3 years",
"9 years",
"< 1 year",
"10+ years",
"4 years",
"8 years",
"10+ years",
"1 year",
"5 years",
"10+ years",
"10+ years",
"10+ years",
null,
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
null,
"8 years",
"3 years",
"< 1 year",
"6 years",
"< 1 year",
"< 1 year",
null,
"5 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"8 years",
"2 years",
"10+ years",
"10+ years",
null,
"7 years",
"< 1 year",
"3 years",
"3 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"3 years",
"8 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"1 year",
null,
"10+ years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"7 years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"7 years",
"10+ years",
"7 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"4 years",
"10+ years",
"4 years",
"5 years",
null,
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"3 years",
"1 year",
"10+ years",
"9 years",
"10+ years",
"2 years",
"3 years",
"< 1 year",
"5 years",
"< 1 year",
"7 years",
"5 years",
"7 years",
"3 years",
"10+ years",
"2 years",
"1 year",
null,
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"7 years",
"2 years",
"4 years",
"8 years",
"4 years",
"< 1 year",
"10+ years",
"4 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"4 years",
"2 years",
"10+ years",
"10+ years",
null,
"4 years",
"< 1 year",
"10+ years",
"9 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"10+ years",
"5 years",
"1 year",
"3 years",
"< 1 year",
"9 years",
"5 years",
"2 years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"7 years",
"4 years",
"10+ years",
"< 1 year",
"2 years",
"7 years",
"10+ years",
"2 years",
"8 years",
"< 1 year",
"10+ years",
"9 years",
"6 years",
"10+ years",
"6 years",
null,
"8 years",
"2 years",
"4 years",
"< 1 year",
"< 1 year",
"4 years",
"1 year",
"6 years",
"10+ years",
"3 years",
"6 years",
"8 years",
"10+ years",
"4 years",
"2 years",
"2 years",
"9 years",
"1 year",
"7 years",
"< 1 year",
"4 years",
"4 years",
"9 years",
"10+ years",
"4 years",
"9 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
null,
"3 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"7 years",
"2 years",
null,
"7 years",
"3 years",
"9 years",
"4 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"6 years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
null,
"10+ years",
"4 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"6 years",
"10+ years",
"9 years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"< 1 year",
"8 years",
"1 year",
"2 years",
"2 years",
"6 years",
"10+ years",
null,
"10+ years",
null,
null,
"9 years",
"10+ years",
"9 years",
"4 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"1 year",
"7 years",
null,
"10+ years",
"7 years",
"2 years",
"6 years",
"8 years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"7 years",
"5 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"2 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"2 years",
null,
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"< 1 year",
"1 year",
"4 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"9 years",
"7 years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"1 year",
"1 year",
"4 years",
"3 years",
"7 years",
"1 year",
"3 years",
"3 years",
"4 years",
"10+ years",
"1 year",
"8 years",
"10+ years",
"1 year",
"10+ years",
"8 years",
"2 years",
"10+ years",
"< 1 year",
null,
"6 years",
"3 years",
"10+ years",
"9 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"1 year",
"7 years",
"3 years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"1 year",
"5 years",
"4 years",
"4 years",
"1 year",
"2 years",
"5 years",
"10+ years",
"2 years",
null,
"3 years",
"4 years",
"2 years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"6 years",
"2 years",
"10+ years",
"1 year",
"2 years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"2 years",
"4 years",
"3 years",
"5 years",
"10+ years",
null,
"2 years",
null,
"9 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"10+ years",
null,
"2 years",
"3 years",
"4 years",
"6 years",
"9 years",
"< 1 year",
"3 years",
"10+ years",
"2 years",
"8 years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"7 years",
"6 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"9 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
null,
"10+ years",
"1 year",
"10+ years",
"1 year",
"6 years",
"2 years",
"10+ years",
"2 years",
"9 years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"6 years",
"2 years",
"10+ years",
"5 years",
"< 1 year",
"5 years",
"6 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"7 years",
"10+ years",
"6 years",
"10+ years",
null,
"10+ years",
"5 years",
"5 years",
"6 years",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
null,
"10+ years",
"9 years",
"5 years",
"7 years",
"10+ years",
"10+ years",
"5 years",
"5 years",
"5 years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"9 years",
"6 years",
"< 1 year",
"4 years",
"4 years",
"10+ years",
"10+ years",
"1 year",
"6 years",
"3 years",
"5 years",
"10+ years",
"6 years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"1 year",
"8 years",
"1 year",
"7 years",
null,
"5 years",
"9 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"4 years",
"3 years",
"6 years",
"4 years",
"10+ years",
"10+ years",
"7 years",
"6 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"5 years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"7 years",
"9 years",
"10+ years",
"8 years",
"2 years",
"2 years",
"7 years",
"6 years",
"10+ years",
"2 years",
"1 year",
"7 years",
"10+ years",
"9 years",
"1 year",
"< 1 year",
"6 years",
null,
"10+ years",
"8 years",
"< 1 year",
"2 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"8 years",
"10+ years",
"2 years",
null,
"3 years",
"10+ years",
"8 years",
"5 years",
"< 1 year",
"6 years",
null,
"5 years",
null,
"4 years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"6 years",
"3 years",
"4 years",
"9 years",
"5 years",
"2 years",
"7 years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"6 years",
"10+ years",
"7 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"3 years",
"8 years",
"2 years",
"4 years",
"10+ years",
"1 year",
"2 years",
"10+ years",
"10+ years",
null,
"6 years",
"8 years",
"3 years",
"3 years",
"10+ years",
"9 years",
"2 years",
"7 years",
"10+ years",
"4 years",
"8 years",
"5 years",
null,
"10+ years",
"< 1 year",
"3 years",
"6 years",
"4 years",
"7 years",
"< 1 year",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"4 years",
"2 years",
"7 years",
"10+ years",
"3 years",
"1 year",
"7 years",
"10+ years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"4 years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"9 years",
"4 years",
"8 years",
"10+ years",
"< 1 year",
"< 1 year",
"5 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"< 1 year",
"10+ years",
"5 years",
"3 years",
"8 years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"5 years",
"3 years",
"1 year",
null,
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"3 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"3 years",
"2 years",
"4 years",
"4 years",
"10+ years",
"8 years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"5 years",
"2 years",
"2 years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"10+ years",
"9 years",
"7 years",
"5 years",
"9 years",
"6 years",
"5 years",
"10+ years",
"9 years",
"2 years",
"10+ years",
"< 1 year",
"1 year",
"3 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"9 years",
"10+ years",
"1 year",
"7 years",
"< 1 year",
"7 years",
"8 years",
"6 years",
"3 years",
"9 years",
"10+ years",
"6 years",
"1 year",
"10+ years",
"7 years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"9 years",
"5 years",
"< 1 year",
"3 years",
"1 year",
"< 1 year",
"10+ years",
"4 years",
"3 years",
"10+ years",
"5 years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"3 years",
"9 years",
null,
"< 1 year",
"10+ years",
"2 years",
"5 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"1 year",
"7 years",
"< 1 year",
"10+ years",
"6 years",
null,
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"9 years",
"3 years",
"9 years",
"3 years",
"8 years",
null,
null,
"7 years",
"5 years",
"10+ years",
"1 year",
"1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"9 years",
"10+ years",
"10+ years",
"8 years",
"7 years",
"2 years",
"10+ years",
"8 years",
"8 years",
"1 year",
"5 years",
"3 years",
"< 1 year",
"9 years",
null,
"10+ years",
"< 1 year",
"4 years",
"< 1 year",
"6 years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"7 years",
"2 years",
"1 year",
"2 years",
"1 year",
"10+ years",
"10+ years",
null,
"10+ years",
"6 years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"< 1 year",
"8 years",
"4 years",
null,
"5 years",
"10+ years",
"5 years",
"2 years",
"6 years",
"4 years",
"1 year",
"9 years",
"8 years",
"2 years",
"6 years",
"3 years",
"6 years",
"10+ years",
null,
"7 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"< 1 year",
"6 years",
"4 years",
"6 years",
null,
"3 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"2 years",
"10+ years",
null,
"3 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"3 years",
"10+ years",
null,
"8 years",
"6 years",
"3 years",
"9 years",
"10+ years",
"8 years",
"2 years",
"4 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"6 years",
"< 1 year",
"8 years",
"5 years",
"2 years",
null,
"< 1 year",
"1 year",
"9 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
null,
"10+ years",
"4 years",
null,
"10+ years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"2 years",
"1 year",
null,
"2 years",
"9 years",
"2 years",
"9 years",
"10+ years",
"2 years",
"4 years",
"< 1 year",
"8 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"4 years",
"10+ years",
null,
"3 years",
"< 1 year",
"3 years",
"10+ years",
"7 years",
"3 years",
null,
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"8 years",
"4 years",
"9 years",
"3 years",
"8 years",
"4 years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"1 year",
"3 years",
"10+ years",
"< 1 year",
"3 years",
"4 years",
"< 1 year",
"10+ years",
"3 years",
"< 1 year",
"1 year",
"10+ years",
"2 years",
"9 years",
"3 years",
"3 years",
"3 years",
"4 years",
"9 years",
"< 1 year",
"4 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"2 years",
"1 year",
"8 years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"8 years",
"9 years",
"4 years",
"1 year",
null,
"10+ years",
"10+ years",
"8 years",
"8 years",
"9 years",
"10+ years",
"< 1 year",
"< 1 year",
"4 years",
"4 years",
"6 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"2 years",
"< 1 year",
"2 years",
"5 years",
"5 years",
"10+ years",
"< 1 year",
"1 year",
"7 years",
"4 years",
null,
"10+ years",
"2 years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"4 years",
"4 years",
"2 years",
"2 years",
"10+ years",
"9 years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"7 years",
"2 years",
"10+ years",
"5 years",
"4 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"2 years",
"10+ years",
null,
"7 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
null,
"10+ years",
"< 1 year",
"10+ years",
null,
"10+ years",
"8 years",
"6 years",
"2 years",
"9 years",
"6 years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
null,
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"< 1 year",
"8 years",
"7 years",
"2 years",
"3 years",
"5 years",
"5 years",
"2 years",
"10+ years",
"3 years",
"2 years",
"4 years",
"< 1 year",
"4 years",
"1 year",
"9 years",
"3 years",
"10+ years",
"2 years",
"3 years",
"1 year",
"7 years",
"10+ years",
"1 year",
"10+ years",
"2 years",
"2 years",
"4 years",
"3 years",
"9 years",
"10+ years",
null,
"10+ years",
"1 year",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"1 year",
"4 years",
"7 years",
"6 years",
"< 1 year",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
null,
"4 years",
"2 years",
"10+ years",
"10+ years",
"6 years",
null,
"< 1 year",
"5 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"7 years",
"1 year",
"3 years",
"5 years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"8 years",
"1 year",
"< 1 year",
"2 years",
"3 years",
"4 years",
"8 years",
"1 year",
"4 years",
"3 years",
"10+ years",
null,
"1 year",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"4 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"1 year",
"4 years",
"7 years",
"7 years",
"7 years",
"10+ years",
"9 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"10+ years",
null,
"5 years",
"9 years",
"6 years",
"7 years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"9 years",
"6 years",
"5 years",
"10+ years",
"2 years",
null,
"3 years",
"2 years",
"9 years",
"1 year",
"4 years",
"4 years",
"4 years",
"3 years",
null,
"7 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"9 years",
"9 years",
"5 years",
"10+ years",
"< 1 year",
"3 years",
"9 years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"7 years",
"10+ years",
"7 years",
"< 1 year",
"3 years",
"5 years",
"8 years",
null,
null,
"1 year",
"5 years",
"5 years",
"6 years",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"3 years",
"5 years",
"7 years",
"9 years",
"10+ years",
"1 year",
"4 years",
"10+ years",
"< 1 year",
"9 years",
"6 years",
"3 years",
"2 years",
"3 years",
"3 years",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"9 years",
"< 1 year",
"6 years",
"4 years",
"10+ years",
"9 years",
null,
"10+ years",
"2 years",
"10+ years",
null,
"7 years",
null,
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"6 years",
"3 years",
"5 years",
"1 year",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"9 years",
"4 years",
"1 year",
"1 year",
"9 years",
"7 years",
"8 years",
null,
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"2 years",
"8 years",
null,
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"3 years",
null,
"1 year",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"9 years",
"9 years",
"3 years",
"5 years",
null,
"1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
null,
"2 years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"< 1 year",
"5 years",
"8 years",
"6 years",
"10+ years",
"10+ years",
"7 years",
"< 1 year",
"8 years",
"10+ years",
"3 years",
"2 years",
"5 years",
"10+ years",
"< 1 year",
"5 years",
"3 years",
"< 1 year",
"9 years",
"10+ years",
"6 years",
"8 years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"6 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"3 years",
null,
"4 years",
"10+ years",
"5 years",
"4 years",
"2 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"8 years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"9 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"7 years",
"3 years",
"4 years",
"6 years",
"9 years",
"10+ years",
"10+ years",
"6 years",
"5 years",
"9 years",
"< 1 year",
"7 years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
null,
"< 1 year",
"9 years",
"10+ years",
"2 years",
"2 years",
"1 year",
"6 years",
"2 years",
"< 1 year",
"10+ years",
"6 years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"2 years",
null,
"10+ years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"2 years",
"8 years",
"5 years",
"4 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"2 years",
"2 years",
null,
"6 years",
"3 years",
"7 years",
"7 years",
"8 years",
"10+ years",
"4 years",
"2 years",
"10+ years",
"7 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"4 years",
"9 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"3 years",
"4 years",
"4 years",
"3 years",
"2 years",
"10+ years",
"1 year",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"7 years",
"4 years",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"4 years",
"< 1 year",
"6 years",
"5 years",
"7 years",
"6 years",
"1 year",
null,
"2 years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"1 year",
"9 years",
"< 1 year",
"3 years",
"1 year",
"10+ years",
"1 year",
"6 years",
"5 years",
"4 years",
null,
"10+ years",
"6 years",
"6 years",
"10+ years",
"10+ years",
"5 years",
"6 years",
"10+ years",
"7 years",
"9 years",
"< 1 year",
"9 years",
"8 years",
"9 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"4 years",
"6 years",
"2 years",
"10+ years",
"5 years",
"6 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"7 years",
"10+ years",
null,
"2 years",
"3 years",
"10+ years",
null,
"4 years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
null,
"4 years",
"2 years",
"1 year",
"2 years",
"8 years",
"4 years",
"2 years",
"< 1 year",
"10+ years",
"7 years",
"< 1 year",
"3 years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"2 years",
"3 years",
"5 years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"6 years",
"6 years",
"7 years",
"7 years",
"< 1 year",
null,
"1 year",
"9 years",
"2 years",
"9 years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"8 years",
"3 years",
"10+ years",
"5 years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"2 years",
"10+ years",
"1 year",
"3 years",
"8 years",
"9 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
null,
"2 years",
"7 years",
"10+ years",
"4 years",
"9 years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"1 year",
"2 years",
null,
"10+ years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"3 years",
"5 years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"6 years",
"2 years",
"3 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"9 years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"10+ years",
"5 years",
"6 years",
"10+ years",
"4 years",
"6 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"8 years",
"< 1 year",
"2 years",
null,
"4 years",
"< 1 year",
"5 years",
"< 1 year",
"4 years",
"8 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"4 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"2 years",
"< 1 year",
"2 years",
"5 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"4 years",
"8 years",
"10+ years",
"1 year",
"9 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"3 years",
"7 years",
"5 years",
"3 years",
"10+ years",
"4 years",
"2 years",
"6 years",
"8 years",
"3 years",
"6 years",
"8 years",
"10+ years",
"1 year",
null,
"10+ years",
"< 1 year",
"2 years",
"8 years",
"1 year",
"3 years",
"10+ years",
"3 years",
"6 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"2 years",
"< 1 year",
"5 years",
null,
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"4 years",
null,
null,
"6 years",
"5 years",
"1 year",
"4 years",
"5 years",
"4 years",
"3 years",
"2 years",
"4 years",
"3 years",
"7 years",
null,
"2 years",
"3 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"< 1 year",
"3 years",
"< 1 year",
"7 years",
"3 years",
"10+ years",
"8 years",
"3 years",
"2 years",
"4 years",
"4 years",
"10+ years",
"8 years",
"6 years",
"2 years",
"8 years",
null,
"9 years",
"9 years",
"8 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
null,
"5 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"4 years",
"1 year",
null,
"7 years",
"< 1 year",
"9 years",
"8 years",
"2 years",
null,
"1 year",
"< 1 year",
"1 year",
"5 years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"3 years",
"< 1 year",
"8 years",
"1 year",
"10+ years",
"4 years",
"3 years",
"5 years",
"10+ years",
"< 1 year",
"1 year",
null,
"2 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"7 years",
"10+ years",
"9 years",
"4 years",
"7 years",
"6 years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
null,
"10+ years",
"7 years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
null,
"3 years",
"10+ years",
"5 years",
"8 years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"9 years",
"10+ years",
"1 year",
"10+ years",
"5 years",
"3 years",
"10+ years",
"9 years",
"2 years",
null,
"3 years",
"3 years",
"6 years",
"9 years",
"10+ years",
"1 year",
"10+ years",
"8 years",
"3 years",
"10+ years",
"9 years",
null,
"1 year",
"6 years",
"10+ years",
"1 year",
"1 year",
"1 year",
"10+ years",
"10+ years",
"1 year",
"8 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"3 years",
"8 years",
"10+ years",
"10+ years",
null,
"5 years",
"1 year",
"6 years",
"3 years",
"10+ years",
"1 year",
"1 year",
"2 years",
"4 years",
"10+ years",
"4 years",
"8 years",
"6 years",
"9 years",
"5 years",
"4 years",
"< 1 year",
"6 years",
"2 years",
"5 years",
"9 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"1 year",
null,
"10+ years",
"7 years",
"2 years",
"5 years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
null,
"10+ years",
"5 years",
"3 years",
"3 years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"2 years",
"10+ years",
"2 years",
"2 years",
"1 year",
"10+ years",
"3 years",
"9 years",
"3 years",
"< 1 year",
"10+ years",
"8 years",
"5 years",
"9 years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"9 years",
"2 years",
"7 years",
"10+ years",
"2 years",
"4 years",
"8 years",
"10+ years",
"4 years",
"1 year",
"8 years",
"10+ years",
"8 years",
"7 years",
"10+ years",
"10+ years",
"8 years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"9 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"4 years",
"1 year",
"9 years",
null,
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
null,
"5 years",
"10+ years",
null,
"6 years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"5 years",
"7 years",
"7 years",
"9 years",
"10+ years",
"1 year",
"8 years",
"4 years",
null,
null,
"5 years",
null,
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"9 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
null,
"1 year",
"6 years",
null,
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"2 years",
"6 years",
"8 years",
"10+ years",
"7 years",
"9 years",
"7 years",
"5 years",
"1 year",
"5 years",
"9 years",
"10+ years",
"2 years",
"2 years",
"8 years",
"5 years",
"6 years",
"10+ years",
"8 years",
"10+ years",
null,
"7 years",
"10+ years",
null,
"4 years",
"4 years",
"10+ years",
"4 years",
"3 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"6 years",
"7 years",
"4 years",
"5 years",
"5 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"4 years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"< 1 year",
"3 years",
"4 years",
"5 years",
"9 years",
"2 years",
"10+ years",
"3 years",
"5 years",
"1 year",
"10+ years",
"3 years",
"2 years",
"10+ years",
"2 years",
"5 years",
"1 year",
"8 years",
"< 1 year",
"10+ years",
"5 years",
"7 years",
"2 years",
"10+ years",
"6 years",
"8 years",
"< 1 year",
"2 years",
"1 year",
null,
"10+ years",
"3 years",
"2 years",
"< 1 year",
"3 years",
"1 year",
"4 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"8 years",
"5 years",
"10+ years",
"6 years",
"4 years",
"10+ years",
"7 years",
null,
"8 years",
"3 years",
null,
"10+ years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
null,
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"7 years",
"< 1 year",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"8 years",
null,
"10+ years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"6 years",
"2 years",
"10+ years",
"3 years",
"9 years",
"2 years",
"5 years",
"2 years",
"5 years",
"10+ years",
"3 years",
null,
"3 years",
"5 years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"4 years",
"4 years",
"2 years",
"< 1 year",
"< 1 year",
"< 1 year",
"7 years",
"< 1 year",
"2 years",
null,
"10+ years",
"3 years",
"10+ years",
"6 years",
"2 years",
null,
"10+ years",
"7 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"3 years",
"7 years",
"3 years",
"10+ years",
"7 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"7 years",
"3 years",
"10+ years",
"7 years",
"7 years",
"2 years",
"10+ years",
"7 years",
"3 years",
"5 years",
"3 years",
"10+ years",
"9 years",
"8 years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"5 years",
"5 years",
"10+ years",
null,
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"2 years",
"3 years",
"< 1 year",
"< 1 year",
"2 years",
"2 years",
"10+ years",
"10+ years",
"9 years",
"8 years",
"2 years",
"1 year",
"5 years",
null,
"2 years",
"7 years",
"5 years",
null,
"10+ years",
"4 years",
"10+ years",
"1 year",
"3 years",
"< 1 year",
"8 years",
"< 1 year",
null,
"2 years",
"10+ years",
"1 year",
"8 years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"9 years",
"10+ years",
"5 years",
"5 years",
"10+ years",
"2 years",
"< 1 year",
"9 years",
"5 years",
"3 years",
"1 year",
"3 years",
"10+ years",
"5 years",
"5 years",
"5 years",
"8 years",
"10+ years",
"10+ years",
null,
"1 year",
"10+ years",
"2 years",
"3 years",
"10+ years",
"5 years",
"8 years",
"10+ years",
"5 years",
"7 years",
"7 years",
"8 years",
"10+ years",
null,
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"< 1 year",
"7 years",
"< 1 year",
null,
"3 years",
"4 years",
null,
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"10+ years",
"5 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"8 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"5 years",
"2 years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"2 years",
"9 years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"3 years",
"1 year",
"4 years",
"10+ years",
"10+ years",
"7 years",
"9 years",
"5 years",
"< 1 year",
"< 1 year",
"1 year",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"5 years",
"8 years",
"9 years",
"2 years",
"< 1 year",
"8 years",
"9 years",
"5 years",
"9 years",
"< 1 year",
"8 years",
"7 years",
"10+ years",
null,
"5 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"8 years",
"2 years",
"2 years",
"10+ years",
"9 years",
"5 years",
"10+ years",
"6 years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"6 years",
"8 years",
"6 years",
null,
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"8 years",
"6 years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"7 years",
"1 year",
"< 1 year",
"7 years",
"8 years",
null,
"10+ years",
"7 years",
"1 year",
"8 years",
"2 years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"8 years",
"8 years",
"5 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"4 years",
null,
"10+ years",
null,
"3 years",
"8 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"1 year",
"2 years",
"2 years",
"1 year",
null,
"10+ years",
null,
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"5 years",
"10+ years",
null,
"9 years",
"1 year",
"7 years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"8 years",
"6 years",
"10+ years",
"6 years",
"7 years",
"10+ years",
"7 years",
"5 years",
"4 years",
"8 years",
"7 years",
"3 years",
"10+ years",
"4 years",
"4 years",
null,
"10+ years",
"1 year",
"10+ years",
"3 years",
"3 years",
"6 years",
"10+ years",
"10+ years",
"5 years",
null,
"5 years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"2 years",
"1 year",
"7 years",
"3 years",
"2 years",
"1 year",
"2 years",
"2 years",
"3 years",
"10+ years",
"6 years",
"4 years",
"7 years",
"8 years",
"10+ years",
"10+ years",
"6 years",
"1 year",
"3 years",
"4 years",
"7 years",
"4 years",
"9 years",
"10+ years",
"1 year",
"4 years",
"3 years",
null,
"10+ years",
null,
"10+ years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"4 years",
null,
"4 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"5 years",
null,
"10+ years",
"5 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"9 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"6 years",
"< 1 year",
"8 years",
"6 years",
"10+ years",
null,
"6 years",
"1 year",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"8 years",
null,
"9 years",
"10+ years",
"7 years",
"10+ years",
"< 1 year",
"< 1 year",
"6 years",
"1 year",
"6 years",
"9 years",
"9 years",
"10+ years",
"5 years",
"8 years",
"4 years",
"10+ years",
"8 years",
"3 years",
"10+ years",
null,
"5 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"1 year",
"1 year",
"4 years",
"5 years",
"2 years",
"2 years",
"8 years",
"4 years",
"3 years",
"7 years",
"6 years",
"6 years",
"1 year",
"10+ years",
"7 years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"1 year",
"3 years",
"1 year",
"5 years",
"5 years",
"5 years",
"10+ years",
"5 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"4 years",
"10+ years",
"< 1 year",
"9 years",
"< 1 year",
"10+ years",
null,
"2 years",
"7 years",
"4 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"1 year",
"2 years",
"10+ years",
"< 1 year",
"4 years",
"4 years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"5 years",
"9 years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"1 year",
"10+ years",
"8 years",
"< 1 year",
"6 years",
"4 years",
"2 years",
"4 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"1 year",
null,
"10+ years",
"10+ years",
"4 years",
"7 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"4 years",
null,
"3 years",
"1 year",
"3 years",
"10+ years",
"7 years",
"9 years",
null,
"< 1 year",
"10+ years",
"6 years",
"2 years",
null,
"2 years",
"< 1 year",
"< 1 year",
"3 years",
"3 years",
"< 1 year",
"4 years",
"10+ years",
"6 years",
"4 years",
"5 years",
"5 years",
"6 years",
"5 years",
"< 1 year",
"10+ years",
"3 years",
"2 years",
"< 1 year",
"10+ years",
"9 years",
"< 1 year",
"7 years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"2 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"9 years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"4 years",
"9 years",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"6 years",
"1 year",
"10+ years",
"< 1 year",
"4 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"9 years",
"10+ years",
"9 years",
"8 years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"1 year",
"8 years",
"2 years",
"10+ years",
"1 year",
null,
"< 1 year",
"8 years",
"1 year",
"10+ years",
"3 years",
"7 years",
"< 1 year",
"3 years",
"10+ years",
"9 years",
"2 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"8 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"2 years",
"2 years",
"4 years",
"< 1 year",
"4 years",
null,
"6 years",
null,
"2 years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"9 years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"2 years",
null,
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"8 years",
"7 years",
"2 years",
"1 year",
"6 years",
"2 years",
"3 years",
"2 years",
"3 years",
"10+ years",
"3 years",
"4 years",
"10+ years",
null,
"10+ years",
"2 years",
"3 years",
"7 years",
"< 1 year",
"4 years",
"2 years",
"7 years",
"10+ years",
"9 years",
"3 years",
"4 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"9 years",
null,
"5 years",
"1 year",
"8 years",
"6 years",
"9 years",
"6 years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"5 years",
"5 years",
"3 years",
"5 years",
"2 years",
"5 years",
"< 1 year",
"10+ years",
"3 years",
"< 1 year",
"1 year",
"6 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"7 years",
"6 years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
null,
"8 years",
"10+ years",
"7 years",
"10+ years",
"6 years",
"10+ years",
"4 years",
"5 years",
null,
"6 years",
"2 years",
"3 years",
"3 years",
"10+ years",
null,
"5 years",
"3 years",
"2 years",
"2 years",
"10+ years",
"5 years",
"7 years",
"8 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"2 years",
"3 years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"6 years",
"6 years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"7 years",
"6 years",
"< 1 year",
"3 years",
"5 years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"9 years",
"4 years",
"3 years",
"10+ years",
"3 years",
"6 years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"8 years",
"1 year",
"3 years",
"10+ years",
"1 year",
"5 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"9 years",
"7 years",
"< 1 year",
"8 years",
"1 year",
"10+ years",
"5 years",
"10+ years",
"1 year",
"< 1 year",
"2 years",
null,
"5 years",
"10+ years",
"2 years",
"1 year",
"2 years",
"7 years",
"4 years",
"4 years",
"3 years",
"2 years",
"10+ years",
null,
"8 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"4 years",
"1 year",
"8 years",
"10+ years",
"7 years",
"4 years",
"10+ years",
"6 years",
"10+ years",
"8 years",
"9 years",
"10+ years",
"10+ years",
"8 years",
null,
"6 years",
"4 years",
"3 years",
"10+ years",
"2 years",
"1 year",
"1 year",
"< 1 year",
"10+ years",
"< 1 year",
null,
"4 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"7 years",
"< 1 year",
"3 years",
"4 years",
"< 1 year",
"1 year",
"5 years",
"10+ years",
"1 year",
"6 years",
"10+ years",
"7 years",
"5 years",
"9 years",
"9 years",
"10+ years",
"10+ years",
"6 years",
"< 1 year",
"< 1 year",
"2 years",
"9 years",
"10+ years",
"10+ years",
"5 years",
"5 years",
"10+ years",
"1 year",
"9 years",
"7 years",
"8 years",
"5 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
null,
"9 years",
"5 years",
"3 years",
"4 years",
"8 years",
"3 years",
"9 years",
"< 1 year",
"10+ years",
"8 years",
"9 years",
"2 years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"6 years",
"5 years",
"8 years",
"10+ years",
"1 year",
null,
"4 years",
"4 years",
"5 years",
"10+ years",
"9 years",
"1 year",
"10+ years",
"1 year",
"1 year",
"6 years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"5 years",
"1 year",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"8 years",
"7 years",
"10+ years",
"4 years",
"5 years",
"10+ years",
null,
"10+ years",
"6 years",
null,
"7 years",
"7 years",
"10+ years",
"8 years",
"6 years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"7 years",
"< 1 year",
"10+ years",
"6 years",
"1 year",
"2 years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"8 years",
"4 years",
"2 years",
"2 years",
"3 years",
"8 years",
"5 years",
"10+ years",
"3 years",
"2 years",
"8 years",
"5 years",
"1 year",
"9 years",
"10+ years",
"8 years",
"6 years",
"1 year",
"1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"1 year",
"9 years",
"3 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"9 years",
"10+ years",
null,
"10+ years",
"7 years",
"5 years",
"9 years",
null,
"10+ years",
"10+ years",
"4 years",
"1 year",
"8 years",
"2 years",
"10+ years",
"2 years",
"9 years",
"1 year",
"10+ years",
"1 year",
"5 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"3 years",
"6 years",
"2 years",
"8 years",
"2 years",
"7 years",
"2 years",
"8 years",
null,
"3 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"1 year",
"6 years",
"2 years",
"10+ years",
"8 years",
"4 years",
"10+ years",
"6 years",
"3 years",
"6 years",
"< 1 year",
"7 years",
"4 years",
"8 years",
"10+ years",
null,
"10+ years",
"6 years",
"10+ years",
"4 years",
"4 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"6 years",
"4 years",
"7 years",
"5 years",
null,
"10+ years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"10+ years",
null,
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"3 years",
"10+ years",
"2 years",
"< 1 year",
"3 years",
"5 years",
"10+ years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"< 1 year",
null,
"4 years",
null,
"3 years",
"3 years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"4 years",
"< 1 year",
"10+ years",
"5 years",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
null,
null,
"9 years",
"2 years",
"2 years",
"1 year",
"1 year",
"3 years",
null,
"1 year",
"8 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"8 years",
"7 years",
"7 years",
"4 years",
"1 year",
"1 year",
"8 years",
"7 years",
"10+ years",
"3 years",
"5 years",
"3 years",
"2 years",
"9 years",
"10+ years",
"3 years",
null,
"3 years",
"3 years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"2 years",
null,
"< 1 year",
"7 years",
"10+ years",
"6 years",
"7 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"5 years",
"2 years",
"7 years",
"2 years",
null,
"3 years",
"8 years",
"5 years",
"6 years",
"10+ years",
"1 year",
"6 years",
"3 years",
"5 years",
"10+ years",
null,
"1 year",
"10+ years",
"4 years",
"3 years",
"1 year",
"2 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"5 years",
"4 years",
"9 years",
"3 years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"3 years",
"10+ years",
null,
"1 year",
"3 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"7 years",
"10+ years",
"8 years",
"3 years",
"< 1 year",
"5 years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"2 years",
null,
"8 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"2 years",
"< 1 year",
"5 years",
"5 years",
"2 years",
"7 years",
"< 1 year",
"10+ years",
null,
"10+ years",
"5 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"9 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
null,
"6 years",
"5 years",
"8 years",
"6 years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"6 years",
"4 years",
"1 year",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"8 years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"7 years",
"1 year",
"5 years",
"10+ years",
null,
"10+ years",
"2 years",
"6 years",
"4 years",
"< 1 year",
"3 years",
"8 years",
"10+ years",
"10+ years",
"4 years",
"4 years",
"6 years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"7 years",
"8 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"6 years",
"8 years",
"10+ years",
"9 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"3 years",
null,
"10+ years",
"< 1 year",
null,
"10+ years",
"10+ years",
"7 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"< 1 year",
"3 years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"7 years",
"1 year",
"5 years",
"2 years",
"7 years",
"8 years",
"10+ years",
"2 years",
"5 years",
"3 years",
"1 year",
"< 1 year",
"2 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"7 years",
"1 year",
"10+ years",
"< 1 year",
"2 years",
"8 years",
"10+ years",
"8 years",
"2 years",
"5 years",
"< 1 year",
"2 years",
"1 year",
"2 years",
"1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"2 years",
"9 years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"4 years",
"3 years",
"2 years",
"5 years",
null,
"4 years",
"10+ years",
"< 1 year",
"9 years",
"1 year",
"2 years",
"4 years",
"< 1 year",
"1 year",
"9 years",
"1 year",
"10+ years",
"10+ years",
"7 years",
"1 year",
"3 years",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"6 years",
null,
"5 years",
"1 year",
"7 years",
"2 years",
"5 years",
"1 year",
"< 1 year",
"8 years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"1 year",
"< 1 year",
"8 years",
"2 years",
"5 years",
"10+ years",
"3 years",
"< 1 year",
"3 years",
"10+ years",
"6 years",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"5 years",
"10+ years",
"< 1 year",
null,
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"< 1 year",
"2 years",
"3 years",
"< 1 year",
"6 years",
"3 years",
"10+ years",
"2 years",
null,
"4 years",
"3 years",
"1 year",
"7 years",
"10+ years",
"10+ years",
"8 years",
"1 year",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"5 years",
"1 year",
"4 years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"7 years",
"6 years",
"7 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"< 1 year",
"< 1 year",
"3 years",
"3 years",
"9 years",
"10+ years",
"2 years",
"4 years",
"1 year",
"3 years",
"< 1 year",
"< 1 year",
"7 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"< 1 year",
"< 1 year",
"5 years",
"10+ years",
"< 1 year",
"< 1 year",
"1 year",
"< 1 year",
"8 years",
"10+ years",
"9 years",
"9 years",
"6 years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"6 years",
"1 year",
"2 years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"9 years",
"10+ years",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"8 years",
"8 years",
null,
"10+ years",
"< 1 year",
"10+ years",
null,
"1 year",
"10+ years",
"1 year",
"2 years",
"10+ years",
"8 years",
"2 years",
"2 years",
"1 year",
"3 years",
"< 1 year",
"5 years",
"8 years",
"1 year",
"10+ years",
null,
"9 years",
"3 years",
"8 years",
"2 years",
"< 1 year",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"3 years",
"< 1 year",
"4 years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"4 years",
"5 years",
"10+ years",
null,
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"2 years",
"4 years",
"2 years",
"10+ years",
null,
"5 years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"7 years",
"10+ years",
null,
"< 1 year",
"8 years",
"1 year",
"10+ years",
"1 year",
"3 years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"< 1 year",
"10+ years",
"5 years",
"7 years",
"10+ years",
null,
"5 years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"9 years",
"8 years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"9 years",
"8 years",
"10+ years",
"9 years",
"4 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
null,
null,
"5 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"10+ years",
null,
"10+ years",
"7 years",
"3 years",
"1 year",
"5 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"9 years",
"< 1 year",
"6 years",
"10+ years",
"1 year",
"9 years",
"2 years",
"< 1 year",
"1 year",
"2 years",
"< 1 year",
"10+ years",
"7 years",
"5 years",
"4 years",
"3 years",
"1 year",
"< 1 year",
"5 years",
"1 year",
"8 years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"7 years",
"3 years",
"10+ years",
"1 year",
"2 years",
"4 years",
"5 years",
"10+ years",
"8 years",
"< 1 year",
"< 1 year",
"< 1 year",
"1 year",
"10+ years",
"5 years",
"10+ years",
"7 years",
"10+ years",
"6 years",
"4 years",
"2 years",
"2 years",
null,
"5 years",
"7 years",
"10+ years",
"4 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"7 years",
"3 years",
"< 1 year",
null,
"10+ years",
"7 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"10+ years",
"8 years",
"10+ years",
"6 years",
"1 year",
"10+ years",
"< 1 year",
"7 years",
"8 years",
"10+ years",
"8 years",
"7 years",
"6 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"7 years",
"10+ years",
"1 year",
"7 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
null,
"9 years",
"8 years",
"7 years",
"5 years",
"6 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"9 years",
"7 years",
"7 years",
null,
"1 year",
"10+ years",
"4 years",
null,
"1 year",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"7 years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"3 years",
"10+ years",
null,
"9 years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"9 years",
"5 years",
null,
"10+ years",
"6 years",
"9 years",
"10+ years",
"6 years",
"10+ years",
null,
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"2 years",
"6 years",
"5 years",
"10+ years",
null,
"3 years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"1 year",
"10+ years",
null,
"3 years",
"8 years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"1 year",
"10+ years",
"7 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"5 years",
"2 years",
"1 year",
"< 1 year",
"4 years",
null,
"7 years",
"4 years",
"4 years",
"7 years",
"6 years",
"3 years",
"8 years",
"8 years",
"5 years",
"1 year",
"3 years",
"4 years",
"4 years",
"2 years",
"1 year",
"10+ years",
"2 years",
"5 years",
"8 years",
"< 1 year",
"< 1 year",
"9 years",
"10+ years",
"6 years",
"1 year",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
null,
"9 years",
"< 1 year",
"8 years",
"8 years",
"2 years",
"2 years",
"4 years",
"1 year",
"10+ years",
null,
"5 years",
"< 1 year",
"10+ years",
"5 years",
"3 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"8 years",
"1 year",
"2 years",
"9 years",
"10+ years",
"2 years",
"5 years",
"4 years",
"2 years",
"3 years",
"8 years",
null,
"2 years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"7 years",
"5 years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"1 year",
"4 years",
"10+ years",
"2 years",
"3 years",
"3 years",
"1 year",
"10+ years",
"10+ years",
null,
"10+ years",
"8 years",
"1 year",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"< 1 year",
"4 years",
"5 years",
"3 years",
"4 years",
"7 years",
"5 years",
"3 years",
"8 years",
"1 year",
"10+ years",
"7 years",
"8 years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"7 years",
"3 years",
"5 years",
"8 years",
"7 years",
"4 years",
"6 years",
"7 years",
"3 years",
"4 years",
"10+ years",
"3 years",
"7 years",
"2 years",
"8 years",
"5 years",
"< 1 year",
"4 years",
"< 1 year",
"3 years",
"1 year",
"10+ years",
"3 years",
"9 years",
"8 years",
"3 years",
"10+ years",
"< 1 year",
"1 year",
null,
"10+ years",
"6 years",
"10+ years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"9 years",
"4 years",
"10+ years",
"6 years",
"1 year",
"8 years",
"2 years",
"10+ years",
"1 year",
"6 years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"2 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"5 years",
"3 years",
"6 years",
"9 years",
"2 years",
null,
"10+ years",
"10+ years",
"6 years",
null,
"6 years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
null,
"9 years",
"8 years",
"5 years",
"3 years",
"9 years",
null,
"9 years",
null,
"1 year",
"9 years",
"10+ years",
"< 1 year",
"< 1 year",
"2 years",
"< 1 year",
"10+ years",
"3 years",
"2 years",
"9 years",
"6 years",
"4 years",
"6 years",
"4 years",
"3 years",
"6 years",
"2 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"8 years",
"7 years",
"5 years",
"4 years",
"4 years",
"< 1 year",
"10+ years",
"4 years",
"9 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"7 years",
"4 years",
"3 years",
"< 1 year",
"4 years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"7 years",
"6 years",
"4 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"5 years",
"6 years",
"4 years",
"4 years",
"7 years",
"10+ years",
"7 years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"2 years",
"8 years",
"1 year",
"2 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
null,
"8 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"6 years",
"10+ years",
"2 years",
"2 years",
"5 years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"9 years",
null,
"6 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"6 years",
"10+ years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"10+ years",
"9 years",
"10+ years",
"7 years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
null,
"6 years",
"9 years",
"8 years",
"2 years",
"2 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
null,
"5 years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"4 years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"7 years",
"9 years",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
null,
"6 years",
"10+ years",
"10+ years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"10+ years",
"8 years",
"10+ years",
"6 years",
"4 years",
"10+ years",
"10+ years",
"9 years",
"5 years",
"10+ years",
"7 years",
"8 years",
"6 years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"4 years",
"6 years",
"< 1 year",
"3 years",
null,
"5 years",
"2 years",
"10+ years",
"1 year",
null,
"2 years",
"2 years",
"6 years",
"2 years",
"2 years",
"10+ years",
"6 years",
"8 years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"1 year",
"2 years",
"8 years",
"1 year",
"6 years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"6 years",
"< 1 year",
"2 years",
"8 years",
null,
"4 years",
"6 years",
"5 years",
"7 years",
"2 years",
"7 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"8 years",
null,
"10+ years",
"< 1 year",
"10+ years",
"9 years",
"10+ years",
"5 years",
"4 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"5 years",
"2 years",
"1 year",
"10+ years",
null,
"2 years",
"10+ years",
"7 years",
"6 years",
"7 years",
"10+ years",
"< 1 year",
"6 years",
"7 years",
"3 years",
"7 years",
"1 year",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"6 years",
"5 years",
"4 years",
"8 years",
"2 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"4 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"1 year",
"10+ years",
"2 years",
"7 years",
"10+ years",
null,
"< 1 year",
"3 years",
null,
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"< 1 year",
"8 years",
"7 years",
"6 years",
"< 1 year",
"7 years",
"1 year",
"6 years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
null,
"5 years",
null,
"< 1 year",
"9 years",
"4 years",
"4 years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"8 years",
"10+ years",
"9 years",
"7 years",
"10+ years",
"4 years",
"5 years",
null,
"8 years",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"2 years",
"5 years",
"8 years",
"5 years",
"9 years",
"3 years",
"< 1 year",
"1 year",
"4 years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
null,
"10+ years",
"8 years",
null,
"1 year",
"6 years",
"8 years",
"5 years",
"10+ years",
"1 year",
"7 years",
"< 1 year",
"3 years",
"2 years",
"10+ years",
"10+ years",
null,
"10+ years",
"8 years",
null,
"10+ years",
"4 years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"2 years",
"4 years",
"6 years",
"7 years",
null,
"10+ years",
"3 years",
"10+ years",
"7 years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"1 year",
"10+ years",
"6 years",
"3 years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"< 1 year",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"1 year",
"10+ years",
"5 years",
"6 years",
"8 years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"5 years",
"4 years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"8 years",
"4 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"1 year",
"8 years",
null,
"9 years",
"9 years",
"2 years",
"6 years",
"7 years",
"< 1 year",
"5 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"< 1 year",
"4 years",
"8 years",
"2 years",
"6 years",
"6 years",
null,
"2 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"4 years",
"< 1 year",
"3 years",
"10+ years",
"1 year",
"5 years",
"1 year",
"2 years",
"7 years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"9 years",
"1 year",
"9 years",
"< 1 year",
"5 years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
null,
"10+ years",
"5 years",
null,
"10+ years",
"4 years",
"10+ years",
"7 years",
"10+ years",
"5 years",
"1 year",
"5 years",
"5 years",
"< 1 year",
"5 years",
"6 years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"3 years",
"2 years",
"4 years",
"5 years",
"4 years",
null,
"10+ years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"2 years",
"10+ years",
"2 years",
"1 year",
"9 years",
"2 years",
"8 years",
"< 1 year",
null,
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"2 years",
"7 years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"8 years",
"3 years",
"4 years",
"7 years",
"< 1 year",
"10+ years",
"1 year",
"4 years",
"3 years",
"10+ years",
"5 years",
"3 years",
"< 1 year",
"< 1 year",
"1 year",
"1 year",
"7 years",
"10+ years",
"3 years",
"6 years",
"5 years",
"4 years",
"4 years",
"1 year",
"4 years",
null,
"10+ years",
"7 years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"5 years",
"1 year",
"10+ years",
"10+ years",
"1 year",
"9 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
null,
"8 years",
null,
"8 years",
"1 year",
"2 years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"9 years",
"1 year",
"6 years",
"10+ years",
"1 year",
"7 years",
"2 years",
"10+ years",
"5 years",
"5 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
null,
"10+ years",
"1 year",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"7 years",
"2 years",
"5 years",
null,
"10+ years",
"6 years",
"3 years",
"10+ years",
"< 1 year",
"6 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"4 years",
"8 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"1 year",
"6 years",
"4 years",
"1 year",
"10+ years",
"10+ years",
"7 years",
"6 years",
"7 years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"1 year",
"3 years",
"7 years",
"5 years",
"5 years",
"1 year",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"9 years",
null,
"< 1 year",
"2 years",
"6 years",
"< 1 year",
"3 years",
"10+ years",
"4 years",
"3 years",
"6 years",
"10+ years",
null,
"6 years",
"8 years",
"2 years",
"5 years",
"6 years",
"2 years",
"10+ years",
"3 years",
"8 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"6 years",
"4 years",
"5 years",
"10+ years",
"< 1 year",
"2 years",
"4 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"9 years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"1 year",
"6 years",
"10+ years",
"1 year",
"10+ years",
"8 years",
"1 year",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"5 years",
"4 years",
"10+ years",
"5 years",
"5 years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"6 years",
"10+ years",
"3 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
null,
"7 years",
"3 years",
"2 years",
"6 years",
"10+ years",
null,
"3 years",
"3 years",
"10+ years",
"5 years",
"3 years",
"5 years",
"10+ years",
"8 years",
"10+ years",
"9 years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"4 years",
"3 years",
"2 years",
"1 year",
"3 years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"5 years",
"10+ years",
"4 years",
"10+ years",
"2 years",
null,
"3 years",
"10+ years",
"10+ years",
"7 years",
"< 1 year",
"7 years",
"< 1 year",
null,
"10+ years",
"4 years",
null,
"2 years",
"10+ years",
"2 years",
null,
"5 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"10+ years",
"7 years",
null,
"8 years",
"3 years",
"4 years",
"1 year",
"1 year",
"5 years",
"6 years",
"3 years",
"10+ years",
"5 years",
"5 years",
"9 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"7 years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"7 years",
"2 years",
"< 1 year",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"8 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"< 1 year",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"5 years",
"< 1 year",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"10+ years",
null,
"10+ years",
"3 years",
"2 years",
"9 years",
"< 1 year",
"10+ years",
null,
"10+ years",
"4 years",
"7 years",
"1 year",
"7 years",
"2 years",
"2 years",
"5 years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"9 years",
"3 years",
"< 1 year",
"8 years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"6 years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"3 years",
"4 years",
"2 years",
"2 years",
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"< 1 year",
"3 years",
"1 year",
"4 years",
"8 years",
"4 years",
"4 years",
"8 years",
"3 years",
"8 years",
null,
"1 year",
"10+ years",
"6 years",
"7 years",
"10+ years",
"4 years",
"10+ years",
null,
"10+ years",
"8 years",
"4 years",
null,
"9 years",
"4 years",
"3 years",
"10+ years",
"< 1 year",
"1 year",
"7 years",
"6 years",
"5 years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"3 years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"< 1 year",
"1 year",
"2 years",
"3 years",
"10+ years",
"3 years",
"3 years",
"2 years",
"< 1 year",
"10+ years",
"< 1 year",
"< 1 year",
"5 years",
"6 years",
"6 years",
null,
"10+ years",
"2 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"3 years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"2 years",
"3 years",
"5 years",
"8 years",
"4 years",
"10+ years",
"< 1 year",
"5 years",
null,
"5 years",
"5 years",
"9 years",
"10+ years",
"10+ years",
null,
"7 years",
"10+ years",
null,
"10+ years",
"7 years",
"10+ years",
"6 years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
null,
"7 years",
"5 years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"10+ years",
"1 year",
"4 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"5 years",
"5 years",
"7 years",
null,
"10+ years",
"6 years",
"10+ years",
"7 years",
"3 years",
"1 year",
"5 years",
"10+ years",
"2 years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"8 years",
"2 years",
"10+ years",
"2 years",
"2 years",
"8 years",
"7 years",
"3 years",
null,
"10+ years",
"7 years",
"1 year",
"7 years",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"2 years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"1 year",
"3 years",
"7 years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"6 years",
"4 years",
"2 years",
"6 years",
"9 years",
"3 years",
"10+ years",
null,
"10+ years",
"1 year",
null,
"10+ years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"10+ years",
"2 years",
"4 years",
"10+ years",
null,
"5 years",
"10+ years",
null,
"< 1 year",
"3 years",
"3 years",
null,
"1 year",
"10+ years",
"7 years",
"1 year",
"10+ years",
"4 years",
"4 years",
"5 years",
"< 1 year",
"3 years",
"3 years",
"10+ years",
null,
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
null,
"8 years",
"3 years",
"3 years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"1 year",
"10+ years",
"5 years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"5 years",
"10+ years",
null,
"7 years",
"8 years",
"10+ years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"7 years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"9 years",
"2 years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"3 years",
"2 years",
"8 years",
"1 year",
"10+ years",
null,
"2 years",
"8 years",
"7 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"3 years",
"4 years",
"1 year",
"2 years",
"2 years",
"4 years",
"4 years",
"4 years",
"3 years",
"10+ years",
"6 years",
"3 years",
"9 years",
"4 years",
"9 years",
"10+ years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"2 years",
"1 year",
"< 1 year",
"7 years",
"7 years",
"10+ years",
"9 years",
"10+ years",
"5 years",
"9 years",
"5 years",
"1 year",
"10+ years",
"3 years",
"1 year",
"< 1 year",
"5 years",
"2 years",
"5 years",
"8 years",
"7 years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"< 1 year",
"8 years",
"10+ years",
"2 years",
"< 1 year",
"2 years",
"4 years",
"< 1 year",
"6 years",
"10+ years",
null,
"10+ years",
null,
"1 year",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"7 years",
"5 years",
null,
"3 years",
"10+ years",
"5 years",
"9 years",
"10+ years",
"3 years",
"4 years",
"9 years",
"5 years",
"10+ years",
"10+ years",
"8 years",
"9 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"2 years",
"9 years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"8 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
null,
"< 1 year",
"10+ years",
"9 years",
"6 years",
"3 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"3 years",
"2 years",
"1 year",
"< 1 year",
"< 1 year",
"7 years",
"5 years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"1 year",
"6 years",
"10+ years",
"2 years",
"10+ years",
"8 years",
"7 years",
"1 year",
"10+ years",
"3 years",
"5 years",
"1 year",
"10+ years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"2 years",
"5 years",
"5 years",
"7 years",
"10+ years",
"2 years",
null,
"6 years",
"5 years",
"< 1 year",
"2 years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"< 1 year",
"3 years",
"5 years",
"10+ years",
"< 1 year",
null,
"3 years",
"5 years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"1 year",
"7 years",
"3 years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"4 years",
"4 years",
null,
"10+ years",
"6 years",
"7 years",
"10+ years",
"3 years",
"2 years",
"1 year",
"< 1 year",
"5 years",
"< 1 year",
"8 years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"8 years",
"6 years",
"10+ years",
"1 year",
"7 years",
"< 1 year",
"10+ years",
"3 years",
"4 years",
"5 years",
"2 years",
"10+ years",
"2 years",
"1 year",
"4 years",
"< 1 year",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"6 years",
"9 years",
"10+ years",
"5 years",
"8 years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
null,
"9 years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"4 years",
null,
"8 years",
"10+ years",
"9 years",
"7 years",
"1 year",
null,
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"8 years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"< 1 year",
"7 years",
"2 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"5 years",
"5 years",
"< 1 year",
"10+ years",
"3 years",
"4 years",
"10+ years",
"6 years",
"1 year",
"10+ years",
"4 years",
null,
"10+ years",
"1 year",
"2 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"1 year",
"10+ years",
"2 years",
"4 years",
"8 years",
"4 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"1 year",
"10+ years",
"7 years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"6 years",
"10+ years",
"6 years",
"10+ years",
"4 years",
"9 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"1 year",
"9 years",
"5 years",
"5 years",
"6 years",
"10+ years",
"9 years",
"9 years",
"6 years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"9 years",
"4 years",
null,
"10+ years",
"9 years",
"3 years",
"< 1 year",
"6 years",
"10+ years",
"6 years",
"7 years",
"2 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"3 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"8 years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"3 years",
"5 years",
null,
"5 years",
"10+ years",
"1 year",
"3 years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"4 years",
"9 years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"3 years",
"1 year",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"2 years",
"9 years",
"< 1 year",
"10+ years",
"4 years",
null,
"10+ years",
"6 years",
"7 years",
"2 years",
"10+ years",
"2 years",
"1 year",
"< 1 year",
"8 years",
"2 years",
"7 years",
"10+ years",
"3 years",
"2 years",
null,
"< 1 year",
"1 year",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"5 years",
"3 years",
"5 years",
"7 years",
"7 years",
"3 years",
"5 years",
"8 years",
"7 years",
"1 year",
"5 years",
"< 1 year",
"2 years",
"7 years",
"1 year",
"7 years",
"3 years",
"7 years",
"5 years",
"1 year",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"4 years",
"< 1 year",
"2 years",
"< 1 year",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"4 years",
"6 years",
"9 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"9 years",
"5 years",
"8 years",
null,
"10+ years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"3 years",
"1 year",
"8 years",
"5 years",
"10+ years",
"3 years",
"3 years",
"< 1 year",
"1 year",
"10+ years",
null,
"4 years",
null,
null,
"3 years",
"7 years",
"2 years",
"10+ years",
"2 years",
null,
"6 years",
"2 years",
"9 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
null,
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"2 years",
"10+ years",
"3 years",
"3 years",
"6 years",
"2 years",
"< 1 year",
"3 years",
"2 years",
"3 years",
"10+ years",
"6 years",
"< 1 year",
"< 1 year",
"3 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
null,
"10+ years",
"4 years",
"10+ years",
"7 years",
"10+ years",
null,
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"8 years",
"10+ years",
null,
"10+ years",
"10+ years",
"6 years",
null,
"10+ years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"5 years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"3 years",
"4 years",
null,
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"< 1 year",
"1 year",
"7 years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"4 years",
"8 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"2 years",
"4 years",
"< 1 year",
"10+ years",
"8 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"2 years",
"5 years",
"3 years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"2 years",
"2 years",
null,
null,
"2 years",
"10+ years",
"7 years",
"8 years",
"3 years",
"9 years",
"10+ years",
"7 years",
null,
"2 years",
"5 years",
"1 year",
"9 years",
"5 years",
"7 years",
"10+ years",
"< 1 year",
"9 years",
"8 years",
"9 years",
"10+ years",
"10+ years",
null,
"2 years",
"8 years",
"9 years",
"2 years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"9 years",
null,
"10+ years",
null,
"3 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"8 years",
"5 years",
"10+ years",
"10+ years",
"9 years",
"6 years",
"3 years",
"5 years",
"10+ years",
"5 years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"3 years",
"3 years",
"4 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"3 years",
"5 years",
"2 years",
"7 years",
"3 years",
"2 years",
"9 years",
"6 years",
null,
"2 years",
"4 years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"2 years",
"10+ years",
null,
"10+ years",
"6 years",
"5 years",
"3 years",
"6 years",
"10+ years",
"5 years",
"8 years",
"2 years",
"3 years",
"10+ years",
"3 years",
"9 years",
"4 years",
"10+ years",
"1 year",
"4 years",
"1 year",
"10+ years",
"5 years",
"2 years",
"3 years",
"1 year",
"4 years",
"5 years",
null,
"6 years",
"9 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"7 years",
"1 year",
"7 years",
"10+ years",
"8 years",
"< 1 year",
null,
"5 years",
"5 years",
"10+ years",
"10+ years",
"8 years",
"1 year",
"5 years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
null,
"3 years",
"5 years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"1 year",
null,
"1 year",
"< 1 year",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
null,
"3 years",
null,
"1 year",
"6 years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"2 years",
"< 1 year",
"2 years",
"2 years",
"2 years",
null,
"4 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"5 years",
"10+ years",
"7 years",
"10+ years",
"1 year",
"10+ years",
"8 years",
"2 years",
"9 years",
"5 years",
"5 years",
"10+ years",
"9 years",
"7 years",
"5 years",
"3 years",
"10+ years",
"< 1 year",
null,
"8 years",
"6 years",
"2 years",
"9 years",
"2 years",
"7 years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"8 years",
"1 year",
"2 years",
null,
"2 years",
"1 year",
"4 years",
"6 years",
"2 years",
null,
"6 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"4 years",
"2 years",
"6 years",
"< 1 year",
"< 1 year",
"6 years",
"2 years",
"7 years",
"5 years",
"< 1 year",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"3 years",
"8 years",
"10+ years",
"3 years",
"< 1 year",
"6 years",
"10+ years",
"8 years",
"3 years",
"3 years",
"3 years",
"< 1 year",
"2 years",
"9 years",
"10+ years",
"8 years",
"< 1 year",
"6 years",
"1 year",
"1 year",
"6 years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"5 years",
"6 years",
"5 years",
"10+ years",
"4 years",
"10+ years",
"4 years",
"2 years",
"1 year",
"5 years",
null,
null,
"10+ years",
"10+ years",
null,
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"6 years",
"10+ years",
"5 years",
"7 years",
"3 years",
"10+ years",
"2 years",
"10+ years",
null,
"10+ years",
"4 years",
"10+ years",
"5 years",
"< 1 year",
"6 years",
"7 years",
"1 year",
"< 1 year",
"8 years",
"< 1 year",
"5 years",
"4 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
null,
"10+ years",
"10+ years",
"10+ years",
"7 years",
"5 years",
"4 years",
"9 years",
"4 years",
"8 years",
"9 years",
"10+ years",
"2 years",
"1 year",
"9 years",
"10+ years",
"< 1 year",
"1 year",
"3 years",
"3 years",
"< 1 year",
"2 years",
"6 years",
"10+ years",
"10+ years",
"4 years",
"6 years",
"4 years",
"10+ years",
"10+ years",
null,
"3 years",
"2 years",
"4 years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"< 1 year",
"< 1 year",
"6 years",
"7 years",
"10+ years",
"4 years",
"7 years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"2 years",
"6 years",
"< 1 year",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"6 years",
"10+ years",
"4 years",
"< 1 year",
"9 years",
"5 years",
"10+ years",
null,
"< 1 year",
"3 years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"6 years",
"5 years",
"4 years",
"3 years",
"8 years",
"10+ years",
"2 years",
"1 year",
"1 year",
null,
"8 years",
"10+ years",
"4 years",
null,
null,
"2 years",
"10+ years",
null,
"7 years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"4 years",
"10+ years",
"4 years",
"8 years",
"7 years",
"8 years",
"6 years",
"10+ years",
"7 years",
"4 years",
"3 years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"7 years",
"1 year",
"9 years",
"3 years",
null,
null,
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"1 year",
"10+ years",
"5 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"7 years",
"4 years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"6 years",
"7 years",
"10+ years",
"< 1 year",
"3 years",
"5 years",
"8 years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"10+ years",
"< 1 year",
null,
"4 years",
"10+ years",
"10+ years",
"10+ years",
null,
"6 years",
"9 years",
"7 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"2 years",
"7 years",
"3 years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"3 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"8 years",
"3 years",
"< 1 year",
"4 years",
"< 1 year",
"1 year",
"< 1 year",
null,
"7 years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"4 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"2 years",
"1 year",
"3 years",
"7 years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"8 years",
"3 years",
"6 years",
"10+ years",
"2 years",
"3 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"2 years",
"7 years",
"< 1 year",
"3 years",
null,
"< 1 year",
"3 years",
"4 years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
null,
"10+ years",
"4 years",
"< 1 year",
"3 years",
"4 years",
"2 years",
"10+ years",
null,
"5 years",
"1 year",
"10+ years",
"5 years",
"1 year",
"9 years",
"4 years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"3 years",
"6 years",
"10+ years",
null,
"1 year",
"10+ years",
"2 years",
"3 years",
"< 1 year",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"10+ years",
null,
"3 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"5 years",
"< 1 year",
"2 years",
"10+ years",
"4 years",
"8 years",
"8 years",
"10+ years",
"< 1 year",
"2 years",
"5 years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"10+ years",
null,
"10+ years",
"6 years",
"6 years",
"6 years",
"< 1 year",
null,
"10+ years",
null,
"2 years",
"4 years",
"4 years",
"5 years",
"5 years",
"2 years",
"6 years",
"2 years",
"5 years",
"2 years",
"1 year",
"1 year",
"< 1 year",
"10+ years",
"1 year",
"9 years",
"5 years",
null,
"5 years",
"5 years",
"10+ years",
"7 years",
"1 year",
"7 years",
"4 years",
"< 1 year",
"10+ years",
"2 years",
"3 years",
"< 1 year",
"5 years",
"< 1 year",
"10+ years",
"5 years",
"4 years",
null,
"4 years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"5 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
null,
"10+ years",
"1 year",
"10+ years",
"2 years",
"3 years",
"4 years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"1 year",
"2 years",
"< 1 year",
"2 years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"6 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"8 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"1 year",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"6 years",
"10+ years",
"< 1 year",
"< 1 year",
"< 1 year",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"7 years",
"4 years",
null,
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"9 years",
"3 years",
"10+ years",
"5 years",
"4 years",
"5 years",
null,
"4 years",
"1 year",
"8 years",
"6 years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"6 years",
"3 years",
"10+ years",
"9 years",
"3 years",
"2 years",
"8 years",
"2 years",
"10+ years",
"4 years",
"6 years",
"5 years",
null,
"2 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"3 years",
"2 years",
"4 years",
"10+ years",
"1 year",
"1 year",
"2 years",
"10+ years",
"3 years",
"2 years",
"4 years",
"3 years",
"< 1 year",
"7 years",
null,
"1 year",
"3 years",
"2 years",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"9 years",
"10+ years",
"7 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"6 years",
"< 1 year",
"10+ years",
null,
"1 year",
"7 years",
"6 years",
"9 years",
"3 years",
"5 years",
"4 years",
"8 years",
"8 years",
"9 years",
"2 years",
"< 1 year",
"10+ years",
"6 years",
"1 year",
"10+ years",
"6 years",
"2 years",
"10+ years",
"4 years",
"5 years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"8 years",
"3 years",
"8 years",
"9 years",
"4 years",
"1 year",
null,
"10+ years",
"2 years",
"10+ years",
null,
"2 years",
"3 years",
"< 1 year",
"1 year",
"3 years",
"10+ years",
"4 years",
"1 year",
"1 year",
"8 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"< 1 year",
"2 years",
"5 years",
"10+ years",
"1 year",
"1 year",
"6 years",
"10+ years",
"8 years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
null,
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"3 years",
"6 years",
"1 year",
"10+ years",
"< 1 year",
"8 years",
"8 years",
"2 years",
"9 years",
"9 years",
"8 years",
"10+ years",
"3 years",
"9 years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"7 years",
"7 years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"1 year",
"2 years",
"< 1 year",
"10+ years",
"7 years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"4 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"7 years",
"2 years",
"2 years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"4 years",
"6 years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"9 years",
"5 years",
"6 years",
"5 years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"5 years",
"5 years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"5 years",
"3 years",
"8 years",
"9 years",
"< 1 year",
"7 years",
"10+ years",
"2 years",
"4 years",
"10+ years",
"8 years",
"3 years",
null,
"7 years",
"9 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"3 years",
null,
"4 years",
"9 years",
"10+ years",
"3 years",
"9 years",
"1 year",
"4 years",
"1 year",
"10+ years",
"9 years",
"< 1 year",
"5 years",
"1 year",
"9 years",
"1 year",
"10+ years",
"4 years",
"3 years",
"10+ years",
null,
null,
"7 years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"3 years",
null,
"< 1 year",
"< 1 year",
null,
"1 year",
"7 years",
null,
"5 years",
"10+ years",
"2 years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"2 years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"2 years",
"1 year",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"< 1 year",
"5 years",
"3 years",
"3 years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"1 year",
"6 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
null,
"5 years",
"10+ years",
"10+ years",
"1 year",
"8 years",
"2 years",
"2 years",
"< 1 year",
"6 years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"1 year",
"6 years",
"5 years",
"5 years",
"9 years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"6 years",
"8 years",
"10+ years",
"4 years",
"10+ years",
"1 year",
"2 years",
"2 years",
"< 1 year",
"2 years",
"7 years",
null,
"5 years",
"4 years",
null,
"2 years",
"1 year",
"8 years",
"10+ years",
"10+ years",
"9 years",
"8 years",
"4 years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
"5 years",
"4 years",
null,
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
null,
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"3 years",
"8 years",
"10+ years",
"7 years",
"3 years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"4 years",
"3 years",
"8 years",
null,
"10+ years",
"8 years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"9 years",
null,
"6 years",
"4 years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"3 years",
"8 years",
"9 years",
"< 1 year",
null,
"4 years",
"< 1 year",
"3 years",
"10+ years",
"4 years",
"10+ years",
null,
"2 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"3 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"6 years",
"9 years",
"7 years",
null,
"< 1 year",
"10+ years",
"1 year",
"5 years",
"4 years",
"7 years",
"1 year",
"7 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"< 1 year",
"1 year",
"9 years",
"9 years",
"< 1 year",
"5 years",
"9 years",
"7 years",
"3 years",
"10+ years",
"9 years",
"5 years",
"2 years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"< 1 year",
"8 years",
"1 year",
"2 years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"2 years",
"10+ years",
"5 years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"1 year",
"2 years",
"5 years",
"10+ years",
"5 years",
"10+ years",
null,
"3 years",
"5 years",
"2 years",
"6 years",
"6 years",
"10+ years",
"10+ years",
"8 years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"6 years",
"7 years",
"5 years",
"10+ years",
"7 years",
"1 year",
"9 years",
"5 years",
"10+ years",
"2 years",
"1 year",
"8 years",
"2 years",
"8 years",
"7 years",
"7 years",
"< 1 year",
"1 year",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"1 year",
"9 years",
"4 years",
"10+ years",
null,
"2 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"3 years",
"4 years",
"6 years",
"5 years",
"4 years",
"10+ years",
"9 years",
"3 years",
"5 years",
"10+ years",
"4 years",
"4 years",
"10+ years",
"5 years",
"1 year",
"7 years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"1 year",
"10+ years",
null,
"2 years",
"2 years",
null,
"3 years",
"10+ years",
"9 years",
"4 years",
"1 year",
"10+ years",
"5 years",
"10+ years",
null,
"< 1 year",
"10+ years",
"8 years",
"7 years",
"2 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"6 years",
"2 years",
"6 years",
"6 years",
"8 years",
"10+ years",
"7 years",
"1 year",
"4 years",
"4 years",
null,
"6 years",
"5 years",
"9 years",
"2 years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"1 year",
"2 years",
"9 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"2 years",
"2 years",
"< 1 year",
"10+ years",
"9 years",
"5 years",
"1 year",
"1 year",
"1 year",
null,
"1 year",
null,
"10+ years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"6 years",
"5 years",
"8 years",
"8 years",
"6 years",
"9 years",
"3 years",
null,
"10+ years",
"5 years",
null,
"2 years",
"< 1 year",
"10+ years",
"1 year",
"6 years",
null,
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"4 years",
"9 years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"4 years",
null,
"1 year",
"5 years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"< 1 year",
"6 years",
"4 years",
"7 years",
"3 years",
"2 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
"3 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"7 years",
"3 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"5 years",
"10+ years",
"6 years",
"< 1 year",
"< 1 year",
"9 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"6 years",
"10+ years",
"4 years",
null,
"10+ years",
"5 years",
"< 1 year",
"8 years",
"1 year",
"6 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"4 years",
null,
"7 years",
"1 year",
"8 years",
"4 years",
"10+ years",
"5 years",
"3 years",
"8 years",
"5 years",
"3 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"2 years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"2 years",
"6 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"8 years",
"3 years",
"7 years",
"7 years",
"9 years",
"5 years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"4 years",
"10+ years",
"2 years",
"1 year",
"4 years",
"2 years",
"8 years",
"10+ years",
"7 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"7 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"< 1 year",
"10+ years",
"3 years",
"5 years",
"7 years",
null,
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"9 years",
null,
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"7 years",
"7 years",
"5 years",
"3 years",
"1 year",
"10+ years",
"2 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
null,
"3 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"2 years",
"2 years",
"4 years",
"8 years",
"< 1 year",
"< 1 year",
"1 year",
"2 years",
"5 years",
"5 years",
"10+ years",
"3 years",
null,
"10+ years",
"10+ years",
"4 years",
"8 years",
"6 years",
"4 years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"3 years",
"2 years",
"1 year",
"7 years",
"9 years",
"1 year",
"2 years",
"9 years",
"< 1 year",
"2 years",
"1 year",
"4 years",
null,
"6 years",
"10+ years",
"10+ years",
null,
"5 years",
"4 years",
"6 years",
null,
"1 year",
null,
"10+ years",
"2 years",
"1 year",
"2 years",
"3 years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"2 years",
"7 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
null,
"4 years",
"6 years",
"1 year",
"2 years",
"10+ years",
"4 years",
"5 years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"6 years",
"2 years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"6 years",
"5 years",
"5 years",
"3 years",
"5 years",
"3 years",
null,
null,
null,
"1 year",
"10+ years",
"9 years",
"10+ years",
"8 years",
"3 years",
"9 years",
"< 1 year",
"5 years",
null,
"2 years",
"3 years",
"7 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"8 years",
"8 years",
"< 1 year",
"2 years",
"2 years",
"< 1 year",
"10+ years",
"5 years",
"8 years",
"4 years",
"8 years",
"7 years",
"10+ years",
"8 years",
null,
"4 years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"5 years",
"2 years",
"5 years",
"2 years",
"9 years",
"5 years",
"< 1 year",
"9 years",
"< 1 year",
"1 year",
"2 years",
"1 year",
"8 years",
"8 years",
"10+ years",
"5 years",
"7 years",
"10+ years",
"8 years",
"5 years",
"< 1 year",
"< 1 year",
"1 year",
"9 years",
"10+ years",
"1 year",
"5 years",
"7 years",
"9 years",
"10+ years",
"4 years",
"< 1 year",
"8 years",
"1 year",
"2 years",
"9 years",
"5 years",
"< 1 year",
"5 years",
"10+ years",
"1 year",
"< 1 year",
"2 years",
"8 years",
"4 years",
"2 years",
"4 years",
"1 year",
"10+ years",
"10+ years",
null,
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
null,
"3 years",
"1 year",
"6 years",
"10+ years",
"5 years",
"6 years",
"5 years",
"1 year",
"1 year",
"< 1 year",
"10+ years",
null,
"10+ years",
"4 years",
"2 years",
"10+ years",
"2 years",
"3 years",
"3 years",
"5 years",
"3 years",
"4 years",
"10+ years",
"4 years",
"10+ years",
"2 years",
null,
"1 year",
"7 years",
"2 years",
"2 years",
"10+ years",
"2 years",
null,
"10+ years",
"10+ years",
"6 years",
"5 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"8 years",
null,
"< 1 year",
"< 1 year",
"3 years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"3 years",
"< 1 year",
"1 year",
"2 years",
"6 years",
"5 years",
"1 year",
"10+ years",
"3 years",
"7 years",
"2 years",
"< 1 year",
"< 1 year",
"4 years",
"5 years",
"< 1 year",
"2 years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"4 years",
"8 years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"2 years",
"< 1 year",
"2 years",
"< 1 year",
"1 year",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"8 years",
"10+ years",
"1 year",
"4 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"3 years",
null,
"3 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"1 year",
"10+ years",
"5 years",
"3 years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"6 years",
"6 years",
"2 years",
null,
"4 years",
"5 years",
"4 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"1 year",
"8 years",
"3 years",
"4 years",
"10+ years",
"5 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
null,
"2 years",
"4 years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"6 years",
"3 years",
"5 years",
"2 years",
"8 years",
"3 years",
"10+ years",
"9 years",
"1 year",
"2 years",
"7 years",
"9 years",
"8 years",
null,
"2 years",
"2 years",
null,
"4 years",
"10+ years",
"1 year",
"1 year",
"8 years",
"3 years",
"6 years",
"1 year",
"3 years",
"5 years",
"1 year",
"10+ years",
"2 years",
"9 years",
"3 years",
"9 years",
"9 years",
"10+ years",
"7 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"1 year",
"1 year",
null,
"10+ years",
"10+ years",
"6 years",
"4 years",
"6 years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"4 years",
null,
"1 year",
"1 year",
"3 years",
"10+ years",
"2 years",
"2 years",
"3 years",
"6 years",
"2 years",
"4 years",
"9 years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"5 years",
"1 year",
"4 years",
"5 years",
"3 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"7 years",
"10+ years",
"2 years",
null,
"1 year",
"8 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"6 years",
"8 years",
"< 1 year",
null,
"10+ years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"5 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"9 years",
"1 year",
"6 years",
"10+ years",
null,
"5 years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"4 years",
null,
"7 years",
"4 years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"8 years",
"7 years",
"5 years",
"< 1 year",
"10+ years",
"2 years",
"6 years",
null,
"10+ years",
"8 years",
"10+ years",
"10+ years",
"5 years",
"6 years",
null,
"10+ years",
"7 years",
"8 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"< 1 year",
"6 years",
"3 years",
"6 years",
"10+ years",
"4 years",
"10+ years",
"6 years",
"8 years",
"10+ years",
"5 years",
"1 year",
"9 years",
"10+ years",
"2 years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"< 1 year",
"5 years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"6 years",
"6 years",
"8 years",
"1 year",
"3 years",
"< 1 year",
"6 years",
"< 1 year",
"8 years",
"3 years",
"1 year",
null,
"2 years",
"2 years",
"7 years",
"5 years",
"< 1 year",
"2 years",
"10+ years",
"1 year",
"3 years",
"3 years",
"4 years",
"8 years",
"1 year",
"5 years",
"10+ years",
"9 years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"4 years",
"4 years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"3 years",
"6 years",
"< 1 year",
"8 years",
"3 years",
"9 years",
"3 years",
"10+ years",
"3 years",
"1 year",
"< 1 year",
"3 years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"9 years",
"2 years",
"1 year",
"1 year",
"10+ years",
null,
"5 years",
"10+ years",
"10+ years",
"3 years",
"6 years",
"10+ years",
"1 year",
null,
"10+ years",
"4 years",
"10+ years",
"2 years",
"2 years",
null,
"3 years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"2 years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
null,
"5 years",
null,
"2 years",
"2 years",
null,
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"2 years",
"2 years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"4 years",
"10+ years",
"1 year",
"2 years",
"10+ years",
null,
"< 1 year",
"< 1 year",
"2 years",
"5 years",
"10+ years",
"1 year",
"9 years",
"10+ years",
"7 years",
"2 years",
"9 years",
"10+ years",
"1 year",
"5 years",
"3 years",
"10+ years",
"10+ years",
null,
"< 1 year",
"9 years",
"10+ years",
"6 years",
"9 years",
"10+ years",
"8 years",
"6 years",
"1 year",
"< 1 year",
"3 years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"1 year",
"8 years",
"10+ years",
"4 years",
"1 year",
null,
"2 years",
"8 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
null,
"1 year",
"8 years",
"2 years",
null,
null,
"10+ years",
"10+ years",
null,
"1 year",
"3 years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"7 years",
"9 years",
"7 years",
"< 1 year",
"< 1 year",
"10+ years",
"< 1 year",
null,
"2 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"4 years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"6 years",
"5 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"9 years",
"9 years",
"1 year",
"2 years",
null,
"1 year",
"10+ years",
"10+ years",
"5 years",
"8 years",
"3 years",
"5 years",
"7 years",
"1 year",
"2 years",
null,
"9 years",
"10+ years",
"7 years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"5 years",
"10+ years",
null,
"8 years",
"2 years",
null,
"< 1 year",
null,
"10+ years",
"5 years",
"< 1 year",
"7 years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"9 years",
"1 year",
"5 years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"10+ years",
"6 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
null,
"1 year",
"2 years",
"2 years",
"4 years",
"10+ years",
"2 years",
"6 years",
"10+ years",
null,
null,
"5 years",
null,
"2 years",
null,
"5 years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"6 years",
"4 years",
"10+ years",
"8 years",
"10+ years",
"6 years",
"1 year",
"9 years",
"8 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"5 years",
"4 years",
"5 years",
"6 years",
"1 year",
"6 years",
"3 years",
"2 years",
"8 years",
"2 years",
"< 1 year",
"10+ years",
"9 years",
"1 year",
"7 years",
"10+ years",
"6 years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"1 year",
"8 years",
"2 years",
"7 years",
"3 years",
"6 years",
"3 years",
"2 years",
null,
"7 years",
"10+ years",
"8 years",
"10+ years",
"4 years",
"5 years",
"8 years",
"1 year",
"3 years",
"6 years",
"2 years",
"3 years",
"4 years",
null,
"10+ years",
"4 years",
"10+ years",
"10+ years",
"5 years",
"7 years",
"6 years",
"10+ years",
"3 years",
null,
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"10+ years",
"< 1 year",
"< 1 year",
"3 years",
"9 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"7 years",
"3 years",
"5 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
null,
"2 years",
"10+ years",
"7 years",
"10+ years",
"5 years",
"7 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"3 years",
"2 years",
"2 years",
"10+ years",
"< 1 year",
"5 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"5 years",
"10+ years",
"< 1 year",
"4 years",
"4 years",
"10+ years",
"3 years",
"3 years",
"3 years",
null,
"2 years",
"1 year",
"5 years",
"10+ years",
"1 year",
"2 years",
"3 years",
"10+ years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"2 years",
"4 years",
"7 years",
"8 years",
"3 years",
"8 years",
null,
"8 years",
null,
"10+ years",
"2 years",
"7 years",
"9 years",
"7 years",
"7 years",
"3 years",
"< 1 year",
"8 years",
"1 year",
null,
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"1 year",
"6 years",
"2 years",
"< 1 year",
"9 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"10+ years",
"4 years",
"10+ years",
null,
"10+ years",
"3 years",
"3 years",
"10+ years",
"9 years",
"2 years",
"< 1 year",
"2 years",
"3 years",
"< 1 year",
null,
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"2 years",
"< 1 year",
"1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
null,
"3 years",
"8 years",
"3 years",
"< 1 year",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"5 years",
"8 years",
null,
"10+ years",
"< 1 year",
"9 years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"5 years",
"2 years",
"10+ years",
"7 years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"9 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"7 years",
"6 years",
"5 years",
"3 years",
"9 years",
"9 years",
"3 years",
"10+ years",
"4 years",
"2 years",
"10+ years",
"1 year",
null,
"9 years",
null,
"< 1 year",
"< 1 year",
"10+ years",
"5 years",
"1 year",
null,
"10+ years",
"10+ years",
"7 years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
null,
"5 years",
"2 years",
"9 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"4 years",
null,
"8 years",
"6 years",
"10+ years",
"8 years",
"3 years",
"4 years",
"10+ years",
"4 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"9 years",
"7 years",
"< 1 year",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"1 year",
"7 years",
"6 years",
"10+ years",
"2 years",
"5 years",
"3 years",
null,
"2 years",
"6 years",
"1 year",
"10+ years",
"10+ years",
"6 years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"6 years",
"< 1 year",
"10+ years",
"3 years",
"8 years",
"10+ years",
"< 1 year",
"7 years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"2 years",
"9 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"5 years",
"2 years",
"< 1 year",
"9 years",
"10+ years",
"9 years",
"4 years",
"8 years",
"10+ years",
"8 years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"5 years",
"8 years",
"6 years",
"1 year",
"10+ years",
"9 years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"4 years",
"10+ years",
"5 years",
"1 year",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"9 years",
"10+ years",
"4 years",
"5 years",
"1 year",
"10+ years",
null,
"10+ years",
"< 1 year",
"5 years",
"2 years",
"< 1 year",
"3 years",
"7 years",
"10+ years",
null,
"5 years",
"10+ years",
"9 years",
"10+ years",
"5 years",
"2 years",
"2 years",
"10+ years",
"8 years",
"7 years",
"2 years",
"10+ years",
"9 years",
"9 years",
"4 years",
"2 years",
"9 years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"2 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"3 years",
"9 years",
"6 years",
"2 years",
"5 years",
"8 years",
"6 years",
"2 years",
"7 years",
"2 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"2 years",
"1 year",
"3 years",
"2 years",
"4 years",
"7 years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"6 years",
null,
"< 1 year",
null,
"10+ years",
"2 years",
"6 years",
"5 years",
"< 1 year",
"2 years",
"2 years",
"2 years",
"5 years",
null,
"1 year",
"1 year",
"7 years",
"6 years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
null,
"< 1 year",
"2 years",
"2 years",
"2 years",
"7 years",
null,
"2 years",
"10+ years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"5 years",
"5 years",
"2 years",
"5 years",
null,
"6 years",
"< 1 year",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"2 years",
"3 years",
"5 years",
"2 years",
null,
"2 years",
"5 years",
"9 years",
"3 years",
null,
"< 1 year",
"10+ years",
"7 years",
null,
null,
"1 year",
"5 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"7 years",
"8 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"3 years",
"10+ years",
"10+ years",
null,
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"5 years",
"5 years",
"10+ years",
"8 years",
"10+ years",
"9 years",
"10+ years",
"2 years",
"< 1 year",
"< 1 year",
"2 years",
null,
"10+ years",
"1 year",
"10+ years",
"8 years",
"7 years",
"5 years",
"3 years",
"3 years",
"7 years",
"2 years",
"6 years",
"< 1 year",
"7 years",
"5 years",
"7 years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"6 years",
"2 years",
"7 years",
"10+ years",
"3 years",
"9 years",
"2 years",
"10+ years",
null,
"4 years",
"5 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"3 years",
"8 years",
"3 years",
null,
null,
"1 year",
"< 1 year",
"10+ years",
"7 years",
"4 years",
"2 years",
"10+ years",
"4 years",
"5 years",
"2 years",
null,
"10+ years",
"1 year",
"3 years",
"2 years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"9 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"3 years",
"9 years",
"4 years",
"2 years",
"7 years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"2 years",
null,
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"9 years",
"5 years",
"< 1 year",
"7 years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"6 years",
"2 years",
"1 year",
"1 year",
"4 years",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"10+ years",
"7 years",
"2 years",
"2 years",
"1 year",
"6 years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"6 years",
"6 years",
"1 year",
"10+ years",
"10+ years",
"8 years",
"7 years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"4 years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"8 years",
"4 years",
"7 years",
"2 years",
"3 years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"2 years",
"3 years",
null,
"3 years",
"7 years",
"3 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"7 years",
"7 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"3 years",
"1 year",
"8 years",
"7 years",
"6 years",
"7 years",
"5 years",
"5 years",
"1 year",
"4 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"6 years",
"8 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"6 years",
"10+ years",
"7 years",
null,
"10+ years",
"4 years",
"5 years",
"8 years",
null,
"10+ years",
"3 years",
"3 years",
"5 years",
null,
"10+ years",
"10+ years",
"2 years",
null,
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"9 years",
"10+ years",
"2 years",
"7 years",
"7 years",
"8 years",
"10+ years",
null,
"2 years",
"4 years",
"10+ years",
null,
"2 years",
"1 year",
"1 year",
"3 years",
"4 years",
"10+ years",
"6 years",
"7 years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"7 years",
null,
null,
"5 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"1 year",
"8 years",
"4 years",
"5 years",
"7 years",
"5 years",
"10+ years",
"< 1 year",
"7 years",
null,
"< 1 year",
"1 year",
"10+ years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"6 years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"8 years",
"2 years",
null,
"4 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"2 years",
"7 years",
"2 years",
"8 years",
"6 years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"1 year",
"9 years",
"< 1 year",
"< 1 year",
"10+ years",
null,
"3 years",
"3 years",
"10+ years",
"1 year",
"4 years",
"5 years",
"2 years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"6 years",
"8 years",
"1 year",
"4 years",
"< 1 year",
"7 years",
null,
"< 1 year",
"10+ years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"1 year",
"2 years",
"4 years",
"10+ years",
"8 years",
"< 1 year",
null,
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"6 years",
"10+ years",
null,
"10+ years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"7 years",
"6 years",
"10+ years",
"4 years",
"< 1 year",
"2 years",
"5 years",
"9 years",
"10+ years",
"3 years",
"5 years",
"7 years",
null,
"3 years",
"4 years",
"< 1 year",
"5 years",
"6 years",
"4 years",
null,
"4 years",
"6 years",
"< 1 year",
"9 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"6 years",
"10+ years",
"7 years",
"3 years",
"10+ years",
"6 years",
"3 years",
"< 1 year",
"2 years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"6 years",
"10+ years",
"6 years",
"3 years",
"< 1 year",
"5 years",
"6 years",
"1 year",
"10+ years",
"10+ years",
"9 years",
"4 years",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"1 year",
"7 years",
"5 years",
"5 years",
"6 years",
"< 1 year",
null,
"10+ years",
"9 years",
"10+ years",
null,
"10+ years",
null,
"< 1 year",
"10+ years",
"4 years",
"4 years",
"6 years",
"10+ years",
"7 years",
"6 years",
"10+ years",
"9 years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"1 year",
"2 years",
"1 year",
null,
"9 years",
"5 years",
"5 years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"4 years",
"8 years",
"10+ years",
"7 years",
null,
"6 years",
"2 years",
"2 years",
"3 years",
null,
"6 years",
"2 years",
"5 years",
"8 years",
"10+ years",
"2 years",
"2 years",
"6 years",
"2 years",
null,
"1 year",
"1 year",
null,
"2 years",
"< 1 year",
"8 years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"5 years",
null,
"8 years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"7 years",
"8 years",
null,
"10+ years",
"1 year",
"5 years",
"2 years",
"10+ years",
"2 years",
"3 years",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"5 years",
"3 years",
"6 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"8 years",
"3 years",
"8 years",
null,
"10+ years",
"9 years",
"5 years",
"4 years",
"< 1 year",
"9 years",
"10+ years",
"10+ years",
null,
"7 years",
"10+ years",
"5 years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
null,
"7 years",
"4 years",
"7 years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"< 1 year",
"< 1 year",
"10+ years",
"4 years",
"2 years",
"5 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"2 years",
"2 years",
"3 years",
"1 year",
"10+ years",
null,
"8 years",
"5 years",
"10+ years",
"5 years",
"8 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"7 years",
"< 1 year",
"3 years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"2 years",
"1 year",
"1 year",
null,
"2 years",
"8 years",
"10+ years",
"10+ years",
null,
"6 years",
"7 years",
"10+ years",
"7 years",
"3 years",
"10+ years",
"7 years",
"10+ years",
"4 years",
"6 years",
"10+ years",
"3 years",
"10+ years",
null,
"2 years",
"10+ years",
"3 years",
"1 year",
"3 years",
"2 years",
"6 years",
"8 years",
"10+ years",
"5 years",
"1 year",
"2 years",
"5 years",
"4 years",
"10+ years",
"7 years",
"< 1 year",
"7 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"6 years",
"1 year",
"2 years",
"10+ years",
"9 years",
"10+ years",
"2 years",
"7 years",
null,
"10+ years",
"2 years",
"10+ years",
"4 years",
null,
"5 years",
"6 years",
"10+ years",
"< 1 year",
"< 1 year",
null,
"2 years",
null,
"10+ years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"< 1 year",
"3 years",
"8 years",
"10+ years",
"6 years",
"3 years",
"6 years",
"< 1 year",
"2 years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"6 years",
"9 years",
"7 years",
"2 years",
"3 years",
"2 years",
"7 years",
"10+ years",
"5 years",
"2 years",
null,
"2 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"4 years",
"< 1 year",
"10+ years",
"9 years",
"< 1 year",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"2 years",
"8 years",
"5 years",
"10+ years",
"6 years",
"8 years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"3 years",
null,
"10+ years",
"10+ years",
"8 years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"< 1 year",
"3 years",
"4 years",
"10+ years",
"< 1 year",
"< 1 year",
"4 years",
"10+ years",
"< 1 year",
"< 1 year",
"3 years",
"6 years",
"8 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"6 years",
"< 1 year",
"7 years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"9 years",
null,
"10+ years",
"10+ years",
null,
"9 years",
"< 1 year",
"6 years",
"2 years",
"8 years",
"7 years",
"10+ years",
"10+ years",
null,
"2 years",
"7 years",
null,
"4 years",
"10+ years",
null,
"10+ years",
null,
"2 years",
"8 years",
"10+ years",
"2 years",
"1 year",
null,
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"6 years",
"5 years",
"3 years",
"1 year",
"10+ years",
"7 years",
null,
"3 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"8 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"2 years",
"7 years",
"2 years",
"7 years",
"4 years",
"4 years",
"9 years",
"9 years",
"6 years",
"10+ years",
"7 years",
"8 years",
"10+ years",
"6 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"2 years",
"9 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"1 year",
"8 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"2 years",
"5 years",
"1 year",
"3 years",
"10+ years",
"1 year",
null,
"3 years",
"10+ years",
"4 years",
"5 years",
"2 years",
null,
"10+ years",
"4 years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"1 year",
"< 1 year",
"1 year",
"5 years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"8 years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"2 years",
"< 1 year",
"2 years",
"9 years",
"9 years",
"10+ years",
"3 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"7 years",
"4 years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"7 years",
"6 years",
"7 years",
"< 1 year",
"10+ years",
"4 years",
"3 years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
null,
"8 years",
"1 year",
"1 year",
"6 years",
"3 years",
"2 years",
"10+ years",
"< 1 year",
"1 year",
"4 years",
"9 years",
"10+ years",
"5 years",
"3 years",
"3 years",
"5 years",
"4 years",
"10+ years",
"8 years",
"9 years",
"7 years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"< 1 year",
"6 years",
"10+ years",
null,
"7 years",
"3 years",
"6 years",
"7 years",
"10+ years",
"3 years",
"< 1 year",
"4 years",
"1 year",
"1 year",
"7 years",
"4 years",
"5 years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"3 years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"9 years",
null,
"5 years",
"7 years",
"2 years",
"6 years",
"4 years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"8 years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"3 years",
"1 year",
"< 1 year",
"10+ years",
"2 years",
"1 year",
"3 years",
"10+ years",
"9 years",
"3 years",
"1 year",
"10+ years",
"7 years",
"2 years",
"9 years",
"6 years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"7 years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"4 years",
"4 years",
"5 years",
"9 years",
"4 years",
"10+ years",
"< 1 year",
"2 years",
"3 years",
null,
"10+ years",
null,
"6 years",
null,
"10+ years",
"10+ years",
null,
"10+ years",
"6 years",
"7 years",
"3 years",
"< 1 year",
"9 years",
"2 years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"9 years",
"10+ years",
"7 years",
"3 years",
"< 1 year",
null,
"4 years",
null,
"2 years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"4 years",
"5 years",
null,
"3 years",
"7 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"< 1 year",
"6 years",
"8 years",
"5 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"2 years",
"5 years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"4 years",
"10+ years",
"10+ years",
null,
"3 years",
"2 years",
"< 1 year",
"6 years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"3 years",
"8 years",
"4 years",
"9 years",
"7 years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"3 years",
"8 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
null,
"2 years",
"6 years",
"10+ years",
"7 years",
"8 years",
"< 1 year",
"10+ years",
"2 years",
"2 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"6 years",
"8 years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"1 year",
"10+ years",
null,
null,
"10+ years",
"1 year",
"4 years",
"1 year",
"3 years",
"3 years",
"10+ years",
"2 years",
"5 years",
"3 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
null,
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"6 years",
"8 years",
"7 years",
null,
"5 years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"1 year",
"10+ years",
"4 years",
"3 years",
"< 1 year",
"10+ years",
"< 1 year",
"4 years",
"1 year",
"1 year",
"5 years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"3 years",
"2 years",
"10+ years",
"1 year",
"8 years",
"10+ years",
"8 years",
"10+ years",
null,
"2 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"5 years",
"10+ years",
"6 years",
null,
"3 years",
"8 years",
"2 years",
"6 years",
null,
"3 years",
"5 years",
"4 years",
"5 years",
"2 years",
null,
"< 1 year",
"< 1 year",
"10+ years",
"3 years",
"7 years",
"2 years",
"< 1 year",
"3 years",
"10+ years",
"3 years",
"2 years",
null,
"4 years",
"< 1 year",
"8 years",
"7 years",
"6 years",
"8 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"8 years",
"8 years",
"9 years",
"10+ years",
"8 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"< 1 year",
"10+ years",
"9 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"7 years",
"2 years",
"6 years",
"1 year",
"2 years",
"10+ years",
"4 years",
"3 years",
"5 years",
"2 years",
"2 years",
null,
"10+ years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"6 years",
"10+ years",
"6 years",
"< 1 year",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"3 years",
"< 1 year",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"7 years",
null,
"10+ years",
"7 years",
"10+ years",
"2 years",
"3 years",
"< 1 year",
"9 years",
null,
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"2 years",
"8 years",
"6 years",
"< 1 year",
"2 years",
"1 year",
"2 years",
"2 years",
null,
"10+ years",
"5 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"1 year",
"2 years",
"8 years",
"10+ years",
"10+ years",
"1 year",
"9 years",
"1 year",
"< 1 year",
"5 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"4 years",
null,
"10+ years",
"6 years",
"7 years",
"< 1 year",
"1 year",
"6 years",
"6 years",
"5 years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"7 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"4 years",
"7 years",
"4 years",
"10+ years",
"5 years",
"7 years",
"6 years",
"8 years",
"2 years",
"10+ years",
"6 years",
"8 years",
"4 years",
null,
"4 years",
"4 years",
"3 years",
"1 year",
"4 years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"4 years",
"7 years",
"1 year",
null,
"10+ years",
"2 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"6 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"4 years",
"< 1 year",
"7 years",
"3 years",
"2 years",
"4 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"8 years",
"4 years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"8 years",
"1 year",
"3 years",
"1 year",
"2 years",
"4 years",
"10+ years",
"5 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
null,
"1 year",
"3 years",
"8 years",
"6 years",
"< 1 year",
"2 years",
"7 years",
"4 years",
"5 years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"2 years",
"7 years",
"3 years",
"10+ years",
"3 years",
"7 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"6 years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"4 years",
"9 years",
"10+ years",
"2 years",
"10+ years",
"4 years",
"2 years",
"1 year",
"9 years",
"10+ years",
"< 1 year",
"< 1 year",
"8 years",
"10+ years",
"2 years",
"10+ years",
null,
"3 years",
"1 year",
"< 1 year",
"7 years",
"1 year",
"6 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"3 years",
"4 years",
"8 years",
"< 1 year",
"6 years",
"7 years",
"10+ years",
"8 years",
null,
"7 years",
"10+ years",
"3 years",
"10+ years",
null,
"5 years",
"6 years",
"< 1 year",
"10+ years",
"4 years",
"2 years",
null,
"10+ years",
"2 years",
"8 years",
"9 years",
"2 years",
"4 years",
"5 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"8 years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"4 years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
null,
"2 years",
"3 years",
"10+ years",
"1 year",
"5 years",
"1 year",
"5 years",
"10+ years",
"7 years",
"10+ years",
"1 year",
"3 years",
"9 years",
"5 years",
"6 years",
"10+ years",
"4 years",
"2 years",
"7 years",
"2 years",
"7 years",
"10+ years",
"7 years",
"8 years",
"10+ years",
"6 years",
"5 years",
"10+ years",
"6 years",
"8 years",
"6 years",
"3 years",
"10+ years",
"8 years",
"7 years",
"10+ years",
"< 1 year",
null,
"7 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"3 years",
"1 year",
"9 years",
"10+ years",
"10+ years",
null,
"3 years",
"10+ years",
null,
"2 years",
"10+ years",
"5 years",
"1 year",
"5 years",
"< 1 year",
"8 years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"6 years",
null,
"7 years",
"1 year",
"10+ years",
"6 years",
"8 years",
"6 years",
"8 years",
"5 years",
"8 years",
"< 1 year",
"10+ years",
"1 year",
"8 years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"1 year",
"4 years",
"4 years",
null,
"6 years",
"10+ years",
"10+ years",
"6 years",
"5 years",
"1 year",
"6 years",
"1 year",
"8 years",
"7 years",
"4 years",
"< 1 year",
"5 years",
"5 years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"1 year",
"4 years",
"7 years",
"2 years",
"5 years",
"4 years",
"1 year",
"10+ years",
"5 years",
null,
"4 years",
"1 year",
"10+ years",
"1 year",
"1 year",
null,
"10+ years",
"6 years",
"7 years",
"3 years",
"2 years",
"8 years",
"1 year",
"3 years",
"3 years",
"< 1 year",
"10+ years",
"5 years",
"5 years",
"10+ years",
"< 1 year",
"4 years",
"3 years",
"4 years",
"10+ years",
"4 years",
"10+ years",
null,
"2 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
null,
"5 years",
"7 years",
null,
"3 years",
"2 years",
"1 year",
"7 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"4 years",
"1 year",
"5 years",
"10+ years",
"6 years",
"10+ years",
"3 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"7 years",
"< 1 year",
"9 years",
"4 years",
"2 years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"8 years",
"2 years",
"3 years",
"10+ years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"2 years",
null,
"6 years",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"3 years",
"7 years",
"10+ years",
null,
"6 years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"8 years",
null,
"3 years",
"1 year",
"6 years",
"10+ years",
"1 year",
"2 years",
"2 years",
null,
"10+ years",
"10+ years",
"6 years",
"< 1 year",
"6 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
null,
"7 years",
"10+ years",
"6 years",
"7 years",
"10+ years",
"10+ years",
null,
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"7 years",
"7 years",
"< 1 year",
"3 years",
"1 year",
"8 years",
"3 years",
"6 years",
"4 years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
null,
"10+ years",
"2 years",
"3 years",
"4 years",
"10+ years",
"7 years",
"< 1 year",
"6 years",
"5 years",
"4 years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"5 years",
"< 1 year",
null,
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"1 year",
"2 years",
"1 year",
"1 year",
"< 1 year",
"10+ years",
"8 years",
null,
null,
"6 years",
"4 years",
"5 years",
"10+ years",
"4 years",
"< 1 year",
"< 1 year",
"2 years",
"3 years",
"10+ years",
"9 years",
"4 years",
"2 years",
"6 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"9 years",
"9 years",
"7 years",
"9 years",
"2 years",
"5 years",
"2 years",
"1 year",
null,
"< 1 year",
"8 years",
"2 years",
null,
"7 years",
"7 years",
"3 years",
"8 years",
"10+ years",
"9 years",
"6 years",
"10+ years",
"8 years",
"9 years",
"10+ years",
"10+ years",
"7 years",
null,
"10+ years",
"9 years",
"1 year",
"2 years",
"< 1 year",
"6 years",
"10+ years",
"8 years",
"< 1 year",
"3 years",
"10+ years",
"4 years",
"1 year",
"3 years",
"9 years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"6 years",
"1 year",
"10+ years",
"3 years",
"8 years",
"10+ years",
"3 years",
"7 years",
"3 years",
"3 years",
null,
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"4 years",
"10+ years",
"10+ years",
"8 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"8 years",
"8 years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"10+ years",
"9 years",
"1 year",
null,
"5 years",
"< 1 year",
"10+ years",
"< 1 year",
"4 years",
null,
"< 1 year",
"1 year",
"10+ years",
"3 years",
"7 years",
"8 years",
"9 years",
"3 years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"2 years",
"5 years",
"1 year",
"2 years",
"3 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"8 years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"4 years",
"7 years",
"10+ years",
"10+ years",
null,
null,
null,
"< 1 year",
"10+ years",
"4 years",
"3 years",
"10+ years",
"5 years",
"< 1 year",
"2 years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"9 years",
null,
"10+ years",
"6 years",
"9 years",
"5 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
null,
"5 years",
"5 years",
"2 years",
"10+ years",
null,
"10+ years",
"9 years",
"10+ years",
"2 years",
"10+ years",
"8 years",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"1 year",
"3 years",
"7 years",
"2 years",
"3 years",
"7 years",
"5 years",
"2 years",
"10+ years",
"10+ years",
null,
"5 years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"2 years",
"6 years",
"9 years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"3 years",
"9 years",
"3 years",
"9 years",
"4 years",
"8 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
null,
"4 years",
"9 years",
"5 years",
"9 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
null,
"< 1 year",
"1 year",
"9 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"7 years",
"< 1 year",
"9 years",
"8 years",
"4 years",
null,
"10+ years",
"1 year",
"4 years",
"9 years",
"10+ years",
"10+ years",
"6 years",
null,
"3 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"1 year",
"10+ years",
"1 year",
"6 years",
"10+ years",
"7 years",
"5 years",
"8 years",
"7 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"8 years",
"< 1 year",
"6 years",
"6 years",
"10+ years",
"1 year",
"3 years",
"2 years",
null,
"< 1 year",
"5 years",
"10+ years",
"6 years",
"5 years",
"10+ years",
"3 years",
"10+ years",
null,
"10+ years",
"7 years",
"10+ years",
"5 years",
"7 years",
null,
"3 years",
"< 1 year",
"2 years",
"10+ years",
"2 years",
"10+ years",
"6 years",
"4 years",
"7 years",
"7 years",
"8 years",
"2 years",
"10+ years",
"3 years",
"3 years",
"4 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
null,
"10+ years",
"5 years",
"6 years",
"10+ years",
"1 year",
"1 year",
"7 years",
"8 years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"1 year",
"9 years",
null,
"2 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"3 years",
"6 years",
"10+ years",
"7 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"10+ years",
"9 years",
"5 years",
"1 year",
"10+ years",
"2 years",
null,
"1 year",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"4 years",
"10+ years",
"8 years",
"6 years",
"3 years",
"2 years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"1 year",
"2 years",
"4 years",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"1 year",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"8 years",
"2 years",
"2 years",
"6 years",
"10+ years",
"6 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"1 year",
"10+ years",
"2 years",
"< 1 year",
"3 years",
"2 years",
"10+ years",
"7 years",
"4 years",
null,
"10+ years",
"10+ years",
"8 years",
null,
"10+ years",
"10+ years",
"4 years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"2 years",
null,
"< 1 year",
"5 years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"7 years",
"4 years",
null,
"8 years",
"2 years",
"1 year",
"10+ years",
"2 years",
"1 year",
"7 years",
"3 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"10+ years",
"5 years",
"3 years",
"9 years",
"3 years",
"1 year",
"10+ years",
"9 years",
"5 years",
"3 years",
"4 years",
"3 years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
null,
"9 years",
"10+ years",
"10+ years",
"8 years",
null,
"5 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"7 years",
"10+ years",
"4 years",
null,
null,
"10+ years",
"10+ years",
"6 years",
"2 years",
"2 years",
"4 years",
"8 years",
"4 years",
null,
"6 years",
"1 year",
null,
"2 years",
"4 years",
"10+ years",
"10+ years",
"1 year",
"3 years",
null,
"10+ years",
"4 years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"6 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"< 1 year",
"1 year",
"5 years",
"8 years",
"6 years",
"10+ years",
"3 years",
"2 years",
"4 years",
"1 year",
"2 years",
"3 years",
"7 years",
"5 years",
"1 year",
"10+ years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"6 years",
"5 years",
"6 years",
null,
"3 years",
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"4 years",
"6 years",
"4 years",
"< 1 year",
"1 year",
"10+ years",
"9 years",
"10+ years",
"3 years",
"3 years",
"< 1 year",
"< 1 year",
"1 year",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"6 years",
"5 years",
"< 1 year",
"6 years",
"10+ years",
"7 years",
"4 years",
"2 years",
"5 years",
"1 year",
"7 years",
"8 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"8 years",
"6 years",
null,
"4 years",
"10+ years",
"4 years",
"9 years",
"10+ years",
"2 years",
"7 years",
"8 years",
"10+ years",
"10+ years",
null,
null,
"10+ years",
"2 years",
"1 year",
"10+ years",
"2 years",
null,
"6 years",
null,
"2 years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"5 years",
"4 years",
"10+ years",
"6 years",
"8 years",
"5 years",
"1 year",
"8 years",
"7 years",
"3 years",
"3 years",
"10+ years",
"4 years",
"3 years",
null,
"9 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"4 years",
"1 year",
null,
"10+ years",
"3 years",
"10+ years",
"2 years",
"7 years",
"5 years",
"3 years",
"5 years",
"1 year",
"10+ years",
null,
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"3 years",
"10+ years",
"7 years",
"5 years",
"10+ years",
"10+ years",
"6 years",
"9 years",
"4 years",
"10+ years",
"6 years",
"9 years",
"< 1 year",
"< 1 year",
"10+ years",
"2 years",
"4 years",
"10+ years",
"1 year",
"2 years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"2 years",
"3 years",
"10+ years",
"10+ years",
null,
"10+ years",
"4 years",
"< 1 year",
"3 years",
null,
"2 years",
"2 years",
"2 years",
"10+ years",
"< 1 year",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"6 years",
"7 years",
"7 years",
"10+ years",
"9 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"6 years",
"2 years",
"7 years",
"8 years",
"5 years",
"3 years",
"10+ years",
"7 years",
"2 years",
"8 years",
"2 years",
"4 years",
"4 years",
"2 years",
"10+ years",
"4 years",
"7 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"2 years",
"< 1 year",
"6 years",
"7 years",
"3 years",
"1 year",
null,
"1 year",
"10+ years",
"2 years",
"< 1 year",
"9 years",
"9 years",
"10+ years",
"9 years",
"2 years",
"10+ years",
"10+ years",
"1 year",
null,
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"5 years",
"1 year",
"1 year",
"2 years",
"10+ years",
"9 years",
"4 years",
"8 years",
"< 1 year",
"9 years",
null,
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"8 years",
"1 year",
"4 years",
"3 years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"6 years",
"2 years",
"4 years",
"6 years",
"1 year",
"1 year",
"10+ years",
null,
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"9 years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"4 years",
"10+ years",
null,
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"2 years",
"5 years",
"< 1 year",
"10+ years",
"< 1 year",
"1 year",
"5 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"1 year",
"1 year",
null,
"10+ years",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"8 years",
"8 years",
"4 years",
null,
"10+ years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
null,
"4 years",
"10+ years",
"5 years",
"2 years",
"4 years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"9 years",
"4 years",
"3 years",
"5 years",
"2 years",
"10+ years",
"3 years",
"5 years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"1 year",
"4 years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"7 years",
"< 1 year",
"2 years",
"10+ years",
"8 years",
"8 years",
"6 years",
"3 years",
"7 years",
"7 years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"5 years",
"8 years",
"8 years",
"8 years",
"9 years",
"8 years",
"4 years",
"4 years",
"8 years",
"10+ years",
null,
"6 years",
"10+ years",
"< 1 year",
"5 years",
"2 years",
"8 years",
null,
"4 years",
"4 years",
"5 years",
"3 years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
null,
"< 1 year",
"2 years",
null,
"10+ years",
"6 years",
"4 years",
"2 years",
"4 years",
"10+ years",
"8 years",
"1 year",
"10+ years",
"4 years",
"1 year",
"4 years",
"7 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"4 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"9 years",
"3 years",
"9 years",
"1 year",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"< 1 year",
"5 years",
"7 years",
"< 1 year",
"8 years",
"< 1 year",
"8 years",
"1 year",
"5 years",
"10+ years",
"5 years",
"< 1 year",
"5 years",
"10+ years",
null,
"1 year",
"10+ years",
"6 years",
"7 years",
"6 years",
"< 1 year",
"5 years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"9 years",
"< 1 year",
"4 years",
"9 years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
null,
"9 years",
"10+ years",
"8 years",
"8 years",
"6 years",
"< 1 year",
"7 years",
"8 years",
"8 years",
"7 years",
"6 years",
"2 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"1 year",
"10+ years",
"7 years",
"6 years",
"7 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"9 years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"7 years",
"3 years",
"6 years",
"10+ years",
"2 years",
"2 years",
"2 years",
"7 years",
"9 years",
"1 year",
"10+ years",
"5 years",
"< 1 year",
"2 years",
"2 years",
"< 1 year",
"2 years",
"3 years",
"6 years",
"9 years",
"6 years",
"3 years",
"10+ years",
"1 year",
null,
null,
"9 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"4 years",
"3 years",
"10+ years",
"< 1 year",
"8 years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"8 years",
"2 years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"4 years",
"2 years",
"3 years",
"< 1 year",
null,
"10+ years",
null,
"10+ years",
"10+ years",
"2 years",
"2 years",
"4 years",
"4 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"2 years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"9 years",
"4 years",
"1 year",
"5 years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"10+ years",
"6 years",
"4 years",
"7 years",
"10+ years",
"9 years",
"6 years",
"6 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"7 years",
"7 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"7 years",
"< 1 year",
"4 years",
"10+ years",
"7 years",
"7 years",
"10+ years",
"8 years",
"4 years",
"2 years",
"2 years",
"4 years",
null,
"10+ years",
"1 year",
"1 year",
"< 1 year",
"5 years",
"1 year",
"8 years",
"8 years",
"< 1 year",
"1 year",
"8 years",
"7 years",
"8 years",
"4 years",
"4 years",
null,
"2 years",
"< 1 year",
"< 1 year",
"3 years",
"1 year",
"5 years",
"2 years",
"2 years",
"4 years",
"9 years",
null,
"1 year",
"8 years",
"4 years",
"10+ years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"6 years",
"4 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"< 1 year",
null,
"10+ years",
"5 years",
"10+ years",
null,
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"9 years",
"7 years",
"6 years",
"4 years",
"3 years",
"< 1 year",
"10+ years",
"< 1 year",
"6 years",
"6 years",
"7 years",
"10+ years",
"3 years",
"3 years",
"8 years",
"2 years",
"9 years",
"< 1 year",
"1 year",
"< 1 year",
"1 year",
"< 1 year",
null,
"10+ years",
"6 years",
"5 years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
null,
"2 years",
"10+ years",
"6 years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"10+ years",
null,
"3 years",
"10+ years",
"10+ years",
null,
"5 years",
"2 years",
"10+ years",
"10+ years",
"9 years",
"5 years",
"2 years",
"10+ years",
"2 years",
"4 years",
"< 1 year",
"3 years",
"5 years",
"5 years",
"10+ years",
"5 years",
"1 year",
"< 1 year",
"10+ years",
"< 1 year",
"2 years",
"< 1 year",
"9 years",
"10+ years",
"2 years",
"4 years",
"9 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
null,
"5 years",
null,
"8 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"2 years",
"3 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"8 years",
"3 years",
"< 1 year",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"3 years",
"2 years",
"4 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"3 years",
null,
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"6 years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"6 years",
"10+ years",
"3 years",
"< 1 year",
"5 years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"5 years",
"8 years",
"2 years",
"6 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"6 years",
"7 years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"10+ years",
"3 years",
"< 1 year",
"7 years",
"5 years",
"4 years",
"< 1 year",
"6 years",
"10+ years",
"1 year",
"3 years",
"9 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"4 years",
"< 1 year",
null,
"8 years",
"4 years",
"3 years",
"10+ years",
"6 years",
"4 years",
"10+ years",
"10+ years",
"3 years",
"1 year",
null,
"10+ years",
"10+ years",
"1 year",
"5 years",
null,
"10+ years",
"9 years",
"5 years",
null,
"3 years",
"10+ years",
"10+ years",
null,
"10+ years",
"6 years",
"10+ years",
"7 years",
null,
"1 year",
"10+ years",
"2 years",
"7 years",
"4 years",
"5 years",
"4 years",
"9 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"1 year",
"2 years",
"9 years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"6 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"2 years",
"8 years",
"2 years",
"5 years",
"1 year",
"2 years",
"6 years",
null,
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"1 year",
"< 1 year",
"< 1 year",
"6 years",
"10+ years",
"1 year",
"8 years",
"2 years",
"6 years",
"6 years",
"5 years",
"2 years",
"8 years",
"1 year",
null,
"9 years",
"3 years",
"7 years",
"3 years",
"10+ years",
"1 year",
null,
"10+ years",
"7 years",
"10+ years",
"1 year",
"6 years",
"2 years",
"10+ years",
"7 years",
"< 1 year",
"4 years",
"6 years",
"2 years",
"10+ years",
"6 years",
"3 years",
"2 years",
"3 years",
"10+ years",
"6 years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"5 years",
"2 years",
"10+ years",
"9 years",
null,
"< 1 year",
"1 year",
"5 years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"8 years",
"9 years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"1 year",
null,
"10+ years",
"1 year",
"< 1 year",
"4 years",
"2 years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"4 years",
"7 years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"< 1 year",
"3 years",
"5 years",
"10+ years",
"< 1 year",
"4 years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"9 years",
"4 years",
"2 years",
"3 years",
"10+ years",
"8 years",
"4 years",
"10+ years",
"1 year",
"4 years",
"3 years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"7 years",
"< 1 year",
null,
"3 years",
"2 years",
null,
"10+ years",
"8 years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
null,
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"7 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"3 years",
"1 year",
"< 1 year",
"4 years",
"10+ years",
"< 1 year",
"2 years",
"< 1 year",
"< 1 year",
"8 years",
"10+ years",
"8 years",
"6 years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"1 year",
"3 years",
"1 year",
"1 year",
"5 years",
"10+ years",
"5 years",
"2 years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"1 year",
"2 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
null,
"2 years",
"1 year",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"3 years",
null,
"1 year",
"10+ years",
"9 years",
"7 years",
"8 years",
"4 years",
"7 years",
"10+ years",
"1 year",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"4 years",
"1 year",
"4 years",
"2 years",
"2 years",
null,
"< 1 year",
"10+ years",
"4 years",
"8 years",
"10+ years",
"9 years",
"3 years",
"7 years",
"5 years",
"< 1 year",
"10+ years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"8 years",
"6 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"7 years",
"7 years",
"9 years",
"1 year",
"2 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"< 1 year",
null,
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
null,
"< 1 year",
"2 years",
null,
"8 years",
"1 year",
"6 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"9 years",
"< 1 year",
"10+ years",
"2 years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
null,
"1 year",
"8 years",
"2 years",
"1 year",
"10+ years",
"4 years",
"8 years",
"1 year",
"1 year",
"9 years",
"10+ years",
"10+ years",
"4 years",
"7 years",
null,
"10+ years",
"1 year",
"2 years",
"6 years",
"4 years",
"3 years",
"5 years",
"8 years",
"3 years",
"1 year",
"7 years",
"5 years",
"10+ years",
"3 years",
"1 year",
"10+ years",
"5 years",
"10+ years",
"2 years",
"4 years",
"10+ years",
"7 years",
"10+ years",
"5 years",
"8 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"7 years",
"1 year",
"9 years",
"7 years",
"8 years",
"4 years",
"8 years",
"10+ years",
"10+ years",
"1 year",
"9 years",
"5 years",
"< 1 year",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"6 years",
"4 years",
"2 years",
"2 years",
"8 years",
"6 years",
"1 year",
"3 years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"7 years",
null,
"10+ years",
"< 1 year",
"6 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"3 years",
"2 years",
"2 years",
"10+ years",
"9 years",
"6 years",
"4 years",
"8 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"2 years",
"7 years",
"10+ years",
"9 years",
"3 years",
"< 1 year",
"2 years",
"10+ years",
"1 year",
"3 years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"7 years",
"3 years",
"< 1 year",
"6 years",
null,
"10+ years",
"< 1 year",
null,
"2 years",
null,
"1 year",
"< 1 year",
"7 years",
"1 year",
"3 years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"2 years",
"5 years",
"1 year",
"5 years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"3 years",
"< 1 year",
"3 years",
"4 years",
"2 years",
"10+ years",
"3 years",
"1 year",
"4 years",
null,
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"9 years",
"10+ years",
"5 years",
"6 years",
"10+ years",
"6 years",
null,
"5 years",
null,
"4 years",
"2 years",
"4 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"4 years",
"6 years",
"6 years",
"1 year",
"< 1 year",
"6 years",
"2 years",
"4 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"3 years",
"6 years",
"2 years",
"10+ years",
"6 years",
"6 years",
"10+ years",
"6 years",
"8 years",
"2 years",
"10+ years",
"1 year",
"2 years",
"2 years",
"7 years",
"1 year",
"4 years",
"10+ years",
"6 years",
"9 years",
"1 year",
"7 years",
"< 1 year",
"6 years",
"< 1 year",
"8 years",
"3 years",
"6 years",
"1 year",
"6 years",
"4 years",
"2 years",
"10+ years",
"6 years",
"6 years",
"10+ years",
"9 years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"7 years",
"1 year",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"9 years",
null,
"10+ years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"2 years",
"6 years",
"8 years",
"8 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"6 years",
"8 years",
"2 years",
null,
"8 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"< 1 year",
"1 year",
"< 1 year",
"6 years",
"10+ years",
"2 years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"4 years",
"5 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"8 years",
"10+ years",
null,
"10+ years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"5 years",
"9 years",
"6 years",
"10+ years",
"3 years",
"9 years",
"10+ years",
"10+ years",
"9 years",
null,
"< 1 year",
"5 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"5 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
null,
null,
"5 years",
"7 years",
"3 years",
"5 years",
"< 1 year",
"8 years",
"10+ years",
"3 years",
null,
"10+ years",
"4 years",
"10+ years",
null,
"3 years",
"9 years",
"3 years",
"1 year",
"10+ years",
"1 year",
"5 years",
"3 years",
"10+ years",
"6 years",
"9 years",
null,
"4 years",
null,
"5 years",
"10+ years",
"3 years",
"5 years",
"5 years",
"6 years",
"2 years",
"9 years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"6 years",
"5 years",
"10+ years",
"1 year",
"8 years",
"2 years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"2 years",
"9 years",
"10+ years",
null,
"10+ years",
"< 1 year",
"< 1 year",
"4 years",
"10+ years",
"2 years",
"1 year",
"5 years",
"1 year",
"2 years",
"9 years",
"8 years",
null,
"2 years",
"10+ years",
"< 1 year",
"2 years",
"6 years",
"< 1 year",
"7 years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"9 years",
"1 year",
"7 years",
"7 years",
"8 years",
"5 years",
"4 years",
"10+ years",
"8 years",
"4 years",
"2 years",
"5 years",
"10+ years",
"2 years",
"4 years",
"4 years",
"< 1 year",
"10+ years",
"7 years",
"< 1 year",
"2 years",
"10+ years",
"< 1 year",
"< 1 year",
"2 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
null,
"3 years",
"7 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"4 years",
"1 year",
"8 years",
"2 years",
"3 years",
"5 years",
"9 years",
"5 years",
"1 year",
"5 years",
"10+ years",
"8 years",
"< 1 year",
"< 1 year",
"3 years",
"5 years",
"2 years",
"10+ years",
null,
"6 years",
null,
null,
"2 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"< 1 year",
null,
"2 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"7 years",
"2 years",
"1 year",
"4 years",
"6 years",
"7 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"9 years",
"1 year",
"9 years",
"4 years",
"1 year",
"4 years",
"5 years",
"10+ years",
"8 years",
"6 years",
"3 years",
"10+ years",
"2 years",
null,
"10+ years",
"< 1 year",
"2 years",
"3 years",
"7 years",
"10+ years",
"4 years",
"1 year",
"2 years",
"1 year",
"< 1 year",
"10+ years",
"7 years",
"8 years",
"9 years",
"2 years",
"10+ years",
"9 years",
"2 years",
"4 years",
"4 years",
null,
"10+ years",
"3 years",
"10+ years",
"2 years",
"4 years",
"< 1 year",
"< 1 year",
"10+ years",
"< 1 year",
"2 years",
"< 1 year",
null,
"1 year",
"10+ years",
"10+ years",
null,
"2 years",
"< 1 year",
"7 years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"1 year",
"< 1 year",
"3 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"4 years",
"3 years",
"2 years",
"10+ years",
"1 year",
"9 years",
"1 year",
"1 year",
"10+ years",
"1 year",
"5 years",
"10+ years",
"1 year",
"10+ years",
"4 years",
"7 years",
"2 years",
"2 years",
"10+ years",
"6 years",
"5 years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"8 years",
"5 years",
"4 years",
"2 years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"8 years",
"5 years",
"2 years",
"2 years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"4 years",
"10+ years",
"4 years",
"10+ years",
"4 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"9 years",
"3 years",
"< 1 year",
"10+ years",
"1 year",
"3 years",
"1 year",
"< 1 year",
"2 years",
"8 years",
null,
"4 years",
"2 years",
"6 years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"5 years",
"10+ years",
null,
"8 years",
"7 years",
"5 years",
"10+ years",
null,
"1 year",
"8 years",
null,
"8 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"7 years",
"8 years",
"9 years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"7 years",
"5 years",
"10+ years",
"< 1 year",
"2 years",
"3 years",
"10+ years",
"6 years",
null,
"2 years",
"8 years",
"1 year",
"10+ years",
"3 years",
"6 years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"4 years",
"10+ years",
"7 years",
"4 years",
"< 1 year",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"2 years",
"3 years",
"7 years",
"7 years",
"4 years",
"< 1 year",
null,
"1 year",
"1 year",
"8 years",
"6 years",
"2 years",
"3 years",
"< 1 year",
"4 years",
"1 year",
"4 years",
"4 years",
"5 years",
"10+ years",
"< 1 year",
"1 year",
"4 years",
"4 years",
"3 years",
"4 years",
"6 years",
"4 years",
"4 years",
"10+ years",
"8 years",
"2 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"< 1 year",
"5 years",
"< 1 year",
"3 years",
"3 years",
null,
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"5 years",
"10+ years",
null,
"1 year",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"5 years",
"7 years",
"2 years",
"9 years",
"10+ years",
"4 years",
null,
"10+ years",
null,
"10+ years",
"< 1 year",
null,
"3 years",
"8 years",
"< 1 year",
"8 years",
"9 years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"5 years",
"7 years",
"6 years",
"10+ years",
"3 years",
"4 years",
"1 year",
"10+ years",
"10+ years",
"7 years",
"3 years",
"8 years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"7 years",
"1 year",
"1 year",
null,
"2 years",
"9 years",
"< 1 year",
"5 years",
"10+ years",
null,
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"2 years",
"3 years",
"1 year",
"6 years",
"6 years",
"< 1 year",
"4 years",
"3 years",
"3 years",
"10+ years",
"6 years",
null,
"10+ years",
"3 years",
"10+ years",
"5 years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"6 years",
"2 years",
"2 years",
null,
null,
"10+ years",
"10+ years",
"4 years",
"9 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"8 years",
"2 years",
"9 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"4 years",
"< 1 year",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"8 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"6 years",
"4 years",
"10+ years",
"3 years",
null,
"8 years",
"10+ years",
"6 years",
"< 1 year",
"3 years",
"5 years",
"10+ years",
"2 years",
"2 years",
"2 years",
"4 years",
"2 years",
"9 years",
"3 years",
"7 years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"< 1 year",
"8 years",
"3 years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"9 years",
"6 years",
"10+ years",
"7 years",
"5 years",
"5 years",
"7 years",
"< 1 year",
"10+ years",
null,
"1 year",
"10+ years",
"1 year",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"4 years",
"< 1 year",
"6 years",
null,
"4 years",
"9 years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"9 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"5 years",
"3 years",
"2 years",
"10+ years",
"8 years",
"3 years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"8 years",
"< 1 year",
"1 year",
"10+ years",
"8 years",
"4 years",
"10+ years",
null,
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"< 1 year",
"< 1 year",
null,
null,
"3 years",
"4 years",
"7 years",
"< 1 year",
"8 years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"7 years",
"9 years",
"7 years",
"2 years",
"10+ years",
null,
"10+ years",
"10+ years",
"9 years",
"< 1 year",
null,
"10+ years",
"10+ years",
"9 years",
"3 years",
"9 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"7 years",
"10+ years",
"10+ years",
"6 years",
"4 years",
"5 years",
"5 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
null,
"1 year",
null,
"4 years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"6 years",
"1 year",
"8 years",
"8 years",
"7 years",
null,
"8 years",
"3 years",
"10+ years",
"5 years",
"7 years",
"5 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"9 years",
"8 years",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"< 1 year",
"6 years",
"4 years",
"7 years",
"1 year",
null,
"6 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"6 years",
null,
"10+ years",
"3 years",
"5 years",
"7 years",
"7 years",
"9 years",
"< 1 year",
"8 years",
"2 years",
"5 years",
"2 years",
"5 years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"5 years",
"3 years",
"2 years",
"9 years",
"< 1 year",
"7 years",
"5 years",
"4 years",
"3 years",
"10+ years",
"9 years",
"2 years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
null,
"< 1 year",
"< 1 year",
"8 years",
"10+ years",
"7 years",
"3 years",
"8 years",
"4 years",
"7 years",
"< 1 year",
"4 years",
"7 years",
"1 year",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"4 years",
"3 years",
null,
"4 years",
"4 years",
null,
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"9 years",
"3 years",
"1 year",
"5 years",
"< 1 year",
"2 years",
null,
"3 years",
"6 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"6 years",
"2 years",
"7 years",
"2 years",
"2 years",
"10+ years",
"2 years",
"2 years",
"6 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
null,
"5 years",
"1 year",
"5 years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"4 years",
"1 year",
"8 years",
"10+ years",
"10+ years",
null,
"4 years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"5 years",
"3 years",
"< 1 year",
"7 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
null,
"3 years",
"4 years",
"1 year",
"6 years",
"5 years",
"8 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
null,
"< 1 year",
"5 years",
"4 years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"< 1 year",
"1 year",
"7 years",
"3 years",
"3 years",
"10+ years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"6 years",
"1 year",
"1 year",
"9 years",
"9 years",
null,
"< 1 year",
"4 years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
null,
"10+ years",
"8 years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"6 years",
"4 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"< 1 year",
"1 year",
"2 years",
"< 1 year",
"5 years",
"< 1 year",
"4 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"2 years",
"9 years",
"6 years",
"6 years",
"< 1 year",
"7 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"6 years",
"1 year",
"10+ years",
"5 years",
"8 years",
"1 year",
"10+ years",
"3 years",
"8 years",
"10+ years",
"10+ years",
"7 years",
"< 1 year",
"< 1 year",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"3 years",
"2 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"1 year",
"4 years",
"10+ years",
"4 years",
"7 years",
"2 years",
"10+ years",
"8 years",
"7 years",
"10+ years",
"2 years",
null,
null,
"9 years",
"1 year",
"2 years",
"< 1 year",
null,
"10+ years",
"2 years",
"9 years",
"5 years",
"8 years",
"2 years",
"9 years",
null,
"10+ years",
"1 year",
"10+ years",
"2 years",
"6 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"8 years",
"5 years",
"5 years",
"10+ years",
"8 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
null,
"4 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"3 years",
null,
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"5 years",
"7 years",
"5 years",
"1 year",
null,
"3 years",
"8 years",
"1 year",
"4 years",
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"6 years",
"2 years",
"10+ years",
"3 years",
"3 years",
"9 years",
"9 years",
"3 years",
"5 years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
null,
"2 years",
"2 years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"5 years",
"7 years",
"1 year",
"10+ years",
"< 1 year",
"2 years",
"4 years",
"< 1 year",
"10+ years",
"< 1 year",
"3 years",
"5 years",
"4 years",
"10+ years",
null,
"10+ years",
"2 years",
"10+ years",
"8 years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"2 years",
"< 1 year",
"3 years",
"2 years",
"10+ years",
"10+ years",
null,
"4 years",
"1 year",
"10+ years",
"2 years",
"< 1 year",
"3 years",
"1 year",
"10+ years",
null,
"10+ years",
"5 years",
"10+ years",
"3 years",
"1 year",
"8 years",
"1 year",
"10+ years",
"6 years",
"2 years",
"1 year",
"3 years",
"1 year",
null,
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"6 years",
"10+ years",
"2 years",
"6 years",
"9 years",
"< 1 year",
"9 years",
"7 years",
"7 years",
"10+ years",
null,
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"5 years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"1 year",
"3 years",
"< 1 year",
"10+ years",
null,
null,
"10+ years",
"< 1 year",
"4 years",
"8 years",
"2 years",
"3 years",
"10+ years",
"2 years",
null,
"7 years",
"2 years",
"< 1 year",
"< 1 year",
null,
"4 years",
"7 years",
null,
"9 years",
"8 years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"7 years",
"10+ years",
"2 years",
"1 year",
"3 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"< 1 year",
"1 year",
"< 1 year",
"< 1 year",
"8 years",
"10+ years",
"1 year",
"7 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"6 years",
"< 1 year",
"2 years",
"10+ years",
"2 years",
"2 years",
"< 1 year",
"4 years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"3 years",
"5 years",
"1 year",
"10+ years",
"6 years",
"8 years",
"6 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"6 years",
"10+ years",
"10+ years",
"5 years",
"8 years",
"10+ years",
"< 1 year",
"5 years",
"8 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"9 years",
"10+ years",
"8 years",
"4 years",
"8 years",
"8 years",
"2 years",
null,
"10+ years",
"7 years",
"10+ years",
null,
"4 years",
null,
"10+ years",
"9 years",
"10+ years",
"2 years",
"3 years",
"< 1 year",
"4 years",
"4 years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"7 years",
"1 year",
"4 years",
"10+ years",
"2 years",
"9 years",
"10+ years",
"< 1 year",
"2 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"6 years",
"< 1 year",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"7 years",
"6 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"2 years",
null,
"4 years",
"7 years",
"2 years",
"5 years",
null,
"10+ years",
"7 years",
"5 years",
null,
"5 years",
"6 years",
"< 1 year",
"10+ years",
"2 years",
"1 year",
"5 years",
"3 years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"4 years",
"3 years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"1 year",
null,
"5 years",
"10+ years",
"10+ years",
"5 years",
"9 years",
"4 years",
"4 years",
"8 years",
"6 years",
"< 1 year",
"10+ years",
"9 years",
"5 years",
"10+ years",
null,
"6 years",
null,
"2 years",
"3 years",
"5 years",
null,
"10+ years",
"10+ years",
"10+ years",
null,
"2 years",
"3 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"7 years",
"1 year",
"9 years",
"9 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"6 years",
"< 1 year",
"3 years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"8 years",
"3 years",
"10+ years",
null,
"10+ years",
null,
"7 years",
"2 years",
"10+ years",
null,
"< 1 year",
null,
"8 years",
null,
null,
"2 years",
"2 years",
null,
"1 year",
"2 years",
"1 year",
null,
"10+ years",
"8 years",
"8 years",
null,
"7 years",
"3 years",
"5 years",
"5 years",
"< 1 year",
"8 years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
null,
"6 years",
"6 years",
"10+ years",
"< 1 year",
"7 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"2 years",
"1 year",
"10+ years",
"1 year",
"2 years",
"10+ years",
null,
"10+ years",
"10+ years",
"2 years",
"4 years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"9 years",
"10+ years",
"3 years",
"2 years",
"< 1 year",
null,
"9 years",
"7 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"1 year",
"3 years",
"9 years",
"7 years",
"9 years",
null,
"10+ years",
"7 years",
"2 years",
null,
"5 years",
"2 years",
"1 year",
"10+ years",
"8 years",
"5 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"1 year",
"8 years",
"10+ years",
"9 years",
"6 years",
"< 1 year",
"4 years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"1 year",
"9 years",
"3 years",
"2 years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"5 years",
"5 years",
"6 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
null,
"2 years",
"1 year",
"2 years",
"10+ years",
"1 year",
null,
"10+ years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"1 year",
"3 years",
null,
"8 years",
null,
"10+ years",
"4 years",
"10+ years",
"9 years",
"10+ years",
"7 years",
"5 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"1 year",
"2 years",
"4 years",
"2 years",
"10+ years",
"3 years",
"1 year",
"10+ years",
"2 years",
"3 years",
"10+ years",
"5 years",
null,
"3 years",
"8 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
null,
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
null,
"2 years",
"8 years",
"8 years",
"7 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"1 year",
null,
"7 years",
"10+ years",
"4 years",
null,
"3 years",
"10+ years",
"1 year",
"2 years",
"6 years",
"10+ years",
"2 years",
"3 years",
"< 1 year",
"2 years",
null,
"3 years",
"8 years",
"7 years",
"6 years",
"3 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"2 years",
"< 1 year",
"5 years",
"6 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
null,
"1 year",
"8 years",
"4 years",
"2 years",
null,
"< 1 year",
"10+ years",
"6 years",
"7 years",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"2 years",
"3 years",
null,
"4 years",
"10+ years",
"10+ years",
"7 years",
"5 years",
"10+ years",
"4 years",
"2 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"8 years",
"10+ years",
"2 years",
null,
"6 years",
null,
"8 years",
"10+ years",
"10+ years",
null,
"4 years",
"4 years",
"8 years",
"3 years",
"< 1 year",
"2 years",
"2 years",
"2 years",
"6 years",
"1 year",
"< 1 year",
"1 year",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"3 years",
"2 years",
"6 years",
null,
"< 1 year",
"2 years",
"10+ years",
null,
"< 1 year",
"5 years",
"< 1 year",
"10+ years",
"3 years",
"4 years",
"5 years",
"7 years",
"10+ years",
"3 years",
"8 years",
"2 years",
"9 years",
"8 years",
"< 1 year",
"< 1 year",
"5 years",
"2 years",
"3 years",
"6 years",
"3 years",
"< 1 year",
"7 years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"3 years",
"3 years",
"10+ years",
"9 years",
"10+ years",
"7 years",
"6 years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"2 years",
"9 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"6 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"7 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"6 years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"2 years",
"7 years",
"< 1 year",
"1 year",
"2 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"4 years",
"4 years",
"6 years",
"2 years",
"2 years",
"7 years",
"2 years",
"1 year",
"10+ years",
null,
"10+ years",
"3 years",
"10+ years",
"1 year",
"9 years",
"1 year",
"4 years",
"6 years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"4 years",
"8 years",
"7 years",
"8 years",
"8 years",
"8 years",
"3 years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"8 years",
"< 1 year",
null,
"5 years",
"3 years",
"10+ years",
"3 years",
"1 year",
"4 years",
"10+ years",
"9 years",
"3 years",
"9 years",
"2 years",
"1 year",
"2 years",
null,
"3 years",
"1 year",
"< 1 year",
"3 years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"9 years",
"5 years",
null,
"9 years",
"< 1 year",
"3 years",
"4 years",
"5 years",
"8 years",
"6 years",
null,
"1 year",
"1 year",
"9 years",
"2 years",
"10+ years",
"2 years",
"8 years",
"1 year",
"< 1 year",
"3 years",
"4 years",
"6 years",
"9 years",
"3 years",
"1 year",
"2 years",
"2 years",
null,
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"3 years",
"7 years",
"10+ years",
null,
"10+ years",
null,
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
null,
"4 years",
"10+ years",
null,
"2 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"7 years",
"2 years",
"4 years",
null,
null,
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"1 year",
"10+ years",
"7 years",
null,
"10+ years",
"7 years",
"6 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"2 years",
"1 year",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"10+ years",
"6 years",
"2 years",
"4 years",
"10+ years",
"10+ years",
null,
"10+ years",
"5 years",
"4 years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"1 year",
null,
"6 years",
"6 years",
"8 years",
"5 years",
"< 1 year",
"4 years",
"1 year",
"2 years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"4 years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"6 years",
"8 years",
"9 years",
"5 years",
"5 years",
null,
"2 years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"9 years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"4 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"2 years",
"6 years",
"1 year",
"10+ years",
"2 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"1 year",
"< 1 year",
null,
"2 years",
"3 years",
"9 years",
"< 1 year",
null,
"2 years",
"< 1 year",
"6 years",
"1 year",
null,
"10+ years",
"7 years",
"9 years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"9 years",
"1 year",
"5 years",
"7 years",
"1 year",
"2 years",
"6 years",
"10+ years",
"2 years",
"5 years",
"6 years",
"3 years",
null,
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"2 years",
"3 years",
"< 1 year",
"5 years",
"1 year",
"1 year",
"6 years",
"1 year",
"4 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"5 years",
"2 years",
"9 years",
"2 years",
"5 years",
"10+ years",
"9 years",
"2 years",
"10+ years",
"4 years",
"3 years",
"10+ years",
"1 year",
"7 years",
"9 years",
"10+ years",
"7 years",
"5 years",
null,
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"3 years",
"1 year",
"< 1 year",
"7 years",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"9 years",
"10+ years",
"6 years",
"10+ years",
"8 years",
"< 1 year",
"2 years",
"< 1 year",
"4 years",
"3 years",
"7 years",
"10+ years",
"10+ years",
null,
"5 years",
"< 1 year",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"< 1 year",
"7 years",
"10+ years",
null,
"10+ years",
"3 years",
"10+ years",
"4 years",
"4 years",
null,
"2 years",
"5 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"5 years",
"8 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"3 years",
"3 years",
"7 years",
"< 1 year",
"2 years",
"< 1 year",
"5 years",
"5 years",
"1 year",
"3 years",
"2 years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"9 years",
"10+ years",
"8 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"8 years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"7 years",
"6 years",
"2 years",
"2 years",
"10+ years",
"9 years",
"7 years",
null,
"8 years",
null,
"10+ years",
"5 years",
"5 years",
"2 years",
"10+ years",
"2 years",
"1 year",
"2 years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"9 years",
"5 years",
"6 years",
"2 years",
"7 years",
"7 years",
"1 year",
"7 years",
"10+ years",
"1 year",
"9 years",
"4 years",
"10+ years",
"8 years",
"6 years",
"10+ years",
"9 years",
"6 years",
null,
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"6 years",
null,
"3 years",
"10+ years",
"6 years",
"3 years",
"5 years",
"10+ years",
"< 1 year",
"3 years",
null,
"2 years",
"2 years",
"9 years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"2 years",
null,
"6 years",
"8 years",
"4 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"10+ years",
null,
"10+ years",
"6 years",
"10+ years",
"2 years",
"3 years",
"< 1 year",
"10+ years",
"2 years",
"6 years",
"3 years",
"10+ years",
"5 years",
"6 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"6 years",
"5 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
null,
null,
"10+ years",
"8 years",
"10+ years",
"2 years",
"< 1 year",
"2 years",
"10+ years",
"3 years",
null,
"10+ years",
"1 year",
"< 1 year",
"8 years",
"9 years",
"8 years",
"5 years",
"< 1 year",
"< 1 year",
"10+ years",
"5 years",
"2 years",
null,
"5 years",
"2 years",
"< 1 year",
"4 years",
"9 years",
"8 years",
"2 years",
"6 years",
"7 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"8 years",
"< 1 year",
"1 year",
null,
"10+ years",
"5 years",
"2 years",
"4 years",
"< 1 year",
"2 years",
"10+ years",
"4 years",
"2 years",
"10+ years",
"6 years",
"4 years",
"10+ years",
"3 years",
"10+ years",
null,
"7 years",
"6 years",
"10+ years",
"4 years",
"10+ years",
"1 year",
"7 years",
"9 years",
"10+ years",
"6 years",
"6 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"3 years",
"9 years",
"10+ years",
"< 1 year",
"6 years",
"3 years",
null,
"2 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"6 years",
"< 1 year",
"7 years",
"9 years",
null,
"< 1 year",
"3 years",
"10+ years",
"1 year",
"8 years",
null,
"10+ years",
"8 years",
"9 years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"8 years",
"4 years",
"10+ years",
"3 years",
null,
"10+ years",
"6 years",
"1 year",
"< 1 year",
"3 years",
"2 years",
"10+ years",
"9 years",
"10+ years",
null,
"4 years",
"2 years",
"6 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"8 years",
"10+ years",
"3 years",
"5 years",
"< 1 year",
"10+ years",
null,
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"5 years",
"< 1 year",
"1 year",
"5 years",
"4 years",
"10+ years",
"2 years",
null,
"< 1 year",
null,
"7 years",
"4 years",
null,
"5 years",
"9 years",
"7 years",
"1 year",
"3 years",
"6 years",
"1 year",
"1 year",
"3 years",
null,
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
null,
"9 years",
"10+ years",
"8 years",
"9 years",
"2 years",
"5 years",
"5 years",
null,
"8 years",
"1 year",
"10+ years",
"9 years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"7 years",
"10+ years",
"2 years",
"7 years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"6 years",
"9 years",
"4 years",
"< 1 year",
"8 years",
null,
"2 years",
"6 years",
"6 years",
"8 years",
"2 years",
"2 years",
"5 years",
"3 years",
"9 years",
"2 years",
"1 year",
"< 1 year",
"6 years",
"10+ years",
null,
"10+ years",
"6 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
null,
null,
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"4 years",
"9 years",
"2 years",
"4 years",
"10+ years",
"10+ years",
"5 years",
"8 years",
"3 years",
"1 year",
"1 year",
"5 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"9 years",
"3 years",
"10+ years",
"1 year",
"2 years",
"8 years",
"2 years",
"10+ years",
null,
"10+ years",
"6 years",
"9 years",
"5 years",
"8 years",
"10+ years",
"7 years",
"3 years",
"6 years",
"10+ years",
"5 years",
"8 years",
"9 years",
"1 year",
"< 1 year",
"9 years",
null,
"5 years",
"2 years",
null,
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"2 years",
"3 years",
"10+ years",
"4 years",
null,
"10+ years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"4 years",
"4 years",
null,
"10+ years",
null,
"5 years",
"8 years",
"4 years",
"8 years",
"10+ years",
null,
"10+ years",
"2 years",
"7 years",
"< 1 year",
null,
"9 years",
"3 years",
"2 years",
"5 years",
"10+ years",
"8 years",
"10+ years",
"8 years",
"9 years",
"8 years",
"10+ years",
"4 years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"< 1 year",
"3 years",
"10+ years",
"3 years",
null,
"2 years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"< 1 year",
"6 years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"7 years",
null,
"10+ years",
"5 years",
"7 years",
"10+ years",
"3 years",
"< 1 year",
"9 years",
"8 years",
"7 years",
"10+ years",
"5 years",
"10+ years",
"6 years",
"2 years",
"1 year",
"1 year",
"4 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"2 years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"6 years",
null,
"10+ years",
"5 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
null,
"10+ years",
"9 years",
"10+ years",
"1 year",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"7 years",
"5 years",
"< 1 year",
"9 years",
"10+ years",
"6 years",
"9 years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"< 1 year",
"5 years",
"6 years",
"1 year",
"7 years",
"8 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"5 years",
"4 years",
"< 1 year",
"10+ years",
"2 years",
"6 years",
"8 years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"4 years",
"7 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"5 years",
"9 years",
"8 years",
"8 years",
"10+ years",
null,
"5 years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"1 year",
"4 years",
"10+ years",
"5 years",
"2 years",
"7 years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"5 years",
"1 year",
"10+ years",
"< 1 year",
null,
"< 1 year",
"10+ years",
"6 years",
"3 years",
"1 year",
"2 years",
"9 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"4 years",
"10+ years",
"1 year",
"7 years",
"10+ years",
null,
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"1 year",
"6 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"9 years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"9 years",
"10+ years",
"10+ years",
"4 years",
"5 years",
"5 years",
"10+ years",
"10+ years",
"7 years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
null,
"10+ years",
"< 1 year",
"1 year",
"1 year",
"10+ years",
"< 1 year",
"7 years",
"5 years",
"6 years",
"< 1 year",
"10+ years",
"5 years",
"2 years",
"9 years",
null,
"10+ years",
"10+ years",
null,
null,
"< 1 year",
"3 years",
"< 1 year",
"1 year",
"10+ years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"< 1 year",
"2 years",
"2 years",
"1 year",
"3 years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"9 years",
"7 years",
"2 years",
null,
"2 years",
"9 years",
"5 years",
null,
null,
"6 years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"2 years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"4 years",
"6 years",
"5 years",
"10+ years",
"1 year",
"1 year",
"1 year",
"1 year",
"4 years",
"8 years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"9 years",
null,
"5 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"1 year",
"3 years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"3 years",
"3 years",
null,
"9 years",
null,
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"9 years",
"10+ years",
"3 years",
null,
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"4 years",
"5 years",
"3 years",
"10+ years",
"4 years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"6 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"6 years",
"9 years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"< 1 year",
"< 1 year",
"10+ years",
"6 years",
"5 years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"9 years",
"1 year",
"3 years",
"4 years",
"3 years",
"5 years",
"2 years",
"4 years",
"2 years",
"4 years",
"4 years",
"3 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"9 years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"< 1 year",
"6 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"6 years",
"1 year",
"10+ years",
"9 years",
"2 years",
"6 years",
"10+ years",
"6 years",
"10+ years",
null,
"5 years",
"1 year",
"10+ years",
"8 years",
"2 years",
"4 years",
"6 years",
"10+ years",
"2 years",
null,
"8 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"7 years",
"10+ years",
"5 years",
"5 years",
"5 years",
"10+ years",
null,
"10+ years",
"2 years",
"2 years",
"10+ years",
"5 years",
"1 year",
null,
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
"2 years",
"4 years",
"6 years",
"5 years",
"10+ years",
"< 1 year",
"9 years",
"10+ years",
"5 years",
"5 years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"1 year",
"2 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
null,
"1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"7 years",
null,
"2 years",
"3 years",
"9 years",
"7 years",
"4 years",
"< 1 year",
"2 years",
"2 years",
"2 years",
"10+ years",
"4 years",
"< 1 year",
null,
"10+ years",
"3 years",
"2 years",
"10+ years",
"< 1 year",
"4 years",
null,
"10+ years",
"10+ years",
"10+ years",
"7 years",
"4 years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"9 years",
"10+ years",
"10+ years",
null,
"10+ years",
"7 years",
"9 years",
"< 1 year",
"< 1 year",
"7 years",
"5 years",
"4 years",
"8 years",
"1 year",
"6 years",
"6 years",
"< 1 year",
"5 years",
"2 years",
"9 years",
"1 year",
"9 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"9 years",
"10+ years",
"10+ years",
"8 years",
null,
"4 years",
"2 years",
"8 years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"1 year",
"2 years",
"4 years",
"6 years",
"3 years",
"2 years",
"1 year",
"10+ years",
"1 year",
"< 1 year",
"5 years",
"8 years",
"10+ years",
"5 years",
"4 years",
"10+ years",
"10+ years",
"6 years",
"9 years",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"8 years",
"8 years",
null,
"< 1 year",
"4 years",
null,
"10+ years",
"5 years",
"10+ years",
"7 years",
null,
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"9 years",
null,
null,
"< 1 year",
"< 1 year",
"5 years",
"7 years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"9 years",
"2 years",
"< 1 year",
"2 years",
"2 years",
"10+ years",
"3 years",
"9 years",
"10+ years",
"9 years",
"10+ years",
"7 years",
"6 years",
"10+ years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"6 years",
"< 1 year",
"5 years",
"5 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"4 years",
"7 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"1 year",
"10+ years",
"9 years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"6 years",
"4 years",
"10+ years",
"10+ years",
"4 years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"5 years",
"< 1 year",
"10+ years",
null,
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"1 year",
"< 1 year",
"1 year",
"5 years",
"2 years",
"10+ years",
"5 years",
null,
"5 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"5 years",
"6 years",
"2 years",
"10+ years",
"2 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
null,
"6 years",
"1 year",
"2 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"2 years",
"1 year",
"1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"1 year",
"3 years",
"4 years",
"6 years",
"4 years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"5 years",
"10+ years",
null,
"10+ years",
"7 years",
"2 years",
"2 years",
"2 years",
"10+ years",
"8 years",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"< 1 year",
"6 years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"2 years",
"9 years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"1 year",
"3 years",
"10+ years",
"5 years",
"8 years",
"2 years",
"7 years",
"3 years",
"10+ years",
"10+ years",
"3 years",
null,
"6 years",
"2 years",
"3 years",
"2 years",
"10+ years",
"3 years",
"2 years",
"5 years",
"4 years",
"2 years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"5 years",
"6 years",
"< 1 year",
"6 years",
"7 years",
"10+ years",
"5 years",
"2 years",
"8 years",
"10+ years",
"2 years",
"6 years",
"8 years",
"< 1 year",
"1 year",
"10+ years",
"6 years",
"1 year",
"10+ years",
null,
"< 1 year",
"1 year",
"6 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"6 years",
null,
"10+ years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"6 years",
"< 1 year",
"10+ years",
null,
"7 years",
"10+ years",
"10+ years",
null,
"10+ years",
"4 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"4 years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"4 years",
"6 years",
"3 years",
"3 years",
"10+ years",
"7 years",
"3 years",
"4 years",
"10+ years",
"9 years",
"1 year",
"10+ years",
"5 years",
"2 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"3 years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"9 years",
"4 years",
"2 years",
"6 years",
"7 years",
"9 years",
"< 1 year",
"10+ years",
"< 1 year",
"6 years",
"4 years",
"4 years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"5 years",
"3 years",
"< 1 year",
"10+ years",
"2 years",
"< 1 year",
"7 years",
"1 year",
"7 years",
"10+ years",
null,
null,
"8 years",
"6 years",
"10+ years",
"8 years",
"4 years",
"10+ years",
"10+ years",
"4 years",
"4 years",
"10+ years",
null,
"4 years",
"10+ years",
"7 years",
"< 1 year",
null,
"10+ years",
null,
"7 years",
"8 years",
"3 years",
"2 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"9 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"10+ years",
null,
"6 years",
"3 years",
"2 years",
"5 years",
"5 years",
"6 years",
"2 years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"9 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"4 years",
"9 years",
"2 years",
"10+ years",
"10+ years",
"9 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"9 years",
"3 years",
"9 years",
"4 years",
"5 years",
"3 years",
"4 years",
"1 year",
"2 years",
null,
"3 years",
"7 years",
"2 years",
"< 1 year",
"6 years",
null,
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"1 year",
"6 years",
"7 years",
"6 years",
"< 1 year",
"10+ years",
"9 years",
null,
"10+ years",
"8 years",
"5 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"8 years",
"4 years",
"2 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"5 years",
"< 1 year",
"< 1 year",
"10+ years",
"2 years",
"9 years",
"2 years",
"6 years",
"10+ years",
"9 years",
"< 1 year",
"2 years",
"2 years",
"10+ years",
null,
"1 year",
"10+ years",
"8 years",
"< 1 year",
"5 years",
null,
"3 years",
"2 years",
"3 years",
"10+ years",
"9 years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
null,
null,
"10+ years",
"5 years",
"4 years",
"9 years",
"2 years",
"< 1 year",
"3 years",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"6 years",
"3 years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"3 years",
null,
"10+ years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"4 years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
null,
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"8 years",
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"8 years",
"4 years",
"2 years",
"10+ years",
"6 years",
"1 year",
"2 years",
"< 1 year",
null,
"10+ years",
"6 years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"6 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
null,
"4 years",
"10+ years",
"4 years",
"2 years",
"4 years",
"4 years",
"8 years",
"10+ years",
null,
"5 years",
"9 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"6 years",
"2 years",
"9 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"< 1 year",
"2 years",
"5 years",
"2 years",
"1 year",
"3 years",
"10+ years",
null,
"3 years",
"10+ years",
null,
"10+ years",
"2 years",
"< 1 year",
"9 years",
"7 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
null,
"< 1 year",
null,
"9 years",
"1 year",
"7 years",
"3 years",
"10+ years",
"4 years",
null,
"2 years",
"4 years",
"1 year",
null,
"4 years",
"9 years",
"< 1 year",
"4 years",
"9 years",
"< 1 year",
"7 years",
"3 years",
"10+ years",
"5 years",
"3 years",
"9 years",
"8 years",
"4 years",
"< 1 year",
"1 year",
"4 years",
"7 years",
null,
"2 years",
"2 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"5 years",
"10+ years",
"9 years",
"2 years",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"9 years",
"1 year",
"< 1 year",
"10+ years",
"2 years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"3 years",
"< 1 year",
"6 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"1 year",
"2 years",
"10+ years",
"10+ years",
null,
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"3 years",
null,
"5 years",
"2 years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"5 years",
null,
"10+ years",
"6 years",
"2 years",
"< 1 year",
null,
null,
"1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"5 years",
"1 year",
"6 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
null,
"< 1 year",
"8 years",
"1 year",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"7 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"9 years",
null,
"2 years",
"< 1 year",
"2 years",
"2 years",
"3 years",
"4 years",
"4 years",
"10+ years",
"2 years",
"2 years",
"5 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"6 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"7 years",
"6 years",
"3 years",
"1 year",
"10+ years",
"4 years",
"8 years",
"7 years",
"4 years",
"3 years",
"10+ years",
"5 years",
"5 years",
"2 years",
"10+ years",
"8 years",
"1 year",
"5 years",
"5 years",
"3 years",
"10+ years",
"7 years",
"10+ years",
"1 year",
"2 years",
"6 years",
"2 years",
"2 years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"2 years",
null,
"< 1 year",
"1 year",
null,
"10+ years",
"6 years",
"10+ years",
"5 years",
"2 years",
"6 years",
"4 years",
"10+ years",
"4 years",
null,
"5 years",
"10+ years",
"10+ years",
"5 years",
"1 year",
"7 years",
"5 years",
"1 year",
"< 1 year",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"9 years",
"8 years",
"2 years",
"1 year",
"2 years",
"10+ years",
"5 years",
"3 years",
"6 years",
"1 year",
"4 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"2 years",
"6 years",
"< 1 year",
null,
"3 years",
"5 years",
"10+ years",
"8 years",
"10+ years",
"6 years",
"< 1 year",
null,
"6 years",
"10+ years",
"2 years",
"2 years",
"8 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"7 years",
"6 years",
"5 years",
"6 years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
null,
"2 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"6 years",
"1 year",
"10+ years",
"1 year",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"9 years",
"2 years",
"7 years",
"9 years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"6 years",
"10+ years",
"7 years",
"3 years",
"10+ years",
null,
"< 1 year",
"10+ years",
"9 years",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
null,
"10+ years",
"2 years",
null,
"10+ years",
"4 years",
"5 years",
"3 years",
"8 years",
"< 1 year",
"2 years",
"10+ years",
"7 years",
"7 years",
"4 years",
"5 years",
"1 year",
"4 years",
"< 1 year",
"2 years",
"1 year",
"1 year",
"4 years",
"< 1 year",
"7 years",
"10+ years",
null,
"10+ years",
"4 years",
"8 years",
"10+ years",
"7 years",
"7 years",
"1 year",
"10+ years",
null,
"2 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"5 years",
"5 years",
"4 years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"2 years",
"4 years",
"10+ years",
"8 years",
"2 years",
"7 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"6 years",
"4 years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"10+ years",
null,
"10+ years",
"7 years",
"7 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"4 years",
"1 year",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"5 years",
"3 years",
"6 years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"7 years",
null,
"7 years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"2 years",
"8 years",
null,
"< 1 year",
null,
"3 years",
"7 years",
"2 years",
"9 years",
"2 years",
"3 years",
"10+ years",
"5 years",
"3 years",
"4 years",
"3 years",
"8 years",
"4 years",
"10+ years",
"3 years",
"8 years",
"2 years",
"10+ years",
"3 years",
null,
"10+ years",
"< 1 year",
null,
"1 year",
"1 year",
"2 years",
"10+ years",
"1 year",
"1 year",
"8 years",
"9 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
null,
null,
"10+ years",
"4 years",
"10+ years",
"5 years",
null,
"1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"3 years",
"7 years",
"8 years",
"5 years",
"3 years",
"10+ years",
"1 year",
"3 years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"9 years",
"2 years",
"2 years",
null,
"< 1 year",
null,
"10+ years",
"< 1 year",
"7 years",
"1 year",
"7 years",
"< 1 year",
"3 years",
"10+ years",
"1 year",
null,
"1 year",
"10+ years",
"4 years",
"10+ years",
"7 years",
"6 years",
"3 years",
"1 year",
"10+ years",
null,
"3 years",
"3 years",
"1 year",
"2 years",
"4 years",
"10+ years",
"9 years",
"2 years",
"6 years",
"10+ years",
"10+ years",
"8 years",
"3 years",
null,
"8 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"2 years",
"6 years",
null,
"10+ years",
"1 year",
"< 1 year",
"3 years",
"8 years",
"1 year",
null,
"10+ years",
"9 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"8 years",
"7 years",
"9 years",
null,
"10+ years",
"10+ years",
"2 years",
"3 years",
"7 years",
"9 years",
"7 years",
"4 years",
"10+ years",
"8 years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"4 years",
"8 years",
"1 year",
"3 years",
"10+ years",
"1 year",
"4 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"8 years",
"2 years",
"2 years",
"3 years",
"2 years",
"7 years",
"8 years",
"10+ years",
"4 years",
"5 years",
"6 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"8 years",
"4 years",
"3 years",
"2 years",
"1 year",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"1 year",
"7 years",
"7 years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"5 years",
"10+ years",
"1 year",
"2 years",
"4 years",
"1 year",
"2 years",
null,
"8 years",
"10+ years",
"4 years",
"< 1 year",
"6 years",
"8 years",
"7 years",
"1 year",
"5 years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"1 year",
"4 years",
"3 years",
"4 years",
"< 1 year",
"5 years",
"3 years",
"2 years",
"5 years",
"4 years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"3 years",
null,
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"5 years",
"8 years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"7 years",
"2 years",
"6 years",
"3 years",
"4 years",
"2 years",
"6 years",
"8 years",
"10+ years",
"10+ years",
"7 years",
"5 years",
"1 year",
"10+ years",
"7 years",
null,
"3 years",
"4 years",
"< 1 year",
"10+ years",
"2 years",
"9 years",
"2 years",
"1 year",
"10+ years",
"3 years",
"< 1 year",
"8 years",
"< 1 year",
"2 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
null,
"5 years",
"9 years",
"10+ years",
"5 years",
"4 years",
"10+ years",
"1 year",
"4 years",
"8 years",
"10+ years",
"8 years",
null,
"10+ years",
"10+ years",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
null,
"6 years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"3 years",
"6 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"3 years",
"< 1 year",
"10+ years",
"< 1 year",
"1 year",
"3 years",
"6 years",
"3 years",
"4 years",
"6 years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"6 years",
"10+ years",
"5 years",
"10+ years",
"8 years",
"1 year",
"3 years",
null,
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"< 1 year",
"8 years",
"< 1 year",
"10+ years",
"4 years",
"9 years",
null,
"3 years",
"< 1 year",
"5 years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"7 years",
"3 years",
"6 years",
"10+ years",
"10+ years",
"8 years",
"2 years",
"7 years",
"3 years",
"9 years",
"7 years",
"< 1 year",
"4 years",
"5 years",
"7 years",
"6 years",
"10+ years",
"2 years",
"10+ years",
"8 years",
"6 years",
"< 1 year",
"2 years",
"< 1 year",
"6 years",
null,
"< 1 year",
"< 1 year",
"8 years",
"9 years",
"10+ years",
"1 year",
"< 1 year",
"9 years",
"3 years",
"10+ years",
null,
"8 years",
"10+ years",
"6 years",
"2 years",
null,
"10+ years",
"4 years",
"8 years",
"< 1 year",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
null,
"4 years",
"2 years",
"4 years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"4 years",
"9 years",
null,
"2 years",
"10+ years",
null,
"5 years",
"7 years",
"1 year",
"10+ years",
"< 1 year",
"< 1 year",
"2 years",
"3 years",
"2 years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
null,
"10+ years",
"5 years",
null,
"10+ years",
"7 years",
"< 1 year",
"2 years",
"5 years",
null,
"7 years",
"5 years",
"3 years",
"1 year",
"1 year",
"7 years",
"7 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"5 years",
"< 1 year",
"10+ years",
"2 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"5 years",
"2 years",
"6 years",
"4 years",
"1 year",
"3 years",
"10+ years",
"3 years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"2 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"7 years",
"6 years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
null,
"< 1 year",
null,
"2 years",
"5 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"2 years",
"10+ years",
"2 years",
"5 years",
null,
"8 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
null,
"5 years",
"2 years",
"6 years",
"10+ years",
"1 year",
"2 years",
"9 years",
"7 years",
"3 years",
"5 years",
"4 years",
"5 years",
"3 years",
"5 years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"9 years",
"7 years",
"10+ years",
"10+ years",
"8 years",
"7 years",
"10+ years",
null,
"6 years",
null,
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"1 year",
null,
"10+ years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"2 years",
"< 1 year",
"5 years",
"1 year",
"4 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"7 years",
"< 1 year",
"< 1 year",
"10+ years",
"7 years",
"< 1 year",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
null,
"3 years",
"5 years",
null,
"7 years",
"3 years",
"< 1 year",
"4 years",
"1 year",
"5 years",
"< 1 year",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"6 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
null,
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"2 years",
"10+ years",
"1 year",
"4 years",
"10+ years",
"4 years",
null,
"3 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"9 years",
"1 year",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"2 years",
"3 years",
null,
"10+ years",
"10+ years",
"1 year",
"4 years",
"4 years",
"5 years",
null,
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"7 years",
null,
"2 years",
"< 1 year",
"6 years",
"2 years",
"10+ years",
"< 1 year",
"4 years",
"3 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
null,
null,
"6 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"6 years",
"4 years",
"10+ years",
null,
"< 1 year",
"8 years",
null,
"1 year",
"10+ years",
null,
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"3 years",
"4 years",
"9 years",
"10+ years",
"9 years",
"2 years",
"1 year",
"7 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
null,
"10+ years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
null,
"6 years",
"10+ years",
"10+ years",
"2 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
null,
"9 years",
"1 year",
"8 years",
"< 1 year",
"2 years",
"1 year",
"4 years",
"2 years",
null,
"< 1 year",
"10+ years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
null,
"5 years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"2 years",
"3 years",
"10+ years",
"1 year",
"2 years",
"2 years",
"8 years",
"3 years",
"4 years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"4 years",
"1 year",
"6 years",
"9 years",
"6 years",
"1 year",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"< 1 year",
"2 years",
"5 years",
"8 years",
"7 years",
"10+ years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"9 years",
"3 years",
"9 years",
"1 year",
"3 years",
"< 1 year",
"6 years",
"6 years",
"5 years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"2 years",
"7 years",
"10+ years",
"3 years",
"2 years",
"2 years",
"8 years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"1 year",
"1 year",
null,
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"4 years",
null,
"7 years",
"6 years",
"10+ years",
"2 years",
"7 years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"7 years",
"4 years",
"5 years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"6 years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"8 years",
"6 years",
null,
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"< 1 year",
"4 years",
"2 years",
"5 years",
"4 years",
"7 years",
"1 year",
"10+ years",
"7 years",
null,
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
null,
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"7 years",
"4 years",
"10+ years",
"< 1 year",
"3 years",
"4 years",
"< 1 year",
"4 years",
"10+ years",
"9 years",
"< 1 year",
"1 year",
"1 year",
"3 years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"8 years",
"2 years",
"9 years",
"10+ years",
"10+ years",
"9 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"4 years",
"10+ years",
"9 years",
"10+ years",
"4 years",
"1 year",
"3 years",
"10+ years",
"8 years",
"10+ years",
"4 years",
"6 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"< 1 year",
"3 years",
"2 years",
"7 years",
"5 years",
"8 years",
"1 year",
"10+ years",
"10+ years",
null,
"2 years",
null,
"5 years",
"5 years",
"3 years",
"10+ years",
"4 years",
"1 year",
"9 years",
"4 years",
"2 years",
"10+ years",
"1 year",
"1 year",
"< 1 year",
"10+ years",
"2 years",
"4 years",
"10+ years",
"< 1 year",
"3 years",
"9 years",
null,
"7 years",
"2 years",
"1 year",
"3 years",
"2 years",
"10+ years",
null,
null,
"5 years",
"1 year",
"6 years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"8 years",
null,
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"3 years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"2 years",
"6 years",
"2 years",
"1 year",
"3 years",
"2 years",
"7 years",
"2 years",
"4 years",
"3 years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"1 year",
"4 years",
"1 year",
"10+ years",
"2 years",
"5 years",
"10+ years",
null,
"1 year",
"7 years",
"3 years",
"< 1 year",
"9 years",
"10+ years",
"8 years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"7 years",
"5 years",
"4 years",
"10+ years",
"1 year",
"4 years",
"3 years",
"4 years",
null,
"4 years",
"4 years",
"10+ years",
null,
"7 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"6 years",
"4 years",
"4 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"1 year",
"7 years",
"10+ years",
"6 years",
"1 year",
"< 1 year",
"8 years",
"10+ years",
"1 year",
"10+ years",
"5 years",
"10+ years",
"6 years",
"3 years",
"6 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"7 years",
"7 years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"10+ years",
"7 years",
"10+ years",
"8 years",
null,
"7 years",
"2 years",
"4 years",
"9 years",
"10+ years",
"3 years",
"< 1 year",
"4 years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"3 years",
"2 years",
"2 years",
"3 years",
"9 years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"8 years",
"2 years",
"10+ years",
"8 years",
"9 years",
null,
"5 years",
"2 years",
"< 1 year",
"< 1 year",
"10+ years",
"2 years",
"2 years",
"3 years",
"6 years",
"10+ years",
null,
"10+ years",
"10+ years",
"4 years",
"2 years",
"8 years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"5 years",
"6 years",
"3 years",
"7 years",
"3 years",
"10+ years",
"1 year",
"7 years",
"3 years",
"5 years",
"10+ years",
"1 year",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"9 years",
"10+ years",
"9 years",
"10+ years",
"5 years",
"9 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"6 years",
"8 years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"6 years",
"10+ years",
"1 year",
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"2 years",
"< 1 year",
"2 years",
"9 years",
"< 1 year",
"8 years",
"5 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"< 1 year",
"6 years",
"10+ years",
"7 years",
"7 years",
"2 years",
"5 years",
"8 years",
"10+ years",
"7 years",
"1 year",
"9 years",
"3 years",
"2 years",
"3 years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"4 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
null,
"< 1 year",
"10+ years",
"6 years",
"4 years",
"2 years",
"8 years",
"< 1 year",
"3 years",
"7 years",
"2 years",
"10+ years",
"5 years",
"2 years",
"1 year",
"5 years",
"8 years",
"8 years",
"7 years",
"10+ years",
"< 1 year",
"3 years",
"< 1 year",
"4 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"7 years",
"7 years",
"6 years",
"10+ years",
"< 1 year",
"4 years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"7 years",
"< 1 year",
"10+ years",
"2 years",
"3 years",
"< 1 year",
"9 years",
"< 1 year",
"5 years",
"3 years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"3 years",
"8 years",
"10+ years",
"10+ years",
null,
"5 years",
"9 years",
"10+ years",
"8 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"< 1 year",
"8 years",
"7 years",
"9 years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"5 years",
"1 year",
"10+ years",
"9 years",
"6 years",
"< 1 year",
"7 years",
"7 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
null,
null,
"6 years",
"2 years",
"4 years",
"10+ years",
"4 years",
"2 years",
"8 years",
"8 years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
"3 years",
"< 1 year",
"3 years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"5 years",
"< 1 year",
"10+ years",
"< 1 year",
"8 years",
"2 years",
"7 years",
"< 1 year",
"3 years",
"5 years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"1 year",
"9 years",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"2 years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"8 years",
"< 1 year",
"5 years",
"10+ years",
"9 years",
"4 years",
"4 years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"8 years",
"4 years",
"5 years",
"7 years",
"< 1 year",
"7 years",
"< 1 year",
"3 years",
null,
"2 years",
"7 years",
"6 years",
"10+ years",
"5 years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"5 years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
null,
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"2 years",
"6 years",
"5 years",
"10+ years",
"5 years",
"< 1 year",
"1 year",
"10+ years",
"7 years",
"1 year",
"2 years",
"6 years",
"7 years",
"4 years",
"8 years",
"1 year",
"10+ years",
"8 years",
"4 years",
"7 years",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"8 years",
"5 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"7 years",
"3 years",
"9 years",
"9 years",
"6 years",
"1 year",
"2 years",
"4 years",
"2 years",
"< 1 year",
"9 years",
"10+ years",
"3 years",
"1 year",
null,
"8 years",
"6 years",
"2 years",
"7 years",
"10+ years",
null,
"1 year",
"10+ years",
"5 years",
"5 years",
"7 years",
"6 years",
"5 years",
"7 years",
"< 1 year",
"7 years",
"1 year",
"9 years",
null,
"3 years",
"< 1 year",
"3 years",
"3 years",
null,
"10+ years",
"10+ years",
"4 years",
"10+ years",
"7 years",
"2 years",
"< 1 year",
"5 years",
"8 years",
"2 years",
"10+ years",
null,
"10+ years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"2 years",
"< 1 year",
"5 years",
"5 years",
"4 years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"6 years",
"1 year",
null,
"10+ years",
"6 years",
"3 years",
"10+ years",
"9 years",
"9 years",
"3 years",
"7 years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"6 years",
"2 years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"< 1 year",
"10+ years",
"3 years",
"1 year",
"6 years",
"4 years",
"9 years",
"1 year",
"10+ years",
"4 years",
"5 years",
"8 years",
"3 years",
"9 years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"4 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"8 years",
"9 years",
"4 years",
"3 years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"8 years",
"5 years",
"9 years",
"10+ years",
"10+ years",
"1 year",
"7 years",
"10+ years",
"2 years",
"< 1 year",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"2 years",
"3 years",
"9 years",
"2 years",
"2 years",
"3 years",
"1 year",
null,
null,
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"< 1 year",
"10+ years",
"5 years",
"6 years",
"5 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"10+ years",
null,
"5 years",
"< 1 year",
"10+ years",
"2 years",
"3 years",
"5 years",
"< 1 year",
"2 years",
"6 years",
"5 years",
"1 year",
"8 years",
"6 years",
"2 years",
"4 years",
"9 years",
"10+ years",
"10+ years",
null,
"< 1 year",
"3 years",
"< 1 year",
"5 years",
"2 years",
"5 years",
"8 years",
null,
null,
"10+ years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"8 years",
"5 years",
"6 years",
"4 years",
"2 years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"5 years",
"3 years",
"10+ years",
"5 years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
null,
"8 years",
"4 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"6 years",
"2 years",
"2 years",
"< 1 year",
"9 years",
"2 years",
"10+ years",
"8 years",
null,
"5 years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"1 year",
"1 year",
null,
"10+ years",
"3 years",
"1 year",
"7 years",
"8 years",
"< 1 year",
"10+ years",
"2 years",
"2 years",
"4 years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"5 years",
"2 years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"7 years",
"10+ years",
"4 years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"9 years",
null,
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"7 years",
"7 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"6 years",
"< 1 year",
"8 years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"4 years",
"7 years",
"7 years",
"< 1 year",
"10+ years",
"3 years",
"8 years",
"2 years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"10+ years",
"8 years",
"2 years",
"2 years",
"6 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"2 years",
null,
"2 years",
"5 years",
"9 years",
"7 years",
"5 years",
"2 years",
"9 years",
"3 years",
"3 years",
null,
"10+ years",
"< 1 year",
"3 years",
null,
"10+ years",
"10+ years",
"6 years",
"4 years",
"10+ years",
"9 years",
"10+ years",
"7 years",
"6 years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"< 1 year",
"< 1 year",
"5 years",
"5 years",
"3 years",
"10+ years",
null,
"5 years",
null,
"5 years",
"6 years",
"< 1 year",
"< 1 year",
"9 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"1 year",
"3 years",
"10+ years",
"5 years",
"5 years",
"7 years",
null,
"9 years",
"7 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"2 years",
"9 years",
"9 years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"5 years",
"10+ years",
null,
null,
"10+ years",
"6 years",
"< 1 year",
"7 years",
"8 years",
"3 years",
"8 years",
"3 years",
null,
"10+ years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"10+ years",
"3 years",
"8 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"1 year",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"7 years",
null,
"9 years",
"1 year",
"10+ years",
"2 years",
"< 1 year",
null,
"6 years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"6 years",
"6 years",
"10+ years",
"3 years",
"2 years",
"1 year",
"10+ years",
"1 year",
"2 years",
"1 year",
"9 years",
"10+ years",
"10+ years",
null,
"4 years",
"10+ years",
"10+ years",
null,
"5 years",
null,
"6 years",
"8 years",
"7 years",
"6 years",
"9 years",
"10+ years",
"6 years",
"10+ years",
"9 years",
"4 years",
"2 years",
"2 years",
"< 1 year",
"2 years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"8 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"9 years",
"4 years",
"8 years",
"< 1 year",
null,
"9 years",
"9 years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"4 years",
"5 years",
"6 years",
"8 years",
"5 years",
"2 years",
"1 year",
"10+ years",
null,
"9 years",
"6 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"2 years",
"2 years",
"1 year",
"4 years",
"6 years",
"10+ years",
"10+ years",
"9 years",
null,
"2 years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"6 years",
"1 year",
"2 years",
"1 year",
"5 years",
"3 years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
null,
"10+ years",
"7 years",
"9 years",
"2 years",
"1 year",
"< 1 year",
null,
"5 years",
"2 years",
null,
"10+ years",
"10+ years",
"8 years",
"1 year",
"3 years",
"1 year",
"< 1 year",
"6 years",
"4 years",
"< 1 year",
"8 years",
"10+ years",
"5 years",
"10+ years",
"1 year",
null,
"10+ years",
"< 1 year",
"3 years",
"< 1 year",
"2 years",
"8 years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"5 years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"7 years",
"5 years",
"7 years",
"10+ years",
null,
"5 years",
"2 years",
"6 years",
"7 years",
"2 years",
"10+ years",
"1 year",
"8 years",
"4 years",
"< 1 year",
null,
"9 years",
"8 years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"7 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"8 years",
"1 year",
"6 years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"5 years",
"10+ years",
"4 years",
"8 years",
"< 1 year",
"4 years",
"2 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
null,
"3 years",
"8 years",
"10+ years",
"9 years",
"5 years",
"8 years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"2 years",
"4 years",
"7 years",
"1 year",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"5 years",
"5 years",
"10+ years",
"6 years",
"1 year",
"10+ years",
null,
"10+ years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"3 years",
"4 years",
"2 years",
"1 year",
"5 years",
"2 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"1 year",
"10+ years",
"8 years",
"2 years",
"10+ years",
"4 years",
"5 years",
"4 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"8 years",
"8 years",
"4 years",
"10+ years",
"10+ years",
"6 years",
"5 years",
"3 years",
"10+ years",
"1 year",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"2 years",
"1 year",
"8 years",
"10+ years",
"1 year",
"3 years",
"7 years",
"10+ years",
"6 years",
"3 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"2 years",
"< 1 year",
"10+ years",
null,
"< 1 year",
"10+ years",
null,
"10+ years",
"10+ years",
null,
"10+ years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"10+ years",
null,
"10+ years",
"10+ years",
"3 years",
"5 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"7 years",
"3 years",
"< 1 year",
"< 1 year",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"5 years",
"3 years",
null,
"6 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
null,
"8 years",
"10+ years",
"4 years",
"4 years",
"7 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"1 year",
"4 years",
"5 years",
"< 1 year",
"7 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"9 years",
"2 years",
"8 years",
"< 1 year",
"< 1 year",
"< 1 year",
"1 year",
"2 years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"4 years",
"4 years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"8 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"1 year",
"7 years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"2 years",
"10+ years",
"1 year",
"2 years",
"3 years",
"6 years",
"9 years",
"10+ years",
"8 years",
"3 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"8 years",
"9 years",
"9 years",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
null,
"8 years",
"7 years",
"2 years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"< 1 year",
"< 1 year",
"4 years",
"< 1 year",
"7 years",
"2 years",
"< 1 year",
"10+ years",
"9 years",
"4 years",
"3 years",
"3 years",
"10+ years",
"2 years",
"5 years",
"7 years",
"3 years",
"2 years",
null,
"5 years",
"4 years",
"4 years",
"9 years",
"5 years",
null,
"2 years",
"10+ years",
null,
"10+ years",
"5 years",
null,
"4 years",
"5 years",
"10+ years",
null,
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"10+ years",
null,
"10+ years",
"< 1 year",
"4 years",
null,
"2 years",
"7 years",
"2 years",
"10+ years",
"6 years",
"8 years",
"10+ years",
"8 years",
"10+ years",
"1 year",
"< 1 year",
null,
"10+ years",
"6 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"2 years",
null,
null,
"7 years",
"1 year",
"< 1 year",
"8 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"4 years",
"< 1 year",
"10+ years",
"3 years",
"8 years",
"2 years",
"6 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"1 year",
"8 years",
"8 years",
"10+ years",
"2 years",
"8 years",
"9 years",
"2 years",
"7 years",
"3 years",
"2 years",
"< 1 year",
"7 years",
"10+ years",
"9 years",
"2 years",
"5 years",
null,
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
null,
"7 years",
"10+ years",
null,
null,
"7 years",
"3 years",
"2 years",
"10+ years",
"< 1 year",
"< 1 year",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"< 1 year",
"10+ years",
"5 years",
"9 years",
"1 year",
"10+ years",
"7 years",
"4 years",
"1 year",
"10+ years",
"5 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"4 years",
"1 year",
"< 1 year",
"3 years",
null,
"1 year",
"7 years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"10+ years",
"4 years",
"3 years",
"10+ years",
"8 years",
"2 years",
"1 year",
"4 years",
"2 years",
"10+ years",
"6 years",
"< 1 year",
"8 years",
"10+ years",
"3 years",
"5 years",
"2 years",
"4 years",
"6 years",
"5 years",
"8 years",
"< 1 year",
"10+ years",
"3 years",
"3 years",
"3 years",
"10+ years",
"4 years",
"4 years",
"10+ years",
"2 years",
"8 years",
"9 years",
"8 years",
"10+ years",
"4 years",
null,
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
null,
"1 year",
"10+ years",
"4 years",
"3 years",
"5 years",
"1 year",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"5 years",
"6 years",
"7 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"1 year",
"5 years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
null,
"3 years",
"10+ years",
"10+ years",
"9 years",
"2 years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
null,
null,
null,
"7 years",
"7 years",
"10+ years",
"6 years",
"3 years",
"4 years",
"< 1 year",
"2 years",
"2 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"3 years",
"2 years",
"4 years",
"8 years",
"4 years",
"< 1 year",
null,
null,
"10+ years",
"3 years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"7 years",
"4 years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"3 years",
"7 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"10+ years",
null,
"9 years",
"10+ years",
"6 years",
"10+ years",
null,
null,
"5 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"7 years",
"6 years",
"1 year",
"3 years",
"2 years",
"2 years",
"10+ years",
"5 years",
"6 years",
"10+ years",
"1 year",
"10+ years",
"6 years",
"< 1 year",
"4 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"5 years",
"1 year",
"< 1 year",
"10+ years",
"1 year",
"1 year",
"10+ years",
"7 years",
"3 years",
"< 1 year",
"10+ years",
"4 years",
null,
"< 1 year",
"6 years",
null,
"2 years",
"4 years",
"1 year",
"7 years",
"10+ years",
null,
"5 years",
"2 years",
"8 years",
"8 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"10+ years",
null,
"4 years",
"5 years",
"5 years",
"9 years",
"10+ years",
"3 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"9 years",
"4 years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
null,
"9 years",
"2 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"< 1 year",
"4 years",
"5 years",
"10+ years",
"7 years",
"5 years",
"6 years",
"6 years",
"2 years",
"< 1 year",
"3 years",
"8 years",
"8 years",
"5 years",
"10+ years",
"3 years",
"< 1 year",
"4 years",
"4 years",
"2 years",
"8 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"9 years",
"10+ years",
"7 years",
"3 years",
"5 years",
"6 years",
"4 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"6 years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"< 1 year",
"4 years",
"7 years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"5 years",
"1 year",
"1 year",
"4 years",
"3 years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"10+ years",
null,
"3 years",
"3 years",
"10+ years",
"1 year",
"4 years",
"1 year",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"2 years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"6 years",
"7 years",
"2 years",
null,
"9 years",
null,
"2 years",
"< 1 year",
"9 years",
"2 years",
"8 years",
"2 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"2 years",
"9 years",
"6 years",
"10+ years",
"1 year",
"4 years",
"9 years",
"5 years",
"9 years",
"< 1 year",
"9 years",
"2 years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"5 years",
null,
"4 years",
"6 years",
"6 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"3 years",
"7 years",
"1 year",
"3 years",
"3 years",
"4 years",
"3 years",
"2 years",
"1 year",
"3 years",
null,
"7 years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"6 years",
"3 years",
"8 years",
"1 year",
null,
"10+ years",
"8 years",
"10+ years",
"6 years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"5 years",
"9 years",
"3 years",
"5 years",
null,
"10+ years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"2 years",
"10+ years",
"2 years",
"< 1 year",
"1 year",
"1 year",
"2 years",
"3 years",
"< 1 year",
"5 years",
"2 years",
"10+ years",
"3 years",
"9 years",
"10+ years",
"8 years",
"6 years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"9 years",
null,
"7 years",
"1 year",
"7 years",
"7 years",
"8 years",
"5 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"< 1 year",
"< 1 year",
"3 years",
"< 1 year",
"5 years",
"8 years",
"5 years",
"1 year",
"5 years",
"< 1 year",
"8 years",
"4 years",
"6 years",
"1 year",
"2 years",
"5 years",
"10+ years",
"6 years",
"3 years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
null,
"5 years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"2 years",
"4 years",
"2 years",
"10+ years",
"2 years",
"7 years",
"2 years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"< 1 year",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"5 years",
"6 years",
"5 years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"8 years",
"6 years",
"7 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"1 year",
"4 years",
"9 years",
"10+ years",
"< 1 year",
null,
"6 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"6 years",
"2 years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"3 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
null,
"1 year",
"7 years",
null,
null,
"2 years",
"10+ years",
"5 years",
"6 years",
"3 years",
"10+ years",
"3 years",
"6 years",
"1 year",
"7 years",
"1 year",
"2 years",
"8 years",
"2 years",
"4 years",
"10+ years",
"10+ years",
null,
null,
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"8 years",
"6 years",
"3 years",
"2 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
null,
null,
"9 years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"6 years",
"2 years",
"10+ years",
"2 years",
"7 years",
"5 years",
"10+ years",
"1 year",
"9 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"8 years",
"9 years",
"2 years",
"6 years",
"< 1 year",
"5 years",
null,
"6 years",
"10+ years",
"8 years",
"8 years",
"2 years",
"10+ years",
"4 years",
"2 years",
"3 years",
"1 year",
"2 years",
"< 1 year",
"9 years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"1 year",
null,
"1 year",
"2 years",
"10+ years",
"10+ years",
"8 years",
"2 years",
"8 years",
"8 years",
"10+ years",
"6 years",
"3 years",
"< 1 year",
"7 years",
"3 years",
"2 years",
"8 years",
"2 years",
"10+ years",
"2 years",
"3 years",
"4 years",
"10+ years",
"2 years",
"4 years",
"9 years",
"7 years",
"2 years",
"< 1 year",
"< 1 year",
"10+ years",
"< 1 year",
"1 year",
"2 years",
"10+ years",
"8 years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"6 years",
"3 years",
null,
"6 years",
"4 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"6 years",
"6 years",
"7 years",
"10+ years",
"3 years",
null,
"5 years",
"10+ years",
"6 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"7 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"5 years",
"6 years",
"2 years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"2 years",
"7 years",
"3 years",
"3 years",
"4 years",
"4 years",
"7 years",
"5 years",
"10+ years",
"9 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"7 years",
"4 years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"9 years",
null,
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"9 years",
"7 years",
"1 year",
"< 1 year",
"5 years",
"6 years",
"5 years",
"9 years",
"5 years",
"5 years",
null,
"5 years",
"10+ years",
"1 year",
"3 years",
"6 years",
"7 years",
"2 years",
"10+ years",
"< 1 year",
"3 years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"< 1 year",
"3 years",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"3 years",
"9 years",
"10+ years",
null,
"3 years",
"8 years",
"10+ years",
"6 years",
null,
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"4 years",
"3 years",
"6 years",
"10+ years",
"2 years",
"9 years",
"5 years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
null,
"8 years",
"1 year",
"3 years",
"1 year",
"3 years",
"6 years",
"10+ years",
"4 years",
null,
"4 years",
"10+ years",
"10+ years",
"6 years",
"4 years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"8 years",
null,
"1 year",
"4 years",
"10+ years",
"3 years",
"< 1 year",
"7 years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"6 years",
"5 years",
"2 years",
"10+ years",
"6 years",
"1 year",
"2 years",
null,
"10+ years",
"3 years",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"8 years",
"10+ years",
"4 years",
null,
"10+ years",
null,
"10+ years",
null,
"4 years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"4 years",
"6 years",
"4 years",
"8 years",
"1 year",
"7 years",
"< 1 year",
"7 years",
"6 years",
"9 years",
"10+ years",
"2 years",
"1 year",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"7 years",
"10+ years",
"6 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"8 years",
null,
"10+ years",
"1 year",
"3 years",
"10+ years",
"1 year",
"7 years",
"10+ years",
"1 year",
"5 years",
"10+ years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"1 year",
"8 years",
"7 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"7 years",
"2 years",
"< 1 year",
"1 year",
"1 year",
"5 years",
"4 years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"8 years",
"2 years",
"1 year",
"10+ years",
"1 year",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"9 years",
"2 years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"5 years",
"7 years",
"9 years",
"6 years",
"5 years",
"< 1 year",
"2 years",
"< 1 year",
"9 years",
"4 years",
"10+ years",
"2 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"2 years",
"7 years",
"7 years",
null,
"< 1 year",
"6 years",
"10+ years",
"7 years",
"3 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"9 years",
"2 years",
"< 1 year",
"1 year",
"5 years",
"< 1 year",
"9 years",
"2 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"1 year",
"3 years",
"10+ years",
"5 years",
"4 years",
"5 years",
"8 years",
"10+ years",
null,
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"4 years",
null,
"3 years",
"10+ years",
null,
null,
"6 years",
"< 1 year",
"8 years",
"10+ years",
"1 year",
"< 1 year",
null,
"10+ years",
null,
"10+ years",
"3 years",
"10+ years",
"1 year",
"5 years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"3 years",
"6 years",
"< 1 year",
"1 year",
"7 years",
"10+ years",
"2 years",
"< 1 year",
"3 years",
"< 1 year",
"3 years",
"2 years",
"3 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"5 years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"5 years",
"9 years",
"4 years",
"1 year",
"10+ years",
"8 years",
"10+ years",
"1 year",
null,
"10+ years",
"2 years",
"10+ years",
"4 years",
"2 years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"9 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"4 years",
"10+ years",
"1 year",
"10+ years",
null,
"10+ years",
"4 years",
"10+ years",
"5 years",
"10+ years",
"9 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"2 years",
"3 years",
"< 1 year",
"< 1 year",
"10+ years",
"5 years",
null,
"6 years",
"1 year",
"5 years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"9 years",
"8 years",
"8 years",
"6 years",
null,
"6 years",
"7 years",
"< 1 year",
null,
"10+ years",
"10+ years",
"3 years",
"10+ years",
null,
"8 years",
"9 years",
"8 years",
"5 years",
"5 years",
null,
"2 years",
"2 years",
"5 years",
"10+ years",
"2 years",
"2 years",
"1 year",
"8 years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"3 years",
"3 years",
null,
"10+ years",
"4 years",
null,
"10+ years",
"10+ years",
null,
"10+ years",
"6 years",
"10+ years",
"9 years",
"< 1 year",
"5 years",
"8 years",
"1 year",
"9 years",
"8 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"1 year",
"4 years",
"< 1 year",
"10+ years",
"2 years",
"3 years",
"10+ years",
"3 years",
"3 years",
"1 year",
"8 years",
"< 1 year",
"< 1 year",
"5 years",
null,
"10+ years",
"1 year",
"3 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"< 1 year",
"6 years",
"7 years",
"3 years",
"9 years",
"10+ years",
"9 years",
"2 years",
"6 years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"2 years",
"4 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
null,
"< 1 year",
"4 years",
"1 year",
"1 year",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"7 years",
"10+ years",
null,
"7 years",
"10+ years",
"9 years",
"5 years",
"5 years",
"1 year",
"< 1 year",
"< 1 year",
"5 years",
"2 years",
"6 years",
"2 years",
null,
"6 years",
"4 years",
"7 years",
"3 years",
"2 years",
"4 years",
"10+ years",
"5 years",
"3 years",
"4 years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"6 years",
"< 1 year",
"9 years",
"4 years",
"3 years",
"3 years",
"< 1 year",
"8 years",
"3 years",
"5 years",
"5 years",
"10+ years",
"10+ years",
null,
null,
"10+ years",
"8 years",
"10+ years",
"8 years",
"9 years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"7 years",
"6 years",
"2 years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
null,
"2 years",
"7 years",
"3 years",
"1 year",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"7 years",
"6 years",
"10+ years",
"< 1 year",
null,
"4 years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
null,
"1 year",
"10+ years",
"10+ years",
"2 years",
null,
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
null,
"10+ years",
"7 years",
"2 years",
"2 years",
"7 years",
"2 years",
"1 year",
null,
"10+ years",
"10+ years",
"4 years",
"4 years",
"5 years",
"< 1 year",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"6 years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"7 years",
"2 years",
null,
"10+ years",
"9 years",
"1 year",
"2 years",
"2 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"8 years",
"3 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"5 years",
"2 years",
"6 years",
"4 years",
"1 year",
"10+ years",
"6 years",
"10+ years",
"5 years",
"< 1 year",
"3 years",
null,
"2 years",
"7 years",
"1 year",
"5 years",
"3 years",
"10+ years",
"5 years",
null,
"8 years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"10+ years",
"7 years",
"< 1 year",
"3 years",
"4 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
null,
"7 years",
"1 year",
"9 years",
"8 years",
"9 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"5 years",
"7 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
null,
"10+ years",
"8 years",
"7 years",
null,
"7 years",
"7 years",
"1 year",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"5 years",
"4 years",
"9 years",
"1 year",
"< 1 year",
"8 years",
"8 years",
"5 years",
"10+ years",
"6 years",
"3 years",
"8 years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"6 years",
"8 years",
"6 years",
"10+ years",
"4 years",
"< 1 year",
"< 1 year",
"8 years",
"10+ years",
"4 years",
"1 year",
"3 years",
"1 year",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"3 years",
"9 years",
"< 1 year",
"10+ years",
"1 year",
"5 years",
"7 years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"3 years",
"3 years",
"5 years",
"< 1 year",
"8 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"4 years",
"6 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"6 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"9 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"6 years",
"5 years",
"5 years",
"3 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"9 years",
"10+ years",
"1 year",
"2 years",
null,
"2 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"1 year",
"9 years",
"5 years",
"< 1 year",
"3 years",
"3 years",
"< 1 year",
"9 years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"6 years",
"5 years",
"9 years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"5 years",
"9 years",
"7 years",
"1 year",
"10+ years",
null,
"10+ years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"7 years",
"10+ years",
"5 years",
"6 years",
"< 1 year",
"9 years",
"6 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"1 year",
"3 years",
"1 year",
"10+ years",
null,
"3 years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
null,
"7 years",
"6 years",
"8 years",
"10+ years",
"8 years",
"10+ years",
"7 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"10+ years",
"9 years",
"< 1 year",
null,
null,
"10+ years",
"2 years",
"10+ years",
"1 year",
"10+ years",
null,
null,
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"2 years",
"10+ years",
"5 years",
"9 years",
"4 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"7 years",
"2 years",
"10+ years",
null,
"10+ years",
"10+ years",
"1 year",
"6 years",
"7 years",
"4 years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"1 year",
"2 years",
"3 years",
"10+ years",
"2 years",
"2 years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"3 years",
"< 1 year",
"1 year",
"4 years",
"6 years",
"7 years",
"10+ years",
"10+ years",
"3 years",
"9 years",
"10+ years",
"6 years",
"6 years",
"< 1 year",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
null,
"10+ years",
"3 years",
"1 year",
"10+ years",
"5 years",
"10+ years",
"6 years",
"< 1 year",
"10+ years",
null,
null,
"5 years",
"3 years",
"10+ years",
"7 years",
"2 years",
"3 years",
"1 year",
"3 years",
"10+ years",
null,
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"5 years",
"5 years",
"5 years",
"7 years",
"8 years",
"9 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"1 year",
"3 years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"4 years",
"2 years",
null,
"10+ years",
"6 years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"1 year",
"9 years",
"10+ years",
null,
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"6 years",
"3 years",
"10+ years",
"6 years",
null,
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"9 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"7 years",
null,
"10+ years",
"6 years",
"2 years",
"10+ years",
"9 years",
"9 years",
"< 1 year",
null,
"9 years",
"10+ years",
null,
"1 year",
"10+ years",
"4 years",
"1 year",
"5 years",
"4 years",
"6 years",
null,
"2 years",
"5 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
null,
"7 years",
"1 year",
"4 years",
"< 1 year",
"10+ years",
"1 year",
"2 years",
"4 years",
"7 years",
"7 years",
"1 year",
"8 years",
"7 years",
"2 years",
"9 years",
"8 years",
"2 years",
"3 years",
"9 years",
"1 year",
null,
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"1 year",
"3 years",
"7 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"2 years",
"2 years",
"10+ years",
"8 years",
"7 years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"7 years",
"3 years",
"5 years",
"10+ years",
null,
"10+ years",
"6 years",
"7 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"1 year",
"10+ years",
"2 years",
"4 years",
"8 years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"8 years",
"1 year",
"10+ years",
"10+ years",
"7 years",
"2 years",
"6 years",
"7 years",
"3 years",
"2 years",
"< 1 year",
"5 years",
"7 years",
"7 years",
"10+ years",
"5 years",
"9 years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
null,
"1 year",
"< 1 year",
"10+ years",
null,
"4 years",
"9 years",
"7 years",
"5 years",
"10+ years",
"10+ years",
null,
"7 years",
"10+ years",
"< 1 year",
"2 years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"6 years",
"2 years",
"< 1 year",
"10+ years",
null,
"2 years",
"1 year",
"7 years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"10+ years",
"4 years",
"7 years",
null,
"10+ years",
"6 years",
"6 years",
"3 years",
"8 years",
"< 1 year",
null,
"3 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
null,
null,
"4 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"6 years",
"10+ years",
"7 years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"1 year",
"4 years",
"10+ years",
"10+ years",
"6 years",
"< 1 year",
"3 years",
"7 years",
"9 years",
"8 years",
null,
"6 years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"1 year",
"5 years",
null,
"< 1 year",
"7 years",
null,
"10+ years",
"3 years",
null,
"10+ years",
"4 years",
"2 years",
null,
"< 1 year",
"2 years",
"< 1 year",
"9 years",
"3 years",
"1 year",
null,
"5 years",
"8 years",
"1 year",
"2 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"6 years",
"3 years",
"6 years",
"< 1 year",
"5 years",
"5 years",
"5 years",
"6 years",
"2 years",
"4 years",
"10+ years",
"1 year",
"8 years",
"< 1 year",
null,
"4 years",
"9 years",
"< 1 year",
"3 years",
"1 year",
"2 years",
"1 year",
"10+ years",
"10+ years",
"5 years",
null,
"6 years",
"3 years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"2 years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"8 years",
"5 years",
"5 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"5 years",
"5 years",
"9 years",
"5 years",
"< 1 year",
"1 year",
"10+ years",
"2 years",
"8 years",
"1 year",
"< 1 year",
"1 year",
"4 years",
"< 1 year",
"5 years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
null,
"6 years",
"< 1 year",
null,
"< 1 year",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"6 years",
"4 years",
"2 years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"8 years",
"10+ years",
"10+ years",
"5 years",
null,
"5 years",
"5 years",
"6 years",
"10+ years",
"10+ years",
"9 years",
"3 years",
"5 years",
"< 1 year",
"10+ years",
"6 years",
"1 year",
"2 years",
"8 years",
"< 1 year",
"3 years",
"< 1 year",
"7 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"3 years",
"10+ years",
"8 years",
"2 years",
"6 years",
"9 years",
"1 year",
"9 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"7 years",
"4 years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"5 years",
"6 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"6 years",
"4 years",
"3 years",
"8 years",
"4 years",
"10+ years",
"6 years",
"< 1 year",
"10+ years",
"9 years",
"9 years",
"< 1 year",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"< 1 year",
null,
null,
null,
"2 years",
"6 years",
"3 years",
"4 years",
"1 year",
"3 years",
"10+ years",
"7 years",
"5 years",
"2 years",
"3 years",
"8 years",
null,
"10+ years",
"< 1 year",
"1 year",
"9 years",
"10+ years",
"8 years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"7 years",
"7 years",
"10+ years",
"< 1 year",
"9 years",
"5 years",
"6 years",
"6 years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"7 years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"4 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"10+ years",
"3 years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"2 years",
"5 years",
"9 years",
"3 years",
"10+ years",
"3 years",
"1 year",
"3 years",
"2 years",
"9 years",
"10+ years",
null,
"10+ years",
"7 years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"4 years",
"1 year",
"9 years",
"< 1 year",
"3 years",
null,
"< 1 year",
"10+ years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"5 years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"8 years",
"10+ years",
"8 years",
"10+ years",
"4 years",
"6 years",
null,
"4 years",
"2 years",
"< 1 year",
"3 years",
"10+ years",
"2 years",
"4 years",
"6 years",
null,
"3 years",
"9 years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"1 year",
"2 years",
"4 years",
"4 years",
"10+ years",
"8 years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"1 year",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"6 years",
"3 years",
"10+ years",
"3 years",
"5 years",
"5 years",
"1 year",
"10+ years",
"6 years",
"2 years",
"2 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"6 years",
null,
"10+ years",
"5 years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"1 year",
null,
"4 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"9 years",
"7 years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"5 years",
"10+ years",
"3 years",
"1 year",
"6 years",
"10+ years",
"9 years",
"4 years",
null,
"2 years",
"10+ years",
"7 years",
"4 years",
"3 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"4 years",
"6 years",
"9 years",
"10+ years",
"1 year",
"2 years",
"2 years",
"10+ years",
"2 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"3 years",
"3 years",
"9 years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"8 years",
"3 years",
"3 years",
"< 1 year",
"3 years",
"7 years",
"< 1 year",
"6 years",
"3 years",
"< 1 year",
"10+ years",
"2 years",
null,
"1 year",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"2 years",
"7 years",
"8 years",
"10+ years",
"7 years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"6 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"7 years",
null,
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"1 year",
"7 years",
"9 years",
"6 years",
"5 years",
"9 years",
"6 years",
"10+ years",
"2 years",
"< 1 year",
"3 years",
"6 years",
"4 years",
"4 years",
"6 years",
"2 years",
"4 years",
"8 years",
"2 years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"< 1 year",
"< 1 year",
"7 years",
"10+ years",
"1 year",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"2 years",
"3 years",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"9 years",
"2 years",
"9 years",
"4 years",
"4 years",
"10+ years",
"8 years",
"8 years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"2 years",
"2 years",
"1 year",
"2 years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"3 years",
null,
"10+ years",
"10+ years",
"8 years",
"5 years",
"< 1 year",
"3 years",
"3 years",
null,
"10+ years",
"6 years",
"10+ years",
null,
"3 years",
null,
"10+ years",
"6 years",
"9 years",
"< 1 year",
"9 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"2 years",
"9 years",
"2 years",
"3 years",
"1 year",
"3 years",
"8 years",
"2 years",
"5 years",
"10+ years",
null,
"2 years",
"10+ years",
"8 years",
"9 years",
"9 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"4 years",
"2 years",
"1 year",
"5 years",
null,
"10+ years",
"10+ years",
"9 years",
"1 year",
"2 years",
"10+ years",
"6 years",
"1 year",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"2 years",
null,
"< 1 year",
null,
"10+ years",
"5 years",
"10+ years",
"4 years",
null,
"< 1 year",
"3 years",
"2 years",
"10+ years",
"5 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"6 years",
"10+ years",
"10+ years",
"2 years",
"7 years",
"1 year",
"4 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"9 years",
"6 years",
null,
"10+ years",
"6 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"4 years",
"8 years",
"8 years",
"10+ years",
"7 years",
"9 years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"9 years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"9 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"3 years",
"4 years",
"5 years",
"6 years",
"9 years",
"8 years",
"10+ years",
"10+ years",
null,
"8 years",
"< 1 year",
"2 years",
"10+ years",
"2 years",
"9 years",
null,
"10+ years",
"< 1 year",
null,
"3 years",
"9 years",
"10+ years",
"7 years",
"8 years",
null,
"7 years",
"10+ years",
"10+ years",
"1 year",
"4 years",
"9 years",
"10+ years",
"4 years",
"3 years",
"< 1 year",
"10+ years",
null,
"10+ years",
"7 years",
"10+ years",
"1 year",
"10+ years",
"4 years",
"4 years",
"< 1 year",
"2 years",
"10+ years",
"2 years",
"3 years",
"< 1 year",
"10+ years",
"2 years",
"8 years",
"10+ years",
"9 years",
"< 1 year",
"8 years",
"7 years",
"3 years",
"4 years",
"10+ years",
"9 years",
null,
"4 years",
"5 years",
"< 1 year",
"10+ years",
"6 years",
"5 years",
"6 years",
"3 years",
"2 years",
"2 years",
"10+ years",
"3 years",
"6 years",
"6 years",
"10+ years",
"1 year",
"9 years",
"3 years",
"< 1 year",
"6 years",
"10+ years",
null,
"10+ years",
"5 years",
null,
"10+ years",
"6 years",
"10+ years",
null,
"1 year",
"7 years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"9 years",
"9 years",
"10+ years",
"10+ years",
"5 years",
"6 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"7 years",
"3 years",
"4 years",
"7 years",
null,
"< 1 year",
"< 1 year",
"10+ years",
"4 years",
"2 years",
"2 years",
"8 years",
"10+ years",
"4 years",
"2 years",
"4 years",
"10+ years",
"1 year",
"10+ years",
"8 years",
"1 year",
"5 years",
"8 years",
"10+ years",
"3 years",
"4 years",
"7 years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
null,
null,
"9 years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"9 years",
null,
"6 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"2 years",
null,
"10+ years",
"5 years",
"10+ years",
"4 years",
"7 years",
"6 years",
null,
"10+ years",
"4 years",
"3 years",
"1 year",
"7 years",
"< 1 year",
"3 years",
"10+ years",
"7 years",
"< 1 year",
"8 years",
"2 years",
"10+ years",
null,
"6 years",
"3 years",
"1 year",
"3 years",
"8 years",
"< 1 year",
"1 year",
"8 years",
"10+ years",
"8 years",
"9 years",
"3 years",
"8 years",
"2 years",
"2 years",
"2 years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"1 year",
null,
"10+ years",
"1 year",
"3 years",
"1 year",
"< 1 year",
"10+ years",
"1 year",
null,
"7 years",
"10+ years",
"< 1 year",
null,
"2 years",
"10+ years",
"9 years",
"< 1 year",
"1 year",
"8 years",
"5 years",
"10+ years",
"7 years",
null,
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"6 years",
"1 year",
"9 years",
"7 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"2 years",
"3 years",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"7 years",
"10+ years",
"7 years",
"4 years",
"3 years",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"9 years",
"1 year",
"8 years",
"10+ years",
"1 year",
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
null,
"< 1 year",
"10+ years",
"6 years",
"< 1 year",
"10+ years",
"< 1 year",
"2 years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
null,
"5 years",
"3 years",
"2 years",
"10+ years",
"5 years",
"5 years",
"10+ years",
"3 years",
"5 years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
null,
"< 1 year",
"3 years",
"6 years",
"6 years",
"8 years",
"8 years",
"6 years",
"7 years",
null,
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"< 1 year",
"2 years",
"4 years",
"3 years",
"5 years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"6 years",
"< 1 year",
"8 years",
"< 1 year",
"1 year",
null,
"2 years",
"< 1 year",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"4 years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"2 years",
"< 1 year",
"4 years",
"6 years",
"8 years",
"10+ years",
"1 year",
"3 years",
"2 years",
"10+ years",
"8 years",
"5 years",
"4 years",
"< 1 year",
"5 years",
"4 years",
"1 year",
"1 year",
"10+ years",
"8 years",
"4 years",
"3 years",
"1 year",
null,
"1 year",
"3 years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"10+ years",
"1 year",
"5 years",
"10+ years",
"6 years",
"8 years",
"10+ years",
"10+ years",
"8 years",
"9 years",
"7 years",
"4 years",
"10+ years",
"7 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"4 years",
"9 years",
"10+ years",
"10+ years",
"6 years",
"8 years",
"2 years",
null,
"9 years",
"10+ years",
"5 years",
"8 years",
"10+ years",
"2 years",
"2 years",
"4 years",
"3 years",
"2 years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"6 years",
"10+ years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"4 years",
"1 year",
"6 years",
"8 years",
"4 years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
null,
"4 years",
"3 years",
"10+ years",
"7 years",
"4 years",
"5 years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"< 1 year",
"8 years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"1 year",
null,
"5 years",
"10+ years",
"< 1 year",
"< 1 year",
"6 years",
"< 1 year",
"7 years",
"3 years",
"7 years",
"3 years",
"10+ years",
"7 years",
"5 years",
"1 year",
"7 years",
null,
"3 years",
"10+ years",
null,
"8 years",
"10+ years",
"10+ years",
null,
"2 years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"2 years",
"1 year",
"8 years",
"9 years",
"10+ years",
"7 years",
"3 years",
"2 years",
"8 years",
"1 year",
"10+ years",
"1 year",
"4 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"2 years",
"3 years",
"5 years",
"3 years",
"9 years",
"10+ years",
"3 years",
"7 years",
"9 years",
"< 1 year",
"3 years",
"10+ years",
"2 years",
"2 years",
"< 1 year",
"10+ years",
null,
"10+ years",
"5 years",
"5 years",
"10+ years",
"1 year",
"3 years",
"6 years",
"10+ years",
"10+ years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"7 years",
"5 years",
"8 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"9 years",
"5 years",
"10+ years",
"3 years",
"3 years",
"< 1 year",
"10+ years",
"1 year",
"8 years",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"4 years",
"1 year",
"1 year",
"3 years",
"8 years",
"6 years",
"2 years",
"4 years",
"10+ years",
"3 years",
"5 years",
"4 years",
null,
"2 years",
"7 years",
"3 years",
"6 years",
"4 years",
"10+ years",
"10+ years",
null,
"1 year",
"10+ years",
"7 years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"7 years",
"6 years",
"7 years",
"4 years",
"4 years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
null,
"5 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"9 years",
"2 years",
"1 year",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"1 year",
"5 years",
"7 years",
"10+ years",
"8 years",
"7 years",
"8 years",
"9 years",
"8 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"7 years",
"8 years",
"5 years",
"10+ years",
"2 years",
"2 years",
null,
"5 years",
"2 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"3 years",
null,
"10+ years",
"10+ years",
"3 years",
"2 years",
"8 years",
"8 years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"5 years",
"8 years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"9 years",
"3 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"3 years",
"4 years",
"2 years",
"10+ years",
"6 years",
"6 years",
"4 years",
"10+ years",
"6 years",
"1 year",
"10+ years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"7 years",
null,
"7 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"7 years",
"4 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"4 years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"3 years",
null,
"3 years",
"1 year",
"1 year",
"10+ years",
null,
"1 year",
"4 years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
null,
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"3 years",
"7 years",
"4 years",
"10+ years",
"2 years",
"2 years",
"6 years",
null,
"1 year",
"8 years",
"3 years",
"9 years",
"10+ years",
"10+ years",
"6 years",
"< 1 year",
null,
"10+ years",
null,
"8 years",
null,
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"10+ years",
"1 year",
"3 years",
null,
"10+ years",
"6 years",
"2 years",
null,
"2 years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"5 years",
"2 years",
"2 years",
"8 years",
"6 years",
"10+ years",
"1 year",
"5 years",
"2 years",
"8 years",
"6 years",
"5 years",
"10+ years",
"< 1 year",
"3 years",
null,
"< 1 year",
null,
"10+ years",
"< 1 year",
"8 years",
"7 years",
"< 1 year",
"9 years",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"< 1 year",
"1 year",
"3 years",
"< 1 year",
"2 years",
"4 years",
"7 years",
"9 years",
"6 years",
"10+ years",
"9 years",
null,
"9 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"6 years",
"4 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"2 years",
"2 years",
"3 years",
"< 1 year",
"10+ years",
"9 years",
null,
"10+ years",
"9 years",
"10+ years",
"3 years",
null,
"2 years",
"7 years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
null,
"5 years",
"6 years",
"3 years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"< 1 year",
"1 year",
"5 years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"7 years",
"3 years",
"9 years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"1 year",
"4 years",
"5 years",
"1 year",
"3 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
null,
"6 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"6 years",
"2 years",
"5 years",
"8 years",
null,
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"6 years",
"1 year",
"3 years",
null,
"3 years",
null,
null,
"1 year",
"10+ years",
"10+ years",
"3 years",
"5 years",
"5 years",
"5 years",
"1 year",
"7 years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"1 year",
"5 years",
"3 years",
"10+ years",
"1 year",
"9 years",
"10+ years",
"10+ years",
"8 years",
"1 year",
"10+ years",
"4 years",
"10+ years",
"5 years",
"2 years",
"4 years",
"8 years",
"3 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"5 years",
"1 year",
"1 year",
"1 year",
"3 years",
"9 years",
"7 years",
"< 1 year",
"7 years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"10+ years",
null,
"5 years",
null,
"10+ years",
"3 years",
"5 years",
"6 years",
"< 1 year",
"3 years",
"10+ years",
"6 years",
"5 years",
"1 year",
"< 1 year",
"10+ years",
"8 years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
null,
"3 years",
"5 years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"< 1 year",
null,
"10+ years",
null,
"7 years",
"10+ years",
null,
"7 years",
"4 years",
"3 years",
"5 years",
"10+ years",
"1 year",
"2 years",
"< 1 year",
"< 1 year",
"3 years",
"7 years",
"10+ years",
"7 years",
"4 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"2 years",
"3 years",
null,
"10+ years",
"2 years",
"10+ years",
"9 years",
"2 years",
"4 years",
"< 1 year",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"8 years",
"5 years",
"3 years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"1 year",
"< 1 year",
null,
"3 years",
"10+ years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"10+ years",
"6 years",
"1 year",
null,
"10+ years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"2 years",
"10+ years",
"9 years",
"10+ years",
"1 year",
"6 years",
"< 1 year",
"5 years",
"< 1 year",
"10+ years",
"6 years",
"7 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"3 years",
null,
"10+ years",
"8 years",
"1 year",
"6 years",
"10+ years",
"9 years",
"10+ years",
"2 years",
null,
"3 years",
"1 year",
"2 years",
"7 years",
"10+ years",
"8 years",
"3 years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"2 years",
"< 1 year",
"10+ years",
"9 years",
null,
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
null,
"2 years",
"5 years",
"10+ years",
"6 years",
null,
"6 years",
"3 years",
"6 years",
"10+ years",
"10+ years",
"4 years",
null,
"10+ years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"6 years",
"3 years",
"< 1 year",
"2 years",
"6 years",
"7 years",
"1 year",
"3 years",
"2 years",
"10+ years",
"2 years",
"4 years",
"10+ years",
"< 1 year",
"3 years",
"4 years",
"10+ years",
null,
"5 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"4 years",
"10+ years",
null,
"10+ years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"2 years",
"4 years",
"7 years",
"3 years",
"< 1 year",
null,
"7 years",
"< 1 year",
"5 years",
"10+ years",
"9 years",
"4 years",
"4 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
null,
"10+ years",
"7 years",
"5 years",
"7 years",
"2 years",
"4 years",
"< 1 year",
"2 years",
"10+ years",
"1 year",
"10+ years",
"4 years",
"3 years",
"3 years",
"2 years",
"10+ years",
"5 years",
null,
"1 year",
"10+ years",
"10+ years",
"4 years",
"3 years",
null,
"9 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"6 years",
"1 year",
"2 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"2 years",
"2 years",
"4 years",
"3 years",
"10+ years",
"9 years",
"7 years",
"< 1 year",
"2 years",
"< 1 year",
"5 years",
"5 years",
"10+ years",
"9 years",
"3 years",
"5 years",
"4 years",
"6 years",
"4 years",
"2 years",
"3 years",
"< 1 year",
"9 years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"4 years",
null,
"4 years",
"5 years",
"8 years",
"9 years",
"10+ years",
"9 years",
"3 years",
"10+ years",
"1 year",
"2 years",
"4 years",
"2 years",
"7 years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"5 years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"9 years",
"10+ years",
"7 years",
"5 years",
"1 year",
"10+ years",
"9 years",
"10+ years",
null,
"9 years",
"5 years",
"10+ years",
"< 1 year",
"9 years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"9 years",
"10+ years",
"3 years",
"< 1 year",
"9 years",
"< 1 year",
"10+ years",
"5 years",
"< 1 year",
"6 years",
"1 year",
"2 years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"9 years",
"< 1 year",
"2 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"9 years",
"7 years",
"7 years",
"10+ years",
"3 years",
"8 years",
"1 year",
"2 years",
"< 1 year",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"3 years",
"3 years",
"5 years",
null,
"10+ years",
null,
"10+ years",
"10+ years",
"7 years",
"6 years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"10+ years",
null,
"3 years",
"7 years",
null,
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"5 years",
"10+ years",
"8 years",
"9 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"9 years",
"10+ years",
"6 years",
"8 years",
"5 years",
"6 years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"2 years",
"3 years",
"10+ years",
"5 years",
null,
"5 years",
"2 years",
"3 years",
"10+ years",
"2 years",
"< 1 year",
"6 years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"5 years",
"9 years",
"9 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"5 years",
"3 years",
"10+ years",
"9 years",
null,
"10+ years",
"8 years",
"10+ years",
"4 years",
"3 years",
"8 years",
"6 years",
null,
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"9 years",
"7 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"7 years",
"6 years",
"9 years",
"10+ years",
"8 years",
"6 years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"8 years",
"9 years",
"3 years",
"10+ years",
"8 years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"7 years",
"10+ years",
"< 1 year",
"9 years",
"10+ years",
"4 years",
"8 years",
"10+ years",
"5 years",
"< 1 year",
"6 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"8 years",
"2 years",
"8 years",
"10+ years",
"6 years",
"9 years",
"3 years",
"10+ years",
"< 1 year",
"6 years",
"2 years",
"6 years",
"5 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"3 years",
"2 years",
"4 years",
"6 years",
"3 years",
"< 1 year",
"3 years",
"1 year",
"2 years",
null,
"3 years",
null,
"10+ years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"< 1 year",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"5 years",
null,
"10+ years",
null,
"10+ years",
"4 years",
"10+ years",
"4 years",
"< 1 year",
"9 years",
"7 years",
"10+ years",
"10+ years",
"8 years",
"7 years",
"10+ years",
"3 years",
"< 1 year",
"3 years",
"6 years",
null,
"5 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"< 1 year",
"5 years",
null,
"10+ years",
"2 years",
"2 years",
"1 year",
null,
"10+ years",
"7 years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"9 years",
"5 years",
"4 years",
"8 years",
"1 year",
"6 years",
"10+ years",
"< 1 year",
null,
null,
"9 years",
null,
"1 year",
"10+ years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"4 years",
"8 years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"5 years",
"7 years",
"10+ years",
"6 years",
"5 years",
"5 years",
"10+ years",
"10+ years",
null,
"3 years",
"1 year",
"1 year",
"2 years",
"10+ years",
"< 1 year",
"5 years",
"3 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"5 years",
null,
"10+ years",
"7 years",
"10+ years",
"9 years",
"7 years",
"7 years",
"10+ years",
"1 year",
"10+ years",
"2 years",
"5 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"8 years",
"10+ years",
"2 years",
"6 years",
"2 years",
"1 year",
"4 years",
null,
"2 years",
"< 1 year",
"10+ years",
"2 years",
"1 year",
"7 years",
"7 years",
"5 years",
"2 years",
"2 years",
"8 years",
null,
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"9 years",
"6 years",
"5 years",
"10+ years",
"4 years",
null,
"3 years",
"5 years",
"2 years",
"10+ years",
null,
"5 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"4 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"9 years",
"< 1 year",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"7 years",
"< 1 year",
"4 years",
"2 years",
"8 years",
"< 1 year",
"9 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"5 years",
"10+ years",
"8 years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"6 years",
"4 years",
"1 year",
"5 years",
"2 years",
"2 years",
"5 years",
"1 year",
"5 years",
"2 years",
"10+ years",
"2 years",
"3 years",
"5 years",
"4 years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"8 years",
"1 year",
"1 year",
"< 1 year",
"10+ years",
"8 years",
"9 years",
"5 years",
"3 years",
"10+ years",
"8 years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"2 years",
"< 1 year",
"7 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"3 years",
"6 years",
"4 years",
"6 years",
"4 years",
null,
null,
"9 years",
"3 years",
"4 years",
"2 years",
"10+ years",
"6 years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"9 years",
"4 years",
null,
"2 years",
"1 year",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"5 years",
null,
"1 year",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"8 years",
"7 years",
"5 years",
null,
"3 years",
"6 years",
"7 years",
"4 years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"4 years",
"5 years",
"7 years",
"6 years",
"5 years",
"5 years",
"7 years",
"< 1 year",
"3 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"8 years",
"7 years",
"7 years",
"3 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"6 years",
"1 year",
"7 years",
"4 years",
"2 years",
"< 1 year",
"4 years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"6 years",
"2 years",
"4 years",
"4 years",
"< 1 year",
"3 years",
"10+ years",
"8 years",
"5 years",
"5 years",
"8 years",
"7 years",
"6 years",
"2 years",
"10+ years",
"8 years",
"4 years",
"10+ years",
"4 years",
null,
"7 years",
"10+ years",
"3 years",
"5 years",
"5 years",
"6 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"9 years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"9 years",
null,
"2 years",
"< 1 year",
"10+ years",
"< 1 year",
"4 years",
"8 years",
"7 years",
"4 years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"3 years",
"9 years",
"7 years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"5 years",
"10+ years",
"< 1 year",
"2 years",
"5 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"9 years",
"10+ years",
"8 years",
"5 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"4 years",
"< 1 year",
"4 years",
null,
"4 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"< 1 year",
"2 years",
"7 years",
"5 years",
"4 years",
"< 1 year",
"6 years",
"2 years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"8 years",
null,
"3 years",
"5 years",
"9 years",
"8 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"10+ years",
"5 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"5 years",
"2 years",
"2 years",
"< 1 year",
null,
"2 years",
"< 1 year",
null,
"1 year",
"10+ years",
"2 years",
"8 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"2 years",
"10+ years",
"10+ years",
"10+ years",
null,
"7 years",
null,
"10+ years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"8 years",
"10+ years",
"3 years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"2 years",
null,
"10+ years",
"4 years",
"4 years",
"9 years",
"4 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"10+ years",
null,
"1 year",
"10+ years",
"2 years",
"4 years",
"10+ years",
"1 year",
"2 years",
"1 year",
"10+ years",
"7 years",
"10+ years",
"< 1 year",
"5 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"6 years",
"3 years",
"5 years",
"5 years",
"7 years",
"10+ years",
null,
"3 years",
"4 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"8 years",
"10+ years",
"6 years",
"< 1 year",
"4 years",
"6 years",
"< 1 year",
"8 years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"8 years",
"< 1 year",
"8 years",
"7 years",
"8 years",
"10+ years",
"1 year",
"2 years",
"4 years",
"< 1 year",
"7 years",
"10+ years",
"< 1 year",
"4 years",
"3 years",
"10+ years",
"2 years",
"7 years",
"4 years",
"10+ years",
"5 years",
"7 years",
"7 years",
"6 years",
"10+ years",
"8 years",
null,
"10+ years",
"3 years",
"< 1 year",
"2 years",
"5 years",
"9 years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"9 years",
"2 years",
"10+ years",
"6 years",
"8 years",
"5 years",
"< 1 year",
"5 years",
"10+ years",
"6 years",
"10+ years",
"1 year",
"4 years",
"< 1 year",
null,
"4 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"4 years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"5 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"4 years",
"5 years",
"5 years",
"5 years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"1 year",
"2 years",
"2 years",
null,
"10+ years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"4 years",
"4 years",
"6 years",
"10+ years",
"10+ years",
"7 years",
null,
"10+ years",
"5 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"2 years",
"9 years",
"3 years",
"10+ years",
null,
"4 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"6 years",
"7 years",
"3 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"8 years",
"< 1 year",
"1 year",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"< 1 year",
"< 1 year",
"1 year",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"6 years",
"10+ years",
null,
"10+ years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"4 years",
"10+ years",
"4 years",
"9 years",
null,
"9 years",
"3 years",
"10+ years",
"3 years",
"5 years",
"4 years",
"8 years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"2 years",
"< 1 year",
"9 years",
"3 years",
"4 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"9 years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"5 years",
"10+ years",
"10+ years",
"8 years",
"2 years",
"< 1 year",
"< 1 year",
"3 years",
null,
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"7 years",
"10+ years",
"7 years",
"1 year",
null,
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"3 years",
"< 1 year",
"< 1 year",
"10+ years",
"8 years",
"8 years",
"1 year",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"8 years",
"7 years",
"10+ years",
"< 1 year",
"7 years",
null,
"10+ years",
"2 years",
"10+ years",
"7 years",
"< 1 year",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"8 years",
"2 years",
"10+ years",
"4 years",
"8 years",
"10+ years",
"9 years",
"< 1 year",
"2 years",
"8 years",
"6 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"1 year",
"10+ years",
"10+ years",
"9 years",
"4 years",
"4 years",
"3 years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"1 year",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"1 year",
null,
"3 years",
"7 years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
null,
"5 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
null,
null,
"10+ years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"4 years",
"9 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"3 years",
"< 1 year",
"6 years",
"1 year",
"4 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"3 years",
"3 years",
"10+ years",
"4 years",
"10+ years",
"7 years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"< 1 year",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"9 years",
"< 1 year",
null,
"3 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"2 years",
"10+ years",
"4 years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"5 years",
"1 year",
"5 years",
"10+ years",
"3 years",
"5 years",
"7 years",
"1 year",
"3 years",
"10+ years",
"6 years",
"3 years",
"8 years",
"10+ years",
"4 years",
"8 years",
"< 1 year",
"6 years",
"10+ years",
"6 years",
"6 years",
"5 years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
null,
null,
"10+ years",
null,
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"9 years",
"6 years",
"10+ years",
"6 years",
"8 years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
null,
null,
"9 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"1 year",
"2 years",
"< 1 year",
"1 year",
"10+ years",
"9 years",
"5 years",
"< 1 year",
"7 years",
"1 year",
"< 1 year",
"1 year",
null,
"10+ years",
"10+ years",
"1 year",
"10+ years",
"4 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"1 year",
"3 years",
"4 years",
"6 years",
"1 year",
"2 years",
"7 years",
"10+ years",
"6 years",
"6 years",
"< 1 year",
"10+ years",
"4 years",
null,
"5 years",
"2 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"1 year",
null,
"10+ years",
null,
"< 1 year",
"4 years",
"< 1 year",
null,
"5 years",
"10+ years",
"9 years",
"8 years",
"9 years",
null,
null,
"4 years",
"< 1 year",
"< 1 year",
"< 1 year",
"8 years",
null,
"10+ years",
"8 years",
"1 year",
"8 years",
"9 years",
"8 years",
"5 years",
"10+ years",
"5 years",
"4 years",
"10+ years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"5 years",
"3 years",
"1 year",
null,
"4 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"3 years",
"10+ years",
"6 years",
"3 years",
"6 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"1 year",
"10+ years",
"7 years",
"10+ years",
"8 years",
"1 year",
"3 years",
"4 years",
"10+ years",
"7 years",
"5 years",
"< 1 year",
"9 years",
"4 years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"2 years",
"2 years",
"9 years",
"3 years",
"3 years",
"2 years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"8 years",
"10+ years",
"1 year",
null,
"8 years",
"7 years",
"7 years",
"10+ years",
"10+ years",
null,
"< 1 year",
"8 years",
"9 years",
"5 years",
"4 years",
"10+ years",
"10+ years",
"5 years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"3 years",
"2 years",
"1 year",
null,
"10+ years",
"8 years",
"10+ years",
null,
"10+ years",
"2 years",
"10+ years",
"6 years",
null,
"6 years",
"2 years",
"5 years",
"7 years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"1 year",
"7 years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"8 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
null,
"< 1 year",
"3 years",
null,
"6 years",
"6 years",
null,
"8 years",
"9 years",
"8 years",
null,
"9 years",
"3 years",
"1 year",
"8 years",
"8 years",
"7 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"5 years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"6 years",
"5 years",
"7 years",
"8 years",
"7 years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"6 years",
"3 years",
"7 years",
null,
"10+ years",
"2 years",
"9 years",
"< 1 year",
"7 years",
"5 years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"1 year",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"9 years",
"10+ years",
"6 years",
"1 year",
null,
"7 years",
"10+ years",
null,
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"3 years",
"< 1 year",
"7 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"< 1 year",
"2 years",
"10+ years",
"6 years",
"6 years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"4 years",
"4 years",
"3 years",
"2 years",
"6 years",
"4 years",
"3 years",
null,
null,
"5 years",
"4 years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"8 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"4 years",
"10+ years",
"10+ years",
"7 years",
"5 years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"3 years",
"9 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"2 years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"7 years",
"< 1 year",
"5 years",
"7 years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"9 years",
"5 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"3 years",
"6 years",
"< 1 year",
"8 years",
"10+ years",
"6 years",
"1 year",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"9 years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"3 years",
"< 1 year",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"7 years",
"10+ years",
"4 years",
"3 years",
"7 years",
"5 years",
"2 years",
"5 years",
"10+ years",
"2 years",
null,
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"1 year",
"2 years",
"3 years",
"9 years",
"< 1 year",
"4 years",
"6 years",
"< 1 year",
"1 year",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
null,
"5 years",
"6 years",
"< 1 year",
"5 years",
"10+ years",
"2 years",
"8 years",
"7 years",
"4 years",
"10+ years",
"< 1 year",
"6 years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"1 year",
"< 1 year",
"7 years",
"7 years",
"10+ years",
"1 year",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"8 years",
"10+ years",
"9 years",
"4 years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"1 year",
"4 years",
"9 years",
"2 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"9 years",
"10+ years",
"5 years",
"7 years",
null,
"2 years",
"10+ years",
"7 years",
"5 years",
"10+ years",
"< 1 year",
null,
"5 years",
"7 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"10+ years",
null,
"1 year",
"10+ years",
"3 years",
"3 years",
"7 years",
"3 years",
"2 years",
"6 years",
"10+ years",
"8 years",
"10+ years",
"1 year",
"7 years",
"1 year",
null,
"5 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"9 years",
"1 year",
"9 years",
"1 year",
"1 year",
"7 years",
"1 year",
null,
"10+ years",
"3 years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"< 1 year",
"< 1 year",
"1 year",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"1 year",
"2 years",
"7 years",
"8 years",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"2 years",
"< 1 year",
"10+ years",
"4 years",
"8 years",
"10+ years",
"10+ years",
"6 years",
"4 years",
"1 year",
"1 year",
"3 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"5 years",
"9 years",
"4 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"4 years",
"< 1 year",
"10+ years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"4 years",
"4 years",
"< 1 year",
"6 years",
"5 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
null,
"10+ years",
"< 1 year",
"5 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"8 years",
"< 1 year",
"5 years",
"10+ years",
"8 years",
"10+ years",
"8 years",
"1 year",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"8 years",
"3 years",
"5 years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"1 year",
"4 years",
"2 years",
"1 year",
"7 years",
"8 years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"5 years",
"3 years",
"8 years",
"10+ years",
"6 years",
null,
"5 years",
"10+ years",
"5 years",
"5 years",
"1 year",
"4 years",
"2 years",
"9 years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"6 years",
"9 years",
"1 year",
"7 years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"9 years",
"9 years",
"2 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"7 years",
"9 years",
"5 years",
"9 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"9 years",
"3 years",
"2 years",
"< 1 year",
"10+ years",
"2 years",
"4 years",
"4 years",
"10+ years",
"2 years",
"7 years",
"5 years",
"10+ years",
"10+ years",
"7 years",
"3 years",
null,
"4 years",
"6 years",
"7 years",
"1 year",
"3 years",
"3 years",
"3 years",
null,
"4 years",
"5 years",
"2 years",
"3 years",
"10+ years",
"7 years",
"3 years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"1 year",
"7 years",
"3 years",
null,
null,
"8 years",
"< 1 year",
"< 1 year",
"5 years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"1 year",
"2 years",
"10+ years",
"2 years",
"6 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"5 years",
"4 years",
"10+ years",
"10+ years",
"4 years",
null,
"1 year",
"10+ years",
"3 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"7 years",
null,
"10+ years",
null,
"2 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"6 years",
"10+ years",
"3 years",
"7 years",
"4 years",
"3 years",
"10+ years",
"7 years",
"1 year",
"1 year",
"8 years",
"10+ years",
"3 years",
"6 years",
"9 years",
"2 years",
"5 years",
"7 years",
"10+ years",
"3 years",
"3 years",
"5 years",
"3 years",
"2 years",
"10+ years",
"2 years",
"2 years",
"7 years",
"2 years",
"2 years",
"1 year",
"1 year",
"8 years",
"6 years",
"1 year",
"3 years",
"3 years",
"3 years",
"4 years",
"2 years",
"4 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"9 years",
"10+ years",
null,
"10+ years",
"10+ years",
"7 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"6 years",
"4 years",
null,
"4 years",
null,
"8 years",
"10+ years",
"10+ years",
"7 years",
"3 years",
"< 1 year",
null,
"2 years",
"< 1 year",
null,
null,
"10+ years",
"10+ years",
"3 years",
"5 years",
"5 years",
"5 years",
"< 1 year",
"1 year",
"10+ years",
null,
"2 years",
"4 years",
"7 years",
"10+ years",
"5 years",
"9 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"1 year",
"4 years",
"10+ years",
"1 year",
"< 1 year",
"2 years",
"4 years",
"10+ years",
"1 year",
"5 years",
"10+ years",
"7 years",
"7 years",
"10+ years",
"7 years",
"10+ years",
"2 years",
null,
null,
null,
"10+ years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"1 year",
"4 years",
null,
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"3 years",
"8 years",
"9 years",
"7 years",
null,
"5 years",
"4 years",
"< 1 year",
null,
"10+ years",
"6 years",
"10+ years",
"4 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"2 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"1 year",
"8 years",
"5 years",
"5 years",
"5 years",
"7 years",
"< 1 year",
"6 years",
"8 years",
"10+ years",
"3 years",
null,
"9 years",
"< 1 year",
"1 year",
"2 years",
"2 years",
"2 years",
"5 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"4 years",
"9 years",
"8 years",
"2 years",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"8 years",
"9 years",
"10+ years",
null,
"2 years",
"10+ years",
"9 years",
"2 years",
"3 years",
"3 years",
"4 years",
null,
"2 years",
"10+ years",
"10+ years",
"5 years",
"9 years",
"8 years",
"8 years",
"6 years",
"10+ years",
"8 years",
"9 years",
"< 1 year",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"3 years",
"4 years",
"3 years",
"< 1 year",
"4 years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"7 years",
"5 years",
"7 years",
"3 years",
"2 years",
"5 years",
"8 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"7 years",
"< 1 year",
"3 years",
null,
"< 1 year",
"3 years",
"10+ years",
"5 years",
"10+ years",
null,
"10+ years",
"2 years",
"5 years",
"7 years",
"6 years",
"8 years",
"8 years",
null,
"10+ years",
null,
"8 years",
"10+ years",
"8 years",
"5 years",
"4 years",
"1 year",
"3 years",
"6 years",
"10+ years",
"5 years",
"7 years",
"4 years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"3 years",
"< 1 year",
"3 years",
null,
"10+ years",
"10+ years",
"10+ years",
"8 years",
"6 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"1 year",
"2 years",
"< 1 year",
"4 years",
"9 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"7 years",
"3 years",
"1 year",
"10+ years",
"2 years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"6 years",
null,
"2 years",
"2 years",
"10+ years",
"2 years",
"2 years",
"1 year",
"10+ years",
"5 years",
"3 years",
"< 1 year",
null,
"5 years",
"8 years",
"4 years",
"10+ years",
"7 years",
"1 year",
"2 years",
"10+ years",
"5 years",
"10+ years",
null,
"10+ years",
"10+ years",
"2 years",
"8 years",
"8 years",
"2 years",
"< 1 year",
"3 years",
"2 years",
"4 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"9 years",
"9 years",
"7 years",
"10+ years",
null,
"7 years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"9 years",
"9 years",
"4 years",
"< 1 year",
"< 1 year",
"5 years",
"10+ years",
"5 years",
"7 years",
null,
"3 years",
"2 years",
"7 years",
"7 years",
"< 1 year",
"10+ years",
"< 1 year",
"1 year",
"1 year",
"7 years",
"9 years",
"1 year",
"7 years",
"6 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
null,
"3 years",
"8 years",
"5 years",
"5 years",
"5 years",
"10+ years",
"1 year",
"8 years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
null,
"10+ years",
null,
"6 years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"1 year",
null,
"< 1 year",
"8 years",
"2 years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"8 years",
null,
"10+ years",
"10+ years",
"10+ years",
"4 years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"6 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"9 years",
null,
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"7 years",
"6 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"4 years",
"9 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
null,
"7 years",
"2 years",
"5 years",
"2 years",
"4 years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"1 year",
"1 year",
"7 years",
"10+ years",
"1 year",
"9 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"3 years",
"< 1 year",
"3 years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"4 years",
"2 years",
"10+ years",
"9 years",
"8 years",
"< 1 year",
"10+ years",
null,
"9 years",
"10+ years",
null,
"3 years",
"7 years",
"4 years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"5 years",
"3 years",
"< 1 year",
"2 years",
"10+ years",
"8 years",
"5 years",
"1 year",
"10+ years",
"10+ years",
null,
"< 1 year",
"< 1 year",
"< 1 year",
"10+ years",
"7 years",
"< 1 year",
"< 1 year",
"4 years",
"5 years",
"10+ years",
null,
"8 years",
"3 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"3 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"6 years",
"1 year",
"10+ years",
"6 years",
"10+ years",
"6 years",
"10+ years",
"8 years",
"8 years",
null,
"7 years",
"< 1 year",
"4 years",
"8 years",
"10+ years",
null,
"5 years",
"3 years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"8 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"7 years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
null,
"2 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"8 years",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"5 years",
"10+ years",
null,
"< 1 year",
"2 years",
"< 1 year",
"< 1 year",
null,
"7 years",
"3 years",
"10+ years",
"1 year",
"9 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"5 years",
"7 years",
"3 years",
"2 years",
"9 years",
"10+ years",
"10+ years",
"7 years",
null,
"5 years",
"10+ years",
"1 year",
"< 1 year",
"1 year",
"9 years",
"< 1 year",
"10+ years",
"3 years",
"3 years",
"2 years",
"9 years",
"4 years",
"4 years",
"7 years",
"2 years",
"5 years",
null,
"5 years",
"< 1 year",
"3 years",
"10+ years",
"4 years",
"2 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
null,
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"2 years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"9 years",
"6 years",
"5 years",
"4 years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"9 years",
null,
"3 years",
"4 years",
"5 years",
"6 years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"2 years",
"5 years",
"4 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"5 years",
"4 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"6 years",
"< 1 year",
"5 years",
"2 years",
"< 1 year",
"5 years",
"9 years",
null,
"< 1 year",
null,
"10+ years",
"10+ years",
"2 years",
"5 years",
"3 years",
"4 years",
"6 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"4 years",
"4 years",
"10+ years",
null,
"3 years",
"6 years",
"10+ years",
"4 years",
"5 years",
"3 years",
"5 years",
"10+ years",
"6 years",
"6 years",
"10+ years",
"2 years",
"10+ years",
"7 years",
"8 years",
"8 years",
"3 years",
"6 years",
"< 1 year",
"7 years",
"1 year",
"1 year",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"10+ years",
"1 year",
"10+ years",
null,
"10+ years",
"8 years",
"10+ years",
"6 years",
"10+ years",
"6 years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"2 years",
"7 years",
"5 years",
"4 years",
"5 years",
"8 years",
"8 years",
"10+ years",
"7 years",
"2 years",
"1 year",
"5 years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"6 years",
"4 years",
"< 1 year",
"3 years",
"2 years",
"2 years",
"10+ years",
"1 year",
"6 years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"7 years",
"9 years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"5 years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"3 years",
"9 years",
"4 years",
"10+ years",
"2 years",
null,
"4 years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
null,
"3 years",
"10+ years",
"10+ years",
null,
"2 years",
"8 years",
"8 years",
"10+ years",
"5 years",
"5 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"9 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"1 year",
"7 years",
"5 years",
"5 years",
"6 years",
"5 years",
"10+ years",
"5 years",
"2 years",
"10+ years",
null,
"< 1 year",
"1 year",
"10+ years",
"7 years",
"10+ years",
"8 years",
"2 years",
"10+ years",
"10+ years",
null,
"1 year",
"5 years",
"10+ years",
"4 years",
"2 years",
"7 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"6 years",
"9 years",
"< 1 year",
null,
"8 years",
"3 years",
"6 years",
"6 years",
"8 years",
"6 years",
"7 years",
"2 years",
"9 years",
"< 1 year",
"7 years",
"1 year",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"5 years",
"9 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"2 years",
"< 1 year",
"4 years",
"7 years",
"5 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"3 years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"9 years",
"10+ years",
null,
"5 years",
"8 years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"1 year",
null,
"3 years",
"10+ years",
"4 years",
"2 years",
"10+ years",
"6 years",
"2 years",
"2 years",
"4 years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"9 years",
null,
"2 years",
"2 years",
"9 years",
"3 years",
"10+ years",
"1 year",
"6 years",
"4 years",
"< 1 year",
"2 years",
"8 years",
"10+ years",
"10+ years",
"6 years",
"8 years",
null,
"10+ years",
"10+ years",
"3 years",
"5 years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"7 years",
"7 years",
"7 years",
"6 years",
"6 years",
"2 years",
"10+ years",
"1 year",
null,
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"9 years",
"1 year",
"9 years",
"8 years",
"3 years",
"2 years",
"10+ years",
"4 years",
"2 years",
"7 years",
"2 years",
"9 years",
"2 years",
"10+ years",
"6 years",
"5 years",
"1 year",
"2 years",
"< 1 year",
"10+ years",
"9 years",
"6 years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"9 years",
null,
"9 years",
"9 years",
"2 years",
"1 year",
"< 1 year",
"8 years",
"7 years",
"8 years",
"5 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"4 years",
"4 years",
"10+ years",
"7 years",
"7 years",
"< 1 year",
"8 years",
"2 years",
"3 years",
"5 years",
"3 years",
"4 years",
"10+ years",
"1 year",
"10+ years",
"8 years",
"8 years",
"3 years",
"9 years",
"2 years",
"7 years",
"< 1 year",
"10+ years",
"5 years",
"5 years",
"1 year",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
null,
null,
"6 years",
"5 years",
"10+ years",
null,
"10+ years",
"2 years",
"7 years",
null,
"10+ years",
"7 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"2 years",
"2 years",
"4 years",
"10+ years",
"2 years",
"9 years",
null,
"2 years",
"8 years",
"10+ years",
"6 years",
"3 years",
"5 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
null,
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"2 years",
"6 years",
"5 years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"< 1 year",
"4 years",
"8 years",
"8 years",
"10+ years",
"5 years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"9 years",
"2 years",
"10+ years",
null,
"1 year",
"1 year",
"4 years",
"8 years",
"3 years",
"4 years",
"< 1 year",
"4 years",
"3 years",
"10+ years",
"2 years",
"7 years",
"< 1 year",
"7 years",
"10+ years",
"4 years",
"3 years",
"10+ years",
"10+ years",
null,
"5 years",
"9 years",
"8 years",
"5 years",
"5 years",
null,
"5 years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"8 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"1 year",
"3 years",
"3 years",
"< 1 year",
"8 years",
"2 years",
"9 years",
"8 years",
"10+ years",
"10+ years",
"1 year",
"4 years",
"2 years",
"10+ years",
"2 years",
"1 year",
"1 year",
"10+ years",
"3 years",
"1 year",
"2 years",
"10+ years",
"2 years",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"3 years",
"3 years",
"10+ years",
"3 years",
"6 years",
"10+ years",
null,
"10+ years",
"7 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"4 years",
"5 years",
"2 years",
"5 years",
"4 years",
"10+ years",
"6 years",
"7 years",
"7 years",
"10+ years",
"10+ years",
"8 years",
"6 years",
"10+ years",
"7 years",
"5 years",
"7 years",
null,
"5 years",
"2 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"4 years",
"9 years",
"10+ years",
null,
null,
"< 1 year",
"4 years",
"6 years",
"10+ years",
"5 years",
"6 years",
"< 1 year",
"8 years",
"10+ years",
null,
"5 years",
"10+ years",
"3 years",
"9 years",
"10+ years",
"5 years",
"8 years",
"4 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"5 years",
"3 years",
"10+ years",
"3 years",
"2 years",
"4 years",
"8 years",
"6 years",
"4 years",
"4 years",
"3 years",
"1 year",
"1 year",
"10+ years",
"2 years",
"9 years",
"1 year",
"10+ years",
"1 year",
null,
null,
"6 years",
"6 years",
"10+ years",
"10+ years",
null,
"6 years",
"2 years",
"5 years",
"< 1 year",
null,
null,
"10+ years",
"< 1 year",
"3 years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
null,
"6 years",
"5 years",
null,
"2 years",
"4 years",
"10+ years",
"1 year",
"7 years",
null,
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"2 years",
"10+ years",
null,
"3 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"5 years",
"5 years",
"6 years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"3 years",
"9 years",
"4 years",
"5 years",
"1 year",
"3 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"3 years",
"2 years",
"2 years",
"5 years",
"5 years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"5 years",
"10+ years",
"2 years",
"4 years",
"4 years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"< 1 year",
"6 years",
"7 years",
"10+ years",
"4 years",
"5 years",
"2 years",
"10+ years",
null,
"2 years",
"4 years",
null,
"4 years",
"1 year",
"9 years",
"2 years",
"10+ years",
"2 years",
null,
"< 1 year",
"9 years",
"2 years",
"3 years",
"5 years",
null,
"5 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"8 years",
null,
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
null,
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"7 years",
"< 1 year",
"4 years",
"2 years",
"10+ years",
"4 years",
"3 years",
"2 years",
"8 years",
"1 year",
"6 years",
"< 1 year",
null,
"10+ years",
"1 year",
"9 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"2 years",
"2 years",
"10+ years",
"1 year",
"5 years",
"9 years",
"3 years",
"10+ years",
null,
"2 years",
null,
"5 years",
"10+ years",
"< 1 year",
"2 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"< 1 year",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"2 years",
"7 years",
"3 years",
"< 1 year",
"10+ years",
null,
"4 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
null,
"5 years",
"9 years",
"10+ years",
"< 1 year",
"6 years",
null,
"6 years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"4 years",
"7 years",
"4 years",
"10+ years",
"1 year",
"10+ years",
"6 years",
"10+ years",
"9 years",
"3 years",
"5 years",
"2 years",
"< 1 year",
"1 year",
"9 years",
"9 years",
"2 years",
"10+ years",
"6 years",
"5 years",
"7 years",
null,
"4 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"3 years",
"2 years",
"10+ years",
"2 years",
"2 years",
"1 year",
"8 years",
"10+ years",
null,
"5 years",
"6 years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
null,
"4 years",
"8 years",
"10+ years",
"8 years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"< 1 year",
"7 years",
"1 year",
"6 years",
"7 years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"2 years",
"8 years",
"< 1 year",
"1 year",
"10+ years",
"7 years",
"< 1 year",
"< 1 year",
"3 years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
null,
"10+ years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"9 years",
"3 years",
"2 years",
"10+ years",
null,
"4 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"5 years",
"6 years",
"5 years",
"5 years",
"10+ years",
null,
"9 years",
"2 years",
"4 years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"7 years",
"9 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"6 years",
null,
"2 years",
"< 1 year",
"10+ years",
"6 years",
"4 years",
"3 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"1 year",
"4 years",
"4 years",
"10+ years",
"2 years",
"7 years",
"2 years",
"3 years",
"2 years",
"9 years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"4 years",
"2 years",
"2 years",
"3 years",
"10+ years",
"9 years",
"4 years",
"5 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"5 years",
"5 years",
"10+ years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"5 years",
"6 years",
"10+ years",
"4 years",
"4 years",
"10+ years",
"8 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"7 years",
"3 years",
"9 years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"7 years",
"6 years",
"10+ years",
null,
"10+ years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"1 year",
"8 years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"6 years",
"8 years",
"7 years",
"6 years",
"10+ years",
"8 years",
"7 years",
"10+ years",
"3 years",
null,
"10+ years",
"7 years",
"< 1 year",
"3 years",
"6 years",
"4 years",
"2 years",
"10+ years",
"4 years",
"< 1 year",
"2 years",
"10+ years",
"8 years",
"6 years",
"< 1 year",
"9 years",
"7 years",
"1 year",
"5 years",
null,
"6 years",
"5 years",
"3 years",
null,
"10+ years",
"3 years",
"3 years",
"10+ years",
"7 years",
"< 1 year",
"9 years",
"5 years",
"5 years",
"3 years",
"< 1 year",
"8 years",
"8 years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
null,
"3 years",
"8 years",
"2 years",
"2 years",
null,
"3 years",
"6 years",
"10+ years",
"6 years",
"9 years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"< 1 year",
"6 years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"9 years",
"10+ years",
"5 years",
"8 years",
"7 years",
"10+ years",
"10+ years",
"9 years",
"7 years",
null,
"8 years",
"10+ years",
"5 years",
"< 1 year",
"6 years",
"4 years",
"10+ years",
"8 years",
"7 years",
"7 years",
"10+ years",
"4 years",
null,
"10+ years",
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"5 years",
"4 years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"7 years",
"10+ years",
"10+ years",
"1 year",
null,
"2 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"3 years",
"10+ years",
"7 years",
"4 years",
"7 years",
"10+ years",
"6 years",
null,
"< 1 year",
"10+ years",
"4 years",
"8 years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"4 years",
"5 years",
"6 years",
null,
"10+ years",
"1 year",
"1 year",
"10+ years",
"1 year",
"9 years",
"10+ years",
"10+ years",
"6 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"1 year",
"6 years",
"8 years",
"10+ years",
"10+ years",
"7 years",
"8 years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"1 year",
"4 years",
"< 1 year",
"6 years",
"2 years",
"10+ years",
"5 years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"6 years",
"10+ years",
"3 years",
"1 year",
"6 years",
"8 years",
"6 years",
"7 years",
"2 years",
"9 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"2 years",
"10+ years",
null,
null,
"10+ years",
"5 years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"2 years",
"2 years",
"5 years",
"1 year",
"2 years",
"4 years",
"< 1 year",
"8 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
null,
"8 years",
null,
"10+ years",
"10+ years",
"4 years",
"10+ years",
null,
"7 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
null,
null,
"6 years",
"< 1 year",
"< 1 year",
"< 1 year",
"7 years",
"6 years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"4 years",
null,
"10+ years",
"5 years",
"< 1 year",
"5 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"6 years",
"6 years",
"8 years",
"5 years",
null,
"4 years",
"7 years",
"3 years",
"9 years",
"5 years",
"< 1 year",
"10+ years",
"7 years",
"5 years",
"4 years",
"8 years",
"10+ years",
"7 years",
"10+ years",
"5 years",
"4 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"< 1 year",
"9 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"7 years",
"1 year",
"6 years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"3 years",
null,
"5 years",
"4 years",
"1 year",
"2 years",
"2 years",
"6 years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"3 years",
"2 years",
"5 years",
"< 1 year",
"8 years",
"< 1 year",
"2 years",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"< 1 year",
"10+ years",
"9 years",
"10+ years",
"7 years",
"8 years",
"10+ years",
"10+ years",
"8 years",
"8 years",
"4 years",
null,
"3 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
null,
"2 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"4 years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"5 years",
"10+ years",
"2 years",
"4 years",
"5 years",
"10+ years",
"10+ years",
"6 years",
"< 1 year",
"2 years",
"2 years",
"< 1 year",
"2 years",
"6 years",
"2 years",
"9 years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"3 years",
"2 years",
"3 years",
"3 years",
"8 years",
"9 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
null,
"4 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
null,
"4 years",
null,
"10+ years",
"< 1 year",
"1 year",
"2 years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"2 years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"8 years",
"7 years",
"10+ years",
null,
"6 years",
null,
"8 years",
"10+ years",
"10+ years",
"8 years",
"8 years",
"< 1 year",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"9 years",
null,
"10+ years",
"7 years",
"10+ years",
"10+ years",
"4 years",
"4 years",
"10+ years",
null,
"< 1 year",
"10+ years",
"5 years",
"4 years",
"10+ years",
"4 years",
"1 year",
"6 years",
"3 years",
"< 1 year",
"4 years",
"10+ years",
null,
null,
"2 years",
"3 years",
"4 years",
"1 year",
"6 years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"9 years",
"9 years",
"4 years",
"3 years",
"10+ years",
"10+ years",
null,
"2 years",
"10+ years",
null,
"7 years",
"1 year",
"4 years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"4 years",
"6 years",
"2 years",
"4 years",
"3 years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"1 year",
"2 years",
"4 years",
"9 years",
"10+ years",
"5 years",
"< 1 year",
"6 years",
"4 years",
"10+ years",
"5 years",
"3 years",
"8 years",
"1 year",
null,
"10+ years",
null,
"2 years",
"2 years",
"7 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"2 years",
"4 years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"< 1 year",
"8 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"4 years",
null,
"10+ years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"7 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"9 years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"5 years",
"8 years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"2 years",
"3 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"6 years",
"6 years",
"< 1 year",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"5 years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"8 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"2 years",
"4 years",
"4 years",
"2 years",
"10+ years",
"10+ years",
null,
"1 year",
"3 years",
null,
"2 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"5 years",
"4 years",
null,
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"3 years",
"10+ years",
"4 years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"6 years",
"9 years",
"10+ years",
"4 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"5 years",
"7 years",
"4 years",
"< 1 year",
"8 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"5 years",
"2 years",
"5 years",
"4 years",
"9 years",
"5 years",
"< 1 year",
"3 years",
"2 years",
"6 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"7 years",
"8 years",
"< 1 year",
"8 years",
"10+ years",
"5 years",
"5 years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"3 years",
"10+ years",
null,
"5 years",
"10+ years",
"10+ years",
"5 years",
"5 years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"4 years",
"10+ years",
"2 years",
"3 years",
"< 1 year",
"7 years",
"9 years",
"1 year",
"1 year",
"9 years",
"< 1 year",
"2 years",
"2 years",
"8 years",
"10+ years",
"4 years",
"2 years",
"8 years",
null,
"8 years",
"8 years",
"6 years",
"1 year",
"2 years",
"7 years",
"10+ years",
"< 1 year",
"< 1 year",
"< 1 year",
"< 1 year",
"3 years",
"7 years",
"2 years",
"10+ years",
"3 years",
"9 years",
"8 years",
"3 years",
"3 years",
"3 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
null,
"8 years",
"5 years",
null,
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"3 years",
"4 years",
"5 years",
"2 years",
"4 years",
"5 years",
"3 years",
"7 years",
"3 years",
"10+ years",
null,
"< 1 year",
"10+ years",
"4 years",
"3 years",
"< 1 year",
"10+ years",
"9 years",
"3 years",
"10+ years",
"5 years",
"4 years",
"10+ years",
"10+ years",
"1 year",
"6 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"3 years",
"2 years",
"10+ years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"6 years",
"2 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"1 year",
"3 years",
"5 years",
"8 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"5 years",
"10+ years",
"2 years",
"9 years",
"8 years",
"< 1 year",
"10+ years",
"5 years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"1 year",
null,
"10+ years",
"2 years",
"< 1 year",
"3 years",
"6 years",
null,
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"9 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"3 years",
"7 years",
"5 years",
"3 years",
"8 years",
"6 years",
"9 years",
"7 years",
"< 1 year",
"1 year",
"1 year",
"9 years",
"8 years",
"10+ years",
"4 years",
"2 years",
"2 years",
"5 years",
"6 years",
"3 years",
"7 years",
null,
"1 year",
"10+ years",
"5 years",
"9 years",
"8 years",
"2 years",
"6 years",
"1 year",
"3 years",
"7 years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"2 years",
null,
"2 years",
"4 years",
"6 years",
"9 years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"1 year",
"6 years",
"< 1 year",
"8 years",
"1 year",
"3 years",
"7 years",
"10+ years",
"2 years",
"< 1 year",
"2 years",
"6 years",
"7 years",
"3 years",
"1 year",
"7 years",
"2 years",
"< 1 year",
"9 years",
"1 year",
"2 years",
"1 year",
"1 year",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"4 years",
"6 years",
"10+ years",
"8 years",
"7 years",
"10+ years",
"10+ years",
"6 years",
"5 years",
"10+ years",
"7 years",
null,
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"9 years",
"7 years",
"9 years",
"1 year",
"8 years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"3 years",
"8 years",
"8 years",
"2 years",
"3 years",
"6 years",
"8 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"6 years",
null,
"10+ years",
"< 1 year",
"4 years",
"8 years",
"7 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"9 years",
"10+ years",
"3 years",
"2 years",
null,
"< 1 year",
"9 years",
"10+ years",
"3 years",
"4 years",
"5 years",
"10+ years",
"10+ years",
null,
"1 year",
"9 years",
"10+ years",
"6 years",
"2 years",
"10+ years",
null,
"< 1 year",
"7 years",
"10+ years",
"10+ years",
null,
"7 years",
"1 year",
"7 years",
"3 years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"9 years",
"3 years",
"10+ years",
null,
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"< 1 year",
"10+ years",
"2 years",
"7 years",
"4 years",
"8 years",
"7 years",
"2 years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"9 years",
"6 years",
"10+ years",
"6 years",
"3 years",
"4 years",
"3 years",
"10+ years",
"7 years",
"5 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"2 years",
"< 1 year",
"6 years",
"2 years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"2 years",
"3 years",
"5 years",
"3 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"6 years",
"9 years",
"< 1 year",
"1 year",
"< 1 year",
"5 years",
"10+ years",
"5 years",
"5 years",
"10+ years",
"9 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"2 years",
"1 year",
"8 years",
"4 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"5 years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"3 years",
"< 1 year",
"6 years",
null,
"8 years",
"2 years",
"9 years",
"5 years",
"1 year",
"8 years",
"10+ years",
"5 years",
"4 years",
"1 year",
"< 1 year",
"< 1 year",
null,
"10+ years",
"10+ years",
"< 1 year",
null,
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"9 years",
"10+ years",
"< 1 year",
null,
"5 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"1 year",
"< 1 year",
"3 years",
"4 years",
"10+ years",
"3 years",
"1 year",
"1 year",
"2 years",
"10+ years",
"7 years",
"3 years",
"5 years",
"1 year",
"10+ years",
"2 years",
"8 years",
"10+ years",
"3 years",
"2 years",
"4 years",
"10+ years",
"3 years",
"5 years",
"7 years",
"5 years",
"10+ years",
"4 years",
"< 1 year",
"6 years",
"3 years",
null,
"5 years",
"2 years",
"4 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"7 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"1 year",
"1 year",
"4 years",
"7 years",
"10+ years",
"4 years",
"< 1 year",
"1 year",
"10+ years",
"7 years",
"4 years",
"< 1 year",
"7 years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"4 years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"2 years",
"10+ years",
null,
"10+ years",
null,
"< 1 year",
"10+ years",
null,
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"7 years",
"8 years",
"< 1 year",
"8 years",
"< 1 year",
"5 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"9 years",
null,
"< 1 year",
"6 years",
"10+ years",
"< 1 year",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"1 year",
"8 years",
"8 years",
"7 years",
null,
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"5 years",
"8 years",
"10+ years",
"5 years",
"8 years",
null,
"10+ years",
"1 year",
"10+ years",
null,
"2 years",
"7 years",
"4 years",
"2 years",
"2 years",
"< 1 year",
"1 year",
"10+ years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"8 years",
"< 1 year",
"7 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"1 year",
"6 years",
null,
"4 years",
"10+ years",
null,
"10+ years",
"6 years",
"7 years",
"3 years",
"6 years",
null,
"9 years",
"7 years",
"10+ years",
"10+ years",
"5 years",
"4 years",
"4 years",
"10+ years",
"6 years",
"< 1 year",
"10+ years",
"7 years",
"1 year",
null,
"10+ years",
"5 years",
"8 years",
"10+ years",
"1 year",
"< 1 year",
"4 years",
"7 years",
"5 years",
"3 years",
"10+ years",
"6 years",
"9 years",
"8 years",
"10+ years",
"3 years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
null,
"10+ years",
"3 years",
"3 years",
"10+ years",
"< 1 year",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"10+ years",
null,
"10+ years",
"7 years",
"7 years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"1 year",
"7 years",
"5 years",
"4 years",
"10+ years",
"4 years",
"6 years",
"2 years",
"4 years",
"10+ years",
"8 years",
"6 years",
"10+ years",
"2 years",
"3 years",
"5 years",
"10+ years",
"2 years",
null,
"10+ years",
"8 years",
"10+ years",
"8 years",
"5 years",
"< 1 year",
"8 years",
"8 years",
"< 1 year",
"2 years",
"4 years",
"3 years",
"5 years",
"10+ years",
null,
"10+ years",
"< 1 year",
null,
"10+ years",
"10+ years",
"1 year",
"2 years",
"2 years",
"2 years",
"7 years",
"10+ years",
"1 year",
"1 year",
"10+ years",
null,
"2 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
null,
"8 years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"9 years",
"2 years",
"1 year",
"5 years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"3 years",
"< 1 year",
"3 years",
"3 years",
"10+ years",
"7 years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"4 years",
"2 years",
"5 years",
"10+ years",
"7 years",
"1 year",
"4 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"1 year",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"8 years",
"5 years",
null,
"9 years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
null,
"10+ years",
"7 years",
"4 years",
"9 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"9 years",
"6 years",
"6 years",
"4 years",
"1 year",
"10+ years",
null,
"9 years",
"3 years",
"10+ years",
"< 1 year",
null,
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
null,
"< 1 year",
"3 years",
"2 years",
"10+ years",
"< 1 year",
"3 years",
"2 years",
"9 years",
"10+ years",
"< 1 year",
"2 years",
"3 years",
null,
null,
"7 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"5 years",
"5 years",
"2 years",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"3 years",
"7 years",
null,
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"9 years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"6 years",
"< 1 year",
"10+ years",
null,
"2 years",
"2 years",
"1 year",
"10+ years",
"1 year",
"1 year",
"8 years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"< 1 year",
"1 year",
"3 years",
"1 year",
"10+ years",
null,
"2 years",
"9 years",
"10+ years",
null,
"< 1 year",
"10+ years",
null,
"10+ years",
"3 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"2 years",
"2 years",
"2 years",
"4 years",
"< 1 year",
"8 years",
"10+ years",
"5 years",
"< 1 year",
"4 years",
"1 year",
"5 years",
"1 year",
"9 years",
"4 years",
"6 years",
"5 years",
"8 years",
"9 years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"2 years",
"< 1 year",
"10+ years",
"9 years",
"1 year",
"4 years",
"10+ years",
"< 1 year",
"2 years",
"2 years",
"7 years",
null,
"5 years",
"10+ years",
"3 years",
"1 year",
"3 years",
"3 years",
null,
"10+ years",
"8 years",
"10+ years",
"10+ years",
"6 years",
null,
"3 years",
"3 years",
"2 years",
"10+ years",
"2 years",
"4 years",
"3 years",
"< 1 year",
"10+ years",
"3 years",
"7 years",
"2 years",
"2 years",
"10+ years",
"2 years",
"3 years",
"1 year",
"3 years",
"< 1 year",
"1 year",
"< 1 year",
"10+ years",
"3 years",
"4 years",
"2 years",
null,
"< 1 year",
"10+ years",
"5 years",
"2 years",
"10+ years",
null,
"3 years",
"9 years",
"4 years",
"1 year",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"9 years",
"3 years",
null,
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"4 years",
"8 years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"1 year",
"4 years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
null,
"< 1 year",
"3 years",
"3 years",
"3 years",
"< 1 year",
"4 years",
"10+ years",
"< 1 year",
"5 years",
"< 1 year",
"5 years",
"4 years",
null,
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"6 years",
"9 years",
"3 years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"< 1 year",
"5 years",
"7 years",
"5 years",
"6 years",
"1 year",
"2 years",
"< 1 year",
"< 1 year",
"10+ years",
null,
"10+ years",
"2 years",
"10+ years",
"1 year",
"7 years",
"7 years",
"4 years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"8 years",
"9 years",
"5 years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"4 years",
"1 year",
"< 1 year",
"9 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"9 years",
"8 years",
"10+ years",
"2 years",
"4 years",
"7 years",
"10+ years",
"5 years",
"1 year",
"< 1 year",
"5 years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"6 years",
"< 1 year",
"7 years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"3 years",
"7 years",
"5 years",
"< 1 year",
"8 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"2 years",
"< 1 year",
"2 years",
"3 years",
"< 1 year",
"1 year",
"1 year",
"8 years",
null,
null,
"10+ years",
"7 years",
null,
"9 years",
"2 years",
"7 years",
"10+ years",
"5 years",
null,
"2 years",
"10+ years",
"10+ years",
"4 years",
null,
"10+ years",
"10+ years",
null,
"7 years",
"4 years",
"7 years",
"2 years",
null,
"2 years",
"7 years",
null,
"5 years",
"10+ years",
"1 year",
"10+ years",
"5 years",
null,
"10+ years",
"1 year",
"10+ years",
"3 years",
"8 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"5 years",
"2 years",
"< 1 year",
"7 years",
"5 years",
"10+ years",
"1 year",
"10+ years",
"5 years",
null,
"1 year",
"10+ years",
null,
"9 years",
"< 1 year",
"< 1 year",
"3 years",
"1 year",
"10+ years",
"10+ years",
"2 years",
null,
"8 years",
"5 years",
"9 years",
"< 1 year",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"1 year",
"10+ years",
"3 years",
"10+ years",
"8 years",
"10+ years",
"3 years",
null,
"5 years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"2 years",
"3 years",
"< 1 year",
"4 years",
null,
"< 1 year",
"< 1 year",
"8 years",
"8 years",
"4 years",
"5 years",
null,
"3 years",
"5 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"3 years",
"3 years",
"7 years",
"4 years",
"< 1 year",
"2 years",
"6 years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"6 years",
"2 years",
"1 year",
"3 years",
"1 year",
"2 years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"9 years",
"2 years",
null,
"10+ years",
"2 years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"< 1 year",
"9 years",
"2 years",
"10+ years",
"6 years",
"3 years",
null,
"10+ years",
"9 years",
"9 years",
"10+ years",
"5 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
null,
"8 years",
"10+ years",
"6 years",
"< 1 year",
"8 years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"6 years",
"5 years",
"10+ years",
"1 year",
"2 years",
"10+ years",
"7 years",
"7 years",
"10+ years",
"5 years",
"3 years",
"1 year",
"5 years",
"10+ years",
"6 years",
"3 years",
"1 year",
"7 years",
"4 years",
"10+ years",
"7 years",
"1 year",
"5 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"2 years",
"< 1 year",
"10+ years",
"4 years",
"1 year",
"4 years",
"10+ years",
null,
"5 years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"< 1 year",
"6 years",
"4 years",
"1 year",
"10+ years",
"10+ years",
"6 years",
"2 years",
"9 years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"2 years",
"4 years",
"7 years",
"8 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"7 years",
"7 years",
"1 year",
"10+ years",
"1 year",
"1 year",
"1 year",
"7 years",
null,
"3 years",
"7 years",
"10+ years",
"10+ years",
"6 years",
"6 years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
null,
"< 1 year",
"10+ years",
"5 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"4 years",
null,
"10+ years",
"4 years",
"10+ years",
null,
"10+ years",
"8 years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"1 year",
"1 year",
"2 years",
"10+ years",
"4 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"1 year",
"2 years",
"8 years",
"10+ years",
"5 years",
"2 years",
"2 years",
"6 years",
"5 years",
"3 years",
"< 1 year",
"10+ years",
"8 years",
"3 years",
"10+ years",
"7 years",
"2 years",
"8 years",
"10+ years",
"8 years",
"4 years",
"4 years",
null,
"< 1 year",
"1 year",
"6 years",
"9 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"< 1 year",
"2 years",
"2 years",
"3 years",
"5 years"
]
}
],
"layout": {
"barmode": "overlay",
"legend": {
"bgcolor": "#F5F6F9",
"font": {
"color": "#4D5663"
}
},
"paper_bgcolor": "#F5F6F9",
"plot_bgcolor": "#F5F6F9",
"template": {
"data": {
"bar": [
{
"error_x": {
"color": "#2a3f5f"
},
"error_y": {
"color": "#2a3f5f"
},
"marker": {
"line": {
"color": "#E5ECF6",
"width": 0.5
}
},
"type": "bar"
}
],
"barpolar": [
{
"marker": {
"line": {
"color": "#E5ECF6",
"width": 0.5
}
},
"type": "barpolar"
}
],
"carpet": [
{
"aaxis": {
"endlinecolor": "#2a3f5f",
"gridcolor": "white",
"linecolor": "white",
"minorgridcolor": "white",
"startlinecolor": "#2a3f5f"
},
"baxis": {
"endlinecolor": "#2a3f5f",
"gridcolor": "white",
"linecolor": "white",
"minorgridcolor": "white",
"startlinecolor": "#2a3f5f"
},
"type": "carpet"
}
],
"choropleth": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "choropleth"
}
],
"contour": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "contour"
}
],
"contourcarpet": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "contourcarpet"
}
],
"heatmap": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "heatmap"
}
],
"heatmapgl": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "heatmapgl"
}
],
"histogram": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "histogram"
}
],
"histogram2d": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "histogram2d"
}
],
"histogram2dcontour": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "histogram2dcontour"
}
],
"mesh3d": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "mesh3d"
}
],
"parcoords": [
{
"line": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "parcoords"
}
],
"pie": [
{
"automargin": true,
"type": "pie"
}
],
"scatter": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatter"
}
],
"scatter3d": [
{
"line": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatter3d"
}
],
"scattercarpet": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattercarpet"
}
],
"scattergeo": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattergeo"
}
],
"scattergl": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattergl"
}
],
"scattermapbox": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattermapbox"
}
],
"scatterpolar": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterpolar"
}
],
"scatterpolargl": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterpolargl"
}
],
"scatterternary": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterternary"
}
],
"surface": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "surface"
}
],
"table": [
{
"cells": {
"fill": {
"color": "#EBF0F8"
},
"line": {
"color": "white"
}
},
"header": {
"fill": {
"color": "#C8D4E3"
},
"line": {
"color": "white"
}
},
"type": "table"
}
]
},
"layout": {
"annotationdefaults": {
"arrowcolor": "#2a3f5f",
"arrowhead": 0,
"arrowwidth": 1
},
"coloraxis": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"colorscale": {
"diverging": [
[
0,
"#8e0152"
],
[
0.1,
"#c51b7d"
],
[
0.2,
"#de77ae"
],
[
0.3,
"#f1b6da"
],
[
0.4,
"#fde0ef"
],
[
0.5,
"#f7f7f7"
],
[
0.6,
"#e6f5d0"
],
[
0.7,
"#b8e186"
],
[
0.8,
"#7fbc41"
],
[
0.9,
"#4d9221"
],
[
1,
"#276419"
]
],
"sequential": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"sequentialminus": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
]
},
"colorway": [
"#636efa",
"#EF553B",
"#00cc96",
"#ab63fa",
"#FFA15A",
"#19d3f3",
"#FF6692",
"#B6E880",
"#FF97FF",
"#FECB52"
],
"font": {
"color": "#2a3f5f"
},
"geo": {
"bgcolor": "white",
"lakecolor": "white",
"landcolor": "#E5ECF6",
"showlakes": true,
"showland": true,
"subunitcolor": "white"
},
"hoverlabel": {
"align": "left"
},
"hovermode": "closest",
"mapbox": {
"style": "light"
},
"paper_bgcolor": "white",
"plot_bgcolor": "#E5ECF6",
"polar": {
"angularaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"bgcolor": "#E5ECF6",
"radialaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
}
},
"scene": {
"xaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
},
"yaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
},
"zaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
}
},
"shapedefaults": {
"line": {
"color": "#2a3f5f"
}
},
"ternary": {
"aaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"baxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"bgcolor": "#E5ECF6",
"caxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
}
},
"title": {
"x": 0.05
},
"xaxis": {
"automargin": true,
"gridcolor": "white",
"linecolor": "white",
"ticks": "",
"title": {
"standoff": 15
},
"zerolinecolor": "white",
"zerolinewidth": 2
},
"yaxis": {
"automargin": true,
"gridcolor": "white",
"linecolor": "white",
"ticks": "",
"title": {
"standoff": 15
},
"zerolinecolor": "white",
"zerolinewidth": 2
}
}
},
"title": {
"font": {
"color": "#4D5663"
},
"text": "emp_length Distribution"
},
"xaxis": {
"gridcolor": "#E1E5ED",
"showgrid": true,
"tickfont": {
"color": "#4D5663"
},
"title": {
"font": {
"color": "#4D5663"
},
"text": ""
},
"zerolinecolor": "#E1E5ED"
},
"yaxis": {
"gridcolor": "#E1E5ED",
"showgrid": true,
"tickfont": {
"color": "#4D5663"
},
"title": {
"font": {
"color": "#4D5663"
},
"text": ""
},
"zerolinecolor": "#E1E5ED"
}
}
},
"text/html": [
"\n",
" \n",
" \n",
" \n",
" \n",
" "
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"application/vnd.plotly.v1+json": {
"config": {
"linkText": "Export to plot.ly",
"plotlyServerURL": "https://plot.ly",
"showLink": true
},
"data": [
{
"boxpoints": false,
"line": {
"width": 1.3
},
"marker": {
"color": "rgba(255, 153, 51, 1.0)"
},
"name": "emp_length",
"orientation": "v",
"type": "box",
"y": [
"9 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"8 years",
"7 years",
"2 years",
"10+ years",
"4 years",
"7 years",
"10+ years",
"10+ years",
"4 years",
"9 years",
null,
"7 years",
"7 years",
"9 years",
"2 years",
"10+ years",
"7 years",
"< 1 year",
"4 years",
"2 years",
"1 year",
"3 years",
"2 years",
"10+ years",
"8 years",
"2 years",
"9 years",
"10+ years",
null,
null,
"10+ years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"3 years",
"10+ years",
"9 years",
"4 years",
"7 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"6 years",
"2 years",
"10+ years",
"2 years",
"< 1 year",
"4 years",
"1 year",
"9 years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"< 1 year",
"2 years",
"9 years",
"8 years",
"3 years",
"3 years",
"8 years",
"2 years",
"7 years",
"10+ years",
"7 years",
"1 year",
"10+ years",
null,
"10+ years",
"8 years",
"5 years",
"6 years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"4 years",
null,
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"1 year",
"10+ years",
"5 years",
"8 years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"8 years",
"2 years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"4 years",
"1 year",
"3 years",
"8 years",
"3 years",
"2 years",
null,
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"1 year",
"2 years",
"8 years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"3 years",
"9 years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"3 years",
"4 years",
"4 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
null,
"4 years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"< 1 year",
"10+ years",
"2 years",
"4 years",
"2 years",
"< 1 year",
"4 years",
"2 years",
"1 year",
"5 years",
"4 years",
"3 years",
"9 years",
"5 years",
null,
"10+ years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"6 years",
"10+ years",
"1 year",
"7 years",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"5 years",
"10+ years",
"3 years",
null,
"10+ years",
null,
"10+ years",
"8 years",
"2 years",
"7 years",
"7 years",
"10+ years",
"8 years",
"6 years",
"9 years",
"3 years",
"4 years",
"5 years",
"< 1 year",
"< 1 year",
"7 years",
"7 years",
"< 1 year",
"1 year",
"< 1 year",
null,
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"6 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"8 years",
"1 year",
"< 1 year",
"4 years",
"1 year",
"7 years",
"< 1 year",
"3 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"6 years",
null,
"< 1 year",
"2 years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"9 years",
"4 years",
"3 years",
"10+ years",
"7 years",
null,
null,
"10+ years",
"2 years",
null,
"5 years",
"< 1 year",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"< 1 year",
"10+ years",
"2 years",
null,
"7 years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"5 years",
"< 1 year",
"< 1 year",
"4 years",
"3 years",
"3 years",
"8 years",
"2 years",
"1 year",
"10+ years",
"3 years",
"3 years",
"4 years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"1 year",
null,
"5 years",
"< 1 year",
"4 years",
"3 years",
"2 years",
"3 years",
"1 year",
"9 years",
"7 years",
"1 year",
"10+ years",
"10+ years",
"2 years",
null,
"3 years",
"3 years",
"< 1 year",
"2 years",
"1 year",
"10+ years",
"10+ years",
null,
"10+ years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
null,
null,
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
null,
"4 years",
"10+ years",
"7 years",
"2 years",
"6 years",
"10+ years",
"2 years",
"2 years",
"4 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"6 years",
"6 years",
"8 years",
"1 year",
"3 years",
"5 years",
"6 years",
"9 years",
"3 years",
null,
"7 years",
"5 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"9 years",
"3 years",
"2 years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"6 years",
"< 1 year",
"8 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"6 years",
"2 years",
"9 years",
"3 years",
"8 years",
"8 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"4 years",
"7 years",
"3 years",
"8 years",
"2 years",
"9 years",
"6 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"7 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"< 1 year",
"2 years",
"9 years",
"8 years",
"3 years",
"10+ years",
"8 years",
"10+ years",
"6 years",
"7 years",
"10+ years",
"5 years",
"10+ years",
"1 year",
"1 year",
null,
"3 years",
"10+ years",
"3 years",
"4 years",
"4 years",
"2 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"7 years",
"10+ years",
null,
"2 years",
"< 1 year",
"2 years",
"1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"8 years",
"7 years",
"5 years",
"2 years",
"10+ years",
"1 year",
"7 years",
"10+ years",
null,
"10+ years",
"8 years",
"10+ years",
"4 years",
"8 years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"7 years",
"3 years",
"5 years",
"1 year",
"10+ years",
"6 years",
"10+ years",
null,
"9 years",
"5 years",
"7 years",
"6 years",
"3 years",
"8 years",
"10+ years",
"7 years",
"5 years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"10+ years",
"6 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"1 year",
"8 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"7 years",
"5 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"4 years",
"3 years",
"8 years",
"1 year",
null,
"5 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"4 years",
"10+ years",
"5 years",
"< 1 year",
"2 years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"6 years",
null,
"10+ years",
"5 years",
"4 years",
"9 years",
"6 years",
"4 years",
"4 years",
"< 1 year",
"4 years",
"8 years",
"10+ years",
null,
"1 year",
"7 years",
"9 years",
"1 year",
"8 years",
"8 years",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"9 years",
"10+ years",
"6 years",
"10+ years",
"6 years",
"5 years",
null,
"2 years",
"3 years",
null,
"10+ years",
"3 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"6 years",
"< 1 year",
"10+ years",
null,
"9 years",
"3 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"7 years",
"7 years",
"1 year",
"10+ years",
"7 years",
"10+ years",
"< 1 year",
"8 years",
"2 years",
"8 years",
"4 years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"7 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"8 years",
"3 years",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"8 years",
"5 years",
"10+ years",
"5 years",
"5 years",
"3 years",
"< 1 year",
"10+ years",
"1 year",
"4 years",
"10+ years",
"3 years",
null,
"5 years",
"6 years",
"2 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"3 years",
null,
"< 1 year",
"9 years",
"10+ years",
"10+ years",
"7 years",
"1 year",
"7 years",
"5 years",
"8 years",
"10+ years",
"5 years",
"4 years",
"4 years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"9 years",
"2 years",
"3 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"4 years",
"4 years",
"5 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"1 year",
"2 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"9 years",
"2 years",
"10+ years",
null,
"6 years",
"3 years",
"3 years",
null,
null,
"7 years",
"2 years",
"4 years",
"1 year",
"< 1 year",
"6 years",
"9 years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"2 years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"5 years",
"< 1 year",
"9 years",
"8 years",
"10+ years",
"7 years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"6 years",
"8 years",
"10+ years",
"7 years",
"10+ years",
"5 years",
"3 years",
null,
"6 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
null,
"2 years",
"3 years",
"4 years",
"2 years",
"10+ years",
"5 years",
"9 years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"7 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"7 years",
"3 years",
"5 years",
null,
"10+ years",
"10+ years",
"2 years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"8 years",
"1 year",
"6 years",
"7 years",
"10+ years",
null,
"5 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"3 years",
"< 1 year",
"< 1 year",
"3 years",
"9 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"1 year",
"10+ years",
"4 years",
"6 years",
"10+ years",
"3 years",
"< 1 year",
null,
"10+ years",
"1 year",
"5 years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"8 years",
"10+ years",
"< 1 year",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"4 years",
"< 1 year",
"1 year",
"8 years",
"9 years",
"< 1 year",
"6 years",
"8 years",
"10+ years",
"10+ years",
"9 years",
"6 years",
null,
"< 1 year",
"10+ years",
"5 years",
"5 years",
"10+ years",
"8 years",
"5 years",
"1 year",
"2 years",
"5 years",
"7 years",
"4 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"4 years",
"10+ years",
"3 years",
"7 years",
"4 years",
"9 years",
"3 years",
"9 years",
"7 years",
"10+ years",
"1 year",
"5 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"< 1 year",
"1 year",
"8 years",
"8 years",
"10+ years",
"7 years",
"4 years",
"6 years",
"8 years",
"< 1 year",
"4 years",
"4 years",
"7 years",
"1 year",
"1 year",
"10+ years",
"5 years",
"8 years",
"5 years",
"10+ years",
"7 years",
"8 years",
"5 years",
"2 years",
"10+ years",
"4 years",
null,
null,
"8 years",
"2 years",
"5 years",
"10+ years",
"5 years",
null,
"3 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"3 years",
"3 years",
"9 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"4 years",
"10+ years",
"< 1 year",
"5 years",
null,
"2 years",
"10+ years",
"4 years",
"< 1 year",
"8 years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"4 years",
null,
"9 years",
null,
"7 years",
"7 years",
"2 years",
"1 year",
"1 year",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"6 years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
null,
"5 years",
"< 1 year",
"6 years",
"3 years",
"7 years",
"< 1 year",
"10+ years",
"5 years",
"8 years",
"10+ years",
"7 years",
"1 year",
"4 years",
"10+ years",
"10+ years",
"5 years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"6 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"9 years",
"7 years",
"10+ years",
"6 years",
"8 years",
"2 years",
"3 years",
"3 years",
"10+ years",
"2 years",
"8 years",
"9 years",
"2 years",
"10+ years",
"4 years",
"1 year",
"2 years",
"7 years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
null,
"10+ years",
"6 years",
null,
"10+ years",
"7 years",
null,
"10+ years",
"6 years",
"3 years",
"4 years",
"5 years",
"7 years",
"3 years",
"10+ years",
"6 years",
null,
"< 1 year",
"8 years",
"3 years",
"7 years",
"2 years",
"9 years",
"10+ years",
"2 years",
"7 years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"5 years",
null,
"2 years",
"4 years",
"6 years",
"6 years",
"6 years",
"6 years",
"1 year",
"10+ years",
"3 years",
null,
"10+ years",
"7 years",
"2 years",
"< 1 year",
"4 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
null,
"6 years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
"8 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"1 year",
"10+ years",
"7 years",
"7 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"1 year",
"7 years",
"< 1 year",
"3 years",
"5 years",
"2 years",
"3 years",
"10+ years",
null,
"2 years",
null,
"< 1 year",
"10+ years",
null,
"2 years",
"7 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"5 years",
"1 year",
"1 year",
"3 years",
"4 years",
"6 years",
"3 years",
"2 years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"9 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"1 year",
"< 1 year",
"< 1 year",
"7 years",
"8 years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"8 years",
"3 years",
"4 years",
"< 1 year",
"< 1 year",
"2 years",
"9 years",
"5 years",
"6 years",
"5 years",
"< 1 year",
"10+ years",
"< 1 year",
"1 year",
"7 years",
"1 year",
"10+ years",
"5 years",
"10+ years",
"1 year",
"10+ years",
"2 years",
"2 years",
"2 years",
"3 years",
"7 years",
"7 years",
"8 years",
"10+ years",
null,
null,
null,
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"9 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"6 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"1 year",
"< 1 year",
"10+ years",
"2 years",
"5 years",
"4 years",
"9 years",
"10+ years",
"10+ years",
"3 years",
"9 years",
null,
"8 years",
"1 year",
"10+ years",
"4 years",
"10+ years",
"7 years",
"10+ years",
"1 year",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"3 years",
null,
"5 years",
"1 year",
"1 year",
"10+ years",
"10+ years",
null,
"4 years",
"9 years",
null,
"10+ years",
"10+ years",
"7 years",
"5 years",
null,
"< 1 year",
"2 years",
"2 years",
"1 year",
"10+ years",
"4 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"4 years",
"2 years",
"2 years",
"3 years",
"1 year",
"9 years",
"2 years",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"6 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"4 years",
"6 years",
"9 years",
"1 year",
"2 years",
"2 years",
"6 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"7 years",
"5 years",
"1 year",
"3 years",
"6 years",
"4 years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
null,
"10+ years",
"7 years",
"2 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"3 years",
null,
"10+ years",
"8 years",
"5 years",
"1 year",
"3 years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"7 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"< 1 year",
"6 years",
"8 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"1 year",
"< 1 year",
"< 1 year",
"6 years",
"9 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"8 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"7 years",
"4 years",
"7 years",
"9 years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"8 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"5 years",
"6 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"9 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"8 years",
"6 years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"3 years",
"3 years",
"7 years",
"10+ years",
"6 years",
"7 years",
"4 years",
"4 years",
"2 years",
"< 1 year",
"1 year",
"10+ years",
"2 years",
"10+ years",
"8 years",
null,
"10+ years",
"10+ years",
"2 years",
"3 years",
"1 year",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"3 years",
"7 years",
"6 years",
null,
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
null,
null,
"4 years",
"4 years",
"7 years",
"3 years",
"1 year",
null,
"8 years",
"6 years",
"2 years",
"10+ years",
"2 years",
"< 1 year",
"2 years",
"9 years",
"5 years",
"8 years",
"5 years",
"6 years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
null,
"2 years",
"6 years",
null,
"10+ years",
"3 years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"1 year",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"8 years",
"2 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"5 years",
"7 years",
null,
"1 year",
"10+ years",
"2 years",
"3 years",
"< 1 year",
null,
"10+ years",
"10+ years",
"2 years",
"< 1 year",
null,
"3 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"2 years",
"4 years",
"10+ years",
"< 1 year",
"6 years",
"8 years",
"4 years",
"10+ years",
"1 year",
"5 years",
"9 years",
"10+ years",
null,
"1 year",
"10+ years",
"4 years",
"3 years",
"9 years",
"< 1 year",
"3 years",
"7 years",
"5 years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"8 years",
"< 1 year",
"10+ years",
"7 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"1 year",
"6 years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"7 years",
"10+ years",
"3 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"< 1 year",
"4 years",
"3 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"9 years",
null,
"< 1 year",
"6 years",
"4 years",
"8 years",
"3 years",
"5 years",
"1 year",
"8 years",
"5 years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"2 years",
"3 years",
"< 1 year",
"5 years",
"10+ years",
"5 years",
"9 years",
"2 years",
"4 years",
"5 years",
"6 years",
null,
"7 years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"6 years",
"8 years",
"2 years",
null,
"7 years",
"7 years",
"10+ years",
"7 years",
"< 1 year",
"6 years",
"8 years",
"1 year",
"6 years",
"2 years",
"3 years",
"4 years",
"6 years",
"10+ years",
"8 years",
"6 years",
null,
"5 years",
"7 years",
"3 years",
"2 years",
"10+ years",
"9 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"4 years",
"1 year",
"10+ years",
"5 years",
null,
"10+ years",
"10+ years",
"6 years",
"10+ years",
null,
"6 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"7 years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"2 years",
null,
"10+ years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"10+ years",
"4 years",
"10+ years",
"8 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
null,
"1 year",
"10+ years",
"1 year",
"2 years",
"10+ years",
"< 1 year",
"1 year",
"3 years",
"2 years",
null,
"10+ years",
"10+ years",
"4 years",
null,
"3 years",
"3 years",
"< 1 year",
"9 years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
null,
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"3 years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
null,
"< 1 year",
null,
"3 years",
"3 years",
"4 years",
"2 years",
"10+ years",
"2 years",
"< 1 year",
null,
"10+ years",
"4 years",
"7 years",
"< 1 year",
"9 years",
"2 years",
"4 years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"< 1 year",
"8 years",
"8 years",
"5 years",
"10+ years",
null,
"9 years",
"1 year",
"10+ years",
"5 years",
null,
"7 years",
null,
"6 years",
null,
"5 years",
"5 years",
"3 years",
"9 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"4 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"4 years",
"10+ years",
"8 years",
"7 years",
"< 1 year",
null,
"6 years",
"1 year",
"10+ years",
"5 years",
"5 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"10+ years",
null,
"2 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
null,
"< 1 year",
"< 1 year",
"10+ years",
"2 years",
"4 years",
"1 year",
"2 years",
"10+ years",
"2 years",
"7 years",
"2 years",
"3 years",
"2 years",
"10+ years",
"6 years",
"10+ years",
"7 years",
"3 years",
"4 years",
"7 years",
"2 years",
"1 year",
"6 years",
"1 year",
"10+ years",
"< 1 year",
"4 years",
"5 years",
"5 years",
"7 years",
"< 1 year",
null,
"10+ years",
"9 years",
"4 years",
"3 years",
"9 years",
null,
"10+ years",
"10+ years",
"7 years",
"4 years",
"2 years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"4 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"4 years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"3 years",
"8 years",
"10+ years",
"1 year",
"4 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"8 years",
"1 year",
"8 years",
"6 years",
"4 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
null,
"1 year",
"10+ years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"6 years",
"1 year",
"9 years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"7 years",
"3 years",
"3 years",
"10+ years",
"5 years",
"1 year",
"1 year",
null,
"5 years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"3 years",
"< 1 year",
"7 years",
"3 years",
"5 years",
"10+ years",
null,
"10+ years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"8 years",
"9 years",
"4 years",
"10+ years",
"5 years",
"7 years",
"10+ years",
"10+ years",
"9 years",
"1 year",
"10+ years",
"1 year",
"1 year",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"9 years",
"2 years",
"2 years",
"< 1 year",
"2 years",
"3 years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"4 years",
"9 years",
"3 years",
"3 years",
"10+ years",
"1 year",
"6 years",
"10+ years",
"7 years",
"1 year",
"6 years",
"9 years",
"8 years",
"4 years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"10+ years",
null,
"5 years",
"10+ years",
"10+ years",
"8 years",
"1 year",
"6 years",
null,
null,
"6 years",
"3 years",
"1 year",
"< 1 year",
"7 years",
"2 years",
null,
"2 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"4 years",
"10+ years",
null,
"4 years",
"4 years",
"6 years",
"4 years",
"10+ years",
"10+ years",
"4 years",
null,
"10+ years",
"4 years",
"3 years",
"2 years",
"3 years",
"4 years",
"8 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
null,
"4 years",
"2 years",
"7 years",
"4 years",
"10+ years",
"2 years",
"9 years",
"2 years",
"2 years",
"< 1 year",
"10+ years",
"4 years",
"9 years",
"1 year",
"10+ years",
"3 years",
"3 years",
"10+ years",
"5 years",
"6 years",
"7 years",
"3 years",
"10+ years",
"3 years",
null,
"1 year",
"2 years",
"10+ years",
"7 years",
"8 years",
"10+ years",
"8 years",
"3 years",
"9 years",
"< 1 year",
"9 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
null,
"6 years",
"10+ years",
"3 years",
"8 years",
"6 years",
"5 years",
"< 1 year",
"2 years",
"10+ years",
"2 years",
"10+ years",
null,
"10+ years",
"5 years",
"7 years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"3 years",
"2 years",
"1 year",
"2 years",
"< 1 year",
"2 years",
"3 years",
"3 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"3 years",
null,
"< 1 year",
"3 years",
"< 1 year",
"< 1 year",
"10+ years",
"3 years",
"7 years",
"10+ years",
"2 years",
"4 years",
"2 years",
"10+ years",
"6 years",
"6 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"< 1 year",
"8 years",
"10+ years",
"5 years",
"3 years",
"1 year",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"8 years",
"4 years",
"2 years",
"2 years",
"9 years",
"10+ years",
"7 years",
"10+ years",
"< 1 year",
"9 years",
"2 years",
"< 1 year",
null,
"6 years",
"2 years",
"2 years",
"10+ years",
"4 years",
null,
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"7 years",
"10+ years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"2 years",
"10+ years",
"9 years",
"6 years",
null,
null,
"3 years",
"5 years",
"10+ years",
"8 years",
"5 years",
"6 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"5 years",
"6 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"1 year",
"2 years",
"10+ years",
"6 years",
"9 years",
"9 years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"9 years",
"2 years",
null,
"10+ years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"< 1 year",
null,
"4 years",
null,
"10+ years",
null,
"10+ years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"6 years",
"8 years",
"8 years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"3 years",
"10+ years",
"5 years",
null,
"< 1 year",
"10+ years",
"< 1 year",
"2 years",
"1 year",
"10+ years",
"9 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"3 years",
"9 years",
"5 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"3 years",
"1 year",
"7 years",
"7 years",
"8 years",
"2 years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"< 1 year",
"3 years",
"5 years",
"3 years",
"2 years",
"10+ years",
"3 years",
"8 years",
"5 years",
"7 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
null,
"3 years",
"5 years",
"7 years",
"10+ years",
"2 years",
"2 years",
null,
"3 years",
"4 years",
"8 years",
"10+ years",
"1 year",
"1 year",
"9 years",
"8 years",
"5 years",
"2 years",
"8 years",
"< 1 year",
"6 years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"7 years",
null,
"7 years",
"5 years",
"1 year",
"10+ years",
"10+ years",
"8 years",
"4 years",
"10+ years",
"10+ years",
null,
"10+ years",
"8 years",
"8 years",
"10+ years",
"5 years",
"7 years",
"9 years",
"8 years",
"10+ years",
"4 years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"6 years",
"10+ years",
"10+ years",
null,
"10+ years",
"1 year",
"< 1 year",
null,
"2 years",
"8 years",
"7 years",
"4 years",
"10+ years",
"2 years",
"4 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"7 years",
"10+ years",
"4 years",
"< 1 year",
"2 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"4 years",
"3 years",
"10+ years",
"8 years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"8 years",
"9 years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"2 years",
"9 years",
"10+ years",
"2 years",
"10+ years",
"9 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
null,
"10+ years",
"10+ years",
"1 year",
"3 years",
"5 years",
"8 years",
"7 years",
"6 years",
"2 years",
"5 years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"2 years",
"10+ years",
"1 year",
"3 years",
"2 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"8 years",
"10+ years",
"4 years",
"2 years",
"< 1 year",
"6 years",
"4 years",
"3 years",
"< 1 year",
"10+ years",
"1 year",
"4 years",
"7 years",
"3 years",
"1 year",
"5 years",
"3 years",
"7 years",
"10+ years",
"2 years",
"1 year",
"4 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"1 year",
"2 years",
null,
"7 years",
"10+ years",
null,
"10+ years",
"10+ years",
"3 years",
"5 years",
"1 year",
"10+ years",
"10+ years",
"8 years",
"1 year",
"10+ years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"10+ years",
null,
"10+ years",
"< 1 year",
null,
"2 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"3 years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"2 years",
"3 years",
"2 years",
"10+ years",
"3 years",
"1 year",
"9 years",
"1 year",
"9 years",
"10+ years",
null,
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
null,
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
null,
"7 years",
"3 years",
"1 year",
"4 years",
"9 years",
"1 year",
"5 years",
"10+ years",
"2 years",
"10+ years",
null,
null,
"10+ years",
"2 years",
"10+ years",
"7 years",
"2 years",
"2 years",
null,
"2 years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"9 years",
"3 years",
"2 years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"1 year",
"2 years",
"10+ years",
"1 year",
"2 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"6 years",
"2 years",
"2 years",
"6 years",
"5 years",
"< 1 year",
"3 years",
"7 years",
"8 years",
"8 years",
"4 years",
"9 years",
"7 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"3 years",
null,
"1 year",
"10+ years",
"1 year",
"10+ years",
"5 years",
"5 years",
"2 years",
"9 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"1 year",
"1 year",
"2 years",
"< 1 year",
"10+ years",
null,
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"4 years",
"9 years",
"10+ years",
"9 years",
"3 years",
"6 years",
"6 years",
"3 years",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"2 years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"5 years",
"10+ years",
"3 years",
"6 years",
"10+ years",
"7 years",
"< 1 year",
"9 years",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"6 years",
"< 1 year",
"1 year",
"2 years",
"9 years",
"1 year",
"1 year",
"6 years",
"6 years",
"8 years",
"7 years",
"6 years",
"4 years",
"4 years",
"10+ years",
null,
"9 years",
"4 years",
null,
"3 years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"2 years",
"6 years",
"6 years",
"5 years",
"5 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"3 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"6 years",
"10+ years",
"4 years",
"3 years",
"9 years",
"10+ years",
"10+ years",
"6 years",
"5 years",
"5 years",
"10+ years",
"10+ years",
"4 years",
null,
"< 1 year",
"5 years",
"6 years",
"1 year",
"< 1 year",
"2 years",
"10+ years",
null,
"10+ years",
"< 1 year",
"1 year",
"8 years",
"< 1 year",
"10+ years",
"2 years",
"9 years",
"10+ years",
"1 year",
"< 1 year",
"< 1 year",
"4 years",
"5 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"3 years",
"7 years",
"2 years",
"< 1 year",
"9 years",
"1 year",
"3 years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"8 years",
"7 years",
"7 years",
null,
"10+ years",
"5 years",
"6 years",
"1 year",
"7 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
null,
"2 years",
"5 years",
"9 years",
"3 years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"6 years",
null,
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"5 years",
"10+ years",
"7 years",
"1 year",
null,
"2 years",
"10+ years",
"4 years",
"10+ years",
null,
null,
"10+ years",
"3 years",
"< 1 year",
"6 years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
null,
"2 years",
"2 years",
"2 years",
"8 years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"1 year",
"3 years",
"7 years",
"7 years",
"5 years",
"< 1 year",
"8 years",
"7 years",
"7 years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"1 year",
"4 years",
null,
"10+ years",
"8 years",
"9 years",
"1 year",
null,
"< 1 year",
"1 year",
"1 year",
null,
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"9 years",
null,
"2 years",
"10+ years",
"6 years",
"2 years",
"10+ years",
null,
"10+ years",
"8 years",
"3 years",
"5 years",
null,
"3 years",
"4 years",
"5 years",
"2 years",
"9 years",
"2 years",
"1 year",
"5 years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"3 years",
"5 years",
"1 year",
"7 years",
"10+ years",
"8 years",
"1 year",
"2 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"6 years",
"7 years",
"10+ years",
"8 years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"5 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"4 years",
"8 years",
"10+ years",
"6 years",
"1 year",
"6 years",
"3 years",
"9 years",
"5 years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"1 year",
"6 years",
"2 years",
"1 year",
"1 year",
"10+ years",
"1 year",
"10+ years",
"8 years",
"10+ years",
null,
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"3 years",
null,
"10+ years",
"9 years",
"10+ years",
"6 years",
"9 years",
"1 year",
"< 1 year",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"5 years",
"4 years",
"8 years",
null,
"10+ years",
"4 years",
null,
"2 years",
"10+ years",
"6 years",
"< 1 year",
"10+ years",
null,
"2 years",
null,
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"6 years",
"< 1 year",
"4 years",
"9 years",
"7 years",
"3 years",
"9 years",
"4 years",
"10+ years",
"2 years",
"3 years",
null,
"3 years",
null,
"4 years",
"4 years",
"< 1 year",
"5 years",
"2 years",
"3 years",
"10+ years",
"2 years",
"8 years",
"2 years",
"10+ years",
"9 years",
"1 year",
"7 years",
"7 years",
"9 years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"8 years",
"2 years",
"2 years",
null,
"5 years",
"6 years",
"< 1 year",
"4 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"6 years",
"4 years",
"7 years",
null,
"1 year",
"3 years",
"8 years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"7 years",
"3 years",
"7 years",
"< 1 year",
"8 years",
"2 years",
"2 years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"9 years",
"4 years",
"< 1 year",
"2 years",
"< 1 year",
"8 years",
"7 years",
"10+ years",
"< 1 year",
"< 1 year",
"9 years",
"4 years",
"3 years",
"< 1 year",
"4 years",
"< 1 year",
"9 years",
"10+ years",
"6 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"6 years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"2 years",
"10+ years",
"7 years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
null,
"10+ years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"1 year",
"6 years",
"4 years",
"5 years",
"3 years",
"10+ years",
"9 years",
"8 years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"1 year",
"10+ years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"8 years",
null,
"10+ years",
"10+ years",
"10+ years",
"8 years",
"2 years",
"6 years",
"10+ years",
null,
"7 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"9 years",
"5 years",
"6 years",
"5 years",
"1 year",
"5 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"7 years",
"2 years",
"5 years",
"6 years",
"10+ years",
"< 1 year",
"3 years",
"4 years",
"2 years",
"8 years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"1 year",
"7 years",
"7 years",
"10+ years",
"10+ years",
"7 years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"6 years",
"5 years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"7 years",
"10+ years",
null,
"7 years",
"5 years",
"5 years",
"3 years",
"10+ years",
"9 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"1 year",
"1 year",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"3 years",
null,
"3 years",
"6 years",
"8 years",
"7 years",
"2 years",
"7 years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"< 1 year",
"1 year",
"3 years",
"9 years",
"10+ years",
"2 years",
"10+ years",
"4 years",
"2 years",
"4 years",
"10+ years",
"6 years",
"10+ years",
null,
"9 years",
"7 years",
"7 years",
"1 year",
"1 year",
"5 years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"2 years",
"9 years",
"5 years",
"6 years",
"2 years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"7 years",
"10+ years",
"6 years",
"6 years",
"6 years",
"10+ years",
"6 years",
null,
"10+ years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"2 years",
null,
"10+ years",
"10+ years",
null,
"8 years",
"1 year",
"4 years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"8 years",
"10+ years",
"6 years",
"7 years",
"1 year",
"2 years",
"8 years",
"10+ years",
"1 year",
"3 years",
"< 1 year",
"< 1 year",
null,
"10+ years",
"10+ years",
"3 years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"6 years",
"10+ years",
"10+ years",
"6 years",
"6 years",
"< 1 year",
"5 years",
"5 years",
"1 year",
"4 years",
"8 years",
"10+ years",
"8 years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"3 years",
"7 years",
"4 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"8 years",
"4 years",
"3 years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"8 years",
"9 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"9 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"2 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"3 years",
"4 years",
"9 years",
"10+ years",
"9 years",
"4 years",
"10+ years",
"1 year",
"6 years",
"< 1 year",
null,
"10+ years",
"2 years",
"10+ years",
"9 years",
"4 years",
"< 1 year",
"10+ years",
"1 year",
"2 years",
"10+ years",
"2 years",
null,
"< 1 year",
"10+ years",
"1 year",
"3 years",
"2 years",
"8 years",
null,
"9 years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"9 years",
"6 years",
"< 1 year",
"2 years",
"5 years",
"9 years",
"1 year",
"4 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"4 years",
"3 years",
"10+ years",
"10+ years",
null,
"1 year",
null,
"< 1 year",
"3 years",
"5 years",
"3 years",
"7 years",
null,
"10+ years",
"9 years",
"2 years",
null,
"10+ years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"7 years",
"< 1 year",
null,
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"1 year",
"10+ years",
"2 years",
"9 years",
"3 years",
"3 years",
"< 1 year",
"1 year",
"2 years",
"2 years",
"6 years",
"7 years",
"10+ years",
"< 1 year",
"1 year",
"3 years",
"2 years",
"10+ years",
"5 years",
"2 years",
"7 years",
"3 years",
"1 year",
"8 years",
"2 years",
"6 years",
"2 years",
"4 years",
"3 years",
"8 years",
"1 year",
"10+ years",
"5 years",
"< 1 year",
"4 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"2 years",
"2 years",
"3 years",
"10+ years",
"7 years",
"10+ years",
null,
"2 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"< 1 year",
"3 years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"2 years",
"9 years",
"3 years",
"1 year",
"6 years",
"1 year",
"1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"3 years",
null,
"7 years",
"1 year",
"8 years",
"< 1 year",
"4 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"7 years",
"10+ years",
"< 1 year",
null,
"4 years",
"9 years",
"10+ years",
"2 years",
null,
"7 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"4 years",
"6 years",
"10+ years",
"8 years",
"< 1 year",
"2 years",
"6 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"6 years",
"7 years",
"1 year",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"5 years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"4 years",
"< 1 year",
"10+ years",
null,
"7 years",
"3 years",
"9 years",
"6 years",
null,
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"< 1 year",
"10+ years",
"8 years",
null,
"1 year",
null,
"5 years",
null,
"10+ years",
null,
"10+ years",
"5 years",
"< 1 year",
"4 years",
"5 years",
"10+ years",
"1 year",
"1 year",
"8 years",
"7 years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"4 years",
"4 years",
"2 years",
"7 years",
null,
"10+ years",
"5 years",
null,
"10+ years",
"10+ years",
"10+ years",
"1 year",
"7 years",
"8 years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"6 years",
"10+ years",
"9 years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"6 years",
"6 years",
"2 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
null,
"2 years",
"10+ years",
"3 years",
"8 years",
"< 1 year",
"6 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"4 years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
null,
"10+ years",
null,
"9 years",
"4 years",
"5 years",
"4 years",
"10+ years",
null,
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"10+ years",
"1 year",
"10+ years",
"8 years",
"10+ years",
null,
"3 years",
"8 years",
"3 years",
"3 years",
"2 years",
"2 years",
"6 years",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"9 years",
"< 1 year",
"< 1 year",
"4 years",
"< 1 year",
"1 year",
"3 years",
null,
"3 years",
"6 years",
"8 years",
"6 years",
"7 years",
"10+ years",
"8 years",
null,
"10+ years",
"9 years",
"7 years",
"2 years",
"10+ years",
"2 years",
"2 years",
null,
"10+ years",
"7 years",
"2 years",
"2 years",
"10+ years",
"9 years",
"< 1 year",
"8 years",
"8 years",
"< 1 year",
"10+ years",
"8 years",
"3 years",
"4 years",
null,
"10+ years",
"6 years",
"4 years",
"7 years",
"5 years",
"2 years",
"3 years",
"1 year",
"< 1 year",
"5 years",
"1 year",
null,
"10+ years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"4 years",
"8 years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"1 year",
"2 years",
null,
"10+ years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"7 years",
"3 years",
"10+ years",
"4 years",
"1 year",
"7 years",
"10+ years",
"3 years",
"2 years",
"9 years",
"10+ years",
"8 years",
null,
"2 years",
"2 years",
"7 years",
"10+ years",
"3 years",
null,
"4 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"1 year",
"< 1 year",
"2 years",
"< 1 year",
"10+ years",
"9 years",
"6 years",
"8 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"9 years",
"10+ years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"4 years",
"< 1 year",
"3 years",
"3 years",
"8 years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"6 years",
"< 1 year",
"7 years",
"5 years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"7 years",
"5 years",
"10+ years",
"10+ years",
null,
null,
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"1 year",
"10+ years",
"10+ years",
"8 years",
"9 years",
"10+ years",
"1 year",
"3 years",
"5 years",
"5 years",
"2 years",
"8 years",
"10+ years",
"3 years",
"3 years",
"4 years",
null,
"10+ years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"5 years",
"< 1 year",
"3 years",
"8 years",
"6 years",
"6 years",
"5 years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"6 years",
"10+ years",
"2 years",
"3 years",
"6 years",
"10+ years",
"8 years",
"7 years",
null,
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"8 years",
"3 years",
"< 1 year",
"4 years",
"< 1 year",
"10+ years",
"6 years",
"3 years",
"8 years",
"< 1 year",
"1 year",
"10+ years",
"4 years",
"9 years",
"1 year",
"3 years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
null,
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"6 years",
"3 years",
"10+ years",
"< 1 year",
null,
"10+ years",
"4 years",
"10+ years",
"3 years",
"1 year",
"10+ years",
"2 years",
null,
"< 1 year",
"3 years",
"2 years",
"3 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"6 years",
"9 years",
"5 years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"< 1 year",
"7 years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
null,
"2 years",
"5 years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"2 years",
"10+ years",
"9 years",
"2 years",
"5 years",
"6 years",
"3 years",
"10+ years",
"5 years",
"2 years",
"8 years",
"10+ years",
"< 1 year",
"6 years",
"< 1 year",
"5 years",
"5 years",
"10+ years",
"10+ years",
null,
"1 year",
"2 years",
"2 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"6 years",
"5 years",
"9 years",
"1 year",
"2 years",
"10+ years",
"3 years",
"< 1 year",
"8 years",
"7 years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"8 years",
null,
null,
"10+ years",
"5 years",
"2 years",
"2 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"9 years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"2 years",
"8 years",
"< 1 year",
"8 years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"8 years",
null,
"3 years",
"10+ years",
"2 years",
"10+ years",
"6 years",
"1 year",
"10+ years",
"7 years",
"10+ years",
"7 years",
"3 years",
"1 year",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"2 years",
"10+ years",
"5 years",
"4 years",
"6 years",
"5 years",
"9 years",
"1 year",
"8 years",
"< 1 year",
"10+ years",
"9 years",
"< 1 year",
"7 years",
null,
null,
"10+ years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"2 years",
"2 years",
"4 years",
"< 1 year",
"9 years",
"9 years",
"7 years",
null,
"2 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
null,
"10+ years",
"3 years",
"< 1 year",
"7 years",
"8 years",
"3 years",
"3 years",
"10+ years",
"3 years",
"9 years",
"5 years",
"7 years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"3 years",
"3 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
null,
"3 years",
"3 years",
"1 year",
"< 1 year",
"2 years",
null,
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"7 years",
"10+ years",
"1 year",
"1 year",
"5 years",
"< 1 year",
"3 years",
"3 years",
"4 years",
"8 years",
"< 1 year",
"7 years",
"2 years",
"10+ years",
null,
"4 years",
"5 years",
"1 year",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"6 years",
"5 years",
"8 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"8 years",
null,
"< 1 year",
"6 years",
"10+ years",
"7 years",
"3 years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"8 years",
"2 years",
"< 1 year",
"4 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"4 years",
"3 years",
"10+ years",
"5 years",
"< 1 year",
"9 years",
"4 years",
null,
"3 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"7 years",
"1 year",
"3 years",
"10+ years",
"5 years",
"2 years",
"1 year",
"5 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"7 years",
"5 years",
"7 years",
"5 years",
"2 years",
"10+ years",
"4 years",
"8 years",
"10+ years",
"2 years",
"5 years",
null,
null,
"10+ years",
"10+ years",
"8 years",
"5 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"8 years",
"2 years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"4 years",
"5 years",
"5 years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"1 year",
"8 years",
"10+ years",
"5 years",
"8 years",
null,
"10+ years",
"< 1 year",
"8 years",
"4 years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"2 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"4 years",
"< 1 year",
"8 years",
null,
"10+ years",
"9 years",
"1 year",
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"9 years",
"5 years",
"2 years",
"6 years",
"< 1 year",
"10+ years",
"9 years",
"6 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"4 years",
"7 years",
"5 years",
"10+ years",
"3 years",
"4 years",
null,
"10+ years",
"7 years",
"9 years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"< 1 year",
"10+ years",
"7 years",
"7 years",
"3 years",
"10+ years",
"3 years",
"< 1 year",
"6 years",
"< 1 year",
"10+ years",
"2 years",
"7 years",
"10+ years",
"< 1 year",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"2 years",
"1 year",
"8 years",
null,
"1 year",
"2 years",
"10+ years",
"5 years",
"10+ years",
null,
"1 year",
"2 years",
"10+ years",
"5 years",
"2 years",
"1 year",
"3 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"1 year",
null,
"10+ years",
"7 years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"8 years",
"2 years",
"2 years",
"8 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
null,
"10+ years",
"2 years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"4 years",
"5 years",
"8 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"3 years",
"2 years",
null,
"3 years",
"2 years",
"10+ years",
"3 years",
null,
"8 years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"10+ years",
"8 years",
"2 years",
"6 years",
"4 years",
"6 years",
"7 years",
"9 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"3 years",
"9 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"4 years",
"8 years",
"< 1 year",
"10+ years",
"6 years",
"9 years",
"2 years",
"3 years",
"10+ years",
"4 years",
"10+ years",
"8 years",
"7 years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"1 year",
"5 years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"3 years",
"3 years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"1 year",
"8 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"6 years",
"< 1 year",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"8 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"5 years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"2 years",
"7 years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"4 years",
"8 years",
null,
"5 years",
"2 years",
null,
"10+ years",
"10+ years",
"1 year",
"4 years",
null,
"9 years",
"1 year",
"2 years",
"9 years",
"6 years",
"3 years",
"4 years",
"1 year",
"4 years",
"10+ years",
"3 years",
"6 years",
"10+ years",
"4 years",
"2 years",
"3 years",
"2 years",
"10+ years",
"6 years",
"8 years",
"8 years",
"2 years",
"9 years",
"4 years",
"3 years",
"9 years",
"4 years",
"7 years",
"5 years",
"5 years",
"7 years",
"6 years",
"1 year",
"9 years",
"< 1 year",
"< 1 year",
"< 1 year",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"8 years",
"8 years",
"< 1 year",
"9 years",
"3 years",
"9 years",
"9 years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"7 years",
"5 years",
"6 years",
"10+ years",
null,
"10+ years",
"3 years",
"9 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"5 years",
null,
"3 years",
"10+ years",
"8 years",
"7 years",
"8 years",
"1 year",
"2 years",
"3 years",
"10+ years",
"8 years",
"1 year",
"1 year",
"10+ years",
"4 years",
null,
"3 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
null,
"3 years",
"9 years",
"2 years",
"2 years",
"6 years",
"4 years",
"3 years",
"1 year",
"< 1 year",
"6 years",
"2 years",
"9 years",
"4 years",
"2 years",
"10+ years",
"4 years",
"2 years",
"7 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"10+ years",
null,
"2 years",
"1 year",
"4 years",
"2 years",
"4 years",
"2 years",
"4 years",
"10+ years",
"6 years",
"1 year",
null,
"10+ years",
"4 years",
"10+ years",
"1 year",
"2 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"8 years",
"3 years",
"10+ years",
"8 years",
"5 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"4 years",
"< 1 year",
"2 years",
"10+ years",
"1 year",
"9 years",
"1 year",
"3 years",
"1 year",
"6 years",
"6 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
null,
"1 year",
"10+ years",
null,
"7 years",
"10+ years",
"6 years",
"10+ years",
null,
"10+ years",
"5 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"9 years",
"< 1 year",
"7 years",
"5 years",
"10+ years",
"2 years",
"9 years",
"10+ years",
"3 years",
"9 years",
"5 years",
"10+ years",
"10+ years",
"9 years",
"7 years",
"10+ years",
"5 years",
"1 year",
"5 years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"3 years",
"10+ years",
null,
"5 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"3 years",
"3 years",
"2 years",
"6 years",
"10+ years",
"3 years",
"7 years",
"8 years",
"5 years",
null,
"10+ years",
"10+ years",
"5 years",
"1 year",
"3 years",
"10+ years",
"4 years",
"6 years",
"5 years",
"1 year",
"10+ years",
"6 years",
null,
"2 years",
"7 years",
"10+ years",
"1 year",
"< 1 year",
"9 years",
"10+ years",
"7 years",
"4 years",
"7 years",
"3 years",
"1 year",
"8 years",
"3 years",
"2 years",
"8 years",
"10+ years",
"5 years",
"7 years",
null,
"10+ years",
"4 years",
"7 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"8 years",
"10+ years",
"7 years",
"9 years",
"8 years",
"3 years",
"7 years",
"2 years",
"5 years",
"10+ years",
"5 years",
"4 years",
"9 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"9 years",
"2 years",
"4 years",
"1 year",
"2 years",
"2 years",
"< 1 year",
"4 years",
"10+ years",
"3 years",
"8 years",
"8 years",
"< 1 year",
"3 years",
"4 years",
"4 years",
"5 years",
"10+ years",
"5 years",
"4 years",
"7 years",
"2 years",
"3 years",
null,
"8 years",
"2 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
null,
"3 years",
"4 years",
"10+ years",
"6 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"3 years",
null,
"5 years",
"5 years",
"2 years",
"4 years",
"2 years",
"< 1 year",
"< 1 year",
"< 1 year",
null,
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"< 1 year",
"1 year",
"6 years",
null,
null,
"10+ years",
"5 years",
"10+ years",
"6 years",
"10+ years",
"7 years",
"6 years",
"10+ years",
"5 years",
"7 years",
"3 years",
"10+ years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"5 years",
"< 1 year",
"7 years",
"5 years",
"5 years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"1 year",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"3 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"2 years",
"10+ years",
"2 years",
"2 years",
"3 years",
"< 1 year",
"8 years",
"10+ years",
"5 years",
"3 years",
"4 years",
"2 years",
"9 years",
"9 years",
"6 years",
"4 years",
"2 years",
"10+ years",
"1 year",
"8 years",
"5 years",
"5 years",
"5 years",
"3 years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"1 year",
"3 years",
null,
null,
"2 years",
"10+ years",
"9 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"7 years",
"2 years",
"5 years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"8 years",
"5 years",
"< 1 year",
"3 years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"10+ years",
null,
"4 years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"3 years",
"10+ years",
"6 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
null,
"3 years",
"8 years",
"2 years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"7 years",
"4 years",
null,
"10+ years",
"10+ years",
"2 years",
"5 years",
"9 years",
"1 year",
"10+ years",
"10+ years",
"4 years",
null,
"10+ years",
"10+ years",
"7 years",
"3 years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"< 1 year",
"6 years",
"2 years",
"6 years",
"9 years",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"4 years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"4 years",
"3 years",
"4 years",
"1 year",
"10+ years",
"5 years",
"3 years",
"3 years",
"< 1 year",
"10+ years",
"< 1 year",
"1 year",
"1 year",
"5 years",
"1 year",
"10+ years",
"2 years",
"8 years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"1 year",
"3 years",
"6 years",
"1 year",
"7 years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"8 years",
"5 years",
"< 1 year",
"10+ years",
"3 years",
"1 year",
"6 years",
"10+ years",
"< 1 year",
"1 year",
"3 years",
"5 years",
"3 years",
"8 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"7 years",
"10+ years",
"10+ years",
"10+ years",
null,
"6 years",
"3 years",
"10+ years",
"5 years",
"6 years",
null,
"2 years",
"2 years",
"10+ years",
"< 1 year",
null,
"9 years",
"6 years",
"2 years",
"< 1 year",
"< 1 year",
"10+ years",
"6 years",
"5 years",
"6 years",
"< 1 year",
"4 years",
"6 years",
"1 year",
"3 years",
"10+ years",
"9 years",
"2 years",
"8 years",
"8 years",
"7 years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"3 years",
"9 years",
"2 years",
"< 1 year",
"3 years",
"4 years",
"3 years",
"8 years",
"3 years",
"2 years",
"3 years",
"10+ years",
"2 years",
"9 years",
"10+ years",
"6 years",
"3 years",
"6 years",
"9 years",
"7 years",
"1 year",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"4 years",
"7 years",
"10+ years",
"1 year",
"3 years",
"1 year",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"< 1 year",
"< 1 year",
"3 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"1 year",
"4 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"5 years",
"2 years",
"10+ years",
"4 years",
"7 years",
"7 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"8 years",
"4 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
null,
null,
"9 years",
null,
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"5 years",
"8 years",
"6 years",
"7 years",
"1 year",
"2 years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"8 years",
"1 year",
"1 year",
"10+ years",
"2 years",
"3 years",
"10+ years",
"4 years",
"8 years",
"10+ years",
"1 year",
"4 years",
"10+ years",
"8 years",
"2 years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
"9 years",
"6 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
null,
"4 years",
null,
"7 years",
"2 years",
"2 years",
"6 years",
"6 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"8 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
null,
"10+ years",
"5 years",
"3 years",
"6 years",
"3 years",
"9 years",
"5 years",
"1 year",
"4 years",
"10+ years",
"< 1 year",
"1 year",
"< 1 year",
"6 years",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"2 years",
"1 year",
"10+ years",
"5 years",
"10+ years",
"2 years",
"10+ years",
null,
"9 years",
"10+ years",
"6 years",
"3 years",
"< 1 year",
"10+ years",
"7 years",
"5 years",
"10+ years",
"5 years",
"2 years",
"6 years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"3 years",
"< 1 year",
"1 year",
"< 1 year",
"5 years",
"3 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"2 years",
"8 years",
"2 years",
null,
"10+ years",
"8 years",
"< 1 year",
"< 1 year",
"5 years",
"10+ years",
"1 year",
"8 years",
null,
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"9 years",
"10+ years",
"3 years",
null,
"5 years",
"1 year",
"1 year",
"3 years",
"4 years",
null,
"5 years",
"10+ years",
"8 years",
"4 years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
null,
"10+ years",
"5 years",
null,
"1 year",
"4 years",
"2 years",
"10+ years",
"4 years",
"3 years",
"2 years",
"10+ years",
"3 years",
"3 years",
"8 years",
"4 years",
"8 years",
"5 years",
"2 years",
"10+ years",
"7 years",
"4 years",
"2 years",
"3 years",
"6 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
null,
"4 years",
"10+ years",
"9 years",
null,
"8 years",
"9 years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"6 years",
"8 years",
"10+ years",
"10+ years",
"6 years",
"9 years",
"< 1 year",
"3 years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"1 year",
"9 years",
null,
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"6 years",
"5 years",
null,
"3 years",
"2 years",
"6 years",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"2 years",
"< 1 year",
"< 1 year",
"7 years",
"10+ years",
"1 year",
"2 years",
"4 years",
"6 years",
"4 years",
"10+ years",
"1 year",
"< 1 year",
"2 years",
"8 years",
"10+ years",
"< 1 year",
"9 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"4 years",
"5 years",
"4 years",
null,
"10+ years",
"10+ years",
"4 years",
"3 years",
"< 1 year",
"10+ years",
"1 year",
"7 years",
null,
"4 years",
"5 years",
"6 years",
"3 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"3 years",
null,
"1 year",
"1 year",
"5 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"9 years",
"10+ years",
"5 years",
"2 years",
"5 years",
"10+ years",
"< 1 year",
"1 year",
"4 years",
"< 1 year",
"< 1 year",
"8 years",
"4 years",
"2 years",
"4 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"7 years",
"6 years",
"< 1 year",
"8 years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"8 years",
"3 years",
"2 years",
"10+ years",
"9 years",
"10+ years",
"2 years",
"4 years",
"7 years",
"9 years",
"3 years",
"< 1 year",
"2 years",
"6 years",
"< 1 year",
"5 years",
"2 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
null,
"6 years",
"4 years",
"1 year",
"3 years",
"4 years",
"1 year",
"1 year",
"< 1 year",
"1 year",
"10+ years",
"7 years",
"8 years",
"9 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"5 years",
"9 years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"8 years",
"8 years",
"8 years",
"8 years",
"6 years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"< 1 year",
"< 1 year",
"7 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"2 years",
"8 years",
"1 year",
"1 year",
null,
"10+ years",
"10+ years",
"2 years",
"5 years",
"< 1 year",
"5 years",
"2 years",
"10+ years",
null,
"10+ years",
"7 years",
"6 years",
"6 years",
"5 years",
"5 years",
"4 years",
"10+ years",
"1 year",
"5 years",
"9 years",
"2 years",
"9 years",
"5 years",
"8 years",
"2 years",
"10+ years",
"< 1 year",
"< 1 year",
"2 years",
null,
"7 years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"7 years",
"7 years",
null,
"2 years",
"8 years",
"5 years",
"9 years",
"10+ years",
"9 years",
"8 years",
"9 years",
"10+ years",
null,
"10+ years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"5 years",
"7 years",
"10+ years",
"6 years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"8 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"4 years",
"10+ years",
"1 year",
"8 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"6 years",
"8 years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"7 years",
"3 years",
"5 years",
"1 year",
"< 1 year",
"2 years",
"4 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"9 years",
"9 years",
"7 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"< 1 year",
"10+ years",
null,
"8 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"< 1 year",
"4 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"7 years",
"10+ years",
"5 years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
null,
"2 years",
"8 years",
"9 years",
null,
"< 1 year",
"10+ years",
"< 1 year",
"< 1 year",
"1 year",
"2 years",
"1 year",
"3 years",
"2 years",
"1 year",
"4 years",
"< 1 year",
"1 year",
"10+ years",
"< 1 year",
"3 years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"9 years",
"< 1 year",
null,
"2 years",
"3 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"6 years",
"9 years",
"2 years",
"3 years",
"4 years",
"10+ years",
"1 year",
"5 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"4 years",
"8 years",
"2 years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"5 years",
"1 year",
"9 years",
"7 years",
"1 year",
"8 years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"3 years",
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"6 years",
"4 years",
"10+ years",
"10+ years",
"7 years",
"7 years",
"3 years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"< 1 year",
"3 years",
"2 years",
"2 years",
"10+ years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"6 years",
"10+ years",
"3 years",
"10+ years",
null,
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"8 years",
"7 years",
"9 years",
"3 years",
"3 years",
"2 years",
"4 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"6 years",
"5 years",
"10+ years",
"8 years",
"9 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"9 years",
null,
"6 years",
"9 years",
"5 years",
"4 years",
"10+ years",
"10+ years",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"9 years",
"3 years",
"3 years",
"2 years",
"2 years",
"5 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"2 years",
"8 years",
"8 years",
"3 years",
null,
"3 years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"3 years",
"8 years",
"4 years",
"4 years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"1 year",
"4 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"7 years",
"< 1 year",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"3 years",
null,
"3 years",
"10+ years",
"7 years",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
null,
"8 years",
"10+ years",
"< 1 year",
"8 years",
"3 years",
"10+ years",
"10+ years",
null,
"1 year",
"7 years",
"< 1 year",
"3 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"8 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"5 years",
"10+ years",
null,
"1 year",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"9 years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
null,
"3 years",
"2 years",
"8 years",
"2 years",
"10+ years",
"< 1 year",
"3 years",
"< 1 year",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"5 years",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"5 years",
null,
"2 years",
"8 years",
"1 year",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"5 years",
"3 years",
"10+ years",
"5 years",
"4 years",
"8 years",
"5 years",
null,
"5 years",
"10+ years",
"2 years",
"2 years",
"< 1 year",
"10+ years",
"7 years",
"3 years",
"2 years",
"< 1 year",
"1 year",
"7 years",
"2 years",
"10+ years",
"4 years",
"3 years",
"8 years",
"3 years",
"8 years",
"< 1 year",
"2 years",
"1 year",
"2 years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"2 years",
"5 years",
"< 1 year",
"< 1 year",
"6 years",
"10+ years",
"3 years",
"7 years",
null,
"3 years",
null,
"5 years",
"2 years",
"10+ years",
"7 years",
"3 years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"1 year",
"8 years",
"7 years",
"6 years",
"10+ years",
"7 years",
"10+ years",
"9 years",
"< 1 year",
"3 years",
"5 years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"8 years",
"5 years",
"3 years",
"9 years",
"1 year",
"10+ years",
null,
"3 years",
"5 years",
"8 years",
"3 years",
"7 years",
"3 years",
"7 years",
"3 years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"4 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"8 years",
"8 years",
"1 year",
"4 years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"< 1 year",
"1 year",
"7 years",
"6 years",
"3 years",
"< 1 year",
"3 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"< 1 year",
"9 years",
"2 years",
"9 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
null,
"2 years",
"< 1 year",
"< 1 year",
"4 years",
"7 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"1 year",
"1 year",
"10+ years",
"4 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"7 years",
"< 1 year",
"2 years",
"10+ years",
"5 years",
"8 years",
"2 years",
"3 years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"1 year",
"6 years",
"6 years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"6 years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"3 years",
"8 years",
null,
"7 years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"4 years",
"3 years",
"10+ years",
"3 years",
"7 years",
"9 years",
"10+ years",
"10+ years",
"8 years",
"3 years",
"2 years",
"10+ years",
"9 years",
"8 years",
"< 1 year",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"< 1 year",
"5 years",
"10+ years",
"5 years",
"8 years",
"10+ years",
"9 years",
"10+ years",
"5 years",
"10+ years",
"3 years",
"1 year",
"3 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"6 years",
"3 years",
"10+ years",
"8 years",
"5 years",
"7 years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"1 year",
"8 years",
"10+ years",
"2 years",
"7 years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
null,
"10+ years",
"9 years",
"9 years",
"< 1 year",
"2 years",
"4 years",
"< 1 year",
"5 years",
"5 years",
"3 years",
"10+ years",
"< 1 year",
null,
"10+ years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"7 years",
"10+ years",
"< 1 year",
"9 years",
"9 years",
"2 years",
"9 years",
"8 years",
null,
null,
"10+ years",
"5 years",
"6 years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"9 years",
"4 years",
"2 years",
"3 years",
"1 year",
"10+ years",
"6 years",
"< 1 year",
"8 years",
"3 years",
"5 years",
"10+ years",
"10+ years",
null,
"< 1 year",
null,
"10+ years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"4 years",
"1 year",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
null,
"1 year",
"5 years",
"4 years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"8 years",
"8 years",
"6 years",
"8 years",
"3 years",
"2 years",
"10+ years",
"8 years",
"1 year",
"10+ years",
null,
"4 years",
"4 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"1 year",
"5 years",
"6 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"3 years",
"5 years",
"3 years",
"2 years",
"6 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"7 years",
"2 years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"3 years",
"9 years",
"< 1 year",
"10+ years",
"9 years",
"< 1 year",
"3 years",
"< 1 year",
"4 years",
"2 years",
"5 years",
"7 years",
"10+ years",
"< 1 year",
"2 years",
"4 years",
"1 year",
"6 years",
"1 year",
"10+ years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"3 years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"1 year",
"8 years",
"< 1 year",
"< 1 year",
"4 years",
"10+ years",
null,
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"8 years",
null,
"2 years",
"9 years",
"2 years",
"10+ years",
"8 years",
"3 years",
"8 years",
"10+ years",
"9 years",
"8 years",
"10+ years",
"4 years",
null,
"2 years",
"< 1 year",
"8 years",
"4 years",
"4 years",
"10+ years",
"3 years",
"3 years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"5 years",
"9 years",
"9 years",
"2 years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"2 years",
"6 years",
"5 years",
null,
"5 years",
"< 1 year",
"2 years",
null,
"3 years",
"3 years",
"5 years",
"8 years",
"8 years",
"5 years",
"2 years",
"10+ years",
"7 years",
"8 years",
"2 years",
"5 years",
"10+ years",
"7 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
null,
"7 years",
"3 years",
"7 years",
"6 years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"1 year",
"4 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"3 years",
"7 years",
"2 years",
"7 years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"8 years",
"2 years",
"4 years",
"1 year",
"4 years",
null,
"4 years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"9 years",
"7 years",
"< 1 year",
null,
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"< 1 year",
"4 years",
"5 years",
"< 1 year",
"6 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
null,
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"7 years",
null,
"4 years",
"10+ years",
"9 years",
null,
"9 years",
"10+ years",
"< 1 year",
null,
"3 years",
"8 years",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"7 years",
"9 years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"7 years",
"4 years",
"8 years",
"7 years",
"6 years",
"3 years",
"1 year",
"< 1 year",
"10+ years",
"4 years",
"3 years",
"< 1 year",
"3 years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"9 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
null,
"2 years",
"< 1 year",
"< 1 year",
"4 years",
"8 years",
"4 years",
null,
"10+ years",
"1 year",
"< 1 year",
"1 year",
"< 1 year",
"< 1 year",
"5 years",
"2 years",
"8 years",
"10+ years",
"6 years",
"6 years",
"7 years",
"10+ years",
"4 years",
"2 years",
null,
"< 1 year",
"3 years",
"3 years",
"10+ years",
null,
"2 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"1 year",
"10+ years",
"4 years",
"7 years",
"1 year",
null,
"10+ years",
"4 years",
"2 years",
"2 years",
"5 years",
"9 years",
"2 years",
"5 years",
"10+ years",
"9 years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"3 years",
"1 year",
"8 years",
"5 years",
"4 years",
"9 years",
"2 years",
"10+ years",
"10+ years",
null,
"5 years",
"2 years",
"7 years",
"10+ years",
"1 year",
"8 years",
"5 years",
"9 years",
"7 years",
"6 years",
"7 years",
"4 years",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
null,
"10+ years",
"5 years",
"10+ years",
"9 years",
"8 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"7 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"4 years",
"8 years",
"10+ years",
"10+ years",
"6 years",
"4 years",
"2 years",
"9 years",
"6 years",
"3 years",
"10+ years",
"5 years",
"7 years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"7 years",
null,
"< 1 year",
"10+ years",
"2 years",
"5 years",
"2 years",
"2 years",
"2 years",
null,
"10+ years",
"10+ years",
"8 years",
"2 years",
"3 years",
"3 years",
"4 years",
"6 years",
"8 years",
"10+ years",
"2 years",
null,
"2 years",
"1 year",
"10+ years",
null,
"10+ years",
null,
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"6 years",
"5 years",
"10+ years",
null,
"10+ years",
"10+ years",
"3 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"< 1 year",
"9 years",
null,
"10+ years",
"8 years",
"10+ years",
"10+ years",
"6 years",
null,
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"6 years",
"7 years",
"1 year",
"8 years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"6 years",
"10+ years",
null,
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"3 years",
null,
"10+ years",
"4 years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"< 1 year",
"4 years",
"5 years",
"3 years",
null,
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"9 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"8 years",
null,
"1 year",
"6 years",
"2 years",
"< 1 year",
"6 years",
"9 years",
"10+ years",
"5 years",
"2 years",
"4 years",
"3 years",
"6 years",
"2 years",
"2 years",
"3 years",
null,
"3 years",
null,
"9 years",
"< 1 year",
"1 year",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"9 years",
"2 years",
"5 years",
"4 years",
"7 years",
"9 years",
"10+ years",
"3 years",
"1 year",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"1 year",
"3 years",
"6 years",
"10+ years",
"7 years",
"10+ years",
"7 years",
"3 years",
"6 years",
"10+ years",
"3 years",
"4 years",
null,
"2 years",
"< 1 year",
"3 years",
"10+ years",
"5 years",
null,
"< 1 year",
"6 years",
"1 year",
"4 years",
"3 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
null,
"10+ years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"5 years",
"5 years",
"4 years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"7 years",
"10+ years",
"2 years",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"8 years",
"7 years",
"10+ years",
null,
"< 1 year",
"8 years",
"7 years",
"6 years",
"10+ years",
"9 years",
"2 years",
"5 years",
"1 year",
"5 years",
"10+ years",
"2 years",
"10+ years",
"6 years",
"9 years",
"1 year",
"9 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"5 years",
"5 years",
"10+ years",
"9 years",
"10+ years",
"3 years",
"2 years",
"1 year",
"9 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"5 years",
null,
"5 years",
"10+ years",
"10+ years",
"2 years",
"7 years",
null,
"5 years",
"8 years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"7 years",
"4 years",
"5 years",
"4 years",
"< 1 year",
"5 years",
"10+ years",
"3 years",
"6 years",
"4 years",
null,
null,
"10+ years",
null,
null,
"5 years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"7 years",
"2 years",
"7 years",
"1 year",
"< 1 year",
"3 years",
"1 year",
"10+ years",
"8 years",
"5 years",
"2 years",
"7 years",
"5 years",
"9 years",
"8 years",
"10+ years",
"2 years",
"< 1 year",
"8 years",
"2 years",
"2 years",
"1 year",
"< 1 year",
"5 years",
"2 years",
"5 years",
"10+ years",
"8 years",
"6 years",
"4 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"4 years",
"5 years",
"2 years",
"5 years",
"10+ years",
"1 year",
"4 years",
"6 years",
"3 years",
"8 years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"7 years",
"1 year",
"10+ years",
"6 years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"5 years",
"10+ years",
null,
"3 years",
"8 years",
"8 years",
"10+ years",
"3 years",
"5 years",
"< 1 year",
"10+ years",
"2 years",
"3 years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
null,
"< 1 year",
"6 years",
"3 years",
"5 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"3 years",
"10+ years",
"< 1 year",
"2 years",
"2 years",
"6 years",
"9 years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"4 years",
"2 years",
"2 years",
null,
"10+ years",
"< 1 year",
null,
"1 year",
null,
"10+ years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"9 years",
"1 year",
"7 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"6 years",
"5 years",
"2 years",
"4 years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"4 years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"8 years",
"< 1 year",
"4 years",
"1 year",
null,
"10+ years",
"10+ years",
"10+ years",
"3 years",
null,
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"1 year",
"2 years",
null,
"7 years",
"2 years",
"10+ years",
null,
null,
"2 years",
"1 year",
"7 years",
"10+ years",
"< 1 year",
"5 years",
"5 years",
null,
"10+ years",
"6 years",
null,
"10+ years",
"2 years",
"6 years",
"9 years",
"< 1 year",
"9 years",
"10+ years",
"2 years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"2 years",
"6 years",
"10+ years",
"4 years",
"4 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"5 years",
"5 years",
null,
"4 years",
"5 years",
"2 years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"3 years",
"5 years",
"4 years",
"7 years",
"10+ years",
"7 years",
"10+ years",
"< 1 year",
"2 years",
"9 years",
"1 year",
"3 years",
"10+ years",
"2 years",
"7 years",
"9 years",
"10+ years",
null,
"9 years",
"4 years",
"2 years",
"6 years",
null,
"10+ years",
"1 year",
"3 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"9 years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"8 years",
"8 years",
"1 year",
"10+ years",
"10+ years",
"9 years",
"4 years",
"3 years",
"4 years",
"10+ years",
"2 years",
"1 year",
"7 years",
null,
"1 year",
"10+ years",
"7 years",
"7 years",
"7 years",
"2 years",
"< 1 year",
"9 years",
"4 years",
"2 years",
"10+ years",
"2 years",
"4 years",
"10+ years",
"2 years",
"8 years",
"1 year",
"8 years",
"10+ years",
"3 years",
"9 years",
"8 years",
null,
"10+ years",
"3 years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"1 year",
"2 years",
"5 years",
"2 years",
"5 years",
"5 years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"3 years",
null,
"8 years",
null,
"10+ years",
"5 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"9 years",
"2 years",
"3 years",
"10+ years",
"4 years",
"< 1 year",
"1 year",
"5 years",
"4 years",
"10+ years",
"10+ years",
null,
"4 years",
"10+ years",
"10+ years",
null,
"3 years",
"1 year",
"2 years",
"7 years",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
null,
"10+ years",
"1 year",
"3 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"7 years",
"6 years",
"2 years",
"10+ years",
"6 years",
"4 years",
"10+ years",
"9 years",
"3 years",
"2 years",
"10+ years",
"2 years",
"1 year",
"8 years",
"< 1 year",
"3 years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"4 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"1 year",
"4 years",
"8 years",
"10+ years",
"6 years",
"10+ years",
"5 years",
"10+ years",
"8 years",
"1 year",
"1 year",
"7 years",
"7 years",
"< 1 year",
"8 years",
"10+ years",
null,
"< 1 year",
"8 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
null,
"2 years",
"3 years",
"10+ years",
"3 years",
"4 years",
"8 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"8 years",
"< 1 year",
"4 years",
"5 years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"9 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"3 years",
"5 years",
"1 year",
"8 years",
"10+ years",
"< 1 year",
"8 years",
"2 years",
"1 year",
null,
"10+ years",
"10+ years",
"2 years",
"5 years",
null,
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"8 years",
"10+ years",
"6 years",
"6 years",
"3 years",
"8 years",
"7 years",
null,
null,
"10+ years",
"2 years",
"10+ years",
"2 years",
"1 year",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"9 years",
"4 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"8 years",
"2 years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"6 years",
"7 years",
"5 years",
"8 years",
"10+ years",
"< 1 year",
"< 1 year",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"9 years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"7 years",
"10+ years",
"8 years",
null,
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"5 years",
null,
"10+ years",
null,
"1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"< 1 year",
"1 year",
"5 years",
"4 years",
"2 years",
"10+ years",
"2 years",
"2 years",
"3 years",
null,
"10+ years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"6 years",
"6 years",
"10+ years",
"2 years",
"< 1 year",
"8 years",
"10+ years",
"5 years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
null,
"5 years",
"1 year",
"1 year",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"8 years",
"8 years",
"10+ years",
"4 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"< 1 year",
"8 years",
"1 year",
"4 years",
"8 years",
"2 years",
"10+ years",
"< 1 year",
"2 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
null,
"1 year",
"4 years",
"3 years",
"< 1 year",
"9 years",
"6 years",
"6 years",
null,
"10+ years",
"7 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"8 years",
"8 years",
"8 years",
"4 years",
"4 years",
"< 1 year",
"1 year",
"1 year",
"7 years",
"7 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"4 years",
"3 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"7 years",
"< 1 year",
"5 years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"2 years",
"7 years",
null,
"10+ years",
"10+ years",
"9 years",
"5 years",
"2 years",
"10+ years",
"6 years",
"7 years",
"10+ years",
"4 years",
"3 years",
null,
"10+ years",
"9 years",
"2 years",
"5 years",
"< 1 year",
"7 years",
"4 years",
"2 years",
"2 years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"1 year",
"9 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"4 years",
"10+ years",
null,
"2 years",
"10+ years",
"8 years",
"3 years",
"< 1 year",
"4 years",
"10+ years",
"8 years",
"1 year",
"3 years",
"10+ years",
"1 year",
"10+ years",
"2 years",
"6 years",
"10+ years",
"3 years",
"3 years",
"9 years",
"7 years",
"10+ years",
"3 years",
"1 year",
null,
"2 years",
"6 years",
"6 years",
"< 1 year",
"8 years",
"10+ years",
"2 years",
"6 years",
"5 years",
"6 years",
"3 years",
"6 years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"8 years",
"3 years",
"5 years",
"9 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
null,
"< 1 year",
"10+ years",
"7 years",
"2 years",
"1 year",
"1 year",
"3 years",
"4 years",
"10+ years",
"7 years",
"2 years",
"< 1 year",
"1 year",
"10+ years",
"3 years",
"< 1 year",
"2 years",
"9 years",
"8 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"6 years",
"< 1 year",
"4 years",
"6 years",
"6 years",
"6 years",
"2 years",
"5 years",
"8 years",
null,
"< 1 year",
"6 years",
"6 years",
"4 years",
"7 years",
"7 years",
"7 years",
"7 years",
"10+ years",
null,
"6 years",
"8 years",
"3 years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"4 years",
"9 years",
"9 years",
"8 years",
"3 years",
"1 year",
"9 years",
null,
"< 1 year",
null,
"1 year",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"2 years",
"8 years",
"2 years",
"5 years",
"1 year",
"10+ years",
"7 years",
"2 years",
"8 years",
null,
"6 years",
"< 1 year",
"10+ years",
"7 years",
"9 years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"7 years",
"10+ years",
null,
"10+ years",
"9 years",
"< 1 year",
null,
"10+ years",
"10+ years",
"7 years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"3 years",
"< 1 year",
null,
"5 years",
"10+ years",
"10+ years",
"1 year",
"8 years",
"10+ years",
"6 years",
"8 years",
"2 years",
"10+ years",
"6 years",
"10+ years",
"7 years",
"5 years",
"4 years",
"10+ years",
"1 year",
"7 years",
"1 year",
"< 1 year",
"3 years",
"5 years",
"7 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"2 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"4 years",
"2 years",
"5 years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"< 1 year",
"< 1 year",
"2 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"4 years",
"1 year",
"10+ years",
"10+ years",
"1 year",
"4 years",
"5 years",
"3 years",
"7 years",
"3 years",
"3 years",
"1 year",
"10+ years",
null,
"10+ years",
"3 years",
"9 years",
"< 1 year",
"10+ years",
"7 years",
"1 year",
"2 years",
"< 1 year",
"2 years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"4 years",
null,
"4 years",
"3 years",
"< 1 year",
"5 years",
"5 years",
"5 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"1 year",
"3 years",
"9 years",
"3 years",
"10+ years",
"3 years",
null,
null,
"6 years",
"< 1 year",
"6 years",
"10+ years",
"4 years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"5 years",
"6 years",
"4 years",
"10+ years",
"< 1 year",
null,
"10+ years",
"8 years",
"5 years",
null,
"3 years",
"< 1 year",
"7 years",
"9 years",
"2 years",
"4 years",
"10+ years",
"5 years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"1 year",
"7 years",
"7 years",
"< 1 year",
"6 years",
"5 years",
"7 years",
"10+ years",
"2 years",
null,
"2 years",
"3 years",
"9 years",
"10+ years",
"10+ years",
"8 years",
"6 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"7 years",
"9 years",
"1 year",
null,
"10+ years",
"1 year",
"1 year",
"3 years",
"10+ years",
"5 years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
null,
"< 1 year",
"7 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"6 years",
"10+ years",
null,
"4 years",
"2 years",
"8 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"1 year",
"< 1 year",
"4 years",
"1 year",
"< 1 year",
"8 years",
"10+ years",
"3 years",
"3 years",
"4 years",
"10+ years",
"< 1 year",
"2 years",
"4 years",
"5 years",
"5 years",
"10+ years",
"9 years",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"1 year",
"5 years",
"10+ years",
"5 years",
"5 years",
null,
"6 years",
"10+ years",
"< 1 year",
"6 years",
"7 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"1 year",
"3 years",
"3 years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"< 1 year",
"8 years",
"6 years",
"< 1 year",
"< 1 year",
"1 year",
"1 year",
"7 years",
"4 years",
"1 year",
"2 years",
"6 years",
"< 1 year",
"7 years",
"1 year",
"2 years",
"10+ years",
"6 years",
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"3 years",
"5 years",
"10+ years",
"6 years",
"3 years",
"4 years",
"4 years",
null,
"7 years",
"7 years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"7 years",
"10+ years",
"8 years",
"< 1 year",
"6 years",
"< 1 year",
"9 years",
"1 year",
"10+ years",
"2 years",
"5 years",
null,
"1 year",
"2 years",
"2 years",
"10+ years",
"< 1 year",
"5 years",
"< 1 year",
"9 years",
"10+ years",
"3 years",
"1 year",
"2 years",
"10+ years",
"7 years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"5 years",
null,
"1 year",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
null,
"10+ years",
"9 years",
"7 years",
"1 year",
null,
"10+ years",
"< 1 year",
null,
"10+ years",
null,
"10+ years",
"2 years",
"7 years",
"< 1 year",
null,
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"8 years",
"7 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"8 years",
"10+ years",
null,
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"9 years",
"< 1 year",
"10+ years",
"2 years",
"4 years",
"6 years",
"4 years",
"5 years",
null,
"10+ years",
"5 years",
"8 years",
"8 years",
"3 years",
"8 years",
"1 year",
"2 years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"6 years",
"8 years",
"8 years",
"10+ years",
"6 years",
"1 year",
"10+ years",
"6 years",
"< 1 year",
"9 years",
"7 years",
"< 1 year",
"8 years",
"4 years",
null,
null,
"3 years",
"10+ years",
"3 years",
"5 years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"9 years",
"< 1 year",
"< 1 year",
"3 years",
"8 years",
"4 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"8 years",
"7 years",
"10+ years",
"5 years",
"2 years",
"8 years",
"7 years",
"10+ years",
"2 years",
null,
"8 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"7 years",
"7 years",
"7 years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"6 years",
"7 years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"6 years",
"3 years",
"10+ years",
"5 years",
"2 years",
"4 years",
"5 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
null,
"9 years",
"10+ years",
"7 years",
"2 years",
"2 years",
"1 year",
"8 years",
"8 years",
null,
"10+ years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"6 years",
"10+ years",
"6 years",
"9 years",
null,
"3 years",
"10+ years",
"1 year",
"3 years",
"1 year",
"5 years",
"10+ years",
"7 years",
"< 1 year",
"5 years",
null,
"10+ years",
"10+ years",
"9 years",
null,
"10+ years",
"2 years",
"3 years",
"1 year",
"10+ years",
"5 years",
"6 years",
"4 years",
"3 years",
"3 years",
"2 years",
"10+ years",
"4 years",
"2 years",
"3 years",
null,
null,
"10+ years",
"10+ years",
"10+ years",
"4 years",
"9 years",
null,
"9 years",
"3 years",
"1 year",
"10+ years",
"3 years",
"4 years",
"10+ years",
"5 years",
null,
"2 years",
"9 years",
"10+ years",
"5 years",
"8 years",
"2 years",
"2 years",
"10+ years",
"2 years",
"8 years",
"6 years",
"< 1 year",
"4 years",
"3 years",
"10+ years",
"2 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"2 years",
null,
"4 years",
"3 years",
"10+ years",
"4 years",
"2 years",
"5 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"5 years",
"7 years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"5 years",
"8 years",
"10+ years",
"10+ years",
"8 years",
null,
"7 years",
"5 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"2 years",
"4 years",
"6 years",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"< 1 year",
"5 years",
"3 years",
"2 years",
"6 years",
"8 years",
"4 years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"< 1 year",
"2 years",
"2 years",
"4 years",
"< 1 year",
null,
"6 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"6 years",
"8 years",
"5 years",
"5 years",
"4 years",
"4 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
null,
"2 years",
"10+ years",
"4 years",
null,
"10+ years",
"1 year",
"10+ years",
"10+ years",
"7 years",
"9 years",
"5 years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"6 years",
"3 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"4 years",
"4 years",
"10+ years",
"9 years",
"2 years",
"10+ years",
null,
null,
"1 year",
"< 1 year",
"3 years",
"5 years",
null,
"1 year",
"7 years",
"10+ years",
"1 year",
"4 years",
"10+ years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"4 years",
"2 years",
"3 years",
"6 years",
"2 years",
"6 years",
"3 years",
"9 years",
"3 years",
"3 years",
"8 years",
"1 year",
"9 years",
"1 year",
null,
"4 years",
"2 years",
"< 1 year",
"8 years",
"3 years",
"10+ years",
"7 years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"4 years",
"3 years",
"6 years",
"2 years",
"3 years",
"10+ years",
null,
"10+ years",
"10+ years",
"8 years",
"7 years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
null,
"3 years",
"9 years",
null,
"5 years",
"10+ years",
null,
"2 years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"8 years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"9 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"3 years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"5 years",
"3 years",
null,
"9 years",
"< 1 year",
"< 1 year",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"2 years",
"10+ years",
null,
"7 years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"8 years",
"9 years",
"7 years",
"9 years",
"1 year",
"10+ years",
"1 year",
"9 years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"1 year",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"8 years",
"2 years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"8 years",
"3 years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"4 years",
"10+ years",
"8 years",
null,
"< 1 year",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"8 years",
"< 1 year",
"4 years",
"2 years",
"6 years",
"4 years",
"1 year",
"< 1 year",
"10+ years",
"9 years",
"9 years",
"3 years",
null,
null,
"10+ years",
"< 1 year",
"5 years",
"9 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"5 years",
null,
"< 1 year",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"3 years",
null,
"6 years",
"2 years",
"5 years",
"10+ years",
"8 years",
"9 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"5 years",
"2 years",
"4 years",
"10+ years",
"2 years",
"5 years",
"1 year",
"8 years",
"< 1 year",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"8 years",
"2 years",
"10+ years",
"1 year",
null,
"10+ years",
"5 years",
"2 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
null,
null,
"9 years",
"7 years",
null,
"5 years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"2 years",
"< 1 year",
"2 years",
"5 years",
"7 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"1 year",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"7 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"8 years",
"8 years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"3 years",
"1 year",
"8 years",
"10+ years",
"8 years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"4 years",
"6 years",
"10+ years",
"4 years",
"10+ years",
"1 year",
"10+ years",
"6 years",
"9 years",
"10+ years",
"3 years",
"5 years",
null,
"10+ years",
null,
"6 years",
"9 years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"7 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
null,
"1 year",
"3 years",
"< 1 year",
"5 years",
"7 years",
"5 years",
"1 year",
"7 years",
"2 years",
"10+ years",
null,
"3 years",
"4 years",
"10+ years",
"8 years",
"< 1 year",
null,
"3 years",
"3 years",
"1 year",
"5 years",
"6 years",
"9 years",
"5 years",
"6 years",
"5 years",
"3 years",
"8 years",
"3 years",
"3 years",
"2 years",
"10+ years",
"< 1 year",
"4 years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"5 years",
"5 years",
"10+ years",
"4 years",
"5 years",
"1 year",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"4 years",
"9 years",
"3 years",
"6 years",
"4 years",
"9 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"1 year",
null,
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"7 years",
"2 years",
"1 year",
"9 years",
"4 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"4 years",
"< 1 year",
"10+ years",
"9 years",
null,
"7 years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"3 years",
"3 years",
"4 years",
"1 year",
"1 year",
null,
"4 years",
"2 years",
"4 years",
"4 years",
"10+ years",
"3 years",
"< 1 year",
"9 years",
"1 year",
"1 year",
"< 1 year",
"3 years",
"2 years",
"5 years",
"3 years",
"10+ years",
"3 years",
"5 years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
null,
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"2 years",
"< 1 year",
"2 years",
"6 years",
"10+ years",
null,
"6 years",
"2 years",
"1 year",
null,
"10+ years",
null,
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"6 years",
"7 years",
"9 years",
"6 years",
"2 years",
null,
"2 years",
"10+ years",
"5 years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"< 1 year",
"4 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"7 years",
"10+ years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"3 years",
"8 years",
"5 years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"1 year",
"1 year",
"4 years",
"5 years",
null,
"< 1 year",
"1 year",
"10+ years",
null,
"10+ years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"3 years",
"8 years",
null,
"10+ years",
"< 1 year",
"6 years",
"10+ years",
null,
"8 years",
"2 years",
"10+ years",
"6 years",
"7 years",
"2 years",
"6 years",
"4 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"5 years",
"5 years",
"10+ years",
"7 years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"1 year",
"10+ years",
null,
"1 year",
"5 years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"8 years",
"8 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"3 years",
"9 years",
"5 years",
"10+ years",
"1 year",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"7 years",
"4 years",
"4 years",
"8 years",
"4 years",
"10+ years",
"3 years",
"3 years",
"6 years",
"3 years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"1 year",
"3 years",
"10+ years",
null,
"2 years",
"10+ years",
"8 years",
"10+ years",
"7 years",
"5 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"7 years",
"5 years",
"4 years",
"7 years",
"7 years",
"< 1 year",
"3 years",
"10+ years",
"< 1 year",
"2 years",
"7 years",
"8 years",
"10+ years",
null,
"10+ years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"2 years",
"7 years",
"8 years",
"8 years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"3 years",
"5 years",
"5 years",
"9 years",
"2 years",
"10+ years",
"1 year",
"6 years",
"4 years",
"10+ years",
"< 1 year",
"8 years",
"5 years",
"10+ years",
null,
"4 years",
"3 years",
"1 year",
"4 years",
"10+ years",
"3 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"9 years",
"4 years",
"8 years",
"5 years",
"3 years",
"10+ years",
"7 years",
"4 years",
null,
null,
"10+ years",
"4 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"4 years",
"10+ years",
"7 years",
"8 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
null,
"7 years",
"6 years",
"1 year",
"4 years",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"4 years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"4 years",
"3 years",
"7 years",
null,
"5 years",
"< 1 year",
"1 year",
"10+ years",
"6 years",
"4 years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"6 years",
"5 years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"1 year",
"3 years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"10+ years",
"2 years",
null,
"10+ years",
"9 years",
"10+ years",
"10+ years",
"9 years",
"8 years",
"5 years",
"10+ years",
"< 1 year",
"7 years",
"2 years",
"3 years",
"5 years",
"10+ years",
null,
"3 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"2 years",
"8 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"4 years",
"1 year",
"5 years",
"3 years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"5 years",
"2 years",
null,
"6 years",
"1 year",
"1 year",
"7 years",
"5 years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"5 years",
"2 years",
"10+ years",
"1 year",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"5 years",
"2 years",
"3 years",
"2 years",
"< 1 year",
"6 years",
"3 years",
"2 years",
"7 years",
"5 years",
"7 years",
"4 years",
"10+ years",
"< 1 year",
"< 1 year",
"4 years",
"8 years",
null,
"10+ years",
"10+ years",
"6 years",
"2 years",
"10+ years",
null,
"1 year",
"1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"4 years",
"< 1 year",
"3 years",
"8 years",
"10+ years",
"8 years",
"2 years",
"9 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"5 years",
"2 years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"6 years",
"8 years",
"4 years",
"7 years",
"5 years",
"4 years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"5 years",
"5 years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"3 years",
"10+ years",
"6 years",
"4 years",
"10+ years",
"1 year",
"6 years",
"10+ years",
"5 years",
"4 years",
"5 years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"6 years",
"< 1 year",
"10+ years",
"2 years",
"1 year",
"10+ years",
"2 years",
"8 years",
"4 years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"6 years",
"3 years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"7 years",
"7 years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
null,
"6 years",
"< 1 year",
"< 1 year",
"10+ years",
"4 years",
"9 years",
"< 1 year",
null,
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
"5 years",
"6 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"1 year",
"9 years",
"4 years",
"3 years",
"2 years",
"9 years",
"10+ years",
"2 years",
"4 years",
"1 year",
"3 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
null,
"10+ years",
"< 1 year",
"3 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"8 years",
"9 years",
"10+ years",
"1 year",
"10+ years",
"4 years",
"2 years",
"5 years",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"6 years",
"10+ years",
null,
"10+ years",
"< 1 year",
"8 years",
"6 years",
"5 years",
"1 year",
"3 years",
"1 year",
"7 years",
"9 years",
"2 years",
"8 years",
"9 years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
null,
"10+ years",
"10+ years",
"9 years",
"8 years",
"5 years",
"10+ years",
"4 years",
"8 years",
"10+ years",
"5 years",
"1 year",
"7 years",
"10+ years",
"1 year",
"8 years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"1 year",
"< 1 year",
"9 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"4 years",
"8 years",
"4 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"8 years",
null,
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"3 years",
"10+ years",
"7 years",
"6 years",
"8 years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"7 years",
"10+ years",
"6 years",
"5 years",
"3 years",
"1 year",
"10+ years",
"4 years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"4 years",
"2 years",
null,
"10+ years",
"1 year",
"6 years",
"10+ years",
"6 years",
"5 years",
"10+ years",
"2 years",
"5 years",
"7 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"1 year",
"2 years",
"8 years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"5 years",
"5 years",
"3 years",
"9 years",
"2 years",
"2 years",
"2 years",
"< 1 year",
"2 years",
"10+ years",
"9 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"9 years",
"1 year",
"7 years",
"5 years",
"10+ years",
"10+ years",
"6 years",
"9 years",
"< 1 year",
"5 years",
"6 years",
null,
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"7 years",
null,
"1 year",
"10+ years",
"10+ years",
"8 years",
"2 years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"9 years",
null,
"10+ years",
"3 years",
"10+ years",
"4 years",
"10+ years",
"9 years",
"5 years",
"10+ years",
null,
"< 1 year",
"6 years",
"6 years",
"4 years",
"4 years",
"1 year",
"10+ years",
"< 1 year",
"< 1 year",
"8 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"5 years",
"< 1 year",
"6 years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"10+ years",
"6 years",
null,
"6 years",
"6 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"< 1 year",
"< 1 year",
"7 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"8 years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"< 1 year",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"3 years",
null,
"10+ years",
"1 year",
"8 years",
"7 years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"1 year",
null,
"< 1 year",
"4 years",
"4 years",
"4 years",
"5 years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"5 years",
"10+ years",
"4 years",
"10+ years",
"4 years",
"3 years",
"9 years",
"< 1 year",
"1 year",
"5 years",
"9 years",
"6 years",
null,
"2 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"7 years",
"6 years",
"5 years",
"5 years",
"8 years",
null,
"< 1 year",
"6 years",
"6 years",
"3 years",
"4 years",
"10+ years",
"8 years",
"< 1 year",
"< 1 year",
"6 years",
"10+ years",
"10+ years",
null,
"< 1 year",
"2 years",
"9 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"4 years",
"4 years",
"< 1 year",
"9 years",
"10+ years",
"10+ years",
"1 year",
"6 years",
"8 years",
"9 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"3 years",
"2 years",
"< 1 year",
"3 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"6 years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"1 year",
null,
"3 years",
"2 years",
"4 years",
"10+ years",
"4 years",
"8 years",
"5 years",
"2 years",
"4 years",
"3 years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"2 years",
"< 1 year",
"5 years",
"8 years",
"9 years",
"10+ years",
"10+ years",
"3 years",
null,
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"4 years",
"1 year",
"5 years",
"2 years",
"6 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"6 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"9 years",
"6 years",
"8 years",
"1 year",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"6 years",
null,
"6 years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"2 years",
"1 year",
"10+ years",
"7 years",
"3 years",
"< 1 year",
"10+ years",
"4 years",
"3 years",
"< 1 year",
"5 years",
"7 years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"5 years",
"9 years",
"1 year",
"3 years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"6 years",
null,
"8 years",
"10+ years",
"5 years",
"< 1 year",
"2 years",
"6 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"10+ years",
"7 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"6 years",
null,
"< 1 year",
"< 1 year",
"10+ years",
"3 years",
"7 years",
"< 1 year",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"4 years",
"3 years",
"10+ years",
"9 years",
"10+ years",
"4 years",
"8 years",
"10+ years",
"6 years",
"< 1 year",
null,
"10+ years",
"8 years",
"7 years",
"4 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"3 years",
"< 1 year",
"4 years",
"9 years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"8 years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"9 years",
"2 years",
"6 years",
"10+ years",
"< 1 year",
"3 years",
"9 years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"5 years",
"9 years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"6 years",
"10+ years",
"3 years",
null,
null,
"10+ years",
null,
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"4 years",
"5 years",
"4 years",
"1 year",
null,
"6 years",
"10+ years",
"6 years",
"4 years",
"10+ years",
"< 1 year",
"2 years",
"9 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"8 years",
"3 years",
"5 years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"7 years",
"4 years",
"10+ years",
null,
"7 years",
"2 years",
"6 years",
"9 years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"8 years",
"< 1 year",
"3 years",
"1 year",
"2 years",
"9 years",
"9 years",
"2 years",
"8 years",
"10+ years",
"7 years",
"6 years",
"9 years",
"5 years",
null,
null,
"2 years",
"7 years",
"9 years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"6 years",
"9 years",
"10+ years",
"10+ years",
"2 years",
null,
"3 years",
"5 years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"3 years",
"7 years",
"6 years",
null,
"< 1 year",
"4 years",
"6 years",
"7 years",
"< 1 year",
"< 1 year",
"3 years",
"2 years",
"3 years",
"1 year",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"9 years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"7 years",
"3 years",
"3 years",
"8 years",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"8 years",
"6 years",
"6 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"1 year",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"5 years",
"2 years",
"1 year",
"2 years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"4 years",
"10+ years",
"1 year",
"< 1 year",
"6 years",
"10+ years",
"2 years",
"4 years",
"4 years",
"1 year",
"9 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"7 years",
"5 years",
"6 years",
"3 years",
"10+ years",
null,
null,
"10+ years",
"< 1 year",
"1 year",
"8 years",
"7 years",
"< 1 year",
"10+ years",
null,
"5 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"3 years",
"6 years",
"2 years",
"2 years",
null,
null,
"10+ years",
"7 years",
"10+ years",
"7 years",
"5 years",
"7 years",
"10+ years",
null,
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
null,
"< 1 year",
"3 years",
"4 years",
"10+ years",
"6 years",
"9 years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"9 years",
"10+ years",
"7 years",
"4 years",
"5 years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"7 years",
"9 years",
"8 years",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
"2 years",
"2 years",
"4 years",
"< 1 year",
"1 year",
"4 years",
"10+ years",
"2 years",
"< 1 year",
"6 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"2 years",
"4 years",
"8 years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"3 years",
"< 1 year",
"< 1 year",
"6 years",
"2 years",
"5 years",
"7 years",
"< 1 year",
"6 years",
"2 years",
"2 years",
"9 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"8 years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"7 years",
"5 years",
"10+ years",
"4 years",
"1 year",
null,
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"6 years",
"7 years",
"5 years",
"8 years",
"4 years",
"8 years",
"4 years",
null,
"7 years",
"1 year",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
null,
"7 years",
"< 1 year",
"10+ years",
"8 years",
"5 years",
"10+ years",
"5 years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
null,
"5 years",
"2 years",
null,
"3 years",
"7 years",
"2 years",
"1 year",
"10+ years",
"4 years",
"7 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"1 year",
"2 years",
"1 year",
"8 years",
"5 years",
"8 years",
"9 years",
"< 1 year",
"9 years",
"10+ years",
"1 year",
"9 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"7 years",
"4 years",
"10+ years",
"< 1 year",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"2 years",
"10+ years",
"8 years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
null,
"< 1 year",
"10+ years",
"3 years",
null,
"1 year",
"6 years",
"5 years",
"8 years",
"2 years",
"2 years",
"4 years",
null,
"5 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"3 years",
null,
"10+ years",
"8 years",
"< 1 year",
"1 year",
"10+ years",
"2 years",
"4 years",
"1 year",
"< 1 year",
"2 years",
"10+ years",
"< 1 year",
"2 years",
"6 years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"10+ years",
null,
"10+ years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"5 years",
"5 years",
"2 years",
"1 year",
"< 1 year",
"3 years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"1 year",
"1 year",
"10+ years",
"1 year",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
null,
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
null,
"3 years",
"3 years",
"< 1 year",
"< 1 year",
"10+ years",
"1 year",
"7 years",
"2 years",
"9 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
null,
"10+ years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"4 years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"8 years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"7 years",
"10+ years",
null,
"10+ years",
"10+ years",
"3 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"9 years",
"10+ years",
"10+ years",
"5 years",
"8 years",
"10+ years",
"10+ years",
null,
"1 year",
"< 1 year",
"4 years",
"10+ years",
"7 years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"5 years",
"3 years",
"5 years",
"5 years",
"8 years",
"8 years",
"4 years",
"3 years",
"3 years",
"8 years",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
null,
"10+ years",
"4 years",
"5 years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"6 years",
"2 years",
"1 year",
"1 year",
"9 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"1 year",
"< 1 year",
"1 year",
"3 years",
"4 years",
"2 years",
"7 years",
"5 years",
"1 year",
"10+ years",
"< 1 year",
"4 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
null,
"3 years",
"10+ years",
"2 years",
null,
"3 years",
"4 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
null,
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"4 years",
"2 years",
"5 years",
"2 years",
"8 years",
"4 years",
"2 years",
"10+ years",
"5 years",
null,
"2 years",
"< 1 year",
"9 years",
"5 years",
"3 years",
"10+ years",
"10+ years",
null,
"2 years",
"6 years",
"10+ years",
"2 years",
"9 years",
"6 years",
"2 years",
"< 1 year",
"6 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
null,
"7 years",
"1 year",
"10+ years",
"1 year",
"5 years",
null,
"2 years",
null,
"10+ years",
"1 year",
"5 years",
"10+ years",
"10+ years",
"5 years",
null,
"10+ years",
"10+ years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"2 years",
"1 year",
"3 years",
"8 years",
"< 1 year",
"10+ years",
"6 years",
"2 years",
"9 years",
"2 years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"6 years",
"3 years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"8 years",
"10+ years",
"4 years",
"1 year",
"1 year",
"10+ years",
"6 years",
"2 years",
"1 year",
"7 years",
"8 years",
"5 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"8 years",
"4 years",
"1 year",
"2 years",
"2 years",
"8 years",
"10+ years",
"< 1 year",
"1 year",
"8 years",
"3 years",
"5 years",
"5 years",
"1 year",
"10+ years",
"3 years",
"4 years",
"2 years",
"9 years",
"< 1 year",
"8 years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
null,
"6 years",
null,
"6 years",
"5 years",
"9 years",
null,
"< 1 year",
"5 years",
"8 years",
"4 years",
"9 years",
null,
"1 year",
"10+ years",
"3 years",
"< 1 year",
"5 years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"1 year",
"1 year",
"10+ years",
"8 years",
null,
"3 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"9 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"8 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"1 year",
"4 years",
"8 years",
"3 years",
"6 years",
"10+ years",
"10+ years",
"8 years",
"7 years",
"10+ years",
"2 years",
"5 years",
"6 years",
null,
"< 1 year",
"7 years",
"5 years",
"5 years",
"10+ years",
"< 1 year",
"8 years",
"< 1 year",
"10+ years",
"7 years",
"9 years",
"1 year",
"3 years",
"2 years",
"3 years",
"< 1 year",
"8 years",
null,
"10+ years",
"8 years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
null,
"< 1 year",
"9 years",
"7 years",
"10+ years",
"3 years",
"7 years",
null,
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"6 years",
"7 years",
"6 years",
"10+ years",
null,
"4 years",
"2 years",
"< 1 year",
"6 years",
"10+ years",
"10+ years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"6 years",
"10+ years",
"2 years",
"4 years",
"5 years",
"6 years",
null,
"2 years",
"7 years",
"1 year",
"2 years",
"8 years",
"7 years",
"8 years",
"10+ years",
"< 1 year",
null,
"10+ years",
"3 years",
"4 years",
"10+ years",
"6 years",
"7 years",
"2 years",
"4 years",
"3 years",
"7 years",
"8 years",
"4 years",
"4 years",
"5 years",
"4 years",
"5 years",
"< 1 year",
null,
"3 years",
"4 years",
"10+ years",
"8 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"1 year",
"6 years",
"1 year",
"3 years",
"< 1 year",
"< 1 year",
"2 years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"6 years",
"1 year",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
null,
"3 years",
"6 years",
"< 1 year",
"< 1 year",
"10+ years",
"8 years",
"< 1 year",
"2 years",
"10+ years",
"< 1 year",
"6 years",
null,
"< 1 year",
"4 years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
null,
"< 1 year",
"6 years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"5 years",
"6 years",
"2 years",
"2 years",
"10+ years",
"6 years",
"7 years",
"4 years",
"7 years",
"< 1 year",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
null,
"5 years",
"< 1 year",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"8 years",
"< 1 year",
"1 year",
"5 years",
"2 years",
"1 year",
"7 years",
"7 years",
"4 years",
"3 years",
"2 years",
"7 years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"1 year",
"3 years",
"10+ years",
"4 years",
"3 years",
"10+ years",
"9 years",
"1 year",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
null,
"4 years",
"3 years",
null,
"< 1 year",
"5 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"3 years",
"6 years",
"< 1 year",
"2 years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"5 years",
"4 years",
"10+ years",
"10+ years",
null,
"1 year",
"10+ years",
"5 years",
"5 years",
"1 year",
"3 years",
"2 years",
"9 years",
"9 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"7 years",
"10+ years",
"6 years",
"2 years",
null,
"7 years",
"2 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
null,
null,
"2 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"6 years",
"2 years",
null,
"4 years",
"8 years",
"3 years",
"< 1 year",
"2 years",
"3 years",
"2 years",
"2 years",
"9 years",
"6 years",
"9 years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"5 years",
"10+ years",
"< 1 year",
"4 years",
"2 years",
null,
"8 years",
"8 years",
"< 1 year",
"4 years",
"< 1 year",
null,
"10+ years",
"2 years",
null,
null,
"8 years",
"8 years",
"4 years",
"4 years",
"10+ years",
"5 years",
"2 years",
"1 year",
"3 years",
"10+ years",
"2 years",
"2 years",
"8 years",
"6 years",
"4 years",
"5 years",
"5 years",
"10+ years",
"2 years",
"2 years",
"5 years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"< 1 year",
"8 years",
"10+ years",
"7 years",
"7 years",
"5 years",
"10+ years",
"10+ years",
null,
"2 years",
"2 years",
"4 years",
"5 years",
"10+ years",
null,
"3 years",
"2 years",
"10+ years",
"10+ years",
null,
"2 years",
"8 years",
"10+ years",
"5 years",
"3 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"9 years",
"6 years",
"8 years",
"8 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
null,
"10+ years",
"5 years",
"10+ years",
"4 years",
"7 years",
"10+ years",
"6 years",
"6 years",
null,
"8 years",
"3 years",
"10+ years",
"6 years",
"10+ years",
"6 years",
"< 1 year",
"1 year",
"6 years",
null,
"3 years",
"5 years",
"2 years",
"9 years",
"10+ years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"4 years",
"5 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
null,
"10+ years",
"10+ years",
"8 years",
"7 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"9 years",
null,
"< 1 year",
"2 years",
"10+ years",
"6 years",
"< 1 year",
"9 years",
"9 years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"4 years",
"4 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"1 year",
"4 years",
"7 years",
"5 years",
"10+ years",
"3 years",
"2 years",
null,
"3 years",
"10+ years",
"9 years",
"< 1 year",
"1 year",
"5 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"2 years",
"4 years",
"9 years",
"1 year",
"10+ years",
"10+ years",
"4 years",
"9 years",
"7 years",
"7 years",
"< 1 year",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"1 year",
"7 years",
null,
"4 years",
"6 years",
"< 1 year",
"1 year",
"7 years",
"5 years",
"2 years",
"8 years",
"5 years",
"10+ years",
"6 years",
"10+ years",
null,
"10+ years",
"6 years",
"4 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"2 years",
"3 years",
"4 years",
"5 years",
"6 years",
"10+ years",
"7 years",
"5 years",
"2 years",
"< 1 year",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"7 years",
"9 years",
"10+ years",
"10+ years",
"5 years",
"5 years",
"5 years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"3 years",
"8 years",
"4 years",
"2 years",
"1 year",
"< 1 year",
"6 years",
"7 years",
"3 years",
"6 years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"5 years",
"7 years",
"10+ years",
"7 years",
"10+ years",
"7 years",
"4 years",
"6 years",
"2 years",
"10+ years",
"8 years",
"9 years",
"8 years",
"10+ years",
"5 years",
"9 years",
"5 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"5 years",
"9 years",
"9 years",
"2 years",
"3 years",
"4 years",
"10+ years",
"7 years",
"< 1 year",
"2 years",
"2 years",
"3 years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"9 years",
"4 years",
"6 years",
"8 years",
"5 years",
"6 years",
"2 years",
"10+ years",
"3 years",
"3 years",
"8 years",
"4 years",
null,
"5 years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"< 1 year",
"7 years",
"10+ years",
"7 years",
"10+ years",
"4 years",
"7 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"9 years",
"4 years",
"< 1 year",
"3 years",
"3 years",
"6 years",
"8 years",
"9 years",
"2 years",
"10+ years",
"2 years",
"5 years",
"9 years",
"5 years",
"10+ years",
"8 years",
null,
"2 years",
"6 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"5 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"4 years",
"10+ years",
"7 years",
"10+ years",
"< 1 year",
null,
"1 year",
"10+ years",
"8 years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"8 years",
"< 1 year",
"2 years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"1 year",
"6 years",
"6 years",
"7 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"4 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
null,
"< 1 year",
"1 year",
"9 years",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"3 years",
"3 years",
"5 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
null,
"2 years",
"10+ years",
"2 years",
"2 years",
"7 years",
"7 years",
"9 years",
"5 years",
"< 1 year",
"10+ years",
"5 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"4 years",
"8 years",
"3 years",
"10+ years",
"5 years",
"9 years",
"10+ years",
"7 years",
"8 years",
"5 years",
"4 years",
"8 years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
null,
"< 1 year",
null,
"2 years",
null,
"10+ years",
null,
"2 years",
"3 years",
"10+ years",
"1 year",
"7 years",
"5 years",
"< 1 year",
"< 1 year",
"10+ years",
"5 years",
"2 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"6 years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"8 years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"4 years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"2 years",
null,
"10+ years",
"10+ years",
"6 years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
null,
"10+ years",
"6 years",
"10+ years",
"1 year",
"2 years",
"4 years",
null,
"2 years",
"8 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"1 year",
null,
"1 year",
null,
"5 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"4 years",
"< 1 year",
"5 years",
"2 years",
"3 years",
"6 years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"9 years",
"3 years",
"5 years",
"1 year",
"< 1 year",
"10+ years",
"1 year",
"2 years",
"1 year",
"4 years",
"9 years",
"3 years",
null,
"2 years",
"8 years",
"10+ years",
null,
"10+ years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"4 years",
"4 years",
null,
"10+ years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"5 years",
"8 years",
"< 1 year",
"2 years",
"4 years",
"2 years",
"7 years",
"6 years",
"3 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"9 years",
"3 years",
"7 years",
"8 years",
null,
"1 year",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
null,
"8 years",
"1 year",
"10+ years",
"5 years",
"< 1 year",
null,
"9 years",
"10+ years",
"7 years",
"10+ years",
"1 year",
"2 years",
"2 years",
"1 year",
"5 years",
"2 years",
"10+ years",
"10+ years",
"8 years",
null,
"1 year",
"10+ years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"6 years",
"7 years",
"10+ years",
"9 years",
"9 years",
"10+ years",
"8 years",
"2 years",
"5 years",
null,
"< 1 year",
"10+ years",
"1 year",
"9 years",
"3 years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"< 1 year",
null,
"4 years",
"2 years",
"8 years",
"6 years",
"3 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"5 years",
"1 year",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"< 1 year",
"1 year",
"9 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"7 years",
"6 years",
"1 year",
"1 year",
null,
null,
"6 years",
"4 years",
"3 years",
"< 1 year",
"7 years",
null,
"5 years",
"6 years",
"1 year",
"6 years",
"7 years",
"3 years",
"10+ years",
"9 years",
"3 years",
"5 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"6 years",
"1 year",
"10+ years",
"1 year",
"2 years",
"3 years",
"1 year",
"10+ years",
"2 years",
"4 years",
"8 years",
"< 1 year",
"6 years",
"8 years",
"10+ years",
"2 years",
"10+ years",
null,
"6 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"< 1 year",
"4 years",
"8 years",
"4 years",
"10+ years",
null,
"2 years",
"5 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"3 years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"< 1 year",
"5 years",
"5 years",
"< 1 year",
"< 1 year",
"10+ years",
"1 year",
"6 years",
"10+ years",
"7 years",
"3 years",
"< 1 year",
"2 years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"7 years",
"3 years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"8 years",
"10+ years",
"6 years",
"10+ years",
"1 year",
"6 years",
"10+ years",
"2 years",
"9 years",
"5 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"1 year",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"< 1 year",
"6 years",
"10+ years",
"6 years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"9 years",
"3 years",
"5 years",
"4 years",
"10+ years",
"5 years",
"3 years",
null,
"10+ years",
"7 years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"8 years",
"6 years",
"2 years",
"< 1 year",
"3 years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"9 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"8 years",
"1 year",
"3 years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"1 year",
"6 years",
null,
"10+ years",
"1 year",
"2 years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"7 years",
"2 years",
"1 year",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"4 years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"4 years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"7 years",
"< 1 year",
"< 1 year",
"6 years",
"8 years",
"2 years",
"10+ years",
"1 year",
"7 years",
"10+ years",
"2 years",
"3 years",
"4 years",
"1 year",
"5 years",
"2 years",
"1 year",
"< 1 year",
"4 years",
"10+ years",
"6 years",
"8 years",
"10+ years",
"< 1 year",
"9 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"3 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"6 years",
null,
"8 years",
"3 years",
"5 years",
"1 year",
"3 years",
"2 years",
"10+ years",
null,
"6 years",
"7 years",
"10+ years",
"10+ years",
"8 years",
"6 years",
"4 years",
"3 years",
"7 years",
"< 1 year",
"6 years",
"5 years",
"8 years",
"7 years",
"4 years",
"5 years",
null,
"< 1 year",
null,
"8 years",
"5 years",
"6 years",
"10+ years",
null,
"3 years",
"4 years",
"4 years",
"5 years",
"1 year",
null,
"1 year",
"7 years",
"5 years",
null,
"8 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"1 year",
"< 1 year",
"8 years",
"< 1 year",
"10+ years",
"6 years",
"9 years",
"3 years",
"5 years",
"2 years",
"8 years",
"3 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"9 years",
null,
"7 years",
"3 years",
null,
"6 years",
"10+ years",
"2 years",
"4 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"10+ years",
"5 years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"7 years",
"10+ years",
"10+ years",
null,
"10+ years",
"5 years",
"10+ years",
"9 years",
"< 1 year",
null,
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
null,
"1 year",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"6 years",
null,
"10+ years",
"10+ years",
"9 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"1 year",
null,
"< 1 year",
"< 1 year",
"4 years",
"6 years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"5 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"4 years",
"< 1 year",
"2 years",
"3 years",
"7 years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"7 years",
"10+ years",
"9 years",
"10+ years",
"5 years",
"1 year",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"3 years",
"< 1 year",
"2 years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"8 years",
"8 years",
"6 years",
"< 1 year",
"3 years",
"1 year",
"10+ years",
"5 years",
"10+ years",
"9 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"3 years",
"8 years",
null,
"10+ years",
null,
"2 years",
"8 years",
"5 years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"6 years",
"10+ years",
null,
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"7 years",
"8 years",
"7 years",
null,
"8 years",
"8 years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"7 years",
"1 year",
"7 years",
"10+ years",
null,
"7 years",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"5 years",
"2 years",
"9 years",
"< 1 year",
null,
"3 years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"4 years",
"3 years",
"10+ years",
"1 year",
"3 years",
"1 year",
"5 years",
"10+ years",
null,
"8 years",
"3 years",
null,
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"1 year",
"6 years",
"5 years",
null,
"< 1 year",
"2 years",
"2 years",
"9 years",
"10+ years",
"3 years",
"2 years",
"< 1 year",
"2 years",
"< 1 year",
"3 years",
"1 year",
"10+ years",
"3 years",
"6 years",
"7 years",
"10+ years",
"7 years",
"10+ years",
null,
"8 years",
"2 years",
"2 years",
"5 years",
"10+ years",
"5 years",
"5 years",
"10+ years",
"3 years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"1 year",
"10+ years",
"6 years",
"6 years",
"7 years",
"4 years",
"1 year",
"10+ years",
"7 years",
"2 years",
"4 years",
"8 years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"8 years",
"10+ years",
"3 years",
"6 years",
"10+ years",
"5 years",
"< 1 year",
"1 year",
"7 years",
"6 years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"2 years",
"5 years",
null,
"10+ years",
"7 years",
"4 years",
"3 years",
"6 years",
"9 years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"4 years",
"2 years",
"5 years",
"3 years",
null,
"10+ years",
"5 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
null,
"10+ years",
"4 years",
"1 year",
"10+ years",
"6 years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"6 years",
null,
"3 years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"8 years",
"7 years",
"7 years",
null,
"< 1 year",
"10+ years",
"2 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"2 years",
"3 years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"< 1 year",
"7 years",
"7 years",
"9 years",
"9 years",
"9 years",
"8 years",
"2 years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"< 1 year",
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
null,
"10+ years",
"5 years",
"8 years",
"7 years",
"10+ years",
"4 years",
"9 years",
"3 years",
"7 years",
"4 years",
"5 years",
"4 years",
"4 years",
"10+ years",
"2 years",
"< 1 year",
"2 years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"8 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"9 years",
"1 year",
"3 years",
null,
"10+ years",
"6 years",
"< 1 year",
"5 years",
"2 years",
"10+ years",
"9 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"5 years",
"< 1 year",
"3 years",
"6 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"6 years",
"5 years",
"10+ years",
"10+ years",
null,
"10+ years",
"1 year",
"5 years",
"4 years",
"2 years",
"4 years",
"1 year",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"7 years",
"8 years",
"10+ years",
"1 year",
"6 years",
"7 years",
"10+ years",
"3 years",
"4 years",
"4 years",
"4 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"7 years",
"3 years",
"2 years",
"2 years",
"10+ years",
"3 years",
"3 years",
"< 1 year",
"3 years",
"10+ years",
"3 years",
"6 years",
"7 years",
"5 years",
"5 years",
"< 1 year",
"10+ years",
"3 years",
"5 years",
"8 years",
null,
"1 year",
null,
null,
"1 year",
"4 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"< 1 year",
"2 years",
"1 year",
"10+ years",
"9 years",
"10+ years",
"8 years",
"2 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"2 years",
"5 years",
"2 years",
"4 years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"9 years",
"10+ years",
"3 years",
null,
"< 1 year",
"10+ years",
"10+ years",
"4 years",
null,
"< 1 year",
"2 years",
"10+ years",
"7 years",
"9 years",
"3 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"3 years",
null,
"10+ years",
"7 years",
"3 years",
"10+ years",
"7 years",
"1 year",
"2 years",
"10+ years",
"8 years",
"1 year",
"10+ years",
"3 years",
"7 years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
null,
"10+ years",
"10+ years",
"4 years",
"7 years",
"2 years",
"1 year",
"8 years",
"7 years",
"5 years",
"6 years",
null,
"10+ years",
"3 years",
"< 1 year",
"2 years",
"10+ years",
"3 years",
"1 year",
"5 years",
"10+ years",
"9 years",
"10+ years",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"4 years",
null,
"10+ years",
"9 years",
"3 years",
"1 year",
"4 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"6 years",
"5 years",
null,
"3 years",
"7 years",
"5 years",
"6 years",
"7 years",
"10+ years",
"10+ years",
"9 years",
"4 years",
"5 years",
"1 year",
"3 years",
"9 years",
"7 years",
"10+ years",
"10+ years",
"4 years",
"6 years",
"8 years",
"8 years",
"4 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"7 years",
"< 1 year",
"10+ years",
"9 years",
"5 years",
"10+ years",
"7 years",
"< 1 year",
"2 years",
"2 years",
"5 years",
"7 years",
"3 years",
"2 years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"8 years",
"7 years",
"3 years",
null,
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"1 year",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"< 1 year",
"6 years",
"10+ years",
null,
"5 years",
"5 years",
"7 years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"7 years",
"< 1 year",
"1 year",
"< 1 year",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
null,
"10+ years",
"< 1 year",
"10+ years",
"9 years",
"1 year",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"9 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"1 year",
"10+ years",
"4 years",
"7 years",
"< 1 year",
"7 years",
"5 years",
"6 years",
"< 1 year",
"< 1 year",
"10+ years",
"2 years",
"< 1 year",
"6 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"5 years",
"4 years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"1 year",
"8 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"6 years",
"10+ years",
"7 years",
"2 years",
"4 years",
"7 years",
"7 years",
"4 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"5 years",
"7 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"5 years",
"9 years",
"2 years",
"10+ years",
"3 years",
"4 years",
"1 year",
"8 years",
"4 years",
"10+ years",
"4 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"2 years",
"1 year",
"1 year",
"10+ years",
"< 1 year",
"8 years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"7 years",
"5 years",
"10+ years",
"5 years",
"10+ years",
null,
"2 years",
"3 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"8 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"7 years",
"< 1 year",
"3 years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"7 years",
"10+ years",
"8 years",
"7 years",
"9 years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"4 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"2 years",
"10+ years",
"8 years",
"< 1 year",
"1 year",
"8 years",
"10+ years",
"4 years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"1 year",
"9 years",
"3 years",
"7 years",
"9 years",
"10+ years",
"10+ years",
"5 years",
"7 years",
"< 1 year",
"5 years",
"8 years",
"10+ years",
"< 1 year",
"5 years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"3 years",
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"8 years",
"6 years",
"7 years",
"3 years",
"2 years",
"2 years",
"5 years",
"2 years",
"2 years",
"10+ years",
"6 years",
"10+ years",
"2 years",
null,
"10+ years",
"6 years",
"3 years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"5 years",
"7 years",
"6 years",
null,
"8 years",
null,
"10+ years",
"4 years",
"10+ years",
"5 years",
"2 years",
"8 years",
"5 years",
"7 years",
null,
"1 year",
"10+ years",
"10+ years",
"1 year",
"2 years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"7 years",
"< 1 year",
null,
null,
"6 years",
"10+ years",
"2 years",
"10+ years",
"7 years",
"9 years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"10+ years",
"7 years",
"4 years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"1 year",
"5 years",
null,
"10+ years",
"< 1 year",
"3 years",
null,
"10+ years",
"10+ years",
"6 years",
"5 years",
"2 years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
null,
"6 years",
"1 year",
"5 years",
"9 years",
null,
"10+ years",
"10+ years",
"2 years",
"6 years",
"4 years",
"1 year",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"6 years",
null,
"6 years",
"2 years",
"8 years",
"1 year",
"10+ years",
"< 1 year",
null,
"10+ years",
"10+ years",
"10+ years",
"4 years",
"8 years",
"10+ years",
"6 years",
"3 years",
"6 years",
"< 1 year",
"10+ years",
null,
null,
"10+ years",
"2 years",
"10+ years",
"5 years",
"5 years",
"3 years",
"8 years",
"10+ years",
"5 years",
"6 years",
"8 years",
"10+ years",
"2 years",
"1 year",
"7 years",
"3 years",
"3 years",
"10+ years",
"4 years",
"6 years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"4 years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"< 1 year",
"9 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"8 years",
"10+ years",
null,
"< 1 year",
"< 1 year",
"10+ years",
"1 year",
"2 years",
"7 years",
"9 years",
"10+ years",
"4 years",
"4 years",
"7 years",
"10+ years",
"< 1 year",
null,
"4 years",
"3 years",
"3 years",
null,
"1 year",
"8 years",
"3 years",
"2 years",
"< 1 year",
"< 1 year",
"2 years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"8 years",
"1 year",
"7 years",
"2 years",
"7 years",
"2 years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"9 years",
"5 years",
"10+ years",
"9 years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"3 years",
"6 years",
"< 1 year",
"2 years",
"7 years",
null,
"< 1 year",
"< 1 year",
"7 years",
"7 years",
"6 years",
"2 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"6 years",
"< 1 year",
"8 years",
"10+ years",
"6 years",
"10+ years",
"8 years",
"9 years",
"1 year",
"10+ years",
null,
"10+ years",
"3 years",
"2 years",
"5 years",
"4 years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"1 year",
"1 year",
"10+ years",
"8 years",
"10+ years",
"8 years",
"4 years",
"< 1 year",
"8 years",
"10+ years",
"< 1 year",
"1 year",
"7 years",
null,
"3 years",
"< 1 year",
"6 years",
"10+ years",
"8 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"9 years",
"5 years",
"10+ years",
"7 years",
"< 1 year",
"6 years",
"10+ years",
"5 years",
"< 1 year",
"< 1 year",
"< 1 year",
"3 years",
"6 years",
"10+ years",
"9 years",
"7 years",
"2 years",
null,
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
null,
"10+ years",
"< 1 year",
null,
"< 1 year",
"< 1 year",
"< 1 year",
"10+ years",
"9 years",
"5 years",
"< 1 year",
"10+ years",
"< 1 year",
"8 years",
null,
"5 years",
"10+ years",
"10+ years",
"6 years",
null,
"3 years",
"10+ years",
"7 years",
"10+ years",
"5 years",
"1 year",
"2 years",
"< 1 year",
"10+ years",
"4 years",
"1 year",
"4 years",
"5 years",
"10+ years",
"9 years",
"3 years",
"5 years",
"2 years",
"10+ years",
"1 year",
"5 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
null,
"4 years",
"10+ years",
"9 years",
"1 year",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"4 years",
"< 1 year",
"8 years",
"3 years",
"3 years",
"7 years",
"4 years",
"10+ years",
"5 years",
"10+ years",
"6 years",
"4 years",
"8 years",
"3 years",
"9 years",
"3 years",
"4 years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"10+ years",
null,
"10+ years",
"1 year",
"10+ years",
"10+ years",
null,
"10+ years",
"6 years",
"9 years",
"8 years",
"< 1 year",
"7 years",
"2 years",
"6 years",
"3 years",
"7 years",
null,
"3 years",
"7 years",
"3 years",
"3 years",
"5 years",
"10+ years",
"8 years",
"< 1 year",
"1 year",
"10+ years",
"4 years",
"2 years",
"10+ years",
"1 year",
"8 years",
"10+ years",
"8 years",
"3 years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"9 years",
"< 1 year",
"2 years",
"5 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"6 years",
"6 years",
"8 years",
"10+ years",
"7 years",
"8 years",
"3 years",
"10+ years",
"4 years",
"7 years",
"8 years",
"< 1 year",
"2 years",
"4 years",
"8 years",
"9 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"4 years",
"9 years",
"1 year",
"2 years",
"6 years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"4 years",
"8 years",
"10+ years",
"5 years",
"7 years",
"5 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"8 years",
"4 years",
"8 years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"9 years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"4 years",
"8 years",
"4 years",
"8 years",
"10+ years",
"9 years",
"3 years",
"10+ years",
"3 years",
"2 years",
"6 years",
"3 years",
null,
"10+ years",
"7 years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"9 years",
null,
"4 years",
"4 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"9 years",
"3 years",
"4 years",
"4 years",
"7 years",
"5 years",
"10+ years",
"< 1 year",
"< 1 year",
"4 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"6 years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"6 years",
"4 years",
"8 years",
"< 1 year",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"< 1 year",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"6 years",
"8 years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
null,
"10+ years",
"3 years",
"7 years",
null,
"10+ years",
"5 years",
"10+ years",
"3 years",
"3 years",
"6 years",
"5 years",
"5 years",
"< 1 year",
"< 1 year",
"4 years",
"3 years",
"< 1 year",
"10+ years",
null,
"10+ years",
"10+ years",
"7 years",
"3 years",
"5 years",
"6 years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
null,
"10+ years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"6 years",
"10+ years",
"< 1 year",
"4 years",
"6 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"< 1 year",
"9 years",
"< 1 year",
"6 years",
"< 1 year",
"< 1 year",
"4 years",
"1 year",
"6 years",
"10+ years",
"10+ years",
null,
"10+ years",
"1 year",
null,
"10+ years",
"8 years",
"6 years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"10+ years",
"1 year",
"7 years",
"1 year",
"2 years",
"9 years",
"9 years",
"8 years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"6 years",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"5 years",
"2 years",
"9 years",
"10+ years",
"< 1 year",
"5 years",
"4 years",
"7 years",
"8 years",
"< 1 year",
"1 year",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"1 year",
"9 years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"8 years",
"3 years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"10+ years",
null,
"5 years",
"2 years",
"6 years",
"10+ years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"2 years",
"1 year",
"2 years",
"10+ years",
null,
"10+ years",
"10+ years",
"9 years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"9 years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"7 years",
"7 years",
"10+ years",
null,
"4 years",
"10+ years",
null,
null,
"4 years",
"5 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"6 years",
"< 1 year",
"10+ years",
"2 years",
"2 years",
"5 years",
"6 years",
"4 years",
"6 years",
"4 years",
"< 1 year",
"10+ years",
"8 years",
"4 years",
"9 years",
"10+ years",
"5 years",
"< 1 year",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"3 years",
"2 years",
"1 year",
"4 years",
"3 years",
"10+ years",
"8 years",
"7 years",
"6 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"4 years",
"2 years",
"6 years",
"10+ years",
null,
"4 years",
"10+ years",
null,
"3 years",
"3 years",
"10+ years",
"10+ years",
"6 years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"9 years",
"5 years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"9 years",
"< 1 year",
"2 years",
"10+ years",
"3 years",
"4 years",
"8 years",
"4 years",
"2 years",
"6 years",
"< 1 year",
"10+ years",
"7 years",
"3 years",
"8 years",
"4 years",
"9 years",
"1 year",
"8 years",
"9 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"5 years",
"4 years",
"4 years",
"7 years",
"10+ years",
"10+ years",
"5 years",
"1 year",
"2 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
null,
"10+ years",
"3 years",
"< 1 year",
"1 year",
"< 1 year",
"< 1 year",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"2 years",
"< 1 year",
"5 years",
"9 years",
"2 years",
"10+ years",
"3 years",
null,
"4 years",
null,
null,
"5 years",
"4 years",
"3 years",
"9 years",
"10+ years",
"2 years",
"5 years",
"9 years",
"8 years",
"4 years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"9 years",
"2 years",
"10+ years",
"4 years",
null,
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
null,
"1 year",
"10+ years",
"10+ years",
null,
"5 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"< 1 year",
"5 years",
"< 1 year",
"5 years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"6 years",
null,
"10+ years",
"4 years",
"4 years",
"5 years",
"10+ years",
null,
"2 years",
null,
"8 years",
"1 year",
"10+ years",
"6 years",
"7 years",
"4 years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"2 years",
"4 years",
"4 years",
"7 years",
"1 year",
"3 years",
"2 years",
"2 years",
"8 years",
"9 years",
"10+ years",
"9 years",
"7 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"6 years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"4 years",
null,
"4 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"3 years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"4 years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"9 years",
"3 years",
null,
"7 years",
"2 years",
"6 years",
"10+ years",
"1 year",
"10+ years",
"8 years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"3 years",
"9 years",
"10+ years",
"10+ years",
"2 years",
"7 years",
"< 1 year",
"1 year",
"3 years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"8 years",
"1 year",
"8 years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"8 years",
"2 years",
"3 years",
"3 years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"3 years",
null,
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"< 1 year",
"4 years",
"1 year",
"2 years",
"6 years",
"8 years",
null,
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"1 year",
"1 year",
"4 years",
"6 years",
"7 years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"3 years",
null,
"10+ years",
"6 years",
"< 1 year",
"6 years",
"10+ years",
null,
"1 year",
"10+ years",
"9 years",
"2 years",
"4 years",
"2 years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"7 years",
"9 years",
"8 years",
null,
"< 1 year",
"4 years",
"< 1 year",
"< 1 year",
"8 years",
"2 years",
"3 years",
"10+ years",
"4 years",
"10+ years",
"9 years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
null,
"3 years",
null,
"1 year",
"1 year",
"10+ years",
"8 years",
"6 years",
"10+ years",
"1 year",
"10+ years",
"2 years",
"1 year",
"5 years",
"5 years",
"5 years",
"4 years",
"10+ years",
"10+ years",
"6 years",
"1 year",
"< 1 year",
null,
"4 years",
"10+ years",
"3 years",
null,
"10+ years",
"10+ years",
null,
"1 year",
"2 years",
"6 years",
"10+ years",
"< 1 year",
null,
"2 years",
"7 years",
"3 years",
"10+ years",
"3 years",
null,
"3 years",
null,
"8 years",
"7 years",
"1 year",
"3 years",
null,
"10+ years",
"5 years",
"3 years",
"5 years",
"2 years",
"9 years",
"7 years",
"5 years",
"10+ years",
"2 years",
"9 years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"6 years",
"< 1 year",
"4 years",
null,
"3 years",
"10+ years",
"2 years",
"7 years",
"5 years",
"10+ years",
"9 years",
"8 years",
"10+ years",
"10+ years",
"6 years",
"5 years",
"10+ years",
"5 years",
"7 years",
"8 years",
"5 years",
"2 years",
"< 1 year",
"2 years",
"6 years",
"6 years",
"10+ years",
null,
"7 years",
"8 years",
"10+ years",
null,
"10+ years",
"3 years",
"7 years",
"8 years",
"5 years",
"7 years",
"10+ years",
"8 years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"1 year",
"4 years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"8 years",
"2 years",
"10+ years",
"7 years",
null,
"9 years",
"10+ years",
"5 years",
"< 1 year",
"9 years",
"10+ years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"3 years",
"8 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"7 years",
"3 years",
"9 years",
"< 1 year",
"10+ years",
"2 years",
"1 year",
"9 years",
"7 years",
"5 years",
"10+ years",
"< 1 year",
"6 years",
"3 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"4 years",
"< 1 year",
"10+ years",
"< 1 year",
"5 years",
"3 years",
"< 1 year",
"3 years",
"10+ years",
"2 years",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"2 years",
"1 year",
"2 years",
"7 years",
"6 years",
"9 years",
"5 years",
"7 years",
"10+ years",
"2 years",
"3 years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
null,
"2 years",
"3 years",
"9 years",
"7 years",
"10+ years",
"9 years",
"2 years",
"5 years",
"7 years",
"9 years",
"< 1 year",
"< 1 year",
"3 years",
"10+ years",
null,
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"5 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"8 years",
"10+ years",
"8 years",
"5 years",
"7 years",
"1 year",
"10+ years",
null,
"10+ years",
"10+ years",
"5 years",
"10+ years",
null,
"10+ years",
"4 years",
"2 years",
null,
null,
"10+ years",
"3 years",
"10+ years",
null,
"6 years",
"2 years",
"5 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
null,
"2 years",
"1 year",
"10+ years",
"< 1 year",
"8 years",
"8 years",
"1 year",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"6 years",
"6 years",
"3 years",
"5 years",
"10+ years",
"9 years",
"1 year",
"< 1 year",
null,
"10+ years",
"1 year",
"4 years",
"2 years",
"8 years",
"8 years",
"5 years",
"3 years",
"5 years",
"< 1 year",
"8 years",
"9 years",
"4 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"8 years",
"6 years",
"< 1 year",
"10+ years",
"7 years",
"9 years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"10+ years",
"4 years",
"9 years",
"10+ years",
"10+ years",
null,
"10+ years",
"5 years",
null,
"9 years",
"8 years",
"4 years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"7 years",
"< 1 year",
"3 years",
"2 years",
"10+ years",
"4 years",
"1 year",
"1 year",
"10+ years",
"5 years",
"3 years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"9 years",
"4 years",
"5 years",
"8 years",
"10+ years",
"< 1 year",
"3 years",
"4 years",
"10+ years",
"9 years",
"10+ years",
"8 years",
"8 years",
null,
"2 years",
"4 years",
"6 years",
"2 years",
"7 years",
"5 years",
"4 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"10+ years",
"6 years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"7 years",
"10+ years",
"4 years",
"8 years",
"2 years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"6 years",
"3 years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"4 years",
"10+ years",
"4 years",
null,
"9 years",
"4 years",
"5 years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"< 1 year",
"4 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"3 years",
"5 years",
"10+ years",
null,
"< 1 year",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"1 year",
"2 years",
null,
null,
"10+ years",
null,
"3 years",
"1 year",
"2 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"4 years",
"3 years",
"2 years",
"< 1 year",
"5 years",
"3 years",
"9 years",
"< 1 year",
"10+ years",
"5 years",
null,
"8 years",
null,
"10+ years",
"9 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"6 years",
"< 1 year",
"1 year",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
null,
"10+ years",
"7 years",
"< 1 year",
"6 years",
"< 1 year",
"< 1 year",
"10+ years",
null,
"10+ years",
"10+ years",
null,
"4 years",
"4 years",
"10+ years",
"3 years",
"7 years",
"8 years",
"2 years",
null,
"10+ years",
"< 1 year",
"8 years",
"2 years",
"< 1 year",
"4 years",
"3 years",
"5 years",
"10+ years",
"4 years",
"< 1 year",
"9 years",
"10+ years",
"9 years",
"3 years",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"8 years",
"4 years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"7 years",
"< 1 year",
"1 year",
"8 years",
"8 years",
"10+ years",
"7 years",
"3 years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"9 years",
"4 years",
"4 years",
"8 years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"9 years",
null,
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"6 years",
"2 years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"3 years",
"2 years",
"< 1 year",
"< 1 year",
"< 1 year",
"10+ years",
"7 years",
"< 1 year",
null,
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"3 years",
"3 years",
"3 years",
"4 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"8 years",
"7 years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"6 years",
"10+ years",
null,
"6 years",
"9 years",
"2 years",
"1 year",
"6 years",
"1 year",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"9 years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"2 years",
"5 years",
"3 years",
"2 years",
"10+ years",
"9 years",
"6 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"2 years",
"6 years",
"5 years",
null,
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"1 year",
"9 years",
"10+ years",
"1 year",
"9 years",
"3 years",
"3 years",
"3 years",
"< 1 year",
"< 1 year",
"4 years",
"9 years",
"5 years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
null,
"5 years",
"4 years",
"5 years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"8 years",
"7 years",
"7 years",
"10+ years",
"6 years",
"10+ years",
"9 years",
"2 years",
"10+ years",
"2 years",
"9 years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
null,
"10+ years",
"8 years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"1 year",
"3 years",
"2 years",
"< 1 year",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"6 years",
null,
"< 1 year",
"2 years",
"1 year",
"10+ years",
null,
"6 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"8 years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"9 years",
"9 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"4 years",
"10+ years",
"7 years",
"9 years",
"3 years",
"10+ years",
"8 years",
"3 years",
"3 years",
"3 years",
"< 1 year",
"< 1 year",
"10+ years",
"4 years",
"3 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"6 years",
"8 years",
"1 year",
"4 years",
"9 years",
null,
"1 year",
"4 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"3 years",
"2 years",
"1 year",
"5 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"1 year",
"2 years",
"10+ years",
"7 years",
"4 years",
"7 years",
"6 years",
null,
"< 1 year",
"1 year",
"3 years",
"2 years",
"10+ years",
"1 year",
"2 years",
"5 years",
"4 years",
"6 years",
"< 1 year",
"10+ years",
null,
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"2 years",
"10+ years",
"4 years",
"4 years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"1 year",
"7 years",
"9 years",
"4 years",
"4 years",
"1 year",
"10+ years",
"2 years",
"< 1 year",
"6 years",
"1 year",
null,
"7 years",
"10+ years",
null,
"< 1 year",
"3 years",
"10+ years",
"3 years",
"1 year",
"< 1 year",
"10+ years",
"8 years",
"< 1 year",
"3 years",
null,
"2 years",
"10+ years",
"8 years",
null,
"4 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
null,
"7 years",
"< 1 year",
"3 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"8 years",
"9 years",
"6 years",
null,
"10+ years",
"< 1 year",
null,
"10+ years",
"5 years",
"6 years",
"2 years",
"10+ years",
"6 years",
null,
"7 years",
"10+ years",
"4 years",
null,
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"5 years",
"3 years",
"8 years",
"8 years",
"1 year",
null,
"10+ years",
"7 years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"10+ years",
null,
"2 years",
"5 years",
"10+ years",
"6 years",
"< 1 year",
"5 years",
"5 years",
"4 years",
"3 years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
null,
"1 year",
"8 years",
"6 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"7 years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"9 years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"10+ years",
"4 years",
"3 years",
"10+ years",
null,
"10+ years",
"7 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"6 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"2 years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"5 years",
"5 years",
"10+ years",
"5 years",
"7 years",
"2 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"4 years",
"8 years",
"5 years",
"3 years",
null,
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"3 years",
"5 years",
null,
"9 years",
"10+ years",
"10+ years",
"7 years",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"9 years",
"1 year",
"1 year",
"5 years",
"2 years",
"2 years",
"7 years",
null,
"8 years",
"5 years",
"7 years",
null,
"1 year",
"8 years",
"3 years",
"10+ years",
"8 years",
"10+ years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"2 years",
"3 years",
"4 years",
"2 years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"2 years",
"3 years",
"10+ years",
"9 years",
"< 1 year",
null,
"10+ years",
"8 years",
"4 years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"4 years",
"3 years",
"10+ years",
null,
"7 years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"4 years",
"5 years",
"10+ years",
"3 years",
"8 years",
"3 years",
null,
"3 years",
"7 years",
"2 years",
"< 1 year",
"5 years",
"3 years",
"< 1 year",
"1 year",
"5 years",
"5 years",
"7 years",
"< 1 year",
"5 years",
"< 1 year",
"1 year",
"4 years",
"5 years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"7 years",
"2 years",
"10+ years",
"1 year",
"7 years",
"2 years",
"2 years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"8 years",
"1 year",
"2 years",
"< 1 year",
"< 1 year",
"5 years",
"8 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"2 years",
"10+ years",
"9 years",
"< 1 year",
"6 years",
"1 year",
"< 1 year",
"< 1 year",
"9 years",
"< 1 year",
"6 years",
"< 1 year",
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"2 years",
"4 years",
"< 1 year",
"8 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"4 years",
"7 years",
"5 years",
"5 years",
"7 years",
"5 years",
"4 years",
"3 years",
"10+ years",
"7 years",
"10+ years",
"5 years",
"9 years",
"3 years",
"4 years",
"10+ years",
null,
"9 years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"2 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"1 year",
"6 years",
"9 years",
"10+ years",
"9 years",
"< 1 year",
null,
"8 years",
"2 years",
"6 years",
"2 years",
"10+ years",
"9 years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"8 years",
"6 years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
null,
"1 year",
"10+ years",
"5 years",
"2 years",
"6 years",
"3 years",
"10+ years",
"5 years",
"3 years",
"1 year",
"3 years",
"8 years",
"8 years",
"1 year",
"5 years",
"8 years",
"5 years",
"1 year",
"8 years",
"< 1 year",
"2 years",
"< 1 year",
null,
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"2 years",
null,
"3 years",
"< 1 year",
"2 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"5 years",
"10+ years",
null,
"8 years",
"5 years",
"3 years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"4 years",
"10+ years",
"1 year",
"4 years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"7 years",
"< 1 year",
"< 1 year",
"1 year",
"1 year",
"8 years",
"4 years",
"3 years",
"3 years",
"6 years",
"4 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"6 years",
"3 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
null,
"5 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"6 years",
"6 years",
"5 years",
null,
"5 years",
"7 years",
"7 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"< 1 year",
"3 years",
"10+ years",
"9 years",
"5 years",
"10+ years",
"7 years",
"3 years",
"8 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"1 year",
"< 1 year",
"1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"7 years",
"10+ years",
"7 years",
"2 years",
"< 1 year",
"10+ years",
null,
"5 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"< 1 year",
"1 year",
"4 years",
"1 year",
"4 years",
null,
"3 years",
"3 years",
"5 years",
"5 years",
"10+ years",
null,
null,
"< 1 year",
"2 years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"5 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"2 years",
"5 years",
"9 years",
"7 years",
"1 year",
"5 years",
"2 years",
"10+ years",
"1 year",
"4 years",
"2 years",
"2 years",
"< 1 year",
"6 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"< 1 year",
"< 1 year",
"10+ years",
"1 year",
"< 1 year",
"7 years",
null,
"10+ years",
"10+ years",
"4 years",
"1 year",
"< 1 year",
"2 years",
"5 years",
"1 year",
"3 years",
"1 year",
"10+ years",
"5 years",
"4 years",
"8 years",
"1 year",
"10+ years",
"9 years",
"10+ years",
"2 years",
"3 years",
"5 years",
"4 years",
"3 years",
"2 years",
"1 year",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"8 years",
"7 years",
null,
"4 years",
"< 1 year",
"10+ years",
"2 years",
null,
"10+ years",
"7 years",
"4 years",
"6 years",
"10+ years",
"5 years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"4 years",
null,
null,
"< 1 year",
"10+ years",
"2 years",
"1 year",
"10+ years",
null,
"1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"6 years",
"4 years",
"2 years",
"2 years",
"10+ years",
"5 years",
"7 years",
"3 years",
"10+ years",
null,
"7 years",
"10+ years",
"10+ years",
null,
"1 year",
"10+ years",
"8 years",
null,
"< 1 year",
"< 1 year",
"1 year",
"10+ years",
"2 years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"7 years",
null,
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"1 year",
null,
"8 years",
"6 years",
"10+ years",
"2 years",
"8 years",
"< 1 year",
"3 years",
"5 years",
"4 years",
"3 years",
"8 years",
"9 years",
"4 years",
"4 years",
"3 years",
"3 years",
"5 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"3 years",
"6 years",
"1 year",
"6 years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"10+ years",
null,
"2 years",
"10+ years",
"6 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"< 1 year",
"4 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"3 years",
"9 years",
"1 year",
"7 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"6 years",
"2 years",
"1 year",
"8 years",
"< 1 year",
"7 years",
"3 years",
"9 years",
"8 years",
"1 year",
"10+ years",
"6 years",
"4 years",
"10+ years",
null,
"5 years",
"6 years",
"7 years",
"5 years",
"< 1 year",
"6 years",
"10+ years",
"8 years",
"< 1 year",
"3 years",
"3 years",
"10+ years",
"1 year",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"8 years",
"7 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"8 years",
"8 years",
"1 year",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"3 years",
"8 years",
"9 years",
"6 years",
"7 years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"9 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
null,
"10+ years",
"8 years",
"10+ years",
"9 years",
"3 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"8 years",
"10+ years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"2 years",
"2 years",
"5 years",
"6 years",
"8 years",
"10+ years",
"3 years",
"7 years",
null,
"2 years",
"5 years",
"10+ years",
"8 years",
"10+ years",
"4 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"1 year",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"5 years",
"1 year",
"4 years",
"< 1 year",
"4 years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"2 years",
"10+ years",
"5 years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"2 years",
null,
"5 years",
"1 year",
"10+ years",
"2 years",
"6 years",
"3 years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"1 year",
"9 years",
"6 years",
"1 year",
"8 years",
"8 years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"1 year",
null,
null,
"7 years",
"6 years",
"4 years",
"2 years",
"3 years",
"8 years",
null,
"10+ years",
"6 years",
"2 years",
"10+ years",
"< 1 year",
"< 1 year",
"1 year",
"1 year",
"5 years",
"2 years",
"2 years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"2 years",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"9 years",
null,
"10+ years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"9 years",
"10+ years",
"5 years",
"1 year",
null,
"10+ years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"3 years",
"4 years",
null,
"7 years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"< 1 year",
null,
"5 years",
"1 year",
"1 year",
"10+ years",
"4 years",
"10+ years",
"2 years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"8 years",
"4 years",
"5 years",
"2 years",
null,
"10+ years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"7 years",
"1 year",
"3 years",
"5 years",
"5 years",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"10+ years",
"8 years",
"2 years",
"8 years",
"10+ years",
null,
"10+ years",
"< 1 year",
"10+ years",
null,
"3 years",
"< 1 year",
"< 1 year",
"6 years",
null,
"10+ years",
"10+ years",
"2 years",
"6 years",
"< 1 year",
"7 years",
"< 1 year",
"7 years",
"3 years",
"7 years",
"3 years",
"1 year",
"10+ years",
"2 years",
"7 years",
"3 years",
"1 year",
"10+ years",
"2 years",
"5 years",
"4 years",
"10+ years",
"1 year",
"10+ years",
"6 years",
"3 years",
"10+ years",
null,
"10+ years",
"10+ years",
null,
"6 years",
"8 years",
"7 years",
"9 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"6 years",
"4 years",
"2 years",
"6 years",
"5 years",
null,
"3 years",
"3 years",
"5 years",
"8 years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"6 years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"3 years",
"1 year",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"7 years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"6 years",
"4 years",
null,
null,
"1 year",
"< 1 year",
"7 years",
"10+ years",
null,
"6 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"1 year",
"5 years",
"5 years",
"1 year",
"8 years",
"10+ years",
null,
"1 year",
null,
"1 year",
"3 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"1 year",
"< 1 year",
"1 year",
"< 1 year",
"2 years",
"3 years",
"6 years",
"1 year",
"10+ years",
"8 years",
"9 years",
"10+ years",
"7 years",
"10+ years",
"3 years",
null,
"5 years",
"6 years",
"5 years",
"3 years",
"10+ years",
null,
"9 years",
"8 years",
"10+ years",
"6 years",
"7 years",
"8 years",
"6 years",
"4 years",
"4 years",
"3 years",
"6 years",
"7 years",
"10+ years",
"4 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"1 year",
"9 years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
null,
"10+ years",
"2 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"< 1 year",
"5 years",
"10+ years",
null,
"1 year",
"3 years",
"1 year",
"10+ years",
"2 years",
"8 years",
"6 years",
"< 1 year",
"7 years",
"2 years",
"6 years",
"< 1 year",
"2 years",
"4 years",
"8 years",
"8 years",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"3 years",
null,
"10+ years",
"2 years",
"7 years",
"4 years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"1 year",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
null,
"3 years",
"8 years",
"4 years",
"4 years",
"6 years",
"1 year",
"10+ years",
"2 years",
"4 years",
null,
"7 years",
"9 years",
"5 years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"3 years",
"6 years",
"9 years",
"< 1 year",
"10+ years",
"4 years",
"1 year",
"< 1 year",
"10+ years",
"4 years",
"3 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"9 years",
"4 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"1 year",
"5 years",
"3 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"1 year",
null,
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"6 years",
"1 year",
"10+ years",
"6 years",
"10+ years",
"8 years",
"10+ years",
"8 years",
"10+ years",
null,
"2 years",
null,
"1 year",
"2 years",
"10+ years",
"5 years",
"1 year",
"3 years",
"3 years",
"< 1 year",
"2 years",
"10+ years",
"6 years",
"7 years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"5 years",
"1 year",
"5 years",
"10+ years",
"9 years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"5 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
null,
"6 years",
"10+ years",
"1 year",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"8 years",
"3 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"10+ years",
"4 years",
"< 1 year",
"3 years",
"10+ years",
null,
null,
"10+ years",
"5 years",
"9 years",
null,
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"4 years",
"3 years",
"4 years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"1 year",
null,
"9 years",
"< 1 year",
"5 years",
null,
"< 1 year",
"5 years",
"4 years",
"3 years",
"3 years",
"1 year",
"5 years",
"10+ years",
null,
"10+ years",
"1 year",
"2 years",
null,
"8 years",
"3 years",
"3 years",
"10+ years",
"1 year",
"5 years",
"5 years",
"10+ years",
"4 years",
"6 years",
"3 years",
"2 years",
"5 years",
"6 years",
"< 1 year",
"3 years",
"2 years",
"6 years",
"9 years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"4 years",
"2 years",
"< 1 year",
"9 years",
"10+ years",
"9 years",
"10+ years",
"6 years",
"3 years",
"2 years",
"8 years",
"10+ years",
null,
"10+ years",
"6 years",
"4 years",
"10+ years",
null,
"10+ years",
"5 years",
null,
"10+ years",
"10+ years",
"4 years",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"< 1 year",
"4 years",
"< 1 year",
"4 years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"8 years",
"2 years",
"10+ years",
"< 1 year",
"5 years",
"6 years",
"6 years",
"10+ years",
"2 years",
"4 years",
"10+ years",
"6 years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"2 years",
"4 years",
null,
null,
"2 years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"9 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"6 years",
"7 years",
"10+ years",
null,
"10+ years",
"10+ years",
"7 years",
"2 years",
"< 1 year",
"5 years",
"10+ years",
"5 years",
"7 years",
"3 years",
"10+ years",
"5 years",
null,
"< 1 year",
"3 years",
"4 years",
"10+ years",
"5 years",
"< 1 year",
"4 years",
"3 years",
"2 years",
"4 years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"3 years",
"5 years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"2 years",
"10+ years",
"8 years",
"< 1 year",
"8 years",
null,
"7 years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"7 years",
"4 years",
"10+ years",
"10+ years",
"9 years",
"1 year",
"10+ years",
"3 years",
"9 years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"1 year",
null,
"10+ years",
"3 years",
"6 years",
"9 years",
"4 years",
"10+ years",
"9 years",
"10+ years",
"8 years",
"10+ years",
"9 years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"< 1 year",
null,
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"< 1 year",
"3 years",
"5 years",
"10+ years",
"7 years",
"8 years",
"3 years",
"2 years",
"2 years",
"1 year",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"7 years",
"3 years",
"4 years",
"6 years",
null,
"2 years",
"< 1 year",
"7 years",
"1 year",
null,
"< 1 year",
"8 years",
"10+ years",
"7 years",
"2 years",
null,
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"6 years",
"1 year",
"3 years",
"10+ years",
"3 years",
"2 years",
"1 year",
"9 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"3 years",
null,
"4 years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
null,
"10+ years",
"10+ years",
"5 years",
"3 years",
"1 year",
"10+ years",
null,
"10+ years",
"9 years",
"4 years",
"4 years",
"6 years",
"10+ years",
"3 years",
"5 years",
"2 years",
"10+ years",
"8 years",
"4 years",
null,
"10+ years",
"3 years",
"< 1 year",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"7 years",
"6 years",
"10+ years",
"< 1 year",
"9 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"6 years",
"8 years",
"8 years",
"10+ years",
"< 1 year",
"2 years",
"< 1 year",
"4 years",
"6 years",
"3 years",
"< 1 year",
"8 years",
"10+ years",
"1 year",
"< 1 year",
"8 years",
"4 years",
"1 year",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"< 1 year",
"2 years",
"1 year",
"9 years",
"7 years",
"10+ years",
"1 year",
"10+ years",
null,
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"5 years",
"6 years",
"10+ years",
"1 year",
"3 years",
"5 years",
"7 years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"8 years",
"3 years",
"10+ years",
"10+ years",
null,
"< 1 year",
"8 years",
"1 year",
null,
"10+ years",
"10+ years",
"3 years",
"6 years",
"2 years",
"7 years",
"10+ years",
"1 year",
"9 years",
"3 years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"< 1 year",
"10+ years",
"6 years",
"4 years",
null,
"7 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"4 years",
"9 years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"3 years",
"2 years",
"1 year",
"4 years",
"9 years",
"10+ years",
"7 years",
"2 years",
"< 1 year",
"5 years",
"9 years",
"10+ years",
"9 years",
"4 years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"3 years",
"< 1 year",
"8 years",
"10+ years",
"1 year",
"2 years",
"3 years",
"3 years",
"2 years",
"5 years",
"6 years",
"6 years",
"5 years",
null,
"4 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"1 year",
"4 years",
"4 years",
"3 years",
"10+ years",
"6 years",
"1 year",
"3 years",
"2 years",
"1 year",
null,
null,
"1 year",
"< 1 year",
null,
"1 year",
"10+ years",
"10+ years",
null,
"10+ years",
"5 years",
null,
null,
"2 years",
"8 years",
"5 years",
"10+ years",
"5 years",
"1 year",
"10+ years",
null,
"10+ years",
"7 years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"10+ years",
null,
"< 1 year",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"5 years",
"9 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
null,
"10+ years",
"1 year",
"2 years",
"4 years",
"10+ years",
"1 year",
null,
"10+ years",
"9 years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"8 years",
"< 1 year",
null,
"7 years",
"5 years",
"4 years",
"7 years",
"10+ years",
"7 years",
"3 years",
"6 years",
"10+ years",
"< 1 year",
null,
"5 years",
"6 years",
"3 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"9 years",
"10+ years",
"7 years",
"9 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"4 years",
"8 years",
"8 years",
"7 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"3 years",
"< 1 year",
"2 years",
"< 1 year",
"5 years",
"2 years",
"1 year",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"6 years",
"5 years",
"10+ years",
"8 years",
"10+ years",
"6 years",
"3 years",
"6 years",
"2 years",
"< 1 year",
"10+ years",
"2 years",
"2 years",
"< 1 year",
"10+ years",
"8 years",
"1 year",
"7 years",
"6 years",
"6 years",
"1 year",
"< 1 year",
"1 year",
"10+ years",
"2 years",
"9 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"1 year",
"10+ years",
"3 years",
"3 years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"5 years",
"6 years",
"4 years",
null,
"10+ years",
"1 year",
"8 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"4 years",
"1 year",
"7 years",
"5 years",
"4 years",
"2 years",
"3 years",
"6 years",
"4 years",
"10+ years",
"9 years",
"6 years",
"4 years",
"10+ years",
"< 1 year",
"4 years",
"3 years",
null,
"10+ years",
"10+ years",
"8 years",
"10+ years",
"1 year",
"4 years",
"7 years",
"4 years",
"2 years",
"7 years",
"10+ years",
"4 years",
"8 years",
"2 years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"9 years",
"10+ years",
"1 year",
"10+ years",
"7 years",
"1 year",
"4 years",
"1 year",
"8 years",
"3 years",
"6 years",
"7 years",
"2 years",
"8 years",
"9 years",
"2 years",
"< 1 year",
null,
"10+ years",
"2 years",
"3 years",
"10+ years",
"6 years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"7 years",
"< 1 year",
"< 1 year",
"3 years",
"9 years",
"< 1 year",
"6 years",
"5 years",
"3 years",
"10+ years",
"6 years",
"6 years",
"9 years",
"4 years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"9 years",
"4 years",
"3 years",
"6 years",
"10+ years",
"10+ years",
"7 years",
"6 years",
"1 year",
"< 1 year",
"10+ years",
"9 years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"6 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"7 years",
"4 years",
"10+ years",
"10+ years",
"1 year",
null,
"10+ years",
"10+ years",
"2 years",
"10+ years",
"6 years",
"< 1 year",
"5 years",
"5 years",
"10+ years",
"10+ years",
null,
"3 years",
"3 years",
"6 years",
"8 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"2 years",
"3 years",
"7 years",
"8 years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
null,
"< 1 year",
"< 1 year",
"5 years",
"5 years",
"8 years",
"9 years",
"7 years",
null,
"4 years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"6 years",
"< 1 year",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"4 years",
"10+ years",
"2 years",
null,
"1 year",
"8 years",
"8 years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"5 years",
"10+ years",
"5 years",
"8 years",
"1 year",
"9 years",
null,
null,
"10+ years",
"5 years",
"8 years",
"10+ years",
"9 years",
"5 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"6 years",
null,
"3 years",
"< 1 year",
"10+ years",
"7 years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"< 1 year",
"10+ years",
null,
"5 years",
"6 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"2 years",
"4 years",
"2 years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"7 years",
"10+ years",
"7 years",
"< 1 year",
"2 years",
"3 years",
"1 year",
"1 year",
"5 years",
"10+ years",
"10+ years",
"10+ years",
null,
"3 years",
"5 years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"7 years",
"3 years",
"10+ years",
"4 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"3 years",
"3 years",
"10+ years",
null,
"7 years",
"2 years",
"10+ years",
"9 years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"9 years",
"10+ years",
"2 years",
"9 years",
"7 years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"4 years",
"1 year",
"3 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"5 years",
"< 1 year",
"3 years",
"< 1 year",
"< 1 year",
"2 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"4 years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"9 years",
"8 years",
"4 years",
"4 years",
"7 years",
null,
"10+ years",
"2 years",
"9 years",
"10+ years",
"2 years",
"10+ years",
"6 years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"5 years",
"2 years",
"8 years",
"4 years",
"10+ years",
"< 1 year",
"5 years",
null,
"4 years",
"1 year",
"1 year",
"5 years",
null,
"2 years",
"9 years",
"9 years",
"5 years",
"8 years",
"3 years",
"8 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"5 years",
"10+ years",
"5 years",
"3 years",
"5 years",
"9 years",
"4 years",
"1 year",
"8 years",
"8 years",
"1 year",
"7 years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"3 years",
"8 years",
"10+ years",
"5 years",
"< 1 year",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"7 years",
"10+ years",
null,
"1 year",
null,
"9 years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"7 years",
"6 years",
"10+ years",
"1 year",
null,
"10+ years",
"4 years",
"< 1 year",
"7 years",
"8 years",
"10+ years",
"3 years",
"7 years",
"5 years",
null,
null,
"7 years",
"< 1 year",
"6 years",
"10+ years",
"4 years",
"< 1 year",
"4 years",
"10+ years",
"9 years",
"4 years",
"< 1 year",
"8 years",
"10+ years",
"< 1 year",
"< 1 year",
null,
"8 years",
"< 1 year",
"1 year",
"2 years",
"8 years",
"8 years",
"6 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"8 years",
"9 years",
"< 1 year",
"7 years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"3 years",
"3 years",
"7 years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"6 years",
"5 years",
"3 years",
"1 year",
"3 years",
"7 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"7 years",
null,
"10+ years",
"9 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"4 years",
"8 years",
"8 years",
"4 years",
"3 years",
"1 year",
"2 years",
"9 years",
"9 years",
"10+ years",
"1 year",
"2 years",
"10+ years",
"7 years",
"3 years",
"9 years",
null,
"5 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
null,
"1 year",
"2 years",
"5 years",
"6 years",
"3 years",
"7 years",
"10+ years",
"8 years",
"8 years",
"5 years",
"1 year",
null,
"10+ years",
null,
"4 years",
"8 years",
"1 year",
"10+ years",
"6 years",
"8 years",
"8 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"8 years",
"2 years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"8 years",
"7 years",
"10+ years",
"5 years",
"8 years",
"< 1 year",
"10+ years",
"3 years",
"8 years",
"7 years",
"4 years",
"5 years",
"9 years",
"3 years",
"1 year",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"7 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
null,
"5 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"8 years",
"6 years",
"3 years",
"5 years",
"6 years",
"< 1 year",
"7 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"3 years",
"4 years",
"7 years",
"2 years",
"2 years",
"10+ years",
"6 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
null,
"6 years",
"1 year",
"10+ years",
"6 years",
"10+ years",
"3 years",
"2 years",
null,
"10+ years",
"9 years",
"< 1 year",
"1 year",
null,
"5 years",
"5 years",
"5 years",
"5 years",
"10+ years",
null,
"2 years",
"10+ years",
"8 years",
"10+ years",
"6 years",
"3 years",
"< 1 year",
"4 years",
"4 years",
"3 years",
"4 years",
"10+ years",
"9 years",
"7 years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"4 years",
"8 years",
"4 years",
"10+ years",
"1 year",
"10+ years",
"8 years",
"3 years",
"2 years",
null,
"< 1 year",
"8 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"3 years",
null,
"10+ years",
"4 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
null,
"10+ years",
"9 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
null,
"4 years",
"7 years",
"8 years",
"8 years",
"9 years",
"2 years",
"1 year",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"5 years",
"3 years",
"5 years",
"10+ years",
"< 1 year",
"5 years",
"6 years",
"4 years",
"3 years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
null,
"1 year",
"10+ years",
"10+ years",
"2 years",
"9 years",
"2 years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"4 years",
"10+ years",
"7 years",
"1 year",
"2 years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"1 year",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"6 years",
null,
"9 years",
"4 years",
"2 years",
null,
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"3 years",
"1 year",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
null,
"4 years",
"10+ years",
"10+ years",
"9 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"9 years",
"9 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"8 years",
"3 years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"4 years",
"2 years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
null,
"10+ years",
"6 years",
"10+ years",
"7 years",
"7 years",
"1 year",
"5 years",
"8 years",
null,
"6 years",
null,
"10+ years",
"4 years",
"6 years",
null,
"10+ years",
"7 years",
"9 years",
"4 years",
"5 years",
"2 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"6 years",
"10+ years",
null,
"8 years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"4 years",
"4 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"2 years",
"2 years",
"9 years",
"3 years",
null,
"2 years",
"9 years",
"8 years",
"10+ years",
"4 years",
"10+ years",
"6 years",
"4 years",
"10+ years",
"1 year",
"2 years",
"< 1 year",
"5 years",
"2 years",
"10+ years",
"4 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"3 years",
"10+ years",
null,
"10+ years",
"8 years",
"< 1 year",
"8 years",
"1 year",
"10+ years",
"2 years",
"5 years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"3 years",
"< 1 year",
"6 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
null,
"8 years",
"2 years",
"9 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
null,
"8 years",
"10+ years",
"4 years",
"10+ years",
"6 years",
"6 years",
"1 year",
"2 years",
"6 years",
"10+ years",
"< 1 year",
"< 1 year",
"2 years",
"2 years",
"< 1 year",
"5 years",
"7 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"10+ years",
"7 years",
"< 1 year",
"4 years",
"6 years",
"6 years",
"10+ years",
"3 years",
"10+ years",
null,
"4 years",
"7 years",
"5 years",
"2 years",
"4 years",
null,
"10+ years",
"< 1 year",
"7 years",
"4 years",
null,
"1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"7 years",
null,
null,
"1 year",
"< 1 year",
"5 years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"7 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"2 years",
"< 1 year",
"4 years",
"6 years",
"10+ years",
"7 years",
"2 years",
"1 year",
"4 years",
"10+ years",
"7 years",
"< 1 year",
"1 year",
"10+ years",
"3 years",
"6 years",
"9 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"1 year",
"6 years",
"1 year",
"9 years",
"9 years",
"10+ years",
"8 years",
"9 years",
"6 years",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"< 1 year",
"8 years",
"10+ years",
"4 years",
"10+ years",
null,
"2 years",
"2 years",
"< 1 year",
null,
"9 years",
"8 years",
"3 years",
"< 1 year",
"5 years",
"10+ years",
"6 years",
"6 years",
"10+ years",
"5 years",
"7 years",
"3 years",
"2 years",
"1 year",
"10+ years",
"2 years",
"9 years",
"10+ years",
"4 years",
"< 1 year",
"8 years",
"9 years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"3 years",
"< 1 year",
"4 years",
"1 year",
"< 1 year",
"2 years",
"3 years",
"8 years",
"10+ years",
null,
"10+ years",
"5 years",
null,
"9 years",
"5 years",
"5 years",
"10+ years",
"3 years",
"3 years",
null,
"< 1 year",
"7 years",
"5 years",
"10+ years",
"8 years",
"3 years",
"2 years",
null,
"6 years",
"< 1 year",
"< 1 year",
"5 years",
"< 1 year",
"10+ years",
"3 years",
"5 years",
"2 years",
"2 years",
"7 years",
"9 years",
"7 years",
"9 years",
null,
"9 years",
"< 1 year",
"10+ years",
"9 years",
"9 years",
"2 years",
"8 years",
"3 years",
"4 years",
"8 years",
"5 years",
"10+ years",
"3 years",
"4 years",
"8 years",
"3 years",
"3 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"3 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"7 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"2 years",
"< 1 year",
"10+ years",
"9 years",
"9 years",
"4 years",
"4 years",
"3 years",
null,
"3 years",
"5 years",
"7 years",
null,
null,
"6 years",
null,
"10+ years",
"10+ years",
"6 years",
"1 year",
"5 years",
"3 years",
null,
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"2 years",
"4 years",
"10+ years",
"9 years",
"6 years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"9 years",
"10+ years",
"10+ years",
"9 years",
"4 years",
"5 years",
"1 year",
"4 years",
"7 years",
"9 years",
"10+ years",
"9 years",
"8 years",
null,
"4 years",
"< 1 year",
"1 year",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"9 years",
"10+ years",
"3 years",
null,
null,
"10+ years",
"3 years",
"1 year",
"7 years",
"4 years",
"10+ years",
"3 years",
"1 year",
"7 years",
"10+ years",
"3 years",
"10+ years",
null,
"2 years",
"10+ years",
"10+ years",
"5 years",
"9 years",
"5 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"5 years",
"5 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"7 years",
"3 years",
"10+ years",
"10+ years",
null,
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"9 years",
"2 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"2 years",
"< 1 year",
"10+ years",
null,
null,
"9 years",
"10+ years",
null,
"10+ years",
"4 years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"4 years",
"2 years",
"10+ years",
"3 years",
"< 1 year",
"1 year",
"3 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"4 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"8 years",
"5 years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"2 years",
"3 years",
"10+ years",
"6 years",
"1 year",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"1 year",
"9 years",
"4 years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"6 years",
"< 1 year",
"1 year",
"3 years",
"2 years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"6 years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"10+ years",
"2 years",
"6 years",
"3 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"5 years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"3 years",
"8 years",
"10+ years",
"6 years",
"3 years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"5 years",
null,
"2 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"8 years",
"9 years",
"3 years",
null,
"2 years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"6 years",
"3 years",
"2 years",
"< 1 year",
"4 years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"2 years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"6 years",
"2 years",
"< 1 year",
"5 years",
"3 years",
"< 1 year",
"< 1 year",
"< 1 year",
"4 years",
"4 years",
"3 years",
"10+ years",
null,
"4 years",
"3 years",
"< 1 year",
"2 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"6 years",
"10+ years",
"< 1 year",
"2 years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
null,
"7 years",
"7 years",
"5 years",
"10+ years",
"6 years",
null,
"2 years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
null,
"10+ years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"6 years",
"3 years",
null,
"8 years",
"5 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"4 years",
"< 1 year",
"9 years",
"1 year",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"4 years",
"10+ years",
"1 year",
"10+ years",
"5 years",
"3 years",
"2 years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"8 years",
"< 1 year",
"9 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"4 years",
"3 years",
"10+ years",
"< 1 year",
"7 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"1 year",
"< 1 year",
"3 years",
"10+ years",
"1 year",
"4 years",
"2 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"7 years",
"4 years",
"3 years",
"1 year",
"4 years",
"2 years",
"7 years",
"1 year",
"8 years",
"10+ years",
null,
"5 years",
"4 years",
"10+ years",
"7 years",
"8 years",
"3 years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
"8 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"7 years",
null,
"4 years",
"< 1 year",
"10+ years",
"5 years",
"1 year",
"2 years",
"7 years",
"7 years",
"6 years",
"4 years",
"10+ years",
"6 years",
"10+ years",
"8 years",
"< 1 year",
"5 years",
"2 years",
"4 years",
"9 years",
"4 years",
null,
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"8 years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"1 year",
"3 years",
"3 years",
"10+ years",
"10+ years",
null,
"9 years",
"10+ years",
"10+ years",
"9 years",
"3 years",
null,
"10+ years",
"10+ years",
"4 years",
"4 years",
"8 years",
"1 year",
"2 years",
"8 years",
"10+ years",
"10+ years",
"6 years",
"< 1 year",
"10+ years",
null,
"4 years",
"4 years",
"9 years",
"4 years",
"10+ years",
"4 years",
"2 years",
"< 1 year",
"10+ years",
null,
"3 years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"< 1 year",
"7 years",
"4 years",
"10+ years",
null,
"10+ years",
"6 years",
"9 years",
"9 years",
"< 1 year",
"2 years",
"8 years",
"< 1 year",
"1 year",
"4 years",
"2 years",
null,
"6 years",
"2 years",
"3 years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"8 years",
"1 year",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"7 years",
"6 years",
"3 years",
"5 years",
"10+ years",
"7 years",
"10+ years",
"1 year",
"10+ years",
"5 years",
"3 years",
"7 years",
"8 years",
"10+ years",
"10+ years",
"5 years",
"4 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"2 years",
null,
"7 years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"2 years",
"10+ years",
"7 years",
"5 years",
"5 years",
"10+ years",
"7 years",
"< 1 year",
"5 years",
"2 years",
"10+ years",
"8 years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"2 years",
"4 years",
"10+ years",
"1 year",
"6 years",
"4 years",
"7 years",
"9 years",
"3 years",
"8 years",
"10+ years",
"< 1 year",
"5 years",
"< 1 year",
"8 years",
"10+ years",
"1 year",
"10+ years",
"7 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"2 years",
"9 years",
"3 years",
"10+ years",
"2 years",
"1 year",
"8 years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"8 years",
"3 years",
"7 years",
"9 years",
"3 years",
"2 years",
"10+ years",
"1 year",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"8 years",
"3 years",
null,
"10+ years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"1 year",
"10+ years",
"5 years",
"3 years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"8 years",
"8 years",
"1 year",
"10+ years",
"3 years",
null,
"10+ years",
"8 years",
"1 year",
"3 years",
"2 years",
null,
"1 year",
"3 years",
"10+ years",
"6 years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"2 years",
"< 1 year",
"10+ years",
null,
"6 years",
"< 1 year",
"10+ years",
"2 years",
"3 years",
"5 years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"7 years",
"1 year",
"3 years",
"1 year",
"< 1 year",
"9 years",
"3 years",
"7 years",
"2 years",
"< 1 year",
"2 years",
"7 years",
"8 years",
"10+ years",
"< 1 year",
"3 years",
"2 years",
"2 years",
"1 year",
"10+ years",
"5 years",
"< 1 year",
"3 years",
"2 years",
"10+ years",
"1 year",
"2 years",
"5 years",
"5 years",
"4 years",
"5 years",
"8 years",
"7 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"9 years",
"< 1 year",
"5 years",
"2 years",
"3 years",
"9 years",
"7 years",
"10+ years",
"6 years",
"2 years",
null,
"2 years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"3 years",
null,
"3 years",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"1 year",
null,
"9 years",
"8 years",
"3 years",
null,
"4 years",
"10+ years",
"2 years",
"5 years",
"5 years",
"3 years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"4 years",
"1 year",
"10+ years",
null,
"3 years",
"2 years",
"10+ years",
null,
"10+ years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"8 years",
"8 years",
"10+ years",
"1 year",
"8 years",
null,
"10+ years",
"4 years",
"< 1 year",
"5 years",
"5 years",
"10+ years",
"6 years",
"10+ years",
"9 years",
"2 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"< 1 year",
"3 years",
"4 years",
"4 years",
"9 years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"2 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"1 year",
"4 years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"3 years",
"1 year",
"9 years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"1 year",
"10+ years",
"9 years",
null,
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"9 years",
"7 years",
"10+ years",
"8 years",
"3 years",
"7 years",
"10+ years",
"5 years",
"< 1 year",
"< 1 year",
"3 years",
"10+ years",
"5 years",
"7 years",
"1 year",
"10+ years",
"3 years",
"6 years",
"1 year",
"10+ years",
"2 years",
"2 years",
"5 years",
"6 years",
"7 years",
"4 years",
"10+ years",
"< 1 year",
"5 years",
"< 1 year",
"6 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"9 years",
"10+ years",
"10+ years",
"4 years",
"6 years",
"4 years",
"10+ years",
"1 year",
"10+ years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"5 years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"2 years",
"< 1 year",
"< 1 year",
"4 years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
null,
"1 year",
"10+ years",
"2 years",
"5 years",
"8 years",
"2 years",
"< 1 year",
"10+ years",
"1 year",
"9 years",
"< 1 year",
"7 years",
"4 years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"2 years",
"3 years",
"9 years",
"1 year",
"3 years",
"5 years",
"3 years",
"5 years",
"10+ years",
"1 year",
"< 1 year",
"1 year",
null,
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"5 years",
"4 years",
"8 years",
"4 years",
"5 years",
"6 years",
"10+ years",
"6 years",
"1 year",
"1 year",
null,
"3 years",
"2 years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"8 years",
"9 years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"9 years",
"10+ years",
"< 1 year",
"3 years",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"7 years",
"6 years",
"10+ years",
"9 years",
"2 years",
"7 years",
"5 years",
"1 year",
"7 years",
"10+ years",
"< 1 year",
null,
"10+ years",
"9 years",
"5 years",
"7 years",
"< 1 year",
"10+ years",
"2 years",
"4 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"6 years",
null,
"< 1 year",
"1 year",
"2 years",
"9 years",
"7 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
null,
"10+ years",
null,
"7 years",
"3 years",
"2 years",
"< 1 year",
"3 years",
"5 years",
"2 years",
"4 years",
"10+ years",
null,
"< 1 year",
"< 1 year",
"4 years",
"4 years",
"2 years",
"10+ years",
"3 years",
"9 years",
"10+ years",
"< 1 year",
"9 years",
"4 years",
"7 years",
null,
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"4 years",
"5 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"8 years",
"< 1 year",
null,
"5 years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"7 years",
"3 years",
"2 years",
"10+ years",
"2 years",
"6 years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"6 years",
"7 years",
"10+ years",
null,
"2 years",
"3 years",
"2 years",
null,
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"6 years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"10+ years",
null,
"2 years",
"10+ years",
"7 years",
"10+ years",
"9 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"1 year",
"10+ years",
"5 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"3 years",
null,
"2 years",
"8 years",
"< 1 year",
"10+ years",
"1 year",
null,
"7 years",
"1 year",
"4 years",
null,
"5 years",
"10+ years",
null,
"8 years",
"1 year",
"< 1 year",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"3 years",
"3 years",
"< 1 year",
"10+ years",
"< 1 year",
"2 years",
"8 years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"1 year",
"8 years",
"4 years",
"10+ years",
"1 year",
"9 years",
"5 years",
"7 years",
"1 year",
"6 years",
"3 years",
"7 years",
"2 years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"1 year",
"3 years",
"9 years",
"< 1 year",
"2 years",
"10+ years",
"8 years",
"7 years",
"2 years",
"6 years",
"< 1 year",
"< 1 year",
"1 year",
"10+ years",
"5 years",
"10+ years",
"4 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"8 years",
"1 year",
"10+ years",
null,
"3 years",
"4 years",
"6 years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"1 year",
"5 years",
"2 years",
"6 years",
"6 years",
"7 years",
"3 years",
"8 years",
"10+ years",
"10+ years",
"4 years",
"7 years",
"9 years",
"10+ years",
"4 years",
"9 years",
"< 1 year",
"3 years",
"9 years",
"< 1 year",
"10+ years",
"2 years",
"1 year",
"3 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"7 years",
null,
"10+ years",
"10+ years",
null,
"7 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"5 years",
"< 1 year",
"6 years",
"3 years",
"< 1 year",
"2 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"9 years",
"10+ years",
"6 years",
"1 year",
"< 1 year",
"2 years",
"9 years",
"10+ years",
"< 1 year",
null,
"10+ years",
"< 1 year",
"5 years",
"9 years",
"6 years",
"10+ years",
"1 year",
"4 years",
"3 years",
"3 years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"6 years",
"3 years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"2 years",
"7 years",
"8 years",
"10+ years",
"10+ years",
null,
"1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"7 years",
"10+ years",
"10+ years",
null,
"6 years",
"5 years",
"< 1 year",
"5 years",
"7 years",
"1 year",
"3 years",
"8 years",
"7 years",
null,
null,
"10+ years",
"2 years",
"< 1 year",
null,
"10+ years",
"5 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"8 years",
"5 years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"2 years",
null,
"10+ years",
"8 years",
"6 years",
"9 years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
null,
"4 years",
"7 years",
null,
"8 years",
"10+ years",
"7 years",
"7 years",
"1 year",
"1 year",
"10+ years",
"5 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"3 years",
"3 years",
"9 years",
"4 years",
"1 year",
null,
"3 years",
"2 years",
"3 years",
"4 years",
"10+ years",
"9 years",
"10+ years",
"8 years",
"1 year",
"7 years",
"1 year",
"< 1 year",
"10+ years",
"1 year",
"8 years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"1 year",
null,
"< 1 year",
"2 years",
"2 years",
"10+ years",
null,
"4 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"5 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"7 years",
"2 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"< 1 year",
"8 years",
"6 years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"1 year",
"2 years",
"8 years",
"2 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"10+ years",
"6 years",
"5 years",
"< 1 year",
"3 years",
"4 years",
"1 year",
"8 years",
"6 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"6 years",
"4 years",
"10+ years",
"5 years",
"10+ years",
"6 years",
"4 years",
"10+ years",
"7 years",
"10+ years",
null,
"< 1 year",
"4 years",
"< 1 year",
"4 years",
"2 years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"4 years",
"< 1 year",
"1 year",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"4 years",
"9 years",
"< 1 year",
"10+ years",
"9 years",
"5 years",
"2 years",
"3 years",
"4 years",
"10+ years",
"7 years",
"4 years",
"< 1 year",
"10+ years",
"< 1 year",
"4 years",
"3 years",
"2 years",
"8 years",
"7 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
null,
"10+ years",
"8 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"9 years",
"4 years",
"9 years",
"5 years",
"1 year",
"10+ years",
null,
"3 years",
"10+ years",
"< 1 year",
"4 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"9 years",
"9 years",
"7 years",
"10+ years",
"4 years",
"5 years",
"5 years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
null,
"4 years",
"< 1 year",
"8 years",
"4 years",
"10+ years",
"3 years",
"5 years",
null,
"6 years",
"10+ years",
"10+ years",
"1 year",
"9 years",
"5 years",
"10+ years",
"< 1 year",
null,
"10+ years",
"2 years",
"10+ years",
null,
"5 years",
"4 years",
"5 years",
"9 years",
"< 1 year",
null,
"1 year",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"1 year",
"9 years",
"7 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
null,
"10+ years",
"2 years",
"6 years",
"6 years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"4 years",
null,
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
null,
"6 years",
null,
"10+ years",
"4 years",
"10+ years",
"1 year",
"2 years",
"2 years",
"7 years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"7 years",
"4 years",
"8 years",
"9 years",
"10+ years",
"10+ years",
"8 years",
"1 year",
"3 years",
"6 years",
"3 years",
"1 year",
"1 year",
"4 years",
"5 years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"4 years",
"6 years",
"3 years",
"10+ years",
null,
"10+ years",
"10+ years",
"1 year",
"9 years",
"2 years",
"6 years",
"10+ years",
"9 years",
"10+ years",
"4 years",
"7 years",
"10+ years",
"1 year",
"10+ years",
"5 years",
null,
"10+ years",
"7 years",
"10+ years",
"6 years",
"8 years",
"1 year",
"4 years",
"5 years",
"7 years",
"4 years",
"10+ years",
"1 year",
"< 1 year",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"5 years",
"7 years",
"2 years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"4 years",
null,
"3 years",
"2 years",
"7 years",
"7 years",
"5 years",
"10+ years",
"1 year",
null,
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"6 years",
"10+ years",
"4 years",
"9 years",
"10+ years",
"< 1 year",
"8 years",
"2 years",
"10+ years",
"8 years",
"1 year",
"10+ years",
"3 years",
"6 years",
"10+ years",
"3 years",
"9 years",
"8 years",
"4 years",
"3 years",
"10+ years",
"4 years",
"5 years",
"2 years",
"2 years",
"8 years",
"10+ years",
"10+ years",
null,
"3 years",
"7 years",
"8 years",
"4 years",
"10+ years",
"< 1 year",
"9 years",
"3 years",
"10+ years",
"5 years",
"3 years",
"8 years",
"10+ years",
"3 years",
"5 years",
"8 years",
"1 year",
"1 year",
"10+ years",
"8 years",
"< 1 year",
"2 years",
"2 years",
"3 years",
"2 years",
"8 years",
"10+ years",
"< 1 year",
"8 years",
"3 years",
"4 years",
null,
"10+ years",
"10+ years",
"8 years",
null,
"10+ years",
"6 years",
"9 years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"5 years",
"3 years",
"10+ years",
"7 years",
"10+ years",
"7 years",
"7 years",
"4 years",
"8 years",
"10+ years",
null,
"10+ years",
"10+ years",
"2 years",
"9 years",
"1 year",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"8 years",
"< 1 year",
"< 1 year",
"10+ years",
null,
"10+ years",
"7 years",
"6 years",
"9 years",
"10+ years",
"10+ years",
"9 years",
"4 years",
"2 years",
"2 years",
"10+ years",
"2 years",
"1 year",
"5 years",
null,
"2 years",
"4 years",
"10+ years",
"9 years",
"3 years",
"< 1 year",
"1 year",
"10+ years",
"7 years",
"6 years",
"4 years",
"4 years",
"3 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
null,
"10+ years",
"9 years",
"< 1 year",
"3 years",
"3 years",
"4 years",
"4 years",
"4 years",
"9 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"< 1 year",
"4 years",
"5 years",
"< 1 year",
"2 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"4 years",
"< 1 year",
"10+ years",
"6 years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"8 years",
"3 years",
null,
"5 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"8 years",
"9 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"8 years",
"4 years",
"4 years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"7 years",
"5 years",
"3 years",
"4 years",
"5 years",
"9 years",
"3 years",
"9 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"9 years",
"10+ years",
"4 years",
"7 years",
"6 years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"6 years",
"4 years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"1 year",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"< 1 year",
"< 1 year",
"5 years",
"8 years",
"2 years",
"10+ years",
"5 years",
null,
null,
"1 year",
null,
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"3 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"7 years",
"9 years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"8 years",
"9 years",
"1 year",
"8 years",
"2 years",
"10+ years",
"6 years",
"3 years",
"10+ years",
"2 years",
"6 years",
"9 years",
"2 years",
"10+ years",
null,
null,
"2 years",
"9 years",
"3 years",
"10+ years",
"3 years",
"4 years",
"1 year",
"1 year",
"< 1 year",
"6 years",
"1 year",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"2 years",
"9 years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"8 years",
"4 years",
"6 years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"7 years",
"10+ years",
"2 years",
"< 1 year",
"7 years",
"10+ years",
"2 years",
"3 years",
"1 year",
"4 years",
"3 years",
"3 years",
"9 years",
"1 year",
"4 years",
"2 years",
"7 years",
"3 years",
"9 years",
"1 year",
"10+ years",
null,
"7 years",
"5 years",
"6 years",
"< 1 year",
"10+ years",
"< 1 year",
"7 years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"1 year",
"5 years",
"1 year",
"3 years",
"4 years",
"< 1 year",
"6 years",
"10+ years",
"3 years",
"10+ years",
null,
"10+ years",
"9 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"9 years",
"5 years",
"2 years",
"< 1 year",
"10+ years",
"1 year",
"7 years",
"10+ years",
"10+ years",
"9 years",
"7 years",
"7 years",
"8 years",
"10+ years",
"5 years",
"10+ years",
"1 year",
"4 years",
"10+ years",
"6 years",
"10+ years",
"9 years",
"1 year",
"6 years",
"< 1 year",
"10+ years",
null,
null,
"10+ years",
"< 1 year",
"3 years",
"3 years",
"1 year",
"4 years",
null,
"5 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
null,
"7 years",
"1 year",
"7 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
null,
"5 years",
"6 years",
"8 years",
null,
"4 years",
"1 year",
"2 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"8 years",
"6 years",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"3 years",
"9 years",
"5 years",
"9 years",
"2 years",
null,
"10+ years",
"5 years",
"9 years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"2 years",
"< 1 year",
"3 years",
"7 years",
"10+ years",
"5 years",
"2 years",
"2 years",
"3 years",
"< 1 year",
"10+ years",
"2 years",
"3 years",
"2 years",
"4 years",
"10+ years",
"4 years",
"5 years",
"6 years",
"10+ years",
"7 years",
"3 years",
"2 years",
"5 years",
"4 years",
"< 1 year",
"3 years",
null,
"10+ years",
null,
"10+ years",
"9 years",
"2 years",
"< 1 year",
"3 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"10+ years",
null,
"1 year",
null,
"2 years",
"4 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"7 years",
"3 years",
"4 years",
"4 years",
null,
"10+ years",
"2 years",
"2 years",
"8 years",
"9 years",
"1 year",
"4 years",
"< 1 year",
"4 years",
"10+ years",
"< 1 year",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"8 years",
"10+ years",
"10+ years",
null,
"5 years",
"2 years",
"7 years",
"10+ years",
"7 years",
"5 years",
"5 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"6 years",
"5 years",
"< 1 year",
"10+ years",
"4 years",
"4 years",
"7 years",
"8 years",
"2 years",
"7 years",
"8 years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"2 years",
null,
"4 years",
"2 years",
"< 1 year",
"2 years",
"9 years",
"2 years",
"10+ years",
"9 years",
null,
"1 year",
"7 years",
"4 years",
"9 years",
"5 years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"< 1 year",
"3 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"6 years",
"10+ years",
"< 1 year",
"< 1 year",
"9 years",
"5 years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
null,
"3 years",
"10+ years",
"< 1 year",
"2 years",
null,
"6 years",
"8 years",
"1 year",
"< 1 year",
"3 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
null,
"10+ years",
"5 years",
"4 years",
"8 years",
"2 years",
"10+ years",
"9 years",
null,
"5 years",
"9 years",
"2 years",
"7 years",
"10+ years",
"5 years",
"2 years",
"7 years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"4 years",
"5 years",
"10+ years",
"< 1 year",
"1 year",
"2 years",
"10+ years",
null,
"10+ years",
"10+ years",
"6 years",
null,
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"2 years",
null,
"3 years",
"10+ years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"8 years",
"9 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"2 years",
"3 years",
"8 years",
"10+ years",
"8 years",
"6 years",
"3 years",
"1 year",
"10+ years",
"4 years",
"2 years",
"3 years",
"5 years",
"5 years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"3 years",
"8 years",
null,
"10+ years",
"< 1 year",
"3 years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"2 years",
"2 years",
"6 years",
"9 years",
"10+ years",
"3 years",
"8 years",
null,
"2 years",
"10+ years",
"10+ years",
"4 years",
"9 years",
"2 years",
"1 year",
"10+ years",
"6 years",
"3 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"6 years",
"7 years",
"4 years",
"10+ years",
"10+ years",
"3 years",
null,
"2 years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"4 years",
"4 years",
"< 1 year",
"10+ years",
null,
"8 years",
"10+ years",
"8 years",
"3 years",
"< 1 year",
"10+ years",
"1 year",
"5 years",
"3 years",
"10+ years",
"1 year",
"2 years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"9 years",
"10+ years",
"1 year",
"4 years",
"3 years",
"1 year",
"10+ years",
"< 1 year",
"8 years",
"4 years",
"5 years",
"8 years",
"10+ years",
null,
"10+ years",
"10+ years",
"2 years",
"4 years",
"3 years",
null,
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"3 years",
"10+ years",
"< 1 year",
"6 years",
"5 years",
"3 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"1 year",
"2 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"6 years",
"6 years",
"10+ years",
"6 years",
"7 years",
"1 year",
"10+ years",
"10+ years",
"9 years",
null,
"4 years",
"9 years",
"3 years",
"6 years",
"< 1 year",
null,
"2 years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"4 years",
"2 years",
"< 1 year",
"5 years",
"2 years",
"2 years",
null,
"8 years",
"< 1 year",
null,
"3 years",
"1 year",
"1 year",
"9 years",
"< 1 year",
"8 years",
"1 year",
"< 1 year",
"10+ years",
"8 years",
"7 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
null,
"< 1 year",
"5 years",
"3 years",
"10+ years",
"3 years",
"4 years",
"2 years",
"4 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"1 year",
"2 years",
"7 years",
"7 years",
"2 years",
"5 years",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"5 years",
"4 years",
"4 years",
"< 1 year",
"10+ years",
"1 year",
"6 years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"6 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"< 1 year",
"4 years",
"7 years",
"2 years",
"3 years",
"3 years",
"7 years",
"10+ years",
"2 years",
"5 years",
"8 years",
"1 year",
"4 years",
"1 year",
"10+ years",
"6 years",
"4 years",
"< 1 year",
"3 years",
"8 years",
"3 years",
"< 1 year",
"1 year",
"1 year",
"10+ years",
"3 years",
"10+ years",
"5 years",
"6 years",
null,
"10+ years",
"7 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"2 years",
"1 year",
"4 years",
"10+ years",
"7 years",
"10+ years",
"7 years",
"7 years",
"10+ years",
"8 years",
null,
"10+ years",
"4 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"5 years",
"10+ years",
"2 years",
"< 1 year",
null,
"7 years",
null,
"6 years",
"< 1 year",
"10+ years",
"3 years",
null,
"5 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"8 years",
"6 years",
"< 1 year",
"10+ years",
"7 years",
"6 years",
null,
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"4 years",
"8 years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"3 years",
"5 years",
"6 years",
"< 1 year",
"1 year",
"10+ years",
"< 1 year",
"5 years",
"8 years",
"10+ years",
"2 years",
"< 1 year",
null,
"8 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"3 years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"4 years",
"3 years",
"10+ years",
"9 years",
"6 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
null,
"2 years",
"8 years",
"9 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"3 years",
null,
"10+ years",
"8 years",
null,
"5 years",
null,
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"3 years",
"10+ years",
"9 years",
"5 years",
"5 years",
"2 years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"5 years",
"6 years",
"8 years",
"2 years",
"9 years",
"5 years",
null,
"7 years",
"7 years",
"3 years",
"5 years",
"9 years",
"6 years",
"2 years",
"7 years",
"10+ years",
null,
"3 years",
"10+ years",
"7 years",
"4 years",
"7 years",
"5 years",
"2 years",
"< 1 year",
"2 years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"8 years",
"< 1 year",
"5 years",
null,
"10+ years",
"5 years",
"4 years",
"2 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"6 years",
"3 years",
"10+ years",
"6 years",
"4 years",
"10+ years",
"8 years",
"5 years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"10+ years",
"< 1 year",
"8 years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"7 years",
"< 1 year",
"8 years",
"1 year",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"< 1 year",
"5 years",
"4 years",
"1 year",
"10+ years",
"3 years",
"8 years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
null,
"< 1 year",
"10+ years",
null,
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"5 years",
"2 years",
"5 years",
"10+ years",
"3 years",
"3 years",
"1 year",
"4 years",
"1 year",
"4 years",
null,
null,
"3 years",
"< 1 year",
"3 years",
"< 1 year",
"5 years",
"10+ years",
"4 years",
"2 years",
"5 years",
"7 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"1 year",
"5 years",
"5 years",
"10+ years",
null,
"< 1 year",
"4 years",
"2 years",
null,
"10+ years",
"10+ years",
"4 years",
"6 years",
"3 years",
null,
"10+ years",
"10+ years",
"4 years",
"1 year",
"4 years",
null,
"1 year",
"9 years",
"5 years",
"9 years",
"4 years",
"< 1 year",
"2 years",
"8 years",
"3 years",
"1 year",
"2 years",
"3 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"< 1 year",
"5 years",
"< 1 year",
null,
"3 years",
"10+ years",
"8 years",
"7 years",
"8 years",
"8 years",
"7 years",
"9 years",
"5 years",
"6 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"9 years",
"10+ years",
null,
"2 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
null,
"8 years",
"4 years",
"10+ years",
"10+ years",
"9 years",
null,
"< 1 year",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"4 years",
"8 years",
"10+ years",
null,
"< 1 year",
"3 years",
"< 1 year",
"6 years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"1 year",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"6 years",
"1 year",
"4 years",
"10+ years",
"3 years",
"7 years",
"4 years",
null,
"10+ years",
"6 years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"7 years",
"1 year",
"< 1 year",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"2 years",
"2 years",
"4 years",
"< 1 year",
"1 year",
"4 years",
"7 years",
"1 year",
"2 years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"2 years",
"7 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"8 years",
"< 1 year",
"3 years",
"10+ years",
"< 1 year",
"1 year",
"5 years",
"< 1 year",
"1 year",
"8 years",
"4 years",
null,
"10+ years",
"7 years",
"4 years",
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"2 years",
"8 years",
"< 1 year",
"2 years",
"9 years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"7 years",
null,
"10+ years",
"2 years",
"3 years",
"7 years",
"10+ years",
null,
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"4 years",
"3 years",
"10+ years",
"9 years",
"10+ years",
"9 years",
"8 years",
"10+ years",
"9 years",
"4 years",
"6 years",
"5 years",
"8 years",
null,
"9 years",
"3 years",
"2 years",
"1 year",
"8 years",
"7 years",
"2 years",
"10+ years",
"4 years",
"< 1 year",
null,
"6 years",
"7 years",
"10+ years",
"8 years",
"3 years",
"7 years",
"10+ years",
null,
"3 years",
"7 years",
"10+ years",
"7 years",
"10+ years",
"5 years",
"10+ years",
"1 year",
"9 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"5 years",
"10+ years",
"4 years",
"2 years",
"4 years",
"5 years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"2 years",
"7 years",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
"9 years",
"4 years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"8 years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"4 years",
"6 years",
"2 years",
"< 1 year",
"10+ years",
"5 years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"5 years",
"10+ years",
"8 years",
"6 years",
"< 1 year",
"3 years",
"4 years",
"10+ years",
"1 year",
"7 years",
"2 years",
"6 years",
"4 years",
"7 years",
"10+ years",
null,
"< 1 year",
"3 years",
"< 1 year",
"9 years",
"5 years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"6 years",
"10+ years",
"2 years",
"7 years",
"1 year",
"10+ years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
null,
"7 years",
"10+ years",
"2 years",
"4 years",
"2 years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"9 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"< 1 year",
"3 years",
"5 years",
"9 years",
"5 years",
"< 1 year",
"1 year",
"8 years",
"10+ years",
"5 years",
null,
"2 years",
null,
"8 years",
"6 years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"4 years",
"5 years",
"3 years",
"10+ years",
"1 year",
"1 year",
"6 years",
"10+ years",
"4 years",
"1 year",
"9 years",
"< 1 year",
"10+ years",
"9 years",
"10+ years",
"10+ years",
null,
"10+ years",
"6 years",
"10+ years",
"7 years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
null,
"6 years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"3 years",
"10+ years",
null,
null,
"10+ years",
"9 years",
"2 years",
"10+ years",
"2 years",
"7 years",
null,
"2 years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
null,
"10+ years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"5 years",
"6 years",
"4 years",
"< 1 year",
"1 year",
"10+ years",
"1 year",
"8 years",
"3 years",
"9 years",
"6 years",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"7 years",
"10+ years",
"6 years",
"3 years",
"8 years",
"1 year",
"10+ years",
"7 years",
"3 years",
"4 years",
"6 years",
"2 years",
"< 1 year",
"10+ years",
"3 years",
"4 years",
"10+ years",
"1 year",
"9 years",
null,
"7 years",
"8 years",
"6 years",
"10+ years",
"10+ years",
"9 years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"6 years",
"5 years",
"6 years",
"< 1 year",
"10+ years",
"5 years",
"8 years",
"3 years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"< 1 year",
"< 1 year",
null,
"4 years",
"10+ years",
"9 years",
"3 years",
"2 years",
"< 1 year",
"10+ years",
"5 years",
"3 years",
"9 years",
"4 years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"2 years",
"10+ years",
"9 years",
"7 years",
"10+ years",
null,
"10+ years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"1 year",
"8 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"4 years",
"6 years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"3 years",
"6 years",
"< 1 year",
"2 years",
"6 years",
"2 years",
"3 years",
"10+ years",
null,
"10+ years",
"10+ years",
"6 years",
"7 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"4 years",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"6 years",
"4 years",
"10+ years",
"7 years",
"9 years",
"5 years",
"10+ years",
"7 years",
"10+ years",
null,
"10+ years",
"1 year",
null,
"< 1 year",
"1 year",
"3 years",
"10+ years",
"6 years",
"9 years",
"10+ years",
"2 years",
"5 years",
"7 years",
"10+ years",
"2 years",
"3 years",
null,
"3 years",
"6 years",
"2 years",
"2 years",
"6 years",
"1 year",
"3 years",
"< 1 year",
null,
"4 years",
"5 years",
"< 1 year",
"6 years",
"5 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"5 years",
"4 years",
null,
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"2 years",
"10+ years",
null,
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"9 years",
"8 years",
null,
"< 1 year",
"6 years",
"1 year",
"2 years",
null,
"2 years",
"8 years",
"10+ years",
"2 years",
"10+ years",
"9 years",
"2 years",
"2 years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"9 years",
"4 years",
"< 1 year",
"2 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"1 year",
"< 1 year",
"10+ years",
"7 years",
"1 year",
"5 years",
"1 year",
"10+ years",
"6 years",
"10+ years",
"3 years",
"< 1 year",
"2 years",
"< 1 year",
"4 years",
"2 years",
"2 years",
"2 years",
"8 years",
"4 years",
"10+ years",
"8 years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
null,
"9 years",
"2 years",
"3 years",
"< 1 year",
"3 years",
"2 years",
"8 years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"5 years",
"6 years",
"1 year",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"< 1 year",
"2 years",
"10+ years",
"2 years",
"5 years",
"4 years",
"10+ years",
"2 years",
"< 1 year",
"< 1 year",
"5 years",
"< 1 year",
"10+ years",
"4 years",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"5 years",
"9 years",
"2 years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"1 year",
"2 years",
null,
"10+ years",
"10+ years",
"7 years",
"10+ years",
"5 years",
"< 1 year",
"8 years",
"2 years",
"10+ years",
"10+ years",
"1 year",
"9 years",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"9 years",
"3 years",
null,
"7 years",
"7 years",
"10+ years",
null,
"7 years",
"2 years",
"4 years",
"2 years",
"4 years",
"8 years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"6 years",
"8 years",
"7 years",
"8 years",
"1 year",
"10+ years",
"2 years",
"1 year",
"1 year",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"6 years",
null,
"6 years",
"10+ years",
"10+ years",
"8 years",
"6 years",
"1 year",
"4 years",
"3 years",
"10+ years",
"< 1 year",
"4 years",
"2 years",
"10+ years",
"5 years",
"2 years",
"9 years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"1 year",
"6 years",
"8 years",
"6 years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"10+ years",
null,
"5 years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"4 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"1 year",
"2 years",
"1 year",
"10+ years",
"4 years",
"< 1 year",
null,
"10+ years",
"7 years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"3 years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"4 years",
"7 years",
"8 years",
"10+ years",
"3 years",
"5 years",
"4 years",
"1 year",
"4 years",
"9 years",
"3 years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"4 years",
"4 years",
"10+ years",
"1 year",
"9 years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"3 years",
"7 years",
"4 years",
"2 years",
"1 year",
"1 year",
"< 1 year",
"< 1 year",
"2 years",
"8 years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"5 years",
"3 years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"9 years",
"4 years",
"10+ years",
"4 years",
"2 years",
"2 years",
"10+ years",
"4 years",
"7 years",
"3 years",
"10+ years",
"9 years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
null,
"10+ years",
"6 years",
"8 years",
"2 years",
"10+ years",
"2 years",
"6 years",
"< 1 year",
"9 years",
"1 year",
"4 years",
null,
"2 years",
null,
"10+ years",
null,
"5 years",
"4 years",
"10+ years",
"7 years",
"6 years",
"1 year",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"9 years",
"10+ years",
null,
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"1 year",
"10+ years",
null,
"9 years",
"3 years",
"3 years",
"4 years",
"4 years",
"8 years",
"4 years",
"9 years",
"5 years",
"9 years",
"1 year",
"2 years",
"4 years",
"4 years",
"10+ years",
null,
"< 1 year",
"5 years",
"5 years",
"2 years",
"< 1 year",
"5 years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"3 years",
"5 years",
"8 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
null,
"< 1 year",
"1 year",
"8 years",
"7 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"2 years",
"4 years",
"8 years",
"2 years",
"7 years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"2 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"7 years",
"3 years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"9 years",
"6 years",
"10+ years",
"4 years",
"1 year",
"9 years",
"7 years",
"8 years",
"1 year",
"8 years",
"10+ years",
"4 years",
"3 years",
"5 years",
"3 years",
"< 1 year",
"4 years",
"10+ years",
null,
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"4 years",
null,
"7 years",
null,
"10+ years",
"6 years",
null,
"5 years",
"8 years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"2 years",
null,
"10+ years",
"10+ years",
"5 years",
"2 years",
"7 years",
"< 1 year",
"3 years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"6 years",
"6 years",
"10+ years",
"1 year",
"7 years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"4 years",
"1 year",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"2 years",
"5 years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"6 years",
"10+ years",
"5 years",
"10+ years",
"1 year",
"3 years",
"8 years",
"3 years",
"10+ years",
"8 years",
"7 years",
"10+ years",
"1 year",
"5 years",
"8 years",
"3 years",
"7 years",
"5 years",
"2 years",
"< 1 year",
"10+ years",
"< 1 year",
"7 years",
"1 year",
"5 years",
"5 years",
"10+ years",
"3 years",
"6 years",
"10+ years",
"6 years",
"8 years",
"8 years",
"< 1 year",
"3 years",
"4 years",
"4 years",
"3 years",
"3 years",
"< 1 year",
"9 years",
"10+ years",
"3 years",
null,
"3 years",
"1 year",
"5 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
null,
"10+ years",
"10+ years",
"2 years",
"2 years",
"2 years",
"8 years",
"2 years",
"6 years",
"10+ years",
"1 year",
"6 years",
"2 years",
"7 years",
"< 1 year",
"10+ years",
"< 1 year",
"2 years",
"9 years",
"10+ years",
"7 years",
"3 years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"2 years",
"4 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"3 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"4 years",
null,
"6 years",
"2 years",
"8 years",
"< 1 year",
"3 years",
"< 1 year",
null,
"< 1 year",
"6 years",
"4 years",
"1 year",
"10+ years",
"1 year",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"< 1 year",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"9 years",
"5 years",
null,
"9 years",
"10+ years",
"2 years",
"8 years",
"3 years",
null,
"2 years",
"10+ years",
"1 year",
"10+ years",
"7 years",
"3 years",
"2 years",
"8 years",
"9 years",
"6 years",
"10+ years",
"10+ years",
"1 year",
"7 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"2 years",
"< 1 year",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
"9 years",
"6 years",
"10+ years",
"10+ years",
"7 years",
"9 years",
"1 year",
"2 years",
"7 years",
"10+ years",
null,
"10+ years",
"1 year",
"10+ years",
"< 1 year",
null,
"2 years",
"10+ years",
"9 years",
"10+ years",
"3 years",
"3 years",
"< 1 year",
"9 years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
null,
"3 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"7 years",
"6 years",
"4 years",
"5 years",
"4 years",
"5 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"< 1 year",
"10+ years",
"5 years",
"5 years",
"< 1 year",
"3 years",
"10+ years",
"7 years",
"10+ years",
"< 1 year",
"8 years",
"5 years",
"10+ years",
"< 1 year",
"9 years",
"9 years",
"4 years",
"5 years",
"10+ years",
"< 1 year",
"2 years",
null,
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"1 year",
"< 1 year",
"4 years",
"< 1 year",
"1 year",
"8 years",
"8 years",
"3 years",
"7 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"3 years",
"< 1 year",
null,
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"1 year",
"1 year",
"1 year",
"8 years",
"7 years",
"10+ years",
"2 years",
"1 year",
"3 years",
"4 years",
"7 years",
"< 1 year",
null,
"9 years",
"5 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"8 years",
"10+ years",
"10+ years",
"3 years",
null,
"10+ years",
"< 1 year",
"1 year",
"1 year",
"2 years",
"10+ years",
"10+ years",
"1 year",
"8 years",
null,
null,
"< 1 year",
"1 year",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"3 years",
"10+ years",
"6 years",
"< 1 year",
null,
"2 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"5 years",
"2 years",
"2 years",
"3 years",
"3 years",
"10+ years",
"3 years",
"1 year",
"6 years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"2 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"1 year",
"3 years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"3 years",
"2 years",
"9 years",
"10+ years",
"< 1 year",
null,
"8 years",
"10+ years",
"5 years",
"9 years",
null,
"5 years",
"2 years",
"10+ years",
"2 years",
"1 year",
"6 years",
"4 years",
"3 years",
"7 years",
"6 years",
"1 year",
"4 years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"8 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"1 year",
null,
"2 years",
"5 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"2 years",
"9 years",
"10+ years",
"10+ years",
"4 years",
"7 years",
"7 years",
null,
"7 years",
"1 year",
"9 years",
"4 years",
"10+ years",
null,
"10+ years",
"5 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
null,
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"3 years",
"4 years",
"1 year",
"10+ years",
"4 years",
"10+ years",
"7 years",
"10+ years",
"9 years",
"5 years",
"< 1 year",
"10+ years",
"1 year",
"8 years",
"9 years",
"1 year",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"2 years",
"1 year",
"10+ years",
"5 years",
"8 years",
"< 1 year",
"1 year",
"< 1 year",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"2 years",
"< 1 year",
"< 1 year",
"3 years",
"7 years",
"10+ years",
"2 years",
"< 1 year",
"9 years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"7 years",
"5 years",
"10+ years",
"2 years",
"< 1 year",
"9 years",
"< 1 year",
"7 years",
"5 years",
null,
"1 year",
"10+ years",
"1 year",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"9 years",
"6 years",
"10+ years",
null,
"1 year",
"8 years",
"7 years",
"10+ years",
"8 years",
"4 years",
"10+ years",
"5 years",
"6 years",
"6 years",
"6 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"10+ years",
null,
"3 years",
"10+ years",
"2 years",
"6 years",
"8 years",
"6 years",
"3 years",
"5 years",
"7 years",
"7 years",
"10+ years",
null,
"10+ years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"3 years",
null,
"5 years",
"10+ years",
"< 1 year",
"6 years",
"1 year",
"4 years",
"10+ years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"2 years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"8 years",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"2 years",
null,
"3 years",
"7 years",
"7 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"10+ years",
"1 year",
"< 1 year",
"5 years",
"< 1 year",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"5 years",
"8 years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
null,
"< 1 year",
"2 years",
"10+ years",
"9 years",
"3 years",
"4 years",
"2 years",
"2 years",
"10+ years",
"1 year",
"< 1 year",
"< 1 year",
"9 years",
"< 1 year",
"8 years",
"10+ years",
null,
"3 years",
"8 years",
"6 years",
"9 years",
"7 years",
"6 years",
"2 years",
"4 years",
"9 years",
"3 years",
null,
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"6 years",
"10+ years",
"8 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"3 years",
"< 1 year",
"2 years",
"2 years",
"10+ years",
"8 years",
"3 years",
"2 years",
"10+ years",
"1 year",
"5 years",
"4 years",
"1 year",
"9 years",
"10+ years",
"7 years",
"7 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"1 year",
"9 years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"1 year",
"6 years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"3 years",
null,
null,
"10+ years",
"4 years",
"7 years",
"8 years",
null,
"10+ years",
"3 years",
"7 years",
"1 year",
"6 years",
"10+ years",
"< 1 year",
"< 1 year",
"7 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"3 years",
"9 years",
"8 years",
"1 year",
"< 1 year",
"7 years",
null,
"1 year",
"10+ years",
"5 years",
"8 years",
"8 years",
"< 1 year",
"6 years",
"< 1 year",
"2 years",
"1 year",
"10+ years",
"5 years",
"4 years",
"3 years",
"4 years",
"10+ years",
"3 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"7 years",
"7 years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"3 years",
"9 years",
"< 1 year",
"2 years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"8 years",
"2 years",
"9 years",
null,
"4 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"6 years",
"5 years",
"2 years",
"7 years",
"2 years",
"10+ years",
"5 years",
"4 years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"9 years",
"5 years",
"6 years",
"3 years",
"10+ years",
"3 years",
"3 years",
"2 years",
"10+ years",
null,
"10+ years",
"3 years",
"2 years",
"2 years",
"1 year",
"7 years",
"2 years",
"2 years",
"4 years",
"8 years",
"8 years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"9 years",
"4 years",
"< 1 year",
"10+ years",
"1 year",
"2 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"1 year",
"< 1 year",
"4 years",
"3 years",
"3 years",
"4 years",
null,
"10+ years",
"1 year",
"8 years",
"2 years",
"2 years",
"9 years",
"3 years",
"1 year",
"< 1 year",
"10+ years",
"8 years",
"6 years",
"< 1 year",
"10+ years",
"7 years",
"2 years",
"2 years",
null,
"9 years",
"2 years",
"6 years",
"10+ years",
"7 years",
"3 years",
"5 years",
"5 years",
"1 year",
"10+ years",
null,
"2 years",
"5 years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"8 years",
"4 years",
"< 1 year",
"8 years",
"2 years",
"10+ years",
"4 years",
"< 1 year",
"5 years",
"1 year",
"5 years",
"3 years",
"4 years",
"10+ years",
"10+ years",
null,
"< 1 year",
"< 1 year",
"8 years",
"4 years",
"10+ years",
null,
"< 1 year",
"9 years",
"< 1 year",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"2 years",
"9 years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"5 years",
"5 years",
"10+ years",
"6 years",
"4 years",
"3 years",
"1 year",
"5 years",
"2 years",
"5 years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"1 year",
"2 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"6 years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"7 years",
"4 years",
"6 years",
"10+ years",
"10+ years",
"5 years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
null,
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"< 1 year",
"6 years",
"4 years",
"10+ years",
"5 years",
"4 years",
"10+ years",
"6 years",
"1 year",
"10+ years",
"10+ years",
"9 years",
"2 years",
"5 years",
"5 years",
"9 years",
"2 years",
"10+ years",
"2 years",
"2 years",
"< 1 year",
"4 years",
"7 years",
"< 1 year",
"< 1 year",
"5 years",
"< 1 year",
"8 years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"2 years",
"5 years",
"5 years",
"4 years",
"4 years",
"7 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"4 years",
"< 1 year",
"4 years",
"3 years",
"5 years",
null,
null,
"3 years",
"5 years",
"4 years",
"1 year",
"10+ years",
"5 years",
"10+ years",
"9 years",
"10+ years",
"7 years",
"7 years",
"10+ years",
"8 years",
"9 years",
"1 year",
"2 years",
"1 year",
"8 years",
"10+ years",
"10+ years",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"4 years",
null,
"< 1 year",
"10+ years",
"< 1 year",
"2 years",
null,
"2 years",
"4 years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"1 year",
"4 years",
"4 years",
"7 years",
"3 years",
"6 years",
"10+ years",
"7 years",
"4 years",
"4 years",
"10+ years",
null,
"6 years",
"< 1 year",
"< 1 year",
"10+ years",
"3 years",
"< 1 year",
"3 years",
null,
"8 years",
"2 years",
"1 year",
"10+ years",
"10+ years",
null,
"5 years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"< 1 year",
"9 years",
"8 years",
"10+ years",
"6 years",
"2 years",
"1 year",
"6 years",
"< 1 year",
"7 years",
"7 years",
"3 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"< 1 year",
"1 year",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"5 years",
"2 years",
null,
"8 years",
"10+ years",
"< 1 year",
null,
"2 years",
"8 years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"6 years",
"< 1 year",
null,
"3 years",
null,
"< 1 year",
"4 years",
"6 years",
"6 years",
"1 year",
"2 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"8 years",
"< 1 year",
"10+ years",
"8 years",
"6 years",
"2 years",
"3 years",
"4 years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"7 years",
"1 year",
"7 years",
null,
"10+ years",
"2 years",
"1 year",
"10+ years",
"8 years",
"6 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"8 years",
"7 years",
"< 1 year",
"2 years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"8 years",
null,
"9 years",
null,
"2 years",
"< 1 year",
"9 years",
"< 1 year",
"10+ years",
"7 years",
"3 years",
"1 year",
"3 years",
"8 years",
"3 years",
"10+ years",
"5 years",
"7 years",
"10+ years",
"9 years",
"4 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"4 years",
null,
"10+ years",
"3 years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"1 year",
"2 years",
"7 years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"8 years",
"8 years",
"3 years",
"5 years",
"10+ years",
"3 years",
"8 years",
"4 years",
"< 1 year",
"8 years",
"4 years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"5 years",
"8 years",
"4 years",
"10+ years",
"5 years",
"8 years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"6 years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"8 years",
"2 years",
"3 years",
"4 years",
"< 1 year",
"< 1 year",
"4 years",
null,
"1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"5 years",
"9 years",
"< 1 year",
"2 years",
"2 years",
"6 years",
"1 year",
"3 years",
"3 years",
"10+ years",
"< 1 year",
null,
"3 years",
"10+ years",
"5 years",
"10+ years",
"1 year",
"< 1 year",
null,
"9 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
null,
"10+ years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
null,
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"4 years",
"10+ years",
"3 years",
"< 1 year",
"3 years",
null,
"5 years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"2 years",
null,
"< 1 year",
"4 years",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"4 years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"7 years",
"6 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"8 years",
"8 years",
"4 years",
"10+ years",
"9 years",
null,
"6 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"7 years",
"9 years",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
null,
"4 years",
"3 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"5 years",
null,
"10+ years",
"7 years",
null,
"10+ years",
"4 years",
"4 years",
"5 years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"7 years",
null,
"8 years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"3 years",
null,
"< 1 year",
null,
"3 years",
"2 years",
null,
"10+ years",
"6 years",
"10+ years",
"< 1 year",
null,
"10+ years",
null,
"4 years",
"2 years",
"5 years",
"10+ years",
"8 years",
"5 years",
"3 years",
"7 years",
"7 years",
"10+ years",
"5 years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"4 years",
"6 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"1 year",
"9 years",
"2 years",
"< 1 year",
"10+ years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"7 years",
"5 years",
"10+ years",
null,
"10+ years",
"10+ years",
"9 years",
"8 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"< 1 year",
"5 years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"10+ years",
null,
"10+ years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"3 years",
"8 years",
"10+ years",
"6 years",
"4 years",
"< 1 year",
"5 years",
"6 years",
"4 years",
"2 years",
"10+ years",
"8 years",
"5 years",
"3 years",
"5 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"3 years",
"5 years",
"9 years",
"2 years",
"2 years",
"5 years",
"2 years",
"7 years",
"10+ years",
"< 1 year",
"5 years",
"7 years",
"8 years",
"2 years",
"10+ years",
"5 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"8 years",
"8 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"5 years",
"2 years",
"< 1 year",
"6 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"6 years",
"4 years",
"6 years",
"10+ years",
"2 years",
"10+ years",
"6 years",
"2 years",
"1 year",
null,
"7 years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"8 years",
"9 years",
"7 years",
"10+ years",
"3 years",
"8 years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"8 years",
"7 years",
"6 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
null,
"3 years",
"6 years",
"< 1 year",
"2 years",
null,
"4 years",
"3 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"5 years",
"< 1 year",
"6 years",
"2 years",
"< 1 year",
"< 1 year",
null,
"10+ years",
"1 year",
"5 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"9 years",
"10+ years",
"9 years",
"2 years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"5 years",
"10+ years",
null,
"2 years",
"5 years",
"8 years",
"10+ years",
"1 year",
"2 years",
"10+ years",
"8 years",
"< 1 year",
"2 years",
"3 years",
null,
"10+ years",
null,
"10+ years",
"10+ years",
"8 years",
"1 year",
"6 years",
"4 years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"5 years",
"1 year",
"< 1 year",
"4 years",
null,
"1 year",
null,
"10+ years",
"9 years",
"9 years",
null,
"10+ years",
"10+ years",
"5 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"< 1 year",
"9 years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"5 years",
"< 1 year",
"3 years",
"4 years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"3 years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"3 years",
"< 1 year",
"10+ years",
"2 years",
"7 years",
"10+ years",
"8 years",
"6 years",
"8 years",
"10+ years",
"2 years",
"5 years",
null,
"10+ years",
"4 years",
"5 years",
null,
"4 years",
"10+ years",
null,
"10+ years",
"3 years",
"9 years",
"5 years",
"8 years",
"3 years",
"2 years",
"3 years",
"6 years",
"< 1 year",
"1 year",
"3 years",
"3 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"6 years",
"7 years",
"10+ years",
"2 years",
null,
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"4 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
null,
"10+ years",
"10+ years",
"6 years",
"8 years",
"5 years",
"2 years",
"4 years",
"2 years",
"1 year",
"6 years",
"9 years",
"3 years",
"1 year",
"9 years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"5 years",
"10+ years",
"9 years",
"10+ years",
"7 years",
"3 years",
null,
"6 years",
"1 year",
"2 years",
"< 1 year",
"1 year",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
null,
"10+ years",
"6 years",
"3 years",
"3 years",
"10+ years",
"1 year",
"3 years",
"1 year",
"10+ years",
"10+ years",
"9 years",
"7 years",
"6 years",
"6 years",
"8 years",
"10+ years",
"8 years",
"3 years",
"9 years",
"10+ years",
"7 years",
null,
null,
"6 years",
"4 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"8 years",
"5 years",
"5 years",
"2 years",
"9 years",
"< 1 year",
"4 years",
"5 years",
"10+ years",
"9 years",
"10+ years",
"2 years",
"2 years",
"9 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"3 years",
"4 years",
"6 years",
"10+ years",
"9 years",
"8 years",
"7 years",
"4 years",
"10+ years",
"< 1 year",
"5 years",
"4 years",
"10+ years",
"7 years",
"7 years",
"3 years",
"< 1 year",
"10+ years",
"3 years",
"3 years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"4 years",
"< 1 year",
"6 years",
"10+ years",
"5 years",
null,
"1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
null,
"5 years",
"5 years",
"2 years",
"8 years",
"1 year",
"5 years",
"10+ years",
"1 year",
"10+ years",
"9 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"6 years",
null,
null,
"2 years",
"7 years",
"5 years",
"10+ years",
"5 years",
"1 year",
"3 years",
"5 years",
"10+ years",
"2 years",
"6 years",
"7 years",
"< 1 year",
"7 years",
"7 years",
"10+ years",
"< 1 year",
"9 years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"3 years",
"1 year",
"7 years",
"5 years",
null,
"10+ years",
"9 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"9 years",
"2 years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"9 years",
"3 years",
null,
"6 years",
"2 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"5 years",
"10+ years",
"1 year",
"6 years",
"1 year",
"5 years",
"1 year",
"6 years",
"< 1 year",
"2 years",
"3 years",
"10+ years",
"1 year",
"2 years",
"4 years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"5 years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"6 years",
"5 years",
"10+ years",
"4 years",
"9 years",
"1 year",
"1 year",
"10+ years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"8 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"3 years",
"10+ years",
"3 years",
"1 year",
"< 1 year",
"4 years",
"10+ years",
null,
"8 years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"4 years",
"4 years",
"3 years",
"5 years",
"2 years",
"< 1 year",
"1 year",
"< 1 year",
"2 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
null,
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"5 years",
null,
"10+ years",
"2 years",
"10+ years",
"5 years",
"2 years",
"8 years",
"7 years",
"8 years",
"10+ years",
"1 year",
"5 years",
"10+ years",
"8 years",
"10+ years",
"1 year",
"2 years",
"9 years",
"7 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"9 years",
"9 years",
"< 1 year",
"8 years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"7 years",
"10+ years",
"5 years",
"8 years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"8 years",
"10+ years",
null,
"4 years",
"2 years",
"10+ years",
"1 year",
null,
"1 year",
"3 years",
"10+ years",
"1 year",
"6 years",
"5 years",
"4 years",
"< 1 year",
"2 years",
"1 year",
"1 year",
"5 years",
"5 years",
"< 1 year",
"< 1 year",
"10+ years",
"6 years",
"1 year",
"4 years",
"10+ years",
"10+ years",
"4 years",
"7 years",
null,
"10+ years",
"2 years",
"6 years",
"1 year",
"10+ years",
"< 1 year",
"1 year",
"1 year",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"1 year",
"2 years",
"7 years",
"1 year",
"10+ years",
"< 1 year",
"2 years",
"3 years",
"5 years",
"10+ years",
"8 years",
"2 years",
"3 years",
"10+ years",
null,
"8 years",
"< 1 year",
"2 years",
"4 years",
null,
"4 years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
null,
"2 years",
"3 years",
"7 years",
"10+ years",
"< 1 year",
"1 year",
"2 years",
"1 year",
"10+ years",
"7 years",
"< 1 year",
"8 years",
"2 years",
"10+ years",
"5 years",
"1 year",
null,
"< 1 year",
"2 years",
"10+ years",
"9 years",
"< 1 year",
"8 years",
"10+ years",
"1 year",
"4 years",
"3 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"3 years",
null,
"10+ years",
"10+ years",
"6 years",
"2 years",
"4 years",
"10+ years",
"10+ years",
"7 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"1 year",
"< 1 year",
"10+ years",
"1 year",
"7 years",
null,
"< 1 year",
"2 years",
"10+ years",
"2 years",
"9 years",
"6 years",
"7 years",
"3 years",
"10+ years",
"4 years",
"10+ years",
"9 years",
"10+ years",
"3 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
null,
null,
"10+ years",
"4 years",
"10+ years",
"< 1 year",
null,
"2 years",
"4 years",
"< 1 year",
"5 years",
"2 years",
"10+ years",
null,
"9 years",
"< 1 year",
"3 years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"5 years",
"10+ years",
null,
"5 years",
"2 years",
"10+ years",
"7 years",
"9 years",
"1 year",
"5 years",
"2 years",
"3 years",
"3 years",
"8 years",
null,
"8 years",
"2 years",
"7 years",
"1 year",
"3 years",
"1 year",
"3 years",
"5 years",
"1 year",
"5 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"8 years",
"8 years",
"10+ years",
"6 years",
"4 years",
"6 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"1 year",
"3 years",
"2 years",
"< 1 year",
"4 years",
"6 years",
"4 years",
"1 year",
"8 years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"6 years",
"1 year",
null,
"8 years",
"10+ years",
"9 years",
"5 years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"9 years",
"7 years",
"10+ years",
"2 years",
"3 years",
"7 years",
"3 years",
"2 years",
"3 years",
"7 years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"2 years",
"8 years",
"2 years",
"3 years",
"8 years",
null,
"10+ years",
"10+ years",
"10+ years",
"7 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"< 1 year",
"6 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"2 years",
null,
"10+ years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
null,
"3 years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"7 years",
"7 years",
null,
"2 years",
"10+ years",
"4 years",
null,
"3 years",
"3 years",
"8 years",
"5 years",
"10+ years",
"10+ years",
"6 years",
"< 1 year",
"1 year",
"1 year",
"4 years",
"7 years",
"4 years",
"10+ years",
"10+ years",
"8 years",
null,
"10+ years",
null,
"3 years",
"< 1 year",
"2 years",
"10+ years",
null,
"10+ years",
"8 years",
"10+ years",
"8 years",
"5 years",
"9 years",
"10+ years",
null,
"10+ years",
"3 years",
"6 years",
"5 years",
null,
"< 1 year",
"10+ years",
null,
"< 1 year",
"3 years",
"< 1 year",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"2 years",
"6 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"4 years",
"7 years",
"3 years",
"10+ years",
"1 year",
"5 years",
"10+ years",
"< 1 year",
null,
"10+ years",
null,
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"9 years",
null,
"3 years",
"< 1 year",
"6 years",
"2 years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
null,
"< 1 year",
"7 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
null,
"5 years",
null,
"10+ years",
"7 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
null,
"10+ years",
"9 years",
"7 years",
"4 years",
null,
"1 year",
"10+ years",
"10+ years",
"1 year",
"8 years",
"2 years",
"10+ years",
"7 years",
"7 years",
"2 years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"5 years",
"8 years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"7 years",
"4 years",
null,
"10+ years",
"7 years",
"2 years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
null,
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"8 years",
"3 years",
"< 1 year",
"2 years",
"1 year",
"10+ years",
"7 years",
"4 years",
"7 years",
"10+ years",
"10+ years",
null,
"5 years",
"10+ years",
"6 years",
"10+ years",
"9 years",
"1 year",
null,
"< 1 year",
"10+ years",
"5 years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"3 years",
"9 years",
"1 year",
"6 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"3 years",
"2 years",
null,
"10+ years",
"10+ years",
"10+ years",
"1 year",
"7 years",
"10+ years",
null,
"2 years",
null,
"10+ years",
null,
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"9 years",
"2 years",
"4 years",
null,
"7 years",
"3 years",
"1 year",
"1 year",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"8 years",
"< 1 year",
"6 years",
"8 years",
"10+ years",
"< 1 year",
"1 year",
"1 year",
"< 1 year",
"5 years",
"4 years",
"9 years",
"5 years",
"< 1 year",
"3 years",
"10+ years",
"6 years",
"5 years",
"2 years",
"8 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"5 years",
"4 years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
null,
"10+ years",
"4 years",
"3 years",
"< 1 year",
"10+ years",
null,
"2 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"1 year",
"2 years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"6 years",
"9 years",
"10+ years",
"< 1 year",
"3 years",
"2 years",
"10+ years",
"2 years",
"1 year",
"4 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"10+ years",
"3 years",
"3 years",
"7 years",
"4 years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"4 years",
"7 years",
"9 years",
"3 years",
"1 year",
"1 year",
"8 years",
"3 years",
"< 1 year",
"10+ years",
"7 years",
"1 year",
"10+ years",
"8 years",
"2 years",
"10+ years",
"1 year",
null,
"7 years",
"10+ years",
"7 years",
"3 years",
"10+ years",
"10+ years",
"6 years",
"< 1 year",
"< 1 year",
"5 years",
"6 years",
"4 years",
"10+ years",
"7 years",
"10+ years",
"1 year",
null,
"6 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"3 years",
"6 years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"4 years",
"7 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
null,
"2 years",
"10+ years",
"8 years",
"1 year",
"1 year",
null,
"5 years",
"10+ years",
"8 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"7 years",
null,
"< 1 year",
"2 years",
"9 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"2 years",
"1 year",
"10+ years",
"4 years",
"2 years",
"3 years",
"5 years",
"4 years",
null,
"10+ years",
"4 years",
"10+ years",
"1 year",
"6 years",
"< 1 year",
"< 1 year",
"10+ years",
"1 year",
"< 1 year",
"1 year",
"4 years",
"5 years",
"4 years",
"< 1 year",
null,
"10+ years",
"2 years",
"3 years",
"1 year",
"1 year",
"7 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"6 years",
"1 year",
"< 1 year",
"10+ years",
"7 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"4 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"8 years",
null,
"< 1 year",
null,
"10+ years",
"2 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"4 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
null,
"< 1 year",
"2 years",
"6 years",
"8 years",
"1 year",
"10+ years",
"3 years",
"2 years",
"10+ years",
"2 years",
null,
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"3 years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"7 years",
null,
"5 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"4 years",
"2 years",
"2 years",
"3 years",
"9 years",
"6 years",
null,
"10+ years",
"10+ years",
"2 years",
"10+ years",
null,
"3 years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"2 years",
"3 years",
"7 years",
"2 years",
"< 1 year",
"10+ years",
"9 years",
"10+ years",
"4 years",
"5 years",
"3 years",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
"9 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
null,
"5 years",
"10+ years",
"< 1 year",
"4 years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"8 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"8 years",
"5 years",
null,
"3 years",
"4 years",
"7 years",
"2 years",
"3 years",
"10+ years",
"10+ years",
null,
"10+ years",
"6 years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"4 years",
"9 years",
"2 years",
"4 years",
"2 years",
"2 years",
"2 years",
"1 year",
"2 years",
"6 years",
"10+ years",
"< 1 year",
"5 years",
"< 1 year",
null,
"2 years",
"7 years",
null,
"1 year",
"3 years",
"2 years",
"5 years",
"1 year",
"10+ years",
"8 years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"7 years",
"< 1 year",
"6 years",
"7 years",
"2 years",
"9 years",
"< 1 year",
"8 years",
"10+ years",
"3 years",
"< 1 year",
"3 years",
"10+ years",
"7 years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"8 years",
"2 years",
"< 1 year",
"5 years",
"7 years",
"10+ years",
"10+ years",
"6 years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"8 years",
"2 years",
"3 years",
"5 years",
null,
"10+ years",
"6 years",
"10+ years",
"2 years",
"2 years",
"4 years",
"10+ years",
"1 year",
"2 years",
"1 year",
"4 years",
"< 1 year",
"7 years",
"7 years",
"10+ years",
null,
"8 years",
"3 years",
"2 years",
"< 1 year",
"1 year",
"2 years",
"3 years",
"10+ years",
"5 years",
null,
"6 years",
"10+ years",
"3 years",
"7 years",
"< 1 year",
"3 years",
"4 years",
"3 years",
"10+ years",
"8 years",
"5 years",
"9 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"8 years",
"8 years",
"9 years",
"3 years",
"< 1 year",
"9 years",
"5 years",
"10+ years",
"2 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
null,
"6 years",
"10+ years",
null,
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"7 years",
"5 years",
"2 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"10+ years",
"1 year",
"5 years",
"7 years",
"1 year",
"8 years",
"10+ years",
"4 years",
"10+ years",
null,
"5 years",
"1 year",
"8 years",
"< 1 year",
"4 years",
"7 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
null,
"3 years",
"1 year",
"4 years",
"2 years",
"7 years",
"1 year",
"8 years",
"8 years",
null,
"1 year",
"10+ years",
"1 year",
"10+ years",
"8 years",
"5 years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"3 years",
"7 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"4 years",
null,
"10+ years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"5 years",
null,
"1 year",
"10+ years",
"7 years",
"4 years",
"6 years",
"10+ years",
"< 1 year",
"1 year",
"9 years",
"10+ years",
"2 years",
"3 years",
"5 years",
"3 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
null,
"1 year",
null,
"9 years",
"3 years",
null,
"1 year",
"1 year",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"2 years",
"6 years",
"5 years",
"5 years",
"10+ years",
"< 1 year",
"4 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"3 years",
"9 years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"5 years",
"7 years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"2 years",
"4 years",
"4 years",
"< 1 year",
"4 years",
"5 years",
null,
"7 years",
"2 years",
"1 year",
"2 years",
"2 years",
"5 years",
null,
"3 years",
"2 years",
"10+ years",
"2 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"6 years",
"3 years",
"4 years",
"9 years",
"10+ years",
"2 years",
"2 years",
"1 year",
"6 years",
"7 years",
null,
"10+ years",
"6 years",
"5 years",
"4 years",
"10+ years",
"3 years",
"3 years",
"8 years",
"10+ years",
"3 years",
"2 years",
"7 years",
"3 years",
"4 years",
null,
"3 years",
"10+ years",
"7 years",
"6 years",
"1 year",
"9 years",
"4 years",
"2 years",
"2 years",
"6 years",
"< 1 year",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"9 years",
"6 years",
"3 years",
"10+ years",
"4 years",
"8 years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"8 years",
"7 years",
null,
"< 1 year",
"< 1 year",
"10+ years",
"5 years",
"9 years",
null,
"10+ years",
"7 years",
"6 years",
"10+ years",
"< 1 year",
null,
"10+ years",
"6 years",
"10+ years",
"8 years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"2 years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"9 years",
"3 years",
"6 years",
"1 year",
null,
"5 years",
"7 years",
"10+ years",
"2 years",
"5 years",
"10+ years",
null,
"10+ years",
null,
"6 years",
"7 years",
"10+ years",
null,
"3 years",
"5 years",
"< 1 year",
"< 1 year",
"3 years",
"10+ years",
"2 years",
"3 years",
"7 years",
"5 years",
"9 years",
"4 years",
"1 year",
"2 years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"4 years",
null,
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"4 years",
"2 years",
"< 1 year",
"8 years",
null,
"10+ years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"7 years",
"2 years",
"10+ years",
"2 years",
"9 years",
"10+ years",
"7 years",
"6 years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"1 year",
"7 years",
"2 years",
"4 years",
null,
"2 years",
"8 years",
"3 years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"4 years",
"2 years",
"3 years",
"< 1 year",
"2 years",
"6 years",
"10+ years",
"5 years",
"7 years",
"3 years",
"8 years",
"3 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"1 year",
"10+ years",
null,
"6 years",
"3 years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"1 year",
"6 years",
null,
"10+ years",
null,
"< 1 year",
"7 years",
"3 years",
"10+ years",
"5 years",
"7 years",
null,
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
null,
"6 years",
"1 year",
"< 1 year",
"< 1 year",
"10+ years",
"2 years",
"1 year",
null,
"10+ years",
"7 years",
"1 year",
"8 years",
"3 years",
"5 years",
"1 year",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"3 years",
null,
"10+ years",
"6 years",
"8 years",
"10+ years",
"10+ years",
"1 year",
"6 years",
"6 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"2 years",
"8 years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"3 years",
"2 years",
null,
"10+ years",
"< 1 year",
"6 years",
"8 years",
"< 1 year",
"< 1 year",
"3 years",
"4 years",
"< 1 year",
"2 years",
"10+ years",
"6 years",
"8 years",
"6 years",
"10+ years",
"2 years",
"6 years",
"5 years",
"8 years",
"3 years",
"10+ years",
"4 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"< 1 year",
"7 years",
"2 years",
"4 years",
"10+ years",
"5 years",
"10+ years",
"3 years",
null,
null,
"1 year",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"1 year",
"4 years",
null,
"10+ years",
"3 years",
"2 years",
"10+ years",
null,
"10+ years",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"7 years",
"2 years",
"8 years",
"8 years",
"4 years",
"3 years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"7 years",
"7 years",
"10+ years",
"10+ years",
"1 year",
"4 years",
"7 years",
"6 years",
null,
"3 years",
"1 year",
"10+ years",
"3 years",
"6 years",
"7 years",
"3 years",
"< 1 year",
"< 1 year",
"10+ years",
"< 1 year",
null,
"10+ years",
"6 years",
"1 year",
"4 years",
"6 years",
"< 1 year",
"4 years",
"3 years",
"10+ years",
"1 year",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"< 1 year",
"8 years",
"5 years",
"7 years",
"2 years",
"3 years",
"1 year",
"5 years",
"5 years",
"2 years",
"2 years",
"5 years",
"10+ years",
null,
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"5 years",
"5 years",
"2 years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"4 years",
"2 years",
"10+ years",
null,
"< 1 year",
null,
"4 years",
"2 years",
"6 years",
"8 years",
"3 years",
null,
"1 year",
null,
"2 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"4 years",
"5 years",
"5 years",
"9 years",
"2 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"9 years",
"10+ years",
"2 years",
"7 years",
"3 years",
"3 years",
"7 years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"3 years",
"6 years",
"8 years",
"10+ years",
"8 years",
null,
"10+ years",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
null,
"8 years",
"< 1 year",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"6 years",
"5 years",
"4 years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"3 years",
"10+ years",
null,
"9 years",
"10+ years",
"9 years",
"10+ years",
"2 years",
null,
"10+ years",
"10+ years",
"9 years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"1 year",
"7 years",
"10+ years",
"8 years",
"2 years",
"< 1 year",
"7 years",
"5 years",
"7 years",
"5 years",
null,
"< 1 year",
"< 1 year",
"4 years",
"8 years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"9 years",
"6 years",
"7 years",
"7 years",
"8 years",
"10+ years",
"10+ years",
"2 years",
null,
"10+ years",
"7 years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"4 years",
"10+ years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"8 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"6 years",
"< 1 year",
"5 years",
"10+ years",
null,
"9 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"8 years",
"8 years",
"4 years",
"2 years",
"8 years",
"10+ years",
"4 years",
"4 years",
"< 1 year",
"7 years",
"10+ years",
"9 years",
"8 years",
"9 years",
"< 1 year",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"7 years",
"8 years",
"8 years",
"< 1 year",
"6 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
null,
"1 year",
"2 years",
"2 years",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"9 years",
"8 years",
"10+ years",
"6 years",
"3 years",
"10+ years",
"10+ years",
"9 years",
"1 year",
"10+ years",
"2 years",
"4 years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"< 1 year",
"10+ years",
"4 years",
"2 years",
"5 years",
"1 year",
"10+ years",
"3 years",
"6 years",
"2 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"2 years",
"4 years",
"10+ years",
"10+ years",
"1 year",
"9 years",
"3 years",
null,
"1 year",
"7 years",
"10+ years",
"3 years",
"2 years",
"< 1 year",
"4 years",
"1 year",
"10+ years",
"1 year",
"2 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"< 1 year",
"1 year",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"5 years",
"4 years",
"2 years",
"< 1 year",
"1 year",
"7 years",
"7 years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"< 1 year",
"8 years",
"3 years",
"3 years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"7 years",
"1 year",
"10+ years",
"4 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"2 years",
"8 years",
"9 years",
"6 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"6 years",
"2 years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"9 years",
"10+ years",
"1 year",
"6 years",
"3 years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
null,
"2 years",
"5 years",
"4 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
null,
"9 years",
"10+ years",
"9 years",
"2 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
null,
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"6 years",
"2 years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"9 years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"7 years",
"4 years",
"9 years",
"7 years",
null,
"10+ years",
"5 years",
"10+ years",
"3 years",
"7 years",
"6 years",
"6 years",
"10+ years",
"10+ years",
"8 years",
"6 years",
"8 years",
"< 1 year",
"3 years",
"9 years",
"9 years",
"7 years",
"2 years",
"5 years",
"10+ years",
"< 1 year",
"4 years",
"5 years",
"7 years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"4 years",
"10+ years",
null,
"1 year",
"2 years",
"9 years",
"3 years",
"8 years",
"10+ years",
"5 years",
"6 years",
"6 years",
"3 years",
"1 year",
null,
"2 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"4 years",
"8 years",
"5 years",
"6 years",
"8 years",
"5 years",
"10+ years",
"10+ years",
"7 years",
"6 years",
"10+ years",
"2 years",
"2 years",
"4 years",
"3 years",
"10+ years",
"8 years",
"5 years",
"10+ years",
null,
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"9 years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"6 years",
"10+ years",
"7 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"7 years",
"5 years",
"6 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"4 years",
"10+ years",
"9 years",
"3 years",
"7 years",
"1 year",
"1 year",
"10+ years",
"5 years",
"9 years",
"2 years",
"10+ years",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"2 years",
"< 1 year",
"3 years",
"5 years",
"1 year",
"6 years",
"5 years",
"3 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"5 years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"4 years",
"7 years",
"8 years",
"1 year",
"10+ years",
"3 years",
"7 years",
"3 years",
"10+ years",
"9 years",
"1 year",
"< 1 year",
"< 1 year",
"8 years",
"2 years",
"9 years",
null,
"10+ years",
"< 1 year",
"7 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"2 years",
"7 years",
"5 years",
"9 years",
"3 years",
"< 1 year",
"3 years",
"9 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"8 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"4 years",
"4 years",
"9 years",
"4 years",
"10+ years",
null,
"10+ years",
"10+ years",
"2 years",
"3 years",
"2 years",
"10+ years",
"2 years",
"8 years",
"6 years",
"5 years",
"10+ years",
"6 years",
"10+ years",
"4 years",
"8 years",
null,
"3 years",
"2 years",
"10+ years",
"10+ years",
"9 years",
"7 years",
"3 years",
"2 years",
"< 1 year",
"< 1 year",
"10+ years",
"2 years",
"8 years",
"1 year",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"8 years",
"10+ years",
null,
"2 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"7 years",
null,
"10+ years",
"9 years",
"5 years",
"1 year",
"2 years",
"10+ years",
"< 1 year",
"4 years",
"5 years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"4 years",
"10+ years",
null,
"9 years",
"5 years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"8 years",
"1 year",
"10+ years",
"6 years",
"3 years",
"10+ years",
"1 year",
"5 years",
"8 years",
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"2 years",
"2 years",
"7 years",
"10+ years",
"8 years",
"< 1 year",
"4 years",
"10+ years",
null,
"2 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"8 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"3 years",
"3 years",
null,
null,
"10+ years",
"5 years",
"3 years",
"4 years",
"8 years",
"2 years",
null,
"3 years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"10+ years",
"9 years",
"1 year",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"1 year",
"6 years",
"6 years",
"10+ years",
"10+ years",
"8 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"5 years",
"6 years",
"1 year",
"8 years",
"2 years",
"8 years",
"3 years",
"2 years",
"1 year",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"2 years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"9 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"1 year",
"4 years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"5 years",
"10+ years",
"1 year",
"8 years",
"7 years",
"10+ years",
"10+ years",
"3 years",
null,
"2 years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"4 years",
"5 years",
"8 years",
"10+ years",
"10+ years",
null,
"3 years",
"< 1 year",
"10+ years",
"7 years",
"6 years",
"3 years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
null,
"8 years",
"< 1 year",
"7 years",
"10+ years",
null,
"2 years",
"5 years",
"1 year",
null,
"9 years",
"4 years",
"6 years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"6 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"5 years",
"6 years",
"10+ years",
"1 year",
"10+ years",
"2 years",
null,
"10+ years",
"5 years",
"9 years",
"6 years",
"10+ years",
"3 years",
"< 1 year",
"1 year",
"2 years",
"< 1 year",
null,
"10+ years",
"4 years",
"3 years",
"5 years",
"10+ years",
"4 years",
"8 years",
"< 1 year",
"10+ years",
"1 year",
"4 years",
"2 years",
null,
"3 years",
"3 years",
"10+ years",
"8 years",
"5 years",
"8 years",
"6 years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"1 year",
"7 years",
"4 years",
"7 years",
"7 years",
"7 years",
"6 years",
"10+ years",
"7 years",
"8 years",
null,
"1 year",
"3 years",
"4 years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"3 years",
"9 years",
"7 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"1 year",
"1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"< 1 year",
"< 1 year",
"10+ years",
"2 years",
"2 years",
"5 years",
"3 years",
"3 years",
"8 years",
"5 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"< 1 year",
"< 1 year",
"10+ years",
"1 year",
"1 year",
"4 years",
"1 year",
"9 years",
"4 years",
"10+ years",
"7 years",
"5 years",
"8 years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"2 years",
null,
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"9 years",
"< 1 year",
"8 years",
"3 years",
"2 years",
"2 years",
"6 years",
"10+ years",
"1 year",
"4 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"4 years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"6 years",
"7 years",
"4 years",
"2 years",
null,
"7 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"5 years",
"10+ years",
"2 years",
"4 years",
"10+ years",
null,
null,
"7 years",
"3 years",
"4 years",
"< 1 year",
"9 years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"5 years",
"3 years",
"3 years",
"2 years",
"10+ years",
"8 years",
"9 years",
null,
null,
"3 years",
"2 years",
"4 years",
"1 year",
"7 years",
"10+ years",
"8 years",
"8 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"7 years",
"7 years",
"2 years",
"2 years",
"10+ years",
"9 years",
"3 years",
"2 years",
"4 years",
"3 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"9 years",
null,
null,
"6 years",
"7 years",
"10+ years",
null,
"7 years",
"5 years",
"10+ years",
"< 1 year",
"1 year",
"9 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"2 years",
"10+ years",
null,
"10+ years",
"7 years",
"3 years",
"10+ years",
null,
"4 years",
"7 years",
"10+ years",
"6 years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"2 years",
"1 year",
"3 years",
null,
"9 years",
"10+ years",
"2 years",
"5 years",
"7 years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"3 years",
"< 1 year",
"8 years",
"4 years",
"8 years",
"10+ years",
"5 years",
"7 years",
"10+ years",
"10+ years",
"3 years",
null,
"2 years",
"10+ years",
null,
"4 years",
"10+ years",
"6 years",
"6 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"10+ years",
null,
"5 years",
"3 years",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"9 years",
"1 year",
null,
"1 year",
"10+ years",
"7 years",
"10+ years",
"9 years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"2 years",
"1 year",
"2 years",
"9 years",
"1 year",
"< 1 year",
"9 years",
"5 years",
"10+ years",
"9 years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
null,
"7 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"8 years",
"9 years",
"9 years",
"10+ years",
"1 year",
"2 years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"1 year",
"10+ years",
"9 years",
"5 years",
"7 years",
"2 years",
"2 years",
"10+ years",
"6 years",
"3 years",
"1 year",
"5 years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"9 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"9 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"7 years",
"9 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"7 years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"3 years",
"< 1 year",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"4 years",
"10+ years",
"8 years",
"1 year",
"4 years",
"10+ years",
"2 years",
"2 years",
"4 years",
"5 years",
"< 1 year",
"10+ years",
"7 years",
"3 years",
"6 years",
"8 years",
"3 years",
"< 1 year",
"1 year",
"1 year",
"1 year",
"8 years",
"10+ years",
"6 years",
"4 years",
"10+ years",
"6 years",
"2 years",
"3 years",
null,
"8 years",
"10+ years",
"8 years",
"< 1 year",
"4 years",
"< 1 year",
"6 years",
"10+ years",
"6 years",
"10+ years",
"7 years",
"5 years",
"5 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"9 years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"8 years",
"3 years",
"4 years",
"10+ years",
"4 years",
"10+ years",
"4 years",
"8 years",
"6 years",
"10+ years",
"< 1 year",
"1 year",
"7 years",
"5 years",
"6 years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"5 years",
"5 years",
"2 years",
"7 years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"3 years",
"2 years",
"7 years",
"10+ years",
"6 years",
"5 years",
null,
"< 1 year",
"10+ years",
"7 years",
"8 years",
null,
"< 1 year",
"3 years",
"4 years",
"4 years",
null,
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"9 years",
null,
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"1 year",
"2 years",
"1 year",
"7 years",
"10+ years",
"10+ years",
"5 years",
"8 years",
"2 years",
null,
"7 years",
"2 years",
"< 1 year",
"10+ years",
"3 years",
"9 years",
null,
"< 1 year",
null,
"< 1 year",
"4 years",
"10+ years",
"2 years",
"8 years",
"< 1 year",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"3 years",
"6 years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"9 years",
"6 years",
"10+ years",
"6 years",
"3 years",
"10+ years",
"9 years",
"8 years",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"< 1 year",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"3 years",
"2 years",
"1 year",
"6 years",
"5 years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
null,
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"2 years",
"8 years",
"6 years",
"2 years",
"1 year",
"2 years",
"< 1 year",
"1 year",
"1 year",
"1 year",
"8 years",
"4 years",
"10+ years",
"1 year",
"6 years",
null,
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"8 years",
"1 year",
"10+ years",
"7 years",
"5 years",
"2 years",
"9 years",
"5 years",
"9 years",
"8 years",
"3 years",
"5 years",
"3 years",
"10+ years",
"8 years",
"< 1 year",
"3 years",
null,
"6 years",
"2 years",
"3 years",
"9 years",
"8 years",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"1 year",
"4 years",
"1 year",
null,
"4 years",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
null,
"2 years",
"5 years",
"2 years",
"10+ years",
"7 years",
"7 years",
"4 years",
"7 years",
"7 years",
"4 years",
"5 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"1 year",
"3 years",
"9 years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"6 years",
"2 years",
"2 years",
"1 year",
"5 years",
null,
"10+ years",
"1 year",
"8 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"3 years",
"7 years",
"3 years",
"6 years",
"9 years",
"3 years",
null,
"2 years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"2 years",
"8 years",
null,
"10+ years",
"8 years",
"4 years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"< 1 year",
"6 years",
"8 years",
"7 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
null,
"4 years",
"8 years",
"10+ years",
"4 years",
"7 years",
"6 years",
"10+ years",
"1 year",
"9 years",
"10+ years",
"6 years",
"7 years",
"9 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"8 years",
null,
"8 years",
"4 years",
"7 years",
"8 years",
"< 1 year",
"8 years",
null,
"10+ years",
"3 years",
"2 years",
"1 year",
"1 year",
"10+ years",
"5 years",
null,
"3 years",
"10+ years",
"1 year",
"6 years",
"2 years",
"7 years",
"4 years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"2 years",
"4 years",
"10+ years",
"9 years",
"6 years",
"10+ years",
"8 years",
null,
"10+ years",
"10+ years",
"2 years",
"10+ years",
"9 years",
"4 years",
"3 years",
"10+ years",
"7 years",
"2 years",
"8 years",
"< 1 year",
"6 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"6 years",
"2 years",
"5 years",
"5 years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"6 years",
"2 years",
"9 years",
"3 years",
"6 years",
"9 years",
"10+ years",
"< 1 year",
"4 years",
"< 1 year",
"4 years",
"10+ years",
null,
"10+ years",
"7 years",
null,
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"< 1 year",
"9 years",
"2 years",
"2 years",
"3 years",
"4 years",
"6 years",
"9 years",
"9 years",
"4 years",
"6 years",
null,
"10+ years",
"2 years",
"< 1 year",
null,
"10+ years",
"3 years",
"3 years",
"10+ years",
"5 years",
"9 years",
"9 years",
"10+ years",
"3 years",
"< 1 year",
"1 year",
"3 years",
"10+ years",
"1 year",
"10+ years",
"2 years",
"4 years",
"9 years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"3 years",
"1 year",
"7 years",
null,
"10+ years",
"10+ years",
"6 years",
"2 years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"1 year",
"4 years",
"< 1 year",
"9 years",
"10+ years",
"2 years",
"6 years",
"2 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
null,
null,
"7 years",
"10+ years",
"2 years",
"5 years",
"6 years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"5 years",
"1 year",
"2 years",
"5 years",
"8 years",
"10+ years",
"2 years",
"2 years",
"5 years",
"1 year",
"10+ years",
"2 years",
"2 years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
null,
"2 years",
"10+ years",
"1 year",
"10+ years",
"9 years",
"10+ years",
"7 years",
"8 years",
"4 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"5 years",
"1 year",
"1 year",
"8 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"7 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"3 years",
"7 years",
"6 years",
null,
"10+ years",
"9 years",
"1 year",
"10+ years",
"9 years",
"9 years",
"10+ years",
"1 year",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"6 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"6 years",
"< 1 year",
"6 years",
"10+ years",
"1 year",
"< 1 year",
"4 years",
"8 years",
"< 1 year",
null,
"10+ years",
"7 years",
"6 years",
"10+ years",
"3 years",
"3 years",
"4 years",
"3 years",
"< 1 year",
"10+ years",
"8 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"6 years",
"7 years",
"7 years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"7 years",
"4 years",
"9 years",
"4 years",
"< 1 year",
"10+ years",
"9 years",
"2 years",
"8 years",
"5 years",
"3 years",
"2 years",
"9 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"3 years",
"< 1 year",
"8 years",
"< 1 year",
"3 years",
"8 years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"5 years",
"< 1 year",
"3 years",
"7 years",
"10+ years",
"6 years",
"6 years",
"4 years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"5 years",
"2 years",
"2 years",
"8 years",
"7 years",
"6 years",
"3 years",
"7 years",
"6 years",
"4 years",
"8 years",
"7 years",
"10+ years",
"1 year",
"4 years",
null,
"7 years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"1 year",
"< 1 year",
"10+ years",
"7 years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
null,
"4 years",
"6 years",
"< 1 year",
"10+ years",
"5 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"6 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"5 years",
"< 1 year",
"3 years",
"10+ years",
"6 years",
"5 years",
"1 year",
"10+ years",
"7 years",
"8 years",
"8 years",
null,
"3 years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"2 years",
"3 years",
"< 1 year",
"5 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"9 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"7 years",
null,
"10+ years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
null,
"10+ years",
"7 years",
null,
"2 years",
"3 years",
"5 years",
"5 years",
"10+ years",
"5 years",
"9 years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"7 years",
"6 years",
"7 years",
"10+ years",
"4 years",
"7 years",
null,
"< 1 year",
"< 1 year",
"1 year",
"7 years",
"3 years",
"1 year",
"< 1 year",
"2 years",
"3 years",
"10+ years",
"5 years",
null,
"10+ years",
"10+ years",
"9 years",
"4 years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"3 years",
"3 years",
null,
"1 year",
null,
"1 year",
"10+ years",
"3 years",
"8 years",
"5 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"7 years",
"2 years",
"4 years",
"10+ years",
"3 years",
"2 years",
"2 years",
"5 years",
"10+ years",
"9 years",
"6 years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"6 years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
null,
"3 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"7 years",
"6 years",
"1 year",
"< 1 year",
"< 1 year",
"10+ years",
"2 years",
"5 years",
"2 years",
"1 year",
"9 years",
"10+ years",
"10+ years",
"5 years",
"1 year",
"1 year",
"< 1 year",
"10+ years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"3 years",
"9 years",
"< 1 year",
"10+ years",
"4 years",
"8 years",
"10+ years",
"1 year",
"5 years",
"10+ years",
"10+ years",
"10+ years",
null,
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
null,
"8 years",
"3 years",
"< 1 year",
"6 years",
"< 1 year",
"< 1 year",
null,
"5 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"8 years",
"2 years",
"10+ years",
"10+ years",
null,
"7 years",
"< 1 year",
"3 years",
"3 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"3 years",
"8 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"1 year",
null,
"10+ years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"7 years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"7 years",
"10+ years",
"7 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"4 years",
"10+ years",
"4 years",
"5 years",
null,
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"3 years",
"1 year",
"10+ years",
"9 years",
"10+ years",
"2 years",
"3 years",
"< 1 year",
"5 years",
"< 1 year",
"7 years",
"5 years",
"7 years",
"3 years",
"10+ years",
"2 years",
"1 year",
null,
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"7 years",
"2 years",
"4 years",
"8 years",
"4 years",
"< 1 year",
"10+ years",
"4 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"4 years",
"2 years",
"10+ years",
"10+ years",
null,
"4 years",
"< 1 year",
"10+ years",
"9 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"10+ years",
"5 years",
"1 year",
"3 years",
"< 1 year",
"9 years",
"5 years",
"2 years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"7 years",
"4 years",
"10+ years",
"< 1 year",
"2 years",
"7 years",
"10+ years",
"2 years",
"8 years",
"< 1 year",
"10+ years",
"9 years",
"6 years",
"10+ years",
"6 years",
null,
"8 years",
"2 years",
"4 years",
"< 1 year",
"< 1 year",
"4 years",
"1 year",
"6 years",
"10+ years",
"3 years",
"6 years",
"8 years",
"10+ years",
"4 years",
"2 years",
"2 years",
"9 years",
"1 year",
"7 years",
"< 1 year",
"4 years",
"4 years",
"9 years",
"10+ years",
"4 years",
"9 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
null,
"3 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"7 years",
"2 years",
null,
"7 years",
"3 years",
"9 years",
"4 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"6 years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
null,
"10+ years",
"4 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"6 years",
"10+ years",
"9 years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"< 1 year",
"8 years",
"1 year",
"2 years",
"2 years",
"6 years",
"10+ years",
null,
"10+ years",
null,
null,
"9 years",
"10+ years",
"9 years",
"4 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"1 year",
"7 years",
null,
"10+ years",
"7 years",
"2 years",
"6 years",
"8 years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"7 years",
"5 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"2 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"2 years",
null,
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"< 1 year",
"1 year",
"4 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"9 years",
"7 years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"1 year",
"1 year",
"4 years",
"3 years",
"7 years",
"1 year",
"3 years",
"3 years",
"4 years",
"10+ years",
"1 year",
"8 years",
"10+ years",
"1 year",
"10+ years",
"8 years",
"2 years",
"10+ years",
"< 1 year",
null,
"6 years",
"3 years",
"10+ years",
"9 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"1 year",
"7 years",
"3 years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"1 year",
"5 years",
"4 years",
"4 years",
"1 year",
"2 years",
"5 years",
"10+ years",
"2 years",
null,
"3 years",
"4 years",
"2 years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"6 years",
"2 years",
"10+ years",
"1 year",
"2 years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"2 years",
"4 years",
"3 years",
"5 years",
"10+ years",
null,
"2 years",
null,
"9 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"10+ years",
null,
"2 years",
"3 years",
"4 years",
"6 years",
"9 years",
"< 1 year",
"3 years",
"10+ years",
"2 years",
"8 years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"7 years",
"6 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"9 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
null,
"10+ years",
"1 year",
"10+ years",
"1 year",
"6 years",
"2 years",
"10+ years",
"2 years",
"9 years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"6 years",
"2 years",
"10+ years",
"5 years",
"< 1 year",
"5 years",
"6 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"7 years",
"10+ years",
"6 years",
"10+ years",
null,
"10+ years",
"5 years",
"5 years",
"6 years",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
null,
"10+ years",
"9 years",
"5 years",
"7 years",
"10+ years",
"10+ years",
"5 years",
"5 years",
"5 years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"9 years",
"6 years",
"< 1 year",
"4 years",
"4 years",
"10+ years",
"10+ years",
"1 year",
"6 years",
"3 years",
"5 years",
"10+ years",
"6 years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"1 year",
"8 years",
"1 year",
"7 years",
null,
"5 years",
"9 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"4 years",
"3 years",
"6 years",
"4 years",
"10+ years",
"10+ years",
"7 years",
"6 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"5 years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"7 years",
"9 years",
"10+ years",
"8 years",
"2 years",
"2 years",
"7 years",
"6 years",
"10+ years",
"2 years",
"1 year",
"7 years",
"10+ years",
"9 years",
"1 year",
"< 1 year",
"6 years",
null,
"10+ years",
"8 years",
"< 1 year",
"2 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"8 years",
"10+ years",
"2 years",
null,
"3 years",
"10+ years",
"8 years",
"5 years",
"< 1 year",
"6 years",
null,
"5 years",
null,
"4 years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"6 years",
"3 years",
"4 years",
"9 years",
"5 years",
"2 years",
"7 years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"6 years",
"10+ years",
"7 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"3 years",
"8 years",
"2 years",
"4 years",
"10+ years",
"1 year",
"2 years",
"10+ years",
"10+ years",
null,
"6 years",
"8 years",
"3 years",
"3 years",
"10+ years",
"9 years",
"2 years",
"7 years",
"10+ years",
"4 years",
"8 years",
"5 years",
null,
"10+ years",
"< 1 year",
"3 years",
"6 years",
"4 years",
"7 years",
"< 1 year",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"4 years",
"2 years",
"7 years",
"10+ years",
"3 years",
"1 year",
"7 years",
"10+ years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"4 years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"9 years",
"4 years",
"8 years",
"10+ years",
"< 1 year",
"< 1 year",
"5 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"< 1 year",
"10+ years",
"5 years",
"3 years",
"8 years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"5 years",
"3 years",
"1 year",
null,
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"3 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"3 years",
"2 years",
"4 years",
"4 years",
"10+ years",
"8 years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"5 years",
"2 years",
"2 years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"10+ years",
"9 years",
"7 years",
"5 years",
"9 years",
"6 years",
"5 years",
"10+ years",
"9 years",
"2 years",
"10+ years",
"< 1 year",
"1 year",
"3 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"9 years",
"10+ years",
"1 year",
"7 years",
"< 1 year",
"7 years",
"8 years",
"6 years",
"3 years",
"9 years",
"10+ years",
"6 years",
"1 year",
"10+ years",
"7 years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"9 years",
"5 years",
"< 1 year",
"3 years",
"1 year",
"< 1 year",
"10+ years",
"4 years",
"3 years",
"10+ years",
"5 years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"3 years",
"9 years",
null,
"< 1 year",
"10+ years",
"2 years",
"5 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"1 year",
"7 years",
"< 1 year",
"10+ years",
"6 years",
null,
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"9 years",
"3 years",
"9 years",
"3 years",
"8 years",
null,
null,
"7 years",
"5 years",
"10+ years",
"1 year",
"1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"9 years",
"10+ years",
"10+ years",
"8 years",
"7 years",
"2 years",
"10+ years",
"8 years",
"8 years",
"1 year",
"5 years",
"3 years",
"< 1 year",
"9 years",
null,
"10+ years",
"< 1 year",
"4 years",
"< 1 year",
"6 years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"7 years",
"2 years",
"1 year",
"2 years",
"1 year",
"10+ years",
"10+ years",
null,
"10+ years",
"6 years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"< 1 year",
"8 years",
"4 years",
null,
"5 years",
"10+ years",
"5 years",
"2 years",
"6 years",
"4 years",
"1 year",
"9 years",
"8 years",
"2 years",
"6 years",
"3 years",
"6 years",
"10+ years",
null,
"7 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"< 1 year",
"6 years",
"4 years",
"6 years",
null,
"3 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"2 years",
"10+ years",
null,
"3 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"3 years",
"10+ years",
null,
"8 years",
"6 years",
"3 years",
"9 years",
"10+ years",
"8 years",
"2 years",
"4 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"6 years",
"< 1 year",
"8 years",
"5 years",
"2 years",
null,
"< 1 year",
"1 year",
"9 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
null,
"10+ years",
"4 years",
null,
"10+ years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"2 years",
"1 year",
null,
"2 years",
"9 years",
"2 years",
"9 years",
"10+ years",
"2 years",
"4 years",
"< 1 year",
"8 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"4 years",
"10+ years",
null,
"3 years",
"< 1 year",
"3 years",
"10+ years",
"7 years",
"3 years",
null,
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"8 years",
"4 years",
"9 years",
"3 years",
"8 years",
"4 years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"1 year",
"3 years",
"10+ years",
"< 1 year",
"3 years",
"4 years",
"< 1 year",
"10+ years",
"3 years",
"< 1 year",
"1 year",
"10+ years",
"2 years",
"9 years",
"3 years",
"3 years",
"3 years",
"4 years",
"9 years",
"< 1 year",
"4 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"2 years",
"1 year",
"8 years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"8 years",
"9 years",
"4 years",
"1 year",
null,
"10+ years",
"10+ years",
"8 years",
"8 years",
"9 years",
"10+ years",
"< 1 year",
"< 1 year",
"4 years",
"4 years",
"6 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"2 years",
"< 1 year",
"2 years",
"5 years",
"5 years",
"10+ years",
"< 1 year",
"1 year",
"7 years",
"4 years",
null,
"10+ years",
"2 years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"4 years",
"4 years",
"2 years",
"2 years",
"10+ years",
"9 years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"7 years",
"2 years",
"10+ years",
"5 years",
"4 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"2 years",
"10+ years",
null,
"7 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
null,
"10+ years",
"< 1 year",
"10+ years",
null,
"10+ years",
"8 years",
"6 years",
"2 years",
"9 years",
"6 years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
null,
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"< 1 year",
"8 years",
"7 years",
"2 years",
"3 years",
"5 years",
"5 years",
"2 years",
"10+ years",
"3 years",
"2 years",
"4 years",
"< 1 year",
"4 years",
"1 year",
"9 years",
"3 years",
"10+ years",
"2 years",
"3 years",
"1 year",
"7 years",
"10+ years",
"1 year",
"10+ years",
"2 years",
"2 years",
"4 years",
"3 years",
"9 years",
"10+ years",
null,
"10+ years",
"1 year",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"1 year",
"4 years",
"7 years",
"6 years",
"< 1 year",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
null,
"4 years",
"2 years",
"10+ years",
"10+ years",
"6 years",
null,
"< 1 year",
"5 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"7 years",
"1 year",
"3 years",
"5 years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"8 years",
"1 year",
"< 1 year",
"2 years",
"3 years",
"4 years",
"8 years",
"1 year",
"4 years",
"3 years",
"10+ years",
null,
"1 year",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"4 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"1 year",
"4 years",
"7 years",
"7 years",
"7 years",
"10+ years",
"9 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"10+ years",
null,
"5 years",
"9 years",
"6 years",
"7 years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"9 years",
"6 years",
"5 years",
"10+ years",
"2 years",
null,
"3 years",
"2 years",
"9 years",
"1 year",
"4 years",
"4 years",
"4 years",
"3 years",
null,
"7 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"9 years",
"9 years",
"5 years",
"10+ years",
"< 1 year",
"3 years",
"9 years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"7 years",
"10+ years",
"7 years",
"< 1 year",
"3 years",
"5 years",
"8 years",
null,
null,
"1 year",
"5 years",
"5 years",
"6 years",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"3 years",
"5 years",
"7 years",
"9 years",
"10+ years",
"1 year",
"4 years",
"10+ years",
"< 1 year",
"9 years",
"6 years",
"3 years",
"2 years",
"3 years",
"3 years",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"9 years",
"< 1 year",
"6 years",
"4 years",
"10+ years",
"9 years",
null,
"10+ years",
"2 years",
"10+ years",
null,
"7 years",
null,
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"6 years",
"3 years",
"5 years",
"1 year",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"9 years",
"4 years",
"1 year",
"1 year",
"9 years",
"7 years",
"8 years",
null,
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"2 years",
"8 years",
null,
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"3 years",
null,
"1 year",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"9 years",
"9 years",
"3 years",
"5 years",
null,
"1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
null,
"2 years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"< 1 year",
"5 years",
"8 years",
"6 years",
"10+ years",
"10+ years",
"7 years",
"< 1 year",
"8 years",
"10+ years",
"3 years",
"2 years",
"5 years",
"10+ years",
"< 1 year",
"5 years",
"3 years",
"< 1 year",
"9 years",
"10+ years",
"6 years",
"8 years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"6 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"3 years",
null,
"4 years",
"10+ years",
"5 years",
"4 years",
"2 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"8 years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"9 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"7 years",
"3 years",
"4 years",
"6 years",
"9 years",
"10+ years",
"10+ years",
"6 years",
"5 years",
"9 years",
"< 1 year",
"7 years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
null,
"< 1 year",
"9 years",
"10+ years",
"2 years",
"2 years",
"1 year",
"6 years",
"2 years",
"< 1 year",
"10+ years",
"6 years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"2 years",
null,
"10+ years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"2 years",
"8 years",
"5 years",
"4 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"2 years",
"2 years",
null,
"6 years",
"3 years",
"7 years",
"7 years",
"8 years",
"10+ years",
"4 years",
"2 years",
"10+ years",
"7 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"4 years",
"9 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"3 years",
"4 years",
"4 years",
"3 years",
"2 years",
"10+ years",
"1 year",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"7 years",
"4 years",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"4 years",
"< 1 year",
"6 years",
"5 years",
"7 years",
"6 years",
"1 year",
null,
"2 years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"1 year",
"9 years",
"< 1 year",
"3 years",
"1 year",
"10+ years",
"1 year",
"6 years",
"5 years",
"4 years",
null,
"10+ years",
"6 years",
"6 years",
"10+ years",
"10+ years",
"5 years",
"6 years",
"10+ years",
"7 years",
"9 years",
"< 1 year",
"9 years",
"8 years",
"9 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"4 years",
"6 years",
"2 years",
"10+ years",
"5 years",
"6 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"7 years",
"10+ years",
null,
"2 years",
"3 years",
"10+ years",
null,
"4 years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
null,
"4 years",
"2 years",
"1 year",
"2 years",
"8 years",
"4 years",
"2 years",
"< 1 year",
"10+ years",
"7 years",
"< 1 year",
"3 years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"2 years",
"3 years",
"5 years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"6 years",
"6 years",
"7 years",
"7 years",
"< 1 year",
null,
"1 year",
"9 years",
"2 years",
"9 years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"8 years",
"3 years",
"10+ years",
"5 years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"2 years",
"10+ years",
"1 year",
"3 years",
"8 years",
"9 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
null,
"2 years",
"7 years",
"10+ years",
"4 years",
"9 years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"1 year",
"2 years",
null,
"10+ years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"3 years",
"5 years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"6 years",
"2 years",
"3 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"9 years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"10+ years",
"5 years",
"6 years",
"10+ years",
"4 years",
"6 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"8 years",
"< 1 year",
"2 years",
null,
"4 years",
"< 1 year",
"5 years",
"< 1 year",
"4 years",
"8 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"4 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"2 years",
"< 1 year",
"2 years",
"5 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"4 years",
"8 years",
"10+ years",
"1 year",
"9 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"3 years",
"7 years",
"5 years",
"3 years",
"10+ years",
"4 years",
"2 years",
"6 years",
"8 years",
"3 years",
"6 years",
"8 years",
"10+ years",
"1 year",
null,
"10+ years",
"< 1 year",
"2 years",
"8 years",
"1 year",
"3 years",
"10+ years",
"3 years",
"6 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"2 years",
"< 1 year",
"5 years",
null,
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"4 years",
null,
null,
"6 years",
"5 years",
"1 year",
"4 years",
"5 years",
"4 years",
"3 years",
"2 years",
"4 years",
"3 years",
"7 years",
null,
"2 years",
"3 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"< 1 year",
"3 years",
"< 1 year",
"7 years",
"3 years",
"10+ years",
"8 years",
"3 years",
"2 years",
"4 years",
"4 years",
"10+ years",
"8 years",
"6 years",
"2 years",
"8 years",
null,
"9 years",
"9 years",
"8 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
null,
"5 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"4 years",
"1 year",
null,
"7 years",
"< 1 year",
"9 years",
"8 years",
"2 years",
null,
"1 year",
"< 1 year",
"1 year",
"5 years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"3 years",
"< 1 year",
"8 years",
"1 year",
"10+ years",
"4 years",
"3 years",
"5 years",
"10+ years",
"< 1 year",
"1 year",
null,
"2 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"7 years",
"10+ years",
"9 years",
"4 years",
"7 years",
"6 years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
null,
"10+ years",
"7 years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
null,
"3 years",
"10+ years",
"5 years",
"8 years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"9 years",
"10+ years",
"1 year",
"10+ years",
"5 years",
"3 years",
"10+ years",
"9 years",
"2 years",
null,
"3 years",
"3 years",
"6 years",
"9 years",
"10+ years",
"1 year",
"10+ years",
"8 years",
"3 years",
"10+ years",
"9 years",
null,
"1 year",
"6 years",
"10+ years",
"1 year",
"1 year",
"1 year",
"10+ years",
"10+ years",
"1 year",
"8 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"3 years",
"8 years",
"10+ years",
"10+ years",
null,
"5 years",
"1 year",
"6 years",
"3 years",
"10+ years",
"1 year",
"1 year",
"2 years",
"4 years",
"10+ years",
"4 years",
"8 years",
"6 years",
"9 years",
"5 years",
"4 years",
"< 1 year",
"6 years",
"2 years",
"5 years",
"9 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"1 year",
null,
"10+ years",
"7 years",
"2 years",
"5 years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
null,
"10+ years",
"5 years",
"3 years",
"3 years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"2 years",
"10+ years",
"2 years",
"2 years",
"1 year",
"10+ years",
"3 years",
"9 years",
"3 years",
"< 1 year",
"10+ years",
"8 years",
"5 years",
"9 years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"9 years",
"2 years",
"7 years",
"10+ years",
"2 years",
"4 years",
"8 years",
"10+ years",
"4 years",
"1 year",
"8 years",
"10+ years",
"8 years",
"7 years",
"10+ years",
"10+ years",
"8 years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"9 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"4 years",
"1 year",
"9 years",
null,
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
null,
"5 years",
"10+ years",
null,
"6 years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"5 years",
"7 years",
"7 years",
"9 years",
"10+ years",
"1 year",
"8 years",
"4 years",
null,
null,
"5 years",
null,
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"9 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
null,
"1 year",
"6 years",
null,
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"2 years",
"6 years",
"8 years",
"10+ years",
"7 years",
"9 years",
"7 years",
"5 years",
"1 year",
"5 years",
"9 years",
"10+ years",
"2 years",
"2 years",
"8 years",
"5 years",
"6 years",
"10+ years",
"8 years",
"10+ years",
null,
"7 years",
"10+ years",
null,
"4 years",
"4 years",
"10+ years",
"4 years",
"3 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"6 years",
"7 years",
"4 years",
"5 years",
"5 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"4 years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"< 1 year",
"3 years",
"4 years",
"5 years",
"9 years",
"2 years",
"10+ years",
"3 years",
"5 years",
"1 year",
"10+ years",
"3 years",
"2 years",
"10+ years",
"2 years",
"5 years",
"1 year",
"8 years",
"< 1 year",
"10+ years",
"5 years",
"7 years",
"2 years",
"10+ years",
"6 years",
"8 years",
"< 1 year",
"2 years",
"1 year",
null,
"10+ years",
"3 years",
"2 years",
"< 1 year",
"3 years",
"1 year",
"4 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"8 years",
"5 years",
"10+ years",
"6 years",
"4 years",
"10+ years",
"7 years",
null,
"8 years",
"3 years",
null,
"10+ years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
null,
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"7 years",
"< 1 year",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"8 years",
null,
"10+ years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"6 years",
"2 years",
"10+ years",
"3 years",
"9 years",
"2 years",
"5 years",
"2 years",
"5 years",
"10+ years",
"3 years",
null,
"3 years",
"5 years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"4 years",
"4 years",
"2 years",
"< 1 year",
"< 1 year",
"< 1 year",
"7 years",
"< 1 year",
"2 years",
null,
"10+ years",
"3 years",
"10+ years",
"6 years",
"2 years",
null,
"10+ years",
"7 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"3 years",
"7 years",
"3 years",
"10+ years",
"7 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"7 years",
"3 years",
"10+ years",
"7 years",
"7 years",
"2 years",
"10+ years",
"7 years",
"3 years",
"5 years",
"3 years",
"10+ years",
"9 years",
"8 years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"5 years",
"5 years",
"10+ years",
null,
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"2 years",
"3 years",
"< 1 year",
"< 1 year",
"2 years",
"2 years",
"10+ years",
"10+ years",
"9 years",
"8 years",
"2 years",
"1 year",
"5 years",
null,
"2 years",
"7 years",
"5 years",
null,
"10+ years",
"4 years",
"10+ years",
"1 year",
"3 years",
"< 1 year",
"8 years",
"< 1 year",
null,
"2 years",
"10+ years",
"1 year",
"8 years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"9 years",
"10+ years",
"5 years",
"5 years",
"10+ years",
"2 years",
"< 1 year",
"9 years",
"5 years",
"3 years",
"1 year",
"3 years",
"10+ years",
"5 years",
"5 years",
"5 years",
"8 years",
"10+ years",
"10+ years",
null,
"1 year",
"10+ years",
"2 years",
"3 years",
"10+ years",
"5 years",
"8 years",
"10+ years",
"5 years",
"7 years",
"7 years",
"8 years",
"10+ years",
null,
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"< 1 year",
"7 years",
"< 1 year",
null,
"3 years",
"4 years",
null,
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"10+ years",
"5 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"8 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"5 years",
"2 years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"2 years",
"9 years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"3 years",
"1 year",
"4 years",
"10+ years",
"10+ years",
"7 years",
"9 years",
"5 years",
"< 1 year",
"< 1 year",
"1 year",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"5 years",
"8 years",
"9 years",
"2 years",
"< 1 year",
"8 years",
"9 years",
"5 years",
"9 years",
"< 1 year",
"8 years",
"7 years",
"10+ years",
null,
"5 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"8 years",
"2 years",
"2 years",
"10+ years",
"9 years",
"5 years",
"10+ years",
"6 years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"6 years",
"8 years",
"6 years",
null,
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"8 years",
"6 years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"7 years",
"1 year",
"< 1 year",
"7 years",
"8 years",
null,
"10+ years",
"7 years",
"1 year",
"8 years",
"2 years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"8 years",
"8 years",
"5 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"4 years",
null,
"10+ years",
null,
"3 years",
"8 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"1 year",
"2 years",
"2 years",
"1 year",
null,
"10+ years",
null,
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"5 years",
"10+ years",
null,
"9 years",
"1 year",
"7 years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"8 years",
"6 years",
"10+ years",
"6 years",
"7 years",
"10+ years",
"7 years",
"5 years",
"4 years",
"8 years",
"7 years",
"3 years",
"10+ years",
"4 years",
"4 years",
null,
"10+ years",
"1 year",
"10+ years",
"3 years",
"3 years",
"6 years",
"10+ years",
"10+ years",
"5 years",
null,
"5 years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"2 years",
"1 year",
"7 years",
"3 years",
"2 years",
"1 year",
"2 years",
"2 years",
"3 years",
"10+ years",
"6 years",
"4 years",
"7 years",
"8 years",
"10+ years",
"10+ years",
"6 years",
"1 year",
"3 years",
"4 years",
"7 years",
"4 years",
"9 years",
"10+ years",
"1 year",
"4 years",
"3 years",
null,
"10+ years",
null,
"10+ years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"4 years",
null,
"4 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"5 years",
null,
"10+ years",
"5 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"9 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"6 years",
"< 1 year",
"8 years",
"6 years",
"10+ years",
null,
"6 years",
"1 year",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"8 years",
null,
"9 years",
"10+ years",
"7 years",
"10+ years",
"< 1 year",
"< 1 year",
"6 years",
"1 year",
"6 years",
"9 years",
"9 years",
"10+ years",
"5 years",
"8 years",
"4 years",
"10+ years",
"8 years",
"3 years",
"10+ years",
null,
"5 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"1 year",
"1 year",
"4 years",
"5 years",
"2 years",
"2 years",
"8 years",
"4 years",
"3 years",
"7 years",
"6 years",
"6 years",
"1 year",
"10+ years",
"7 years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"1 year",
"3 years",
"1 year",
"5 years",
"5 years",
"5 years",
"10+ years",
"5 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"4 years",
"10+ years",
"< 1 year",
"9 years",
"< 1 year",
"10+ years",
null,
"2 years",
"7 years",
"4 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"1 year",
"2 years",
"10+ years",
"< 1 year",
"4 years",
"4 years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"5 years",
"9 years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"1 year",
"10+ years",
"8 years",
"< 1 year",
"6 years",
"4 years",
"2 years",
"4 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"1 year",
null,
"10+ years",
"10+ years",
"4 years",
"7 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"4 years",
null,
"3 years",
"1 year",
"3 years",
"10+ years",
"7 years",
"9 years",
null,
"< 1 year",
"10+ years",
"6 years",
"2 years",
null,
"2 years",
"< 1 year",
"< 1 year",
"3 years",
"3 years",
"< 1 year",
"4 years",
"10+ years",
"6 years",
"4 years",
"5 years",
"5 years",
"6 years",
"5 years",
"< 1 year",
"10+ years",
"3 years",
"2 years",
"< 1 year",
"10+ years",
"9 years",
"< 1 year",
"7 years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"2 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"9 years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"4 years",
"9 years",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"6 years",
"1 year",
"10+ years",
"< 1 year",
"4 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"9 years",
"10+ years",
"9 years",
"8 years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"1 year",
"8 years",
"2 years",
"10+ years",
"1 year",
null,
"< 1 year",
"8 years",
"1 year",
"10+ years",
"3 years",
"7 years",
"< 1 year",
"3 years",
"10+ years",
"9 years",
"2 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"8 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"2 years",
"2 years",
"4 years",
"< 1 year",
"4 years",
null,
"6 years",
null,
"2 years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"9 years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"2 years",
null,
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"8 years",
"7 years",
"2 years",
"1 year",
"6 years",
"2 years",
"3 years",
"2 years",
"3 years",
"10+ years",
"3 years",
"4 years",
"10+ years",
null,
"10+ years",
"2 years",
"3 years",
"7 years",
"< 1 year",
"4 years",
"2 years",
"7 years",
"10+ years",
"9 years",
"3 years",
"4 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"9 years",
null,
"5 years",
"1 year",
"8 years",
"6 years",
"9 years",
"6 years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"5 years",
"5 years",
"3 years",
"5 years",
"2 years",
"5 years",
"< 1 year",
"10+ years",
"3 years",
"< 1 year",
"1 year",
"6 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"7 years",
"6 years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
null,
"8 years",
"10+ years",
"7 years",
"10+ years",
"6 years",
"10+ years",
"4 years",
"5 years",
null,
"6 years",
"2 years",
"3 years",
"3 years",
"10+ years",
null,
"5 years",
"3 years",
"2 years",
"2 years",
"10+ years",
"5 years",
"7 years",
"8 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"2 years",
"3 years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"6 years",
"6 years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"7 years",
"6 years",
"< 1 year",
"3 years",
"5 years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"9 years",
"4 years",
"3 years",
"10+ years",
"3 years",
"6 years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"8 years",
"1 year",
"3 years",
"10+ years",
"1 year",
"5 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"9 years",
"7 years",
"< 1 year",
"8 years",
"1 year",
"10+ years",
"5 years",
"10+ years",
"1 year",
"< 1 year",
"2 years",
null,
"5 years",
"10+ years",
"2 years",
"1 year",
"2 years",
"7 years",
"4 years",
"4 years",
"3 years",
"2 years",
"10+ years",
null,
"8 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"4 years",
"1 year",
"8 years",
"10+ years",
"7 years",
"4 years",
"10+ years",
"6 years",
"10+ years",
"8 years",
"9 years",
"10+ years",
"10+ years",
"8 years",
null,
"6 years",
"4 years",
"3 years",
"10+ years",
"2 years",
"1 year",
"1 year",
"< 1 year",
"10+ years",
"< 1 year",
null,
"4 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"7 years",
"< 1 year",
"3 years",
"4 years",
"< 1 year",
"1 year",
"5 years",
"10+ years",
"1 year",
"6 years",
"10+ years",
"7 years",
"5 years",
"9 years",
"9 years",
"10+ years",
"10+ years",
"6 years",
"< 1 year",
"< 1 year",
"2 years",
"9 years",
"10+ years",
"10+ years",
"5 years",
"5 years",
"10+ years",
"1 year",
"9 years",
"7 years",
"8 years",
"5 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
null,
"9 years",
"5 years",
"3 years",
"4 years",
"8 years",
"3 years",
"9 years",
"< 1 year",
"10+ years",
"8 years",
"9 years",
"2 years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"6 years",
"5 years",
"8 years",
"10+ years",
"1 year",
null,
"4 years",
"4 years",
"5 years",
"10+ years",
"9 years",
"1 year",
"10+ years",
"1 year",
"1 year",
"6 years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"5 years",
"1 year",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"8 years",
"7 years",
"10+ years",
"4 years",
"5 years",
"10+ years",
null,
"10+ years",
"6 years",
null,
"7 years",
"7 years",
"10+ years",
"8 years",
"6 years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"7 years",
"< 1 year",
"10+ years",
"6 years",
"1 year",
"2 years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"8 years",
"4 years",
"2 years",
"2 years",
"3 years",
"8 years",
"5 years",
"10+ years",
"3 years",
"2 years",
"8 years",
"5 years",
"1 year",
"9 years",
"10+ years",
"8 years",
"6 years",
"1 year",
"1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"1 year",
"9 years",
"3 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"9 years",
"10+ years",
null,
"10+ years",
"7 years",
"5 years",
"9 years",
null,
"10+ years",
"10+ years",
"4 years",
"1 year",
"8 years",
"2 years",
"10+ years",
"2 years",
"9 years",
"1 year",
"10+ years",
"1 year",
"5 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"3 years",
"6 years",
"2 years",
"8 years",
"2 years",
"7 years",
"2 years",
"8 years",
null,
"3 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"1 year",
"6 years",
"2 years",
"10+ years",
"8 years",
"4 years",
"10+ years",
"6 years",
"3 years",
"6 years",
"< 1 year",
"7 years",
"4 years",
"8 years",
"10+ years",
null,
"10+ years",
"6 years",
"10+ years",
"4 years",
"4 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"6 years",
"4 years",
"7 years",
"5 years",
null,
"10+ years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"10+ years",
null,
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"3 years",
"10+ years",
"2 years",
"< 1 year",
"3 years",
"5 years",
"10+ years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"< 1 year",
null,
"4 years",
null,
"3 years",
"3 years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"4 years",
"< 1 year",
"10+ years",
"5 years",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
null,
null,
"9 years",
"2 years",
"2 years",
"1 year",
"1 year",
"3 years",
null,
"1 year",
"8 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"8 years",
"7 years",
"7 years",
"4 years",
"1 year",
"1 year",
"8 years",
"7 years",
"10+ years",
"3 years",
"5 years",
"3 years",
"2 years",
"9 years",
"10+ years",
"3 years",
null,
"3 years",
"3 years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"2 years",
null,
"< 1 year",
"7 years",
"10+ years",
"6 years",
"7 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"5 years",
"2 years",
"7 years",
"2 years",
null,
"3 years",
"8 years",
"5 years",
"6 years",
"10+ years",
"1 year",
"6 years",
"3 years",
"5 years",
"10+ years",
null,
"1 year",
"10+ years",
"4 years",
"3 years",
"1 year",
"2 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"5 years",
"4 years",
"9 years",
"3 years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"3 years",
"10+ years",
null,
"1 year",
"3 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"7 years",
"10+ years",
"8 years",
"3 years",
"< 1 year",
"5 years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"2 years",
null,
"8 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"2 years",
"< 1 year",
"5 years",
"5 years",
"2 years",
"7 years",
"< 1 year",
"10+ years",
null,
"10+ years",
"5 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"9 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
null,
"6 years",
"5 years",
"8 years",
"6 years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"6 years",
"4 years",
"1 year",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"8 years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"7 years",
"1 year",
"5 years",
"10+ years",
null,
"10+ years",
"2 years",
"6 years",
"4 years",
"< 1 year",
"3 years",
"8 years",
"10+ years",
"10+ years",
"4 years",
"4 years",
"6 years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"7 years",
"8 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"6 years",
"8 years",
"10+ years",
"9 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"3 years",
null,
"10+ years",
"< 1 year",
null,
"10+ years",
"10+ years",
"7 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"< 1 year",
"3 years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"7 years",
"1 year",
"5 years",
"2 years",
"7 years",
"8 years",
"10+ years",
"2 years",
"5 years",
"3 years",
"1 year",
"< 1 year",
"2 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"7 years",
"1 year",
"10+ years",
"< 1 year",
"2 years",
"8 years",
"10+ years",
"8 years",
"2 years",
"5 years",
"< 1 year",
"2 years",
"1 year",
"2 years",
"1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"2 years",
"9 years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"4 years",
"3 years",
"2 years",
"5 years",
null,
"4 years",
"10+ years",
"< 1 year",
"9 years",
"1 year",
"2 years",
"4 years",
"< 1 year",
"1 year",
"9 years",
"1 year",
"10+ years",
"10+ years",
"7 years",
"1 year",
"3 years",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"6 years",
null,
"5 years",
"1 year",
"7 years",
"2 years",
"5 years",
"1 year",
"< 1 year",
"8 years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"1 year",
"< 1 year",
"8 years",
"2 years",
"5 years",
"10+ years",
"3 years",
"< 1 year",
"3 years",
"10+ years",
"6 years",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"5 years",
"10+ years",
"< 1 year",
null,
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"< 1 year",
"2 years",
"3 years",
"< 1 year",
"6 years",
"3 years",
"10+ years",
"2 years",
null,
"4 years",
"3 years",
"1 year",
"7 years",
"10+ years",
"10+ years",
"8 years",
"1 year",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"5 years",
"1 year",
"4 years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"7 years",
"6 years",
"7 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"< 1 year",
"< 1 year",
"3 years",
"3 years",
"9 years",
"10+ years",
"2 years",
"4 years",
"1 year",
"3 years",
"< 1 year",
"< 1 year",
"7 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"< 1 year",
"< 1 year",
"5 years",
"10+ years",
"< 1 year",
"< 1 year",
"1 year",
"< 1 year",
"8 years",
"10+ years",
"9 years",
"9 years",
"6 years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"6 years",
"1 year",
"2 years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"9 years",
"10+ years",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"8 years",
"8 years",
null,
"10+ years",
"< 1 year",
"10+ years",
null,
"1 year",
"10+ years",
"1 year",
"2 years",
"10+ years",
"8 years",
"2 years",
"2 years",
"1 year",
"3 years",
"< 1 year",
"5 years",
"8 years",
"1 year",
"10+ years",
null,
"9 years",
"3 years",
"8 years",
"2 years",
"< 1 year",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"3 years",
"< 1 year",
"4 years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"4 years",
"5 years",
"10+ years",
null,
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"2 years",
"4 years",
"2 years",
"10+ years",
null,
"5 years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"7 years",
"10+ years",
null,
"< 1 year",
"8 years",
"1 year",
"10+ years",
"1 year",
"3 years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"< 1 year",
"10+ years",
"5 years",
"7 years",
"10+ years",
null,
"5 years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"9 years",
"8 years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"9 years",
"8 years",
"10+ years",
"9 years",
"4 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
null,
null,
"5 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"10+ years",
null,
"10+ years",
"7 years",
"3 years",
"1 year",
"5 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"9 years",
"< 1 year",
"6 years",
"10+ years",
"1 year",
"9 years",
"2 years",
"< 1 year",
"1 year",
"2 years",
"< 1 year",
"10+ years",
"7 years",
"5 years",
"4 years",
"3 years",
"1 year",
"< 1 year",
"5 years",
"1 year",
"8 years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"7 years",
"3 years",
"10+ years",
"1 year",
"2 years",
"4 years",
"5 years",
"10+ years",
"8 years",
"< 1 year",
"< 1 year",
"< 1 year",
"1 year",
"10+ years",
"5 years",
"10+ years",
"7 years",
"10+ years",
"6 years",
"4 years",
"2 years",
"2 years",
null,
"5 years",
"7 years",
"10+ years",
"4 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"7 years",
"3 years",
"< 1 year",
null,
"10+ years",
"7 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"10+ years",
"8 years",
"10+ years",
"6 years",
"1 year",
"10+ years",
"< 1 year",
"7 years",
"8 years",
"10+ years",
"8 years",
"7 years",
"6 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"7 years",
"10+ years",
"1 year",
"7 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
null,
"9 years",
"8 years",
"7 years",
"5 years",
"6 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"9 years",
"7 years",
"7 years",
null,
"1 year",
"10+ years",
"4 years",
null,
"1 year",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"7 years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"3 years",
"10+ years",
null,
"9 years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"9 years",
"5 years",
null,
"10+ years",
"6 years",
"9 years",
"10+ years",
"6 years",
"10+ years",
null,
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"2 years",
"6 years",
"5 years",
"10+ years",
null,
"3 years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"1 year",
"10+ years",
null,
"3 years",
"8 years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"1 year",
"10+ years",
"7 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"5 years",
"2 years",
"1 year",
"< 1 year",
"4 years",
null,
"7 years",
"4 years",
"4 years",
"7 years",
"6 years",
"3 years",
"8 years",
"8 years",
"5 years",
"1 year",
"3 years",
"4 years",
"4 years",
"2 years",
"1 year",
"10+ years",
"2 years",
"5 years",
"8 years",
"< 1 year",
"< 1 year",
"9 years",
"10+ years",
"6 years",
"1 year",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
null,
"9 years",
"< 1 year",
"8 years",
"8 years",
"2 years",
"2 years",
"4 years",
"1 year",
"10+ years",
null,
"5 years",
"< 1 year",
"10+ years",
"5 years",
"3 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"8 years",
"1 year",
"2 years",
"9 years",
"10+ years",
"2 years",
"5 years",
"4 years",
"2 years",
"3 years",
"8 years",
null,
"2 years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"7 years",
"5 years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"1 year",
"4 years",
"10+ years",
"2 years",
"3 years",
"3 years",
"1 year",
"10+ years",
"10+ years",
null,
"10+ years",
"8 years",
"1 year",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"< 1 year",
"4 years",
"5 years",
"3 years",
"4 years",
"7 years",
"5 years",
"3 years",
"8 years",
"1 year",
"10+ years",
"7 years",
"8 years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"7 years",
"3 years",
"5 years",
"8 years",
"7 years",
"4 years",
"6 years",
"7 years",
"3 years",
"4 years",
"10+ years",
"3 years",
"7 years",
"2 years",
"8 years",
"5 years",
"< 1 year",
"4 years",
"< 1 year",
"3 years",
"1 year",
"10+ years",
"3 years",
"9 years",
"8 years",
"3 years",
"10+ years",
"< 1 year",
"1 year",
null,
"10+ years",
"6 years",
"10+ years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"9 years",
"4 years",
"10+ years",
"6 years",
"1 year",
"8 years",
"2 years",
"10+ years",
"1 year",
"6 years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"2 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"5 years",
"3 years",
"6 years",
"9 years",
"2 years",
null,
"10+ years",
"10+ years",
"6 years",
null,
"6 years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
null,
"9 years",
"8 years",
"5 years",
"3 years",
"9 years",
null,
"9 years",
null,
"1 year",
"9 years",
"10+ years",
"< 1 year",
"< 1 year",
"2 years",
"< 1 year",
"10+ years",
"3 years",
"2 years",
"9 years",
"6 years",
"4 years",
"6 years",
"4 years",
"3 years",
"6 years",
"2 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"8 years",
"7 years",
"5 years",
"4 years",
"4 years",
"< 1 year",
"10+ years",
"4 years",
"9 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"7 years",
"4 years",
"3 years",
"< 1 year",
"4 years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"7 years",
"6 years",
"4 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"5 years",
"6 years",
"4 years",
"4 years",
"7 years",
"10+ years",
"7 years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"2 years",
"8 years",
"1 year",
"2 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
null,
"8 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"6 years",
"10+ years",
"2 years",
"2 years",
"5 years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"9 years",
null,
"6 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"6 years",
"10+ years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"10+ years",
"9 years",
"10+ years",
"7 years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
null,
"6 years",
"9 years",
"8 years",
"2 years",
"2 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
null,
"5 years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"4 years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"7 years",
"9 years",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
null,
"6 years",
"10+ years",
"10+ years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"10+ years",
"8 years",
"10+ years",
"6 years",
"4 years",
"10+ years",
"10+ years",
"9 years",
"5 years",
"10+ years",
"7 years",
"8 years",
"6 years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"4 years",
"6 years",
"< 1 year",
"3 years",
null,
"5 years",
"2 years",
"10+ years",
"1 year",
null,
"2 years",
"2 years",
"6 years",
"2 years",
"2 years",
"10+ years",
"6 years",
"8 years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"1 year",
"2 years",
"8 years",
"1 year",
"6 years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"6 years",
"< 1 year",
"2 years",
"8 years",
null,
"4 years",
"6 years",
"5 years",
"7 years",
"2 years",
"7 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"8 years",
null,
"10+ years",
"< 1 year",
"10+ years",
"9 years",
"10+ years",
"5 years",
"4 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"5 years",
"2 years",
"1 year",
"10+ years",
null,
"2 years",
"10+ years",
"7 years",
"6 years",
"7 years",
"10+ years",
"< 1 year",
"6 years",
"7 years",
"3 years",
"7 years",
"1 year",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"6 years",
"5 years",
"4 years",
"8 years",
"2 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"4 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"1 year",
"10+ years",
"2 years",
"7 years",
"10+ years",
null,
"< 1 year",
"3 years",
null,
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"< 1 year",
"8 years",
"7 years",
"6 years",
"< 1 year",
"7 years",
"1 year",
"6 years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
null,
"5 years",
null,
"< 1 year",
"9 years",
"4 years",
"4 years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"8 years",
"10+ years",
"9 years",
"7 years",
"10+ years",
"4 years",
"5 years",
null,
"8 years",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"2 years",
"5 years",
"8 years",
"5 years",
"9 years",
"3 years",
"< 1 year",
"1 year",
"4 years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
null,
"10+ years",
"8 years",
null,
"1 year",
"6 years",
"8 years",
"5 years",
"10+ years",
"1 year",
"7 years",
"< 1 year",
"3 years",
"2 years",
"10+ years",
"10+ years",
null,
"10+ years",
"8 years",
null,
"10+ years",
"4 years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"2 years",
"4 years",
"6 years",
"7 years",
null,
"10+ years",
"3 years",
"10+ years",
"7 years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"1 year",
"10+ years",
"6 years",
"3 years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"< 1 year",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"1 year",
"10+ years",
"5 years",
"6 years",
"8 years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"5 years",
"4 years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"8 years",
"4 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"1 year",
"8 years",
null,
"9 years",
"9 years",
"2 years",
"6 years",
"7 years",
"< 1 year",
"5 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"< 1 year",
"4 years",
"8 years",
"2 years",
"6 years",
"6 years",
null,
"2 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"4 years",
"< 1 year",
"3 years",
"10+ years",
"1 year",
"5 years",
"1 year",
"2 years",
"7 years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"9 years",
"1 year",
"9 years",
"< 1 year",
"5 years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
null,
"10+ years",
"5 years",
null,
"10+ years",
"4 years",
"10+ years",
"7 years",
"10+ years",
"5 years",
"1 year",
"5 years",
"5 years",
"< 1 year",
"5 years",
"6 years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"3 years",
"2 years",
"4 years",
"5 years",
"4 years",
null,
"10+ years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"2 years",
"10+ years",
"2 years",
"1 year",
"9 years",
"2 years",
"8 years",
"< 1 year",
null,
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"2 years",
"7 years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"8 years",
"3 years",
"4 years",
"7 years",
"< 1 year",
"10+ years",
"1 year",
"4 years",
"3 years",
"10+ years",
"5 years",
"3 years",
"< 1 year",
"< 1 year",
"1 year",
"1 year",
"7 years",
"10+ years",
"3 years",
"6 years",
"5 years",
"4 years",
"4 years",
"1 year",
"4 years",
null,
"10+ years",
"7 years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"5 years",
"1 year",
"10+ years",
"10+ years",
"1 year",
"9 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
null,
"8 years",
null,
"8 years",
"1 year",
"2 years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"9 years",
"1 year",
"6 years",
"10+ years",
"1 year",
"7 years",
"2 years",
"10+ years",
"5 years",
"5 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
null,
"10+ years",
"1 year",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"7 years",
"2 years",
"5 years",
null,
"10+ years",
"6 years",
"3 years",
"10+ years",
"< 1 year",
"6 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"4 years",
"8 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"1 year",
"6 years",
"4 years",
"1 year",
"10+ years",
"10+ years",
"7 years",
"6 years",
"7 years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"1 year",
"3 years",
"7 years",
"5 years",
"5 years",
"1 year",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"9 years",
null,
"< 1 year",
"2 years",
"6 years",
"< 1 year",
"3 years",
"10+ years",
"4 years",
"3 years",
"6 years",
"10+ years",
null,
"6 years",
"8 years",
"2 years",
"5 years",
"6 years",
"2 years",
"10+ years",
"3 years",
"8 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"6 years",
"4 years",
"5 years",
"10+ years",
"< 1 year",
"2 years",
"4 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"9 years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"1 year",
"6 years",
"10+ years",
"1 year",
"10+ years",
"8 years",
"1 year",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"5 years",
"4 years",
"10+ years",
"5 years",
"5 years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"6 years",
"10+ years",
"3 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
null,
"7 years",
"3 years",
"2 years",
"6 years",
"10+ years",
null,
"3 years",
"3 years",
"10+ years",
"5 years",
"3 years",
"5 years",
"10+ years",
"8 years",
"10+ years",
"9 years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"4 years",
"3 years",
"2 years",
"1 year",
"3 years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"5 years",
"10+ years",
"4 years",
"10+ years",
"2 years",
null,
"3 years",
"10+ years",
"10+ years",
"7 years",
"< 1 year",
"7 years",
"< 1 year",
null,
"10+ years",
"4 years",
null,
"2 years",
"10+ years",
"2 years",
null,
"5 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"10+ years",
"7 years",
null,
"8 years",
"3 years",
"4 years",
"1 year",
"1 year",
"5 years",
"6 years",
"3 years",
"10+ years",
"5 years",
"5 years",
"9 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"7 years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"7 years",
"2 years",
"< 1 year",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"8 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"< 1 year",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"5 years",
"< 1 year",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"10+ years",
null,
"10+ years",
"3 years",
"2 years",
"9 years",
"< 1 year",
"10+ years",
null,
"10+ years",
"4 years",
"7 years",
"1 year",
"7 years",
"2 years",
"2 years",
"5 years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"9 years",
"3 years",
"< 1 year",
"8 years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"6 years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"3 years",
"4 years",
"2 years",
"2 years",
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"< 1 year",
"3 years",
"1 year",
"4 years",
"8 years",
"4 years",
"4 years",
"8 years",
"3 years",
"8 years",
null,
"1 year",
"10+ years",
"6 years",
"7 years",
"10+ years",
"4 years",
"10+ years",
null,
"10+ years",
"8 years",
"4 years",
null,
"9 years",
"4 years",
"3 years",
"10+ years",
"< 1 year",
"1 year",
"7 years",
"6 years",
"5 years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"3 years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"< 1 year",
"1 year",
"2 years",
"3 years",
"10+ years",
"3 years",
"3 years",
"2 years",
"< 1 year",
"10+ years",
"< 1 year",
"< 1 year",
"5 years",
"6 years",
"6 years",
null,
"10+ years",
"2 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"3 years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"2 years",
"3 years",
"5 years",
"8 years",
"4 years",
"10+ years",
"< 1 year",
"5 years",
null,
"5 years",
"5 years",
"9 years",
"10+ years",
"10+ years",
null,
"7 years",
"10+ years",
null,
"10+ years",
"7 years",
"10+ years",
"6 years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
null,
"7 years",
"5 years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"10+ years",
"1 year",
"4 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"5 years",
"5 years",
"7 years",
null,
"10+ years",
"6 years",
"10+ years",
"7 years",
"3 years",
"1 year",
"5 years",
"10+ years",
"2 years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"8 years",
"2 years",
"10+ years",
"2 years",
"2 years",
"8 years",
"7 years",
"3 years",
null,
"10+ years",
"7 years",
"1 year",
"7 years",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"2 years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"1 year",
"3 years",
"7 years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"6 years",
"4 years",
"2 years",
"6 years",
"9 years",
"3 years",
"10+ years",
null,
"10+ years",
"1 year",
null,
"10+ years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"10+ years",
"2 years",
"4 years",
"10+ years",
null,
"5 years",
"10+ years",
null,
"< 1 year",
"3 years",
"3 years",
null,
"1 year",
"10+ years",
"7 years",
"1 year",
"10+ years",
"4 years",
"4 years",
"5 years",
"< 1 year",
"3 years",
"3 years",
"10+ years",
null,
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
null,
"8 years",
"3 years",
"3 years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"1 year",
"10+ years",
"5 years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"5 years",
"10+ years",
null,
"7 years",
"8 years",
"10+ years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"7 years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"9 years",
"2 years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"3 years",
"2 years",
"8 years",
"1 year",
"10+ years",
null,
"2 years",
"8 years",
"7 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"3 years",
"4 years",
"1 year",
"2 years",
"2 years",
"4 years",
"4 years",
"4 years",
"3 years",
"10+ years",
"6 years",
"3 years",
"9 years",
"4 years",
"9 years",
"10+ years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"2 years",
"1 year",
"< 1 year",
"7 years",
"7 years",
"10+ years",
"9 years",
"10+ years",
"5 years",
"9 years",
"5 years",
"1 year",
"10+ years",
"3 years",
"1 year",
"< 1 year",
"5 years",
"2 years",
"5 years",
"8 years",
"7 years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"< 1 year",
"8 years",
"10+ years",
"2 years",
"< 1 year",
"2 years",
"4 years",
"< 1 year",
"6 years",
"10+ years",
null,
"10+ years",
null,
"1 year",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"7 years",
"5 years",
null,
"3 years",
"10+ years",
"5 years",
"9 years",
"10+ years",
"3 years",
"4 years",
"9 years",
"5 years",
"10+ years",
"10+ years",
"8 years",
"9 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"2 years",
"9 years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"8 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
null,
"< 1 year",
"10+ years",
"9 years",
"6 years",
"3 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"3 years",
"2 years",
"1 year",
"< 1 year",
"< 1 year",
"7 years",
"5 years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"1 year",
"6 years",
"10+ years",
"2 years",
"10+ years",
"8 years",
"7 years",
"1 year",
"10+ years",
"3 years",
"5 years",
"1 year",
"10+ years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"2 years",
"5 years",
"5 years",
"7 years",
"10+ years",
"2 years",
null,
"6 years",
"5 years",
"< 1 year",
"2 years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"< 1 year",
"3 years",
"5 years",
"10+ years",
"< 1 year",
null,
"3 years",
"5 years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"1 year",
"7 years",
"3 years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"4 years",
"4 years",
null,
"10+ years",
"6 years",
"7 years",
"10+ years",
"3 years",
"2 years",
"1 year",
"< 1 year",
"5 years",
"< 1 year",
"8 years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"8 years",
"6 years",
"10+ years",
"1 year",
"7 years",
"< 1 year",
"10+ years",
"3 years",
"4 years",
"5 years",
"2 years",
"10+ years",
"2 years",
"1 year",
"4 years",
"< 1 year",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"6 years",
"9 years",
"10+ years",
"5 years",
"8 years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
null,
"9 years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"4 years",
null,
"8 years",
"10+ years",
"9 years",
"7 years",
"1 year",
null,
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"8 years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"< 1 year",
"7 years",
"2 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"5 years",
"5 years",
"< 1 year",
"10+ years",
"3 years",
"4 years",
"10+ years",
"6 years",
"1 year",
"10+ years",
"4 years",
null,
"10+ years",
"1 year",
"2 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"1 year",
"10+ years",
"2 years",
"4 years",
"8 years",
"4 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"1 year",
"10+ years",
"7 years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"6 years",
"10+ years",
"6 years",
"10+ years",
"4 years",
"9 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"1 year",
"9 years",
"5 years",
"5 years",
"6 years",
"10+ years",
"9 years",
"9 years",
"6 years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"9 years",
"4 years",
null,
"10+ years",
"9 years",
"3 years",
"< 1 year",
"6 years",
"10+ years",
"6 years",
"7 years",
"2 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"3 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"8 years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"3 years",
"5 years",
null,
"5 years",
"10+ years",
"1 year",
"3 years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"4 years",
"9 years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"3 years",
"1 year",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"2 years",
"9 years",
"< 1 year",
"10+ years",
"4 years",
null,
"10+ years",
"6 years",
"7 years",
"2 years",
"10+ years",
"2 years",
"1 year",
"< 1 year",
"8 years",
"2 years",
"7 years",
"10+ years",
"3 years",
"2 years",
null,
"< 1 year",
"1 year",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"5 years",
"3 years",
"5 years",
"7 years",
"7 years",
"3 years",
"5 years",
"8 years",
"7 years",
"1 year",
"5 years",
"< 1 year",
"2 years",
"7 years",
"1 year",
"7 years",
"3 years",
"7 years",
"5 years",
"1 year",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"4 years",
"< 1 year",
"2 years",
"< 1 year",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"4 years",
"6 years",
"9 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"9 years",
"5 years",
"8 years",
null,
"10+ years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"3 years",
"1 year",
"8 years",
"5 years",
"10+ years",
"3 years",
"3 years",
"< 1 year",
"1 year",
"10+ years",
null,
"4 years",
null,
null,
"3 years",
"7 years",
"2 years",
"10+ years",
"2 years",
null,
"6 years",
"2 years",
"9 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
null,
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"2 years",
"10+ years",
"3 years",
"3 years",
"6 years",
"2 years",
"< 1 year",
"3 years",
"2 years",
"3 years",
"10+ years",
"6 years",
"< 1 year",
"< 1 year",
"3 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
null,
"10+ years",
"4 years",
"10+ years",
"7 years",
"10+ years",
null,
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"8 years",
"10+ years",
null,
"10+ years",
"10+ years",
"6 years",
null,
"10+ years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"5 years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"3 years",
"4 years",
null,
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"< 1 year",
"1 year",
"7 years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"4 years",
"8 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"2 years",
"4 years",
"< 1 year",
"10+ years",
"8 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"2 years",
"5 years",
"3 years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"2 years",
"2 years",
null,
null,
"2 years",
"10+ years",
"7 years",
"8 years",
"3 years",
"9 years",
"10+ years",
"7 years",
null,
"2 years",
"5 years",
"1 year",
"9 years",
"5 years",
"7 years",
"10+ years",
"< 1 year",
"9 years",
"8 years",
"9 years",
"10+ years",
"10+ years",
null,
"2 years",
"8 years",
"9 years",
"2 years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"9 years",
null,
"10+ years",
null,
"3 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"8 years",
"5 years",
"10+ years",
"10+ years",
"9 years",
"6 years",
"3 years",
"5 years",
"10+ years",
"5 years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"3 years",
"3 years",
"4 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"3 years",
"5 years",
"2 years",
"7 years",
"3 years",
"2 years",
"9 years",
"6 years",
null,
"2 years",
"4 years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"2 years",
"10+ years",
null,
"10+ years",
"6 years",
"5 years",
"3 years",
"6 years",
"10+ years",
"5 years",
"8 years",
"2 years",
"3 years",
"10+ years",
"3 years",
"9 years",
"4 years",
"10+ years",
"1 year",
"4 years",
"1 year",
"10+ years",
"5 years",
"2 years",
"3 years",
"1 year",
"4 years",
"5 years",
null,
"6 years",
"9 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"7 years",
"1 year",
"7 years",
"10+ years",
"8 years",
"< 1 year",
null,
"5 years",
"5 years",
"10+ years",
"10+ years",
"8 years",
"1 year",
"5 years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
null,
"3 years",
"5 years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"1 year",
null,
"1 year",
"< 1 year",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
null,
"3 years",
null,
"1 year",
"6 years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"2 years",
"< 1 year",
"2 years",
"2 years",
"2 years",
null,
"4 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"5 years",
"10+ years",
"7 years",
"10+ years",
"1 year",
"10+ years",
"8 years",
"2 years",
"9 years",
"5 years",
"5 years",
"10+ years",
"9 years",
"7 years",
"5 years",
"3 years",
"10+ years",
"< 1 year",
null,
"8 years",
"6 years",
"2 years",
"9 years",
"2 years",
"7 years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"8 years",
"1 year",
"2 years",
null,
"2 years",
"1 year",
"4 years",
"6 years",
"2 years",
null,
"6 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"4 years",
"2 years",
"6 years",
"< 1 year",
"< 1 year",
"6 years",
"2 years",
"7 years",
"5 years",
"< 1 year",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"3 years",
"8 years",
"10+ years",
"3 years",
"< 1 year",
"6 years",
"10+ years",
"8 years",
"3 years",
"3 years",
"3 years",
"< 1 year",
"2 years",
"9 years",
"10+ years",
"8 years",
"< 1 year",
"6 years",
"1 year",
"1 year",
"6 years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"5 years",
"6 years",
"5 years",
"10+ years",
"4 years",
"10+ years",
"4 years",
"2 years",
"1 year",
"5 years",
null,
null,
"10+ years",
"10+ years",
null,
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"6 years",
"10+ years",
"5 years",
"7 years",
"3 years",
"10+ years",
"2 years",
"10+ years",
null,
"10+ years",
"4 years",
"10+ years",
"5 years",
"< 1 year",
"6 years",
"7 years",
"1 year",
"< 1 year",
"8 years",
"< 1 year",
"5 years",
"4 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
null,
"10+ years",
"10+ years",
"10+ years",
"7 years",
"5 years",
"4 years",
"9 years",
"4 years",
"8 years",
"9 years",
"10+ years",
"2 years",
"1 year",
"9 years",
"10+ years",
"< 1 year",
"1 year",
"3 years",
"3 years",
"< 1 year",
"2 years",
"6 years",
"10+ years",
"10+ years",
"4 years",
"6 years",
"4 years",
"10+ years",
"10+ years",
null,
"3 years",
"2 years",
"4 years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"< 1 year",
"< 1 year",
"6 years",
"7 years",
"10+ years",
"4 years",
"7 years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"2 years",
"6 years",
"< 1 year",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"6 years",
"10+ years",
"4 years",
"< 1 year",
"9 years",
"5 years",
"10+ years",
null,
"< 1 year",
"3 years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"6 years",
"5 years",
"4 years",
"3 years",
"8 years",
"10+ years",
"2 years",
"1 year",
"1 year",
null,
"8 years",
"10+ years",
"4 years",
null,
null,
"2 years",
"10+ years",
null,
"7 years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"4 years",
"10+ years",
"4 years",
"8 years",
"7 years",
"8 years",
"6 years",
"10+ years",
"7 years",
"4 years",
"3 years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"7 years",
"1 year",
"9 years",
"3 years",
null,
null,
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"1 year",
"10+ years",
"5 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"7 years",
"4 years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"6 years",
"7 years",
"10+ years",
"< 1 year",
"3 years",
"5 years",
"8 years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"10+ years",
"< 1 year",
null,
"4 years",
"10+ years",
"10+ years",
"10+ years",
null,
"6 years",
"9 years",
"7 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"2 years",
"7 years",
"3 years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"3 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"8 years",
"3 years",
"< 1 year",
"4 years",
"< 1 year",
"1 year",
"< 1 year",
null,
"7 years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"4 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"2 years",
"1 year",
"3 years",
"7 years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"8 years",
"3 years",
"6 years",
"10+ years",
"2 years",
"3 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"2 years",
"7 years",
"< 1 year",
"3 years",
null,
"< 1 year",
"3 years",
"4 years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
null,
"10+ years",
"4 years",
"< 1 year",
"3 years",
"4 years",
"2 years",
"10+ years",
null,
"5 years",
"1 year",
"10+ years",
"5 years",
"1 year",
"9 years",
"4 years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"3 years",
"6 years",
"10+ years",
null,
"1 year",
"10+ years",
"2 years",
"3 years",
"< 1 year",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"10+ years",
null,
"3 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"5 years",
"< 1 year",
"2 years",
"10+ years",
"4 years",
"8 years",
"8 years",
"10+ years",
"< 1 year",
"2 years",
"5 years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"10+ years",
null,
"10+ years",
"6 years",
"6 years",
"6 years",
"< 1 year",
null,
"10+ years",
null,
"2 years",
"4 years",
"4 years",
"5 years",
"5 years",
"2 years",
"6 years",
"2 years",
"5 years",
"2 years",
"1 year",
"1 year",
"< 1 year",
"10+ years",
"1 year",
"9 years",
"5 years",
null,
"5 years",
"5 years",
"10+ years",
"7 years",
"1 year",
"7 years",
"4 years",
"< 1 year",
"10+ years",
"2 years",
"3 years",
"< 1 year",
"5 years",
"< 1 year",
"10+ years",
"5 years",
"4 years",
null,
"4 years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"5 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
null,
"10+ years",
"1 year",
"10+ years",
"2 years",
"3 years",
"4 years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"1 year",
"2 years",
"< 1 year",
"2 years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"6 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"8 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"1 year",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"6 years",
"10+ years",
"< 1 year",
"< 1 year",
"< 1 year",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"7 years",
"4 years",
null,
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"9 years",
"3 years",
"10+ years",
"5 years",
"4 years",
"5 years",
null,
"4 years",
"1 year",
"8 years",
"6 years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"6 years",
"3 years",
"10+ years",
"9 years",
"3 years",
"2 years",
"8 years",
"2 years",
"10+ years",
"4 years",
"6 years",
"5 years",
null,
"2 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"3 years",
"2 years",
"4 years",
"10+ years",
"1 year",
"1 year",
"2 years",
"10+ years",
"3 years",
"2 years",
"4 years",
"3 years",
"< 1 year",
"7 years",
null,
"1 year",
"3 years",
"2 years",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"9 years",
"10+ years",
"7 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"6 years",
"< 1 year",
"10+ years",
null,
"1 year",
"7 years",
"6 years",
"9 years",
"3 years",
"5 years",
"4 years",
"8 years",
"8 years",
"9 years",
"2 years",
"< 1 year",
"10+ years",
"6 years",
"1 year",
"10+ years",
"6 years",
"2 years",
"10+ years",
"4 years",
"5 years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"8 years",
"3 years",
"8 years",
"9 years",
"4 years",
"1 year",
null,
"10+ years",
"2 years",
"10+ years",
null,
"2 years",
"3 years",
"< 1 year",
"1 year",
"3 years",
"10+ years",
"4 years",
"1 year",
"1 year",
"8 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"< 1 year",
"2 years",
"5 years",
"10+ years",
"1 year",
"1 year",
"6 years",
"10+ years",
"8 years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
null,
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"3 years",
"6 years",
"1 year",
"10+ years",
"< 1 year",
"8 years",
"8 years",
"2 years",
"9 years",
"9 years",
"8 years",
"10+ years",
"3 years",
"9 years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"7 years",
"7 years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"1 year",
"2 years",
"< 1 year",
"10+ years",
"7 years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"4 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"7 years",
"2 years",
"2 years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"4 years",
"6 years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"9 years",
"5 years",
"6 years",
"5 years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"5 years",
"5 years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"5 years",
"3 years",
"8 years",
"9 years",
"< 1 year",
"7 years",
"10+ years",
"2 years",
"4 years",
"10+ years",
"8 years",
"3 years",
null,
"7 years",
"9 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"3 years",
null,
"4 years",
"9 years",
"10+ years",
"3 years",
"9 years",
"1 year",
"4 years",
"1 year",
"10+ years",
"9 years",
"< 1 year",
"5 years",
"1 year",
"9 years",
"1 year",
"10+ years",
"4 years",
"3 years",
"10+ years",
null,
null,
"7 years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"3 years",
null,
"< 1 year",
"< 1 year",
null,
"1 year",
"7 years",
null,
"5 years",
"10+ years",
"2 years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"2 years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"2 years",
"1 year",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"< 1 year",
"5 years",
"3 years",
"3 years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"1 year",
"6 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
null,
"5 years",
"10+ years",
"10+ years",
"1 year",
"8 years",
"2 years",
"2 years",
"< 1 year",
"6 years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"1 year",
"6 years",
"5 years",
"5 years",
"9 years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"6 years",
"8 years",
"10+ years",
"4 years",
"10+ years",
"1 year",
"2 years",
"2 years",
"< 1 year",
"2 years",
"7 years",
null,
"5 years",
"4 years",
null,
"2 years",
"1 year",
"8 years",
"10+ years",
"10+ years",
"9 years",
"8 years",
"4 years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
"5 years",
"4 years",
null,
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
null,
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"3 years",
"8 years",
"10+ years",
"7 years",
"3 years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"4 years",
"3 years",
"8 years",
null,
"10+ years",
"8 years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"9 years",
null,
"6 years",
"4 years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"3 years",
"8 years",
"9 years",
"< 1 year",
null,
"4 years",
"< 1 year",
"3 years",
"10+ years",
"4 years",
"10+ years",
null,
"2 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"3 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"6 years",
"9 years",
"7 years",
null,
"< 1 year",
"10+ years",
"1 year",
"5 years",
"4 years",
"7 years",
"1 year",
"7 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"< 1 year",
"1 year",
"9 years",
"9 years",
"< 1 year",
"5 years",
"9 years",
"7 years",
"3 years",
"10+ years",
"9 years",
"5 years",
"2 years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"< 1 year",
"8 years",
"1 year",
"2 years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"2 years",
"10+ years",
"5 years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"1 year",
"2 years",
"5 years",
"10+ years",
"5 years",
"10+ years",
null,
"3 years",
"5 years",
"2 years",
"6 years",
"6 years",
"10+ years",
"10+ years",
"8 years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"6 years",
"7 years",
"5 years",
"10+ years",
"7 years",
"1 year",
"9 years",
"5 years",
"10+ years",
"2 years",
"1 year",
"8 years",
"2 years",
"8 years",
"7 years",
"7 years",
"< 1 year",
"1 year",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"1 year",
"9 years",
"4 years",
"10+ years",
null,
"2 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"3 years",
"4 years",
"6 years",
"5 years",
"4 years",
"10+ years",
"9 years",
"3 years",
"5 years",
"10+ years",
"4 years",
"4 years",
"10+ years",
"5 years",
"1 year",
"7 years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"1 year",
"10+ years",
null,
"2 years",
"2 years",
null,
"3 years",
"10+ years",
"9 years",
"4 years",
"1 year",
"10+ years",
"5 years",
"10+ years",
null,
"< 1 year",
"10+ years",
"8 years",
"7 years",
"2 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"6 years",
"2 years",
"6 years",
"6 years",
"8 years",
"10+ years",
"7 years",
"1 year",
"4 years",
"4 years",
null,
"6 years",
"5 years",
"9 years",
"2 years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"1 year",
"2 years",
"9 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"2 years",
"2 years",
"< 1 year",
"10+ years",
"9 years",
"5 years",
"1 year",
"1 year",
"1 year",
null,
"1 year",
null,
"10+ years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"6 years",
"5 years",
"8 years",
"8 years",
"6 years",
"9 years",
"3 years",
null,
"10+ years",
"5 years",
null,
"2 years",
"< 1 year",
"10+ years",
"1 year",
"6 years",
null,
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"4 years",
"9 years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"4 years",
null,
"1 year",
"5 years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"< 1 year",
"6 years",
"4 years",
"7 years",
"3 years",
"2 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
"3 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"7 years",
"3 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"5 years",
"10+ years",
"6 years",
"< 1 year",
"< 1 year",
"9 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"6 years",
"10+ years",
"4 years",
null,
"10+ years",
"5 years",
"< 1 year",
"8 years",
"1 year",
"6 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"4 years",
null,
"7 years",
"1 year",
"8 years",
"4 years",
"10+ years",
"5 years",
"3 years",
"8 years",
"5 years",
"3 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"2 years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"2 years",
"6 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"8 years",
"3 years",
"7 years",
"7 years",
"9 years",
"5 years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"4 years",
"10+ years",
"2 years",
"1 year",
"4 years",
"2 years",
"8 years",
"10+ years",
"7 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"7 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"< 1 year",
"10+ years",
"3 years",
"5 years",
"7 years",
null,
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"9 years",
null,
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"7 years",
"7 years",
"5 years",
"3 years",
"1 year",
"10+ years",
"2 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
null,
"3 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"2 years",
"2 years",
"4 years",
"8 years",
"< 1 year",
"< 1 year",
"1 year",
"2 years",
"5 years",
"5 years",
"10+ years",
"3 years",
null,
"10+ years",
"10+ years",
"4 years",
"8 years",
"6 years",
"4 years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"3 years",
"2 years",
"1 year",
"7 years",
"9 years",
"1 year",
"2 years",
"9 years",
"< 1 year",
"2 years",
"1 year",
"4 years",
null,
"6 years",
"10+ years",
"10+ years",
null,
"5 years",
"4 years",
"6 years",
null,
"1 year",
null,
"10+ years",
"2 years",
"1 year",
"2 years",
"3 years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"2 years",
"7 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
null,
"4 years",
"6 years",
"1 year",
"2 years",
"10+ years",
"4 years",
"5 years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"6 years",
"2 years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"6 years",
"5 years",
"5 years",
"3 years",
"5 years",
"3 years",
null,
null,
null,
"1 year",
"10+ years",
"9 years",
"10+ years",
"8 years",
"3 years",
"9 years",
"< 1 year",
"5 years",
null,
"2 years",
"3 years",
"7 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"8 years",
"8 years",
"< 1 year",
"2 years",
"2 years",
"< 1 year",
"10+ years",
"5 years",
"8 years",
"4 years",
"8 years",
"7 years",
"10+ years",
"8 years",
null,
"4 years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"5 years",
"2 years",
"5 years",
"2 years",
"9 years",
"5 years",
"< 1 year",
"9 years",
"< 1 year",
"1 year",
"2 years",
"1 year",
"8 years",
"8 years",
"10+ years",
"5 years",
"7 years",
"10+ years",
"8 years",
"5 years",
"< 1 year",
"< 1 year",
"1 year",
"9 years",
"10+ years",
"1 year",
"5 years",
"7 years",
"9 years",
"10+ years",
"4 years",
"< 1 year",
"8 years",
"1 year",
"2 years",
"9 years",
"5 years",
"< 1 year",
"5 years",
"10+ years",
"1 year",
"< 1 year",
"2 years",
"8 years",
"4 years",
"2 years",
"4 years",
"1 year",
"10+ years",
"10+ years",
null,
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
null,
"3 years",
"1 year",
"6 years",
"10+ years",
"5 years",
"6 years",
"5 years",
"1 year",
"1 year",
"< 1 year",
"10+ years",
null,
"10+ years",
"4 years",
"2 years",
"10+ years",
"2 years",
"3 years",
"3 years",
"5 years",
"3 years",
"4 years",
"10+ years",
"4 years",
"10+ years",
"2 years",
null,
"1 year",
"7 years",
"2 years",
"2 years",
"10+ years",
"2 years",
null,
"10+ years",
"10+ years",
"6 years",
"5 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"8 years",
null,
"< 1 year",
"< 1 year",
"3 years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"3 years",
"< 1 year",
"1 year",
"2 years",
"6 years",
"5 years",
"1 year",
"10+ years",
"3 years",
"7 years",
"2 years",
"< 1 year",
"< 1 year",
"4 years",
"5 years",
"< 1 year",
"2 years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"4 years",
"8 years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"2 years",
"< 1 year",
"2 years",
"< 1 year",
"1 year",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"8 years",
"10+ years",
"1 year",
"4 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"3 years",
null,
"3 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"1 year",
"10+ years",
"5 years",
"3 years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"6 years",
"6 years",
"2 years",
null,
"4 years",
"5 years",
"4 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"1 year",
"8 years",
"3 years",
"4 years",
"10+ years",
"5 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
null,
"2 years",
"4 years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"6 years",
"3 years",
"5 years",
"2 years",
"8 years",
"3 years",
"10+ years",
"9 years",
"1 year",
"2 years",
"7 years",
"9 years",
"8 years",
null,
"2 years",
"2 years",
null,
"4 years",
"10+ years",
"1 year",
"1 year",
"8 years",
"3 years",
"6 years",
"1 year",
"3 years",
"5 years",
"1 year",
"10+ years",
"2 years",
"9 years",
"3 years",
"9 years",
"9 years",
"10+ years",
"7 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"1 year",
"1 year",
null,
"10+ years",
"10+ years",
"6 years",
"4 years",
"6 years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"4 years",
null,
"1 year",
"1 year",
"3 years",
"10+ years",
"2 years",
"2 years",
"3 years",
"6 years",
"2 years",
"4 years",
"9 years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"5 years",
"1 year",
"4 years",
"5 years",
"3 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"7 years",
"10+ years",
"2 years",
null,
"1 year",
"8 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"6 years",
"8 years",
"< 1 year",
null,
"10+ years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"5 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"9 years",
"1 year",
"6 years",
"10+ years",
null,
"5 years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"4 years",
null,
"7 years",
"4 years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"8 years",
"7 years",
"5 years",
"< 1 year",
"10+ years",
"2 years",
"6 years",
null,
"10+ years",
"8 years",
"10+ years",
"10+ years",
"5 years",
"6 years",
null,
"10+ years",
"7 years",
"8 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"< 1 year",
"6 years",
"3 years",
"6 years",
"10+ years",
"4 years",
"10+ years",
"6 years",
"8 years",
"10+ years",
"5 years",
"1 year",
"9 years",
"10+ years",
"2 years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"< 1 year",
"5 years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"6 years",
"6 years",
"8 years",
"1 year",
"3 years",
"< 1 year",
"6 years",
"< 1 year",
"8 years",
"3 years",
"1 year",
null,
"2 years",
"2 years",
"7 years",
"5 years",
"< 1 year",
"2 years",
"10+ years",
"1 year",
"3 years",
"3 years",
"4 years",
"8 years",
"1 year",
"5 years",
"10+ years",
"9 years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"4 years",
"4 years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"3 years",
"6 years",
"< 1 year",
"8 years",
"3 years",
"9 years",
"3 years",
"10+ years",
"3 years",
"1 year",
"< 1 year",
"3 years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"9 years",
"2 years",
"1 year",
"1 year",
"10+ years",
null,
"5 years",
"10+ years",
"10+ years",
"3 years",
"6 years",
"10+ years",
"1 year",
null,
"10+ years",
"4 years",
"10+ years",
"2 years",
"2 years",
null,
"3 years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"2 years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
null,
"5 years",
null,
"2 years",
"2 years",
null,
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"2 years",
"2 years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"4 years",
"10+ years",
"1 year",
"2 years",
"10+ years",
null,
"< 1 year",
"< 1 year",
"2 years",
"5 years",
"10+ years",
"1 year",
"9 years",
"10+ years",
"7 years",
"2 years",
"9 years",
"10+ years",
"1 year",
"5 years",
"3 years",
"10+ years",
"10+ years",
null,
"< 1 year",
"9 years",
"10+ years",
"6 years",
"9 years",
"10+ years",
"8 years",
"6 years",
"1 year",
"< 1 year",
"3 years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"1 year",
"8 years",
"10+ years",
"4 years",
"1 year",
null,
"2 years",
"8 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
null,
"1 year",
"8 years",
"2 years",
null,
null,
"10+ years",
"10+ years",
null,
"1 year",
"3 years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"7 years",
"9 years",
"7 years",
"< 1 year",
"< 1 year",
"10+ years",
"< 1 year",
null,
"2 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"4 years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"6 years",
"5 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"9 years",
"9 years",
"1 year",
"2 years",
null,
"1 year",
"10+ years",
"10+ years",
"5 years",
"8 years",
"3 years",
"5 years",
"7 years",
"1 year",
"2 years",
null,
"9 years",
"10+ years",
"7 years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"5 years",
"10+ years",
null,
"8 years",
"2 years",
null,
"< 1 year",
null,
"10+ years",
"5 years",
"< 1 year",
"7 years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"9 years",
"1 year",
"5 years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"10+ years",
"6 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
null,
"1 year",
"2 years",
"2 years",
"4 years",
"10+ years",
"2 years",
"6 years",
"10+ years",
null,
null,
"5 years",
null,
"2 years",
null,
"5 years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"6 years",
"4 years",
"10+ years",
"8 years",
"10+ years",
"6 years",
"1 year",
"9 years",
"8 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"5 years",
"4 years",
"5 years",
"6 years",
"1 year",
"6 years",
"3 years",
"2 years",
"8 years",
"2 years",
"< 1 year",
"10+ years",
"9 years",
"1 year",
"7 years",
"10+ years",
"6 years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"1 year",
"8 years",
"2 years",
"7 years",
"3 years",
"6 years",
"3 years",
"2 years",
null,
"7 years",
"10+ years",
"8 years",
"10+ years",
"4 years",
"5 years",
"8 years",
"1 year",
"3 years",
"6 years",
"2 years",
"3 years",
"4 years",
null,
"10+ years",
"4 years",
"10+ years",
"10+ years",
"5 years",
"7 years",
"6 years",
"10+ years",
"3 years",
null,
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"10+ years",
"< 1 year",
"< 1 year",
"3 years",
"9 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"7 years",
"3 years",
"5 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
null,
"2 years",
"10+ years",
"7 years",
"10+ years",
"5 years",
"7 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"3 years",
"2 years",
"2 years",
"10+ years",
"< 1 year",
"5 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"5 years",
"10+ years",
"< 1 year",
"4 years",
"4 years",
"10+ years",
"3 years",
"3 years",
"3 years",
null,
"2 years",
"1 year",
"5 years",
"10+ years",
"1 year",
"2 years",
"3 years",
"10+ years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"2 years",
"4 years",
"7 years",
"8 years",
"3 years",
"8 years",
null,
"8 years",
null,
"10+ years",
"2 years",
"7 years",
"9 years",
"7 years",
"7 years",
"3 years",
"< 1 year",
"8 years",
"1 year",
null,
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"1 year",
"6 years",
"2 years",
"< 1 year",
"9 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"10+ years",
"4 years",
"10+ years",
null,
"10+ years",
"3 years",
"3 years",
"10+ years",
"9 years",
"2 years",
"< 1 year",
"2 years",
"3 years",
"< 1 year",
null,
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"2 years",
"< 1 year",
"1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
null,
"3 years",
"8 years",
"3 years",
"< 1 year",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"5 years",
"8 years",
null,
"10+ years",
"< 1 year",
"9 years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"5 years",
"2 years",
"10+ years",
"7 years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"9 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"7 years",
"6 years",
"5 years",
"3 years",
"9 years",
"9 years",
"3 years",
"10+ years",
"4 years",
"2 years",
"10+ years",
"1 year",
null,
"9 years",
null,
"< 1 year",
"< 1 year",
"10+ years",
"5 years",
"1 year",
null,
"10+ years",
"10+ years",
"7 years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
null,
"5 years",
"2 years",
"9 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"4 years",
null,
"8 years",
"6 years",
"10+ years",
"8 years",
"3 years",
"4 years",
"10+ years",
"4 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"9 years",
"7 years",
"< 1 year",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"1 year",
"7 years",
"6 years",
"10+ years",
"2 years",
"5 years",
"3 years",
null,
"2 years",
"6 years",
"1 year",
"10+ years",
"10+ years",
"6 years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"6 years",
"< 1 year",
"10+ years",
"3 years",
"8 years",
"10+ years",
"< 1 year",
"7 years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"2 years",
"9 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"5 years",
"2 years",
"< 1 year",
"9 years",
"10+ years",
"9 years",
"4 years",
"8 years",
"10+ years",
"8 years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"5 years",
"8 years",
"6 years",
"1 year",
"10+ years",
"9 years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"4 years",
"10+ years",
"5 years",
"1 year",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"9 years",
"10+ years",
"4 years",
"5 years",
"1 year",
"10+ years",
null,
"10+ years",
"< 1 year",
"5 years",
"2 years",
"< 1 year",
"3 years",
"7 years",
"10+ years",
null,
"5 years",
"10+ years",
"9 years",
"10+ years",
"5 years",
"2 years",
"2 years",
"10+ years",
"8 years",
"7 years",
"2 years",
"10+ years",
"9 years",
"9 years",
"4 years",
"2 years",
"9 years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"2 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"3 years",
"9 years",
"6 years",
"2 years",
"5 years",
"8 years",
"6 years",
"2 years",
"7 years",
"2 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"2 years",
"1 year",
"3 years",
"2 years",
"4 years",
"7 years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"6 years",
null,
"< 1 year",
null,
"10+ years",
"2 years",
"6 years",
"5 years",
"< 1 year",
"2 years",
"2 years",
"2 years",
"5 years",
null,
"1 year",
"1 year",
"7 years",
"6 years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
null,
"< 1 year",
"2 years",
"2 years",
"2 years",
"7 years",
null,
"2 years",
"10+ years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"5 years",
"5 years",
"2 years",
"5 years",
null,
"6 years",
"< 1 year",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"2 years",
"3 years",
"5 years",
"2 years",
null,
"2 years",
"5 years",
"9 years",
"3 years",
null,
"< 1 year",
"10+ years",
"7 years",
null,
null,
"1 year",
"5 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"7 years",
"8 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"3 years",
"10+ years",
"10+ years",
null,
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"5 years",
"5 years",
"10+ years",
"8 years",
"10+ years",
"9 years",
"10+ years",
"2 years",
"< 1 year",
"< 1 year",
"2 years",
null,
"10+ years",
"1 year",
"10+ years",
"8 years",
"7 years",
"5 years",
"3 years",
"3 years",
"7 years",
"2 years",
"6 years",
"< 1 year",
"7 years",
"5 years",
"7 years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"6 years",
"2 years",
"7 years",
"10+ years",
"3 years",
"9 years",
"2 years",
"10+ years",
null,
"4 years",
"5 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"3 years",
"8 years",
"3 years",
null,
null,
"1 year",
"< 1 year",
"10+ years",
"7 years",
"4 years",
"2 years",
"10+ years",
"4 years",
"5 years",
"2 years",
null,
"10+ years",
"1 year",
"3 years",
"2 years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"9 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"3 years",
"9 years",
"4 years",
"2 years",
"7 years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"2 years",
null,
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"9 years",
"5 years",
"< 1 year",
"7 years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"6 years",
"2 years",
"1 year",
"1 year",
"4 years",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"10+ years",
"7 years",
"2 years",
"2 years",
"1 year",
"6 years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"6 years",
"6 years",
"1 year",
"10+ years",
"10+ years",
"8 years",
"7 years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"4 years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"8 years",
"4 years",
"7 years",
"2 years",
"3 years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"2 years",
"3 years",
null,
"3 years",
"7 years",
"3 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"7 years",
"7 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"3 years",
"1 year",
"8 years",
"7 years",
"6 years",
"7 years",
"5 years",
"5 years",
"1 year",
"4 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"6 years",
"8 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"6 years",
"10+ years",
"7 years",
null,
"10+ years",
"4 years",
"5 years",
"8 years",
null,
"10+ years",
"3 years",
"3 years",
"5 years",
null,
"10+ years",
"10+ years",
"2 years",
null,
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"9 years",
"10+ years",
"2 years",
"7 years",
"7 years",
"8 years",
"10+ years",
null,
"2 years",
"4 years",
"10+ years",
null,
"2 years",
"1 year",
"1 year",
"3 years",
"4 years",
"10+ years",
"6 years",
"7 years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"7 years",
null,
null,
"5 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"1 year",
"8 years",
"4 years",
"5 years",
"7 years",
"5 years",
"10+ years",
"< 1 year",
"7 years",
null,
"< 1 year",
"1 year",
"10+ years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"6 years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"8 years",
"2 years",
null,
"4 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"2 years",
"7 years",
"2 years",
"8 years",
"6 years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"1 year",
"9 years",
"< 1 year",
"< 1 year",
"10+ years",
null,
"3 years",
"3 years",
"10+ years",
"1 year",
"4 years",
"5 years",
"2 years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"6 years",
"8 years",
"1 year",
"4 years",
"< 1 year",
"7 years",
null,
"< 1 year",
"10+ years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"1 year",
"2 years",
"4 years",
"10+ years",
"8 years",
"< 1 year",
null,
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"6 years",
"10+ years",
null,
"10+ years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"7 years",
"6 years",
"10+ years",
"4 years",
"< 1 year",
"2 years",
"5 years",
"9 years",
"10+ years",
"3 years",
"5 years",
"7 years",
null,
"3 years",
"4 years",
"< 1 year",
"5 years",
"6 years",
"4 years",
null,
"4 years",
"6 years",
"< 1 year",
"9 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"6 years",
"10+ years",
"7 years",
"3 years",
"10+ years",
"6 years",
"3 years",
"< 1 year",
"2 years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"6 years",
"10+ years",
"6 years",
"3 years",
"< 1 year",
"5 years",
"6 years",
"1 year",
"10+ years",
"10+ years",
"9 years",
"4 years",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"1 year",
"7 years",
"5 years",
"5 years",
"6 years",
"< 1 year",
null,
"10+ years",
"9 years",
"10+ years",
null,
"10+ years",
null,
"< 1 year",
"10+ years",
"4 years",
"4 years",
"6 years",
"10+ years",
"7 years",
"6 years",
"10+ years",
"9 years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"1 year",
"2 years",
"1 year",
null,
"9 years",
"5 years",
"5 years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"4 years",
"8 years",
"10+ years",
"7 years",
null,
"6 years",
"2 years",
"2 years",
"3 years",
null,
"6 years",
"2 years",
"5 years",
"8 years",
"10+ years",
"2 years",
"2 years",
"6 years",
"2 years",
null,
"1 year",
"1 year",
null,
"2 years",
"< 1 year",
"8 years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"5 years",
null,
"8 years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"7 years",
"8 years",
null,
"10+ years",
"1 year",
"5 years",
"2 years",
"10+ years",
"2 years",
"3 years",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"5 years",
"3 years",
"6 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"8 years",
"3 years",
"8 years",
null,
"10+ years",
"9 years",
"5 years",
"4 years",
"< 1 year",
"9 years",
"10+ years",
"10+ years",
null,
"7 years",
"10+ years",
"5 years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
null,
"7 years",
"4 years",
"7 years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"< 1 year",
"< 1 year",
"10+ years",
"4 years",
"2 years",
"5 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"2 years",
"2 years",
"3 years",
"1 year",
"10+ years",
null,
"8 years",
"5 years",
"10+ years",
"5 years",
"8 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"7 years",
"< 1 year",
"3 years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"2 years",
"1 year",
"1 year",
null,
"2 years",
"8 years",
"10+ years",
"10+ years",
null,
"6 years",
"7 years",
"10+ years",
"7 years",
"3 years",
"10+ years",
"7 years",
"10+ years",
"4 years",
"6 years",
"10+ years",
"3 years",
"10+ years",
null,
"2 years",
"10+ years",
"3 years",
"1 year",
"3 years",
"2 years",
"6 years",
"8 years",
"10+ years",
"5 years",
"1 year",
"2 years",
"5 years",
"4 years",
"10+ years",
"7 years",
"< 1 year",
"7 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"6 years",
"1 year",
"2 years",
"10+ years",
"9 years",
"10+ years",
"2 years",
"7 years",
null,
"10+ years",
"2 years",
"10+ years",
"4 years",
null,
"5 years",
"6 years",
"10+ years",
"< 1 year",
"< 1 year",
null,
"2 years",
null,
"10+ years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"< 1 year",
"3 years",
"8 years",
"10+ years",
"6 years",
"3 years",
"6 years",
"< 1 year",
"2 years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"6 years",
"9 years",
"7 years",
"2 years",
"3 years",
"2 years",
"7 years",
"10+ years",
"5 years",
"2 years",
null,
"2 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"4 years",
"< 1 year",
"10+ years",
"9 years",
"< 1 year",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"2 years",
"8 years",
"5 years",
"10+ years",
"6 years",
"8 years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"3 years",
null,
"10+ years",
"10+ years",
"8 years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"< 1 year",
"3 years",
"4 years",
"10+ years",
"< 1 year",
"< 1 year",
"4 years",
"10+ years",
"< 1 year",
"< 1 year",
"3 years",
"6 years",
"8 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"6 years",
"< 1 year",
"7 years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"9 years",
null,
"10+ years",
"10+ years",
null,
"9 years",
"< 1 year",
"6 years",
"2 years",
"8 years",
"7 years",
"10+ years",
"10+ years",
null,
"2 years",
"7 years",
null,
"4 years",
"10+ years",
null,
"10+ years",
null,
"2 years",
"8 years",
"10+ years",
"2 years",
"1 year",
null,
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"6 years",
"5 years",
"3 years",
"1 year",
"10+ years",
"7 years",
null,
"3 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"8 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"2 years",
"7 years",
"2 years",
"7 years",
"4 years",
"4 years",
"9 years",
"9 years",
"6 years",
"10+ years",
"7 years",
"8 years",
"10+ years",
"6 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"2 years",
"9 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"1 year",
"8 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"2 years",
"5 years",
"1 year",
"3 years",
"10+ years",
"1 year",
null,
"3 years",
"10+ years",
"4 years",
"5 years",
"2 years",
null,
"10+ years",
"4 years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"1 year",
"< 1 year",
"1 year",
"5 years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"8 years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"2 years",
"< 1 year",
"2 years",
"9 years",
"9 years",
"10+ years",
"3 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"7 years",
"4 years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"7 years",
"6 years",
"7 years",
"< 1 year",
"10+ years",
"4 years",
"3 years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
null,
"8 years",
"1 year",
"1 year",
"6 years",
"3 years",
"2 years",
"10+ years",
"< 1 year",
"1 year",
"4 years",
"9 years",
"10+ years",
"5 years",
"3 years",
"3 years",
"5 years",
"4 years",
"10+ years",
"8 years",
"9 years",
"7 years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"< 1 year",
"6 years",
"10+ years",
null,
"7 years",
"3 years",
"6 years",
"7 years",
"10+ years",
"3 years",
"< 1 year",
"4 years",
"1 year",
"1 year",
"7 years",
"4 years",
"5 years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"3 years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"9 years",
null,
"5 years",
"7 years",
"2 years",
"6 years",
"4 years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"8 years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"3 years",
"1 year",
"< 1 year",
"10+ years",
"2 years",
"1 year",
"3 years",
"10+ years",
"9 years",
"3 years",
"1 year",
"10+ years",
"7 years",
"2 years",
"9 years",
"6 years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"7 years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"4 years",
"4 years",
"5 years",
"9 years",
"4 years",
"10+ years",
"< 1 year",
"2 years",
"3 years",
null,
"10+ years",
null,
"6 years",
null,
"10+ years",
"10+ years",
null,
"10+ years",
"6 years",
"7 years",
"3 years",
"< 1 year",
"9 years",
"2 years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"9 years",
"10+ years",
"7 years",
"3 years",
"< 1 year",
null,
"4 years",
null,
"2 years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"4 years",
"5 years",
null,
"3 years",
"7 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"< 1 year",
"6 years",
"8 years",
"5 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"2 years",
"5 years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"4 years",
"10+ years",
"10+ years",
null,
"3 years",
"2 years",
"< 1 year",
"6 years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"3 years",
"8 years",
"4 years",
"9 years",
"7 years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"3 years",
"8 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
null,
"2 years",
"6 years",
"10+ years",
"7 years",
"8 years",
"< 1 year",
"10+ years",
"2 years",
"2 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"6 years",
"8 years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"1 year",
"10+ years",
null,
null,
"10+ years",
"1 year",
"4 years",
"1 year",
"3 years",
"3 years",
"10+ years",
"2 years",
"5 years",
"3 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
null,
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"6 years",
"8 years",
"7 years",
null,
"5 years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"1 year",
"10+ years",
"4 years",
"3 years",
"< 1 year",
"10+ years",
"< 1 year",
"4 years",
"1 year",
"1 year",
"5 years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"3 years",
"2 years",
"10+ years",
"1 year",
"8 years",
"10+ years",
"8 years",
"10+ years",
null,
"2 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"5 years",
"10+ years",
"6 years",
null,
"3 years",
"8 years",
"2 years",
"6 years",
null,
"3 years",
"5 years",
"4 years",
"5 years",
"2 years",
null,
"< 1 year",
"< 1 year",
"10+ years",
"3 years",
"7 years",
"2 years",
"< 1 year",
"3 years",
"10+ years",
"3 years",
"2 years",
null,
"4 years",
"< 1 year",
"8 years",
"7 years",
"6 years",
"8 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"8 years",
"8 years",
"9 years",
"10+ years",
"8 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"< 1 year",
"10+ years",
"9 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"7 years",
"2 years",
"6 years",
"1 year",
"2 years",
"10+ years",
"4 years",
"3 years",
"5 years",
"2 years",
"2 years",
null,
"10+ years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"6 years",
"10+ years",
"6 years",
"< 1 year",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"3 years",
"< 1 year",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"7 years",
null,
"10+ years",
"7 years",
"10+ years",
"2 years",
"3 years",
"< 1 year",
"9 years",
null,
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"2 years",
"8 years",
"6 years",
"< 1 year",
"2 years",
"1 year",
"2 years",
"2 years",
null,
"10+ years",
"5 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"1 year",
"2 years",
"8 years",
"10+ years",
"10+ years",
"1 year",
"9 years",
"1 year",
"< 1 year",
"5 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"4 years",
null,
"10+ years",
"6 years",
"7 years",
"< 1 year",
"1 year",
"6 years",
"6 years",
"5 years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"7 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"4 years",
"7 years",
"4 years",
"10+ years",
"5 years",
"7 years",
"6 years",
"8 years",
"2 years",
"10+ years",
"6 years",
"8 years",
"4 years",
null,
"4 years",
"4 years",
"3 years",
"1 year",
"4 years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"4 years",
"7 years",
"1 year",
null,
"10+ years",
"2 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"6 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"4 years",
"< 1 year",
"7 years",
"3 years",
"2 years",
"4 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"8 years",
"4 years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"8 years",
"1 year",
"3 years",
"1 year",
"2 years",
"4 years",
"10+ years",
"5 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
null,
"1 year",
"3 years",
"8 years",
"6 years",
"< 1 year",
"2 years",
"7 years",
"4 years",
"5 years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"2 years",
"7 years",
"3 years",
"10+ years",
"3 years",
"7 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"6 years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"4 years",
"9 years",
"10+ years",
"2 years",
"10+ years",
"4 years",
"2 years",
"1 year",
"9 years",
"10+ years",
"< 1 year",
"< 1 year",
"8 years",
"10+ years",
"2 years",
"10+ years",
null,
"3 years",
"1 year",
"< 1 year",
"7 years",
"1 year",
"6 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"3 years",
"4 years",
"8 years",
"< 1 year",
"6 years",
"7 years",
"10+ years",
"8 years",
null,
"7 years",
"10+ years",
"3 years",
"10+ years",
null,
"5 years",
"6 years",
"< 1 year",
"10+ years",
"4 years",
"2 years",
null,
"10+ years",
"2 years",
"8 years",
"9 years",
"2 years",
"4 years",
"5 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"8 years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"4 years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
null,
"2 years",
"3 years",
"10+ years",
"1 year",
"5 years",
"1 year",
"5 years",
"10+ years",
"7 years",
"10+ years",
"1 year",
"3 years",
"9 years",
"5 years",
"6 years",
"10+ years",
"4 years",
"2 years",
"7 years",
"2 years",
"7 years",
"10+ years",
"7 years",
"8 years",
"10+ years",
"6 years",
"5 years",
"10+ years",
"6 years",
"8 years",
"6 years",
"3 years",
"10+ years",
"8 years",
"7 years",
"10+ years",
"< 1 year",
null,
"7 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"3 years",
"1 year",
"9 years",
"10+ years",
"10+ years",
null,
"3 years",
"10+ years",
null,
"2 years",
"10+ years",
"5 years",
"1 year",
"5 years",
"< 1 year",
"8 years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"6 years",
null,
"7 years",
"1 year",
"10+ years",
"6 years",
"8 years",
"6 years",
"8 years",
"5 years",
"8 years",
"< 1 year",
"10+ years",
"1 year",
"8 years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"1 year",
"4 years",
"4 years",
null,
"6 years",
"10+ years",
"10+ years",
"6 years",
"5 years",
"1 year",
"6 years",
"1 year",
"8 years",
"7 years",
"4 years",
"< 1 year",
"5 years",
"5 years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"1 year",
"4 years",
"7 years",
"2 years",
"5 years",
"4 years",
"1 year",
"10+ years",
"5 years",
null,
"4 years",
"1 year",
"10+ years",
"1 year",
"1 year",
null,
"10+ years",
"6 years",
"7 years",
"3 years",
"2 years",
"8 years",
"1 year",
"3 years",
"3 years",
"< 1 year",
"10+ years",
"5 years",
"5 years",
"10+ years",
"< 1 year",
"4 years",
"3 years",
"4 years",
"10+ years",
"4 years",
"10+ years",
null,
"2 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
null,
"5 years",
"7 years",
null,
"3 years",
"2 years",
"1 year",
"7 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"4 years",
"1 year",
"5 years",
"10+ years",
"6 years",
"10+ years",
"3 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"7 years",
"< 1 year",
"9 years",
"4 years",
"2 years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"8 years",
"2 years",
"3 years",
"10+ years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"2 years",
null,
"6 years",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"3 years",
"7 years",
"10+ years",
null,
"6 years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"8 years",
null,
"3 years",
"1 year",
"6 years",
"10+ years",
"1 year",
"2 years",
"2 years",
null,
"10+ years",
"10+ years",
"6 years",
"< 1 year",
"6 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
null,
"7 years",
"10+ years",
"6 years",
"7 years",
"10+ years",
"10+ years",
null,
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"7 years",
"7 years",
"< 1 year",
"3 years",
"1 year",
"8 years",
"3 years",
"6 years",
"4 years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
null,
"10+ years",
"2 years",
"3 years",
"4 years",
"10+ years",
"7 years",
"< 1 year",
"6 years",
"5 years",
"4 years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"5 years",
"< 1 year",
null,
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"1 year",
"2 years",
"1 year",
"1 year",
"< 1 year",
"10+ years",
"8 years",
null,
null,
"6 years",
"4 years",
"5 years",
"10+ years",
"4 years",
"< 1 year",
"< 1 year",
"2 years",
"3 years",
"10+ years",
"9 years",
"4 years",
"2 years",
"6 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"9 years",
"9 years",
"7 years",
"9 years",
"2 years",
"5 years",
"2 years",
"1 year",
null,
"< 1 year",
"8 years",
"2 years",
null,
"7 years",
"7 years",
"3 years",
"8 years",
"10+ years",
"9 years",
"6 years",
"10+ years",
"8 years",
"9 years",
"10+ years",
"10+ years",
"7 years",
null,
"10+ years",
"9 years",
"1 year",
"2 years",
"< 1 year",
"6 years",
"10+ years",
"8 years",
"< 1 year",
"3 years",
"10+ years",
"4 years",
"1 year",
"3 years",
"9 years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"6 years",
"1 year",
"10+ years",
"3 years",
"8 years",
"10+ years",
"3 years",
"7 years",
"3 years",
"3 years",
null,
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"4 years",
"10+ years",
"10+ years",
"8 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"8 years",
"8 years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"10+ years",
"9 years",
"1 year",
null,
"5 years",
"< 1 year",
"10+ years",
"< 1 year",
"4 years",
null,
"< 1 year",
"1 year",
"10+ years",
"3 years",
"7 years",
"8 years",
"9 years",
"3 years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"2 years",
"5 years",
"1 year",
"2 years",
"3 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"8 years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"4 years",
"7 years",
"10+ years",
"10+ years",
null,
null,
null,
"< 1 year",
"10+ years",
"4 years",
"3 years",
"10+ years",
"5 years",
"< 1 year",
"2 years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"9 years",
null,
"10+ years",
"6 years",
"9 years",
"5 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
null,
"5 years",
"5 years",
"2 years",
"10+ years",
null,
"10+ years",
"9 years",
"10+ years",
"2 years",
"10+ years",
"8 years",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"1 year",
"3 years",
"7 years",
"2 years",
"3 years",
"7 years",
"5 years",
"2 years",
"10+ years",
"10+ years",
null,
"5 years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"2 years",
"6 years",
"9 years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"3 years",
"9 years",
"3 years",
"9 years",
"4 years",
"8 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
null,
"4 years",
"9 years",
"5 years",
"9 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
null,
"< 1 year",
"1 year",
"9 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"7 years",
"< 1 year",
"9 years",
"8 years",
"4 years",
null,
"10+ years",
"1 year",
"4 years",
"9 years",
"10+ years",
"10+ years",
"6 years",
null,
"3 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"1 year",
"10+ years",
"1 year",
"6 years",
"10+ years",
"7 years",
"5 years",
"8 years",
"7 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"8 years",
"< 1 year",
"6 years",
"6 years",
"10+ years",
"1 year",
"3 years",
"2 years",
null,
"< 1 year",
"5 years",
"10+ years",
"6 years",
"5 years",
"10+ years",
"3 years",
"10+ years",
null,
"10+ years",
"7 years",
"10+ years",
"5 years",
"7 years",
null,
"3 years",
"< 1 year",
"2 years",
"10+ years",
"2 years",
"10+ years",
"6 years",
"4 years",
"7 years",
"7 years",
"8 years",
"2 years",
"10+ years",
"3 years",
"3 years",
"4 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
null,
"10+ years",
"5 years",
"6 years",
"10+ years",
"1 year",
"1 year",
"7 years",
"8 years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"1 year",
"9 years",
null,
"2 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"3 years",
"6 years",
"10+ years",
"7 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"10+ years",
"9 years",
"5 years",
"1 year",
"10+ years",
"2 years",
null,
"1 year",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"4 years",
"10+ years",
"8 years",
"6 years",
"3 years",
"2 years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"1 year",
"2 years",
"4 years",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"1 year",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"8 years",
"2 years",
"2 years",
"6 years",
"10+ years",
"6 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"1 year",
"10+ years",
"2 years",
"< 1 year",
"3 years",
"2 years",
"10+ years",
"7 years",
"4 years",
null,
"10+ years",
"10+ years",
"8 years",
null,
"10+ years",
"10+ years",
"4 years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"2 years",
null,
"< 1 year",
"5 years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"7 years",
"4 years",
null,
"8 years",
"2 years",
"1 year",
"10+ years",
"2 years",
"1 year",
"7 years",
"3 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"10+ years",
"5 years",
"3 years",
"9 years",
"3 years",
"1 year",
"10+ years",
"9 years",
"5 years",
"3 years",
"4 years",
"3 years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
null,
"9 years",
"10+ years",
"10+ years",
"8 years",
null,
"5 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"7 years",
"10+ years",
"4 years",
null,
null,
"10+ years",
"10+ years",
"6 years",
"2 years",
"2 years",
"4 years",
"8 years",
"4 years",
null,
"6 years",
"1 year",
null,
"2 years",
"4 years",
"10+ years",
"10+ years",
"1 year",
"3 years",
null,
"10+ years",
"4 years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"6 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"< 1 year",
"1 year",
"5 years",
"8 years",
"6 years",
"10+ years",
"3 years",
"2 years",
"4 years",
"1 year",
"2 years",
"3 years",
"7 years",
"5 years",
"1 year",
"10+ years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"6 years",
"5 years",
"6 years",
null,
"3 years",
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"4 years",
"6 years",
"4 years",
"< 1 year",
"1 year",
"10+ years",
"9 years",
"10+ years",
"3 years",
"3 years",
"< 1 year",
"< 1 year",
"1 year",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"6 years",
"5 years",
"< 1 year",
"6 years",
"10+ years",
"7 years",
"4 years",
"2 years",
"5 years",
"1 year",
"7 years",
"8 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"8 years",
"6 years",
null,
"4 years",
"10+ years",
"4 years",
"9 years",
"10+ years",
"2 years",
"7 years",
"8 years",
"10+ years",
"10+ years",
null,
null,
"10+ years",
"2 years",
"1 year",
"10+ years",
"2 years",
null,
"6 years",
null,
"2 years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"5 years",
"4 years",
"10+ years",
"6 years",
"8 years",
"5 years",
"1 year",
"8 years",
"7 years",
"3 years",
"3 years",
"10+ years",
"4 years",
"3 years",
null,
"9 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"4 years",
"1 year",
null,
"10+ years",
"3 years",
"10+ years",
"2 years",
"7 years",
"5 years",
"3 years",
"5 years",
"1 year",
"10+ years",
null,
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"3 years",
"10+ years",
"7 years",
"5 years",
"10+ years",
"10+ years",
"6 years",
"9 years",
"4 years",
"10+ years",
"6 years",
"9 years",
"< 1 year",
"< 1 year",
"10+ years",
"2 years",
"4 years",
"10+ years",
"1 year",
"2 years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"2 years",
"3 years",
"10+ years",
"10+ years",
null,
"10+ years",
"4 years",
"< 1 year",
"3 years",
null,
"2 years",
"2 years",
"2 years",
"10+ years",
"< 1 year",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"6 years",
"7 years",
"7 years",
"10+ years",
"9 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"6 years",
"2 years",
"7 years",
"8 years",
"5 years",
"3 years",
"10+ years",
"7 years",
"2 years",
"8 years",
"2 years",
"4 years",
"4 years",
"2 years",
"10+ years",
"4 years",
"7 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"2 years",
"< 1 year",
"6 years",
"7 years",
"3 years",
"1 year",
null,
"1 year",
"10+ years",
"2 years",
"< 1 year",
"9 years",
"9 years",
"10+ years",
"9 years",
"2 years",
"10+ years",
"10+ years",
"1 year",
null,
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"5 years",
"1 year",
"1 year",
"2 years",
"10+ years",
"9 years",
"4 years",
"8 years",
"< 1 year",
"9 years",
null,
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"8 years",
"1 year",
"4 years",
"3 years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"6 years",
"2 years",
"4 years",
"6 years",
"1 year",
"1 year",
"10+ years",
null,
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"9 years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"4 years",
"10+ years",
null,
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"2 years",
"5 years",
"< 1 year",
"10+ years",
"< 1 year",
"1 year",
"5 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"1 year",
"1 year",
null,
"10+ years",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"8 years",
"8 years",
"4 years",
null,
"10+ years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
null,
"4 years",
"10+ years",
"5 years",
"2 years",
"4 years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"9 years",
"4 years",
"3 years",
"5 years",
"2 years",
"10+ years",
"3 years",
"5 years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"1 year",
"4 years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"7 years",
"< 1 year",
"2 years",
"10+ years",
"8 years",
"8 years",
"6 years",
"3 years",
"7 years",
"7 years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"5 years",
"8 years",
"8 years",
"8 years",
"9 years",
"8 years",
"4 years",
"4 years",
"8 years",
"10+ years",
null,
"6 years",
"10+ years",
"< 1 year",
"5 years",
"2 years",
"8 years",
null,
"4 years",
"4 years",
"5 years",
"3 years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
null,
"< 1 year",
"2 years",
null,
"10+ years",
"6 years",
"4 years",
"2 years",
"4 years",
"10+ years",
"8 years",
"1 year",
"10+ years",
"4 years",
"1 year",
"4 years",
"7 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"4 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"9 years",
"3 years",
"9 years",
"1 year",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"< 1 year",
"5 years",
"7 years",
"< 1 year",
"8 years",
"< 1 year",
"8 years",
"1 year",
"5 years",
"10+ years",
"5 years",
"< 1 year",
"5 years",
"10+ years",
null,
"1 year",
"10+ years",
"6 years",
"7 years",
"6 years",
"< 1 year",
"5 years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"9 years",
"< 1 year",
"4 years",
"9 years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
null,
"9 years",
"10+ years",
"8 years",
"8 years",
"6 years",
"< 1 year",
"7 years",
"8 years",
"8 years",
"7 years",
"6 years",
"2 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"1 year",
"10+ years",
"7 years",
"6 years",
"7 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"9 years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"7 years",
"3 years",
"6 years",
"10+ years",
"2 years",
"2 years",
"2 years",
"7 years",
"9 years",
"1 year",
"10+ years",
"5 years",
"< 1 year",
"2 years",
"2 years",
"< 1 year",
"2 years",
"3 years",
"6 years",
"9 years",
"6 years",
"3 years",
"10+ years",
"1 year",
null,
null,
"9 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"4 years",
"3 years",
"10+ years",
"< 1 year",
"8 years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"8 years",
"2 years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"4 years",
"2 years",
"3 years",
"< 1 year",
null,
"10+ years",
null,
"10+ years",
"10+ years",
"2 years",
"2 years",
"4 years",
"4 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"2 years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"9 years",
"4 years",
"1 year",
"5 years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"10+ years",
"6 years",
"4 years",
"7 years",
"10+ years",
"9 years",
"6 years",
"6 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"7 years",
"7 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"7 years",
"< 1 year",
"4 years",
"10+ years",
"7 years",
"7 years",
"10+ years",
"8 years",
"4 years",
"2 years",
"2 years",
"4 years",
null,
"10+ years",
"1 year",
"1 year",
"< 1 year",
"5 years",
"1 year",
"8 years",
"8 years",
"< 1 year",
"1 year",
"8 years",
"7 years",
"8 years",
"4 years",
"4 years",
null,
"2 years",
"< 1 year",
"< 1 year",
"3 years",
"1 year",
"5 years",
"2 years",
"2 years",
"4 years",
"9 years",
null,
"1 year",
"8 years",
"4 years",
"10+ years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"6 years",
"4 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"< 1 year",
null,
"10+ years",
"5 years",
"10+ years",
null,
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"9 years",
"7 years",
"6 years",
"4 years",
"3 years",
"< 1 year",
"10+ years",
"< 1 year",
"6 years",
"6 years",
"7 years",
"10+ years",
"3 years",
"3 years",
"8 years",
"2 years",
"9 years",
"< 1 year",
"1 year",
"< 1 year",
"1 year",
"< 1 year",
null,
"10+ years",
"6 years",
"5 years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
null,
"2 years",
"10+ years",
"6 years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"10+ years",
null,
"3 years",
"10+ years",
"10+ years",
null,
"5 years",
"2 years",
"10+ years",
"10+ years",
"9 years",
"5 years",
"2 years",
"10+ years",
"2 years",
"4 years",
"< 1 year",
"3 years",
"5 years",
"5 years",
"10+ years",
"5 years",
"1 year",
"< 1 year",
"10+ years",
"< 1 year",
"2 years",
"< 1 year",
"9 years",
"10+ years",
"2 years",
"4 years",
"9 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
null,
"5 years",
null,
"8 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"2 years",
"3 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"8 years",
"3 years",
"< 1 year",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"3 years",
"2 years",
"4 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"3 years",
null,
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"6 years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"6 years",
"10+ years",
"3 years",
"< 1 year",
"5 years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"5 years",
"8 years",
"2 years",
"6 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"6 years",
"7 years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"10+ years",
"3 years",
"< 1 year",
"7 years",
"5 years",
"4 years",
"< 1 year",
"6 years",
"10+ years",
"1 year",
"3 years",
"9 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"4 years",
"< 1 year",
null,
"8 years",
"4 years",
"3 years",
"10+ years",
"6 years",
"4 years",
"10+ years",
"10+ years",
"3 years",
"1 year",
null,
"10+ years",
"10+ years",
"1 year",
"5 years",
null,
"10+ years",
"9 years",
"5 years",
null,
"3 years",
"10+ years",
"10+ years",
null,
"10+ years",
"6 years",
"10+ years",
"7 years",
null,
"1 year",
"10+ years",
"2 years",
"7 years",
"4 years",
"5 years",
"4 years",
"9 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"1 year",
"2 years",
"9 years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"6 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"2 years",
"8 years",
"2 years",
"5 years",
"1 year",
"2 years",
"6 years",
null,
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"1 year",
"< 1 year",
"< 1 year",
"6 years",
"10+ years",
"1 year",
"8 years",
"2 years",
"6 years",
"6 years",
"5 years",
"2 years",
"8 years",
"1 year",
null,
"9 years",
"3 years",
"7 years",
"3 years",
"10+ years",
"1 year",
null,
"10+ years",
"7 years",
"10+ years",
"1 year",
"6 years",
"2 years",
"10+ years",
"7 years",
"< 1 year",
"4 years",
"6 years",
"2 years",
"10+ years",
"6 years",
"3 years",
"2 years",
"3 years",
"10+ years",
"6 years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"5 years",
"2 years",
"10+ years",
"9 years",
null,
"< 1 year",
"1 year",
"5 years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"8 years",
"9 years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"1 year",
null,
"10+ years",
"1 year",
"< 1 year",
"4 years",
"2 years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"4 years",
"7 years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"< 1 year",
"3 years",
"5 years",
"10+ years",
"< 1 year",
"4 years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"9 years",
"4 years",
"2 years",
"3 years",
"10+ years",
"8 years",
"4 years",
"10+ years",
"1 year",
"4 years",
"3 years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"7 years",
"< 1 year",
null,
"3 years",
"2 years",
null,
"10+ years",
"8 years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
null,
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"7 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"3 years",
"1 year",
"< 1 year",
"4 years",
"10+ years",
"< 1 year",
"2 years",
"< 1 year",
"< 1 year",
"8 years",
"10+ years",
"8 years",
"6 years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"1 year",
"3 years",
"1 year",
"1 year",
"5 years",
"10+ years",
"5 years",
"2 years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"1 year",
"2 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
null,
"2 years",
"1 year",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"3 years",
null,
"1 year",
"10+ years",
"9 years",
"7 years",
"8 years",
"4 years",
"7 years",
"10+ years",
"1 year",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"4 years",
"1 year",
"4 years",
"2 years",
"2 years",
null,
"< 1 year",
"10+ years",
"4 years",
"8 years",
"10+ years",
"9 years",
"3 years",
"7 years",
"5 years",
"< 1 year",
"10+ years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"8 years",
"6 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"7 years",
"7 years",
"9 years",
"1 year",
"2 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"< 1 year",
null,
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
null,
"< 1 year",
"2 years",
null,
"8 years",
"1 year",
"6 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"9 years",
"< 1 year",
"10+ years",
"2 years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
null,
"1 year",
"8 years",
"2 years",
"1 year",
"10+ years",
"4 years",
"8 years",
"1 year",
"1 year",
"9 years",
"10+ years",
"10+ years",
"4 years",
"7 years",
null,
"10+ years",
"1 year",
"2 years",
"6 years",
"4 years",
"3 years",
"5 years",
"8 years",
"3 years",
"1 year",
"7 years",
"5 years",
"10+ years",
"3 years",
"1 year",
"10+ years",
"5 years",
"10+ years",
"2 years",
"4 years",
"10+ years",
"7 years",
"10+ years",
"5 years",
"8 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"7 years",
"1 year",
"9 years",
"7 years",
"8 years",
"4 years",
"8 years",
"10+ years",
"10+ years",
"1 year",
"9 years",
"5 years",
"< 1 year",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"6 years",
"4 years",
"2 years",
"2 years",
"8 years",
"6 years",
"1 year",
"3 years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"7 years",
null,
"10+ years",
"< 1 year",
"6 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"3 years",
"2 years",
"2 years",
"10+ years",
"9 years",
"6 years",
"4 years",
"8 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"2 years",
"7 years",
"10+ years",
"9 years",
"3 years",
"< 1 year",
"2 years",
"10+ years",
"1 year",
"3 years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"7 years",
"3 years",
"< 1 year",
"6 years",
null,
"10+ years",
"< 1 year",
null,
"2 years",
null,
"1 year",
"< 1 year",
"7 years",
"1 year",
"3 years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"2 years",
"5 years",
"1 year",
"5 years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"3 years",
"< 1 year",
"3 years",
"4 years",
"2 years",
"10+ years",
"3 years",
"1 year",
"4 years",
null,
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"9 years",
"10+ years",
"5 years",
"6 years",
"10+ years",
"6 years",
null,
"5 years",
null,
"4 years",
"2 years",
"4 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"4 years",
"6 years",
"6 years",
"1 year",
"< 1 year",
"6 years",
"2 years",
"4 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"3 years",
"6 years",
"2 years",
"10+ years",
"6 years",
"6 years",
"10+ years",
"6 years",
"8 years",
"2 years",
"10+ years",
"1 year",
"2 years",
"2 years",
"7 years",
"1 year",
"4 years",
"10+ years",
"6 years",
"9 years",
"1 year",
"7 years",
"< 1 year",
"6 years",
"< 1 year",
"8 years",
"3 years",
"6 years",
"1 year",
"6 years",
"4 years",
"2 years",
"10+ years",
"6 years",
"6 years",
"10+ years",
"9 years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"7 years",
"1 year",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"9 years",
null,
"10+ years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"2 years",
"6 years",
"8 years",
"8 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"6 years",
"8 years",
"2 years",
null,
"8 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"< 1 year",
"1 year",
"< 1 year",
"6 years",
"10+ years",
"2 years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"4 years",
"5 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"8 years",
"10+ years",
null,
"10+ years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"5 years",
"9 years",
"6 years",
"10+ years",
"3 years",
"9 years",
"10+ years",
"10+ years",
"9 years",
null,
"< 1 year",
"5 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"5 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
null,
null,
"5 years",
"7 years",
"3 years",
"5 years",
"< 1 year",
"8 years",
"10+ years",
"3 years",
null,
"10+ years",
"4 years",
"10+ years",
null,
"3 years",
"9 years",
"3 years",
"1 year",
"10+ years",
"1 year",
"5 years",
"3 years",
"10+ years",
"6 years",
"9 years",
null,
"4 years",
null,
"5 years",
"10+ years",
"3 years",
"5 years",
"5 years",
"6 years",
"2 years",
"9 years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"6 years",
"5 years",
"10+ years",
"1 year",
"8 years",
"2 years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"2 years",
"9 years",
"10+ years",
null,
"10+ years",
"< 1 year",
"< 1 year",
"4 years",
"10+ years",
"2 years",
"1 year",
"5 years",
"1 year",
"2 years",
"9 years",
"8 years",
null,
"2 years",
"10+ years",
"< 1 year",
"2 years",
"6 years",
"< 1 year",
"7 years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"9 years",
"1 year",
"7 years",
"7 years",
"8 years",
"5 years",
"4 years",
"10+ years",
"8 years",
"4 years",
"2 years",
"5 years",
"10+ years",
"2 years",
"4 years",
"4 years",
"< 1 year",
"10+ years",
"7 years",
"< 1 year",
"2 years",
"10+ years",
"< 1 year",
"< 1 year",
"2 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
null,
"3 years",
"7 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"4 years",
"1 year",
"8 years",
"2 years",
"3 years",
"5 years",
"9 years",
"5 years",
"1 year",
"5 years",
"10+ years",
"8 years",
"< 1 year",
"< 1 year",
"3 years",
"5 years",
"2 years",
"10+ years",
null,
"6 years",
null,
null,
"2 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"< 1 year",
null,
"2 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"7 years",
"2 years",
"1 year",
"4 years",
"6 years",
"7 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"9 years",
"1 year",
"9 years",
"4 years",
"1 year",
"4 years",
"5 years",
"10+ years",
"8 years",
"6 years",
"3 years",
"10+ years",
"2 years",
null,
"10+ years",
"< 1 year",
"2 years",
"3 years",
"7 years",
"10+ years",
"4 years",
"1 year",
"2 years",
"1 year",
"< 1 year",
"10+ years",
"7 years",
"8 years",
"9 years",
"2 years",
"10+ years",
"9 years",
"2 years",
"4 years",
"4 years",
null,
"10+ years",
"3 years",
"10+ years",
"2 years",
"4 years",
"< 1 year",
"< 1 year",
"10+ years",
"< 1 year",
"2 years",
"< 1 year",
null,
"1 year",
"10+ years",
"10+ years",
null,
"2 years",
"< 1 year",
"7 years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"1 year",
"< 1 year",
"3 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"4 years",
"3 years",
"2 years",
"10+ years",
"1 year",
"9 years",
"1 year",
"1 year",
"10+ years",
"1 year",
"5 years",
"10+ years",
"1 year",
"10+ years",
"4 years",
"7 years",
"2 years",
"2 years",
"10+ years",
"6 years",
"5 years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"8 years",
"5 years",
"4 years",
"2 years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"8 years",
"5 years",
"2 years",
"2 years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"4 years",
"10+ years",
"4 years",
"10+ years",
"4 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"9 years",
"3 years",
"< 1 year",
"10+ years",
"1 year",
"3 years",
"1 year",
"< 1 year",
"2 years",
"8 years",
null,
"4 years",
"2 years",
"6 years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"5 years",
"10+ years",
null,
"8 years",
"7 years",
"5 years",
"10+ years",
null,
"1 year",
"8 years",
null,
"8 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"7 years",
"8 years",
"9 years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"7 years",
"5 years",
"10+ years",
"< 1 year",
"2 years",
"3 years",
"10+ years",
"6 years",
null,
"2 years",
"8 years",
"1 year",
"10+ years",
"3 years",
"6 years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"4 years",
"10+ years",
"7 years",
"4 years",
"< 1 year",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"2 years",
"3 years",
"7 years",
"7 years",
"4 years",
"< 1 year",
null,
"1 year",
"1 year",
"8 years",
"6 years",
"2 years",
"3 years",
"< 1 year",
"4 years",
"1 year",
"4 years",
"4 years",
"5 years",
"10+ years",
"< 1 year",
"1 year",
"4 years",
"4 years",
"3 years",
"4 years",
"6 years",
"4 years",
"4 years",
"10+ years",
"8 years",
"2 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"< 1 year",
"5 years",
"< 1 year",
"3 years",
"3 years",
null,
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"5 years",
"10+ years",
null,
"1 year",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"5 years",
"7 years",
"2 years",
"9 years",
"10+ years",
"4 years",
null,
"10+ years",
null,
"10+ years",
"< 1 year",
null,
"3 years",
"8 years",
"< 1 year",
"8 years",
"9 years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"5 years",
"7 years",
"6 years",
"10+ years",
"3 years",
"4 years",
"1 year",
"10+ years",
"10+ years",
"7 years",
"3 years",
"8 years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"7 years",
"1 year",
"1 year",
null,
"2 years",
"9 years",
"< 1 year",
"5 years",
"10+ years",
null,
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"2 years",
"3 years",
"1 year",
"6 years",
"6 years",
"< 1 year",
"4 years",
"3 years",
"3 years",
"10+ years",
"6 years",
null,
"10+ years",
"3 years",
"10+ years",
"5 years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"6 years",
"2 years",
"2 years",
null,
null,
"10+ years",
"10+ years",
"4 years",
"9 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"8 years",
"2 years",
"9 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"4 years",
"< 1 year",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"8 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"6 years",
"4 years",
"10+ years",
"3 years",
null,
"8 years",
"10+ years",
"6 years",
"< 1 year",
"3 years",
"5 years",
"10+ years",
"2 years",
"2 years",
"2 years",
"4 years",
"2 years",
"9 years",
"3 years",
"7 years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"< 1 year",
"8 years",
"3 years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"9 years",
"6 years",
"10+ years",
"7 years",
"5 years",
"5 years",
"7 years",
"< 1 year",
"10+ years",
null,
"1 year",
"10+ years",
"1 year",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"4 years",
"< 1 year",
"6 years",
null,
"4 years",
"9 years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"9 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"5 years",
"3 years",
"2 years",
"10+ years",
"8 years",
"3 years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"8 years",
"< 1 year",
"1 year",
"10+ years",
"8 years",
"4 years",
"10+ years",
null,
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"< 1 year",
"< 1 year",
null,
null,
"3 years",
"4 years",
"7 years",
"< 1 year",
"8 years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"7 years",
"9 years",
"7 years",
"2 years",
"10+ years",
null,
"10+ years",
"10+ years",
"9 years",
"< 1 year",
null,
"10+ years",
"10+ years",
"9 years",
"3 years",
"9 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"7 years",
"10+ years",
"10+ years",
"6 years",
"4 years",
"5 years",
"5 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
null,
"1 year",
null,
"4 years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"6 years",
"1 year",
"8 years",
"8 years",
"7 years",
null,
"8 years",
"3 years",
"10+ years",
"5 years",
"7 years",
"5 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"9 years",
"8 years",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"< 1 year",
"6 years",
"4 years",
"7 years",
"1 year",
null,
"6 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"6 years",
null,
"10+ years",
"3 years",
"5 years",
"7 years",
"7 years",
"9 years",
"< 1 year",
"8 years",
"2 years",
"5 years",
"2 years",
"5 years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"5 years",
"3 years",
"2 years",
"9 years",
"< 1 year",
"7 years",
"5 years",
"4 years",
"3 years",
"10+ years",
"9 years",
"2 years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
null,
"< 1 year",
"< 1 year",
"8 years",
"10+ years",
"7 years",
"3 years",
"8 years",
"4 years",
"7 years",
"< 1 year",
"4 years",
"7 years",
"1 year",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"4 years",
"3 years",
null,
"4 years",
"4 years",
null,
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"9 years",
"3 years",
"1 year",
"5 years",
"< 1 year",
"2 years",
null,
"3 years",
"6 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"6 years",
"2 years",
"7 years",
"2 years",
"2 years",
"10+ years",
"2 years",
"2 years",
"6 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
null,
"5 years",
"1 year",
"5 years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"4 years",
"1 year",
"8 years",
"10+ years",
"10+ years",
null,
"4 years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"5 years",
"3 years",
"< 1 year",
"7 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
null,
"3 years",
"4 years",
"1 year",
"6 years",
"5 years",
"8 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
null,
"< 1 year",
"5 years",
"4 years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"< 1 year",
"1 year",
"7 years",
"3 years",
"3 years",
"10+ years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"6 years",
"1 year",
"1 year",
"9 years",
"9 years",
null,
"< 1 year",
"4 years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
null,
"10+ years",
"8 years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"6 years",
"4 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"< 1 year",
"1 year",
"2 years",
"< 1 year",
"5 years",
"< 1 year",
"4 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"2 years",
"9 years",
"6 years",
"6 years",
"< 1 year",
"7 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"6 years",
"1 year",
"10+ years",
"5 years",
"8 years",
"1 year",
"10+ years",
"3 years",
"8 years",
"10+ years",
"10+ years",
"7 years",
"< 1 year",
"< 1 year",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"3 years",
"2 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"1 year",
"4 years",
"10+ years",
"4 years",
"7 years",
"2 years",
"10+ years",
"8 years",
"7 years",
"10+ years",
"2 years",
null,
null,
"9 years",
"1 year",
"2 years",
"< 1 year",
null,
"10+ years",
"2 years",
"9 years",
"5 years",
"8 years",
"2 years",
"9 years",
null,
"10+ years",
"1 year",
"10+ years",
"2 years",
"6 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"8 years",
"5 years",
"5 years",
"10+ years",
"8 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
null,
"4 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"3 years",
null,
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"5 years",
"7 years",
"5 years",
"1 year",
null,
"3 years",
"8 years",
"1 year",
"4 years",
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"6 years",
"2 years",
"10+ years",
"3 years",
"3 years",
"9 years",
"9 years",
"3 years",
"5 years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
null,
"2 years",
"2 years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"5 years",
"7 years",
"1 year",
"10+ years",
"< 1 year",
"2 years",
"4 years",
"< 1 year",
"10+ years",
"< 1 year",
"3 years",
"5 years",
"4 years",
"10+ years",
null,
"10+ years",
"2 years",
"10+ years",
"8 years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"2 years",
"< 1 year",
"3 years",
"2 years",
"10+ years",
"10+ years",
null,
"4 years",
"1 year",
"10+ years",
"2 years",
"< 1 year",
"3 years",
"1 year",
"10+ years",
null,
"10+ years",
"5 years",
"10+ years",
"3 years",
"1 year",
"8 years",
"1 year",
"10+ years",
"6 years",
"2 years",
"1 year",
"3 years",
"1 year",
null,
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"6 years",
"10+ years",
"2 years",
"6 years",
"9 years",
"< 1 year",
"9 years",
"7 years",
"7 years",
"10+ years",
null,
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"5 years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"1 year",
"3 years",
"< 1 year",
"10+ years",
null,
null,
"10+ years",
"< 1 year",
"4 years",
"8 years",
"2 years",
"3 years",
"10+ years",
"2 years",
null,
"7 years",
"2 years",
"< 1 year",
"< 1 year",
null,
"4 years",
"7 years",
null,
"9 years",
"8 years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"7 years",
"10+ years",
"2 years",
"1 year",
"3 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"< 1 year",
"1 year",
"< 1 year",
"< 1 year",
"8 years",
"10+ years",
"1 year",
"7 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"6 years",
"< 1 year",
"2 years",
"10+ years",
"2 years",
"2 years",
"< 1 year",
"4 years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"3 years",
"5 years",
"1 year",
"10+ years",
"6 years",
"8 years",
"6 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"6 years",
"10+ years",
"10+ years",
"5 years",
"8 years",
"10+ years",
"< 1 year",
"5 years",
"8 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"9 years",
"10+ years",
"8 years",
"4 years",
"8 years",
"8 years",
"2 years",
null,
"10+ years",
"7 years",
"10+ years",
null,
"4 years",
null,
"10+ years",
"9 years",
"10+ years",
"2 years",
"3 years",
"< 1 year",
"4 years",
"4 years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"7 years",
"1 year",
"4 years",
"10+ years",
"2 years",
"9 years",
"10+ years",
"< 1 year",
"2 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"6 years",
"< 1 year",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"7 years",
"6 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"2 years",
null,
"4 years",
"7 years",
"2 years",
"5 years",
null,
"10+ years",
"7 years",
"5 years",
null,
"5 years",
"6 years",
"< 1 year",
"10+ years",
"2 years",
"1 year",
"5 years",
"3 years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"4 years",
"3 years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"1 year",
null,
"5 years",
"10+ years",
"10+ years",
"5 years",
"9 years",
"4 years",
"4 years",
"8 years",
"6 years",
"< 1 year",
"10+ years",
"9 years",
"5 years",
"10+ years",
null,
"6 years",
null,
"2 years",
"3 years",
"5 years",
null,
"10+ years",
"10+ years",
"10+ years",
null,
"2 years",
"3 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"7 years",
"1 year",
"9 years",
"9 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"6 years",
"< 1 year",
"3 years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"8 years",
"3 years",
"10+ years",
null,
"10+ years",
null,
"7 years",
"2 years",
"10+ years",
null,
"< 1 year",
null,
"8 years",
null,
null,
"2 years",
"2 years",
null,
"1 year",
"2 years",
"1 year",
null,
"10+ years",
"8 years",
"8 years",
null,
"7 years",
"3 years",
"5 years",
"5 years",
"< 1 year",
"8 years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
null,
"6 years",
"6 years",
"10+ years",
"< 1 year",
"7 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"2 years",
"1 year",
"10+ years",
"1 year",
"2 years",
"10+ years",
null,
"10+ years",
"10+ years",
"2 years",
"4 years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"9 years",
"10+ years",
"3 years",
"2 years",
"< 1 year",
null,
"9 years",
"7 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"1 year",
"3 years",
"9 years",
"7 years",
"9 years",
null,
"10+ years",
"7 years",
"2 years",
null,
"5 years",
"2 years",
"1 year",
"10+ years",
"8 years",
"5 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"1 year",
"8 years",
"10+ years",
"9 years",
"6 years",
"< 1 year",
"4 years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"1 year",
"9 years",
"3 years",
"2 years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"5 years",
"5 years",
"6 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
null,
"2 years",
"1 year",
"2 years",
"10+ years",
"1 year",
null,
"10+ years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"1 year",
"3 years",
null,
"8 years",
null,
"10+ years",
"4 years",
"10+ years",
"9 years",
"10+ years",
"7 years",
"5 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"1 year",
"2 years",
"4 years",
"2 years",
"10+ years",
"3 years",
"1 year",
"10+ years",
"2 years",
"3 years",
"10+ years",
"5 years",
null,
"3 years",
"8 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
null,
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
null,
"2 years",
"8 years",
"8 years",
"7 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"1 year",
null,
"7 years",
"10+ years",
"4 years",
null,
"3 years",
"10+ years",
"1 year",
"2 years",
"6 years",
"10+ years",
"2 years",
"3 years",
"< 1 year",
"2 years",
null,
"3 years",
"8 years",
"7 years",
"6 years",
"3 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"2 years",
"< 1 year",
"5 years",
"6 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
null,
"1 year",
"8 years",
"4 years",
"2 years",
null,
"< 1 year",
"10+ years",
"6 years",
"7 years",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"2 years",
"3 years",
null,
"4 years",
"10+ years",
"10+ years",
"7 years",
"5 years",
"10+ years",
"4 years",
"2 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"8 years",
"10+ years",
"2 years",
null,
"6 years",
null,
"8 years",
"10+ years",
"10+ years",
null,
"4 years",
"4 years",
"8 years",
"3 years",
"< 1 year",
"2 years",
"2 years",
"2 years",
"6 years",
"1 year",
"< 1 year",
"1 year",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"3 years",
"2 years",
"6 years",
null,
"< 1 year",
"2 years",
"10+ years",
null,
"< 1 year",
"5 years",
"< 1 year",
"10+ years",
"3 years",
"4 years",
"5 years",
"7 years",
"10+ years",
"3 years",
"8 years",
"2 years",
"9 years",
"8 years",
"< 1 year",
"< 1 year",
"5 years",
"2 years",
"3 years",
"6 years",
"3 years",
"< 1 year",
"7 years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"3 years",
"3 years",
"10+ years",
"9 years",
"10+ years",
"7 years",
"6 years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"2 years",
"9 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"6 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"7 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"6 years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"2 years",
"7 years",
"< 1 year",
"1 year",
"2 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"4 years",
"4 years",
"6 years",
"2 years",
"2 years",
"7 years",
"2 years",
"1 year",
"10+ years",
null,
"10+ years",
"3 years",
"10+ years",
"1 year",
"9 years",
"1 year",
"4 years",
"6 years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"4 years",
"8 years",
"7 years",
"8 years",
"8 years",
"8 years",
"3 years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"8 years",
"< 1 year",
null,
"5 years",
"3 years",
"10+ years",
"3 years",
"1 year",
"4 years",
"10+ years",
"9 years",
"3 years",
"9 years",
"2 years",
"1 year",
"2 years",
null,
"3 years",
"1 year",
"< 1 year",
"3 years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"9 years",
"5 years",
null,
"9 years",
"< 1 year",
"3 years",
"4 years",
"5 years",
"8 years",
"6 years",
null,
"1 year",
"1 year",
"9 years",
"2 years",
"10+ years",
"2 years",
"8 years",
"1 year",
"< 1 year",
"3 years",
"4 years",
"6 years",
"9 years",
"3 years",
"1 year",
"2 years",
"2 years",
null,
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"3 years",
"7 years",
"10+ years",
null,
"10+ years",
null,
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
null,
"4 years",
"10+ years",
null,
"2 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"7 years",
"2 years",
"4 years",
null,
null,
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"1 year",
"10+ years",
"7 years",
null,
"10+ years",
"7 years",
"6 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"2 years",
"1 year",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"10+ years",
"6 years",
"2 years",
"4 years",
"10+ years",
"10+ years",
null,
"10+ years",
"5 years",
"4 years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"1 year",
null,
"6 years",
"6 years",
"8 years",
"5 years",
"< 1 year",
"4 years",
"1 year",
"2 years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"4 years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"6 years",
"8 years",
"9 years",
"5 years",
"5 years",
null,
"2 years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"9 years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"4 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"2 years",
"6 years",
"1 year",
"10+ years",
"2 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"1 year",
"< 1 year",
null,
"2 years",
"3 years",
"9 years",
"< 1 year",
null,
"2 years",
"< 1 year",
"6 years",
"1 year",
null,
"10+ years",
"7 years",
"9 years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"9 years",
"1 year",
"5 years",
"7 years",
"1 year",
"2 years",
"6 years",
"10+ years",
"2 years",
"5 years",
"6 years",
"3 years",
null,
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"2 years",
"3 years",
"< 1 year",
"5 years",
"1 year",
"1 year",
"6 years",
"1 year",
"4 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"5 years",
"2 years",
"9 years",
"2 years",
"5 years",
"10+ years",
"9 years",
"2 years",
"10+ years",
"4 years",
"3 years",
"10+ years",
"1 year",
"7 years",
"9 years",
"10+ years",
"7 years",
"5 years",
null,
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"3 years",
"1 year",
"< 1 year",
"7 years",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"9 years",
"10+ years",
"6 years",
"10+ years",
"8 years",
"< 1 year",
"2 years",
"< 1 year",
"4 years",
"3 years",
"7 years",
"10+ years",
"10+ years",
null,
"5 years",
"< 1 year",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"< 1 year",
"7 years",
"10+ years",
null,
"10+ years",
"3 years",
"10+ years",
"4 years",
"4 years",
null,
"2 years",
"5 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"5 years",
"8 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"3 years",
"3 years",
"7 years",
"< 1 year",
"2 years",
"< 1 year",
"5 years",
"5 years",
"1 year",
"3 years",
"2 years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"9 years",
"10+ years",
"8 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"8 years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"7 years",
"6 years",
"2 years",
"2 years",
"10+ years",
"9 years",
"7 years",
null,
"8 years",
null,
"10+ years",
"5 years",
"5 years",
"2 years",
"10+ years",
"2 years",
"1 year",
"2 years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"9 years",
"5 years",
"6 years",
"2 years",
"7 years",
"7 years",
"1 year",
"7 years",
"10+ years",
"1 year",
"9 years",
"4 years",
"10+ years",
"8 years",
"6 years",
"10+ years",
"9 years",
"6 years",
null,
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"6 years",
null,
"3 years",
"10+ years",
"6 years",
"3 years",
"5 years",
"10+ years",
"< 1 year",
"3 years",
null,
"2 years",
"2 years",
"9 years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"2 years",
null,
"6 years",
"8 years",
"4 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"10+ years",
null,
"10+ years",
"6 years",
"10+ years",
"2 years",
"3 years",
"< 1 year",
"10+ years",
"2 years",
"6 years",
"3 years",
"10+ years",
"5 years",
"6 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"6 years",
"5 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
null,
null,
"10+ years",
"8 years",
"10+ years",
"2 years",
"< 1 year",
"2 years",
"10+ years",
"3 years",
null,
"10+ years",
"1 year",
"< 1 year",
"8 years",
"9 years",
"8 years",
"5 years",
"< 1 year",
"< 1 year",
"10+ years",
"5 years",
"2 years",
null,
"5 years",
"2 years",
"< 1 year",
"4 years",
"9 years",
"8 years",
"2 years",
"6 years",
"7 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"8 years",
"< 1 year",
"1 year",
null,
"10+ years",
"5 years",
"2 years",
"4 years",
"< 1 year",
"2 years",
"10+ years",
"4 years",
"2 years",
"10+ years",
"6 years",
"4 years",
"10+ years",
"3 years",
"10+ years",
null,
"7 years",
"6 years",
"10+ years",
"4 years",
"10+ years",
"1 year",
"7 years",
"9 years",
"10+ years",
"6 years",
"6 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"3 years",
"9 years",
"10+ years",
"< 1 year",
"6 years",
"3 years",
null,
"2 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"6 years",
"< 1 year",
"7 years",
"9 years",
null,
"< 1 year",
"3 years",
"10+ years",
"1 year",
"8 years",
null,
"10+ years",
"8 years",
"9 years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"8 years",
"4 years",
"10+ years",
"3 years",
null,
"10+ years",
"6 years",
"1 year",
"< 1 year",
"3 years",
"2 years",
"10+ years",
"9 years",
"10+ years",
null,
"4 years",
"2 years",
"6 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"8 years",
"10+ years",
"3 years",
"5 years",
"< 1 year",
"10+ years",
null,
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"5 years",
"< 1 year",
"1 year",
"5 years",
"4 years",
"10+ years",
"2 years",
null,
"< 1 year",
null,
"7 years",
"4 years",
null,
"5 years",
"9 years",
"7 years",
"1 year",
"3 years",
"6 years",
"1 year",
"1 year",
"3 years",
null,
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
null,
"9 years",
"10+ years",
"8 years",
"9 years",
"2 years",
"5 years",
"5 years",
null,
"8 years",
"1 year",
"10+ years",
"9 years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"7 years",
"10+ years",
"2 years",
"7 years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"6 years",
"9 years",
"4 years",
"< 1 year",
"8 years",
null,
"2 years",
"6 years",
"6 years",
"8 years",
"2 years",
"2 years",
"5 years",
"3 years",
"9 years",
"2 years",
"1 year",
"< 1 year",
"6 years",
"10+ years",
null,
"10+ years",
"6 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
null,
null,
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"4 years",
"9 years",
"2 years",
"4 years",
"10+ years",
"10+ years",
"5 years",
"8 years",
"3 years",
"1 year",
"1 year",
"5 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"9 years",
"3 years",
"10+ years",
"1 year",
"2 years",
"8 years",
"2 years",
"10+ years",
null,
"10+ years",
"6 years",
"9 years",
"5 years",
"8 years",
"10+ years",
"7 years",
"3 years",
"6 years",
"10+ years",
"5 years",
"8 years",
"9 years",
"1 year",
"< 1 year",
"9 years",
null,
"5 years",
"2 years",
null,
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"2 years",
"3 years",
"10+ years",
"4 years",
null,
"10+ years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"4 years",
"4 years",
null,
"10+ years",
null,
"5 years",
"8 years",
"4 years",
"8 years",
"10+ years",
null,
"10+ years",
"2 years",
"7 years",
"< 1 year",
null,
"9 years",
"3 years",
"2 years",
"5 years",
"10+ years",
"8 years",
"10+ years",
"8 years",
"9 years",
"8 years",
"10+ years",
"4 years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"< 1 year",
"3 years",
"10+ years",
"3 years",
null,
"2 years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"< 1 year",
"6 years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"7 years",
null,
"10+ years",
"5 years",
"7 years",
"10+ years",
"3 years",
"< 1 year",
"9 years",
"8 years",
"7 years",
"10+ years",
"5 years",
"10+ years",
"6 years",
"2 years",
"1 year",
"1 year",
"4 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"2 years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"6 years",
null,
"10+ years",
"5 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
null,
"10+ years",
"9 years",
"10+ years",
"1 year",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"7 years",
"5 years",
"< 1 year",
"9 years",
"10+ years",
"6 years",
"9 years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"< 1 year",
"5 years",
"6 years",
"1 year",
"7 years",
"8 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"5 years",
"4 years",
"< 1 year",
"10+ years",
"2 years",
"6 years",
"8 years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"4 years",
"7 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"5 years",
"9 years",
"8 years",
"8 years",
"10+ years",
null,
"5 years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"1 year",
"4 years",
"10+ years",
"5 years",
"2 years",
"7 years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"5 years",
"1 year",
"10+ years",
"< 1 year",
null,
"< 1 year",
"10+ years",
"6 years",
"3 years",
"1 year",
"2 years",
"9 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"4 years",
"10+ years",
"1 year",
"7 years",
"10+ years",
null,
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"1 year",
"6 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"9 years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"9 years",
"10+ years",
"10+ years",
"4 years",
"5 years",
"5 years",
"10+ years",
"10+ years",
"7 years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
null,
"10+ years",
"< 1 year",
"1 year",
"1 year",
"10+ years",
"< 1 year",
"7 years",
"5 years",
"6 years",
"< 1 year",
"10+ years",
"5 years",
"2 years",
"9 years",
null,
"10+ years",
"10+ years",
null,
null,
"< 1 year",
"3 years",
"< 1 year",
"1 year",
"10+ years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"< 1 year",
"2 years",
"2 years",
"1 year",
"3 years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"9 years",
"7 years",
"2 years",
null,
"2 years",
"9 years",
"5 years",
null,
null,
"6 years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"2 years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"4 years",
"6 years",
"5 years",
"10+ years",
"1 year",
"1 year",
"1 year",
"1 year",
"4 years",
"8 years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"9 years",
null,
"5 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"1 year",
"3 years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"3 years",
"3 years",
null,
"9 years",
null,
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"9 years",
"10+ years",
"3 years",
null,
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"4 years",
"5 years",
"3 years",
"10+ years",
"4 years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"6 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"6 years",
"9 years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"< 1 year",
"< 1 year",
"10+ years",
"6 years",
"5 years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"9 years",
"1 year",
"3 years",
"4 years",
"3 years",
"5 years",
"2 years",
"4 years",
"2 years",
"4 years",
"4 years",
"3 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"9 years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"< 1 year",
"6 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"6 years",
"1 year",
"10+ years",
"9 years",
"2 years",
"6 years",
"10+ years",
"6 years",
"10+ years",
null,
"5 years",
"1 year",
"10+ years",
"8 years",
"2 years",
"4 years",
"6 years",
"10+ years",
"2 years",
null,
"8 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"7 years",
"10+ years",
"5 years",
"5 years",
"5 years",
"10+ years",
null,
"10+ years",
"2 years",
"2 years",
"10+ years",
"5 years",
"1 year",
null,
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
"2 years",
"4 years",
"6 years",
"5 years",
"10+ years",
"< 1 year",
"9 years",
"10+ years",
"5 years",
"5 years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"1 year",
"2 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
null,
"1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"7 years",
null,
"2 years",
"3 years",
"9 years",
"7 years",
"4 years",
"< 1 year",
"2 years",
"2 years",
"2 years",
"10+ years",
"4 years",
"< 1 year",
null,
"10+ years",
"3 years",
"2 years",
"10+ years",
"< 1 year",
"4 years",
null,
"10+ years",
"10+ years",
"10+ years",
"7 years",
"4 years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"9 years",
"10+ years",
"10+ years",
null,
"10+ years",
"7 years",
"9 years",
"< 1 year",
"< 1 year",
"7 years",
"5 years",
"4 years",
"8 years",
"1 year",
"6 years",
"6 years",
"< 1 year",
"5 years",
"2 years",
"9 years",
"1 year",
"9 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"9 years",
"10+ years",
"10+ years",
"8 years",
null,
"4 years",
"2 years",
"8 years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"1 year",
"2 years",
"4 years",
"6 years",
"3 years",
"2 years",
"1 year",
"10+ years",
"1 year",
"< 1 year",
"5 years",
"8 years",
"10+ years",
"5 years",
"4 years",
"10+ years",
"10+ years",
"6 years",
"9 years",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"8 years",
"8 years",
null,
"< 1 year",
"4 years",
null,
"10+ years",
"5 years",
"10+ years",
"7 years",
null,
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"9 years",
null,
null,
"< 1 year",
"< 1 year",
"5 years",
"7 years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"9 years",
"2 years",
"< 1 year",
"2 years",
"2 years",
"10+ years",
"3 years",
"9 years",
"10+ years",
"9 years",
"10+ years",
"7 years",
"6 years",
"10+ years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"6 years",
"< 1 year",
"5 years",
"5 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"4 years",
"7 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"1 year",
"10+ years",
"9 years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"6 years",
"4 years",
"10+ years",
"10+ years",
"4 years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"5 years",
"< 1 year",
"10+ years",
null,
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"1 year",
"< 1 year",
"1 year",
"5 years",
"2 years",
"10+ years",
"5 years",
null,
"5 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"5 years",
"6 years",
"2 years",
"10+ years",
"2 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
null,
"6 years",
"1 year",
"2 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"2 years",
"1 year",
"1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"1 year",
"3 years",
"4 years",
"6 years",
"4 years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"5 years",
"10+ years",
null,
"10+ years",
"7 years",
"2 years",
"2 years",
"2 years",
"10+ years",
"8 years",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"< 1 year",
"6 years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"2 years",
"9 years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"1 year",
"3 years",
"10+ years",
"5 years",
"8 years",
"2 years",
"7 years",
"3 years",
"10+ years",
"10+ years",
"3 years",
null,
"6 years",
"2 years",
"3 years",
"2 years",
"10+ years",
"3 years",
"2 years",
"5 years",
"4 years",
"2 years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"5 years",
"6 years",
"< 1 year",
"6 years",
"7 years",
"10+ years",
"5 years",
"2 years",
"8 years",
"10+ years",
"2 years",
"6 years",
"8 years",
"< 1 year",
"1 year",
"10+ years",
"6 years",
"1 year",
"10+ years",
null,
"< 1 year",
"1 year",
"6 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"6 years",
null,
"10+ years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"6 years",
"< 1 year",
"10+ years",
null,
"7 years",
"10+ years",
"10+ years",
null,
"10+ years",
"4 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"4 years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"4 years",
"6 years",
"3 years",
"3 years",
"10+ years",
"7 years",
"3 years",
"4 years",
"10+ years",
"9 years",
"1 year",
"10+ years",
"5 years",
"2 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"3 years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"9 years",
"4 years",
"2 years",
"6 years",
"7 years",
"9 years",
"< 1 year",
"10+ years",
"< 1 year",
"6 years",
"4 years",
"4 years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"5 years",
"3 years",
"< 1 year",
"10+ years",
"2 years",
"< 1 year",
"7 years",
"1 year",
"7 years",
"10+ years",
null,
null,
"8 years",
"6 years",
"10+ years",
"8 years",
"4 years",
"10+ years",
"10+ years",
"4 years",
"4 years",
"10+ years",
null,
"4 years",
"10+ years",
"7 years",
"< 1 year",
null,
"10+ years",
null,
"7 years",
"8 years",
"3 years",
"2 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"9 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"10+ years",
null,
"6 years",
"3 years",
"2 years",
"5 years",
"5 years",
"6 years",
"2 years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"9 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"4 years",
"9 years",
"2 years",
"10+ years",
"10+ years",
"9 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"9 years",
"3 years",
"9 years",
"4 years",
"5 years",
"3 years",
"4 years",
"1 year",
"2 years",
null,
"3 years",
"7 years",
"2 years",
"< 1 year",
"6 years",
null,
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"1 year",
"6 years",
"7 years",
"6 years",
"< 1 year",
"10+ years",
"9 years",
null,
"10+ years",
"8 years",
"5 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"8 years",
"4 years",
"2 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"5 years",
"< 1 year",
"< 1 year",
"10+ years",
"2 years",
"9 years",
"2 years",
"6 years",
"10+ years",
"9 years",
"< 1 year",
"2 years",
"2 years",
"10+ years",
null,
"1 year",
"10+ years",
"8 years",
"< 1 year",
"5 years",
null,
"3 years",
"2 years",
"3 years",
"10+ years",
"9 years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
null,
null,
"10+ years",
"5 years",
"4 years",
"9 years",
"2 years",
"< 1 year",
"3 years",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"6 years",
"3 years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"3 years",
null,
"10+ years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"4 years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
null,
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"8 years",
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"8 years",
"4 years",
"2 years",
"10+ years",
"6 years",
"1 year",
"2 years",
"< 1 year",
null,
"10+ years",
"6 years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"6 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
null,
"4 years",
"10+ years",
"4 years",
"2 years",
"4 years",
"4 years",
"8 years",
"10+ years",
null,
"5 years",
"9 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"6 years",
"2 years",
"9 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"< 1 year",
"2 years",
"5 years",
"2 years",
"1 year",
"3 years",
"10+ years",
null,
"3 years",
"10+ years",
null,
"10+ years",
"2 years",
"< 1 year",
"9 years",
"7 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
null,
"< 1 year",
null,
"9 years",
"1 year",
"7 years",
"3 years",
"10+ years",
"4 years",
null,
"2 years",
"4 years",
"1 year",
null,
"4 years",
"9 years",
"< 1 year",
"4 years",
"9 years",
"< 1 year",
"7 years",
"3 years",
"10+ years",
"5 years",
"3 years",
"9 years",
"8 years",
"4 years",
"< 1 year",
"1 year",
"4 years",
"7 years",
null,
"2 years",
"2 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"5 years",
"10+ years",
"9 years",
"2 years",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"9 years",
"1 year",
"< 1 year",
"10+ years",
"2 years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"3 years",
"< 1 year",
"6 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"1 year",
"2 years",
"10+ years",
"10+ years",
null,
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"3 years",
null,
"5 years",
"2 years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"5 years",
null,
"10+ years",
"6 years",
"2 years",
"< 1 year",
null,
null,
"1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"5 years",
"1 year",
"6 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
null,
"< 1 year",
"8 years",
"1 year",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"7 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"9 years",
null,
"2 years",
"< 1 year",
"2 years",
"2 years",
"3 years",
"4 years",
"4 years",
"10+ years",
"2 years",
"2 years",
"5 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"6 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"7 years",
"6 years",
"3 years",
"1 year",
"10+ years",
"4 years",
"8 years",
"7 years",
"4 years",
"3 years",
"10+ years",
"5 years",
"5 years",
"2 years",
"10+ years",
"8 years",
"1 year",
"5 years",
"5 years",
"3 years",
"10+ years",
"7 years",
"10+ years",
"1 year",
"2 years",
"6 years",
"2 years",
"2 years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"2 years",
null,
"< 1 year",
"1 year",
null,
"10+ years",
"6 years",
"10+ years",
"5 years",
"2 years",
"6 years",
"4 years",
"10+ years",
"4 years",
null,
"5 years",
"10+ years",
"10+ years",
"5 years",
"1 year",
"7 years",
"5 years",
"1 year",
"< 1 year",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"9 years",
"8 years",
"2 years",
"1 year",
"2 years",
"10+ years",
"5 years",
"3 years",
"6 years",
"1 year",
"4 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"2 years",
"6 years",
"< 1 year",
null,
"3 years",
"5 years",
"10+ years",
"8 years",
"10+ years",
"6 years",
"< 1 year",
null,
"6 years",
"10+ years",
"2 years",
"2 years",
"8 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"7 years",
"6 years",
"5 years",
"6 years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
null,
"2 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"6 years",
"1 year",
"10+ years",
"1 year",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"9 years",
"2 years",
"7 years",
"9 years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"6 years",
"10+ years",
"7 years",
"3 years",
"10+ years",
null,
"< 1 year",
"10+ years",
"9 years",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
null,
"10+ years",
"2 years",
null,
"10+ years",
"4 years",
"5 years",
"3 years",
"8 years",
"< 1 year",
"2 years",
"10+ years",
"7 years",
"7 years",
"4 years",
"5 years",
"1 year",
"4 years",
"< 1 year",
"2 years",
"1 year",
"1 year",
"4 years",
"< 1 year",
"7 years",
"10+ years",
null,
"10+ years",
"4 years",
"8 years",
"10+ years",
"7 years",
"7 years",
"1 year",
"10+ years",
null,
"2 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"5 years",
"5 years",
"4 years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"2 years",
"4 years",
"10+ years",
"8 years",
"2 years",
"7 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"6 years",
"4 years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"10+ years",
null,
"10+ years",
"7 years",
"7 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"4 years",
"1 year",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"5 years",
"3 years",
"6 years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"7 years",
null,
"7 years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"2 years",
"8 years",
null,
"< 1 year",
null,
"3 years",
"7 years",
"2 years",
"9 years",
"2 years",
"3 years",
"10+ years",
"5 years",
"3 years",
"4 years",
"3 years",
"8 years",
"4 years",
"10+ years",
"3 years",
"8 years",
"2 years",
"10+ years",
"3 years",
null,
"10+ years",
"< 1 year",
null,
"1 year",
"1 year",
"2 years",
"10+ years",
"1 year",
"1 year",
"8 years",
"9 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
null,
null,
"10+ years",
"4 years",
"10+ years",
"5 years",
null,
"1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"3 years",
"7 years",
"8 years",
"5 years",
"3 years",
"10+ years",
"1 year",
"3 years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"9 years",
"2 years",
"2 years",
null,
"< 1 year",
null,
"10+ years",
"< 1 year",
"7 years",
"1 year",
"7 years",
"< 1 year",
"3 years",
"10+ years",
"1 year",
null,
"1 year",
"10+ years",
"4 years",
"10+ years",
"7 years",
"6 years",
"3 years",
"1 year",
"10+ years",
null,
"3 years",
"3 years",
"1 year",
"2 years",
"4 years",
"10+ years",
"9 years",
"2 years",
"6 years",
"10+ years",
"10+ years",
"8 years",
"3 years",
null,
"8 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"2 years",
"6 years",
null,
"10+ years",
"1 year",
"< 1 year",
"3 years",
"8 years",
"1 year",
null,
"10+ years",
"9 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"8 years",
"7 years",
"9 years",
null,
"10+ years",
"10+ years",
"2 years",
"3 years",
"7 years",
"9 years",
"7 years",
"4 years",
"10+ years",
"8 years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"4 years",
"8 years",
"1 year",
"3 years",
"10+ years",
"1 year",
"4 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"8 years",
"2 years",
"2 years",
"3 years",
"2 years",
"7 years",
"8 years",
"10+ years",
"4 years",
"5 years",
"6 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"8 years",
"4 years",
"3 years",
"2 years",
"1 year",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"1 year",
"7 years",
"7 years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"5 years",
"10+ years",
"1 year",
"2 years",
"4 years",
"1 year",
"2 years",
null,
"8 years",
"10+ years",
"4 years",
"< 1 year",
"6 years",
"8 years",
"7 years",
"1 year",
"5 years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"1 year",
"4 years",
"3 years",
"4 years",
"< 1 year",
"5 years",
"3 years",
"2 years",
"5 years",
"4 years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"3 years",
null,
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"5 years",
"8 years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"7 years",
"2 years",
"6 years",
"3 years",
"4 years",
"2 years",
"6 years",
"8 years",
"10+ years",
"10+ years",
"7 years",
"5 years",
"1 year",
"10+ years",
"7 years",
null,
"3 years",
"4 years",
"< 1 year",
"10+ years",
"2 years",
"9 years",
"2 years",
"1 year",
"10+ years",
"3 years",
"< 1 year",
"8 years",
"< 1 year",
"2 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
null,
"5 years",
"9 years",
"10+ years",
"5 years",
"4 years",
"10+ years",
"1 year",
"4 years",
"8 years",
"10+ years",
"8 years",
null,
"10+ years",
"10+ years",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
null,
"6 years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"3 years",
"6 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"3 years",
"< 1 year",
"10+ years",
"< 1 year",
"1 year",
"3 years",
"6 years",
"3 years",
"4 years",
"6 years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"6 years",
"10+ years",
"5 years",
"10+ years",
"8 years",
"1 year",
"3 years",
null,
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"< 1 year",
"8 years",
"< 1 year",
"10+ years",
"4 years",
"9 years",
null,
"3 years",
"< 1 year",
"5 years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"7 years",
"3 years",
"6 years",
"10+ years",
"10+ years",
"8 years",
"2 years",
"7 years",
"3 years",
"9 years",
"7 years",
"< 1 year",
"4 years",
"5 years",
"7 years",
"6 years",
"10+ years",
"2 years",
"10+ years",
"8 years",
"6 years",
"< 1 year",
"2 years",
"< 1 year",
"6 years",
null,
"< 1 year",
"< 1 year",
"8 years",
"9 years",
"10+ years",
"1 year",
"< 1 year",
"9 years",
"3 years",
"10+ years",
null,
"8 years",
"10+ years",
"6 years",
"2 years",
null,
"10+ years",
"4 years",
"8 years",
"< 1 year",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
null,
"4 years",
"2 years",
"4 years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"4 years",
"9 years",
null,
"2 years",
"10+ years",
null,
"5 years",
"7 years",
"1 year",
"10+ years",
"< 1 year",
"< 1 year",
"2 years",
"3 years",
"2 years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
null,
"10+ years",
"5 years",
null,
"10+ years",
"7 years",
"< 1 year",
"2 years",
"5 years",
null,
"7 years",
"5 years",
"3 years",
"1 year",
"1 year",
"7 years",
"7 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"5 years",
"< 1 year",
"10+ years",
"2 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"5 years",
"2 years",
"6 years",
"4 years",
"1 year",
"3 years",
"10+ years",
"3 years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"2 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"7 years",
"6 years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
null,
"< 1 year",
null,
"2 years",
"5 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"2 years",
"10+ years",
"2 years",
"5 years",
null,
"8 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
null,
"5 years",
"2 years",
"6 years",
"10+ years",
"1 year",
"2 years",
"9 years",
"7 years",
"3 years",
"5 years",
"4 years",
"5 years",
"3 years",
"5 years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"9 years",
"7 years",
"10+ years",
"10+ years",
"8 years",
"7 years",
"10+ years",
null,
"6 years",
null,
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"1 year",
null,
"10+ years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"2 years",
"< 1 year",
"5 years",
"1 year",
"4 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"7 years",
"< 1 year",
"< 1 year",
"10+ years",
"7 years",
"< 1 year",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
null,
"3 years",
"5 years",
null,
"7 years",
"3 years",
"< 1 year",
"4 years",
"1 year",
"5 years",
"< 1 year",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"6 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
null,
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"2 years",
"10+ years",
"1 year",
"4 years",
"10+ years",
"4 years",
null,
"3 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"9 years",
"1 year",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"2 years",
"3 years",
null,
"10+ years",
"10+ years",
"1 year",
"4 years",
"4 years",
"5 years",
null,
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"7 years",
null,
"2 years",
"< 1 year",
"6 years",
"2 years",
"10+ years",
"< 1 year",
"4 years",
"3 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
null,
null,
"6 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"6 years",
"4 years",
"10+ years",
null,
"< 1 year",
"8 years",
null,
"1 year",
"10+ years",
null,
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"3 years",
"4 years",
"9 years",
"10+ years",
"9 years",
"2 years",
"1 year",
"7 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
null,
"10+ years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
null,
"6 years",
"10+ years",
"10+ years",
"2 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
null,
"9 years",
"1 year",
"8 years",
"< 1 year",
"2 years",
"1 year",
"4 years",
"2 years",
null,
"< 1 year",
"10+ years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
null,
"5 years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"2 years",
"3 years",
"10+ years",
"1 year",
"2 years",
"2 years",
"8 years",
"3 years",
"4 years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"4 years",
"1 year",
"6 years",
"9 years",
"6 years",
"1 year",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"< 1 year",
"2 years",
"5 years",
"8 years",
"7 years",
"10+ years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"9 years",
"3 years",
"9 years",
"1 year",
"3 years",
"< 1 year",
"6 years",
"6 years",
"5 years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"2 years",
"7 years",
"10+ years",
"3 years",
"2 years",
"2 years",
"8 years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"1 year",
"1 year",
null,
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"4 years",
null,
"7 years",
"6 years",
"10+ years",
"2 years",
"7 years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"7 years",
"4 years",
"5 years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"6 years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"8 years",
"6 years",
null,
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"< 1 year",
"4 years",
"2 years",
"5 years",
"4 years",
"7 years",
"1 year",
"10+ years",
"7 years",
null,
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
null,
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"7 years",
"4 years",
"10+ years",
"< 1 year",
"3 years",
"4 years",
"< 1 year",
"4 years",
"10+ years",
"9 years",
"< 1 year",
"1 year",
"1 year",
"3 years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"8 years",
"2 years",
"9 years",
"10+ years",
"10+ years",
"9 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"4 years",
"10+ years",
"9 years",
"10+ years",
"4 years",
"1 year",
"3 years",
"10+ years",
"8 years",
"10+ years",
"4 years",
"6 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"< 1 year",
"3 years",
"2 years",
"7 years",
"5 years",
"8 years",
"1 year",
"10+ years",
"10+ years",
null,
"2 years",
null,
"5 years",
"5 years",
"3 years",
"10+ years",
"4 years",
"1 year",
"9 years",
"4 years",
"2 years",
"10+ years",
"1 year",
"1 year",
"< 1 year",
"10+ years",
"2 years",
"4 years",
"10+ years",
"< 1 year",
"3 years",
"9 years",
null,
"7 years",
"2 years",
"1 year",
"3 years",
"2 years",
"10+ years",
null,
null,
"5 years",
"1 year",
"6 years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"8 years",
null,
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"3 years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"2 years",
"6 years",
"2 years",
"1 year",
"3 years",
"2 years",
"7 years",
"2 years",
"4 years",
"3 years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"1 year",
"4 years",
"1 year",
"10+ years",
"2 years",
"5 years",
"10+ years",
null,
"1 year",
"7 years",
"3 years",
"< 1 year",
"9 years",
"10+ years",
"8 years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"7 years",
"5 years",
"4 years",
"10+ years",
"1 year",
"4 years",
"3 years",
"4 years",
null,
"4 years",
"4 years",
"10+ years",
null,
"7 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"6 years",
"4 years",
"4 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"1 year",
"7 years",
"10+ years",
"6 years",
"1 year",
"< 1 year",
"8 years",
"10+ years",
"1 year",
"10+ years",
"5 years",
"10+ years",
"6 years",
"3 years",
"6 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"7 years",
"7 years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"10+ years",
"7 years",
"10+ years",
"8 years",
null,
"7 years",
"2 years",
"4 years",
"9 years",
"10+ years",
"3 years",
"< 1 year",
"4 years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"3 years",
"2 years",
"2 years",
"3 years",
"9 years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"8 years",
"2 years",
"10+ years",
"8 years",
"9 years",
null,
"5 years",
"2 years",
"< 1 year",
"< 1 year",
"10+ years",
"2 years",
"2 years",
"3 years",
"6 years",
"10+ years",
null,
"10+ years",
"10+ years",
"4 years",
"2 years",
"8 years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"5 years",
"6 years",
"3 years",
"7 years",
"3 years",
"10+ years",
"1 year",
"7 years",
"3 years",
"5 years",
"10+ years",
"1 year",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"9 years",
"10+ years",
"9 years",
"10+ years",
"5 years",
"9 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"6 years",
"8 years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"6 years",
"10+ years",
"1 year",
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"2 years",
"< 1 year",
"2 years",
"9 years",
"< 1 year",
"8 years",
"5 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"< 1 year",
"6 years",
"10+ years",
"7 years",
"7 years",
"2 years",
"5 years",
"8 years",
"10+ years",
"7 years",
"1 year",
"9 years",
"3 years",
"2 years",
"3 years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"4 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
null,
"< 1 year",
"10+ years",
"6 years",
"4 years",
"2 years",
"8 years",
"< 1 year",
"3 years",
"7 years",
"2 years",
"10+ years",
"5 years",
"2 years",
"1 year",
"5 years",
"8 years",
"8 years",
"7 years",
"10+ years",
"< 1 year",
"3 years",
"< 1 year",
"4 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"7 years",
"7 years",
"6 years",
"10+ years",
"< 1 year",
"4 years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"7 years",
"< 1 year",
"10+ years",
"2 years",
"3 years",
"< 1 year",
"9 years",
"< 1 year",
"5 years",
"3 years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"3 years",
"8 years",
"10+ years",
"10+ years",
null,
"5 years",
"9 years",
"10+ years",
"8 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"< 1 year",
"8 years",
"7 years",
"9 years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"5 years",
"1 year",
"10+ years",
"9 years",
"6 years",
"< 1 year",
"7 years",
"7 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
null,
null,
"6 years",
"2 years",
"4 years",
"10+ years",
"4 years",
"2 years",
"8 years",
"8 years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
"3 years",
"< 1 year",
"3 years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"5 years",
"< 1 year",
"10+ years",
"< 1 year",
"8 years",
"2 years",
"7 years",
"< 1 year",
"3 years",
"5 years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"1 year",
"9 years",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"2 years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"8 years",
"< 1 year",
"5 years",
"10+ years",
"9 years",
"4 years",
"4 years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"8 years",
"4 years",
"5 years",
"7 years",
"< 1 year",
"7 years",
"< 1 year",
"3 years",
null,
"2 years",
"7 years",
"6 years",
"10+ years",
"5 years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"5 years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
null,
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"2 years",
"6 years",
"5 years",
"10+ years",
"5 years",
"< 1 year",
"1 year",
"10+ years",
"7 years",
"1 year",
"2 years",
"6 years",
"7 years",
"4 years",
"8 years",
"1 year",
"10+ years",
"8 years",
"4 years",
"7 years",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"8 years",
"5 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"7 years",
"3 years",
"9 years",
"9 years",
"6 years",
"1 year",
"2 years",
"4 years",
"2 years",
"< 1 year",
"9 years",
"10+ years",
"3 years",
"1 year",
null,
"8 years",
"6 years",
"2 years",
"7 years",
"10+ years",
null,
"1 year",
"10+ years",
"5 years",
"5 years",
"7 years",
"6 years",
"5 years",
"7 years",
"< 1 year",
"7 years",
"1 year",
"9 years",
null,
"3 years",
"< 1 year",
"3 years",
"3 years",
null,
"10+ years",
"10+ years",
"4 years",
"10+ years",
"7 years",
"2 years",
"< 1 year",
"5 years",
"8 years",
"2 years",
"10+ years",
null,
"10+ years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"2 years",
"< 1 year",
"5 years",
"5 years",
"4 years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"6 years",
"1 year",
null,
"10+ years",
"6 years",
"3 years",
"10+ years",
"9 years",
"9 years",
"3 years",
"7 years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"6 years",
"2 years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"< 1 year",
"10+ years",
"3 years",
"1 year",
"6 years",
"4 years",
"9 years",
"1 year",
"10+ years",
"4 years",
"5 years",
"8 years",
"3 years",
"9 years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"4 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"8 years",
"9 years",
"4 years",
"3 years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"8 years",
"5 years",
"9 years",
"10+ years",
"10+ years",
"1 year",
"7 years",
"10+ years",
"2 years",
"< 1 year",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"2 years",
"3 years",
"9 years",
"2 years",
"2 years",
"3 years",
"1 year",
null,
null,
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"< 1 year",
"10+ years",
"5 years",
"6 years",
"5 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"10+ years",
null,
"5 years",
"< 1 year",
"10+ years",
"2 years",
"3 years",
"5 years",
"< 1 year",
"2 years",
"6 years",
"5 years",
"1 year",
"8 years",
"6 years",
"2 years",
"4 years",
"9 years",
"10+ years",
"10+ years",
null,
"< 1 year",
"3 years",
"< 1 year",
"5 years",
"2 years",
"5 years",
"8 years",
null,
null,
"10+ years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"8 years",
"5 years",
"6 years",
"4 years",
"2 years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"5 years",
"3 years",
"10+ years",
"5 years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
null,
"8 years",
"4 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"6 years",
"2 years",
"2 years",
"< 1 year",
"9 years",
"2 years",
"10+ years",
"8 years",
null,
"5 years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"1 year",
"1 year",
null,
"10+ years",
"3 years",
"1 year",
"7 years",
"8 years",
"< 1 year",
"10+ years",
"2 years",
"2 years",
"4 years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"5 years",
"2 years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"7 years",
"10+ years",
"4 years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"9 years",
null,
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"7 years",
"7 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"6 years",
"< 1 year",
"8 years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"4 years",
"7 years",
"7 years",
"< 1 year",
"10+ years",
"3 years",
"8 years",
"2 years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"10+ years",
"8 years",
"2 years",
"2 years",
"6 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"2 years",
null,
"2 years",
"5 years",
"9 years",
"7 years",
"5 years",
"2 years",
"9 years",
"3 years",
"3 years",
null,
"10+ years",
"< 1 year",
"3 years",
null,
"10+ years",
"10+ years",
"6 years",
"4 years",
"10+ years",
"9 years",
"10+ years",
"7 years",
"6 years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"< 1 year",
"< 1 year",
"5 years",
"5 years",
"3 years",
"10+ years",
null,
"5 years",
null,
"5 years",
"6 years",
"< 1 year",
"< 1 year",
"9 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"1 year",
"3 years",
"10+ years",
"5 years",
"5 years",
"7 years",
null,
"9 years",
"7 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"2 years",
"9 years",
"9 years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"5 years",
"10+ years",
null,
null,
"10+ years",
"6 years",
"< 1 year",
"7 years",
"8 years",
"3 years",
"8 years",
"3 years",
null,
"10+ years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"10+ years",
"3 years",
"8 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"1 year",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"7 years",
null,
"9 years",
"1 year",
"10+ years",
"2 years",
"< 1 year",
null,
"6 years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"6 years",
"6 years",
"10+ years",
"3 years",
"2 years",
"1 year",
"10+ years",
"1 year",
"2 years",
"1 year",
"9 years",
"10+ years",
"10+ years",
null,
"4 years",
"10+ years",
"10+ years",
null,
"5 years",
null,
"6 years",
"8 years",
"7 years",
"6 years",
"9 years",
"10+ years",
"6 years",
"10+ years",
"9 years",
"4 years",
"2 years",
"2 years",
"< 1 year",
"2 years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"8 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"9 years",
"4 years",
"8 years",
"< 1 year",
null,
"9 years",
"9 years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"4 years",
"5 years",
"6 years",
"8 years",
"5 years",
"2 years",
"1 year",
"10+ years",
null,
"9 years",
"6 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"2 years",
"2 years",
"1 year",
"4 years",
"6 years",
"10+ years",
"10+ years",
"9 years",
null,
"2 years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"6 years",
"1 year",
"2 years",
"1 year",
"5 years",
"3 years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
null,
"10+ years",
"7 years",
"9 years",
"2 years",
"1 year",
"< 1 year",
null,
"5 years",
"2 years",
null,
"10+ years",
"10+ years",
"8 years",
"1 year",
"3 years",
"1 year",
"< 1 year",
"6 years",
"4 years",
"< 1 year",
"8 years",
"10+ years",
"5 years",
"10+ years",
"1 year",
null,
"10+ years",
"< 1 year",
"3 years",
"< 1 year",
"2 years",
"8 years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"5 years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"7 years",
"5 years",
"7 years",
"10+ years",
null,
"5 years",
"2 years",
"6 years",
"7 years",
"2 years",
"10+ years",
"1 year",
"8 years",
"4 years",
"< 1 year",
null,
"9 years",
"8 years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"7 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"8 years",
"1 year",
"6 years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"5 years",
"10+ years",
"4 years",
"8 years",
"< 1 year",
"4 years",
"2 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
null,
"3 years",
"8 years",
"10+ years",
"9 years",
"5 years",
"8 years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"2 years",
"4 years",
"7 years",
"1 year",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"5 years",
"5 years",
"10+ years",
"6 years",
"1 year",
"10+ years",
null,
"10+ years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"3 years",
"4 years",
"2 years",
"1 year",
"5 years",
"2 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"1 year",
"10+ years",
"8 years",
"2 years",
"10+ years",
"4 years",
"5 years",
"4 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"8 years",
"8 years",
"4 years",
"10+ years",
"10+ years",
"6 years",
"5 years",
"3 years",
"10+ years",
"1 year",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"2 years",
"1 year",
"8 years",
"10+ years",
"1 year",
"3 years",
"7 years",
"10+ years",
"6 years",
"3 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"2 years",
"< 1 year",
"10+ years",
null,
"< 1 year",
"10+ years",
null,
"10+ years",
"10+ years",
null,
"10+ years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"10+ years",
null,
"10+ years",
"10+ years",
"3 years",
"5 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"7 years",
"3 years",
"< 1 year",
"< 1 year",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"5 years",
"3 years",
null,
"6 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
null,
"8 years",
"10+ years",
"4 years",
"4 years",
"7 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"1 year",
"4 years",
"5 years",
"< 1 year",
"7 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"9 years",
"2 years",
"8 years",
"< 1 year",
"< 1 year",
"< 1 year",
"1 year",
"2 years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"4 years",
"4 years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"8 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"1 year",
"7 years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"2 years",
"10+ years",
"1 year",
"2 years",
"3 years",
"6 years",
"9 years",
"10+ years",
"8 years",
"3 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"8 years",
"9 years",
"9 years",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
null,
"8 years",
"7 years",
"2 years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"< 1 year",
"< 1 year",
"4 years",
"< 1 year",
"7 years",
"2 years",
"< 1 year",
"10+ years",
"9 years",
"4 years",
"3 years",
"3 years",
"10+ years",
"2 years",
"5 years",
"7 years",
"3 years",
"2 years",
null,
"5 years",
"4 years",
"4 years",
"9 years",
"5 years",
null,
"2 years",
"10+ years",
null,
"10+ years",
"5 years",
null,
"4 years",
"5 years",
"10+ years",
null,
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"10+ years",
null,
"10+ years",
"< 1 year",
"4 years",
null,
"2 years",
"7 years",
"2 years",
"10+ years",
"6 years",
"8 years",
"10+ years",
"8 years",
"10+ years",
"1 year",
"< 1 year",
null,
"10+ years",
"6 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"2 years",
null,
null,
"7 years",
"1 year",
"< 1 year",
"8 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"4 years",
"< 1 year",
"10+ years",
"3 years",
"8 years",
"2 years",
"6 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"1 year",
"8 years",
"8 years",
"10+ years",
"2 years",
"8 years",
"9 years",
"2 years",
"7 years",
"3 years",
"2 years",
"< 1 year",
"7 years",
"10+ years",
"9 years",
"2 years",
"5 years",
null,
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
null,
"7 years",
"10+ years",
null,
null,
"7 years",
"3 years",
"2 years",
"10+ years",
"< 1 year",
"< 1 year",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"< 1 year",
"10+ years",
"5 years",
"9 years",
"1 year",
"10+ years",
"7 years",
"4 years",
"1 year",
"10+ years",
"5 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"4 years",
"1 year",
"< 1 year",
"3 years",
null,
"1 year",
"7 years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"10+ years",
"4 years",
"3 years",
"10+ years",
"8 years",
"2 years",
"1 year",
"4 years",
"2 years",
"10+ years",
"6 years",
"< 1 year",
"8 years",
"10+ years",
"3 years",
"5 years",
"2 years",
"4 years",
"6 years",
"5 years",
"8 years",
"< 1 year",
"10+ years",
"3 years",
"3 years",
"3 years",
"10+ years",
"4 years",
"4 years",
"10+ years",
"2 years",
"8 years",
"9 years",
"8 years",
"10+ years",
"4 years",
null,
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
null,
"1 year",
"10+ years",
"4 years",
"3 years",
"5 years",
"1 year",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"5 years",
"6 years",
"7 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"1 year",
"5 years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
null,
"3 years",
"10+ years",
"10+ years",
"9 years",
"2 years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
null,
null,
null,
"7 years",
"7 years",
"10+ years",
"6 years",
"3 years",
"4 years",
"< 1 year",
"2 years",
"2 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"3 years",
"2 years",
"4 years",
"8 years",
"4 years",
"< 1 year",
null,
null,
"10+ years",
"3 years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"7 years",
"4 years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"3 years",
"7 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"10+ years",
null,
"9 years",
"10+ years",
"6 years",
"10+ years",
null,
null,
"5 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"7 years",
"6 years",
"1 year",
"3 years",
"2 years",
"2 years",
"10+ years",
"5 years",
"6 years",
"10+ years",
"1 year",
"10+ years",
"6 years",
"< 1 year",
"4 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"5 years",
"1 year",
"< 1 year",
"10+ years",
"1 year",
"1 year",
"10+ years",
"7 years",
"3 years",
"< 1 year",
"10+ years",
"4 years",
null,
"< 1 year",
"6 years",
null,
"2 years",
"4 years",
"1 year",
"7 years",
"10+ years",
null,
"5 years",
"2 years",
"8 years",
"8 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"10+ years",
null,
"4 years",
"5 years",
"5 years",
"9 years",
"10+ years",
"3 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"9 years",
"4 years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
null,
"9 years",
"2 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"< 1 year",
"4 years",
"5 years",
"10+ years",
"7 years",
"5 years",
"6 years",
"6 years",
"2 years",
"< 1 year",
"3 years",
"8 years",
"8 years",
"5 years",
"10+ years",
"3 years",
"< 1 year",
"4 years",
"4 years",
"2 years",
"8 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"9 years",
"10+ years",
"7 years",
"3 years",
"5 years",
"6 years",
"4 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"6 years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"< 1 year",
"4 years",
"7 years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"5 years",
"1 year",
"1 year",
"4 years",
"3 years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"10+ years",
null,
"3 years",
"3 years",
"10+ years",
"1 year",
"4 years",
"1 year",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"2 years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"6 years",
"7 years",
"2 years",
null,
"9 years",
null,
"2 years",
"< 1 year",
"9 years",
"2 years",
"8 years",
"2 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"2 years",
"9 years",
"6 years",
"10+ years",
"1 year",
"4 years",
"9 years",
"5 years",
"9 years",
"< 1 year",
"9 years",
"2 years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"5 years",
null,
"4 years",
"6 years",
"6 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"3 years",
"7 years",
"1 year",
"3 years",
"3 years",
"4 years",
"3 years",
"2 years",
"1 year",
"3 years",
null,
"7 years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"6 years",
"3 years",
"8 years",
"1 year",
null,
"10+ years",
"8 years",
"10+ years",
"6 years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"5 years",
"9 years",
"3 years",
"5 years",
null,
"10+ years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"2 years",
"10+ years",
"2 years",
"< 1 year",
"1 year",
"1 year",
"2 years",
"3 years",
"< 1 year",
"5 years",
"2 years",
"10+ years",
"3 years",
"9 years",
"10+ years",
"8 years",
"6 years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"9 years",
null,
"7 years",
"1 year",
"7 years",
"7 years",
"8 years",
"5 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"< 1 year",
"< 1 year",
"3 years",
"< 1 year",
"5 years",
"8 years",
"5 years",
"1 year",
"5 years",
"< 1 year",
"8 years",
"4 years",
"6 years",
"1 year",
"2 years",
"5 years",
"10+ years",
"6 years",
"3 years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
null,
"5 years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"2 years",
"4 years",
"2 years",
"10+ years",
"2 years",
"7 years",
"2 years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"< 1 year",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"5 years",
"6 years",
"5 years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"8 years",
"6 years",
"7 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"1 year",
"4 years",
"9 years",
"10+ years",
"< 1 year",
null,
"6 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"6 years",
"2 years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"3 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
null,
"1 year",
"7 years",
null,
null,
"2 years",
"10+ years",
"5 years",
"6 years",
"3 years",
"10+ years",
"3 years",
"6 years",
"1 year",
"7 years",
"1 year",
"2 years",
"8 years",
"2 years",
"4 years",
"10+ years",
"10+ years",
null,
null,
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"8 years",
"6 years",
"3 years",
"2 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
null,
null,
"9 years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"6 years",
"2 years",
"10+ years",
"2 years",
"7 years",
"5 years",
"10+ years",
"1 year",
"9 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"8 years",
"9 years",
"2 years",
"6 years",
"< 1 year",
"5 years",
null,
"6 years",
"10+ years",
"8 years",
"8 years",
"2 years",
"10+ years",
"4 years",
"2 years",
"3 years",
"1 year",
"2 years",
"< 1 year",
"9 years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"1 year",
null,
"1 year",
"2 years",
"10+ years",
"10+ years",
"8 years",
"2 years",
"8 years",
"8 years",
"10+ years",
"6 years",
"3 years",
"< 1 year",
"7 years",
"3 years",
"2 years",
"8 years",
"2 years",
"10+ years",
"2 years",
"3 years",
"4 years",
"10+ years",
"2 years",
"4 years",
"9 years",
"7 years",
"2 years",
"< 1 year",
"< 1 year",
"10+ years",
"< 1 year",
"1 year",
"2 years",
"10+ years",
"8 years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"6 years",
"3 years",
null,
"6 years",
"4 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"6 years",
"6 years",
"7 years",
"10+ years",
"3 years",
null,
"5 years",
"10+ years",
"6 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"7 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"5 years",
"6 years",
"2 years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"2 years",
"7 years",
"3 years",
"3 years",
"4 years",
"4 years",
"7 years",
"5 years",
"10+ years",
"9 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"7 years",
"4 years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"9 years",
null,
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"9 years",
"7 years",
"1 year",
"< 1 year",
"5 years",
"6 years",
"5 years",
"9 years",
"5 years",
"5 years",
null,
"5 years",
"10+ years",
"1 year",
"3 years",
"6 years",
"7 years",
"2 years",
"10+ years",
"< 1 year",
"3 years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"< 1 year",
"3 years",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"3 years",
"9 years",
"10+ years",
null,
"3 years",
"8 years",
"10+ years",
"6 years",
null,
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"4 years",
"3 years",
"6 years",
"10+ years",
"2 years",
"9 years",
"5 years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
null,
"8 years",
"1 year",
"3 years",
"1 year",
"3 years",
"6 years",
"10+ years",
"4 years",
null,
"4 years",
"10+ years",
"10+ years",
"6 years",
"4 years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"8 years",
null,
"1 year",
"4 years",
"10+ years",
"3 years",
"< 1 year",
"7 years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"6 years",
"5 years",
"2 years",
"10+ years",
"6 years",
"1 year",
"2 years",
null,
"10+ years",
"3 years",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"8 years",
"10+ years",
"4 years",
null,
"10+ years",
null,
"10+ years",
null,
"4 years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"4 years",
"6 years",
"4 years",
"8 years",
"1 year",
"7 years",
"< 1 year",
"7 years",
"6 years",
"9 years",
"10+ years",
"2 years",
"1 year",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"7 years",
"10+ years",
"6 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"8 years",
null,
"10+ years",
"1 year",
"3 years",
"10+ years",
"1 year",
"7 years",
"10+ years",
"1 year",
"5 years",
"10+ years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"1 year",
"8 years",
"7 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"7 years",
"2 years",
"< 1 year",
"1 year",
"1 year",
"5 years",
"4 years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"8 years",
"2 years",
"1 year",
"10+ years",
"1 year",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"9 years",
"2 years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"5 years",
"7 years",
"9 years",
"6 years",
"5 years",
"< 1 year",
"2 years",
"< 1 year",
"9 years",
"4 years",
"10+ years",
"2 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"2 years",
"7 years",
"7 years",
null,
"< 1 year",
"6 years",
"10+ years",
"7 years",
"3 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"9 years",
"2 years",
"< 1 year",
"1 year",
"5 years",
"< 1 year",
"9 years",
"2 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"1 year",
"3 years",
"10+ years",
"5 years",
"4 years",
"5 years",
"8 years",
"10+ years",
null,
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"4 years",
null,
"3 years",
"10+ years",
null,
null,
"6 years",
"< 1 year",
"8 years",
"10+ years",
"1 year",
"< 1 year",
null,
"10+ years",
null,
"10+ years",
"3 years",
"10+ years",
"1 year",
"5 years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"3 years",
"6 years",
"< 1 year",
"1 year",
"7 years",
"10+ years",
"2 years",
"< 1 year",
"3 years",
"< 1 year",
"3 years",
"2 years",
"3 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"5 years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"5 years",
"9 years",
"4 years",
"1 year",
"10+ years",
"8 years",
"10+ years",
"1 year",
null,
"10+ years",
"2 years",
"10+ years",
"4 years",
"2 years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"9 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"4 years",
"10+ years",
"1 year",
"10+ years",
null,
"10+ years",
"4 years",
"10+ years",
"5 years",
"10+ years",
"9 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"2 years",
"3 years",
"< 1 year",
"< 1 year",
"10+ years",
"5 years",
null,
"6 years",
"1 year",
"5 years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"9 years",
"8 years",
"8 years",
"6 years",
null,
"6 years",
"7 years",
"< 1 year",
null,
"10+ years",
"10+ years",
"3 years",
"10+ years",
null,
"8 years",
"9 years",
"8 years",
"5 years",
"5 years",
null,
"2 years",
"2 years",
"5 years",
"10+ years",
"2 years",
"2 years",
"1 year",
"8 years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"3 years",
"3 years",
null,
"10+ years",
"4 years",
null,
"10+ years",
"10+ years",
null,
"10+ years",
"6 years",
"10+ years",
"9 years",
"< 1 year",
"5 years",
"8 years",
"1 year",
"9 years",
"8 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"1 year",
"4 years",
"< 1 year",
"10+ years",
"2 years",
"3 years",
"10+ years",
"3 years",
"3 years",
"1 year",
"8 years",
"< 1 year",
"< 1 year",
"5 years",
null,
"10+ years",
"1 year",
"3 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"< 1 year",
"6 years",
"7 years",
"3 years",
"9 years",
"10+ years",
"9 years",
"2 years",
"6 years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"2 years",
"4 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
null,
"< 1 year",
"4 years",
"1 year",
"1 year",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"7 years",
"10+ years",
null,
"7 years",
"10+ years",
"9 years",
"5 years",
"5 years",
"1 year",
"< 1 year",
"< 1 year",
"5 years",
"2 years",
"6 years",
"2 years",
null,
"6 years",
"4 years",
"7 years",
"3 years",
"2 years",
"4 years",
"10+ years",
"5 years",
"3 years",
"4 years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"6 years",
"< 1 year",
"9 years",
"4 years",
"3 years",
"3 years",
"< 1 year",
"8 years",
"3 years",
"5 years",
"5 years",
"10+ years",
"10+ years",
null,
null,
"10+ years",
"8 years",
"10+ years",
"8 years",
"9 years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"7 years",
"6 years",
"2 years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
null,
"2 years",
"7 years",
"3 years",
"1 year",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"7 years",
"6 years",
"10+ years",
"< 1 year",
null,
"4 years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
null,
"1 year",
"10+ years",
"10+ years",
"2 years",
null,
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
null,
"10+ years",
"7 years",
"2 years",
"2 years",
"7 years",
"2 years",
"1 year",
null,
"10+ years",
"10+ years",
"4 years",
"4 years",
"5 years",
"< 1 year",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"6 years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"7 years",
"2 years",
null,
"10+ years",
"9 years",
"1 year",
"2 years",
"2 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"8 years",
"3 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"5 years",
"2 years",
"6 years",
"4 years",
"1 year",
"10+ years",
"6 years",
"10+ years",
"5 years",
"< 1 year",
"3 years",
null,
"2 years",
"7 years",
"1 year",
"5 years",
"3 years",
"10+ years",
"5 years",
null,
"8 years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"10+ years",
"7 years",
"< 1 year",
"3 years",
"4 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
null,
"7 years",
"1 year",
"9 years",
"8 years",
"9 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"5 years",
"7 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
null,
"10+ years",
"8 years",
"7 years",
null,
"7 years",
"7 years",
"1 year",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"5 years",
"4 years",
"9 years",
"1 year",
"< 1 year",
"8 years",
"8 years",
"5 years",
"10+ years",
"6 years",
"3 years",
"8 years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"6 years",
"8 years",
"6 years",
"10+ years",
"4 years",
"< 1 year",
"< 1 year",
"8 years",
"10+ years",
"4 years",
"1 year",
"3 years",
"1 year",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"3 years",
"9 years",
"< 1 year",
"10+ years",
"1 year",
"5 years",
"7 years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"3 years",
"3 years",
"5 years",
"< 1 year",
"8 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"4 years",
"6 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"6 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"9 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"6 years",
"5 years",
"5 years",
"3 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"9 years",
"10+ years",
"1 year",
"2 years",
null,
"2 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"1 year",
"9 years",
"5 years",
"< 1 year",
"3 years",
"3 years",
"< 1 year",
"9 years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"6 years",
"5 years",
"9 years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"5 years",
"9 years",
"7 years",
"1 year",
"10+ years",
null,
"10+ years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"7 years",
"10+ years",
"5 years",
"6 years",
"< 1 year",
"9 years",
"6 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"1 year",
"3 years",
"1 year",
"10+ years",
null,
"3 years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
null,
"7 years",
"6 years",
"8 years",
"10+ years",
"8 years",
"10+ years",
"7 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"10+ years",
"9 years",
"< 1 year",
null,
null,
"10+ years",
"2 years",
"10+ years",
"1 year",
"10+ years",
null,
null,
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"2 years",
"10+ years",
"5 years",
"9 years",
"4 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"7 years",
"2 years",
"10+ years",
null,
"10+ years",
"10+ years",
"1 year",
"6 years",
"7 years",
"4 years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"1 year",
"2 years",
"3 years",
"10+ years",
"2 years",
"2 years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"3 years",
"< 1 year",
"1 year",
"4 years",
"6 years",
"7 years",
"10+ years",
"10+ years",
"3 years",
"9 years",
"10+ years",
"6 years",
"6 years",
"< 1 year",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
null,
"10+ years",
"3 years",
"1 year",
"10+ years",
"5 years",
"10+ years",
"6 years",
"< 1 year",
"10+ years",
null,
null,
"5 years",
"3 years",
"10+ years",
"7 years",
"2 years",
"3 years",
"1 year",
"3 years",
"10+ years",
null,
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"5 years",
"5 years",
"5 years",
"7 years",
"8 years",
"9 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"1 year",
"3 years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"4 years",
"2 years",
null,
"10+ years",
"6 years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"1 year",
"9 years",
"10+ years",
null,
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"6 years",
"3 years",
"10+ years",
"6 years",
null,
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"9 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"7 years",
null,
"10+ years",
"6 years",
"2 years",
"10+ years",
"9 years",
"9 years",
"< 1 year",
null,
"9 years",
"10+ years",
null,
"1 year",
"10+ years",
"4 years",
"1 year",
"5 years",
"4 years",
"6 years",
null,
"2 years",
"5 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
null,
"7 years",
"1 year",
"4 years",
"< 1 year",
"10+ years",
"1 year",
"2 years",
"4 years",
"7 years",
"7 years",
"1 year",
"8 years",
"7 years",
"2 years",
"9 years",
"8 years",
"2 years",
"3 years",
"9 years",
"1 year",
null,
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"1 year",
"3 years",
"7 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"2 years",
"2 years",
"10+ years",
"8 years",
"7 years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"7 years",
"3 years",
"5 years",
"10+ years",
null,
"10+ years",
"6 years",
"7 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"1 year",
"10+ years",
"2 years",
"4 years",
"8 years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"8 years",
"1 year",
"10+ years",
"10+ years",
"7 years",
"2 years",
"6 years",
"7 years",
"3 years",
"2 years",
"< 1 year",
"5 years",
"7 years",
"7 years",
"10+ years",
"5 years",
"9 years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
null,
"1 year",
"< 1 year",
"10+ years",
null,
"4 years",
"9 years",
"7 years",
"5 years",
"10+ years",
"10+ years",
null,
"7 years",
"10+ years",
"< 1 year",
"2 years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"6 years",
"2 years",
"< 1 year",
"10+ years",
null,
"2 years",
"1 year",
"7 years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"10+ years",
"4 years",
"7 years",
null,
"10+ years",
"6 years",
"6 years",
"3 years",
"8 years",
"< 1 year",
null,
"3 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
null,
null,
"4 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"6 years",
"10+ years",
"7 years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"1 year",
"4 years",
"10+ years",
"10+ years",
"6 years",
"< 1 year",
"3 years",
"7 years",
"9 years",
"8 years",
null,
"6 years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"1 year",
"5 years",
null,
"< 1 year",
"7 years",
null,
"10+ years",
"3 years",
null,
"10+ years",
"4 years",
"2 years",
null,
"< 1 year",
"2 years",
"< 1 year",
"9 years",
"3 years",
"1 year",
null,
"5 years",
"8 years",
"1 year",
"2 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"6 years",
"3 years",
"6 years",
"< 1 year",
"5 years",
"5 years",
"5 years",
"6 years",
"2 years",
"4 years",
"10+ years",
"1 year",
"8 years",
"< 1 year",
null,
"4 years",
"9 years",
"< 1 year",
"3 years",
"1 year",
"2 years",
"1 year",
"10+ years",
"10+ years",
"5 years",
null,
"6 years",
"3 years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"2 years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"8 years",
"5 years",
"5 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"5 years",
"5 years",
"9 years",
"5 years",
"< 1 year",
"1 year",
"10+ years",
"2 years",
"8 years",
"1 year",
"< 1 year",
"1 year",
"4 years",
"< 1 year",
"5 years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
null,
"6 years",
"< 1 year",
null,
"< 1 year",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"6 years",
"4 years",
"2 years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"8 years",
"10+ years",
"10+ years",
"5 years",
null,
"5 years",
"5 years",
"6 years",
"10+ years",
"10+ years",
"9 years",
"3 years",
"5 years",
"< 1 year",
"10+ years",
"6 years",
"1 year",
"2 years",
"8 years",
"< 1 year",
"3 years",
"< 1 year",
"7 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"3 years",
"10+ years",
"8 years",
"2 years",
"6 years",
"9 years",
"1 year",
"9 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"7 years",
"4 years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"5 years",
"6 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"6 years",
"4 years",
"3 years",
"8 years",
"4 years",
"10+ years",
"6 years",
"< 1 year",
"10+ years",
"9 years",
"9 years",
"< 1 year",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"< 1 year",
null,
null,
null,
"2 years",
"6 years",
"3 years",
"4 years",
"1 year",
"3 years",
"10+ years",
"7 years",
"5 years",
"2 years",
"3 years",
"8 years",
null,
"10+ years",
"< 1 year",
"1 year",
"9 years",
"10+ years",
"8 years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"7 years",
"7 years",
"10+ years",
"< 1 year",
"9 years",
"5 years",
"6 years",
"6 years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"7 years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"4 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"10+ years",
"3 years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"2 years",
"5 years",
"9 years",
"3 years",
"10+ years",
"3 years",
"1 year",
"3 years",
"2 years",
"9 years",
"10+ years",
null,
"10+ years",
"7 years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"4 years",
"1 year",
"9 years",
"< 1 year",
"3 years",
null,
"< 1 year",
"10+ years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"5 years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"8 years",
"10+ years",
"8 years",
"10+ years",
"4 years",
"6 years",
null,
"4 years",
"2 years",
"< 1 year",
"3 years",
"10+ years",
"2 years",
"4 years",
"6 years",
null,
"3 years",
"9 years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"1 year",
"2 years",
"4 years",
"4 years",
"10+ years",
"8 years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"1 year",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"6 years",
"3 years",
"10+ years",
"3 years",
"5 years",
"5 years",
"1 year",
"10+ years",
"6 years",
"2 years",
"2 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"6 years",
null,
"10+ years",
"5 years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"1 year",
null,
"4 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"9 years",
"7 years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"5 years",
"10+ years",
"3 years",
"1 year",
"6 years",
"10+ years",
"9 years",
"4 years",
null,
"2 years",
"10+ years",
"7 years",
"4 years",
"3 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"4 years",
"6 years",
"9 years",
"10+ years",
"1 year",
"2 years",
"2 years",
"10+ years",
"2 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"3 years",
"3 years",
"9 years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"8 years",
"3 years",
"3 years",
"< 1 year",
"3 years",
"7 years",
"< 1 year",
"6 years",
"3 years",
"< 1 year",
"10+ years",
"2 years",
null,
"1 year",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"2 years",
"7 years",
"8 years",
"10+ years",
"7 years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"6 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"7 years",
null,
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"1 year",
"7 years",
"9 years",
"6 years",
"5 years",
"9 years",
"6 years",
"10+ years",
"2 years",
"< 1 year",
"3 years",
"6 years",
"4 years",
"4 years",
"6 years",
"2 years",
"4 years",
"8 years",
"2 years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"< 1 year",
"< 1 year",
"7 years",
"10+ years",
"1 year",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"2 years",
"3 years",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"9 years",
"2 years",
"9 years",
"4 years",
"4 years",
"10+ years",
"8 years",
"8 years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"2 years",
"2 years",
"1 year",
"2 years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"3 years",
null,
"10+ years",
"10+ years",
"8 years",
"5 years",
"< 1 year",
"3 years",
"3 years",
null,
"10+ years",
"6 years",
"10+ years",
null,
"3 years",
null,
"10+ years",
"6 years",
"9 years",
"< 1 year",
"9 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"2 years",
"9 years",
"2 years",
"3 years",
"1 year",
"3 years",
"8 years",
"2 years",
"5 years",
"10+ years",
null,
"2 years",
"10+ years",
"8 years",
"9 years",
"9 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"4 years",
"2 years",
"1 year",
"5 years",
null,
"10+ years",
"10+ years",
"9 years",
"1 year",
"2 years",
"10+ years",
"6 years",
"1 year",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"2 years",
null,
"< 1 year",
null,
"10+ years",
"5 years",
"10+ years",
"4 years",
null,
"< 1 year",
"3 years",
"2 years",
"10+ years",
"5 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"6 years",
"10+ years",
"10+ years",
"2 years",
"7 years",
"1 year",
"4 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"9 years",
"6 years",
null,
"10+ years",
"6 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"4 years",
"8 years",
"8 years",
"10+ years",
"7 years",
"9 years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"9 years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"9 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"3 years",
"4 years",
"5 years",
"6 years",
"9 years",
"8 years",
"10+ years",
"10+ years",
null,
"8 years",
"< 1 year",
"2 years",
"10+ years",
"2 years",
"9 years",
null,
"10+ years",
"< 1 year",
null,
"3 years",
"9 years",
"10+ years",
"7 years",
"8 years",
null,
"7 years",
"10+ years",
"10+ years",
"1 year",
"4 years",
"9 years",
"10+ years",
"4 years",
"3 years",
"< 1 year",
"10+ years",
null,
"10+ years",
"7 years",
"10+ years",
"1 year",
"10+ years",
"4 years",
"4 years",
"< 1 year",
"2 years",
"10+ years",
"2 years",
"3 years",
"< 1 year",
"10+ years",
"2 years",
"8 years",
"10+ years",
"9 years",
"< 1 year",
"8 years",
"7 years",
"3 years",
"4 years",
"10+ years",
"9 years",
null,
"4 years",
"5 years",
"< 1 year",
"10+ years",
"6 years",
"5 years",
"6 years",
"3 years",
"2 years",
"2 years",
"10+ years",
"3 years",
"6 years",
"6 years",
"10+ years",
"1 year",
"9 years",
"3 years",
"< 1 year",
"6 years",
"10+ years",
null,
"10+ years",
"5 years",
null,
"10+ years",
"6 years",
"10+ years",
null,
"1 year",
"7 years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"9 years",
"9 years",
"10+ years",
"10+ years",
"5 years",
"6 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"7 years",
"3 years",
"4 years",
"7 years",
null,
"< 1 year",
"< 1 year",
"10+ years",
"4 years",
"2 years",
"2 years",
"8 years",
"10+ years",
"4 years",
"2 years",
"4 years",
"10+ years",
"1 year",
"10+ years",
"8 years",
"1 year",
"5 years",
"8 years",
"10+ years",
"3 years",
"4 years",
"7 years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
null,
null,
"9 years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"9 years",
null,
"6 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"2 years",
null,
"10+ years",
"5 years",
"10+ years",
"4 years",
"7 years",
"6 years",
null,
"10+ years",
"4 years",
"3 years",
"1 year",
"7 years",
"< 1 year",
"3 years",
"10+ years",
"7 years",
"< 1 year",
"8 years",
"2 years",
"10+ years",
null,
"6 years",
"3 years",
"1 year",
"3 years",
"8 years",
"< 1 year",
"1 year",
"8 years",
"10+ years",
"8 years",
"9 years",
"3 years",
"8 years",
"2 years",
"2 years",
"2 years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"1 year",
null,
"10+ years",
"1 year",
"3 years",
"1 year",
"< 1 year",
"10+ years",
"1 year",
null,
"7 years",
"10+ years",
"< 1 year",
null,
"2 years",
"10+ years",
"9 years",
"< 1 year",
"1 year",
"8 years",
"5 years",
"10+ years",
"7 years",
null,
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"6 years",
"1 year",
"9 years",
"7 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"2 years",
"3 years",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"7 years",
"10+ years",
"7 years",
"4 years",
"3 years",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"9 years",
"1 year",
"8 years",
"10+ years",
"1 year",
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
null,
"< 1 year",
"10+ years",
"6 years",
"< 1 year",
"10+ years",
"< 1 year",
"2 years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
null,
"5 years",
"3 years",
"2 years",
"10+ years",
"5 years",
"5 years",
"10+ years",
"3 years",
"5 years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
null,
"< 1 year",
"3 years",
"6 years",
"6 years",
"8 years",
"8 years",
"6 years",
"7 years",
null,
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"< 1 year",
"2 years",
"4 years",
"3 years",
"5 years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"6 years",
"< 1 year",
"8 years",
"< 1 year",
"1 year",
null,
"2 years",
"< 1 year",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"4 years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"2 years",
"< 1 year",
"4 years",
"6 years",
"8 years",
"10+ years",
"1 year",
"3 years",
"2 years",
"10+ years",
"8 years",
"5 years",
"4 years",
"< 1 year",
"5 years",
"4 years",
"1 year",
"1 year",
"10+ years",
"8 years",
"4 years",
"3 years",
"1 year",
null,
"1 year",
"3 years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"10+ years",
"1 year",
"5 years",
"10+ years",
"6 years",
"8 years",
"10+ years",
"10+ years",
"8 years",
"9 years",
"7 years",
"4 years",
"10+ years",
"7 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"4 years",
"9 years",
"10+ years",
"10+ years",
"6 years",
"8 years",
"2 years",
null,
"9 years",
"10+ years",
"5 years",
"8 years",
"10+ years",
"2 years",
"2 years",
"4 years",
"3 years",
"2 years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"6 years",
"10+ years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"4 years",
"1 year",
"6 years",
"8 years",
"4 years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
null,
"4 years",
"3 years",
"10+ years",
"7 years",
"4 years",
"5 years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"< 1 year",
"8 years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"1 year",
null,
"5 years",
"10+ years",
"< 1 year",
"< 1 year",
"6 years",
"< 1 year",
"7 years",
"3 years",
"7 years",
"3 years",
"10+ years",
"7 years",
"5 years",
"1 year",
"7 years",
null,
"3 years",
"10+ years",
null,
"8 years",
"10+ years",
"10+ years",
null,
"2 years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"2 years",
"1 year",
"8 years",
"9 years",
"10+ years",
"7 years",
"3 years",
"2 years",
"8 years",
"1 year",
"10+ years",
"1 year",
"4 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"2 years",
"3 years",
"5 years",
"3 years",
"9 years",
"10+ years",
"3 years",
"7 years",
"9 years",
"< 1 year",
"3 years",
"10+ years",
"2 years",
"2 years",
"< 1 year",
"10+ years",
null,
"10+ years",
"5 years",
"5 years",
"10+ years",
"1 year",
"3 years",
"6 years",
"10+ years",
"10+ years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"7 years",
"5 years",
"8 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"9 years",
"5 years",
"10+ years",
"3 years",
"3 years",
"< 1 year",
"10+ years",
"1 year",
"8 years",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"4 years",
"1 year",
"1 year",
"3 years",
"8 years",
"6 years",
"2 years",
"4 years",
"10+ years",
"3 years",
"5 years",
"4 years",
null,
"2 years",
"7 years",
"3 years",
"6 years",
"4 years",
"10+ years",
"10+ years",
null,
"1 year",
"10+ years",
"7 years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"7 years",
"6 years",
"7 years",
"4 years",
"4 years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
null,
"5 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"9 years",
"2 years",
"1 year",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"1 year",
"5 years",
"7 years",
"10+ years",
"8 years",
"7 years",
"8 years",
"9 years",
"8 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"7 years",
"8 years",
"5 years",
"10+ years",
"2 years",
"2 years",
null,
"5 years",
"2 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"3 years",
null,
"10+ years",
"10+ years",
"3 years",
"2 years",
"8 years",
"8 years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"5 years",
"8 years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"9 years",
"3 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"3 years",
"4 years",
"2 years",
"10+ years",
"6 years",
"6 years",
"4 years",
"10+ years",
"6 years",
"1 year",
"10+ years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"7 years",
null,
"7 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"7 years",
"4 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"4 years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"3 years",
null,
"3 years",
"1 year",
"1 year",
"10+ years",
null,
"1 year",
"4 years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
null,
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"3 years",
"7 years",
"4 years",
"10+ years",
"2 years",
"2 years",
"6 years",
null,
"1 year",
"8 years",
"3 years",
"9 years",
"10+ years",
"10+ years",
"6 years",
"< 1 year",
null,
"10+ years",
null,
"8 years",
null,
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"10+ years",
"1 year",
"3 years",
null,
"10+ years",
"6 years",
"2 years",
null,
"2 years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"5 years",
"2 years",
"2 years",
"8 years",
"6 years",
"10+ years",
"1 year",
"5 years",
"2 years",
"8 years",
"6 years",
"5 years",
"10+ years",
"< 1 year",
"3 years",
null,
"< 1 year",
null,
"10+ years",
"< 1 year",
"8 years",
"7 years",
"< 1 year",
"9 years",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"< 1 year",
"1 year",
"3 years",
"< 1 year",
"2 years",
"4 years",
"7 years",
"9 years",
"6 years",
"10+ years",
"9 years",
null,
"9 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"6 years",
"4 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"2 years",
"2 years",
"3 years",
"< 1 year",
"10+ years",
"9 years",
null,
"10+ years",
"9 years",
"10+ years",
"3 years",
null,
"2 years",
"7 years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
null,
"5 years",
"6 years",
"3 years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"< 1 year",
"1 year",
"5 years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"7 years",
"3 years",
"9 years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"1 year",
"4 years",
"5 years",
"1 year",
"3 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
null,
"6 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"6 years",
"2 years",
"5 years",
"8 years",
null,
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"6 years",
"1 year",
"3 years",
null,
"3 years",
null,
null,
"1 year",
"10+ years",
"10+ years",
"3 years",
"5 years",
"5 years",
"5 years",
"1 year",
"7 years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"1 year",
"5 years",
"3 years",
"10+ years",
"1 year",
"9 years",
"10+ years",
"10+ years",
"8 years",
"1 year",
"10+ years",
"4 years",
"10+ years",
"5 years",
"2 years",
"4 years",
"8 years",
"3 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"5 years",
"1 year",
"1 year",
"1 year",
"3 years",
"9 years",
"7 years",
"< 1 year",
"7 years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"10+ years",
null,
"5 years",
null,
"10+ years",
"3 years",
"5 years",
"6 years",
"< 1 year",
"3 years",
"10+ years",
"6 years",
"5 years",
"1 year",
"< 1 year",
"10+ years",
"8 years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
null,
"3 years",
"5 years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"< 1 year",
null,
"10+ years",
null,
"7 years",
"10+ years",
null,
"7 years",
"4 years",
"3 years",
"5 years",
"10+ years",
"1 year",
"2 years",
"< 1 year",
"< 1 year",
"3 years",
"7 years",
"10+ years",
"7 years",
"4 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"2 years",
"3 years",
null,
"10+ years",
"2 years",
"10+ years",
"9 years",
"2 years",
"4 years",
"< 1 year",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"8 years",
"5 years",
"3 years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"1 year",
"< 1 year",
null,
"3 years",
"10+ years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"10+ years",
"6 years",
"1 year",
null,
"10+ years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"2 years",
"10+ years",
"9 years",
"10+ years",
"1 year",
"6 years",
"< 1 year",
"5 years",
"< 1 year",
"10+ years",
"6 years",
"7 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"3 years",
null,
"10+ years",
"8 years",
"1 year",
"6 years",
"10+ years",
"9 years",
"10+ years",
"2 years",
null,
"3 years",
"1 year",
"2 years",
"7 years",
"10+ years",
"8 years",
"3 years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"2 years",
"< 1 year",
"10+ years",
"9 years",
null,
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
null,
"2 years",
"5 years",
"10+ years",
"6 years",
null,
"6 years",
"3 years",
"6 years",
"10+ years",
"10+ years",
"4 years",
null,
"10+ years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"6 years",
"3 years",
"< 1 year",
"2 years",
"6 years",
"7 years",
"1 year",
"3 years",
"2 years",
"10+ years",
"2 years",
"4 years",
"10+ years",
"< 1 year",
"3 years",
"4 years",
"10+ years",
null,
"5 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"4 years",
"10+ years",
null,
"10+ years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"2 years",
"4 years",
"7 years",
"3 years",
"< 1 year",
null,
"7 years",
"< 1 year",
"5 years",
"10+ years",
"9 years",
"4 years",
"4 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
null,
"10+ years",
"7 years",
"5 years",
"7 years",
"2 years",
"4 years",
"< 1 year",
"2 years",
"10+ years",
"1 year",
"10+ years",
"4 years",
"3 years",
"3 years",
"2 years",
"10+ years",
"5 years",
null,
"1 year",
"10+ years",
"10+ years",
"4 years",
"3 years",
null,
"9 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"6 years",
"1 year",
"2 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"2 years",
"2 years",
"4 years",
"3 years",
"10+ years",
"9 years",
"7 years",
"< 1 year",
"2 years",
"< 1 year",
"5 years",
"5 years",
"10+ years",
"9 years",
"3 years",
"5 years",
"4 years",
"6 years",
"4 years",
"2 years",
"3 years",
"< 1 year",
"9 years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"4 years",
null,
"4 years",
"5 years",
"8 years",
"9 years",
"10+ years",
"9 years",
"3 years",
"10+ years",
"1 year",
"2 years",
"4 years",
"2 years",
"7 years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"5 years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"9 years",
"10+ years",
"7 years",
"5 years",
"1 year",
"10+ years",
"9 years",
"10+ years",
null,
"9 years",
"5 years",
"10+ years",
"< 1 year",
"9 years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"9 years",
"10+ years",
"3 years",
"< 1 year",
"9 years",
"< 1 year",
"10+ years",
"5 years",
"< 1 year",
"6 years",
"1 year",
"2 years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"9 years",
"< 1 year",
"2 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"9 years",
"7 years",
"7 years",
"10+ years",
"3 years",
"8 years",
"1 year",
"2 years",
"< 1 year",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"3 years",
"3 years",
"5 years",
null,
"10+ years",
null,
"10+ years",
"10+ years",
"7 years",
"6 years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"10+ years",
null,
"3 years",
"7 years",
null,
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"5 years",
"10+ years",
"8 years",
"9 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"9 years",
"10+ years",
"6 years",
"8 years",
"5 years",
"6 years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"2 years",
"3 years",
"10+ years",
"5 years",
null,
"5 years",
"2 years",
"3 years",
"10+ years",
"2 years",
"< 1 year",
"6 years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"5 years",
"9 years",
"9 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"5 years",
"3 years",
"10+ years",
"9 years",
null,
"10+ years",
"8 years",
"10+ years",
"4 years",
"3 years",
"8 years",
"6 years",
null,
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"9 years",
"7 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"7 years",
"6 years",
"9 years",
"10+ years",
"8 years",
"6 years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"8 years",
"9 years",
"3 years",
"10+ years",
"8 years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"7 years",
"10+ years",
"< 1 year",
"9 years",
"10+ years",
"4 years",
"8 years",
"10+ years",
"5 years",
"< 1 year",
"6 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"8 years",
"2 years",
"8 years",
"10+ years",
"6 years",
"9 years",
"3 years",
"10+ years",
"< 1 year",
"6 years",
"2 years",
"6 years",
"5 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"3 years",
"2 years",
"4 years",
"6 years",
"3 years",
"< 1 year",
"3 years",
"1 year",
"2 years",
null,
"3 years",
null,
"10+ years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"< 1 year",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"5 years",
null,
"10+ years",
null,
"10+ years",
"4 years",
"10+ years",
"4 years",
"< 1 year",
"9 years",
"7 years",
"10+ years",
"10+ years",
"8 years",
"7 years",
"10+ years",
"3 years",
"< 1 year",
"3 years",
"6 years",
null,
"5 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"< 1 year",
"5 years",
null,
"10+ years",
"2 years",
"2 years",
"1 year",
null,
"10+ years",
"7 years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"9 years",
"5 years",
"4 years",
"8 years",
"1 year",
"6 years",
"10+ years",
"< 1 year",
null,
null,
"9 years",
null,
"1 year",
"10+ years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"4 years",
"8 years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"5 years",
"7 years",
"10+ years",
"6 years",
"5 years",
"5 years",
"10+ years",
"10+ years",
null,
"3 years",
"1 year",
"1 year",
"2 years",
"10+ years",
"< 1 year",
"5 years",
"3 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"5 years",
null,
"10+ years",
"7 years",
"10+ years",
"9 years",
"7 years",
"7 years",
"10+ years",
"1 year",
"10+ years",
"2 years",
"5 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"8 years",
"10+ years",
"2 years",
"6 years",
"2 years",
"1 year",
"4 years",
null,
"2 years",
"< 1 year",
"10+ years",
"2 years",
"1 year",
"7 years",
"7 years",
"5 years",
"2 years",
"2 years",
"8 years",
null,
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"9 years",
"6 years",
"5 years",
"10+ years",
"4 years",
null,
"3 years",
"5 years",
"2 years",
"10+ years",
null,
"5 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"4 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"9 years",
"< 1 year",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"7 years",
"< 1 year",
"4 years",
"2 years",
"8 years",
"< 1 year",
"9 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"5 years",
"10+ years",
"8 years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"6 years",
"4 years",
"1 year",
"5 years",
"2 years",
"2 years",
"5 years",
"1 year",
"5 years",
"2 years",
"10+ years",
"2 years",
"3 years",
"5 years",
"4 years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"8 years",
"1 year",
"1 year",
"< 1 year",
"10+ years",
"8 years",
"9 years",
"5 years",
"3 years",
"10+ years",
"8 years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"2 years",
"< 1 year",
"7 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"3 years",
"6 years",
"4 years",
"6 years",
"4 years",
null,
null,
"9 years",
"3 years",
"4 years",
"2 years",
"10+ years",
"6 years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"9 years",
"4 years",
null,
"2 years",
"1 year",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"5 years",
null,
"1 year",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"8 years",
"7 years",
"5 years",
null,
"3 years",
"6 years",
"7 years",
"4 years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"4 years",
"5 years",
"7 years",
"6 years",
"5 years",
"5 years",
"7 years",
"< 1 year",
"3 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"8 years",
"7 years",
"7 years",
"3 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"6 years",
"1 year",
"7 years",
"4 years",
"2 years",
"< 1 year",
"4 years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"6 years",
"2 years",
"4 years",
"4 years",
"< 1 year",
"3 years",
"10+ years",
"8 years",
"5 years",
"5 years",
"8 years",
"7 years",
"6 years",
"2 years",
"10+ years",
"8 years",
"4 years",
"10+ years",
"4 years",
null,
"7 years",
"10+ years",
"3 years",
"5 years",
"5 years",
"6 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"9 years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"9 years",
null,
"2 years",
"< 1 year",
"10+ years",
"< 1 year",
"4 years",
"8 years",
"7 years",
"4 years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"3 years",
"9 years",
"7 years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"5 years",
"10+ years",
"< 1 year",
"2 years",
"5 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"9 years",
"10+ years",
"8 years",
"5 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"4 years",
"< 1 year",
"4 years",
null,
"4 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"< 1 year",
"2 years",
"7 years",
"5 years",
"4 years",
"< 1 year",
"6 years",
"2 years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"8 years",
null,
"3 years",
"5 years",
"9 years",
"8 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"10+ years",
"5 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"5 years",
"2 years",
"2 years",
"< 1 year",
null,
"2 years",
"< 1 year",
null,
"1 year",
"10+ years",
"2 years",
"8 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"2 years",
"10+ years",
"10+ years",
"10+ years",
null,
"7 years",
null,
"10+ years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"8 years",
"10+ years",
"3 years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"2 years",
null,
"10+ years",
"4 years",
"4 years",
"9 years",
"4 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"10+ years",
null,
"1 year",
"10+ years",
"2 years",
"4 years",
"10+ years",
"1 year",
"2 years",
"1 year",
"10+ years",
"7 years",
"10+ years",
"< 1 year",
"5 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"6 years",
"3 years",
"5 years",
"5 years",
"7 years",
"10+ years",
null,
"3 years",
"4 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"8 years",
"10+ years",
"6 years",
"< 1 year",
"4 years",
"6 years",
"< 1 year",
"8 years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"8 years",
"< 1 year",
"8 years",
"7 years",
"8 years",
"10+ years",
"1 year",
"2 years",
"4 years",
"< 1 year",
"7 years",
"10+ years",
"< 1 year",
"4 years",
"3 years",
"10+ years",
"2 years",
"7 years",
"4 years",
"10+ years",
"5 years",
"7 years",
"7 years",
"6 years",
"10+ years",
"8 years",
null,
"10+ years",
"3 years",
"< 1 year",
"2 years",
"5 years",
"9 years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"9 years",
"2 years",
"10+ years",
"6 years",
"8 years",
"5 years",
"< 1 year",
"5 years",
"10+ years",
"6 years",
"10+ years",
"1 year",
"4 years",
"< 1 year",
null,
"4 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"4 years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"5 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"4 years",
"5 years",
"5 years",
"5 years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"1 year",
"2 years",
"2 years",
null,
"10+ years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"4 years",
"4 years",
"6 years",
"10+ years",
"10+ years",
"7 years",
null,
"10+ years",
"5 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"2 years",
"9 years",
"3 years",
"10+ years",
null,
"4 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"6 years",
"7 years",
"3 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"8 years",
"< 1 year",
"1 year",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"< 1 year",
"< 1 year",
"1 year",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"6 years",
"10+ years",
null,
"10+ years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"4 years",
"10+ years",
"4 years",
"9 years",
null,
"9 years",
"3 years",
"10+ years",
"3 years",
"5 years",
"4 years",
"8 years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"2 years",
"< 1 year",
"9 years",
"3 years",
"4 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"9 years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"5 years",
"10+ years",
"10+ years",
"8 years",
"2 years",
"< 1 year",
"< 1 year",
"3 years",
null,
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"7 years",
"10+ years",
"7 years",
"1 year",
null,
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"3 years",
"< 1 year",
"< 1 year",
"10+ years",
"8 years",
"8 years",
"1 year",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"8 years",
"7 years",
"10+ years",
"< 1 year",
"7 years",
null,
"10+ years",
"2 years",
"10+ years",
"7 years",
"< 1 year",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"8 years",
"2 years",
"10+ years",
"4 years",
"8 years",
"10+ years",
"9 years",
"< 1 year",
"2 years",
"8 years",
"6 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"1 year",
"10+ years",
"10+ years",
"9 years",
"4 years",
"4 years",
"3 years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"1 year",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"1 year",
null,
"3 years",
"7 years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
null,
"5 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
null,
null,
"10+ years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"4 years",
"9 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"3 years",
"< 1 year",
"6 years",
"1 year",
"4 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"3 years",
"3 years",
"10+ years",
"4 years",
"10+ years",
"7 years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"< 1 year",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"9 years",
"< 1 year",
null,
"3 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"2 years",
"10+ years",
"4 years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"5 years",
"1 year",
"5 years",
"10+ years",
"3 years",
"5 years",
"7 years",
"1 year",
"3 years",
"10+ years",
"6 years",
"3 years",
"8 years",
"10+ years",
"4 years",
"8 years",
"< 1 year",
"6 years",
"10+ years",
"6 years",
"6 years",
"5 years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
null,
null,
"10+ years",
null,
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"9 years",
"6 years",
"10+ years",
"6 years",
"8 years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
null,
null,
"9 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"1 year",
"2 years",
"< 1 year",
"1 year",
"10+ years",
"9 years",
"5 years",
"< 1 year",
"7 years",
"1 year",
"< 1 year",
"1 year",
null,
"10+ years",
"10+ years",
"1 year",
"10+ years",
"4 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"1 year",
"3 years",
"4 years",
"6 years",
"1 year",
"2 years",
"7 years",
"10+ years",
"6 years",
"6 years",
"< 1 year",
"10+ years",
"4 years",
null,
"5 years",
"2 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"1 year",
null,
"10+ years",
null,
"< 1 year",
"4 years",
"< 1 year",
null,
"5 years",
"10+ years",
"9 years",
"8 years",
"9 years",
null,
null,
"4 years",
"< 1 year",
"< 1 year",
"< 1 year",
"8 years",
null,
"10+ years",
"8 years",
"1 year",
"8 years",
"9 years",
"8 years",
"5 years",
"10+ years",
"5 years",
"4 years",
"10+ years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"5 years",
"3 years",
"1 year",
null,
"4 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"3 years",
"10+ years",
"6 years",
"3 years",
"6 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"1 year",
"10+ years",
"7 years",
"10+ years",
"8 years",
"1 year",
"3 years",
"4 years",
"10+ years",
"7 years",
"5 years",
"< 1 year",
"9 years",
"4 years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"2 years",
"2 years",
"9 years",
"3 years",
"3 years",
"2 years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"8 years",
"10+ years",
"1 year",
null,
"8 years",
"7 years",
"7 years",
"10+ years",
"10+ years",
null,
"< 1 year",
"8 years",
"9 years",
"5 years",
"4 years",
"10+ years",
"10+ years",
"5 years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"3 years",
"2 years",
"1 year",
null,
"10+ years",
"8 years",
"10+ years",
null,
"10+ years",
"2 years",
"10+ years",
"6 years",
null,
"6 years",
"2 years",
"5 years",
"7 years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"1 year",
"7 years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"8 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
null,
"< 1 year",
"3 years",
null,
"6 years",
"6 years",
null,
"8 years",
"9 years",
"8 years",
null,
"9 years",
"3 years",
"1 year",
"8 years",
"8 years",
"7 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"5 years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"6 years",
"5 years",
"7 years",
"8 years",
"7 years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"6 years",
"3 years",
"7 years",
null,
"10+ years",
"2 years",
"9 years",
"< 1 year",
"7 years",
"5 years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"1 year",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"9 years",
"10+ years",
"6 years",
"1 year",
null,
"7 years",
"10+ years",
null,
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"3 years",
"< 1 year",
"7 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"< 1 year",
"2 years",
"10+ years",
"6 years",
"6 years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"4 years",
"4 years",
"3 years",
"2 years",
"6 years",
"4 years",
"3 years",
null,
null,
"5 years",
"4 years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"8 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"4 years",
"10+ years",
"10+ years",
"7 years",
"5 years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"3 years",
"9 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"2 years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"7 years",
"< 1 year",
"5 years",
"7 years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"9 years",
"5 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"3 years",
"6 years",
"< 1 year",
"8 years",
"10+ years",
"6 years",
"1 year",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"9 years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"3 years",
"< 1 year",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"7 years",
"10+ years",
"4 years",
"3 years",
"7 years",
"5 years",
"2 years",
"5 years",
"10+ years",
"2 years",
null,
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"1 year",
"2 years",
"3 years",
"9 years",
"< 1 year",
"4 years",
"6 years",
"< 1 year",
"1 year",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
null,
"5 years",
"6 years",
"< 1 year",
"5 years",
"10+ years",
"2 years",
"8 years",
"7 years",
"4 years",
"10+ years",
"< 1 year",
"6 years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"1 year",
"< 1 year",
"7 years",
"7 years",
"10+ years",
"1 year",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"8 years",
"10+ years",
"9 years",
"4 years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"1 year",
"4 years",
"9 years",
"2 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"9 years",
"10+ years",
"5 years",
"7 years",
null,
"2 years",
"10+ years",
"7 years",
"5 years",
"10+ years",
"< 1 year",
null,
"5 years",
"7 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"10+ years",
null,
"1 year",
"10+ years",
"3 years",
"3 years",
"7 years",
"3 years",
"2 years",
"6 years",
"10+ years",
"8 years",
"10+ years",
"1 year",
"7 years",
"1 year",
null,
"5 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"9 years",
"1 year",
"9 years",
"1 year",
"1 year",
"7 years",
"1 year",
null,
"10+ years",
"3 years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"< 1 year",
"< 1 year",
"1 year",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"1 year",
"2 years",
"7 years",
"8 years",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"2 years",
"< 1 year",
"10+ years",
"4 years",
"8 years",
"10+ years",
"10+ years",
"6 years",
"4 years",
"1 year",
"1 year",
"3 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"5 years",
"9 years",
"4 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"4 years",
"< 1 year",
"10+ years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"4 years",
"4 years",
"< 1 year",
"6 years",
"5 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
null,
"10+ years",
"< 1 year",
"5 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"8 years",
"< 1 year",
"5 years",
"10+ years",
"8 years",
"10+ years",
"8 years",
"1 year",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"8 years",
"3 years",
"5 years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"1 year",
"4 years",
"2 years",
"1 year",
"7 years",
"8 years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"5 years",
"3 years",
"8 years",
"10+ years",
"6 years",
null,
"5 years",
"10+ years",
"5 years",
"5 years",
"1 year",
"4 years",
"2 years",
"9 years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"6 years",
"9 years",
"1 year",
"7 years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"9 years",
"9 years",
"2 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"7 years",
"9 years",
"5 years",
"9 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"9 years",
"3 years",
"2 years",
"< 1 year",
"10+ years",
"2 years",
"4 years",
"4 years",
"10+ years",
"2 years",
"7 years",
"5 years",
"10+ years",
"10+ years",
"7 years",
"3 years",
null,
"4 years",
"6 years",
"7 years",
"1 year",
"3 years",
"3 years",
"3 years",
null,
"4 years",
"5 years",
"2 years",
"3 years",
"10+ years",
"7 years",
"3 years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"1 year",
"7 years",
"3 years",
null,
null,
"8 years",
"< 1 year",
"< 1 year",
"5 years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"1 year",
"2 years",
"10+ years",
"2 years",
"6 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"5 years",
"4 years",
"10+ years",
"10+ years",
"4 years",
null,
"1 year",
"10+ years",
"3 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"7 years",
null,
"10+ years",
null,
"2 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"6 years",
"10+ years",
"3 years",
"7 years",
"4 years",
"3 years",
"10+ years",
"7 years",
"1 year",
"1 year",
"8 years",
"10+ years",
"3 years",
"6 years",
"9 years",
"2 years",
"5 years",
"7 years",
"10+ years",
"3 years",
"3 years",
"5 years",
"3 years",
"2 years",
"10+ years",
"2 years",
"2 years",
"7 years",
"2 years",
"2 years",
"1 year",
"1 year",
"8 years",
"6 years",
"1 year",
"3 years",
"3 years",
"3 years",
"4 years",
"2 years",
"4 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"9 years",
"10+ years",
null,
"10+ years",
"10+ years",
"7 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"6 years",
"4 years",
null,
"4 years",
null,
"8 years",
"10+ years",
"10+ years",
"7 years",
"3 years",
"< 1 year",
null,
"2 years",
"< 1 year",
null,
null,
"10+ years",
"10+ years",
"3 years",
"5 years",
"5 years",
"5 years",
"< 1 year",
"1 year",
"10+ years",
null,
"2 years",
"4 years",
"7 years",
"10+ years",
"5 years",
"9 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"1 year",
"4 years",
"10+ years",
"1 year",
"< 1 year",
"2 years",
"4 years",
"10+ years",
"1 year",
"5 years",
"10+ years",
"7 years",
"7 years",
"10+ years",
"7 years",
"10+ years",
"2 years",
null,
null,
null,
"10+ years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"1 year",
"4 years",
null,
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"3 years",
"8 years",
"9 years",
"7 years",
null,
"5 years",
"4 years",
"< 1 year",
null,
"10+ years",
"6 years",
"10+ years",
"4 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"2 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"1 year",
"8 years",
"5 years",
"5 years",
"5 years",
"7 years",
"< 1 year",
"6 years",
"8 years",
"10+ years",
"3 years",
null,
"9 years",
"< 1 year",
"1 year",
"2 years",
"2 years",
"2 years",
"5 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"4 years",
"9 years",
"8 years",
"2 years",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"8 years",
"9 years",
"10+ years",
null,
"2 years",
"10+ years",
"9 years",
"2 years",
"3 years",
"3 years",
"4 years",
null,
"2 years",
"10+ years",
"10+ years",
"5 years",
"9 years",
"8 years",
"8 years",
"6 years",
"10+ years",
"8 years",
"9 years",
"< 1 year",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"3 years",
"4 years",
"3 years",
"< 1 year",
"4 years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"7 years",
"5 years",
"7 years",
"3 years",
"2 years",
"5 years",
"8 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"7 years",
"< 1 year",
"3 years",
null,
"< 1 year",
"3 years",
"10+ years",
"5 years",
"10+ years",
null,
"10+ years",
"2 years",
"5 years",
"7 years",
"6 years",
"8 years",
"8 years",
null,
"10+ years",
null,
"8 years",
"10+ years",
"8 years",
"5 years",
"4 years",
"1 year",
"3 years",
"6 years",
"10+ years",
"5 years",
"7 years",
"4 years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"3 years",
"< 1 year",
"3 years",
null,
"10+ years",
"10+ years",
"10+ years",
"8 years",
"6 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"1 year",
"2 years",
"< 1 year",
"4 years",
"9 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"7 years",
"3 years",
"1 year",
"10+ years",
"2 years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"6 years",
null,
"2 years",
"2 years",
"10+ years",
"2 years",
"2 years",
"1 year",
"10+ years",
"5 years",
"3 years",
"< 1 year",
null,
"5 years",
"8 years",
"4 years",
"10+ years",
"7 years",
"1 year",
"2 years",
"10+ years",
"5 years",
"10+ years",
null,
"10+ years",
"10+ years",
"2 years",
"8 years",
"8 years",
"2 years",
"< 1 year",
"3 years",
"2 years",
"4 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"9 years",
"9 years",
"7 years",
"10+ years",
null,
"7 years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"9 years",
"9 years",
"4 years",
"< 1 year",
"< 1 year",
"5 years",
"10+ years",
"5 years",
"7 years",
null,
"3 years",
"2 years",
"7 years",
"7 years",
"< 1 year",
"10+ years",
"< 1 year",
"1 year",
"1 year",
"7 years",
"9 years",
"1 year",
"7 years",
"6 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
null,
"3 years",
"8 years",
"5 years",
"5 years",
"5 years",
"10+ years",
"1 year",
"8 years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
null,
"10+ years",
null,
"6 years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"1 year",
null,
"< 1 year",
"8 years",
"2 years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"8 years",
null,
"10+ years",
"10+ years",
"10+ years",
"4 years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"6 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"9 years",
null,
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"7 years",
"6 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"4 years",
"9 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
null,
"7 years",
"2 years",
"5 years",
"2 years",
"4 years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"1 year",
"1 year",
"7 years",
"10+ years",
"1 year",
"9 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"3 years",
"< 1 year",
"3 years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"4 years",
"2 years",
"10+ years",
"9 years",
"8 years",
"< 1 year",
"10+ years",
null,
"9 years",
"10+ years",
null,
"3 years",
"7 years",
"4 years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"5 years",
"3 years",
"< 1 year",
"2 years",
"10+ years",
"8 years",
"5 years",
"1 year",
"10+ years",
"10+ years",
null,
"< 1 year",
"< 1 year",
"< 1 year",
"10+ years",
"7 years",
"< 1 year",
"< 1 year",
"4 years",
"5 years",
"10+ years",
null,
"8 years",
"3 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"3 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"6 years",
"1 year",
"10+ years",
"6 years",
"10+ years",
"6 years",
"10+ years",
"8 years",
"8 years",
null,
"7 years",
"< 1 year",
"4 years",
"8 years",
"10+ years",
null,
"5 years",
"3 years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"8 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"7 years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
null,
"2 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"8 years",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"5 years",
"10+ years",
null,
"< 1 year",
"2 years",
"< 1 year",
"< 1 year",
null,
"7 years",
"3 years",
"10+ years",
"1 year",
"9 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"5 years",
"7 years",
"3 years",
"2 years",
"9 years",
"10+ years",
"10+ years",
"7 years",
null,
"5 years",
"10+ years",
"1 year",
"< 1 year",
"1 year",
"9 years",
"< 1 year",
"10+ years",
"3 years",
"3 years",
"2 years",
"9 years",
"4 years",
"4 years",
"7 years",
"2 years",
"5 years",
null,
"5 years",
"< 1 year",
"3 years",
"10+ years",
"4 years",
"2 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
null,
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"2 years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"9 years",
"6 years",
"5 years",
"4 years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"9 years",
null,
"3 years",
"4 years",
"5 years",
"6 years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"2 years",
"5 years",
"4 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"5 years",
"4 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"6 years",
"< 1 year",
"5 years",
"2 years",
"< 1 year",
"5 years",
"9 years",
null,
"< 1 year",
null,
"10+ years",
"10+ years",
"2 years",
"5 years",
"3 years",
"4 years",
"6 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"4 years",
"4 years",
"10+ years",
null,
"3 years",
"6 years",
"10+ years",
"4 years",
"5 years",
"3 years",
"5 years",
"10+ years",
"6 years",
"6 years",
"10+ years",
"2 years",
"10+ years",
"7 years",
"8 years",
"8 years",
"3 years",
"6 years",
"< 1 year",
"7 years",
"1 year",
"1 year",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"10+ years",
"1 year",
"10+ years",
null,
"10+ years",
"8 years",
"10+ years",
"6 years",
"10+ years",
"6 years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"2 years",
"7 years",
"5 years",
"4 years",
"5 years",
"8 years",
"8 years",
"10+ years",
"7 years",
"2 years",
"1 year",
"5 years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"6 years",
"4 years",
"< 1 year",
"3 years",
"2 years",
"2 years",
"10+ years",
"1 year",
"6 years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"7 years",
"9 years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"5 years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"3 years",
"9 years",
"4 years",
"10+ years",
"2 years",
null,
"4 years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
null,
"3 years",
"10+ years",
"10+ years",
null,
"2 years",
"8 years",
"8 years",
"10+ years",
"5 years",
"5 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"9 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"1 year",
"7 years",
"5 years",
"5 years",
"6 years",
"5 years",
"10+ years",
"5 years",
"2 years",
"10+ years",
null,
"< 1 year",
"1 year",
"10+ years",
"7 years",
"10+ years",
"8 years",
"2 years",
"10+ years",
"10+ years",
null,
"1 year",
"5 years",
"10+ years",
"4 years",
"2 years",
"7 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"6 years",
"9 years",
"< 1 year",
null,
"8 years",
"3 years",
"6 years",
"6 years",
"8 years",
"6 years",
"7 years",
"2 years",
"9 years",
"< 1 year",
"7 years",
"1 year",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"5 years",
"9 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"2 years",
"< 1 year",
"4 years",
"7 years",
"5 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"3 years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"9 years",
"10+ years",
null,
"5 years",
"8 years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"1 year",
null,
"3 years",
"10+ years",
"4 years",
"2 years",
"10+ years",
"6 years",
"2 years",
"2 years",
"4 years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"9 years",
null,
"2 years",
"2 years",
"9 years",
"3 years",
"10+ years",
"1 year",
"6 years",
"4 years",
"< 1 year",
"2 years",
"8 years",
"10+ years",
"10+ years",
"6 years",
"8 years",
null,
"10+ years",
"10+ years",
"3 years",
"5 years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"7 years",
"7 years",
"7 years",
"6 years",
"6 years",
"2 years",
"10+ years",
"1 year",
null,
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"9 years",
"1 year",
"9 years",
"8 years",
"3 years",
"2 years",
"10+ years",
"4 years",
"2 years",
"7 years",
"2 years",
"9 years",
"2 years",
"10+ years",
"6 years",
"5 years",
"1 year",
"2 years",
"< 1 year",
"10+ years",
"9 years",
"6 years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"9 years",
null,
"9 years",
"9 years",
"2 years",
"1 year",
"< 1 year",
"8 years",
"7 years",
"8 years",
"5 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"4 years",
"4 years",
"10+ years",
"7 years",
"7 years",
"< 1 year",
"8 years",
"2 years",
"3 years",
"5 years",
"3 years",
"4 years",
"10+ years",
"1 year",
"10+ years",
"8 years",
"8 years",
"3 years",
"9 years",
"2 years",
"7 years",
"< 1 year",
"10+ years",
"5 years",
"5 years",
"1 year",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
null,
null,
"6 years",
"5 years",
"10+ years",
null,
"10+ years",
"2 years",
"7 years",
null,
"10+ years",
"7 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"2 years",
"2 years",
"4 years",
"10+ years",
"2 years",
"9 years",
null,
"2 years",
"8 years",
"10+ years",
"6 years",
"3 years",
"5 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
null,
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"2 years",
"6 years",
"5 years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"< 1 year",
"4 years",
"8 years",
"8 years",
"10+ years",
"5 years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"9 years",
"2 years",
"10+ years",
null,
"1 year",
"1 year",
"4 years",
"8 years",
"3 years",
"4 years",
"< 1 year",
"4 years",
"3 years",
"10+ years",
"2 years",
"7 years",
"< 1 year",
"7 years",
"10+ years",
"4 years",
"3 years",
"10+ years",
"10+ years",
null,
"5 years",
"9 years",
"8 years",
"5 years",
"5 years",
null,
"5 years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"8 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"1 year",
"3 years",
"3 years",
"< 1 year",
"8 years",
"2 years",
"9 years",
"8 years",
"10+ years",
"10+ years",
"1 year",
"4 years",
"2 years",
"10+ years",
"2 years",
"1 year",
"1 year",
"10+ years",
"3 years",
"1 year",
"2 years",
"10+ years",
"2 years",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"3 years",
"3 years",
"10+ years",
"3 years",
"6 years",
"10+ years",
null,
"10+ years",
"7 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"4 years",
"5 years",
"2 years",
"5 years",
"4 years",
"10+ years",
"6 years",
"7 years",
"7 years",
"10+ years",
"10+ years",
"8 years",
"6 years",
"10+ years",
"7 years",
"5 years",
"7 years",
null,
"5 years",
"2 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"4 years",
"9 years",
"10+ years",
null,
null,
"< 1 year",
"4 years",
"6 years",
"10+ years",
"5 years",
"6 years",
"< 1 year",
"8 years",
"10+ years",
null,
"5 years",
"10+ years",
"3 years",
"9 years",
"10+ years",
"5 years",
"8 years",
"4 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"5 years",
"3 years",
"10+ years",
"3 years",
"2 years",
"4 years",
"8 years",
"6 years",
"4 years",
"4 years",
"3 years",
"1 year",
"1 year",
"10+ years",
"2 years",
"9 years",
"1 year",
"10+ years",
"1 year",
null,
null,
"6 years",
"6 years",
"10+ years",
"10+ years",
null,
"6 years",
"2 years",
"5 years",
"< 1 year",
null,
null,
"10+ years",
"< 1 year",
"3 years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
null,
"6 years",
"5 years",
null,
"2 years",
"4 years",
"10+ years",
"1 year",
"7 years",
null,
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"2 years",
"10+ years",
null,
"3 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"5 years",
"5 years",
"6 years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"3 years",
"9 years",
"4 years",
"5 years",
"1 year",
"3 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"3 years",
"2 years",
"2 years",
"5 years",
"5 years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"5 years",
"10+ years",
"2 years",
"4 years",
"4 years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"< 1 year",
"6 years",
"7 years",
"10+ years",
"4 years",
"5 years",
"2 years",
"10+ years",
null,
"2 years",
"4 years",
null,
"4 years",
"1 year",
"9 years",
"2 years",
"10+ years",
"2 years",
null,
"< 1 year",
"9 years",
"2 years",
"3 years",
"5 years",
null,
"5 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"8 years",
null,
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
null,
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"7 years",
"< 1 year",
"4 years",
"2 years",
"10+ years",
"4 years",
"3 years",
"2 years",
"8 years",
"1 year",
"6 years",
"< 1 year",
null,
"10+ years",
"1 year",
"9 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"2 years",
"2 years",
"10+ years",
"1 year",
"5 years",
"9 years",
"3 years",
"10+ years",
null,
"2 years",
null,
"5 years",
"10+ years",
"< 1 year",
"2 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"< 1 year",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"2 years",
"7 years",
"3 years",
"< 1 year",
"10+ years",
null,
"4 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
null,
"5 years",
"9 years",
"10+ years",
"< 1 year",
"6 years",
null,
"6 years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"4 years",
"7 years",
"4 years",
"10+ years",
"1 year",
"10+ years",
"6 years",
"10+ years",
"9 years",
"3 years",
"5 years",
"2 years",
"< 1 year",
"1 year",
"9 years",
"9 years",
"2 years",
"10+ years",
"6 years",
"5 years",
"7 years",
null,
"4 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"3 years",
"2 years",
"10+ years",
"2 years",
"2 years",
"1 year",
"8 years",
"10+ years",
null,
"5 years",
"6 years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
null,
"4 years",
"8 years",
"10+ years",
"8 years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"< 1 year",
"7 years",
"1 year",
"6 years",
"7 years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"2 years",
"8 years",
"< 1 year",
"1 year",
"10+ years",
"7 years",
"< 1 year",
"< 1 year",
"3 years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
null,
"10+ years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"9 years",
"3 years",
"2 years",
"10+ years",
null,
"4 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"5 years",
"6 years",
"5 years",
"5 years",
"10+ years",
null,
"9 years",
"2 years",
"4 years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"7 years",
"9 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"6 years",
null,
"2 years",
"< 1 year",
"10+ years",
"6 years",
"4 years",
"3 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"1 year",
"4 years",
"4 years",
"10+ years",
"2 years",
"7 years",
"2 years",
"3 years",
"2 years",
"9 years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"4 years",
"2 years",
"2 years",
"3 years",
"10+ years",
"9 years",
"4 years",
"5 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"5 years",
"5 years",
"10+ years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"5 years",
"6 years",
"10+ years",
"4 years",
"4 years",
"10+ years",
"8 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"7 years",
"3 years",
"9 years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"7 years",
"6 years",
"10+ years",
null,
"10+ years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"1 year",
"8 years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"6 years",
"8 years",
"7 years",
"6 years",
"10+ years",
"8 years",
"7 years",
"10+ years",
"3 years",
null,
"10+ years",
"7 years",
"< 1 year",
"3 years",
"6 years",
"4 years",
"2 years",
"10+ years",
"4 years",
"< 1 year",
"2 years",
"10+ years",
"8 years",
"6 years",
"< 1 year",
"9 years",
"7 years",
"1 year",
"5 years",
null,
"6 years",
"5 years",
"3 years",
null,
"10+ years",
"3 years",
"3 years",
"10+ years",
"7 years",
"< 1 year",
"9 years",
"5 years",
"5 years",
"3 years",
"< 1 year",
"8 years",
"8 years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
null,
"3 years",
"8 years",
"2 years",
"2 years",
null,
"3 years",
"6 years",
"10+ years",
"6 years",
"9 years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"< 1 year",
"6 years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"9 years",
"10+ years",
"5 years",
"8 years",
"7 years",
"10+ years",
"10+ years",
"9 years",
"7 years",
null,
"8 years",
"10+ years",
"5 years",
"< 1 year",
"6 years",
"4 years",
"10+ years",
"8 years",
"7 years",
"7 years",
"10+ years",
"4 years",
null,
"10+ years",
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"5 years",
"4 years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"7 years",
"10+ years",
"10+ years",
"1 year",
null,
"2 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"3 years",
"10+ years",
"7 years",
"4 years",
"7 years",
"10+ years",
"6 years",
null,
"< 1 year",
"10+ years",
"4 years",
"8 years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"4 years",
"5 years",
"6 years",
null,
"10+ years",
"1 year",
"1 year",
"10+ years",
"1 year",
"9 years",
"10+ years",
"10+ years",
"6 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"1 year",
"6 years",
"8 years",
"10+ years",
"10+ years",
"7 years",
"8 years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"1 year",
"4 years",
"< 1 year",
"6 years",
"2 years",
"10+ years",
"5 years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"6 years",
"10+ years",
"3 years",
"1 year",
"6 years",
"8 years",
"6 years",
"7 years",
"2 years",
"9 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"2 years",
"10+ years",
null,
null,
"10+ years",
"5 years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"2 years",
"2 years",
"5 years",
"1 year",
"2 years",
"4 years",
"< 1 year",
"8 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
null,
"8 years",
null,
"10+ years",
"10+ years",
"4 years",
"10+ years",
null,
"7 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
null,
null,
"6 years",
"< 1 year",
"< 1 year",
"< 1 year",
"7 years",
"6 years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"4 years",
null,
"10+ years",
"5 years",
"< 1 year",
"5 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"6 years",
"6 years",
"8 years",
"5 years",
null,
"4 years",
"7 years",
"3 years",
"9 years",
"5 years",
"< 1 year",
"10+ years",
"7 years",
"5 years",
"4 years",
"8 years",
"10+ years",
"7 years",
"10+ years",
"5 years",
"4 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"< 1 year",
"9 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"7 years",
"1 year",
"6 years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"3 years",
null,
"5 years",
"4 years",
"1 year",
"2 years",
"2 years",
"6 years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"3 years",
"2 years",
"5 years",
"< 1 year",
"8 years",
"< 1 year",
"2 years",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"< 1 year",
"10+ years",
"9 years",
"10+ years",
"7 years",
"8 years",
"10+ years",
"10+ years",
"8 years",
"8 years",
"4 years",
null,
"3 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
null,
"2 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"4 years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"5 years",
"10+ years",
"2 years",
"4 years",
"5 years",
"10+ years",
"10+ years",
"6 years",
"< 1 year",
"2 years",
"2 years",
"< 1 year",
"2 years",
"6 years",
"2 years",
"9 years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"3 years",
"2 years",
"3 years",
"3 years",
"8 years",
"9 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
null,
"4 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
null,
"4 years",
null,
"10+ years",
"< 1 year",
"1 year",
"2 years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"2 years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"8 years",
"7 years",
"10+ years",
null,
"6 years",
null,
"8 years",
"10+ years",
"10+ years",
"8 years",
"8 years",
"< 1 year",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"9 years",
null,
"10+ years",
"7 years",
"10+ years",
"10+ years",
"4 years",
"4 years",
"10+ years",
null,
"< 1 year",
"10+ years",
"5 years",
"4 years",
"10+ years",
"4 years",
"1 year",
"6 years",
"3 years",
"< 1 year",
"4 years",
"10+ years",
null,
null,
"2 years",
"3 years",
"4 years",
"1 year",
"6 years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"9 years",
"9 years",
"4 years",
"3 years",
"10+ years",
"10+ years",
null,
"2 years",
"10+ years",
null,
"7 years",
"1 year",
"4 years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"4 years",
"6 years",
"2 years",
"4 years",
"3 years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"1 year",
"2 years",
"4 years",
"9 years",
"10+ years",
"5 years",
"< 1 year",
"6 years",
"4 years",
"10+ years",
"5 years",
"3 years",
"8 years",
"1 year",
null,
"10+ years",
null,
"2 years",
"2 years",
"7 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"2 years",
"4 years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"< 1 year",
"8 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"4 years",
null,
"10+ years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"7 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"9 years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"5 years",
"8 years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"2 years",
"3 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"6 years",
"6 years",
"< 1 year",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"5 years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"8 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"2 years",
"4 years",
"4 years",
"2 years",
"10+ years",
"10+ years",
null,
"1 year",
"3 years",
null,
"2 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"5 years",
"4 years",
null,
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"3 years",
"10+ years",
"4 years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"6 years",
"9 years",
"10+ years",
"4 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"5 years",
"7 years",
"4 years",
"< 1 year",
"8 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"5 years",
"2 years",
"5 years",
"4 years",
"9 years",
"5 years",
"< 1 year",
"3 years",
"2 years",
"6 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"7 years",
"8 years",
"< 1 year",
"8 years",
"10+ years",
"5 years",
"5 years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"3 years",
"10+ years",
null,
"5 years",
"10+ years",
"10+ years",
"5 years",
"5 years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"4 years",
"10+ years",
"2 years",
"3 years",
"< 1 year",
"7 years",
"9 years",
"1 year",
"1 year",
"9 years",
"< 1 year",
"2 years",
"2 years",
"8 years",
"10+ years",
"4 years",
"2 years",
"8 years",
null,
"8 years",
"8 years",
"6 years",
"1 year",
"2 years",
"7 years",
"10+ years",
"< 1 year",
"< 1 year",
"< 1 year",
"< 1 year",
"3 years",
"7 years",
"2 years",
"10+ years",
"3 years",
"9 years",
"8 years",
"3 years",
"3 years",
"3 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
null,
"8 years",
"5 years",
null,
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"3 years",
"4 years",
"5 years",
"2 years",
"4 years",
"5 years",
"3 years",
"7 years",
"3 years",
"10+ years",
null,
"< 1 year",
"10+ years",
"4 years",
"3 years",
"< 1 year",
"10+ years",
"9 years",
"3 years",
"10+ years",
"5 years",
"4 years",
"10+ years",
"10+ years",
"1 year",
"6 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"3 years",
"2 years",
"10+ years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"6 years",
"2 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"1 year",
"3 years",
"5 years",
"8 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"5 years",
"10+ years",
"2 years",
"9 years",
"8 years",
"< 1 year",
"10+ years",
"5 years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"1 year",
null,
"10+ years",
"2 years",
"< 1 year",
"3 years",
"6 years",
null,
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"9 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"3 years",
"7 years",
"5 years",
"3 years",
"8 years",
"6 years",
"9 years",
"7 years",
"< 1 year",
"1 year",
"1 year",
"9 years",
"8 years",
"10+ years",
"4 years",
"2 years",
"2 years",
"5 years",
"6 years",
"3 years",
"7 years",
null,
"1 year",
"10+ years",
"5 years",
"9 years",
"8 years",
"2 years",
"6 years",
"1 year",
"3 years",
"7 years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"2 years",
null,
"2 years",
"4 years",
"6 years",
"9 years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"1 year",
"6 years",
"< 1 year",
"8 years",
"1 year",
"3 years",
"7 years",
"10+ years",
"2 years",
"< 1 year",
"2 years",
"6 years",
"7 years",
"3 years",
"1 year",
"7 years",
"2 years",
"< 1 year",
"9 years",
"1 year",
"2 years",
"1 year",
"1 year",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"4 years",
"6 years",
"10+ years",
"8 years",
"7 years",
"10+ years",
"10+ years",
"6 years",
"5 years",
"10+ years",
"7 years",
null,
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"9 years",
"7 years",
"9 years",
"1 year",
"8 years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"3 years",
"8 years",
"8 years",
"2 years",
"3 years",
"6 years",
"8 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"6 years",
null,
"10+ years",
"< 1 year",
"4 years",
"8 years",
"7 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"9 years",
"10+ years",
"3 years",
"2 years",
null,
"< 1 year",
"9 years",
"10+ years",
"3 years",
"4 years",
"5 years",
"10+ years",
"10+ years",
null,
"1 year",
"9 years",
"10+ years",
"6 years",
"2 years",
"10+ years",
null,
"< 1 year",
"7 years",
"10+ years",
"10+ years",
null,
"7 years",
"1 year",
"7 years",
"3 years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"9 years",
"3 years",
"10+ years",
null,
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"< 1 year",
"10+ years",
"2 years",
"7 years",
"4 years",
"8 years",
"7 years",
"2 years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"9 years",
"6 years",
"10+ years",
"6 years",
"3 years",
"4 years",
"3 years",
"10+ years",
"7 years",
"5 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"2 years",
"< 1 year",
"6 years",
"2 years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"2 years",
"3 years",
"5 years",
"3 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"6 years",
"9 years",
"< 1 year",
"1 year",
"< 1 year",
"5 years",
"10+ years",
"5 years",
"5 years",
"10+ years",
"9 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"2 years",
"1 year",
"8 years",
"4 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"5 years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"3 years",
"< 1 year",
"6 years",
null,
"8 years",
"2 years",
"9 years",
"5 years",
"1 year",
"8 years",
"10+ years",
"5 years",
"4 years",
"1 year",
"< 1 year",
"< 1 year",
null,
"10+ years",
"10+ years",
"< 1 year",
null,
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"9 years",
"10+ years",
"< 1 year",
null,
"5 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"1 year",
"< 1 year",
"3 years",
"4 years",
"10+ years",
"3 years",
"1 year",
"1 year",
"2 years",
"10+ years",
"7 years",
"3 years",
"5 years",
"1 year",
"10+ years",
"2 years",
"8 years",
"10+ years",
"3 years",
"2 years",
"4 years",
"10+ years",
"3 years",
"5 years",
"7 years",
"5 years",
"10+ years",
"4 years",
"< 1 year",
"6 years",
"3 years",
null,
"5 years",
"2 years",
"4 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"7 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"1 year",
"1 year",
"4 years",
"7 years",
"10+ years",
"4 years",
"< 1 year",
"1 year",
"10+ years",
"7 years",
"4 years",
"< 1 year",
"7 years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"4 years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"2 years",
"10+ years",
null,
"10+ years",
null,
"< 1 year",
"10+ years",
null,
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"7 years",
"8 years",
"< 1 year",
"8 years",
"< 1 year",
"5 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"9 years",
null,
"< 1 year",
"6 years",
"10+ years",
"< 1 year",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"1 year",
"8 years",
"8 years",
"7 years",
null,
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"5 years",
"8 years",
"10+ years",
"5 years",
"8 years",
null,
"10+ years",
"1 year",
"10+ years",
null,
"2 years",
"7 years",
"4 years",
"2 years",
"2 years",
"< 1 year",
"1 year",
"10+ years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"8 years",
"< 1 year",
"7 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"1 year",
"6 years",
null,
"4 years",
"10+ years",
null,
"10+ years",
"6 years",
"7 years",
"3 years",
"6 years",
null,
"9 years",
"7 years",
"10+ years",
"10+ years",
"5 years",
"4 years",
"4 years",
"10+ years",
"6 years",
"< 1 year",
"10+ years",
"7 years",
"1 year",
null,
"10+ years",
"5 years",
"8 years",
"10+ years",
"1 year",
"< 1 year",
"4 years",
"7 years",
"5 years",
"3 years",
"10+ years",
"6 years",
"9 years",
"8 years",
"10+ years",
"3 years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
null,
"10+ years",
"3 years",
"3 years",
"10+ years",
"< 1 year",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"10+ years",
null,
"10+ years",
"7 years",
"7 years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"1 year",
"7 years",
"5 years",
"4 years",
"10+ years",
"4 years",
"6 years",
"2 years",
"4 years",
"10+ years",
"8 years",
"6 years",
"10+ years",
"2 years",
"3 years",
"5 years",
"10+ years",
"2 years",
null,
"10+ years",
"8 years",
"10+ years",
"8 years",
"5 years",
"< 1 year",
"8 years",
"8 years",
"< 1 year",
"2 years",
"4 years",
"3 years",
"5 years",
"10+ years",
null,
"10+ years",
"< 1 year",
null,
"10+ years",
"10+ years",
"1 year",
"2 years",
"2 years",
"2 years",
"7 years",
"10+ years",
"1 year",
"1 year",
"10+ years",
null,
"2 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
null,
"8 years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"9 years",
"2 years",
"1 year",
"5 years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"3 years",
"< 1 year",
"3 years",
"3 years",
"10+ years",
"7 years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"4 years",
"2 years",
"5 years",
"10+ years",
"7 years",
"1 year",
"4 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"1 year",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"8 years",
"5 years",
null,
"9 years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
null,
"10+ years",
"7 years",
"4 years",
"9 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"9 years",
"6 years",
"6 years",
"4 years",
"1 year",
"10+ years",
null,
"9 years",
"3 years",
"10+ years",
"< 1 year",
null,
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
null,
"< 1 year",
"3 years",
"2 years",
"10+ years",
"< 1 year",
"3 years",
"2 years",
"9 years",
"10+ years",
"< 1 year",
"2 years",
"3 years",
null,
null,
"7 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"5 years",
"5 years",
"2 years",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"3 years",
"7 years",
null,
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"9 years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"6 years",
"< 1 year",
"10+ years",
null,
"2 years",
"2 years",
"1 year",
"10+ years",
"1 year",
"1 year",
"8 years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"< 1 year",
"1 year",
"3 years",
"1 year",
"10+ years",
null,
"2 years",
"9 years",
"10+ years",
null,
"< 1 year",
"10+ years",
null,
"10+ years",
"3 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"2 years",
"2 years",
"2 years",
"4 years",
"< 1 year",
"8 years",
"10+ years",
"5 years",
"< 1 year",
"4 years",
"1 year",
"5 years",
"1 year",
"9 years",
"4 years",
"6 years",
"5 years",
"8 years",
"9 years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"2 years",
"< 1 year",
"10+ years",
"9 years",
"1 year",
"4 years",
"10+ years",
"< 1 year",
"2 years",
"2 years",
"7 years",
null,
"5 years",
"10+ years",
"3 years",
"1 year",
"3 years",
"3 years",
null,
"10+ years",
"8 years",
"10+ years",
"10+ years",
"6 years",
null,
"3 years",
"3 years",
"2 years",
"10+ years",
"2 years",
"4 years",
"3 years",
"< 1 year",
"10+ years",
"3 years",
"7 years",
"2 years",
"2 years",
"10+ years",
"2 years",
"3 years",
"1 year",
"3 years",
"< 1 year",
"1 year",
"< 1 year",
"10+ years",
"3 years",
"4 years",
"2 years",
null,
"< 1 year",
"10+ years",
"5 years",
"2 years",
"10+ years",
null,
"3 years",
"9 years",
"4 years",
"1 year",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"9 years",
"3 years",
null,
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"4 years",
"8 years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"1 year",
"4 years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
null,
"< 1 year",
"3 years",
"3 years",
"3 years",
"< 1 year",
"4 years",
"10+ years",
"< 1 year",
"5 years",
"< 1 year",
"5 years",
"4 years",
null,
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"6 years",
"9 years",
"3 years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"< 1 year",
"5 years",
"7 years",
"5 years",
"6 years",
"1 year",
"2 years",
"< 1 year",
"< 1 year",
"10+ years",
null,
"10+ years",
"2 years",
"10+ years",
"1 year",
"7 years",
"7 years",
"4 years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"8 years",
"9 years",
"5 years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"4 years",
"1 year",
"< 1 year",
"9 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"9 years",
"8 years",
"10+ years",
"2 years",
"4 years",
"7 years",
"10+ years",
"5 years",
"1 year",
"< 1 year",
"5 years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"6 years",
"< 1 year",
"7 years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"3 years",
"7 years",
"5 years",
"< 1 year",
"8 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"2 years",
"< 1 year",
"2 years",
"3 years",
"< 1 year",
"1 year",
"1 year",
"8 years",
null,
null,
"10+ years",
"7 years",
null,
"9 years",
"2 years",
"7 years",
"10+ years",
"5 years",
null,
"2 years",
"10+ years",
"10+ years",
"4 years",
null,
"10+ years",
"10+ years",
null,
"7 years",
"4 years",
"7 years",
"2 years",
null,
"2 years",
"7 years",
null,
"5 years",
"10+ years",
"1 year",
"10+ years",
"5 years",
null,
"10+ years",
"1 year",
"10+ years",
"3 years",
"8 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"5 years",
"2 years",
"< 1 year",
"7 years",
"5 years",
"10+ years",
"1 year",
"10+ years",
"5 years",
null,
"1 year",
"10+ years",
null,
"9 years",
"< 1 year",
"< 1 year",
"3 years",
"1 year",
"10+ years",
"10+ years",
"2 years",
null,
"8 years",
"5 years",
"9 years",
"< 1 year",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"1 year",
"10+ years",
"3 years",
"10+ years",
"8 years",
"10+ years",
"3 years",
null,
"5 years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"2 years",
"3 years",
"< 1 year",
"4 years",
null,
"< 1 year",
"< 1 year",
"8 years",
"8 years",
"4 years",
"5 years",
null,
"3 years",
"5 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"3 years",
"3 years",
"7 years",
"4 years",
"< 1 year",
"2 years",
"6 years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"6 years",
"2 years",
"1 year",
"3 years",
"1 year",
"2 years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"9 years",
"2 years",
null,
"10+ years",
"2 years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"< 1 year",
"9 years",
"2 years",
"10+ years",
"6 years",
"3 years",
null,
"10+ years",
"9 years",
"9 years",
"10+ years",
"5 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
null,
"8 years",
"10+ years",
"6 years",
"< 1 year",
"8 years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"6 years",
"5 years",
"10+ years",
"1 year",
"2 years",
"10+ years",
"7 years",
"7 years",
"10+ years",
"5 years",
"3 years",
"1 year",
"5 years",
"10+ years",
"6 years",
"3 years",
"1 year",
"7 years",
"4 years",
"10+ years",
"7 years",
"1 year",
"5 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"2 years",
"< 1 year",
"10+ years",
"4 years",
"1 year",
"4 years",
"10+ years",
null,
"5 years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"< 1 year",
"6 years",
"4 years",
"1 year",
"10+ years",
"10+ years",
"6 years",
"2 years",
"9 years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"2 years",
"4 years",
"7 years",
"8 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"7 years",
"7 years",
"1 year",
"10+ years",
"1 year",
"1 year",
"1 year",
"7 years",
null,
"3 years",
"7 years",
"10+ years",
"10+ years",
"6 years",
"6 years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
null,
"< 1 year",
"10+ years",
"5 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"4 years",
null,
"10+ years",
"4 years",
"10+ years",
null,
"10+ years",
"8 years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"1 year",
"1 year",
"2 years",
"10+ years",
"4 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"1 year",
"2 years",
"8 years",
"10+ years",
"5 years",
"2 years",
"2 years",
"6 years",
"5 years",
"3 years",
"< 1 year",
"10+ years",
"8 years",
"3 years",
"10+ years",
"7 years",
"2 years",
"8 years",
"10+ years",
"8 years",
"4 years",
"4 years",
null,
"< 1 year",
"1 year",
"6 years",
"9 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"< 1 year",
"2 years",
"2 years",
"3 years",
"5 years"
]
}
],
"layout": {
"legend": {
"bgcolor": "#F5F6F9",
"font": {
"color": "#4D5663"
}
},
"paper_bgcolor": "#F5F6F9",
"plot_bgcolor": "#F5F6F9",
"template": {
"data": {
"bar": [
{
"error_x": {
"color": "#2a3f5f"
},
"error_y": {
"color": "#2a3f5f"
},
"marker": {
"line": {
"color": "#E5ECF6",
"width": 0.5
}
},
"type": "bar"
}
],
"barpolar": [
{
"marker": {
"line": {
"color": "#E5ECF6",
"width": 0.5
}
},
"type": "barpolar"
}
],
"carpet": [
{
"aaxis": {
"endlinecolor": "#2a3f5f",
"gridcolor": "white",
"linecolor": "white",
"minorgridcolor": "white",
"startlinecolor": "#2a3f5f"
},
"baxis": {
"endlinecolor": "#2a3f5f",
"gridcolor": "white",
"linecolor": "white",
"minorgridcolor": "white",
"startlinecolor": "#2a3f5f"
},
"type": "carpet"
}
],
"choropleth": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "choropleth"
}
],
"contour": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "contour"
}
],
"contourcarpet": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "contourcarpet"
}
],
"heatmap": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "heatmap"
}
],
"heatmapgl": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "heatmapgl"
}
],
"histogram": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "histogram"
}
],
"histogram2d": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "histogram2d"
}
],
"histogram2dcontour": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "histogram2dcontour"
}
],
"mesh3d": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "mesh3d"
}
],
"parcoords": [
{
"line": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "parcoords"
}
],
"pie": [
{
"automargin": true,
"type": "pie"
}
],
"scatter": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatter"
}
],
"scatter3d": [
{
"line": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatter3d"
}
],
"scattercarpet": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattercarpet"
}
],
"scattergeo": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattergeo"
}
],
"scattergl": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattergl"
}
],
"scattermapbox": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattermapbox"
}
],
"scatterpolar": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterpolar"
}
],
"scatterpolargl": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterpolargl"
}
],
"scatterternary": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterternary"
}
],
"surface": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "surface"
}
],
"table": [
{
"cells": {
"fill": {
"color": "#EBF0F8"
},
"line": {
"color": "white"
}
},
"header": {
"fill": {
"color": "#C8D4E3"
},
"line": {
"color": "white"
}
},
"type": "table"
}
]
},
"layout": {
"annotationdefaults": {
"arrowcolor": "#2a3f5f",
"arrowhead": 0,
"arrowwidth": 1
},
"coloraxis": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"colorscale": {
"diverging": [
[
0,
"#8e0152"
],
[
0.1,
"#c51b7d"
],
[
0.2,
"#de77ae"
],
[
0.3,
"#f1b6da"
],
[
0.4,
"#fde0ef"
],
[
0.5,
"#f7f7f7"
],
[
0.6,
"#e6f5d0"
],
[
0.7,
"#b8e186"
],
[
0.8,
"#7fbc41"
],
[
0.9,
"#4d9221"
],
[
1,
"#276419"
]
],
"sequential": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"sequentialminus": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
]
},
"colorway": [
"#636efa",
"#EF553B",
"#00cc96",
"#ab63fa",
"#FFA15A",
"#19d3f3",
"#FF6692",
"#B6E880",
"#FF97FF",
"#FECB52"
],
"font": {
"color": "#2a3f5f"
},
"geo": {
"bgcolor": "white",
"lakecolor": "white",
"landcolor": "#E5ECF6",
"showlakes": true,
"showland": true,
"subunitcolor": "white"
},
"hoverlabel": {
"align": "left"
},
"hovermode": "closest",
"mapbox": {
"style": "light"
},
"paper_bgcolor": "white",
"plot_bgcolor": "#E5ECF6",
"polar": {
"angularaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"bgcolor": "#E5ECF6",
"radialaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
}
},
"scene": {
"xaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
},
"yaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
},
"zaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
}
},
"shapedefaults": {
"line": {
"color": "#2a3f5f"
}
},
"ternary": {
"aaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"baxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"bgcolor": "#E5ECF6",
"caxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
}
},
"title": {
"x": 0.05
},
"xaxis": {
"automargin": true,
"gridcolor": "white",
"linecolor": "white",
"ticks": "",
"title": {
"standoff": 15
},
"zerolinecolor": "white",
"zerolinewidth": 2
},
"yaxis": {
"automargin": true,
"gridcolor": "white",
"linecolor": "white",
"ticks": "",
"title": {
"standoff": 15
},
"zerolinecolor": "white",
"zerolinewidth": 2
}
}
},
"title": {
"font": {
"color": "#4D5663"
},
"text": "emp_length Box plot"
},
"xaxis": {
"gridcolor": "#E1E5ED",
"showgrid": true,
"tickfont": {
"color": "#4D5663"
},
"title": {
"font": {
"color": "#4D5663"
},
"text": ""
},
"zerolinecolor": "#E1E5ED"
},
"yaxis": {
"gridcolor": "#E1E5ED",
"showgrid": true,
"tickfont": {
"color": "#4D5663"
},
"title": {
"font": {
"color": "#4D5663"
},
"text": ""
},
"zerolinecolor": "#E1E5ED"
}
}
},
"text/html": [
"\n",
" \n",
" \n",
" \n",
" \n",
" "
]
},
"metadata": {},
"output_type": "display_data"
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"Null value summary: \n",
" Total Percent\n",
"verification_status_joint 63971 99.956249\n",
"desc 54849 85.702902\n",
"mths_since_last_record 54349 84.921639\n",
"mths_since_last_major_derog 48155 75.243363\n",
"mths_since_last_delinq 32831 51.299239\n",
"batch_enrolled 10264 16.037751\n",
"tot_cur_bal 5124 8.006375\n",
"tot_coll_amt 5124 8.006375\n",
"total_rev_hi_lim 5124 8.006375\n",
"emp_title 3826 5.978218\n",
"emp_length 3324 5.193831\n",
"revol_util 29 0.045313\n",
"title 13 0.020313\n",
"collections_12_mths_ex_med 8 0.012500\n",
"columns dropped Index(['verification_status_joint', 'desc', 'mths_since_last_record',\n",
" 'mths_since_last_major_derog', 'mths_since_last_delinq'],\n",
" dtype='object')\n",
"\n",
"\n",
"columns dropped \n",
"\n",
" ['verification_status_joint', 'desc', 'mths_since_last_record', 'mths_since_last_major_derog', 'mths_since_last_delinq'] \n",
" ['member_id', 'pymnt_plan', 'batch_enrolled']\n"
]
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAe0AAAIRCAYAAABnDOUEAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADt0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjByYzEsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy/xvVyzAAAgAElEQVR4nOzdeZgsZXn38e+PTTZRkYM7i0ZRREVzxPVFEDXivqNxQ2NQY1DcNYniGiOKS4wacUMTVxDUqKiIoBHcQNkUNAoIuIGigCib3O8fVSN9+vTM6XNOT9dUz/dzXX1N19JVd/X0zN3PU8+SqkKSJC19G3QdgCRJGo9JW5KknjBpS5LUEyZtSZJ6wqQtSVJPmLQlSeoJk7bWWZJXJamBxy+SfCrJrbqObW0leUmSPRb5HIcmOXGpHm894vhNklet5WsekOSACcawqO9FkocnOSPJlUnOmfCxJ/peaLaZtLW+Lgbu0T5eBOwKHJNki06jWnsvAfZY5HO8Fth3CR9vmh4A9CJRJdkQ+DBwCnBf4JETPkVv3gt1b6OuA1DvXV1V32qffyvJucD/Ag8CDluXAybZrKr+NKkAl4qq+ulSPp7mdRNgK+CjVfWNroNZk1n9+1HDkrYm7aT25w4ASTZNclCS85JckeSUJA8afEGSc5IcnOQVSc4HLmnXb5jk5Ul+3L72/CSHDr324UlOTHJ5kl+159p4YPur2urbOyf5VpI/Jvl+kv83eH7ghsCBA1X9e4y6uCR7tNv3SvKZJJcl+b+2inPDJG9qz/fzJC8Yeu0qVbhJrp/kfe1thcuTnJvkvQPbb57kk0kuSPKnJD9N8toFjrdvG9sdkhzdxnZmkkcNxZEkr22Pe0mSDyR5fPvaHUZd98Brd29/h5cnOSnJPUfs8+D2/HPH/1aSBwz+ToAXAtsPvN+HttvukeSz7XtyWZKTkzxxoZiGzv2I9povT/KNJDsPbDssybEjXvPqJL8e/NwMbNsXOK9d/Ewb66vabRskeVmSn7Sfzx8neeoE34vjkhw+dLy5z98u7fIO7fITk3w4ye+B/2m3bZ3kPe21XZ7khCR3G/e91NJkSVuTtkP781ftz8OB3YADgZ8CjwM+m2RlVZ088Lq/BX4A/APXfi7fAzwFOAj4GrA18Ji5FyR5HPCxdr9/Am4FvIHmy+iLBo69OfAh4K1tXAcCRybZrqr+SFPdeWwb6/va1/xwDdf5nvbxTpqq9cOBjwBpr+XBwMFJThioiRj2FuCewPPbuG4B7D6w/cPAZsB+wO+BWwK3XUNcAB8FDgHeBOwPfDzJLavq/Hb7ATTv1+uBbwAPp3mPF5TkpsBRwHdofg83ba9586Fdd6RJHG8GrgH2Bo5KsntVHU/zHt+aVauaL2x/bg8cD/wncDlwL+CDSa6pqo+tIcTtad7TVwB/Al4NfCnJravq8va8RyXZsarObq8pNJ+x/66qq0Yc8/PAo4AjaD5TxwNz7+M7gKcCrwG+B9wf+ECS31bV5ybwXqyNN7cxPhb4c5LrAF8Brg+8GLgAeDbwlfb9+NW8R9LSVlU+fKzTA3gV8BuaJLsRcBua5HcJTZXiXkAB9xl63deBwwaWzwF+CWw6sO627WufO8+5A/wM+ODQ+qfT/MO+4UCMBdx3YJ9d23UPHFj3G+BVY1zzHu1rDxxYt3O77qsD6zagScRvHFh3KHDiwPLpwP4LnOsPwEMX2D58vH3bOJ4+sO6GwNXAs9rlDdv3+p1Dx/pC+9odFjjfQcBvgc0H1j2xfd3I9659HzYCvgR8YGD9m4Fz1vBep33tewbf2wXeiwLuObBu+6Fr36D9zLx6YJ/7tq/bZYFj79Du85CBdX9Fk4SfOrTvh4HvTuK9AI4DDp/n87fLUGxHDu33d8CVwK0H1m1E88X5TWv6nPtYug+rx7W+bghc1T5+RFMa3KeqfgncjyZxHZ9ko7kHcAywcug4x1RTGpqzZ/vz0HnOextgO+CTQ8f+KrApsMvAvlfR/AOcM1eKvvnYV7m6Ywae/6T9+dW5FVV1DXAWcLMFjnEy8OIk/5DkNvNsf0Nb7b3dWsT25YE4fktTypq71lsANwY+O/Sa4eVRdgOOrqZ2Ys4Rwzu11fofSvJzmqR5FU1jq1HXOPzaGyT59yQ/49rP1X7jvBa4oKpOmFuoqp/R3K7ZrV2+hubz9JS2hA3NF50Tq+r0MY4/aC+apH3kiM/2rmkar63Xe7GWPj+0fD+aaz97IDZoaqyG//bUI1aPa31dTPMPomgS9C+q/VoPbEOTIEZVO/55aPnXQ8s3BC6rqkvmOe827c8vzLP9FgPPL2n/YQNQVVe2/7M3nee14/j9iOP9fmifK9dwjn+kqVp9JfDOJD8BXlFVH2+370NThf1W4PpJTgFeWFXHjDzaiNhGxHHj9udwFew4VbI3Bk4dXFFVf0ryh7nlJBvQfAG4Ls11/QS4jOY6tx3jHIcCd6dpGf9DmlqbZ9NU4a/JBfOsu8nA8gdpqs/3TPJd4NGseitlXNvQ1FpcPM/2myT5Bev3XqyN4b+fbWjex1F/ezZg7DGTttbX1VU1X//Yi4CfA48Y4zjDc8T+FtgiyVbzJO6L2p/7Ad8fsf3sMc7Zqar6PfBc4LlJ7khzb/wjSU6tqh9W1c+BfdtEuBtNVf9n23vxv13H087dy1wxtH54eb7XrpJskmwGbDmw6q+AOwN7V9UXh/ZbUJJNadoC/GNV/efA+nFrBEclwm1p2koAUFXnJPkKTQl7R5oq6zXdKx/lIpqS871oStzDLmA93ovW5cAmQ+u2nmff4b+fi4ATab7wDLtizPNrCTJpazEdQ9My9g9VdeZavnauqvkpwH+M2P4jmi8EO1TVe0dsX1trKhUvqqo6NcmLae4R35aBhnBtLcG3krwaOIHmXu26Ju3zaJLvw2nurc552Biv/S7w9CSbD1SRP2pon7mE9JfEkGR7muQ2WEof9X5fh6b0Ovja67axDSelUbZNcs+5KvL2lsJdaErXg94PfAC4PfDp9svT2vpqG+v1quroUTsMJOd1eS+gafC2+9C6+48Z3zE01fDnVtWoGgj1lElbi+lomsRwdJI30pR4tqJpCLZpVb18vhdW1Y+SHELTAntbmsZr1wceU1WPr6prkrwQ+K8kW9G0ar6S5p76I9r9/jjf8Uc4E3hwki/SNAD7UVVdurYXvDaSfAM4kqZBWgF/T1N9+p0k16N57z4M/Jgmob2QJuGesa7nrKo/J3kT8KYkF9K0hn4YcId2l1GlxjlvA54DfC7JW2haj7+cpuHfnDNpks3BSV5BUzX8apovWAztd6O2S9XpwG/aUvB3gVcmuaSN5WU0VdBbjXF5v6H5PMy1Hn8NTYn30KH9Pg28iyahz/sZXEj7+fxPmpb5B9GUajel+SJwm6p6Buv5XtB8Nv4uyVtp7lnvCfzNmCF+GHgWcFySN9O0r7ghTY3Nr6rqrety3VoCum4J56O/D9rW42vY5zo0/6h+QpNUfwV8EXjwwD7nAG8e8doNabomndW+9nxWby2+N81gLpfR3P88GXgdsNFCMdIkyX8cWP5r4FvtcQrYY57r2YMRrY2Hj9euO46B1r+s3tr7TcBpwKU096GPBf7fwPv2XpoahT/SJKTPAXdY4Hj7tnFsORTHKu8vTavs19Lcx76UptvWs9vXXn8Nv889aEqJV7Tv9b0YankP3JWmW9ifgP9r4xqOdVOaEvAF7XkPbdf/FU0p9jLgXJpbBuN8zg6lSZyPovmScwXNF5KRrcKB/26Pv8EYn/MdGGo9PvA+HkDzZfSK9v38GvCUSbwX7baX09SOXNrGPFfrMNx6/CEj4r4e8Pb29XN/P0cA9+r6f4ePdX+k/eVKWsaSvA+4f1Vt33Usi61tSf0zmm5Xr+g6HmltWD0uLTPtaFr70Nwfnxvw42nAS7uMa7El2QS4E83gNzek6f8t9YpJW1p+LgPuTdPlbAuaUudLgYO7DGoKbkpTVX0B8My6doQ4qTesHpckqSccEU2SpJ4waUuS1BNL/p72NttsUzvssEPXYUiSNBUnnXTSb6pq5CiFSz5p77DDDpx44nyjZEqSNFvaCXNGsnpckqSeMGlLktQTJm1JknrCpC1JUk+YtCVJ6gmTtiRJPWHSliSpJ0zakiT1hElbkqSeMGlLktQTU0/aSZ6f5AdJTk/ysSSbTjsGSZL6aKpJO8nNgOcCK6tqF2BD4PHTjEGSpL7qonp8I2CzJBsBmwO/6CAGSZJ6Z6qzfFXVz5O8GTgX+BPw5ar68vB+SfYD9gPYbrvtVjvOngfvuciRTt6xLzx27H29vqVlba5NkhbTtKvHbwA8HNgRuCmwRZInDe9XVYdU1cqqWrlixcgpRSVJWnamXT1+P+Dsqrqwqq4CjgDuOeUYJEnqpWkn7XOBuyfZPEmAvYAzphyDJEm9NNWkXVXfBg4Hvgec1p7/kGnGIElSX021IRpAVR0IHDjt80qS1HeOiCZJUk+YtCVJ6gmTtiRJPWHSliSpJ0zakiT1hElbkqSeMGlLktQTJm1JknrCpC1JUk+YtCVJ6gmTtiRJPWHSliSpJ0zakiT1hElbkqSeMGlLktQTJm1JknrCpC1JUk+YtCVJ6gmTtiRJPWHSliSpJ0zakiT1hElbkqSeMGlLktQTJm1JknrCpC1JUk+YtCVJ6gmTtiRJPWHSliSpJ0zakiT1hElbkqSemGrSTrJTkpMHHpckOWCaMUiS1FcbTfNkVfUjYFeAJBsCPweOnGYMkiT1VZfV43sBP62qn3UYgyRJvdFl0n488LFRG5Lsl+TEJCdeeOGFUw5LkqSlqZOknWQT4GHAYaO2V9UhVbWyqlauWLFiusFJkrREdVXS3hv4XlX9uqPzS5LUO10l7ScwT9W4JEkabepJO8nmwP2BI6Z9bkmS+myqXb4AquqPwA2nfV5JkvrOEdEkSeoJk7YkST1h0pYkqSdM2pIk9YRJW5KknjBpS5LUEyZtSZJ6wqQtSVJPmLQlSeqJsZJ2kv+X5OEDy9sk+WiSk5McnGTjxQtRkiTB+CXtg4BdBpbfDuwFfAvYF3j1ZMOSJEnDxk3aOwEnwV8m/Hgk8LyqehbwEmCfxQlPkiTNGTdpbwJc3j6/F81EI59vl38M3GTCcUmSpCHjJu0zgQe2z58IfLOqLm2XbwpcNOnAJEnSqsadmvM1wGFJ/g64HvDwgW0PBL4/6cAkSdKqxkraVfXZJLcD7gycVlU/Htj8TeDUxQhOkiRda9ySNlV1FnDWiPWHTDQiSZI00tiDqyS5Y5JPJPlpkiuS3KVd//okey9eiJIkCcYfXGVvmi5fNwY+DAwOpnIFsP/kQ5MkSYPGLWm/ATi0qu4DvH5o28nArhONSpIkrWbcpH1b4BPt8xradgmw9cQikiRJI42btC8AbjnPttsD504mHEmSNJ9xk/bHgdckuffAukpyG+ClwEcmHpkkSVrFuF2+XgHsDHwN+FW77jM0DdO+DPzr5EOTJEmDxh1c5QrgIUn2opndaxuaoUuPqaqjFzE+SZLUGntwFYCqOgY4ZpFikSRJCxgraSfZeU37VNUP1z8cSZI0n3FL2qezelevYRuuZyySJGkB4ybtPUes2xp4QPt43sQikiRJI43bEO1r82w6MsnrgMcBn5tYVJIkaTVjTxiygGNZdX7tBSW5fpLDk5yZ5Iwk95hADJIkzby1aj0+jwcDv1+L/d8OfLGqHpNkE2DzCcQgSdLMG7f1+CdHrN6EZkzyWwP/NOZxtgJ2B/YFqKorgSvHea0kScvduCXtFSPWXQ78L/CCqvrCmMe5JXAh8MEkd6KZ7vN5VXXZ4E5J9gP2A9huu+3GPLQkSbNt3IZoo1qPr+v57gLsX1XfTvJ24GU0w6QOnu8Q4BCAlStXrqmrmbSk7HnwpP5cpuPYFx7bdQiSxjSJhmhr43zg/Kr6drt8OE0SlyRJazBvSTvJQWtxnKqql46x06+SnJdkp6r6Ec045o6kJknSGBaqHn/sWhynaKboHMf+wEfaluNnAU9bi/NIkrRszZu0q2rHxThhVZ0MrFyMY0uSNMumfU9bkiSto7EHV0kS4F7AbYBNh7dX1bsmGJckSRoy7uAqN6KZR3tnmvvXaTcNdscyaUuStIjGrR4/GLgYuAVNwr4bsANN/+r/oyl9S5KkRTRu9fh9aKbf/GW7nKo6F/jXJBvQlLL/ZhHikyRJrXFL2tcHLqyqa4BLgG0Htp0A3HPSgUmSpFWNm7TPBm7SPv8B8MSBbQ8FLppkUJIkaXXjVo9/HngA8EngdcBnkpwPXAVsx/gDq0iSpHU07oQhLx94flSSewKPBDYDjq6qoxYpPkmS1Bq7n/agqjoROHHCsUiSpAWMdU87yTlJ3pjkzosdkCRJGm3chmiHA/sAJyb5cZLXJNllEeOSJElDxkraVfWiqtoBuDfwBeDpwClJTk/yiiS3XsQYJUkSazlhSFV9s6oOoBkZbQ/gOJqpNs+YeGSSJGkV6zrL1xY0Xb22B64HXDGxiCRJ0khjJ+0kmyV5XJJPARcA76eZMOTpwI0WKT5JktQad5avTwAPBq4DfBV4DnBkVf1+EWOTJEkDxu2nfSPgRcDhVfWbRYxHkiTNY9wR0fZY5DgkSdIarGtDNEmSNGUmbUmSesKkLUlST5i0JUnqCZO2JEk9MW4/7VcusPka4BLglKr62kSikiRJqxm3n/b+wKY0w5cC/AHYsn1+WXuc6yQ5Gdi7qn490SglLQl7Hrxn1yGstWNfeGzXIUgTM271+IOAX9JMz7lZVW0FbAY8vl1/P2B3YAVw8CLEKUnSsjduSfs/gH+rqsPmVlTVFcAnk1wXeEdV3SXJ64DXLUKckiQte+OWtO8I/Gqebb8Ebtc+PxO47voGJUmSVjduSfvHwPOSfKWqrpxbmeQ6wPOBH7WrbgwseD87yTnApcCfgaurauXaBi1J0nI0btJ+HvB54PwkRwMX0ty/vj9N47QHtfvdGThijOPt6cQjkiStnXEnDDkuya1pStUrgbvQVJcfCrytqn7R7veyRYpTkqRlb9ySNm1ifvEEzlnAl5MU8J6qOmQCx5QkaeaNnbQn6F5V9Ysk2wJHJzmzqr4+uEOS/YD9ALbbbrsOQpQkaekZq/V4ko2TvCjJCUnOTXLB8GPcEw5UpV8AHAnsNmKfQ6pqZVWtXLFixbiHliRppo1b0n4r8Ezgc8CxwJUL7z5aki2ADarq0vb5A4DXrMuxJElabsZN2o8FXlZV6zva2Y2AI5PMnfujVfXF9TymJEnLwrhJO8Cp63uyqjoLuNP6HkeSpOVo3BHR3gs8YTEDkSRJCxu3pP1r4IlJjgWOBn4/tL2q6t0TjUySJK1i3KT9tvbndsB9RmwvwKQtSdIiGndEtHGr0SVJ0iIxGUuS1BPzlrST7Az8tKquaJ8vqKp+ONHIJEnSKhaqHj8duDvwnfZ5zbNf2m0bTjY0SZI0aKGkvSfww4HnkiSpQ/Mm7ar62qjnkiSpG+NOGLJtkh0HlpNkvyRvS/LQxQtPkiTNGbf1+KHA8weWXw28C3ggzVji+042LEmSNGzcpH0X4KsASTYAng38U1XdFng9cMDihCdJkuaMm7SvB/y2ff7XwNbAR9rlrwJ/NeG4JEnSkHGT9vnAXF/tBwNnVtXP2+XrAZdPOjBJkrSqccce/wBwUJL70STtlw9suztwxqQDkyRJqxp37PE3JPk5cFdgf5okPmdr4H2LEJskSRowbkmbqvow8OER65810YgkSdJI4/bTvl2Suw8sb57kX5N8Osn+ixeeJEmaM25DtHcBg4OovAl4HrAp8MYkL550YJIkaVXjJu1dgG8CJNkYeBJwQFU9EPgn4OmLE54kSZozbtLeArikfX73dvmIdvl7wPYTjkuSJA0ZN2mfRZOsAR4JfL+q5gZb2Qa4dNKBSZKkVY3bevytwLuTPBa4M/C0gW17AKdOOC5JkjRk3H7a70/yfzT9tF9WVccMbL4IeNtiBCdJkq61Nv20vw58fcT6V00yIEmSNNq8STvJzsBPq+qK9vmCquqHE41MkiStYqGS9uk0jc++0z6vefZLu23DyYYmSZIGLZS09wR+OPBckiR1aN6kXVVfG/VckiR1Y+yGaHOSbARsMry+qv44kYgkSdJI404Ycr0k70ryS+BymsFUhh9jS7Jhku8n+dzaBixJ0nI1bkn7UOA+wHuBnwBXrud5nwecAWy1nseRJGnZGDdp7wU8s6o+tr4nTHJz4MHA64EXrO/xJElaLsYde/xcYFL3rN8GvAS4Zr4dkuyX5MQkJ1544YUTOq0kSf02btJ+CfAvSbZbn5MleQhwQVWdtNB+VXVIVa2sqpUrVqxYn1NKkjQzxh17/AtJ7gf8JMk5wO9H7LPbGIe6F/CwJA8CNgW2SvLfVfWktYhZkqRlaaykneTNwAHAd1mPhmhV9XLg5e0x9wBeZMKWJGk84zZEewbwz1X1hsUMRpIkzW/cpP1HYMH70Gurqo4DjpvkMSVJmmXjNkR7O7BfkixmMJIkaX7jlrS3Ae4G/CjJcazeEK2q6qWTDEySJK1q3KT9GOBqYGPg/iO2F2DSliRpEY3b5WvHxQ5EkiQtbNx72pIkqWMmbUmSesKkLUlST5i0JUnqiXmTdpLdk2w5zWAkSdL8FippHwvsDJDkrCR3mk5IkiRplIWS9qXADdrnOwCbLHo0kiRpXgv10z4BeF+Sb7fLb0hy0Tz7VlXtM9nQJEnSoIWS9tOBfwZuSzPi2Q2ADacRlCRJWt28SbuqfgXsD5DkGuDZVfWdaQUmSZJWNe4wpnYNkySpY+NOGEKS6wPPBO4NbA1cBPwvcEhVDc/6JUmSJmysEnSSWwGnAa8BtgDObX++Bji13S5JkhbRuCXtt9LMoX33qvr53MokNwOOAt4CPHzy4UmSpDnj3qveA3jlYMIGaJdfDew54bgkSdKQcZN2MX93rw3a7ZIkaRGNm7SPBV6bZPvBle3ya4BjJh2YJEla1bj3tA8Avgr8X5LvAb8GtgX+GjgPeMHihCdJkuaMVdKuqnNoRkZ7LvADYGPgh8A/Ardrt0uSpEU0dj/tqroS+M/2IUmSpsyRziRJ6gmTtiRJPWHSliSpJ0zakiT1xLhjj++eZMt5tm2ZZPfJhiVJkoatzeAqO8+zbad2uyRJWkTjJu0ssG1L4I9jHSTZNMl3kpyS5AdJXj3m+SVJWvbm7afdVnnvMbDqGUkeOLTbpsCDaabtHMcVwH2r6g9JNga+keSoqvrWWsQsSdKytNDgKncD9m+fF/BY4Oqhfa4EzgRePM7JqqqAP7SLG7cPJxuRJGkM8ybtqnoT8CaAJGcDj6iqU9b3hEk2BE4C/gp4Z1V9e8Q++wH7AWy33Xbre0pJkmbCuGOP7ziJhN0e689VtStwc2C3JLuM2OeQqlpZVStXrFgxidNKktR7Y489nmRTYHeaZLvp0OaqqnevzYmr6vdJjgMeCJy+Nq+VJGk5GitpJ7k3cASwzTy7FLDGpJ1kBXBVm7A3A+4HvHHMWCVJWtbGLWn/O/BT4P7AD6vqqnU8302AD7X3tTcAPllVn1vHY0mStKyMm7R3Ah61vve1q+pU4M7rcwxJkparcQdXORW48WIGIkmSFjZu0n428Pwk91nMYCRJ0vzGrR4/Gtgc+GqSq4BLhneoqm0nGZgkSVrVuEn7nThymSRJnRoraVfVqxY5DkmStAZjD64CkOQGwC7ALYCjqup37aArV1bVNYsRoCRJaozVEC3JRkkOAs4Hvgb8F7Bju/lTwIGLE54kSZozbuvx1wN/D/wjcEtWnV/7M8BDJxyXJEkaMm71+FOAl1XVB9vRzAb9lCaRS5KkRTRuSfv6NMl5lE2A4UQuSZImbNykfTrw8Hm27Q18bzLhSJKk+YxbPf464FPtzFyH0fTZ3jXJI4FnAg9bpPgkSVJrrJJ2VX0G+FuaqTSPommI9j5gX+DJVfWlxQpQkiQ1xu6nXVWfBD6Z5DY082pfBPyoqhwpTZKkKVirwVUAqurHwI8XIRZJkrSAcQdX+UCST8yz7WNJ3jfZsCRJ0rBxW4/fHzh8nm2fAh4wmXAkSdJ8xk3aK2juYY/yO8BpOSVJWmTjJu2fAbvPs213mjHJJUnSIho3aR8KvDTJc5JsCZBkyyT/ALyEpvuXJElaROO2Hn8jcCvgHcC/J7kM2IKmv/Yh7XZJkrSIxkra7VzZz0jyJmBP4IbAb4Gvtl3AJEnSIltj0k6yKXAxsE9VfRr40aJHJUmSVrPGe9pVdTlwAXD14ocjSZLmM25DtPcAz02y8WIGI0mS5jduQ7TrA7sA5yQ5Bvg1zUxfc6qqXjrp4CRJ0rXGTdqPBq5on/+/EdsLMGlLkrSIxm09vuNiByJJkhY27j1tSZLUsbGTdpI7JvlEkp8muSLJXdr1r0+y9+KFKEmSYPypOfcGTgJuDHwYGGxFfgWw/5jHuUWSY5OckeQHSZ63tgFLkrRcjVvSfgNwaFXdB3j90LaTgV3HPM7VwAur6nbA3YHnJNl5zNdKkrSsjZu0bwt8on1eQ9suAbYe5yBV9cuq+l77/FLgDOBmY8YgSdKyNm7SvgC45Tzbbg+cu7YnTrIDcGfg2yO27ZfkxCQnXnjhhWt7aEmSZtK4SfvjwGuS3HtgXSW5DU3/7I+szUnb6T0/BRxQVZcMb6+qQ6pqZVWtXLFixdocWpKkmTXu4CqvAHYGvg78sl33GZqGaV8G/nXcE7ZDoX4K+EhVHTF+qJIkLW/jDq5yBfCQJHsBewHbABcBx1TV0eOeLEmA9wNnVNVb1iFeSZKWrQWTdpLNgAcBO9CUsI+pqmPW43z3Ap4MnJbk5HbdP1XVF9bjmJIkLQvzJu0ktwS+QpOw51yS5HFV9eV1OVlVfQPIurxWkqTlbqGGaAcB19BMELI5TSvx79NM0ylJkqZsoaR9D+Bfqur4qrq8qs4Anglsl+Qm0wlPkiTNWShp3wQ4a2jdT2mqt2+8aBFJkqSR1tRPe3j0M0mS1JE1dfn6UpKrR6w/Znh9VW07ubAkSdKwhZL2q6cWhSRJWqN5k3ZVmbQlSVpCxh17XJIkdcykLUlST5i0JUnqCZO2JKYzuVwAAB7NSURBVEk9YdKWJKknTNqSJPWESVuSpJ4waUuS1BMmbUmSesKkLUlST5i0JUnqCZO2JEk9YdKWJKknTNqSJPWESVuSpJ4waUuS1BMmbUmSesKkLUlST5i0JUnqCZO2JEk9YdKWJKknTNqSJPWESVuSpJ6YatJO8oEkFyQ5fZrnlSRpFky7pH0o8MApn1OSpJkw1aRdVV8HLprmOSVJmhVL8p52kv2SnJjkxAsvvLDrcCRJWhKWZNKuqkOqamVVrVyxYkXX4UiStCQsyaQtSZJWZ9KWJKknpt3l62PAN4Gdkpyf5O+meX5Jkvpso2merKqeMM3zSZI0S6welySpJ0zakiT1hElbkqSeMGlLktQTJm1JknrCpC1JUk+YtCVJ6gmTtiRJPWHSliSpJ0zakiT1hElbkqSeMGlLktQTJm1JknrCpC1JUk+YtCVJ6gmTtiRJPWHSliSpJ0zakiT1hElbkqSeMGlLktQTJm1JknrCpC1JUk+YtCVJ6gmTtiRJPWHSliSpJ0zakiT1hElbkqSeMGlLktQTJm1Jknpi6kk7yQOT/CjJT5K8bNrnlySpr6aatJNsCLwT2BvYGXhCkp2nGYMkSX210ZTPtxvwk6o6CyDJx4GHAz+cchyStJo9D96z6xDW2rEvPLbrEDRF007aNwPOG1g+H7jblGOQpGVp1r+U9O361uULV6pqEUKZ52TJY4G/qapntMtPBnarqv2H9tsP2K9d3An40ZRC3Ab4zZTO1QWvr9+8vv6a5WsDr2/Stq+qFaM2TLukfT5wi4HlmwO/GN6pqg4BDplWUHOSnFhVK6d93mnx+vrN6+uvWb428Pqmadqtx78L3DrJjkk2AR4PfHbKMUiS1EtTLWlX1dVJ/hH4ErAh8IGq+sE0Y5Akqa+mXT1OVX0B+MK0zzumqVfJT5nX129eX3/N8rWB1zc1U22IJkmS1p3DmEqS1BMmbUmSesKkLUlST0y9IdpSkWTrhbZX1UXTimUxJXlsVR22pnVa2pJsUVWXdR3HYmjnJLgRA/+Pqurc7iLSuGbxc5nkLgttr6rvTSuWUZZtQ7QkZwMFZMTmqqpbTjmkRZHke1V1lzWt66v2H/6DgR1Y9Z/+W7qKaZKS3BN4H7BlVW2X5E7AM6vqHzoObSKS7A8cCPwauKZdXVV1x+6iWn9JTqP5/7LaJmbj+mb2c5lkbmzRTYGVwCk0v7c7At+uqnt3FRss45J2Ve3YdQyLKcnewIOAmyX594FNWwFXdxPVovgf4HLgNK79pz9L3gr8De0gRFV1SpLduw1pop4H7FRVv+06kAl7SNcBLLKZ/VxW1Z7wlwmt9quq09rlXYAXdRkbLOOkPSjJDYBb03yzAqCqvt5dRBPxC+BE4GHASQPrLwWe30lEi+PmfS+1rElVnZesUiH0565iWQTnARd3HcSkVdXPuo5hsc345xLgtnMJG6CqTk+ya5cBgUmbJM+g+bZ/c+Bk4O7AN4H7dhnX+qqqU4BTkny0qq7qOp5FdFSSB1TVl7sOZJGc11ZFVjv073OBMzqOab0leUH79CzguCSfB66Y29732xtJvlFV905yKatWk89Vj2/VUWiTMpOfyyFnJHkf8N80v8MnsQSucdne057T3nu6K/Ctqto1yW2BV1fVPh2HNhFJHgK8Ftie5kvarPzTACDJI2n+qDYArmL2rm8b4O3A/Wiu7cvA8/penZzkwAU2V1W9ZmrBaK3N6udyUJJNgWcDc9X+XwfeXVWXdxeVSZsk362quyY5GbhbVV2R5OSq6rwaZBKS/AR4FHBazeAvO8lZwCOY0eubdbPeuyHJf1XVk9e0TktTks2A7apqWtNDr9Gyrx4Hzk9yfeDTwNFJfseI6UJ77Dzg9BlOaP/HDF5fkncwuvUxAFX13CmGs5heDgwn6FHr+ur2gwtJNgL+uqNY1tsy+lyS5GHAm4BNgB3b+9mvqaqHdRnXsk/aVfXI9umr2qb+1wO+2GFIk/YS4AtJvsYM3TMc8Euae6JHMVvXd2LXASymWe/dkOTlwD8BmyW5ZG41cCVLaPKJdTDTn8shBwK7AccBVNXJSXboMB7ApA38pTP9vWm+QR5fVVd2HNIkvR74A03L+E06jmUxnN0+NmGGrq+qPgTzVx93E9VEzXTvhqp6A/CGJG+oqpd3Hc+kLIPP5aCrq+rioRbynfOedvJK4LHAEe2qRwCHVdXruotqcpKcWFUru45D62YZDI6z8Sz3bpiv73Lfu5TO+ucSIMn7gWOAlwGPpmkhv3FVPavTuEzaOQO481yLwLbhwfeq6nbdRjYZSf4N+OqsdYlK8raqOiDJ/zDiHlvX953W10D18eOATwxs2grYuap26ySwCZtn5LCLaUrhr+t7a+T28zlnU5rq1pOqqpddSpfL5xIgyebAPwMPoLm18SXgtV23Hrd6HM6h+WOa+0VcB/hpZ9FM3nOAlyS5gtnqEvVf7c83dxrF4pnp6uMBR9EMyvHRdvnxNJ/Ri4FDgYd2E9ZkVNUq8Se5BXBQR+FMwnL5XFJVf6RJ2v/cdSyDlm1Je6AV5HY0/bSPbpfvD3yjqh7fYXgS0LQ2rqreN8yaT5Ljq+peo9YlOa2q7tBVbIshzQ3SU/t+XbN+WwMgyUqaxoQ7sOq8Bp2OwLicS9pzrSBPAo4cWH/c9ENZXLM4TOsCEzIA3f9hra8kn6yqxwHfTzKq+r/X1zdgyyR3q6pvAyTZDdiy3db7LytDXaQ2AHalmYCilwY+l9+b8c8lwEeAF7PE5jVYtiXtcSX5VFU9uus41tV8w7T29Z7anCTbL7S972M/J7lJVf1yvuvs+/XNSXJX4AM0iTrAJcAzgB8AD66qT3YY3npL8tSBxauBc6rq+K7iWV8Dn8tP0iS0v2wCDmoT+kyYG4q26ziGmbTXIMn3q+rOXcexrmZ9mNY1SfLNqrpH13GsqyRvrKqXrmld3yW5Hs3/o993Hcs09bVQME/r8VNnqaSdZC/gCTQtyAfHgDhi3hdNwXKuHh9X37/VXF5VlychyXWq6swkO3Ud1BRtuuZdlrT7A8MJeu8R63opyXVoutPsAGw01yd2GY09fsuuA1gbSZ4N/ANwyySnDmy6LtDbGoR5PA24LbAxA3O9c2334E6YtGffrA/Tuia9/NK1jP45foampfhJDJRmlpG+fT4/StPi/w00/ZfnXFpVF3UT0qK501JsMGj1+Br0vXp8UJL70A7TOjfqW5IbVNXvuo1s8fR1wIe2uvgGrOGfY99/f0lOr6pduo6jK339fC4HSd4LvLWqfth1LIOWdUk7yYbAh6rqSQvsNhPVkABV9bURq48BZvmfxtIag3BMVXUxTQn0CWvYte+/vxOS3KGqTus6kI708vO5TNwbeGqSs2lqgebGuLDLV1eq6s9JViTZZL7xxmdtJLERZv2fxqxPgdj339+9gX2X2j/GKZqZQsEMeuBCG7uq5VrWSbt1DnB8ks8Cl82tnIFZosbVy/sjc90xklzKqtewyohvVXV6JwFOTy9/fwP27jqAxbDAOAKrfClZBoWC3hqjW2UntVwm7aZR1i9oBj64bsexaExz/Seryt9Zj1XVz5LcG7h1VX0wyQquHVylzx7SdQBadJ3Uci37pF1Vr+46ho71vXp1rm3CjVh1qMFzu4toqnr9+0tyILAS2An4IE33mv8G7rXQ65a6wVJakhvRjJUA8J2quqCbqDRhndRyLfukneRYRs8S1fcRw7ZeaPtAC+S9phDOokmyP81k9b9m1b6UM3NPdMR8798b2Nzr3x/wSODOwPcAquoXSWam9iTJ44A30QyPHOAdSV5cVYd3Gph6a9knbeBFA883pRnoofdjHtP0ey1Gl8SKdlCHGehb+Txgp75P4TifEfO9fzDJX+Z7n4Hf35VVVXPjWCfZouuAJuyfgbvOla7b6v+vACbt/rN6vAtVddLQquOTjOoa1StVtWPXMUzJeTRdo2bVE1h1vvd/oymVvq7TqCbnk0neA1w/yd8DTwfe23FMk7TBUHX4b2naz2iJS3K/qvrK0LqnVtWH2sVOarmWfdIeqkbeAPhr4MYdhTMxbZXqvIaqWHsnyQvap2cBxyX5PKuODzwrrf/PYYbne6+qNye5P81EITsBr6yqozsOa5K+mORLwMfa5X2AL3QYj8b3yiSPpqmN3RJ4H83/mA9Bd7Vcy35EtLZ/6Fw18tXA2cBrquobnQa2ntp79fOpGbhnf+BC22elgWGSTzNivnfgAoCqem530WkcSR5F0yYhwNer6sg1vERLQDv3+QuBZ7arXllVH1vgJVOx7JO2ZluSd1TV/l3Hsa6GpnZczUBVXa+M6F//l00M9LPvuyTPBw6rqvO7jkVrp62FfQ9NV+Cb0/RqeGN1nDStHk+eA3xkbkrAJDcAnlBV7+o2sslIsjHwbGD3dtVxwHuq6qrOgpquvncd6mVSXpNx+9f3fWx1YCvgS0kuAj4OHF5Vv+44Jo3nW8C/VdUHkmwGvJFmsp57dhnUsi9pJzm5qnYdWjdLk4S8j6bv69w//ycDf66qZ3QX1fT0fUKGJA8BXgtsT/Mle6ZKomvS99/fnCR3pLmf/Wjg/Kq6X8chaQ2SbDc83kOS3avq613FBJa0ATZIkrkqj3agjk06jmmS7lpVdxpY/mqSUzqLRmvrbcCjgNO6rpbrSK8HjxlwAfArmtbj23Yci8bzmySvALarqr9PcmuampNO2fUAvkTT7WSvJPelaeX5xY5jmqQ/J7nV3EKSWwJ/7jCeaev7P/3zgNOXacKGno+tnuTZSY6jGad6G+Dvl9FkKH33QZrW4vdol89nCXS1tKTdzLKzH8193wBfpmnaPyteDByb5Cya69seeFq3IU1OkjtX1fcX2OXtUwtmcbwE+EI7dsAsdmmbddsDB1TVyV0HorV2q6raJ8kTAKrqT22L8k4t+3vaa5LkU1X16K7jWB9JrkPTBzbAmVV1xRpe0htt17abAIcBH6+qH3Qc0kQl+TLwB+A0rh2mdWa6tK3JLLQvGTUhSlWd3XVcWliSE2gGUDm+qu7S1lh+rKp26zQuk/bC+v5PY9ZbxwMkuTHwOJqGPlsBn5gb5rPvkpxYVSu7jmMxLTS2epKt+zxU6+CEKFV1myQ3pekC1uteDctBO+jPvwA709TA3gvYt6qO6zQuk/bC+t56ddZbxw9Kcgea6uR9qmomGhO2w5Z+dVbnXR4xtvojaJLarHzpOpl2QpS5v7kkp3pfux+S3BC4O00t5beq6jcD227fRc2e97Rn30y3jk9yO5oS9mOB39D0hX1hp0FN1nOAFye5EriK2evyNetjq8/6hCgzrZ2I6PPzbP4vYOoFOpP2mnXe8GA9zbWO/0+a6sdnMVut4z9I0+L//lX1i66DWQTXA54I7FhVr0myHc09/FlxDjM6tnrbaOlzMz4hynLWSW5Y9tXjSZ5XVW+fb12SB/S5ajLJBjSt4+/HQOv4qpqZbl/taEXbVdWPuo5l0pK8m6YB2n2r6nZtm4QvV9VdOw5tImZ9bPUk36PpofIAmr+/L83YhCjLVle3Tk3aI974Wb3nO0rfW8cneSjwZmCTqtoxya40E748rOPQJmLu8zn4mUxyytCAOb01q2Orz0nyTuDQqvpu17FosrpK2su2erzte/e3wI5JPjuw6bo0oxYtF7fsOoD19CpgN5ox1amqk5Ps0F04E3dV2w5h7p7oCga6fvVd35PyGPYEnpnkZ8BlcyttiDYTruzipMs2aQMnAL+kGaXo4IH1lwKndhJRN/pe1XJ1VV28BMY8WCz/DhwJbJvk9cBjaLqhzIRlMLb63l0HoHWT5F7AyVV1WZIn0TQ6e3tV/Qygqu7eSVzLvXocIMmNaO6rAXynqi7oMp5pmoEube+nGSLyZTSTMTwX2LiqntVpYBOU5LY0gzwEOKaqzug4pIlJ8hOW99jqWqKSnArcCbgjTUvx9wOPqqr7dBnXsh97PMljge/QdBl6HPDtJI/pNqqp6nsRdX/g9jRDfH4UuBg4oNOIJqyqzqyqd1bVf8xSwm4t97HVtXRd3X4uH05Twn47ze3TTi37knY749X950rX7T3Dr8xQQ5+ZbR3f3uv9ktMc9leSu9JUjzu2upaUdrz/L9LM1bA7cCFNdfkduoxr2Ze0gQ2GqsN/y2y9L6Na5+4796SvCRug7bb2xyTX6zoWrbPXA3+k6at93YGH1LV9aL5I/l1V/Qq4GfCmbkNa3g3R5hyV5Es0A3RA84v6QofxTMQyah1/OXBakqNZtXVur/v3LiNbV9UDug5CGtYm6rcMLJ8LfLi7iBom7ab19HtoJiwIcAjNWLN9t1xax3+e+YcZ1NL3lT7fotHsSvIo4I3AtjS5YUn0bPCe9ujBVWZqQP9l3jq+14PHzLoklwKb0/R5ncWx1dVTbc+Ghy61xp+zdO92rSR5dpLTgJ2SnDrwOJsZKonaOr73g8fMuuvRtLF4Q5uob08zlKnUtV8vtYQNy7ik3TZeugHwBpo+vnMu7fP8vcNmvXX8mvS9H/qsm/Wx1dU/bbU4wH2AGwOfZtWeDUeMet20LNt72lV1MU2f3id0Hcsim/XW8eq3u82NrQ5QVb9LMjNTx6qXHjrw/I80k73MKa6d+70TyzZpLyMz2Tp+LfR98JhZN9Njq6t/qupp0AxjWlXHD25rhzbtlCWu2TfXOv6ONEPyHdJtOFP30q4D0IKGx1b/BvCv3YYkAfCOMddN1bK9p71czGrr+LYR4agP71zr415f33Iyy2Orq3+S3AO4J81wyG8d2LQV8Miu2wNZPT6jkjwb+Afglu3A93OuCxw/+lW98pCuA9BkVNWZwJldxyG1NgG2pMmPg6PzXUIzy16nLGnPqOXSOl6SFkOS7eem4VxKTNrqtSR3p7nPdDuab8gbApc5OIek9ZFkJfDPXDvXOwBd33qzelx99x/A44HDgJXAU4C/6jQiSbPgI8CLgdNYQj0aTNrqvar6SZIN21m/PpjkhK5jktR7F1bVZ9e823SZtNV3f2wH4zg5yUE0k6Rs0XFMkvrvwCTvA45hCY2I5j1t9VqS7YFf09zPfj7NWNbvrKqfdhqYpF5L8t/AbYEfcG31eFXV07uLyqStnkvyvKp6+5rWSdLaSHJaVd2h6ziGOSKa+u6pI9btO+0gJM2cbyXZuesghlnSVi8leQLwt8C9gf8d2LQVcHVV3a+TwCTNhCRnALcCzqa5p70kRlu0IZr66gSaRmfbAAcPrL+UGZoPXVJnHrjQxiQ3qKrfTSuYv5zXkrb6LsmNgLn5l78zNBWpJE3cqHkdpsF72uq1JI8FvgM8Fngc8O0knY8PLGnmdTLtr9Xj6rt/Ae46V7pu52P+CnB4p1FJmnWdVFNb0lbfbTBUHf5b/FxLmlGWtNV3RyX5EvCxdnkf4AsdxiNpeeiketwSifqugPcAdwTuBBzSbTiSlom9ujiprcfVa6NacCY5teu+lJL6KckdgPcCNwOOAl4617UryXeqarcu47OkrV5K8uwkpwE7JTl14HE29tOWtO7eDbwKuAPwY+AbSW7Vbtu4q6DmWNJWLyW5HnAD4A3AywY2XVpVF3UTlaS+S3JyVe06sLwnzW23JwPv6qJv9iCTtiRJrSSnALtX1cUD6+4IfArYuqpu2FlwWD0uSdKgNwK3G1xRVafSNDzrdC5tsKQtSVJvWNKWJGkMSTrvUurgKpIktZJsPd8m4EHTjGUUk7YkSde6EPgZq454Vu3ytp1ENMCkLUnStc4C9qqqc4c3JDmvg3hW4T1tSZKu9TaaMSBGOWiagYxi63FJktZSkvtX1dFTP69JW5KktTNq3oNpsHpckqS159SckiT1RCfV1CZtSZJ6wqQtSdLaO6eLk5q0JUkakuSxSa7bPv+XJEck+UvDs6p6VBdxmbQlSVrdK6rq0iT3Bv4G+BDw7o5jMmlLkjTCn9ufDwbeXVWfATbpMB7ApC1J0ig/T/Ie4HHAF5JchyWQMx1cRZKkIUk2Bx4InFZV/5fkJsAdqurLncZl0pYkaXVJNgRuxMDkWqMmEpkmZ/mSJGlIkv2BA4FfA9e0qwu4Y2dBYUlbkqTVJPkJcLeq+m3XsQzq/Ka6JElL0HnAxV0HMczqcUmSVncWcFySzwNXzK2sqrd0F5JJW5KkUc5tH5uwBPpnz/GetiRJ82iHMq2q+kPXsYD3tCVJWk2SXZJ8Hzgd+EGSk5Lcvuu4TNqSJK3uEOAFVbV9VW0PvBB4b8cxmbQlSRphi6o6dm6hqo4DtugunIYN0SRJWt1ZSV4B/Fe7/CTg7A7jASxpS5I0ytOBFcARwJHt86d1GhG2HpckqTesHpckqZXkbVV1QJL/oRlrfBVV9bAOwvoLk7YkSdeau4f95k6jmIdJW5KkVlWd1D7dtarePrgtyfOAr00/qmvZEE2SpNU9dcS6facdxDBL2pIktZI8AfhbYMcknx3YdF2g82k6TdqSJF3rBOCXwDbAwQPrLwVO7SSiAXb5kiRpSJJbAr+oqsvb5c2AG1XVOV3G5T1tSZJW90ngmoHlPwOHdRTLX5i0JUla3UZVdeXcQvu883m1TdqSJK3uwiR/GUglycOB33QYTxOH97QlSVpVklsBHwFuRjMy2vnAU6rqJ53GZdKWJGm0JFvS5MpLu44FrB6XJGk1SW6U5P3AYVV1aZKdk/xd13GZtCVJWt2hwJeAm7bLPwYO6CyalklbkqTVbVNVf+n2VVVX03T76pRJW5Kk1V2W5Ia003MmuTtwcbchOYypJEmjvAD4LHCrJMcDK4DHdBuSrcclSRopyUbATkCAH1XVVR2HZNKWJGlOkkcttL2qjphWLKNYPS5J0rUeusC2AjpN2pa0JUnqCUvakiS1krxgoe1V9ZZpxTKKSVuSpGtdt+sAFmL1uCRJPeHgKpIkDUly8yRHJrkgya+TfCrJzbuOy6QtSdLqPkgzuMpNaabn/J92XaesHpckaUiSk6tq1zWtmzZL2pIkre43SZ6UZMP28STgt10HZUlbkqQhSbYD/gO4B82gKicAz62qczuNy6QtSdKqknwIOKCqftcubw28uaqe3mVcVo9LkrS6O84lbICqugi4c4fxACZtSZJG2SDJDeYW2pJ25wOSdR6AJElL0MHACUkOp7mn/Tjg9d2G5D1tSZJGSrIzcF+a+bSPqaofdhySSVuSpL7wnrYkST1h0pYkqSdM2tISluRVSWrE4ysTPMduSV41qeNJWjy2HpeWvouBB45YNym7AQcCr5rgMSUtApO2tPRdXVXf6jqIcSXZrKr+1HUc0iyyelzqsSTPSPKDJFck+VmSlwxtv0eSzyb5RZLLkpyc5IkD2/cF3tE+n6t6P65dPjTJiUPH26Hd5yED6yrJC5K8LcmFwGnt+k2THJTkvDa+U5I8aOh4D0tyUhvb75J8O8l9JvsuSbPDkrbUA0mG/1b/DLwI+FfgIOA44K+B1yb5Y1X9R7vf9sDxwH8ClwP3Aj6Y5Jqq+hjweZpBJF5IMzECwCXrEOKLga8DT+bawsDhXFv1/lOawSk+m2RlVZ2c5FbtPm9vX79pew1br8P5pWXBpC0tfTcErhpa93CaZPi6qnp1u+7oJJsD/5Lk3VX156r6+NwLkoQmsd4c+HvgY1V1YZJzANazCv5XVbXPwLn2Ah4M7FFV/7+9+wmxKYzDOP59kKYmMykiJTbG1oJiJYVS8q+UWLEgpcZGiCxYMSVjZSINCxaSPzViNFMakuz8y6w0hUhN7lCGkZ/Fe6aucxtz5S7mzH0+dbr3vPe95/y6m6fznl/nPsiGuyW1AEeAraTnOH+JiANlx7nzHzWYTXpeHjeb+ErAstwmoBG4Jmna6Ab0AnNIwYykmZLOShogBf8IsBtoqXGNXbn91cAH4FGuvh5gaTbnOdAs6ZKktZIaa1yT2aTjK22zie9nROTvLS/O3r4c4zvzgQGgE1gOnABekZa+95Ku1GvpY25/FjCXyhUCSEv7RES/pI3AIdIV9oikG0BrRHyqcX1mk4JD26yYBrPX9VQGJkC/pAbSEvW+iDg3+oGkalfYhoHpubGx7jfnn4c8CLwDNv3tBBHRBXRJas5qPUNqjNtWZY1mdcWhbVZMj4FvwLws+CpkQTgV+F42NgPYwJ8h+yP7rCEihsvG3wILc+Nrqqyvh9Tc9jUiXo83OSJKwJWsc3zFePPN6pVD26yAIuJz9hSzdkkLSA1mU0j3qldFxOaIKEl6ChyTNAT8Ii1Fl4CmssONhmqrpF5gKCL6gZvAceCCpE5S49jOKku8D9wjNcedJC3jNwFLgIaIOCxpDymg7wLvgUWkBrXL//yDmNUJN6KZFVREnCI1la0DbgFXgR1AX9m07cAbUhC2A9epDMU+oA1oBZ4AHdnxXwC7SMF6G1iZ7VdTWwBbgIvAflKAd2THephNewbMBk4D3cBR4DxwsJpzmNUj/zWnmZlZQfhK28zMrCAc2mZmZgXh0DYzMysIh7aZmVlBOLTNzMwKwqFtZmZWEA5tMzOzgnBom5mZFYRD28zMrCB+A5ww+nHYccp/AAAAAElFTkSuQmCC\n",
"text/plain": [
""
]
},
"metadata": {
"needs_background": "light"
},
"output_type": "display_data"
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"\n",
"columns inputed with : unknown are ['emp_title', 'title']\n",
"\n",
" unknown Filled inplace of NaNs\n",
"\n",
"\n",
" unknown Filled inplace of NaNs\n",
"\n"
]
},
{
"data": {
"application/vnd.plotly.v1+json": {
"config": {
"linkText": "Export to plot.ly",
"plotlyServerURL": "https://plot.ly",
"showLink": true
},
"data": [
{
"histfunc": "count",
"histnorm": "",
"marker": {
"color": "rgba(255, 153, 51, 1.0)",
"line": {
"color": "#4D5663",
"width": 1.3
}
},
"name": "revol_util",
"opacity": 0.8,
"orientation": "v",
"type": "histogram",
"x": [
73.1,
23.2,
31.2,
55.5,
76.2,
64.5,
23.9,
29.5,
76.6,
90.5,
50.8,
71.9,
34.2,
27.2,
41.4,
35.4,
96.2,
99.4,
54.7,
76.7,
68.7,
12.2,
82.4,
60.6,
54.2,
46.7,
32,
87.3,
48.4,
58.1,
69.6,
70.7,
97.5,
52.7,
12.3,
54.9,
82.2,
48.3,
64.1,
65.2,
78.2,
36.7,
26.2,
30.5,
70.5,
95.8,
33.2,
80,
51.7,
76.9,
45.7,
51.2,
1.7,
71.4,
19.5,
70,
38.4,
36.6,
45.7,
15.9,
40.2,
78.4,
15.3,
68,
5.5,
53.7,
2.9,
80.1,
63.6,
35.7,
67.8,
76.2,
78.4,
58.2,
93.4,
70.7,
53.3,
79.2,
44.4,
85.1,
45,
18.1,
97,
67.4,
44.7,
76,
44.3,
57.9,
19.1,
81.1,
96.3,
77,
null,
57.5,
66.8,
37,
49.1,
86.4,
48.8,
65.1,
37.5,
61.5,
46.6,
18.2,
68.5,
38.4,
49.3,
61,
33,
26.9,
13.7,
47.7,
49.3,
38.9,
25.8,
38.2,
58,
20.3,
43.1,
84.3,
54.2,
80.7,
12.2,
69,
55.2,
75.9,
21.3,
20.5,
85.1,
77.7,
58.7,
65,
65.6,
42.5,
46.2,
76.9,
39,
45.2,
22.2,
45.1,
41.1,
36,
77.9,
55,
96.3,
53,
68.5,
47.4,
52.9,
68.3,
93.2,
67.6,
88.7,
52.9,
88.4,
50.3,
26.4,
10,
34.7,
66.8,
33.2,
57.6,
40.8,
96.3,
3.4,
85.2,
103.5,
11.5,
8.2,
74.2,
54,
26.1,
27.4,
41.1,
15.9,
76.3,
25.3,
51.3,
62.9,
66.3,
20.2,
62.2,
53.6,
53.3,
58.9,
49.7,
97.6,
22.9,
82.4,
62.1,
71.7,
52.1,
42.4,
57.4,
28.1,
64.8,
35.1,
13.2,
51.4,
68.8,
42,
32.4,
49,
47.2,
67.4,
77.7,
89.4,
88.1,
93.1,
73.7,
62,
18.1,
69.1,
52.5,
40.3,
36.2,
74.8,
85.5,
26.3,
41.3,
47.9,
67.3,
57.6,
67.4,
48.6,
18.2,
46.5,
95.1,
57.3,
14.4,
47.3,
40.6,
27.1,
23.9,
39.2,
21.1,
33.2,
66.8,
25,
53.8,
74.1,
54.4,
69.6,
43.9,
86.3,
81,
62.7,
69.1,
49.4,
84.9,
28.7,
93.9,
77.3,
31.1,
69.3,
73.2,
16.4,
78.8,
46,
33.7,
51.1,
77.4,
95.6,
81.3,
80,
49.6,
59.7,
27,
46.1,
69.4,
52.5,
99.1,
23.9,
52,
72.7,
54.1,
57,
78.8,
48.6,
64.7,
34.2,
55,
49.2,
66.4,
30,
93.5,
95.6,
62.3,
37.3,
39.2,
82.8,
26.6,
67.5,
14,
45,
97,
21.5,
57.8,
13.8,
74,
50.1,
81.4,
5.8,
66,
64.7,
49.3,
50.6,
90,
71,
50,
29.7,
23.4,
86.3,
25.5,
37.1,
61.5,
83.2,
31.5,
50.5,
51.4,
55.8,
69.5,
55.4,
76.7,
55.8,
44.5,
66.5,
77.1,
47.7,
69.3,
46.2,
28.2,
29.4,
88.6,
44.5,
95.8,
41.2,
56.7,
12.1,
88.3,
47,
73.2,
58.3,
25.5,
96,
33.6,
24.9,
15.9,
102.7,
64.1,
81.1,
76.8,
53.3,
64.8,
5.2,
40.8,
64.7,
56.5,
26.8,
68.1,
19.7,
80.6,
28.5,
76.2,
52,
1.9,
78.6,
69.2,
39.8,
53.9,
39.1,
76.7,
56,
34.1,
28.8,
10,
58.7,
58.3,
27.1,
77.8,
65.6,
89,
76.9,
9.7,
76.5,
56.9,
41.8,
79.1,
85.9,
43.3,
53.3,
30.6,
58.4,
78.8,
69.8,
19.7,
93.6,
71.7,
91.3,
42.1,
32.8,
63.3,
27.5,
50.1,
54.2,
49.9,
63.5,
90.2,
67.3,
42.7,
26.3,
25.6,
38.7,
93.2,
34.7,
59.7,
55.3,
88.2,
86.3,
31.6,
61.6,
80.2,
27.5,
48.2,
68.7,
58.5,
35.1,
45.1,
44.8,
57.2,
61.9,
74.5,
56.1,
56.4,
34,
98.9,
14.2,
48.6,
48.6,
28.7,
60,
18.4,
69.3,
56.8,
43.4,
71.5,
47.6,
94.3,
45.5,
70.6,
43.9,
21.3,
26.3,
28.5,
26.3,
98.7,
80.6,
51.3,
28,
25.1,
98.4,
71.5,
54.6,
26.9,
19.8,
53.3,
36.7,
94.2,
47.7,
89.9,
95.8,
55.8,
19.9,
85.4,
38.2,
35.1,
86.1,
58.8,
91.5,
88.8,
96.1,
68.5,
57.9,
27.6,
60.5,
39.4,
62.7,
60.1,
27.6,
91.6,
38.2,
27.6,
69.8,
79.1,
73.5,
82.6,
32.3,
35.8,
93.1,
44.3,
84.4,
71.9,
47,
89.8,
66.3,
66.3,
68.9,
78,
85.9,
50,
85,
34.1,
66.8,
85.3,
65.9,
52.5,
37.7,
61.1,
52.5,
71,
86.3,
39.6,
82.5,
43.5,
53.3,
51.6,
76,
55.1,
37.6,
37.7,
32.3,
54.8,
40.3,
32.9,
57.3,
66.9,
43.1,
76.1,
51.3,
49.9,
83.7,
57.9,
31.9,
14.9,
8,
92.5,
45.8,
46.6,
63.8,
90.7,
55.8,
83.5,
59.5,
15.4,
66.6,
67.1,
43.5,
89.7,
58.2,
97.6,
58.4,
77.7,
57.3,
52.4,
49.4,
41.2,
42.7,
17.6,
24.3,
61.4,
67.6,
87.9,
38.4,
76.5,
95.4,
59.2,
65.2,
51.1,
63,
29.1,
39,
24.1,
54,
44.8,
71.1,
58.4,
33.1,
52.1,
86.8,
86.7,
64.2,
86.4,
37.8,
92.8,
43.5,
50.2,
48.6,
43.8,
44.9,
36.4,
43.8,
43.2,
66.5,
10.9,
67.4,
64.1,
35.3,
74.5,
59.7,
53.4,
71.6,
73.7,
51.4,
75.4,
57.5,
40.1,
95.4,
32.2,
79.5,
29.3,
78.2,
46.5,
63.3,
61.4,
50,
92.9,
30.8,
32.1,
19.2,
60.5,
74.9,
50.2,
26.9,
76.5,
87.3,
79.1,
57.5,
55.6,
47.4,
35,
68.8,
2.8,
86.8,
51.3,
20,
45.8,
48.8,
80.9,
92.5,
31.5,
90.5,
25.8,
10.8,
63.3,
65.2,
9.3,
33.3,
30.1,
18.5,
81.2,
33.5,
71.8,
95.1,
89.1,
71.7,
66.3,
22.9,
37.3,
85.2,
60.1,
29.5,
85.9,
3.3,
4,
75.9,
37.1,
94.5,
36.4,
57.7,
47.9,
10.3,
98,
30.8,
84.3,
100.7,
39.9,
52.4,
32.3,
27.4,
55.2,
48.8,
69,
92.3,
18.8,
65.8,
35.1,
43,
89.9,
26.4,
42.3,
57.1,
53,
64.3,
11.8,
76.5,
26.2,
50.9,
40.5,
57.6,
56.2,
44.2,
26.2,
29.9,
36.3,
54.9,
76.2,
27.8,
95.9,
43,
24,
87.6,
61.8,
54,
14.7,
27,
51.5,
61.7,
47.6,
16.2,
81.8,
16,
63.1,
35.3,
28.1,
70.5,
59.6,
55.8,
46.3,
59.4,
91.1,
45.9,
50.4,
67.6,
93.4,
93,
71.2,
28,
60.2,
17.8,
77.8,
66.9,
24.9,
49.6,
61.4,
78.8,
46.3,
53.3,
27.6,
86.9,
27.3,
77.6,
88,
41.7,
61.4,
46.1,
53.7,
67.1,
87.7,
46.3,
50.1,
91,
36.7,
61.4,
40.2,
55.7,
1.7,
41.9,
98.3,
65.1,
39,
41.5,
38.1,
53.1,
93.6,
64.3,
34.8,
45.2,
66.1,
96,
49.6,
52,
29,
62.2,
66.7,
51.1,
48,
86.2,
83.5,
73,
67.2,
68.4,
77.1,
49.3,
47.8,
80.3,
36.5,
89,
89.2,
96.8,
74,
31,
94.4,
70.6,
57.2,
61.6,
43.7,
75.4,
60.1,
83.5,
66.3,
12.6,
55.9,
59,
43.9,
57.8,
53.3,
78.1,
91.2,
13.3,
32.5,
70.4,
69,
66.2,
80.8,
26.2,
80.4,
65,
87.7,
53.2,
57.7,
74.2,
28.3,
59.1,
69.5,
79.3,
49.4,
44.9,
73.9,
66.7,
73.3,
86.9,
9.9,
98.4,
67.1,
38.5,
54.3,
57,
90.6,
61.5,
83.9,
37.7,
77.9,
73.7,
41.8,
65,
77.9,
16,
91.9,
null,
39.1,
72.5,
25.3,
82.6,
38.4,
65.9,
85.4,
29,
67,
24.8,
84.9,
17.7,
88.1,
48.3,
66.7,
42.3,
46.5,
75,
62,
54.3,
46.7,
54.3,
42.5,
46.6,
53.2,
26.4,
56.9,
86,
67.6,
54.5,
46.5,
32.3,
74,
47.1,
37.6,
26.6,
16,
50.6,
65,
52.7,
16,
95,
39.3,
90.3,
89.4,
38.5,
27.8,
74.2,
38.5,
42.1,
76,
12,
66.8,
69.5,
74,
24.9,
48.4,
83.4,
52,
99.5,
1.8,
69.5,
59.6,
63,
28.8,
49.3,
73.4,
87.3,
4.3,
70.7,
92.3,
47.7,
47.3,
73.9,
79,
77.8,
6.8,
84.6,
20.9,
15,
53.7,
89.5,
67.2,
61.1,
45.7,
89.4,
95.7,
49,
51.6,
23.9,
55.5,
52.6,
22.2,
93.1,
84.8,
61.8,
69.7,
51.7,
9.9,
25.2,
97,
24.2,
76.3,
29.1,
61.5,
91.9,
23.1,
64.1,
27.3,
52.2,
22.4,
54.3,
50.7,
81.6,
66.8,
73,
69.6,
10.8,
16.2,
74.8,
86,
49.2,
67.6,
52,
71.5,
99,
73.5,
64.5,
61.4,
44,
32.9,
44.5,
87.6,
38.5,
49.2,
20.4,
78,
79.2,
55.4,
80.1,
91.1,
44.3,
74.1,
24.1,
41.8,
87.6,
71,
62.1,
81.1,
72.7,
61.7,
88.2,
24.4,
54.9,
52.7,
44.4,
58.2,
73.4,
57.7,
70.1,
49,
86.7,
44.3,
84.2,
81,
92.7,
73.9,
33.6,
61.6,
76.7,
40,
48,
56.9,
40.6,
47.6,
47.6,
10.1,
58.5,
15.6,
3.1,
40.9,
72.7,
18,
24.1,
42.9,
57.1,
38.6,
67.7,
65.2,
61.5,
68.1,
46.5,
60.7,
79.1,
65.8,
32.6,
66,
6.2,
29.3,
36.6,
94.1,
67,
73.7,
69.1,
13.2,
59.5,
63.2,
66,
31.6,
31.8,
69.3,
78.8,
78.5,
73.5,
81.9,
33.6,
49.8,
98.7,
62.9,
70,
99.7,
66,
61.2,
52.4,
56.8,
56.8,
66,
76.7,
22.1,
80.1,
26.6,
49.1,
52.6,
67.8,
57.2,
41.5,
85.9,
33.4,
58.4,
55.2,
22.3,
21.8,
74.4,
42.3,
52.5,
90,
46.7,
61.7,
72.1,
97.6,
57.5,
54.8,
42.6,
23,
57.5,
37.7,
6.7,
91.8,
59.8,
48.2,
69.8,
42.8,
31.4,
11,
76.6,
69,
18.6,
68.5,
65,
5,
52.5,
87.2,
76.3,
77.9,
58.2,
83.2,
37.3,
28.5,
77.8,
82.9,
77.2,
1.3,
59,
84.7,
41.8,
74.9,
57.3,
55.3,
65.9,
51.4,
25.1,
70.7,
57.2,
59.2,
79.3,
86.8,
96.9,
67.9,
74.8,
80.8,
61.9,
29.2,
86.8,
29.1,
42,
24.3,
86.7,
88.2,
44.2,
83.5,
43.1,
36.2,
89.4,
62.8,
30.4,
61.7,
62.6,
71.6,
87.4,
23.8,
34.5,
35.9,
85,
32.4,
97.9,
96.4,
95.2,
42.1,
53.6,
3.3,
64,
20.3,
51,
59.3,
34,
8.9,
39.7,
25.6,
100.1,
26.8,
95.8,
0.3,
77.9,
33.4,
51.2,
45,
39,
69.6,
61.1,
38.6,
38.8,
55.1,
78.2,
24.8,
1.1,
82,
59,
65.5,
33.5,
65.3,
35.6,
48.8,
64,
19.9,
68.6,
55.4,
57.8,
49.1,
64.8,
6.3,
49.1,
62,
69.5,
22.6,
83.7,
81.6,
66.1,
34,
38,
0,
95.6,
58.5,
58.6,
47,
51.6,
52.8,
15.6,
73.7,
63.9,
67.7,
20.6,
50.8,
85.3,
50.2,
50.1,
91.9,
32.5,
14.6,
61.6,
63.4,
18.7,
78.5,
45.2,
58.1,
29.6,
47.9,
38.2,
54.6,
74.5,
74.2,
69.9,
72.9,
44.4,
47.7,
99.9,
39.1,
64.1,
86.9,
40.4,
67.2,
33,
46.4,
11.1,
83.8,
83.9,
27.5,
59.2,
0,
92.1,
39,
70,
38.6,
66,
56.5,
3,
19.5,
26,
80.3,
41,
30.7,
74.4,
56,
63.4,
77.9,
74.6,
80.3,
67.6,
32.2,
43,
52.9,
50.7,
10.5,
20.5,
63.5,
36.2,
30,
60.7,
67.9,
84.4,
75,
8.7,
45.7,
33.3,
73,
20.9,
24.2,
32.1,
94.9,
58,
51.3,
59.5,
40.8,
2.6,
63.9,
47.4,
66.5,
47.4,
51.3,
63.4,
43.1,
33.5,
24.2,
29.2,
68.7,
56.5,
48.7,
31.5,
28.2,
57,
61.3,
25.7,
60.6,
24.1,
36.7,
11.1,
85.4,
83.3,
51.2,
43.1,
17.7,
9.2,
86.4,
12.3,
32.9,
44.4,
42.2,
81,
93.9,
59.5,
45.8,
12.2,
55.1,
69.8,
69.3,
66.2,
48.6,
28.4,
85,
83.1,
87.8,
45.7,
40.4,
31,
52,
33.5,
58.4,
68.8,
73.5,
77.7,
85,
46,
71.4,
88.7,
13.1,
2.8,
17.5,
39.7,
22.4,
83.1,
93.6,
24.4,
43.8,
57.4,
87.9,
76.4,
60,
37,
43.4,
74.4,
47,
61.1,
59.9,
77.4,
51,
10.9,
92.8,
23.4,
61.1,
49.5,
42.5,
52.5,
22,
23.3,
87.1,
41,
30.6,
84.2,
49.1,
97.5,
19.2,
62.5,
29,
72.3,
73,
68.3,
12.6,
90.8,
65.8,
72.4,
11.9,
74.4,
58.8,
43.4,
31.2,
27.8,
45.6,
46.9,
79.9,
47.3,
90.4,
12.1,
43.6,
67,
47.9,
90.2,
26.2,
66.2,
59.4,
54.5,
38.8,
26.6,
49.1,
76.1,
70,
43.2,
54.8,
54,
89.7,
61.1,
50.3,
43,
70.3,
58.1,
21.1,
62.1,
6.6,
64.4,
37.4,
52.7,
97.3,
62.7,
33.4,
38.1,
96,
69.2,
82.8,
45.7,
28.1,
84.7,
65.3,
20.7,
74.1,
14.5,
54.2,
46,
52.9,
11.5,
19.4,
89,
64,
52.8,
48.2,
15.8,
62,
74.7,
70.3,
17,
16.1,
30.6,
34.3,
73.8,
93.2,
46.9,
78.5,
56.9,
42.6,
98.3,
54.9,
63.5,
76.6,
6.3,
23.1,
71.6,
46,
39.6,
32,
57,
35.2,
58.5,
83,
53.7,
59.1,
72.2,
44.8,
62.6,
64,
44,
36.4,
54.1,
33.9,
51.5,
59.8,
92,
82,
51.4,
62.1,
84.3,
96.1,
49.4,
62.1,
50.2,
67.4,
26.8,
49.7,
37.6,
46.1,
82.4,
43.7,
49.8,
0,
98.8,
41.9,
57.3,
37.8,
75,
68.6,
37.7,
63.7,
40.7,
98.8,
50.5,
86.2,
78.9,
48.8,
67.8,
35.2,
49.6,
68,
67.8,
94.5,
70.4,
8.3,
65.4,
56.7,
44.8,
17.1,
91.4,
94.7,
90.4,
54.1,
59.7,
82.1,
38.4,
52.2,
58.3,
63.9,
30.6,
45,
26,
55.2,
73.5,
89,
50.1,
51.4,
48.7,
81.2,
35.6,
43,
76.3,
90.7,
60.2,
99.3,
23.8,
32.7,
55,
81.7,
70.9,
48.8,
63.3,
55.8,
48.4,
0,
76.2,
38.2,
54.7,
69.7,
98.7,
62.8,
84.9,
95.7,
70.5,
69.9,
79.8,
34.9,
9.3,
98.1,
31.3,
15.8,
55.1,
81.1,
80.9,
84.4,
69,
89.5,
91.7,
52.5,
64.4,
18.9,
64.6,
36.3,
90.6,
53.1,
66.5,
54.2,
81.9,
84.5,
18.2,
58.1,
49.7,
32.4,
40.1,
72.1,
37.5,
37.4,
41.4,
50,
53.9,
56,
24,
49.7,
28.7,
6.9,
10,
58.7,
65.2,
17,
69.1,
10,
27,
50.7,
65.8,
31.5,
57.5,
77.4,
90.9,
84,
62.6,
26.8,
17.4,
58.3,
24.2,
36.9,
64.2,
100.4,
46.5,
31.2,
36.1,
48.9,
26.3,
38.1,
20.5,
92.5,
70.1,
59,
19.6,
79.9,
65.6,
57.5,
69,
11.4,
83.2,
85.1,
73.3,
78.7,
86.6,
64.3,
57.9,
86.6,
41.2,
82.4,
53,
96.3,
79.3,
28.8,
58.8,
62.6,
92.8,
65.9,
25.2,
13,
26.3,
47.9,
39.7,
27.3,
31.6,
36.8,
34.9,
56.3,
38,
34.5,
40.6,
67.8,
100.6,
59.3,
null,
60.6,
56.1,
43.8,
70.7,
99.3,
59,
41.5,
32.6,
40.1,
33.8,
48.7,
93.2,
67.4,
51.1,
62.2,
19.7,
69.6,
36.3,
92.9,
55.8,
51.8,
7.2,
41.1,
29.1,
93.1,
55.9,
92.2,
45,
35.2,
20.8,
49.5,
29.7,
89.5,
52,
45.4,
63.7,
46.8,
46.1,
65.1,
54,
33.7,
42.8,
84.6,
65,
33.8,
80.6,
36,
41.2,
45.1,
75,
41.3,
32.2,
68.8,
40.4,
59.9,
66.7,
22.8,
83.8,
51.6,
42.6,
46.5,
65,
27.7,
66.9,
28.2,
57.7,
21,
55.4,
77.3,
72,
16.4,
62.2,
68,
80.7,
87.4,
53.1,
39.1,
58.9,
61.5,
67.4,
50,
64.8,
27.4,
65.2,
37.4,
66,
65.6,
51.9,
26,
14,
56.9,
78.5,
70,
72.7,
75.5,
38.1,
50.9,
23.8,
80.9,
28.5,
47.3,
71.8,
64.4,
24.4,
44,
52.2,
88.8,
51.8,
45.6,
94.3,
57,
12.4,
78.5,
80,
36,
69.2,
64.2,
35.1,
54.1,
61.6,
40.1,
41.5,
57.8,
31.4,
59.9,
39,
77.2,
73.3,
24.1,
66.3,
53.2,
40.4,
33.9,
76,
33.6,
85.5,
53,
94,
85,
66.3,
40.8,
59,
18.7,
46.8,
28.3,
76,
23.3,
18.3,
60.9,
89.6,
51.9,
53.1,
88.7,
63.2,
28.4,
29.9,
46.1,
62,
48.4,
19.7,
78.5,
59.1,
47.9,
61.7,
56,
64.5,
51.9,
56.8,
56,
61.5,
47,
97.2,
73.5,
34.7,
76.3,
83.2,
76.5,
30.2,
16.5,
77.9,
29.6,
32.4,
50.7,
88.2,
55.6,
47.1,
72.1,
65.8,
75.8,
83.6,
11.8,
0,
14.8,
85,
27.4,
7.5,
31.3,
28.5,
90.8,
28.5,
83.6,
20.7,
73,
34,
49.1,
53.2,
54,
84.5,
77,
65.8,
28.5,
82.2,
5.3,
22.2,
35.2,
60.8,
82.1,
61.6,
49.6,
30.8,
99.7,
87.2,
61.4,
49.8,
66.6,
93.5,
35.2,
70.3,
62.8,
46.1,
56.4,
56.9,
51,
53.2,
42.4,
63.9,
80.8,
87.9,
61,
64.2,
24.5,
33.1,
38.7,
41.4,
35.6,
64.1,
60,
57.5,
29,
74.6,
76.1,
70.2,
37.1,
39,
73,
27,
86.7,
90.3,
19.4,
99.4,
91.2,
16.6,
35.4,
82.7,
0,
80.1,
65.7,
87.1,
49.6,
42.5,
29.2,
26.7,
88.5,
58.8,
75.7,
85.4,
25.8,
53.1,
59.8,
83.2,
88.8,
48.4,
44,
38.9,
82.4,
93.3,
37.1,
26.5,
18.2,
99.1,
48.8,
35.6,
91.7,
67.9,
16.3,
17.6,
61.6,
49.5,
54.8,
28.2,
36.4,
24,
44,
105.4,
41.1,
19.7,
57.8,
38.9,
46.4,
42.7,
101.2,
52.8,
25.6,
56,
59.3,
77.1,
18.5,
74.5,
27.4,
54.6,
16.8,
7.2,
62.7,
64.7,
60.5,
46.5,
30,
88,
48.9,
5,
55.7,
32.5,
53.9,
54.7,
45.3,
37.4,
41.7,
18.3,
69.7,
68.5,
76.9,
86.2,
50.8,
34.1,
55.6,
14.7,
27.7,
49,
33.4,
11.2,
81.4,
63.8,
42.1,
61.6,
25.3,
42.4,
54.1,
21.7,
52.4,
70.9,
60.2,
35.9,
43.9,
52,
76.6,
59.3,
63.1,
30.2,
40,
83,
39,
9.3,
69,
58.3,
43.7,
40.4,
66.2,
37.7,
90.6,
52.3,
90.2,
64.9,
0,
13,
42.1,
6.3,
19,
21.1,
76.8,
43,
44.5,
93.1,
65.5,
61.4,
91.3,
41,
79.1,
51.5,
31.4,
48.7,
58,
86.1,
43,
67.3,
28.4,
89.2,
63.5,
33.6,
22.3,
27.9,
67.2,
100,
20.2,
46,
92.2,
79.9,
60.9,
73,
82.9,
49.7,
31,
46.1,
89.2,
50.7,
65.5,
59.6,
51.3,
52.7,
74.6,
85,
97.4,
36.2,
35.7,
86.7,
47.6,
0,
43.2,
44.7,
59,
43.6,
14.9,
46.8,
86.8,
40.5,
30.4,
34.1,
98.5,
56.2,
26.5,
25.7,
72.5,
50,
10.4,
81,
80,
10,
58.9,
28.1,
37,
56.1,
73.6,
8.4,
75.5,
31.2,
73.2,
80.4,
75.1,
35.8,
14.9,
98.1,
2.3,
91.7,
8.9,
97,
63.3,
47,
81.9,
86,
52.2,
54.6,
97.2,
73.5,
38.1,
56.7,
91.9,
28.4,
95.2,
96.4,
93.5,
66.6,
85.8,
35.9,
69.4,
75,
21.6,
46.1,
38.8,
90.2,
26,
74.5,
54.1,
48.8,
18.2,
87.6,
39.7,
77.6,
27.9,
33.9,
29.9,
74.4,
28.9,
60.5,
75.9,
29.6,
27.4,
82.7,
96.2,
58.1,
41.2,
28.2,
46.9,
31.8,
38.7,
93.4,
63.2,
95.7,
35.3,
42.6,
48.5,
86.8,
45,
70.4,
93.1,
75.8,
40.7,
59.2,
46.8,
72.9,
43.6,
7.3,
46.7,
72,
76.4,
66.7,
29.8,
19.5,
45.2,
32.4,
51.9,
15.5,
90.7,
45.1,
86.6,
42.5,
59.7,
56.7,
90.5,
39.6,
56.2,
93.2,
75,
90.6,
30.9,
82.4,
62,
61.3,
81.2,
64.3,
32,
63,
85.9,
55,
60.9,
55.8,
22.4,
42.7,
75.5,
45.4,
95,
61.2,
97.4,
59.1,
40.9,
40.7,
76.6,
30.4,
44.1,
38.2,
54.7,
44.6,
34.7,
76.6,
69.7,
102.7,
83.1,
35.1,
32.7,
34.7,
44.3,
23.3,
64.3,
72.7,
51.1,
20.6,
11.5,
74.7,
50.2,
42.9,
13.6,
43.8,
82.8,
94.7,
33.1,
34.2,
53.6,
16,
63,
78.5,
75.8,
59.3,
41.1,
18.8,
51.4,
64.1,
34.3,
11,
69.7,
54.4,
41,
24.3,
37.3,
29.4,
37.6,
87,
38.4,
69.3,
79,
33.9,
76.6,
17.9,
71.1,
66.3,
62.2,
51.5,
31,
87.5,
53,
31.2,
61.6,
59,
73.6,
30.3,
82.6,
83.2,
66.1,
28.5,
21.9,
61.7,
46.5,
52.9,
88,
63.6,
51.7,
65.3,
97.2,
25.4,
68.2,
48,
86.7,
71.4,
97.1,
38.1,
80.7,
39.1,
35.4,
34.5,
66.6,
0.7,
66.3,
39.4,
16.4,
48,
38.5,
53,
18.9,
27.8,
83.3,
75.1,
82.7,
28.2,
42.4,
26,
2.2,
45,
67.5,
60.2,
66.8,
41.5,
84.6,
45.2,
24.1,
31.7,
63,
52.4,
14,
52.9,
0,
38.2,
12.2,
86,
81.7,
29.1,
33.2,
79.4,
71.5,
15.9,
90.7,
63.9,
95.5,
34.5,
43,
96.2,
76.3,
48.2,
60.1,
58,
80.2,
31.5,
63.1,
98,
51,
68,
37.1,
82.5,
24.6,
32.5,
32.1,
68.1,
88.7,
30.1,
50.9,
49.9,
97,
88.8,
71.4,
22,
50.7,
60.1,
90.5,
45,
11.3,
78.6,
68.4,
61,
29.3,
62.9,
84.3,
90.7,
83,
60,
92.3,
64.4,
65.7,
54.9,
65.6,
30.6,
24.2,
45,
59.8,
74.1,
58.7,
68.6,
58.2,
80.8,
53.3,
50.6,
58.7,
44.7,
67.4,
28.2,
40.7,
32.3,
46,
57.4,
65.5,
52.8,
18.5,
55.5,
55.9,
76.1,
63.8,
18.5,
17.2,
34,
67.5,
24.3,
71.6,
92.7,
60.5,
43.7,
70.9,
62.9,
57.1,
22.3,
79.6,
19.4,
54.2,
58.4,
96.1,
84.9,
55.3,
49.8,
39.6,
85.9,
74.5,
4.8,
10.8,
68,
80.4,
79.9,
47.7,
38.5,
55.9,
62.6,
33.9,
39.4,
22.2,
57.8,
82.6,
55.7,
70.8,
92.8,
92.3,
76.7,
63,
40.8,
46.1,
43.7,
9.9,
76.6,
44.3,
58.3,
46.7,
65.7,
36.9,
88.4,
33,
57.1,
30.2,
7.5,
24.4,
16.4,
92.9,
23.2,
54.3,
50.9,
12.8,
48.4,
23.2,
36.2,
94.6,
64.8,
16.4,
62.3,
33.5,
47.8,
53.6,
47.5,
50.2,
79.5,
53.5,
28.8,
34,
34.4,
43.8,
74.2,
38.7,
33.2,
50.3,
43,
43.5,
67.9,
66.3,
54.4,
51.3,
74.1,
43.3,
44,
85.4,
31.2,
37,
68.5,
43.3,
37.8,
69,
55.7,
32,
93.7,
59,
92,
78.4,
87.8,
69.7,
76.8,
35,
47.1,
48.7,
6.2,
22,
32.8,
39.9,
62,
47.2,
54.1,
92,
54,
35.1,
16.2,
91.9,
93.9,
76.4,
58.1,
81.5,
70.2,
35.4,
57.6,
35.7,
76.9,
35.1,
38.6,
59.7,
47.4,
90.3,
90.2,
79.7,
45.9,
69.9,
48.7,
64.9,
68.5,
69.4,
98.3,
31.4,
44.5,
51.5,
88.9,
34.1,
31.7,
39.3,
46.5,
66.8,
21.4,
91.4,
89,
89.7,
61.1,
22.9,
36.5,
32.8,
85.7,
31.3,
24.9,
75.2,
21.3,
61.8,
53.1,
48.1,
59.6,
65.9,
19.3,
51.6,
45.4,
71.7,
51.5,
26.7,
77.7,
86.1,
95,
83.4,
56.1,
68.8,
79.8,
31.2,
51.9,
44,
25.4,
57.5,
66.8,
78.6,
15.9,
42.2,
63.7,
67.5,
57.3,
45.7,
16,
80.8,
99,
89,
94.7,
75,
63.4,
56.8,
20.3,
99.4,
46.7,
43.3,
36.3,
61.8,
92.4,
16.4,
68.3,
52.4,
80,
4.8,
63.8,
22.9,
82.9,
64.3,
69.8,
32.5,
24.1,
66.1,
61.9,
51.7,
39.7,
44.8,
67.4,
26.8,
71.2,
24.1,
19.7,
75.4,
78,
50,
78.8,
39.6,
70.1,
61.9,
25.6,
42.6,
37.7,
40.6,
60.8,
85.8,
29.5,
45.9,
44,
60.9,
49,
76.6,
73.1,
62.9,
49.9,
45.9,
57.6,
72.8,
12,
43.1,
80.8,
55.1,
52.9,
61.2,
43.8,
39.7,
76.7,
67.8,
71,
37.3,
78.4,
87.9,
7.4,
72,
22.3,
82.7,
98.9,
35.6,
100,
80.9,
56.7,
92.4,
23.8,
63.6,
11.9,
62.7,
97.8,
70.4,
95.2,
43.6,
96.8,
52.1,
51.8,
77.2,
51.6,
83.1,
42.9,
38.5,
84.6,
25.9,
67.1,
35.4,
46.6,
72.1,
72.4,
47,
37.8,
4.9,
66.7,
50.6,
50.5,
94.6,
35.6,
55.4,
60.7,
58.8,
68.8,
74.5,
35,
69.9,
32.7,
80.3,
36.7,
44.4,
28.3,
68.3,
44.6,
81.6,
52.1,
42.7,
33.4,
8.4,
34.5,
78.4,
52.1,
43.9,
14.8,
22.8,
87.7,
34.6,
47.4,
41,
52.8,
84.1,
70.4,
79.4,
54.3,
76.5,
80.7,
74.2,
60.3,
38.9,
32.4,
59.7,
84.2,
15.4,
59.5,
90.8,
70.6,
90.4,
20.3,
70.6,
62.7,
91,
68.6,
91,
53.2,
42.6,
73.5,
0,
42.1,
91,
73.2,
16.8,
73.5,
10.6,
92.8,
34.6,
56.2,
67.5,
74.1,
79.2,
37.7,
26.7,
82,
58.6,
33.5,
67.9,
47.7,
42.9,
95.3,
61.2,
37.4,
66,
93.9,
30.7,
42.2,
16.2,
40.1,
1.4,
64.9,
49.4,
8.7,
8,
75.3,
21.1,
43.4,
72.4,
40,
57.1,
0,
63.9,
27.1,
8.8,
82.4,
7,
74.2,
60.8,
72.1,
77.7,
87.6,
74.6,
13.9,
72.9,
32.4,
56.5,
72.8,
76,
85,
68,
70.9,
55.2,
10.4,
62,
63.5,
36.8,
78.9,
41.6,
48.9,
40.4,
97.7,
89,
53.5,
0.3,
15.6,
62.9,
59.4,
58.8,
51.2,
44.5,
28.3,
90.9,
76.3,
52.7,
32.9,
51.5,
80.8,
74.6,
47.6,
73.4,
74.3,
39.9,
44.8,
68,
86.1,
46.7,
70.2,
30.5,
83.4,
44.9,
16.9,
37.3,
106.6,
58.6,
48.1,
58.9,
60.1,
79.6,
61.1,
29.6,
25.3,
20.7,
36.4,
37.1,
23.8,
51.4,
53.7,
89.7,
55.5,
32.4,
26.6,
29.8,
91.1,
89.9,
73.6,
53.7,
55.2,
33.1,
81.4,
75.8,
74.5,
66.9,
65.8,
65.8,
94.1,
65.7,
74,
18.6,
64.3,
0,
60.9,
50.9,
50.2,
73.7,
89.4,
99.6,
51.2,
61.5,
55.9,
57.5,
47,
51.3,
26.5,
93.2,
83.1,
27,
61,
55.1,
43.2,
69.3,
74.9,
54.2,
59.1,
42.9,
90.5,
25.2,
57.6,
28.3,
75,
82.6,
34.5,
84.5,
55.2,
44.6,
72,
49,
91.6,
53,
68.3,
38.2,
32,
42.3,
93,
95.2,
82.7,
89.9,
56.7,
55.5,
68.9,
80.3,
26.6,
59.3,
35.8,
29.1,
99.8,
59.5,
68.9,
65.2,
48.6,
73.9,
51.2,
39.3,
33.9,
61.4,
75.4,
33.1,
60.9,
37.8,
69.9,
22.2,
75.7,
82.1,
49,
94.1,
53.2,
46.7,
92.8,
19.2,
88,
74.9,
91.4,
49.1,
76.1,
71.3,
43.8,
94.1,
54.2,
42.2,
84,
65.4,
37.7,
53.4,
97.7,
52.9,
64.2,
84.1,
12.8,
58,
77.2,
19.9,
76.4,
87.1,
93.9,
45.9,
50.1,
93.3,
41.5,
78.7,
34.8,
74.5,
88,
58.9,
32.2,
0,
39.9,
83.2,
51.7,
82,
84.4,
58,
12,
28.6,
68.8,
103,
95.6,
45.3,
70.8,
81.7,
47,
95,
68.3,
76.1,
72.7,
98.6,
60.8,
87.6,
37.2,
40.5,
55.9,
60.8,
32.5,
68.2,
62.5,
84.6,
42.5,
78.8,
29.5,
38.3,
77.5,
40.3,
24.5,
11.6,
55,
80.3,
59.6,
53,
46.5,
44.1,
90.7,
28,
39.8,
80.6,
58.5,
61.1,
19.1,
46.3,
49.5,
83.1,
25.9,
20.4,
82.6,
48.4,
82.7,
39.6,
91.6,
70.3,
66.4,
92.8,
52.8,
33.9,
84.9,
82.3,
38.4,
47.4,
28.1,
44.3,
30.9,
32.6,
96.5,
70.3,
21.7,
3.5,
55.1,
64.3,
29.1,
7.2,
63.6,
32,
44,
56,
29.7,
13.2,
100.7,
73.3,
52.8,
4.5,
19.9,
56.6,
48,
96,
46,
56.4,
83,
17.4,
7.8,
12.8,
42.8,
67.3,
21.3,
51,
72.4,
46.5,
45,
53.8,
74.6,
80.3,
69.8,
68,
83.9,
63.7,
0.3,
59.2,
29.1,
63.4,
82.6,
58.5,
53.2,
30.1,
53.2,
73.9,
23.1,
79.6,
82.7,
35.5,
72.1,
26.8,
68.4,
77.1,
60,
40.5,
57.6,
8.8,
18.1,
48,
29.3,
32.7,
39.8,
47.7,
64.9,
24.4,
88.5,
40.3,
30.9,
48.9,
50.2,
81.3,
22,
6.1,
58.9,
26.8,
33.9,
21.7,
53.2,
90.6,
80.1,
31.7,
70.9,
26.6,
93.1,
83.8,
36,
66.9,
62.4,
29.6,
12.8,
86.2,
98.9,
44.4,
93.6,
29.6,
16.6,
93.6,
84,
65.1,
51.3,
21.2,
96,
78.2,
52.1,
81.1,
76.3,
61.8,
22.7,
27.9,
24.8,
64.7,
43.6,
23.4,
16.9,
57.7,
82.1,
34.7,
68.3,
35.9,
67.5,
54,
74,
15.9,
69.1,
11.1,
44.3,
41.3,
5.3,
91.3,
82.8,
29,
49.1,
78.9,
46.9,
40,
80.4,
96.9,
25.4,
31.3,
77.6,
9,
99.8,
81.9,
62.9,
52,
83.3,
17.2,
51.8,
76.1,
51,
0,
4.2,
81.9,
54.1,
76.8,
59.1,
72.8,
45,
55.8,
49.8,
54,
48.7,
88.9,
56.5,
88.5,
52.9,
12.8,
44.9,
86.6,
97.3,
16,
71.9,
89.7,
53.1,
95.4,
75.6,
81.4,
28.2,
31.4,
67.1,
53.6,
3,
58.3,
71.7,
33.4,
70.7,
39.6,
40.6,
62.7,
59.4,
10,
84.3,
60.3,
17.9,
57.1,
27.2,
75.3,
91,
74.2,
58.6,
56,
34.6,
81.4,
43.1,
72.1,
73.7,
33,
41.3,
38.3,
86.1,
43.8,
48.1,
32.2,
91.7,
81.8,
88.5,
89.9,
34.1,
31.9,
58,
2.6,
51,
27.3,
61.9,
64.5,
84.5,
10,
47.6,
87.9,
50,
67.5,
32.5,
79.6,
63.2,
35.7,
80.1,
36.6,
31.7,
55,
77.4,
50,
74.7,
34.2,
49.3,
64.6,
64.2,
64.1,
12.4,
52.3,
57.6,
85.6,
34.3,
92.3,
76.4,
77.7,
91.8,
71.6,
9.7,
65.9,
0,
70.1,
72.9,
70.1,
25.7,
66.6,
92.1,
64.3,
7.1,
56.3,
56,
63.1,
64,
56.5,
56.4,
75.1,
71.2,
42.9,
46.3,
40.2,
64.1,
74.4,
70.8,
52.4,
84.1,
40.5,
29.4,
53.9,
89,
54.8,
42.4,
17.8,
74,
64,
85.7,
83.9,
26.2,
55.6,
41.2,
77.9,
72.9,
21.4,
74.8,
77.1,
34.9,
58.4,
51.1,
82.6,
25.7,
43.7,
35,
59.2,
78,
73.4,
83.4,
49.2,
40.7,
68.7,
59.2,
41.7,
21.1,
39.8,
95.8,
59,
70.9,
28.7,
69.5,
96.3,
48.8,
97.9,
96.5,
86,
43.4,
9.5,
48.2,
88.6,
36.9,
65.1,
27.9,
99.6,
33.5,
35.7,
40,
0,
37.6,
11.1,
42.8,
80.8,
54.4,
95.8,
33.2,
6.3,
48,
75.9,
40.6,
39.3,
73.4,
40.3,
19.8,
81.4,
49.3,
10.7,
40,
65.7,
31.4,
0,
62.9,
63,
59.9,
63.5,
38.9,
71.5,
28,
50.2,
92.9,
71.4,
83.1,
12.6,
44,
54.9,
61.6,
37.5,
87.8,
77.3,
92.6,
31.9,
85.7,
88.3,
30.3,
54.7,
40.4,
18.5,
73.7,
43.1,
80.6,
72.3,
31.2,
22.8,
4.4,
60.9,
72,
25.7,
20.6,
57.8,
39.8,
30.8,
63.2,
95.7,
61.4,
66.7,
62.7,
50.2,
40.9,
53.9,
41.6,
85.6,
31.3,
36,
20.3,
68.3,
38.4,
53,
8.9,
58.4,
47.4,
48.8,
6.5,
59.5,
58.9,
59.3,
81.7,
74.8,
54.1,
73.6,
26,
81.2,
54.8,
77.3,
76.6,
78.6,
78,
71,
75.5,
56,
46.7,
60.4,
50,
46.6,
49.6,
83.2,
20.7,
75,
94.9,
40.2,
24.7,
6.3,
94.9,
83,
70,
42.9,
86.3,
74,
85.6,
77.1,
69.4,
39.9,
72.5,
72.5,
16.1,
33.3,
70.5,
23.1,
58.4,
42.2,
27,
13.2,
22.1,
70.5,
53.4,
38.6,
88.4,
95.1,
45,
28.2,
53.1,
76.7,
83.6,
43.7,
68.2,
53.7,
31.6,
0,
61.3,
76.1,
74.8,
35.8,
25.3,
98.1,
84.7,
83.8,
14.9,
67,
85.3,
61,
38.2,
72.1,
71,
83.5,
84.6,
72.3,
85.5,
51.1,
36.9,
48.3,
72.6,
93.1,
49.7,
70.1,
72.7,
3.5,
63.2,
37.6,
21.5,
6,
57.6,
69.2,
73.6,
47.6,
27.4,
61.6,
49.8,
74.1,
42.4,
44.7,
89.6,
67.5,
41.5,
71.5,
43.8,
70,
29.1,
79.1,
23.7,
74.3,
93.3,
34,
61.1,
57.5,
51.1,
29.3,
60.6,
40,
86.3,
60,
50.5,
50.9,
76.4,
43.1,
68,
21.2,
47.8,
44.8,
15,
29,
88,
44.4,
81.8,
78.2,
64.3,
39.7,
71.4,
49.4,
82.5,
7.5,
46.7,
45.6,
63.1,
58.3,
91.3,
78,
23.8,
70.7,
6.1,
12.6,
56,
41.2,
28.3,
36.1,
74.9,
71.5,
36,
77.3,
30.8,
80.6,
67.1,
91.5,
58.2,
51.5,
41.6,
13,
53.6,
58,
76,
13.6,
93.4,
100.5,
70.5,
31.4,
35.4,
75.5,
16.8,
64.6,
77.1,
51.3,
68.7,
93.8,
28.8,
41.6,
29.4,
58.8,
18.8,
91.1,
74.7,
36.4,
45.3,
59.9,
14.1,
81.5,
49,
83.4,
62.2,
90.9,
33.5,
31,
45.2,
61.6,
81.4,
92.7,
26.6,
43.9,
84.6,
17.8,
61.8,
49.3,
4,
65.8,
32.2,
78,
40.3,
64.4,
50.4,
70,
89.5,
54.3,
0,
27.6,
73,
40,
45.6,
50.5,
62.7,
84.9,
21.6,
29.5,
92.1,
93.6,
61.8,
3.8,
72.7,
28,
76.4,
84.3,
70.2,
72.4,
29.3,
54.1,
84.4,
50.4,
60.1,
0,
52.8,
0,
63,
39.3,
41.4,
40.9,
79.1,
29.4,
72.4,
91.9,
44.9,
70.6,
26.9,
40.5,
73.9,
71.6,
2.5,
79.9,
22,
47.2,
35.2,
66.2,
56.7,
28.9,
31,
49.4,
70.7,
71.1,
58.3,
19.1,
58,
50.1,
66.8,
80,
23.5,
32,
23.5,
33.5,
10.8,
33,
63.5,
33.5,
20.4,
81,
66.4,
45.6,
63,
59.1,
44,
72.6,
70,
65,
45.1,
69.2,
100.7,
41.7,
49.3,
49.9,
61,
79.9,
36.9,
98.3,
88,
14.8,
48.1,
1.8,
61,
32.2,
63.5,
17.1,
8.1,
68.9,
50.3,
58,
2.3,
79.8,
85.1,
45.6,
74,
20,
45.5,
79.7,
60.4,
62.7,
78.1,
26.1,
43.7,
71.1,
30.3,
52.6,
66,
56.2,
54.2,
54.2,
0.9,
50.4,
51.1,
77.2,
71.6,
79.3,
32.1,
52.6,
90.3,
44.8,
63.1,
80.3,
35.6,
66.7,
57.8,
69.6,
67.6,
40,
55.9,
35,
65.7,
53.6,
43,
9.2,
76.2,
64.6,
62.5,
77.7,
5.3,
49.4,
66.8,
58.1,
67.1,
72,
18.7,
26.8,
50.9,
88.1,
64.1,
77.8,
30.8,
83.2,
29.3,
55.8,
66.9,
77.2,
48.1,
44.9,
26.7,
47.1,
18.4,
32,
50.6,
63,
49.9,
78.5,
67.3,
88.8,
60.1,
94.9,
74.3,
50.3,
53.8,
21,
54.8,
21.7,
68.4,
33.7,
60.6,
79,
65.6,
56.8,
50.8,
88.2,
32.7,
54.1,
26.9,
26,
43.6,
66.5,
35.3,
43.2,
61.4,
39.9,
55,
35.3,
39.5,
51,
40.5,
78.2,
0,
51.5,
51.7,
89.3,
28.4,
23.9,
46.9,
29.2,
29.7,
17.9,
0,
55,
40,
77.1,
42.3,
47,
32.7,
76.9,
71.1,
59.1,
59.6,
27.4,
68.3,
17.6,
61.7,
75,
57.6,
55.5,
59.2,
50.3,
45.5,
55.4,
69.9,
52.5,
54.7,
48.2,
76.8,
83.2,
40.9,
87.7,
39.5,
68.7,
52.3,
72,
17.1,
39.5,
55.2,
48.8,
64.3,
95.7,
41.1,
52.1,
39.5,
79.3,
89.2,
68.8,
20.8,
90.6,
43.5,
31.3,
37.5,
70.6,
68.4,
47.1,
77,
60.6,
43.6,
50,
0,
84,
22,
50.5,
49.3,
72.8,
33.3,
23.2,
6.5,
60.4,
50.8,
31.8,
36.3,
77.4,
49,
40.2,
29,
37.1,
0,
76.7,
49.8,
79.2,
85,
41,
54.8,
100.2,
51.2,
63.1,
66.5,
35.3,
39.1,
35.9,
15.2,
58.8,
32.1,
95.2,
54.7,
69.3,
13.1,
3.5,
84.6,
38.8,
50.7,
1.5,
46,
11.2,
65.6,
84.4,
97.1,
47.7,
35.3,
81,
21.7,
40.9,
44.9,
63.4,
82.8,
33.9,
53.9,
40.1,
null,
96.2,
75.4,
7.5,
38.5,
7.7,
16.1,
37.1,
31.1,
46.7,
46.9,
95.6,
44,
24.8,
79.7,
61.9,
29.3,
65,
46.7,
70.8,
56.2,
18,
37.7,
55,
64.5,
39.6,
22.2,
72.2,
29.7,
49.2,
19.4,
65,
13,
11.6,
1.9,
30,
13.5,
80.5,
48.6,
104.6,
48.4,
55.7,
49.2,
59.8,
58.6,
46,
76.9,
26.8,
0,
43.5,
68.3,
46.9,
22.5,
90,
90.3,
50.1,
36.1,
99.8,
82.4,
97.8,
80.6,
78.8,
64.9,
66.7,
28.7,
22.3,
53.8,
72.3,
6.4,
34.7,
26.4,
48.4,
85.1,
48.5,
79.4,
80.8,
57.5,
67.8,
87.7,
55.9,
95.4,
31.7,
47,
60,
77,
99.5,
57.7,
76.6,
49.5,
58,
59.3,
69.4,
57.2,
67.8,
64.2,
38.8,
11.4,
65,
16.2,
13.1,
79.2,
37.8,
62.2,
89.4,
86.7,
81.8,
8.9,
15.7,
29,
25.8,
36.5,
82.8,
32.3,
70,
33.8,
18.8,
90.1,
73,
56.4,
23.6,
70.6,
53.4,
60.3,
84,
23.4,
47.6,
38.3,
20,
54.3,
61.2,
77.2,
65.4,
48.8,
56.2,
51.3,
70.3,
74,
39.5,
58.4,
77.6,
66.7,
34.5,
21.7,
61.4,
55.1,
89.3,
58.1,
59.9,
22.7,
64.9,
26.4,
12.3,
61.1,
44.5,
63.6,
18.6,
77,
98.8,
60.3,
53.3,
26.4,
46.6,
65.9,
89.7,
80.3,
61.9,
90.7,
36.6,
49.8,
15.7,
78.2,
45.2,
54.7,
74,
22.9,
68.8,
38.4,
88.8,
74.7,
33.8,
72.4,
72,
56.1,
42.7,
43.8,
54.4,
89.4,
32.9,
53.4,
40,
65.6,
52.7,
60.1,
87.5,
70.4,
28.5,
49,
79.3,
49.9,
83.8,
61.3,
57.1,
62.1,
39.9,
82,
50.9,
93,
74.3,
35.4,
52.9,
14.5,
87,
88,
49.9,
48.6,
31.3,
87.2,
63.3,
74.8,
85.4,
27.7,
79.9,
58,
24.6,
85.5,
33.6,
72.8,
70.5,
60.6,
63,
29.4,
100.9,
31.2,
37.8,
37.1,
42.8,
56.5,
72.6,
52.3,
35.8,
74.5,
53.1,
40.3,
5.2,
83.9,
53.1,
74,
67.5,
48,
7.9,
55.8,
32.8,
23.9,
78.4,
35.6,
84.6,
81.1,
39.7,
72.9,
63.2,
49.8,
47.4,
49.7,
46.7,
84.1,
20.4,
61.2,
60.4,
59,
83.5,
24.8,
85.9,
8.9,
48.6,
50.2,
66.7,
45,
24.7,
39,
50,
23.3,
25,
13,
61,
92.8,
32.8,
70.5,
97.2,
0.4,
91.7,
79.5,
52.2,
46.3,
73.1,
64.8,
47.8,
52.4,
39,
71,
54.2,
50.1,
46.5,
75.1,
69.3,
64.3,
38.9,
48.7,
70.5,
33.3,
66.2,
24.5,
41.7,
81.4,
53.4,
54.4,
74,
4,
58.6,
37,
68.2,
48.7,
46.2,
85.2,
37.6,
46.9,
96.9,
70.3,
62.8,
90.3,
49.1,
34.3,
89.6,
72.6,
56.7,
82,
50.1,
19.3,
58.7,
12.1,
33.6,
93.3,
58.7,
94.9,
94.8,
90,
92,
49.8,
96.6,
90.7,
54.6,
47.6,
65.4,
69.8,
39,
1.3,
71.9,
40.8,
15.2,
46.5,
79.6,
72.9,
0,
49.4,
55.1,
10,
34.7,
41.3,
49.1,
87.6,
45.2,
80.1,
63.2,
91,
33.3,
36.1,
49.5,
69.7,
95,
66.5,
34.8,
77.4,
33.1,
4,
72.1,
16.5,
19.2,
34.6,
61.5,
16.1,
68.5,
16.9,
30.5,
35.4,
42,
53.9,
12.8,
84.3,
91,
67.4,
50,
88.6,
50.3,
8,
82,
75.2,
95.5,
45.8,
12.3,
71,
68,
63.9,
64.8,
68.4,
14,
31.4,
7.8,
74.1,
77.4,
53.6,
49.6,
38.5,
64.5,
54.2,
48.9,
93.4,
66.8,
87.4,
82.1,
27.3,
97.6,
54.8,
9.6,
4.9,
88,
81.8,
34.4,
50.2,
57.7,
70.1,
49.2,
46.5,
62.1,
41,
25.9,
103.3,
73.3,
12.8,
0.3,
49.7,
52,
59.7,
35.7,
5.5,
21.5,
51,
93.7,
27.9,
82.6,
46.7,
10.7,
35.6,
48.2,
53.8,
77.8,
56.3,
45.1,
80.3,
74,
85.9,
78.7,
26,
81.5,
19.1,
53.7,
88.4,
70.6,
41.3,
72.8,
61.8,
92.3,
20.5,
67.3,
48.3,
56.2,
35.2,
61.5,
29.2,
70.9,
89.5,
36.1,
86.2,
48.7,
80.1,
28.3,
33.3,
51.6,
55.2,
24.7,
67.6,
54.4,
69.5,
0.8,
67.4,
78.6,
74.1,
73.9,
60.2,
21.8,
51.9,
45.3,
94.9,
81.4,
18.1,
63.9,
92.3,
34.5,
61.4,
71.1,
37.4,
25.4,
95.5,
89.4,
22.6,
61.5,
70.9,
94.2,
95.1,
58.9,
72.8,
32,
89.4,
75.7,
42.1,
21.7,
77.8,
43.2,
86.9,
85.3,
62.7,
40.3,
6.2,
22.5,
38.9,
62,
68.4,
93,
42.7,
23.6,
91,
21.5,
51.2,
41.6,
22,
76.9,
83.4,
80.1,
49.3,
72,
71.6,
70.1,
59.8,
55.8,
53.9,
68.3,
27.3,
10.1,
97.1,
51.6,
62.1,
67,
65,
73.2,
82.2,
53.2,
113.5,
80.9,
2.9,
36.4,
43.7,
66.7,
85.4,
47.9,
59.4,
46.5,
84,
78.8,
56.3,
52.6,
77.4,
64.6,
46.2,
96.1,
9.5,
51.5,
42.8,
50.6,
76.1,
80.2,
58.2,
61.1,
39.7,
59.1,
85.8,
81.1,
51.4,
88.4,
68,
58.7,
36.6,
33.9,
42.3,
12.9,
53.8,
62.5,
72.5,
48.5,
96.7,
10.1,
85.7,
57.7,
28.9,
17,
87,
36.8,
81.8,
67.5,
13.7,
28.3,
45.7,
59.2,
31.7,
55.2,
43,
59.9,
35.7,
72,
48.1,
26,
44.2,
88.5,
95,
85.9,
76.1,
48.4,
52.7,
38.7,
79.5,
88.8,
29.1,
40.8,
82.3,
80.7,
46.8,
73.7,
72.2,
49.8,
48,
30.8,
61.5,
48.6,
26.4,
28.9,
62.8,
64.6,
13.4,
89.1,
11.9,
51.3,
40,
95.8,
42.2,
20.1,
51.9,
83.2,
50.5,
60.9,
35.3,
34.3,
66.3,
54.1,
58.8,
61.4,
68.6,
32.6,
34,
27,
94.1,
36.7,
57.6,
19.9,
32.4,
41.5,
45.2,
48.5,
64.6,
55.3,
58.9,
53.2,
17.1,
61.2,
38.2,
13.9,
33.1,
75.1,
54.9,
65.6,
55.8,
76.8,
55.9,
55.7,
32.8,
30.6,
29.1,
45.9,
73.5,
57.8,
61.2,
44.8,
64,
60.2,
75.1,
65.9,
19.6,
55.2,
89.9,
39.6,
23.5,
11.4,
69.2,
87.2,
56.6,
84.6,
23.2,
60.3,
52.3,
58.7,
6.7,
74.9,
88.8,
85.3,
77.6,
70,
65.5,
52.6,
75,
41.8,
88.5,
34.3,
86.5,
78.3,
4.1,
93.1,
59.2,
21.1,
90,
24.3,
15.4,
66.5,
66.6,
74.5,
88.1,
71.9,
85,
55.1,
84.3,
42.1,
27.2,
48.3,
1.1,
84.5,
68.8,
71.7,
30.6,
55.3,
52.8,
31.7,
82.6,
46.6,
41.6,
4.1,
83.2,
43.9,
34.5,
60.4,
40.3,
71.1,
69.2,
57.5,
48.7,
46,
48.8,
78.1,
31.9,
73.4,
75.3,
48.3,
72.7,
98.8,
16.9,
86.3,
55,
82.4,
24.1,
55,
20.8,
93.2,
75.6,
69,
65.2,
7.4,
62.8,
22,
52.8,
66.2,
52.2,
83.7,
32.1,
71.2,
79.7,
83,
76.2,
37,
54.2,
17.7,
79.2,
44.7,
53.1,
53.3,
47.8,
39,
73.3,
31.2,
3.6,
21.5,
45.8,
83.1,
92.8,
84.1,
94.3,
79.5,
47.2,
29.6,
13.3,
75.1,
10.1,
8.8,
67,
66.8,
65.7,
55.2,
83.6,
38.3,
81.4,
91.7,
50.4,
30,
53.3,
97.9,
75.7,
83,
62.3,
40.5,
63.7,
80.1,
64.6,
3.7,
46.6,
25,
89.6,
56.5,
64.2,
62.3,
51.5,
65.3,
68.8,
68.2,
5.2,
63.2,
31.9,
61.5,
50.3,
19.2,
73.7,
21.2,
36.1,
19.4,
80.5,
24.2,
63.6,
78.1,
71.1,
44.2,
82.7,
53.8,
27.2,
89,
65.7,
47.8,
71.9,
38.2,
91.8,
83.3,
38.4,
0.5,
20.3,
56.9,
95.6,
86.4,
71.2,
61.8,
81.9,
75.8,
48,
47.7,
88,
34.1,
55.8,
47.7,
28,
62.6,
87.3,
71.6,
79.1,
49.9,
68.6,
20.8,
22.1,
64,
40,
53.6,
81.6,
18.3,
49.3,
28.4,
30.5,
69.3,
19.1,
58.8,
36,
82,
19.9,
74.4,
46.9,
52.1,
56.6,
32.5,
82.4,
22.8,
56.3,
15.8,
74.5,
70.1,
57.4,
37,
54.2,
17.4,
51.3,
71.9,
80.6,
50.7,
47.4,
76.8,
37.6,
66,
19.5,
90.2,
58.2,
83.4,
29.9,
17,
72,
82.3,
49.7,
94.8,
81.5,
37.8,
60.1,
66.4,
3,
41.5,
80.9,
63.7,
37.8,
53.7,
79.4,
65.2,
73.7,
27,
50.5,
22.4,
70.1,
52.7,
32.6,
57.5,
50.3,
77.8,
92.6,
47,
62.7,
71.3,
57.2,
70.2,
93.8,
54.8,
41.8,
39.5,
82.5,
38.7,
69.9,
48.5,
29.1,
34.1,
77.6,
30.2,
62.9,
15.6,
63.1,
56.4,
76.6,
87.5,
90.9,
36.4,
46.7,
5,
65.1,
23,
75.5,
89.6,
62.5,
83.3,
1,
32.4,
79.1,
63.8,
64.5,
33.8,
45.8,
3.3,
93,
70.9,
29.2,
39.8,
81.4,
89.5,
87.7,
68.6,
32.8,
53.9,
33,
53.9,
70.1,
37.7,
40.8,
10.1,
90.6,
47.7,
76.8,
9.6,
54.1,
51.9,
48.2,
64,
86.4,
64.5,
65.1,
92.1,
62.4,
75.1,
46,
78.2,
55.7,
23,
81.7,
51.1,
78.4,
28.3,
31,
26.7,
32.1,
42.2,
95.9,
72,
97,
93,
49.4,
28.3,
69.5,
61.2,
12.5,
86.8,
28.1,
85.7,
97.3,
75.4,
96.9,
76.2,
92.1,
78,
57.1,
12.3,
33.7,
51,
70.8,
72,
12.6,
12.2,
55.4,
0.3,
51.7,
34.2,
66.6,
81.3,
46.8,
51.2,
95.6,
32.4,
49.9,
83.7,
17.1,
89.6,
100.2,
42.2,
74.6,
61,
62.2,
68.2,
54.1,
86.2,
66.1,
37.4,
41.4,
38.2,
83.4,
100.1,
44,
21.1,
18.4,
38,
48.5,
56.3,
85.5,
22.6,
14.8,
90.7,
52.2,
74.4,
87.2,
78.1,
95.6,
73.1,
6.6,
75.2,
93.8,
68,
75.9,
67,
55,
45.5,
83.3,
62.2,
84.7,
66.4,
42.4,
85.2,
38,
42.4,
40.3,
63.6,
82.7,
80.7,
37,
67.8,
67.4,
57,
70.1,
52.4,
75.8,
75.5,
93.2,
66.7,
26.7,
53,
17.1,
2.9,
62.7,
74.6,
35.7,
58.3,
49.7,
79.5,
71.5,
86.7,
58.7,
91.9,
6.3,
83.9,
48.5,
76.6,
84.4,
78.1,
76.3,
57.6,
16,
82,
58.4,
73.6,
73.9,
82.3,
57.6,
15.1,
31.6,
22.2,
50.5,
28.1,
35.1,
52.5,
58,
0,
52.9,
73.1,
87.8,
60.4,
10,
4,
45.4,
42.9,
21.9,
8.3,
10.5,
59.3,
23.9,
36,
54.7,
27.6,
38.6,
19.3,
41.6,
38.5,
55.1,
88.7,
25.4,
49.1,
67.1,
80.4,
95,
48.6,
50.8,
61.4,
42.3,
38.4,
11.1,
27.9,
49.5,
61.1,
70.1,
52.6,
42,
89.7,
60.6,
79,
44.4,
82.1,
36.6,
92.1,
69.1,
41.7,
55,
49.8,
70,
83.4,
81.7,
62,
38.8,
68.3,
82.6,
45.1,
94.6,
89.8,
81.8,
72.6,
49.9,
83.2,
84,
83.3,
48.4,
68.4,
54.3,
24.8,
53,
60.8,
44.3,
92.8,
29.4,
22.8,
34.6,
33.1,
93.7,
23,
92.3,
54.9,
95.8,
69.5,
92.9,
5.3,
46.5,
38.1,
39.8,
81.9,
55.6,
88.7,
19.8,
72,
64,
66.2,
20.9,
76,
48.8,
57.5,
93.2,
70.7,
89.9,
52,
7.7,
52.7,
69.2,
35.6,
59.4,
78.3,
64.2,
43.2,
1.3,
43,
52.3,
49.9,
23.2,
39.2,
86.2,
62.6,
72.9,
57.6,
94.3,
61.8,
29.2,
58,
68,
53.7,
62.9,
80.1,
6.3,
30.8,
42.2,
72,
86.2,
81.9,
45.8,
41,
79.7,
38.5,
29.4,
54.4,
37.1,
38.8,
73.7,
29.6,
12,
82.6,
15.8,
46.3,
77.3,
17.6,
16.2,
92,
56,
72.6,
63.6,
27.2,
84.9,
48.3,
22.5,
61,
87.6,
96.5,
92.4,
27,
50.8,
67.1,
57.3,
68.7,
79.9,
73,
28.3,
37.5,
54.9,
75.7,
17.8,
62.7,
73.6,
77.4,
86.9,
29.6,
62.5,
0.2,
68,
36.3,
52.1,
55.6,
70.8,
29.6,
25.6,
44.8,
63.2,
40.3,
51.9,
45.5,
83.4,
2.1,
91.1,
39.1,
61.6,
60.3,
70.9,
74.4,
4.3,
26.4,
46.5,
30.2,
71.4,
47.7,
25.1,
47.1,
66.5,
83.5,
22.4,
48.6,
57,
7.4,
77.5,
36.5,
82,
90.2,
90.9,
22.9,
64.9,
40.2,
8.2,
47.7,
69.2,
91.3,
76.7,
62.8,
81.1,
85.6,
33,
60.4,
28,
36.4,
33.8,
66.8,
46.6,
14.8,
46,
59.5,
42.8,
35.8,
16.7,
26,
3.4,
52.2,
37.1,
22.2,
23.7,
66.4,
8.6,
10.5,
32.9,
87.2,
40,
83.8,
79.7,
44.8,
28.7,
58.3,
52.2,
59,
7,
15.3,
19.8,
49,
92.2,
73.3,
97.7,
17,
60.3,
38.4,
68,
57.7,
11.1,
48.6,
34.8,
67.1,
75,
27.9,
49.3,
48.9,
76,
79.6,
62.4,
77.4,
26,
59.2,
53.3,
35.4,
18.2,
73.9,
42.8,
66.6,
89.8,
59.1,
48.4,
51.5,
38.5,
39.8,
94.3,
86.1,
84.5,
63.3,
52.8,
31.2,
36.6,
70.3,
54.1,
0.2,
20.6,
89,
54.6,
68.9,
18.2,
84.9,
55.3,
94.7,
61.1,
74.3,
56.6,
66,
30,
67.6,
87.6,
60.6,
25.7,
77.6,
72.4,
78.1,
60,
65.4,
78,
34.4,
66.7,
33.3,
29.5,
7.7,
52.2,
80.9,
83.8,
88.1,
45.9,
94,
91.2,
38.5,
33.8,
40.9,
77.9,
83.9,
80.4,
68,
74.2,
63.7,
52.1,
91.8,
53.9,
41.5,
26.3,
31.7,
53.7,
96.5,
63.4,
25.9,
74.7,
98.7,
98.7,
31.9,
77.8,
37.2,
30.7,
9.5,
30.2,
40.3,
84.2,
54.4,
83.6,
62.1,
90.6,
76.7,
25.2,
76.5,
66,
35.9,
27.7,
90.7,
74.3,
44.8,
87.7,
71.9,
60.9,
3.7,
99.7,
68.7,
78.5,
95.4,
28.6,
65.3,
78.1,
81.4,
81.7,
70.5,
64.7,
76.2,
34.2,
59.7,
66,
43.6,
45.3,
45.2,
55.9,
5.9,
32.6,
73.1,
48.2,
81.4,
51.8,
63.6,
64,
48.3,
43.1,
72.5,
38.9,
64.1,
43.7,
18.3,
34.4,
90.2,
91,
48.5,
92.4,
33.4,
58.7,
66.7,
78.3,
52.2,
82.8,
30.8,
71.1,
26.2,
52.2,
56,
79.1,
18.7,
47.3,
36.8,
26.5,
66.8,
80.4,
31.9,
71.7,
80.3,
66.6,
83.4,
49.2,
33.3,
53.5,
23.7,
84.5,
49.9,
11,
68.9,
41.1,
88,
40,
49.4,
7.6,
75,
65.2,
52,
39,
48.2,
44.2,
58.3,
46.6,
76,
75.6,
87.8,
25.9,
48,
40.4,
43.2,
8.6,
70.2,
64.7,
39.4,
46.9,
70.3,
79.9,
85.6,
72.9,
45.3,
58.2,
58.9,
32.9,
67.9,
58.6,
41.4,
34.2,
43.7,
10.6,
59.9,
52.4,
32,
45.8,
19.6,
27,
90.6,
96.8,
52.9,
36.2,
45.4,
27,
0,
41.8,
64.2,
43.1,
46.4,
70.6,
51.1,
36.7,
31.3,
63.3,
38.1,
82.5,
56.8,
38.1,
78.2,
78,
78,
68.3,
71.3,
61.2,
71.1,
20.7,
80.6,
87.5,
38,
54.5,
44.4,
99.6,
32.8,
63.4,
10.6,
70.7,
66,
27.8,
69.5,
65.4,
64.3,
76.5,
41.7,
65.1,
65.3,
39.1,
61.4,
98.5,
57.2,
43.1,
72.5,
45.4,
75.9,
21.3,
75,
24.3,
72.5,
27.2,
50.9,
31.3,
52.8,
34.8,
30.2,
67.2,
59.7,
85.7,
51.2,
72.5,
40.6,
41.8,
50.3,
67.8,
18,
83.9,
54.8,
60.9,
49.5,
83,
3.9,
63.1,
87.2,
86.1,
54.6,
72.4,
40.9,
16.3,
79.5,
11.5,
54.8,
70,
0,
98.7,
49.8,
40.3,
23.9,
50.9,
84.3,
67.8,
35.7,
67.5,
43.5,
37,
74.1,
86.4,
71.6,
3.6,
79.4,
11.5,
42.2,
43.8,
47.6,
50.2,
79.5,
56.2,
85.8,
46.1,
14.8,
48.9,
51.7,
73.6,
35.7,
24.5,
51.2,
66.2,
42.8,
73.9,
81.9,
31.3,
51.4,
51.8,
36.2,
30.4,
67.7,
69.3,
63,
45.3,
45,
20.6,
46.1,
33.7,
23.6,
48.5,
97.4,
65.4,
72.2,
90,
63.1,
50.4,
57.7,
8.7,
79.4,
44.8,
61.5,
26.9,
51.5,
69.7,
51.4,
62,
42,
0,
83.9,
85.2,
53.9,
19.7,
31.1,
17.5,
10.9,
58.7,
36.9,
91.8,
67.4,
66.7,
3,
97,
71,
47.6,
43,
71.2,
2.7,
62.5,
95.1,
59.1,
45.7,
83.1,
41.5,
54.8,
45.3,
6.2,
19.1,
47.4,
38.2,
50.9,
43.1,
65.8,
32,
49.2,
4.8,
62.6,
30.9,
50.7,
32,
97.1,
31.3,
84,
74.5,
71.4,
74.5,
69.7,
59.2,
69.9,
73,
71.2,
100.3,
49,
100.8,
77.3,
0.7,
47,
1.8,
76.6,
17.9,
32.9,
51.3,
56,
88.8,
32.3,
29,
45.3,
62,
48.4,
66.3,
23.2,
56.3,
59.9,
64.4,
5.4,
56.2,
19.7,
54.4,
51.8,
28.5,
36.6,
89.1,
86.1,
21.8,
81.8,
46.4,
99.5,
85.1,
74.2,
69.1,
58,
38.8,
86.7,
97.4,
51.5,
67.6,
53.5,
88,
50.2,
27.8,
58.2,
65.9,
57.6,
2,
77.6,
55.7,
47.6,
63.3,
69.8,
40.1,
24.2,
59.7,
38.9,
77,
60.5,
7.1,
77,
14.7,
44.3,
83.6,
63.5,
90.8,
59.8,
24.2,
51.8,
48.7,
76,
54.8,
53.6,
25.1,
61.9,
87.5,
62,
79.8,
108.1,
15.9,
64.3,
51.6,
80,
31.6,
37.7,
66.4,
62.5,
94.6,
90.2,
16.7,
45.7,
61.3,
96.4,
98.3,
87.4,
52,
64.1,
70.6,
60.9,
31.1,
37,
80,
30.9,
70.4,
5,
51.8,
88,
24.8,
59.5,
75.1,
49,
84.1,
44.4,
78.3,
26.6,
83.5,
63.5,
14.4,
39.7,
18.6,
67.9,
87.4,
40.9,
46.7,
69.8,
52.1,
82.4,
37.7,
43.3,
51.7,
69.5,
61.1,
58.9,
21.4,
16,
68.4,
41.8,
12.7,
35.8,
62,
60.7,
71.1,
34,
79.5,
55.8,
86.3,
75.2,
78.5,
33.2,
97.1,
15.6,
15.2,
90.1,
56.1,
55.3,
85.9,
72.7,
37.8,
86.2,
84.8,
55.5,
52.3,
62.5,
38.8,
42.5,
66.3,
58.9,
0,
36.9,
45.8,
63.9,
33.7,
66.2,
53.2,
59,
24.2,
70.6,
25.8,
46.3,
6.2,
67.2,
76.7,
36.9,
55,
6.6,
63.9,
83.3,
67.2,
21.5,
69.4,
67.7,
88.6,
34.6,
76.7,
11.2,
46.7,
72.2,
20.2,
38.3,
57,
64.3,
7.5,
55.2,
98.2,
45.8,
58.9,
29.8,
89.4,
30.5,
39,
55.9,
56.3,
59.8,
56.1,
76.9,
57,
11.4,
85.2,
26.7,
79.8,
71,
76.4,
22.1,
64.6,
70,
41.4,
54,
49.4,
66.8,
28.1,
37.8,
60.1,
66.7,
89.7,
86.2,
71.6,
47.4,
69.1,
80.3,
89.4,
69.6,
71.9,
90.2,
91.4,
75,
64.4,
45.1,
75,
49.3,
56.4,
61.4,
32.3,
32.1,
74.6,
86.3,
11.9,
48.1,
95.9,
72.9,
49.9,
59.8,
59.2,
76.5,
69.8,
22.1,
89.3,
58.6,
53.1,
53.2,
85.3,
56,
56.7,
40.6,
28.4,
95.7,
88.4,
84.6,
100.4,
11.3,
19.6,
14.2,
45.2,
65,
14.9,
53.2,
92,
72.8,
39.4,
30.8,
25.1,
75.7,
30,
41.1,
36.3,
54.6,
48.7,
97.2,
79.1,
34.2,
82.9,
50.6,
60,
97.6,
80.7,
25.2,
55.4,
19.6,
53.2,
36.5,
33.3,
7.8,
52.9,
10.3,
70.6,
78.1,
75.2,
60.7,
57.5,
80.1,
60.5,
51.2,
45.2,
25.3,
85.6,
78.4,
60.6,
88.5,
61.7,
64.7,
9.6,
25.1,
38.1,
99.5,
56.3,
10.1,
16.2,
44.9,
95.9,
46.2,
78.6,
70.2,
28.4,
62.8,
73.8,
37.6,
68,
85.9,
88,
90.2,
37,
39.5,
77.5,
89.6,
78.6,
53.8,
65.6,
75.6,
92.2,
26.5,
55.1,
25,
94.4,
64.6,
63.1,
40.6,
53.9,
70.2,
66.7,
88.2,
68,
57.8,
9.5,
86.5,
24.7,
98.5,
78.5,
89.6,
62.1,
13.6,
28.1,
78.1,
57.7,
39.9,
62.5,
40.5,
77.4,
87.5,
25.3,
39,
56,
76.6,
90.9,
11.5,
76,
38.3,
73.8,
48.5,
92,
49.9,
7.8,
99.9,
40.2,
61.3,
52.3,
42.1,
97.1,
39.1,
80.5,
35.2,
30.3,
51.4,
27.5,
64.9,
97.3,
56.9,
31.9,
87.9,
51,
48.6,
52.8,
53.5,
23.8,
44,
28.5,
52.4,
52.5,
20,
64,
74.5,
92,
29.7,
82.5,
44.1,
66.6,
5.1,
61.9,
70.3,
58.3,
81.4,
61.1,
78.4,
67.5,
25.3,
57.7,
54.4,
70.8,
82.8,
69.6,
86.9,
32.6,
67.4,
82.8,
31.4,
39.2,
66.8,
33.8,
96.8,
42.5,
32.4,
44.8,
58.8,
71.3,
74.1,
55.7,
43.5,
69.9,
63.7,
54.7,
38.9,
95.7,
44.3,
56.2,
49.4,
43.2,
68.9,
4.8,
48.3,
16.7,
93.9,
52.9,
82.4,
38.2,
46.1,
46.6,
8.5,
48.3,
53.2,
51.1,
15.5,
25.5,
81.9,
95.4,
47.6,
54.9,
64.8,
80.9,
61.2,
62.8,
63.5,
34,
21.1,
87.4,
75.1,
77.4,
56.7,
67.8,
51.5,
13.2,
35.9,
87.3,
53,
47.2,
37,
77.5,
85.6,
58.5,
23.7,
47.4,
31.6,
79.4,
44,
34.9,
38.2,
2.3,
73,
88,
58.6,
43.2,
38.8,
50,
26.6,
74.4,
74.4,
36.3,
61.4,
76.9,
54.4,
83.3,
53,
79.8,
21.4,
96.4,
58,
99.1,
61.7,
62,
23,
92.1,
30.9,
79.5,
39.8,
41.7,
48,
67.9,
92.2,
43.8,
68.7,
32.4,
91,
16.3,
74.8,
80,
22,
75,
34.4,
82,
41.4,
66.2,
54.6,
63.3,
31.2,
16.5,
68.3,
73,
46.4,
34,
82.8,
39,
95.3,
50.2,
96,
60,
77.1,
48.9,
99.3,
4,
61.3,
35.9,
47.6,
21.5,
10.6,
58.9,
34,
43.6,
59.8,
58.5,
12.9,
72.8,
73.9,
87,
76.5,
41.8,
45.2,
46.3,
96.2,
88.7,
64.4,
8.2,
53.5,
46.3,
69.4,
58,
66.5,
71.1,
44.8,
17.2,
83.2,
116.1,
61,
5.4,
65.7,
55,
63.6,
18.4,
21.7,
20.5,
70.8,
1.4,
89.6,
63.3,
83.5,
45.2,
20.9,
18.4,
73.1,
24.9,
97.5,
51.1,
3.6,
19.8,
6.8,
36.7,
89.1,
49.7,
48,
31.2,
65.7,
24.5,
52,
57.8,
73.4,
71.7,
62.2,
77.7,
62.6,
54.2,
31.3,
65,
29,
53.8,
71.1,
49.2,
32.9,
4.6,
56.3,
22.8,
61.7,
50.5,
64.5,
49.4,
91.3,
65.3,
71.8,
47,
37.7,
70.7,
58,
27.4,
31,
43.5,
20.9,
30.6,
52.5,
60.2,
55.7,
53.9,
76.7,
47.8,
32,
75.9,
96.9,
68.9,
91.1,
67.1,
74.5,
17.7,
61.5,
73.5,
57.5,
27,
48.9,
47.3,
82.9,
63.2,
76.6,
56.3,
69.1,
35.3,
87.5,
47.9,
44.1,
77.8,
47.9,
70.4,
32.5,
12.6,
72.9,
72.2,
93.4,
24.3,
28,
43.7,
75.6,
38.7,
84.6,
72.3,
50.8,
84.3,
86.1,
50.4,
94,
29.1,
23,
48,
37.3,
65.1,
6.2,
35.9,
39.6,
44.3,
89.2,
9,
29.9,
78,
96.7,
84,
99.4,
51.3,
85.6,
49.7,
44.1,
68.4,
56.3,
82.7,
98.9,
94.9,
56.7,
8.1,
59,
72.7,
53.7,
88.3,
40.6,
63.9,
0.4,
74.2,
90,
41.2,
96.5,
29.3,
42.2,
65.9,
99.6,
77.8,
28.8,
89.2,
72.3,
67.6,
52.3,
49.9,
74.3,
66.2,
37.8,
33.6,
35.6,
21.3,
86.1,
18.7,
65.4,
49.8,
43.7,
40.4,
0.3,
41.9,
31.5,
90.6,
50.5,
85,
23.7,
73.4,
7.9,
48.9,
28.3,
33.4,
87.5,
52.6,
43,
85.6,
37.6,
88.7,
82,
14.3,
74.8,
68.8,
53.6,
19.4,
83.9,
54.8,
88.4,
46.4,
72.1,
57.3,
60.7,
64.6,
57,
76.1,
40.4,
27,
55.1,
50.7,
53.4,
73.7,
45.9,
23,
22.4,
22,
28.8,
48.9,
42.8,
54.1,
43.8,
35.5,
65.2,
42,
98.7,
56.9,
33.2,
67.3,
76.1,
49.3,
28.7,
80.5,
68.8,
57.2,
58.8,
0,
73.3,
84.8,
47.6,
72.2,
50.1,
22.8,
25.6,
85.5,
42.9,
61.6,
25.7,
77.4,
57,
50.8,
47.2,
77.1,
89.4,
59.2,
49.8,
96.2,
82.7,
27.5,
68.2,
23.1,
86.3,
51.4,
55.6,
53.4,
46.2,
72.6,
81.9,
52.9,
62.4,
87.8,
92.7,
44.6,
67.6,
37.2,
74.1,
66.2,
88.8,
23.3,
35.1,
96.8,
48.1,
35.7,
69.3,
31,
15.3,
89.5,
52.8,
80.2,
38.2,
23.7,
52.7,
77.2,
6.2,
45.8,
52.9,
61.1,
60.6,
95.7,
78.2,
79,
2.1,
56,
93.3,
11.5,
94.6,
22.8,
50,
88,
12.1,
38,
10.4,
93.1,
64.7,
59.6,
52.4,
52,
58.3,
25.7,
1.1,
72.1,
67.6,
50.7,
65.4,
13.5,
61.4,
46.2,
45.4,
74.7,
43.4,
67.8,
68.8,
4.1,
83.9,
42.2,
33.2,
55.3,
62.9,
77.8,
12.8,
24.2,
39.9,
71.4,
13.5,
59.5,
6.8,
45.4,
61,
41.4,
80.1,
54.1,
60.1,
47.8,
28.1,
23.5,
22,
68.8,
29.1,
50.8,
40.5,
86.8,
24.6,
44.5,
76.6,
53.4,
28.6,
69.6,
92.5,
39,
51.8,
25.2,
58.8,
57.2,
70.8,
100,
44.9,
54.4,
44.2,
90.8,
82.3,
72.1,
50.4,
62.3,
34.7,
41.5,
99.6,
79.3,
24.9,
81.6,
83.3,
39.2,
0,
72.3,
56.8,
93.9,
92.7,
84.1,
21.5,
80,
57.2,
30.2,
35.7,
57,
45.6,
59.8,
38.4,
56.3,
84,
76.2,
73.9,
34.9,
44.8,
86.8,
21.4,
80.6,
75.4,
61.6,
71.9,
26.1,
46.4,
56.7,
72.7,
41.1,
41.7,
14.2,
35.3,
24.2,
73.7,
35.5,
39.2,
50.2,
67.4,
43.1,
40.3,
88.4,
5.1,
46.5,
80.6,
59.6,
63.5,
47,
30.6,
45.2,
60.3,
78.7,
58.5,
39.1,
56.2,
24.3,
82.8,
38.4,
62.5,
61.2,
48.6,
78.7,
39.9,
61.1,
69.1,
40.5,
28.5,
102.1,
55.2,
50,
74.8,
46.5,
54,
33.8,
86.9,
64.4,
93.6,
35.8,
93.2,
28.5,
56.7,
73.4,
44.2,
33.5,
43.4,
76.3,
17.1,
21.5,
42.2,
50.3,
77.4,
54.1,
10.3,
71.5,
62.3,
13,
26.7,
101.6,
57,
58.6,
2.5,
87.3,
44.5,
83.5,
37.9,
41.9,
74.3,
33.2,
73,
60.3,
61.4,
15.9,
72.9,
49.4,
13.4,
44.6,
40.3,
69,
6.6,
17.6,
45.6,
81.6,
25.1,
85.3,
89.3,
57.9,
27.6,
45.5,
98.7,
62.6,
26.3,
70,
21.9,
47.3,
97,
94.4,
50.8,
61.9,
80.8,
45.5,
92,
31.8,
84,
41.7,
62,
65.9,
45,
20.4,
28.2,
80.7,
61.7,
15.1,
47.7,
68.2,
34.4,
64.5,
31.4,
47.9,
52.9,
12.8,
54.8,
89.5,
23.9,
1.9,
100,
39.2,
55.9,
84.1,
80.7,
55.7,
26.8,
4.3,
47.4,
52.4,
79.4,
79.8,
44,
70,
52.2,
40.7,
42,
26,
56.1,
55.9,
65.3,
18.7,
35.8,
49.2,
89.6,
86.4,
27.7,
61,
54,
74.7,
95.4,
68.1,
79.5,
87.9,
50.3,
96.2,
55,
20.3,
21.1,
82,
32.1,
4.7,
85.8,
45.2,
76.6,
67,
74.3,
26.9,
75.7,
71.4,
81.3,
70.5,
57.2,
93.7,
48.9,
29.7,
1.1,
38.9,
88.2,
83.1,
23.1,
61.1,
27.6,
69.7,
39,
29.7,
57.9,
74.4,
79,
56,
71.8,
47.9,
71.5,
72.8,
32.1,
55.8,
87.8,
71.8,
30.5,
57.9,
15.5,
47.1,
21.6,
51.2,
75.2,
66.5,
57.4,
69.6,
24.6,
27.3,
63.1,
72,
48.6,
79.9,
45.8,
38.6,
55.6,
80.6,
35.2,
85,
92.5,
10.7,
14.5,
76.3,
87.6,
86.9,
47.8,
28.4,
54.9,
47.2,
52.9,
28.9,
73.1,
97.2,
55,
68.3,
87.4,
32.5,
52,
47.5,
26,
44.9,
29.2,
39.2,
48,
54.2,
51.6,
77.5,
44.3,
2.7,
12.8,
41.9,
61.7,
40.2,
26.8,
65.5,
49.5,
58.5,
83,
75.9,
26.5,
62.4,
39,
74.8,
37.1,
91.8,
35.3,
15.1,
13.3,
25.6,
47.9,
16.4,
40.9,
19.8,
19.7,
59.5,
38.4,
79.1,
37,
68.2,
0,
60.7,
59.8,
74,
33.7,
49.5,
78.9,
67.2,
57.5,
48.2,
57.6,
40.6,
0,
63,
54.4,
39.2,
13,
70.2,
29.7,
27.3,
30.8,
46,
79,
73.4,
23.8,
73,
61.6,
44.7,
55.1,
46.1,
70.1,
49.9,
32.3,
45.6,
41.5,
26.5,
67.2,
44.2,
47.8,
98,
45.9,
52,
72.4,
82.8,
52.3,
52.8,
43.5,
49,
30.3,
69.9,
11.5,
44.1,
64.1,
56.8,
36.6,
87.9,
67.8,
64,
77.5,
32.3,
85.5,
82,
82.3,
64.1,
40.7,
49.8,
86.2,
81.8,
39.6,
78.4,
77.6,
47.4,
51,
95,
58.8,
49.9,
95.8,
21.8,
49,
85.5,
39,
47.8,
30.1,
82.8,
91.8,
69.7,
91.1,
69.6,
63.5,
40.7,
55.5,
32.5,
48.6,
16.7,
59.7,
67,
51,
94.8,
22.7,
94.5,
67,
93.3,
55,
43.8,
77.2,
11.6,
41.6,
57.5,
36.3,
46.6,
56.8,
49.2,
48.5,
20,
69.6,
38.9,
50.8,
75.5,
74.3,
79.4,
22.2,
56.5,
37.2,
53.6,
51.5,
39.1,
37.9,
88,
83.4,
84.1,
53.5,
10,
55.2,
66.6,
81.4,
33.6,
80,
61.4,
72.1,
46.4,
78.4,
42.8,
81.2,
43.6,
71.5,
64.3,
40.9,
32.9,
66,
93.6,
70.4,
83.5,
51.2,
2.9,
33.2,
99.2,
66.4,
73.5,
76,
17,
40,
3.3,
45.8,
28,
40.6,
28,
45.2,
68.3,
30.2,
88.6,
15.9,
56.7,
28.8,
28.9,
89.7,
19.7,
0,
35.6,
41.6,
52.1,
57.9,
28.8,
54.7,
75.9,
75.2,
83.1,
75,
98.5,
96.8,
38.2,
18.1,
47.7,
67.3,
45,
70.9,
79.5,
48.2,
74.5,
81.2,
48.7,
58.7,
72.4,
43.6,
64.1,
11.6,
81.9,
83.2,
68.8,
80.2,
50.8,
26.9,
76.8,
56.7,
16.6,
74.4,
54.8,
82,
72,
47.1,
21.2,
71.9,
29.3,
68.5,
43.4,
86.5,
81.3,
2.7,
19.5,
4.5,
67,
62.5,
15.7,
56.1,
64,
97.3,
59.6,
0,
77.5,
71.5,
100.2,
98.7,
96.1,
90.8,
84.9,
48.6,
89.4,
56.7,
94.9,
95.3,
85.3,
4,
74.4,
2,
18.8,
53.2,
79,
35.8,
60.9,
61.6,
26.4,
36.3,
35.8,
29.6,
67.1,
61.9,
39.6,
80.3,
0,
53,
67.6,
70.8,
65,
59.8,
71.4,
99.9,
89.8,
73.3,
65.3,
71,
75.2,
64.6,
30.3,
38.3,
60.3,
4.1,
29.8,
50.1,
89.8,
46.8,
75,
97.4,
7,
89.7,
65,
54.1,
46.6,
37,
81.3,
47.8,
40.7,
88.3,
31,
47.6,
83.4,
93.4,
65.5,
26.3,
58.9,
35.8,
76.1,
40.1,
61.7,
27.4,
84.8,
70.8,
37.5,
63.9,
65.8,
36,
66.7,
85.1,
78.2,
47.3,
38.3,
72.4,
88.4,
64.8,
82.8,
98.3,
70.2,
54.8,
95.8,
56.1,
48,
63.1,
53.7,
0.3,
61.3,
21,
57.2,
89.4,
46.1,
39.9,
34.5,
54.4,
91.8,
85.5,
48,
64.5,
37,
89.3,
67.2,
39.6,
39.6,
63.2,
97.1,
49.2,
64.2,
61.2,
67.9,
56.6,
78.2,
92.8,
49.5,
87.5,
93.4,
85.5,
67.2,
13.9,
48.4,
71.5,
63.5,
57.6,
34.3,
92.6,
96,
39.4,
92.6,
47.5,
45.8,
69.2,
41.2,
62.5,
71.3,
30,
65.5,
8.1,
52.7,
73.8,
49,
52.3,
36.5,
81.6,
47.7,
86.1,
93.1,
60,
32,
27.9,
31.5,
54.8,
42.5,
101,
67.9,
20.3,
37.2,
69.3,
54.3,
67.1,
92.5,
84.5,
83.6,
82.3,
32.9,
64.7,
24.5,
37.4,
75.7,
61.3,
17.7,
78,
58.9,
48,
39.1,
29.7,
48,
53.3,
52.2,
62.4,
42.9,
6.7,
85.9,
14,
36.5,
39,
54.1,
28,
70.7,
82.4,
84.9,
25,
73.9,
67.7,
46.2,
58.3,
54.5,
24.7,
12.7,
51.1,
42.3,
67.9,
27.8,
63.4,
41.3,
48.3,
84.2,
65,
48.6,
53.3,
66.7,
60.4,
68.8,
67.8,
87.3,
81.3,
64.4,
44,
21.4,
38.9,
37,
42.7,
79.2,
42.8,
18.5,
91.4,
17.2,
56.7,
69.7,
41.1,
31,
34.6,
55.5,
43.1,
74.1,
55.7,
21.5,
66.3,
30.8,
94.7,
79.1,
3.2,
80.3,
85.5,
81.3,
63.6,
38.9,
71.8,
10.2,
25.6,
37.9,
13.4,
16.8,
88.3,
57.6,
83,
43.6,
19.5,
64.6,
51.5,
40.4,
36.3,
77.9,
54.5,
71.4,
68.1,
72.9,
35.4,
52.2,
63,
33.1,
78.8,
73.7,
19.3,
45.5,
52,
62.4,
23.8,
65,
48.5,
46.4,
58.9,
70.7,
82.5,
2,
86.1,
50,
90.7,
45.3,
83.5,
95.2,
60.6,
21.2,
99,
68.5,
66,
66.7,
47.4,
71.3,
89,
58.8,
17.7,
41.3,
57,
46.3,
4.5,
63.1,
54.7,
49.5,
67.2,
47.8,
34.6,
60,
38.7,
13,
46.5,
46.4,
74.1,
44.4,
27.1,
51.5,
47.9,
8.5,
79.9,
46.8,
93.7,
70.8,
93.1,
69.6,
62.7,
87.3,
96.5,
97.9,
81.6,
57.8,
33.6,
26.5,
85.1,
19.4,
84.9,
86.3,
75.4,
22.6,
53.7,
47.5,
71.2,
30.8,
15,
45.5,
62.2,
54.8,
39.9,
51.9,
23,
52,
54.5,
44.3,
77.6,
53.6,
40.5,
47.4,
46.4,
30.2,
61.8,
35.5,
10.6,
58.3,
65,
40.2,
59.5,
40,
63.1,
47.1,
60.7,
61.5,
5.3,
97.5,
59.9,
96.8,
46.4,
96.5,
64.3,
20,
26.3,
73.1,
29.2,
81.4,
80.8,
54.2,
49.2,
55.3,
64.5,
30.5,
61.3,
40.3,
56.1,
79.5,
20.2,
9.6,
50.3,
83,
4.4,
85.2,
36,
74.6,
22.4,
100,
89.1,
57.2,
54.9,
76.8,
39.9,
82.4,
0.1,
51,
81.4,
10.5,
68.9,
12.7,
48.6,
81.4,
40.5,
63.2,
76.6,
77.2,
0.3,
48.6,
38.9,
22.3,
25.5,
68.3,
82.8,
17.4,
36.6,
52.6,
72.3,
33.7,
86.6,
68.3,
59.8,
16.7,
86.1,
54.9,
83.4,
39.6,
72.2,
15.4,
44.1,
51.7,
89,
54.9,
49.6,
89.7,
77,
59,
78.1,
39.4,
35.2,
54.1,
46.8,
53.9,
74,
79.2,
63.8,
59.3,
48.6,
91.2,
34.2,
91.6,
96.2,
66.4,
41.6,
59.4,
11.8,
40.2,
50.1,
68.5,
22.1,
71,
78,
18.7,
93.8,
54,
42.2,
96.1,
85.5,
49.4,
31.9,
85.6,
66.3,
65.3,
39,
79.8,
61.9,
98.7,
29.7,
36.7,
52.3,
43.7,
46.6,
13.1,
63.5,
72.1,
56.2,
75.5,
30.3,
81.5,
95.6,
53.6,
26.1,
86,
18.7,
74.8,
83.9,
40.5,
6,
0.5,
21.8,
85.1,
65.4,
39.7,
89.8,
56.5,
26.6,
36.4,
48.4,
94.9,
59.4,
48.4,
65.4,
28.6,
59,
40.6,
56.2,
57.9,
98.3,
77.8,
48.4,
23.5,
80.2,
7.7,
80,
29.5,
35.9,
35.8,
19.9,
67,
79.9,
12.4,
51.2,
61.2,
48.2,
88.5,
76.8,
57,
86.2,
9.6,
56.6,
84.5,
64.1,
49.6,
42.9,
37.4,
93,
21.1,
63.6,
69.9,
41.3,
53.1,
41.6,
60.6,
77.3,
60.2,
67.6,
43.8,
27.7,
59.5,
74.9,
79.9,
55.9,
29.2,
34.2,
98.1,
66.7,
66.7,
70.6,
26.6,
46.1,
90.1,
30,
36.3,
59,
70.2,
36.4,
93.8,
73.5,
65.6,
52.3,
42.2,
52.2,
36.7,
67.2,
63.8,
67.7,
29.9,
53.1,
81.5,
22.4,
26.8,
83.7,
39.1,
44.9,
56.8,
28.2,
47.9,
94.9,
42,
61.8,
33.4,
34.2,
87.7,
34.6,
68,
5.6,
37.1,
47.9,
11.4,
40.7,
50.2,
21.4,
62.8,
69,
48.8,
30,
80.8,
0,
67.5,
79.3,
80.6,
57.4,
31.6,
93.2,
94.1,
37.4,
75.5,
25.9,
39.6,
57.6,
43.3,
57.6,
46.3,
49.2,
43.8,
24,
62,
27.4,
17.7,
50,
22,
59.8,
35.6,
63.3,
40.6,
59.9,
52.6,
45.1,
46,
50.2,
98.4,
58.2,
34.2,
69.4,
44.3,
54.7,
62.3,
53,
99.3,
78.5,
8.7,
53.6,
81.5,
6.4,
80.4,
21.4,
87.2,
1.7,
10,
70.5,
53.3,
66.9,
80,
83.2,
24.1,
87.1,
32.6,
59.4,
72.8,
70,
18.3,
75.1,
66.8,
85.7,
87.1,
44.7,
63.8,
0.5,
51.9,
43.2,
29.6,
15.6,
68.8,
92.2,
86.2,
69.9,
37.8,
94.5,
69.5,
88.1,
71.4,
30.2,
62.5,
57.7,
62.1,
67.4,
37.1,
67.7,
54,
75.8,
100,
73.9,
11.3,
34.3,
79.3,
88.5,
24.6,
70.3,
32.3,
65.3,
81.5,
25.4,
26.6,
69,
22.1,
82.5,
77.9,
6.8,
27.7,
23.2,
58.7,
null,
18.8,
49.3,
47.7,
33.3,
19.7,
48.3,
49.9,
58.7,
32.7,
74.9,
88.2,
32.9,
73,
74.5,
56.8,
76.1,
68.8,
64.1,
24.6,
45.3,
30.2,
38.8,
32.2,
50.9,
50,
38,
80.7,
36.6,
60.4,
97,
27.7,
41.7,
58.3,
68.7,
92,
56.8,
15.5,
41.4,
29.6,
35.2,
79.1,
59.5,
13.8,
41.3,
42.5,
16.7,
88.1,
56.9,
10.9,
55,
54.1,
29.7,
80.7,
59.1,
73.1,
72.4,
88.5,
24.4,
80.8,
35.9,
94.4,
40.4,
71.2,
37.9,
68.3,
53.4,
84.5,
69.4,
42.7,
31.4,
67.6,
38.7,
26.1,
51.7,
40.1,
11.9,
81.8,
77.4,
21,
23.9,
35.5,
58.7,
82.4,
38.5,
39.7,
65.7,
62.9,
41.3,
50.7,
61.7,
62,
11.7,
47.1,
70.4,
87.3,
87.1,
76.3,
80.2,
47.4,
17.9,
43.3,
10.7,
70.3,
28.2,
82,
22.9,
22.4,
48.2,
59.3,
20.2,
92.7,
76.4,
59.6,
24.9,
39.6,
42.9,
80.8,
41.5,
0.2,
51.5,
3.4,
67,
98.7,
15.4,
35.3,
70.7,
69.3,
58.6,
88.2,
44.1,
57.5,
38.4,
26.5,
46.6,
50.4,
61.5,
83.5,
42.9,
55.7,
8.3,
43.7,
18.8,
68.6,
48.1,
63.2,
44,
98.7,
38.8,
50.7,
72.7,
96.8,
69.1,
61.9,
70.1,
72.9,
59.5,
63,
78.3,
60.8,
84.2,
60.1,
7.4,
62.2,
55.7,
66,
82.1,
66.5,
39.3,
69.6,
70.6,
50.4,
50.8,
25.3,
83.1,
56.4,
1.3,
98.3,
21.4,
87,
92,
97.1,
53.2,
87.2,
14.4,
36.7,
34,
62.2,
35,
44.9,
57,
25,
69.2,
57,
63.6,
70.3,
43,
45.1,
8.7,
97.1,
16.5,
30.9,
28.7,
23.2,
17.4,
27.2,
40,
39.1,
43.2,
58.1,
55.4,
75,
75.2,
59,
62.4,
52.9,
60.9,
40.5,
93,
53,
72,
67.8,
53.9,
85.2,
33.1,
77.1,
11,
88.7,
58.8,
56.5,
71.4,
53.9,
42.7,
51,
73.8,
31.1,
41.6,
37.5,
57.2,
65.6,
25.5,
91,
77.8,
73.7,
91.2,
19.7,
96.9,
44,
50.4,
97.6,
81.2,
52,
90.3,
6.7,
54.7,
25.7,
58.6,
41,
66.3,
99.3,
24.2,
61.1,
17.3,
49.6,
30.7,
38.7,
49.1,
45.6,
45.1,
83.6,
50.2,
32.5,
90,
48.6,
52.8,
48.6,
46.6,
67.5,
66.6,
20.8,
35.3,
42.2,
49.4,
56.9,
30.2,
83,
41.9,
73.9,
44.1,
42.3,
26.3,
73.4,
7.7,
104.1,
22.5,
88.6,
60.2,
99.6,
37,
12.7,
24.6,
27.1,
35.5,
54.5,
83.1,
18.6,
60.5,
73.8,
55.8,
71.9,
43.4,
33.1,
94.4,
56.9,
62,
76.5,
53.4,
75.1,
104.5,
83.5,
54.1,
74.5,
48.6,
8.5,
62.2,
63.5,
51.3,
35.9,
83.8,
77.5,
18.6,
19.1,
52.2,
69.1,
56.7,
78.7,
59.1,
57.2,
70.4,
42.5,
63.9,
73.3,
26.9,
83.4,
29.1,
23.2,
77.6,
32.5,
61.5,
97.2,
66.5,
81.2,
23.8,
48.7,
51,
65,
73.2,
31.4,
65.1,
49.9,
15.8,
82,
86.2,
39.4,
39.8,
64.6,
11,
44.9,
69.3,
87.8,
41.6,
70.9,
77.1,
30.7,
50.2,
37.7,
87,
44.7,
83.2,
82,
37.7,
57,
74.2,
36.8,
77,
43.6,
26.4,
40.7,
19.7,
22.3,
67.1,
67.8,
60,
22.1,
10.5,
69.1,
38.6,
31,
20.9,
42.1,
69.2,
77.5,
31.9,
69.8,
80.4,
50,
41.8,
61,
78.3,
22,
35.6,
15.6,
2.9,
69.1,
43.9,
69.7,
51,
72.2,
56,
85.4,
39,
13.4,
58.7,
46.7,
24.1,
31.9,
66.1,
82.5,
94.1,
67.1,
20.6,
34.5,
73,
26,
82.2,
37.9,
89.6,
28.1,
50.6,
55.5,
16.4,
6.3,
67.2,
19.4,
98.5,
60.5,
43,
40.5,
51.3,
79.4,
54.3,
27,
26.3,
77.1,
60.4,
49.5,
76,
72.8,
53.4,
11.5,
61.3,
72.9,
29.6,
54.3,
76,
29.2,
57.7,
65.8,
65.2,
36.6,
43.3,
41.1,
43.8,
74.5,
49,
71.3,
18.6,
63.2,
78.8,
53.5,
52.9,
34.9,
33.6,
59.9,
38.5,
43.9,
44,
56,
32.3,
88.9,
59.1,
8,
99.6,
23.9,
99.2,
54.7,
8.4,
89.1,
84.1,
71.7,
68.1,
101.8,
62.4,
79.8,
55,
79.2,
63.7,
48.1,
69,
70,
2.9,
47.3,
44.1,
9,
27.1,
62.4,
77.6,
59.3,
66.9,
62.2,
92.8,
44.4,
40.1,
42.7,
12.5,
50.9,
47.2,
27.2,
53,
43.8,
42.6,
80.8,
80.8,
63.6,
28.5,
9.1,
46.1,
40.9,
82.5,
3.6,
36.5,
67.3,
69.3,
51.4,
40.6,
87.7,
8.2,
51.5,
80.8,
71.7,
37.6,
26.6,
45.6,
38.9,
53.8,
41.6,
51.2,
68.4,
51,
16.3,
57.2,
43,
51.7,
60.5,
81.3,
52.4,
43,
61,
84.7,
65.4,
51.1,
69.6,
46,
16.8,
68.8,
95.7,
21.8,
91.4,
51.6,
62.1,
71.5,
17.4,
24.8,
87.5,
88.6,
75,
59.1,
48.5,
99.1,
38.4,
41.3,
69.8,
25.7,
48.7,
51.4,
68.1,
41.5,
49.5,
44,
24.4,
35.6,
67.1,
36.6,
68.4,
72.2,
73.9,
80,
70.1,
61.3,
77,
62.2,
51.1,
79.4,
46.8,
17,
69.5,
58.9,
8.8,
13,
8.6,
58.4,
62.1,
82.5,
48.9,
89.2,
59.2,
26.5,
66,
58.3,
19.2,
88.5,
8.7,
21.5,
67.2,
91.8,
42.1,
32.3,
80.3,
81.5,
67.5,
65.5,
65.9,
39.7,
67.6,
59.5,
70.1,
41.7,
81,
26.6,
55,
90.7,
51.1,
53.1,
70.5,
22.4,
77.3,
17.8,
54.3,
32.7,
41.4,
10.2,
42,
24.6,
79.8,
59.5,
73,
42.9,
53.2,
59.9,
31,
51.7,
66.6,
71.5,
99.1,
47,
96.8,
40.5,
88,
53.8,
55.7,
40.7,
7.1,
53,
45.1,
85.5,
80.7,
50.1,
20.6,
33.9,
58.6,
54.2,
58.5,
82.9,
28.4,
39.8,
39.2,
2.9,
83.3,
57.5,
80.3,
42.1,
51.7,
68.7,
52,
65.4,
51.8,
52.7,
92.6,
44.7,
61.5,
28.2,
91.5,
32.9,
69,
34.1,
27.2,
47,
0,
37.9,
19,
93.2,
76.4,
94.5,
91.4,
43.3,
30.5,
21.6,
77.3,
55.5,
48.5,
46.9,
74.2,
25.4,
75.9,
61.4,
9.5,
32.6,
92.1,
85.5,
19.3,
66.2,
63.8,
10,
95.2,
51,
77.4,
70,
54.2,
45.9,
35.9,
60.4,
36.6,
27,
78.7,
55,
60.3,
79,
28.3,
10.9,
11.4,
47.7,
71.9,
73.6,
49.2,
74.8,
78.8,
15.1,
80.8,
42.7,
26.7,
77.7,
null,
52.6,
87.8,
84.5,
83.6,
25.3,
40.7,
42.2,
58.9,
12.7,
2.4,
76.2,
77.7,
69.3,
70.5,
32.6,
35.5,
4.5,
54.6,
10.5,
41.6,
58.2,
35.7,
78.7,
27.9,
89.6,
0,
55.6,
8.6,
49.1,
91.3,
70.7,
82.5,
43.9,
65.7,
35.7,
42.2,
34.3,
14.4,
47.9,
50.6,
53.3,
86.3,
59.7,
34.7,
54.2,
38,
16.7,
32,
75.9,
24.9,
49.3,
61.7,
39.2,
59.9,
90,
81.4,
11.2,
21.2,
96,
61.9,
28.1,
74.2,
85,
32,
19.6,
51.4,
43.6,
58.7,
1.4,
33,
18.7,
69.7,
45.3,
68.8,
89.3,
47.8,
48.5,
51.1,
44.9,
62,
87.2,
66.4,
60.1,
21.5,
44,
45.4,
71.1,
35.8,
36.8,
55.8,
50.7,
61.3,
46,
45.6,
80,
44.3,
57.3,
50.1,
52.5,
74.9,
60.9,
16,
96.1,
67.9,
55.9,
57.6,
37.1,
81.1,
70.4,
66.4,
89.1,
39.5,
0,
77,
44.4,
4,
45.8,
23.7,
22.7,
95.6,
72,
51.4,
22.2,
36.6,
60.3,
5.4,
32.7,
40,
58.4,
80.4,
61.3,
95.5,
40,
77.2,
17.5,
77.4,
61.5,
59.5,
73.3,
40.4,
49.4,
75.4,
33,
15.1,
14,
73.9,
34.6,
92.4,
43.7,
45.2,
39.6,
34.3,
30.4,
54.9,
83.7,
40.8,
94.3,
66.5,
78.1,
39.1,
74.8,
24.7,
17.9,
13,
26.3,
73.7,
67.4,
68.7,
30.5,
66.6,
64.6,
56.9,
36.6,
56.1,
7.4,
62.9,
93.4,
96.5,
54,
55.8,
10.3,
66.7,
76,
91.9,
43.9,
66.2,
76.8,
44.4,
86.2,
23.4,
92.3,
47,
19.7,
73.6,
30.5,
12.3,
74.2,
7.7,
64.3,
43,
78.1,
11.5,
95.5,
50.7,
55.9,
24.4,
49.9,
62,
34.5,
91,
57.1,
22.9,
67.7,
86.4,
89.5,
45.5,
97.9,
52,
40.2,
53,
23.9,
77,
38,
10.8,
87.3,
41.3,
85.2,
53.7,
81.9,
77.8,
58.2,
27,
14.9,
77.3,
26.8,
57.7,
0.2,
58.4,
67,
40.1,
51,
33.6,
97.3,
60.5,
81.4,
84.9,
38.3,
47,
22.5,
52.3,
47.2,
50,
53,
39,
68.5,
10.3,
39.5,
45.2,
25.8,
30,
67.9,
33.7,
11.3,
71.5,
79.7,
91.3,
64.1,
13.4,
67.4,
23.1,
83.8,
36.7,
49.2,
23,
20.1,
47.7,
36,
15,
34.9,
88.2,
53.5,
70.2,
61.4,
58.5,
16.8,
18.5,
10.4,
31.8,
17,
64.6,
26.7,
49.5,
90.5,
61,
84.7,
89.2,
56.7,
93.7,
53.1,
65,
85.3,
79.9,
87.6,
54.2,
90.9,
60.8,
45.6,
81,
12.7,
47.9,
48.2,
42.6,
30.8,
27.4,
94.5,
36.4,
56.2,
65.1,
67.4,
83.8,
28,
27.9,
49.2,
99.9,
61,
99.4,
60.4,
63.1,
68.2,
43.4,
0,
84.8,
29.6,
91,
78.3,
31.5,
76.6,
31,
100.3,
40.4,
34.1,
60.7,
62.6,
70.8,
70.7,
21.2,
6,
77.2,
35.4,
23.8,
60.9,
21.6,
13.5,
64.5,
46,
46.8,
41.9,
85.2,
17.3,
71.4,
63.3,
80.1,
69.2,
56,
40.7,
87.9,
43.8,
91.3,
11.8,
86.4,
29.4,
36.6,
58.1,
79.7,
49.1,
38.2,
74.7,
42.7,
47.4,
68.1,
63.5,
73.7,
97.9,
49.9,
99.3,
81.6,
36.4,
78.4,
96.6,
75.1,
41.6,
43.1,
49.5,
80.3,
75.5,
74,
34.1,
51.3,
56.2,
38.8,
67.9,
27,
49.3,
85.9,
58.7,
40.2,
49.3,
34.2,
82.7,
81.6,
76.6,
53.6,
65.5,
71.6,
24.3,
28.5,
82.9,
48.5,
37.6,
52.4,
90.9,
37.7,
49.1,
54,
16.4,
59.7,
14.7,
30.2,
68,
53.3,
68.8,
50.4,
86.8,
23.5,
35.8,
59.8,
44.2,
43,
98.4,
81.6,
41.4,
92.4,
66.9,
62.3,
54.6,
42,
22.9,
21.3,
42.9,
44.9,
94.6,
74.5,
21.4,
73.8,
10.9,
66,
54.1,
47.5,
94.3,
50.7,
74.3,
49.2,
48.6,
43.9,
94.1,
51.1,
48.2,
77.5,
60.69,
99.3,
42,
64.1,
25.1,
47.1,
56,
42.7,
27.3,
29.1,
65.8,
51.8,
76.2,
75.3,
49.4,
15.4,
68.5,
85.8,
39.1,
40.6,
27.3,
70.8,
29.2,
45.6,
90.6,
71.6,
86.2,
20.1,
54.2,
90.2,
20.3,
26.8,
44.4,
60.1,
93.4,
23.8,
54.4,
72.8,
91.8,
65.7,
38.5,
65.1,
15.6,
77,
39.4,
101.8,
66.6,
40.7,
43.1,
92.5,
59.7,
62.1,
8.1,
21.4,
64.4,
62.5,
75.5,
22.3,
62,
70.4,
83.8,
19.6,
20.6,
56.2,
62.1,
11.5,
29.4,
55,
21.9,
53.8,
65.2,
85.6,
35.1,
83,
69.3,
30.2,
67.2,
95.5,
15.7,
37.4,
75.6,
83.2,
32.9,
81,
15.9,
12,
32.8,
42.4,
67.3,
43.2,
53.9,
97.5,
63.9,
67.7,
83.3,
67.6,
43.3,
54.4,
72.7,
31,
69.8,
53.6,
84,
58.7,
89.3,
19.5,
50,
84.1,
58.4,
65.6,
83.9,
48.3,
45,
47,
33,
56.5,
27.5,
52.5,
51.8,
98.9,
48.9,
28.6,
77.4,
65.7,
38.8,
39.5,
30.2,
46.4,
86.2,
63,
56.4,
60.5,
79.6,
55.1,
37.3,
82,
78.1,
52.5,
62,
80,
59,
73.6,
59.5,
36.2,
47.7,
37.7,
17.8,
40.6,
52.9,
12,
16.2,
50,
45.4,
41.6,
56.4,
92.7,
58.2,
51.2,
45.5,
68.1,
71,
13.7,
85.8,
64.4,
34.1,
85.7,
72.5,
6.9,
34.9,
63.7,
42.6,
16.3,
82.2,
83.5,
8.4,
55.1,
89.8,
78,
20.5,
0,
67.2,
67.5,
77.1,
23.2,
30,
64.7,
62.9,
0,
23,
48.5,
89.7,
79.3,
35.4,
39.2,
59.7,
11.3,
37.1,
51,
90.6,
69.1,
32.6,
97.3,
4.7,
46.7,
65.4,
38,
73.9,
91.4,
42.4,
32.3,
101.8,
59.4,
62.1,
3.3,
75.5,
20.4,
50.8,
16.8,
26.2,
46.8,
72.2,
90.8,
15.8,
47.1,
79.3,
49,
72.4,
74.2,
52,
33,
40.7,
71.5,
19.8,
44.9,
24.7,
82.2,
73.4,
43.2,
22.9,
80.9,
13.7,
71.9,
7.8,
44.2,
52.9,
67.5,
50,
58.3,
45,
42.5,
87.1,
64.3,
23.5,
26.9,
91.5,
63.9,
67.4,
50,
79.1,
4.5,
66.2,
68,
39.5,
31.4,
96.2,
27.9,
91.5,
96.9,
31.1,
89.9,
55.8,
27,
63.4,
72.4,
17.7,
59.1,
20.5,
60.3,
54.1,
46.5,
45.5,
44.6,
71.1,
73,
80.3,
64.6,
41.3,
70.8,
48.1,
72,
53.4,
44.6,
92.9,
34.5,
53,
40.4,
18.6,
24.8,
52.5,
62,
58.4,
88.5,
55.5,
54.5,
54.8,
52.1,
47,
18,
69,
63.5,
54.7,
23.6,
61.6,
81.7,
44.1,
46.6,
62.9,
66.1,
47.1,
43.6,
31.2,
22,
88,
0.4,
23.9,
36.3,
48.9,
80.3,
32.9,
43.9,
92.6,
86.3,
59.8,
87.5,
44.4,
90,
82.4,
89.6,
32.5,
92.4,
72.3,
33.8,
39.2,
29.6,
50.4,
101.3,
57.9,
56,
47.5,
61.2,
70.1,
91.5,
41.9,
97.1,
78.5,
11.3,
52.7,
43.4,
83.7,
73.9,
80.4,
49.6,
89.3,
88.7,
42.2,
58.2,
8.3,
80.2,
20.2,
49,
66.9,
77.9,
24.5,
22.7,
65.2,
63.5,
93.2,
65.8,
41.2,
51.4,
40.2,
75.1,
47.7,
70.5,
54.1,
83.3,
57.7,
75.7,
67,
33.9,
38.7,
84.1,
23.6,
30.4,
15.7,
47,
68.7,
54.5,
59.3,
13.5,
4.9,
68.3,
42.1,
38.2,
87.9,
70.5,
51.4,
36.4,
86.6,
89.6,
100.5,
65.6,
68.6,
53.1,
89.3,
46,
68.4,
44.4,
84,
82.8,
49.4,
37.9,
41.3,
81,
64.5,
39.3,
88.7,
49.6,
6.3,
51.8,
68,
52.6,
63.6,
87.9,
48,
58.5,
85.4,
70.8,
63.9,
77.8,
89.4,
42.3,
80.9,
90.1,
12.5,
45.7,
16,
43.9,
35.3,
15.2,
38.9,
46,
75.8,
73.5,
48,
65.8,
48,
61.4,
58.7,
56.8,
54.8,
77.8,
57.6,
25,
70.7,
89.6,
66.4,
82.1,
77.7,
85.9,
58,
13.1,
51.3,
65.4,
44.3,
53.2,
61,
77.1,
58.5,
69.5,
82,
53.6,
67.4,
63,
25.4,
32.3,
62.5,
81.3,
90.7,
84.8,
96.9,
78.2,
51.1,
67.3,
52.1,
61.1,
50,
40.9,
94,
75.6,
24.6,
33,
38.4,
43.8,
71,
12.6,
61,
39,
10.1,
47.8,
41,
91.8,
15.9,
67.2,
37.3,
86.9,
98.9,
80.9,
24.2,
76.6,
50.4,
47.4,
28.9,
26,
88.3,
88.3,
49.5,
27.6,
66.5,
81.1,
13.7,
59.9,
56.1,
39,
75.4,
95.7,
40.5,
87.4,
78.9,
58.5,
87.2,
49.6,
3.5,
63.7,
81,
83.9,
87.1,
51.7,
88.3,
21.8,
85.1,
35.4,
58.9,
80.3,
12.9,
9.9,
67.3,
94,
37.2,
25.2,
75,
24.2,
25.2,
63.6,
31.6,
77.8,
26.6,
55.8,
66.4,
59.5,
37.7,
62.1,
70.4,
13,
48.4,
46.8,
19.3,
35.8,
43.7,
37.7,
75.3,
42.8,
69,
76.8,
70.8,
55.9,
68.1,
58.9,
34.4,
81.7,
20.5,
61.5,
64.2,
65.2,
47.8,
78.4,
35.3,
96,
73.2,
53.5,
27,
45,
50.9,
43.6,
99.7,
32.8,
68.5,
41.4,
43.2,
40.4,
27.2,
43.3,
67,
92,
91.3,
31.8,
30.5,
44.3,
66.7,
52.6,
42.9,
30.5,
6.5,
41,
68.5,
77.4,
49.9,
53.5,
45.9,
28.2,
76.4,
87,
31,
83.2,
99.2,
56.2,
88.6,
54.5,
84.3,
32.7,
75.3,
83,
81.1,
70,
94.8,
75.2,
42.4,
47.3,
34.7,
60.1,
35.2,
13.5,
96.8,
65.1,
55.9,
24.7,
67.9,
66.7,
33.2,
29.8,
38.9,
64.9,
82,
41.2,
89.5,
48.9,
52.8,
22.2,
36.3,
75.3,
67.9,
33.6,
35.6,
46.7,
74.3,
12,
54.3,
73.2,
90.3,
31,
59.8,
84.6,
53.9,
47.1,
3.7,
74.7,
41.2,
59.9,
61.1,
71.1,
42.6,
0,
16.1,
32.9,
7.8,
69.3,
68.6,
10,
18,
69.9,
22.3,
8.9,
94.7,
45.1,
33,
78.5,
10.2,
33.9,
48.6,
54.9,
73.5,
49.3,
60.2,
61,
43.2,
63.7,
90.7,
36.4,
1.7,
9.8,
22.5,
26,
92.8,
73.5,
51.6,
37,
74.7,
57.4,
52,
44,
65,
71.9,
15.2,
0,
9.3,
41.2,
34.8,
72.5,
53.5,
39.6,
48.5,
29.2,
9,
29.2,
19.8,
21.4,
76.3,
40,
58,
52.5,
64.4,
24.3,
0,
92.7,
69.5,
84.3,
76.3,
45.3,
28.9,
67.3,
15.1,
45.7,
40.5,
10.2,
73.2,
44,
93.1,
85.1,
75.1,
35.4,
43.6,
78.8,
70.2,
29.8,
87.2,
17,
46.1,
45.1,
30.3,
56.7,
71.3,
47.7,
82.5,
77.5,
29.9,
49.4,
41.5,
85.3,
37.4,
12,
53.6,
72.2,
96.1,
87.5,
63.1,
89,
63,
35.6,
31.5,
62.2,
61.1,
29.9,
51.8,
34,
41.2,
23,
75,
54.7,
35.8,
61.9,
1.8,
88.3,
83.5,
98.4,
68.9,
52.9,
79.8,
75.6,
43,
82.9,
60.7,
43.6,
23.6,
87.3,
61.2,
52.6,
9,
87,
40.9,
35.9,
57.8,
31.2,
72.2,
60,
50.6,
54.8,
72,
70.3,
85.9,
54.4,
5.8,
3.6,
77.3,
19.3,
26.7,
5.4,
84.8,
34.3,
27.6,
45.9,
53.3,
45.4,
54.3,
97.7,
62.6,
41.7,
89.1,
10.1,
42.5,
80.5,
54.2,
44.9,
48.3,
60,
75.7,
13.2,
74,
36,
72.3,
77.5,
83.5,
61,
78.8,
60.5,
56.9,
94.5,
77.8,
97.7,
86.5,
71.9,
62.7,
46,
93.3,
61.8,
64.9,
71,
96.8,
29.2,
67.3,
68.5,
74.7,
36.7,
77.7,
72.6,
19.3,
25.9,
43,
15,
83.4,
16.8,
34.8,
29.6,
76.7,
29.9,
81.4,
95.3,
29,
31.9,
57.3,
76.8,
61.4,
37.6,
55.2,
78,
76.5,
55.6,
57.7,
39.3,
44.2,
60.4,
33.2,
12.4,
72.1,
17.4,
16.8,
50.8,
24.7,
63.8,
3.3,
44.9,
78.5,
53.1,
59.4,
44,
55.4,
41.6,
69.9,
80.3,
41.7,
29.8,
0.6,
51.1,
90.3,
39,
90.5,
23.8,
69.3,
52.3,
85.6,
53.9,
68.5,
69.9,
77.7,
69.6,
53.4,
46.4,
40.3,
89.4,
49.8,
82.6,
18.4,
29.3,
56.2,
98.7,
16.6,
36.8,
58.8,
72.2,
64.3,
40,
70.6,
50.3,
96.8,
51.7,
17.3,
11.6,
40.4,
57.8,
61.4,
86.3,
70.5,
25.4,
55.9,
92,
14.2,
39.9,
49.9,
96.5,
12.9,
27,
63.8,
87.5,
78.6,
72.2,
25.2,
40.8,
37.2,
68.2,
31.9,
93.6,
53.4,
86.1,
57.5,
37.4,
51.5,
66,
69.8,
65.9,
83.2,
94.3,
51.8,
43.2,
93,
44.9,
43.8,
57.5,
59.4,
27.8,
59.6,
65,
62.7,
56.5,
42.8,
24.3,
77.4,
74.6,
67.5,
22.4,
58.1,
66.8,
43,
84.2,
39.8,
85.4,
56.5,
26.6,
71.5,
28.7,
62.9,
53.4,
63.4,
10,
50.2,
48.2,
80.5,
62.7,
35.1,
58.9,
19.3,
19.4,
40.4,
43.3,
31,
24,
13.5,
48.4,
27.3,
89.8,
59.8,
44.7,
81.1,
67.2,
64,
23.2,
28.2,
3.1,
48.4,
62.5,
90.3,
84.6,
45.2,
50.2,
31.1,
35.6,
42,
12.2,
72.2,
88.6,
63.4,
47.9,
55.8,
66.1,
49.3,
35.3,
58.8,
19.2,
74.6,
14.9,
95.6,
6,
5.2,
82.9,
75.8,
63.4,
38.4,
87.2,
28.8,
53.8,
82.8,
98.1,
80.9,
34.7,
53,
52.9,
25.9,
17.2,
39.7,
6.5,
86.4,
52.6,
55.7,
99,
59.9,
22.3,
57,
37.3,
58,
76.2,
61.3,
100.2,
71.2,
81.9,
80.8,
39.2,
21,
32.9,
71.2,
7,
45.9,
47.8,
54.7,
26.3,
41.5,
31.3,
49.3,
26.9,
38.3,
45.5,
52.6,
95.5,
15.1,
72.4,
60.8,
75.8,
52.8,
59.5,
97.7,
33.7,
74.9,
40.7,
14.1,
32,
91.5,
66.4,
5.2,
44.2,
71.8,
46.2,
5.3,
69.3,
62.1,
58.6,
53.9,
80,
87,
12.1,
72.2,
72.7,
50.9,
68.4,
57.7,
64.9,
76.2,
10.5,
71.7,
71.2,
65.1,
40,
73.1,
20.6,
99.2,
64.4,
94.9,
25.5,
38.1,
50.1,
56.6,
64.5,
47.4,
67.6,
11.4,
63.4,
97.3,
44.1,
55.3,
56,
52.5,
30.4,
13.9,
66,
74.8,
63.7,
68.2,
76,
29.6,
25.6,
85.3,
0,
94.2,
33.9,
59.5,
15.5,
70.5,
62.8,
22.6,
56.3,
88.7,
64.8,
78.5,
75.7,
24.1,
41.6,
69.7,
19.7,
29.1,
63.2,
10.5,
47.8,
51,
6.8,
32.6,
33.8,
41.1,
49.4,
60.7,
75.9,
28,
2.6,
14.3,
58.1,
52.1,
38.3,
36.8,
30.8,
33.6,
69.1,
62.8,
98.7,
72.8,
0,
92.9,
49.4,
38.1,
50.9,
62.7,
45,
83.6,
16.7,
38.2,
75.4,
42.7,
75.1,
35.6,
75.2,
31,
28.5,
75,
29,
41.7,
77.5,
54.1,
47.7,
26.4,
44.1,
76,
50.2,
42.7,
72.3,
95.2,
9.7,
10,
27.6,
7.5,
51,
64.9,
83.4,
62.9,
17.2,
76.7,
72.7,
80.3,
56.8,
83.9,
44.6,
10.4,
82.2,
27.3,
98.5,
27.1,
65.9,
87.6,
84,
31.5,
35.9,
54.8,
55.3,
83.9,
55.3,
60,
86.3,
47.9,
36.1,
64.4,
31.5,
61.6,
69.5,
65.3,
39.3,
35.8,
53.8,
43.8,
45.3,
43.7,
57.5,
29.3,
29.5,
93.8,
51.5,
71.5,
45.5,
93.3,
52.4,
34.1,
51.6,
68.4,
87,
39.2,
86.5,
71.7,
26.8,
72.8,
55.3,
83.7,
83.7,
50.7,
20.5,
92.8,
36.7,
45.1,
43.7,
34.6,
57.5,
81.5,
81.2,
81.5,
48.6,
21.4,
55.3,
18.1,
83.5,
45.6,
47.2,
96.5,
14.9,
0,
45,
52,
81.2,
21.4,
75.1,
65.6,
43.8,
68.2,
6.7,
73.2,
43.2,
80.3,
57.9,
72,
42.4,
91.4,
45.3,
33.8,
87.7,
87.1,
78,
41.6,
36.4,
60,
87.9,
80.2,
33.1,
42.5,
45.4,
60.8,
44,
97.3,
60.7,
44.6,
76.9,
55.2,
73.9,
48.7,
32.1,
69,
47.6,
36.4,
56.1,
17,
68.6,
58.1,
69.9,
64.3,
29.1,
64.3,
48.1,
74.2,
8.3,
9.4,
59.5,
30.8,
32.3,
40.8,
51.7,
83.6,
19.9,
48.6,
40.8,
12.8,
40.2,
53.5,
63.3,
51.7,
32.2,
43.7,
56.1,
63.4,
84.1,
29.8,
77.5,
30.3,
52.8,
75.1,
32.1,
90,
52,
83.4,
69.5,
60,
7.2,
96.6,
51.2,
58.9,
52.6,
17.6,
81,
1.9,
10.4,
6.8,
60.8,
53.8,
55,
58.5,
37.4,
73.5,
39.5,
28,
83.3,
1.3,
66.7,
63.5,
65.6,
89.3,
84.2,
37.7,
83.9,
20.8,
61.4,
47,
65.1,
76.5,
34,
63.2,
27.1,
32.3,
55.9,
37.8,
73.2,
91.2,
80.9,
43.5,
16.2,
47,
71.8,
69.1,
33.5,
82,
48.7,
61.1,
86.7,
61.4,
16.5,
61.5,
57.8,
31.5,
49.8,
67,
78.3,
80.4,
17.5,
50.8,
57.1,
50.6,
35.9,
51.1,
53.1,
63.9,
50.5,
53.6,
71.4,
54.5,
97.4,
41,
55.9,
91.5,
67.9,
44.9,
16.1,
76.9,
94,
61,
41.7,
85.4,
48,
53.4,
61.4,
19.7,
14.2,
91.1,
95,
58,
68.3,
18.7,
38.7,
61.4,
40,
54,
90,
47.4,
70.2,
56.7,
74.9,
38.4,
51.8,
null,
42.5,
76.5,
79.6,
69.3,
83,
58.4,
31.7,
44.8,
64,
46.5,
62.2,
52.1,
77.2,
48,
56.8,
47.3,
34.9,
57,
35.1,
74.5,
57.1,
25.8,
79.6,
52.4,
70.4,
59.9,
61.2,
79.2,
89.5,
69,
65.2,
73.8,
33.2,
63.2,
93,
45.8,
63.2,
83.6,
67.7,
68.8,
38,
3.2,
36,
91.1,
94.4,
58.5,
72.4,
70.5,
55,
54,
82.6,
17.5,
21.5,
46,
38.8,
57.1,
2.8,
43.8,
41.3,
38.1,
62.9,
74.3,
65.8,
57.8,
16.1,
70.9,
42,
61.1,
85.4,
83.7,
90.1,
70.6,
30.2,
70.4,
96.2,
43.1,
48.9,
58.9,
21.4,
91.3,
58.4,
7.3,
88.7,
79.7,
78,
56.9,
54.6,
57.8,
83.5,
96.2,
81.7,
44.9,
55.9,
47.5,
29.3,
55.5,
63.5,
29.3,
18.6,
38.5,
13.2,
32.1,
39.5,
57,
79.3,
33.7,
81.8,
29.5,
55.2,
66.8,
1,
26.6,
39.4,
77.5,
22.4,
27,
35.7,
29.1,
74.4,
27.4,
54.9,
83,
63,
52.4,
58,
55.7,
36,
0.4,
75.8,
57.4,
83.2,
50.1,
73.6,
51,
73.1,
47.1,
51.6,
74,
57,
66.8,
91.3,
71.8,
94.4,
26.8,
64.6,
97.2,
64.5,
98.2,
68.6,
71,
53.3,
53.3,
56.2,
77.4,
91.6,
62,
46.1,
75.6,
84.9,
48.7,
36.4,
71.1,
90.8,
74.1,
50.6,
26,
40.1,
17.8,
50.5,
64.7,
81.8,
6.5,
28.1,
69.4,
65.5,
12,
54.6,
55.3,
86.5,
96,
38.4,
46.8,
24.9,
31.6,
67.4,
63.4,
62.8,
44,
66,
24,
51.9,
96.2,
47.3,
77.3,
83.1,
70.4,
36.8,
98,
26.4,
74,
94.6,
64.6,
31.5,
30.8,
73.3,
71.1,
96.8,
94.5,
62.7,
78,
42.5,
43.3,
85.5,
14.1,
42.8,
32.5,
56.2,
66.6,
47.1,
33.9,
85.8,
36.1,
53.7,
39.1,
23.1,
55.6,
73.8,
78.4,
42.8,
44.7,
22,
46.3,
81,
72.1,
32.3,
75.4,
84.3,
68.1,
31.1,
69.2,
65.4,
40,
23.5,
38.5,
40.7,
57.9,
78.5,
60,
69.1,
11.2,
48,
52,
80.1,
38.8,
32.4,
26.7,
33.9,
93.1,
21.9,
66.8,
30.9,
81.9,
25.9,
39.5,
14,
65,
24.9,
58,
83.2,
85.3,
60,
18,
19.7,
68.1,
16.7,
56.8,
78.2,
44.5,
30,
80.1,
89.7,
47.8,
0,
62.3,
51.6,
84.5,
52.4,
63.1,
19.5,
66.2,
22.5,
77.1,
12.8,
81.3,
47.7,
69.4,
51.4,
13.4,
72.2,
35.8,
91.6,
73.1,
49.3,
70.4,
1.5,
37.6,
72.8,
94.7,
60.2,
68,
44.2,
52.4,
75.3,
52.1,
76.2,
6.4,
31.1,
11.1,
93.3,
71.7,
51.4,
27,
27.6,
96.6,
53.5,
39.4,
55.6,
94.1,
87.6,
21.9,
39.9,
94.5,
97,
65.9,
70.2,
72.5,
76.7,
22.3,
55.4,
23.6,
29.6,
96.1,
64.5,
0,
39,
63.3,
78.2,
83.2,
100.3,
17.6,
50.8,
80.4,
61.7,
42.5,
47.1,
58,
41.5,
65.5,
71.7,
51.9,
56.9,
69.6,
45.4,
44.7,
91.5,
29.3,
40.6,
56,
40,
19.2,
94.2,
60.1,
65.2,
61.6,
81.6,
57,
24.2,
62.2,
48.1,
48.9,
70.1,
34.6,
45,
0.1,
40.9,
45,
26.4,
57.4,
66.6,
61.1,
93.1,
40.4,
13.4,
62.2,
28.3,
68.1,
41.4,
73.6,
75.2,
90.2,
89.1,
19.5,
75.2,
55.8,
51.3,
61.3,
81.8,
51.3,
83.6,
31.5,
54.8,
33.1,
38.1,
94.5,
64.3,
79.4,
74.7,
62.5,
76.9,
58.1,
76.4,
69.5,
60.1,
74.9,
67.9,
22.7,
0,
53.9,
94.9,
86,
96,
80.5,
65.5,
81.8,
43.2,
32.2,
88.5,
44.7,
77.9,
25,
66.8,
29,
75.8,
70.4,
4.5,
64.6,
93.9,
67,
84.2,
45.8,
54.4,
33.2,
18.7,
35.3,
25.2,
43.3,
87,
75,
60.8,
40.2,
63.1,
34.8,
47.7,
3.6,
45.9,
52,
13.5,
75.3,
33.2,
43.4,
58.7,
51.1,
71.4,
63.7,
63.6,
59.6,
58.5,
43.1,
70.6,
79.6,
2,
43.9,
9.1,
80.6,
45.9,
84.9,
87.6,
61.9,
59.2,
61.2,
54.2,
48.6,
91.7,
71.9,
46.7,
94.2,
82.8,
64,
93.2,
95.8,
36.9,
53.6,
59.7,
75,
76.3,
65.7,
96,
95.6,
55.2,
27.8,
24.6,
39.4,
34.5,
52.8,
14.3,
76.9,
73.9,
60.2,
47.8,
55.3,
61.9,
43.8,
56.7,
64.9,
63.6,
61.4,
54.3,
101,
44.6,
39.3,
56.4,
2.3,
62.5,
11.5,
44.4,
79.7,
77.3,
92.4,
57.9,
70.8,
44.8,
39,
11.6,
63.4,
61,
70.6,
59.1,
65.6,
92.3,
54.7,
9.9,
40,
43,
51.1,
83.4,
60,
36.4,
89.6,
59.1,
66.8,
33.2,
17.5,
27.5,
34.8,
35.6,
80.6,
78.4,
36.2,
63.9,
16.4,
31.3,
40.1,
53.3,
48.4,
76.3,
62.8,
88.8,
33.7,
81.5,
67.5,
89.3,
60.4,
50.1,
22.2,
80.1,
55.6,
69.5,
88.7,
67.7,
69,
56.1,
66.8,
65,
7.8,
51.9,
20,
96.6,
39.9,
69.8,
52.7,
96.8,
2.2,
68,
93.1,
35.5,
80.7,
8.3,
51.9,
89.3,
60.6,
48.5,
52.8,
33.1,
28.3,
64,
75.2,
48.5,
71.3,
36,
99,
44.6,
27.6,
86.7,
78.2,
5.5,
76.3,
2.2,
98.2,
31,
65,
65.4,
96.4,
66.3,
43.4,
9.2,
78.3,
67.1,
43.8,
62.6,
87.3,
52.1,
84.6,
58,
80.1,
83.6,
39,
62.1,
42.8,
69.1,
72,
66.5,
55.5,
43.7,
42.9,
72.5,
23.9,
36,
50.7,
0.4,
82.2,
73.9,
14.2,
95.3,
50.8,
59,
66.5,
54.1,
72.4,
66.8,
72.4,
55.3,
45.4,
36.5,
45.7,
86.5,
90.8,
36.5,
36.3,
75,
62.9,
68.5,
90.1,
57.6,
69.6,
72.3,
37.4,
66.1,
57.3,
82.2,
9.3,
70.8,
31.6,
53.4,
59.8,
13.2,
61.7,
71.2,
77.9,
57.3,
55.7,
91.2,
22.4,
52.1,
57.3,
70.2,
60.4,
66.1,
60.2,
63.7,
69.1,
48,
42.3,
15.5,
66.9,
60.1,
81,
43.9,
33.4,
15.5,
80.2,
53.6,
87.3,
54,
90.6,
31,
8.4,
36.2,
36.2,
32.8,
15.3,
28.4,
31.4,
52.6,
78.3,
71.5,
94.1,
45.9,
11.8,
58.1,
59.5,
90.9,
67,
37,
85.2,
68.8,
81.4,
27.4,
17.4,
85.7,
61.2,
89.5,
22.2,
22.9,
89.7,
69.3,
54.7,
96.5,
13.9,
46.9,
66.6,
63.3,
46.5,
11.4,
90.1,
44.5,
32.4,
76.6,
58.4,
47.1,
60.3,
69.9,
83.5,
70.7,
41.4,
78,
59.9,
87.4,
84.2,
11,
64.7,
102.1,
20.2,
73.3,
70.7,
29.6,
37.2,
47.8,
19.5,
64.1,
57.8,
72.8,
88,
28.5,
78.2,
28.6,
74.3,
22.7,
0,
59.1,
12,
54.7,
89.5,
67.7,
20.2,
53,
43.5,
27.2,
54.1,
64,
60.9,
65.6,
43.3,
45.6,
43.8,
77,
21.8,
35.2,
49.9,
29.1,
51,
1.2,
51.5,
22.1,
56.6,
49.6,
41,
60.5,
15,
76.6,
24.7,
38.5,
31.6,
85.7,
81.1,
82.4,
15.5,
89.5,
26.5,
81.2,
25.6,
18.4,
85.7,
80,
75.4,
64.9,
95.5,
34.3,
46.2,
19.4,
80.7,
47.4,
38.9,
53.4,
73.7,
69.8,
24.9,
76.8,
93.5,
70.7,
4.1,
54,
28.7,
12.3,
48.2,
80.3,
80.2,
12.8,
45.5,
14.3,
17.1,
72.4,
40.5,
20.8,
60,
71.2,
50.7,
63.8,
61.9,
47.3,
57.5,
19.9,
80.6,
78,
16.7,
43.8,
96.2,
91.5,
83.8,
89.8,
65.5,
26.8,
76.2,
68.6,
7.4,
50,
88.1,
80.2,
77.4,
28.6,
81.9,
55,
48.9,
44.3,
27.9,
50.9,
33.2,
51.1,
60.1,
22.1,
17.5,
36.6,
4.2,
79.6,
15.5,
15.1,
54,
54.5,
59.9,
5.5,
53.2,
49.2,
57.3,
37.1,
50.7,
83.5,
28,
19.2,
31,
44,
78.4,
67,
0,
72.4,
62,
74.5,
68,
36.2,
60.5,
25.5,
1.5,
75.2,
54.1,
52,
59.4,
79.5,
35.2,
50.8,
26,
90.3,
80.1,
71.7,
47.6,
34,
48.1,
61.6,
22.7,
49.6,
55.8,
32.2,
24.8,
23,
61.1,
63.4,
84.6,
67.2,
41.6,
63.7,
83.7,
69.5,
56.1,
17.8,
66.9,
46.9,
66.3,
76.6,
40.5,
82,
90,
42.5,
63.8,
59,
85.3,
81.7,
99.1,
9.1,
60.9,
61.7,
55.2,
61.1,
72.6,
9.2,
32.5,
39.8,
72.4,
28.8,
54.7,
66.4,
51.8,
30.9,
75.1,
70,
78.9,
80.1,
71.4,
87.2,
44.5,
48.7,
46.9,
85.5,
90.4,
90.7,
82.2,
65.1,
55.5,
38.1,
47.9,
56.4,
47.7,
47.3,
49.7,
83.2,
77,
61,
59.5,
50.6,
3.4,
22.8,
41.2,
27.5,
93.2,
78.5,
46.9,
41.8,
38.9,
16.5,
43.9,
34.6,
76.7,
0,
68.1,
71.1,
61.6,
78.6,
77.5,
47,
64.7,
56.1,
73.5,
71.3,
68.3,
53,
6.6,
42.5,
47.5,
75.9,
10.3,
74.3,
36,
19.3,
70,
59.4,
94,
36.5,
94.6,
32.4,
55.1,
7.8,
96.1,
12.8,
61,
41.6,
62.4,
69,
47.2,
57.2,
45.4,
73.5,
79.1,
66.8,
81.2,
25.9,
52.7,
55.7,
49.9,
55,
81.9,
84.5,
80,
99.2,
11.8,
34.3,
58.2,
42,
56.5,
26,
68.8,
59.4,
77.3,
54.7,
47,
81.9,
29.6,
61.5,
27,
23.6,
28.2,
69.3,
29.9,
41.2,
50.4,
38.8,
86.8,
21.1,
27.2,
83.8,
76,
96,
31.7,
59.3,
43,
57.6,
83.4,
72.7,
49.5,
100.3,
89.6,
53.3,
18.8,
9.5,
54.9,
22.8,
50.8,
43.4,
88.1,
88,
70.9,
99.5,
80,
76.3,
66.6,
66.7,
41.8,
46.6,
94,
40.2,
49.3,
25.1,
31.5,
36,
22.1,
94.8,
64.9,
35.7,
56.5,
95.4,
58.3,
89.2,
51.4,
37.5,
94.1,
40.5,
21.4,
7.9,
39.1,
8.4,
3.4,
20.7,
76.9,
42.4,
64.6,
63.6,
82.4,
59,
33,
16.7,
31.6,
78,
40.2,
48.3,
76.3,
28.8,
49,
78.6,
47.8,
70,
89.2,
68,
95.6,
62,
80.4,
39.2,
50.3,
38,
67.2,
46,
88.5,
28.9,
37,
26.5,
63.6,
46,
8.3,
87.8,
21.4,
41.2,
35.6,
42.7,
76.8,
59.6,
26.9,
32.1,
32.9,
58.8,
47.5,
30.9,
45.3,
33,
49,
33.5,
67.5,
56.1,
92.6,
12,
9.5,
71.6,
28.2,
24.1,
50.9,
89.3,
58.4,
22.3,
85.4,
5.1,
40.3,
49.3,
39.5,
68.9,
42.8,
71.1,
52.7,
78.5,
60.9,
49.6,
19.4,
82.6,
78.7,
78.6,
8.6,
47.5,
34.6,
41.6,
20,
85.4,
84.3,
63,
67.9,
25.6,
84.3,
26.3,
49,
56.7,
30.8,
76,
57,
64.6,
86.2,
42.3,
17.6,
57.3,
39.9,
46.4,
83.5,
55.6,
11.4,
73.6,
52.8,
29,
34.3,
20.1,
11,
29.3,
48.4,
72,
13.1,
74.4,
65,
20.5,
50.2,
82.5,
3,
51.3,
69,
78.9,
74.5,
39.5,
51.9,
68.1,
91.6,
33.8,
67.6,
31.6,
60.9,
30.2,
78.4,
96.3,
19.2,
6.1,
75.6,
38.5,
83.4,
39.7,
72.9,
90.1,
75.5,
56.5,
48.1,
70.4,
53.7,
59,
70,
33.4,
71.4,
76.8,
61.9,
16.2,
82,
99,
85.2,
28,
17.5,
45.9,
67.7,
13.5,
63.1,
65.3,
67.5,
62.3,
70.7,
58.6,
18.8,
77,
76.8,
35,
48.2,
25.8,
24,
64.1,
38.6,
19.6,
24.3,
58.4,
64.7,
22,
40.6,
0,
95.5,
51.8,
52.6,
55.6,
7.7,
30,
65.3,
92,
92.9,
77,
66.5,
54.8,
15.3,
56.2,
72.1,
60.8,
71.2,
0.7,
20.6,
89.9,
67.9,
94.1,
52.4,
53.4,
82.8,
72.7,
98.1,
36.5,
21,
27.1,
54.9,
58.5,
62.9,
69,
75.5,
70.3,
6.9,
68.1,
83.6,
58.5,
73.1,
36,
70.7,
48.5,
27.6,
42.8,
37.7,
37.9,
81.4,
19.9,
6.5,
50.3,
56.9,
84.8,
19.6,
46,
72.9,
80.3,
35.5,
64.2,
87.4,
83.3,
76.2,
72.6,
89.9,
57,
72.1,
84.6,
68,
80.2,
48.3,
67.3,
26.8,
44.8,
71.5,
65.3,
18.9,
67.2,
54.6,
4.3,
46.6,
75.9,
91.7,
58.5,
61.5,
58.3,
21.2,
38.7,
22.6,
61.3,
71.9,
48,
28.4,
58.9,
65.3,
79.1,
36.2,
34.8,
49.6,
39,
17.7,
42.2,
70.9,
22.2,
69.3,
70.5,
69.2,
35.7,
48.9,
53.4,
55.8,
36.8,
40.5,
74.8,
62,
18.2,
72.7,
70.1,
80.9,
17.5,
63.6,
19.5,
102,
47.2,
53.9,
79.8,
50.2,
21.7,
24.1,
46.7,
24.8,
92.5,
0.7,
62.9,
8.3,
11.4,
22,
55.7,
75.7,
26.2,
86.3,
60,
53.2,
63.2,
91,
25.3,
36.7,
71.9,
47,
21.8,
54.9,
84.8,
94.2,
90.7,
56.1,
52.4,
31.2,
56.1,
9.2,
45,
7.5,
50.6,
47.2,
61.3,
74.7,
9.2,
97.5,
65.4,
31.1,
84.9,
69.6,
97.1,
21,
87.8,
48,
75,
69.5,
0,
95.6,
92.6,
14.5,
57,
89.9,
63.8,
31.3,
93.7,
67.6,
16.7,
43.2,
46.7,
79.7,
63.4,
29.4,
89.7,
55,
29.3,
44.7,
28.5,
47,
25,
66.3,
89.1,
98.5,
87.1,
69,
10.7,
58.9,
58.5,
25.9,
13.2,
29.6,
29.7,
76.1,
7.7,
90.9,
39,
69.5,
39.9,
28.9,
27.4,
93.5,
63.9,
31.5,
68.6,
80.7,
45,
50.1,
76.4,
28.5,
83.6,
61,
28.8,
67.8,
21.9,
0,
74.4,
46.2,
57.8,
22.9,
18.9,
54.3,
64.9,
62.9,
63.2,
19.9,
89,
48.4,
53,
70.2,
88.4,
21.4,
20,
70.8,
71,
91.3,
17.4,
68.3,
16.7,
48.2,
72.5,
90.5,
55.8,
83.8,
53,
36.2,
56.9,
86,
67.9,
70.5,
27.3,
48.3,
80.2,
57.7,
40.3,
46.4,
63.9,
9.4,
93.3,
82.7,
80.2,
46,
70,
49.8,
57.2,
19.3,
82.3,
83,
78.7,
30.1,
63.2,
58.9,
45.6,
30,
69.9,
31.5,
54,
33.2,
91.3,
78.1,
44.1,
74.6,
6.5,
33.2,
54.3,
75.7,
28,
73,
70.7,
97.9,
83.1,
11.1,
31.7,
61.9,
53.9,
59.5,
95.4,
38,
51.6,
86.5,
83.3,
8.4,
37.4,
50.9,
35.1,
54.8,
67.2,
60.8,
91,
82.4,
27.7,
54.1,
69.7,
41.4,
58.8,
39.2,
41.4,
42.4,
90.7,
82.7,
74.4,
52.3,
45.2,
55.7,
0.4,
67.9,
48,
51.4,
37.7,
46.3,
12,
31.9,
32.1,
33.9,
54.3,
76,
39.5,
49.8,
76.8,
67.9,
76.2,
65.3,
20.3,
72.7,
77.6,
36.9,
88.3,
84.8,
33.8,
47.3,
47.6,
35.2,
40.1,
61.6,
34.7,
24.5,
40.4,
76.6,
22.1,
61.7,
62.1,
95.5,
43.4,
60.3,
90.7,
75,
27.8,
34.4,
27.7,
98.1,
96.2,
66.8,
86,
50.9,
61.9,
63.7,
79.8,
39,
23.4,
82.1,
41.6,
48.8,
53.8,
25.3,
31.5,
33.2,
52.9,
44.6,
78,
48.2,
59.8,
50.1,
67.6,
36.5,
54.3,
12.4,
47.8,
76.6,
56,
34.3,
44.9,
32.9,
70.5,
54.6,
79.9,
20.1,
21.5,
72.5,
86.1,
90.3,
73.8,
26.6,
25.9,
41.5,
62.3,
73.4,
19.9,
27,
51.6,
60,
47.1,
61.7,
57.1,
62.8,
28.9,
52.4,
60.6,
48.9,
47,
13.7,
93.1,
77.6,
18,
78.6,
54.9,
61.9,
43.1,
65.1,
51.3,
73.1,
55,
50,
65.5,
27,
88.6,
36.2,
99.1,
47.6,
89.3,
34.8,
72.1,
32,
66.6,
64.2,
87.5,
75.3,
70.5,
42.2,
75.9,
33.6,
58.5,
30.6,
86,
48.2,
40.5,
51.6,
29.2,
94.5,
35.8,
98.5,
43.5,
81.4,
71.4,
64.6,
63.6,
51.7,
28.6,
97,
80.8,
46.6,
39,
26.7,
52.2,
76.9,
42.3,
71.4,
30.2,
15.8,
27.9,
41.1,
25,
54.3,
48.9,
30.5,
71.8,
79,
83.3,
66.2,
24.5,
38.6,
35.2,
67.8,
30.2,
45.6,
58,
79.3,
15.8,
45.6,
85.8,
31,
1.9,
55.8,
79.8,
42.6,
57.9,
58.4,
32.6,
56,
71.4,
75.5,
75.6,
63.1,
36.9,
91,
46.2,
61.5,
32.3,
88.8,
71.8,
37.4,
83.4,
90.5,
34.6,
32.9,
69.2,
81.6,
16.9,
13.9,
50.3,
24.1,
96.4,
57.8,
25,
83.3,
74.3,
1.7,
48.1,
58.8,
71.3,
61,
83.6,
55.6,
25.2,
83.9,
33.2,
27.5,
28.8,
31.1,
46.5,
43,
89.6,
36.3,
25.8,
96.4,
77.6,
51.1,
48,
46.3,
4,
88.9,
50.1,
39,
22.2,
81.5,
39,
53.4,
62.6,
90.7,
39.8,
33.9,
20.9,
84.8,
40.4,
60.1,
59,
98.8,
75,
59,
52.5,
45.5,
63.1,
35.1,
85.4,
54.4,
13.6,
72.5,
87.5,
64.9,
84.5,
41.9,
27.8,
23,
77.3,
91.1,
70.9,
68.1,
12.6,
37.4,
98.8,
55.3,
90,
23.5,
69.9,
28.9,
21.1,
64.2,
16.8,
97.8,
28.9,
77.9,
43.7,
24.9,
46.4,
74.6,
77,
69.7,
99.5,
68.6,
61.1,
67.2,
71.1,
58.2,
38.9,
101.2,
68.4,
33.8,
6.7,
52.6,
40.5,
50.7,
77.9,
80.9,
67.8,
48.8,
56.6,
95,
56.6,
76,
45.6,
45.3,
94.4,
60,
40.9,
15,
84.5,
38,
83.3,
81.2,
83.3,
27,
26,
17.9,
48.8,
90.8,
72.9,
50.8,
22,
71.2,
49,
71.8,
19.8,
65.1,
53.1,
19.9,
74.2,
38.3,
61,
53.2,
93.6,
53.7,
87.7,
54.5,
47.7,
64.7,
27.9,
83.7,
51.6,
64.4,
58.6,
44.1,
47,
8.9,
69.8,
49.3,
56.9,
52.4,
57.7,
60.2,
28.8,
25.1,
63.8,
59.7,
69.8,
45.8,
86.9,
10.5,
36,
48.1,
63.3,
93.9,
104.7,
62.8,
32.9,
21,
59,
93.8,
65.5,
70.6,
60.5,
27.4,
75.9,
65.3,
55.7,
84.1,
72.1,
78.8,
70.8,
48.3,
16.5,
50.9,
48,
63,
80,
93.8,
98.7,
28.8,
40.9,
49.6,
34.9,
27.4,
38.2,
52,
33.5,
38.4,
55.2,
16.8,
70.5,
33.4,
48.7,
41.2,
60.4,
35.7,
31.3,
65.7,
28.8,
7.7,
42.2,
28.2,
34,
34.7,
10.7,
52.7,
87.7,
19.9,
55.3,
74.6,
18.3,
2.3,
23.4,
44.8,
92.4,
70.6,
46.5,
87.9,
0,
33.8,
70,
91.5,
46.1,
0.1,
59.8,
36.8,
75,
80.7,
39.6,
58.8,
16.8,
26,
0,
57.5,
73.8,
60.6,
72.2,
3.8,
59.9,
85,
98.7,
39.1,
44.9,
68.8,
33.7,
83.9,
59.7,
64.7,
49.9,
83.5,
38.5,
46.5,
25.7,
26.5,
50.3,
32.5,
29.9,
66,
83,
45.9,
73.6,
44.8,
48.8,
85,
99.2,
40.6,
33.2,
57.7,
36.5,
77,
57.3,
50.2,
48.4,
99,
86.8,
103.7,
61.5,
45.7,
81.4,
65.1,
36.5,
38.2,
84.9,
35,
84.3,
30.4,
38.7,
49.5,
43.1,
84.5,
89.7,
47,
76.6,
33.4,
29.7,
65.3,
94.6,
94.8,
91.7,
44.9,
57.6,
53.3,
64.9,
61.6,
66.1,
56.9,
27.3,
35,
91.5,
29.4,
50.2,
22.3,
90.1,
48.1,
86.7,
44.4,
74.5,
88,
26.2,
42.4,
42.7,
60.4,
67.7,
63.6,
49.1,
72.7,
94.3,
59.3,
20.6,
67.7,
74.3,
73.9,
37.5,
33.4,
62,
73.3,
77.8,
74.5,
66.7,
18.1,
38,
57.3,
56.1,
27.4,
74.2,
58,
44.4,
9.4,
98.5,
97.5,
88.1,
16.8,
26.3,
90.6,
42.2,
81.1,
80,
61.6,
81.9,
76,
62.1,
57.9,
59.2,
24.3,
49.4,
48.1,
78.4,
67.8,
84,
86.5,
6.1,
53.7,
50.3,
51.4,
46.8,
43.5,
59.4,
86.3,
46.6,
7.5,
47.2,
39.7,
51.9,
61.5,
1.6,
46.9,
60.4,
88.4,
66,
5.7,
53.8,
28.5,
12.8,
88.8,
57.2,
55.3,
37,
31,
5.4,
31.5,
52.4,
100.5,
79.8,
47.1,
84.1,
62.2,
64.1,
88.2,
94.3,
61.6,
37.3,
53.1,
60,
36.5,
96.3,
45.8,
93.8,
8.7,
33.6,
54.3,
10.1,
46,
29.6,
84.3,
49.5,
69.9,
66.3,
77.2,
8.3,
56.7,
70.8,
0,
31.1,
80.8,
20.2,
15,
72.4,
25.3,
77.8,
70.1,
59.5,
84.8,
65.8,
34.5,
97.3,
87.6,
53.1,
39.7,
71.1,
14.9,
91.1,
56.6,
75.8,
49.9,
67.1,
40.2,
79.8,
25.8,
41.9,
45.8,
55.9,
67.6,
62.7,
84.5,
28.6,
77.2,
35.7,
68.1,
64.6,
46.9,
72.8,
73.7,
35.4,
63.9,
89.7,
62.7,
55.6,
93.1,
75.5,
99,
57.8,
87.1,
86.4,
32.9,
30.2,
30.2,
59.1,
25,
85,
61.1,
47,
60.6,
48.9,
73.4,
96.9,
49.1,
90,
69,
41.3,
85.9,
80.9,
44.9,
72.3,
73.4,
37.6,
49.2,
53.9,
70.4,
38.8,
46.4,
69.4,
62,
38.8,
5.8,
85,
91,
69.8,
86.7,
86.5,
65.8,
52.3,
82.7,
33.1,
82.4,
32.5,
80.2,
92.7,
44.5,
52,
20.3,
33.4,
21.2,
54.3,
41,
45.4,
70.8,
70,
91.5,
57.9,
31.6,
41.6,
41,
30.4,
93.8,
53,
21.1,
0,
28.4,
61.4,
56,
50.1,
65.6,
45.4,
9.8,
24.6,
53.7,
93.5,
65.6,
0.5,
69,
80.3,
74.9,
76,
85.4,
32.9,
70.6,
38.9,
41.6,
30,
30.2,
67.8,
48,
78,
41.9,
53.7,
27.2,
58.3,
37,
24,
17.7,
47.4,
91.3,
74.7,
56.7,
58.7,
75.9,
31.2,
68.5,
68,
55.5,
63.5,
45.2,
43.7,
30.3,
72.4,
62.5,
46.2,
66.6,
24.2,
40.5,
86.2,
38.8,
42.4,
44.4,
64,
36.7,
84,
26.7,
23.8,
78,
27.9,
53.3,
51.3,
83.9,
84.5,
79.9,
70.9,
73.2,
82.6,
34,
34.2,
66.9,
47.3,
81.4,
72.6,
70.4,
49,
49.7,
18.1,
99.5,
50.7,
57.4,
84.6,
64.8,
8.4,
32.1,
70.3,
90.5,
42.6,
90.7,
77,
91.4,
64.4,
60.7,
57.9,
42.6,
90.2,
47.9,
53.5,
51.9,
76.3,
35,
77.7,
55.9,
62.6,
85.1,
71.9,
76.6,
81.9,
75.8,
2,
29.6,
23.4,
78.8,
36,
88,
51.6,
84,
87.2,
95.8,
23.3,
47.8,
43.5,
43.8,
33.3,
88.4,
43.6,
84.1,
47.9,
32.3,
74.2,
85.2,
80.6,
49.5,
17.8,
52.5,
18.9,
90.7,
23.6,
75.5,
25.4,
31.2,
56.7,
38.6,
93.9,
55,
44.6,
100.1,
53.9,
39.6,
10.8,
35.3,
84.5,
64.5,
93.7,
39.3,
9.4,
96.3,
56.5,
49.3,
39,
93.3,
56.6,
90.2,
50.2,
35.7,
57.5,
31.8,
2.3,
82.1,
81,
48,
79.4,
23.2,
66.6,
89.5,
48.9,
6.7,
55.6,
67.7,
51.4,
68.8,
47.8,
74.8,
45.3,
79.4,
62.2,
60,
64.6,
55.4,
53.7,
12.8,
34.3,
58.9,
7.9,
14,
38.5,
22.1,
0.2,
76.6,
58.9,
27.3,
73.4,
64.6,
95.3,
68.3,
26.7,
93.9,
72.7,
5.5,
64.4,
60.2,
12.3,
32.4,
4.6,
57.6,
55.2,
51.2,
45.7,
76.9,
63,
90.8,
37.4,
41.4,
61,
69,
29.4,
69.2,
41,
26.7,
57.9,
100.1,
78.8,
75.7,
26.9,
94.8,
27.2,
55.1,
62.6,
13.5,
53.7,
53.6,
47.6,
55.6,
79.6,
18.4,
32.8,
34.7,
21,
23,
65.9,
2.4,
44.2,
89.2,
58.6,
47.3,
4.2,
13.4,
16,
74.2,
94.7,
28.4,
31.6,
38.2,
96.4,
82,
71.4,
87.4,
71.8,
2.9,
58.2,
80.2,
38.6,
68.3,
29.2,
21.5,
8.3,
32.2,
52.6,
91.3,
52.8,
39.1,
91.4,
17.9,
2.3,
79.6,
58.6,
28.3,
28.9,
68.8,
44.1,
19.8,
14.1,
40.4,
40.4,
53.4,
42.4,
67.2,
68.5,
12.4,
51.6,
33.5,
93.1,
3.3,
64.5,
78.5,
27.9,
38.6,
51.3,
78.1,
60.7,
41.5,
43.1,
65.2,
31.7,
27.2,
44.2,
18.7,
69.2,
96.3,
53.1,
72,
85,
83.9,
36.8,
67.7,
40.6,
27.3,
30.3,
90.5,
20.3,
29.1,
34.7,
32.4,
64.2,
21.1,
66.2,
51,
30.7,
71.6,
81,
64,
57,
27,
95.7,
51.5,
42.2,
76.9,
28,
58.9,
58.7,
50,
26.6,
60.8,
62,
35.6,
63,
76.2,
86.5,
70.3,
48.8,
75.3,
63.8,
54.5,
84.3,
41.3,
36.1,
19.1,
65.9,
65.3,
84.1,
0.7,
42.5,
32.5,
46.4,
75.6,
89,
94.5,
65.8,
93.1,
50,
68.8,
33.8,
54.7,
41.9,
25.4,
44.9,
26.5,
50,
5.4,
39.9,
38.9,
97.1,
75,
79.6,
47.8,
72.7,
34.8,
98.6,
58.1,
102.2,
44.3,
59.9,
7.2,
49,
38.1,
34.2,
29.5,
58.4,
61.2,
37.5,
55,
18.6,
86.9,
39.4,
23.7,
99.7,
56.1,
76.8,
91.5,
45.8,
24,
65.2,
35.9,
76,
69,
64.2,
44.6,
59.6,
38.7,
91.7,
65.3,
56.1,
75.1,
40,
31.4,
78.2,
47.2,
64.8,
30.4,
61.1,
56.3,
58.8,
100.6,
85,
45.4,
76.6,
58.5,
21.4,
65.9,
62.1,
53.6,
50.9,
46.2,
75.9,
70.7,
98.5,
82,
50.6,
27.3,
45.8,
20.9,
43.7,
69.7,
41.2,
76.1,
48.2,
26.9,
56.8,
74,
94.6,
45.9,
82.3,
59,
44.7,
65.4,
31.2,
87.1,
48.1,
80.6,
95.3,
50.6,
27.6,
88.8,
37.8,
54.4,
18.4,
3.9,
56,
72,
70.2,
75.4,
84.8,
76.4,
61.3,
68.9,
54.6,
81.3,
99.2,
65.1,
78.6,
18,
61.5,
59.8,
10.4,
92.6,
81.2,
34.9,
90.5,
59.4,
30.8,
70.7,
68.6,
70.4,
97.3,
90.5,
25.9,
13.8,
36,
30.5,
64,
30.9,
38.5,
68.1,
40.7,
49.2,
0.8,
62.3,
47.9,
58.4,
54.3,
47.9,
44.7,
73.8,
74.9,
98,
50.5,
58.5,
72.5,
72.9,
96.4,
48,
48,
35.8,
34.1,
22,
52.7,
87.5,
37.1,
57.4,
80.2,
67.1,
6,
54.4,
76.1,
60.6,
58.1,
20.6,
82.4,
76.9,
62.2,
96.2,
83.5,
26.6,
66,
31.8,
29.7,
3.9,
85.9,
25.9,
69.5,
15.9,
55.7,
95,
30.2,
33.3,
72.2,
30.1,
57,
78.8,
78.9,
29.8,
61.8,
40,
78.4,
62.3,
37.8,
71.9,
93.6,
48.4,
63.9,
53.7,
17.8,
89.6,
40,
48.6,
42.9,
83.1,
70.4,
84.6,
18.3,
23.3,
30,
75.9,
84,
27.3,
77.3,
84.9,
7.8,
84,
51.9,
91.9,
45.3,
33.6,
53.9,
40.4,
41.3,
52.4,
2,
53.1,
77.2,
9.7,
87.2,
63.2,
91.6,
79.7,
62,
18.3,
49.9,
63.5,
42.4,
88.1,
50.2,
43.3,
43.3,
63.5,
42.3,
56.1,
55,
79.3,
47,
68.3,
73.5,
58.7,
86.4,
50.6,
32.7,
88.2,
86.8,
34.8,
50,
33.1,
76.2,
65.4,
44,
80.6,
70.6,
74.4,
61,
44.6,
52.8,
61.6,
38,
28,
72,
76.5,
80.1,
74.2,
81.7,
82.2,
6.8,
56.5,
35.7,
83.3,
41.8,
72.6,
37,
70.7,
46.4,
84.3,
66.5,
25.4,
12.4,
92.2,
65,
90.7,
17.2,
68,
74.4,
36.7,
97.1,
35.3,
6.3,
19.7,
38.6,
0,
69,
78,
67.9,
99.9,
36.6,
34.6,
45.5,
58,
48.1,
42.9,
48.7,
65.1,
80.9,
87.7,
75.1,
59.2,
44,
65.1,
15,
100.7,
81.4,
54.3,
17,
75.7,
46.4,
44.7,
31,
73.2,
62.9,
99.3,
80.2,
70.1,
56.4,
77.3,
58.1,
39.3,
52.7,
70.6,
38.3,
1,
93.6,
70.1,
30.6,
20,
66.4,
33.9,
36.9,
42.3,
69,
95.2,
62.7,
50.9,
66.1,
4,
35.4,
99.8,
62,
35.7,
57.2,
73.5,
95.4,
53.5,
24.3,
29.9,
25,
35.4,
86.8,
9.6,
64.8,
62.3,
59,
41.8,
62.5,
69.2,
51.5,
50,
96.8,
75.2,
86.6,
73.4,
24.9,
83,
13.9,
83.4,
57,
58.4,
42.4,
76.3,
68.2,
56.4,
70.8,
28.8,
51.7,
92.6,
63.2,
11.1,
44.2,
40.1,
49.6,
8.9,
10.4,
91.7,
4.3,
44.7,
72.5,
61.6,
59.6,
58.8,
50.7,
82.9,
72.6,
6,
29.3,
43.3,
49.5,
67.4,
26.1,
74.2,
100,
72.5,
93.9,
24.2,
81.5,
91,
64.7,
74.3,
61.9,
34,
60.4,
65,
57.1,
73,
48.5,
63.9,
67.6,
72.1,
54.4,
87.1,
33.1,
46,
70.6,
53.8,
63.1,
95.4,
85,
61.1,
49.8,
72.1,
53.1,
83.7,
96.3,
91,
65.4,
30,
51.8,
89.6,
39.9,
72.1,
97,
38.9,
41.9,
48.3,
58.1,
71.6,
35,
45.4,
27.6,
71.1,
37,
22.6,
65.5,
51,
53.4,
52.8,
75,
4.9,
25.2,
18.3,
87.3,
56.8,
73.8,
84.3,
76,
36.5,
25.3,
46.8,
28,
34.2,
73.2,
39.5,
81.9,
82.6,
69.8,
35.8,
71.3,
99.7,
21.3,
17.5,
67.9,
47.3,
34.6,
29.9,
84.3,
41.5,
64.4,
34.7,
37.5,
45.7,
64.1,
37.1,
7.1,
87.7,
56.5,
100,
69.7,
58.8,
73.1,
94.6,
86,
21.7,
56,
33.3,
49,
30.9,
47.3,
18.4,
19.9,
22.1,
66.7,
15.2,
53.6,
43.2,
50.6,
41.4,
63.5,
37.7,
56.8,
69,
22,
83.8,
24.4,
86.8,
83.3,
45.8,
19,
82.3,
58,
46.9,
80.9,
75.4,
50.3,
76.5,
66.5,
51.2,
47.6,
77.4,
95.1,
50.1,
57.8,
35.8,
71.4,
63,
48.5,
86,
52.7,
5.7,
65.1,
86.4,
55.2,
72.4,
89.7,
53.6,
41,
37.9,
63.7,
84.1,
87.4,
63.6,
64.1,
38.6,
77.6,
20.4,
35.6,
71,
71.9,
79.4,
69.9,
51.3,
67.5,
88.4,
13.7,
97.4,
67.1,
62.5,
76.6,
88.2,
74.5,
43.7,
29,
23.7,
44.4,
15.8,
90.6,
45.6,
46.7,
70.3,
69.9,
72.6,
82,
63.3,
20,
70.1,
33.1,
42.6,
69.9,
69.4,
49.1,
74.8,
47.6,
25.4,
69.8,
77.5,
60.3,
62.1,
68.3,
78.8,
89.8,
58.4,
11.2,
84.2,
96.1,
58.4,
60.4,
65.1,
66.3,
84,
20.4,
58.9,
61.5,
50.8,
76.1,
88.4,
65.3,
61.7,
41.4,
67.9,
55.1,
35,
29.8,
62.6,
15.1,
95.6,
77,
80.3,
42.5,
57.3,
69.4,
75.3,
74.1,
72.5,
22.2,
57.9,
21.5,
27.5,
9.1,
44.7,
93.6,
50.5,
52.8,
21.3,
67.7,
33.6,
65.5,
83.2,
65.6,
61.7,
47,
55,
61.8,
48,
25,
42.7,
9,
13.4,
24.2,
88.8,
62.5,
97,
61,
80.8,
34.8,
75.3,
56.6,
61.6,
59.9,
98.6,
75,
91.8,
68.7,
92.1,
59,
51.4,
72.3,
57.2,
36.2,
84.5,
67.8,
77.3,
62,
74.4,
91.9,
59.6,
77.2,
84,
65.2,
61.1,
80.5,
29.6,
48.8,
18.4,
47.2,
55.8,
64,
31.5,
93.6,
100.4,
46.3,
78.1,
41.6,
8.9,
40.1,
51.2,
92.4,
92.9,
51.1,
72.5,
22.7,
54.6,
61.4,
59.4,
21.1,
84.9,
81.8,
53.8,
73.5,
39,
35,
60.7,
44.4,
29.8,
48.2,
64.2,
34.5,
18,
23,
18.9,
50.4,
50,
49.8,
92.5,
55.9,
18.3,
62.8,
50.8,
36.9,
93.5,
78.9,
63.3,
51,
29.2,
69.6,
41.4,
35.1,
3.9,
36.3,
61,
38.5,
26.3,
52.7,
81.1,
68,
79.2,
80.5,
59.8,
76.8,
56.1,
8.7,
96.5,
94.3,
67,
63.9,
92.7,
78.1,
58.2,
43,
47,
82.2,
71.9,
40.1,
41,
19.8,
25.7,
74.2,
21.5,
60,
3.8,
61.8,
79.5,
62.8,
70.3,
26.1,
82.7,
59,
53.2,
72.2,
49.8,
57.5,
54.8,
21.4,
47.9,
66.3,
81.2,
95,
67.8,
58.7,
44.9,
53.4,
6.6,
42.3,
50.2,
26.6,
46.3,
36.9,
60.9,
80.2,
90.8,
75,
88.6,
43.6,
43.1,
61.2,
64.4,
87.7,
74.3,
45.8,
32.7,
49.1,
82.4,
87.2,
44.2,
19.1,
39.8,
92.3,
40.3,
20.5,
72.9,
97.6,
82.7,
35.9,
90.2,
33,
37.5,
59.8,
47.9,
34.7,
85.9,
40.3,
58.2,
26.4,
80.5,
81.1,
5.7,
58.9,
49.5,
47.4,
61.2,
22.4,
38.4,
99.9,
61.2,
90.6,
22.5,
79,
35.5,
45.7,
55.8,
80.5,
74.6,
20.6,
53.5,
17.9,
38,
5.2,
33.8,
23.9,
26.6,
90.6,
89.1,
91.9,
24.1,
64.4,
56.2,
92.5,
88.2,
55.4,
53.2,
77.3,
75.4,
24.2,
43.3,
46.5,
67.5,
67.9,
41.8,
90.4,
62.8,
21.6,
97.8,
28.8,
76.2,
82,
92.6,
87.2,
26.7,
64.3,
67,
33,
11.4,
88.8,
57.7,
74.4,
53.8,
25.6,
24.6,
79.1,
70.8,
95.7,
77.5,
22.2,
78.9,
55.7,
59.1,
75.3,
27.4,
36.3,
47.5,
45.6,
60.4,
85.6,
37.7,
67.4,
44.2,
32.1,
43.4,
65.5,
75.2,
49.6,
59.2,
48.8,
18.4,
41.8,
78.5,
9.3,
88.3,
56.1,
38.9,
94.2,
97,
66.7,
39.7,
92,
12.7,
73.6,
63.8,
72.2,
42.8,
59.2,
54.8,
45.8,
79.1,
37,
62.8,
51.8,
88.4,
51.1,
34.2,
59.8,
96,
59.9,
65.5,
44.9,
63.3,
69.6,
27.1,
69.1,
47,
61.6,
62.2,
1.5,
45.7,
50.8,
63.5,
36.8,
81.8,
35,
57.5,
70.6,
85.8,
25.7,
97,
42,
77.3,
17.8,
41.4,
64.5,
81.1,
84.9,
40.3,
88.1,
13.8,
89.3,
73.9,
47.4,
39.8,
66.5,
78.6,
63.6,
79.5,
91,
79,
22.5,
31,
85.6,
15.1,
32.4,
10.7,
17.3,
38.5,
25.8,
76,
90,
85.4,
25.5,
4.6,
46.2,
83.5,
71,
33.2,
59.9,
82.2,
83.7,
88.2,
36.7,
18.7,
35.9,
14.2,
64.4,
70.1,
51.1,
89,
59.8,
74,
91.5,
76.8,
86.3,
56.1,
74.8,
69.1,
80.3,
54.2,
68.5,
88.7,
57.3,
65.2,
70.1,
35.2,
71.5,
23.4,
90.6,
54.8,
26.1,
59.7,
20.9,
44,
67.2,
20.2,
51.2,
36.8,
60.9,
97.5,
61.4,
92.5,
19.9,
72.4,
51.9,
78,
34.6,
72.3,
78.9,
74.2,
51,
70.3,
78.9,
36.6,
61.6,
76.2,
84.5,
88,
24.4,
57.2,
47.5,
36.3,
31.8,
55,
49.6,
75.9,
10.4,
68.6,
35.4,
91.2,
88.6,
34.1,
90.3,
53.3,
61,
55,
58.5,
89.1,
13.8,
66.1,
2.8,
37,
17.9,
42.9,
71.7,
15.9,
0.1,
22.5,
42.6,
73.6,
54.1,
50,
90.1,
86.8,
45.2,
66.2,
84.4,
80.5,
84.9,
80.5,
42.6,
30,
54.1,
13.1,
66.3,
90.4,
72.3,
82.7,
72.7,
81.5,
77.6,
27.6,
77.7,
62.4,
52.6,
18.2,
80.3,
11.4,
98.1,
14.9,
69.7,
58.1,
27.8,
88.8,
4.6,
82.8,
35.4,
7.9,
59.1,
93.5,
62.9,
49.9,
71.7,
38.9,
55.9,
40.7,
72,
96.6,
95.9,
55.6,
53.2,
88.5,
42.3,
18.1,
74,
29.9,
96.3,
42.2,
39.6,
22.2,
62.3,
64.3,
49.9,
56,
66.8,
41.8,
40,
64.3,
53.5,
76.9,
69.4,
27.8,
34.3,
40.3,
90.1,
95.9,
35.8,
94.7,
99.4,
94.4,
66.2,
46.2,
55.9,
38.6,
48,
19.9,
97.9,
47.5,
86,
41.7,
58,
76.3,
81.4,
55.2,
56.4,
64.2,
46.3,
57.7,
59.2,
76.3,
64.7,
53,
56.8,
52,
51,
62.2,
83.3,
52,
63.1,
73.8,
69.6,
97.9,
74.1,
28.9,
39.5,
42.4,
72.7,
21.8,
83.1,
55,
59,
76.1,
47.6,
85.5,
65.9,
32.3,
6.8,
60.6,
67.3,
48.9,
84.6,
42.5,
58,
23.9,
93,
17.2,
70.2,
69.8,
70.6,
71.4,
17.9,
59,
33.8,
89.7,
70.9,
60.9,
62.2,
94.3,
79.6,
38.6,
68.3,
67.4,
53.2,
96.5,
87.9,
73.7,
27.5,
28,
75.6,
78.3,
74.7,
46.6,
70.5,
97.1,
23.9,
26.7,
66.7,
85.3,
51.9,
18.6,
63.7,
47.4,
14.1,
40.1,
61.2,
15.9,
21.2,
21.3,
70.6,
59.1,
29.6,
78,
70.5,
89.3,
85.7,
89.3,
95.9,
71.7,
34.3,
61.8,
24.4,
43.8,
51.2,
63.3,
40.3,
44.7,
64,
0,
85.5,
36,
77.1,
48.6,
62.3,
39.4,
66.1,
94.8,
84.9,
80.6,
53.9,
28.3,
50.9,
82.6,
91.7,
33,
8.5,
57.2,
91.1,
57.7,
33.8,
48.9,
33.9,
30.2,
66.3,
11.5,
90,
76.9,
50.8,
62.7,
24.3,
70.3,
55.1,
39.3,
30.6,
27.1,
34.1,
71,
72.1,
72.5,
51.2,
81.3,
97.7,
52.9,
36.9,
77.9,
58.8,
51.5,
81.7,
61.1,
76.1,
61.9,
89.2,
75.5,
67.1,
92.6,
68.1,
41.6,
19.4,
33.6,
84.3,
34.4,
27.8,
46.6,
71.4,
25.7,
63.4,
83.9,
74,
68.4,
75.8,
45,
46.9,
63.8,
43.5,
47.1,
32.6,
45.2,
68.5,
44.6,
72.2,
49.7,
44.1,
95.7,
24,
74.6,
38.7,
94.5,
62,
68.6,
59.3,
72.7,
86.9,
24.3,
67.3,
73.9,
32.4,
30.6,
62.1,
28.7,
73.6,
74.6,
88.5,
55.2,
61.5,
55.1,
47.7,
43.4,
30.6,
86.7,
46.6,
32.3,
90.7,
18.9,
23,
58.6,
58.2,
82.8,
94.6,
44.5,
66.7,
51.4,
8.5,
75.1,
61.3,
76.1,
38.2,
71,
30.6,
94.6,
59,
45.7,
65.2,
79.4,
68.4,
75.4,
45.1,
64,
41.4,
46.7,
96.2,
39.2,
16.6,
25.1,
5.6,
62,
24.5,
98.6,
78,
74.6,
100.7,
53.6,
51.8,
96.4,
7.8,
43.7,
48.9,
29.5,
77.1,
67.6,
68.9,
75.9,
89.3,
62.9,
44.1,
43.5,
58.3,
69.7,
65.7,
24.5,
23.9,
50.5,
66.2,
13.9,
28.3,
65.6,
26,
86.5,
33.7,
63.3,
61.1,
57.9,
79,
49.4,
49.8,
32.8,
70,
70.4,
58.3,
69.4,
33,
24.6,
81.9,
71.8,
38.3,
89.8,
81.9,
57.4,
57.4,
50,
69.9,
52.9,
52.5,
27.3,
82.6,
16.4,
35.7,
73.9,
90.7,
74.3,
53.5,
93,
79.5,
48.9,
36.4,
49.3,
55.3,
39.5,
26.1,
39.1,
78.8,
54.1,
72,
77,
66,
51.8,
75.4,
72.8,
93.8,
76.4,
78.5,
35.8,
79.2,
95.4,
38.7,
27.3,
45.1,
61.7,
29.9,
9.6,
31,
61.7,
98,
60.8,
43.1,
63.9,
32.5,
42.5,
11.1,
48.8,
70.8,
69.9,
69.8,
72.1,
91,
56.9,
76.8,
19.1,
89.6,
23.7,
45.7,
55.3,
76.5,
68,
38.3,
38.8,
47.3,
78.3,
41.7,
44.1,
89.8,
88.4,
21.8,
3.9,
44.5,
41.7,
64.9,
63.5,
21.5,
96.9,
59.7,
43.4,
61.7,
34.7,
53.2,
66.7,
57.6,
97,
79,
68.8,
51.7,
58.8,
30.8,
98.2,
30.3,
43.6,
52.6,
58.1,
89.6,
35.5,
10.8,
67.4,
51.4,
94.8,
71,
45.5,
19.7,
85.3,
47.7,
65,
82.4,
94.8,
94.3,
62.2,
56.8,
27.2,
50.3,
54.2,
34.8,
54,
64.7,
33,
64.6,
62.1,
97.4,
36.1,
85.3,
42.7,
55.6,
21.4,
18.9,
38.8,
50.4,
50.3,
15.6,
43.1,
48.4,
69.2,
86.2,
28.9,
86,
82.7,
52.3,
35,
71.1,
52.3,
57,
74.3,
25.1,
56.5,
40.4,
16.4,
40.6,
66.1,
20.1,
50.4,
90,
25.6,
51.9,
87.9,
42,
26.5,
50,
61.7,
26.3,
53.7,
69.7,
11.4,
0,
55.1,
47.2,
38.5,
74.2,
93.3,
90.5,
68,
59.4,
74.6,
67.9,
57.8,
23.2,
38.8,
69.4,
27.9,
68.3,
31.1,
88.4,
62,
62.1,
45.1,
77.1,
43.9,
54,
42.7,
66,
56.8,
31.6,
83.8,
56,
94.5,
92.9,
46.8,
27,
42.4,
82.9,
97.9,
4.9,
48.1,
48.3,
78,
41.3,
76.7,
59.5,
89.9,
29.1,
27.8,
49.1,
27.6,
51.5,
80.2,
83.2,
19.1,
63.9,
55.1,
85.5,
63.3,
67.7,
70.6,
78.7,
19.4,
26.1,
71.5,
64.4,
4.3,
55,
91.4,
43.8,
50,
51.6,
66.6,
77.2,
27.8,
61.7,
73.7,
90,
51.1,
46.5,
42.7,
93.7,
42.9,
8,
105.1,
94,
73.1,
37.5,
48.8,
69.6,
94.1,
84.7,
27.4,
59.5,
25.8,
75.1,
70.3,
44.2,
18.9,
61.1,
42.8,
19.5,
74,
53.2,
72.3,
54.2,
15.5,
57.9,
42,
82.9,
90.9,
24,
54.3,
10.9,
32.7,
78.8,
14.9,
87.7,
40,
73.3,
40.6,
66.5,
85,
76.9,
49.7,
51.2,
52.6,
85.5,
78.5,
65.4,
46,
28.9,
63.6,
79.7,
79.2,
82.1,
95,
75.6,
65.3,
82.3,
84.7,
64,
79.9,
56.1,
50,
71.1,
29.5,
27.4,
62.5,
55.6,
60.4,
88.5,
59.2,
55.5,
22.9,
19.2,
47.7,
53,
71.3,
96.8,
54.5,
16.5,
42.2,
79,
96.1,
31.6,
83,
74.8,
65.7,
59.7,
26.6,
39.2,
24.6,
38.4,
69.1,
89,
61.1,
50.5,
60.9,
45.6,
26.7,
74.7,
56.7,
66.7,
66.3,
37.5,
90.7,
85.1,
35,
27.5,
62.3,
23.8,
55.9,
79.9,
25.9,
44,
5.1,
25,
85,
50.7,
30.7,
61.5,
63.2,
95.6,
71.5,
84,
23.8,
91.9,
67.3,
39.5,
85.5,
26.4,
67.6,
36.9,
49.8,
79.3,
68.7,
56.2,
34.9,
26.2,
56.3,
69.2,
20.8,
61.4,
81.7,
35.6,
73.5,
24,
91.3,
77.8,
78.6,
9.7,
89.9,
92.9,
0,
77.3,
17.6,
75.8,
76.1,
9.8,
68.1,
40.2,
81.2,
28.7,
4.9,
77.7,
0,
10.2,
54,
75.2,
53.5,
8.1,
13.9,
39.5,
59.4,
78.3,
58.3,
23.1,
55.8,
12.5,
63.9,
81.1,
95.5,
53.5,
74,
19.9,
85.1,
52,
35.4,
96.2,
68.1,
93.6,
44.6,
null,
81.3,
52.7,
72.5,
19.4,
24.5,
59.9,
71.3,
42,
61.5,
44.1,
66,
14.9,
64.6,
81,
80,
78.6,
58.1,
89.6,
84.3,
15.4,
28.4,
71.4,
28.1,
61.3,
74.2,
20.2,
49.5,
70.5,
31.7,
33.7,
34.3,
64.3,
35.6,
66.8,
59,
11.6,
84.6,
63.3,
70.1,
56.1,
43.6,
43.2,
81.1,
45.6,
44.7,
51.3,
24,
83.7,
54.6,
54.1,
19.8,
60.7,
35.3,
96.6,
77.9,
23.2,
2.9,
42.1,
63.9,
72.1,
44.8,
78.4,
13,
73.9,
69.5,
70.6,
41,
94,
28.7,
75.2,
69.7,
38.5,
44,
40.8,
48.3,
35.8,
52.4,
55.4,
56.6,
50.4,
60.7,
96.9,
93.7,
75,
81.2,
35.6,
25.4,
97.1,
54.1,
47.7,
59.2,
42.5,
89.4,
55.4,
98.9,
63.7,
93.9,
54.2,
92.8,
43.6,
64.1,
73.1,
36.5,
77.6,
91.6,
54,
64.7,
43.3,
67.5,
25.7,
64.4,
53.9,
11,
77.9,
92.5,
74,
35.4,
90.1,
87.5,
18.9,
67.8,
95.3,
12.2,
75.5,
26.5,
86.4,
87.3,
64.4,
70,
0,
52.1,
77.9,
99.2,
56.2,
82.2,
11.7,
46.7,
85.9,
42.8,
35.6,
58.6,
71.9,
2.9,
15.5,
73.1,
23,
72.6,
88.6,
81.7,
87.9,
27.8,
38.5,
35.4,
81.2,
8.5,
83.5,
68.5,
41,
52.5,
67.5,
35.5,
43.3,
52.5,
82.2,
43,
16.7,
8.1,
47.3,
22.5,
40.1,
69.9,
20.2,
4.7,
36.5,
94.2,
71.4,
58.8,
43.3,
79.5,
65.5,
76.3,
69.2,
45.7,
72.3,
59.8,
95.6,
69.9,
47.6,
100.2,
36.8,
63.6,
86.3,
44.6,
56.7,
79.9,
48.5,
83.6,
28.2,
89.9,
72.8,
31.2,
68,
75.1,
62.8,
62.7,
77.5,
56.3,
36.5,
69,
93.9,
33,
33.5,
82.6,
85.4,
64,
71.8,
12.8,
63.7,
78.1,
39.3,
30,
71.1,
69.4,
73,
81.4,
41.9,
49.6,
21.4,
58.5,
17.1,
57.4,
46.6,
35.2,
50.9,
39,
85.4,
4.6,
70.2,
45.9,
58.8,
47.8,
37.4,
81.9,
55.7,
55.1,
22,
49.6,
12.6,
44.1,
94.5,
38.3,
87,
62.5,
71.4,
72,
79,
60.6,
50.9,
11.3,
20.9,
47,
99.2,
41,
60,
47.6,
36.3,
32.9,
46.1,
44.1,
21.6,
75.7,
62.4,
67.2,
65,
53.5,
33.5,
88.7,
90.1,
13.8,
47.4,
62.6,
89.1,
66.9,
69.8,
33.8,
52.1,
45.4,
39,
46.8,
58.2,
34.4,
25,
21.8,
78.5,
67.5,
69,
0.5,
43.6,
26.7,
6,
77.6,
56.2,
49.9,
64.6,
77.8,
28.6,
59,
26.5,
66.5,
82,
42.2,
28.4,
82.4,
85.9,
130.8,
53.1,
55.2,
77.5,
80.4,
36.8,
76.8,
89.1,
9.9,
92.9,
99.3,
55.5,
88.7,
17.7,
89.1,
34.2,
96.3,
94.5,
65.3,
25,
24.5,
62.4,
45.2,
83.8,
28,
36.9,
59.4,
61.2,
25.4,
70,
54,
77,
0.2,
66,
62.7,
83.2,
52.2,
50.7,
29.7,
42.1,
13.8,
66.7,
67.6,
75.4,
16.6,
1.9,
88.8,
47.4,
39.6,
86.5,
51.5,
82.1,
82.6,
91.4,
79.1,
53.4,
8.1,
53.3,
18,
82.6,
54.3,
75,
50.6,
91.5,
46.9,
45.8,
41,
32.2,
6.8,
28.2,
69.2,
53.7,
97.2,
49.5,
86.4,
75.4,
22.1,
28.6,
10,
78.9,
66.5,
48.1,
66.1,
15.7,
87.9,
72.4,
68.6,
35.5,
68.5,
32.5,
12.2,
66,
90.2,
32.4,
81,
18,
0.8,
51.4,
28.4,
90,
29.4,
54,
39.7,
34.1,
63.1,
35.7,
42.3,
72,
95.3,
30,
39,
53.4,
20,
60.1,
12.1,
60.1,
91.8,
93.6,
34.2,
96.3,
64,
44.9,
30.2,
87.3,
47.4,
24.9,
67.1,
94.8,
63,
90,
82.4,
97.2,
36.7,
56.9,
68.6,
59.3,
47.6,
64.3,
50.6,
89.9,
46.8,
45.1,
95.9,
68,
85.4,
17.6,
76.1,
8.6,
0.9,
26.8,
47.1,
81.1,
47.7,
82.3,
28.7,
43.5,
49,
53,
73.8,
71.9,
64,
50.5,
39.8,
23.4,
28,
8.2,
34.2,
28.3,
65.4,
32.4,
64.6,
58.1,
66.9,
32.5,
46.2,
89.7,
59,
72.4,
27.4,
66.5,
45,
20.7,
62.5,
95.8,
35.9,
43.1,
80.6,
87.6,
63.5,
59.5,
62.5,
20.8,
24.3,
28.2,
23.7,
31.3,
22.4,
84.8,
55.8,
96.6,
45,
66.1,
66.9,
32,
30.9,
67.5,
59.5,
93.7,
32,
83.4,
60.3,
13.9,
13.7,
94.7,
50.9,
82.3,
0.8,
92.5,
38.8,
64.8,
84.6,
66.7,
95.4,
26,
51.8,
34.7,
37.3,
53.2,
22.4,
84.2,
45.9,
72.7,
81.9,
59.9,
23.2,
72.6,
92.6,
64.5,
67.4,
14.6,
56.6,
31.3,
46,
85.6,
69.8,
21,
61.4,
4.9,
47.3,
77.3,
44.8,
45.3,
64.4,
52.2,
14.5,
76.7,
46.7,
32.5,
71.8,
56.5,
75.7,
92.4,
52.6,
35.3,
94.7,
88.8,
42.7,
55.2,
38.7,
73.5,
88,
8.5,
49,
74.2,
43.2,
56.6,
92,
93.2,
76.3,
29.5,
48.9,
29,
23.4,
64,
66.8,
96.4,
62.6,
42.8,
50.2,
87.9,
62.3,
32.7,
43.4,
12.6,
50.6,
36.8,
41.9,
82.3,
37,
79.4,
71.6,
46,
46.8,
91.8,
50.8,
92.5,
64.6,
37.5,
80.1,
19,
94,
71.7,
72.3,
33.4,
87.6,
54.2,
12.2,
52.1,
61.2,
98.2,
84.9,
94.2,
6.5,
33.9,
67.3,
74,
30.8,
25.1,
79.8,
63.8,
69,
83.5,
47.6,
60.5,
61.4,
74,
35.2,
53.3,
85,
45.6,
96,
45.5,
39.3,
89.1,
19.3,
68,
44.5,
29.3,
60.7,
85.5,
87.2,
80.5,
55.7,
88.2,
55.4,
30.1,
25.2,
95,
71.1,
62.9,
79.9,
53.1,
22.9,
24.8,
74.9,
62.5,
81.4,
66.6,
2.5,
18.9,
44.6,
19.4,
82.7,
66.5,
23.4,
88.3,
15.8,
31.8,
87.9,
36.9,
54.6,
51.8,
87.5,
42.4,
37.4,
31.2,
60,
51.3,
84.3,
26.3,
74.4,
27.4,
44.4,
28.3,
54.7,
37.4,
57.8,
47,
67.9,
40.2,
43.2,
29.1,
45.6,
81.4,
79.8,
76.8,
49.9,
89,
51.2,
28.3,
14.7,
72.4,
95.1,
61.8,
81.6,
69.9,
91.7,
42,
55,
82.7,
18.6,
72,
32.9,
28.5,
35,
68.5,
58.6,
61.8,
69.9,
85.3,
57.5,
55,
49.3,
82,
49.5,
65.8,
79.4,
89.5,
74.8,
90,
80.2,
75,
39,
38.2,
24.6,
77.5,
15.3,
36.7,
45.1,
41.8,
56.3,
82,
43.3,
28.8,
50.4,
72.1,
52.3,
48.5,
91.8,
13.9,
46,
87,
68.4,
65.3,
47.4,
90.1,
57,
68.9,
53.8,
65.6,
36.1,
37.9,
11.1,
60.4,
90.7,
64.4,
41.4,
40.3,
73.4,
31.9,
38,
88.3,
80.4,
91,
30.3,
60.5,
65.2,
22.1,
86.8,
58.5,
49.3,
100.5,
34.7,
76.8,
63.7,
39.2,
32.7,
31.8,
43.4,
7.2,
59,
40.2,
73,
71.4,
48.3,
53,
95.7,
37.8,
33.1,
42.3,
25.1,
60.2,
28.5,
61,
12.9,
87.4,
37.5,
70.7,
38.8,
24.9,
72,
36,
7.2,
66.9,
89.7,
69.9,
11,
51.2,
63.9,
35,
39,
75.7,
30.6,
11.2,
57,
42.3,
83.4,
67.3,
11.7,
92.6,
89.1,
97.4,
66.3,
56.7,
57.3,
55.7,
95.5,
46,
75.2,
64.5,
81.1,
42.1,
58.8,
26.9,
46.3,
48.7,
33.5,
17.5,
24.4,
35.5,
60,
41.9,
70.7,
38.3,
68.2,
24.4,
0,
54.3,
51.2,
86.9,
52.2,
23.2,
6.5,
87.7,
34.5,
36.7,
72.6,
100,
68.6,
89.9,
90,
78.6,
59.5,
89.8,
45.3,
73,
31.1,
83.1,
73.7,
1.7,
83.7,
0.3,
34.5,
47.7,
83,
81.9,
98.7,
55.2,
80.5,
43.8,
23.6,
65.4,
49.9,
72.8,
42.6,
38.2,
13.7,
78.8,
75.3,
45.8,
45,
45.3,
66.5,
81.4,
69.8,
85.2,
39,
74,
42.2,
7.4,
50.9,
85.9,
50.1,
53.2,
13.9,
88,
58.9,
57.1,
32.9,
59.9,
9.8,
46.1,
48,
82.6,
75.7,
49.3,
100.5,
90.5,
65,
7.4,
56.3,
59.4,
63.4,
62.5,
51.8,
33.3,
50.9,
67.3,
75.8,
76,
59.7,
36,
83,
40,
67.3,
60.2,
66.4,
81.8,
43.5,
65.4,
49.7,
63.4,
48.6,
44.3,
91.8,
24.2,
101,
20.2,
29.6,
75.7,
37.8,
77.4,
25.2,
76,
69.7,
43.7,
44.4,
66.7,
63.9,
54.7,
82.5,
75.6,
32.7,
62.2,
34.2,
99.1,
44.6,
46.7,
83.7,
50.2,
47.9,
88.1,
102,
8.6,
60.7,
44,
56,
58,
24.5,
73.3,
69.2,
53.6,
45,
71.3,
30.7,
45.1,
37.4,
38.1,
93.7,
56.4,
75.9,
72,
46.6,
29.4,
36.6,
55.4,
95.7,
19.6,
64.4,
51.7,
80.9,
86,
82.9,
84.3,
40,
19.8,
68.1,
57,
71.8,
70.7,
53.8,
30.5,
69.3,
71.6,
70.2,
38.8,
15.4,
60.7,
88.2,
53.4,
19.6,
74,
71.2,
58.1,
81.3,
33.4,
44.3,
77.1,
8.6,
59.4,
60.3,
38.6,
8.8,
75.1,
94.7,
20.6,
88,
45.1,
28.2,
78.6,
66.8,
80.7,
77.5,
12.9,
69.8,
84.1,
66.6,
68.3,
69.1,
21.9,
69.8,
37.8,
76,
44.8,
88,
57.1,
63,
67.8,
53.8,
52.2,
69.5,
91.3,
44.8,
81.7,
73.4,
16,
42.4,
80.8,
88.8,
38.7,
83,
101.4,
49.4,
36.4,
53.8,
45.1,
43.3,
63,
41.1,
75.3,
44,
91.4,
35.1,
17.1,
70.1,
17.8,
70.7,
22.1,
76.5,
74,
18.7,
62.9,
92.3,
82,
65.7,
82,
14.3,
97.6,
61.8,
3,
64.4,
27.2,
49.3,
64.5,
46.1,
48.6,
34.4,
80.1,
26.5,
24.3,
32.6,
40.3,
64.3,
33.1,
80.2,
67.7,
81,
62.2,
97.2,
68.1,
79,
19,
67,
78.4,
71.2,
93.1,
81.8,
67.4,
50.3,
80.3,
65.7,
0.8,
73.6,
44.7,
11.1,
19.8,
26,
83.1,
51.3,
54,
54.6,
5.9,
37.3,
26.1,
60.4,
17.4,
66.9,
20.9,
20.7,
94.1,
64.1,
84.4,
92.2,
32.8,
69.5,
33.9,
56.6,
26.3,
61.6,
40.7,
64.1,
43.4,
56.9,
81.7,
41.1,
85.5,
71,
54.1,
84.9,
30.1,
31,
82.6,
48.1,
28.3,
29.2,
39.5,
58.1,
51.3,
82.1,
72.3,
57.9,
19.6,
41.2,
68.4,
36.8,
55.8,
70.9,
46.2,
34.5,
51.7,
59,
74.1,
52,
93.9,
36.5,
75.9,
87.1,
47.3,
35.9,
71.5,
71.4,
72.8,
44.5,
60.8,
66.5,
33,
30.4,
38,
49.4,
55.4,
57.7,
60.4,
44,
48.2,
40.6,
55.1,
48.2,
77,
77.6,
56.9,
75.5,
34.1,
35.9,
51.8,
37.8,
97.5,
15.8,
32,
77.5,
48.7,
19.9,
45,
63.8,
92.8,
57.3,
63.6,
42.6,
80.6,
63.9,
45.1,
62.4,
92.8,
66.7,
84.9,
58.2,
81.3,
50.9,
43.7,
38.9,
53.1,
35,
74.8,
32.2,
54.6,
41.4,
33.3,
3.2,
71.4,
72,
55.4,
4.8,
60.3,
56.1,
20.3,
49.6,
76.4,
92,
20.6,
51.2,
64.1,
71.2,
77.4,
1.7,
45.8,
35.1,
39.5,
57.2,
97.2,
83.9,
94.3,
16.8,
38.4,
68.3,
72.8,
90.8,
57.4,
42.4,
47.4,
12.3,
33.5,
66.7,
68.9,
20.3,
19.1,
36.8,
53,
39.3,
40.7,
55.5,
61.9,
52.8,
73.8,
58.4,
61.3,
77.6,
10,
88,
33.6,
27.6,
57.7,
57.8,
43.1,
98.6,
43,
65.8,
89,
74.5,
95.3,
22.8,
62.8,
43.2,
37.1,
50.4,
83.4,
63.4,
79.8,
52.6,
7.6,
9.5,
75.8,
34.6,
44.7,
87.2,
63.7,
70.7,
98.3,
46.1,
78,
64,
28,
60.8,
64.5,
57.3,
66.6,
57.3,
79.6,
65.8,
60.3,
46.2,
25.6,
64.9,
82.3,
66,
66.4,
63.7,
65.2,
43.8,
45.4,
64,
39,
82.6,
29.3,
27.7,
84.5,
56.5,
18.2,
50.7,
81.3,
67.2,
67.7,
73.6,
53.8,
52,
16,
26.9,
18,
68.4,
73.1,
40.7,
44.8,
53.1,
53,
11.4,
38.9,
14.7,
49.9,
52.1,
66.5,
35.4,
55,
95.4,
47.5,
55.8,
74.8,
62.6,
46.6,
60.7,
72.1,
20.4,
77.1,
48.4,
62.6,
79.1,
84.9,
87.3,
53.7,
54.6,
25.8,
33.8,
26,
85.3,
58.8,
27.2,
42,
33.7,
91.8,
48.8,
25.8,
57.8,
57.7,
90,
13.7,
32.9,
26.9,
87.2,
40.8,
77.8,
61.4,
48.8,
46.3,
45.4,
37.4,
81,
32.5,
63.1,
79.4,
51.4,
37.1,
48.3,
49.1,
45.1,
37.4,
65.6,
66.5,
66.9,
36.8,
44.7,
54.4,
88.2,
65.3,
84.4,
40,
46.7,
87.2,
97.5,
38.1,
73.5,
42,
58.5,
83.9,
54.3,
36.7,
91.2,
59.3,
94.6,
30.2,
48.7,
52.1,
86.7,
3.8,
68.1,
63,
26.4,
48,
73,
25.8,
87.4,
27,
70.5,
44.2,
74.5,
61.6,
87.9,
42,
58.4,
54.3,
66.9,
76,
83.7,
73.7,
77.8,
68,
91.1,
72.5,
45.3,
90.2,
71.3,
66.4,
63.4,
48.9,
20,
26.2,
67.8,
56,
88,
59.3,
35,
78.1,
104.6,
70.4,
75,
56.5,
84.2,
55.9,
69.8,
87.6,
45.4,
91.8,
65,
92.3,
54.4,
79.3,
39,
32.7,
56,
64.6,
8.9,
67.7,
16.4,
62,
56.5,
38.8,
82.2,
72.8,
59.2,
30.1,
40.2,
64.3,
51.7,
69.5,
39.9,
5.5,
64,
65.5,
63.1,
48.3,
45.2,
36.6,
75.4,
51.2,
76.3,
82.2,
33.1,
72.2,
38.5,
46,
44.5,
65,
85.6,
53.1,
4,
38.2,
41.1,
62.6,
20.3,
81.8,
5.9,
93.9,
93.2,
35.3,
85.7,
66,
98.6,
8.3,
2.3,
9.5,
53.5,
83.1,
18.9,
77,
55.2,
26.7,
39.1,
66,
89.5,
22.3,
88.3,
51.1,
90,
16.1,
64,
72.9,
87.4,
77.7,
21.7,
17,
43,
56.5,
54.1,
68.2,
84.9,
76,
43.7,
71,
92.4,
76,
71.7,
14.9,
66.6,
39.1,
81,
75,
63.4,
27.2,
59.3,
35.8,
17.7,
40,
65.6,
34.4,
77.4,
90.2,
61.4,
61.5,
84.9,
26.4,
89.9,
29.1,
72.9,
37.1,
96.5,
48.5,
15.2,
43.5,
8.4,
70.9,
49.7,
60.8,
88.2,
44.6,
70.7,
31.6,
53.6,
54.6,
72.3,
93.9,
38.4,
12.4,
29,
49.4,
43.8,
12.9,
33.2,
92.1,
20.6,
75.6,
59,
91.1,
50.2,
53.5,
69.1,
60.2,
49.9,
17.6,
68.1,
82.4,
62.9,
73.1,
24,
58.7,
41.9,
48.3,
30.4,
41.2,
90.1,
31,
63.2,
49.8,
40.7,
47.1,
80.6,
95.8,
56.4,
78,
84.9,
26.4,
75.3,
55.1,
82.7,
40.9,
18.3,
0,
41.6,
95.5,
19.6,
28.1,
96.6,
33.1,
57.4,
71.7,
81.3,
36.4,
56.9,
67.1,
48,
49.5,
88.6,
63.6,
85.6,
77.6,
54.7,
16,
87.8,
54,
90.8,
17.7,
66.4,
64.9,
60.7,
19,
80.7,
20.7,
47.9,
35.4,
84.5,
73,
50.9,
24.2,
13.6,
21.5,
58.5,
80.9,
96,
55.8,
24,
49.4,
92.3,
63.3,
59.8,
90,
60.1,
94.5,
26.9,
51.6,
48.8,
64.4,
0,
58.1,
64.1,
16.8,
73.5,
28.4,
94.6,
34.5,
95.7,
84.1,
56.6,
81.3,
65.6,
22.9,
40.3,
70.2,
79.3,
45.8,
83.7,
26.8,
33.3,
41,
46.4,
22.1,
19.2,
56,
77.3,
44.5,
16,
96.4,
46.3,
73.1,
43.6,
55.2,
16.8,
45.6,
77.8,
86.3,
82.2,
62.4,
55.4,
32.3,
67.8,
35.1,
77.7,
65.6,
59.6,
71.9,
54.2,
33,
62,
52.8,
5.8,
82.5,
71.8,
34.5,
66.4,
77.7,
76.4,
52,
45.5,
34.1,
85,
45.6,
57.1,
31.6,
59.9,
93.2,
68.8,
60.5,
58.2,
39.5,
53.7,
30.1,
17,
57.5,
36.6,
76,
83.1,
79.3,
35.8,
41.8,
54.3,
60,
38.5,
30.2,
60,
26.3,
39.6,
82.3,
52.6,
61.3,
83.2,
90.1,
70.6,
61.1,
47.7,
54,
84.6,
90.8,
94.1,
10.2,
74,
86.3,
63.7,
59.9,
22.8,
31.3,
19.6,
24.9,
79.6,
27.1,
67.2,
21.3,
71.2,
56,
50.2,
53.1,
68.8,
57.2,
4.9,
36,
55.8,
50.4,
9.7,
17.3,
54.3,
39.7,
86.8,
82.1,
42,
26.2,
31.2,
75.2,
33.3,
32.5,
66.1,
48.7,
50.7,
67.1,
67.7,
52.5,
66.5,
65.2,
45.2,
49.8,
70.1,
76.9,
80.2,
30.2,
91.5,
29,
39.3,
52,
49.1,
30.3,
63.4,
34.5,
82.4,
94.9,
76.6,
61.5,
73.6,
85.1,
12.2,
89.1,
24.9,
63.6,
16.1,
69.9,
9.2,
8.5,
78.9,
22.3,
58.1,
19.6,
91.8,
44.3,
40.8,
75.9,
30,
54.5,
64.7,
91,
30.2,
66.6,
71.4,
65.2,
59.9,
99.1,
68.4,
69.4,
63.2,
49.5,
79.4,
42.9,
95.4,
59.7,
67.8,
48.7,
42.5,
20.8,
96.9,
56,
94.8,
84,
82,
58.9,
27.5,
53.2,
79.3,
82.1,
85.1,
36.7,
24.1,
41.6,
79,
78,
33.8,
92.9,
51.5,
39.6,
59.7,
31.1,
51.4,
97,
35.5,
60.4,
19.9,
87.2,
29.2,
64.4,
39,
39.8,
78,
66.6,
81.3,
58,
96.8,
86.2,
79.3,
97.8,
59.9,
22.2,
68.8,
30.6,
61.5,
36,
92.5,
36.9,
48.7,
45.1,
48,
36.4,
78.8,
82.8,
45.5,
74.3,
21.3,
77.1,
23.4,
76.8,
104.2,
39.1,
24.6,
34.7,
81,
61.8,
23,
54,
80.2,
85.6,
9.1,
19.1,
33,
48.6,
93.7,
81.1,
48.7,
17.2,
67,
27.4,
65.7,
76,
34.7,
49.7,
39.1,
51.2,
48.9,
40.3,
56.4,
43.3,
99.2,
75.8,
69.2,
77.4,
71.8,
51.1,
46.6,
45.9,
0.6,
39.2,
42.1,
53.6,
44.1,
68.6,
85.6,
54.9,
54.6,
95.2,
20.5,
1.4,
68.6,
95.5,
9.7,
49.3,
39.3,
86.9,
22.3,
79.7,
94.5,
68.6,
48.3,
73.5,
101.6,
73.6,
47.2,
58.5,
59.9,
8.4,
81.4,
24.2,
59.3,
30,
35.9,
74.8,
62.4,
33.8,
58.1,
21,
65.2,
57.3,
40.2,
70.2,
83.8,
66.3,
27.4,
32.7,
71.6,
50.4,
3.1,
88.2,
40,
68.5,
42.6,
85.9,
48.4,
85,
1.5,
40.5,
57.1,
81.8,
56.6,
32.5,
61.3,
94.4,
84.7,
90.5,
31.7,
50.5,
31,
32.3,
15.7,
44.1,
66.3,
63.6,
85.9,
65.3,
4.2,
23.2,
69,
95,
57.2,
64.3,
77.9,
54.9,
75.6,
54.6,
87.1,
32.5,
60,
15.3,
55,
78.7,
30.7,
42.9,
99,
73.6,
57.7,
89.8,
41.3,
81.5,
56.2,
87,
10.9,
61.3,
63.7,
51,
27.5,
93.7,
100,
60.2,
87.8,
54.2,
50.1,
55.9,
81.9,
20.4,
65.2,
72.4,
8.3,
55.1,
74.5,
71.4,
21.2,
27.7,
47.7,
37.7,
78,
80.8,
83.9,
31,
75.1,
77.5,
28.6,
31.7,
11.8,
25.2,
32.7,
41.9,
38.9,
38.2,
53,
46.8,
25.1,
89.1,
14.5,
62.5,
71.6,
52.6,
40.9,
47.2,
97,
33.3,
28.6,
36.6,
93.6,
64.3,
46.4,
71.2,
45.5,
36.2,
48.2,
51.9,
76.2,
30.4,
53.4,
93.7,
38.8,
46.4,
92.3,
26.6,
32.9,
78.7,
89.8,
74.3,
65,
78.4,
58.6,
38.9,
36,
41.9,
66.8,
56.9,
73.6,
63.9,
63.8,
40.1,
20.9,
58.7,
74,
80.2,
37,
49.5,
40.8,
66.3,
50.8,
11.9,
24.3,
35.9,
11.3,
58.4,
27.2,
36.6,
77.8,
23.2,
37.7,
47.1,
33.2,
37.1,
93.9,
17.4,
46.4,
88.2,
74.1,
46.7,
97.7,
33.7,
40.9,
65.3,
70,
65.1,
84.4,
18.7,
66.2,
24.7,
92.1,
37.4,
81.3,
14.6,
90.9,
53,
73.6,
85.3,
41.1,
48.9,
53.6,
48.2,
45,
93.1,
33.2,
75.7,
56.5,
43,
49.4,
54.5,
43.8,
59.2,
67,
68.2,
30.6,
65.6,
58.8,
76.2,
92.6,
80,
99.6,
56.5,
82,
43.7,
44.9,
67.6,
37.7,
29.9,
46.6,
90,
52.1,
72,
61.4,
30.5,
36.9,
40.1,
90.9,
82.9,
32.6,
92.1,
35.5,
66.3,
53.3,
63.1,
93.1,
56.4,
85,
69.3,
71,
36.3,
28.7,
58,
84,
32.6,
15.8,
74.7,
82.8,
81.4,
30.9,
56.3,
53,
65.6,
41.6,
83.5,
48.4,
24.9,
74.4,
86,
65.2,
74.8,
18.5,
59.1,
47.5,
46.4,
63.7,
16.6,
18.7,
30.5,
41.1,
81,
19.8,
80.5,
24.1,
92.3,
71.8,
78.3,
35.9,
89.5,
87,
46.7,
4.6,
40.4,
17.6,
71.1,
35.9,
20.2,
70.7,
79.2,
28,
36.7,
46.3,
57.2,
16.2,
45.4,
44.7,
74.9,
93.5,
41.9,
91.3,
59.4,
42,
66.1,
78,
0.1,
78,
70,
39.2,
47.8,
50.9,
48.1,
86.1,
76.6,
40.1,
9.9,
90,
25.2,
79.6,
45.3,
70.9,
62,
52,
51.5,
74.8,
28.8,
60.5,
55.1,
83.4,
1.5,
44.9,
67.4,
45.9,
54.9,
85.4,
30,
34.4,
97.5,
92.7,
27.6,
65.1,
53.7,
21.2,
0.8,
39.3,
63,
75.2,
78.5,
59.8,
61.4,
34.5,
20,
17.6,
72,
41.6,
99.6,
43.2,
14.1,
70.9,
15,
50.3,
75.8,
33.9,
38.9,
34.5,
43.6,
86.7,
88.6,
89.6,
88.9,
51,
84.2,
43,
66.3,
13.2,
36.3,
61.9,
78.2,
76.9,
60.3,
85.5,
38.9,
64,
53.4,
14.3,
99.9,
38.8,
20.5,
76,
46.7,
62.6,
64.9,
94.5,
29.9,
65.3,
50.4,
68.7,
48.8,
62.6,
44.7,
64.2,
72.2,
25.7,
69.6,
54.3,
43.2,
44.4,
28.5,
90.4,
71.7,
62.6,
89.5,
42,
89.1,
85,
57.4,
66.3,
49.6,
52.5,
42.7,
46,
24.1,
25.5,
42.2,
88.3,
39.7,
89.7,
72.4,
90.3,
37,
86.3,
94,
50.5,
88.5,
24.9,
66.2,
57.8,
101,
25.6,
51,
23.7,
71.1,
93.8,
43,
77.2,
50.2,
42.8,
11.1,
71.3,
43.4,
37.4,
50.6,
38.9,
29,
74.9,
47.4,
50.4,
58.1,
88.1,
47.6,
69.2,
51.4,
59,
27.4,
38.8,
10.5,
12.5,
80,
73,
1.3,
88.1,
38.9,
82.3,
75.5,
29.4,
77.4,
51.9,
33.2,
75.1,
71.4,
37.1,
31.7,
100.3,
55.9,
65.7,
36,
26.3,
38.8,
84.1,
56.5,
90.5,
87.1,
26,
56.4,
84.4,
11.8,
74.4,
50.7,
90.4,
66.7,
22.8,
54.9,
95.8,
51.8,
76.9,
84.3,
48.9,
71.2,
65,
42.7,
91.7,
83.7,
83.5,
39.8,
78,
66.7,
66.9,
66.1,
61.3,
26.6,
30.9,
62,
49.8,
33,
44.8,
37.3,
31.8,
9.9,
7.3,
87.6,
70.5,
48.7,
53.7,
97.4,
86,
19.1,
79.7,
84.5,
52.5,
42.8,
29.1,
84.9,
73.6,
44.7,
58.3,
76.1,
74.5,
73.8,
77,
59.3,
23.9,
81.4,
53.7,
40.7,
77.7,
75.6,
32.9,
37.5,
53.5,
101.9,
62.3,
27.4,
30.7,
32.5,
81.6,
78.5,
59.8,
33,
60.7,
75.6,
95,
34.5,
96.5,
49.3,
18.7,
57.7,
69.9,
42.8,
27.4,
51.7,
38.8,
29.5,
36,
48.5,
61.4,
17.1,
49.3,
95.4,
67.9,
32.1,
17.3,
81.8,
94.9,
34.2,
56.1,
66.8,
67.7,
35.2,
56.5,
32.6,
38.5,
38.8,
50.7,
37.7,
33.2,
66.1,
32.3,
39.5,
41,
31.7,
72.2,
52.5,
59.3,
94.8,
29,
61.5,
46,
72.6,
74.2,
2.5,
80.8,
43,
60,
37.1,
65.8,
91,
71.1,
48.1,
82.9,
43.2,
49.6,
79.1,
56.2,
74.8,
74.5,
37,
65.7,
31.2,
79,
91.5,
57.2,
46.1,
77,
65.6,
38.2,
63.9,
59.7,
30.1,
35.5,
74.5,
70.7,
25.5,
85.1,
65.4,
64.6,
49.6,
96.3,
53.7,
26.7,
56.4,
75.7,
42,
97.7,
96.3,
48.2,
67.2,
57,
67.6,
86,
82.4,
48.9,
50.5,
64.3,
51.3,
89.7,
36.8,
60.7,
91.2,
81,
72.2,
40.6,
88.7,
67.8,
33.5,
84.4,
28,
53.3,
53.9,
38,
40.5,
25.2,
59.7,
50.9,
54.2,
64.7,
71.1,
56.1,
80.1,
81.2,
47.8,
51.5,
28,
37.3,
75.3,
45.6,
94.6,
77.3,
31.5,
26,
59.2,
65.7,
34.8,
30.9,
49.4,
51,
64.4,
5.6,
59.7,
42.8,
40.6,
90.7,
80.9,
44.8,
75.2,
21.9,
72.8,
66.1,
67.1,
32.2,
50,
49,
42,
54.8,
35.5,
69.7,
36,
47.4,
41.9,
66.9,
80.6,
79.5,
79.2,
23,
43.8,
27.5,
65.3,
79.2,
21.9,
51.1,
15.5,
74.3,
85.7,
58.8,
43.6,
42.5,
100,
10.4,
74.9,
79.7,
72.6,
27.8,
31.2,
57.6,
89.4,
35.5,
72.6,
61,
31,
43.3,
69,
45.5,
46,
68.6,
96.3,
51.6,
74.1,
24,
51.1,
5.4,
62.6,
82.2,
37.6,
16.5,
81.1,
39,
68.6,
39.2,
69.8,
74.1,
38.2,
55.5,
23.6,
34,
0,
31.3,
67.6,
89.7,
66.4,
87.5,
39.1,
86.1,
36.5,
11.7,
53.5,
22,
19.2,
38.8,
55.6,
64.4,
61.9,
97.1,
50.8,
92.5,
20.7,
28,
75.1,
33.6,
51.5,
50.5,
32.5,
31.5,
63.9,
74.3,
48.8,
42.5,
17,
46.7,
40.7,
0,
55,
74.5,
19,
67.5,
66.3,
89.2,
83.1,
49.9,
77.5,
51.3,
18.9,
24.5,
32.9,
77,
47.6,
21.4,
73.5,
41.5,
49.1,
35.1,
77.4,
36.9,
18.5,
60.9,
79.4,
100.5,
48,
55.4,
10,
68.8,
36.9,
73,
65,
47,
59.5,
78.8,
37.4,
75.7,
29.5,
64,
99.6,
67,
58.8,
74.6,
64.6,
47.1,
93.5,
21.9,
54.3,
81.4,
54.2,
65.2,
77.6,
35,
79.4,
66.1,
80.7,
36,
51.5,
39.6,
1.7,
55.9,
44.8,
10,
29.9,
72.9,
91,
64.1,
61.7,
33.5,
21.9,
6,
33.9,
50.4,
47.4,
70.5,
83.5,
75.9,
85.5,
37.3,
77.8,
47.6,
78.7,
6.8,
23.8,
60.7,
47.7,
48.9,
44.1,
45.4,
25.3,
11.4,
68.4,
84.4,
19.6,
45.3,
63.8,
89.6,
45.9,
90,
48.2,
88.8,
85.7,
78.4,
77.1,
39.2,
32.3,
66.7,
16.5,
69.8,
64.7,
35.5,
58.3,
75.5,
61.9,
22.6,
15.6,
72.1,
47.7,
26.8,
87.2,
37.3,
34.2,
75,
45.2,
67.8,
44.7,
42,
71.9,
72.7,
96.2,
71.7,
23.9,
30,
54.5,
85,
53.6,
70.7,
3.2,
40,
50.9,
91.1,
43.3,
85.3,
98.3,
87.8,
29.2,
79.8,
81.5,
37.5,
11.7,
47.8,
86.9,
25.7,
43,
64.3,
80.6,
44.9,
83.8,
43.8,
74.8,
67.6,
95.4,
73.1,
65.3,
68.4,
22.3,
66.4,
46.3,
44,
58,
61.8,
38.8,
53.6,
86.5,
32.6,
47.7,
77.9,
37,
42.3,
76.9,
67.3,
57.9,
43.3,
58,
83,
42.3,
55.3,
28.2,
48.5,
45.9,
70.4,
26.7,
42.8,
30,
53.7,
22.4,
26.7,
54.4,
71.5,
33.4,
84.7,
9.4,
67.3,
12.2,
54.7,
82.5,
6.6,
58.2,
72.4,
10.1,
61.3,
89.2,
55.7,
62.1,
2.5,
36.1,
43.1,
91.2,
49.2,
47.6,
81.4,
41,
77.2,
13.1,
39.4,
78,
113.4,
72,
49,
24.8,
67.6,
1.6,
5.9,
30.7,
78.9,
34.7,
75.9,
47.4,
62.9,
31.4,
46.5,
61.7,
49.7,
8.7,
68.6,
35.5,
16.4,
22.6,
20.4,
31.7,
22.2,
58,
97.4,
95.1,
67.2,
82.5,
61.5,
45.3,
69,
32.4,
65.2,
34.5,
86.4,
75,
31.2,
69.3,
17.6,
56.4,
92,
38.5,
33.3,
89.8,
84,
44.1,
16.7,
12.1,
63.7,
45.4,
55.4,
75.3,
61.7,
83.7,
35.1,
76.2,
83.1,
35.1,
59.8,
71.8,
67.2,
98,
72.8,
53.5,
87.2,
75.5,
53.4,
52.8,
90.2,
36.7,
72.4,
70.2,
92,
62.6,
42.6,
38.9,
25.5,
53.3,
73.9,
80.7,
87.1,
54,
59.5,
95.9,
6,
25,
26.4,
27.1,
49.5,
41.2,
91.7,
27.8,
90,
28.9,
76.3,
42.3,
19.6,
73,
56.9,
40.3,
70,
40.9,
63.3,
33.1,
18.4,
24.7,
48.6,
35.1,
64.7,
21.9,
61.3,
64.6,
24.3,
65.4,
47.9,
58.5,
56.3,
58.7,
44.9,
87.4,
86.5,
47.7,
29.4,
12.8,
33.1,
60.5,
54.3,
83.7,
72.8,
71.8,
31.2,
33.9,
90.7,
70.2,
65.9,
46,
64.7,
54.4,
73.6,
79.9,
22.7,
15,
27.4,
92.6,
44.8,
71.8,
50.4,
79.5,
26.6,
93,
26.7,
55.6,
51.5,
36.8,
18.1,
57.1,
90.7,
46,
55.2,
70.5,
76.3,
66.8,
57.5,
42.8,
68.7,
76.8,
53,
64.6,
7.1,
54.3,
32.2,
47.3,
35.4,
69.1,
37.8,
64.4,
46.9,
68.1,
31.9,
24.7,
73.2,
32.2,
52.2,
76,
43.2,
14.8,
49,
55.5,
33.3,
76.2,
66.3,
44,
91.3,
66,
43.4,
72.4,
66.8,
83.8,
33.7,
44.1,
70.5,
87.3,
13.5,
43.9,
73.1,
69.3,
32.5,
92.4,
65.9,
61.5,
95.7,
27,
69.6,
43.3,
29.6,
46,
93.7,
47.9,
9.5,
58.7,
26.7,
57.2,
88.5,
23.7,
35.6,
6.2,
22.8,
40,
26.9,
50.6,
17.9,
82.9,
24.1,
63.7,
57.8,
82.4,
53.8,
78.7,
64.3,
54,
89.7,
45.1,
74.2,
65.1,
77.8,
85.3,
60.5,
27.6,
44.4,
95.2,
8.3,
66.1,
54.5,
76.2,
93.6,
38.3,
null,
33.5,
57.5,
57.8,
33.4,
36,
85.9,
80.8,
63.1,
24.9,
58.4,
98.4,
69.8,
61.2,
45.5,
60,
75.5,
86.3,
69.2,
69,
81.6,
38,
32.8,
35.2,
61.3,
72.6,
69.4,
79.6,
47.1,
63.3,
74.1,
69.1,
61.5,
26.9,
77.4,
63.7,
62,
19.4,
37.2,
64.1,
51,
51,
74.2,
41.4,
29.7,
77.9,
48,
77.1,
55,
45.2,
63.2,
18.7,
36.1,
40.9,
78.1,
80.4,
48,
37.3,
35.6,
28.9,
69.3,
21,
69.9,
47.2,
95.1,
61.1,
89,
38,
31.7,
44.4,
72,
68.4,
22.4,
84.7,
4.5,
1.6,
44.5,
63.9,
22.4,
69.1,
46,
19.2,
68.1,
46.8,
78.5,
83.1,
91,
38.2,
88.3,
17.8,
94.2,
2.8,
17.9,
53.8,
74.6,
60.5,
60.3,
47.3,
44.5,
2.6,
72.5,
80.1,
83.4,
35.6,
41.6,
34.2,
61.9,
82.9,
95.4,
4.1,
98.5,
75.4,
28.8,
51.9,
87.6,
57.3,
96.8,
73.7,
70.8,
25.2,
19,
100.5,
46.5,
26.1,
46.3,
53.1,
93.1,
60.7,
54.9,
79.9,
66.6,
75.6,
70.4,
39.8,
33.2,
74,
71.4,
82.4,
52.7,
77.7,
28.3,
71.1,
64.7,
82.6,
64.6,
86.1,
50.6,
42.3,
50.4,
68.8,
44.8,
44.1,
66.7,
65.8,
39,
66.7,
75.8,
45.8,
30.4,
10.8,
94.5,
63,
79.1,
46.5,
0.4,
79,
72.9,
30.5,
79.2,
53.6,
73.7,
32.3,
45.9,
58.5,
88.7,
85.8,
67.3,
88.7,
81,
37.5,
83.1,
90.7,
76.3,
44.6,
32.1,
77.8,
37.6,
48.2,
3.1,
40,
56.2,
20.9,
41.6,
85.6,
52.6,
36.2,
37,
90,
37.2,
8.9,
53.1,
41.4,
57.1,
47.3,
46,
64.2,
82.5,
60.8,
65.1,
43.7,
64.4,
71.8,
82.6,
10.2,
58,
41.8,
26.5,
16.2,
53,
64.4,
36.3,
58.8,
47.2,
96.4,
23.8,
43.9,
79.5,
35.8,
55,
59.4,
32.3,
34.2,
65,
76.8,
77.7,
96.4,
77.6,
3.9,
51.3,
67.1,
65.3,
76.4,
27.8,
39,
75.1,
56.3,
97.9,
74.7,
54.9,
59.8,
21.7,
33.6,
62,
62.6,
29.6,
32.2,
34.5,
49.5,
9.7,
57.1,
55,
82.4,
82.8,
81.4,
39.9,
48,
6.5,
89.4,
46.8,
94.3,
65.4,
53.2,
77,
63.3,
26.9,
98,
82.4,
14.1,
53.1,
77.2,
45.8,
46.2,
72.6,
71.4,
47.8,
51.7,
95,
44,
82.3,
48.6,
50,
56.8,
73.5,
76.7,
55.3,
36.2,
77,
49.7,
26.7,
81.8,
34.8,
17.9,
55.5,
32.6,
9,
88.5,
31.1,
74.1,
47,
64.5,
27.7,
43.2,
51.1,
23.7,
96.7,
28.7,
29.9,
11.4,
52.8,
31.1,
51.5,
37,
79.7,
37.6,
77.3,
28.6,
64.1,
68.3,
80.5,
48,
47.8,
52.1,
81.7,
54.9,
71.6,
39.5,
61.1,
58.6,
62.5,
16.5,
69,
33.6,
48.7,
80.1,
44.3,
79.2,
73.2,
90.4,
69.4,
14.8,
37.6,
67.4,
23.3,
94.9,
74,
56.3,
86,
46.5,
22,
44.1,
35.8,
1.7,
21.3,
30.1,
7.6,
66.8,
62.5,
77.5,
46.6,
0,
45.7,
53,
27.9,
42.9,
69,
47.7,
50.1,
67.8,
45.6,
66.9,
14.8,
83.5,
92.3,
100.7,
17.7,
38,
45.1,
39,
49.2,
83.7,
17.8,
46.3,
66.3,
37.2,
67.9,
50.8,
63.6,
43.3,
34,
42.1,
23.4,
39.7,
0,
85.6,
61.8,
64.9,
60,
69.6,
41.5,
97.9,
42.7,
16.1,
40.7,
63.1,
44.8,
94.5,
30.2,
50.3,
4.4,
16.6,
41.1,
65.8,
34,
75.5,
50.3,
50.9,
76.5,
0.2,
75.6,
77.5,
91.1,
96.1,
47.5,
27.3,
57.1,
38.4,
64.8,
46.3,
42.3,
73.7,
34,
87.4,
84.4,
33.7,
49.7,
66.1,
87,
55.8,
1.2,
24.4,
87.1,
77.7,
80.2,
96.6,
94,
5.7,
12.3,
78.2,
4.2,
23.8,
43.6,
61.4,
74.7,
48.2,
64.6,
23,
16.5,
52.7,
7.4,
66.4,
51.6,
52.5,
70,
93,
51.3,
81.6,
70,
71.3,
61.3,
73.7,
14.2,
73,
39.6,
57.7,
24.8,
62.6,
40,
23.1,
90.5,
70.1,
37,
71.3,
24.5,
36.5,
31.9,
0,
41.4,
54.6,
69.7,
28.4,
73,
34.6,
11,
68.7,
74.9,
10.1,
67.6,
64,
38.6,
52.5,
36,
39.7,
52,
49,
56.9,
65,
40.2,
72.4,
57.3,
82.6,
0.3,
65.4,
94.1,
30.6,
5.6,
0,
70.3,
53.9,
56.6,
61.7,
95.5,
41.5,
12.5,
34.6,
70.9,
19.4,
78.1,
76,
48.8,
24.7,
85,
80,
71.1,
61.8,
78.6,
5.9,
59.2,
1.3,
68.6,
78.9,
63.5,
24.8,
61.9,
97.1,
56.5,
55.6,
21.9,
69.8,
28.4,
73.9,
69.5,
61.2,
21.1,
38.7,
42,
35.3,
46,
85.5,
55.6,
49.9,
61.8,
1.9,
49.8,
51.5,
17.5,
99.1,
37.9,
59.9,
86.2,
49,
93.1,
49.9,
29.2,
24.7,
44.2,
53,
51.5,
53.8,
26.8,
47.6,
11.9,
17.6,
38.2,
74.8,
95.2,
67.7,
84.1,
66.9,
17.6,
66.6,
92.1,
73.7,
40.3,
0,
59.5,
67.1,
43.6,
28.6,
91.8,
85.9,
74.8,
43.5,
55.9,
35.2,
37.4,
64.5,
61.4,
44.8,
40.5,
62.2,
55.9,
19.3,
46.2,
22.1,
22.6,
63,
73.5,
34.2,
72.5,
84.4,
29.8,
14,
66.3,
69.8,
61.4,
75.5,
45.5,
49.2,
80.6,
48.8,
86.4,
21.9,
19.3,
26.3,
24.3,
88.4,
69.9,
4.6,
78.8,
51.8,
23.4,
69.6,
77.5,
87.5,
67.1,
15.3,
5.3,
69,
27.4,
59.9,
24.7,
67.4,
41.6,
51.3,
15,
40.9,
89.5,
28.3,
91.3,
44.2,
91.8,
62.2,
33.4,
52.3,
7.8,
97,
32.7,
29.7,
40.6,
42.4,
83.2,
43.2,
81.7,
32.3,
61.1,
67.2,
53.2,
79.7,
79.1,
55.1,
63.7,
67.6,
72.7,
22.7,
72.6,
33.9,
54.2,
16.8,
45.6,
15,
24.9,
22.8,
85,
19.5,
48.9,
87.7,
77.5,
74,
46.3,
33.1,
31.3,
43.3,
10.1,
64.4,
18,
23.5,
67.8,
21.7,
70.6,
98.5,
64.2,
55.7,
89.1,
28.4,
28.7,
72.1,
74.3,
55,
39.2,
46.3,
40.7,
9.5,
56.5,
68.7,
64.7,
52.8,
96,
82.4,
55.8,
71.1,
68.2,
28.8,
44.9,
38.6,
31.8,
48,
70.4,
28.8,
19.4,
59.1,
65.5,
16,
36.7,
43,
49.6,
93.5,
55.7,
27.8,
96.4,
39.6,
95.5,
70.4,
75.4,
4.8,
58,
52,
38.7,
54.4,
38.1,
60.6,
71.5,
76.9,
63.2,
70.5,
21.5,
47.6,
21.6,
34.9,
92.9,
75.5,
78,
6,
32.2,
66.8,
56.9,
20.9,
85.7,
74.6,
80.3,
40,
49.4,
47.9,
31.1,
73.9,
3.9,
47.5,
29.1,
34.2,
59.5,
44.8,
91.2,
33.3,
29.1,
86.4,
59.8,
50,
35.5,
61.2,
31.8,
28.2,
96.1,
57.3,
22.7,
0.7,
5.1,
46.1,
55.9,
58.8,
63.5,
55.4,
63.8,
23.3,
66,
5.4,
52,
14.9,
52.6,
46.1,
71,
57.1,
67.7,
85.4,
98.1,
55.8,
84.1,
65.5,
43.7,
15.1,
55,
49.9,
11.8,
85.2,
51.5,
75.5,
53.7,
46.6,
72.4,
42.9,
22.2,
66.7,
24.4,
89.7,
69,
47.9,
66.2,
13,
53.1,
57.9,
35.1,
48.7,
95.2,
88.5,
40,
44.9,
90.3,
42.5,
86.9,
22.9,
6.4,
96.2,
54.3,
98.9,
52.7,
85.1,
73.4,
69.5,
62.9,
68,
48.4,
55.8,
103.6,
73,
37.8,
88.1,
28.3,
59.1,
93.4,
32,
27,
36.6,
36.7,
30.6,
40.4,
63.3,
55.7,
53.4,
46.6,
79.4,
60.3,
35,
71.4,
43.8,
99.3,
51.3,
24.7,
60.8,
29.4,
29.2,
83,
37.8,
92.4,
50.1,
30.1,
78.6,
7.7,
68.6,
80.2,
27.4,
48.2,
40.9,
71.1,
28.4,
40,
71.5,
78.1,
70,
83.1,
40.2,
54.2,
35,
78.7,
55.6,
94.6,
57.6,
10.8,
92.3,
48,
15.5,
90.2,
39.2,
75,
40.8,
95.5,
16.6,
83.1,
71.1,
49.7,
72,
75.7,
18.6,
96.3,
32.9,
21.7,
0,
75.1,
60.4,
67.9,
30.1,
22.7,
56.8,
78,
52.2,
64.1,
67.4,
58.7,
83.4,
70,
44.8,
68.9,
26.3,
0,
21.2,
31.1,
33.5,
45.3,
42.2,
60.4,
45.8,
98.2,
73.9,
85.7,
46.6,
17.7,
30.3,
49.2,
67.6,
32.2,
30.2,
39.1,
48.6,
77,
71.4,
81.9,
13.5,
70.4,
73.7,
50.9,
62.6,
78.4,
88,
48.6,
56.8,
102.6,
73.6,
38.4,
64,
23,
91.9,
55,
70.5,
39.6,
55.7,
32.8,
53.7,
56.5,
48.8,
94,
69.3,
62.1,
48.9,
27.9,
37.6,
47.2,
92.3,
38.4,
40.2,
48.5,
66.9,
23.8,
73,
2.2,
39.2,
77.7,
69.1,
99,
98.2,
65.8,
34.5,
45.5,
71.8,
39.3,
58.2,
63.3,
50.5,
97.4,
70.5,
89.1,
42.6,
65.1,
76.1,
89.3,
97.5,
22.1,
81.1,
31.4,
24.7,
25.1,
80.2,
78.9,
54.5,
31.7,
53,
95,
50.5,
58,
61.5,
84.9,
73,
87.1,
37.5,
3.4,
35,
90,
39.7,
49,
11.4,
78.4,
81.2,
59,
0.9,
97.3,
15.3,
44.2,
92,
72.3,
19.5,
62,
56.1,
39.9,
97.2,
73.7,
32.3,
24.2,
77.5,
34.4,
84.7,
76.3,
92.8,
48.7,
72,
74.6,
34.4,
67.3,
65.4,
94.1,
68,
53.3,
68,
38.3,
57.2,
71.9,
83.6,
43.4,
62.5,
96.5,
10.9,
31.4,
71.6,
94,
43.2,
79.6,
81.4,
18.4,
56.6,
30.3,
50.4,
46.2,
36.3,
39.4,
48,
34.2,
61.3,
35.3,
83.5,
48.9,
43.9,
75.3,
19.4,
33.5,
45.7,
69.1,
66.9,
77.5,
90.6,
43.5,
0.1,
51.9,
84.9,
46,
28.4,
6.4,
1.5,
58.8,
40.8,
4.2,
95.2,
54.8,
28,
52.4,
52.7,
68.5,
64.3,
95.7,
31.9,
86,
84.6,
13.5,
48.5,
98.2,
32.4,
64.6,
66.6,
49.3,
52.8,
78,
36.3,
60.6,
86,
68.5,
80.6,
39.8,
66.1,
85.2,
64.6,
32.5,
76.8,
69.6,
92.8,
38.9,
40.5,
65.5,
95.6,
43.7,
58.4,
30.2,
29.1,
84.5,
73.2,
79.9,
32.8,
47.3,
96.5,
58.8,
47.9,
11,
92.2,
39.6,
79.9,
41.5,
82.6,
83,
41.7,
80.3,
30.4,
27,
79.4,
46.7,
55.4,
80.5,
38.4,
68,
2.3,
78.8,
70.1,
86.4,
81,
62.3,
37.8,
53.8,
44.6,
68.4,
12.2,
97.5,
35.8,
49.4,
72.1,
74.9,
24.4,
53.2,
48.2,
60.4,
69.9,
37.6,
81,
50.8,
25.3,
78.1,
10.1,
34.6,
52.7,
9.6,
64.3,
63.3,
86.6,
30.7,
37.6,
61.4,
0.1,
5.4,
68.5,
73.9,
62,
23.1,
59.8,
55.7,
35.9,
22.4,
67.8,
30.7,
54.7,
89.9,
41.5,
56,
92.1,
34.9,
86,
87.9,
90,
44.1,
63.9,
93.8,
90.3,
97.5,
36.4,
51,
85.2,
35.2,
86.9,
76.2,
95.1,
79,
68.1,
78.4,
81.9,
74.5,
72.6,
54.5,
47.8,
91.6,
33,
12.7,
43.8,
48.4,
33.1,
49.4,
80.8,
68.5,
47.5,
68.2,
69.1,
78.4,
24.3,
35,
63.1,
38.9,
52.5,
45.9,
3.8,
97.2,
51.7,
61.2,
91.7,
4.1,
53,
4.2,
35.1,
27.4,
61,
14.8,
65.1,
38.7,
31.4,
26.7,
96.3,
92.6,
51.5,
62.1,
78,
83,
79.7,
36.5,
58.5,
67.9,
43.4,
74.8,
53.6,
83.7,
98.8,
58.8,
64.5,
67,
52.5,
24.6,
15,
75.3,
84.5,
22.6,
10.6,
90.8,
16.9,
61.3,
58.9,
83,
34.1,
98.5,
71.4,
70,
47.2,
6,
28.6,
58.6,
94.6,
86.6,
70.3,
92.7,
30.3,
28.8,
39,
39,
20.7,
51.6,
46.9,
58.6,
51.1,
55.2,
30.5,
23.6,
58.7,
90.1,
67.7,
36.7,
81.3,
30.6,
51,
78.4,
46.1,
94.4,
57,
49.7,
68.7,
86.5,
63.3,
93.1,
66.6,
61,
48,
15,
71.8,
53.9,
84.1,
25.7,
19.2,
63.2,
38.2,
39.9,
53.4,
43,
88.2,
53.3,
71.6,
32.8,
36.2,
23.8,
73.3,
29.3,
23,
87.4,
80.9,
50.6,
85.4,
37.6,
62.6,
16.3,
75.1,
14,
98,
11.3,
92.6,
12.6,
33.1,
66.9,
32.1,
70.7,
14.3,
89.8,
72,
46.7,
70.7,
19.7,
100.1,
72.1,
31.7,
96.3,
48,
45.9,
98.8,
75,
53.3,
85.5,
72.2,
83.8,
0,
43,
25,
31.6,
63.1,
49.7,
31.1,
63.9,
18.1,
82.9,
62.7,
58.3,
33,
61.2,
76.3,
60,
76,
42.3,
49.1,
29.6,
66.6,
69.9,
30.1,
23,
46.5,
48.9,
68.9,
28,
46.4,
19.7,
66.4,
60.6,
44.3,
17.4,
78.6,
47.4,
80.6,
77.5,
53.1,
81.5,
44.2,
61,
49.2,
82.5,
50.6,
62.7,
57.1,
49.6,
40.8,
62.7,
71.8,
8.3,
74.5,
27.5,
96.4,
74.5,
52.1,
32.5,
55.9,
60.9,
77.8,
55.8,
44.4,
44.5,
18.9,
64.3,
25.9,
83.5,
84.9,
65.8,
7.5,
90.5,
94.4,
79.6,
16.7,
96.3,
8.2,
32.9,
8,
27.2,
87.6,
76.1,
42.2,
30.4,
72.5,
80.8,
77.4,
19.3,
76.7,
92.1,
43,
33.2,
64.2,
69.9,
94.8,
9.6,
36.6,
82.6,
62.5,
87.7,
48,
78,
93.1,
57,
69.2,
27.9,
22.6,
88,
88.7,
87.3,
51.6,
75.4,
66.5,
98.3,
30.1,
9,
34.3,
77,
77.8,
93.1,
53,
39.5,
46.1,
91.3,
67.2,
75.3,
75.3,
37,
62.1,
37.2,
35.5,
13.9,
92.9,
54.4,
8.3,
85,
10.8,
93.2,
66,
50.7,
13.3,
36.7,
43.9,
67.8,
64.6,
56.7,
82.3,
49.7,
71,
80.8,
99,
77.5,
80.3,
77.3,
74.9,
40.2,
69.8,
81.3,
17.2,
39.9,
85,
90.4,
58.3,
87,
92.6,
47.8,
39.8,
78.4,
44.4,
14.3,
36.9,
38.4,
26.8,
77.6,
66,
85,
69.7,
26.5,
55.7,
96.5,
9.5,
20.8,
38.4,
40.1,
81.7,
75.9,
60.2,
71.9,
42.7,
23.3,
53.6,
97.5,
62.2,
39.5,
46.6,
92.5,
90.9,
37,
81.6,
3.6,
62.3,
77,
68.3,
59.4,
9.5,
5.6,
81,
39.8,
30.6,
69.1,
63,
85.5,
90.4,
35.6,
58.1,
79.6,
29.7,
51.6,
29.6,
84,
40.2,
75.7,
50.8,
52.4,
96.4,
85.5,
44.3,
54.6,
64.1,
33.3,
66.1,
28,
33,
44.3,
76.3,
34.6,
62.8,
52.5,
70.9,
40.3,
76.4,
41.6,
90.5,
45.7,
42.7,
85.2,
35.4,
39.9,
12.7,
37.3,
59.7,
79.2,
55,
13.6,
47.1,
78,
47.8,
39.5,
13.4,
17.2,
88.9,
47.6,
68,
18.2,
39.9,
86.3,
58.6,
61.3,
72,
0.3,
96,
92.5,
48.9,
36.4,
66.5,
22.7,
70.9,
50.5,
36.1,
72,
68,
32.4,
52.9,
25.7,
88.9,
33.8,
70.1,
88.7,
79.6,
60.2,
65,
73.9,
81.8,
31.7,
80.3,
44.2,
73.6,
15.7,
75.9,
86.6,
50.7,
19.3,
59.3,
41.1,
65.9,
67.5,
59.2,
40.8,
29.7,
64.8,
22.2,
79.9,
25.5,
33.6,
47.8,
70.9,
80.3,
97.5,
73.2,
48.8,
68.6,
89.1,
71.7,
77.8,
56.4,
10.9,
53.6,
92.6,
61.2,
82.7,
6.1,
16.9,
59.2,
82.4,
54,
76.5,
69.4,
63.8,
13.1,
46.3,
83.3,
59.7,
6.1,
88.8,
18.5,
86.6,
55.4,
89.1,
65.1,
78.8,
49.1,
98.5,
53.2,
39.8,
36.7,
37.8,
86.2,
48.1,
55.7,
55.3,
57.8,
61.2,
52.3,
72.5,
66.6,
77.9,
78.3,
13.2,
97.2,
101,
51.1,
42.5,
39.1,
81.2,
46.3,
70.5,
78.6,
9.6,
68.1,
89.6,
34.8,
68.8,
62.3,
26,
68.4,
83.2,
13.4,
78.7,
40.4,
75.5,
42.8,
16.9,
60.7,
45,
29.7,
63.1,
95.7,
36.6,
92.1,
68.5,
38.8,
47.5,
8.7,
49.6,
30,
62.3,
57.6,
10,
35.5,
47.8,
81.3,
15.1,
97.6,
92.5,
27,
57.2,
36.5,
66,
25.3,
81,
82.5,
87.8,
32.2,
29.8,
75.8,
15.1,
74.5,
39.8,
89.4,
75.2,
44.8,
31.5,
42.9,
18.7,
52.8,
77.1,
40.1,
66,
64.9,
62.8,
84.9,
59,
6.8,
30.8,
20.7,
25.3,
34.9,
69.9,
61,
12.7,
62.4,
26.3,
38.9,
87.7,
81.3,
12.6,
67.3,
46.1,
61.3,
65.7,
27.3,
48.7,
4.9,
86,
75.2,
78.9,
41.6,
61.6,
41,
65.2,
36.8,
98.7,
73,
12.6,
46.4,
45.9,
75.6,
78.3,
37,
19.8,
82,
52.1,
47.9,
14.2,
25.4,
67.5,
100.9,
73.1,
76.1,
64.8,
68.1,
53,
81.8,
5.8,
72,
56.1,
42.4,
85.6,
57.9,
95.6,
23,
50.2,
45.4,
77.2,
0.5,
78.4,
48.9,
59.8,
69.4,
52.8,
16.1,
53,
60,
70.7,
56.4,
77.5,
83.3,
42.3,
60.5,
88.3,
32,
41.8,
46.5,
30.1,
22.9,
44.2,
29.4,
72.8,
12,
46.5,
34.3,
88.1,
24.9,
45.7,
45.1,
37.2,
28.8,
55.1,
89.8,
42.4,
88.5,
43.5,
32.7,
100.4,
75.6,
63.7,
46,
46,
66.8,
81.8,
41.6,
24.2,
76.2,
45.6,
21.4,
66.3,
56.6,
49.9,
33.3,
37.2,
21.9,
78.2,
79.7,
30.7,
79.9,
29,
74.8,
51.5,
74.8,
67.2,
32.5,
77.3,
74.2,
92.7,
62.7,
68,
96.8,
39.8,
67.1,
42.9,
49.9,
85.5,
55.1,
22.1,
68.2,
26.7,
50.7,
60.9,
24.3,
48.1,
54.1,
99.7,
22.5,
60.7,
57.1,
49.1,
59.8,
64.8,
40.1,
12.3,
57.1,
74,
22.3,
0,
44.3,
61.1,
55.5,
65.9,
61.5,
75.5,
31,
76.8,
72.2,
54.7,
51.4,
83.2,
36.4,
64,
19.5,
85.5,
43.6,
89.3,
81.3,
38.2,
85.2,
54,
41,
74,
44.9,
7.5,
62.6,
85.3,
2.5,
30,
31,
34.7,
99.4,
48.8,
67.7,
70.4,
14.6,
25.7,
65.1,
43.6,
92.2,
82.4,
78.2,
78.2,
22.7,
25.8,
50.8,
91,
42.4,
88.5,
36.8,
7.9,
58.6,
74.4,
28.9,
40.2,
84.8,
86.2,
32.3,
71.2,
92.6,
77.5,
30,
22,
46.3,
40.9,
59,
45.7,
33.6,
69.9,
70.2,
54.1,
48.6,
41.1,
63,
42.9,
38,
29.4,
30.9,
50.9,
59.4,
47.1,
48.6,
83,
23.1,
57.8,
41.8,
83.5,
68.7,
48.5,
67.8,
32.2,
50.9,
36.2,
89,
82.8,
46.7,
32.4,
41.3,
29.7,
68.5,
65.3,
67.6,
98.9,
90.1,
68.7,
98.7,
79.8,
57,
53,
22.1,
60.6,
59.8,
49.7,
48.8,
54.2,
20.6,
82.7,
43.4,
16.5,
40.1,
65.6,
36.2,
36.1,
93,
71.4,
80.5,
61.9,
33.6,
81.2,
98.1,
23.3,
94,
85.2,
77.3,
71.2,
70,
73.4,
15.6,
88.8,
43.3,
28.4,
66.3,
30.8,
53.1,
0,
30,
61.7,
74.4,
21.7,
56.8,
0,
68.5,
88,
84.2,
65.7,
1.1,
26.6,
94.3,
56.7,
38.6,
63.4,
29.7,
69.8,
44.5,
44.2,
85.2,
68.5,
45.1,
33,
48.5,
69.3,
82.1,
40.5,
68,
63.3,
54.7,
0,
47.5,
63.9,
44.7,
72.2,
44.2,
53.9,
88.3,
44.6,
59.4,
38.2,
58.8,
80.3,
14.3,
42.8,
75.4,
46.5,
68.6,
42.5,
98.6,
74.7,
39.5,
75,
26.5,
54,
52.5,
26.7,
70.4,
5.9,
62.1,
66.4,
76.8,
34.9,
66.3,
53.9,
92.6,
43.8,
60.9,
14.4,
66.7,
43.4,
53.4,
69.1,
38,
78.8,
52.3,
70.4,
79.2,
56.6,
74.5,
47.8,
68.5,
45,
70.4,
47.9,
58.8,
61.1,
20.3,
45.4,
91,
53,
86.3,
69.5,
81.3,
27.7,
25.7,
41.3,
80.8,
24.8,
76.2,
38,
92.2,
57.2,
71.2,
51.7,
52.9,
95.9,
46.1,
7.3,
73.4,
23.7,
85,
23.9,
58.9,
37.6,
41.4,
61.3,
48.3,
22.4,
49,
36.1,
52.8,
49.4,
78,
45.6,
35.3,
35.3,
33.4,
58.5,
6.4,
68.6,
24.5,
36.2,
22.2,
54.4,
36.7,
64.8,
87.2,
55.3,
61.9,
54.4,
47.3,
50.2,
38.2,
32.1,
76.1,
34.4,
12.8,
38.5,
48.6,
43.6,
72.8,
14.1,
55.5,
58,
84.5,
74.1,
68.4,
52.2,
68.3,
42.2,
97.4,
88.6,
74.2,
45.4,
65.1,
13.6,
35.2,
81.8,
33.7,
83.9,
65,
48.9,
38.7,
4.1,
49.4,
33.6,
79.4,
35.9,
71.1,
79,
44.2,
34.8,
48.5,
33.9,
62.1,
22.3,
24.7,
59.4,
70.6,
54.6,
86.7,
52.4,
61.5,
22.6,
50.1,
29.9,
51.6,
46.6,
34,
62.8,
48.6,
63.9,
72.5,
38,
45.9,
87.6,
55.7,
80.5,
92.8,
92,
58.9,
78.4,
58.8,
59.3,
31.9,
null,
41.3,
33.9,
43.9,
65.7,
35,
30.3,
83.7,
62.8,
56.7,
44.3,
37.3,
54.8,
64.4,
81.9,
22.6,
47.2,
27,
18,
72.5,
46,
79,
36.7,
21.5,
42.3,
37.6,
47.3,
50.6,
33.2,
57,
74.3,
53.4,
44.3,
51.6,
72.1,
44.1,
90.1,
43.8,
40.4,
78.3,
72.3,
60.8,
88.5,
87,
29.6,
57.7,
22.8,
87.2,
52.9,
18.6,
56.5,
48,
25.7,
22.9,
88.7,
40.3,
99.3,
86,
35,
34.7,
34.6,
42.4,
71.3,
64.6,
82.1,
43.9,
75.4,
38.4,
9.6,
45.9,
49.9,
75.6,
2,
30.2,
35.7,
52.9,
29.3,
45.6,
44.9,
79.4,
45,
25.9,
66.1,
14.9,
79.3,
12.3,
33.2,
86.5,
67.4,
19.8,
25.8,
99.1,
90.5,
64.7,
63.8,
88.5,
35.5,
49.1,
50.6,
50.9,
35.6,
32.7,
93.7,
2.1,
55.7,
92.3,
49.4,
46,
81.2,
94.9,
39.1,
50.1,
44.4,
82.4,
68.6,
39.3,
68.3,
52.6,
48.4,
73.9,
47.9,
66.1,
28.1,
61.8,
41.2,
43.9,
45,
77.8,
28.5,
57.4,
93.5,
81,
60.5,
66.7,
49.6,
64.2,
80.6,
70.5,
42.7,
34.5,
78,
27.3,
46.9,
78.3,
63.8,
78.7,
40,
26.2,
73.9,
23.7,
43,
51.4,
73.1,
42.2,
83.6,
76.7,
16.8,
51.8,
56.6,
59.2,
36.9,
26.2,
17.6,
22.2,
68.3,
83,
43.5,
52,
33.4,
34.9,
34.1,
34,
98.2,
78.5,
62.6,
48.3,
40.9,
92.5,
91.2,
65,
79.9,
81.5,
15.8,
52.8,
73.9,
51.4,
97.9,
58.5,
59,
7.8,
26.5,
79.9,
22.1,
45.2,
50.6,
97.3,
12.7,
13.9,
5.6,
43.4,
54.2,
95.7,
25.2,
37.9,
57.1,
83.3,
71.5,
53.9,
77.9,
32.4,
38.1,
54,
54.2,
96.6,
24.5,
12.6,
68.6,
17.8,
74,
48.7,
89.1,
36.8,
66.4,
38.8,
70,
100.2,
2.3,
54,
45.4,
69.6,
47.6,
71.2,
78.7,
75.4,
47.8,
53.6,
34.5,
73.7,
40.8,
48.5,
70.1,
85.6,
18.4,
64.8,
88.5,
29,
60,
89.2,
36.6,
85.3,
34.1,
29.2,
58.2,
81.3,
52.7,
46.3,
21.1,
72.3,
97.3,
82.1,
14.5,
29.1,
24.6,
41,
56.9,
32.6,
31.1,
37.2,
92.2,
54.7,
76,
60,
59.6,
24.5,
58.6,
0.3,
49.6,
16.7,
51.4,
65,
31.2,
13.9,
73.9,
57.3,
31.4,
75.6,
29.7,
87.4,
74.4,
63.4,
75.3,
44.5,
17.8,
15.6,
51.7,
89.9,
56.4,
51.6,
57.3,
79.1,
68.5,
62.6,
29,
72.2,
38.4,
5.3,
37.3,
71,
63.5,
79,
70.1,
69,
67,
44.2,
73.6,
83.6,
43.4,
64.3,
19.1,
50.8,
33.8,
22.4,
58.6,
6.1,
19.8,
49.4,
55.6,
43,
95.4,
67,
40.5,
64.7,
52.4,
71.7,
44.3,
53.9,
50.5,
49.8,
52.6,
71.8,
60,
42.4,
67,
34.3,
40.9,
6.2,
44.4,
78.9,
74.3,
40.4,
32,
48.4,
98.3,
65.4,
53.5,
77,
34.8,
92.2,
94.3,
65.4,
83.7,
36.2,
83.5,
45.3,
55.6,
66.7,
75.6,
43.8,
28.5,
35.4,
57.7,
85.3,
34,
2.2,
65.3,
98.1,
72.2,
38.9,
85.1,
96.2,
17.2,
86.2,
59.3,
79.3,
66.5,
61.7,
76.3,
69.7,
53.5,
33.1,
41.8,
81.1,
31.2,
29.7,
72.6,
77.1,
17.1,
65.3,
79.4,
38,
1.9,
70.2,
80.6,
64.2,
83,
10.2,
61.6,
62,
25.2,
38.5,
7.4,
24.5,
57.1,
77.4,
56.9,
50.1,
59.3,
58.3,
94.9,
34.6,
3.5,
63.3,
64.4,
75.3,
79.9,
11.5,
9.4,
70.4,
77.9,
64,
95.8,
30.1,
66.2,
70.4,
60.8,
11.5,
42.9,
37.5,
44.7,
36.4,
49,
62.8,
71.6,
83.1,
14.5,
80.2,
27.5,
98.5,
81.8,
46.7,
84.5,
5.6,
62.7,
63.5,
48.1,
61.9,
18.2,
48.6,
75,
60.2,
59.3,
56.3,
31.1,
44.8,
33.6,
92.2,
74,
33.8,
63.7,
47.4,
77,
69.8,
93.8,
36.5,
42.5,
33.2,
13.4,
34,
95.6,
53,
83.5,
52.6,
80.5,
46.1,
36.7,
79.4,
61.9,
63.5,
71.2,
80.3,
89.7,
46,
54.7,
38,
96.2,
37.2,
56.9,
72.3,
58.4,
92.6,
62.2,
33,
31.9,
84.1,
84.7,
36.5,
60.1,
81.5,
41.1,
53.9,
87.8,
49.5,
57.2,
49.7,
98.3,
62.3,
94.3,
40.7,
86.9,
8.7,
61.4,
57.5,
68,
87,
52.7,
21.8,
66.8,
63.3,
44,
61.7,
58.7,
76,
60.6,
88,
79.2,
94,
54.6,
99.1,
null,
85.2,
40.7,
70.5,
58,
51.8,
81.1,
53.8,
58.2,
83.7,
57.1,
66.8,
45.9,
77,
77.6,
69.4,
25.7,
63.5,
58.9,
72.2,
46.4,
96.5,
79.1,
50,
74.5,
71.7,
88.1,
77.9,
47.4,
49.6,
55,
66.2,
52.5,
73.3,
85,
70.4,
29.9,
47.7,
56.8,
76.3,
63.8,
46,
44.9,
9,
82.6,
53.7,
23.7,
78.8,
42.6,
17.3,
34.8,
16.1,
9.7,
51.4,
39.5,
69.8,
9,
24.2,
9.9,
92.8,
89.7,
44.6,
95,
18.7,
25.4,
53.8,
62.7,
62.3,
44.7,
84.9,
1.2,
84.4,
36.3,
14.5,
87,
87.3,
58.7,
91.1,
55.2,
88.9,
38.2,
67.8,
29.6,
87.8,
50.7,
50.9,
75.1,
75.6,
37.1,
8.9,
45.1,
59.1,
38.9,
58,
60,
90.1,
37.6,
67.9,
40.6,
33.8,
65,
61,
60.8,
74,
65.3,
63.1,
57.4,
84.1,
48.3,
59.1,
62,
71.4,
67.7,
58.1,
22.8,
20.2,
39.2,
64.3,
79.7,
64.7,
93,
64.5,
42.2,
82.8,
28.9,
34.5,
90.6,
32.9,
59.7,
20.7,
25.1,
19.1,
39,
91.6,
69.3,
88.7,
26.7,
57.3,
30.8,
89.1,
47.1,
72.6,
37.2,
72.9,
81,
91.6,
9.3,
48.9,
38,
91,
91.8,
92.6,
70.3,
25.2,
92.8,
9.9,
5.8,
48.8,
70,
47.5,
80.8,
54.2,
56.6,
46.9,
56,
74.1,
62.7,
85.3,
35.9,
55.6,
99.7,
65.8,
78.5,
81.7,
90.9,
88.3,
48,
41.5,
30.2,
51.2,
21,
56.1,
63.3,
94.4,
40,
74.2,
42.9,
91,
53,
74.1,
25.5,
45.7,
46.3,
80.9,
47.1,
54.1,
76,
91.8,
83.8,
62.6,
41.4,
47.6,
50.1,
47.9,
63.1,
62.3,
49.1,
67.3,
33.8,
28.6,
80.2,
79.5,
51.5,
33.6,
39,
56.8,
78.3,
83.9,
8.9,
41.9,
16.4,
42.6,
43.2,
60.6,
62.7,
62.5,
91.4,
70.5,
82.1,
82.3,
81,
34.7,
23.8,
98.8,
76.7,
87.1,
65,
13.6,
96.8,
57.9,
84.9,
53.3,
0.3,
51.8,
56.8,
51.1,
76.9,
38.3,
72.5,
44,
73.8,
70.2,
63.9,
41,
61.4,
82.3,
65.2,
82.5,
62.9,
90.8,
33.3,
8,
45.2,
88.3,
50,
23.2,
41,
59.1,
46,
83.7,
90.9,
59.9,
46.1,
28.3,
20.2,
44,
55.3,
78.6,
74.2,
43.7,
45,
24.7,
35.2,
8.2,
24.3,
12.5,
50,
27.8,
63.8,
65.5,
45.5,
54.6,
0.7,
52.8,
26.3,
46.5,
70.1,
87.3,
1.7,
67.3,
32.2,
28,
44.3,
76.7,
82,
64.7,
93.5,
87.8,
92.3,
23.4,
55.9,
66.1,
46,
60.8,
87.7,
27,
48.7,
77.8,
56.7,
24,
78.9,
39.2,
86.4,
53.4,
45.6,
60.9,
34.7,
61.2,
61,
30.3,
96.2,
57.9,
32.3,
15.8,
62.4,
60.6,
21.2,
0,
56.5,
39.7,
91,
36.2,
24.1,
42.1,
42.3,
10.4,
84.4,
87,
81.7,
41.1,
71.4,
70.1,
39.2,
76.1,
62.7,
57.3,
69.6,
56.4,
13.3,
72.9,
58.8,
43.7,
31,
79.5,
25.5,
24,
53.2,
97.6,
51.3,
87.3,
44,
59.7,
47.4,
65,
49.6,
80.3,
54.7,
62.5,
78.2,
58.5,
70.5,
71.7,
17.6,
42.3,
42.5,
47.8,
15.7,
13.2,
51.3,
97.7,
29.8,
34.7,
73,
38,
17.9,
41.5,
43.9,
70.5,
83.3,
61,
85.5,
89.1,
50.3,
30.9,
28.3,
12,
91.4,
18.2,
51.6,
82.6,
84.5,
79.2,
38.5,
32,
45.7,
24.9,
21.1,
29.9,
50.1,
77.8,
18.8,
64.4,
51,
79.6,
78.4,
14.1,
101.4,
31.4,
53.6,
57.2,
78.8,
19.7,
98,
59.2,
63.3,
84.3,
50.4,
96.5,
49.5,
51.9,
68.6,
30,
5.8,
67.3,
10.8,
33.9,
53.2,
72.1,
86.7,
100.3,
94.5,
59.5,
62.9,
83.4,
63.9,
4.9,
43.6,
32.1,
35,
51.4,
9.5,
74,
37.2,
15.1,
54.5,
51.2,
30.2,
64.2,
85.1,
73.9,
26.5,
83.2,
32.5,
20.6,
63.3,
23.3,
45.8,
51.3,
72.4,
70.6,
84.9,
6.2,
37.5,
17.5,
94.1,
68.8,
23.9,
57.3,
41,
45.4,
33.3,
46.4,
76.5,
69.9,
96.3,
44.7,
24.4,
94.6,
83.1,
2.6,
76.7,
65.9,
34.3,
34,
74.5,
60.5,
23.3,
37.5,
94.4,
66.6,
47.9,
99.4,
46.5,
57,
78,
71.2,
68.6,
22.3,
34.9,
34.9,
39.4,
93.1,
23.5,
68.8,
51.7,
23.1,
31,
38.5,
57.4,
98.3,
19.4,
27.1,
43.6,
68.1,
45.6,
35.9,
79.8,
93.7,
44.8,
41.4,
35,
41.2,
77,
97.8,
35.6,
12.8,
43.6,
64.3,
92.8,
73,
46.4,
16,
5.3,
62.8,
65,
90.8,
70.8,
49.1,
62.4,
68,
2.6,
63.5,
9.8,
54.4,
38.4,
4.2,
56.7,
26.7,
0.3,
67,
62.9,
46.4,
69.8,
53.8,
28.5,
5.9,
47.3,
43.4,
67.5,
24.1,
67.2,
99,
91.6,
96.1,
36.3,
43.2,
60.1,
71.8,
45.5,
22.1,
57.5,
48.7,
76.3,
47.6,
81.4,
59.1,
48.9,
57.9,
77.7,
50.6,
35,
56.1,
54.8,
14.2,
34.7,
24.3,
40.6,
56,
69.6,
60,
14.5,
27.7,
29.9,
66.3,
74.1,
90.4,
84.7,
47.5,
67.6,
64.3,
99,
86.8,
74.3,
64.6,
73.3,
31.6,
92.5,
40.2,
14.7,
76.4,
71,
46.1,
75.8,
98.5,
57,
92.7,
56.2,
67.8,
57.6,
95.5,
51.5,
62.3,
37.3,
37.4,
30.8,
93,
64,
49.4,
36.8,
70.5,
86.3,
92,
65.1,
71.2,
77.8,
55.9,
62.2,
93,
21,
29.3,
81.3,
54.8,
101.5,
59.1,
95.3,
80.4,
50.6,
91.9,
59.9,
77,
31.3,
26.9,
34.5,
51.1,
9.6,
32.6,
12.8,
46,
88.1,
86.3,
89,
72,
24.7,
36.2,
86.9,
53.8,
40.9,
85.5,
29.6,
82.9,
95,
88.6,
83.7,
7.2,
48.4,
29.9,
90.9,
51.8,
99.1,
49.5,
95.4,
93.3,
102.3,
72.2,
93,
47.2,
93.5,
43.3,
9.2,
43.6,
19.5,
81.4,
67.3,
38.5,
43.8,
69.2,
78.6,
94.2,
67.5,
56.6,
65,
64.8,
60,
42.1,
94.2,
53.3,
51.2,
28.6,
58.5,
54.9,
18.7,
31.6,
60,
85.4,
51.6,
72.6,
62.7,
91.4,
86.6,
46.5,
66,
1.7,
74.6,
105.4,
66.1,
97.9,
69.8,
72.5,
77.7,
9.2,
54.2,
27.3,
54.7,
45.8,
58.5,
92.4,
75.5,
65.3,
75,
2,
81.4,
63.9,
1.1,
77.2,
43.8,
56,
43.2,
51.1,
87.2,
38.1,
37.5,
8.2,
38.2,
78.3,
38,
47.6,
92.4,
49.9,
36.1,
42.9,
74.2,
42.6,
76,
88.4,
33.3,
23.3,
95,
51.8,
98.9,
54.5,
49.3,
84.6,
50.2,
33,
12.5,
20.7,
55.8,
30.2,
91,
68.2,
37.9,
60.1,
74.1,
36.5,
82.3,
87,
54.8,
42.1,
64.7,
36.5,
98.7,
47.5,
56.1,
53.6,
27.1,
55.1,
40.6,
20.8,
55.2,
49.3,
80,
62.9,
99.1,
91.7,
44.1,
37.1,
23.7,
80.8,
10.2,
27.3,
66.6,
41.2,
45.8,
0.4,
86.4,
51.1,
78.2,
68.2,
58.8,
48.4,
42.4,
81.8,
51.6,
57.2,
69,
74.7,
91.9,
92.6,
77.2,
60.4,
58.3,
53.1,
78,
41.7,
55.3,
72.4,
26.9,
40.2,
24.9,
35.7,
79.7,
64.7,
71.9,
56.1,
44.1,
86.9,
66,
14.5,
51,
30.2,
21,
2.4,
21.7,
20.7,
66.5,
55.5,
79.9,
92.1,
85,
49.2,
51.4,
32.7,
55,
69.4,
55.8,
58.1,
7,
81.8,
94.1,
72.1,
33.5,
31.5,
90.1,
31.2,
53.9,
69.7,
79.5,
25.3,
36.3,
92.6,
60.4,
88.2,
75,
50.9,
52.3,
1.8,
71.7,
80.8,
18.6,
60.8,
75.3,
10.5,
78.2,
51.6,
99.5,
8.8,
95.1,
76,
3.7,
40.1,
91.8,
7.9,
77.2,
47.6,
15.1,
75.4,
43.5,
71.8,
80.6,
66.6,
82.4,
25.4,
15.4,
89.8,
57.1,
38.3,
85.8,
71.4,
45,
43.3,
30.5,
72.1,
53.8,
85.7,
56.8,
30.3,
67.1,
68,
60.1,
5.2,
76.8,
35.2,
92.6,
81.6,
39.8,
48.6,
89.1,
46.3,
31.9,
28.8,
77.1,
76.5,
83,
32.1,
49,
33.8,
4.4,
83.4,
73,
19.4,
54.9,
60.7,
70.4,
70.7,
28.7,
38,
56.8,
36.7,
65.9,
46.6,
35.6,
72.6,
18.2,
58,
45.2,
74.2,
61.6,
4.2,
20.5,
81.1,
58.3,
44.9,
28.8,
31.2,
75.9,
49.5,
89.7,
91,
51.8,
70,
81.2,
61.6,
43.6,
65.2,
58.2,
38.4,
64.8,
79.8,
80.3,
57,
14.1,
45.7,
94.7,
23.8,
83.6,
54.6,
85.8,
77.7,
81.5,
54.9,
45.6,
38.5,
44.7,
15,
74.2,
35.8,
43,
76.3,
36.4,
87.9,
46.5,
71.6,
34.8,
51.2,
52.9,
47.6,
40.3,
31.9,
0,
39,
50.4,
71.4,
48.4,
60.1,
51.2,
43.8,
50.7,
54.3,
63.2,
32.5,
35.8,
20.8,
88,
67,
95,
80.9,
87.6,
78.5,
48,
31.5,
50.2,
12.8,
46.8,
35.2,
58.5,
41.4,
94.2,
39.2,
43.7,
44.6,
87.2,
30,
82.2,
49.2,
5.2,
96.9,
64.2,
80.6,
84.7,
32.4,
36.2,
13.8,
39,
56.8,
98.3,
52.7,
59.5,
82.1,
65,
26.4,
10,
55.4,
61.8,
16.5,
82.2,
31,
10.5,
93.9,
12,
74.3,
39.2,
30.6,
61.3,
53.9,
58,
33,
0.7,
38.2,
43.4,
67.8,
40.9,
83.8,
61.6,
34.2,
33.6,
49.9,
74.7,
27.6,
47,
88.9,
57.7,
19.5,
73.1,
27.6,
96.1,
77,
43.9,
16.2,
54.8,
70.9,
76.3,
98.2,
64.3,
49.4,
18.3,
76.1,
48.4,
43.3,
46.5,
46.8,
12,
89.4,
44.9,
35.6,
96.1,
14.8,
72.4,
54,
59.8,
23.9,
53.3,
46.9,
75.7,
67,
55.2,
92.2,
6.7,
36,
41.7,
68.1,
68,
49.9,
81.7,
57.7,
63.7,
70.3,
32.1,
25.5,
90.3,
73.8,
67.6,
55.9,
48.1,
54,
95.7,
60,
47.6,
55.1,
39.9,
63.4,
46.2,
52.4,
68.6,
79.2,
55.7,
14.9,
88,
67.5,
78.8,
64.8,
33,
47.5,
9.3,
22.1,
34.5,
32,
76.8,
47,
52.9,
78.3,
39.6,
60.4,
64.4,
54.1,
82.5,
42.7,
36.9,
10,
76.2,
20.2,
10.8,
66.7,
20.4,
43.2,
97.5,
82.6,
52.4,
49.8,
48.7,
72.8,
93.6,
36.7,
68.3,
32.6,
68,
81,
30.5,
7.3,
83.9,
99.8,
48.1,
48.8,
62.7,
76.9,
74.9,
24,
23.2,
93.5,
75.7,
74.1,
48.5,
90.4,
56.3,
47.7,
82.6,
78.5,
3.2,
42.6,
42.5,
43.8,
22.2,
22.6,
55,
78.1,
79.4,
20.5,
43.3,
34.4,
59.6,
33.3,
81.4,
39,
69.4,
82.5,
70.6,
51.7,
29.3,
32,
64.6,
41.8,
82.5,
67.6,
71.4,
41.3,
62,
38.5,
42.8,
70.2,
64.9,
77.5,
68.2,
74.5,
79,
64.4,
60.8,
73.4,
43.8,
58.4,
7.6,
56.8,
26.4,
83.5,
13,
27.2,
74.7,
74.5,
83.3,
34,
83.8,
71.3,
39.8,
97.3,
58.8,
73.8,
57,
59,
16.3,
71.9,
66.9,
33.9,
85.6,
21.5,
38.4,
49.6,
40.7,
null,
48.1,
71.3,
78.4,
81.5,
88.4,
23.3,
57.7,
73.3,
20.8,
67.6,
60.2,
60.2,
53.2,
35,
80.6,
45,
46.8,
48.6,
55.8,
28.1,
64.1,
87.4,
51.2,
99.4,
57.8,
56,
33.4,
34.8,
43.5,
44.9,
60.1,
49,
38.2,
36.9,
52.9,
1.2,
58.7,
94,
57.3,
49.3,
15.3,
88.8,
87.8,
95.4,
62.7,
15.9,
68.6,
51.4,
94.9,
75.2,
60.6,
22.6,
43.1,
51.1,
18.2,
76.1,
20.9,
74.8,
51,
91,
31.4,
98.9,
37.9,
70.1,
40.4,
92,
75.4,
89,
94.6,
64.3,
89.7,
49.9,
46.9,
77.4,
56.9,
73.6,
43,
79.7,
18.5,
82.9,
44.6,
10.2,
69.3,
55.8,
89.3,
99.6,
57.2,
43.1,
42.3,
78.7,
94.3,
83.1,
82.3,
56.1,
58.2,
59.9,
33.9,
30.9,
35.7,
71.8,
88.2,
42.1,
40.4,
44,
77.2,
13.3,
24.5,
43,
33,
23.4,
20.6,
30.2,
84.3,
48.6,
41.2,
33,
30,
15,
30.9,
49,
76.9,
50.7,
98.8,
36.9,
36.4,
83.4,
61.1,
47.9,
8.3,
89.2,
53.7,
27.1,
70.1,
58.9,
101.9,
39.4,
61.3,
27.6,
27,
60.6,
20.6,
70.1,
64.2,
60,
47.7,
52.9,
51,
39.5,
54.7,
16.4,
94.9,
73.6,
96.9,
64.4,
68.8,
84.8,
68.1,
41.7,
24.5,
22.7,
32,
42,
29.6,
62.4,
38.6,
95.4,
66,
50,
9.2,
75.8,
56.3,
20.2,
56.8,
55.1,
8.2,
22.1,
4.7,
31.7,
46.1,
50.3,
31.3,
92.7,
10.6,
7.5,
64,
4.9,
30.5,
56.2,
87.1,
59.7,
39.8,
72.3,
70,
69.9,
12.8,
38.1,
55.9,
16.7,
85.8,
54.6,
47.2,
50.5,
19.6,
65.4,
87.4,
70.9,
83.3,
22.4,
57.5,
45.9,
70.7,
21.1,
95.2,
23.8,
77.7,
47.4,
80,
88.3,
35.7,
42.5,
38.2,
73.8,
35.7,
11.5,
72.3,
77.2,
46.2,
65.3,
83.7,
71,
71.8,
21.8,
54.2,
38.1,
71.4,
81,
73.8,
50.3,
58.9,
41.3,
94.9,
12.9,
11.1,
28,
17.1,
59.4,
33.8,
93.3,
31,
29.5,
0,
20.7,
20.9,
68.9,
66.6,
36.3,
72.7,
87.1,
38.9,
61.8,
29.5,
61.7,
31.5,
90.6,
75.1,
69.7,
25.3,
45.7,
70.7,
39.1,
56.2,
16.7,
34.1,
67.6,
4.1,
53.9,
44.4,
45.3,
36.9,
44.3,
90.6,
30.7,
27.2,
77.7,
90.9,
74.3,
36.7,
72.1,
75.4,
38,
6.7,
18.2,
45.2,
85.5,
79.5,
77.1,
73,
19,
97.1,
44.7,
81,
56.8,
75.1,
65.2,
58.5,
82.1,
45.4,
74.1,
64.1,
70.2,
31,
75.9,
55.4,
99,
65.9,
56.4,
32.4,
55,
38.2,
46.7,
30.5,
37.8,
88.6,
46.8,
70.2,
37.9,
75.9,
47.6,
56.7,
62,
60,
37.8,
69.1,
68.2,
37.7,
32.2,
79.1,
35.1,
38.4,
85.3,
84.8,
101.3,
27,
20.7,
97,
81.7,
64.4,
54.9,
24.4,
72.6,
63.7,
63.5,
63.8,
38.8,
73.6,
53.1,
21.2,
31.4,
50.5,
89.9,
68.4,
43.1,
68.1,
1.5,
58.1,
58.9,
92.7,
55.1,
41.3,
61.1,
17.7,
94.8,
62.8,
48.8,
66.2,
94.8,
34,
52,
85.6,
21.3,
36.3,
58.7,
12.5,
56.1,
59.2,
56.4,
21.4,
12,
71.5,
21,
68.6,
44.5,
42.7,
0,
40.8,
35.5,
77.3,
34.2,
19,
5.4,
78.2,
55.9,
87.2,
52.9,
42.9,
36.2,
91.8,
61,
30.3,
59.1,
29.3,
54.6,
98.5,
55,
76,
72.4,
52.4,
52.2,
81.8,
81,
58.5,
72.9,
43.2,
89.4,
29.4,
36.4,
27.3,
33.9,
50,
66.1,
26.5,
32.6,
32.9,
83.1,
61.8,
16.3,
24.9,
38,
93.2,
61,
69.4,
26.3,
51,
42.8,
80.9,
68.9,
59.7,
38.2,
96.5,
38,
51.2,
81.2,
44.6,
80.2,
50.2,
48.3,
72.3,
35.5,
35.5,
68.6,
82.5,
59,
75.6,
72.1,
84,
52.3,
70.3,
71.7,
0.1,
46,
7.8,
46.3,
54.6,
49.6,
82.2,
3.5,
44.7,
31.3,
58.6,
63.4,
58.6,
66.3,
36.8,
66,
93.5,
48.9,
57,
24.5,
39.7,
61.4,
78.1,
64,
87.5,
51.4,
37,
12.4,
44.4,
34.9,
66.6,
42,
69.3,
65.1,
49.4,
85.6,
93.8,
79.6,
54.6,
88.9,
93.2,
59.7,
78,
50.2,
87.1,
52.9,
53.1,
67.6,
27.8,
29,
38.1,
49.3,
66.6,
42.4,
66.9,
60.7,
47.7,
6.4,
87.6,
79.2,
98.1,
57.4,
80,
34,
49.2,
19.5,
8.8,
32.8,
91.9,
47.2,
33.7,
53.4,
28.5,
61,
13.9,
73.6,
93.4,
84.9,
30.4,
59.1,
23.9,
9.2,
66.7,
51.9,
87.9,
49.1,
88.8,
66.3,
69.7,
28.9,
84.8,
38.7,
12,
31.7,
24.6,
54.2,
31,
59.5,
87.9,
10.5,
61.3,
22.9,
17.7,
84.3,
47.7,
45,
70.9,
30.4,
64.3,
77.4,
51.4,
73.6,
77,
38.8,
65.3,
39.6,
42.9,
56.5,
23.6,
73.8,
57.6,
31.8,
46.4,
35.3,
43.3,
48.5,
33.7,
20.7,
32.8,
32.4,
64,
28,
37.9,
64.9,
51.5,
57,
28.1,
50.6,
78.6,
96.2,
63.9,
36.5,
62,
25.7,
63.7,
74.1,
81.5,
65.3,
65.8,
38.9,
46.9,
72.7,
91.9,
68,
88.5,
81.9,
24,
35.5,
10.9,
41.7,
73.3,
81,
91.5,
35.5,
64.5,
86.8,
53.3,
83.1,
97.5,
16.3,
53.6,
29.5,
87.3,
39,
46.8,
69.8,
25,
92.2,
32.8,
82.2,
68.8,
44.5,
51.1,
14.5,
19.8,
55.2,
38.1,
78,
75.7,
91.1,
29.9,
14.1,
58,
39.5,
93.2,
80,
86.4,
36.1,
18,
22,
57.3,
86.1,
47.7,
32.8,
30.7,
58,
71.3,
68.3,
69.3,
31.3,
55.2,
11.9,
56.9,
32,
59.4,
17.8,
61,
5.4,
36.9,
57,
65,
50.7,
91.7,
56.1,
88.7,
18.8,
44.3,
32,
60.4,
71.1,
27.4,
34.1,
48.7,
39.2,
29.5,
24.9,
39.9,
90.8,
45.9,
24.2,
75.7,
97.3,
37.7,
59.9,
32.5,
73.3,
52.4,
38.6,
71.8,
89.4,
53.3,
59.3,
67.1,
97.6,
8.8,
29.9,
11,
39.6,
43.1,
71,
38.2,
72.2,
24.3,
59.1,
67.9,
41.3,
73.4,
33.4,
60,
66.6,
1.4,
29.7,
63.6,
74.6,
33.5,
78.6,
36.7,
16,
68,
66.5,
65.4,
78.9,
30.2,
16.7,
94.6,
68.1,
12.9,
48.4,
29.6,
20.6,
59.5,
46.5,
54.4,
47.8,
77.7,
19.8,
71,
38.3,
76,
27.5,
64.1,
90.5,
61.6,
54.9,
83.6,
36.4,
18.4,
38.7,
49.1,
36.1,
79.4,
42.8,
56.9,
59.1,
55.8,
41,
68.4,
27.2,
25.4,
43.5,
40.2,
31,
3.8,
83.7,
83.5,
16.5,
71.7,
79.3,
30.1,
79.5,
15.6,
17.6,
53,
67.3,
63.7,
27.9,
95.5,
56.7,
66,
102.1,
45.5,
79.7,
38,
80,
87.1,
33.1,
79.8,
37.8,
41.4,
34.5,
37,
32,
37.3,
84.6,
47.6,
97.2,
75,
88.5,
48.3,
17.4,
35.7,
50.2,
45,
47.1,
72,
11.9,
37.2,
79.4,
60.3,
31.7,
91.8,
76.4,
46,
54.7,
38,
98.3,
34.3,
71.7,
51.4,
18.5,
68.8,
84.6,
72.5,
10.9,
20,
53,
37.5,
28,
3,
61.8,
67.5,
68.6,
94.1,
53,
46.2,
55.5,
42.9,
48.9,
66.9,
67.7,
61,
30.1,
80,
87.7,
71.6,
57.2,
69,
35.7,
59.7,
41.8,
43.6,
88.7,
74.9,
53.4,
24.2,
31.3,
42.7,
59.8,
55.2,
60.2,
88.2,
54.5,
77.3,
25.1,
65.3,
90.6,
51.7,
49.2,
80.4,
54.6,
48.8,
78.5,
61,
14.1,
68.6,
59.4,
55.3,
19,
57.5,
36.1,
30.6,
22.9,
57.7,
67,
47,
24.4,
45.9,
42.3,
89.2,
88.5,
50.9,
71.4,
48.6,
18,
53.1,
62.5,
65.5,
60.8,
26.9,
29.4,
26,
53.4,
45.4,
31.7,
70.9,
59.3,
76.1,
42.1,
25.9,
55.3,
58.6,
98.6,
37,
61.1,
60.5,
34.2,
49.3,
66,
6.3,
52.3,
39.5,
53.4,
44.6,
58.6,
15.3,
99.3,
41.5,
22.3,
36.6,
32.5,
52.7,
71.9,
84.1,
75.3,
67.4,
90,
80.8,
5.6,
75,
72.1,
70.3,
94.9,
74.4,
92.5,
25.8,
64.1,
36,
25.3,
91.6,
8.3,
48.9,
47.3,
53.9,
30.7,
64.9,
36.2,
39.8,
54.2,
99,
78,
31.3,
63,
83.1,
44.5,
51.7,
59.5,
65.5,
93.1,
53.1,
85,
2.2,
69.3,
91.7,
80.4,
44.3,
64.9,
44.3,
77.1,
52.3,
54.9,
25.7,
62.5,
82.1,
57.6,
28.8,
72.5,
13,
49.9,
66,
61.2,
71.2,
43.2,
65.5,
30,
26.1,
52,
42.5,
75.2,
48.8,
46.4,
95.2,
56.6,
57.4,
56.9,
50.6,
63.6,
77.4,
94.7,
32.3,
59.7,
67.2,
42.9,
65.8,
85.7,
53.6,
56.9,
36.6,
21,
32.7,
25.5,
56.3,
72.5,
64.7,
69.1,
82,
83.1,
32.8,
66,
16.8,
40.8,
34.2,
50.7,
30.2,
95.4,
92.6,
68.1,
67.1,
77.8,
38.7,
18.7,
5.4,
49.8,
74.1,
62.7,
31.6,
79.1,
36.6,
47.5,
89.1,
56.4,
79.2,
71.8,
5.1,
52.5,
44.4,
17.9,
87.8,
48.9,
96.8,
95.8,
64,
5,
72.1,
31.9,
97.4,
98.9,
4.2,
72.6,
60,
59.7,
64.4,
52.3,
62.8,
90.9,
31,
83.2,
87.9,
49.5,
58.1,
93,
14.7,
72.8,
71.4,
21.7,
26.3,
95.9,
33,
49.3,
61,
64.9,
42.6,
54,
36.5,
29.6,
85.9,
54.8,
91.5,
27.2,
54.1,
98,
50.7,
42.5,
43,
21.2,
57.2,
72.7,
77.1,
55.5,
60.5,
21.8,
33.1,
36,
40.3,
78.4,
60.5,
47.6,
74,
82.3,
77.1,
71.8,
72.6,
84.5,
61.1,
46.1,
60.8,
71.3,
66.3,
52.4,
84.8,
59.7,
56.5,
58.3,
78.5,
81.5,
53.7,
44,
23.4,
87.2,
32.4,
88.2,
52.5,
72,
22.9,
79,
45.7,
56.7,
27.7,
43.5,
54.8,
94.3,
59.1,
0.4,
63.5,
46.3,
61.8,
69.4,
53.3,
52.2,
82.1,
69.1,
70.9,
25.8,
70.2,
44.4,
28.3,
54.5,
100.5,
74.5,
51.4,
65.2,
60,
82.2,
14.9,
35.2,
67.2,
36.7,
65.9,
60.7,
69.5,
31.6,
36,
52.6,
49.7,
100.9,
15.4,
43.8,
18.2,
75.5,
93.6,
45.1,
48.3,
39,
66.7,
27.1,
86.5,
92.8,
59.3,
82.2,
53.6,
2.6,
68.6,
59.4,
75.7,
18.2,
7.9,
84.9,
66.8,
70,
52.7,
77,
76.4,
77.7,
57.4,
23.1,
74.9,
20.3,
63.6,
71.5,
9.5,
33.8,
48.3,
61,
64.9,
43,
47.3,
44.5,
73.3,
24.3,
59.4,
55.9,
74.2,
66.2,
58.7,
51.5,
63.6,
68.3,
22.4,
38.8,
88.3,
22.9,
62.9,
62.6,
69,
71,
43.4,
92.9,
36.9,
68,
53,
44.2,
88.7,
64.4,
37.1,
37.7,
15.3,
97.4,
53.7,
78,
79.2,
49.9,
91.8,
62.7,
52.1,
13.7,
36,
28.2,
46.6,
17.4,
37.2,
94.6,
73.1,
60.2,
70.7,
72.7,
13.5,
75.6,
32.6,
44.9,
64.5,
47.3,
44,
69,
40.7,
40.6,
64.2,
91.7,
87.9,
94.5,
14.3,
55,
89.7,
77.8,
78.7,
39.7,
75.6,
41.2,
16.6,
89.9,
49.6,
92.2,
16.7,
30.2,
54.8,
50.5,
49.5,
62.4,
64.6,
16.2,
43.9,
82.5,
76.7,
66.6,
78.1,
98.7,
69.3,
88.9,
54.3,
79,
57.9,
44.4,
42.7,
85,
48,
89.7,
84.2,
75,
70.8,
29.9,
77.3,
45.3,
28.4,
49.6,
17.6,
26,
56.4,
12.1,
22.7,
72.8,
41.8,
71.1,
22.2,
97.7,
50.7,
41.6,
59,
34.8,
45.3,
48.2,
36.4,
65.9,
23.4,
69.9,
71.5,
68.9,
8.7,
45.3,
21.7,
39.3,
40.7,
51.6,
63.6,
41,
52,
93,
48,
23.2,
52.3,
51.1,
50.8,
98.2,
81.5,
52.9,
96,
29.1,
77.9,
99,
59.3,
40.9,
25.6,
46.3,
50.5,
53.3,
26.2,
57.1,
31.8,
37.7,
17.2,
58.2,
55.9,
69.5,
51.7,
48.8,
41.4,
61.1,
88.1,
27,
18.3,
78,
45,
79,
63.5,
29.4,
64.7,
15.9,
18.4,
67.3,
46.5,
52.3,
87.4,
56.8,
25.1,
46.2,
78.6,
45.8,
52.3,
64,
61.5,
53.4,
77.5,
17,
59.2,
64.4,
43.5,
87.9,
44,
69.9,
29.5,
74.4,
45.8,
70.3,
22.1,
30,
30.8,
53,
59.5,
37.8,
67.8,
44.1,
97,
69,
72.7,
89.5,
73.9,
58.8,
95,
91,
67.8,
24.3,
21.8,
52.5,
37,
51.9,
15.1,
52.3,
58.5,
28.6,
86.5,
98,
42.8,
48,
71.1,
46.3,
55.1,
26.3,
75.1,
56.1,
80.9,
56.2,
63,
55.3,
79.3,
73.2,
53.8,
29.4,
77.8,
63,
62.7,
57.4,
60.3,
70.4,
37.5,
95.4,
67.1,
67.5,
88.2,
34.4,
17.2,
79.5,
62.4,
64.5,
85.5,
72.1,
60.2,
6.5,
76.1,
75.2,
95,
57.1,
68.3,
68.7,
61.7,
34.4,
18.9,
35.5,
73.1,
61.9,
8.2,
58.6,
85.7,
89.1,
54.7,
53.1,
92.6,
100.9,
49.1,
94.7,
41,
78.7,
93.7,
64.6,
78,
72.7,
43.7,
70.4,
75,
55.2,
96.3,
58.3,
42.3,
90.1,
100.2,
59.3,
54.7,
41,
23.5,
52.1,
33,
49.5,
42.5,
43.4,
57.7,
73.9,
67.9,
42.1,
35.8,
37.5,
41.5,
26.2,
45.9,
42.6,
62,
61.9,
71.2,
21.5,
82.8,
59.5,
12.4,
15,
60.7,
53.1,
38.5,
86.9,
66,
44.3,
62.4,
75.4,
71.5,
41.2,
31.5,
48.2,
53.5,
37,
66.5,
46.6,
26.7,
88.9,
96.5,
24.3,
20.6,
87,
76.3,
58.8,
69,
39.5,
20.5,
64,
81,
47.1,
49.4,
51.2,
71.2,
79.6,
50.7,
38,
81.7,
99.2,
53.1,
70.6,
78.7,
19.9,
52.2,
61.3,
22.1,
56.9,
63.7,
71.9,
65.5,
26.6,
83.4,
22.6,
16.1,
41.5,
98.1,
94.3,
39.5,
68,
95.9,
67.8,
82.9,
97.3,
52.2,
58.1,
62.6,
41.4,
56.7,
16.5,
57.5,
27.6,
57.8,
9.1,
38.1,
42.8,
46.8,
68.6,
20.1,
51.7,
7.1,
24,
93.2,
54.6,
15.7,
25.1,
25.5,
70.8,
72.7,
28.1,
8.3,
79.4,
76.1,
90.7,
55.3,
36.8,
60.3,
97.1,
46.8,
37.6,
61.2,
61.2,
54.4,
18.8,
60.9,
84.8,
64.8,
38.8,
88.6,
46.3,
52.3,
90.6,
64.2,
55.9,
48.5,
56.3,
30.5,
66.3,
41.5,
42.8,
62.8,
25.1,
33.7,
55.9,
0,
88.9,
102.1,
31,
79.5,
31.6,
19.6,
51.3,
69.5,
18.6,
6.2,
57.3,
99.3,
5.2,
45.1,
84,
54.7,
61.7,
61.2,
84.8,
45.5,
9.5,
65.4,
48.4,
76.1,
76.8,
64.9,
64,
43.2,
22.2,
66.1,
85.1,
91.7,
71,
46,
43.1,
99.3,
47.8,
88,
58.2,
29,
57.6,
70.8,
53.5,
54.1,
60.6,
17.1,
61.2,
24.5,
47.6,
40.5,
47.2,
21.1,
79.9,
60.6,
56.2,
30.9,
77.2,
98.1,
25.3,
32.2,
42.8,
0,
44,
56.4,
72,
77,
87.2,
59.9,
97.3,
85,
32.7,
51,
50,
58.7,
59.8,
21.5,
90.3,
43.4,
59.4,
41.3,
76.3,
40.8,
33.2,
24.4,
70.2,
60,
87.4,
20.7,
54.4,
93.2,
38,
78.3,
94,
4.9,
59.9,
57.9,
83.2,
37.1,
54.2,
52.8,
22.4,
51,
62.4,
64.8,
43.5,
59.6,
54,
96.7,
26.4,
74.2,
57,
94.7,
75.6,
55.6,
72.7,
51.7,
51.5,
63.8,
48.3,
38.2,
16.9,
92,
47.1,
56.8,
62.1,
74.2,
5.2,
66.5,
70.2,
40.2,
56.5,
42.9,
81.9,
8.3,
14,
92.4,
76.9,
66.7,
61.8,
21.2,
68.7,
32.8,
43.8,
78.5,
38.4,
61.2,
60.1,
8.4,
83.2,
82.9,
43.4,
39.9,
27.1,
21.8,
77.1,
45.4,
53.9,
48.5,
72.6,
47.7,
65.7,
60.6,
50.7,
92.8,
82.1,
90,
59.6,
32.6,
54.7,
16.5,
56.4,
74.8,
60.9,
80.9,
30.3,
17.6,
29.9,
55,
19.1,
69.3,
35.2,
66.8,
34.9,
41.6,
69.1,
49.4,
35.9,
0,
44.3,
85.5,
70.4,
85.7,
89.3,
89.6,
75,
39.6,
56.8,
75.2,
39.9,
64.5,
46.7,
55.2,
14.6,
46.4,
54.1,
79.2,
59.3,
53.9,
67.6,
65.8,
57,
25.3,
46.1,
76.8,
99.2,
44.8,
28.2,
3.5,
73.9,
36.5,
27.9,
54.7,
40,
25.4,
44.8,
26.4,
57.4,
53.2,
91.8,
3.2,
81.5,
38.7,
93.1,
62.8,
17.6,
38.6,
79.9,
91.1,
52,
52.2,
61,
44.1,
54.7,
59.1,
11.8,
78.7,
42,
97.8,
55.9,
51.6,
72.9,
63.2,
34,
42.8,
28.3,
84.4,
26.1,
52.1,
37.3,
78.6,
53.4,
84.7,
64.1,
57.7,
57.1,
56.3,
56.3,
66.6,
42.4,
52.9,
48.2,
30.7,
65.8,
59.9,
10.3,
77.1,
79.5,
62.1,
39.1,
60.7,
48.9,
12.4,
67.9,
29.1,
47.3,
11.5,
74.3,
56,
58.3,
61.8,
70.3,
62.1,
60.5,
62.9,
23.5,
47.7,
71,
48.7,
64.1,
68.6,
42.7,
65.9,
68.5,
17.7,
29.9,
26.6,
62.8,
31.7,
52.8,
65.4,
21.3,
67.1,
98.4,
46.5,
43.4,
45,
66.7,
36.9,
89.6,
33,
86.1,
95.9,
85.8,
67.2,
8.9,
37.5,
63.9,
44.6,
21.4,
40.2,
53.9,
72.5,
12.6,
45.2,
87.3,
48.9,
24.7,
68.3,
47.1,
72.9,
10.3,
68.7,
65,
25.2,
83.7,
48.6,
45.6,
66.5,
34.6,
6,
77.2,
59,
90,
28.3,
48,
58.7,
58,
67.6,
55.2,
68.2,
65.3,
74.4,
49.3,
38.4,
81.2,
64.5,
85.2,
13.1,
38,
15.4,
50,
32.5,
58.2,
98,
42.2,
95.9,
39.5,
11.7,
75,
52.9,
87.8,
92,
79.6,
45.4,
62.5,
26.5,
20.3,
89.2,
67.1,
84.6,
48.1,
70,
68.9,
50.6,
81.9,
94.6,
7.3,
37.8,
94.4,
20.8,
74.2,
35.8,
49.1,
31.9,
19.4,
66.7,
91,
64.4,
53.8,
36.6,
84.9,
0,
57.3,
15.8,
46.7,
59.6,
72.7,
86.7,
79.9,
40.1,
81,
41.2,
57.1,
9.6,
80.7,
71.6,
42.5,
41.5,
48.4,
41.2,
59.3,
83.9,
92,
37,
77.9,
62.8,
71.2,
72.3,
50.3,
38.5,
45.4,
89.2,
72,
57.3,
52.4,
68,
36.2,
60.9,
98.6,
59.5,
32.9,
34.4,
95.1,
57.5,
66.8,
60.2,
34.5,
56.4,
72.4,
8.9,
56.5,
20.1,
45.2,
60.1,
78.8,
64,
35.1,
51.7,
58.3,
83.2,
58.2,
18,
54.9,
45.1,
61.3,
79.2,
51.5,
98.8,
57.8,
44,
76.4,
24,
45,
41.3,
23.7,
54.2,
77.6,
42.6,
75.1,
54.7,
77.7,
71.7,
11.8,
40.1,
63.1,
60.4,
43,
46.9,
98.1,
56.8,
6.9,
42.2,
87.3,
43.7,
82.2,
100.5,
33,
45.9,
59.7,
66.6,
81.2,
75,
63.5,
44.8,
52.9,
89,
44.1,
33.2,
84.8,
3.3,
10,
56.7,
63,
43.2,
34.8,
56.3,
33.9,
35.9,
59.2,
74.6,
75.4,
82.9,
14.4,
78,
93,
37.1,
61,
29.3,
3.8,
44.9,
75.9,
73.7,
91.2,
53.7,
96.7,
65.1,
32.4,
37.2,
76.4,
87.4,
66.9,
48.8,
48.9,
11.2,
60.7,
81,
15.3,
74.1,
65.2,
70.9,
8.7,
61.6,
54.7,
89.6,
78,
11.7,
34.1,
66.1,
56,
36.4,
49.4,
72.7,
92.5,
40.7,
11.8,
24.2,
33,
75.5,
80.6,
84.7,
37,
20.6,
55.3,
97.5,
76.8,
68.5,
55,
89.4,
71.3,
68.3,
24.2,
98.1,
53.8,
69.2,
76.8,
1,
72,
41.3,
12,
34.7,
94.9,
44.8,
55.6,
32.9,
29.1,
86.3,
70,
30.1,
0,
53.5,
64.7,
19.8,
25.9,
40.4,
33.1,
64.3,
88.4,
54.2,
22.5,
73.2,
37.1,
75.2,
97.4,
90.8,
70.6,
23.6,
77.1,
33.1,
70.8,
49.2,
84,
58.6,
66.5,
71.3,
99.8,
15.7,
29.7,
69.2,
68.9,
45.7,
64.8,
70.7,
95.9,
62.7,
26.9,
56.5,
40.4,
19,
43.8,
88.1,
61.6,
56.2,
42.7,
47.9,
53.9,
29.5,
27.3,
61.3,
54,
85.7,
88.6,
49.7,
56.2,
29.2,
27.7,
57.2,
17.3,
24.1,
75.7,
38,
39.7,
21.2,
80,
43,
35.7,
46.6,
7.3,
39.9,
68,
105.9,
75.2,
53.3,
86.4,
8.8,
4,
7.3,
33.8,
25.4,
32.1,
12,
50.5,
64.7,
64,
72.5,
14.7,
75.4,
22.6,
88.5,
47.8,
71.6,
20.6,
64.8,
47.8,
7.7,
11.8,
32.4,
77.6,
56.4,
49.2,
87.7,
63.5,
28.2,
49,
61.6,
100,
67.7,
71.4,
13.2,
78.9,
91.7,
15.8,
54.1,
50.5,
27.9,
55.8,
38,
66,
85.2,
78.2,
77,
16.9,
51.9,
7.7,
63.2,
70,
71.4,
31.8,
18.1,
33,
38.7,
86,
49,
62,
59.3,
62.7,
30,
69.9,
49,
55.7,
32.8,
54.2,
46.8,
85.9,
29.5,
37.3,
85.1,
58.9,
4.6,
6.8,
67.6,
47.2,
60.8,
29.6,
74.9,
4.6,
72.2,
95.8,
38.4,
56.6,
65,
88.2,
49.7,
73.7,
24.1,
59.3,
62.1,
39.3,
41.5,
5,
30,
72.1,
93.5,
30.1,
60.8,
89,
92.1,
63.8,
41.8,
54.6,
91.1,
66.1,
36.1,
25.1,
87.1,
14.9,
122.8,
23.3,
68.8,
82.5,
70.3,
95.4,
29,
7.6,
60.2,
92.3,
55.2,
25.6,
54.5,
55.7,
94.5,
62,
28.8,
21,
65.9,
42.8,
55.6,
0,
36.8,
4.6,
76.6,
92.9,
7.5,
79.6,
34,
76.7,
35.7,
96.1,
2.2,
73,
85.7,
43,
81.4,
47.8,
55.9,
52,
28.9,
49.9,
59.5,
48,
70.8,
41.5,
57.8,
71.7,
39.7,
80.6,
58.5,
24.2,
50.1,
81,
58.8,
55.4,
96,
94.6,
83,
83.4,
100.9,
34.2,
44.9,
96.8,
68.6,
48.1,
24.1,
69.9,
46.7,
34.2,
58.2,
2.8,
91.7,
31.9,
33.6,
66.5,
26.7,
45.3,
49.4,
51.3,
58.8,
34.3,
77.8,
81.2,
38,
35.3,
65.3,
22.9,
75,
75.2,
60,
56.4,
38.8,
34,
82.2,
88,
15.9,
69.1,
40.7,
60.7,
59.4,
65.9,
21,
50.4,
95.9,
66.2,
9.9,
19,
54,
42.2,
56.2,
75.8,
76.2,
82.4,
80.2,
63,
49,
67.3,
79.1,
61.6,
45.5,
59.8,
27.7,
54.7,
75,
48.2,
36.1,
34,
63.8,
80.2,
59.6,
83.1,
88.8,
19.4,
71,
62.9,
3.4,
88.8,
12.1,
94.3,
86.2,
57.4,
92.4,
86,
66.9,
97.1,
63.9,
63.3,
51.6,
48.5,
63.4,
58.6,
36.4,
83.7,
87.5,
73,
60.8,
55,
78.8,
33.5,
27.5,
64,
63.2,
87.5,
24.6,
26.6,
37.6,
97.4,
54.5,
57.7,
29.8,
33.4,
43.4,
35.1,
78.6,
56.1,
61,
28.9,
96.8,
23.8,
49.4,
46.9,
75.4,
83.5,
53.4,
36.3,
82.7,
95.7,
19.8,
67.5,
17.3,
85,
61,
49,
33.2,
72.5,
23.5,
22.2,
17,
46.3,
16.3,
25.5,
71.9,
68.4,
43.5,
26.6,
40,
94.7,
67.5,
35.8,
77.4,
36.3,
15.2,
74.2,
63.8,
75.5,
22.4,
83.5,
37.9,
30.5,
83,
95.3,
47.3,
49.9,
49.5,
31.3,
36.2,
24.9,
22,
88.5,
11.9,
43.5,
66.3,
53,
21,
57,
38.6,
97.4,
66.3,
73,
92.4,
45.7,
50.3,
34.6,
59.2,
68.6,
24.3,
61.3,
43.8,
60,
61.7,
60.8,
71.7,
81.3,
10.5,
31.7,
50.9,
57,
83.7,
99.8,
31.6,
79.7,
73.5,
61.8,
47.1,
57,
56,
50.1,
62.8,
49,
94.2,
94.2,
85.9,
83.1,
81.3,
73.4,
94.5,
58,
76.7,
79.7,
15.7,
81,
92.3,
43.4,
66.9,
23.8,
31.2,
10.9,
59.4,
90.3,
74.2,
48.1,
38.1,
66.3,
58.2,
51.4,
79.6,
31.7,
69.7,
23.8,
17,
83.5,
37.5,
32.8,
66.7,
3.3,
82.4,
25.1,
73.9,
60.2,
7.7,
91.8,
33.2,
49.8,
90.9,
81.6,
67.2,
80.1,
16.5,
44.4,
26.4,
0,
37.1,
83.4,
16.3,
88.4,
42.2,
53.3,
52,
36.4,
79.3,
49.3,
19,
33.3,
3.6,
38.8,
75.5,
41.8,
89.4,
54.5,
84.8,
72,
51.7,
52.7,
85.8,
96.4,
65,
91.6,
86,
41.5,
83.2,
25.9,
49.5,
95.9,
58,
75.8,
48.6,
18.8,
52,
86,
39.2,
51.6,
19.3,
41.2,
53.8,
70.1,
33.6,
82.1,
43.5,
43.2,
52.3,
71.2,
60.3,
48.9,
64.3,
57.4,
55.9,
67.6,
79.1,
42.1,
62.8,
90,
16.3,
68.8,
36.7,
34.9,
47.8,
35.7,
26.8,
2.8,
78.8,
36.5,
81.1,
21.9,
89,
43.7,
0,
56.5,
81.3,
27,
64,
55.2,
20.1,
61.3,
39.2,
42.2,
45.9,
42.2,
20,
22.4,
56.2,
58.1,
49.3,
34,
72.1,
97,
68.6,
64.2,
24.6,
53.6,
66,
29,
78.9,
50.1,
69,
56.1,
58.7,
61.5,
1.2,
48.8,
45,
85.6,
57.8,
29.1,
77.5,
67.7,
32,
38.3,
73.8,
69.2,
66.9,
75.1,
12.6,
41.6,
46.8,
20.6,
4.1,
38,
74.3,
57.5,
79.1,
31.1,
43,
65.9,
31.2,
63.6,
55.2,
18.1,
36.8,
87.1,
66.6,
20.8,
7,
88,
9.4,
69.5,
40.9,
80.9,
44,
60.8,
94.5,
17.9,
66.6,
59.8,
40.2,
47.2,
97.1,
76,
65.1,
36.4,
75.3,
74,
81,
59,
68.1,
58.4,
29.6,
49.3,
84.7,
23.4,
64.3,
60.3,
55.7,
33.6,
58.9,
45.5,
66.7,
69.7,
92.3,
87.6,
28.3,
68.6,
39,
45.6,
60.5,
61.9,
64.7,
76.5,
83.2,
44.6,
68.4,
54,
105.2,
67.9,
69.4,
57.6,
83.4,
70.8,
59.1,
56.2,
88.6,
26.4,
85.5,
46.6,
65.7,
49.4,
62.9,
53.6,
50.2,
25,
80.8,
95.8,
86.8,
26.8,
19.9,
84.8,
31.8,
47.2,
37.5,
83,
76.2,
63.8,
61.2,
36.9,
68.6,
60.1,
59.7,
36.8,
74.9,
29.3,
80.5,
86.6,
59.9,
63.9,
57.1,
85.3,
29,
44,
72.2,
38.4,
58.8,
62.8,
44.2,
65.8,
59.5,
75.3,
38.1,
32.9,
41,
75.1,
34.9,
73.7,
88,
59,
74.5,
42.3,
30.4,
31.1,
98.6,
35.5,
44.4,
83.4,
34,
4.2,
81.8,
77.2,
68,
38.1,
34,
38.1,
19.1,
16.7,
38.2,
53.6,
82.5,
62.8,
66.2,
95.1,
62.1,
63,
95.5,
64.1,
18.4,
61.7,
44.2,
54.5,
31.2,
28.5,
45.7,
42.9,
74,
38.7,
62.1,
74.6,
22.7,
31.7,
40.8,
98.5,
64,
89.2,
15.9,
76.2,
52.8,
87,
21.3,
61.1,
55.2,
68.5,
43.8,
60.9,
81,
52.6,
72.8,
30.4,
63.6,
41.3,
19.6,
58.2,
48.1,
99.9,
46,
80.8,
89.3,
71,
40.1,
20.8,
70.3,
97.8,
91.7,
51.5,
84.1,
68.2,
93.4,
56.3,
67.8,
88.6,
61.6,
81.3,
15.5,
67.1,
51.4,
33.6,
67,
65.8,
59.2,
7.4,
1,
59.5,
72.5,
66.7,
40.7,
95.7,
95.1,
23.9,
43.5,
84.5,
48.6,
69.9,
32.7,
39.4,
68.5,
36.5,
45.4,
16.7,
85,
42.7,
39.3,
4.7,
92.8,
18.9,
98.9,
19.8,
62.8,
68,
36.5,
30.6,
57.7,
25.5,
18,
72.8,
24.2,
9.2,
36.3,
41.7,
82.5,
68,
34.4,
41.9,
89.1,
28.6,
70.9,
56.4,
8,
86.7,
4.8,
86.4,
90.9,
46.9,
69.6,
46.7,
36.8,
27.8,
50.3,
45.4,
74.9,
36.7,
25.3,
23,
28.7,
67,
71.1,
72.2,
79.9,
31.3,
90.6,
57.9,
38.2,
29,
52.5,
69.9,
59.6,
88.3,
16.3,
46.3,
42.4,
58.5,
47.6,
76.9,
47.3,
71.9,
68.2,
53,
64.9,
49.5,
21.1,
57.6,
59,
70.4,
30,
50.7,
54.3,
33,
25.2,
27.2,
11.5,
59.6,
97.7,
82.6,
85.6,
39.6,
86.8,
23.2,
44.2,
42.1,
66.2,
37.6,
70.1,
63.8,
21.5,
38.6,
58.6,
56,
80,
37.8,
12.1,
68.6,
81.9,
53.2,
36.2,
46.2,
75.6,
22.5,
63.8,
89.4,
85.3,
40.1,
80.1,
79.7,
78.6,
31.8,
96.6,
77.4,
79.5,
54.2,
66.3,
74.8,
27.8,
35,
19.3,
65.6,
52.5,
20.6,
38.5,
86.6,
75.2,
13.5,
53.2,
71.5,
23.6,
84.6,
48,
82.1,
52.9,
30,
96,
82.2,
77.9,
39.4,
70.5,
81.1,
98.5,
89.7,
55.7,
79.7,
62.7,
48.3,
20.8,
64.4,
81.9,
67.1,
80.7,
65.1,
34.4,
44,
47.8,
20.7,
73.1,
17.5,
43.8,
51.4,
50.6,
51.7,
72.8,
96.1,
65.5,
64.3,
2.5,
31.1,
11.3,
43.6,
13.8,
87.2,
46.2,
83.6,
49.2,
63.6,
31.6,
70.3,
88.8,
20,
32.4,
37.1,
43.4,
69,
65.2,
47.5,
57.2,
51.8,
50.2,
82.8,
3.6,
62.6,
83.7,
79,
61.3,
43.5,
81.4,
97.4,
95.6,
56.7,
65.6,
64,
43.8,
77.1,
97.1,
51.5,
96.9,
68.3,
50,
56.4,
24,
65.6,
67.1,
49.2,
39.8,
76.7,
44.3,
72.6,
31,
69,
58.9,
71.6,
95.9,
40.1,
64.6,
59,
38.2,
73.6,
4.8,
62.8,
27.5,
46.6,
36.5,
28.5,
88.1,
75.4,
50.6,
5.8,
57.4,
72.1,
76.9,
72.8,
57.7,
15,
59.4,
71.8,
46.3,
94.7,
27.3,
35.6,
71.7,
56.7,
36.5,
62.9,
50.9,
59.1,
83.7,
12.3,
36.5,
57.7,
84.2,
34.1,
60.9,
58.5,
31.9,
68.9,
46.6,
72.3,
66.1,
55.2,
57.4,
46.6,
26.3,
33.3,
72,
45,
68.7,
62.9,
92.8,
80.6,
55,
20.9,
48.1,
47.3,
48.7,
66.6,
84.4,
42.4,
45.4,
61.4,
37.2,
54.7,
93.7,
16,
51.3,
37,
57.5,
90,
38.9,
79.6,
55.4,
54.6,
32,
61.7,
61.9,
83.1,
0,
2.9,
90.6,
91.8,
61.8,
60.5,
38.4,
89.1,
87.2,
41.4,
52.5,
73.8,
95.8,
20.1,
26.6,
53.3,
68.4,
67.7,
17.8,
48.4,
37.3,
36.4,
87.5,
28.7,
58.5,
17,
30.5,
30,
34.9,
33.9,
68.8,
43,
55.6,
66.1,
27.6,
71.5,
61.9,
72.5,
76,
65.5,
78,
46.7,
30.4,
93,
83.3,
46,
84.2,
84.8,
17.8,
30,
97.7,
73.5,
41.2,
47.7,
54,
21.2,
85.1,
21.3,
51.7,
33.1,
14.8,
2.6,
77,
11.6,
81.1,
71,
47.1,
33,
68.2,
63.1,
70.1,
46.1,
21.7,
80.3,
98.3,
90,
79.9,
77.2,
82.5,
49.6,
82.2,
32,
13.1,
69.5,
82.6,
69.6,
90.2,
74.9,
67.3,
37.7,
40.3,
37.1,
90.3,
71.8,
24.9,
35.2,
65.2,
81.2,
92.8,
22.1,
78.8,
46.3,
2.9,
82,
65.5,
80.8,
29.3,
26.5,
56.1,
85.4,
80.4,
48.2,
59.5,
58.1,
90.7,
60,
92.5,
65.1,
87.9,
47.3,
93.2,
19.2,
89.1,
87.8,
73,
29.5,
7,
54.3,
84.9,
94.2,
41.5,
47,
45.2,
64.8,
22.1,
43.7,
47,
63.2,
54.2,
69.3,
48.9,
42.2,
63.2,
41.2,
68.8,
33.8,
55.6,
63.8,
36.8,
59.5,
67.3,
88.9,
55.9,
13.1,
61.9,
48.1,
69.1,
38.4,
20.2,
87.1,
17.3,
66.2,
76.9,
50.7,
90.5,
96.5,
54.7,
19.5,
51.8,
90.1,
37.7,
57.5,
35.5,
38.6,
51.8,
45.7,
39.6,
87.5,
50.5,
90.4,
79,
79.1,
80.1,
41.7,
39.7,
81,
52.2,
85.7,
27.7,
50.6,
63.3,
82,
78.9,
94.9,
56.2,
87.8,
53.3,
70.6,
73.8,
94.3,
41.3,
37.4,
32,
69.3,
27.4,
87.3,
57,
49.6,
58.3,
47.7,
57.5,
70,
84,
50.7,
60.4,
36.7,
72.1,
29.3,
25.7,
66.4,
35.3,
42.5,
38.5,
43.4,
64.6,
72.9,
84.3,
38.9,
50.8,
3.9,
58.5,
87,
4.5,
94.4,
18.6,
32.6,
61.5,
50.9,
69.4,
79,
71.3,
14.7,
92.7,
54.7,
84.5,
55.8,
53.3,
7.3,
96.3,
46,
66.7,
29.7,
94.2,
35.3,
82.6,
85.9,
89.8,
84.2,
49.3,
49.4,
20.1,
67.1,
70,
57.8,
69.1,
46.9,
58.5,
37.9,
58.5,
82.4,
47.8,
28.1,
57.1,
48.6,
51.6,
39.7,
6.8,
36.7,
56.8,
57.9,
18.8,
28.6,
32.6,
57.1,
84.2,
23.9,
22.5,
34.6,
70.9,
30.2,
62.8,
48.1,
35,
46.5,
73.5,
30.9,
37.3,
65.7,
80,
43.9,
63.1,
63,
51.7,
71.5,
79.6,
0,
92.7,
100.4,
46,
49.5,
89.7,
63.1,
52.5,
23.4,
44.6,
38.2,
99.7,
37.6,
80.7,
74.2,
100.8,
74,
70.1,
53.4,
13.8,
57.1,
0,
48.1,
74,
40.6,
32.3,
11.9,
5.6,
13.3,
71.8,
43,
46.4,
6.3,
14.2,
1.2,
64,
17,
66.9,
31.8,
37,
39.6,
54.2,
71.7,
61.6,
74.9,
72.8,
43.3,
25,
45.4,
23.2,
56.8,
69.6,
49,
68.3,
20.9,
89.1,
23,
59.1,
88.4,
46.8,
37.9,
66,
39.8,
88.6,
44.5,
40,
46.7,
61.2,
8.7,
74.6,
60.4,
70.9,
76.4,
88.6,
64.7,
36.5,
41.7,
25,
53.9,
64,
5.3,
48.4,
81.5,
17.8,
35.4,
57.5,
26.7,
96.3,
86.9,
63.5,
57.4,
86.5,
5.6,
56.3,
70.4,
47.2,
60.7,
51.4,
56.8,
18.1,
56.7,
30.4,
50,
48,
66.9,
97.2,
29,
87.6,
34,
61,
49.4,
69,
49.9,
66,
58.8,
59.4,
4.1,
55.3,
92.8,
60.1,
58.9,
79,
94.6,
12.5,
39,
12.2,
62,
47.3,
41.7,
86.5,
53.7,
61.8,
43.7,
38.9,
34.1,
24.8,
11,
44.6,
80.3,
21.4,
61.8,
41.9,
70.2,
57.7,
97.9,
91.1,
42.9,
49.5,
50.8,
37.6,
78.2,
14.9,
56.2,
69.1,
79.1,
83.7,
18.1,
80.9,
39.7,
60.5,
85.1,
83.9,
46.2,
82.7,
0.1,
19,
44.2,
55.6,
22,
23.8,
67.8,
65.2,
40.9,
66,
68.6,
90.3,
2.8,
94.6,
26.1,
31.2,
68.1,
70.3,
51.7,
44.7,
71.3,
86.8,
49.5,
50.8,
57,
34,
78.8,
5.7,
85.7,
82.6,
64.6,
27.5,
31.8,
54.3,
79.6,
96.9,
82.6,
65.8,
57.8,
22.9,
69.5,
89.1,
69.8,
36.3,
80.7,
24,
72.1,
59.3,
46,
77.6,
84.6,
89.5,
90.8,
38.4,
56.2,
30.4,
97.9,
36.3,
73.1,
49.7,
55.7,
65.9,
42.4,
64,
60.7,
32.6,
48.5,
31.9,
28.6,
3.7,
23,
39.4,
37.7,
65.9,
28.7,
29,
39,
84.4,
34.8,
38.6,
43.1,
55.3,
59.1,
48.3,
7.6,
51.7,
78,
71.9,
59.3,
52.2,
57.9,
63,
49.7,
15.3,
96.3,
78.5,
6.5,
63.1,
55.1,
56.2,
76.2,
70.5,
70.1,
37,
34.5,
83.5,
64.3,
72.8,
71.9,
35.5,
30.2,
47.6,
9.7,
49.7,
38.4,
17,
85.9,
66.3,
78.8,
96.2,
49.9,
33.4,
35.5,
57.9,
57.2,
54.3,
59.1,
27.5,
57.2,
65.4,
30.9,
98.9,
93.6,
27.8,
92.7,
6,
81.6,
73.5,
59.2,
38.6,
0,
66.3,
97,
37.7,
54.9,
79,
36.7,
19,
23.1,
60.6,
62.1,
28,
48.9,
90.6,
73.5,
57.5,
69.8,
85.9,
32.9,
87,
90,
46.4,
90.9,
60.5,
41.7,
37.5,
14.5,
36.5,
41.8,
28.2,
66.2,
76.6,
68,
1.6,
11.7,
64.6,
47,
44.1,
65.6,
58.6,
65.9,
51.3,
66.6,
1.9,
32.2,
69.5,
42,
50,
4.4,
54.4,
10.1,
57,
69.1,
80,
79.4,
72.7,
47.9,
56.6,
56.4,
41.8,
77.9,
18.7,
27.8,
47.1,
52,
35,
50,
35.5,
29.5,
1.9,
47,
95.3,
13.3,
50.9,
43.2,
56.4,
23.2,
25.9,
64.8,
33.9,
27.9,
13.2,
74,
70.8,
80,
40.2,
39.5,
96.1,
80.3,
72.1,
36.3,
76,
60.3,
36.7,
51.7,
61.2,
77.9,
59.2,
65.8,
76.7,
13.5,
86.3,
98.5,
62.3,
40.9,
56.4,
82.1,
80.1,
92.6,
27.3,
34.1,
61.9,
42.1,
61.2,
72.1,
36.3,
65,
64.4,
58.2,
38.6,
29.3,
70.2,
53.3,
82.3,
44.1,
68.7,
58.2,
83.8,
43.7,
29.1,
34,
81.8,
60.2,
60,
60.5,
76.6,
49,
85,
50.4,
52.8,
88.4,
62.1,
92,
52.7,
50.2,
67.9,
55,
53.9,
43.4,
55.2,
73.3,
63,
81.6,
75.4,
15,
88.6,
43.1,
53.2,
22.9,
25.6,
49.3,
36.4,
15.1,
63.9,
12.1,
87.7,
44.6,
81.8,
31.8,
18.9,
44.4,
94.2,
59.9,
83.2,
59,
80.6,
95.3,
36.8,
35.8,
57.8,
61.4,
94.4,
91.1,
56.9,
40.3,
37.1,
34.4,
70.4,
55,
65.7,
70.8,
67.8,
84.8,
53.5,
49.9,
63.1,
37.1,
68.8,
54.5,
92.5,
68.8,
65.1,
50.2,
21.9,
92.4,
25.5,
35.1,
49.3,
47.1,
17,
98.9,
42.4,
54,
24,
74.8,
80,
94.1,
30.8,
25.1,
66.6,
54.6,
15.5,
68.9,
60.8,
37,
69.7,
45.5,
87.9,
24.3,
54.2,
63.4,
15.2,
22.8,
60.9,
72.9,
68.9,
93.9,
36.4,
29.9,
36.7,
48.6,
0.9,
72.3,
35.6,
47.1,
91.2,
19,
22.4,
48.5,
72.3,
19.6,
28.6,
69.7,
46.2,
36.8,
55.2,
66.5,
25.9,
62.3,
18.8,
36.1,
73.6,
90.2,
55.8,
75.2,
67.7,
36.8,
26.1,
56.7,
91.6,
60.8,
31.1,
94.9,
47.9,
55,
84.6,
71.4,
72.2,
71,
97.1,
2,
87.5,
38,
95,
61,
46.3,
35.1,
7.9,
66.6,
89.2,
47.2,
94.4,
50.5,
84.2,
46.4,
17.4,
85.1,
65.8,
67,
64.4,
61.4,
86.8,
60.5,
48.8,
36.9,
50.4,
44.8,
95.2,
74.4,
7.8,
79.3,
52.3,
34.8,
75.5,
52.1,
65.8,
81.1,
21.5,
45.6,
52.9,
14.1,
42.6,
59.9,
71.1,
55,
40.4,
95.8,
59.8,
60.4,
80.3,
48,
52.6,
57.6,
90.9,
83.7,
16.8,
80.7,
85,
73.4,
66.7,
65.3,
76.2,
15.5,
89.8,
88.8,
51.8,
74.2,
70.6,
81.7,
44.9,
95.4,
52.2,
32.2,
96.6,
65.6,
76.2,
87,
64.6,
25.4,
93.9,
59.4,
20.3,
61.6,
4.7,
71.7,
96.9,
77.1,
67.3,
69.1,
64.9,
66.6,
32.8,
61.5,
55.9,
94.2,
25.9,
46.9,
11.5,
28,
40,
37.4,
60.4,
78.1,
47.9,
44.1,
26.5,
16.4,
8.7,
85.9,
79.3,
87,
65.9,
33.4,
60.7,
60.5,
25.5,
75.3,
59.1,
18.8,
54.3,
61,
27.4,
63.2,
54.6,
82,
52.5,
56.5,
59.1,
73.4,
30.2,
58.2,
87.4,
78.9,
101,
83.5,
38.2,
48.2,
81.5,
43,
81.1,
89.6,
73.1,
83.4,
10.7,
5.8,
86,
62,
35.7,
48.4,
97.7,
16.1,
24.8,
33,
56.1,
37.3,
23.3,
76.2,
97.4,
46.5,
48.7,
89.6,
45.5,
49.1,
43.5,
35.1,
62.4,
87.9,
17.6,
64.5,
94.3,
38.1,
59,
74.5,
68.4,
47.7,
49.8,
44,
55.9,
39.7,
41.4,
45.2,
14,
10.2,
69.5,
83.1,
23.3,
63.3,
86.6,
8.6,
17.2,
50.6,
54.1,
74.2,
31.5,
74.3,
89.4,
97.6,
15,
67.2,
53.5,
49.9,
89.1,
64.1,
78.2,
64.3,
79.5,
75.6,
32.3,
63.4,
38.8,
19,
88,
37.8,
49.3,
47.1,
27.4,
74.4,
86.1,
87,
43.6,
92.4,
28.3,
79.5,
89,
80.5,
86.2,
15.7,
90.2,
36,
66.3,
65,
75.8,
64.6,
66.8,
53.2,
78.5,
17,
49.6,
34.5,
94.8,
69.3,
32,
6.1,
44.6,
84.8,
49.7,
25.2,
46,
49.8,
49.6,
65.9,
58.4,
78.9,
38.8,
43.2,
84.3,
63.8,
35.1,
42.6,
67.1,
68.4,
20.7,
52.4,
76.7,
56.3,
68.6,
58,
53.9,
96,
65.3,
75.8,
68.1,
38.3,
41.1,
65.5,
79,
60,
2.7,
67.2,
40.9,
18.1,
41.2,
63.2,
19,
50.1,
75.2,
63.8,
41,
70.2,
32.4,
70.4,
23.4,
46.5,
31.1,
1.9,
11.2,
83.3,
41.3,
23.7,
89.2,
82.2,
81.5,
21.6,
66.2,
91.5,
29.1,
9.9,
66.4,
61.6,
33.3,
35.7,
49.7,
66.7,
91.8,
67.8,
15.4,
38.4,
48.3,
7.2,
85.7,
71.2,
40.6,
75,
37.6,
70.3,
26.2,
85,
71.7,
60.8,
44.2,
63.5,
72.8,
106.4,
8.6,
10.1,
50.6,
43.8,
74.7,
87.8,
38.5,
50.7,
63.7,
43.6,
74.5,
77.9,
60,
2.6,
93.2,
81.5,
78.5,
45.8,
53.4,
55.5,
61.5,
56.6,
65.9,
60,
88.9,
84.1,
9.7,
76,
72.8,
94.2,
57.2,
12.9,
27.7,
19.5,
86.4,
31.2,
81.2,
57.1,
56,
63,
62.5,
54.7,
73.6,
10.6,
50.1,
82.6,
17.2,
47,
55.9,
41.2,
83.4,
61,
79.3,
67.1,
11.6,
59.2,
51.6,
61,
41.8,
53.7,
62.6,
45,
65.1,
32.4,
34.8,
90.1,
98.3,
48.7,
50.3,
71.7,
54.5,
51.7,
40.6,
75.9,
92.3,
80.2,
52.9,
45.5,
90.7,
55.3,
24.7,
0.7,
49,
72,
43,
85.3,
14.5,
38.3,
34.9,
78.1,
4.8,
93.7,
1.7,
14.4,
47.6,
8.9,
43.9,
47.4,
38.9,
56.7,
63,
90.3,
66.1,
68.6,
56.5,
44.6,
37.3,
75.3,
55.1,
48.6,
70.7,
51,
52.9,
70.9,
26.8,
70,
42.6,
74.9,
37.6,
75.2,
54.7,
65.6,
66.8,
23.4,
77.1,
92.9,
89,
34,
46.9,
69.4,
72.8,
9.4,
61.1,
53.6,
14,
30.7,
50.6,
65.8,
57.5,
26.1,
36,
1.6,
79.9,
61,
64.9,
71.8,
35.4,
75.7,
22.4,
13.2,
80.3,
47.2,
78.3,
32.1,
79.3,
65.4,
48.2,
79.2,
40.2,
59.5,
45,
42.1,
72.4,
79.6,
59.9,
45.6,
69,
49.1,
70.8,
65.2,
65.9,
49.4,
51.6,
7.1,
29.9,
64.6,
41.1,
16,
77,
79.3,
46.6,
57.6,
81.3,
91.3,
56.9,
58.9,
52.4,
77.3,
48.9,
98.9,
68.3,
62.7,
34.8,
94.4,
50.5,
46.7,
70.1,
83,
44.4,
69.6,
45.5,
82.5,
74.2,
60.8,
81.8,
15.3,
22.7,
36.6,
89.5,
49.5,
89.5,
84.6,
60.8,
58,
44.8,
65.3,
87.8,
65,
89,
48.1,
62.7,
73.4,
77.8,
64.5,
49,
53.3,
25,
60,
77.4,
7.6,
81.9,
40.5,
58.2,
19.8,
1.4,
89.7,
17.3,
45.5,
50.3,
62.9,
39.5,
22.4,
49.3,
63.8,
68.9,
58.7,
61.5,
97.4,
32,
59,
73.1,
48.6,
64.6,
63.8,
20.6,
70.9,
29.5,
50.4,
47.9,
48.3,
72.3,
92,
38.9,
32.5,
26.6,
56.1,
79.9,
68.7,
86.5,
54.2,
53.5,
78,
34.3,
28.2,
68.9,
21.1,
85.7,
45.2,
72.8,
38.9,
34.3,
44.9,
35.7,
32.1,
29.7,
12.2,
76.6,
53.9,
64.4,
75.4,
54,
32.1,
84.3,
57.6,
0,
77.3,
33.7,
39.7,
76.7,
99.6,
13.2,
65.8,
36.9,
70,
101.5,
81.9,
98.4,
80.3,
93.4,
50.8,
77.5,
69.5,
67.2,
22.2,
61.5,
56.3,
13.1,
95.9,
43.1,
65,
32.5,
49.5,
61.7,
87.7,
42.3,
87.9,
12.7,
75.6,
59.4,
43.8,
96.1,
22.1,
66.1,
36.8,
50,
79,
69.4,
73.6,
43.3,
88,
88.8,
37.9,
45.5,
63.7,
69.9,
33.8,
15.1,
88.2,
2.3,
54,
85.1,
73.1,
53.5,
81.8,
52.9,
69.2,
91.9,
100.1,
21.7,
35.4,
96.9,
54.7,
82.6,
52.3,
97.3,
70.2,
64.5,
29.8,
61.1,
20.9,
65,
88.7,
82.1,
23.1,
48.5,
41.9,
62.2,
49.4,
45.6,
83.3,
84.1,
96.1,
38.8,
66.3,
49.5,
65.8,
86.3,
35.5,
26.3,
57.9,
43.5,
17,
96.9,
7.9,
85.9,
70,
86.7,
77.8,
66.8,
65.8,
71.4,
39.9,
25,
71.3,
25.7,
60.9,
90.1,
16.4,
77.8,
49,
19.6,
83.1,
39.2,
55.8,
74.1,
72.5,
23.2,
39.8,
64,
97.9,
36.6,
79.3,
41.4,
77.4,
71.7,
63.8,
26.5,
38,
55.3,
76.1,
55,
43.2,
19,
75.2,
68.3,
39,
72.8,
44.9,
49.9,
102.5,
54.1,
11.5,
59,
43.1,
95.1,
47,
42.2,
56.5,
41.1,
83.2,
0,
38,
1.2,
152.7,
65.2,
88.4,
49,
79.2,
31.9,
40.8,
43.8,
91.4,
79.4,
15.1,
72.2,
39.2,
79.6,
52.1,
92,
56.9,
53.9,
93,
47.9,
39.2,
62.8,
47,
100,
52.3,
50.7,
16.7,
84.3,
63.4,
49.2,
86.3,
73,
54.6,
92.4,
75.8,
73.3,
59.9,
31,
42.6,
55.7,
42,
46.3,
47.2,
91.1,
75.6,
62.9,
54,
48.1,
62,
81.1,
70,
53.1,
39.9,
75.9,
50.7,
30.2,
72.2,
7.3,
49.1,
72.3,
89.4,
81.3,
28.7,
22.3,
69,
90.2,
59.1,
74.7,
75.5,
93.2,
41.8,
79.4,
71.7,
42.9,
43.6,
0.5,
26.1,
49.4,
58.6,
31.1,
45.2,
63.6,
48.5,
8.7,
75.7,
62.1,
56.5,
19.2,
67,
43.1,
65.4,
83.3,
17,
92.3,
80.2,
59.4,
39,
48,
22.6,
29.2,
21.9,
49.1,
28.2,
93,
40.8,
53.1,
36.7,
65,
79,
81.9,
64.3,
79.5,
53.3,
76.8,
4.5,
19.7,
32.5,
45.5,
4.3,
35.7,
63.1,
58.6,
41.8,
27.8,
55.1,
23,
72,
86.5,
37.1,
30.5,
38.5,
42.1,
54.3,
30.5,
26.1,
45.5,
44.9,
52.9,
67.2,
55,
24.3,
48.1,
57,
38.3,
81,
68.8,
69.8,
30.2,
75.3,
64.2,
34.6,
19.8,
85.4,
69.6,
55.1,
61.4,
60.7,
66.7,
63.4,
33.7,
63.9,
41.4,
25.8,
82.6,
26.1,
91,
59,
71.7,
71.9,
44.4,
33.6,
14.9,
41.9,
38,
36.5,
57.3,
59.8,
44.4,
65.6,
42.3,
78.1,
17.6,
43.2,
52.6,
10.2,
80.3,
98.9,
79.3,
58,
22.3,
34.5,
49.6,
67.5,
93.7,
85.3,
77.1,
72.6,
10.7,
61,
29.1,
17.5,
13.2,
65,
13.6,
70.2,
76.8,
23.8,
50,
35.1,
52,
28.7,
72.3,
70.4,
44,
52.3,
79.3,
80.1,
42.3,
89.1,
27.9,
73.1,
96,
47.8,
56.3,
76.4,
61.3,
82.9,
97.3,
16.3,
95.4,
72.2,
90.8,
81.6,
61.7,
39.7,
17.2,
54.9,
20.3,
23,
55.1,
68.3,
82.5,
38.1,
14.1,
31.6,
56,
19.2,
63.7,
59.2,
76.3,
22.8,
90.4,
31.5,
70.3,
52.4,
54.3,
50,
55.5,
91.2,
84,
22.9,
57.1,
50.4,
78.2,
47.5,
74.6,
60.3,
22.2,
66,
21.6,
20.7,
73.1,
32.6,
37.6,
42.4,
84.9,
54.6,
46.9,
20.6,
22.7,
3,
45,
77.7,
86.5,
48.7,
33.6,
35.4,
79.5,
65.7,
68.5,
19.7,
38.1,
80.9,
79.3,
3.9,
45.4,
86.1,
47,
26.3,
47.2,
42.2,
42.2,
46.5,
55.2,
24.4,
85.9,
22.2,
45.7,
64.9,
93.9,
77.5,
59.9,
29.2,
87.2,
46.6,
53.3,
82.5,
72.9,
85,
18.5,
58.9,
61.3,
63.2,
50.3,
21.8,
86.6,
71.6,
91.1,
16.6,
54.6,
39.5,
77.6,
22.4,
93.3,
68.9,
87.6,
75,
10.2,
40.9,
90.6,
65,
90.9,
75.6,
54.2,
31.2,
72,
71.7,
12.6,
83.4,
70,
22.4,
47.6,
28.6,
68,
51.1,
88,
10.6,
40,
46.3,
40.1,
89.2,
57.8,
77.8,
46,
25.7,
53.6,
53,
78.9,
66.1,
24.1,
91.2,
90.6,
42.9,
65.6,
60,
92.3,
61.2,
15,
38.9,
61.6,
39,
86.8,
23.1,
24.6,
47.9,
67,
63.2,
93.2,
62.7,
4.5,
67.3,
68.9,
52,
73.2,
57.5,
77.5,
6.6,
34,
86.4,
66.8,
97.7,
42.8,
54.3,
83.1,
61.7,
75.1,
33.4,
67.3,
71.8,
70,
39,
58.5,
40.9,
58.8,
84,
85.8,
57.3,
53.8,
66.4,
53.4,
77.3,
34.5,
63.7,
38.2,
9.3,
59,
68.2,
53.2,
63,
55.7,
81.6,
24.6,
50,
92.2,
35.8,
48.4,
98.8,
83.1,
3.4,
53.6,
54.5,
77,
57.6,
69.1,
43.4,
66.1,
61.2,
81,
2.3,
75,
94.3,
88.6,
16.3,
54,
75,
71.6,
35.5,
21.6,
82.6,
49.8,
67,
38.9,
80.4,
36.9,
57.2,
38.7,
30.2,
62.9,
94.6,
41.8,
47.1,
85.2,
99.3,
35.2,
78,
21.5,
21.5,
85.4,
57.4,
35,
79.4,
21.8,
82.5,
68.6,
87.5,
83.3,
23.6,
36.6,
69.3,
52,
99.3,
44.4,
35.6,
73,
50.2,
46.7,
4.5,
65.2,
10.8,
46.4,
79,
92.9,
71.8,
94.3,
22.4,
53.4,
95,
85.8,
37.5,
30.2,
30,
38.9,
74.7,
33.2,
74.9,
49.9,
54.2,
87.1,
77.9,
52.5,
26.3,
60.4,
46.9,
31.7,
28.2,
22.9,
59.1,
30.7,
27,
86,
34.7,
39.1,
34.5,
36.1,
27.8,
39.8,
63.1,
1.3,
76.8,
36.5,
92.6,
47.2,
59.5,
74.2,
32,
13.5,
78.3,
16.3,
45.3,
39.7,
48.4,
23.9,
28.6,
23.3,
78.6,
34.2,
11.3,
20.3,
58.6,
71.5,
24.9,
41,
46.6,
53.5,
60.1,
17.3,
22.4,
20.1,
53.3,
12.4,
78.4,
41.5,
76.3,
38.4,
83.5,
26.9,
21.2,
23.5,
17.5,
75,
93.2,
49.5,
72.8,
67.7,
55.1,
22.2,
57,
39.2,
40.4,
77.2,
75.1,
85.3,
47.3,
44,
70.8,
34,
65.5,
19.5,
52.9,
33.7,
15.3,
32.5,
55.5,
67.8,
36.6,
96.2,
42,
87.3,
92.4,
85.9,
90.6,
52.1,
33.4,
32.2,
94.5,
43.1,
80.6,
29.4,
10.3,
66.7,
0,
53.9,
58.5,
62.7,
55.4,
66.9,
25.2,
56.9,
52.2,
63.2,
74,
1.6,
30.6,
48.5,
56.7,
3.2,
57.6,
28,
58.3,
54.6,
63.5,
52.7,
50.3,
81.1,
70.4,
66.7,
7.1,
4.5,
78.9,
35.7,
46.7,
96.7,
82,
13.8,
48.7,
57.8,
29.7,
57.4,
92.8,
38.8,
79.4,
62.6,
83.1,
45.1,
83.6,
43.3,
62.3,
35.9,
94.2,
58.2,
56.2,
56,
47,
73.2,
65.2,
52.9,
29.9,
72.7,
70.7,
70.1,
78,
50,
55.4,
61.6,
10.6,
58.3,
70.7,
33.3,
98.5,
42,
91.6,
41.3,
69.4,
43.5,
60.4,
73.7,
84.2,
51.5,
97,
47.6,
83.7,
38.4,
62.4,
39.6,
66.4,
16.3,
67.4,
65.3,
29.6,
82.8,
83,
82.2,
50.7,
0,
66.4,
47,
49.1,
56.2,
67.9,
55.2,
37.9,
19.9,
43.1,
6.2,
33.5,
44.3,
86.9,
40,
55,
43.7,
66.6,
92.9,
60.8,
46.6,
47,
70.9,
41.3,
65.7,
31.2,
0.5,
15.1,
50.1,
44.4,
55.6,
89.7,
34.4,
95.3,
84,
69.8,
80.5,
25.6,
34.9,
74,
60.7,
57.8,
89.3,
80.9,
101,
61.7,
56.5,
59.6,
55.2,
11.5,
41.9,
85.5,
16.2,
53.9,
81.8,
82.5,
0.1,
89.6,
29.4,
59.7,
88.2,
26.1,
52.6,
96.3,
11.2,
57.8,
31.7,
73.4,
20.7,
76.5,
21.9,
62.2,
75,
40,
72.1,
68.3,
66.1,
27.7,
54.8,
39.4,
86.9,
66.4,
32.4,
27.3,
52.2,
33.3,
30.8,
94,
34.3,
67.3,
38.3,
59,
87.3,
66.3,
34.6,
75.4,
59.8,
77,
64.3,
70.5,
26.7,
60.5,
76.1,
1.1,
70,
34.6,
83.8,
24,
98.7,
53.6,
28.9,
85,
25.6,
51.4,
80.6,
88,
85.3,
74.7,
57.1,
67.2,
53.5,
64.2,
35,
48.5,
81.4,
88.3,
22,
34.9,
40,
65.7,
16.6,
55,
30.2,
36.8,
21.4,
19.4,
66.7,
6.5,
76.6,
50.6,
20.4,
60.7,
44.5,
59.3,
0,
38.7,
88.9,
41.4,
70.3,
70.6,
78.3,
30.6,
69.7,
85.9,
84.2,
71.4,
42,
27.1,
82.1,
51.2,
55,
67.5,
67.1,
77.3,
58.3,
61.9,
46,
31.6,
41,
77.4,
91.1,
76.8,
61.1,
15.1,
74.3,
24.1,
92.9,
57.7,
96.4,
93.5,
74.1,
60.3,
98.3,
29.8,
57.4,
56.7,
4.5,
68.4,
47,
37.8,
83.5,
8.9,
81.1,
74.9,
64.1,
77.5,
8.8,
89,
37.8,
75.4,
58.4,
70,
50,
13,
58.9,
60.2,
101.5,
93.8,
61.3,
48,
9.5,
42.2,
95.5,
58.4,
59.3,
52.1,
28.9,
53,
62.6,
17.1,
42.5,
57.2,
89,
78.4,
60.4,
48.5,
22.2,
49.6,
21.5,
33.7,
55.7,
46,
54.7,
51.9,
69.4,
97.9,
31.5,
53.2,
57.5,
83,
60.4,
86.6,
71.5,
51.2,
80.7,
96,
1.4,
17.1,
51.4,
97.1,
81.8,
51.6,
40.5,
93,
44.5,
59.1,
44.1,
91.1,
89.8,
69.7,
63.5,
41.5,
68.7,
94.6,
39.9,
86.4,
54.4,
71.1,
64.8,
23.4,
29.7,
77.9,
37.6,
88.6,
73.7,
45.8,
84.6,
53.2,
59.9,
68.8,
86.5,
12,
82.3,
65.6,
84.8,
44.8,
51.9,
4.4,
42,
45.3,
54.2,
47.5,
15.5,
29.2,
23.7,
95,
20.5,
51.4,
59.5,
29.9,
86.7,
58,
68.7,
21.7,
89.9,
64.5,
51.4,
88.1,
16.2,
61.2,
38.6,
58.2,
65.7,
95.4,
80.4,
43.4,
45.5,
85.4,
36.3,
50,
45.4,
93.5,
70.4,
47.4,
52.2,
65.7,
26.5,
75.2,
66.9,
47.7,
66.4,
77,
51.2,
64,
93.7,
40.1,
83.6,
47,
42.6,
82.7,
84,
7.5,
88,
75,
43.5,
99.6,
40.1,
75.2,
25.4,
67.2,
0.5,
8.9,
76.8,
57.9,
28.6,
40.3,
47.8,
47.3,
47.2,
84.5,
31.5,
0,
58.2,
24,
39.7,
17,
83.4,
45.7,
68.8,
91.5,
52.1,
25.2,
38.2,
27.1,
46.3,
36.3,
31,
6,
50.4,
44.4,
45.4,
55.8,
31.7,
62.1,
92.4,
22.1,
45.6,
79.4,
80.7,
57.7,
64.8,
81.8,
0.2,
26.5,
59.5,
91.2,
39.2,
60.6,
62.9,
54,
92.1,
83,
59.8,
98,
52.6,
53.4,
35.9,
29.1,
61.9,
43.3,
64.8,
61.6,
9.2,
47,
60.8,
32.7,
62,
58.1,
90.6,
21.9,
50.3,
85,
56.3,
52,
63.2,
97.5,
78.5,
62.7,
26.6,
45.6,
55.1,
62.8,
76.7,
78.3,
56.9,
74,
25.6,
75.1,
58.6,
32.7,
37,
24.9,
31.3,
35.2,
67.4,
91.1,
39.7,
32.4,
96.2,
70.1,
59.7,
68.4,
14.9,
43.5,
98.6,
34.8,
24.5,
36.9,
35.8,
76.5,
53.2,
51.4,
16,
49.2,
23.1,
27.8,
37.6,
62.3,
34.6,
47.2,
25.9,
51,
82.6,
39.1,
78.5,
51.5,
84,
65.3,
69.1,
12.8,
97.8,
98.9,
0,
69.7,
69.9,
37.9,
48.4,
83,
63.6,
66.1,
57.3,
71.6,
52.5,
38.7,
85.6,
23.2,
62,
7,
42.1,
15.4,
8.8,
60.2,
40.8,
14.6,
33.9,
69.6,
75,
92.7,
95.6,
72.8,
28.3,
63.2,
98,
9,
37.1,
79,
85.9,
15.9,
86.5,
73,
67.4,
41,
49.9,
75.3,
15.5,
66.1,
63,
30.1,
73.1,
24.3,
70.7,
7.8,
27.4,
91.5,
33.9,
91.3,
75.1,
59.2,
75.1,
78.1,
65.3,
72.2,
84.4,
29.8,
51.8,
79.6,
26.8,
16.4,
46.2,
72.3,
47.7,
4.9,
26.9,
81.2,
48.1,
84.5,
32.7,
63.9,
74.6,
40.7,
86.7,
67.5,
68.2,
41.7,
45,
73,
88.8,
87.4,
23.4,
81.2,
58.5,
95.1,
55.1,
49.7,
54,
72,
82.4,
68.1,
54.4,
48.5,
77.5,
21.3,
92.1,
24.9,
75.1,
90.3,
72,
33.6,
86.8,
62.7,
68,
81,
96,
72.8,
60.1,
100,
46.7,
39.4,
81.3,
102,
59.3,
70.9,
65.9,
87.3,
73.6,
7.28,
46.9,
48.9,
88.4,
82,
62.3,
8.5,
34,
25.3,
62,
40.9,
36.7,
87.1,
33.1,
60.2,
58.6,
68.7,
59.5,
54.8,
63.1,
48.9,
23.5,
67.9,
54.1,
47.1,
9.2,
94.6,
74.6,
13.9,
40.3,
64.2,
82.4,
53,
73.6,
71.4,
78.9,
69.8,
60.3,
94.1,
76.7,
35.4,
37.1,
50.5,
0,
84.2,
5.3,
70.1,
69.6,
65.4,
55.3,
32.6,
52.8,
58,
31,
94.5,
32.8,
62.8,
41.8,
18.1,
10,
67.1,
74.2,
62.1,
84.7,
58.3,
10.4,
90.1,
81.1,
51,
50,
58,
58,
38.8,
93.4,
60,
48.9,
39.6,
29.3,
59.1,
13.7,
48.6,
96.6,
39.9,
78.3,
67.7,
12.4,
62,
73.1,
66,
85,
73.9,
31,
29.4,
46.4,
70.1,
82.4,
66,
52,
90.8,
84.4,
68.4,
59.5,
65.6,
87,
20.8,
71.2,
56.4,
26.2,
41.3,
54.4,
102.5,
10.8,
17.7,
78.7,
66.6,
48.8,
64.9,
62.3,
24.9,
71.9,
53,
79.9,
46.9,
0,
65.8,
51.2,
67.7,
62.4,
54.2,
37,
70.9,
75.2,
38.3,
81.7,
100.7,
72.8,
52.2,
56.3,
58.1,
74.1,
54.9,
0,
92.3,
50.1,
58.4,
82.9,
37.6,
14,
84.4,
80.7,
39.4,
55.4,
24.8,
94.4,
9.9,
52.3,
99.4,
87.4,
50.4,
51,
7.5,
52.4,
61.6,
79.2,
34.8,
13.1,
62,
77.3,
34.7,
75.3,
49.6,
53.8,
45.8,
63.1,
99.4,
67.9,
40.9,
20.7,
90.9,
56.6,
65.3,
43.5,
38.6,
29.5,
32.2,
29.6,
58.4,
70.7,
97.4,
74.6,
43.7,
59,
31.1,
67.3,
53,
64.3,
70.1,
30.2,
50.8,
59.2,
33.2,
46.5,
61.5,
57.9,
31.5,
39.3,
93.9,
27.2,
58.8,
58.3,
75.1,
44,
96,
35.1,
27.6,
31.8,
44.3,
10.4,
62,
42,
37.9,
39.3,
54.1,
34.3,
89.5,
31.9,
36.7,
92.5,
35.9,
82.7,
82,
58.9,
76.3,
47.1,
0,
31.6,
41.7,
29.8,
69.5,
10.5,
62.7,
83.1,
79.7,
42.6,
50.6,
49.5,
83.5,
44.4,
54.6,
11.6,
94,
51.8,
40,
71.8,
66.7,
93.7,
44,
44.9,
55.1,
52.8,
32.8,
64.6,
85.8,
43.7,
88.4,
10.2,
74.4,
59.3,
42.4,
3.4,
38.5,
46.9,
11.7,
54.6,
86.6,
32.3,
76.1,
90.5,
15.6,
87.4,
17,
37.1,
30.5,
66.5,
69.1,
71.3,
63.3,
82.3,
33.3,
90.3,
48.7,
79.8,
68.8,
30.7,
52.9,
69.8,
71.2,
50.1,
46.7,
4,
88.3,
34.5,
84.4,
44.8,
49.7,
7.6,
18.2,
88.2,
53.6,
20,
55.2,
45.2,
44.8,
74.5,
25.7,
41.3,
40.5,
87.1,
48.7,
83.8,
63.6,
87.7,
100.4,
96.7,
85.1,
97.7,
89.9,
35.4,
43.3,
28.9,
95,
25.8,
5.3,
66.8,
71.6,
79,
45.3,
5.7,
70.2,
56.9,
76.4,
28.4,
75.4,
79.6,
71.5,
97,
63,
53.6,
66.6,
92,
71.8,
73.3,
46.7,
39.2,
68.6,
18.8,
48.3,
51.8,
54,
24.8,
31.3,
17.8,
97,
87.2,
71.5,
63.6,
72.9,
85.8,
69,
56,
26.8,
96.9,
47.3,
96.4,
95.7,
58,
23,
83.6,
87.4,
39.6,
0.8,
47.7,
0,
31.7,
58,
70.1,
72.1,
43.6,
76.4,
82.2,
44.8,
10.9,
72.9,
15,
66.9,
50.9,
83.8,
77.2,
67.8,
74.4,
93.6,
49.4,
56.6,
52.4,
47.2,
44.6,
36.7,
77,
89.2,
48,
37,
56.5,
null,
63.7,
82.9,
52.2,
8.7,
107.4,
58.6,
52.4,
51.5,
71.7,
36.2,
63.5,
77.6,
50.7,
49.3,
27,
40.8,
83.1,
84.8,
37.9,
57.8,
76.5,
51.7,
50.7,
35,
40.8,
24,
88,
48.4,
71.7,
48,
58.1,
49.1,
11.8,
80.8,
12.8,
20.3,
90.8,
72.5,
59.9,
75.1,
33.9,
93.8,
66.1,
84.6,
61.6,
88.2,
39.7,
17.1,
67.8,
74.2,
1.6,
75,
51.3,
79.3,
40.9,
70.1,
13.3,
48.7,
71.3,
85,
60,
56.2,
74.8,
80.3,
81.8,
40.7,
80.3,
46.2,
46.8,
63.1,
39.9,
45.8,
74.9,
87.1,
24,
63.8,
32.1,
55.9,
32,
32.5,
66.4,
68.7,
72,
19.6,
57.9,
21.1,
36,
56.7,
64.8,
77.4,
37.2,
56.4,
71,
60.5,
22.8,
21.2,
77,
36.9,
62,
21.2,
42.8,
67.6,
39,
61,
49.6,
37.2,
8.8,
52.8,
91,
92.3,
33.9,
29.3,
72.6,
49.6,
40.4,
94.9,
79.9,
58.3,
57.9,
72.4,
94.9,
45.3,
66.7,
36.4,
55.8,
18.1,
59.9,
73.5,
49.6,
72.8,
62.3,
62,
15.2,
59.9,
86.6,
34.1,
58.8,
94.9,
47,
61.1,
56.9,
90.2,
69.4,
87.5,
41.5,
48.2,
57.3,
108,
9.6,
13.7,
88.7,
73.7,
99.2,
75.6,
59.6,
89.9,
60.5,
86,
48.6,
57.3,
72.9,
73.2,
34,
42.7,
39,
29,
5.3,
74,
126.4,
95.9,
82,
65,
71.1,
58,
1.1,
90.9,
26.7,
93.3,
63,
89,
91.2,
65,
54.4,
37.9,
48.4,
77.4,
54.9,
47.8,
71,
81,
12.5,
67.5,
17.8,
85.4,
82,
40.1,
95.2,
90,
65.9,
35.3,
65.3,
95.6,
0,
15.3,
49.5,
20.5,
36.8,
60.3,
72.5,
41.8,
26.7,
30.8,
59.3,
84.6,
78.5,
74.3,
69.7,
37.4,
67.9,
63,
78,
95.5,
46,
86.8,
72.5,
85.1,
66,
62.7,
32.8,
92,
68.8,
53.2,
88.1,
92.9,
21,
45.6,
63.1,
45.4,
49.8,
58.2,
68.9,
66.7,
16.4,
74.8,
71.3,
68.4,
72.2,
43.7,
57.2,
52,
43.8,
46.2,
67.3,
65.9,
19.7,
56,
53.8,
35.6,
65.7,
42.1,
82.2,
89.7,
37.2,
81,
28.3,
22.4,
20.5,
55,
32.6,
67.1,
59.2,
31.5,
64.7,
60,
29,
70,
93,
52.9,
96.3,
60.5,
91.9,
52.3,
53.6,
14.1,
88,
77.9,
89.1,
11.4,
76.1,
42.1,
58.8,
7.3,
52.2,
63.7,
27,
10.1,
21.5,
68.6,
57.1,
24.3,
33.9,
70.4,
9.2,
73.5,
64.4,
65.7,
4.3,
19.5,
31.2,
95.1,
27,
77.9,
67.8,
56.8,
94.5,
78.7,
50.6,
42.1,
65.3,
55.8,
74.2,
38.5,
70.6,
55.8,
73.8,
60.8,
51.1,
27.6,
31.9,
40.8,
37.4,
46.8,
72,
36,
93.5,
3.2,
17.3,
18.5,
50.1,
37,
27.8,
85.9,
89.7,
59.4,
38.2,
69,
50.8,
39,
51,
64.1,
61.9,
79.2,
30.9,
87,
23,
65.9,
67.9,
28,
36,
75,
34.4,
57.7,
9.6,
85.4,
35.3,
59,
41.1,
64.1,
34.7,
82.3,
82.8,
48.4,
85.1,
21.4,
48.3,
58.1,
86,
81.2,
52.1,
47.1,
81.6,
93,
77.5,
79.6,
33.4,
36.1,
69.3,
60.3,
29.1,
78,
30.6,
76.9,
74.2,
25,
82.3,
82.2,
94.1,
46.5,
27.3,
76,
37.8,
58.1,
72.7,
40.4,
37.3,
84.2,
54.8,
41.6,
61.4,
33.4,
48.5,
51.7,
8.5,
36.8,
78.7,
51.1,
84.6,
74.4,
32.8,
49.8,
82.2,
36.8,
56.5,
48.2,
49.1,
63.7,
74.4,
83.1,
72.1,
10.6,
45.3,
39,
95.7,
83.2,
72.7,
63.3,
82.9,
39.8,
48.1,
74,
56.8,
83.5,
56.2,
38.1,
50.8,
15.4,
88.8,
78.9,
64.9,
52,
30.7,
62.4,
67.6,
46.7,
67.4,
40.5,
50.2,
84.9,
72.4,
43.2,
14.6,
19,
78.1,
87.2,
36.1,
19.9,
73,
89,
41.6,
25.5,
90,
5.8,
28.4,
33,
58.5,
24,
23.9,
34,
78.7,
65.8,
52.3,
43.4,
28.5,
30.7,
79.7,
0,
21.9,
48.5,
89,
45.9,
25.1,
73.5,
9.5,
42.8,
40.2,
73.5,
69.5,
40.7,
8.8,
76.6,
31.6,
57.8,
36.1,
64.5,
69.9,
69.9,
92,
28.6,
19.1,
30.1,
26.8,
53.8,
27.9,
94.9,
80.7,
51.6,
22.1,
80.4,
55.3,
88.7,
52.3,
58.6,
24.2,
77.8,
65,
96.6,
18,
87.2,
75.8,
21.6,
21.2,
52,
33,
59,
79.1,
86.7,
69.1,
56.9,
78.8,
81,
47.7,
63.7,
55.2,
86.1,
27.8,
23.11,
53.1,
64.5,
26.5,
73.7,
91.9,
62.3,
18.3,
64,
65.7,
17.1,
48.9,
29.8,
56.3,
88.8,
52.6,
83.9,
76.8,
47.6,
69.2,
73.5,
57.6,
88.7,
87.7,
70.2,
36.7,
27.2,
79.9,
0.3,
88.5,
59.2,
88.2,
52.7,
89,
64.4,
100,
51.4,
10.6,
76.3,
38.6,
31.1,
85.6,
38.9,
69.7,
46.3,
48,
91.1,
91.4,
82,
53.1,
60.7,
16.9,
51.2,
49.9,
57.5,
12.7,
28.2,
67.3,
39.2,
35.8,
70.3,
33.8,
11,
58.2,
69.8,
26.2,
79.2,
58.9,
35.9,
24.7,
62.5,
45.3,
77,
56.6,
94.1,
43,
48,
53.5,
70.7,
61,
6.4,
99,
71.4,
61.6,
66,
56.2,
37.5,
49.6,
63.1,
62.3,
73.6,
69.6,
40.3,
12,
85.5,
43.8,
62.5,
41.7,
94.5,
68.3,
13.5,
21.1,
69,
67.8,
68.3,
44.3,
20.3,
51.6,
15.5,
36.2,
59.9,
47,
87,
13.6,
72.6,
41.7,
83.3,
36.7,
35.8,
61.8,
47.6,
31.5,
56.4,
37.6,
63.8,
87.6,
34.8,
79.4,
86.1,
40.8,
60.6,
57.3,
54.3,
53,
20.4,
55.5,
69.1,
70.6,
22.9,
63.2,
33.7,
29.5,
74.4,
26.6,
77.4,
70,
14.5,
81.4,
65.3,
53.3,
66.1,
81.8,
75,
69.9,
72,
51.5,
64.8,
57.4,
12.7,
92.3,
18.7,
94.7,
81.2,
44.2,
89.3,
77.2,
54,
40.1,
34.6,
80.6,
59,
21.3,
36.3,
80.8,
69.6,
49.9,
92.2,
15,
46.8,
56.2,
73,
61,
63.9,
56.5,
55.7,
91.8,
50,
86.9,
67.8,
7.5,
60.4,
39.7,
39.3,
87.8,
31,
91.5,
44.7,
56.7,
85,
34.1,
56.3,
84.9,
69.5,
67.8,
75.7,
50.1,
37.7,
75.2,
55,
49.3,
56.5,
73.7,
15.9,
48.2,
4.4,
31.5,
69.9,
86.8,
67,
9.3,
62.1,
73.5,
1.8,
10.3,
26.9,
33.9,
84.3,
57.6,
24.9,
63.2,
20.7,
34,
12.9,
14,
92.9,
71.5,
40.1,
97.8,
44.4,
93.9,
40.8,
87.1,
77.1,
31.4,
46.3,
46.3,
50.3,
56,
51.9,
48.9,
20.1,
77.2,
98.6,
8,
59.6,
66.1,
87.6,
78.4,
3.7,
83.2,
55.6,
65.1,
33.1,
52.8,
86.7,
35.7,
0,
58.9,
3.6,
33.6,
50.6,
35.7,
47.5,
24.8,
60.5,
30.9,
55.3,
73.8,
77.9,
63.4,
26.5,
79.1,
93.5,
49.7,
31,
49.1,
24.4,
89.9,
43.5,
49.3,
25.7,
34.7,
94.4,
42.2,
66,
73.5,
16.3,
61.1,
45.2,
60.3,
43,
70.6,
36.1,
41,
82.8,
19.7,
78.4,
48.9,
29.7,
55.4,
6.6,
83.6,
51.2,
50.6,
83.7,
85.2,
49.2,
56.3,
48.6,
96.3,
32.9,
92.7,
46.8,
47,
92.9,
57.8,
48.7,
27.7,
63,
74.5,
76.6,
48.8,
52,
44,
89.2,
67.9,
39.9,
27.9,
48.4,
96.5,
30.5,
68.5,
24.3,
66.3,
8.4,
56.8,
48.7,
37,
9.2,
75.3,
63.6,
14.5,
54.7,
23.1,
34.3,
63,
39.8,
34.8,
49.6,
58.6,
13.4,
50,
76.8,
83.8,
90.7,
69.7,
40,
88.9,
15.9,
55.6,
84.3,
81.9,
59.5,
81,
81.1,
56.4,
44,
80.1,
19.8,
27.5,
50.9,
83.6,
17.7,
40,
45,
88.3,
0.2,
45.6,
98,
80.5,
69.6,
39.2,
36.2,
82,
57.8,
79.1,
39.4,
59,
34.2,
56.5,
72.4,
85.6,
85,
24,
45.5,
53.6,
89.4,
29.5,
62.2,
37,
84,
9.6,
76.3,
33.9,
63.3,
45.8,
71.5,
51.2,
26.6,
69.5,
54.5,
21.3,
38,
23.1,
21.8,
53.7,
61.7,
65.9,
66.7,
38.3,
39,
18.3,
62.6,
37,
45.8,
76.9,
58.6,
84.8,
33.9,
50,
87.5,
99.1,
84.9,
36.2,
9.5,
89.9,
65.6,
65,
46.9,
55.4,
78.1,
23.1,
56.6,
88.4,
53.5,
73,
85.8,
84,
55.6,
46.8,
78.1,
94.1,
49.4,
55.2,
18.6,
87,
31.1,
83.9,
47,
49,
34.7,
32.4,
65.7,
88.2,
35.2,
97,
56.2,
68.4,
79.5,
40.6,
86,
3.1,
10.1,
48.8,
42.9,
40.6,
77.2,
40.9,
39.5,
39.9,
46.5,
47.1,
17.9,
74,
55.4,
64.9,
97,
80.3,
64.9,
46.1,
39.4,
69.8,
50.7,
69.1,
96.1,
64.7,
93.3,
28.8,
1.3,
74.7,
84.9,
49.3,
93.5,
58.4,
92.7,
71.2,
62.7,
45.3,
88,
67.3,
38.1,
59.1,
65.4,
64.9,
78,
48.1,
51.9,
72.7,
83,
74.6,
60.4,
79.6,
11.8,
83,
82.4,
14.7,
28.3,
58.6,
78.3,
49.1,
59.2,
71.1,
55.1,
70.1,
78.1,
73.4,
45.9,
70.3,
61.1,
37.3,
47.7,
82.3,
62.6,
50.3,
24.1,
61.2,
49.2,
66.2,
72.3,
40.7,
57,
80.2,
52.9,
60.4,
55.6,
57.4,
67.7,
91.7,
3.9,
35.3,
65.4,
87.4,
55.1,
66.6,
88.4,
0,
79,
25,
90.3,
18.9,
60.1,
73.1,
57.7,
65,
13.2,
39.1,
78.2,
69.9,
15.5,
93.6,
74.3,
27.8,
59.9,
28.6,
12.3,
59.5,
60.7,
44.4,
76,
8.6,
14.3,
36.2,
29.3,
57.5,
75.3,
40.6,
11.4,
65.9,
28.5,
52.7,
42.4,
78.4,
82,
39.6,
46.2,
67,
64.5,
50.3,
24.8,
80.9,
74.3,
37.6,
67.3,
55.4,
69.7,
61.3,
55.5,
57.7,
23.6,
25.4,
65.7,
93.9,
35,
62,
73,
32,
43,
22,
48.1,
61.3,
78,
60.5,
75,
36.7,
39,
77.4,
64.2,
56.7,
70.9,
74.1,
85.3,
76,
46,
32.3,
54.7,
77.8,
68,
46.6,
73,
40.3,
65.2,
73.4,
91.6,
55,
35.2,
65.1,
38.8,
24.9,
54.8,
32.2,
19,
33.6,
54.7,
62.2,
34.1,
86.4,
63.2,
83,
83.7,
12.9,
89.1,
29.9,
89.5,
82.3,
31.3,
66.8,
69,
36.5,
46.7,
75.9,
82.5,
70.7,
83.5,
97.2,
84.3,
11.4,
91.5,
39.9,
56,
54.8,
60,
53.2,
72,
117.5,
86,
71.7,
80.6,
19.1,
73.4,
82.2,
43.3,
64.1,
71.8,
54.2,
72.3,
23,
74.2,
56.1,
62.5,
48.1,
64.1,
34.4,
20.4,
80.6,
91.4,
36.5,
26.7,
23.8,
17.3,
55.5,
61.9,
12.8,
48.4,
79.2,
72.3,
44.7,
53,
70.8,
49.1,
65.9,
69.7,
59.2,
73.6,
31.4,
54.3,
61.3,
39,
67.6,
89.1,
85.3,
50,
48.3,
13.4,
82.5,
32.6,
21.6,
21,
36.2,
82.4,
29.1,
82.2,
32.4,
56.8,
63,
41.5,
88.3,
33.2,
19.6,
67.7,
64.9,
38.3,
55.9,
24.7,
78.9,
83.5,
91.4,
49.7,
65.6,
10.2,
79,
27.7,
25.3,
75,
64.6,
45.7,
36.4,
9.7,
76.5,
58.3,
40.2,
30.1,
59.6,
12,
84,
72.9,
52,
96.1,
72.5,
23.2,
43.1,
51.6,
38.5,
51.2,
47.7,
60.2,
89.9,
59.7,
46,
42.6,
63.6,
88.1,
73.2,
36.6,
96.9,
55.5,
37.5,
89.8,
82.7,
52.1,
91.4,
18.4,
31.2,
48.8,
56.5,
84.8,
35,
69.6,
38.8,
1.2,
50.4,
9.7,
50,
59.1,
26,
1.3,
90.2,
38.4,
59,
40.1,
35.9,
79.4,
86.9,
66.9,
44.4,
57.7,
54.5,
86,
87.1,
56.7,
66.5,
68.3,
87.2,
87.7,
25.9,
89.8,
37.6,
100.3,
65,
80.6,
34.4,
86.8,
77.8,
57,
63.7,
72.9,
91.4,
51.8,
37,
44.4,
96.4,
98.4,
91,
46.1,
28.6,
49.3,
91.8,
81.8,
27,
71.5,
92.3,
16.3,
33,
62.9,
64,
68.3,
50.6,
41.5,
99,
45.2,
67.6,
83.4,
85.6,
72.3,
70,
62.3,
72.3,
28,
45.5,
81,
90.2,
64.7,
26.1,
57.3,
66.8,
10.3,
17,
46.3,
41.1,
92,
65,
97,
59.7,
55.9,
34.8,
70.8,
76.9,
76.5,
73,
87.4,
69.4,
60,
63.7,
28.6,
41.8,
86.7,
73.5,
79.4,
80.2,
63.1,
64.8,
41.4,
39.7,
59.6,
52.5,
57.2,
79.5,
63.8,
68.5,
91,
69.9,
94,
71.3,
41.7,
49.3,
84.9,
50.8,
77,
78.9,
85.6,
85.8,
62.7,
52.3,
25.1,
94.1,
57.1,
29,
23.6,
4.7,
44.9,
57.1,
10.4,
86.8,
60.7,
30.9,
46,
64.9,
85.3,
71.1,
63.5,
61.3,
26,
96.5,
39.3,
20.7,
58,
18.6,
80.5,
40.4,
54.9,
27.5,
73.9,
2.2,
40.8,
42.5,
35.4,
70.9,
78.3,
52.5,
80.5,
88,
89.5,
58,
55.5,
2.1,
26.8,
39.1,
35.1,
16.1,
0,
64.6,
29,
40.6,
61.7,
68,
87.9,
22.2,
89.3,
21,
40.8,
28.5,
28.9,
65.3,
19.1,
58.4,
59.1,
116.1,
84.6,
70.5,
36.1,
88.9,
52.6,
75.9,
83.4,
30.2,
10,
57.4,
25.4,
15.2,
73.5,
40.9,
86.1,
97.3,
91.5,
75.7,
66.3,
68.2,
87.8,
21.5,
37.2,
90.8,
37,
54.1,
78.9,
93,
47.8,
96.3,
60.4,
74.3,
91.9,
20.3,
38.2,
61.3,
51.9,
32.3,
65.5,
96.7,
93.6,
39,
79.7,
96.9,
4.3,
72.3,
91.7,
95,
44.2,
87.3,
44.9,
20.4,
85.3,
55.7,
78.3,
48,
5.9,
55.2,
31.1,
95.9,
43.1,
26.9,
94.9,
79.3,
50.7,
17.6,
51.7,
53.7,
32.8,
90.3,
86.6,
27.1,
36.1,
28.5,
68.3,
40,
29.6,
70.1,
90.6,
28.3,
63.4,
83.8,
63,
89.5,
98.2,
44.9,
75.1,
78.3,
54.3,
35.7,
1.5,
81.9,
65.6,
47.7,
17.9,
65.2,
78.8,
51.2,
67.2,
61.8,
48.9,
11.1,
46,
45.3,
94.2,
66.4,
2.3,
59.3,
20.9,
46.7,
98,
50.2,
65.5,
95.1,
74,
89.9,
60.9,
38.5,
47.4,
99.5,
88.4,
34,
36.3,
92.7,
26.8,
52.6,
47.3,
31,
48.5,
89.7,
21.3,
38.1,
77.5,
55.7,
33.4,
36.6,
99.1,
74.7,
32.3,
78.7,
58.3,
78.6,
30,
43.1,
39.2,
56.4,
84,
52.6,
51.3,
77.4,
79.3,
0,
66.4,
56.8,
53.7,
91.6,
54.7,
29.5,
70.8,
12.1,
37,
25.5,
86.3,
61.9,
58,
14,
39.4,
77.3,
76.7,
57.8,
16,
63,
34.2,
96.2,
49.8,
28.6,
88.3,
80.5,
27.3,
51.4,
96.9,
46.8,
31.6,
37.6,
8.5,
52.2,
4.5,
69.2,
52.5,
4.6,
56.3,
82.2,
63.9,
53.9,
25.1,
33.9,
37.2,
42.8,
43.4,
78.4,
41,
86,
58.6,
59.9,
20.7,
13.4,
17.6,
41.2,
12.4,
42.7,
56.2,
67.9,
83.1,
49,
33,
61.5,
68.5,
26.1,
72.8,
12.1,
69,
52.6,
71.1,
67.6,
51.9,
37.3,
62,
52.8,
19.7,
88.7,
28.5,
51.6,
52.6,
69.8,
53.2,
46.3,
54.1,
17.5,
62.2,
5.7,
71.3,
63,
38.9,
91,
36.3,
12.6,
87.7,
32.6,
71,
52.9,
23.9,
62.7,
59.2,
78.4,
60,
7.8,
76.4,
81.7,
83.5,
72.7,
59,
69.9,
43.7,
43.7,
47.5,
88.3,
90.2,
39.9,
60.2,
55.3,
80.2,
33.2,
35.6,
68.8,
69.8,
92.8,
41.2,
73.5,
49.7,
17.5,
16.1,
55.9,
56.2,
90.1,
89.2,
62.2,
59.2,
47.7,
76.1,
81.5,
14.5,
40.4,
32.6,
50.3,
53,
41.1,
77.7,
93.6,
84.3,
91.7,
7.1,
77.8,
87.7,
84.8,
38.8,
43.7,
60.8,
70.6,
23.7,
61.8,
28.6,
18.5,
84.5,
55.8,
54.5,
28,
37.5,
91.4,
80.6,
47.4,
71.9,
14.3,
88.6,
29.5,
51.8,
55,
25.9,
100.2,
12.7,
82,
69.2,
84.3,
45.2,
74.2,
97.7,
80.9,
68.5,
61.1,
42.1,
97.5,
32.7,
64.8,
47.6,
14.7,
86.5,
79.9,
24.2,
83.8,
49.8,
61.3,
81.6,
73,
53.3,
37.1,
57.4,
72.1,
8.7,
50.3,
54,
22.9,
17,
41.5,
80.3,
16.6,
23,
79.9,
84.7,
40.4,
76.4,
74.3,
40.1,
7.6,
49,
44.8,
91.5,
8.6,
55.7,
21.6,
91.2,
56.4,
31.6,
71.6,
65,
79.8,
65.1,
71.6,
38.3,
75.8,
42.9,
56.3,
66.7,
34,
33.3,
71.8,
49.2,
80.5,
69,
10.5,
52.7,
50.1,
46.8,
84,
88.8,
64.9,
30.5,
88.4,
70.6,
75.6,
61.2,
34.6,
39.7,
41.4,
42.4,
90.1,
28,
59.5,
77.4,
70,
71.4,
45.4,
25.8,
33.4,
75,
48.8,
91.6,
75.5,
93,
32.8,
43.7,
43.1,
31.4,
79.5,
15.7,
41.4,
89.3,
47.1,
58.3,
90.5,
37.6,
84.3,
20.8,
52.2,
79.9,
18.6,
46.5,
53.3,
75.4,
27.9,
73.8,
97.6,
86.5,
77.6,
69.6,
52.4,
85,
81.6,
76.3,
97.7,
35.1,
20,
86.2,
49.1,
55,
75.1,
18.6,
63.2,
41.2,
48.8,
86.9,
62.1,
79.1,
65.4,
69.2,
43.1,
39.9,
48.8,
37.1,
18.5,
43.4,
21.9,
4.7,
76.4,
38,
45.3,
17.7,
20.1,
64,
93.3,
51.1,
58.7,
50,
82.8,
28.8,
53.4,
42.5,
50.9,
47.4,
26,
65.1,
35.6,
76,
62.4,
34.9,
35.5,
47.1,
71.1,
60.6,
13,
29.4,
26.4,
35.7,
63.4,
17,
59.2,
53,
59.9,
22.1,
93.6,
72.7,
69.1,
72.7,
47.3,
79.4,
78.7,
43.1,
39,
65.7,
89.9,
69.2,
5.4,
65.9,
74.1,
68,
17.2,
83.6,
89.9,
63.1,
70.1,
63.9,
12.2,
64.5,
62,
57.3,
37.3,
91,
74.8,
35.6,
67.9,
4.6,
41.4,
40.5,
73.9,
32,
78.3,
75.3,
25,
41.2,
68.1,
60.5,
42.6,
39.7,
2.7,
88.5,
55.1,
34.8,
57.6,
14.6,
20.3,
45.6,
36,
69,
32.5,
76.6,
81.1,
63.4,
67.9,
15.8,
79.1,
82.4,
60.2,
40.2,
66.1,
43.3,
68.6,
41.6,
41.2,
70.2,
85.1,
12.2,
20.2,
53.7,
46.3,
32.5,
68.6,
25.8,
73,
73.1,
43.5,
31.3,
76.6,
57.7,
72.9,
86,
15.5,
8.9,
66.5,
63.9,
59.1,
86.7,
71.1,
30.9,
15.6,
57.2,
0,
32.5,
57.3,
74,
76.3,
57.9,
13.4,
93.8,
36.6,
34,
83.2,
4.1,
89.4,
44.7,
35,
23.3,
82.7,
2.2,
58.6,
42.2,
23.6,
38.2,
82.5,
71.7,
46.5,
89.5,
76,
103.1,
67.2,
15.6,
60.4,
97.8,
53.4,
95.5,
58.8,
88,
53,
93.9,
45.6,
56.7,
51.8,
0,
75.4,
23.5,
53.5,
61.8,
13.1,
40,
94.3,
24.8,
49.4,
68.4,
75.4,
38.8,
67.6,
70.6,
33.9,
62,
84.6,
25.9,
36.8,
69.7,
58.8,
8.4,
38.5,
14.2,
67.6,
66.9,
55.4,
49.9,
50.6,
45.4,
48.4,
23.5,
56.3,
79.8,
52.8,
32,
68,
60.5,
42.5,
29.4,
95.3,
32.4,
51.2,
53,
35.1,
51.8,
75.5,
15.1,
55.7,
47,
15,
42,
38.8,
46.5,
22.9,
39.3,
88,
30.8,
62.8,
72.4,
76,
42.7,
78.7,
0,
47.1,
23.7,
20,
83.9,
58.4,
70.7,
53,
60.8,
94.8,
60,
43.8,
92.9,
97.9,
80.4,
35.7,
25.3,
74.4,
22.2,
61.8,
61.8,
33.8,
52.2,
21.7,
89.5,
72.6,
41.6,
58.9,
30.1,
84.8,
25.5,
54.6,
63.4,
56.6,
4,
9.7,
100.8,
59,
10.8,
66.5,
43.6,
61.2,
51.2,
44.3,
78.4,
51.8,
68.4,
36.5,
82.2,
85.1,
53.3,
42.3,
12,
69.9,
54.3,
53.9,
13.2,
54.9,
64.4,
50,
17.7,
40.8,
54.8,
97.7,
60,
57.3,
53.1,
39.9,
1,
35.9,
58.4,
37.5,
68.2,
36.9,
49.6,
1.3,
40.6,
0,
61.1,
61.3,
9.9,
49.4,
50.8,
58.2,
31,
44.8,
94,
74.9,
51.7,
67,
95.4,
34.9,
55.2,
30.4,
48,
42.1,
33.5,
52.8,
44.8,
57.7,
0.2,
41.8,
51.1,
41.2,
65.8,
99.7,
50,
44.6,
16.9,
23.7,
44.5,
34.5,
52.8,
52.8,
85.8,
5.5,
0,
59.2,
27.4,
19.1,
36.5,
79.5,
31.3,
55.8,
56.8,
58.7,
53.9,
38.3,
67.8,
34.5,
64.8,
64,
59.3,
41.7,
88.5,
25.5,
59.7,
65.1,
71,
27.2,
103.5,
24.8,
36.4,
87.6,
76,
38.4,
56.6,
4,
9.3,
28.6,
58.2,
33.3,
67.9,
66.9,
16.9,
46.3,
60,
33.5,
4.2,
27.7,
33.3,
58.7,
88.7,
33.7,
89.7,
56.3,
12.5,
57,
106.6,
49,
94.4,
47.8,
41.4,
38.3,
9.6,
60.8,
68.9,
63.8,
12.1,
71.6,
71.8,
10.5,
83.6,
50.2,
56,
55.4,
46,
80.1,
98.9,
61.5,
73.9,
67.4,
69.3,
67.3,
62.8,
40.7,
63,
16.2,
50.4,
67.9,
88,
62.8,
45,
49.1,
44,
68,
14.3,
60.7,
31.6,
48,
83.3,
0.3,
50.6,
58.5,
93.3,
55.6,
55.4,
34.6,
77.3,
46.9,
59.9,
80.5,
12.7,
89.4,
59.6,
64.5,
0,
57.6,
96.5,
2.7,
72.1,
65.4,
42.6,
46.7,
92.5,
99.1,
49.3,
28.8,
56.9,
77.1,
60.5,
88.5,
56.3,
60,
57.2,
22,
67.3,
79.3,
96,
50.8,
42.3,
37.7,
57.7,
42.4,
85.3,
73.1,
97.6,
39,
1.8,
44,
29,
63,
77.7,
19.8,
8.9,
65,
36,
50.8,
64.5,
65.8,
46.9,
21.6,
78.4,
67.8,
46,
30.8,
46.2,
79.2,
88.4,
101.2,
73.7,
9.5,
64.1,
25.1,
13.1,
54.4,
22.7,
69.1,
59.8,
73.4,
90.5,
66.9,
46.3,
97.6,
89.1,
74,
7.5,
49.8,
18.2,
62.6,
2.9,
35.1,
67.6,
46.1,
47,
23.4,
85.6,
31.9,
22.6,
8.3,
89,
25,
46.1,
37.6,
58.4,
48.8,
48,
95.4,
57.1,
37.3,
60,
50.1,
19.1,
37,
62.1,
30.7,
33.9,
94.3,
72.4,
28,
75.6,
53.4,
46.6,
42.5,
44.1,
61.9,
65.1,
48.7,
88.2,
46.7,
45.2,
56.6,
43.1,
21.2,
41.1,
50.3,
70.6,
96.7,
62.7,
42.7,
55.3,
70.6,
11,
84.4,
42.8,
60.9,
32.9,
84.4,
52.5,
47.2,
72.1,
71.3,
54.2,
52,
53.4,
88.8,
76.4,
28.5,
61.1,
61.8,
35.7,
73.6,
46.4,
31.2,
75,
64.8,
18.1,
57,
42.7,
97.2,
43.9,
40.7,
42.3,
81.7,
61.7,
41.2,
45.5,
59.5,
30,
20.4,
39.3,
22.4,
10.6,
77.5,
73.7,
42.2,
74,
63.5,
31.7,
17,
85.6,
62.5,
10.9,
71.9,
20.7,
75,
7.2,
60.7,
67.6,
46.2,
48.1,
93.3,
65.3,
12.6,
2.6,
79.4,
66.5,
56.7,
76,
67.8,
86.7,
64.9,
5.5,
95.6,
63.3,
30.6,
99.1,
90.2,
44.5,
33.3,
47.9,
31,
69.5,
24.4,
34.8,
54.1,
42.5,
53.6,
25.1,
65.2,
35.9,
68,
85.7,
53,
83.2,
77.3,
86.4,
82.6,
61.8,
53.9,
59.8,
79.5,
90.4,
65.2,
24.2,
93.6,
68,
61.1,
43.6,
100.3,
58.4,
49,
18.7,
46.7,
52.6,
90.3,
40.1,
70.3,
92.2,
74.7,
58.7,
84.3,
48.9,
82.8,
89.3,
71.2,
23.6,
72.6,
16.8,
69.9,
84.3,
29.9,
54.7,
27.1,
58.4,
35.4,
51,
7.2,
64,
81.8,
82.5,
67.4,
54.3,
57.1,
89,
50,
67,
23.5,
10,
28.4,
47.4,
87.7,
33.9,
72.4,
71.7,
59.5,
49.4,
87,
48.8,
11.7,
68.2,
47.1,
63.7,
52,
42.1,
48.1,
69.1,
82.9,
40.9,
51.9,
45.7,
74.5,
70.2,
76.2,
76.4,
46.1,
96.3,
68.4,
84.9,
32,
63.1,
52.1,
61.1,
17.7,
65.5,
70.5,
81.1,
55.7,
56.1,
35.4,
93.2,
96.3,
56.9,
56.3,
32.8,
93.4,
44.7,
41.3,
67.1,
40.6,
18.6,
29.2,
45,
60.7,
84.3,
26.7,
56.5,
38.7,
60.7,
57.8,
37.8,
89.6,
48.1,
1.3,
65.4,
51.2,
45.8,
17.6,
98.4,
98.4,
5.4,
28.6,
36.9,
96.1,
76.5,
85.1,
52.5,
37,
83,
14.4,
90.6,
14.5,
88.5,
82.3,
97.4,
80.4,
28.6,
43.3,
81.5,
5.6,
98.5,
47.5,
18.6,
74.5,
61.1,
47.2,
42.2,
0.4,
83.6,
64,
72.2,
82.8,
53.6,
60.1,
70.4,
79.5,
31.1,
16,
75.5,
75.4,
17.6,
50.1,
62.9,
63.6,
81.6,
46.6,
20.1,
56.5,
75.3,
83.5,
29,
75.5,
77.7,
68.3,
83.5,
72.1,
5.9,
87.1,
39.5,
61.8,
79.3,
67.2,
66.5,
68.9,
34.5,
102.7,
71.2,
49,
36.5,
43.3,
42.7,
93.5,
58.1,
85.9,
37.7,
96.7,
96.7,
44.7,
67.1,
47.7,
36.1,
85,
44.7,
43.1,
99.5,
53.7,
89.4,
49.9,
27.8,
24.1,
60,
58.8,
20.8,
77.1,
26.8,
58,
43,
53.9,
65,
95.9,
71.4,
55.5,
23.8,
80.4,
48.4,
30.4,
84.8,
39.2,
74.2,
55.6,
69.8,
55.5,
64.8,
46,
77.3,
63.1,
33.9,
5.4,
31.3,
44.3,
32.6,
40,
80.6,
56.4,
66.2,
81.3,
81.6,
37.4,
76.9,
36.6,
73.4,
14.3,
10.9,
74.7,
48.5,
53.3,
96.4,
59.4,
43.1,
92.3,
49,
87.9,
45.5,
37.5,
52.7,
60.4,
64.2,
68.9,
66.4,
59.4,
33.1,
39.3,
1.8,
81.1,
52.7,
50.2,
58.1,
85.1,
39.2,
94,
18.4,
40,
50.3,
31.2,
70.2,
71.2,
85.1,
25.5,
63.5,
86.5,
32.4,
45.4,
61.9,
91.6,
25.8,
38.9,
47,
57.5,
64.2,
70.4,
85,
38,
38.7,
13.6,
29.3,
93,
65.4,
64.9,
68.3,
47.6,
63.1,
94.1,
66.1,
75.8,
46.7,
74.9,
8.5,
23.9,
6.6,
64.8,
59.9,
46.3,
68.4,
43.8,
41.7,
67.2,
19.5,
49.9,
56,
49.4,
61.7,
32.9,
83,
53,
85.2,
86.8,
84.8,
74.1,
77.5,
67.4,
18,
54.1,
40.9,
41,
34.1,
78.3,
27.2,
42.9,
82.3,
63.3,
34.6,
67,
47.6,
4.7,
26.3,
66.1,
44.2,
73.2,
88.1,
76.2,
54,
53.9,
63.7,
95.2,
46.9,
85,
59.6,
29.2,
44.8,
45,
97.3,
51.6,
97.9,
61.1,
61.2,
45.4,
48.2,
38,
47.7,
47.5,
18.1,
51.1,
68.1,
74.9,
57.5,
69.5,
57.2,
11.6,
46.5,
54.6,
6.7,
68.1,
41.7,
86.1,
10,
13.5,
0.5,
39.8,
65.2,
84.4,
55.3,
3.8,
43.1,
14.6,
83.4,
72.2,
25,
17.4,
41.4,
38.6,
74.2,
93.6,
72.2,
61.7,
32.6,
82.1,
95.3,
24.7,
22.1,
83.1,
22.4,
43.6,
28.6,
65.2,
54.2,
39.6,
48.3,
85.6,
49.7,
31.3,
54.1,
37,
42.5,
87.3,
80.7,
56.3,
60.3,
61.6,
38.3,
27.6,
65.4,
61.8,
16,
63.7,
7.3,
75.1,
60.4,
67.5,
16.1,
57.6,
80.8,
69.9,
43.3,
54.8,
40.3,
52.1,
64.9,
73.3,
95.7,
83.8,
24.1,
32.1,
25,
61.6,
87,
78.1,
59.8,
56.9,
52.4,
5.79,
37.2,
74.2,
73.5,
50.5,
47.9,
42.3,
47.5,
80.1,
24.6,
46.3,
63,
77.2,
2,
0.5,
84.2,
32.5,
99.7,
75.8,
76.8,
38,
10.9,
29.4,
76.4,
88.4,
63.7,
90.8,
50.9,
18.6,
35,
51.7,
38.8,
90,
51.2,
42.9,
65.3,
75.9,
69.7,
72.5,
51.6,
74.4,
72.2,
101.3,
86.7,
70.6,
100.9,
33.4,
63.2,
57.7,
31.7,
72.9,
57.9,
63.2,
54.6,
58,
93.6,
91,
45.8,
68.3,
43.7,
18.5,
59.5,
85.4,
80,
32.1,
54.4,
86.9,
47.8,
86.3,
44.5,
37.7,
99,
52.9,
73,
30.6,
58.6,
19.7,
95.4,
84.2,
88.3,
80.3,
66.6,
78,
59.2,
32.9,
71.1,
99.2,
21.3,
25.7,
70.4,
56.6,
49.2,
57.9,
19.3,
57,
51,
48.6,
53.8,
54.4,
54.2,
24.3,
48.6,
16.4,
18.5,
53.4,
48.9,
21.8,
47.3,
50.6,
84.7,
51.1,
11,
87.7,
52.2,
57.3,
34.5,
48.4,
60.9,
15.6,
63.5,
21,
23.2,
52.6,
8.8,
74.1,
61.6,
43,
75.9,
43.8,
49.8,
28.2,
57.2,
50,
47,
27.3,
84.3,
22.6,
85,
53.8,
72.9,
53.4,
52.3,
47.9,
77.6,
79.5,
56.6,
67.6,
40.1,
58.6,
76.3,
38.9,
25,
69.1,
36.6,
47.8,
56.5,
45.2,
81.5,
53.8,
77.4,
57.3,
41.1,
28.1,
44.9,
74.1,
51.6,
58,
70.9,
63.2,
37.1,
47.8,
62.8,
67,
100.2,
47.4,
80.8,
92.2,
73.2,
67,
0.2,
60,
34.2,
56,
44.1,
31.2,
45.4,
34.8,
48.2,
41.7,
66.1,
70.1,
75.8,
0,
66.8,
46,
62,
28,
0,
52,
55.2,
84.2,
84.9,
83.1,
32.6,
82.8,
40.9,
25.8,
30.4,
58.2,
68.3,
94.6,
49.8,
17.9,
38.6,
49.9,
50.7,
77,
65.9,
97.4,
48.4,
91,
58.3,
57.5,
30.2,
7.5,
92.4,
58.1,
64.5,
15.1,
52.9,
79.7,
45.9,
48.2,
56.9,
34,
11.1,
23.9,
37.6,
37.2,
39.1,
43.5,
86.6,
54,
8.5,
34.7,
39.4,
69.4,
8.3,
86.8,
40.2,
59.3,
69.1,
86.8,
63,
42.6,
38.2,
56.1,
32.1,
34.9,
22.2,
82.1,
77.1,
47.1,
95.7,
47.6,
62.1,
62.1,
33.2,
85.4,
61.6,
41.7,
88.4,
52.3,
78.5,
95.9,
14.9,
51.7,
45.5,
23.7,
23.4,
70.2,
35.7,
67.3,
52.5,
31.8,
42.3,
43.5,
12.2,
10.6,
73.8,
31.1,
47.8,
29.4,
82.2,
37,
82.2,
25.1,
93.1,
85.9,
60.8,
89.2,
69.4,
79.9,
45.2,
54.2,
35,
53.8,
1.1,
30.8,
16,
55.4,
89.8,
76,
35.3,
30.9,
79.3,
35.5,
50.1,
92.2,
49.8,
88.3,
68.4,
79.7,
53,
84.9,
31.3,
75.9,
61.6,
67.7,
54.1,
61.6,
49.1,
62.9,
24.5,
62.8,
64.1,
45.2,
65.6,
7.1,
23.6,
93,
81.4,
15.6,
51.8,
95.9,
33.8,
68.4,
63.9,
44.9,
22.9,
48.7,
66.9,
67.2,
24.6,
53,
52.9,
61.4,
92.6,
19.6,
72.2,
69.6,
87.6,
64.3,
99.1,
89.1,
88.7,
70.5,
43,
74.8,
13.8,
50.2,
47.5,
81,
31.9,
48.4,
64.5,
40.9,
47.1,
83.4,
63.4,
44.7,
55.1,
65.6,
27.8,
75.6,
30.9,
47.7,
84.1,
49.2,
5.6,
53.8,
33.4,
49.2,
60.4,
33.3,
26,
39,
33.8,
6.3,
30.3,
96.8,
42.1,
74.7,
74.6,
74,
81,
33.5,
61.6,
10.8,
52.5,
82.5,
52,
47,
78,
43.4,
42.8,
25.5,
39.7,
42.8,
37,
5,
25.8,
42.3,
24,
59.9,
49.4,
35.8,
44.2,
77.1,
17.5,
71.7,
92.1,
92.2,
92.6,
98.4,
29.3,
69,
80,
82.9,
25.3,
86,
38.1,
100.4,
23.4,
52.1,
65.3,
16.9,
57,
54.1,
38.6,
69.4,
98.8,
37.9,
46.9,
55.7,
39.4,
50,
84.3,
69.9,
69.3,
56,
8.5,
52.7,
2,
26,
66.5,
83.7,
28.1,
23.1,
53.2,
91.7,
42.6,
16,
31.6,
69.2,
45,
6.1,
44.2,
76.1,
34.6,
60.5,
83.9,
42.4,
63.3,
51.2,
61.2,
84,
44.7,
54.2,
76.5,
80.4,
64.2,
83.6,
82.8,
82.9,
41.7,
61.6,
61.6,
83.2,
96.9,
41.2,
25.1,
45.3,
18.6,
77.6,
54.8,
31.9,
52.8,
54.6,
31.3,
45.3,
38.7,
69.2,
66.8,
13.9,
14,
68.7,
17,
46.3,
27.1,
55.3,
37.6,
30,
68.2,
22.5,
59.4,
81.1,
30.5,
51.8,
35.5,
34,
89.9,
70.2,
53.9,
61.2,
44.1,
42.9,
58.3,
78.4,
88,
18.2,
40,
63.6,
82.1,
46.5,
73.4,
31.7,
60.5,
70.3,
60,
33.8,
1,
98.5,
45.4,
17.9,
72.6,
59.5,
33.4,
17.6,
68.7,
9.8,
59.4,
49.6,
60,
48.4,
47.4,
52.8,
31.4,
55.7,
58.4,
100,
23.5,
38.3,
30.9,
39.4,
84.6,
67.1,
28.6,
52.2,
43.3,
74.8,
48.4,
81.5,
39.2,
47.6,
50.2,
89.4,
83,
44.4,
59.1,
85.4,
15.7,
91.7,
42,
73.5,
15.6,
36.4,
45.1,
34.1,
54.1,
37.4,
66.4,
37.8,
3.3,
51,
42,
68.8,
82.8,
48.3,
98.1,
56.2,
71.5,
66.1,
37.3,
47,
67.8,
46.8,
30,
60.7,
93.4,
74,
35.7,
37,
84.2,
73.7,
92.6,
84.1,
40,
40.9,
83.7,
73,
49.4,
35.2,
52.4,
47.3,
59.3,
64.4,
11.5,
50,
49.6,
50,
88.3,
72.8,
50.7,
65.1,
64.9,
22,
75.1,
59.2,
32,
58.3,
39,
31.5,
26.3,
64.1,
74.9,
55.7,
50,
60.3,
57.9,
70.2,
87.6,
43,
60.2,
51.8,
77,
33.4,
93.8,
63.2,
70.3,
25.8,
42.4,
53.4,
75.9,
54,
7.9,
71.2,
21.2,
86.3,
58.3,
76.2,
95.6,
48.6,
75,
77.7,
52,
41.7,
49,
35,
72.6,
60,
62.3,
60.3,
44.1,
19.1,
83.7,
88.5,
63.3,
81.2,
30.6,
51.7,
30.9,
50.5,
79.2,
56.3,
44.5,
41.8,
30,
58.8,
82.8,
67.9,
50.6,
47.5,
2.5,
40.1,
92.6,
21.3,
30,
40,
8.5,
83.4,
55.4,
92.8,
32.2,
84.6,
64.9,
59.6,
37.4,
47.4,
68.8,
53.3,
96.5,
34.4,
84.8,
82.3,
75.5,
68.1,
91.7,
83.7,
37.4,
29.1,
63.3,
47,
27.2,
48.3,
54.6,
52.1,
86.3,
65.9,
77.8,
54.9,
7,
94.7,
68.1,
6.8,
79.2,
34.7,
23.3,
49.2,
83.3,
1.1,
67.2,
11.5,
78.6,
72.3,
23.4,
19,
41.5,
60.6,
55.8,
51.1,
73.1,
61.6,
52,
39.5,
33.1,
65.5,
2,
44,
1.7,
40.4,
77.8,
56.2,
57.5,
27.9,
94.4,
74.5,
71.7,
53.5,
69.9,
62,
91,
40.2,
74.9,
40.1,
42.2,
98,
44.7,
50.6,
39.8,
3.9,
41.5,
25.8,
19.2,
78.2,
54.3,
44,
21.7,
94.9,
40.6,
60.8,
25.8,
34.9,
47.9,
11.9,
77.6,
26.8,
73.1,
66.8,
18.6,
66.9,
53.8,
50.8,
25.9,
7.9,
93.7,
67,
63.2,
27.8,
41,
69.9,
35,
60.1,
6.6,
59.3,
52.8,
70,
63.4,
34.5,
23.1,
39,
43.6,
87.7,
14.5,
80.5,
33.4,
19,
79.4,
0.7,
32.7,
84.5,
55.8,
51.9,
28.4,
56.4,
96.4,
64.6,
91.2,
45.2,
50.4,
68.5,
62.7,
72.2,
99.4,
69.5,
38,
44.4,
73.1,
57,
79,
79.2,
67,
58.5,
28.7,
0.7,
75,
86,
35,
31.9,
60.4,
56.2,
38,
61.5,
77.5,
54.9,
65.2,
26.3,
67.9,
16.2,
70.9,
33.2,
79.8,
76.7,
98.3,
24.4,
89.7,
62.7,
18.2,
92.4,
29.2,
50.1,
54.4,
57.1,
43.9,
40.7,
79,
74.8,
89.1,
95.7,
83.6,
15.5,
76.5,
95.6,
64.7,
72.6,
23.9,
62.6,
75,
62.8,
63.5,
60.4,
13.2,
37.9,
46.8,
83.8,
26,
55.1,
47.1,
53,
80.1,
62.7,
90.2,
41.6,
58.9,
41,
7.1,
42.6,
34.9,
16.7,
75.1,
90.2,
69.6,
50.5,
80.2,
15.6,
31.1,
9.1,
26.6,
67,
12.2,
96.2,
24.3,
66.9,
46,
21.2,
33.9,
37.7,
69.4,
84.7,
0.3,
67.6,
69.6,
60.9,
75.5,
49.9,
84.1,
93.6,
30.7,
67,
47.2,
0.6,
52,
50.2,
65.6,
71.5,
40,
98.5,
88.4,
91.4,
97.7,
46.3,
31.2,
17.4,
59.2,
97.9,
48.5,
0.5,
43.2,
44.9,
85,
57.2,
49.6,
60.4,
81.9,
37.2,
7,
50.5,
61.5,
89.3,
37.8,
70.2,
70.5,
22.8,
47.2,
38.1,
36.1,
92.1,
26,
28.8,
22.3,
71.8,
12.6,
13.9,
69.5,
43.1,
71.6,
49.7,
18,
49.8,
63.5,
63.6,
48.1,
47.5,
58.9,
68.2,
60,
97.2,
68.9,
67.7,
80.7,
81.6,
54.2,
73.3,
77.7,
29,
13.9,
67.7,
20.8,
17.5,
24.9,
85.8,
70.1,
90.6,
91.5,
84.8,
6.5,
92.5,
32.4,
35,
53.4,
25.9,
48.2,
56.3,
73.7,
49.7,
78.4,
69.2,
79.5,
44,
31,
49.8,
85.8,
65.8,
96.1,
36.6,
48.2,
13.2,
83.9,
85.2,
55,
74.6,
90.3,
43.9,
43,
60.2,
32,
null,
86.8,
47.3,
57.8,
46,
65.7,
65.9,
40.1,
68.8,
20,
63.7,
47.2,
8.8,
47.7,
66,
83.2,
79.8,
53.6,
67.1,
24.4,
59.4,
15.8,
96.9,
74.6,
33.8,
36,
70.2,
78.3,
90,
62,
44,
81.5,
41,
94.2,
79.3,
39.2,
15.2,
87.5,
14.3,
61.2,
79.5,
25.6,
22,
54.4,
35.8,
54,
25.8,
47.2,
76.3,
22.5,
80.2,
89.4,
43.9,
27.2,
60.4,
8.9,
5.6,
63.7,
29,
49,
33.6,
7.2,
56.9,
90.1,
79.1,
32.3,
84.8,
71.1,
62.6,
73.4,
15.6,
95.8,
57.1,
27.1,
55.7,
31.5,
67.2,
16.6,
29.9,
54.2,
60.4,
28.9,
61.7,
54.2,
25,
90.6,
72,
4.6,
73.1,
95,
66,
50.7,
35,
52,
43.9,
59.4,
59,
32.1,
54.2,
50.3,
34.2,
72.4,
2.2,
79.2,
24.4,
40.8,
44.6,
56.5,
59.8,
63.9,
43.3,
48.2,
34.5,
30.1,
52.9,
30.3,
93.4,
13.3,
81.6,
70.7,
90.8,
74,
9.4,
56,
68.9,
61.1,
49.8,
36.7,
64.6,
38.6,
73,
18.6,
39.7,
21.8,
49.8,
96.6,
80,
79.5,
87.6,
51.4,
95.8,
55.9,
82.2,
16.1,
65.6,
73,
37,
86.7,
88.9,
15.7,
69.6,
55.1,
38.9,
0,
16.9,
66.3,
81.9,
55.6,
49.7,
66.4,
37,
61.8,
34.5,
75.6,
26.3,
56.9,
58.7,
34.7,
45.6,
93.6,
50.8,
83.3,
38.2,
69.7,
49.8,
60.8,
54,
41.3,
28.9,
47.8,
100,
64.2,
66,
80.1,
96.1,
29.9,
23.4,
46.4,
75.4,
40.4,
22.9,
46,
42.4,
82.1,
61.1,
69.3,
94,
25.5,
20,
46,
35.3,
37.5,
26.8,
93.3,
44.5,
59.6,
29.5,
10,
63.6,
75.6,
29.8,
73.2,
3.7,
78.2,
41.6,
97,
72.1,
82.7,
82.3,
53.4,
26.2,
53.7,
55.7,
94.6,
69.6,
73.7,
72,
22.6,
43.3,
60.4,
86.3,
70.6,
29.6,
69.7,
71.9,
70.6,
60,
54.3,
57,
48.6,
26.9,
49.8,
71.4,
32.2,
15.6,
58.2,
99.8,
36.9,
68.4,
73.3,
59.4,
74,
82.3,
41,
41.2,
22,
57,
43.7,
63.5,
14.1,
70.2,
41.7,
50.4,
77.7,
53.2,
55.5,
48.7,
61.3,
78,
53.4,
45.6,
47.3,
5.1,
50.8,
61,
46.9,
43.7,
43.9,
35.8,
61.8,
71.2,
68.1,
40.1,
19.3,
48.6,
82.5,
91.2,
75.2,
51,
42.8,
23.4,
79.1,
45.8,
81.2,
38.3,
93,
78.2,
41.8,
64.4,
65.3,
21.7,
11.2,
26.2,
60.7,
8.8,
89.2,
38.6,
95.2,
47.9,
73.4,
30.6,
23,
68.6,
9.5,
83.6,
90.8,
76.3,
83.3,
66.5,
73.8,
92.7,
90.1,
69.1,
91.7,
83.3,
81.8,
58.8,
88.4,
47,
40,
4.5,
73.3,
58.8,
47.6,
52.9,
54.1,
59.3,
42.9,
50.7,
91.3,
97,
42.1,
29.5,
69.3,
53.5,
85,
38,
45.7,
47,
15.8,
59,
36,
20,
100.1,
54.3,
36.7,
10.3,
40.5,
37.1,
47.3,
86.4,
51.6,
74.5,
75.5,
55.7,
79.7,
57.7,
40.3,
44.6,
24.9,
39.4,
29.5,
71.7,
76.8,
76.7,
1,
82.5,
30.3,
9.4,
61.4,
73.6,
35,
73.5,
1.6,
29,
54.8,
8,
47,
63.1,
54.6,
26.6,
33.7,
53.9,
27.1,
86.2,
39,
76.1,
57.1,
66.6,
53.7,
34.1,
0,
46.2,
51.2,
49,
31.6,
84.3,
42.3,
21.2,
27.6,
83.8,
34.1,
22.4,
35.3,
34.4,
63,
76.6,
87.3,
16.1,
57.4,
49.4,
41,
61.3,
75.6,
40.4,
72.6,
70.5,
26.4,
83,
85.6,
76.7,
77.6,
78.5,
86.5,
64,
68,
87.6,
29.9,
38.9,
40.5,
75.3,
27.1,
88.5,
40.6,
80.7,
58.3,
48.7,
31.4,
92.4,
54.7,
45,
72.5,
62.6,
86.2,
95.5,
48.3,
29.7,
61.9,
61.9,
72.7,
28.9,
24.1,
64.3,
98.2,
13.8,
60.2,
47.7,
3.7,
32.6,
3.4,
68.4,
73.1,
61.5,
48.7,
52.4,
60.1,
29.8,
70.2,
64.3,
84.7,
41.8,
72,
63.6,
78,
23.2,
75.1,
24.7,
52.3,
87,
45.6,
30.5,
78,
22,
21,
58.9,
56.8,
95.7,
50.8,
53.6,
53,
98.6,
5.7,
37.8,
77.9,
56.7,
72,
23.4,
70,
72.3,
86.5,
45.9,
56.1,
84.9,
47.6,
20.7,
34.5,
52.8,
76,
5.4,
77.1,
5.6,
76.7,
41.5,
62.4,
86.6,
101,
81.9,
91.4,
74.4,
73.9,
66.7,
88.1,
68.8,
95.3,
23,
68.3,
51.4,
52.6,
49,
40.6,
43.4,
6.2,
41.7,
80.9,
58.4,
49.6,
5.3,
90.1,
0,
67.2,
99.3,
38.4,
2.2,
35.4,
94.1,
33.7,
64.7,
48.4,
62.7,
64.2,
87.4,
44.9,
99,
96.3,
67,
75.3,
51,
41.3,
94.5,
31.7,
67.3,
69.4,
83.1,
82.9,
60.7,
13.7,
54.4,
39.1,
46.4,
53.6,
84.5,
44.3,
25.4,
77.6,
67.2,
102.9,
27.1,
63.9,
39.7,
74.2,
86.2,
54,
51.6,
69.3,
70.5,
58.7,
77.8,
82.9,
39.1,
44.4,
57,
60,
66,
72.4,
36.2,
27.6,
15.6,
44.8,
69.4,
35.8,
46.8,
100.3,
7.5,
84.3,
64.4,
57.1,
76.9,
65,
73.2,
80.6,
83.3,
100,
34.9,
57.7,
61.7,
36.7,
58.9,
74.1,
61.3,
58.6,
76.5,
63.8,
49.3,
77.5,
59.8,
94,
47.5,
15.5,
37,
20.2,
22.8,
58,
45.9,
62,
39.5,
60.2,
53.5,
14.7,
38,
59.7,
58.7,
68.1,
49.6,
42.5,
53.6,
31.3,
92,
28.3,
72.4,
39.3,
71.7,
7.1,
76.1,
93.7,
38,
42.7,
96,
32.7,
58.3,
91.8,
53,
72.1,
86.4,
16.8,
20.7,
72.8,
44.1,
46.2,
65.8,
12.6,
51.6,
18,
68.2,
67.3,
45.9,
82.4,
84.4,
65.5,
81.4,
46.1,
53.4,
28.2,
87.3,
33.5,
76.8,
81.2,
65,
58.5,
81.6,
41.7,
14.3,
65.4,
17,
89.7,
65.1,
66.4,
79.5,
42.8,
32.8,
56.9,
63.3,
82.3,
50.9,
8.3,
37.2,
72,
16.3,
85.9,
47.2,
90.3,
26.4,
7.7,
49,
13.2,
78,
88.1,
18.9,
76.1,
13.7,
0.6,
84.2,
29.9,
23.9,
30.3,
43.4,
42.3,
66.8,
84.4,
93.8,
67.5,
72.5,
67.3,
64.6,
83.5,
67.1,
71,
63.1,
48.1,
71,
34.1,
51.8,
54.4,
38.2,
77.6,
95,
47.1,
59.5,
9.7,
53.5,
29.7,
56.8,
76.2,
37.7,
49.8,
33.7,
31.3,
57.9,
72,
61.6,
51.6,
94.7,
3.5,
67.2,
84.6,
42.3,
59.3,
3.5,
35.9,
94.6,
42.8,
58,
74,
21.4,
83.7,
34.6,
81.5,
80.5,
97.8,
38.2,
61.5,
62.6,
61.9,
12.1,
33.6,
49.1,
51.4,
52.8,
57.3,
81,
83.6,
41.2,
57.4,
3.2,
49.9,
65.5,
69.3,
57.4,
50.1,
31.3,
73,
63.8,
19.5,
64.1,
83.6,
66,
92.4,
43.4,
70.3,
65.8,
20.2,
51.5,
54.2,
37.3,
73.7,
39.2,
38.8,
39.1,
10.3,
45.7,
0,
71,
76.2,
60,
70.6,
96.4,
8.7,
54,
62.1,
94.8,
67.9,
48.2,
64,
71.8,
77.6,
49,
57.1,
41.7,
61.2,
94.8,
53.8,
49.1,
27.1,
43.5,
29.7,
66.5,
54.5,
38.3,
45,
59.8,
5.5,
12,
50.2,
57.1,
39.3,
59.7,
56.6,
30,
27.9,
57.1,
39.3,
82.2,
40.3,
68,
69.3,
47.3,
90.6,
56.7,
31.3,
36.5,
28.8,
27.6,
58.6,
91.6,
50,
51.7,
76.3,
74.9,
39.8,
83.5,
13,
53.4,
18.9,
59.8,
50.7,
33.1,
76.5,
55,
70.2,
67.9,
97.6,
40.2,
51.7,
42.2,
31.1,
94.1,
40.5,
55.7,
65,
25.1,
85.6,
63,
7.7,
50.7,
86.3,
70,
25.5,
10,
92.7,
73.4,
34.9,
55.5,
39.7,
56.5,
59.6,
89.7,
68.5,
37.2,
73,
82.1,
71.6,
57.3,
92.2,
23.3,
53.4,
87.2,
38,
64.7,
64.2,
86.5,
8.8,
75.7,
35.8,
38.7,
60.2,
37.6,
41.2,
55.3,
65.7,
59,
82.9,
79.4,
59.5,
98.6,
20.7,
56.4,
59.9,
90.9,
71.2,
80.2,
83.6,
20,
65.7,
9.8,
48.2,
44.7,
81.4,
29.9,
42.8,
21.8,
91.2,
32.6,
29.5,
76.6,
40.3,
95.1,
49.2,
35.3,
29.4,
34.7,
11.4,
54.1,
30.7,
91.4,
16.9,
33,
95.6,
47.5,
78.5,
47.3,
16.9,
38.3,
73.8,
87.2,
39.9,
34.2,
52.3,
36.8,
45.2,
47.7,
83.5,
29.8,
66.9,
50,
82.5,
95.1,
56.4,
48,
63.9,
49.7,
64.6,
47.2,
42.7,
94.1,
79,
29.9,
69.4,
61.9,
53.9,
54.1,
37,
32.5,
73.1,
11.7,
63.6,
88.8,
28.4,
73,
54.2,
40,
93.8,
95,
40.5,
28.1,
61,
44.8,
21.4,
24.5,
24.8,
62,
58.2,
64,
54.3,
73,
75.6,
23.8,
58.2,
87.9,
78.9,
41,
91.3,
83.8,
40.8,
33.4,
49.9,
12.3,
57.2,
69.3,
39.4,
43.5,
46.1,
53.3,
29.1,
82,
42.1,
4.1,
47.6,
38.8,
41.2,
33.1,
69,
87.9,
30.8,
31.9,
70.6,
60.2,
48.6,
88.2,
55.7,
55,
46.8,
66.9,
64,
36.9,
5.2,
38.7,
60.5,
61.4,
51.4,
40,
46.2,
84.1,
31,
81.2,
99.7,
70.7,
41.2,
59.9,
59,
74.9,
37.5,
47.2,
13.2,
30.8,
8.6,
46.4,
56.7,
74.7,
50.2,
77.8,
64.6,
35.2,
31.5,
49,
22.1,
82.2,
58.1,
44,
46.8,
40.6,
44.1,
83.7,
59.7,
59.9,
28.3,
48.2,
73.5,
24.3,
53.2,
40,
27.8,
71.6,
66.3,
60.6,
63.9,
67.7,
26,
13.3,
64,
35.2,
30.4,
95.4,
0,
10.8,
80.8,
49.3,
53.5,
40.8,
102.9,
65.5,
87.5,
33.7,
88.5,
54.7,
20.3,
68.6,
76.8,
0.4,
86.7,
69.9,
40.2,
97.5,
105.3,
92.7,
91.1,
33.3,
40.6,
69.8,
37,
97.4,
49,
47.1,
90.9,
43,
24.3,
11.7,
96.2,
54.4,
89,
85.2,
65.2,
57.8,
43.8,
56.7,
43.6,
51.2,
4.2,
58.8,
61.4,
88,
77.5,
56.9,
84.2,
44.2,
69.1,
55.2,
80.4,
14.4,
68.7,
53.3,
24.3,
36.6,
61.5,
76.5,
61.4,
28.3,
80.9,
47,
43.8,
45,
46,
37,
82.1,
36.7,
27.3,
15.1,
52,
34.2,
56.5,
79.7,
38.6,
57.3,
61.1,
38.2,
48.9,
62.1,
77.1,
55.4,
55.7,
56.6,
87.3,
96.8,
32.7,
81.5,
40.6,
85.9,
77.6,
48.5,
48.1,
71,
64.4,
53.8,
17,
51,
76.9,
69.1,
49.4,
47.3,
79.2,
22.8,
56.9,
50.4,
77.5,
30.2,
9.2,
71.4,
92.5,
14.3,
71.6,
87.3,
48.5,
31,
75.7,
36.5,
75.2,
96.1,
0.6,
100,
52.4,
65.1,
71,
59.7,
61.9,
64.7,
51.5,
64.3,
57.9,
70.4,
92.1,
58.8,
16.4,
65.3,
35.7,
92.8,
54.3,
20.1,
69,
54.1,
51.3,
72.8,
12.7,
80.8,
70,
71.6,
40,
74.7,
43.3,
84,
81,
60.6,
2.4,
45.7,
101.9,
15.1,
26.5,
31.2,
95.3,
38.8,
45.2,
66.3,
27.3,
93.9,
33.9,
50.5,
5.4,
63,
6.7,
68,
88.2,
64.3,
95.6,
42.9,
85.3,
75.5,
74,
51.6,
88.5,
57.7,
77.6,
41.9,
22.6,
12,
22.1,
27.7,
64,
57.2,
63.3,
68.2,
18.7,
58.1,
65.1,
66,
34.7,
62.1,
24.7,
86.5,
62.6,
49,
28.8,
50.4,
41.4,
58.5,
29,
64.8,
9.1,
38.7,
48.6,
64.5,
37.8,
30.5,
80,
88.4,
76.4,
20.3,
60.5,
64.1,
70.7,
41.4,
92.5,
41.2,
18.2,
25.5,
101.8,
43.5,
57.9,
17.6,
82.8,
91,
69.9,
69.9,
57.9,
46,
70.6,
93.9,
32,
0,
74.8,
28.1,
37.4,
56.1,
29.8,
80.6,
58.7,
22.3,
46.8,
58.1,
42.8,
45.4,
93.9,
25.3,
99.7,
48.5,
31.7,
47.2,
79.8,
36.1,
29.4,
58,
58.6,
79.7,
51.1,
44.5,
92.5,
68.2,
56.6,
25.9,
93.3,
63.5,
0.3,
79.9,
78.3,
89.4,
97.5,
0,
73.4,
37.9,
92.2,
59.4,
61.5,
42.2,
85.4,
20,
52.8,
43.5,
49.9,
92.9,
91.9,
69.4,
1.2,
80.3,
76.2,
47.4,
84.5,
39.5,
64.6,
51.2,
86.6,
46.1,
55.9,
41.5,
27,
33.9,
22.2,
37.6,
58.1,
59.3,
63.5,
37.8,
95.7,
74.7,
50.7,
72.3,
79,
39.2,
83.8,
51.5,
61.6,
40,
80.6,
75.6,
77.1,
70.5,
78,
98.2,
0.3,
69.6,
15.6,
78.3,
30.6,
92.4,
28.4,
12.3,
29.5,
98.5,
59,
64.5,
15.1,
53,
31.7,
65.7,
72.8,
28.4,
96.7,
75.3,
27.6,
63.1,
40.9,
43.6,
9.1,
16,
96.5,
43.8,
52.3,
70.3,
61.5,
38.1,
23.1,
30.7,
58,
65.6,
40,
50.7,
62.8,
31.9,
70.4,
47.5,
85.4,
44.8,
59.1,
53.5,
63.6,
61.3,
28.6,
29.8,
73.6,
84.4,
22.3,
71.9,
58,
47.4,
6.5,
20.8,
35,
46,
72.8,
43.3,
30.5,
61.6,
4.1,
44.6,
76.3,
86.5,
71.3,
76.2,
27.6,
47.7,
97.8,
67.3,
35.5,
20.6,
76.2,
46.1,
81.4,
46,
64.3,
70.4,
60.5,
28.5,
52.3,
43.8,
67.6,
26.4,
57.4,
67.8,
61.9,
52.7,
73.4,
72.3,
90.2,
74.2,
66.8,
48.8,
41.1,
7,
32.9,
41.1,
67.3,
47.6,
15.7,
42.7,
73.6,
16.8,
37.8,
39,
86,
63.6,
66.4,
82,
29.3,
44.2,
67.1,
52.8,
32.1,
60.4,
48.9,
4.7,
64.7,
55.6,
51.3,
16.7,
95.5,
68,
48.8,
26.2,
75.4,
91.2,
64.1,
89.2,
45.9,
12.6,
77.2,
42.7,
66,
60.4,
89,
86.1,
54.8,
78.7,
42.5,
65.4,
83.3,
55.7,
70.9,
49.3,
27.4,
38.7,
68.5,
55.1,
79.5,
30.3,
39.7,
50,
38,
54.8,
39.3,
76.1,
68.7,
31.4,
60.5,
40,
60.2,
40.9,
38.8,
70.7,
49,
71.7,
73.8,
96.9,
52.2,
37.4,
71.4,
66.9,
52.1,
85.8,
87,
66.7,
88.7,
56.1,
80.3,
97.7,
23.8,
72.3,
63,
10.4,
80.5,
63.8,
70.7,
12.9,
59.6,
61.4,
87,
47.8,
23.6,
63.9,
43,
68,
70.4,
76,
80.6,
61,
76.7,
70.7,
39.8,
42.3,
32.9,
24.4,
79.9,
88.6,
0.6,
13.4,
8.2,
93.7,
25.7,
71.5,
87.2,
40.3,
30.6,
81.5,
43,
78,
55.1,
65,
29.4,
38.9,
53.9,
42.4,
57.5,
38.1,
32.2,
74.7,
81.9,
58.7,
13.3,
61.5,
60.3,
91.3,
1.4,
54.3,
42,
47.8,
18.9,
83.1,
78.7,
13.5,
97.8,
23.8,
22.1,
61.6,
73,
77,
39.8,
31.5,
98.1,
84.5,
53,
59.1,
45.4,
29.5,
86.4,
18.2,
29.7,
55,
67.6,
84.2,
53.8,
43.6,
66.1,
52.4,
61.1,
83.1,
43.4,
37,
49.9,
20.1,
37.2,
37.1,
81.5,
29.9,
84,
72.6,
43,
73.1,
59.2,
26,
58,
53.6,
79.3,
68.9,
34.6,
84.8,
49.8,
30,
92.7,
81.9,
65.6,
44.9,
80.1,
87.7,
61.2,
72.2,
83.7,
15.1,
37,
52.9,
93.4,
31.1,
58.4,
98,
62.7,
49.3,
95.4,
19.9,
69.4,
76.6,
91.8,
70.8,
29.5,
81.9,
49.8,
53.5,
48.9,
13.3,
64.3,
40.8,
87.3,
56.3,
45.8,
53.7,
91,
68.1,
66.6,
58.7,
54.7,
15.3,
11.2,
22.3,
57.4,
52,
83.6,
98.8,
25.1,
43.7,
90.3,
92.5,
69.7,
91.6,
36.7,
60.5,
34.5,
77.8,
48.7,
61.2,
79,
70.1,
14.2,
48.2,
45.7,
68.8,
77.6,
51.4,
83.1,
20.2,
72.3,
78.5,
25.1,
91.2,
73.3,
41.1,
60.7,
92.6,
2.6,
64.7,
55.4,
94.9,
4.6,
22.8,
8.9,
47,
79.3,
16.3,
55,
57.9,
33.9,
95.5,
79,
91.3,
48.9,
54.2,
74.6,
78.3,
31.8,
85.5,
66.9,
83.9,
38.7,
28,
41.7,
76,
66.5,
86.1,
38.4,
58.8,
44.2,
80.8,
68.8,
58.8,
61.4,
50.1,
83.1,
0,
73.1,
71.5,
51.3,
76.4,
46.1,
64.6,
55.8,
48.9,
70,
18.9,
36.3,
21.2,
57.3,
63.2,
77.1,
73.6,
85.4,
82.5,
60.7,
98.3,
36.8,
93.6,
57.7,
14.3,
31.4,
47.3,
79.8,
28.8,
77.8,
79.5,
72.9,
20.7,
30,
59.4,
63.7,
58.4,
80.5,
49.7,
34.9,
57.5,
39.7,
55.1,
63.6,
25.8,
59.3,
66.7,
15.3,
38.8,
0,
63.7,
76.5,
13.5,
71.9,
36.4,
32.9,
76,
33.2,
48.4,
73.6,
50,
93.5,
79.9,
86.2,
40.4,
49.9,
81.2,
71.9,
62.8,
51.1,
95.7,
58.4,
41.7,
81.1,
79.5,
60.3,
43,
41.1,
45.4,
65.8,
77.3,
64.2,
54.8,
57,
42.2,
25.9,
10.7,
51.1,
42,
65.6,
89.3,
87.1,
null,
34.1,
67.1,
73.2,
41.1,
31.1,
1,
51.4,
75.4,
43.8,
64.1,
90.3,
54.7,
28,
26.2,
34.8,
30.3,
54,
26.5,
90.5,
50.3,
46.7,
5,
70.9,
93.6,
95.4,
43.1,
71.9,
32.2,
26.1,
80.4,
43.3,
61.5,
16.7,
66.2,
75.6,
96.7,
36.7,
61.2,
54.1,
32,
9.2,
70.3,
60.6,
43.7,
67.8,
60.3,
76.5,
75.6,
57.8,
84.2,
53.3,
92.2,
19.3,
71.5,
75.7,
37.6,
78.4,
11.3,
39.1,
43.3,
82.3,
60,
55.4,
71.3,
56.9,
19.9,
7,
62.5,
20.2,
64.4,
63.8,
16.2,
0,
36,
57.9,
21.6,
51,
83,
62,
70.9,
50.6,
34.9,
60,
96.9,
43.5,
36.2,
13.3,
21,
84,
39.6,
15.2,
11.4,
6.1,
78,
42.9,
56.8,
31.1,
80,
17.9,
41.7,
35.6,
53.1,
63.8,
16.2,
53.5,
76.2,
14.2,
91.4,
64.3,
31.8,
43.7,
43.4,
21.8,
40.9,
53.4,
79.2,
46.1,
29.2,
79.4,
80.7,
62.3,
59.9,
80.8,
6.3,
34.2,
0,
0,
53.5,
47.3,
68.6,
73,
52.1,
42.7,
39,
38.5,
52.4,
17.2,
87.5,
15.7,
74.5,
66.6,
62.6,
58.2,
21.4,
57.4,
60.4,
42.7,
26.2,
66.9,
94.1,
74.6,
81.6,
65.1,
85.6,
61.7,
72.2,
66.5,
76.1,
19.1,
64.2,
70.2,
26,
27.5,
73.4,
20.2,
25.7,
5.7,
96.8,
80.1,
5.1,
49.6,
54.1,
32,
58,
23.1,
59.1,
84.6,
58,
21.7,
56.1,
94.8,
54.9,
75,
37.8,
37,
36.7,
21,
62.8,
42.2,
95.1,
39,
62.4,
47.4,
36,
61.9,
87.9,
18.6,
66,
27.8,
21.5,
72.3,
31.8,
87.7,
55.8,
39.1,
50.1,
83.2,
44.1,
85.3,
11.3,
68,
68.8,
69.5,
65.9,
79.9,
42.9,
87.4,
94.8,
45.2,
45.1,
64.4,
62.5,
58.6,
42.6,
12.9,
89.4,
75.9,
80.5,
89,
1.5,
31.2,
42.2,
55,
7.1,
56.1,
36.1,
64,
62,
80.6,
33.3,
46.5,
47.8,
70.5,
59.6,
15.7,
79.5,
46,
20.8,
27.8,
50.9,
49.6,
62.4,
56,
86.1,
44.2,
13.3,
42.8,
61.6,
43.1,
79.7,
4.3,
6.1,
68.1,
70.2,
7.6,
22.1,
46.5,
89.2,
46,
64.3,
65.6,
61,
54.9,
83.6,
49.7,
51.3,
37,
68.1,
27.7,
44.7,
16.1,
43.1,
90.4,
77.4,
81.8,
9.4,
83.6,
37.5,
29.2,
50.4,
17.4,
80.8,
55.4,
70,
0,
56.1,
75.5,
34.6,
5.6,
84.4,
36,
46.5,
64.8,
52.6,
67.5,
26,
49.3,
42.8,
21.3,
51.1,
84.1,
35.6,
50.6,
55.6,
88.2,
57.7,
57.5,
56.4,
32.7,
23.6,
73.5,
89.1,
95,
47.4,
36.4,
50.5,
84.7,
79,
57.2,
46.5,
77.4,
12.8,
75.4,
64.2,
32.9,
85.6,
21.2,
58.4,
55.1,
43.3,
32.3,
59.5,
81.3,
32,
70,
91.6,
61,
49.5,
51.2,
36,
58.6,
94.1,
52.9,
43.4,
0,
27.3,
40.3,
87.9,
35.3,
64.5,
50.9,
21.6,
85.9,
9.8,
77.8,
90.5,
39.5,
97,
47.5,
39.7,
46.5,
28.7,
19.8,
62,
94.6,
74.1,
51.1,
57.4,
85.3,
73.3,
25.1,
64.8,
54.3,
48,
86.1,
73.5,
87.9,
62.8,
98.7,
94.8,
60.8,
56,
76,
80.1,
58.5,
33.2,
51.4,
10.7,
21.1,
78.2,
66.3,
23,
64.4,
57,
53.3,
53.7,
48.7,
30,
42.8,
8.8,
89.2,
53.3,
48.9,
78.1,
54.3,
36.9,
47.9,
51.3,
100.4,
72.8,
56.9,
25.7,
63.5,
76,
59,
51.6,
78.9,
58.2,
57.3,
28.6,
76,
62.3,
89.5,
85.1,
57.6,
33.9,
77.1,
97,
41.8,
56.6,
65.7,
33.4,
78.6,
48,
59,
34.8,
39.3,
62.5,
86.2,
41.9,
16,
26.4,
26.1,
24.1,
50.5,
42.4,
18.2,
73.1,
62.6,
80.8,
86.9,
42.9,
16.2,
67.9,
8.1,
50.4,
54.3,
49.8,
43.1,
68.6,
53.6,
73,
88.3,
0,
7.3,
73.4,
2.1,
41.5,
48,
8.7,
42.5,
64.2,
94.8,
85.4,
83.9,
38.5,
50,
33.9,
81.1,
84.3,
62.9,
39.1,
49.8,
98.1,
86.7,
47.4,
63.5,
34.8,
95.4,
37.1,
90,
78.9,
64.6,
63.5,
71.5,
69.8,
53.5,
88.5,
71.8,
43.3,
68.4,
49.9,
95.6,
43.2,
67.9,
19.3,
8.4,
24.8,
77.3,
81.3,
98.5,
54.9,
47.8,
54.9,
44.3,
96.6,
26.4,
48.1,
36.4,
41.5,
39,
67.2,
63.8,
64,
59.4,
23.3,
83.2,
64.5,
49.5,
51.6,
80.1,
35.7,
93,
92.8,
60.7,
42.8,
57.6,
14.7,
62.9,
67.9,
52.2,
53.2,
35.5,
62.7,
10.4,
22.5,
19.5,
44.6,
29.6,
23.4,
84.2,
45.4,
46.6,
29.8,
62.7,
99.2,
46.7,
54.4,
17.8,
73.1,
56.6,
50.4,
89.6,
32.9,
49.8,
24.3,
49.1,
69.7,
69.5,
33.4,
49.3,
90.5,
40.9,
71.3,
72.3,
30,
55.2,
50.7,
55,
54.5,
48.1,
45.8,
43.3,
53,
47.2,
80,
70.3,
37,
38.2,
41.2,
75.6,
76.7,
79.3,
94.3,
56.9,
28.8,
85.7,
66.7,
29.6,
23.1,
74.4,
43.2,
5.3,
30.8,
19.5,
58.6,
67.1,
91.2,
56.2,
74.5,
75.6,
23.2,
45.2,
60.7,
91.6,
65.9,
88.6,
56.1,
46,
100.1,
53.5,
49.1,
75.1,
6,
20.2,
0,
101.5,
50.3,
84.1,
45.9,
39.4,
55.1,
44.8,
81.6,
91.1,
61.8,
64.1,
69.2,
62.9,
6.3,
87,
82.4,
79.1,
94.7,
83.1,
11.8,
49.6,
44.9,
87.1,
67.9,
84.6,
59.2,
42,
28.2,
69.6,
38.4,
76.1,
28.7,
94.1,
23.7,
95,
55.1,
37.5,
86.6,
43.5,
71.5,
32.1,
93.7,
26.9,
41.2,
66.1,
18.2,
54.5,
12.2,
91.2,
54.7,
15.6,
21,
27.1,
45.6,
24.1,
54.9,
33.8,
0,
48.6,
38.3,
75.4,
40.6,
46.9,
36.3,
35.2,
73.5,
49.1,
26.3,
62,
64.6,
94.2,
49,
87,
32.1,
56.1,
77.3,
42.3,
20.4,
17,
87.9,
62.6,
57.7,
26.4,
37,
27.6,
54.9,
1.1,
55.4,
95.3,
21.8,
39.1,
69.7,
52.1,
94.2,
76.3,
15.2,
49.7,
87.7,
24,
38.2,
50.9,
47.5,
68.9,
87.2,
44.4,
78.3,
87.2,
91.6,
27.7,
97.1,
40.9,
71.1,
51.7,
87.3,
82.6,
67.6,
67.6,
51.7,
72.7,
42.1,
54,
12.3,
76.3,
72.3,
88.3,
32.4,
48.6,
0.8,
56.1,
81.2,
60.4,
64.4,
67.5,
32.7,
38.2,
79.2,
42.1,
79.4,
69.3,
66.6,
76.9,
1.5,
97.4,
78,
78.3,
81.3,
54.3,
60.9,
42.2,
48.7,
54.9,
19.9,
63.9,
76.5,
84,
92,
53.9,
68.9,
20.2,
81.8,
93.6,
11.2,
91,
86.2,
41.4,
63.9,
35.6,
87.7,
46.1,
64.5,
84.2,
2.1,
66.8,
33.7,
58.3,
76.7,
67.7,
84.4,
15.4,
74.3,
81.7,
24.3,
59.3,
82.3,
13.4,
81,
82.8,
18.2,
0,
41.5,
39.1,
27.5,
60,
56.9,
63.8,
78.2,
55.3,
84.6,
42.7,
98.9,
61.2,
38.8,
73.3,
23.9,
46.1,
58.3,
38.7,
73.6,
18.4,
86.8,
65.3,
92.8,
1.4,
89.6,
79.7,
31.6,
55.1,
59.1,
86.8,
33,
70.3,
88.2,
34.5,
6,
33,
39.7,
69.6,
56.3,
17,
82.1,
93.2,
56.5,
33.4,
31.1,
45.2,
69.6,
47.8,
66.4,
35.2,
64.4,
88.7,
76.9,
5.5,
64.4,
73.8,
76.4,
69.7,
49.2,
72.1,
38.1,
63,
83.1,
31.2,
20.1,
80.8,
44,
52,
15.7,
78.9,
37.7,
95.1,
23.9,
54.4,
33.4,
54.5,
52.2,
69.1,
83,
61.1,
11,
38.3,
67.8,
43.3,
38.2,
78.4,
27.3,
58.7,
5.9,
70.8,
38.7,
78.7,
94.5,
47.2,
44.8,
72.4,
68,
45.4,
40.7,
26.1,
85.2,
26.4,
70.9,
20.6,
86.7,
99.3,
72.3,
76.9,
3.6,
42,
30.4,
96,
62.6,
80.4,
74.7,
79.9,
57.2,
38.3,
64.1,
42,
46.1,
57.9,
46.7,
77.3,
82.1,
70.8,
79.6,
52.7,
15.4,
37.2,
71,
88.2,
34,
13.5,
44,
24.4,
73.8,
19.4,
10.1,
48.9,
59.9,
91.8,
55,
40.6,
61.1,
46.6,
56.1,
46.2,
31.1,
54,
44.2,
52.7,
45,
50.8,
45.2,
31.3,
82.9,
98,
91.3,
87.9,
69.5,
83.3,
30.8,
74,
60.8,
72.8,
13.6,
43.6,
95.7,
89.2,
48.1,
84.3,
13.9,
57.4,
81.2,
83.7,
81,
75.4,
56.2,
80.3,
88,
22.1,
53.3,
33.4,
88.5,
87.7,
28,
76.4,
68.5,
32.5,
31.5,
74.3,
21,
41.1,
58.7,
34.3,
84.4,
67.1,
75.5,
65.1,
45.5,
72.1,
49.8,
11.7,
69.3,
80.5,
79.7,
34.1,
71.4,
82.4,
46.6,
65.6,
83.4,
49.4,
42,
43.2,
24.8,
67.3,
59.9,
47.7,
88.8,
8.4,
39.5,
78.8,
74,
50.9,
91.8,
37.6,
82.6,
73.9,
71.2,
34.2,
51.1,
95.1,
68,
54.7,
72.1,
24.3,
39.1,
41.3,
93.6,
91.8,
48.1,
92,
87,
14.4,
66.2,
56.4,
57.6,
63.4,
44.9,
77.9,
60.9,
42.8,
21.4,
45.2,
73.1,
21,
80.8,
72.3,
56.6,
78.4,
18.2,
37.4,
14.2,
53.4,
63.2,
94.3,
36,
61.3,
55,
53.4,
47,
38.2,
50,
48.7,
42.4,
36.4,
87.4,
70.7,
79.8,
22.2,
36.9,
58.1,
30.2,
58.6,
63.4,
78.7,
70,
54.7,
45.3,
86.2,
35.8,
64.6,
22.9,
36.3,
37.1,
89.7,
71.2,
95.7,
28.7,
76.8,
71.3,
25,
76.5,
84.1,
55.3,
41.2,
19.9,
41.2,
81.6,
12.9,
15.9,
14.6,
81.5,
62.4,
23.9,
62.8,
65.7,
65,
40.5,
81.8,
91.2,
66.6,
35,
90.2,
27.2,
49.4,
27,
98.6,
58.4,
21.9,
90.8,
37.1,
48.3,
51.1,
65,
31.1,
57.9,
28,
37.1,
65.2,
87.2,
55.4,
52,
65.8,
35.8,
57.5,
59.5,
55.4,
72,
60.4,
75.5,
39.7,
65.9,
64.3,
74,
67,
72.3,
81.8,
64.8,
26.7,
75.1,
75.6,
62.7,
50.9,
87.6,
56.9,
38.2,
53.6,
21.1,
98.6,
88,
31.8,
66,
5,
41,
53,
12.2,
93,
27.8,
41.5,
21.9,
37.6,
59,
72,
41.4,
70.1,
69.7,
76.7,
45.3,
24.4,
4.5,
8.8,
48.9,
32.3,
67.9,
85.3,
76.6,
89.9,
76,
38,
38.2,
89.1,
50.1,
57.5,
42,
29.1,
79,
71.9,
86.2,
86.7,
38.5,
77.8,
68,
38.1,
20.8,
0,
59.5,
81.6,
97.4,
28,
37.8,
96.7,
36.3,
48.2,
94,
76.3,
83.1,
68.4,
52.9,
87.8,
46.7,
15.9,
77.8,
34.6,
41.6,
79.1,
58.2,
68.9,
46,
46,
52.1,
84.2,
22.2,
54,
35.3,
93.3,
97.1,
0,
26.9,
63.8,
64.7,
63.3,
54.7,
39.1,
50.3,
45.6,
57.3,
69.4,
36.6,
24.4,
16.6,
78.7,
10.8,
76.8,
80.9,
16.7,
50.6,
56.8,
38.2,
64.3,
72,
61.5,
72,
52.4,
48,
59,
82.5,
52.6,
50.4,
56.1,
82.9,
35.9,
20.7,
36.4,
58.7,
81.6,
47.8,
52.2,
53.9,
0.5,
25,
101.3,
31.5,
37.4,
49.8,
50.6,
22.6,
45.1,
17,
69.2,
87.7,
39.3,
41.8,
52.8,
58.7,
88.8,
65.8,
66.2,
43.9,
71.3,
10.5,
77.7,
71.1,
17.9,
92.6,
77.9,
33,
29.8,
82.2,
66.5,
47,
21.6,
51,
49.4,
5.2,
73.4,
35.6,
85.6,
48,
16.1,
35.9,
32.9,
54,
82.1,
25.7,
2.9,
69.2,
81.6,
75.8,
33.8,
65.4,
54.5,
77.8,
49.9,
47.3,
54.5,
94.6,
49.8,
95.4,
62.2,
60.1,
61.8,
40.6,
19.8,
31.9,
86.3,
33.7,
80.9,
24.4,
70.9,
83.2,
40.3,
27.7,
92.9,
75.1,
77.6,
30.1,
65.1,
32.4,
86.1,
75.7,
32,
63.5,
13.3,
17.1,
68.6,
60.2,
60.2,
79,
89.6,
79.3,
62.3,
35.7,
58.6,
57.3,
14,
72.7,
44.4,
33.3,
68.3,
9.7,
79.7,
51.1,
20.7,
90.3,
60.2,
16.2,
64.7,
68.1,
35.1,
74.5,
65.7,
75.5,
17.9,
61.4,
68.5,
21.4,
53.7,
7.7,
76.8,
70.2,
63.6,
67.9,
68.3,
79.1,
47.3,
60.4,
68.8,
50.1,
42.8,
48.3,
70.7,
65.2,
87.8,
74.7,
92.9,
86.6,
92.9,
65,
45,
35.5,
70.5,
49,
46.7,
17.4,
50.8,
79.6,
72.3,
33.1,
46.2,
35.4,
53.5,
40.5,
46.4,
78.5,
63.1,
51.8,
94.1,
32.6,
85.6,
81.3,
73.5,
58.3,
64.4,
55.1,
62.6,
45.2,
67.5,
46.2,
84.1,
60.1,
65.4,
52.7,
76.4,
93,
67.5,
35.2,
69.1,
74.3,
18.1,
72.4,
88.9,
55.7,
71.7,
53.2,
40,
57.4,
44,
65.9,
82.9,
83.5,
79.4,
42.8,
38,
31.8,
47.7,
53.7,
72.5,
73.4,
81.7,
36.3,
9,
76.4,
51.4,
79.5,
66.6,
73.6,
102,
36.6,
28.2,
61.4,
34.3,
29.9,
52.1,
65.9,
91.3,
31,
61.1,
59.5,
25.4,
64.1,
82.4,
67.8,
63.4,
29.8,
66.1,
24.2,
10.9,
46.9,
65.5,
19.6,
39,
58.9,
32.6,
37.3,
6,
21,
89.1,
30.1,
2.2,
49.7,
63.2,
83.7,
95.7,
27.9,
61.7,
82.9,
71.6,
66.2,
24.7,
27.5,
20.4,
16,
71.9,
47.6,
20.9,
87.4,
2.5,
49.9,
97.4,
54.9,
55.1,
61.1,
47.3,
69.4,
47.7,
83.5,
33.1,
58.2,
57.1,
54,
68.4,
49,
46.7,
71.4,
29.9,
36.3,
83.2,
56.2,
90,
39.1,
41.8,
58.8,
43,
58,
27.4,
60.1,
31.3,
72.3,
50.1,
50.3,
41.7,
52.7,
48.5,
75.7,
75.9,
72,
33.2,
64.4,
85.7,
68.5,
48,
42,
77.6,
55.1,
33.8,
90.5,
33.5,
18,
50.4,
49.6,
25.5,
60.7,
71.7,
71.4,
35.8,
33,
55.8,
92.5,
36.6,
43.1,
24.3,
79.7,
64.1,
53.7,
50.8,
79.2,
70.6,
50,
37.2,
33.1,
69.9,
87.4,
31.1,
85.8,
44.1,
86,
22.3,
84.7,
59.3,
79.9,
36.2,
8.5,
64.6,
7.1,
48,
51.9,
59.1,
56,
50.3,
86.5,
67,
62.8,
95.9,
77.5,
97.3,
83,
57.4,
83.8,
93.6,
43,
83,
45.6,
73.6,
60.6,
99.7,
39.8,
65,
79.1,
78.2,
85.7,
79.4,
74,
19.4,
82.6,
88.6,
53.8,
37.7,
34.8,
85.2,
12.4,
96.9,
79.9,
63.1,
64.6,
10.7,
62.7,
49,
86.1,
70.4,
9.1,
34.4,
72.5,
48.5,
22.3,
72.6,
54.4,
73.8,
62.9,
21.9,
67.3,
81.9,
48.6,
77,
75.7,
17.7,
30.1,
36.5,
76.9,
37.8,
66.1,
81,
69.6,
63.6,
65.7,
28.8,
84.5,
96.4,
48.6,
53.2,
38.8,
2.2,
65.2,
65.2,
52.3,
51.2,
40.7,
30.8,
96,
57.2,
61.9,
27.7,
82.9,
37.2,
69.5,
91,
67.6,
31.9,
58.5,
54.2,
71.5,
34,
62,
16.2,
84.1,
78.4,
89.1,
50.1,
37.1,
56.1,
27.1,
42.8,
69.5,
61.8,
44.8,
51.7,
40.8,
76.3,
34.2,
43.1,
64.7,
62,
95,
75.7,
28.2,
50.8,
38.5,
32,
34.3,
73.4,
35.7,
46.4,
85.5,
59.3,
20.6,
65.3,
72.6,
78.5,
75.4,
4,
32,
47,
86.7,
70.1,
57.5,
30.7,
62.2,
53.3,
56.4,
53.7,
40.8,
74.5,
41,
80,
74.5,
54.2,
76.5,
40.2,
60,
55.4,
68.2,
38.7,
10.1,
70.7,
94.9,
34,
37.9,
84.3,
37.4,
42.1,
57.6,
80.1,
56.4,
56,
31.9,
45.6,
40,
31.8,
83.1,
62.9,
36.4,
33.8,
80.4,
84.4,
32.2,
86.5,
56.6,
42.5,
39,
39.5,
80,
53.8,
54.2,
47.1,
61.9,
8.2,
80.6,
58.2,
47.5,
76.7,
42.1,
63.9,
85.8,
75,
1.2,
77.6,
62.7,
62.1,
80.3,
47.1,
14.7,
70.8,
95.1,
2.6,
66.8,
77.4,
34.5,
80.2,
42.3,
61.9,
85.2,
89.1,
76.8,
44.4,
71,
59.6,
64.7,
33,
22.3,
59.6,
17.5,
85.1,
85.9,
58.3,
47,
56.5,
43.9,
77.7,
51.6,
81.1,
82.9,
54.1,
21.8,
55.4,
7.4,
56.9,
66.1,
59.8,
40.1,
15.9,
93.3,
27.5,
31.9,
39.7,
57.6,
69,
60.9,
88,
89,
59.1,
60.8,
96,
17,
33.3,
45.7,
65.5,
86.1,
76.5,
17.3,
76.7,
33.8,
66.5,
73.9,
30.9,
26.9,
84.9,
60.8,
89.1,
19.2,
28.4,
91.3,
20.4,
32.3,
59,
85.1,
25.5,
98.1,
83.7,
89.4,
9.9,
31.6,
82.1,
62.5,
25.8,
24.8,
74.3,
28.7,
93.2,
56.5,
24.1,
49.1,
54.5,
38.2,
22,
37,
53.2,
25,
54,
80.5,
49.4,
20.4,
39.3,
15.2,
49.8,
41.7,
42.3,
80.9,
35.9,
36,
5.9,
80.2,
44.9,
32.6,
93,
86,
40.2,
78.7,
49.3,
65.4,
82.5,
89.1,
48.4,
65,
64.2,
88.3,
58.3,
25.2,
48.9,
87.7,
39.2,
59.5,
40.8,
24.8,
60.6,
87.5,
61.4,
85.7,
79.6,
10,
32.3,
65.2,
1.3,
78.9,
51,
47.6,
47.8,
76,
74.8,
55.9,
57.1,
43.8,
48.9,
20.9,
39.9,
44.5,
63.4,
6.1,
38.5,
83.5,
64.6,
80.1,
68.2,
61,
89.8,
7.4,
5.4,
60.3,
62.8,
53.5,
92.4,
67.5,
53.9,
70.7,
79.8,
57.8,
56.3,
75.9,
87.5,
74.8,
58.1,
21.9,
68.9,
26.6,
69.6,
51.7,
62.6,
75.5,
58.1,
42.7,
0,
40.6,
51.4,
99.2,
16.8,
74.9,
49.1,
98.3,
45.1,
83.3,
72.5,
41.2,
89.4,
73.7,
29.3,
66.7,
20.8,
12.3,
42,
61.6,
2.5,
63.5,
25.4,
88.3,
41,
37.7,
87.9,
83.2,
77.3,
6.4,
78.7,
95.3,
69.8,
30.1,
22.1,
61.2,
28.5,
31.8,
78.9,
54.2,
43.3,
89.9,
45.7,
98.4,
64,
51.1,
62,
47.6,
59.3,
98.1,
59.5,
84.6,
71,
55.9,
52.6,
93.4,
63.6,
96.1,
49.5,
28.8,
14,
33.2,
45.2,
57.6,
29,
33,
66.2,
74.4,
14.8,
16.9,
65.7,
55.3,
93.3,
50.6,
34.7,
10.2,
38,
59.6,
76.8,
46.2,
51.1,
59.8,
64.2,
73.1,
52,
95.3,
36.4,
71.1,
65.4,
82.7,
99.4,
72.5,
62.7,
40.8,
94,
51.2,
61.4,
18.7,
64,
24.2,
57.2,
85,
85.3,
8.2,
9.5,
62.8,
75.4,
73.9,
48.1,
84.3,
52.3,
40.3,
22.5,
55.2,
88.1,
53.7,
51.7,
74,
76.3,
65.4,
3.5,
66.4,
76.3,
59.8,
73.3,
86.2,
98.7,
57.1,
41.4,
91.2,
41.5,
76.7,
44.7,
39.5,
23.3,
38.2,
46,
64.1,
42.5,
70.8,
86.3,
94.2,
68.1,
36.4,
84.1,
35.8,
62.1,
79.8,
51.6,
90.9,
75.1,
41.9,
58.5,
25.2,
39,
65.7,
40.7,
85.1,
70.2,
30.8,
35.1,
43.8,
83.9,
69.4,
60.9,
79.9,
48.4,
44.7,
50.2,
24.3,
29.5,
60.4,
57.5,
49.1,
43.5,
26.5,
49.6,
91.1,
22.1,
46.8,
57.2,
2.2,
91.5,
30.5,
40.6,
63,
23.6,
63.1,
59.6,
31.1,
83.1,
33.8,
35.2,
84.2,
53.6,
74.2,
22.6,
66.3,
79.5,
85.6,
80.9,
89.5,
48.5,
84.7,
84,
31.7,
62.3,
36,
63.9,
55.4,
57.2,
68.4,
44.1,
38,
28.8,
60.3,
16.7,
49.6,
21.5,
36,
51.7,
59.6,
6.5,
13.8,
66.8,
41.8,
37.8,
83.3,
43.3,
44.3,
47.3,
26.8,
43.3,
66,
93.7,
39.6,
35.5,
28.9,
12.4,
39.1,
26.7,
53.2,
46.1,
68.9,
31.4,
93.2,
38.9,
87.8,
53.3,
48.1,
37,
64.7,
77,
74.1,
47.2,
25.3,
18,
30.9,
61.3,
55,
61.4,
67.5,
78,
48.5,
44.3,
54.6,
47.4,
5.4,
59.1,
4.9,
77.7,
27.9,
52.6,
58.9,
7.1,
40.6,
79.4,
28,
76.6,
89.6,
52.9,
8.4,
35.5,
94.3,
82.6,
67.5,
56.2,
61.9,
70.3,
44.1,
81,
55.2,
67.4,
73.9,
37.8,
95,
26,
62,
1.3,
62,
32.5,
54.5,
63,
50.9,
80.5,
4.9,
45.9,
50.7,
69.2,
0,
55.8,
74.4,
32.9,
0,
32.4,
40.8,
64,
84,
38.2,
80.7,
79.4,
29.8,
15.3,
42.8,
73.6,
79.9,
35.2,
26.1,
39.9,
79.4,
61.9,
61.1,
66.9,
19.5,
42.7,
100,
20.8,
69.3,
32.2,
68.2,
56,
81.3,
38.6,
18.7,
28.6,
67,
42.7,
50.8,
82.2,
34.6,
60.1,
46,
24.9,
85.7,
85.4,
95.3,
62.6,
86,
81.4,
46.4,
15.2,
37.8,
89.1,
97,
76.8,
46.1,
99.6,
59.7,
16.7,
74.1,
79.4,
34.5,
78.4,
52.4,
72.9,
35.4,
28.2,
48.4,
69,
46.8,
78.2,
69.5,
85.8,
38.4,
2.7,
73,
73.7,
7.1,
54,
50.9,
34.7,
93.3,
36.6,
29.1,
29.9,
58.6,
38.2,
45.5,
55.1,
41.5,
29.7,
16.6,
64.3,
75.4,
78.8,
56.9,
59.8,
56.6,
30.2,
42.4,
42.9,
69.6,
70.9,
89.5,
88,
67.1,
82.2,
17.9,
49.9,
26.2,
66.8,
11.6,
77.1,
54,
40.8,
78.7,
62.5,
85,
52.7,
80.6,
20.3,
29.7,
81.9,
68.6,
24.7,
68.1,
8,
82.8,
76.7,
43.8,
55.1,
19.1,
61.2,
46,
70.2,
64.6,
58,
48.7,
22,
37.7,
56.4,
76.5,
77.5,
55.9,
82.7,
23.2,
104.9,
23,
61,
91,
36.3,
5.4,
68.1,
91.9,
95.9,
90.5,
39.5,
35.1,
85,
24,
57.8,
100.7,
81.8,
94,
66.3,
45.6,
92,
29.8,
96,
17.9,
89.2,
81,
17,
75.3,
54,
25.4,
38,
38.9,
113.8,
97.9,
42.5,
13.8,
54,
8.4,
97.2,
32.4,
65.3,
73.5,
77.7,
42.9,
35.7,
36.1,
45,
42.4,
48.9,
61.6,
25.6,
73.7,
47.4,
61.6,
46.8,
46.1,
23.1,
55.2,
67.5,
65.5,
40.9,
33.1,
18.9,
64.3,
79,
60.4,
70.7,
77.9,
44,
48.1,
70.8,
5.8,
68.4,
36.2,
77.4,
41.8,
41.9,
6.7,
100,
27.9,
82.7,
68.6,
84,
72.9,
47.1,
35.4,
5.1,
69.9,
12,
100.2,
96.5,
38.2,
5.3,
58,
28.5,
46.4,
89,
20.6,
67.2,
94.9,
56.8,
66.9,
69.1,
1.8,
50.4,
93.5,
71.7,
65.5,
59.9,
76.2,
73.3,
67.1,
86.9,
39.2,
49,
77.8,
20.7,
18.7,
30.2,
48.7,
62.4,
95.9,
102.6,
21.2,
62.4,
7.2,
92,
37.2,
53.6,
50.2,
82.4,
71,
47,
60.5,
44.3,
38.6,
71.7,
100.9,
3.8,
62.3,
33.1,
9.7,
71.9,
75.2,
69.9,
28.7,
74.3,
59.8,
71,
41.3,
43.6,
70.2,
22.5,
63.5,
52.3,
52.1,
60.7,
55.5,
47.7,
13.3,
85.8,
80.8,
71.1,
67.2,
70.4,
40.1,
87.8,
45.7,
39.6,
91.4,
51.3,
54.3,
82.8,
50.5,
67.5,
40,
54.8,
93,
51.5,
58.7,
51.6,
39.5,
30.5,
15.9,
87.1,
70.4,
29.7,
15.3,
66.2,
23.7,
52.2,
59.7,
63.3,
58.1,
59.8,
74.1,
57.3,
62.9,
48.4,
53.9,
70.1,
72.7,
72.9,
31.4,
27.8,
46,
7.9,
45.2,
77.4,
81.8,
89.7,
69,
61.2,
47.6,
98.7,
43.9,
31.1,
11.9,
74.1,
28.8,
46.3,
68,
46.8,
78.1,
61.5,
62.2,
45.3,
12,
27.7,
17.5,
77.7,
28.3,
28.8,
48.7,
62.8,
48.9,
44,
39,
39.3,
45.3,
83.1,
61.8,
21.5,
54.8,
29.3,
67.4,
66.7,
53.2,
28.4,
89.7,
46.9,
27,
0.2,
59.4,
95,
40.1,
54,
77,
50,
58.7,
27.6,
7.7,
64.3,
57.1,
27,
62.2,
29.4,
39.1,
36.1,
48.5,
83.2,
38.3,
null,
73.8,
46.6,
71.9,
63.9,
80,
71.5,
78.3,
0,
85.7,
100.4,
48.8,
91.9,
37.9,
18.5,
65.3,
11.6,
46.4,
30.6,
34.6,
69.8,
58.8,
66.8,
64.2,
43.3,
68.1,
66.7,
46.7,
54.6,
61.7,
85.8,
83.4,
39,
92.5,
78,
39.8,
89,
42,
87.7,
54.1,
55.1,
62,
44.5,
92.5,
68.1,
85.2,
77.1,
63.4,
93.7,
63.9,
56,
8.8,
8.6,
41,
61.1,
31.7,
71.1,
68,
50.6,
30.3,
38,
62.4,
78,
76.6,
51.4,
13.6,
87,
53.2,
76,
81.2,
43.9,
71.1,
51.3,
54.5,
61,
53.9,
65.5,
37.3,
42.7,
58.3,
61.7,
37.3,
45.9,
32,
78.8,
37.6,
77.8,
70.4,
44.6,
74.4,
75.2,
86.3,
50.2,
19.8,
65.2,
49.8,
32.3,
75,
59.2,
43.7,
95.5,
68.5,
63.8,
19.8,
91.8,
89.3,
83.9,
71,
92.5,
27.9,
32.1,
40.1,
86.6,
84.2,
57.6,
85.2,
61.3,
88.9,
53.3,
57,
65.9,
58.3,
82.4,
66.9,
32.7,
41.5,
79.3,
30.2,
87.3,
99.3,
37,
90.8,
51.5,
62.7,
52.5,
66.2,
88,
71.7,
9.9,
10.4,
40.9,
43,
53.1,
71.1,
61.5,
10,
32.8,
75,
87.2,
81.8,
50,
41.7,
97.6,
71.8,
52.8,
89.1,
53,
56.2,
56.8,
22.8,
71.6,
76.7,
54.2,
10.3,
88.2,
43.4,
88,
36.5,
80.2,
78.5,
40.6,
82.7,
34,
63.5,
55.5,
44.6,
81.9,
22.4,
47.1,
83.8,
27,
54,
64.3,
63.2,
58,
80.2,
61,
87.9,
80.9,
25.3,
55.3,
43.2,
55.2,
29.6,
56.3,
10.6,
64.3,
96.2,
90.7,
71,
72.6,
26.6,
97.2,
98.5,
69.1,
61.2,
36.1,
46.4,
67.1,
98.9,
20.6,
72.1,
100.1,
85.4,
23,
0,
38,
66.4,
47.3,
53,
29.6,
50.2,
91,
56.3,
65.2,
34.2,
17.5,
16,
85.9,
61.3,
51.2,
70.8,
96.5,
8.2,
54.9,
82.3,
83,
76.4,
78.5,
75.9,
18.9,
29.2,
87.9,
53.2,
94,
38.8,
35.1,
37,
37.7,
55.5,
62.1,
45.8,
15.5,
8.8,
79.8,
74.8,
13,
75.3,
87,
21.2,
48.8,
86.8,
85.2,
5.2,
72.8,
58.7,
43.7,
98,
36,
37.9,
86.4,
26.4,
75.4,
56.1,
65.2,
59.2,
43.3,
45.4,
71,
48.4,
36.8,
92.3,
87.9,
35.9,
0.9,
34.1,
65.6,
90,
50.9,
55.6,
50.5,
53.1,
39.9,
61.9,
79.3,
69.6,
33.6,
26.5,
64.3,
53.1,
60.5,
44.9,
79.3,
80.7,
85.3,
45.8,
1.9,
47.6,
61.8,
49,
43,
68.7,
31.9,
28.9,
51.1,
55.1,
35.2,
85.5,
90.6,
69,
51.7,
31,
71.9,
40.4,
37.3,
39.1,
69,
24.8,
90,
100.9,
25.7,
39.4,
61.6,
63.7,
46.3,
41.2,
77,
68.7,
43.2,
86.2,
17,
95.7,
29.9,
93,
42.6,
76.6,
30.3,
72.9,
48.5,
43.3,
74.7,
67.7,
68.5,
30.4,
59.6,
30.4,
68.3,
44,
63.7,
72,
47,
53.2,
73.6,
68.4,
71.8,
43.9,
25.3,
39,
30.8,
54.3,
46,
27,
55.7,
92.6,
36.9,
43.5,
28.8,
98,
93,
73.4,
50.9,
28.2,
15,
98.9,
46.7,
80.8,
101,
77,
83.7,
34.8,
87.5,
42.4,
55.7,
48.2,
38.7,
80.9,
59.1,
30.6,
73.3,
62.3,
14.1,
86.6,
88.9,
36.3,
69.6,
56.8,
27.1,
95.7,
45.1,
32.8,
53.3,
38.7,
44.9,
47.1,
55.7,
54.2,
64.7,
4.2,
56.5,
94.2,
62.2,
87,
15.4,
31.9,
50.7,
64.8,
72,
16.1,
93.7,
89.3,
26.4,
81.2,
56.4,
16.4,
45,
74.6,
46,
84.4,
75.6,
63.7,
45,
17.3,
68.8,
82.6,
57.2,
72.5,
47,
52.1,
24.8,
77.1,
26.2,
48.2,
66.9,
97.8,
23.2,
32.9,
38.3,
60.6,
6.6,
25,
43.8,
86.3,
63.7,
63.9,
24.5,
22.2,
86,
92.8,
26,
39.4,
72.8,
30.1,
39.1,
69.2,
87.8,
60.1,
57.8,
36.8,
47.8,
11.5,
38.9,
50.5,
69.4,
12.3,
26.2,
85.9,
92.3,
61.8,
26.3,
23.1,
74.9,
62.8,
56.7,
67.5,
67.1,
42.3,
51.6,
87,
82.3,
74.4,
61,
34.3,
89.3,
1.1,
112,
80.1,
5,
39,
68.6,
75.9,
87.2,
39.1,
76,
83.9,
39.1,
92,
71.4,
98.3,
62.7,
63.1,
55,
60.2,
59.9,
41,
43.1,
34.8,
35,
58.3,
64.7,
54.9,
79.8,
52.1,
36.8,
87.9,
12.3,
36,
36.1,
62.9,
101.8,
40.9,
59.3,
71.7,
75.8,
83.8,
94.5,
72,
32.3,
45.9,
35.1,
45.6,
49.4,
68.3,
79,
12.9,
57.3,
44.4,
85.1,
1.4,
54.6,
50.1,
18.7,
78,
39.8,
58.4,
56.4,
54.9,
33.3,
67.3,
26.5,
28,
91.9,
75.3,
46.6,
68.4,
55.6,
85.4,
97,
41.6,
51.2,
31.1,
36.8,
50.4,
74,
33.4,
68.2,
76.8,
55,
88.5,
25.8,
63,
22.8,
62.7,
29.8,
32.2,
43.2,
64.8,
16.3,
94.8,
32.8,
72.3,
90.3,
47.1,
35.3,
90.5,
8.7,
65.6,
90.2,
65,
76.5,
97.4,
14.8,
49.4,
56.3,
27.1,
49.7,
41.9,
8.4,
79,
83.3,
67.6,
54,
79.3,
44.4,
50.6,
70,
57.4,
41.5,
50,
69.5,
28.5,
28.1,
20.5,
83.4,
59.5,
38.4,
52.4,
65.8,
81.7,
77.7,
56.5,
80.9,
52.6,
13.6,
76.7,
57.1,
65.7,
56.6,
51.9,
94,
95.8,
82.3,
91.6,
47.1,
98.8,
72,
69.8,
64.7,
49.1,
43.2,
52.2,
63.6,
56,
9.5,
28.7,
2.8,
59.5,
97.5,
89.4,
32,
38,
49.6,
26,
20.6,
29.4,
56.9,
68.9,
43,
75.6,
38.8,
63.4,
82.2,
29.6,
18.2,
28.3,
26.2,
26.2,
26.8,
9,
56.3,
51.6,
31.4,
62.3,
68.3,
56.6,
70.9,
78.8,
36.5,
68,
82.7,
18.6,
36,
48.3,
92.1,
86.3,
13.4,
22.2,
37.5,
31,
45.4,
40,
44.9,
73.2,
5.2,
18.1,
3.7,
60.5,
70.8,
61.2,
48.2,
39.6,
56.8,
39.8,
11.6,
82.4,
19.2,
41.7,
96.1,
29.6,
82.4,
61,
31.4,
31.3,
47.8,
24,
87.1,
95.9,
35.6,
20,
55,
24.1,
60.2,
59.9,
65.6,
40.1,
90.5,
68.6,
81,
51.5,
44.6,
2.4,
38.5,
79.2,
72.4,
50.8,
9,
99,
32.3,
51,
69.2,
61,
79,
65.9,
76.1,
58,
69.1,
62.8,
39.1,
87.8,
75.2,
27.9,
51.9,
32.8,
96.6,
23,
78.7,
88.3,
22.7,
67.7,
83.5,
52.2,
68.8,
43.7,
44.6,
52,
39.9,
98,
72.2,
19.6,
59.4,
59.9,
68.1,
63.1,
48.8,
47.4,
70.4,
49.5,
66.2,
62.7,
5.2,
97,
72.5,
65.8,
88.9,
77.2,
40.4,
46.3,
40.8,
36.1,
67.7,
48.5,
86.7,
58.1,
48.1,
30.8,
64.3,
18,
45.4,
40.1,
69.3,
58.6,
41.7,
62.5,
86.1,
80.2,
59.8,
52.4,
59.2,
54.9,
48.1,
49.1,
37.6,
80.6,
52.1,
52.7,
98.8,
87.9,
70.1,
99.8,
47,
1.8,
28.8,
55.2,
37.7,
66.7,
64,
79.6,
18.9,
82.7,
40.6,
38.3,
91.3,
62.9,
94.9,
98,
48.9,
38.6,
61,
51.3,
34.2,
35.4,
49.1,
32.7,
34.9,
44.5,
39.8,
41.2,
78.6,
95.1,
60.1,
28.1,
54.8,
2.5,
35.2,
70.7,
61.4,
22.2,
56.5,
36.8,
41.6,
24.3,
69.9,
45.1,
70.2,
30.6,
91.8,
82.7,
41.2,
49.3,
96.1,
45.5,
43.4,
55.2,
91.7,
16.1,
70.9,
66.6,
9.5,
28.4,
63.6,
67.2,
50,
67,
45.4,
39.2,
58,
87.5,
54.1,
30.7,
52,
73.3,
44.7,
7.9,
91,
98.5,
34.6,
54.8,
56.3,
31.8,
0.3,
85.9,
46,
21.8,
4.4,
44.6,
94.6,
42.5,
40.9,
32.6,
22.8,
27.5,
25.8,
41.5,
89.6,
41,
16.7,
57.9,
48.2,
82.1,
43.8,
54.9,
32.8,
31.9,
7.6,
41,
19.7,
53.4,
56.5,
40.7,
63.2,
6.3,
52.7,
37.9,
90.5,
33.8,
63.8,
75.9,
58.3,
50.5,
44,
70.9,
88.2,
84.2,
81,
55.2,
92.9,
88.1,
86.3,
10,
91.6,
56.3,
81.8,
35.5,
78,
53.3,
53.6,
78.2,
61.4,
59,
54.9,
66.1,
69.9,
42.8,
65.6,
59.9,
81.4,
20.4,
72.2,
22.4,
55.9,
52,
56.8,
37,
11.8,
59.8,
76.1,
21.9,
59.8,
89.5,
88,
88.1,
46.7,
73.8,
45.6,
82.2,
82.9,
52.3,
65.3,
43.1,
59.3,
33.4,
73.4,
81.9,
30.1,
98.5,
50.8,
29.1,
18.6,
43.3,
66.7,
13.7,
25.8,
61.7,
52.2,
76.7,
47.1,
74.3,
8.8,
86.5,
66.6,
74.2,
28,
48.3,
60.4,
43.2,
44.2,
52.7,
43.3,
74.2,
34,
16.8,
99.2,
13,
73.7,
77.7,
16.8,
86.1,
68.7,
53.2,
7.2,
60.7,
53.8,
48.2,
45.3,
97.4,
64.3,
44,
85.8,
93.5,
61.3,
71.4,
56.8,
82.6,
86.1,
51.1,
76.2,
70.5,
41.9,
45.8,
68.9,
46,
44.8,
56.6,
30.5,
56.3,
59.8,
44.6,
31.2,
92.1,
79.2,
73.4,
44.2,
88.9,
82.5,
52.3,
78.5,
41.3,
77.7,
82.5,
74.6,
25.7,
47.1,
24.6,
38.8,
35.5,
40.5,
44.8,
33.14,
68.9,
37.2,
49.3,
2.5,
83,
30.6,
89.8,
34.5,
84.7,
36.9,
56.8,
83.1,
24.4,
69,
95.6,
19.2,
75.5,
3.5,
95,
84.1,
52.3,
23.3,
46.2,
85.8,
87,
48.9,
60.2,
48.9,
43.1,
63.1,
77.2,
3.6,
64.8,
69.1,
47.4,
43.7,
55.4,
78.6,
66.9,
73.2,
32.4,
56.4,
57.4,
54.5,
87.1,
79.7,
61.6,
91.7,
71.8,
31.4,
45.4,
40.7,
35.8,
85,
59.9,
75,
24.6,
77.8,
11,
40.6,
85.7,
44.8,
39.1,
68.9,
76.8,
23.2,
67,
55.6,
32.1,
11.7,
39.5,
39.2,
42.5,
50.4,
54.8,
59.7,
42.2,
90.7,
73.8,
80.7,
27.5,
41.4,
91.9,
83.4,
94.9,
62.7,
24.1,
85.2,
72.3,
0,
18.9,
59.5,
44.9,
18.5,
57.5,
87.8,
60.3,
20.1,
77,
55,
64,
60.9,
82.3,
39.5,
74.4,
81.9,
75.2,
56.8,
39.5,
45.3,
37.5,
48.9,
79.7,
83.1,
47.7,
62.9,
50.5,
88.6,
67.4,
82.2,
68.8,
48,
54.1,
69.9,
50.2,
50.7,
57.4,
81.7,
81.6,
37.9,
35.8,
93.9,
80.3,
41.7,
50.3,
59.4,
88.8,
90.7,
95.2,
23.9,
33.3,
61.2,
77.3,
80.2,
69.5,
50.5,
49.6,
33.8,
18.8,
42.8,
29.9,
96.4,
25.7,
55.7,
54.2,
36.5,
37.5,
53.1,
56.3,
70.6,
65.1,
54.1,
52.4,
39.8,
93.9,
66.7,
47.8,
78,
60,
96.9,
90.6,
19.8,
34.9,
58.3,
18.4,
42,
72.8,
37,
48.6,
73.6,
42.4,
92.6,
38.9,
65.4,
75.4,
49.6,
43.5,
38.9,
78.6,
83.7,
62.2,
48.4,
98.6,
91.6,
61.9,
86.4,
72.2,
52.4,
88.1,
66.8,
88,
31.9,
40.8,
32.5,
17.7,
62.1,
75.1,
76,
66.2,
43.6,
41.4,
40.2,
77.2,
71.4,
41.9,
79.2,
91.8,
92.7,
39,
34.4,
82.3,
46.8,
44,
37.1,
71.1,
23.9,
68,
52,
48.1,
59.4,
49.3,
83.3,
39.7,
30.4,
31.5,
48.8,
30,
58.1,
64.7,
52,
58.8,
76.1,
73.5,
73.3,
87.3,
95.3,
55,
23.6,
39.3,
105.1,
80.2,
68.5,
44.2,
60.8,
18.7,
73.9,
78.2,
48,
62.5,
56.4,
14.2,
33.3,
85.3,
9.2,
95.2,
47.4,
66.4,
56.4,
28.3,
6,
20.1,
78.4,
25.5,
69.7,
48.9,
27.3,
5.3,
73.5,
50.9,
29.9,
31.3,
38.8,
96.7,
17.4,
38.3,
45.4,
52,
52.3,
79.8,
71,
25.1,
99,
48.2,
79.3,
17.5,
43.8,
53.9,
14.9,
62.4,
22,
71.9,
18.4,
4.2,
43.4,
87.2,
45.4,
100.8,
62.3,
92.4,
39.1,
41.2,
87.7,
31.6,
70.3,
65.9,
69.6,
30,
20,
5.1,
76.4,
60.6,
38.2,
90.3,
71.4,
92.2,
59,
22.8,
21.4,
17.2,
66.1,
35.9,
8.2,
38.7,
17.5,
57.4,
66.9,
58.8,
82.7,
73,
59.2,
13.7,
62.6,
49.3,
61.2,
25.3,
69.7,
49.6,
71.2,
94,
82.6,
83.9,
66.4,
23.4,
49.9,
82.4,
40.5,
62,
36.7,
52.4,
62,
71.9,
34.6,
22.9,
38.2,
59.5,
5.2,
88,
26.3,
29.9,
90.4,
46.6,
30.4,
41.5,
0.8,
57.7,
36.4,
26.7,
56.5,
69.2,
52.6,
77.9,
23.5,
41.5,
37.5,
23.8,
24.1,
35.7,
76.9,
36.5,
72.2,
88.2,
44.2,
20.8,
88.4,
63.9,
94.2,
70.9,
46.3,
21.2,
56.9,
57.4,
44.3,
74,
74.9,
56.7,
80.1,
54.1,
52.6,
46.4,
60.2,
87.8,
81.5,
65.3,
80.4,
28.9,
47.9,
63.1,
95,
57.4,
17,
71.2,
73,
26.9,
52.1,
61.7,
84.3,
83.4,
78.1,
28.8,
57.3,
39.1,
37.7,
90.9,
41.1,
62.1,
87.3,
36.9,
39.5,
68,
62.6,
46.5,
34.9,
77.7,
63.5,
53.6,
61.7,
59.3,
73.7,
31.6,
31.6,
55.7,
96.3,
85.9,
45.9,
9.2,
86.7,
54.2,
71.1,
60.4,
8.6,
51.5,
56.3,
44.8,
66.7,
75.1,
17.6,
53.9,
61.4,
76.5,
69.6,
14.1,
84.8,
34,
41.1,
49.3,
62,
85.6,
35.1,
74.3,
71,
10.6,
45.7,
62.8,
4.3,
34.5,
22.6,
84.4,
67.4,
3,
23.5,
63.5,
84.6,
49.1,
38.1,
50.2,
52.4,
34.1,
72.4,
51.1,
38.7,
84.7,
41.1,
44.1,
56,
30.5,
43.3,
92.7,
72,
67.8,
39.6,
48.1,
14.3,
61.4,
34.5,
69.4,
69.2,
63.8,
94.4,
97.1,
85.5,
33.3,
32.5,
87,
43.6,
45.2,
34.6,
86.7,
34.4,
55.4,
98,
21.1,
54.4,
24.3,
33.2,
46.1,
85.3,
57,
33.4,
65.8,
70.1,
81,
59.6,
82.7,
67.3,
70.2,
51.7,
95,
83.8,
93,
41.2,
8.4,
51.8,
37.5,
42.9,
67.8,
66,
37.2,
75.8,
64.2,
14.8,
63.7,
38.5,
49,
23.1,
66.9,
92.1,
29.1,
89.3,
68.6,
64.9,
90.1,
47.1,
59.4,
93.8,
27.6,
69.4,
19.7,
62.9,
33.8,
10,
85.3,
72.6,
25.3,
74.6,
77.8,
45.1,
32,
65.5,
40.3,
89.4,
66.1,
16.3,
79.1,
50.6,
62.7,
97.2,
59.9,
51,
39.8,
76.9,
51.9,
54.8,
35.7,
44,
52,
52.4,
71,
62.7,
52.3,
99.3,
79.1,
27.8,
31.2,
88.3,
37.1,
36,
73.2,
61.1,
84.2,
83.9,
21.5,
68.4,
66,
40.6,
45.4,
75.5,
39.9,
64,
85,
42,
24.6,
91.5,
31.2,
85.4,
103.8,
29,
44.6,
34.6,
51.3,
72.8,
82.7,
63.6,
89.3,
113.1,
70,
66.5,
25.2,
16.2,
29.3,
57,
67.5,
53.6,
23.7,
93.9,
63.1,
69.6,
6.6,
67.1,
23.4,
12.1,
54.4,
40.9,
78,
79.1,
83.1,
81.6,
94.9,
18.1,
76,
43.7,
38.7,
90.2,
66.1,
71.2,
28.1,
53.9,
33.7,
17.3,
31.4,
86.1,
54,
48.3,
51.4,
30,
null,
85.1,
54.5,
73.7,
72.8,
62.3,
18.2,
39.1,
84.6,
62.2,
76.7,
65.3,
33.1,
64.7,
27.1,
57.5,
43.8,
68.1,
5.6,
74.4,
0.4,
29.9,
39.7,
97.4,
68.2,
67.7,
32.5,
54.8,
79.6,
32.6,
72.7,
69.3,
57,
35.2,
93.5,
47.4,
14.8,
88,
85.1,
95.9,
88.7,
71.9,
80.9,
57.8,
61.8,
24.8,
78.9,
65.3,
94.7,
22.5,
72.3,
77.7,
81.2,
62.5,
62.7,
96.1,
57.9,
21.7,
88.5,
62.6,
53.5,
67.5,
75.7,
0.7,
47.4,
48,
67.2,
22.4,
67.3,
44.4,
77.9,
47.7,
67.2,
83.2,
70.4,
42.4,
54.3,
77.8,
39.9,
94.8,
54.9,
26.6,
45.2,
32.4,
28.4,
78.9,
7.7,
1.9,
47.3,
84.1,
88.1,
58.6,
6.3,
26.2,
37.7,
55.9,
42,
85.9,
15,
62.5,
42.5,
58.6,
65.5,
66.3,
79.7,
70.9,
14.4,
50,
29.7,
49.8,
50.1,
86.9,
76.3,
62.8,
52,
28.2,
59.5,
72,
82.8,
15,
76,
38.5,
73.1,
32.3,
36.2,
56.2,
73.2,
99.8,
58.7,
52,
71.9,
56,
41.5,
35,
79.3,
32.6,
53.7,
29.5,
37.9,
87.5,
56.9,
60.3,
79.1,
34,
75.1,
43.5,
81.2,
97,
38,
20.7,
33.7,
17.6,
67.6,
25,
0.6,
82.9,
32.9,
29.6,
4.3,
24,
15.1,
14.5,
82.4,
94.3,
98,
43.4,
70.8,
57.1,
51.3,
70.9,
54.2,
4.9,
77.1,
88.7,
58.7,
22,
19.2,
28.2,
73.7,
67.2,
0,
61.5,
43,
19.3,
33.4,
3,
68.2,
76.9,
66.8,
43.6,
71.8,
39.3,
66,
80.7,
52.8,
69,
90.2,
73,
32.1,
53.6,
49,
87.4,
17.8,
51,
82.8,
32.7,
34.1,
67.2,
55.1,
25.2,
50.1,
90.4,
52.6,
70.5,
23.3,
70.8,
35.2,
58.2,
32.3,
92.1,
80.4,
53.8,
39.7,
56.2,
78.7,
101.9,
56.6,
91.4,
33.4,
103.7,
40,
75.9,
56.9,
61.9,
67.9,
63,
0.5,
77.7,
37.8,
43.8,
3.1,
63,
70.1,
63,
56.6,
77,
82.1,
42,
47,
63.8,
18.8,
66.5,
86.4,
45.3,
69,
59.1,
36.4,
56.8,
70.9,
81.3,
72,
49.7,
46.1,
60.4,
47.8,
15.3,
11.1,
41.2,
31.5,
81.9,
66.6,
71.6,
46,
57.9,
61.1,
48,
50.7,
72.4,
44.9,
44,
7.4,
20.2,
20,
71.3,
11.9,
47.9,
72,
0.3,
80.4,
73.1,
31.3,
54.6,
83.8,
63.9,
51,
64.4,
12.1,
89.1,
39.7,
9.9,
40.6,
92.4,
38.6,
55.6,
78.5,
44.4,
80.7,
97.3,
65.5,
22.5,
23.2,
15.4,
74,
80.3,
28.8,
81,
48.4,
59.3,
72.1,
24.3,
68.5,
82.5,
77.4,
13.2,
69.6,
45.8,
22.4,
47.4,
73.4,
33.4,
68.6,
80,
43,
21.3,
74.2,
80.4,
28.3,
39.2,
35.4,
61.9,
55,
81.4,
65.4,
38.5,
12.5,
63,
60.2,
61,
73.5,
44,
56.3,
92.8,
93.6,
55.5,
6.6,
37.6,
63.5,
54,
42,
34,
83.5,
13.8,
45.8,
42.7,
91.3,
76.3,
67.6,
82.4,
93.3,
94.8,
86.5,
68,
96.2,
62,
51.7,
47.9,
82.8,
34.5,
31,
37.9,
40.9,
53.8,
92.2,
46.4,
20,
42.7,
81.3,
52.8,
81.1,
57.5,
79.5,
45.1,
52.2,
75.9,
43.1,
2.5,
60.1,
42.5,
41.5,
21.7,
94.1,
19.2,
70,
71.7,
37.5,
92.7,
91.4,
39.9,
23.1,
94.4,
64.5,
78.7,
50.5,
18.7,
29.7,
63,
39.9,
37.5,
97.5,
42,
64.7,
17.3,
8.4,
49.4,
91.9,
81.9,
46.3,
70.1,
52.7,
80.6,
34.6,
81,
70,
50.4,
49.8,
84.9,
75.8,
77,
50.6,
63.9,
36.4,
43.3,
47.1,
66.8,
75.2,
65.8,
58.3,
94.6,
65,
44.9,
45.3,
75,
39.1,
73.6,
58.2,
47.7,
39.1,
64,
71.8,
67.7,
72.4,
69.8,
75.6,
10,
40.9,
41.1,
51.1,
31.8,
83.1,
72.3,
79.8,
58.3,
69,
54.3,
71.9,
42.2,
83.4,
41,
88.4,
70,
21.7,
56.5,
9.8,
93.2,
35.6,
19.6,
56,
40.6,
61,
56,
65.4,
41,
62.8,
47.9,
59,
61,
90.1,
91.8,
60.9,
28.7,
36.2,
3.2,
87,
51.4,
33.7,
57.5,
21.8,
86.2,
67.5,
67.5,
24.2,
77.3,
77.3,
24.1,
51.6,
68.4,
91.6,
9.4,
61.4,
50.3,
53.4,
92.4,
27.7,
68.5,
20.9,
78.8,
84.1,
94.8,
43.6,
95,
50.5,
25.2,
19.2,
57.9,
82.9,
52.4,
52.3,
49,
65.5,
78,
74.8,
47.3,
62.3,
42.2,
60.2,
74,
58.8,
47.8,
89.3,
44.4,
42.9,
59,
96.7,
74.1,
37.2,
10.3,
18.3,
65.4,
57.2,
68.3,
68.9,
14.7,
66.2,
75.8,
23.7,
53.6,
22.1,
68.3,
32,
54.2,
70.9,
27.1,
50.2,
33.8,
39.2,
28.6,
60.4,
54.6,
82.2,
29.7,
43.7,
48.9,
74,
74.1,
42.1,
37.2,
70.7,
74.8,
81.2,
21.1,
74.6,
45.3,
68.8,
43.6,
66.8,
97.7,
72.1,
28.7,
68,
64.5,
24.4,
88.3,
85,
59.8,
54.3,
95.7,
67.9,
89.5,
71.7,
40.4,
32.1,
76,
70.1,
1.4,
92.8,
50.6,
37.7,
10.5,
63.8,
69,
50.5,
87.7,
53.4,
46.1,
80.7,
76.3,
14.3,
72.9,
35.8,
99.5,
66,
5.1,
70.2,
96.5,
50.4,
43,
82.8,
32.2,
13.7,
89.9,
2.5,
71.6,
23.2,
41.3,
78.8,
46,
10.5,
59.2,
45.7,
53,
57.5,
20.9,
7.2,
38.5,
30.8,
62.1,
98.9,
95.3,
15,
50,
53.1,
36,
34.4,
88.7,
29.7,
71.7,
61,
57.6,
75.7,
29.1,
49.2,
22,
58.4,
69.5,
51.1,
63.2,
26.1,
65.1,
25.9,
52.4,
11.6,
79.8,
49.5,
26.7,
58.2,
9.2,
22.4,
92.4,
47,
74.6,
48.9,
99,
82.6,
41.6,
9.8,
61.7,
80.3,
39.7,
88.9,
11.2,
95.5,
77.6,
78.7,
33.1,
38.1,
71.8,
100.7,
77.3,
50.9,
23.7,
31.1,
36.5,
51.4,
42.8,
52,
88.2,
59.9,
55,
79.6,
53.4,
4.8,
81.5,
80.8,
17.7,
68.7,
55,
77.4,
84.8,
16.3,
0.4,
60.9,
37.7,
55.8,
80.4,
83.8,
85.5,
27.3,
53.8,
57.9,
94.4,
82,
64.8,
0,
99,
84.4,
80.3,
24.4,
39.7,
0,
24,
51.3,
60.2,
77.1,
50.7,
62.4,
21.7,
22.5,
49.4,
0,
78.8,
13.6,
17.2,
62.8,
47.7,
62.9,
85.7,
92.1,
43.9,
68.4,
72.2,
60.8,
20.2,
85.5,
84.5,
36.8,
37.5,
77.2,
24.4,
21.1,
76,
51.9,
40.9,
45.4,
71.8,
49.9,
45.5,
36.4,
33.7,
95.5,
79.1,
60.6,
78.4,
86.1,
54.8,
91,
90.8,
84.7,
45,
56.6,
63.3,
73.5,
34.6,
18.2,
76.6,
66.8,
29.2,
75.6,
34.7,
62.9,
71.3,
47.5,
37.7,
78.9,
36.2,
62.4,
44.4,
79.1,
72.1,
16.3,
55.3,
73,
61.5,
41.8,
66.5,
27.9,
19.6,
80.3,
63.9,
58.3,
52.9,
71.1,
83.5,
51.7,
61.5,
80,
0,
67.6,
80.8,
56,
55.1,
15.5,
44,
2.4,
77.9,
100.5,
49.2,
67.3,
14.7,
52.7,
71.5,
35.4,
4.1,
87,
83.1,
81.1,
49.4,
79.7,
35.2,
41.9,
50.7,
23.8,
57.3,
46.9,
22.8,
33.6,
93.6,
33.5,
85.7,
72.5,
96.4,
64,
87.2,
63.8,
8.7,
65.9,
94.6,
35.3,
10.9,
42.7,
96,
88.7,
76.6,
57.1,
35.3,
46.4,
79,
115.3,
63.5,
82.4,
79.8,
53.2,
15.1,
19.6,
60,
29.7,
87.5,
53.3,
96.7,
77.5,
29.7,
32.2,
46.6,
47.5,
30.6,
25.1,
46.4,
26.8,
90.2,
69.7,
72,
63.9,
93.3,
16.8,
29.8,
45.9,
39.7,
78.7,
81.9,
44.7,
85.8,
34,
48.1,
58,
56.8,
44.2,
52.6,
59.9,
28.1,
57.2,
55.3,
37.7,
59.1,
79.7,
0,
85.7,
79.9,
59.9,
60,
60.1,
15.5,
60,
48.7,
70.5,
69.5,
56.9,
40.7,
55,
87.8,
20.2,
12.6,
59.2,
19.3,
87.6,
83.5,
62.9,
89.1,
68,
48.7,
78.5,
30.4,
86.1,
61,
31.8,
59,
46.1,
43.1,
45,
50.8,
78.2,
81.1,
48.8,
64.5,
52.1,
73,
73.4,
64.6,
74.7,
48.6,
78.3,
35.3,
53.4,
84.7,
71.6,
86.1,
25.8,
66.2,
45.7,
89.9,
59.5,
78.5,
49.3,
82.2,
73.8,
55.2,
25.5,
69.9,
67,
73.5,
101.3,
92.8,
78.6,
77.9,
8,
74.6,
65.6,
40.2,
93.1,
39.9,
99,
60.3,
70.4,
26.4,
46.8,
21.8,
75.5,
91.4,
39,
11.6,
91.5,
87.3,
9.9,
78.9,
54.6,
18.1,
21.5,
62,
57.3,
79.4,
50.8,
58,
62.6,
34.9,
43,
0.8,
77.9,
64.6,
99.5,
49.9,
75,
68.8,
15.5,
52.5,
90.4,
24.7,
63,
69.5,
66.6,
39.1,
88.2,
65,
67.1,
27,
76.6,
86,
73.3,
31.1,
77.2,
87,
72.4,
24.5,
84.5,
48.1,
72.5,
52.3,
18.9,
78.4,
78.9,
47.5,
77.2,
0,
87.9,
77.6,
61.3,
18.1,
25,
67.2,
52.6,
66.5,
21.5,
47.4,
87.5,
25,
89.4,
72.4,
69.5,
84.9,
39.6,
65,
43.3,
69.2,
52.6,
40.2,
66.6,
60.2,
87.1,
80.1,
68.2,
2.2,
23.1,
86.7,
82.4,
22.3,
81.2,
72.3,
57.7,
46.9,
90.4,
96.7,
94.3,
0,
96.7,
78.2,
17.6,
79,
55.2,
90.2,
74.8,
57.7,
55,
70.6,
76,
25,
33.5,
78.1,
45.3,
86.2,
36.1,
56.2,
70,
56.5,
55.4,
40.5,
91.8,
66,
63,
99.3,
44.2,
18.4,
38.6,
47.4,
56.3,
57.6,
91.7,
40.4,
45.6,
58,
57.4,
76,
85.8,
74.8,
87.3,
52.7,
74.2,
71,
68.2,
54.5,
74.5,
81.7,
74.9,
50.5,
80.5,
35.5,
57.7,
52,
62,
58,
42.7,
93.5,
87.1,
37.2,
52.3,
38.9,
25.2,
69.9,
42.8,
38.1,
26.6,
68.8,
50.7,
72.1,
34.8,
82.6,
42.8,
53.4,
82.3,
60.2,
39.9,
52.7,
64.8,
77.4,
61.9,
80.9,
34,
48,
29,
28.3,
54.7,
82.7,
28,
25.5,
67.9,
63.4,
48.2,
82.1,
83.5,
48.7,
56,
59.3,
65.7,
56.1,
32.8,
59.7,
45.9,
48.4,
75.4,
92.3,
33,
75.4,
33.2,
60.3,
8.7,
40.9,
50.4,
72.2,
20.3,
42.3,
88,
49.5,
92.9,
88.7,
56.6,
83.1,
98,
50.1,
1.3,
36,
85.5,
12,
39,
62,
4,
58.9,
52.4,
67.5,
41.7,
55.3,
97.6,
50.4,
75.8,
74,
16,
89.7,
58,
32.3,
58.5,
34.1,
47.5,
69.7,
60.3,
39.4,
68.3,
67.9,
52.7,
53,
23.7,
57,
61.7,
53.8,
16.6,
52,
39,
27.4,
91.8,
95.3,
20.3,
80,
53.9,
41.2,
38.4,
62.5,
72.3,
53.1,
50.7,
48.8,
59.9,
83.3,
33.8,
53.2,
77.8,
49.9,
49.3,
68.6,
13.2,
72.2,
60.9,
49.2,
16.1,
82.8,
58.5,
79.6,
32.3,
51.2,
88.6,
69.6,
59.7,
81.6,
47.1,
66.3,
67.2,
22,
80.7,
66.7,
55.6,
94.6,
18.5,
47.6,
58.7,
46.5,
84.2,
69.2,
13.9,
11.6,
14.5,
80.3,
53.9,
39.4,
52,
58,
71.1,
13,
40.7,
51.3,
43.1,
81,
27.1,
50,
86.3,
37,
36.2,
79.4,
35.4,
71.4,
98,
31.9,
33.9,
68.3,
36.8,
80.1,
32.7,
71.8,
18.7,
94.9,
18.3,
36.4,
59,
96.3,
11.2,
52.1,
63.2,
63.7,
97.4,
23.2,
45.5,
30.5,
2.3,
12,
83.9,
43.4,
72.6,
72.3,
59.4,
66.3,
80.2,
62.6,
49.7,
62.1,
28.3,
56.6,
80,
55,
56,
45.7,
86.4,
54,
50.8,
73.4,
14.3,
45.8,
97.5,
36.2,
0,
68.8,
8.8,
49.3,
49.8,
86.8,
41.5,
48,
75.8,
49.8,
93.9,
63.5,
92.8,
55.4,
57.2,
35,
42.6,
50.2,
62.5,
32.5,
62.2,
50.4,
52.2,
84.5,
71.7,
74.8,
26.1,
40,
61.5,
76.2,
39.3,
46.4,
86.9,
57.7,
45.1,
80.1,
64.1,
76.5,
54.8,
48.3,
52.6,
79.4,
12.2,
96.7,
87,
73.3,
10.1,
66.3,
71,
70,
77.5,
53.1,
78.7,
36.1,
42.2,
55,
56.3,
80.5,
64.8,
81.3,
61.9,
47.2,
73.6,
69.5,
23.8,
61,
53.6,
95.8,
75.2,
36.2,
79.1,
68,
96.3,
100.1,
9.7,
46.8,
76.2,
72.8,
30,
87,
77.7,
52,
72.2,
51.7,
38.4,
63.4,
55.3,
50.9,
82.9,
82,
72.4,
11.9,
41.2,
19.6,
83.9,
37.4,
76.8,
40.4,
6.5,
80.3,
49.8,
46.4,
78.7,
50,
20.4,
46,
33.7,
15.7,
71.4,
26.8,
27.1,
86.2,
64.4,
47.9,
71.2,
40.2,
83.9,
65.8,
84.6,
38.6,
60.3,
34.3,
36.3,
77.6,
69.6,
1.1,
7.7,
41.3,
66.2,
6.5,
28.8,
54.8,
84.4,
59.7,
79.3,
73,
78,
45.7,
52.3,
59.6,
70.9,
38.5,
64.2,
61.8,
40.9,
55.3,
25.4,
44.7,
41.8,
0.1,
72.2,
42.8,
64.4,
59.6,
60.1,
27.7,
83.6,
53.5,
86,
58.2,
24.8,
41.9,
26.1,
64.6,
35.2,
56.2,
35.7,
78.9,
67.9,
82.8,
45.6,
46,
29.8,
23.8,
26.9,
19.5,
56,
30.5,
76.1,
47.8,
69.6,
83.7,
45.6,
6.2,
67.3,
36.1,
56.7,
53.8,
89.6,
88.4,
35,
7.1,
72.2,
72.6,
44.9,
23.2,
96.9,
50.9,
66.5,
46.7,
62.2,
84.2,
57.5,
93.5,
69.1,
36.3,
35.7,
72.1,
80.2,
67,
49.7,
30.2,
40.3,
94.9,
29.6,
33.1,
82.2,
95.4,
36.4,
55.5,
65.2,
37.8,
47.3,
67.6,
10.4,
64.6,
66.6,
35.4,
51.3,
67.4,
42.2,
77.1,
54.3,
73,
54.6,
49.2,
62.2,
101.5,
89.9,
22.1,
21.4,
36.7,
90.1,
26.3,
22.4,
54,
36.2,
57.7,
55,
28.4,
62.9,
4.5,
50.8,
60.5,
65,
66.8,
94.6,
71.8,
9.7,
85,
86,
63.8,
31.3,
18.9,
85.8,
63.5,
28.2,
20.7,
24.3,
98.4,
23.7,
59.9,
62.7,
51.6,
66.5,
67.8,
62.5,
79.1,
38.6,
14.5,
81.7,
51.4,
60.1,
15.5,
74,
78.4,
64.5,
29,
37.9,
70.4,
24.3,
34.1,
67.5,
87.6,
15.8,
74,
67.7,
48.2,
78.2,
59.6,
50.2,
44.9,
49,
42,
44.3,
48,
68.7,
79.2,
68.3,
46.5,
66.6,
92.9,
65,
66.6,
26.5,
59.9,
93.8,
67.8,
63.2,
36,
63.8,
31.1,
43.7,
36.5,
56,
29.9,
16.3,
87.1,
53.8,
52.8,
61.9,
92.4,
67,
48.1,
61.2,
93,
90.5,
79.9,
11.1,
67.4,
100.1,
20.4,
15.7,
56.2,
8,
68.8,
85.3,
96.4,
73.3,
47.6,
10.7,
57.6,
18.7,
68.1,
79.4,
34.5,
78.4,
53.3,
25.3,
98.5,
25.3,
46.7,
45.3,
83.9,
60.3,
10.8,
70.4,
69.6,
49.4,
66.9,
58.2,
57.6,
92.8,
47.8,
58.8,
29.5,
53.5,
53.7,
81,
53.4,
76.4,
4.3,
80.1,
25.4,
67.5,
95,
98.6,
71.2,
78.3,
69.9,
67.3,
39.6,
53.2,
21.8,
55.3,
44.1,
42.4,
71.6,
52,
15.5,
78.6,
94.3,
49.6,
86,
70,
58.1,
24.6,
33,
33.5,
59.3,
52,
81.6,
62.5,
97.6,
80.4,
8,
81.7,
33.3,
64.1,
79.3,
83.4,
92.1,
5.7,
74.2,
98,
5,
3.8,
35,
92,
81.8,
74.9,
35,
59,
64.4,
68.4,
59.1,
44.3,
61.9,
72.9,
12.4,
69.9,
68.6,
61.4,
77.3,
77.7,
41.2,
56.2,
35.7,
20.9,
47.9,
63.8,
37.3,
39.4,
97.9,
43.3,
16.5,
7.6,
50.7,
59.1,
62,
69.3,
27.5,
81.7,
81.5,
44.8,
63.4,
100.7,
55.9,
92.8,
85.7,
38.5,
63.6,
56.5,
51.4,
34.7,
73.8,
7.5,
85.9,
41.1,
93.4,
67.1,
58.2,
65.9,
89.8,
73.5,
20.5,
98.1,
38.6,
24.6,
21.8,
57.2,
45.8,
92.6,
81.4,
79,
56,
91.8,
69.2,
83.9,
0.6,
90.7,
28.4,
18.1,
49.7,
51.4,
75.8,
35.5,
92.8,
47.7,
88,
70.2,
56.9,
31,
52.7,
0,
92.5,
71,
63.4,
82.3,
92.9,
59.7,
52.4,
42.1,
24.6,
22,
38.5,
82,
75,
60.3,
78,
59.8,
42.6,
41.9,
29.3,
70.7,
57.8,
46.8,
66.1,
67.9,
82,
92,
49.8,
36.9,
48.4,
93.4,
32.4,
87.2,
70.2,
89.2,
69.3,
16.3,
45.8,
77.7,
96,
56,
54.2,
65.2,
87,
42.4,
22.5,
21.4,
7.3,
55.2,
82.8,
78.2,
68.4,
94.3,
66.2,
59.5,
59.8,
93.9,
30.9,
44.3,
68.9,
44.5,
44.7,
98.9,
92.4,
32.6,
53.1,
21.4,
50.5,
29.7,
55.7,
26.4,
14.6,
70.6,
75.1,
67.4,
12.8,
52.4,
29.1,
56.4,
30,
23,
60.2,
79.1,
42.1,
34,
73,
20.5,
95.7,
33.2,
13,
93.9,
47.9,
2.3,
84.9,
86.5,
41.2,
41.3,
63,
53.9,
46.4,
23.2,
44.3,
77,
87.1,
49.3,
76.5,
10.3,
78.5,
55.2,
60.4,
81.6,
58.7,
36.7,
29.5,
56.4,
77.3,
43.4,
32.2,
39.6,
78.6,
79.9,
63.9,
64,
67.7,
47,
71.9,
76.2,
41.8,
4.4,
0.8,
37.4,
73.3,
79.8,
38.3,
58.6,
26,
76,
22.7,
64.3,
43.2,
37.7,
62.6,
73.1,
82.6,
52.4,
45,
43.1,
23.9,
38.6,
27.5,
54.4,
80,
88.2,
31.3,
90,
68.8,
65,
12.7,
77.6,
62.3,
83.1,
39.3,
40,
40.7,
38.1,
25.5,
39.4,
51.7,
46.8,
65.6,
80,
88.2,
38.8,
45.7,
69.4,
40,
93,
62.8,
39.4,
79.9,
71,
71,
56.8,
28.9,
68.2,
45.5,
8.4,
62,
95.9,
44,
53.6,
87,
69.9,
61.5,
57,
41.2,
53.4,
100.3,
96.7,
25.7,
68.9,
73.3,
91.5,
25.7,
64.2,
53.2,
62.8,
27.1,
39.8,
63.3,
42.6,
25.6,
20.3,
66.1,
55.1,
67.8,
63,
17.3,
64.8,
78.4,
94.3,
11.2,
91,
9,
74.6,
48.5,
50.8,
33.5,
2.2,
62,
66.8,
54.2,
54.7,
70.9,
62.4,
71,
83.2,
43.7,
47.5,
50.1,
55.8,
77.6,
52.8,
28.8,
83,
67.1,
87.6,
69.6,
46,
47.9,
91.9,
57.4,
35.7,
69.5,
33.3,
61.9,
5.7,
57.9,
39.4,
83.5,
80.8,
50.2,
71.3,
86.4,
73.7,
82,
97.3,
76.5,
41.4,
76.9,
93.8,
52.1,
47.2,
81.5,
71.9,
65.8,
26.3,
47.2,
60.6,
13.9,
51.3,
47.8,
72.3,
91.3,
59.4,
23.2,
77.6,
59.3,
31.7,
75.6,
95.3,
74.8,
35.3,
72.6,
39.8,
74.3,
69.6,
64.9,
48.7,
10.7,
59.7,
37.5,
84.5,
72.4,
90.8,
64.7,
78.4,
71,
6.5,
61.5,
25.9,
32.1,
77,
56.2,
23.7,
53.3,
27.3,
74.8,
43.1,
24.7,
29.2,
53.8,
42.4,
67.2,
77.9,
87.6,
86.7,
94.7,
25.6,
50.9,
43.9,
59.1,
94.3,
47.8,
76.7,
39,
42.5,
51.6,
58.9,
65.6,
93.5,
81.8,
69.7,
60.6,
62.9,
59,
28.8,
85.8,
86.4,
57.2,
44.4,
45.9,
32.5,
67.9,
87.8,
48.6,
82.5,
77.7,
59.2,
27.9,
7.9,
36.7,
76,
94.8,
22.5,
46.6,
60.3,
36.6,
31.9,
51,
99.3,
59.5,
71.1,
33.2,
27.9,
38.4,
38.5,
80.7,
70.1,
72.5,
69,
46.9,
48.6,
52.7,
78.6,
55.8,
77.4,
51.9,
15,
49.8,
37,
33.8,
37.3,
46.4,
63.6,
8.7,
62.2,
30.4,
35.5,
96.9,
53,
53.6,
74.4,
11.5,
97.8,
24.3,
57.3,
72.2,
46.6,
43.6,
85.2,
30.4,
62.4,
63,
55,
79.7,
14.4,
100.3,
61.5,
42.4,
59.2,
42.5,
29.8,
69.9,
37.1,
54,
54.3,
47.2,
80.4,
15.1,
39.1,
39.3,
6.2,
31.3,
91.1,
28.4,
56.5,
46.5,
66.5,
36.6,
67.6,
7.9,
52.2,
34.1,
15.9,
35.8,
58.4,
41,
33.7,
59.6,
68.5,
72.9,
53.5,
56.4,
73.6,
21.7,
55.5,
15.1,
42.8,
83.2,
62.7,
97.4,
39.1,
31.1,
44,
78.8,
55.3,
83.7,
13.3,
44.9,
67.7,
57.8,
63.6,
86.3,
91.6,
55.9,
42.9,
45.9,
49.1,
57.9,
68,
9.8,
18.9,
54.2,
9.1,
33.4,
96,
74.7,
51,
26.7,
61.6,
62.8,
27.6,
80.6,
26.3,
23.9,
68.6,
52,
32.6,
32.7,
96.7,
90.7,
20.7,
62.6,
59.4,
43.9,
66.5,
44.7,
10.3,
94.3,
41.6,
49.7,
97.8,
29.3,
42.1,
31,
14.2,
20.5,
44.8,
32.8,
89.1,
64.2,
34.3,
90,
54,
53.4,
39,
51.7,
26.5,
27.7,
86.1,
75.6,
54.7,
70.5,
77.4,
20.5,
80.8,
53,
88.5,
29.9,
53.5,
46.5,
33.2,
50.7,
75.4,
81.4,
52.3,
29.3,
22.6,
12.3,
45.3,
55.8,
67.9,
50.5,
68,
29.2,
84.1,
39.6,
82.4,
35.5,
12.2,
40.9,
69.9,
41.4,
47.2,
73.1,
50.6,
66.7,
29.8,
78.4,
93.8,
88.6,
11.7,
19,
42,
67,
29.7,
72.7,
59.6,
28.4,
61.1,
66.9,
44.7,
48.6,
53.1,
49.1,
35.6,
48.6,
97.7,
51.9,
39.7,
39.9,
31.3,
40.5,
50.9,
70.1,
50.8,
33.4,
75.7,
85.3,
63.2,
59.5,
44,
70.8,
13.1,
67.3,
39.6,
80,
60.4,
90,
22.7,
85.8,
71.7,
15.4,
25.8,
22,
39.6,
40.8,
39.3,
76.6,
76.3,
88.7,
84.7,
89.6,
35.6,
62.5,
22.9,
60,
48,
38,
80,
53.3,
61.2,
75.8,
65.3,
45.8,
52.5,
44.4,
66,
8,
36.3,
25.5,
64.1,
59.3,
61.6,
75.5,
62.2,
5.7,
92.5,
30,
17.5,
33.1,
45.3,
58.3,
74.8,
79,
80.5,
5.6,
60.5,
75,
74.3,
36.2,
66.7,
25.3,
58,
37.2,
56,
43.9,
17.6,
48.8,
39,
29,
45.7,
41.7,
69.7,
68.7,
31.3,
28.2,
66,
78.7,
57.1,
48.2,
30,
48.9,
39.9,
72.3,
60.1,
72.1,
21.3,
71.7,
23.8,
41.4,
62.5,
57,
58.3,
80.4,
67,
92,
7.4,
69.2,
65.3,
74,
51,
80.7,
96.3,
96.3,
61,
27.2,
73.9,
44.9,
83.9,
32.4,
61.5,
48.1,
62.6,
96.1,
66.3,
23.1,
56.9,
34.2,
92.9,
21.2,
79.8,
16.7,
19.8,
19.2,
26.7,
78,
52,
40.1,
65.9,
35.6,
62.5,
48.3,
60.7,
34.4,
55.1,
35.9,
10.1,
26.9,
19.6,
26.1,
70.1,
65.3,
67.7,
54.3,
65.7,
39.7,
38,
92.5,
98.8,
54.7,
34.4,
46.3,
25.6,
81.8,
75.3,
15.8,
67.3,
54.4,
34.9,
81.8,
97.1,
34.5,
94,
68.8,
70.6,
23.4,
16.7,
59.5,
32.8,
62.2,
81.4,
49.7,
70.2,
15.7,
28.9,
46.5,
51.3,
48.1,
81.4,
41.4,
28.2,
81.6,
51.1,
23.1,
91.3,
38.5,
71.1,
86.6,
71.1,
55.3,
56.6,
73.9,
30.1,
2.4,
33.8,
46.4,
81.1,
35.4,
70.7,
60.7,
22.1,
61.2,
92.2,
94.9,
63,
18.6,
29.8,
7.7,
76.5,
97,
68,
68,
29.7,
9.9,
33.8,
36.1,
95.4,
56,
75.5,
57.5,
48.8,
71.7,
96.7,
71.6,
82.9,
37.7,
47.9,
68.1,
19.5,
80.1,
35.6,
62.2,
17,
86.8,
74.7,
25.2,
62.6,
84.9,
64.7,
41.7,
82.8,
25.2,
68,
27,
69.1,
53.2,
24.9,
53.6,
46.6,
89.3,
81.4,
77.7,
76.7,
96.9,
51.9,
68.9,
55.8,
74.1,
73.1,
81.8,
55.3,
70.4,
18.8,
67.7,
81.9,
70,
34.5,
72.6,
58.8,
54.2,
53.6,
89.9,
38.2,
60.3,
88.5,
62.9,
29.4,
34.6,
40.9,
17.8,
46.3,
81.1,
70.1,
33.8,
85.4,
40.8,
63.1,
92.5,
37.7,
61.2,
63.2,
64.1,
47.4,
26.5,
90.4,
47,
47.2,
63.6,
36,
99.3,
87.9,
71.1,
90.2,
36.8,
12.1,
58.5,
30.5,
56.1,
24.9,
57.2,
45.7,
64.7,
65.6,
77.8,
24,
53.2,
4.7,
76.7,
63.4,
53.3,
63,
53.3,
81.3,
70.9,
95.2,
47.8,
14.8,
59.9,
90.8,
94.6,
10.8,
75.5,
42.1,
19.2,
48.4,
48.5,
51.9,
48.6,
66.1,
49.3,
6.1,
27.5,
77.7,
37.9,
90.6,
71,
56.7,
38.7,
51.6,
45,
49.3,
56.4,
60.8,
64,
86.2,
83.6,
36,
56.8,
79.7,
88,
32.2,
29.5,
58.3,
71.8,
63.2,
64.7,
13.1,
38.8,
101.9,
70.2,
16.8,
37.6,
78.1,
37.9,
20.1,
26.4,
91.2,
16.8,
53.8,
32.2,
40,
42.9,
71.7,
23.4,
0,
0.3,
75.2,
72.7,
53.7,
75.4,
66.6,
64,
50.3,
61.6,
43,
52.4,
40.8,
34.4,
62.2,
54.8,
46.2,
48.4,
64.3,
13.4,
41.8,
86.6,
44.6,
50.3,
84.1,
68.5,
60.2,
44,
46.5,
99.7,
12.4,
68.9,
41.8,
97.5,
78,
75.3,
60.4,
81,
36.2,
64,
59.1,
42.6,
33,
69.2,
97.8,
55.7,
45.2,
72.2,
71.9,
99,
7.8,
76.4,
87,
77,
44,
65.1,
35.9,
69.7,
20.9,
42.9,
28.1,
70.7,
69.1,
46.6,
42.4,
65.8,
23.9,
42.9,
75.2,
81.4,
66.7,
73.2,
83.5,
44,
83.4,
89,
60.4,
64.9,
58.2,
10.3,
60,
52.7,
35.3,
52.1,
94.6,
86.4,
61.1,
76.1,
65.6,
35.1,
30.3,
46.3,
29,
27.4,
40.9,
70.8,
50.8,
74.6,
31.8,
44,
73.9,
77.7,
34.3,
65.7,
62.3,
31,
30.7,
54.4,
83.8,
70.2,
73.3,
77.5,
55.9,
69.3,
61.3,
70,
82,
20.8,
72.5,
93.9,
37.8,
46.3,
75.5,
44.5,
73.6,
39.4,
36.8,
40.5,
47.5,
54.5,
22,
61.9,
49,
54.3,
28.2,
42.6,
36,
64.4,
53.8,
51.4,
64.2,
61.4,
61.1,
35.3,
79.6,
45.6,
0,
53.3,
58.3,
88.3,
52.9,
57.2,
48.2,
96.2,
12.6,
44,
81.6,
46,
50.3,
39.2,
15.7,
26.6,
72.7,
75,
35,
99.6,
84.4,
33.4,
99.7,
53.9,
36.8,
66.2,
82.2,
75.4,
51.6,
75.2,
60.4,
60.3,
95.3,
7,
94.3,
38.4,
42,
46.8,
63.2,
37,
80.1,
85.8,
49.2,
62.4,
0.2,
52,
29,
35.9,
81.2,
99,
28.4,
55.5,
31.9,
49,
21.7,
72.3,
31.2,
86.5,
64.4,
83.6,
29,
39.7,
30,
94.5,
54.6,
73.6,
53.5,
null,
79.3,
79.7,
73.2,
90.7,
24,
76,
87.8,
51.2,
24.5,
32.3,
80.4,
41.7,
76.5,
20,
37,
37.8,
58,
87.5,
11.8,
24.1,
88,
30.1,
30.7,
78.6,
80.4,
40.1,
68.5,
60.3,
75.1,
54.3,
85.3,
79.1,
33.3,
63.8,
76,
38.4,
79,
31.8,
31.5,
0.1,
73.2,
65.5,
68.6,
95.6,
44.1,
53.7,
60.5,
50.2,
56.7,
81.7,
59.3,
32.2,
40,
71.6,
37.1,
68.6,
44.3,
41.3,
24.6,
11,
20.9,
45.7,
54.3,
60.6,
40.6,
49.3,
17.1,
59.3,
37.8,
75.1,
80.7,
41.4,
32.1,
55.3,
10.6,
64.8,
63,
68.2,
46.2,
94.3,
49.7,
84.9,
20,
32.7,
85.8,
48.9,
52.9,
45.5,
73.7,
85.7,
63,
28,
97.3,
95.2,
52.4,
56.9,
77.3,
80.2,
40.6,
71.9,
15.4,
60,
32.3,
33.9,
77.5,
43.9,
56.5,
36,
19.3,
6.9,
70,
37.1,
20.7,
49.5,
43,
50.5,
78.6,
6.7,
47.8,
31.3,
60.3,
29.4,
83.5,
54.7,
57.5,
89.4,
16.1,
37.5,
80.9,
84.3,
64.9,
24.5,
91,
29.7,
17.3,
50.9,
43.8,
86.7,
59.5,
75.4,
33.3,
26.3,
49.1,
74.8,
63.1,
10.8,
65.4,
73,
21.1,
4.9,
70.3,
24,
0.1,
57.2,
38.2,
16.7,
30.1,
83,
14.5,
34,
65.2,
19.5,
30.7,
35,
51,
49.8,
77.4,
44.4,
43.4,
43,
7.9,
40,
65.7,
47.8,
52.5,
64.9,
26.8,
47.7,
89.7,
68,
4.9,
43.4,
64.9,
63.2,
70,
59.9,
13.2,
64,
10.2,
83.3,
43.6,
14.3,
64.3,
62.3,
45.9,
63.2,
54,
95.5,
88.5,
75.8,
50,
10.9,
44.4,
44.4,
35.8,
11.5,
73,
14.7,
86.6,
35.7,
28.6,
99.4,
38.5,
41.2,
42.3,
75.3,
28.5,
58,
54.8,
60.6,
54.8,
7,
72,
44.6,
49.1,
50.6,
50.3,
54.2,
29.6,
9.4,
56.3,
35.5,
10,
93.8,
18,
15.1,
85.3,
74.6,
51.1,
87.5,
70.1,
80.9,
74.3,
43.7,
78.9,
15.6,
53.6,
48.5,
68.6,
47.3,
26.9,
98.2,
51.2,
54.6,
79.7,
69.3,
48.8,
50.3,
24.9,
24.8,
96,
35.4,
66.3,
49.3,
35,
46.8,
40,
16.8,
33.8,
69.4,
55.2,
81.8,
38.4,
55.2,
61.6,
48.7,
38.6,
80.9,
21,
56.5,
53.8,
44.4,
54.6,
40.3,
76.8,
48.9,
53.1,
81.8,
44.2,
91.7,
39.8,
19.4,
91.4,
65,
51,
63.4,
47.8,
35.8,
60.6,
70.8,
64.9,
58.3,
60.7,
6.8,
51.1,
61.8,
77.8,
60.8,
65.5,
68.7,
72.5,
41.8,
74.2,
50.7,
88.7,
74.1,
51.5,
95.6,
55.7,
40.1,
55.4,
35.5,
24.2,
39.2,
45.6,
59.1,
60.5,
45,
94.6,
11.1,
37.3,
26,
90.5,
97.3,
39.7,
86.5,
25.4,
53.9,
63,
74.9,
61,
84,
58.1,
54.8,
81.4,
43.6,
76.2,
69.5,
23,
65,
67.8,
27.5,
51,
42.1,
56.2,
49,
92.4,
3,
42,
71,
18.9,
58.9,
89,
66,
41.3,
93.1,
13.2,
64.1,
61.6,
89.2,
102,
79.8,
38.5,
79.5,
70.3,
76.4,
8.8,
35.5,
80.6,
13.2,
36.9,
57.9,
61.3,
15.4,
23.3,
73.4,
15.3,
70.9,
37.9,
16.1,
47.1,
30,
88.6,
76.5,
31,
72.9,
37.4,
64,
94.8,
32.8,
39.4,
56.2,
40.4,
1.2,
87.8,
69.9,
56.4,
44.2,
59.4,
69.6,
32.1,
70.7,
18.5,
98.6,
50.7,
42.5,
33,
59.5,
76.7,
60.5,
62.3,
67,
98.1,
87.1,
51.3,
68.5,
85.6,
70.1,
74.4,
90.9,
27.3,
43.5,
57.2,
26.5,
37.5,
55.3,
99.4,
58,
50.5,
21.2,
1.1,
42.3,
91.4,
67.7,
62.6,
80.2,
48.4,
57.9,
60.1,
98.4,
67.4,
35.7,
72.6,
57.4,
83.9,
24.9,
94.8,
27.8,
60.9,
66.8,
86.5,
0.2,
51,
62.8,
40.8,
58.1,
11.4,
41.3,
46.9,
69.8,
19.1,
77.3,
78.3,
18.1,
50.9,
79.7,
23.7,
38.3,
37.3,
67.5,
20.9,
98.1,
81.2,
18.2,
95.5,
48.7,
62,
89.7,
77.1,
73.4,
43.9,
60.3,
41.2,
78.2,
30.8,
88.9,
57.1,
92.6,
49.5,
99.7,
42.8,
32.4,
36.8,
34.5,
16.2,
68.9,
18.9,
51.3,
62.9,
80.6,
87.3,
83.9,
63.3,
86.2,
62.3,
94.6,
62,
40.7,
56.6,
68.1,
34.4,
62.2,
60.7,
82.9,
72.4,
50,
74.7,
16,
4.2,
24.6,
43.5,
18.5,
44.2,
54,
41.1,
48.4,
19,
31.5,
77.1,
44.9,
61,
42.7,
27.9,
66.2,
63.3,
26.9,
78.1,
84,
21.6,
48.6,
33.6,
21.7,
64.4,
18.4,
43.9,
41.5,
54.3,
81.5,
50.4,
40.8,
79.2,
77,
56.1,
33.2,
62.6,
28.4,
26.7,
92.4,
53.8,
93.1,
31.4,
86.9,
34.4,
56.8,
61.6,
84.6,
67.4,
74.7,
34.3,
43.8,
33.5,
74.8,
68.4,
59.2,
68.8,
80.1,
80.8,
28.6,
63.9,
26.8,
49.7,
23.2,
43,
65.5,
66.4,
75.6,
17.9,
42.2,
55.5,
85.5,
85.9,
78,
94.1,
93.3,
23.8,
36,
38.8,
52.4,
68.6,
86.8,
36.4,
38.9,
36.7,
23.9,
93.8,
76.2,
55.5,
69.6,
55.1,
24.6,
38.6,
73.7,
29.8,
50.8,
78.8,
75.9,
67.3,
24,
62.8,
21.1,
54.3,
53.3,
52.4,
27.3,
85.7,
42.9,
43.9,
0.9,
46.2,
89.6,
74.3,
53,
78.2,
9.4,
46.4,
24.7,
24.7,
39.9,
1.2,
97.5,
76,
25.3,
85.8,
79.2,
71.1,
19.3,
80.6,
85.1,
71.8,
49.1,
92.6,
0,
34.2,
72.1,
48.7,
16.3,
86.9,
71.3,
41.6,
95.3,
62.1,
78.3,
75.9,
71.6,
66.4,
49.3,
71.1,
52.4,
33.7,
0.4,
69.5,
47.2,
54.2,
63.4,
12,
33.3,
46.8,
84.5,
37.4,
82.8,
32.4,
81.7,
46.3,
63.9,
47.8,
40.5,
60.9,
62.9,
74.4,
26.2,
27,
33.1,
85.8,
94.2,
8,
71.4,
47,
45.8,
22.5,
52.2,
63.2,
77.5,
79,
67.5,
15,
80.2,
38.2,
34,
53,
50.9,
39.1,
11.6,
74.4,
92.2,
88.3,
64.8,
54.7,
90.6,
41,
42.2,
39.5,
54.6,
30.2,
38.4,
86.3,
29.6,
34.3,
47.5,
55.8,
71.8,
56.9,
79.3,
53.5,
62.4,
54.5,
46.4,
23.1,
59.6,
51.6,
58.8,
19.1,
30.7,
4.6,
15.5,
73,
21.3,
71.2,
62.5,
49.8,
32,
57.4,
61.2,
74.6,
66.1,
34.9,
25.8,
61.8,
48.6,
33.9,
66.2,
72,
47.9,
100.5,
71.5,
70.6,
77.8,
81.3,
103.9,
57.3,
16.4,
82.9,
38,
81.3,
40.4,
16.3,
55.5,
22.1,
80,
55.1,
52.2,
49.1,
69.9,
64.8,
53.8,
65.5,
48.5,
9.9,
47,
35.4,
50.6,
22.3,
41,
29.6,
73.5,
85.2,
46.8,
88.7,
27.8,
64.3,
54.7,
50.7,
97.2,
29.5,
40.5,
47.3,
60.6,
41.1,
0.1,
63,
0,
35.3,
65.2,
98.1,
49.8,
86.1,
67.3,
73.1,
41.5,
45.1,
27.6,
16.8,
30.7,
57.7,
28.3,
40.8,
15.3,
98.5,
27.3,
45.2,
70.4,
73.8,
35,
27.5,
35.9,
62.8,
69.3,
27.1,
55.6,
97.6,
17.1,
74.8,
47.5,
42.9,
62.9,
94.3,
74.6,
81.5,
28.4,
81.4,
40.5,
78.3,
43.3,
60.9,
73.8,
39.9,
56.2,
57.6,
32.4,
14.6,
49.4,
70.1,
73.8,
18.6,
49.8,
12.3,
30.8,
96.6,
87.9,
50.2,
77,
40.4,
56.7,
72.5,
10.1,
56.6,
35.6,
40.8,
34.1,
81.3,
16.7,
78.8,
33.7,
9.3,
21,
16.5,
56,
43.8,
94.5,
57,
84.6,
81.4,
50.6,
32,
32.1,
33.2,
95.2,
14.9,
75.8,
93.3,
58.3,
52.4,
49.2,
44,
71.3,
49.3,
27.1,
58.1,
52.3,
57.6,
76.5,
77.7,
76.4,
33.7,
94.3,
72.5,
9,
87.5,
65.5,
61.8,
64.6,
40.9,
50.8,
30.3,
40,
31,
65.3,
49.4,
93.5,
61.2,
92.1,
28.5,
86.5,
61.2,
83.8,
37.7,
48.6,
25.9,
82,
56.3,
45.2,
49.8,
71.6,
73,
78.9,
69.7,
43.3,
53.8,
66.9,
80.6,
55.4,
2.4,
80.5,
4.1,
73.9,
83.2,
56.8,
23.8,
52,
59.2,
51.1,
54.6,
37.9,
60.7,
32.9,
26.6,
67.6,
71.7,
56,
59.9,
46.2,
41.3,
71.6,
31.2,
43.8,
86.5,
55,
42,
38.5,
69.2,
72.6,
79.4,
66.7,
71,
41.4,
75,
29.6,
84.8,
78.1,
54.9,
28.6,
41.1,
75.7,
12.7,
37.6,
97.1,
71.8,
38.4,
85.9,
58,
55.5,
35.9,
97.2,
59.7,
30.1,
80.7,
62,
98.3,
10.3,
51,
47.6,
81.5,
52,
67.5,
68.9,
78.8,
60.6,
76.6,
45.1,
20.2,
81.9,
49.1,
22.1,
58.7,
66.3,
34.9,
55.2,
90.1,
43.6,
40.4,
80.7,
35.2,
69,
73.2,
84.2,
13.9,
82.8,
54.1,
57.7,
59.7,
60.4,
17.2,
40.2,
47.5,
70.5,
46.4,
22,
64,
34.3,
30.1,
67.7,
43.6,
53.1,
87.7,
22.4,
68.7,
44.2,
70.7,
73.9,
85.5,
21,
61.7,
97.2,
69.2,
42.8,
79,
56.6,
64.4,
60.8,
87.6,
44.1,
95.8,
70.9,
60.7,
15.6,
39.9,
79.4,
65.6,
68.9,
78.6,
63.5,
30.4,
23.9,
63.1,
35.1,
22.1,
41,
88.9,
38.8,
62.8,
67.8,
72,
20.6,
46.6,
65.9,
33.2,
73.7,
45.5,
15.6,
69.7,
0,
15.7,
33.6,
66.6,
49.9,
31.7,
60,
49.8,
40.5,
8.4,
55.6,
79.3,
62.2,
16.3,
38.5,
57,
51.8,
18.5,
6,
90.5,
88.7,
32.7,
98.7,
43.6,
73.1,
83.3,
30,
81.2,
51.9,
30.2,
42.1,
51,
70.7,
36.9,
62.9,
68.7,
75.8,
81.4,
48.5,
105.1,
58.4,
54.4,
76.6,
75.1,
26.1,
26.7,
47.5,
89.8,
54.3,
75.6,
52.1,
92.3,
63.7,
57.5,
84.5,
16.5,
40.3,
47.1,
21.1,
29.7,
56.1,
21.4,
53,
5.9,
53.9,
45.3,
43.5,
43.3,
31.9,
53.8,
82,
97.1,
41.9,
29.8,
76.2,
84.8,
70.5,
35.4,
47,
34.3,
53.1,
71.3,
19.2,
49.2,
81,
70.8,
37.7,
35.9,
35.3,
50.4,
44,
72.1,
44.8,
56.2,
48.5,
47.2,
65.1,
50.1,
82.7,
38.8,
51.5,
76.4,
77.9,
55.8,
52.4,
24.9,
13,
98.3,
36.2,
75.5,
29.5,
84.2,
8.2,
44.6,
0,
78.2,
86.6,
67.9,
47.1,
53,
37,
60.8,
59.8,
32.7,
70.2,
21.8,
93,
76.9,
37.1,
87.1,
41.6,
46.7,
70.4,
36,
17.5,
97.5,
15.6,
81.3,
61.8,
56.5,
37,
60.7,
80,
42.7,
60.5,
64.3,
14.7,
46,
47.1,
70.2,
62.7,
42.4,
22.6,
61.2,
62.2,
78,
92.3,
11,
35.5,
44.7,
39.3,
54.4,
37.3,
74.6,
22.6,
98.2,
78.7,
82.1,
77.8,
28,
65.8,
97.2,
50.3,
68.5,
76,
85,
76.5,
23.5,
87.5,
51.4,
44.8,
57.6,
63.3,
15.2,
54,
39.3,
89.8,
35,
29.4,
106.2,
28.5,
54.4,
75,
20.3,
90.5,
65.2,
15.3,
55.7,
82.1,
21.7,
82.2,
3.4,
77.6,
64,
47,
50.5,
48.5,
47,
27.3,
57.1,
62,
51.2,
11.1,
86.6,
52.9,
51,
99,
63,
24.8,
26.2,
79.8,
42.6,
45.7,
72.6,
27.6,
61.7,
32.4,
48,
35,
87.6,
83.4,
45.2,
31,
41.3,
67.6,
60,
32.4,
82.2,
16.9,
94,
62.4,
78.1,
59.3,
70.7,
72.9,
71.6,
98.4,
65.3,
34.3,
69.5,
50,
58.2,
14.1,
51.1,
87.5,
52.8,
95.7,
37.1,
13.5,
10.8,
25.5,
99.3,
41.6,
11.8,
55.7,
32.6,
2.3,
48,
59.3,
73.6,
50.7,
21.1,
35.7,
48.5,
81.9,
85.9,
82.1,
73,
56.2,
88.8,
56.6,
81.1,
92.8,
41.2,
66.3,
71.7,
59.3,
88.6,
53.9,
33.8,
68.1,
27.5,
37.8,
65.4,
83,
14.7,
59.2,
71.5,
48.8,
9,
79.2,
81.5,
60.4,
93.3,
9.7,
62.9,
62.9,
88.2,
36.8,
61.8,
55.7,
52.3,
88.3,
74.1,
53.1,
18.8,
61.3,
48.4,
32.5,
55.5,
46,
69.8,
72.5,
57.2,
34,
38.7,
74.4,
20.3,
81.5,
33.4,
54.7,
57.2,
80.3,
29.1,
91.5,
62.2,
63.4,
34.4,
10.2,
65,
88.9,
51.3,
67.3,
52.5,
40.4,
26.9,
70,
56.5,
45.9,
19.6,
85.6,
46.7,
91.7,
54.8,
74.1,
49,
61.9,
45.7,
54.6,
45.8,
52.3,
49.7,
63,
67.1,
75.9,
41.3,
36.9,
4.7,
56.1,
10.3,
43.7,
97.2,
74,
41.5,
36.1,
93.5,
50.6,
69,
50,
77.3,
46.2,
70.5,
5,
66.7,
53,
20.4,
72.8,
58.9,
86.3,
92.2,
48,
38.5,
74.8,
87.8,
77.5,
86.3,
53.7,
72.9,
69.3,
36.8,
74,
47.5,
33.5,
45.9,
51.4,
91.4,
70,
69.2,
61.3,
65.1,
44.7,
66.4,
86.3,
6.1,
69,
16.7,
62.8,
70.7,
33.6,
60.7,
54.8,
73.2,
32.1,
58,
65.6,
65,
35.2,
92.4,
66.8,
50.4,
24.7,
27.6,
31.8,
55.2,
86.2,
79.3,
69.9,
83.9,
82.2,
35.5,
64,
82.7,
67.6,
80.5,
null,
36.3,
48,
37.9,
89.3,
66.6,
34,
41.1,
51.1,
45.4,
29.7,
50.1,
93.5,
35.7,
36.8,
42.2,
2.8,
74.2,
92.5,
95.1,
41,
16.3,
47.3,
66.5,
18.5,
68.2,
78.1,
40,
65.1,
27,
52.6,
97.4,
38.6,
66.5,
84.7,
51.9,
56.4,
32,
14.4,
60.9,
73.3,
76.9,
19.9,
60.2,
50.3,
34.5,
52.4,
81.8,
37.1,
47.7,
27.5,
90.7,
11.6,
42.7,
7.4,
64.8,
49.9,
48.1,
47.9,
82.8,
34.9,
65.3,
33.5,
49.1,
53,
49.9,
25.6,
52,
82.4,
47.7,
51.6,
98.6,
75.7,
78.8,
56.3,
16.9,
14.2,
15.4,
64.7,
78.7,
51.9,
21.6,
61.2,
17.7,
55.3,
26,
59.3,
66.7,
52.2,
1.5,
58.5,
87,
64.4,
54.7,
83.3,
73.9,
41.6,
62.9,
64.7,
11.5,
40.2,
59.8,
41.6,
91.7,
43,
50.3,
58.1,
46.3,
75.5,
69.2,
74.6,
44.2,
40.1,
63.1,
50.4,
55.8,
37.4,
72.4,
30.6,
49,
38.6,
25.3,
44.2,
7.6,
58.8,
60.6,
77,
55.8,
26,
58.8,
83.2,
83.7,
74.8,
50,
41.3,
51.8,
39.3,
83.9,
58.8,
66.1,
56.9,
49.2,
78.9,
40.8,
25,
57.6,
74.5,
49.9,
84.4,
72.3,
42.2,
79.6,
67,
49,
64.8,
42.9,
49.6,
47.6,
15.6,
82.7,
54.1,
67.9,
45.2,
29.7,
61.4,
13.3,
94.3,
48.4,
46.9,
9.9,
62.7,
49.2,
61.1,
58.7,
20.5,
47.2,
15.9,
73.8,
19,
61.8,
70,
86.1,
47.5,
0.7,
39.5,
41.2,
66.7,
68.3,
53.6,
10.2,
89.5,
49,
50.7,
22.6,
55,
64.2,
53.5,
67,
74.2,
64.7,
85,
42.4,
97.3,
61.2,
21.2,
46.2,
66.1,
78.2,
16.1,
45.8,
17.3,
49,
51,
94,
53.6,
9.6,
68.7,
64.1,
75.2,
0,
84.1,
60.6,
88.3,
53.2,
66.6,
33,
30.1,
40.9,
59.7,
32.5,
79.1,
53.2,
73.5,
70.8,
29.3,
46.1,
60.1,
96,
68,
24.2,
70.7,
47.9,
76.1,
18,
71.4,
17,
82.7,
27.4,
68,
15.1,
81.3,
84.3,
63.7,
50.6,
87.9,
26,
45.5,
9.6,
14.3,
62.7,
17.8,
7.4,
44.5,
76.9,
42.5,
57.2,
67.6,
67.5,
67.1,
4.1,
81.2,
28,
65.2,
47.5,
55.8,
19.6,
54.7,
9.9,
51.1,
50.7,
37.2,
50.1,
59.7,
70.7,
89.3,
60.1,
49.2,
91.8,
70.5,
53.5,
47.1,
11.5,
60,
76.5,
69.4,
84.2,
89,
64.5,
97,
10.1,
37.7,
53.1,
34,
41.7,
79.4,
40.9,
40,
44.1,
62.1,
35.4,
63.2,
98.5,
38.6,
25.4,
99.1,
32.5,
40.6,
13.3,
73.3,
20,
63.7,
58,
88.3,
67.1,
71.7,
74,
17.7,
56.3,
74.8,
77.8,
84.5,
40.5,
30,
0,
83.9,
45.4,
28.1,
65.1,
85.7,
20.5,
44.5,
66.4,
69.4,
88.5,
59.1,
12.3,
78.8,
50.5,
57.6,
84.7,
48.6,
56,
54.5,
29.9,
31.7,
46.8,
64.3,
42.7,
53.6,
56.5,
78.4,
34.4,
75.5,
39.8,
70.4,
99.7,
39.6,
44.9,
30.8,
8.3,
37.8,
63,
68.5,
33.2,
85.4,
66,
18.2,
61.5,
56.7,
25,
41.1,
42.4,
75,
62.9,
78,
52.2,
71.8,
49.3,
74.8,
87.6,
31.9,
70.5,
93.3,
65.8,
12.2,
64.4,
65.3,
19.8,
48.5,
50.5,
42.9,
93.3,
74.2,
15.4,
42.4,
44.8,
52.9,
40.9,
71.1,
43.1,
71.3,
31.5,
57,
95.1,
76.6,
27.4,
95.4,
16.1,
47.1,
56.6,
32.8,
59.2,
96.3,
37.7,
90.1,
5.3,
80.7,
76.5,
52.1,
14.4,
57.8,
79.6,
69.6,
25.6,
37.7,
14.7,
72.1,
78.5,
34.7,
38.1,
31,
38.3,
57.7,
20.2,
46.5,
24.8,
72.8,
98.1,
60.4,
92.2,
89.9,
64.6,
99,
55.8,
29.3,
47.9,
91.7,
69.7,
88.2,
33.9,
15.1,
75.5,
72.4,
30.5,
40.3,
88,
39.4,
20.9,
51.9,
46.1,
48.2,
62.9,
60.1,
22,
89.4,
78.8,
53.6,
71.4,
25.2,
82.2,
22.1,
30.1,
82.1,
49.5,
71.5,
69.2,
30.1,
47.4,
94.8,
72.1,
37.8,
81.5,
49.7,
73.4,
35.4,
104,
35.5,
35.6,
59.9,
69.2,
65.4,
61.2,
37.6,
49.1,
40.4,
62.7,
86.6,
67.6,
78.5,
72.8,
64.5,
36.7,
39.2,
50.9,
82.9,
88.9,
32,
80,
52.6,
9.4,
92.8,
65.1,
46.9,
54.4,
57.8,
60.4,
25.7,
30.5,
51.9,
34.1,
66.8,
18.9,
46,
36.4,
82.2,
89.3,
10.1,
44.2,
67.5,
42.3,
9.9,
86,
94.2,
62.7,
55,
52.5,
37.9,
54.9,
76.8,
59.4,
63.7,
21.5,
56.6,
32.4,
71.8,
58,
81.8,
66,
56.1,
49.7,
38.9,
73.4,
66.4,
48.7,
11.4,
7.1,
77.2,
52.7,
45.7,
60.1,
71.2,
15.2,
25.9,
44,
89,
65,
60,
12.4,
38.4,
95.3,
80.8,
81.5,
34.2,
29.5,
94,
71.3,
22.1,
17.6,
53.6,
30.1,
41.5,
82.8,
91.1,
13.1,
89.7,
35.1,
35.3,
43.2,
20.5,
70.4,
39.7,
10.3,
54.9,
49.3,
88.7,
43.7,
47.7,
74.9,
61.4,
44.8,
29,
47.1,
31.7,
1.9,
34,
86.4,
82.6,
39.8,
76.3,
20.1,
42.3,
77.6,
14.7,
58.9,
52,
52,
96.9,
62.6,
27,
40.3,
69.6,
63.3,
22.4,
84.2,
41.2,
58.9,
73.3,
75.1,
68.4,
43.5,
57.6,
27.6,
24.2,
31.2,
69.1,
47.9,
40.6,
66.8,
81.8,
60.5,
76.2,
39.4,
17.3,
25.3,
43.8,
65.4,
25.9,
34.9,
81.2,
42.2,
76.9,
77.8,
25.3,
89.9,
62.4,
48.9,
52.7,
48.5,
94.2,
79,
97.9,
61.2,
64.9,
8.4,
34.8,
50,
44.4,
75.4,
81.3,
54,
52.9,
52.6,
73.4,
47.9,
85.8,
72.7,
76.2,
72.9,
38.2,
53.2,
42.9,
47.9,
69.1,
53.9,
20.2,
72.4,
40.6,
27.7,
29.1,
37.2,
48.4,
74.7,
64.5,
30.8,
8.5,
92.2,
74.4,
88,
72.7,
88.5,
87.5,
74.1,
59.6,
39.7,
46.5,
59.3,
95.7,
40.4,
47.5,
64.3,
85.1,
24.1,
61.4,
20.7,
56,
53.6,
35.9,
101,
67.2,
80.5,
73.2,
49.6,
24.8,
71.2,
66.9,
62.6,
89.9,
48.7,
83.5,
92.6,
85.3,
37.2,
73.9,
90.4,
47.4,
81.9,
69.6,
52.1,
45.2,
73.6,
85,
25.2,
80.1,
86.1,
10.5,
60,
53.1,
20.9,
51.6,
70.1,
28.9,
33.7,
42.4,
22.4,
62.9,
50.8,
34.6,
22,
66.9,
97.5,
20,
47.9,
54.5,
57.5,
44.7,
87.6,
77.6,
0,
34.8,
45.2,
66,
70.6,
45.7,
85.2,
58.8,
1.9,
72.1,
37.1,
95.2,
46.7,
36.5,
75,
38.9,
48.9,
60.3,
84,
74,
80.2,
35.8,
63.8,
60.9,
94.5,
73.2,
72.7,
76.5,
79.5,
59.5,
6.2,
35.6,
72.5,
33.8,
54.2,
76.7,
52.7,
45.8,
50.8,
56,
60.4,
35.4,
48.3,
81,
33.3,
90.8,
61.6,
23.6,
40.7,
57.1,
41.4,
43.6,
62.9,
95,
25.8,
45.3,
94.5,
78.2,
92.9,
71.7,
47,
56.6,
79.3,
68.9,
82.5,
21.8,
40.6,
38.3,
27,
16.5,
77.1,
68.6,
9.1,
58.8,
24.9,
38.7,
62,
83.8,
65.2,
59.5,
80,
23.7,
80.9,
49.3,
23.1,
18.4,
44.5,
46.7,
48.6,
82,
88.5,
84.8,
34.1,
62.4,
73.9,
67.9,
75.6,
95.9,
45.9,
57.5,
75.1,
5.3,
50.5,
78.4,
73.6,
65.6,
70.2,
57.6,
57.4,
51.5,
60.7,
66.9,
81.5,
26.5,
57.2,
79.8,
4,
69.6,
18.5,
40.8,
63.3,
66,
56.4,
56.2,
32.4,
100,
16.1,
22.5,
31.3,
39.9,
69.4,
70.2,
62.3,
70.6,
90.7,
77.1,
95.2,
25,
73.1,
53,
60.9,
58,
99.7,
49.5,
83.4,
52.1,
24.4,
64.9,
48.6,
46.4,
71.1,
34.9,
33.3,
13.5,
61,
30.1,
42.3,
97.8,
46.9,
74.3,
29,
60.2,
30.5,
49.8,
40,
22.2,
57.5,
67.1,
11,
64.4,
52.6,
25.7,
82.6,
54,
51,
89.1,
83.8,
76.7,
61.4,
39.5,
84.4,
35.9,
34,
51.9,
50.3,
34.9,
56.1,
51.5,
56.6,
23.8,
96.8,
32.9,
46.9,
40.5,
66.5,
16.4,
66.4,
47.5,
50.4,
47.8,
97.1,
57.3,
39.9,
95.5,
11.8,
98.3,
82.3,
43.5,
7.9,
86.5,
83.7,
47.2,
96.4,
39.6,
74.9,
57.8,
22.6,
24.9,
70.6,
85.9,
72.1,
98.1,
59.4,
52.8,
52.4,
41.3,
76.3,
93.9,
84.7,
60,
59.3,
35.3,
1.8,
68,
91.9,
72.8,
20.3,
71.9,
38.3,
96.3,
29.8,
51.3,
99.1,
59.9,
43,
76.1,
62.7,
69.9,
55.1,
58.3,
78,
40.6,
14.6,
48.4,
11.4,
56.1,
54.6,
46.8,
80.4,
46.6,
55.3,
80.1,
28.4,
61.9,
70.4,
56.4,
81.2,
63.5,
72.6,
76,
79.3,
38.1,
71.7,
44.9,
45.9,
43.9,
82.6,
81.2,
74.3,
36,
88.1,
81.3,
54.9,
2.7,
26,
52.4,
31.2,
51.6,
59.2,
43.2,
17.2,
51.6,
32.6,
31.2,
18.7,
98.2,
51.2,
82.9,
15.4,
57.2,
85.1,
20.7,
79.4,
38.6,
100,
53.6,
64.9,
21,
76.7,
67.6,
53.5,
80.9,
63.5,
95.4,
34.2,
11.5,
56.9,
66.2,
52.5,
48.7,
35,
23.8,
57.6,
19.9,
78.9,
20.3,
85.9,
44.3,
57.6,
87.6,
62.9,
56.7,
62.6,
29.1,
39.4,
27.6,
62,
28.9,
99.7,
52.1,
42.6,
56.1,
34.6,
72.1,
22.4,
17.7,
43.3,
58.7,
76.7,
20.3,
57.1,
67,
36.4,
19,
72.3,
70.6,
38.7,
37.7,
73.1,
52,
74.4,
40,
86.5,
59.1,
48,
76.5,
44.7,
66.7,
54.6,
49.6,
25.3,
83.8,
64.7,
34.3,
29.9,
78.7,
84.7,
72.9,
61.1,
22,
64.9,
49.5,
93.7,
91.7,
41,
42.5,
81.7,
43.8,
0,
23.3,
70.5,
3.8,
14.7,
11.1,
96.9,
9.9,
60.5,
75.2,
55.4,
77.6,
73.6,
18.6,
36.5,
41,
62.6,
73.9,
25.7,
25.5,
41.2,
68.1,
61.2,
91.1,
17.7,
40.9,
88.7,
41.1,
46.5,
56.4,
43.3,
35.8,
58.5,
26.4,
32.8,
47.2,
53,
81.8,
71.4,
49.7,
34.7,
28.7,
17.4,
43.3,
49.4,
35.1,
97.4,
73.2,
69.3,
23.8,
66.2,
6.6,
102.4,
49.6,
47.2,
95.5,
2.1,
76.9,
29.8,
89.8,
55.8,
84.4,
74.1,
43.2,
92.5,
59.5,
25,
63,
80,
60.6,
54.3,
55.9,
91.9,
52.6,
38,
54.1,
41.5,
29,
66.2,
83.7,
43.8,
89.7,
57.3,
10.1,
7.5,
18.2,
99.7,
23.9,
92.8,
61.6,
76.6,
87.1,
78.7,
59.1,
93.3,
94,
39.1,
86.2,
34.7,
83.7,
77.2,
60.8,
54.6,
60.8,
42.7,
37,
38.5,
82.5,
59.2,
23.8,
68.8,
63.4,
72.2,
10.2,
96.1,
14.4,
76.6,
11.5,
51.7,
44.1,
88,
62.8,
39.4,
62.2,
53.4,
77,
48.1,
64.8,
47,
44,
1.5,
45.6,
57.4,
66.4,
39.5,
77.2,
35.7,
77.6,
89.5,
36.5,
67.2,
84.3,
72.5,
15.9,
54.2,
27.6,
72.1,
3.5,
90.3,
87.6,
57.8,
82.3,
57.9,
66.7,
88.7,
48.9,
69.7,
66.7,
39.4,
27.6,
36.7,
65.1,
66.1,
82.6,
90.7,
43.2,
6.7,
22.8,
40.4,
78.1,
36.8,
62.2,
79.5,
55.2,
42.5,
62.3,
16.3,
94.5,
77.6,
65.2,
53.3,
54.3,
71.3,
57.1,
31.3,
61.3,
0.3,
41.2,
64.4,
1.2,
69.8,
66.5,
44.7,
68.2,
50.6,
64.4,
67.3,
41.6,
47.8,
24,
26.9,
59.1,
55.4,
55.8,
16.2,
84.8,
33.6,
20.2,
53.8,
70,
90.8,
78.5,
88.2,
26.8,
45,
82.5,
30,
12.4,
71.3,
20.9,
68.6,
15.7,
42.5,
51.8,
90.7,
31.1,
91.1,
74.1,
44,
78.3,
73.4,
94.3,
90,
80,
59.1,
83.9,
54.7,
50,
33.7,
56.7,
63.1,
8.9,
94.5,
58.1,
16.7,
75,
47.3,
32.7,
26,
70.8,
76.4,
70.4,
73.4,
27,
83.3,
49.2,
36.2,
15.2,
81.4,
64.1,
49.3,
87,
43.7,
49.7,
9.6,
71,
54.8,
66.9,
90.2,
75.3,
68.3,
49.5,
79.4,
40.6,
8.3,
62.1,
8.5,
46.9,
39.2,
46.4,
66.5,
50.3,
63.7,
32.3,
78.2,
50,
51.6,
88.8,
31.9,
92.2,
78.1,
85.5,
87.2,
36.9,
95.8,
55.9,
100.6,
2.1,
53.9,
98.9,
58.4,
70.6,
73.8,
52.9,
90.6,
21.6,
0.8,
70.2,
56,
41.7,
80,
54.9,
40.3,
9.2,
28.5,
92,
19.8,
29.2,
27,
50.8,
56,
32.9,
71.3,
55.2,
73,
83.7,
41.2,
69.1,
84.6,
3.6,
58.8,
86.8,
77,
58.5,
4.6,
55.3,
67,
57.9,
96.7,
28,
0.3,
38,
45.2,
37.7,
59,
42.7,
99.1,
48.8,
34.1,
49.4,
76,
55.1,
91.1,
36.5,
88.2,
28.9,
48.5,
56.2,
62.7,
85.2,
70.2,
16.7,
56.4,
17,
68.8,
16.9,
51.1,
33.2,
27.5,
38.4,
80,
72.3,
99.7,
81.2,
53.2,
25.5,
20.3,
78.5,
60.6,
27.5,
42.7,
46,
68.9,
20,
90.1,
68.7,
62.4,
68.1,
34.1,
49.7,
67.5,
92.5,
94.1,
68.8,
85.7,
58.7,
95.8,
52.5,
47.9,
60.1,
66.3,
53.9,
83.3,
57.4,
5.5,
48.5,
69.4,
16.2,
96.1,
33.7,
9.5,
63.2,
57.8,
45.8,
94.7,
35.3,
68.3,
84.5,
64.3,
60.7,
17.7,
28.6,
54.6,
99.9,
44.2,
49.1,
87.4,
28.7,
39.2,
28.6,
85.6,
64.5,
74.1,
95.3,
52,
61.9,
49,
14,
59.9,
49.8,
12.4,
63.7,
36.6,
53.2,
7.5,
41.9,
70.9,
85.3,
52.5,
56,
28.3,
48,
94.4,
51.8,
23.4,
47.1,
51.3,
83.6,
58.2,
41.4,
91.7,
44,
30.3,
80.2,
35.6,
12.8,
82.5,
20.7,
49,
39.2,
58.5,
40.5,
90.8,
33.1,
48.3,
39.5,
34.9,
44.9,
22.8,
67.6,
0,
34.6,
4,
88.2,
77.6,
85,
74.5,
22.2,
62.1,
67.3,
72.1,
1.3,
55.7,
25,
29.7,
54.1,
82.3,
35.4,
85.8,
15,
56.3,
102.4,
12.9,
89.9,
75.6,
43.7,
43.3,
90.2,
64.1,
24.5,
75.1,
13.7,
55,
22.3,
67,
23.6,
80.8,
21.6,
48.7,
49.1,
39.2,
50.4,
68.3,
69.9,
87.4,
41.5,
88.7,
28.5,
27,
59.5,
82.9,
46.5,
0.2,
97.3,
87.9,
86.6,
12.2,
34.4,
48.7,
56.8,
79,
66.2,
27.9,
75.2,
66.7,
71.4,
35.2,
78.9,
87.3,
60.8,
68.6,
68.2,
7.8,
80,
5.5,
34.1,
43.4,
91.3,
20.5,
60,
29.7,
96,
82,
71.3,
55,
23.3,
88.4,
46.5,
70.5,
38.5,
78.1,
18.9,
79,
53.7,
50.3,
69.7,
103.3,
20.2,
64.9,
72,
49.5,
68.3,
40.4,
38.8,
52.6,
59.7,
51.9,
28.8,
57.5,
56.5,
77.7,
89.3,
86.1,
82.9,
44.8,
60.6,
39,
34.6,
59,
45,
85,
74.5,
74.2,
45.1,
72.2,
55.1,
84,
19.5,
76.3,
79.1,
28.2,
50,
68.8,
38.4,
81.8,
51.5,
53,
73.6,
32,
24.6,
50.8,
33.5,
39.3,
57.6,
67.4,
47,
54.2,
26.3,
25,
89.8,
20.2,
31.1,
51.1,
61.3,
57.3,
78.6,
64.7,
10.7,
65.2,
72.9,
59.9,
62,
67.5,
33.2,
74.7,
18.9,
43,
77.2,
56.3,
81.7,
48.8,
38.8,
37.8,
77,
69.1,
90.3,
111.4,
85.2,
37,
8.4,
54.2,
51.6,
34.1,
61.4,
67.3,
0,
57.7,
80.4,
78,
71,
52.2,
69,
94.3,
63.3,
63,
90.1,
45.8,
74.3,
68.8,
60.5,
102.7,
53.5,
23.5,
94.4,
21.9,
69.1,
76.7,
77.3,
90.5,
75.3,
35.3,
84.9,
62.9,
56.2,
59.1,
56.8,
22.4,
80.9,
53.3,
94.3,
30.9,
43,
40.2,
60.6,
68.2,
94.1,
73.7,
31,
51.9,
45.2,
16.9,
97.8,
62.8,
40.2,
75,
99.8,
29.6,
61.3,
81.9,
42.2,
76.9,
75.9,
84.5,
78.6,
21.8,
44.8,
50,
27.8,
71.5,
81.7,
26.4,
75,
63.9,
62.3,
28.8,
43.8,
46,
77.3,
67.9,
46.9,
69.9,
45.7,
68.7,
100,
84.3,
29.8,
45.7,
92.1,
46.6,
93.1,
59.8,
57.1,
68.9,
55.7,
47.7,
60.6,
86.1,
10,
57.5,
57.8,
50.6,
51.4,
92.1,
63.6,
78.1,
37,
56,
27.7,
71.2,
89.6,
51.5,
68.9,
66.8,
14.6,
78.4,
14.3,
65.5,
48.7,
35.5,
47.3,
84,
83.5,
53.1,
27,
44,
22.3,
86.5,
46.4,
14.5,
40.5,
53.2,
81,
69.3,
81.5,
81.4,
19.5,
54.9,
66.3,
29.4,
59,
46.3,
63,
77.3,
13.6,
55.3,
54,
55.2,
92.9,
37.6,
91.1,
4.6,
81.9,
51,
30.2,
49.5,
35.5,
50.4,
67.3,
62.9,
92.5,
36.3,
78.3,
34.2,
0,
44,
87.7,
22.5,
57.3,
77.5,
71.4,
32.5,
77.1,
43,
30.1,
98.6,
42.8,
30.6,
68.8,
83.7,
70.4,
83.1,
48.7,
16.2,
64.2,
58.6,
82.9,
72.8,
51.5,
30.4,
43.7,
52.1,
16.7,
78.4,
30.3,
89.5,
87.8,
26.4,
6.7,
47.4,
80.2,
93.6,
79.6,
76.1,
62.3,
35.1,
41,
71.9,
85.7,
54.3,
84,
90.9,
41.7,
86.6,
79.7,
82.5,
66.9,
37.4,
83.5,
49.6,
2,
63.2,
83.7,
72,
94.4,
61.9,
64.1,
49.5,
99,
33.5,
30.4,
42.5,
47.7,
64.6,
47.3,
33.2,
59.1,
85.8,
86.3,
97.4,
52,
22.5,
80.6,
34.5,
91.9,
61.3,
48.2,
79,
80.7,
48.5,
31.3,
93.3,
30.6,
75.3,
59.6,
44.9,
18.6,
14.6,
51.1,
74.1,
74.8,
58.5,
56.6,
73.7,
79.3,
40.9,
90.8,
86,
91.5,
46.1,
70.5,
49,
29.5,
68.9,
98.4,
61.5,
56.1,
40.5,
63.3,
89.3,
39.9,
54.6,
94.6,
57.1,
29.3,
19,
65.7,
84,
62.2,
86.1,
41.3,
68.9,
6.1,
68.5,
66.5,
48.5,
58.7,
82.6,
97.6,
89.9,
27.6,
38.4,
61.1,
91,
57.3,
10.8,
43.8,
43.6,
34.3,
54.6,
61.4,
61.5,
94.8,
57.7,
62.9,
59.3,
56.5,
88,
83.8,
82.1,
28.7,
4.6,
77.1,
97.7,
67.6,
41.1,
46.9,
74.7,
70.6,
56.3,
17.7,
81.4,
93.1,
50.3,
98.8,
54.9,
46.3,
31.8,
58.7,
63.5,
50.3,
55.5,
21.9,
38.3,
13.1,
61.9,
79.5,
20.2,
52.6,
49.4,
66.1,
56,
19.4,
56.9,
32,
9.7,
20.2,
77.7,
19.5,
44.6,
44.7,
83.8,
24.2,
77.9,
100.5,
71.8,
42,
32.4,
31.7,
84.8,
69.4,
0,
74.3,
50.5,
64.6,
46.5,
91.4,
60.9,
84.1,
79.8,
99.7,
70.6,
51.4,
54.6,
57.2,
60.5,
52.4,
75.3,
64.5,
87.1,
72.5,
36.4,
53.5,
80,
78.8,
39.7,
21.1,
63.6,
57,
62.7,
74.9,
50,
76.3,
58.8,
50.9,
39.7,
52.4,
75.3,
86.1,
93.8,
48.9,
40.5,
15.2,
41.7,
99.5,
49.3,
10,
60.9,
43.4,
25.5,
22.8,
88.1,
96.5,
0,
80,
21.8,
62.2,
54.6,
60.2,
37.8,
52.3,
94.4,
55.3,
56.4,
32.1,
65.7,
12.8,
99.9,
43,
46.9,
88.4,
22.9,
34.9,
88.4,
94.2,
84.2,
72.2,
34.7,
100.4,
55.6,
0,
70.9,
78.8,
89,
4.7,
69.2,
34.9,
90.1,
46.8,
70.1,
78.1,
22.1,
20.7,
36.9,
93.4,
70,
52.2,
68,
23.2,
82.6,
77.1,
90.3,
68.8,
90.8,
92.7,
72.4,
31.9,
69.3,
40.1,
93.8,
96.5,
34.5,
59.3,
23.8,
13.5,
77.8,
24.9,
66.3,
64.2,
41.2,
53.8,
42.4,
24.3,
58,
66,
11.5,
43.5,
40.1,
57.5,
35.5,
88.4,
49.4,
57.7,
34.4,
65.2,
21,
25.2,
84.3,
38.6,
64.9,
55,
58.1,
67.9,
78.9,
35,
46.5,
91.4,
93.7,
78.9,
37.6,
3.8,
70.5,
55.4,
61.2,
23.3,
86,
8.7,
53.4,
63.6,
35.9,
57,
69,
79,
101.1,
63.3,
55.6,
72.7,
86.6,
89.2,
54.7,
69.5,
25.2,
33.1,
38.8,
57.3,
81,
97.1,
16.2,
37.4,
38.2,
40.7,
27.2,
83.7,
84.9,
66.1,
35.8,
32.6,
61.3,
85.5,
38.9,
52.1,
65.2,
81.9,
51,
80,
26.9,
60.2,
47.1,
91.9,
23.2,
25.7,
71.6,
45,
50.3,
38,
46.9,
67.3,
35.9,
69.4,
36.7,
56.1,
60.1,
55.2,
70.5,
78.8,
62.3,
89.1,
58.9,
54.3,
11.6,
60.6,
66.6,
78.6,
87.3,
88.5,
18.3,
80.4,
68.3,
36.4,
39.1,
79.1,
100,
58.3,
82.5,
47.2,
42.9,
12.5,
25.5,
64.2,
67,
67.9,
60,
97.6,
45,
52.2,
68.2,
19.6,
43.9,
22.6,
48.1,
46.4,
61,
47.9,
59.7,
91,
76.3,
99,
17.3,
75.5,
66,
32.1,
76.1,
36.4,
29.8,
51.4,
25.8,
46.5,
25,
83.5,
60.1,
46.3,
28.7,
80.1,
71.4,
69.4,
36.7,
8.8,
57.3,
59.8,
44.5,
51.4,
41.1,
9.4,
38.2,
61.6,
77.3,
76.9,
104.2,
50.7,
49.5,
44,
80.9,
62.5,
34.2,
51.8,
58.5,
44.5,
86.4,
42.3,
58.6,
63.7,
13.7,
89.6,
20.2,
28.6,
68,
52.1,
26.8,
65.3,
52,
51.7,
58,
69.8,
2.1,
51.4,
64.4,
86.3,
43.1,
35,
85.7,
64.1,
84,
21.3,
49.8,
86.7,
47.5,
32.4,
67.4,
33.8,
42.2,
29.8,
95.4,
58.5,
22.2,
81.4,
58.3,
83.4,
3.7,
58.8,
70.1,
83.3,
49.4,
46.8,
25.2,
55.8,
55.6,
62.2,
52.9,
3.5,
96.6,
80.9,
13.9,
68.7,
40.4,
27.3,
52,
27.5,
41,
27.9,
61.9,
67.5,
64,
76.8,
94.5,
53.4,
79.4,
83.2,
83.7,
61.3,
39.8,
41.1,
81.8,
87.6,
70.6,
22.8,
56,
46,
76,
89.1,
60,
36.4,
25.6,
60,
71.8,
52.4,
46.7,
44.2,
28.4,
72.2,
72.3,
88.2,
31.7,
1.8,
94.9,
56.3,
22.7,
66.6,
83.1,
48,
53.9,
83.8,
30.9,
75.9,
71.9,
45,
67.1,
72.9,
65.3,
73.9,
43.4,
49.4,
44.8,
35.5,
78.2,
43.5,
82,
64.1,
36.2,
79.8,
81.9,
71.6,
41.5,
0,
4.5,
58.5,
79.4,
35.5,
93.5,
59,
33.1,
27.9,
51,
92,
21.9,
42.9,
79.8,
60,
63.6,
79.5,
72.5,
76,
45.8,
77.6,
29.4,
60,
65.3,
35.1,
85.3,
67.9,
50.9,
68.9,
99.2,
67.1,
88.8,
65.9,
32.4,
39.2,
85.2,
22.2,
7.8,
30.7,
60.5,
63.5,
50,
85.9,
51.1,
56.4,
62.7,
96.3,
55.9,
60.8,
62.6,
39.4,
21.5,
70.4,
17.7,
43.5,
60.6,
37.7,
16,
67.4,
24,
64.7,
46.3,
85.7,
77.3,
92.5,
49.3,
48.7,
40.9,
49,
90.4,
60,
42.7,
49.2,
34.4,
51.6,
39.6,
47.9,
33,
18.4,
69.2,
42.3,
39.9,
3,
93.6,
67.2,
84.2,
35.5,
33.7,
37.6,
92.9,
0,
69.2,
39.5,
29.4,
93.8,
73.3,
18.5,
86.2,
45.6,
23.8,
47.3,
49.3,
54.3,
50,
65.9,
15.3,
93.7,
73.3,
38.3,
94.6,
25.9,
88.3,
87.1,
95.4,
39.5,
78.3,
94.3,
53.3,
37.3,
62,
53.8,
94.2,
63,
57.2,
49.9,
72.6,
54,
36.1,
78.2,
68.2,
44.3,
32,
22.3,
8.5,
87,
84.3,
90.6,
61.8,
36.8,
17.8,
87.7,
43.7,
59.8,
46.8,
65,
7.7,
86,
39.4,
76.8,
4.8,
44.9,
38.6,
1.2,
66.4,
71.9,
85.2,
65,
28.5,
34.2,
46,
50.7,
61.5,
95.1,
75.7,
68.1,
91.3,
55.4,
85.9,
56,
42.8,
73.9,
77,
42.9,
13.7,
57.3,
48.9,
42.7,
46.3,
83.9,
44.8,
93.4,
60.7,
52.1,
19.8,
45.8,
43.7,
43.2,
45.9,
24.5,
57.7,
48.9,
97.1,
31.1,
34.9,
41.9,
92,
3.3,
17.7,
75.5,
64.4,
99.2,
66.1,
34.8,
71.2,
71,
25.6,
42,
78.6,
45.9,
83.3,
25.5,
51.8,
44.6,
43.4,
47.6,
65.4,
65.7,
69.2,
67.3,
52.5,
72.2,
54.7,
76,
33.7,
91.8,
41.7,
72.6,
69,
38.1,
46.2,
95.4,
51.2,
87,
59.2,
70.7,
35.3,
36.4,
61.2,
9.5,
32.8,
38.1,
13.7,
58.6,
77.8,
94.5,
74.1,
18.4,
75.5,
24.1,
51.2,
34,
32.9,
36.3,
44.4,
15.8,
12.4,
51,
56.5,
24.9,
93.2,
52.5,
82.2,
40.6,
58.4,
16.3,
88.2,
64,
78.8,
34.2,
53.1,
57.1,
58.5,
100.1,
69.3,
70.3,
5.2,
47.5,
72.7,
26.7,
43.6,
20.9,
34,
88.7,
28.9,
62,
68.2,
53.4,
60.4,
58,
60.6,
92.6,
81.3,
17.8,
17.2,
40.8,
76,
81.2,
68.5,
70.8,
36.8,
15.6,
63,
79.9,
36.5,
57.3,
37.6,
53.8,
36,
84,
0.6,
19.6,
46,
49.7,
57.6,
41.6,
86.9,
66,
44.7,
78,
90.9,
52.7,
61,
58.6,
74,
62.9,
71.3,
81.8,
51.5,
88.2,
42.5,
87,
49.1,
59.8,
9.2,
36.9,
69.8,
14,
31,
87,
64.7,
32.6,
49.5,
57.7,
78.5,
73.6,
49.7,
100.6,
25.9,
51.5,
37.2,
78.8,
60.6,
78.1,
45.5,
51.3,
92.5,
47.3,
81.8,
52.5,
110.4,
73.5,
97.3,
47.8,
61.6,
93.9,
21.6,
25.8,
60.3,
70.6,
61,
88.5,
36,
66,
9.2,
67.7,
58,
62.7,
56.4,
27.3,
60.6,
40.1,
40.3,
65.7,
54.5,
0,
101.1,
11.1,
47.9,
83.2,
65.9,
74.5,
76.5,
43.4,
35.7,
91.5,
74.4,
88,
6.7,
87.4,
95.1,
52,
47.3,
62.4,
64.4,
50.2,
71,
78,
98.4,
89.5,
44.2,
81.4,
69.2,
49.4,
37.1,
94.7,
44.9,
64.6,
50.4,
72.1,
94.7,
87.2,
79.3,
6.2,
70.6,
33.8,
12.1,
62.4,
81.9,
72.1,
68.2,
34.2,
56,
26.8,
88.3,
50.5,
79,
48.6,
79.3,
29.3,
68.7,
38,
24.1,
50,
62.7,
58.7,
42.7,
48.4,
57.9,
48.1,
79.2,
90.8,
49.3,
56.1,
24.8,
63.2,
54.1,
71.2,
62.7,
57.8,
95.4,
61.5,
62.6,
87.9,
68,
27.4,
67.4,
71.5,
99.6,
59.5,
68,
15.6,
44.7,
65.4,
31.8,
51.4,
77.5,
66.2,
31,
74.6,
83.4,
33,
73.8,
73.4,
43.2,
17,
72.1,
34.1,
33.5,
60.2,
45.9,
41.8,
38.7,
7.5,
44.8,
33.3,
89.1,
27,
53.8,
54.9,
46.6,
78.4,
28.9,
49,
61.7,
58.5,
83.6,
60.4,
43.1,
17.9,
88.3,
41.5,
42.6,
49.5,
89.4,
83.4,
41.9,
48.8,
66.5,
36.2,
96.2,
34,
33.1,
86.7,
57.8,
28.4,
49.9,
44.8,
51.5,
51.2,
63,
86.7,
92.9,
71.2,
17,
61.6,
56.1,
13.2,
27.8,
80.3,
64.9,
52.1,
69.7,
93.2,
10.5,
51,
77.9,
75.5,
3.6,
76.6,
81.2,
43.1,
45.4,
51.8,
67.9,
74.4,
44.5,
40.7,
60.9,
83.4,
57.1,
61.9,
68.2,
47.6,
89.7,
78.2,
50.5,
63.5,
48.2,
0,
62.3,
57.8,
78.6,
62.2,
27.1,
104.6,
86.5,
38.6,
38,
71.7,
93.3,
47.7,
88.8,
79.6,
57,
35.3,
75.3,
0,
63.8,
89.1,
56,
30.9,
55.2,
88.5,
94.8,
83.3,
41.1,
79.7,
48.5,
33.5,
41.9,
61.5,
29.6,
82.6,
48.8,
36.6,
90,
72.8,
46,
76.3,
67.6,
49.7,
31.3,
71,
33,
73,
58.5,
81.7,
39.1,
57.3,
17.3,
25.1,
44.9,
50.3,
77.2,
10.9,
52.8,
48.8,
36.7,
10.6,
61,
78,
41.2,
42,
91.5,
81.6,
31.8,
73.6,
26.5,
80.1,
62.6,
101.7,
4.3,
72.4,
1.5,
43.4,
45,
74.4,
64.3,
55.4,
64.3,
82.4,
51.2,
59.2,
71.2,
17.9,
77.2,
6.1,
75.6,
67.8,
49.8,
37.4,
79,
72.3,
58.3,
58.4,
13.8,
40.3,
59,
29.7,
70,
45.9,
38,
55.7,
62.3,
69.2,
74.1,
42.2,
71.8,
31.3,
98,
95.6,
29.1,
49.3,
77.4,
92.6,
75.7,
74.9,
27,
70.4,
30.5,
73.7,
38.3,
44.6,
32.3,
50.9,
64.3,
14.4,
55.5,
28,
7.6,
48.9,
64,
88.1,
30.4,
79.8,
87.8,
23.1,
8.6,
76.4,
56.3,
30,
79.6,
100.2,
73.2,
84.8,
15,
85.8,
65.4,
58.5,
81.4,
18.6,
73.2,
77.1,
57.7,
73.4,
60.7,
49,
37.6,
86.3,
62.1,
44.8,
38.7,
74.9,
71,
34.3,
70.3,
58.1,
51.7,
99.1,
55,
46.8,
50.2,
67.4,
18.1,
79.4,
70.8,
28.6,
47,
83.7,
47.4,
64,
75,
87.5,
43.4,
55.2,
67.4,
47.2,
15.6,
77,
38.4,
42.5,
56.4,
68.9,
66.4,
47.4,
88.3,
64.2,
91.9,
56.6,
52,
43.3,
60.8,
57.7,
60.3,
19.3,
48.5,
0,
35.4,
2,
36.2,
30.7,
86.4,
65.1,
60.1,
40.2,
49.1,
10.5,
39.7,
38,
43.7,
76.5,
32.7,
69.4,
88.1,
20.4,
62.9,
86.3,
51.7,
48.2,
57.5,
15.8,
54,
8.1,
94.2,
74.7,
6.9,
39.4,
53.6,
81.5,
59.3,
38.4,
77.1,
89.3,
59.8,
63.8,
32.1,
42.6,
37.4,
41.2,
21,
94.9,
82.1,
38.5,
61.6,
75.3,
34.4,
4.5,
33.3,
79.1,
66.1,
39.7,
69.1,
40,
75.5,
84.2,
41.4,
72.3,
55.5,
23.9,
79.6,
28.8,
38.1,
59.8,
58.5,
86.4,
66.3,
55,
70.5,
24,
25.7,
69.6,
55.3,
45.7,
78.3,
82.4,
91.7,
45.8,
0,
66.4,
95,
30.7,
10.5,
41.6,
59.3,
34.3,
96.2,
90.2,
73.3,
72.5,
75,
53.7,
59.5,
88.1,
27.9,
21.7,
84.9,
18.2,
58.2,
76.5,
0,
77.3,
54.4,
56.5,
54.6,
66,
7.4,
51.5,
76.2,
65.1,
70.1,
49.4,
70.4,
57.2,
30.9,
43.9,
44.3,
37.7,
70.3,
14.6,
64.4,
71.8,
23,
41.7,
19.5,
57.2,
55.5,
85.3,
22.8,
79.9,
87.2,
73.1,
75.2,
22.9,
35.7,
46.8,
17.2,
80,
44.9,
43.7,
24,
79.4,
37.8,
68.5,
17.5,
41.8,
88.2,
44.8,
87.1,
60.1,
40.7,
27.9,
61.2,
90.4,
27.8,
68.6,
69.8,
64.8,
95.6,
96.7,
8.3,
60.3,
78.2,
34,
96.5,
20,
39.6,
63.2,
91.4,
65.3,
70.6,
28.8,
40,
37.3,
37.6,
101.1,
28.9,
54,
48.2,
81.7,
51.7,
56.4,
24.9,
47,
33.2,
53.9,
46.1,
69.4,
86.1,
62.1,
18.3,
5.7,
60.9,
29.1,
56,
21.9,
69.5,
75.4,
88,
28.8,
26,
19.4,
69.1,
79.1,
67.5,
97.9,
93.6,
62.7,
80.6,
10.5,
56.8,
69.8,
69.3,
54,
25.5,
77.1,
82.4,
64.3,
77.3,
24.4,
33.4,
58.7,
95.8,
67,
34.9,
74.3,
94,
64,
83.2,
36.5,
101.1,
99.3,
70.1,
69.6,
11.3,
25.8,
81,
73.1,
89.5,
102.6,
19.5,
89.5,
51.8,
46.6,
56.8,
73.4,
80.1,
89.1,
21.8,
52.7,
17.8,
25.7,
52.3,
44,
72.9,
74.6,
73.5,
26.1,
91,
52.2,
84.7,
23,
61.7,
94.5,
51.6,
34.9,
88.3,
60,
26.4,
49,
59.2,
27.5,
46,
75.5,
60.7,
41,
75.6,
17.8,
48.8,
43.3,
79.1,
74.2,
29.2,
25.1,
26,
66.9,
91.6,
79.6,
15.9,
77.6,
57.2,
18.9,
63.4,
28.3,
51.5,
76,
52.6,
59,
52.5,
45.4,
84.9,
59.6,
82,
53.3,
44.7,
45.2,
83.5,
57.9,
63.3,
62.2,
50.3,
81.9,
5.3,
73.2,
0,
48.4,
60.2,
39.1,
95.2,
67,
53.5,
83.9,
81.3,
54.8,
44.4,
62.3,
22.9,
18.8,
36.1,
24.5,
92.3,
80.6,
92,
50.5,
79.9,
37.9,
25.2,
41.7,
60.7,
68,
44.9,
43.7,
61,
25.5,
15,
26,
78.4,
58.2,
27.3,
65.2,
57.3,
76.6,
94.6,
56.1,
61.8,
86.3,
47.7,
85.5,
62.9,
55.9,
84.8,
61.8,
89,
21,
38.5,
97.8,
42.9,
26.8,
69.1,
42.2,
78.1,
86.1,
65.8,
75.2,
70.6,
42.4,
15.1,
81.6,
15.4,
39.8,
7,
55.8,
76.1,
10,
57.3,
0.5,
60.3,
50.6,
83.8,
87.7,
49.1,
72.9,
66.9,
26.7,
77.1,
45.7,
34.3,
68.6,
86.2,
20.2,
45.7,
3.4,
29.9,
22.2,
42.6,
33.5,
80,
82.9,
32.4,
89.4,
77.6,
19.4,
68.1,
84.7,
49.9,
53.7,
30.3,
61.7,
68.3,
68.3,
26.1,
16.5,
80.3,
50.3,
70.4,
65,
33,
68.3,
34.9,
89.8,
28.2,
71.7,
75.5,
35,
40.5,
43.1,
50.5,
41.9,
58.7,
84.3,
42.8,
70.2,
null,
79.6,
64.2,
51.1,
68.9,
95.3,
42.1,
7.5,
67.9,
52.4,
11.2,
86.2,
53,
77.9,
12.4,
88.2,
49.1,
27,
69.4,
99.3,
84.4,
89.3,
2.7,
21.1,
47.9,
47.8,
97.4,
88.2,
43.8,
37.7,
22.4,
15.8,
87.3,
66.2,
47.2,
13.4,
74,
98.5,
40.9,
89.2,
74.5,
23.3,
61,
39.3,
12,
27.9,
25,
74.3,
42.6,
70.9,
62.5,
48.6,
55.8,
97.6,
34,
79.3,
5.5,
52.1,
49.3,
48.3,
60.6,
80.3,
38.4,
27.4,
90.9,
33.7,
9.2,
57.7,
61.3,
73,
33.2,
44.3,
92.7,
47.2,
28.2,
31.6,
71.1,
27.7,
14.9,
42.5,
44.7,
40.6,
97.6,
56.5,
54.2,
84.5,
61.7,
62.8,
27.9,
87.5,
91.7,
65.7,
57.8,
59.9,
33.6,
56.2,
14.6,
80,
53,
18,
50.4,
18.6,
49.3,
102.2,
33.6,
98.3,
2.9,
30.2,
32.4,
0,
0.8,
76.5,
50.8,
40.3,
10.7,
45.4,
34.5,
31.6,
51.6,
45,
13.1,
66.2,
78.9,
88.6,
62.3,
60.2,
49.5,
64.4,
70.7,
79,
70,
25.7,
20.8,
89.6,
35.5,
96.6,
38.3,
96,
49.9,
16.9,
31,
52.7,
24.3,
32.7,
10.3,
75,
68.6,
95.9,
53.7,
48,
41.2,
46.4,
26.7,
25.7,
65.1,
48.1,
38.3,
28.5,
33.2,
64,
70.3,
81.1,
15.8,
43.4,
63,
27.1,
70.4,
45.4,
88.7,
50.7,
74.8,
44.3,
30.1,
73.4,
85.7,
44,
42.1,
76.8,
31.2,
85,
50.6,
37.3,
47.4,
39.8,
36.2,
26,
20.5,
26.2,
65.6,
26,
31.2,
55.3,
99.8,
69.1,
59.8,
60.6,
41.7,
32.6,
84.8,
49.3,
61.5,
83.3,
31.4,
0,
85.1,
28.5,
66.9,
39.8,
61.4,
65.3,
38.1,
39.5,
33.2,
79.9,
86.1,
31.6,
37,
57.9,
68.8,
62.1,
86.1,
70.2,
71.1,
73.9,
21.8,
52.5,
66.4,
85.2,
53.4,
27.4,
29.4,
29.5,
69.6,
57.4,
48,
22.4,
83.5,
84.8,
34.2,
28.5,
70.6,
76.7,
88.3,
60.8,
63,
66.9,
90.5,
61.1,
60.7,
86.4,
67.1,
81.5,
42.2,
13.3,
66.4,
60.2,
75,
73.3,
40.7,
25.3,
82.7,
74.9,
52.8,
27.6,
37.3,
42.7,
50.4,
49.6,
35.9,
26.4,
79.1,
53.1,
75.4,
39,
33.8,
62.9,
69.6,
58.8,
53.3,
54.1,
72.8,
79.7,
61.2,
85.4,
100,
48.4,
81.1,
11.1,
97.4,
34,
37.8,
39.9,
70.1,
25,
81.6,
26.3,
22.8,
28.7,
49.9,
73,
76.1,
57.1,
54.9,
81.3,
47.9,
87.3,
78.4,
21.3,
65.7,
34.1,
79.4,
80.5,
52.3,
49,
81.8,
73.8,
46.5,
79.3,
76.6,
55.6,
18.9,
79,
63.7,
84.8,
62.8,
54.5,
33.6,
84.7,
80,
17.7,
36.5,
17.4,
53.5,
53.6,
52.3,
47,
18.3,
53.2,
93.1,
81,
84.8,
94.4,
51.4,
25.6,
30.2,
18.2,
27.6,
24.7,
53.5,
34.9,
96.2,
47.5,
84.7,
63.2,
22,
60.2,
54.3,
93.3,
69.2,
51.7,
4.6,
75.4,
14.7,
35.7,
31.1,
36.3,
59.5,
58.6,
40.4,
43.6,
20.6,
70.7,
52.3,
53.9,
61.6,
79.6,
82,
47.9,
91.5,
36.2,
0.2,
32.2,
26,
78.4,
11.1,
67.8,
47.7,
6.3,
19.8,
72.2,
45.5,
84.9,
73.7,
10.5,
61.8,
80.2,
42.3,
69,
11.4,
53.6,
80.9,
16.9,
42.3,
60,
97.8,
99,
25.5,
47.2,
58.9,
3.7,
57.1,
75,
27.6,
94.7,
54.8,
85.1,
84.2,
32.1,
18.3,
55.6,
79.7,
82.4,
45.7,
33.2,
51.6,
51.7,
68.1,
48.2,
76.3,
81.6,
69,
30.6,
27.9,
74,
49.3,
44,
81,
29.2,
63.7,
77.2,
38.4,
60,
66.1,
95.4,
31.6,
36.1,
52.9,
34.1,
84.2,
42,
73.8,
82.3,
40.2,
15.4,
87.3,
87.7,
82.1,
41.1,
75.2,
28,
23.1,
71.6,
53.7,
67.8,
90.3,
30.2,
50.7,
43.4,
27.8,
38.9,
67.3,
53.6,
27.3,
29.6,
16.6,
52.8,
13.4,
51.4,
75.2,
25.9,
38.8,
89.8,
62.7,
59.3,
31.1,
81.6,
13.2,
18.8,
44.3,
60.6,
66,
49.9,
63,
17,
81.7,
60.6,
69,
26.1,
53.8,
36.2,
60.8,
72.3,
56.3,
84,
73.7,
79.5,
17.6,
36,
35.5,
59,
83.4,
67,
19.9,
47.5,
52.4,
81.8,
78.6,
50.9,
21.8,
70.8,
55.7,
65.1,
39.6,
33.4,
99.9,
50,
33.3,
92.6,
22.6,
83.1,
73.8,
66.5,
58.2,
55.6,
67.5,
83.2,
42.1,
85.4,
79.7,
47.1,
71.1,
55.1,
100,
28.9,
92.9,
16.9,
47.7,
101.8,
82.2,
60,
64.7,
93.2,
19.9,
33.3,
34.9,
44.5,
86.9,
72.5,
37.8,
74.5,
43.6,
40,
91,
17,
67.8,
12.2,
30.5,
32.7,
66,
70.7,
29.2,
62.3,
28.2,
80.4,
60.1,
57.2,
57.4,
43.3,
93.4,
30.9,
84.4,
54.4,
91.6,
85.8,
67.5,
81.9,
78,
48,
83.6,
85.1,
42.2,
45.3,
76.6,
43.4,
50.9,
61.1,
56,
96.6,
70.1,
23,
79.5,
67.1,
58,
58.2,
39.2,
80.3,
54,
22.2,
30.8,
50.9,
79.9,
80.1,
57,
85.6,
34.5,
71.6,
53.6,
91.7,
50.4,
88.8,
40,
87.7,
60.5,
12.1,
60.5,
74.2,
62.9,
93.8,
30.9,
38.4,
56.9,
58.1,
58.8,
67.9,
14.4,
56.7,
43.2,
9.9,
90.9,
76.9,
48.3,
51.8,
48.9,
40.4,
65.4,
20.4,
45.5,
90,
44.2,
37.6,
66,
48,
63.4,
73.9,
27.8,
61.6,
10.7,
81.3,
45.4,
84.9,
41,
57.1,
20.9,
68,
12.3,
60.9,
94.9,
95.2,
50.5,
88.7,
95.1,
81.1,
91.6,
74.4,
63,
15.7,
51,
62.7,
14.4,
18,
40.7,
35.7,
66.6,
51.5,
52.9,
88.5,
93.1,
43.3,
81.4,
57.1,
73.2,
50.7,
2.2,
63.2,
63.4,
94.9,
28.7,
2,
7.6,
69.8,
32.6,
66.6,
88.6,
69.6,
89.4,
70.3,
50.2,
53.2,
33,
27,
80.2,
32,
1.3,
44.3,
36.3,
15.6,
31.8,
91,
25.7,
74.6,
28.2,
90.8,
72,
25.2,
68.1,
50.5,
51.3,
42.9,
59.9,
61.2,
25,
56.8,
71,
66.1,
14.9,
58.7,
86.3,
59.9,
75.6,
98.6,
40.3,
50.6,
5.7,
86.4,
41.1,
51.1,
26.2,
81.4,
12.4,
65.2,
63.5,
57.2,
61.9,
23.8,
30,
28,
54.7,
39.7,
92.3,
48,
58.9,
15.9,
33.6,
61.5,
68.5,
78.7,
46.2,
75.1,
77.1,
95.4,
57.2,
89.3,
30.1,
34.1,
31.4,
65.2,
41.3,
19.3,
40.1,
57,
89.6,
35.5,
33.8,
51.5,
87.8,
39,
68.7,
67.4,
65.9,
74.1,
25.6,
50.9,
77.8,
73.5,
37.3,
71.7,
30.9,
86.3,
84.4,
65.3,
55.8,
67.2,
4.9,
41.8,
73,
46.2,
97.3,
24.6,
73,
46.1,
85.3,
12.7,
49.3,
93.1,
29.5,
60.4,
70,
73.8,
87.1,
32.4,
70.8,
24.1,
72.3,
45.8,
24.7,
24.5,
70.8,
76.5,
52.1,
92.1,
60.6,
28.4,
33.2,
99.8,
35,
32.6,
58.3,
67.5,
72.7,
66.2,
64.4,
84.2,
54.9,
2.4,
80.4,
25.7,
51.4,
48.9,
82.4,
87,
27.6,
66.9,
52.9,
46.5,
77.5,
59.2,
31.7,
46.9,
20.6,
99.2,
54,
18.9,
69.5,
52.2,
24.3,
79.3,
36.6,
98.7,
90,
72.4,
56.5,
51.6,
62.8,
49,
59.6,
37.3,
55.4,
1.4,
30.9,
22.1,
77.3,
39.7,
68.8,
83.5,
50,
74.1,
34.6,
62.4,
77.2,
82.1,
35.4,
21.9,
8.5,
62,
73.7,
85.5,
58.3,
51.7,
43.1,
48.4,
86.2,
35.5,
57.6,
61.2,
72.3,
18.4,
63.6,
36,
51.7,
70.2,
77.5,
60.2,
78.6,
85.5,
15.2,
92.7,
71.6,
91.4,
85.1,
55.5,
80.7,
72.7,
44.1,
75.3,
67.5,
37.5,
75.7,
31.7,
38.6,
59.5,
26.2,
20.6,
88.8,
72.5,
11.8,
81.8,
43.1,
51.4,
38.5,
84.3,
61.2,
21.2,
48.4,
71.5,
38.2,
52.6,
43,
73.5,
83.2,
19.1,
58.4,
81.1,
22.1,
55.3,
48.4,
5.8,
73.3,
72.9,
28.2,
83.3,
79.1,
57.9,
73,
41.4,
72.9,
57.7,
78.8,
48.5,
76.1,
98,
47.7,
55.5,
5,
44.8,
38.4,
63.8,
18.5,
37.7,
76.2,
58.8,
42.5,
47,
87.7,
37.6,
55.8,
57.1,
43.3,
69.6,
92.4,
42.2,
65.1,
29.5,
77.1,
90.4,
67.7,
56.5,
90.2,
74.8,
79.9,
98.1,
24.4,
91.3,
59.7,
65,
30.2,
79.4,
100.7,
50.4,
87.6,
85.6,
36.5,
9,
5.9,
92.9,
75,
6.5,
84,
21.1,
62.2,
45.4,
37.9,
11.8,
77.5,
84.2,
65.3,
73.1,
30.5,
74.7,
77.2,
12.1,
69.4,
63.7,
79.5,
85.5,
61.4,
63.7,
95.8,
46,
101,
79.9,
59,
86.1,
94.6,
58.2,
34.4,
62.5,
44.1,
21.3,
91.8,
27.9,
76,
70.5,
17.5,
90.5,
65.7,
68.5,
90,
64.3,
65.7,
88.3,
94,
38.1,
36,
12.2,
52.8,
20.6,
14.3,
27.6,
43.9,
73.7,
49.2,
63.6,
20.8,
34.6,
22.6,
81.7,
74.1,
61.1,
87.5,
82.8,
53.6,
61.1,
40.8,
50,
87,
69.4,
29.7,
72.8,
36.2,
77.9,
66.9,
63,
44.3,
0.7,
56.5,
57.3,
33.8,
86.4,
65.2,
44,
66.6,
74.9,
46.1,
31.8,
50,
61.2,
77.9,
93.3,
68.8,
62.6,
10.8,
49.9,
79.6,
0,
24.2,
45,
77.9,
58.6,
67.9,
84.1,
41.1,
77,
31.1,
8.2,
42.2,
73,
86.9,
22.7,
50.3,
41,
3.7,
92.9,
78.2,
56.9,
66,
75.4,
87.7,
42.9,
38.4,
69.1,
37.8,
76.6,
58.1,
73.2,
48.3,
63,
72.9,
56.3,
38.7,
51.5,
80.7,
64.3,
55.6,
24.6,
44.8,
27.4,
82.8,
30.9,
57.2,
48.6,
49.9,
50.7,
64.2,
13.4,
33.3,
86.2,
30.6,
19.8,
77.4,
59.2,
87.6,
83.9,
46,
66.6,
61.5,
39.7,
82.6,
57.5,
85.7,
39.2,
59.4,
50.1,
77.5,
58.4,
77.1,
81.6,
46.7,
73.9,
40.3,
82.1,
82.3,
6,
44.4,
46.7,
63.6,
0.2,
16.4,
13.8,
92.3,
28.9,
75.8,
70.1,
33.5,
74.4,
83,
46.7,
44.4,
29.4,
49.7,
23,
58.9,
26.5,
3.5,
45.4,
30.8,
21.5,
70.2,
48,
44,
90.4,
17.3,
58.7,
56.3,
89.8,
41.8,
69.9,
54.9,
85.2,
84.7,
39.3,
72.1,
70.8,
36.3,
72.1,
9.5,
66.6,
68,
76.8,
60.4,
50.5,
73.4,
23.1,
37.4,
44.5,
85.1,
31.5,
78.2,
19.8,
45.5,
70.5,
77.9,
91.5,
54.6,
76.2,
45.7,
72.5,
36.1,
90.1,
41.5,
49.2,
52.1,
24.9,
58.8,
39.1,
89.3,
0.5,
7.2,
68.6,
31.7,
79.7,
39.6,
76.3,
72.7,
31.1,
35,
54.1,
70.7,
53,
70.1,
79.4,
69.8,
67.1,
41.6,
82.5,
71.1,
32.6,
20.5,
71.6,
79.1,
16.3,
91.5,
45.9,
92.2,
0,
55.1,
49,
25.6,
51.7,
45,
45,
32.8,
80.2,
74.4,
31.8,
46.8,
49,
32.1,
64,
47.8,
49.1,
65.1,
65,
56.8,
44,
65.1,
70.6,
34.4,
77,
72.9,
81.5,
57.6,
48.1,
51.6,
54,
61.2,
91.4,
47.1,
33.7,
28.5,
61.2,
32.9,
46,
67.7,
88,
4.9,
88.5,
73.3,
71.4,
60,
53.1,
70.7,
95.2,
39.1,
66.4,
87.4,
53.6,
84.5,
78.9,
77.1,
54.6,
57.3,
42.9,
98.4,
55,
25.7,
46.5,
74.8,
62.2,
46.6,
31.1,
40.1,
82.6,
59.9,
38.8,
71.6,
63,
26.1,
76.6,
41.1,
17,
22.9,
57.2,
36.4,
45.9,
49.3,
69.8,
83.8,
83.3,
54.3,
73.4,
56,
35.4,
87.9,
71,
94.3,
78.6,
0,
37.7,
23.6,
85.4,
38.9,
41.2,
5.1,
50.2,
79.8,
62.7,
32.1,
73.8,
73.2,
54.2,
73.1,
87.3,
50.2,
23.8,
30.2,
74.6,
40,
70,
23.8,
76,
86.1,
50,
58.6,
71.8,
26.4,
8.9,
55.5,
69.9,
45,
74.3,
35.4,
97.7,
26.4,
27.9,
79.7,
92.8,
63.6,
0,
43,
61.1,
14.1,
62,
39.2,
74.2,
55.3,
45.1,
74,
83.9,
77.9,
69.1,
27.3,
42.8,
0,
22.8,
33,
56,
14.1,
0,
56.4,
50.7,
79.4,
67.3,
87.2,
81.7,
46.3,
64.7,
84.9,
55.2,
68.7,
38.8,
48.7,
90.8,
51.4,
63.8,
29,
47.5,
0,
96,
26.8,
54.2,
17.7,
50.5,
24.8,
73.4,
7.6,
81.6,
41.4,
30.7,
53,
28.7,
21,
20.7,
64,
38.9,
65.3,
72.3,
27.7,
73.4,
83.3,
65,
80.7,
99.8,
98.5,
86.6,
72.1,
50,
44.4,
65.7,
48.9,
51.2,
72.5,
51,
85.3,
63.5,
39.5,
54.7,
45.3,
55.7,
97,
68.3,
55.5,
73.8,
84.1,
85.1,
46.3,
26.8,
28.8,
30.8,
49.4,
47.2,
54.9,
49.2,
43.7,
71.8,
99.2,
39.3,
82.5,
66,
21.7,
35,
90.5,
75.2,
69.3,
28,
88.9,
93.3,
87.6,
99.2,
55.5,
34,
43.3,
74.2,
60.9,
50.2,
49,
60.8,
17.4,
33.6,
25.3,
57.1,
56.3,
20,
45.7,
59.1,
34.9,
3.8,
73,
54.4,
39.9,
51.4,
39.1,
82.7,
6.2,
59.3,
63,
66.5,
76.9,
28.2,
57.7,
73.7,
49.7,
21.2,
63.9,
4.1,
11.5,
22,
38.2,
63.1,
45.5,
49.9,
34.2,
18.5,
70.8,
79.9,
76.1,
39.4,
9.8,
96.3,
32.2,
67.6,
58.2,
94.2,
86.3,
31.7,
40.6,
7.8,
76.7,
63.7,
24.7,
54.9,
63.7,
66.1,
79.8,
91.2,
102.4,
56.9,
86.9,
89.3,
51.3,
76.4,
21.5,
59.5,
40.8,
58.8,
41.3,
71.1,
55.5,
79,
62.8,
34.4,
78.7,
89.6,
10.6,
41.6,
26.9,
19,
62.5,
39.4,
86.9,
82.4,
39,
69.1,
74.3,
82.4,
91.6,
81,
40.5,
78.5,
84.3,
33.4,
95.5,
23.6,
36.2,
58.3,
64.7,
49.2,
44.2,
48.2,
80.5,
64.7,
28.3,
97.2,
78.6,
96,
97.3,
56,
84.5,
34.4,
25.7,
69.9,
64.6,
52.3,
128.4,
41.2,
64.7,
69.1,
54.7,
87.7,
64.2,
94.9,
43.6,
43.3,
58.6,
57.4,
88,
45.4,
57.8,
81.2,
50.5,
77,
60.3,
9.1,
47.8,
23.5,
10.5,
68.9,
38.6,
52,
53.9,
35.1,
48.6,
88.9,
57.7,
89,
71.9,
12.1,
10.5,
63,
76.7,
13.9,
27.1,
47.1,
77,
77.6,
56.8,
54.1,
59.1,
15.1,
55.6,
64.8,
21,
48.1,
73.4,
81.7,
41.6,
12.7,
50.9,
36.3,
21.7,
57.9,
30.8,
51.8,
30.3,
46.2,
16.4,
48.1,
17,
25.2,
54.3,
20.3,
90,
48.1,
4,
89.5,
22.5,
87.4,
65.1,
17.7,
97,
60.4,
61.8,
34,
27.6,
52,
64.9,
57.2,
71.2,
33.1,
73.7,
74.8,
84.1,
72.6,
45.5,
67.1,
48.3,
55.4,
14.6,
76.7,
80.8,
47.1,
70.3,
58.8,
33.5,
29.7,
79.2,
35.7,
21,
78.4,
76.4,
69.2,
82.7,
46.3,
22.1,
51.8,
36.8,
92.9,
78.9,
88.4,
44.6,
60.7,
71.8,
28.9,
58.3,
53,
33.4,
46.6,
41,
57.4,
54.3,
70.2,
40.3,
62.8,
97,
62.5,
34.7,
54.6,
38.2,
76.2,
64,
65.2,
56.4,
90.4,
63.6,
95.3,
69.1,
76.9,
51.2,
76,
24.5,
42.3,
37.7,
61.4,
92.5,
90.8,
56,
51.3,
82.7,
62.9,
53.5,
67,
61.8,
25.8,
98.5,
40,
71.7,
82.5,
66.1,
69.7,
26.8,
49.3,
86.1,
57.3,
27.6,
16.2,
95.9,
42.8,
66,
43.3,
44.8,
64.7,
78.3,
69,
36.4,
75,
95.7,
45.1,
24.9,
50.3,
73.2,
35.9,
101.9,
98.3,
65,
71.6,
78.2,
59.2,
42.2,
56.6,
83.8,
54,
63,
44.4,
94.6,
7.2,
32.9,
44.3,
60.3,
41.2,
79.1,
97,
10.2,
71.5,
13.7,
11.3,
45.1,
41.3,
33.8,
51.2,
92.1,
49.6,
58,
55.3,
2.7,
21.5,
35.2,
58.5,
45.6,
61.4,
89.8,
64.6,
54.5,
43.2,
33.7,
51.6,
86.7,
88.4,
54.2,
16.4,
0.8,
60.5,
69.7,
21.9,
70.2,
22.3,
39.9,
74.4,
53.3,
42.1,
46.7,
22.1,
63.6,
49.9,
19.9,
22.7,
76.9,
58.4,
38.9,
43.4,
73.8,
89.8,
53.3,
92.1,
65.6,
54.4,
64.8,
56.2,
56.9,
90,
19.7,
46.6,
26.7,
26.3,
48.6,
0,
17.9,
80.6,
71.1,
63.7,
0.4,
74.1,
73.9,
50.2,
38.6,
24.2,
31.7,
35.4,
64.2,
79.6,
65,
43.9,
20.1,
50,
29.9,
16.8,
28.1,
44.5,
28.7,
33.2,
17.2,
61.5,
23.6,
30.8,
38.4,
77.1,
63.1,
87.3,
14.7,
73.7,
70,
61.8,
51.1,
56.7,
26.8,
70.7,
38.1,
55.9,
55.1,
66.5,
84,
78.4,
77.3,
80.2,
59.8,
95.8,
42.4,
58.3,
52.3,
94.5,
97.3,
73.6,
60.2,
24.3,
46.1,
79.2,
39.3,
62.4,
40.7,
null,
60.8,
27.6,
85.4,
27.8,
71,
90.6,
42.8,
89.3,
64.8,
67.8,
33.2,
83.1,
59,
39.6,
81.8,
77.2,
32.2,
62.2,
27,
38.3,
78.8,
50.8,
87.4,
73.8,
91,
41.6,
91.1,
51.4,
46.9,
55.2,
79.3,
49.8,
49.7,
82.3,
69.9,
19,
47.3,
52.5,
75.9,
62.9,
67.5,
40.2,
85.2,
90.8,
86.3,
84.7,
21.5,
51.1,
72.2,
31.9,
64,
43.5,
59.3,
100.9,
2.3,
2.5,
58.1,
45,
33.9,
31.2,
31.3,
46.5,
94.2,
58.1,
51,
52.4,
65.6,
82.5,
21.9,
62.2,
38.2,
63.9,
57,
90.2,
93.1,
54.9,
56.4,
48.2,
60.8,
50.7,
55.4,
87.3,
96.4,
66.2,
13.4,
80.6,
73,
13.7,
21.2,
55.4,
66.9,
19.6,
70.6,
42.2,
64,
67.6,
11.8,
88.6,
79.4,
57.3,
76.6,
82.1,
45.2,
85.3,
90.8,
65.7,
86.8,
24.8,
99.3,
96.2,
40.3,
55.1,
52,
44.8,
13.9,
60.6,
99,
67.2,
90,
33.8,
59.8,
68.3,
90.1,
44,
57.2,
84.7,
58.6,
61.7,
52,
47.8,
72.5,
63.9,
16.4,
35.4,
42.1,
3.1,
62.6,
59.1,
17.6,
57.2,
67.1,
35.1,
77.7,
32.2,
36.9,
78.7,
79.4,
77.5,
48.3,
80.2,
47.5,
94.7,
50.8,
37,
55.7,
45.6,
93.6,
82.8,
63,
56.3,
46.1,
35.6,
47.4,
49.7,
96.2,
2.7,
65.4,
47.5,
74,
10.9,
51.9,
88.4,
50.7,
83.7,
44.7,
31.1,
76,
58.8,
83.9,
82,
45,
24.3,
48,
35.8,
56.2,
13.9,
20.2,
52,
55.1,
30.2,
35.9,
15.9,
65.6,
96.5,
13.5,
77,
42.4,
46,
77.6,
41.4,
44.4,
50,
55.8,
87.5,
96.2,
67,
40.8,
47.1,
16.2,
45.5,
68,
19.2,
94.8,
71.1,
24.4,
48.7,
84.4,
67.4,
62.9,
69.7,
88.6,
62.4,
70.9,
44.2,
79.8,
36.6,
57.5,
56.2,
22.4,
88.7,
54.7,
66.4,
59.3,
64.3,
69.7,
86.5,
61.1,
62.2,
55,
51.9,
19.3,
92.3,
43.5,
69.9,
58.1,
89.7,
94.1,
47.5,
46.8,
83.6,
54.2,
75.2,
67.5,
51.9,
77.7,
92.9,
80.5,
19.7,
97.4,
74,
45.6,
101,
4.7,
90.7,
64.6,
40.2,
49.7,
63.1,
92.6,
3.3,
34,
79.1,
59.5,
14,
0.8,
44.3,
57.2,
68.2,
5.8,
63.3,
60.3,
49.1,
67.9,
52.5,
87.2,
0,
17.7,
46.6,
65.5,
57.4,
83.6,
3.7,
53.4,
19.3,
83.8,
38.1,
78.1,
20.5,
52.4,
29.5,
82,
74.9,
74.6,
69.6,
65.3,
45.3,
72.6,
40.3,
20,
91.7,
45.6,
7.1,
35,
53.2,
44.1,
21.9,
39.1,
68.9,
48.1,
52.9,
34.2,
19,
47.1,
37.8,
38.7,
93.5,
77,
36.1,
53.4,
37,
55.3,
42.8,
29.5,
56.8,
67.3,
0,
80.7,
46.8,
54,
72.2,
98.7,
73,
59,
73.4,
35.3,
14,
9.7,
42.9,
61.8,
38,
66.2,
97.3,
41.1,
11.6,
56,
18.3,
28.9,
6.2,
71.7,
56.3,
81.1,
45.4,
48.8,
41.3,
66.4,
53.3,
86,
26.7,
59.8,
10.9,
77.2,
41,
72.1,
71.4,
null,
88.9,
50.7,
33.6,
4.9,
47,
26.5,
92.5,
50.4,
23.7,
45.5,
71,
24.8,
94.1,
13,
90.1,
33.7,
69.6,
43.5,
71.6,
76,
63.7,
49.7,
37.4,
64.2,
21.7,
8.5,
74.7,
48.1,
17.4,
52,
43.4,
29.8,
88.1,
65.4,
28.2,
78.3,
47.8,
65.1,
95.2,
27.4,
42.9,
80.2,
38.7,
68,
6.3,
55.9,
49,
47.7,
73.9,
38.6,
6.4,
52.7,
93.3,
64.4,
44.4,
73.2,
46.4,
99.1,
84.3,
33.1,
75.3,
84.9,
44.5,
66.8,
71.6,
66.2,
84.1,
93.5,
56.3,
42.2,
23,
66.1,
48.6,
63,
44.8,
77.7,
68.1,
59.8,
93,
32.7,
91.9,
83.6,
26.5,
66.2,
31.5,
36,
62.4,
57.2,
69.4,
36.8,
39.2,
59.4,
58.8,
46.2,
29.3,
101.4,
44.5,
59,
53,
6.8,
42.1,
82.6,
76.5,
27.4,
10.4,
27.4,
93.9,
37.4,
43.4,
50.7,
67.1,
60.1,
31,
39.4,
29.1,
67,
78.1,
56.1,
67.9,
90.1,
86.9,
39.5,
88.8,
65.2,
42.2,
70,
51.7,
34.7,
81.7,
25.1,
60.2,
32.8,
27.3,
34.8,
98.5,
54.9,
30.9,
82.1,
25,
78.8,
37.2,
89,
91.2,
40.5,
54.9,
67.7,
42.4,
53.4,
46.3,
34.8,
59.1,
80.6,
67.2,
83,
87.5,
13.2,
62.4,
67.5,
45.9,
76.1,
35.9,
54.4,
73.5,
15.3,
66.5,
73.2,
68.1,
48.7,
75.7,
70,
65.6,
73.2,
62.5,
48.5,
73.8,
79.4,
65.8,
44.2,
49.3,
67.4,
80.4,
64.8,
74.3,
54,
56.5,
97.2,
25.8,
52.3,
38.3,
88.6,
46.4,
82.7,
31.4,
36.1,
84.7,
44.7,
44.6,
56.3,
14.4,
83.7,
60.8,
48.9,
34.3,
29.3,
51.9,
87.6,
16.4,
42.2,
94.9,
69.1,
57.8,
44.5,
23.5,
75.6,
77.3,
39.6,
81.4,
97.5,
36.1,
37.4,
90.6,
60.1,
81.9,
85.4,
78.7,
66.9,
1.6,
46.9,
29.3,
85.2,
70.8,
8.7,
41.2,
44.2,
71.6,
75.4,
65.8,
37.1,
0,
32.9,
29.1,
32.1,
66.1,
37.4,
36.6,
44.8,
88.1,
21.6,
95.9,
55.6,
27.7,
37.4,
68.5,
52.7,
29.7,
10.2,
97.8,
49,
36.2,
18.7,
43,
55.8,
77.8,
53.4,
64,
36,
58.2,
38,
60.5,
75.1,
36.4,
82,
80.9,
55.8,
29.3,
83.6,
87.6,
50.4,
58.4,
1.5,
69.8,
118.4,
39.9,
20.7,
12.4,
59.8,
90.6,
23,
16.2,
26.9,
52.8,
33.4,
28.6,
57.1,
66.8,
53.5,
65.1,
59.4,
49,
90.6,
29.5,
46.6,
61.5,
74.1,
15.2,
7.3,
79.5,
59.6,
42.6,
24.7,
39.5,
71.1,
90.2,
41.1,
61.7,
32.7,
56.6,
8.1,
78.6,
77,
98.2,
47.9,
37,
84.1,
62.9,
78.2,
66.5,
53.8,
62.8,
51.2,
72.2,
64.8,
14.6,
34.8,
37.5,
75.6,
46.1,
37.5,
52.3,
6.4,
16,
41.4,
35.7,
10.9,
22.3,
53.4,
78.1,
40.4,
80.6,
70.9,
46.2,
97,
26.7,
86,
48.7,
86.3,
16.9,
64,
72,
62.6,
87.6,
57.6,
14.1,
84.8,
71.4,
22.3,
83,
77.1,
61.5,
54.9,
76.4,
51,
34,
62.3,
20.9,
72.3,
33.8,
57.6,
30.8,
67.5,
93.6,
26.8,
26.2,
52,
39.2,
27.1,
64.7,
93.6,
62.6,
91.8,
86.4,
41.5,
null,
58.2,
81,
68.1,
54.8,
23.1,
32,
29.8,
86.8,
67.5,
49.5,
86.9,
86.6,
38.5,
57.5,
51.8,
51.6,
24.2,
32.2,
40,
46.1,
73.5,
61.8,
62.2,
33.9,
72.9,
69.4,
57.3,
45.2,
26.6,
43.9,
66.5,
76,
97.2,
50.4,
31.7,
21.5,
78.4,
77,
13.6,
38.8,
86.9,
57.9,
83.7,
52.4,
31.9,
22.3,
67.7,
44.8,
41.9,
46.8,
40,
54.3,
72.6,
86.9,
74.7,
62.6,
50.5,
13.3,
39.7,
26.8,
19.4,
0.7,
62,
35.9,
30.5,
75.2,
78,
80.2,
52.3,
69.7,
69.8,
69.7,
8.2,
53.3,
38.7,
56.2,
73,
94.7,
66.6,
26.1,
58.1,
51.5,
80.8,
63.4,
85.3,
60.2,
13.4,
65.1,
24.3,
46.8,
34.3,
98,
81.2,
97.8,
70.9,
87.4,
57.9,
23.8,
31.3,
61.1,
49.9,
70.6,
93.3,
73.1,
15,
36.4,
44.1,
78.8,
65.8,
30.4,
82.4,
68.5,
71,
73.6,
19.9,
52.2,
52.8,
91,
89.2,
0.8,
65.2,
82.1,
72.6,
48.3,
75.3,
82,
67.2,
33.2,
37.2,
33.9,
52.4,
46.2,
36,
53.3,
71.8,
9.3,
73.6,
50.4,
95.3,
89.2,
64,
70.3,
18.5,
81.8,
31.5,
17.4,
null,
62,
50.9,
75.9,
29,
2.8,
48.7,
83.7,
23.9,
91.4,
47.7,
28.1,
83.7,
103.9,
47.6,
10,
57.6,
69.2,
55.1,
2.6,
37,
97.3,
35.5,
97.8,
31.3,
63.2,
16.3,
84.6,
77.2,
54.4,
69.4,
80,
73,
58.9,
7.4,
70.2,
95.3,
58.6,
68.1,
76.6,
72.8,
87.7,
67.6,
46.4,
65.8,
74.4,
66,
38.5,
31.1,
50.7,
32.9,
90.8,
66.6,
69.3,
95.1,
39,
19.3,
50.3,
69.7,
83.9,
87.1,
40.5,
64.8,
59.5,
55.9,
49.1,
81,
92.8,
78.9,
82,
1.3,
49.8,
33.5,
12.1,
0.6,
78.1,
87.5,
88.9,
36.3,
85.6,
78.5,
97.7,
61,
79.4,
37.3,
77.3,
3,
24.5,
79.9,
55.2,
45.1,
42,
45.9,
46.9,
74.3,
77.6,
57.7,
11.3,
40.8,
45,
43,
5.3,
85.4,
89.9,
69.3,
69.3,
88.9,
41,
97.9,
13.7,
39.6,
47.9,
5.7,
57.6,
48.2,
71.3,
20.2,
36.2,
28.7,
42.2,
63.4,
42.5,
51.8,
66.9,
30.4,
80.1,
12.2,
65.6,
51.5,
26.5,
101.6,
72.8,
28,
59.5,
83.2,
54.1,
82.7,
85.9,
79,
51.8,
80.4,
74.7,
32.6,
88.5,
53,
91.3,
37,
64.8,
34,
49.2,
46.7,
80.2,
58.1,
60.1,
47.9,
49.9,
29.7,
100.6,
16.7,
83.2,
83.9,
51.1,
30.9,
66,
94.3,
74.6,
56.6,
21,
39.1,
91.8,
39.2,
36,
34,
83.6,
83.1,
57.4,
100.4,
45.3,
77.5,
38.8,
12,
87.2,
39.2,
85,
56,
39.8,
37.3,
84.6,
46.2,
46.2,
45.1,
35.4,
69.7,
96,
73.3,
57.6,
79,
37.7,
32.7,
59.3,
46.9,
17.4,
58.7,
71.7,
67.7,
69.9,
45.4,
79.2,
17.7,
62.7,
80.3,
19.9,
69.6,
61.6,
79.1,
60.5,
41.9,
82.1,
85.9,
78.2,
81.1,
74.6,
76.6,
17.4,
56.9,
46.5,
33.4,
33.7,
58.9,
62.5,
62.8,
84,
85.1,
47.1,
77.9,
59.3,
94.7,
19.8,
48.9,
2.4,
37.3,
65.9,
59.1,
36,
65.1,
44.8,
30.5,
65.2,
28.4,
72.6,
74.9,
30.6,
38.2,
62.9,
41.9,
67.8,
66.1,
55.4,
5.7,
41.9,
75.3,
83.1,
45.5,
66.1,
44.3,
73.6,
70.1,
81.7,
8.1,
61.2,
89.5,
79.7,
74.7,
76.8,
45.8,
71.1,
98.7,
45.3,
75.8,
41.9,
65.7,
89,
11.4,
74.2,
48.3,
68,
69.1,
42.5,
70.7,
94.1,
21.8,
68.3,
22.9,
36.2,
87.1,
69,
52.9,
51.3,
93.8,
42.6,
31.8,
62.2,
47.2,
23.9,
null,
29.6,
37.3,
60.4,
29.3,
79.7,
51.4,
35,
59.2,
82.6,
69.9,
51.3,
53.8,
39.1,
53.7,
15.7,
68.8,
62,
78.5,
71.6,
87.1,
61.4,
93.7,
31.8,
75,
84.3,
62.7,
59.1,
29.5,
38.4,
49.7,
91,
70.6,
22,
59.6,
11.7,
74,
92.4,
43.8,
39.6,
33.6,
60.1,
61.7,
28,
80.8,
72.9,
60,
66.3,
41.7,
82.8,
41.8,
57.3,
22.7,
72.6,
10,
41.6,
40.4,
91.2,
48,
37.1,
55.7,
10.4,
6.5,
41.3,
78.4,
6.4,
98.3,
98.3,
97.5,
42.2,
52,
46.7,
88.4,
99.8,
53.7,
48.8,
63.9,
62.4,
46.5,
39.8,
94.7,
25.3,
15.7,
13.8,
9.4,
65.9,
47.9,
53,
85.7,
22.2,
72.8,
32.4,
51.2,
87.4,
42,
82.8,
78.8,
58.7,
59.9,
33.5,
26.5,
12,
27.8,
37.7,
31.1,
37.6,
86.7,
70.3,
51.8,
53.6,
37.1,
77.4,
25.8,
43.9,
96.4,
73,
21,
25.7,
44.3,
60.4,
56.4,
61.4,
38.5,
56.5,
43.9,
37.6,
15.4,
11,
10.7,
17.8,
52.8,
50,
66.4,
92.8,
71.9,
85.5,
49.8,
68.3,
85.6,
68.5,
56.9,
36,
85.8,
84,
87.7,
65,
53.6,
42.2,
38.2,
37,
88.4,
39,
58.7,
54.3,
81.2,
51.9,
75.3,
39.9,
95.2,
61.9,
51.5,
58.2,
53.2,
71,
18.4,
92.6,
40.6,
40.1,
59.2,
41.8,
50.9,
87.8,
58.7,
15.7,
52.6,
68.6,
24.4,
12.8,
40.8,
82,
70.5,
48.6,
78.2,
74.4,
43.1,
65.4,
63.6,
57.4,
27.8,
66.5,
47.8,
26.1,
41.8,
90.8,
28.8,
68,
60.4,
59,
33.4,
58.3,
44.9,
97.7,
61.7,
59.6,
44.4,
68.6,
22.4,
18.3,
86.1,
69.9,
80.3,
75.7,
90.9,
39.6,
86.9,
50.7,
80.2,
46.1,
21,
71.3,
94.6,
56.4,
39.9,
68.7,
85.3,
55.3,
57.4,
66.6,
47.7,
48.5,
67.2,
92.1,
61.8,
50.8,
68.5,
72.3,
6,
52.9,
70.4,
35.4,
68.2,
80.6,
69.5,
19.4,
38.4,
81.8,
63.7,
95.3,
52.5,
70.8,
69.6,
30.5,
82.5,
67.9,
25.4,
56.7,
47.3,
55.6,
36.4,
79.6,
24.2,
98.3,
94,
34.3,
91.7,
62.9,
43.4,
46,
64,
80.2,
55.4,
77.3,
71.2,
50.7,
68.7,
84.4,
60,
50.2,
36.5,
15.4,
79,
79.2,
92.6,
69.5,
71.2,
52.6,
34.7,
63.3,
97.2,
65.9,
97.2,
81.7,
91.3,
75.8,
66.8,
32.5,
41.4,
19,
68.9,
62.9,
44.7,
36.3,
43.7,
56.8,
79,
62.3,
37.9,
71.8,
28.2,
95.9,
87.4,
58.9,
16.3,
84.1,
51.3,
25.7,
40.7,
27.2,
57.4,
61,
87.2,
81.6,
22.5,
13.8,
93.9,
9.1,
7.7,
35.5,
71.9,
9.1,
70.9,
35.4,
40.6,
48.8,
57.7,
60.7,
34,
21.9,
7.1,
55.9,
92.6,
24.9,
35.6,
81.2,
88.6,
11.7,
65.9,
68.7,
81.4,
77.9,
64.3,
68.4,
0.1,
51.8,
69.2,
96.6,
65.3,
38.5,
27.7,
68.1,
44.6,
29.4,
38.2,
71.2,
51.4,
59.3,
72.4,
64.9,
81,
23.1,
68,
16.4,
95.1,
60.9,
23.5,
64.3,
66.8,
78.4,
85.7,
44.8,
21.7,
18.8,
56,
48.4,
18.5,
77.5,
58.2,
33.6,
72.4,
61.3,
77.8,
83.2,
32.7,
40.4,
51,
69,
54.8,
73.8,
43.6,
38.5,
54.4,
85.9,
10.2,
77.2,
77.4,
33.9,
55.2,
56.3,
53.8,
24.2,
40.2,
95.6,
97.8,
69.1,
81.5,
32.3,
34.7,
79,
25.4,
44.2,
31.5,
51.4,
100,
64.4,
65.6,
54.8,
42.7,
53.5,
66.9,
41.4,
37.9,
37.3,
80.2,
28.5,
5.4,
2.1,
95.4,
55.8,
87.6,
35.8,
47.9,
20.6,
82.2,
94.3,
32,
68,
34.4,
41,
57.1,
66.4,
30.9,
47.5,
51,
48.4,
62.6,
64.2,
88.9,
47,
21.4,
21.8,
68.9,
42.5,
5.6,
19.5,
55,
63.3,
24.8,
21.4,
31.9,
79.3,
34.9,
77.8,
40.7,
57.9,
10.8,
50,
67.7,
48.6,
63.4,
42.1,
68.2,
99.9,
20.5,
23.3,
64.8,
72.7,
68.1,
99,
51.3,
38.9,
44.7,
0.2,
27.6,
25,
62.1,
34.2,
78,
42.1,
81.2,
98.3,
14.7,
87.6,
91,
70.2,
90.2,
49.4,
77,
51.9,
42.8,
42,
66.9,
37.3,
55.8,
41.3,
42.9,
30.3,
40,
69.4,
81.6,
23.8,
9.8,
77.6,
25.4,
36.2,
87.7,
67.1,
24.5,
56.8,
26.1,
48.5,
23.7,
46.4,
81,
45.4,
80.9,
75.4,
55.1,
69.2,
49.3,
89.7,
20.4,
12.2,
25.4,
30,
40.8,
47.3,
78.8,
89.9,
48.1,
65.4,
67.5,
62.6,
96.7,
61.6,
0.5,
15.7,
47,
45,
65.8,
47.9,
78.8,
52.9,
85.8,
34.8,
36.2,
86.4,
31.3,
42.5,
89,
65.7,
43.3,
56.2,
58.2,
70,
73.8,
20.5,
76.3,
72,
27.5,
59.6,
54.8,
75.1,
57.7,
82.8,
66,
50.3,
75.4,
52.1,
7.7,
100.2,
32.3,
29,
50.2,
37.4,
39.5,
48,
0.2,
56.4,
58.6,
69.7,
78.2,
0,
47.2,
64.5,
64.7,
71.7,
61.8,
35.6,
26.7,
65.8,
33.9,
81.5,
0.1,
36,
81.1,
66.3,
49.2,
23.7,
36.7,
62.7,
44.1,
28.6,
43.5,
21,
49.5,
34.5,
72,
67,
86.2,
95.5,
2.2,
19.5,
39.3,
24.2,
67,
13.2,
27,
85,
22,
47.5,
87.8,
52.5,
40,
39.4,
31.4,
61.1,
90.1,
17.7,
24,
48.1,
30.7,
73.6,
75,
64.6,
54.5,
45.3,
59,
3.1,
28.9,
79.8,
63.9,
16.6,
30.8,
42.1,
47,
72.1,
68.8,
91.1,
69.2,
29.5,
57.6,
29.8,
33.9,
61.1,
21.7,
61.4,
67.8,
6.3,
84,
78.1,
23.2,
59.7,
49.5,
85.2,
27.8,
75.9,
73,
58.3,
71.4,
72.6,
30.1,
42.9,
46,
30,
35.4,
61,
63,
65.4,
42.8,
94.3,
74.5,
91.7,
51,
50.8,
28.2,
40.7,
59.8,
63.2,
56.9,
42.2,
57.3,
54.3,
74.3,
73.4,
36.9,
81.4,
56.8,
91.7,
53,
50.8,
24.3,
84.7,
91.2,
52.3,
65.6,
57.4,
49.6,
61.4,
64.7,
79.7,
69.7,
43.5,
92.9,
44.8,
42.5,
37.4,
49,
44.2,
84.2,
11.8,
59.5,
69.8,
33.9,
60,
62.2,
47.6,
27.4,
101.6,
68.9,
85.1,
54.6,
60.3,
62,
47.2,
8.7,
36,
67.3,
77.3,
23.6,
48.5,
92.3,
41.3,
94.8,
27.6,
46.7,
94.3,
3.7,
54.1,
41.4,
74.5,
53,
62.7,
96.9,
89.4,
91.3,
64.9,
54.9,
36.9,
74.5,
74,
49.8,
48.5,
96.2,
67.3,
34.4,
64.2,
89.8,
86.6,
35.8,
28,
82.6,
73.7,
27.1,
69.6,
52.1,
50.9,
36,
60.7,
42.5,
44.6,
36,
30.3,
43.6,
37.4,
55.3,
32.5,
53.8,
97.5,
23.3,
80,
56,
80.4,
98.6,
99.1,
62.6,
20.6,
65.3,
70.4,
80.8,
10.3,
69.1,
0,
47.6,
65.8,
86.7,
78.9,
60.6,
13.1,
15.2,
84.6,
28.3,
52.7,
35.6,
65.2,
72,
18.6,
26.1,
50.6,
50.7,
62.7,
55.6,
83.1,
51.1,
67.7,
10.3,
47.4,
43.9,
36.3,
20,
88.1,
41.6,
69.3,
83.1,
45.8,
69,
51.3,
63.8,
8.7,
40,
52.9,
51.4,
16.6,
53.4,
15.8,
70.9,
73,
28.2,
141.1,
89.6,
61.1,
46.4,
98.7,
88.2,
62.1,
94,
53.9,
49,
79.4,
38,
23.3,
88.4,
67.3,
31.1,
58.1,
61.7,
63.7,
67.5,
67.9,
11.6,
10.2,
86.7,
40.9,
59,
47.9,
54.4,
57,
56.7,
7.5,
35.8,
57.8,
79.5,
43.8,
41.7,
40,
45.6,
73.5,
90.9,
53.8,
72.3,
52.6,
34.1,
73.7,
1.7,
20.3,
48.8,
59.3,
41,
77.9,
48,
38.2,
74,
96.3,
42.3,
82.1,
40,
61.9,
68.8,
34.8,
34,
57.1,
64.6,
76.5,
45.9,
78.4,
66.3,
65,
81.2,
50.3,
69.7,
47.2,
62.6,
67.5,
56.1,
62.2,
11.7,
84.7,
65.5,
90.8,
99.1,
43,
78.7,
50.5,
46.3,
89.5,
1.4,
35.7,
65.4,
34.9,
23.2,
44.5,
31.4,
46.1,
60.5,
22.4,
94.4,
16.7,
1.1,
7.1,
45.7,
41.4,
18.1,
8.3,
36,
36.7,
61.2,
56.3,
75.5,
66.1,
54.9,
56,
46.3,
70.8,
64.3,
65.1,
30.8,
32.2,
94.7,
57.1,
72.7,
61,
82.8,
70.6,
3.1,
77.5,
82.5,
37.4,
72,
51.7,
45.8,
96.6,
24.3,
47.4,
78.7,
62.6,
31,
63.7,
56.8,
70.7,
87.2,
47.4,
23.5,
97.1,
34.4,
45.9,
36.9,
35.6,
21.9,
40.8,
58.3,
38.6,
28.8,
99.2,
83.8,
14.9,
35.5,
24.8,
42.8,
65,
15.3,
78,
95.4,
98.8,
76.7,
60.4,
85.7,
20,
71.7,
83.8,
79.5,
47.1,
63.7,
35.3,
49.4,
52.9,
83.9,
99.3,
34.3,
56.2,
47.8,
26,
94.3,
51.8,
45,
66.6,
53,
54.2,
95,
17.4,
54.1,
96.9,
64.6,
64.6,
64.7,
36,
74.2,
83.7,
93.8,
54.2,
57.2,
67,
95.9,
64.1,
83.1,
67.6,
61.3,
2,
97.5,
91.8,
13,
64.7,
40.2,
38.4,
43.2,
77.4,
59.1,
26.6,
36.4,
55.5,
41.4,
83.7,
36.7,
73.8,
29.2,
54.8,
58.5,
76,
69.2,
80.5,
67.9,
64.4,
73.5,
30.6,
46.6,
29.7,
51.3,
71,
88.5,
53.8,
60.7,
27.6,
71,
32.9,
5.5,
12,
28.5,
57,
21,
35.7,
86.5,
39.9,
55.8,
54.5,
32.4,
59.8,
77.1,
30.5,
58.5,
44.4,
63.5,
95,
51.6,
39.6,
74.9,
10.8,
22.8,
49.5,
53.3,
33.9,
59,
64.7,
57.8,
66.8,
13.9,
38.8,
47.2,
19.2,
31,
80.3,
78.1,
56.9,
34.3,
13.8,
88.8,
80.6,
17.9,
75.2,
10.6,
37.8,
60.8,
55.1,
16.8,
15.9,
51.2,
66.4,
74.8,
51.2,
91.9,
63.8,
51.6,
81.8,
52.1,
77.5,
41.7,
58.9,
65.6,
47.1,
29.2,
32.1,
92.8,
82.3,
87.8,
47.7,
69,
15.2,
39.7,
73.5,
48.1,
91.1,
40.5,
86.9,
57.3,
36,
67.3,
86.5,
60.3,
60.4,
52.3,
72.8,
82.4,
27.8,
54,
50.6,
57.9,
76.9,
74.5,
96.6,
45.9,
23.5,
49.3,
52.9,
60.1,
71.2,
57.2,
36.8,
53.5,
49.4,
62.7,
69.7,
32.7,
25.7,
58.2,
25.9,
59,
57,
83.6,
44,
72.7,
46.9,
83.2,
60.7,
53.9,
81,
86.9,
89.3,
18.9,
35,
47.3,
49.4,
28.4,
73.3,
99,
75.9,
69.7,
50.4,
57.8,
48.9,
69,
69.8,
50,
57.4,
70.4,
56.6,
55.1,
58.7,
13.9,
42.9,
92.1,
72.8,
75,
40,
73.2,
58.1,
17.9,
46.9,
50.9,
94,
41.5,
38.1,
57.3,
81.8,
62.9,
76.5,
45.5,
70,
28.4,
60.5,
74,
92.2,
93.8,
28.5,
17.1,
38.2,
89.8,
54.5,
50.8,
80.5,
60,
62.5,
37.8,
42,
2.2,
57.7,
39.8,
84.3,
25.5,
36,
30.1,
19.5,
36.5,
97.9,
29.9,
91.4,
9,
11.2,
41.1,
33,
84,
38.7,
90.7,
56.5,
66.9,
21.8,
43.5,
67.4,
49.9,
84.3,
58,
88.7,
51.3,
57.1,
11.9,
93.9,
44.9,
79.7,
3.2,
37,
37.7,
97.2,
87.4,
65.1,
60.3,
74.3,
34.5,
39,
13.2,
25.5,
37.4,
71.2,
81.2,
27.5,
78.7,
63.4,
63.1,
32,
69.3,
12.1,
65.7,
60.4,
71.2,
87.6,
66.3,
95,
24.8,
31.5,
89.8,
99.3,
39,
52.6,
80,
43.7,
59.1,
54.7,
47.8,
65.5,
39.4,
72.5,
85.5,
89.8,
72.1,
91,
46.7,
74,
61.8,
45.9,
36.3,
33.1,
1.2,
3.3,
14.1,
51.1,
63.2,
22.3,
35.8,
58.1,
92.7,
74.2,
56,
34.4,
79,
5.5,
68.1,
72.5,
83.6,
75,
70.2,
60.7,
61.1,
0.2,
41.2,
95.8,
53.9,
44.6,
72.7,
29.8,
57.8,
12.6,
76.2,
28.9,
59.1,
10.5,
54.5,
58.1,
43,
75,
53.4,
95.3,
57.3,
45.1,
78.6,
87.3,
54.8,
97.2,
51.8,
74.8,
92.7,
43.8,
31.3,
50.1,
48.7,
35.7,
7.4,
36.3,
66.8,
67.6,
46.7,
92.7,
27.6,
48.1,
9,
71.4,
90.7,
92.9,
75.9,
68.2,
68.7,
74.5,
47.5,
35.1,
17.7,
8.6,
0,
65.3,
45.1,
44.8,
69.2,
70.6,
48.5,
57.8,
52,
17.8,
92.3,
46.5,
44.4,
53.6,
49.9,
49.2,
66.7,
31.5,
29.4,
40,
52.4,
81.1,
23.9,
11.9,
25.5,
10.7,
59.3,
64.3,
26.8,
90.9,
51.9,
35.3,
58.7,
78.2,
66.2,
10.4,
77.5,
102.8,
56.2,
58.1,
9,
43.9,
26,
85,
34.1,
66.2,
61.6,
68,
44.8,
37.1,
73.7,
64.1,
75.3,
23.1,
14.9,
34.7,
51.5,
34.1,
38.2,
66.8,
56.1,
75,
63,
6.3,
39.5,
52.9,
32.7,
27.9,
84.4,
87.6,
39.5,
67.7,
64.4,
60.6,
79.8,
54.2,
62.9,
97.7,
71.3,
64.4,
18.4,
61.4,
38.2,
39.5,
58.3,
62.6,
51.7,
51.2,
97.8,
63.2,
57.8,
46.4,
38.4,
90.3,
68.9,
92.9,
88.9,
73,
21.6,
56.5,
63.4,
26.2,
70.3,
97.5,
81.3,
4.4,
25.8,
70.4,
23.8,
44.8,
19.9,
32.5,
65.5,
23.6,
4.4,
37.2,
83.2,
46.7,
54.4,
73.3,
65.6,
48.6,
57.4,
46.5,
60.4,
76.6,
64,
52.4,
61.2,
24.9,
86.5,
25,
97.1,
49.3,
81.3,
27.7,
23.2,
53.9,
41,
30.1,
5.6,
33.9,
70.3,
56,
64,
56.6,
71.2,
27,
39.9,
71.5,
30.4,
67.5,
53.9,
44.1,
48.8,
73.2,
47.5,
86.7,
56.4,
83.2,
28,
47.7,
14.4,
40.1,
55.3,
97.9,
36.1,
49.1,
40.5,
43.5,
44.3,
62.1,
83.1,
18.6,
22.1,
64.1,
60.7,
88,
59,
43.1,
35.4,
86.6,
73.1,
47.4,
94.2,
7.2,
71,
57.4,
33,
82.1,
38.8,
31.3,
77.8,
62.9,
34,
74.7,
84.6,
34.9,
79.4,
52.4,
32.3,
75,
10.7,
80.9,
20.5,
81.7,
56.1,
92.8,
63,
98.9,
62.6,
86,
46.4,
69.9,
48.8,
87.2,
51.8,
67.2,
32.9,
38.3,
81.5,
56.2,
77.9,
32.4,
66.7,
86.9,
41.5,
12,
59.6,
28.2,
57,
48.3,
56,
96.4,
31.8,
72,
93,
90.8,
35.6,
33.1,
75.2,
58.5,
47.3,
57.8,
60.1,
62.2,
57.2,
31.9,
88.6,
60.8,
82.6,
53.6,
99.1,
41.1,
90,
44.5,
68.1,
19.1,
90.4,
80.7,
58.9,
13.6,
16.3,
68.5,
92.8,
35.6,
68,
69.1,
19.7,
0,
91,
79.6,
19.3,
20,
81.8,
67.7,
62.7,
33,
55,
14.7,
55.8,
81.5,
11.9,
49,
47.8,
59,
87.1,
49.6,
35.7,
40.3,
49,
58.7,
78.9,
9.2,
54.8,
47.4,
50.1,
43.5,
72.2,
14.4,
69.3,
31.7,
44.1,
52.7,
55.3,
57.6,
19.1,
31.8,
46.6,
21,
22,
68.4,
16.1,
72,
31.7,
86.2,
81.3,
80.7,
45.1,
46,
70.1,
51.4,
48.4,
30.6,
77.8,
69.7,
88.5,
47.7,
81.9,
15.2,
35.6,
92.9,
48.1,
81.3,
67.2,
25.1,
41.1,
55.1,
24.5,
42.1,
69.6,
55.4,
40.2,
60.1,
35.6,
91,
97.7,
29.7,
84.8,
23.9,
68.6,
27.3,
19.3,
44.8,
98.5,
70.4,
84.5,
70,
94.1,
36.6,
43,
43.3,
49.7,
55,
43.6,
30.7,
84.1,
20,
53.1,
83.9,
94.8,
86.8,
69.3,
81.3,
47.8,
64,
43.1,
68.2,
44.4,
60.1,
10.9,
58,
52.1,
11.6,
52,
58.6,
29.4,
18.1,
96.2,
36.1,
27.9,
73.7,
75,
68.3,
24.7,
32.3,
101,
54.2,
47.5,
81.6,
77.4,
67.2,
79.1,
28.6,
92.6,
69.7,
60.7,
22.4,
87.7,
7.7,
86.9,
61.2,
93.6,
56.6,
48.7,
64.1,
80,
72.2,
44.9,
49.9,
58.9,
89,
57.1,
82.5,
32,
46.2,
64.9,
17.2,
36,
62.4,
36.2,
42.5,
33.2,
68.4,
38.8,
49,
37.8,
20.3,
46.1,
68.4,
72.6,
70.3,
17.7,
21.8,
75,
64.3,
48,
89.4,
42.7,
37.4,
43.9,
51.2,
62.1,
38.1,
97.2,
20.9,
48.4,
47.5,
76,
66.9,
53,
91.2,
34.1,
30.8,
68,
51.1,
84.8,
47.4,
38.3,
77.8,
76.4,
83.7,
83.8,
33.7,
2.3,
73,
51.6,
88.1,
55.3,
50.9,
55.7,
58.7,
89.1,
39.2,
63.3,
57,
59.9,
64.2,
47.7,
92.3,
24.6,
76.8,
18.8,
61.5,
23.7,
80.5,
78,
47,
50.5,
80.3,
79,
59.4,
94.9,
54.2,
99.6,
53.1,
0,
37.3,
51.5,
43.9,
36.7,
14.3,
31.8,
21.9,
30.2,
57.3,
55.3,
3.4,
31.1,
44,
32.5,
81.8,
54.8,
91.1,
82.3,
24.3,
51.3,
63.1,
82.9,
41,
75.2,
49.7,
60.2,
45.6,
30.1,
37.6,
91.5,
71.7,
70.9,
52.2,
85.6,
93.9,
80.3,
40.5,
81.7,
25.8,
0.3,
16.8,
17.2,
62.1,
30.6,
66,
85,
68.1,
51.2,
58.8,
101.6,
95.1,
55.5,
64.3,
93,
48.9,
59.6,
83.2,
86.9,
25,
67,
21.9,
33.6,
68.5,
63.1,
93.6,
67.4,
76.6,
29.6,
92.9,
27.2,
84.7,
67,
13.5,
58,
92.2,
71.5,
38.9,
54.4,
3.3,
58.2,
46.5,
87.9,
55.6,
82.4,
42.1,
43.7,
44.2,
83,
95,
63.5,
60.2,
51.9,
50.8,
59.7,
98.1,
41.1,
55.8,
78.7,
19.1,
7,
36.2,
93.4,
72.5,
51.6,
49,
8.2,
66.1,
36.78,
74.1,
49.8,
81.2,
41.5,
19.6,
39.2,
70.6,
42.4,
19.5,
56.9,
62.4,
56.8,
86.3,
23.3,
2.5,
30.4,
76.3,
29.8,
55,
23.6,
23.6,
62.6,
17.6,
76.7,
64.6,
9.5,
67.5,
59.7,
20.7,
48.5,
58,
11.1,
30.6,
15.1,
71,
99.7,
49.4,
38.5,
94.5,
9.5,
81.6,
40.1,
70,
70.5,
63.6,
53.9,
58.8,
15.2,
62.3,
62.6,
64.1,
60.7,
34.8,
69,
55.9,
26,
47.3,
71.9,
55,
54.7,
70,
45.5,
70.6,
25.3,
55.8,
64.6,
88,
44.3,
15.9,
20.2,
50.2,
26,
88.1,
56.6,
21.9,
9.6,
55.3,
73,
81.4,
91.4,
30.5,
43.1,
13.4,
91.5,
46.9,
3.2,
60.8,
14.6,
47.1,
33,
96.4,
88.8,
15,
61.4,
21.3,
33,
62.9,
27.6,
68.9,
40.6,
68.3,
77.8,
73.7,
55.8,
40.6,
52.6,
55.1,
33.2,
52.1,
71.1,
65.7,
63.1,
83,
44.1,
78.5,
93.5,
66.3,
101.2,
62.4,
78.8,
22.6,
36.9,
69,
67.3,
25.6,
70,
21.7,
18.4,
23.8,
26.7,
57.7,
30.9,
12.2,
86,
11.3,
41.2,
29.9,
69.9,
79.2,
86.2,
28.7,
20.7,
61.3,
41,
70.6,
63.3,
37.3,
67.9,
76.9,
20.6,
35.4,
82.4,
67.8,
89,
68.9,
70.6,
80.8,
90.6,
58.9,
87.4,
72,
26.2,
74.7,
62.8,
87.3,
47.2,
69.6,
49.7,
41.4,
65.9,
83.8,
59.5,
10,
51.9,
18.9,
34.1,
3.6,
38,
54.2,
79.3,
56.5,
34.7,
28.9,
50.7,
37.4,
26.7,
57.5,
48.6,
66.1,
10,
47.3,
75.4,
62.4,
56.1,
50.5,
50.7,
38.3,
52.4,
56.1,
58.1,
86.8,
46.4,
53.3,
40.1,
51.1,
60.9,
81.7,
0,
37.5,
45.3,
42.5,
70.8,
47,
61,
38,
35.9,
12.9,
29.3,
22.4,
76.7,
20.4,
68,
37.3,
65.8,
36.5,
76.1,
24.1,
48.6,
34.6,
34.7,
9.5,
74.2,
94.5,
10.4,
28.9,
81.2,
32,
69.7,
54.9,
32.9,
87.3,
92.4,
84.9,
66.7,
28.3,
51.7,
70.5,
77.4,
10,
41.3,
42.3,
57,
35.1,
72.8,
73.3,
62.2,
77.3,
68.9,
84.5,
65.1,
60.9,
45.9,
68.4,
59.3,
47.2,
25.5,
87.6,
77.4,
21.5,
57.6,
79.1,
32.4,
35.3,
77.9,
77.8,
59.8,
24.5,
25.3,
25,
88.1,
31.3,
44.9,
56.5,
73.4,
27.5,
80.4,
83.9,
44.4,
72.6,
46.5,
62.5,
46.5,
78.4,
36.9,
16.3,
49.1,
30.5,
91.8,
67.3,
43.9,
10.3,
25.7,
36.7,
86.7,
26.5,
93.3,
18.7,
60,
38.7,
48.8,
71.6,
22.9,
76.4,
23.1,
90.8,
37.4,
13,
1.8,
89.8,
89,
70.1,
83,
42.9,
76.7,
45.1,
83.9,
80.6,
59.2,
87,
93.2,
62.2,
48.2,
36.3,
48.1,
83.6,
81.3,
91.1,
8.8,
26.8,
110.4,
44.9,
67.7,
58.1,
92,
29.7,
73.7,
53.5,
15.4,
62.9,
91,
79.5,
42.2,
3.6,
5.3,
20.9,
33.8,
13.8,
43.1,
64.7,
57.7,
26.8,
18,
68.6,
45.7,
19.4,
59.4,
72.8,
22.8,
46.7,
92.1,
80.6,
54.2,
54.9,
76.4,
49.9,
0.5,
64,
64.2,
75.6,
80.2,
79.8,
69.5,
2,
95,
44,
55.7,
47.5,
50.2,
82.8,
49.6,
43.8,
41.9,
66.2,
54.2,
45,
67.9,
59.7,
66.3,
69.4,
33.9,
34.3,
20.8,
32.5,
19.2,
0,
54.2,
99.2,
92.7,
74,
54.4,
43.9,
81.2,
94,
61.7,
56.6,
40.4,
22.7,
40.2,
61.2,
69.7,
63.6,
19.8,
40.2,
14.6,
72.4,
76.2,
54.8,
35,
55.7,
74.7,
2.2,
19.3,
88.8,
63.3,
50.9,
71.5,
1.7,
17.1,
99.4,
79.4,
50.4,
71,
61.8,
65.9,
35.8,
21.5,
47.7,
76.5,
94.1,
29.3,
80.6,
62,
52.6,
91.1,
78.5,
81.4,
21.3,
46.3,
44.3,
66.2,
16,
77.4,
54.5,
63.2,
10.4,
12.3,
67.2,
84.6,
50.7,
33.7,
32.8,
63.8,
41.9,
67.7,
39.4,
58.9,
29.1,
26.1,
84.3,
65,
1.2,
77.3,
67.7,
60.2,
85.7,
78.8,
63.2,
49.1,
63.8,
35.9,
47.4,
59.3,
61.9,
85.1,
77.6,
75.3,
16.9,
24.7,
46.5,
47.6,
27.6,
62,
54.4,
42.6,
38.7,
39.1,
65.9,
87.8,
65.9,
59.6,
70.5,
22.8,
61.9,
76.4,
5.9,
31.8,
26.5,
13.1,
48.5,
82.5,
52.1,
60.3,
88.2,
65.6,
62.9,
82.8,
66,
24.2,
54,
62.8,
81.3,
17.7,
32.9,
4.6,
39,
28.9,
18,
72.1,
66.1,
69.6,
83.3,
47.7,
27.3,
57.7,
72.7,
84.7,
55.8,
70.6,
74.9,
33.9,
43.8,
67.3,
42.7,
67.2,
59.7,
22,
22.9,
82,
79.6,
42.8,
15.3,
25.9,
55.8,
91.6,
22,
84.9,
48.4,
85.6,
29.5,
73.4,
80.1,
72.1,
75.9,
90.5,
22.4,
45.6,
51.8,
90.7,
53,
31.6,
54,
14.6,
87,
102.2,
60.6,
73.7,
99.5,
44.3,
91.5,
45.2,
47.2,
84.2,
93.3,
31.6,
72.9,
21.7,
68.5,
69,
44.2,
30.3,
61.2,
98.6,
46.1,
33.7,
84.4,
96.7,
24.2,
73.2,
76.1,
54.2,
56.1,
27.8,
51.2,
24.3,
74.5,
55.4,
42.1,
50.9,
113,
47,
21.8,
89.4,
63.7,
8.3,
40,
68.1,
58,
42.9,
73.4,
37.7,
86.3,
79.7,
69,
81.9,
43.1,
82.1,
96.8,
50.4,
38.2,
29.9,
48.2,
43.7,
22,
37.9,
65,
77.6,
93.6,
57.9,
44.8,
67.3,
58,
61.6,
74.5,
63.1,
97.2,
33.6,
99.7,
30.4,
19.7,
49.3,
54.5,
25,
0.9,
48.3,
3.1,
21.4,
56.6,
79.2,
30.4,
82.6,
94,
84.5,
69.2,
21.5,
48.8,
47.2,
29.3,
19.5,
91.6,
68,
77.5,
65.6,
87,
31.8,
75.8,
60.6,
42.1,
63.9,
54.5,
41.9,
52.8,
2.8,
31.9,
90.4,
97.9,
85.7,
18.1,
72.7,
70,
44.2,
94.3,
86.1,
25.9,
78.7,
56.5,
40.8,
76.9,
84.1,
69.2,
90.6,
102.7,
89.6,
37.8,
56.4,
52,
55.5,
22.6,
51,
62.9,
62.7,
75.8,
54.2,
41.6,
40.1,
26,
33.3,
13.5,
23.5,
74.3,
35.7,
97.9,
45.8,
54.3,
49,
68.4,
64.7,
15.1,
34.9,
24.3,
37.6,
69.6,
40.7,
28.7,
65.7,
0,
67.8,
58,
55,
68.2,
59,
76.9,
60.1,
35.9,
31.4,
46.9,
48.1,
54.4,
11.4,
70.3,
93.2,
85.5,
57.4,
56.5,
42,
92.8,
58.6,
70.1,
25.4,
38,
62.9,
88,
25.2,
14,
91.4,
56.1,
38.3,
76.9,
16.1,
38.8,
63.2,
52.8,
28.9,
12.4,
24.1,
66.2,
57.8,
73.3,
65.4,
41.5,
69.1,
37.8,
63.5,
54.3,
10.6,
60.2,
49.7,
7.6,
38,
57.2,
45.4,
38.6,
31.7,
94.3,
80.6,
56.6,
42.7,
69.3,
94,
70.7,
83.8,
16.4,
35.5,
15.5,
38.6,
67.1,
60.2,
94.3,
62.3,
50.5,
15.5,
33.4,
67.7,
19.2,
7,
36.5,
68.1,
59,
71.8,
72.8,
5.4,
64.6,
54.9,
46.5,
80.2,
91.9,
64.6,
5.1,
44,
20.6,
91.3,
69.9,
56.3,
55.5,
95.2,
42.8,
48.7,
80.9,
40.2,
11.6,
19.1,
20,
54.7,
26.6,
95,
80,
86.8,
58.4,
48.7,
70.7,
48.7,
46.5,
92.5,
86.6,
62.9,
79.9,
74.7,
17.8,
49,
62.9,
27.4,
84.9,
97.6,
72.6,
42.7,
73.7,
70.7,
63.8,
79.7,
66.6,
85.4,
33.9,
45.3,
68.2,
67.1,
32.1,
83.4,
66.6,
69.9,
31.7,
10.7,
68.3,
45.4,
53.6,
92.9,
74.6,
55.4,
77.8,
73.3,
51.3,
45.6,
38.9,
87.7,
66.2,
34.2,
64,
78.1,
81.9,
68.9,
71,
68.6,
43.4,
63.4,
38.7,
72.1,
27.1,
37.2,
40.5,
19.2,
119.1,
53.4,
54.3,
33.3,
93.1,
79.9,
41.7,
33.2,
17.3,
36.7,
86.3,
77.6,
60.9,
39.6,
81.2,
54.7,
51.7,
60.2,
31.2,
80.3,
82.2,
80.3,
79.1,
26.5,
67.3,
92.3,
42.4,
76.5,
67,
66.8,
39.5,
58.8,
60.4,
58.6,
29.7,
17.5,
95,
18.2,
4.8,
86.7,
41.3,
23,
66.8,
53.4,
35.9,
10.4,
16.3,
50.5,
33.5,
66,
68.4,
33.8,
75.7,
38.5,
34.7,
79.1,
86.2,
83.9,
59.2,
80,
76.2,
89.1,
52.6,
77.8,
44.7,
51.9,
81.5,
33.9,
34.4,
85.2,
35.8,
34.8,
62.3,
70.4,
79.3,
18.6,
0,
61.5,
52.9,
53.3,
35.6,
27.9,
61.5,
88.8,
37.4,
73.2,
31.4,
45.1,
56.3,
48.1,
66.8,
82.2,
29.9,
14.5,
79.4,
45.9,
45.1,
35.9,
39.3,
99.4,
47,
34.7,
30.2,
71.1,
95.3,
74.3,
31.1,
80.6,
99.3,
78.2,
52.4,
94,
32.6,
38.3,
23.1,
19,
46.6,
127.6,
20,
62.7,
75,
28.3,
49,
70.7,
17.5,
13.4,
85.9,
54,
43.6,
8.4,
39.3,
50.3,
50.1,
89.3,
63.6,
55.1,
37.6,
29.8,
99.2,
67.6,
85.7,
51.4,
20.2,
75.4,
29.9,
50.1,
88.5,
53.7,
89.7,
23.6,
70,
78,
38,
40.6,
39.8,
70.1,
37.4,
74,
37.7,
62.2,
54.6,
24.8,
37,
12.3,
72.7,
29.3,
23.5,
52.8,
20.4,
17.1,
16.1,
53.6,
42,
27.3,
31.2,
78,
72.3,
57.3,
47.9,
89.3,
77.9,
57.5,
24.7,
46,
36,
57,
76.9,
38.6,
62,
84.2,
24.5,
73.3,
86.4,
82.5,
92.7,
59.6,
34.4,
20.9,
45.2,
96.6,
77.6,
51.1,
53.3,
66,
76.2,
88.9,
80.8,
52.6,
0,
83.2,
55.2,
20.5,
41,
81.9,
64.7,
85.9,
73,
21,
65.2,
37.5,
15.6,
38.3,
86.9,
66.5,
86.9,
35.2,
75.9,
39.1,
18.7,
11.2,
47.5,
36.8,
91.7,
45.7,
33.5,
61.5,
24.6,
61.9,
43.3,
75.5,
41.2,
87.7,
16.3,
62.9,
77.3,
90.2,
63.9,
63.6,
55.8,
35.1,
66.1,
58.8,
80.2,
40.1,
13.8,
45.5,
81.9,
71.3,
61.1,
59.6,
75.8,
48.2,
27.3,
80.8,
54.3,
29.1,
34.5,
58.7,
35.4,
24.6,
58.8,
30.6,
41.7,
53,
37,
12.4,
16.2,
57.7,
39.5,
42.5,
38.5,
92.6,
3.1,
54.1,
73.1,
86.5,
8.4,
74.4,
37.8,
54,
85.6,
39,
73.1,
70.3,
69,
0.5,
47.8,
30.9,
43.4,
65.8,
81.6,
17.2,
31,
76.5,
70.1,
91.8,
56.7,
31.9,
58.6,
32.8,
33.5,
38.4,
7.9,
97.7,
24.7,
27.3,
56,
61.9,
46.8,
97.8,
45.5,
88.4,
72.4,
16.8,
63.4,
20.3,
23.5,
28,
79,
64.1,
36.7,
18,
51.4,
50.9,
83.8,
80.3,
47,
94.1,
43.3,
91.8,
90,
68.5,
74.1,
99.1,
39.9,
52.2,
62.3,
26,
75.2,
31.8,
22.4,
69,
79.9,
77.4,
57.3,
59.6,
0.9,
20.8,
65.5,
70.7,
31,
45.9,
59.6,
66.3,
43.1,
48.1,
86.1,
51.7,
90.4,
87,
30.6,
95.4,
95.5,
38,
83,
5,
71.9,
45.9,
65.2,
21.4,
71.4,
45.3,
23.8,
74.5,
48.9,
35,
73,
19.1,
98.7,
25.1,
80.8,
55.3,
34.1,
94.9,
12.8,
7.2,
60.4,
46.1,
52.3,
52.6,
46.6,
76.5,
58.9,
63.7,
36,
70.7,
43.6,
41.5,
39.2,
21,
61.8,
29.4,
39.5,
64.1,
64.4,
75.5,
72.6,
15.6,
10.2,
29.2,
78.1,
85.5,
39.3,
24.4,
90,
50.1,
85.7,
14.7,
23.9,
12.5,
29,
15.6,
9,
14.8,
80,
18.6,
76.8,
73.5,
67.3,
29.9,
91.4,
16.8,
34.8,
37.4,
25.9,
77.9,
73.7,
39.3,
45.2,
56,
22.5,
100.4,
97.4,
60.2,
91.9,
37.1,
26.1,
76.4,
19.5,
64.6,
62.6,
43.1,
55.6,
50.9,
22.3,
74.3,
56.8,
61.1,
16.7,
40.3,
42.9,
76,
30.1,
36.6,
48.9,
58.5,
47.7,
75.8,
14.9,
41.2,
18.3,
25,
84.7,
54.5,
63.8,
87.6,
67.7,
79.1,
51.7,
85.9,
9.2,
87.8,
70,
89.5,
51.8,
42.7,
54.7,
84.7,
55.5,
18.4,
41.7,
30.9,
76.3,
35.7,
49,
16.1,
72.3,
70.5,
19.2,
33,
3.1,
41.8,
38.8,
51.6,
51.9,
49.3,
75.3,
77.8,
49.4,
85.5,
5.8,
90.5,
84.3,
81.7,
70.4,
46.9,
31,
30.1,
66.9,
54.7,
72.7,
38.9,
17.5,
66.5,
47.1,
45.7,
73.1,
71,
47.6,
64.6,
53.4,
71.9,
27,
56.2,
81.4,
72.4,
31.9,
100,
35.7,
38.1,
37.3,
34.7,
67.9,
90.3,
80.4,
28.8,
12.1,
27,
5.1,
61.9,
54.7,
32.5,
61.4,
45.3,
97.8,
88.2,
96.2,
94.9,
4,
22.4,
71.1,
64.6,
93.7,
90.1,
79.1,
91.7,
46.4,
44.4,
71.9,
18.1,
59.6,
75.6,
74.3,
57.6,
98.9,
33,
71,
87.6,
72.9,
33.6,
66,
83.8,
74.5,
91.2,
39.5,
44.4,
28.5,
40.6,
27.5,
48.6,
68.6,
88.5,
43.2,
61.9,
32.7,
26.8,
48.4,
49.6,
46,
63.7,
54.3,
80.6,
69.2,
39.5,
36.2,
64.8,
52.8,
49.4,
27.6,
73.9,
19.9,
48,
31,
69.7,
39.3,
97.7,
46,
78.3,
59.5,
57.6,
56.1,
40.5,
71.4,
13.4,
40.2,
33,
42,
30,
86.9,
53.6,
68.7,
88.9,
79.7,
22.1,
40.3,
64.4,
91.8,
37.8,
39,
51.9,
32.9,
84.8,
30.7,
67.5,
45.5,
28.5,
67.9,
56.6,
0,
55.1,
72.7,
95.1,
62.9,
43.6,
10.1,
80.6,
72.8,
26.7,
73.6,
36.9,
15.1,
84.8,
39.1,
75.2,
42.1,
34.4,
30.3,
64,
74.7,
98.3,
35.3,
83.4,
81.4,
96,
97.2,
78.6,
40.6,
47.3,
68.9,
90.6,
22.3,
21.5,
31.3,
36.5,
44.6,
54.1,
81.4,
35.5,
45.6,
8.6,
28.5,
61.7,
94.9,
66.5,
90.7,
77,
71.1,
69.1,
66.8,
37.4,
70.6,
44.1,
42.3,
62,
75.4,
76.9,
39.7,
25.1,
0,
75.8,
65.1,
46,
37.3,
54.1,
58.6,
15.1,
81.2,
47.6,
28.2,
77.6,
92.9,
63.9,
79.3,
98.1,
55,
86.5,
70.7,
42.8,
54,
85.5,
83.9,
44.4,
57.6,
19.7,
14.5,
95,
37.8,
60.7,
10.9,
74.6,
92.4,
84.5,
68.8,
66.4,
62.4,
35.5,
61.4,
80.7,
49.4,
69.4,
82.2,
31.3,
43.2,
64.1,
56.1,
50.9,
49.7,
51,
96,
92.3,
70.3,
46.9,
73,
46.9,
34.5,
73.6,
54.9,
74,
23,
46.3,
70.8,
88,
70.4,
21.4,
49,
93.8,
44.2,
94.6,
4,
77.5,
87.1,
93,
68.6,
3.9,
91.9,
63.3,
20.3,
45.7,
46.2,
58.4,
68,
90.4,
34.6,
73.1,
53.9,
83.9,
36.4,
85.1,
83.5,
3.8,
52.9,
59,
32.8,
85,
54.2,
76.6,
67.1,
35.9,
42.5,
20.3,
22.2,
84.9,
56,
48.3,
77.6,
77.7,
0,
76,
74.6,
55.2,
85.9,
68.5,
39.5,
20.4,
6.6,
62.2,
81.2,
35,
22.6,
40.4,
84,
65.8,
55.1,
97.5,
76.1,
77.7,
55.2,
62.3,
44.2,
50.2,
69.3,
7.1,
13.3,
79.8,
18.3,
26.5,
60.5,
67.5,
101.6,
70.5,
13.1,
34.4,
89.6,
4.1,
65.4,
66.5,
77.6,
28.4,
86.8,
58.6,
21.3,
55.8,
81.9,
73.3,
63.3,
50.6,
54.5,
51.6,
65.8,
20.5,
98.6,
98.1,
22.1,
76.2,
64.4,
37.8,
48.5,
34.3,
46.9,
75.5,
91.9,
34.4,
41.2,
45.8,
30.4,
60.1,
18,
59.4,
44.6,
38.3,
70,
63.2,
75.1,
60.4,
35.3,
64.3,
36.8,
68.2,
57.1,
89,
71.9,
12.3,
6.2,
49.6,
84.1,
85.5,
62.9,
13.6,
49.8,
49.7,
51.9,
64.1,
71.6,
18,
6.9,
53.9,
42,
55,
77.6,
25.9,
70.4,
78.1,
90.7,
86.8,
96.8,
1.8,
94.1,
72,
96.6,
54.7,
44.8,
37.8,
78,
7.6,
75,
93.7,
33,
50.6,
35.6,
28,
28.4,
75.3,
47.8,
54,
46.4,
45.5,
10.5,
17.3,
48.7,
30.3,
38.5,
70.7,
51.2,
82.2,
89.4,
59.9,
80.3,
3.1,
75.6,
75.5,
62.9,
34,
84.4,
77.8,
29.6,
15.2,
73.6,
73.3,
47,
85,
70.7,
84.5,
79.1,
68.8,
71.9,
35.9,
22,
46.1,
72.1,
97.7,
52.5,
70.2,
22.2,
36.2,
46.9,
59.4,
40.8,
86.2,
99,
66.5,
53.1,
65.3,
56.4,
40.6,
61.2,
28.3,
79.2,
63,
42.5,
67.9,
50,
58.7,
23.8,
64.1,
69,
35.6,
77.4,
33.4,
20.5,
64.7,
47.9,
94.7,
34.7,
27.2,
25.6,
73.6,
49,
8.2,
17.5,
72,
53.6,
69.1,
41.6,
29.3,
55,
80.2,
55.9,
1.3,
69.5,
51.3,
84.2,
90.8,
69.9,
54.8,
85.8,
83.7,
78.1,
53.3,
45.2,
48.3,
65.6,
28.5,
97,
14.5,
18.9,
79,
40.2,
74.4,
83.5,
37,
43,
71.1,
62.1,
61.2,
72.5,
45.9,
79.7,
69.6,
67.2,
56.5,
59.9,
52.7,
17.5,
32.6,
79.9,
27,
38.3,
98.4,
61.8,
23.6,
67.7,
92.4,
75.8,
19.9,
50.6,
24.8,
26.8,
67.6,
44.2,
59.6,
69.6,
46,
68.5,
26.6,
50.9,
69.1,
55.6,
26.3,
90.5,
47.9,
24,
60,
45.5,
37.8,
86,
85.4,
64.8,
60.5,
58.6,
37.7,
35.8,
81.2,
74.1,
80,
41.3,
84.8,
60.8,
91.1,
30.8,
78,
49.9,
65.8,
42,
75.9,
46.6,
21.1,
29.3,
56.6,
26.7,
24.7,
74.3,
79.5,
41.7,
94.5,
85.6,
28.5,
98.1,
13.2,
39.9,
56.9,
92.5,
31.9,
75,
3.4,
62.3,
46.4,
77.6,
40.3,
49.1,
44.7,
46,
28.8,
84.8,
40.4,
55,
3.3,
73.7,
94.4,
73.6,
71.3,
41.4,
49.2,
79.3,
61.8,
43.4,
64.2,
97,
48.5,
57.2,
76.5,
50.4,
56.3,
53.9,
43.1,
16.7,
73.9,
54.4,
88.7,
92.9,
98.7,
37.4,
51.1,
33.3,
81,
18.5,
69.5,
74.4,
51,
74.9,
30,
27.7,
52.7,
90.8,
54.4,
0,
77.4,
62.7,
80.3,
71.3,
43.4,
76.9,
42.2,
72.9,
22.4,
39.1,
82.3,
9.2,
94.6,
79.4,
27.5,
59.6,
36.5,
44.6,
49.6,
68,
65.7,
null,
18.6,
32.6,
76.6,
31.4,
19.9,
78.7,
80.5,
10.2,
58.3,
24.7,
111.2,
32.9,
28.2,
42.2,
71.3,
18,
35.6,
17.2,
40.8,
81.9,
15.6,
51.7,
78.1,
11.8,
30.5,
63.9,
23.8,
49.6,
52.7,
89.2,
55.5,
53.7,
24.5,
66.6,
79.8,
40.4,
48.9,
28.6,
15.1,
48.5,
28.6,
59.9,
50.6,
80.9,
19.6,
31,
61.6,
77.2,
70.8,
19.2,
38,
97.4,
46.5,
67.2,
93.6,
25,
32.1,
42.8,
42.9,
12.2,
73,
14,
51.8,
69.1,
63.8,
32.5,
21.2,
18.3,
22.8,
14.7,
55,
50.9,
82.3,
83,
52.1,
26.6,
71.4,
64.6,
49.8,
78.2,
88.3,
86.3,
80.2,
80.2,
38.1,
47.7,
24.3,
62,
4.1,
83.5,
70.2,
54,
23.8,
72.5,
20.6,
92.3,
78.1,
51.6,
89.4,
77.3,
75.4,
52.4,
28,
24.6,
56.5,
81.8,
17.3,
48.4,
55.2,
89.3,
29.3,
23,
96.4,
50.2,
58.3,
23.5,
64.6,
97.4,
95.2,
59.5,
19.2,
7,
69.4,
40.3,
86.9,
96,
46.1,
30.6,
73.7,
35.7,
41.8,
92,
15.7,
67.9,
82.9,
37.7,
84.5,
60.8,
91.5,
56,
42.9,
46.7,
99.3,
79.8,
38.3,
93.4,
57.2,
57,
72.1,
8,
58.6,
34.5,
102.3,
74.4,
46,
93.8,
95,
73,
86.9,
74,
63.9,
47.8,
16.3,
45.6,
28.4,
67.5,
65.1,
1.4,
57.1,
48.6,
25.1,
65.6,
43.7,
67,
96.5,
74.8,
58.2,
35,
94.1,
72.6,
17.3,
24.8,
47,
51.2,
43.2,
40.3,
83.6,
41.6,
86.5,
32.4,
34.2,
49.8,
58.3,
35.8,
76.2,
32.9,
71.7,
56.2,
33,
88.4,
64.6,
18.6,
91.2,
63.5,
40.8,
57.9,
65.5,
27.9,
61.3,
10.4,
12.9,
78.8,
69,
25.9,
26.8,
59.9,
0.1,
82.1,
60.2,
51.5,
6.9,
69.1,
31.7,
96.1,
75.4,
18.8,
70.1,
90.2,
37,
39.1,
59.1,
70,
25.9,
37.8,
84.2,
46.7,
73.6,
67.1,
47.3,
57.4,
54.7,
66.2,
53.1,
91.6,
59.6,
33.6,
62.5,
13.9,
22.7,
93,
44.8,
44.7,
73.4,
43.8,
50,
87.8,
13.5,
42.4,
53,
63,
85.2,
46.3,
1.4,
54,
16.9,
41.4,
36.8,
11.6,
79.6,
57.9,
61.7,
74.2,
76.8,
56,
33.1,
79.5,
72.4,
65.2,
44.2,
54.2,
70.2,
55.3,
93.5,
50.8,
87.2,
24.7,
52.4,
46.7,
93.6,
87.9,
43,
12.9,
57.3,
54.8,
27.4,
72.5,
42.7,
66.7,
81.3,
48.2,
66.1,
30.5,
14,
54.8,
80.4,
44.3,
87.4,
22.3,
65.7,
41.5,
37.9,
81.5,
52.9,
70.7,
25.6,
65.8,
74.8,
82.1,
53,
80.8,
28.4,
56.7,
16.3,
40,
47.2,
72.1,
96.2,
56.2,
21.8,
44,
16.1,
43.7,
64.2,
80,
66.9,
15.4,
28.9,
66.6,
66,
41.8,
27.3,
64.3,
26.4,
73,
61.8,
58.7,
29,
3.6,
20.6,
45.1,
90.4,
11.7,
20.1,
39.6,
37.1,
62.6,
11.9,
54.3,
6.2,
93,
57.6,
14.6,
8.2,
78.6,
41.2,
86.5,
90.2,
69.6,
7.4,
31.5,
71,
93.6,
50.5,
45.2,
0.4,
67.1,
66.1,
78.6,
53.9,
46.6,
73.9,
62.2,
75.7,
51.4,
56,
36.9,
83,
53.6,
54,
41.5,
93.7,
48,
15.1,
22,
87.4,
98.1,
60.7,
93,
94.2,
76.6,
19.1,
50.8,
32.3,
79.9,
62.3,
74.2,
9.2,
42.7,
82.9,
61,
88.8,
73.7,
60.4,
19.5,
68.1,
36.8,
57.1,
7.1,
7.6,
84,
66.4,
45.3,
81.5,
66.5,
60.6,
32.9,
85.8,
49.9,
78.4,
39.5,
44,
15,
76.6,
80.6,
68.4,
19.4,
75,
48.3,
46.6,
19,
35.4,
58.4,
75.3,
56.4,
79.6,
93.1,
48.5,
68.4,
86,
64.9,
55.1,
78.6,
76.8,
92.3,
74.5,
77.4,
13.4,
62.4,
77.2,
51.7,
67,
69.3,
51.7,
57.6,
98.6,
6.9,
78.1,
38.4,
86,
26.3,
51.2,
62,
92.4,
90.6,
77,
47.7,
34.6,
40.7,
93.8,
49.9,
85.5,
66.3,
76,
55.4,
68.6,
57.5,
21,
37.9,
78.4,
70,
44.5,
41.3,
49.4,
77.4,
63.9,
40,
38.8,
52.2,
62.2,
56.2,
62,
3,
67.4,
88,
71.8,
9.9,
62.3,
76,
25.5,
86.2,
76.1,
20.7,
0,
52.8,
50.3,
32.8,
84.9,
63.6,
43.4,
57.3,
72.1,
71.6,
26.1,
50.6,
82.5,
46.8,
72.9,
48.8,
75.8,
94.9,
92.3,
34,
76.6,
50.9,
67.8,
52.6,
71.1,
49.9,
74.9,
46.4,
95,
23.4,
76.5,
43.7,
44.3,
43.7,
70,
51.1,
75.6,
62.2,
86.7,
7.6,
32.5,
50.5,
41.5,
45.9,
80.9,
88.1,
59.8,
78.9,
88.5,
80,
56.8,
75.8,
89.9,
34.7,
53.4,
44.9,
85.8,
80.4,
58.7,
29.7,
18.6,
23.8,
72,
79.3,
43.7,
38.3,
67.6,
46.5,
95.2,
89,
13.5,
66.9,
0,
27.8,
83,
24.3,
5,
76.1,
77.3,
43.9,
83.1,
67.7,
69.7,
38.7,
95.4,
63.6,
13.4,
66.5,
25.2,
35.3,
38,
30.9,
63.2,
47.6,
40.7,
27.4,
96,
30,
39.4,
72.2,
32.4,
10.7,
61,
54.5,
40.5,
86.3,
58.9,
34.8,
84.1,
87.6,
90,
64.6,
82.3,
72.3,
49.2,
60.4,
5,
56.7,
11.7,
42.6,
78.1,
26.3,
73.6,
74.3,
62.3,
19.4,
37.6,
25.2,
63.6,
78.8,
55.8,
72.7,
52.2,
80.7,
35,
68.5,
94.4,
75.6,
34,
54.1,
57.1,
14.9,
50,
80.3,
71.8,
88.8,
39.3,
76.2,
52.7,
73.1,
44.8,
37.6,
63.9,
34.6,
93.7,
74.6,
80.8,
94.6,
71.6,
1.9,
29.5,
54.1,
65.8,
48.4,
56.2,
37,
72,
98.6,
79.4,
18.2,
92.9,
54.7,
33.1,
37.4,
87.9,
78.7,
33.8,
14.7,
50.6,
90.9,
76.3,
66.2,
22.9,
94.1,
33.9,
63.2,
46.4,
47.9,
71.2,
80.2,
47.9,
70.2,
63.3,
58.5,
92,
69.5,
80.5,
45.5,
73.6,
94.1,
86.6,
60.4,
61.9,
37,
3.4,
77.2,
65,
51.7,
55.4,
66.7,
83.4,
83.5,
47,
22.9,
81.1,
62.1,
32.9,
43.6,
72.9,
42.1,
6.6,
90.7,
53,
58.3,
40.2,
58.9,
28.7,
56.2,
70.3,
82,
89.5,
19.8,
23.7,
89.1,
77.8,
38.8,
59.8,
9,
84,
82.9,
61,
0,
27.6,
94.7,
64,
53.7,
63.5,
100.8,
64.3,
59,
62.5,
46.6,
37.9,
91.7,
61.6,
93.8,
40.4,
64.1,
7.4,
26.4,
71.8,
90.6,
59,
41.4,
67.5,
39.2,
63.3,
28.2,
95.5,
41.2,
80.7,
17.9,
79,
20.8,
62.7,
22.2,
73.3,
29.3,
44.2,
70.7,
23.5,
91.4,
42.1,
94.9,
18.4,
76,
76.4,
85.1,
76.1,
9.6,
60.5,
39.3,
21.7,
18.1,
42.7,
69,
67.1,
70.8,
10.6,
76.6,
85.6,
68.6,
5.6,
75,
9,
49.9,
78.9,
59.2,
25.9,
49.7,
82,
57.4,
59.1,
59.9,
22.3,
25.4,
22.1,
68.6,
38.1,
58.3,
16,
47.8,
63.7,
25.1,
76.5,
47.9,
39,
61.2,
66.2,
78.9,
87.8,
68.8,
70.3,
73.1,
64.2,
40.4,
10,
65.5,
67.5,
55.1,
48,
84,
86.2,
96.9,
80.5,
14.7,
51.8,
31.3,
46.6,
49.8,
72.4,
27.1,
57.2,
90.5,
0,
3.7,
35.2,
90.9,
10.9,
63,
45.7,
25.1,
20.5,
75,
70.5,
74.9,
19,
52.2,
47.1,
64.6,
58.4,
29.6,
67.1,
42.2,
39.1,
47.3,
28.4,
53.2,
64.3,
85.1,
81.3,
51.1,
78.8,
55,
31,
93.2,
56,
40.4,
0.8,
56,
80.1,
33.9,
52.8,
47.4,
53.3,
68.1,
56.7,
38.6,
73.2,
35.6,
71.2,
79.2,
51.5,
74.7,
58.9,
14.5,
28.3,
73.2,
91.1,
70,
35.3,
79.4,
35.4,
71.1,
55,
70.7,
56.7,
85.1,
38.4,
58.3,
80,
92.6,
23.2,
13.9,
80.3,
56.3,
40.5,
29.4,
55.1,
82.6,
28.7,
70.9,
38.6,
9.1,
16.2,
53.1,
21,
1.5,
35.4,
71,
49.3,
84.6,
83.7,
58.8,
58.9,
48.3,
62.9,
18.2,
8.2,
59.5,
67.3,
38.9,
22.8,
57.2,
33.4,
48.5,
50,
24.6,
58.4,
68.2,
54.7,
69.1,
52.1,
32.5,
60.9,
44.1,
59.8,
42.5,
35.6,
29.1,
83.3,
84.6,
70.2,
82.3,
77.1,
73.9,
42.4,
43.1,
67.2,
54.1,
44.2,
75,
66.3,
65.1,
21.2,
56.4,
97.3,
75,
59.4,
69.1,
61.6,
38.8,
77.4,
69.2,
71.1,
84.7,
58.2,
38.8,
69,
24.6,
57,
34,
43.1,
90.5,
55.6,
65.6,
56.2,
37.2,
25.3,
6.9,
56.1,
70.2,
41.5,
102,
43.9,
72,
48.3,
63.6,
49.2,
80.6,
60,
84,
83.7,
28.4,
81.2,
30.4,
83.7,
91.8,
65.8,
33,
52.3,
64,
44.5,
91,
48.7,
57.9,
61.6,
59.8,
58.1,
93.3,
60.8,
95.3,
39.2,
74.3,
28.4,
37.2,
25.5,
27,
13.8,
47.6,
65,
48.4,
43.4,
79,
29.2,
85.3,
63.4,
46.1,
80.7,
49.9,
92,
88.5,
64.5,
64.3,
7.4,
63.9,
44.8,
56.1,
49.3,
44,
57.7,
72.4,
59,
63.2,
52.8,
23.9,
60.6,
70,
47.1,
23.3,
62.9,
37.5,
69.4,
57.9,
63.7,
50.2,
79.6,
55.4,
54.6,
51.8,
44.4,
82.4,
57.4,
67.6,
53.8,
58.8,
36.7,
59.6,
39.5,
86,
4,
47.2,
61.1,
66.8,
58,
74.1,
91.7,
78.2,
61.7,
59.9,
18.4,
67.7,
17.4,
55.1,
28,
12.3,
86.7,
31.6,
60.1,
58,
68.8,
74.4,
66.3,
87.5,
45.1,
54.2,
35.9,
62.2,
78.5,
94.5,
68.7,
82.4,
69.6,
63.9,
96.8,
41.2,
0.2,
8.3,
83.1,
66.5,
43.3,
29.1,
29.7,
42.7,
84.7,
49.3,
71.8,
59.1,
56.1,
76.6,
66,
83,
49.5,
61.4,
72.3,
47.5,
80.3,
15.2,
73.9,
79.1,
88.1,
9.9,
67.5,
5.8,
94.7,
38.9,
null,
89.9,
36.7,
71.5,
25.8,
78.4,
96.7,
69.9,
83,
34.1,
65,
70.8,
27.6,
57.8,
98.6,
39.7,
62.3,
65.1,
52.6,
40.4,
58.1,
97.8,
59.4,
68,
88.4,
66.7,
20.9,
71.4,
43.2,
79.4,
63.9,
83,
77.8,
53.1,
97,
70.4,
61,
20,
73.7,
7,
91.2,
59,
39.5,
96,
68.9,
36.6,
24.2,
22.8,
77.9,
36.8,
49.4,
36.5,
56.8,
26.8,
76.4,
30.8,
0.9,
49.4,
83.7,
94.5,
54.9,
68.1,
59.5,
57.1,
52,
63.6,
89.7,
53,
86.3,
56.4,
45.5,
62.1,
67.5,
11.7,
48.1,
68,
57,
82.3,
57.5,
63.6,
52.9,
84.1,
82.8,
79.4,
28.1,
21.2,
40.6,
37,
94.4,
19.7,
74.7,
60.8,
24.8,
57.4,
52.3,
93.8,
68.6,
66.4,
41.7,
75.4,
44.4,
30.3,
60.7,
65.7,
85.5,
39.1,
93.3,
55.5,
80,
33.8,
84.6,
73.1,
95.7,
5.5,
53.4,
68.3,
49,
29.3,
66.8,
2.9,
68.9,
31.3,
56.5,
27.7,
91.9,
54,
63.7,
49,
35.3,
64.9,
67,
77,
83.6,
35.9,
37.8,
37.3,
9.7,
15.2,
24.2,
44.3,
85.1,
84.3,
72.9,
75.2,
44.9,
61.6,
1.7,
56.8,
65.6,
40.8,
44.3,
63.2,
75,
87.5,
12,
47.3,
83.5,
20.9,
33.7,
56.2,
68,
37.4,
78.5,
82.1,
87.4,
64.1,
52.6,
88.3,
32.5,
72.6,
0,
100,
86.3,
93.7,
23,
72.7,
47,
75.3,
18.1,
79.6,
61.2,
79.5,
45.7,
58.9,
75.2,
98.8,
38,
56.8,
45.2,
69.8,
44.6,
61.3,
61.2,
27.2,
56.1,
40.4,
53.7,
35.7,
87.9,
32.3,
48.3,
33.9,
98.7,
85.2,
61.4,
46.6,
29,
85.3,
76.7,
56.6,
49,
67.2,
60.4,
69,
82.3,
33.2,
8.7,
40.7,
89.1,
7.1,
74.9,
69.4,
19.9,
43.3,
78.7,
49.9,
58.5,
79.8,
72.2,
42.3,
32.9,
71.4,
56.4,
26.9,
88.1,
30.3,
68.2,
96.4,
44.7,
94.5,
70.9,
80.8,
46.4,
7.6,
70.7,
59.9,
14.1,
80.4,
28.4,
31.6,
36.7,
47.7,
31,
62.2,
59.3,
57.1,
96.3,
73.1,
22.3,
10.8,
75.5,
33.9,
41.3,
75.3,
17,
21.7,
77.8,
48.2,
86.1,
15.2,
26.5,
43,
47.9,
6.8,
19,
59.5,
55.5,
86.2,
77.7,
25.7,
47.6,
54,
50.1,
69.3,
80,
57.7,
42.3,
15.9,
61.2,
43.3,
49.1,
58.4,
39.4,
80.4,
37.9,
77.4,
8.6,
24,
76.4,
32.2,
45,
23.3,
10.5,
75.2,
53.2,
59.8,
78.9,
23.7,
45.5,
28.3,
25,
4.5,
51.9,
42.9,
96.6,
82,
12,
60.9,
38.9,
1.7,
20.6,
82,
42.7,
71.8,
66.4,
26.4,
76.2,
53.3,
6,
89.3,
54.5,
2.9,
98.5,
50,
46,
26.8,
69.9,
26.3,
36.4,
27.7,
19.9,
90.3,
38,
11.3,
62.1,
64.7,
73.6,
37.1,
75,
59,
27.3,
25,
60.6,
63.8,
25.5,
80,
74.7,
63.2,
89.4,
75.3,
29.9,
60.4,
78.3,
98.2,
43.1,
59.4,
24.4,
74.5,
25,
57.1,
63.6,
12.8,
32,
85.3,
39.8,
25.7,
56.8,
68.8,
71.5,
97.6,
37.6,
53.5,
28.4,
89.2,
90.1,
9.3,
43,
40.7,
57.8,
27.8,
32.1,
14.3,
39.2,
91.2,
26.6,
78.7,
96.1,
33.5,
41.1,
100.9,
81.7,
43.1,
77.2,
38.8,
21.2,
6.1,
17.4,
3.6,
31,
32.5,
73.4,
19.4,
82.2,
92.4,
83.3,
35.3,
63.3,
90.1,
22.1,
81.2,
13.6,
43.5,
26.1,
10.3,
72.6,
13.6,
23.4,
66.7,
45.3,
99,
97.6,
23.5,
62.9,
41.6,
97.5,
11.1,
82.5,
93.1,
12.3,
65.7,
41.5,
61.9,
77.6,
17.2,
27,
78.2,
61.3,
41.8,
89.3,
39,
97.9,
5.7,
92,
34.6,
14.3,
52.8,
93.7,
70.5,
82.4,
13.8,
42.3,
59.4,
75.7,
16.3,
67.2,
19.7,
34.9,
43.2,
77,
65,
37,
77.1,
66.9,
84,
74,
90.3,
27.1,
46.7,
46,
63.4,
18,
89.3,
45.4,
75.3,
74.1,
61.2,
96.7,
70.6,
62.4,
84.3,
49.4,
90.1,
68.7,
89.7,
58.6,
86.4,
77,
69.4,
57.1,
62,
57.4,
52.6,
96.6,
88.7,
31.7,
31.1,
96.6,
50,
72.1,
34.1,
58,
28.5,
82.7,
97.5,
78.5,
42,
44,
42.3,
7,
47.6,
49.6,
31.3,
30,
85.4,
82,
73.5,
90.7,
66.7,
91.2,
75.1,
46.2,
55.9,
57.4,
43.1,
33.3,
24.9,
48.8,
62,
49.4,
36.4,
42.6,
56,
29.7,
53.5,
0,
74.8,
63.5,
39.1,
70.5,
28.7,
50,
9.8,
87.2,
59.7,
62,
63.1,
68.7,
64.9,
30.3,
95.5,
28.7,
95.6,
48.4,
72.8,
88,
50,
25.8,
15.9,
46.1,
66.7,
81.6,
39.6,
82.6,
48.2,
62.8,
89,
0,
84.7,
64.9,
65.2,
18,
86.5,
33.7,
81.8,
67.1,
65.9,
4.1,
88.2,
52.3,
1.1,
45.1,
44.1,
78.7,
27.4,
86.1,
84.2,
70,
41.1,
53.7,
26.6,
19.8,
56.4,
57.6,
6.5,
76.4,
91.1,
84,
87.6,
82.1,
62,
84.4,
55.7,
42.4,
44.1,
78.9,
39,
65.5,
34.3,
59.5,
38.2,
70,
88.9,
83.7,
62.6,
71.4,
49,
24.6,
42.4,
41.6,
74.9,
62,
49.8,
80.2,
69.8,
86.4,
16.1,
30,
64.5,
78.7,
34.6,
68.9,
56.3,
38.6,
74.2,
90.1,
93.6,
56.4,
24.9,
41,
31.5,
34.6,
54.1,
70.5,
56.7,
63.5,
78.1,
25.5,
16.7,
51.3,
43.5,
49.7,
97.8,
42.6,
29.6,
49.6,
41.4,
95.1,
92.2,
59.4,
83.7,
31.7,
26.9,
89.2,
64.5,
33.2,
57.1,
2.3,
69.6,
94.6,
95.4,
51.6,
15.8,
57,
74.7,
92.7,
47.9,
31.1,
96.3,
29.3,
76.8,
41.7,
16.2,
55.3,
78.4,
36.1,
69.5,
82.2,
59.4,
63.4,
41.9,
79.7,
53,
12.8,
46.4,
100.4,
59.4,
98.7,
78.2,
89.5,
50,
47.8,
81.3,
77.3,
81.9,
71.2,
86.3,
83,
41,
70.3,
50.1,
77.5,
49.8,
69.9,
23.2,
70.8,
63.8,
65.9,
75.5,
59.4,
54,
53.5,
83.9,
1.3,
71.7,
12,
33.4,
19.6,
37.9,
59.5,
40.2,
78.7,
89.9,
60.2,
77.7,
48.4,
75.4,
72,
49.1,
63,
48.8,
31.8,
55.8,
1.8,
85.1,
33,
67.7,
97.5,
66.5,
21.5,
49.7,
59.7,
42.1,
35.9,
29.1,
51.5,
73.8,
33.2,
37.6,
60.2,
48.1,
30.4,
84.1,
63.7,
46.5,
34.2,
80.7,
4.6,
45.2,
93.3,
48,
53.6,
42.6,
53.4,
83.3,
49.3,
74.9,
60.6,
21.2,
28.4,
28.8,
76.5,
90.9,
81,
39.9,
37.4,
60.7,
86.7,
27.1,
59,
43.2,
95.1,
45.3,
31.7,
80.6,
27.8,
85.2,
102.8,
36.5,
31.7,
43,
52.6,
26.5,
6.3,
60.7,
75,
51.4,
52.9,
31.2,
74.2,
88.7,
14.5,
80.8,
79.2,
45,
57.1,
41.1,
45.5,
25.2,
73.9,
76,
93.9,
4.3,
0,
80.7,
55.3,
98,
53,
75.9,
44.3,
53.3,
61.4,
24.8,
67.8,
52.7,
63.4,
69.1,
13.9,
4,
23.7,
0,
29.8,
24.9,
42,
61,
6.3,
66.5,
21,
40,
10.5,
76.6,
38.9,
41.6,
36.8,
42.6,
61.6,
37.5,
66.7,
45.2,
67.9,
37.2,
62,
54.9,
30.1,
51,
0,
3.7,
52.4,
66.1,
54.3,
71,
58.4,
53.8,
62,
32.3,
37.3,
0.5,
71.5,
77.4,
78.3,
47.5,
50.1,
48.9,
57.9,
48.6,
8.8,
48.4,
72.2,
35.2,
97,
54.7,
42.6,
55,
98.4,
84.4,
68.7,
48,
97.3,
27,
54.4,
100.2,
28.8,
42.5,
5.8,
10.7,
58.5,
31.1,
39.1,
32.7,
26.3,
73,
88.1,
73.3,
86.4,
36,
55.2,
26.5,
75.2,
78.6,
65.9,
88.7,
60.7,
80,
38.4,
46.6,
28.8,
28.4,
80.2,
84.3,
61,
65,
98.4,
94.8,
76.4,
48.7,
80,
47.4,
29.9,
54.4,
55.6,
53.7,
45.3,
88.8,
64.8,
32.9,
100,
29,
48.5,
77.8,
58.2,
85.5,
18.9,
57.2,
54,
26,
39.6,
65.6,
14.1,
71.7,
67.4,
59.4,
71.5,
40.7,
68.3,
85.4,
36.5,
32.1,
51,
50.4,
92.7,
43.6,
30.7,
70.6,
64.7,
28.9,
36.4,
20.4,
17.3,
98.2,
69.1,
99.9,
50.3,
79.4,
22.4,
11.6,
69,
90,
57.4,
77.8,
55.9,
43.6,
45.2,
77.1,
50.9,
50.8,
0,
14.2,
90,
71.9,
52.7,
50.4,
25.2,
35.7,
76.1,
37.8,
28.3,
58,
72.9,
56.6,
50.4,
94.3,
80.6,
97.7,
68.1,
53.8,
72,
1.5,
64.3,
37.1,
13,
92.9,
41.7,
95.8,
94.4,
97.7,
84.5,
50.8,
49.3,
31.9,
69.7,
75.8,
72.3,
23.6,
0.12,
92.2,
82.3,
68.3,
78.5,
41.6,
67,
51.1,
11.4,
61.7,
68,
26.6,
95.3,
78,
59.2,
45.5,
23.5,
90.8,
38.9,
42.4,
35.6,
40.3,
67.6,
26.2,
41.4,
74,
28.8,
49.2,
23.1,
87.8,
68.4,
35.2,
83.6,
75.4,
54.3,
56.4,
59.9,
30.5,
36.7,
33.2,
12.9,
89.3,
19.2,
33.3,
62,
44.8,
71.4,
83.5,
42.5,
91.9,
23.1,
8,
62.5,
48.8,
52.5,
72.1,
90.2,
45.8,
53,
76.5,
64.1,
39.5,
35.9,
28.5,
58.3,
null,
53,
79.7,
119.8,
67.4,
54.9,
67.3,
63,
66.7,
67.2,
33.3,
43.5,
66,
93.7,
68,
85.5,
59.3,
54.2,
53.7,
94.5,
61.6,
25.8,
92.7,
49,
59.2,
96.9,
54.1,
95.9,
88.6,
65.8,
32.2,
3.2,
66.5,
65.1,
86.4,
100.5,
60.3,
70.4,
61.5,
34.1,
78,
80.3,
69.8,
94.1,
11.3,
23,
100.8,
45.4,
72,
80.4,
5,
66.1,
53.5,
25.9,
58,
40.6,
89.6,
66.1,
54.3,
39,
94.8,
78.3,
59.8,
98.7,
47.4,
59,
43.7,
63.9,
48.6,
26.2,
57.7,
53,
77.7,
63.3,
44.7,
3.9,
59.1,
85.9,
50.7,
23.4,
62.5,
46.2,
78.9,
61.4,
40.4,
73.1,
25.5,
38.8,
93.3,
43.6,
99.8,
41.2,
84.7,
53.7,
64.1,
100.9,
51.9,
1.8,
43.4,
45.5,
33.6,
19.9,
63.6,
97.3,
53.5,
59.5,
23.9,
45.9,
67.5,
40.3,
49.3,
0.8,
62.5,
34.7,
25.7,
51.4,
54.8,
48.5,
36.5,
67.9,
83.1,
98.9,
74.5,
57.9,
22.7,
98.4,
61.6,
43,
36.8,
66.7,
25.9,
48,
29.1,
10.4,
86,
50.8,
27.6,
68.1,
55,
52.2,
26.4,
73.3,
92.5,
23,
11.4,
49.4,
36.3,
63.3,
64.9,
38.8,
67.3,
26.1,
33.7,
30.6,
66.2,
97.3,
33,
69.1,
23.1,
41.1,
76.5,
81,
82.2,
57,
33.1,
48.8,
72.6,
26.6,
54.3,
53.1,
31.2,
9,
48.5,
24.6,
28.6,
68.3,
52.6,
29.5,
51.6,
45.2,
64.9,
35.1,
66.6,
42,
49,
42,
85.1,
100,
63,
91,
67.3,
0,
60.2,
46,
20.9,
31,
48.5,
96.6,
52.6,
86.3,
58.4,
14.5,
54.1,
84.2,
49.9,
60.9,
58.4,
8.1,
68.9,
37.4,
7.7,
41.1,
81.5,
10.4,
52.4,
90.8,
58.6,
50.4,
44.3,
87.1,
81,
87.1,
58.7,
47.1,
65.6,
36.2,
79.4,
50.4,
43,
68.5,
40.3,
40.6,
91.8,
70.9,
45.3,
22.2,
7.8,
24.7,
95.6,
25.9,
44.4,
71.4,
50.1,
70.8,
65.8,
48.7,
69.1,
25.9,
69,
36.8,
69.3,
27.4,
44.5,
75.5,
54,
31.3,
43.4,
70.5,
56.1,
55.5,
29.2,
75.2,
7.4,
20.6,
48.2,
15.1,
0.3,
32.4,
17.7,
40.9,
12.2,
54.1,
89.8,
48.7,
81,
46.3,
77.5,
61.6,
60.9,
82.3,
46.3,
35.9,
92.8,
56.8,
33,
45.4,
64.9,
24.6,
72.7,
77.2,
42.6,
7,
49.9,
74.5,
54.2,
49,
58.7,
34.8,
65.5,
72.9,
22.2,
77.2,
91.3,
10.1,
19,
44.2,
88.1,
79.9,
37.4,
79.9,
62.1,
87.7,
10.3,
60.7,
30.4,
40.2,
77.4,
17.8,
68.6,
53.1,
40.5,
42.9,
54,
9.2,
43.3,
5.2,
42.1,
81.1,
97.2,
69.1,
89,
62.6,
80.1,
63,
61.7,
69.2,
59.7,
70.2,
27.9,
80.9,
49,
54.1,
26.4,
16.2,
34.4,
63.7,
41.6,
68.1,
83.2,
61.2,
47.4,
72.6,
86.7,
24,
5.2,
21.1,
88.8,
7.9,
59,
70.2,
59.1,
86.8,
64,
50.7,
57.9,
70.4,
67,
56.9,
79.3,
30.3,
83.3,
26.4,
37.3,
79.3,
37.2,
41.5,
60.4,
88.3,
66.2,
89.3,
23.4,
48.5,
82.6,
94.1,
20.6,
83.3,
41.8,
41.5,
25.8,
53.9,
50,
60.3,
38.1,
19.3,
16,
36,
45.3,
98,
66.4,
83.5,
18,
81.3,
62,
51.3,
54.9,
41.9,
76.2,
33.8,
47.9,
26.6,
34.8,
28.1,
87.4,
27.6,
25.1,
46.7,
62.6,
37.8,
90.3,
68.4,
88.2,
61.6,
22.5,
61.1,
83.4,
71.1,
73.7,
52,
55.1,
49,
31,
87.4,
72,
47.5,
54.3,
19.6,
82.6,
50.9,
44,
51.9,
34.3,
69.5,
65.9,
71.4,
50.7,
56,
15.4,
95,
69.8,
62.7,
61.1,
78.8,
90.9,
84.3,
71,
47.9,
59.2,
40.4,
54.4,
71.7,
14.4,
76.3,
90.5,
70.5,
77,
101.5,
46.4,
16.6,
78.1,
61.1,
80.2,
57.1,
12.7,
59.6,
69.7,
54.1,
27.1,
32.1,
62.5,
71.4,
91.2,
45.3,
34.7,
45,
76.6,
30.9,
29.9,
66.2,
51.1,
68.3,
53.9,
38.4,
66.5,
51.7,
55.7,
56,
63.1,
26.1,
95.3,
96.3,
80.3,
35.1,
71.3,
61.4,
88.7,
38.9,
71.9,
66.4,
52.1,
53,
89,
86.9,
27.7,
83.3,
44.6,
71.1,
94.6,
22.6,
53.8,
43.5,
8.4,
32.9,
57.3,
40.8,
11.9,
93.7,
71,
20.7,
29.5,
58.8,
64,
76,
58.1,
91,
41.7,
42.6,
69.7,
85.8,
43.9,
62.6,
65.5,
38.5,
37.1,
65.9,
68.7,
35.3,
90.6,
49.4,
23.4,
31.1,
77.4,
30.4,
58.6,
68.5,
71.3,
85.8,
41.4,
67,
76.6,
53,
6,
71.8,
58,
78.5,
49.6,
58.5,
55.8,
17.1,
59.7,
45.9,
77.2,
32.9,
76.5,
21.8,
45.2,
54.7,
88.3,
84.7,
52.4,
38.3,
8.2,
82.3,
32.7,
46.9,
7.1,
51.6,
52,
61.2,
43.4,
42.4,
78.6,
81.8,
52.7,
67.3,
84.9,
73.1,
59.1,
35.1,
55,
14.5,
8.7,
56.3,
85,
71.6,
57.7,
49.7,
68,
65.8,
66.7,
93,
66.1,
84.7,
71.9,
85.5,
37.1,
49.2,
89.4,
65.7,
85.7,
40,
73.6,
42.5,
93.8,
50.4,
72.2,
25.4,
77.1,
57.1,
61.2,
28.3,
53,
46.9,
56.6,
50.9,
86.8,
72.6,
49.6,
79,
4.3,
56.4,
97,
62.5,
2.8,
35.7,
8.6,
52.1,
55,
77,
39.8,
30.8,
86,
37.8,
44.1,
36.1,
71.4,
44.5,
27.6,
22,
85.4,
85.8,
66,
89.1,
97.7,
50.8,
23.8,
72.5,
45.7,
76.3,
56.7,
76.8,
68,
75.9,
35.1,
33.6,
76.2,
66.8,
46.3,
65.1,
92.1,
38.8,
8.1,
73.5,
91.5,
40.3,
70.4,
68.3,
79.4,
25.6,
59.4,
32.4,
53.4,
61,
63.1,
25.5,
18.4,
78.7,
72.1,
27.3,
34.4,
56.6,
62.5,
74.8,
54.6,
71.8,
53.9,
62.1,
32.6,
52.7,
84.9,
22.4,
31.6,
26.8,
38.7,
72.4,
96.5,
37.5,
43.9,
0,
95.5,
48,
26,
32.2,
49.5,
37.9,
28.5,
89,
85.1,
37.1,
89.8,
64.5,
51.3,
55.7,
27.6,
29.9,
2.5,
62.1,
62.2,
83.9,
96.4,
15.7,
94,
56.4,
55.4,
56.6,
55.5,
48,
56.2,
43,
58,
50.8,
42.2,
50.5,
71.4,
56.6,
21.4,
66,
38.6,
44,
79,
56.6,
21.8,
60.6,
56.1,
24.3,
65.7,
54.3,
60.8,
58.7,
64,
7.5,
35,
20.1,
64.9,
56.8,
81.1,
3.4,
32.2,
8.6,
47.7,
70,
21,
7.6,
90.5,
78.1,
69,
39.2,
5.3,
47.5,
50.2,
18.6,
21.3,
21.3,
77.8,
66.2,
9.3,
48.8,
66,
31,
46.3,
98.1,
60.5,
53,
57.5,
14.9,
31,
71.5,
77.5,
22.4,
82.3,
28.8,
56.1,
65.6,
35.5,
74.7,
18.7,
29,
15,
50.5,
81,
42.9,
55.5,
48.2,
90.9,
77.4,
44.4,
19.5,
72.9,
42.2,
47.6,
45,
69.4,
84,
43.5,
92.4,
60.4,
44.6,
27.3,
35.9,
60.8,
87.8,
82.4,
77,
85,
46,
87.4,
66.4,
89.9,
47.6,
51.2,
78.4,
41.1,
59.4,
63,
35.7,
66.4,
96.5,
36,
74.4,
78.2,
67.1,
77,
27.7,
46.5,
45,
69.7,
67,
75.1,
49.7,
58.3,
45.4,
54.7,
28.8,
59.2,
66,
70.6,
51.1,
65.2,
86.7,
35.2,
75.8,
89.1,
52.3,
84.4,
9.3,
44.3,
31.4,
60.8,
65.1,
47.8,
64.5,
27.6,
74.1,
90.5,
35.7,
58.4,
31.1,
67.5,
30.2,
77.9,
49.9,
27.5,
36.1,
78,
10.6,
42.9,
30.8,
8.4,
34.3,
50.3,
59.3,
76.4,
46.9,
38.9,
84.8,
11.5,
60,
0.3,
53,
54.8,
57.8,
69.5,
69.1,
94.2,
32.7,
11.8,
77.9,
1,
61.7,
52.6,
59.2,
22.2,
95.7,
66.6,
73,
71.6,
71.3,
38.2,
11,
67.1,
66.7,
50,
90.4,
57.6,
58.7,
70,
42.6,
26.4,
61.2,
56.3,
95.8,
53.9,
12.8,
55.9,
16.3,
93.7,
74.9,
65,
12.2,
96.4,
59.4,
63.3,
59.7,
87.5,
88,
81.8,
72.6,
58.7,
61,
71.6,
16.5,
45.8,
67.8,
36,
81.7,
38.6,
75.9,
61.5,
5.3,
21.1,
8.3,
47.8,
90.9,
55.2,
66.2,
78.9,
56.4,
51.3,
52.2,
44.1,
86.8,
76.8,
41.3,
63.9,
53.8,
59.7,
13.4,
40,
69.5,
71.4,
92.5,
68.9,
64,
97.4,
76,
78.4,
62.3,
68.4,
10.6,
58.8,
66.6,
14.1,
46.2,
62.2,
51.3,
63,
88.7,
98.4,
58,
65.2,
40.1,
69,
43.5,
54.4,
26.4,
100,
5.8,
56.3,
36.5,
90.1,
30.5,
87.6,
67.4,
71.7,
66.2,
56.5,
72.5,
53.1,
32.7,
19.2,
90.7,
68.4,
68.2,
94.1,
30.3,
32.5,
90,
40.3,
86.4,
43.5,
41.4,
64,
46,
48.9,
32,
33.6,
67.6,
13.8,
81.3,
62.6,
60.3,
60.8,
25.1,
92.4,
83.1,
26.5,
37.4,
50.2,
73.6,
71.2,
50.3,
44,
49.5,
89.1,
67.2,
99.7,
59.8,
56.9,
50.6,
79.6,
96.3,
32.5,
85,
38.5,
54.5,
67.4,
22.7,
92.6,
80.8,
45.1,
86.2,
20.2,
49.7,
78.1,
72.3,
6.1,
37.6,
53.5,
34.7,
87.2,
77.9,
64.8,
80.5,
48.5,
31,
71.9,
73.3,
66.5,
58.9,
28.1,
74,
17.5,
16.4,
44.6,
81.3,
47.9,
68.9,
89.8,
57.9,
55.2,
48.4,
47.1,
71.4,
66.9,
44.2,
8.2,
12,
52.8,
43.3,
55.8,
59,
43.2,
58.5,
56.4,
65.7,
24.6,
65,
67.8,
19.7,
50.4,
0.7,
71.5,
76.2,
46.3,
50,
86.3,
55.4,
80.7,
56.6,
25,
16.6,
18.9,
53.4,
2.5,
90.1,
51.3,
90.4,
80.4,
12.2,
39.6,
14.6,
8,
99.4,
95.2,
73.7,
25.5,
57.9,
36.6,
25.7,
80.9,
58,
67.1,
49.3,
86.3,
79.6,
48.1,
37.7,
59.4,
71,
30.5,
2.5,
54.6,
34.7,
81.8,
95.2,
78.3,
62.5,
64.2,
62.4,
86.4,
81.7,
34.5,
5.1,
56.7,
55.2,
67.5,
14.5,
96.8,
18.4,
68.2,
57.7,
83.2,
87,
67.5,
93.6,
18,
37.7,
45.8,
97.6,
99.5,
80.6,
34,
63.5,
60,
45.1,
57,
29,
91.6,
87,
82.5,
42.3,
12,
93.5,
58.6,
66.6,
17,
48,
77.4,
56.2,
24.3,
66.3,
83.2,
53.7,
42.4,
92.4,
97.7,
7.9,
91.9,
9.2,
42.5,
0,
78.3,
2,
40.4,
29.4,
28.8,
75.1,
7.3,
64.6,
53.4,
70.5,
38.6,
43.8,
84.2,
71.4,
80,
47.3,
53.8,
72.8,
51.8,
86.6,
57.2,
50.3,
39.4,
55.6,
27.4,
55.8,
15.4,
62.6,
74.5,
43.1,
50,
55.5,
56.8,
65.1,
68.9,
8,
17.4,
60.9,
84.8,
63.3,
91.4,
52,
71.6,
71,
42.8,
57.4,
38.2,
49,
63,
100.6,
26.7,
33.2,
83.8,
27.9,
73,
72.9,
90.1,
29.9,
60.1,
37.9,
92.1,
30.8,
5.8,
73,
49.4,
81.3,
33.2,
75.6,
75,
73.4,
40,
36.5,
74.3,
68.6,
45.5,
63,
48.5,
75.6,
71.9,
47.8,
0,
12,
38.7,
31.7,
82.4,
58.1,
59,
56.6,
82.9,
16,
0.5,
60.6,
73.1,
4.6,
48.2,
28.8,
85.1,
70,
47.2,
82.9,
87.7,
71.4,
7.4,
38,
57.9,
39.6,
78,
44.4,
60.5,
51.9,
43.2,
72.3,
30.8,
35,
75.6,
66.9,
49,
65,
48.8,
44.6,
81.9,
78.3,
66.1,
86.6,
68.1,
74.6,
30.4,
12,
78.3,
67.9,
48.8,
40.5,
69.3,
69.9,
57.6,
5.7,
92.9,
66.4,
31.9,
65,
78.6,
57,
86.3,
81.3,
69,
33,
89.5,
29,
41.5,
72.6,
49.9,
41.3,
80.7,
48.8,
29.9,
94,
58,
55.9,
82,
2,
83.1,
56.5,
40.2,
55,
40.2,
61.4,
68.1,
74.4,
20.8,
12.4,
74.5,
71.7,
37.9,
86.2,
7.7,
3,
24.4,
42,
21.3,
73.6,
29,
71.6,
58.7,
38.7,
50.5,
69.5,
51.1,
43.5,
77.7,
67,
14.8,
90.9,
30.7,
37.9,
41.8,
75.2,
27,
38,
64.2,
39.6,
82.4,
39.5,
92.9,
20.3,
20.2,
28.3,
49.2,
60.9,
43.3,
60.9,
76.6,
32.1,
55,
53.3,
83.9,
23.9,
88.7,
58.7,
88.4,
47.4,
63.6,
65.2,
71.1,
61.9,
72.2,
60.6,
94.9,
19.9,
18,
41,
85.5,
30.8,
36.3,
42.7,
67.4,
78.6,
59.9,
56.8,
76.5,
74.6,
33,
37.7,
68.2,
23.1,
76.4,
6.6,
86.2,
28.3,
53.1,
37.3,
88.5,
83.2,
39,
78.3,
57.8,
89.7,
53,
84.7,
9.7,
31.1,
30.8,
71.5,
36.9,
91.1,
54.5,
78.9,
20.2,
69,
50.2,
48.3,
21.5,
60.5,
78.8,
14.1,
67.6,
48.8,
57,
61.3,
38.5,
65.4,
68.3,
0.1,
29.4,
57,
40.6,
67.9,
70,
57.8,
76,
63.2,
60.4,
51.8,
90.1,
54,
40.1,
78.7,
38.6,
34.3,
76.3,
84.5,
57.1,
55.8,
15.1,
55.3,
59.5,
44.9,
33.1,
61.8,
12.7,
74.1,
54.8,
61.2,
98,
45.3,
44.7,
39.3,
18.3,
79.4,
30.2,
42.7,
71.1,
47.6,
86.9,
68.3,
68.2,
52,
72,
64,
66.6,
14.2,
11.6,
37.4,
69.6,
67.3,
64,
96.9,
77.3,
60.1,
31.8,
57.2,
67.6,
27.4,
88.2,
62,
40.9,
98.3,
87,
72.6,
45.6,
60.8,
74.8,
44.5,
40.5,
51.2,
64.8,
83.6,
62.5,
43.2,
60.8,
2.8,
51.5,
61.9,
45,
65.1,
2,
52.7,
78.6,
13.3,
82.7,
65.3,
70.5,
82.4,
51.9,
90.8,
50.7,
74.3,
91.8,
61.1,
51.6,
90.9,
42.4,
81.7,
52.4,
88.1,
55.1,
70,
50.6,
71.1,
37.1,
63.1,
90.5,
40,
45.2,
29.5,
25,
41.5,
35.8,
25.5,
8.8,
0.6,
53.4,
46.2,
58.3,
59.6,
44,
80.7,
53.2,
82.7,
35,
63.3,
59.6,
52.1,
69.7,
70.6,
80.5,
41.5,
49.5,
43.2,
86.3,
69.7,
71.4,
50.2,
28.7,
66.5,
62.7,
38.2,
28.7,
49.5,
55.7,
12.3,
30.5,
89.7,
23.7,
95.2,
93.1,
26.1,
9.5,
36.1,
51.2,
84.2,
63.1,
92.2,
34.9,
56.7,
30.7,
93,
71,
89.4,
30.2,
85.8,
32.2,
56.1,
91.9,
32.7,
19.5,
64,
11.7,
90.2,
75.5,
20.2,
44,
58.2,
78.5,
43.4,
64.9,
71.3,
56.4,
41.7,
36.8,
91.1,
43.6,
61,
37,
39.7,
93.2,
26.4,
25,
25.2,
3.6,
32.7,
30.1,
31.2,
59,
43.2,
41.3,
52.5,
93.1,
59.8,
48.7,
46.1,
71.8,
53.7,
71.2,
106.5,
71.9,
87.9,
42.3,
62.1,
62.5,
73,
76,
96,
10.8,
97.4,
31.3,
50.7,
69.4,
59.8,
72.1,
61,
95.1,
22.2,
53.8,
80.1,
22.5,
93.3,
54,
66.4,
32.3,
90.9,
19.1,
50.7,
50.8,
10.4,
73.4,
12.8,
77.5,
20.4,
79,
53.4,
1.5,
17.5,
72.9,
35.8,
60.9,
64,
67.9,
74.4,
98.6,
40.7,
43,
78.4,
31.1,
44.5,
51.1,
64.8,
49.8,
49.5,
86.1,
11.3,
72.6,
21.9,
44.7,
49,
4.85,
52.1,
84.8,
35,
63.1,
43.8,
80.8,
41.4,
58.4,
41.7,
92.5,
49.7,
38.9,
36.9,
66.2,
19.6,
64.3,
39.6,
85.4,
41.5,
70.5,
92.2,
83.8,
65.4,
95.9,
66.2,
76.6,
84.5,
46.2,
80.9,
30.3,
74.4,
12,
52.5,
7.1,
67.9,
78.5,
59.5,
81.7,
36.2,
41.8,
79.8,
85.7,
88.7,
47,
21.4,
88.1,
40,
81.4,
89.3,
47.7,
76.4,
60.5,
78.9,
65.9,
56.6,
48.2,
91.3,
58.1,
83.8,
0.4,
70.6,
58.5,
51.7,
77.8,
92.5,
73.3,
77.5,
38.3,
63.5,
60.3,
9.4,
69.9,
41,
76.5,
13.4,
73.4,
70.3,
98.6,
21.1,
35.7,
65.7,
72.8,
55.3,
28.5,
70.6,
57.3,
77,
61.2,
19.3,
13.4,
21.6,
88.9,
63.6,
66.7,
25.9,
28.8,
30,
69.8,
83.9,
44.9,
70.7,
48.6,
66,
22,
46.6,
40.8,
35.1,
31.6,
84.9,
25.7,
52.2,
12,
32.8,
25.8,
66.9,
84.9,
57.8,
86.2,
85.3,
72.8,
72.8,
88.8,
55.4,
71.5,
68.3,
42,
53.9,
41,
59.9,
68.1,
81,
43.8,
7.6,
31.4,
36.4,
58.3,
24,
76.8,
54.6,
69.8,
80.8,
89.7,
13,
53.5,
7.1,
72.3,
56,
63,
4,
40.7,
43.4,
73.7,
76.3,
65.8,
93,
24.5,
70.3,
1,
58.9,
58.7,
67.4,
98.1,
93.2,
69.4,
97.7,
20.6,
59.7,
40.3,
20.7,
84,
44.6,
29.5,
43.9,
33,
79.3,
50.9,
72,
24.8,
50.7,
50.6,
83.6,
54.9,
60.2,
83.3,
68.2,
47.3,
19.9,
27.4,
70.3,
69.1,
99,
26.7,
49.1,
72.7,
63.4,
52.8,
54.3,
62.2,
54.5,
81.3,
55.3,
97.8,
21.8,
72.9,
40.5,
63.6,
68.4,
40.4,
100,
56.5,
75.5,
84.7,
81.5,
61.6,
47.8,
53.5,
28,
50.7,
70.6,
65.1,
52.8,
25.2,
26.7,
39.5,
59.1,
49.4,
60.2,
89.1,
48.1,
43,
88.7,
55.7,
53.7,
43.3,
91.6,
20.1,
96,
69.7,
53.7,
88.5,
74.6,
30,
58.7,
26.7,
85.2,
43.4,
24.9,
43.1,
98,
67.4,
79,
67.4,
null,
31,
72.8,
56,
28.4,
98.8,
74.3,
24.4,
68.7,
9.5,
25.8,
54.4,
79.7,
80.6,
26.6,
20.2,
0,
87.4,
60.7,
57.5,
53.3,
10.2,
48.2,
66.1,
31.3,
52.7,
56.5,
100.6,
84.8,
71.2,
94.6,
69.1,
64.6,
48,
0.9,
43.7,
75.4,
98.4,
27,
59.3,
32.7,
64.9,
77.5,
27.4,
47.1,
73,
1.5,
46.2,
63.8,
35.8,
16.6,
85.1,
84.1,
74.4,
80.9,
64,
63.5,
50.6,
60.1,
69,
61,
43,
92,
41.3,
30.4,
67.2,
9.1,
35.8,
37.4,
74.5,
74.1,
16.6,
48.6,
45.2,
64.4,
59.6,
68.6,
39.4,
12.2,
21.6,
38.3,
49.8,
77.7,
50.1,
37.5,
54,
98.1,
24.5,
4.7,
64.8,
34.2,
44.4,
87,
77.6,
58.4,
77.5,
63.8,
77.5,
48.9,
86.2,
45.7,
40.4,
57,
67.2,
29.8,
78.1,
74.2,
70.6,
50.3,
72.6,
29.6,
56.6,
70.2,
91,
21.7,
98.4,
25.4,
94.4,
64.3,
72.9,
36.6,
59.5,
40,
56.8,
96.3,
60.2,
47.6,
59.4,
88.4,
16.2,
68.8,
9.3,
43.8,
64.5,
51.8,
47.4,
81.1,
91.8,
93.6,
53.7,
89.8,
21.1,
43.1,
66.8,
84.4,
98,
62.6,
52.9,
97.9,
35.9,
74,
38.1,
19.2,
42.5,
59.2,
21.7,
47.9,
33.8,
62.4,
46.9,
50.6,
57.5,
40,
76.1,
57.5,
68.3,
44.1,
50.6,
83.3,
76.9,
75.9,
29.8,
92.9,
34,
76,
45.1,
88,
38.7,
78.3,
50.2,
33.5,
85.9,
87.5,
7,
31.5,
44.1,
38.2,
52.3,
32.8,
89.5,
26,
31.4,
41.6,
19.2,
55.5,
51.7,
49.3,
61.5,
19.6,
34.1,
18.7,
56.1,
37.8,
57.6,
47.5,
82,
63.6,
73,
38.5,
45.1,
78.8,
98.2,
18.4,
51.4,
9.7,
28.2,
33.6,
42.7,
85.2,
20.7,
80.4,
21.9,
38.6,
37.1,
20.4,
65.4,
56.2,
38.3,
57.5,
26.3,
17.5,
33.7,
78.4,
59.7,
51.7,
84.8,
32.5,
12.5,
92.2,
41.8,
75.8,
18.4,
67.8,
85.4,
48.4,
91,
79.8,
90.9,
55.5,
75.2,
51.2,
57.3,
76.3,
99.8,
48.4,
22.1,
44.1,
78,
28.2,
60.5,
57.6,
54.1,
6.5,
53.6,
48.2,
67.8,
71,
71.8,
22.2,
69.9,
91.8,
80,
33.1,
58.7,
78,
79,
39.5,
26,
70.1,
19.8,
63.3,
91.3,
55.1,
76.4,
53.2,
88.8,
56,
44.9,
67,
63.6,
52.7,
44.2,
36.3,
85,
49.4,
14,
72.6,
73.9,
3.9,
65.5,
63.6,
45.2,
40.3,
63.9,
31.3,
62.8,
8.9,
66.9,
86.7,
0,
63.4,
79.7,
17.7,
27.6,
98.6,
65.4,
29.4,
46.7,
56.3,
85.1,
69.7,
42.9,
89.7,
43.2,
85.5,
60.7,
72.4,
24,
63.3,
66.2,
71.8,
68.3,
9.4,
40.1,
60.7,
40,
76,
6,
89.4,
81.5,
56.2,
31.6,
68,
63.9,
73.9,
82.5,
69.7,
42.1,
78.6,
64.3,
32.6,
70.7,
63.5,
66.2,
47.1,
44,
34,
85.1,
78.8,
47.3,
41.9,
48.4,
24.5,
41,
74.4,
77.4,
74.5,
40.4,
72.5,
34,
64.7,
18.6,
50.5,
60,
43.5,
57.9,
30.3,
74,
32.2,
73.4,
51.8,
21,
29.8,
85.5,
46,
72.5,
70.2,
79.4,
43.4,
73.1,
45.8,
39.7,
34.1,
45.1,
61.5,
72.1,
85.6,
70.2,
24.2,
68.3,
50.1,
67,
60.8,
30.3,
20.9,
83.8,
16.3,
59.4,
48.4,
43.6,
48.5,
86.2,
83.6,
37.3,
101.9,
75.7,
100.3,
71.7,
72.7,
18.1,
36.8,
83.3,
43.2,
22.9,
91.3,
63,
69.6,
7,
61.9,
52.5,
95.3,
42.1,
65.5,
58.4,
59.4,
90.2,
30.1,
44.1,
12.1,
54.2,
62.4,
23.9,
84.6,
33.8,
47.2,
57.7,
9,
19.4,
84.7,
55.1,
53.2,
70.5,
62.2,
59.9,
65.6,
51.2,
40,
91.8,
49.5,
91.1,
101,
88.6,
33.4,
71.9,
14.8,
26.2,
75.3,
78.5,
57.4,
24.7,
64.5,
16.6,
89,
68.9,
48.6,
71.8,
54.5,
28.5,
41.2,
40.6,
52.7,
64,
19.4,
86.6,
54.2,
75,
87.5,
42.7,
78.8,
65.1,
76.2,
68.8,
24.4,
85.6,
28.1,
41.2,
41.3,
89.9,
72.8,
53.5,
35.2,
56.7,
66.2,
83.5,
68.7,
26.3,
67,
44.3,
75.1,
54.8,
30.9,
71.7,
85,
46.8,
47.7,
47.6,
75.1,
26.6,
75.1,
43,
43.9,
81.3,
44.9,
59.2,
75.6,
55.3,
32.2,
37,
48.1,
91.3,
69.5,
15,
2.9,
46.6,
53.1,
16.1,
91.2,
77.9,
51.8,
4.1,
27.4,
41.7,
50.1,
73.3,
43.1,
26.9,
29.4,
38,
53.3,
80,
57.3,
72.1,
77,
14.8,
36,
17.5,
40.8,
22.5,
75.7,
66.5,
6.2,
13.1,
43.7,
77,
16.7,
63.5,
26.6,
24.3,
84.7,
79.5,
61.8,
54.2,
85.2,
54.4,
58.5,
56,
95.9,
37.4,
44.9,
71.5,
49.9,
62.5,
80,
46,
39.9,
51.8,
44.1,
38.9,
98.1,
56.7,
41.9,
50.6,
45.8,
46.8,
69.4,
4.5,
16.3,
32.8,
59.1,
35.6,
35.8,
83.6,
15.1,
13.7,
12.4,
79.9,
33.1,
55.4,
24.6,
80.9,
76.5,
36.4,
92.1,
61,
81.8,
48,
78.1,
1.7,
25.5,
62.6,
63.8,
46.8,
41.8,
56.7,
21.6,
51.7,
94,
48.3,
66.3,
24.8,
65.7,
31.4,
95.4,
61.5,
14.9,
65.5,
17.7,
52.5,
36.9,
32,
41,
3,
89.4,
60.6,
82.7,
73.4,
21.2,
65.6,
56.8,
35.8,
50.5,
62.3,
65.9,
48.6,
39.5,
18.9,
45.3,
79.2,
46.4,
78.6,
3.5,
43.5,
79,
43.5,
44.2,
78.8,
83.3,
63.6,
57.4,
78.3,
45.6,
42.9,
37.7,
96.1,
61.4,
59.1,
16.3,
91.2,
64,
75,
25.6,
41.4,
68.5,
49.5,
68.4,
66.8,
67.2,
35.3,
60.9,
10.1,
35.2,
23.7,
47.8,
63.1,
84.7,
83.3,
61.2,
65.3,
46.1,
65.1,
89.9,
59.7,
33.8,
27.6,
5.7,
61.6,
74.3,
93.8,
72.2,
69.8,
74.8,
51.7,
66.6,
74.9,
64.3,
97.5,
45.8,
64.9,
80.7,
50,
33.5,
61.6,
45.5,
35.2,
47,
39.6,
33.8,
36.5,
55.8,
86.4,
69,
54.5,
66.8,
10.6,
21.9,
43.2,
64.8,
98,
90.6,
4.5,
29,
58,
40.3,
26.4,
66.6,
82.7,
92.2,
44.7,
21.5,
49.9,
47.5,
82.2,
36.8,
53.5,
42.1,
102,
89,
78.4,
94.9,
71,
72.3,
53.3,
87.1,
84.3,
80.6,
27.4,
52,
98,
0,
94.4,
30.1,
89.9,
39.9,
45.4,
52.5,
46.9,
14.2,
60,
62.6,
52.9,
24.6,
74,
20.7,
48.6,
76.6,
38,
90.4,
24.5,
46.5,
22.7,
47.8,
78.3,
57.6,
89.3,
22.1,
75,
40.9,
45.2,
58.5,
28.7,
40.7,
70.1,
72.9,
36,
58.9,
83.8,
83.9,
63.2,
67.8,
35.2,
74.3,
92.8,
88.8,
46.9,
58.3,
63,
60.5,
93.1,
54.6,
100.4,
63.8,
38,
26.7,
63.2,
89,
63.5,
86,
7.3,
77.8,
19.6,
25.3,
62.8,
58.5,
38.6,
8.2,
61.9,
78.1,
33.4,
30,
70.5,
0.3,
39.4,
79.8,
59.7,
34.7,
2.3,
48,
6,
85,
92,
58.5,
27.9,
96.3,
57.1,
27.6,
67.8,
98.3,
18.7,
84,
71.5,
76.2,
69.7,
62.6,
1,
72.8,
27.1,
51.2,
44,
40.9,
5.7,
91.5,
20.1,
88.3,
64.1,
60.4,
16.3,
100.4,
47.6,
54.7,
61.9,
84,
57.9,
76.1,
61.2,
67.3,
50.5,
98,
31.1,
51.1,
67.6,
75.8,
61,
40.9,
51.6,
54.2,
73.7,
92.8,
49.9,
75.3,
61.5,
21.6,
37.5,
89.9,
52.9,
68.9,
63.5,
60,
52.9,
65.5,
76.6,
86.8,
73.6,
53.7,
59.9,
67.6,
63,
41,
62.8,
71.7,
34.2,
2.5,
84.3,
31.7,
16,
57.8,
45.3,
59.7,
18.9,
46.7,
27.5,
64,
90,
23.3,
72.3,
2.4,
76.6,
91.7,
91,
21.5,
82.7,
49.1,
73.7,
76.2,
7.8,
33.5,
11.6,
70.9,
43.9,
47,
100.1,
37.5,
87.6,
78.6,
55.7,
28.2,
87.4,
87.8,
32.7,
89,
42.6,
30,
66.4,
84.1,
8.1,
56.1,
56.9,
7,
33.4,
0.3,
21.2,
36.3,
62.9,
16,
92.6,
71.6,
19.1,
71.7,
74.2,
42,
65.9,
39.3,
61.5,
43.9,
93.6,
47.7,
76.9,
45.6,
48,
48.8,
51.6,
77.5,
91.4,
77,
35.1,
38.5,
61.7,
64.3,
28.4,
53.1,
32.9,
43.7,
37.8,
28.7,
85.9,
81,
85.8,
59.4,
54.5,
35,
75.7,
91.3,
18.5,
65.7,
62.7,
33.2,
83.9,
88.5,
22,
90.2,
52.8,
51.7,
74.3,
7.4,
68.6,
91.9,
81,
71.8,
64.7,
35.1,
56.8,
0.5,
40.8,
67,
38.7,
61.4,
73.8,
85.5,
86.1,
78.1,
3.9,
84,
48.5,
63.8,
58,
94,
31.9,
79.4,
72.6,
0,
27.6,
49.2,
84.7,
69,
14.9,
43.5,
37.5,
59.7,
39.5,
72.1,
35.2,
95.4,
49.2,
75,
68.1,
57.2,
74.5,
52.9,
45.4,
25.3,
76.2,
91.7,
62.8,
92,
47.3,
34.7,
43.6,
31.6,
94.2,
56.8,
54,
25.2,
8.1,
23,
16.8,
62.6,
0.8,
54,
51.6,
30.3,
77.6,
72.7,
15.8,
81.6,
62.4,
39.2,
79.3,
28.2,
80,
42.3,
73.8,
33.6,
12.7,
61.2,
11.4,
75.5,
85,
95.8,
86,
100.8,
82.3,
54.9,
75.6,
38,
76.1,
49.4,
33.9,
53.4,
38.2,
24.4,
31.2,
39.8,
68.8,
85.6,
66.2,
86,
57.9,
90.7,
64.2,
22.4,
79.6,
22.4,
76.3,
47.9,
11.3,
62.7,
57.2,
31.7,
84.2,
35.4,
64.7,
78.9,
25.9,
70.8,
23.8,
62.9,
24.8,
37.6,
81.5,
28,
73.9,
71.5,
62.7,
92.1,
59.9,
68.2,
20.6,
69,
94.6,
9.2,
62,
52.2,
49.3,
33.9,
45.2,
65.8,
78.6,
11,
55.9,
94.8,
48.6,
61.9,
79,
67,
26.4,
54.4,
95.3,
29.5,
26.6,
85,
60,
33.2,
48.8,
62.6,
79.5,
53.5,
81.7,
10.5,
79.3,
98.6,
31.3,
37.2,
64.7,
54.8,
89.3,
31.1,
96.5,
63.1,
20.2,
60.3,
54.6,
53.8,
43.4,
11.6,
83.2,
77.4,
81,
112.9,
64.9,
70.9,
46.6,
27.6,
48.9,
63,
49.8,
56,
25.7,
48,
53.5,
67.8,
50.8,
58.9,
46.5,
51.5,
4,
45.7,
20.4,
92.9,
42.7,
42.5,
33,
86.4,
29.7,
27.4,
25.8,
60,
57.1,
65.1,
30.2,
32.4,
11.2,
44.5,
73.5,
48.8,
28.6,
78.2,
30,
83.3,
17.1,
28,
93.3,
36.7,
59.9,
69.8,
74,
70.4,
88.7,
81.9,
39,
12.7,
64.3,
78.4,
59.4,
27,
67.6,
77.4,
75.2,
32.8,
33,
55.2,
62.8,
45,
54.4,
50.7,
83.7,
70.7,
56.8,
66.7,
33.3,
50.2,
25.3,
70.9,
32.2,
45.5,
7,
31.5,
14.5,
62,
50.8,
43.9,
36.1,
26.7,
43,
73.8,
97,
69,
51.1,
21.9,
89.7,
61.2,
53.8,
60.4,
75,
45.6,
49.9,
31.4,
68.8,
63.7,
72.3,
55.1,
44.7,
0,
18.7,
49.5,
31.8,
30.2,
73.2,
37.7,
58.2,
54.8,
49.4,
26.2,
46.5,
79.9,
25,
51.3,
43.8,
66.9,
40.6,
28.6,
98.7,
61.8,
58,
80.9,
93.4,
43.4,
64.4,
64,
36,
5,
84.7,
11,
41.6,
25.4,
85,
96.7,
39,
24.9,
33.2,
25.8,
63.9,
60.9,
56.7,
63.3,
49.9,
79.2,
94.7,
84.2,
39.9,
8.6,
97.2,
30.8,
73.2,
53.3,
38.7,
26.6,
23.7,
35.9,
49.2,
72.5,
55.9,
36,
72,
97.4,
84.4,
35.1,
62.4,
83.2,
91.3,
24.2,
64.6,
9.7,
50.9,
86.9,
16.3,
32.4,
75.4,
65.8,
89.1,
84.6,
16,
77.1,
26.8,
42.2,
48.7,
38.2,
10.2,
78.1,
56.6,
77.9,
15,
63.2,
42.3,
86,
69.3,
40.6,
68.2,
49.7,
35.6,
87.7,
62.8,
0,
39.1,
57.6,
52.4,
60.6,
57.9,
42.7,
73.5,
64.4,
25,
63.9,
27.7,
95.4,
28.7,
2.3,
86.6,
53.6,
66.3,
61.2,
58.2,
37.9,
58.4,
71.8,
11.4,
9.5,
74,
37.8,
40.9,
86.9,
84.4,
44.1,
64.9,
58.7,
74.6,
80.1,
75,
68.9,
74.7,
40.7,
1.5,
36.2,
48.8,
45.7,
42.7,
29.7,
29.9,
4.2,
76,
83.9,
50,
62.4,
60.1,
17,
44.1,
56.8,
26.2,
86.6,
25.8,
47,
97.7,
35.9,
2.7,
20.4,
40.8,
66.9,
39.8,
59.1,
88.9,
16.4,
95.9,
44.4,
57.1,
50.2,
62.3,
19.4,
24,
27.2,
70.6,
10.7,
45.2,
84.4,
91.6,
36.9,
94.8,
3.8,
41.9,
64.6,
14.4,
29,
91,
86.6,
95.2,
40.6,
69.2,
5.7,
33.7,
59.7,
46.2,
101.8,
78.5,
88.9,
14,
35.6,
74.9,
50.3,
64.3,
8.5,
70.1,
65.2,
71.7,
61.1,
56.8,
37.1,
35.9,
95.4,
62.2,
57,
63,
53.9,
64.1,
85.7,
74.7,
97.6,
53.1,
62.4,
98.6,
25.8,
34.1,
84.1,
42,
59.3,
43.2,
54,
51,
48.3,
25.9,
90,
89.5,
67.8,
72,
44,
56,
50.2,
36,
70.8,
12.1,
36,
41.3,
97.8,
87.5,
36.7,
41.1,
46.5,
20.6,
60.7,
45.2,
37,
90.2,
72,
9.8,
81.1,
34.6,
52.3,
79.6,
36.7,
35.7,
48.9,
26.4,
13.6,
74.7,
67.1,
86,
66,
56,
75.1,
81.7,
10.6,
13.2,
26.5,
57.4,
12.7,
71.8,
49.7,
86.8,
63.9,
61.3,
85.4,
31.9,
54.7,
8.7,
23.1,
93.4,
51.5,
39.2,
95.3,
33.2,
73.3,
54.8,
55.4,
25.2,
63.8,
71.3,
72.9,
25,
37.3,
49.9,
43.1,
54.4,
52.9,
77.6,
16.9,
7.3,
36.1,
43.5,
50,
37.9,
55.3,
28.3,
69.9,
108.6,
74.6,
58,
14.1,
86.7,
27.6,
49,
7.5,
56.5,
95.5,
38.7,
60.4,
40.8,
37,
45.4,
72.2,
98.2,
96.4,
63,
70.4,
48.9,
72.3,
29.8,
58.7,
61,
97.2,
78.4,
41.4,
80.7,
52.5,
71.8,
63.4,
73.4,
11.2,
30.4,
45.5,
80.4,
46.1,
72.8,
8,
42,
43.4,
71.7,
48.1,
82.3,
44,
25,
35.8,
59,
14.1,
38.6,
64.9,
83.3,
67.4,
20.2,
16.7,
40,
77.2,
65.1,
69.4,
84.9,
51.7,
41.1,
7.4,
15.4,
26.3,
70.5,
93.5,
60,
54.7,
11.3,
48.8,
72.6,
9.3,
50.7,
78.5,
60.4,
55,
2.4,
65.5,
86.8,
50.8,
64.7,
44,
83.8,
46.6,
59,
50.5,
36.4,
54.2,
81.4,
58.9,
63.8,
79.8,
28.6,
10.6,
16.1,
74.8,
87,
58.2,
30,
64.7,
13.4,
39.5,
52.4,
81.4,
69.9,
89.9,
95.4,
58.3,
17.5,
67.8,
87.6,
60.5,
25.3,
71.2,
57.7,
94.3,
38.3,
62.4,
97.4,
36.2,
43.8,
41,
55.2,
47.3,
59.9,
100.7,
62,
93.3,
22.5,
43.3,
31.5,
83.5,
68,
20.9,
61.8,
79.1,
20.5,
48.9,
53,
69.1,
49.6,
62.6,
22.8,
46.5,
52.7,
36.3,
83,
75,
86.7,
26.6,
28.9,
44,
80.1,
46.5,
49.9,
36.1,
96.7,
70.9,
62.1,
35.6,
9.3,
62.2,
58.4,
33.2,
50.8,
74.5,
79.8,
17.7,
74.5,
15.4,
23.9,
74,
42.6,
64.6,
69.6,
50.5,
11,
49.1,
54.1,
68,
63.3,
30.9,
19.6,
85.1,
77.9,
81.9,
41.6,
56.7,
96.4,
64.6,
70.9,
28.4,
39.4,
66.7,
17.8,
79.3,
72.5,
58.1,
52.2,
41.9,
66.2,
40.7,
120.5,
92.4,
62,
26.9,
23.1,
84,
54.2,
54.2,
45.5,
67.4,
75,
94.2,
67.5,
22.7,
85.2,
29.3,
94.6,
79.2,
57,
59.9,
56.4,
90.9,
16.2,
28,
29.2,
85.3,
28.9,
72.4,
89.7,
56.2,
80,
47.3,
55.4,
55.3,
42.5,
44.8,
76.6,
17.2,
12.8,
29.2,
65.5,
3.4,
32.6,
8.4,
42.4,
45.3,
94.4,
91.7,
52.7,
77.9,
67.6,
80.2,
23.2,
31.3,
66.8,
93.9,
44.6,
56.6,
85.1,
16.7,
92.8,
45.4,
41.8,
51.5,
58.3,
18,
18.1,
63.9,
45.4,
0.2,
18,
21.9,
54.9,
87.3,
93.6,
10.5,
80.8,
22.6,
66.5,
47.1,
29.8,
35.4,
85,
23.6,
38.7,
90.5,
77.4,
59.9,
61.1,
59.5,
39.3,
92.5,
43,
92.7,
74.6,
34,
59.5,
70.6,
13.9,
74.7,
69.9,
68.1,
35.9,
67,
23,
71.1,
51.3,
11.9,
31.7,
22.4,
43.7,
96.9,
52.1,
57.7,
81.6,
74.2,
33.3,
95.3,
73.8,
73.8,
44.1,
42,
83.4,
37.7,
49.7,
27.2,
95.9,
92.7,
57,
64.6,
53.3,
44.9,
43.3,
25,
79.2,
57.7,
84.9,
75.1,
76,
46.9,
73.2,
31,
91.3,
42.8,
20.6,
49.5,
25.9,
78.8,
52.7,
37.8,
73.8,
59.6,
77.9,
38.1,
75.5,
37,
56.4,
18.9,
89.6,
74.8,
23.8,
58.8,
96.3,
56.2,
22.6,
21.1,
94.8,
57.4,
51,
33.9,
69.5,
81.1,
45.3,
98.9,
52.6,
59.4,
32,
4.1,
88.9,
68.2,
52.8,
70.3,
6.7,
7.2,
84,
58.9,
38.3,
92.5,
56,
85.7,
33.5,
50,
65.2,
25.2,
47.4,
57.3,
25.8,
60.9,
60.7,
3.6,
98.8,
87.3,
21.8,
48.1,
57.8,
83.5,
85.3,
36.6,
72.6,
65,
7.2,
57.3,
49.6,
64.5,
31.2,
69.9,
57,
62.1,
66.6,
49.5,
78.7,
74.1,
64.8,
95.9,
84.3,
42.7,
33.8,
87.3,
69.3,
57.2,
78,
42.4,
47.1,
14,
46,
20.7,
91.8,
27,
18.5,
81,
88.4,
83.1,
7.7,
90.7,
33.7,
24.1,
64.1,
92.5,
79.1,
24,
46.2,
66.1,
25.2,
90.7,
22.6,
27.7,
83.5,
80.6,
91.3,
8,
79.6,
72.2,
65.1,
48.6,
73.3,
85.3,
71.3,
40.7,
29,
14.4,
75.7,
93.9,
76.4,
73.8,
81.3,
68.2,
35.8,
85.3,
65,
63.6,
94.2,
54.3,
42.8,
56,
53.3,
60.7,
24.1,
83.3,
62.6,
83.9,
84.3,
13.9,
71.9,
34.9,
13.7,
45,
7.7
]
}
],
"layout": {
"barmode": "overlay",
"legend": {
"bgcolor": "#F5F6F9",
"font": {
"color": "#4D5663"
}
},
"paper_bgcolor": "#F5F6F9",
"plot_bgcolor": "#F5F6F9",
"template": {
"data": {
"bar": [
{
"error_x": {
"color": "#2a3f5f"
},
"error_y": {
"color": "#2a3f5f"
},
"marker": {
"line": {
"color": "#E5ECF6",
"width": 0.5
}
},
"type": "bar"
}
],
"barpolar": [
{
"marker": {
"line": {
"color": "#E5ECF6",
"width": 0.5
}
},
"type": "barpolar"
}
],
"carpet": [
{
"aaxis": {
"endlinecolor": "#2a3f5f",
"gridcolor": "white",
"linecolor": "white",
"minorgridcolor": "white",
"startlinecolor": "#2a3f5f"
},
"baxis": {
"endlinecolor": "#2a3f5f",
"gridcolor": "white",
"linecolor": "white",
"minorgridcolor": "white",
"startlinecolor": "#2a3f5f"
},
"type": "carpet"
}
],
"choropleth": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "choropleth"
}
],
"contour": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "contour"
}
],
"contourcarpet": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "contourcarpet"
}
],
"heatmap": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "heatmap"
}
],
"heatmapgl": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "heatmapgl"
}
],
"histogram": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "histogram"
}
],
"histogram2d": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "histogram2d"
}
],
"histogram2dcontour": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "histogram2dcontour"
}
],
"mesh3d": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "mesh3d"
}
],
"parcoords": [
{
"line": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "parcoords"
}
],
"pie": [
{
"automargin": true,
"type": "pie"
}
],
"scatter": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatter"
}
],
"scatter3d": [
{
"line": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatter3d"
}
],
"scattercarpet": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattercarpet"
}
],
"scattergeo": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattergeo"
}
],
"scattergl": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattergl"
}
],
"scattermapbox": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattermapbox"
}
],
"scatterpolar": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterpolar"
}
],
"scatterpolargl": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterpolargl"
}
],
"scatterternary": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterternary"
}
],
"surface": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "surface"
}
],
"table": [
{
"cells": {
"fill": {
"color": "#EBF0F8"
},
"line": {
"color": "white"
}
},
"header": {
"fill": {
"color": "#C8D4E3"
},
"line": {
"color": "white"
}
},
"type": "table"
}
]
},
"layout": {
"annotationdefaults": {
"arrowcolor": "#2a3f5f",
"arrowhead": 0,
"arrowwidth": 1
},
"coloraxis": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"colorscale": {
"diverging": [
[
0,
"#8e0152"
],
[
0.1,
"#c51b7d"
],
[
0.2,
"#de77ae"
],
[
0.3,
"#f1b6da"
],
[
0.4,
"#fde0ef"
],
[
0.5,
"#f7f7f7"
],
[
0.6,
"#e6f5d0"
],
[
0.7,
"#b8e186"
],
[
0.8,
"#7fbc41"
],
[
0.9,
"#4d9221"
],
[
1,
"#276419"
]
],
"sequential": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"sequentialminus": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
]
},
"colorway": [
"#636efa",
"#EF553B",
"#00cc96",
"#ab63fa",
"#FFA15A",
"#19d3f3",
"#FF6692",
"#B6E880",
"#FF97FF",
"#FECB52"
],
"font": {
"color": "#2a3f5f"
},
"geo": {
"bgcolor": "white",
"lakecolor": "white",
"landcolor": "#E5ECF6",
"showlakes": true,
"showland": true,
"subunitcolor": "white"
},
"hoverlabel": {
"align": "left"
},
"hovermode": "closest",
"mapbox": {
"style": "light"
},
"paper_bgcolor": "white",
"plot_bgcolor": "#E5ECF6",
"polar": {
"angularaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"bgcolor": "#E5ECF6",
"radialaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
}
},
"scene": {
"xaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
},
"yaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
},
"zaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
}
},
"shapedefaults": {
"line": {
"color": "#2a3f5f"
}
},
"ternary": {
"aaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"baxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"bgcolor": "#E5ECF6",
"caxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
}
},
"title": {
"x": 0.05
},
"xaxis": {
"automargin": true,
"gridcolor": "white",
"linecolor": "white",
"ticks": "",
"title": {
"standoff": 15
},
"zerolinecolor": "white",
"zerolinewidth": 2
},
"yaxis": {
"automargin": true,
"gridcolor": "white",
"linecolor": "white",
"ticks": "",
"title": {
"standoff": 15
},
"zerolinecolor": "white",
"zerolinewidth": 2
}
}
},
"title": {
"font": {
"color": "#4D5663"
},
"text": "revol_util Distribution"
},
"xaxis": {
"gridcolor": "#E1E5ED",
"showgrid": true,
"tickfont": {
"color": "#4D5663"
},
"title": {
"font": {
"color": "#4D5663"
},
"text": ""
},
"zerolinecolor": "#E1E5ED"
},
"yaxis": {
"gridcolor": "#E1E5ED",
"showgrid": true,
"tickfont": {
"color": "#4D5663"
},
"title": {
"font": {
"color": "#4D5663"
},
"text": ""
},
"zerolinecolor": "#E1E5ED"
}
}
},
"text/html": [
"\n",
" \n",
" \n",
" \n",
" \n",
" "
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"application/vnd.plotly.v1+json": {
"config": {
"linkText": "Export to plot.ly",
"plotlyServerURL": "https://plot.ly",
"showLink": true
},
"data": [
{
"boxpoints": false,
"line": {
"width": 1.3
},
"marker": {
"color": "rgba(255, 153, 51, 1.0)"
},
"name": "revol_util",
"orientation": "v",
"type": "box",
"y": [
73.1,
23.2,
31.2,
55.5,
76.2,
64.5,
23.9,
29.5,
76.6,
90.5,
50.8,
71.9,
34.2,
27.2,
41.4,
35.4,
96.2,
99.4,
54.7,
76.7,
68.7,
12.2,
82.4,
60.6,
54.2,
46.7,
32,
87.3,
48.4,
58.1,
69.6,
70.7,
97.5,
52.7,
12.3,
54.9,
82.2,
48.3,
64.1,
65.2,
78.2,
36.7,
26.2,
30.5,
70.5,
95.8,
33.2,
80,
51.7,
76.9,
45.7,
51.2,
1.7,
71.4,
19.5,
70,
38.4,
36.6,
45.7,
15.9,
40.2,
78.4,
15.3,
68,
5.5,
53.7,
2.9,
80.1,
63.6,
35.7,
67.8,
76.2,
78.4,
58.2,
93.4,
70.7,
53.3,
79.2,
44.4,
85.1,
45,
18.1,
97,
67.4,
44.7,
76,
44.3,
57.9,
19.1,
81.1,
96.3,
77,
null,
57.5,
66.8,
37,
49.1,
86.4,
48.8,
65.1,
37.5,
61.5,
46.6,
18.2,
68.5,
38.4,
49.3,
61,
33,
26.9,
13.7,
47.7,
49.3,
38.9,
25.8,
38.2,
58,
20.3,
43.1,
84.3,
54.2,
80.7,
12.2,
69,
55.2,
75.9,
21.3,
20.5,
85.1,
77.7,
58.7,
65,
65.6,
42.5,
46.2,
76.9,
39,
45.2,
22.2,
45.1,
41.1,
36,
77.9,
55,
96.3,
53,
68.5,
47.4,
52.9,
68.3,
93.2,
67.6,
88.7,
52.9,
88.4,
50.3,
26.4,
10,
34.7,
66.8,
33.2,
57.6,
40.8,
96.3,
3.4,
85.2,
103.5,
11.5,
8.2,
74.2,
54,
26.1,
27.4,
41.1,
15.9,
76.3,
25.3,
51.3,
62.9,
66.3,
20.2,
62.2,
53.6,
53.3,
58.9,
49.7,
97.6,
22.9,
82.4,
62.1,
71.7,
52.1,
42.4,
57.4,
28.1,
64.8,
35.1,
13.2,
51.4,
68.8,
42,
32.4,
49,
47.2,
67.4,
77.7,
89.4,
88.1,
93.1,
73.7,
62,
18.1,
69.1,
52.5,
40.3,
36.2,
74.8,
85.5,
26.3,
41.3,
47.9,
67.3,
57.6,
67.4,
48.6,
18.2,
46.5,
95.1,
57.3,
14.4,
47.3,
40.6,
27.1,
23.9,
39.2,
21.1,
33.2,
66.8,
25,
53.8,
74.1,
54.4,
69.6,
43.9,
86.3,
81,
62.7,
69.1,
49.4,
84.9,
28.7,
93.9,
77.3,
31.1,
69.3,
73.2,
16.4,
78.8,
46,
33.7,
51.1,
77.4,
95.6,
81.3,
80,
49.6,
59.7,
27,
46.1,
69.4,
52.5,
99.1,
23.9,
52,
72.7,
54.1,
57,
78.8,
48.6,
64.7,
34.2,
55,
49.2,
66.4,
30,
93.5,
95.6,
62.3,
37.3,
39.2,
82.8,
26.6,
67.5,
14,
45,
97,
21.5,
57.8,
13.8,
74,
50.1,
81.4,
5.8,
66,
64.7,
49.3,
50.6,
90,
71,
50,
29.7,
23.4,
86.3,
25.5,
37.1,
61.5,
83.2,
31.5,
50.5,
51.4,
55.8,
69.5,
55.4,
76.7,
55.8,
44.5,
66.5,
77.1,
47.7,
69.3,
46.2,
28.2,
29.4,
88.6,
44.5,
95.8,
41.2,
56.7,
12.1,
88.3,
47,
73.2,
58.3,
25.5,
96,
33.6,
24.9,
15.9,
102.7,
64.1,
81.1,
76.8,
53.3,
64.8,
5.2,
40.8,
64.7,
56.5,
26.8,
68.1,
19.7,
80.6,
28.5,
76.2,
52,
1.9,
78.6,
69.2,
39.8,
53.9,
39.1,
76.7,
56,
34.1,
28.8,
10,
58.7,
58.3,
27.1,
77.8,
65.6,
89,
76.9,
9.7,
76.5,
56.9,
41.8,
79.1,
85.9,
43.3,
53.3,
30.6,
58.4,
78.8,
69.8,
19.7,
93.6,
71.7,
91.3,
42.1,
32.8,
63.3,
27.5,
50.1,
54.2,
49.9,
63.5,
90.2,
67.3,
42.7,
26.3,
25.6,
38.7,
93.2,
34.7,
59.7,
55.3,
88.2,
86.3,
31.6,
61.6,
80.2,
27.5,
48.2,
68.7,
58.5,
35.1,
45.1,
44.8,
57.2,
61.9,
74.5,
56.1,
56.4,
34,
98.9,
14.2,
48.6,
48.6,
28.7,
60,
18.4,
69.3,
56.8,
43.4,
71.5,
47.6,
94.3,
45.5,
70.6,
43.9,
21.3,
26.3,
28.5,
26.3,
98.7,
80.6,
51.3,
28,
25.1,
98.4,
71.5,
54.6,
26.9,
19.8,
53.3,
36.7,
94.2,
47.7,
89.9,
95.8,
55.8,
19.9,
85.4,
38.2,
35.1,
86.1,
58.8,
91.5,
88.8,
96.1,
68.5,
57.9,
27.6,
60.5,
39.4,
62.7,
60.1,
27.6,
91.6,
38.2,
27.6,
69.8,
79.1,
73.5,
82.6,
32.3,
35.8,
93.1,
44.3,
84.4,
71.9,
47,
89.8,
66.3,
66.3,
68.9,
78,
85.9,
50,
85,
34.1,
66.8,
85.3,
65.9,
52.5,
37.7,
61.1,
52.5,
71,
86.3,
39.6,
82.5,
43.5,
53.3,
51.6,
76,
55.1,
37.6,
37.7,
32.3,
54.8,
40.3,
32.9,
57.3,
66.9,
43.1,
76.1,
51.3,
49.9,
83.7,
57.9,
31.9,
14.9,
8,
92.5,
45.8,
46.6,
63.8,
90.7,
55.8,
83.5,
59.5,
15.4,
66.6,
67.1,
43.5,
89.7,
58.2,
97.6,
58.4,
77.7,
57.3,
52.4,
49.4,
41.2,
42.7,
17.6,
24.3,
61.4,
67.6,
87.9,
38.4,
76.5,
95.4,
59.2,
65.2,
51.1,
63,
29.1,
39,
24.1,
54,
44.8,
71.1,
58.4,
33.1,
52.1,
86.8,
86.7,
64.2,
86.4,
37.8,
92.8,
43.5,
50.2,
48.6,
43.8,
44.9,
36.4,
43.8,
43.2,
66.5,
10.9,
67.4,
64.1,
35.3,
74.5,
59.7,
53.4,
71.6,
73.7,
51.4,
75.4,
57.5,
40.1,
95.4,
32.2,
79.5,
29.3,
78.2,
46.5,
63.3,
61.4,
50,
92.9,
30.8,
32.1,
19.2,
60.5,
74.9,
50.2,
26.9,
76.5,
87.3,
79.1,
57.5,
55.6,
47.4,
35,
68.8,
2.8,
86.8,
51.3,
20,
45.8,
48.8,
80.9,
92.5,
31.5,
90.5,
25.8,
10.8,
63.3,
65.2,
9.3,
33.3,
30.1,
18.5,
81.2,
33.5,
71.8,
95.1,
89.1,
71.7,
66.3,
22.9,
37.3,
85.2,
60.1,
29.5,
85.9,
3.3,
4,
75.9,
37.1,
94.5,
36.4,
57.7,
47.9,
10.3,
98,
30.8,
84.3,
100.7,
39.9,
52.4,
32.3,
27.4,
55.2,
48.8,
69,
92.3,
18.8,
65.8,
35.1,
43,
89.9,
26.4,
42.3,
57.1,
53,
64.3,
11.8,
76.5,
26.2,
50.9,
40.5,
57.6,
56.2,
44.2,
26.2,
29.9,
36.3,
54.9,
76.2,
27.8,
95.9,
43,
24,
87.6,
61.8,
54,
14.7,
27,
51.5,
61.7,
47.6,
16.2,
81.8,
16,
63.1,
35.3,
28.1,
70.5,
59.6,
55.8,
46.3,
59.4,
91.1,
45.9,
50.4,
67.6,
93.4,
93,
71.2,
28,
60.2,
17.8,
77.8,
66.9,
24.9,
49.6,
61.4,
78.8,
46.3,
53.3,
27.6,
86.9,
27.3,
77.6,
88,
41.7,
61.4,
46.1,
53.7,
67.1,
87.7,
46.3,
50.1,
91,
36.7,
61.4,
40.2,
55.7,
1.7,
41.9,
98.3,
65.1,
39,
41.5,
38.1,
53.1,
93.6,
64.3,
34.8,
45.2,
66.1,
96,
49.6,
52,
29,
62.2,
66.7,
51.1,
48,
86.2,
83.5,
73,
67.2,
68.4,
77.1,
49.3,
47.8,
80.3,
36.5,
89,
89.2,
96.8,
74,
31,
94.4,
70.6,
57.2,
61.6,
43.7,
75.4,
60.1,
83.5,
66.3,
12.6,
55.9,
59,
43.9,
57.8,
53.3,
78.1,
91.2,
13.3,
32.5,
70.4,
69,
66.2,
80.8,
26.2,
80.4,
65,
87.7,
53.2,
57.7,
74.2,
28.3,
59.1,
69.5,
79.3,
49.4,
44.9,
73.9,
66.7,
73.3,
86.9,
9.9,
98.4,
67.1,
38.5,
54.3,
57,
90.6,
61.5,
83.9,
37.7,
77.9,
73.7,
41.8,
65,
77.9,
16,
91.9,
null,
39.1,
72.5,
25.3,
82.6,
38.4,
65.9,
85.4,
29,
67,
24.8,
84.9,
17.7,
88.1,
48.3,
66.7,
42.3,
46.5,
75,
62,
54.3,
46.7,
54.3,
42.5,
46.6,
53.2,
26.4,
56.9,
86,
67.6,
54.5,
46.5,
32.3,
74,
47.1,
37.6,
26.6,
16,
50.6,
65,
52.7,
16,
95,
39.3,
90.3,
89.4,
38.5,
27.8,
74.2,
38.5,
42.1,
76,
12,
66.8,
69.5,
74,
24.9,
48.4,
83.4,
52,
99.5,
1.8,
69.5,
59.6,
63,
28.8,
49.3,
73.4,
87.3,
4.3,
70.7,
92.3,
47.7,
47.3,
73.9,
79,
77.8,
6.8,
84.6,
20.9,
15,
53.7,
89.5,
67.2,
61.1,
45.7,
89.4,
95.7,
49,
51.6,
23.9,
55.5,
52.6,
22.2,
93.1,
84.8,
61.8,
69.7,
51.7,
9.9,
25.2,
97,
24.2,
76.3,
29.1,
61.5,
91.9,
23.1,
64.1,
27.3,
52.2,
22.4,
54.3,
50.7,
81.6,
66.8,
73,
69.6,
10.8,
16.2,
74.8,
86,
49.2,
67.6,
52,
71.5,
99,
73.5,
64.5,
61.4,
44,
32.9,
44.5,
87.6,
38.5,
49.2,
20.4,
78,
79.2,
55.4,
80.1,
91.1,
44.3,
74.1,
24.1,
41.8,
87.6,
71,
62.1,
81.1,
72.7,
61.7,
88.2,
24.4,
54.9,
52.7,
44.4,
58.2,
73.4,
57.7,
70.1,
49,
86.7,
44.3,
84.2,
81,
92.7,
73.9,
33.6,
61.6,
76.7,
40,
48,
56.9,
40.6,
47.6,
47.6,
10.1,
58.5,
15.6,
3.1,
40.9,
72.7,
18,
24.1,
42.9,
57.1,
38.6,
67.7,
65.2,
61.5,
68.1,
46.5,
60.7,
79.1,
65.8,
32.6,
66,
6.2,
29.3,
36.6,
94.1,
67,
73.7,
69.1,
13.2,
59.5,
63.2,
66,
31.6,
31.8,
69.3,
78.8,
78.5,
73.5,
81.9,
33.6,
49.8,
98.7,
62.9,
70,
99.7,
66,
61.2,
52.4,
56.8,
56.8,
66,
76.7,
22.1,
80.1,
26.6,
49.1,
52.6,
67.8,
57.2,
41.5,
85.9,
33.4,
58.4,
55.2,
22.3,
21.8,
74.4,
42.3,
52.5,
90,
46.7,
61.7,
72.1,
97.6,
57.5,
54.8,
42.6,
23,
57.5,
37.7,
6.7,
91.8,
59.8,
48.2,
69.8,
42.8,
31.4,
11,
76.6,
69,
18.6,
68.5,
65,
5,
52.5,
87.2,
76.3,
77.9,
58.2,
83.2,
37.3,
28.5,
77.8,
82.9,
77.2,
1.3,
59,
84.7,
41.8,
74.9,
57.3,
55.3,
65.9,
51.4,
25.1,
70.7,
57.2,
59.2,
79.3,
86.8,
96.9,
67.9,
74.8,
80.8,
61.9,
29.2,
86.8,
29.1,
42,
24.3,
86.7,
88.2,
44.2,
83.5,
43.1,
36.2,
89.4,
62.8,
30.4,
61.7,
62.6,
71.6,
87.4,
23.8,
34.5,
35.9,
85,
32.4,
97.9,
96.4,
95.2,
42.1,
53.6,
3.3,
64,
20.3,
51,
59.3,
34,
8.9,
39.7,
25.6,
100.1,
26.8,
95.8,
0.3,
77.9,
33.4,
51.2,
45,
39,
69.6,
61.1,
38.6,
38.8,
55.1,
78.2,
24.8,
1.1,
82,
59,
65.5,
33.5,
65.3,
35.6,
48.8,
64,
19.9,
68.6,
55.4,
57.8,
49.1,
64.8,
6.3,
49.1,
62,
69.5,
22.6,
83.7,
81.6,
66.1,
34,
38,
0,
95.6,
58.5,
58.6,
47,
51.6,
52.8,
15.6,
73.7,
63.9,
67.7,
20.6,
50.8,
85.3,
50.2,
50.1,
91.9,
32.5,
14.6,
61.6,
63.4,
18.7,
78.5,
45.2,
58.1,
29.6,
47.9,
38.2,
54.6,
74.5,
74.2,
69.9,
72.9,
44.4,
47.7,
99.9,
39.1,
64.1,
86.9,
40.4,
67.2,
33,
46.4,
11.1,
83.8,
83.9,
27.5,
59.2,
0,
92.1,
39,
70,
38.6,
66,
56.5,
3,
19.5,
26,
80.3,
41,
30.7,
74.4,
56,
63.4,
77.9,
74.6,
80.3,
67.6,
32.2,
43,
52.9,
50.7,
10.5,
20.5,
63.5,
36.2,
30,
60.7,
67.9,
84.4,
75,
8.7,
45.7,
33.3,
73,
20.9,
24.2,
32.1,
94.9,
58,
51.3,
59.5,
40.8,
2.6,
63.9,
47.4,
66.5,
47.4,
51.3,
63.4,
43.1,
33.5,
24.2,
29.2,
68.7,
56.5,
48.7,
31.5,
28.2,
57,
61.3,
25.7,
60.6,
24.1,
36.7,
11.1,
85.4,
83.3,
51.2,
43.1,
17.7,
9.2,
86.4,
12.3,
32.9,
44.4,
42.2,
81,
93.9,
59.5,
45.8,
12.2,
55.1,
69.8,
69.3,
66.2,
48.6,
28.4,
85,
83.1,
87.8,
45.7,
40.4,
31,
52,
33.5,
58.4,
68.8,
73.5,
77.7,
85,
46,
71.4,
88.7,
13.1,
2.8,
17.5,
39.7,
22.4,
83.1,
93.6,
24.4,
43.8,
57.4,
87.9,
76.4,
60,
37,
43.4,
74.4,
47,
61.1,
59.9,
77.4,
51,
10.9,
92.8,
23.4,
61.1,
49.5,
42.5,
52.5,
22,
23.3,
87.1,
41,
30.6,
84.2,
49.1,
97.5,
19.2,
62.5,
29,
72.3,
73,
68.3,
12.6,
90.8,
65.8,
72.4,
11.9,
74.4,
58.8,
43.4,
31.2,
27.8,
45.6,
46.9,
79.9,
47.3,
90.4,
12.1,
43.6,
67,
47.9,
90.2,
26.2,
66.2,
59.4,
54.5,
38.8,
26.6,
49.1,
76.1,
70,
43.2,
54.8,
54,
89.7,
61.1,
50.3,
43,
70.3,
58.1,
21.1,
62.1,
6.6,
64.4,
37.4,
52.7,
97.3,
62.7,
33.4,
38.1,
96,
69.2,
82.8,
45.7,
28.1,
84.7,
65.3,
20.7,
74.1,
14.5,
54.2,
46,
52.9,
11.5,
19.4,
89,
64,
52.8,
48.2,
15.8,
62,
74.7,
70.3,
17,
16.1,
30.6,
34.3,
73.8,
93.2,
46.9,
78.5,
56.9,
42.6,
98.3,
54.9,
63.5,
76.6,
6.3,
23.1,
71.6,
46,
39.6,
32,
57,
35.2,
58.5,
83,
53.7,
59.1,
72.2,
44.8,
62.6,
64,
44,
36.4,
54.1,
33.9,
51.5,
59.8,
92,
82,
51.4,
62.1,
84.3,
96.1,
49.4,
62.1,
50.2,
67.4,
26.8,
49.7,
37.6,
46.1,
82.4,
43.7,
49.8,
0,
98.8,
41.9,
57.3,
37.8,
75,
68.6,
37.7,
63.7,
40.7,
98.8,
50.5,
86.2,
78.9,
48.8,
67.8,
35.2,
49.6,
68,
67.8,
94.5,
70.4,
8.3,
65.4,
56.7,
44.8,
17.1,
91.4,
94.7,
90.4,
54.1,
59.7,
82.1,
38.4,
52.2,
58.3,
63.9,
30.6,
45,
26,
55.2,
73.5,
89,
50.1,
51.4,
48.7,
81.2,
35.6,
43,
76.3,
90.7,
60.2,
99.3,
23.8,
32.7,
55,
81.7,
70.9,
48.8,
63.3,
55.8,
48.4,
0,
76.2,
38.2,
54.7,
69.7,
98.7,
62.8,
84.9,
95.7,
70.5,
69.9,
79.8,
34.9,
9.3,
98.1,
31.3,
15.8,
55.1,
81.1,
80.9,
84.4,
69,
89.5,
91.7,
52.5,
64.4,
18.9,
64.6,
36.3,
90.6,
53.1,
66.5,
54.2,
81.9,
84.5,
18.2,
58.1,
49.7,
32.4,
40.1,
72.1,
37.5,
37.4,
41.4,
50,
53.9,
56,
24,
49.7,
28.7,
6.9,
10,
58.7,
65.2,
17,
69.1,
10,
27,
50.7,
65.8,
31.5,
57.5,
77.4,
90.9,
84,
62.6,
26.8,
17.4,
58.3,
24.2,
36.9,
64.2,
100.4,
46.5,
31.2,
36.1,
48.9,
26.3,
38.1,
20.5,
92.5,
70.1,
59,
19.6,
79.9,
65.6,
57.5,
69,
11.4,
83.2,
85.1,
73.3,
78.7,
86.6,
64.3,
57.9,
86.6,
41.2,
82.4,
53,
96.3,
79.3,
28.8,
58.8,
62.6,
92.8,
65.9,
25.2,
13,
26.3,
47.9,
39.7,
27.3,
31.6,
36.8,
34.9,
56.3,
38,
34.5,
40.6,
67.8,
100.6,
59.3,
null,
60.6,
56.1,
43.8,
70.7,
99.3,
59,
41.5,
32.6,
40.1,
33.8,
48.7,
93.2,
67.4,
51.1,
62.2,
19.7,
69.6,
36.3,
92.9,
55.8,
51.8,
7.2,
41.1,
29.1,
93.1,
55.9,
92.2,
45,
35.2,
20.8,
49.5,
29.7,
89.5,
52,
45.4,
63.7,
46.8,
46.1,
65.1,
54,
33.7,
42.8,
84.6,
65,
33.8,
80.6,
36,
41.2,
45.1,
75,
41.3,
32.2,
68.8,
40.4,
59.9,
66.7,
22.8,
83.8,
51.6,
42.6,
46.5,
65,
27.7,
66.9,
28.2,
57.7,
21,
55.4,
77.3,
72,
16.4,
62.2,
68,
80.7,
87.4,
53.1,
39.1,
58.9,
61.5,
67.4,
50,
64.8,
27.4,
65.2,
37.4,
66,
65.6,
51.9,
26,
14,
56.9,
78.5,
70,
72.7,
75.5,
38.1,
50.9,
23.8,
80.9,
28.5,
47.3,
71.8,
64.4,
24.4,
44,
52.2,
88.8,
51.8,
45.6,
94.3,
57,
12.4,
78.5,
80,
36,
69.2,
64.2,
35.1,
54.1,
61.6,
40.1,
41.5,
57.8,
31.4,
59.9,
39,
77.2,
73.3,
24.1,
66.3,
53.2,
40.4,
33.9,
76,
33.6,
85.5,
53,
94,
85,
66.3,
40.8,
59,
18.7,
46.8,
28.3,
76,
23.3,
18.3,
60.9,
89.6,
51.9,
53.1,
88.7,
63.2,
28.4,
29.9,
46.1,
62,
48.4,
19.7,
78.5,
59.1,
47.9,
61.7,
56,
64.5,
51.9,
56.8,
56,
61.5,
47,
97.2,
73.5,
34.7,
76.3,
83.2,
76.5,
30.2,
16.5,
77.9,
29.6,
32.4,
50.7,
88.2,
55.6,
47.1,
72.1,
65.8,
75.8,
83.6,
11.8,
0,
14.8,
85,
27.4,
7.5,
31.3,
28.5,
90.8,
28.5,
83.6,
20.7,
73,
34,
49.1,
53.2,
54,
84.5,
77,
65.8,
28.5,
82.2,
5.3,
22.2,
35.2,
60.8,
82.1,
61.6,
49.6,
30.8,
99.7,
87.2,
61.4,
49.8,
66.6,
93.5,
35.2,
70.3,
62.8,
46.1,
56.4,
56.9,
51,
53.2,
42.4,
63.9,
80.8,
87.9,
61,
64.2,
24.5,
33.1,
38.7,
41.4,
35.6,
64.1,
60,
57.5,
29,
74.6,
76.1,
70.2,
37.1,
39,
73,
27,
86.7,
90.3,
19.4,
99.4,
91.2,
16.6,
35.4,
82.7,
0,
80.1,
65.7,
87.1,
49.6,
42.5,
29.2,
26.7,
88.5,
58.8,
75.7,
85.4,
25.8,
53.1,
59.8,
83.2,
88.8,
48.4,
44,
38.9,
82.4,
93.3,
37.1,
26.5,
18.2,
99.1,
48.8,
35.6,
91.7,
67.9,
16.3,
17.6,
61.6,
49.5,
54.8,
28.2,
36.4,
24,
44,
105.4,
41.1,
19.7,
57.8,
38.9,
46.4,
42.7,
101.2,
52.8,
25.6,
56,
59.3,
77.1,
18.5,
74.5,
27.4,
54.6,
16.8,
7.2,
62.7,
64.7,
60.5,
46.5,
30,
88,
48.9,
5,
55.7,
32.5,
53.9,
54.7,
45.3,
37.4,
41.7,
18.3,
69.7,
68.5,
76.9,
86.2,
50.8,
34.1,
55.6,
14.7,
27.7,
49,
33.4,
11.2,
81.4,
63.8,
42.1,
61.6,
25.3,
42.4,
54.1,
21.7,
52.4,
70.9,
60.2,
35.9,
43.9,
52,
76.6,
59.3,
63.1,
30.2,
40,
83,
39,
9.3,
69,
58.3,
43.7,
40.4,
66.2,
37.7,
90.6,
52.3,
90.2,
64.9,
0,
13,
42.1,
6.3,
19,
21.1,
76.8,
43,
44.5,
93.1,
65.5,
61.4,
91.3,
41,
79.1,
51.5,
31.4,
48.7,
58,
86.1,
43,
67.3,
28.4,
89.2,
63.5,
33.6,
22.3,
27.9,
67.2,
100,
20.2,
46,
92.2,
79.9,
60.9,
73,
82.9,
49.7,
31,
46.1,
89.2,
50.7,
65.5,
59.6,
51.3,
52.7,
74.6,
85,
97.4,
36.2,
35.7,
86.7,
47.6,
0,
43.2,
44.7,
59,
43.6,
14.9,
46.8,
86.8,
40.5,
30.4,
34.1,
98.5,
56.2,
26.5,
25.7,
72.5,
50,
10.4,
81,
80,
10,
58.9,
28.1,
37,
56.1,
73.6,
8.4,
75.5,
31.2,
73.2,
80.4,
75.1,
35.8,
14.9,
98.1,
2.3,
91.7,
8.9,
97,
63.3,
47,
81.9,
86,
52.2,
54.6,
97.2,
73.5,
38.1,
56.7,
91.9,
28.4,
95.2,
96.4,
93.5,
66.6,
85.8,
35.9,
69.4,
75,
21.6,
46.1,
38.8,
90.2,
26,
74.5,
54.1,
48.8,
18.2,
87.6,
39.7,
77.6,
27.9,
33.9,
29.9,
74.4,
28.9,
60.5,
75.9,
29.6,
27.4,
82.7,
96.2,
58.1,
41.2,
28.2,
46.9,
31.8,
38.7,
93.4,
63.2,
95.7,
35.3,
42.6,
48.5,
86.8,
45,
70.4,
93.1,
75.8,
40.7,
59.2,
46.8,
72.9,
43.6,
7.3,
46.7,
72,
76.4,
66.7,
29.8,
19.5,
45.2,
32.4,
51.9,
15.5,
90.7,
45.1,
86.6,
42.5,
59.7,
56.7,
90.5,
39.6,
56.2,
93.2,
75,
90.6,
30.9,
82.4,
62,
61.3,
81.2,
64.3,
32,
63,
85.9,
55,
60.9,
55.8,
22.4,
42.7,
75.5,
45.4,
95,
61.2,
97.4,
59.1,
40.9,
40.7,
76.6,
30.4,
44.1,
38.2,
54.7,
44.6,
34.7,
76.6,
69.7,
102.7,
83.1,
35.1,
32.7,
34.7,
44.3,
23.3,
64.3,
72.7,
51.1,
20.6,
11.5,
74.7,
50.2,
42.9,
13.6,
43.8,
82.8,
94.7,
33.1,
34.2,
53.6,
16,
63,
78.5,
75.8,
59.3,
41.1,
18.8,
51.4,
64.1,
34.3,
11,
69.7,
54.4,
41,
24.3,
37.3,
29.4,
37.6,
87,
38.4,
69.3,
79,
33.9,
76.6,
17.9,
71.1,
66.3,
62.2,
51.5,
31,
87.5,
53,
31.2,
61.6,
59,
73.6,
30.3,
82.6,
83.2,
66.1,
28.5,
21.9,
61.7,
46.5,
52.9,
88,
63.6,
51.7,
65.3,
97.2,
25.4,
68.2,
48,
86.7,
71.4,
97.1,
38.1,
80.7,
39.1,
35.4,
34.5,
66.6,
0.7,
66.3,
39.4,
16.4,
48,
38.5,
53,
18.9,
27.8,
83.3,
75.1,
82.7,
28.2,
42.4,
26,
2.2,
45,
67.5,
60.2,
66.8,
41.5,
84.6,
45.2,
24.1,
31.7,
63,
52.4,
14,
52.9,
0,
38.2,
12.2,
86,
81.7,
29.1,
33.2,
79.4,
71.5,
15.9,
90.7,
63.9,
95.5,
34.5,
43,
96.2,
76.3,
48.2,
60.1,
58,
80.2,
31.5,
63.1,
98,
51,
68,
37.1,
82.5,
24.6,
32.5,
32.1,
68.1,
88.7,
30.1,
50.9,
49.9,
97,
88.8,
71.4,
22,
50.7,
60.1,
90.5,
45,
11.3,
78.6,
68.4,
61,
29.3,
62.9,
84.3,
90.7,
83,
60,
92.3,
64.4,
65.7,
54.9,
65.6,
30.6,
24.2,
45,
59.8,
74.1,
58.7,
68.6,
58.2,
80.8,
53.3,
50.6,
58.7,
44.7,
67.4,
28.2,
40.7,
32.3,
46,
57.4,
65.5,
52.8,
18.5,
55.5,
55.9,
76.1,
63.8,
18.5,
17.2,
34,
67.5,
24.3,
71.6,
92.7,
60.5,
43.7,
70.9,
62.9,
57.1,
22.3,
79.6,
19.4,
54.2,
58.4,
96.1,
84.9,
55.3,
49.8,
39.6,
85.9,
74.5,
4.8,
10.8,
68,
80.4,
79.9,
47.7,
38.5,
55.9,
62.6,
33.9,
39.4,
22.2,
57.8,
82.6,
55.7,
70.8,
92.8,
92.3,
76.7,
63,
40.8,
46.1,
43.7,
9.9,
76.6,
44.3,
58.3,
46.7,
65.7,
36.9,
88.4,
33,
57.1,
30.2,
7.5,
24.4,
16.4,
92.9,
23.2,
54.3,
50.9,
12.8,
48.4,
23.2,
36.2,
94.6,
64.8,
16.4,
62.3,
33.5,
47.8,
53.6,
47.5,
50.2,
79.5,
53.5,
28.8,
34,
34.4,
43.8,
74.2,
38.7,
33.2,
50.3,
43,
43.5,
67.9,
66.3,
54.4,
51.3,
74.1,
43.3,
44,
85.4,
31.2,
37,
68.5,
43.3,
37.8,
69,
55.7,
32,
93.7,
59,
92,
78.4,
87.8,
69.7,
76.8,
35,
47.1,
48.7,
6.2,
22,
32.8,
39.9,
62,
47.2,
54.1,
92,
54,
35.1,
16.2,
91.9,
93.9,
76.4,
58.1,
81.5,
70.2,
35.4,
57.6,
35.7,
76.9,
35.1,
38.6,
59.7,
47.4,
90.3,
90.2,
79.7,
45.9,
69.9,
48.7,
64.9,
68.5,
69.4,
98.3,
31.4,
44.5,
51.5,
88.9,
34.1,
31.7,
39.3,
46.5,
66.8,
21.4,
91.4,
89,
89.7,
61.1,
22.9,
36.5,
32.8,
85.7,
31.3,
24.9,
75.2,
21.3,
61.8,
53.1,
48.1,
59.6,
65.9,
19.3,
51.6,
45.4,
71.7,
51.5,
26.7,
77.7,
86.1,
95,
83.4,
56.1,
68.8,
79.8,
31.2,
51.9,
44,
25.4,
57.5,
66.8,
78.6,
15.9,
42.2,
63.7,
67.5,
57.3,
45.7,
16,
80.8,
99,
89,
94.7,
75,
63.4,
56.8,
20.3,
99.4,
46.7,
43.3,
36.3,
61.8,
92.4,
16.4,
68.3,
52.4,
80,
4.8,
63.8,
22.9,
82.9,
64.3,
69.8,
32.5,
24.1,
66.1,
61.9,
51.7,
39.7,
44.8,
67.4,
26.8,
71.2,
24.1,
19.7,
75.4,
78,
50,
78.8,
39.6,
70.1,
61.9,
25.6,
42.6,
37.7,
40.6,
60.8,
85.8,
29.5,
45.9,
44,
60.9,
49,
76.6,
73.1,
62.9,
49.9,
45.9,
57.6,
72.8,
12,
43.1,
80.8,
55.1,
52.9,
61.2,
43.8,
39.7,
76.7,
67.8,
71,
37.3,
78.4,
87.9,
7.4,
72,
22.3,
82.7,
98.9,
35.6,
100,
80.9,
56.7,
92.4,
23.8,
63.6,
11.9,
62.7,
97.8,
70.4,
95.2,
43.6,
96.8,
52.1,
51.8,
77.2,
51.6,
83.1,
42.9,
38.5,
84.6,
25.9,
67.1,
35.4,
46.6,
72.1,
72.4,
47,
37.8,
4.9,
66.7,
50.6,
50.5,
94.6,
35.6,
55.4,
60.7,
58.8,
68.8,
74.5,
35,
69.9,
32.7,
80.3,
36.7,
44.4,
28.3,
68.3,
44.6,
81.6,
52.1,
42.7,
33.4,
8.4,
34.5,
78.4,
52.1,
43.9,
14.8,
22.8,
87.7,
34.6,
47.4,
41,
52.8,
84.1,
70.4,
79.4,
54.3,
76.5,
80.7,
74.2,
60.3,
38.9,
32.4,
59.7,
84.2,
15.4,
59.5,
90.8,
70.6,
90.4,
20.3,
70.6,
62.7,
91,
68.6,
91,
53.2,
42.6,
73.5,
0,
42.1,
91,
73.2,
16.8,
73.5,
10.6,
92.8,
34.6,
56.2,
67.5,
74.1,
79.2,
37.7,
26.7,
82,
58.6,
33.5,
67.9,
47.7,
42.9,
95.3,
61.2,
37.4,
66,
93.9,
30.7,
42.2,
16.2,
40.1,
1.4,
64.9,
49.4,
8.7,
8,
75.3,
21.1,
43.4,
72.4,
40,
57.1,
0,
63.9,
27.1,
8.8,
82.4,
7,
74.2,
60.8,
72.1,
77.7,
87.6,
74.6,
13.9,
72.9,
32.4,
56.5,
72.8,
76,
85,
68,
70.9,
55.2,
10.4,
62,
63.5,
36.8,
78.9,
41.6,
48.9,
40.4,
97.7,
89,
53.5,
0.3,
15.6,
62.9,
59.4,
58.8,
51.2,
44.5,
28.3,
90.9,
76.3,
52.7,
32.9,
51.5,
80.8,
74.6,
47.6,
73.4,
74.3,
39.9,
44.8,
68,
86.1,
46.7,
70.2,
30.5,
83.4,
44.9,
16.9,
37.3,
106.6,
58.6,
48.1,
58.9,
60.1,
79.6,
61.1,
29.6,
25.3,
20.7,
36.4,
37.1,
23.8,
51.4,
53.7,
89.7,
55.5,
32.4,
26.6,
29.8,
91.1,
89.9,
73.6,
53.7,
55.2,
33.1,
81.4,
75.8,
74.5,
66.9,
65.8,
65.8,
94.1,
65.7,
74,
18.6,
64.3,
0,
60.9,
50.9,
50.2,
73.7,
89.4,
99.6,
51.2,
61.5,
55.9,
57.5,
47,
51.3,
26.5,
93.2,
83.1,
27,
61,
55.1,
43.2,
69.3,
74.9,
54.2,
59.1,
42.9,
90.5,
25.2,
57.6,
28.3,
75,
82.6,
34.5,
84.5,
55.2,
44.6,
72,
49,
91.6,
53,
68.3,
38.2,
32,
42.3,
93,
95.2,
82.7,
89.9,
56.7,
55.5,
68.9,
80.3,
26.6,
59.3,
35.8,
29.1,
99.8,
59.5,
68.9,
65.2,
48.6,
73.9,
51.2,
39.3,
33.9,
61.4,
75.4,
33.1,
60.9,
37.8,
69.9,
22.2,
75.7,
82.1,
49,
94.1,
53.2,
46.7,
92.8,
19.2,
88,
74.9,
91.4,
49.1,
76.1,
71.3,
43.8,
94.1,
54.2,
42.2,
84,
65.4,
37.7,
53.4,
97.7,
52.9,
64.2,
84.1,
12.8,
58,
77.2,
19.9,
76.4,
87.1,
93.9,
45.9,
50.1,
93.3,
41.5,
78.7,
34.8,
74.5,
88,
58.9,
32.2,
0,
39.9,
83.2,
51.7,
82,
84.4,
58,
12,
28.6,
68.8,
103,
95.6,
45.3,
70.8,
81.7,
47,
95,
68.3,
76.1,
72.7,
98.6,
60.8,
87.6,
37.2,
40.5,
55.9,
60.8,
32.5,
68.2,
62.5,
84.6,
42.5,
78.8,
29.5,
38.3,
77.5,
40.3,
24.5,
11.6,
55,
80.3,
59.6,
53,
46.5,
44.1,
90.7,
28,
39.8,
80.6,
58.5,
61.1,
19.1,
46.3,
49.5,
83.1,
25.9,
20.4,
82.6,
48.4,
82.7,
39.6,
91.6,
70.3,
66.4,
92.8,
52.8,
33.9,
84.9,
82.3,
38.4,
47.4,
28.1,
44.3,
30.9,
32.6,
96.5,
70.3,
21.7,
3.5,
55.1,
64.3,
29.1,
7.2,
63.6,
32,
44,
56,
29.7,
13.2,
100.7,
73.3,
52.8,
4.5,
19.9,
56.6,
48,
96,
46,
56.4,
83,
17.4,
7.8,
12.8,
42.8,
67.3,
21.3,
51,
72.4,
46.5,
45,
53.8,
74.6,
80.3,
69.8,
68,
83.9,
63.7,
0.3,
59.2,
29.1,
63.4,
82.6,
58.5,
53.2,
30.1,
53.2,
73.9,
23.1,
79.6,
82.7,
35.5,
72.1,
26.8,
68.4,
77.1,
60,
40.5,
57.6,
8.8,
18.1,
48,
29.3,
32.7,
39.8,
47.7,
64.9,
24.4,
88.5,
40.3,
30.9,
48.9,
50.2,
81.3,
22,
6.1,
58.9,
26.8,
33.9,
21.7,
53.2,
90.6,
80.1,
31.7,
70.9,
26.6,
93.1,
83.8,
36,
66.9,
62.4,
29.6,
12.8,
86.2,
98.9,
44.4,
93.6,
29.6,
16.6,
93.6,
84,
65.1,
51.3,
21.2,
96,
78.2,
52.1,
81.1,
76.3,
61.8,
22.7,
27.9,
24.8,
64.7,
43.6,
23.4,
16.9,
57.7,
82.1,
34.7,
68.3,
35.9,
67.5,
54,
74,
15.9,
69.1,
11.1,
44.3,
41.3,
5.3,
91.3,
82.8,
29,
49.1,
78.9,
46.9,
40,
80.4,
96.9,
25.4,
31.3,
77.6,
9,
99.8,
81.9,
62.9,
52,
83.3,
17.2,
51.8,
76.1,
51,
0,
4.2,
81.9,
54.1,
76.8,
59.1,
72.8,
45,
55.8,
49.8,
54,
48.7,
88.9,
56.5,
88.5,
52.9,
12.8,
44.9,
86.6,
97.3,
16,
71.9,
89.7,
53.1,
95.4,
75.6,
81.4,
28.2,
31.4,
67.1,
53.6,
3,
58.3,
71.7,
33.4,
70.7,
39.6,
40.6,
62.7,
59.4,
10,
84.3,
60.3,
17.9,
57.1,
27.2,
75.3,
91,
74.2,
58.6,
56,
34.6,
81.4,
43.1,
72.1,
73.7,
33,
41.3,
38.3,
86.1,
43.8,
48.1,
32.2,
91.7,
81.8,
88.5,
89.9,
34.1,
31.9,
58,
2.6,
51,
27.3,
61.9,
64.5,
84.5,
10,
47.6,
87.9,
50,
67.5,
32.5,
79.6,
63.2,
35.7,
80.1,
36.6,
31.7,
55,
77.4,
50,
74.7,
34.2,
49.3,
64.6,
64.2,
64.1,
12.4,
52.3,
57.6,
85.6,
34.3,
92.3,
76.4,
77.7,
91.8,
71.6,
9.7,
65.9,
0,
70.1,
72.9,
70.1,
25.7,
66.6,
92.1,
64.3,
7.1,
56.3,
56,
63.1,
64,
56.5,
56.4,
75.1,
71.2,
42.9,
46.3,
40.2,
64.1,
74.4,
70.8,
52.4,
84.1,
40.5,
29.4,
53.9,
89,
54.8,
42.4,
17.8,
74,
64,
85.7,
83.9,
26.2,
55.6,
41.2,
77.9,
72.9,
21.4,
74.8,
77.1,
34.9,
58.4,
51.1,
82.6,
25.7,
43.7,
35,
59.2,
78,
73.4,
83.4,
49.2,
40.7,
68.7,
59.2,
41.7,
21.1,
39.8,
95.8,
59,
70.9,
28.7,
69.5,
96.3,
48.8,
97.9,
96.5,
86,
43.4,
9.5,
48.2,
88.6,
36.9,
65.1,
27.9,
99.6,
33.5,
35.7,
40,
0,
37.6,
11.1,
42.8,
80.8,
54.4,
95.8,
33.2,
6.3,
48,
75.9,
40.6,
39.3,
73.4,
40.3,
19.8,
81.4,
49.3,
10.7,
40,
65.7,
31.4,
0,
62.9,
63,
59.9,
63.5,
38.9,
71.5,
28,
50.2,
92.9,
71.4,
83.1,
12.6,
44,
54.9,
61.6,
37.5,
87.8,
77.3,
92.6,
31.9,
85.7,
88.3,
30.3,
54.7,
40.4,
18.5,
73.7,
43.1,
80.6,
72.3,
31.2,
22.8,
4.4,
60.9,
72,
25.7,
20.6,
57.8,
39.8,
30.8,
63.2,
95.7,
61.4,
66.7,
62.7,
50.2,
40.9,
53.9,
41.6,
85.6,
31.3,
36,
20.3,
68.3,
38.4,
53,
8.9,
58.4,
47.4,
48.8,
6.5,
59.5,
58.9,
59.3,
81.7,
74.8,
54.1,
73.6,
26,
81.2,
54.8,
77.3,
76.6,
78.6,
78,
71,
75.5,
56,
46.7,
60.4,
50,
46.6,
49.6,
83.2,
20.7,
75,
94.9,
40.2,
24.7,
6.3,
94.9,
83,
70,
42.9,
86.3,
74,
85.6,
77.1,
69.4,
39.9,
72.5,
72.5,
16.1,
33.3,
70.5,
23.1,
58.4,
42.2,
27,
13.2,
22.1,
70.5,
53.4,
38.6,
88.4,
95.1,
45,
28.2,
53.1,
76.7,
83.6,
43.7,
68.2,
53.7,
31.6,
0,
61.3,
76.1,
74.8,
35.8,
25.3,
98.1,
84.7,
83.8,
14.9,
67,
85.3,
61,
38.2,
72.1,
71,
83.5,
84.6,
72.3,
85.5,
51.1,
36.9,
48.3,
72.6,
93.1,
49.7,
70.1,
72.7,
3.5,
63.2,
37.6,
21.5,
6,
57.6,
69.2,
73.6,
47.6,
27.4,
61.6,
49.8,
74.1,
42.4,
44.7,
89.6,
67.5,
41.5,
71.5,
43.8,
70,
29.1,
79.1,
23.7,
74.3,
93.3,
34,
61.1,
57.5,
51.1,
29.3,
60.6,
40,
86.3,
60,
50.5,
50.9,
76.4,
43.1,
68,
21.2,
47.8,
44.8,
15,
29,
88,
44.4,
81.8,
78.2,
64.3,
39.7,
71.4,
49.4,
82.5,
7.5,
46.7,
45.6,
63.1,
58.3,
91.3,
78,
23.8,
70.7,
6.1,
12.6,
56,
41.2,
28.3,
36.1,
74.9,
71.5,
36,
77.3,
30.8,
80.6,
67.1,
91.5,
58.2,
51.5,
41.6,
13,
53.6,
58,
76,
13.6,
93.4,
100.5,
70.5,
31.4,
35.4,
75.5,
16.8,
64.6,
77.1,
51.3,
68.7,
93.8,
28.8,
41.6,
29.4,
58.8,
18.8,
91.1,
74.7,
36.4,
45.3,
59.9,
14.1,
81.5,
49,
83.4,
62.2,
90.9,
33.5,
31,
45.2,
61.6,
81.4,
92.7,
26.6,
43.9,
84.6,
17.8,
61.8,
49.3,
4,
65.8,
32.2,
78,
40.3,
64.4,
50.4,
70,
89.5,
54.3,
0,
27.6,
73,
40,
45.6,
50.5,
62.7,
84.9,
21.6,
29.5,
92.1,
93.6,
61.8,
3.8,
72.7,
28,
76.4,
84.3,
70.2,
72.4,
29.3,
54.1,
84.4,
50.4,
60.1,
0,
52.8,
0,
63,
39.3,
41.4,
40.9,
79.1,
29.4,
72.4,
91.9,
44.9,
70.6,
26.9,
40.5,
73.9,
71.6,
2.5,
79.9,
22,
47.2,
35.2,
66.2,
56.7,
28.9,
31,
49.4,
70.7,
71.1,
58.3,
19.1,
58,
50.1,
66.8,
80,
23.5,
32,
23.5,
33.5,
10.8,
33,
63.5,
33.5,
20.4,
81,
66.4,
45.6,
63,
59.1,
44,
72.6,
70,
65,
45.1,
69.2,
100.7,
41.7,
49.3,
49.9,
61,
79.9,
36.9,
98.3,
88,
14.8,
48.1,
1.8,
61,
32.2,
63.5,
17.1,
8.1,
68.9,
50.3,
58,
2.3,
79.8,
85.1,
45.6,
74,
20,
45.5,
79.7,
60.4,
62.7,
78.1,
26.1,
43.7,
71.1,
30.3,
52.6,
66,
56.2,
54.2,
54.2,
0.9,
50.4,
51.1,
77.2,
71.6,
79.3,
32.1,
52.6,
90.3,
44.8,
63.1,
80.3,
35.6,
66.7,
57.8,
69.6,
67.6,
40,
55.9,
35,
65.7,
53.6,
43,
9.2,
76.2,
64.6,
62.5,
77.7,
5.3,
49.4,
66.8,
58.1,
67.1,
72,
18.7,
26.8,
50.9,
88.1,
64.1,
77.8,
30.8,
83.2,
29.3,
55.8,
66.9,
77.2,
48.1,
44.9,
26.7,
47.1,
18.4,
32,
50.6,
63,
49.9,
78.5,
67.3,
88.8,
60.1,
94.9,
74.3,
50.3,
53.8,
21,
54.8,
21.7,
68.4,
33.7,
60.6,
79,
65.6,
56.8,
50.8,
88.2,
32.7,
54.1,
26.9,
26,
43.6,
66.5,
35.3,
43.2,
61.4,
39.9,
55,
35.3,
39.5,
51,
40.5,
78.2,
0,
51.5,
51.7,
89.3,
28.4,
23.9,
46.9,
29.2,
29.7,
17.9,
0,
55,
40,
77.1,
42.3,
47,
32.7,
76.9,
71.1,
59.1,
59.6,
27.4,
68.3,
17.6,
61.7,
75,
57.6,
55.5,
59.2,
50.3,
45.5,
55.4,
69.9,
52.5,
54.7,
48.2,
76.8,
83.2,
40.9,
87.7,
39.5,
68.7,
52.3,
72,
17.1,
39.5,
55.2,
48.8,
64.3,
95.7,
41.1,
52.1,
39.5,
79.3,
89.2,
68.8,
20.8,
90.6,
43.5,
31.3,
37.5,
70.6,
68.4,
47.1,
77,
60.6,
43.6,
50,
0,
84,
22,
50.5,
49.3,
72.8,
33.3,
23.2,
6.5,
60.4,
50.8,
31.8,
36.3,
77.4,
49,
40.2,
29,
37.1,
0,
76.7,
49.8,
79.2,
85,
41,
54.8,
100.2,
51.2,
63.1,
66.5,
35.3,
39.1,
35.9,
15.2,
58.8,
32.1,
95.2,
54.7,
69.3,
13.1,
3.5,
84.6,
38.8,
50.7,
1.5,
46,
11.2,
65.6,
84.4,
97.1,
47.7,
35.3,
81,
21.7,
40.9,
44.9,
63.4,
82.8,
33.9,
53.9,
40.1,
null,
96.2,
75.4,
7.5,
38.5,
7.7,
16.1,
37.1,
31.1,
46.7,
46.9,
95.6,
44,
24.8,
79.7,
61.9,
29.3,
65,
46.7,
70.8,
56.2,
18,
37.7,
55,
64.5,
39.6,
22.2,
72.2,
29.7,
49.2,
19.4,
65,
13,
11.6,
1.9,
30,
13.5,
80.5,
48.6,
104.6,
48.4,
55.7,
49.2,
59.8,
58.6,
46,
76.9,
26.8,
0,
43.5,
68.3,
46.9,
22.5,
90,
90.3,
50.1,
36.1,
99.8,
82.4,
97.8,
80.6,
78.8,
64.9,
66.7,
28.7,
22.3,
53.8,
72.3,
6.4,
34.7,
26.4,
48.4,
85.1,
48.5,
79.4,
80.8,
57.5,
67.8,
87.7,
55.9,
95.4,
31.7,
47,
60,
77,
99.5,
57.7,
76.6,
49.5,
58,
59.3,
69.4,
57.2,
67.8,
64.2,
38.8,
11.4,
65,
16.2,
13.1,
79.2,
37.8,
62.2,
89.4,
86.7,
81.8,
8.9,
15.7,
29,
25.8,
36.5,
82.8,
32.3,
70,
33.8,
18.8,
90.1,
73,
56.4,
23.6,
70.6,
53.4,
60.3,
84,
23.4,
47.6,
38.3,
20,
54.3,
61.2,
77.2,
65.4,
48.8,
56.2,
51.3,
70.3,
74,
39.5,
58.4,
77.6,
66.7,
34.5,
21.7,
61.4,
55.1,
89.3,
58.1,
59.9,
22.7,
64.9,
26.4,
12.3,
61.1,
44.5,
63.6,
18.6,
77,
98.8,
60.3,
53.3,
26.4,
46.6,
65.9,
89.7,
80.3,
61.9,
90.7,
36.6,
49.8,
15.7,
78.2,
45.2,
54.7,
74,
22.9,
68.8,
38.4,
88.8,
74.7,
33.8,
72.4,
72,
56.1,
42.7,
43.8,
54.4,
89.4,
32.9,
53.4,
40,
65.6,
52.7,
60.1,
87.5,
70.4,
28.5,
49,
79.3,
49.9,
83.8,
61.3,
57.1,
62.1,
39.9,
82,
50.9,
93,
74.3,
35.4,
52.9,
14.5,
87,
88,
49.9,
48.6,
31.3,
87.2,
63.3,
74.8,
85.4,
27.7,
79.9,
58,
24.6,
85.5,
33.6,
72.8,
70.5,
60.6,
63,
29.4,
100.9,
31.2,
37.8,
37.1,
42.8,
56.5,
72.6,
52.3,
35.8,
74.5,
53.1,
40.3,
5.2,
83.9,
53.1,
74,
67.5,
48,
7.9,
55.8,
32.8,
23.9,
78.4,
35.6,
84.6,
81.1,
39.7,
72.9,
63.2,
49.8,
47.4,
49.7,
46.7,
84.1,
20.4,
61.2,
60.4,
59,
83.5,
24.8,
85.9,
8.9,
48.6,
50.2,
66.7,
45,
24.7,
39,
50,
23.3,
25,
13,
61,
92.8,
32.8,
70.5,
97.2,
0.4,
91.7,
79.5,
52.2,
46.3,
73.1,
64.8,
47.8,
52.4,
39,
71,
54.2,
50.1,
46.5,
75.1,
69.3,
64.3,
38.9,
48.7,
70.5,
33.3,
66.2,
24.5,
41.7,
81.4,
53.4,
54.4,
74,
4,
58.6,
37,
68.2,
48.7,
46.2,
85.2,
37.6,
46.9,
96.9,
70.3,
62.8,
90.3,
49.1,
34.3,
89.6,
72.6,
56.7,
82,
50.1,
19.3,
58.7,
12.1,
33.6,
93.3,
58.7,
94.9,
94.8,
90,
92,
49.8,
96.6,
90.7,
54.6,
47.6,
65.4,
69.8,
39,
1.3,
71.9,
40.8,
15.2,
46.5,
79.6,
72.9,
0,
49.4,
55.1,
10,
34.7,
41.3,
49.1,
87.6,
45.2,
80.1,
63.2,
91,
33.3,
36.1,
49.5,
69.7,
95,
66.5,
34.8,
77.4,
33.1,
4,
72.1,
16.5,
19.2,
34.6,
61.5,
16.1,
68.5,
16.9,
30.5,
35.4,
42,
53.9,
12.8,
84.3,
91,
67.4,
50,
88.6,
50.3,
8,
82,
75.2,
95.5,
45.8,
12.3,
71,
68,
63.9,
64.8,
68.4,
14,
31.4,
7.8,
74.1,
77.4,
53.6,
49.6,
38.5,
64.5,
54.2,
48.9,
93.4,
66.8,
87.4,
82.1,
27.3,
97.6,
54.8,
9.6,
4.9,
88,
81.8,
34.4,
50.2,
57.7,
70.1,
49.2,
46.5,
62.1,
41,
25.9,
103.3,
73.3,
12.8,
0.3,
49.7,
52,
59.7,
35.7,
5.5,
21.5,
51,
93.7,
27.9,
82.6,
46.7,
10.7,
35.6,
48.2,
53.8,
77.8,
56.3,
45.1,
80.3,
74,
85.9,
78.7,
26,
81.5,
19.1,
53.7,
88.4,
70.6,
41.3,
72.8,
61.8,
92.3,
20.5,
67.3,
48.3,
56.2,
35.2,
61.5,
29.2,
70.9,
89.5,
36.1,
86.2,
48.7,
80.1,
28.3,
33.3,
51.6,
55.2,
24.7,
67.6,
54.4,
69.5,
0.8,
67.4,
78.6,
74.1,
73.9,
60.2,
21.8,
51.9,
45.3,
94.9,
81.4,
18.1,
63.9,
92.3,
34.5,
61.4,
71.1,
37.4,
25.4,
95.5,
89.4,
22.6,
61.5,
70.9,
94.2,
95.1,
58.9,
72.8,
32,
89.4,
75.7,
42.1,
21.7,
77.8,
43.2,
86.9,
85.3,
62.7,
40.3,
6.2,
22.5,
38.9,
62,
68.4,
93,
42.7,
23.6,
91,
21.5,
51.2,
41.6,
22,
76.9,
83.4,
80.1,
49.3,
72,
71.6,
70.1,
59.8,
55.8,
53.9,
68.3,
27.3,
10.1,
97.1,
51.6,
62.1,
67,
65,
73.2,
82.2,
53.2,
113.5,
80.9,
2.9,
36.4,
43.7,
66.7,
85.4,
47.9,
59.4,
46.5,
84,
78.8,
56.3,
52.6,
77.4,
64.6,
46.2,
96.1,
9.5,
51.5,
42.8,
50.6,
76.1,
80.2,
58.2,
61.1,
39.7,
59.1,
85.8,
81.1,
51.4,
88.4,
68,
58.7,
36.6,
33.9,
42.3,
12.9,
53.8,
62.5,
72.5,
48.5,
96.7,
10.1,
85.7,
57.7,
28.9,
17,
87,
36.8,
81.8,
67.5,
13.7,
28.3,
45.7,
59.2,
31.7,
55.2,
43,
59.9,
35.7,
72,
48.1,
26,
44.2,
88.5,
95,
85.9,
76.1,
48.4,
52.7,
38.7,
79.5,
88.8,
29.1,
40.8,
82.3,
80.7,
46.8,
73.7,
72.2,
49.8,
48,
30.8,
61.5,
48.6,
26.4,
28.9,
62.8,
64.6,
13.4,
89.1,
11.9,
51.3,
40,
95.8,
42.2,
20.1,
51.9,
83.2,
50.5,
60.9,
35.3,
34.3,
66.3,
54.1,
58.8,
61.4,
68.6,
32.6,
34,
27,
94.1,
36.7,
57.6,
19.9,
32.4,
41.5,
45.2,
48.5,
64.6,
55.3,
58.9,
53.2,
17.1,
61.2,
38.2,
13.9,
33.1,
75.1,
54.9,
65.6,
55.8,
76.8,
55.9,
55.7,
32.8,
30.6,
29.1,
45.9,
73.5,
57.8,
61.2,
44.8,
64,
60.2,
75.1,
65.9,
19.6,
55.2,
89.9,
39.6,
23.5,
11.4,
69.2,
87.2,
56.6,
84.6,
23.2,
60.3,
52.3,
58.7,
6.7,
74.9,
88.8,
85.3,
77.6,
70,
65.5,
52.6,
75,
41.8,
88.5,
34.3,
86.5,
78.3,
4.1,
93.1,
59.2,
21.1,
90,
24.3,
15.4,
66.5,
66.6,
74.5,
88.1,
71.9,
85,
55.1,
84.3,
42.1,
27.2,
48.3,
1.1,
84.5,
68.8,
71.7,
30.6,
55.3,
52.8,
31.7,
82.6,
46.6,
41.6,
4.1,
83.2,
43.9,
34.5,
60.4,
40.3,
71.1,
69.2,
57.5,
48.7,
46,
48.8,
78.1,
31.9,
73.4,
75.3,
48.3,
72.7,
98.8,
16.9,
86.3,
55,
82.4,
24.1,
55,
20.8,
93.2,
75.6,
69,
65.2,
7.4,
62.8,
22,
52.8,
66.2,
52.2,
83.7,
32.1,
71.2,
79.7,
83,
76.2,
37,
54.2,
17.7,
79.2,
44.7,
53.1,
53.3,
47.8,
39,
73.3,
31.2,
3.6,
21.5,
45.8,
83.1,
92.8,
84.1,
94.3,
79.5,
47.2,
29.6,
13.3,
75.1,
10.1,
8.8,
67,
66.8,
65.7,
55.2,
83.6,
38.3,
81.4,
91.7,
50.4,
30,
53.3,
97.9,
75.7,
83,
62.3,
40.5,
63.7,
80.1,
64.6,
3.7,
46.6,
25,
89.6,
56.5,
64.2,
62.3,
51.5,
65.3,
68.8,
68.2,
5.2,
63.2,
31.9,
61.5,
50.3,
19.2,
73.7,
21.2,
36.1,
19.4,
80.5,
24.2,
63.6,
78.1,
71.1,
44.2,
82.7,
53.8,
27.2,
89,
65.7,
47.8,
71.9,
38.2,
91.8,
83.3,
38.4,
0.5,
20.3,
56.9,
95.6,
86.4,
71.2,
61.8,
81.9,
75.8,
48,
47.7,
88,
34.1,
55.8,
47.7,
28,
62.6,
87.3,
71.6,
79.1,
49.9,
68.6,
20.8,
22.1,
64,
40,
53.6,
81.6,
18.3,
49.3,
28.4,
30.5,
69.3,
19.1,
58.8,
36,
82,
19.9,
74.4,
46.9,
52.1,
56.6,
32.5,
82.4,
22.8,
56.3,
15.8,
74.5,
70.1,
57.4,
37,
54.2,
17.4,
51.3,
71.9,
80.6,
50.7,
47.4,
76.8,
37.6,
66,
19.5,
90.2,
58.2,
83.4,
29.9,
17,
72,
82.3,
49.7,
94.8,
81.5,
37.8,
60.1,
66.4,
3,
41.5,
80.9,
63.7,
37.8,
53.7,
79.4,
65.2,
73.7,
27,
50.5,
22.4,
70.1,
52.7,
32.6,
57.5,
50.3,
77.8,
92.6,
47,
62.7,
71.3,
57.2,
70.2,
93.8,
54.8,
41.8,
39.5,
82.5,
38.7,
69.9,
48.5,
29.1,
34.1,
77.6,
30.2,
62.9,
15.6,
63.1,
56.4,
76.6,
87.5,
90.9,
36.4,
46.7,
5,
65.1,
23,
75.5,
89.6,
62.5,
83.3,
1,
32.4,
79.1,
63.8,
64.5,
33.8,
45.8,
3.3,
93,
70.9,
29.2,
39.8,
81.4,
89.5,
87.7,
68.6,
32.8,
53.9,
33,
53.9,
70.1,
37.7,
40.8,
10.1,
90.6,
47.7,
76.8,
9.6,
54.1,
51.9,
48.2,
64,
86.4,
64.5,
65.1,
92.1,
62.4,
75.1,
46,
78.2,
55.7,
23,
81.7,
51.1,
78.4,
28.3,
31,
26.7,
32.1,
42.2,
95.9,
72,
97,
93,
49.4,
28.3,
69.5,
61.2,
12.5,
86.8,
28.1,
85.7,
97.3,
75.4,
96.9,
76.2,
92.1,
78,
57.1,
12.3,
33.7,
51,
70.8,
72,
12.6,
12.2,
55.4,
0.3,
51.7,
34.2,
66.6,
81.3,
46.8,
51.2,
95.6,
32.4,
49.9,
83.7,
17.1,
89.6,
100.2,
42.2,
74.6,
61,
62.2,
68.2,
54.1,
86.2,
66.1,
37.4,
41.4,
38.2,
83.4,
100.1,
44,
21.1,
18.4,
38,
48.5,
56.3,
85.5,
22.6,
14.8,
90.7,
52.2,
74.4,
87.2,
78.1,
95.6,
73.1,
6.6,
75.2,
93.8,
68,
75.9,
67,
55,
45.5,
83.3,
62.2,
84.7,
66.4,
42.4,
85.2,
38,
42.4,
40.3,
63.6,
82.7,
80.7,
37,
67.8,
67.4,
57,
70.1,
52.4,
75.8,
75.5,
93.2,
66.7,
26.7,
53,
17.1,
2.9,
62.7,
74.6,
35.7,
58.3,
49.7,
79.5,
71.5,
86.7,
58.7,
91.9,
6.3,
83.9,
48.5,
76.6,
84.4,
78.1,
76.3,
57.6,
16,
82,
58.4,
73.6,
73.9,
82.3,
57.6,
15.1,
31.6,
22.2,
50.5,
28.1,
35.1,
52.5,
58,
0,
52.9,
73.1,
87.8,
60.4,
10,
4,
45.4,
42.9,
21.9,
8.3,
10.5,
59.3,
23.9,
36,
54.7,
27.6,
38.6,
19.3,
41.6,
38.5,
55.1,
88.7,
25.4,
49.1,
67.1,
80.4,
95,
48.6,
50.8,
61.4,
42.3,
38.4,
11.1,
27.9,
49.5,
61.1,
70.1,
52.6,
42,
89.7,
60.6,
79,
44.4,
82.1,
36.6,
92.1,
69.1,
41.7,
55,
49.8,
70,
83.4,
81.7,
62,
38.8,
68.3,
82.6,
45.1,
94.6,
89.8,
81.8,
72.6,
49.9,
83.2,
84,
83.3,
48.4,
68.4,
54.3,
24.8,
53,
60.8,
44.3,
92.8,
29.4,
22.8,
34.6,
33.1,
93.7,
23,
92.3,
54.9,
95.8,
69.5,
92.9,
5.3,
46.5,
38.1,
39.8,
81.9,
55.6,
88.7,
19.8,
72,
64,
66.2,
20.9,
76,
48.8,
57.5,
93.2,
70.7,
89.9,
52,
7.7,
52.7,
69.2,
35.6,
59.4,
78.3,
64.2,
43.2,
1.3,
43,
52.3,
49.9,
23.2,
39.2,
86.2,
62.6,
72.9,
57.6,
94.3,
61.8,
29.2,
58,
68,
53.7,
62.9,
80.1,
6.3,
30.8,
42.2,
72,
86.2,
81.9,
45.8,
41,
79.7,
38.5,
29.4,
54.4,
37.1,
38.8,
73.7,
29.6,
12,
82.6,
15.8,
46.3,
77.3,
17.6,
16.2,
92,
56,
72.6,
63.6,
27.2,
84.9,
48.3,
22.5,
61,
87.6,
96.5,
92.4,
27,
50.8,
67.1,
57.3,
68.7,
79.9,
73,
28.3,
37.5,
54.9,
75.7,
17.8,
62.7,
73.6,
77.4,
86.9,
29.6,
62.5,
0.2,
68,
36.3,
52.1,
55.6,
70.8,
29.6,
25.6,
44.8,
63.2,
40.3,
51.9,
45.5,
83.4,
2.1,
91.1,
39.1,
61.6,
60.3,
70.9,
74.4,
4.3,
26.4,
46.5,
30.2,
71.4,
47.7,
25.1,
47.1,
66.5,
83.5,
22.4,
48.6,
57,
7.4,
77.5,
36.5,
82,
90.2,
90.9,
22.9,
64.9,
40.2,
8.2,
47.7,
69.2,
91.3,
76.7,
62.8,
81.1,
85.6,
33,
60.4,
28,
36.4,
33.8,
66.8,
46.6,
14.8,
46,
59.5,
42.8,
35.8,
16.7,
26,
3.4,
52.2,
37.1,
22.2,
23.7,
66.4,
8.6,
10.5,
32.9,
87.2,
40,
83.8,
79.7,
44.8,
28.7,
58.3,
52.2,
59,
7,
15.3,
19.8,
49,
92.2,
73.3,
97.7,
17,
60.3,
38.4,
68,
57.7,
11.1,
48.6,
34.8,
67.1,
75,
27.9,
49.3,
48.9,
76,
79.6,
62.4,
77.4,
26,
59.2,
53.3,
35.4,
18.2,
73.9,
42.8,
66.6,
89.8,
59.1,
48.4,
51.5,
38.5,
39.8,
94.3,
86.1,
84.5,
63.3,
52.8,
31.2,
36.6,
70.3,
54.1,
0.2,
20.6,
89,
54.6,
68.9,
18.2,
84.9,
55.3,
94.7,
61.1,
74.3,
56.6,
66,
30,
67.6,
87.6,
60.6,
25.7,
77.6,
72.4,
78.1,
60,
65.4,
78,
34.4,
66.7,
33.3,
29.5,
7.7,
52.2,
80.9,
83.8,
88.1,
45.9,
94,
91.2,
38.5,
33.8,
40.9,
77.9,
83.9,
80.4,
68,
74.2,
63.7,
52.1,
91.8,
53.9,
41.5,
26.3,
31.7,
53.7,
96.5,
63.4,
25.9,
74.7,
98.7,
98.7,
31.9,
77.8,
37.2,
30.7,
9.5,
30.2,
40.3,
84.2,
54.4,
83.6,
62.1,
90.6,
76.7,
25.2,
76.5,
66,
35.9,
27.7,
90.7,
74.3,
44.8,
87.7,
71.9,
60.9,
3.7,
99.7,
68.7,
78.5,
95.4,
28.6,
65.3,
78.1,
81.4,
81.7,
70.5,
64.7,
76.2,
34.2,
59.7,
66,
43.6,
45.3,
45.2,
55.9,
5.9,
32.6,
73.1,
48.2,
81.4,
51.8,
63.6,
64,
48.3,
43.1,
72.5,
38.9,
64.1,
43.7,
18.3,
34.4,
90.2,
91,
48.5,
92.4,
33.4,
58.7,
66.7,
78.3,
52.2,
82.8,
30.8,
71.1,
26.2,
52.2,
56,
79.1,
18.7,
47.3,
36.8,
26.5,
66.8,
80.4,
31.9,
71.7,
80.3,
66.6,
83.4,
49.2,
33.3,
53.5,
23.7,
84.5,
49.9,
11,
68.9,
41.1,
88,
40,
49.4,
7.6,
75,
65.2,
52,
39,
48.2,
44.2,
58.3,
46.6,
76,
75.6,
87.8,
25.9,
48,
40.4,
43.2,
8.6,
70.2,
64.7,
39.4,
46.9,
70.3,
79.9,
85.6,
72.9,
45.3,
58.2,
58.9,
32.9,
67.9,
58.6,
41.4,
34.2,
43.7,
10.6,
59.9,
52.4,
32,
45.8,
19.6,
27,
90.6,
96.8,
52.9,
36.2,
45.4,
27,
0,
41.8,
64.2,
43.1,
46.4,
70.6,
51.1,
36.7,
31.3,
63.3,
38.1,
82.5,
56.8,
38.1,
78.2,
78,
78,
68.3,
71.3,
61.2,
71.1,
20.7,
80.6,
87.5,
38,
54.5,
44.4,
99.6,
32.8,
63.4,
10.6,
70.7,
66,
27.8,
69.5,
65.4,
64.3,
76.5,
41.7,
65.1,
65.3,
39.1,
61.4,
98.5,
57.2,
43.1,
72.5,
45.4,
75.9,
21.3,
75,
24.3,
72.5,
27.2,
50.9,
31.3,
52.8,
34.8,
30.2,
67.2,
59.7,
85.7,
51.2,
72.5,
40.6,
41.8,
50.3,
67.8,
18,
83.9,
54.8,
60.9,
49.5,
83,
3.9,
63.1,
87.2,
86.1,
54.6,
72.4,
40.9,
16.3,
79.5,
11.5,
54.8,
70,
0,
98.7,
49.8,
40.3,
23.9,
50.9,
84.3,
67.8,
35.7,
67.5,
43.5,
37,
74.1,
86.4,
71.6,
3.6,
79.4,
11.5,
42.2,
43.8,
47.6,
50.2,
79.5,
56.2,
85.8,
46.1,
14.8,
48.9,
51.7,
73.6,
35.7,
24.5,
51.2,
66.2,
42.8,
73.9,
81.9,
31.3,
51.4,
51.8,
36.2,
30.4,
67.7,
69.3,
63,
45.3,
45,
20.6,
46.1,
33.7,
23.6,
48.5,
97.4,
65.4,
72.2,
90,
63.1,
50.4,
57.7,
8.7,
79.4,
44.8,
61.5,
26.9,
51.5,
69.7,
51.4,
62,
42,
0,
83.9,
85.2,
53.9,
19.7,
31.1,
17.5,
10.9,
58.7,
36.9,
91.8,
67.4,
66.7,
3,
97,
71,
47.6,
43,
71.2,
2.7,
62.5,
95.1,
59.1,
45.7,
83.1,
41.5,
54.8,
45.3,
6.2,
19.1,
47.4,
38.2,
50.9,
43.1,
65.8,
32,
49.2,
4.8,
62.6,
30.9,
50.7,
32,
97.1,
31.3,
84,
74.5,
71.4,
74.5,
69.7,
59.2,
69.9,
73,
71.2,
100.3,
49,
100.8,
77.3,
0.7,
47,
1.8,
76.6,
17.9,
32.9,
51.3,
56,
88.8,
32.3,
29,
45.3,
62,
48.4,
66.3,
23.2,
56.3,
59.9,
64.4,
5.4,
56.2,
19.7,
54.4,
51.8,
28.5,
36.6,
89.1,
86.1,
21.8,
81.8,
46.4,
99.5,
85.1,
74.2,
69.1,
58,
38.8,
86.7,
97.4,
51.5,
67.6,
53.5,
88,
50.2,
27.8,
58.2,
65.9,
57.6,
2,
77.6,
55.7,
47.6,
63.3,
69.8,
40.1,
24.2,
59.7,
38.9,
77,
60.5,
7.1,
77,
14.7,
44.3,
83.6,
63.5,
90.8,
59.8,
24.2,
51.8,
48.7,
76,
54.8,
53.6,
25.1,
61.9,
87.5,
62,
79.8,
108.1,
15.9,
64.3,
51.6,
80,
31.6,
37.7,
66.4,
62.5,
94.6,
90.2,
16.7,
45.7,
61.3,
96.4,
98.3,
87.4,
52,
64.1,
70.6,
60.9,
31.1,
37,
80,
30.9,
70.4,
5,
51.8,
88,
24.8,
59.5,
75.1,
49,
84.1,
44.4,
78.3,
26.6,
83.5,
63.5,
14.4,
39.7,
18.6,
67.9,
87.4,
40.9,
46.7,
69.8,
52.1,
82.4,
37.7,
43.3,
51.7,
69.5,
61.1,
58.9,
21.4,
16,
68.4,
41.8,
12.7,
35.8,
62,
60.7,
71.1,
34,
79.5,
55.8,
86.3,
75.2,
78.5,
33.2,
97.1,
15.6,
15.2,
90.1,
56.1,
55.3,
85.9,
72.7,
37.8,
86.2,
84.8,
55.5,
52.3,
62.5,
38.8,
42.5,
66.3,
58.9,
0,
36.9,
45.8,
63.9,
33.7,
66.2,
53.2,
59,
24.2,
70.6,
25.8,
46.3,
6.2,
67.2,
76.7,
36.9,
55,
6.6,
63.9,
83.3,
67.2,
21.5,
69.4,
67.7,
88.6,
34.6,
76.7,
11.2,
46.7,
72.2,
20.2,
38.3,
57,
64.3,
7.5,
55.2,
98.2,
45.8,
58.9,
29.8,
89.4,
30.5,
39,
55.9,
56.3,
59.8,
56.1,
76.9,
57,
11.4,
85.2,
26.7,
79.8,
71,
76.4,
22.1,
64.6,
70,
41.4,
54,
49.4,
66.8,
28.1,
37.8,
60.1,
66.7,
89.7,
86.2,
71.6,
47.4,
69.1,
80.3,
89.4,
69.6,
71.9,
90.2,
91.4,
75,
64.4,
45.1,
75,
49.3,
56.4,
61.4,
32.3,
32.1,
74.6,
86.3,
11.9,
48.1,
95.9,
72.9,
49.9,
59.8,
59.2,
76.5,
69.8,
22.1,
89.3,
58.6,
53.1,
53.2,
85.3,
56,
56.7,
40.6,
28.4,
95.7,
88.4,
84.6,
100.4,
11.3,
19.6,
14.2,
45.2,
65,
14.9,
53.2,
92,
72.8,
39.4,
30.8,
25.1,
75.7,
30,
41.1,
36.3,
54.6,
48.7,
97.2,
79.1,
34.2,
82.9,
50.6,
60,
97.6,
80.7,
25.2,
55.4,
19.6,
53.2,
36.5,
33.3,
7.8,
52.9,
10.3,
70.6,
78.1,
75.2,
60.7,
57.5,
80.1,
60.5,
51.2,
45.2,
25.3,
85.6,
78.4,
60.6,
88.5,
61.7,
64.7,
9.6,
25.1,
38.1,
99.5,
56.3,
10.1,
16.2,
44.9,
95.9,
46.2,
78.6,
70.2,
28.4,
62.8,
73.8,
37.6,
68,
85.9,
88,
90.2,
37,
39.5,
77.5,
89.6,
78.6,
53.8,
65.6,
75.6,
92.2,
26.5,
55.1,
25,
94.4,
64.6,
63.1,
40.6,
53.9,
70.2,
66.7,
88.2,
68,
57.8,
9.5,
86.5,
24.7,
98.5,
78.5,
89.6,
62.1,
13.6,
28.1,
78.1,
57.7,
39.9,
62.5,
40.5,
77.4,
87.5,
25.3,
39,
56,
76.6,
90.9,
11.5,
76,
38.3,
73.8,
48.5,
92,
49.9,
7.8,
99.9,
40.2,
61.3,
52.3,
42.1,
97.1,
39.1,
80.5,
35.2,
30.3,
51.4,
27.5,
64.9,
97.3,
56.9,
31.9,
87.9,
51,
48.6,
52.8,
53.5,
23.8,
44,
28.5,
52.4,
52.5,
20,
64,
74.5,
92,
29.7,
82.5,
44.1,
66.6,
5.1,
61.9,
70.3,
58.3,
81.4,
61.1,
78.4,
67.5,
25.3,
57.7,
54.4,
70.8,
82.8,
69.6,
86.9,
32.6,
67.4,
82.8,
31.4,
39.2,
66.8,
33.8,
96.8,
42.5,
32.4,
44.8,
58.8,
71.3,
74.1,
55.7,
43.5,
69.9,
63.7,
54.7,
38.9,
95.7,
44.3,
56.2,
49.4,
43.2,
68.9,
4.8,
48.3,
16.7,
93.9,
52.9,
82.4,
38.2,
46.1,
46.6,
8.5,
48.3,
53.2,
51.1,
15.5,
25.5,
81.9,
95.4,
47.6,
54.9,
64.8,
80.9,
61.2,
62.8,
63.5,
34,
21.1,
87.4,
75.1,
77.4,
56.7,
67.8,
51.5,
13.2,
35.9,
87.3,
53,
47.2,
37,
77.5,
85.6,
58.5,
23.7,
47.4,
31.6,
79.4,
44,
34.9,
38.2,
2.3,
73,
88,
58.6,
43.2,
38.8,
50,
26.6,
74.4,
74.4,
36.3,
61.4,
76.9,
54.4,
83.3,
53,
79.8,
21.4,
96.4,
58,
99.1,
61.7,
62,
23,
92.1,
30.9,
79.5,
39.8,
41.7,
48,
67.9,
92.2,
43.8,
68.7,
32.4,
91,
16.3,
74.8,
80,
22,
75,
34.4,
82,
41.4,
66.2,
54.6,
63.3,
31.2,
16.5,
68.3,
73,
46.4,
34,
82.8,
39,
95.3,
50.2,
96,
60,
77.1,
48.9,
99.3,
4,
61.3,
35.9,
47.6,
21.5,
10.6,
58.9,
34,
43.6,
59.8,
58.5,
12.9,
72.8,
73.9,
87,
76.5,
41.8,
45.2,
46.3,
96.2,
88.7,
64.4,
8.2,
53.5,
46.3,
69.4,
58,
66.5,
71.1,
44.8,
17.2,
83.2,
116.1,
61,
5.4,
65.7,
55,
63.6,
18.4,
21.7,
20.5,
70.8,
1.4,
89.6,
63.3,
83.5,
45.2,
20.9,
18.4,
73.1,
24.9,
97.5,
51.1,
3.6,
19.8,
6.8,
36.7,
89.1,
49.7,
48,
31.2,
65.7,
24.5,
52,
57.8,
73.4,
71.7,
62.2,
77.7,
62.6,
54.2,
31.3,
65,
29,
53.8,
71.1,
49.2,
32.9,
4.6,
56.3,
22.8,
61.7,
50.5,
64.5,
49.4,
91.3,
65.3,
71.8,
47,
37.7,
70.7,
58,
27.4,
31,
43.5,
20.9,
30.6,
52.5,
60.2,
55.7,
53.9,
76.7,
47.8,
32,
75.9,
96.9,
68.9,
91.1,
67.1,
74.5,
17.7,
61.5,
73.5,
57.5,
27,
48.9,
47.3,
82.9,
63.2,
76.6,
56.3,
69.1,
35.3,
87.5,
47.9,
44.1,
77.8,
47.9,
70.4,
32.5,
12.6,
72.9,
72.2,
93.4,
24.3,
28,
43.7,
75.6,
38.7,
84.6,
72.3,
50.8,
84.3,
86.1,
50.4,
94,
29.1,
23,
48,
37.3,
65.1,
6.2,
35.9,
39.6,
44.3,
89.2,
9,
29.9,
78,
96.7,
84,
99.4,
51.3,
85.6,
49.7,
44.1,
68.4,
56.3,
82.7,
98.9,
94.9,
56.7,
8.1,
59,
72.7,
53.7,
88.3,
40.6,
63.9,
0.4,
74.2,
90,
41.2,
96.5,
29.3,
42.2,
65.9,
99.6,
77.8,
28.8,
89.2,
72.3,
67.6,
52.3,
49.9,
74.3,
66.2,
37.8,
33.6,
35.6,
21.3,
86.1,
18.7,
65.4,
49.8,
43.7,
40.4,
0.3,
41.9,
31.5,
90.6,
50.5,
85,
23.7,
73.4,
7.9,
48.9,
28.3,
33.4,
87.5,
52.6,
43,
85.6,
37.6,
88.7,
82,
14.3,
74.8,
68.8,
53.6,
19.4,
83.9,
54.8,
88.4,
46.4,
72.1,
57.3,
60.7,
64.6,
57,
76.1,
40.4,
27,
55.1,
50.7,
53.4,
73.7,
45.9,
23,
22.4,
22,
28.8,
48.9,
42.8,
54.1,
43.8,
35.5,
65.2,
42,
98.7,
56.9,
33.2,
67.3,
76.1,
49.3,
28.7,
80.5,
68.8,
57.2,
58.8,
0,
73.3,
84.8,
47.6,
72.2,
50.1,
22.8,
25.6,
85.5,
42.9,
61.6,
25.7,
77.4,
57,
50.8,
47.2,
77.1,
89.4,
59.2,
49.8,
96.2,
82.7,
27.5,
68.2,
23.1,
86.3,
51.4,
55.6,
53.4,
46.2,
72.6,
81.9,
52.9,
62.4,
87.8,
92.7,
44.6,
67.6,
37.2,
74.1,
66.2,
88.8,
23.3,
35.1,
96.8,
48.1,
35.7,
69.3,
31,
15.3,
89.5,
52.8,
80.2,
38.2,
23.7,
52.7,
77.2,
6.2,
45.8,
52.9,
61.1,
60.6,
95.7,
78.2,
79,
2.1,
56,
93.3,
11.5,
94.6,
22.8,
50,
88,
12.1,
38,
10.4,
93.1,
64.7,
59.6,
52.4,
52,
58.3,
25.7,
1.1,
72.1,
67.6,
50.7,
65.4,
13.5,
61.4,
46.2,
45.4,
74.7,
43.4,
67.8,
68.8,
4.1,
83.9,
42.2,
33.2,
55.3,
62.9,
77.8,
12.8,
24.2,
39.9,
71.4,
13.5,
59.5,
6.8,
45.4,
61,
41.4,
80.1,
54.1,
60.1,
47.8,
28.1,
23.5,
22,
68.8,
29.1,
50.8,
40.5,
86.8,
24.6,
44.5,
76.6,
53.4,
28.6,
69.6,
92.5,
39,
51.8,
25.2,
58.8,
57.2,
70.8,
100,
44.9,
54.4,
44.2,
90.8,
82.3,
72.1,
50.4,
62.3,
34.7,
41.5,
99.6,
79.3,
24.9,
81.6,
83.3,
39.2,
0,
72.3,
56.8,
93.9,
92.7,
84.1,
21.5,
80,
57.2,
30.2,
35.7,
57,
45.6,
59.8,
38.4,
56.3,
84,
76.2,
73.9,
34.9,
44.8,
86.8,
21.4,
80.6,
75.4,
61.6,
71.9,
26.1,
46.4,
56.7,
72.7,
41.1,
41.7,
14.2,
35.3,
24.2,
73.7,
35.5,
39.2,
50.2,
67.4,
43.1,
40.3,
88.4,
5.1,
46.5,
80.6,
59.6,
63.5,
47,
30.6,
45.2,
60.3,
78.7,
58.5,
39.1,
56.2,
24.3,
82.8,
38.4,
62.5,
61.2,
48.6,
78.7,
39.9,
61.1,
69.1,
40.5,
28.5,
102.1,
55.2,
50,
74.8,
46.5,
54,
33.8,
86.9,
64.4,
93.6,
35.8,
93.2,
28.5,
56.7,
73.4,
44.2,
33.5,
43.4,
76.3,
17.1,
21.5,
42.2,
50.3,
77.4,
54.1,
10.3,
71.5,
62.3,
13,
26.7,
101.6,
57,
58.6,
2.5,
87.3,
44.5,
83.5,
37.9,
41.9,
74.3,
33.2,
73,
60.3,
61.4,
15.9,
72.9,
49.4,
13.4,
44.6,
40.3,
69,
6.6,
17.6,
45.6,
81.6,
25.1,
85.3,
89.3,
57.9,
27.6,
45.5,
98.7,
62.6,
26.3,
70,
21.9,
47.3,
97,
94.4,
50.8,
61.9,
80.8,
45.5,
92,
31.8,
84,
41.7,
62,
65.9,
45,
20.4,
28.2,
80.7,
61.7,
15.1,
47.7,
68.2,
34.4,
64.5,
31.4,
47.9,
52.9,
12.8,
54.8,
89.5,
23.9,
1.9,
100,
39.2,
55.9,
84.1,
80.7,
55.7,
26.8,
4.3,
47.4,
52.4,
79.4,
79.8,
44,
70,
52.2,
40.7,
42,
26,
56.1,
55.9,
65.3,
18.7,
35.8,
49.2,
89.6,
86.4,
27.7,
61,
54,
74.7,
95.4,
68.1,
79.5,
87.9,
50.3,
96.2,
55,
20.3,
21.1,
82,
32.1,
4.7,
85.8,
45.2,
76.6,
67,
74.3,
26.9,
75.7,
71.4,
81.3,
70.5,
57.2,
93.7,
48.9,
29.7,
1.1,
38.9,
88.2,
83.1,
23.1,
61.1,
27.6,
69.7,
39,
29.7,
57.9,
74.4,
79,
56,
71.8,
47.9,
71.5,
72.8,
32.1,
55.8,
87.8,
71.8,
30.5,
57.9,
15.5,
47.1,
21.6,
51.2,
75.2,
66.5,
57.4,
69.6,
24.6,
27.3,
63.1,
72,
48.6,
79.9,
45.8,
38.6,
55.6,
80.6,
35.2,
85,
92.5,
10.7,
14.5,
76.3,
87.6,
86.9,
47.8,
28.4,
54.9,
47.2,
52.9,
28.9,
73.1,
97.2,
55,
68.3,
87.4,
32.5,
52,
47.5,
26,
44.9,
29.2,
39.2,
48,
54.2,
51.6,
77.5,
44.3,
2.7,
12.8,
41.9,
61.7,
40.2,
26.8,
65.5,
49.5,
58.5,
83,
75.9,
26.5,
62.4,
39,
74.8,
37.1,
91.8,
35.3,
15.1,
13.3,
25.6,
47.9,
16.4,
40.9,
19.8,
19.7,
59.5,
38.4,
79.1,
37,
68.2,
0,
60.7,
59.8,
74,
33.7,
49.5,
78.9,
67.2,
57.5,
48.2,
57.6,
40.6,
0,
63,
54.4,
39.2,
13,
70.2,
29.7,
27.3,
30.8,
46,
79,
73.4,
23.8,
73,
61.6,
44.7,
55.1,
46.1,
70.1,
49.9,
32.3,
45.6,
41.5,
26.5,
67.2,
44.2,
47.8,
98,
45.9,
52,
72.4,
82.8,
52.3,
52.8,
43.5,
49,
30.3,
69.9,
11.5,
44.1,
64.1,
56.8,
36.6,
87.9,
67.8,
64,
77.5,
32.3,
85.5,
82,
82.3,
64.1,
40.7,
49.8,
86.2,
81.8,
39.6,
78.4,
77.6,
47.4,
51,
95,
58.8,
49.9,
95.8,
21.8,
49,
85.5,
39,
47.8,
30.1,
82.8,
91.8,
69.7,
91.1,
69.6,
63.5,
40.7,
55.5,
32.5,
48.6,
16.7,
59.7,
67,
51,
94.8,
22.7,
94.5,
67,
93.3,
55,
43.8,
77.2,
11.6,
41.6,
57.5,
36.3,
46.6,
56.8,
49.2,
48.5,
20,
69.6,
38.9,
50.8,
75.5,
74.3,
79.4,
22.2,
56.5,
37.2,
53.6,
51.5,
39.1,
37.9,
88,
83.4,
84.1,
53.5,
10,
55.2,
66.6,
81.4,
33.6,
80,
61.4,
72.1,
46.4,
78.4,
42.8,
81.2,
43.6,
71.5,
64.3,
40.9,
32.9,
66,
93.6,
70.4,
83.5,
51.2,
2.9,
33.2,
99.2,
66.4,
73.5,
76,
17,
40,
3.3,
45.8,
28,
40.6,
28,
45.2,
68.3,
30.2,
88.6,
15.9,
56.7,
28.8,
28.9,
89.7,
19.7,
0,
35.6,
41.6,
52.1,
57.9,
28.8,
54.7,
75.9,
75.2,
83.1,
75,
98.5,
96.8,
38.2,
18.1,
47.7,
67.3,
45,
70.9,
79.5,
48.2,
74.5,
81.2,
48.7,
58.7,
72.4,
43.6,
64.1,
11.6,
81.9,
83.2,
68.8,
80.2,
50.8,
26.9,
76.8,
56.7,
16.6,
74.4,
54.8,
82,
72,
47.1,
21.2,
71.9,
29.3,
68.5,
43.4,
86.5,
81.3,
2.7,
19.5,
4.5,
67,
62.5,
15.7,
56.1,
64,
97.3,
59.6,
0,
77.5,
71.5,
100.2,
98.7,
96.1,
90.8,
84.9,
48.6,
89.4,
56.7,
94.9,
95.3,
85.3,
4,
74.4,
2,
18.8,
53.2,
79,
35.8,
60.9,
61.6,
26.4,
36.3,
35.8,
29.6,
67.1,
61.9,
39.6,
80.3,
0,
53,
67.6,
70.8,
65,
59.8,
71.4,
99.9,
89.8,
73.3,
65.3,
71,
75.2,
64.6,
30.3,
38.3,
60.3,
4.1,
29.8,
50.1,
89.8,
46.8,
75,
97.4,
7,
89.7,
65,
54.1,
46.6,
37,
81.3,
47.8,
40.7,
88.3,
31,
47.6,
83.4,
93.4,
65.5,
26.3,
58.9,
35.8,
76.1,
40.1,
61.7,
27.4,
84.8,
70.8,
37.5,
63.9,
65.8,
36,
66.7,
85.1,
78.2,
47.3,
38.3,
72.4,
88.4,
64.8,
82.8,
98.3,
70.2,
54.8,
95.8,
56.1,
48,
63.1,
53.7,
0.3,
61.3,
21,
57.2,
89.4,
46.1,
39.9,
34.5,
54.4,
91.8,
85.5,
48,
64.5,
37,
89.3,
67.2,
39.6,
39.6,
63.2,
97.1,
49.2,
64.2,
61.2,
67.9,
56.6,
78.2,
92.8,
49.5,
87.5,
93.4,
85.5,
67.2,
13.9,
48.4,
71.5,
63.5,
57.6,
34.3,
92.6,
96,
39.4,
92.6,
47.5,
45.8,
69.2,
41.2,
62.5,
71.3,
30,
65.5,
8.1,
52.7,
73.8,
49,
52.3,
36.5,
81.6,
47.7,
86.1,
93.1,
60,
32,
27.9,
31.5,
54.8,
42.5,
101,
67.9,
20.3,
37.2,
69.3,
54.3,
67.1,
92.5,
84.5,
83.6,
82.3,
32.9,
64.7,
24.5,
37.4,
75.7,
61.3,
17.7,
78,
58.9,
48,
39.1,
29.7,
48,
53.3,
52.2,
62.4,
42.9,
6.7,
85.9,
14,
36.5,
39,
54.1,
28,
70.7,
82.4,
84.9,
25,
73.9,
67.7,
46.2,
58.3,
54.5,
24.7,
12.7,
51.1,
42.3,
67.9,
27.8,
63.4,
41.3,
48.3,
84.2,
65,
48.6,
53.3,
66.7,
60.4,
68.8,
67.8,
87.3,
81.3,
64.4,
44,
21.4,
38.9,
37,
42.7,
79.2,
42.8,
18.5,
91.4,
17.2,
56.7,
69.7,
41.1,
31,
34.6,
55.5,
43.1,
74.1,
55.7,
21.5,
66.3,
30.8,
94.7,
79.1,
3.2,
80.3,
85.5,
81.3,
63.6,
38.9,
71.8,
10.2,
25.6,
37.9,
13.4,
16.8,
88.3,
57.6,
83,
43.6,
19.5,
64.6,
51.5,
40.4,
36.3,
77.9,
54.5,
71.4,
68.1,
72.9,
35.4,
52.2,
63,
33.1,
78.8,
73.7,
19.3,
45.5,
52,
62.4,
23.8,
65,
48.5,
46.4,
58.9,
70.7,
82.5,
2,
86.1,
50,
90.7,
45.3,
83.5,
95.2,
60.6,
21.2,
99,
68.5,
66,
66.7,
47.4,
71.3,
89,
58.8,
17.7,
41.3,
57,
46.3,
4.5,
63.1,
54.7,
49.5,
67.2,
47.8,
34.6,
60,
38.7,
13,
46.5,
46.4,
74.1,
44.4,
27.1,
51.5,
47.9,
8.5,
79.9,
46.8,
93.7,
70.8,
93.1,
69.6,
62.7,
87.3,
96.5,
97.9,
81.6,
57.8,
33.6,
26.5,
85.1,
19.4,
84.9,
86.3,
75.4,
22.6,
53.7,
47.5,
71.2,
30.8,
15,
45.5,
62.2,
54.8,
39.9,
51.9,
23,
52,
54.5,
44.3,
77.6,
53.6,
40.5,
47.4,
46.4,
30.2,
61.8,
35.5,
10.6,
58.3,
65,
40.2,
59.5,
40,
63.1,
47.1,
60.7,
61.5,
5.3,
97.5,
59.9,
96.8,
46.4,
96.5,
64.3,
20,
26.3,
73.1,
29.2,
81.4,
80.8,
54.2,
49.2,
55.3,
64.5,
30.5,
61.3,
40.3,
56.1,
79.5,
20.2,
9.6,
50.3,
83,
4.4,
85.2,
36,
74.6,
22.4,
100,
89.1,
57.2,
54.9,
76.8,
39.9,
82.4,
0.1,
51,
81.4,
10.5,
68.9,
12.7,
48.6,
81.4,
40.5,
63.2,
76.6,
77.2,
0.3,
48.6,
38.9,
22.3,
25.5,
68.3,
82.8,
17.4,
36.6,
52.6,
72.3,
33.7,
86.6,
68.3,
59.8,
16.7,
86.1,
54.9,
83.4,
39.6,
72.2,
15.4,
44.1,
51.7,
89,
54.9,
49.6,
89.7,
77,
59,
78.1,
39.4,
35.2,
54.1,
46.8,
53.9,
74,
79.2,
63.8,
59.3,
48.6,
91.2,
34.2,
91.6,
96.2,
66.4,
41.6,
59.4,
11.8,
40.2,
50.1,
68.5,
22.1,
71,
78,
18.7,
93.8,
54,
42.2,
96.1,
85.5,
49.4,
31.9,
85.6,
66.3,
65.3,
39,
79.8,
61.9,
98.7,
29.7,
36.7,
52.3,
43.7,
46.6,
13.1,
63.5,
72.1,
56.2,
75.5,
30.3,
81.5,
95.6,
53.6,
26.1,
86,
18.7,
74.8,
83.9,
40.5,
6,
0.5,
21.8,
85.1,
65.4,
39.7,
89.8,
56.5,
26.6,
36.4,
48.4,
94.9,
59.4,
48.4,
65.4,
28.6,
59,
40.6,
56.2,
57.9,
98.3,
77.8,
48.4,
23.5,
80.2,
7.7,
80,
29.5,
35.9,
35.8,
19.9,
67,
79.9,
12.4,
51.2,
61.2,
48.2,
88.5,
76.8,
57,
86.2,
9.6,
56.6,
84.5,
64.1,
49.6,
42.9,
37.4,
93,
21.1,
63.6,
69.9,
41.3,
53.1,
41.6,
60.6,
77.3,
60.2,
67.6,
43.8,
27.7,
59.5,
74.9,
79.9,
55.9,
29.2,
34.2,
98.1,
66.7,
66.7,
70.6,
26.6,
46.1,
90.1,
30,
36.3,
59,
70.2,
36.4,
93.8,
73.5,
65.6,
52.3,
42.2,
52.2,
36.7,
67.2,
63.8,
67.7,
29.9,
53.1,
81.5,
22.4,
26.8,
83.7,
39.1,
44.9,
56.8,
28.2,
47.9,
94.9,
42,
61.8,
33.4,
34.2,
87.7,
34.6,
68,
5.6,
37.1,
47.9,
11.4,
40.7,
50.2,
21.4,
62.8,
69,
48.8,
30,
80.8,
0,
67.5,
79.3,
80.6,
57.4,
31.6,
93.2,
94.1,
37.4,
75.5,
25.9,
39.6,
57.6,
43.3,
57.6,
46.3,
49.2,
43.8,
24,
62,
27.4,
17.7,
50,
22,
59.8,
35.6,
63.3,
40.6,
59.9,
52.6,
45.1,
46,
50.2,
98.4,
58.2,
34.2,
69.4,
44.3,
54.7,
62.3,
53,
99.3,
78.5,
8.7,
53.6,
81.5,
6.4,
80.4,
21.4,
87.2,
1.7,
10,
70.5,
53.3,
66.9,
80,
83.2,
24.1,
87.1,
32.6,
59.4,
72.8,
70,
18.3,
75.1,
66.8,
85.7,
87.1,
44.7,
63.8,
0.5,
51.9,
43.2,
29.6,
15.6,
68.8,
92.2,
86.2,
69.9,
37.8,
94.5,
69.5,
88.1,
71.4,
30.2,
62.5,
57.7,
62.1,
67.4,
37.1,
67.7,
54,
75.8,
100,
73.9,
11.3,
34.3,
79.3,
88.5,
24.6,
70.3,
32.3,
65.3,
81.5,
25.4,
26.6,
69,
22.1,
82.5,
77.9,
6.8,
27.7,
23.2,
58.7,
null,
18.8,
49.3,
47.7,
33.3,
19.7,
48.3,
49.9,
58.7,
32.7,
74.9,
88.2,
32.9,
73,
74.5,
56.8,
76.1,
68.8,
64.1,
24.6,
45.3,
30.2,
38.8,
32.2,
50.9,
50,
38,
80.7,
36.6,
60.4,
97,
27.7,
41.7,
58.3,
68.7,
92,
56.8,
15.5,
41.4,
29.6,
35.2,
79.1,
59.5,
13.8,
41.3,
42.5,
16.7,
88.1,
56.9,
10.9,
55,
54.1,
29.7,
80.7,
59.1,
73.1,
72.4,
88.5,
24.4,
80.8,
35.9,
94.4,
40.4,
71.2,
37.9,
68.3,
53.4,
84.5,
69.4,
42.7,
31.4,
67.6,
38.7,
26.1,
51.7,
40.1,
11.9,
81.8,
77.4,
21,
23.9,
35.5,
58.7,
82.4,
38.5,
39.7,
65.7,
62.9,
41.3,
50.7,
61.7,
62,
11.7,
47.1,
70.4,
87.3,
87.1,
76.3,
80.2,
47.4,
17.9,
43.3,
10.7,
70.3,
28.2,
82,
22.9,
22.4,
48.2,
59.3,
20.2,
92.7,
76.4,
59.6,
24.9,
39.6,
42.9,
80.8,
41.5,
0.2,
51.5,
3.4,
67,
98.7,
15.4,
35.3,
70.7,
69.3,
58.6,
88.2,
44.1,
57.5,
38.4,
26.5,
46.6,
50.4,
61.5,
83.5,
42.9,
55.7,
8.3,
43.7,
18.8,
68.6,
48.1,
63.2,
44,
98.7,
38.8,
50.7,
72.7,
96.8,
69.1,
61.9,
70.1,
72.9,
59.5,
63,
78.3,
60.8,
84.2,
60.1,
7.4,
62.2,
55.7,
66,
82.1,
66.5,
39.3,
69.6,
70.6,
50.4,
50.8,
25.3,
83.1,
56.4,
1.3,
98.3,
21.4,
87,
92,
97.1,
53.2,
87.2,
14.4,
36.7,
34,
62.2,
35,
44.9,
57,
25,
69.2,
57,
63.6,
70.3,
43,
45.1,
8.7,
97.1,
16.5,
30.9,
28.7,
23.2,
17.4,
27.2,
40,
39.1,
43.2,
58.1,
55.4,
75,
75.2,
59,
62.4,
52.9,
60.9,
40.5,
93,
53,
72,
67.8,
53.9,
85.2,
33.1,
77.1,
11,
88.7,
58.8,
56.5,
71.4,
53.9,
42.7,
51,
73.8,
31.1,
41.6,
37.5,
57.2,
65.6,
25.5,
91,
77.8,
73.7,
91.2,
19.7,
96.9,
44,
50.4,
97.6,
81.2,
52,
90.3,
6.7,
54.7,
25.7,
58.6,
41,
66.3,
99.3,
24.2,
61.1,
17.3,
49.6,
30.7,
38.7,
49.1,
45.6,
45.1,
83.6,
50.2,
32.5,
90,
48.6,
52.8,
48.6,
46.6,
67.5,
66.6,
20.8,
35.3,
42.2,
49.4,
56.9,
30.2,
83,
41.9,
73.9,
44.1,
42.3,
26.3,
73.4,
7.7,
104.1,
22.5,
88.6,
60.2,
99.6,
37,
12.7,
24.6,
27.1,
35.5,
54.5,
83.1,
18.6,
60.5,
73.8,
55.8,
71.9,
43.4,
33.1,
94.4,
56.9,
62,
76.5,
53.4,
75.1,
104.5,
83.5,
54.1,
74.5,
48.6,
8.5,
62.2,
63.5,
51.3,
35.9,
83.8,
77.5,
18.6,
19.1,
52.2,
69.1,
56.7,
78.7,
59.1,
57.2,
70.4,
42.5,
63.9,
73.3,
26.9,
83.4,
29.1,
23.2,
77.6,
32.5,
61.5,
97.2,
66.5,
81.2,
23.8,
48.7,
51,
65,
73.2,
31.4,
65.1,
49.9,
15.8,
82,
86.2,
39.4,
39.8,
64.6,
11,
44.9,
69.3,
87.8,
41.6,
70.9,
77.1,
30.7,
50.2,
37.7,
87,
44.7,
83.2,
82,
37.7,
57,
74.2,
36.8,
77,
43.6,
26.4,
40.7,
19.7,
22.3,
67.1,
67.8,
60,
22.1,
10.5,
69.1,
38.6,
31,
20.9,
42.1,
69.2,
77.5,
31.9,
69.8,
80.4,
50,
41.8,
61,
78.3,
22,
35.6,
15.6,
2.9,
69.1,
43.9,
69.7,
51,
72.2,
56,
85.4,
39,
13.4,
58.7,
46.7,
24.1,
31.9,
66.1,
82.5,
94.1,
67.1,
20.6,
34.5,
73,
26,
82.2,
37.9,
89.6,
28.1,
50.6,
55.5,
16.4,
6.3,
67.2,
19.4,
98.5,
60.5,
43,
40.5,
51.3,
79.4,
54.3,
27,
26.3,
77.1,
60.4,
49.5,
76,
72.8,
53.4,
11.5,
61.3,
72.9,
29.6,
54.3,
76,
29.2,
57.7,
65.8,
65.2,
36.6,
43.3,
41.1,
43.8,
74.5,
49,
71.3,
18.6,
63.2,
78.8,
53.5,
52.9,
34.9,
33.6,
59.9,
38.5,
43.9,
44,
56,
32.3,
88.9,
59.1,
8,
99.6,
23.9,
99.2,
54.7,
8.4,
89.1,
84.1,
71.7,
68.1,
101.8,
62.4,
79.8,
55,
79.2,
63.7,
48.1,
69,
70,
2.9,
47.3,
44.1,
9,
27.1,
62.4,
77.6,
59.3,
66.9,
62.2,
92.8,
44.4,
40.1,
42.7,
12.5,
50.9,
47.2,
27.2,
53,
43.8,
42.6,
80.8,
80.8,
63.6,
28.5,
9.1,
46.1,
40.9,
82.5,
3.6,
36.5,
67.3,
69.3,
51.4,
40.6,
87.7,
8.2,
51.5,
80.8,
71.7,
37.6,
26.6,
45.6,
38.9,
53.8,
41.6,
51.2,
68.4,
51,
16.3,
57.2,
43,
51.7,
60.5,
81.3,
52.4,
43,
61,
84.7,
65.4,
51.1,
69.6,
46,
16.8,
68.8,
95.7,
21.8,
91.4,
51.6,
62.1,
71.5,
17.4,
24.8,
87.5,
88.6,
75,
59.1,
48.5,
99.1,
38.4,
41.3,
69.8,
25.7,
48.7,
51.4,
68.1,
41.5,
49.5,
44,
24.4,
35.6,
67.1,
36.6,
68.4,
72.2,
73.9,
80,
70.1,
61.3,
77,
62.2,
51.1,
79.4,
46.8,
17,
69.5,
58.9,
8.8,
13,
8.6,
58.4,
62.1,
82.5,
48.9,
89.2,
59.2,
26.5,
66,
58.3,
19.2,
88.5,
8.7,
21.5,
67.2,
91.8,
42.1,
32.3,
80.3,
81.5,
67.5,
65.5,
65.9,
39.7,
67.6,
59.5,
70.1,
41.7,
81,
26.6,
55,
90.7,
51.1,
53.1,
70.5,
22.4,
77.3,
17.8,
54.3,
32.7,
41.4,
10.2,
42,
24.6,
79.8,
59.5,
73,
42.9,
53.2,
59.9,
31,
51.7,
66.6,
71.5,
99.1,
47,
96.8,
40.5,
88,
53.8,
55.7,
40.7,
7.1,
53,
45.1,
85.5,
80.7,
50.1,
20.6,
33.9,
58.6,
54.2,
58.5,
82.9,
28.4,
39.8,
39.2,
2.9,
83.3,
57.5,
80.3,
42.1,
51.7,
68.7,
52,
65.4,
51.8,
52.7,
92.6,
44.7,
61.5,
28.2,
91.5,
32.9,
69,
34.1,
27.2,
47,
0,
37.9,
19,
93.2,
76.4,
94.5,
91.4,
43.3,
30.5,
21.6,
77.3,
55.5,
48.5,
46.9,
74.2,
25.4,
75.9,
61.4,
9.5,
32.6,
92.1,
85.5,
19.3,
66.2,
63.8,
10,
95.2,
51,
77.4,
70,
54.2,
45.9,
35.9,
60.4,
36.6,
27,
78.7,
55,
60.3,
79,
28.3,
10.9,
11.4,
47.7,
71.9,
73.6,
49.2,
74.8,
78.8,
15.1,
80.8,
42.7,
26.7,
77.7,
null,
52.6,
87.8,
84.5,
83.6,
25.3,
40.7,
42.2,
58.9,
12.7,
2.4,
76.2,
77.7,
69.3,
70.5,
32.6,
35.5,
4.5,
54.6,
10.5,
41.6,
58.2,
35.7,
78.7,
27.9,
89.6,
0,
55.6,
8.6,
49.1,
91.3,
70.7,
82.5,
43.9,
65.7,
35.7,
42.2,
34.3,
14.4,
47.9,
50.6,
53.3,
86.3,
59.7,
34.7,
54.2,
38,
16.7,
32,
75.9,
24.9,
49.3,
61.7,
39.2,
59.9,
90,
81.4,
11.2,
21.2,
96,
61.9,
28.1,
74.2,
85,
32,
19.6,
51.4,
43.6,
58.7,
1.4,
33,
18.7,
69.7,
45.3,
68.8,
89.3,
47.8,
48.5,
51.1,
44.9,
62,
87.2,
66.4,
60.1,
21.5,
44,
45.4,
71.1,
35.8,
36.8,
55.8,
50.7,
61.3,
46,
45.6,
80,
44.3,
57.3,
50.1,
52.5,
74.9,
60.9,
16,
96.1,
67.9,
55.9,
57.6,
37.1,
81.1,
70.4,
66.4,
89.1,
39.5,
0,
77,
44.4,
4,
45.8,
23.7,
22.7,
95.6,
72,
51.4,
22.2,
36.6,
60.3,
5.4,
32.7,
40,
58.4,
80.4,
61.3,
95.5,
40,
77.2,
17.5,
77.4,
61.5,
59.5,
73.3,
40.4,
49.4,
75.4,
33,
15.1,
14,
73.9,
34.6,
92.4,
43.7,
45.2,
39.6,
34.3,
30.4,
54.9,
83.7,
40.8,
94.3,
66.5,
78.1,
39.1,
74.8,
24.7,
17.9,
13,
26.3,
73.7,
67.4,
68.7,
30.5,
66.6,
64.6,
56.9,
36.6,
56.1,
7.4,
62.9,
93.4,
96.5,
54,
55.8,
10.3,
66.7,
76,
91.9,
43.9,
66.2,
76.8,
44.4,
86.2,
23.4,
92.3,
47,
19.7,
73.6,
30.5,
12.3,
74.2,
7.7,
64.3,
43,
78.1,
11.5,
95.5,
50.7,
55.9,
24.4,
49.9,
62,
34.5,
91,
57.1,
22.9,
67.7,
86.4,
89.5,
45.5,
97.9,
52,
40.2,
53,
23.9,
77,
38,
10.8,
87.3,
41.3,
85.2,
53.7,
81.9,
77.8,
58.2,
27,
14.9,
77.3,
26.8,
57.7,
0.2,
58.4,
67,
40.1,
51,
33.6,
97.3,
60.5,
81.4,
84.9,
38.3,
47,
22.5,
52.3,
47.2,
50,
53,
39,
68.5,
10.3,
39.5,
45.2,
25.8,
30,
67.9,
33.7,
11.3,
71.5,
79.7,
91.3,
64.1,
13.4,
67.4,
23.1,
83.8,
36.7,
49.2,
23,
20.1,
47.7,
36,
15,
34.9,
88.2,
53.5,
70.2,
61.4,
58.5,
16.8,
18.5,
10.4,
31.8,
17,
64.6,
26.7,
49.5,
90.5,
61,
84.7,
89.2,
56.7,
93.7,
53.1,
65,
85.3,
79.9,
87.6,
54.2,
90.9,
60.8,
45.6,
81,
12.7,
47.9,
48.2,
42.6,
30.8,
27.4,
94.5,
36.4,
56.2,
65.1,
67.4,
83.8,
28,
27.9,
49.2,
99.9,
61,
99.4,
60.4,
63.1,
68.2,
43.4,
0,
84.8,
29.6,
91,
78.3,
31.5,
76.6,
31,
100.3,
40.4,
34.1,
60.7,
62.6,
70.8,
70.7,
21.2,
6,
77.2,
35.4,
23.8,
60.9,
21.6,
13.5,
64.5,
46,
46.8,
41.9,
85.2,
17.3,
71.4,
63.3,
80.1,
69.2,
56,
40.7,
87.9,
43.8,
91.3,
11.8,
86.4,
29.4,
36.6,
58.1,
79.7,
49.1,
38.2,
74.7,
42.7,
47.4,
68.1,
63.5,
73.7,
97.9,
49.9,
99.3,
81.6,
36.4,
78.4,
96.6,
75.1,
41.6,
43.1,
49.5,
80.3,
75.5,
74,
34.1,
51.3,
56.2,
38.8,
67.9,
27,
49.3,
85.9,
58.7,
40.2,
49.3,
34.2,
82.7,
81.6,
76.6,
53.6,
65.5,
71.6,
24.3,
28.5,
82.9,
48.5,
37.6,
52.4,
90.9,
37.7,
49.1,
54,
16.4,
59.7,
14.7,
30.2,
68,
53.3,
68.8,
50.4,
86.8,
23.5,
35.8,
59.8,
44.2,
43,
98.4,
81.6,
41.4,
92.4,
66.9,
62.3,
54.6,
42,
22.9,
21.3,
42.9,
44.9,
94.6,
74.5,
21.4,
73.8,
10.9,
66,
54.1,
47.5,
94.3,
50.7,
74.3,
49.2,
48.6,
43.9,
94.1,
51.1,
48.2,
77.5,
60.69,
99.3,
42,
64.1,
25.1,
47.1,
56,
42.7,
27.3,
29.1,
65.8,
51.8,
76.2,
75.3,
49.4,
15.4,
68.5,
85.8,
39.1,
40.6,
27.3,
70.8,
29.2,
45.6,
90.6,
71.6,
86.2,
20.1,
54.2,
90.2,
20.3,
26.8,
44.4,
60.1,
93.4,
23.8,
54.4,
72.8,
91.8,
65.7,
38.5,
65.1,
15.6,
77,
39.4,
101.8,
66.6,
40.7,
43.1,
92.5,
59.7,
62.1,
8.1,
21.4,
64.4,
62.5,
75.5,
22.3,
62,
70.4,
83.8,
19.6,
20.6,
56.2,
62.1,
11.5,
29.4,
55,
21.9,
53.8,
65.2,
85.6,
35.1,
83,
69.3,
30.2,
67.2,
95.5,
15.7,
37.4,
75.6,
83.2,
32.9,
81,
15.9,
12,
32.8,
42.4,
67.3,
43.2,
53.9,
97.5,
63.9,
67.7,
83.3,
67.6,
43.3,
54.4,
72.7,
31,
69.8,
53.6,
84,
58.7,
89.3,
19.5,
50,
84.1,
58.4,
65.6,
83.9,
48.3,
45,
47,
33,
56.5,
27.5,
52.5,
51.8,
98.9,
48.9,
28.6,
77.4,
65.7,
38.8,
39.5,
30.2,
46.4,
86.2,
63,
56.4,
60.5,
79.6,
55.1,
37.3,
82,
78.1,
52.5,
62,
80,
59,
73.6,
59.5,
36.2,
47.7,
37.7,
17.8,
40.6,
52.9,
12,
16.2,
50,
45.4,
41.6,
56.4,
92.7,
58.2,
51.2,
45.5,
68.1,
71,
13.7,
85.8,
64.4,
34.1,
85.7,
72.5,
6.9,
34.9,
63.7,
42.6,
16.3,
82.2,
83.5,
8.4,
55.1,
89.8,
78,
20.5,
0,
67.2,
67.5,
77.1,
23.2,
30,
64.7,
62.9,
0,
23,
48.5,
89.7,
79.3,
35.4,
39.2,
59.7,
11.3,
37.1,
51,
90.6,
69.1,
32.6,
97.3,
4.7,
46.7,
65.4,
38,
73.9,
91.4,
42.4,
32.3,
101.8,
59.4,
62.1,
3.3,
75.5,
20.4,
50.8,
16.8,
26.2,
46.8,
72.2,
90.8,
15.8,
47.1,
79.3,
49,
72.4,
74.2,
52,
33,
40.7,
71.5,
19.8,
44.9,
24.7,
82.2,
73.4,
43.2,
22.9,
80.9,
13.7,
71.9,
7.8,
44.2,
52.9,
67.5,
50,
58.3,
45,
42.5,
87.1,
64.3,
23.5,
26.9,
91.5,
63.9,
67.4,
50,
79.1,
4.5,
66.2,
68,
39.5,
31.4,
96.2,
27.9,
91.5,
96.9,
31.1,
89.9,
55.8,
27,
63.4,
72.4,
17.7,
59.1,
20.5,
60.3,
54.1,
46.5,
45.5,
44.6,
71.1,
73,
80.3,
64.6,
41.3,
70.8,
48.1,
72,
53.4,
44.6,
92.9,
34.5,
53,
40.4,
18.6,
24.8,
52.5,
62,
58.4,
88.5,
55.5,
54.5,
54.8,
52.1,
47,
18,
69,
63.5,
54.7,
23.6,
61.6,
81.7,
44.1,
46.6,
62.9,
66.1,
47.1,
43.6,
31.2,
22,
88,
0.4,
23.9,
36.3,
48.9,
80.3,
32.9,
43.9,
92.6,
86.3,
59.8,
87.5,
44.4,
90,
82.4,
89.6,
32.5,
92.4,
72.3,
33.8,
39.2,
29.6,
50.4,
101.3,
57.9,
56,
47.5,
61.2,
70.1,
91.5,
41.9,
97.1,
78.5,
11.3,
52.7,
43.4,
83.7,
73.9,
80.4,
49.6,
89.3,
88.7,
42.2,
58.2,
8.3,
80.2,
20.2,
49,
66.9,
77.9,
24.5,
22.7,
65.2,
63.5,
93.2,
65.8,
41.2,
51.4,
40.2,
75.1,
47.7,
70.5,
54.1,
83.3,
57.7,
75.7,
67,
33.9,
38.7,
84.1,
23.6,
30.4,
15.7,
47,
68.7,
54.5,
59.3,
13.5,
4.9,
68.3,
42.1,
38.2,
87.9,
70.5,
51.4,
36.4,
86.6,
89.6,
100.5,
65.6,
68.6,
53.1,
89.3,
46,
68.4,
44.4,
84,
82.8,
49.4,
37.9,
41.3,
81,
64.5,
39.3,
88.7,
49.6,
6.3,
51.8,
68,
52.6,
63.6,
87.9,
48,
58.5,
85.4,
70.8,
63.9,
77.8,
89.4,
42.3,
80.9,
90.1,
12.5,
45.7,
16,
43.9,
35.3,
15.2,
38.9,
46,
75.8,
73.5,
48,
65.8,
48,
61.4,
58.7,
56.8,
54.8,
77.8,
57.6,
25,
70.7,
89.6,
66.4,
82.1,
77.7,
85.9,
58,
13.1,
51.3,
65.4,
44.3,
53.2,
61,
77.1,
58.5,
69.5,
82,
53.6,
67.4,
63,
25.4,
32.3,
62.5,
81.3,
90.7,
84.8,
96.9,
78.2,
51.1,
67.3,
52.1,
61.1,
50,
40.9,
94,
75.6,
24.6,
33,
38.4,
43.8,
71,
12.6,
61,
39,
10.1,
47.8,
41,
91.8,
15.9,
67.2,
37.3,
86.9,
98.9,
80.9,
24.2,
76.6,
50.4,
47.4,
28.9,
26,
88.3,
88.3,
49.5,
27.6,
66.5,
81.1,
13.7,
59.9,
56.1,
39,
75.4,
95.7,
40.5,
87.4,
78.9,
58.5,
87.2,
49.6,
3.5,
63.7,
81,
83.9,
87.1,
51.7,
88.3,
21.8,
85.1,
35.4,
58.9,
80.3,
12.9,
9.9,
67.3,
94,
37.2,
25.2,
75,
24.2,
25.2,
63.6,
31.6,
77.8,
26.6,
55.8,
66.4,
59.5,
37.7,
62.1,
70.4,
13,
48.4,
46.8,
19.3,
35.8,
43.7,
37.7,
75.3,
42.8,
69,
76.8,
70.8,
55.9,
68.1,
58.9,
34.4,
81.7,
20.5,
61.5,
64.2,
65.2,
47.8,
78.4,
35.3,
96,
73.2,
53.5,
27,
45,
50.9,
43.6,
99.7,
32.8,
68.5,
41.4,
43.2,
40.4,
27.2,
43.3,
67,
92,
91.3,
31.8,
30.5,
44.3,
66.7,
52.6,
42.9,
30.5,
6.5,
41,
68.5,
77.4,
49.9,
53.5,
45.9,
28.2,
76.4,
87,
31,
83.2,
99.2,
56.2,
88.6,
54.5,
84.3,
32.7,
75.3,
83,
81.1,
70,
94.8,
75.2,
42.4,
47.3,
34.7,
60.1,
35.2,
13.5,
96.8,
65.1,
55.9,
24.7,
67.9,
66.7,
33.2,
29.8,
38.9,
64.9,
82,
41.2,
89.5,
48.9,
52.8,
22.2,
36.3,
75.3,
67.9,
33.6,
35.6,
46.7,
74.3,
12,
54.3,
73.2,
90.3,
31,
59.8,
84.6,
53.9,
47.1,
3.7,
74.7,
41.2,
59.9,
61.1,
71.1,
42.6,
0,
16.1,
32.9,
7.8,
69.3,
68.6,
10,
18,
69.9,
22.3,
8.9,
94.7,
45.1,
33,
78.5,
10.2,
33.9,
48.6,
54.9,
73.5,
49.3,
60.2,
61,
43.2,
63.7,
90.7,
36.4,
1.7,
9.8,
22.5,
26,
92.8,
73.5,
51.6,
37,
74.7,
57.4,
52,
44,
65,
71.9,
15.2,
0,
9.3,
41.2,
34.8,
72.5,
53.5,
39.6,
48.5,
29.2,
9,
29.2,
19.8,
21.4,
76.3,
40,
58,
52.5,
64.4,
24.3,
0,
92.7,
69.5,
84.3,
76.3,
45.3,
28.9,
67.3,
15.1,
45.7,
40.5,
10.2,
73.2,
44,
93.1,
85.1,
75.1,
35.4,
43.6,
78.8,
70.2,
29.8,
87.2,
17,
46.1,
45.1,
30.3,
56.7,
71.3,
47.7,
82.5,
77.5,
29.9,
49.4,
41.5,
85.3,
37.4,
12,
53.6,
72.2,
96.1,
87.5,
63.1,
89,
63,
35.6,
31.5,
62.2,
61.1,
29.9,
51.8,
34,
41.2,
23,
75,
54.7,
35.8,
61.9,
1.8,
88.3,
83.5,
98.4,
68.9,
52.9,
79.8,
75.6,
43,
82.9,
60.7,
43.6,
23.6,
87.3,
61.2,
52.6,
9,
87,
40.9,
35.9,
57.8,
31.2,
72.2,
60,
50.6,
54.8,
72,
70.3,
85.9,
54.4,
5.8,
3.6,
77.3,
19.3,
26.7,
5.4,
84.8,
34.3,
27.6,
45.9,
53.3,
45.4,
54.3,
97.7,
62.6,
41.7,
89.1,
10.1,
42.5,
80.5,
54.2,
44.9,
48.3,
60,
75.7,
13.2,
74,
36,
72.3,
77.5,
83.5,
61,
78.8,
60.5,
56.9,
94.5,
77.8,
97.7,
86.5,
71.9,
62.7,
46,
93.3,
61.8,
64.9,
71,
96.8,
29.2,
67.3,
68.5,
74.7,
36.7,
77.7,
72.6,
19.3,
25.9,
43,
15,
83.4,
16.8,
34.8,
29.6,
76.7,
29.9,
81.4,
95.3,
29,
31.9,
57.3,
76.8,
61.4,
37.6,
55.2,
78,
76.5,
55.6,
57.7,
39.3,
44.2,
60.4,
33.2,
12.4,
72.1,
17.4,
16.8,
50.8,
24.7,
63.8,
3.3,
44.9,
78.5,
53.1,
59.4,
44,
55.4,
41.6,
69.9,
80.3,
41.7,
29.8,
0.6,
51.1,
90.3,
39,
90.5,
23.8,
69.3,
52.3,
85.6,
53.9,
68.5,
69.9,
77.7,
69.6,
53.4,
46.4,
40.3,
89.4,
49.8,
82.6,
18.4,
29.3,
56.2,
98.7,
16.6,
36.8,
58.8,
72.2,
64.3,
40,
70.6,
50.3,
96.8,
51.7,
17.3,
11.6,
40.4,
57.8,
61.4,
86.3,
70.5,
25.4,
55.9,
92,
14.2,
39.9,
49.9,
96.5,
12.9,
27,
63.8,
87.5,
78.6,
72.2,
25.2,
40.8,
37.2,
68.2,
31.9,
93.6,
53.4,
86.1,
57.5,
37.4,
51.5,
66,
69.8,
65.9,
83.2,
94.3,
51.8,
43.2,
93,
44.9,
43.8,
57.5,
59.4,
27.8,
59.6,
65,
62.7,
56.5,
42.8,
24.3,
77.4,
74.6,
67.5,
22.4,
58.1,
66.8,
43,
84.2,
39.8,
85.4,
56.5,
26.6,
71.5,
28.7,
62.9,
53.4,
63.4,
10,
50.2,
48.2,
80.5,
62.7,
35.1,
58.9,
19.3,
19.4,
40.4,
43.3,
31,
24,
13.5,
48.4,
27.3,
89.8,
59.8,
44.7,
81.1,
67.2,
64,
23.2,
28.2,
3.1,
48.4,
62.5,
90.3,
84.6,
45.2,
50.2,
31.1,
35.6,
42,
12.2,
72.2,
88.6,
63.4,
47.9,
55.8,
66.1,
49.3,
35.3,
58.8,
19.2,
74.6,
14.9,
95.6,
6,
5.2,
82.9,
75.8,
63.4,
38.4,
87.2,
28.8,
53.8,
82.8,
98.1,
80.9,
34.7,
53,
52.9,
25.9,
17.2,
39.7,
6.5,
86.4,
52.6,
55.7,
99,
59.9,
22.3,
57,
37.3,
58,
76.2,
61.3,
100.2,
71.2,
81.9,
80.8,
39.2,
21,
32.9,
71.2,
7,
45.9,
47.8,
54.7,
26.3,
41.5,
31.3,
49.3,
26.9,
38.3,
45.5,
52.6,
95.5,
15.1,
72.4,
60.8,
75.8,
52.8,
59.5,
97.7,
33.7,
74.9,
40.7,
14.1,
32,
91.5,
66.4,
5.2,
44.2,
71.8,
46.2,
5.3,
69.3,
62.1,
58.6,
53.9,
80,
87,
12.1,
72.2,
72.7,
50.9,
68.4,
57.7,
64.9,
76.2,
10.5,
71.7,
71.2,
65.1,
40,
73.1,
20.6,
99.2,
64.4,
94.9,
25.5,
38.1,
50.1,
56.6,
64.5,
47.4,
67.6,
11.4,
63.4,
97.3,
44.1,
55.3,
56,
52.5,
30.4,
13.9,
66,
74.8,
63.7,
68.2,
76,
29.6,
25.6,
85.3,
0,
94.2,
33.9,
59.5,
15.5,
70.5,
62.8,
22.6,
56.3,
88.7,
64.8,
78.5,
75.7,
24.1,
41.6,
69.7,
19.7,
29.1,
63.2,
10.5,
47.8,
51,
6.8,
32.6,
33.8,
41.1,
49.4,
60.7,
75.9,
28,
2.6,
14.3,
58.1,
52.1,
38.3,
36.8,
30.8,
33.6,
69.1,
62.8,
98.7,
72.8,
0,
92.9,
49.4,
38.1,
50.9,
62.7,
45,
83.6,
16.7,
38.2,
75.4,
42.7,
75.1,
35.6,
75.2,
31,
28.5,
75,
29,
41.7,
77.5,
54.1,
47.7,
26.4,
44.1,
76,
50.2,
42.7,
72.3,
95.2,
9.7,
10,
27.6,
7.5,
51,
64.9,
83.4,
62.9,
17.2,
76.7,
72.7,
80.3,
56.8,
83.9,
44.6,
10.4,
82.2,
27.3,
98.5,
27.1,
65.9,
87.6,
84,
31.5,
35.9,
54.8,
55.3,
83.9,
55.3,
60,
86.3,
47.9,
36.1,
64.4,
31.5,
61.6,
69.5,
65.3,
39.3,
35.8,
53.8,
43.8,
45.3,
43.7,
57.5,
29.3,
29.5,
93.8,
51.5,
71.5,
45.5,
93.3,
52.4,
34.1,
51.6,
68.4,
87,
39.2,
86.5,
71.7,
26.8,
72.8,
55.3,
83.7,
83.7,
50.7,
20.5,
92.8,
36.7,
45.1,
43.7,
34.6,
57.5,
81.5,
81.2,
81.5,
48.6,
21.4,
55.3,
18.1,
83.5,
45.6,
47.2,
96.5,
14.9,
0,
45,
52,
81.2,
21.4,
75.1,
65.6,
43.8,
68.2,
6.7,
73.2,
43.2,
80.3,
57.9,
72,
42.4,
91.4,
45.3,
33.8,
87.7,
87.1,
78,
41.6,
36.4,
60,
87.9,
80.2,
33.1,
42.5,
45.4,
60.8,
44,
97.3,
60.7,
44.6,
76.9,
55.2,
73.9,
48.7,
32.1,
69,
47.6,
36.4,
56.1,
17,
68.6,
58.1,
69.9,
64.3,
29.1,
64.3,
48.1,
74.2,
8.3,
9.4,
59.5,
30.8,
32.3,
40.8,
51.7,
83.6,
19.9,
48.6,
40.8,
12.8,
40.2,
53.5,
63.3,
51.7,
32.2,
43.7,
56.1,
63.4,
84.1,
29.8,
77.5,
30.3,
52.8,
75.1,
32.1,
90,
52,
83.4,
69.5,
60,
7.2,
96.6,
51.2,
58.9,
52.6,
17.6,
81,
1.9,
10.4,
6.8,
60.8,
53.8,
55,
58.5,
37.4,
73.5,
39.5,
28,
83.3,
1.3,
66.7,
63.5,
65.6,
89.3,
84.2,
37.7,
83.9,
20.8,
61.4,
47,
65.1,
76.5,
34,
63.2,
27.1,
32.3,
55.9,
37.8,
73.2,
91.2,
80.9,
43.5,
16.2,
47,
71.8,
69.1,
33.5,
82,
48.7,
61.1,
86.7,
61.4,
16.5,
61.5,
57.8,
31.5,
49.8,
67,
78.3,
80.4,
17.5,
50.8,
57.1,
50.6,
35.9,
51.1,
53.1,
63.9,
50.5,
53.6,
71.4,
54.5,
97.4,
41,
55.9,
91.5,
67.9,
44.9,
16.1,
76.9,
94,
61,
41.7,
85.4,
48,
53.4,
61.4,
19.7,
14.2,
91.1,
95,
58,
68.3,
18.7,
38.7,
61.4,
40,
54,
90,
47.4,
70.2,
56.7,
74.9,
38.4,
51.8,
null,
42.5,
76.5,
79.6,
69.3,
83,
58.4,
31.7,
44.8,
64,
46.5,
62.2,
52.1,
77.2,
48,
56.8,
47.3,
34.9,
57,
35.1,
74.5,
57.1,
25.8,
79.6,
52.4,
70.4,
59.9,
61.2,
79.2,
89.5,
69,
65.2,
73.8,
33.2,
63.2,
93,
45.8,
63.2,
83.6,
67.7,
68.8,
38,
3.2,
36,
91.1,
94.4,
58.5,
72.4,
70.5,
55,
54,
82.6,
17.5,
21.5,
46,
38.8,
57.1,
2.8,
43.8,
41.3,
38.1,
62.9,
74.3,
65.8,
57.8,
16.1,
70.9,
42,
61.1,
85.4,
83.7,
90.1,
70.6,
30.2,
70.4,
96.2,
43.1,
48.9,
58.9,
21.4,
91.3,
58.4,
7.3,
88.7,
79.7,
78,
56.9,
54.6,
57.8,
83.5,
96.2,
81.7,
44.9,
55.9,
47.5,
29.3,
55.5,
63.5,
29.3,
18.6,
38.5,
13.2,
32.1,
39.5,
57,
79.3,
33.7,
81.8,
29.5,
55.2,
66.8,
1,
26.6,
39.4,
77.5,
22.4,
27,
35.7,
29.1,
74.4,
27.4,
54.9,
83,
63,
52.4,
58,
55.7,
36,
0.4,
75.8,
57.4,
83.2,
50.1,
73.6,
51,
73.1,
47.1,
51.6,
74,
57,
66.8,
91.3,
71.8,
94.4,
26.8,
64.6,
97.2,
64.5,
98.2,
68.6,
71,
53.3,
53.3,
56.2,
77.4,
91.6,
62,
46.1,
75.6,
84.9,
48.7,
36.4,
71.1,
90.8,
74.1,
50.6,
26,
40.1,
17.8,
50.5,
64.7,
81.8,
6.5,
28.1,
69.4,
65.5,
12,
54.6,
55.3,
86.5,
96,
38.4,
46.8,
24.9,
31.6,
67.4,
63.4,
62.8,
44,
66,
24,
51.9,
96.2,
47.3,
77.3,
83.1,
70.4,
36.8,
98,
26.4,
74,
94.6,
64.6,
31.5,
30.8,
73.3,
71.1,
96.8,
94.5,
62.7,
78,
42.5,
43.3,
85.5,
14.1,
42.8,
32.5,
56.2,
66.6,
47.1,
33.9,
85.8,
36.1,
53.7,
39.1,
23.1,
55.6,
73.8,
78.4,
42.8,
44.7,
22,
46.3,
81,
72.1,
32.3,
75.4,
84.3,
68.1,
31.1,
69.2,
65.4,
40,
23.5,
38.5,
40.7,
57.9,
78.5,
60,
69.1,
11.2,
48,
52,
80.1,
38.8,
32.4,
26.7,
33.9,
93.1,
21.9,
66.8,
30.9,
81.9,
25.9,
39.5,
14,
65,
24.9,
58,
83.2,
85.3,
60,
18,
19.7,
68.1,
16.7,
56.8,
78.2,
44.5,
30,
80.1,
89.7,
47.8,
0,
62.3,
51.6,
84.5,
52.4,
63.1,
19.5,
66.2,
22.5,
77.1,
12.8,
81.3,
47.7,
69.4,
51.4,
13.4,
72.2,
35.8,
91.6,
73.1,
49.3,
70.4,
1.5,
37.6,
72.8,
94.7,
60.2,
68,
44.2,
52.4,
75.3,
52.1,
76.2,
6.4,
31.1,
11.1,
93.3,
71.7,
51.4,
27,
27.6,
96.6,
53.5,
39.4,
55.6,
94.1,
87.6,
21.9,
39.9,
94.5,
97,
65.9,
70.2,
72.5,
76.7,
22.3,
55.4,
23.6,
29.6,
96.1,
64.5,
0,
39,
63.3,
78.2,
83.2,
100.3,
17.6,
50.8,
80.4,
61.7,
42.5,
47.1,
58,
41.5,
65.5,
71.7,
51.9,
56.9,
69.6,
45.4,
44.7,
91.5,
29.3,
40.6,
56,
40,
19.2,
94.2,
60.1,
65.2,
61.6,
81.6,
57,
24.2,
62.2,
48.1,
48.9,
70.1,
34.6,
45,
0.1,
40.9,
45,
26.4,
57.4,
66.6,
61.1,
93.1,
40.4,
13.4,
62.2,
28.3,
68.1,
41.4,
73.6,
75.2,
90.2,
89.1,
19.5,
75.2,
55.8,
51.3,
61.3,
81.8,
51.3,
83.6,
31.5,
54.8,
33.1,
38.1,
94.5,
64.3,
79.4,
74.7,
62.5,
76.9,
58.1,
76.4,
69.5,
60.1,
74.9,
67.9,
22.7,
0,
53.9,
94.9,
86,
96,
80.5,
65.5,
81.8,
43.2,
32.2,
88.5,
44.7,
77.9,
25,
66.8,
29,
75.8,
70.4,
4.5,
64.6,
93.9,
67,
84.2,
45.8,
54.4,
33.2,
18.7,
35.3,
25.2,
43.3,
87,
75,
60.8,
40.2,
63.1,
34.8,
47.7,
3.6,
45.9,
52,
13.5,
75.3,
33.2,
43.4,
58.7,
51.1,
71.4,
63.7,
63.6,
59.6,
58.5,
43.1,
70.6,
79.6,
2,
43.9,
9.1,
80.6,
45.9,
84.9,
87.6,
61.9,
59.2,
61.2,
54.2,
48.6,
91.7,
71.9,
46.7,
94.2,
82.8,
64,
93.2,
95.8,
36.9,
53.6,
59.7,
75,
76.3,
65.7,
96,
95.6,
55.2,
27.8,
24.6,
39.4,
34.5,
52.8,
14.3,
76.9,
73.9,
60.2,
47.8,
55.3,
61.9,
43.8,
56.7,
64.9,
63.6,
61.4,
54.3,
101,
44.6,
39.3,
56.4,
2.3,
62.5,
11.5,
44.4,
79.7,
77.3,
92.4,
57.9,
70.8,
44.8,
39,
11.6,
63.4,
61,
70.6,
59.1,
65.6,
92.3,
54.7,
9.9,
40,
43,
51.1,
83.4,
60,
36.4,
89.6,
59.1,
66.8,
33.2,
17.5,
27.5,
34.8,
35.6,
80.6,
78.4,
36.2,
63.9,
16.4,
31.3,
40.1,
53.3,
48.4,
76.3,
62.8,
88.8,
33.7,
81.5,
67.5,
89.3,
60.4,
50.1,
22.2,
80.1,
55.6,
69.5,
88.7,
67.7,
69,
56.1,
66.8,
65,
7.8,
51.9,
20,
96.6,
39.9,
69.8,
52.7,
96.8,
2.2,
68,
93.1,
35.5,
80.7,
8.3,
51.9,
89.3,
60.6,
48.5,
52.8,
33.1,
28.3,
64,
75.2,
48.5,
71.3,
36,
99,
44.6,
27.6,
86.7,
78.2,
5.5,
76.3,
2.2,
98.2,
31,
65,
65.4,
96.4,
66.3,
43.4,
9.2,
78.3,
67.1,
43.8,
62.6,
87.3,
52.1,
84.6,
58,
80.1,
83.6,
39,
62.1,
42.8,
69.1,
72,
66.5,
55.5,
43.7,
42.9,
72.5,
23.9,
36,
50.7,
0.4,
82.2,
73.9,
14.2,
95.3,
50.8,
59,
66.5,
54.1,
72.4,
66.8,
72.4,
55.3,
45.4,
36.5,
45.7,
86.5,
90.8,
36.5,
36.3,
75,
62.9,
68.5,
90.1,
57.6,
69.6,
72.3,
37.4,
66.1,
57.3,
82.2,
9.3,
70.8,
31.6,
53.4,
59.8,
13.2,
61.7,
71.2,
77.9,
57.3,
55.7,
91.2,
22.4,
52.1,
57.3,
70.2,
60.4,
66.1,
60.2,
63.7,
69.1,
48,
42.3,
15.5,
66.9,
60.1,
81,
43.9,
33.4,
15.5,
80.2,
53.6,
87.3,
54,
90.6,
31,
8.4,
36.2,
36.2,
32.8,
15.3,
28.4,
31.4,
52.6,
78.3,
71.5,
94.1,
45.9,
11.8,
58.1,
59.5,
90.9,
67,
37,
85.2,
68.8,
81.4,
27.4,
17.4,
85.7,
61.2,
89.5,
22.2,
22.9,
89.7,
69.3,
54.7,
96.5,
13.9,
46.9,
66.6,
63.3,
46.5,
11.4,
90.1,
44.5,
32.4,
76.6,
58.4,
47.1,
60.3,
69.9,
83.5,
70.7,
41.4,
78,
59.9,
87.4,
84.2,
11,
64.7,
102.1,
20.2,
73.3,
70.7,
29.6,
37.2,
47.8,
19.5,
64.1,
57.8,
72.8,
88,
28.5,
78.2,
28.6,
74.3,
22.7,
0,
59.1,
12,
54.7,
89.5,
67.7,
20.2,
53,
43.5,
27.2,
54.1,
64,
60.9,
65.6,
43.3,
45.6,
43.8,
77,
21.8,
35.2,
49.9,
29.1,
51,
1.2,
51.5,
22.1,
56.6,
49.6,
41,
60.5,
15,
76.6,
24.7,
38.5,
31.6,
85.7,
81.1,
82.4,
15.5,
89.5,
26.5,
81.2,
25.6,
18.4,
85.7,
80,
75.4,
64.9,
95.5,
34.3,
46.2,
19.4,
80.7,
47.4,
38.9,
53.4,
73.7,
69.8,
24.9,
76.8,
93.5,
70.7,
4.1,
54,
28.7,
12.3,
48.2,
80.3,
80.2,
12.8,
45.5,
14.3,
17.1,
72.4,
40.5,
20.8,
60,
71.2,
50.7,
63.8,
61.9,
47.3,
57.5,
19.9,
80.6,
78,
16.7,
43.8,
96.2,
91.5,
83.8,
89.8,
65.5,
26.8,
76.2,
68.6,
7.4,
50,
88.1,
80.2,
77.4,
28.6,
81.9,
55,
48.9,
44.3,
27.9,
50.9,
33.2,
51.1,
60.1,
22.1,
17.5,
36.6,
4.2,
79.6,
15.5,
15.1,
54,
54.5,
59.9,
5.5,
53.2,
49.2,
57.3,
37.1,
50.7,
83.5,
28,
19.2,
31,
44,
78.4,
67,
0,
72.4,
62,
74.5,
68,
36.2,
60.5,
25.5,
1.5,
75.2,
54.1,
52,
59.4,
79.5,
35.2,
50.8,
26,
90.3,
80.1,
71.7,
47.6,
34,
48.1,
61.6,
22.7,
49.6,
55.8,
32.2,
24.8,
23,
61.1,
63.4,
84.6,
67.2,
41.6,
63.7,
83.7,
69.5,
56.1,
17.8,
66.9,
46.9,
66.3,
76.6,
40.5,
82,
90,
42.5,
63.8,
59,
85.3,
81.7,
99.1,
9.1,
60.9,
61.7,
55.2,
61.1,
72.6,
9.2,
32.5,
39.8,
72.4,
28.8,
54.7,
66.4,
51.8,
30.9,
75.1,
70,
78.9,
80.1,
71.4,
87.2,
44.5,
48.7,
46.9,
85.5,
90.4,
90.7,
82.2,
65.1,
55.5,
38.1,
47.9,
56.4,
47.7,
47.3,
49.7,
83.2,
77,
61,
59.5,
50.6,
3.4,
22.8,
41.2,
27.5,
93.2,
78.5,
46.9,
41.8,
38.9,
16.5,
43.9,
34.6,
76.7,
0,
68.1,
71.1,
61.6,
78.6,
77.5,
47,
64.7,
56.1,
73.5,
71.3,
68.3,
53,
6.6,
42.5,
47.5,
75.9,
10.3,
74.3,
36,
19.3,
70,
59.4,
94,
36.5,
94.6,
32.4,
55.1,
7.8,
96.1,
12.8,
61,
41.6,
62.4,
69,
47.2,
57.2,
45.4,
73.5,
79.1,
66.8,
81.2,
25.9,
52.7,
55.7,
49.9,
55,
81.9,
84.5,
80,
99.2,
11.8,
34.3,
58.2,
42,
56.5,
26,
68.8,
59.4,
77.3,
54.7,
47,
81.9,
29.6,
61.5,
27,
23.6,
28.2,
69.3,
29.9,
41.2,
50.4,
38.8,
86.8,
21.1,
27.2,
83.8,
76,
96,
31.7,
59.3,
43,
57.6,
83.4,
72.7,
49.5,
100.3,
89.6,
53.3,
18.8,
9.5,
54.9,
22.8,
50.8,
43.4,
88.1,
88,
70.9,
99.5,
80,
76.3,
66.6,
66.7,
41.8,
46.6,
94,
40.2,
49.3,
25.1,
31.5,
36,
22.1,
94.8,
64.9,
35.7,
56.5,
95.4,
58.3,
89.2,
51.4,
37.5,
94.1,
40.5,
21.4,
7.9,
39.1,
8.4,
3.4,
20.7,
76.9,
42.4,
64.6,
63.6,
82.4,
59,
33,
16.7,
31.6,
78,
40.2,
48.3,
76.3,
28.8,
49,
78.6,
47.8,
70,
89.2,
68,
95.6,
62,
80.4,
39.2,
50.3,
38,
67.2,
46,
88.5,
28.9,
37,
26.5,
63.6,
46,
8.3,
87.8,
21.4,
41.2,
35.6,
42.7,
76.8,
59.6,
26.9,
32.1,
32.9,
58.8,
47.5,
30.9,
45.3,
33,
49,
33.5,
67.5,
56.1,
92.6,
12,
9.5,
71.6,
28.2,
24.1,
50.9,
89.3,
58.4,
22.3,
85.4,
5.1,
40.3,
49.3,
39.5,
68.9,
42.8,
71.1,
52.7,
78.5,
60.9,
49.6,
19.4,
82.6,
78.7,
78.6,
8.6,
47.5,
34.6,
41.6,
20,
85.4,
84.3,
63,
67.9,
25.6,
84.3,
26.3,
49,
56.7,
30.8,
76,
57,
64.6,
86.2,
42.3,
17.6,
57.3,
39.9,
46.4,
83.5,
55.6,
11.4,
73.6,
52.8,
29,
34.3,
20.1,
11,
29.3,
48.4,
72,
13.1,
74.4,
65,
20.5,
50.2,
82.5,
3,
51.3,
69,
78.9,
74.5,
39.5,
51.9,
68.1,
91.6,
33.8,
67.6,
31.6,
60.9,
30.2,
78.4,
96.3,
19.2,
6.1,
75.6,
38.5,
83.4,
39.7,
72.9,
90.1,
75.5,
56.5,
48.1,
70.4,
53.7,
59,
70,
33.4,
71.4,
76.8,
61.9,
16.2,
82,
99,
85.2,
28,
17.5,
45.9,
67.7,
13.5,
63.1,
65.3,
67.5,
62.3,
70.7,
58.6,
18.8,
77,
76.8,
35,
48.2,
25.8,
24,
64.1,
38.6,
19.6,
24.3,
58.4,
64.7,
22,
40.6,
0,
95.5,
51.8,
52.6,
55.6,
7.7,
30,
65.3,
92,
92.9,
77,
66.5,
54.8,
15.3,
56.2,
72.1,
60.8,
71.2,
0.7,
20.6,
89.9,
67.9,
94.1,
52.4,
53.4,
82.8,
72.7,
98.1,
36.5,
21,
27.1,
54.9,
58.5,
62.9,
69,
75.5,
70.3,
6.9,
68.1,
83.6,
58.5,
73.1,
36,
70.7,
48.5,
27.6,
42.8,
37.7,
37.9,
81.4,
19.9,
6.5,
50.3,
56.9,
84.8,
19.6,
46,
72.9,
80.3,
35.5,
64.2,
87.4,
83.3,
76.2,
72.6,
89.9,
57,
72.1,
84.6,
68,
80.2,
48.3,
67.3,
26.8,
44.8,
71.5,
65.3,
18.9,
67.2,
54.6,
4.3,
46.6,
75.9,
91.7,
58.5,
61.5,
58.3,
21.2,
38.7,
22.6,
61.3,
71.9,
48,
28.4,
58.9,
65.3,
79.1,
36.2,
34.8,
49.6,
39,
17.7,
42.2,
70.9,
22.2,
69.3,
70.5,
69.2,
35.7,
48.9,
53.4,
55.8,
36.8,
40.5,
74.8,
62,
18.2,
72.7,
70.1,
80.9,
17.5,
63.6,
19.5,
102,
47.2,
53.9,
79.8,
50.2,
21.7,
24.1,
46.7,
24.8,
92.5,
0.7,
62.9,
8.3,
11.4,
22,
55.7,
75.7,
26.2,
86.3,
60,
53.2,
63.2,
91,
25.3,
36.7,
71.9,
47,
21.8,
54.9,
84.8,
94.2,
90.7,
56.1,
52.4,
31.2,
56.1,
9.2,
45,
7.5,
50.6,
47.2,
61.3,
74.7,
9.2,
97.5,
65.4,
31.1,
84.9,
69.6,
97.1,
21,
87.8,
48,
75,
69.5,
0,
95.6,
92.6,
14.5,
57,
89.9,
63.8,
31.3,
93.7,
67.6,
16.7,
43.2,
46.7,
79.7,
63.4,
29.4,
89.7,
55,
29.3,
44.7,
28.5,
47,
25,
66.3,
89.1,
98.5,
87.1,
69,
10.7,
58.9,
58.5,
25.9,
13.2,
29.6,
29.7,
76.1,
7.7,
90.9,
39,
69.5,
39.9,
28.9,
27.4,
93.5,
63.9,
31.5,
68.6,
80.7,
45,
50.1,
76.4,
28.5,
83.6,
61,
28.8,
67.8,
21.9,
0,
74.4,
46.2,
57.8,
22.9,
18.9,
54.3,
64.9,
62.9,
63.2,
19.9,
89,
48.4,
53,
70.2,
88.4,
21.4,
20,
70.8,
71,
91.3,
17.4,
68.3,
16.7,
48.2,
72.5,
90.5,
55.8,
83.8,
53,
36.2,
56.9,
86,
67.9,
70.5,
27.3,
48.3,
80.2,
57.7,
40.3,
46.4,
63.9,
9.4,
93.3,
82.7,
80.2,
46,
70,
49.8,
57.2,
19.3,
82.3,
83,
78.7,
30.1,
63.2,
58.9,
45.6,
30,
69.9,
31.5,
54,
33.2,
91.3,
78.1,
44.1,
74.6,
6.5,
33.2,
54.3,
75.7,
28,
73,
70.7,
97.9,
83.1,
11.1,
31.7,
61.9,
53.9,
59.5,
95.4,
38,
51.6,
86.5,
83.3,
8.4,
37.4,
50.9,
35.1,
54.8,
67.2,
60.8,
91,
82.4,
27.7,
54.1,
69.7,
41.4,
58.8,
39.2,
41.4,
42.4,
90.7,
82.7,
74.4,
52.3,
45.2,
55.7,
0.4,
67.9,
48,
51.4,
37.7,
46.3,
12,
31.9,
32.1,
33.9,
54.3,
76,
39.5,
49.8,
76.8,
67.9,
76.2,
65.3,
20.3,
72.7,
77.6,
36.9,
88.3,
84.8,
33.8,
47.3,
47.6,
35.2,
40.1,
61.6,
34.7,
24.5,
40.4,
76.6,
22.1,
61.7,
62.1,
95.5,
43.4,
60.3,
90.7,
75,
27.8,
34.4,
27.7,
98.1,
96.2,
66.8,
86,
50.9,
61.9,
63.7,
79.8,
39,
23.4,
82.1,
41.6,
48.8,
53.8,
25.3,
31.5,
33.2,
52.9,
44.6,
78,
48.2,
59.8,
50.1,
67.6,
36.5,
54.3,
12.4,
47.8,
76.6,
56,
34.3,
44.9,
32.9,
70.5,
54.6,
79.9,
20.1,
21.5,
72.5,
86.1,
90.3,
73.8,
26.6,
25.9,
41.5,
62.3,
73.4,
19.9,
27,
51.6,
60,
47.1,
61.7,
57.1,
62.8,
28.9,
52.4,
60.6,
48.9,
47,
13.7,
93.1,
77.6,
18,
78.6,
54.9,
61.9,
43.1,
65.1,
51.3,
73.1,
55,
50,
65.5,
27,
88.6,
36.2,
99.1,
47.6,
89.3,
34.8,
72.1,
32,
66.6,
64.2,
87.5,
75.3,
70.5,
42.2,
75.9,
33.6,
58.5,
30.6,
86,
48.2,
40.5,
51.6,
29.2,
94.5,
35.8,
98.5,
43.5,
81.4,
71.4,
64.6,
63.6,
51.7,
28.6,
97,
80.8,
46.6,
39,
26.7,
52.2,
76.9,
42.3,
71.4,
30.2,
15.8,
27.9,
41.1,
25,
54.3,
48.9,
30.5,
71.8,
79,
83.3,
66.2,
24.5,
38.6,
35.2,
67.8,
30.2,
45.6,
58,
79.3,
15.8,
45.6,
85.8,
31,
1.9,
55.8,
79.8,
42.6,
57.9,
58.4,
32.6,
56,
71.4,
75.5,
75.6,
63.1,
36.9,
91,
46.2,
61.5,
32.3,
88.8,
71.8,
37.4,
83.4,
90.5,
34.6,
32.9,
69.2,
81.6,
16.9,
13.9,
50.3,
24.1,
96.4,
57.8,
25,
83.3,
74.3,
1.7,
48.1,
58.8,
71.3,
61,
83.6,
55.6,
25.2,
83.9,
33.2,
27.5,
28.8,
31.1,
46.5,
43,
89.6,
36.3,
25.8,
96.4,
77.6,
51.1,
48,
46.3,
4,
88.9,
50.1,
39,
22.2,
81.5,
39,
53.4,
62.6,
90.7,
39.8,
33.9,
20.9,
84.8,
40.4,
60.1,
59,
98.8,
75,
59,
52.5,
45.5,
63.1,
35.1,
85.4,
54.4,
13.6,
72.5,
87.5,
64.9,
84.5,
41.9,
27.8,
23,
77.3,
91.1,
70.9,
68.1,
12.6,
37.4,
98.8,
55.3,
90,
23.5,
69.9,
28.9,
21.1,
64.2,
16.8,
97.8,
28.9,
77.9,
43.7,
24.9,
46.4,
74.6,
77,
69.7,
99.5,
68.6,
61.1,
67.2,
71.1,
58.2,
38.9,
101.2,
68.4,
33.8,
6.7,
52.6,
40.5,
50.7,
77.9,
80.9,
67.8,
48.8,
56.6,
95,
56.6,
76,
45.6,
45.3,
94.4,
60,
40.9,
15,
84.5,
38,
83.3,
81.2,
83.3,
27,
26,
17.9,
48.8,
90.8,
72.9,
50.8,
22,
71.2,
49,
71.8,
19.8,
65.1,
53.1,
19.9,
74.2,
38.3,
61,
53.2,
93.6,
53.7,
87.7,
54.5,
47.7,
64.7,
27.9,
83.7,
51.6,
64.4,
58.6,
44.1,
47,
8.9,
69.8,
49.3,
56.9,
52.4,
57.7,
60.2,
28.8,
25.1,
63.8,
59.7,
69.8,
45.8,
86.9,
10.5,
36,
48.1,
63.3,
93.9,
104.7,
62.8,
32.9,
21,
59,
93.8,
65.5,
70.6,
60.5,
27.4,
75.9,
65.3,
55.7,
84.1,
72.1,
78.8,
70.8,
48.3,
16.5,
50.9,
48,
63,
80,
93.8,
98.7,
28.8,
40.9,
49.6,
34.9,
27.4,
38.2,
52,
33.5,
38.4,
55.2,
16.8,
70.5,
33.4,
48.7,
41.2,
60.4,
35.7,
31.3,
65.7,
28.8,
7.7,
42.2,
28.2,
34,
34.7,
10.7,
52.7,
87.7,
19.9,
55.3,
74.6,
18.3,
2.3,
23.4,
44.8,
92.4,
70.6,
46.5,
87.9,
0,
33.8,
70,
91.5,
46.1,
0.1,
59.8,
36.8,
75,
80.7,
39.6,
58.8,
16.8,
26,
0,
57.5,
73.8,
60.6,
72.2,
3.8,
59.9,
85,
98.7,
39.1,
44.9,
68.8,
33.7,
83.9,
59.7,
64.7,
49.9,
83.5,
38.5,
46.5,
25.7,
26.5,
50.3,
32.5,
29.9,
66,
83,
45.9,
73.6,
44.8,
48.8,
85,
99.2,
40.6,
33.2,
57.7,
36.5,
77,
57.3,
50.2,
48.4,
99,
86.8,
103.7,
61.5,
45.7,
81.4,
65.1,
36.5,
38.2,
84.9,
35,
84.3,
30.4,
38.7,
49.5,
43.1,
84.5,
89.7,
47,
76.6,
33.4,
29.7,
65.3,
94.6,
94.8,
91.7,
44.9,
57.6,
53.3,
64.9,
61.6,
66.1,
56.9,
27.3,
35,
91.5,
29.4,
50.2,
22.3,
90.1,
48.1,
86.7,
44.4,
74.5,
88,
26.2,
42.4,
42.7,
60.4,
67.7,
63.6,
49.1,
72.7,
94.3,
59.3,
20.6,
67.7,
74.3,
73.9,
37.5,
33.4,
62,
73.3,
77.8,
74.5,
66.7,
18.1,
38,
57.3,
56.1,
27.4,
74.2,
58,
44.4,
9.4,
98.5,
97.5,
88.1,
16.8,
26.3,
90.6,
42.2,
81.1,
80,
61.6,
81.9,
76,
62.1,
57.9,
59.2,
24.3,
49.4,
48.1,
78.4,
67.8,
84,
86.5,
6.1,
53.7,
50.3,
51.4,
46.8,
43.5,
59.4,
86.3,
46.6,
7.5,
47.2,
39.7,
51.9,
61.5,
1.6,
46.9,
60.4,
88.4,
66,
5.7,
53.8,
28.5,
12.8,
88.8,
57.2,
55.3,
37,
31,
5.4,
31.5,
52.4,
100.5,
79.8,
47.1,
84.1,
62.2,
64.1,
88.2,
94.3,
61.6,
37.3,
53.1,
60,
36.5,
96.3,
45.8,
93.8,
8.7,
33.6,
54.3,
10.1,
46,
29.6,
84.3,
49.5,
69.9,
66.3,
77.2,
8.3,
56.7,
70.8,
0,
31.1,
80.8,
20.2,
15,
72.4,
25.3,
77.8,
70.1,
59.5,
84.8,
65.8,
34.5,
97.3,
87.6,
53.1,
39.7,
71.1,
14.9,
91.1,
56.6,
75.8,
49.9,
67.1,
40.2,
79.8,
25.8,
41.9,
45.8,
55.9,
67.6,
62.7,
84.5,
28.6,
77.2,
35.7,
68.1,
64.6,
46.9,
72.8,
73.7,
35.4,
63.9,
89.7,
62.7,
55.6,
93.1,
75.5,
99,
57.8,
87.1,
86.4,
32.9,
30.2,
30.2,
59.1,
25,
85,
61.1,
47,
60.6,
48.9,
73.4,
96.9,
49.1,
90,
69,
41.3,
85.9,
80.9,
44.9,
72.3,
73.4,
37.6,
49.2,
53.9,
70.4,
38.8,
46.4,
69.4,
62,
38.8,
5.8,
85,
91,
69.8,
86.7,
86.5,
65.8,
52.3,
82.7,
33.1,
82.4,
32.5,
80.2,
92.7,
44.5,
52,
20.3,
33.4,
21.2,
54.3,
41,
45.4,
70.8,
70,
91.5,
57.9,
31.6,
41.6,
41,
30.4,
93.8,
53,
21.1,
0,
28.4,
61.4,
56,
50.1,
65.6,
45.4,
9.8,
24.6,
53.7,
93.5,
65.6,
0.5,
69,
80.3,
74.9,
76,
85.4,
32.9,
70.6,
38.9,
41.6,
30,
30.2,
67.8,
48,
78,
41.9,
53.7,
27.2,
58.3,
37,
24,
17.7,
47.4,
91.3,
74.7,
56.7,
58.7,
75.9,
31.2,
68.5,
68,
55.5,
63.5,
45.2,
43.7,
30.3,
72.4,
62.5,
46.2,
66.6,
24.2,
40.5,
86.2,
38.8,
42.4,
44.4,
64,
36.7,
84,
26.7,
23.8,
78,
27.9,
53.3,
51.3,
83.9,
84.5,
79.9,
70.9,
73.2,
82.6,
34,
34.2,
66.9,
47.3,
81.4,
72.6,
70.4,
49,
49.7,
18.1,
99.5,
50.7,
57.4,
84.6,
64.8,
8.4,
32.1,
70.3,
90.5,
42.6,
90.7,
77,
91.4,
64.4,
60.7,
57.9,
42.6,
90.2,
47.9,
53.5,
51.9,
76.3,
35,
77.7,
55.9,
62.6,
85.1,
71.9,
76.6,
81.9,
75.8,
2,
29.6,
23.4,
78.8,
36,
88,
51.6,
84,
87.2,
95.8,
23.3,
47.8,
43.5,
43.8,
33.3,
88.4,
43.6,
84.1,
47.9,
32.3,
74.2,
85.2,
80.6,
49.5,
17.8,
52.5,
18.9,
90.7,
23.6,
75.5,
25.4,
31.2,
56.7,
38.6,
93.9,
55,
44.6,
100.1,
53.9,
39.6,
10.8,
35.3,
84.5,
64.5,
93.7,
39.3,
9.4,
96.3,
56.5,
49.3,
39,
93.3,
56.6,
90.2,
50.2,
35.7,
57.5,
31.8,
2.3,
82.1,
81,
48,
79.4,
23.2,
66.6,
89.5,
48.9,
6.7,
55.6,
67.7,
51.4,
68.8,
47.8,
74.8,
45.3,
79.4,
62.2,
60,
64.6,
55.4,
53.7,
12.8,
34.3,
58.9,
7.9,
14,
38.5,
22.1,
0.2,
76.6,
58.9,
27.3,
73.4,
64.6,
95.3,
68.3,
26.7,
93.9,
72.7,
5.5,
64.4,
60.2,
12.3,
32.4,
4.6,
57.6,
55.2,
51.2,
45.7,
76.9,
63,
90.8,
37.4,
41.4,
61,
69,
29.4,
69.2,
41,
26.7,
57.9,
100.1,
78.8,
75.7,
26.9,
94.8,
27.2,
55.1,
62.6,
13.5,
53.7,
53.6,
47.6,
55.6,
79.6,
18.4,
32.8,
34.7,
21,
23,
65.9,
2.4,
44.2,
89.2,
58.6,
47.3,
4.2,
13.4,
16,
74.2,
94.7,
28.4,
31.6,
38.2,
96.4,
82,
71.4,
87.4,
71.8,
2.9,
58.2,
80.2,
38.6,
68.3,
29.2,
21.5,
8.3,
32.2,
52.6,
91.3,
52.8,
39.1,
91.4,
17.9,
2.3,
79.6,
58.6,
28.3,
28.9,
68.8,
44.1,
19.8,
14.1,
40.4,
40.4,
53.4,
42.4,
67.2,
68.5,
12.4,
51.6,
33.5,
93.1,
3.3,
64.5,
78.5,
27.9,
38.6,
51.3,
78.1,
60.7,
41.5,
43.1,
65.2,
31.7,
27.2,
44.2,
18.7,
69.2,
96.3,
53.1,
72,
85,
83.9,
36.8,
67.7,
40.6,
27.3,
30.3,
90.5,
20.3,
29.1,
34.7,
32.4,
64.2,
21.1,
66.2,
51,
30.7,
71.6,
81,
64,
57,
27,
95.7,
51.5,
42.2,
76.9,
28,
58.9,
58.7,
50,
26.6,
60.8,
62,
35.6,
63,
76.2,
86.5,
70.3,
48.8,
75.3,
63.8,
54.5,
84.3,
41.3,
36.1,
19.1,
65.9,
65.3,
84.1,
0.7,
42.5,
32.5,
46.4,
75.6,
89,
94.5,
65.8,
93.1,
50,
68.8,
33.8,
54.7,
41.9,
25.4,
44.9,
26.5,
50,
5.4,
39.9,
38.9,
97.1,
75,
79.6,
47.8,
72.7,
34.8,
98.6,
58.1,
102.2,
44.3,
59.9,
7.2,
49,
38.1,
34.2,
29.5,
58.4,
61.2,
37.5,
55,
18.6,
86.9,
39.4,
23.7,
99.7,
56.1,
76.8,
91.5,
45.8,
24,
65.2,
35.9,
76,
69,
64.2,
44.6,
59.6,
38.7,
91.7,
65.3,
56.1,
75.1,
40,
31.4,
78.2,
47.2,
64.8,
30.4,
61.1,
56.3,
58.8,
100.6,
85,
45.4,
76.6,
58.5,
21.4,
65.9,
62.1,
53.6,
50.9,
46.2,
75.9,
70.7,
98.5,
82,
50.6,
27.3,
45.8,
20.9,
43.7,
69.7,
41.2,
76.1,
48.2,
26.9,
56.8,
74,
94.6,
45.9,
82.3,
59,
44.7,
65.4,
31.2,
87.1,
48.1,
80.6,
95.3,
50.6,
27.6,
88.8,
37.8,
54.4,
18.4,
3.9,
56,
72,
70.2,
75.4,
84.8,
76.4,
61.3,
68.9,
54.6,
81.3,
99.2,
65.1,
78.6,
18,
61.5,
59.8,
10.4,
92.6,
81.2,
34.9,
90.5,
59.4,
30.8,
70.7,
68.6,
70.4,
97.3,
90.5,
25.9,
13.8,
36,
30.5,
64,
30.9,
38.5,
68.1,
40.7,
49.2,
0.8,
62.3,
47.9,
58.4,
54.3,
47.9,
44.7,
73.8,
74.9,
98,
50.5,
58.5,
72.5,
72.9,
96.4,
48,
48,
35.8,
34.1,
22,
52.7,
87.5,
37.1,
57.4,
80.2,
67.1,
6,
54.4,
76.1,
60.6,
58.1,
20.6,
82.4,
76.9,
62.2,
96.2,
83.5,
26.6,
66,
31.8,
29.7,
3.9,
85.9,
25.9,
69.5,
15.9,
55.7,
95,
30.2,
33.3,
72.2,
30.1,
57,
78.8,
78.9,
29.8,
61.8,
40,
78.4,
62.3,
37.8,
71.9,
93.6,
48.4,
63.9,
53.7,
17.8,
89.6,
40,
48.6,
42.9,
83.1,
70.4,
84.6,
18.3,
23.3,
30,
75.9,
84,
27.3,
77.3,
84.9,
7.8,
84,
51.9,
91.9,
45.3,
33.6,
53.9,
40.4,
41.3,
52.4,
2,
53.1,
77.2,
9.7,
87.2,
63.2,
91.6,
79.7,
62,
18.3,
49.9,
63.5,
42.4,
88.1,
50.2,
43.3,
43.3,
63.5,
42.3,
56.1,
55,
79.3,
47,
68.3,
73.5,
58.7,
86.4,
50.6,
32.7,
88.2,
86.8,
34.8,
50,
33.1,
76.2,
65.4,
44,
80.6,
70.6,
74.4,
61,
44.6,
52.8,
61.6,
38,
28,
72,
76.5,
80.1,
74.2,
81.7,
82.2,
6.8,
56.5,
35.7,
83.3,
41.8,
72.6,
37,
70.7,
46.4,
84.3,
66.5,
25.4,
12.4,
92.2,
65,
90.7,
17.2,
68,
74.4,
36.7,
97.1,
35.3,
6.3,
19.7,
38.6,
0,
69,
78,
67.9,
99.9,
36.6,
34.6,
45.5,
58,
48.1,
42.9,
48.7,
65.1,
80.9,
87.7,
75.1,
59.2,
44,
65.1,
15,
100.7,
81.4,
54.3,
17,
75.7,
46.4,
44.7,
31,
73.2,
62.9,
99.3,
80.2,
70.1,
56.4,
77.3,
58.1,
39.3,
52.7,
70.6,
38.3,
1,
93.6,
70.1,
30.6,
20,
66.4,
33.9,
36.9,
42.3,
69,
95.2,
62.7,
50.9,
66.1,
4,
35.4,
99.8,
62,
35.7,
57.2,
73.5,
95.4,
53.5,
24.3,
29.9,
25,
35.4,
86.8,
9.6,
64.8,
62.3,
59,
41.8,
62.5,
69.2,
51.5,
50,
96.8,
75.2,
86.6,
73.4,
24.9,
83,
13.9,
83.4,
57,
58.4,
42.4,
76.3,
68.2,
56.4,
70.8,
28.8,
51.7,
92.6,
63.2,
11.1,
44.2,
40.1,
49.6,
8.9,
10.4,
91.7,
4.3,
44.7,
72.5,
61.6,
59.6,
58.8,
50.7,
82.9,
72.6,
6,
29.3,
43.3,
49.5,
67.4,
26.1,
74.2,
100,
72.5,
93.9,
24.2,
81.5,
91,
64.7,
74.3,
61.9,
34,
60.4,
65,
57.1,
73,
48.5,
63.9,
67.6,
72.1,
54.4,
87.1,
33.1,
46,
70.6,
53.8,
63.1,
95.4,
85,
61.1,
49.8,
72.1,
53.1,
83.7,
96.3,
91,
65.4,
30,
51.8,
89.6,
39.9,
72.1,
97,
38.9,
41.9,
48.3,
58.1,
71.6,
35,
45.4,
27.6,
71.1,
37,
22.6,
65.5,
51,
53.4,
52.8,
75,
4.9,
25.2,
18.3,
87.3,
56.8,
73.8,
84.3,
76,
36.5,
25.3,
46.8,
28,
34.2,
73.2,
39.5,
81.9,
82.6,
69.8,
35.8,
71.3,
99.7,
21.3,
17.5,
67.9,
47.3,
34.6,
29.9,
84.3,
41.5,
64.4,
34.7,
37.5,
45.7,
64.1,
37.1,
7.1,
87.7,
56.5,
100,
69.7,
58.8,
73.1,
94.6,
86,
21.7,
56,
33.3,
49,
30.9,
47.3,
18.4,
19.9,
22.1,
66.7,
15.2,
53.6,
43.2,
50.6,
41.4,
63.5,
37.7,
56.8,
69,
22,
83.8,
24.4,
86.8,
83.3,
45.8,
19,
82.3,
58,
46.9,
80.9,
75.4,
50.3,
76.5,
66.5,
51.2,
47.6,
77.4,
95.1,
50.1,
57.8,
35.8,
71.4,
63,
48.5,
86,
52.7,
5.7,
65.1,
86.4,
55.2,
72.4,
89.7,
53.6,
41,
37.9,
63.7,
84.1,
87.4,
63.6,
64.1,
38.6,
77.6,
20.4,
35.6,
71,
71.9,
79.4,
69.9,
51.3,
67.5,
88.4,
13.7,
97.4,
67.1,
62.5,
76.6,
88.2,
74.5,
43.7,
29,
23.7,
44.4,
15.8,
90.6,
45.6,
46.7,
70.3,
69.9,
72.6,
82,
63.3,
20,
70.1,
33.1,
42.6,
69.9,
69.4,
49.1,
74.8,
47.6,
25.4,
69.8,
77.5,
60.3,
62.1,
68.3,
78.8,
89.8,
58.4,
11.2,
84.2,
96.1,
58.4,
60.4,
65.1,
66.3,
84,
20.4,
58.9,
61.5,
50.8,
76.1,
88.4,
65.3,
61.7,
41.4,
67.9,
55.1,
35,
29.8,
62.6,
15.1,
95.6,
77,
80.3,
42.5,
57.3,
69.4,
75.3,
74.1,
72.5,
22.2,
57.9,
21.5,
27.5,
9.1,
44.7,
93.6,
50.5,
52.8,
21.3,
67.7,
33.6,
65.5,
83.2,
65.6,
61.7,
47,
55,
61.8,
48,
25,
42.7,
9,
13.4,
24.2,
88.8,
62.5,
97,
61,
80.8,
34.8,
75.3,
56.6,
61.6,
59.9,
98.6,
75,
91.8,
68.7,
92.1,
59,
51.4,
72.3,
57.2,
36.2,
84.5,
67.8,
77.3,
62,
74.4,
91.9,
59.6,
77.2,
84,
65.2,
61.1,
80.5,
29.6,
48.8,
18.4,
47.2,
55.8,
64,
31.5,
93.6,
100.4,
46.3,
78.1,
41.6,
8.9,
40.1,
51.2,
92.4,
92.9,
51.1,
72.5,
22.7,
54.6,
61.4,
59.4,
21.1,
84.9,
81.8,
53.8,
73.5,
39,
35,
60.7,
44.4,
29.8,
48.2,
64.2,
34.5,
18,
23,
18.9,
50.4,
50,
49.8,
92.5,
55.9,
18.3,
62.8,
50.8,
36.9,
93.5,
78.9,
63.3,
51,
29.2,
69.6,
41.4,
35.1,
3.9,
36.3,
61,
38.5,
26.3,
52.7,
81.1,
68,
79.2,
80.5,
59.8,
76.8,
56.1,
8.7,
96.5,
94.3,
67,
63.9,
92.7,
78.1,
58.2,
43,
47,
82.2,
71.9,
40.1,
41,
19.8,
25.7,
74.2,
21.5,
60,
3.8,
61.8,
79.5,
62.8,
70.3,
26.1,
82.7,
59,
53.2,
72.2,
49.8,
57.5,
54.8,
21.4,
47.9,
66.3,
81.2,
95,
67.8,
58.7,
44.9,
53.4,
6.6,
42.3,
50.2,
26.6,
46.3,
36.9,
60.9,
80.2,
90.8,
75,
88.6,
43.6,
43.1,
61.2,
64.4,
87.7,
74.3,
45.8,
32.7,
49.1,
82.4,
87.2,
44.2,
19.1,
39.8,
92.3,
40.3,
20.5,
72.9,
97.6,
82.7,
35.9,
90.2,
33,
37.5,
59.8,
47.9,
34.7,
85.9,
40.3,
58.2,
26.4,
80.5,
81.1,
5.7,
58.9,
49.5,
47.4,
61.2,
22.4,
38.4,
99.9,
61.2,
90.6,
22.5,
79,
35.5,
45.7,
55.8,
80.5,
74.6,
20.6,
53.5,
17.9,
38,
5.2,
33.8,
23.9,
26.6,
90.6,
89.1,
91.9,
24.1,
64.4,
56.2,
92.5,
88.2,
55.4,
53.2,
77.3,
75.4,
24.2,
43.3,
46.5,
67.5,
67.9,
41.8,
90.4,
62.8,
21.6,
97.8,
28.8,
76.2,
82,
92.6,
87.2,
26.7,
64.3,
67,
33,
11.4,
88.8,
57.7,
74.4,
53.8,
25.6,
24.6,
79.1,
70.8,
95.7,
77.5,
22.2,
78.9,
55.7,
59.1,
75.3,
27.4,
36.3,
47.5,
45.6,
60.4,
85.6,
37.7,
67.4,
44.2,
32.1,
43.4,
65.5,
75.2,
49.6,
59.2,
48.8,
18.4,
41.8,
78.5,
9.3,
88.3,
56.1,
38.9,
94.2,
97,
66.7,
39.7,
92,
12.7,
73.6,
63.8,
72.2,
42.8,
59.2,
54.8,
45.8,
79.1,
37,
62.8,
51.8,
88.4,
51.1,
34.2,
59.8,
96,
59.9,
65.5,
44.9,
63.3,
69.6,
27.1,
69.1,
47,
61.6,
62.2,
1.5,
45.7,
50.8,
63.5,
36.8,
81.8,
35,
57.5,
70.6,
85.8,
25.7,
97,
42,
77.3,
17.8,
41.4,
64.5,
81.1,
84.9,
40.3,
88.1,
13.8,
89.3,
73.9,
47.4,
39.8,
66.5,
78.6,
63.6,
79.5,
91,
79,
22.5,
31,
85.6,
15.1,
32.4,
10.7,
17.3,
38.5,
25.8,
76,
90,
85.4,
25.5,
4.6,
46.2,
83.5,
71,
33.2,
59.9,
82.2,
83.7,
88.2,
36.7,
18.7,
35.9,
14.2,
64.4,
70.1,
51.1,
89,
59.8,
74,
91.5,
76.8,
86.3,
56.1,
74.8,
69.1,
80.3,
54.2,
68.5,
88.7,
57.3,
65.2,
70.1,
35.2,
71.5,
23.4,
90.6,
54.8,
26.1,
59.7,
20.9,
44,
67.2,
20.2,
51.2,
36.8,
60.9,
97.5,
61.4,
92.5,
19.9,
72.4,
51.9,
78,
34.6,
72.3,
78.9,
74.2,
51,
70.3,
78.9,
36.6,
61.6,
76.2,
84.5,
88,
24.4,
57.2,
47.5,
36.3,
31.8,
55,
49.6,
75.9,
10.4,
68.6,
35.4,
91.2,
88.6,
34.1,
90.3,
53.3,
61,
55,
58.5,
89.1,
13.8,
66.1,
2.8,
37,
17.9,
42.9,
71.7,
15.9,
0.1,
22.5,
42.6,
73.6,
54.1,
50,
90.1,
86.8,
45.2,
66.2,
84.4,
80.5,
84.9,
80.5,
42.6,
30,
54.1,
13.1,
66.3,
90.4,
72.3,
82.7,
72.7,
81.5,
77.6,
27.6,
77.7,
62.4,
52.6,
18.2,
80.3,
11.4,
98.1,
14.9,
69.7,
58.1,
27.8,
88.8,
4.6,
82.8,
35.4,
7.9,
59.1,
93.5,
62.9,
49.9,
71.7,
38.9,
55.9,
40.7,
72,
96.6,
95.9,
55.6,
53.2,
88.5,
42.3,
18.1,
74,
29.9,
96.3,
42.2,
39.6,
22.2,
62.3,
64.3,
49.9,
56,
66.8,
41.8,
40,
64.3,
53.5,
76.9,
69.4,
27.8,
34.3,
40.3,
90.1,
95.9,
35.8,
94.7,
99.4,
94.4,
66.2,
46.2,
55.9,
38.6,
48,
19.9,
97.9,
47.5,
86,
41.7,
58,
76.3,
81.4,
55.2,
56.4,
64.2,
46.3,
57.7,
59.2,
76.3,
64.7,
53,
56.8,
52,
51,
62.2,
83.3,
52,
63.1,
73.8,
69.6,
97.9,
74.1,
28.9,
39.5,
42.4,
72.7,
21.8,
83.1,
55,
59,
76.1,
47.6,
85.5,
65.9,
32.3,
6.8,
60.6,
67.3,
48.9,
84.6,
42.5,
58,
23.9,
93,
17.2,
70.2,
69.8,
70.6,
71.4,
17.9,
59,
33.8,
89.7,
70.9,
60.9,
62.2,
94.3,
79.6,
38.6,
68.3,
67.4,
53.2,
96.5,
87.9,
73.7,
27.5,
28,
75.6,
78.3,
74.7,
46.6,
70.5,
97.1,
23.9,
26.7,
66.7,
85.3,
51.9,
18.6,
63.7,
47.4,
14.1,
40.1,
61.2,
15.9,
21.2,
21.3,
70.6,
59.1,
29.6,
78,
70.5,
89.3,
85.7,
89.3,
95.9,
71.7,
34.3,
61.8,
24.4,
43.8,
51.2,
63.3,
40.3,
44.7,
64,
0,
85.5,
36,
77.1,
48.6,
62.3,
39.4,
66.1,
94.8,
84.9,
80.6,
53.9,
28.3,
50.9,
82.6,
91.7,
33,
8.5,
57.2,
91.1,
57.7,
33.8,
48.9,
33.9,
30.2,
66.3,
11.5,
90,
76.9,
50.8,
62.7,
24.3,
70.3,
55.1,
39.3,
30.6,
27.1,
34.1,
71,
72.1,
72.5,
51.2,
81.3,
97.7,
52.9,
36.9,
77.9,
58.8,
51.5,
81.7,
61.1,
76.1,
61.9,
89.2,
75.5,
67.1,
92.6,
68.1,
41.6,
19.4,
33.6,
84.3,
34.4,
27.8,
46.6,
71.4,
25.7,
63.4,
83.9,
74,
68.4,
75.8,
45,
46.9,
63.8,
43.5,
47.1,
32.6,
45.2,
68.5,
44.6,
72.2,
49.7,
44.1,
95.7,
24,
74.6,
38.7,
94.5,
62,
68.6,
59.3,
72.7,
86.9,
24.3,
67.3,
73.9,
32.4,
30.6,
62.1,
28.7,
73.6,
74.6,
88.5,
55.2,
61.5,
55.1,
47.7,
43.4,
30.6,
86.7,
46.6,
32.3,
90.7,
18.9,
23,
58.6,
58.2,
82.8,
94.6,
44.5,
66.7,
51.4,
8.5,
75.1,
61.3,
76.1,
38.2,
71,
30.6,
94.6,
59,
45.7,
65.2,
79.4,
68.4,
75.4,
45.1,
64,
41.4,
46.7,
96.2,
39.2,
16.6,
25.1,
5.6,
62,
24.5,
98.6,
78,
74.6,
100.7,
53.6,
51.8,
96.4,
7.8,
43.7,
48.9,
29.5,
77.1,
67.6,
68.9,
75.9,
89.3,
62.9,
44.1,
43.5,
58.3,
69.7,
65.7,
24.5,
23.9,
50.5,
66.2,
13.9,
28.3,
65.6,
26,
86.5,
33.7,
63.3,
61.1,
57.9,
79,
49.4,
49.8,
32.8,
70,
70.4,
58.3,
69.4,
33,
24.6,
81.9,
71.8,
38.3,
89.8,
81.9,
57.4,
57.4,
50,
69.9,
52.9,
52.5,
27.3,
82.6,
16.4,
35.7,
73.9,
90.7,
74.3,
53.5,
93,
79.5,
48.9,
36.4,
49.3,
55.3,
39.5,
26.1,
39.1,
78.8,
54.1,
72,
77,
66,
51.8,
75.4,
72.8,
93.8,
76.4,
78.5,
35.8,
79.2,
95.4,
38.7,
27.3,
45.1,
61.7,
29.9,
9.6,
31,
61.7,
98,
60.8,
43.1,
63.9,
32.5,
42.5,
11.1,
48.8,
70.8,
69.9,
69.8,
72.1,
91,
56.9,
76.8,
19.1,
89.6,
23.7,
45.7,
55.3,
76.5,
68,
38.3,
38.8,
47.3,
78.3,
41.7,
44.1,
89.8,
88.4,
21.8,
3.9,
44.5,
41.7,
64.9,
63.5,
21.5,
96.9,
59.7,
43.4,
61.7,
34.7,
53.2,
66.7,
57.6,
97,
79,
68.8,
51.7,
58.8,
30.8,
98.2,
30.3,
43.6,
52.6,
58.1,
89.6,
35.5,
10.8,
67.4,
51.4,
94.8,
71,
45.5,
19.7,
85.3,
47.7,
65,
82.4,
94.8,
94.3,
62.2,
56.8,
27.2,
50.3,
54.2,
34.8,
54,
64.7,
33,
64.6,
62.1,
97.4,
36.1,
85.3,
42.7,
55.6,
21.4,
18.9,
38.8,
50.4,
50.3,
15.6,
43.1,
48.4,
69.2,
86.2,
28.9,
86,
82.7,
52.3,
35,
71.1,
52.3,
57,
74.3,
25.1,
56.5,
40.4,
16.4,
40.6,
66.1,
20.1,
50.4,
90,
25.6,
51.9,
87.9,
42,
26.5,
50,
61.7,
26.3,
53.7,
69.7,
11.4,
0,
55.1,
47.2,
38.5,
74.2,
93.3,
90.5,
68,
59.4,
74.6,
67.9,
57.8,
23.2,
38.8,
69.4,
27.9,
68.3,
31.1,
88.4,
62,
62.1,
45.1,
77.1,
43.9,
54,
42.7,
66,
56.8,
31.6,
83.8,
56,
94.5,
92.9,
46.8,
27,
42.4,
82.9,
97.9,
4.9,
48.1,
48.3,
78,
41.3,
76.7,
59.5,
89.9,
29.1,
27.8,
49.1,
27.6,
51.5,
80.2,
83.2,
19.1,
63.9,
55.1,
85.5,
63.3,
67.7,
70.6,
78.7,
19.4,
26.1,
71.5,
64.4,
4.3,
55,
91.4,
43.8,
50,
51.6,
66.6,
77.2,
27.8,
61.7,
73.7,
90,
51.1,
46.5,
42.7,
93.7,
42.9,
8,
105.1,
94,
73.1,
37.5,
48.8,
69.6,
94.1,
84.7,
27.4,
59.5,
25.8,
75.1,
70.3,
44.2,
18.9,
61.1,
42.8,
19.5,
74,
53.2,
72.3,
54.2,
15.5,
57.9,
42,
82.9,
90.9,
24,
54.3,
10.9,
32.7,
78.8,
14.9,
87.7,
40,
73.3,
40.6,
66.5,
85,
76.9,
49.7,
51.2,
52.6,
85.5,
78.5,
65.4,
46,
28.9,
63.6,
79.7,
79.2,
82.1,
95,
75.6,
65.3,
82.3,
84.7,
64,
79.9,
56.1,
50,
71.1,
29.5,
27.4,
62.5,
55.6,
60.4,
88.5,
59.2,
55.5,
22.9,
19.2,
47.7,
53,
71.3,
96.8,
54.5,
16.5,
42.2,
79,
96.1,
31.6,
83,
74.8,
65.7,
59.7,
26.6,
39.2,
24.6,
38.4,
69.1,
89,
61.1,
50.5,
60.9,
45.6,
26.7,
74.7,
56.7,
66.7,
66.3,
37.5,
90.7,
85.1,
35,
27.5,
62.3,
23.8,
55.9,
79.9,
25.9,
44,
5.1,
25,
85,
50.7,
30.7,
61.5,
63.2,
95.6,
71.5,
84,
23.8,
91.9,
67.3,
39.5,
85.5,
26.4,
67.6,
36.9,
49.8,
79.3,
68.7,
56.2,
34.9,
26.2,
56.3,
69.2,
20.8,
61.4,
81.7,
35.6,
73.5,
24,
91.3,
77.8,
78.6,
9.7,
89.9,
92.9,
0,
77.3,
17.6,
75.8,
76.1,
9.8,
68.1,
40.2,
81.2,
28.7,
4.9,
77.7,
0,
10.2,
54,
75.2,
53.5,
8.1,
13.9,
39.5,
59.4,
78.3,
58.3,
23.1,
55.8,
12.5,
63.9,
81.1,
95.5,
53.5,
74,
19.9,
85.1,
52,
35.4,
96.2,
68.1,
93.6,
44.6,
null,
81.3,
52.7,
72.5,
19.4,
24.5,
59.9,
71.3,
42,
61.5,
44.1,
66,
14.9,
64.6,
81,
80,
78.6,
58.1,
89.6,
84.3,
15.4,
28.4,
71.4,
28.1,
61.3,
74.2,
20.2,
49.5,
70.5,
31.7,
33.7,
34.3,
64.3,
35.6,
66.8,
59,
11.6,
84.6,
63.3,
70.1,
56.1,
43.6,
43.2,
81.1,
45.6,
44.7,
51.3,
24,
83.7,
54.6,
54.1,
19.8,
60.7,
35.3,
96.6,
77.9,
23.2,
2.9,
42.1,
63.9,
72.1,
44.8,
78.4,
13,
73.9,
69.5,
70.6,
41,
94,
28.7,
75.2,
69.7,
38.5,
44,
40.8,
48.3,
35.8,
52.4,
55.4,
56.6,
50.4,
60.7,
96.9,
93.7,
75,
81.2,
35.6,
25.4,
97.1,
54.1,
47.7,
59.2,
42.5,
89.4,
55.4,
98.9,
63.7,
93.9,
54.2,
92.8,
43.6,
64.1,
73.1,
36.5,
77.6,
91.6,
54,
64.7,
43.3,
67.5,
25.7,
64.4,
53.9,
11,
77.9,
92.5,
74,
35.4,
90.1,
87.5,
18.9,
67.8,
95.3,
12.2,
75.5,
26.5,
86.4,
87.3,
64.4,
70,
0,
52.1,
77.9,
99.2,
56.2,
82.2,
11.7,
46.7,
85.9,
42.8,
35.6,
58.6,
71.9,
2.9,
15.5,
73.1,
23,
72.6,
88.6,
81.7,
87.9,
27.8,
38.5,
35.4,
81.2,
8.5,
83.5,
68.5,
41,
52.5,
67.5,
35.5,
43.3,
52.5,
82.2,
43,
16.7,
8.1,
47.3,
22.5,
40.1,
69.9,
20.2,
4.7,
36.5,
94.2,
71.4,
58.8,
43.3,
79.5,
65.5,
76.3,
69.2,
45.7,
72.3,
59.8,
95.6,
69.9,
47.6,
100.2,
36.8,
63.6,
86.3,
44.6,
56.7,
79.9,
48.5,
83.6,
28.2,
89.9,
72.8,
31.2,
68,
75.1,
62.8,
62.7,
77.5,
56.3,
36.5,
69,
93.9,
33,
33.5,
82.6,
85.4,
64,
71.8,
12.8,
63.7,
78.1,
39.3,
30,
71.1,
69.4,
73,
81.4,
41.9,
49.6,
21.4,
58.5,
17.1,
57.4,
46.6,
35.2,
50.9,
39,
85.4,
4.6,
70.2,
45.9,
58.8,
47.8,
37.4,
81.9,
55.7,
55.1,
22,
49.6,
12.6,
44.1,
94.5,
38.3,
87,
62.5,
71.4,
72,
79,
60.6,
50.9,
11.3,
20.9,
47,
99.2,
41,
60,
47.6,
36.3,
32.9,
46.1,
44.1,
21.6,
75.7,
62.4,
67.2,
65,
53.5,
33.5,
88.7,
90.1,
13.8,
47.4,
62.6,
89.1,
66.9,
69.8,
33.8,
52.1,
45.4,
39,
46.8,
58.2,
34.4,
25,
21.8,
78.5,
67.5,
69,
0.5,
43.6,
26.7,
6,
77.6,
56.2,
49.9,
64.6,
77.8,
28.6,
59,
26.5,
66.5,
82,
42.2,
28.4,
82.4,
85.9,
130.8,
53.1,
55.2,
77.5,
80.4,
36.8,
76.8,
89.1,
9.9,
92.9,
99.3,
55.5,
88.7,
17.7,
89.1,
34.2,
96.3,
94.5,
65.3,
25,
24.5,
62.4,
45.2,
83.8,
28,
36.9,
59.4,
61.2,
25.4,
70,
54,
77,
0.2,
66,
62.7,
83.2,
52.2,
50.7,
29.7,
42.1,
13.8,
66.7,
67.6,
75.4,
16.6,
1.9,
88.8,
47.4,
39.6,
86.5,
51.5,
82.1,
82.6,
91.4,
79.1,
53.4,
8.1,
53.3,
18,
82.6,
54.3,
75,
50.6,
91.5,
46.9,
45.8,
41,
32.2,
6.8,
28.2,
69.2,
53.7,
97.2,
49.5,
86.4,
75.4,
22.1,
28.6,
10,
78.9,
66.5,
48.1,
66.1,
15.7,
87.9,
72.4,
68.6,
35.5,
68.5,
32.5,
12.2,
66,
90.2,
32.4,
81,
18,
0.8,
51.4,
28.4,
90,
29.4,
54,
39.7,
34.1,
63.1,
35.7,
42.3,
72,
95.3,
30,
39,
53.4,
20,
60.1,
12.1,
60.1,
91.8,
93.6,
34.2,
96.3,
64,
44.9,
30.2,
87.3,
47.4,
24.9,
67.1,
94.8,
63,
90,
82.4,
97.2,
36.7,
56.9,
68.6,
59.3,
47.6,
64.3,
50.6,
89.9,
46.8,
45.1,
95.9,
68,
85.4,
17.6,
76.1,
8.6,
0.9,
26.8,
47.1,
81.1,
47.7,
82.3,
28.7,
43.5,
49,
53,
73.8,
71.9,
64,
50.5,
39.8,
23.4,
28,
8.2,
34.2,
28.3,
65.4,
32.4,
64.6,
58.1,
66.9,
32.5,
46.2,
89.7,
59,
72.4,
27.4,
66.5,
45,
20.7,
62.5,
95.8,
35.9,
43.1,
80.6,
87.6,
63.5,
59.5,
62.5,
20.8,
24.3,
28.2,
23.7,
31.3,
22.4,
84.8,
55.8,
96.6,
45,
66.1,
66.9,
32,
30.9,
67.5,
59.5,
93.7,
32,
83.4,
60.3,
13.9,
13.7,
94.7,
50.9,
82.3,
0.8,
92.5,
38.8,
64.8,
84.6,
66.7,
95.4,
26,
51.8,
34.7,
37.3,
53.2,
22.4,
84.2,
45.9,
72.7,
81.9,
59.9,
23.2,
72.6,
92.6,
64.5,
67.4,
14.6,
56.6,
31.3,
46,
85.6,
69.8,
21,
61.4,
4.9,
47.3,
77.3,
44.8,
45.3,
64.4,
52.2,
14.5,
76.7,
46.7,
32.5,
71.8,
56.5,
75.7,
92.4,
52.6,
35.3,
94.7,
88.8,
42.7,
55.2,
38.7,
73.5,
88,
8.5,
49,
74.2,
43.2,
56.6,
92,
93.2,
76.3,
29.5,
48.9,
29,
23.4,
64,
66.8,
96.4,
62.6,
42.8,
50.2,
87.9,
62.3,
32.7,
43.4,
12.6,
50.6,
36.8,
41.9,
82.3,
37,
79.4,
71.6,
46,
46.8,
91.8,
50.8,
92.5,
64.6,
37.5,
80.1,
19,
94,
71.7,
72.3,
33.4,
87.6,
54.2,
12.2,
52.1,
61.2,
98.2,
84.9,
94.2,
6.5,
33.9,
67.3,
74,
30.8,
25.1,
79.8,
63.8,
69,
83.5,
47.6,
60.5,
61.4,
74,
35.2,
53.3,
85,
45.6,
96,
45.5,
39.3,
89.1,
19.3,
68,
44.5,
29.3,
60.7,
85.5,
87.2,
80.5,
55.7,
88.2,
55.4,
30.1,
25.2,
95,
71.1,
62.9,
79.9,
53.1,
22.9,
24.8,
74.9,
62.5,
81.4,
66.6,
2.5,
18.9,
44.6,
19.4,
82.7,
66.5,
23.4,
88.3,
15.8,
31.8,
87.9,
36.9,
54.6,
51.8,
87.5,
42.4,
37.4,
31.2,
60,
51.3,
84.3,
26.3,
74.4,
27.4,
44.4,
28.3,
54.7,
37.4,
57.8,
47,
67.9,
40.2,
43.2,
29.1,
45.6,
81.4,
79.8,
76.8,
49.9,
89,
51.2,
28.3,
14.7,
72.4,
95.1,
61.8,
81.6,
69.9,
91.7,
42,
55,
82.7,
18.6,
72,
32.9,
28.5,
35,
68.5,
58.6,
61.8,
69.9,
85.3,
57.5,
55,
49.3,
82,
49.5,
65.8,
79.4,
89.5,
74.8,
90,
80.2,
75,
39,
38.2,
24.6,
77.5,
15.3,
36.7,
45.1,
41.8,
56.3,
82,
43.3,
28.8,
50.4,
72.1,
52.3,
48.5,
91.8,
13.9,
46,
87,
68.4,
65.3,
47.4,
90.1,
57,
68.9,
53.8,
65.6,
36.1,
37.9,
11.1,
60.4,
90.7,
64.4,
41.4,
40.3,
73.4,
31.9,
38,
88.3,
80.4,
91,
30.3,
60.5,
65.2,
22.1,
86.8,
58.5,
49.3,
100.5,
34.7,
76.8,
63.7,
39.2,
32.7,
31.8,
43.4,
7.2,
59,
40.2,
73,
71.4,
48.3,
53,
95.7,
37.8,
33.1,
42.3,
25.1,
60.2,
28.5,
61,
12.9,
87.4,
37.5,
70.7,
38.8,
24.9,
72,
36,
7.2,
66.9,
89.7,
69.9,
11,
51.2,
63.9,
35,
39,
75.7,
30.6,
11.2,
57,
42.3,
83.4,
67.3,
11.7,
92.6,
89.1,
97.4,
66.3,
56.7,
57.3,
55.7,
95.5,
46,
75.2,
64.5,
81.1,
42.1,
58.8,
26.9,
46.3,
48.7,
33.5,
17.5,
24.4,
35.5,
60,
41.9,
70.7,
38.3,
68.2,
24.4,
0,
54.3,
51.2,
86.9,
52.2,
23.2,
6.5,
87.7,
34.5,
36.7,
72.6,
100,
68.6,
89.9,
90,
78.6,
59.5,
89.8,
45.3,
73,
31.1,
83.1,
73.7,
1.7,
83.7,
0.3,
34.5,
47.7,
83,
81.9,
98.7,
55.2,
80.5,
43.8,
23.6,
65.4,
49.9,
72.8,
42.6,
38.2,
13.7,
78.8,
75.3,
45.8,
45,
45.3,
66.5,
81.4,
69.8,
85.2,
39,
74,
42.2,
7.4,
50.9,
85.9,
50.1,
53.2,
13.9,
88,
58.9,
57.1,
32.9,
59.9,
9.8,
46.1,
48,
82.6,
75.7,
49.3,
100.5,
90.5,
65,
7.4,
56.3,
59.4,
63.4,
62.5,
51.8,
33.3,
50.9,
67.3,
75.8,
76,
59.7,
36,
83,
40,
67.3,
60.2,
66.4,
81.8,
43.5,
65.4,
49.7,
63.4,
48.6,
44.3,
91.8,
24.2,
101,
20.2,
29.6,
75.7,
37.8,
77.4,
25.2,
76,
69.7,
43.7,
44.4,
66.7,
63.9,
54.7,
82.5,
75.6,
32.7,
62.2,
34.2,
99.1,
44.6,
46.7,
83.7,
50.2,
47.9,
88.1,
102,
8.6,
60.7,
44,
56,
58,
24.5,
73.3,
69.2,
53.6,
45,
71.3,
30.7,
45.1,
37.4,
38.1,
93.7,
56.4,
75.9,
72,
46.6,
29.4,
36.6,
55.4,
95.7,
19.6,
64.4,
51.7,
80.9,
86,
82.9,
84.3,
40,
19.8,
68.1,
57,
71.8,
70.7,
53.8,
30.5,
69.3,
71.6,
70.2,
38.8,
15.4,
60.7,
88.2,
53.4,
19.6,
74,
71.2,
58.1,
81.3,
33.4,
44.3,
77.1,
8.6,
59.4,
60.3,
38.6,
8.8,
75.1,
94.7,
20.6,
88,
45.1,
28.2,
78.6,
66.8,
80.7,
77.5,
12.9,
69.8,
84.1,
66.6,
68.3,
69.1,
21.9,
69.8,
37.8,
76,
44.8,
88,
57.1,
63,
67.8,
53.8,
52.2,
69.5,
91.3,
44.8,
81.7,
73.4,
16,
42.4,
80.8,
88.8,
38.7,
83,
101.4,
49.4,
36.4,
53.8,
45.1,
43.3,
63,
41.1,
75.3,
44,
91.4,
35.1,
17.1,
70.1,
17.8,
70.7,
22.1,
76.5,
74,
18.7,
62.9,
92.3,
82,
65.7,
82,
14.3,
97.6,
61.8,
3,
64.4,
27.2,
49.3,
64.5,
46.1,
48.6,
34.4,
80.1,
26.5,
24.3,
32.6,
40.3,
64.3,
33.1,
80.2,
67.7,
81,
62.2,
97.2,
68.1,
79,
19,
67,
78.4,
71.2,
93.1,
81.8,
67.4,
50.3,
80.3,
65.7,
0.8,
73.6,
44.7,
11.1,
19.8,
26,
83.1,
51.3,
54,
54.6,
5.9,
37.3,
26.1,
60.4,
17.4,
66.9,
20.9,
20.7,
94.1,
64.1,
84.4,
92.2,
32.8,
69.5,
33.9,
56.6,
26.3,
61.6,
40.7,
64.1,
43.4,
56.9,
81.7,
41.1,
85.5,
71,
54.1,
84.9,
30.1,
31,
82.6,
48.1,
28.3,
29.2,
39.5,
58.1,
51.3,
82.1,
72.3,
57.9,
19.6,
41.2,
68.4,
36.8,
55.8,
70.9,
46.2,
34.5,
51.7,
59,
74.1,
52,
93.9,
36.5,
75.9,
87.1,
47.3,
35.9,
71.5,
71.4,
72.8,
44.5,
60.8,
66.5,
33,
30.4,
38,
49.4,
55.4,
57.7,
60.4,
44,
48.2,
40.6,
55.1,
48.2,
77,
77.6,
56.9,
75.5,
34.1,
35.9,
51.8,
37.8,
97.5,
15.8,
32,
77.5,
48.7,
19.9,
45,
63.8,
92.8,
57.3,
63.6,
42.6,
80.6,
63.9,
45.1,
62.4,
92.8,
66.7,
84.9,
58.2,
81.3,
50.9,
43.7,
38.9,
53.1,
35,
74.8,
32.2,
54.6,
41.4,
33.3,
3.2,
71.4,
72,
55.4,
4.8,
60.3,
56.1,
20.3,
49.6,
76.4,
92,
20.6,
51.2,
64.1,
71.2,
77.4,
1.7,
45.8,
35.1,
39.5,
57.2,
97.2,
83.9,
94.3,
16.8,
38.4,
68.3,
72.8,
90.8,
57.4,
42.4,
47.4,
12.3,
33.5,
66.7,
68.9,
20.3,
19.1,
36.8,
53,
39.3,
40.7,
55.5,
61.9,
52.8,
73.8,
58.4,
61.3,
77.6,
10,
88,
33.6,
27.6,
57.7,
57.8,
43.1,
98.6,
43,
65.8,
89,
74.5,
95.3,
22.8,
62.8,
43.2,
37.1,
50.4,
83.4,
63.4,
79.8,
52.6,
7.6,
9.5,
75.8,
34.6,
44.7,
87.2,
63.7,
70.7,
98.3,
46.1,
78,
64,
28,
60.8,
64.5,
57.3,
66.6,
57.3,
79.6,
65.8,
60.3,
46.2,
25.6,
64.9,
82.3,
66,
66.4,
63.7,
65.2,
43.8,
45.4,
64,
39,
82.6,
29.3,
27.7,
84.5,
56.5,
18.2,
50.7,
81.3,
67.2,
67.7,
73.6,
53.8,
52,
16,
26.9,
18,
68.4,
73.1,
40.7,
44.8,
53.1,
53,
11.4,
38.9,
14.7,
49.9,
52.1,
66.5,
35.4,
55,
95.4,
47.5,
55.8,
74.8,
62.6,
46.6,
60.7,
72.1,
20.4,
77.1,
48.4,
62.6,
79.1,
84.9,
87.3,
53.7,
54.6,
25.8,
33.8,
26,
85.3,
58.8,
27.2,
42,
33.7,
91.8,
48.8,
25.8,
57.8,
57.7,
90,
13.7,
32.9,
26.9,
87.2,
40.8,
77.8,
61.4,
48.8,
46.3,
45.4,
37.4,
81,
32.5,
63.1,
79.4,
51.4,
37.1,
48.3,
49.1,
45.1,
37.4,
65.6,
66.5,
66.9,
36.8,
44.7,
54.4,
88.2,
65.3,
84.4,
40,
46.7,
87.2,
97.5,
38.1,
73.5,
42,
58.5,
83.9,
54.3,
36.7,
91.2,
59.3,
94.6,
30.2,
48.7,
52.1,
86.7,
3.8,
68.1,
63,
26.4,
48,
73,
25.8,
87.4,
27,
70.5,
44.2,
74.5,
61.6,
87.9,
42,
58.4,
54.3,
66.9,
76,
83.7,
73.7,
77.8,
68,
91.1,
72.5,
45.3,
90.2,
71.3,
66.4,
63.4,
48.9,
20,
26.2,
67.8,
56,
88,
59.3,
35,
78.1,
104.6,
70.4,
75,
56.5,
84.2,
55.9,
69.8,
87.6,
45.4,
91.8,
65,
92.3,
54.4,
79.3,
39,
32.7,
56,
64.6,
8.9,
67.7,
16.4,
62,
56.5,
38.8,
82.2,
72.8,
59.2,
30.1,
40.2,
64.3,
51.7,
69.5,
39.9,
5.5,
64,
65.5,
63.1,
48.3,
45.2,
36.6,
75.4,
51.2,
76.3,
82.2,
33.1,
72.2,
38.5,
46,
44.5,
65,
85.6,
53.1,
4,
38.2,
41.1,
62.6,
20.3,
81.8,
5.9,
93.9,
93.2,
35.3,
85.7,
66,
98.6,
8.3,
2.3,
9.5,
53.5,
83.1,
18.9,
77,
55.2,
26.7,
39.1,
66,
89.5,
22.3,
88.3,
51.1,
90,
16.1,
64,
72.9,
87.4,
77.7,
21.7,
17,
43,
56.5,
54.1,
68.2,
84.9,
76,
43.7,
71,
92.4,
76,
71.7,
14.9,
66.6,
39.1,
81,
75,
63.4,
27.2,
59.3,
35.8,
17.7,
40,
65.6,
34.4,
77.4,
90.2,
61.4,
61.5,
84.9,
26.4,
89.9,
29.1,
72.9,
37.1,
96.5,
48.5,
15.2,
43.5,
8.4,
70.9,
49.7,
60.8,
88.2,
44.6,
70.7,
31.6,
53.6,
54.6,
72.3,
93.9,
38.4,
12.4,
29,
49.4,
43.8,
12.9,
33.2,
92.1,
20.6,
75.6,
59,
91.1,
50.2,
53.5,
69.1,
60.2,
49.9,
17.6,
68.1,
82.4,
62.9,
73.1,
24,
58.7,
41.9,
48.3,
30.4,
41.2,
90.1,
31,
63.2,
49.8,
40.7,
47.1,
80.6,
95.8,
56.4,
78,
84.9,
26.4,
75.3,
55.1,
82.7,
40.9,
18.3,
0,
41.6,
95.5,
19.6,
28.1,
96.6,
33.1,
57.4,
71.7,
81.3,
36.4,
56.9,
67.1,
48,
49.5,
88.6,
63.6,
85.6,
77.6,
54.7,
16,
87.8,
54,
90.8,
17.7,
66.4,
64.9,
60.7,
19,
80.7,
20.7,
47.9,
35.4,
84.5,
73,
50.9,
24.2,
13.6,
21.5,
58.5,
80.9,
96,
55.8,
24,
49.4,
92.3,
63.3,
59.8,
90,
60.1,
94.5,
26.9,
51.6,
48.8,
64.4,
0,
58.1,
64.1,
16.8,
73.5,
28.4,
94.6,
34.5,
95.7,
84.1,
56.6,
81.3,
65.6,
22.9,
40.3,
70.2,
79.3,
45.8,
83.7,
26.8,
33.3,
41,
46.4,
22.1,
19.2,
56,
77.3,
44.5,
16,
96.4,
46.3,
73.1,
43.6,
55.2,
16.8,
45.6,
77.8,
86.3,
82.2,
62.4,
55.4,
32.3,
67.8,
35.1,
77.7,
65.6,
59.6,
71.9,
54.2,
33,
62,
52.8,
5.8,
82.5,
71.8,
34.5,
66.4,
77.7,
76.4,
52,
45.5,
34.1,
85,
45.6,
57.1,
31.6,
59.9,
93.2,
68.8,
60.5,
58.2,
39.5,
53.7,
30.1,
17,
57.5,
36.6,
76,
83.1,
79.3,
35.8,
41.8,
54.3,
60,
38.5,
30.2,
60,
26.3,
39.6,
82.3,
52.6,
61.3,
83.2,
90.1,
70.6,
61.1,
47.7,
54,
84.6,
90.8,
94.1,
10.2,
74,
86.3,
63.7,
59.9,
22.8,
31.3,
19.6,
24.9,
79.6,
27.1,
67.2,
21.3,
71.2,
56,
50.2,
53.1,
68.8,
57.2,
4.9,
36,
55.8,
50.4,
9.7,
17.3,
54.3,
39.7,
86.8,
82.1,
42,
26.2,
31.2,
75.2,
33.3,
32.5,
66.1,
48.7,
50.7,
67.1,
67.7,
52.5,
66.5,
65.2,
45.2,
49.8,
70.1,
76.9,
80.2,
30.2,
91.5,
29,
39.3,
52,
49.1,
30.3,
63.4,
34.5,
82.4,
94.9,
76.6,
61.5,
73.6,
85.1,
12.2,
89.1,
24.9,
63.6,
16.1,
69.9,
9.2,
8.5,
78.9,
22.3,
58.1,
19.6,
91.8,
44.3,
40.8,
75.9,
30,
54.5,
64.7,
91,
30.2,
66.6,
71.4,
65.2,
59.9,
99.1,
68.4,
69.4,
63.2,
49.5,
79.4,
42.9,
95.4,
59.7,
67.8,
48.7,
42.5,
20.8,
96.9,
56,
94.8,
84,
82,
58.9,
27.5,
53.2,
79.3,
82.1,
85.1,
36.7,
24.1,
41.6,
79,
78,
33.8,
92.9,
51.5,
39.6,
59.7,
31.1,
51.4,
97,
35.5,
60.4,
19.9,
87.2,
29.2,
64.4,
39,
39.8,
78,
66.6,
81.3,
58,
96.8,
86.2,
79.3,
97.8,
59.9,
22.2,
68.8,
30.6,
61.5,
36,
92.5,
36.9,
48.7,
45.1,
48,
36.4,
78.8,
82.8,
45.5,
74.3,
21.3,
77.1,
23.4,
76.8,
104.2,
39.1,
24.6,
34.7,
81,
61.8,
23,
54,
80.2,
85.6,
9.1,
19.1,
33,
48.6,
93.7,
81.1,
48.7,
17.2,
67,
27.4,
65.7,
76,
34.7,
49.7,
39.1,
51.2,
48.9,
40.3,
56.4,
43.3,
99.2,
75.8,
69.2,
77.4,
71.8,
51.1,
46.6,
45.9,
0.6,
39.2,
42.1,
53.6,
44.1,
68.6,
85.6,
54.9,
54.6,
95.2,
20.5,
1.4,
68.6,
95.5,
9.7,
49.3,
39.3,
86.9,
22.3,
79.7,
94.5,
68.6,
48.3,
73.5,
101.6,
73.6,
47.2,
58.5,
59.9,
8.4,
81.4,
24.2,
59.3,
30,
35.9,
74.8,
62.4,
33.8,
58.1,
21,
65.2,
57.3,
40.2,
70.2,
83.8,
66.3,
27.4,
32.7,
71.6,
50.4,
3.1,
88.2,
40,
68.5,
42.6,
85.9,
48.4,
85,
1.5,
40.5,
57.1,
81.8,
56.6,
32.5,
61.3,
94.4,
84.7,
90.5,
31.7,
50.5,
31,
32.3,
15.7,
44.1,
66.3,
63.6,
85.9,
65.3,
4.2,
23.2,
69,
95,
57.2,
64.3,
77.9,
54.9,
75.6,
54.6,
87.1,
32.5,
60,
15.3,
55,
78.7,
30.7,
42.9,
99,
73.6,
57.7,
89.8,
41.3,
81.5,
56.2,
87,
10.9,
61.3,
63.7,
51,
27.5,
93.7,
100,
60.2,
87.8,
54.2,
50.1,
55.9,
81.9,
20.4,
65.2,
72.4,
8.3,
55.1,
74.5,
71.4,
21.2,
27.7,
47.7,
37.7,
78,
80.8,
83.9,
31,
75.1,
77.5,
28.6,
31.7,
11.8,
25.2,
32.7,
41.9,
38.9,
38.2,
53,
46.8,
25.1,
89.1,
14.5,
62.5,
71.6,
52.6,
40.9,
47.2,
97,
33.3,
28.6,
36.6,
93.6,
64.3,
46.4,
71.2,
45.5,
36.2,
48.2,
51.9,
76.2,
30.4,
53.4,
93.7,
38.8,
46.4,
92.3,
26.6,
32.9,
78.7,
89.8,
74.3,
65,
78.4,
58.6,
38.9,
36,
41.9,
66.8,
56.9,
73.6,
63.9,
63.8,
40.1,
20.9,
58.7,
74,
80.2,
37,
49.5,
40.8,
66.3,
50.8,
11.9,
24.3,
35.9,
11.3,
58.4,
27.2,
36.6,
77.8,
23.2,
37.7,
47.1,
33.2,
37.1,
93.9,
17.4,
46.4,
88.2,
74.1,
46.7,
97.7,
33.7,
40.9,
65.3,
70,
65.1,
84.4,
18.7,
66.2,
24.7,
92.1,
37.4,
81.3,
14.6,
90.9,
53,
73.6,
85.3,
41.1,
48.9,
53.6,
48.2,
45,
93.1,
33.2,
75.7,
56.5,
43,
49.4,
54.5,
43.8,
59.2,
67,
68.2,
30.6,
65.6,
58.8,
76.2,
92.6,
80,
99.6,
56.5,
82,
43.7,
44.9,
67.6,
37.7,
29.9,
46.6,
90,
52.1,
72,
61.4,
30.5,
36.9,
40.1,
90.9,
82.9,
32.6,
92.1,
35.5,
66.3,
53.3,
63.1,
93.1,
56.4,
85,
69.3,
71,
36.3,
28.7,
58,
84,
32.6,
15.8,
74.7,
82.8,
81.4,
30.9,
56.3,
53,
65.6,
41.6,
83.5,
48.4,
24.9,
74.4,
86,
65.2,
74.8,
18.5,
59.1,
47.5,
46.4,
63.7,
16.6,
18.7,
30.5,
41.1,
81,
19.8,
80.5,
24.1,
92.3,
71.8,
78.3,
35.9,
89.5,
87,
46.7,
4.6,
40.4,
17.6,
71.1,
35.9,
20.2,
70.7,
79.2,
28,
36.7,
46.3,
57.2,
16.2,
45.4,
44.7,
74.9,
93.5,
41.9,
91.3,
59.4,
42,
66.1,
78,
0.1,
78,
70,
39.2,
47.8,
50.9,
48.1,
86.1,
76.6,
40.1,
9.9,
90,
25.2,
79.6,
45.3,
70.9,
62,
52,
51.5,
74.8,
28.8,
60.5,
55.1,
83.4,
1.5,
44.9,
67.4,
45.9,
54.9,
85.4,
30,
34.4,
97.5,
92.7,
27.6,
65.1,
53.7,
21.2,
0.8,
39.3,
63,
75.2,
78.5,
59.8,
61.4,
34.5,
20,
17.6,
72,
41.6,
99.6,
43.2,
14.1,
70.9,
15,
50.3,
75.8,
33.9,
38.9,
34.5,
43.6,
86.7,
88.6,
89.6,
88.9,
51,
84.2,
43,
66.3,
13.2,
36.3,
61.9,
78.2,
76.9,
60.3,
85.5,
38.9,
64,
53.4,
14.3,
99.9,
38.8,
20.5,
76,
46.7,
62.6,
64.9,
94.5,
29.9,
65.3,
50.4,
68.7,
48.8,
62.6,
44.7,
64.2,
72.2,
25.7,
69.6,
54.3,
43.2,
44.4,
28.5,
90.4,
71.7,
62.6,
89.5,
42,
89.1,
85,
57.4,
66.3,
49.6,
52.5,
42.7,
46,
24.1,
25.5,
42.2,
88.3,
39.7,
89.7,
72.4,
90.3,
37,
86.3,
94,
50.5,
88.5,
24.9,
66.2,
57.8,
101,
25.6,
51,
23.7,
71.1,
93.8,
43,
77.2,
50.2,
42.8,
11.1,
71.3,
43.4,
37.4,
50.6,
38.9,
29,
74.9,
47.4,
50.4,
58.1,
88.1,
47.6,
69.2,
51.4,
59,
27.4,
38.8,
10.5,
12.5,
80,
73,
1.3,
88.1,
38.9,
82.3,
75.5,
29.4,
77.4,
51.9,
33.2,
75.1,
71.4,
37.1,
31.7,
100.3,
55.9,
65.7,
36,
26.3,
38.8,
84.1,
56.5,
90.5,
87.1,
26,
56.4,
84.4,
11.8,
74.4,
50.7,
90.4,
66.7,
22.8,
54.9,
95.8,
51.8,
76.9,
84.3,
48.9,
71.2,
65,
42.7,
91.7,
83.7,
83.5,
39.8,
78,
66.7,
66.9,
66.1,
61.3,
26.6,
30.9,
62,
49.8,
33,
44.8,
37.3,
31.8,
9.9,
7.3,
87.6,
70.5,
48.7,
53.7,
97.4,
86,
19.1,
79.7,
84.5,
52.5,
42.8,
29.1,
84.9,
73.6,
44.7,
58.3,
76.1,
74.5,
73.8,
77,
59.3,
23.9,
81.4,
53.7,
40.7,
77.7,
75.6,
32.9,
37.5,
53.5,
101.9,
62.3,
27.4,
30.7,
32.5,
81.6,
78.5,
59.8,
33,
60.7,
75.6,
95,
34.5,
96.5,
49.3,
18.7,
57.7,
69.9,
42.8,
27.4,
51.7,
38.8,
29.5,
36,
48.5,
61.4,
17.1,
49.3,
95.4,
67.9,
32.1,
17.3,
81.8,
94.9,
34.2,
56.1,
66.8,
67.7,
35.2,
56.5,
32.6,
38.5,
38.8,
50.7,
37.7,
33.2,
66.1,
32.3,
39.5,
41,
31.7,
72.2,
52.5,
59.3,
94.8,
29,
61.5,
46,
72.6,
74.2,
2.5,
80.8,
43,
60,
37.1,
65.8,
91,
71.1,
48.1,
82.9,
43.2,
49.6,
79.1,
56.2,
74.8,
74.5,
37,
65.7,
31.2,
79,
91.5,
57.2,
46.1,
77,
65.6,
38.2,
63.9,
59.7,
30.1,
35.5,
74.5,
70.7,
25.5,
85.1,
65.4,
64.6,
49.6,
96.3,
53.7,
26.7,
56.4,
75.7,
42,
97.7,
96.3,
48.2,
67.2,
57,
67.6,
86,
82.4,
48.9,
50.5,
64.3,
51.3,
89.7,
36.8,
60.7,
91.2,
81,
72.2,
40.6,
88.7,
67.8,
33.5,
84.4,
28,
53.3,
53.9,
38,
40.5,
25.2,
59.7,
50.9,
54.2,
64.7,
71.1,
56.1,
80.1,
81.2,
47.8,
51.5,
28,
37.3,
75.3,
45.6,
94.6,
77.3,
31.5,
26,
59.2,
65.7,
34.8,
30.9,
49.4,
51,
64.4,
5.6,
59.7,
42.8,
40.6,
90.7,
80.9,
44.8,
75.2,
21.9,
72.8,
66.1,
67.1,
32.2,
50,
49,
42,
54.8,
35.5,
69.7,
36,
47.4,
41.9,
66.9,
80.6,
79.5,
79.2,
23,
43.8,
27.5,
65.3,
79.2,
21.9,
51.1,
15.5,
74.3,
85.7,
58.8,
43.6,
42.5,
100,
10.4,
74.9,
79.7,
72.6,
27.8,
31.2,
57.6,
89.4,
35.5,
72.6,
61,
31,
43.3,
69,
45.5,
46,
68.6,
96.3,
51.6,
74.1,
24,
51.1,
5.4,
62.6,
82.2,
37.6,
16.5,
81.1,
39,
68.6,
39.2,
69.8,
74.1,
38.2,
55.5,
23.6,
34,
0,
31.3,
67.6,
89.7,
66.4,
87.5,
39.1,
86.1,
36.5,
11.7,
53.5,
22,
19.2,
38.8,
55.6,
64.4,
61.9,
97.1,
50.8,
92.5,
20.7,
28,
75.1,
33.6,
51.5,
50.5,
32.5,
31.5,
63.9,
74.3,
48.8,
42.5,
17,
46.7,
40.7,
0,
55,
74.5,
19,
67.5,
66.3,
89.2,
83.1,
49.9,
77.5,
51.3,
18.9,
24.5,
32.9,
77,
47.6,
21.4,
73.5,
41.5,
49.1,
35.1,
77.4,
36.9,
18.5,
60.9,
79.4,
100.5,
48,
55.4,
10,
68.8,
36.9,
73,
65,
47,
59.5,
78.8,
37.4,
75.7,
29.5,
64,
99.6,
67,
58.8,
74.6,
64.6,
47.1,
93.5,
21.9,
54.3,
81.4,
54.2,
65.2,
77.6,
35,
79.4,
66.1,
80.7,
36,
51.5,
39.6,
1.7,
55.9,
44.8,
10,
29.9,
72.9,
91,
64.1,
61.7,
33.5,
21.9,
6,
33.9,
50.4,
47.4,
70.5,
83.5,
75.9,
85.5,
37.3,
77.8,
47.6,
78.7,
6.8,
23.8,
60.7,
47.7,
48.9,
44.1,
45.4,
25.3,
11.4,
68.4,
84.4,
19.6,
45.3,
63.8,
89.6,
45.9,
90,
48.2,
88.8,
85.7,
78.4,
77.1,
39.2,
32.3,
66.7,
16.5,
69.8,
64.7,
35.5,
58.3,
75.5,
61.9,
22.6,
15.6,
72.1,
47.7,
26.8,
87.2,
37.3,
34.2,
75,
45.2,
67.8,
44.7,
42,
71.9,
72.7,
96.2,
71.7,
23.9,
30,
54.5,
85,
53.6,
70.7,
3.2,
40,
50.9,
91.1,
43.3,
85.3,
98.3,
87.8,
29.2,
79.8,
81.5,
37.5,
11.7,
47.8,
86.9,
25.7,
43,
64.3,
80.6,
44.9,
83.8,
43.8,
74.8,
67.6,
95.4,
73.1,
65.3,
68.4,
22.3,
66.4,
46.3,
44,
58,
61.8,
38.8,
53.6,
86.5,
32.6,
47.7,
77.9,
37,
42.3,
76.9,
67.3,
57.9,
43.3,
58,
83,
42.3,
55.3,
28.2,
48.5,
45.9,
70.4,
26.7,
42.8,
30,
53.7,
22.4,
26.7,
54.4,
71.5,
33.4,
84.7,
9.4,
67.3,
12.2,
54.7,
82.5,
6.6,
58.2,
72.4,
10.1,
61.3,
89.2,
55.7,
62.1,
2.5,
36.1,
43.1,
91.2,
49.2,
47.6,
81.4,
41,
77.2,
13.1,
39.4,
78,
113.4,
72,
49,
24.8,
67.6,
1.6,
5.9,
30.7,
78.9,
34.7,
75.9,
47.4,
62.9,
31.4,
46.5,
61.7,
49.7,
8.7,
68.6,
35.5,
16.4,
22.6,
20.4,
31.7,
22.2,
58,
97.4,
95.1,
67.2,
82.5,
61.5,
45.3,
69,
32.4,
65.2,
34.5,
86.4,
75,
31.2,
69.3,
17.6,
56.4,
92,
38.5,
33.3,
89.8,
84,
44.1,
16.7,
12.1,
63.7,
45.4,
55.4,
75.3,
61.7,
83.7,
35.1,
76.2,
83.1,
35.1,
59.8,
71.8,
67.2,
98,
72.8,
53.5,
87.2,
75.5,
53.4,
52.8,
90.2,
36.7,
72.4,
70.2,
92,
62.6,
42.6,
38.9,
25.5,
53.3,
73.9,
80.7,
87.1,
54,
59.5,
95.9,
6,
25,
26.4,
27.1,
49.5,
41.2,
91.7,
27.8,
90,
28.9,
76.3,
42.3,
19.6,
73,
56.9,
40.3,
70,
40.9,
63.3,
33.1,
18.4,
24.7,
48.6,
35.1,
64.7,
21.9,
61.3,
64.6,
24.3,
65.4,
47.9,
58.5,
56.3,
58.7,
44.9,
87.4,
86.5,
47.7,
29.4,
12.8,
33.1,
60.5,
54.3,
83.7,
72.8,
71.8,
31.2,
33.9,
90.7,
70.2,
65.9,
46,
64.7,
54.4,
73.6,
79.9,
22.7,
15,
27.4,
92.6,
44.8,
71.8,
50.4,
79.5,
26.6,
93,
26.7,
55.6,
51.5,
36.8,
18.1,
57.1,
90.7,
46,
55.2,
70.5,
76.3,
66.8,
57.5,
42.8,
68.7,
76.8,
53,
64.6,
7.1,
54.3,
32.2,
47.3,
35.4,
69.1,
37.8,
64.4,
46.9,
68.1,
31.9,
24.7,
73.2,
32.2,
52.2,
76,
43.2,
14.8,
49,
55.5,
33.3,
76.2,
66.3,
44,
91.3,
66,
43.4,
72.4,
66.8,
83.8,
33.7,
44.1,
70.5,
87.3,
13.5,
43.9,
73.1,
69.3,
32.5,
92.4,
65.9,
61.5,
95.7,
27,
69.6,
43.3,
29.6,
46,
93.7,
47.9,
9.5,
58.7,
26.7,
57.2,
88.5,
23.7,
35.6,
6.2,
22.8,
40,
26.9,
50.6,
17.9,
82.9,
24.1,
63.7,
57.8,
82.4,
53.8,
78.7,
64.3,
54,
89.7,
45.1,
74.2,
65.1,
77.8,
85.3,
60.5,
27.6,
44.4,
95.2,
8.3,
66.1,
54.5,
76.2,
93.6,
38.3,
null,
33.5,
57.5,
57.8,
33.4,
36,
85.9,
80.8,
63.1,
24.9,
58.4,
98.4,
69.8,
61.2,
45.5,
60,
75.5,
86.3,
69.2,
69,
81.6,
38,
32.8,
35.2,
61.3,
72.6,
69.4,
79.6,
47.1,
63.3,
74.1,
69.1,
61.5,
26.9,
77.4,
63.7,
62,
19.4,
37.2,
64.1,
51,
51,
74.2,
41.4,
29.7,
77.9,
48,
77.1,
55,
45.2,
63.2,
18.7,
36.1,
40.9,
78.1,
80.4,
48,
37.3,
35.6,
28.9,
69.3,
21,
69.9,
47.2,
95.1,
61.1,
89,
38,
31.7,
44.4,
72,
68.4,
22.4,
84.7,
4.5,
1.6,
44.5,
63.9,
22.4,
69.1,
46,
19.2,
68.1,
46.8,
78.5,
83.1,
91,
38.2,
88.3,
17.8,
94.2,
2.8,
17.9,
53.8,
74.6,
60.5,
60.3,
47.3,
44.5,
2.6,
72.5,
80.1,
83.4,
35.6,
41.6,
34.2,
61.9,
82.9,
95.4,
4.1,
98.5,
75.4,
28.8,
51.9,
87.6,
57.3,
96.8,
73.7,
70.8,
25.2,
19,
100.5,
46.5,
26.1,
46.3,
53.1,
93.1,
60.7,
54.9,
79.9,
66.6,
75.6,
70.4,
39.8,
33.2,
74,
71.4,
82.4,
52.7,
77.7,
28.3,
71.1,
64.7,
82.6,
64.6,
86.1,
50.6,
42.3,
50.4,
68.8,
44.8,
44.1,
66.7,
65.8,
39,
66.7,
75.8,
45.8,
30.4,
10.8,
94.5,
63,
79.1,
46.5,
0.4,
79,
72.9,
30.5,
79.2,
53.6,
73.7,
32.3,
45.9,
58.5,
88.7,
85.8,
67.3,
88.7,
81,
37.5,
83.1,
90.7,
76.3,
44.6,
32.1,
77.8,
37.6,
48.2,
3.1,
40,
56.2,
20.9,
41.6,
85.6,
52.6,
36.2,
37,
90,
37.2,
8.9,
53.1,
41.4,
57.1,
47.3,
46,
64.2,
82.5,
60.8,
65.1,
43.7,
64.4,
71.8,
82.6,
10.2,
58,
41.8,
26.5,
16.2,
53,
64.4,
36.3,
58.8,
47.2,
96.4,
23.8,
43.9,
79.5,
35.8,
55,
59.4,
32.3,
34.2,
65,
76.8,
77.7,
96.4,
77.6,
3.9,
51.3,
67.1,
65.3,
76.4,
27.8,
39,
75.1,
56.3,
97.9,
74.7,
54.9,
59.8,
21.7,
33.6,
62,
62.6,
29.6,
32.2,
34.5,
49.5,
9.7,
57.1,
55,
82.4,
82.8,
81.4,
39.9,
48,
6.5,
89.4,
46.8,
94.3,
65.4,
53.2,
77,
63.3,
26.9,
98,
82.4,
14.1,
53.1,
77.2,
45.8,
46.2,
72.6,
71.4,
47.8,
51.7,
95,
44,
82.3,
48.6,
50,
56.8,
73.5,
76.7,
55.3,
36.2,
77,
49.7,
26.7,
81.8,
34.8,
17.9,
55.5,
32.6,
9,
88.5,
31.1,
74.1,
47,
64.5,
27.7,
43.2,
51.1,
23.7,
96.7,
28.7,
29.9,
11.4,
52.8,
31.1,
51.5,
37,
79.7,
37.6,
77.3,
28.6,
64.1,
68.3,
80.5,
48,
47.8,
52.1,
81.7,
54.9,
71.6,
39.5,
61.1,
58.6,
62.5,
16.5,
69,
33.6,
48.7,
80.1,
44.3,
79.2,
73.2,
90.4,
69.4,
14.8,
37.6,
67.4,
23.3,
94.9,
74,
56.3,
86,
46.5,
22,
44.1,
35.8,
1.7,
21.3,
30.1,
7.6,
66.8,
62.5,
77.5,
46.6,
0,
45.7,
53,
27.9,
42.9,
69,
47.7,
50.1,
67.8,
45.6,
66.9,
14.8,
83.5,
92.3,
100.7,
17.7,
38,
45.1,
39,
49.2,
83.7,
17.8,
46.3,
66.3,
37.2,
67.9,
50.8,
63.6,
43.3,
34,
42.1,
23.4,
39.7,
0,
85.6,
61.8,
64.9,
60,
69.6,
41.5,
97.9,
42.7,
16.1,
40.7,
63.1,
44.8,
94.5,
30.2,
50.3,
4.4,
16.6,
41.1,
65.8,
34,
75.5,
50.3,
50.9,
76.5,
0.2,
75.6,
77.5,
91.1,
96.1,
47.5,
27.3,
57.1,
38.4,
64.8,
46.3,
42.3,
73.7,
34,
87.4,
84.4,
33.7,
49.7,
66.1,
87,
55.8,
1.2,
24.4,
87.1,
77.7,
80.2,
96.6,
94,
5.7,
12.3,
78.2,
4.2,
23.8,
43.6,
61.4,
74.7,
48.2,
64.6,
23,
16.5,
52.7,
7.4,
66.4,
51.6,
52.5,
70,
93,
51.3,
81.6,
70,
71.3,
61.3,
73.7,
14.2,
73,
39.6,
57.7,
24.8,
62.6,
40,
23.1,
90.5,
70.1,
37,
71.3,
24.5,
36.5,
31.9,
0,
41.4,
54.6,
69.7,
28.4,
73,
34.6,
11,
68.7,
74.9,
10.1,
67.6,
64,
38.6,
52.5,
36,
39.7,
52,
49,
56.9,
65,
40.2,
72.4,
57.3,
82.6,
0.3,
65.4,
94.1,
30.6,
5.6,
0,
70.3,
53.9,
56.6,
61.7,
95.5,
41.5,
12.5,
34.6,
70.9,
19.4,
78.1,
76,
48.8,
24.7,
85,
80,
71.1,
61.8,
78.6,
5.9,
59.2,
1.3,
68.6,
78.9,
63.5,
24.8,
61.9,
97.1,
56.5,
55.6,
21.9,
69.8,
28.4,
73.9,
69.5,
61.2,
21.1,
38.7,
42,
35.3,
46,
85.5,
55.6,
49.9,
61.8,
1.9,
49.8,
51.5,
17.5,
99.1,
37.9,
59.9,
86.2,
49,
93.1,
49.9,
29.2,
24.7,
44.2,
53,
51.5,
53.8,
26.8,
47.6,
11.9,
17.6,
38.2,
74.8,
95.2,
67.7,
84.1,
66.9,
17.6,
66.6,
92.1,
73.7,
40.3,
0,
59.5,
67.1,
43.6,
28.6,
91.8,
85.9,
74.8,
43.5,
55.9,
35.2,
37.4,
64.5,
61.4,
44.8,
40.5,
62.2,
55.9,
19.3,
46.2,
22.1,
22.6,
63,
73.5,
34.2,
72.5,
84.4,
29.8,
14,
66.3,
69.8,
61.4,
75.5,
45.5,
49.2,
80.6,
48.8,
86.4,
21.9,
19.3,
26.3,
24.3,
88.4,
69.9,
4.6,
78.8,
51.8,
23.4,
69.6,
77.5,
87.5,
67.1,
15.3,
5.3,
69,
27.4,
59.9,
24.7,
67.4,
41.6,
51.3,
15,
40.9,
89.5,
28.3,
91.3,
44.2,
91.8,
62.2,
33.4,
52.3,
7.8,
97,
32.7,
29.7,
40.6,
42.4,
83.2,
43.2,
81.7,
32.3,
61.1,
67.2,
53.2,
79.7,
79.1,
55.1,
63.7,
67.6,
72.7,
22.7,
72.6,
33.9,
54.2,
16.8,
45.6,
15,
24.9,
22.8,
85,
19.5,
48.9,
87.7,
77.5,
74,
46.3,
33.1,
31.3,
43.3,
10.1,
64.4,
18,
23.5,
67.8,
21.7,
70.6,
98.5,
64.2,
55.7,
89.1,
28.4,
28.7,
72.1,
74.3,
55,
39.2,
46.3,
40.7,
9.5,
56.5,
68.7,
64.7,
52.8,
96,
82.4,
55.8,
71.1,
68.2,
28.8,
44.9,
38.6,
31.8,
48,
70.4,
28.8,
19.4,
59.1,
65.5,
16,
36.7,
43,
49.6,
93.5,
55.7,
27.8,
96.4,
39.6,
95.5,
70.4,
75.4,
4.8,
58,
52,
38.7,
54.4,
38.1,
60.6,
71.5,
76.9,
63.2,
70.5,
21.5,
47.6,
21.6,
34.9,
92.9,
75.5,
78,
6,
32.2,
66.8,
56.9,
20.9,
85.7,
74.6,
80.3,
40,
49.4,
47.9,
31.1,
73.9,
3.9,
47.5,
29.1,
34.2,
59.5,
44.8,
91.2,
33.3,
29.1,
86.4,
59.8,
50,
35.5,
61.2,
31.8,
28.2,
96.1,
57.3,
22.7,
0.7,
5.1,
46.1,
55.9,
58.8,
63.5,
55.4,
63.8,
23.3,
66,
5.4,
52,
14.9,
52.6,
46.1,
71,
57.1,
67.7,
85.4,
98.1,
55.8,
84.1,
65.5,
43.7,
15.1,
55,
49.9,
11.8,
85.2,
51.5,
75.5,
53.7,
46.6,
72.4,
42.9,
22.2,
66.7,
24.4,
89.7,
69,
47.9,
66.2,
13,
53.1,
57.9,
35.1,
48.7,
95.2,
88.5,
40,
44.9,
90.3,
42.5,
86.9,
22.9,
6.4,
96.2,
54.3,
98.9,
52.7,
85.1,
73.4,
69.5,
62.9,
68,
48.4,
55.8,
103.6,
73,
37.8,
88.1,
28.3,
59.1,
93.4,
32,
27,
36.6,
36.7,
30.6,
40.4,
63.3,
55.7,
53.4,
46.6,
79.4,
60.3,
35,
71.4,
43.8,
99.3,
51.3,
24.7,
60.8,
29.4,
29.2,
83,
37.8,
92.4,
50.1,
30.1,
78.6,
7.7,
68.6,
80.2,
27.4,
48.2,
40.9,
71.1,
28.4,
40,
71.5,
78.1,
70,
83.1,
40.2,
54.2,
35,
78.7,
55.6,
94.6,
57.6,
10.8,
92.3,
48,
15.5,
90.2,
39.2,
75,
40.8,
95.5,
16.6,
83.1,
71.1,
49.7,
72,
75.7,
18.6,
96.3,
32.9,
21.7,
0,
75.1,
60.4,
67.9,
30.1,
22.7,
56.8,
78,
52.2,
64.1,
67.4,
58.7,
83.4,
70,
44.8,
68.9,
26.3,
0,
21.2,
31.1,
33.5,
45.3,
42.2,
60.4,
45.8,
98.2,
73.9,
85.7,
46.6,
17.7,
30.3,
49.2,
67.6,
32.2,
30.2,
39.1,
48.6,
77,
71.4,
81.9,
13.5,
70.4,
73.7,
50.9,
62.6,
78.4,
88,
48.6,
56.8,
102.6,
73.6,
38.4,
64,
23,
91.9,
55,
70.5,
39.6,
55.7,
32.8,
53.7,
56.5,
48.8,
94,
69.3,
62.1,
48.9,
27.9,
37.6,
47.2,
92.3,
38.4,
40.2,
48.5,
66.9,
23.8,
73,
2.2,
39.2,
77.7,
69.1,
99,
98.2,
65.8,
34.5,
45.5,
71.8,
39.3,
58.2,
63.3,
50.5,
97.4,
70.5,
89.1,
42.6,
65.1,
76.1,
89.3,
97.5,
22.1,
81.1,
31.4,
24.7,
25.1,
80.2,
78.9,
54.5,
31.7,
53,
95,
50.5,
58,
61.5,
84.9,
73,
87.1,
37.5,
3.4,
35,
90,
39.7,
49,
11.4,
78.4,
81.2,
59,
0.9,
97.3,
15.3,
44.2,
92,
72.3,
19.5,
62,
56.1,
39.9,
97.2,
73.7,
32.3,
24.2,
77.5,
34.4,
84.7,
76.3,
92.8,
48.7,
72,
74.6,
34.4,
67.3,
65.4,
94.1,
68,
53.3,
68,
38.3,
57.2,
71.9,
83.6,
43.4,
62.5,
96.5,
10.9,
31.4,
71.6,
94,
43.2,
79.6,
81.4,
18.4,
56.6,
30.3,
50.4,
46.2,
36.3,
39.4,
48,
34.2,
61.3,
35.3,
83.5,
48.9,
43.9,
75.3,
19.4,
33.5,
45.7,
69.1,
66.9,
77.5,
90.6,
43.5,
0.1,
51.9,
84.9,
46,
28.4,
6.4,
1.5,
58.8,
40.8,
4.2,
95.2,
54.8,
28,
52.4,
52.7,
68.5,
64.3,
95.7,
31.9,
86,
84.6,
13.5,
48.5,
98.2,
32.4,
64.6,
66.6,
49.3,
52.8,
78,
36.3,
60.6,
86,
68.5,
80.6,
39.8,
66.1,
85.2,
64.6,
32.5,
76.8,
69.6,
92.8,
38.9,
40.5,
65.5,
95.6,
43.7,
58.4,
30.2,
29.1,
84.5,
73.2,
79.9,
32.8,
47.3,
96.5,
58.8,
47.9,
11,
92.2,
39.6,
79.9,
41.5,
82.6,
83,
41.7,
80.3,
30.4,
27,
79.4,
46.7,
55.4,
80.5,
38.4,
68,
2.3,
78.8,
70.1,
86.4,
81,
62.3,
37.8,
53.8,
44.6,
68.4,
12.2,
97.5,
35.8,
49.4,
72.1,
74.9,
24.4,
53.2,
48.2,
60.4,
69.9,
37.6,
81,
50.8,
25.3,
78.1,
10.1,
34.6,
52.7,
9.6,
64.3,
63.3,
86.6,
30.7,
37.6,
61.4,
0.1,
5.4,
68.5,
73.9,
62,
23.1,
59.8,
55.7,
35.9,
22.4,
67.8,
30.7,
54.7,
89.9,
41.5,
56,
92.1,
34.9,
86,
87.9,
90,
44.1,
63.9,
93.8,
90.3,
97.5,
36.4,
51,
85.2,
35.2,
86.9,
76.2,
95.1,
79,
68.1,
78.4,
81.9,
74.5,
72.6,
54.5,
47.8,
91.6,
33,
12.7,
43.8,
48.4,
33.1,
49.4,
80.8,
68.5,
47.5,
68.2,
69.1,
78.4,
24.3,
35,
63.1,
38.9,
52.5,
45.9,
3.8,
97.2,
51.7,
61.2,
91.7,
4.1,
53,
4.2,
35.1,
27.4,
61,
14.8,
65.1,
38.7,
31.4,
26.7,
96.3,
92.6,
51.5,
62.1,
78,
83,
79.7,
36.5,
58.5,
67.9,
43.4,
74.8,
53.6,
83.7,
98.8,
58.8,
64.5,
67,
52.5,
24.6,
15,
75.3,
84.5,
22.6,
10.6,
90.8,
16.9,
61.3,
58.9,
83,
34.1,
98.5,
71.4,
70,
47.2,
6,
28.6,
58.6,
94.6,
86.6,
70.3,
92.7,
30.3,
28.8,
39,
39,
20.7,
51.6,
46.9,
58.6,
51.1,
55.2,
30.5,
23.6,
58.7,
90.1,
67.7,
36.7,
81.3,
30.6,
51,
78.4,
46.1,
94.4,
57,
49.7,
68.7,
86.5,
63.3,
93.1,
66.6,
61,
48,
15,
71.8,
53.9,
84.1,
25.7,
19.2,
63.2,
38.2,
39.9,
53.4,
43,
88.2,
53.3,
71.6,
32.8,
36.2,
23.8,
73.3,
29.3,
23,
87.4,
80.9,
50.6,
85.4,
37.6,
62.6,
16.3,
75.1,
14,
98,
11.3,
92.6,
12.6,
33.1,
66.9,
32.1,
70.7,
14.3,
89.8,
72,
46.7,
70.7,
19.7,
100.1,
72.1,
31.7,
96.3,
48,
45.9,
98.8,
75,
53.3,
85.5,
72.2,
83.8,
0,
43,
25,
31.6,
63.1,
49.7,
31.1,
63.9,
18.1,
82.9,
62.7,
58.3,
33,
61.2,
76.3,
60,
76,
42.3,
49.1,
29.6,
66.6,
69.9,
30.1,
23,
46.5,
48.9,
68.9,
28,
46.4,
19.7,
66.4,
60.6,
44.3,
17.4,
78.6,
47.4,
80.6,
77.5,
53.1,
81.5,
44.2,
61,
49.2,
82.5,
50.6,
62.7,
57.1,
49.6,
40.8,
62.7,
71.8,
8.3,
74.5,
27.5,
96.4,
74.5,
52.1,
32.5,
55.9,
60.9,
77.8,
55.8,
44.4,
44.5,
18.9,
64.3,
25.9,
83.5,
84.9,
65.8,
7.5,
90.5,
94.4,
79.6,
16.7,
96.3,
8.2,
32.9,
8,
27.2,
87.6,
76.1,
42.2,
30.4,
72.5,
80.8,
77.4,
19.3,
76.7,
92.1,
43,
33.2,
64.2,
69.9,
94.8,
9.6,
36.6,
82.6,
62.5,
87.7,
48,
78,
93.1,
57,
69.2,
27.9,
22.6,
88,
88.7,
87.3,
51.6,
75.4,
66.5,
98.3,
30.1,
9,
34.3,
77,
77.8,
93.1,
53,
39.5,
46.1,
91.3,
67.2,
75.3,
75.3,
37,
62.1,
37.2,
35.5,
13.9,
92.9,
54.4,
8.3,
85,
10.8,
93.2,
66,
50.7,
13.3,
36.7,
43.9,
67.8,
64.6,
56.7,
82.3,
49.7,
71,
80.8,
99,
77.5,
80.3,
77.3,
74.9,
40.2,
69.8,
81.3,
17.2,
39.9,
85,
90.4,
58.3,
87,
92.6,
47.8,
39.8,
78.4,
44.4,
14.3,
36.9,
38.4,
26.8,
77.6,
66,
85,
69.7,
26.5,
55.7,
96.5,
9.5,
20.8,
38.4,
40.1,
81.7,
75.9,
60.2,
71.9,
42.7,
23.3,
53.6,
97.5,
62.2,
39.5,
46.6,
92.5,
90.9,
37,
81.6,
3.6,
62.3,
77,
68.3,
59.4,
9.5,
5.6,
81,
39.8,
30.6,
69.1,
63,
85.5,
90.4,
35.6,
58.1,
79.6,
29.7,
51.6,
29.6,
84,
40.2,
75.7,
50.8,
52.4,
96.4,
85.5,
44.3,
54.6,
64.1,
33.3,
66.1,
28,
33,
44.3,
76.3,
34.6,
62.8,
52.5,
70.9,
40.3,
76.4,
41.6,
90.5,
45.7,
42.7,
85.2,
35.4,
39.9,
12.7,
37.3,
59.7,
79.2,
55,
13.6,
47.1,
78,
47.8,
39.5,
13.4,
17.2,
88.9,
47.6,
68,
18.2,
39.9,
86.3,
58.6,
61.3,
72,
0.3,
96,
92.5,
48.9,
36.4,
66.5,
22.7,
70.9,
50.5,
36.1,
72,
68,
32.4,
52.9,
25.7,
88.9,
33.8,
70.1,
88.7,
79.6,
60.2,
65,
73.9,
81.8,
31.7,
80.3,
44.2,
73.6,
15.7,
75.9,
86.6,
50.7,
19.3,
59.3,
41.1,
65.9,
67.5,
59.2,
40.8,
29.7,
64.8,
22.2,
79.9,
25.5,
33.6,
47.8,
70.9,
80.3,
97.5,
73.2,
48.8,
68.6,
89.1,
71.7,
77.8,
56.4,
10.9,
53.6,
92.6,
61.2,
82.7,
6.1,
16.9,
59.2,
82.4,
54,
76.5,
69.4,
63.8,
13.1,
46.3,
83.3,
59.7,
6.1,
88.8,
18.5,
86.6,
55.4,
89.1,
65.1,
78.8,
49.1,
98.5,
53.2,
39.8,
36.7,
37.8,
86.2,
48.1,
55.7,
55.3,
57.8,
61.2,
52.3,
72.5,
66.6,
77.9,
78.3,
13.2,
97.2,
101,
51.1,
42.5,
39.1,
81.2,
46.3,
70.5,
78.6,
9.6,
68.1,
89.6,
34.8,
68.8,
62.3,
26,
68.4,
83.2,
13.4,
78.7,
40.4,
75.5,
42.8,
16.9,
60.7,
45,
29.7,
63.1,
95.7,
36.6,
92.1,
68.5,
38.8,
47.5,
8.7,
49.6,
30,
62.3,
57.6,
10,
35.5,
47.8,
81.3,
15.1,
97.6,
92.5,
27,
57.2,
36.5,
66,
25.3,
81,
82.5,
87.8,
32.2,
29.8,
75.8,
15.1,
74.5,
39.8,
89.4,
75.2,
44.8,
31.5,
42.9,
18.7,
52.8,
77.1,
40.1,
66,
64.9,
62.8,
84.9,
59,
6.8,
30.8,
20.7,
25.3,
34.9,
69.9,
61,
12.7,
62.4,
26.3,
38.9,
87.7,
81.3,
12.6,
67.3,
46.1,
61.3,
65.7,
27.3,
48.7,
4.9,
86,
75.2,
78.9,
41.6,
61.6,
41,
65.2,
36.8,
98.7,
73,
12.6,
46.4,
45.9,
75.6,
78.3,
37,
19.8,
82,
52.1,
47.9,
14.2,
25.4,
67.5,
100.9,
73.1,
76.1,
64.8,
68.1,
53,
81.8,
5.8,
72,
56.1,
42.4,
85.6,
57.9,
95.6,
23,
50.2,
45.4,
77.2,
0.5,
78.4,
48.9,
59.8,
69.4,
52.8,
16.1,
53,
60,
70.7,
56.4,
77.5,
83.3,
42.3,
60.5,
88.3,
32,
41.8,
46.5,
30.1,
22.9,
44.2,
29.4,
72.8,
12,
46.5,
34.3,
88.1,
24.9,
45.7,
45.1,
37.2,
28.8,
55.1,
89.8,
42.4,
88.5,
43.5,
32.7,
100.4,
75.6,
63.7,
46,
46,
66.8,
81.8,
41.6,
24.2,
76.2,
45.6,
21.4,
66.3,
56.6,
49.9,
33.3,
37.2,
21.9,
78.2,
79.7,
30.7,
79.9,
29,
74.8,
51.5,
74.8,
67.2,
32.5,
77.3,
74.2,
92.7,
62.7,
68,
96.8,
39.8,
67.1,
42.9,
49.9,
85.5,
55.1,
22.1,
68.2,
26.7,
50.7,
60.9,
24.3,
48.1,
54.1,
99.7,
22.5,
60.7,
57.1,
49.1,
59.8,
64.8,
40.1,
12.3,
57.1,
74,
22.3,
0,
44.3,
61.1,
55.5,
65.9,
61.5,
75.5,
31,
76.8,
72.2,
54.7,
51.4,
83.2,
36.4,
64,
19.5,
85.5,
43.6,
89.3,
81.3,
38.2,
85.2,
54,
41,
74,
44.9,
7.5,
62.6,
85.3,
2.5,
30,
31,
34.7,
99.4,
48.8,
67.7,
70.4,
14.6,
25.7,
65.1,
43.6,
92.2,
82.4,
78.2,
78.2,
22.7,
25.8,
50.8,
91,
42.4,
88.5,
36.8,
7.9,
58.6,
74.4,
28.9,
40.2,
84.8,
86.2,
32.3,
71.2,
92.6,
77.5,
30,
22,
46.3,
40.9,
59,
45.7,
33.6,
69.9,
70.2,
54.1,
48.6,
41.1,
63,
42.9,
38,
29.4,
30.9,
50.9,
59.4,
47.1,
48.6,
83,
23.1,
57.8,
41.8,
83.5,
68.7,
48.5,
67.8,
32.2,
50.9,
36.2,
89,
82.8,
46.7,
32.4,
41.3,
29.7,
68.5,
65.3,
67.6,
98.9,
90.1,
68.7,
98.7,
79.8,
57,
53,
22.1,
60.6,
59.8,
49.7,
48.8,
54.2,
20.6,
82.7,
43.4,
16.5,
40.1,
65.6,
36.2,
36.1,
93,
71.4,
80.5,
61.9,
33.6,
81.2,
98.1,
23.3,
94,
85.2,
77.3,
71.2,
70,
73.4,
15.6,
88.8,
43.3,
28.4,
66.3,
30.8,
53.1,
0,
30,
61.7,
74.4,
21.7,
56.8,
0,
68.5,
88,
84.2,
65.7,
1.1,
26.6,
94.3,
56.7,
38.6,
63.4,
29.7,
69.8,
44.5,
44.2,
85.2,
68.5,
45.1,
33,
48.5,
69.3,
82.1,
40.5,
68,
63.3,
54.7,
0,
47.5,
63.9,
44.7,
72.2,
44.2,
53.9,
88.3,
44.6,
59.4,
38.2,
58.8,
80.3,
14.3,
42.8,
75.4,
46.5,
68.6,
42.5,
98.6,
74.7,
39.5,
75,
26.5,
54,
52.5,
26.7,
70.4,
5.9,
62.1,
66.4,
76.8,
34.9,
66.3,
53.9,
92.6,
43.8,
60.9,
14.4,
66.7,
43.4,
53.4,
69.1,
38,
78.8,
52.3,
70.4,
79.2,
56.6,
74.5,
47.8,
68.5,
45,
70.4,
47.9,
58.8,
61.1,
20.3,
45.4,
91,
53,
86.3,
69.5,
81.3,
27.7,
25.7,
41.3,
80.8,
24.8,
76.2,
38,
92.2,
57.2,
71.2,
51.7,
52.9,
95.9,
46.1,
7.3,
73.4,
23.7,
85,
23.9,
58.9,
37.6,
41.4,
61.3,
48.3,
22.4,
49,
36.1,
52.8,
49.4,
78,
45.6,
35.3,
35.3,
33.4,
58.5,
6.4,
68.6,
24.5,
36.2,
22.2,
54.4,
36.7,
64.8,
87.2,
55.3,
61.9,
54.4,
47.3,
50.2,
38.2,
32.1,
76.1,
34.4,
12.8,
38.5,
48.6,
43.6,
72.8,
14.1,
55.5,
58,
84.5,
74.1,
68.4,
52.2,
68.3,
42.2,
97.4,
88.6,
74.2,
45.4,
65.1,
13.6,
35.2,
81.8,
33.7,
83.9,
65,
48.9,
38.7,
4.1,
49.4,
33.6,
79.4,
35.9,
71.1,
79,
44.2,
34.8,
48.5,
33.9,
62.1,
22.3,
24.7,
59.4,
70.6,
54.6,
86.7,
52.4,
61.5,
22.6,
50.1,
29.9,
51.6,
46.6,
34,
62.8,
48.6,
63.9,
72.5,
38,
45.9,
87.6,
55.7,
80.5,
92.8,
92,
58.9,
78.4,
58.8,
59.3,
31.9,
null,
41.3,
33.9,
43.9,
65.7,
35,
30.3,
83.7,
62.8,
56.7,
44.3,
37.3,
54.8,
64.4,
81.9,
22.6,
47.2,
27,
18,
72.5,
46,
79,
36.7,
21.5,
42.3,
37.6,
47.3,
50.6,
33.2,
57,
74.3,
53.4,
44.3,
51.6,
72.1,
44.1,
90.1,
43.8,
40.4,
78.3,
72.3,
60.8,
88.5,
87,
29.6,
57.7,
22.8,
87.2,
52.9,
18.6,
56.5,
48,
25.7,
22.9,
88.7,
40.3,
99.3,
86,
35,
34.7,
34.6,
42.4,
71.3,
64.6,
82.1,
43.9,
75.4,
38.4,
9.6,
45.9,
49.9,
75.6,
2,
30.2,
35.7,
52.9,
29.3,
45.6,
44.9,
79.4,
45,
25.9,
66.1,
14.9,
79.3,
12.3,
33.2,
86.5,
67.4,
19.8,
25.8,
99.1,
90.5,
64.7,
63.8,
88.5,
35.5,
49.1,
50.6,
50.9,
35.6,
32.7,
93.7,
2.1,
55.7,
92.3,
49.4,
46,
81.2,
94.9,
39.1,
50.1,
44.4,
82.4,
68.6,
39.3,
68.3,
52.6,
48.4,
73.9,
47.9,
66.1,
28.1,
61.8,
41.2,
43.9,
45,
77.8,
28.5,
57.4,
93.5,
81,
60.5,
66.7,
49.6,
64.2,
80.6,
70.5,
42.7,
34.5,
78,
27.3,
46.9,
78.3,
63.8,
78.7,
40,
26.2,
73.9,
23.7,
43,
51.4,
73.1,
42.2,
83.6,
76.7,
16.8,
51.8,
56.6,
59.2,
36.9,
26.2,
17.6,
22.2,
68.3,
83,
43.5,
52,
33.4,
34.9,
34.1,
34,
98.2,
78.5,
62.6,
48.3,
40.9,
92.5,
91.2,
65,
79.9,
81.5,
15.8,
52.8,
73.9,
51.4,
97.9,
58.5,
59,
7.8,
26.5,
79.9,
22.1,
45.2,
50.6,
97.3,
12.7,
13.9,
5.6,
43.4,
54.2,
95.7,
25.2,
37.9,
57.1,
83.3,
71.5,
53.9,
77.9,
32.4,
38.1,
54,
54.2,
96.6,
24.5,
12.6,
68.6,
17.8,
74,
48.7,
89.1,
36.8,
66.4,
38.8,
70,
100.2,
2.3,
54,
45.4,
69.6,
47.6,
71.2,
78.7,
75.4,
47.8,
53.6,
34.5,
73.7,
40.8,
48.5,
70.1,
85.6,
18.4,
64.8,
88.5,
29,
60,
89.2,
36.6,
85.3,
34.1,
29.2,
58.2,
81.3,
52.7,
46.3,
21.1,
72.3,
97.3,
82.1,
14.5,
29.1,
24.6,
41,
56.9,
32.6,
31.1,
37.2,
92.2,
54.7,
76,
60,
59.6,
24.5,
58.6,
0.3,
49.6,
16.7,
51.4,
65,
31.2,
13.9,
73.9,
57.3,
31.4,
75.6,
29.7,
87.4,
74.4,
63.4,
75.3,
44.5,
17.8,
15.6,
51.7,
89.9,
56.4,
51.6,
57.3,
79.1,
68.5,
62.6,
29,
72.2,
38.4,
5.3,
37.3,
71,
63.5,
79,
70.1,
69,
67,
44.2,
73.6,
83.6,
43.4,
64.3,
19.1,
50.8,
33.8,
22.4,
58.6,
6.1,
19.8,
49.4,
55.6,
43,
95.4,
67,
40.5,
64.7,
52.4,
71.7,
44.3,
53.9,
50.5,
49.8,
52.6,
71.8,
60,
42.4,
67,
34.3,
40.9,
6.2,
44.4,
78.9,
74.3,
40.4,
32,
48.4,
98.3,
65.4,
53.5,
77,
34.8,
92.2,
94.3,
65.4,
83.7,
36.2,
83.5,
45.3,
55.6,
66.7,
75.6,
43.8,
28.5,
35.4,
57.7,
85.3,
34,
2.2,
65.3,
98.1,
72.2,
38.9,
85.1,
96.2,
17.2,
86.2,
59.3,
79.3,
66.5,
61.7,
76.3,
69.7,
53.5,
33.1,
41.8,
81.1,
31.2,
29.7,
72.6,
77.1,
17.1,
65.3,
79.4,
38,
1.9,
70.2,
80.6,
64.2,
83,
10.2,
61.6,
62,
25.2,
38.5,
7.4,
24.5,
57.1,
77.4,
56.9,
50.1,
59.3,
58.3,
94.9,
34.6,
3.5,
63.3,
64.4,
75.3,
79.9,
11.5,
9.4,
70.4,
77.9,
64,
95.8,
30.1,
66.2,
70.4,
60.8,
11.5,
42.9,
37.5,
44.7,
36.4,
49,
62.8,
71.6,
83.1,
14.5,
80.2,
27.5,
98.5,
81.8,
46.7,
84.5,
5.6,
62.7,
63.5,
48.1,
61.9,
18.2,
48.6,
75,
60.2,
59.3,
56.3,
31.1,
44.8,
33.6,
92.2,
74,
33.8,
63.7,
47.4,
77,
69.8,
93.8,
36.5,
42.5,
33.2,
13.4,
34,
95.6,
53,
83.5,
52.6,
80.5,
46.1,
36.7,
79.4,
61.9,
63.5,
71.2,
80.3,
89.7,
46,
54.7,
38,
96.2,
37.2,
56.9,
72.3,
58.4,
92.6,
62.2,
33,
31.9,
84.1,
84.7,
36.5,
60.1,
81.5,
41.1,
53.9,
87.8,
49.5,
57.2,
49.7,
98.3,
62.3,
94.3,
40.7,
86.9,
8.7,
61.4,
57.5,
68,
87,
52.7,
21.8,
66.8,
63.3,
44,
61.7,
58.7,
76,
60.6,
88,
79.2,
94,
54.6,
99.1,
null,
85.2,
40.7,
70.5,
58,
51.8,
81.1,
53.8,
58.2,
83.7,
57.1,
66.8,
45.9,
77,
77.6,
69.4,
25.7,
63.5,
58.9,
72.2,
46.4,
96.5,
79.1,
50,
74.5,
71.7,
88.1,
77.9,
47.4,
49.6,
55,
66.2,
52.5,
73.3,
85,
70.4,
29.9,
47.7,
56.8,
76.3,
63.8,
46,
44.9,
9,
82.6,
53.7,
23.7,
78.8,
42.6,
17.3,
34.8,
16.1,
9.7,
51.4,
39.5,
69.8,
9,
24.2,
9.9,
92.8,
89.7,
44.6,
95,
18.7,
25.4,
53.8,
62.7,
62.3,
44.7,
84.9,
1.2,
84.4,
36.3,
14.5,
87,
87.3,
58.7,
91.1,
55.2,
88.9,
38.2,
67.8,
29.6,
87.8,
50.7,
50.9,
75.1,
75.6,
37.1,
8.9,
45.1,
59.1,
38.9,
58,
60,
90.1,
37.6,
67.9,
40.6,
33.8,
65,
61,
60.8,
74,
65.3,
63.1,
57.4,
84.1,
48.3,
59.1,
62,
71.4,
67.7,
58.1,
22.8,
20.2,
39.2,
64.3,
79.7,
64.7,
93,
64.5,
42.2,
82.8,
28.9,
34.5,
90.6,
32.9,
59.7,
20.7,
25.1,
19.1,
39,
91.6,
69.3,
88.7,
26.7,
57.3,
30.8,
89.1,
47.1,
72.6,
37.2,
72.9,
81,
91.6,
9.3,
48.9,
38,
91,
91.8,
92.6,
70.3,
25.2,
92.8,
9.9,
5.8,
48.8,
70,
47.5,
80.8,
54.2,
56.6,
46.9,
56,
74.1,
62.7,
85.3,
35.9,
55.6,
99.7,
65.8,
78.5,
81.7,
90.9,
88.3,
48,
41.5,
30.2,
51.2,
21,
56.1,
63.3,
94.4,
40,
74.2,
42.9,
91,
53,
74.1,
25.5,
45.7,
46.3,
80.9,
47.1,
54.1,
76,
91.8,
83.8,
62.6,
41.4,
47.6,
50.1,
47.9,
63.1,
62.3,
49.1,
67.3,
33.8,
28.6,
80.2,
79.5,
51.5,
33.6,
39,
56.8,
78.3,
83.9,
8.9,
41.9,
16.4,
42.6,
43.2,
60.6,
62.7,
62.5,
91.4,
70.5,
82.1,
82.3,
81,
34.7,
23.8,
98.8,
76.7,
87.1,
65,
13.6,
96.8,
57.9,
84.9,
53.3,
0.3,
51.8,
56.8,
51.1,
76.9,
38.3,
72.5,
44,
73.8,
70.2,
63.9,
41,
61.4,
82.3,
65.2,
82.5,
62.9,
90.8,
33.3,
8,
45.2,
88.3,
50,
23.2,
41,
59.1,
46,
83.7,
90.9,
59.9,
46.1,
28.3,
20.2,
44,
55.3,
78.6,
74.2,
43.7,
45,
24.7,
35.2,
8.2,
24.3,
12.5,
50,
27.8,
63.8,
65.5,
45.5,
54.6,
0.7,
52.8,
26.3,
46.5,
70.1,
87.3,
1.7,
67.3,
32.2,
28,
44.3,
76.7,
82,
64.7,
93.5,
87.8,
92.3,
23.4,
55.9,
66.1,
46,
60.8,
87.7,
27,
48.7,
77.8,
56.7,
24,
78.9,
39.2,
86.4,
53.4,
45.6,
60.9,
34.7,
61.2,
61,
30.3,
96.2,
57.9,
32.3,
15.8,
62.4,
60.6,
21.2,
0,
56.5,
39.7,
91,
36.2,
24.1,
42.1,
42.3,
10.4,
84.4,
87,
81.7,
41.1,
71.4,
70.1,
39.2,
76.1,
62.7,
57.3,
69.6,
56.4,
13.3,
72.9,
58.8,
43.7,
31,
79.5,
25.5,
24,
53.2,
97.6,
51.3,
87.3,
44,
59.7,
47.4,
65,
49.6,
80.3,
54.7,
62.5,
78.2,
58.5,
70.5,
71.7,
17.6,
42.3,
42.5,
47.8,
15.7,
13.2,
51.3,
97.7,
29.8,
34.7,
73,
38,
17.9,
41.5,
43.9,
70.5,
83.3,
61,
85.5,
89.1,
50.3,
30.9,
28.3,
12,
91.4,
18.2,
51.6,
82.6,
84.5,
79.2,
38.5,
32,
45.7,
24.9,
21.1,
29.9,
50.1,
77.8,
18.8,
64.4,
51,
79.6,
78.4,
14.1,
101.4,
31.4,
53.6,
57.2,
78.8,
19.7,
98,
59.2,
63.3,
84.3,
50.4,
96.5,
49.5,
51.9,
68.6,
30,
5.8,
67.3,
10.8,
33.9,
53.2,
72.1,
86.7,
100.3,
94.5,
59.5,
62.9,
83.4,
63.9,
4.9,
43.6,
32.1,
35,
51.4,
9.5,
74,
37.2,
15.1,
54.5,
51.2,
30.2,
64.2,
85.1,
73.9,
26.5,
83.2,
32.5,
20.6,
63.3,
23.3,
45.8,
51.3,
72.4,
70.6,
84.9,
6.2,
37.5,
17.5,
94.1,
68.8,
23.9,
57.3,
41,
45.4,
33.3,
46.4,
76.5,
69.9,
96.3,
44.7,
24.4,
94.6,
83.1,
2.6,
76.7,
65.9,
34.3,
34,
74.5,
60.5,
23.3,
37.5,
94.4,
66.6,
47.9,
99.4,
46.5,
57,
78,
71.2,
68.6,
22.3,
34.9,
34.9,
39.4,
93.1,
23.5,
68.8,
51.7,
23.1,
31,
38.5,
57.4,
98.3,
19.4,
27.1,
43.6,
68.1,
45.6,
35.9,
79.8,
93.7,
44.8,
41.4,
35,
41.2,
77,
97.8,
35.6,
12.8,
43.6,
64.3,
92.8,
73,
46.4,
16,
5.3,
62.8,
65,
90.8,
70.8,
49.1,
62.4,
68,
2.6,
63.5,
9.8,
54.4,
38.4,
4.2,
56.7,
26.7,
0.3,
67,
62.9,
46.4,
69.8,
53.8,
28.5,
5.9,
47.3,
43.4,
67.5,
24.1,
67.2,
99,
91.6,
96.1,
36.3,
43.2,
60.1,
71.8,
45.5,
22.1,
57.5,
48.7,
76.3,
47.6,
81.4,
59.1,
48.9,
57.9,
77.7,
50.6,
35,
56.1,
54.8,
14.2,
34.7,
24.3,
40.6,
56,
69.6,
60,
14.5,
27.7,
29.9,
66.3,
74.1,
90.4,
84.7,
47.5,
67.6,
64.3,
99,
86.8,
74.3,
64.6,
73.3,
31.6,
92.5,
40.2,
14.7,
76.4,
71,
46.1,
75.8,
98.5,
57,
92.7,
56.2,
67.8,
57.6,
95.5,
51.5,
62.3,
37.3,
37.4,
30.8,
93,
64,
49.4,
36.8,
70.5,
86.3,
92,
65.1,
71.2,
77.8,
55.9,
62.2,
93,
21,
29.3,
81.3,
54.8,
101.5,
59.1,
95.3,
80.4,
50.6,
91.9,
59.9,
77,
31.3,
26.9,
34.5,
51.1,
9.6,
32.6,
12.8,
46,
88.1,
86.3,
89,
72,
24.7,
36.2,
86.9,
53.8,
40.9,
85.5,
29.6,
82.9,
95,
88.6,
83.7,
7.2,
48.4,
29.9,
90.9,
51.8,
99.1,
49.5,
95.4,
93.3,
102.3,
72.2,
93,
47.2,
93.5,
43.3,
9.2,
43.6,
19.5,
81.4,
67.3,
38.5,
43.8,
69.2,
78.6,
94.2,
67.5,
56.6,
65,
64.8,
60,
42.1,
94.2,
53.3,
51.2,
28.6,
58.5,
54.9,
18.7,
31.6,
60,
85.4,
51.6,
72.6,
62.7,
91.4,
86.6,
46.5,
66,
1.7,
74.6,
105.4,
66.1,
97.9,
69.8,
72.5,
77.7,
9.2,
54.2,
27.3,
54.7,
45.8,
58.5,
92.4,
75.5,
65.3,
75,
2,
81.4,
63.9,
1.1,
77.2,
43.8,
56,
43.2,
51.1,
87.2,
38.1,
37.5,
8.2,
38.2,
78.3,
38,
47.6,
92.4,
49.9,
36.1,
42.9,
74.2,
42.6,
76,
88.4,
33.3,
23.3,
95,
51.8,
98.9,
54.5,
49.3,
84.6,
50.2,
33,
12.5,
20.7,
55.8,
30.2,
91,
68.2,
37.9,
60.1,
74.1,
36.5,
82.3,
87,
54.8,
42.1,
64.7,
36.5,
98.7,
47.5,
56.1,
53.6,
27.1,
55.1,
40.6,
20.8,
55.2,
49.3,
80,
62.9,
99.1,
91.7,
44.1,
37.1,
23.7,
80.8,
10.2,
27.3,
66.6,
41.2,
45.8,
0.4,
86.4,
51.1,
78.2,
68.2,
58.8,
48.4,
42.4,
81.8,
51.6,
57.2,
69,
74.7,
91.9,
92.6,
77.2,
60.4,
58.3,
53.1,
78,
41.7,
55.3,
72.4,
26.9,
40.2,
24.9,
35.7,
79.7,
64.7,
71.9,
56.1,
44.1,
86.9,
66,
14.5,
51,
30.2,
21,
2.4,
21.7,
20.7,
66.5,
55.5,
79.9,
92.1,
85,
49.2,
51.4,
32.7,
55,
69.4,
55.8,
58.1,
7,
81.8,
94.1,
72.1,
33.5,
31.5,
90.1,
31.2,
53.9,
69.7,
79.5,
25.3,
36.3,
92.6,
60.4,
88.2,
75,
50.9,
52.3,
1.8,
71.7,
80.8,
18.6,
60.8,
75.3,
10.5,
78.2,
51.6,
99.5,
8.8,
95.1,
76,
3.7,
40.1,
91.8,
7.9,
77.2,
47.6,
15.1,
75.4,
43.5,
71.8,
80.6,
66.6,
82.4,
25.4,
15.4,
89.8,
57.1,
38.3,
85.8,
71.4,
45,
43.3,
30.5,
72.1,
53.8,
85.7,
56.8,
30.3,
67.1,
68,
60.1,
5.2,
76.8,
35.2,
92.6,
81.6,
39.8,
48.6,
89.1,
46.3,
31.9,
28.8,
77.1,
76.5,
83,
32.1,
49,
33.8,
4.4,
83.4,
73,
19.4,
54.9,
60.7,
70.4,
70.7,
28.7,
38,
56.8,
36.7,
65.9,
46.6,
35.6,
72.6,
18.2,
58,
45.2,
74.2,
61.6,
4.2,
20.5,
81.1,
58.3,
44.9,
28.8,
31.2,
75.9,
49.5,
89.7,
91,
51.8,
70,
81.2,
61.6,
43.6,
65.2,
58.2,
38.4,
64.8,
79.8,
80.3,
57,
14.1,
45.7,
94.7,
23.8,
83.6,
54.6,
85.8,
77.7,
81.5,
54.9,
45.6,
38.5,
44.7,
15,
74.2,
35.8,
43,
76.3,
36.4,
87.9,
46.5,
71.6,
34.8,
51.2,
52.9,
47.6,
40.3,
31.9,
0,
39,
50.4,
71.4,
48.4,
60.1,
51.2,
43.8,
50.7,
54.3,
63.2,
32.5,
35.8,
20.8,
88,
67,
95,
80.9,
87.6,
78.5,
48,
31.5,
50.2,
12.8,
46.8,
35.2,
58.5,
41.4,
94.2,
39.2,
43.7,
44.6,
87.2,
30,
82.2,
49.2,
5.2,
96.9,
64.2,
80.6,
84.7,
32.4,
36.2,
13.8,
39,
56.8,
98.3,
52.7,
59.5,
82.1,
65,
26.4,
10,
55.4,
61.8,
16.5,
82.2,
31,
10.5,
93.9,
12,
74.3,
39.2,
30.6,
61.3,
53.9,
58,
33,
0.7,
38.2,
43.4,
67.8,
40.9,
83.8,
61.6,
34.2,
33.6,
49.9,
74.7,
27.6,
47,
88.9,
57.7,
19.5,
73.1,
27.6,
96.1,
77,
43.9,
16.2,
54.8,
70.9,
76.3,
98.2,
64.3,
49.4,
18.3,
76.1,
48.4,
43.3,
46.5,
46.8,
12,
89.4,
44.9,
35.6,
96.1,
14.8,
72.4,
54,
59.8,
23.9,
53.3,
46.9,
75.7,
67,
55.2,
92.2,
6.7,
36,
41.7,
68.1,
68,
49.9,
81.7,
57.7,
63.7,
70.3,
32.1,
25.5,
90.3,
73.8,
67.6,
55.9,
48.1,
54,
95.7,
60,
47.6,
55.1,
39.9,
63.4,
46.2,
52.4,
68.6,
79.2,
55.7,
14.9,
88,
67.5,
78.8,
64.8,
33,
47.5,
9.3,
22.1,
34.5,
32,
76.8,
47,
52.9,
78.3,
39.6,
60.4,
64.4,
54.1,
82.5,
42.7,
36.9,
10,
76.2,
20.2,
10.8,
66.7,
20.4,
43.2,
97.5,
82.6,
52.4,
49.8,
48.7,
72.8,
93.6,
36.7,
68.3,
32.6,
68,
81,
30.5,
7.3,
83.9,
99.8,
48.1,
48.8,
62.7,
76.9,
74.9,
24,
23.2,
93.5,
75.7,
74.1,
48.5,
90.4,
56.3,
47.7,
82.6,
78.5,
3.2,
42.6,
42.5,
43.8,
22.2,
22.6,
55,
78.1,
79.4,
20.5,
43.3,
34.4,
59.6,
33.3,
81.4,
39,
69.4,
82.5,
70.6,
51.7,
29.3,
32,
64.6,
41.8,
82.5,
67.6,
71.4,
41.3,
62,
38.5,
42.8,
70.2,
64.9,
77.5,
68.2,
74.5,
79,
64.4,
60.8,
73.4,
43.8,
58.4,
7.6,
56.8,
26.4,
83.5,
13,
27.2,
74.7,
74.5,
83.3,
34,
83.8,
71.3,
39.8,
97.3,
58.8,
73.8,
57,
59,
16.3,
71.9,
66.9,
33.9,
85.6,
21.5,
38.4,
49.6,
40.7,
null,
48.1,
71.3,
78.4,
81.5,
88.4,
23.3,
57.7,
73.3,
20.8,
67.6,
60.2,
60.2,
53.2,
35,
80.6,
45,
46.8,
48.6,
55.8,
28.1,
64.1,
87.4,
51.2,
99.4,
57.8,
56,
33.4,
34.8,
43.5,
44.9,
60.1,
49,
38.2,
36.9,
52.9,
1.2,
58.7,
94,
57.3,
49.3,
15.3,
88.8,
87.8,
95.4,
62.7,
15.9,
68.6,
51.4,
94.9,
75.2,
60.6,
22.6,
43.1,
51.1,
18.2,
76.1,
20.9,
74.8,
51,
91,
31.4,
98.9,
37.9,
70.1,
40.4,
92,
75.4,
89,
94.6,
64.3,
89.7,
49.9,
46.9,
77.4,
56.9,
73.6,
43,
79.7,
18.5,
82.9,
44.6,
10.2,
69.3,
55.8,
89.3,
99.6,
57.2,
43.1,
42.3,
78.7,
94.3,
83.1,
82.3,
56.1,
58.2,
59.9,
33.9,
30.9,
35.7,
71.8,
88.2,
42.1,
40.4,
44,
77.2,
13.3,
24.5,
43,
33,
23.4,
20.6,
30.2,
84.3,
48.6,
41.2,
33,
30,
15,
30.9,
49,
76.9,
50.7,
98.8,
36.9,
36.4,
83.4,
61.1,
47.9,
8.3,
89.2,
53.7,
27.1,
70.1,
58.9,
101.9,
39.4,
61.3,
27.6,
27,
60.6,
20.6,
70.1,
64.2,
60,
47.7,
52.9,
51,
39.5,
54.7,
16.4,
94.9,
73.6,
96.9,
64.4,
68.8,
84.8,
68.1,
41.7,
24.5,
22.7,
32,
42,
29.6,
62.4,
38.6,
95.4,
66,
50,
9.2,
75.8,
56.3,
20.2,
56.8,
55.1,
8.2,
22.1,
4.7,
31.7,
46.1,
50.3,
31.3,
92.7,
10.6,
7.5,
64,
4.9,
30.5,
56.2,
87.1,
59.7,
39.8,
72.3,
70,
69.9,
12.8,
38.1,
55.9,
16.7,
85.8,
54.6,
47.2,
50.5,
19.6,
65.4,
87.4,
70.9,
83.3,
22.4,
57.5,
45.9,
70.7,
21.1,
95.2,
23.8,
77.7,
47.4,
80,
88.3,
35.7,
42.5,
38.2,
73.8,
35.7,
11.5,
72.3,
77.2,
46.2,
65.3,
83.7,
71,
71.8,
21.8,
54.2,
38.1,
71.4,
81,
73.8,
50.3,
58.9,
41.3,
94.9,
12.9,
11.1,
28,
17.1,
59.4,
33.8,
93.3,
31,
29.5,
0,
20.7,
20.9,
68.9,
66.6,
36.3,
72.7,
87.1,
38.9,
61.8,
29.5,
61.7,
31.5,
90.6,
75.1,
69.7,
25.3,
45.7,
70.7,
39.1,
56.2,
16.7,
34.1,
67.6,
4.1,
53.9,
44.4,
45.3,
36.9,
44.3,
90.6,
30.7,
27.2,
77.7,
90.9,
74.3,
36.7,
72.1,
75.4,
38,
6.7,
18.2,
45.2,
85.5,
79.5,
77.1,
73,
19,
97.1,
44.7,
81,
56.8,
75.1,
65.2,
58.5,
82.1,
45.4,
74.1,
64.1,
70.2,
31,
75.9,
55.4,
99,
65.9,
56.4,
32.4,
55,
38.2,
46.7,
30.5,
37.8,
88.6,
46.8,
70.2,
37.9,
75.9,
47.6,
56.7,
62,
60,
37.8,
69.1,
68.2,
37.7,
32.2,
79.1,
35.1,
38.4,
85.3,
84.8,
101.3,
27,
20.7,
97,
81.7,
64.4,
54.9,
24.4,
72.6,
63.7,
63.5,
63.8,
38.8,
73.6,
53.1,
21.2,
31.4,
50.5,
89.9,
68.4,
43.1,
68.1,
1.5,
58.1,
58.9,
92.7,
55.1,
41.3,
61.1,
17.7,
94.8,
62.8,
48.8,
66.2,
94.8,
34,
52,
85.6,
21.3,
36.3,
58.7,
12.5,
56.1,
59.2,
56.4,
21.4,
12,
71.5,
21,
68.6,
44.5,
42.7,
0,
40.8,
35.5,
77.3,
34.2,
19,
5.4,
78.2,
55.9,
87.2,
52.9,
42.9,
36.2,
91.8,
61,
30.3,
59.1,
29.3,
54.6,
98.5,
55,
76,
72.4,
52.4,
52.2,
81.8,
81,
58.5,
72.9,
43.2,
89.4,
29.4,
36.4,
27.3,
33.9,
50,
66.1,
26.5,
32.6,
32.9,
83.1,
61.8,
16.3,
24.9,
38,
93.2,
61,
69.4,
26.3,
51,
42.8,
80.9,
68.9,
59.7,
38.2,
96.5,
38,
51.2,
81.2,
44.6,
80.2,
50.2,
48.3,
72.3,
35.5,
35.5,
68.6,
82.5,
59,
75.6,
72.1,
84,
52.3,
70.3,
71.7,
0.1,
46,
7.8,
46.3,
54.6,
49.6,
82.2,
3.5,
44.7,
31.3,
58.6,
63.4,
58.6,
66.3,
36.8,
66,
93.5,
48.9,
57,
24.5,
39.7,
61.4,
78.1,
64,
87.5,
51.4,
37,
12.4,
44.4,
34.9,
66.6,
42,
69.3,
65.1,
49.4,
85.6,
93.8,
79.6,
54.6,
88.9,
93.2,
59.7,
78,
50.2,
87.1,
52.9,
53.1,
67.6,
27.8,
29,
38.1,
49.3,
66.6,
42.4,
66.9,
60.7,
47.7,
6.4,
87.6,
79.2,
98.1,
57.4,
80,
34,
49.2,
19.5,
8.8,
32.8,
91.9,
47.2,
33.7,
53.4,
28.5,
61,
13.9,
73.6,
93.4,
84.9,
30.4,
59.1,
23.9,
9.2,
66.7,
51.9,
87.9,
49.1,
88.8,
66.3,
69.7,
28.9,
84.8,
38.7,
12,
31.7,
24.6,
54.2,
31,
59.5,
87.9,
10.5,
61.3,
22.9,
17.7,
84.3,
47.7,
45,
70.9,
30.4,
64.3,
77.4,
51.4,
73.6,
77,
38.8,
65.3,
39.6,
42.9,
56.5,
23.6,
73.8,
57.6,
31.8,
46.4,
35.3,
43.3,
48.5,
33.7,
20.7,
32.8,
32.4,
64,
28,
37.9,
64.9,
51.5,
57,
28.1,
50.6,
78.6,
96.2,
63.9,
36.5,
62,
25.7,
63.7,
74.1,
81.5,
65.3,
65.8,
38.9,
46.9,
72.7,
91.9,
68,
88.5,
81.9,
24,
35.5,
10.9,
41.7,
73.3,
81,
91.5,
35.5,
64.5,
86.8,
53.3,
83.1,
97.5,
16.3,
53.6,
29.5,
87.3,
39,
46.8,
69.8,
25,
92.2,
32.8,
82.2,
68.8,
44.5,
51.1,
14.5,
19.8,
55.2,
38.1,
78,
75.7,
91.1,
29.9,
14.1,
58,
39.5,
93.2,
80,
86.4,
36.1,
18,
22,
57.3,
86.1,
47.7,
32.8,
30.7,
58,
71.3,
68.3,
69.3,
31.3,
55.2,
11.9,
56.9,
32,
59.4,
17.8,
61,
5.4,
36.9,
57,
65,
50.7,
91.7,
56.1,
88.7,
18.8,
44.3,
32,
60.4,
71.1,
27.4,
34.1,
48.7,
39.2,
29.5,
24.9,
39.9,
90.8,
45.9,
24.2,
75.7,
97.3,
37.7,
59.9,
32.5,
73.3,
52.4,
38.6,
71.8,
89.4,
53.3,
59.3,
67.1,
97.6,
8.8,
29.9,
11,
39.6,
43.1,
71,
38.2,
72.2,
24.3,
59.1,
67.9,
41.3,
73.4,
33.4,
60,
66.6,
1.4,
29.7,
63.6,
74.6,
33.5,
78.6,
36.7,
16,
68,
66.5,
65.4,
78.9,
30.2,
16.7,
94.6,
68.1,
12.9,
48.4,
29.6,
20.6,
59.5,
46.5,
54.4,
47.8,
77.7,
19.8,
71,
38.3,
76,
27.5,
64.1,
90.5,
61.6,
54.9,
83.6,
36.4,
18.4,
38.7,
49.1,
36.1,
79.4,
42.8,
56.9,
59.1,
55.8,
41,
68.4,
27.2,
25.4,
43.5,
40.2,
31,
3.8,
83.7,
83.5,
16.5,
71.7,
79.3,
30.1,
79.5,
15.6,
17.6,
53,
67.3,
63.7,
27.9,
95.5,
56.7,
66,
102.1,
45.5,
79.7,
38,
80,
87.1,
33.1,
79.8,
37.8,
41.4,
34.5,
37,
32,
37.3,
84.6,
47.6,
97.2,
75,
88.5,
48.3,
17.4,
35.7,
50.2,
45,
47.1,
72,
11.9,
37.2,
79.4,
60.3,
31.7,
91.8,
76.4,
46,
54.7,
38,
98.3,
34.3,
71.7,
51.4,
18.5,
68.8,
84.6,
72.5,
10.9,
20,
53,
37.5,
28,
3,
61.8,
67.5,
68.6,
94.1,
53,
46.2,
55.5,
42.9,
48.9,
66.9,
67.7,
61,
30.1,
80,
87.7,
71.6,
57.2,
69,
35.7,
59.7,
41.8,
43.6,
88.7,
74.9,
53.4,
24.2,
31.3,
42.7,
59.8,
55.2,
60.2,
88.2,
54.5,
77.3,
25.1,
65.3,
90.6,
51.7,
49.2,
80.4,
54.6,
48.8,
78.5,
61,
14.1,
68.6,
59.4,
55.3,
19,
57.5,
36.1,
30.6,
22.9,
57.7,
67,
47,
24.4,
45.9,
42.3,
89.2,
88.5,
50.9,
71.4,
48.6,
18,
53.1,
62.5,
65.5,
60.8,
26.9,
29.4,
26,
53.4,
45.4,
31.7,
70.9,
59.3,
76.1,
42.1,
25.9,
55.3,
58.6,
98.6,
37,
61.1,
60.5,
34.2,
49.3,
66,
6.3,
52.3,
39.5,
53.4,
44.6,
58.6,
15.3,
99.3,
41.5,
22.3,
36.6,
32.5,
52.7,
71.9,
84.1,
75.3,
67.4,
90,
80.8,
5.6,
75,
72.1,
70.3,
94.9,
74.4,
92.5,
25.8,
64.1,
36,
25.3,
91.6,
8.3,
48.9,
47.3,
53.9,
30.7,
64.9,
36.2,
39.8,
54.2,
99,
78,
31.3,
63,
83.1,
44.5,
51.7,
59.5,
65.5,
93.1,
53.1,
85,
2.2,
69.3,
91.7,
80.4,
44.3,
64.9,
44.3,
77.1,
52.3,
54.9,
25.7,
62.5,
82.1,
57.6,
28.8,
72.5,
13,
49.9,
66,
61.2,
71.2,
43.2,
65.5,
30,
26.1,
52,
42.5,
75.2,
48.8,
46.4,
95.2,
56.6,
57.4,
56.9,
50.6,
63.6,
77.4,
94.7,
32.3,
59.7,
67.2,
42.9,
65.8,
85.7,
53.6,
56.9,
36.6,
21,
32.7,
25.5,
56.3,
72.5,
64.7,
69.1,
82,
83.1,
32.8,
66,
16.8,
40.8,
34.2,
50.7,
30.2,
95.4,
92.6,
68.1,
67.1,
77.8,
38.7,
18.7,
5.4,
49.8,
74.1,
62.7,
31.6,
79.1,
36.6,
47.5,
89.1,
56.4,
79.2,
71.8,
5.1,
52.5,
44.4,
17.9,
87.8,
48.9,
96.8,
95.8,
64,
5,
72.1,
31.9,
97.4,
98.9,
4.2,
72.6,
60,
59.7,
64.4,
52.3,
62.8,
90.9,
31,
83.2,
87.9,
49.5,
58.1,
93,
14.7,
72.8,
71.4,
21.7,
26.3,
95.9,
33,
49.3,
61,
64.9,
42.6,
54,
36.5,
29.6,
85.9,
54.8,
91.5,
27.2,
54.1,
98,
50.7,
42.5,
43,
21.2,
57.2,
72.7,
77.1,
55.5,
60.5,
21.8,
33.1,
36,
40.3,
78.4,
60.5,
47.6,
74,
82.3,
77.1,
71.8,
72.6,
84.5,
61.1,
46.1,
60.8,
71.3,
66.3,
52.4,
84.8,
59.7,
56.5,
58.3,
78.5,
81.5,
53.7,
44,
23.4,
87.2,
32.4,
88.2,
52.5,
72,
22.9,
79,
45.7,
56.7,
27.7,
43.5,
54.8,
94.3,
59.1,
0.4,
63.5,
46.3,
61.8,
69.4,
53.3,
52.2,
82.1,
69.1,
70.9,
25.8,
70.2,
44.4,
28.3,
54.5,
100.5,
74.5,
51.4,
65.2,
60,
82.2,
14.9,
35.2,
67.2,
36.7,
65.9,
60.7,
69.5,
31.6,
36,
52.6,
49.7,
100.9,
15.4,
43.8,
18.2,
75.5,
93.6,
45.1,
48.3,
39,
66.7,
27.1,
86.5,
92.8,
59.3,
82.2,
53.6,
2.6,
68.6,
59.4,
75.7,
18.2,
7.9,
84.9,
66.8,
70,
52.7,
77,
76.4,
77.7,
57.4,
23.1,
74.9,
20.3,
63.6,
71.5,
9.5,
33.8,
48.3,
61,
64.9,
43,
47.3,
44.5,
73.3,
24.3,
59.4,
55.9,
74.2,
66.2,
58.7,
51.5,
63.6,
68.3,
22.4,
38.8,
88.3,
22.9,
62.9,
62.6,
69,
71,
43.4,
92.9,
36.9,
68,
53,
44.2,
88.7,
64.4,
37.1,
37.7,
15.3,
97.4,
53.7,
78,
79.2,
49.9,
91.8,
62.7,
52.1,
13.7,
36,
28.2,
46.6,
17.4,
37.2,
94.6,
73.1,
60.2,
70.7,
72.7,
13.5,
75.6,
32.6,
44.9,
64.5,
47.3,
44,
69,
40.7,
40.6,
64.2,
91.7,
87.9,
94.5,
14.3,
55,
89.7,
77.8,
78.7,
39.7,
75.6,
41.2,
16.6,
89.9,
49.6,
92.2,
16.7,
30.2,
54.8,
50.5,
49.5,
62.4,
64.6,
16.2,
43.9,
82.5,
76.7,
66.6,
78.1,
98.7,
69.3,
88.9,
54.3,
79,
57.9,
44.4,
42.7,
85,
48,
89.7,
84.2,
75,
70.8,
29.9,
77.3,
45.3,
28.4,
49.6,
17.6,
26,
56.4,
12.1,
22.7,
72.8,
41.8,
71.1,
22.2,
97.7,
50.7,
41.6,
59,
34.8,
45.3,
48.2,
36.4,
65.9,
23.4,
69.9,
71.5,
68.9,
8.7,
45.3,
21.7,
39.3,
40.7,
51.6,
63.6,
41,
52,
93,
48,
23.2,
52.3,
51.1,
50.8,
98.2,
81.5,
52.9,
96,
29.1,
77.9,
99,
59.3,
40.9,
25.6,
46.3,
50.5,
53.3,
26.2,
57.1,
31.8,
37.7,
17.2,
58.2,
55.9,
69.5,
51.7,
48.8,
41.4,
61.1,
88.1,
27,
18.3,
78,
45,
79,
63.5,
29.4,
64.7,
15.9,
18.4,
67.3,
46.5,
52.3,
87.4,
56.8,
25.1,
46.2,
78.6,
45.8,
52.3,
64,
61.5,
53.4,
77.5,
17,
59.2,
64.4,
43.5,
87.9,
44,
69.9,
29.5,
74.4,
45.8,
70.3,
22.1,
30,
30.8,
53,
59.5,
37.8,
67.8,
44.1,
97,
69,
72.7,
89.5,
73.9,
58.8,
95,
91,
67.8,
24.3,
21.8,
52.5,
37,
51.9,
15.1,
52.3,
58.5,
28.6,
86.5,
98,
42.8,
48,
71.1,
46.3,
55.1,
26.3,
75.1,
56.1,
80.9,
56.2,
63,
55.3,
79.3,
73.2,
53.8,
29.4,
77.8,
63,
62.7,
57.4,
60.3,
70.4,
37.5,
95.4,
67.1,
67.5,
88.2,
34.4,
17.2,
79.5,
62.4,
64.5,
85.5,
72.1,
60.2,
6.5,
76.1,
75.2,
95,
57.1,
68.3,
68.7,
61.7,
34.4,
18.9,
35.5,
73.1,
61.9,
8.2,
58.6,
85.7,
89.1,
54.7,
53.1,
92.6,
100.9,
49.1,
94.7,
41,
78.7,
93.7,
64.6,
78,
72.7,
43.7,
70.4,
75,
55.2,
96.3,
58.3,
42.3,
90.1,
100.2,
59.3,
54.7,
41,
23.5,
52.1,
33,
49.5,
42.5,
43.4,
57.7,
73.9,
67.9,
42.1,
35.8,
37.5,
41.5,
26.2,
45.9,
42.6,
62,
61.9,
71.2,
21.5,
82.8,
59.5,
12.4,
15,
60.7,
53.1,
38.5,
86.9,
66,
44.3,
62.4,
75.4,
71.5,
41.2,
31.5,
48.2,
53.5,
37,
66.5,
46.6,
26.7,
88.9,
96.5,
24.3,
20.6,
87,
76.3,
58.8,
69,
39.5,
20.5,
64,
81,
47.1,
49.4,
51.2,
71.2,
79.6,
50.7,
38,
81.7,
99.2,
53.1,
70.6,
78.7,
19.9,
52.2,
61.3,
22.1,
56.9,
63.7,
71.9,
65.5,
26.6,
83.4,
22.6,
16.1,
41.5,
98.1,
94.3,
39.5,
68,
95.9,
67.8,
82.9,
97.3,
52.2,
58.1,
62.6,
41.4,
56.7,
16.5,
57.5,
27.6,
57.8,
9.1,
38.1,
42.8,
46.8,
68.6,
20.1,
51.7,
7.1,
24,
93.2,
54.6,
15.7,
25.1,
25.5,
70.8,
72.7,
28.1,
8.3,
79.4,
76.1,
90.7,
55.3,
36.8,
60.3,
97.1,
46.8,
37.6,
61.2,
61.2,
54.4,
18.8,
60.9,
84.8,
64.8,
38.8,
88.6,
46.3,
52.3,
90.6,
64.2,
55.9,
48.5,
56.3,
30.5,
66.3,
41.5,
42.8,
62.8,
25.1,
33.7,
55.9,
0,
88.9,
102.1,
31,
79.5,
31.6,
19.6,
51.3,
69.5,
18.6,
6.2,
57.3,
99.3,
5.2,
45.1,
84,
54.7,
61.7,
61.2,
84.8,
45.5,
9.5,
65.4,
48.4,
76.1,
76.8,
64.9,
64,
43.2,
22.2,
66.1,
85.1,
91.7,
71,
46,
43.1,
99.3,
47.8,
88,
58.2,
29,
57.6,
70.8,
53.5,
54.1,
60.6,
17.1,
61.2,
24.5,
47.6,
40.5,
47.2,
21.1,
79.9,
60.6,
56.2,
30.9,
77.2,
98.1,
25.3,
32.2,
42.8,
0,
44,
56.4,
72,
77,
87.2,
59.9,
97.3,
85,
32.7,
51,
50,
58.7,
59.8,
21.5,
90.3,
43.4,
59.4,
41.3,
76.3,
40.8,
33.2,
24.4,
70.2,
60,
87.4,
20.7,
54.4,
93.2,
38,
78.3,
94,
4.9,
59.9,
57.9,
83.2,
37.1,
54.2,
52.8,
22.4,
51,
62.4,
64.8,
43.5,
59.6,
54,
96.7,
26.4,
74.2,
57,
94.7,
75.6,
55.6,
72.7,
51.7,
51.5,
63.8,
48.3,
38.2,
16.9,
92,
47.1,
56.8,
62.1,
74.2,
5.2,
66.5,
70.2,
40.2,
56.5,
42.9,
81.9,
8.3,
14,
92.4,
76.9,
66.7,
61.8,
21.2,
68.7,
32.8,
43.8,
78.5,
38.4,
61.2,
60.1,
8.4,
83.2,
82.9,
43.4,
39.9,
27.1,
21.8,
77.1,
45.4,
53.9,
48.5,
72.6,
47.7,
65.7,
60.6,
50.7,
92.8,
82.1,
90,
59.6,
32.6,
54.7,
16.5,
56.4,
74.8,
60.9,
80.9,
30.3,
17.6,
29.9,
55,
19.1,
69.3,
35.2,
66.8,
34.9,
41.6,
69.1,
49.4,
35.9,
0,
44.3,
85.5,
70.4,
85.7,
89.3,
89.6,
75,
39.6,
56.8,
75.2,
39.9,
64.5,
46.7,
55.2,
14.6,
46.4,
54.1,
79.2,
59.3,
53.9,
67.6,
65.8,
57,
25.3,
46.1,
76.8,
99.2,
44.8,
28.2,
3.5,
73.9,
36.5,
27.9,
54.7,
40,
25.4,
44.8,
26.4,
57.4,
53.2,
91.8,
3.2,
81.5,
38.7,
93.1,
62.8,
17.6,
38.6,
79.9,
91.1,
52,
52.2,
61,
44.1,
54.7,
59.1,
11.8,
78.7,
42,
97.8,
55.9,
51.6,
72.9,
63.2,
34,
42.8,
28.3,
84.4,
26.1,
52.1,
37.3,
78.6,
53.4,
84.7,
64.1,
57.7,
57.1,
56.3,
56.3,
66.6,
42.4,
52.9,
48.2,
30.7,
65.8,
59.9,
10.3,
77.1,
79.5,
62.1,
39.1,
60.7,
48.9,
12.4,
67.9,
29.1,
47.3,
11.5,
74.3,
56,
58.3,
61.8,
70.3,
62.1,
60.5,
62.9,
23.5,
47.7,
71,
48.7,
64.1,
68.6,
42.7,
65.9,
68.5,
17.7,
29.9,
26.6,
62.8,
31.7,
52.8,
65.4,
21.3,
67.1,
98.4,
46.5,
43.4,
45,
66.7,
36.9,
89.6,
33,
86.1,
95.9,
85.8,
67.2,
8.9,
37.5,
63.9,
44.6,
21.4,
40.2,
53.9,
72.5,
12.6,
45.2,
87.3,
48.9,
24.7,
68.3,
47.1,
72.9,
10.3,
68.7,
65,
25.2,
83.7,
48.6,
45.6,
66.5,
34.6,
6,
77.2,
59,
90,
28.3,
48,
58.7,
58,
67.6,
55.2,
68.2,
65.3,
74.4,
49.3,
38.4,
81.2,
64.5,
85.2,
13.1,
38,
15.4,
50,
32.5,
58.2,
98,
42.2,
95.9,
39.5,
11.7,
75,
52.9,
87.8,
92,
79.6,
45.4,
62.5,
26.5,
20.3,
89.2,
67.1,
84.6,
48.1,
70,
68.9,
50.6,
81.9,
94.6,
7.3,
37.8,
94.4,
20.8,
74.2,
35.8,
49.1,
31.9,
19.4,
66.7,
91,
64.4,
53.8,
36.6,
84.9,
0,
57.3,
15.8,
46.7,
59.6,
72.7,
86.7,
79.9,
40.1,
81,
41.2,
57.1,
9.6,
80.7,
71.6,
42.5,
41.5,
48.4,
41.2,
59.3,
83.9,
92,
37,
77.9,
62.8,
71.2,
72.3,
50.3,
38.5,
45.4,
89.2,
72,
57.3,
52.4,
68,
36.2,
60.9,
98.6,
59.5,
32.9,
34.4,
95.1,
57.5,
66.8,
60.2,
34.5,
56.4,
72.4,
8.9,
56.5,
20.1,
45.2,
60.1,
78.8,
64,
35.1,
51.7,
58.3,
83.2,
58.2,
18,
54.9,
45.1,
61.3,
79.2,
51.5,
98.8,
57.8,
44,
76.4,
24,
45,
41.3,
23.7,
54.2,
77.6,
42.6,
75.1,
54.7,
77.7,
71.7,
11.8,
40.1,
63.1,
60.4,
43,
46.9,
98.1,
56.8,
6.9,
42.2,
87.3,
43.7,
82.2,
100.5,
33,
45.9,
59.7,
66.6,
81.2,
75,
63.5,
44.8,
52.9,
89,
44.1,
33.2,
84.8,
3.3,
10,
56.7,
63,
43.2,
34.8,
56.3,
33.9,
35.9,
59.2,
74.6,
75.4,
82.9,
14.4,
78,
93,
37.1,
61,
29.3,
3.8,
44.9,
75.9,
73.7,
91.2,
53.7,
96.7,
65.1,
32.4,
37.2,
76.4,
87.4,
66.9,
48.8,
48.9,
11.2,
60.7,
81,
15.3,
74.1,
65.2,
70.9,
8.7,
61.6,
54.7,
89.6,
78,
11.7,
34.1,
66.1,
56,
36.4,
49.4,
72.7,
92.5,
40.7,
11.8,
24.2,
33,
75.5,
80.6,
84.7,
37,
20.6,
55.3,
97.5,
76.8,
68.5,
55,
89.4,
71.3,
68.3,
24.2,
98.1,
53.8,
69.2,
76.8,
1,
72,
41.3,
12,
34.7,
94.9,
44.8,
55.6,
32.9,
29.1,
86.3,
70,
30.1,
0,
53.5,
64.7,
19.8,
25.9,
40.4,
33.1,
64.3,
88.4,
54.2,
22.5,
73.2,
37.1,
75.2,
97.4,
90.8,
70.6,
23.6,
77.1,
33.1,
70.8,
49.2,
84,
58.6,
66.5,
71.3,
99.8,
15.7,
29.7,
69.2,
68.9,
45.7,
64.8,
70.7,
95.9,
62.7,
26.9,
56.5,
40.4,
19,
43.8,
88.1,
61.6,
56.2,
42.7,
47.9,
53.9,
29.5,
27.3,
61.3,
54,
85.7,
88.6,
49.7,
56.2,
29.2,
27.7,
57.2,
17.3,
24.1,
75.7,
38,
39.7,
21.2,
80,
43,
35.7,
46.6,
7.3,
39.9,
68,
105.9,
75.2,
53.3,
86.4,
8.8,
4,
7.3,
33.8,
25.4,
32.1,
12,
50.5,
64.7,
64,
72.5,
14.7,
75.4,
22.6,
88.5,
47.8,
71.6,
20.6,
64.8,
47.8,
7.7,
11.8,
32.4,
77.6,
56.4,
49.2,
87.7,
63.5,
28.2,
49,
61.6,
100,
67.7,
71.4,
13.2,
78.9,
91.7,
15.8,
54.1,
50.5,
27.9,
55.8,
38,
66,
85.2,
78.2,
77,
16.9,
51.9,
7.7,
63.2,
70,
71.4,
31.8,
18.1,
33,
38.7,
86,
49,
62,
59.3,
62.7,
30,
69.9,
49,
55.7,
32.8,
54.2,
46.8,
85.9,
29.5,
37.3,
85.1,
58.9,
4.6,
6.8,
67.6,
47.2,
60.8,
29.6,
74.9,
4.6,
72.2,
95.8,
38.4,
56.6,
65,
88.2,
49.7,
73.7,
24.1,
59.3,
62.1,
39.3,
41.5,
5,
30,
72.1,
93.5,
30.1,
60.8,
89,
92.1,
63.8,
41.8,
54.6,
91.1,
66.1,
36.1,
25.1,
87.1,
14.9,
122.8,
23.3,
68.8,
82.5,
70.3,
95.4,
29,
7.6,
60.2,
92.3,
55.2,
25.6,
54.5,
55.7,
94.5,
62,
28.8,
21,
65.9,
42.8,
55.6,
0,
36.8,
4.6,
76.6,
92.9,
7.5,
79.6,
34,
76.7,
35.7,
96.1,
2.2,
73,
85.7,
43,
81.4,
47.8,
55.9,
52,
28.9,
49.9,
59.5,
48,
70.8,
41.5,
57.8,
71.7,
39.7,
80.6,
58.5,
24.2,
50.1,
81,
58.8,
55.4,
96,
94.6,
83,
83.4,
100.9,
34.2,
44.9,
96.8,
68.6,
48.1,
24.1,
69.9,
46.7,
34.2,
58.2,
2.8,
91.7,
31.9,
33.6,
66.5,
26.7,
45.3,
49.4,
51.3,
58.8,
34.3,
77.8,
81.2,
38,
35.3,
65.3,
22.9,
75,
75.2,
60,
56.4,
38.8,
34,
82.2,
88,
15.9,
69.1,
40.7,
60.7,
59.4,
65.9,
21,
50.4,
95.9,
66.2,
9.9,
19,
54,
42.2,
56.2,
75.8,
76.2,
82.4,
80.2,
63,
49,
67.3,
79.1,
61.6,
45.5,
59.8,
27.7,
54.7,
75,
48.2,
36.1,
34,
63.8,
80.2,
59.6,
83.1,
88.8,
19.4,
71,
62.9,
3.4,
88.8,
12.1,
94.3,
86.2,
57.4,
92.4,
86,
66.9,
97.1,
63.9,
63.3,
51.6,
48.5,
63.4,
58.6,
36.4,
83.7,
87.5,
73,
60.8,
55,
78.8,
33.5,
27.5,
64,
63.2,
87.5,
24.6,
26.6,
37.6,
97.4,
54.5,
57.7,
29.8,
33.4,
43.4,
35.1,
78.6,
56.1,
61,
28.9,
96.8,
23.8,
49.4,
46.9,
75.4,
83.5,
53.4,
36.3,
82.7,
95.7,
19.8,
67.5,
17.3,
85,
61,
49,
33.2,
72.5,
23.5,
22.2,
17,
46.3,
16.3,
25.5,
71.9,
68.4,
43.5,
26.6,
40,
94.7,
67.5,
35.8,
77.4,
36.3,
15.2,
74.2,
63.8,
75.5,
22.4,
83.5,
37.9,
30.5,
83,
95.3,
47.3,
49.9,
49.5,
31.3,
36.2,
24.9,
22,
88.5,
11.9,
43.5,
66.3,
53,
21,
57,
38.6,
97.4,
66.3,
73,
92.4,
45.7,
50.3,
34.6,
59.2,
68.6,
24.3,
61.3,
43.8,
60,
61.7,
60.8,
71.7,
81.3,
10.5,
31.7,
50.9,
57,
83.7,
99.8,
31.6,
79.7,
73.5,
61.8,
47.1,
57,
56,
50.1,
62.8,
49,
94.2,
94.2,
85.9,
83.1,
81.3,
73.4,
94.5,
58,
76.7,
79.7,
15.7,
81,
92.3,
43.4,
66.9,
23.8,
31.2,
10.9,
59.4,
90.3,
74.2,
48.1,
38.1,
66.3,
58.2,
51.4,
79.6,
31.7,
69.7,
23.8,
17,
83.5,
37.5,
32.8,
66.7,
3.3,
82.4,
25.1,
73.9,
60.2,
7.7,
91.8,
33.2,
49.8,
90.9,
81.6,
67.2,
80.1,
16.5,
44.4,
26.4,
0,
37.1,
83.4,
16.3,
88.4,
42.2,
53.3,
52,
36.4,
79.3,
49.3,
19,
33.3,
3.6,
38.8,
75.5,
41.8,
89.4,
54.5,
84.8,
72,
51.7,
52.7,
85.8,
96.4,
65,
91.6,
86,
41.5,
83.2,
25.9,
49.5,
95.9,
58,
75.8,
48.6,
18.8,
52,
86,
39.2,
51.6,
19.3,
41.2,
53.8,
70.1,
33.6,
82.1,
43.5,
43.2,
52.3,
71.2,
60.3,
48.9,
64.3,
57.4,
55.9,
67.6,
79.1,
42.1,
62.8,
90,
16.3,
68.8,
36.7,
34.9,
47.8,
35.7,
26.8,
2.8,
78.8,
36.5,
81.1,
21.9,
89,
43.7,
0,
56.5,
81.3,
27,
64,
55.2,
20.1,
61.3,
39.2,
42.2,
45.9,
42.2,
20,
22.4,
56.2,
58.1,
49.3,
34,
72.1,
97,
68.6,
64.2,
24.6,
53.6,
66,
29,
78.9,
50.1,
69,
56.1,
58.7,
61.5,
1.2,
48.8,
45,
85.6,
57.8,
29.1,
77.5,
67.7,
32,
38.3,
73.8,
69.2,
66.9,
75.1,
12.6,
41.6,
46.8,
20.6,
4.1,
38,
74.3,
57.5,
79.1,
31.1,
43,
65.9,
31.2,
63.6,
55.2,
18.1,
36.8,
87.1,
66.6,
20.8,
7,
88,
9.4,
69.5,
40.9,
80.9,
44,
60.8,
94.5,
17.9,
66.6,
59.8,
40.2,
47.2,
97.1,
76,
65.1,
36.4,
75.3,
74,
81,
59,
68.1,
58.4,
29.6,
49.3,
84.7,
23.4,
64.3,
60.3,
55.7,
33.6,
58.9,
45.5,
66.7,
69.7,
92.3,
87.6,
28.3,
68.6,
39,
45.6,
60.5,
61.9,
64.7,
76.5,
83.2,
44.6,
68.4,
54,
105.2,
67.9,
69.4,
57.6,
83.4,
70.8,
59.1,
56.2,
88.6,
26.4,
85.5,
46.6,
65.7,
49.4,
62.9,
53.6,
50.2,
25,
80.8,
95.8,
86.8,
26.8,
19.9,
84.8,
31.8,
47.2,
37.5,
83,
76.2,
63.8,
61.2,
36.9,
68.6,
60.1,
59.7,
36.8,
74.9,
29.3,
80.5,
86.6,
59.9,
63.9,
57.1,
85.3,
29,
44,
72.2,
38.4,
58.8,
62.8,
44.2,
65.8,
59.5,
75.3,
38.1,
32.9,
41,
75.1,
34.9,
73.7,
88,
59,
74.5,
42.3,
30.4,
31.1,
98.6,
35.5,
44.4,
83.4,
34,
4.2,
81.8,
77.2,
68,
38.1,
34,
38.1,
19.1,
16.7,
38.2,
53.6,
82.5,
62.8,
66.2,
95.1,
62.1,
63,
95.5,
64.1,
18.4,
61.7,
44.2,
54.5,
31.2,
28.5,
45.7,
42.9,
74,
38.7,
62.1,
74.6,
22.7,
31.7,
40.8,
98.5,
64,
89.2,
15.9,
76.2,
52.8,
87,
21.3,
61.1,
55.2,
68.5,
43.8,
60.9,
81,
52.6,
72.8,
30.4,
63.6,
41.3,
19.6,
58.2,
48.1,
99.9,
46,
80.8,
89.3,
71,
40.1,
20.8,
70.3,
97.8,
91.7,
51.5,
84.1,
68.2,
93.4,
56.3,
67.8,
88.6,
61.6,
81.3,
15.5,
67.1,
51.4,
33.6,
67,
65.8,
59.2,
7.4,
1,
59.5,
72.5,
66.7,
40.7,
95.7,
95.1,
23.9,
43.5,
84.5,
48.6,
69.9,
32.7,
39.4,
68.5,
36.5,
45.4,
16.7,
85,
42.7,
39.3,
4.7,
92.8,
18.9,
98.9,
19.8,
62.8,
68,
36.5,
30.6,
57.7,
25.5,
18,
72.8,
24.2,
9.2,
36.3,
41.7,
82.5,
68,
34.4,
41.9,
89.1,
28.6,
70.9,
56.4,
8,
86.7,
4.8,
86.4,
90.9,
46.9,
69.6,
46.7,
36.8,
27.8,
50.3,
45.4,
74.9,
36.7,
25.3,
23,
28.7,
67,
71.1,
72.2,
79.9,
31.3,
90.6,
57.9,
38.2,
29,
52.5,
69.9,
59.6,
88.3,
16.3,
46.3,
42.4,
58.5,
47.6,
76.9,
47.3,
71.9,
68.2,
53,
64.9,
49.5,
21.1,
57.6,
59,
70.4,
30,
50.7,
54.3,
33,
25.2,
27.2,
11.5,
59.6,
97.7,
82.6,
85.6,
39.6,
86.8,
23.2,
44.2,
42.1,
66.2,
37.6,
70.1,
63.8,
21.5,
38.6,
58.6,
56,
80,
37.8,
12.1,
68.6,
81.9,
53.2,
36.2,
46.2,
75.6,
22.5,
63.8,
89.4,
85.3,
40.1,
80.1,
79.7,
78.6,
31.8,
96.6,
77.4,
79.5,
54.2,
66.3,
74.8,
27.8,
35,
19.3,
65.6,
52.5,
20.6,
38.5,
86.6,
75.2,
13.5,
53.2,
71.5,
23.6,
84.6,
48,
82.1,
52.9,
30,
96,
82.2,
77.9,
39.4,
70.5,
81.1,
98.5,
89.7,
55.7,
79.7,
62.7,
48.3,
20.8,
64.4,
81.9,
67.1,
80.7,
65.1,
34.4,
44,
47.8,
20.7,
73.1,
17.5,
43.8,
51.4,
50.6,
51.7,
72.8,
96.1,
65.5,
64.3,
2.5,
31.1,
11.3,
43.6,
13.8,
87.2,
46.2,
83.6,
49.2,
63.6,
31.6,
70.3,
88.8,
20,
32.4,
37.1,
43.4,
69,
65.2,
47.5,
57.2,
51.8,
50.2,
82.8,
3.6,
62.6,
83.7,
79,
61.3,
43.5,
81.4,
97.4,
95.6,
56.7,
65.6,
64,
43.8,
77.1,
97.1,
51.5,
96.9,
68.3,
50,
56.4,
24,
65.6,
67.1,
49.2,
39.8,
76.7,
44.3,
72.6,
31,
69,
58.9,
71.6,
95.9,
40.1,
64.6,
59,
38.2,
73.6,
4.8,
62.8,
27.5,
46.6,
36.5,
28.5,
88.1,
75.4,
50.6,
5.8,
57.4,
72.1,
76.9,
72.8,
57.7,
15,
59.4,
71.8,
46.3,
94.7,
27.3,
35.6,
71.7,
56.7,
36.5,
62.9,
50.9,
59.1,
83.7,
12.3,
36.5,
57.7,
84.2,
34.1,
60.9,
58.5,
31.9,
68.9,
46.6,
72.3,
66.1,
55.2,
57.4,
46.6,
26.3,
33.3,
72,
45,
68.7,
62.9,
92.8,
80.6,
55,
20.9,
48.1,
47.3,
48.7,
66.6,
84.4,
42.4,
45.4,
61.4,
37.2,
54.7,
93.7,
16,
51.3,
37,
57.5,
90,
38.9,
79.6,
55.4,
54.6,
32,
61.7,
61.9,
83.1,
0,
2.9,
90.6,
91.8,
61.8,
60.5,
38.4,
89.1,
87.2,
41.4,
52.5,
73.8,
95.8,
20.1,
26.6,
53.3,
68.4,
67.7,
17.8,
48.4,
37.3,
36.4,
87.5,
28.7,
58.5,
17,
30.5,
30,
34.9,
33.9,
68.8,
43,
55.6,
66.1,
27.6,
71.5,
61.9,
72.5,
76,
65.5,
78,
46.7,
30.4,
93,
83.3,
46,
84.2,
84.8,
17.8,
30,
97.7,
73.5,
41.2,
47.7,
54,
21.2,
85.1,
21.3,
51.7,
33.1,
14.8,
2.6,
77,
11.6,
81.1,
71,
47.1,
33,
68.2,
63.1,
70.1,
46.1,
21.7,
80.3,
98.3,
90,
79.9,
77.2,
82.5,
49.6,
82.2,
32,
13.1,
69.5,
82.6,
69.6,
90.2,
74.9,
67.3,
37.7,
40.3,
37.1,
90.3,
71.8,
24.9,
35.2,
65.2,
81.2,
92.8,
22.1,
78.8,
46.3,
2.9,
82,
65.5,
80.8,
29.3,
26.5,
56.1,
85.4,
80.4,
48.2,
59.5,
58.1,
90.7,
60,
92.5,
65.1,
87.9,
47.3,
93.2,
19.2,
89.1,
87.8,
73,
29.5,
7,
54.3,
84.9,
94.2,
41.5,
47,
45.2,
64.8,
22.1,
43.7,
47,
63.2,
54.2,
69.3,
48.9,
42.2,
63.2,
41.2,
68.8,
33.8,
55.6,
63.8,
36.8,
59.5,
67.3,
88.9,
55.9,
13.1,
61.9,
48.1,
69.1,
38.4,
20.2,
87.1,
17.3,
66.2,
76.9,
50.7,
90.5,
96.5,
54.7,
19.5,
51.8,
90.1,
37.7,
57.5,
35.5,
38.6,
51.8,
45.7,
39.6,
87.5,
50.5,
90.4,
79,
79.1,
80.1,
41.7,
39.7,
81,
52.2,
85.7,
27.7,
50.6,
63.3,
82,
78.9,
94.9,
56.2,
87.8,
53.3,
70.6,
73.8,
94.3,
41.3,
37.4,
32,
69.3,
27.4,
87.3,
57,
49.6,
58.3,
47.7,
57.5,
70,
84,
50.7,
60.4,
36.7,
72.1,
29.3,
25.7,
66.4,
35.3,
42.5,
38.5,
43.4,
64.6,
72.9,
84.3,
38.9,
50.8,
3.9,
58.5,
87,
4.5,
94.4,
18.6,
32.6,
61.5,
50.9,
69.4,
79,
71.3,
14.7,
92.7,
54.7,
84.5,
55.8,
53.3,
7.3,
96.3,
46,
66.7,
29.7,
94.2,
35.3,
82.6,
85.9,
89.8,
84.2,
49.3,
49.4,
20.1,
67.1,
70,
57.8,
69.1,
46.9,
58.5,
37.9,
58.5,
82.4,
47.8,
28.1,
57.1,
48.6,
51.6,
39.7,
6.8,
36.7,
56.8,
57.9,
18.8,
28.6,
32.6,
57.1,
84.2,
23.9,
22.5,
34.6,
70.9,
30.2,
62.8,
48.1,
35,
46.5,
73.5,
30.9,
37.3,
65.7,
80,
43.9,
63.1,
63,
51.7,
71.5,
79.6,
0,
92.7,
100.4,
46,
49.5,
89.7,
63.1,
52.5,
23.4,
44.6,
38.2,
99.7,
37.6,
80.7,
74.2,
100.8,
74,
70.1,
53.4,
13.8,
57.1,
0,
48.1,
74,
40.6,
32.3,
11.9,
5.6,
13.3,
71.8,
43,
46.4,
6.3,
14.2,
1.2,
64,
17,
66.9,
31.8,
37,
39.6,
54.2,
71.7,
61.6,
74.9,
72.8,
43.3,
25,
45.4,
23.2,
56.8,
69.6,
49,
68.3,
20.9,
89.1,
23,
59.1,
88.4,
46.8,
37.9,
66,
39.8,
88.6,
44.5,
40,
46.7,
61.2,
8.7,
74.6,
60.4,
70.9,
76.4,
88.6,
64.7,
36.5,
41.7,
25,
53.9,
64,
5.3,
48.4,
81.5,
17.8,
35.4,
57.5,
26.7,
96.3,
86.9,
63.5,
57.4,
86.5,
5.6,
56.3,
70.4,
47.2,
60.7,
51.4,
56.8,
18.1,
56.7,
30.4,
50,
48,
66.9,
97.2,
29,
87.6,
34,
61,
49.4,
69,
49.9,
66,
58.8,
59.4,
4.1,
55.3,
92.8,
60.1,
58.9,
79,
94.6,
12.5,
39,
12.2,
62,
47.3,
41.7,
86.5,
53.7,
61.8,
43.7,
38.9,
34.1,
24.8,
11,
44.6,
80.3,
21.4,
61.8,
41.9,
70.2,
57.7,
97.9,
91.1,
42.9,
49.5,
50.8,
37.6,
78.2,
14.9,
56.2,
69.1,
79.1,
83.7,
18.1,
80.9,
39.7,
60.5,
85.1,
83.9,
46.2,
82.7,
0.1,
19,
44.2,
55.6,
22,
23.8,
67.8,
65.2,
40.9,
66,
68.6,
90.3,
2.8,
94.6,
26.1,
31.2,
68.1,
70.3,
51.7,
44.7,
71.3,
86.8,
49.5,
50.8,
57,
34,
78.8,
5.7,
85.7,
82.6,
64.6,
27.5,
31.8,
54.3,
79.6,
96.9,
82.6,
65.8,
57.8,
22.9,
69.5,
89.1,
69.8,
36.3,
80.7,
24,
72.1,
59.3,
46,
77.6,
84.6,
89.5,
90.8,
38.4,
56.2,
30.4,
97.9,
36.3,
73.1,
49.7,
55.7,
65.9,
42.4,
64,
60.7,
32.6,
48.5,
31.9,
28.6,
3.7,
23,
39.4,
37.7,
65.9,
28.7,
29,
39,
84.4,
34.8,
38.6,
43.1,
55.3,
59.1,
48.3,
7.6,
51.7,
78,
71.9,
59.3,
52.2,
57.9,
63,
49.7,
15.3,
96.3,
78.5,
6.5,
63.1,
55.1,
56.2,
76.2,
70.5,
70.1,
37,
34.5,
83.5,
64.3,
72.8,
71.9,
35.5,
30.2,
47.6,
9.7,
49.7,
38.4,
17,
85.9,
66.3,
78.8,
96.2,
49.9,
33.4,
35.5,
57.9,
57.2,
54.3,
59.1,
27.5,
57.2,
65.4,
30.9,
98.9,
93.6,
27.8,
92.7,
6,
81.6,
73.5,
59.2,
38.6,
0,
66.3,
97,
37.7,
54.9,
79,
36.7,
19,
23.1,
60.6,
62.1,
28,
48.9,
90.6,
73.5,
57.5,
69.8,
85.9,
32.9,
87,
90,
46.4,
90.9,
60.5,
41.7,
37.5,
14.5,
36.5,
41.8,
28.2,
66.2,
76.6,
68,
1.6,
11.7,
64.6,
47,
44.1,
65.6,
58.6,
65.9,
51.3,
66.6,
1.9,
32.2,
69.5,
42,
50,
4.4,
54.4,
10.1,
57,
69.1,
80,
79.4,
72.7,
47.9,
56.6,
56.4,
41.8,
77.9,
18.7,
27.8,
47.1,
52,
35,
50,
35.5,
29.5,
1.9,
47,
95.3,
13.3,
50.9,
43.2,
56.4,
23.2,
25.9,
64.8,
33.9,
27.9,
13.2,
74,
70.8,
80,
40.2,
39.5,
96.1,
80.3,
72.1,
36.3,
76,
60.3,
36.7,
51.7,
61.2,
77.9,
59.2,
65.8,
76.7,
13.5,
86.3,
98.5,
62.3,
40.9,
56.4,
82.1,
80.1,
92.6,
27.3,
34.1,
61.9,
42.1,
61.2,
72.1,
36.3,
65,
64.4,
58.2,
38.6,
29.3,
70.2,
53.3,
82.3,
44.1,
68.7,
58.2,
83.8,
43.7,
29.1,
34,
81.8,
60.2,
60,
60.5,
76.6,
49,
85,
50.4,
52.8,
88.4,
62.1,
92,
52.7,
50.2,
67.9,
55,
53.9,
43.4,
55.2,
73.3,
63,
81.6,
75.4,
15,
88.6,
43.1,
53.2,
22.9,
25.6,
49.3,
36.4,
15.1,
63.9,
12.1,
87.7,
44.6,
81.8,
31.8,
18.9,
44.4,
94.2,
59.9,
83.2,
59,
80.6,
95.3,
36.8,
35.8,
57.8,
61.4,
94.4,
91.1,
56.9,
40.3,
37.1,
34.4,
70.4,
55,
65.7,
70.8,
67.8,
84.8,
53.5,
49.9,
63.1,
37.1,
68.8,
54.5,
92.5,
68.8,
65.1,
50.2,
21.9,
92.4,
25.5,
35.1,
49.3,
47.1,
17,
98.9,
42.4,
54,
24,
74.8,
80,
94.1,
30.8,
25.1,
66.6,
54.6,
15.5,
68.9,
60.8,
37,
69.7,
45.5,
87.9,
24.3,
54.2,
63.4,
15.2,
22.8,
60.9,
72.9,
68.9,
93.9,
36.4,
29.9,
36.7,
48.6,
0.9,
72.3,
35.6,
47.1,
91.2,
19,
22.4,
48.5,
72.3,
19.6,
28.6,
69.7,
46.2,
36.8,
55.2,
66.5,
25.9,
62.3,
18.8,
36.1,
73.6,
90.2,
55.8,
75.2,
67.7,
36.8,
26.1,
56.7,
91.6,
60.8,
31.1,
94.9,
47.9,
55,
84.6,
71.4,
72.2,
71,
97.1,
2,
87.5,
38,
95,
61,
46.3,
35.1,
7.9,
66.6,
89.2,
47.2,
94.4,
50.5,
84.2,
46.4,
17.4,
85.1,
65.8,
67,
64.4,
61.4,
86.8,
60.5,
48.8,
36.9,
50.4,
44.8,
95.2,
74.4,
7.8,
79.3,
52.3,
34.8,
75.5,
52.1,
65.8,
81.1,
21.5,
45.6,
52.9,
14.1,
42.6,
59.9,
71.1,
55,
40.4,
95.8,
59.8,
60.4,
80.3,
48,
52.6,
57.6,
90.9,
83.7,
16.8,
80.7,
85,
73.4,
66.7,
65.3,
76.2,
15.5,
89.8,
88.8,
51.8,
74.2,
70.6,
81.7,
44.9,
95.4,
52.2,
32.2,
96.6,
65.6,
76.2,
87,
64.6,
25.4,
93.9,
59.4,
20.3,
61.6,
4.7,
71.7,
96.9,
77.1,
67.3,
69.1,
64.9,
66.6,
32.8,
61.5,
55.9,
94.2,
25.9,
46.9,
11.5,
28,
40,
37.4,
60.4,
78.1,
47.9,
44.1,
26.5,
16.4,
8.7,
85.9,
79.3,
87,
65.9,
33.4,
60.7,
60.5,
25.5,
75.3,
59.1,
18.8,
54.3,
61,
27.4,
63.2,
54.6,
82,
52.5,
56.5,
59.1,
73.4,
30.2,
58.2,
87.4,
78.9,
101,
83.5,
38.2,
48.2,
81.5,
43,
81.1,
89.6,
73.1,
83.4,
10.7,
5.8,
86,
62,
35.7,
48.4,
97.7,
16.1,
24.8,
33,
56.1,
37.3,
23.3,
76.2,
97.4,
46.5,
48.7,
89.6,
45.5,
49.1,
43.5,
35.1,
62.4,
87.9,
17.6,
64.5,
94.3,
38.1,
59,
74.5,
68.4,
47.7,
49.8,
44,
55.9,
39.7,
41.4,
45.2,
14,
10.2,
69.5,
83.1,
23.3,
63.3,
86.6,
8.6,
17.2,
50.6,
54.1,
74.2,
31.5,
74.3,
89.4,
97.6,
15,
67.2,
53.5,
49.9,
89.1,
64.1,
78.2,
64.3,
79.5,
75.6,
32.3,
63.4,
38.8,
19,
88,
37.8,
49.3,
47.1,
27.4,
74.4,
86.1,
87,
43.6,
92.4,
28.3,
79.5,
89,
80.5,
86.2,
15.7,
90.2,
36,
66.3,
65,
75.8,
64.6,
66.8,
53.2,
78.5,
17,
49.6,
34.5,
94.8,
69.3,
32,
6.1,
44.6,
84.8,
49.7,
25.2,
46,
49.8,
49.6,
65.9,
58.4,
78.9,
38.8,
43.2,
84.3,
63.8,
35.1,
42.6,
67.1,
68.4,
20.7,
52.4,
76.7,
56.3,
68.6,
58,
53.9,
96,
65.3,
75.8,
68.1,
38.3,
41.1,
65.5,
79,
60,
2.7,
67.2,
40.9,
18.1,
41.2,
63.2,
19,
50.1,
75.2,
63.8,
41,
70.2,
32.4,
70.4,
23.4,
46.5,
31.1,
1.9,
11.2,
83.3,
41.3,
23.7,
89.2,
82.2,
81.5,
21.6,
66.2,
91.5,
29.1,
9.9,
66.4,
61.6,
33.3,
35.7,
49.7,
66.7,
91.8,
67.8,
15.4,
38.4,
48.3,
7.2,
85.7,
71.2,
40.6,
75,
37.6,
70.3,
26.2,
85,
71.7,
60.8,
44.2,
63.5,
72.8,
106.4,
8.6,
10.1,
50.6,
43.8,
74.7,
87.8,
38.5,
50.7,
63.7,
43.6,
74.5,
77.9,
60,
2.6,
93.2,
81.5,
78.5,
45.8,
53.4,
55.5,
61.5,
56.6,
65.9,
60,
88.9,
84.1,
9.7,
76,
72.8,
94.2,
57.2,
12.9,
27.7,
19.5,
86.4,
31.2,
81.2,
57.1,
56,
63,
62.5,
54.7,
73.6,
10.6,
50.1,
82.6,
17.2,
47,
55.9,
41.2,
83.4,
61,
79.3,
67.1,
11.6,
59.2,
51.6,
61,
41.8,
53.7,
62.6,
45,
65.1,
32.4,
34.8,
90.1,
98.3,
48.7,
50.3,
71.7,
54.5,
51.7,
40.6,
75.9,
92.3,
80.2,
52.9,
45.5,
90.7,
55.3,
24.7,
0.7,
49,
72,
43,
85.3,
14.5,
38.3,
34.9,
78.1,
4.8,
93.7,
1.7,
14.4,
47.6,
8.9,
43.9,
47.4,
38.9,
56.7,
63,
90.3,
66.1,
68.6,
56.5,
44.6,
37.3,
75.3,
55.1,
48.6,
70.7,
51,
52.9,
70.9,
26.8,
70,
42.6,
74.9,
37.6,
75.2,
54.7,
65.6,
66.8,
23.4,
77.1,
92.9,
89,
34,
46.9,
69.4,
72.8,
9.4,
61.1,
53.6,
14,
30.7,
50.6,
65.8,
57.5,
26.1,
36,
1.6,
79.9,
61,
64.9,
71.8,
35.4,
75.7,
22.4,
13.2,
80.3,
47.2,
78.3,
32.1,
79.3,
65.4,
48.2,
79.2,
40.2,
59.5,
45,
42.1,
72.4,
79.6,
59.9,
45.6,
69,
49.1,
70.8,
65.2,
65.9,
49.4,
51.6,
7.1,
29.9,
64.6,
41.1,
16,
77,
79.3,
46.6,
57.6,
81.3,
91.3,
56.9,
58.9,
52.4,
77.3,
48.9,
98.9,
68.3,
62.7,
34.8,
94.4,
50.5,
46.7,
70.1,
83,
44.4,
69.6,
45.5,
82.5,
74.2,
60.8,
81.8,
15.3,
22.7,
36.6,
89.5,
49.5,
89.5,
84.6,
60.8,
58,
44.8,
65.3,
87.8,
65,
89,
48.1,
62.7,
73.4,
77.8,
64.5,
49,
53.3,
25,
60,
77.4,
7.6,
81.9,
40.5,
58.2,
19.8,
1.4,
89.7,
17.3,
45.5,
50.3,
62.9,
39.5,
22.4,
49.3,
63.8,
68.9,
58.7,
61.5,
97.4,
32,
59,
73.1,
48.6,
64.6,
63.8,
20.6,
70.9,
29.5,
50.4,
47.9,
48.3,
72.3,
92,
38.9,
32.5,
26.6,
56.1,
79.9,
68.7,
86.5,
54.2,
53.5,
78,
34.3,
28.2,
68.9,
21.1,
85.7,
45.2,
72.8,
38.9,
34.3,
44.9,
35.7,
32.1,
29.7,
12.2,
76.6,
53.9,
64.4,
75.4,
54,
32.1,
84.3,
57.6,
0,
77.3,
33.7,
39.7,
76.7,
99.6,
13.2,
65.8,
36.9,
70,
101.5,
81.9,
98.4,
80.3,
93.4,
50.8,
77.5,
69.5,
67.2,
22.2,
61.5,
56.3,
13.1,
95.9,
43.1,
65,
32.5,
49.5,
61.7,
87.7,
42.3,
87.9,
12.7,
75.6,
59.4,
43.8,
96.1,
22.1,
66.1,
36.8,
50,
79,
69.4,
73.6,
43.3,
88,
88.8,
37.9,
45.5,
63.7,
69.9,
33.8,
15.1,
88.2,
2.3,
54,
85.1,
73.1,
53.5,
81.8,
52.9,
69.2,
91.9,
100.1,
21.7,
35.4,
96.9,
54.7,
82.6,
52.3,
97.3,
70.2,
64.5,
29.8,
61.1,
20.9,
65,
88.7,
82.1,
23.1,
48.5,
41.9,
62.2,
49.4,
45.6,
83.3,
84.1,
96.1,
38.8,
66.3,
49.5,
65.8,
86.3,
35.5,
26.3,
57.9,
43.5,
17,
96.9,
7.9,
85.9,
70,
86.7,
77.8,
66.8,
65.8,
71.4,
39.9,
25,
71.3,
25.7,
60.9,
90.1,
16.4,
77.8,
49,
19.6,
83.1,
39.2,
55.8,
74.1,
72.5,
23.2,
39.8,
64,
97.9,
36.6,
79.3,
41.4,
77.4,
71.7,
63.8,
26.5,
38,
55.3,
76.1,
55,
43.2,
19,
75.2,
68.3,
39,
72.8,
44.9,
49.9,
102.5,
54.1,
11.5,
59,
43.1,
95.1,
47,
42.2,
56.5,
41.1,
83.2,
0,
38,
1.2,
152.7,
65.2,
88.4,
49,
79.2,
31.9,
40.8,
43.8,
91.4,
79.4,
15.1,
72.2,
39.2,
79.6,
52.1,
92,
56.9,
53.9,
93,
47.9,
39.2,
62.8,
47,
100,
52.3,
50.7,
16.7,
84.3,
63.4,
49.2,
86.3,
73,
54.6,
92.4,
75.8,
73.3,
59.9,
31,
42.6,
55.7,
42,
46.3,
47.2,
91.1,
75.6,
62.9,
54,
48.1,
62,
81.1,
70,
53.1,
39.9,
75.9,
50.7,
30.2,
72.2,
7.3,
49.1,
72.3,
89.4,
81.3,
28.7,
22.3,
69,
90.2,
59.1,
74.7,
75.5,
93.2,
41.8,
79.4,
71.7,
42.9,
43.6,
0.5,
26.1,
49.4,
58.6,
31.1,
45.2,
63.6,
48.5,
8.7,
75.7,
62.1,
56.5,
19.2,
67,
43.1,
65.4,
83.3,
17,
92.3,
80.2,
59.4,
39,
48,
22.6,
29.2,
21.9,
49.1,
28.2,
93,
40.8,
53.1,
36.7,
65,
79,
81.9,
64.3,
79.5,
53.3,
76.8,
4.5,
19.7,
32.5,
45.5,
4.3,
35.7,
63.1,
58.6,
41.8,
27.8,
55.1,
23,
72,
86.5,
37.1,
30.5,
38.5,
42.1,
54.3,
30.5,
26.1,
45.5,
44.9,
52.9,
67.2,
55,
24.3,
48.1,
57,
38.3,
81,
68.8,
69.8,
30.2,
75.3,
64.2,
34.6,
19.8,
85.4,
69.6,
55.1,
61.4,
60.7,
66.7,
63.4,
33.7,
63.9,
41.4,
25.8,
82.6,
26.1,
91,
59,
71.7,
71.9,
44.4,
33.6,
14.9,
41.9,
38,
36.5,
57.3,
59.8,
44.4,
65.6,
42.3,
78.1,
17.6,
43.2,
52.6,
10.2,
80.3,
98.9,
79.3,
58,
22.3,
34.5,
49.6,
67.5,
93.7,
85.3,
77.1,
72.6,
10.7,
61,
29.1,
17.5,
13.2,
65,
13.6,
70.2,
76.8,
23.8,
50,
35.1,
52,
28.7,
72.3,
70.4,
44,
52.3,
79.3,
80.1,
42.3,
89.1,
27.9,
73.1,
96,
47.8,
56.3,
76.4,
61.3,
82.9,
97.3,
16.3,
95.4,
72.2,
90.8,
81.6,
61.7,
39.7,
17.2,
54.9,
20.3,
23,
55.1,
68.3,
82.5,
38.1,
14.1,
31.6,
56,
19.2,
63.7,
59.2,
76.3,
22.8,
90.4,
31.5,
70.3,
52.4,
54.3,
50,
55.5,
91.2,
84,
22.9,
57.1,
50.4,
78.2,
47.5,
74.6,
60.3,
22.2,
66,
21.6,
20.7,
73.1,
32.6,
37.6,
42.4,
84.9,
54.6,
46.9,
20.6,
22.7,
3,
45,
77.7,
86.5,
48.7,
33.6,
35.4,
79.5,
65.7,
68.5,
19.7,
38.1,
80.9,
79.3,
3.9,
45.4,
86.1,
47,
26.3,
47.2,
42.2,
42.2,
46.5,
55.2,
24.4,
85.9,
22.2,
45.7,
64.9,
93.9,
77.5,
59.9,
29.2,
87.2,
46.6,
53.3,
82.5,
72.9,
85,
18.5,
58.9,
61.3,
63.2,
50.3,
21.8,
86.6,
71.6,
91.1,
16.6,
54.6,
39.5,
77.6,
22.4,
93.3,
68.9,
87.6,
75,
10.2,
40.9,
90.6,
65,
90.9,
75.6,
54.2,
31.2,
72,
71.7,
12.6,
83.4,
70,
22.4,
47.6,
28.6,
68,
51.1,
88,
10.6,
40,
46.3,
40.1,
89.2,
57.8,
77.8,
46,
25.7,
53.6,
53,
78.9,
66.1,
24.1,
91.2,
90.6,
42.9,
65.6,
60,
92.3,
61.2,
15,
38.9,
61.6,
39,
86.8,
23.1,
24.6,
47.9,
67,
63.2,
93.2,
62.7,
4.5,
67.3,
68.9,
52,
73.2,
57.5,
77.5,
6.6,
34,
86.4,
66.8,
97.7,
42.8,
54.3,
83.1,
61.7,
75.1,
33.4,
67.3,
71.8,
70,
39,
58.5,
40.9,
58.8,
84,
85.8,
57.3,
53.8,
66.4,
53.4,
77.3,
34.5,
63.7,
38.2,
9.3,
59,
68.2,
53.2,
63,
55.7,
81.6,
24.6,
50,
92.2,
35.8,
48.4,
98.8,
83.1,
3.4,
53.6,
54.5,
77,
57.6,
69.1,
43.4,
66.1,
61.2,
81,
2.3,
75,
94.3,
88.6,
16.3,
54,
75,
71.6,
35.5,
21.6,
82.6,
49.8,
67,
38.9,
80.4,
36.9,
57.2,
38.7,
30.2,
62.9,
94.6,
41.8,
47.1,
85.2,
99.3,
35.2,
78,
21.5,
21.5,
85.4,
57.4,
35,
79.4,
21.8,
82.5,
68.6,
87.5,
83.3,
23.6,
36.6,
69.3,
52,
99.3,
44.4,
35.6,
73,
50.2,
46.7,
4.5,
65.2,
10.8,
46.4,
79,
92.9,
71.8,
94.3,
22.4,
53.4,
95,
85.8,
37.5,
30.2,
30,
38.9,
74.7,
33.2,
74.9,
49.9,
54.2,
87.1,
77.9,
52.5,
26.3,
60.4,
46.9,
31.7,
28.2,
22.9,
59.1,
30.7,
27,
86,
34.7,
39.1,
34.5,
36.1,
27.8,
39.8,
63.1,
1.3,
76.8,
36.5,
92.6,
47.2,
59.5,
74.2,
32,
13.5,
78.3,
16.3,
45.3,
39.7,
48.4,
23.9,
28.6,
23.3,
78.6,
34.2,
11.3,
20.3,
58.6,
71.5,
24.9,
41,
46.6,
53.5,
60.1,
17.3,
22.4,
20.1,
53.3,
12.4,
78.4,
41.5,
76.3,
38.4,
83.5,
26.9,
21.2,
23.5,
17.5,
75,
93.2,
49.5,
72.8,
67.7,
55.1,
22.2,
57,
39.2,
40.4,
77.2,
75.1,
85.3,
47.3,
44,
70.8,
34,
65.5,
19.5,
52.9,
33.7,
15.3,
32.5,
55.5,
67.8,
36.6,
96.2,
42,
87.3,
92.4,
85.9,
90.6,
52.1,
33.4,
32.2,
94.5,
43.1,
80.6,
29.4,
10.3,
66.7,
0,
53.9,
58.5,
62.7,
55.4,
66.9,
25.2,
56.9,
52.2,
63.2,
74,
1.6,
30.6,
48.5,
56.7,
3.2,
57.6,
28,
58.3,
54.6,
63.5,
52.7,
50.3,
81.1,
70.4,
66.7,
7.1,
4.5,
78.9,
35.7,
46.7,
96.7,
82,
13.8,
48.7,
57.8,
29.7,
57.4,
92.8,
38.8,
79.4,
62.6,
83.1,
45.1,
83.6,
43.3,
62.3,
35.9,
94.2,
58.2,
56.2,
56,
47,
73.2,
65.2,
52.9,
29.9,
72.7,
70.7,
70.1,
78,
50,
55.4,
61.6,
10.6,
58.3,
70.7,
33.3,
98.5,
42,
91.6,
41.3,
69.4,
43.5,
60.4,
73.7,
84.2,
51.5,
97,
47.6,
83.7,
38.4,
62.4,
39.6,
66.4,
16.3,
67.4,
65.3,
29.6,
82.8,
83,
82.2,
50.7,
0,
66.4,
47,
49.1,
56.2,
67.9,
55.2,
37.9,
19.9,
43.1,
6.2,
33.5,
44.3,
86.9,
40,
55,
43.7,
66.6,
92.9,
60.8,
46.6,
47,
70.9,
41.3,
65.7,
31.2,
0.5,
15.1,
50.1,
44.4,
55.6,
89.7,
34.4,
95.3,
84,
69.8,
80.5,
25.6,
34.9,
74,
60.7,
57.8,
89.3,
80.9,
101,
61.7,
56.5,
59.6,
55.2,
11.5,
41.9,
85.5,
16.2,
53.9,
81.8,
82.5,
0.1,
89.6,
29.4,
59.7,
88.2,
26.1,
52.6,
96.3,
11.2,
57.8,
31.7,
73.4,
20.7,
76.5,
21.9,
62.2,
75,
40,
72.1,
68.3,
66.1,
27.7,
54.8,
39.4,
86.9,
66.4,
32.4,
27.3,
52.2,
33.3,
30.8,
94,
34.3,
67.3,
38.3,
59,
87.3,
66.3,
34.6,
75.4,
59.8,
77,
64.3,
70.5,
26.7,
60.5,
76.1,
1.1,
70,
34.6,
83.8,
24,
98.7,
53.6,
28.9,
85,
25.6,
51.4,
80.6,
88,
85.3,
74.7,
57.1,
67.2,
53.5,
64.2,
35,
48.5,
81.4,
88.3,
22,
34.9,
40,
65.7,
16.6,
55,
30.2,
36.8,
21.4,
19.4,
66.7,
6.5,
76.6,
50.6,
20.4,
60.7,
44.5,
59.3,
0,
38.7,
88.9,
41.4,
70.3,
70.6,
78.3,
30.6,
69.7,
85.9,
84.2,
71.4,
42,
27.1,
82.1,
51.2,
55,
67.5,
67.1,
77.3,
58.3,
61.9,
46,
31.6,
41,
77.4,
91.1,
76.8,
61.1,
15.1,
74.3,
24.1,
92.9,
57.7,
96.4,
93.5,
74.1,
60.3,
98.3,
29.8,
57.4,
56.7,
4.5,
68.4,
47,
37.8,
83.5,
8.9,
81.1,
74.9,
64.1,
77.5,
8.8,
89,
37.8,
75.4,
58.4,
70,
50,
13,
58.9,
60.2,
101.5,
93.8,
61.3,
48,
9.5,
42.2,
95.5,
58.4,
59.3,
52.1,
28.9,
53,
62.6,
17.1,
42.5,
57.2,
89,
78.4,
60.4,
48.5,
22.2,
49.6,
21.5,
33.7,
55.7,
46,
54.7,
51.9,
69.4,
97.9,
31.5,
53.2,
57.5,
83,
60.4,
86.6,
71.5,
51.2,
80.7,
96,
1.4,
17.1,
51.4,
97.1,
81.8,
51.6,
40.5,
93,
44.5,
59.1,
44.1,
91.1,
89.8,
69.7,
63.5,
41.5,
68.7,
94.6,
39.9,
86.4,
54.4,
71.1,
64.8,
23.4,
29.7,
77.9,
37.6,
88.6,
73.7,
45.8,
84.6,
53.2,
59.9,
68.8,
86.5,
12,
82.3,
65.6,
84.8,
44.8,
51.9,
4.4,
42,
45.3,
54.2,
47.5,
15.5,
29.2,
23.7,
95,
20.5,
51.4,
59.5,
29.9,
86.7,
58,
68.7,
21.7,
89.9,
64.5,
51.4,
88.1,
16.2,
61.2,
38.6,
58.2,
65.7,
95.4,
80.4,
43.4,
45.5,
85.4,
36.3,
50,
45.4,
93.5,
70.4,
47.4,
52.2,
65.7,
26.5,
75.2,
66.9,
47.7,
66.4,
77,
51.2,
64,
93.7,
40.1,
83.6,
47,
42.6,
82.7,
84,
7.5,
88,
75,
43.5,
99.6,
40.1,
75.2,
25.4,
67.2,
0.5,
8.9,
76.8,
57.9,
28.6,
40.3,
47.8,
47.3,
47.2,
84.5,
31.5,
0,
58.2,
24,
39.7,
17,
83.4,
45.7,
68.8,
91.5,
52.1,
25.2,
38.2,
27.1,
46.3,
36.3,
31,
6,
50.4,
44.4,
45.4,
55.8,
31.7,
62.1,
92.4,
22.1,
45.6,
79.4,
80.7,
57.7,
64.8,
81.8,
0.2,
26.5,
59.5,
91.2,
39.2,
60.6,
62.9,
54,
92.1,
83,
59.8,
98,
52.6,
53.4,
35.9,
29.1,
61.9,
43.3,
64.8,
61.6,
9.2,
47,
60.8,
32.7,
62,
58.1,
90.6,
21.9,
50.3,
85,
56.3,
52,
63.2,
97.5,
78.5,
62.7,
26.6,
45.6,
55.1,
62.8,
76.7,
78.3,
56.9,
74,
25.6,
75.1,
58.6,
32.7,
37,
24.9,
31.3,
35.2,
67.4,
91.1,
39.7,
32.4,
96.2,
70.1,
59.7,
68.4,
14.9,
43.5,
98.6,
34.8,
24.5,
36.9,
35.8,
76.5,
53.2,
51.4,
16,
49.2,
23.1,
27.8,
37.6,
62.3,
34.6,
47.2,
25.9,
51,
82.6,
39.1,
78.5,
51.5,
84,
65.3,
69.1,
12.8,
97.8,
98.9,
0,
69.7,
69.9,
37.9,
48.4,
83,
63.6,
66.1,
57.3,
71.6,
52.5,
38.7,
85.6,
23.2,
62,
7,
42.1,
15.4,
8.8,
60.2,
40.8,
14.6,
33.9,
69.6,
75,
92.7,
95.6,
72.8,
28.3,
63.2,
98,
9,
37.1,
79,
85.9,
15.9,
86.5,
73,
67.4,
41,
49.9,
75.3,
15.5,
66.1,
63,
30.1,
73.1,
24.3,
70.7,
7.8,
27.4,
91.5,
33.9,
91.3,
75.1,
59.2,
75.1,
78.1,
65.3,
72.2,
84.4,
29.8,
51.8,
79.6,
26.8,
16.4,
46.2,
72.3,
47.7,
4.9,
26.9,
81.2,
48.1,
84.5,
32.7,
63.9,
74.6,
40.7,
86.7,
67.5,
68.2,
41.7,
45,
73,
88.8,
87.4,
23.4,
81.2,
58.5,
95.1,
55.1,
49.7,
54,
72,
82.4,
68.1,
54.4,
48.5,
77.5,
21.3,
92.1,
24.9,
75.1,
90.3,
72,
33.6,
86.8,
62.7,
68,
81,
96,
72.8,
60.1,
100,
46.7,
39.4,
81.3,
102,
59.3,
70.9,
65.9,
87.3,
73.6,
7.28,
46.9,
48.9,
88.4,
82,
62.3,
8.5,
34,
25.3,
62,
40.9,
36.7,
87.1,
33.1,
60.2,
58.6,
68.7,
59.5,
54.8,
63.1,
48.9,
23.5,
67.9,
54.1,
47.1,
9.2,
94.6,
74.6,
13.9,
40.3,
64.2,
82.4,
53,
73.6,
71.4,
78.9,
69.8,
60.3,
94.1,
76.7,
35.4,
37.1,
50.5,
0,
84.2,
5.3,
70.1,
69.6,
65.4,
55.3,
32.6,
52.8,
58,
31,
94.5,
32.8,
62.8,
41.8,
18.1,
10,
67.1,
74.2,
62.1,
84.7,
58.3,
10.4,
90.1,
81.1,
51,
50,
58,
58,
38.8,
93.4,
60,
48.9,
39.6,
29.3,
59.1,
13.7,
48.6,
96.6,
39.9,
78.3,
67.7,
12.4,
62,
73.1,
66,
85,
73.9,
31,
29.4,
46.4,
70.1,
82.4,
66,
52,
90.8,
84.4,
68.4,
59.5,
65.6,
87,
20.8,
71.2,
56.4,
26.2,
41.3,
54.4,
102.5,
10.8,
17.7,
78.7,
66.6,
48.8,
64.9,
62.3,
24.9,
71.9,
53,
79.9,
46.9,
0,
65.8,
51.2,
67.7,
62.4,
54.2,
37,
70.9,
75.2,
38.3,
81.7,
100.7,
72.8,
52.2,
56.3,
58.1,
74.1,
54.9,
0,
92.3,
50.1,
58.4,
82.9,
37.6,
14,
84.4,
80.7,
39.4,
55.4,
24.8,
94.4,
9.9,
52.3,
99.4,
87.4,
50.4,
51,
7.5,
52.4,
61.6,
79.2,
34.8,
13.1,
62,
77.3,
34.7,
75.3,
49.6,
53.8,
45.8,
63.1,
99.4,
67.9,
40.9,
20.7,
90.9,
56.6,
65.3,
43.5,
38.6,
29.5,
32.2,
29.6,
58.4,
70.7,
97.4,
74.6,
43.7,
59,
31.1,
67.3,
53,
64.3,
70.1,
30.2,
50.8,
59.2,
33.2,
46.5,
61.5,
57.9,
31.5,
39.3,
93.9,
27.2,
58.8,
58.3,
75.1,
44,
96,
35.1,
27.6,
31.8,
44.3,
10.4,
62,
42,
37.9,
39.3,
54.1,
34.3,
89.5,
31.9,
36.7,
92.5,
35.9,
82.7,
82,
58.9,
76.3,
47.1,
0,
31.6,
41.7,
29.8,
69.5,
10.5,
62.7,
83.1,
79.7,
42.6,
50.6,
49.5,
83.5,
44.4,
54.6,
11.6,
94,
51.8,
40,
71.8,
66.7,
93.7,
44,
44.9,
55.1,
52.8,
32.8,
64.6,
85.8,
43.7,
88.4,
10.2,
74.4,
59.3,
42.4,
3.4,
38.5,
46.9,
11.7,
54.6,
86.6,
32.3,
76.1,
90.5,
15.6,
87.4,
17,
37.1,
30.5,
66.5,
69.1,
71.3,
63.3,
82.3,
33.3,
90.3,
48.7,
79.8,
68.8,
30.7,
52.9,
69.8,
71.2,
50.1,
46.7,
4,
88.3,
34.5,
84.4,
44.8,
49.7,
7.6,
18.2,
88.2,
53.6,
20,
55.2,
45.2,
44.8,
74.5,
25.7,
41.3,
40.5,
87.1,
48.7,
83.8,
63.6,
87.7,
100.4,
96.7,
85.1,
97.7,
89.9,
35.4,
43.3,
28.9,
95,
25.8,
5.3,
66.8,
71.6,
79,
45.3,
5.7,
70.2,
56.9,
76.4,
28.4,
75.4,
79.6,
71.5,
97,
63,
53.6,
66.6,
92,
71.8,
73.3,
46.7,
39.2,
68.6,
18.8,
48.3,
51.8,
54,
24.8,
31.3,
17.8,
97,
87.2,
71.5,
63.6,
72.9,
85.8,
69,
56,
26.8,
96.9,
47.3,
96.4,
95.7,
58,
23,
83.6,
87.4,
39.6,
0.8,
47.7,
0,
31.7,
58,
70.1,
72.1,
43.6,
76.4,
82.2,
44.8,
10.9,
72.9,
15,
66.9,
50.9,
83.8,
77.2,
67.8,
74.4,
93.6,
49.4,
56.6,
52.4,
47.2,
44.6,
36.7,
77,
89.2,
48,
37,
56.5,
null,
63.7,
82.9,
52.2,
8.7,
107.4,
58.6,
52.4,
51.5,
71.7,
36.2,
63.5,
77.6,
50.7,
49.3,
27,
40.8,
83.1,
84.8,
37.9,
57.8,
76.5,
51.7,
50.7,
35,
40.8,
24,
88,
48.4,
71.7,
48,
58.1,
49.1,
11.8,
80.8,
12.8,
20.3,
90.8,
72.5,
59.9,
75.1,
33.9,
93.8,
66.1,
84.6,
61.6,
88.2,
39.7,
17.1,
67.8,
74.2,
1.6,
75,
51.3,
79.3,
40.9,
70.1,
13.3,
48.7,
71.3,
85,
60,
56.2,
74.8,
80.3,
81.8,
40.7,
80.3,
46.2,
46.8,
63.1,
39.9,
45.8,
74.9,
87.1,
24,
63.8,
32.1,
55.9,
32,
32.5,
66.4,
68.7,
72,
19.6,
57.9,
21.1,
36,
56.7,
64.8,
77.4,
37.2,
56.4,
71,
60.5,
22.8,
21.2,
77,
36.9,
62,
21.2,
42.8,
67.6,
39,
61,
49.6,
37.2,
8.8,
52.8,
91,
92.3,
33.9,
29.3,
72.6,
49.6,
40.4,
94.9,
79.9,
58.3,
57.9,
72.4,
94.9,
45.3,
66.7,
36.4,
55.8,
18.1,
59.9,
73.5,
49.6,
72.8,
62.3,
62,
15.2,
59.9,
86.6,
34.1,
58.8,
94.9,
47,
61.1,
56.9,
90.2,
69.4,
87.5,
41.5,
48.2,
57.3,
108,
9.6,
13.7,
88.7,
73.7,
99.2,
75.6,
59.6,
89.9,
60.5,
86,
48.6,
57.3,
72.9,
73.2,
34,
42.7,
39,
29,
5.3,
74,
126.4,
95.9,
82,
65,
71.1,
58,
1.1,
90.9,
26.7,
93.3,
63,
89,
91.2,
65,
54.4,
37.9,
48.4,
77.4,
54.9,
47.8,
71,
81,
12.5,
67.5,
17.8,
85.4,
82,
40.1,
95.2,
90,
65.9,
35.3,
65.3,
95.6,
0,
15.3,
49.5,
20.5,
36.8,
60.3,
72.5,
41.8,
26.7,
30.8,
59.3,
84.6,
78.5,
74.3,
69.7,
37.4,
67.9,
63,
78,
95.5,
46,
86.8,
72.5,
85.1,
66,
62.7,
32.8,
92,
68.8,
53.2,
88.1,
92.9,
21,
45.6,
63.1,
45.4,
49.8,
58.2,
68.9,
66.7,
16.4,
74.8,
71.3,
68.4,
72.2,
43.7,
57.2,
52,
43.8,
46.2,
67.3,
65.9,
19.7,
56,
53.8,
35.6,
65.7,
42.1,
82.2,
89.7,
37.2,
81,
28.3,
22.4,
20.5,
55,
32.6,
67.1,
59.2,
31.5,
64.7,
60,
29,
70,
93,
52.9,
96.3,
60.5,
91.9,
52.3,
53.6,
14.1,
88,
77.9,
89.1,
11.4,
76.1,
42.1,
58.8,
7.3,
52.2,
63.7,
27,
10.1,
21.5,
68.6,
57.1,
24.3,
33.9,
70.4,
9.2,
73.5,
64.4,
65.7,
4.3,
19.5,
31.2,
95.1,
27,
77.9,
67.8,
56.8,
94.5,
78.7,
50.6,
42.1,
65.3,
55.8,
74.2,
38.5,
70.6,
55.8,
73.8,
60.8,
51.1,
27.6,
31.9,
40.8,
37.4,
46.8,
72,
36,
93.5,
3.2,
17.3,
18.5,
50.1,
37,
27.8,
85.9,
89.7,
59.4,
38.2,
69,
50.8,
39,
51,
64.1,
61.9,
79.2,
30.9,
87,
23,
65.9,
67.9,
28,
36,
75,
34.4,
57.7,
9.6,
85.4,
35.3,
59,
41.1,
64.1,
34.7,
82.3,
82.8,
48.4,
85.1,
21.4,
48.3,
58.1,
86,
81.2,
52.1,
47.1,
81.6,
93,
77.5,
79.6,
33.4,
36.1,
69.3,
60.3,
29.1,
78,
30.6,
76.9,
74.2,
25,
82.3,
82.2,
94.1,
46.5,
27.3,
76,
37.8,
58.1,
72.7,
40.4,
37.3,
84.2,
54.8,
41.6,
61.4,
33.4,
48.5,
51.7,
8.5,
36.8,
78.7,
51.1,
84.6,
74.4,
32.8,
49.8,
82.2,
36.8,
56.5,
48.2,
49.1,
63.7,
74.4,
83.1,
72.1,
10.6,
45.3,
39,
95.7,
83.2,
72.7,
63.3,
82.9,
39.8,
48.1,
74,
56.8,
83.5,
56.2,
38.1,
50.8,
15.4,
88.8,
78.9,
64.9,
52,
30.7,
62.4,
67.6,
46.7,
67.4,
40.5,
50.2,
84.9,
72.4,
43.2,
14.6,
19,
78.1,
87.2,
36.1,
19.9,
73,
89,
41.6,
25.5,
90,
5.8,
28.4,
33,
58.5,
24,
23.9,
34,
78.7,
65.8,
52.3,
43.4,
28.5,
30.7,
79.7,
0,
21.9,
48.5,
89,
45.9,
25.1,
73.5,
9.5,
42.8,
40.2,
73.5,
69.5,
40.7,
8.8,
76.6,
31.6,
57.8,
36.1,
64.5,
69.9,
69.9,
92,
28.6,
19.1,
30.1,
26.8,
53.8,
27.9,
94.9,
80.7,
51.6,
22.1,
80.4,
55.3,
88.7,
52.3,
58.6,
24.2,
77.8,
65,
96.6,
18,
87.2,
75.8,
21.6,
21.2,
52,
33,
59,
79.1,
86.7,
69.1,
56.9,
78.8,
81,
47.7,
63.7,
55.2,
86.1,
27.8,
23.11,
53.1,
64.5,
26.5,
73.7,
91.9,
62.3,
18.3,
64,
65.7,
17.1,
48.9,
29.8,
56.3,
88.8,
52.6,
83.9,
76.8,
47.6,
69.2,
73.5,
57.6,
88.7,
87.7,
70.2,
36.7,
27.2,
79.9,
0.3,
88.5,
59.2,
88.2,
52.7,
89,
64.4,
100,
51.4,
10.6,
76.3,
38.6,
31.1,
85.6,
38.9,
69.7,
46.3,
48,
91.1,
91.4,
82,
53.1,
60.7,
16.9,
51.2,
49.9,
57.5,
12.7,
28.2,
67.3,
39.2,
35.8,
70.3,
33.8,
11,
58.2,
69.8,
26.2,
79.2,
58.9,
35.9,
24.7,
62.5,
45.3,
77,
56.6,
94.1,
43,
48,
53.5,
70.7,
61,
6.4,
99,
71.4,
61.6,
66,
56.2,
37.5,
49.6,
63.1,
62.3,
73.6,
69.6,
40.3,
12,
85.5,
43.8,
62.5,
41.7,
94.5,
68.3,
13.5,
21.1,
69,
67.8,
68.3,
44.3,
20.3,
51.6,
15.5,
36.2,
59.9,
47,
87,
13.6,
72.6,
41.7,
83.3,
36.7,
35.8,
61.8,
47.6,
31.5,
56.4,
37.6,
63.8,
87.6,
34.8,
79.4,
86.1,
40.8,
60.6,
57.3,
54.3,
53,
20.4,
55.5,
69.1,
70.6,
22.9,
63.2,
33.7,
29.5,
74.4,
26.6,
77.4,
70,
14.5,
81.4,
65.3,
53.3,
66.1,
81.8,
75,
69.9,
72,
51.5,
64.8,
57.4,
12.7,
92.3,
18.7,
94.7,
81.2,
44.2,
89.3,
77.2,
54,
40.1,
34.6,
80.6,
59,
21.3,
36.3,
80.8,
69.6,
49.9,
92.2,
15,
46.8,
56.2,
73,
61,
63.9,
56.5,
55.7,
91.8,
50,
86.9,
67.8,
7.5,
60.4,
39.7,
39.3,
87.8,
31,
91.5,
44.7,
56.7,
85,
34.1,
56.3,
84.9,
69.5,
67.8,
75.7,
50.1,
37.7,
75.2,
55,
49.3,
56.5,
73.7,
15.9,
48.2,
4.4,
31.5,
69.9,
86.8,
67,
9.3,
62.1,
73.5,
1.8,
10.3,
26.9,
33.9,
84.3,
57.6,
24.9,
63.2,
20.7,
34,
12.9,
14,
92.9,
71.5,
40.1,
97.8,
44.4,
93.9,
40.8,
87.1,
77.1,
31.4,
46.3,
46.3,
50.3,
56,
51.9,
48.9,
20.1,
77.2,
98.6,
8,
59.6,
66.1,
87.6,
78.4,
3.7,
83.2,
55.6,
65.1,
33.1,
52.8,
86.7,
35.7,
0,
58.9,
3.6,
33.6,
50.6,
35.7,
47.5,
24.8,
60.5,
30.9,
55.3,
73.8,
77.9,
63.4,
26.5,
79.1,
93.5,
49.7,
31,
49.1,
24.4,
89.9,
43.5,
49.3,
25.7,
34.7,
94.4,
42.2,
66,
73.5,
16.3,
61.1,
45.2,
60.3,
43,
70.6,
36.1,
41,
82.8,
19.7,
78.4,
48.9,
29.7,
55.4,
6.6,
83.6,
51.2,
50.6,
83.7,
85.2,
49.2,
56.3,
48.6,
96.3,
32.9,
92.7,
46.8,
47,
92.9,
57.8,
48.7,
27.7,
63,
74.5,
76.6,
48.8,
52,
44,
89.2,
67.9,
39.9,
27.9,
48.4,
96.5,
30.5,
68.5,
24.3,
66.3,
8.4,
56.8,
48.7,
37,
9.2,
75.3,
63.6,
14.5,
54.7,
23.1,
34.3,
63,
39.8,
34.8,
49.6,
58.6,
13.4,
50,
76.8,
83.8,
90.7,
69.7,
40,
88.9,
15.9,
55.6,
84.3,
81.9,
59.5,
81,
81.1,
56.4,
44,
80.1,
19.8,
27.5,
50.9,
83.6,
17.7,
40,
45,
88.3,
0.2,
45.6,
98,
80.5,
69.6,
39.2,
36.2,
82,
57.8,
79.1,
39.4,
59,
34.2,
56.5,
72.4,
85.6,
85,
24,
45.5,
53.6,
89.4,
29.5,
62.2,
37,
84,
9.6,
76.3,
33.9,
63.3,
45.8,
71.5,
51.2,
26.6,
69.5,
54.5,
21.3,
38,
23.1,
21.8,
53.7,
61.7,
65.9,
66.7,
38.3,
39,
18.3,
62.6,
37,
45.8,
76.9,
58.6,
84.8,
33.9,
50,
87.5,
99.1,
84.9,
36.2,
9.5,
89.9,
65.6,
65,
46.9,
55.4,
78.1,
23.1,
56.6,
88.4,
53.5,
73,
85.8,
84,
55.6,
46.8,
78.1,
94.1,
49.4,
55.2,
18.6,
87,
31.1,
83.9,
47,
49,
34.7,
32.4,
65.7,
88.2,
35.2,
97,
56.2,
68.4,
79.5,
40.6,
86,
3.1,
10.1,
48.8,
42.9,
40.6,
77.2,
40.9,
39.5,
39.9,
46.5,
47.1,
17.9,
74,
55.4,
64.9,
97,
80.3,
64.9,
46.1,
39.4,
69.8,
50.7,
69.1,
96.1,
64.7,
93.3,
28.8,
1.3,
74.7,
84.9,
49.3,
93.5,
58.4,
92.7,
71.2,
62.7,
45.3,
88,
67.3,
38.1,
59.1,
65.4,
64.9,
78,
48.1,
51.9,
72.7,
83,
74.6,
60.4,
79.6,
11.8,
83,
82.4,
14.7,
28.3,
58.6,
78.3,
49.1,
59.2,
71.1,
55.1,
70.1,
78.1,
73.4,
45.9,
70.3,
61.1,
37.3,
47.7,
82.3,
62.6,
50.3,
24.1,
61.2,
49.2,
66.2,
72.3,
40.7,
57,
80.2,
52.9,
60.4,
55.6,
57.4,
67.7,
91.7,
3.9,
35.3,
65.4,
87.4,
55.1,
66.6,
88.4,
0,
79,
25,
90.3,
18.9,
60.1,
73.1,
57.7,
65,
13.2,
39.1,
78.2,
69.9,
15.5,
93.6,
74.3,
27.8,
59.9,
28.6,
12.3,
59.5,
60.7,
44.4,
76,
8.6,
14.3,
36.2,
29.3,
57.5,
75.3,
40.6,
11.4,
65.9,
28.5,
52.7,
42.4,
78.4,
82,
39.6,
46.2,
67,
64.5,
50.3,
24.8,
80.9,
74.3,
37.6,
67.3,
55.4,
69.7,
61.3,
55.5,
57.7,
23.6,
25.4,
65.7,
93.9,
35,
62,
73,
32,
43,
22,
48.1,
61.3,
78,
60.5,
75,
36.7,
39,
77.4,
64.2,
56.7,
70.9,
74.1,
85.3,
76,
46,
32.3,
54.7,
77.8,
68,
46.6,
73,
40.3,
65.2,
73.4,
91.6,
55,
35.2,
65.1,
38.8,
24.9,
54.8,
32.2,
19,
33.6,
54.7,
62.2,
34.1,
86.4,
63.2,
83,
83.7,
12.9,
89.1,
29.9,
89.5,
82.3,
31.3,
66.8,
69,
36.5,
46.7,
75.9,
82.5,
70.7,
83.5,
97.2,
84.3,
11.4,
91.5,
39.9,
56,
54.8,
60,
53.2,
72,
117.5,
86,
71.7,
80.6,
19.1,
73.4,
82.2,
43.3,
64.1,
71.8,
54.2,
72.3,
23,
74.2,
56.1,
62.5,
48.1,
64.1,
34.4,
20.4,
80.6,
91.4,
36.5,
26.7,
23.8,
17.3,
55.5,
61.9,
12.8,
48.4,
79.2,
72.3,
44.7,
53,
70.8,
49.1,
65.9,
69.7,
59.2,
73.6,
31.4,
54.3,
61.3,
39,
67.6,
89.1,
85.3,
50,
48.3,
13.4,
82.5,
32.6,
21.6,
21,
36.2,
82.4,
29.1,
82.2,
32.4,
56.8,
63,
41.5,
88.3,
33.2,
19.6,
67.7,
64.9,
38.3,
55.9,
24.7,
78.9,
83.5,
91.4,
49.7,
65.6,
10.2,
79,
27.7,
25.3,
75,
64.6,
45.7,
36.4,
9.7,
76.5,
58.3,
40.2,
30.1,
59.6,
12,
84,
72.9,
52,
96.1,
72.5,
23.2,
43.1,
51.6,
38.5,
51.2,
47.7,
60.2,
89.9,
59.7,
46,
42.6,
63.6,
88.1,
73.2,
36.6,
96.9,
55.5,
37.5,
89.8,
82.7,
52.1,
91.4,
18.4,
31.2,
48.8,
56.5,
84.8,
35,
69.6,
38.8,
1.2,
50.4,
9.7,
50,
59.1,
26,
1.3,
90.2,
38.4,
59,
40.1,
35.9,
79.4,
86.9,
66.9,
44.4,
57.7,
54.5,
86,
87.1,
56.7,
66.5,
68.3,
87.2,
87.7,
25.9,
89.8,
37.6,
100.3,
65,
80.6,
34.4,
86.8,
77.8,
57,
63.7,
72.9,
91.4,
51.8,
37,
44.4,
96.4,
98.4,
91,
46.1,
28.6,
49.3,
91.8,
81.8,
27,
71.5,
92.3,
16.3,
33,
62.9,
64,
68.3,
50.6,
41.5,
99,
45.2,
67.6,
83.4,
85.6,
72.3,
70,
62.3,
72.3,
28,
45.5,
81,
90.2,
64.7,
26.1,
57.3,
66.8,
10.3,
17,
46.3,
41.1,
92,
65,
97,
59.7,
55.9,
34.8,
70.8,
76.9,
76.5,
73,
87.4,
69.4,
60,
63.7,
28.6,
41.8,
86.7,
73.5,
79.4,
80.2,
63.1,
64.8,
41.4,
39.7,
59.6,
52.5,
57.2,
79.5,
63.8,
68.5,
91,
69.9,
94,
71.3,
41.7,
49.3,
84.9,
50.8,
77,
78.9,
85.6,
85.8,
62.7,
52.3,
25.1,
94.1,
57.1,
29,
23.6,
4.7,
44.9,
57.1,
10.4,
86.8,
60.7,
30.9,
46,
64.9,
85.3,
71.1,
63.5,
61.3,
26,
96.5,
39.3,
20.7,
58,
18.6,
80.5,
40.4,
54.9,
27.5,
73.9,
2.2,
40.8,
42.5,
35.4,
70.9,
78.3,
52.5,
80.5,
88,
89.5,
58,
55.5,
2.1,
26.8,
39.1,
35.1,
16.1,
0,
64.6,
29,
40.6,
61.7,
68,
87.9,
22.2,
89.3,
21,
40.8,
28.5,
28.9,
65.3,
19.1,
58.4,
59.1,
116.1,
84.6,
70.5,
36.1,
88.9,
52.6,
75.9,
83.4,
30.2,
10,
57.4,
25.4,
15.2,
73.5,
40.9,
86.1,
97.3,
91.5,
75.7,
66.3,
68.2,
87.8,
21.5,
37.2,
90.8,
37,
54.1,
78.9,
93,
47.8,
96.3,
60.4,
74.3,
91.9,
20.3,
38.2,
61.3,
51.9,
32.3,
65.5,
96.7,
93.6,
39,
79.7,
96.9,
4.3,
72.3,
91.7,
95,
44.2,
87.3,
44.9,
20.4,
85.3,
55.7,
78.3,
48,
5.9,
55.2,
31.1,
95.9,
43.1,
26.9,
94.9,
79.3,
50.7,
17.6,
51.7,
53.7,
32.8,
90.3,
86.6,
27.1,
36.1,
28.5,
68.3,
40,
29.6,
70.1,
90.6,
28.3,
63.4,
83.8,
63,
89.5,
98.2,
44.9,
75.1,
78.3,
54.3,
35.7,
1.5,
81.9,
65.6,
47.7,
17.9,
65.2,
78.8,
51.2,
67.2,
61.8,
48.9,
11.1,
46,
45.3,
94.2,
66.4,
2.3,
59.3,
20.9,
46.7,
98,
50.2,
65.5,
95.1,
74,
89.9,
60.9,
38.5,
47.4,
99.5,
88.4,
34,
36.3,
92.7,
26.8,
52.6,
47.3,
31,
48.5,
89.7,
21.3,
38.1,
77.5,
55.7,
33.4,
36.6,
99.1,
74.7,
32.3,
78.7,
58.3,
78.6,
30,
43.1,
39.2,
56.4,
84,
52.6,
51.3,
77.4,
79.3,
0,
66.4,
56.8,
53.7,
91.6,
54.7,
29.5,
70.8,
12.1,
37,
25.5,
86.3,
61.9,
58,
14,
39.4,
77.3,
76.7,
57.8,
16,
63,
34.2,
96.2,
49.8,
28.6,
88.3,
80.5,
27.3,
51.4,
96.9,
46.8,
31.6,
37.6,
8.5,
52.2,
4.5,
69.2,
52.5,
4.6,
56.3,
82.2,
63.9,
53.9,
25.1,
33.9,
37.2,
42.8,
43.4,
78.4,
41,
86,
58.6,
59.9,
20.7,
13.4,
17.6,
41.2,
12.4,
42.7,
56.2,
67.9,
83.1,
49,
33,
61.5,
68.5,
26.1,
72.8,
12.1,
69,
52.6,
71.1,
67.6,
51.9,
37.3,
62,
52.8,
19.7,
88.7,
28.5,
51.6,
52.6,
69.8,
53.2,
46.3,
54.1,
17.5,
62.2,
5.7,
71.3,
63,
38.9,
91,
36.3,
12.6,
87.7,
32.6,
71,
52.9,
23.9,
62.7,
59.2,
78.4,
60,
7.8,
76.4,
81.7,
83.5,
72.7,
59,
69.9,
43.7,
43.7,
47.5,
88.3,
90.2,
39.9,
60.2,
55.3,
80.2,
33.2,
35.6,
68.8,
69.8,
92.8,
41.2,
73.5,
49.7,
17.5,
16.1,
55.9,
56.2,
90.1,
89.2,
62.2,
59.2,
47.7,
76.1,
81.5,
14.5,
40.4,
32.6,
50.3,
53,
41.1,
77.7,
93.6,
84.3,
91.7,
7.1,
77.8,
87.7,
84.8,
38.8,
43.7,
60.8,
70.6,
23.7,
61.8,
28.6,
18.5,
84.5,
55.8,
54.5,
28,
37.5,
91.4,
80.6,
47.4,
71.9,
14.3,
88.6,
29.5,
51.8,
55,
25.9,
100.2,
12.7,
82,
69.2,
84.3,
45.2,
74.2,
97.7,
80.9,
68.5,
61.1,
42.1,
97.5,
32.7,
64.8,
47.6,
14.7,
86.5,
79.9,
24.2,
83.8,
49.8,
61.3,
81.6,
73,
53.3,
37.1,
57.4,
72.1,
8.7,
50.3,
54,
22.9,
17,
41.5,
80.3,
16.6,
23,
79.9,
84.7,
40.4,
76.4,
74.3,
40.1,
7.6,
49,
44.8,
91.5,
8.6,
55.7,
21.6,
91.2,
56.4,
31.6,
71.6,
65,
79.8,
65.1,
71.6,
38.3,
75.8,
42.9,
56.3,
66.7,
34,
33.3,
71.8,
49.2,
80.5,
69,
10.5,
52.7,
50.1,
46.8,
84,
88.8,
64.9,
30.5,
88.4,
70.6,
75.6,
61.2,
34.6,
39.7,
41.4,
42.4,
90.1,
28,
59.5,
77.4,
70,
71.4,
45.4,
25.8,
33.4,
75,
48.8,
91.6,
75.5,
93,
32.8,
43.7,
43.1,
31.4,
79.5,
15.7,
41.4,
89.3,
47.1,
58.3,
90.5,
37.6,
84.3,
20.8,
52.2,
79.9,
18.6,
46.5,
53.3,
75.4,
27.9,
73.8,
97.6,
86.5,
77.6,
69.6,
52.4,
85,
81.6,
76.3,
97.7,
35.1,
20,
86.2,
49.1,
55,
75.1,
18.6,
63.2,
41.2,
48.8,
86.9,
62.1,
79.1,
65.4,
69.2,
43.1,
39.9,
48.8,
37.1,
18.5,
43.4,
21.9,
4.7,
76.4,
38,
45.3,
17.7,
20.1,
64,
93.3,
51.1,
58.7,
50,
82.8,
28.8,
53.4,
42.5,
50.9,
47.4,
26,
65.1,
35.6,
76,
62.4,
34.9,
35.5,
47.1,
71.1,
60.6,
13,
29.4,
26.4,
35.7,
63.4,
17,
59.2,
53,
59.9,
22.1,
93.6,
72.7,
69.1,
72.7,
47.3,
79.4,
78.7,
43.1,
39,
65.7,
89.9,
69.2,
5.4,
65.9,
74.1,
68,
17.2,
83.6,
89.9,
63.1,
70.1,
63.9,
12.2,
64.5,
62,
57.3,
37.3,
91,
74.8,
35.6,
67.9,
4.6,
41.4,
40.5,
73.9,
32,
78.3,
75.3,
25,
41.2,
68.1,
60.5,
42.6,
39.7,
2.7,
88.5,
55.1,
34.8,
57.6,
14.6,
20.3,
45.6,
36,
69,
32.5,
76.6,
81.1,
63.4,
67.9,
15.8,
79.1,
82.4,
60.2,
40.2,
66.1,
43.3,
68.6,
41.6,
41.2,
70.2,
85.1,
12.2,
20.2,
53.7,
46.3,
32.5,
68.6,
25.8,
73,
73.1,
43.5,
31.3,
76.6,
57.7,
72.9,
86,
15.5,
8.9,
66.5,
63.9,
59.1,
86.7,
71.1,
30.9,
15.6,
57.2,
0,
32.5,
57.3,
74,
76.3,
57.9,
13.4,
93.8,
36.6,
34,
83.2,
4.1,
89.4,
44.7,
35,
23.3,
82.7,
2.2,
58.6,
42.2,
23.6,
38.2,
82.5,
71.7,
46.5,
89.5,
76,
103.1,
67.2,
15.6,
60.4,
97.8,
53.4,
95.5,
58.8,
88,
53,
93.9,
45.6,
56.7,
51.8,
0,
75.4,
23.5,
53.5,
61.8,
13.1,
40,
94.3,
24.8,
49.4,
68.4,
75.4,
38.8,
67.6,
70.6,
33.9,
62,
84.6,
25.9,
36.8,
69.7,
58.8,
8.4,
38.5,
14.2,
67.6,
66.9,
55.4,
49.9,
50.6,
45.4,
48.4,
23.5,
56.3,
79.8,
52.8,
32,
68,
60.5,
42.5,
29.4,
95.3,
32.4,
51.2,
53,
35.1,
51.8,
75.5,
15.1,
55.7,
47,
15,
42,
38.8,
46.5,
22.9,
39.3,
88,
30.8,
62.8,
72.4,
76,
42.7,
78.7,
0,
47.1,
23.7,
20,
83.9,
58.4,
70.7,
53,
60.8,
94.8,
60,
43.8,
92.9,
97.9,
80.4,
35.7,
25.3,
74.4,
22.2,
61.8,
61.8,
33.8,
52.2,
21.7,
89.5,
72.6,
41.6,
58.9,
30.1,
84.8,
25.5,
54.6,
63.4,
56.6,
4,
9.7,
100.8,
59,
10.8,
66.5,
43.6,
61.2,
51.2,
44.3,
78.4,
51.8,
68.4,
36.5,
82.2,
85.1,
53.3,
42.3,
12,
69.9,
54.3,
53.9,
13.2,
54.9,
64.4,
50,
17.7,
40.8,
54.8,
97.7,
60,
57.3,
53.1,
39.9,
1,
35.9,
58.4,
37.5,
68.2,
36.9,
49.6,
1.3,
40.6,
0,
61.1,
61.3,
9.9,
49.4,
50.8,
58.2,
31,
44.8,
94,
74.9,
51.7,
67,
95.4,
34.9,
55.2,
30.4,
48,
42.1,
33.5,
52.8,
44.8,
57.7,
0.2,
41.8,
51.1,
41.2,
65.8,
99.7,
50,
44.6,
16.9,
23.7,
44.5,
34.5,
52.8,
52.8,
85.8,
5.5,
0,
59.2,
27.4,
19.1,
36.5,
79.5,
31.3,
55.8,
56.8,
58.7,
53.9,
38.3,
67.8,
34.5,
64.8,
64,
59.3,
41.7,
88.5,
25.5,
59.7,
65.1,
71,
27.2,
103.5,
24.8,
36.4,
87.6,
76,
38.4,
56.6,
4,
9.3,
28.6,
58.2,
33.3,
67.9,
66.9,
16.9,
46.3,
60,
33.5,
4.2,
27.7,
33.3,
58.7,
88.7,
33.7,
89.7,
56.3,
12.5,
57,
106.6,
49,
94.4,
47.8,
41.4,
38.3,
9.6,
60.8,
68.9,
63.8,
12.1,
71.6,
71.8,
10.5,
83.6,
50.2,
56,
55.4,
46,
80.1,
98.9,
61.5,
73.9,
67.4,
69.3,
67.3,
62.8,
40.7,
63,
16.2,
50.4,
67.9,
88,
62.8,
45,
49.1,
44,
68,
14.3,
60.7,
31.6,
48,
83.3,
0.3,
50.6,
58.5,
93.3,
55.6,
55.4,
34.6,
77.3,
46.9,
59.9,
80.5,
12.7,
89.4,
59.6,
64.5,
0,
57.6,
96.5,
2.7,
72.1,
65.4,
42.6,
46.7,
92.5,
99.1,
49.3,
28.8,
56.9,
77.1,
60.5,
88.5,
56.3,
60,
57.2,
22,
67.3,
79.3,
96,
50.8,
42.3,
37.7,
57.7,
42.4,
85.3,
73.1,
97.6,
39,
1.8,
44,
29,
63,
77.7,
19.8,
8.9,
65,
36,
50.8,
64.5,
65.8,
46.9,
21.6,
78.4,
67.8,
46,
30.8,
46.2,
79.2,
88.4,
101.2,
73.7,
9.5,
64.1,
25.1,
13.1,
54.4,
22.7,
69.1,
59.8,
73.4,
90.5,
66.9,
46.3,
97.6,
89.1,
74,
7.5,
49.8,
18.2,
62.6,
2.9,
35.1,
67.6,
46.1,
47,
23.4,
85.6,
31.9,
22.6,
8.3,
89,
25,
46.1,
37.6,
58.4,
48.8,
48,
95.4,
57.1,
37.3,
60,
50.1,
19.1,
37,
62.1,
30.7,
33.9,
94.3,
72.4,
28,
75.6,
53.4,
46.6,
42.5,
44.1,
61.9,
65.1,
48.7,
88.2,
46.7,
45.2,
56.6,
43.1,
21.2,
41.1,
50.3,
70.6,
96.7,
62.7,
42.7,
55.3,
70.6,
11,
84.4,
42.8,
60.9,
32.9,
84.4,
52.5,
47.2,
72.1,
71.3,
54.2,
52,
53.4,
88.8,
76.4,
28.5,
61.1,
61.8,
35.7,
73.6,
46.4,
31.2,
75,
64.8,
18.1,
57,
42.7,
97.2,
43.9,
40.7,
42.3,
81.7,
61.7,
41.2,
45.5,
59.5,
30,
20.4,
39.3,
22.4,
10.6,
77.5,
73.7,
42.2,
74,
63.5,
31.7,
17,
85.6,
62.5,
10.9,
71.9,
20.7,
75,
7.2,
60.7,
67.6,
46.2,
48.1,
93.3,
65.3,
12.6,
2.6,
79.4,
66.5,
56.7,
76,
67.8,
86.7,
64.9,
5.5,
95.6,
63.3,
30.6,
99.1,
90.2,
44.5,
33.3,
47.9,
31,
69.5,
24.4,
34.8,
54.1,
42.5,
53.6,
25.1,
65.2,
35.9,
68,
85.7,
53,
83.2,
77.3,
86.4,
82.6,
61.8,
53.9,
59.8,
79.5,
90.4,
65.2,
24.2,
93.6,
68,
61.1,
43.6,
100.3,
58.4,
49,
18.7,
46.7,
52.6,
90.3,
40.1,
70.3,
92.2,
74.7,
58.7,
84.3,
48.9,
82.8,
89.3,
71.2,
23.6,
72.6,
16.8,
69.9,
84.3,
29.9,
54.7,
27.1,
58.4,
35.4,
51,
7.2,
64,
81.8,
82.5,
67.4,
54.3,
57.1,
89,
50,
67,
23.5,
10,
28.4,
47.4,
87.7,
33.9,
72.4,
71.7,
59.5,
49.4,
87,
48.8,
11.7,
68.2,
47.1,
63.7,
52,
42.1,
48.1,
69.1,
82.9,
40.9,
51.9,
45.7,
74.5,
70.2,
76.2,
76.4,
46.1,
96.3,
68.4,
84.9,
32,
63.1,
52.1,
61.1,
17.7,
65.5,
70.5,
81.1,
55.7,
56.1,
35.4,
93.2,
96.3,
56.9,
56.3,
32.8,
93.4,
44.7,
41.3,
67.1,
40.6,
18.6,
29.2,
45,
60.7,
84.3,
26.7,
56.5,
38.7,
60.7,
57.8,
37.8,
89.6,
48.1,
1.3,
65.4,
51.2,
45.8,
17.6,
98.4,
98.4,
5.4,
28.6,
36.9,
96.1,
76.5,
85.1,
52.5,
37,
83,
14.4,
90.6,
14.5,
88.5,
82.3,
97.4,
80.4,
28.6,
43.3,
81.5,
5.6,
98.5,
47.5,
18.6,
74.5,
61.1,
47.2,
42.2,
0.4,
83.6,
64,
72.2,
82.8,
53.6,
60.1,
70.4,
79.5,
31.1,
16,
75.5,
75.4,
17.6,
50.1,
62.9,
63.6,
81.6,
46.6,
20.1,
56.5,
75.3,
83.5,
29,
75.5,
77.7,
68.3,
83.5,
72.1,
5.9,
87.1,
39.5,
61.8,
79.3,
67.2,
66.5,
68.9,
34.5,
102.7,
71.2,
49,
36.5,
43.3,
42.7,
93.5,
58.1,
85.9,
37.7,
96.7,
96.7,
44.7,
67.1,
47.7,
36.1,
85,
44.7,
43.1,
99.5,
53.7,
89.4,
49.9,
27.8,
24.1,
60,
58.8,
20.8,
77.1,
26.8,
58,
43,
53.9,
65,
95.9,
71.4,
55.5,
23.8,
80.4,
48.4,
30.4,
84.8,
39.2,
74.2,
55.6,
69.8,
55.5,
64.8,
46,
77.3,
63.1,
33.9,
5.4,
31.3,
44.3,
32.6,
40,
80.6,
56.4,
66.2,
81.3,
81.6,
37.4,
76.9,
36.6,
73.4,
14.3,
10.9,
74.7,
48.5,
53.3,
96.4,
59.4,
43.1,
92.3,
49,
87.9,
45.5,
37.5,
52.7,
60.4,
64.2,
68.9,
66.4,
59.4,
33.1,
39.3,
1.8,
81.1,
52.7,
50.2,
58.1,
85.1,
39.2,
94,
18.4,
40,
50.3,
31.2,
70.2,
71.2,
85.1,
25.5,
63.5,
86.5,
32.4,
45.4,
61.9,
91.6,
25.8,
38.9,
47,
57.5,
64.2,
70.4,
85,
38,
38.7,
13.6,
29.3,
93,
65.4,
64.9,
68.3,
47.6,
63.1,
94.1,
66.1,
75.8,
46.7,
74.9,
8.5,
23.9,
6.6,
64.8,
59.9,
46.3,
68.4,
43.8,
41.7,
67.2,
19.5,
49.9,
56,
49.4,
61.7,
32.9,
83,
53,
85.2,
86.8,
84.8,
74.1,
77.5,
67.4,
18,
54.1,
40.9,
41,
34.1,
78.3,
27.2,
42.9,
82.3,
63.3,
34.6,
67,
47.6,
4.7,
26.3,
66.1,
44.2,
73.2,
88.1,
76.2,
54,
53.9,
63.7,
95.2,
46.9,
85,
59.6,
29.2,
44.8,
45,
97.3,
51.6,
97.9,
61.1,
61.2,
45.4,
48.2,
38,
47.7,
47.5,
18.1,
51.1,
68.1,
74.9,
57.5,
69.5,
57.2,
11.6,
46.5,
54.6,
6.7,
68.1,
41.7,
86.1,
10,
13.5,
0.5,
39.8,
65.2,
84.4,
55.3,
3.8,
43.1,
14.6,
83.4,
72.2,
25,
17.4,
41.4,
38.6,
74.2,
93.6,
72.2,
61.7,
32.6,
82.1,
95.3,
24.7,
22.1,
83.1,
22.4,
43.6,
28.6,
65.2,
54.2,
39.6,
48.3,
85.6,
49.7,
31.3,
54.1,
37,
42.5,
87.3,
80.7,
56.3,
60.3,
61.6,
38.3,
27.6,
65.4,
61.8,
16,
63.7,
7.3,
75.1,
60.4,
67.5,
16.1,
57.6,
80.8,
69.9,
43.3,
54.8,
40.3,
52.1,
64.9,
73.3,
95.7,
83.8,
24.1,
32.1,
25,
61.6,
87,
78.1,
59.8,
56.9,
52.4,
5.79,
37.2,
74.2,
73.5,
50.5,
47.9,
42.3,
47.5,
80.1,
24.6,
46.3,
63,
77.2,
2,
0.5,
84.2,
32.5,
99.7,
75.8,
76.8,
38,
10.9,
29.4,
76.4,
88.4,
63.7,
90.8,
50.9,
18.6,
35,
51.7,
38.8,
90,
51.2,
42.9,
65.3,
75.9,
69.7,
72.5,
51.6,
74.4,
72.2,
101.3,
86.7,
70.6,
100.9,
33.4,
63.2,
57.7,
31.7,
72.9,
57.9,
63.2,
54.6,
58,
93.6,
91,
45.8,
68.3,
43.7,
18.5,
59.5,
85.4,
80,
32.1,
54.4,
86.9,
47.8,
86.3,
44.5,
37.7,
99,
52.9,
73,
30.6,
58.6,
19.7,
95.4,
84.2,
88.3,
80.3,
66.6,
78,
59.2,
32.9,
71.1,
99.2,
21.3,
25.7,
70.4,
56.6,
49.2,
57.9,
19.3,
57,
51,
48.6,
53.8,
54.4,
54.2,
24.3,
48.6,
16.4,
18.5,
53.4,
48.9,
21.8,
47.3,
50.6,
84.7,
51.1,
11,
87.7,
52.2,
57.3,
34.5,
48.4,
60.9,
15.6,
63.5,
21,
23.2,
52.6,
8.8,
74.1,
61.6,
43,
75.9,
43.8,
49.8,
28.2,
57.2,
50,
47,
27.3,
84.3,
22.6,
85,
53.8,
72.9,
53.4,
52.3,
47.9,
77.6,
79.5,
56.6,
67.6,
40.1,
58.6,
76.3,
38.9,
25,
69.1,
36.6,
47.8,
56.5,
45.2,
81.5,
53.8,
77.4,
57.3,
41.1,
28.1,
44.9,
74.1,
51.6,
58,
70.9,
63.2,
37.1,
47.8,
62.8,
67,
100.2,
47.4,
80.8,
92.2,
73.2,
67,
0.2,
60,
34.2,
56,
44.1,
31.2,
45.4,
34.8,
48.2,
41.7,
66.1,
70.1,
75.8,
0,
66.8,
46,
62,
28,
0,
52,
55.2,
84.2,
84.9,
83.1,
32.6,
82.8,
40.9,
25.8,
30.4,
58.2,
68.3,
94.6,
49.8,
17.9,
38.6,
49.9,
50.7,
77,
65.9,
97.4,
48.4,
91,
58.3,
57.5,
30.2,
7.5,
92.4,
58.1,
64.5,
15.1,
52.9,
79.7,
45.9,
48.2,
56.9,
34,
11.1,
23.9,
37.6,
37.2,
39.1,
43.5,
86.6,
54,
8.5,
34.7,
39.4,
69.4,
8.3,
86.8,
40.2,
59.3,
69.1,
86.8,
63,
42.6,
38.2,
56.1,
32.1,
34.9,
22.2,
82.1,
77.1,
47.1,
95.7,
47.6,
62.1,
62.1,
33.2,
85.4,
61.6,
41.7,
88.4,
52.3,
78.5,
95.9,
14.9,
51.7,
45.5,
23.7,
23.4,
70.2,
35.7,
67.3,
52.5,
31.8,
42.3,
43.5,
12.2,
10.6,
73.8,
31.1,
47.8,
29.4,
82.2,
37,
82.2,
25.1,
93.1,
85.9,
60.8,
89.2,
69.4,
79.9,
45.2,
54.2,
35,
53.8,
1.1,
30.8,
16,
55.4,
89.8,
76,
35.3,
30.9,
79.3,
35.5,
50.1,
92.2,
49.8,
88.3,
68.4,
79.7,
53,
84.9,
31.3,
75.9,
61.6,
67.7,
54.1,
61.6,
49.1,
62.9,
24.5,
62.8,
64.1,
45.2,
65.6,
7.1,
23.6,
93,
81.4,
15.6,
51.8,
95.9,
33.8,
68.4,
63.9,
44.9,
22.9,
48.7,
66.9,
67.2,
24.6,
53,
52.9,
61.4,
92.6,
19.6,
72.2,
69.6,
87.6,
64.3,
99.1,
89.1,
88.7,
70.5,
43,
74.8,
13.8,
50.2,
47.5,
81,
31.9,
48.4,
64.5,
40.9,
47.1,
83.4,
63.4,
44.7,
55.1,
65.6,
27.8,
75.6,
30.9,
47.7,
84.1,
49.2,
5.6,
53.8,
33.4,
49.2,
60.4,
33.3,
26,
39,
33.8,
6.3,
30.3,
96.8,
42.1,
74.7,
74.6,
74,
81,
33.5,
61.6,
10.8,
52.5,
82.5,
52,
47,
78,
43.4,
42.8,
25.5,
39.7,
42.8,
37,
5,
25.8,
42.3,
24,
59.9,
49.4,
35.8,
44.2,
77.1,
17.5,
71.7,
92.1,
92.2,
92.6,
98.4,
29.3,
69,
80,
82.9,
25.3,
86,
38.1,
100.4,
23.4,
52.1,
65.3,
16.9,
57,
54.1,
38.6,
69.4,
98.8,
37.9,
46.9,
55.7,
39.4,
50,
84.3,
69.9,
69.3,
56,
8.5,
52.7,
2,
26,
66.5,
83.7,
28.1,
23.1,
53.2,
91.7,
42.6,
16,
31.6,
69.2,
45,
6.1,
44.2,
76.1,
34.6,
60.5,
83.9,
42.4,
63.3,
51.2,
61.2,
84,
44.7,
54.2,
76.5,
80.4,
64.2,
83.6,
82.8,
82.9,
41.7,
61.6,
61.6,
83.2,
96.9,
41.2,
25.1,
45.3,
18.6,
77.6,
54.8,
31.9,
52.8,
54.6,
31.3,
45.3,
38.7,
69.2,
66.8,
13.9,
14,
68.7,
17,
46.3,
27.1,
55.3,
37.6,
30,
68.2,
22.5,
59.4,
81.1,
30.5,
51.8,
35.5,
34,
89.9,
70.2,
53.9,
61.2,
44.1,
42.9,
58.3,
78.4,
88,
18.2,
40,
63.6,
82.1,
46.5,
73.4,
31.7,
60.5,
70.3,
60,
33.8,
1,
98.5,
45.4,
17.9,
72.6,
59.5,
33.4,
17.6,
68.7,
9.8,
59.4,
49.6,
60,
48.4,
47.4,
52.8,
31.4,
55.7,
58.4,
100,
23.5,
38.3,
30.9,
39.4,
84.6,
67.1,
28.6,
52.2,
43.3,
74.8,
48.4,
81.5,
39.2,
47.6,
50.2,
89.4,
83,
44.4,
59.1,
85.4,
15.7,
91.7,
42,
73.5,
15.6,
36.4,
45.1,
34.1,
54.1,
37.4,
66.4,
37.8,
3.3,
51,
42,
68.8,
82.8,
48.3,
98.1,
56.2,
71.5,
66.1,
37.3,
47,
67.8,
46.8,
30,
60.7,
93.4,
74,
35.7,
37,
84.2,
73.7,
92.6,
84.1,
40,
40.9,
83.7,
73,
49.4,
35.2,
52.4,
47.3,
59.3,
64.4,
11.5,
50,
49.6,
50,
88.3,
72.8,
50.7,
65.1,
64.9,
22,
75.1,
59.2,
32,
58.3,
39,
31.5,
26.3,
64.1,
74.9,
55.7,
50,
60.3,
57.9,
70.2,
87.6,
43,
60.2,
51.8,
77,
33.4,
93.8,
63.2,
70.3,
25.8,
42.4,
53.4,
75.9,
54,
7.9,
71.2,
21.2,
86.3,
58.3,
76.2,
95.6,
48.6,
75,
77.7,
52,
41.7,
49,
35,
72.6,
60,
62.3,
60.3,
44.1,
19.1,
83.7,
88.5,
63.3,
81.2,
30.6,
51.7,
30.9,
50.5,
79.2,
56.3,
44.5,
41.8,
30,
58.8,
82.8,
67.9,
50.6,
47.5,
2.5,
40.1,
92.6,
21.3,
30,
40,
8.5,
83.4,
55.4,
92.8,
32.2,
84.6,
64.9,
59.6,
37.4,
47.4,
68.8,
53.3,
96.5,
34.4,
84.8,
82.3,
75.5,
68.1,
91.7,
83.7,
37.4,
29.1,
63.3,
47,
27.2,
48.3,
54.6,
52.1,
86.3,
65.9,
77.8,
54.9,
7,
94.7,
68.1,
6.8,
79.2,
34.7,
23.3,
49.2,
83.3,
1.1,
67.2,
11.5,
78.6,
72.3,
23.4,
19,
41.5,
60.6,
55.8,
51.1,
73.1,
61.6,
52,
39.5,
33.1,
65.5,
2,
44,
1.7,
40.4,
77.8,
56.2,
57.5,
27.9,
94.4,
74.5,
71.7,
53.5,
69.9,
62,
91,
40.2,
74.9,
40.1,
42.2,
98,
44.7,
50.6,
39.8,
3.9,
41.5,
25.8,
19.2,
78.2,
54.3,
44,
21.7,
94.9,
40.6,
60.8,
25.8,
34.9,
47.9,
11.9,
77.6,
26.8,
73.1,
66.8,
18.6,
66.9,
53.8,
50.8,
25.9,
7.9,
93.7,
67,
63.2,
27.8,
41,
69.9,
35,
60.1,
6.6,
59.3,
52.8,
70,
63.4,
34.5,
23.1,
39,
43.6,
87.7,
14.5,
80.5,
33.4,
19,
79.4,
0.7,
32.7,
84.5,
55.8,
51.9,
28.4,
56.4,
96.4,
64.6,
91.2,
45.2,
50.4,
68.5,
62.7,
72.2,
99.4,
69.5,
38,
44.4,
73.1,
57,
79,
79.2,
67,
58.5,
28.7,
0.7,
75,
86,
35,
31.9,
60.4,
56.2,
38,
61.5,
77.5,
54.9,
65.2,
26.3,
67.9,
16.2,
70.9,
33.2,
79.8,
76.7,
98.3,
24.4,
89.7,
62.7,
18.2,
92.4,
29.2,
50.1,
54.4,
57.1,
43.9,
40.7,
79,
74.8,
89.1,
95.7,
83.6,
15.5,
76.5,
95.6,
64.7,
72.6,
23.9,
62.6,
75,
62.8,
63.5,
60.4,
13.2,
37.9,
46.8,
83.8,
26,
55.1,
47.1,
53,
80.1,
62.7,
90.2,
41.6,
58.9,
41,
7.1,
42.6,
34.9,
16.7,
75.1,
90.2,
69.6,
50.5,
80.2,
15.6,
31.1,
9.1,
26.6,
67,
12.2,
96.2,
24.3,
66.9,
46,
21.2,
33.9,
37.7,
69.4,
84.7,
0.3,
67.6,
69.6,
60.9,
75.5,
49.9,
84.1,
93.6,
30.7,
67,
47.2,
0.6,
52,
50.2,
65.6,
71.5,
40,
98.5,
88.4,
91.4,
97.7,
46.3,
31.2,
17.4,
59.2,
97.9,
48.5,
0.5,
43.2,
44.9,
85,
57.2,
49.6,
60.4,
81.9,
37.2,
7,
50.5,
61.5,
89.3,
37.8,
70.2,
70.5,
22.8,
47.2,
38.1,
36.1,
92.1,
26,
28.8,
22.3,
71.8,
12.6,
13.9,
69.5,
43.1,
71.6,
49.7,
18,
49.8,
63.5,
63.6,
48.1,
47.5,
58.9,
68.2,
60,
97.2,
68.9,
67.7,
80.7,
81.6,
54.2,
73.3,
77.7,
29,
13.9,
67.7,
20.8,
17.5,
24.9,
85.8,
70.1,
90.6,
91.5,
84.8,
6.5,
92.5,
32.4,
35,
53.4,
25.9,
48.2,
56.3,
73.7,
49.7,
78.4,
69.2,
79.5,
44,
31,
49.8,
85.8,
65.8,
96.1,
36.6,
48.2,
13.2,
83.9,
85.2,
55,
74.6,
90.3,
43.9,
43,
60.2,
32,
null,
86.8,
47.3,
57.8,
46,
65.7,
65.9,
40.1,
68.8,
20,
63.7,
47.2,
8.8,
47.7,
66,
83.2,
79.8,
53.6,
67.1,
24.4,
59.4,
15.8,
96.9,
74.6,
33.8,
36,
70.2,
78.3,
90,
62,
44,
81.5,
41,
94.2,
79.3,
39.2,
15.2,
87.5,
14.3,
61.2,
79.5,
25.6,
22,
54.4,
35.8,
54,
25.8,
47.2,
76.3,
22.5,
80.2,
89.4,
43.9,
27.2,
60.4,
8.9,
5.6,
63.7,
29,
49,
33.6,
7.2,
56.9,
90.1,
79.1,
32.3,
84.8,
71.1,
62.6,
73.4,
15.6,
95.8,
57.1,
27.1,
55.7,
31.5,
67.2,
16.6,
29.9,
54.2,
60.4,
28.9,
61.7,
54.2,
25,
90.6,
72,
4.6,
73.1,
95,
66,
50.7,
35,
52,
43.9,
59.4,
59,
32.1,
54.2,
50.3,
34.2,
72.4,
2.2,
79.2,
24.4,
40.8,
44.6,
56.5,
59.8,
63.9,
43.3,
48.2,
34.5,
30.1,
52.9,
30.3,
93.4,
13.3,
81.6,
70.7,
90.8,
74,
9.4,
56,
68.9,
61.1,
49.8,
36.7,
64.6,
38.6,
73,
18.6,
39.7,
21.8,
49.8,
96.6,
80,
79.5,
87.6,
51.4,
95.8,
55.9,
82.2,
16.1,
65.6,
73,
37,
86.7,
88.9,
15.7,
69.6,
55.1,
38.9,
0,
16.9,
66.3,
81.9,
55.6,
49.7,
66.4,
37,
61.8,
34.5,
75.6,
26.3,
56.9,
58.7,
34.7,
45.6,
93.6,
50.8,
83.3,
38.2,
69.7,
49.8,
60.8,
54,
41.3,
28.9,
47.8,
100,
64.2,
66,
80.1,
96.1,
29.9,
23.4,
46.4,
75.4,
40.4,
22.9,
46,
42.4,
82.1,
61.1,
69.3,
94,
25.5,
20,
46,
35.3,
37.5,
26.8,
93.3,
44.5,
59.6,
29.5,
10,
63.6,
75.6,
29.8,
73.2,
3.7,
78.2,
41.6,
97,
72.1,
82.7,
82.3,
53.4,
26.2,
53.7,
55.7,
94.6,
69.6,
73.7,
72,
22.6,
43.3,
60.4,
86.3,
70.6,
29.6,
69.7,
71.9,
70.6,
60,
54.3,
57,
48.6,
26.9,
49.8,
71.4,
32.2,
15.6,
58.2,
99.8,
36.9,
68.4,
73.3,
59.4,
74,
82.3,
41,
41.2,
22,
57,
43.7,
63.5,
14.1,
70.2,
41.7,
50.4,
77.7,
53.2,
55.5,
48.7,
61.3,
78,
53.4,
45.6,
47.3,
5.1,
50.8,
61,
46.9,
43.7,
43.9,
35.8,
61.8,
71.2,
68.1,
40.1,
19.3,
48.6,
82.5,
91.2,
75.2,
51,
42.8,
23.4,
79.1,
45.8,
81.2,
38.3,
93,
78.2,
41.8,
64.4,
65.3,
21.7,
11.2,
26.2,
60.7,
8.8,
89.2,
38.6,
95.2,
47.9,
73.4,
30.6,
23,
68.6,
9.5,
83.6,
90.8,
76.3,
83.3,
66.5,
73.8,
92.7,
90.1,
69.1,
91.7,
83.3,
81.8,
58.8,
88.4,
47,
40,
4.5,
73.3,
58.8,
47.6,
52.9,
54.1,
59.3,
42.9,
50.7,
91.3,
97,
42.1,
29.5,
69.3,
53.5,
85,
38,
45.7,
47,
15.8,
59,
36,
20,
100.1,
54.3,
36.7,
10.3,
40.5,
37.1,
47.3,
86.4,
51.6,
74.5,
75.5,
55.7,
79.7,
57.7,
40.3,
44.6,
24.9,
39.4,
29.5,
71.7,
76.8,
76.7,
1,
82.5,
30.3,
9.4,
61.4,
73.6,
35,
73.5,
1.6,
29,
54.8,
8,
47,
63.1,
54.6,
26.6,
33.7,
53.9,
27.1,
86.2,
39,
76.1,
57.1,
66.6,
53.7,
34.1,
0,
46.2,
51.2,
49,
31.6,
84.3,
42.3,
21.2,
27.6,
83.8,
34.1,
22.4,
35.3,
34.4,
63,
76.6,
87.3,
16.1,
57.4,
49.4,
41,
61.3,
75.6,
40.4,
72.6,
70.5,
26.4,
83,
85.6,
76.7,
77.6,
78.5,
86.5,
64,
68,
87.6,
29.9,
38.9,
40.5,
75.3,
27.1,
88.5,
40.6,
80.7,
58.3,
48.7,
31.4,
92.4,
54.7,
45,
72.5,
62.6,
86.2,
95.5,
48.3,
29.7,
61.9,
61.9,
72.7,
28.9,
24.1,
64.3,
98.2,
13.8,
60.2,
47.7,
3.7,
32.6,
3.4,
68.4,
73.1,
61.5,
48.7,
52.4,
60.1,
29.8,
70.2,
64.3,
84.7,
41.8,
72,
63.6,
78,
23.2,
75.1,
24.7,
52.3,
87,
45.6,
30.5,
78,
22,
21,
58.9,
56.8,
95.7,
50.8,
53.6,
53,
98.6,
5.7,
37.8,
77.9,
56.7,
72,
23.4,
70,
72.3,
86.5,
45.9,
56.1,
84.9,
47.6,
20.7,
34.5,
52.8,
76,
5.4,
77.1,
5.6,
76.7,
41.5,
62.4,
86.6,
101,
81.9,
91.4,
74.4,
73.9,
66.7,
88.1,
68.8,
95.3,
23,
68.3,
51.4,
52.6,
49,
40.6,
43.4,
6.2,
41.7,
80.9,
58.4,
49.6,
5.3,
90.1,
0,
67.2,
99.3,
38.4,
2.2,
35.4,
94.1,
33.7,
64.7,
48.4,
62.7,
64.2,
87.4,
44.9,
99,
96.3,
67,
75.3,
51,
41.3,
94.5,
31.7,
67.3,
69.4,
83.1,
82.9,
60.7,
13.7,
54.4,
39.1,
46.4,
53.6,
84.5,
44.3,
25.4,
77.6,
67.2,
102.9,
27.1,
63.9,
39.7,
74.2,
86.2,
54,
51.6,
69.3,
70.5,
58.7,
77.8,
82.9,
39.1,
44.4,
57,
60,
66,
72.4,
36.2,
27.6,
15.6,
44.8,
69.4,
35.8,
46.8,
100.3,
7.5,
84.3,
64.4,
57.1,
76.9,
65,
73.2,
80.6,
83.3,
100,
34.9,
57.7,
61.7,
36.7,
58.9,
74.1,
61.3,
58.6,
76.5,
63.8,
49.3,
77.5,
59.8,
94,
47.5,
15.5,
37,
20.2,
22.8,
58,
45.9,
62,
39.5,
60.2,
53.5,
14.7,
38,
59.7,
58.7,
68.1,
49.6,
42.5,
53.6,
31.3,
92,
28.3,
72.4,
39.3,
71.7,
7.1,
76.1,
93.7,
38,
42.7,
96,
32.7,
58.3,
91.8,
53,
72.1,
86.4,
16.8,
20.7,
72.8,
44.1,
46.2,
65.8,
12.6,
51.6,
18,
68.2,
67.3,
45.9,
82.4,
84.4,
65.5,
81.4,
46.1,
53.4,
28.2,
87.3,
33.5,
76.8,
81.2,
65,
58.5,
81.6,
41.7,
14.3,
65.4,
17,
89.7,
65.1,
66.4,
79.5,
42.8,
32.8,
56.9,
63.3,
82.3,
50.9,
8.3,
37.2,
72,
16.3,
85.9,
47.2,
90.3,
26.4,
7.7,
49,
13.2,
78,
88.1,
18.9,
76.1,
13.7,
0.6,
84.2,
29.9,
23.9,
30.3,
43.4,
42.3,
66.8,
84.4,
93.8,
67.5,
72.5,
67.3,
64.6,
83.5,
67.1,
71,
63.1,
48.1,
71,
34.1,
51.8,
54.4,
38.2,
77.6,
95,
47.1,
59.5,
9.7,
53.5,
29.7,
56.8,
76.2,
37.7,
49.8,
33.7,
31.3,
57.9,
72,
61.6,
51.6,
94.7,
3.5,
67.2,
84.6,
42.3,
59.3,
3.5,
35.9,
94.6,
42.8,
58,
74,
21.4,
83.7,
34.6,
81.5,
80.5,
97.8,
38.2,
61.5,
62.6,
61.9,
12.1,
33.6,
49.1,
51.4,
52.8,
57.3,
81,
83.6,
41.2,
57.4,
3.2,
49.9,
65.5,
69.3,
57.4,
50.1,
31.3,
73,
63.8,
19.5,
64.1,
83.6,
66,
92.4,
43.4,
70.3,
65.8,
20.2,
51.5,
54.2,
37.3,
73.7,
39.2,
38.8,
39.1,
10.3,
45.7,
0,
71,
76.2,
60,
70.6,
96.4,
8.7,
54,
62.1,
94.8,
67.9,
48.2,
64,
71.8,
77.6,
49,
57.1,
41.7,
61.2,
94.8,
53.8,
49.1,
27.1,
43.5,
29.7,
66.5,
54.5,
38.3,
45,
59.8,
5.5,
12,
50.2,
57.1,
39.3,
59.7,
56.6,
30,
27.9,
57.1,
39.3,
82.2,
40.3,
68,
69.3,
47.3,
90.6,
56.7,
31.3,
36.5,
28.8,
27.6,
58.6,
91.6,
50,
51.7,
76.3,
74.9,
39.8,
83.5,
13,
53.4,
18.9,
59.8,
50.7,
33.1,
76.5,
55,
70.2,
67.9,
97.6,
40.2,
51.7,
42.2,
31.1,
94.1,
40.5,
55.7,
65,
25.1,
85.6,
63,
7.7,
50.7,
86.3,
70,
25.5,
10,
92.7,
73.4,
34.9,
55.5,
39.7,
56.5,
59.6,
89.7,
68.5,
37.2,
73,
82.1,
71.6,
57.3,
92.2,
23.3,
53.4,
87.2,
38,
64.7,
64.2,
86.5,
8.8,
75.7,
35.8,
38.7,
60.2,
37.6,
41.2,
55.3,
65.7,
59,
82.9,
79.4,
59.5,
98.6,
20.7,
56.4,
59.9,
90.9,
71.2,
80.2,
83.6,
20,
65.7,
9.8,
48.2,
44.7,
81.4,
29.9,
42.8,
21.8,
91.2,
32.6,
29.5,
76.6,
40.3,
95.1,
49.2,
35.3,
29.4,
34.7,
11.4,
54.1,
30.7,
91.4,
16.9,
33,
95.6,
47.5,
78.5,
47.3,
16.9,
38.3,
73.8,
87.2,
39.9,
34.2,
52.3,
36.8,
45.2,
47.7,
83.5,
29.8,
66.9,
50,
82.5,
95.1,
56.4,
48,
63.9,
49.7,
64.6,
47.2,
42.7,
94.1,
79,
29.9,
69.4,
61.9,
53.9,
54.1,
37,
32.5,
73.1,
11.7,
63.6,
88.8,
28.4,
73,
54.2,
40,
93.8,
95,
40.5,
28.1,
61,
44.8,
21.4,
24.5,
24.8,
62,
58.2,
64,
54.3,
73,
75.6,
23.8,
58.2,
87.9,
78.9,
41,
91.3,
83.8,
40.8,
33.4,
49.9,
12.3,
57.2,
69.3,
39.4,
43.5,
46.1,
53.3,
29.1,
82,
42.1,
4.1,
47.6,
38.8,
41.2,
33.1,
69,
87.9,
30.8,
31.9,
70.6,
60.2,
48.6,
88.2,
55.7,
55,
46.8,
66.9,
64,
36.9,
5.2,
38.7,
60.5,
61.4,
51.4,
40,
46.2,
84.1,
31,
81.2,
99.7,
70.7,
41.2,
59.9,
59,
74.9,
37.5,
47.2,
13.2,
30.8,
8.6,
46.4,
56.7,
74.7,
50.2,
77.8,
64.6,
35.2,
31.5,
49,
22.1,
82.2,
58.1,
44,
46.8,
40.6,
44.1,
83.7,
59.7,
59.9,
28.3,
48.2,
73.5,
24.3,
53.2,
40,
27.8,
71.6,
66.3,
60.6,
63.9,
67.7,
26,
13.3,
64,
35.2,
30.4,
95.4,
0,
10.8,
80.8,
49.3,
53.5,
40.8,
102.9,
65.5,
87.5,
33.7,
88.5,
54.7,
20.3,
68.6,
76.8,
0.4,
86.7,
69.9,
40.2,
97.5,
105.3,
92.7,
91.1,
33.3,
40.6,
69.8,
37,
97.4,
49,
47.1,
90.9,
43,
24.3,
11.7,
96.2,
54.4,
89,
85.2,
65.2,
57.8,
43.8,
56.7,
43.6,
51.2,
4.2,
58.8,
61.4,
88,
77.5,
56.9,
84.2,
44.2,
69.1,
55.2,
80.4,
14.4,
68.7,
53.3,
24.3,
36.6,
61.5,
76.5,
61.4,
28.3,
80.9,
47,
43.8,
45,
46,
37,
82.1,
36.7,
27.3,
15.1,
52,
34.2,
56.5,
79.7,
38.6,
57.3,
61.1,
38.2,
48.9,
62.1,
77.1,
55.4,
55.7,
56.6,
87.3,
96.8,
32.7,
81.5,
40.6,
85.9,
77.6,
48.5,
48.1,
71,
64.4,
53.8,
17,
51,
76.9,
69.1,
49.4,
47.3,
79.2,
22.8,
56.9,
50.4,
77.5,
30.2,
9.2,
71.4,
92.5,
14.3,
71.6,
87.3,
48.5,
31,
75.7,
36.5,
75.2,
96.1,
0.6,
100,
52.4,
65.1,
71,
59.7,
61.9,
64.7,
51.5,
64.3,
57.9,
70.4,
92.1,
58.8,
16.4,
65.3,
35.7,
92.8,
54.3,
20.1,
69,
54.1,
51.3,
72.8,
12.7,
80.8,
70,
71.6,
40,
74.7,
43.3,
84,
81,
60.6,
2.4,
45.7,
101.9,
15.1,
26.5,
31.2,
95.3,
38.8,
45.2,
66.3,
27.3,
93.9,
33.9,
50.5,
5.4,
63,
6.7,
68,
88.2,
64.3,
95.6,
42.9,
85.3,
75.5,
74,
51.6,
88.5,
57.7,
77.6,
41.9,
22.6,
12,
22.1,
27.7,
64,
57.2,
63.3,
68.2,
18.7,
58.1,
65.1,
66,
34.7,
62.1,
24.7,
86.5,
62.6,
49,
28.8,
50.4,
41.4,
58.5,
29,
64.8,
9.1,
38.7,
48.6,
64.5,
37.8,
30.5,
80,
88.4,
76.4,
20.3,
60.5,
64.1,
70.7,
41.4,
92.5,
41.2,
18.2,
25.5,
101.8,
43.5,
57.9,
17.6,
82.8,
91,
69.9,
69.9,
57.9,
46,
70.6,
93.9,
32,
0,
74.8,
28.1,
37.4,
56.1,
29.8,
80.6,
58.7,
22.3,
46.8,
58.1,
42.8,
45.4,
93.9,
25.3,
99.7,
48.5,
31.7,
47.2,
79.8,
36.1,
29.4,
58,
58.6,
79.7,
51.1,
44.5,
92.5,
68.2,
56.6,
25.9,
93.3,
63.5,
0.3,
79.9,
78.3,
89.4,
97.5,
0,
73.4,
37.9,
92.2,
59.4,
61.5,
42.2,
85.4,
20,
52.8,
43.5,
49.9,
92.9,
91.9,
69.4,
1.2,
80.3,
76.2,
47.4,
84.5,
39.5,
64.6,
51.2,
86.6,
46.1,
55.9,
41.5,
27,
33.9,
22.2,
37.6,
58.1,
59.3,
63.5,
37.8,
95.7,
74.7,
50.7,
72.3,
79,
39.2,
83.8,
51.5,
61.6,
40,
80.6,
75.6,
77.1,
70.5,
78,
98.2,
0.3,
69.6,
15.6,
78.3,
30.6,
92.4,
28.4,
12.3,
29.5,
98.5,
59,
64.5,
15.1,
53,
31.7,
65.7,
72.8,
28.4,
96.7,
75.3,
27.6,
63.1,
40.9,
43.6,
9.1,
16,
96.5,
43.8,
52.3,
70.3,
61.5,
38.1,
23.1,
30.7,
58,
65.6,
40,
50.7,
62.8,
31.9,
70.4,
47.5,
85.4,
44.8,
59.1,
53.5,
63.6,
61.3,
28.6,
29.8,
73.6,
84.4,
22.3,
71.9,
58,
47.4,
6.5,
20.8,
35,
46,
72.8,
43.3,
30.5,
61.6,
4.1,
44.6,
76.3,
86.5,
71.3,
76.2,
27.6,
47.7,
97.8,
67.3,
35.5,
20.6,
76.2,
46.1,
81.4,
46,
64.3,
70.4,
60.5,
28.5,
52.3,
43.8,
67.6,
26.4,
57.4,
67.8,
61.9,
52.7,
73.4,
72.3,
90.2,
74.2,
66.8,
48.8,
41.1,
7,
32.9,
41.1,
67.3,
47.6,
15.7,
42.7,
73.6,
16.8,
37.8,
39,
86,
63.6,
66.4,
82,
29.3,
44.2,
67.1,
52.8,
32.1,
60.4,
48.9,
4.7,
64.7,
55.6,
51.3,
16.7,
95.5,
68,
48.8,
26.2,
75.4,
91.2,
64.1,
89.2,
45.9,
12.6,
77.2,
42.7,
66,
60.4,
89,
86.1,
54.8,
78.7,
42.5,
65.4,
83.3,
55.7,
70.9,
49.3,
27.4,
38.7,
68.5,
55.1,
79.5,
30.3,
39.7,
50,
38,
54.8,
39.3,
76.1,
68.7,
31.4,
60.5,
40,
60.2,
40.9,
38.8,
70.7,
49,
71.7,
73.8,
96.9,
52.2,
37.4,
71.4,
66.9,
52.1,
85.8,
87,
66.7,
88.7,
56.1,
80.3,
97.7,
23.8,
72.3,
63,
10.4,
80.5,
63.8,
70.7,
12.9,
59.6,
61.4,
87,
47.8,
23.6,
63.9,
43,
68,
70.4,
76,
80.6,
61,
76.7,
70.7,
39.8,
42.3,
32.9,
24.4,
79.9,
88.6,
0.6,
13.4,
8.2,
93.7,
25.7,
71.5,
87.2,
40.3,
30.6,
81.5,
43,
78,
55.1,
65,
29.4,
38.9,
53.9,
42.4,
57.5,
38.1,
32.2,
74.7,
81.9,
58.7,
13.3,
61.5,
60.3,
91.3,
1.4,
54.3,
42,
47.8,
18.9,
83.1,
78.7,
13.5,
97.8,
23.8,
22.1,
61.6,
73,
77,
39.8,
31.5,
98.1,
84.5,
53,
59.1,
45.4,
29.5,
86.4,
18.2,
29.7,
55,
67.6,
84.2,
53.8,
43.6,
66.1,
52.4,
61.1,
83.1,
43.4,
37,
49.9,
20.1,
37.2,
37.1,
81.5,
29.9,
84,
72.6,
43,
73.1,
59.2,
26,
58,
53.6,
79.3,
68.9,
34.6,
84.8,
49.8,
30,
92.7,
81.9,
65.6,
44.9,
80.1,
87.7,
61.2,
72.2,
83.7,
15.1,
37,
52.9,
93.4,
31.1,
58.4,
98,
62.7,
49.3,
95.4,
19.9,
69.4,
76.6,
91.8,
70.8,
29.5,
81.9,
49.8,
53.5,
48.9,
13.3,
64.3,
40.8,
87.3,
56.3,
45.8,
53.7,
91,
68.1,
66.6,
58.7,
54.7,
15.3,
11.2,
22.3,
57.4,
52,
83.6,
98.8,
25.1,
43.7,
90.3,
92.5,
69.7,
91.6,
36.7,
60.5,
34.5,
77.8,
48.7,
61.2,
79,
70.1,
14.2,
48.2,
45.7,
68.8,
77.6,
51.4,
83.1,
20.2,
72.3,
78.5,
25.1,
91.2,
73.3,
41.1,
60.7,
92.6,
2.6,
64.7,
55.4,
94.9,
4.6,
22.8,
8.9,
47,
79.3,
16.3,
55,
57.9,
33.9,
95.5,
79,
91.3,
48.9,
54.2,
74.6,
78.3,
31.8,
85.5,
66.9,
83.9,
38.7,
28,
41.7,
76,
66.5,
86.1,
38.4,
58.8,
44.2,
80.8,
68.8,
58.8,
61.4,
50.1,
83.1,
0,
73.1,
71.5,
51.3,
76.4,
46.1,
64.6,
55.8,
48.9,
70,
18.9,
36.3,
21.2,
57.3,
63.2,
77.1,
73.6,
85.4,
82.5,
60.7,
98.3,
36.8,
93.6,
57.7,
14.3,
31.4,
47.3,
79.8,
28.8,
77.8,
79.5,
72.9,
20.7,
30,
59.4,
63.7,
58.4,
80.5,
49.7,
34.9,
57.5,
39.7,
55.1,
63.6,
25.8,
59.3,
66.7,
15.3,
38.8,
0,
63.7,
76.5,
13.5,
71.9,
36.4,
32.9,
76,
33.2,
48.4,
73.6,
50,
93.5,
79.9,
86.2,
40.4,
49.9,
81.2,
71.9,
62.8,
51.1,
95.7,
58.4,
41.7,
81.1,
79.5,
60.3,
43,
41.1,
45.4,
65.8,
77.3,
64.2,
54.8,
57,
42.2,
25.9,
10.7,
51.1,
42,
65.6,
89.3,
87.1,
null,
34.1,
67.1,
73.2,
41.1,
31.1,
1,
51.4,
75.4,
43.8,
64.1,
90.3,
54.7,
28,
26.2,
34.8,
30.3,
54,
26.5,
90.5,
50.3,
46.7,
5,
70.9,
93.6,
95.4,
43.1,
71.9,
32.2,
26.1,
80.4,
43.3,
61.5,
16.7,
66.2,
75.6,
96.7,
36.7,
61.2,
54.1,
32,
9.2,
70.3,
60.6,
43.7,
67.8,
60.3,
76.5,
75.6,
57.8,
84.2,
53.3,
92.2,
19.3,
71.5,
75.7,
37.6,
78.4,
11.3,
39.1,
43.3,
82.3,
60,
55.4,
71.3,
56.9,
19.9,
7,
62.5,
20.2,
64.4,
63.8,
16.2,
0,
36,
57.9,
21.6,
51,
83,
62,
70.9,
50.6,
34.9,
60,
96.9,
43.5,
36.2,
13.3,
21,
84,
39.6,
15.2,
11.4,
6.1,
78,
42.9,
56.8,
31.1,
80,
17.9,
41.7,
35.6,
53.1,
63.8,
16.2,
53.5,
76.2,
14.2,
91.4,
64.3,
31.8,
43.7,
43.4,
21.8,
40.9,
53.4,
79.2,
46.1,
29.2,
79.4,
80.7,
62.3,
59.9,
80.8,
6.3,
34.2,
0,
0,
53.5,
47.3,
68.6,
73,
52.1,
42.7,
39,
38.5,
52.4,
17.2,
87.5,
15.7,
74.5,
66.6,
62.6,
58.2,
21.4,
57.4,
60.4,
42.7,
26.2,
66.9,
94.1,
74.6,
81.6,
65.1,
85.6,
61.7,
72.2,
66.5,
76.1,
19.1,
64.2,
70.2,
26,
27.5,
73.4,
20.2,
25.7,
5.7,
96.8,
80.1,
5.1,
49.6,
54.1,
32,
58,
23.1,
59.1,
84.6,
58,
21.7,
56.1,
94.8,
54.9,
75,
37.8,
37,
36.7,
21,
62.8,
42.2,
95.1,
39,
62.4,
47.4,
36,
61.9,
87.9,
18.6,
66,
27.8,
21.5,
72.3,
31.8,
87.7,
55.8,
39.1,
50.1,
83.2,
44.1,
85.3,
11.3,
68,
68.8,
69.5,
65.9,
79.9,
42.9,
87.4,
94.8,
45.2,
45.1,
64.4,
62.5,
58.6,
42.6,
12.9,
89.4,
75.9,
80.5,
89,
1.5,
31.2,
42.2,
55,
7.1,
56.1,
36.1,
64,
62,
80.6,
33.3,
46.5,
47.8,
70.5,
59.6,
15.7,
79.5,
46,
20.8,
27.8,
50.9,
49.6,
62.4,
56,
86.1,
44.2,
13.3,
42.8,
61.6,
43.1,
79.7,
4.3,
6.1,
68.1,
70.2,
7.6,
22.1,
46.5,
89.2,
46,
64.3,
65.6,
61,
54.9,
83.6,
49.7,
51.3,
37,
68.1,
27.7,
44.7,
16.1,
43.1,
90.4,
77.4,
81.8,
9.4,
83.6,
37.5,
29.2,
50.4,
17.4,
80.8,
55.4,
70,
0,
56.1,
75.5,
34.6,
5.6,
84.4,
36,
46.5,
64.8,
52.6,
67.5,
26,
49.3,
42.8,
21.3,
51.1,
84.1,
35.6,
50.6,
55.6,
88.2,
57.7,
57.5,
56.4,
32.7,
23.6,
73.5,
89.1,
95,
47.4,
36.4,
50.5,
84.7,
79,
57.2,
46.5,
77.4,
12.8,
75.4,
64.2,
32.9,
85.6,
21.2,
58.4,
55.1,
43.3,
32.3,
59.5,
81.3,
32,
70,
91.6,
61,
49.5,
51.2,
36,
58.6,
94.1,
52.9,
43.4,
0,
27.3,
40.3,
87.9,
35.3,
64.5,
50.9,
21.6,
85.9,
9.8,
77.8,
90.5,
39.5,
97,
47.5,
39.7,
46.5,
28.7,
19.8,
62,
94.6,
74.1,
51.1,
57.4,
85.3,
73.3,
25.1,
64.8,
54.3,
48,
86.1,
73.5,
87.9,
62.8,
98.7,
94.8,
60.8,
56,
76,
80.1,
58.5,
33.2,
51.4,
10.7,
21.1,
78.2,
66.3,
23,
64.4,
57,
53.3,
53.7,
48.7,
30,
42.8,
8.8,
89.2,
53.3,
48.9,
78.1,
54.3,
36.9,
47.9,
51.3,
100.4,
72.8,
56.9,
25.7,
63.5,
76,
59,
51.6,
78.9,
58.2,
57.3,
28.6,
76,
62.3,
89.5,
85.1,
57.6,
33.9,
77.1,
97,
41.8,
56.6,
65.7,
33.4,
78.6,
48,
59,
34.8,
39.3,
62.5,
86.2,
41.9,
16,
26.4,
26.1,
24.1,
50.5,
42.4,
18.2,
73.1,
62.6,
80.8,
86.9,
42.9,
16.2,
67.9,
8.1,
50.4,
54.3,
49.8,
43.1,
68.6,
53.6,
73,
88.3,
0,
7.3,
73.4,
2.1,
41.5,
48,
8.7,
42.5,
64.2,
94.8,
85.4,
83.9,
38.5,
50,
33.9,
81.1,
84.3,
62.9,
39.1,
49.8,
98.1,
86.7,
47.4,
63.5,
34.8,
95.4,
37.1,
90,
78.9,
64.6,
63.5,
71.5,
69.8,
53.5,
88.5,
71.8,
43.3,
68.4,
49.9,
95.6,
43.2,
67.9,
19.3,
8.4,
24.8,
77.3,
81.3,
98.5,
54.9,
47.8,
54.9,
44.3,
96.6,
26.4,
48.1,
36.4,
41.5,
39,
67.2,
63.8,
64,
59.4,
23.3,
83.2,
64.5,
49.5,
51.6,
80.1,
35.7,
93,
92.8,
60.7,
42.8,
57.6,
14.7,
62.9,
67.9,
52.2,
53.2,
35.5,
62.7,
10.4,
22.5,
19.5,
44.6,
29.6,
23.4,
84.2,
45.4,
46.6,
29.8,
62.7,
99.2,
46.7,
54.4,
17.8,
73.1,
56.6,
50.4,
89.6,
32.9,
49.8,
24.3,
49.1,
69.7,
69.5,
33.4,
49.3,
90.5,
40.9,
71.3,
72.3,
30,
55.2,
50.7,
55,
54.5,
48.1,
45.8,
43.3,
53,
47.2,
80,
70.3,
37,
38.2,
41.2,
75.6,
76.7,
79.3,
94.3,
56.9,
28.8,
85.7,
66.7,
29.6,
23.1,
74.4,
43.2,
5.3,
30.8,
19.5,
58.6,
67.1,
91.2,
56.2,
74.5,
75.6,
23.2,
45.2,
60.7,
91.6,
65.9,
88.6,
56.1,
46,
100.1,
53.5,
49.1,
75.1,
6,
20.2,
0,
101.5,
50.3,
84.1,
45.9,
39.4,
55.1,
44.8,
81.6,
91.1,
61.8,
64.1,
69.2,
62.9,
6.3,
87,
82.4,
79.1,
94.7,
83.1,
11.8,
49.6,
44.9,
87.1,
67.9,
84.6,
59.2,
42,
28.2,
69.6,
38.4,
76.1,
28.7,
94.1,
23.7,
95,
55.1,
37.5,
86.6,
43.5,
71.5,
32.1,
93.7,
26.9,
41.2,
66.1,
18.2,
54.5,
12.2,
91.2,
54.7,
15.6,
21,
27.1,
45.6,
24.1,
54.9,
33.8,
0,
48.6,
38.3,
75.4,
40.6,
46.9,
36.3,
35.2,
73.5,
49.1,
26.3,
62,
64.6,
94.2,
49,
87,
32.1,
56.1,
77.3,
42.3,
20.4,
17,
87.9,
62.6,
57.7,
26.4,
37,
27.6,
54.9,
1.1,
55.4,
95.3,
21.8,
39.1,
69.7,
52.1,
94.2,
76.3,
15.2,
49.7,
87.7,
24,
38.2,
50.9,
47.5,
68.9,
87.2,
44.4,
78.3,
87.2,
91.6,
27.7,
97.1,
40.9,
71.1,
51.7,
87.3,
82.6,
67.6,
67.6,
51.7,
72.7,
42.1,
54,
12.3,
76.3,
72.3,
88.3,
32.4,
48.6,
0.8,
56.1,
81.2,
60.4,
64.4,
67.5,
32.7,
38.2,
79.2,
42.1,
79.4,
69.3,
66.6,
76.9,
1.5,
97.4,
78,
78.3,
81.3,
54.3,
60.9,
42.2,
48.7,
54.9,
19.9,
63.9,
76.5,
84,
92,
53.9,
68.9,
20.2,
81.8,
93.6,
11.2,
91,
86.2,
41.4,
63.9,
35.6,
87.7,
46.1,
64.5,
84.2,
2.1,
66.8,
33.7,
58.3,
76.7,
67.7,
84.4,
15.4,
74.3,
81.7,
24.3,
59.3,
82.3,
13.4,
81,
82.8,
18.2,
0,
41.5,
39.1,
27.5,
60,
56.9,
63.8,
78.2,
55.3,
84.6,
42.7,
98.9,
61.2,
38.8,
73.3,
23.9,
46.1,
58.3,
38.7,
73.6,
18.4,
86.8,
65.3,
92.8,
1.4,
89.6,
79.7,
31.6,
55.1,
59.1,
86.8,
33,
70.3,
88.2,
34.5,
6,
33,
39.7,
69.6,
56.3,
17,
82.1,
93.2,
56.5,
33.4,
31.1,
45.2,
69.6,
47.8,
66.4,
35.2,
64.4,
88.7,
76.9,
5.5,
64.4,
73.8,
76.4,
69.7,
49.2,
72.1,
38.1,
63,
83.1,
31.2,
20.1,
80.8,
44,
52,
15.7,
78.9,
37.7,
95.1,
23.9,
54.4,
33.4,
54.5,
52.2,
69.1,
83,
61.1,
11,
38.3,
67.8,
43.3,
38.2,
78.4,
27.3,
58.7,
5.9,
70.8,
38.7,
78.7,
94.5,
47.2,
44.8,
72.4,
68,
45.4,
40.7,
26.1,
85.2,
26.4,
70.9,
20.6,
86.7,
99.3,
72.3,
76.9,
3.6,
42,
30.4,
96,
62.6,
80.4,
74.7,
79.9,
57.2,
38.3,
64.1,
42,
46.1,
57.9,
46.7,
77.3,
82.1,
70.8,
79.6,
52.7,
15.4,
37.2,
71,
88.2,
34,
13.5,
44,
24.4,
73.8,
19.4,
10.1,
48.9,
59.9,
91.8,
55,
40.6,
61.1,
46.6,
56.1,
46.2,
31.1,
54,
44.2,
52.7,
45,
50.8,
45.2,
31.3,
82.9,
98,
91.3,
87.9,
69.5,
83.3,
30.8,
74,
60.8,
72.8,
13.6,
43.6,
95.7,
89.2,
48.1,
84.3,
13.9,
57.4,
81.2,
83.7,
81,
75.4,
56.2,
80.3,
88,
22.1,
53.3,
33.4,
88.5,
87.7,
28,
76.4,
68.5,
32.5,
31.5,
74.3,
21,
41.1,
58.7,
34.3,
84.4,
67.1,
75.5,
65.1,
45.5,
72.1,
49.8,
11.7,
69.3,
80.5,
79.7,
34.1,
71.4,
82.4,
46.6,
65.6,
83.4,
49.4,
42,
43.2,
24.8,
67.3,
59.9,
47.7,
88.8,
8.4,
39.5,
78.8,
74,
50.9,
91.8,
37.6,
82.6,
73.9,
71.2,
34.2,
51.1,
95.1,
68,
54.7,
72.1,
24.3,
39.1,
41.3,
93.6,
91.8,
48.1,
92,
87,
14.4,
66.2,
56.4,
57.6,
63.4,
44.9,
77.9,
60.9,
42.8,
21.4,
45.2,
73.1,
21,
80.8,
72.3,
56.6,
78.4,
18.2,
37.4,
14.2,
53.4,
63.2,
94.3,
36,
61.3,
55,
53.4,
47,
38.2,
50,
48.7,
42.4,
36.4,
87.4,
70.7,
79.8,
22.2,
36.9,
58.1,
30.2,
58.6,
63.4,
78.7,
70,
54.7,
45.3,
86.2,
35.8,
64.6,
22.9,
36.3,
37.1,
89.7,
71.2,
95.7,
28.7,
76.8,
71.3,
25,
76.5,
84.1,
55.3,
41.2,
19.9,
41.2,
81.6,
12.9,
15.9,
14.6,
81.5,
62.4,
23.9,
62.8,
65.7,
65,
40.5,
81.8,
91.2,
66.6,
35,
90.2,
27.2,
49.4,
27,
98.6,
58.4,
21.9,
90.8,
37.1,
48.3,
51.1,
65,
31.1,
57.9,
28,
37.1,
65.2,
87.2,
55.4,
52,
65.8,
35.8,
57.5,
59.5,
55.4,
72,
60.4,
75.5,
39.7,
65.9,
64.3,
74,
67,
72.3,
81.8,
64.8,
26.7,
75.1,
75.6,
62.7,
50.9,
87.6,
56.9,
38.2,
53.6,
21.1,
98.6,
88,
31.8,
66,
5,
41,
53,
12.2,
93,
27.8,
41.5,
21.9,
37.6,
59,
72,
41.4,
70.1,
69.7,
76.7,
45.3,
24.4,
4.5,
8.8,
48.9,
32.3,
67.9,
85.3,
76.6,
89.9,
76,
38,
38.2,
89.1,
50.1,
57.5,
42,
29.1,
79,
71.9,
86.2,
86.7,
38.5,
77.8,
68,
38.1,
20.8,
0,
59.5,
81.6,
97.4,
28,
37.8,
96.7,
36.3,
48.2,
94,
76.3,
83.1,
68.4,
52.9,
87.8,
46.7,
15.9,
77.8,
34.6,
41.6,
79.1,
58.2,
68.9,
46,
46,
52.1,
84.2,
22.2,
54,
35.3,
93.3,
97.1,
0,
26.9,
63.8,
64.7,
63.3,
54.7,
39.1,
50.3,
45.6,
57.3,
69.4,
36.6,
24.4,
16.6,
78.7,
10.8,
76.8,
80.9,
16.7,
50.6,
56.8,
38.2,
64.3,
72,
61.5,
72,
52.4,
48,
59,
82.5,
52.6,
50.4,
56.1,
82.9,
35.9,
20.7,
36.4,
58.7,
81.6,
47.8,
52.2,
53.9,
0.5,
25,
101.3,
31.5,
37.4,
49.8,
50.6,
22.6,
45.1,
17,
69.2,
87.7,
39.3,
41.8,
52.8,
58.7,
88.8,
65.8,
66.2,
43.9,
71.3,
10.5,
77.7,
71.1,
17.9,
92.6,
77.9,
33,
29.8,
82.2,
66.5,
47,
21.6,
51,
49.4,
5.2,
73.4,
35.6,
85.6,
48,
16.1,
35.9,
32.9,
54,
82.1,
25.7,
2.9,
69.2,
81.6,
75.8,
33.8,
65.4,
54.5,
77.8,
49.9,
47.3,
54.5,
94.6,
49.8,
95.4,
62.2,
60.1,
61.8,
40.6,
19.8,
31.9,
86.3,
33.7,
80.9,
24.4,
70.9,
83.2,
40.3,
27.7,
92.9,
75.1,
77.6,
30.1,
65.1,
32.4,
86.1,
75.7,
32,
63.5,
13.3,
17.1,
68.6,
60.2,
60.2,
79,
89.6,
79.3,
62.3,
35.7,
58.6,
57.3,
14,
72.7,
44.4,
33.3,
68.3,
9.7,
79.7,
51.1,
20.7,
90.3,
60.2,
16.2,
64.7,
68.1,
35.1,
74.5,
65.7,
75.5,
17.9,
61.4,
68.5,
21.4,
53.7,
7.7,
76.8,
70.2,
63.6,
67.9,
68.3,
79.1,
47.3,
60.4,
68.8,
50.1,
42.8,
48.3,
70.7,
65.2,
87.8,
74.7,
92.9,
86.6,
92.9,
65,
45,
35.5,
70.5,
49,
46.7,
17.4,
50.8,
79.6,
72.3,
33.1,
46.2,
35.4,
53.5,
40.5,
46.4,
78.5,
63.1,
51.8,
94.1,
32.6,
85.6,
81.3,
73.5,
58.3,
64.4,
55.1,
62.6,
45.2,
67.5,
46.2,
84.1,
60.1,
65.4,
52.7,
76.4,
93,
67.5,
35.2,
69.1,
74.3,
18.1,
72.4,
88.9,
55.7,
71.7,
53.2,
40,
57.4,
44,
65.9,
82.9,
83.5,
79.4,
42.8,
38,
31.8,
47.7,
53.7,
72.5,
73.4,
81.7,
36.3,
9,
76.4,
51.4,
79.5,
66.6,
73.6,
102,
36.6,
28.2,
61.4,
34.3,
29.9,
52.1,
65.9,
91.3,
31,
61.1,
59.5,
25.4,
64.1,
82.4,
67.8,
63.4,
29.8,
66.1,
24.2,
10.9,
46.9,
65.5,
19.6,
39,
58.9,
32.6,
37.3,
6,
21,
89.1,
30.1,
2.2,
49.7,
63.2,
83.7,
95.7,
27.9,
61.7,
82.9,
71.6,
66.2,
24.7,
27.5,
20.4,
16,
71.9,
47.6,
20.9,
87.4,
2.5,
49.9,
97.4,
54.9,
55.1,
61.1,
47.3,
69.4,
47.7,
83.5,
33.1,
58.2,
57.1,
54,
68.4,
49,
46.7,
71.4,
29.9,
36.3,
83.2,
56.2,
90,
39.1,
41.8,
58.8,
43,
58,
27.4,
60.1,
31.3,
72.3,
50.1,
50.3,
41.7,
52.7,
48.5,
75.7,
75.9,
72,
33.2,
64.4,
85.7,
68.5,
48,
42,
77.6,
55.1,
33.8,
90.5,
33.5,
18,
50.4,
49.6,
25.5,
60.7,
71.7,
71.4,
35.8,
33,
55.8,
92.5,
36.6,
43.1,
24.3,
79.7,
64.1,
53.7,
50.8,
79.2,
70.6,
50,
37.2,
33.1,
69.9,
87.4,
31.1,
85.8,
44.1,
86,
22.3,
84.7,
59.3,
79.9,
36.2,
8.5,
64.6,
7.1,
48,
51.9,
59.1,
56,
50.3,
86.5,
67,
62.8,
95.9,
77.5,
97.3,
83,
57.4,
83.8,
93.6,
43,
83,
45.6,
73.6,
60.6,
99.7,
39.8,
65,
79.1,
78.2,
85.7,
79.4,
74,
19.4,
82.6,
88.6,
53.8,
37.7,
34.8,
85.2,
12.4,
96.9,
79.9,
63.1,
64.6,
10.7,
62.7,
49,
86.1,
70.4,
9.1,
34.4,
72.5,
48.5,
22.3,
72.6,
54.4,
73.8,
62.9,
21.9,
67.3,
81.9,
48.6,
77,
75.7,
17.7,
30.1,
36.5,
76.9,
37.8,
66.1,
81,
69.6,
63.6,
65.7,
28.8,
84.5,
96.4,
48.6,
53.2,
38.8,
2.2,
65.2,
65.2,
52.3,
51.2,
40.7,
30.8,
96,
57.2,
61.9,
27.7,
82.9,
37.2,
69.5,
91,
67.6,
31.9,
58.5,
54.2,
71.5,
34,
62,
16.2,
84.1,
78.4,
89.1,
50.1,
37.1,
56.1,
27.1,
42.8,
69.5,
61.8,
44.8,
51.7,
40.8,
76.3,
34.2,
43.1,
64.7,
62,
95,
75.7,
28.2,
50.8,
38.5,
32,
34.3,
73.4,
35.7,
46.4,
85.5,
59.3,
20.6,
65.3,
72.6,
78.5,
75.4,
4,
32,
47,
86.7,
70.1,
57.5,
30.7,
62.2,
53.3,
56.4,
53.7,
40.8,
74.5,
41,
80,
74.5,
54.2,
76.5,
40.2,
60,
55.4,
68.2,
38.7,
10.1,
70.7,
94.9,
34,
37.9,
84.3,
37.4,
42.1,
57.6,
80.1,
56.4,
56,
31.9,
45.6,
40,
31.8,
83.1,
62.9,
36.4,
33.8,
80.4,
84.4,
32.2,
86.5,
56.6,
42.5,
39,
39.5,
80,
53.8,
54.2,
47.1,
61.9,
8.2,
80.6,
58.2,
47.5,
76.7,
42.1,
63.9,
85.8,
75,
1.2,
77.6,
62.7,
62.1,
80.3,
47.1,
14.7,
70.8,
95.1,
2.6,
66.8,
77.4,
34.5,
80.2,
42.3,
61.9,
85.2,
89.1,
76.8,
44.4,
71,
59.6,
64.7,
33,
22.3,
59.6,
17.5,
85.1,
85.9,
58.3,
47,
56.5,
43.9,
77.7,
51.6,
81.1,
82.9,
54.1,
21.8,
55.4,
7.4,
56.9,
66.1,
59.8,
40.1,
15.9,
93.3,
27.5,
31.9,
39.7,
57.6,
69,
60.9,
88,
89,
59.1,
60.8,
96,
17,
33.3,
45.7,
65.5,
86.1,
76.5,
17.3,
76.7,
33.8,
66.5,
73.9,
30.9,
26.9,
84.9,
60.8,
89.1,
19.2,
28.4,
91.3,
20.4,
32.3,
59,
85.1,
25.5,
98.1,
83.7,
89.4,
9.9,
31.6,
82.1,
62.5,
25.8,
24.8,
74.3,
28.7,
93.2,
56.5,
24.1,
49.1,
54.5,
38.2,
22,
37,
53.2,
25,
54,
80.5,
49.4,
20.4,
39.3,
15.2,
49.8,
41.7,
42.3,
80.9,
35.9,
36,
5.9,
80.2,
44.9,
32.6,
93,
86,
40.2,
78.7,
49.3,
65.4,
82.5,
89.1,
48.4,
65,
64.2,
88.3,
58.3,
25.2,
48.9,
87.7,
39.2,
59.5,
40.8,
24.8,
60.6,
87.5,
61.4,
85.7,
79.6,
10,
32.3,
65.2,
1.3,
78.9,
51,
47.6,
47.8,
76,
74.8,
55.9,
57.1,
43.8,
48.9,
20.9,
39.9,
44.5,
63.4,
6.1,
38.5,
83.5,
64.6,
80.1,
68.2,
61,
89.8,
7.4,
5.4,
60.3,
62.8,
53.5,
92.4,
67.5,
53.9,
70.7,
79.8,
57.8,
56.3,
75.9,
87.5,
74.8,
58.1,
21.9,
68.9,
26.6,
69.6,
51.7,
62.6,
75.5,
58.1,
42.7,
0,
40.6,
51.4,
99.2,
16.8,
74.9,
49.1,
98.3,
45.1,
83.3,
72.5,
41.2,
89.4,
73.7,
29.3,
66.7,
20.8,
12.3,
42,
61.6,
2.5,
63.5,
25.4,
88.3,
41,
37.7,
87.9,
83.2,
77.3,
6.4,
78.7,
95.3,
69.8,
30.1,
22.1,
61.2,
28.5,
31.8,
78.9,
54.2,
43.3,
89.9,
45.7,
98.4,
64,
51.1,
62,
47.6,
59.3,
98.1,
59.5,
84.6,
71,
55.9,
52.6,
93.4,
63.6,
96.1,
49.5,
28.8,
14,
33.2,
45.2,
57.6,
29,
33,
66.2,
74.4,
14.8,
16.9,
65.7,
55.3,
93.3,
50.6,
34.7,
10.2,
38,
59.6,
76.8,
46.2,
51.1,
59.8,
64.2,
73.1,
52,
95.3,
36.4,
71.1,
65.4,
82.7,
99.4,
72.5,
62.7,
40.8,
94,
51.2,
61.4,
18.7,
64,
24.2,
57.2,
85,
85.3,
8.2,
9.5,
62.8,
75.4,
73.9,
48.1,
84.3,
52.3,
40.3,
22.5,
55.2,
88.1,
53.7,
51.7,
74,
76.3,
65.4,
3.5,
66.4,
76.3,
59.8,
73.3,
86.2,
98.7,
57.1,
41.4,
91.2,
41.5,
76.7,
44.7,
39.5,
23.3,
38.2,
46,
64.1,
42.5,
70.8,
86.3,
94.2,
68.1,
36.4,
84.1,
35.8,
62.1,
79.8,
51.6,
90.9,
75.1,
41.9,
58.5,
25.2,
39,
65.7,
40.7,
85.1,
70.2,
30.8,
35.1,
43.8,
83.9,
69.4,
60.9,
79.9,
48.4,
44.7,
50.2,
24.3,
29.5,
60.4,
57.5,
49.1,
43.5,
26.5,
49.6,
91.1,
22.1,
46.8,
57.2,
2.2,
91.5,
30.5,
40.6,
63,
23.6,
63.1,
59.6,
31.1,
83.1,
33.8,
35.2,
84.2,
53.6,
74.2,
22.6,
66.3,
79.5,
85.6,
80.9,
89.5,
48.5,
84.7,
84,
31.7,
62.3,
36,
63.9,
55.4,
57.2,
68.4,
44.1,
38,
28.8,
60.3,
16.7,
49.6,
21.5,
36,
51.7,
59.6,
6.5,
13.8,
66.8,
41.8,
37.8,
83.3,
43.3,
44.3,
47.3,
26.8,
43.3,
66,
93.7,
39.6,
35.5,
28.9,
12.4,
39.1,
26.7,
53.2,
46.1,
68.9,
31.4,
93.2,
38.9,
87.8,
53.3,
48.1,
37,
64.7,
77,
74.1,
47.2,
25.3,
18,
30.9,
61.3,
55,
61.4,
67.5,
78,
48.5,
44.3,
54.6,
47.4,
5.4,
59.1,
4.9,
77.7,
27.9,
52.6,
58.9,
7.1,
40.6,
79.4,
28,
76.6,
89.6,
52.9,
8.4,
35.5,
94.3,
82.6,
67.5,
56.2,
61.9,
70.3,
44.1,
81,
55.2,
67.4,
73.9,
37.8,
95,
26,
62,
1.3,
62,
32.5,
54.5,
63,
50.9,
80.5,
4.9,
45.9,
50.7,
69.2,
0,
55.8,
74.4,
32.9,
0,
32.4,
40.8,
64,
84,
38.2,
80.7,
79.4,
29.8,
15.3,
42.8,
73.6,
79.9,
35.2,
26.1,
39.9,
79.4,
61.9,
61.1,
66.9,
19.5,
42.7,
100,
20.8,
69.3,
32.2,
68.2,
56,
81.3,
38.6,
18.7,
28.6,
67,
42.7,
50.8,
82.2,
34.6,
60.1,
46,
24.9,
85.7,
85.4,
95.3,
62.6,
86,
81.4,
46.4,
15.2,
37.8,
89.1,
97,
76.8,
46.1,
99.6,
59.7,
16.7,
74.1,
79.4,
34.5,
78.4,
52.4,
72.9,
35.4,
28.2,
48.4,
69,
46.8,
78.2,
69.5,
85.8,
38.4,
2.7,
73,
73.7,
7.1,
54,
50.9,
34.7,
93.3,
36.6,
29.1,
29.9,
58.6,
38.2,
45.5,
55.1,
41.5,
29.7,
16.6,
64.3,
75.4,
78.8,
56.9,
59.8,
56.6,
30.2,
42.4,
42.9,
69.6,
70.9,
89.5,
88,
67.1,
82.2,
17.9,
49.9,
26.2,
66.8,
11.6,
77.1,
54,
40.8,
78.7,
62.5,
85,
52.7,
80.6,
20.3,
29.7,
81.9,
68.6,
24.7,
68.1,
8,
82.8,
76.7,
43.8,
55.1,
19.1,
61.2,
46,
70.2,
64.6,
58,
48.7,
22,
37.7,
56.4,
76.5,
77.5,
55.9,
82.7,
23.2,
104.9,
23,
61,
91,
36.3,
5.4,
68.1,
91.9,
95.9,
90.5,
39.5,
35.1,
85,
24,
57.8,
100.7,
81.8,
94,
66.3,
45.6,
92,
29.8,
96,
17.9,
89.2,
81,
17,
75.3,
54,
25.4,
38,
38.9,
113.8,
97.9,
42.5,
13.8,
54,
8.4,
97.2,
32.4,
65.3,
73.5,
77.7,
42.9,
35.7,
36.1,
45,
42.4,
48.9,
61.6,
25.6,
73.7,
47.4,
61.6,
46.8,
46.1,
23.1,
55.2,
67.5,
65.5,
40.9,
33.1,
18.9,
64.3,
79,
60.4,
70.7,
77.9,
44,
48.1,
70.8,
5.8,
68.4,
36.2,
77.4,
41.8,
41.9,
6.7,
100,
27.9,
82.7,
68.6,
84,
72.9,
47.1,
35.4,
5.1,
69.9,
12,
100.2,
96.5,
38.2,
5.3,
58,
28.5,
46.4,
89,
20.6,
67.2,
94.9,
56.8,
66.9,
69.1,
1.8,
50.4,
93.5,
71.7,
65.5,
59.9,
76.2,
73.3,
67.1,
86.9,
39.2,
49,
77.8,
20.7,
18.7,
30.2,
48.7,
62.4,
95.9,
102.6,
21.2,
62.4,
7.2,
92,
37.2,
53.6,
50.2,
82.4,
71,
47,
60.5,
44.3,
38.6,
71.7,
100.9,
3.8,
62.3,
33.1,
9.7,
71.9,
75.2,
69.9,
28.7,
74.3,
59.8,
71,
41.3,
43.6,
70.2,
22.5,
63.5,
52.3,
52.1,
60.7,
55.5,
47.7,
13.3,
85.8,
80.8,
71.1,
67.2,
70.4,
40.1,
87.8,
45.7,
39.6,
91.4,
51.3,
54.3,
82.8,
50.5,
67.5,
40,
54.8,
93,
51.5,
58.7,
51.6,
39.5,
30.5,
15.9,
87.1,
70.4,
29.7,
15.3,
66.2,
23.7,
52.2,
59.7,
63.3,
58.1,
59.8,
74.1,
57.3,
62.9,
48.4,
53.9,
70.1,
72.7,
72.9,
31.4,
27.8,
46,
7.9,
45.2,
77.4,
81.8,
89.7,
69,
61.2,
47.6,
98.7,
43.9,
31.1,
11.9,
74.1,
28.8,
46.3,
68,
46.8,
78.1,
61.5,
62.2,
45.3,
12,
27.7,
17.5,
77.7,
28.3,
28.8,
48.7,
62.8,
48.9,
44,
39,
39.3,
45.3,
83.1,
61.8,
21.5,
54.8,
29.3,
67.4,
66.7,
53.2,
28.4,
89.7,
46.9,
27,
0.2,
59.4,
95,
40.1,
54,
77,
50,
58.7,
27.6,
7.7,
64.3,
57.1,
27,
62.2,
29.4,
39.1,
36.1,
48.5,
83.2,
38.3,
null,
73.8,
46.6,
71.9,
63.9,
80,
71.5,
78.3,
0,
85.7,
100.4,
48.8,
91.9,
37.9,
18.5,
65.3,
11.6,
46.4,
30.6,
34.6,
69.8,
58.8,
66.8,
64.2,
43.3,
68.1,
66.7,
46.7,
54.6,
61.7,
85.8,
83.4,
39,
92.5,
78,
39.8,
89,
42,
87.7,
54.1,
55.1,
62,
44.5,
92.5,
68.1,
85.2,
77.1,
63.4,
93.7,
63.9,
56,
8.8,
8.6,
41,
61.1,
31.7,
71.1,
68,
50.6,
30.3,
38,
62.4,
78,
76.6,
51.4,
13.6,
87,
53.2,
76,
81.2,
43.9,
71.1,
51.3,
54.5,
61,
53.9,
65.5,
37.3,
42.7,
58.3,
61.7,
37.3,
45.9,
32,
78.8,
37.6,
77.8,
70.4,
44.6,
74.4,
75.2,
86.3,
50.2,
19.8,
65.2,
49.8,
32.3,
75,
59.2,
43.7,
95.5,
68.5,
63.8,
19.8,
91.8,
89.3,
83.9,
71,
92.5,
27.9,
32.1,
40.1,
86.6,
84.2,
57.6,
85.2,
61.3,
88.9,
53.3,
57,
65.9,
58.3,
82.4,
66.9,
32.7,
41.5,
79.3,
30.2,
87.3,
99.3,
37,
90.8,
51.5,
62.7,
52.5,
66.2,
88,
71.7,
9.9,
10.4,
40.9,
43,
53.1,
71.1,
61.5,
10,
32.8,
75,
87.2,
81.8,
50,
41.7,
97.6,
71.8,
52.8,
89.1,
53,
56.2,
56.8,
22.8,
71.6,
76.7,
54.2,
10.3,
88.2,
43.4,
88,
36.5,
80.2,
78.5,
40.6,
82.7,
34,
63.5,
55.5,
44.6,
81.9,
22.4,
47.1,
83.8,
27,
54,
64.3,
63.2,
58,
80.2,
61,
87.9,
80.9,
25.3,
55.3,
43.2,
55.2,
29.6,
56.3,
10.6,
64.3,
96.2,
90.7,
71,
72.6,
26.6,
97.2,
98.5,
69.1,
61.2,
36.1,
46.4,
67.1,
98.9,
20.6,
72.1,
100.1,
85.4,
23,
0,
38,
66.4,
47.3,
53,
29.6,
50.2,
91,
56.3,
65.2,
34.2,
17.5,
16,
85.9,
61.3,
51.2,
70.8,
96.5,
8.2,
54.9,
82.3,
83,
76.4,
78.5,
75.9,
18.9,
29.2,
87.9,
53.2,
94,
38.8,
35.1,
37,
37.7,
55.5,
62.1,
45.8,
15.5,
8.8,
79.8,
74.8,
13,
75.3,
87,
21.2,
48.8,
86.8,
85.2,
5.2,
72.8,
58.7,
43.7,
98,
36,
37.9,
86.4,
26.4,
75.4,
56.1,
65.2,
59.2,
43.3,
45.4,
71,
48.4,
36.8,
92.3,
87.9,
35.9,
0.9,
34.1,
65.6,
90,
50.9,
55.6,
50.5,
53.1,
39.9,
61.9,
79.3,
69.6,
33.6,
26.5,
64.3,
53.1,
60.5,
44.9,
79.3,
80.7,
85.3,
45.8,
1.9,
47.6,
61.8,
49,
43,
68.7,
31.9,
28.9,
51.1,
55.1,
35.2,
85.5,
90.6,
69,
51.7,
31,
71.9,
40.4,
37.3,
39.1,
69,
24.8,
90,
100.9,
25.7,
39.4,
61.6,
63.7,
46.3,
41.2,
77,
68.7,
43.2,
86.2,
17,
95.7,
29.9,
93,
42.6,
76.6,
30.3,
72.9,
48.5,
43.3,
74.7,
67.7,
68.5,
30.4,
59.6,
30.4,
68.3,
44,
63.7,
72,
47,
53.2,
73.6,
68.4,
71.8,
43.9,
25.3,
39,
30.8,
54.3,
46,
27,
55.7,
92.6,
36.9,
43.5,
28.8,
98,
93,
73.4,
50.9,
28.2,
15,
98.9,
46.7,
80.8,
101,
77,
83.7,
34.8,
87.5,
42.4,
55.7,
48.2,
38.7,
80.9,
59.1,
30.6,
73.3,
62.3,
14.1,
86.6,
88.9,
36.3,
69.6,
56.8,
27.1,
95.7,
45.1,
32.8,
53.3,
38.7,
44.9,
47.1,
55.7,
54.2,
64.7,
4.2,
56.5,
94.2,
62.2,
87,
15.4,
31.9,
50.7,
64.8,
72,
16.1,
93.7,
89.3,
26.4,
81.2,
56.4,
16.4,
45,
74.6,
46,
84.4,
75.6,
63.7,
45,
17.3,
68.8,
82.6,
57.2,
72.5,
47,
52.1,
24.8,
77.1,
26.2,
48.2,
66.9,
97.8,
23.2,
32.9,
38.3,
60.6,
6.6,
25,
43.8,
86.3,
63.7,
63.9,
24.5,
22.2,
86,
92.8,
26,
39.4,
72.8,
30.1,
39.1,
69.2,
87.8,
60.1,
57.8,
36.8,
47.8,
11.5,
38.9,
50.5,
69.4,
12.3,
26.2,
85.9,
92.3,
61.8,
26.3,
23.1,
74.9,
62.8,
56.7,
67.5,
67.1,
42.3,
51.6,
87,
82.3,
74.4,
61,
34.3,
89.3,
1.1,
112,
80.1,
5,
39,
68.6,
75.9,
87.2,
39.1,
76,
83.9,
39.1,
92,
71.4,
98.3,
62.7,
63.1,
55,
60.2,
59.9,
41,
43.1,
34.8,
35,
58.3,
64.7,
54.9,
79.8,
52.1,
36.8,
87.9,
12.3,
36,
36.1,
62.9,
101.8,
40.9,
59.3,
71.7,
75.8,
83.8,
94.5,
72,
32.3,
45.9,
35.1,
45.6,
49.4,
68.3,
79,
12.9,
57.3,
44.4,
85.1,
1.4,
54.6,
50.1,
18.7,
78,
39.8,
58.4,
56.4,
54.9,
33.3,
67.3,
26.5,
28,
91.9,
75.3,
46.6,
68.4,
55.6,
85.4,
97,
41.6,
51.2,
31.1,
36.8,
50.4,
74,
33.4,
68.2,
76.8,
55,
88.5,
25.8,
63,
22.8,
62.7,
29.8,
32.2,
43.2,
64.8,
16.3,
94.8,
32.8,
72.3,
90.3,
47.1,
35.3,
90.5,
8.7,
65.6,
90.2,
65,
76.5,
97.4,
14.8,
49.4,
56.3,
27.1,
49.7,
41.9,
8.4,
79,
83.3,
67.6,
54,
79.3,
44.4,
50.6,
70,
57.4,
41.5,
50,
69.5,
28.5,
28.1,
20.5,
83.4,
59.5,
38.4,
52.4,
65.8,
81.7,
77.7,
56.5,
80.9,
52.6,
13.6,
76.7,
57.1,
65.7,
56.6,
51.9,
94,
95.8,
82.3,
91.6,
47.1,
98.8,
72,
69.8,
64.7,
49.1,
43.2,
52.2,
63.6,
56,
9.5,
28.7,
2.8,
59.5,
97.5,
89.4,
32,
38,
49.6,
26,
20.6,
29.4,
56.9,
68.9,
43,
75.6,
38.8,
63.4,
82.2,
29.6,
18.2,
28.3,
26.2,
26.2,
26.8,
9,
56.3,
51.6,
31.4,
62.3,
68.3,
56.6,
70.9,
78.8,
36.5,
68,
82.7,
18.6,
36,
48.3,
92.1,
86.3,
13.4,
22.2,
37.5,
31,
45.4,
40,
44.9,
73.2,
5.2,
18.1,
3.7,
60.5,
70.8,
61.2,
48.2,
39.6,
56.8,
39.8,
11.6,
82.4,
19.2,
41.7,
96.1,
29.6,
82.4,
61,
31.4,
31.3,
47.8,
24,
87.1,
95.9,
35.6,
20,
55,
24.1,
60.2,
59.9,
65.6,
40.1,
90.5,
68.6,
81,
51.5,
44.6,
2.4,
38.5,
79.2,
72.4,
50.8,
9,
99,
32.3,
51,
69.2,
61,
79,
65.9,
76.1,
58,
69.1,
62.8,
39.1,
87.8,
75.2,
27.9,
51.9,
32.8,
96.6,
23,
78.7,
88.3,
22.7,
67.7,
83.5,
52.2,
68.8,
43.7,
44.6,
52,
39.9,
98,
72.2,
19.6,
59.4,
59.9,
68.1,
63.1,
48.8,
47.4,
70.4,
49.5,
66.2,
62.7,
5.2,
97,
72.5,
65.8,
88.9,
77.2,
40.4,
46.3,
40.8,
36.1,
67.7,
48.5,
86.7,
58.1,
48.1,
30.8,
64.3,
18,
45.4,
40.1,
69.3,
58.6,
41.7,
62.5,
86.1,
80.2,
59.8,
52.4,
59.2,
54.9,
48.1,
49.1,
37.6,
80.6,
52.1,
52.7,
98.8,
87.9,
70.1,
99.8,
47,
1.8,
28.8,
55.2,
37.7,
66.7,
64,
79.6,
18.9,
82.7,
40.6,
38.3,
91.3,
62.9,
94.9,
98,
48.9,
38.6,
61,
51.3,
34.2,
35.4,
49.1,
32.7,
34.9,
44.5,
39.8,
41.2,
78.6,
95.1,
60.1,
28.1,
54.8,
2.5,
35.2,
70.7,
61.4,
22.2,
56.5,
36.8,
41.6,
24.3,
69.9,
45.1,
70.2,
30.6,
91.8,
82.7,
41.2,
49.3,
96.1,
45.5,
43.4,
55.2,
91.7,
16.1,
70.9,
66.6,
9.5,
28.4,
63.6,
67.2,
50,
67,
45.4,
39.2,
58,
87.5,
54.1,
30.7,
52,
73.3,
44.7,
7.9,
91,
98.5,
34.6,
54.8,
56.3,
31.8,
0.3,
85.9,
46,
21.8,
4.4,
44.6,
94.6,
42.5,
40.9,
32.6,
22.8,
27.5,
25.8,
41.5,
89.6,
41,
16.7,
57.9,
48.2,
82.1,
43.8,
54.9,
32.8,
31.9,
7.6,
41,
19.7,
53.4,
56.5,
40.7,
63.2,
6.3,
52.7,
37.9,
90.5,
33.8,
63.8,
75.9,
58.3,
50.5,
44,
70.9,
88.2,
84.2,
81,
55.2,
92.9,
88.1,
86.3,
10,
91.6,
56.3,
81.8,
35.5,
78,
53.3,
53.6,
78.2,
61.4,
59,
54.9,
66.1,
69.9,
42.8,
65.6,
59.9,
81.4,
20.4,
72.2,
22.4,
55.9,
52,
56.8,
37,
11.8,
59.8,
76.1,
21.9,
59.8,
89.5,
88,
88.1,
46.7,
73.8,
45.6,
82.2,
82.9,
52.3,
65.3,
43.1,
59.3,
33.4,
73.4,
81.9,
30.1,
98.5,
50.8,
29.1,
18.6,
43.3,
66.7,
13.7,
25.8,
61.7,
52.2,
76.7,
47.1,
74.3,
8.8,
86.5,
66.6,
74.2,
28,
48.3,
60.4,
43.2,
44.2,
52.7,
43.3,
74.2,
34,
16.8,
99.2,
13,
73.7,
77.7,
16.8,
86.1,
68.7,
53.2,
7.2,
60.7,
53.8,
48.2,
45.3,
97.4,
64.3,
44,
85.8,
93.5,
61.3,
71.4,
56.8,
82.6,
86.1,
51.1,
76.2,
70.5,
41.9,
45.8,
68.9,
46,
44.8,
56.6,
30.5,
56.3,
59.8,
44.6,
31.2,
92.1,
79.2,
73.4,
44.2,
88.9,
82.5,
52.3,
78.5,
41.3,
77.7,
82.5,
74.6,
25.7,
47.1,
24.6,
38.8,
35.5,
40.5,
44.8,
33.14,
68.9,
37.2,
49.3,
2.5,
83,
30.6,
89.8,
34.5,
84.7,
36.9,
56.8,
83.1,
24.4,
69,
95.6,
19.2,
75.5,
3.5,
95,
84.1,
52.3,
23.3,
46.2,
85.8,
87,
48.9,
60.2,
48.9,
43.1,
63.1,
77.2,
3.6,
64.8,
69.1,
47.4,
43.7,
55.4,
78.6,
66.9,
73.2,
32.4,
56.4,
57.4,
54.5,
87.1,
79.7,
61.6,
91.7,
71.8,
31.4,
45.4,
40.7,
35.8,
85,
59.9,
75,
24.6,
77.8,
11,
40.6,
85.7,
44.8,
39.1,
68.9,
76.8,
23.2,
67,
55.6,
32.1,
11.7,
39.5,
39.2,
42.5,
50.4,
54.8,
59.7,
42.2,
90.7,
73.8,
80.7,
27.5,
41.4,
91.9,
83.4,
94.9,
62.7,
24.1,
85.2,
72.3,
0,
18.9,
59.5,
44.9,
18.5,
57.5,
87.8,
60.3,
20.1,
77,
55,
64,
60.9,
82.3,
39.5,
74.4,
81.9,
75.2,
56.8,
39.5,
45.3,
37.5,
48.9,
79.7,
83.1,
47.7,
62.9,
50.5,
88.6,
67.4,
82.2,
68.8,
48,
54.1,
69.9,
50.2,
50.7,
57.4,
81.7,
81.6,
37.9,
35.8,
93.9,
80.3,
41.7,
50.3,
59.4,
88.8,
90.7,
95.2,
23.9,
33.3,
61.2,
77.3,
80.2,
69.5,
50.5,
49.6,
33.8,
18.8,
42.8,
29.9,
96.4,
25.7,
55.7,
54.2,
36.5,
37.5,
53.1,
56.3,
70.6,
65.1,
54.1,
52.4,
39.8,
93.9,
66.7,
47.8,
78,
60,
96.9,
90.6,
19.8,
34.9,
58.3,
18.4,
42,
72.8,
37,
48.6,
73.6,
42.4,
92.6,
38.9,
65.4,
75.4,
49.6,
43.5,
38.9,
78.6,
83.7,
62.2,
48.4,
98.6,
91.6,
61.9,
86.4,
72.2,
52.4,
88.1,
66.8,
88,
31.9,
40.8,
32.5,
17.7,
62.1,
75.1,
76,
66.2,
43.6,
41.4,
40.2,
77.2,
71.4,
41.9,
79.2,
91.8,
92.7,
39,
34.4,
82.3,
46.8,
44,
37.1,
71.1,
23.9,
68,
52,
48.1,
59.4,
49.3,
83.3,
39.7,
30.4,
31.5,
48.8,
30,
58.1,
64.7,
52,
58.8,
76.1,
73.5,
73.3,
87.3,
95.3,
55,
23.6,
39.3,
105.1,
80.2,
68.5,
44.2,
60.8,
18.7,
73.9,
78.2,
48,
62.5,
56.4,
14.2,
33.3,
85.3,
9.2,
95.2,
47.4,
66.4,
56.4,
28.3,
6,
20.1,
78.4,
25.5,
69.7,
48.9,
27.3,
5.3,
73.5,
50.9,
29.9,
31.3,
38.8,
96.7,
17.4,
38.3,
45.4,
52,
52.3,
79.8,
71,
25.1,
99,
48.2,
79.3,
17.5,
43.8,
53.9,
14.9,
62.4,
22,
71.9,
18.4,
4.2,
43.4,
87.2,
45.4,
100.8,
62.3,
92.4,
39.1,
41.2,
87.7,
31.6,
70.3,
65.9,
69.6,
30,
20,
5.1,
76.4,
60.6,
38.2,
90.3,
71.4,
92.2,
59,
22.8,
21.4,
17.2,
66.1,
35.9,
8.2,
38.7,
17.5,
57.4,
66.9,
58.8,
82.7,
73,
59.2,
13.7,
62.6,
49.3,
61.2,
25.3,
69.7,
49.6,
71.2,
94,
82.6,
83.9,
66.4,
23.4,
49.9,
82.4,
40.5,
62,
36.7,
52.4,
62,
71.9,
34.6,
22.9,
38.2,
59.5,
5.2,
88,
26.3,
29.9,
90.4,
46.6,
30.4,
41.5,
0.8,
57.7,
36.4,
26.7,
56.5,
69.2,
52.6,
77.9,
23.5,
41.5,
37.5,
23.8,
24.1,
35.7,
76.9,
36.5,
72.2,
88.2,
44.2,
20.8,
88.4,
63.9,
94.2,
70.9,
46.3,
21.2,
56.9,
57.4,
44.3,
74,
74.9,
56.7,
80.1,
54.1,
52.6,
46.4,
60.2,
87.8,
81.5,
65.3,
80.4,
28.9,
47.9,
63.1,
95,
57.4,
17,
71.2,
73,
26.9,
52.1,
61.7,
84.3,
83.4,
78.1,
28.8,
57.3,
39.1,
37.7,
90.9,
41.1,
62.1,
87.3,
36.9,
39.5,
68,
62.6,
46.5,
34.9,
77.7,
63.5,
53.6,
61.7,
59.3,
73.7,
31.6,
31.6,
55.7,
96.3,
85.9,
45.9,
9.2,
86.7,
54.2,
71.1,
60.4,
8.6,
51.5,
56.3,
44.8,
66.7,
75.1,
17.6,
53.9,
61.4,
76.5,
69.6,
14.1,
84.8,
34,
41.1,
49.3,
62,
85.6,
35.1,
74.3,
71,
10.6,
45.7,
62.8,
4.3,
34.5,
22.6,
84.4,
67.4,
3,
23.5,
63.5,
84.6,
49.1,
38.1,
50.2,
52.4,
34.1,
72.4,
51.1,
38.7,
84.7,
41.1,
44.1,
56,
30.5,
43.3,
92.7,
72,
67.8,
39.6,
48.1,
14.3,
61.4,
34.5,
69.4,
69.2,
63.8,
94.4,
97.1,
85.5,
33.3,
32.5,
87,
43.6,
45.2,
34.6,
86.7,
34.4,
55.4,
98,
21.1,
54.4,
24.3,
33.2,
46.1,
85.3,
57,
33.4,
65.8,
70.1,
81,
59.6,
82.7,
67.3,
70.2,
51.7,
95,
83.8,
93,
41.2,
8.4,
51.8,
37.5,
42.9,
67.8,
66,
37.2,
75.8,
64.2,
14.8,
63.7,
38.5,
49,
23.1,
66.9,
92.1,
29.1,
89.3,
68.6,
64.9,
90.1,
47.1,
59.4,
93.8,
27.6,
69.4,
19.7,
62.9,
33.8,
10,
85.3,
72.6,
25.3,
74.6,
77.8,
45.1,
32,
65.5,
40.3,
89.4,
66.1,
16.3,
79.1,
50.6,
62.7,
97.2,
59.9,
51,
39.8,
76.9,
51.9,
54.8,
35.7,
44,
52,
52.4,
71,
62.7,
52.3,
99.3,
79.1,
27.8,
31.2,
88.3,
37.1,
36,
73.2,
61.1,
84.2,
83.9,
21.5,
68.4,
66,
40.6,
45.4,
75.5,
39.9,
64,
85,
42,
24.6,
91.5,
31.2,
85.4,
103.8,
29,
44.6,
34.6,
51.3,
72.8,
82.7,
63.6,
89.3,
113.1,
70,
66.5,
25.2,
16.2,
29.3,
57,
67.5,
53.6,
23.7,
93.9,
63.1,
69.6,
6.6,
67.1,
23.4,
12.1,
54.4,
40.9,
78,
79.1,
83.1,
81.6,
94.9,
18.1,
76,
43.7,
38.7,
90.2,
66.1,
71.2,
28.1,
53.9,
33.7,
17.3,
31.4,
86.1,
54,
48.3,
51.4,
30,
null,
85.1,
54.5,
73.7,
72.8,
62.3,
18.2,
39.1,
84.6,
62.2,
76.7,
65.3,
33.1,
64.7,
27.1,
57.5,
43.8,
68.1,
5.6,
74.4,
0.4,
29.9,
39.7,
97.4,
68.2,
67.7,
32.5,
54.8,
79.6,
32.6,
72.7,
69.3,
57,
35.2,
93.5,
47.4,
14.8,
88,
85.1,
95.9,
88.7,
71.9,
80.9,
57.8,
61.8,
24.8,
78.9,
65.3,
94.7,
22.5,
72.3,
77.7,
81.2,
62.5,
62.7,
96.1,
57.9,
21.7,
88.5,
62.6,
53.5,
67.5,
75.7,
0.7,
47.4,
48,
67.2,
22.4,
67.3,
44.4,
77.9,
47.7,
67.2,
83.2,
70.4,
42.4,
54.3,
77.8,
39.9,
94.8,
54.9,
26.6,
45.2,
32.4,
28.4,
78.9,
7.7,
1.9,
47.3,
84.1,
88.1,
58.6,
6.3,
26.2,
37.7,
55.9,
42,
85.9,
15,
62.5,
42.5,
58.6,
65.5,
66.3,
79.7,
70.9,
14.4,
50,
29.7,
49.8,
50.1,
86.9,
76.3,
62.8,
52,
28.2,
59.5,
72,
82.8,
15,
76,
38.5,
73.1,
32.3,
36.2,
56.2,
73.2,
99.8,
58.7,
52,
71.9,
56,
41.5,
35,
79.3,
32.6,
53.7,
29.5,
37.9,
87.5,
56.9,
60.3,
79.1,
34,
75.1,
43.5,
81.2,
97,
38,
20.7,
33.7,
17.6,
67.6,
25,
0.6,
82.9,
32.9,
29.6,
4.3,
24,
15.1,
14.5,
82.4,
94.3,
98,
43.4,
70.8,
57.1,
51.3,
70.9,
54.2,
4.9,
77.1,
88.7,
58.7,
22,
19.2,
28.2,
73.7,
67.2,
0,
61.5,
43,
19.3,
33.4,
3,
68.2,
76.9,
66.8,
43.6,
71.8,
39.3,
66,
80.7,
52.8,
69,
90.2,
73,
32.1,
53.6,
49,
87.4,
17.8,
51,
82.8,
32.7,
34.1,
67.2,
55.1,
25.2,
50.1,
90.4,
52.6,
70.5,
23.3,
70.8,
35.2,
58.2,
32.3,
92.1,
80.4,
53.8,
39.7,
56.2,
78.7,
101.9,
56.6,
91.4,
33.4,
103.7,
40,
75.9,
56.9,
61.9,
67.9,
63,
0.5,
77.7,
37.8,
43.8,
3.1,
63,
70.1,
63,
56.6,
77,
82.1,
42,
47,
63.8,
18.8,
66.5,
86.4,
45.3,
69,
59.1,
36.4,
56.8,
70.9,
81.3,
72,
49.7,
46.1,
60.4,
47.8,
15.3,
11.1,
41.2,
31.5,
81.9,
66.6,
71.6,
46,
57.9,
61.1,
48,
50.7,
72.4,
44.9,
44,
7.4,
20.2,
20,
71.3,
11.9,
47.9,
72,
0.3,
80.4,
73.1,
31.3,
54.6,
83.8,
63.9,
51,
64.4,
12.1,
89.1,
39.7,
9.9,
40.6,
92.4,
38.6,
55.6,
78.5,
44.4,
80.7,
97.3,
65.5,
22.5,
23.2,
15.4,
74,
80.3,
28.8,
81,
48.4,
59.3,
72.1,
24.3,
68.5,
82.5,
77.4,
13.2,
69.6,
45.8,
22.4,
47.4,
73.4,
33.4,
68.6,
80,
43,
21.3,
74.2,
80.4,
28.3,
39.2,
35.4,
61.9,
55,
81.4,
65.4,
38.5,
12.5,
63,
60.2,
61,
73.5,
44,
56.3,
92.8,
93.6,
55.5,
6.6,
37.6,
63.5,
54,
42,
34,
83.5,
13.8,
45.8,
42.7,
91.3,
76.3,
67.6,
82.4,
93.3,
94.8,
86.5,
68,
96.2,
62,
51.7,
47.9,
82.8,
34.5,
31,
37.9,
40.9,
53.8,
92.2,
46.4,
20,
42.7,
81.3,
52.8,
81.1,
57.5,
79.5,
45.1,
52.2,
75.9,
43.1,
2.5,
60.1,
42.5,
41.5,
21.7,
94.1,
19.2,
70,
71.7,
37.5,
92.7,
91.4,
39.9,
23.1,
94.4,
64.5,
78.7,
50.5,
18.7,
29.7,
63,
39.9,
37.5,
97.5,
42,
64.7,
17.3,
8.4,
49.4,
91.9,
81.9,
46.3,
70.1,
52.7,
80.6,
34.6,
81,
70,
50.4,
49.8,
84.9,
75.8,
77,
50.6,
63.9,
36.4,
43.3,
47.1,
66.8,
75.2,
65.8,
58.3,
94.6,
65,
44.9,
45.3,
75,
39.1,
73.6,
58.2,
47.7,
39.1,
64,
71.8,
67.7,
72.4,
69.8,
75.6,
10,
40.9,
41.1,
51.1,
31.8,
83.1,
72.3,
79.8,
58.3,
69,
54.3,
71.9,
42.2,
83.4,
41,
88.4,
70,
21.7,
56.5,
9.8,
93.2,
35.6,
19.6,
56,
40.6,
61,
56,
65.4,
41,
62.8,
47.9,
59,
61,
90.1,
91.8,
60.9,
28.7,
36.2,
3.2,
87,
51.4,
33.7,
57.5,
21.8,
86.2,
67.5,
67.5,
24.2,
77.3,
77.3,
24.1,
51.6,
68.4,
91.6,
9.4,
61.4,
50.3,
53.4,
92.4,
27.7,
68.5,
20.9,
78.8,
84.1,
94.8,
43.6,
95,
50.5,
25.2,
19.2,
57.9,
82.9,
52.4,
52.3,
49,
65.5,
78,
74.8,
47.3,
62.3,
42.2,
60.2,
74,
58.8,
47.8,
89.3,
44.4,
42.9,
59,
96.7,
74.1,
37.2,
10.3,
18.3,
65.4,
57.2,
68.3,
68.9,
14.7,
66.2,
75.8,
23.7,
53.6,
22.1,
68.3,
32,
54.2,
70.9,
27.1,
50.2,
33.8,
39.2,
28.6,
60.4,
54.6,
82.2,
29.7,
43.7,
48.9,
74,
74.1,
42.1,
37.2,
70.7,
74.8,
81.2,
21.1,
74.6,
45.3,
68.8,
43.6,
66.8,
97.7,
72.1,
28.7,
68,
64.5,
24.4,
88.3,
85,
59.8,
54.3,
95.7,
67.9,
89.5,
71.7,
40.4,
32.1,
76,
70.1,
1.4,
92.8,
50.6,
37.7,
10.5,
63.8,
69,
50.5,
87.7,
53.4,
46.1,
80.7,
76.3,
14.3,
72.9,
35.8,
99.5,
66,
5.1,
70.2,
96.5,
50.4,
43,
82.8,
32.2,
13.7,
89.9,
2.5,
71.6,
23.2,
41.3,
78.8,
46,
10.5,
59.2,
45.7,
53,
57.5,
20.9,
7.2,
38.5,
30.8,
62.1,
98.9,
95.3,
15,
50,
53.1,
36,
34.4,
88.7,
29.7,
71.7,
61,
57.6,
75.7,
29.1,
49.2,
22,
58.4,
69.5,
51.1,
63.2,
26.1,
65.1,
25.9,
52.4,
11.6,
79.8,
49.5,
26.7,
58.2,
9.2,
22.4,
92.4,
47,
74.6,
48.9,
99,
82.6,
41.6,
9.8,
61.7,
80.3,
39.7,
88.9,
11.2,
95.5,
77.6,
78.7,
33.1,
38.1,
71.8,
100.7,
77.3,
50.9,
23.7,
31.1,
36.5,
51.4,
42.8,
52,
88.2,
59.9,
55,
79.6,
53.4,
4.8,
81.5,
80.8,
17.7,
68.7,
55,
77.4,
84.8,
16.3,
0.4,
60.9,
37.7,
55.8,
80.4,
83.8,
85.5,
27.3,
53.8,
57.9,
94.4,
82,
64.8,
0,
99,
84.4,
80.3,
24.4,
39.7,
0,
24,
51.3,
60.2,
77.1,
50.7,
62.4,
21.7,
22.5,
49.4,
0,
78.8,
13.6,
17.2,
62.8,
47.7,
62.9,
85.7,
92.1,
43.9,
68.4,
72.2,
60.8,
20.2,
85.5,
84.5,
36.8,
37.5,
77.2,
24.4,
21.1,
76,
51.9,
40.9,
45.4,
71.8,
49.9,
45.5,
36.4,
33.7,
95.5,
79.1,
60.6,
78.4,
86.1,
54.8,
91,
90.8,
84.7,
45,
56.6,
63.3,
73.5,
34.6,
18.2,
76.6,
66.8,
29.2,
75.6,
34.7,
62.9,
71.3,
47.5,
37.7,
78.9,
36.2,
62.4,
44.4,
79.1,
72.1,
16.3,
55.3,
73,
61.5,
41.8,
66.5,
27.9,
19.6,
80.3,
63.9,
58.3,
52.9,
71.1,
83.5,
51.7,
61.5,
80,
0,
67.6,
80.8,
56,
55.1,
15.5,
44,
2.4,
77.9,
100.5,
49.2,
67.3,
14.7,
52.7,
71.5,
35.4,
4.1,
87,
83.1,
81.1,
49.4,
79.7,
35.2,
41.9,
50.7,
23.8,
57.3,
46.9,
22.8,
33.6,
93.6,
33.5,
85.7,
72.5,
96.4,
64,
87.2,
63.8,
8.7,
65.9,
94.6,
35.3,
10.9,
42.7,
96,
88.7,
76.6,
57.1,
35.3,
46.4,
79,
115.3,
63.5,
82.4,
79.8,
53.2,
15.1,
19.6,
60,
29.7,
87.5,
53.3,
96.7,
77.5,
29.7,
32.2,
46.6,
47.5,
30.6,
25.1,
46.4,
26.8,
90.2,
69.7,
72,
63.9,
93.3,
16.8,
29.8,
45.9,
39.7,
78.7,
81.9,
44.7,
85.8,
34,
48.1,
58,
56.8,
44.2,
52.6,
59.9,
28.1,
57.2,
55.3,
37.7,
59.1,
79.7,
0,
85.7,
79.9,
59.9,
60,
60.1,
15.5,
60,
48.7,
70.5,
69.5,
56.9,
40.7,
55,
87.8,
20.2,
12.6,
59.2,
19.3,
87.6,
83.5,
62.9,
89.1,
68,
48.7,
78.5,
30.4,
86.1,
61,
31.8,
59,
46.1,
43.1,
45,
50.8,
78.2,
81.1,
48.8,
64.5,
52.1,
73,
73.4,
64.6,
74.7,
48.6,
78.3,
35.3,
53.4,
84.7,
71.6,
86.1,
25.8,
66.2,
45.7,
89.9,
59.5,
78.5,
49.3,
82.2,
73.8,
55.2,
25.5,
69.9,
67,
73.5,
101.3,
92.8,
78.6,
77.9,
8,
74.6,
65.6,
40.2,
93.1,
39.9,
99,
60.3,
70.4,
26.4,
46.8,
21.8,
75.5,
91.4,
39,
11.6,
91.5,
87.3,
9.9,
78.9,
54.6,
18.1,
21.5,
62,
57.3,
79.4,
50.8,
58,
62.6,
34.9,
43,
0.8,
77.9,
64.6,
99.5,
49.9,
75,
68.8,
15.5,
52.5,
90.4,
24.7,
63,
69.5,
66.6,
39.1,
88.2,
65,
67.1,
27,
76.6,
86,
73.3,
31.1,
77.2,
87,
72.4,
24.5,
84.5,
48.1,
72.5,
52.3,
18.9,
78.4,
78.9,
47.5,
77.2,
0,
87.9,
77.6,
61.3,
18.1,
25,
67.2,
52.6,
66.5,
21.5,
47.4,
87.5,
25,
89.4,
72.4,
69.5,
84.9,
39.6,
65,
43.3,
69.2,
52.6,
40.2,
66.6,
60.2,
87.1,
80.1,
68.2,
2.2,
23.1,
86.7,
82.4,
22.3,
81.2,
72.3,
57.7,
46.9,
90.4,
96.7,
94.3,
0,
96.7,
78.2,
17.6,
79,
55.2,
90.2,
74.8,
57.7,
55,
70.6,
76,
25,
33.5,
78.1,
45.3,
86.2,
36.1,
56.2,
70,
56.5,
55.4,
40.5,
91.8,
66,
63,
99.3,
44.2,
18.4,
38.6,
47.4,
56.3,
57.6,
91.7,
40.4,
45.6,
58,
57.4,
76,
85.8,
74.8,
87.3,
52.7,
74.2,
71,
68.2,
54.5,
74.5,
81.7,
74.9,
50.5,
80.5,
35.5,
57.7,
52,
62,
58,
42.7,
93.5,
87.1,
37.2,
52.3,
38.9,
25.2,
69.9,
42.8,
38.1,
26.6,
68.8,
50.7,
72.1,
34.8,
82.6,
42.8,
53.4,
82.3,
60.2,
39.9,
52.7,
64.8,
77.4,
61.9,
80.9,
34,
48,
29,
28.3,
54.7,
82.7,
28,
25.5,
67.9,
63.4,
48.2,
82.1,
83.5,
48.7,
56,
59.3,
65.7,
56.1,
32.8,
59.7,
45.9,
48.4,
75.4,
92.3,
33,
75.4,
33.2,
60.3,
8.7,
40.9,
50.4,
72.2,
20.3,
42.3,
88,
49.5,
92.9,
88.7,
56.6,
83.1,
98,
50.1,
1.3,
36,
85.5,
12,
39,
62,
4,
58.9,
52.4,
67.5,
41.7,
55.3,
97.6,
50.4,
75.8,
74,
16,
89.7,
58,
32.3,
58.5,
34.1,
47.5,
69.7,
60.3,
39.4,
68.3,
67.9,
52.7,
53,
23.7,
57,
61.7,
53.8,
16.6,
52,
39,
27.4,
91.8,
95.3,
20.3,
80,
53.9,
41.2,
38.4,
62.5,
72.3,
53.1,
50.7,
48.8,
59.9,
83.3,
33.8,
53.2,
77.8,
49.9,
49.3,
68.6,
13.2,
72.2,
60.9,
49.2,
16.1,
82.8,
58.5,
79.6,
32.3,
51.2,
88.6,
69.6,
59.7,
81.6,
47.1,
66.3,
67.2,
22,
80.7,
66.7,
55.6,
94.6,
18.5,
47.6,
58.7,
46.5,
84.2,
69.2,
13.9,
11.6,
14.5,
80.3,
53.9,
39.4,
52,
58,
71.1,
13,
40.7,
51.3,
43.1,
81,
27.1,
50,
86.3,
37,
36.2,
79.4,
35.4,
71.4,
98,
31.9,
33.9,
68.3,
36.8,
80.1,
32.7,
71.8,
18.7,
94.9,
18.3,
36.4,
59,
96.3,
11.2,
52.1,
63.2,
63.7,
97.4,
23.2,
45.5,
30.5,
2.3,
12,
83.9,
43.4,
72.6,
72.3,
59.4,
66.3,
80.2,
62.6,
49.7,
62.1,
28.3,
56.6,
80,
55,
56,
45.7,
86.4,
54,
50.8,
73.4,
14.3,
45.8,
97.5,
36.2,
0,
68.8,
8.8,
49.3,
49.8,
86.8,
41.5,
48,
75.8,
49.8,
93.9,
63.5,
92.8,
55.4,
57.2,
35,
42.6,
50.2,
62.5,
32.5,
62.2,
50.4,
52.2,
84.5,
71.7,
74.8,
26.1,
40,
61.5,
76.2,
39.3,
46.4,
86.9,
57.7,
45.1,
80.1,
64.1,
76.5,
54.8,
48.3,
52.6,
79.4,
12.2,
96.7,
87,
73.3,
10.1,
66.3,
71,
70,
77.5,
53.1,
78.7,
36.1,
42.2,
55,
56.3,
80.5,
64.8,
81.3,
61.9,
47.2,
73.6,
69.5,
23.8,
61,
53.6,
95.8,
75.2,
36.2,
79.1,
68,
96.3,
100.1,
9.7,
46.8,
76.2,
72.8,
30,
87,
77.7,
52,
72.2,
51.7,
38.4,
63.4,
55.3,
50.9,
82.9,
82,
72.4,
11.9,
41.2,
19.6,
83.9,
37.4,
76.8,
40.4,
6.5,
80.3,
49.8,
46.4,
78.7,
50,
20.4,
46,
33.7,
15.7,
71.4,
26.8,
27.1,
86.2,
64.4,
47.9,
71.2,
40.2,
83.9,
65.8,
84.6,
38.6,
60.3,
34.3,
36.3,
77.6,
69.6,
1.1,
7.7,
41.3,
66.2,
6.5,
28.8,
54.8,
84.4,
59.7,
79.3,
73,
78,
45.7,
52.3,
59.6,
70.9,
38.5,
64.2,
61.8,
40.9,
55.3,
25.4,
44.7,
41.8,
0.1,
72.2,
42.8,
64.4,
59.6,
60.1,
27.7,
83.6,
53.5,
86,
58.2,
24.8,
41.9,
26.1,
64.6,
35.2,
56.2,
35.7,
78.9,
67.9,
82.8,
45.6,
46,
29.8,
23.8,
26.9,
19.5,
56,
30.5,
76.1,
47.8,
69.6,
83.7,
45.6,
6.2,
67.3,
36.1,
56.7,
53.8,
89.6,
88.4,
35,
7.1,
72.2,
72.6,
44.9,
23.2,
96.9,
50.9,
66.5,
46.7,
62.2,
84.2,
57.5,
93.5,
69.1,
36.3,
35.7,
72.1,
80.2,
67,
49.7,
30.2,
40.3,
94.9,
29.6,
33.1,
82.2,
95.4,
36.4,
55.5,
65.2,
37.8,
47.3,
67.6,
10.4,
64.6,
66.6,
35.4,
51.3,
67.4,
42.2,
77.1,
54.3,
73,
54.6,
49.2,
62.2,
101.5,
89.9,
22.1,
21.4,
36.7,
90.1,
26.3,
22.4,
54,
36.2,
57.7,
55,
28.4,
62.9,
4.5,
50.8,
60.5,
65,
66.8,
94.6,
71.8,
9.7,
85,
86,
63.8,
31.3,
18.9,
85.8,
63.5,
28.2,
20.7,
24.3,
98.4,
23.7,
59.9,
62.7,
51.6,
66.5,
67.8,
62.5,
79.1,
38.6,
14.5,
81.7,
51.4,
60.1,
15.5,
74,
78.4,
64.5,
29,
37.9,
70.4,
24.3,
34.1,
67.5,
87.6,
15.8,
74,
67.7,
48.2,
78.2,
59.6,
50.2,
44.9,
49,
42,
44.3,
48,
68.7,
79.2,
68.3,
46.5,
66.6,
92.9,
65,
66.6,
26.5,
59.9,
93.8,
67.8,
63.2,
36,
63.8,
31.1,
43.7,
36.5,
56,
29.9,
16.3,
87.1,
53.8,
52.8,
61.9,
92.4,
67,
48.1,
61.2,
93,
90.5,
79.9,
11.1,
67.4,
100.1,
20.4,
15.7,
56.2,
8,
68.8,
85.3,
96.4,
73.3,
47.6,
10.7,
57.6,
18.7,
68.1,
79.4,
34.5,
78.4,
53.3,
25.3,
98.5,
25.3,
46.7,
45.3,
83.9,
60.3,
10.8,
70.4,
69.6,
49.4,
66.9,
58.2,
57.6,
92.8,
47.8,
58.8,
29.5,
53.5,
53.7,
81,
53.4,
76.4,
4.3,
80.1,
25.4,
67.5,
95,
98.6,
71.2,
78.3,
69.9,
67.3,
39.6,
53.2,
21.8,
55.3,
44.1,
42.4,
71.6,
52,
15.5,
78.6,
94.3,
49.6,
86,
70,
58.1,
24.6,
33,
33.5,
59.3,
52,
81.6,
62.5,
97.6,
80.4,
8,
81.7,
33.3,
64.1,
79.3,
83.4,
92.1,
5.7,
74.2,
98,
5,
3.8,
35,
92,
81.8,
74.9,
35,
59,
64.4,
68.4,
59.1,
44.3,
61.9,
72.9,
12.4,
69.9,
68.6,
61.4,
77.3,
77.7,
41.2,
56.2,
35.7,
20.9,
47.9,
63.8,
37.3,
39.4,
97.9,
43.3,
16.5,
7.6,
50.7,
59.1,
62,
69.3,
27.5,
81.7,
81.5,
44.8,
63.4,
100.7,
55.9,
92.8,
85.7,
38.5,
63.6,
56.5,
51.4,
34.7,
73.8,
7.5,
85.9,
41.1,
93.4,
67.1,
58.2,
65.9,
89.8,
73.5,
20.5,
98.1,
38.6,
24.6,
21.8,
57.2,
45.8,
92.6,
81.4,
79,
56,
91.8,
69.2,
83.9,
0.6,
90.7,
28.4,
18.1,
49.7,
51.4,
75.8,
35.5,
92.8,
47.7,
88,
70.2,
56.9,
31,
52.7,
0,
92.5,
71,
63.4,
82.3,
92.9,
59.7,
52.4,
42.1,
24.6,
22,
38.5,
82,
75,
60.3,
78,
59.8,
42.6,
41.9,
29.3,
70.7,
57.8,
46.8,
66.1,
67.9,
82,
92,
49.8,
36.9,
48.4,
93.4,
32.4,
87.2,
70.2,
89.2,
69.3,
16.3,
45.8,
77.7,
96,
56,
54.2,
65.2,
87,
42.4,
22.5,
21.4,
7.3,
55.2,
82.8,
78.2,
68.4,
94.3,
66.2,
59.5,
59.8,
93.9,
30.9,
44.3,
68.9,
44.5,
44.7,
98.9,
92.4,
32.6,
53.1,
21.4,
50.5,
29.7,
55.7,
26.4,
14.6,
70.6,
75.1,
67.4,
12.8,
52.4,
29.1,
56.4,
30,
23,
60.2,
79.1,
42.1,
34,
73,
20.5,
95.7,
33.2,
13,
93.9,
47.9,
2.3,
84.9,
86.5,
41.2,
41.3,
63,
53.9,
46.4,
23.2,
44.3,
77,
87.1,
49.3,
76.5,
10.3,
78.5,
55.2,
60.4,
81.6,
58.7,
36.7,
29.5,
56.4,
77.3,
43.4,
32.2,
39.6,
78.6,
79.9,
63.9,
64,
67.7,
47,
71.9,
76.2,
41.8,
4.4,
0.8,
37.4,
73.3,
79.8,
38.3,
58.6,
26,
76,
22.7,
64.3,
43.2,
37.7,
62.6,
73.1,
82.6,
52.4,
45,
43.1,
23.9,
38.6,
27.5,
54.4,
80,
88.2,
31.3,
90,
68.8,
65,
12.7,
77.6,
62.3,
83.1,
39.3,
40,
40.7,
38.1,
25.5,
39.4,
51.7,
46.8,
65.6,
80,
88.2,
38.8,
45.7,
69.4,
40,
93,
62.8,
39.4,
79.9,
71,
71,
56.8,
28.9,
68.2,
45.5,
8.4,
62,
95.9,
44,
53.6,
87,
69.9,
61.5,
57,
41.2,
53.4,
100.3,
96.7,
25.7,
68.9,
73.3,
91.5,
25.7,
64.2,
53.2,
62.8,
27.1,
39.8,
63.3,
42.6,
25.6,
20.3,
66.1,
55.1,
67.8,
63,
17.3,
64.8,
78.4,
94.3,
11.2,
91,
9,
74.6,
48.5,
50.8,
33.5,
2.2,
62,
66.8,
54.2,
54.7,
70.9,
62.4,
71,
83.2,
43.7,
47.5,
50.1,
55.8,
77.6,
52.8,
28.8,
83,
67.1,
87.6,
69.6,
46,
47.9,
91.9,
57.4,
35.7,
69.5,
33.3,
61.9,
5.7,
57.9,
39.4,
83.5,
80.8,
50.2,
71.3,
86.4,
73.7,
82,
97.3,
76.5,
41.4,
76.9,
93.8,
52.1,
47.2,
81.5,
71.9,
65.8,
26.3,
47.2,
60.6,
13.9,
51.3,
47.8,
72.3,
91.3,
59.4,
23.2,
77.6,
59.3,
31.7,
75.6,
95.3,
74.8,
35.3,
72.6,
39.8,
74.3,
69.6,
64.9,
48.7,
10.7,
59.7,
37.5,
84.5,
72.4,
90.8,
64.7,
78.4,
71,
6.5,
61.5,
25.9,
32.1,
77,
56.2,
23.7,
53.3,
27.3,
74.8,
43.1,
24.7,
29.2,
53.8,
42.4,
67.2,
77.9,
87.6,
86.7,
94.7,
25.6,
50.9,
43.9,
59.1,
94.3,
47.8,
76.7,
39,
42.5,
51.6,
58.9,
65.6,
93.5,
81.8,
69.7,
60.6,
62.9,
59,
28.8,
85.8,
86.4,
57.2,
44.4,
45.9,
32.5,
67.9,
87.8,
48.6,
82.5,
77.7,
59.2,
27.9,
7.9,
36.7,
76,
94.8,
22.5,
46.6,
60.3,
36.6,
31.9,
51,
99.3,
59.5,
71.1,
33.2,
27.9,
38.4,
38.5,
80.7,
70.1,
72.5,
69,
46.9,
48.6,
52.7,
78.6,
55.8,
77.4,
51.9,
15,
49.8,
37,
33.8,
37.3,
46.4,
63.6,
8.7,
62.2,
30.4,
35.5,
96.9,
53,
53.6,
74.4,
11.5,
97.8,
24.3,
57.3,
72.2,
46.6,
43.6,
85.2,
30.4,
62.4,
63,
55,
79.7,
14.4,
100.3,
61.5,
42.4,
59.2,
42.5,
29.8,
69.9,
37.1,
54,
54.3,
47.2,
80.4,
15.1,
39.1,
39.3,
6.2,
31.3,
91.1,
28.4,
56.5,
46.5,
66.5,
36.6,
67.6,
7.9,
52.2,
34.1,
15.9,
35.8,
58.4,
41,
33.7,
59.6,
68.5,
72.9,
53.5,
56.4,
73.6,
21.7,
55.5,
15.1,
42.8,
83.2,
62.7,
97.4,
39.1,
31.1,
44,
78.8,
55.3,
83.7,
13.3,
44.9,
67.7,
57.8,
63.6,
86.3,
91.6,
55.9,
42.9,
45.9,
49.1,
57.9,
68,
9.8,
18.9,
54.2,
9.1,
33.4,
96,
74.7,
51,
26.7,
61.6,
62.8,
27.6,
80.6,
26.3,
23.9,
68.6,
52,
32.6,
32.7,
96.7,
90.7,
20.7,
62.6,
59.4,
43.9,
66.5,
44.7,
10.3,
94.3,
41.6,
49.7,
97.8,
29.3,
42.1,
31,
14.2,
20.5,
44.8,
32.8,
89.1,
64.2,
34.3,
90,
54,
53.4,
39,
51.7,
26.5,
27.7,
86.1,
75.6,
54.7,
70.5,
77.4,
20.5,
80.8,
53,
88.5,
29.9,
53.5,
46.5,
33.2,
50.7,
75.4,
81.4,
52.3,
29.3,
22.6,
12.3,
45.3,
55.8,
67.9,
50.5,
68,
29.2,
84.1,
39.6,
82.4,
35.5,
12.2,
40.9,
69.9,
41.4,
47.2,
73.1,
50.6,
66.7,
29.8,
78.4,
93.8,
88.6,
11.7,
19,
42,
67,
29.7,
72.7,
59.6,
28.4,
61.1,
66.9,
44.7,
48.6,
53.1,
49.1,
35.6,
48.6,
97.7,
51.9,
39.7,
39.9,
31.3,
40.5,
50.9,
70.1,
50.8,
33.4,
75.7,
85.3,
63.2,
59.5,
44,
70.8,
13.1,
67.3,
39.6,
80,
60.4,
90,
22.7,
85.8,
71.7,
15.4,
25.8,
22,
39.6,
40.8,
39.3,
76.6,
76.3,
88.7,
84.7,
89.6,
35.6,
62.5,
22.9,
60,
48,
38,
80,
53.3,
61.2,
75.8,
65.3,
45.8,
52.5,
44.4,
66,
8,
36.3,
25.5,
64.1,
59.3,
61.6,
75.5,
62.2,
5.7,
92.5,
30,
17.5,
33.1,
45.3,
58.3,
74.8,
79,
80.5,
5.6,
60.5,
75,
74.3,
36.2,
66.7,
25.3,
58,
37.2,
56,
43.9,
17.6,
48.8,
39,
29,
45.7,
41.7,
69.7,
68.7,
31.3,
28.2,
66,
78.7,
57.1,
48.2,
30,
48.9,
39.9,
72.3,
60.1,
72.1,
21.3,
71.7,
23.8,
41.4,
62.5,
57,
58.3,
80.4,
67,
92,
7.4,
69.2,
65.3,
74,
51,
80.7,
96.3,
96.3,
61,
27.2,
73.9,
44.9,
83.9,
32.4,
61.5,
48.1,
62.6,
96.1,
66.3,
23.1,
56.9,
34.2,
92.9,
21.2,
79.8,
16.7,
19.8,
19.2,
26.7,
78,
52,
40.1,
65.9,
35.6,
62.5,
48.3,
60.7,
34.4,
55.1,
35.9,
10.1,
26.9,
19.6,
26.1,
70.1,
65.3,
67.7,
54.3,
65.7,
39.7,
38,
92.5,
98.8,
54.7,
34.4,
46.3,
25.6,
81.8,
75.3,
15.8,
67.3,
54.4,
34.9,
81.8,
97.1,
34.5,
94,
68.8,
70.6,
23.4,
16.7,
59.5,
32.8,
62.2,
81.4,
49.7,
70.2,
15.7,
28.9,
46.5,
51.3,
48.1,
81.4,
41.4,
28.2,
81.6,
51.1,
23.1,
91.3,
38.5,
71.1,
86.6,
71.1,
55.3,
56.6,
73.9,
30.1,
2.4,
33.8,
46.4,
81.1,
35.4,
70.7,
60.7,
22.1,
61.2,
92.2,
94.9,
63,
18.6,
29.8,
7.7,
76.5,
97,
68,
68,
29.7,
9.9,
33.8,
36.1,
95.4,
56,
75.5,
57.5,
48.8,
71.7,
96.7,
71.6,
82.9,
37.7,
47.9,
68.1,
19.5,
80.1,
35.6,
62.2,
17,
86.8,
74.7,
25.2,
62.6,
84.9,
64.7,
41.7,
82.8,
25.2,
68,
27,
69.1,
53.2,
24.9,
53.6,
46.6,
89.3,
81.4,
77.7,
76.7,
96.9,
51.9,
68.9,
55.8,
74.1,
73.1,
81.8,
55.3,
70.4,
18.8,
67.7,
81.9,
70,
34.5,
72.6,
58.8,
54.2,
53.6,
89.9,
38.2,
60.3,
88.5,
62.9,
29.4,
34.6,
40.9,
17.8,
46.3,
81.1,
70.1,
33.8,
85.4,
40.8,
63.1,
92.5,
37.7,
61.2,
63.2,
64.1,
47.4,
26.5,
90.4,
47,
47.2,
63.6,
36,
99.3,
87.9,
71.1,
90.2,
36.8,
12.1,
58.5,
30.5,
56.1,
24.9,
57.2,
45.7,
64.7,
65.6,
77.8,
24,
53.2,
4.7,
76.7,
63.4,
53.3,
63,
53.3,
81.3,
70.9,
95.2,
47.8,
14.8,
59.9,
90.8,
94.6,
10.8,
75.5,
42.1,
19.2,
48.4,
48.5,
51.9,
48.6,
66.1,
49.3,
6.1,
27.5,
77.7,
37.9,
90.6,
71,
56.7,
38.7,
51.6,
45,
49.3,
56.4,
60.8,
64,
86.2,
83.6,
36,
56.8,
79.7,
88,
32.2,
29.5,
58.3,
71.8,
63.2,
64.7,
13.1,
38.8,
101.9,
70.2,
16.8,
37.6,
78.1,
37.9,
20.1,
26.4,
91.2,
16.8,
53.8,
32.2,
40,
42.9,
71.7,
23.4,
0,
0.3,
75.2,
72.7,
53.7,
75.4,
66.6,
64,
50.3,
61.6,
43,
52.4,
40.8,
34.4,
62.2,
54.8,
46.2,
48.4,
64.3,
13.4,
41.8,
86.6,
44.6,
50.3,
84.1,
68.5,
60.2,
44,
46.5,
99.7,
12.4,
68.9,
41.8,
97.5,
78,
75.3,
60.4,
81,
36.2,
64,
59.1,
42.6,
33,
69.2,
97.8,
55.7,
45.2,
72.2,
71.9,
99,
7.8,
76.4,
87,
77,
44,
65.1,
35.9,
69.7,
20.9,
42.9,
28.1,
70.7,
69.1,
46.6,
42.4,
65.8,
23.9,
42.9,
75.2,
81.4,
66.7,
73.2,
83.5,
44,
83.4,
89,
60.4,
64.9,
58.2,
10.3,
60,
52.7,
35.3,
52.1,
94.6,
86.4,
61.1,
76.1,
65.6,
35.1,
30.3,
46.3,
29,
27.4,
40.9,
70.8,
50.8,
74.6,
31.8,
44,
73.9,
77.7,
34.3,
65.7,
62.3,
31,
30.7,
54.4,
83.8,
70.2,
73.3,
77.5,
55.9,
69.3,
61.3,
70,
82,
20.8,
72.5,
93.9,
37.8,
46.3,
75.5,
44.5,
73.6,
39.4,
36.8,
40.5,
47.5,
54.5,
22,
61.9,
49,
54.3,
28.2,
42.6,
36,
64.4,
53.8,
51.4,
64.2,
61.4,
61.1,
35.3,
79.6,
45.6,
0,
53.3,
58.3,
88.3,
52.9,
57.2,
48.2,
96.2,
12.6,
44,
81.6,
46,
50.3,
39.2,
15.7,
26.6,
72.7,
75,
35,
99.6,
84.4,
33.4,
99.7,
53.9,
36.8,
66.2,
82.2,
75.4,
51.6,
75.2,
60.4,
60.3,
95.3,
7,
94.3,
38.4,
42,
46.8,
63.2,
37,
80.1,
85.8,
49.2,
62.4,
0.2,
52,
29,
35.9,
81.2,
99,
28.4,
55.5,
31.9,
49,
21.7,
72.3,
31.2,
86.5,
64.4,
83.6,
29,
39.7,
30,
94.5,
54.6,
73.6,
53.5,
null,
79.3,
79.7,
73.2,
90.7,
24,
76,
87.8,
51.2,
24.5,
32.3,
80.4,
41.7,
76.5,
20,
37,
37.8,
58,
87.5,
11.8,
24.1,
88,
30.1,
30.7,
78.6,
80.4,
40.1,
68.5,
60.3,
75.1,
54.3,
85.3,
79.1,
33.3,
63.8,
76,
38.4,
79,
31.8,
31.5,
0.1,
73.2,
65.5,
68.6,
95.6,
44.1,
53.7,
60.5,
50.2,
56.7,
81.7,
59.3,
32.2,
40,
71.6,
37.1,
68.6,
44.3,
41.3,
24.6,
11,
20.9,
45.7,
54.3,
60.6,
40.6,
49.3,
17.1,
59.3,
37.8,
75.1,
80.7,
41.4,
32.1,
55.3,
10.6,
64.8,
63,
68.2,
46.2,
94.3,
49.7,
84.9,
20,
32.7,
85.8,
48.9,
52.9,
45.5,
73.7,
85.7,
63,
28,
97.3,
95.2,
52.4,
56.9,
77.3,
80.2,
40.6,
71.9,
15.4,
60,
32.3,
33.9,
77.5,
43.9,
56.5,
36,
19.3,
6.9,
70,
37.1,
20.7,
49.5,
43,
50.5,
78.6,
6.7,
47.8,
31.3,
60.3,
29.4,
83.5,
54.7,
57.5,
89.4,
16.1,
37.5,
80.9,
84.3,
64.9,
24.5,
91,
29.7,
17.3,
50.9,
43.8,
86.7,
59.5,
75.4,
33.3,
26.3,
49.1,
74.8,
63.1,
10.8,
65.4,
73,
21.1,
4.9,
70.3,
24,
0.1,
57.2,
38.2,
16.7,
30.1,
83,
14.5,
34,
65.2,
19.5,
30.7,
35,
51,
49.8,
77.4,
44.4,
43.4,
43,
7.9,
40,
65.7,
47.8,
52.5,
64.9,
26.8,
47.7,
89.7,
68,
4.9,
43.4,
64.9,
63.2,
70,
59.9,
13.2,
64,
10.2,
83.3,
43.6,
14.3,
64.3,
62.3,
45.9,
63.2,
54,
95.5,
88.5,
75.8,
50,
10.9,
44.4,
44.4,
35.8,
11.5,
73,
14.7,
86.6,
35.7,
28.6,
99.4,
38.5,
41.2,
42.3,
75.3,
28.5,
58,
54.8,
60.6,
54.8,
7,
72,
44.6,
49.1,
50.6,
50.3,
54.2,
29.6,
9.4,
56.3,
35.5,
10,
93.8,
18,
15.1,
85.3,
74.6,
51.1,
87.5,
70.1,
80.9,
74.3,
43.7,
78.9,
15.6,
53.6,
48.5,
68.6,
47.3,
26.9,
98.2,
51.2,
54.6,
79.7,
69.3,
48.8,
50.3,
24.9,
24.8,
96,
35.4,
66.3,
49.3,
35,
46.8,
40,
16.8,
33.8,
69.4,
55.2,
81.8,
38.4,
55.2,
61.6,
48.7,
38.6,
80.9,
21,
56.5,
53.8,
44.4,
54.6,
40.3,
76.8,
48.9,
53.1,
81.8,
44.2,
91.7,
39.8,
19.4,
91.4,
65,
51,
63.4,
47.8,
35.8,
60.6,
70.8,
64.9,
58.3,
60.7,
6.8,
51.1,
61.8,
77.8,
60.8,
65.5,
68.7,
72.5,
41.8,
74.2,
50.7,
88.7,
74.1,
51.5,
95.6,
55.7,
40.1,
55.4,
35.5,
24.2,
39.2,
45.6,
59.1,
60.5,
45,
94.6,
11.1,
37.3,
26,
90.5,
97.3,
39.7,
86.5,
25.4,
53.9,
63,
74.9,
61,
84,
58.1,
54.8,
81.4,
43.6,
76.2,
69.5,
23,
65,
67.8,
27.5,
51,
42.1,
56.2,
49,
92.4,
3,
42,
71,
18.9,
58.9,
89,
66,
41.3,
93.1,
13.2,
64.1,
61.6,
89.2,
102,
79.8,
38.5,
79.5,
70.3,
76.4,
8.8,
35.5,
80.6,
13.2,
36.9,
57.9,
61.3,
15.4,
23.3,
73.4,
15.3,
70.9,
37.9,
16.1,
47.1,
30,
88.6,
76.5,
31,
72.9,
37.4,
64,
94.8,
32.8,
39.4,
56.2,
40.4,
1.2,
87.8,
69.9,
56.4,
44.2,
59.4,
69.6,
32.1,
70.7,
18.5,
98.6,
50.7,
42.5,
33,
59.5,
76.7,
60.5,
62.3,
67,
98.1,
87.1,
51.3,
68.5,
85.6,
70.1,
74.4,
90.9,
27.3,
43.5,
57.2,
26.5,
37.5,
55.3,
99.4,
58,
50.5,
21.2,
1.1,
42.3,
91.4,
67.7,
62.6,
80.2,
48.4,
57.9,
60.1,
98.4,
67.4,
35.7,
72.6,
57.4,
83.9,
24.9,
94.8,
27.8,
60.9,
66.8,
86.5,
0.2,
51,
62.8,
40.8,
58.1,
11.4,
41.3,
46.9,
69.8,
19.1,
77.3,
78.3,
18.1,
50.9,
79.7,
23.7,
38.3,
37.3,
67.5,
20.9,
98.1,
81.2,
18.2,
95.5,
48.7,
62,
89.7,
77.1,
73.4,
43.9,
60.3,
41.2,
78.2,
30.8,
88.9,
57.1,
92.6,
49.5,
99.7,
42.8,
32.4,
36.8,
34.5,
16.2,
68.9,
18.9,
51.3,
62.9,
80.6,
87.3,
83.9,
63.3,
86.2,
62.3,
94.6,
62,
40.7,
56.6,
68.1,
34.4,
62.2,
60.7,
82.9,
72.4,
50,
74.7,
16,
4.2,
24.6,
43.5,
18.5,
44.2,
54,
41.1,
48.4,
19,
31.5,
77.1,
44.9,
61,
42.7,
27.9,
66.2,
63.3,
26.9,
78.1,
84,
21.6,
48.6,
33.6,
21.7,
64.4,
18.4,
43.9,
41.5,
54.3,
81.5,
50.4,
40.8,
79.2,
77,
56.1,
33.2,
62.6,
28.4,
26.7,
92.4,
53.8,
93.1,
31.4,
86.9,
34.4,
56.8,
61.6,
84.6,
67.4,
74.7,
34.3,
43.8,
33.5,
74.8,
68.4,
59.2,
68.8,
80.1,
80.8,
28.6,
63.9,
26.8,
49.7,
23.2,
43,
65.5,
66.4,
75.6,
17.9,
42.2,
55.5,
85.5,
85.9,
78,
94.1,
93.3,
23.8,
36,
38.8,
52.4,
68.6,
86.8,
36.4,
38.9,
36.7,
23.9,
93.8,
76.2,
55.5,
69.6,
55.1,
24.6,
38.6,
73.7,
29.8,
50.8,
78.8,
75.9,
67.3,
24,
62.8,
21.1,
54.3,
53.3,
52.4,
27.3,
85.7,
42.9,
43.9,
0.9,
46.2,
89.6,
74.3,
53,
78.2,
9.4,
46.4,
24.7,
24.7,
39.9,
1.2,
97.5,
76,
25.3,
85.8,
79.2,
71.1,
19.3,
80.6,
85.1,
71.8,
49.1,
92.6,
0,
34.2,
72.1,
48.7,
16.3,
86.9,
71.3,
41.6,
95.3,
62.1,
78.3,
75.9,
71.6,
66.4,
49.3,
71.1,
52.4,
33.7,
0.4,
69.5,
47.2,
54.2,
63.4,
12,
33.3,
46.8,
84.5,
37.4,
82.8,
32.4,
81.7,
46.3,
63.9,
47.8,
40.5,
60.9,
62.9,
74.4,
26.2,
27,
33.1,
85.8,
94.2,
8,
71.4,
47,
45.8,
22.5,
52.2,
63.2,
77.5,
79,
67.5,
15,
80.2,
38.2,
34,
53,
50.9,
39.1,
11.6,
74.4,
92.2,
88.3,
64.8,
54.7,
90.6,
41,
42.2,
39.5,
54.6,
30.2,
38.4,
86.3,
29.6,
34.3,
47.5,
55.8,
71.8,
56.9,
79.3,
53.5,
62.4,
54.5,
46.4,
23.1,
59.6,
51.6,
58.8,
19.1,
30.7,
4.6,
15.5,
73,
21.3,
71.2,
62.5,
49.8,
32,
57.4,
61.2,
74.6,
66.1,
34.9,
25.8,
61.8,
48.6,
33.9,
66.2,
72,
47.9,
100.5,
71.5,
70.6,
77.8,
81.3,
103.9,
57.3,
16.4,
82.9,
38,
81.3,
40.4,
16.3,
55.5,
22.1,
80,
55.1,
52.2,
49.1,
69.9,
64.8,
53.8,
65.5,
48.5,
9.9,
47,
35.4,
50.6,
22.3,
41,
29.6,
73.5,
85.2,
46.8,
88.7,
27.8,
64.3,
54.7,
50.7,
97.2,
29.5,
40.5,
47.3,
60.6,
41.1,
0.1,
63,
0,
35.3,
65.2,
98.1,
49.8,
86.1,
67.3,
73.1,
41.5,
45.1,
27.6,
16.8,
30.7,
57.7,
28.3,
40.8,
15.3,
98.5,
27.3,
45.2,
70.4,
73.8,
35,
27.5,
35.9,
62.8,
69.3,
27.1,
55.6,
97.6,
17.1,
74.8,
47.5,
42.9,
62.9,
94.3,
74.6,
81.5,
28.4,
81.4,
40.5,
78.3,
43.3,
60.9,
73.8,
39.9,
56.2,
57.6,
32.4,
14.6,
49.4,
70.1,
73.8,
18.6,
49.8,
12.3,
30.8,
96.6,
87.9,
50.2,
77,
40.4,
56.7,
72.5,
10.1,
56.6,
35.6,
40.8,
34.1,
81.3,
16.7,
78.8,
33.7,
9.3,
21,
16.5,
56,
43.8,
94.5,
57,
84.6,
81.4,
50.6,
32,
32.1,
33.2,
95.2,
14.9,
75.8,
93.3,
58.3,
52.4,
49.2,
44,
71.3,
49.3,
27.1,
58.1,
52.3,
57.6,
76.5,
77.7,
76.4,
33.7,
94.3,
72.5,
9,
87.5,
65.5,
61.8,
64.6,
40.9,
50.8,
30.3,
40,
31,
65.3,
49.4,
93.5,
61.2,
92.1,
28.5,
86.5,
61.2,
83.8,
37.7,
48.6,
25.9,
82,
56.3,
45.2,
49.8,
71.6,
73,
78.9,
69.7,
43.3,
53.8,
66.9,
80.6,
55.4,
2.4,
80.5,
4.1,
73.9,
83.2,
56.8,
23.8,
52,
59.2,
51.1,
54.6,
37.9,
60.7,
32.9,
26.6,
67.6,
71.7,
56,
59.9,
46.2,
41.3,
71.6,
31.2,
43.8,
86.5,
55,
42,
38.5,
69.2,
72.6,
79.4,
66.7,
71,
41.4,
75,
29.6,
84.8,
78.1,
54.9,
28.6,
41.1,
75.7,
12.7,
37.6,
97.1,
71.8,
38.4,
85.9,
58,
55.5,
35.9,
97.2,
59.7,
30.1,
80.7,
62,
98.3,
10.3,
51,
47.6,
81.5,
52,
67.5,
68.9,
78.8,
60.6,
76.6,
45.1,
20.2,
81.9,
49.1,
22.1,
58.7,
66.3,
34.9,
55.2,
90.1,
43.6,
40.4,
80.7,
35.2,
69,
73.2,
84.2,
13.9,
82.8,
54.1,
57.7,
59.7,
60.4,
17.2,
40.2,
47.5,
70.5,
46.4,
22,
64,
34.3,
30.1,
67.7,
43.6,
53.1,
87.7,
22.4,
68.7,
44.2,
70.7,
73.9,
85.5,
21,
61.7,
97.2,
69.2,
42.8,
79,
56.6,
64.4,
60.8,
87.6,
44.1,
95.8,
70.9,
60.7,
15.6,
39.9,
79.4,
65.6,
68.9,
78.6,
63.5,
30.4,
23.9,
63.1,
35.1,
22.1,
41,
88.9,
38.8,
62.8,
67.8,
72,
20.6,
46.6,
65.9,
33.2,
73.7,
45.5,
15.6,
69.7,
0,
15.7,
33.6,
66.6,
49.9,
31.7,
60,
49.8,
40.5,
8.4,
55.6,
79.3,
62.2,
16.3,
38.5,
57,
51.8,
18.5,
6,
90.5,
88.7,
32.7,
98.7,
43.6,
73.1,
83.3,
30,
81.2,
51.9,
30.2,
42.1,
51,
70.7,
36.9,
62.9,
68.7,
75.8,
81.4,
48.5,
105.1,
58.4,
54.4,
76.6,
75.1,
26.1,
26.7,
47.5,
89.8,
54.3,
75.6,
52.1,
92.3,
63.7,
57.5,
84.5,
16.5,
40.3,
47.1,
21.1,
29.7,
56.1,
21.4,
53,
5.9,
53.9,
45.3,
43.5,
43.3,
31.9,
53.8,
82,
97.1,
41.9,
29.8,
76.2,
84.8,
70.5,
35.4,
47,
34.3,
53.1,
71.3,
19.2,
49.2,
81,
70.8,
37.7,
35.9,
35.3,
50.4,
44,
72.1,
44.8,
56.2,
48.5,
47.2,
65.1,
50.1,
82.7,
38.8,
51.5,
76.4,
77.9,
55.8,
52.4,
24.9,
13,
98.3,
36.2,
75.5,
29.5,
84.2,
8.2,
44.6,
0,
78.2,
86.6,
67.9,
47.1,
53,
37,
60.8,
59.8,
32.7,
70.2,
21.8,
93,
76.9,
37.1,
87.1,
41.6,
46.7,
70.4,
36,
17.5,
97.5,
15.6,
81.3,
61.8,
56.5,
37,
60.7,
80,
42.7,
60.5,
64.3,
14.7,
46,
47.1,
70.2,
62.7,
42.4,
22.6,
61.2,
62.2,
78,
92.3,
11,
35.5,
44.7,
39.3,
54.4,
37.3,
74.6,
22.6,
98.2,
78.7,
82.1,
77.8,
28,
65.8,
97.2,
50.3,
68.5,
76,
85,
76.5,
23.5,
87.5,
51.4,
44.8,
57.6,
63.3,
15.2,
54,
39.3,
89.8,
35,
29.4,
106.2,
28.5,
54.4,
75,
20.3,
90.5,
65.2,
15.3,
55.7,
82.1,
21.7,
82.2,
3.4,
77.6,
64,
47,
50.5,
48.5,
47,
27.3,
57.1,
62,
51.2,
11.1,
86.6,
52.9,
51,
99,
63,
24.8,
26.2,
79.8,
42.6,
45.7,
72.6,
27.6,
61.7,
32.4,
48,
35,
87.6,
83.4,
45.2,
31,
41.3,
67.6,
60,
32.4,
82.2,
16.9,
94,
62.4,
78.1,
59.3,
70.7,
72.9,
71.6,
98.4,
65.3,
34.3,
69.5,
50,
58.2,
14.1,
51.1,
87.5,
52.8,
95.7,
37.1,
13.5,
10.8,
25.5,
99.3,
41.6,
11.8,
55.7,
32.6,
2.3,
48,
59.3,
73.6,
50.7,
21.1,
35.7,
48.5,
81.9,
85.9,
82.1,
73,
56.2,
88.8,
56.6,
81.1,
92.8,
41.2,
66.3,
71.7,
59.3,
88.6,
53.9,
33.8,
68.1,
27.5,
37.8,
65.4,
83,
14.7,
59.2,
71.5,
48.8,
9,
79.2,
81.5,
60.4,
93.3,
9.7,
62.9,
62.9,
88.2,
36.8,
61.8,
55.7,
52.3,
88.3,
74.1,
53.1,
18.8,
61.3,
48.4,
32.5,
55.5,
46,
69.8,
72.5,
57.2,
34,
38.7,
74.4,
20.3,
81.5,
33.4,
54.7,
57.2,
80.3,
29.1,
91.5,
62.2,
63.4,
34.4,
10.2,
65,
88.9,
51.3,
67.3,
52.5,
40.4,
26.9,
70,
56.5,
45.9,
19.6,
85.6,
46.7,
91.7,
54.8,
74.1,
49,
61.9,
45.7,
54.6,
45.8,
52.3,
49.7,
63,
67.1,
75.9,
41.3,
36.9,
4.7,
56.1,
10.3,
43.7,
97.2,
74,
41.5,
36.1,
93.5,
50.6,
69,
50,
77.3,
46.2,
70.5,
5,
66.7,
53,
20.4,
72.8,
58.9,
86.3,
92.2,
48,
38.5,
74.8,
87.8,
77.5,
86.3,
53.7,
72.9,
69.3,
36.8,
74,
47.5,
33.5,
45.9,
51.4,
91.4,
70,
69.2,
61.3,
65.1,
44.7,
66.4,
86.3,
6.1,
69,
16.7,
62.8,
70.7,
33.6,
60.7,
54.8,
73.2,
32.1,
58,
65.6,
65,
35.2,
92.4,
66.8,
50.4,
24.7,
27.6,
31.8,
55.2,
86.2,
79.3,
69.9,
83.9,
82.2,
35.5,
64,
82.7,
67.6,
80.5,
null,
36.3,
48,
37.9,
89.3,
66.6,
34,
41.1,
51.1,
45.4,
29.7,
50.1,
93.5,
35.7,
36.8,
42.2,
2.8,
74.2,
92.5,
95.1,
41,
16.3,
47.3,
66.5,
18.5,
68.2,
78.1,
40,
65.1,
27,
52.6,
97.4,
38.6,
66.5,
84.7,
51.9,
56.4,
32,
14.4,
60.9,
73.3,
76.9,
19.9,
60.2,
50.3,
34.5,
52.4,
81.8,
37.1,
47.7,
27.5,
90.7,
11.6,
42.7,
7.4,
64.8,
49.9,
48.1,
47.9,
82.8,
34.9,
65.3,
33.5,
49.1,
53,
49.9,
25.6,
52,
82.4,
47.7,
51.6,
98.6,
75.7,
78.8,
56.3,
16.9,
14.2,
15.4,
64.7,
78.7,
51.9,
21.6,
61.2,
17.7,
55.3,
26,
59.3,
66.7,
52.2,
1.5,
58.5,
87,
64.4,
54.7,
83.3,
73.9,
41.6,
62.9,
64.7,
11.5,
40.2,
59.8,
41.6,
91.7,
43,
50.3,
58.1,
46.3,
75.5,
69.2,
74.6,
44.2,
40.1,
63.1,
50.4,
55.8,
37.4,
72.4,
30.6,
49,
38.6,
25.3,
44.2,
7.6,
58.8,
60.6,
77,
55.8,
26,
58.8,
83.2,
83.7,
74.8,
50,
41.3,
51.8,
39.3,
83.9,
58.8,
66.1,
56.9,
49.2,
78.9,
40.8,
25,
57.6,
74.5,
49.9,
84.4,
72.3,
42.2,
79.6,
67,
49,
64.8,
42.9,
49.6,
47.6,
15.6,
82.7,
54.1,
67.9,
45.2,
29.7,
61.4,
13.3,
94.3,
48.4,
46.9,
9.9,
62.7,
49.2,
61.1,
58.7,
20.5,
47.2,
15.9,
73.8,
19,
61.8,
70,
86.1,
47.5,
0.7,
39.5,
41.2,
66.7,
68.3,
53.6,
10.2,
89.5,
49,
50.7,
22.6,
55,
64.2,
53.5,
67,
74.2,
64.7,
85,
42.4,
97.3,
61.2,
21.2,
46.2,
66.1,
78.2,
16.1,
45.8,
17.3,
49,
51,
94,
53.6,
9.6,
68.7,
64.1,
75.2,
0,
84.1,
60.6,
88.3,
53.2,
66.6,
33,
30.1,
40.9,
59.7,
32.5,
79.1,
53.2,
73.5,
70.8,
29.3,
46.1,
60.1,
96,
68,
24.2,
70.7,
47.9,
76.1,
18,
71.4,
17,
82.7,
27.4,
68,
15.1,
81.3,
84.3,
63.7,
50.6,
87.9,
26,
45.5,
9.6,
14.3,
62.7,
17.8,
7.4,
44.5,
76.9,
42.5,
57.2,
67.6,
67.5,
67.1,
4.1,
81.2,
28,
65.2,
47.5,
55.8,
19.6,
54.7,
9.9,
51.1,
50.7,
37.2,
50.1,
59.7,
70.7,
89.3,
60.1,
49.2,
91.8,
70.5,
53.5,
47.1,
11.5,
60,
76.5,
69.4,
84.2,
89,
64.5,
97,
10.1,
37.7,
53.1,
34,
41.7,
79.4,
40.9,
40,
44.1,
62.1,
35.4,
63.2,
98.5,
38.6,
25.4,
99.1,
32.5,
40.6,
13.3,
73.3,
20,
63.7,
58,
88.3,
67.1,
71.7,
74,
17.7,
56.3,
74.8,
77.8,
84.5,
40.5,
30,
0,
83.9,
45.4,
28.1,
65.1,
85.7,
20.5,
44.5,
66.4,
69.4,
88.5,
59.1,
12.3,
78.8,
50.5,
57.6,
84.7,
48.6,
56,
54.5,
29.9,
31.7,
46.8,
64.3,
42.7,
53.6,
56.5,
78.4,
34.4,
75.5,
39.8,
70.4,
99.7,
39.6,
44.9,
30.8,
8.3,
37.8,
63,
68.5,
33.2,
85.4,
66,
18.2,
61.5,
56.7,
25,
41.1,
42.4,
75,
62.9,
78,
52.2,
71.8,
49.3,
74.8,
87.6,
31.9,
70.5,
93.3,
65.8,
12.2,
64.4,
65.3,
19.8,
48.5,
50.5,
42.9,
93.3,
74.2,
15.4,
42.4,
44.8,
52.9,
40.9,
71.1,
43.1,
71.3,
31.5,
57,
95.1,
76.6,
27.4,
95.4,
16.1,
47.1,
56.6,
32.8,
59.2,
96.3,
37.7,
90.1,
5.3,
80.7,
76.5,
52.1,
14.4,
57.8,
79.6,
69.6,
25.6,
37.7,
14.7,
72.1,
78.5,
34.7,
38.1,
31,
38.3,
57.7,
20.2,
46.5,
24.8,
72.8,
98.1,
60.4,
92.2,
89.9,
64.6,
99,
55.8,
29.3,
47.9,
91.7,
69.7,
88.2,
33.9,
15.1,
75.5,
72.4,
30.5,
40.3,
88,
39.4,
20.9,
51.9,
46.1,
48.2,
62.9,
60.1,
22,
89.4,
78.8,
53.6,
71.4,
25.2,
82.2,
22.1,
30.1,
82.1,
49.5,
71.5,
69.2,
30.1,
47.4,
94.8,
72.1,
37.8,
81.5,
49.7,
73.4,
35.4,
104,
35.5,
35.6,
59.9,
69.2,
65.4,
61.2,
37.6,
49.1,
40.4,
62.7,
86.6,
67.6,
78.5,
72.8,
64.5,
36.7,
39.2,
50.9,
82.9,
88.9,
32,
80,
52.6,
9.4,
92.8,
65.1,
46.9,
54.4,
57.8,
60.4,
25.7,
30.5,
51.9,
34.1,
66.8,
18.9,
46,
36.4,
82.2,
89.3,
10.1,
44.2,
67.5,
42.3,
9.9,
86,
94.2,
62.7,
55,
52.5,
37.9,
54.9,
76.8,
59.4,
63.7,
21.5,
56.6,
32.4,
71.8,
58,
81.8,
66,
56.1,
49.7,
38.9,
73.4,
66.4,
48.7,
11.4,
7.1,
77.2,
52.7,
45.7,
60.1,
71.2,
15.2,
25.9,
44,
89,
65,
60,
12.4,
38.4,
95.3,
80.8,
81.5,
34.2,
29.5,
94,
71.3,
22.1,
17.6,
53.6,
30.1,
41.5,
82.8,
91.1,
13.1,
89.7,
35.1,
35.3,
43.2,
20.5,
70.4,
39.7,
10.3,
54.9,
49.3,
88.7,
43.7,
47.7,
74.9,
61.4,
44.8,
29,
47.1,
31.7,
1.9,
34,
86.4,
82.6,
39.8,
76.3,
20.1,
42.3,
77.6,
14.7,
58.9,
52,
52,
96.9,
62.6,
27,
40.3,
69.6,
63.3,
22.4,
84.2,
41.2,
58.9,
73.3,
75.1,
68.4,
43.5,
57.6,
27.6,
24.2,
31.2,
69.1,
47.9,
40.6,
66.8,
81.8,
60.5,
76.2,
39.4,
17.3,
25.3,
43.8,
65.4,
25.9,
34.9,
81.2,
42.2,
76.9,
77.8,
25.3,
89.9,
62.4,
48.9,
52.7,
48.5,
94.2,
79,
97.9,
61.2,
64.9,
8.4,
34.8,
50,
44.4,
75.4,
81.3,
54,
52.9,
52.6,
73.4,
47.9,
85.8,
72.7,
76.2,
72.9,
38.2,
53.2,
42.9,
47.9,
69.1,
53.9,
20.2,
72.4,
40.6,
27.7,
29.1,
37.2,
48.4,
74.7,
64.5,
30.8,
8.5,
92.2,
74.4,
88,
72.7,
88.5,
87.5,
74.1,
59.6,
39.7,
46.5,
59.3,
95.7,
40.4,
47.5,
64.3,
85.1,
24.1,
61.4,
20.7,
56,
53.6,
35.9,
101,
67.2,
80.5,
73.2,
49.6,
24.8,
71.2,
66.9,
62.6,
89.9,
48.7,
83.5,
92.6,
85.3,
37.2,
73.9,
90.4,
47.4,
81.9,
69.6,
52.1,
45.2,
73.6,
85,
25.2,
80.1,
86.1,
10.5,
60,
53.1,
20.9,
51.6,
70.1,
28.9,
33.7,
42.4,
22.4,
62.9,
50.8,
34.6,
22,
66.9,
97.5,
20,
47.9,
54.5,
57.5,
44.7,
87.6,
77.6,
0,
34.8,
45.2,
66,
70.6,
45.7,
85.2,
58.8,
1.9,
72.1,
37.1,
95.2,
46.7,
36.5,
75,
38.9,
48.9,
60.3,
84,
74,
80.2,
35.8,
63.8,
60.9,
94.5,
73.2,
72.7,
76.5,
79.5,
59.5,
6.2,
35.6,
72.5,
33.8,
54.2,
76.7,
52.7,
45.8,
50.8,
56,
60.4,
35.4,
48.3,
81,
33.3,
90.8,
61.6,
23.6,
40.7,
57.1,
41.4,
43.6,
62.9,
95,
25.8,
45.3,
94.5,
78.2,
92.9,
71.7,
47,
56.6,
79.3,
68.9,
82.5,
21.8,
40.6,
38.3,
27,
16.5,
77.1,
68.6,
9.1,
58.8,
24.9,
38.7,
62,
83.8,
65.2,
59.5,
80,
23.7,
80.9,
49.3,
23.1,
18.4,
44.5,
46.7,
48.6,
82,
88.5,
84.8,
34.1,
62.4,
73.9,
67.9,
75.6,
95.9,
45.9,
57.5,
75.1,
5.3,
50.5,
78.4,
73.6,
65.6,
70.2,
57.6,
57.4,
51.5,
60.7,
66.9,
81.5,
26.5,
57.2,
79.8,
4,
69.6,
18.5,
40.8,
63.3,
66,
56.4,
56.2,
32.4,
100,
16.1,
22.5,
31.3,
39.9,
69.4,
70.2,
62.3,
70.6,
90.7,
77.1,
95.2,
25,
73.1,
53,
60.9,
58,
99.7,
49.5,
83.4,
52.1,
24.4,
64.9,
48.6,
46.4,
71.1,
34.9,
33.3,
13.5,
61,
30.1,
42.3,
97.8,
46.9,
74.3,
29,
60.2,
30.5,
49.8,
40,
22.2,
57.5,
67.1,
11,
64.4,
52.6,
25.7,
82.6,
54,
51,
89.1,
83.8,
76.7,
61.4,
39.5,
84.4,
35.9,
34,
51.9,
50.3,
34.9,
56.1,
51.5,
56.6,
23.8,
96.8,
32.9,
46.9,
40.5,
66.5,
16.4,
66.4,
47.5,
50.4,
47.8,
97.1,
57.3,
39.9,
95.5,
11.8,
98.3,
82.3,
43.5,
7.9,
86.5,
83.7,
47.2,
96.4,
39.6,
74.9,
57.8,
22.6,
24.9,
70.6,
85.9,
72.1,
98.1,
59.4,
52.8,
52.4,
41.3,
76.3,
93.9,
84.7,
60,
59.3,
35.3,
1.8,
68,
91.9,
72.8,
20.3,
71.9,
38.3,
96.3,
29.8,
51.3,
99.1,
59.9,
43,
76.1,
62.7,
69.9,
55.1,
58.3,
78,
40.6,
14.6,
48.4,
11.4,
56.1,
54.6,
46.8,
80.4,
46.6,
55.3,
80.1,
28.4,
61.9,
70.4,
56.4,
81.2,
63.5,
72.6,
76,
79.3,
38.1,
71.7,
44.9,
45.9,
43.9,
82.6,
81.2,
74.3,
36,
88.1,
81.3,
54.9,
2.7,
26,
52.4,
31.2,
51.6,
59.2,
43.2,
17.2,
51.6,
32.6,
31.2,
18.7,
98.2,
51.2,
82.9,
15.4,
57.2,
85.1,
20.7,
79.4,
38.6,
100,
53.6,
64.9,
21,
76.7,
67.6,
53.5,
80.9,
63.5,
95.4,
34.2,
11.5,
56.9,
66.2,
52.5,
48.7,
35,
23.8,
57.6,
19.9,
78.9,
20.3,
85.9,
44.3,
57.6,
87.6,
62.9,
56.7,
62.6,
29.1,
39.4,
27.6,
62,
28.9,
99.7,
52.1,
42.6,
56.1,
34.6,
72.1,
22.4,
17.7,
43.3,
58.7,
76.7,
20.3,
57.1,
67,
36.4,
19,
72.3,
70.6,
38.7,
37.7,
73.1,
52,
74.4,
40,
86.5,
59.1,
48,
76.5,
44.7,
66.7,
54.6,
49.6,
25.3,
83.8,
64.7,
34.3,
29.9,
78.7,
84.7,
72.9,
61.1,
22,
64.9,
49.5,
93.7,
91.7,
41,
42.5,
81.7,
43.8,
0,
23.3,
70.5,
3.8,
14.7,
11.1,
96.9,
9.9,
60.5,
75.2,
55.4,
77.6,
73.6,
18.6,
36.5,
41,
62.6,
73.9,
25.7,
25.5,
41.2,
68.1,
61.2,
91.1,
17.7,
40.9,
88.7,
41.1,
46.5,
56.4,
43.3,
35.8,
58.5,
26.4,
32.8,
47.2,
53,
81.8,
71.4,
49.7,
34.7,
28.7,
17.4,
43.3,
49.4,
35.1,
97.4,
73.2,
69.3,
23.8,
66.2,
6.6,
102.4,
49.6,
47.2,
95.5,
2.1,
76.9,
29.8,
89.8,
55.8,
84.4,
74.1,
43.2,
92.5,
59.5,
25,
63,
80,
60.6,
54.3,
55.9,
91.9,
52.6,
38,
54.1,
41.5,
29,
66.2,
83.7,
43.8,
89.7,
57.3,
10.1,
7.5,
18.2,
99.7,
23.9,
92.8,
61.6,
76.6,
87.1,
78.7,
59.1,
93.3,
94,
39.1,
86.2,
34.7,
83.7,
77.2,
60.8,
54.6,
60.8,
42.7,
37,
38.5,
82.5,
59.2,
23.8,
68.8,
63.4,
72.2,
10.2,
96.1,
14.4,
76.6,
11.5,
51.7,
44.1,
88,
62.8,
39.4,
62.2,
53.4,
77,
48.1,
64.8,
47,
44,
1.5,
45.6,
57.4,
66.4,
39.5,
77.2,
35.7,
77.6,
89.5,
36.5,
67.2,
84.3,
72.5,
15.9,
54.2,
27.6,
72.1,
3.5,
90.3,
87.6,
57.8,
82.3,
57.9,
66.7,
88.7,
48.9,
69.7,
66.7,
39.4,
27.6,
36.7,
65.1,
66.1,
82.6,
90.7,
43.2,
6.7,
22.8,
40.4,
78.1,
36.8,
62.2,
79.5,
55.2,
42.5,
62.3,
16.3,
94.5,
77.6,
65.2,
53.3,
54.3,
71.3,
57.1,
31.3,
61.3,
0.3,
41.2,
64.4,
1.2,
69.8,
66.5,
44.7,
68.2,
50.6,
64.4,
67.3,
41.6,
47.8,
24,
26.9,
59.1,
55.4,
55.8,
16.2,
84.8,
33.6,
20.2,
53.8,
70,
90.8,
78.5,
88.2,
26.8,
45,
82.5,
30,
12.4,
71.3,
20.9,
68.6,
15.7,
42.5,
51.8,
90.7,
31.1,
91.1,
74.1,
44,
78.3,
73.4,
94.3,
90,
80,
59.1,
83.9,
54.7,
50,
33.7,
56.7,
63.1,
8.9,
94.5,
58.1,
16.7,
75,
47.3,
32.7,
26,
70.8,
76.4,
70.4,
73.4,
27,
83.3,
49.2,
36.2,
15.2,
81.4,
64.1,
49.3,
87,
43.7,
49.7,
9.6,
71,
54.8,
66.9,
90.2,
75.3,
68.3,
49.5,
79.4,
40.6,
8.3,
62.1,
8.5,
46.9,
39.2,
46.4,
66.5,
50.3,
63.7,
32.3,
78.2,
50,
51.6,
88.8,
31.9,
92.2,
78.1,
85.5,
87.2,
36.9,
95.8,
55.9,
100.6,
2.1,
53.9,
98.9,
58.4,
70.6,
73.8,
52.9,
90.6,
21.6,
0.8,
70.2,
56,
41.7,
80,
54.9,
40.3,
9.2,
28.5,
92,
19.8,
29.2,
27,
50.8,
56,
32.9,
71.3,
55.2,
73,
83.7,
41.2,
69.1,
84.6,
3.6,
58.8,
86.8,
77,
58.5,
4.6,
55.3,
67,
57.9,
96.7,
28,
0.3,
38,
45.2,
37.7,
59,
42.7,
99.1,
48.8,
34.1,
49.4,
76,
55.1,
91.1,
36.5,
88.2,
28.9,
48.5,
56.2,
62.7,
85.2,
70.2,
16.7,
56.4,
17,
68.8,
16.9,
51.1,
33.2,
27.5,
38.4,
80,
72.3,
99.7,
81.2,
53.2,
25.5,
20.3,
78.5,
60.6,
27.5,
42.7,
46,
68.9,
20,
90.1,
68.7,
62.4,
68.1,
34.1,
49.7,
67.5,
92.5,
94.1,
68.8,
85.7,
58.7,
95.8,
52.5,
47.9,
60.1,
66.3,
53.9,
83.3,
57.4,
5.5,
48.5,
69.4,
16.2,
96.1,
33.7,
9.5,
63.2,
57.8,
45.8,
94.7,
35.3,
68.3,
84.5,
64.3,
60.7,
17.7,
28.6,
54.6,
99.9,
44.2,
49.1,
87.4,
28.7,
39.2,
28.6,
85.6,
64.5,
74.1,
95.3,
52,
61.9,
49,
14,
59.9,
49.8,
12.4,
63.7,
36.6,
53.2,
7.5,
41.9,
70.9,
85.3,
52.5,
56,
28.3,
48,
94.4,
51.8,
23.4,
47.1,
51.3,
83.6,
58.2,
41.4,
91.7,
44,
30.3,
80.2,
35.6,
12.8,
82.5,
20.7,
49,
39.2,
58.5,
40.5,
90.8,
33.1,
48.3,
39.5,
34.9,
44.9,
22.8,
67.6,
0,
34.6,
4,
88.2,
77.6,
85,
74.5,
22.2,
62.1,
67.3,
72.1,
1.3,
55.7,
25,
29.7,
54.1,
82.3,
35.4,
85.8,
15,
56.3,
102.4,
12.9,
89.9,
75.6,
43.7,
43.3,
90.2,
64.1,
24.5,
75.1,
13.7,
55,
22.3,
67,
23.6,
80.8,
21.6,
48.7,
49.1,
39.2,
50.4,
68.3,
69.9,
87.4,
41.5,
88.7,
28.5,
27,
59.5,
82.9,
46.5,
0.2,
97.3,
87.9,
86.6,
12.2,
34.4,
48.7,
56.8,
79,
66.2,
27.9,
75.2,
66.7,
71.4,
35.2,
78.9,
87.3,
60.8,
68.6,
68.2,
7.8,
80,
5.5,
34.1,
43.4,
91.3,
20.5,
60,
29.7,
96,
82,
71.3,
55,
23.3,
88.4,
46.5,
70.5,
38.5,
78.1,
18.9,
79,
53.7,
50.3,
69.7,
103.3,
20.2,
64.9,
72,
49.5,
68.3,
40.4,
38.8,
52.6,
59.7,
51.9,
28.8,
57.5,
56.5,
77.7,
89.3,
86.1,
82.9,
44.8,
60.6,
39,
34.6,
59,
45,
85,
74.5,
74.2,
45.1,
72.2,
55.1,
84,
19.5,
76.3,
79.1,
28.2,
50,
68.8,
38.4,
81.8,
51.5,
53,
73.6,
32,
24.6,
50.8,
33.5,
39.3,
57.6,
67.4,
47,
54.2,
26.3,
25,
89.8,
20.2,
31.1,
51.1,
61.3,
57.3,
78.6,
64.7,
10.7,
65.2,
72.9,
59.9,
62,
67.5,
33.2,
74.7,
18.9,
43,
77.2,
56.3,
81.7,
48.8,
38.8,
37.8,
77,
69.1,
90.3,
111.4,
85.2,
37,
8.4,
54.2,
51.6,
34.1,
61.4,
67.3,
0,
57.7,
80.4,
78,
71,
52.2,
69,
94.3,
63.3,
63,
90.1,
45.8,
74.3,
68.8,
60.5,
102.7,
53.5,
23.5,
94.4,
21.9,
69.1,
76.7,
77.3,
90.5,
75.3,
35.3,
84.9,
62.9,
56.2,
59.1,
56.8,
22.4,
80.9,
53.3,
94.3,
30.9,
43,
40.2,
60.6,
68.2,
94.1,
73.7,
31,
51.9,
45.2,
16.9,
97.8,
62.8,
40.2,
75,
99.8,
29.6,
61.3,
81.9,
42.2,
76.9,
75.9,
84.5,
78.6,
21.8,
44.8,
50,
27.8,
71.5,
81.7,
26.4,
75,
63.9,
62.3,
28.8,
43.8,
46,
77.3,
67.9,
46.9,
69.9,
45.7,
68.7,
100,
84.3,
29.8,
45.7,
92.1,
46.6,
93.1,
59.8,
57.1,
68.9,
55.7,
47.7,
60.6,
86.1,
10,
57.5,
57.8,
50.6,
51.4,
92.1,
63.6,
78.1,
37,
56,
27.7,
71.2,
89.6,
51.5,
68.9,
66.8,
14.6,
78.4,
14.3,
65.5,
48.7,
35.5,
47.3,
84,
83.5,
53.1,
27,
44,
22.3,
86.5,
46.4,
14.5,
40.5,
53.2,
81,
69.3,
81.5,
81.4,
19.5,
54.9,
66.3,
29.4,
59,
46.3,
63,
77.3,
13.6,
55.3,
54,
55.2,
92.9,
37.6,
91.1,
4.6,
81.9,
51,
30.2,
49.5,
35.5,
50.4,
67.3,
62.9,
92.5,
36.3,
78.3,
34.2,
0,
44,
87.7,
22.5,
57.3,
77.5,
71.4,
32.5,
77.1,
43,
30.1,
98.6,
42.8,
30.6,
68.8,
83.7,
70.4,
83.1,
48.7,
16.2,
64.2,
58.6,
82.9,
72.8,
51.5,
30.4,
43.7,
52.1,
16.7,
78.4,
30.3,
89.5,
87.8,
26.4,
6.7,
47.4,
80.2,
93.6,
79.6,
76.1,
62.3,
35.1,
41,
71.9,
85.7,
54.3,
84,
90.9,
41.7,
86.6,
79.7,
82.5,
66.9,
37.4,
83.5,
49.6,
2,
63.2,
83.7,
72,
94.4,
61.9,
64.1,
49.5,
99,
33.5,
30.4,
42.5,
47.7,
64.6,
47.3,
33.2,
59.1,
85.8,
86.3,
97.4,
52,
22.5,
80.6,
34.5,
91.9,
61.3,
48.2,
79,
80.7,
48.5,
31.3,
93.3,
30.6,
75.3,
59.6,
44.9,
18.6,
14.6,
51.1,
74.1,
74.8,
58.5,
56.6,
73.7,
79.3,
40.9,
90.8,
86,
91.5,
46.1,
70.5,
49,
29.5,
68.9,
98.4,
61.5,
56.1,
40.5,
63.3,
89.3,
39.9,
54.6,
94.6,
57.1,
29.3,
19,
65.7,
84,
62.2,
86.1,
41.3,
68.9,
6.1,
68.5,
66.5,
48.5,
58.7,
82.6,
97.6,
89.9,
27.6,
38.4,
61.1,
91,
57.3,
10.8,
43.8,
43.6,
34.3,
54.6,
61.4,
61.5,
94.8,
57.7,
62.9,
59.3,
56.5,
88,
83.8,
82.1,
28.7,
4.6,
77.1,
97.7,
67.6,
41.1,
46.9,
74.7,
70.6,
56.3,
17.7,
81.4,
93.1,
50.3,
98.8,
54.9,
46.3,
31.8,
58.7,
63.5,
50.3,
55.5,
21.9,
38.3,
13.1,
61.9,
79.5,
20.2,
52.6,
49.4,
66.1,
56,
19.4,
56.9,
32,
9.7,
20.2,
77.7,
19.5,
44.6,
44.7,
83.8,
24.2,
77.9,
100.5,
71.8,
42,
32.4,
31.7,
84.8,
69.4,
0,
74.3,
50.5,
64.6,
46.5,
91.4,
60.9,
84.1,
79.8,
99.7,
70.6,
51.4,
54.6,
57.2,
60.5,
52.4,
75.3,
64.5,
87.1,
72.5,
36.4,
53.5,
80,
78.8,
39.7,
21.1,
63.6,
57,
62.7,
74.9,
50,
76.3,
58.8,
50.9,
39.7,
52.4,
75.3,
86.1,
93.8,
48.9,
40.5,
15.2,
41.7,
99.5,
49.3,
10,
60.9,
43.4,
25.5,
22.8,
88.1,
96.5,
0,
80,
21.8,
62.2,
54.6,
60.2,
37.8,
52.3,
94.4,
55.3,
56.4,
32.1,
65.7,
12.8,
99.9,
43,
46.9,
88.4,
22.9,
34.9,
88.4,
94.2,
84.2,
72.2,
34.7,
100.4,
55.6,
0,
70.9,
78.8,
89,
4.7,
69.2,
34.9,
90.1,
46.8,
70.1,
78.1,
22.1,
20.7,
36.9,
93.4,
70,
52.2,
68,
23.2,
82.6,
77.1,
90.3,
68.8,
90.8,
92.7,
72.4,
31.9,
69.3,
40.1,
93.8,
96.5,
34.5,
59.3,
23.8,
13.5,
77.8,
24.9,
66.3,
64.2,
41.2,
53.8,
42.4,
24.3,
58,
66,
11.5,
43.5,
40.1,
57.5,
35.5,
88.4,
49.4,
57.7,
34.4,
65.2,
21,
25.2,
84.3,
38.6,
64.9,
55,
58.1,
67.9,
78.9,
35,
46.5,
91.4,
93.7,
78.9,
37.6,
3.8,
70.5,
55.4,
61.2,
23.3,
86,
8.7,
53.4,
63.6,
35.9,
57,
69,
79,
101.1,
63.3,
55.6,
72.7,
86.6,
89.2,
54.7,
69.5,
25.2,
33.1,
38.8,
57.3,
81,
97.1,
16.2,
37.4,
38.2,
40.7,
27.2,
83.7,
84.9,
66.1,
35.8,
32.6,
61.3,
85.5,
38.9,
52.1,
65.2,
81.9,
51,
80,
26.9,
60.2,
47.1,
91.9,
23.2,
25.7,
71.6,
45,
50.3,
38,
46.9,
67.3,
35.9,
69.4,
36.7,
56.1,
60.1,
55.2,
70.5,
78.8,
62.3,
89.1,
58.9,
54.3,
11.6,
60.6,
66.6,
78.6,
87.3,
88.5,
18.3,
80.4,
68.3,
36.4,
39.1,
79.1,
100,
58.3,
82.5,
47.2,
42.9,
12.5,
25.5,
64.2,
67,
67.9,
60,
97.6,
45,
52.2,
68.2,
19.6,
43.9,
22.6,
48.1,
46.4,
61,
47.9,
59.7,
91,
76.3,
99,
17.3,
75.5,
66,
32.1,
76.1,
36.4,
29.8,
51.4,
25.8,
46.5,
25,
83.5,
60.1,
46.3,
28.7,
80.1,
71.4,
69.4,
36.7,
8.8,
57.3,
59.8,
44.5,
51.4,
41.1,
9.4,
38.2,
61.6,
77.3,
76.9,
104.2,
50.7,
49.5,
44,
80.9,
62.5,
34.2,
51.8,
58.5,
44.5,
86.4,
42.3,
58.6,
63.7,
13.7,
89.6,
20.2,
28.6,
68,
52.1,
26.8,
65.3,
52,
51.7,
58,
69.8,
2.1,
51.4,
64.4,
86.3,
43.1,
35,
85.7,
64.1,
84,
21.3,
49.8,
86.7,
47.5,
32.4,
67.4,
33.8,
42.2,
29.8,
95.4,
58.5,
22.2,
81.4,
58.3,
83.4,
3.7,
58.8,
70.1,
83.3,
49.4,
46.8,
25.2,
55.8,
55.6,
62.2,
52.9,
3.5,
96.6,
80.9,
13.9,
68.7,
40.4,
27.3,
52,
27.5,
41,
27.9,
61.9,
67.5,
64,
76.8,
94.5,
53.4,
79.4,
83.2,
83.7,
61.3,
39.8,
41.1,
81.8,
87.6,
70.6,
22.8,
56,
46,
76,
89.1,
60,
36.4,
25.6,
60,
71.8,
52.4,
46.7,
44.2,
28.4,
72.2,
72.3,
88.2,
31.7,
1.8,
94.9,
56.3,
22.7,
66.6,
83.1,
48,
53.9,
83.8,
30.9,
75.9,
71.9,
45,
67.1,
72.9,
65.3,
73.9,
43.4,
49.4,
44.8,
35.5,
78.2,
43.5,
82,
64.1,
36.2,
79.8,
81.9,
71.6,
41.5,
0,
4.5,
58.5,
79.4,
35.5,
93.5,
59,
33.1,
27.9,
51,
92,
21.9,
42.9,
79.8,
60,
63.6,
79.5,
72.5,
76,
45.8,
77.6,
29.4,
60,
65.3,
35.1,
85.3,
67.9,
50.9,
68.9,
99.2,
67.1,
88.8,
65.9,
32.4,
39.2,
85.2,
22.2,
7.8,
30.7,
60.5,
63.5,
50,
85.9,
51.1,
56.4,
62.7,
96.3,
55.9,
60.8,
62.6,
39.4,
21.5,
70.4,
17.7,
43.5,
60.6,
37.7,
16,
67.4,
24,
64.7,
46.3,
85.7,
77.3,
92.5,
49.3,
48.7,
40.9,
49,
90.4,
60,
42.7,
49.2,
34.4,
51.6,
39.6,
47.9,
33,
18.4,
69.2,
42.3,
39.9,
3,
93.6,
67.2,
84.2,
35.5,
33.7,
37.6,
92.9,
0,
69.2,
39.5,
29.4,
93.8,
73.3,
18.5,
86.2,
45.6,
23.8,
47.3,
49.3,
54.3,
50,
65.9,
15.3,
93.7,
73.3,
38.3,
94.6,
25.9,
88.3,
87.1,
95.4,
39.5,
78.3,
94.3,
53.3,
37.3,
62,
53.8,
94.2,
63,
57.2,
49.9,
72.6,
54,
36.1,
78.2,
68.2,
44.3,
32,
22.3,
8.5,
87,
84.3,
90.6,
61.8,
36.8,
17.8,
87.7,
43.7,
59.8,
46.8,
65,
7.7,
86,
39.4,
76.8,
4.8,
44.9,
38.6,
1.2,
66.4,
71.9,
85.2,
65,
28.5,
34.2,
46,
50.7,
61.5,
95.1,
75.7,
68.1,
91.3,
55.4,
85.9,
56,
42.8,
73.9,
77,
42.9,
13.7,
57.3,
48.9,
42.7,
46.3,
83.9,
44.8,
93.4,
60.7,
52.1,
19.8,
45.8,
43.7,
43.2,
45.9,
24.5,
57.7,
48.9,
97.1,
31.1,
34.9,
41.9,
92,
3.3,
17.7,
75.5,
64.4,
99.2,
66.1,
34.8,
71.2,
71,
25.6,
42,
78.6,
45.9,
83.3,
25.5,
51.8,
44.6,
43.4,
47.6,
65.4,
65.7,
69.2,
67.3,
52.5,
72.2,
54.7,
76,
33.7,
91.8,
41.7,
72.6,
69,
38.1,
46.2,
95.4,
51.2,
87,
59.2,
70.7,
35.3,
36.4,
61.2,
9.5,
32.8,
38.1,
13.7,
58.6,
77.8,
94.5,
74.1,
18.4,
75.5,
24.1,
51.2,
34,
32.9,
36.3,
44.4,
15.8,
12.4,
51,
56.5,
24.9,
93.2,
52.5,
82.2,
40.6,
58.4,
16.3,
88.2,
64,
78.8,
34.2,
53.1,
57.1,
58.5,
100.1,
69.3,
70.3,
5.2,
47.5,
72.7,
26.7,
43.6,
20.9,
34,
88.7,
28.9,
62,
68.2,
53.4,
60.4,
58,
60.6,
92.6,
81.3,
17.8,
17.2,
40.8,
76,
81.2,
68.5,
70.8,
36.8,
15.6,
63,
79.9,
36.5,
57.3,
37.6,
53.8,
36,
84,
0.6,
19.6,
46,
49.7,
57.6,
41.6,
86.9,
66,
44.7,
78,
90.9,
52.7,
61,
58.6,
74,
62.9,
71.3,
81.8,
51.5,
88.2,
42.5,
87,
49.1,
59.8,
9.2,
36.9,
69.8,
14,
31,
87,
64.7,
32.6,
49.5,
57.7,
78.5,
73.6,
49.7,
100.6,
25.9,
51.5,
37.2,
78.8,
60.6,
78.1,
45.5,
51.3,
92.5,
47.3,
81.8,
52.5,
110.4,
73.5,
97.3,
47.8,
61.6,
93.9,
21.6,
25.8,
60.3,
70.6,
61,
88.5,
36,
66,
9.2,
67.7,
58,
62.7,
56.4,
27.3,
60.6,
40.1,
40.3,
65.7,
54.5,
0,
101.1,
11.1,
47.9,
83.2,
65.9,
74.5,
76.5,
43.4,
35.7,
91.5,
74.4,
88,
6.7,
87.4,
95.1,
52,
47.3,
62.4,
64.4,
50.2,
71,
78,
98.4,
89.5,
44.2,
81.4,
69.2,
49.4,
37.1,
94.7,
44.9,
64.6,
50.4,
72.1,
94.7,
87.2,
79.3,
6.2,
70.6,
33.8,
12.1,
62.4,
81.9,
72.1,
68.2,
34.2,
56,
26.8,
88.3,
50.5,
79,
48.6,
79.3,
29.3,
68.7,
38,
24.1,
50,
62.7,
58.7,
42.7,
48.4,
57.9,
48.1,
79.2,
90.8,
49.3,
56.1,
24.8,
63.2,
54.1,
71.2,
62.7,
57.8,
95.4,
61.5,
62.6,
87.9,
68,
27.4,
67.4,
71.5,
99.6,
59.5,
68,
15.6,
44.7,
65.4,
31.8,
51.4,
77.5,
66.2,
31,
74.6,
83.4,
33,
73.8,
73.4,
43.2,
17,
72.1,
34.1,
33.5,
60.2,
45.9,
41.8,
38.7,
7.5,
44.8,
33.3,
89.1,
27,
53.8,
54.9,
46.6,
78.4,
28.9,
49,
61.7,
58.5,
83.6,
60.4,
43.1,
17.9,
88.3,
41.5,
42.6,
49.5,
89.4,
83.4,
41.9,
48.8,
66.5,
36.2,
96.2,
34,
33.1,
86.7,
57.8,
28.4,
49.9,
44.8,
51.5,
51.2,
63,
86.7,
92.9,
71.2,
17,
61.6,
56.1,
13.2,
27.8,
80.3,
64.9,
52.1,
69.7,
93.2,
10.5,
51,
77.9,
75.5,
3.6,
76.6,
81.2,
43.1,
45.4,
51.8,
67.9,
74.4,
44.5,
40.7,
60.9,
83.4,
57.1,
61.9,
68.2,
47.6,
89.7,
78.2,
50.5,
63.5,
48.2,
0,
62.3,
57.8,
78.6,
62.2,
27.1,
104.6,
86.5,
38.6,
38,
71.7,
93.3,
47.7,
88.8,
79.6,
57,
35.3,
75.3,
0,
63.8,
89.1,
56,
30.9,
55.2,
88.5,
94.8,
83.3,
41.1,
79.7,
48.5,
33.5,
41.9,
61.5,
29.6,
82.6,
48.8,
36.6,
90,
72.8,
46,
76.3,
67.6,
49.7,
31.3,
71,
33,
73,
58.5,
81.7,
39.1,
57.3,
17.3,
25.1,
44.9,
50.3,
77.2,
10.9,
52.8,
48.8,
36.7,
10.6,
61,
78,
41.2,
42,
91.5,
81.6,
31.8,
73.6,
26.5,
80.1,
62.6,
101.7,
4.3,
72.4,
1.5,
43.4,
45,
74.4,
64.3,
55.4,
64.3,
82.4,
51.2,
59.2,
71.2,
17.9,
77.2,
6.1,
75.6,
67.8,
49.8,
37.4,
79,
72.3,
58.3,
58.4,
13.8,
40.3,
59,
29.7,
70,
45.9,
38,
55.7,
62.3,
69.2,
74.1,
42.2,
71.8,
31.3,
98,
95.6,
29.1,
49.3,
77.4,
92.6,
75.7,
74.9,
27,
70.4,
30.5,
73.7,
38.3,
44.6,
32.3,
50.9,
64.3,
14.4,
55.5,
28,
7.6,
48.9,
64,
88.1,
30.4,
79.8,
87.8,
23.1,
8.6,
76.4,
56.3,
30,
79.6,
100.2,
73.2,
84.8,
15,
85.8,
65.4,
58.5,
81.4,
18.6,
73.2,
77.1,
57.7,
73.4,
60.7,
49,
37.6,
86.3,
62.1,
44.8,
38.7,
74.9,
71,
34.3,
70.3,
58.1,
51.7,
99.1,
55,
46.8,
50.2,
67.4,
18.1,
79.4,
70.8,
28.6,
47,
83.7,
47.4,
64,
75,
87.5,
43.4,
55.2,
67.4,
47.2,
15.6,
77,
38.4,
42.5,
56.4,
68.9,
66.4,
47.4,
88.3,
64.2,
91.9,
56.6,
52,
43.3,
60.8,
57.7,
60.3,
19.3,
48.5,
0,
35.4,
2,
36.2,
30.7,
86.4,
65.1,
60.1,
40.2,
49.1,
10.5,
39.7,
38,
43.7,
76.5,
32.7,
69.4,
88.1,
20.4,
62.9,
86.3,
51.7,
48.2,
57.5,
15.8,
54,
8.1,
94.2,
74.7,
6.9,
39.4,
53.6,
81.5,
59.3,
38.4,
77.1,
89.3,
59.8,
63.8,
32.1,
42.6,
37.4,
41.2,
21,
94.9,
82.1,
38.5,
61.6,
75.3,
34.4,
4.5,
33.3,
79.1,
66.1,
39.7,
69.1,
40,
75.5,
84.2,
41.4,
72.3,
55.5,
23.9,
79.6,
28.8,
38.1,
59.8,
58.5,
86.4,
66.3,
55,
70.5,
24,
25.7,
69.6,
55.3,
45.7,
78.3,
82.4,
91.7,
45.8,
0,
66.4,
95,
30.7,
10.5,
41.6,
59.3,
34.3,
96.2,
90.2,
73.3,
72.5,
75,
53.7,
59.5,
88.1,
27.9,
21.7,
84.9,
18.2,
58.2,
76.5,
0,
77.3,
54.4,
56.5,
54.6,
66,
7.4,
51.5,
76.2,
65.1,
70.1,
49.4,
70.4,
57.2,
30.9,
43.9,
44.3,
37.7,
70.3,
14.6,
64.4,
71.8,
23,
41.7,
19.5,
57.2,
55.5,
85.3,
22.8,
79.9,
87.2,
73.1,
75.2,
22.9,
35.7,
46.8,
17.2,
80,
44.9,
43.7,
24,
79.4,
37.8,
68.5,
17.5,
41.8,
88.2,
44.8,
87.1,
60.1,
40.7,
27.9,
61.2,
90.4,
27.8,
68.6,
69.8,
64.8,
95.6,
96.7,
8.3,
60.3,
78.2,
34,
96.5,
20,
39.6,
63.2,
91.4,
65.3,
70.6,
28.8,
40,
37.3,
37.6,
101.1,
28.9,
54,
48.2,
81.7,
51.7,
56.4,
24.9,
47,
33.2,
53.9,
46.1,
69.4,
86.1,
62.1,
18.3,
5.7,
60.9,
29.1,
56,
21.9,
69.5,
75.4,
88,
28.8,
26,
19.4,
69.1,
79.1,
67.5,
97.9,
93.6,
62.7,
80.6,
10.5,
56.8,
69.8,
69.3,
54,
25.5,
77.1,
82.4,
64.3,
77.3,
24.4,
33.4,
58.7,
95.8,
67,
34.9,
74.3,
94,
64,
83.2,
36.5,
101.1,
99.3,
70.1,
69.6,
11.3,
25.8,
81,
73.1,
89.5,
102.6,
19.5,
89.5,
51.8,
46.6,
56.8,
73.4,
80.1,
89.1,
21.8,
52.7,
17.8,
25.7,
52.3,
44,
72.9,
74.6,
73.5,
26.1,
91,
52.2,
84.7,
23,
61.7,
94.5,
51.6,
34.9,
88.3,
60,
26.4,
49,
59.2,
27.5,
46,
75.5,
60.7,
41,
75.6,
17.8,
48.8,
43.3,
79.1,
74.2,
29.2,
25.1,
26,
66.9,
91.6,
79.6,
15.9,
77.6,
57.2,
18.9,
63.4,
28.3,
51.5,
76,
52.6,
59,
52.5,
45.4,
84.9,
59.6,
82,
53.3,
44.7,
45.2,
83.5,
57.9,
63.3,
62.2,
50.3,
81.9,
5.3,
73.2,
0,
48.4,
60.2,
39.1,
95.2,
67,
53.5,
83.9,
81.3,
54.8,
44.4,
62.3,
22.9,
18.8,
36.1,
24.5,
92.3,
80.6,
92,
50.5,
79.9,
37.9,
25.2,
41.7,
60.7,
68,
44.9,
43.7,
61,
25.5,
15,
26,
78.4,
58.2,
27.3,
65.2,
57.3,
76.6,
94.6,
56.1,
61.8,
86.3,
47.7,
85.5,
62.9,
55.9,
84.8,
61.8,
89,
21,
38.5,
97.8,
42.9,
26.8,
69.1,
42.2,
78.1,
86.1,
65.8,
75.2,
70.6,
42.4,
15.1,
81.6,
15.4,
39.8,
7,
55.8,
76.1,
10,
57.3,
0.5,
60.3,
50.6,
83.8,
87.7,
49.1,
72.9,
66.9,
26.7,
77.1,
45.7,
34.3,
68.6,
86.2,
20.2,
45.7,
3.4,
29.9,
22.2,
42.6,
33.5,
80,
82.9,
32.4,
89.4,
77.6,
19.4,
68.1,
84.7,
49.9,
53.7,
30.3,
61.7,
68.3,
68.3,
26.1,
16.5,
80.3,
50.3,
70.4,
65,
33,
68.3,
34.9,
89.8,
28.2,
71.7,
75.5,
35,
40.5,
43.1,
50.5,
41.9,
58.7,
84.3,
42.8,
70.2,
null,
79.6,
64.2,
51.1,
68.9,
95.3,
42.1,
7.5,
67.9,
52.4,
11.2,
86.2,
53,
77.9,
12.4,
88.2,
49.1,
27,
69.4,
99.3,
84.4,
89.3,
2.7,
21.1,
47.9,
47.8,
97.4,
88.2,
43.8,
37.7,
22.4,
15.8,
87.3,
66.2,
47.2,
13.4,
74,
98.5,
40.9,
89.2,
74.5,
23.3,
61,
39.3,
12,
27.9,
25,
74.3,
42.6,
70.9,
62.5,
48.6,
55.8,
97.6,
34,
79.3,
5.5,
52.1,
49.3,
48.3,
60.6,
80.3,
38.4,
27.4,
90.9,
33.7,
9.2,
57.7,
61.3,
73,
33.2,
44.3,
92.7,
47.2,
28.2,
31.6,
71.1,
27.7,
14.9,
42.5,
44.7,
40.6,
97.6,
56.5,
54.2,
84.5,
61.7,
62.8,
27.9,
87.5,
91.7,
65.7,
57.8,
59.9,
33.6,
56.2,
14.6,
80,
53,
18,
50.4,
18.6,
49.3,
102.2,
33.6,
98.3,
2.9,
30.2,
32.4,
0,
0.8,
76.5,
50.8,
40.3,
10.7,
45.4,
34.5,
31.6,
51.6,
45,
13.1,
66.2,
78.9,
88.6,
62.3,
60.2,
49.5,
64.4,
70.7,
79,
70,
25.7,
20.8,
89.6,
35.5,
96.6,
38.3,
96,
49.9,
16.9,
31,
52.7,
24.3,
32.7,
10.3,
75,
68.6,
95.9,
53.7,
48,
41.2,
46.4,
26.7,
25.7,
65.1,
48.1,
38.3,
28.5,
33.2,
64,
70.3,
81.1,
15.8,
43.4,
63,
27.1,
70.4,
45.4,
88.7,
50.7,
74.8,
44.3,
30.1,
73.4,
85.7,
44,
42.1,
76.8,
31.2,
85,
50.6,
37.3,
47.4,
39.8,
36.2,
26,
20.5,
26.2,
65.6,
26,
31.2,
55.3,
99.8,
69.1,
59.8,
60.6,
41.7,
32.6,
84.8,
49.3,
61.5,
83.3,
31.4,
0,
85.1,
28.5,
66.9,
39.8,
61.4,
65.3,
38.1,
39.5,
33.2,
79.9,
86.1,
31.6,
37,
57.9,
68.8,
62.1,
86.1,
70.2,
71.1,
73.9,
21.8,
52.5,
66.4,
85.2,
53.4,
27.4,
29.4,
29.5,
69.6,
57.4,
48,
22.4,
83.5,
84.8,
34.2,
28.5,
70.6,
76.7,
88.3,
60.8,
63,
66.9,
90.5,
61.1,
60.7,
86.4,
67.1,
81.5,
42.2,
13.3,
66.4,
60.2,
75,
73.3,
40.7,
25.3,
82.7,
74.9,
52.8,
27.6,
37.3,
42.7,
50.4,
49.6,
35.9,
26.4,
79.1,
53.1,
75.4,
39,
33.8,
62.9,
69.6,
58.8,
53.3,
54.1,
72.8,
79.7,
61.2,
85.4,
100,
48.4,
81.1,
11.1,
97.4,
34,
37.8,
39.9,
70.1,
25,
81.6,
26.3,
22.8,
28.7,
49.9,
73,
76.1,
57.1,
54.9,
81.3,
47.9,
87.3,
78.4,
21.3,
65.7,
34.1,
79.4,
80.5,
52.3,
49,
81.8,
73.8,
46.5,
79.3,
76.6,
55.6,
18.9,
79,
63.7,
84.8,
62.8,
54.5,
33.6,
84.7,
80,
17.7,
36.5,
17.4,
53.5,
53.6,
52.3,
47,
18.3,
53.2,
93.1,
81,
84.8,
94.4,
51.4,
25.6,
30.2,
18.2,
27.6,
24.7,
53.5,
34.9,
96.2,
47.5,
84.7,
63.2,
22,
60.2,
54.3,
93.3,
69.2,
51.7,
4.6,
75.4,
14.7,
35.7,
31.1,
36.3,
59.5,
58.6,
40.4,
43.6,
20.6,
70.7,
52.3,
53.9,
61.6,
79.6,
82,
47.9,
91.5,
36.2,
0.2,
32.2,
26,
78.4,
11.1,
67.8,
47.7,
6.3,
19.8,
72.2,
45.5,
84.9,
73.7,
10.5,
61.8,
80.2,
42.3,
69,
11.4,
53.6,
80.9,
16.9,
42.3,
60,
97.8,
99,
25.5,
47.2,
58.9,
3.7,
57.1,
75,
27.6,
94.7,
54.8,
85.1,
84.2,
32.1,
18.3,
55.6,
79.7,
82.4,
45.7,
33.2,
51.6,
51.7,
68.1,
48.2,
76.3,
81.6,
69,
30.6,
27.9,
74,
49.3,
44,
81,
29.2,
63.7,
77.2,
38.4,
60,
66.1,
95.4,
31.6,
36.1,
52.9,
34.1,
84.2,
42,
73.8,
82.3,
40.2,
15.4,
87.3,
87.7,
82.1,
41.1,
75.2,
28,
23.1,
71.6,
53.7,
67.8,
90.3,
30.2,
50.7,
43.4,
27.8,
38.9,
67.3,
53.6,
27.3,
29.6,
16.6,
52.8,
13.4,
51.4,
75.2,
25.9,
38.8,
89.8,
62.7,
59.3,
31.1,
81.6,
13.2,
18.8,
44.3,
60.6,
66,
49.9,
63,
17,
81.7,
60.6,
69,
26.1,
53.8,
36.2,
60.8,
72.3,
56.3,
84,
73.7,
79.5,
17.6,
36,
35.5,
59,
83.4,
67,
19.9,
47.5,
52.4,
81.8,
78.6,
50.9,
21.8,
70.8,
55.7,
65.1,
39.6,
33.4,
99.9,
50,
33.3,
92.6,
22.6,
83.1,
73.8,
66.5,
58.2,
55.6,
67.5,
83.2,
42.1,
85.4,
79.7,
47.1,
71.1,
55.1,
100,
28.9,
92.9,
16.9,
47.7,
101.8,
82.2,
60,
64.7,
93.2,
19.9,
33.3,
34.9,
44.5,
86.9,
72.5,
37.8,
74.5,
43.6,
40,
91,
17,
67.8,
12.2,
30.5,
32.7,
66,
70.7,
29.2,
62.3,
28.2,
80.4,
60.1,
57.2,
57.4,
43.3,
93.4,
30.9,
84.4,
54.4,
91.6,
85.8,
67.5,
81.9,
78,
48,
83.6,
85.1,
42.2,
45.3,
76.6,
43.4,
50.9,
61.1,
56,
96.6,
70.1,
23,
79.5,
67.1,
58,
58.2,
39.2,
80.3,
54,
22.2,
30.8,
50.9,
79.9,
80.1,
57,
85.6,
34.5,
71.6,
53.6,
91.7,
50.4,
88.8,
40,
87.7,
60.5,
12.1,
60.5,
74.2,
62.9,
93.8,
30.9,
38.4,
56.9,
58.1,
58.8,
67.9,
14.4,
56.7,
43.2,
9.9,
90.9,
76.9,
48.3,
51.8,
48.9,
40.4,
65.4,
20.4,
45.5,
90,
44.2,
37.6,
66,
48,
63.4,
73.9,
27.8,
61.6,
10.7,
81.3,
45.4,
84.9,
41,
57.1,
20.9,
68,
12.3,
60.9,
94.9,
95.2,
50.5,
88.7,
95.1,
81.1,
91.6,
74.4,
63,
15.7,
51,
62.7,
14.4,
18,
40.7,
35.7,
66.6,
51.5,
52.9,
88.5,
93.1,
43.3,
81.4,
57.1,
73.2,
50.7,
2.2,
63.2,
63.4,
94.9,
28.7,
2,
7.6,
69.8,
32.6,
66.6,
88.6,
69.6,
89.4,
70.3,
50.2,
53.2,
33,
27,
80.2,
32,
1.3,
44.3,
36.3,
15.6,
31.8,
91,
25.7,
74.6,
28.2,
90.8,
72,
25.2,
68.1,
50.5,
51.3,
42.9,
59.9,
61.2,
25,
56.8,
71,
66.1,
14.9,
58.7,
86.3,
59.9,
75.6,
98.6,
40.3,
50.6,
5.7,
86.4,
41.1,
51.1,
26.2,
81.4,
12.4,
65.2,
63.5,
57.2,
61.9,
23.8,
30,
28,
54.7,
39.7,
92.3,
48,
58.9,
15.9,
33.6,
61.5,
68.5,
78.7,
46.2,
75.1,
77.1,
95.4,
57.2,
89.3,
30.1,
34.1,
31.4,
65.2,
41.3,
19.3,
40.1,
57,
89.6,
35.5,
33.8,
51.5,
87.8,
39,
68.7,
67.4,
65.9,
74.1,
25.6,
50.9,
77.8,
73.5,
37.3,
71.7,
30.9,
86.3,
84.4,
65.3,
55.8,
67.2,
4.9,
41.8,
73,
46.2,
97.3,
24.6,
73,
46.1,
85.3,
12.7,
49.3,
93.1,
29.5,
60.4,
70,
73.8,
87.1,
32.4,
70.8,
24.1,
72.3,
45.8,
24.7,
24.5,
70.8,
76.5,
52.1,
92.1,
60.6,
28.4,
33.2,
99.8,
35,
32.6,
58.3,
67.5,
72.7,
66.2,
64.4,
84.2,
54.9,
2.4,
80.4,
25.7,
51.4,
48.9,
82.4,
87,
27.6,
66.9,
52.9,
46.5,
77.5,
59.2,
31.7,
46.9,
20.6,
99.2,
54,
18.9,
69.5,
52.2,
24.3,
79.3,
36.6,
98.7,
90,
72.4,
56.5,
51.6,
62.8,
49,
59.6,
37.3,
55.4,
1.4,
30.9,
22.1,
77.3,
39.7,
68.8,
83.5,
50,
74.1,
34.6,
62.4,
77.2,
82.1,
35.4,
21.9,
8.5,
62,
73.7,
85.5,
58.3,
51.7,
43.1,
48.4,
86.2,
35.5,
57.6,
61.2,
72.3,
18.4,
63.6,
36,
51.7,
70.2,
77.5,
60.2,
78.6,
85.5,
15.2,
92.7,
71.6,
91.4,
85.1,
55.5,
80.7,
72.7,
44.1,
75.3,
67.5,
37.5,
75.7,
31.7,
38.6,
59.5,
26.2,
20.6,
88.8,
72.5,
11.8,
81.8,
43.1,
51.4,
38.5,
84.3,
61.2,
21.2,
48.4,
71.5,
38.2,
52.6,
43,
73.5,
83.2,
19.1,
58.4,
81.1,
22.1,
55.3,
48.4,
5.8,
73.3,
72.9,
28.2,
83.3,
79.1,
57.9,
73,
41.4,
72.9,
57.7,
78.8,
48.5,
76.1,
98,
47.7,
55.5,
5,
44.8,
38.4,
63.8,
18.5,
37.7,
76.2,
58.8,
42.5,
47,
87.7,
37.6,
55.8,
57.1,
43.3,
69.6,
92.4,
42.2,
65.1,
29.5,
77.1,
90.4,
67.7,
56.5,
90.2,
74.8,
79.9,
98.1,
24.4,
91.3,
59.7,
65,
30.2,
79.4,
100.7,
50.4,
87.6,
85.6,
36.5,
9,
5.9,
92.9,
75,
6.5,
84,
21.1,
62.2,
45.4,
37.9,
11.8,
77.5,
84.2,
65.3,
73.1,
30.5,
74.7,
77.2,
12.1,
69.4,
63.7,
79.5,
85.5,
61.4,
63.7,
95.8,
46,
101,
79.9,
59,
86.1,
94.6,
58.2,
34.4,
62.5,
44.1,
21.3,
91.8,
27.9,
76,
70.5,
17.5,
90.5,
65.7,
68.5,
90,
64.3,
65.7,
88.3,
94,
38.1,
36,
12.2,
52.8,
20.6,
14.3,
27.6,
43.9,
73.7,
49.2,
63.6,
20.8,
34.6,
22.6,
81.7,
74.1,
61.1,
87.5,
82.8,
53.6,
61.1,
40.8,
50,
87,
69.4,
29.7,
72.8,
36.2,
77.9,
66.9,
63,
44.3,
0.7,
56.5,
57.3,
33.8,
86.4,
65.2,
44,
66.6,
74.9,
46.1,
31.8,
50,
61.2,
77.9,
93.3,
68.8,
62.6,
10.8,
49.9,
79.6,
0,
24.2,
45,
77.9,
58.6,
67.9,
84.1,
41.1,
77,
31.1,
8.2,
42.2,
73,
86.9,
22.7,
50.3,
41,
3.7,
92.9,
78.2,
56.9,
66,
75.4,
87.7,
42.9,
38.4,
69.1,
37.8,
76.6,
58.1,
73.2,
48.3,
63,
72.9,
56.3,
38.7,
51.5,
80.7,
64.3,
55.6,
24.6,
44.8,
27.4,
82.8,
30.9,
57.2,
48.6,
49.9,
50.7,
64.2,
13.4,
33.3,
86.2,
30.6,
19.8,
77.4,
59.2,
87.6,
83.9,
46,
66.6,
61.5,
39.7,
82.6,
57.5,
85.7,
39.2,
59.4,
50.1,
77.5,
58.4,
77.1,
81.6,
46.7,
73.9,
40.3,
82.1,
82.3,
6,
44.4,
46.7,
63.6,
0.2,
16.4,
13.8,
92.3,
28.9,
75.8,
70.1,
33.5,
74.4,
83,
46.7,
44.4,
29.4,
49.7,
23,
58.9,
26.5,
3.5,
45.4,
30.8,
21.5,
70.2,
48,
44,
90.4,
17.3,
58.7,
56.3,
89.8,
41.8,
69.9,
54.9,
85.2,
84.7,
39.3,
72.1,
70.8,
36.3,
72.1,
9.5,
66.6,
68,
76.8,
60.4,
50.5,
73.4,
23.1,
37.4,
44.5,
85.1,
31.5,
78.2,
19.8,
45.5,
70.5,
77.9,
91.5,
54.6,
76.2,
45.7,
72.5,
36.1,
90.1,
41.5,
49.2,
52.1,
24.9,
58.8,
39.1,
89.3,
0.5,
7.2,
68.6,
31.7,
79.7,
39.6,
76.3,
72.7,
31.1,
35,
54.1,
70.7,
53,
70.1,
79.4,
69.8,
67.1,
41.6,
82.5,
71.1,
32.6,
20.5,
71.6,
79.1,
16.3,
91.5,
45.9,
92.2,
0,
55.1,
49,
25.6,
51.7,
45,
45,
32.8,
80.2,
74.4,
31.8,
46.8,
49,
32.1,
64,
47.8,
49.1,
65.1,
65,
56.8,
44,
65.1,
70.6,
34.4,
77,
72.9,
81.5,
57.6,
48.1,
51.6,
54,
61.2,
91.4,
47.1,
33.7,
28.5,
61.2,
32.9,
46,
67.7,
88,
4.9,
88.5,
73.3,
71.4,
60,
53.1,
70.7,
95.2,
39.1,
66.4,
87.4,
53.6,
84.5,
78.9,
77.1,
54.6,
57.3,
42.9,
98.4,
55,
25.7,
46.5,
74.8,
62.2,
46.6,
31.1,
40.1,
82.6,
59.9,
38.8,
71.6,
63,
26.1,
76.6,
41.1,
17,
22.9,
57.2,
36.4,
45.9,
49.3,
69.8,
83.8,
83.3,
54.3,
73.4,
56,
35.4,
87.9,
71,
94.3,
78.6,
0,
37.7,
23.6,
85.4,
38.9,
41.2,
5.1,
50.2,
79.8,
62.7,
32.1,
73.8,
73.2,
54.2,
73.1,
87.3,
50.2,
23.8,
30.2,
74.6,
40,
70,
23.8,
76,
86.1,
50,
58.6,
71.8,
26.4,
8.9,
55.5,
69.9,
45,
74.3,
35.4,
97.7,
26.4,
27.9,
79.7,
92.8,
63.6,
0,
43,
61.1,
14.1,
62,
39.2,
74.2,
55.3,
45.1,
74,
83.9,
77.9,
69.1,
27.3,
42.8,
0,
22.8,
33,
56,
14.1,
0,
56.4,
50.7,
79.4,
67.3,
87.2,
81.7,
46.3,
64.7,
84.9,
55.2,
68.7,
38.8,
48.7,
90.8,
51.4,
63.8,
29,
47.5,
0,
96,
26.8,
54.2,
17.7,
50.5,
24.8,
73.4,
7.6,
81.6,
41.4,
30.7,
53,
28.7,
21,
20.7,
64,
38.9,
65.3,
72.3,
27.7,
73.4,
83.3,
65,
80.7,
99.8,
98.5,
86.6,
72.1,
50,
44.4,
65.7,
48.9,
51.2,
72.5,
51,
85.3,
63.5,
39.5,
54.7,
45.3,
55.7,
97,
68.3,
55.5,
73.8,
84.1,
85.1,
46.3,
26.8,
28.8,
30.8,
49.4,
47.2,
54.9,
49.2,
43.7,
71.8,
99.2,
39.3,
82.5,
66,
21.7,
35,
90.5,
75.2,
69.3,
28,
88.9,
93.3,
87.6,
99.2,
55.5,
34,
43.3,
74.2,
60.9,
50.2,
49,
60.8,
17.4,
33.6,
25.3,
57.1,
56.3,
20,
45.7,
59.1,
34.9,
3.8,
73,
54.4,
39.9,
51.4,
39.1,
82.7,
6.2,
59.3,
63,
66.5,
76.9,
28.2,
57.7,
73.7,
49.7,
21.2,
63.9,
4.1,
11.5,
22,
38.2,
63.1,
45.5,
49.9,
34.2,
18.5,
70.8,
79.9,
76.1,
39.4,
9.8,
96.3,
32.2,
67.6,
58.2,
94.2,
86.3,
31.7,
40.6,
7.8,
76.7,
63.7,
24.7,
54.9,
63.7,
66.1,
79.8,
91.2,
102.4,
56.9,
86.9,
89.3,
51.3,
76.4,
21.5,
59.5,
40.8,
58.8,
41.3,
71.1,
55.5,
79,
62.8,
34.4,
78.7,
89.6,
10.6,
41.6,
26.9,
19,
62.5,
39.4,
86.9,
82.4,
39,
69.1,
74.3,
82.4,
91.6,
81,
40.5,
78.5,
84.3,
33.4,
95.5,
23.6,
36.2,
58.3,
64.7,
49.2,
44.2,
48.2,
80.5,
64.7,
28.3,
97.2,
78.6,
96,
97.3,
56,
84.5,
34.4,
25.7,
69.9,
64.6,
52.3,
128.4,
41.2,
64.7,
69.1,
54.7,
87.7,
64.2,
94.9,
43.6,
43.3,
58.6,
57.4,
88,
45.4,
57.8,
81.2,
50.5,
77,
60.3,
9.1,
47.8,
23.5,
10.5,
68.9,
38.6,
52,
53.9,
35.1,
48.6,
88.9,
57.7,
89,
71.9,
12.1,
10.5,
63,
76.7,
13.9,
27.1,
47.1,
77,
77.6,
56.8,
54.1,
59.1,
15.1,
55.6,
64.8,
21,
48.1,
73.4,
81.7,
41.6,
12.7,
50.9,
36.3,
21.7,
57.9,
30.8,
51.8,
30.3,
46.2,
16.4,
48.1,
17,
25.2,
54.3,
20.3,
90,
48.1,
4,
89.5,
22.5,
87.4,
65.1,
17.7,
97,
60.4,
61.8,
34,
27.6,
52,
64.9,
57.2,
71.2,
33.1,
73.7,
74.8,
84.1,
72.6,
45.5,
67.1,
48.3,
55.4,
14.6,
76.7,
80.8,
47.1,
70.3,
58.8,
33.5,
29.7,
79.2,
35.7,
21,
78.4,
76.4,
69.2,
82.7,
46.3,
22.1,
51.8,
36.8,
92.9,
78.9,
88.4,
44.6,
60.7,
71.8,
28.9,
58.3,
53,
33.4,
46.6,
41,
57.4,
54.3,
70.2,
40.3,
62.8,
97,
62.5,
34.7,
54.6,
38.2,
76.2,
64,
65.2,
56.4,
90.4,
63.6,
95.3,
69.1,
76.9,
51.2,
76,
24.5,
42.3,
37.7,
61.4,
92.5,
90.8,
56,
51.3,
82.7,
62.9,
53.5,
67,
61.8,
25.8,
98.5,
40,
71.7,
82.5,
66.1,
69.7,
26.8,
49.3,
86.1,
57.3,
27.6,
16.2,
95.9,
42.8,
66,
43.3,
44.8,
64.7,
78.3,
69,
36.4,
75,
95.7,
45.1,
24.9,
50.3,
73.2,
35.9,
101.9,
98.3,
65,
71.6,
78.2,
59.2,
42.2,
56.6,
83.8,
54,
63,
44.4,
94.6,
7.2,
32.9,
44.3,
60.3,
41.2,
79.1,
97,
10.2,
71.5,
13.7,
11.3,
45.1,
41.3,
33.8,
51.2,
92.1,
49.6,
58,
55.3,
2.7,
21.5,
35.2,
58.5,
45.6,
61.4,
89.8,
64.6,
54.5,
43.2,
33.7,
51.6,
86.7,
88.4,
54.2,
16.4,
0.8,
60.5,
69.7,
21.9,
70.2,
22.3,
39.9,
74.4,
53.3,
42.1,
46.7,
22.1,
63.6,
49.9,
19.9,
22.7,
76.9,
58.4,
38.9,
43.4,
73.8,
89.8,
53.3,
92.1,
65.6,
54.4,
64.8,
56.2,
56.9,
90,
19.7,
46.6,
26.7,
26.3,
48.6,
0,
17.9,
80.6,
71.1,
63.7,
0.4,
74.1,
73.9,
50.2,
38.6,
24.2,
31.7,
35.4,
64.2,
79.6,
65,
43.9,
20.1,
50,
29.9,
16.8,
28.1,
44.5,
28.7,
33.2,
17.2,
61.5,
23.6,
30.8,
38.4,
77.1,
63.1,
87.3,
14.7,
73.7,
70,
61.8,
51.1,
56.7,
26.8,
70.7,
38.1,
55.9,
55.1,
66.5,
84,
78.4,
77.3,
80.2,
59.8,
95.8,
42.4,
58.3,
52.3,
94.5,
97.3,
73.6,
60.2,
24.3,
46.1,
79.2,
39.3,
62.4,
40.7,
null,
60.8,
27.6,
85.4,
27.8,
71,
90.6,
42.8,
89.3,
64.8,
67.8,
33.2,
83.1,
59,
39.6,
81.8,
77.2,
32.2,
62.2,
27,
38.3,
78.8,
50.8,
87.4,
73.8,
91,
41.6,
91.1,
51.4,
46.9,
55.2,
79.3,
49.8,
49.7,
82.3,
69.9,
19,
47.3,
52.5,
75.9,
62.9,
67.5,
40.2,
85.2,
90.8,
86.3,
84.7,
21.5,
51.1,
72.2,
31.9,
64,
43.5,
59.3,
100.9,
2.3,
2.5,
58.1,
45,
33.9,
31.2,
31.3,
46.5,
94.2,
58.1,
51,
52.4,
65.6,
82.5,
21.9,
62.2,
38.2,
63.9,
57,
90.2,
93.1,
54.9,
56.4,
48.2,
60.8,
50.7,
55.4,
87.3,
96.4,
66.2,
13.4,
80.6,
73,
13.7,
21.2,
55.4,
66.9,
19.6,
70.6,
42.2,
64,
67.6,
11.8,
88.6,
79.4,
57.3,
76.6,
82.1,
45.2,
85.3,
90.8,
65.7,
86.8,
24.8,
99.3,
96.2,
40.3,
55.1,
52,
44.8,
13.9,
60.6,
99,
67.2,
90,
33.8,
59.8,
68.3,
90.1,
44,
57.2,
84.7,
58.6,
61.7,
52,
47.8,
72.5,
63.9,
16.4,
35.4,
42.1,
3.1,
62.6,
59.1,
17.6,
57.2,
67.1,
35.1,
77.7,
32.2,
36.9,
78.7,
79.4,
77.5,
48.3,
80.2,
47.5,
94.7,
50.8,
37,
55.7,
45.6,
93.6,
82.8,
63,
56.3,
46.1,
35.6,
47.4,
49.7,
96.2,
2.7,
65.4,
47.5,
74,
10.9,
51.9,
88.4,
50.7,
83.7,
44.7,
31.1,
76,
58.8,
83.9,
82,
45,
24.3,
48,
35.8,
56.2,
13.9,
20.2,
52,
55.1,
30.2,
35.9,
15.9,
65.6,
96.5,
13.5,
77,
42.4,
46,
77.6,
41.4,
44.4,
50,
55.8,
87.5,
96.2,
67,
40.8,
47.1,
16.2,
45.5,
68,
19.2,
94.8,
71.1,
24.4,
48.7,
84.4,
67.4,
62.9,
69.7,
88.6,
62.4,
70.9,
44.2,
79.8,
36.6,
57.5,
56.2,
22.4,
88.7,
54.7,
66.4,
59.3,
64.3,
69.7,
86.5,
61.1,
62.2,
55,
51.9,
19.3,
92.3,
43.5,
69.9,
58.1,
89.7,
94.1,
47.5,
46.8,
83.6,
54.2,
75.2,
67.5,
51.9,
77.7,
92.9,
80.5,
19.7,
97.4,
74,
45.6,
101,
4.7,
90.7,
64.6,
40.2,
49.7,
63.1,
92.6,
3.3,
34,
79.1,
59.5,
14,
0.8,
44.3,
57.2,
68.2,
5.8,
63.3,
60.3,
49.1,
67.9,
52.5,
87.2,
0,
17.7,
46.6,
65.5,
57.4,
83.6,
3.7,
53.4,
19.3,
83.8,
38.1,
78.1,
20.5,
52.4,
29.5,
82,
74.9,
74.6,
69.6,
65.3,
45.3,
72.6,
40.3,
20,
91.7,
45.6,
7.1,
35,
53.2,
44.1,
21.9,
39.1,
68.9,
48.1,
52.9,
34.2,
19,
47.1,
37.8,
38.7,
93.5,
77,
36.1,
53.4,
37,
55.3,
42.8,
29.5,
56.8,
67.3,
0,
80.7,
46.8,
54,
72.2,
98.7,
73,
59,
73.4,
35.3,
14,
9.7,
42.9,
61.8,
38,
66.2,
97.3,
41.1,
11.6,
56,
18.3,
28.9,
6.2,
71.7,
56.3,
81.1,
45.4,
48.8,
41.3,
66.4,
53.3,
86,
26.7,
59.8,
10.9,
77.2,
41,
72.1,
71.4,
null,
88.9,
50.7,
33.6,
4.9,
47,
26.5,
92.5,
50.4,
23.7,
45.5,
71,
24.8,
94.1,
13,
90.1,
33.7,
69.6,
43.5,
71.6,
76,
63.7,
49.7,
37.4,
64.2,
21.7,
8.5,
74.7,
48.1,
17.4,
52,
43.4,
29.8,
88.1,
65.4,
28.2,
78.3,
47.8,
65.1,
95.2,
27.4,
42.9,
80.2,
38.7,
68,
6.3,
55.9,
49,
47.7,
73.9,
38.6,
6.4,
52.7,
93.3,
64.4,
44.4,
73.2,
46.4,
99.1,
84.3,
33.1,
75.3,
84.9,
44.5,
66.8,
71.6,
66.2,
84.1,
93.5,
56.3,
42.2,
23,
66.1,
48.6,
63,
44.8,
77.7,
68.1,
59.8,
93,
32.7,
91.9,
83.6,
26.5,
66.2,
31.5,
36,
62.4,
57.2,
69.4,
36.8,
39.2,
59.4,
58.8,
46.2,
29.3,
101.4,
44.5,
59,
53,
6.8,
42.1,
82.6,
76.5,
27.4,
10.4,
27.4,
93.9,
37.4,
43.4,
50.7,
67.1,
60.1,
31,
39.4,
29.1,
67,
78.1,
56.1,
67.9,
90.1,
86.9,
39.5,
88.8,
65.2,
42.2,
70,
51.7,
34.7,
81.7,
25.1,
60.2,
32.8,
27.3,
34.8,
98.5,
54.9,
30.9,
82.1,
25,
78.8,
37.2,
89,
91.2,
40.5,
54.9,
67.7,
42.4,
53.4,
46.3,
34.8,
59.1,
80.6,
67.2,
83,
87.5,
13.2,
62.4,
67.5,
45.9,
76.1,
35.9,
54.4,
73.5,
15.3,
66.5,
73.2,
68.1,
48.7,
75.7,
70,
65.6,
73.2,
62.5,
48.5,
73.8,
79.4,
65.8,
44.2,
49.3,
67.4,
80.4,
64.8,
74.3,
54,
56.5,
97.2,
25.8,
52.3,
38.3,
88.6,
46.4,
82.7,
31.4,
36.1,
84.7,
44.7,
44.6,
56.3,
14.4,
83.7,
60.8,
48.9,
34.3,
29.3,
51.9,
87.6,
16.4,
42.2,
94.9,
69.1,
57.8,
44.5,
23.5,
75.6,
77.3,
39.6,
81.4,
97.5,
36.1,
37.4,
90.6,
60.1,
81.9,
85.4,
78.7,
66.9,
1.6,
46.9,
29.3,
85.2,
70.8,
8.7,
41.2,
44.2,
71.6,
75.4,
65.8,
37.1,
0,
32.9,
29.1,
32.1,
66.1,
37.4,
36.6,
44.8,
88.1,
21.6,
95.9,
55.6,
27.7,
37.4,
68.5,
52.7,
29.7,
10.2,
97.8,
49,
36.2,
18.7,
43,
55.8,
77.8,
53.4,
64,
36,
58.2,
38,
60.5,
75.1,
36.4,
82,
80.9,
55.8,
29.3,
83.6,
87.6,
50.4,
58.4,
1.5,
69.8,
118.4,
39.9,
20.7,
12.4,
59.8,
90.6,
23,
16.2,
26.9,
52.8,
33.4,
28.6,
57.1,
66.8,
53.5,
65.1,
59.4,
49,
90.6,
29.5,
46.6,
61.5,
74.1,
15.2,
7.3,
79.5,
59.6,
42.6,
24.7,
39.5,
71.1,
90.2,
41.1,
61.7,
32.7,
56.6,
8.1,
78.6,
77,
98.2,
47.9,
37,
84.1,
62.9,
78.2,
66.5,
53.8,
62.8,
51.2,
72.2,
64.8,
14.6,
34.8,
37.5,
75.6,
46.1,
37.5,
52.3,
6.4,
16,
41.4,
35.7,
10.9,
22.3,
53.4,
78.1,
40.4,
80.6,
70.9,
46.2,
97,
26.7,
86,
48.7,
86.3,
16.9,
64,
72,
62.6,
87.6,
57.6,
14.1,
84.8,
71.4,
22.3,
83,
77.1,
61.5,
54.9,
76.4,
51,
34,
62.3,
20.9,
72.3,
33.8,
57.6,
30.8,
67.5,
93.6,
26.8,
26.2,
52,
39.2,
27.1,
64.7,
93.6,
62.6,
91.8,
86.4,
41.5,
null,
58.2,
81,
68.1,
54.8,
23.1,
32,
29.8,
86.8,
67.5,
49.5,
86.9,
86.6,
38.5,
57.5,
51.8,
51.6,
24.2,
32.2,
40,
46.1,
73.5,
61.8,
62.2,
33.9,
72.9,
69.4,
57.3,
45.2,
26.6,
43.9,
66.5,
76,
97.2,
50.4,
31.7,
21.5,
78.4,
77,
13.6,
38.8,
86.9,
57.9,
83.7,
52.4,
31.9,
22.3,
67.7,
44.8,
41.9,
46.8,
40,
54.3,
72.6,
86.9,
74.7,
62.6,
50.5,
13.3,
39.7,
26.8,
19.4,
0.7,
62,
35.9,
30.5,
75.2,
78,
80.2,
52.3,
69.7,
69.8,
69.7,
8.2,
53.3,
38.7,
56.2,
73,
94.7,
66.6,
26.1,
58.1,
51.5,
80.8,
63.4,
85.3,
60.2,
13.4,
65.1,
24.3,
46.8,
34.3,
98,
81.2,
97.8,
70.9,
87.4,
57.9,
23.8,
31.3,
61.1,
49.9,
70.6,
93.3,
73.1,
15,
36.4,
44.1,
78.8,
65.8,
30.4,
82.4,
68.5,
71,
73.6,
19.9,
52.2,
52.8,
91,
89.2,
0.8,
65.2,
82.1,
72.6,
48.3,
75.3,
82,
67.2,
33.2,
37.2,
33.9,
52.4,
46.2,
36,
53.3,
71.8,
9.3,
73.6,
50.4,
95.3,
89.2,
64,
70.3,
18.5,
81.8,
31.5,
17.4,
null,
62,
50.9,
75.9,
29,
2.8,
48.7,
83.7,
23.9,
91.4,
47.7,
28.1,
83.7,
103.9,
47.6,
10,
57.6,
69.2,
55.1,
2.6,
37,
97.3,
35.5,
97.8,
31.3,
63.2,
16.3,
84.6,
77.2,
54.4,
69.4,
80,
73,
58.9,
7.4,
70.2,
95.3,
58.6,
68.1,
76.6,
72.8,
87.7,
67.6,
46.4,
65.8,
74.4,
66,
38.5,
31.1,
50.7,
32.9,
90.8,
66.6,
69.3,
95.1,
39,
19.3,
50.3,
69.7,
83.9,
87.1,
40.5,
64.8,
59.5,
55.9,
49.1,
81,
92.8,
78.9,
82,
1.3,
49.8,
33.5,
12.1,
0.6,
78.1,
87.5,
88.9,
36.3,
85.6,
78.5,
97.7,
61,
79.4,
37.3,
77.3,
3,
24.5,
79.9,
55.2,
45.1,
42,
45.9,
46.9,
74.3,
77.6,
57.7,
11.3,
40.8,
45,
43,
5.3,
85.4,
89.9,
69.3,
69.3,
88.9,
41,
97.9,
13.7,
39.6,
47.9,
5.7,
57.6,
48.2,
71.3,
20.2,
36.2,
28.7,
42.2,
63.4,
42.5,
51.8,
66.9,
30.4,
80.1,
12.2,
65.6,
51.5,
26.5,
101.6,
72.8,
28,
59.5,
83.2,
54.1,
82.7,
85.9,
79,
51.8,
80.4,
74.7,
32.6,
88.5,
53,
91.3,
37,
64.8,
34,
49.2,
46.7,
80.2,
58.1,
60.1,
47.9,
49.9,
29.7,
100.6,
16.7,
83.2,
83.9,
51.1,
30.9,
66,
94.3,
74.6,
56.6,
21,
39.1,
91.8,
39.2,
36,
34,
83.6,
83.1,
57.4,
100.4,
45.3,
77.5,
38.8,
12,
87.2,
39.2,
85,
56,
39.8,
37.3,
84.6,
46.2,
46.2,
45.1,
35.4,
69.7,
96,
73.3,
57.6,
79,
37.7,
32.7,
59.3,
46.9,
17.4,
58.7,
71.7,
67.7,
69.9,
45.4,
79.2,
17.7,
62.7,
80.3,
19.9,
69.6,
61.6,
79.1,
60.5,
41.9,
82.1,
85.9,
78.2,
81.1,
74.6,
76.6,
17.4,
56.9,
46.5,
33.4,
33.7,
58.9,
62.5,
62.8,
84,
85.1,
47.1,
77.9,
59.3,
94.7,
19.8,
48.9,
2.4,
37.3,
65.9,
59.1,
36,
65.1,
44.8,
30.5,
65.2,
28.4,
72.6,
74.9,
30.6,
38.2,
62.9,
41.9,
67.8,
66.1,
55.4,
5.7,
41.9,
75.3,
83.1,
45.5,
66.1,
44.3,
73.6,
70.1,
81.7,
8.1,
61.2,
89.5,
79.7,
74.7,
76.8,
45.8,
71.1,
98.7,
45.3,
75.8,
41.9,
65.7,
89,
11.4,
74.2,
48.3,
68,
69.1,
42.5,
70.7,
94.1,
21.8,
68.3,
22.9,
36.2,
87.1,
69,
52.9,
51.3,
93.8,
42.6,
31.8,
62.2,
47.2,
23.9,
null,
29.6,
37.3,
60.4,
29.3,
79.7,
51.4,
35,
59.2,
82.6,
69.9,
51.3,
53.8,
39.1,
53.7,
15.7,
68.8,
62,
78.5,
71.6,
87.1,
61.4,
93.7,
31.8,
75,
84.3,
62.7,
59.1,
29.5,
38.4,
49.7,
91,
70.6,
22,
59.6,
11.7,
74,
92.4,
43.8,
39.6,
33.6,
60.1,
61.7,
28,
80.8,
72.9,
60,
66.3,
41.7,
82.8,
41.8,
57.3,
22.7,
72.6,
10,
41.6,
40.4,
91.2,
48,
37.1,
55.7,
10.4,
6.5,
41.3,
78.4,
6.4,
98.3,
98.3,
97.5,
42.2,
52,
46.7,
88.4,
99.8,
53.7,
48.8,
63.9,
62.4,
46.5,
39.8,
94.7,
25.3,
15.7,
13.8,
9.4,
65.9,
47.9,
53,
85.7,
22.2,
72.8,
32.4,
51.2,
87.4,
42,
82.8,
78.8,
58.7,
59.9,
33.5,
26.5,
12,
27.8,
37.7,
31.1,
37.6,
86.7,
70.3,
51.8,
53.6,
37.1,
77.4,
25.8,
43.9,
96.4,
73,
21,
25.7,
44.3,
60.4,
56.4,
61.4,
38.5,
56.5,
43.9,
37.6,
15.4,
11,
10.7,
17.8,
52.8,
50,
66.4,
92.8,
71.9,
85.5,
49.8,
68.3,
85.6,
68.5,
56.9,
36,
85.8,
84,
87.7,
65,
53.6,
42.2,
38.2,
37,
88.4,
39,
58.7,
54.3,
81.2,
51.9,
75.3,
39.9,
95.2,
61.9,
51.5,
58.2,
53.2,
71,
18.4,
92.6,
40.6,
40.1,
59.2,
41.8,
50.9,
87.8,
58.7,
15.7,
52.6,
68.6,
24.4,
12.8,
40.8,
82,
70.5,
48.6,
78.2,
74.4,
43.1,
65.4,
63.6,
57.4,
27.8,
66.5,
47.8,
26.1,
41.8,
90.8,
28.8,
68,
60.4,
59,
33.4,
58.3,
44.9,
97.7,
61.7,
59.6,
44.4,
68.6,
22.4,
18.3,
86.1,
69.9,
80.3,
75.7,
90.9,
39.6,
86.9,
50.7,
80.2,
46.1,
21,
71.3,
94.6,
56.4,
39.9,
68.7,
85.3,
55.3,
57.4,
66.6,
47.7,
48.5,
67.2,
92.1,
61.8,
50.8,
68.5,
72.3,
6,
52.9,
70.4,
35.4,
68.2,
80.6,
69.5,
19.4,
38.4,
81.8,
63.7,
95.3,
52.5,
70.8,
69.6,
30.5,
82.5,
67.9,
25.4,
56.7,
47.3,
55.6,
36.4,
79.6,
24.2,
98.3,
94,
34.3,
91.7,
62.9,
43.4,
46,
64,
80.2,
55.4,
77.3,
71.2,
50.7,
68.7,
84.4,
60,
50.2,
36.5,
15.4,
79,
79.2,
92.6,
69.5,
71.2,
52.6,
34.7,
63.3,
97.2,
65.9,
97.2,
81.7,
91.3,
75.8,
66.8,
32.5,
41.4,
19,
68.9,
62.9,
44.7,
36.3,
43.7,
56.8,
79,
62.3,
37.9,
71.8,
28.2,
95.9,
87.4,
58.9,
16.3,
84.1,
51.3,
25.7,
40.7,
27.2,
57.4,
61,
87.2,
81.6,
22.5,
13.8,
93.9,
9.1,
7.7,
35.5,
71.9,
9.1,
70.9,
35.4,
40.6,
48.8,
57.7,
60.7,
34,
21.9,
7.1,
55.9,
92.6,
24.9,
35.6,
81.2,
88.6,
11.7,
65.9,
68.7,
81.4,
77.9,
64.3,
68.4,
0.1,
51.8,
69.2,
96.6,
65.3,
38.5,
27.7,
68.1,
44.6,
29.4,
38.2,
71.2,
51.4,
59.3,
72.4,
64.9,
81,
23.1,
68,
16.4,
95.1,
60.9,
23.5,
64.3,
66.8,
78.4,
85.7,
44.8,
21.7,
18.8,
56,
48.4,
18.5,
77.5,
58.2,
33.6,
72.4,
61.3,
77.8,
83.2,
32.7,
40.4,
51,
69,
54.8,
73.8,
43.6,
38.5,
54.4,
85.9,
10.2,
77.2,
77.4,
33.9,
55.2,
56.3,
53.8,
24.2,
40.2,
95.6,
97.8,
69.1,
81.5,
32.3,
34.7,
79,
25.4,
44.2,
31.5,
51.4,
100,
64.4,
65.6,
54.8,
42.7,
53.5,
66.9,
41.4,
37.9,
37.3,
80.2,
28.5,
5.4,
2.1,
95.4,
55.8,
87.6,
35.8,
47.9,
20.6,
82.2,
94.3,
32,
68,
34.4,
41,
57.1,
66.4,
30.9,
47.5,
51,
48.4,
62.6,
64.2,
88.9,
47,
21.4,
21.8,
68.9,
42.5,
5.6,
19.5,
55,
63.3,
24.8,
21.4,
31.9,
79.3,
34.9,
77.8,
40.7,
57.9,
10.8,
50,
67.7,
48.6,
63.4,
42.1,
68.2,
99.9,
20.5,
23.3,
64.8,
72.7,
68.1,
99,
51.3,
38.9,
44.7,
0.2,
27.6,
25,
62.1,
34.2,
78,
42.1,
81.2,
98.3,
14.7,
87.6,
91,
70.2,
90.2,
49.4,
77,
51.9,
42.8,
42,
66.9,
37.3,
55.8,
41.3,
42.9,
30.3,
40,
69.4,
81.6,
23.8,
9.8,
77.6,
25.4,
36.2,
87.7,
67.1,
24.5,
56.8,
26.1,
48.5,
23.7,
46.4,
81,
45.4,
80.9,
75.4,
55.1,
69.2,
49.3,
89.7,
20.4,
12.2,
25.4,
30,
40.8,
47.3,
78.8,
89.9,
48.1,
65.4,
67.5,
62.6,
96.7,
61.6,
0.5,
15.7,
47,
45,
65.8,
47.9,
78.8,
52.9,
85.8,
34.8,
36.2,
86.4,
31.3,
42.5,
89,
65.7,
43.3,
56.2,
58.2,
70,
73.8,
20.5,
76.3,
72,
27.5,
59.6,
54.8,
75.1,
57.7,
82.8,
66,
50.3,
75.4,
52.1,
7.7,
100.2,
32.3,
29,
50.2,
37.4,
39.5,
48,
0.2,
56.4,
58.6,
69.7,
78.2,
0,
47.2,
64.5,
64.7,
71.7,
61.8,
35.6,
26.7,
65.8,
33.9,
81.5,
0.1,
36,
81.1,
66.3,
49.2,
23.7,
36.7,
62.7,
44.1,
28.6,
43.5,
21,
49.5,
34.5,
72,
67,
86.2,
95.5,
2.2,
19.5,
39.3,
24.2,
67,
13.2,
27,
85,
22,
47.5,
87.8,
52.5,
40,
39.4,
31.4,
61.1,
90.1,
17.7,
24,
48.1,
30.7,
73.6,
75,
64.6,
54.5,
45.3,
59,
3.1,
28.9,
79.8,
63.9,
16.6,
30.8,
42.1,
47,
72.1,
68.8,
91.1,
69.2,
29.5,
57.6,
29.8,
33.9,
61.1,
21.7,
61.4,
67.8,
6.3,
84,
78.1,
23.2,
59.7,
49.5,
85.2,
27.8,
75.9,
73,
58.3,
71.4,
72.6,
30.1,
42.9,
46,
30,
35.4,
61,
63,
65.4,
42.8,
94.3,
74.5,
91.7,
51,
50.8,
28.2,
40.7,
59.8,
63.2,
56.9,
42.2,
57.3,
54.3,
74.3,
73.4,
36.9,
81.4,
56.8,
91.7,
53,
50.8,
24.3,
84.7,
91.2,
52.3,
65.6,
57.4,
49.6,
61.4,
64.7,
79.7,
69.7,
43.5,
92.9,
44.8,
42.5,
37.4,
49,
44.2,
84.2,
11.8,
59.5,
69.8,
33.9,
60,
62.2,
47.6,
27.4,
101.6,
68.9,
85.1,
54.6,
60.3,
62,
47.2,
8.7,
36,
67.3,
77.3,
23.6,
48.5,
92.3,
41.3,
94.8,
27.6,
46.7,
94.3,
3.7,
54.1,
41.4,
74.5,
53,
62.7,
96.9,
89.4,
91.3,
64.9,
54.9,
36.9,
74.5,
74,
49.8,
48.5,
96.2,
67.3,
34.4,
64.2,
89.8,
86.6,
35.8,
28,
82.6,
73.7,
27.1,
69.6,
52.1,
50.9,
36,
60.7,
42.5,
44.6,
36,
30.3,
43.6,
37.4,
55.3,
32.5,
53.8,
97.5,
23.3,
80,
56,
80.4,
98.6,
99.1,
62.6,
20.6,
65.3,
70.4,
80.8,
10.3,
69.1,
0,
47.6,
65.8,
86.7,
78.9,
60.6,
13.1,
15.2,
84.6,
28.3,
52.7,
35.6,
65.2,
72,
18.6,
26.1,
50.6,
50.7,
62.7,
55.6,
83.1,
51.1,
67.7,
10.3,
47.4,
43.9,
36.3,
20,
88.1,
41.6,
69.3,
83.1,
45.8,
69,
51.3,
63.8,
8.7,
40,
52.9,
51.4,
16.6,
53.4,
15.8,
70.9,
73,
28.2,
141.1,
89.6,
61.1,
46.4,
98.7,
88.2,
62.1,
94,
53.9,
49,
79.4,
38,
23.3,
88.4,
67.3,
31.1,
58.1,
61.7,
63.7,
67.5,
67.9,
11.6,
10.2,
86.7,
40.9,
59,
47.9,
54.4,
57,
56.7,
7.5,
35.8,
57.8,
79.5,
43.8,
41.7,
40,
45.6,
73.5,
90.9,
53.8,
72.3,
52.6,
34.1,
73.7,
1.7,
20.3,
48.8,
59.3,
41,
77.9,
48,
38.2,
74,
96.3,
42.3,
82.1,
40,
61.9,
68.8,
34.8,
34,
57.1,
64.6,
76.5,
45.9,
78.4,
66.3,
65,
81.2,
50.3,
69.7,
47.2,
62.6,
67.5,
56.1,
62.2,
11.7,
84.7,
65.5,
90.8,
99.1,
43,
78.7,
50.5,
46.3,
89.5,
1.4,
35.7,
65.4,
34.9,
23.2,
44.5,
31.4,
46.1,
60.5,
22.4,
94.4,
16.7,
1.1,
7.1,
45.7,
41.4,
18.1,
8.3,
36,
36.7,
61.2,
56.3,
75.5,
66.1,
54.9,
56,
46.3,
70.8,
64.3,
65.1,
30.8,
32.2,
94.7,
57.1,
72.7,
61,
82.8,
70.6,
3.1,
77.5,
82.5,
37.4,
72,
51.7,
45.8,
96.6,
24.3,
47.4,
78.7,
62.6,
31,
63.7,
56.8,
70.7,
87.2,
47.4,
23.5,
97.1,
34.4,
45.9,
36.9,
35.6,
21.9,
40.8,
58.3,
38.6,
28.8,
99.2,
83.8,
14.9,
35.5,
24.8,
42.8,
65,
15.3,
78,
95.4,
98.8,
76.7,
60.4,
85.7,
20,
71.7,
83.8,
79.5,
47.1,
63.7,
35.3,
49.4,
52.9,
83.9,
99.3,
34.3,
56.2,
47.8,
26,
94.3,
51.8,
45,
66.6,
53,
54.2,
95,
17.4,
54.1,
96.9,
64.6,
64.6,
64.7,
36,
74.2,
83.7,
93.8,
54.2,
57.2,
67,
95.9,
64.1,
83.1,
67.6,
61.3,
2,
97.5,
91.8,
13,
64.7,
40.2,
38.4,
43.2,
77.4,
59.1,
26.6,
36.4,
55.5,
41.4,
83.7,
36.7,
73.8,
29.2,
54.8,
58.5,
76,
69.2,
80.5,
67.9,
64.4,
73.5,
30.6,
46.6,
29.7,
51.3,
71,
88.5,
53.8,
60.7,
27.6,
71,
32.9,
5.5,
12,
28.5,
57,
21,
35.7,
86.5,
39.9,
55.8,
54.5,
32.4,
59.8,
77.1,
30.5,
58.5,
44.4,
63.5,
95,
51.6,
39.6,
74.9,
10.8,
22.8,
49.5,
53.3,
33.9,
59,
64.7,
57.8,
66.8,
13.9,
38.8,
47.2,
19.2,
31,
80.3,
78.1,
56.9,
34.3,
13.8,
88.8,
80.6,
17.9,
75.2,
10.6,
37.8,
60.8,
55.1,
16.8,
15.9,
51.2,
66.4,
74.8,
51.2,
91.9,
63.8,
51.6,
81.8,
52.1,
77.5,
41.7,
58.9,
65.6,
47.1,
29.2,
32.1,
92.8,
82.3,
87.8,
47.7,
69,
15.2,
39.7,
73.5,
48.1,
91.1,
40.5,
86.9,
57.3,
36,
67.3,
86.5,
60.3,
60.4,
52.3,
72.8,
82.4,
27.8,
54,
50.6,
57.9,
76.9,
74.5,
96.6,
45.9,
23.5,
49.3,
52.9,
60.1,
71.2,
57.2,
36.8,
53.5,
49.4,
62.7,
69.7,
32.7,
25.7,
58.2,
25.9,
59,
57,
83.6,
44,
72.7,
46.9,
83.2,
60.7,
53.9,
81,
86.9,
89.3,
18.9,
35,
47.3,
49.4,
28.4,
73.3,
99,
75.9,
69.7,
50.4,
57.8,
48.9,
69,
69.8,
50,
57.4,
70.4,
56.6,
55.1,
58.7,
13.9,
42.9,
92.1,
72.8,
75,
40,
73.2,
58.1,
17.9,
46.9,
50.9,
94,
41.5,
38.1,
57.3,
81.8,
62.9,
76.5,
45.5,
70,
28.4,
60.5,
74,
92.2,
93.8,
28.5,
17.1,
38.2,
89.8,
54.5,
50.8,
80.5,
60,
62.5,
37.8,
42,
2.2,
57.7,
39.8,
84.3,
25.5,
36,
30.1,
19.5,
36.5,
97.9,
29.9,
91.4,
9,
11.2,
41.1,
33,
84,
38.7,
90.7,
56.5,
66.9,
21.8,
43.5,
67.4,
49.9,
84.3,
58,
88.7,
51.3,
57.1,
11.9,
93.9,
44.9,
79.7,
3.2,
37,
37.7,
97.2,
87.4,
65.1,
60.3,
74.3,
34.5,
39,
13.2,
25.5,
37.4,
71.2,
81.2,
27.5,
78.7,
63.4,
63.1,
32,
69.3,
12.1,
65.7,
60.4,
71.2,
87.6,
66.3,
95,
24.8,
31.5,
89.8,
99.3,
39,
52.6,
80,
43.7,
59.1,
54.7,
47.8,
65.5,
39.4,
72.5,
85.5,
89.8,
72.1,
91,
46.7,
74,
61.8,
45.9,
36.3,
33.1,
1.2,
3.3,
14.1,
51.1,
63.2,
22.3,
35.8,
58.1,
92.7,
74.2,
56,
34.4,
79,
5.5,
68.1,
72.5,
83.6,
75,
70.2,
60.7,
61.1,
0.2,
41.2,
95.8,
53.9,
44.6,
72.7,
29.8,
57.8,
12.6,
76.2,
28.9,
59.1,
10.5,
54.5,
58.1,
43,
75,
53.4,
95.3,
57.3,
45.1,
78.6,
87.3,
54.8,
97.2,
51.8,
74.8,
92.7,
43.8,
31.3,
50.1,
48.7,
35.7,
7.4,
36.3,
66.8,
67.6,
46.7,
92.7,
27.6,
48.1,
9,
71.4,
90.7,
92.9,
75.9,
68.2,
68.7,
74.5,
47.5,
35.1,
17.7,
8.6,
0,
65.3,
45.1,
44.8,
69.2,
70.6,
48.5,
57.8,
52,
17.8,
92.3,
46.5,
44.4,
53.6,
49.9,
49.2,
66.7,
31.5,
29.4,
40,
52.4,
81.1,
23.9,
11.9,
25.5,
10.7,
59.3,
64.3,
26.8,
90.9,
51.9,
35.3,
58.7,
78.2,
66.2,
10.4,
77.5,
102.8,
56.2,
58.1,
9,
43.9,
26,
85,
34.1,
66.2,
61.6,
68,
44.8,
37.1,
73.7,
64.1,
75.3,
23.1,
14.9,
34.7,
51.5,
34.1,
38.2,
66.8,
56.1,
75,
63,
6.3,
39.5,
52.9,
32.7,
27.9,
84.4,
87.6,
39.5,
67.7,
64.4,
60.6,
79.8,
54.2,
62.9,
97.7,
71.3,
64.4,
18.4,
61.4,
38.2,
39.5,
58.3,
62.6,
51.7,
51.2,
97.8,
63.2,
57.8,
46.4,
38.4,
90.3,
68.9,
92.9,
88.9,
73,
21.6,
56.5,
63.4,
26.2,
70.3,
97.5,
81.3,
4.4,
25.8,
70.4,
23.8,
44.8,
19.9,
32.5,
65.5,
23.6,
4.4,
37.2,
83.2,
46.7,
54.4,
73.3,
65.6,
48.6,
57.4,
46.5,
60.4,
76.6,
64,
52.4,
61.2,
24.9,
86.5,
25,
97.1,
49.3,
81.3,
27.7,
23.2,
53.9,
41,
30.1,
5.6,
33.9,
70.3,
56,
64,
56.6,
71.2,
27,
39.9,
71.5,
30.4,
67.5,
53.9,
44.1,
48.8,
73.2,
47.5,
86.7,
56.4,
83.2,
28,
47.7,
14.4,
40.1,
55.3,
97.9,
36.1,
49.1,
40.5,
43.5,
44.3,
62.1,
83.1,
18.6,
22.1,
64.1,
60.7,
88,
59,
43.1,
35.4,
86.6,
73.1,
47.4,
94.2,
7.2,
71,
57.4,
33,
82.1,
38.8,
31.3,
77.8,
62.9,
34,
74.7,
84.6,
34.9,
79.4,
52.4,
32.3,
75,
10.7,
80.9,
20.5,
81.7,
56.1,
92.8,
63,
98.9,
62.6,
86,
46.4,
69.9,
48.8,
87.2,
51.8,
67.2,
32.9,
38.3,
81.5,
56.2,
77.9,
32.4,
66.7,
86.9,
41.5,
12,
59.6,
28.2,
57,
48.3,
56,
96.4,
31.8,
72,
93,
90.8,
35.6,
33.1,
75.2,
58.5,
47.3,
57.8,
60.1,
62.2,
57.2,
31.9,
88.6,
60.8,
82.6,
53.6,
99.1,
41.1,
90,
44.5,
68.1,
19.1,
90.4,
80.7,
58.9,
13.6,
16.3,
68.5,
92.8,
35.6,
68,
69.1,
19.7,
0,
91,
79.6,
19.3,
20,
81.8,
67.7,
62.7,
33,
55,
14.7,
55.8,
81.5,
11.9,
49,
47.8,
59,
87.1,
49.6,
35.7,
40.3,
49,
58.7,
78.9,
9.2,
54.8,
47.4,
50.1,
43.5,
72.2,
14.4,
69.3,
31.7,
44.1,
52.7,
55.3,
57.6,
19.1,
31.8,
46.6,
21,
22,
68.4,
16.1,
72,
31.7,
86.2,
81.3,
80.7,
45.1,
46,
70.1,
51.4,
48.4,
30.6,
77.8,
69.7,
88.5,
47.7,
81.9,
15.2,
35.6,
92.9,
48.1,
81.3,
67.2,
25.1,
41.1,
55.1,
24.5,
42.1,
69.6,
55.4,
40.2,
60.1,
35.6,
91,
97.7,
29.7,
84.8,
23.9,
68.6,
27.3,
19.3,
44.8,
98.5,
70.4,
84.5,
70,
94.1,
36.6,
43,
43.3,
49.7,
55,
43.6,
30.7,
84.1,
20,
53.1,
83.9,
94.8,
86.8,
69.3,
81.3,
47.8,
64,
43.1,
68.2,
44.4,
60.1,
10.9,
58,
52.1,
11.6,
52,
58.6,
29.4,
18.1,
96.2,
36.1,
27.9,
73.7,
75,
68.3,
24.7,
32.3,
101,
54.2,
47.5,
81.6,
77.4,
67.2,
79.1,
28.6,
92.6,
69.7,
60.7,
22.4,
87.7,
7.7,
86.9,
61.2,
93.6,
56.6,
48.7,
64.1,
80,
72.2,
44.9,
49.9,
58.9,
89,
57.1,
82.5,
32,
46.2,
64.9,
17.2,
36,
62.4,
36.2,
42.5,
33.2,
68.4,
38.8,
49,
37.8,
20.3,
46.1,
68.4,
72.6,
70.3,
17.7,
21.8,
75,
64.3,
48,
89.4,
42.7,
37.4,
43.9,
51.2,
62.1,
38.1,
97.2,
20.9,
48.4,
47.5,
76,
66.9,
53,
91.2,
34.1,
30.8,
68,
51.1,
84.8,
47.4,
38.3,
77.8,
76.4,
83.7,
83.8,
33.7,
2.3,
73,
51.6,
88.1,
55.3,
50.9,
55.7,
58.7,
89.1,
39.2,
63.3,
57,
59.9,
64.2,
47.7,
92.3,
24.6,
76.8,
18.8,
61.5,
23.7,
80.5,
78,
47,
50.5,
80.3,
79,
59.4,
94.9,
54.2,
99.6,
53.1,
0,
37.3,
51.5,
43.9,
36.7,
14.3,
31.8,
21.9,
30.2,
57.3,
55.3,
3.4,
31.1,
44,
32.5,
81.8,
54.8,
91.1,
82.3,
24.3,
51.3,
63.1,
82.9,
41,
75.2,
49.7,
60.2,
45.6,
30.1,
37.6,
91.5,
71.7,
70.9,
52.2,
85.6,
93.9,
80.3,
40.5,
81.7,
25.8,
0.3,
16.8,
17.2,
62.1,
30.6,
66,
85,
68.1,
51.2,
58.8,
101.6,
95.1,
55.5,
64.3,
93,
48.9,
59.6,
83.2,
86.9,
25,
67,
21.9,
33.6,
68.5,
63.1,
93.6,
67.4,
76.6,
29.6,
92.9,
27.2,
84.7,
67,
13.5,
58,
92.2,
71.5,
38.9,
54.4,
3.3,
58.2,
46.5,
87.9,
55.6,
82.4,
42.1,
43.7,
44.2,
83,
95,
63.5,
60.2,
51.9,
50.8,
59.7,
98.1,
41.1,
55.8,
78.7,
19.1,
7,
36.2,
93.4,
72.5,
51.6,
49,
8.2,
66.1,
36.78,
74.1,
49.8,
81.2,
41.5,
19.6,
39.2,
70.6,
42.4,
19.5,
56.9,
62.4,
56.8,
86.3,
23.3,
2.5,
30.4,
76.3,
29.8,
55,
23.6,
23.6,
62.6,
17.6,
76.7,
64.6,
9.5,
67.5,
59.7,
20.7,
48.5,
58,
11.1,
30.6,
15.1,
71,
99.7,
49.4,
38.5,
94.5,
9.5,
81.6,
40.1,
70,
70.5,
63.6,
53.9,
58.8,
15.2,
62.3,
62.6,
64.1,
60.7,
34.8,
69,
55.9,
26,
47.3,
71.9,
55,
54.7,
70,
45.5,
70.6,
25.3,
55.8,
64.6,
88,
44.3,
15.9,
20.2,
50.2,
26,
88.1,
56.6,
21.9,
9.6,
55.3,
73,
81.4,
91.4,
30.5,
43.1,
13.4,
91.5,
46.9,
3.2,
60.8,
14.6,
47.1,
33,
96.4,
88.8,
15,
61.4,
21.3,
33,
62.9,
27.6,
68.9,
40.6,
68.3,
77.8,
73.7,
55.8,
40.6,
52.6,
55.1,
33.2,
52.1,
71.1,
65.7,
63.1,
83,
44.1,
78.5,
93.5,
66.3,
101.2,
62.4,
78.8,
22.6,
36.9,
69,
67.3,
25.6,
70,
21.7,
18.4,
23.8,
26.7,
57.7,
30.9,
12.2,
86,
11.3,
41.2,
29.9,
69.9,
79.2,
86.2,
28.7,
20.7,
61.3,
41,
70.6,
63.3,
37.3,
67.9,
76.9,
20.6,
35.4,
82.4,
67.8,
89,
68.9,
70.6,
80.8,
90.6,
58.9,
87.4,
72,
26.2,
74.7,
62.8,
87.3,
47.2,
69.6,
49.7,
41.4,
65.9,
83.8,
59.5,
10,
51.9,
18.9,
34.1,
3.6,
38,
54.2,
79.3,
56.5,
34.7,
28.9,
50.7,
37.4,
26.7,
57.5,
48.6,
66.1,
10,
47.3,
75.4,
62.4,
56.1,
50.5,
50.7,
38.3,
52.4,
56.1,
58.1,
86.8,
46.4,
53.3,
40.1,
51.1,
60.9,
81.7,
0,
37.5,
45.3,
42.5,
70.8,
47,
61,
38,
35.9,
12.9,
29.3,
22.4,
76.7,
20.4,
68,
37.3,
65.8,
36.5,
76.1,
24.1,
48.6,
34.6,
34.7,
9.5,
74.2,
94.5,
10.4,
28.9,
81.2,
32,
69.7,
54.9,
32.9,
87.3,
92.4,
84.9,
66.7,
28.3,
51.7,
70.5,
77.4,
10,
41.3,
42.3,
57,
35.1,
72.8,
73.3,
62.2,
77.3,
68.9,
84.5,
65.1,
60.9,
45.9,
68.4,
59.3,
47.2,
25.5,
87.6,
77.4,
21.5,
57.6,
79.1,
32.4,
35.3,
77.9,
77.8,
59.8,
24.5,
25.3,
25,
88.1,
31.3,
44.9,
56.5,
73.4,
27.5,
80.4,
83.9,
44.4,
72.6,
46.5,
62.5,
46.5,
78.4,
36.9,
16.3,
49.1,
30.5,
91.8,
67.3,
43.9,
10.3,
25.7,
36.7,
86.7,
26.5,
93.3,
18.7,
60,
38.7,
48.8,
71.6,
22.9,
76.4,
23.1,
90.8,
37.4,
13,
1.8,
89.8,
89,
70.1,
83,
42.9,
76.7,
45.1,
83.9,
80.6,
59.2,
87,
93.2,
62.2,
48.2,
36.3,
48.1,
83.6,
81.3,
91.1,
8.8,
26.8,
110.4,
44.9,
67.7,
58.1,
92,
29.7,
73.7,
53.5,
15.4,
62.9,
91,
79.5,
42.2,
3.6,
5.3,
20.9,
33.8,
13.8,
43.1,
64.7,
57.7,
26.8,
18,
68.6,
45.7,
19.4,
59.4,
72.8,
22.8,
46.7,
92.1,
80.6,
54.2,
54.9,
76.4,
49.9,
0.5,
64,
64.2,
75.6,
80.2,
79.8,
69.5,
2,
95,
44,
55.7,
47.5,
50.2,
82.8,
49.6,
43.8,
41.9,
66.2,
54.2,
45,
67.9,
59.7,
66.3,
69.4,
33.9,
34.3,
20.8,
32.5,
19.2,
0,
54.2,
99.2,
92.7,
74,
54.4,
43.9,
81.2,
94,
61.7,
56.6,
40.4,
22.7,
40.2,
61.2,
69.7,
63.6,
19.8,
40.2,
14.6,
72.4,
76.2,
54.8,
35,
55.7,
74.7,
2.2,
19.3,
88.8,
63.3,
50.9,
71.5,
1.7,
17.1,
99.4,
79.4,
50.4,
71,
61.8,
65.9,
35.8,
21.5,
47.7,
76.5,
94.1,
29.3,
80.6,
62,
52.6,
91.1,
78.5,
81.4,
21.3,
46.3,
44.3,
66.2,
16,
77.4,
54.5,
63.2,
10.4,
12.3,
67.2,
84.6,
50.7,
33.7,
32.8,
63.8,
41.9,
67.7,
39.4,
58.9,
29.1,
26.1,
84.3,
65,
1.2,
77.3,
67.7,
60.2,
85.7,
78.8,
63.2,
49.1,
63.8,
35.9,
47.4,
59.3,
61.9,
85.1,
77.6,
75.3,
16.9,
24.7,
46.5,
47.6,
27.6,
62,
54.4,
42.6,
38.7,
39.1,
65.9,
87.8,
65.9,
59.6,
70.5,
22.8,
61.9,
76.4,
5.9,
31.8,
26.5,
13.1,
48.5,
82.5,
52.1,
60.3,
88.2,
65.6,
62.9,
82.8,
66,
24.2,
54,
62.8,
81.3,
17.7,
32.9,
4.6,
39,
28.9,
18,
72.1,
66.1,
69.6,
83.3,
47.7,
27.3,
57.7,
72.7,
84.7,
55.8,
70.6,
74.9,
33.9,
43.8,
67.3,
42.7,
67.2,
59.7,
22,
22.9,
82,
79.6,
42.8,
15.3,
25.9,
55.8,
91.6,
22,
84.9,
48.4,
85.6,
29.5,
73.4,
80.1,
72.1,
75.9,
90.5,
22.4,
45.6,
51.8,
90.7,
53,
31.6,
54,
14.6,
87,
102.2,
60.6,
73.7,
99.5,
44.3,
91.5,
45.2,
47.2,
84.2,
93.3,
31.6,
72.9,
21.7,
68.5,
69,
44.2,
30.3,
61.2,
98.6,
46.1,
33.7,
84.4,
96.7,
24.2,
73.2,
76.1,
54.2,
56.1,
27.8,
51.2,
24.3,
74.5,
55.4,
42.1,
50.9,
113,
47,
21.8,
89.4,
63.7,
8.3,
40,
68.1,
58,
42.9,
73.4,
37.7,
86.3,
79.7,
69,
81.9,
43.1,
82.1,
96.8,
50.4,
38.2,
29.9,
48.2,
43.7,
22,
37.9,
65,
77.6,
93.6,
57.9,
44.8,
67.3,
58,
61.6,
74.5,
63.1,
97.2,
33.6,
99.7,
30.4,
19.7,
49.3,
54.5,
25,
0.9,
48.3,
3.1,
21.4,
56.6,
79.2,
30.4,
82.6,
94,
84.5,
69.2,
21.5,
48.8,
47.2,
29.3,
19.5,
91.6,
68,
77.5,
65.6,
87,
31.8,
75.8,
60.6,
42.1,
63.9,
54.5,
41.9,
52.8,
2.8,
31.9,
90.4,
97.9,
85.7,
18.1,
72.7,
70,
44.2,
94.3,
86.1,
25.9,
78.7,
56.5,
40.8,
76.9,
84.1,
69.2,
90.6,
102.7,
89.6,
37.8,
56.4,
52,
55.5,
22.6,
51,
62.9,
62.7,
75.8,
54.2,
41.6,
40.1,
26,
33.3,
13.5,
23.5,
74.3,
35.7,
97.9,
45.8,
54.3,
49,
68.4,
64.7,
15.1,
34.9,
24.3,
37.6,
69.6,
40.7,
28.7,
65.7,
0,
67.8,
58,
55,
68.2,
59,
76.9,
60.1,
35.9,
31.4,
46.9,
48.1,
54.4,
11.4,
70.3,
93.2,
85.5,
57.4,
56.5,
42,
92.8,
58.6,
70.1,
25.4,
38,
62.9,
88,
25.2,
14,
91.4,
56.1,
38.3,
76.9,
16.1,
38.8,
63.2,
52.8,
28.9,
12.4,
24.1,
66.2,
57.8,
73.3,
65.4,
41.5,
69.1,
37.8,
63.5,
54.3,
10.6,
60.2,
49.7,
7.6,
38,
57.2,
45.4,
38.6,
31.7,
94.3,
80.6,
56.6,
42.7,
69.3,
94,
70.7,
83.8,
16.4,
35.5,
15.5,
38.6,
67.1,
60.2,
94.3,
62.3,
50.5,
15.5,
33.4,
67.7,
19.2,
7,
36.5,
68.1,
59,
71.8,
72.8,
5.4,
64.6,
54.9,
46.5,
80.2,
91.9,
64.6,
5.1,
44,
20.6,
91.3,
69.9,
56.3,
55.5,
95.2,
42.8,
48.7,
80.9,
40.2,
11.6,
19.1,
20,
54.7,
26.6,
95,
80,
86.8,
58.4,
48.7,
70.7,
48.7,
46.5,
92.5,
86.6,
62.9,
79.9,
74.7,
17.8,
49,
62.9,
27.4,
84.9,
97.6,
72.6,
42.7,
73.7,
70.7,
63.8,
79.7,
66.6,
85.4,
33.9,
45.3,
68.2,
67.1,
32.1,
83.4,
66.6,
69.9,
31.7,
10.7,
68.3,
45.4,
53.6,
92.9,
74.6,
55.4,
77.8,
73.3,
51.3,
45.6,
38.9,
87.7,
66.2,
34.2,
64,
78.1,
81.9,
68.9,
71,
68.6,
43.4,
63.4,
38.7,
72.1,
27.1,
37.2,
40.5,
19.2,
119.1,
53.4,
54.3,
33.3,
93.1,
79.9,
41.7,
33.2,
17.3,
36.7,
86.3,
77.6,
60.9,
39.6,
81.2,
54.7,
51.7,
60.2,
31.2,
80.3,
82.2,
80.3,
79.1,
26.5,
67.3,
92.3,
42.4,
76.5,
67,
66.8,
39.5,
58.8,
60.4,
58.6,
29.7,
17.5,
95,
18.2,
4.8,
86.7,
41.3,
23,
66.8,
53.4,
35.9,
10.4,
16.3,
50.5,
33.5,
66,
68.4,
33.8,
75.7,
38.5,
34.7,
79.1,
86.2,
83.9,
59.2,
80,
76.2,
89.1,
52.6,
77.8,
44.7,
51.9,
81.5,
33.9,
34.4,
85.2,
35.8,
34.8,
62.3,
70.4,
79.3,
18.6,
0,
61.5,
52.9,
53.3,
35.6,
27.9,
61.5,
88.8,
37.4,
73.2,
31.4,
45.1,
56.3,
48.1,
66.8,
82.2,
29.9,
14.5,
79.4,
45.9,
45.1,
35.9,
39.3,
99.4,
47,
34.7,
30.2,
71.1,
95.3,
74.3,
31.1,
80.6,
99.3,
78.2,
52.4,
94,
32.6,
38.3,
23.1,
19,
46.6,
127.6,
20,
62.7,
75,
28.3,
49,
70.7,
17.5,
13.4,
85.9,
54,
43.6,
8.4,
39.3,
50.3,
50.1,
89.3,
63.6,
55.1,
37.6,
29.8,
99.2,
67.6,
85.7,
51.4,
20.2,
75.4,
29.9,
50.1,
88.5,
53.7,
89.7,
23.6,
70,
78,
38,
40.6,
39.8,
70.1,
37.4,
74,
37.7,
62.2,
54.6,
24.8,
37,
12.3,
72.7,
29.3,
23.5,
52.8,
20.4,
17.1,
16.1,
53.6,
42,
27.3,
31.2,
78,
72.3,
57.3,
47.9,
89.3,
77.9,
57.5,
24.7,
46,
36,
57,
76.9,
38.6,
62,
84.2,
24.5,
73.3,
86.4,
82.5,
92.7,
59.6,
34.4,
20.9,
45.2,
96.6,
77.6,
51.1,
53.3,
66,
76.2,
88.9,
80.8,
52.6,
0,
83.2,
55.2,
20.5,
41,
81.9,
64.7,
85.9,
73,
21,
65.2,
37.5,
15.6,
38.3,
86.9,
66.5,
86.9,
35.2,
75.9,
39.1,
18.7,
11.2,
47.5,
36.8,
91.7,
45.7,
33.5,
61.5,
24.6,
61.9,
43.3,
75.5,
41.2,
87.7,
16.3,
62.9,
77.3,
90.2,
63.9,
63.6,
55.8,
35.1,
66.1,
58.8,
80.2,
40.1,
13.8,
45.5,
81.9,
71.3,
61.1,
59.6,
75.8,
48.2,
27.3,
80.8,
54.3,
29.1,
34.5,
58.7,
35.4,
24.6,
58.8,
30.6,
41.7,
53,
37,
12.4,
16.2,
57.7,
39.5,
42.5,
38.5,
92.6,
3.1,
54.1,
73.1,
86.5,
8.4,
74.4,
37.8,
54,
85.6,
39,
73.1,
70.3,
69,
0.5,
47.8,
30.9,
43.4,
65.8,
81.6,
17.2,
31,
76.5,
70.1,
91.8,
56.7,
31.9,
58.6,
32.8,
33.5,
38.4,
7.9,
97.7,
24.7,
27.3,
56,
61.9,
46.8,
97.8,
45.5,
88.4,
72.4,
16.8,
63.4,
20.3,
23.5,
28,
79,
64.1,
36.7,
18,
51.4,
50.9,
83.8,
80.3,
47,
94.1,
43.3,
91.8,
90,
68.5,
74.1,
99.1,
39.9,
52.2,
62.3,
26,
75.2,
31.8,
22.4,
69,
79.9,
77.4,
57.3,
59.6,
0.9,
20.8,
65.5,
70.7,
31,
45.9,
59.6,
66.3,
43.1,
48.1,
86.1,
51.7,
90.4,
87,
30.6,
95.4,
95.5,
38,
83,
5,
71.9,
45.9,
65.2,
21.4,
71.4,
45.3,
23.8,
74.5,
48.9,
35,
73,
19.1,
98.7,
25.1,
80.8,
55.3,
34.1,
94.9,
12.8,
7.2,
60.4,
46.1,
52.3,
52.6,
46.6,
76.5,
58.9,
63.7,
36,
70.7,
43.6,
41.5,
39.2,
21,
61.8,
29.4,
39.5,
64.1,
64.4,
75.5,
72.6,
15.6,
10.2,
29.2,
78.1,
85.5,
39.3,
24.4,
90,
50.1,
85.7,
14.7,
23.9,
12.5,
29,
15.6,
9,
14.8,
80,
18.6,
76.8,
73.5,
67.3,
29.9,
91.4,
16.8,
34.8,
37.4,
25.9,
77.9,
73.7,
39.3,
45.2,
56,
22.5,
100.4,
97.4,
60.2,
91.9,
37.1,
26.1,
76.4,
19.5,
64.6,
62.6,
43.1,
55.6,
50.9,
22.3,
74.3,
56.8,
61.1,
16.7,
40.3,
42.9,
76,
30.1,
36.6,
48.9,
58.5,
47.7,
75.8,
14.9,
41.2,
18.3,
25,
84.7,
54.5,
63.8,
87.6,
67.7,
79.1,
51.7,
85.9,
9.2,
87.8,
70,
89.5,
51.8,
42.7,
54.7,
84.7,
55.5,
18.4,
41.7,
30.9,
76.3,
35.7,
49,
16.1,
72.3,
70.5,
19.2,
33,
3.1,
41.8,
38.8,
51.6,
51.9,
49.3,
75.3,
77.8,
49.4,
85.5,
5.8,
90.5,
84.3,
81.7,
70.4,
46.9,
31,
30.1,
66.9,
54.7,
72.7,
38.9,
17.5,
66.5,
47.1,
45.7,
73.1,
71,
47.6,
64.6,
53.4,
71.9,
27,
56.2,
81.4,
72.4,
31.9,
100,
35.7,
38.1,
37.3,
34.7,
67.9,
90.3,
80.4,
28.8,
12.1,
27,
5.1,
61.9,
54.7,
32.5,
61.4,
45.3,
97.8,
88.2,
96.2,
94.9,
4,
22.4,
71.1,
64.6,
93.7,
90.1,
79.1,
91.7,
46.4,
44.4,
71.9,
18.1,
59.6,
75.6,
74.3,
57.6,
98.9,
33,
71,
87.6,
72.9,
33.6,
66,
83.8,
74.5,
91.2,
39.5,
44.4,
28.5,
40.6,
27.5,
48.6,
68.6,
88.5,
43.2,
61.9,
32.7,
26.8,
48.4,
49.6,
46,
63.7,
54.3,
80.6,
69.2,
39.5,
36.2,
64.8,
52.8,
49.4,
27.6,
73.9,
19.9,
48,
31,
69.7,
39.3,
97.7,
46,
78.3,
59.5,
57.6,
56.1,
40.5,
71.4,
13.4,
40.2,
33,
42,
30,
86.9,
53.6,
68.7,
88.9,
79.7,
22.1,
40.3,
64.4,
91.8,
37.8,
39,
51.9,
32.9,
84.8,
30.7,
67.5,
45.5,
28.5,
67.9,
56.6,
0,
55.1,
72.7,
95.1,
62.9,
43.6,
10.1,
80.6,
72.8,
26.7,
73.6,
36.9,
15.1,
84.8,
39.1,
75.2,
42.1,
34.4,
30.3,
64,
74.7,
98.3,
35.3,
83.4,
81.4,
96,
97.2,
78.6,
40.6,
47.3,
68.9,
90.6,
22.3,
21.5,
31.3,
36.5,
44.6,
54.1,
81.4,
35.5,
45.6,
8.6,
28.5,
61.7,
94.9,
66.5,
90.7,
77,
71.1,
69.1,
66.8,
37.4,
70.6,
44.1,
42.3,
62,
75.4,
76.9,
39.7,
25.1,
0,
75.8,
65.1,
46,
37.3,
54.1,
58.6,
15.1,
81.2,
47.6,
28.2,
77.6,
92.9,
63.9,
79.3,
98.1,
55,
86.5,
70.7,
42.8,
54,
85.5,
83.9,
44.4,
57.6,
19.7,
14.5,
95,
37.8,
60.7,
10.9,
74.6,
92.4,
84.5,
68.8,
66.4,
62.4,
35.5,
61.4,
80.7,
49.4,
69.4,
82.2,
31.3,
43.2,
64.1,
56.1,
50.9,
49.7,
51,
96,
92.3,
70.3,
46.9,
73,
46.9,
34.5,
73.6,
54.9,
74,
23,
46.3,
70.8,
88,
70.4,
21.4,
49,
93.8,
44.2,
94.6,
4,
77.5,
87.1,
93,
68.6,
3.9,
91.9,
63.3,
20.3,
45.7,
46.2,
58.4,
68,
90.4,
34.6,
73.1,
53.9,
83.9,
36.4,
85.1,
83.5,
3.8,
52.9,
59,
32.8,
85,
54.2,
76.6,
67.1,
35.9,
42.5,
20.3,
22.2,
84.9,
56,
48.3,
77.6,
77.7,
0,
76,
74.6,
55.2,
85.9,
68.5,
39.5,
20.4,
6.6,
62.2,
81.2,
35,
22.6,
40.4,
84,
65.8,
55.1,
97.5,
76.1,
77.7,
55.2,
62.3,
44.2,
50.2,
69.3,
7.1,
13.3,
79.8,
18.3,
26.5,
60.5,
67.5,
101.6,
70.5,
13.1,
34.4,
89.6,
4.1,
65.4,
66.5,
77.6,
28.4,
86.8,
58.6,
21.3,
55.8,
81.9,
73.3,
63.3,
50.6,
54.5,
51.6,
65.8,
20.5,
98.6,
98.1,
22.1,
76.2,
64.4,
37.8,
48.5,
34.3,
46.9,
75.5,
91.9,
34.4,
41.2,
45.8,
30.4,
60.1,
18,
59.4,
44.6,
38.3,
70,
63.2,
75.1,
60.4,
35.3,
64.3,
36.8,
68.2,
57.1,
89,
71.9,
12.3,
6.2,
49.6,
84.1,
85.5,
62.9,
13.6,
49.8,
49.7,
51.9,
64.1,
71.6,
18,
6.9,
53.9,
42,
55,
77.6,
25.9,
70.4,
78.1,
90.7,
86.8,
96.8,
1.8,
94.1,
72,
96.6,
54.7,
44.8,
37.8,
78,
7.6,
75,
93.7,
33,
50.6,
35.6,
28,
28.4,
75.3,
47.8,
54,
46.4,
45.5,
10.5,
17.3,
48.7,
30.3,
38.5,
70.7,
51.2,
82.2,
89.4,
59.9,
80.3,
3.1,
75.6,
75.5,
62.9,
34,
84.4,
77.8,
29.6,
15.2,
73.6,
73.3,
47,
85,
70.7,
84.5,
79.1,
68.8,
71.9,
35.9,
22,
46.1,
72.1,
97.7,
52.5,
70.2,
22.2,
36.2,
46.9,
59.4,
40.8,
86.2,
99,
66.5,
53.1,
65.3,
56.4,
40.6,
61.2,
28.3,
79.2,
63,
42.5,
67.9,
50,
58.7,
23.8,
64.1,
69,
35.6,
77.4,
33.4,
20.5,
64.7,
47.9,
94.7,
34.7,
27.2,
25.6,
73.6,
49,
8.2,
17.5,
72,
53.6,
69.1,
41.6,
29.3,
55,
80.2,
55.9,
1.3,
69.5,
51.3,
84.2,
90.8,
69.9,
54.8,
85.8,
83.7,
78.1,
53.3,
45.2,
48.3,
65.6,
28.5,
97,
14.5,
18.9,
79,
40.2,
74.4,
83.5,
37,
43,
71.1,
62.1,
61.2,
72.5,
45.9,
79.7,
69.6,
67.2,
56.5,
59.9,
52.7,
17.5,
32.6,
79.9,
27,
38.3,
98.4,
61.8,
23.6,
67.7,
92.4,
75.8,
19.9,
50.6,
24.8,
26.8,
67.6,
44.2,
59.6,
69.6,
46,
68.5,
26.6,
50.9,
69.1,
55.6,
26.3,
90.5,
47.9,
24,
60,
45.5,
37.8,
86,
85.4,
64.8,
60.5,
58.6,
37.7,
35.8,
81.2,
74.1,
80,
41.3,
84.8,
60.8,
91.1,
30.8,
78,
49.9,
65.8,
42,
75.9,
46.6,
21.1,
29.3,
56.6,
26.7,
24.7,
74.3,
79.5,
41.7,
94.5,
85.6,
28.5,
98.1,
13.2,
39.9,
56.9,
92.5,
31.9,
75,
3.4,
62.3,
46.4,
77.6,
40.3,
49.1,
44.7,
46,
28.8,
84.8,
40.4,
55,
3.3,
73.7,
94.4,
73.6,
71.3,
41.4,
49.2,
79.3,
61.8,
43.4,
64.2,
97,
48.5,
57.2,
76.5,
50.4,
56.3,
53.9,
43.1,
16.7,
73.9,
54.4,
88.7,
92.9,
98.7,
37.4,
51.1,
33.3,
81,
18.5,
69.5,
74.4,
51,
74.9,
30,
27.7,
52.7,
90.8,
54.4,
0,
77.4,
62.7,
80.3,
71.3,
43.4,
76.9,
42.2,
72.9,
22.4,
39.1,
82.3,
9.2,
94.6,
79.4,
27.5,
59.6,
36.5,
44.6,
49.6,
68,
65.7,
null,
18.6,
32.6,
76.6,
31.4,
19.9,
78.7,
80.5,
10.2,
58.3,
24.7,
111.2,
32.9,
28.2,
42.2,
71.3,
18,
35.6,
17.2,
40.8,
81.9,
15.6,
51.7,
78.1,
11.8,
30.5,
63.9,
23.8,
49.6,
52.7,
89.2,
55.5,
53.7,
24.5,
66.6,
79.8,
40.4,
48.9,
28.6,
15.1,
48.5,
28.6,
59.9,
50.6,
80.9,
19.6,
31,
61.6,
77.2,
70.8,
19.2,
38,
97.4,
46.5,
67.2,
93.6,
25,
32.1,
42.8,
42.9,
12.2,
73,
14,
51.8,
69.1,
63.8,
32.5,
21.2,
18.3,
22.8,
14.7,
55,
50.9,
82.3,
83,
52.1,
26.6,
71.4,
64.6,
49.8,
78.2,
88.3,
86.3,
80.2,
80.2,
38.1,
47.7,
24.3,
62,
4.1,
83.5,
70.2,
54,
23.8,
72.5,
20.6,
92.3,
78.1,
51.6,
89.4,
77.3,
75.4,
52.4,
28,
24.6,
56.5,
81.8,
17.3,
48.4,
55.2,
89.3,
29.3,
23,
96.4,
50.2,
58.3,
23.5,
64.6,
97.4,
95.2,
59.5,
19.2,
7,
69.4,
40.3,
86.9,
96,
46.1,
30.6,
73.7,
35.7,
41.8,
92,
15.7,
67.9,
82.9,
37.7,
84.5,
60.8,
91.5,
56,
42.9,
46.7,
99.3,
79.8,
38.3,
93.4,
57.2,
57,
72.1,
8,
58.6,
34.5,
102.3,
74.4,
46,
93.8,
95,
73,
86.9,
74,
63.9,
47.8,
16.3,
45.6,
28.4,
67.5,
65.1,
1.4,
57.1,
48.6,
25.1,
65.6,
43.7,
67,
96.5,
74.8,
58.2,
35,
94.1,
72.6,
17.3,
24.8,
47,
51.2,
43.2,
40.3,
83.6,
41.6,
86.5,
32.4,
34.2,
49.8,
58.3,
35.8,
76.2,
32.9,
71.7,
56.2,
33,
88.4,
64.6,
18.6,
91.2,
63.5,
40.8,
57.9,
65.5,
27.9,
61.3,
10.4,
12.9,
78.8,
69,
25.9,
26.8,
59.9,
0.1,
82.1,
60.2,
51.5,
6.9,
69.1,
31.7,
96.1,
75.4,
18.8,
70.1,
90.2,
37,
39.1,
59.1,
70,
25.9,
37.8,
84.2,
46.7,
73.6,
67.1,
47.3,
57.4,
54.7,
66.2,
53.1,
91.6,
59.6,
33.6,
62.5,
13.9,
22.7,
93,
44.8,
44.7,
73.4,
43.8,
50,
87.8,
13.5,
42.4,
53,
63,
85.2,
46.3,
1.4,
54,
16.9,
41.4,
36.8,
11.6,
79.6,
57.9,
61.7,
74.2,
76.8,
56,
33.1,
79.5,
72.4,
65.2,
44.2,
54.2,
70.2,
55.3,
93.5,
50.8,
87.2,
24.7,
52.4,
46.7,
93.6,
87.9,
43,
12.9,
57.3,
54.8,
27.4,
72.5,
42.7,
66.7,
81.3,
48.2,
66.1,
30.5,
14,
54.8,
80.4,
44.3,
87.4,
22.3,
65.7,
41.5,
37.9,
81.5,
52.9,
70.7,
25.6,
65.8,
74.8,
82.1,
53,
80.8,
28.4,
56.7,
16.3,
40,
47.2,
72.1,
96.2,
56.2,
21.8,
44,
16.1,
43.7,
64.2,
80,
66.9,
15.4,
28.9,
66.6,
66,
41.8,
27.3,
64.3,
26.4,
73,
61.8,
58.7,
29,
3.6,
20.6,
45.1,
90.4,
11.7,
20.1,
39.6,
37.1,
62.6,
11.9,
54.3,
6.2,
93,
57.6,
14.6,
8.2,
78.6,
41.2,
86.5,
90.2,
69.6,
7.4,
31.5,
71,
93.6,
50.5,
45.2,
0.4,
67.1,
66.1,
78.6,
53.9,
46.6,
73.9,
62.2,
75.7,
51.4,
56,
36.9,
83,
53.6,
54,
41.5,
93.7,
48,
15.1,
22,
87.4,
98.1,
60.7,
93,
94.2,
76.6,
19.1,
50.8,
32.3,
79.9,
62.3,
74.2,
9.2,
42.7,
82.9,
61,
88.8,
73.7,
60.4,
19.5,
68.1,
36.8,
57.1,
7.1,
7.6,
84,
66.4,
45.3,
81.5,
66.5,
60.6,
32.9,
85.8,
49.9,
78.4,
39.5,
44,
15,
76.6,
80.6,
68.4,
19.4,
75,
48.3,
46.6,
19,
35.4,
58.4,
75.3,
56.4,
79.6,
93.1,
48.5,
68.4,
86,
64.9,
55.1,
78.6,
76.8,
92.3,
74.5,
77.4,
13.4,
62.4,
77.2,
51.7,
67,
69.3,
51.7,
57.6,
98.6,
6.9,
78.1,
38.4,
86,
26.3,
51.2,
62,
92.4,
90.6,
77,
47.7,
34.6,
40.7,
93.8,
49.9,
85.5,
66.3,
76,
55.4,
68.6,
57.5,
21,
37.9,
78.4,
70,
44.5,
41.3,
49.4,
77.4,
63.9,
40,
38.8,
52.2,
62.2,
56.2,
62,
3,
67.4,
88,
71.8,
9.9,
62.3,
76,
25.5,
86.2,
76.1,
20.7,
0,
52.8,
50.3,
32.8,
84.9,
63.6,
43.4,
57.3,
72.1,
71.6,
26.1,
50.6,
82.5,
46.8,
72.9,
48.8,
75.8,
94.9,
92.3,
34,
76.6,
50.9,
67.8,
52.6,
71.1,
49.9,
74.9,
46.4,
95,
23.4,
76.5,
43.7,
44.3,
43.7,
70,
51.1,
75.6,
62.2,
86.7,
7.6,
32.5,
50.5,
41.5,
45.9,
80.9,
88.1,
59.8,
78.9,
88.5,
80,
56.8,
75.8,
89.9,
34.7,
53.4,
44.9,
85.8,
80.4,
58.7,
29.7,
18.6,
23.8,
72,
79.3,
43.7,
38.3,
67.6,
46.5,
95.2,
89,
13.5,
66.9,
0,
27.8,
83,
24.3,
5,
76.1,
77.3,
43.9,
83.1,
67.7,
69.7,
38.7,
95.4,
63.6,
13.4,
66.5,
25.2,
35.3,
38,
30.9,
63.2,
47.6,
40.7,
27.4,
96,
30,
39.4,
72.2,
32.4,
10.7,
61,
54.5,
40.5,
86.3,
58.9,
34.8,
84.1,
87.6,
90,
64.6,
82.3,
72.3,
49.2,
60.4,
5,
56.7,
11.7,
42.6,
78.1,
26.3,
73.6,
74.3,
62.3,
19.4,
37.6,
25.2,
63.6,
78.8,
55.8,
72.7,
52.2,
80.7,
35,
68.5,
94.4,
75.6,
34,
54.1,
57.1,
14.9,
50,
80.3,
71.8,
88.8,
39.3,
76.2,
52.7,
73.1,
44.8,
37.6,
63.9,
34.6,
93.7,
74.6,
80.8,
94.6,
71.6,
1.9,
29.5,
54.1,
65.8,
48.4,
56.2,
37,
72,
98.6,
79.4,
18.2,
92.9,
54.7,
33.1,
37.4,
87.9,
78.7,
33.8,
14.7,
50.6,
90.9,
76.3,
66.2,
22.9,
94.1,
33.9,
63.2,
46.4,
47.9,
71.2,
80.2,
47.9,
70.2,
63.3,
58.5,
92,
69.5,
80.5,
45.5,
73.6,
94.1,
86.6,
60.4,
61.9,
37,
3.4,
77.2,
65,
51.7,
55.4,
66.7,
83.4,
83.5,
47,
22.9,
81.1,
62.1,
32.9,
43.6,
72.9,
42.1,
6.6,
90.7,
53,
58.3,
40.2,
58.9,
28.7,
56.2,
70.3,
82,
89.5,
19.8,
23.7,
89.1,
77.8,
38.8,
59.8,
9,
84,
82.9,
61,
0,
27.6,
94.7,
64,
53.7,
63.5,
100.8,
64.3,
59,
62.5,
46.6,
37.9,
91.7,
61.6,
93.8,
40.4,
64.1,
7.4,
26.4,
71.8,
90.6,
59,
41.4,
67.5,
39.2,
63.3,
28.2,
95.5,
41.2,
80.7,
17.9,
79,
20.8,
62.7,
22.2,
73.3,
29.3,
44.2,
70.7,
23.5,
91.4,
42.1,
94.9,
18.4,
76,
76.4,
85.1,
76.1,
9.6,
60.5,
39.3,
21.7,
18.1,
42.7,
69,
67.1,
70.8,
10.6,
76.6,
85.6,
68.6,
5.6,
75,
9,
49.9,
78.9,
59.2,
25.9,
49.7,
82,
57.4,
59.1,
59.9,
22.3,
25.4,
22.1,
68.6,
38.1,
58.3,
16,
47.8,
63.7,
25.1,
76.5,
47.9,
39,
61.2,
66.2,
78.9,
87.8,
68.8,
70.3,
73.1,
64.2,
40.4,
10,
65.5,
67.5,
55.1,
48,
84,
86.2,
96.9,
80.5,
14.7,
51.8,
31.3,
46.6,
49.8,
72.4,
27.1,
57.2,
90.5,
0,
3.7,
35.2,
90.9,
10.9,
63,
45.7,
25.1,
20.5,
75,
70.5,
74.9,
19,
52.2,
47.1,
64.6,
58.4,
29.6,
67.1,
42.2,
39.1,
47.3,
28.4,
53.2,
64.3,
85.1,
81.3,
51.1,
78.8,
55,
31,
93.2,
56,
40.4,
0.8,
56,
80.1,
33.9,
52.8,
47.4,
53.3,
68.1,
56.7,
38.6,
73.2,
35.6,
71.2,
79.2,
51.5,
74.7,
58.9,
14.5,
28.3,
73.2,
91.1,
70,
35.3,
79.4,
35.4,
71.1,
55,
70.7,
56.7,
85.1,
38.4,
58.3,
80,
92.6,
23.2,
13.9,
80.3,
56.3,
40.5,
29.4,
55.1,
82.6,
28.7,
70.9,
38.6,
9.1,
16.2,
53.1,
21,
1.5,
35.4,
71,
49.3,
84.6,
83.7,
58.8,
58.9,
48.3,
62.9,
18.2,
8.2,
59.5,
67.3,
38.9,
22.8,
57.2,
33.4,
48.5,
50,
24.6,
58.4,
68.2,
54.7,
69.1,
52.1,
32.5,
60.9,
44.1,
59.8,
42.5,
35.6,
29.1,
83.3,
84.6,
70.2,
82.3,
77.1,
73.9,
42.4,
43.1,
67.2,
54.1,
44.2,
75,
66.3,
65.1,
21.2,
56.4,
97.3,
75,
59.4,
69.1,
61.6,
38.8,
77.4,
69.2,
71.1,
84.7,
58.2,
38.8,
69,
24.6,
57,
34,
43.1,
90.5,
55.6,
65.6,
56.2,
37.2,
25.3,
6.9,
56.1,
70.2,
41.5,
102,
43.9,
72,
48.3,
63.6,
49.2,
80.6,
60,
84,
83.7,
28.4,
81.2,
30.4,
83.7,
91.8,
65.8,
33,
52.3,
64,
44.5,
91,
48.7,
57.9,
61.6,
59.8,
58.1,
93.3,
60.8,
95.3,
39.2,
74.3,
28.4,
37.2,
25.5,
27,
13.8,
47.6,
65,
48.4,
43.4,
79,
29.2,
85.3,
63.4,
46.1,
80.7,
49.9,
92,
88.5,
64.5,
64.3,
7.4,
63.9,
44.8,
56.1,
49.3,
44,
57.7,
72.4,
59,
63.2,
52.8,
23.9,
60.6,
70,
47.1,
23.3,
62.9,
37.5,
69.4,
57.9,
63.7,
50.2,
79.6,
55.4,
54.6,
51.8,
44.4,
82.4,
57.4,
67.6,
53.8,
58.8,
36.7,
59.6,
39.5,
86,
4,
47.2,
61.1,
66.8,
58,
74.1,
91.7,
78.2,
61.7,
59.9,
18.4,
67.7,
17.4,
55.1,
28,
12.3,
86.7,
31.6,
60.1,
58,
68.8,
74.4,
66.3,
87.5,
45.1,
54.2,
35.9,
62.2,
78.5,
94.5,
68.7,
82.4,
69.6,
63.9,
96.8,
41.2,
0.2,
8.3,
83.1,
66.5,
43.3,
29.1,
29.7,
42.7,
84.7,
49.3,
71.8,
59.1,
56.1,
76.6,
66,
83,
49.5,
61.4,
72.3,
47.5,
80.3,
15.2,
73.9,
79.1,
88.1,
9.9,
67.5,
5.8,
94.7,
38.9,
null,
89.9,
36.7,
71.5,
25.8,
78.4,
96.7,
69.9,
83,
34.1,
65,
70.8,
27.6,
57.8,
98.6,
39.7,
62.3,
65.1,
52.6,
40.4,
58.1,
97.8,
59.4,
68,
88.4,
66.7,
20.9,
71.4,
43.2,
79.4,
63.9,
83,
77.8,
53.1,
97,
70.4,
61,
20,
73.7,
7,
91.2,
59,
39.5,
96,
68.9,
36.6,
24.2,
22.8,
77.9,
36.8,
49.4,
36.5,
56.8,
26.8,
76.4,
30.8,
0.9,
49.4,
83.7,
94.5,
54.9,
68.1,
59.5,
57.1,
52,
63.6,
89.7,
53,
86.3,
56.4,
45.5,
62.1,
67.5,
11.7,
48.1,
68,
57,
82.3,
57.5,
63.6,
52.9,
84.1,
82.8,
79.4,
28.1,
21.2,
40.6,
37,
94.4,
19.7,
74.7,
60.8,
24.8,
57.4,
52.3,
93.8,
68.6,
66.4,
41.7,
75.4,
44.4,
30.3,
60.7,
65.7,
85.5,
39.1,
93.3,
55.5,
80,
33.8,
84.6,
73.1,
95.7,
5.5,
53.4,
68.3,
49,
29.3,
66.8,
2.9,
68.9,
31.3,
56.5,
27.7,
91.9,
54,
63.7,
49,
35.3,
64.9,
67,
77,
83.6,
35.9,
37.8,
37.3,
9.7,
15.2,
24.2,
44.3,
85.1,
84.3,
72.9,
75.2,
44.9,
61.6,
1.7,
56.8,
65.6,
40.8,
44.3,
63.2,
75,
87.5,
12,
47.3,
83.5,
20.9,
33.7,
56.2,
68,
37.4,
78.5,
82.1,
87.4,
64.1,
52.6,
88.3,
32.5,
72.6,
0,
100,
86.3,
93.7,
23,
72.7,
47,
75.3,
18.1,
79.6,
61.2,
79.5,
45.7,
58.9,
75.2,
98.8,
38,
56.8,
45.2,
69.8,
44.6,
61.3,
61.2,
27.2,
56.1,
40.4,
53.7,
35.7,
87.9,
32.3,
48.3,
33.9,
98.7,
85.2,
61.4,
46.6,
29,
85.3,
76.7,
56.6,
49,
67.2,
60.4,
69,
82.3,
33.2,
8.7,
40.7,
89.1,
7.1,
74.9,
69.4,
19.9,
43.3,
78.7,
49.9,
58.5,
79.8,
72.2,
42.3,
32.9,
71.4,
56.4,
26.9,
88.1,
30.3,
68.2,
96.4,
44.7,
94.5,
70.9,
80.8,
46.4,
7.6,
70.7,
59.9,
14.1,
80.4,
28.4,
31.6,
36.7,
47.7,
31,
62.2,
59.3,
57.1,
96.3,
73.1,
22.3,
10.8,
75.5,
33.9,
41.3,
75.3,
17,
21.7,
77.8,
48.2,
86.1,
15.2,
26.5,
43,
47.9,
6.8,
19,
59.5,
55.5,
86.2,
77.7,
25.7,
47.6,
54,
50.1,
69.3,
80,
57.7,
42.3,
15.9,
61.2,
43.3,
49.1,
58.4,
39.4,
80.4,
37.9,
77.4,
8.6,
24,
76.4,
32.2,
45,
23.3,
10.5,
75.2,
53.2,
59.8,
78.9,
23.7,
45.5,
28.3,
25,
4.5,
51.9,
42.9,
96.6,
82,
12,
60.9,
38.9,
1.7,
20.6,
82,
42.7,
71.8,
66.4,
26.4,
76.2,
53.3,
6,
89.3,
54.5,
2.9,
98.5,
50,
46,
26.8,
69.9,
26.3,
36.4,
27.7,
19.9,
90.3,
38,
11.3,
62.1,
64.7,
73.6,
37.1,
75,
59,
27.3,
25,
60.6,
63.8,
25.5,
80,
74.7,
63.2,
89.4,
75.3,
29.9,
60.4,
78.3,
98.2,
43.1,
59.4,
24.4,
74.5,
25,
57.1,
63.6,
12.8,
32,
85.3,
39.8,
25.7,
56.8,
68.8,
71.5,
97.6,
37.6,
53.5,
28.4,
89.2,
90.1,
9.3,
43,
40.7,
57.8,
27.8,
32.1,
14.3,
39.2,
91.2,
26.6,
78.7,
96.1,
33.5,
41.1,
100.9,
81.7,
43.1,
77.2,
38.8,
21.2,
6.1,
17.4,
3.6,
31,
32.5,
73.4,
19.4,
82.2,
92.4,
83.3,
35.3,
63.3,
90.1,
22.1,
81.2,
13.6,
43.5,
26.1,
10.3,
72.6,
13.6,
23.4,
66.7,
45.3,
99,
97.6,
23.5,
62.9,
41.6,
97.5,
11.1,
82.5,
93.1,
12.3,
65.7,
41.5,
61.9,
77.6,
17.2,
27,
78.2,
61.3,
41.8,
89.3,
39,
97.9,
5.7,
92,
34.6,
14.3,
52.8,
93.7,
70.5,
82.4,
13.8,
42.3,
59.4,
75.7,
16.3,
67.2,
19.7,
34.9,
43.2,
77,
65,
37,
77.1,
66.9,
84,
74,
90.3,
27.1,
46.7,
46,
63.4,
18,
89.3,
45.4,
75.3,
74.1,
61.2,
96.7,
70.6,
62.4,
84.3,
49.4,
90.1,
68.7,
89.7,
58.6,
86.4,
77,
69.4,
57.1,
62,
57.4,
52.6,
96.6,
88.7,
31.7,
31.1,
96.6,
50,
72.1,
34.1,
58,
28.5,
82.7,
97.5,
78.5,
42,
44,
42.3,
7,
47.6,
49.6,
31.3,
30,
85.4,
82,
73.5,
90.7,
66.7,
91.2,
75.1,
46.2,
55.9,
57.4,
43.1,
33.3,
24.9,
48.8,
62,
49.4,
36.4,
42.6,
56,
29.7,
53.5,
0,
74.8,
63.5,
39.1,
70.5,
28.7,
50,
9.8,
87.2,
59.7,
62,
63.1,
68.7,
64.9,
30.3,
95.5,
28.7,
95.6,
48.4,
72.8,
88,
50,
25.8,
15.9,
46.1,
66.7,
81.6,
39.6,
82.6,
48.2,
62.8,
89,
0,
84.7,
64.9,
65.2,
18,
86.5,
33.7,
81.8,
67.1,
65.9,
4.1,
88.2,
52.3,
1.1,
45.1,
44.1,
78.7,
27.4,
86.1,
84.2,
70,
41.1,
53.7,
26.6,
19.8,
56.4,
57.6,
6.5,
76.4,
91.1,
84,
87.6,
82.1,
62,
84.4,
55.7,
42.4,
44.1,
78.9,
39,
65.5,
34.3,
59.5,
38.2,
70,
88.9,
83.7,
62.6,
71.4,
49,
24.6,
42.4,
41.6,
74.9,
62,
49.8,
80.2,
69.8,
86.4,
16.1,
30,
64.5,
78.7,
34.6,
68.9,
56.3,
38.6,
74.2,
90.1,
93.6,
56.4,
24.9,
41,
31.5,
34.6,
54.1,
70.5,
56.7,
63.5,
78.1,
25.5,
16.7,
51.3,
43.5,
49.7,
97.8,
42.6,
29.6,
49.6,
41.4,
95.1,
92.2,
59.4,
83.7,
31.7,
26.9,
89.2,
64.5,
33.2,
57.1,
2.3,
69.6,
94.6,
95.4,
51.6,
15.8,
57,
74.7,
92.7,
47.9,
31.1,
96.3,
29.3,
76.8,
41.7,
16.2,
55.3,
78.4,
36.1,
69.5,
82.2,
59.4,
63.4,
41.9,
79.7,
53,
12.8,
46.4,
100.4,
59.4,
98.7,
78.2,
89.5,
50,
47.8,
81.3,
77.3,
81.9,
71.2,
86.3,
83,
41,
70.3,
50.1,
77.5,
49.8,
69.9,
23.2,
70.8,
63.8,
65.9,
75.5,
59.4,
54,
53.5,
83.9,
1.3,
71.7,
12,
33.4,
19.6,
37.9,
59.5,
40.2,
78.7,
89.9,
60.2,
77.7,
48.4,
75.4,
72,
49.1,
63,
48.8,
31.8,
55.8,
1.8,
85.1,
33,
67.7,
97.5,
66.5,
21.5,
49.7,
59.7,
42.1,
35.9,
29.1,
51.5,
73.8,
33.2,
37.6,
60.2,
48.1,
30.4,
84.1,
63.7,
46.5,
34.2,
80.7,
4.6,
45.2,
93.3,
48,
53.6,
42.6,
53.4,
83.3,
49.3,
74.9,
60.6,
21.2,
28.4,
28.8,
76.5,
90.9,
81,
39.9,
37.4,
60.7,
86.7,
27.1,
59,
43.2,
95.1,
45.3,
31.7,
80.6,
27.8,
85.2,
102.8,
36.5,
31.7,
43,
52.6,
26.5,
6.3,
60.7,
75,
51.4,
52.9,
31.2,
74.2,
88.7,
14.5,
80.8,
79.2,
45,
57.1,
41.1,
45.5,
25.2,
73.9,
76,
93.9,
4.3,
0,
80.7,
55.3,
98,
53,
75.9,
44.3,
53.3,
61.4,
24.8,
67.8,
52.7,
63.4,
69.1,
13.9,
4,
23.7,
0,
29.8,
24.9,
42,
61,
6.3,
66.5,
21,
40,
10.5,
76.6,
38.9,
41.6,
36.8,
42.6,
61.6,
37.5,
66.7,
45.2,
67.9,
37.2,
62,
54.9,
30.1,
51,
0,
3.7,
52.4,
66.1,
54.3,
71,
58.4,
53.8,
62,
32.3,
37.3,
0.5,
71.5,
77.4,
78.3,
47.5,
50.1,
48.9,
57.9,
48.6,
8.8,
48.4,
72.2,
35.2,
97,
54.7,
42.6,
55,
98.4,
84.4,
68.7,
48,
97.3,
27,
54.4,
100.2,
28.8,
42.5,
5.8,
10.7,
58.5,
31.1,
39.1,
32.7,
26.3,
73,
88.1,
73.3,
86.4,
36,
55.2,
26.5,
75.2,
78.6,
65.9,
88.7,
60.7,
80,
38.4,
46.6,
28.8,
28.4,
80.2,
84.3,
61,
65,
98.4,
94.8,
76.4,
48.7,
80,
47.4,
29.9,
54.4,
55.6,
53.7,
45.3,
88.8,
64.8,
32.9,
100,
29,
48.5,
77.8,
58.2,
85.5,
18.9,
57.2,
54,
26,
39.6,
65.6,
14.1,
71.7,
67.4,
59.4,
71.5,
40.7,
68.3,
85.4,
36.5,
32.1,
51,
50.4,
92.7,
43.6,
30.7,
70.6,
64.7,
28.9,
36.4,
20.4,
17.3,
98.2,
69.1,
99.9,
50.3,
79.4,
22.4,
11.6,
69,
90,
57.4,
77.8,
55.9,
43.6,
45.2,
77.1,
50.9,
50.8,
0,
14.2,
90,
71.9,
52.7,
50.4,
25.2,
35.7,
76.1,
37.8,
28.3,
58,
72.9,
56.6,
50.4,
94.3,
80.6,
97.7,
68.1,
53.8,
72,
1.5,
64.3,
37.1,
13,
92.9,
41.7,
95.8,
94.4,
97.7,
84.5,
50.8,
49.3,
31.9,
69.7,
75.8,
72.3,
23.6,
0.12,
92.2,
82.3,
68.3,
78.5,
41.6,
67,
51.1,
11.4,
61.7,
68,
26.6,
95.3,
78,
59.2,
45.5,
23.5,
90.8,
38.9,
42.4,
35.6,
40.3,
67.6,
26.2,
41.4,
74,
28.8,
49.2,
23.1,
87.8,
68.4,
35.2,
83.6,
75.4,
54.3,
56.4,
59.9,
30.5,
36.7,
33.2,
12.9,
89.3,
19.2,
33.3,
62,
44.8,
71.4,
83.5,
42.5,
91.9,
23.1,
8,
62.5,
48.8,
52.5,
72.1,
90.2,
45.8,
53,
76.5,
64.1,
39.5,
35.9,
28.5,
58.3,
null,
53,
79.7,
119.8,
67.4,
54.9,
67.3,
63,
66.7,
67.2,
33.3,
43.5,
66,
93.7,
68,
85.5,
59.3,
54.2,
53.7,
94.5,
61.6,
25.8,
92.7,
49,
59.2,
96.9,
54.1,
95.9,
88.6,
65.8,
32.2,
3.2,
66.5,
65.1,
86.4,
100.5,
60.3,
70.4,
61.5,
34.1,
78,
80.3,
69.8,
94.1,
11.3,
23,
100.8,
45.4,
72,
80.4,
5,
66.1,
53.5,
25.9,
58,
40.6,
89.6,
66.1,
54.3,
39,
94.8,
78.3,
59.8,
98.7,
47.4,
59,
43.7,
63.9,
48.6,
26.2,
57.7,
53,
77.7,
63.3,
44.7,
3.9,
59.1,
85.9,
50.7,
23.4,
62.5,
46.2,
78.9,
61.4,
40.4,
73.1,
25.5,
38.8,
93.3,
43.6,
99.8,
41.2,
84.7,
53.7,
64.1,
100.9,
51.9,
1.8,
43.4,
45.5,
33.6,
19.9,
63.6,
97.3,
53.5,
59.5,
23.9,
45.9,
67.5,
40.3,
49.3,
0.8,
62.5,
34.7,
25.7,
51.4,
54.8,
48.5,
36.5,
67.9,
83.1,
98.9,
74.5,
57.9,
22.7,
98.4,
61.6,
43,
36.8,
66.7,
25.9,
48,
29.1,
10.4,
86,
50.8,
27.6,
68.1,
55,
52.2,
26.4,
73.3,
92.5,
23,
11.4,
49.4,
36.3,
63.3,
64.9,
38.8,
67.3,
26.1,
33.7,
30.6,
66.2,
97.3,
33,
69.1,
23.1,
41.1,
76.5,
81,
82.2,
57,
33.1,
48.8,
72.6,
26.6,
54.3,
53.1,
31.2,
9,
48.5,
24.6,
28.6,
68.3,
52.6,
29.5,
51.6,
45.2,
64.9,
35.1,
66.6,
42,
49,
42,
85.1,
100,
63,
91,
67.3,
0,
60.2,
46,
20.9,
31,
48.5,
96.6,
52.6,
86.3,
58.4,
14.5,
54.1,
84.2,
49.9,
60.9,
58.4,
8.1,
68.9,
37.4,
7.7,
41.1,
81.5,
10.4,
52.4,
90.8,
58.6,
50.4,
44.3,
87.1,
81,
87.1,
58.7,
47.1,
65.6,
36.2,
79.4,
50.4,
43,
68.5,
40.3,
40.6,
91.8,
70.9,
45.3,
22.2,
7.8,
24.7,
95.6,
25.9,
44.4,
71.4,
50.1,
70.8,
65.8,
48.7,
69.1,
25.9,
69,
36.8,
69.3,
27.4,
44.5,
75.5,
54,
31.3,
43.4,
70.5,
56.1,
55.5,
29.2,
75.2,
7.4,
20.6,
48.2,
15.1,
0.3,
32.4,
17.7,
40.9,
12.2,
54.1,
89.8,
48.7,
81,
46.3,
77.5,
61.6,
60.9,
82.3,
46.3,
35.9,
92.8,
56.8,
33,
45.4,
64.9,
24.6,
72.7,
77.2,
42.6,
7,
49.9,
74.5,
54.2,
49,
58.7,
34.8,
65.5,
72.9,
22.2,
77.2,
91.3,
10.1,
19,
44.2,
88.1,
79.9,
37.4,
79.9,
62.1,
87.7,
10.3,
60.7,
30.4,
40.2,
77.4,
17.8,
68.6,
53.1,
40.5,
42.9,
54,
9.2,
43.3,
5.2,
42.1,
81.1,
97.2,
69.1,
89,
62.6,
80.1,
63,
61.7,
69.2,
59.7,
70.2,
27.9,
80.9,
49,
54.1,
26.4,
16.2,
34.4,
63.7,
41.6,
68.1,
83.2,
61.2,
47.4,
72.6,
86.7,
24,
5.2,
21.1,
88.8,
7.9,
59,
70.2,
59.1,
86.8,
64,
50.7,
57.9,
70.4,
67,
56.9,
79.3,
30.3,
83.3,
26.4,
37.3,
79.3,
37.2,
41.5,
60.4,
88.3,
66.2,
89.3,
23.4,
48.5,
82.6,
94.1,
20.6,
83.3,
41.8,
41.5,
25.8,
53.9,
50,
60.3,
38.1,
19.3,
16,
36,
45.3,
98,
66.4,
83.5,
18,
81.3,
62,
51.3,
54.9,
41.9,
76.2,
33.8,
47.9,
26.6,
34.8,
28.1,
87.4,
27.6,
25.1,
46.7,
62.6,
37.8,
90.3,
68.4,
88.2,
61.6,
22.5,
61.1,
83.4,
71.1,
73.7,
52,
55.1,
49,
31,
87.4,
72,
47.5,
54.3,
19.6,
82.6,
50.9,
44,
51.9,
34.3,
69.5,
65.9,
71.4,
50.7,
56,
15.4,
95,
69.8,
62.7,
61.1,
78.8,
90.9,
84.3,
71,
47.9,
59.2,
40.4,
54.4,
71.7,
14.4,
76.3,
90.5,
70.5,
77,
101.5,
46.4,
16.6,
78.1,
61.1,
80.2,
57.1,
12.7,
59.6,
69.7,
54.1,
27.1,
32.1,
62.5,
71.4,
91.2,
45.3,
34.7,
45,
76.6,
30.9,
29.9,
66.2,
51.1,
68.3,
53.9,
38.4,
66.5,
51.7,
55.7,
56,
63.1,
26.1,
95.3,
96.3,
80.3,
35.1,
71.3,
61.4,
88.7,
38.9,
71.9,
66.4,
52.1,
53,
89,
86.9,
27.7,
83.3,
44.6,
71.1,
94.6,
22.6,
53.8,
43.5,
8.4,
32.9,
57.3,
40.8,
11.9,
93.7,
71,
20.7,
29.5,
58.8,
64,
76,
58.1,
91,
41.7,
42.6,
69.7,
85.8,
43.9,
62.6,
65.5,
38.5,
37.1,
65.9,
68.7,
35.3,
90.6,
49.4,
23.4,
31.1,
77.4,
30.4,
58.6,
68.5,
71.3,
85.8,
41.4,
67,
76.6,
53,
6,
71.8,
58,
78.5,
49.6,
58.5,
55.8,
17.1,
59.7,
45.9,
77.2,
32.9,
76.5,
21.8,
45.2,
54.7,
88.3,
84.7,
52.4,
38.3,
8.2,
82.3,
32.7,
46.9,
7.1,
51.6,
52,
61.2,
43.4,
42.4,
78.6,
81.8,
52.7,
67.3,
84.9,
73.1,
59.1,
35.1,
55,
14.5,
8.7,
56.3,
85,
71.6,
57.7,
49.7,
68,
65.8,
66.7,
93,
66.1,
84.7,
71.9,
85.5,
37.1,
49.2,
89.4,
65.7,
85.7,
40,
73.6,
42.5,
93.8,
50.4,
72.2,
25.4,
77.1,
57.1,
61.2,
28.3,
53,
46.9,
56.6,
50.9,
86.8,
72.6,
49.6,
79,
4.3,
56.4,
97,
62.5,
2.8,
35.7,
8.6,
52.1,
55,
77,
39.8,
30.8,
86,
37.8,
44.1,
36.1,
71.4,
44.5,
27.6,
22,
85.4,
85.8,
66,
89.1,
97.7,
50.8,
23.8,
72.5,
45.7,
76.3,
56.7,
76.8,
68,
75.9,
35.1,
33.6,
76.2,
66.8,
46.3,
65.1,
92.1,
38.8,
8.1,
73.5,
91.5,
40.3,
70.4,
68.3,
79.4,
25.6,
59.4,
32.4,
53.4,
61,
63.1,
25.5,
18.4,
78.7,
72.1,
27.3,
34.4,
56.6,
62.5,
74.8,
54.6,
71.8,
53.9,
62.1,
32.6,
52.7,
84.9,
22.4,
31.6,
26.8,
38.7,
72.4,
96.5,
37.5,
43.9,
0,
95.5,
48,
26,
32.2,
49.5,
37.9,
28.5,
89,
85.1,
37.1,
89.8,
64.5,
51.3,
55.7,
27.6,
29.9,
2.5,
62.1,
62.2,
83.9,
96.4,
15.7,
94,
56.4,
55.4,
56.6,
55.5,
48,
56.2,
43,
58,
50.8,
42.2,
50.5,
71.4,
56.6,
21.4,
66,
38.6,
44,
79,
56.6,
21.8,
60.6,
56.1,
24.3,
65.7,
54.3,
60.8,
58.7,
64,
7.5,
35,
20.1,
64.9,
56.8,
81.1,
3.4,
32.2,
8.6,
47.7,
70,
21,
7.6,
90.5,
78.1,
69,
39.2,
5.3,
47.5,
50.2,
18.6,
21.3,
21.3,
77.8,
66.2,
9.3,
48.8,
66,
31,
46.3,
98.1,
60.5,
53,
57.5,
14.9,
31,
71.5,
77.5,
22.4,
82.3,
28.8,
56.1,
65.6,
35.5,
74.7,
18.7,
29,
15,
50.5,
81,
42.9,
55.5,
48.2,
90.9,
77.4,
44.4,
19.5,
72.9,
42.2,
47.6,
45,
69.4,
84,
43.5,
92.4,
60.4,
44.6,
27.3,
35.9,
60.8,
87.8,
82.4,
77,
85,
46,
87.4,
66.4,
89.9,
47.6,
51.2,
78.4,
41.1,
59.4,
63,
35.7,
66.4,
96.5,
36,
74.4,
78.2,
67.1,
77,
27.7,
46.5,
45,
69.7,
67,
75.1,
49.7,
58.3,
45.4,
54.7,
28.8,
59.2,
66,
70.6,
51.1,
65.2,
86.7,
35.2,
75.8,
89.1,
52.3,
84.4,
9.3,
44.3,
31.4,
60.8,
65.1,
47.8,
64.5,
27.6,
74.1,
90.5,
35.7,
58.4,
31.1,
67.5,
30.2,
77.9,
49.9,
27.5,
36.1,
78,
10.6,
42.9,
30.8,
8.4,
34.3,
50.3,
59.3,
76.4,
46.9,
38.9,
84.8,
11.5,
60,
0.3,
53,
54.8,
57.8,
69.5,
69.1,
94.2,
32.7,
11.8,
77.9,
1,
61.7,
52.6,
59.2,
22.2,
95.7,
66.6,
73,
71.6,
71.3,
38.2,
11,
67.1,
66.7,
50,
90.4,
57.6,
58.7,
70,
42.6,
26.4,
61.2,
56.3,
95.8,
53.9,
12.8,
55.9,
16.3,
93.7,
74.9,
65,
12.2,
96.4,
59.4,
63.3,
59.7,
87.5,
88,
81.8,
72.6,
58.7,
61,
71.6,
16.5,
45.8,
67.8,
36,
81.7,
38.6,
75.9,
61.5,
5.3,
21.1,
8.3,
47.8,
90.9,
55.2,
66.2,
78.9,
56.4,
51.3,
52.2,
44.1,
86.8,
76.8,
41.3,
63.9,
53.8,
59.7,
13.4,
40,
69.5,
71.4,
92.5,
68.9,
64,
97.4,
76,
78.4,
62.3,
68.4,
10.6,
58.8,
66.6,
14.1,
46.2,
62.2,
51.3,
63,
88.7,
98.4,
58,
65.2,
40.1,
69,
43.5,
54.4,
26.4,
100,
5.8,
56.3,
36.5,
90.1,
30.5,
87.6,
67.4,
71.7,
66.2,
56.5,
72.5,
53.1,
32.7,
19.2,
90.7,
68.4,
68.2,
94.1,
30.3,
32.5,
90,
40.3,
86.4,
43.5,
41.4,
64,
46,
48.9,
32,
33.6,
67.6,
13.8,
81.3,
62.6,
60.3,
60.8,
25.1,
92.4,
83.1,
26.5,
37.4,
50.2,
73.6,
71.2,
50.3,
44,
49.5,
89.1,
67.2,
99.7,
59.8,
56.9,
50.6,
79.6,
96.3,
32.5,
85,
38.5,
54.5,
67.4,
22.7,
92.6,
80.8,
45.1,
86.2,
20.2,
49.7,
78.1,
72.3,
6.1,
37.6,
53.5,
34.7,
87.2,
77.9,
64.8,
80.5,
48.5,
31,
71.9,
73.3,
66.5,
58.9,
28.1,
74,
17.5,
16.4,
44.6,
81.3,
47.9,
68.9,
89.8,
57.9,
55.2,
48.4,
47.1,
71.4,
66.9,
44.2,
8.2,
12,
52.8,
43.3,
55.8,
59,
43.2,
58.5,
56.4,
65.7,
24.6,
65,
67.8,
19.7,
50.4,
0.7,
71.5,
76.2,
46.3,
50,
86.3,
55.4,
80.7,
56.6,
25,
16.6,
18.9,
53.4,
2.5,
90.1,
51.3,
90.4,
80.4,
12.2,
39.6,
14.6,
8,
99.4,
95.2,
73.7,
25.5,
57.9,
36.6,
25.7,
80.9,
58,
67.1,
49.3,
86.3,
79.6,
48.1,
37.7,
59.4,
71,
30.5,
2.5,
54.6,
34.7,
81.8,
95.2,
78.3,
62.5,
64.2,
62.4,
86.4,
81.7,
34.5,
5.1,
56.7,
55.2,
67.5,
14.5,
96.8,
18.4,
68.2,
57.7,
83.2,
87,
67.5,
93.6,
18,
37.7,
45.8,
97.6,
99.5,
80.6,
34,
63.5,
60,
45.1,
57,
29,
91.6,
87,
82.5,
42.3,
12,
93.5,
58.6,
66.6,
17,
48,
77.4,
56.2,
24.3,
66.3,
83.2,
53.7,
42.4,
92.4,
97.7,
7.9,
91.9,
9.2,
42.5,
0,
78.3,
2,
40.4,
29.4,
28.8,
75.1,
7.3,
64.6,
53.4,
70.5,
38.6,
43.8,
84.2,
71.4,
80,
47.3,
53.8,
72.8,
51.8,
86.6,
57.2,
50.3,
39.4,
55.6,
27.4,
55.8,
15.4,
62.6,
74.5,
43.1,
50,
55.5,
56.8,
65.1,
68.9,
8,
17.4,
60.9,
84.8,
63.3,
91.4,
52,
71.6,
71,
42.8,
57.4,
38.2,
49,
63,
100.6,
26.7,
33.2,
83.8,
27.9,
73,
72.9,
90.1,
29.9,
60.1,
37.9,
92.1,
30.8,
5.8,
73,
49.4,
81.3,
33.2,
75.6,
75,
73.4,
40,
36.5,
74.3,
68.6,
45.5,
63,
48.5,
75.6,
71.9,
47.8,
0,
12,
38.7,
31.7,
82.4,
58.1,
59,
56.6,
82.9,
16,
0.5,
60.6,
73.1,
4.6,
48.2,
28.8,
85.1,
70,
47.2,
82.9,
87.7,
71.4,
7.4,
38,
57.9,
39.6,
78,
44.4,
60.5,
51.9,
43.2,
72.3,
30.8,
35,
75.6,
66.9,
49,
65,
48.8,
44.6,
81.9,
78.3,
66.1,
86.6,
68.1,
74.6,
30.4,
12,
78.3,
67.9,
48.8,
40.5,
69.3,
69.9,
57.6,
5.7,
92.9,
66.4,
31.9,
65,
78.6,
57,
86.3,
81.3,
69,
33,
89.5,
29,
41.5,
72.6,
49.9,
41.3,
80.7,
48.8,
29.9,
94,
58,
55.9,
82,
2,
83.1,
56.5,
40.2,
55,
40.2,
61.4,
68.1,
74.4,
20.8,
12.4,
74.5,
71.7,
37.9,
86.2,
7.7,
3,
24.4,
42,
21.3,
73.6,
29,
71.6,
58.7,
38.7,
50.5,
69.5,
51.1,
43.5,
77.7,
67,
14.8,
90.9,
30.7,
37.9,
41.8,
75.2,
27,
38,
64.2,
39.6,
82.4,
39.5,
92.9,
20.3,
20.2,
28.3,
49.2,
60.9,
43.3,
60.9,
76.6,
32.1,
55,
53.3,
83.9,
23.9,
88.7,
58.7,
88.4,
47.4,
63.6,
65.2,
71.1,
61.9,
72.2,
60.6,
94.9,
19.9,
18,
41,
85.5,
30.8,
36.3,
42.7,
67.4,
78.6,
59.9,
56.8,
76.5,
74.6,
33,
37.7,
68.2,
23.1,
76.4,
6.6,
86.2,
28.3,
53.1,
37.3,
88.5,
83.2,
39,
78.3,
57.8,
89.7,
53,
84.7,
9.7,
31.1,
30.8,
71.5,
36.9,
91.1,
54.5,
78.9,
20.2,
69,
50.2,
48.3,
21.5,
60.5,
78.8,
14.1,
67.6,
48.8,
57,
61.3,
38.5,
65.4,
68.3,
0.1,
29.4,
57,
40.6,
67.9,
70,
57.8,
76,
63.2,
60.4,
51.8,
90.1,
54,
40.1,
78.7,
38.6,
34.3,
76.3,
84.5,
57.1,
55.8,
15.1,
55.3,
59.5,
44.9,
33.1,
61.8,
12.7,
74.1,
54.8,
61.2,
98,
45.3,
44.7,
39.3,
18.3,
79.4,
30.2,
42.7,
71.1,
47.6,
86.9,
68.3,
68.2,
52,
72,
64,
66.6,
14.2,
11.6,
37.4,
69.6,
67.3,
64,
96.9,
77.3,
60.1,
31.8,
57.2,
67.6,
27.4,
88.2,
62,
40.9,
98.3,
87,
72.6,
45.6,
60.8,
74.8,
44.5,
40.5,
51.2,
64.8,
83.6,
62.5,
43.2,
60.8,
2.8,
51.5,
61.9,
45,
65.1,
2,
52.7,
78.6,
13.3,
82.7,
65.3,
70.5,
82.4,
51.9,
90.8,
50.7,
74.3,
91.8,
61.1,
51.6,
90.9,
42.4,
81.7,
52.4,
88.1,
55.1,
70,
50.6,
71.1,
37.1,
63.1,
90.5,
40,
45.2,
29.5,
25,
41.5,
35.8,
25.5,
8.8,
0.6,
53.4,
46.2,
58.3,
59.6,
44,
80.7,
53.2,
82.7,
35,
63.3,
59.6,
52.1,
69.7,
70.6,
80.5,
41.5,
49.5,
43.2,
86.3,
69.7,
71.4,
50.2,
28.7,
66.5,
62.7,
38.2,
28.7,
49.5,
55.7,
12.3,
30.5,
89.7,
23.7,
95.2,
93.1,
26.1,
9.5,
36.1,
51.2,
84.2,
63.1,
92.2,
34.9,
56.7,
30.7,
93,
71,
89.4,
30.2,
85.8,
32.2,
56.1,
91.9,
32.7,
19.5,
64,
11.7,
90.2,
75.5,
20.2,
44,
58.2,
78.5,
43.4,
64.9,
71.3,
56.4,
41.7,
36.8,
91.1,
43.6,
61,
37,
39.7,
93.2,
26.4,
25,
25.2,
3.6,
32.7,
30.1,
31.2,
59,
43.2,
41.3,
52.5,
93.1,
59.8,
48.7,
46.1,
71.8,
53.7,
71.2,
106.5,
71.9,
87.9,
42.3,
62.1,
62.5,
73,
76,
96,
10.8,
97.4,
31.3,
50.7,
69.4,
59.8,
72.1,
61,
95.1,
22.2,
53.8,
80.1,
22.5,
93.3,
54,
66.4,
32.3,
90.9,
19.1,
50.7,
50.8,
10.4,
73.4,
12.8,
77.5,
20.4,
79,
53.4,
1.5,
17.5,
72.9,
35.8,
60.9,
64,
67.9,
74.4,
98.6,
40.7,
43,
78.4,
31.1,
44.5,
51.1,
64.8,
49.8,
49.5,
86.1,
11.3,
72.6,
21.9,
44.7,
49,
4.85,
52.1,
84.8,
35,
63.1,
43.8,
80.8,
41.4,
58.4,
41.7,
92.5,
49.7,
38.9,
36.9,
66.2,
19.6,
64.3,
39.6,
85.4,
41.5,
70.5,
92.2,
83.8,
65.4,
95.9,
66.2,
76.6,
84.5,
46.2,
80.9,
30.3,
74.4,
12,
52.5,
7.1,
67.9,
78.5,
59.5,
81.7,
36.2,
41.8,
79.8,
85.7,
88.7,
47,
21.4,
88.1,
40,
81.4,
89.3,
47.7,
76.4,
60.5,
78.9,
65.9,
56.6,
48.2,
91.3,
58.1,
83.8,
0.4,
70.6,
58.5,
51.7,
77.8,
92.5,
73.3,
77.5,
38.3,
63.5,
60.3,
9.4,
69.9,
41,
76.5,
13.4,
73.4,
70.3,
98.6,
21.1,
35.7,
65.7,
72.8,
55.3,
28.5,
70.6,
57.3,
77,
61.2,
19.3,
13.4,
21.6,
88.9,
63.6,
66.7,
25.9,
28.8,
30,
69.8,
83.9,
44.9,
70.7,
48.6,
66,
22,
46.6,
40.8,
35.1,
31.6,
84.9,
25.7,
52.2,
12,
32.8,
25.8,
66.9,
84.9,
57.8,
86.2,
85.3,
72.8,
72.8,
88.8,
55.4,
71.5,
68.3,
42,
53.9,
41,
59.9,
68.1,
81,
43.8,
7.6,
31.4,
36.4,
58.3,
24,
76.8,
54.6,
69.8,
80.8,
89.7,
13,
53.5,
7.1,
72.3,
56,
63,
4,
40.7,
43.4,
73.7,
76.3,
65.8,
93,
24.5,
70.3,
1,
58.9,
58.7,
67.4,
98.1,
93.2,
69.4,
97.7,
20.6,
59.7,
40.3,
20.7,
84,
44.6,
29.5,
43.9,
33,
79.3,
50.9,
72,
24.8,
50.7,
50.6,
83.6,
54.9,
60.2,
83.3,
68.2,
47.3,
19.9,
27.4,
70.3,
69.1,
99,
26.7,
49.1,
72.7,
63.4,
52.8,
54.3,
62.2,
54.5,
81.3,
55.3,
97.8,
21.8,
72.9,
40.5,
63.6,
68.4,
40.4,
100,
56.5,
75.5,
84.7,
81.5,
61.6,
47.8,
53.5,
28,
50.7,
70.6,
65.1,
52.8,
25.2,
26.7,
39.5,
59.1,
49.4,
60.2,
89.1,
48.1,
43,
88.7,
55.7,
53.7,
43.3,
91.6,
20.1,
96,
69.7,
53.7,
88.5,
74.6,
30,
58.7,
26.7,
85.2,
43.4,
24.9,
43.1,
98,
67.4,
79,
67.4,
null,
31,
72.8,
56,
28.4,
98.8,
74.3,
24.4,
68.7,
9.5,
25.8,
54.4,
79.7,
80.6,
26.6,
20.2,
0,
87.4,
60.7,
57.5,
53.3,
10.2,
48.2,
66.1,
31.3,
52.7,
56.5,
100.6,
84.8,
71.2,
94.6,
69.1,
64.6,
48,
0.9,
43.7,
75.4,
98.4,
27,
59.3,
32.7,
64.9,
77.5,
27.4,
47.1,
73,
1.5,
46.2,
63.8,
35.8,
16.6,
85.1,
84.1,
74.4,
80.9,
64,
63.5,
50.6,
60.1,
69,
61,
43,
92,
41.3,
30.4,
67.2,
9.1,
35.8,
37.4,
74.5,
74.1,
16.6,
48.6,
45.2,
64.4,
59.6,
68.6,
39.4,
12.2,
21.6,
38.3,
49.8,
77.7,
50.1,
37.5,
54,
98.1,
24.5,
4.7,
64.8,
34.2,
44.4,
87,
77.6,
58.4,
77.5,
63.8,
77.5,
48.9,
86.2,
45.7,
40.4,
57,
67.2,
29.8,
78.1,
74.2,
70.6,
50.3,
72.6,
29.6,
56.6,
70.2,
91,
21.7,
98.4,
25.4,
94.4,
64.3,
72.9,
36.6,
59.5,
40,
56.8,
96.3,
60.2,
47.6,
59.4,
88.4,
16.2,
68.8,
9.3,
43.8,
64.5,
51.8,
47.4,
81.1,
91.8,
93.6,
53.7,
89.8,
21.1,
43.1,
66.8,
84.4,
98,
62.6,
52.9,
97.9,
35.9,
74,
38.1,
19.2,
42.5,
59.2,
21.7,
47.9,
33.8,
62.4,
46.9,
50.6,
57.5,
40,
76.1,
57.5,
68.3,
44.1,
50.6,
83.3,
76.9,
75.9,
29.8,
92.9,
34,
76,
45.1,
88,
38.7,
78.3,
50.2,
33.5,
85.9,
87.5,
7,
31.5,
44.1,
38.2,
52.3,
32.8,
89.5,
26,
31.4,
41.6,
19.2,
55.5,
51.7,
49.3,
61.5,
19.6,
34.1,
18.7,
56.1,
37.8,
57.6,
47.5,
82,
63.6,
73,
38.5,
45.1,
78.8,
98.2,
18.4,
51.4,
9.7,
28.2,
33.6,
42.7,
85.2,
20.7,
80.4,
21.9,
38.6,
37.1,
20.4,
65.4,
56.2,
38.3,
57.5,
26.3,
17.5,
33.7,
78.4,
59.7,
51.7,
84.8,
32.5,
12.5,
92.2,
41.8,
75.8,
18.4,
67.8,
85.4,
48.4,
91,
79.8,
90.9,
55.5,
75.2,
51.2,
57.3,
76.3,
99.8,
48.4,
22.1,
44.1,
78,
28.2,
60.5,
57.6,
54.1,
6.5,
53.6,
48.2,
67.8,
71,
71.8,
22.2,
69.9,
91.8,
80,
33.1,
58.7,
78,
79,
39.5,
26,
70.1,
19.8,
63.3,
91.3,
55.1,
76.4,
53.2,
88.8,
56,
44.9,
67,
63.6,
52.7,
44.2,
36.3,
85,
49.4,
14,
72.6,
73.9,
3.9,
65.5,
63.6,
45.2,
40.3,
63.9,
31.3,
62.8,
8.9,
66.9,
86.7,
0,
63.4,
79.7,
17.7,
27.6,
98.6,
65.4,
29.4,
46.7,
56.3,
85.1,
69.7,
42.9,
89.7,
43.2,
85.5,
60.7,
72.4,
24,
63.3,
66.2,
71.8,
68.3,
9.4,
40.1,
60.7,
40,
76,
6,
89.4,
81.5,
56.2,
31.6,
68,
63.9,
73.9,
82.5,
69.7,
42.1,
78.6,
64.3,
32.6,
70.7,
63.5,
66.2,
47.1,
44,
34,
85.1,
78.8,
47.3,
41.9,
48.4,
24.5,
41,
74.4,
77.4,
74.5,
40.4,
72.5,
34,
64.7,
18.6,
50.5,
60,
43.5,
57.9,
30.3,
74,
32.2,
73.4,
51.8,
21,
29.8,
85.5,
46,
72.5,
70.2,
79.4,
43.4,
73.1,
45.8,
39.7,
34.1,
45.1,
61.5,
72.1,
85.6,
70.2,
24.2,
68.3,
50.1,
67,
60.8,
30.3,
20.9,
83.8,
16.3,
59.4,
48.4,
43.6,
48.5,
86.2,
83.6,
37.3,
101.9,
75.7,
100.3,
71.7,
72.7,
18.1,
36.8,
83.3,
43.2,
22.9,
91.3,
63,
69.6,
7,
61.9,
52.5,
95.3,
42.1,
65.5,
58.4,
59.4,
90.2,
30.1,
44.1,
12.1,
54.2,
62.4,
23.9,
84.6,
33.8,
47.2,
57.7,
9,
19.4,
84.7,
55.1,
53.2,
70.5,
62.2,
59.9,
65.6,
51.2,
40,
91.8,
49.5,
91.1,
101,
88.6,
33.4,
71.9,
14.8,
26.2,
75.3,
78.5,
57.4,
24.7,
64.5,
16.6,
89,
68.9,
48.6,
71.8,
54.5,
28.5,
41.2,
40.6,
52.7,
64,
19.4,
86.6,
54.2,
75,
87.5,
42.7,
78.8,
65.1,
76.2,
68.8,
24.4,
85.6,
28.1,
41.2,
41.3,
89.9,
72.8,
53.5,
35.2,
56.7,
66.2,
83.5,
68.7,
26.3,
67,
44.3,
75.1,
54.8,
30.9,
71.7,
85,
46.8,
47.7,
47.6,
75.1,
26.6,
75.1,
43,
43.9,
81.3,
44.9,
59.2,
75.6,
55.3,
32.2,
37,
48.1,
91.3,
69.5,
15,
2.9,
46.6,
53.1,
16.1,
91.2,
77.9,
51.8,
4.1,
27.4,
41.7,
50.1,
73.3,
43.1,
26.9,
29.4,
38,
53.3,
80,
57.3,
72.1,
77,
14.8,
36,
17.5,
40.8,
22.5,
75.7,
66.5,
6.2,
13.1,
43.7,
77,
16.7,
63.5,
26.6,
24.3,
84.7,
79.5,
61.8,
54.2,
85.2,
54.4,
58.5,
56,
95.9,
37.4,
44.9,
71.5,
49.9,
62.5,
80,
46,
39.9,
51.8,
44.1,
38.9,
98.1,
56.7,
41.9,
50.6,
45.8,
46.8,
69.4,
4.5,
16.3,
32.8,
59.1,
35.6,
35.8,
83.6,
15.1,
13.7,
12.4,
79.9,
33.1,
55.4,
24.6,
80.9,
76.5,
36.4,
92.1,
61,
81.8,
48,
78.1,
1.7,
25.5,
62.6,
63.8,
46.8,
41.8,
56.7,
21.6,
51.7,
94,
48.3,
66.3,
24.8,
65.7,
31.4,
95.4,
61.5,
14.9,
65.5,
17.7,
52.5,
36.9,
32,
41,
3,
89.4,
60.6,
82.7,
73.4,
21.2,
65.6,
56.8,
35.8,
50.5,
62.3,
65.9,
48.6,
39.5,
18.9,
45.3,
79.2,
46.4,
78.6,
3.5,
43.5,
79,
43.5,
44.2,
78.8,
83.3,
63.6,
57.4,
78.3,
45.6,
42.9,
37.7,
96.1,
61.4,
59.1,
16.3,
91.2,
64,
75,
25.6,
41.4,
68.5,
49.5,
68.4,
66.8,
67.2,
35.3,
60.9,
10.1,
35.2,
23.7,
47.8,
63.1,
84.7,
83.3,
61.2,
65.3,
46.1,
65.1,
89.9,
59.7,
33.8,
27.6,
5.7,
61.6,
74.3,
93.8,
72.2,
69.8,
74.8,
51.7,
66.6,
74.9,
64.3,
97.5,
45.8,
64.9,
80.7,
50,
33.5,
61.6,
45.5,
35.2,
47,
39.6,
33.8,
36.5,
55.8,
86.4,
69,
54.5,
66.8,
10.6,
21.9,
43.2,
64.8,
98,
90.6,
4.5,
29,
58,
40.3,
26.4,
66.6,
82.7,
92.2,
44.7,
21.5,
49.9,
47.5,
82.2,
36.8,
53.5,
42.1,
102,
89,
78.4,
94.9,
71,
72.3,
53.3,
87.1,
84.3,
80.6,
27.4,
52,
98,
0,
94.4,
30.1,
89.9,
39.9,
45.4,
52.5,
46.9,
14.2,
60,
62.6,
52.9,
24.6,
74,
20.7,
48.6,
76.6,
38,
90.4,
24.5,
46.5,
22.7,
47.8,
78.3,
57.6,
89.3,
22.1,
75,
40.9,
45.2,
58.5,
28.7,
40.7,
70.1,
72.9,
36,
58.9,
83.8,
83.9,
63.2,
67.8,
35.2,
74.3,
92.8,
88.8,
46.9,
58.3,
63,
60.5,
93.1,
54.6,
100.4,
63.8,
38,
26.7,
63.2,
89,
63.5,
86,
7.3,
77.8,
19.6,
25.3,
62.8,
58.5,
38.6,
8.2,
61.9,
78.1,
33.4,
30,
70.5,
0.3,
39.4,
79.8,
59.7,
34.7,
2.3,
48,
6,
85,
92,
58.5,
27.9,
96.3,
57.1,
27.6,
67.8,
98.3,
18.7,
84,
71.5,
76.2,
69.7,
62.6,
1,
72.8,
27.1,
51.2,
44,
40.9,
5.7,
91.5,
20.1,
88.3,
64.1,
60.4,
16.3,
100.4,
47.6,
54.7,
61.9,
84,
57.9,
76.1,
61.2,
67.3,
50.5,
98,
31.1,
51.1,
67.6,
75.8,
61,
40.9,
51.6,
54.2,
73.7,
92.8,
49.9,
75.3,
61.5,
21.6,
37.5,
89.9,
52.9,
68.9,
63.5,
60,
52.9,
65.5,
76.6,
86.8,
73.6,
53.7,
59.9,
67.6,
63,
41,
62.8,
71.7,
34.2,
2.5,
84.3,
31.7,
16,
57.8,
45.3,
59.7,
18.9,
46.7,
27.5,
64,
90,
23.3,
72.3,
2.4,
76.6,
91.7,
91,
21.5,
82.7,
49.1,
73.7,
76.2,
7.8,
33.5,
11.6,
70.9,
43.9,
47,
100.1,
37.5,
87.6,
78.6,
55.7,
28.2,
87.4,
87.8,
32.7,
89,
42.6,
30,
66.4,
84.1,
8.1,
56.1,
56.9,
7,
33.4,
0.3,
21.2,
36.3,
62.9,
16,
92.6,
71.6,
19.1,
71.7,
74.2,
42,
65.9,
39.3,
61.5,
43.9,
93.6,
47.7,
76.9,
45.6,
48,
48.8,
51.6,
77.5,
91.4,
77,
35.1,
38.5,
61.7,
64.3,
28.4,
53.1,
32.9,
43.7,
37.8,
28.7,
85.9,
81,
85.8,
59.4,
54.5,
35,
75.7,
91.3,
18.5,
65.7,
62.7,
33.2,
83.9,
88.5,
22,
90.2,
52.8,
51.7,
74.3,
7.4,
68.6,
91.9,
81,
71.8,
64.7,
35.1,
56.8,
0.5,
40.8,
67,
38.7,
61.4,
73.8,
85.5,
86.1,
78.1,
3.9,
84,
48.5,
63.8,
58,
94,
31.9,
79.4,
72.6,
0,
27.6,
49.2,
84.7,
69,
14.9,
43.5,
37.5,
59.7,
39.5,
72.1,
35.2,
95.4,
49.2,
75,
68.1,
57.2,
74.5,
52.9,
45.4,
25.3,
76.2,
91.7,
62.8,
92,
47.3,
34.7,
43.6,
31.6,
94.2,
56.8,
54,
25.2,
8.1,
23,
16.8,
62.6,
0.8,
54,
51.6,
30.3,
77.6,
72.7,
15.8,
81.6,
62.4,
39.2,
79.3,
28.2,
80,
42.3,
73.8,
33.6,
12.7,
61.2,
11.4,
75.5,
85,
95.8,
86,
100.8,
82.3,
54.9,
75.6,
38,
76.1,
49.4,
33.9,
53.4,
38.2,
24.4,
31.2,
39.8,
68.8,
85.6,
66.2,
86,
57.9,
90.7,
64.2,
22.4,
79.6,
22.4,
76.3,
47.9,
11.3,
62.7,
57.2,
31.7,
84.2,
35.4,
64.7,
78.9,
25.9,
70.8,
23.8,
62.9,
24.8,
37.6,
81.5,
28,
73.9,
71.5,
62.7,
92.1,
59.9,
68.2,
20.6,
69,
94.6,
9.2,
62,
52.2,
49.3,
33.9,
45.2,
65.8,
78.6,
11,
55.9,
94.8,
48.6,
61.9,
79,
67,
26.4,
54.4,
95.3,
29.5,
26.6,
85,
60,
33.2,
48.8,
62.6,
79.5,
53.5,
81.7,
10.5,
79.3,
98.6,
31.3,
37.2,
64.7,
54.8,
89.3,
31.1,
96.5,
63.1,
20.2,
60.3,
54.6,
53.8,
43.4,
11.6,
83.2,
77.4,
81,
112.9,
64.9,
70.9,
46.6,
27.6,
48.9,
63,
49.8,
56,
25.7,
48,
53.5,
67.8,
50.8,
58.9,
46.5,
51.5,
4,
45.7,
20.4,
92.9,
42.7,
42.5,
33,
86.4,
29.7,
27.4,
25.8,
60,
57.1,
65.1,
30.2,
32.4,
11.2,
44.5,
73.5,
48.8,
28.6,
78.2,
30,
83.3,
17.1,
28,
93.3,
36.7,
59.9,
69.8,
74,
70.4,
88.7,
81.9,
39,
12.7,
64.3,
78.4,
59.4,
27,
67.6,
77.4,
75.2,
32.8,
33,
55.2,
62.8,
45,
54.4,
50.7,
83.7,
70.7,
56.8,
66.7,
33.3,
50.2,
25.3,
70.9,
32.2,
45.5,
7,
31.5,
14.5,
62,
50.8,
43.9,
36.1,
26.7,
43,
73.8,
97,
69,
51.1,
21.9,
89.7,
61.2,
53.8,
60.4,
75,
45.6,
49.9,
31.4,
68.8,
63.7,
72.3,
55.1,
44.7,
0,
18.7,
49.5,
31.8,
30.2,
73.2,
37.7,
58.2,
54.8,
49.4,
26.2,
46.5,
79.9,
25,
51.3,
43.8,
66.9,
40.6,
28.6,
98.7,
61.8,
58,
80.9,
93.4,
43.4,
64.4,
64,
36,
5,
84.7,
11,
41.6,
25.4,
85,
96.7,
39,
24.9,
33.2,
25.8,
63.9,
60.9,
56.7,
63.3,
49.9,
79.2,
94.7,
84.2,
39.9,
8.6,
97.2,
30.8,
73.2,
53.3,
38.7,
26.6,
23.7,
35.9,
49.2,
72.5,
55.9,
36,
72,
97.4,
84.4,
35.1,
62.4,
83.2,
91.3,
24.2,
64.6,
9.7,
50.9,
86.9,
16.3,
32.4,
75.4,
65.8,
89.1,
84.6,
16,
77.1,
26.8,
42.2,
48.7,
38.2,
10.2,
78.1,
56.6,
77.9,
15,
63.2,
42.3,
86,
69.3,
40.6,
68.2,
49.7,
35.6,
87.7,
62.8,
0,
39.1,
57.6,
52.4,
60.6,
57.9,
42.7,
73.5,
64.4,
25,
63.9,
27.7,
95.4,
28.7,
2.3,
86.6,
53.6,
66.3,
61.2,
58.2,
37.9,
58.4,
71.8,
11.4,
9.5,
74,
37.8,
40.9,
86.9,
84.4,
44.1,
64.9,
58.7,
74.6,
80.1,
75,
68.9,
74.7,
40.7,
1.5,
36.2,
48.8,
45.7,
42.7,
29.7,
29.9,
4.2,
76,
83.9,
50,
62.4,
60.1,
17,
44.1,
56.8,
26.2,
86.6,
25.8,
47,
97.7,
35.9,
2.7,
20.4,
40.8,
66.9,
39.8,
59.1,
88.9,
16.4,
95.9,
44.4,
57.1,
50.2,
62.3,
19.4,
24,
27.2,
70.6,
10.7,
45.2,
84.4,
91.6,
36.9,
94.8,
3.8,
41.9,
64.6,
14.4,
29,
91,
86.6,
95.2,
40.6,
69.2,
5.7,
33.7,
59.7,
46.2,
101.8,
78.5,
88.9,
14,
35.6,
74.9,
50.3,
64.3,
8.5,
70.1,
65.2,
71.7,
61.1,
56.8,
37.1,
35.9,
95.4,
62.2,
57,
63,
53.9,
64.1,
85.7,
74.7,
97.6,
53.1,
62.4,
98.6,
25.8,
34.1,
84.1,
42,
59.3,
43.2,
54,
51,
48.3,
25.9,
90,
89.5,
67.8,
72,
44,
56,
50.2,
36,
70.8,
12.1,
36,
41.3,
97.8,
87.5,
36.7,
41.1,
46.5,
20.6,
60.7,
45.2,
37,
90.2,
72,
9.8,
81.1,
34.6,
52.3,
79.6,
36.7,
35.7,
48.9,
26.4,
13.6,
74.7,
67.1,
86,
66,
56,
75.1,
81.7,
10.6,
13.2,
26.5,
57.4,
12.7,
71.8,
49.7,
86.8,
63.9,
61.3,
85.4,
31.9,
54.7,
8.7,
23.1,
93.4,
51.5,
39.2,
95.3,
33.2,
73.3,
54.8,
55.4,
25.2,
63.8,
71.3,
72.9,
25,
37.3,
49.9,
43.1,
54.4,
52.9,
77.6,
16.9,
7.3,
36.1,
43.5,
50,
37.9,
55.3,
28.3,
69.9,
108.6,
74.6,
58,
14.1,
86.7,
27.6,
49,
7.5,
56.5,
95.5,
38.7,
60.4,
40.8,
37,
45.4,
72.2,
98.2,
96.4,
63,
70.4,
48.9,
72.3,
29.8,
58.7,
61,
97.2,
78.4,
41.4,
80.7,
52.5,
71.8,
63.4,
73.4,
11.2,
30.4,
45.5,
80.4,
46.1,
72.8,
8,
42,
43.4,
71.7,
48.1,
82.3,
44,
25,
35.8,
59,
14.1,
38.6,
64.9,
83.3,
67.4,
20.2,
16.7,
40,
77.2,
65.1,
69.4,
84.9,
51.7,
41.1,
7.4,
15.4,
26.3,
70.5,
93.5,
60,
54.7,
11.3,
48.8,
72.6,
9.3,
50.7,
78.5,
60.4,
55,
2.4,
65.5,
86.8,
50.8,
64.7,
44,
83.8,
46.6,
59,
50.5,
36.4,
54.2,
81.4,
58.9,
63.8,
79.8,
28.6,
10.6,
16.1,
74.8,
87,
58.2,
30,
64.7,
13.4,
39.5,
52.4,
81.4,
69.9,
89.9,
95.4,
58.3,
17.5,
67.8,
87.6,
60.5,
25.3,
71.2,
57.7,
94.3,
38.3,
62.4,
97.4,
36.2,
43.8,
41,
55.2,
47.3,
59.9,
100.7,
62,
93.3,
22.5,
43.3,
31.5,
83.5,
68,
20.9,
61.8,
79.1,
20.5,
48.9,
53,
69.1,
49.6,
62.6,
22.8,
46.5,
52.7,
36.3,
83,
75,
86.7,
26.6,
28.9,
44,
80.1,
46.5,
49.9,
36.1,
96.7,
70.9,
62.1,
35.6,
9.3,
62.2,
58.4,
33.2,
50.8,
74.5,
79.8,
17.7,
74.5,
15.4,
23.9,
74,
42.6,
64.6,
69.6,
50.5,
11,
49.1,
54.1,
68,
63.3,
30.9,
19.6,
85.1,
77.9,
81.9,
41.6,
56.7,
96.4,
64.6,
70.9,
28.4,
39.4,
66.7,
17.8,
79.3,
72.5,
58.1,
52.2,
41.9,
66.2,
40.7,
120.5,
92.4,
62,
26.9,
23.1,
84,
54.2,
54.2,
45.5,
67.4,
75,
94.2,
67.5,
22.7,
85.2,
29.3,
94.6,
79.2,
57,
59.9,
56.4,
90.9,
16.2,
28,
29.2,
85.3,
28.9,
72.4,
89.7,
56.2,
80,
47.3,
55.4,
55.3,
42.5,
44.8,
76.6,
17.2,
12.8,
29.2,
65.5,
3.4,
32.6,
8.4,
42.4,
45.3,
94.4,
91.7,
52.7,
77.9,
67.6,
80.2,
23.2,
31.3,
66.8,
93.9,
44.6,
56.6,
85.1,
16.7,
92.8,
45.4,
41.8,
51.5,
58.3,
18,
18.1,
63.9,
45.4,
0.2,
18,
21.9,
54.9,
87.3,
93.6,
10.5,
80.8,
22.6,
66.5,
47.1,
29.8,
35.4,
85,
23.6,
38.7,
90.5,
77.4,
59.9,
61.1,
59.5,
39.3,
92.5,
43,
92.7,
74.6,
34,
59.5,
70.6,
13.9,
74.7,
69.9,
68.1,
35.9,
67,
23,
71.1,
51.3,
11.9,
31.7,
22.4,
43.7,
96.9,
52.1,
57.7,
81.6,
74.2,
33.3,
95.3,
73.8,
73.8,
44.1,
42,
83.4,
37.7,
49.7,
27.2,
95.9,
92.7,
57,
64.6,
53.3,
44.9,
43.3,
25,
79.2,
57.7,
84.9,
75.1,
76,
46.9,
73.2,
31,
91.3,
42.8,
20.6,
49.5,
25.9,
78.8,
52.7,
37.8,
73.8,
59.6,
77.9,
38.1,
75.5,
37,
56.4,
18.9,
89.6,
74.8,
23.8,
58.8,
96.3,
56.2,
22.6,
21.1,
94.8,
57.4,
51,
33.9,
69.5,
81.1,
45.3,
98.9,
52.6,
59.4,
32,
4.1,
88.9,
68.2,
52.8,
70.3,
6.7,
7.2,
84,
58.9,
38.3,
92.5,
56,
85.7,
33.5,
50,
65.2,
25.2,
47.4,
57.3,
25.8,
60.9,
60.7,
3.6,
98.8,
87.3,
21.8,
48.1,
57.8,
83.5,
85.3,
36.6,
72.6,
65,
7.2,
57.3,
49.6,
64.5,
31.2,
69.9,
57,
62.1,
66.6,
49.5,
78.7,
74.1,
64.8,
95.9,
84.3,
42.7,
33.8,
87.3,
69.3,
57.2,
78,
42.4,
47.1,
14,
46,
20.7,
91.8,
27,
18.5,
81,
88.4,
83.1,
7.7,
90.7,
33.7,
24.1,
64.1,
92.5,
79.1,
24,
46.2,
66.1,
25.2,
90.7,
22.6,
27.7,
83.5,
80.6,
91.3,
8,
79.6,
72.2,
65.1,
48.6,
73.3,
85.3,
71.3,
40.7,
29,
14.4,
75.7,
93.9,
76.4,
73.8,
81.3,
68.2,
35.8,
85.3,
65,
63.6,
94.2,
54.3,
42.8,
56,
53.3,
60.7,
24.1,
83.3,
62.6,
83.9,
84.3,
13.9,
71.9,
34.9,
13.7,
45,
7.7
]
}
],
"layout": {
"legend": {
"bgcolor": "#F5F6F9",
"font": {
"color": "#4D5663"
}
},
"paper_bgcolor": "#F5F6F9",
"plot_bgcolor": "#F5F6F9",
"template": {
"data": {
"bar": [
{
"error_x": {
"color": "#2a3f5f"
},
"error_y": {
"color": "#2a3f5f"
},
"marker": {
"line": {
"color": "#E5ECF6",
"width": 0.5
}
},
"type": "bar"
}
],
"barpolar": [
{
"marker": {
"line": {
"color": "#E5ECF6",
"width": 0.5
}
},
"type": "barpolar"
}
],
"carpet": [
{
"aaxis": {
"endlinecolor": "#2a3f5f",
"gridcolor": "white",
"linecolor": "white",
"minorgridcolor": "white",
"startlinecolor": "#2a3f5f"
},
"baxis": {
"endlinecolor": "#2a3f5f",
"gridcolor": "white",
"linecolor": "white",
"minorgridcolor": "white",
"startlinecolor": "#2a3f5f"
},
"type": "carpet"
}
],
"choropleth": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "choropleth"
}
],
"contour": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "contour"
}
],
"contourcarpet": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "contourcarpet"
}
],
"heatmap": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "heatmap"
}
],
"heatmapgl": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "heatmapgl"
}
],
"histogram": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "histogram"
}
],
"histogram2d": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "histogram2d"
}
],
"histogram2dcontour": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "histogram2dcontour"
}
],
"mesh3d": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "mesh3d"
}
],
"parcoords": [
{
"line": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "parcoords"
}
],
"pie": [
{
"automargin": true,
"type": "pie"
}
],
"scatter": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatter"
}
],
"scatter3d": [
{
"line": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatter3d"
}
],
"scattercarpet": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattercarpet"
}
],
"scattergeo": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattergeo"
}
],
"scattergl": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattergl"
}
],
"scattermapbox": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattermapbox"
}
],
"scatterpolar": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterpolar"
}
],
"scatterpolargl": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterpolargl"
}
],
"scatterternary": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterternary"
}
],
"surface": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "surface"
}
],
"table": [
{
"cells": {
"fill": {
"color": "#EBF0F8"
},
"line": {
"color": "white"
}
},
"header": {
"fill": {
"color": "#C8D4E3"
},
"line": {
"color": "white"
}
},
"type": "table"
}
]
},
"layout": {
"annotationdefaults": {
"arrowcolor": "#2a3f5f",
"arrowhead": 0,
"arrowwidth": 1
},
"coloraxis": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"colorscale": {
"diverging": [
[
0,
"#8e0152"
],
[
0.1,
"#c51b7d"
],
[
0.2,
"#de77ae"
],
[
0.3,
"#f1b6da"
],
[
0.4,
"#fde0ef"
],
[
0.5,
"#f7f7f7"
],
[
0.6,
"#e6f5d0"
],
[
0.7,
"#b8e186"
],
[
0.8,
"#7fbc41"
],
[
0.9,
"#4d9221"
],
[
1,
"#276419"
]
],
"sequential": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"sequentialminus": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
]
},
"colorway": [
"#636efa",
"#EF553B",
"#00cc96",
"#ab63fa",
"#FFA15A",
"#19d3f3",
"#FF6692",
"#B6E880",
"#FF97FF",
"#FECB52"
],
"font": {
"color": "#2a3f5f"
},
"geo": {
"bgcolor": "white",
"lakecolor": "white",
"landcolor": "#E5ECF6",
"showlakes": true,
"showland": true,
"subunitcolor": "white"
},
"hoverlabel": {
"align": "left"
},
"hovermode": "closest",
"mapbox": {
"style": "light"
},
"paper_bgcolor": "white",
"plot_bgcolor": "#E5ECF6",
"polar": {
"angularaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"bgcolor": "#E5ECF6",
"radialaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
}
},
"scene": {
"xaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
},
"yaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
},
"zaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
}
},
"shapedefaults": {
"line": {
"color": "#2a3f5f"
}
},
"ternary": {
"aaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"baxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"bgcolor": "#E5ECF6",
"caxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
}
},
"title": {
"x": 0.05
},
"xaxis": {
"automargin": true,
"gridcolor": "white",
"linecolor": "white",
"ticks": "",
"title": {
"standoff": 15
},
"zerolinecolor": "white",
"zerolinewidth": 2
},
"yaxis": {
"automargin": true,
"gridcolor": "white",
"linecolor": "white",
"ticks": "",
"title": {
"standoff": 15
},
"zerolinecolor": "white",
"zerolinewidth": 2
}
}
},
"title": {
"font": {
"color": "#4D5663"
},
"text": "revol_util Box plot"
},
"xaxis": {
"gridcolor": "#E1E5ED",
"showgrid": true,
"tickfont": {
"color": "#4D5663"
},
"title": {
"font": {
"color": "#4D5663"
},
"text": ""
},
"zerolinecolor": "#E1E5ED"
},
"yaxis": {
"gridcolor": "#E1E5ED",
"showgrid": true,
"tickfont": {
"color": "#4D5663"
},
"title": {
"font": {
"color": "#4D5663"
},
"text": ""
},
"zerolinecolor": "#E1E5ED"
}
}
},
"text/html": [
"\n",
" \n",
" \n",
" \n",
" \n",
" "
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"application/vnd.plotly.v1+json": {
"config": {
"linkText": "Export to plot.ly",
"plotlyServerURL": "https://plot.ly",
"showLink": true
},
"data": [
{
"histfunc": "count",
"histnorm": "",
"marker": {
"color": "rgba(255, 153, 51, 1.0)",
"line": {
"color": "#4D5663",
"width": 1.3
}
},
"name": "tot_cur_bal",
"opacity": 0.8,
"orientation": "v",
"type": "histogram",
"x": [
28699,
9974,
38295,
55564,
47159,
350619,
13272,
272579,
281521,
76034,
72193,
39152,
194011,
165164,
39634,
48488,
71191,
221335,
34538,
125903,
66738,
null,
282808,
71697,
147448,
327930,
8589,
447388,
114298,
31445,
391749,
1385358,
68057,
6485,
23697,
4890,
5422,
176391,
10707,
141797,
53454,
229995,
13054,
42542,
624417,
38829,
28163,
null,
421664,
71646,
8312,
311014,
234697,
290962,
195008,
13166,
34752,
359326,
137019,
235231,
161107,
316510,
22198,
272177,
124248,
442155,
null,
null,
447154,
46867,
28862,
250586,
58396,
223151,
null,
103681,
123905,
405177,
77893,
22459,
174517,
244772,
23784,
28233,
27435,
275755,
142744,
37237,
15017,
408391,
106591,
35398,
24895,
null,
68650,
239603,
605585,
139788,
41237,
186934,
78372,
43807,
35449,
245928,
9943,
158699,
254138,
261143,
46625,
220405,
12172,
61294,
31225,
38746,
40749,
301791,
263725,
357941,
212529,
32825,
111460,
10163,
381787,
null,
618061,
58182,
23744,
105315,
31458,
14203,
null,
8328,
24353,
697738,
31254,
324254,
253332,
66287,
34248,
15736,
32296,
31773,
491917,
127882,
27519,
128115,
336159,
303569,
137534,
132687,
null,
57534,
null,
29284,
49328,
43998,
18955,
4161,
44318,
9687,
217361,
51448,
15567,
11346,
76398,
41374,
11900,
57897,
146182,
25315,
42886,
12743,
26807,
41719,
214384,
161474,
41019,
108745,
403512,
98749,
14677,
25608,
52348,
168733,
795423,
237669,
24110,
33335,
381762,
317022,
74344,
6557,
357373,
null,
207856,
null,
187785,
null,
45602,
20964,
23927,
74619,
18613,
36054,
28773,
2540,
209503,
null,
null,
189210,
12725,
67211,
31287,
141512,
17022,
38935,
397113,
268952,
30098,
null,
185010,
20974,
30163,
352644,
371710,
49447,
729286,
1275731,
369867,
10989,
142058,
109299,
419933,
236818,
230826,
197387,
38375,
21810,
null,
15550,
26955,
52359,
149955,
120660,
null,
59812,
21024,
130027,
10814,
315571,
2755,
null,
25885,
22363,
259654,
26566,
5713,
38691,
82172,
344169,
583364,
261450,
145255,
220734,
326635,
15925,
66547,
61199,
99488,
24981,
40106,
39636,
27105,
39497,
55926,
152124,
53692,
119007,
84473,
154943,
160755,
39752,
104546,
null,
35816,
32579,
61080,
329538,
33373,
178923,
37951,
256274,
162464,
347081,
216061,
295126,
null,
30235,
null,
13889,
351928,
300411,
38990,
null,
136956,
22720,
317207,
34706,
186750,
223548,
9657,
35975,
214793,
95565,
238017,
null,
50324,
394034,
20088,
20449,
130501,
164189,
13347,
179994,
17899,
39404,
287180,
56496,
41139,
10615,
658834,
63379,
68865,
354452,
30353,
null,
null,
411273,
46002,
55669,
53735,
99289,
180899,
18348,
747460,
25407,
43083,
236639,
29046,
35438,
34710,
14137,
23746,
146392,
214638,
312703,
28856,
56332,
6289,
9874,
93245,
null,
25218,
116274,
null,
144950,
13295,
43470,
81987,
198266,
41790,
null,
11304,
201921,
366823,
165886,
13288,
18299,
14262,
17403,
406681,
74413,
33086,
null,
61335,
60210,
35353,
null,
8183,
92860,
46894,
148501,
null,
57821,
170930,
15989,
233837,
244934,
240085,
211374,
103485,
139857,
22391,
184799,
264915,
57953,
129420,
111848,
327823,
26787,
64033,
254355,
101576,
556185,
23200,
null,
207625,
65485,
248611,
373534,
81863,
null,
14147,
null,
172831,
187073,
58250,
23287,
31369,
109651,
502944,
541157,
295656,
108124,
null,
33281,
216288,
106123,
34497,
41194,
56446,
19549,
180351,
40388,
70227,
258381,
27220,
24723,
22735,
14328,
151107,
468840,
4708,
122656,
19877,
263047,
71862,
124365,
21121,
148297,
32874,
75112,
376138,
5537,
24188,
69719,
159439,
40697,
8095,
366064,
213954,
210739,
null,
33582,
25085,
121160,
128656,
26913,
23672,
null,
203507,
163716,
165726,
183502,
15968,
54040,
278870,
92302,
152437,
16193,
230077,
131268,
135767,
154295,
48385,
210663,
124963,
34831,
null,
33079,
24878,
36930,
62949,
90030,
29880,
164515,
40347,
13177,
null,
447617,
177716,
12305,
null,
232601,
70078,
19900,
175950,
33874,
22444,
37039,
446278,
92948,
775376,
221904,
23696,
39890,
154730,
55151,
36726,
131678,
158221,
18632,
33280,
251220,
99581,
32863,
364241,
204018,
85343,
55869,
26448,
215033,
339858,
1234441,
141083,
15485,
102598,
158359,
24546,
180586,
58044,
17456,
50796,
20858,
16163,
372969,
64707,
271565,
185938,
null,
157226,
244426,
250201,
45336,
60407,
54924,
37839,
null,
18899,
202801,
null,
66981,
null,
27075,
60204,
175944,
32356,
212609,
161552,
17505,
null,
null,
15521,
215318,
76675,
20990,
31506,
15354,
null,
197356,
151870,
508277,
166089,
328730,
352961,
195109,
null,
null,
42394,
431407,
215895,
247430,
371149,
4185,
30496,
46613,
346859,
12438,
186158,
null,
195129,
45378,
255576,
14516,
98931,
77424,
301087,
204350,
20572,
43760,
230481,
64424,
35722,
130003,
569382,
129046,
100007,
338999,
34954,
179582,
15354,
31960,
43722,
53169,
47467,
277011,
39375,
70697,
459512,
10181,
288236,
40494,
1119620,
103771,
72539,
56368,
331686,
268631,
null,
21408,
18698,
160139,
751327,
61632,
25237,
144622,
11780,
1654,
177427,
null,
26847,
84876,
52458,
147071,
37677,
362232,
92482,
21099,
31232,
162622,
15685,
35217,
null,
13862,
171443,
40211,
47624,
17474,
41254,
69585,
4871,
262966,
33869,
2051680,
40168,
4780,
223359,
75802,
8822,
17695,
175182,
17870,
42759,
29655,
22696,
43035,
9621,
182034,
91870,
233656,
70569,
33436,
160967,
30480,
122956,
18235,
523816,
24449,
27678,
23189,
319370,
17448,
null,
143547,
165504,
331551,
16945,
145396,
7628,
16023,
334570,
27039,
300135,
null,
15441,
43020,
14267,
200947,
39517,
323104,
16238,
168329,
40044,
152851,
83950,
189558,
37026,
249444,
219679,
3917,
159744,
204239,
211916,
null,
649659,
248348,
13387,
61090,
39738,
108741,
183133,
28953,
2083,
null,
48858,
7641,
88149,
285279,
266350,
317918,
35547,
109845,
152573,
464373,
136494,
11589,
156615,
220896,
162212,
3455,
188825,
44121,
124109,
1332695,
257146,
332717,
532571,
99214,
null,
19856,
16862,
108141,
229954,
29900,
47451,
12041,
111218,
null,
18205,
73426,
8339,
238645,
269442,
55479,
353179,
50540,
48102,
103067,
39593,
35919,
31025,
97740,
159207,
111939,
149447,
7586,
25048,
74795,
null,
182475,
305232,
274663,
303129,
33624,
245780,
18149,
184455,
83420,
40938,
163459,
347024,
null,
33900,
11108,
24447,
null,
152177,
242499,
187876,
27377,
20078,
51845,
26433,
40217,
69090,
314302,
184109,
29714,
82175,
41940,
32048,
19750,
104870,
null,
177052,
12361,
130643,
39264,
120280,
24652,
104369,
141322,
27048,
74544,
157615,
229713,
102940,
283813,
20455,
24540,
200548,
30430,
453703,
40474,
1361016,
97388,
36910,
161786,
39954,
45661,
190690,
487234,
31397,
83891,
16998,
263086,
19968,
28757,
13052,
160096,
235173,
72132,
246771,
344875,
482448,
9398,
63337,
10688,
43421,
17370,
188555,
21189,
22481,
145197,
33175,
3926,
19542,
165551,
327709,
107965,
43369,
297064,
186147,
93547,
125549,
139951,
227205,
62735,
18094,
null,
416887,
46412,
125646,
null,
178347,
53034,
404034,
null,
293366,
29222,
8417,
260009,
7789,
44627,
89035,
195407,
293814,
53332,
79736,
195921,
106917,
441190,
41321,
198763,
241583,
6903,
44218,
215378,
221350,
736534,
199782,
179646,
21168,
220092,
72180,
285233,
null,
25505,
24617,
62296,
75364,
205002,
23046,
390172,
587516,
130805,
53443,
105006,
90903,
53434,
16338,
42889,
58161,
140595,
662752,
317097,
17831,
14924,
250749,
242372,
36937,
8246,
49249,
null,
13937,
190050,
39024,
null,
215143,
140054,
243071,
375143,
149073,
360615,
82230,
95921,
16222,
197496,
214187,
112820,
11707,
388146,
43745,
414011,
275721,
349168,
188142,
23505,
223350,
11279,
null,
121093,
38390,
39950,
25529,
4140,
35331,
135542,
44434,
189563,
156771,
390202,
null,
51434,
38587,
263842,
187006,
39707,
451200,
31468,
160563,
568085,
126705,
378709,
16774,
255080,
32348,
43492,
null,
45401,
183898,
294414,
839313,
null,
14519,
180375,
182819,
16927,
112677,
40710,
15706,
null,
19625,
12089,
53541,
null,
513741,
37126,
217490,
292718,
31749,
41969,
13425,
35085,
52898,
36175,
766037,
null,
13100,
185600,
29934,
372426,
32106,
69936,
35805,
null,
10770,
null,
24647,
178067,
65953,
322998,
null,
59736,
367936,
333261,
25027,
505867,
65182,
160399,
31577,
57566,
173610,
412881,
119411,
27884,
129321,
125016,
80937,
223263,
203705,
586647,
123495,
29786,
156212,
311958,
74497,
336577,
47861,
95506,
null,
38334,
280406,
14754,
17620,
39161,
123144,
361629,
347885,
213808,
124847,
46619,
528105,
9286,
21758,
55848,
117001,
36355,
30920,
29160,
173532,
17521,
30276,
10521,
414919,
252482,
157972,
89640,
65016,
53746,
217250,
52821,
119254,
133923,
187653,
215514,
28079,
24598,
191137,
37107,
55205,
156320,
null,
262786,
15650,
13148,
59362,
43873,
56882,
364366,
2951,
34868,
243513,
16285,
24372,
116276,
104112,
238341,
7971,
26043,
46525,
117800,
88498,
445227,
82287,
169664,
16378,
289657,
18637,
124490,
205685,
58759,
155187,
79634,
349560,
102449,
null,
39553,
37717,
3834,
162946,
209414,
42569,
161412,
15304,
58667,
76289,
24133,
null,
202599,
23320,
320292,
23866,
null,
385311,
122573,
20608,
319983,
null,
176240,
426261,
27852,
88451,
117411,
null,
36310,
8997,
576551,
267660,
14084,
341474,
66196,
34326,
null,
30589,
11373,
28241,
31879,
null,
101883,
12742,
1299833,
218018,
null,
44123,
30859,
357596,
14424,
5550,
29238,
139575,
5586,
53599,
null,
54459,
34634,
8951,
95828,
3068,
176068,
68241,
160416,
9583,
61841,
242955,
20408,
262383,
307991,
89473,
38055,
274980,
94191,
128468,
22540,
164164,
110677,
454209,
831171,
664011,
26766,
148132,
99391,
13366,
45624,
247677,
17151,
2054,
37908,
175814,
207044,
44825,
319276,
79233,
21395,
271011,
5498,
117477,
118844,
46116,
26437,
null,
293333,
224957,
null,
50096,
39734,
91806,
174888,
175085,
291528,
26258,
24889,
null,
220856,
null,
45196,
25625,
513291,
14181,
8501,
45642,
52658,
102677,
224552,
138025,
37736,
37288,
157472,
308045,
556906,
34662,
459505,
104325,
null,
234701,
27932,
56349,
57748,
104817,
17139,
2963,
272278,
null,
171835,
51680,
72649,
121215,
229613,
21493,
403165,
444914,
6856,
187261,
46013,
262923,
107379,
260335,
65038,
312245,
90268,
267052,
17676,
null,
5494,
27424,
102951,
9875,
424123,
176397,
23203,
54459,
67563,
106697,
23389,
9198,
33920,
34032,
103932,
185650,
129209,
97167,
null,
19299,
18332,
364168,
83437,
270092,
35769,
187305,
234095,
44392,
26364,
5619,
13095,
57182,
null,
null,
149090,
234080,
387297,
122672,
null,
82139,
264033,
16357,
804103,
168514,
29663,
24468,
84155,
70429,
192343,
24292,
69404,
52919,
234813,
387315,
45478,
null,
162380,
47648,
58390,
417928,
26485,
null,
21717,
202395,
75762,
null,
null,
62237,
28017,
206565,
359844,
17047,
null,
175620,
53940,
264836,
97845,
28124,
40233,
23859,
38349,
208745,
60489,
11852,
21366,
null,
45368,
null,
341561,
10238,
17176,
6643,
15162,
89264,
223596,
10241,
44838,
88258,
211338,
108213,
686794,
null,
178649,
335650,
24294,
null,
95096,
14741,
42209,
182366,
298929,
16862,
143117,
44064,
38384,
179761,
52351,
166311,
null,
291915,
40517,
99474,
455324,
8311,
109474,
100652,
73403,
31589,
163404,
null,
34623,
null,
49064,
218487,
60971,
349399,
191818,
137206,
17137,
20387,
341508,
356506,
16850,
126406,
35777,
44009,
15382,
null,
49889,
337240,
178172,
83087,
145334,
40584,
141749,
172682,
4296,
19605,
152319,
70369,
240658,
32280,
4595,
53430,
null,
201067,
16415,
32267,
32790,
408449,
198935,
403766,
23000,
7769,
63145,
53214,
232225,
null,
35481,
235408,
137246,
33368,
270069,
32240,
35143,
111602,
2982,
3258,
161352,
432949,
null,
18771,
35313,
22493,
187215,
569795,
31885,
360462,
47689,
10122,
475417,
445207,
66797,
34151,
33797,
33146,
211668,
34024,
null,
82279,
38433,
173726,
35478,
80550,
128762,
71736,
264016,
366882,
45453,
24199,
128111,
143073,
193880,
281967,
5032,
27566,
93031,
463860,
13530,
146633,
35252,
22585,
205560,
9374,
295344,
63503,
3437,
19906,
120133,
43435,
48595,
258284,
114869,
312731,
23541,
24092,
17511,
8093,
180805,
607673,
64746,
10005,
75671,
245623,
22723,
249170,
41661,
null,
85724,
106180,
411984,
55008,
250014,
88069,
13387,
217322,
239063,
149064,
19604,
89953,
24772,
41150,
172615,
377265,
22068,
48774,
46287,
405948,
41771,
234036,
89900,
27069,
38996,
45842,
218988,
17223,
16503,
null,
36960,
11194,
38185,
39166,
169984,
8630,
29369,
58396,
130734,
37248,
94562,
356299,
10112,
434862,
62696,
45710,
231330,
118221,
380990,
81845,
232212,
177204,
93032,
5113,
304632,
171628,
394150,
12911,
117003,
38560,
6310,
81696,
126067,
39064,
59522,
137647,
null,
100740,
38366,
null,
13460,
8678,
162780,
156847,
6471,
6064,
64169,
67493,
257173,
1167,
147027,
66755,
36013,
164454,
102165,
131125,
229172,
44094,
190750,
17261,
null,
81167,
15632,
222496,
210477,
80421,
183953,
208805,
253103,
10882,
39439,
442571,
157604,
121537,
30564,
20731,
238956,
326810,
416225,
56929,
295787,
null,
8170,
3357,
null,
405752,
82293,
null,
26325,
45819,
206121,
15867,
168705,
null,
61964,
433141,
49578,
182257,
158521,
8510,
629574,
37378,
26377,
120261,
87153,
8330,
321231,
43767,
null,
30171,
27146,
null,
126381,
22968,
304738,
495308,
163278,
40606,
15290,
30290,
25139,
11795,
null,
149849,
81651,
291641,
214563,
30031,
292038,
56415,
212243,
170208,
21491,
131867,
49872,
332464,
null,
102397,
26335,
48249,
122238,
null,
968125,
222822,
294971,
12770,
155016,
24979,
84125,
null,
65400,
241469,
34394,
165540,
18446,
44477,
56164,
250746,
31339,
6876,
65183,
22593,
54630,
538885,
16185,
352880,
10192,
175832,
126548,
200723,
42402,
22955,
269477,
362901,
470919,
51075,
19672,
163416,
33761,
49446,
53623,
214515,
484750,
185104,
451210,
731992,
234575,
null,
170461,
198520,
20669,
39989,
30928,
null,
33417,
5375,
24547,
388397,
25439,
23633,
57048,
376272,
36983,
113806,
29220,
17389,
83942,
131238,
392068,
254123,
52980,
24054,
6132,
980303,
28589,
22034,
254472,
100770,
15525,
null,
17751,
50934,
18115,
72219,
251142,
23685,
309298,
333386,
30462,
34028,
78060,
402250,
264969,
316581,
394245,
243030,
37667,
179121,
177912,
18413,
113166,
215831,
121835,
60434,
9883,
77925,
201308,
null,
12097,
283116,
142452,
37233,
172538,
467529,
9299,
201711,
210472,
64325,
157729,
37113,
188282,
538664,
89956,
46339,
17929,
260671,
283386,
13870,
105177,
254292,
313501,
343132,
53600,
156815,
7908,
414134,
390557,
3015,
470369,
59761,
139555,
152501,
121043,
324187,
10994,
12328,
null,
198708,
35139,
92846,
303010,
168090,
238734,
76009,
325499,
125555,
18310,
215660,
141000,
91448,
221476,
22142,
null,
283907,
158244,
85269,
58209,
324346,
8866,
56545,
129915,
45601,
58041,
482985,
48,
null,
337125,
197889,
138070,
130273,
16619,
18066,
153654,
458376,
42119,
78441,
259296,
209524,
35414,
160188,
1084326,
116035,
65064,
3848,
341365,
6417,
null,
91727,
106532,
37855,
225008,
6397,
132006,
225046,
54819,
null,
54587,
247424,
346819,
78450,
197933,
81052,
26678,
68622,
null,
null,
7078,
14626,
21978,
35059,
10195,
96531,
56502,
135637,
8283,
211335,
21696,
30608,
43797,
390085,
111519,
9639,
112937,
115485,
23294,
66833,
10291,
223730,
19454,
null,
null,
29567,
71118,
20104,
98280,
5765,
38547,
210355,
159793,
324151,
9409,
85607,
55878,
39199,
6311,
572434,
274477,
387876,
296683,
131135,
null,
101094,
null,
230588,
29682,
425774,
261176,
null,
211716,
11565,
21716,
386566,
42582,
141691,
131737,
196260,
188149,
2872,
204166,
198812,
8902,
50895,
109137,
8594,
339984,
25392,
45640,
368934,
196170,
211544,
195241,
96860,
104588,
48199,
17924,
344522,
717176,
13714,
null,
113964,
331514,
35226,
55692,
224252,
210875,
83186,
385993,
61091,
30571,
10831,
61242,
469787,
233600,
26903,
12113,
54356,
57296,
201289,
44216,
212442,
129417,
405277,
27397,
126177,
56944,
134854,
205914,
32620,
215936,
11190,
30137,
56335,
29466,
42498,
null,
39368,
184791,
6024,
252396,
25806,
null,
24192,
467700,
166000,
69541,
96198,
242582,
294141,
171366,
null,
72260,
163007,
155408,
291393,
209633,
107369,
20908,
121759,
190975,
58783,
161954,
72715,
293137,
null,
272909,
175440,
175530,
10563,
91801,
43687,
145497,
39518,
118090,
30421,
40606,
14894,
394342,
121656,
42623,
42422,
57098,
96355,
75289,
34624,
394894,
19350,
73401,
null,
194409,
212971,
7263,
34472,
6383,
15104,
156296,
33899,
196450,
null,
134310,
80385,
14163,
182726,
306792,
235773,
43143,
41714,
16403,
568845,
314293,
257401,
9066,
28293,
45704,
129161,
236646,
42997,
47301,
366365,
1303602,
283843,
36097,
68628,
46184,
null,
161430,
174295,
21056,
16652,
9312,
79549,
12989,
40137,
11928,
275922,
96614,
551318,
38910,
314926,
27965,
92293,
192801,
283662,
null,
98726,
238412,
24636,
208467,
284849,
84341,
249271,
39738,
54991,
345979,
null,
77555,
32171,
94692,
31427,
118928,
82920,
754414,
25733,
42456,
155332,
215553,
30150,
95117,
317765,
null,
38562,
436252,
226669,
25944,
22860,
12174,
57487,
113322,
189874,
52491,
41862,
null,
null,
null,
40275,
17755,
81518,
159950,
59699,
469053,
14153,
33832,
236699,
19800,
32343,
8115,
165760,
40136,
18212,
8233,
68619,
379952,
57374,
201205,
3608,
195767,
69833,
96771,
188727,
5919,
63034,
284610,
12252,
200626,
758189,
266569,
673419,
20743,
53068,
362147,
254705,
38934,
19881,
24244,
102326,
54135,
299011,
28788,
22709,
44260,
175207,
6422,
282736,
23519,
331651,
380681,
null,
237264,
213139,
25308,
7160,
191456,
31362,
187460,
3244,
null,
788382,
367577,
153979,
29752,
null,
183313,
9137,
61849,
213859,
215758,
211749,
265065,
189612,
171945,
null,
166535,
509708,
16911,
18418,
250087,
33279,
317034,
463385,
4740,
72620,
121266,
142013,
15759,
123088,
27361,
78998,
370612,
null,
13459,
null,
103157,
31378,
198672,
278376,
null,
79078,
null,
8470,
62515,
213463,
37632,
86183,
64638,
1826285,
null,
170438,
50579,
27665,
231941,
133545,
134858,
80185,
35496,
25119,
81007,
7190,
264260,
75340,
186164,
298938,
289560,
141733,
91626,
200277,
167584,
114121,
123917,
18761,
55569,
100588,
349028,
28482,
67472,
22570,
197665,
78342,
76541,
111399,
10411,
33697,
12862,
132552,
211105,
198590,
22458,
87842,
253479,
174456,
7000,
null,
158418,
319301,
280858,
36458,
125498,
31723,
329754,
null,
80325,
22231,
171550,
105643,
173796,
null,
8229,
330280,
71948,
106367,
8874,
362658,
177608,
39497,
128264,
33494,
110282,
null,
310434,
16128,
204188,
203458,
20162,
115455,
15558,
224654,
23723,
2780,
166975,
26147,
167992,
299056,
225522,
16793,
577172,
15057,
69159,
32305,
20029,
null,
23151,
null,
191416,
689956,
196115,
32851,
199438,
46711,
92286,
72536,
55119,
22304,
196324,
38363,
614368,
85680,
246340,
395264,
null,
null,
11676,
172703,
76226,
41701,
47667,
95830,
411457,
31445,
297988,
19799,
210829,
143576,
223450,
316448,
183477,
58692,
null,
15901,
332226,
394411,
21448,
331363,
42576,
470018,
18501,
6351,
189804,
136355,
193001,
56330,
43492,
30897,
278418,
336397,
22689,
29728,
132111,
21479,
11098,
34496,
43474,
256538,
24543,
17784,
210537,
null,
35769,
8801,
28182,
591644,
7689,
null,
2279,
368810,
13822,
null,
null,
4146,
207784,
27117,
34616,
48518,
134321,
260260,
746358,
244486,
80810,
254431,
121924,
null,
263495,
391729,
null,
203359,
15084,
72037,
378224,
251380,
171895,
40943,
146051,
147458,
126976,
12493,
117983,
32320,
null,
211401,
null,
72777,
5895,
533734,
23052,
350443,
45636,
20430,
439387,
33937,
null,
323610,
126367,
122399,
null,
628219,
null,
90720,
38642,
58988,
339878,
204449,
27286,
13870,
30044,
1042,
22532,
377861,
26479,
38754,
252269,
67395,
386016,
3431,
260145,
null,
22142,
14497,
63024,
41788,
321939,
null,
10028,
252647,
41359,
44403,
48945,
185887,
108102,
6929,
77574,
91415,
null,
12534,
63928,
22849,
45740,
87886,
35961,
224759,
367490,
154880,
334109,
198663,
154700,
47354,
139412,
94870,
171324,
120978,
31924,
168994,
128721,
43978,
46435,
131540,
65831,
34414,
40580,
199771,
107047,
39633,
218356,
26454,
23021,
36622,
310455,
45461,
13558,
18788,
91527,
null,
292879,
51127,
43140,
66066,
92389,
207447,
49313,
9250,
39642,
163465,
305620,
20795,
43057,
357477,
137104,
280422,
24349,
53574,
34568,
231788,
94305,
25154,
133195,
63881,
49095,
5551,
83173,
41320,
null,
30384,
29895,
18194,
236725,
402720,
145033,
133899,
10933,
null,
76918,
146441,
91640,
99500,
6315,
43865,
32831,
153525,
null,
59183,
356911,
19442,
9045,
null,
87950,
289056,
null,
69109,
null,
135972,
300548,
17403,
41716,
43910,
77022,
257338,
167989,
174814,
49830,
254707,
617363,
17195,
46548,
70950,
46618,
237326,
53624,
16907,
114717,
40920,
45076,
143051,
127990,
37385,
26636,
67145,
null,
140204,
163408,
230270,
11967,
159125,
57743,
18815,
369353,
194557,
170027,
323297,
79173,
318886,
53202,
12430,
null,
null,
35960,
94496,
33498,
207884,
53552,
134162,
169256,
null,
19433,
15284,
24444,
122182,
18907,
166058,
65787,
39910,
152435,
84199,
4014,
93547,
279562,
32752,
264236,
284462,
132000,
134405,
47508,
228780,
14265,
171645,
360160,
4859,
27292,
146256,
277431,
55470,
44981,
36795,
382802,
15678,
217205,
365770,
20473,
47199,
41213,
null,
null,
20373,
47344,
104135,
15973,
184154,
74905,
138322,
32818,
118836,
162308,
164530,
100357,
266195,
93821,
186819,
13238,
24235,
137167,
568141,
323160,
301293,
165507,
16717,
305320,
37279,
22148,
21723,
27950,
196911,
204374,
141033,
64443,
93024,
42674,
206850,
6476,
85602,
27631,
null,
174966,
92070,
38244,
240354,
132195,
20957,
22689,
119395,
295585,
6127,
113667,
214807,
310546,
161773,
33315,
164573,
390022,
73906,
195573,
205920,
8046,
51882,
49740,
58330,
32743,
209447,
15564,
28106,
152866,
51626,
183074,
61614,
59191,
261979,
6414,
78210,
439902,
25511,
13831,
58200,
33640,
241677,
5805,
91774,
336533,
21988,
38824,
190334,
71566,
379201,
15725,
162819,
594026,
545031,
123323,
338339,
71772,
28904,
226004,
33435,
65573,
62523,
8837,
186035,
52188,
11573,
90249,
261459,
41039,
116609,
385915,
6100,
49652,
13838,
13285,
78950,
null,
66344,
122942,
46432,
246197,
15308,
145789,
14536,
181273,
30462,
20641,
40305,
29354,
74140,
223624,
225071,
56406,
291405,
285644,
129075,
49340,
124692,
89279,
30842,
179109,
null,
110365,
34963,
178216,
null,
138736,
173881,
1718,
30599,
257269,
null,
88309,
226469,
30593,
null,
null,
24402,
136887,
72706,
null,
6702,
70046,
38370,
87756,
29620,
21419,
null,
112639,
369947,
22279,
21443,
69110,
7645,
18204,
347985,
32329,
4358,
25171,
null,
33144,
254218,
213630,
228339,
344979,
364449,
13158,
207373,
377128,
504441,
281198,
44409,
14150,
349386,
6702,
15156,
3938,
221251,
35873,
41643,
71389,
14518,
51906,
219145,
null,
null,
192525,
53016,
100117,
213535,
486757,
46611,
33276,
44690,
419006,
158704,
25543,
275286,
240909,
20185,
166283,
98601,
140532,
168605,
183672,
47555,
495423,
104278,
140928,
413188,
21419,
244781,
83575,
34348,
134708,
345050,
12230,
367907,
423946,
null,
59162,
393724,
26468,
17675,
74296,
305687,
124734,
205608,
157363,
252191,
27448,
369585,
224189,
14734,
315177,
12372,
298537,
129632,
8054,
null,
382701,
7511,
46666,
363291,
79322,
109705,
33122,
64187,
375777,
62007,
7311,
194947,
5862,
131819,
395676,
58225,
null,
190500,
465253,
29959,
283779,
167726,
189062,
337550,
108935,
29179,
14876,
400581,
129624,
4241,
42087,
155753,
237208,
null,
221140,
194586,
219563,
163701,
73044,
31700,
181481,
224335,
46746,
428522,
41875,
null,
224134,
39075,
41983,
22087,
36827,
209614,
135021,
30629,
343902,
40946,
65277,
184206,
50593,
55231,
35133,
350947,
302146,
18983,
40394,
87127,
26725,
182950,
279617,
21527,
277902,
11010,
164446,
303863,
43769,
185507,
32726,
253986,
28279,
246102,
298555,
311719,
null,
282661,
null,
null,
27573,
221429,
203646,
252406,
13207,
101395,
null,
420559,
140537,
34192,
56861,
9411,
73996,
338156,
13621,
47704,
392178,
22631,
27467,
16319,
18749,
36164,
200982,
null,
21076,
null,
23786,
null,
66576,
261270,
5954,
15456,
null,
215601,
null,
59015,
21000,
216134,
49909,
558723,
39428,
216000,
51579,
40203,
58437,
26226,
14487,
14571,
229562,
33787,
null,
487814,
30629,
17511,
32649,
99737,
43528,
354580,
62922,
24272,
338422,
165449,
43305,
null,
14176,
86242,
199901,
219311,
120251,
51468,
null,
78918,
3628,
37221,
150977,
366325,
28888,
15935,
340126,
41407,
185510,
78259,
37568,
96642,
36514,
45259,
259894,
null,
136029,
71306,
9698,
497222,
161516,
273093,
45024,
25119,
264498,
9057,
224222,
352980,
25193,
26029,
85640,
305410,
22768,
6589,
416103,
156239,
14656,
242922,
null,
14652,
175885,
107464,
47594,
160237,
null,
28944,
35379,
null,
321297,
null,
351228,
700336,
538256,
5633,
663937,
44218,
50919,
125950,
181617,
50368,
397625,
null,
40301,
191172,
null,
39082,
23925,
63842,
110289,
86092,
32036,
19137,
55665,
59003,
22402,
112662,
80895,
200792,
51434,
35875,
164658,
277228,
62200,
146539,
26204,
312208,
52352,
212366,
63022,
null,
105697,
124944,
24357,
10180,
45758,
55995,
170922,
null,
27033,
45546,
22713,
200179,
156212,
106832,
262327,
null,
501628,
160435,
660003,
1107,
210764,
37600,
68095,
42051,
66471,
null,
128710,
54505,
45996,
15844,
17204,
630340,
59901,
242717,
35262,
60790,
189237,
48785,
193893,
53675,
124114,
33629,
111384,
89445,
5088,
138396,
282176,
32952,
135225,
47283,
23776,
null,
161566,
432950,
4010,
213927,
null,
293144,
475197,
55532,
83782,
39006,
43676,
null,
11797,
null,
54294,
75528,
6001,
19865,
374264,
null,
23877,
8269,
45500,
545717,
428305,
136395,
36969,
226120,
30887,
15511,
314778,
4306,
172317,
178663,
16289,
51965,
null,
22907,
5132,
14165,
30611,
null,
null,
229078,
22676,
24547,
54925,
101914,
13456,
39481,
70449,
59448,
55667,
null,
9613,
244237,
null,
199809,
231907,
259334,
446611,
4204,
10061,
null,
19638,
117127,
449762,
36593,
113989,
9151,
39513,
28909,
114581,
228968,
14450,
155738,
227530,
200805,
260931,
22847,
22311,
null,
34946,
null,
20321,
144508,
321820,
172812,
423167,
201303,
547765,
30321,
11483,
null,
43230,
null,
278727,
162304,
153104,
86143,
444836,
212489,
136138,
176193,
null,
null,
63090,
125136,
664508,
325373,
170454,
286378,
26632,
22494,
56818,
73233,
254406,
null,
586934,
189210,
35634,
171622,
43447,
14413,
null,
7015,
151228,
24220,
170924,
52605,
226790,
null,
null,
161135,
219274,
30577,
183853,
272241,
null,
19033,
133501,
49966,
17045,
26927,
13210,
243454,
112949,
20458,
1393,
46910,
null,
369309,
25705,
16957,
1041916,
242012,
26994,
40128,
42975,
205820,
162233,
252462,
27166,
21477,
23467,
129487,
18984,
90687,
246224,
50448,
24209,
262925,
194886,
33360,
null,
27399,
104541,
87862,
290737,
401126,
81741,
123294,
222900,
109654,
372050,
17391,
181954,
15535,
19558,
66351,
54193,
178335,
131306,
127890,
244420,
18339,
178059,
84138,
271058,
159692,
77578,
75944,
178216,
404411,
438136,
4216,
270214,
49694,
21888,
723796,
null,
null,
54348,
48517,
135243,
53041,
null,
683078,
164696,
null,
null,
72271,
150053,
46556,
318675,
417746,
null,
68783,
64893,
98682,
30540,
57288,
44512,
875,
69440,
52096,
117689,
15750,
78102,
null,
63839,
64165,
389361,
17591,
28153,
482138,
225921,
73509,
null,
141355,
132399,
63097,
283427,
56790,
156532,
412800,
17054,
71658,
32416,
41692,
2643,
214958,
103828,
175148,
127867,
70942,
51837,
null,
39604,
137181,
32248,
null,
null,
97233,
96406,
10159,
13977,
118427,
10425,
71390,
116680,
168621,
322754,
28401,
17360,
12265,
342588,
30364,
57826,
114975,
31317,
177319,
175787,
159329,
22411,
4901,
98793,
318555,
162866,
8674,
null,
null,
9457,
null,
209165,
450574,
75503,
92036,
13861,
64217,
91663,
26474,
62944,
159888,
11529,
142925,
null,
210670,
63707,
458905,
69399,
114409,
4866,
181209,
91732,
97301,
116064,
112361,
114071,
156739,
165540,
null,
230306,
24857,
124422,
122903,
177550,
28736,
185289,
38444,
291673,
214551,
52892,
67163,
303878,
771664,
240971,
19406,
212015,
33028,
350719,
96205,
30233,
null,
75098,
22447,
201306,
12400,
64051,
null,
null,
17077,
15070,
null,
74833,
123969,
15497,
200314,
12813,
112191,
38943,
250522,
95149,
389790,
312236,
null,
18360,
78523,
137833,
288867,
234936,
13470,
748851,
null,
14809,
94815,
112075,
4415,
137207,
321104,
220316,
167327,
23670,
99012,
137664,
314518,
33562,
83186,
155247,
26571,
272348,
151687,
null,
5454,
292910,
13377,
333032,
13536,
71267,
15279,
22613,
86560,
490922,
152438,
21177,
34021,
87028,
27662,
25997,
27238,
138536,
108321,
300882,
33936,
23596,
126043,
27671,
158995,
294334,
15094,
8289,
42847,
null,
203259,
77765,
28093,
44863,
122458,
60717,
403122,
159180,
36079,
233129,
11694,
47125,
25413,
574594,
48705,
209291,
200280,
199612,
74410,
202752,
45217,
8098,
566959,
null,
46053,
48363,
337475,
256389,
9290,
466301,
61798,
168573,
null,
16829,
64995,
178226,
236626,
11720,
17404,
180222,
312198,
67257,
1010322,
311798,
null,
30065,
136131,
177566,
310748,
183149,
21915,
23884,
9003,
19462,
262371,
68173,
450736,
260261,
28973,
23669,
4909,
24603,
383631,
52231,
34689,
36075,
268285,
29104,
null,
251394,
15338,
132216,
37518,
134036,
31040,
386582,
262726,
356653,
154408,
132016,
22893,
28118,
349466,
244289,
13647,
8824,
107590,
159902,
10978,
8077,
112662,
32214,
31043,
8712,
12611,
32674,
125288,
27910,
179407,
530675,
21954,
null,
50047,
47996,
18809,
57982,
365072,
75521,
155485,
176521,
53865,
48647,
null,
55126,
41345,
null,
48408,
410422,
30008,
42119,
152385,
119414,
159259,
363890,
50259,
33369,
272306,
189232,
573300,
298776,
34642,
269301,
494167,
282374,
20714,
133163,
6262,
132882,
null,
253570,
341345,
163728,
42539,
307018,
null,
103344,
28451,
255828,
30055,
200722,
345780,
47400,
92926,
44983,
200311,
null,
37893,
46364,
298692,
282040,
84803,
13108,
135764,
280380,
141850,
720248,
435630,
159905,
31178,
251100,
19551,
271683,
159483,
37414,
246029,
407100,
166560,
185790,
90872,
11050,
182395,
72092,
144981,
463131,
27512,
36625,
null,
7530,
10239,
101140,
40119,
15439,
35701,
32306,
454547,
470814,
134646,
null,
48779,
8009,
464310,
10387,
189410,
272084,
57812,
145736,
164799,
25585,
5127,
18266,
363418,
null,
144765,
398427,
234664,
10596,
9303,
178297,
null,
12898,
24732,
54179,
426743,
13843,
387518,
317653,
219417,
237866,
226026,
null,
235349,
20327,
197020,
20747,
142758,
39619,
47202,
204145,
205875,
117882,
162151,
357144,
191042,
308369,
201361,
42246,
288683,
21982,
277271,
110179,
279011,
194964,
116523,
20532,
314873,
465156,
10977,
6624,
377383,
28824,
54375,
96425,
269898,
183709,
288408,
391757,
176367,
54366,
34755,
22418,
12396,
94712,
211442,
42470,
105965,
4817,
null,
24864,
181809,
28894,
146721,
3134,
26287,
22696,
9072,
7967,
34582,
62233,
17844,
101654,
342144,
27308,
361564,
589658,
23879,
59604,
45905,
14569,
102198,
28139,
105305,
254561,
null,
45854,
153039,
24618,
null,
37578,
70375,
401394,
110344,
60032,
136329,
247211,
318326,
59740,
85897,
50885,
273600,
73387,
37979,
null,
41791,
44311,
127394,
5483,
null,
428364,
9301,
31307,
103303,
24108,
209626,
117102,
263234,
22280,
236597,
3306,
59715,
264021,
354403,
31810,
31493,
348830,
167649,
377623,
32711,
26284,
24118,
83008,
90565,
24420,
4875,
null,
142432,
371175,
72936,
121664,
18920,
16017,
65744,
198850,
151858,
166794,
244372,
157395,
102672,
44071,
16605,
183739,
41790,
66571,
197798,
163085,
239734,
19074,
94238,
103212,
18876,
535847,
11033,
null,
30730,
207817,
68090,
157166,
8210,
654336,
97106,
null,
585824,
38384,
46596,
266568,
138427,
117370,
71620,
3246,
264659,
2742,
16962,
11057,
21065,
35580,
141953,
33617,
13373,
45911,
null,
104549,
31921,
46487,
13661,
45083,
20402,
359972,
84367,
164574,
335835,
76587,
7964,
556312,
207176,
50571,
522939,
207454,
320492,
33610,
null,
235846,
11424,
187804,
302417,
9692,
181959,
12074,
25131,
921640,
410156,
57250,
343079,
56201,
214391,
118438,
419082,
12243,
null,
219959,
162203,
null,
15951,
null,
55673,
305966,
170391,
61551,
375378,
175072,
34525,
14796,
311628,
171845,
112236,
36427,
356246,
92414,
358943,
15630,
292119,
38840,
402059,
7080,
189942,
599910,
5814,
115657,
252525,
123989,
null,
111586,
30191,
187741,
190044,
239548,
34487,
3031,
298384,
null,
218829,
29391,
8484,
24003,
7057,
16897,
160481,
56018,
402170,
76888,
33638,
51315,
170714,
55022,
null,
354466,
33952,
295879,
270006,
76073,
98224,
169334,
184720,
99383,
null,
197468,
103062,
25123,
357765,
186228,
62030,
null,
59656,
21227,
162790,
198040,
425734,
29502,
75203,
237273,
197199,
74047,
177883,
292439,
39595,
33364,
196414,
23368,
33959,
665264,
20410,
510968,
589272,
116226,
197043,
75465,
48537,
179251,
113566,
null,
20166,
292228,
null,
121453,
123626,
199594,
276618,
240437,
28460,
186766,
249909,
31406,
669956,
135402,
59441,
3616,
null,
90400,
264413,
120704,
5937,
208403,
46551,
24598,
206357,
417573,
24910,
69542,
267592,
258195,
346207,
257273,
53114,
4444,
423518,
147053,
183138,
19443,
23888,
361666,
216833,
154600,
89071,
237884,
28747,
92841,
31834,
76898,
115857,
20855,
63237,
292212,
14426,
148607,
9033,
291037,
4436,
null,
422373,
20221,
10442,
16461,
14400,
11603,
7875,
61439,
41042,
61205,
75838,
18151,
7887,
387996,
17276,
60180,
255052,
9144,
472675,
138071,
66108,
471787,
157676,
226085,
381154,
17402,
133182,
null,
309983,
14482,
52952,
433440,
8196,
50012,
24837,
null,
170087,
null,
617886,
31329,
23460,
20332,
162810,
33451,
120050,
138324,
162473,
257163,
18171,
157742,
24887,
null,
268462,
57513,
null,
null,
38955,
99267,
321911,
null,
224673,
238337,
108576,
430967,
371094,
9745,
258994,
9060,
122969,
395289,
298218,
77601,
132355,
243449,
34550,
28929,
52797,
228140,
225881,
42644,
null,
null,
292150,
95486,
179122,
null,
295042,
19304,
52056,
26987,
null,
33857,
41328,
null,
36967,
178871,
null,
201949,
485810,
null,
112875,
null,
234912,
7814,
385845,
200693,
27041,
84082,
2836,
182720,
67509,
742838,
120247,
97074,
69470,
8283,
28419,
60432,
253354,
204334,
22618,
34619,
24135,
23761,
485196,
null,
357950,
194181,
20115,
182825,
35010,
340594,
281065,
91584,
67050,
137444,
230533,
null,
287274,
207240,
6496,
23544,
27230,
254314,
644761,
209098,
121047,
17226,
111352,
31640,
241981,
25791,
703395,
312435,
38295,
209294,
23326,
8544,
147367,
1911,
83258,
163191,
17142,
275354,
496015,
null,
68265,
229145,
68411,
382822,
58159,
819319,
137880,
7707,
343426,
55163,
15254,
77250,
31457,
64623,
333774,
92787,
446584,
142603,
30360,
48581,
13357,
290621,
333382,
null,
null,
145611,
60466,
123776,
282340,
33108,
137781,
177450,
8773,
9790,
220697,
34901,
74533,
211805,
null,
61582,
308093,
14404,
27325,
466004,
289173,
878339,
189046,
175128,
23917,
11874,
137578,
null,
345012,
21716,
null,
34744,
26864,
null,
162671,
23550,
274228,
1537,
19034,
20939,
151126,
15604,
53865,
228520,
14511,
null,
73718,
98029,
null,
3540,
66045,
40317,
35670,
53314,
21807,
114517,
19729,
null,
1329807,
20835,
34952,
63001,
193582,
195037,
34736,
239798,
26532,
206540,
275255,
960818,
15169,
290429,
177262,
56673,
106404,
435469,
18199,
5727,
149795,
14926,
315280,
29599,
372031,
391914,
209844,
10135,
63727,
60982,
37443,
321980,
null,
12907,
22285,
172126,
42783,
186795,
28777,
226692,
27993,
6047,
14541,
170778,
98659,
20928,
57123,
9113,
232257,
198794,
47832,
63518,
43945,
24348,
51344,
17809,
null,
null,
null,
48929,
276795,
612298,
34975,
196303,
54226,
64748,
278944,
166432,
27972,
324490,
219063,
28805,
null,
361629,
65698,
26541,
282806,
53271,
127138,
33309,
46757,
113185,
90364,
17065,
192671,
23842,
22283,
280046,
null,
7784,
253373,
null,
61498,
361834,
134774,
13138,
217689,
309121,
50502,
131464,
301687,
229831,
147109,
235376,
233056,
39090,
20885,
36304,
12983,
192507,
67154,
null,
30206,
126607,
61495,
19369,
94424,
9262,
43847,
42809,
44914,
197961,
154604,
79534,
10712,
315761,
42108,
6195,
138599,
56724,
126379,
37541,
215836,
98491,
126922,
502915,
101104,
48996,
140214,
72305,
416272,
48813,
44933,
30845,
239907,
146547,
176739,
109488,
309294,
929860,
139642,
16025,
35036,
327910,
9772,
37388,
205143,
null,
45581,
23879,
187685,
108460,
374203,
null,
154684,
11443,
273546,
148866,
202877,
28802,
66005,
5959,
52096,
134091,
52012,
127959,
25104,
10755,
39950,
8988,
47939,
153842,
52084,
40475,
4573,
173634,
69081,
45894,
33040,
108720,
98278,
32838,
143490,
null,
708735,
21956,
45367,
27663,
20513,
153931,
230585,
7567,
37350,
176021,
7295,
57465,
38186,
241536,
15678,
172155,
27468,
6384,
79276,
null,
65092,
74578,
35722,
31828,
79306,
68660,
null,
443972,
26501,
24427,
266577,
15628,
33667,
314520,
54045,
146439,
18136,
42884,
121731,
308546,
308372,
152706,
46048,
569331,
40485,
82674,
217230,
31797,
18290,
1805,
30520,
21540,
25820,
31149,
3536,
47859,
55293,
33027,
241260,
69423,
180935,
41813,
465061,
174589,
148628,
48034,
30577,
313942,
428071,
320178,
527832,
69407,
19417,
23114,
39963,
110904,
168018,
38208,
null,
111949,
2274,
47393,
29624,
32447,
20765,
9482,
562627,
390053,
234319,
23790,
102263,
163898,
28028,
77282,
25298,
318888,
136240,
209556,
253209,
null,
167094,
471998,
5016,
16765,
130243,
140929,
28711,
292419,
37818,
286422,
232985,
55501,
102910,
16800,
188191,
622282,
249409,
170125,
191425,
18278,
null,
217805,
16041,
255946,
25804,
null,
109283,
null,
107458,
162402,
57397,
74400,
40721,
194693,
161198,
389663,
47232,
9769,
31012,
null,
15366,
255638,
131471,
null,
131471,
15354,
7482,
63541,
null,
234202,
77710,
212455,
21429,
161185,
301037,
401124,
18954,
19858,
553842,
192261,
410054,
109731,
168356,
546320,
20666,
213128,
48814,
79415,
39168,
211779,
61194,
483935,
226820,
5989,
13792,
235967,
null,
35422,
203267,
168996,
41987,
330177,
250484,
null,
304395,
132558,
55663,
223170,
18139,
32966,
174056,
71589,
21616,
16803,
199110,
610775,
null,
142447,
109492,
42286,
348903,
10118,
32812,
null,
91076,
125011,
55849,
169268,
97908,
230656,
755595,
92398,
16095,
5836,
22337,
90523,
122255,
41339,
156097,
null,
55975,
22723,
371359,
20674,
26700,
272214,
227005,
203905,
30033,
20962,
30683,
13409,
125503,
null,
189893,
30206,
70275,
319303,
92760,
62229,
18589,
278510,
146169,
327311,
391172,
null,
null,
101778,
15237,
406556,
53255,
20342,
89938,
286085,
167289,
59084,
11118,
41089,
117163,
244026,
248410,
15693,
23730,
263908,
38535,
33073,
133605,
27257,
29794,
null,
165206,
231406,
225828,
324912,
19030,
307713,
80154,
null,
579513,
23270,
22217,
46380,
41997,
65062,
95408,
37637,
11989,
33719,
62058,
null,
90005,
219950,
37028,
185514,
142250,
59003,
639918,
165806,
50202,
203827,
156714,
null,
27533,
297881,
null,
166190,
184998,
186501,
54009,
72821,
62613,
30317,
132493,
21100,
49140,
145197,
17219,
4397,
263094,
11906,
39883,
null,
160904,
30520,
295564,
49445,
487431,
233786,
23800,
586046,
279035,
26274,
51608,
null,
7652,
24024,
40229,
9577,
27539,
null,
16632,
82227,
507928,
134118,
49985,
186068,
44179,
28238,
7288,
202494,
44798,
208073,
140494,
237039,
50036,
20164,
413280,
19606,
21469,
70948,
255682,
3084,
157746,
330603,
340825,
70279,
54240,
36703,
141167,
147226,
null,
402012,
292396,
79074,
46804,
40256,
84239,
433796,
123244,
26564,
192490,
105466,
121708,
197470,
273001,
null,
48694,
null,
21592,
20673,
51255,
null,
6062,
23519,
29126,
119599,
35061,
270495,
181188,
154167,
null,
79241,
18820,
null,
417259,
87551,
130228,
430588,
8970,
131701,
40976,
null,
22709,
123897,
9540,
40477,
245664,
329033,
332221,
268725,
114959,
21551,
48537,
25618,
168877,
42709,
11915,
97700,
302021,
70719,
13859,
62604,
106834,
415050,
639211,
40720,
133244,
44964,
217813,
null,
15907,
null,
62866,
21018,
17890,
59251,
122722,
4726,
351755,
112068,
44532,
29723,
428498,
16725,
30146,
103201,
17441,
null,
85076,
42590,
399699,
307488,
22275,
232064,
69274,
51400,
null,
47179,
358529,
31799,
172993,
146749,
26922,
60212,
520225,
68813,
287943,
9842,
392270,
229860,
14029,
10928,
21362,
32109,
5435,
40758,
748170,
244439,
164908,
330492,
225314,
77532,
29610,
523282,
55374,
null,
185701,
227935,
86080,
12048,
40276,
25122,
160943,
49333,
153673,
9685,
null,
38253,
20,
16861,
273560,
29991,
78209,
81290,
193013,
140021,
53460,
47869,
67049,
130782,
385297,
38890,
143772,
15672,
23534,
37090,
103569,
72998,
15363,
425887,
22319,
49719,
9240,
17112,
73948,
11963,
16976,
591866,
77364,
null,
17214,
39654,
65154,
203519,
45923,
198094,
18051,
287671,
141752,
423294,
52121,
null,
68498,
196249,
20412,
371290,
512352,
17099,
20978,
46261,
16769,
43947,
101117,
21371,
26672,
null,
29031,
221269,
36047,
156996,
239891,
51427,
211152,
58603,
20556,
40083,
23027,
null,
88152,
29384,
14547,
48777,
26950,
40464,
182295,
384048,
288176,
78463,
10268,
null,
51625,
44808,
132935,
185859,
193323,
9751,
264756,
4896,
261318,
455855,
112050,
309246,
341353,
730276,
115435,
36250,
74797,
49652,
244767,
69922,
53013,
64270,
237326,
41757,
10899,
175390,
null,
31722,
null,
197396,
60154,
42489,
100267,
72929,
167461,
40288,
8792,
51209,
34093,
160690,
25762,
17393,
null,
20945,
47035,
186676,
30364,
null,
96663,
42113,
283976,
263336,
42572,
41835,
62927,
195204,
48224,
18746,
157953,
null,
3766,
53443,
324380,
20487,
74507,
19934,
51057,
77020,
234474,
36486,
175851,
6397,
null,
13720,
10132,
278062,
null,
27816,
88248,
14702,
216212,
null,
143016,
8921,
303922,
68898,
441571,
33274,
20029,
34213,
35358,
35267,
21482,
353248,
268054,
214270,
30984,
310649,
228861,
299962,
33232,
181744,
55849,
7452,
32860,
33230,
31100,
39057,
91607,
14292,
38209,
215128,
119933,
null,
201868,
59899,
null,
20004,
145048,
288304,
9506,
45584,
174315,
243723,
526048,
222758,
24083,
9081,
281251,
315249,
49983,
17437,
null,
541549,
372918,
493123,
196139,
30267,
null,
222608,
null,
22222,
32045,
8337,
44033,
56291,
10429,
101613,
220023,
26789,
13573,
112109,
132638,
23160,
24973,
null,
21483,
365899,
50372,
138434,
343952,
37497,
313044,
26882,
81328,
13619,
35917,
427731,
6832,
null,
78201,
33330,
53100,
4914,
109857,
258540,
null,
null,
60693,
null,
10079,
null,
380153,
14023,
382638,
513564,
15369,
94490,
300502,
null,
275466,
18652,
212775,
625580,
16064,
168314,
145703,
34888,
88779,
14848,
31925,
20854,
228116,
275725,
110407,
172116,
34628,
8756,
42838,
572512,
19941,
113624,
28520,
233763,
170216,
29554,
169065,
null,
82642,
114174,
118898,
260155,
3143,
768948,
173570,
12418,
31554,
null,
451209,
205147,
12734,
212786,
24635,
59104,
31967,
224635,
17854,
132953,
280088,
53654,
7868,
null,
166439,
22351,
527193,
296599,
17763,
24595,
31002,
760945,
149053,
44137,
70132,
40260,
76177,
6720,
162304,
66450,
659214,
24164,
275095,
null,
null,
10825,
22696,
108910,
49144,
128063,
37459,
49754,
120977,
61554,
140785,
187005,
14929,
29060,
null,
null,
59267,
98880,
7743,
null,
354632,
199151,
106643,
null,
214813,
214086,
198726,
422842,
224879,
12493,
48598,
204772,
279681,
57121,
154603,
100931,
242631,
189623,
177354,
108427,
16606,
315174,
565470,
4825,
63098,
125671,
11899,
47859,
10605,
371537,
130632,
246857,
194602,
138527,
7325,
138779,
76733,
32558,
4794,
9378,
null,
22023,
114661,
188910,
null,
39273,
15796,
214840,
292573,
36428,
39752,
305894,
39547,
26066,
378788,
158727,
111599,
171961,
594745,
63546,
521566,
65576,
25914,
166945,
45616,
52823,
448966,
100223,
35505,
136894,
20765,
320858,
258573,
23436,
60566,
76687,
158942,
12954,
79100,
4776,
267145,
195452,
216088,
35013,
119847,
115678,
null,
11128,
781456,
null,
null,
null,
15126,
null,
432679,
306403,
null,
233652,
286548,
9130,
14052,
34724,
19877,
13140,
27282,
null,
35075,
null,
253614,
174615,
53990,
196519,
145283,
267732,
142862,
327309,
83531,
699459,
14956,
11908,
111117,
426613,
null,
150657,
6006,
18597,
27594,
3845,
28443,
22191,
12429,
28563,
222130,
188229,
34351,
6816,
66307,
26651,
7120,
109245,
6707,
49840,
46691,
176861,
null,
75479,
328676,
7356,
275003,
34141,
271788,
193748,
150708,
213602,
136335,
306661,
63294,
56975,
54882,
208139,
183099,
112824,
287458,
10872,
309012,
32478,
null,
null,
null,
120182,
12708,
86110,
330121,
139653,
7461,
61626,
19205,
15843,
19696,
204243,
535756,
null,
20246,
145426,
23299,
144125,
249830,
213967,
16400,
254055,
292131,
741294,
252259,
218880,
22141,
9337,
25071,
66513,
null,
104022,
161400,
51534,
52697,
60562,
246481,
null,
15951,
19661,
75957,
392214,
282450,
22237,
384028,
30860,
544639,
20168,
6050,
989,
349126,
207475,
40615,
53289,
17004,
307151,
151422,
35219,
68428,
23366,
208579,
5956,
449193,
193155,
35800,
25128,
47260,
23340,
207090,
70900,
10054,
11045,
248688,
null,
null,
444429,
24615,
69982,
143875,
354289,
132430,
75274,
82577,
4024,
189038,
123800,
8982,
86717,
180951,
154615,
453602,
185823,
49572,
170851,
68891,
87829,
null,
132850,
59152,
318183,
248437,
62148,
737629,
24770,
69440,
229975,
136747,
615784,
443198,
28547,
19794,
166194,
159632,
107263,
14031,
58512,
223015,
15193,
44539,
341202,
265409,
262486,
223996,
147176,
131599,
46864,
371764,
584532,
null,
107974,
174607,
346852,
31966,
177122,
11526,
119968,
27057,
13959,
6513,
272341,
191402,
95092,
28035,
186706,
31088,
276363,
555807,
74938,
292342,
116538,
121524,
28124,
356286,
32048,
null,
6447,
315998,
null,
119734,
503448,
349183,
178110,
21004,
134017,
6800,
110034,
57238,
14194,
92642,
19510,
null,
73716,
21977,
153891,
31462,
321247,
109454,
49406,
345329,
null,
16882,
311967,
null,
292243,
133913,
121105,
14847,
27704,
269705,
335433,
9444,
42561,
111722,
585069,
21850,
246444,
28106,
12333,
38431,
420784,
9330,
246868,
null,
147254,
307795,
36741,
111290,
10728,
664776,
93105,
356934,
121599,
384544,
null,
5529,
null,
198717,
68326,
20926,
515632,
13258,
183052,
3333,
295335,
16146,
null,
28981,
13912,
28914,
26221,
371546,
272698,
24218,
212670,
9858,
42852,
327137,
220038,
115812,
344252,
43001,
null,
191181,
null,
77279,
34727,
390004,
null,
265034,
8743,
994739,
null,
14600,
null,
437974,
110334,
null,
null,
6049,
52416,
136300,
26052,
105329,
198712,
null,
78802,
8937,
39904,
181651,
63532,
null,
627549,
61170,
110731,
28977,
149265,
45227,
160354,
5053,
244986,
null,
36817,
131876,
132523,
39559,
null,
21451,
null,
null,
415590,
null,
null,
7397,
21113,
31550,
null,
243154,
30247,
165333,
261546,
null,
29259,
34010,
37340,
6116,
28328,
162609,
102758,
null,
167877,
2793,
22030,
114841,
107791,
179548,
null,
139487,
57680,
4498,
33940,
137287,
21364,
19942,
null,
419850,
578308,
145406,
260039,
106975,
4358,
35319,
267458,
null,
28850,
23518,
254371,
null,
null,
261022,
23074,
13699,
67650,
27537,
533992,
257600,
64977,
100465,
42365,
null,
68286,
null,
151733,
21703,
72430,
17563,
200951,
6355,
37538,
80415,
300833,
74020,
34132,
14403,
23771,
130430,
200989,
269809,
89321,
161458,
101170,
109573,
23135,
285497,
29407,
372662,
280525,
80427,
170707,
35763,
68317,
35545,
39903,
333627,
81191,
44939,
16501,
154083,
271885,
375927,
62834,
230444,
17596,
60890,
17889,
32713,
144622,
81444,
5500,
null,
40388,
41889,
46472,
74167,
333093,
38559,
28962,
98934,
244854,
99964,
75527,
294059,
254090,
13649,
306986,
null,
54908,
190772,
518560,
113031,
232046,
16391,
61389,
201092,
219010,
95871,
461564,
82909,
54115,
37887,
65472,
45006,
405338,
17272,
16266,
192073,
201529,
12879,
43471,
4856,
242237,
null,
238314,
55639,
40156,
331254,
42063,
18640,
null,
240432,
331044,
21678,
20425,
31686,
239605,
125288,
240751,
25541,
58392,
38941,
3776,
232784,
147045,
39556,
67168,
178732,
265677,
12291,
170823,
34021,
12234,
null,
30500,
234365,
287338,
563049,
24251,
95632,
44222,
284720,
12485,
183367,
23468,
null,
27248,
26763,
58991,
26337,
20516,
519706,
185713,
16623,
716836,
137436,
null,
559930,
440035,
145264,
65517,
138605,
449970,
218508,
193226,
23405,
138679,
213225,
52850,
2134998,
277356,
14777,
373708,
169987,
76694,
19717,
37454,
233281,
523640,
134100,
369532,
238096,
198740,
96777,
499760,
584204,
null,
138861,
54943,
31167,
null,
7006,
23576,
66354,
117509,
383750,
27982,
38203,
177193,
158694,
179632,
61750,
82353,
13709,
282244,
396257,
27061,
16409,
33163,
13218,
236550,
null,
149234,
51033,
373066,
96961,
68113,
261489,
49928,
121431,
39957,
153534,
305248,
19549,
254146,
118712,
195901,
5387,
336442,
267095,
185238,
61641,
159678,
208213,
26231,
219315,
307676,
null,
273822,
15876,
26277,
503511,
192625,
30500,
38288,
32274,
7270,
76654,
431952,
23866,
57953,
69189,
19289,
378638,
266930,
221768,
47451,
null,
49631,
15128,
7736,
135386,
246714,
55481,
113649,
169656,
126593,
17612,
27813,
43612,
83343,
66501,
304548,
140565,
91133,
289219,
15092,
19263,
null,
8891,
62606,
150702,
50072,
36055,
25395,
144676,
51233,
163301,
38566,
57544,
37853,
87164,
107503,
29675,
18522,
20684,
46352,
55209,
null,
183156,
23530,
31951,
17745,
34069,
47763,
48812,
84947,
47075,
17542,
223050,
53919,
334943,
370250,
335133,
69309,
24918,
83994,
null,
5157,
768976,
67414,
51390,
88427,
199200,
255628,
94191,
34259,
151242,
124572,
102794,
223774,
57977,
19603,
34006,
314800,
25894,
132790,
23302,
252752,
81867,
146180,
25413,
252668,
489096,
157533,
30253,
25424,
21272,
null,
8078,
323731,
31360,
57542,
92980,
50835,
45591,
457952,
304849,
358020,
185190,
62412,
142344,
221657,
46295,
27170,
25709,
11232,
13352,
39441,
100829,
8494,
118048,
77323,
304517,
224915,
55783,
32651,
205463,
27155,
120680,
18687,
157495,
606137,
28530,
225936,
100838,
null,
13237,
38987,
38607,
15592,
255390,
133458,
18430,
54228,
69580,
468950,
38806,
414671,
55819,
80992,
568245,
88903,
121504,
44647,
null,
161929,
23863,
820745,
34486,
114687,
11033,
145838,
12481,
7224,
48145,
735258,
null,
76720,
258147,
145210,
11103,
null,
35675,
202394,
83480,
460627,
17183,
68394,
158454,
85498,
64329,
135152,
79980,
14326,
168333,
15776,
null,
535395,
77144,
19048,
196454,
46762,
29657,
43791,
13677,
14417,
null,
148298,
151033,
53925,
12975,
334711,
75154,
104930,
14498,
null,
42788,
17940,
47589,
176315,
33103,
349206,
128262,
12708,
17499,
112382,
293100,
null,
161198,
154749,
4946,
60768,
46744,
36032,
453016,
319819,
152327,
47471,
59196,
34321,
23560,
22913,
214404,
99445,
174363,
243366,
30600,
203534,
173507,
81420,
32125,
16607,
26395,
19101,
30113,
80864,
52569,
63434,
null,
5748,
null,
25049,
174485,
26729,
259071,
69981,
162188,
120625,
294264,
61729,
198805,
439275,
44819,
195053,
25698,
423008,
198312,
26125,
254855,
7818,
80933,
272458,
86530,
165458,
null,
14803,
204222,
292762,
44543,
109006,
74986,
580866,
176800,
214321,
16158,
27372,
41174,
25744,
328280,
287711,
11683,
270441,
1620,
14757,
263198,
69423,
null,
37783,
129560,
528707,
38907,
112575,
14832,
35042,
233129,
200066,
125519,
240321,
107270,
4665,
17711,
419378,
null,
15988,
6674,
null,
142373,
426628,
179459,
39453,
175271,
217982,
36614,
18128,
null,
29690,
404596,
13848,
110992,
266959,
25129,
169691,
12430,
112383,
83824,
145257,
191689,
107568,
52478,
399475,
null,
199953,
10932,
100090,
10195,
138820,
260841,
313398,
45218,
176979,
158368,
25979,
353807,
4033,
24349,
226122,
4290,
331404,
17188,
37752,
17689,
51125,
50056,
207992,
722663,
189777,
67276,
314204,
113848,
null,
220204,
377020,
746402,
2739,
26958,
168870,
112499,
147090,
192886,
44137,
377688,
32662,
22342,
25130,
36716,
43996,
146729,
55399,
4191,
162961,
315816,
245690,
106687,
57164,
11430,
null,
123839,
72438,
139693,
92909,
25295,
41245,
32839,
18983,
24244,
172291,
177188,
239170,
43510,
57996,
34333,
188959,
208109,
6936,
43122,
null,
161914,
345298,
89006,
48894,
42818,
23550,
30519,
304408,
73150,
140013,
null,
26580,
67922,
null,
168527,
349896,
20187,
322598,
19635,
281071,
79744,
203673,
160321,
97968,
29371,
null,
null,
28175,
116657,
48110,
127132,
31968,
209886,
47477,
28058,
642004,
111925,
8833,
76803,
6335,
27965,
56866,
414407,
127342,
32243,
11329,
109965,
14580,
40650,
378770,
196342,
62739,
175049,
30670,
69744,
134463,
30755,
21301,
151190,
59201,
110929,
162632,
47652,
28488,
null,
55059,
21452,
28303,
31335,
null,
16994,
276462,
345336,
108414,
19630,
30402,
93089,
12651,
200311,
204551,
64115,
196622,
257753,
48371,
65090,
24738,
104389,
452644,
132526,
null,
27650,
33897,
172651,
31055,
31858,
24111,
138587,
null,
47643,
36937,
152766,
109808,
217073,
38334,
227668,
18186,
70626,
292848,
39923,
504628,
65260,
109424,
272569,
166637,
null,
138013,
76410,
225465,
360655,
321829,
62648,
28775,
106449,
168236,
10620,
42642,
16056,
40613,
43796,
null,
280689,
15196,
277516,
419070,
209704,
156893,
37575,
8348,
29297,
68100,
136416,
191039,
194645,
139689,
191238,
49965,
43162,
178097,
19289,
16784,
169473,
182429,
283880,
84978,
37822,
51571,
325114,
null,
25603,
29379,
458487,
23812,
null,
166396,
324551,
null,
88409,
34819,
384088,
243072,
66441,
253137,
131855,
116968,
35566,
421577,
27496,
34887,
26401,
118915,
22833,
42644,
36081,
354609,
47508,
157062,
270811,
7504,
6498,
75380,
29434,
41535,
null,
389723,
318271,
44043,
null,
11133,
null,
48633,
68943,
null,
221091,
344841,
122236,
12475,
140970,
29919,
60152,
5730,
null,
21540,
54120,
306956,
100332,
210861,
342581,
157383,
129757,
293089,
179158,
null,
81002,
272065,
164399,
30313,
234742,
82841,
223591,
211968,
188359,
344811,
304118,
37535,
320684,
35701,
37011,
36916,
10103,
7441,
39919,
259497,
23945,
3805,
13258,
18532,
31050,
94197,
12050,
270900,
364659,
84781,
15332,
296355,
54255,
113462,
null,
468677,
130489,
null,
37893,
null,
57776,
412901,
4814,
115408,
30317,
10447,
41046,
36712,
326925,
101117,
41005,
255609,
203527,
33268,
7364,
16732,
130926,
111233,
54595,
58726,
40734,
253999,
151115,
218588,
10629,
26512,
302389,
17952,
75971,
null,
31197,
15648,
7234,
289290,
180821,
20263,
43924,
63073,
283884,
6593,
null,
339238,
366921,
153258,
23191,
9023,
75891,
75883,
155992,
47010,
348128,
null,
148984,
84600,
338612,
341631,
134555,
115562,
325954,
154145,
43652,
156916,
27926,
44106,
214998,
234808,
33157,
21272,
183899,
305799,
439139,
264631,
102534,
157872,
23223,
76052,
244854,
126947,
217742,
680681,
31210,
379542,
null,
48983,
165251,
29012,
85383,
4551,
74937,
132432,
316258,
null,
38880,
208131,
200239,
184679,
175219,
191585,
18431,
108059,
26723,
1066302,
210119,
34873,
4425,
14459,
317477,
24090,
779859,
100307,
null,
39311,
223118,
16503,
161926,
null,
49659,
171019,
22884,
6836,
39837,
69600,
24616,
88099,
54507,
9275,
348808,
9123,
null,
22983,
null,
489138,
262751,
151685,
21178,
233723,
386286,
80076,
534969,
23001,
49792,
168389,
96890,
27705,
95697,
33972,
30292,
171998,
10815,
43154,
10520,
30338,
272714,
433144,
318161,
32284,
481172,
268190,
32734,
null,
325047,
20031,
null,
null,
240135,
149449,
242717,
421535,
5726,
236055,
null,
41291,
206235,
1765,
209598,
31540,
43416,
null,
70715,
211601,
194300,
null,
432768,
206462,
36048,
363960,
10994,
78655,
54712,
123116,
12142,
187096,
278586,
50603,
66973,
317434,
103436,
50201,
33444,
null,
null,
163244,
335891,
284191,
189438,
32754,
null,
452550,
621289,
26026,
221895,
39320,
37314,
290738,
null,
10576,
28413,
80425,
7938,
22482,
41241,
33036,
212098,
140633,
null,
112109,
275144,
13866,
85957,
250130,
234420,
298450,
null,
141781,
32759,
240899,
24189,
12687,
200165,
59602,
19031,
217888,
18377,
19745,
237776,
348564,
191258,
210890,
40204,
29431,
458904,
12802,
50548,
279104,
217750,
22370,
25663,
null,
null,
7086,
200154,
38088,
61387,
28491,
226959,
44755,
511253,
48215,
34914,
43440,
15824,
32685,
68536,
224099,
567894,
null,
104189,
63259,
null,
6018,
648725,
24021,
370739,
59997,
5915,
23444,
18214,
31594,
66960,
409442,
91350,
null,
509939,
69419,
17608,
357584,
435080,
101576,
38486,
176155,
193671,
17326,
208806,
255191,
79080,
136513,
39832,
45107,
30185,
243058,
9077,
7684,
327528,
86072,
25403,
13120,
150999,
28409,
239700,
166383,
8945,
16027,
84462,
160788,
200295,
189027,
54123,
146186,
17639,
18226,
32446,
230118,
null,
184166,
20774,
null,
223553,
67730,
400966,
6647,
30726,
86974,
21718,
120941,
164909,
208115,
34556,
67106,
null,
12122,
19661,
226542,
59344,
118740,
78460,
84691,
21111,
null,
79512,
130069,
36120,
52902,
57101,
30628,
130693,
64855,
3766,
801,
49668,
212779,
368922,
35294,
149280,
33570,
19568,
100295,
32572,
11064,
96398,
306431,
235682,
129162,
4439,
22384,
114165,
34081,
193959,
22114,
null,
179039,
115494,
null,
29671,
74953,
4897,
117759,
15242,
45255,
96842,
469458,
26641,
225924,
38672,
195933,
234062,
33110,
null,
52848,
13294,
430010,
332808,
232401,
16924,
241697,
143879,
381653,
431647,
257527,
56277,
null,
25811,
343806,
37037,
22573,
9509,
468691,
223013,
124154,
17708,
104229,
107261,
491984,
11642,
48254,
183689,
167673,
37198,
12247,
22077,
22581,
374153,
50234,
53560,
519513,
27536,
18706,
34267,
49972,
15471,
11103,
660012,
25788,
254978,
34673,
9344,
20124,
57066,
24767,
89117,
293275,
76147,
15976,
129523,
149280,
148919,
90779,
263547,
38926,
38097,
360022,
207067,
146657,
150772,
9346,
68139,
342965,
null,
328767,
216512,
13912,
325783,
264423,
25374,
56070,
269316,
23306,
116444,
null,
54035,
477725,
28190,
41543,
30615,
24225,
23972,
20760,
38012,
330707,
366858,
2815,
225205,
36224,
316421,
141481,
142442,
67466,
51676,
69752,
80857,
29649,
2599,
10761,
null,
28508,
9592,
30270,
23578,
15094,
166008,
179281,
42178,
38542,
27402,
109516,
112161,
56618,
7990,
621505,
17114,
281522,
531101,
11765,
1392,
36759,
212622,
21780,
233173,
48652,
101093,
311172,
19851,
null,
247971,
150363,
312243,
28640,
163821,
43863,
120899,
345604,
41685,
null,
52696,
null,
34910,
0,
18962,
42742,
69236,
25338,
162096,
108153,
27826,
47244,
226960,
14812,
61542,
44469,
76665,
72396,
null,
591017,
25482,
218343,
239078,
218573,
37716,
9993,
20317,
7461,
101355,
46265,
29853,
249207,
17251,
118839,
286062,
null,
292373,
326648,
105247,
null,
65498,
73254,
409318,
35665,
495216,
15354,
null,
45350,
46681,
26718,
11198,
174804,
14090,
52724,
3783,
193620,
320435,
29031,
139581,
141030,
19963,
91635,
97106,
96013,
80816,
24027,
343824,
32680,
130987,
135140,
28716,
315111,
347368,
40230,
58043,
52959,
293969,
661,
23512,
231695,
136464,
181563,
33910,
37943,
25935,
25119,
28926,
142470,
30851,
322740,
41080,
311888,
289910,
18092,
20654,
6938,
210437,
17286,
205747,
55482,
11488,
348824,
null,
178337,
299628,
84971,
259006,
190396,
null,
33171,
35781,
null,
200379,
133159,
null,
86874,
212290,
297117,
null,
25090,
131552,
5631,
null,
38811,
34851,
131780,
66048,
302908,
null,
225759,
159308,
124206,
38570,
27433,
99397,
19381,
189015,
336538,
16393,
106413,
127579,
292358,
104523,
161890,
162514,
48086,
278644,
null,
373293,
1787391,
249806,
29069,
19329,
32946,
445485,
205582,
214813,
8796,
21843,
27673,
null,
127143,
130943,
215609,
170461,
9820,
333292,
39139,
6130,
8912,
177568,
24158,
403221,
198389,
43012,
15019,
null,
95665,
89318,
31018,
821605,
245531,
131678,
187181,
180277,
343537,
36134,
109764,
29112,
13100,
17579,
234450,
11579,
50565,
64032,
2531,
2372,
155812,
98622,
468673,
270404,
37720,
80837,
30775,
19756,
199637,
49961,
78460,
13377,
126457,
16214,
177009,
24986,
129706,
13785,
18497,
211643,
23110,
68655,
30517,
372506,
24333,
518188,
129905,
13423,
583234,
264533,
null,
170765,
217940,
341906,
17015,
24224,
194754,
58652,
87783,
22209,
441460,
601146,
356216,
null,
205988,
108710,
60198,
438183,
59604,
null,
122488,
69087,
59899,
45437,
333521,
21731,
null,
44316,
56973,
3516,
2143,
141851,
5886,
225376,
6123,
222648,
230219,
178343,
448776,
155022,
42091,
353587,
24806,
32711,
32544,
22233,
27026,
89825,
190814,
39956,
10863,
197976,
196788,
125194,
145187,
23715,
null,
216807,
509534,
123894,
28191,
599198,
79273,
62319,
22349,
184059,
220467,
251839,
288852,
76419,
9631,
167580,
207117,
34984,
null,
null,
10396,
329306,
145986,
311603,
841012,
271662,
14764,
22661,
12508,
28282,
168458,
67907,
139998,
null,
null,
244081,
244229,
null,
223227,
208480,
null,
39741,
141643,
34482,
26377,
133051,
null,
174442,
140928,
206823,
25730,
null,
null,
38403,
53221,
29337,
91943,
91609,
52533,
90509,
1556,
53525,
185954,
60036,
147927,
28413,
16891,
38978,
305627,
148361,
133396,
287624,
37497,
129002,
12880,
30537,
349442,
19057,
203144,
264853,
null,
35665,
48944,
102483,
39733,
46060,
224115,
null,
277429,
208657,
26493,
36393,
215341,
16112,
355132,
7271,
35901,
3657,
null,
332568,
179584,
44576,
220594,
134998,
58296,
187380,
41326,
2308,
160550,
76027,
396271,
460038,
53579,
null,
null,
437724,
122600,
18052,
156280,
330926,
14065,
278220,
null,
150239,
122462,
24742,
18363,
69293,
192639,
35511,
45330,
154452,
266827,
28440,
null,
112875,
131606,
90299,
224188,
40557,
167923,
169896,
203955,
1273080,
93753,
336794,
22616,
208003,
60198,
219783,
null,
144405,
81748,
4914,
78239,
19714,
143505,
68731,
339675,
13683,
18070,
312915,
14989,
32274,
12808,
982076,
217582,
null,
72085,
153884,
219550,
18511,
99387,
7716,
9987,
246386,
174946,
30182,
96113,
191967,
251205,
278245,
57400,
156123,
36502,
60217,
180553,
25563,
10946,
123439,
219571,
7629,
64686,
12041,
253560,
54160,
7450,
221136,
30229,
38643,
122662,
317813,
125343,
79272,
40103,
9397,
38,
166435,
143073,
344131,
null,
null,
19862,
6184,
109470,
258526,
58168,
145007,
null,
170013,
290661,
154785,
30158,
67150,
11256,
21642,
378192,
123269,
8097,
22992,
124373,
9020,
202559,
44138,
19686,
218349,
110631,
12743,
5197,
615687,
265779,
64927,
171088,
343980,
9326,
201079,
6405,
33801,
161752,
35748,
77766,
207066,
69270,
33540,
187643,
95559,
63577,
null,
17499,
39201,
279008,
53924,
51982,
32821,
null,
20287,
64238,
132776,
37921,
78681,
null,
175042,
138989,
85020,
407421,
40701,
13751,
131583,
47807,
39516,
110237,
192455,
13459,
16650,
7754,
106944,
244119,
43941,
null,
228419,
27325,
208226,
269234,
32831,
100000,
256938,
146540,
null,
52415,
null,
166161,
39761,
21506,
54883,
null,
100379,
83871,
5346,
110255,
84149,
150711,
26558,
6735,
92344,
262707,
408136,
135040,
194001,
19079,
206447,
123367,
14837,
132343,
305229,
38040,
16979,
106377,
141030,
12768,
null,
358737,
958527,
30056,
46382,
5416,
214524,
168189,
436371,
8233,
103440,
204575,
178528,
22591,
176281,
49895,
14330,
63143,
207372,
30865,
243224,
71750,
674222,
46089,
68196,
111426,
226548,
276763,
null,
630539,
200325,
null,
22281,
263654,
null,
542565,
10382,
59606,
94167,
null,
62585,
100887,
null,
20000,
3125,
53331,
135469,
null,
81705,
209268,
184983,
81409,
23391,
20160,
30020,
430687,
23646,
40613,
13024,
204668,
null,
16398,
136966,
102783,
29957,
159206,
75237,
14812,
142142,
111493,
156869,
null,
417275,
291970,
52265,
44834,
3236,
null,
97744,
388785,
66723,
33138,
232760,
185485,
58663,
274741,
25112,
34152,
56782,
521659,
77206,
296588,
null,
200825,
22916,
92356,
24076,
171738,
20595,
140178,
8249,
null,
115557,
28318,
62388,
9593,
35204,
15517,
146929,
31413,
262518,
11409,
32491,
217658,
117882,
28785,
101077,
null,
342253,
null,
1063,
15948,
296698,
137366,
41719,
224308,
126434,
20499,
1080043,
188389,
30500,
50247,
247125,
374297,
12920,
73767,
346309,
null,
25873,
95111,
244817,
null,
null,
15049,
148100,
151948,
39018,
200853,
328987,
233854,
477666,
261998,
10648,
260285,
15557,
90566,
4301,
13156,
324773,
261763,
37739,
206538,
4966,
13223,
27571,
58875,
9934,
120659,
51573,
null,
53438,
34929,
48141,
43881,
420142,
46105,
269068,
73115,
424956,
140619,
39600,
8634,
21805,
8957,
39946,
64642,
97196,
354524,
252644,
150713,
10434,
680759,
90278,
148030,
165596,
73998,
191414,
44468,
141573,
141963,
213465,
361178,
47233,
41750,
null,
157051,
402620,
38249,
109664,
470984,
110668,
null,
244878,
168552,
825092,
149993,
214690,
151257,
92527,
9558,
80827,
44055,
31047,
204122,
103085,
259590,
84732,
328523,
758717,
149267,
238040,
null,
244693,
73881,
67297,
null,
27410,
175774,
32126,
14606,
501255,
13224,
32093,
397918,
127419,
49880,
133532,
126813,
90706,
106202,
8894,
165730,
30281,
161682,
373291,
484111,
214262,
364924,
null,
29201,
56962,
307116,
47774,
308718,
16118,
197487,
394719,
27230,
230304,
167878,
201387,
601523,
196818,
17299,
205157,
12111,
309317,
144864,
null,
197039,
null,
268270,
23440,
null,
147576,
155555,
90380,
150506,
44127,
50977,
190411,
20336,
30246,
266662,
46686,
219437,
149699,
30860,
31829,
18481,
180975,
19302,
24184,
527464,
28744,
86355,
129778,
130443,
387961,
141761,
192113,
201204,
63083,
15340,
68450,
15449,
43546,
15908,
30870,
178009,
11205,
64694,
53993,
299394,
null,
165900,
92773,
62208,
10256,
508052,
144671,
58577,
121317,
30539,
78986,
211548,
150626,
23169,
20628,
72912,
170301,
312333,
28585,
198042,
82162,
319489,
879838,
445062,
43508,
65117,
null,
67385,
375070,
1607,
409589,
76532,
25808,
222681,
287228,
17353,
115633,
21899,
29830,
166047,
247255,
null,
59751,
207753,
53653,
20415,
186857,
7631,
20031,
18444,
null,
16042,
218730,
181392,
6982,
280992,
54026,
56984,
null,
26848,
575314,
23467,
84439,
126248,
204316,
144071,
35552,
4089,
41374,
367016,
46171,
29165,
115110,
103669,
35678,
132550,
12499,
2307,
77401,
48784,
15806,
91909,
213766,
286547,
143250,
36699,
33167,
null,
null,
105825,
33249,
248350,
7463,
177758,
34061,
147570,
11586,
47657,
43989,
32891,
95002,
204305,
20699,
344159,
28509,
177778,
342970,
77569,
184292,
586196,
493205,
16264,
34869,
52690,
221555,
255994,
42941,
161021,
null,
32029,
null,
25362,
100906,
50701,
10603,
17001,
null,
211744,
68456,
62061,
52526,
296742,
42877,
542437,
20837,
374877,
59545,
19634,
241767,
22806,
433258,
36594,
29363,
798107,
60730,
257797,
307456,
18500,
18133,
null,
20940,
22902,
100638,
30556,
4258,
96512,
null,
56116,
47075,
42513,
109494,
null,
52972,
108534,
141171,
null,
176631,
150491,
15480,
5863,
14151,
28102,
83889,
15513,
357178,
131871,
32222,
316773,
50924,
83629,
74436,
577,
16468,
210271,
22995,
14878,
11833,
64169,
903,
4511,
7943,
73052,
131732,
50370,
3215,
32220,
240190,
3571,
128431,
124570,
432529,
25439,
127056,
25830,
54642,
140842,
383511,
881417,
60328,
262023,
263651,
53835,
160677,
31401,
23019,
null,
234511,
null,
223853,
342999,
154040,
277902,
48413,
195944,
198544,
11197,
25342,
121194,
151191,
84972,
26891,
null,
189437,
317831,
404433,
26327,
284890,
22034,
null,
1663,
46119,
15995,
185988,
36900,
149232,
33631,
153272,
47949,
50999,
null,
null,
null,
null,
144078,
595564,
8577,
112013,
35330,
37341,
3082,
143141,
35539,
23610,
170042,
null,
14186,
243905,
96564,
179915,
64959,
318554,
63348,
28640,
66931,
39527,
null,
551060,
51118,
22311,
43753,
38072,
63070,
null,
8250,
51467,
229635,
211712,
119386,
16999,
100591,
46290,
154822,
8014,
192810,
152507,
39073,
9779,
16196,
10151,
17262,
69992,
null,
6987,
196979,
null,
91152,
46069,
406753,
null,
52312,
99257,
5170,
25561,
161083,
null,
266654,
74330,
331152,
512994,
667730,
38073,
243258,
3744,
null,
12100,
236847,
80557,
17793,
303122,
null,
38642,
496126,
21105,
532839,
335356,
67116,
92443,
224397,
302065,
42838,
4904,
44499,
159758,
277591,
24439,
85166,
160811,
9008,
null,
12520,
241799,
102054,
69426,
15715,
265996,
27079,
326060,
147122,
8606,
31215,
100909,
184507,
88896,
18388,
405223,
286677,
4993,
317403,
24395,
172465,
48948,
706357,
21985,
42429,
24214,
17047,
41981,
10620,
124005,
30325,
17624,
36773,
731348,
null,
96428,
11232,
31805,
12633,
342418,
81047,
52213,
17776,
15302,
49062,
362662,
44590,
65433,
180015,
1110701,
49483,
null,
20022,
49009,
17939,
73712,
15048,
8407,
162171,
25527,
71295,
48387,
181449,
77726,
1191,
185544,
32933,
4354,
null,
191105,
160070,
22383,
198863,
9459,
7787,
453873,
149691,
31568,
31156,
122754,
null,
45391,
45077,
3291,
null,
177488,
6636,
52269,
30571,
24178,
21710,
157270,
175044,
8721,
42530,
48056,
null,
278837,
199652,
231357,
190429,
10464,
51737,
266136,
373228,
52623,
38674,
39227,
624896,
null,
16081,
71387,
51434,
147160,
16494,
414576,
5657,
42785,
41748,
19744,
57568,
492952,
129439,
19534,
27016,
48394,
177285,
60223,
275869,
80320,
53346,
179863,
8280,
145373,
null,
15084,
17710,
20505,
249120,
null,
53470,
115534,
108776,
35218,
170173,
116694,
250629,
30247,
6990,
143238,
63835,
6389,
null,
281723,
40704,
70440,
27192,
null,
284486,
29423,
61761,
168038,
72207,
109163,
47416,
334512,
144755,
261724,
179595,
null,
237487,
4213,
25490,
407985,
84658,
2318,
162967,
126032,
null,
215322,
240406,
708680,
548987,
21179,
118810,
10999,
19099,
730486,
11605,
39710,
288439,
33667,
28544,
35833,
null,
134361,
271672,
217064,
44727,
154535,
27527,
184034,
14333,
19222,
null,
191307,
37108,
54465,
74917,
118038,
43780,
176685,
269420,
null,
null,
54570,
618979,
28105,
104882,
67389,
255263,
370251,
161221,
19931,
14288,
247237,
24614,
6370,
81041,
112605,
51566,
56203,
194847,
5425,
270180,
13006,
126715,
383510,
161550,
201274,
127445,
272839,
34785,
37338,
368585,
28220,
31315,
226133,
5681,
196582,
126202,
67706,
141207,
311166,
299756,
104247,
376693,
97963,
28345,
169876,
194793,
1161200,
134432,
292515,
52232,
90055,
32588,
13751,
22644,
24903,
24353,
225925,
43502,
null,
301241,
214324,
93197,
275063,
281360,
81877,
null,
167214,
61534,
114474,
174652,
117129,
79672,
43615,
243663,
263165,
37672,
408928,
59713,
24636,
32329,
17688,
66903,
24917,
425405,
4428,
357189,
42981,
14137,
23957,
367963,
23498,
298846,
33789,
null,
31666,
15484,
249659,
114005,
null,
null,
49707,
262101,
112375,
662041,
134804,
null,
22535,
28940,
228483,
29149,
31891,
111610,
107938,
165581,
24094,
242949,
50999,
372984,
13190,
81115,
164121,
44861,
79392,
157388,
93455,
180226,
null,
40183,
9980,
320060,
177410,
43305,
2489,
28268,
122285,
9627,
null,
155713,
32016,
87423,
262356,
null,
16662,
123525,
128658,
97275,
5298,
49458,
24491,
29759,
107640,
163348,
null,
8806,
9203,
13176,
null,
163797,
28066,
320743,
17040,
29890,
156624,
500367,
65280,
192409,
107903,
250308,
322259,
305052,
141457,
70413,
128559,
227255,
365506,
300720,
989200,
240728,
634878,
288812,
null,
14649,
178581,
27948,
226135,
null,
115109,
null,
532415,
6577,
291098,
23414,
217164,
108803,
19824,
174466,
65997,
6816,
24177,
121502,
556429,
431404,
19018,
21915,
133029,
335697,
655046,
31160,
55956,
36262,
17783,
24528,
123570,
191121,
206816,
57465,
14146,
256446,
247784,
107941,
255197,
377306,
null,
76424,
43179,
232936,
428523,
383240,
165926,
14891,
213064,
107737,
96074,
360208,
264307,
253529,
24070,
267653,
47978,
57463,
240407,
76540,
26255,
null,
577568,
null,
20687,
null,
527786,
323933,
33756,
32373,
165103,
32766,
98530,
278028,
373679,
25330,
null,
null,
281788,
4423,
33439,
217397,
405573,
547036,
35098,
13416,
46971,
25109,
6694,
29771,
18994,
362207,
null,
66847,
295270,
278532,
366228,
65102,
73398,
45166,
222059,
146929,
33152,
437938,
108470,
234900,
183817,
402149,
null,
74528,
370142,
118051,
49460,
196913,
209491,
154118,
553926,
16335,
222416,
152710,
3808,
32391,
136311,
153314,
447925,
247103,
284717,
null,
51625,
350405,
104080,
11751,
140969,
28875,
56892,
267889,
225799,
612595,
79465,
19992,
41690,
47717,
259732,
118141,
263680,
36733,
267741,
150192,
282645,
200523,
83317,
7745,
19241,
11856,
18882,
9485,
39465,
572457,
21363,
null,
39684,
81463,
27916,
133551,
737989,
265998,
290464,
435418,
191741,
5414,
29329,
100881,
23504,
47250,
7401,
236009,
null,
180730,
null,
20501,
null,
68213,
null,
647323,
41160,
174230,
359660,
21605,
17143,
14209,
220382,
20105,
2018,
25388,
null,
null,
4074,
556428,
68349,
28375,
22913,
557890,
117725,
null,
23024,
61241,
79211,
68504,
74916,
219318,
181678,
100226,
242624,
80867,
43922,
132803,
285777,
107604,
36392,
34185,
433011,
114656,
4040,
5779,
41122,
14034,
74720,
34029,
5614,
33296,
16079,
171995,
522685,
60883,
98847,
6381,
166150,
222826,
20086,
353986,
264072,
322185,
null,
177441,
147926,
null,
null,
48391,
226704,
387726,
10497,
204393,
227580,
99461,
172126,
164036,
108830,
44773,
45413,
43307,
14575,
49605,
96336,
228160,
37026,
114655,
9591,
117041,
348502,
148923,
3461,
19857,
5715,
353872,
36630,
232696,
112981,
157919,
67597,
null,
47617,
17619,
18848,
null,
28231,
124336,
211098,
197506,
1348823,
236007,
78306,
334921,
54769,
17763,
43835,
20795,
null,
297361,
754500,
29284,
152262,
134618,
78732,
23836,
17793,
68224,
274916,
323343,
53495,
56947,
101558,
261356,
38264,
46845,
728964,
314028,
41552,
361818,
187664,
null,
65593,
64277,
8117,
39503,
331773,
46308,
24630,
149318,
53429,
null,
20364,
90241,
49847,
31723,
300568,
73485,
103653,
24576,
8319,
49156,
44664,
247918,
50221,
166275,
134321,
33290,
410189,
48712,
74769,
155048,
102572,
367696,
18400,
null,
50253,
6560,
68804,
598885,
22318,
23269,
267540,
18506,
118095,
17526,
null,
302520,
47923,
70191,
21628,
289810,
240933,
162218,
57166,
177811,
203338,
212496,
46561,
286510,
100760,
null,
74532,
null,
607002,
null,
283586,
34781,
207690,
134989,
7774,
22863,
463644,
27907,
214352,
165592,
32942,
429174,
24577,
219527,
493223,
254688,
66087,
158941,
25408,
24200,
18352,
157651,
38793,
null,
28416,
112819,
42248,
351829,
170525,
7115,
27885,
327705,
165449,
49593,
105672,
195495,
69087,
36835,
359284,
36971,
38755,
null,
12471,
684236,
14758,
33871,
92439,
112044,
57085,
null,
7188,
178093,
20460,
155893,
56844,
160836,
34826,
49544,
48215,
230535,
55574,
198659,
112682,
null,
null,
32764,
28530,
214049,
65560,
499758,
9985,
23875,
76341,
null,
291784,
241368,
null,
215700,
198088,
42753,
317104,
8448,
null,
149078,
25312,
312725,
33951,
144346,
5363,
449833,
29875,
75458,
323411,
103637,
38942,
56110,
154214,
1182474,
178109,
224250,
null,
419041,
187028,
31633,
101517,
47715,
210142,
39622,
100817,
48309,
487997,
28638,
351587,
15772,
160734,
20545,
151063,
303292,
51329,
208438,
285039,
327844,
184884,
554896,
31353,
null,
336155,
12762,
null,
92178,
68364,
20326,
43338,
123912,
13207,
121964,
150670,
341375,
105217,
296836,
251977,
298895,
31615,
315112,
55086,
5321,
238722,
47596,
284687,
5635,
26383,
164654,
201179,
182663,
35360,
221306,
74967,
227984,
390368,
69717,
5528,
null,
72615,
318185,
116131,
755579,
175017,
32690,
5097,
75089,
6449,
941851,
1247421,
null,
14650,
242866,
162140,
75878,
160069,
221920,
35852,
389327,
20485,
76482,
147173,
486937,
null,
109786,
78039,
2482331,
632725,
29712,
73412,
51916,
46693,
3594,
122078,
245648,
31435,
17823,
34658,
26422,
33404,
33449,
11403,
39856,
null,
31646,
35937,
490247,
23582,
28455,
null,
168857,
384828,
null,
14810,
8661,
25131,
60555,
240881,
116594,
166988,
254793,
38048,
88699,
126151,
14461,
100919,
130563,
251815,
146197,
126661,
59437,
278324,
13689,
null,
66077,
70074,
null,
407912,
169962,
116895,
27639,
202631,
12657,
137924,
30732,
121850,
null,
55553,
3779,
49931,
102969,
220121,
80927,
16994,
24341,
138718,
82386,
585365,
53118,
null,
null,
62243,
46392,
35948,
32647,
31364,
139546,
96921,
28532,
203619,
11410,
17194,
null,
231286,
18441,
231230,
39334,
35749,
204890,
32907,
30312,
130339,
74354,
65054,
21313,
298030,
148501,
45627,
473477,
null,
136114,
34619,
338103,
127489,
172177,
null,
91289,
575278,
null,
166555,
302760,
47254,
142498,
207210,
12147,
15887,
176207,
92718,
48450,
98318,
26055,
185766,
59820,
6272,
67024,
197109,
61436,
96322,
13907,
2823,
221542,
452544,
36255,
null,
39872,
76696,
230103,
406565,
88746,
null,
27047,
69530,
52062,
518338,
72652,
9791,
42588,
61049,
11409,
394307,
238180,
241764,
152095,
22661,
277174,
355081,
null,
383564,
9353,
185768,
33519,
294702,
75673,
391521,
68212,
null,
null,
1710232,
88782,
14373,
null,
50824,
22960,
44882,
92242,
225251,
187885,
146142,
22802,
26212,
52492,
null,
369531,
95907,
26749,
114949,
null,
41785,
329433,
35955,
11166,
48199,
65767,
46054,
313762,
180805,
57006,
39898,
87192,
null,
14264,
251345,
236818,
322310,
10901,
null,
11191,
33176,
49175,
55292,
337702,
108781,
null,
350620,
81211,
109945,
18244,
null,
55755,
8073,
130531,
18152,
371533,
25478,
138730,
36282,
413225,
129046,
75660,
6156,
15539,
23442,
62267,
26926,
null,
28140,
242362,
9801,
25357,
194192,
138764,
28142,
28907,
null,
321276,
189992,
14390,
359782,
190115,
588696,
56279,
6395,
22614,
196750,
163746,
181664,
221339,
362353,
154625,
357559,
34487,
null,
129786,
97113,
243948,
285989,
45549,
null,
403925,
2151,
208886,
93815,
519250,
45297,
92919,
406839,
15476,
1707,
233105,
189520,
116980,
24809,
24365,
162312,
2866,
891306,
151881,
176466,
15590,
37067,
205401,
28942,
null,
333529,
120894,
149624,
46102,
null,
497712,
null,
360031,
75367,
null,
182207,
291179,
null,
17644,
8124,
331019,
36164,
144728,
4157,
401534,
8930,
29921,
136139,
33594,
null,
45136,
28777,
28790,
174804,
30075,
null,
42962,
253631,
null,
365663,
189683,
61298,
166426,
40944,
null,
61443,
127345,
39679,
135942,
18577,
106784,
201074,
34530,
197147,
84760,
361382,
16732,
14222,
368773,
126124,
156390,
21598,
35491,
228800,
146395,
235156,
112466,
258812,
269781,
163536,
null,
null,
29808,
113128,
84490,
907858,
6397,
410365,
520017,
28019,
5007,
116669,
41361,
366556,
6714,
10549,
106240,
null,
104575,
75099,
52971,
432875,
258158,
256492,
7358,
103282,
91752,
177067,
34109,
15867,
59096,
null,
27299,
47561,
265113,
126798,
241309,
366679,
139859,
385274,
null,
747499,
272692,
372071,
95565,
null,
339816,
197713,
76522,
71028,
39312,
252816,
423970,
23629,
135724,
9980,
21478,
423664,
51006,
223183,
25268,
34684,
null,
123185,
5065,
37897,
26354,
37652,
63640,
35341,
95187,
134695,
243371,
28613,
183820,
22479,
40000,
21975,
149549,
297259,
362927,
19200,
31693,
158677,
71487,
34593,
167722,
52596,
258557,
215904,
177322,
8675,
null,
null,
122747,
33533,
163387,
270529,
49446,
339908,
93275,
340421,
685755,
181480,
216157,
4799,
50320,
4709,
317124,
7233,
237414,
128721,
42223,
33245,
33620,
71422,
50841,
33951,
280317,
36446,
217253,
13768,
200183,
364231,
149154,
1092523,
262440,
82641,
575328,
52140,
605550,
null,
712,
170055,
146374,
202278,
18296,
6182,
372510,
385745,
15057,
20324,
16342,
5957,
28623,
93104,
49508,
315702,
115724,
21111,
76485,
49737,
74143,
245940,
11530,
38344,
118524,
8067,
25586,
156739,
26347,
57919,
134287,
62593,
335416,
356611,
86749,
null,
220765,
344625,
92609,
51559,
183951,
39480,
176563,
20020,
null,
187741,
27783,
190373,
223673,
null,
72840,
262490,
417216,
137646,
374891,
17025,
267709,
103702,
84322,
29824,
15367,
57870,
29547,
18099,
303036,
22879,
400287,
49971,
302946,
51420,
5977,
154778,
13202,
null,
null,
7676,
17104,
264070,
424731,
70173,
363144,
69529,
34478,
61135,
236431,
279011,
15025,
25099,
23024,
161683,
26728,
25652,
198764,
753078,
94109,
44835,
146504,
526338,
null,
65585,
138142,
305208,
340222,
326362,
242664,
92066,
18317,
20209,
38247,
159104,
43121,
59610,
118085,
null,
6304,
295420,
20878,
13695,
148706,
93344,
46697,
10244,
32625,
45826,
null,
266401,
17366,
20996,
null,
287316,
15571,
162875,
30182,
25156,
35293,
108019,
44522,
268278,
41183,
171057,
35879,
315768,
272268,
null,
21097,
null,
250995,
216793,
36736,
254884,
37402,
398496,
123170,
13915,
88169,
198209,
254197,
21063,
null,
159942,
105270,
null,
7630,
21004,
257067,
63372,
40987,
162935,
144988,
21890,
74264,
125566,
null,
20562,
37834,
299936,
92181,
299643,
13480,
349908,
141544,
2881,
79700,
23918,
59803,
112031,
21530,
null,
55822,
184228,
29625,
270841,
215715,
21538,
349723,
30935,
263399,
74180,
62969,
170120,
293891,
197106,
189398,
371013,
30033,
192986,
40759,
6167,
50563,
55280,
13208,
58334,
229918,
160425,
58329,
81239,
85629,
27549,
99993,
311468,
56475,
15050,
174541,
89369,
12600,
318466,
295697,
29947,
10813,
195155,
18936,
39544,
485022,
25489,
370839,
18587,
200177,
4569,
65916,
22956,
7870,
3502,
258612,
265652,
null,
102123,
47610,
198833,
3031,
39288,
223011,
14914,
168642,
36193,
15608,
449220,
null,
28048,
714371,
273035,
88176,
188248,
180368,
17632,
324747,
75906,
63366,
29944,
228433,
36521,
303827,
174155,
21864,
70210,
44089,
122129,
5937,
439941,
73085,
26702,
43298,
38146,
207734,
150406,
37069,
126384,
12070,
158474,
null,
231712,
169903,
null,
138318,
694957,
280127,
359740,
95908,
null,
173782,
47561,
79331,
70048,
4986,
10936,
10460,
66889,
42421,
235952,
19894,
202093,
44823,
12066,
18173,
294880,
26785,
17115,
96723,
16962,
132477,
198182,
169307,
89142,
40096,
null,
51507,
220775,
250801,
19379,
205951,
150934,
19274,
null,
18119,
111356,
15973,
173302,
3008,
38175,
69363,
16950,
152568,
116940,
92880,
null,
null,
9946,
9438,
39233,
110922,
57536,
74087,
46358,
32362,
9865,
20817,
24562,
9420,
221281,
116767,
92423,
159041,
11211,
83293,
null,
192112,
16524,
12377,
107778,
23273,
79385,
20747,
88734,
39797,
41065,
13660,
64888,
25435,
190519,
215503,
73333,
122031,
54479,
24099,
100720,
64555,
223740,
6875,
230726,
59900,
209368,
16177,
100363,
10082,
39080,
99803,
573193,
109339,
141497,
159810,
52183,
21539,
27789,
9775,
25154,
332227,
11488,
null,
91186,
12045,
22664,
58449,
116531,
38986,
162705,
38066,
35431,
77534,
232932,
12931,
179519,
28380,
247169,
29548,
110873,
24428,
77290,
285578,
35330,
74545,
7448,
28877,
109057,
null,
193341,
null,
11734,
15022,
50676,
22451,
294867,
49101,
17929,
206785,
379275,
34594,
null,
14158,
1938,
284860,
73802,
74429,
5162,
8664,
56406,
121039,
null,
9715,
51783,
296858,
111430,
73299,
55544,
259057,
177385,
10406,
113120,
null,
209795,
158572,
368882,
125314,
6762,
42513,
null,
null,
155667,
281547,
34139,
41203,
106946,
56701,
null,
271635,
27691,
352845,
43865,
31949,
17920,
29440,
361749,
214868,
null,
234917,
13125,
311600,
103026,
259426,
192235,
158637,
37000,
19601,
38080,
369351,
172232,
81241,
11591,
305516,
84695,
166677,
75665,
43981,
164867,
14802,
null,
15205,
54971,
111179,
null,
441440,
427400,
350857,
83165,
null,
null,
236766,
160805,
41645,
167969,
16285,
null,
null,
367702,
38136,
67178,
176233,
11504,
313951,
214905,
181853,
126755,
11366,
64127,
null,
533159,
91063,
118544,
212952,
122208,
null,
77793,
153624,
null,
25134,
1859,
null,
39452,
16037,
362426,
68773,
null,
11592,
17008,
335295,
45612,
708475,
14526,
234866,
29898,
5797,
178397,
199495,
43223,
33884,
15874,
9039,
22111,
10624,
82587,
66456,
176199,
349435,
67097,
18934,
97689,
31632,
331079,
459123,
167225,
300255,
228413,
317300,
7962,
43294,
112214,
53190,
39179,
272358,
202022,
294227,
43348,
203004,
269123,
226147,
78054,
453989,
137243,
30521,
308711,
150816,
12726,
null,
132084,
108858,
76474,
14096,
273331,
105035,
124972,
18671,
379229,
60302,
73277,
143738,
280345,
147490,
38884,
28401,
null,
null,
155218,
475308,
34436,
355445,
109651,
416595,
351907,
188911,
37520,
36586,
51626,
61898,
3837,
149956,
174713,
425256,
15554,
214381,
257213,
116944,
null,
43083,
320499,
9938,
60439,
201776,
52386,
48511,
null,
27783,
99051,
355752,
248956,
248742,
607393,
43606,
16073,
22430,
22231,
123779,
165535,
212551,
336182,
117604,
365831,
11166,
null,
15218,
266330,
200717,
33990,
0,
2913,
41574,
8365,
56849,
40984,
234341,
350055,
62858,
null,
294285,
26778,
122311,
92657,
406379,
95744,
24633,
165111,
null,
337891,
7538,
27016,
28065,
47542,
74033,
null,
88705,
null,
162412,
201609,
201373,
152503,
84513,
10652,
37106,
6232,
154688,
387343,
31949,
null,
41737,
200067,
52178,
307568,
68218,
168090,
156224,
240969,
null,
250771,
69802,
32168,
199549,
27023,
null,
14059,
332500,
225032,
11758,
8023,
397661,
11980,
94724,
70545,
200521,
1286,
null,
92801,
56586,
148348,
35417,
104361,
415830,
15549,
43971,
176800,
244807,
172739,
21831,
48749,
196119,
29925,
42670,
5071,
12712,
156512,
363068,
38358,
236450,
30443,
3515,
112849,
null,
200832,
93430,
69857,
10438,
43703,
39316,
null,
16562,
null,
174938,
12661,
91,
4204,
269049,
241577,
225479,
11449,
46829,
397189,
18656,
18259,
13581,
92452,
190344,
184010,
147298,
6879,
25748,
64960,
44289,
null,
14498,
118916,
148694,
13923,
10368,
269281,
133037,
338336,
23020,
20857,
343181,
136306,
159068,
72963,
null,
133416,
227163,
132585,
22212,
284378,
354700,
41132,
61097,
254818,
null,
477692,
304634,
331836,
26006,
256894,
30775,
40949,
55929,
190811,
186107,
9847,
322775,
159773,
22318,
188488,
156764,
991484,
null,
12401,
null,
146323,
8803,
null,
27035,
5854,
348109,
97283,
123331,
224098,
191544,
205286,
366190,
15497,
83561,
303467,
null,
124145,
169701,
234057,
17109,
301909,
68501,
205305,
20120,
17670,
77700,
41090,
16826,
15024,
139883,
265687,
184641,
103960,
13943,
61973,
62210,
13154,
68205,
31710,
null,
65951,
202458,
46862,
252155,
null,
null,
null,
171462,
183292,
221938,
294611,
195402,
null,
38062,
13787,
192814,
63380,
108315,
9485,
98017,
122763,
159795,
128276,
6629,
26721,
189256,
187944,
421567,
38801,
281655,
9980,
null,
108551,
25910,
29180,
217991,
null,
3654,
95,
273305,
32026,
55995,
109216,
179312,
224645,
102487,
61161,
null,
215250,
100113,
31077,
57302,
42720,
148007,
15152,
196912,
85211,
440348,
789521,
222296,
4692,
122555,
10166,
null,
null,
null,
64612,
61594,
97734,
92080,
74414,
null,
238060,
null,
29338,
389743,
60456,
147238,
118382,
83863,
949,
81875,
69386,
205528,
18163,
51238,
42598,
70224,
127188,
114459,
84916,
112586,
null,
16067,
62794,
185978,
273847,
84861,
57364,
287131,
209841,
119591,
34106,
null,
10405,
128082,
12737,
54507,
9507,
31162,
67887,
12905,
263758,
146970,
283799,
92435,
130245,
49662,
199584,
187859,
14791,
180796,
192045,
167990,
132885,
14922,
300489,
39371,
20679,
80159,
10116,
9015,
361428,
33286,
173752,
71211,
585833,
130275,
321254,
12032,
518445,
328465,
114305,
null,
43808,
41324,
137079,
302586,
107160,
293733,
248883,
98454,
227966,
110720,
195559,
27735,
6420,
322617,
89981,
30063,
156833,
26817,
null,
317835,
48022,
14744,
245135,
15217,
76114,
179819,
370367,
53471,
32937,
167908,
133140,
23395,
24820,
16056,
150057,
309163,
5071,
63396,
395817,
22530,
29925,
192621,
200489,
252738,
null,
22217,
155070,
422071,
11952,
330037,
32716,
103770,
557315,
23233,
158553,
176969,
57208,
267448,
null,
41230,
197632,
71426,
480411,
42343,
26677,
45840,
56192,
452283,
null,
88363,
70074,
265021,
19748,
41063,
16516,
87230,
46618,
405642,
438822,
37094,
null,
19287,
16882,
414530,
14299,
311079,
65985,
39295,
151878,
null,
38532,
64309,
22358,
3333,
6810,
374493,
118765,
20297,
25818,
36356,
141737,
220077,
13751,
455627,
24109,
null,
386304,
null,
227435,
42161,
29867,
188902,
19423,
59098,
442732,
23807,
422096,
420223,
167023,
295018,
7676,
23629,
168478,
null,
343984,
225593,
310958,
218886,
228288,
459574,
33275,
55464,
231852,
31616,
139042,
21947,
21990,
304978,
null,
319248,
542086,
123895,
183481,
null,
280648,
168793,
415958,
40865,
30718,
null,
46162,
31399,
1172214,
null,
46269,
112473,
232888,
1362,
95132,
389440,
108333,
null,
38515,
31927,
107118,
12912,
290294,
155407,
null,
284333,
92535,
297872,
18150,
377786,
181162,
274508,
8258,
16983,
104277,
105060,
32014,
27696,
10481,
352295,
null,
301502,
146531,
380922,
12117,
82863,
26592,
16156,
31042,
20433,
null,
52269,
9896,
23558,
70406,
44882,
170556,
124940,
319827,
478290,
15281,
163080,
26061,
22702,
95071,
5654,
61358,
9975,
24937,
80880,
129298,
42506,
246780,
198186,
158224,
345543,
211142,
null,
174536,
6899,
67938,
100660,
199883,
337992,
59133,
141298,
3433,
29975,
204839,
35325,
246300,
25508,
49580,
25333,
17838,
62727,
14210,
28829,
276069,
12977,
276258,
13093,
59868,
137831,
264077,
23380,
156977,
209698,
217839,
null,
27509,
17488,
21117,
49722,
409195,
33554,
null,
91935,
29871,
170377,
18645,
328029,
62399,
158982,
25830,
262209,
495291,
53252,
107159,
27613,
176837,
35369,
292594,
561157,
42632,
4586,
35975,
190026,
135113,
88811,
null,
156487,
150296,
68025,
22683,
52979,
51857,
81178,
55091,
345110,
21376,
453905,
29678,
154508,
51963,
null,
16362,
null,
null,
6452,
188775,
229007,
230553,
76016,
207736,
34486,
50803,
196337,
48459,
155716,
748756,
null,
49873,
42449,
264689,
138753,
223388,
9028,
307368,
316923,
199659,
45933,
46566,
20371,
386703,
49122,
46952,
21000,
42219,
220848,
539868,
392846,
81638,
47189,
320172,
8839,
217783,
22557,
16652,
42655,
50123,
12704,
null,
71217,
465749,
64440,
64843,
255243,
213644,
183667,
38449,
null,
184243,
67199,
252431,
129408,
6710,
181964,
27135,
216132,
89087,
206476,
218715,
190475,
253778,
21359,
31024,
15233,
32924,
98835,
228428,
142276,
90728,
686857,
14305,
435092,
null,
61423,
204011,
235659,
51403,
13938,
36215,
247290,
103643,
162081,
120328,
27087,
170893,
44915,
null,
26505,
41361,
166599,
281571,
19750,
258694,
13778,
19674,
226547,
null,
8741,
26512,
18913,
290047,
41772,
40780,
null,
358858,
33913,
null,
326493,
75752,
86415,
52179,
null,
3005,
349441,
424118,
14878,
300537,
481922,
140155,
13312,
158436,
null,
null,
31589,
16545,
8263,
122290,
415733,
262646,
125523,
299916,
124824,
569245,
64345,
383496,
179572,
30080,
32649,
105520,
360583,
19982,
122405,
189426,
76925,
16291,
372771,
252102,
18514,
24002,
97215,
32306,
43664,
50312,
null,
7229,
null,
7562,
25017,
385738,
10408,
null,
127678,
null,
7033,
35178,
17153,
23235,
null,
232459,
15918,
77611,
26599,
13162,
169456,
37977,
49918,
141436,
155931,
null,
124248,
200627,
53102,
92575,
263752,
406061,
22993,
71913,
143714,
179956,
null,
null,
84205,
34373,
199161,
330398,
375634,
323225,
327640,
227582,
190951,
182011,
36873,
261349,
403435,
9204,
474697,
183090,
null,
57723,
22700,
167632,
302843,
32665,
189138,
null,
381537,
null,
89825,
42936,
230998,
139188,
123756,
166125,
62994,
35979,
36529,
44888,
56366,
233471,
106593,
330595,
353509,
14542,
139422,
47545,
31742,
48317,
139339,
11523,
79353,
5906,
null,
18489,
108069,
389113,
266556,
44042,
38850,
null,
15320,
3695,
52201,
558286,
null,
18188,
71719,
182729,
89425,
56225,
286599,
140050,
61744,
5605,
38941,
5437,
16486,
284815,
93056,
772341,
268146,
62268,
200459,
445209,
49465,
138788,
119643,
49595,
4201,
772475,
45866,
74983,
30593,
93769,
522410,
367097,
55235,
206796,
284245,
38051,
181139,
235683,
109446,
340225,
3874,
184503,
352002,
420969,
25218,
8001,
131938,
22167,
177975,
30117,
6581,
84063,
19567,
21079,
346484,
47343,
84895,
131263,
null,
106803,
null,
null,
145857,
125291,
24374,
69640,
43904,
66994,
null,
62928,
344054,
138610,
388470,
76411,
309871,
11159,
null,
36114,
389315,
77678,
182104,
37258,
3044,
18512,
246044,
396756,
31145,
5835,
41453,
167698,
3723,
210282,
18468,
15482,
270117,
3319,
219216,
356,
49659,
277404,
101489,
null,
381312,
20475,
2188,
12025,
69190,
202234,
37460,
91460,
212230,
186666,
42094,
646224,
9272,
23223,
397681,
20638,
60504,
37099,
23903,
293257,
13555,
262214,
82807,
21995,
215124,
32013,
7832,
23955,
184208,
27450,
13245,
18202,
25069,
null,
55306,
15733,
14301,
28053,
378915,
188819,
89770,
297474,
10605,
36932,
530376,
162975,
242271,
47954,
21281,
219196,
35700,
165146,
44147,
24846,
8850,
196389,
12892,
144094,
25880,
282569,
174642,
351757,
60264,
39353,
298863,
209542,
32857,
150921,
288345,
25565,
303425,
357700,
78938,
20628,
8922,
30539,
103683,
218981,
5017,
96236,
230085,
null,
7371,
132410,
8832,
332816,
null,
384026,
222345,
5410,
29752,
37830,
40550,
74619,
20155,
148451,
248300,
179354,
206160,
37342,
41006,
11257,
3198,
62982,
55653,
271114,
null,
461635,
8696,
223718,
241402,
null,
187668,
145558,
null,
73208,
272735,
241172,
58377,
47477,
30961,
9707,
38588,
34015,
9857,
349126,
140918,
151299,
142648,
34603,
240928,
287948,
14957,
9542,
270813,
41050,
29884,
43282,
10659,
35169,
8693,
219359,
null,
null,
169547,
443474,
390757,
15769,
691016,
372730,
134300,
null,
287652,
27372,
18273,
46618,
23861,
17559,
222717,
19206,
177265,
195697,
77035,
318344,
166836,
1386,
233068,
123695,
41052,
126843,
13784,
52289,
50369,
745510,
62310,
47402,
12828,
16580,
102197,
53686,
63776,
null,
21056,
49770,
null,
58058,
56504,
96909,
46647,
33011,
663911,
210239,
150076,
163586,
23136,
32378,
1926,
53886,
290257,
184280,
38943,
150368,
203384,
72998,
607283,
197595,
28187,
null,
364882,
40102,
null,
179742,
118729,
null,
131662,
115913,
35211,
50811,
475097,
107630,
13422,
408335,
44475,
13951,
46726,
19487,
42563,
12604,
218917,
23900,
34331,
21872,
36262,
144969,
233432,
6298,
2922,
204998,
324536,
160621,
444805,
304970,
147811,
237952,
88384,
14935,
23008,
64777,
104281,
4862,
294332,
15725,
27817,
170197,
23962,
224978,
45072,
192094,
221116,
4596,
57105,
433843,
127964,
47841,
40679,
330106,
81339,
29245,
279881,
913120,
93806,
51501,
367382,
169879,
11532,
141587,
44011,
701652,
33248,
13004,
10569,
76474,
58451,
49207,
70128,
26988,
526587,
44286,
145968,
115460,
266760,
994350,
25003,
15515,
18841,
34223,
426640,
59525,
10639,
51262,
27903,
351071,
22781,
110577,
61008,
59519,
280673,
27891,
28540,
237718,
156084,
97436,
96511,
191877,
72476,
57912,
304647,
212004,
78074,
767183,
70197,
100539,
26074,
103156,
8975,
165896,
90131,
249447,
127981,
152794,
126683,
159780,
61427,
747949,
161136,
14788,
21168,
233143,
34738,
91167,
null,
297771,
12040,
140368,
162727,
184991,
10464,
56821,
23783,
55449,
23501,
474695,
144988,
1800588,
192800,
69297,
149557,
null,
165688,
247962,
42162,
161834,
209547,
32870,
377833,
28831,
null,
6132,
20229,
283583,
16384,
47182,
20067,
205586,
104397,
128262,
null,
14580,
null,
343373,
74646,
23262,
339721,
53692,
24737,
93808,
19022,
63137,
13234,
3926,
354400,
36001,
83275,
316645,
59019,
339743,
16213,
704451,
null,
226296,
8609,
25915,
138919,
104140,
67434,
292009,
null,
21340,
18685,
72951,
7616,
114596,
19591,
27284,
220446,
255044,
313592,
19513,
23252,
221494,
107749,
75435,
8190,
3422,
167771,
328460,
90620,
165033,
134070,
31465,
331785,
null,
26227,
116393,
254046,
382912,
354244,
177831,
26741,
35775,
76171,
180596,
115360,
207196,
390302,
170585,
106718,
607205,
17488,
36520,
null,
36752,
21154,
79282,
504550,
230017,
77113,
182226,
38939,
21861,
282330,
28344,
53694,
25728,
18452,
7438,
265438,
224026,
null,
162610,
212702,
25269,
82441,
null,
200146,
245524,
315765,
293836,
12641,
33510,
159067,
13830,
171286,
null,
78368,
87187,
34044,
59385,
103747,
50274,
9722,
252856,
436916,
6957,
138671,
23700,
null,
198666,
165385,
3571,
323787,
20196,
367594,
46467,
80822,
329994,
84789,
157300,
389842,
27662,
8973,
21875,
187175,
9966,
69127,
124460,
27210,
202936,
null,
41589,
201752,
103867,
null,
null,
114811,
407761,
141632,
268069,
121948,
124918,
25134,
14191,
342132,
301497,
null,
null,
11234,
300859,
84236,
338119,
198673,
19362,
51379,
246323,
40437,
266645,
null,
null,
141821,
99039,
38484,
262527,
4352,
6835,
54690,
456229,
86327,
9181,
100864,
75794,
36178,
8189,
313853,
34618,
69325,
null,
163476,
66797,
4933,
79103,
157537,
138296,
208100,
58100,
20935,
232659,
16857,
126426,
152972,
null,
256758,
30376,
393622,
null,
29790,
25917,
22410,
319713,
96902,
29124,
80717,
94526,
98182,
232378,
null,
312788,
16307,
312373,
45248,
146814,
387310,
36129,
250969,
333882,
9156,
70307,
1557514,
151324,
508251,
15009,
171029,
380064,
185182,
96074,
12095,
177431,
11507,
55567,
145120,
216820,
141066,
185509,
6991,
17811,
17109,
null,
46981,
44139,
8230,
101678,
377267,
332526,
164968,
24868,
null,
41191,
77503,
226791,
31209,
179164,
null,
16813,
237899,
40524,
50621,
154379,
null,
null,
55179,
14942,
128374,
null,
115273,
39785,
16503,
135227,
90720,
27655,
89802,
440509,
742851,
81373,
207151,
30139,
154578,
139549,
171812,
24495,
118392,
201704,
66886,
209882,
314716,
322301,
23817,
20979,
209500,
45622,
212541,
119273,
311569,
230454,
26253,
377813,
22588,
313490,
310755,
124574,
4256,
302838,
51033,
120501,
70861,
301144,
null,
170234,
213050,
312901,
8270,
237296,
80874,
315622,
null,
null,
177226,
null,
67345,
146729,
78306,
181701,
64411,
930024,
25288,
72588,
11510,
383833,
499323,
411977,
303023,
37555,
50026,
32034,
245447,
645999,
61432,
61934,
23700,
26535,
363066,
193096,
null,
552725,
83669,
109193,
63961,
99852,
168937,
null,
14308,
388585,
238244,
344383,
56261,
6290,
45008,
143882,
27063,
133090,
98009,
6023,
91927,
50860,
141723,
35136,
10217,
204699,
92935,
20778,
null,
79904,
41662,
48322,
134298,
435234,
null,
38102,
31897,
262962,
352725,
221961,
122825,
49772,
153502,
360782,
101492,
27005,
95726,
166558,
312420,
271097,
38074,
144374,
19379,
268414,
99850,
348152,
63020,
31589,
29366,
24907,
24568,
44578,
489951,
238403,
null,
493938,
37665,
11753,
144157,
3440,
null,
170088,
396489,
19854,
257903,
103852,
70957,
71421,
57385,
197797,
56784,
null,
155996,
34770,
56649,
9134,
433604,
165830,
94796,
90687,
106025,
null,
64493,
null,
77286,
159436,
139851,
54740,
218322,
140288,
329014,
2024,
21942,
37069,
74415,
36434,
103046,
598694,
295277,
699798,
215228,
392273,
151841,
193798,
10456,
179355,
30402,
29650,
257499,
136677,
299546,
6477,
25639,
203660,
263344,
49337,
305382,
null,
119007,
60477,
18979,
346811,
33339,
38810,
75747,
26634,
6424,
39545,
41295,
null,
null,
155551,
42893,
null,
23901,
75436,
20408,
16406,
198982,
222143,
16334,
66841,
8216,
404742,
179222,
null,
269859,
null,
364129,
null,
278069,
310378,
178265,
58320,
8342,
125499,
735123,
63854,
40329,
24932,
null,
283950,
18761,
24198,
10361,
195095,
328562,
45710,
14751,
null,
23205,
22561,
156517,
271562,
52600,
31808,
16141,
10232,
63610,
377990,
302924,
105096,
78638,
135984,
214891,
527844,
null,
163146,
28567,
30443,
75864,
19359,
343466,
17856,
18379,
10603,
211184,
698801,
71124,
83723,
29480,
null,
73139,
47293,
29860,
22010,
82957,
137478,
26916,
null,
190499,
80343,
20649,
246872,
412207,
11468,
471954,
467019,
362103,
338160,
24923,
9637,
151859,
383398,
446381,
20699,
418654,
40453,
392453,
75386,
59218,
143155,
null,
146618,
30791,
null,
24240,
302015,
null,
18521,
426649,
12382,
null,
393776,
31721,
24277,
null,
293718,
29526,
100368,
53654,
16988,
89178,
78620,
34762,
null,
null,
24829,
245945,
78710,
null,
47561,
32832,
14965,
33767,
152535,
47118,
41519,
44371,
175458,
338551,
452158,
13257,
40928,
null,
350232,
14960,
24841,
13457,
184722,
55430,
308412,
8044,
60090,
66143,
null,
21281,
141879,
16041,
3549,
148515,
26150,
23286,
355758,
261925,
605012,
439865,
35520,
162597,
17621,
44803,
73450,
43382,
40657,
99804,
139257,
9470,
364549,
6991,
462000,
80321,
100734,
336927,
110652,
207259,
91704,
224640,
327492,
74832,
55493,
61128,
395948,
41311,
52001,
null,
50967,
122035,
260706,
366071,
12412,
11302,
114398,
11563,
33898,
490160,
494960,
99511,
318957,
19224,
75556,
58782,
173364,
337989,
268717,
29898,
81734,
200731,
6170,
10859,
130672,
331359,
730776,
null,
176059,
null,
null,
239695,
12262,
200035,
40535,
10180,
132862,
117703,
54229,
82578,
156093,
307141,
5772,
477103,
30013,
12505,
262338,
45592,
675544,
15790,
27086,
168120,
61237,
null,
60566,
35639,
44550,
264103,
94089,
30392,
435507,
11067,
44837,
208755,
12873,
19403,
33450,
22609,
440051,
97275,
197719,
41461,
202255,
307230,
51816,
312759,
745729,
11310,
11253,
341686,
18635,
265249,
39163,
null,
8019,
244850,
56511,
31596,
null,
90261,
260365,
197048,
547053,
196945,
51270,
319095,
32649,
183756,
554850,
511416,
null,
41219,
24778,
973451,
131318,
174087,
7522,
92958,
92013,
27954,
41811,
361061,
6655,
null,
42081,
187865,
45241,
224506,
95197,
112315,
1231,
168868,
289560,
123380,
25124,
null,
161465,
344684,
372681,
32107,
279504,
51687,
195402,
192681,
255607,
149148,
35877,
416681,
24020,
24918,
null,
172128,
246793,
158875,
31116,
37788,
149874,
84008,
123666,
50950,
null,
147052,
42530,
12121,
18399,
35313,
32776,
25208,
101707,
127190,
199382,
null,
null,
249463,
293747,
75682,
176977,
114237,
228230,
136007,
201190,
25149,
37545,
32194,
171811,
null,
80144,
270385,
337627,
154133,
370294,
172753,
null,
249296,
33786,
179650,
24966,
53283,
67321,
133232,
133106,
311312,
25199,
59066,
189850,
70802,
5667,
85776,
null,
47238,
185430,
357763,
184282,
73013,
14365,
222077,
9086,
124100,
15464,
null,
17143,
389152,
391979,
331274,
34135,
478205,
null,
45188,
130231,
479405,
61613,
296107,
26094,
6643,
197981,
16793,
17502,
489685,
90237,
null,
267239,
12914,
510739,
42245,
21214,
247830,
null,
39042,
17165,
81396,
45800,
180012,
54958,
285588,
6064,
21444,
34843,
437676,
276100,
7648,
14234,
null,
null,
7698,
92667,
255708,
134475,
null,
13000,
49825,
54933,
197255,
21285,
335062,
294489,
149686,
79529,
64311,
106677,
1263797,
60184,
null,
97433,
11584,
null,
61796,
257712,
145819,
45873,
326176,
null,
126393,
26296,
24170,
null,
42839,
344503,
18992,
85537,
null,
38073,
243212,
15793,
12622,
65604,
165943,
21198,
15138,
158753,
178311,
422052,
327564,
114020,
62589,
289956,
27682,
null,
36790,
46385,
30764,
314123,
369746,
17012,
395280,
78888,
193695,
null,
244699,
199199,
177430,
20927,
78348,
40554,
221516,
null,
30576,
387207,
24496,
72778,
254155,
239956,
517929,
10344,
374810,
3084,
56151,
42783,
31193,
116999,
300977,
6444,
200677,
16837,
358800,
48529,
172596,
17959,
310643,
121939,
20931,
38995,
274869,
179581,
38933,
914004,
24867,
139090,
106796,
147609,
178147,
297660,
177583,
37489,
26772,
31700,
30310,
17977,
121205,
11798,
31673,
105896,
305285,
197121,
17992,
173300,
38023,
198538,
108218,
null,
null,
28710,
54083,
28901,
41065,
null,
29930,
23257,
304794,
25968,
38323,
183367,
244203,
116765,
22827,
null,
null,
37143,
null,
137271,
281714,
106584,
60912,
null,
340057,
31733,
178224,
24773,
73722,
141228,
417699,
12175,
null,
171161,
371971,
147581,
16756,
453228,
15121,
277686,
9382,
33128,
35280,
53265,
79404,
53996,
15959,
240345,
35461,
33807,
4669,
248318,
12989,
17090,
28563,
44558,
111075,
41757,
127416,
30965,
196967,
32673,
86799,
297219,
384416,
219627,
171999,
null,
55267,
187027,
2402,
24909,
46486,
29004,
164466,
218456,
89388,
21013,
25193,
8175,
30549,
16101,
9749,
83195,
556130,
143114,
8735,
206847,
20336,
18408,
15478,
null,
30328,
363709,
21356,
176623,
3038,
30096,
148486,
89803,
198382,
21464,
90553,
36335,
5733,
379293,
93144,
234149,
null,
133630,
null,
50118,
17888,
31004,
76946,
147990,
75452,
253982,
13601,
6406,
37188,
41414,
36803,
180764,
159849,
85175,
30224,
71505,
38124,
23672,
4736,
195389,
null,
9710,
14511,
83041,
160696,
95856,
15972,
12703,
18047,
12443,
263942,
null,
96012,
90741,
349814,
77282,
7284,
44404,
44592,
56113,
171129,
176424,
47823,
18990,
22286,
29573,
23867,
35892,
200144,
26841,
192018,
213707,
166948,
29954,
8110,
160162,
29552,
18645,
60260,
89845,
227928,
71295,
17804,
227017,
138637,
32426,
40497,
38672,
null,
16774,
45530,
26593,
531508,
49073,
195412,
112112,
34453,
35433,
null,
207552,
62657,
173811,
18001,
166874,
90284,
217998,
8414,
null,
302391,
184309,
52327,
126135,
125061,
17918,
74335,
19885,
1092983,
18280,
50965,
40585,
351866,
45625,
263077,
35930,
245801,
6355,
222593,
null,
754474,
null,
null,
385865,
171430,
55127,
323702,
81906,
47666,
5868,
29164,
176409,
240290,
319704,
163546,
null,
233300,
18649,
3111,
180362,
43416,
37892,
422755,
26031,
202850,
219991,
257410,
34524,
217462,
159679,
26155,
27496,
17663,
164376,
30105,
90433,
263362,
9981,
17374,
25527,
296202,
7243,
13121,
81246,
289353,
37482,
13361,
14298,
233565,
10841,
85667,
296380,
164165,
45544,
76301,
23088,
362187,
232288,
22261,
12774,
166140,
36643,
83571,
null,
81645,
117908,
92925,
13309,
114781,
38446,
73177,
129428,
48702,
392988,
17039,
35649,
40596,
null,
225567,
133901,
null,
118653,
378765,
186121,
62204,
55503,
149107,
116096,
84365,
50305,
470734,
263851,
198245,
87235,
97940,
null,
187437,
151846,
null,
49079,
14086,
9297,
5684,
2919,
33345,
12598,
154068,
198024,
173044,
22666,
207253,
115792,
31242,
375702,
38152,
18350,
95581,
4837,
null,
null,
7691,
138745,
23175,
61353,
118946,
97168,
356001,
null,
65587,
72901,
27611,
21314,
6844,
515095,
229617,
148221,
256330,
37278,
292115,
171566,
null,
56327,
21422,
null,
252879,
177683,
600458,
57937,
9361,
74799,
79187,
186348,
344177,
78551,
239369,
39734,
223261,
19073,
266759,
11634,
191330,
21297,
13062,
48787,
250560,
26652,
326335,
193382,
15182,
262564,
20572,
82043,
11719,
28404,
57399,
8343,
25495,
49816,
292735,
23369,
50261,
41294,
42359,
54816,
3065,
224140,
null,
null,
null,
181388,
135952,
11264,
167877,
481022,
6778,
111060,
139501,
4417,
76805,
318075,
157898,
26355,
8964,
131700,
12498,
null,
157417,
12176,
31899,
4111,
27423,
null,
23373,
46852,
8523,
44444,
317529,
26886,
37794,
27439,
null,
351179,
206121,
28472,
19411,
48102,
74352,
null,
553484,
106805,
null,
265370,
56073,
127088,
46063,
81397,
62137,
21882,
83123,
null,
261154,
24633,
null,
27271,
386930,
196934,
140682,
20222,
8818,
1865,
161806,
177053,
27380,
null,
null,
97619,
39277,
59666,
null,
49656,
176216,
456283,
100587,
null,
35433,
11056,
8712,
315947,
40022,
94936,
26758,
476096,
380378,
null,
31759,
108777,
256032,
437149,
28918,
108914,
null,
293426,
404367,
9844,
null,
46883,
198831,
null,
167594,
26171,
29727,
null,
13951,
251883,
null,
17811,
259292,
159948,
191070,
118835,
195194,
179302,
null,
229333,
59372,
17793,
57287,
null,
283595,
269825,
46469,
10887,
99653,
12659,
377808,
null,
50656,
80253,
142042,
290901,
null,
44789,
307415,
38865,
89095,
288781,
8815,
359331,
310638,
254238,
230284,
289219,
59435,
113415,
25053,
218598,
14898,
266908,
52635,
172186,
214327,
457401,
237193,
231530,
112807,
348712,
81177,
59898,
null,
63774,
101933,
153641,
169047,
81048,
13504,
278871,
205520,
63437,
290874,
179344,
34144,
62217,
12366,
276515,
197152,
159652,
25965,
4897,
20485,
830130,
515844,
173537,
null,
107265,
null,
102189,
null,
58979,
126132,
29461,
146600,
331881,
277958,
199758,
45394,
24213,
19220,
139684,
20235,
6410,
225781,
262444,
20263,
161352,
21053,
145485,
350613,
368008,
178216,
6951,
162793,
34563,
273466,
54694,
217702,
23575,
149762,
40676,
358801,
27332,
358954,
50770,
32576,
150700,
null,
104639,
99551,
28295,
409799,
31991,
149594,
59022,
37804,
30889,
null,
7237,
220069,
163352,
280249,
59805,
30048,
318230,
null,
null,
361141,
389744,
207958,
17202,
188598,
244253,
294861,
61947,
52451,
470586,
322605,
null,
22486,
76888,
26417,
33614,
27399,
93591,
619563,
462390,
163772,
167935,
null,
23713,
318868,
123870,
56901,
5108,
52449,
282314,
18104,
null,
13214,
22955,
6683,
26652,
35569,
352478,
37128,
224386,
298888,
26765,
230343,
null,
63391,
226998,
27422,
240613,
null,
25297,
41583,
177867,
48824,
246957,
168990,
25169,
60843,
30281,
24733,
null,
215863,
2482,
407951,
180825,
33835,
152454,
22184,
47998,
16035,
96117,
249995,
38299,
278984,
1019644,
99484,
31357,
490875,
24655,
6853,
195933,
33841,
289424,
303598,
278598,
51673,
384458,
35621,
5457,
362949,
50999,
165914,
193766,
113901,
null,
16767,
334861,
50379,
37279,
33291,
45116,
132633,
22848,
106374,
214666,
231625,
6330,
null,
176093,
38030,
118948,
170985,
90792,
241045,
19261,
1087835,
152782,
103417,
134070,
60938,
99422,
280017,
48442,
11981,
529770,
149694,
120261,
310116,
36330,
189321,
3512,
21895,
24805,
395167,
25341,
60050,
null,
null,
52047,
267910,
50009,
13559,
30543,
316851,
217778,
30601,
23696,
6288,
358050,
63125,
138421,
297328,
69694,
111527,
204471,
null,
null,
226247,
null,
30561,
20068,
368656,
330933,
null,
42924,
548585,
323756,
20316,
17282,
281527,
938391,
6824,
39116,
58647,
113401,
15076,
248651,
281649,
39849,
null,
null,
398748,
755403,
6458,
null,
154741,
99753,
11626,
54031,
329978,
57553,
121744,
215002,
42513,
57289,
408664,
39598,
293223,
122283,
141648,
47823,
60905,
52948,
11488,
6679,
248347,
39210,
27353,
42778,
30601,
96523,
7526,
47127,
253891,
35553,
271084,
290630,
194651,
63109,
61542,
51532,
765950,
94379,
34060,
263729,
175337,
22303,
60590,
null,
8808,
38252,
386349,
120642,
212470,
407869,
140291,
null,
23285,
218271,
281474,
45171,
670509,
37817,
766371,
76613,
205109,
84760,
286512,
13600,
2645,
200235,
null,
285512,
326094,
417603,
513246,
126023,
291445,
22974,
436255,
65851,
47326,
5294,
24356,
24597,
null,
21366,
7367,
16830,
28846,
31846,
169527,
37059,
297535,
null,
254369,
231947,
148593,
28133,
37063,
339067,
29999,
95228,
56933,
30678,
57202,
13953,
null,
69494,
153982,
129325,
null,
76461,
302985,
53201,
58384,
37076,
444219,
63770,
307306,
125851,
224541,
244289,
206233,
99596,
832587,
86992,
370966,
272429,
70239,
62910,
250645,
370728,
231714,
64025,
150320,
195396,
54627,
397924,
420765,
66155,
703889,
242077,
218253,
7610,
20352,
27191,
205981,
175101,
32576,
null,
173320,
34032,
108232,
9937,
29531,
197546,
39782,
120493,
41891,
30142,
18077,
36096,
301959,
12087,
67583,
33068,
122111,
323113,
197126,
225828,
51580,
308094,
15919,
78410,
264997,
830972,
193547,
null,
25403,
154398,
15815,
266099,
235414,
73807,
33999,
25711,
236649,
24423,
217339,
154686,
346857,
64707,
109058,
116437,
70459,
227152,
74206,
143890,
16860,
19969,
39924,
174051,
null,
436143,
546966,
27218,
null,
227046,
153934,
412013,
44894,
34301,
29845,
14280,
33338,
177921,
446291,
null,
45333,
102052,
208567,
22312,
339909,
null,
76446,
235718,
181311,
9113,
50831,
13390,
18794,
351918,
268918,
237503,
51175,
91320,
114755,
null,
143477,
36641,
107707,
46065,
31184,
238189,
306489,
21590,
19659,
44035,
13866,
4914,
244386,
14014,
28026,
null,
9447,
86311,
109351,
null,
39171,
16061,
227839,
29871,
75813,
30214,
790616,
32693,
279979,
166490,
null,
13686,
30119,
283193,
179013,
212043,
12839,
22824,
923695,
34202,
18505,
143160,
23318,
216008,
34977,
null,
276816,
23277,
250807,
60259,
null,
122805,
184433,
27578,
null,
220117,
null,
30416,
433976,
24284,
192808,
395330,
15415,
207141,
null,
309701,
15125,
36927,
null,
98640,
120339,
17364,
9953,
287922,
314457,
47600,
11888,
null,
14464,
208820,
65760,
null,
35367,
19090,
268382,
164954,
16281,
81301,
29915,
54400,
267528,
70623,
131365,
33795,
25442,
39446,
108257,
245962,
390678,
91543,
1273619,
4755,
49821,
40679,
14245,
251208,
184456,
232705,
14354,
87362,
259771,
342079,
24381,
26840,
219229,
11567,
79504,
204177,
159512,
20856,
355726,
33760,
43462,
8435,
67126,
127847,
276109,
79988,
null,
426996,
268597,
53535,
26621,
106901,
21690,
294997,
21708,
115431,
20706,
254955,
129901,
62862,
15253,
37865,
15165,
227045,
31649,
325082,
3278,
null,
null,
43949,
430385,
238796,
166192,
210710,
127180,
178810,
9052,
510820,
null,
497802,
17375,
168225,
36375,
64034,
46126,
81877,
null,
164783,
13648,
163171,
42232,
72105,
7326,
51652,
146648,
291408,
5372,
210403,
52266,
263268,
4833,
185300,
197041,
346564,
null,
38246,
467569,
110721,
null,
262717,
43731,
23579,
32808,
31896,
207956,
47639,
19329,
212845,
68876,
12669,
82147,
26464,
73484,
361057,
52458,
65961,
322199,
86519,
73820,
null,
83130,
32370,
98102,
13802,
150425,
364006,
178179,
527428,
200792,
13430,
451063,
111399,
164319,
388157,
25716,
74396,
38006,
27675,
36875,
77871,
67164,
23338,
41060,
67422,
234963,
32102,
48993,
101294,
226214,
17643,
149179,
86016,
null,
32337,
108181,
346833,
null,
55684,
89764,
55450,
180181,
47648,
28190,
null,
38740,
24887,
121347,
31105,
99223,
10815,
17878,
45566,
null,
50607,
null,
11551,
297933,
70956,
12969,
37354,
23530,
39931,
192705,
52675,
114519,
4255,
61454,
38299,
34812,
36455,
41307,
25817,
318517,
274832,
43171,
344703,
92353,
186102,
1114,
15668,
181039,
418909,
280280,
147626,
13126,
263292,
27138,
912724,
29513,
34171,
12795,
32440,
14286,
130463,
null,
101915,
19526,
19015,
402580,
42371,
40837,
null,
319043,
12374,
null,
97347,
10136,
108979,
38270,
107772,
10822,
569871,
18389,
26098,
39435,
113631,
731689,
349703,
6492,
null,
194241,
17920,
533958,
114128,
13782,
116348,
44065,
169997,
304841,
28793,
506871,
33520,
193814,
198569,
148721,
21963,
18557,
260553,
325503,
24379,
40685,
17404,
19233,
440231,
157973,
320704,
46442,
402905,
301636,
407241,
16336,
318335,
103588,
10230,
195419,
22006,
46327,
140477,
427007,
245540,
598185,
154762,
11281,
null,
56384,
505996,
null,
453638,
41588,
17229,
56013,
52182,
91246,
43944,
13292,
29626,
null,
7885,
26869,
92161,
155021,
127261,
52789,
239381,
292085,
10827,
173510,
231923,
246246,
40737,
352694,
null,
147790,
98860,
82486,
115434,
7380,
12332,
305794,
24362,
70968,
30235,
203051,
32996,
20809,
3998,
4089,
89242,
null,
99754,
160288,
28979,
169218,
507525,
64044,
216431,
18260,
303393,
16531,
844969,
172685,
22750,
null,
68489,
null,
51289,
55090,
468122,
94945,
43433,
20190,
214866,
154683,
20030,
202855,
null,
257945,
144582,
117155,
164782,
41487,
null,
null,
133785,
32129,
34776,
151107,
435711,
22785,
null,
543072,
754095,
26371,
121550,
79794,
127299,
345435,
36721,
424147,
96755,
595168,
12179,
77890,
54629,
5319,
9868,
215152,
268077,
242156,
63679,
317190,
338549,
4265,
47424,
41051,
39442,
266563,
38010,
42976,
33779,
271897,
146994,
27408,
33764,
278813,
64446,
481816,
309044,
195392,
661354,
75423,
76479,
40258,
53657,
234911,
368411,
151584,
16159,
156554,
202077,
14628,
223249,
20026,
308090,
393453,
155740,
26386,
187833,
4952,
2689,
137814,
13052,
null,
66771,
339392,
179795,
54473,
143452,
17523,
27968,
136334,
1022,
null,
888738,
276262,
200758,
48528,
12714,
240744,
36083,
248100,
9267,
467917,
372024,
21415,
137793,
136746,
303383,
null,
57000,
146687,
42865,
197006,
54818,
50420,
193129,
149962,
193977,
null,
null,
270786,
142298,
59827,
354174,
226920,
672618,
null,
351343,
null,
32800,
211613,
25867,
383908,
19234,
158624,
163417,
66711,
1027321,
37023,
148164,
77531,
103947,
160965,
64202,
189338,
null,
29343,
15566,
null,
446790,
38737,
181461,
9179,
10901,
47805,
670265,
174164,
16760,
11910,
199341,
14994,
25209,
null,
401230,
18807,
31213,
27882,
26670,
41501,
null,
58759,
357741,
25637,
73292,
311133,
196787,
346548,
314949,
null,
212249,
null,
86085,
216261,
212708,
31067,
291380,
53680,
30011,
108051,
30225,
null,
36593,
60218,
null,
14994,
164901,
195069,
29495,
51436,
158902,
82563,
null,
null,
13860,
175147,
145514,
129182,
22634,
19203,
294989,
null,
68299,
25178,
74487,
67637,
218701,
null,
236668,
35568,
532034,
49523,
32623,
579600,
3517,
157415,
13671,
30959,
76709,
194704,
22653,
8750,
79016,
99214,
34344,
13537,
69475,
295751,
17152,
547369,
67114,
62073,
222446,
30568,
12103,
59209,
299926,
26264,
46366,
417086,
239613,
380926,
279715,
208215,
355082,
102604,
146537,
194595,
33158,
30875,
481492,
null,
31644,
24335,
371560,
12485,
129070,
39012,
14894,
8858,
20202,
null,
280668,
347244,
175544,
182132,
null,
4263,
271543,
374614,
null,
40955,
118996,
30761,
173557,
4338,
101855,
359988,
306823,
53618,
42442,
23937,
46779,
null,
null,
400957,
109867,
26721,
36506,
38460,
278472,
180298,
74045,
141745,
null,
145634,
22340,
32720,
33096,
49681,
125440,
116805,
426849,
187616,
332123,
null,
455170,
66142,
58670,
205463,
158465,
7934,
19359,
52155,
null,
46150,
9526,
212418,
154274,
143788,
203128,
48541,
219076,
120310,
453771,
284934,
53559,
279326,
972705,
37966,
438621,
8880,
264766,
84991,
48271,
null,
37976,
6493,
57482,
65294,
120658,
205036,
83812,
127250,
38293,
59782,
143715,
410074,
null,
39981,
null,
39543,
52997,
127755,
332043,
null,
496346,
null,
578219,
43693,
130697,
null,
111296,
98628,
11285,
9478,
17813,
119187,
283268,
101113,
1714681,
null,
234382,
28141,
707853,
269921,
24466,
35221,
47624,
32261,
36156,
48765,
35248,
10132,
16895,
9384,
66144,
136900,
12277,
189598,
22976,
104282,
15565,
86825,
null,
70535,
100502,
352919,
415119,
533259,
119844,
352988,
745191,
26607,
null,
254041,
74388,
10712,
18759,
252683,
58180,
238596,
null,
null,
91389,
17196,
34464,
329565,
21653,
260018,
179124,
395542,
10945,
33188,
34372,
18029,
null,
515482,
252884,
146066,
331934,
577138,
null,
36236,
266311,
27719,
null,
209988,
171467,
209145,
35613,
null,
25127,
138357,
28432,
30717,
217621,
26503,
208658,
122902,
211719,
49661,
60970,
234560,
18955,
39926,
70862,
448640,
33595,
47968,
12239,
39961,
27805,
157685,
289954,
null,
181460,
87113,
28476,
185283,
67948,
63699,
31883,
151655,
20255,
46540,
82779,
112464,
155177,
232910,
432073,
10454,
170830,
null,
95449,
108195,
33978,
54829,
210775,
16780,
7248,
null,
44241,
27892,
305578,
178270,
25623,
7865,
89197,
217671,
324164,
53291,
6135,
37350,
138673,
137036,
125060,
252269,
67998,
202066,
77140,
178428,
69674,
387939,
28742,
49706,
275606,
131244,
20112,
37084,
45871,
37594,
333001,
11934,
62749,
25081,
103290,
16213,
256417,
291275,
null,
404993,
89092,
31433,
null,
52489,
null,
188362,
null,
8124,
177011,
71000,
109086,
400909,
29985,
123259,
12941,
36463,
15723,
470057,
13107,
112597,
245195,
5249,
40824,
188737,
null,
21181,
6672,
27539,
11518,
1043178,
367979,
20706,
18707,
33370,
61388,
28664,
455637,
204736,
58657,
45149,
33365,
358888,
14259,
609758,
null,
49561,
null,
78055,
534788,
487671,
43965,
263543,
103237,
null,
24486,
35809,
281108,
17206,
226712,
95277,
27378,
93458,
222514,
null,
293446,
22183,
105696,
12289,
228325,
143989,
72861,
150769,
131335,
57194,
46217,
240953,
34436,
187190,
94269,
173366,
15058,
251903,
null,
568579,
388288,
null,
35171,
64364,
864809,
97005,
9765,
20862,
504944,
10320,
84064,
null,
218569,
null,
320493,
13823,
107879,
null,
279584,
77711,
146490,
27685,
20052,
144478,
132036,
249125,
150077,
120786,
null,
43586,
103590,
73948,
30435,
173081,
198498,
14534,
52323,
16378,
62211,
95964,
null,
null,
13488,
306523,
286230,
434605,
13826,
260788,
282773,
null,
41767,
212504,
25710,
191779,
80503,
114520,
206342,
281823,
135936,
12975,
72295,
195039,
206160,
240555,
22031,
null,
110597,
null,
169607,
20266,
253574,
61289,
29333,
184007,
216339,
13685,
123935,
11845,
46608,
141915,
22615,
null,
27380,
83117,
86773,
54312,
19648,
721440,
51344,
91345,
10920,
43479,
null,
157530,
89498,
22948,
106449,
415211,
269838,
null,
110980,
null,
403780,
143698,
249445,
322401,
21341,
23760,
49807,
21745,
65892,
229331,
20981,
7849,
260638,
153440,
31284,
11442,
229839,
301477,
36931,
19576,
19303,
210755,
null,
147423,
93642,
32983,
15480,
54168,
463458,
null,
433701,
null,
140309,
193651,
335000,
8930,
139660,
76795,
null,
305679,
57651,
97556,
54565,
71010,
220758,
412666,
101379,
113201,
411586,
22611,
165365,
26608,
585279,
162226,
40361,
null,
228742,
14351,
215129,
39413,
65660,
178270,
13335,
121480,
5944,
19634,
410161,
445532,
8747,
11335,
198059,
172061,
12662,
20444,
55924,
441068,
188136,
97135,
171424,
215733,
505701,
null,
24686,
13081,
null,
null,
454167,
null,
5463,
null,
299811,
186357,
37445,
15640,
258287,
44992,
28631,
355546,
296925,
10111,
101353,
11232,
210923,
43327,
null,
98395,
194146,
null,
590465,
null,
null,
43015,
22497,
401609,
147681,
56326,
103517,
35528,
261131,
178237,
35418,
3858,
368843,
null,
null,
300582,
67931,
175437,
31602,
113144,
44120,
null,
406436,
6539,
79751,
202918,
48917,
null,
163355,
null,
220056,
9746,
7386,
35419,
223080,
4195,
498040,
17350,
34605,
25443,
125697,
385363,
15182,
6302,
null,
55514,
336207,
32536,
426933,
273632,
62949,
95513,
39375,
4271,
38320,
336747,
45694,
218324,
73402,
499254,
14037,
28775,
32426,
312642,
57199,
114068,
62893,
237754,
30090,
49843,
203806,
43977,
21168,
44901,
407320,
16939,
151543,
213979,
23757,
71343,
368954,
28141,
21365,
80118,
39479,
4224,
9576,
89588,
40492,
5179,
14136,
15552,
5442,
456149,
317024,
167181,
123649,
316337,
154218,
14077,
57507,
91300,
37554,
31225,
4206,
41094,
263946,
6573,
327576,
37857,
59329,
176418,
19919,
210433,
17466,
3510,
113698,
104544,
810380,
158687,
72356,
null,
null,
43311,
null,
275501,
266360,
96218,
null,
72073,
59312,
393172,
10190,
243642,
72976,
10233,
22532,
254948,
230776,
172756,
45630,
112965,
42245,
64359,
23804,
43308,
null,
600651,
56107,
80143,
60297,
55407,
76497,
205447,
201168,
338897,
32736,
19299,
21300,
197474,
13222,
78544,
null,
188284,
null,
370051,
51517,
23195,
7811,
140452,
50275,
37994,
null,
163848,
66797,
42974,
522627,
216281,
27804,
25433,
437423,
244733,
null,
79857,
172250,
535832,
20865,
216366,
43010,
165678,
48950,
129773,
35588,
243614,
null,
230325,
349911,
243560,
180114,
23510,
777477,
282253,
176202,
482791,
289810,
144952,
18111,
13103,
92433,
189589,
24876,
217597,
13809,
34071,
26240,
48366,
152347,
48788,
46413,
6036,
706693,
55101,
32549,
174004,
62090,
66606,
162522,
172316,
360020,
152296,
141629,
140302,
null,
264736,
77661,
198676,
120365,
508423,
200697,
44059,
223684,
321610,
172452,
88006,
null,
14369,
5294,
339480,
108900,
20038,
21969,
172236,
263282,
14511,
55911,
17149,
23174,
9537,
153261,
52413,
289605,
22057,
61528,
null,
77090,
36203,
44088,
124683,
5636,
17378,
21431,
5496,
132106,
null,
4263,
163064,
155511,
11504,
563427,
135916,
83295,
44701,
null,
294593,
328745,
42222,
403178,
204528,
null,
342092,
46216,
null,
18229,
59690,
79083,
126316,
37378,
42605,
165039,
46148,
553173,
49614,
120762,
241675,
14224,
279873,
388074,
22496,
9889,
7436,
5125,
23901,
142490,
77983,
null,
null,
160907,
182698,
351959,
153384,
237464,
387199,
14469,
220725,
91114,
null,
127148,
400578,
100381,
45772,
44891,
null,
null,
123020,
null,
190722,
303979,
25238,
285154,
163787,
60558,
34092,
19839,
526699,
143198,
134789,
114448,
321617,
null,
261877,
12714,
108287,
null,
23688,
36569,
16002,
null,
351548,
null,
27526,
46488,
39197,
null,
94775,
null,
258596,
452811,
34719,
205370,
58484,
456571,
248161,
7075,
103990,
41830,
71287,
37758,
87343,
91817,
197573,
13402,
34924,
24569,
39942,
68110,
9575,
109234,
284936,
null,
241021,
null,
78118,
28897,
116057,
66409,
199580,
585917,
329600,
188944,
139669,
4083,
18523,
94427,
22156,
182112,
196261,
6017,
null,
112228,
71650,
37754,
211508,
47454,
201487,
null,
382176,
302484,
228625,
69323,
149723,
25267,
257779,
376437,
27692,
56094,
20938,
20704,
18434,
null,
362567,
13055,
56719,
86937,
56324,
51768,
26645,
102854,
30947,
287696,
null,
29526,
90225,
123743,
42880,
22764,
38679,
18431,
null,
129668,
14482,
224173,
170309,
787802,
103703,
70177,
null,
181744,
4301,
151386,
14003,
26389,
274071,
24772,
30055,
null,
180963,
42130,
48419,
151762,
343770,
28024,
null,
23297,
26720,
191807,
291510,
null,
443900,
46108,
36163,
3633,
86504,
39298,
224224,
373730,
148624,
75912,
96671,
2714,
15127,
306611,
720620,
420041,
null,
10173,
56888,
90686,
396842,
373578,
279319,
6978,
157992,
62485,
24219,
null,
221849,
null,
null,
231367,
69185,
11572,
27933,
56486,
232083,
238173,
38487,
43039,
19446,
12222,
46915,
11721,
26991,
23347,
37916,
28973,
23161,
27104,
10925,
518240,
129510,
197509,
50415,
57520,
212604,
null,
6442,
null,
24777,
null,
15941,
518403,
12720,
23715,
375583,
11482,
28135,
7525,
41246,
339173,
46706,
24704,
20386,
13639,
null,
94739,
308261,
250341,
133258,
162057,
null,
21557,
25006,
308467,
203837,
177014,
317971,
180569,
36815,
14633,
11580,
null,
99335,
404634,
27435,
null,
36933,
39596,
15335,
96659,
125932,
32640,
845854,
153808,
null,
24473,
null,
15705,
45804,
37135,
null,
323686,
51425,
215307,
202309,
null,
33449,
null,
111054,
4756,
206847,
236136,
321982,
39041,
27690,
18212,
314234,
71223,
387681,
125231,
234122,
83193,
213288,
31942,
112945,
77533,
null,
22652,
null,
294614,
228446,
27186,
46905,
44195,
23927,
31942,
137261,
null,
9141,
470800,
21168,
71372,
16784,
40310,
43614,
38041,
55700,
384172,
23097,
49880,
186102,
103959,
null,
150069,
293855,
null,
null,
49677,
16912,
41124,
18425,
82257,
30574,
158717,
82651,
181805,
157627,
167865,
21361,
26817,
89525,
183325,
6570,
10111,
27826,
106767,
122388,
33503,
44915,
53241,
100167,
23859,
426583,
170180,
12495,
null,
21855,
null,
407565,
141094,
19914,
181388,
null,
19017,
25992,
65160,
50684,
248492,
185186,
168586,
73920,
53606,
392194,
14756,
318609,
135251,
37971,
37583,
null,
31479,
48632,
558018,
390358,
52882,
121236,
8318,
260840,
175488,
41487,
16932,
476807,
135412,
51205,
8192,
147435,
null,
218451,
51711,
20317,
101790,
10708,
23314,
105414,
176124,
195628,
180777,
21657,
47277,
212973,
19762,
273165,
null,
null,
20242,
251344,
41954,
103918,
43131,
58612,
205626,
260747,
178090,
208253,
99623,
52304,
null,
496339,
null,
19625,
6475,
59855,
49803,
259924,
3010,
40365,
171010,
58373,
49305,
183451,
219015,
null,
8768,
265204,
286937,
77363,
51538,
17832,
793162,
115438,
null,
326008,
573393,
183912,
137854,
35192,
10419,
125768,
150814,
194933,
199535,
39591,
33378,
44368,
348875,
50884,
16552,
373254,
22846,
80438,
12055,
249451,
64139,
42073,
174290,
5240,
null,
212640,
25821,
616394,
92575,
30052,
498299,
459914,
8987,
301268,
null,
52505,
97376,
278729,
50991,
32635,
346281,
147786,
27821,
72924,
81046,
7516,
52491,
190907,
186862,
212035,
551642,
26226,
6601,
51233,
null,
43792,
194549,
122464,
75396,
57390,
20881,
39235,
332902,
26495,
10342,
6402,
52548,
null,
30587,
15316,
null,
46301,
14586,
54794,
51886,
279163,
118695,
140596,
32205,
211686,
46134,
103866,
160778,
57580,
119126,
206251,
59258,
320446,
51047,
269975,
321010,
275227,
234302,
76739,
null,
299201,
216336,
25911,
193207,
345390,
155918,
57746,
null,
443739,
22058,
47739,
null,
24011,
227619,
13927,
83704,
23793,
96339,
161708,
128688,
46663,
236294,
31359,
8121,
264584,
225853,
164234,
60648,
14544,
18962,
438216,
20615,
null,
131239,
406816,
332825,
130835,
203696,
21757,
3938,
155977,
508040,
49148,
219339,
180369,
20996,
663,
43697,
45547,
331145,
33394,
9793,
428,
302568,
15387,
null,
26264,
121643,
398843,
264065,
3690,
16473,
300310,
333237,
163704,
12377,
49510,
231283,
35856,
16044,
83144,
44698,
81572,
15060,
100776,
97795,
16134,
20436,
246026,
23553,
147157,
266039,
14619,
18672,
27657,
19419,
144114,
227063,
25361,
31612,
346386,
138901,
273643,
9843,
43705,
8910,
28002,
36802,
72487,
266614,
181002,
16115,
null,
127745,
25659,
10300,
303932,
198767,
20067,
49504,
34898,
15571,
21116,
30219,
109135,
482885,
11009,
61111,
198955,
298826,
22230,
9571,
49165,
36170,
198982,
136785,
61858,
32252,
39724,
204382,
40761,
122684,
34612,
196945,
369013,
313861,
163143,
null,
14132,
35507,
17317,
695603,
45377,
212685,
126500,
47738,
42914,
51610,
427117,
11718,
null,
102221,
249174,
25727,
239808,
null,
142413,
316450,
15307,
534297,
246401,
58617,
82451,
1246,
42361,
89272,
64613,
118159,
289230,
526698,
107241,
204307,
22471,
45710,
115785,
168488,
null,
121604,
314383,
22184,
148753,
265411,
102859,
4318,
342301,
28050,
null,
29069,
250864,
174359,
273234,
null,
null,
277969,
23600,
106121,
105767,
216840,
251846,
346686,
232948,
50312,
14395,
21504,
88148,
159359,
26253,
32345,
641633,
410022,
11644,
39240,
12080,
136003,
202246,
26407,
86388,
9967,
8772,
347915,
49471,
41449,
20069,
307670,
185439,
63508,
292464,
63810,
16887,
222861,
null,
158431,
316947,
135061,
57358,
null,
142211,
41001,
246861,
36008,
1153118,
5159,
292118,
410122,
7860,
18305,
35601,
101814,
81871,
261431,
35776,
84472,
17423,
null,
35844,
2168,
null,
382624,
441819,
351593,
289824,
35093,
351102,
29123,
159750,
24058,
235543,
76101,
208950,
null,
78030,
54842,
null,
null,
null,
16,
176260,
52618,
214048,
null,
175880,
176620,
447523,
385855,
22036,
null,
312143,
161598,
276985,
211878,
280692,
522834,
155450,
63098,
79931,
13652,
163617,
297458,
221556,
6682,
209884,
61645,
16560,
303081,
33352,
292036,
74041,
35667,
25069,
171981,
15910,
370336,
17825,
17493,
17432,
12273,
77018,
147093,
394950,
39333,
38017,
null,
23873,
21840,
141603,
5880,
null,
25491,
131056,
315432,
171307,
265447,
141828,
50959,
144329,
142548,
446634,
27431,
4541,
157676,
347894,
28832,
114668,
466918,
69946,
27901,
77551,
29336,
251919,
255879,
115308,
43109,
92279,
33130,
84230,
30789,
null,
39581,
null,
71922,
26902,
65208,
109598,
221020,
103228,
43421,
83168,
170067,
193004,
59214,
64129,
142979,
512257,
84666,
79656,
65417,
127745,
189648,
36607,
2266,
43566,
67386,
42642,
88685,
451127,
187788,
null,
75522,
71627,
149372,
260863,
223148,
178961,
43647,
222916,
123176,
326968,
6418,
124850,
null,
41920,
496261,
214722,
516090,
138384,
299480,
22740,
472257,
240427,
27717,
264701,
null,
24786,
549959,
345286,
74722,
14208,
30707,
49344,
99477,
214598,
null,
528033,
586572,
11929,
48644,
175330,
14868,
47135,
null,
19286,
140405,
103689,
170254,
180738,
453111,
40261,
null,
206690,
5402,
260212,
417525,
210938,
169682,
94694,
null,
33300,
91001,
21249,
6494,
56447,
37819,
567980,
310868,
44128,
40409,
222990,
10670,
35012,
335105,
129785,
138775,
29913,
141458,
66996,
39005,
180015,
29117,
14206,
40627,
22329,
63210,
290338,
643585,
9469,
127189,
null,
231014,
15290,
16266,
28098,
38586,
50979,
44727,
186396,
68124,
62481,
154373,
173516,
null,
17064,
54745,
443736,
16229,
43079,
312232,
124846,
33712,
190673,
254485,
289512,
null,
15114,
null,
153009,
null,
49521,
152562,
10828,
23963,
27214,
1181091,
58458,
15560,
43216,
403978,
250131,
10237,
34680,
46051,
522478,
14674,
30255,
101549,
null,
5003,
215062,
null,
null,
122310,
133519,
117292,
225672,
316589,
18791,
857304,
133996,
211594,
223694,
32143,
22029,
133089,
34802,
183847,
274455,
429987,
27766,
34284,
107685,
179200,
23822,
280723,
62044,
208517,
237762,
25122,
273326,
249459,
439308,
298797,
30290,
69874,
49844,
146660,
136900,
48679,
303547,
269735,
5673,
134720,
103329,
9410,
63142,
102416,
164561,
142688,
177587,
38301,
221138,
405264,
11151,
29269,
407279,
214574,
102289,
37953,
402364,
45684,
30998,
73675,
201281,
52907,
379869,
265392,
42253,
596894,
2138,
478772,
236013,
57539,
170076,
220517,
323278,
191782,
202038,
38045,
4587,
50525,
390951,
322531,
16620,
124099,
82215,
18768,
37500,
85909,
290987,
18569,
93350,
71787,
53043,
285608,
92231,
null,
290993,
null,
27155,
20004,
null,
66321,
23975,
162205,
106595,
271547,
247639,
23254,
153432,
39350,
112996,
25291,
156774,
208253,
null,
45994,
185055,
219740,
null,
163065,
153174,
211072,
32670,
309902,
19251,
null,
295969,
44317,
18985,
413295,
51332,
139130,
62584,
13262,
30826,
13305,
382015,
329971,
6405,
380464,
462513,
221983,
46076,
30969,
144385,
89065,
96841,
267175,
516473,
29622,
9925,
35099,
200558,
20270,
24692,
139036,
77284,
183465,
324799,
865398,
null,
8393,
267728,
66342,
302450,
null,
42851,
280548,
10245,
5631,
null,
284226,
43804,
194105,
36567,
22420,
194938,
145744,
86498,
320155,
94907,
31198,
413228,
6216,
192603,
13778,
139675,
53834,
null,
null,
51039,
218440,
127086,
null,
27928,
196203,
9142,
14038,
169002,
null,
9192,
264339,
143364,
null,
117721,
46517,
15556,
170932,
30021,
27633,
92363,
383152,
286321,
53509,
420242,
253033,
421096,
36542,
234020,
null,
381656,
107120,
13707,
39719,
37162,
119279,
null,
158733,
null,
225153,
130508,
132349,
23783,
6082,
81043,
null,
39613,
5799,
null,
1121630,
35430,
42847,
27481,
null,
23698,
471131,
7069,
3495,
161070,
21866,
115839,
null,
139816,
63075,
26485,
515171,
13904,
null,
185162,
35450,
46121,
42350,
null,
16940,
181669,
255318,
48617,
79097,
30108,
9175,
null,
285944,
193446,
null,
79529,
156742,
22628,
163319,
344156,
189494,
601355,
7571,
null,
null,
117469,
381977,
229989,
13706,
98692,
86123,
162399,
421709,
132553,
141534,
57458,
367323,
781553,
25551,
113775,
391867,
82579,
136969,
26755,
21035,
null,
38256,
348432,
44800,
33111,
514662,
15442,
404840,
263324,
49081,
27319,
114104,
140452,
14232,
167264,
18398,
212531,
16137,
35123,
363112,
223974,
159126,
630634,
113752,
40780,
27747,
null,
20480,
null,
381408,
399996,
248558,
13731,
177641,
201212,
436320,
191265,
7631,
50693,
null,
78590,
18503,
418279,
null,
48254,
117746,
276872,
16263,
null,
2736,
34418,
391030,
128525,
134581,
148797,
176202,
59553,
18672,
145383,
405248,
139158,
157330,
385839,
106269,
148807,
54916,
433911,
78218,
null,
null,
27885,
30501,
667175,
179850,
350453,
39174,
246093,
7922,
135339,
177345,
449149,
122180,
135301,
36314,
138155,
40226,
173479,
214905,
192458,
307492,
114896,
35823,
354819,
37346,
317073,
null,
74350,
null,
3709,
24928,
165522,
133909,
29913,
24518,
42065,
null,
61509,
294531,
146816,
231805,
205957,
57414,
116785,
141841,
27378,
206826,
47114,
147093,
5377,
121436,
6054,
20319,
14857,
126331,
435412,
101105,
56654,
322045,
49956,
397828,
72807,
32249,
80287,
44519,
224980,
144948,
142420,
null,
null,
71060,
100703,
12883,
98416,
43929,
null,
76762,
840845,
177241,
42149,
null,
26830,
87628,
409349,
49392,
36114,
78014,
null,
null,
482802,
null,
26578,
10934,
109599,
47423,
89444,
111441,
80450,
null,
87107,
139249,
19653,
240622,
43408,
44199,
10792,
380039,
111433,
172356,
355442,
178474,
304807,
68862,
284781,
39622,
null,
110305,
21865,
342923,
282669,
362469,
null,
8522,
278561,
54372,
63052,
4364,
null,
29087,
43791,
31885,
180658,
124475,
255922,
341446,
280056,
52451,
null,
55345,
21170,
29787,
91311,
170996,
40662,
18517,
222013,
29734,
37087,
36706,
89261,
null,
8021,
40535,
12410,
120818,
36541,
5525,
61016,
368998,
68854,
425770,
141342,
13479,
183773,
274278,
29891,
126338,
4564,
9812,
12400,
23170,
165563,
615821,
84412,
656906,
40552,
413849,
null,
137711,
48414,
null,
223117,
217506,
85091,
37850,
146667,
210222,
464234,
17179,
354810,
296138,
37816,
24735,
155566,
null,
298886,
138388,
68539,
28798,
18279,
294781,
33907,
44955,
7979,
null,
39996,
167103,
46156,
360507,
58146,
79220,
46008,
285754,
140801,
4889,
211609,
493641,
180875,
225773,
179140,
28557,
24109,
17080,
268130,
26215,
158328,
36062,
100779,
241322,
17728,
null,
15529,
34365,
278512,
773846,
117359,
38090,
467447,
98807,
334263,
32753,
313819,
61739,
40177,
null,
23444,
94506,
19136,
59269,
null,
74718,
79853,
null,
76231,
166855,
120443,
22104,
512662,
95884,
32401,
296336,
25583,
32508,
31293,
46243,
44927,
132033,
33050,
30436,
289711,
210619,
null,
34072,
null,
5763,
163325,
144532,
264306,
151507,
351842,
357236,
273288,
null,
186349,
12092,
420643,
80530,
352184,
152900,
228888,
6793,
93153,
241087,
119393,
168965,
27288,
67032,
365711,
146563,
387303,
501063,
60217,
156778,
14787,
30989,
151090,
10639,
null,
49366,
null,
15895,
121548,
210678,
19807,
16827,
481377,
82914,
203646,
174916,
7391,
165608,
null,
2556,
5547,
151825,
31953,
243736,
262319,
10702,
194579,
6688,
329058,
298782,
23143,
155753,
52779,
39930,
125452,
746460,
null,
98044,
229093,
398728,
76482,
34620,
12322,
9184,
337721,
102681,
411027,
117381,
31276,
71303,
210223,
12249,
15649,
18555,
31876,
246127,
248240,
248129,
9272,
32439,
27165,
243655,
75243,
202212,
227511,
25643,
2840,
46358,
92846,
null,
null,
13105,
6676,
89597,
191688,
266646,
371609,
113849,
44053,
346463,
8192,
633523,
37240,
120739,
null,
410564,
51784,
null,
19897,
76526,
257046,
56265,
178607,
514334,
378216,
43754,
98146,
20240,
217834,
235006,
106976,
28119,
29140,
91938,
202124,
null,
28742,
866133,
146645,
456376,
59954,
237657,
73726,
39755,
62766,
243885,
null,
14849,
375449,
233690,
283096,
242667,
227061,
414787,
51629,
31649,
15939,
19791,
101045,
241580,
335600,
28049,
476684,
326717,
59069,
255666,
339753,
95770,
34406,
null,
260852,
39396,
30183,
13481,
133782,
293885,
22193,
48753,
32300,
73221,
6449,
66401,
63859,
15566,
9869,
53448,
200035,
null,
67324,
57632,
95135,
19724,
32073,
41174,
null,
424699,
145204,
445491,
14608,
41844,
52532,
null,
85510,
157442,
130903,
46839,
35474,
125796,
199082,
203485,
21714,
30346,
57048,
65083,
207460,
10471,
32755,
13111,
6110,
1441,
306491,
330283,
212083,
30223,
14447,
69641,
null,
72048,
56432,
219200,
113201,
36964,
341668,
22100,
133412,
372327,
null,
70034,
270907,
181061,
1916,
172078,
null,
15322,
387051,
212382,
148535,
null,
117553,
16188,
236812,
60640,
33450,
302811,
65735,
4463,
121424,
75966,
21033,
119003,
19698,
27261,
12515,
19900,
52748,
31322,
291462,
108528,
59704,
9475,
183010,
68912,
58976,
100454,
2611,
542518,
null,
304510,
null,
322136,
17131,
115713,
93772,
91600,
232143,
309616,
111672,
685,
278565,
65694,
null,
15110,
48493,
360923,
197894,
346052,
115662,
26655,
10440,
376539,
316117,
118212,
41770,
null,
48951,
35946,
93743,
182550,
32857,
189009,
153411,
341376,
100891,
56025,
16377,
234099,
139998,
107858,
143211,
25054,
174507,
475669,
81185,
133888,
17782,
null,
215503,
209323,
7642,
102048,
44097,
126411,
284809,
67770,
32128,
43884,
51625,
null,
180910,
115839,
248190,
191413,
5269,
316953,
168239,
20766,
198186,
26523,
68616,
12560,
365178,
48852,
549699,
107730,
441737,
221459,
26291,
266943,
212931,
14323,
27846,
62066,
283660,
267780,
11811,
18685,
418919,
47761,
269284,
576989,
71648,
null,
43262,
null,
5939,
396048,
343914,
240727,
30059,
85407,
null,
10735,
661416,
9687,
171793,
null,
73516,
153921,
522992,
17226,
16638,
28474,
37942,
186318,
20277,
null,
2592,
31370,
130442,
169879,
171654,
17044,
22764,
223879,
101438,
608101,
null,
26861,
51105,
180173,
242342,
96934,
null,
29861,
135315,
237992,
277066,
35358,
46658,
27062,
47808,
630857,
77267,
29269,
158334,
157882,
234856,
205076,
59857,
26613,
8229,
388859,
66498,
165730,
55165,
91803,
153294,
30715,
53030,
309119,
390119,
16164,
22187,
null,
32009,
15847,
124684,
611600,
129825,
11216,
397547,
196899,
159517,
12547,
11951,
26048,
128220,
178934,
71944,
92353,
null,
11497,
405013,
308039,
22768,
197189,
238880,
87061,
236204,
7568,
23227,
173712,
91919,
71514,
6475,
null,
411103,
15067,
4518,
26940,
17185,
167500,
34922,
97354,
34635,
73313,
9988,
30181,
367775,
53428,
216879,
52809,
147895,
3472,
238143,
145811,
7191,
304691,
341299,
9035,
460186,
282572,
null,
185551,
233133,
378524,
21081,
15159,
260935,
245403,
153012,
25192,
658975,
443795,
60500,
309198,
160797,
null,
10841,
69937,
null,
46554,
34413,
241089,
414663,
131992,
109290,
117148,
94364,
97740,
141744,
null,
487934,
684136,
44632,
693499,
295489,
194798,
267692,
24749,
33273,
485988,
144596,
195348,
15690,
4477,
380136,
229975,
9907,
null,
253770,
272953,
18933,
288255,
65399,
94461,
179885,
27054,
809402,
218770,
173172,
256455,
215747,
228769,
45196,
64882,
93210,
7092,
28744,
22160,
151540,
231706,
41928,
null,
null,
25905,
256661,
403948,
19434,
2752,
26360,
79229,
4609,
29219,
30017,
7244,
253496,
210655,
1717,
158491,
247523,
17207,
284989,
24329,
91017,
158518,
103515,
519894,
352337,
455847,
15993,
315812,
25117,
17019,
207754,
248790,
194987,
null,
25153,
184323,
40127,
91075,
null,
48507,
null,
null,
47460,
38773,
37401,
11488,
107625,
291414,
29983,
486523,
90683,
32530,
72234,
253938,
40396,
43819,
330634,
50005,
null,
226954,
28881,
null,
456235,
12018,
97612,
17894,
39976,
243079,
95893,
34995,
68943,
52934,
153171,
86268,
163222,
198743,
22942,
232369,
340017,
43554,
681734,
20007,
56946,
201997,
38054,
8507,
32661,
42183,
302375,
null,
31321,
79273,
155582,
41245,
50566,
281224,
149831,
72402,
166964,
126531,
28710,
223623,
14677,
195194,
33753,
262910,
106763,
63956,
383916,
16338,
306370,
43070,
230504,
262521,
null,
6968,
337748,
53316,
17593,
304139,
151496,
253943,
439096,
38173,
15652,
77278,
null,
184659,
104583,
60058,
56732,
null,
20842,
263684,
151687,
149029,
191231,
245773,
33983,
null,
11333,
94943,
47497,
32329,
62649,
76464,
181860,
252988,
5082,
13599,
194410,
153899,
37595,
114567,
67992,
161078,
39757,
355801,
13765,
188139,
5440,
261787,
48903,
134656,
38306,
15644,
113370,
24805,
12775,
25058,
null,
381994,
50864,
41954,
503581,
39770,
16664,
171758,
19811,
null,
132325,
15838,
13694,
177572,
262411,
253076,
54069,
377837,
null,
27786,
13567,
139664,
680626,
null,
201338,
451338,
null,
254271,
208617,
5539,
129832,
19375,
55425,
null,
299666,
34394,
165167,
44278,
31990,
55393,
195256,
6303,
null,
98991,
224261,
451209,
229662,
91855,
674312,
24553,
281123,
408474,
14606,
79555,
26962,
42320,
57003,
5245,
233268,
135875,
368692,
45682,
4423,
50130,
291523,
223356,
259342,
62851,
null,
152148,
null,
253363,
229113,
45633,
18227,
103608,
40860,
41159,
210393,
26023,
null,
457612,
43148,
158779,
390403,
42702,
367585,
80735,
181764,
324157,
72932,
184937,
274372,
null,
217381,
17502,
474033,
101690,
18147,
23396,
34891,
289427,
103801,
30363,
21423,
503727,
19659,
52210,
22966,
242761,
25419,
255470,
27934,
10364,
4670,
29902,
27560,
284265,
279053,
183318,
46566,
34379,
40154,
38024,
13802,
276929,
18177,
16523,
32684,
433273,
369432,
292498,
566715,
3261,
279077,
97649,
310703,
146867,
62891,
214720,
33446,
134457,
59523,
261484,
null,
null,
179220,
null,
296448,
70726,
356571,
272227,
11538,
20842,
56313,
18008,
16700,
114924,
35694,
8004,
null,
117956,
null,
58195,
131302,
119164,
10772,
null,
29082,
297930,
162305,
13466,
45308,
null,
597185,
20916,
584674,
10128,
59992,
56803,
13494,
519654,
289674,
20031,
336577,
134099,
6860,
205987,
130277,
132006,
128555,
41365,
396724,
null,
9569,
null,
187199,
61732,
263503,
73049,
141070,
46840,
146737,
72525,
16582,
89694,
305388,
161649,
6235,
232850,
null,
158525,
37536,
null,
13912,
190821,
262433,
201633,
47745,
113825,
372151,
213918,
61847,
282220,
407879,
156988,
84090,
10825,
18716,
null,
222817,
26598,
383180,
179022,
285698,
42714,
40950,
48069,
48130,
47684,
null,
91489,
null,
262026,
211122,
65759,
40050,
null,
101215,
40261,
127163,
20073,
181811,
32375,
278107,
80589,
44987,
126071,
215834,
11712,
208166,
31351,
81542,
38085,
44352,
null,
29542,
32141,
52394,
209961,
128649,
196824,
65270,
461708,
209860,
500499,
114425,
282724,
387537,
258002,
9564,
37952,
335328,
178147,
33250,
26624,
454097,
47764,
31833,
32979,
35813,
18595,
8563,
null,
5433,
49665,
44865,
83001,
117922,
176239,
364535,
214672,
85480,
99327,
266224,
309281,
7481,
69887,
45364,
292298,
118370,
331687,
29441,
263211,
222162,
229808,
147622,
184226,
54039,
27806,
231253,
40442,
68009,
258310,
295996,
42433,
29098,
159236,
339605,
304727,
23035,
206871,
2150,
40561,
null,
469179,
314375,
28820,
21083,
273992,
176426,
5226,
304342,
34545,
16935,
82594,
36300,
42414,
760364,
43935,
149196,
302405,
6349,
60605,
56979,
null,
260320,
17658,
27850,
80142,
8100,
252277,
25019,
null,
107845,
26307,
127753,
20091,
266992,
275431,
1755,
222646,
173788,
232666,
247627,
197760,
null,
610775,
70222,
30296,
118318,
10099,
12257,
20335,
151063,
649928,
323982,
64073,
303308,
34772,
116180,
187392,
117735,
189834,
463955,
170326,
66212,
231471,
18058,
113395,
92736,
137663,
11956,
216861,
null,
64927,
412748,
20116,
332664,
370693,
85047,
19775,
19067,
297874,
22190,
263807,
37763,
46777,
23293,
235968,
98963,
8262,
170615,
775105,
180911,
45170,
162283,
87587,
192805,
112779,
246160,
null,
9421,
31315,
139443,
199883,
17669,
49422,
32502,
59359,
26978,
302690,
18235,
267446,
25542,
40830,
53821,
361886,
236155,
231529,
19788,
173580,
3841,
19314,
215712,
84223,
21934,
7062,
330529,
261370,
87788,
32446,
1584,
25997,
114926,
19156,
81323,
62121,
420843,
92294,
134934,
49171,
37214,
270135,
78936,
294070,
103692,
38029,
329445,
35578,
415002,
125954,
190763,
54338,
213946,
81179,
355834,
56459,
212062,
4537,
600969,
32301,
207207,
25640,
121665,
null,
25915,
20348,
102629,
45685,
20464,
null,
197792,
78188,
null,
5732,
321575,
27727,
101687,
44400,
177906,
37400,
133975,
24033,
124108,
135216,
25049,
32101,
166105,
228596,
70131,
null,
375436,
319697,
24387,
85877,
33983,
null,
724048,
62473,
95386,
33329,
221799,
166836,
20354,
42945,
13771,
37687,
44055,
21153,
3315,
201717,
148117,
null,
12985,
312315,
null,
47310,
140268,
286821,
null,
123768,
155696,
22870,
27061,
56492,
214387,
58416,
33043,
380205,
140889,
408128,
24924,
22441,
591480,
353550,
135142,
206688,
36554,
147445,
13958,
9923,
29693,
24395,
3633,
57366,
null,
140317,
30565,
416051,
56215,
416766,
41900,
93013,
241218,
334508,
173913,
206335,
72583,
17311,
300436,
43279,
25740,
91819,
136262,
58906,
42100,
null,
191830,
452589,
234678,
207793,
23867,
157051,
24545,
32549,
197183,
178545,
7820,
196017,
33981,
255711,
null,
131525,
27523,
195482,
123984,
138099,
44523,
null,
15,
68554,
46850,
280030,
161969,
24379,
null,
17355,
17287,
234067,
27245,
33568,
419181,
130215,
187179,
251283,
33637,
83646,
15239,
291072,
176400,
30542,
564700,
129806,
68730,
116313,
null,
15023,
31207,
120040,
54936,
138637,
29352,
76051,
192164,
164413,
136923,
73659,
53730,
null,
42697,
41748,
null,
360803,
154802,
578859,
235890,
9847,
null,
351650,
null,
161376,
6527,
196000,
61640,
157914,
12184,
315190,
37941,
175059,
78593,
63665,
64897,
270997,
10646,
23819,
91604,
83447,
17428,
344473,
43699,
183435,
45081,
137405,
76736,
239152,
153788,
318051,
428027,
null,
22566,
209715,
129406,
20353,
353306,
126928,
28527,
null,
274030,
178880,
13782,
7444,
83408,
237262,
18813,
36852,
28588,
59661,
420312,
71209,
365082,
116388,
56014,
32917,
30652,
24335,
9694,
219319,
123193,
19227,
null,
149965,
126659,
44877,
42535,
371372,
1242125,
805545,
178934,
244363,
28692,
337362,
302415,
null,
5584,
35389,
81956,
96067,
null,
272543,
164900,
375714,
27710,
209097,
328822,
45010,
39677,
56454,
662084,
null,
112620,
246182,
214795,
51528,
103865,
225151,
387926,
79819,
354631,
212966,
169668,
null,
180975,
163453,
61865,
221783,
93968,
319956,
147626,
102816,
32727,
69249,
623772,
35352,
223215,
137627,
null,
36369,
5015,
137805,
null,
36938,
594334,
13773,
105326,
123362,
61719,
null,
393810,
86651,
null,
23234,
32011,
18098,
30614,
270246,
195098,
11558,
307449,
169004,
47344,
154516,
150202,
null,
185586,
378786,
161661,
null,
68078,
3763,
15635,
18124,
150973,
299556,
46386,
260143,
25102,
146241,
16462,
55250,
29202,
21458,
84188,
null,
52144,
209617,
6504,
586379,
116753,
100537,
31187,
null,
174898,
328588,
87547,
48979,
10782,
66920,
77194,
382067,
471977,
38247,
94879,
17537,
217445,
48384,
328843,
379059,
148325,
42739,
26618,
247338,
22670,
471336,
null,
38302,
89119,
43523,
25524,
348124,
457196,
67975,
10686,
132805,
195490,
4775,
474667,
17151,
182981,
297978,
37404,
342996,
36755,
184999,
null,
209595,
259597,
257698,
152584,
333454,
356907,
22765,
84284,
99444,
6441,
28807,
431903,
149505,
41224,
8692,
178687,
79019,
175624,
null,
15891,
5764,
169259,
43951,
61804,
19963,
14367,
18427,
239791,
241015,
77205,
271376,
195041,
391209,
75962,
null,
114150,
31685,
484751,
11666,
317090,
365631,
210000,
18567,
174527,
120469,
42641,
229030,
250147,
29571,
362554,
468767,
290957,
37703,
179085,
null,
195185,
147989,
35060,
286649,
null,
8924,
170622,
322634,
30113,
65077,
129183,
272280,
103973,
17960,
289069,
115110,
101225,
128662,
277197,
31533,
99771,
null,
203921,
187799,
null,
185656,
409971,
115891,
23129,
128859,
75126,
12822,
186854,
329844,
40186,
476477,
16762,
72742,
12275,
null,
572941,
8116,
45865,
214280,
210995,
47281,
36284,
9185,
187646,
1318,
171558,
171927,
null,
194071,
15021,
6875,
306304,
33318,
13928,
509,
23846,
19977,
23611,
16082,
28566,
185594,
41319,
365885,
217179,
41464,
27292,
30581,
307342,
27100,
241606,
67454,
38350,
197227,
24440,
116324,
189147,
null,
308211,
25213,
185814,
378700,
11627,
20025,
687293,
74963,
3087,
213841,
530898,
118645,
167260,
243831,
305146,
14834,
23784,
167281,
218446,
52314,
34024,
16973,
39155,
7069,
53978,
214727,
63979,
213499,
158891,
83062,
19770,
13097,
3862,
293082,
22023,
94777,
74778,
7878,
31330,
56649,
159433,
67577,
202891,
146503,
18134,
22703,
517824,
33608,
150932,
34383,
364868,
57730,
23714,
206492,
14861,
117538,
2914,
30285,
285941,
112652,
311405,
17403,
325953,
2935,
24015,
49379,
157901,
179401,
null,
442621,
25273,
12221,
15172,
226467,
225474,
null,
236549,
12269,
131151,
31697,
22158,
null,
20116,
46635,
118640,
198994,
14089,
73215,
21853,
167986,
83224,
29741,
null,
56970,
26285,
38176,
45473,
46163,
null,
17725,
320746,
254038,
98537,
214388,
281349,
66441,
16473,
105756,
67680,
477838,
7370,
106973,
103277,
281844,
237408,
102151,
271990,
143479,
396186,
55092,
226831,
281083,
364943,
30267,
16072,
44178,
9624,
61326,
190195,
125983,
72062,
301109,
183991,
5741,
456545,
12747,
13647,
15743,
360883,
null,
280259,
64900,
48769,
328981,
1154,
420289,
268134,
58977,
64347,
18566,
65449,
105416,
41108,
39897,
42351,
25755,
323840,
28896,
44037,
90061,
68465,
242704,
370289,
15257,
74137,
24053,
57452,
110540,
15627,
29232,
76709,
42592,
387743,
null,
137652,
282981,
null,
420015,
16812,
526484,
20805,
119891,
30146,
2755,
7444,
6961,
301262,
95827,
60731,
399472,
56651,
25608,
482157,
203663,
null,
216567,
445612,
121268,
11109,
63366,
101804,
44410,
517803,
110518,
231050,
16171,
45132,
239551,
36517,
250875,
107503,
42192,
1086281,
165928,
211372,
167604,
25248,
430790,
null,
55845,
88122,
71886,
89863,
250637,
481258,
290287,
5259,
324754,
556945,
116523,
227956,
29884,
169084,
8936,
425128,
21780,
51380,
16605,
84497,
195389,
null,
24087,
47402,
8833,
14584,
379017,
15742,
337053,
null,
331284,
217824,
40391,
192018,
250089,
181449,
38325,
30024,
15398,
7312,
157008,
55208,
56142,
199725,
46198,
100232,
18855,
null,
690580,
52056,
30227,
23420,
45193,
144696,
31670,
398859,
25158,
11497,
193907,
115220,
362278,
17317,
286737,
211080,
496783,
43054,
201744,
284776,
46863,
286249,
290972,
65391,
246793,
49782,
327402,
37815,
252382,
33557,
94577,
698358,
46770,
108057,
58644,
25705,
28856,
178697,
140757,
129712,
57728,
95698,
65449,
757807,
115682,
178717,
null,
261124,
74395,
57519,
376527,
479304,
335398,
107813,
188339,
775958,
null,
38844,
23209,
185302,
69359,
177638,
323035,
37912,
338942,
474694,
27945,
51214,
67584,
1819,
33636,
394991,
54930,
45068,
10816,
15038,
null,
74277,
39475,
91864,
52467,
30153,
374709,
159504,
119349,
null,
null,
95387,
195531,
18008,
422759,
71790,
403606,
118665,
41888,
323527,
null,
44925,
30041,
313542,
31911,
6228,
149596,
null,
12223,
14353,
332571,
120064,
129903,
null,
368669,
193779,
21736,
37566,
31274,
11248,
30598,
60078,
201717,
141868,
160583,
14381,
125728,
null,
25849,
242119,
344871,
127154,
29282,
149719,
25841,
24624,
479302,
75723,
42276,
20944,
53158,
341817,
39552,
81587,
null,
35371,
196345,
268106,
74342,
393099,
87960,
40243,
272260,
121785,
542931,
87444,
133401,
69552,
69004,
286408,
20962,
31636,
282934,
77177,
439838,
33942,
63732,
50090,
30159,
11072,
40740,
285531,
240565,
302724,
18096,
192647,
6979,
30096,
8917,
69998,
96781,
null,
206830,
360020,
14465,
11751,
109199,
108141,
154762,
235086,
374411,
104053,
14543,
39469,
230269,
17181,
87709,
null,
38572,
388973,
54768,
18804,
35765,
23499,
44765,
6450,
null,
29745,
907,
74086,
25441,
42225,
24008,
151548,
57270,
4861,
89128,
100930,
273728,
94155,
281459,
405326,
95451,
88770,
58323,
13543,
6641,
28977,
143098,
403988,
276380,
630678,
134521,
18185,
200669,
89462,
9561,
197328,
55290,
12894,
15476,
18319,
280269,
435032,
12435,
57579,
91189,
null,
37358,
222158,
105486,
216628,
127627,
85302,
253262,
45439,
66079,
50052,
278631,
112335,
280245,
7076,
41663,
152558,
54870,
23257,
28381,
12236,
13560,
148260,
27712,
275328,
28463,
85809,
91445,
null,
14410,
41219,
40195,
221402,
40615,
35497,
132931,
358449,
51023,
null,
345844,
546935,
14765,
369365,
8800,
99587,
26141,
null,
129429,
4775,
33013,
6248,
178122,
19131,
196467,
127777,
470183,
183494,
89600,
828515,
241106,
296596,
13361,
125252,
null,
null,
634674,
210761,
39315,
126383,
164839,
212921,
44462,
387409,
null,
35132,
323859,
93542,
532476,
null,
36518,
213058,
607820,
107671,
183722,
111409,
20251,
142022,
null,
14326,
2128,
null,
24067,
179551,
103838,
null,
33832,
204203,
53535,
91818,
5868,
415211,
194145,
16777,
31770,
12897,
126681,
22165,
65296,
null,
2635,
252071,
25813,
19408,
49065,
37890,
67046,
337602,
34301,
217931,
167516,
526272,
268716,
5207,
358186,
90047,
62999,
null,
37151,
229013,
238048,
130456,
null,
202133,
8097,
38233,
277388,
101010,
449550,
175375,
613134,
22614,
125047,
118040,
null,
102448,
8241,
167684,
37919,
180246,
40212,
56469,
35627,
43765,
259060,
null,
44599,
null,
138764,
152124,
64116,
57985,
38360,
305198,
194352,
17706,
40696,
57383,
171358,
21824,
215226,
12278,
null,
null,
184783,
28362,
115113,
null,
11992,
42405,
310440,
619814,
18814,
373438,
254373,
181027,
5620,
null,
45864,
376975,
171260,
187679,
null,
22038,
464256,
15480,
null,
185726,
322378,
null,
160354,
226387,
81824,
33685,
25584,
133985,
46279,
104491,
24809,
205636,
389675,
null,
19121,
43209,
24602,
42086,
146460,
69440,
524723,
177133,
58489,
367997,
70795,
250735,
21118,
30679,
2285,
38532,
39691,
24673,
25354,
null,
4253,
38540,
43543,
311952,
126304,
36562,
14259,
218213,
156868,
338609,
296496,
269928,
212182,
170199,
37239,
182738,
163646,
452336,
37576,
36617,
42698,
12318,
11648,
null,
395862,
44414,
291261,
4572,
152885,
16865,
139530,
64220,
826111,
47365,
161842,
33009,
96496,
15429,
26264,
20050,
11176,
123391,
52325,
25182,
4710,
17249,
202129,
218088,
10853,
35857,
37920,
83069,
48117,
128370,
27991,
71209,
256799,
null,
295845,
354599,
143311,
18008,
69527,
null,
33186,
71567,
236303,
165906,
15952,
92049,
449,
72852,
218008,
35827,
69153,
58314,
200638,
75934,
16315,
null,
null,
14995,
282246,
12945,
75136,
29866,
269006,
51942,
49946,
134445,
209922,
9924,
null,
359551,
251195,
199426,
526344,
null,
29107,
27162,
null,
21993,
538269,
10148,
211008,
105910,
35084,
79119,
33871,
184736,
90951,
47946,
91196,
7856,
58686,
348923,
19564,
19248,
39264,
224069,
77511,
null,
343859,
16568,
78555,
162706,
39625,
null,
103172,
13495,
11812,
null,
259891,
null,
40268,
22013,
149545,
224669,
69194,
330227,
21890,
9216,
37342,
268214,
618366,
290579,
503557,
63770,
175227,
307789,
172467,
84713,
43714,
2136,
178671,
9870,
128785,
479339,
326896,
358745,
71600,
141740,
33890,
36343,
126657,
13012,
193479,
22174,
26394,
30511,
7622,
44200,
null,
121670,
38039,
169463,
167110,
null,
245218,
68981,
178849,
215980,
158018,
233555,
25625,
277082,
45722,
260538,
36337,
34130,
98256,
192842,
null,
212450,
118719,
46878,
3082,
176332,
194464,
46289,
null,
121120,
32472,
251523,
24256,
135628,
null,
315793,
18536,
null,
12328,
334576,
10011,
381217,
141643,
null,
680491,
294269,
218223,
30202,
217550,
8402,
12573,
401124,
102895,
23568,
12609,
73775,
32111,
379826,
null,
null,
126702,
80538,
369049,
64692,
39971,
326858,
72031,
379997,
152816,
128148,
26624,
7276,
444558,
344499,
45744,
21688,
46637,
45539,
35149,
18925,
44758,
85735,
26591,
357382,
13094,
178721,
195977,
27080,
393540,
229745,
403673,
213890,
340533,
null,
45917,
13406,
74203,
197991,
null,
387248,
null,
330678,
12311,
218507,
19388,
159477,
14425,
null,
39429,
174516,
260232,
70696,
70005,
36676,
381818,
397532,
37670,
null,
137028,
162971,
275445,
417028,
33649,
18164,
38763,
72916,
36966,
5174,
122816,
42762,
157023,
16740,
20556,
21233,
22405,
231503,
72910,
61246,
62992,
6274,
40876,
null,
393265,
362066,
39406,
null,
110776,
115983,
47647,
111296,
23656,
434462,
null,
24073,
null,
478253,
325051,
25260,
9432,
null,
32379,
18366,
94991,
46010,
167623,
39049,
93357,
277587,
70018,
229646,
223071,
309792,
17225,
33250,
43777,
402706,
286123,
77714,
49948,
293848,
11580,
548417,
null,
null,
119088,
15698,
null,
52098,
null,
668719,
23380,
79711,
117418,
47643,
274613,
72839,
41732,
30456,
24390,
211562,
60473,
106278,
22154,
109798,
379991,
9694,
55749,
7793,
18035,
132849,
519037,
142605,
45424,
62786,
254115,
7688,
218169,
198499,
160756,
496526,
null,
11055,
48132,
159567,
207407,
412209,
91710,
235544,
null,
453810,
163770,
54844,
161458,
85814,
118593,
159342,
58096,
257747,
297317,
null,
null,
261854,
583922,
178017,
14490,
101178,
22534,
223672,
324969,
211032,
33133,
604554,
39246,
35426,
7573,
262064,
13906,
219311,
72032,
26114,
283894,
311136,
294691,
376295,
33617,
53519,
82157,
63930,
199339,
19471,
33148,
33345,
16048,
50846,
201816,
null,
127753,
4337,
33343,
21145,
185834,
null,
213548,
230043,
null,
76230,
99366,
4190,
225724,
46595,
185697,
120162,
58289,
207250,
28353,
22902,
76756,
27895,
6289,
33240,
139254,
15798,
551581,
59437,
158718,
15734,
51667,
104398,
165564,
null,
83747,
4448,
null,
36869,
8029,
null,
null,
101254,
59640,
8672,
269686,
173944,
30945,
19466,
78949,
347747,
null,
296541,
28041,
33848,
40221,
68553,
6404,
13378,
58392,
8736,
null,
85901,
239199,
26270,
105873,
63989,
27920,
null,
43872,
78178,
83684,
113715,
6941,
254551,
6807,
16136,
7678,
21120,
null,
419918,
258618,
84664,
93900,
35986,
40951,
34247,
33499,
12057,
11350,
113417,
252272,
20567,
64074,
126567,
19723,
33087,
367627,
228960,
43424,
null,
7648,
33511,
105534,
56369,
167701,
29427,
16394,
86200,
92652,
null,
13739,
null,
243690,
7910,
47717,
311523,
80408,
25753,
36512,
39221,
101453,
169658,
35126,
42960,
76267,
39208,
245900,
118353,
58050,
212007,
117943,
49392,
328345,
62334,
211891,
34990,
17096,
454142,
66107,
89577,
42695,
101943,
118808,
391888,
81532,
200203,
120220,
195511,
null,
23478,
null,
198986,
27177,
339439,
null,
252019,
16189,
86753,
17474,
85712,
123108,
437948,
41603,
7280,
679390,
46174,
22735,
28890,
454248,
62450,
277092,
45902,
130123,
30962,
84238,
56431,
108555,
42939,
128775,
319165,
394631,
125320,
34908,
361899,
136401,
36560,
26169,
29193,
512580,
400640,
46717,
146202,
12220,
9991,
247188,
135652,
226374,
95711,
199035,
7304,
52836,
127056,
193358,
30753,
15122,
162438,
12007,
51353,
278991,
136608,
null,
530361,
2644,
4596,
84229,
140185,
10019,
null,
134696,
170969,
710392,
33705,
288264,
597573,
126996,
23077,
51668,
66576,
87871,
422948,
59754,
504748,
168866,
12413,
427503,
4610,
277014,
218301,
140732,
29075,
17660,
34800,
18985,
1716,
16956,
199733,
45909,
null,
22525,
144242,
71949,
497960,
84806,
142610,
135883,
10662,
12884,
null,
211413,
216680,
44847,
31172,
10892,
88868,
31844,
49074,
57800,
14364,
248350,
69140,
95042,
339472,
43697,
410022,
247575,
203800,
27595,
null,
24019,
35702,
70935,
59318,
18424,
111390,
141778,
19402,
63535,
37599,
243833,
253616,
193051,
71436,
12785,
67707,
44502,
29661,
178319,
null,
1843,
6190,
579225,
23639,
167997,
56862,
null,
102481,
9137,
28141,
59684,
169306,
229131,
95300,
512837,
41805,
20174,
31129,
175050,
165664,
48286,
386295,
null,
204872,
17445,
362916,
643024,
null,
null,
319609,
41817,
36432,
7970,
196864,
null,
10139,
41241,
null,
45981,
54101,
463694,
97683,
1036269,
55740,
166012,
116578,
712861,
null,
null,
222651,
12616,
259252,
323926,
42881,
415320,
2600,
4297,
25490,
231346,
12696,
254313,
107558,
188791,
15371,
13677,
485471,
266133,
189398,
61471,
290567,
73806,
26986,
49950,
55560,
226919,
null,
70683,
171539,
null,
4357,
72609,
150231,
1226768,
31279,
175688,
18374,
215073,
105595,
13102,
null,
26762,
300955,
302977,
null,
null,
51033,
194827,
238227,
107277,
38240,
320093,
45462,
73223,
null,
null,
12213,
174498,
39124,
351236,
77701,
227328,
421562,
502796,
13571,
null,
267454,
9045,
118693,
41000,
436808,
21766,
38259,
44841,
69059,
319155,
293864,
52864,
489795,
337710,
9847,
388358,
169662,
89428,
13471,
134135,
1745,
29470,
10950,
39575,
18704,
34102,
340403,
107902,
25829,
131965,
8720,
298660,
259751,
28250,
178657,
142977,
125527,
40189,
44555,
48610,
219829,
null,
140335,
290965,
111930,
35622,
62977,
3976,
93637,
264452,
53665,
23003,
null,
142169,
154983,
150303,
22110,
null,
52667,
33235,
null,
7844,
37097,
77422,
119722,
822589,
21245,
265265,
500796,
null,
6852,
73088,
31224,
164854,
399997,
13491,
55194,
41302,
695581,
208306,
18755,
220367,
11424,
205422,
null,
692275,
null,
31615,
212286,
327380,
18826,
187088,
44912,
24121,
94717,
31589,
529460,
15799,
23181,
145589,
368773,
20430,
43975,
52951,
267530,
388385,
84276,
24111,
68751,
164522,
598148,
467141,
230588,
147244,
169895,
72625,
533255,
27482,
29681,
40199,
259276,
242277,
13254,
18998,
274393,
60301,
null,
125270,
7837,
71294,
205005,
17693,
130793,
171998,
29481,
51497,
283330,
347836,
2145,
349331,
73127,
11097,
24880,
14030,
18360,
109938,
12537,
16473,
381704,
31615,
null,
236160,
128860,
46541,
46845,
null,
304749,
4841,
39752,
323803,
8042,
582279,
44904,
73871,
19511,
22016,
228646,
117610,
77819,
106591,
149903,
21850,
66885,
234618,
37380,
315395,
null,
25216,
214588,
15399,
48425,
328819,
127791,
176266,
null,
193333,
279847,
17543,
15341,
null,
12780,
133022,
139805,
238867,
33325,
11759,
210395,
50422,
79367,
31973,
182292,
null,
3583,
424680,
101563,
8546,
17610,
325939,
41026,
135579,
252344,
null,
25950,
33480,
408968,
14535,
7601,
67034,
112745,
38867,
7562,
886141,
14699,
48461,
342414,
72026,
null,
8844,
26323,
19035,
290775,
835,
39392,
176765,
78220,
17725,
430809,
250365,
699675,
31435,
140199,
331551,
55469,
null,
39474,
204067,
14224,
65506,
18628,
59365,
166116,
43821,
67058,
342719,
10993,
142218,
543168,
null,
69151,
269194,
165047,
27007,
null,
154317,
33919,
280608,
6989,
44117,
447067,
158984,
35975,
42538,
18083,
null,
81222,
null,
62715,
4998,
248165,
14854,
null,
74330,
421480,
33995,
424864,
null,
19707,
12921,
142010,
37263,
null,
44001,
null,
210717,
89534,
282645,
332258,
9193,
183217,
138373,
293317,
283361,
16930,
41430,
54201,
37880,
58693,
349005,
null,
65481,
2488,
127178,
124748,
443237,
60737,
26652,
301728,
29326,
845049,
22598,
33952,
49936,
322678,
523355,
182836,
64582,
320309,
10105,
308492,
265431,
null,
37236,
19392,
89926,
56077,
151752,
289149,
50855,
263761,
null,
99728,
168287,
45232,
null,
204495,
212945,
170556,
null,
299132,
160099,
21452,
null,
17379,
114233,
68444,
14594,
255689,
351293,
15193,
null,
59894,
46574,
311228,
null,
231858,
159692,
37557,
174465,
156586,
302426,
337930,
613808,
null,
8063,
952528,
265271,
25703,
16053,
170341,
272450,
73397,
46230,
1184,
292310,
175138,
219541,
11965,
177379,
9478,
55217,
41674,
36351,
5040,
42615,
6294,
132540,
52462,
16296,
112186,
301664,
198784,
null,
236575,
20181,
32922,
42404,
18417,
2750,
215439,
5899,
23357,
15455,
69457,
null,
195240,
3955,
268621,
443921,
null,
125355,
55998,
213451,
52280,
22205,
57761,
4185,
47318,
6436,
null,
null,
97144,
22881,
null,
355410,
14616,
133907,
234091,
86162,
417432,
71831,
6033,
372531,
37925,
11849,
487215,
61646,
388941,
73948,
90647,
9944,
34266,
2047,
9136,
188803,
9879,
109528,
97103,
298484,
180954,
368474,
112849,
239765,
45192,
37063,
328845,
103364,
347488,
13585,
326729,
4120,
679198,
359272,
356493,
null,
118973,
93080,
null,
7402,
86578,
220752,
44783,
167572,
138319,
94253,
401211,
10777,
282032,
29043,
null,
14606,
10436,
194351,
177595,
167062,
294812,
320590,
136941,
191477,
32297,
122137,
86593,
22103,
39284,
null,
247563,
315388,
121217,
null,
null,
20004,
null,
5497,
174585,
29688,
30113,
418538,
201698,
84130,
33521,
409612,
187468,
null,
51728,
225687,
330396,
167168,
37200,
null,
46140,
56551,
81890,
85799,
22177,
28865,
105073,
95363,
168230,
45754,
71412,
72478,
72764,
700880,
708222,
12692,
150675,
37009,
96630,
233617,
291500,
34611,
28189,
471938,
439005,
247309,
155187,
24246,
308091,
41633,
285468,
80847,
37974,
217462,
234824,
48346,
22604,
null,
41774,
149902,
242551,
154104,
411121,
59985,
57765,
10273,
16550,
473737,
113481,
366396,
220270,
155952,
29393,
346387,
9508,
29794,
287657,
242462,
170876,
103945,
null,
8543,
13973,
229666,
473579,
80039,
13604,
277749,
null,
47975,
27391,
230103,
19580,
60821,
112345,
26824,
null,
129216,
295391,
168789,
37572,
48730,
314620,
165186,
171813,
65005,
null,
325746,
69200,
299928,
20587,
4352,
54834,
470445,
424447,
359134,
19493,
180205,
2772,
13822,
165822,
null,
52665,
348442,
542044,
null,
111137,
null,
504836,
128221,
25466,
263636,
744007,
159279,
194768,
57329,
18968,
113684,
374235,
44969,
231876,
42427,
228542,
40430,
44993,
35398,
30305,
111101,
195352,
29834,
185126,
372123,
247734,
16319,
174222,
66898,
119786,
61194,
222788,
9277,
574277,
26490,
17382,
17709,
56996,
81572,
48776,
47809,
368302,
28361,
521432,
35096,
202224,
157308,
264201,
401190,
259270,
190399,
55088,
277023,
91675,
null,
32010,
176086,
132582,
118251,
386060,
14992,
24447,
240229,
134655,
6815,
104702,
34852,
116765,
32013,
151536,
28804,
369433,
182967,
48285,
null,
32379,
9816,
11034,
501293,
124564,
null,
null,
null,
312577,
41460,
20311,
158524,
null,
11559,
131306,
165663,
74692,
246583,
11107,
228128,
389004,
58085,
null,
48478,
141027,
308364,
235978,
165809,
75589,
15105,
80909,
81485,
46576,
207399,
21646,
437188,
19470,
null,
23218,
433021,
75262,
303761,
202362,
167784,
32652,
160963,
293619,
316951,
190407,
1568668,
91521,
3639,
2544,
null,
343756,
26855,
356651,
165419,
26860,
164387,
158729,
null,
48459,
203837,
35825,
29366,
62793,
36600,
null,
15797,
204176,
null,
124813,
44306,
358013,
33603,
367320,
26080,
39371,
165468,
24409,
350101,
333294,
null,
23000,
147480,
null,
345,
189554,
69087,
31583,
55799,
70232,
43447,
256347,
130944,
204849,
46690,
12392,
472835,
12847,
205037,
372627,
102516,
198493,
34246,
40047,
72148,
205505,
5175,
106122,
37001,
21921,
28607,
76575,
33356,
186388,
68248,
295643,
55164,
61375,
145738,
null,
238790,
280837,
117758,
20399,
189902,
395094,
285052,
13721,
811664,
162122,
11236,
133088,
231475,
231721,
23063,
114743,
21506,
29294,
18056,
272157,
357750,
129824,
27049,
32850,
427870,
17157,
21226,
6133,
38543,
22080,
28314,
358838,
194684,
283324,
67517,
170608,
37592,
null,
240566,
41377,
176849,
18693,
612831,
164631,
135506,
18943,
137650,
8827,
91637,
24028,
172871,
65974,
null,
162871,
262198,
78430,
337396,
32839,
10162,
null,
113898,
22864,
79445,
13710,
28167,
15863,
null,
164744,
25895,
47707,
45455,
214987,
21682,
200236,
279563,
23294,
11101,
28335,
609117,
403252,
19751,
null,
488263,
380931,
162355,
433943,
31489,
141865,
null,
32706,
232121,
98471,
142804,
137124,
163460,
null,
124026,
21469,
426130,
16073,
25555,
340966,
433958,
29942,
18727,
57902,
28634,
114896,
14270,
19813,
524857,
169043,
34028,
182526,
59971,
165224,
420003,
16217,
57914,
53680,
null,
2078,
46448,
190169,
24292,
353954,
null,
null,
26932,
155760,
20713,
16270,
137528,
52542,
6764,
17513,
145810,
18380,
278121,
132422,
327491,
79503,
39294,
144094,
66186,
null,
31410,
387805,
89571,
39941,
59826,
78123,
20362,
187197,
null,
33471,
63891,
1129,
3869,
241863,
37691,
404457,
99108,
12333,
65971,
397499,
15869,
27183,
202578,
151578,
217698,
33687,
126536,
89421,
117078,
51622,
76705,
null,
147231,
18337,
32344,
240683,
283020,
124946,
29178,
44157,
70662,
299451,
71849,
311351,
146652,
271144,
167359,
306496,
24654,
181590,
94256,
13237,
13115,
321536,
43648,
26536,
238426,
192214,
67599,
552793,
272677,
185434,
415936,
67677,
911561,
28035,
395175,
null,
459784,
52385,
null,
63564,
23489,
null,
13935,
45728,
434472,
33962,
141203,
303021,
31959,
55481,
29523,
24441,
368814,
116581,
61983,
145488,
3176,
279168,
168096,
315737,
46196,
136602,
89493,
181435,
35196,
null,
174968,
12083,
266018,
null,
313976,
36490,
null,
264132,
156884,
87053,
58046,
null,
39159,
26485,
399147,
32373,
432313,
187246,
16531,
52609,
659270,
782206,
13547,
7513,
69086,
null,
291028,
11646,
88459,
262072,
168990,
47699,
242591,
280561,
null,
9487,
117020,
191213,
442289,
299005,
44164,
356363,
205858,
117912,
105416,
89370,
null,
161310,
258715,
121337,
27735,
85254,
64978,
20917,
27959,
7831,
5247,
268532,
217337,
124186,
17253,
296091,
173339,
292041,
11457,
482789,
275351,
283812,
null,
271165,
269301,
215503,
null,
1580,
509021,
294692,
463027,
11438,
null,
31638,
286540,
12069,
274432,
43053,
492584,
81799,
115026,
39474,
18525,
334547,
28375,
37634,
429076,
null,
32516,
154091,
300637,
131014,
24629,
115826,
297135,
375203,
26755,
482632,
null,
422556,
null,
336125,
8183,
193503,
84391,
257216,
290632,
185759,
8262,
6309,
49679,
7025,
54932,
80194,
172953,
471211,
40824,
40482,
null,
265088,
118549,
null,
33518,
38695,
406634,
30345,
null,
24323,
221060,
220679,
475048,
137826,
57343,
141423,
228456,
27565,
21614,
null,
43036,
18079,
null,
53085,
45959,
216918,
299417,
13552,
81059,
59388,
151240,
467630,
17037,
11814,
24512,
null,
235082,
51636,
26882,
8945,
42251,
49838,
245877,
52037,
60075,
8844,
342882,
63711,
64644,
61758,
null,
27981,
43893,
94521,
29561,
53675,
15493,
75193,
18315,
172830,
19926,
43617,
28859,
25218,
23752,
102900,
183641,
123465,
142636,
151407,
107160,
174717,
35345,
150922,
110810,
287026,
50612,
11262,
31124,
123817,
21507,
431099,
null,
185820,
20350,
63130,
15418,
7454,
31966,
57659,
52438,
44958,
143493,
434238,
5626,
59038,
563050,
147247,
14270,
30704,
240502,
2708,
39503,
27799,
39175,
122973,
318562,
67047,
374826,
24355,
588744,
191557,
56999,
167563,
5266,
208061,
154809,
10879,
342728,
99191,
null,
99789,
237289,
112059,
299210,
161439,
4507,
372352,
14998,
87910,
null,
27865,
34788,
499350,
210124,
65166,
347225,
39065,
149660,
32038,
79481,
240019,
25790,
214921,
186714,
10951,
9859,
196722,
210468,
22942,
75493,
280717,
null,
null,
null,
23170,
50480,
73957,
3918,
98859,
75108,
149877,
null,
31134,
22363,
214329,
8962,
21488,
159846,
14365,
114684,
71638,
27020,
55859,
237180,
52852,
152369,
106657,
36475,
10692,
22583,
151103,
183747,
176138,
34851,
109179,
195929,
46639,
113268,
27748,
55223,
25276,
24421,
556098,
65241,
169752,
388737,
74255,
50455,
245861,
348938,
42084,
237730,
3061,
38034,
216691,
41149,
25438,
50053,
165696,
62919,
29345,
null,
563308,
185874,
275573,
74286,
212725,
139768,
19640,
22158,
285785,
371213,
657299,
28612,
17819,
144692,
195338,
29690,
57005,
183853,
53777,
64295,
8947,
49008,
64146,
321018,
127039,
229420,
39977,
278752,
468814,
55945,
118954,
120131,
25107,
186512,
55752,
25972,
27909,
118657,
255300,
2172,
17419,
289586,
44979,
208051,
61676,
87445,
null,
null,
309164,
15932,
71123,
449367,
121023,
67747,
55523,
51295,
882072,
308914,
115979,
98840,
39292,
88189,
175695,
57153,
25129,
101870,
39288,
15480,
404437,
113313,
24243,
289496,
757616,
400988,
325155,
52611,
43337,
569391,
28627,
234112,
48943,
42014,
38362,
18048,
94211,
36067,
61623,
220677,
220347,
414693,
379848,
30235,
153468,
328232,
71272,
null,
58039,
109670,
27073,
43948,
149205,
null,
399595,
1076751,
459261,
88752,
318690,
292598,
25402,
31156,
13885,
11391,
20282,
89149,
29434,
36039,
841214,
28048,
43270,
138668,
20904,
330187,
95404,
193372,
40169,
104907,
null,
29084,
344877,
196778,
470172,
174413,
33780,
19206,
81436,
37019,
245555,
null,
91703,
null,
8538,
20324,
254124,
44568,
17778,
20166,
215915,
10708,
189225,
76733,
14258,
100218,
76067,
null,
9417,
null,
61768,
307285,
341624,
44226,
115365,
63033,
83583,
13559,
627697,
48072,
400272,
121516,
35131,
22574,
38922,
105821,
295712,
21854,
59096,
356460,
33024,
34934,
36509,
77714,
444777,
178279,
null,
246725,
7329,
37082,
26419,
65240,
441030,
18688,
14844,
52084,
382670,
211783,
152139,
18445,
339323,
421260,
438467,
185976,
8782,
248476,
68084,
380074,
30031,
315461,
11989,
49421,
98165,
5282,
69198,
6804,
4139,
229369,
null,
12744,
356299,
null,
455065,
109386,
35625,
402406,
101367,
253353,
null,
139977,
17780,
92165,
303373,
50128,
42380,
null,
102982,
25378,
23970,
128566,
193980,
76621,
1863,
20997,
117392,
128362,
111380,
473919,
461002,
10387,
139270,
305383,
46558,
42794,
218488,
119383,
177717,
341598,
null,
423665,
44440,
14580,
222457,
134789,
null,
185749,
null,
null,
152134,
232058,
398861,
17360,
572571,
43437,
6418,
144464,
8759,
348441,
46591,
40896,
165679,
173126,
7114,
26816,
13338,
33799,
532737,
26762,
22836,
35927,
7663,
281393,
34026,
74656,
110346,
70644,
119690,
9280,
292147,
15594,
282849,
252152,
182857,
4214,
117335,
71623,
25556,
11624,
16314,
101914,
12145,
203650,
18485,
154457,
135306,
16755,
13483,
22607,
43677,
278450,
96866,
239,
19351,
34292,
36911,
19958,
518516,
49301,
15036,
170426,
61933,
78097,
492841,
158677,
260439,
166571,
10519,
64845,
87931,
168757,
27841,
385417,
101281,
295820,
28246,
35148,
450779,
212678,
46227,
5031,
9046,
209173,
12631,
11918,
40908,
132967,
39144,
33577,
207274,
null,
69036,
74117,
117264,
138427,
58602,
66635,
7756,
null,
368712,
235304,
47410,
9160,
197115,
8018,
null,
37955,
19914,
59616,
225916,
15323,
53883,
113415,
70084,
38923,
39263,
57168,
243809,
null,
75371,
215558,
91994,
7502,
31762,
34289,
34076,
125751,
116409,
88697,
null,
363127,
29332,
4020,
36151,
94241,
27703,
82796,
194819,
202395,
33284,
167859,
217436,
null,
35395,
33159,
12674,
51917,
380447,
174695,
140326,
10415,
395742,
28246,
146563,
16610,
38238,
272369,
175471,
16686,
45667,
21896,
114948,
124559,
22135,
59582,
216808,
196052,
58420,
null,
10421,
27778,
1893,
64514,
29903,
194448,
256799,
29517,
null,
9286,
134908,
390649,
26615,
222024,
119562,
19099,
49666,
418828,
424631,
141345,
283285,
46826,
111121,
null,
6644,
192477,
64727,
51677,
352008,
38322,
20522,
null,
20922,
341452,
14591,
43064,
14907,
352933,
38793,
20014,
340844,
41100,
174669,
256432,
31659,
47995,
203182,
24026,
6097,
208534,
79733,
42205,
33446,
82354,
144845,
null,
118815,
27296,
291332,
461012,
39221,
26489,
33037,
105961,
7476,
333566,
4230,
230171,
40098,
244145,
74647,
2670,
14461,
59662,
88773,
458096,
24520,
38306,
394294,
19765,
15284,
132406,
15502,
155555,
null,
409698,
26430,
310329,
15721,
20862,
43136,
89577,
30215,
495469,
32344,
25369,
43472,
null,
202062,
20951,
19830,
344285,
135317,
null,
7825,
136092,
null,
null,
null,
null,
231758,
40055,
32815,
null,
176798,
76213,
null,
10504,
10165,
25066,
132051,
47390,
39159,
215529,
196899,
61867,
27358,
590701,
332870,
null,
null,
312521,
371356,
1938,
19079,
333129,
26791,
510046,
275449,
9424,
174487,
380614,
308630,
24908,
41487,
49092,
92250,
54177,
207003,
16940,
14510,
63530,
63295,
357230,
5998,
25187,
219384,
null,
14090,
31281,
351466,
470463,
138006,
131233,
211852,
36991,
16662,
53281,
20031,
44716,
81011,
106744,
null,
30647,
null,
241730,
59618,
50456,
189723,
276709,
448612,
46509,
359600,
130685,
217221,
33811,
141494,
91188,
67555,
7399,
26065,
234035,
44199,
23418,
214823,
95991,
399672,
24719,
275317,
608364,
365915,
209765,
140918,
44136,
280655,
30561,
55064,
82128,
41154,
34581,
80065,
238215,
null,
170445,
34925,
81651,
12518,
79390,
179497,
21177,
34784,
20490,
29594,
346392,
29060,
22412,
272899,
40869,
44876,
14313,
283049,
227071,
235283,
390597,
5619,
240425,
259922,
12561,
600987,
37969,
273918,
148818,
11684,
184690,
32095,
123056,
270016,
69366,
14565,
48209,
136018,
null,
287263,
367843,
97776,
617,
4690,
37722,
198369,
120283,
191270,
502976,
197596,
26829,
200163,
null,
114949,
44079,
42336,
722659,
299248,
98840,
12094,
172100,
21749,
333103,
344238,
13606,
13368,
13221,
203988,
13296,
4252,
74376,
null,
64964,
109162,
57740,
126727,
198147,
7097,
231156,
34163,
122494,
227201,
91556,
58346,
21167,
67171,
30351,
292259,
338304,
11922,
74877,
24354,
null,
226929,
328998,
37628,
null,
194062,
144675,
34574,
29659,
19614,
181757,
null,
39120,
52757,
34857,
211548,
353913,
55766,
271572,
379455,
98904,
467849,
225740,
140402,
8083,
113868,
184045,
211238,
234522,
85762,
274805,
553627,
null,
null,
21738,
24680,
357909,
289001,
101030,
180511,
357400,
61107,
null,
19804,
35209,
121332,
null,
197004,
29958,
178632,
298972,
145704,
273542,
193349,
null,
46417,
144306,
null,
43445,
10171,
136740,
47593,
10896,
91960,
33699,
127243,
72476,
25862,
null,
120961,
156548,
27229,
109970,
296602,
312459,
207322,
33691,
83158,
31979,
325371,
null,
93374,
71876,
null,
115368,
207554,
237988,
264209,
258283,
158920,
226409,
39078,
68762,
122936,
10922,
null,
213095,
49153,
89313,
1105958,
null,
116910,
84276,
74910,
241133,
52796,
193900,
31955,
250825,
199841,
132425,
174653,
35803,
199917,
13165,
375805,
35166,
14056,
null,
53902,
80549,
35542,
null,
9317,
73152,
12155,
27426,
273430,
22034,
11086,
49571,
10161,
292893,
null,
34052,
216081,
10437,
57592,
189724,
26260,
216604,
328621,
435887,
282441,
378658,
27774,
7563,
36350,
12331,
299783,
104196,
126227,
372036,
null,
264375,
71764,
103176,
111832,
8352,
312323,
172826,
184124,
121823,
400683,
57353,
63470,
375571,
175274,
24765,
144833,
11656,
202048,
235634,
7933,
183044,
200393,
13449,
23845,
19847,
13821,
25625,
40234,
115582,
26209,
null,
139466,
null,
46404,
7928,
37967,
274344,
48352,
39482,
149918,
24627,
183890,
24289,
19341,
358976,
28601,
null,
69523,
77410,
35980,
260133,
47912,
6313,
437731,
38136,
323484,
23056,
32039,
44718,
9697,
null,
null,
55574,
59494,
19871,
83367,
162198,
17718,
80197,
18003,
88718,
180295,
275454,
451198,
213914,
13648,
221611,
96516,
566409,
473947,
123424,
6223,
219550,
289632,
42947,
40913,
15825,
29341,
243164,
177759,
73876,
7776,
24837,
31787,
33499,
131035,
187151,
57874,
244519,
76914,
94742,
null,
497242,
null,
211255,
20851,
506016,
120313,
109871,
276590,
30202,
170535,
36661,
147998,
380527,
31510,
115215,
515636,
57844,
180197,
9033,
18362,
112355,
14599,
173961,
38145,
175395,
24152,
6928,
null,
121347,
32943,
206624,
60344,
null,
185210,
10206,
272218,
148822,
17658,
444791,
null,
158213,
46500,
226918,
7585,
44471,
123742,
179480,
122629,
17446,
null,
347130,
191880,
95452,
85326,
104733,
26316,
41107,
57713,
7435,
432291,
46606,
10371,
56719,
111587,
205670,
173250,
22058,
224247,
296307,
8024,
5026,
41791,
18107,
null,
161533,
72004,
55279,
28386,
18170,
54078,
null,
43784,
133810,
178666,
160050,
null,
237379,
null,
null,
null,
162407,
8795,
183665,
201053,
148267,
228543,
7683,
291253,
22249,
247361,
136141,
38073,
44363,
306792,
118946,
348257,
54356,
46246,
603428,
425505,
41821,
13631,
217858,
285623,
253769,
135621,
23253,
16953,
44689,
514712,
30520,
35867,
79520,
1368650,
662606,
103579,
24607,
26860,
15328,
4479,
189853,
214319,
435048,
295380,
null,
12240,
12402,
null,
121437,
35047,
164766,
35506,
11848,
43119,
22049,
106511,
22351,
991025,
126565,
31837,
279274,
28865,
165226,
189970,
387590,
12165,
58580,
80871,
33359,
17887,
604388,
21346,
353799,
47729,
307034,
597555,
6861,
null,
20798,
30391,
32102,
74203,
158830,
57040,
7448,
197470,
135494,
124742,
568663,
8655,
25606,
332921,
309813,
71089,
null,
290918,
18441,
null,
50899,
9025,
36593,
55003,
400483,
8783,
216176,
187481,
39190,
201042,
85828,
186196,
34822,
455543,
31340,
144195,
116925,
54058,
266652,
null,
497312,
278931,
217274,
24334,
86174,
28821,
351271,
172693,
234958,
9220,
142180,
173234,
150121,
250494,
11267,
20176,
43835,
336704,
18997,
29311,
33057,
55628,
15793,
373773,
356557,
null,
18669,
12081,
172523,
141513,
342423,
99308,
172293,
11080,
444443,
176025,
7165,
137565,
23159,
15586,
181429,
27695,
114548,
42901,
13320,
42342,
39989,
20483,
325538,
50555,
136158,
150333,
318262,
30016,
319640,
31007,
91561,
318311,
31978,
762409,
94871,
48373,
17205,
155695,
61326,
200368,
9233,
107170,
20382,
246248,
409264,
4927,
203128,
32019,
null,
25810,
294643,
330755,
264126,
257554,
16424,
165857,
68005,
185731,
272983,
158793,
248457,
202256,
59963,
12963,
214426,
164733,
18185,
37710,
null,
174538,
30243,
291202,
764017,
3623,
29959,
38420,
351005,
50056,
null,
1667,
33824,
184568,
15353,
7751,
521078,
34554,
166318,
250800,
21021,
526202,
81607,
291585,
22065,
82141,
246032,
141003,
295889,
120667,
574461,
588091,
287870,
14018,
683993,
30462,
65609,
273724,
33444,
89617,
null,
190426,
205707,
343012,
41219,
56018,
19432,
10750,
null,
44036,
65794,
4427,
15061,
6761,
18029,
42027,
12762,
269198,
40734,
34016,
null,
565179,
323105,
13937,
149794,
91638,
567967,
null,
28241,
129567,
46305,
82760,
113263,
208827,
188202,
184007,
289999,
15362,
1526,
11452,
20918,
127101,
8614,
30784,
201404,
16182,
18302,
42473,
524912,
396657,
322077,
316109,
3015,
309340,
130441,
null,
13939,
458834,
4133,
37769,
267382,
279374,
357000,
null,
37064,
237115,
120943,
203435,
null,
null,
219935,
398103,
null,
29841,
330295,
24858,
96320,
15451,
2057,
13432,
34417,
214241,
29840,
44132,
34989,
94063,
46831,
187402,
183020,
29503,
71320,
27681,
47028,
18875,
9497,
3592,
471805,
499384,
10790,
17245,
50747,
39957,
255364,
117996,
177887,
null,
174780,
82619,
50464,
39755,
95754,
153443,
199728,
39599,
22414,
270352,
36502,
57638,
443360,
29584,
32759,
38705,
6637,
342270,
225841,
108462,
93328,
26969,
442942,
21020,
187756,
159203,
13455,
21398,
280989,
17884,
55081,
387154,
235199,
33198,
197686,
39259,
152635,
424062,
106989,
126836,
null,
157442,
null,
145741,
157364,
34409,
null,
42637,
325376,
45564,
421891,
206623,
50419,
47404,
15608,
318428,
360610,
352884,
212482,
11526,
63877,
12601,
33381,
77352,
121669,
163160,
40248,
129557,
374083,
712863,
307828,
25202,
29667,
38937,
36795,
53431,
38977,
40347,
61210,
81217,
22268,
252452,
41021,
9007,
null,
244021,
32932,
238174,
11895,
null,
null,
198534,
75257,
29542,
298309,
160602,
46816,
29913,
621591,
22823,
340542,
38493,
158144,
23460,
162630,
353355,
203378,
46390,
101115,
536105,
9074,
38864,
51024,
null,
13681,
26551,
null,
6624,
53689,
9706,
52171,
14225,
118136,
334282,
16211,
56842,
616041,
21361,
10662,
464925,
238268,
21907,
490860,
16946,
36764,
82132,
null,
26685,
null,
48147,
170482,
17389,
9571,
271402,
299408,
96529,
7251,
436652,
104374,
23888,
176391,
324138,
14206,
58375,
null,
17211,
13963,
631465,
null,
20090,
21076,
312895,
64977,
288736,
275614,
213827,
308147,
347734,
52591,
25693,
16697,
252931,
506589,
25477,
44060,
227085,
115652,
27511,
200956,
30312,
26871,
92976,
30239,
16136,
null,
51550,
132143,
38770,
31997,
17969,
119448,
407592,
8720,
23258,
51053,
191979,
64888,
95955,
108552,
19711,
416621,
181068,
344671,
250420,
23525,
78441,
null,
53731,
16624,
66111,
11396,
44267,
184172,
37379,
130253,
null,
209837,
248513,
35985,
282815,
194973,
193168,
70060,
null,
99251,
36266,
224014,
284914,
67993,
34135,
null,
254572,
21338,
14721,
146451,
104293,
24206,
9554,
155855,
5957,
121868,
31340,
60744,
36598,
119602,
259458,
345392,
262356,
null,
21674,
35499,
13524,
180351,
14616,
112765,
18470,
420484,
23213,
null,
128326,
28368,
29343,
281533,
184551,
60438,
298720,
176136,
93888,
57209,
14126,
221006,
38690,
38490,
233461,
196218,
26010,
35580,
7098,
157717,
73406,
62019,
5387,
43641,
267917,
22359,
135608,
179818,
61199,
574113,
389397,
62485,
29461,
16015,
21277,
22431,
116260,
121450,
368389,
32507,
150275,
19382,
16192,
5859,
175215,
239201,
39932,
13756,
305758,
304845,
416423,
47281,
232170,
314192,
492179,
238433,
100348,
20595,
214913,
35913,
null,
113203,
15742,
151953,
10378,
258195,
104999,
15958,
15909,
12950,
null,
19311,
58030,
146372,
41854,
148752,
79442,
16478,
23248,
54673,
294945,
42506,
130776,
316884,
165659,
126723,
null,
25869,
null,
371123,
26382,
86076,
140936,
null,
28840,
null,
31551,
164924,
187287,
194584,
21417,
61995,
22162,
25577,
7131,
null,
196717,
115336,
92336,
38966,
null,
5209,
14022,
7466,
29635,
316314,
21219,
null,
134321,
186806,
32377,
217501,
144502,
65606,
67797,
65757,
45525,
91751,
55685,
162703,
16821,
156532,
null,
8262,
30174,
32900,
4549,
455423,
14894,
83047,
182535,
111294,
137290,
15811,
180356,
377734,
180455,
87203,
580441,
428759,
43408,
350813,
154366,
5368,
100140,
74344,
17532,
38253,
60939,
556933,
27915,
null,
32867,
254358,
25790,
22374,
25381,
11982,
63131,
null,
201972,
44083,
83736,
284294,
433894,
148109,
278866,
65464,
34360,
null,
13145,
275678,
24719,
24884,
27219,
190781,
412130,
126392,
103480,
9338,
43469,
null,
146335,
9542,
39137,
64522,
null,
5538,
385098,
33006,
1207836,
307848,
309935,
null,
88134,
179164,
null,
178284,
201646,
1205797,
172058,
125831,
80845,
82381,
87958,
null,
457120,
298088,
85619,
144666,
37594,
26201,
231031,
56063,
73977,
17002,
60956,
9871,
176018,
282230,
240769,
4512,
183306,
97488,
65822,
44274,
98849,
156326,
56103,
110585,
29962,
137071,
null,
null,
189014,
236215,
308415,
null,
23778,
60057,
536428,
43624,
13146,
244074,
65128,
55938,
null,
46539,
197470,
2577,
66094,
null,
38118,
108832,
25619,
1015,
null,
262535,
235141,
16304,
139217,
253125,
167721,
96860,
null,
193576,
125669,
43730,
151388,
19285,
13605,
11763,
13903,
213714,
159899,
null,
322511,
199759,
null,
52251,
179360,
13509,
50884,
241005,
110734,
25837,
70431,
39966,
54348,
111705,
103694,
44690,
null,
114044,
212926,
315490,
22593,
75697,
205715,
299663,
30767,
290845,
303664,
165086,
null,
18997,
131953,
94535,
27226,
23972,
null,
18955,
28542,
null,
116968,
414877,
159431,
286602,
363912,
57822,
228199,
25409,
null,
290115,
49541,
327728,
75802,
39000,
40502,
7476,
28777,
48976,
47429,
53191,
48402,
null,
384232,
67423,
null,
null,
15179,
65087,
189973,
171748,
22993,
16256,
53168,
440590,
21962,
348454,
12100,
306700,
30746,
234218,
440987,
null,
104597,
null,
135122,
31093,
168135,
370536,
403154,
16485,
48857,
65803,
97167,
263744,
16260,
71532,
23806,
22954,
94880,
165556,
366404,
163429,
16490,
25242,
31785,
493939,
204168,
68527,
32084,
150047,
14649,
null,
40394,
1127,
null,
39406,
334843,
38096,
321607,
116803,
58674,
29597,
60982,
12315,
136357,
50445,
74936,
274474,
463301,
312784,
110645,
50215,
3780,
233302,
null,
61243,
318610,
87445,
269629,
17738,
67074,
21132,
513573,
null,
181754,
175794,
128216,
310523,
35924,
18452,
61733,
386429,
24268,
95147,
357962,
392614,
125770,
12459,
11159,
18071,
55731,
210826,
100957,
202245,
48536,
308928,
null,
798820,
2128434,
64348,
77711,
67732,
7768,
90654,
377097,
506020,
389969,
207721,
7858,
183436,
null,
5343,
30825,
null,
23180,
5549,
36331,
93966,
121915,
399446,
48190,
136332,
4094,
369057,
171144,
175437,
16568,
234468,
163931,
136151,
92385,
366092,
131961,
128536,
224634,
50678,
202868,
57996,
213674,
null,
26852,
129554,
11540,
46606,
20293,
278394,
8042,
163042,
385899,
331441,
355270,
228464,
53056,
143704,
36587,
412246,
218673,
36893,
312456,
38562,
134080,
447804,
36054,
null,
null,
10150,
23490,
161283,
70747,
251366,
12338,
243786,
172942,
null,
null,
203062,
45500,
41849,
50804,
37028,
433367,
247609,
55725,
119923,
300519,
591751,
130650,
17460,
81503,
221322,
37146,
null,
null,
179507,
28906,
345709,
45656,
65981,
194423,
16407,
83509,
51047,
248245,
170965,
23279,
36740,
326112,
131116,
23444,
104500,
32380,
28065,
74448,
150599,
310287,
5820,
61964,
21085,
52463,
59087,
154321,
150824,
126492,
63906,
22333,
144947,
217615,
300359,
49894,
312581,
128104,
32954,
16427,
477417,
44900,
13426,
null,
35903,
158113,
null,
358192,
598578,
44956,
134707,
6802,
24745,
9367,
13107,
72512,
136803,
36759,
118684,
23078,
10227,
468931,
397924,
19358,
49,
303898,
32416,
7042,
22958,
445498,
172455,
74801,
56524,
53521,
20376,
6391,
93465,
326529,
27511,
410228,
156528,
195263,
297172,
171786,
77359,
142317,
20632,
60070,
9990,
133195,
268367,
13163,
257404,
7101,
null,
118267,
422010,
174382,
42055,
18721,
166862,
216826,
534957,
122006,
null,
133108,
293324,
null,
183785,
297902,
261066,
null,
15877,
null,
91137,
null,
200570,
56307,
185882,
280043,
174558,
169139,
null,
45719,
172545,
71219,
33051,
7191,
409560,
46277,
45344,
99007,
268651,
192444,
110119,
28200,
15748,
26249,
49630,
205191,
13219,
13339,
69995,
37180,
216740,
27107,
null,
175224,
304693,
29067,
10767,
28628,
230134,
379757,
73382,
358731,
null,
498481,
21349,
337235,
634592,
7427,
17472,
null,
242920,
30109,
18253,
181737,
27354,
304951,
33756,
null,
94418,
244017,
53218,
169558,
42812,
493618,
37337,
513634,
70369,
19828,
97345,
275569,
29039,
873953,
16887,
249732,
210971,
81053,
245276,
311420,
217192,
82167,
84039,
473715,
310887,
257136,
53768,
89776,
467907,
11689,
651193,
23288,
432563,
141769,
86396,
49181,
250473,
30480,
null,
55613,
29184,
420658,
384384,
377830,
null,
287892,
281920,
39075,
44809,
null,
48738,
85079,
49015,
72166,
11748,
68055,
102701,
15106,
51969,
280513,
44745,
40064,
3562,
184285,
707939,
47885,
11769,
139173,
406293,
274014,
218871,
10779,
244930,
null,
115937,
140512,
1312,
1025728,
146577,
16595,
63446,
43110,
null,
21930,
83180,
202709,
null,
84323,
137149,
60088,
44074,
175686,
143739,
8442,
295970,
154175,
127379,
2491,
28452,
602838,
38534,
54762,
141975,
20052,
104175,
440300,
71814,
null,
27971,
49955,
143729,
426822,
201254,
null,
2847,
233406,
144905,
null,
39037,
61033,
20516,
null,
45167,
169417,
27489,
4790,
92638,
110271,
74245,
206735,
325487,
319636,
123329,
118887,
33524,
9424,
125671,
168022,
39428,
451872,
103026,
28260,
101838,
40844,
127714,
17376,
44240,
76247,
226922,
44970,
null,
320500,
237184,
223199,
18669,
282728,
45347,
173179,
19257,
166398,
236507,
168891,
99171,
680573,
153321,
176057,
44103,
68898,
351868,
48701,
34118,
173068,
16775,
3787,
131377,
74901,
133791,
17108,
28842,
36390,
54973,
26910,
295145,
234053,
19127,
21734,
null,
11798,
149097,
167197,
15400,
466071,
71971,
107135,
10318,
38104,
11135,
40124,
111824,
22005,
217332,
28057,
237944,
22304,
73980,
258060,
22380,
73721,
92908,
20255,
163780,
284427,
10096,
101648,
63086,
null,
220218,
50592,
24122,
51301,
603925,
62582,
97026,
117488,
9860,
58608,
null,
31347,
null,
271344,
415405,
400024,
113939,
60458,
29791,
107143,
29682,
14282,
98002,
30683,
169940,
103778,
39576,
35022,
199258,
105214,
33756,
null,
15148,
594954,
30069,
61349,
169323,
100130,
174161,
64751,
41784,
52173,
35448,
null,
561958,
49587,
107917,
32817,
293842,
439865,
41012,
247954,
35086,
79290,
394622,
336219,
306056,
57742,
262339,
122399,
47709,
162778,
177432,
146205,
633423,
339378,
168836,
456830,
75719,
380633,
24942,
266361,
43125,
104051,
null,
180930,
188954,
220924,
17846,
673615,
182431,
50784,
30002,
452932,
191989,
59392,
353563,
19229,
17942,
null,
131140,
21746,
44218,
31630,
42039,
35306,
14350,
3590,
297717,
24765,
53778,
182338,
null,
513265,
343017,
459552,
160047,
312918,
23196,
null,
15790,
19378,
481258,
66934,
29487,
70774,
224117,
211261,
352502,
235583,
null,
259463,
164745,
76177,
231486,
75846,
176987,
281297,
23989,
278820,
82299,
21963,
133442,
47008,
119654,
22900,
10240,
354014,
null,
16324,
39410,
246512,
186040,
77749,
403950,
101194,
135059,
219823,
112275,
23353,
58638,
161355,
168131,
20396,
90739,
24453,
86024,
25225,
137549,
12037,
60025,
null,
65619,
371733,
75227,
59297,
14624,
85011,
84582,
38225,
37723,
205398,
293097,
34477,
15871,
315899,
36559,
150571,
31444,
29668,
42191,
9669,
15356,
152190,
162234,
140418,
81464,
30289,
113291,
11784,
171692,
10000,
17350,
null,
115244,
20517,
393000,
122344,
210694,
20781,
97946,
276043,
15281,
170428,
156619,
null,
34920,
41628,
336304,
63068,
51311,
151131,
164259,
367016,
59463,
null,
137409,
28511,
136448,
204254,
32442,
5739,
20616,
25560,
309590,
81272,
240485,
80687,
120914,
47791,
40291,
21578,
40127,
122223,
172541,
88520,
28580,
5683,
51622,
537132,
6029,
264485,
38032,
26576,
55618,
45039,
150576,
null,
39452,
19632,
161650,
62510,
49398,
null,
120324,
269600,
181905,
423084,
73626,
13272,
39996,
10031,
68127,
41790,
56870,
123348,
94941,
null,
40133,
11430,
74201,
288927,
46057,
null,
146780,
27176,
262482,
406367,
29608,
307500,
70074,
48201,
56578,
263174,
51876,
6677,
null,
317847,
22018,
210737,
77752,
121640,
14518,
535570,
388266,
307348,
228418,
34373,
349033,
399928,
13290,
9287,
10316,
388435,
323986,
8613,
15119,
111927,
178546,
336014,
229179,
140959,
202837,
192515,
71157,
201740,
83506,
32304,
164688,
37713,
261055,
241593,
29019,
3762,
41724,
39380,
18724,
420462,
53606,
18876,
38695,
61547,
70273,
104370,
50319,
189828,
54917,
404759,
null,
122970,
238630,
22543,
313813,
51434,
47193,
76790,
656726,
306897,
147446,
31248,
271483,
null,
7931,
181885,
7153,
40561,
94617,
22452,
83537,
14992,
36017,
96562,
null,
64535,
258980,
9103,
17505,
11692,
6841,
1324818,
65522,
27170,
682618,
26880,
95557,
224565,
62817,
37335,
null,
8336,
37342,
16452,
33291,
51519,
110903,
317283,
291702,
348644,
236675,
138450,
186049,
25017,
29515,
16493,
6022,
140798,
99060,
20591,
54508,
41090,
240674,
152842,
358874,
40113,
null,
39675,
136140,
149652,
82756,
null,
286885,
315882,
30375,
18167,
10958,
96523,
79374,
31740,
23441,
153280,
154374,
58435,
321735,
299592,
58705,
13980,
24396,
8777,
32660,
155402,
49886,
14765,
19894,
52046,
37528,
null,
118758,
36142,
153922,
267206,
54544,
72584,
206628,
132037,
136314,
23361,
89258,
77894,
96402,
134009,
null,
374581,
775821,
263886,
308441,
159467,
21255,
22247,
39964,
26877,
25541,
151204,
null,
8288,
68506,
277799,
137373,
34573,
127274,
null,
272767,
182690,
42115,
32131,
314894,
23903,
45476,
240333,
31395,
106879,
25898,
249969,
226988,
193735,
35529,
272032,
null,
105767,
231624,
21392,
143458,
7505,
null,
12676,
38154,
26681,
11575,
495390,
135105,
31918,
45906,
654489,
26289,
24803,
183150,
42271,
11386,
192387,
null,
5803,
null,
180520,
212467,
197029,
189896,
144874,
null,
18762,
523919,
425472,
null,
96409,
20974,
44922,
69144,
36592,
105399,
84675,
87709,
12319,
15333,
14363,
39484,
65772,
270596,
239607,
42563,
182410,
20656,
5960,
117522,
80675,
33799,
23184,
71120,
13636,
186332,
61716,
29042,
56425,
63881,
257138,
240859,
180677,
148332,
43462,
18381,
4099,
52513,
124109,
338828,
90305,
136147,
null,
188588,
470568,
166205,
null,
39679,
103754,
17293,
130347,
208651,
753617,
504244,
2906,
31748,
231069,
199542,
7059,
394044,
null,
28266,
8805,
184888,
31907,
27425,
23747,
27265,
9041,
null,
117466,
57050,
71302,
9535,
56021,
100624,
444942,
46364,
299648,
421289,
288405,
80329,
17984,
50133,
53611,
null,
107876,
52276,
131138,
24897,
299344,
304748,
24092,
105426,
248857,
333935,
null,
244802,
null,
285325,
17003,
46721,
316802,
67186,
374926,
94571,
17006,
73976,
276829,
null,
22194,
238815,
211960,
38686,
38372,
21550,
223054,
292175,
40484,
232825,
18623,
248670,
345365,
174279,
307007,
34642,
93033,
50834,
53688,
180145,
27543,
29814,
43513,
185856,
23292,
548006,
52089,
94631,
76972,
186359,
null,
16590,
14558,
72204,
null,
5874,
132243,
6053,
307421,
47728,
237162,
15820,
360684,
43648,
9064,
227401,
null,
null,
40190,
16730,
50581,
183204,
198958,
58850,
25271,
352039,
32273,
122371,
80704,
77570,
44043,
79835,
25591,
611899,
33240,
9853,
595383,
25149,
null,
44084,
80741,
431561,
218891,
157794,
102339,
202020,
21231,
22487,
11623,
39607,
41414,
49697,
197529,
166451,
40804,
118297,
21622,
137025,
374146,
17724,
49140,
264777,
272283,
525030,
null,
33699,
null,
103386,
422732,
13359,
23806,
557847,
142735,
null,
226404,
337098,
21961,
191784,
32672,
68912,
280700,
51380,
115486,
332508,
15098,
123535,
24710,
26709,
183110,
89279,
33586,
61194,
9057,
null,
24211,
233287,
177885,
208969,
67791,
137285,
29321,
null,
27876,
17936,
42380,
75035,
163093,
10770,
38142,
63532,
15222,
14670,
null,
86452,
146514,
136684,
79819,
83281,
43364,
332264,
27302,
18348,
57864,
31023,
78680,
83630,
15739,
28796,
412974,
23779,
160198,
434844,
71631,
116196,
42467,
9928,
167511,
177115,
19590,
214629,
16859,
37395,
418043,
316453,
33941,
255327,
15598,
24572,
209799,
284227,
172947,
304054,
44501,
14389,
19299,
null,
132902,
266757,
44228,
null,
97461,
469649,
7094,
355893,
316800,
7679,
171045,
74080,
63032,
194170,
15934,
194469,
null,
14084,
199577,
26206,
245907,
252166,
108415,
267591,
156003,
231212,
null,
null,
14474,
484852,
104503,
null,
130815,
31106,
13102,
209030,
30214,
640526,
179717,
159499,
41536,
390680,
108835,
29639,
17232,
84513,
50274,
166951,
7453,
521944,
3183,
14732,
36738,
190028,
159517,
171011,
266810,
133838,
11237,
234156,
null,
588804,
174669,
32888,
41138,
103817,
15023,
40830,
17650,
21024,
22588,
50183,
80934,
5908,
40746,
5539,
196811,
230004,
52166,
19703,
308100,
14283,
135103,
null,
50729,
116126,
null,
260140,
56957,
28428,
66230,
139055,
24249,
23146,
7908,
409658,
319888,
209618,
24730,
357946,
152373,
237670,
null,
11702,
245687,
247983,
378054,
null,
312812,
261648,
243777,
45914,
15120,
41635,
143001,
158458,
35141,
68015,
null,
60130,
46886,
16954,
338917,
53709,
null,
798216,
null,
30296,
62356,
24463,
13884,
46963,
77489,
48991,
7120,
227697,
778056,
411219,
232616,
11620,
21945,
91088,
163542,
27650,
null,
142388,
3411,
131535,
163765,
null,
14583,
56852,
238455,
206441,
126738,
12707,
149179,
72753,
222101,
null,
null,
167388,
187965,
209971,
61244,
169390,
183682,
8772,
29296,
147221,
258011,
57165,
158072,
436670,
348455,
271836,
328507,
136655,
11200,
269511,
26944,
38843,
67497,
235352,
128215,
3139,
200388,
207925,
321430,
235666,
20761,
9780,
152335,
156241,
435423,
null,
72362,
43496,
null,
71978,
330319,
207836,
31440,
55987,
372811,
491278,
204283,
37678,
19468,
177104,
12939,
301153,
390879,
9199,
312082,
82685,
15621,
141539,
null,
53941,
37764,
31574,
323829,
166595,
61579,
143038,
40414,
111171,
399504,
5315,
14744,
51328,
38747,
233221,
32468,
134768,
15981,
523347,
null,
256837,
39597,
102522,
95794,
160671,
316426,
24445,
null,
null,
223175,
227732,
110955,
388152,
189370,
13537,
32982,
305330,
88350,
53071,
321304,
217267,
189162,
null,
375630,
4262,
140111,
null,
76116,
28142,
20039,
31988,
341833,
6813,
205467,
31567,
420096,
33457,
114641,
null,
232541,
327809,
152333,
123351,
23270,
291561,
75301,
314551,
3687,
456152,
null,
null,
227409,
21754,
39817,
19475,
200982,
26918,
247018,
86252,
14433,
38677,
18137,
272433,
14326,
18896,
186251,
1325807,
34166,
192990,
51786,
193543,
164249,
32539,
18017,
198324,
37880,
37085,
308482,
null,
79582,
33414,
32517,
31597,
28033,
null,
null,
44173,
295580,
134042,
466853,
181436,
54075,
110806,
null,
5089,
47427,
55878,
28520,
434695,
176775,
42129,
213551,
33501,
29027,
23895,
113701,
null,
null,
287458,
34025,
288723,
169144,
47415,
170142,
21783,
82062,
3377,
105037,
390655,
null,
51925,
65215,
25652,
92784,
10675,
72422,
207172,
347149,
23904,
22187,
36620,
308270,
18688,
171146,
53748,
7815,
27025,
151825,
171561,
29055,
166404,
null,
6235,
5157,
229560,
51992,
21154,
30450,
687470,
36030,
259694,
468251,
452396,
257165,
34480,
258503,
23591,
84992,
240109,
198503,
29539,
807885,
null,
424265,
294052,
17953,
250747,
20817,
163508,
49969,
21572,
394865,
1486126,
30777,
null,
null,
14007,
45383,
97200,
20946,
267492,
172811,
252221,
71522,
17002,
120502,
191321,
385091,
null,
44852,
516815,
279681,
9964,
17510,
42522,
251193,
37214,
21295,
336205,
24677,
290685,
442530,
35503,
77080,
null,
7462,
25853,
377176,
245417,
174748,
28588,
61746,
37032,
null,
67310,
92458,
632359,
44624,
272963,
30165,
32085,
415715,
68297,
253330,
863988,
60882,
145429,
null,
715576,
249430,
46977,
312245,
313071,
188349,
280590,
81643,
17971,
12782,
92272,
628560,
null,
23736,
66487,
364454,
163156,
72905,
9190,
25936,
91350,
106141,
15436,
465130,
9629,
157179,
451077,
112226,
68531,
244836,
43528,
23823,
551719,
53312,
119521,
4345,
247583,
null,
163705,
57533,
25502,
33196,
35950,
170113,
188928,
45718,
50785,
20716,
252258,
30664,
null,
null,
80206,
325209,
26118,
573076,
428588,
138808,
309439,
74134,
419862,
213768,
268321,
139291,
305649,
41659,
184767,
124860,
364347,
218834,
211725,
11269,
27444,
28230,
172489,
20933,
357635,
186508,
86496,
281674,
null,
155114,
78336,
18205,
16632,
120572,
11005,
11078,
532109,
null,
13412,
151075,
614417,
233682,
255532,
40536,
35811,
31084,
312514,
209961,
236585,
70572,
101011,
57307,
94292,
312630,
69668,
null,
217699,
89957,
116713,
277802,
232392,
336523,
7453,
108967,
34484,
15670,
null,
null,
262681,
53051,
182058,
null,
47603,
30925,
184272,
215490,
17666,
71064,
277521,
143096,
213173,
300229,
34693,
107349,
295449,
313761,
7277,
584602,
104366,
119783,
5389,
158293,
106663,
88368,
275173,
18193,
236964,
18285,
90406,
null,
651765,
null,
56038,
10921,
12595,
23337,
625413,
83073,
132826,
324880,
22148,
5574,
16302,
125524,
null,
854657,
160459,
96030,
28688,
282187,
47167,
19145,
null,
114885,
null,
74461,
122840,
175114,
155761,
null,
null,
53864,
9955,
164312,
206987,
167653,
165958,
647334,
229407,
14738,
297754,
42193,
9188,
223662,
50201,
192849,
229361,
17106,
221882,
20058,
37182,
198553,
332719,
677863,
6179,
null,
162971,
601299,
null,
11303,
229167,
231128,
42821,
35821,
30754,
33069,
135304,
6499,
231091,
123426,
426538,
81432,
null,
null,
68829,
55169,
12326,
72030,
173449,
18179,
31416,
25868,
23367,
9617,
43240,
532222,
38458,
41696,
7545,
null,
65431,
33688,
11409,
68658,
20976,
37483,
6403,
28781,
18267,
34479,
59226,
202079,
122138,
119812,
92796,
254163,
35173,
null,
26607,
null,
133612,
null,
8823,
150150,
93352,
280080,
40915,
308124,
295778,
64021,
39866,
21869,
161935,
128290,
239286,
3895,
12512,
149556,
51395,
38413,
193418,
424930,
203179,
41530,
null,
24704,
65846,
20470,
30104,
153641,
244541,
41214,
327521,
34502,
11166,
21448,
218556,
234227,
394299,
304493,
269090,
454818,
83997,
36379,
9378,
208926,
31359,
153541,
null,
10389,
393807,
25442,
10634,
43996,
28831,
26581,
144999,
412810,
28019,
null,
190625,
15400,
182516,
39364,
641383,
326309,
null,
134110,
151577,
98948,
348098,
28277,
125315,
24861,
46645,
79366,
154920,
25133,
38151,
379607,
88561,
50467,
30416,
51306,
117165,
223003,
null,
41794,
246931,
44232,
123532,
12617,
179292,
570342,
7758,
313343,
92641,
40738,
262230,
52450,
17928,
180223,
23348,
285153,
209545,
53838,
84962,
12026,
28674,
33904,
310987,
12290,
30865,
9638,
159891,
35178,
null,
235227,
61289,
15985,
null,
284364,
39656,
null,
295807,
31982,
39852,
null,
23420,
97881,
84410,
275759,
13143,
157280,
39643,
57422,
11099,
323865,
26435,
748357,
61192,
18807,
null,
317913,
277644,
507776,
890,
null,
8844,
132426,
20179,
32027,
94977,
5553,
195155,
440519,
null,
22985,
34764,
298714,
445573,
66417,
21954,
305470,
31693,
172744,
1114516,
20758,
401327,
229407,
209351,
null,
24092,
8424,
155165,
42186,
9161,
117004,
11411,
null,
13599,
24728,
152370,
485838,
240081,
162681,
182978,
19465,
38993,
21115,
40406,
525070,
null,
166614,
null,
3485,
139017,
37558,
null,
445821,
null,
351372,
236757,
247008,
212254,
64117,
72462,
10064,
160557,
10037,
5525,
8077,
97878,
147833,
146662,
null,
265148,
72937,
314700,
55002,
9991,
28842,
48482,
250384,
255971,
293777,
302975,
245854,
188502,
35733,
54956,
null,
18929,
78660,
49693,
117805,
242529,
22411,
354110,
3693,
100651,
361601,
523820,
199383,
74994,
52559,
13212,
62361,
38119,
247886,
254426,
null,
170583,
245932,
305662,
61773,
17449,
10339,
116486,
119003,
28716,
8201,
228774,
8499,
137635,
295131,
12543,
23148,
146692,
258828,
null,
153620,
258265,
18094,
49171,
284780,
18443,
159242,
348814,
28617,
16717,
329555,
18978,
40675,
175436,
21714,
515298,
218988,
251609,
325661,
391329,
null,
20965,
160558,
null,
225202,
17481,
208213,
14925,
153627,
32251,
170866,
73469,
144979,
138535,
120796,
602227,
54181,
81178,
36731,
17121,
259291,
169558,
187446,
69848,
2534,
24033,
52618,
123881,
534177,
168600,
162477,
18224,
null,
63648,
9108,
null,
552000,
237753,
186054,
24938,
26794,
100766,
221725,
174400,
125985,
3319,
null,
113775,
37186,
235979,
374614,
9736,
40496,
74089,
458599,
109714,
10021,
63326,
166079,
41840,
231441,
26820,
30061,
null,
100967,
27790,
65920,
4246,
323360,
90231,
157312,
83935,
27402,
98868,
28485,
31749,
27190,
186984,
null,
12973,
297939,
17459,
17309,
117818,
21354,
117095,
9187,
null,
202130,
266995,
100796,
479025,
56041,
109860,
48488,
17924,
50664,
118878,
null,
395019,
31930,
227311,
25189,
30780,
17583,
47524,
199671,
null,
383555,
29497,
8876,
5926,
92596,
35914,
299639,
12692,
154154,
161280,
32262,
319177,
204892,
134984,
330902,
50400,
235777,
114985,
133435,
138828,
191932,
307617,
null,
377961,
10306,
167510,
117053,
24325,
201384,
385377,
439907,
24038,
97994,
52358,
132377,
43773,
12533,
164088,
null,
326558,
null,
194286,
221461,
111600,
null,
52278,
19920,
14834,
78717,
16652,
577437,
236997,
37527,
null,
476739,
21573,
225580,
null,
3146,
228804,
305999,
49349,
87272,
394973,
168220,
179768,
127386,
16069,
251907,
222824,
32025,
480334,
6799,
141806,
null,
15996,
114732,
21247,
81880,
61320,
28509,
null,
239179,
130115,
16385,
190840,
521886,
84147,
112327,
null,
4238,
266433,
38866,
37052,
39361,
381386,
null,
167900,
44053,
461442,
null,
51071,
339144,
369998,
96613,
167282,
96324,
203045,
143007,
334404,
32369,
19964,
16405,
188584,
179189,
2806,
8021,
27347,
249014,
8637,
275744,
null,
119177,
199966,
55420,
266637,
33543,
62817,
33639,
178327,
292721,
34431,
39148,
28556,
144736,
385763,
37774,
2712,
null,
38677,
49467,
418427,
null,
32587,
null,
373944,
null,
65904,
42301,
38213,
179054,
131396,
30279,
222518,
20667,
105705,
14383,
null,
33714,
832125,
20349,
30032,
135394,
137801,
110852,
31283,
49936,
16080,
330651,
360682,
180986,
null,
73345,
159999,
207839,
92378,
10422,
186983,
30301,
81402,
22671,
185174,
18596,
9998,
21229,
124906,
122324,
23327,
189993,
207158,
115292,
43921,
13719,
214666,
24823,
20101,
51312,
85908,
55836,
129659,
null,
72132,
260821,
152605,
69284,
27391,
33710,
15866,
32854,
38812,
9245,
311503,
31209,
74707,
null,
33836,
414989,
122556,
95663,
416610,
7872,
50475,
108632,
36108,
29983,
187862,
31051,
144902,
199061,
81746,
58477,
33883,
256320,
14088,
28760,
227619,
31071,
null,
8985,
117362,
104907,
59946,
45786,
352317,
17848,
264637,
80908,
267850,
null,
214116,
133541,
null,
164659,
17396,
526397,
110845,
57712,
68002,
20598,
82406,
300409,
115361,
26606,
9202,
15899,
77255,
82383,
51391,
53818,
122857,
30512,
20565,
4518,
8753,
336360,
162408,
64663,
375373,
296251,
null,
33181,
49695,
84865,
418931,
878,
14908,
143112,
28484,
230879,
41073,
48795,
269690,
110467,
106914,
12979,
18174,
160859,
91055,
39270,
1533,
19721,
109018,
19899,
291532,
null,
13076,
186831,
188871,
15551,
15997,
null,
223419,
60576,
39136,
null,
281237,
365019,
47811,
60667,
319161,
46662,
221108,
41044,
152489,
18833,
62194,
395157,
156281,
335303,
7283,
33695,
17951,
198436,
278092,
18084,
40976,
61058,
49177,
9274,
null,
29561,
23160,
211758,
411242,
307272,
407704,
324977,
51205,
41080,
184541,
11226,
233910,
133135,
75125,
25487,
215448,
103884,
null,
8870,
41709,
22259,
23376,
400908,
189661,
null,
248561,
9735,
288759,
51689,
357313,
52127,
null,
315683,
356524,
23653,
6937,
32641,
33212,
46583,
176875,
387105,
39135,
186722,
161144,
52018,
22208,
20766,
107316,
344266,
63762,
11364,
494,
15177,
11440,
36707,
275790,
144899,
26541,
419414,
110628,
27884,
130375,
215836,
331665,
103339,
625125,
104150,
103322,
59739,
18917,
68786,
29291,
305631,
168319,
27800,
197563,
51951,
165324,
22780,
41527,
38717,
15272,
21790,
10510,
553354,
null,
170046,
93425,
90171,
434934,
null,
52527,
null,
102136,
null,
298266,
141045,
212175,
55863,
90476,
10458,
48698,
13070,
null,
298728,
641699,
7302,
131605,
77044,
38204,
18317,
224885,
62054,
116537,
48996,
166590,
46851,
14609,
292642,
193000,
360446,
null,
371433,
203279,
400194,
2109,
16482,
91287,
129456,
31267,
109985,
401446,
46290,
188945,
24475,
18280,
317525,
79652,
94254,
68640,
166104,
274170,
146166,
36799,
153944,
357569,
56137,
113185,
35297,
99689,
31490,
238991,
312352,
null,
133290,
289600,
195566,
303452,
167426,
95744,
63448,
310229,
267530,
45276,
33882,
10982,
211184,
17900,
277455,
33072,
184439,
23996,
20265,
20083,
20700,
54580,
30511,
128244,
324441,
null,
167882,
11,
40287,
24420,
92341,
151155,
3277,
49934,
30779,
18227,
147440,
176078,
90436,
148587,
null,
25861,
12307,
null,
63154,
343000,
83582,
24757,
62605,
35077,
18100,
25524,
21194,
20803,
2838,
220128,
97834,
165671,
1083902,
12413,
6746,
39029,
21143,
240262,
228915,
151291,
null,
138132,
23807,
438276,
99030,
237958,
152390,
114227,
64728,
163473,
170692,
41374,
222757,
23064,
78232,
10026,
28962,
282673,
205466,
73240,
18856,
9964,
135907,
486262,
31694,
330914,
12057,
106425,
301096,
158741,
152658,
111106,
null,
207847,
110582,
35190,
16269,
53938,
332264,
6509,
23784,
202904,
32501,
151941,
35274,
208331,
280864,
36907,
422908,
null,
5639,
412909,
441478,
11882,
332193,
38117,
354206,
223432,
524380,
494160,
289654,
145948,
20854,
77413,
184845,
183806,
19777,
24673,
221552,
740699,
23467,
17747,
182192,
18812,
32489,
36808,
57872,
37560,
130327,
254109,
165176,
440363,
15914,
166445,
21605,
null,
null,
225620,
67621,
111458,
94582,
383113,
316056,
58813,
null,
224147,
null,
351246,
53283,
287107,
644094,
191834,
83138,
38904,
null,
77353,
392250,
10584,
9364,
22022,
107412,
41048,
39426,
46639,
468698,
357922,
25253,
null,
309199,
205889,
43373,
116054,
224901,
210277,
428893,
60078,
49716,
3868,
122265,
179054,
32770,
52566,
279469,
12085,
13421,
132901,
58667,
467878,
13895,
167323,
null,
232811,
68891,
3454,
null,
6740,
38987,
53668,
214249,
null,
248188,
62688,
554512,
34522,
22877,
41227,
24002,
4693,
132719,
96531,
null,
248362,
444734,
642955,
22681,
36854,
21362,
86187,
26259,
28796,
690227,
8556,
190046,
271306,
13725,
70517,
455962,
19675,
33156,
338196,
44430,
96891,
66302,
105547,
35300,
265718,
20182,
59781,
88788,
103955,
49280,
154463,
null,
69107,
16322,
133567,
242016,
427540,
45127,
188122,
60044,
24568,
204726,
41888,
91804,
377414,
9695,
257312,
230684,
369355,
145890,
119703,
48483,
362675,
414285,
53318,
171042,
89312,
23265,
26275,
749079,
206995,
22930,
88423,
168487,
10838,
32478,
133669,
99227,
65719,
155237,
93521,
222000,
185682,
316697,
70649,
36140,
230675,
7058,
76707,
460965,
125887,
311237,
381294,
16715,
null,
36217,
260813,
8947,
11015,
null,
333934,
65958,
13277,
214266,
10544,
37081,
295340,
21930,
196686,
101349,
136520,
136235,
33619,
341173,
78802,
49385,
41699,
466647,
48435,
207033,
3910,
null,
223428,
418466,
359962,
31999,
45322,
110681,
45920,
47200,
42834,
131491,
474809,
12343,
330727,
null,
null,
479850,
38086,
128747,
8874,
67115,
31568,
38578,
438791,
140267,
3681,
19457,
46771,
558809,
259919,
23062,
175152,
468726,
null,
20253,
126135,
175508,
183869,
23872,
311388,
36469,
118679,
158500,
64751,
256491,
295896,
21359,
2961,
74444,
37483,
49752,
63140,
89307,
147504,
415995,
189316,
281817,
141103,
287569,
172137,
3515,
36941,
213617,
221013,
12816,
35474,
17779,
118626,
142493,
176722,
255241,
81574,
30985,
4470,
34610,
9372,
null,
338044,
43542,
30051,
107724,
13499,
285415,
9696,
203304,
100756,
29146,
227125,
173013,
268421,
133864,
177801,
35367,
5637,
6226,
616118,
36896,
477885,
327541,
14100,
13453,
25206,
25461,
14345,
22751,
781482,
87528,
43084,
18357,
76638,
17348,
245487,
68721,
156729,
97629,
8187,
12881,
111983,
74599,
42927,
250688,
74295,
null,
55020,
18474,
39058,
null,
3080,
22627,
182491,
340539,
545416,
377598,
86950,
58580,
63065,
62235,
224591,
12457,
78157,
54604,
14750,
221617,
20345,
50442,
550769,
115249,
15582,
39813,
265410,
290337,
73236,
457224,
11670,
8250,
76125,
null,
23574,
10398,
36667,
34104,
294665,
35901,
38847,
24563,
113446,
208098,
227422,
32968,
null,
null,
69891,
null,
null,
5301,
24363,
376417,
143491,
null,
346783,
256936,
68711,
72955,
1225,
7455,
67275,
108570,
9298,
251857,
247397,
7746,
163790,
308706,
58453,
196737,
210276,
421179,
19396,
207071,
null,
237171,
136834,
null,
79330,
null,
243892,
172699,
527535,
284658,
209844,
239938,
200942,
24209,
225087,
17118,
130768,
null,
578776,
4361,
400500,
111813,
36738,
321477,
26528,
233873,
327224,
122324,
14340,
91766,
264753,
6148,
19217,
212789,
467074,
5090,
12877,
12930,
53558,
252140,
33493,
48564,
219070,
365790,
299982,
167671,
123900,
null,
50469,
197645,
306431,
35873,
193326,
136330,
124697,
12916,
289832,
31945,
18812,
178457,
14676,
19173,
24740,
176045,
217118,
188057,
181168,
77621,
58553,
206539,
null,
39101,
25296,
null,
null,
290241,
599300,
19893,
160320,
40575,
null,
62731,
710495,
42930,
27667,
124911,
127936,
178793,
54930,
84313,
35022,
null,
137597,
10856,
18682,
29144,
null,
138921,
905596,
5213,
160365,
217805,
30208,
480673,
11164,
198542,
685918,
290030,
536396,
289749,
28369,
24126,
null,
85908,
308483,
null,
240795,
229154,
36739,
188189,
269846,
321460,
null,
241843,
44547,
15640,
15493,
229527,
49697,
263238,
221036,
332975,
12401,
60958,
34603,
202411,
13345,
249899,
7392,
137639,
52427,
189602,
239581,
280634,
32538,
420132,
293435,
72235,
400048,
219244,
6096,
376563,
167422,
420842,
87821,
33680,
43477,
417316,
22121,
345377,
116126,
18504,
null,
34863,
460750,
647520,
33044,
66374,
63646,
57059,
142654,
7517,
13988,
183716,
688729,
31124,
316009,
285192,
6522,
775070,
173653,
19530,
24949,
38460,
258630,
18046,
33049,
7928,
null,
258751,
8751,
8818,
202393,
21967,
13898,
185442,
99784,
14923,
19544,
84644,
638421,
10330,
16636,
217207,
19128,
226118,
45197,
21022,
58314,
null,
21300,
77546,
298085,
15292,
178011,
277878,
159380,
327367,
108266,
null,
51854,
16900,
106855,
39595,
76565,
95871,
12292,
28237,
7819,
216344,
28594,
2072,
200881,
41475,
30806,
81834,
63278,
349130,
19899,
260475,
261538,
97761,
137540,
233626,
23362,
23160,
42016,
49760,
25558,
20266,
28108,
310090,
228278,
null,
null,
30343,
165064,
232728,
null,
38897,
30871,
23718,
128731,
314396,
327336,
25841,
85921,
140977,
null,
10864,
90927,
29103,
24396,
5666,
null,
365831,
387180,
448238,
338909,
5916,
40719,
34414,
8191,
299840,
270261,
67006,
7837,
204046,
302349,
136993,
30828,
344398,
152080,
430474,
580246,
514118,
84646,
300005,
60133,
null,
32988,
58259,
100319,
29987,
93605,
134782,
null,
108889,
255175,
15824,
29985,
null,
92818,
78969,
null,
394441,
null,
114431,
null,
34691,
154606,
372297,
26023,
null,
null,
3038,
49143,
9098,
133326,
5724,
141691,
302326,
252895,
101254,
null,
null,
216493,
31716,
122155,
549702,
34627,
33691,
122330,
null,
257707,
179103,
null,
63932,
53795,
920517,
50921,
320780,
130524,
148292,
40538,
22473,
548547,
290413,
139375,
24362,
null,
111447,
34114,
217342,
null,
26418,
160102,
30804,
230567,
45328,
366804,
120136,
33792,
48462,
213001,
32349,
null,
149342,
null,
14053,
30899,
126130,
58282,
10180,
1894410,
null,
73665,
147435,
null,
14992,
126403,
51075,
251790,
37166,
66657,
26361,
298891,
171843,
133180,
192018,
243058,
5592,
54455,
45822,
77368,
121259,
25814,
31247,
33622,
25168,
218021,
250276,
24434,
436023,
91587,
7076,
239539,
18545,
40722,
347860,
172045,
164382,
null,
36279,
151769,
29279,
192071,
17189,
167672,
201719,
264924,
187150,
184654,
113632,
8774,
362094,
120310,
62395,
57809,
113267,
746503,
175785,
357486,
49422,
393562,
255144,
1641,
248064,
10694,
37211,
150100,
101621,
199940,
147137,
415537,
133879,
124856,
26718,
7839,
181805,
529068,
178193,
565661,
null,
15629,
119721,
51345,
314015,
239262,
205780,
140960,
90502,
48060,
514225,
46206,
7280,
12529,
343062,
294785,
null,
95226,
19024,
11658,
null,
115830,
null,
17224,
123412,
40855,
160581,
13818,
null,
57303,
129996,
27506,
49054,
25535,
1879,
31579,
115255,
20459,
281768,
237027,
80148,
49545,
35172,
163960,
433115,
419317,
18448,
315639,
461285,
185095,
604005,
null,
508570,
238893,
14488,
null,
318715,
14839,
55498,
32859,
null,
224677,
null,
23558,
70500,
294067,
137522,
144785,
289178,
198033,
78329,
36990,
17382,
78702,
63242,
25497,
56227,
459423,
375395,
178453,
46254,
72143,
79535,
290752,
29940,
288858,
765207,
53608,
323725,
165452,
375307,
83873,
175942,
22209,
11529,
318182,
261335,
140263,
66618,
26560,
34396,
229962,
null,
74084,
null,
257348,
20573,
501895,
154557,
41799,
225799,
9626,
11414,
9557,
null,
26317,
7076,
100165,
275673,
40961,
58786,
20065,
28900,
111141,
21835,
381507,
38911,
68338,
null,
53037,
159573,
123986,
18954,
31674,
154862,
15008,
null,
34273,
null,
226593,
300379,
136211,
241199,
132967,
20146,
35462,
35579,
105410,
39822,
111455,
161420,
null,
13872,
64333,
41497,
31616,
93613,
16122,
null,
308422,
506393,
7169,
16832,
null,
39446,
25708,
214488,
37454,
null,
23943,
66545,
19563,
707349,
229103,
504457,
26799,
null,
44709,
37164,
46620,
30732,
54492,
216530,
206509,
38301,
367964,
136491,
3965,
null,
485826,
94416,
12800,
42060,
58342,
126801,
275074,
52835,
228492,
19675,
26851,
187042,
328313,
21271,
28946,
43549,
18878,
31331,
427567,
460446,
94117,
102036,
8334,
null,
45194,
105067,
79552,
19694,
5031,
5915,
467666,
null,
191954,
54684,
24421,
30279,
189587,
29865,
10116,
149138,
102026,
null,
302911,
73723,
28797,
22239,
477744,
127568,
null,
19662,
74354,
72218,
152955,
62751,
105246,
184149,
37018,
237678,
10246,
22313,
47428,
43299,
54733,
106518,
220158,
11744,
24854,
166678,
15575,
16233,
321311,
47966,
29550,
40187,
47309,
93235,
299283,
50555,
46768,
278123,
74053,
8656,
25384,
null,
86813,
241082,
268671,
null,
244461,
152197,
12188,
362701,
59433,
200940,
22288,
null,
190142,
null,
30177,
42716,
169491,
6376,
31671,
622945,
72573,
301754,
null,
263208,
79744,
49043,
53152,
44156,
18906,
42441,
118149,
194653,
119248,
230540,
37542,
55619,
118831,
153669,
216137,
38914,
151996,
58173,
34568,
13139,
4761,
34273,
77237,
233871,
19438,
23161,
31163,
28492,
154567,
418081,
145615,
40988,
109862,
184637,
209399,
27912,
null,
150200,
null,
137518,
92589,
422405,
29843,
null,
240569,
62856,
133587,
34364,
56596,
210873,
8457,
13768,
138656,
196614,
628147,
null,
4288,
234380,
null,
null,
228479,
52984,
14769,
64061,
194643,
26408,
56483,
118710,
174362,
677571,
null,
104297,
null,
null,
195816,
174567,
125775,
null,
35175,
183516,
null,
167181,
6767,
null,
33997,
188174,
218557,
165002,
304332,
23210,
333738,
null,
240091,
75522,
204427,
267234,
288150,
345824,
3960,
12796,
null,
125181,
3389,
57564,
93716,
99871,
8317,
18818,
28301,
null,
12164,
9440,
127235,
55248,
103755,
127122,
null,
null,
6832,
37575,
137213,
null,
53030,
218819,
97966,
21762,
25394,
43142,
74335,
192810,
15083,
158328,
148604,
56053,
214380,
26489,
5589,
635,
49569,
45462,
105573,
191579,
26050,
372491,
278897,
131194,
34648,
55094,
23299,
8718,
162142,
119404,
132220,
23476,
109307,
null,
20978,
36149,
36680,
84933,
54693,
69262,
21073,
624229,
234927,
10915,
336638,
106124,
46781,
265378,
203781,
29505,
165464,
11067,
22918,
8599,
182902,
200225,
324258,
18930,
8497,
107022,
246775,
133814,
47750,
14154,
30293,
93415,
null,
197017,
34392,
17328,
134467,
104616,
139040,
48300,
116198,
70903,
23923,
19818,
247355,
null,
null,
9179,
172219,
26572,
164281,
48660,
null,
113661,
336986,
3140,
249413,
9387,
47471,
50345,
146815,
23893,
34845,
4067,
280559,
166098,
156498,
314249,
375374,
140238,
null,
151478,
154949,
520139,
1583,
319999,
3616,
26154,
3475,
34949,
32358,
156827,
290310,
224851,
135234,
27550,
142788,
477786,
247735,
84465,
386415,
126051,
280299,
818609,
13903,
13298,
909133,
211227,
38195,
3237,
218745,
294103,
76672,
31775,
115437,
137559,
21714,
25064,
9698,
33641,
57665,
268934,
33590,
57015,
290379,
118792,
16735,
50717,
112249,
293221,
7220,
37503,
23669,
219574,
159105,
34145,
51030,
38856,
24179,
154399,
19752,
161903,
12745,
22541,
7550,
276622,
null,
24803,
16167,
24619,
15704,
194791,
33104,
41675,
26060,
46128,
null,
472929,
88101,
458132,
null,
265058,
36618,
67330,
23238,
74334,
18938,
19578,
null,
28050,
233653,
null,
199245,
45985,
154070,
359694,
51621,
null,
183532,
65042,
216586,
41367,
45995,
18817,
32627,
172450,
147805,
null,
297136,
188051,
265657,
11126,
135434,
113686,
189862,
158384,
14368,
245657,
376392,
14985,
28695,
31089,
21016,
217055,
20333,
209723,
142668,
95388,
211872,
178867,
49798,
138805,
21046,
308887,
162215,
38958,
119432,
150287,
183072,
42245,
60268,
24784,
240728,
252856,
11645,
null,
36454,
88287,
null,
129087,
133718,
null,
36116,
32798,
176936,
13347,
40460,
63936,
648,
216432,
49301,
18957,
null,
231993,
336386,
311698,
172540,
47229,
34973,
172013,
91431,
111563,
7243,
121074,
233195,
25429,
18166,
32371,
11824,
44903,
null,
115053,
59804,
305177,
124469,
40247,
302955,
27656,
303908,
623483,
372272,
196430,
25146,
111664,
377664,
28398,
179674,
207644,
51846,
34668,
72261,
null,
169594,
142341,
null,
133024,
null,
3000,
null,
154184,
80287,
39084,
798541,
93165,
726757,
45400,
473115,
237951,
90771,
69004,
661104,
1791,
41268,
20855,
78411,
161075,
94615,
78644,
13137,
86128,
25475,
56295,
221330,
91484,
15559,
250194,
261965,
35361,
343339,
36869,
11672,
384253,
286315,
null,
193292,
217124,
8221,
null,
10384,
7734,
34271,
388138,
82146,
231006,
151614,
262156,
525806,
52838,
null,
1946,
null,
136056,
25671,
251580,
56709,
6775,
116489,
36522,
158371,
215224,
405747,
177679,
10906,
53985,
114500,
15921,
46045,
145679,
151887,
62225,
24572,
44396,
143619,
77373,
449060,
null,
66853,
133778,
48216,
182259,
115746,
436590,
654255,
313919,
27068,
null,
23858,
90941,
208472,
null,
7280,
88294,
9621,
79378,
68769,
33975,
181073,
103298,
40639,
46703,
null,
153663,
233387,
37010,
49030,
30070,
50021,
46078,
122376,
168363,
202828,
81606,
19524,
117439,
115795,
21994,
21851,
280640,
166057,
72246,
8276,
48354,
null,
365805,
344315,
21970,
164672,
null,
55156,
121578,
358843,
42722,
216050,
199543,
null,
229404,
138418,
3591,
255513,
226777,
24645,
1020895,
187876,
43815,
648169,
254317,
31287,
45774,
368902,
53003,
41521,
242311,
17465,
192558,
242091,
348116,
30428,
459333,
45979,
15567,
198221,
76180,
142274,
138034,
27478,
32440,
8784,
429073,
118762,
31188,
71910,
273455,
47277,
14712,
97434,
249369,
313737,
null,
327300,
151509,
57517,
100245,
170271,
39944,
36213,
41439,
12866,
61508,
192184,
null,
13058,
253427,
137977,
54222,
122343,
13875,
1064152,
222943,
2620,
12372,
null,
64814,
29328,
null,
98493,
8520,
213026,
390736,
371963,
117284,
75060,
354031,
321169,
null,
55080,
136816,
119553,
176096,
46551,
7170,
116819,
12148,
36191,
null,
271918,
17963,
16239,
210724,
270554,
239309,
552888,
152521,
21124,
27469,
179065,
19296,
5328,
20204,
7859,
null,
null,
90270,
40810,
35355,
null,
86359,
215603,
39779,
256812,
138084,
42003,
185888,
45379,
192604,
33407,
179998,
314914,
27407,
67096,
39537,
81049,
41401,
54621,
307986,
279760,
35224,
48684,
106837,
484744,
480363,
35092,
16899,
221129,
82677,
319155,
166638,
40817,
44541,
9992,
224733,
477285,
268827,
421856,
20122,
392042,
51389,
29307,
null,
null,
48676,
114902,
185526,
15984,
238105,
201417,
21477,
164443,
24091,
80291,
567006,
38382,
89107,
128203,
298615,
34527,
51123,
19904,
32122,
67228,
287256,
96542,
474487,
35787,
296444,
333736,
26761,
63529,
163324,
125087,
37692,
436747,
null,
72486,
27923,
23579,
262564,
60035,
112290,
6422,
317485,
178504,
63763,
163903,
38453,
187527,
185103,
17844,
248505,
218460,
60314,
22412,
303922,
102851,
8608,
11827,
11050,
40637,
347697,
32702,
7537,
16585,
202542,
82589,
12485,
325863,
309989,
41591,
127146,
467190,
339083,
63399,
333032,
27854,
12283,
51969,
39366,
134779,
426395,
126478,
368376,
115982,
71053,
null,
6809,
169929,
20899,
12283,
159712,
178676,
36797,
293080,
114816,
null,
56979,
35213,
261919,
234866,
40954,
255541,
410517,
46502,
25567,
282432,
247142,
182208,
90734,
null,
57930,
28656,
1026,
44693,
126830,
1135,
45599,
112676,
null,
25868,
203949,
38136,
858706,
128616,
485420,
32438,
214959,
null,
23956,
74675,
190429,
338097,
153416,
null,
184138,
45503,
76066,
6291,
null,
null,
91730,
160790,
51100,
283727,
31248,
422304,
28615,
154969,
143047,
346748,
31591,
94284,
9913,
29948,
null,
32107,
145592,
123081,
222129,
29426,
290290,
118964,
19605,
39740,
217226,
16109,
432688,
223658,
134676,
405009,
178527,
133426,
null,
162645,
14481,
388940,
11507,
42538,
397180,
78577,
33174,
206843,
93330,
31260,
132533,
242325,
166271,
7517,
null,
97851,
467616,
513862,
5194,
536761,
139023,
205122,
48683,
46980,
90818,
49623,
null,
265892,
119395,
115260,
23208,
20034,
826428,
18952,
68957,
160172,
206059,
null,
115242,
53767,
151778,
318328,
49664,
26783,
167434,
47895,
11641,
217614,
50105,
19444,
274353,
278963,
152138,
60761,
194198,
172134,
139860,
226234,
58560,
105693,
19755,
45915,
69809,
199262,
5786,
20994,
28391,
36370,
17772,
59334,
174079,
7271,
35811,
101502,
82256,
102564,
184572,
17177,
30970,
391542,
317748,
366875,
4248,
43080,
null,
9287,
144470,
10244,
270907,
347294,
28323,
53236,
156778,
1332,
309797,
229049,
10874,
225701,
47821,
15786,
329623,
258702,
17396,
191886,
4531,
14836,
84471,
129322,
7827,
323529,
1531324,
47305,
28172,
70628,
175043,
31374,
126742,
208996,
575032,
195074,
22492,
286897,
110329,
4615,
254715,
261829,
341501,
49105,
null,
28392,
107695,
13211,
176081,
382253,
149570,
272545,
37566,
43636,
16498,
264594,
304975,
119796,
null,
112620,
30286,
85349,
411164,
22093,
21594,
41911,
20963,
189856,
48669,
25830,
501653,
76140,
18709,
null,
37052,
389108,
130474,
36114,
290414,
406926,
288991,
27202,
180089,
null,
27432,
46025,
3081,
48269,
305720,
184990,
202912,
34510,
19746,
null,
40108,
29328,
85270,
31481,
412458,
117555,
74266,
25064,
40988,
null,
180100,
20416,
33245,
31688,
12079,
42141,
32923,
213335,
209476,
null,
8335,
128974,
5101,
27992,
44680,
361385,
44614,
null,
22112,
11167,
77602,
229866,
131780,
264415,
238224,
15672,
4689,
25123,
23890,
22188,
301865,
252095,
9584,
9285,
51961,
181498,
21279,
149731,
157608,
303019,
37631,
45780,
282289,
109406,
42575,
null,
null,
121798,
57417,
13705,
35084,
69381,
23871,
18564,
37105,
49169,
136637,
null,
289297,
52700,
219292,
29097,
null,
15218,
492226,
185416,
122897,
198698,
458391,
26237,
29621,
121619,
405974,
20088,
225877,
35829,
277514,
17832,
40571,
179778,
6100,
243192,
32602,
109389,
27906,
37158,
222607,
64378,
33337,
71468,
38647,
32424,
14100,
286928,
16065,
161125,
176271,
134831,
38391,
566094,
161966,
27095,
79646,
402841,
810472,
273634,
null,
390122,
95250,
158509,
19023,
37659,
159839,
226182,
13013,
30412,
89884,
null,
null,
113329,
307194,
272787,
143062,
270996,
17430,
77895,
47415,
176355,
104597,
159228,
315694,
null,
209692,
23413,
159356,
207387,
76163,
202201,
25392,
188672,
197973,
160599,
158275,
107900,
159380,
82817,
null,
493682,
47270,
243352,
198930,
504809,
325171,
24247,
11158,
236575,
43105,
14035,
166238,
152171,
null,
253938,
149387,
26775,
371734,
111125,
373753,
187682,
38082,
null,
240380,
18090,
18687,
304718,
50082,
311761,
8322,
23617,
70663,
30981,
18286,
154780,
291725,
161586,
245021,
375492,
24802,
196032,
275812,
67346,
293382,
171688,
42563,
296056,
6752,
188302,
233570,
6876,
327103,
26650,
480304,
51078,
225011,
null,
177069,
38830,
131856,
null,
43072,
82600,
107925,
33482,
11552,
38846,
139476,
19262,
60687,
140124,
290558,
8065,
95287,
58716,
262530,
184481,
282502,
235282,
25954,
363765,
16876,
22232,
160007,
24454,
121449,
35580,
12222,
103338,
37141,
50996,
86621,
21435,
36456,
null,
36852,
19854,
95121,
225734,
null,
100942,
392595,
437529,
192818,
10934,
23617,
250097,
280707,
143514,
233658,
145674,
12697,
191965,
29798,
24002,
60742,
34619,
108301,
190239,
408617,
179994,
null,
211279,
24529,
182649,
397123,
119737,
356961,
null,
19140,
296910,
147538,
164139,
22350,
40979,
60536,
204206,
10547,
72486,
null,
164668,
42003,
51977,
536130,
null,
1379,
null,
114298,
170954,
341173,
18814,
13530,
20460,
180730,
299799,
408706,
6141,
2331,
495939,
null,
145531,
157539,
621428,
null,
null,
194059,
85988,
null,
26422,
316795,
458380,
397832,
28404,
12571,
43012,
574806,
85827,
101782,
358872,
451892,
38723,
9547,
88900,
9844,
316889,
51825,
153427,
264562,
436297,
113626,
24289,
138910,
70634,
158943,
28536,
23656,
51344,
37554,
30194,
126160,
10000,
9283,
488064,
null,
33642,
52268,
11603,
25931,
991051,
73795,
64054,
163115,
243445,
165243,
82798,
133130,
18277,
31074,
103667,
503714,
168056,
642402,
10159,
169058,
47093,
93561,
null,
158400,
27524,
18852,
122179,
34801,
289986,
891296,
40925,
44781,
225141,
7272,
230614,
null,
32451,
25098,
35130,
null,
31675,
149961,
94159,
15895,
4767,
93748,
5353,
232975,
204720,
451868,
71724,
80646,
16689,
17510,
37828,
77470,
13815,
21263,
267869,
95229,
334687,
44882,
19419,
63109,
35300,
null,
363728,
149160,
9440,
238095,
268420,
183969,
9326,
119858,
65715,
50566,
19956,
296330,
143166,
330443,
197594,
243207,
163337,
166225,
289066,
10079,
71449,
45608,
17856,
77393,
null,
11483,
598300,
254568,
37458,
112489,
144209,
null,
10027,
168084,
167469,
58287,
23983,
182651,
154853,
136906,
808556,
46584,
262205,
857422,
69430,
32534,
48262,
345607,
53686,
202698,
79286,
257162,
382400,
148432,
187827,
295163,
191573,
1225,
10183,
29256,
45023,
4656,
58790,
22164,
22370,
34206,
62469,
15031,
83461,
56960,
449071,
72949,
227079,
10108,
33068,
555514,
185723,
152396,
253303,
null,
35842,
250853,
722094,
222682,
null,
16613,
null,
9654,
107816,
335893,
null,
181743,
67570,
363757,
248386,
42818,
40393,
276005,
59906,
25240,
30622,
215249,
302948,
30976,
208467,
152841,
31904,
626208,
22491,
45771,
410801,
9896,
40873,
258661,
47689,
258769,
205231,
52907,
null,
78885,
190232,
28408,
199959,
82629,
39079,
28927,
116577,
null,
274918,
null,
4720,
83449,
null,
492767,
null,
3806,
75280,
173100,
299657,
1179722,
322114,
31247,
42883,
12056,
null,
214469,
null,
41656,
318520,
197544,
365035,
271100,
6646,
127642,
250503,
19227,
48069,
11646,
17921,
214230,
300738,
20212,
429154,
172024,
27816,
55941,
300595,
4939,
110850,
350900,
17581,
33977,
15295,
343099,
617988,
10984,
20124,
10723,
71739,
198843,
37264,
237204,
364690,
53185,
16867,
12998,
171586,
20316,
230769,
526983,
44790,
203402,
112414,
18823,
null,
null,
383509,
12012,
null,
null,
4655,
67278,
30346,
206963,
56403,
35810,
190885,
300195,
144918,
56479,
166026,
34733,
37361,
358306,
28180,
23321,
95789,
87223,
29093,
161388,
null,
57788,
246149,
603184,
24542,
208717,
6072,
23290,
110962,
341243,
54841,
30929,
null,
58866,
29900,
7464,
13830,
272615,
31500,
12134,
5867,
44176,
11919,
null,
67537,
62262,
552631,
35820,
207793,
103221,
56398,
21314,
200945,
13058,
133399,
31365,
66767,
null,
null,
200082,
108099,
78873,
51967,
46712,
214179,
231699,
21715,
null,
19126,
29933,
26928,
1177,
7674,
115709,
218459,
13276,
458856,
33157,
283386,
209669,
329226,
364936,
296214,
90951,
36550,
47594,
333433,
31387,
163996,
44628,
254080,
239660,
9548,
null,
24661,
207014,
298539,
28249,
148647,
195493,
216873,
86148,
47399,
184701,
719676,
50171,
171574,
212506,
460763,
183856,
52383,
180078,
12632,
218337,
129572,
14531,
88991,
20644,
154566,
276277,
138414,
null,
115337,
91397,
81723,
154615,
369096,
190640,
363472,
11033,
188685,
8909,
54961,
119427,
136465,
361033,
385526,
18187,
23410,
61980,
57804,
206844,
288319,
32185,
227700,
223009,
356089,
25153,
21073,
166275,
13136,
105205,
8001,
13091,
322053,
null,
112419,
null,
141227,
276063,
8349,
240182,
285905,
28310,
32022,
390640,
136674,
null,
null,
132330,
60752,
null,
36652,
209755,
31785,
25525,
17392,
32706,
26378,
91912,
76517,
13039,
null,
205718,
53694,
69322,
9358,
23742,
139008,
30642,
90245,
104833,
31277,
173255,
198110,
208138,
39533,
105409,
121844,
29722,
261745,
38327,
160036,
160499,
222594,
11086,
86342,
2949,
40825,
398713,
702637,
168228,
28072,
42770,
42941,
135565,
28690,
264428,
18158,
9764,
509943,
87511,
168151,
6708,
31894,
87599,
188549,
38406,
null,
245126,
59254,
40525,
36307,
69261,
440927,
6043,
107151,
7763,
28361,
18350,
null,
206640,
null,
190567,
184514,
null,
21867,
481348,
124362,
233302,
735104,
74518,
11117,
185970,
626651,
37382,
null,
203839,
300011,
13569,
29638,
11518,
37009,
31193,
100470,
23304,
178572,
16024,
90360,
17628,
348927,
287932,
27876,
null,
149511,
80325,
105157,
213372,
216038,
287490,
353271,
18286,
530299,
9861,
null,
221873,
285808,
null,
70959,
358473,
8923,
35674,
11796,
322574,
35593,
null,
267664,
184227,
24199,
69723,
184017,
39360,
25202,
220150,
21854,
122635,
21136,
308128,
20924,
51031,
37937,
28175,
134991,
255098,
159272,
283916,
28118,
149653,
229404,
220948,
52368,
11684,
186201,
32502,
107982,
10613,
28488,
301685,
19305,
34979,
61676,
42913,
607411,
12763,
962183,
39147,
12407,
290989,
152891,
193174,
23050,
29272,
46810,
366958,
7582,
2043991,
450064,
60644,
237724,
null,
null,
236246,
58449,
51941,
59397,
171913,
null,
74008,
null,
34324,
46717,
204039,
null,
158986,
20637,
24841,
79029,
257724,
8443,
355888,
null,
140652,
97841,
324283,
22650,
241144,
274885,
344586,
null,
44030,
51832,
58110,
null,
210702,
30139,
120235,
18381,
26393,
253928,
79328,
256161,
200646,
365120,
97339,
3307,
null,
179966,
156695,
191826,
443433,
43235,
30610,
279954,
116019,
213339,
106847,
null,
164661,
10401,
118007,
16626,
78827,
214918,
181108,
622825,
38653,
259200,
77588,
212458,
54801,
31775,
361354,
21740,
188017,
25437,
null,
14431,
109081,
43156,
96746,
31674,
95594,
null,
254058,
4025,
115754,
12193,
4324,
10200,
194317,
130389,
4513,
256565,
364269,
8558,
18610,
null,
279078,
167881,
20848,
149097,
38268,
376716,
28296,
514692,
179341,
5069,
null,
265671,
61348,
317367,
92512,
6682,
13375,
43248,
11031,
10586,
61604,
11126,
73606,
23691,
null,
366548,
40167,
138691,
86886,
43791,
120117,
27589,
167269,
188239,
403249,
427900,
129294,
323021,
37610,
59845,
16881,
47810,
120363,
47935,
38945,
10459,
204919,
59644,
7513,
43025,
97334,
55998,
17640,
62358,
128463,
200773,
694698,
214828,
216781,
370534,
86650,
351773,
30484,
null,
243725,
56139,
24156,
9315,
138397,
352982,
325607,
579255,
16506,
34013,
251099,
41066,
7604,
49285,
10182,
280370,
323471,
11943,
294463,
258492,
4203,
252720,
41204,
330966,
18583,
13436,
45854,
48000,
639429,
20784,
163112,
44528,
427944,
18214,
39463,
null,
111753,
28915,
441962,
null,
85952,
153292,
22912,
68237,
160175,
399663,
103613,
96052,
14674,
252456,
6968,
22643,
12963,
189530,
409403,
null,
null,
55406,
60021,
null,
13885,
33601,
247855,
75855,
124917,
65821,
null,
32755,
237127,
86141,
7686,
null,
14697,
112138,
16323,
21991,
73042,
289701,
296103,
33548,
875664,
30480,
41884,
439778,
123020,
128783,
319195,
60757,
68509,
79749,
290902,
209569,
132019,
null,
25569,
57885,
272805,
50165,
114848,
5020,
38275,
102109,
73998,
null,
519897,
291244,
472365,
26119,
236057,
15454,
5396,
227451,
422331,
70053,
48088,
59443,
33075,
265554,
287740,
9995,
17916,
175067,
103056,
92950,
17255,
60872,
128195,
52863,
17888,
366830,
142159,
204162,
null,
271157,
141801,
102001,
27371,
142065,
273397,
33919,
256014,
33862,
17839,
107746,
358397,
477651,
17996,
262222,
null,
88551,
2127,
89385,
6362,
158073,
21021,
22493,
53405,
22904,
54694,
23865,
301737,
194162,
70151,
20976,
406776,
80735,
233646,
13785,
null,
115665,
308786,
10831,
13411,
243257,
5988,
35545,
41214,
null,
431282,
204353,
6938,
27927,
30797,
469091,
18539,
8507,
1158975,
47576,
null,
28089,
42830,
6016,
23220,
19658,
18887,
21905,
429739,
95339,
200437,
160267,
210103,
null,
null,
35765,
29639,
161968,
484041,
88139,
3599,
74531,
201940,
229749,
286511,
38874,
31144,
35564,
145456,
105553,
30679,
256315,
null,
7270,
260409,
38067,
33873,
105293,
145171,
340312,
94099,
133500,
34630,
24600,
22646,
16072,
371204,
155769,
323693,
267309,
240853,
9393,
268679,
39395,
236290,
46110,
60095,
34589,
7840,
198203,
178765,
null,
787933,
725616,
171893,
38184,
52891,
47580,
28206,
60705,
133225,
28471,
248297,
130169,
null,
31797,
156535,
23862,
403251,
612052,
33749,
23314,
120585,
237655,
null,
78130,
80471,
185572,
452903,
129846,
112798,
12004,
35468,
188507,
14425,
97023,
198204,
154402,
52474,
188030,
40802,
2873,
39805,
449252,
41711,
295625,
485735,
null,
110975,
49558,
24016,
43460,
35279,
67169,
192884,
36109,
48576,
161639,
193442,
null,
16881,
269792,
260654,
16162,
172737,
9722,
620670,
185448,
109484,
50506,
71133,
201403,
306007,
67936,
79657,
53490,
829578,
62095,
33587,
104945,
20912,
40296,
27406,
41907,
16114,
84833,
255467,
107198,
14999,
71960,
431646,
24320,
null,
324945,
81922,
17666,
314913,
28443,
68174,
4247,
16261,
243444,
400325,
49013,
null,
421562,
214441,
228129,
5573,
13345,
51688,
26380,
98006,
256490,
527739,
148124,
199128,
22255,
170331,
6686,
14785,
88905,
135199,
324859,
17998,
30903,
26131,
72839,
192391,
null,
28920,
66859,
45612,
43591,
361464,
41578,
24815,
18838,
17097,
321769,
158320,
null,
14977,
311121,
41424,
null,
76193,
86548,
28486,
108574,
142787,
30058,
38278,
15806,
133908,
19717,
4235,
141516,
160437,
212693,
7182,
309870,
224236,
222824,
224152,
301655,
39927,
177808,
14034,
43436,
59067,
112010,
153538,
40422,
17597,
null,
156838,
366771,
94290,
331366,
57349,
22058,
27740,
195924,
25701,
55999,
129774,
37742,
137841,
36987,
16125,
null,
null,
3737,
15942,
null,
43263,
12796,
5441,
14248,
180811,
17020,
12878,
154913,
71317,
291198,
441664,
221095,
47295,
280687,
343934,
19779,
46603,
417849,
36612,
48596,
256801,
262012,
24703,
23448,
41041,
323232,
431810,
null,
null,
184270,
76446,
14488,
36973,
153270,
31829,
7827,
181438,
168507,
469375,
29111,
96390,
40483,
103233,
17657,
35581,
253761,
208265,
10316,
68614,
null,
23179,
137857,
25523,
213110,
87496,
62147,
36538,
43722,
142817,
62944,
24998,
446710,
129715,
93756,
27962,
16455,
190680,
150102,
165558,
108813,
29857,
50420,
null,
531687,
83165,
143717,
48652,
358495,
348409,
374892,
30897,
464105,
72611,
null,
494595,
159409,
16804,
220530,
null,
364100,
28012,
82831,
9265,
136199,
308468,
206743,
null,
229459,
null,
325551,
360313,
126996,
27274,
83578,
23538,
581814,
109109,
38929,
259215,
25653,
36385,
300147,
21278,
67532,
138071,
59462,
68866,
null,
274891,
154320,
6807,
171270,
59002,
178439,
9365,
212082,
908655,
108642,
331759,
147382,
null,
64831,
29126,
258760,
1925,
126390,
182934,
231821,
null,
102736,
157497,
465710,
210156,
null,
279394,
264389,
137638,
29075,
24375,
55846,
192980,
233463,
151267,
363157,
null,
81149,
64634,
49163,
68389,
19740,
70937,
null,
null,
152246,
13856,
52128,
62094,
200614,
260600,
174210,
421308,
117057,
6696,
41107,
31093,
56840,
176419,
82893,
9664,
21683,
17276,
115973,
55872,
null,
210303,
19726,
108892,
5780,
324592,
71165,
240079,
26855,
99136,
77804,
204453,
68531,
14391,
138961,
27985,
40623,
326044,
2954,
124691,
37946,
156423,
161721,
68475,
349030,
40767,
48331,
41393,
210528,
211937,
279471,
45531,
147908,
121229,
175527,
162095,
167405,
365453,
9614,
21286,
122560,
86183,
22957,
193109,
162086,
197321,
14069,
5159,
19769,
149392,
196470,
34561,
28769,
9118,
22837,
30661,
196702,
10945,
203888,
681911,
null,
329528,
82883,
22133,
480070,
412503,
174947,
186689,
28662,
50884,
380783,
147113,
17214,
33402,
43333,
378356,
334100,
21335,
48305,
265642,
19620,
253843,
null,
21591,
22957,
37707,
157543,
11153,
52990,
55994,
19260,
205925,
431775,
120869,
291331,
23675,
37621,
892602,
17619,
59471,
13635,
120617,
243933,
10425,
null,
71927,
61268,
391009,
11026,
219390,
11823,
40157,
212175,
483122,
124549,
null,
312892,
156131,
38716,
29300,
63682,
15594,
122121,
192938,
374823,
16459,
259587,
140690,
14286,
86868,
27202,
473635,
null,
41258,
242897,
173706,
238525,
null,
268240,
9670,
64157,
93116,
20351,
322321,
13935,
null,
432149,
76175,
35881,
12919,
2700,
17805,
14457,
398402,
258751,
21771,
248001,
79587,
25701,
187021,
148174,
295784,
345037,
189309,
28588,
31850,
135397,
115225,
467607,
44778,
18605,
230549,
162469,
49193,
43547,
14272,
null,
171997,
13976,
21272,
70072,
77788,
5988,
92497,
399945,
67082,
431728,
42592,
125736,
20967,
310323,
null,
null,
10390,
32765,
627361,
139294,
25989,
10019,
136188,
39732,
25291,
15034,
8998,
30232,
109493,
5849,
50107,
24194,
225320,
100049,
251330,
null,
64969,
80496,
31792,
63418,
104595,
230658,
265994,
51022,
200461,
448679,
234588,
16100,
16512,
102114,
396470,
60836,
null,
48517,
426705,
78113,
321946,
176331,
268013,
317006,
32496,
null,
31100,
347954,
null,
null,
null,
12991,
154947,
241184,
46418,
772429,
null,
588207,
218499,
22840,
123553,
251939,
5379,
363063,
47397,
158942,
null,
86239,
28458,
null,
null,
23111,
24499,
78013,
67261,
207331,
null,
137869,
6132,
177720,
24769,
253747,
17524,
null,
37367,
48922,
null,
244085,
395739,
42321,
40073,
24545,
58113,
18047,
79277,
17698,
186607,
271984,
146957,
null,
38208,
301737,
14397,
312868,
106099,
3414,
31056,
305523,
49320,
null,
72482,
99567,
49850,
480495,
32264,
7899,
357902,
28237,
37291,
35966,
11485,
6624,
201206,
279328,
209618,
48614,
93008,
334184,
205425,
47590,
163066,
35516,
61506,
229635,
15419,
69687,
2393,
40327,
16084,
112578,
30698,
8502,
312701,
16743,
28268,
101242,
207335,
41945,
27934,
71628,
50490,
221986,
65563,
310738,
10238,
64770,
33466,
24887,
29390,
299265,
132301,
227825,
149535,
84415,
15103,
257955,
127379,
39050,
73436,
null,
225813,
264924,
null,
26160,
201270,
46845,
298928,
19801,
161408,
22894,
142762,
37823,
53653,
87242,
323587,
28413,
172698,
15683,
71268,
53949,
null,
17762,
412485,
181026,
200559,
275627,
121749,
305103,
44417,
6400,
49910,
37915,
30487,
25743,
240297,
241925,
45400,
355499,
1090199,
67489,
321432,
27359,
27604,
236269,
249011,
83921,
2408,
81552,
15344,
239125,
249324,
205751,
546178,
146598,
184862,
77051,
296234,
34067,
332694,
124163,
228907,
10524,
31270,
250334,
61500,
247415,
65349,
22968,
36861,
134375,
46262,
182962,
null,
304148,
33120,
337677,
null,
205002,
33625,
45624,
345779,
124787,
90114,
61722,
null,
16006,
4660,
27960,
63208,
221175,
42278,
486799,
259944,
365643,
408971,
195896,
212526,
31916,
7090,
7183,
19624,
17470,
11152,
25627,
81451,
30739,
420138,
14761,
192692,
null,
17171,
142190,
222139,
196977,
44847,
263503,
242268,
172329,
149799,
24061,
172513,
93730,
null,
251573,
174244,
145985,
10475,
424404,
null,
88830,
34500,
52126,
293255,
330365,
123386,
74017,
23223,
24591,
752026,
24803,
null,
26476,
295017,
17708,
291831,
26944,
55749,
141684,
98086,
272070,
27798,
174884,
419395,
null,
182398,
171355,
33004,
23796,
65600,
7049,
35655,
105918,
null,
65387,
65931,
null,
227504,
286902,
37055,
33891,
39134,
42295,
85559,
151105,
38611,
48696,
79839,
52415,
88835,
3630,
67599,
410026,
30432,
9277,
null,
78844,
549792,
120124,
115190,
112209,
449740,
19713,
71492,
null,
178791,
96224,
279558,
255792,
286823,
null,
4780,
60259,
31764,
253618,
10802,
339464,
42966,
4294,
10204,
64139,
62838,
235862,
80847,
21422,
44119,
3210,
92477,
228299,
38243,
24074,
18088,
304062,
153321,
40203,
55240,
43252,
null,
261529,
27515,
91427,
null,
5454,
33721,
247673,
101724,
43995,
66160,
124705,
54635,
68773,
44610,
38289,
62297,
381943,
null,
19054,
31874,
242202,
62197,
199602,
31506,
25928,
12854,
10713,
390918,
68207,
5884,
143269,
null,
9485,
72060,
97831,
215551,
227339,
8122,
72049,
303426,
22066,
248620,
51717,
42461,
83301,
31279,
178342,
32277,
33230,
25775,
203931,
23283,
17980,
324431,
101314,
null,
null,
106003,
null,
158834,
9736,
246104,
17953,
168211,
207116,
26709,
25736,
128163,
518370,
311160,
38298,
120566,
391619,
144688,
40148,
15853,
63811,
40063,
16178,
77338,
298006,
null,
34305,
96262,
339371,
252135,
14336,
null,
52401,
72777,
42179,
27588,
35544,
28125,
10686,
16062,
50610,
null,
46627,
64176,
54137,
75567,
30679,
183119,
40607,
43433,
190394,
224121,
53990,
114334,
249067,
67192,
12954,
49575,
1085912,
140760,
262666,
106583,
230731,
7204,
65944,
35704,
33752,
27192,
30945,
95537,
165707,
43584,
14285,
92556,
117643,
13285,
164611,
185263,
174286,
27100,
27138,
125838,
50009,
397655,
52627,
89005,
292743,
913925,
22964,
215585,
35069,
4104,
242942,
149838,
28696,
220751,
91352,
499564,
317943,
null,
3777,
203430,
58000,
145391,
38276,
287688,
30810,
388997,
220091,
26454,
96994,
218453,
95753,
30294,
234594,
null,
129997,
null,
340563,
44550,
51686,
70215,
null,
210515,
58565,
172049,
192971,
18779,
37425,
26375,
68849,
15206,
21729,
11860,
22482,
38458,
163926,
69887,
19049,
250500,
231080,
225127,
23986,
271194,
306669,
31408,
45372,
406900,
17528,
209310,
177332,
31367,
37367,
48194,
null,
null,
67736,
6251,
187039,
354311,
31544,
314869,
98274,
198400,
447953,
137505,
591919,
13129,
26959,
231530,
43406,
137545,
5656,
10573,
550404,
497889,
35666,
99085,
62549,
275690,
367743,
36393,
375189,
19096,
241001,
283124,
45527,
133919,
717036,
20925,
null,
418960,
21844,
null,
null,
291895,
1236650,
181690,
188895,
261171,
139236,
278189,
null,
356768,
47908,
1069743,
75671,
306718,
7900,
257864,
469971,
49714,
186010,
null,
23153,
52814,
181699,
32590,
199030,
144924,
11333,
87829,
2060,
190060,
13710,
279556,
199129,
null,
19033,
209827,
null,
71215,
65906,
35884,
10170,
30444,
342009,
248109,
98442,
36610,
115511,
191720,
233337,
200633,
289920,
58956,
290008,
197189,
19293,
24383,
null,
null,
151576,
6652,
null,
167615,
346460,
50586,
65942,
407473,
261671,
16771,
65974,
149216,
172584,
24599,
379202,
1727023,
24000,
448879,
null,
18847,
51766,
513530,
233460,
53077,
40748,
15648,
211275,
192971,
null,
34944,
32983,
null,
33509,
227199,
146594,
71178,
202339,
180957,
null,
78297,
null,
38935,
23188,
50192,
null,
55896,
6843,
null,
27199,
12205,
170420,
170217,
5667,
209905,
44518,
91991,
31825,
62544,
300641,
40470,
36235,
10589,
64240,
116188,
392394,
312137,
23346,
53693,
26835,
58508,
57331,
14151,
166378,
null,
278516,
182135,
null,
null,
241920,
24279,
50633,
137524,
209599,
831949,
13360,
40066,
2338,
17437,
10744,
244772,
48636,
22646,
74742,
140474,
123449,
null,
171643,
6678,
360650,
159249,
172494,
123936,
368990,
1217,
13906,
344875,
61446,
137380,
79504,
364515,
188467,
319961,
28223,
955426,
106017,
null,
21468,
27826,
100368,
431000,
155251,
13998,
16251,
null,
186667,
null,
62838,
160187,
14829,
6030,
272366,
166947,
3144,
112911,
null,
91182,
31524,
null,
225767,
324848,
40371,
51319,
292231,
null,
28060,
287452,
61146,
337075,
13320,
271303,
5633,
97195,
null,
70292,
12520,
18722,
7455,
null,
64445,
null,
157821,
4992,
3623,
13554,
32806,
51685,
5915,
51717,
34293,
51787,
70942,
401561,
51960,
61584,
null,
18494,
246798,
41136,
96377,
55286,
null,
106590,
901887,
28292,
null,
18395,
14014,
41560,
30705,
302592,
62817,
null,
5990,
36686,
null,
184141,
15905,
4033,
37390,
80160,
14409,
701862,
281024,
53625,
20764,
231807,
55238,
30765,
null,
37529,
7573,
11454,
196399,
36527,
231019,
7743,
40056,
66943,
62773,
20719,
146746,
17749,
24672,
121474,
151579,
null,
41140,
487315,
27223,
46755,
97086,
246595,
281263,
44806,
86363,
73576,
48865,
null,
49538,
433472,
133068,
39311,
31667,
45539,
217752,
52652,
70760,
50142,
137805,
300858,
350629,
354634,
266344,
29296,
5100,
4812,
50681,
200839,
238705,
50659,
5076,
21426,
57739,
25229,
239945,
34329,
3929,
367935,
114525,
79348,
39016,
84253,
8573,
24992,
59793,
62471,
null,
92011,
19137,
592283,
60192,
196423,
9703,
51354,
371395,
155683,
111097,
406376,
47712,
413531,
313269,
72038,
343851,
171356,
null,
105797,
26615,
28241,
385268,
24585,
57406,
185564,
462695,
31203,
25712,
null,
544037,
32567,
15258,
278247,
3321,
null,
59468,
325942,
17515,
274481,
123043,
20774,
134106,
25023,
70683,
23020,
52857,
154802,
null,
42112,
99763,
null,
26112,
29835,
48121,
111102,
15919,
13239,
83931,
22303,
370601,
30408,
487732,
326908,
36861,
null,
183481,
null,
22253,
null,
20023,
102639,
118506,
27790,
310507,
null,
35657,
43588,
329173,
28140,
302777,
217682,
4368,
32469,
29706,
598464,
69434,
108812,
25902,
160055,
349009,
131055,
20184,
43671,
20498,
214110,
252509,
53230,
23319,
148605,
29245,
52174,
null,
10525,
549700,
null,
33207,
56156,
36363,
77264,
14204,
54253,
510740,
214720,
292510,
35676,
null,
null,
17257,
37342,
null,
53847,
19999,
null,
90532,
20650,
23764,
671720,
142712,
3956,
230245,
697466,
130715,
28843,
53843,
48874,
146621,
428407,
355163,
129919,
341386,
21705,
20139,
38861,
307426,
303420,
57026,
156951,
null,
20604,
46951,
221898,
20870,
589479,
17891,
7507,
408625,
null,
138336,
59917,
null,
78902,
14010,
354927,
220044,
38314,
48961,
292492,
9670,
376788,
63359,
9483,
10794,
587691,
47145,
61395,
120473,
25436,
158062,
96255,
296472,
455778,
68545,
40219,
14359,
121974,
49936,
254385,
66447,
102197,
14737,
43736,
11146,
613119,
407876,
29551,
312262,
18622,
6922,
204667,
140436,
116078,
153286,
28613,
309518,
68870,
206976,
147361,
6194,
584365,
39418,
301598,
127751,
68112,
325651,
165040,
24729,
15530,
41387,
96518,
43447,
319032,
61455,
8962,
289002,
null,
203982,
665128,
null,
114602,
49876,
28940,
31374,
61763,
212107,
29720,
31332,
42100,
180587,
37370,
77777,
5040,
36950,
252005,
7881,
25612,
null,
73712,
247594,
null,
40655,
8524,
29081,
241001,
259349,
181399,
42800,
56103,
301178,
71138,
23846,
150142,
121472,
232387,
null,
225585,
12024,
10332,
15825,
14293,
128070,
null,
null,
55690,
100016,
10591,
26972,
null,
125851,
172926,
31590,
394086,
143211,
20513,
314227,
null,
46338,
47561,
4049,
24131,
135194,
28532,
39879,
242166,
null,
41966,
362279,
198926,
283287,
18917,
110543,
17246,
257458,
353998,
403081,
34460,
85834,
300465,
null,
263407,
4528,
59079,
217092,
18180,
49655,
208113,
10854,
50633,
330891,
178193,
114853,
null,
161511,
687429,
46811,
23782,
278223,
null,
291876,
17269,
157194,
38300,
203844,
166324,
58517,
8410,
4747,
612712,
42088,
168779,
70845,
236379,
17430,
11904,
140577,
188752,
185054,
353355,
25916,
586481,
194275,
214588,
105529,
75579,
14563,
206241,
237016,
null,
84572,
null,
154980,
null,
30478,
15442,
41099,
7016,
28151,
176441,
453695,
138554,
28990,
33851,
17342,
137734,
161012,
6682,
15820,
414981,
56328,
69803,
378185,
377214,
188534,
380834,
144791,
289426,
16897,
33392,
13847,
333979,
177033,
254346,
286559,
267803,
28394,
28281,
138943,
71155,
129734,
48524,
208929,
143930,
null,
42662,
17389,
19936,
28743,
null,
87989,
217391,
null,
19314,
46923,
344830,
null,
33159,
13519,
23496,
178592,
null,
24275,
108867,
null,
330662,
187783,
78516,
37078,
207418,
null,
40754,
53932,
259433,
162082,
239593,
null,
207990,
312393,
85844,
null,
16570,
39323,
235318,
391301,
340778,
205075,
25679,
null,
11782,
446087,
61941,
9178,
69039,
72566,
119870,
60201,
123112,
73747,
396131,
73894,
257949,
377279,
121051,
253057,
395751,
215164,
88904,
42714,
30991,
101797,
156659,
240498,
190572,
27305,
48785,
337746,
48055,
140977,
446918,
null,
2022,
277467,
null,
null,
515704,
39490,
340747,
92955,
13980,
37968,
303462,
45469,
184438,
37675,
210190,
57111,
19461,
35631,
566171,
86165,
16567,
206813,
8760,
2390,
36148,
76916,
45622,
192615,
267305,
47606,
10532,
20471,
80793,
3624,
1579,
9913,
24419,
169486,
591562,
118051,
148815,
171065,
140773,
null,
17874,
null,
5436,
208627,
77726,
426976,
1011,
291265,
657266,
15917,
587840,
16126,
385005,
225344,
220524,
21283,
77525,
7756,
23880,
212826,
348763,
273752,
97907,
104840,
30434,
null,
11891,
173940,
26415,
69407,
29984,
131521,
517002,
null,
102770,
241872,
222012,
11800,
207930,
20442,
72223,
22772,
65983,
null,
109981,
77692,
null,
23946,
242009,
19632,
25936,
49718,
474302,
167859,
56247,
97354,
187955,
8987,
479959,
187058,
173497,
486724,
14615,
294962,
126278,
null,
226321,
254121,
332360,
141026,
226663,
null,
7715,
null,
10342,
198942,
30392,
37216,
184852,
45990,
301393,
144642,
246074,
33534,
297264,
30794,
356629,
34089,
902750,
355591,
50418,
null,
42025,
354760,
198301,
5663,
86392,
61756,
28570,
64188,
117162,
48413,
198579,
13652,
238783,
null,
13852,
157437,
82513,
21781,
20061,
241803,
307451,
132621,
130117,
277762,
314325,
6254,
16609,
265791,
34089,
24155,
16286,
19532,
5496,
118794,
231849,
15724,
null,
22560,
76488,
126348,
51698,
263962,
8881,
216275,
null,
213561,
40914,
33059,
208206,
80845,
29426,
29982,
18443,
31051,
26049,
63820,
30885,
21388,
246476,
17997,
240854,
null,
195166,
125946,
13572,
81099,
20849,
260896,
3537,
19004,
31780,
72748,
565478,
167748,
236690,
266508,
24634,
33677,
147963,
21547,
334547,
259944,
91371,
null,
405490,
35949,
34559,
341480,
40786,
48833,
35988,
null,
17094,
77093,
30893,
474337,
13892,
166988,
1647,
4874,
276258,
175989,
null,
81555,
21031,
233207,
null,
1351,
38378,
47402,
141178,
14821,
89144,
261002,
189478,
14906,
228876,
241771,
33651,
174045,
206177,
49838,
null,
181147,
null,
8765,
26940,
88542,
178222,
11181,
33352,
null,
null,
144854,
283620,
47763,
14358,
700136,
85573,
13560,
127914,
2692,
76893,
4541,
26350,
48073,
42008,
321203,
50619,
225568,
79523,
60751,
215136,
29122,
213536,
28603,
363028,
17228,
null,
41536,
320770,
null,
3814,
null,
null,
23071,
212105,
66232,
19244,
202370,
242940,
379025,
25987,
86242,
10098,
43128,
100870,
189180,
69473,
250108,
404489,
224819,
40840,
6096,
129225,
59463,
137224,
314740,
42255,
null,
163076,
10904,
58607,
42946,
370333,
87481,
17902,
180599,
52057,
133464,
39159,
378746,
281556,
57310,
null,
193655,
241170,
325690,
47910,
27699,
50643,
403170,
null,
384342,
177810,
4570,
56655,
145199,
17478,
229554,
18170,
317001,
17231,
94684,
28528,
349903,
170775,
null,
4629,
18675,
79865,
172929,
95451,
151466,
150974,
178945,
null,
9652,
33977,
15725,
null,
34371,
45238,
57223,
287831,
186744,
17519,
219579,
379719,
null,
42952,
334378,
35876,
47473,
10424,
60468,
109071,
362364,
347497,
127841,
415482,
159897,
147526,
71105,
333237,
125437,
211486,
6679,
50384,
31265,
23391,
65866,
179923,
21477,
null,
225870,
280827,
651246,
45915,
39341,
502113,
2288155,
202482,
39024,
136562,
26870,
140952,
null,
23740,
337024,
170966,
49630,
26167,
172257,
279168,
38259,
39650,
374875,
43635,
140803,
30201,
239318,
30961,
30917,
28281,
56459,
124412,
443949,
172798,
20170,
29216,
null,
358595,
69793,
null,
498364,
178418,
27830,
null,
null,
115579,
39298,
33092,
21402,
93087,
35847,
45008,
197745,
11877,
142367,
99822,
142671,
null,
375279,
null,
142544,
null,
26233,
49720,
54087,
162411,
104997,
106703,
37268,
188447,
209500,
452353,
179582,
177489,
287096,
null,
16204,
104093,
49248,
177262,
30429,
19365,
75235,
184699,
173707,
26877,
52843,
283827,
169642,
397500,
89245,
128106,
44021,
6159,
18041,
445414,
65499,
203751,
29167,
58067,
202871,
177000,
61824,
214732,
20389,
17577,
186589,
31489,
353784,
141903,
5415,
294986,
22688,
38377,
43586,
46439,
54620,
309423,
579584,
45523,
6714,
null,
33262,
60914,
267869,
416052,
39748,
276640,
354430,
320894,
93598,
438779,
52725,
186382,
44217,
20681,
141700,
597718,
120307,
579795,
139100,
17759,
38672,
143800,
110209,
178341,
264578,
285419,
37995,
24530,
268026,
167318,
61761,
103425,
178539,
223093,
318019,
626677,
161934,
174528,
340052,
55182,
90811,
null,
351895,
231007,
247991,
638270,
13134,
33355,
18465,
null,
289722,
40611,
13495,
321040,
127905,
419475,
338833,
136994,
16932,
12502,
24367,
18396,
37312,
null,
345354,
63013,
235995,
64258,
7618,
null,
219593,
62081,
143819,
91962,
null,
null,
250900,
41805,
null,
27328,
30251,
77952,
2852,
null,
45129,
302276,
283899,
101696,
43192,
19090,
354806,
43184,
127944,
35365,
93447,
180891,
34971,
204856,
34962,
21941,
39799,
11406,
null,
116479,
230390,
90388,
156363,
61549,
17750,
427959,
11901,
23023,
163464,
315061,
3112,
null,
423367,
303228,
176155,
17070,
299808,
288259,
156649,
366361,
7576,
53102,
5288,
1332,
null,
81386,
277889,
426437,
44740,
4770,
26128,
13117,
85301,
29122,
null,
70909,
30913,
25564,
40742,
16552,
127728,
21144,
12596,
9499,
48253,
44208,
null,
38642,
169726,
66255,
426525,
29386,
306884,
95738,
252183,
208010,
34174,
196082,
205738,
308539,
6019,
null,
233342,
22588,
null,
286760,
280856,
16550,
169119,
8454,
339044,
29145,
308032,
265417,
169007,
49030,
108871,
12543,
867989,
306722,
300723,
47393,
578659,
37612,
23120,
32650,
249688,
216006,
16736,
252927,
204640,
34380,
274412,
25827,
113057,
281958,
26178,
162137,
15629,
173358,
44206,
31674,
20735,
41174,
8254,
17621,
142541,
85553,
22130,
65224,
85228,
30677,
10399,
302413,
45854,
200165,
null,
281572,
517837,
470102,
30370,
194178,
123709,
126399,
21064,
36342,
32976,
48397,
62833,
66122,
14477,
251805,
144725,
null,
26664,
230568,
25032,
429947,
143556,
null,
null,
150446,
608889,
144370,
154610,
436150,
255952,
null,
41885,
319872,
271546,
386417,
26739,
62771,
20781,
13189,
11511,
null,
null,
353496,
22325,
246454,
null,
null,
24989,
6810,
null,
120071,
144224,
528613,
181960,
223782,
215795,
15493,
668267,
33608,
24727,
61178,
39903,
151752,
12462,
54220,
206645,
17265,
null,
199302,
null,
37736,
126749,
69019,
19102,
361817,
247971,
54529,
33479,
23310,
37883,
155647,
19160,
344828,
224472,
524205,
363691,
40227,
20590,
108641,
null,
null,
5752,
21390,
14262,
35077,
62852,
25263,
301619,
54830,
29682,
371584,
83831,
52986,
16567,
56393,
355424,
383762,
313713,
251776,
110629,
270441,
421051,
32165,
11788,
430566,
953950,
172170,
26165,
419059,
null,
16652,
null,
276203,
87354,
12322,
276666,
null,
31914,
null,
53056,
267532,
143882,
11259,
37314,
73210,
21924,
381640,
219961,
50299,
null,
65712,
93708,
159684,
193990,
null,
22046,
18081,
null,
18619,
305052,
8999,
42866,
257432,
249550,
808833,
59629,
14275,
null,
null,
1212030,
166044,
191878,
117750,
460120,
333849,
29021,
18832,
79330,
42598,
295708,
18946,
null,
20436,
93872,
36440,
118412,
29743,
133286,
297249,
169553,
402010,
273535,
121850,
71787,
255101,
38766,
70287,
35621,
152640,
42805,
26339,
null,
386186,
183907,
196406,
10357,
39306,
8594,
130348,
11452,
17768,
301799,
943965,
null,
307238,
42116,
288261,
161802,
81575,
432577,
59107,
172287,
36834,
15288,
366619,
43804,
17337,
5685,
11207,
130547,
58069,
53504,
292248,
41504,
413469,
302803,
null,
40339,
null,
null,
152789,
160472,
331100,
201190,
237251,
24503,
497808,
138770,
6657,
5569,
236844,
74138,
null,
28122,
25027,
108781,
262754,
278822,
64710,
91127,
13197,
31071,
292185,
null,
49725,
31413,
271581,
161373,
176020,
268421,
184320,
null,
62695,
30242,
45705,
49399,
137573,
4988,
null,
48304,
172412,
45131,
352813,
26414,
36611,
26267,
49024,
62332,
42743,
null,
380315,
39402,
328260,
77743,
67655,
null,
null,
null,
521105,
48090,
570585,
85423,
67896,
236,
495507,
231620,
170684,
16198,
21100,
160444,
168950,
22820,
195613,
149281,
26487,
53233,
228956,
243420,
443662,
446434,
60537,
29663,
93676,
31640,
26874,
12782,
310681,
43586,
500657,
null,
251035,
295791,
348600,
null,
155720,
4466,
270587,
171312,
35577,
null,
173248,
null,
205379,
219677,
null,
1867,
44797,
31856,
7091,
278805,
56801,
14317,
null,
null,
25882,
39942,
240157,
18001,
47282,
263675,
155139,
21242,
27594,
77355,
246948,
null,
14401,
218195,
273756,
90734,
234087,
73117,
null,
null,
12754,
23898,
151190,
202144,
98153,
25123,
48850,
null,
38435,
42097,
201044,
18553,
14482,
66412,
273746,
47040,
21183,
28981,
51017,
309916,
15217,
37797,
20962,
137828,
109834,
14987,
22274,
41322,
40062,
10360,
188208,
222,
185663,
234554,
254784,
null,
279711,
76640,
321488,
76089,
238541,
37346,
24506,
94275,
37596,
46891,
32820,
54278,
36067,
null,
212546,
189131,
4049,
212537,
14323,
null,
215574,
286088,
96872,
122705,
53813,
163487,
35030,
29825,
14778,
201090,
254099,
32119,
null,
17959,
261940,
24025,
25836,
118021,
57360,
203627,
82887,
320298,
39449,
566847,
239296,
41782,
208600,
36439,
9188,
59736,
216488,
16642,
34359,
45905,
6091,
null,
14479,
36712,
509758,
null,
268508,
411167,
327514,
142164,
2443,
22166,
7139,
178465,
33173,
98287,
6597,
251438,
80674,
35288,
265678,
82671,
42111,
46189,
173486,
30510,
24897,
156522,
256340,
197301,
183101,
54527,
9877,
38486,
28424,
27674,
12001,
182202,
91976,
93839,
122646,
null,
13742,
142019,
189462,
135871,
45083,
116244,
24284,
49631,
5959,
303747,
33594,
573401,
39361,
418322,
null,
385985,
null,
37413,
3510,
77314,
72823,
null,
1477057,
387559,
23344,
172626,
338242,
102018,
null,
171167,
109620,
286434,
122543,
null,
157460,
75083,
79701,
28435,
114023,
34296,
31441,
44611,
93066,
31945,
33780,
132491,
562062,
48757,
292324,
340350,
74429,
33964,
null,
null,
266491,
101620,
93449,
231508,
28519,
32787,
118822,
626537,
299901,
null,
32798,
139670,
null,
117823,
null,
83180,
39331,
555965,
154189,
42659,
16516,
11333,
392945,
7809,
601954,
9719,
54047,
7771,
null,
24968,
88192,
183582,
10979,
35111,
51429,
35271,
404725,
127804,
null,
280210,
98533,
48148,
62966,
70554,
29581,
113949,
130328,
26556,
175787,
38034,
9731,
166779,
null,
280079,
null,
171463,
260569,
36401,
62634,
225679,
12655,
31114,
12618,
48165,
22859,
9465,
69154,
77524,
225757,
40222,
29829,
369343,
340793,
5457,
418621,
110580,
10148,
351701,
61970,
217816,
630226,
206485,
210481,
134221,
67932,
21138,
23889,
496816,
54851,
296824,
58518,
405339,
110042,
18968,
24008,
210250,
282152,
145353,
16769,
16075,
166909,
251368,
110820,
76093,
9877,
378072,
5289,
null,
24525,
88951,
16434,
35689,
265343,
36572,
15978,
null,
248251,
12976,
null,
491070,
104735,
503816,
30218,
170701,
8857,
103637,
28202,
66604,
3589,
7635,
47816,
377462,
36771,
null,
1004684,
50260,
149951,
42303,
8079,
8238,
null,
12136,
166225,
27894,
38739,
24860,
24514,
107467,
7146,
52550,
131231,
239559,
247772,
291702,
126808,
118826,
1810,
323391,
400558,
33558,
680045,
192198,
236102,
312106,
4038,
12434,
null,
49200,
725328,
107790,
251093,
null,
61631,
576293,
28717,
null,
178411,
333535,
143509,
63552,
37163,
44397,
22443,
65402,
21234,
16811,
32644,
37145,
21043,
13016,
8981,
62567,
70490,
187109,
null,
243721,
202730,
39138,
11579,
180601,
null,
146834,
264619,
37682,
12279,
77215,
41448,
81854,
91000,
null,
67859,
829762,
124459,
173732,
28774,
null,
29246,
119666,
null,
66439,
126224,
null,
8806,
19145,
null,
410345,
49532,
69697,
35079,
19482,
499207,
505,
16110,
171310,
283845,
37906,
223253,
81427,
191951,
446953,
62807,
11549,
null,
25100,
null,
8183,
null,
128174,
111568,
22135,
156248,
65024,
287295,
93544,
22001,
50686,
200102,
17365,
54396,
377631,
63491,
54223,
382863,
33651,
510904,
15621,
164616,
700259,
56229,
12595,
682324,
66363,
22307,
61153,
219622,
34405,
152292,
35204,
41324,
3866,
null,
null,
23293,
14867,
225537,
420162,
24013,
42097,
395102,
628260,
444712,
182219,
252714,
83635,
null,
23579,
182044,
164069,
46411,
23367,
17003,
45182,
505219,
170732,
36919,
9523,
12728,
353920,
33399,
163462,
159727,
329835,
248846,
18566,
334044,
45682,
378737,
null,
null,
9250,
158486,
429850,
88747,
424713,
33558,
76529,
59633,
223928,
null,
null,
116784,
96137,
25733,
38843,
23798,
359827,
837050,
23554,
5438,
232489,
108356,
57061,
12692,
null,
235928,
33298,
268238,
55268,
216246,
12104,
39451,
41264,
390059,
null,
248802,
39891,
134356,
34850,
241906,
54452,
null,
null,
67074,
99656,
23364,
57716,
18786,
18558,
254167,
508303,
15099,
42709,
52204,
218416,
201365,
284831,
31103,
26580,
28298,
289330,
30516,
75024,
62441,
23750,
345109,
25391,
37884,
174599,
80723,
263497,
32006,
42481,
122410,
14369,
15819,
75854,
195055,
305633,
26105,
15024,
8326,
37079,
29931,
14825,
156125,
7176,
52766,
459814,
27834,
42378,
null,
35308,
57866,
108808,
10453,
228899,
125079,
380459,
169902,
474215,
47204,
22872,
17911,
36032,
56898,
null,
25247,
41791,
45613,
47136,
43756,
null,
28570,
87149,
2954,
154842,
51906,
282206,
250349,
29954,
19677,
null,
184266,
226114,
4363,
2109,
20916,
150385,
113372,
47633,
185319,
null,
101880,
19647,
557647,
180484,
12833,
23113,
26573,
337049,
715277,
288601,
174227,
195204,
149800,
null,
40804,
346838,
196721,
27509,
157140,
20887,
11450,
70772,
144508,
101803,
265892,
43066,
2541,
241144,
30080,
14850,
35572,
9217,
240038,
51451,
93832,
40793,
18790,
30257,
107554,
326661,
68938,
19263,
67982,
100264,
20067,
85496,
318786,
55204,
19353,
38801,
90690,
20434,
null,
22959,
37408,
76245,
394536,
null,
null,
321277,
178098,
null,
217652,
38132,
370254,
22164,
466429,
355403,
13817,
129963,
16042,
47634,
519313,
56426,
237639,
126661,
50928,
216228,
null,
null,
136667,
14416,
436337,
null,
129010,
51534,
320477,
21930,
47816,
164649,
null,
41736,
202577,
null,
48027,
395283,
207601,
132306,
null,
148852,
6732,
34486,
22942,
325237,
64049,
317298,
6569,
17015,
167809,
246622,
237630,
293973,
149443,
null,
140104,
null,
15343,
45486,
28525,
154862,
7818,
18267,
201546,
282850,
320817,
15583,
190675,
null,
null,
7767,
35765,
456167,
294421,
323578,
null,
null,
361649,
25253,
325329,
65694,
26567,
112301,
495406,
323722,
324688,
58025,
105773,
52347,
57020,
198983,
26196,
88517,
null,
47974,
58133,
122595,
9774,
72292,
12025,
null,
138701,
null,
19190,
153455,
8211,
80212,
35767,
59044,
11656,
206765,
112599,
44350,
null,
581040,
113439,
21841,
18219,
40177,
157117,
5592,
253912,
39374,
8456,
309337,
null,
130945,
228493,
589573,
179064,
212144,
68750,
22642,
233740,
230,
52333,
71856,
32205,
168227,
207737,
null,
26692,
null,
16094,
521145,
null,
48839,
16895,
11196,
12369,
383595,
16901,
70814,
80062,
352831,
317179,
15775,
32445,
324248,
119920,
57353,
29133,
141035,
18659,
394025,
344760,
33608,
63479,
null,
4963,
203600,
36763,
233408,
21773,
null,
71773,
153350,
20272,
30768,
null,
25270,
222568,
23117,
30738,
29732,
317,
17699,
27047,
16786,
18009,
115440,
51860,
82042,
21131,
16060,
170860,
32793,
28663,
null,
26532,
359270,
20885,
238916,
4440,
209955,
283781,
null,
226026,
17987,
14068,
182951,
311725,
79019,
20354,
null,
274219,
47470,
366890,
10084,
64226,
270842,
44816,
null,
700335,
25111,
106441,
95715,
168251,
9514,
304999,
null,
80184,
22687,
40053,
181256,
234950,
450425,
226532,
9677,
442966,
82211,
269276,
40672,
713978,
121889,
22156,
197290,
48669,
67116,
null,
16589,
247963,
13131,
30839,
85991,
10910,
89229,
152890,
62186,
44681,
304052,
168557,
381518,
122344,
3501,
40078,
null,
260341,
67107,
11991,
273588,
null,
50287,
29724,
4774,
null,
31029,
223371,
62308,
177211,
154105,
858785,
386183,
203853,
49154,
170266,
84921,
698925,
235565,
177090,
100595,
277180,
252023,
105573,
null,
15336,
29649,
19674,
8197,
244098,
189180,
106174,
253193,
163195,
26746,
35453,
355148,
37318,
26016,
233444,
27619,
null,
160119,
35521,
46960,
23616,
472737,
11759,
160647,
null,
189235,
461421,
117869,
11277,
133375,
38867,
6758,
61316,
23665,
15050,
8779,
33744,
41882,
6140,
142506,
19689,
30677,
21192,
46031,
291510,
21121,
87672,
36143,
46689,
22023,
54793,
52427,
33963,
20862,
42538,
171312,
42167,
182527,
9310,
9042,
67318,
218443,
8350,
27909,
37131,
111453,
15710,
133749,
157219,
31467,
137096,
191038,
509729,
52611,
9999,
null,
null,
380957,
154951,
208146,
52268,
315366,
13535,
88514,
304844,
203881,
252447,
null,
284861,
200548,
159379,
303208,
9122,
110001,
14373,
166494,
360324,
236276,
273598,
206731,
20384,
10257,
null,
43501,
881284,
254064,
92367,
null,
81459,
16595,
290880,
null,
81886,
40323,
null,
null,
null,
46447,
171098,
133112,
null,
100146,
240727,
95160,
258779,
375536,
135566,
129984,
178284,
98777,
83873,
3830,
281791,
170058,
59894,
244675,
55699,
39686,
171410,
33527,
null,
95973,
51692,
60585,
28729,
180726,
null,
89098,
29685,
296981,
216408,
19007,
36366,
148998,
12586,
313656,
267467,
50961,
67987,
44714,
6757,
56010,
29244,
11551,
42894,
77677,
null,
null,
189529,
70604,
27086,
355226,
110279,
118929,
22390,
468978,
110060,
608145,
197716,
264430,
273298,
261161,
77735,
22949,
28701,
348426,
66545,
44231,
317058,
174324,
17265,
18274,
153347,
138256,
320422,
497706,
74505,
11874,
20366,
117720,
80826,
32780,
446419,
411512,
36234,
214265,
null,
34474,
31376,
287160,
38121,
210469,
231508,
156815,
340403,
null,
298482,
20392,
32756,
341918,
202083,
6896,
50602,
60296,
224353,
210702,
55584,
11440,
222689,
185811,
44489,
15545,
71024,
124506,
37280,
57133,
327012,
168171,
25990,
6462,
162854,
32808,
37196,
100756,
61932,
307948,
10051,
303353,
32765,
30052,
null,
35617,
114370,
31667,
null,
7453,
363230,
547924,
168738,
23695,
80610,
203802,
38141,
null,
216987,
52120,
35456,
32168,
32626,
23813,
166813,
17760,
127149,
103297,
94909,
247114,
127836,
366330,
10974,
61121,
238147,
188160,
286799,
null,
144689,
4711,
243520,
37245,
126966,
121945,
318692,
16774,
20903,
12227,
null,
31518,
163631,
51507,
6295,
null,
10733,
167837,
19815,
133048,
445544,
38058,
79229,
77982,
34161,
34264,
null,
null,
64607,
291737,
157819,
12662,
16337,
43942,
9230,
381792,
97117,
null,
6430,
8703,
128675,
39969,
49545,
12090,
251761,
23945,
141423,
91177,
387779,
null,
182793,
395524,
17415,
70371,
189323,
46563,
200962,
327013,
228477,
145860,
231681,
null,
285496,
38290,
26757,
47844,
48872,
286939,
221639,
261916,
315500,
92061,
49005,
102878,
223800,
376696,
30362,
200960,
148786,
392809,
39884,
32120,
121588,
null,
117243,
121821,
null,
177299,
89919,
27087,
38762,
14789,
211358,
null,
26839,
314643,
34648,
25572,
1222,
630413,
201255,
59935,
53428,
47423,
161597,
null,
452029,
99170,
7777,
28775,
126497,
15113,
268198,
40956,
456706,
75015,
430199,
184645,
166607,
null,
115500,
16390,
21075,
23547,
104763,
null,
15896,
19282,
28419,
278993,
null,
148706,
192561,
10198,
40876,
49367,
141678,
21174,
39771,
46218,
101397,
15968,
174808,
27280,
null,
366648,
336779,
9512,
67329,
33998,
242559,
41774,
75163,
164320,
134015,
11646,
244125,
55370,
19479,
40709,
78634,
229631,
323077,
109013,
59204,
9039,
16310,
21123,
244688,
94657,
233616,
192060,
14452,
262230,
16631,
12673,
null,
24989,
450293,
44976,
88775,
58889,
157241,
129037,
136950,
29268,
30004,
21508,
122836,
9323,
229977,
31065,
4047,
22885,
77007,
35059,
90911,
167615,
226511,
23455,
97723,
275042,
288126,
237851,
94448,
30443,
25628,
51451,
23977,
154554,
261121,
206239,
null,
38598,
5557,
395403,
23421,
250645,
61807,
128525,
3911,
13339,
10034,
375408,
183015,
153871,
null,
152217,
7547,
281804,
296249,
183339,
473118,
17652,
50340,
67467,
46020,
562128,
83244,
243216,
null,
32621,
null,
8218,
185988,
null,
30358,
287381,
274768,
32577,
138340,
287212,
175576,
64534,
12746,
81676,
41342,
14301,
51037,
271663,
47518,
49672,
248843,
623194,
25940,
11865,
7523,
36573,
25605,
148972,
259694,
418166,
167103,
153118,
234674,
263483,
170191,
261001,
37188,
12890,
25869,
172602,
242468,
273889,
246708,
23384,
213481,
34897,
27263,
7735,
12725,
6551,
15330,
238500,
97932,
50008,
30470,
null,
19702,
352395,
54490,
25139,
428703,
75059,
65457,
224978,
5520,
191855,
22343,
681608,
20057,
42096,
12042,
null,
36112,
361079,
12786,
262841,
385336,
73869,
75725,
43821,
228232,
69927,
5612,
10241,
18801,
351956,
24272,
158349,
43837,
null,
42458,
87772,
29588,
94722,
43051,
276766,
3437,
185578,
56060,
18349,
15719,
20686,
153891,
102644,
11390,
32603,
330956,
228255,
288558,
18392,
40336,
452932,
42322,
34830,
60447,
222635,
21677,
48848,
16599,
441397,
null,
178997,
238339,
39543,
105549,
49509,
59987,
null,
51334,
443653,
10357,
null,
32679,
64429,
33407,
341273,
42628,
62971,
235866,
101328,
13341,
12847,
null,
119699,
13818,
95426,
25857,
274663,
455124,
72282,
null,
159687,
7651,
245518,
304575,
87193,
40535,
520616,
23801,
121580,
132441,
262091,
10874,
23967,
231135,
54610,
17868,
277838,
25000,
74303,
72939,
237291,
15130,
250944,
10303,
207551,
50054,
null,
4416,
164877,
124397,
152691,
5904,
210248,
327698,
42251,
null,
34912,
21719,
72473,
70498,
28252,
210346,
228982,
103067,
317278,
null,
123550,
41682,
230758,
45183,
42112,
null,
239767,
188331,
30437,
61595,
100190,
7310,
137697,
88737,
108362,
35932,
180397,
35912,
71965,
163461,
36037,
57901,
90443,
281718,
59289,
57781,
40484,
33815,
20125,
21284,
10538,
7757,
15411,
27268,
137604,
null,
26741,
1129334,
262982,
38524,
369920,
null,
37500,
5023,
76575,
16938,
198515,
9271,
null,
307296,
184898,
218254,
92062,
358098,
10370,
506712,
259518,
168680,
700404,
505059,
15470,
14341,
517267,
null,
46422,
66246,
66727,
9567,
45771,
62004,
319170,
null,
76340,
93916,
148466,
14885,
138297,
364396,
50189,
242255,
765722,
60425,
38471,
142025,
50667,
79143,
299587,
86433,
298272,
7937,
326010,
12773,
41695,
35982,
251956,
31281,
198937,
99325,
55374,
484084,
222942,
444291,
9035,
35799,
null,
24256,
74699,
45702,
92245,
135609,
150256,
57081,
788,
615520,
73783,
127969,
286260,
172189,
144988,
144573,
7728,
13362,
2875,
165572,
155781,
176929,
9424,
10132,
110095,
18923,
380239,
15662,
19653,
480668,
201901,
37602,
17227,
6726,
141510,
565945,
null,
null,
248586,
190317,
103789,
370437,
4610,
290175,
399850,
14516,
205382,
232084,
194269,
33274,
449655,
241822,
20593,
212180,
16598,
38866,
338615,
7339,
43735,
283227,
null,
171488,
95911,
46126,
175801,
755824,
22944,
268878,
242181,
32310,
395591,
7003,
17744,
6248,
93381,
29378,
98004,
136550,
null,
55277,
28093,
78014,
212759,
null,
30592,
152351,
280902,
402386,
11854,
295927,
268095,
19194,
485174,
3787,
null,
58427,
8958,
842373,
682583,
18600,
85456,
39333,
217625,
11962,
344361,
365571,
137886,
43870,
36619,
8897,
21809,
195801,
120059,
27681,
261425,
67478,
230850,
243071,
119439,
188065,
161012,
37972,
186727,
45099,
41639,
null,
25780,
257267,
8582,
47367,
131286,
4842,
101523,
58227,
160245,
28926,
38075,
8267,
13032,
298065,
209523,
191743,
523793,
49092,
60698,
21396,
55341,
227995,
84688,
108220,
12705,
4783,
8546,
110448,
335454,
177502,
260484,
45286,
495453,
null,
203051,
18800,
10794,
115344,
null,
200551,
20257,
64260,
30404,
null,
33499,
23095,
25814,
39699,
98542,
408823,
46177,
65024,
11679,
48703,
200308,
157899,
255241,
219469,
5509,
182621,
172640,
50039,
32489,
973217,
24973,
108526,
133755,
9801,
null,
28702,
104919,
null,
247618,
445684,
997,
216487,
8703,
202870,
261783,
14676,
58231,
201465,
203186,
231188,
300517,
171003,
null,
null,
317951,
232088,
15295,
248283,
13201,
null,
201262,
495019,
2497,
17837,
117945,
343121,
11519,
63731,
null,
149091,
185647,
171357,
29728,
363696,
535445,
121919,
31907,
196187,
316147,
51516,
30676,
65422,
26717,
null,
65516,
38868,
58884,
9765,
37944,
194833,
321334,
254191,
43642,
281487,
38097,
11789,
391145,
16537,
53485,
41361,
16479,
60532,
28483,
666487,
721173,
19436,
654435,
214773,
null,
9730,
147706,
304110,
157476,
70089,
86895,
163459,
101418,
288962,
248241,
76691,
158585,
85087,
35401,
264271,
93073,
173282,
251864,
152262,
334399,
60097,
81565,
173911,
44293,
222696,
277707,
38716,
32995,
286395,
220290,
436161,
262294,
214562,
null,
153404,
79041,
56497,
277947,
null,
null,
217189,
107148,
84997,
8014,
24945,
416119,
null,
52498,
27000,
80905,
383036,
51014,
13952,
22158,
41508,
22931,
162842,
4875,
35469,
31594,
6421,
null,
132197,
27630,
26979,
649842,
7332,
138315,
223592,
182213,
15016,
224407,
464777,
844206,
null,
42827,
150487,
40646,
103329,
365195,
62028,
45572,
8666,
39377,
214054,
144527,
449165,
315345,
null,
15843,
null,
26035,
83914,
442978,
239828,
93117,
261054,
null,
null,
419361,
27931,
77500,
11411,
118858,
361108,
40855,
359356,
23666,
135711,
20508,
192189,
565490,
13170,
220176,
null,
264508,
6661,
69612,
288158,
null,
30920,
23991,
571504,
319548,
126371,
420353,
88923,
18568,
285359,
615394,
11319,
292365,
21735,
231668,
38911,
27659,
65767,
310163,
null,
13274,
34534,
105285,
40070,
null,
null,
9276,
319056,
418911,
221874,
220866,
199442,
13118,
29554,
12730,
138179,
24919,
257196,
178175,
null,
661566,
593463,
46909,
242831,
15101,
238708,
9873,
6745,
107442,
333885,
53881,
237093,
50080,
43389,
7571,
210032,
379762,
130492,
7263,
23903,
13876,
95636,
30773,
null,
64648,
24153,
199273,
24954,
227899,
94817,
null,
124189,
21030,
25492,
null,
21436,
231038,
29084,
255357,
41642,
13279,
13319,
327848,
8231,
135044,
26457,
11152,
42130,
29661,
142926,
249993,
26727,
215866,
750819,
26489,
496511,
280964,
463096,
76770,
143847,
17533,
154217,
154150,
10864,
494645,
245244,
47924,
322629,
null,
null,
56838,
278266,
17203,
278717,
292001,
218786,
17580,
27207,
361921,
null,
null,
397172,
241539,
null,
53926,
15784,
184638,
20894,
null,
439141,
64674,
22004,
31647,
278694,
68785,
301142,
8812,
71031,
212217,
45240,
511891,
21862,
303126,
null,
2774,
16401,
275783,
108483,
239090,
39315,
420297,
8104,
9764,
94417,
31236,
90415,
11296,
60854,
149992,
237109,
378899,
455206,
93181,
32064,
49110,
51659,
43360,
25703,
14887,
70057,
64436,
35827,
20071,
209616,
23214,
533284,
72950,
89626,
16495,
122960,
35355,
35945,
9817,
272351,
311992,
null,
204657,
14872,
18897,
48807,
31110,
116300,
5878,
263277,
14587,
412215,
392728,
15207,
null,
452387,
72791,
46934,
31977,
12160,
124167,
34926,
null,
181235,
23697,
182876,
145264,
10313,
8554,
26328,
332763,
44757,
66268,
195479,
145291,
195339,
192241,
225304,
113010,
168196,
null,
42051,
null,
22513,
61497,
50868,
null,
20504,
36249,
43305,
41045,
10272,
67376,
89611,
50486,
260421,
3155,
16413,
312735,
565901,
359168,
34718,
59529,
32275,
27889,
197809,
266503,
164050,
189483,
85209,
15433,
70481,
113714,
61705,
344905,
2742,
21394,
82088,
161722,
8411,
186057,
120662,
87176,
6372,
22269,
221400,
337014,
2517,
185538,
null,
22572,
123176,
683135,
46297,
356243,
214215,
286501,
305605,
10696,
28771,
432809,
223269,
9973,
197343,
7721,
21026,
63363,
50690,
27028,
251782,
53688,
57757,
425194,
16020,
134436,
51739,
346762,
5283,
9200,
250982,
48176,
58118,
null,
301936,
37459,
32709,
202911,
20564,
null,
144848,
75736,
355605,
126306,
38836,
305384,
49908,
151456,
127372,
36581,
386598,
74387,
34176,
20202,
181780,
100524,
83267,
308829,
558756,
null,
2685,
77434,
43568,
62837,
null,
180229,
119099,
75423,
203501,
294463,
null,
119872,
155460,
109073,
226455,
12201,
null,
4965,
2874,
null,
16772,
679058,
208574,
51000,
55929,
244083,
72274,
370597,
81185,
68511,
null,
158341,
26316,
90313,
423768,
337493,
34058,
111269,
476005,
1779,
333593,
146950,
null,
null,
216169,
null,
307236,
83955,
75229,
63029,
23401,
196087,
220118,
317801,
114692,
24778,
36627,
248611,
8845,
56589,
635168,
115604,
5902,
12631,
240063,
53953,
70143,
871810,
184560,
22583,
92341,
40990,
47466,
101541,
46526,
681502,
51487,
15722,
143764,
null,
20395,
280496,
21663,
21831,
265515,
66345,
262134,
null,
152953,
197623,
73535,
480530,
13101,
50307,
59436,
215291,
107027,
27343,
53049,
220236,
null,
65941,
7228,
299283,
283355,
211827,
37323,
50208,
61429,
26115,
67756,
57091,
5056,
374227,
186433,
56847,
227977,
196791,
411817,
7675,
18526,
108505,
34273,
289650,
33509,
null,
206529,
178006,
63266,
29199,
55224,
206288,
78318,
11593,
175062,
146703,
180637,
382424,
175367,
205502,
59945,
null,
308757,
291042,
37746,
89734,
149716,
60019,
null,
84928,
303863,
182502,
78836,
148740,
22918,
12694,
160462,
null,
441758,
27605,
209916,
11975,
176216,
7241,
53940,
22538,
59493,
39092,
163169,
5177,
161076,
44797,
40090,
39865,
32484,
282509,
273474,
147765,
231776,
362966,
20758,
206870,
null,
13302,
203131,
34283,
70637,
27163,
209287,
284906,
21327,
250039,
39940,
267029,
69113,
579717,
171851,
169536,
30747,
238868,
43101,
83151,
163701,
null,
271196,
37695,
44899,
56197,
null,
24124,
101174,
71091,
17146,
118646,
366913,
9362,
81034,
152900,
196841,
169536,
23843,
337411,
17545,
151038,
56399,
null,
28891,
null,
466108,
162884,
144195,
357099,
483569,
429429,
280368,
16911,
283323,
429401,
241121,
157982,
23402,
52897,
155677,
1303550,
205158,
6325,
22160,
null,
230352,
50164,
null,
13008,
12492,
null,
149028,
16385,
67640,
47408,
183563,
19317,
86302,
105118,
46993,
57718,
324305,
113176,
22401,
12889,
9799,
14908,
356531,
99456,
306559,
null,
205826,
195121,
29752,
16946,
null,
184672,
123769,
266251,
36134,
241562,
356443,
28356,
191752,
73199,
315766,
187180,
12601,
395174,
290204,
229351,
368347,
171543,
422643,
49340,
50410,
123461,
33184,
318684,
247991,
105867,
248324,
50344,
null,
360372,
141264,
11140,
42544,
148960,
157916,
216870,
42995,
113705,
106962,
686314,
18320,
112280,
428294,
25170,
33574,
17592,
324773,
9297,
21195,
20798,
46261,
77067,
35601,
39562,
62716,
13790,
1185111,
62665,
null,
28523,
392977,
52916,
89758,
108886,
654558,
111956,
90083,
342468,
23812,
179994,
null,
30763,
8828,
84942,
null,
26063,
34550,
26854,
198277,
42073,
17338,
94365,
342639,
16862,
61278,
225690,
183355,
24959,
15625,
248415,
null,
36093,
18976,
44479,
277022,
185807,
103479,
126653,
149551,
257072,
5470,
242897,
13296,
136748,
90740,
896,
55751,
null,
159586,
210143,
9302,
null,
12546,
11337,
37935,
77073,
106771,
301737,
79005,
12664,
null,
27669,
223573,
57145,
141420,
11940,
148425,
15594,
326276,
118870,
324090,
77723,
3787,
32014,
244301,
61870,
355299,
777538,
116218,
51563,
237762,
null,
14962,
37440,
426357,
74923,
31417,
89794,
5419,
249636,
51704,
46065,
136103,
493003,
null,
1138025,
199249,
743793,
4068,
114900,
28827,
374269,
null,
486949,
352172,
38212,
368266,
21453,
112755,
8286,
34944,
9065,
104567,
89969,
54424,
51046,
549117,
368478,
399963,
6839,
587999,
478988,
14254,
21303,
134980,
null,
180287,
26693,
15004,
36071,
null,
34357,
21152,
24516,
24227,
177721,
221533,
24471,
40430,
null,
30251,
250851,
10981,
30614,
null,
169388,
272055,
33966,
281040,
357571,
22218,
77055,
48059,
7496,
124446,
23197,
16693,
125407,
41581,
57515,
null,
52994,
254983,
10525,
71478,
22880,
378395,
7275,
28558,
42032,
56142,
85401,
null,
373996,
76000,
557765,
500570,
135564,
47306,
148092,
17568,
21033,
273586,
46391,
45467,
59064,
40003,
83011,
266153,
25826,
93964,
52846,
36808,
168084,
14198,
83520,
40490,
74350,
39166,
216805,
25062,
62153,
11619,
173563,
22978,
53292,
13181,
37905,
41145,
279232,
254,
401733,
331213,
28626,
35875,
133833,
25452,
10211,
411201,
29900,
4574,
18486,
null,
null,
17281,
25368,
84114,
37857,
15500,
49634,
null,
184696,
null,
57667,
null,
236856,
63815,
382827,
37507,
39985,
278572,
285425,
null,
32768,
246091,
143453,
81087,
20688,
23077,
118071,
144074,
29445,
47078,
361072,
10769,
52410,
24681,
291480,
123790,
167027,
256465,
5430,
11097,
null,
10632,
80877,
386023,
762669,
211839,
136167,
59409,
285220,
null,
40451,
86901,
50191,
22520,
57391,
134190,
38126,
169521,
132807,
101215,
345545,
18977,
122134,
140002,
null,
194161,
42502,
22163,
335894,
9207,
8827,
75692,
2992,
208619,
471138,
76550,
274646,
16616,
35483,
347481,
22760,
114346,
null,
57152,
1324144,
96643,
15818,
401540,
2198,
106801,
69846,
null,
248736,
321502,
29701,
27932,
18422,
62882,
298651,
null,
17585,
20136,
null,
2696,
null,
4942,
329230,
31429,
9465,
335258,
151748,
143852,
310911,
76344,
46898,
180443,
226681,
14838,
37296,
null,
125856,
105977,
28446,
28600,
6385,
243729,
167127,
38074,
156036,
18026,
35311,
469226,
78211,
40242,
42714,
21692,
6890,
410045,
53681,
57888,
129556,
87627,
67192,
null,
26055,
41569,
172272,
49937,
24958,
37416,
51445,
36770,
85212,
8980,
82481,
55852,
37648,
9249,
45140,
95440,
20021,
61514,
78421,
29671,
124328,
208212,
41666,
68280,
1765,
400396,
12006,
22784,
19142,
310538,
49435,
121852,
161945,
40383,
133823,
202866,
313342,
24165,
null,
null,
74840,
257096,
195530,
52998,
83230,
17201,
136235,
121492,
20394,
131119,
187251,
216613,
161602,
330058,
467725,
205601,
49280,
415294,
3941,
47697,
60299,
180897,
171289,
494724,
36640,
202559,
null,
19403,
28351,
469010,
null,
384325,
39104,
136875,
37367,
null,
26385,
74404,
180373,
359644,
8303,
212118,
229791,
15267,
327089,
323120,
344980,
20264,
245305,
133362,
10097,
35301,
4906,
33388,
5170,
null,
519576,
26626,
12277,
64193,
605383,
209464,
393851,
67401,
339847,
21544,
101760,
8451,
null,
null,
9722,
25817,
63335,
22453,
null,
36864,
251800,
868745,
197718,
52162,
16740,
12961,
40627,
148577,
18160,
61877,
152497,
72594,
22480,
353991,
196423,
34669,
38053,
230437,
37548,
276802,
101069,
467152,
104207,
365775,
219167,
68242,
554371,
22781,
116286,
197640,
29999,
180235,
254137,
2506,
73571,
11488,
72757,
22723,
207704,
null,
106480,
309719,
329915,
12818,
null,
98342,
81820,
20975,
null,
42418,
59991,
143713,
34641,
80538,
null,
null,
132950,
47558,
166156,
40927,
297412,
10407,
null,
27012,
22309,
72737,
null,
6373,
145422,
36971,
15380,
null,
207639,
281609,
null,
45297,
424695,
null,
3281,
90182,
33719,
402745,
363035,
40012,
321103,
362590,
22040,
null,
38665,
390496,
84282,
173797,
19761,
372912,
18133,
57719,
412635,
56766,
12183,
224543,
140526,
10276,
57272,
200342,
20122,
64697,
37194,
81735,
null,
217172,
69535,
39674,
null,
43777,
6255,
12002,
187650,
18152,
29615,
38838,
108623,
66707,
42976,
83656,
82270,
59557,
168044,
58948,
null,
182362,
150790,
40243,
22566,
184622,
179325,
34283,
104583,
16526,
10049,
333665,
176825,
77034,
210538,
33100,
203404,
23931,
null,
42599,
13017,
69492,
220339,
316403,
11975,
167741,
72759,
25669,
283279,
45600,
232366,
46166,
null,
51733,
82977,
191272,
172732,
192677,
null,
null,
229375,
30879,
145280,
null,
19567,
489776,
26571,
63106,
31172,
256195,
96145,
15521,
25455,
105673,
19383,
548340,
32251,
116652,
194294,
652224,
252059,
null,
61239,
12539,
19597,
373352,
161705,
258419,
20716,
46437,
167694,
56251,
137171,
28716,
24485,
22682,
420207,
76754,
40685,
174112,
53867,
391102,
45256,
29494,
25799,
240610,
37314,
62145,
214825,
11414,
44218,
36777,
null,
14572,
null,
133165,
10481,
15970,
28661,
34069,
303004,
135276,
265187,
44618,
6613,
31416,
36082,
40401,
281431,
26185,
138096,
41405,
54349,
203538,
43160,
210219,
null,
149729,
18891,
19225,
512315,
414452,
382804,
53414,
212627,
227261,
13352,
21380,
158812,
34035,
162217,
14860,
17821,
26463,
496248,
47239,
47794,
51321,
66917,
104750,
105889,
103750,
116337,
227619,
null,
17145,
44932,
23283,
28383,
135914,
70579,
9034,
null,
182852,
247800,
276501,
267258,
130319,
535811,
3451,
null,
58984,
10502,
82380,
62243,
12458,
373658,
143687,
17357,
100930,
466640,
153379,
32902,
14541,
50686,
200748,
168085,
72691,
35653,
80231,
null,
8448,
348046,
null,
null,
54817,
31698,
15760,
367343,
35431,
60513,
29631,
131236,
274126,
154856,
14634,
null,
20681,
null,
99655,
45243,
265511,
46569,
51461,
207705,
38144,
215884,
25660,
139920,
372967,
421722,
267022,
null,
317784,
181919,
26674,
17556,
274407,
28977,
404894,
14066,
80276,
24897,
null,
43117,
290484,
229424,
139521,
87883,
430246,
32437,
302444,
54785,
8586,
597521,
360227,
243992,
156284,
23238,
23355,
195012,
33101,
123424,
144300,
407029,
21534,
18718,
273485,
177717,
351838,
119299,
150589,
46484,
103532,
221732,
null,
40053,
null,
34047,
212124,
76092,
null,
37959,
43719,
105063,
230479,
null,
35528,
77743,
129918,
94577,
26801,
null,
62790,
23156,
77335,
99579,
46008,
31794,
68888,
279792,
272070,
7918,
423888,
30368,
119102,
null,
5394,
40165,
null,
295273,
9676,
11238,
374972,
41038,
30966,
196474,
5475,
124871,
null,
119163,
48724,
45629,
null,
188299,
57913,
61512,
43335,
52572,
285891,
312974,
91551,
145756,
242413,
784180,
51057,
null,
12636,
761166,
354545,
21171,
276730,
154399,
32149,
32038,
null,
15603,
203600,
47087,
33850,
33003,
87562,
null,
42681,
68261,
464338,
202637,
24107,
174047,
24347,
197533,
null,
572554,
187162,
135691,
33652,
127578,
51949,
325276,
138350,
29579,
170673,
376499,
54924,
324379,
116204,
158676,
296755,
245302,
201069,
181678,
133018,
92462,
49210,
null,
null,
204980,
null,
87303,
15364,
217086,
21935,
252067,
127264,
25728,
4412,
null,
264015,
16457,
444520,
171923,
154494,
292185,
135842,
22985,
72707,
16728,
305889,
13291,
22686,
11361,
17900,
283109,
43600,
164682,
43051,
27305,
50271,
34539,
23319,
2590,
244645,
44913,
79752,
20515,
93848,
154709,
110513,
37840,
16992,
232889,
257611,
null,
43001,
14068,
5114,
11312,
395394,
139934,
40488,
61015,
174726,
57137,
37227,
147426,
142640,
40068,
185017,
null,
82446,
15799,
219633,
16634,
7496,
15933,
31103,
null,
70115,
66364,
266127,
127426,
170860,
20896,
16120,
13712,
167848,
null,
181841,
10170,
266174,
294854,
16028,
234421,
null,
312778,
3960,
4350,
40231,
null,
146248,
35542,
63086,
118909,
148283,
156381,
544717,
142695,
15280,
138875,
39670,
328423,
null,
12813,
46826,
282619,
14294,
139361,
42197,
434955,
182280,
172947,
838923,
182375,
217972,
null,
15500,
103056,
166506,
181571,
132021,
54894,
230261,
null,
48519,
103478,
60975,
22933,
19270,
31309,
116460,
152864,
70492,
25399,
null,
null,
7277,
169033,
28399,
5239,
417075,
21976,
312627,
2343,
523468,
null,
18551,
110602,
170511,
35084,
65251,
122401,
155553,
22712,
133863,
335161,
452226,
256007,
31464,
12102,
214466,
103866,
20362,
6593,
306291,
81844,
51027,
718207,
125838,
96055,
52530,
116087,
42711,
215262,
203456,
189978,
148158,
199230,
24985,
184616,
5351,
246394,
112205,
7954,
36113,
28813,
21784,
264092,
57457,
195098,
40387,
null,
38617,
48036,
153981,
20254,
34450,
84442,
31042,
272590,
108610,
211553,
null,
null,
36783,
212392,
90713,
37945,
null,
28771,
185260,
276223,
285215,
14868,
573271,
407791,
null,
28668,
18871,
36911,
32355,
null,
53352,
70532,
264240,
35102,
232648,
237757,
68555,
296589,
54629,
18604,
338962,
27565,
308065,
29493,
91397,
53284,
14848,
195041,
41107,
215582,
84923,
119945,
233795,
108108,
61544,
147096,
135825,
2756,
4378,
186168,
216707,
279089,
79811,
47022,
null,
12978,
27261,
157121,
371229,
376591,
214587,
153753,
93217,
82806,
67831,
228415,
95732,
119862,
null,
104490,
76882,
644798,
8029,
47862,
91826,
59515,
375393,
null,
42444,
55168,
43188,
227910,
null,
33221,
275647,
56415,
8132,
109974,
2766,
92767,
75094,
168492,
263899,
48369,
36973,
266416,
null,
11781,
92783,
11995,
337839,
217058,
49563,
61646,
null,
114413,
178464,
259353,
null,
125035,
86303,
235061,
165720,
270294,
190794,
28052,
79849,
36431,
13814,
74003,
160351,
188995,
53929,
56173,
439241,
22260,
47830,
142017,
171087,
23570,
6606,
134512,
160703,
452383,
14822,
10065,
38863,
350537,
25521,
null,
108855,
58568,
115662,
80373,
23393,
17803,
null,
294289,
89186,
184335,
55824,
20594,
26525,
100149,
null,
null,
159942,
178145,
35315,
266454,
23616,
23469,
113299,
18479,
43820,
3960,
155591,
8990,
327561,
null,
37495,
23709,
27923,
14491,
323604,
145716,
18568,
55464,
62890,
3858,
47397,
511075,
40601,
null,
142538,
177632,
94396,
292952,
272097,
42920,
82587,
217323,
514077,
489229,
669993,
61931,
237945,
27271,
36877,
53257,
219511,
445265,
40380,
56528,
108174,
null,
427265,
26177,
59147,
157037,
264150,
12129,
49699,
245164,
150547,
null,
161833,
7758,
27639,
426234,
6051,
60161,
38921,
167188,
49311,
28882,
204112,
106893,
33168,
39807,
63301,
338195,
19446,
15045,
29920,
85944,
18197,
180688,
25240,
219648,
8468,
34380,
134604,
15552,
14994,
28013,
37937,
38152,
24351,
63856,
161341,
9270,
150692,
35653,
20350,
228458,
35690,
15827,
60083,
199056,
102882,
231815,
39113,
null,
353974,
106803,
22139,
165047,
145876,
null,
430466,
78557,
550651,
62657,
4680,
106793,
9976,
47704,
794972,
33434,
39874,
43380,
2267,
1354,
null,
20717,
36623,
58521,
19157,
8026,
60272,
null,
325074,
8731,
24054,
33977,
137400,
90476,
304275,
248169,
7619,
38281,
18165,
354538,
10199,
211417,
25812,
null,
null,
129448,
15776,
589189,
345724,
10719,
374451,
182268,
18487,
273886,
43136,
47307,
49170,
89346,
null,
43916,
9596,
57316,
40772,
16402,
36977,
100970,
213143,
39918,
null,
26096,
32087,
154983,
120185,
31544,
136857,
52634,
22584,
11138,
229670,
122375,
199842,
245651,
212386,
24679,
40524,
257485,
61135,
23194,
39338,
328910,
182708,
5931,
21915,
86063,
28632,
187513,
222444,
4790,
55932,
5086,
38241,
36754,
97266,
223741,
208217,
183980,
47787,
88594,
19101,
178193,
null,
null,
25160,
230102,
55493,
47286,
30147,
18833,
114723,
617190,
67099,
57401,
17709,
374307,
148878,
51755,
304482,
41161,
null,
382364,
175775,
45427,
35118,
null,
55296,
92576,
67519,
null,
25502,
57239,
71702,
32073,
85377,
101369,
339686,
36630,
63173,
21232,
227665,
40182,
288180,
28492,
175138,
243359,
85407,
101772,
213316,
166156,
22537,
51333,
340530,
21134,
19492,
851,
452478,
208300,
77259,
41764,
61304,
51734,
180267,
210969,
61567,
66120,
null,
63540,
44534,
266211,
151677,
142178,
101007,
null,
null,
132369,
334769,
238828,
279480,
10938,
18100,
null,
null,
120220,
41048,
137003,
258245,
55519,
23476,
156982,
21471,
361007,
243872,
389466,
127074,
9307,
57148,
343092,
157173,
91392,
215836,
28681,
19090,
45630,
102855,
31079,
161664,
15328,
372436,
60335,
1748,
18667,
15301,
null,
241978,
419159,
11649,
49430,
423286,
101915,
343009,
150692,
468481,
33350,
2128,
246146,
4759,
350087,
258917,
20139,
232041,
21405,
135049,
246913,
59785,
171098,
6618,
167699,
101926,
65389,
56417,
267220,
2154,
9912,
322827,
354223,
702988,
129776,
93822,
363823,
39099,
104913,
285269,
90836,
105724,
388668,
13095,
335433,
81630,
185775,
69112,
175361,
49926,
21618,
5627,
241547,
16655,
26732,
24061,
null,
227866,
176474,
10572,
260655,
39859,
32467,
24315,
410659,
37614,
10007,
93626,
35476,
40877,
48591,
29908,
232585,
81625,
12631,
217310,
14823,
89259,
34932,
395137,
20479,
596462,
118853,
23420,
198510,
411853,
99893,
72409,
238518,
null,
8459,
null,
16216,
294931,
126730,
119184,
null,
259438,
66428,
29811,
65220,
145769,
122511,
217770,
251088,
82872,
81720,
367886,
1109282,
143976,
19933,
50886,
359680,
31316,
9239,
129166,
154711,
104966,
230932,
161549,
null,
249002,
18847,
59765,
216415,
152502,
41484,
205229,
28284,
30956,
122972,
null,
39876,
94759,
null,
400455,
1650,
37746,
3929,
104130,
12189,
17273,
37371,
12929,
9849,
13473,
12772,
39280,
6439,
10938,
27631,
64524,
98343,
264471,
190103,
1871,
145512,
103533,
7802,
30491,
25908,
22986,
179426,
197797,
31165,
45002,
38216,
30199,
498181,
109755,
26676,
104474,
null,
16521,
24966,
null,
126193,
22740,
250765,
145106,
233836,
48069,
199675,
226577,
286079,
390490,
14358,
421626,
34172,
243350,
23181,
390637,
145238,
70730,
14747,
29234,
213351,
81180,
129282,
157285,
98442,
757512,
26088,
193782,
47021,
404184,
22133,
560749,
104162,
12629,
164156,
29769,
null,
172314,
null,
19134,
42935,
244142,
null,
null,
10849,
49293,
22140,
52032,
557664,
237733,
67850,
null,
12327,
32811,
6557,
87377,
95021,
262870,
null,
69606,
16723,
86943,
53810,
42442,
59912,
134638,
null,
13832,
199775,
73725,
38181,
38550,
null,
144177,
7432,
13169,
98288,
305687,
257157,
33206,
42995,
25387,
83429,
206210,
599703,
101815,
408925,
203869,
166177,
195397,
290499,
28247,
9337,
29128,
4965,
26598,
null,
116256,
152393,
27165,
94314,
11040,
27177,
129879,
54627,
140837,
403401,
362492,
41220,
null,
53398,
null,
13026,
202711,
191386,
47204,
23843,
48397,
384853,
558153,
62019,
172041,
62589,
49258,
24354,
326154,
37141,
30410,
489486,
242241,
null,
31119,
31433,
31560,
68678,
382431,
102498,
33648,
44244,
120417,
8419,
46146,
123482,
28910,
344147,
31264,
225026,
455643,
94311,
276391,
17883,
72993,
243176,
47090,
151624,
61365,
51025,
249876,
null,
29861,
5467,
228187,
260323,
48395,
113949,
34694,
294518,
103377,
170461,
125724,
32662,
null,
null,
null,
480820,
19090,
125598,
129845,
345206,
24500,
42252,
87237,
4217,
46358,
315743,
667844,
146148,
300606,
82351,
36099,
134679,
394592,
9703,
28686,
289711,
10401,
112458,
132337,
633392,
9166,
46374,
27525,
324759,
166799,
61998,
257788,
28099,
43916,
232257,
192577,
null,
288015,
90875,
577958,
193877,
171269,
8839,
47860,
null,
null,
283490,
206668,
253546,
310027,
316733,
22123,
27312,
165937,
27985,
12241,
119559,
9687,
10385,
368451,
250132,
111592,
17318,
41033,
49746,
91395,
28103,
7558,
13546,
228666,
32645,
163058,
7476,
129583,
439554,
101205,
45764,
172525,
496303,
308402,
539352,
75001,
107960,
192275,
109587,
146241,
32010,
33536,
55177,
103643,
259049,
299782,
12357,
6177,
103706,
134375,
28941,
284613,
61425,
null,
110740,
79607,
324627,
6282,
70482,
145339,
294544,
43678,
31965,
24183,
138034,
null,
150170,
null,
99875,
null,
50760,
null,
37727,
214927,
null,
242249,
167067,
65941,
256015,
273089,
40654,
193638,
129108,
24122,
67171,
8825,
46013,
76623,
32889,
133508,
42193,
15504,
31642,
254787,
62646,
32445,
null,
21455,
23085,
443714,
4741,
10807,
232084,
27795,
314823,
382897,
280057,
294739,
23006,
45887,
39032,
20456,
50632,
5694,
null,
50938,
89784,
100412,
399184,
9413,
324750,
21904,
null,
null,
null,
73145,
45991,
98601,
3334,
445091,
78765,
220645,
24136,
12792,
28726,
136161,
87510,
32392,
122213,
170885,
160462,
27963,
84534,
36073,
110944,
null,
null,
54367,
393670,
112020,
25702,
24875,
336879,
27881,
80761,
638994,
null,
10932,
165307,
21247,
355594,
157379,
565525,
233913,
342285,
41182,
115611,
173180,
317877,
33128,
51226,
null,
21938,
53021,
20935,
37219,
22116,
21007,
169566,
168623,
275219,
236210,
147285,
38394,
87914,
224048,
33149,
47033,
251087,
47841,
319599,
null,
41815,
117440,
21809,
50935,
37339,
263624,
28175,
273306,
59566,
103298,
37699,
74531,
97493,
73438,
20548,
232542,
14940,
13288,
239343,
24644,
220887,
129540,
242458,
33004,
11075,
94130,
105579,
32157,
16280,
25461,
16718,
109524,
24117,
628255,
127702,
163996,
17219,
81158,
17501,
163875,
8746,
23846,
168293,
151782,
88708,
26824,
null,
84888,
331540,
38561,
9100,
65282,
53240,
210192,
84320,
117446,
75247,
34124,
37607,
1016110,
352733,
243946,
31829,
21264,
160546,
129981,
150861,
61562,
32212,
62017,
36086,
40068,
320032,
305310,
292127,
58964,
22779,
12351,
88824,
59683,
37645,
120383,
37140,
129863,
53253,
244955,
246206,
241162,
240494,
515008,
null,
null,
35327,
87932,
510307,
4574,
403987,
37204,
35060,
659031,
162220,
null,
376156,
460761,
144337,
50416,
104766,
15015,
124231,
208403,
85668,
36826,
392016,
77696,
41339,
38759,
81270,
258360,
94724,
353272,
313976,
3905,
170564,
42570,
34334,
477263,
387067,
369910,
164799,
64561,
166944,
61176,
null,
39090,
35104,
433317,
31693,
33367,
184481,
32390,
8243,
152500,
25244,
91814,
34065,
null,
15411,
31366,
132016,
43250,
null,
8748,
19839,
18157,
56561,
9367,
35721,
198339,
16908,
43800,
12568,
56998,
440538,
23668,
211617,
94445,
56766,
60405,
164576,
26437,
177024,
393795,
17328,
841207,
24771,
42267,
48610,
null,
6181,
22362,
428362,
28709,
5183,
65116,
43701,
88073,
32439,
13722,
12409,
null,
376827,
268532,
33726,
20750,
141312,
11684,
34036,
null,
44161,
null,
null,
72602,
128612,
346701,
113163,
59009,
7246,
219225,
128363,
143292,
497119,
133306,
273565,
243642,
45478,
26884,
32998,
223564,
134088,
null,
23483,
191376,
18004,
257945,
31196,
3174,
46751,
93647,
32182,
270656,
27511,
39718,
474076,
62108,
459844,
217276,
115669,
208470,
157017,
59708,
97692,
96937,
14707,
455055,
315999,
24205,
null,
141495,
37675,
137542,
22682,
17444,
69388,
14669,
19664,
33035,
71514,
147092,
359718,
15661,
18355,
366635,
90875,
178426,
41226,
24613,
5290,
138736,
19860,
98050,
265886,
33956,
13587,
86462,
36300,
38308,
null,
18688,
68869,
33995,
null,
28975,
null,
30940,
null,
42886,
26672,
33640,
274623,
24803,
71567,
86171,
185106,
28146,
14746,
null,
50206,
75599,
477484,
null,
23734,
42396,
null,
182096,
151308,
349829,
206107,
183682,
13656,
34183,
200688,
222637,
263503,
359896,
268831,
260302,
9396,
52467,
394383,
209224,
467037,
407811,
79197,
332671,
54690,
28049,
15060,
18363,
24078,
32289,
89357,
96809,
435274,
125135,
197018,
341353,
17411,
6747,
55807,
73300,
232199,
44978,
null,
242690,
32549,
119165,
410617,
31125,
364316,
42462,
27817,
433703,
null,
482470,
191798,
56483,
138490,
20335,
191356,
123345,
41660,
25828,
264703,
51880,
82395,
2722,
30200,
77060,
14306,
318320,
44207,
1870,
22994,
39287,
58464,
265873,
37643,
117297,
361688,
null,
21996,
76596,
41103,
264887,
211012,
11942,
208868,
9077,
null,
3124,
87891,
108601,
455321,
70243,
28362,
209543,
416882,
21728,
28230,
22343,
129863,
46000,
144963,
248109,
319611,
154488,
461213,
17007,
164462,
null,
161439,
21123,
132540,
41397,
null,
549802,
null,
18532,
176069,
521954,
105471,
46985,
158692,
20689,
null,
272222,
316631,
89080,
null,
149368,
358199,
173517,
16516,
89609,
null,
87040,
328374,
284620,
99469,
13830,
26482,
189862,
224556,
288677,
28109,
null,
15922,
48295,
156010,
46414,
210635,
34279,
169255,
34388,
128405,
205420,
null,
147300,
53045,
214925,
19495,
201274,
23737,
2571,
12318,
1214,
16020,
143985,
547207,
27794,
473899,
139339,
153211,
null,
35422,
102697,
40025,
28583,
106916,
204869,
292549,
128458,
186355,
250640,
24176,
230403,
211909,
null,
23497,
7240,
378324,
167949,
223471,
14281,
41382,
103267,
21788,
72024,
86010,
26864,
146318,
521528,
11368,
212659,
226463,
14046,
null,
null,
17235,
217801,
459759,
47496,
null,
14920,
860702,
null,
7998,
62810,
87457,
57109,
150707,
331303,
94584,
110492,
43544,
9475,
409322,
186168,
146939,
50867,
44007,
39736,
51570,
34356,
288095,
375095,
299516,
null,
129492,
87961,
107401,
79977,
20145,
14363,
32668,
383404,
152618,
18227,
25382,
null,
126979,
20971,
263530,
5330,
220026,
45703,
53067,
4730,
97531,
null,
11264,
18438,
6412,
322655,
279748,
302551,
54695,
113897,
48068,
3978,
130036,
53383,
289119,
26074,
null,
8866,
56158,
null,
19077,
49251,
322768,
154249,
56507,
83356,
226778,
894728,
54557,
87774,
11123,
64685,
153016,
202206,
17955,
35071,
187625,
265047,
205257,
261997,
7628,
null,
35968,
65859,
93880,
null,
51711,
139164,
259434,
412835,
12288,
null,
null,
60090,
null,
380685,
444992,
null,
52526,
658879,
509027,
129896,
9787,
58041,
74998,
628119,
132771,
62840,
13895,
12037,
224388,
29068,
238453,
31646,
38339,
43726,
6803,
80677,
126080,
19643,
33330,
2647,
153235,
134592,
286242,
247295,
124102,
53131,
151764,
77236,
null,
null,
192117,
55586,
526044,
8657,
58130,
15510,
149013,
78905,
null,
61204,
105080,
21543,
59072,
106894,
20603,
159396,
14809,
139487,
197216,
38573,
356123,
31782,
168006,
326186,
null,
18766,
235244,
353515,
122905,
174867,
13543,
370258,
295701,
131937,
null,
325362,
156421,
175236,
82078,
26577,
221642,
23526,
12286,
311573,
68071,
16217,
224209,
76150,
21278,
116611,
97394,
41743,
24813,
44850,
429678,
129609,
19766,
37325,
null,
100397,
null,
92073,
35615,
273828,
101317,
376208,
null,
316020,
null,
113818,
159966,
138839,
null,
50552,
30878,
7589,
30641,
26963,
44978,
null,
null,
42638,
240558,
30563,
37503,
83006,
16307,
340967,
299154,
93428,
36436,
504723,
133745,
31943,
238504,
178052,
56554,
195967,
125528,
85390,
302016,
227166,
145541,
6751,
29898,
310771,
181689,
288989,
178908,
14786,
36767,
131744,
56587,
202907,
49787,
26843,
86020,
51466,
20483,
144123,
78804,
251754,
38541,
108940,
13514,
78899,
54607,
3174,
165328,
87907,
6238,
74143,
33866,
202774,
607412,
74825,
188304,
15725,
92267,
56711,
9522,
42279,
56810,
28714,
137608,
192389,
99276,
212744,
90039,
218072,
36020,
7847,
null,
168296,
12432,
318744,
15035,
32432,
149990,
252621,
83279,
39933,
259104,
51340,
137748,
322425,
25712,
57182,
64863,
27297,
53582,
25460,
null,
7817,
37605,
null,
67021,
47520,
342276,
301493,
389096,
162360,
null,
1020,
null,
41228,
256788,
165345,
null,
171172,
428143,
163203,
23346,
null,
297636,
448556,
null,
114054,
38824,
197469,
286281,
127522,
null,
5236,
28890,
44443,
147351,
null,
10607,
65861,
49163,
171568,
293788,
238692,
6356,
80218,
81298,
93897,
22441,
null,
28350,
45426,
117878,
21223,
33729,
39010,
26322,
50015,
48727,
106002,
null,
141475,
12376,
null,
27346,
408745,
286870,
31923,
203050,
169106,
54692,
12406,
219809,
15522,
14585,
74387,
687213,
67798,
308853,
7140,
66123,
90568,
333107,
35625,
43741,
2829,
214009,
292136,
184753,
126716,
59453,
378755,
184663,
15922,
288956,
9383,
174725,
52612,
182813,
128172,
240062,
null,
null,
93027,
1457,
15635,
9682,
null,
645050,
336269,
106814,
18520,
202091,
70505,
335837,
67948,
39151,
33046,
1053484,
101449,
439734,
61694,
41083,
66755,
19868,
13726,
133752,
177020,
333582,
20273,
193742,
157041,
587954,
15685,
231457,
40198,
35277,
189672,
137412,
95220,
54129,
28295,
33528,
161855,
280120,
277094,
109699,
38702,
236248,
320708,
null,
484581,
218396,
596153,
22835,
58669,
249016,
82973,
19475,
190016,
372539,
234276,
1239155,
351014,
137056,
null,
238425,
160667,
null,
51842,
16208,
203055,
23670,
216937,
147543,
22407,
10265,
49281,
186194,
null,
120790,
33213,
37536,
15269,
144371,
19430,
12325,
29284,
11401,
108249,
587179,
244550,
9368,
365816,
230819,
452539,
59240,
217326,
18376,
268716,
23173,
133383,
99039,
12874,
69638,
257914,
51467,
null,
null,
null,
37758,
271377,
198709,
50368,
29760,
138067,
20980,
119384,
39071,
206890,
44479,
211801,
11873,
35759,
null,
50833,
166954,
38045,
259769,
93724,
213785,
234432,
290623,
55408,
310346,
436120,
123925,
154675,
null,
null,
299319,
16419,
6405,
31787,
34194,
18432,
23315,
297121,
213322,
19463,
9476,
537890,
174718,
209199,
208783,
219101,
null,
224545,
305762,
null,
67154,
45324,
544861,
30441,
359646,
167133,
366723,
32314,
102255,
17169,
158030,
215631,
21896,
31403,
49638,
7089,
null,
36204,
19320,
43246,
431448,
34540,
307067,
null,
576048,
315008,
129979,
29798,
29187,
null,
46110,
34408,
101921,
11078,
298535,
6613,
235800,
37968,
208789,
292760,
197267,
280535,
17510,
41501,
184745,
36833,
66485,
24153,
181247,
135555,
33487,
502970,
287702,
47899,
40317,
25894,
42483,
34436,
250109,
108698,
32006,
44456,
419625,
55048,
22200,
120716,
null,
12890,
38801,
102678,
208579,
130137,
118774,
47300,
68782,
41426,
34063,
59833,
21277,
254499,
89884,
400017,
2170,
96997,
17027,
538191,
21498,
27671,
47640,
10218,
26587,
13613,
124182,
27714,
60589,
92660,
33629,
177294,
43224,
329804,
86340,
67965,
28945,
28130,
252932,
54538,
520243,
263462,
10744,
null,
35641,
284806,
36075,
357138,
217672,
139628,
69343,
26605,
114339,
327313,
18051,
318423,
184264,
null,
43401,
527773,
221930,
15964,
16291,
54720,
169054,
13898,
14096,
77739,
26600,
null,
21533,
34307,
null,
50359,
14348,
18492,
null,
338006,
211676,
80131,
31062,
72634,
87526,
34852,
8593,
86633,
null,
14164,
230001,
15787,
59476,
113952,
102360,
209677,
170494,
38503,
402149,
null,
9822,
148108,
5909,
160908,
179401,
null,
167660,
67925,
15873,
42126,
20285,
34070,
7697,
135619,
29306,
26690,
63909,
12140,
15888,
15709,
9293,
181763,
76911,
281988,
6625,
null,
48614,
7260,
34066,
293109,
241045,
46363,
187454,
2571,
172349,
171364,
null,
12181,
32872,
14731,
235687,
40804,
245461,
77617,
172376,
52395,
61238,
67212,
48823,
20027,
57954,
128763,
260542,
38805,
248678,
390469,
85896,
42360,
450270,
61207,
59262,
20539,
7110,
12395,
240073,
72818,
60402,
69422,
20052,
1825,
4862,
241288,
41292,
70889,
130103,
47650,
225312,
189324,
4351,
347692,
169400,
216113,
null,
174604,
26662,
52290,
69767,
28937,
16765,
22131,
57820,
33981,
32169,
52278,
null,
23663,
24968,
261897,
74181,
18155,
14931,
121855,
6641,
11325,
347688,
112629,
55790,
190815,
276217,
267647,
105938,
null,
29662,
23569,
5880,
133263,
411110,
248068,
264204,
56771,
39721,
9982,
187975,
50642,
15553,
109445,
111557,
192017,
34422,
162788,
null,
6692,
4403,
5665,
null,
256235,
155309,
58302,
352690,
481990,
23908,
219434,
539049,
234999,
18051,
214137,
80597,
5919,
20934,
154807,
258659,
7168,
188602,
43679,
31172,
null,
26635,
217781,
282155,
19619,
208182,
25374,
570199,
45032,
226737,
65748,
3783,
57607,
19291,
17299,
9813,
390747,
null,
75534,
348445,
172654,
25738,
310604,
168005,
18747,
326168,
88805,
35237,
147179,
324186,
15033,
10984,
52952,
25205,
11374,
null,
4798,
167828,
118061,
15405,
196917,
23124,
22960,
11066,
241931,
null,
null,
293350,
125436,
153711,
13208,
269121,
null,
385183,
25895,
312880,
null,
null,
159378,
584792,
275560,
253328,
136399,
15759,
71045,
304087,
204076,
16716,
12565,
76754,
153835,
131176,
259475,
36961,
24937,
315619,
3154,
468958,
582869,
236967,
12895,
26381,
298453,
93165,
352967,
179394,
27777,
27362,
194608,
138587,
224944,
134412,
211118,
519903,
205614,
163110,
16096,
21478,
256806,
401039,
40494,
44494,
null,
142477,
267941,
108654,
142719,
58708,
70526,
58290,
16151,
41165,
358186,
8911,
null,
220572,
84176,
517655,
81325,
14645,
80691,
121956,
51560,
28514,
12520,
15307,
167978,
94460,
140757,
212477,
66559,
380199,
131746,
199365,
18057,
196261,
19927,
54967,
null,
51481,
64686,
56657,
148085,
null,
180276,
144203,
148165,
426157,
237703,
null,
null,
269154,
57162,
161303,
275602,
27346,
18790,
80697,
29120,
3981,
17880,
89403,
250538,
37131,
21650,
17917,
15390,
157807,
28381,
101915,
156744,
null,
650180,
79187,
196069,
294737,
51794,
261902,
48939,
56037,
12975,
4010,
35616,
123866,
174281,
185362,
710543,
23450,
25106,
413308,
null,
58767,
26805,
34128,
267116,
18176,
37442,
171777,
69692,
null,
33541,
235590,
99335,
31086,
455199,
null,
612744,
208428,
347002,
184649,
917,
32640,
28860,
83612,
84906,
25747,
null,
30509,
19502,
160626,
212984,
495902,
14364,
27727,
11839,
171198,
49181,
33945,
469898,
207614,
38252,
39432,
255067,
null,
364717,
235376,
25139,
103255,
161440,
2546,
630054,
8977,
28514,
null,
500573,
21670,
41782,
40156,
16826,
240072,
245734,
299281,
383282,
5973,
265457,
null,
122232,
19071,
150564,
40242,
12180,
374617,
151558,
14576,
425635,
60978,
102573,
11087,
12491,
398045,
39802,
75187,
15930,
null,
59565,
260758,
7178,
149385,
53311,
43729,
172230,
27563,
295424,
49818,
48421,
162859,
42533,
50456,
22060,
329328,
30582,
87652,
61140,
3757,
9343,
45027,
177741,
261429,
432546,
167871,
50232,
74417,
70514,
372648,
23470,
92073,
178418,
167657,
42081,
24916,
37402,
12115,
null,
21536,
6450,
108938,
146252,
324808,
19585,
105501,
35163,
null,
123560,
65896,
18958,
null,
56017,
266589,
227530,
87506,
null,
22136,
232685,
143478,
20430,
null,
123817,
102193,
411637,
291476,
null,
23072,
147038,
26145,
209970,
14725,
44675,
581107,
146941,
45884,
41279,
null,
30000,
13076,
64376,
326287,
249294,
227252,
172353,
44156,
20982,
41528,
217923,
26012,
3032,
375226,
115269,
81333,
214724,
245757,
24508,
199279,
97443,
169517,
null,
19436,
188888,
7801,
41944,
39492,
81368,
40297,
59779,
140854,
29053,
139918,
131278,
28718,
421799,
5129,
39342,
41330,
95094,
5187,
101989,
96695,
342654,
442816,
null,
null,
234030,
129454,
141418,
348041,
412024,
149197,
30399,
10777,
151895,
150095,
38276,
10481,
249223,
null,
9583,
87267,
52135,
85868,
219179,
97284,
153511,
324435,
14041,
77094,
183077,
203714,
11580,
108418,
31427,
33581,
1832,
2108,
null,
143778,
81508,
73704,
null,
160851,
27634,
302016,
13323,
16748,
42467,
10343,
307686,
179015,
205405,
205038,
56274,
69713,
36109,
13731,
null,
9224,
21867,
null,
83576,
308063,
9819,
null,
8534,
49442,
506140,
176512,
562519,
51917,
84007,
21021,
211987,
66465,
75962,
958850,
38451,
23410,
154035,
17540,
null,
415777,
494163,
18087,
38914,
22111,
335938,
9902,
54064,
246100,
null,
87928,
187202,
5175,
222858,
78233,
199923,
169892,
16284,
191651,
73267,
264651,
468,
113495,
18441,
235830,
4902,
141646,
217778,
81012,
47574,
9833,
18769,
7623,
175890,
95764,
28811,
null,
18496,
149292,
341692,
194931,
129314,
26582,
304615,
474187,
549128,
57999,
null,
41519,
282770,
16944,
28978,
3189,
208826,
271273,
32713,
23801,
612171,
13970,
287565,
9122,
222495,
332526,
null,
20037,
14836,
20107,
65497,
28105,
3023,
46482,
160097,
71022,
26433,
136904,
71396,
274914,
223126,
178054,
306921,
47832,
null,
20099,
13016,
261642,
14136,
null,
365730,
null,
null,
175059,
865280,
812007,
27939,
168233,
null,
21083,
17736,
304462,
58675,
33993,
171306,
148369,
11105,
621936,
23082,
34529,
446218,
190531,
254804,
8375,
103000,
812487,
23446,
null,
165450,
141668,
102848,
402901,
17938,
36247,
18784,
22966,
30226,
399083,
39636,
188605,
50908,
13311,
51379,
284780,
165049,
null,
25166,
31733,
5460,
769817,
85686,
68078,
31259,
196713,
51337,
28114,
23122,
94834,
148147,
125316,
13789,
147275,
26586,
8727,
null,
201922,
132585,
160341,
371131,
20276,
124584,
39648,
55959,
40585,
118751,
135185,
null,
17847,
350610,
49279,
118763,
25317,
404906,
null,
563431,
47366,
19238,
18288,
59345,
28326,
91387,
260485,
149863,
36876,
23433,
349890,
9154,
24326,
234722,
173953,
117375,
26331,
261881,
255380,
68252,
340793,
481153,
295063,
433065,
55885,
745883,
65365,
10309,
194934,
4820,
182584,
90983,
202713,
193520,
277774,
21471,
128638,
244907,
3543,
215584,
null,
64567,
452934,
30802,
8446,
170906,
32772,
null,
42081,
8835,
79390,
20246,
164867,
60506,
22403,
88642,
119867,
221469,
null,
432742,
63561,
20682,
299008,
null,
416766,
null,
4781,
94676,
175828,
358982,
48153,
62608,
210471,
77040,
49904,
53274,
181627,
51323,
154511,
3338,
51950,
281945,
40515,
null,
214986,
256968,
832318,
83482,
37503,
20391,
851,
194806,
144712,
null,
14168,
395941,
35455,
463389,
25861,
200875,
308393,
67023,
28839,
172784,
270929,
null,
346714,
263511,
11451,
31270,
35535,
330372,
41643,
27672,
161518,
62716,
181630,
null,
46645,
null,
412519,
189241,
22053,
116398,
null,
27480,
12545,
21682,
160788,
632457,
127024,
218106,
413770,
77343,
198134,
null,
14033,
7635,
22786,
69156,
61218,
36294,
209700,
122568,
338708,
169902,
17730,
371554,
238911,
164242,
33851,
47178,
93817,
83997,
null,
22230,
14772,
63612,
540,
195767,
107998,
21399,
5537,
32737,
29315,
11178,
37606,
9198,
17586,
640945,
76452,
164479,
38866,
128502,
83945,
189644,
34617,
243246,
54370,
9041,
179900,
242295,
196701,
166630,
7554,
70775,
null,
73610,
9244,
null,
32724,
27756,
255242,
21650,
21339,
12064,
272743,
20509,
885735,
29631,
11402,
140612,
193391,
170739,
46473,
312173,
161847,
17925,
10200,
33394,
62930,
7419,
20713,
17272,
24251,
85522,
99034,
191758,
38893,
58716,
299736,
21607,
221010,
23108,
25228,
59099,
28310,
32598,
153617,
747628,
70941,
249723,
113343,
334198,
100405,
32460,
53480,
39894,
77939,
35959,
16832,
493148,
null,
83577,
6707,
14314,
143523,
57237,
22581,
205174,
263503,
153161,
9201,
6346,
194189,
338956,
null,
80500,
130684,
70755,
62436,
223348,
188198,
19186,
31455,
32758,
34136,
101195,
90095,
133204,
7329,
44593,
309356,
82080,
289910,
164025,
null,
272406,
71977,
22842,
85195,
131025,
67106,
450028,
60063,
38030,
27089,
37852,
31324,
49449,
222720,
348875,
11027,
241569,
50880,
21861,
127257,
332941,
184450,
30129,
81268,
34978,
152218,
42277,
33215,
26704,
374326,
169391,
102501,
130782,
29351,
37827,
153231,
16993,
377190,
52926,
82122,
177526,
419149,
62743,
12215,
187971,
324194,
186360,
89204,
45968,
640108,
34027,
null,
144480,
275738,
189154,
11402,
5479,
991366,
45105,
37098,
39405,
7882,
16475,
62116,
271437,
436490,
173176,
83959,
201444,
23966,
260794,
105506,
39750,
199997,
20393,
158600,
2187,
131910,
53614,
580473,
29894,
70326,
16091,
39520,
413349,
112621,
153092,
408900,
31937,
92344,
365478,
315585,
45549,
47005,
424944,
229424,
17763,
38697,
21539,
88882,
98282,
8274,
323910,
null,
13271,
139336,
43242,
109044,
2053,
786752,
97973,
18214,
124257,
484782,
292607,
null,
10227,
6403,
25769,
58135,
125602,
19014,
312872,
23975,
83085,
591976,
null,
null,
70918,
46108,
316337,
null,
56326,
407709,
61671,
209472,
null,
413316,
null,
28534,
null,
12616,
283637,
13929,
64893,
181236,
2185,
348598,
37128,
34789,
null,
123995,
180560,
270668,
275862,
134795,
12290,
34580,
198585,
27884,
161688,
null,
28192,
104721,
3776,
201899,
201290,
36029,
168257,
9689,
36445,
69003,
null,
343336,
4404,
83114,
20582,
8394,
121171,
19136,
497023,
113580,
231867,
null,
21864,
33828,
120768,
42553,
86427,
239154,
35601,
81671,
null,
182324,
19227,
91119,
25429,
173478,
24108,
50226,
1177682,
67525,
48351,
20097,
237068,
147345,
null,
73293,
null,
30733,
296626,
15302,
399794,
231171,
22875,
39208,
null,
406896,
211330,
175794,
74996,
197187,
24613,
126404,
15343,
133360,
45054,
328500,
145416,
31520,
400176,
166977,
341585,
125019,
61931,
15917,
109378,
32099,
299981,
675688,
192221,
null,
18068,
225781,
24370,
234457,
117916,
87145,
43123,
181960,
438883,
262107,
45553,
null,
224435,
375639,
24712,
199311,
null,
167140,
30939,
218766,
166951,
16273,
102297,
5766,
20112,
20591,
241741,
null,
7481,
15702,
33616,
30774,
48367,
null,
304897,
269947,
148361,
33627,
44055,
59074,
123512,
325302,
223496,
26971,
48335,
229576,
null,
18173,
69508,
227508,
105061,
77838,
201770,
37488,
44706,
16391,
182715,
null,
27471,
112555,
310432,
299939,
468199,
12970,
53787,
496886,
261225,
445763,
169680,
56636,
19332,
9624,
null,
31281,
25949,
230751,
793174,
120627,
322225,
485613,
206951,
185544,
10069,
null,
29024,
247241,
14632,
null,
185157,
41108,
18286,
8171,
162969,
97852,
160620,
236039,
5719,
51798,
304830,
55011,
96323,
180315,
28536,
315047,
151227,
259851,
16236,
294534,
58369,
null,
13089,
20866,
null,
5699,
6195,
50250,
14852,
208362,
155302,
281533,
49591,
14527,
168112,
93081,
null,
14961,
58259,
78009,
213898,
155329,
50555,
34420,
174030,
45843,
175185,
38704,
null,
61024,
108220,
45436,
97396,
33003,
null,
271508,
30295,
null,
30912,
150405,
46838,
13195,
197772,
null,
62443,
670654,
5943,
8054,
266348,
117945,
91240,
27298,
339622,
30306,
21000,
338617,
22480,
41098,
354173,
205334,
89528,
17728,
40637,
39780,
179413,
45688,
14483,
306809,
35077,
null,
191348,
289299,
114513,
13752,
109431,
6944,
128420,
29528,
129573,
3091,
142982,
52999,
19259,
70886,
75215,
1321,
201245,
345735,
219385,
144090,
20187,
11025,
89934,
44434,
110059,
331002,
38049,
78719,
352112,
36707,
15768,
53835,
61192,
50616,
null,
90610,
384405,
57235,
7946,
26657,
175615,
null,
52552,
14437,
329686,
368774,
363403,
41318,
233306,
11781,
25707,
1150307,
181635,
199881,
null,
28882,
27958,
329024,
48236,
13056,
154202,
46984,
null,
20175,
73438,
60149,
152696,
267534,
null,
19422,
130067,
86826,
112146,
35279,
18034,
726480,
13541,
37243,
22400,
46061,
64588,
305693,
501500,
194744,
593512,
226051,
218197,
324809,
172061,
null,
24768,
109856,
75919,
256191,
25566,
232098,
34348,
42965,
142398,
384218,
39058,
14748,
165580,
378382,
276598,
321772,
325436,
191103,
41896,
241890,
10601,
411794,
35492,
164501,
38784,
98663,
195691,
235828,
255907,
84715,
43317,
64800,
172817,
21342,
null,
206503,
299638,
28121,
52925,
125535,
467099,
68670,
274508,
236453,
161756,
242469,
111352,
166796,
179373,
14181,
491376,
408314,
181779,
261998,
41973,
37445,
33514,
174069,
186128,
150413,
29875,
null,
22506,
6339,
70045,
72947,
56260,
127014,
5074,
238729,
175865,
181363,
50072,
83512,
111720,
90395,
121133,
null,
249694,
188733,
34916,
227780,
304088,
19238,
163365,
106301,
225120,
43414,
339058,
88651,
379283,
36499,
58224,
309526,
36699,
61391,
17689,
192496,
43256,
null,
11715,
49967,
239408,
23412,
17100,
null,
null,
1684,
43675,
202378,
113863,
55484,
null,
50347,
108327,
35792,
76328,
227828,
null,
null,
222950,
266893,
375424,
201066,
206581,
174394,
8689,
101006,
286635,
17184,
30743,
138630,
129145,
138236,
209103,
231156,
331060,
257496,
590043,
353586,
91866,
32283,
363674,
124296,
27287,
313900,
144911,
null,
32722,
226313,
33015,
291057,
191866,
11220,
41822,
47588,
273607,
139656,
8593,
68066,
262902,
198750,
188134,
58382,
275858,
398124,
null,
287544,
27253,
35073,
2582,
7789,
118357,
220748,
28860,
31035,
88662,
259508,
265363,
1179,
535522,
234110,
91821,
339476,
210972,
48798,
153255,
35116,
27938,
207281,
260460,
22546,
13821,
null,
43874,
149415,
607787,
null,
296498,
95007,
null,
165871,
181368,
307787,
50826,
30009,
31278,
238130,
25021,
30294,
110735,
197453,
37510,
67796,
4572,
177810,
106659,
7712,
61301,
85069,
46916,
37542,
6744,
null,
47933,
null,
3537,
39578,
157995,
197513,
164566,
184803,
40619,
326039,
21221,
14964,
225529,
259865,
null,
163068,
19523,
null,
120223,
39083,
66465,
7648,
79525,
null,
153785,
109705,
21289,
39052,
97152,
10306,
4309,
118980,
97538,
246414,
46936,
78704,
34056,
11061,
170059,
null,
10357,
192586,
17561,
52262,
129657,
21831,
566332,
null,
11125,
143752,
37630,
131627,
30497,
245691,
null,
59043,
44323,
null,
115222,
146617,
1643,
null,
152348,
58453,
118655,
23550,
96954,
236002,
96672,
126669,
240392,
216917,
57590,
77063,
94026,
19120,
19115,
21832,
2836,
251882,
null,
135797,
77544,
82840,
72497,
5141,
258212,
116553,
34009,
166804,
182255,
59320,
272825,
33113,
447076,
50427,
107796,
802109,
75029,
60263,
95616,
163098,
37391,
88344,
247668,
88400,
389112,
7974,
180547,
null,
35469,
75532,
207868,
131062,
39731,
34669,
3823,
164458,
123381,
null,
7163,
215593,
18133,
38129,
204907,
34571,
85686,
null,
68195,
43818,
265655,
123164,
57099,
18779,
37307,
36202,
34644,
281757,
316415,
15684,
9439,
224161,
585925,
3978,
219431,
167488,
341467,
245000,
10927,
11983,
29883,
21670,
3827,
309800,
53407,
19243,
747919,
100990,
338813,
207975,
404580,
28320,
null,
48095,
15067,
201211,
111018,
7596,
null,
176236,
211692,
null,
45896,
49444,
59151,
48824,
43857,
21586,
null,
12539,
null,
4766,
59354,
201713,
217607,
139080,
15590,
195737,
70316,
16058,
13515,
17023,
327041,
93230,
342564,
40511,
36760,
38428,
52303,
610738,
13467,
50797,
154803,
4293,
162144,
null,
63313,
114765,
null,
21728,
780937,
26466,
10479,
14574,
19560,
111249,
21515,
203766,
61422,
71825,
10611,
150431,
34042,
null,
308295,
31368,
34082,
248497,
10936,
219095,
null,
112023,
452517,
343864,
null,
219839,
26348,
32755,
372919,
454179,
90172,
343159,
225287,
15176,
202393,
19193,
8038,
36942,
186161,
138500,
68759,
32169,
null,
13473,
206945,
null,
15830,
215748,
87427,
169519,
60644,
11005,
39436,
67326,
125071,
319878,
202978,
null,
78206,
48863,
8407,
null,
23809,
12106,
216678,
46549,
31791,
null,
60802,
492684,
null,
172725,
13149,
48691,
12614,
3537,
32519,
14360,
9510,
55055,
342226,
null,
189298,
502802,
167367,
46677,
144945,
11021,
16804,
155459,
9660,
220083,
69398,
240789,
55999,
44092,
72414,
215902,
28899,
29370,
177451,
7104,
12528,
34110,
9471,
16317,
58276,
11170,
285390,
316625,
13125,
420593,
239770,
168355,
105505,
null,
20565,
3451,
26908,
113501,
214523,
268976,
196334,
45692,
318684,
null,
293961,
416078,
297054,
12323,
39906,
229255,
13835,
207128,
14872,
33335,
98119,
35186,
null,
286873,
202638,
46841,
4897,
209614,
351168,
519299,
440531,
273093,
93914,
21610,
292191,
166662,
239295,
null,
null,
426516,
50271,
136989,
null,
346294,
245772,
144175,
197195,
89616,
29748,
21328,
316739,
158867,
23692,
99736,
54737,
439965,
253993,
143601,
61451,
128704,
36050,
139403,
344815,
333421,
19062,
99485,
76418,
23280,
18485,
null,
244489,
36589,
120886,
682328,
318801,
188065,
15611,
122220,
552645,
42799,
null,
331273,
184792,
206363,
13970,
158779,
100521,
98788,
457759,
310539,
157182,
32438,
239551,
125056,
null,
45355,
180487,
null,
211553,
127552,
272989,
48525,
265579,
98595,
36933,
79632,
348846,
28675,
48615,
183266,
101449,
null,
null,
null,
127390,
15707,
214911,
348893,
34226,
30892,
33596,
208388,
206991,
6407,
440339,
604219,
287965,
null,
16815,
null,
null,
38553,
133697,
124760,
114951,
435859,
67544,
58793,
152377,
358940,
26420,
11347,
412124,
46849,
15304,
30617,
187743,
387816,
394634,
15902,
512776,
null,
309950,
28549,
3152,
16669,
5087,
172467,
11593,
31930,
21356,
null,
205454,
80402,
37570,
16448,
40206,
138546,
82961,
406262,
240655,
212542,
137855,
321132,
201881,
490565,
25886,
65067,
179244,
139715,
321738,
25796,
225672,
null,
213994,
232779,
63388,
42369,
22785,
177954,
213654,
225646,
null,
5811,
363988,
229868,
null,
215623,
97697,
465716,
494754,
41780,
273392,
null,
null,
26772,
560786,
23528,
20015,
154948,
181339,
287156,
null,
142068,
11454,
92392,
301160,
60239,
58754,
97886,
110074,
459726,
160829,
378093,
11691,
156290,
16365,
233118,
177713,
137816,
381376,
25647,
37839,
195704,
196251,
50532,
null,
126595,
32873,
62149,
15558,
149861,
30770,
18752,
20036,
null,
90568,
85023,
91486,
284780,
42799,
153601,
94856,
144778,
null,
33794,
181798,
543845,
7654,
143911,
55924,
null,
49654,
21678,
24068,
24563,
42557,
5112,
78993,
210620,
54474,
37376,
800946,
179344,
301630,
37250,
107061,
265426,
28695,
34771,
22838,
27838,
null,
33211,
133438,
147628,
60389,
573142,
8742,
23001,
46777,
70812,
26420,
249174,
245370,
66377,
null,
32204,
5214,
291926,
17024,
55107,
30835,
100838,
121029,
156557,
96790,
1864,
30660,
33282,
43278,
59374,
26540,
462524,
28670,
174773,
214992,
394171,
90301,
19287,
38031,
286720,
41075,
61355,
29926,
null,
228827,
167756,
43230,
17579,
182237,
209200,
10537,
74485,
124107,
null,
423271,
67355,
22093,
150814,
98598,
16545,
1867,
64061,
29268,
91486,
57848,
272632,
26128,
15595,
52618,
2073,
448348,
30466,
26422,
317787,
null,
220798,
54302,
30500,
31895,
27860,
128918,
35347,
null,
48292,
40992,
60991,
305898,
33669,
364177,
289224,
121931,
145525,
40305,
122332,
90235,
198232,
526225,
299516,
119929,
187267,
319553,
16241,
28500,
214969,
210281,
668261,
492495,
5091,
236875,
251938,
78205,
199237,
272535,
212617,
179837,
22141,
855238,
59393,
74954,
91520,
121374,
356703,
322018,
43052,
54352,
23232,
100655,
5459,
11404,
16080,
22459,
387712,
75021,
21516,
475467,
38083,
29495,
100261,
82820,
30972,
163450,
5780,
null,
null,
41652,
24275,
20938,
182715,
278597,
214296,
78678,
null,
null,
40767,
36584,
182323,
77038,
null,
322953,
144998,
257148,
117987,
197067,
44548,
406035,
null,
11730,
13285,
335462,
220392,
190295,
177747,
301329,
400291,
195168,
31614,
14894,
29065,
145640,
405920,
16502,
21357,
21686,
37640,
31795,
245421,
157511,
166013,
75700,
51133,
5370,
202761,
24600,
103825,
12982,
10310,
155273,
239576,
31687,
42423,
38476,
25364,
328792,
149931,
17416,
321377,
251479,
19178,
10876,
35260,
null,
215064,
10199,
210525,
247845,
60019,
null,
493907,
9784,
212125,
241586,
139555,
288703,
3512,
198277,
195783,
26265,
248933,
23998,
76677,
507040,
95996,
277412,
287954,
262402,
242754,
152519,
34417,
14869,
318053,
170056,
57164,
12553,
51596,
22179,
517413,
42983,
null,
139623,
45777,
378361,
285073,
364585,
236222,
75158,
279079,
267523,
558382,
177368,
5686,
399072,
15386,
35915,
69160,
85465,
31324,
72462,
47164,
null,
268500,
143597,
61569,
306936,
42088,
88664,
75018,
144930,
25523,
698720,
25063,
99502,
10421,
325119,
10795,
28969,
221123,
140938,
72975,
323402,
198007,
262832,
281169,
155558,
312190,
19807,
null,
27473,
null,
375605,
null,
74152,
222604,
144146,
227386,
544777,
435656,
33277,
43295,
47475,
33139,
192537,
89312,
177990,
23209,
153666,
9386,
309961,
115000,
229099,
29374,
null,
36822,
null,
145535,
324550,
179354,
126562,
673448,
283569,
104937,
187565,
143324,
10588,
13649,
218226,
186915,
100926,
235739,
409797,
44721,
373100,
28275,
536103,
31854,
52388,
4947,
227007,
94141,
10912,
null,
111793,
87090,
2879,
181967,
164284,
61855,
55438,
72696,
702741,
288238,
80481,
567151,
10494,
48221,
7179,
207208,
27429,
349552,
4851,
133837,
82950,
64844,
13884,
27308,
72902,
214847,
203771,
148606,
632420,
256762,
42692,
46994,
286099,
null,
160412,
17225,
150550,
286229,
9740,
72654,
31924,
327335,
34550,
420405,
null,
110633,
17190,
267572,
140196,
116090,
28307,
444141,
null,
254827,
7305,
87285,
237635,
26652,
55545,
560505,
7840,
101567,
214471,
19505,
527980,
22859,
309098,
138014,
164205,
null,
null,
120995,
5485,
381517,
136136,
89526,
336017,
40033,
460896,
30173,
242281,
311206,
23932,
8289,
226102,
333874,
135350,
163088,
111735,
298886,
57293,
6184,
43260,
87120,
13914,
110208,
null,
46671,
109713,
40397,
165136,
70547,
16731,
197563,
59263,
75921,
190967,
76528,
null,
65573,
325217,
156625,
4317,
376448,
22601,
10527,
374868,
247799,
105561,
141699,
11094,
374461,
null,
49547,
78420,
null,
325169,
101134,
12983,
28847,
199990,
440974,
9189,
431724,
162203,
8745,
133611,
64195,
194831,
295288,
183591,
404193,
214986,
171839,
46601,
36033,
394142,
31175,
18800,
19869,
38556,
72881,
37122,
1157584,
264353,
153318,
387868,
188374,
164039,
38254,
191539,
30127,
207603,
20285,
96133,
62840,
98684,
17471,
116031,
170417,
30604,
50287,
237319,
272731,
4221,
170447,
207075,
10125,
5842,
4978,
13022,
519003,
90819,
11535,
106125,
20513,
135787,
89561,
490680,
32461,
486086,
49137,
179476,
11911,
56811,
192739,
61094,
36909,
162599,
229265,
177265,
358290,
655202,
82116,
170464,
24285,
108699,
85313,
36401,
237483,
150335,
17108,
24414,
397677,
102002,
588302,
73416,
120203,
108482,
30562,
153193,
41959,
46150,
50445,
179450,
213494,
15677,
53243,
29184,
275008,
35363,
123168,
67092,
50997,
null,
205817,
138035,
655905,
11717,
null,
null,
238506,
24832,
null,
20842,
255040,
43880,
23528,
10821,
36667,
121423,
136162,
86696,
34885,
42733,
72965,
241163,
13021,
210001,
227060,
822323,
132216,
253747,
152386,
25550,
24295,
61295,
16212,
205999,
1441,
36207,
185889,
42304,
204369,
39080,
126707,
212959,
null,
null,
68017,
11078,
104214,
70713,
232421,
3741,
128982,
29995,
19960,
398153,
21313,
409318,
50270,
485217,
208418,
23069,
14445,
175427,
140219,
41264,
88325,
null,
36180,
4549,
457011,
237260,
266650,
129717,
491431,
23218,
104658,
524579,
532419,
155760,
22901,
28989,
29016,
17821,
44018,
270600,
189617,
44985,
12754,
290670,
29092,
39583,
4341,
180978,
62052,
368293,
426483,
13316,
119840,
42010,
12757,
26658,
14293,
361039,
117915,
141522,
null,
52002,
270713,
370047,
407668,
241176,
null,
195032,
267861,
133678,
47518,
368805,
7736,
47443,
27316,
26993,
188492,
154333,
252276,
130478,
41998,
11732,
220603,
44724,
255474,
142029,
13427,
22907,
10422,
15369,
10085,
14293,
287897,
null,
483877,
338678,
101414,
122362,
29061,
74873,
13651,
137202,
17757,
33506,
19016,
142401,
43680,
14465,
820,
28838,
39947,
18464,
9085,
9472,
299703,
62529,
196342,
24494,
94834,
90751,
159108,
43415,
null,
234570,
35621,
33588,
null,
151929,
369360,
21853,
37162,
74646,
8454,
190955,
9752,
367585,
337422,
38367,
165364,
21830,
40941,
338280,
42235,
170905,
null,
230411,
422388,
null,
381402,
15365,
25247,
45973,
null,
33443,
256238,
72202,
135886,
250541,
22043,
77350,
231708,
195852,
176847,
186005,
32343,
932680,
12429,
178358,
48156,
20858,
null,
36623,
16011,
4002,
32199,
53182,
232541,
37434,
123561,
59102,
202787,
131431,
34858,
23184,
175325,
77565,
83860,
158437,
227980,
337874,
455039,
31577,
12289,
475336,
56036,
33668,
84576,
139037,
296287,
288958,
38839,
null,
12235,
null,
382770,
41389,
328850,
87787,
88993,
141226,
46243,
14649,
28255,
47702,
19165,
206928,
118615,
27356,
125229,
36278,
null,
195402,
273273,
322832,
52061,
415899,
46271,
166629,
210174,
null,
11232,
7190,
19395,
458806,
8315,
91345,
112484,
145461,
94961,
649152,
352751,
175430,
206326,
71646,
178942,
181591,
43103,
null,
35996,
18220,
28099,
17553,
364852,
239555,
321376,
49462,
236960,
null,
229962,
273396,
null,
520366,
159947,
284498,
543500,
250766,
251019,
134640,
6243,
69276,
217482,
166796,
530782,
488248,
28380,
11130,
11681,
46737,
4587,
280078,
69356,
null,
135660,
247749,
127823,
57612,
33442,
34879,
136684,
27484,
215705,
22184,
null,
51388,
189199,
19261,
18007,
null,
54123,
36109,
61066,
314273,
48217,
12759,
212583,
null,
144489,
315551,
null,
20136,
39999,
35931,
536675,
null,
58368,
146856,
299894,
27925,
126150,
337526,
66530,
94476,
32319,
225486,
63104,
99377,
320886,
546642,
null,
24034,
15009,
25341,
12802,
131554,
58909,
32556,
82228,
null,
16179,
14748,
125449,
null,
314524,
94140,
237342,
244140,
13775,
null,
33687,
410309,
219657,
116488,
64927,
25855,
40272,
83483,
189446,
13040,
16145,
null,
22462,
null,
322109,
140949,
9656,
291435,
62024,
null,
395425,
213474,
55088,
36947,
77497,
31684,
292416,
75453,
403328,
10341,
27955,
454892,
94959,
86208,
84121,
45234,
254639,
271517,
140121,
8008,
403107,
35673,
19393,
293871,
38699,
8739,
19417,
25492,
523453,
8366,
589303,
186081,
16707,
28576,
502564,
60178,
272005,
49131,
106508,
282240,
null,
143564,
232350,
206148,
776984,
395571,
166321,
32171,
19706,
34432,
409578,
310876,
307166,
26602,
196381,
247171,
null,
240246,
287421,
113378,
49112,
19923,
4690,
429186,
122083,
179400,
16388,
8518,
5290,
94075,
229394,
44362,
5515,
null,
191732,
122055,
null,
109388,
51386,
28642,
164972,
46288,
22362,
78066,
248412,
157792,
6748,
43418,
277796,
12294,
46837,
null,
175725,
10582,
null,
296768,
271170,
13880,
null,
129844,
155062,
374626,
141736,
9962,
22882,
207117,
361518,
60808,
3856,
127293,
50073,
75171,
79010,
19397,
447333,
null,
null,
32137,
47394,
87371,
28609,
274214,
53865,
20413,
182824,
21004,
40194,
73276,
83637,
158912,
72139,
35963,
195840,
221998,
14960,
42738,
18716,
36568,
null,
253265,
182877,
245545,
576471,
16096,
278754,
269481,
69725,
69931,
10560,
1061100,
263695,
93604,
43639,
232266,
8703,
554525,
44271,
510443,
249076,
145405,
48513,
34638,
161153,
22810,
9401,
7428,
134381,
36413,
226549,
173307,
142814,
80780,
36836,
6380,
15824,
202672,
7464,
278508,
17666,
91580,
null,
26092,
789224,
25925,
325262,
43671,
35190,
3938,
9652,
38377,
228345,
386895,
158803,
144213,
127547,
7678,
40368,
19746,
38331,
320174,
214461,
93501,
428612,
202481,
20328,
20386,
175802,
121891,
180375,
485292,
null,
null,
22211,
21753,
33773,
null,
null,
30761,
25909,
288190,
4541,
13311,
273462,
97819,
362834,
106208,
51168,
26127,
30559,
202503,
150653,
6861,
55052,
51959,
162510,
97219,
303824,
24039,
192337,
381792,
30838,
360773,
null,
141760,
48371,
14994,
7909,
212737,
374244,
138950,
22840,
50174,
143391,
17588,
176574,
41015,
16368,
34815,
37241,
89504,
245572,
197246,
null,
223704,
109626,
3468,
5947,
200920,
120389,
277899,
22349,
236712,
42863,
147200,
4031,
18535,
89562,
12552,
22575,
321938,
198900,
21406,
41424,
238024,
32157,
null,
97022,
144711,
97606,
11417,
54979,
20142,
2068,
104033,
59550,
81121,
114983,
146087,
58762,
195142,
108736,
7020,
16766,
196084,
null,
101889,
18221,
94791,
30753,
344975,
4086,
400741,
100862,
480442,
47345,
18317,
87305,
37936,
513925,
40702,
188315,
258425,
98889,
208117,
7708,
72432,
18776,
17246,
210044,
22087,
221537,
28555,
380233,
524240,
135478,
26796,
49662,
9943,
null,
47756,
121506,
512305,
60624,
193196,
26342,
24470,
73240,
3322,
21651,
38854,
140394,
137186,
68057,
44493,
42149,
10790,
257001,
64960,
null,
8607,
135256,
258795,
27694,
57257,
3951,
143171,
26615,
47005,
16227,
15830,
110873,
null,
244262,
100922,
505896,
39664,
375667,
28913,
null,
31640,
47225,
254462,
246933,
153926,
415546,
336537,
35848,
584890,
33313,
414117,
44737,
378179,
231006,
94622,
182646,
27728,
354544,
null,
127264,
245144,
180644,
10237,
268168,
259962,
null,
76569,
20988,
null,
45117,
101068,
198930,
7192,
null,
83737,
123334,
20179,
17253,
21477,
28836,
190497,
280296,
46313,
338033,
null,
11483,
85081,
88158,
44226,
23409,
611067,
33613,
815086,
436928,
491880,
125764,
null,
132410,
270330,
16508,
76272,
214795,
278719,
12285,
175283,
17902,
63001,
439164,
7170,
252977,
13838,
98697,
86837,
10579,
170098,
42364,
344560,
11346,
2956,
133904,
68603,
96621,
18320,
309731,
36993,
279359,
10322,
54419,
194722,
null,
48088,
17326,
22525,
30566,
47668,
11988,
null,
35982,
282483,
193641,
18146,
305569,
76150,
149222,
12228,
21407,
231244,
143297,
50479,
18041,
null,
18834,
19876,
481575,
40819,
16400,
399764,
292289,
35577,
24137,
39728,
null,
160602,
21782,
null,
48184,
13756,
15191,
235296,
19234,
121599,
40283,
463041,
null,
84299,
57845,
278603,
23053,
5478,
174585,
211000,
449602,
69331,
475212,
237498,
225055,
214905,
158275,
431446,
73963,
32593,
9805,
16764,
236034,
177165,
23655,
640149,
679908,
44399,
34827,
34873,
9657,
336833,
36432,
200013,
null,
421182,
17620,
231924,
316910,
5818,
269599,
10106,
89609,
44534,
null,
454663,
75995,
135860,
null,
21984,
null,
419183,
50012,
138559,
5311,
null,
159649,
218115,
72155,
203446,
22479,
52614,
241777,
66131,
218928,
null,
73730,
28191,
220989,
117053,
24198,
374873,
345401,
6729,
19334,
39763,
178774,
69630,
63803,
5753,
180064,
37460,
72169,
34558,
213326,
158838,
371514,
222531,
159203,
33404,
333540,
null,
256576,
17205,
null,
134576,
150198,
88507,
239501,
null,
222300,
63351,
212634,
12791,
163569,
190182,
11166,
20395,
38572,
45029,
212969,
6916,
33818,
90159,
29724,
21718,
20737,
179840,
125259,
168263,
14695,
132315,
26470,
49824,
347914,
31474,
295578,
122777,
7320,
70087,
null,
319808,
427114,
160595,
5,
41856,
1006121,
146635,
232127,
209484,
11328,
10411,
32098,
52724,
50311,
467086,
22320,
394278,
415926,
174861,
17865,
76924,
49400,
133543,
227185,
43150,
23674,
11465,
86806,
86761,
232627,
46522,
38216,
18296,
37127,
276657,
303040,
228537,
171485,
34219,
9419,
152441,
205504,
144392,
17278,
563844,
227979,
3120,
54893,
84820,
226413,
26989,
81259,
47488,
203547,
66298,
59413,
null,
32729,
234044,
445104,
18785,
7561,
null,
11132,
105254,
25413,
41485,
53752,
75051,
205291,
118,
424909,
52048,
24083,
54558,
127706,
25560,
7504,
387969,
2392,
23999,
20623,
224601,
11336,
153676,
58908,
310403,
21615,
173169,
21843,
115465,
568853,
134882,
25438,
245768,
365754,
290998,
212029,
27695,
86527,
null,
41350,
45336,
203983,
null,
207541,
276032,
57414,
180464,
228106,
277538,
414883,
98236,
317457,
30968,
38947,
218852,
148882,
88552,
30464,
115349,
27608,
null,
51676,
35939,
138880,
283669,
16982,
215717,
21741,
126131,
null,
33114,
null,
466550,
157250,
39065,
224369,
null,
46341,
123336,
null,
330245,
299098,
1942171,
150474,
92186,
15883,
null,
156065,
26158,
23178,
56404,
254736,
32194,
18107,
47908,
18286,
247606,
26752,
18473,
45692,
49603,
73848,
228782,
66115,
46199,
105803,
177078,
27803,
249898,
30659,
36711,
165306,
35816,
35259,
19287,
167884,
30514,
179690,
186470,
null,
80436,
51019,
47927,
93501,
206393,
295437,
141457,
130712,
2743,
302553,
11452,
27770,
275904,
null,
292047,
33408,
83305,
346034,
276397,
462097,
209210,
null,
21414,
84744,
51433,
90189,
39445,
100242,
79094,
266382,
8216,
57244,
141447,
360384,
66367,
247010,
333862,
null,
107374,
null,
148197,
61513,
93697,
52444,
326147,
128882,
93242,
542590,
277160,
47012,
86186,
66923,
130678,
180511,
165629,
195704,
35423,
191601,
22543,
459371,
68036,
59486,
21819,
323760,
7929,
null,
23189,
27816,
null,
60719,
184057,
47885,
230866,
375630,
23068,
66297,
153423,
32442,
39952,
25960,
19755,
null,
27806,
149570,
23717,
175879,
83626,
7065,
234605,
null,
280476,
18006,
123634,
null,
null,
331435,
26679,
null,
39784,
50079,
26689,
null,
842264,
260800,
74520,
16476,
290598,
262208,
316049,
106570,
363826,
9606,
null,
161371,
764451,
64593,
213795,
117145,
26992,
14975,
319286,
375809,
31098,
53830,
19236,
273210,
274529,
648329,
93168,
217827,
30855,
181100,
321651,
208057,
27506,
12918,
66701,
null,
299470,
20448,
499317,
411751,
45597,
21590,
92044,
null,
28821,
92970,
28874,
58229,
121843,
68547,
131283,
198070,
60661,
30280,
23701,
10415,
43117,
81798,
14951,
461422,
11421,
16921,
128285,
46316,
null,
35187,
95551,
33168,
53745,
133336,
4359,
464856,
24977,
179775,
117040,
null,
79306,
340688,
null,
142844,
88218,
135617,
576586,
21735,
15765,
154518,
269224,
3833,
73312,
25138,
111881,
222327,
382826,
2366,
64573,
53160,
161193,
138908,
198448,
4685,
245523,
null,
25704,
49507,
143760,
277260,
null,
null,
30455,
324057,
17053,
null,
3772,
31761,
380274,
null,
null,
546902,
12975,
null,
125597,
120668,
173360,
172092,
117638,
67143,
9086,
48782,
75862,
114739,
18506,
75454,
20366,
36003,
21468,
38779,
59589,
53174,
6792,
192519,
163061,
null,
31956,
197937,
228154,
25257,
336485,
18734,
213799,
21636,
6264,
27580,
288031,
88826,
312354,
236744,
9862,
null,
86787,
15235,
54767,
317755,
40035,
165009,
34276,
74720,
218580,
33128,
32696,
18381,
42226,
null,
304314,
53385,
46070,
19525,
17087,
32548,
154715,
27375,
15176,
164056,
11864,
13901,
140996,
224943,
323675,
null,
25707,
6455,
29479,
135873,
423901,
null,
91397,
414558,
54538,
30408,
172583,
37239,
373790,
46521,
478629,
92971,
null,
349953,
151994,
167804,
30184,
92421,
249491,
366417,
232856,
43139,
21716,
27133,
null,
22245,
31968,
337368,
335974,
167867,
87717,
333766,
148528,
30258,
62713,
384804,
220056,
49672,
231810,
376544,
505816,
39247,
137418,
13113,
245821,
487718,
22280,
23064,
6388,
15892,
273334,
21313,
54783,
66382,
60173,
18154,
439931,
228039,
40050,
440077,
208732,
350664,
270973,
57263,
56133,
19542,
52822,
94730,
null,
32809,
475642,
133942,
149577,
267105,
250243,
10703,
195721,
5348,
9436,
87390,
98465,
141791,
187534,
6300,
13966,
166695,
null,
119904,
35353,
277063,
12318,
8058,
183277,
364508,
205124,
259843,
154162,
102959,
26596,
59560,
174439,
134180,
275050,
181777,
null,
null,
251355,
313676,
4320,
110992,
87548,
265857,
52677,
88125,
71269,
475017,
13081,
16707,
273681,
15496,
134889,
28158,
66383,
181856,
93918,
13230,
176684,
21709,
323338,
null,
24915,
386109,
null,
236450,
14641,
33949,
68292,
333421,
56613,
95449,
154623,
95228,
74389,
209942,
37309,
170928,
13508,
135034,
155939,
127737,
30077,
506449,
32591,
368452,
13516,
null,
114466,
13153,
334919,
227613,
46912,
119814,
734106,
91103,
9517,
217880,
36477,
4466,
null,
121461,
30334,
106988,
31762,
176033,
633003,
0,
54639,
77816,
null,
640105,
43861,
45870,
51149,
43083,
18915,
127212,
91099,
93292,
160006,
42843,
34858,
34730,
47355,
20416,
671981,
104645,
12424,
296389,
27370,
28050,
203396,
11542,
223671,
36689,
66385,
358766,
42924,
195959,
146102,
118142,
166609,
165366,
47291,
43375,
74382,
111361,
null,
26930,
26932,
347202,
52625,
305755,
322460,
160676,
66405,
27711,
63524,
33948,
10465,
22426,
41223,
12150,
205050,
null,
56483,
14947,
193434,
75170,
37122,
36390,
110889,
217101,
22549,
27734,
58054,
34854,
154513,
133934,
241030,
16461,
332381,
196514,
30642,
356807,
19579,
72741,
134744,
24772,
337142,
146644,
60674,
86491,
22479,
339998,
39531,
253274,
210918,
9625,
11908,
122412,
31721,
328642,
266063,
11002,
42741,
null,
22939,
151065,
11999,
352038,
277285,
345401,
236915,
13656,
36308,
153618,
24653,
413240,
33316,
303608,
191774,
69426,
231895,
17545,
256287,
33935,
4680,
598165,
9459,
79155,
17164,
144494,
85031,
124893,
73119,
330975,
170016,
396512,
24615,
null,
23305,
208487,
29528,
28306,
41678,
12648,
3154,
348405,
1689,
55764,
15067,
22950,
247905,
288763,
331340,
14671,
39605,
3895,
25463,
39355,
116112,
67010,
69263,
227903,
43828,
217077,
109185,
219283,
18573,
207290,
122775,
172714,
null,
9919,
176625,
67541,
83947,
291268,
34985,
527849,
93065,
98360,
390006,
null,
77382,
13115,
326394,
31163,
null,
26670,
23692,
80285,
36295,
256738,
227590,
45686,
null,
281929,
196393,
420292,
209432,
2577,
7922,
37403,
null,
124639,
103885,
32611,
110321,
35308,
30893,
132156,
39175,
4785,
4225,
107347,
93483,
122525,
48860,
174810,
98206,
null,
205743,
9335,
135929,
72569,
3282,
801630,
22716,
61565,
82752,
153516,
4578,
51988,
24972,
29516,
108094,
36697,
27374,
160070,
null,
273371,
47218,
55415,
256953,
18031,
23678,
45869,
286154,
null,
389119,
75818,
37227,
39631,
64550,
30722,
11758,
76663,
22223,
127954,
165675,
64420,
41217,
23697,
144239,
45130,
290086,
98286,
13018,
248124,
null,
33486,
23656,
167290,
null,
8585,
58958,
102323,
165499,
234442,
19908,
379421,
78528,
211408,
504057,
300208,
377964,
183700,
204642,
16858,
185380,
14514,
74079,
17397,
51113,
195975,
19938,
null,
92674,
147914,
236339,
35161,
null,
34424,
21591,
31635,
84009,
289402,
298172,
17709,
87639,
25728,
51583,
29263,
147800,
7574,
40358,
155286,
144375,
436447,
12720,
22982,
512913,
27748,
97693,
26011,
null,
187098,
44224,
16877,
397817,
31310,
150516,
579989,
179894,
19625,
272467,
31681,
161628,
297438,
310904,
355421,
14051,
171973,
574148,
82587,
137595,
28909,
413873,
188633,
44765,
null,
11794,
2389,
12278,
32546,
115758,
66342,
336771,
27761,
19485,
204997,
70330,
16135,
124105,
181610,
null,
283144,
12959,
44857,
254042,
52732,
257082,
70851,
402777,
34192,
null,
45741,
253265,
333197,
null,
260345,
87982,
273998,
326786,
55133,
null,
75952,
13734,
12930,
204768,
162158,
211393,
45831,
115521,
38640,
123261,
212501,
288080,
59509,
41067,
63841,
223225,
140906,
144908,
486750,
38271,
26080,
152020,
31966,
70984,
34619,
147428,
159886,
39066,
11805,
31490,
23891,
13464,
67595,
16937,
62438,
null,
137413,
null,
73139,
160299,
10235,
28959,
166249,
17969,
88844,
160006,
167558,
111324,
141572,
110254,
207444,
165942,
201234,
286204,
207687,
159665,
166906,
193630,
256410,
246491,
392483,
27316,
419418,
5743,
348153,
73899,
40263,
93777,
286554,
19178,
13996,
24191,
null,
80320,
69447,
37393,
27960,
13869,
null,
119365,
221959,
168914,
91426,
15721,
11123,
126055,
39970,
464976,
61783,
59642,
76188,
216501,
27519,
64735,
null,
346472,
33663,
229247,
189631,
501121,
null,
11740,
46936,
108228,
183428,
104656,
121378,
62998,
235037,
139839,
11273,
22438,
39854,
48149,
6575,
32792,
73527,
16004,
9829,
354902,
299655,
244399,
59627,
null,
25843,
153969,
618236,
58071,
258422,
347263,
255634,
22625,
21084,
33818,
17162,
477646,
85179,
29744,
151765,
38075,
116797,
153678,
279849,
55841,
205378,
86247,
69329,
78919,
39188,
122612,
57230,
161115,
322169,
62524,
207363,
236772,
70011,
198703,
null,
417009,
224199,
272754,
300108,
304515,
41705,
10553,
11432,
34689,
158339,
11215,
null,
43429,
232579,
213845,
33049,
48390,
168422,
13415,
45131,
162655,
33633,
46502,
8514,
17867,
235331,
120327,
38039,
211702,
25035,
187230,
152030,
53892,
48718,
null,
44231,
27892,
47730,
63526,
240552,
277258,
null,
50232,
597042,
null,
26399,
103438,
55078,
278320,
83387,
59465,
752428,
393847,
null,
12277,
81786,
863497,
303095,
2018,
13226,
325972,
134836,
274092,
null,
172824,
10485,
18945,
23624,
null,
110924,
19836,
33823,
408871,
22771,
24885,
null,
208732,
11035,
25844,
490914,
40969,
256731,
228711,
13030,
35331,
146522,
35395,
29258,
66065,
23761,
312773,
68169,
1248,
342204,
72191,
26713,
161331,
26683,
14775,
138113,
163952,
45592,
214355,
30337,
11489,
572019,
51304,
null,
150553,
230542,
50564,
140794,
111005,
210367,
164626,
156457,
null,
145671,
170305,
223292,
null,
null,
43207,
102054,
261240,
27125,
19892,
8329,
5187,
33840,
82006,
null,
null,
22706,
12025,
546680,
null,
28067,
13701,
null,
327799,
9692,
232112,
null,
25641,
242348,
105331,
582627,
52609,
324801,
36351,
31534,
165859,
42520,
359720,
21846,
27857,
213896,
420784,
15764,
21269,
66313,
115821,
7889,
813,
244992,
null,
290172,
101665,
26407,
211210,
39254,
null,
24625,
43005,
209171,
362545,
73064,
86628,
13214,
111070,
240881,
59693,
57064,
114774,
32618,
217812,
66380,
80563,
8214,
172194,
62438,
384525,
18199,
43871,
229181,
35611,
51563,
null,
85825,
263247,
12322,
30489,
9614,
42284,
27429,
171044,
70352,
36745,
43852,
289734,
21689,
188302,
162710,
154991,
4362,
104434,
58436,
171249,
5414,
null,
43078,
60732,
16111,
null,
434348,
15615,
46090,
73925,
168073,
12270,
41603,
null,
70797,
54012,
11397,
null,
141743,
177335,
3986,
18270,
229032,
558652,
30296,
42931,
66999,
440144,
null,
81632,
27730,
41301,
28321,
63076,
585519,
101917,
225114,
133982,
120729,
293291,
null,
28525,
47380,
49553,
121370,
368520,
93765,
null,
69636,
32735,
63748,
9070,
85601,
null,
43594,
95312,
56700,
9859,
39648,
6164,
319883,
null,
null,
342156,
469455,
17434,
65619,
207040,
7194,
null,
33800,
283527,
162992,
35517,
14622,
null,
63240,
33672,
null,
21281,
38650,
146243,
8733,
136865,
62505,
null,
26441,
53522,
451563,
97469,
12109,
424214,
81571,
50130,
20707,
9284,
null,
185361,
267750,
147820,
230803,
null,
239936,
192192,
44201,
85336,
213818,
18061,
220542,
80526,
363088,
435854,
37441,
111436,
null,
458194,
null,
20296,
24166,
58434,
110073,
34521,
185326,
null,
63545,
139935,
513450,
59779,
274286,
null,
32137,
52981,
null,
61632,
null,
409826,
31833,
42576,
16281,
245389,
452712,
79555,
186560,
6786,
301488,
9796,
243963,
17755,
29147,
11474,
166263,
215261,
27563,
42504,
32306,
39792,
16689,
6050,
487603,
37938,
6025,
20694,
25640,
78490,
10192,
71264,
63231,
16746,
378858,
33921,
288417,
177287,
4361,
54993,
126895,
24620,
null,
225565,
92230,
19038,
100621,
74963,
346189,
null,
24189,
62166,
33026,
null,
299796,
124589,
null,
52127,
8396,
919563,
17621,
433383,
209074,
134572,
25963,
771805,
15665,
344653,
38719,
55218,
216435,
29409,
106677,
48538,
297273,
229781,
12737,
85715,
183607,
217320,
298047,
16246,
24491,
69701,
191835,
38645,
48584,
8045,
189174,
72288,
18583,
90892,
362196,
79663,
null,
14340,
12772,
62621,
23472,
31985,
18836,
19122,
46072,
44057,
68070,
null,
508983,
271194,
538310,
67616,
82911,
18558,
164146,
251229,
57891,
434833,
218671,
49340,
23667,
162607,
339819,
160202,
93880,
78805,
394260,
268931,
39950,
36306,
5451,
122145,
284810,
8721,
144169,
40283,
14182,
34577,
66407,
null,
182017,
null,
321167,
56580,
145130,
5255,
282341,
28830,
276413,
96161,
19275,
48261,
10874,
179324,
null,
29239,
143152,
17938,
4578,
419519,
62810,
146808,
180300,
null,
11819,
155040,
null,
45596,
309550,
66937,
null,
85528,
19660,
null,
117934,
50007,
136278,
538687,
50667,
41823,
19670,
66042,
65360,
167313,
57896,
206370,
159800,
115476,
224625,
77772,
229872,
23427,
18915,
null,
240844,
24710,
73434,
29075,
22767,
47568,
642921,
17436,
413564,
4964,
5097,
null,
20168,
279682,
17275,
184614,
113574,
330056,
97905,
351907,
174107,
829825,
50449,
30285,
164318,
132862,
36743,
17663,
38439,
162679,
12393,
7259,
11089,
204332,
153086,
77215,
190533,
61424,
8196,
57217,
75707,
231565,
31488,
274781,
20269,
197888,
271898,
35787,
28971,
62342,
440850,
18431,
384316,
51039,
15336,
47154,
7259,
387061,
16937,
82297,
434276,
23291,
37768,
null,
16719,
349162,
216633,
420169,
70745,
27682,
203180,
null,
362011,
228461,
79080,
15392,
223213,
191871,
390575,
177889,
null,
13624,
null,
null,
80647,
493966,
196027,
147624,
22076,
43456,
272615,
189260,
50665,
138697,
23541,
372271,
146848,
null,
22095,
null,
78937,
419282,
13271,
25942,
128597,
20272,
153072,
7946,
55532,
36376,
596918,
96952,
166252,
null,
14040,
26700,
171248,
54617,
10615,
15178,
32342,
28213,
107675,
287144,
311334,
70145,
null,
null,
34557,
8102,
137171,
7589,
328647,
159361,
13661,
122296,
125007,
190021,
388757,
19549,
60778,
32173,
210996,
16082,
72184,
null,
45421,
151774,
22244,
33532,
353468,
233112,
49949,
309500,
47973,
164376,
77006,
36850,
156165,
null,
102822,
27023,
143306,
138752,
147702,
17749,
140232,
null,
507679,
31318,
200902,
335552,
161391,
35877,
15796,
204086,
48498,
78652,
20002,
3860,
21238,
394102,
280516,
null,
55014,
112946,
9146,
319502,
null,
158147,
24615,
287430,
null,
251513,
5446,
11975,
42599,
134793,
41507,
null,
147720,
10210,
11181,
48695,
159427,
334694,
226521,
18053,
266167,
4026,
16736,
99444,
101450,
12387,
16233,
25896,
43360,
133216,
265564,
10382,
17121,
46319,
24317,
69653,
205290,
299028,
639604,
23623,
8679,
275541,
94101,
73916,
23117,
231427,
null,
91327,
null,
218253,
57902,
48941,
111636,
251136,
321950,
409407,
109465,
138904,
76290,
220646,
35962,
238922,
68048,
30796,
23021,
66555,
4279,
18110,
214913,
192847,
3989,
33434,
211796,
47493,
36900,
33508,
204744,
346203,
null,
49537,
176272,
362968,
35397,
501809,
31045,
21987,
5884,
190549,
664658,
null,
72865,
152447,
68386,
12512,
1130217,
33426,
46702,
112796,
5443,
7849,
251593,
43113,
248450,
122633,
null,
125684,
null,
18504,
342967,
10730,
4835,
22657,
276995,
51172,
133877,
8913,
550953,
219590,
134917,
404818,
89926,
21647,
99300,
39212,
63770,
412915,
5806,
184737,
50835,
25615,
27080,
291027,
27123,
77658,
19915,
442061,
36979,
26697,
8151,
61021,
7979,
250969,
347095,
62389,
208666,
232320,
null,
110055,
158232,
399057,
127169,
399462,
45094,
145830,
225692,
44361,
233750,
null,
100549,
313787,
29318,
46887,
6688,
23580,
null,
39152,
null,
199700,
349271,
189575,
60779,
17852,
59755,
232067,
17337,
null,
143734,
117065,
365929,
53012,
746647,
47084,
386739,
6592,
null,
31525,
647150,
121609,
6613,
205671,
23537,
477505,
210826,
10390,
34773,
50780,
103512,
29163,
12402,
11796,
119515,
null,
36229,
207393,
216254,
125947,
18061,
null,
17238,
110647,
248489,
165869,
133836,
168996,
257623,
null,
73576,
26163,
11346,
179397,
291662,
19247,
54067,
31266,
50226,
39296,
241897,
34246,
83098,
26815,
457,
33189,
72281,
154711,
135614,
25182,
26642,
57241,
108522,
20133,
49778,
143628,
54408,
535737,
319493,
174306,
23918,
65357,
60606,
22386,
59944,
12996,
199561,
50095,
148003,
191221,
228024,
32080,
40374,
144802,
34048,
4539,
467352,
392651,
285848,
29219,
12257,
102099,
null,
29924,
88393,
34059,
469214,
6699,
228784,
39825,
245486,
159778,
177623,
53569,
4074,
16557,
30330,
53370,
147727,
109765,
41432,
369065,
471587,
50926,
45911,
8143,
12543,
34753,
24725,
169516,
249316,
359670,
80775,
390243,
130040,
24569,
39814,
612156,
13971,
29700,
13515,
48043,
11113,
null,
111004,
12996,
36592,
17750,
94797,
119141,
null,
80843,
208045,
338594,
10202,
225195,
178108,
35563,
39558,
287559,
33861,
153545,
2524,
50695,
211360,
239459,
322479,
21890,
29654,
22931,
66154,
77744,
10214,
127656,
27909,
151047,
62628,
51925,
301056,
8038,
260191,
324106,
157310,
245347,
22578,
136513,
39496,
27781,
247806,
41153,
241685,
151521,
608705,
64380,
288342,
175088,
372618,
62947,
33224,
97189,
44904,
null,
72972,
null,
null,
22767,
16902,
47244,
320160,
443707,
29193,
178822,
314357,
12554,
319490,
58122,
null,
188415,
371631,
444192,
251234,
35139,
234682,
38385,
135676,
114643,
81302,
92474,
8274,
19229,
3881,
263171,
60315,
154591,
32184,
165791,
30940,
223706,
24102,
21226,
205802,
231058,
36673,
189333,
222743,
24166,
348786,
52424,
15493,
15371,
341056,
56059,
450438,
163160,
18042,
37989,
317543,
18105,
76248,
56955,
20930,
14091,
null,
16007,
186861,
25181,
null,
25567,
164193,
140166,
44862,
158206,
187066,
4356,
26957,
32532,
null,
127377,
21300,
82500,
79682,
437175,
142078,
64377,
221634,
164209,
23073,
12708,
129424,
70246,
null,
null,
43422,
107735,
456152,
122266,
177590,
179131,
37639,
12814,
63052,
null,
4980,
27226,
141672,
32255,
null,
146277,
412145,
null,
48395,
211706,
7142,
369276,
14395,
34676,
89180,
233908,
52695,
null,
25048,
51990,
9801,
45215,
4306,
142114,
159446,
186879,
59964,
676621,
null,
34443,
null,
188989,
215369,
233688,
8907,
145803,
116489,
9966,
80508,
71601,
190417,
87664,
null,
197044,
26470,
20209,
204774,
336044,
23420,
9766,
73073,
14232,
240595,
411,
73790,
376563,
65899,
378149,
126278,
121748,
null,
87579,
6869,
265944,
49684,
108463,
183648,
172351,
5907,
35429,
27828,
64455,
10652,
127601,
5980,
295407,
203627,
380794,
4394,
52245,
134230,
5356,
37278,
266083,
470925,
220637,
66553,
47738,
null,
86713,
14031,
251202,
13729,
null,
842241,
110039,
348589,
288712,
65780,
113849,
97878,
51313,
45941,
208042,
70536,
293112,
95783,
16070,
null,
81810,
34543,
156002,
102994,
143883,
194195,
67926,
47070,
296058,
48226,
176926,
null,
110602,
40106,
304490,
172692,
13268,
48808,
41165,
25874,
115787,
888029,
1801,
152689,
9753,
11663,
30920,
12656,
614213,
456180,
54745,
9873,
10786,
74494,
128435,
16903,
35832,
10903,
100817,
9900,
94971,
124780,
479833,
208234,
22088,
99410,
61967,
44043,
216167,
240457,
96387,
367322,
364346,
13163,
60077,
394286,
258688,
17021,
29836,
62007,
35147,
23568,
null,
184144,
9534,
21731,
14955,
278541,
19888,
220179,
143919,
77968,
15930,
44530,
null,
50253,
44994,
52247,
24978,
15157,
38841,
59137,
180392,
38556,
218439,
386869,
262639,
198796,
243464,
135435,
240192,
32585,
14392,
464467,
257208,
8972,
33108,
189581,
122913,
450298,
17223,
9772,
11676,
426399,
168627,
6686,
312841,
256586,
183911,
null,
30247,
null,
7515,
53480,
160052,
418119,
362823,
180613,
null,
17159,
61678,
333964,
269204,
547924,
65853,
221666,
22434,
43137,
329838,
32045,
243966,
95266,
25172,
48419,
9837,
null,
17790,
137035,
178519,
53062,
466907,
30901,
21353,
48253,
null,
null,
429189,
31854,
350864,
25203,
null,
267424,
46199,
10781,
261996,
184858,
15481,
315647,
162812,
12297,
202930,
26172,
null,
97231,
25953,
11229,
126870,
60116,
2056,
207412,
71700,
35883,
445283,
115875,
154720,
118686,
100303,
167017,
25003,
339546,
13100,
11289,
277373,
37211,
null,
17507,
18034,
null,
15156,
26202,
321842,
150419,
24134,
56779,
24309,
23730,
34629,
23313,
21969,
35888,
35564,
92734,
160530,
163057,
null,
41577,
31938,
7795,
50699,
50375,
null,
18012,
null,
41025,
306136,
13300,
450759,
240067,
108717,
30327,
54193,
38164,
118964,
164505,
479234,
33073,
176306,
15152,
134412,
161431,
null,
8304,
35829,
12219,
216713,
128357,
254733,
15397,
null,
221053,
968,
170274,
184676,
143663,
37540,
90283,
185711,
525530,
null,
75098,
50977,
38016,
7045,
295896,
232591,
126599,
null,
84454,
6166,
165714,
41598,
23242,
61241,
32040,
null,
137888,
14618,
null,
208953,
325042,
127582,
8497,
162791,
17066,
20853,
32419,
38293,
172789,
32172,
199282,
21239,
134716,
null,
255781,
71288,
36486,
236530,
43404,
null,
148865,
123086,
199377,
44735,
53978,
48662,
null,
16776,
274646,
10852,
51674,
311178,
25552,
299483,
286870,
235881,
12787,
8646,
56439,
143739,
330124,
19932,
24226,
18555,
44068,
131422,
362078,
32754,
335856,
43217,
1105509,
294628,
35444,
296389,
381071,
10076,
42445,
28734,
316763,
370157,
392028,
13771,
214891,
237625,
401760,
313652,
324360,
64742,
31143,
34808,
null,
112326,
126164,
286064,
18005,
30183,
339783,
null,
40560,
176814,
28618,
251039,
348126,
148309,
106688,
130998,
32953,
28233,
492524,
380177,
163547,
262530,
100842,
438980,
32933,
321631,
240116,
186782,
474440,
17979,
232857,
28974,
168653,
168285,
101781,
356100,
125989,
83515,
40829,
115571,
169858,
792818,
125264,
317134,
190079,
201572,
83044,
6996,
296466,
62240,
322850,
21605,
43896,
18396,
null,
89380,
156949,
434404,
172314,
277455,
316187,
18429,
145909,
32321,
30999,
null,
289647,
null,
102412,
58952,
243208,
111830,
28905,
295403,
142411,
24394,
65390,
4103,
18276,
null,
51811,
38866,
216108,
53541,
null,
3116,
310735,
107945,
13319,
218446,
121556,
250801,
281120,
288660,
10012,
540688,
349456,
41560,
9184,
15302,
140724,
247588,
null,
142650,
209422,
98475,
12903,
null,
87990,
125995,
56146,
7932,
350995,
13913,
119716,
239100,
10816,
34175,
391437,
44293,
25995,
null,
203050,
74496,
253418,
23083,
null,
282529,
29705,
406338,
54054,
128313,
9873,
85000,
58148,
208491,
404188,
221948,
100240,
548248,
140916,
123793,
670200,
595712,
331746,
34989,
17916,
264807,
6615,
28639,
44502,
89849,
504288,
9505,
22887,
151580,
29104,
38195,
51969,
173823,
107564,
49374,
49643,
216450,
149903,
null,
28309,
29584,
62269,
280182,
33378,
256209,
277464,
19218,
288160,
32839,
113781,
84407,
243360,
20184,
247545,
179562,
51757,
127035,
253219,
40917,
364976,
257787,
24668,
187373,
50861,
15884,
34345,
48223,
132807,
358518,
559952,
33159,
14107,
41269,
45336,
32200,
204637,
54582,
67571,
null,
321215,
281197,
123458,
350455,
72580,
243768,
408916,
32910,
171456,
757673,
62203,
22740,
24211,
387488,
253172,
835947,
83248,
null,
28103,
24485,
59783,
616829,
75661,
68790,
null,
247870,
324347,
129494,
10105,
43450,
49974,
null,
64460,
22584,
null,
217988,
419205,
9795,
166983,
218521,
16394,
10284,
44374,
29120,
25504,
147514,
7613,
154313,
92939,
83641,
20085,
null,
35533,
24466,
298955,
null,
61550,
7553,
32407,
284660,
67758,
138224,
57339,
408419,
44859,
392971,
null,
179949,
127392,
5781,
153141,
279416,
254287,
54810,
34775,
232880,
40765,
57075,
151624,
13958,
156806,
37306,
17220,
null,
390933,
252272,
17146,
120613,
7426,
26869,
null,
419099,
80412,
11956,
16079,
15652,
19391,
541955,
154261,
742153,
26589,
33981,
187097,
7274,
203800,
161363,
39478,
60257,
56456,
53785,
76392,
12349,
189519,
165913,
33177,
243597,
123168,
62472,
14306,
176681,
140921,
173280,
null,
335000,
282180,
4970,
28694,
22612,
282894,
212560,
134932,
8368,
76078,
19352,
187592,
638741,
227221,
null,
13252,
88423,
271558,
23626,
60238,
46771,
17752,
63310,
20291,
420182,
81663,
61507,
6651,
104633,
137795,
null,
6149,
283253,
14056,
12478,
12014,
252204,
97442,
155572,
24001,
46115,
548787,
108341,
141596,
124663,
null,
9414,
76043,
179265,
31067,
323494,
null,
77965,
437212,
15624,
315706,
148216,
null,
35670,
85048,
14813,
134890,
118397,
230799,
165748,
312399,
null,
24370,
13752,
21670,
352862,
47655,
10292,
61793,
227941,
64442,
27201,
20481,
21184,
82167,
199614,
411303,
19321,
99726,
97726,
null,
191585,
18491,
60899,
48497,
25288,
18012,
246600,
19554,
null,
40521,
226859,
358155,
49326,
59212,
7523,
7368,
277503,
56741,
66086,
123972,
15867,
305409,
348127,
314109,
30415,
159943,
18817,
298635,
161899,
301580,
15808,
87089,
15079,
325857,
null,
43578,
null,
26528,
10975,
30954,
193438,
86345,
60133,
50981,
93110,
167542,
12262,
79222,
12551,
84858,
null,
71968,
74681,
123281,
170056,
151328,
407860,
74960,
355436,
153068,
160918,
61967,
59227,
286995,
null,
86312,
30309,
129276,
59068,
18104,
960484,
186664,
306122,
79080,
32159,
21356,
13680,
42004,
43826,
21077,
34499,
236437,
631554,
129836,
28438,
290826,
106741,
27296,
15361,
90583,
19911,
308161,
24564,
154274,
15017,
16689,
47824,
324636,
112160,
511459,
43299,
null,
228271,
112861,
30551,
36260,
233972,
23363,
122915,
75778,
282657,
296025,
429666,
null,
24878,
344877,
405338,
null,
180780,
57473,
30572,
275769,
198772,
164914,
7586,
null,
286020,
null,
41567,
115132,
53357,
53169,
52594,
null,
109750,
302488,
38148,
9825,
66194,
89976,
null,
181774,
22698,
45242,
170454,
414960,
31091,
10449,
492378,
63971,
45966,
265726,
27547,
null,
19357,
156160,
31303,
37855,
36943,
null,
387281,
96784,
86591,
null,
188416,
94684,
255334,
null,
52103,
35551,
49900,
9210,
61074,
28203,
247639,
289575,
26868,
66084,
26849,
100618,
430406,
48341,
598839,
null,
290168,
12761,
109477,
177073,
775773,
155411,
10578,
null,
47151,
12122,
27846,
64330,
216301,
21352,
44306,
47241,
40959,
null,
241594,
18510,
21438,
374254,
null,
18206,
644130,
32972,
15944,
41941,
114708,
null,
45783,
33226,
190046,
30187,
59688,
38957,
670231,
null,
26796,
31366,
17690,
229770,
6831,
568444,
175622,
30613,
4383,
160933,
9118,
28334,
16825,
null,
14337,
417237,
4294,
348380,
7167,
95351,
null,
34867,
null,
16315,
33004,
28352,
16133,
35899,
16588,
42045,
515821,
36967,
294899,
33590,
null,
19327,
152204,
356876,
426594,
14251,
97958,
42546,
475841,
31869,
62741,
397615,
null,
49086,
20156,
15611,
329803,
37568,
283393,
110361,
78979,
118276,
258440,
417409,
49117,
23566,
15060,
57643,
32791,
37010,
null,
38774,
415201,
10837,
401533,
283334,
111550,
35120,
95860,
59484,
38219,
286242,
150774,
9801,
35889,
176235,
56719,
226525,
24083,
null,
130037,
21695,
270259,
null,
28835,
10805,
null,
122526,
40179,
182631,
6235,
23744,
78076,
null,
150155,
14503,
26097,
30860,
57965,
140549,
82444,
268373,
43758,
null,
15727,
121326,
180071,
79081,
37087,
233959,
null,
94784,
13084,
50281,
521050,
124088,
169820,
233892,
136115,
32464,
9285,
401510,
313667,
391716,
360329,
35183,
254242,
234494,
421901,
340751,
29605,
124873,
101000,
19805,
24900,
35560,
177704,
120600,
43889,
35513,
635837,
284670,
14753,
296405,
935931,
27466,
350435,
222955,
46216,
18878,
200092,
80119,
304791,
13965,
102663,
249476,
21455,
54942,
13611,
336010,
44771,
50653,
43519,
119213,
171892,
20205,
68658,
308563,
28284,
33287,
null,
41891,
13479,
223079,
193339,
17620,
null,
147707,
486435,
null,
null,
180782,
217014,
18367,
11327,
6507,
354217,
87863,
226339,
271110,
159674,
61150,
125909,
29884,
79412,
147351,
62396,
254711,
46661,
7567,
null,
27245,
83174,
null,
null,
35754,
null,
40861,
65971,
38705,
34573,
34786,
63061,
27980,
153727,
572316,
null,
102497,
210263,
23575,
320751,
17281,
43664,
34538,
11375,
21376,
24467,
17409,
177916,
30223,
null,
55033,
1119115,
20222,
395806,
479500,
51463,
214986,
15016,
159963,
90908,
328356,
158768,
7498,
16342,
22388,
51311,
127658,
33404,
73406,
35119,
64745,
45077,
509592,
283089,
255538,
null,
125729,
109415,
37459,
null,
16427,
40163,
24387,
310689,
192601,
400735,
61759,
309006,
29859,
299110,
67008,
null,
184632,
12418,
10781,
385849,
null,
67033,
18522,
217701,
261431,
166557,
88606,
55250,
28992,
null,
32234,
180087,
4545,
275532,
null,
52943,
null,
16711,
23794,
32232,
499783,
6988,
8377,
4439,
12147,
118818,
19018,
15925,
13003,
null,
156978,
373559,
213097,
34833,
53913,
33525,
57009,
530937,
359203,
114113,
333188,
172566,
34985,
167318,
4738,
12003,
115577,
220807,
77853,
357683,
19651,
588409,
116555,
211023,
291546,
326063,
47242,
399247,
null,
75847,
15147,
null,
55985,
35048,
null,
199649,
68232,
144127,
312588,
134211,
195212,
73565,
389625,
35289,
156879,
null,
14084,
359505,
202470,
306337,
124145,
261985,
284747,
110993,
6044,
550387,
79514,
null,
63992,
78324,
55130,
18782,
115859,
7678,
288329,
213046,
10654,
null,
28397,
61021,
169739,
172023,
279958,
260166,
56753,
26562,
176891,
35953,
392669,
89529,
179926,
196558,
80009,
410286,
53718,
122325,
272584,
774224,
158838,
23183,
38880,
47848,
48821,
18363,
235942,
null,
234636,
38113,
31652,
3336,
267993,
51977,
35399,
245146,
157984,
5720,
33621,
316405,
43297,
60023,
618679,
416262,
202525,
16801,
268820,
274389,
308161,
122535,
12644,
null,
121687,
null,
65939,
18757,
319204,
104731,
198652,
461426,
23300,
27835,
39446,
265700,
5481,
211343,
118891,
137952,
105362,
305027,
451762,
24742,
30332,
30167,
114462,
192235,
35614,
22410,
153699,
21315,
23746,
25770,
366482,
27363,
233206,
65448,
214792,
30202,
106733,
488637,
46522,
238579,
null,
346840,
89612,
84647,
245714,
243038,
234310,
151266,
64836,
31206,
21320,
381289,
19962,
30845,
173349,
41078,
161466,
320641,
159002,
null,
269907,
22085,
71194,
null,
5071,
120159,
329037,
220210,
306003,
63555,
335922,
143228,
34206,
290138,
505436,
null,
null,
null,
20711,
48448,
8845,
5410,
178271,
62822,
327160,
null,
6425,
233923,
131373,
null,
44658,
334557,
99284,
435707,
null,
16012,
426998,
6155,
43414,
151619,
79991,
185022,
190576,
86235,
254770,
12697,
106886,
11554,
148690,
12279,
78021,
12991,
155662,
28484,
70057,
284255,
74798,
432748,
7020,
275078,
255779,
11656,
55020,
141527,
505045,
29801,
27656,
350930,
87027,
5042,
7940,
324215,
95849,
42464,
67409,
117499,
14811,
303367,
5063,
196873,
5483,
560359,
null,
87800,
182836,
null,
301802,
213613,
25247,
38267,
43812,
50636,
44015,
139061,
206357,
31178,
125178,
191140,
64436,
26516,
11214,
57780,
158837,
null,
41043,
39336,
130799,
71685,
15377,
187817,
13423,
179326,
12822,
6948,
294874,
18790,
194861,
26896,
27750,
102923,
466263,
17809,
1100864,
80063,
202265,
240146,
11627,
124025,
148812,
333274,
38984,
157649,
null,
40865,
74244,
196006,
57062,
53083,
32983,
43845,
165714,
230118,
16186,
16837,
23947,
null,
23549,
null,
293461,
440547,
59555,
25240,
17221,
7539,
72838,
86655,
162459,
145723,
243847,
3830,
174184,
16104,
179481,
45791,
330650,
533906,
65751,
298473,
7923,
null,
69464,
65634,
7881,
56254,
43336,
14767,
279268,
28332,
194846,
303709,
38309,
116773,
28841,
36236,
26703,
176148,
null,
80461,
134311,
61341,
null,
213091,
512739,
229672,
284623,
180038,
null,
null,
166146,
171418,
175948,
88109,
340874,
37625,
35806,
356456,
274580,
139084,
34155,
27598,
null,
63661,
27503,
14435,
4907,
118308,
60682,
133790,
13607,
23619,
72191,
171045,
29119,
468149,
212919,
null,
29805,
31518,
280549,
464236,
87369,
44957,
582466,
46960,
43934,
164462,
239354,
33092,
111310,
419786,
20953,
27642,
100697,
58595,
40103,
11160,
27863,
31188,
179645,
62916,
null,
190444,
null,
42348,
61603,
92959,
70516,
304895,
12096,
431382,
17180,
301016,
67363,
385136,
31717,
35721,
198888,
145329,
137977,
93951,
125957,
344035,
46160,
null,
260314,
19280,
211986,
192456,
430666,
38183,
90876,
null,
153695,
136852,
401796,
null,
27095,
null,
67300,
113,
15541,
313326,
51993,
85907,
51698,
294209,
259945,
31162,
552779,
34136,
38278,
null,
195073,
26465,
107271,
125282,
271068,
29129,
26925,
438770,
72737,
123330,
472332,
134083,
163388,
170511,
84926,
254524,
17975,
868690,
45996,
552475,
201533,
23589,
6367,
29479,
309930,
818415,
336377,
406760,
265073,
303826,
49130,
7726,
70494,
786977,
120227,
8505,
157826,
41841,
35806,
203584,
35557,
202646,
154296,
35264,
402371,
12756,
7354,
66788,
381550,
93842,
187664,
288247,
14910,
25086,
273740,
32001,
261315,
20966,
434543,
1109,
null,
null,
61004,
29100,
77529,
17952,
306516,
18785,
2757,
31386,
244159,
252697,
37907,
261458,
291964,
39532,
610996,
null,
231112,
235500,
61771,
28965,
null,
null,
30705,
25059,
20623,
122783,
146441,
163576,
null,
23798,
122569,
11161,
60104,
342896,
21774,
null,
273174,
11234,
15584,
175743,
377287,
224969,
444647,
42795,
20969,
55256,
93137,
116040,
49281,
17142,
183135,
null,
28134,
69922,
26857,
40483,
30662,
155498,
140135,
18968,
330813,
272741,
61032,
149413,
469637,
30500,
25444,
null,
117870,
144995,
109164,
128076,
65115,
188349,
34157,
140468,
23714,
50504,
29961,
69786,
100064,
201283,
22406,
351045,
12355,
24386,
76269,
358383,
41597,
57987,
59730,
177761,
107058,
306732,
106673,
32178,
591111,
27814,
19530,
82564,
10412,
null,
274237,
18837,
176678,
134510,
342611,
35050,
340937,
268474,
12723,
17588,
244307,
30775,
728295,
188156,
24190,
19056,
null,
33922,
50536,
42337,
151496,
10021,
100080,
302162,
83083,
317859,
156984,
145601,
210104,
238905,
null,
137042,
95307,
26537,
20298,
67070,
146424,
484939,
32413,
10638,
108432,
85733,
3084,
56356,
114056,
23650,
26838,
358108,
256585,
135947,
69242,
217656,
null,
225405,
116467,
25942,
34884,
28664,
14385,
17781,
72081,
400127,
199175,
102885,
28064,
38378,
43304,
4802,
40701,
725132,
13618,
223181,
475332,
null,
271745,
60225,
159930,
40023,
4578,
66351,
59039,
79503,
138134,
150984,
241498,
39537,
3762,
84734,
103440,
68006,
26741,
90104,
192911,
17600,
31772,
39038,
306686,
11514,
277116,
87020,
43233,
87801,
null,
null,
147312,
34198,
46384,
24276,
null,
48361,
14232,
60236,
48299,
11556,
45979,
515773,
5651,
47689,
38791,
19998,
16026,
null,
34839,
219162,
20937,
32889,
null,
354844,
148702,
46834,
270109,
103336,
23144,
null,
69617,
214657,
311065,
70977,
122285,
93565,
31411,
null,
122456,
18689,
19565,
353551,
235508,
null,
null,
31488,
null,
298077,
333920,
39142,
146555,
null,
189365,
278187,
147511,
173878,
28731,
50340,
512660,
51793,
174175,
359125,
142950,
21990,
306437,
160060,
null,
213509,
164713,
86911,
349077,
null,
27282,
25430,
39138,
33196,
null,
79232,
null,
158307,
14419,
33502,
31590,
83660,
415261,
null,
17673,
65942,
140785,
271135,
177382,
398760,
359154,
140426,
549498,
null,
248407,
585905,
597000,
462344,
209477,
null,
126379,
337559,
350831,
25597,
null,
28199,
117212,
32741,
16928,
1457,
217900,
30863,
557755,
null,
21646,
656367,
227985,
251063,
17539,
25196,
33350,
25909,
179589,
34433,
93264,
206007,
268333,
203528,
43337,
191794,
18167,
4261,
236851,
48080,
221612,
64560,
31458,
201764,
null,
31954,
208733,
41317,
257223,
104989,
19377,
210092,
137610,
61363,
34297,
221325,
null,
53164,
177677,
307787,
68249,
null,
28888,
49924,
null,
6143,
318112,
370115,
164500,
4534,
53802,
22037,
159971,
41408,
100684,
351074,
313709,
55879,
66427,
18870,
140815,
null,
43564,
33557,
null,
278807,
3474,
131464,
239233,
null,
24746,
60367,
56466,
395742,
1020893,
12195,
482359,
430988,
86369,
95025,
327379,
157635,
16449,
200650,
112239,
142789,
null,
12070,
32717,
25164,
13731,
435128,
84540,
165748,
182238,
12961,
61834,
3577,
152875,
265580,
12842,
33327,
58353,
54305,
278909,
27584,
null,
null,
31782,
237353,
34932,
45400,
257522,
224276,
295195,
228718,
58036,
50591,
194968,
64106,
19536,
434628,
73303,
136352,
41721,
270952,
27354,
37402,
232405,
33779,
284834,
null,
29873,
82390,
197981,
73205,
19463,
146375,
54256,
16410,
115618,
66043,
139705,
118094,
415864,
785063,
232939,
302330,
149237,
17126,
308755,
92576,
21231,
null,
417579,
24899,
null,
318327,
25768,
34464,
299507,
403849,
317891,
5814,
15610,
59383,
137432,
7451,
29817,
89129,
13629,
11589,
96905,
8241,
12583,
299769,
210338,
49721,
538718,
186749,
118647,
86139,
46888,
250162,
117139,
116278,
288058,
240703,
281299,
578806,
45302,
296294,
552654,
null,
195091,
47377,
18951,
229916,
322865,
20993,
169256,
52035,
243263,
43379,
null,
130002,
null,
435550,
null,
23751,
9615,
273275,
239023,
7580,
18336,
1813,
98755,
14455,
205492,
12192,
13462,
13521,
39663,
269073,
91181,
41681,
null,
null,
24105,
38707,
10391,
205768,
13029,
9312,
7025,
38917,
316,
6099,
79227,
352157,
45907,
null,
null,
6934,
11564,
64629,
42093,
178791,
252451,
27851,
19757,
98933,
26255,
182712,
18881,
70104,
44882,
168896,
201481,
215588,
211944,
281790,
17431,
9902,
332015,
62594,
25419,
23860,
27280,
3787,
230103,
228870,
56886,
29706,
128620,
40173,
284833,
49058,
185448,
320327,
84952,
270212,
103165,
600215,
62320,
18470,
179510,
186198,
88051,
43959,
667596,
23943,
46394,
300255,
144681,
null,
185622,
144432,
69189,
205846,
242646,
47852,
41048,
null,
null,
413757,
null,
null,
28997,
96652,
127051,
33810,
264481,
243558,
20315,
316266,
117204,
315841,
257026,
169882,
163363,
26858,
22814,
20336,
377370,
33023,
225619,
109894,
68413,
null,
152934,
94009,
11206,
null,
21445,
17290,
27762,
32136,
216541,
263162,
313700,
231395,
18953,
67324,
388912,
8351,
326324,
160509,
30890,
199127,
501903,
348759,
89339,
29386,
30996,
9045,
177482,
113671,
141920,
137851,
8028,
18291,
38021,
52509,
25684,
38992,
657945,
59236,
36601,
16300,
21308,
24626,
96963,
null,
331433,
184773,
30493,
42952,
4092,
18283,
243424,
272344,
86117,
134926,
9506,
46339,
204668,
null,
110009,
25017,
232023,
2727,
98510,
261438,
71247,
20657,
18418,
193225,
60540,
45041,
49459,
187531,
88813,
28978,
159608,
67365,
260125,
11237,
39795,
7209,
84933,
17641,
176225,
273976,
null,
291612,
37421,
3229,
17632,
14728,
15323,
3404,
62344,
36218,
32612,
247809,
31487,
null,
118229,
11736,
309658,
294392,
41517,
43363,
49467,
14980,
317929,
36026,
157969,
41655,
527184,
71635,
286358,
null,
132555,
471407,
190545,
38887,
70944,
134789,
31931,
364568,
450856,
31013,
68182,
6419,
514534,
65623,
157719,
219727,
148313,
22529,
34670,
82543,
290333,
37034,
15730,
8743,
35580,
null,
546465,
186051,
53121,
28001,
36308,
168084,
184378,
665974,
57124,
3990,
null,
65659,
127738,
151978,
31949,
418395,
157596,
24011,
35155,
392090,
18200,
28510,
156490,
41247,
64089,
122662,
120539,
null,
52897,
175265,
null,
30282,
93111,
169590,
351506,
78749,
60177,
239721,
20462,
268316,
109176,
23593,
22430,
null,
22986,
null,
376006,
456043,
11043,
174456,
134235,
33512,
42642,
33863,
229252,
171189,
155961,
222468,
424118,
160853,
22322,
362741,
305571,
96851,
357849,
null,
26858,
26944,
134478,
186590,
468818,
134445,
233721,
33940,
265865,
461645,
84662,
79409,
348989,
126496,
345885,
444457,
40281,
173663,
52898,
159319,
394916,
43743,
270668,
163212,
222184,
12868,
174753,
171865,
18885,
680973,
295554,
287982,
168394,
283708,
19188,
471351,
170624,
8681,
33375,
137153,
269889,
149898,
25886,
213653,
77551,
34524,
53109,
29054,
86001,
182514,
37124,
19214,
89477,
72701,
130139,
null,
64364,
244598,
46391,
null,
152649,
42084,
170542,
17035,
21597,
null,
76453,
58498,
9399,
315425,
null,
142926,
80958,
116879,
18965,
114277,
373090,
33944,
173807,
175008,
13511,
204665,
84286,
71718,
null,
36989,
201497,
275507,
70896,
386605,
162994,
315155,
77094,
152548,
68372,
77697,
20110,
62772,
117812,
126436,
12820,
34424,
57275,
20980,
18327,
458914,
14096,
59833,
128666,
8364,
157619,
143811,
52560,
37723,
31192,
30929,
41888,
347277,
58705,
249706,
null,
null,
289592,
179016,
12617,
50882,
63630,
187121,
46685,
38376,
487848,
null,
95621,
66002,
12486,
26286,
50087,
31526,
null,
108608,
43727,
109662,
148631,
27997,
11409,
null,
128036,
10923,
53976,
44554,
86754,
220110,
194771,
10925,
null,
61358,
412321,
243174,
15590,
40107,
267058,
110524,
192755,
38940,
126555,
252656,
459309,
247007,
290444,
142632,
232431,
27927,
216923,
282415,
237651,
93787,
202096,
207311,
7535,
389113,
70695,
189806,
4532,
133635,
123476,
53884,
19869,
162684,
128306,
38330,
25925,
40826,
135348,
34096,
192470,
203061,
104289,
null,
211609,
28408,
52796,
32946,
34327,
59814,
391620,
218434,
25773,
172561,
19930,
62380,
273365,
14779,
88057,
184517,
8499,
null,
21737,
288053,
148514,
51456,
75500,
null,
278186,
25505,
35826,
241385,
59320,
190740,
12307,
34915,
41526,
19214,
48156,
16563,
4227,
36873,
284973,
267608,
166382,
219391,
16315,
41662,
38011,
164680,
null,
null,
297682,
30882,
9545,
26570,
642828,
31496,
25561,
113520,
204452,
22114,
460115,
47424,
286319,
22910,
81019,
390559,
27709,
null,
27565,
32362,
63230,
15826,
16501,
287602,
671550,
62547,
369703,
53399,
null,
51767,
null,
273868,
null,
171203,
279909,
10031,
13834,
45512,
149092,
236451,
277407,
137903,
42009,
440608,
46982,
null,
288398,
null,
41862,
9587,
11528,
25309,
66212,
null,
88353,
60263,
null,
782877,
157664,
61521,
null,
170254,
13508,
222117,
477433,
61338,
19384,
31120,
149499,
43171,
null,
265686,
63336,
222683,
30813,
30703,
15677,
272433,
354010,
22108,
177482,
308880,
264167,
49187,
526027,
52094,
119624,
null,
16272,
45472,
null,
41201,
293416,
71176,
40156,
36294,
146567,
2261,
168575,
236050,
194322,
39054,
37901,
61049,
44496,
163197,
174560,
23676,
72048,
29728,
116205,
265684,
148452,
2015,
345354,
707133,
147607,
103864,
305953,
112339,
39180,
558361,
66977,
433315,
12873,
16443,
27783,
17114,
12391,
28778,
41810,
186371,
190279,
70279,
314476,
57872,
527215,
2590,
411284,
161432,
149872,
17689,
655802,
11123,
123123,
261622,
169229,
39148,
104850,
18304,
null,
529185,
276017,
25609,
32565,
175047,
24340,
null,
30997,
84538,
49748,
365983,
43613,
123358,
23472,
25808,
41403,
35696,
179699,
96059,
23508,
169591,
26695,
28792,
9953,
9147,
null,
136452,
286261,
29678,
63850,
284351,
171461,
116064,
182321,
48607,
266942,
68834,
18700,
31443,
50412,
246487,
658,
null,
224256,
342862,
11052,
312663,
135816,
51168,
37722,
34016,
27731,
221433,
41622,
83938,
35973,
84076,
155195,
42155,
252055,
95913,
179014,
14211,
281144,
236577,
166883,
41557,
null,
null,
180469,
350679,
36392,
189081,
205404,
7876,
105506,
14186,
24562,
183903,
37395,
null,
156073,
null,
null,
29580,
90463,
94977,
340638,
3669,
53494,
368802,
184652,
254873,
185348,
48773,
36921,
1294903,
66982,
144955,
30060,
188966,
204657,
30372,
336710,
177950,
18763,
417861,
197585,
19386,
25881,
199222,
149274,
176968,
19980,
178341,
93246,
112810,
328588,
35864,
36410,
61827,
98856,
24178,
138367,
476582,
null,
319557,
134669,
501363,
56566,
181533,
26054,
373795,
30519,
49300,
41111,
143244,
217626,
644332,
231754,
null,
9582,
141499,
13366,
26690,
195190,
null,
257169,
24101,
51233,
196624,
603295,
13620,
115859,
158088,
null,
81262,
16631,
4714,
685496,
76468,
null,
209533,
null,
16123,
270869,
119530,
56806,
6838,
17829,
200248,
35540,
22935,
123455,
null,
null,
146440,
19281,
19726,
196131,
213776,
null,
80032,
null,
201502,
505541,
14932,
23434,
296953,
401432,
50510,
null,
82747,
null,
7767,
15902,
52121,
86393,
170315,
20787,
11910,
180661,
212442,
97204,
144444,
30962,
320829,
199706,
17018,
53948,
25191,
5732,
31269,
213723,
303128,
29386,
98345,
285857,
353419,
25414,
160567,
null,
19893,
20399,
474368,
465934,
27144,
412146,
null,
342305,
10368,
191049,
null,
81556,
73152,
37660,
460588,
25187,
14302,
15373,
455975,
112740,
219458,
138779,
null,
80876,
112264,
271086,
9762,
71404,
138505,
76784,
71124,
179031,
15137,
15684,
191464,
11378,
21039,
107160,
42506,
67212,
217214,
30216,
159233,
null,
null,
74895,
645838,
33363,
146804,
29210,
26112,
45425,
239901,
74413,
56694,
28866,
371889,
117259,
87307,
67882,
271286,
null,
182649,
29569,
241819,
12252,
59667,
368108,
null,
258533,
166017,
null,
290942,
79390,
52322,
60110,
14104,
8392,
31132,
431805,
42280,
89053,
null,
43770,
368583,
2152,
403687,
72230,
88070,
15684,
185623,
143526,
263315,
null,
210418,
137500,
167526,
470945,
51179,
41091,
332695,
158735,
281481,
37292,
42169,
23405,
273514,
19398,
null,
8581,
null,
21149,
42843,
12163,
878127,
463633,
10362,
107945,
279224,
120046,
563031,
281933,
101997,
null,
101318,
92102,
337737,
212966,
149711,
21823,
171507,
329689,
117600,
318191,
12391,
229079,
191293,
6493,
51535,
81695,
8979,
216666,
5815,
315109,
55208,
182289,
141561,
21783,
361836,
17042,
31490,
10684,
147874,
61353,
45116,
28161,
54992,
358891,
165809,
null,
49345,
30968,
29155,
null,
309129,
33525,
278111,
16824,
null,
4200,
47444,
23319,
11324,
134277,
null,
165140,
36571,
8061,
460000,
8875,
null,
60421,
22659,
2784,
24639,
null,
null,
57020,
27910,
228964,
null,
244393,
null,
155641,
47768,
19179,
36868,
19849,
175691,
60018,
66758,
44602,
274395,
415891,
136695,
95672,
38120,
124735,
17214,
22392,
13200,
301843,
207326,
27310,
207166,
529738,
471383,
8018,
418439,
279923,
107355,
21269,
242463,
27464,
15563,
209467,
401101,
26009,
24939,
31809,
177345,
31397,
4209,
22062,
133642,
null,
34561,
29182,
175052,
144446,
212204,
61749,
303338,
274176,
5293,
18495,
15430,
37326,
null,
66971,
37002,
28891,
76486,
222940,
354440,
197868,
null,
154917,
929765,
26836,
5912,
231640,
17968,
44570,
4763,
346691,
214531,
525424,
16769,
145991,
145903,
30190,
83584,
477034,
376008,
121843,
160141,
44609,
48220,
31964,
48472,
27088,
31512,
null,
47975,
21679,
50186,
223627,
257369,
4605,
189821,
40333,
null,
325856,
16162,
91009,
431968,
238815,
null,
82687,
19469,
412695,
396328,
75668,
79654,
24449,
null,
87465,
29987,
32231,
null,
29734,
29470,
null,
8434,
75380,
15591,
313733,
6910,
82740,
5171,
null,
55274,
38236,
69354,
264554,
763089,
35299,
353236,
178017,
85990,
7435,
32605,
null,
9544,
58308,
109443,
418069,
20653,
307958,
45238,
86823,
9907,
331240,
37049,
67152,
175732,
102991,
154218,
276204,
129401,
108443,
25555,
162519,
519684,
140756,
191853,
94027,
324819,
319122,
288226,
35865,
419583,
null,
19029,
4008,
113898,
49701,
21113,
542454,
13699,
611969,
473122,
24020,
210839,
null,
138530,
41684,
34739,
406022,
11311,
220023,
55045,
86685,
135552,
217460,
244312,
85756,
70509,
39597,
null,
null,
132933,
62750,
61033,
135864,
5525,
184944,
null,
134379,
221014,
287480,
57829,
null,
8201,
185044,
56602,
590803,
52827,
12727,
160740,
77460,
103554,
17422,
null,
null,
102425,
110819,
45160,
21918,
46015,
null,
16354,
32828,
114057,
43688,
86425,
82215,
33323,
57064,
4167,
null,
275588,
70686,
91397,
446738,
3384,
462631,
24700,
39876,
124312,
46562,
278207,
47440,
45737,
229439,
39412,
null,
822095,
73010,
261523,
19180,
334538,
45390,
68517,
43136,
null,
29059,
193167,
25804,
38041,
null,
187551,
null,
125355,
9701,
135853,
24478,
34216,
280754,
82604,
140956,
34494,
305863,
157653,
65124,
249409,
25437,
122415,
288643,
null,
248356,
238898,
123522,
548880,
230909,
278277,
49483,
315899,
22255,
39063,
191581,
124011,
238330,
185764,
63610,
213487,
172646,
38598,
49069,
4560,
392617,
112867,
137023,
30156,
29809,
157739,
974449,
316666,
18613,
27261,
326831,
240250,
284292,
30743,
24093,
111311,
45835,
26072,
118171,
189469,
164500,
194668,
443160,
48206,
17401,
15118,
118619,
34225,
211950,
384040,
33810,
123344,
283896,
100149,
173859,
167956,
null,
317951,
77530,
398322,
42214,
381151,
57163,
145940,
2007,
235788,
125676,
20051,
4598,
57139,
198787,
38164,
129382,
9378,
251277,
71484,
526028,
15188,
217832,
130493,
247181,
13470,
9018,
15494,
166797,
132411,
141123,
null,
null,
58329,
148161,
268662,
53840,
457310,
60420,
202263,
31198,
10169,
6841,
null,
282783,
167457,
null,
157120,
217145,
147300,
378467,
100701,
null,
70972,
143221,
302404,
228588,
26690,
8775,
80103,
null,
45677,
251432,
227948,
53687,
9786,
273428,
590420,
236908,
316139,
23860,
12234,
24326,
288552,
315953,
21115,
163578,
722392,
240418,
29435,
150487,
492197,
20685,
132018,
72200,
296617,
20712,
287692,
195471,
5576,
162777,
63882,
82609,
50328,
226932,
338019,
779972,
190074,
null,
364293,
547560,
null,
172182,
251709,
552587,
292508,
130619,
50112,
22446,
164192,
13559,
24701,
179321,
2686,
95322,
212115,
37510,
null,
861063,
162834,
12841,
54492,
115544,
193940,
10690,
62474,
253889,
251556,
363842,
null,
76734,
155509,
22761,
128847,
null,
66730,
26770,
20379,
133445,
236349,
10449,
160501,
7503,
53253,
192511,
83010,
204729,
20450,
164634,
45737,
150830,
9925,
111668,
37408,
13858,
319317,
171413,
139746,
14835,
543641,
null,
386082,
216877,
null,
23818,
8094,
11047,
34371,
199623,
null,
377800,
35536,
39774,
187508,
13287,
24785,
null,
null,
10240,
409268,
23253,
27027,
30677,
332521,
392611,
29909,
42941,
28901,
null,
144966,
39547,
33896,
83997,
null,
383426,
329788,
237710,
8046,
11756,
276169,
33074,
null,
19430,
687955,
35687,
null,
653655,
34034,
13331,
34922,
102069,
123627,
168377,
66633,
333501,
7374,
20219,
37809,
73657,
56968,
27184,
56831,
405381,
null,
87402,
70643,
20340,
8815,
240628,
39604,
326513,
190053,
38756,
234033,
15072,
557401,
98203,
273206,
66603,
441186,
182531,
174656,
22927,
20436,
251048,
40406,
342876,
15531,
144448,
221578,
400319,
42458,
983839,
254281,
3798,
167198,
73182,
53052,
30934,
16395,
359169,
54711,
null,
93238,
null,
16222,
184201,
323063,
75770,
232995,
155584,
null,
83876,
4015,
49965,
113082,
19564,
530074,
103781,
99493,
null,
null,
40021,
53422,
33604,
279973,
17149,
107871,
239629,
50223,
194722,
null,
null,
75643,
16292,
141504,
42616,
143112,
237181,
8659,
321021,
54250,
64568,
46096,
null,
15489,
80818,
15529,
209210,
216484,
34861,
66482,
212934,
35068,
140508,
105032,
110883,
152574,
168188,
74840,
397630,
5081,
234515,
154871,
191472,
217484,
39867,
24787,
39341,
175429,
88248,
null,
141221,
106639,
67067,
72431,
602762,
227133,
56972,
9129,
58236,
23465,
160405,
20960,
194058,
30286,
16072,
18118,
18391,
613657,
5453,
26390,
76028,
36474,
51214,
397647,
141509,
163930,
8401,
37822,
139177,
12527,
237517,
40737,
23147,
234422,
179723,
129820,
26021,
58520,
33124,
245017,
69129,
53077,
134033,
156800,
18754,
429728,
47449,
400550,
289344,
15956,
541465,
12809,
331327,
13660,
29058,
44677,
null,
18965,
31540,
389985,
201250,
333629,
12331,
32577,
441799,
146751,
303716,
6545,
210096,
162031,
null,
195846,
327264,
40076,
240364,
6991,
65267,
462441,
348648,
null,
42205,
43627,
62276,
339852,
null,
11871,
null,
193722,
95568,
7392,
59178,
126665,
18646,
88721,
44181,
null,
null,
null,
170689,
13611,
20131,
309625,
40430,
401227,
null,
122423,
10743,
87171,
317969,
40519,
177345,
624158,
29513,
81046,
12859,
196760,
null,
187620,
27563,
53029,
7040,
34834,
75278,
92499,
108263,
977415,
null,
74725,
3759,
198675,
66534,
109870,
32306,
39444,
500324,
4442,
58906,
369240,
14502,
102853,
75522,
null,
29919,
56753,
8160,
193792,
54965,
11018,
31827,
40081,
64529,
36963,
47585,
211683,
31542,
3231,
179187,
40689,
28059,
19236,
11290,
9636,
393945,
33502,
165093,
461542,
13481,
21472,
33860,
57049,
54920,
21042,
68326,
33640,
68028,
60058,
47769,
131742,
40550,
257350,
172657,
null,
435648,
276268,
23041,
155029,
29367,
null,
144908,
17643,
206520,
97727,
26207,
30557,
23503,
4770,
28498,
440415,
205785,
39075,
36674,
257154,
100554,
10687,
182917,
328136,
27429,
18920,
626685,
8990,
137510,
32950,
166973,
90326,
293704,
212225,
23235,
336125,
177116,
14975,
14975,
196092,
44082,
69482,
60999,
17072,
109631,
28990,
19017,
135710,
21071,
431107,
112232,
31078,
116624,
40435,
33643,
62533,
124103,
116604,
555875,
188094,
3238,
24214,
15034,
48239,
245758,
7816,
184653,
185123,
32986,
565934,
32295,
174332,
266483,
52147,
174753,
428310,
347880,
25337,
12914,
77543,
242216,
36321,
31988,
86249,
249232,
105194,
null,
188230,
16816,
null,
350077,
252720,
142812,
223155,
51232,
688108,
311155,
445036,
48380,
226279,
220994,
44399,
254685,
439927,
18975,
null,
25859,
120289,
166586,
168542,
353556,
285704,
14326,
81058,
32284,
241193,
307284,
44679,
13306,
264721,
279959,
null,
14597,
65429,
34982,
null,
276683,
342766,
28649,
25214,
273508,
82540,
59095,
28054,
15641,
181044,
161188,
30658,
40029,
28488,
211453,
12020,
19206,
126114,
25769,
60552,
140250,
529907,
303696,
260722,
null,
76272,
126226,
207512,
105357,
115245,
321958,
443589,
44723,
170351,
9450,
343442,
137907,
459588,
819257,
20064,
79502,
null,
187869,
106839,
null,
39161,
330700,
317097,
324448,
56523,
null,
209638,
11971,
38626,
54578,
null,
402170,
258975,
310620,
200326,
11163,
70070,
127544,
null,
31274,
26881,
null,
24374,
63795,
9201,
27370,
253894,
28517,
26308,
366373,
42416,
214757,
233849,
1154527,
222277,
155087,
18562,
null,
15110,
90149,
30719,
88177,
24830,
174705,
282732,
40428,
125667,
299696,
325428,
26696,
22011,
43907,
null,
223992,
232020,
5360,
240528,
286441,
11664,
213548,
187341,
7967,
185291,
20372,
51705,
null,
413949,
237897,
176792,
140996,
183928,
153773,
135261,
57042,
84087,
121578,
143105,
107950,
14700,
116374,
75635,
null,
18897,
207977,
221235,
23379,
43644,
526516,
24662,
233467,
422026,
86887,
108300,
277290,
125065,
140851,
474410,
17802,
32258,
124681,
112166,
169054,
250710,
117674,
90564,
154515,
2579,
10899,
320517,
91189,
26842,
30645,
247100,
4381,
null,
37597,
4783,
167082,
263835,
27998,
41885,
51747,
56487,
63924,
19082,
189699,
215814,
389615,
99824,
55652,
null,
116280,
47163,
19070,
26861,
286663,
70629,
11102,
166540,
116763,
122438,
133116,
63626,
12203,
66095,
214494,
439250,
357503,
62175,
575907,
198066,
27616,
29908,
268874,
209982,
166660,
24659,
191187,
10298,
79223,
23566,
25589,
30398,
403776,
619532,
59938,
null,
552878,
28941,
76365,
709217,
22346,
150042,
17965,
502264,
null,
354609,
74638,
87648,
86753,
246285,
60771,
5059,
195985,
36100,
20949,
139670,
63465,
146218,
241244,
8865,
14968,
232867,
8228,
16291,
40374,
269032,
35172,
341879,
43797,
37915,
14606,
332739,
372255,
414330,
29248,
6573,
164076,
146150,
31543,
46415,
26902,
29187,
381957,
22143,
18497,
27005,
191169,
null,
9436,
304637,
11972,
63364,
23971,
83481,
45086,
39741,
17119,
null,
417852,
24520,
52022,
73127,
776453,
672414,
39035,
7889,
255245,
517481,
45075,
39822,
9250,
243249,
76547,
17574,
35008,
239621,
284599,
37791,
289037,
17651,
12513,
4815,
19234,
34839,
null,
91919,
20266,
31080,
42921,
267879,
74855,
495228,
47813,
511572,
248810,
290588,
53370,
14980,
120051,
93713,
102555,
5527,
null,
20023,
37821,
914,
19242,
null,
129774,
null,
3680,
10147,
467424,
61102,
76677,
25331,
364447,
4383,
37709,
22445,
478989,
39720,
301671,
52335,
34123,
296948,
5181,
19185,
null,
39256,
18239,
245112,
41143,
29852,
92527,
28892,
107157,
217248,
282099,
138140,
39206,
null,
null,
36740,
30206,
172829,
146541,
22661,
20054,
65159,
34363,
29648,
104843,
null,
209598,
113869,
17950,
223584,
25266,
45573,
null,
null,
206151,
217587,
625273,
24704,
78083,
55007,
56107,
18944,
387365,
222066,
121781,
217214,
68608,
290200,
17240,
241099,
8507,
130341,
99323,
15644,
22502,
563248,
47785,
106973,
48554,
1802,
73772,
15055,
null,
144267,
27521,
null,
48426,
14180,
141143,
481528,
21192,
262495,
121780,
625,
22219,
330737,
217706,
97131,
33193,
288590,
null,
131388,
101017,
148342,
null,
196871,
20153,
394341,
286342,
181592,
null,
39182,
115608,
320705,
55229,
63579,
286839,
13887,
44712,
60030,
131721,
17220,
267111,
22299,
392723,
409013,
293527,
46787,
382551,
103496,
166963,
67705,
12241,
216705,
null,
19725,
180584,
30753,
283485,
34530,
186373,
245449,
315908,
183721,
177901,
70477,
55206,
410024,
311297,
145673,
6927,
36316,
254143,
8755,
null,
21394,
577941,
17488,
63118,
30898,
10353,
null,
24427,
null,
100571,
303610,
298208,
118636,
185065,
69013,
162735,
18091,
37157,
null,
3235,
313007,
12772,
25810,
null,
296566,
40658,
34280,
6544,
98936,
67620,
null,
25277,
64579,
363237,
82005,
181215,
284518,
null,
122726,
471310,
426585,
76124,
294722,
5855,
26714,
195543,
26853,
103634,
357494,
274153,
100936,
10392,
22664,
53467,
185205,
11315,
134333,
37714,
null,
223734,
74189,
121573,
265572,
216957,
117764,
null,
461086,
3716,
35157,
46881,
71222,
220416,
114995,
65191,
263084,
50323,
313156,
0,
26286,
199809,
340419,
74210,
12820,
77434,
495421,
null,
128434,
1630,
247743,
199402,
617055,
27186,
155415,
613013,
32214,
11935,
42225,
21631,
96075,
79896,
40674,
33958,
37812,
244431,
35021,
24546,
73387,
41531,
421756,
null,
null,
203568,
83191,
23453,
175892,
32828,
11893,
308182,
null,
48396,
44476,
56279,
18687,
null,
134662,
null,
10725,
29612,
89626,
9505,
48817,
116756,
17462,
187216,
224195,
192021,
null,
290672,
319344,
161794,
421927,
361866,
375147,
34753,
7537,
23823,
71231,
156220,
42805,
55137,
39607,
15302,
64418,
7738,
49186,
251239,
185230,
93580,
null,
170022,
null,
508256,
17637,
159165,
14848,
378299,
93440,
91908,
42653,
null,
10944,
146112,
11385,
264595,
94115,
134074,
43802,
63782,
11322,
27853,
210323,
30144,
272502,
null,
269652,
29056,
87236,
18147,
75431,
96772,
250518,
30260,
21096,
45402,
82985,
8447,
204531,
2970,
29901,
81216,
237741,
377652,
622133,
17540,
86638,
106807,
88550,
95197,
311477,
203812,
232090,
6940,
321106,
19812,
28668,
null,
130266,
7736,
183627,
28346,
5125,
1335,
401619,
23868,
102412,
165559,
46789,
43710,
206874,
9581,
246566,
67346,
215755,
152400,
76690,
12944,
161468,
15454,
21462,
526823,
35813,
154678,
80294,
560545,
91878,
394589,
45112,
150233,
54835,
83096,
25675,
97554,
59829,
43187,
29678,
3699,
268368,
16658,
15278,
249141,
102228,
50475,
null,
5597,
223186,
null,
88735,
342519,
6428,
104895,
21818,
null,
214943,
26545,
104358,
24901,
17128,
221571,
252065,
16356,
12987,
191308,
51244,
93581,
null,
58878,
null,
121649,
27593,
null,
null,
66150,
8437,
58033,
19343,
328810,
27505,
27807,
27497,
null,
203910,
208668,
null,
296628,
6079,
5704,
2247,
149099,
260009,
null,
314547,
31759,
41174,
null,
null,
47883,
96490,
162302,
12883,
234515,
498624,
33233,
31605,
237992,
24567,
46602,
178759,
137022,
137308,
397275,
39063,
421339,
86924,
155335,
335728,
15710,
41418,
81439,
36436,
null,
216415,
40951,
257428,
9998,
32981,
null,
14133,
115984,
778258,
21354,
96993,
63875,
267235,
52898,
372649,
142021,
270733,
272419,
346265,
21012,
215365,
24030,
39437,
55958,
44130,
32763,
47725,
189650,
79671,
71310,
119515,
160034,
49003,
30499,
403124,
76811,
318791,
207104,
69874,
45028,
17844,
60113,
321280,
21056,
39227,
43623,
15696,
247672,
119425,
106695,
199663,
21938,
508919,
868,
12051,
null,
2753,
430506,
236591,
29096,
297908,
null,
10951,
4297,
23443,
313671,
51316,
17337,
63279,
102435,
364621,
139052,
35254,
302785,
155860,
60355,
18788,
63328,
4224,
268741,
319499,
117381,
213326,
null,
43599,
288836,
222843,
17343,
81100,
7896,
41038,
25784,
288938,
319763,
64095,
null,
72229,
309180,
17509,
26396,
26950,
55840,
33373,
70773,
805611,
43218,
348986,
80192,
54623,
198650,
351839,
null,
490363,
42052,
365928,
290128,
23269,
317345,
47558,
92095,
24284,
null,
128428,
10676,
45309,
9990,
31695,
18701,
62550,
null,
172443,
9291,
317110,
10204,
18007,
764686,
11333,
87454,
108685,
167595,
176346,
null,
25675,
73046,
241236,
38072,
45250,
338140,
61458,
502292,
null,
50442,
18800,
219045,
124727,
8390,
152243,
328043,
75120,
404969,
74496,
63686,
61658,
94831,
137332,
14265,
315815,
196450,
64245,
145781,
17570,
110261,
11538,
16116,
214696,
203215,
542080,
6538,
62900,
189176,
161826,
115630,
239598,
57253,
147522,
17151,
262410,
37152,
30790,
76561,
17234,
49075,
23983,
16758,
10765,
66435,
17774,
106836,
25277,
184712,
54512,
167789,
23749,
28579,
141576,
334240,
338700,
198607,
35964,
48020,
10947,
78627,
383111,
66397,
15630,
436876,
201384,
166429,
50426,
29847,
62580,
48388,
94942,
355966,
12712,
136036,
396277,
89112,
107358,
287689,
22498,
129015,
19828,
275531,
72951,
null,
3302,
181597,
23719,
176377,
28190,
44809,
33967,
108338,
102365,
45148,
6733,
null,
272875,
8967,
22975,
237556,
33078,
30410,
5325,
16104,
79551,
352913,
115877,
215565,
37254,
135371,
null,
26040,
20625,
7573,
40428,
80046,
203244,
19687,
42573,
92203,
554318,
122155,
286415,
117804,
375626,
null,
120279,
null,
199023,
300486,
20698,
13466,
274720,
30009,
39577,
13502,
175732,
5083,
191312,
39663,
3637,
49274,
183141,
270097,
14740,
202041,
14290,
74244,
16844,
null,
null,
null,
63296,
null,
4076,
292054,
46212,
110076,
230042,
13742,
29260,
41772,
325086,
110455,
382001,
237782,
45471,
278811,
299357,
411014,
355119,
246095,
11256,
112955,
254511,
158050,
73806,
null,
108063,
214801,
215354,
281486,
57400,
38431,
334551,
376939,
306912,
186698,
55830,
419190,
779978,
59624,
36383,
270958,
38115,
551941,
48228,
178012,
33400,
88799,
237712,
17467,
280424,
174862,
141881,
162191,
61325,
15273,
3925,
286533,
442671,
114668,
21645,
189556,
51409,
219193,
73610,
529465,
51728,
20336,
52684,
124851,
32601,
175390,
19404,
50759,
316568,
213849,
43129,
6765,
75545,
38716,
297714,
102858,
190643,
131733,
217565,
42107,
138180,
42968,
83286,
8885,
28100,
644435,
2902,
18056,
9509,
null,
61134,
111659,
137479,
223565,
null,
171537,
382912,
134041,
43873,
62253,
44988,
3378,
null,
180012,
24562,
326725,
544533,
16555,
90109,
329164,
118858,
17103,
179600,
421756,
455987,
35936,
154180,
164380,
42633,
49016,
null,
418977,
251845,
300882,
115018,
59721,
289269,
367571,
484114,
51276,
198035,
null,
179802,
4842,
17038,
29903,
154930,
144136,
53988,
42517,
9376,
55043,
124168,
197007,
130868,
244595,
191696,
43322,
156529,
null,
173740,
16128,
710070,
null,
60697,
232173,
143271,
33225,
60161,
15263,
55209,
null,
97533,
197063,
37848,
null,
45194,
336447,
32352,
28715,
94636,
24561,
56361,
12412,
228608,
12519,
null,
211474,
230605,
32986,
36519,
35913,
134250,
11035,
22980,
null,
131663,
198219,
119527,
26552,
36133,
918956,
13927,
45316,
106411,
8310,
null,
12790,
220747,
313470,
52198,
7016,
251106,
293982,
144465,
4225,
32832,
18258,
24992,
null,
240105,
203177,
130343,
180892,
10707,
null,
8748,
132858,
24351,
75853,
17888,
435608,
8276,
4355,
382590,
21587,
null,
247490,
1162719,
295724,
13008,
140361,
110461,
540036,
216939,
113310,
53913,
190124,
95249,
222110,
20917,
14599,
54668,
105351,
150429,
34647,
42164,
33709,
241156,
44694,
null,
68873,
10886,
79894,
12134,
23865,
null,
21710,
133256,
303919,
196439,
39811,
154666,
76108,
14780,
41002,
363618,
439201,
null,
74010,
139003,
166975,
null,
58348,
469680,
49601,
312851,
131268,
55863,
83944,
28158,
14646,
254060,
66541,
25725,
null,
25910,
75869,
30190,
51098,
234491,
302332,
28842,
18703,
150398,
25078,
null,
15097,
118174,
210552,
57343,
32233,
50633,
9737,
107275,
null,
23047,
null,
33235,
19433,
64293,
16522,
3949,
32807,
null,
15369,
62585,
62038,
null,
36659,
304045,
498625,
99154,
80811,
192028,
28155,
248672,
16767,
23913,
241362,
88970,
89229,
23326,
186208,
45151,
4146,
308240,
42898,
11028,
326835,
3579,
null,
47101,
68295,
413646,
649227,
102709,
168873,
193064,
176426,
153425,
110489,
null,
234484,
null,
83227,
null,
150577,
9289,
186472,
606442,
null,
null,
5421,
18097,
30289,
29097,
90130,
195281,
1358606,
59905,
511103,
240247,
12877,
152925,
39677,
153802,
237915,
270054,
189174,
null,
420584,
9423,
135654,
24013,
16343,
105375,
279090,
31916,
null,
412342,
47138,
23453,
27411,
26061,
389727,
5296,
29033,
472358,
341168,
425201,
2264,
52318,
201737,
503199,
48696,
134827,
146464,
41181,
29374,
null,
20183,
124006,
18773,
91358,
95392,
null,
34551,
15869,
12781,
297155,
25271,
37443,
153111,
380221,
null,
18272,
null,
161822,
430276,
174444,
115952,
null,
35737,
null,
218110,
49066,
81625,
40447,
81784,
27718,
30469,
391193,
150733,
33455,
145007,
162739,
41084,
197884,
200841,
463888,
null,
58280,
74055,
210281,
31970,
null,
60428,
null,
11127,
279936,
198506,
null,
99644,
250032,
119113,
16021,
8886,
18212,
131558,
83183,
17103,
4215,
164921,
75601,
156519,
23880,
203500,
370103,
361595,
22378,
346741,
16935,
232820,
240495,
null,
7948,
377221,
null,
36666,
41581,
251904,
120243,
null,
477825,
null,
17163,
null,
54663,
187273,
41041,
100181,
124534,
47072,
385680,
16714,
null,
27474,
408857,
90178,
137311,
344964,
262449,
279124,
26942,
255591,
null,
363103,
334087,
null,
20281,
18608,
256260,
122099,
18487,
171646,
21486,
41492,
43591,
162739,
190362,
275460,
25256,
3242,
143328,
108555,
54382,
31177,
68487,
16545,
null,
382097,
211490,
168410,
199479,
null,
13263,
310507,
285179,
null,
123695,
3544,
56644,
49652,
242000,
30619,
58531,
28767,
28555,
306437,
93345,
58901,
370683,
39815,
36708,
55918,
20129,
51898,
71223,
225432,
31679,
177207,
3081,
6927,
null,
239504,
15985,
548403,
151808,
295304,
306693,
176871,
51740,
492587,
37070,
225814,
null,
466692,
27702,
3862,
8753,
162897,
145681,
44136,
36671,
null,
249513,
87431,
76700,
131620,
28156,
null,
92444,
250160,
6398,
212656,
null,
16552,
21965,
112995,
null,
23526,
null,
32762,
9582,
394008,
307494,
40658,
4424,
107621,
7611,
498306,
162239,
220331,
15763,
66175,
71043,
64060,
null,
499669,
259897,
63155,
15607,
178897,
385868,
121905,
55085,
324270,
null,
25019,
115148,
7411,
27597,
null,
271149,
70915,
28824,
361567,
null,
null,
13742,
17774,
318751,
32579,
21736,
94272,
22333,
12944,
85324,
54423,
293638,
279755,
null,
306911,
85034,
38507,
42896,
8117,
300950,
469775,
null,
67114,
122150,
24662,
333192,
null,
36785,
38862,
98149,
27370,
179322,
16602,
75391,
90849,
null,
null,
174116,
393276,
30867,
205817,
132379,
null,
755510,
8121,
102602,
401751,
143759,
34770,
197386,
153597,
64907,
119197,
42510,
203918,
230572,
215234,
202647,
189616,
365791,
15758,
76417,
26558,
41326,
267921,
59440,
130395,
113921,
289827,
null,
25303,
93219,
426506,
52775,
41204,
265035,
6323,
45555,
114883,
51792,
251242,
63814,
17438,
23532,
51811,
244038,
786030,
11045,
49982,
null,
134384,
27465,
8779,
266053,
72776,
55042,
15646,
25752,
63468,
null,
353372,
110976,
18003,
406674,
50570,
49643,
440531,
13142,
73492,
54175,
40476,
11911,
289435,
248808,
66568,
161245,
115612,
43762,
144512,
7397,
295752,
35604,
23085,
637603,
165747,
33446,
14058,
25829,
174890,
53531,
277917,
126326,
18893,
25289,
338997,
null,
173492,
36581,
31762,
26721,
13602,
211959,
41303,
41756,
null,
49696,
299278,
120306,
563888,
387807,
102664,
33568,
284339,
37517,
94865,
365495,
232840,
null,
9281,
24113,
11352,
null,
154773,
42472,
125776,
124892,
220843,
116921,
92233,
310189,
80242,
36527,
33059,
27467,
218991,
174228,
24638,
299971,
191361,
19316,
219477,
167650,
13644,
118060,
32382,
22746,
27399,
322314,
17504,
50129,
21643,
40126,
214720,
113433,
16761,
910509,
272252,
141237,
55986,
38661,
59449,
75750,
300051,
609966,
217937,
175737,
55603,
325881,
233540,
20817,
359587,
382687,
99452,
229371,
36239,
51050,
238203,
17934,
28100,
370110,
14912,
28397,
65341,
null,
34008,
195364,
259752,
9961,
266009,
149344,
23648,
null,
117065,
173538,
24643,
38455,
24711,
12504,
77359,
62132,
14412,
19762,
135930,
36317,
125946,
64227,
46096,
39413,
123434,
163825,
231106,
11950,
60618,
439794,
119470,
46491,
27129,
330216,
59965,
342452,
56881,
26867,
142417,
73722,
429439,
10305,
82672,
231685,
355543,
290684,
54279,
21854,
25869,
361059,
10545,
61891,
20212,
14139,
46047,
12189,
107449,
18443,
41299,
35034,
35634,
37487,
181172,
43264,
32913,
26904,
71479,
37876,
null,
111044,
297846,
null,
271862,
83598,
40170,
74604,
161296,
27833,
40081,
28683,
null,
198517,
93686,
4443,
156104,
405165,
31333,
577250,
null,
31549,
70339,
21272,
158064,
48605,
250741,
159662,
15541,
284039,
289744,
null,
60670,
43470,
76281,
19339,
492563,
156858,
116678,
34065,
230505,
38339,
8640,
188431,
94263,
32882,
67952,
20856,
315464,
5163,
168463,
105785,
17476,
314104,
95351,
57079,
15413,
163646,
254067,
91964,
17857,
72325,
null,
6223,
13995,
16859,
31675,
265224,
128500,
296372,
58174,
263968,
155951,
293339,
363189,
130292,
41179,
28101,
54729,
26364,
36319,
47354,
313986,
13343,
157467,
null,
627557,
350661,
7803,
52860,
382680,
17719,
389438,
null,
32952,
null,
518915,
3746,
162873,
432385,
62995,
39038,
18063,
143221,
30028,
417397,
276692,
null,
442603,
702371,
122127,
162109,
51195,
17367,
93551,
232118,
106848,
354004,
200174,
43539,
30723,
144865,
68382,
null,
177665,
28086,
144316,
33789,
33120,
54128,
83652,
215819,
8535,
135695,
500346,
241504,
24953,
328594,
66196,
14926,
null,
15124,
29329,
12919,
80766,
19000,
31951,
169132,
13476,
121477,
189863,
448710,
34491,
156405,
33098,
335025,
119211,
606082,
16820,
null,
338387,
17602,
null,
63454,
157912,
9934,
23148,
559022,
375802,
4419,
204788,
8921,
null,
338005,
17653,
38684,
82669,
7386,
142413,
27838,
17595,
36120,
89556,
214502,
47795,
72387,
18695,
5879,
214289,
51866,
5858,
69522,
31106,
209606,
271909,
156861,
102737,
464271,
417462,
80642,
396122,
35432,
372356,
40168,
5662,
305594,
30461,
19166,
228856,
15057,
398069,
34157,
57484,
38439,
55215,
46206,
68601,
6495,
182317,
49747,
139052,
95816,
37187,
222758,
222034,
3377,
20160,
62660,
297056,
21723,
824165,
37666,
215273,
104139,
31217,
42057,
615883,
93319,
252348,
278678,
36038,
292451,
82680,
256132,
102024,
3672,
88163,
7843,
262203,
655154,
93619,
797943,
25189,
58367,
null,
82308,
312123,
439471,
301165,
91979,
21438,
11363,
10040,
204618,
265220,
163910,
null,
67500,
153444,
31255,
510120,
260139,
157857,
253992,
null,
16711,
null,
247482,
25669,
359552,
336968,
137441,
283762,
null,
750468,
242129,
8515,
148766,
25655,
407690,
72839,
19442,
336774,
null,
142322,
215009,
25212,
25311,
33523,
47432,
43165,
293359,
294960,
401873,
263045,
14990,
188437,
123732,
161196,
437678,
6765,
158036,
20468,
279468,
55376,
62651,
49187,
286398,
162803,
265479,
66430,
21583,
467532,
521808,
42105,
17089,
31141,
35071,
null,
17795,
433981,
369608,
176481,
23145,
227938,
154023,
39560,
28587,
28210,
58962,
12703,
257135,
43432,
201438,
293761,
45921,
19673,
27027,
315498,
55036,
414863,
57799,
66156,
48079,
7010,
17785,
215091,
20511,
9230,
169910,
57039,
215264,
37175,
17611,
45840,
null,
null,
194447,
273998,
19522,
35236,
34073,
11972,
147676,
60297,
24008,
309536,
264166,
76792,
38370,
null,
10084,
118779,
58826,
33449,
70582,
null,
166981,
8559,
40982,
158119,
null,
78802,
16440,
359295,
null,
195197,
24912,
4301,
24512,
36958,
null,
108407,
115748,
41227,
43161,
null,
20528,
8962,
218485,
27705,
null,
75107,
242332,
187223,
null,
257395,
249338,
183274,
null,
221578,
16207,
205451,
null,
61869,
153781,
24207,
216046,
210143,
140390,
106131,
19180,
31269,
161874,
16134,
150266,
40435,
109411,
38279,
193487,
12630,
228218,
416879,
100756,
122916,
257712,
38145,
27414,
4285,
519107,
185766,
373657,
57871,
38391,
57212,
29733,
33985,
234903,
263774,
239336,
75287,
231054,
546864,
null,
22913,
226212,
25413,
2870,
1201215,
210773,
55546,
27865,
50688,
36680,
null,
38852,
95290,
186088,
128739,
285875,
505442,
212189,
9208,
198771,
281644,
62145,
131055,
542627,
25259,
173575,
90228,
11674,
53464,
46208,
612463,
279107,
10022,
null,
128422,
36566,
166510,
null,
26543,
9810,
181777,
29548,
26501,
394955,
52404,
98289,
310361,
9976,
34730,
null,
265647,
39135,
492017,
210693,
66332,
53719,
330880,
84381,
160991,
97779,
17131,
425773,
29269,
123664,
329095,
54786,
230250,
195803,
122206,
null,
117390,
45035,
276844,
131525,
298531,
16254,
null,
null,
751921,
61850,
204614,
435631,
348689,
600234,
189171,
64280,
null,
468043,
65142,
112168,
252493,
150010,
137016,
335122,
219494,
29969,
43046,
138672,
30174,
30505,
481366,
30107,
5304,
null,
117218,
279828,
88154,
122933,
9267,
312875,
622516,
11048,
45540,
158504,
2673,
178962,
175862,
4891,
193990,
104380,
336535,
3291,
39701,
327641,
180764,
36557,
110671,
24806,
37157,
628800,
237485,
29178,
3469,
43641,
129826,
46186,
56707,
307544,
89490,
176578,
16709,
91291,
26069,
13738,
146805,
398424,
42555,
45868,
null,
337620,
304572,
30725,
352121,
216283,
43075,
3706,
55042,
260232,
null,
185939,
82755,
214335,
61174,
6870,
75884,
77079,
null,
null,
348511,
229334,
574244,
43719,
16240,
null,
478349,
236697,
193581,
50430,
null,
102970,
20006,
349892,
80695,
19142,
12748,
17544,
86466,
28629,
25194,
234564,
9811,
201448,
20068,
null,
211341,
33464,
245207,
21924,
null,
96240,
null,
152464,
26293,
169890,
92566,
82414,
45689,
19238,
2885,
143005,
315558,
792145,
421030,
1761299,
222162,
33407,
19513,
null,
24309,
25420,
18300,
138944,
76536,
100044,
56820,
50296,
81106,
35656,
25678,
287700,
148728,
226131,
4978,
53670,
291905,
null,
77266,
124936,
26768,
11608,
197228,
26758,
42020,
21672,
133607,
15059,
22436,
16787,
329985,
62106,
18940,
22853,
339150,
null,
229438,
null,
54775,
199585,
null,
26659,
95094,
133700,
281499,
29930,
108053,
133954,
1064933,
98287,
97824,
16489,
9875,
172083,
194686,
197121,
null,
441457,
19860,
null,
112811,
203300,
97878,
72538,
469522,
24351,
273515,
29165,
120404,
8573,
19559,
418002,
7838,
188734,
58235,
227590,
309449,
null,
4156,
136066,
329635,
16550,
26918,
21930,
10772,
162144,
60231,
27692,
null,
329307,
8122,
7334,
191737,
71475,
57463,
42848,
123846,
165427,
17243,
163426,
258179,
22949,
348938,
201870,
10372,
152866,
97627,
42223,
343603,
277257,
40849,
101732,
9390,
8069,
3070,
25207,
null,
254428,
43987,
134974,
17625,
111688,
231904,
25255,
null,
35459,
26782,
12901,
30600,
72685,
29447,
26210,
532763,
286436,
54800,
35138,
33656,
54133,
421290,
239332,
45917,
3806,
94338,
21216,
255423,
27618,
425380,
149736,
null,
22068,
6161,
539560,
20985,
16592,
14720,
528647,
54145,
242045,
32443,
392685,
152780,
195678,
342064,
55507,
77612,
260285,
12816,
193393,
18357,
34259,
37509,
16559,
18642,
68207,
198084,
434698,
44068,
345727,
65296,
393848,
43632,
187417,
13434,
79282,
241837,
659530,
229884,
27457,
108825,
564881,
21835,
30262,
46396,
426530,
16801,
null,
29931,
265958,
281051,
27039,
24315,
93315,
527558,
540840,
141443,
508516,
24946,
265279,
10096,
19118,
96563,
103218,
9182,
146988,
212491,
18368,
531676,
606772,
386553,
150772,
183254,
30438,
142673,
63596,
160706,
562060,
16758,
14879,
368242,
596781,
14846,
82016,
8613,
306378,
69492,
115714,
34755,
null,
null,
214210,
19078,
458329,
8564,
18719,
20012,
264204,
45749,
152052,
14033,
29993,
43631,
268110,
511073,
152925,
275145,
138662,
null,
11825,
49719,
15316,
211861,
9567,
48560,
63246,
178677,
112028,
109896,
21387,
17648,
42210,
248464,
55688,
53904,
23828,
84189,
562404,
17908,
null,
42302,
69311,
20354,
209885,
142150,
39246,
58219,
null,
5815,
52120,
56405,
6444,
97072,
34794,
null,
13234,
58054,
166596,
5391,
9226,
286009,
89122,
null,
6276,
96245,
209779,
433159,
1042355,
369030,
49857,
212549,
488578,
19635,
18704,
9485,
49047,
172955,
69677,
15378,
26265,
335377,
172334,
25334,
14462,
15226,
171390,
27634,
null,
23885,
14674,
205134,
438240,
231442,
78946,
67593,
480,
31601,
66527,
237697,
317783,
null,
144910,
28958,
30567,
349283,
31401,
222502,
144937,
54796,
48647,
771955,
98747,
null,
6952,
113738,
49420,
58631,
147502,
12238,
96362,
521773,
26083,
11291,
149026,
45536,
25537,
58461,
54929,
10350,
23545,
204543,
null,
36563,
102083,
null,
33136,
227576,
160197,
277453,
83338,
19828,
157217,
21467,
322400,
null,
null,
30169,
22367,
37912,
95563,
101826,
186419,
29449,
274879,
198347,
15568,
23116,
48577,
27679,
21187,
587278,
356808,
51663,
39631,
21530,
43938,
33347,
null,
150986,
25633,
134043,
422689,
223829,
16036,
69308,
17047,
10898,
38427,
271998,
91825,
9902,
57224,
63659,
74248,
null,
170424,
10384,
null,
17286,
78945,
111513,
28960,
57416,
434048,
139692,
11339,
null,
258718,
71221,
235823,
213195,
59686,
756292,
217892,
378917,
null,
510,
null,
12375,
84803,
48093,
237875,
21343,
104844,
171409,
65797,
null,
221999,
10889,
100017,
275686,
27820,
258655,
120171,
104496,
343268,
2153,
931,
29165,
213428,
179437,
49864,
49624,
363988,
10045,
null,
323720,
216189,
146267,
141202,
142182,
16424,
112773,
113681,
150762,
68062,
19954,
null,
14334,
41358,
275177,
192743,
108510,
26082,
14792,
267530,
170468,
144066,
247826,
146313,
52268,
14033,
237363,
201297,
120262,
118866,
27857,
7669,
269871,
179868,
9169,
158619,
32141,
22093,
46894,
null,
34859,
102000,
37796,
43673,
236725,
14175,
42007,
270628,
314452,
101144,
211967,
94303,
203237,
348229,
null,
7069,
3595,
66609,
16448,
39900,
297505,
77059,
11151,
4066,
null,
85814,
238627,
423931,
223434,
7365,
345485,
4891,
387470,
651511,
45644,
null,
30410,
70959,
12292,
33073,
124839,
489844,
null,
145969,
191278,
211326,
286961,
61671,
378182,
437745,
79337,
148011,
153843,
38762,
113090,
28181,
47678,
null,
26582,
174644,
373318,
null,
37236,
23709,
118835,
172206,
229786,
121976,
225330,
null,
74846,
null,
189115,
667410,
26236,
334615,
405241,
18217,
302472,
32993,
106854,
20554,
18889,
27967,
33477,
40380,
161057,
6083,
73485,
35165,
131020,
185813,
224045,
98221,
25981,
251735,
14535,
341543,
null,
20458,
27197,
164200,
273218,
98044,
248418,
6580,
null,
370532,
201701,
253262,
167648,
76779,
13440,
null,
124286,
25165,
360599,
661539,
37935,
191096,
379991,
28176,
51425,
49059,
42448,
72192,
null,
376281,
13159,
556593,
712228,
18870,
127965,
112803,
132015,
259166,
128045,
39096,
21853,
9964,
86202,
25572,
62819,
18973,
209152,
298862,
null,
16527,
19495,
80695,
192792,
444016,
null,
20152,
287161,
252320,
31426,
null,
35211,
78490,
4675,
null,
126838,
204661,
39163,
105832,
314280,
28583,
141598,
33234,
41431,
178267,
15637,
14880,
8775,
23792,
781949,
174290,
46438,
124569,
132045,
30679,
24086,
25825,
77419,
83391,
419129,
79440,
9425,
373981,
25922,
14760,
202565,
16111,
305478,
289867,
26823,
511386,
295995,
34982,
181818,
283050,
174004,
7861,
7027,
215146,
18830,
35525,
26185,
300801,
null,
78202,
36142,
37886,
17293,
34555,
30314,
13629,
13688,
79421,
276343,
206101,
103494,
null,
63851,
320401,
573203,
null,
184856,
260142,
73553,
179800,
143795,
162585,
22461,
255287,
166127,
221913,
6917,
35176,
6112,
397178,
49131,
27930,
818308,
38846,
77773,
157518,
70689,
null,
38024,
17168,
28746,
null,
37673,
152878,
121248,
383155,
163628,
143593,
15402,
30721,
73658,
136597,
281365,
null,
null,
554181,
32787,
10730,
139795,
364383,
90394,
154236,
66941,
502109,
22878,
null,
360832,
170381,
210567,
13034,
101569,
17634,
4102,
94894,
null,
470032,
146855,
154151,
54057,
44047,
39724,
141276,
26945,
298100,
85963,
333,
756144,
31591,
70850,
23931,
68451,
26791,
187848,
105724,
44424,
34136,
321753,
71190,
34664,
175817,
5490,
230528,
57284,
141891,
133534,
270560,
142440,
null,
18955,
10162,
17654,
90138,
206867,
57727,
71038,
87936,
33743,
39921,
471935,
212424,
238434,
118169,
29141,
305101,
62396,
27790,
406510,
81095,
171926,
null,
679,
33742,
1034284,
null,
134311,
56571,
null,
27577,
null,
16401,
103357,
352438,
11585,
184765,
221538,
62661,
474463,
35129,
null,
null,
65354,
21364,
735462,
380263,
279892,
19066,
248853,
51219,
64679,
322580,
21432,
67604,
194476,
311165,
46347,
125697,
21807,
329429,
116630,
22859,
null,
136574,
259676,
140908,
433704,
42872,
70024,
231779,
447048,
11192,
22373,
9302,
605293,
556745,
293043,
39970,
null,
204209,
311447,
83543,
169502,
50556,
236900,
15556,
null,
24785,
49276,
109780,
58637,
178241,
16710,
60095,
77298,
179383,
82921,
52707,
176218,
270138,
15479,
51597,
79402,
41161,
479312,
202407,
null,
5610,
9397,
132162,
15802,
460750,
44727,
47110,
300408,
91664,
null,
423148,
111401,
138101,
277061,
191461,
84768,
37161,
95824,
308871,
32114,
42506,
141590,
71970,
27629,
null,
41828,
188534,
207710,
165521,
279732,
202755,
null,
345366,
1489,
62765,
null,
155981,
37719,
33425,
199601,
606672,
15312,
12838,
36938,
46926,
60842,
292525,
4398,
32798,
12857,
244446,
null,
4539,
52017,
215169,
20311,
147875,
166906,
295523,
57722,
97868,
100725,
23175,
13985,
611509,
109907,
346644,
10185,
43149,
44843,
212012,
106276,
null,
34751,
41472,
278767,
73110,
266449,
48337,
213181,
12076,
325415,
104940,
27913,
228902,
16114,
410303,
null,
35910,
25248,
61570,
315399,
222224,
18914,
null,
48811,
125427,
28275,
200289,
229855,
149020,
6284,
51134,
7321,
114511,
217751,
24497,
4881,
132984,
407402,
30945,
281494,
99690,
213510,
null,
249065,
288242,
99221,
null,
259052,
105810,
343010,
89690,
5711,
35373,
151385,
210607,
374391,
693660,
107413,
21509,
33717,
49732,
25512,
219579,
null,
94491,
35038,
369226,
47991,
155101,
52603,
269141,
107239,
37602,
null,
3711,
38466,
55988,
24050,
231773,
329705,
null,
345272,
255298,
138560,
1990,
161298,
321745,
540173,
19873,
142993,
null,
null,
24150,
34234,
93683,
93213,
124496,
null,
14325,
17529,
172077,
404119,
4549,
241013,
38866,
222439,
67814,
48254,
null,
67518,
49299,
40538,
347624,
349043,
15501,
231429,
170435,
354668,
55488,
158482,
112886,
142059,
603166,
null,
104845,
null,
625053,
90764,
115733,
310901,
30866,
59644,
null,
12684,
5113,
41768,
30366,
4190,
41917,
47926,
196771,
153950,
22244,
66242,
null,
56146,
3516,
330417,
6264,
325037,
165163,
187562,
null,
33643,
31386,
null,
14135,
6939,
1034998,
424481,
26536,
38972,
56559,
40684,
33818,
142377,
17595,
324890,
401006,
144893,
null,
186851,
475488,
15933,
511056,
36885,
24945,
17778,
131292,
null,
70252,
59532,
461858,
142249,
null,
71289,
55977,
20311,
156549,
255869,
5966,
26173,
12682,
null,
202839,
26814,
237621,
14099,
184293,
126519,
null,
291286,
20570,
11430,
5057,
null,
6580,
67040,
15709,
23167,
16824,
20180,
232285,
22430,
12664,
430615,
11257,
152769,
7172,
151136,
353109,
55904,
104697,
34612,
18139,
53918,
115506,
332125,
2716,
318856,
286629,
97410,
4580,
null,
263854,
167096,
56797,
141105,
127131,
150231,
24143,
579688,
506250,
27929,
29737,
217354,
29211,
178402,
372294,
10413,
35475,
378503,
null,
6624,
38664,
16504,
237309,
23456,
225109,
42540,
56693,
30004,
10372,
234313,
34872,
null,
75170,
30511,
10989,
13681,
186837,
307765,
372090,
68469,
40340,
77348,
267245,
742740,
242951,
364069,
2596,
315974,
182908,
41979,
6059,
25134,
45846,
210542,
46033,
192122,
10252,
38352,
null,
36345,
153663,
500744,
189117,
11996,
195998,
391014,
57646,
697813,
158645,
177600,
537050,
null,
245976,
129779,
19172,
36218,
11900,
5683,
34403,
119345,
223676,
null,
291796,
381961,
24712,
311634,
null,
null,
15077,
232404,
38166,
23640,
187873,
157530,
352173,
8246,
19759,
19884,
428870,
585778,
12327,
318282,
37884,
18832,
16329,
461525,
98108,
null,
71845,
55468,
43452,
218189,
19946,
31837,
36974,
null,
58245,
242179,
61360,
22156,
12826,
140608,
66071,
149903,
231621,
413954,
109696,
65784,
145039,
null,
13490,
29626,
7730,
985639,
167428,
547360,
29673,
89856,
49172,
193198,
453686,
null,
470428,
65326,
38030,
42713,
358395,
null,
null,
253491,
176604,
52326,
252238,
562714,
48927,
193151,
null,
43103,
132572,
102481,
22846,
18278,
101384,
2621,
347812,
69738,
239951,
290054,
9716,
165611,
416262,
30328,
15762,
10784,
34503,
31001,
56479,
103641,
39466,
153795,
null,
null,
14204,
5241,
84835,
30752,
59397,
507265,
29008,
23945,
null,
11567,
null,
367127,
133469,
264582,
313669,
216849,
120205,
103618,
454805,
63988,
456758,
null,
15344,
188308,
30441,
43662,
73615,
13490,
282511,
121265,
259649,
64156,
135223,
132149,
19436,
46479,
108610,
174275,
53619,
15201,
53026,
234671,
178973,
69867,
445120,
56048,
8293,
16964,
206094,
10330,
63221,
26762,
8710,
28893,
25243,
20069,
107969,
15480,
3674,
67270,
43703,
381273,
null,
129896,
5571,
11995,
203330,
298050,
32226,
32616,
688875,
221651,
23674,
67603,
28774,
37960,
221480,
288416,
133450,
121755,
341274,
80280,
38861,
null,
24550,
23868,
86324,
null,
106884,
44066,
194237,
164829,
11040,
178163,
null,
157436,
244607,
38056,
35682,
5829,
null,
190081,
240448,
19347,
178172,
18341,
23870,
19417,
72964,
227083,
307139,
203019,
15253,
581150,
39160,
45488,
90189,
22910,
43324,
68481,
53835,
120304,
19816,
null,
357883,
289803,
173467,
148677,
568814,
103890,
15834,
33433,
60224,
1855,
54833,
112592,
296019,
16656,
29801,
131702,
147499,
343448,
null,
243441,
25259,
null,
176602,
19010,
38231,
176375,
16938,
285543,
242301,
33531,
287409,
457075,
166115,
8341,
223386,
35975,
null,
273538,
null,
74369,
389410,
24517,
51960,
464381,
20525,
43199,
173631,
null,
47511,
26403,
62017,
26139,
109203,
79461,
163781,
113116,
92242,
331167,
262310,
967,
38580,
71593,
41499,
142004,
5146,
243126,
410235,
55016,
null,
259454,
10047,
408641,
102603,
145419,
98169,
33643,
119034,
4198,
202156,
null,
116528,
51408,
30390,
25787,
185300,
425217,
128786,
6221,
18302,
70070,
921885,
655372,
58532,
62535,
80142,
160641,
18940,
26144,
47450,
221182,
42824,
389974,
399436,
30415,
164959,
null,
20622,
69822,
85851,
66762,
null,
313883,
30247,
335023,
415614,
117160,
164926,
145076,
131028,
162544,
291759,
7352,
180313,
901113,
401761,
108941,
144026,
45416,
120112,
49314,
132043,
13409,
28760,
10366,
11171,
89591,
16036,
22511,
199832,
70054,
34234,
61292,
142964,
109391,
199498,
10465,
8057,
78520,
148200,
257865,
220942,
null,
16426,
378978,
null,
163736,
324345,
11881,
22407,
31797,
348061,
53793,
10649,
237682,
163995,
20636,
47422,
null,
351474,
113005,
21079,
116133,
79507,
391871,
169450,
249732,
185568,
165596,
18304,
95338,
385290,
198279,
null,
114059,
118866,
23691,
16188,
31811,
178989,
null,
187805,
316440,
675058,
74362,
145881,
null,
5449,
292579,
37319,
15327,
13094,
30709,
358754,
6579,
24471,
36418,
88995,
129817,
112373,
4043,
83805,
30799,
null,
319782,
10070,
32474,
65419,
113699,
81800,
23614,
267831,
21765,
null,
183041,
163976,
159625,
23503,
341825,
277417,
39266,
35128,
214360,
27897,
45207,
null,
44056,
433315,
24518,
null,
27729,
38817,
6479,
61219,
37970,
74361,
73413,
208283,
116939,
40557,
null,
469464,
211224,
267418,
186159,
34674,
46370,
3661,
45469,
261834,
null,
250895,
228486,
256352,
26500,
69564,
160035,
41611,
null,
255399,
55009,
9453,
27024,
19736,
35818,
null,
14432,
458681,
null,
283995,
null,
215887,
25910,
48397,
125642,
33846,
309709,
300298,
127333,
277959,
137917,
279131,
720201,
24828,
143320,
22894,
12263,
10466,
9490,
36252,
200103,
335150,
93397,
22429,
32747,
44353,
null,
46517,
278947,
284530,
93279,
193379,
17236,
154962,
95900,
14678,
75651,
255399,
541811,
13150,
55336,
5658,
147708,
249829,
99353,
418345,
39949,
261645,
423570,
186546,
null,
26829,
102676,
193857,
385676,
124478,
207512,
152941,
295009,
null,
122161,
null,
178732,
177646,
82628,
103643,
26825,
28341,
82097,
33893,
6410,
147256,
6137,
48891,
30461,
211835,
null,
8742,
181799,
76468,
53437,
207510,
null,
347032,
46118,
16095,
169290,
5598,
17039,
72449,
302955,
310714,
23884,
291003,
476439,
62709,
126958,
13591,
null,
20606,
42960,
36594,
82995,
108023,
89743,
331118,
null,
124608,
164974,
4535,
45846,
33476,
155262,
365322,
167542,
102110,
93988,
127436,
171071,
75546,
null,
35608,
39777,
25435,
51267,
null,
null,
375696,
62911,
246312,
395281,
null,
153346,
222037,
103808,
14856,
10856,
40220,
27030,
115838,
443374,
111419,
110979,
40491,
269108,
45867,
19709,
19727,
136841,
316132,
71235,
15639,
57439,
270273,
31701,
28067,
56772,
155830,
194803,
320154,
449285,
409867,
148187,
40171,
220850,
34860,
189663,
34695,
39539,
10168,
null,
244858,
17248,
26974,
144113,
120047,
34497,
61177,
178983,
43380,
null,
101188,
15910,
181286,
24408,
337041,
31440,
68816,
60327,
40422,
22598,
56760,
134091,
null,
46931,
50062,
102333,
354398,
389019,
21003,
null,
167685,
48870,
77011,
22885,
201795,
653630,
6779,
10105,
357843,
26885,
null,
6580,
86578,
197485,
56599,
29325,
84608,
null,
484417,
186204,
336160,
null,
30553,
6115,
117071,
null,
42793,
null,
null,
218860,
56545,
38270,
82400,
9630,
null,
333229,
595588,
198284,
null,
30659,
282983,
348253,
86161,
247622,
26026,
82904,
290634,
15771,
293913,
234998,
5056,
277961,
9948,
83503,
211097,
249751,
192774,
47495,
4637,
380449,
96401,
32407,
28768,
18145,
94626,
337373,
19905,
142397,
87199,
63617,
12657,
229705,
39147,
17264,
3847,
114856,
243447,
128983,
124976,
220717,
170943,
578521,
80387,
null,
8503,
null,
118022,
110851,
248685,
406870,
75274,
23071,
null,
27626,
270427,
48160,
12131,
null,
406923,
333363,
67337,
127763,
59731,
250181,
106981,
235830,
16945,
160114,
328265,
null,
299020,
51664,
83336,
225598,
276896,
208008,
18639,
18505,
27289,
33042,
null,
173949,
22618,
294857,
35419,
96489,
79508,
163499,
92639,
13805,
48238,
636154,
352299,
140008,
367153,
37849,
201909,
20764,
7947,
39007,
29414,
199928,
11535,
5406,
183364,
102970,
33027,
139528,
244311,
213481,
774532,
26988,
540072,
147810,
176683,
62224,
33377,
30392,
20496,
213615,
18261,
24382,
53683,
23293,
136644,
150219,
94272,
108950,
null,
173865,
14346,
26688,
37319,
142059,
1378,
226881,
306494,
19880,
117800,
52143,
51195,
337948,
8303,
363527,
14605,
44712,
null,
55190,
25954,
40230,
21403,
9035,
175516,
25645,
329802,
188914,
36255,
206257,
197597,
68520,
56639,
118155,
182314,
182068,
265480,
202722,
null,
null,
42565,
46782,
24898,
8053,
null,
113950,
297771,
596060,
107876,
90541,
140081,
784,
null,
137178,
118050,
139212,
706394,
237491,
38396,
13548,
37222,
122063,
111387,
1027562,
142383,
25076,
14906,
140323,
267843,
205851,
3286,
154757,
1153375,
150237,
47987,
143950,
240185,
102581,
14474,
66417,
235214,
86705,
152081,
44387,
74075,
3886,
19372,
9597,
75538,
99198,
215735,
8765,
12745,
328048,
77450,
140088,
460516,
265575,
186182,
214155,
144161,
63224,
17389,
32134,
16874,
576013,
87314,
491885,
140744,
594519,
28122,
266713,
96993,
76327,
13806,
176843,
313340,
95798,
19589,
7454,
75209,
166278,
205834,
33408,
718836,
37654,
906895,
36110,
533938,
416241,
25123,
39351,
57047,
26843,
100007,
12051,
538424,
132354,
43574,
null,
22015,
18165,
205838,
65583,
222242,
11432,
285416,
114955,
59272,
350951,
148298,
40865,
24525,
346199,
40183,
138646,
262295,
227982,
75527,
333418,
750820,
19966,
25889,
46875,
null,
214754,
34574,
80804,
288353,
99939,
null,
198756,
19198,
59808,
43773,
39646,
null,
386280,
2813,
204180,
41589,
null,
52534,
25066,
33089,
70964,
261830,
18471,
27178,
20119,
187145,
82480,
126177,
36471,
23471,
259557,
null,
53348,
27430,
17958,
null,
5911,
243908,
31187,
55871,
1587483,
143411,
143648,
24176,
29060,
167023,
null,
523014,
60342,
1223,
322686,
31431,
679983,
105704,
325785,
24042,
222562,
15058,
229611,
1191276,
282057,
207920,
36453,
1834,
324865,
114334,
35709,
null,
387137,
226861,
null,
259096,
178181,
37376,
162025,
89811,
42699,
453858,
104072,
481662,
160041,
32144,
45124,
36185,
336582,
91755,
154781,
93354,
7139,
null,
508544,
20172,
43258,
24891,
21539,
27376,
118825,
154603,
51375,
6196,
137452,
60417,
214466,
80610,
226582,
3611,
36086,
385020,
null,
14627,
29303,
89199,
7454,
213669,
18641,
23148,
8404,
27125,
97640,
40295,
39355,
223803,
190636,
55606,
366559,
null,
31603,
100874,
37300,
10917,
6276,
225457,
38364,
11478,
91746,
9204,
294219,
1950,
284554,
437118,
373890,
177360,
24848,
188142,
369812,
20468,
186618,
165018,
173391,
45406,
35792,
18823,
178722,
null,
8418,
null,
416785,
41804,
83188,
193882,
15668,
454633,
1138612,
59332,
29391,
null,
null,
305081,
114639,
109898,
10675,
26930,
10011,
4677,
14619,
null,
24949,
125790,
78456,
169562,
94357,
null,
174387,
43574,
431859,
222378,
247827,
294521,
262709,
21358,
61778,
177816,
68306,
null,
255620,
26139,
null,
26195,
null,
35330,
983,
105622,
261236,
146266,
61644,
47192,
26408,
23955,
53989,
8283,
3002,
56396,
13938,
15908,
23757,
128159,
null,
111399,
36580,
47708,
12613,
null,
16303,
null,
295711,
94360,
34495,
115527,
38509,
9045,
244745,
205574,
35567,
154369,
53330,
null,
52578,
47021,
null,
19372,
230753,
68322,
42424,
37383,
null,
322858,
26821,
121463,
125585,
71528,
41101,
7573,
58129,
58854,
68216,
322963,
18148,
233397,
3466,
15937,
103658,
227098,
357965,
23182,
11700,
26324,
29006,
115025,
100379,
4257,
168531,
28253,
262768,
226992,
82709,
9264,
21141,
181872,
14889,
215505,
84606,
null,
42309,
9312,
231455,
20364,
14985,
46882,
96615,
146458,
42419,
344032,
77488,
41046,
27932,
147195,
21958,
134263,
292009,
8467,
55500,
295775,
25943,
190137,
20118,
50694,
null,
221764,
11836,
199517,
95181,
32622,
64092,
340630,
4278,
66229,
433150,
269733,
218651,
10766,
158200,
15332,
182400,
55975,
735513,
19562,
325292,
9508,
102601,
115882,
159988,
null,
113067,
341827,
31130,
58369,
162314,
140866,
347724,
42777,
23455,
224610,
42771,
79993,
110587,
1289,
229828,
29926,
31167,
11657,
85035,
178722,
17861,
64302,
802250,
58137,
15456,
336001,
15044,
167639,
45184,
359065,
223439,
null,
225667,
303437,
285012,
51463,
419690,
27768,
41779,
362644,
56035,
19636,
717970,
164757,
76069,
5388,
13544,
63846,
36261,
185866,
147281,
24147,
10146,
17488,
56524,
52922,
192677,
68355,
19010,
238223,
35981,
76072,
458897,
19651,
15373,
277716,
48281,
169544,
178370,
172965,
564333,
437927,
419257,
264202,
30558,
7537,
33480,
20008,
21987,
53177,
null,
null,
227368,
49309,
70885,
null,
27923,
40802,
26030,
null,
57493,
114844,
12635,
55033,
20489,
40416,
5150,
55454,
28240,
190660,
263645,
50017,
15580,
49433,
22071,
36356,
54564,
96740,
14462,
38715,
97734,
215990,
75737,
null,
108858,
71229,
8689,
281422,
2487,
null,
234990,
12522,
null,
40521,
173324,
132508,
243757,
5745,
273458,
19988,
54108,
27642,
null,
62914,
62556,
506461,
160103,
74396,
85976,
83772,
null,
71672,
62475,
22631,
227947,
30265,
276004,
114147,
37428,
18723,
23894,
27363,
20098,
108741,
537529,
98412,
228300,
50325,
178731,
259168,
299375,
281586,
130399,
null,
31889,
181962,
149763,
26793,
289267,
14195,
267620,
335217,
238427,
null,
29534,
18296,
11969,
315381,
260449,
40489,
115968,
191934,
220566,
165346,
7447,
538391,
131640,
202998,
23861,
23962,
254704,
null,
32397,
null,
195143,
14522,
648024,
107075,
324087,
170999,
44067,
36662,
401950,
161835,
23578,
44030,
271629,
169502,
377532,
189524,
340020,
15762,
35229,
208192,
30630,
154001,
100681,
87242,
52673,
234356,
60045,
27498,
null,
null,
180115,
210687,
130729,
24165,
45643,
144009,
23111,
114562,
206549,
106844,
42219,
359871,
41941,
7502,
195591,
260084,
15983,
149719,
78177,
264673,
null,
50589,
null,
45227,
87458,
75043,
12901,
13846,
139572,
217279,
185835,
43579,
10221,
21710,
243935,
224569,
50433,
280166,
374321,
8997,
27962,
138777,
107112,
13564,
65272,
41145,
854422,
403134,
215741,
null,
210120,
220605,
null,
439128,
139089,
118357,
23336,
null,
86688,
13127,
229869,
3461,
53938,
40463,
336103,
193699,
6432,
238325,
205521,
59718,
430191,
11262,
36359,
176960,
null,
104557,
75384,
116729,
62690,
149819,
123599,
8694,
656458,
null,
68210,
72410,
24073,
43264,
8026,
332037,
360718,
36387,
33630,
109956,
445111,
278661,
259890,
133458,
195781,
131319,
null,
37185,
null,
131472,
53842,
85616,
45503,
10860,
487605,
433379,
70217,
11593,
218858,
35678,
238261,
70262,
37942,
401740,
238389,
28628,
14267,
29285,
37690,
84400,
197252,
20699,
128401,
33395,
45443,
113095,
129407,
213097,
317541,
25708,
null,
39583,
44748,
174563,
421315,
105833,
57704,
12175,
99177,
182944,
531076,
18403,
null,
358776,
243267,
131306,
8675,
102468,
298431,
7425,
125787,
474046,
124368,
39940,
115664,
8177,
30910,
81809,
8987,
4013,
96935,
211731,
385991,
204068,
47332,
31348,
12853,
64409,
17130,
156240,
35328,
null,
124352,
139306,
34879,
28966,
71878,
49577,
82971,
52153,
37970,
75898,
296153,
351847,
232634,
69530,
503350,
191553,
4579,
190953,
23649,
12791,
null,
296180,
39963,
53744,
427261,
29785,
37674,
4073,
454311,
79442,
118233,
18738,
22297,
79986,
240674,
145319,
100916,
178310,
29063,
356244,
54355,
null,
138986,
361727,
222534,
155798,
21103,
53852,
46878,
28918,
105352,
478365,
194530,
46782,
null,
170151,
5355,
138277,
68125,
284651,
164785,
418650,
14413,
105594,
17104,
313791,
43794,
234215,
142711,
null,
81689,
57214,
null,
42041,
null,
null,
45522,
8280,
185245,
351187,
32223,
172682,
23116,
363640,
54741,
null,
54134,
10012,
188136,
65563,
41772,
17417,
155858,
17497,
null,
45686,
46857,
147190,
95167,
56892,
26804,
285699,
21440,
154107,
224360,
74395,
5102,
389597,
642283,
58145,
7107,
22510,
72662,
29679,
94459,
358974,
null,
47243,
29268,
255752,
25639,
237277,
null,
null,
null,
269081,
232502,
20441,
331150,
24281,
170627,
395732,
114292,
38086,
215324,
77786,
176148,
22413,
27196,
20357,
45951,
28566,
36794,
111779,
136681,
213057,
38644,
151881,
83119,
null,
164306,
42558,
36644,
12119,
24010,
36977,
61499,
14700,
24416,
275725,
null,
12058,
216030,
74318,
13296,
null,
42014,
25305,
17332,
21404,
55571,
27267,
287326,
15238,
197206,
208840,
35324,
85956,
111342,
158592,
46260,
141387,
406800,
57659,
9357,
8882,
131628,
100833,
41602,
26187,
322322,
29184,
56255,
106782,
180039,
297513,
42245,
28730,
25941,
154690,
180077,
120613,
27446,
90430,
54713,
144736,
36055,
21432,
105064,
50596,
19958,
154199,
300146,
28012,
217248,
77869,
7131,
46741,
null,
17070,
201669,
21046,
496511,
56759,
113329,
25745,
106281,
346946,
44906,
55860,
189919,
9362,
317909,
199616,
547197,
35125,
130351,
48475,
98519,
360120,
36375,
285937,
89732,
91181,
334824,
38378,
13129,
26122,
204451,
162760,
445261,
29210,
10002,
274824,
16365,
317061,
139984,
83714,
128994,
34749,
7982,
172857,
28425,
439361,
96995,
74718,
350985,
65890,
316472,
83224,
143267,
308572,
17175,
456705,
10303,
340391,
null,
255776,
120876,
null,
328060,
129046,
null,
83917,
null,
11618,
298655,
24918,
40457,
33482,
15557,
17836,
52375,
5944,
77025,
41070,
360835,
33965,
99741,
288225,
86962,
81696,
114600,
25571,
257651,
220119,
182512,
9203,
19986,
288118,
105394,
243297,
1028190,
23552,
625680,
29342,
110098,
152338,
89924,
156476,
238035,
81252,
323314,
108381,
188768,
91194,
42728,
261085,
45899,
null,
46052,
274646,
null,
445972,
null,
226697,
47089,
null,
null,
8640,
46276,
264440,
51034,
126425,
21018,
13928,
28994,
32975,
null,
316571,
7285,
33299,
9236,
37161,
24768,
107372,
378661,
303957,
383926,
177409,
28163,
166830,
78655,
13424,
32832,
null,
107451,
49458,
153652,
168784,
75254,
19921,
48866,
50870,
31152,
552710,
12133,
37621,
34055,
21594,
403359,
8732,
308507,
285505,
40558,
33288,
713912,
34978,
205004,
155074,
28579,
820114,
20205,
49252,
9760,
37779,
null,
225467,
380254,
112644,
285774,
51903,
98872,
144882,
null,
null,
213063,
39353,
125243,
37992,
41308,
140203,
15823,
null,
190750,
78978,
137610,
72164,
582211,
80677,
234836,
14756,
37726,
25900,
94732,
194808,
31132,
null,
124971,
12585,
237689,
67581,
230093,
169873,
63448,
40770,
71672,
331964,
36595,
51904,
104998,
142149,
88985,
33167,
173356,
23911,
64702,
37113,
57186,
36182,
53957,
146804,
128236,
148176,
null,
21516,
110578,
2587,
9452,
82169,
372181,
267221,
174911,
24678,
52347,
169043,
203866,
187369,
30900,
19266,
null,
null,
4997,
241694,
306142,
14578,
216905,
441526,
31010,
19565,
55095,
28241,
7425,
322777,
null,
152063,
3084,
58906,
19096,
208522,
19570,
16417,
null,
147460,
213953,
216959,
17285,
248554,
246069,
411240,
232704,
356696,
494009,
320433,
118140,
254116,
266704,
11133,
27709,
54422,
null,
8657,
271562,
339341,
49874,
24008,
14898,
70779,
403544,
19894,
84685,
99628,
371368,
3304,
31471,
47197,
57758,
16280,
113622,
null,
17876,
null,
57758,
261749,
197889,
521007,
30792,
241640,
37631,
171782,
24786,
4186,
42361,
30252,
129260,
4269,
522470,
199053,
10482,
739969,
null,
150032,
164575,
398961,
210528,
60544,
196522,
175598,
117509,
20834,
76421,
116492,
24496,
32728,
46291,
54302,
null,
89134,
29546,
33723,
131822,
59430,
18195,
23417,
482156,
13818,
null,
127191,
60778,
651059,
117809,
442774,
47697,
537461,
147392,
32048,
4311,
231996,
434834,
null,
271056,
132363,
120456,
66855,
68628,
15216,
165839,
30125,
151190,
34896,
50610,
23909,
15704,
37951,
348968,
136108,
12613,
410691,
241029,
21342,
23420,
23984,
308928,
26146,
77095,
16464,
202925,
22565,
14992,
127499,
35672,
85729,
20936,
null,
28499,
null,
14251,
208892,
147510,
473728,
202760,
66706,
75797,
13821,
146628,
136394,
81166,
366824,
887579,
null,
7969,
228102,
126032,
165480,
43696,
303252,
30939,
129060,
30392,
33796,
139923,
49387,
153203,
53678,
43964,
null,
145390,
195174,
77960,
null,
216056,
323811,
534727,
null,
28654,
20968,
40187,
238486,
20295,
155141,
99575,
null,
256311,
334950,
507550,
157558,
564465,
29233,
356108,
73722,
13021,
309517,
252077,
55272,
226487,
79094,
209131,
10128,
9966,
148225,
93422,
26215,
36252,
52125,
179183,
220748,
170672,
169210,
282493,
32332,
null,
140980,
15862,
16278,
16516,
20812,
26656,
272202,
10730,
39142,
20557,
10859,
100013,
104413,
96370,
341059,
307619,
27410,
64781,
77828,
12712,
29645,
125013,
34202,
163377,
116584,
3853,
41771,
172703,
264683,
32504,
67453,
274829,
24957,
99499,
44936,
78364,
12537,
366381,
75825,
145220,
null,
28264,
24987,
17711,
324309,
84394,
null,
191438,
573054,
19077,
55487,
313047,
16126,
257676,
110615,
84372,
187195,
446347,
87796,
59822,
12655,
188144,
25818,
485199,
208235,
204854,
14976,
236825,
97947,
41449,
330657,
217933,
31290,
165789,
7160,
15778,
11497,
7825,
562340,
270618,
60441,
211804,
392737,
315677,
null,
268620,
null,
624699,
25173,
265392,
38420,
10116,
6413,
4615,
250168,
151771,
83343,
22697,
null,
null,
75462,
95365,
99331,
363022,
108808,
24491,
48103,
11349,
39849,
301742,
4670,
98011,
20999,
15199,
258658,
20452,
54303,
78262,
12787,
101358,
77286,
397025,
33031,
211221,
13213,
42769,
51293,
43834,
102639,
21756,
436667,
181023,
126199,
120310,
572843,
18732,
26641,
8315,
21286,
80550,
10581,
93139,
274264,
31951,
7956,
17073,
15570,
27643,
123824,
36016,
221936,
209089,
245941,
null,
70766,
444527,
36320,
318209,
null,
259050,
112926,
64904,
83409,
156321,
11911,
314241,
25946,
258979,
185916,
92773,
32522,
31823,
51674,
42967,
null,
492095,
11348,
338274,
12209,
177998,
22162,
null,
25729,
13966,
2741,
33382,
18894,
147833,
272941,
101306,
317793,
165924,
75178,
null,
48380,
84932,
417426,
182407,
278876,
37272,
113168,
88503,
184719,
272419,
null,
null,
164333,
19337,
88337,
null,
679763,
13991,
67130,
233579,
210370,
282862,
22523,
80050,
247804,
40981,
190635,
21120,
57082,
25037,
54814,
20413,
29011,
550891,
232313,
339110,
11488,
null,
249039,
9556,
273003,
43780,
25567,
194528,
null,
15393,
289424,
248395,
27402,
21003,
173040,
288328,
254737,
20281,
27919,
95703,
246214,
31370,
22154,
197141,
null,
44353,
294180,
365590,
12801,
59422,
25696,
null,
2312,
146415,
6214,
null,
22999,
258997,
13949,
14083,
438693,
134641,
190615,
315515,
30526,
6493,
23140,
46407,
382759,
49462,
12461,
218159,
269841,
60342,
null,
25043,
14563,
26372,
113817,
36618,
77927,
254026,
40854,
25991,
59090,
19076,
167592,
57536,
252547,
1072,
64948,
269961,
18925,
8483,
234056,
247376,
151293,
24904,
11667,
240749,
164265,
34274,
181205,
69676,
73682,
34532,
25051,
407007,
45007,
200423,
52524,
null,
202949,
5536,
397816,
46956,
3163,
401268,
66908,
38938,
26553,
9158,
356321,
null,
33647,
97841,
4723,
25898,
273661,
29315,
165943,
169709,
16917,
428352,
85767,
19498,
38232,
33799,
10099,
37052,
85467,
133392,
113570,
162706,
null,
264130,
277659,
193774,
21065,
197744,
13405,
443884,
59395,
149907,
41660,
225239,
156173,
171381,
177338,
96665,
34141,
18050,
39074,
5009,
14680,
51751,
267604,
5864,
209437,
55257,
196568,
42097,
72628,
9771,
30955,
240955,
18557,
34648,
30046,
244685,
269527,
132932,
2504,
30617,
135359,
14460,
180369,
311036,
10727,
49440,
null,
null,
52239,
31685,
23853,
302783,
2362,
null,
52523,
15619,
58544,
48996,
60666,
72796,
229861,
398535,
176512,
null,
124534,
null,
472553,
163033,
74429,
17127,
212357,
216309,
23864,
43688,
null,
279205,
283426,
269073,
259564,
424553,
13721,
6478,
323284,
35529,
515897,
209913,
28480,
274044,
null,
31250,
32521,
190709,
null,
64551,
33249,
null,
58711,
138752,
198106,
42348,
21635,
7469,
135713,
27965,
286599,
45672,
180695,
408952,
18347,
69032,
214699,
12087,
20361,
39765,
139681,
43697,
34277,
14758,
343772,
80470,
130859,
117801,
335101,
26793,
190266,
104504,
29173,
181134,
120988,
9676,
104842,
86616,
279583,
42925,
126592,
43820,
39452,
null,
153893,
83825,
431445,
136688,
49058,
44187,
230046,
328194,
96685,
26419,
42952,
20623,
31393,
74182,
41217,
null,
47940,
null,
20780,
214141,
77649,
421547,
28702,
null,
209020,
41178,
27485,
174522,
193655,
81227,
85146,
53473,
111251,
262349,
23950,
277014,
10107,
null,
111503,
251588,
0,
166127,
214776,
35737,
259244,
10463,
343093,
null,
116593,
64180,
26703,
20359,
218293,
25323,
29404,
238201,
61833,
67467,
200006,
108767,
77528,
150317,
400565,
316179,
23131,
10577,
38717,
120448,
133731,
38155,
208157,
31186,
24202,
290863,
104693,
12984,
5921,
25384,
56249,
82527,
140710,
99862,
null,
355729,
263970,
213115,
35300,
24289,
52746,
21095,
188942,
null,
190868,
250448,
78079,
167783,
628934,
187078,
15504,
27274,
47021,
185205,
370352,
30316,
null,
181649,
38965,
49683,
66371,
23902,
37647,
19328,
33443,
70585,
99738,
38585,
9309,
560908,
56826,
42556,
128868,
7614,
35533,
4115,
77489,
68191,
97220,
206364,
74485,
12075,
84190,
10196,
223867,
null,
92598,
18712,
28884,
88288,
12637,
382141,
145402,
68996,
95985,
5369,
136317,
6424,
195950,
13206,
null,
22030,
9657,
501783,
48865,
null,
387312,
46407,
28999,
null,
10307,
48809,
16252,
3312,
32115,
null,
364486,
33907,
232905,
40475,
22208,
56544,
26311,
19899,
236024,
317696,
70892,
114963,
49414,
215077,
null,
270417,
4823,
145774,
22400,
24179,
15373,
null,
277408,
13129,
48660,
45384,
245006,
198825,
146437,
119515,
11646,
128302,
34693,
556627,
28479,
50788,
23199,
52638,
null,
106529,
20237,
376742,
238719,
7157,
8958,
null,
178694,
null,
462660,
8124,
217177,
26052,
76319,
38486,
331276,
17216,
260945,
23197,
5866,
77141,
298395,
7448,
17058,
43043,
8622,
28773,
36471,
12748,
44236,
null,
333362,
347475,
114814,
163233,
28014,
209017,
13980,
38895,
103632,
null,
224527,
468477,
30899,
233439,
null,
545283,
33475,
41700,
282597,
27436,
321714,
21656,
61273,
57028,
30833,
26457,
248171,
118431,
null,
142071,
185664,
292524,
392980,
367235,
27618,
192593,
80285,
12986,
null,
58549,
107820,
233229,
264951,
49028,
159215,
550831,
246532,
73312,
113715,
388516,
8668,
422321,
167306,
47068,
45596,
null,
88306,
31223,
140524,
48792,
2838,
110610,
null,
209972,
30952,
null,
12724,
14319,
77063,
23367,
4273,
435222,
null,
185074,
62312,
192061,
157413,
16240,
34207,
324347,
59753,
41174,
81660,
110734,
20581,
null,
22489,
null,
98649,
46455,
45017,
173112,
581986,
25692,
227551,
30848,
41843,
569799,
60332,
null,
118985,
192840,
21872,
185715,
38085,
232340,
72748,
7620,
90625,
409782,
12549,
60953,
412672,
null,
22455,
56306,
288346,
390802,
34890,
18722,
3601,
20538,
119357,
161398,
5644,
48537,
42427,
34839,
231176,
15812,
null,
226699,
186143,
188117,
302386,
71948,
478049,
202,
142066,
242846,
12166,
39908,
5669,
262140,
69700,
11264,
22411,
350843,
51196,
29834,
227115,
38041,
20530,
85498,
212207,
60707,
27242,
38087,
11524,
144597,
59821,
181225,
154750,
157529,
41538,
284790,
272308,
123470,
278673,
null,
321572,
262023,
17213,
349327,
50581,
21707,
98563,
44548,
32049,
2420,
64573,
53578,
60058,
null,
null,
192710,
31594,
6343,
48711,
68472,
209180,
450758,
null,
54614,
36621,
217017,
212736,
181409,
93652,
47810,
74709,
362238,
204808,
46432,
72239,
43838,
19907,
39099,
21072,
208008,
90818,
218596,
23328,
27159,
124192,
107417,
355723,
36027,
179201,
80655,
33036,
95308,
214827,
287177,
96414,
20901,
462705,
129717,
1606,
56476,
45952,
55471,
17613,
35664,
61771,
203164,
121874,
84776,
57236,
3529,
null,
13025,
16832,
35624,
27856,
16034,
94419,
72451,
225431,
16324,
79847,
22872,
285255,
219337,
176990,
74010,
50562,
115662,
268975,
56584,
236326,
48247,
128142,
120671,
85432,
27661,
null,
3892,
28009,
49167,
91814,
null,
65871,
162673,
161242,
12832,
40583,
179859,
111035,
null,
321099,
184040,
283405,
39959,
44696,
19811,
14264,
192046,
127102,
192769,
54219,
47129,
203808,
49640,
33082,
743894,
13613,
298728,
null,
98080,
null,
47115,
119968,
63756,
null,
15495,
23086,
332663,
215127,
14188,
26788,
59141,
122542,
180215,
163809,
258351,
72223,
335007,
125449,
38692,
6694,
18690,
null,
186959,
20714,
4155,
52851,
70580,
265642,
null,
318446,
13493,
null,
378293,
124319,
null,
26085,
9050,
20568,
45128,
269435,
null,
48078,
256326,
69639,
10037,
61182,
33087,
788024,
188302,
null,
34320,
39027,
169371,
55151,
null,
310386,
47200,
81161,
79721,
25797,
731133,
9487,
21505,
393132,
9520,
44969,
295435,
189580,
null,
286199,
44170,
107321,
264765,
31924,
16461,
361740,
113694,
79399,
null,
107903,
19309,
167921,
458992,
24950,
24102,
7051,
58768,
null,
409271,
18023,
23415,
75057,
31624,
27934,
69056,
18933,
173989,
7176,
113443,
291748,
10779,
72841,
111635,
59272,
186453,
202998,
600905,
176690,
70841,
24225,
154435,
265995,
93524,
22203,
25833,
330153,
3242,
36767,
24972,
251566,
42310,
52748,
31977,
202519,
242994,
20605,
365388,
508912,
24844,
55028,
51523,
46493,
15621,
null,
840772,
126151,
202751,
234748,
516806,
143500,
120143,
56860,
362153,
29097,
44856,
31781,
207080,
301018,
null,
22823,
146886,
79289,
234958,
19920,
29776,
155965,
80863,
289442,
154330,
260294,
85784,
68334,
67007,
216494,
203633,
297109,
215239,
286291,
153968,
11953,
31856,
264078,
87862,
31545,
273102,
9566,
346901,
18692,
35217,
166980,
92486,
48375,
58777,
16609,
120280,
41604,
31540,
99101,
52019,
null,
453548,
491108,
535856,
null,
17384,
212568,
45639,
117657,
115480,
5220,
273106,
83552,
34097,
11898,
92582,
282117,
8971,
102262,
98400,
null,
96865,
208046,
75132,
629623,
4464,
null,
282448,
24834,
369198,
124811,
15083,
160185,
275872,
19367,
233246,
264878,
null,
52649,
127882,
358611,
33075,
175223,
16759,
65177,
184930,
36669,
null,
73867,
17384,
357079,
314633,
57688,
179156,
249587,
63228,
153769,
234539,
21552,
11298,
42688,
17172,
194187,
47169,
65498,
202030,
354516,
174776,
149771,
48472,
313044,
250163,
83278,
16834,
97987,
18712,
318229,
26974,
16525,
49008,
540190,
21424,
248929,
13418,
27450,
62361,
55508,
27487,
226421,
46478,
280023,
267290,
null,
20822,
74304,
23023,
158276,
189925,
37420,
38721,
225134,
189360,
170718,
54617,
15010,
111676,
9880,
482397,
145708,
36033,
81856,
43289,
291302,
36273,
65325,
25722,
13991,
108426,
308581,
9631,
17374,
17875,
20247,
27177,
52023,
68366,
3183,
182052,
77757,
39843,
255309,
22777,
222548,
69822,
null,
21676,
205529,
782108,
77202,
145413,
220470,
null,
284056,
219064,
257069,
44308,
67638,
182505,
382018,
58751,
18998,
359109,
null,
null,
72122,
null,
217517,
53236,
null,
8758,
82411,
52885,
59410,
107038,
154957,
232102,
67413,
186789,
38086,
176017,
177654,
340082,
381585,
216982,
277256,
7806,
165643,
121191,
492773,
27640,
22894,
32403,
319665,
null,
null,
27812,
37103,
155919,
433649,
203594,
217766,
500183,
20320,
216962,
105793,
197957,
4894,
120571,
49750,
24712,
167313,
88949,
null,
342161,
10782,
16832,
16240,
82328,
42015,
63718,
179496,
34715,
7860,
222034,
293405,
177116,
118327,
282719,
14944,
174035,
14830,
3717,
27042,
62730,
95493,
102127,
6401,
18465,
564461,
14807,
241813,
79284,
42939,
null,
31452,
null,
173663,
168037,
327195,
13349,
60118,
7805,
226598,
33629,
19639,
24021,
46055,
67690,
53199,
93692,
199873,
396407,
22772,
81758,
310760,
37892,
149102,
14031,
26265,
41745,
250813,
590731,
41831,
44430,
64155,
160817,
4568,
154002,
323301,
null,
null,
21503,
212842,
9067,
null,
139797,
745617,
320794,
null,
14900,
182697,
32769,
null,
24774,
305032,
51161,
303825,
23564,
378443,
38794,
74624,
318347,
119506,
345426,
184034,
null,
123553,
252389,
53465,
17420,
13673,
23630,
10884,
351395,
65356,
485726,
null,
10904,
476496,
108025,
22180,
20487,
255701,
409353,
7580,
532532,
32433,
73149,
35518,
41640,
144361,
null,
330599,
6521,
39028,
9993,
174643,
30227,
293237,
79656,
433405,
137999,
77025,
284859,
4070,
37622,
106673,
121469,
224017,
20103,
49859,
22878,
71022,
24100,
8829,
78552,
400399,
67924,
125026,
236716,
2513,
4177,
null,
32784,
22863,
164042,
84139,
246046,
186501,
44431,
29150,
15940,
31689,
63579,
793270,
54462,
169097,
342623,
147247,
5823,
19300,
13511,
86208,
41752,
98257,
null,
270867,
258699,
259454,
53828,
31279,
12124,
63226,
45081,
293458,
181069,
19300,
45935,
68993,
null,
20858,
86967,
24462,
40969,
null,
33515,
null,
298614,
265295,
629859,
477880,
75649,
66030,
4691,
190325,
263022,
748276,
11136,
28222,
305067,
35059,
172297,
12560,
66477,
3965,
11602,
289187,
39991,
29001,
49321,
12738,
138622,
48184,
432718,
24040,
159574,
33678,
141959,
36196,
75176,
12178,
24498,
198267,
347936,
100438,
null,
37939,
211243,
21345,
21367,
51354,
492441,
22013,
343364,
70324,
61690,
330510,
77284,
88419,
260156,
7902,
35002,
41630,
167818,
46070,
541305,
305616,
321438,
20426,
33990,
null,
6157,
16072,
40371,
206258,
25913,
365926,
44286,
16547,
1420912,
144903,
36569,
null,
24397,
9976,
217884,
226030,
237703,
316417,
null,
21547,
14023,
55965,
43816,
210709,
47700,
68191,
792357,
321711,
426650,
273508,
145038,
131709,
27532,
168225,
72037,
43357,
117850,
458633,
301355,
216204,
93206,
160630,
453946,
83932,
null,
57566,
103284,
21056,
276598,
27465,
144174,
221969,
32739,
453418,
296160,
47058,
520250,
18151,
322814,
186587,
22527,
47189,
7611,
452752,
343441,
90654,
3978,
72056,
33204,
56875,
46866,
41935,
358502,
null,
395568,
173726,
283855,
26743,
31136,
null,
113996,
null,
6957,
86452,
102620,
184481,
430452,
147668,
38659,
12325,
114819,
85903,
158303,
191746,
18393,
18229,
18444,
19220,
null,
63677,
4759,
415346,
57687,
278734,
875487,
20577,
244390,
300589,
54550,
338838,
12246,
46128,
31244,
295865,
346467,
36987,
6974,
36858,
168791,
173725,
347322,
11074,
39167,
165408,
83874,
335492,
170761,
1992,
40858,
244894,
240715,
57706,
16868,
187390,
66951,
null,
null,
125307,
4955,
294228,
332699,
null,
22920,
28317,
248294,
136299,
19891,
48737,
8678,
466481,
121611,
37171,
199545,
149050,
6150,
43274,
195578,
384089,
21183,
62691,
174839,
44785,
44239,
19905,
425048,
11364,
230121,
48716,
223238,
42453,
48507,
358421,
17635,
350707,
10826,
33332,
29318,
208896,
389535,
217214,
13268,
12640,
118533,
47385,
383542,
285406,
97913,
9973,
258113,
19274,
60995,
239780,
90194,
16917,
249399,
26571,
129101,
20161,
85599,
105239,
32835,
4294,
null,
35228,
26710,
16728,
447096,
4041,
155457,
226507,
76859,
30963,
172885,
51950,
166457,
127488,
102382,
145013,
42763,
31267,
16718,
8792,
37401,
204849,
null,
672236,
32975,
96731,
306553,
152244,
34445,
213748,
104022,
16847,
436908,
192851,
40714,
420422,
7378,
11229,
237278,
33268,
119429,
89418,
14041,
409073,
144974,
60657,
317668,
321028,
46782,
209580,
33868,
4458,
64800,
390689,
229634,
260482,
237273,
18676,
36727,
null,
688463,
38270,
411532,
122640,
null,
165573,
null,
64989,
573213,
44484,
39943,
188888,
13368,
null,
38613,
29612,
24318,
7986,
148657,
375958,
null,
370309,
17504,
259792,
202747,
null,
24373,
174640,
9022,
8575,
285290,
383191,
140609,
303136,
84910,
252076,
185185,
668681,
11031,
null,
35778,
34196,
18241,
133313,
27144,
56653,
582310,
35228,
null,
49266,
328734,
32655,
130647,
20477,
22477,
98746,
null,
42804,
382170,
198304,
19578,
11422,
53155,
361227,
158812,
null,
692763,
23733,
153315,
301791,
203441,
119760,
null,
187714,
240377,
43644,
null,
53560,
191927,
21498,
115839,
71136,
15400,
675709,
71552,
143699,
18907,
26505,
355672,
50329,
98395,
37900,
34713,
10410,
531222,
276238,
104869,
20784,
317703,
4991,
29260,
31185,
11419,
5632,
26632,
62777,
48322,
49039,
42658,
95627,
341523,
133002,
316015,
190660,
null,
323857,
11917,
31235,
35134,
386239,
243836,
274701,
15846,
30897,
23693,
208156,
287918,
192398,
171553,
115345,
155681,
34168,
41148,
null,
14200,
null,
81347,
83274,
62204,
21551,
51004,
41690,
158766,
37822,
176060,
46920,
67251,
71358,
71222,
10484,
212674,
26278,
52653,
77030,
68738,
253742,
94711,
123896,
28656,
12380,
43977,
412406,
21378,
45136,
37112,
null,
43177,
115782,
357827,
71338,
227960,
260559,
46447,
188308,
26424,
310230,
27533,
159360,
149089,
null,
56097,
null,
17055,
605251,
17016,
14788,
113801,
255003,
88879,
224739,
35601,
49555,
18269,
164571,
46535,
37351,
13146,
360405,
255517,
null,
36849,
524205,
130390,
276456,
null,
60890,
363214,
336139,
15202,
18835,
29393,
139352,
null,
326315,
10202,
141748,
152333,
26289,
7761,
null,
27312,
29267,
305568,
336414,
325579,
30704,
130877,
58165,
245390,
58175,
317888,
9032,
499265,
138117,
31144,
33669,
253211,
13556,
25017,
207343,
124625,
67124,
103216,
283348,
31819,
221313,
64401,
43163,
130827,
32510,
143864,
160078,
32599,
89837,
37802,
17832,
18329,
289671,
24562,
29750,
215954,
429390,
14880,
396254,
null,
417718,
50318,
113336,
1919,
182740,
209313,
191521,
null,
45349,
13047,
329940,
129166,
57154,
103133,
8124,
10807,
337519,
74856,
40773,
308636,
35880,
3633,
14033,
9306,
238134,
8767,
39031,
13166,
32298,
13061,
250449,
329061,
134619,
114530,
246586,
177240,
567649,
37660,
214871,
232748,
427937,
75474,
154228,
31120,
500519,
166318,
240356,
13862,
80971,
97374,
66130,
48398,
213342,
146461,
25150,
17958,
28024,
5850,
2471,
206847,
1433115,
96055,
210416,
129209,
645331,
366794,
181431,
54687,
17597,
18440,
30222,
58198,
13153,
null,
58522,
295608,
84331,
47245,
92024,
23471,
185537,
30131,
null,
175229,
107487,
275831,
44003,
171695,
null,
15845,
34402,
125508,
133141,
26939,
51066,
295788,
15991,
null,
356255,
134475,
430602,
166475,
113883,
30497,
null,
39133,
23223,
834566,
259776,
173753,
28016,
null,
72813,
3455,
217441,
31705,
9307,
381541,
120942,
5532,
null,
135675,
null,
14571,
228610,
852059,
234681,
236181,
null,
83924,
null,
451496,
82556,
12100,
50020,
25818,
15637,
null,
152419,
197028,
154453,
154777,
140320,
271995,
228999,
255755,
340368,
26026,
26905,
223789,
5199,
82030,
243947,
171280,
50322,
69584,
null,
12157,
276812,
null,
81344,
152101,
18788,
305141,
161519,
null,
9547,
6628,
7823,
54480,
49450,
304582,
34093,
373867,
79902,
58406,
163353,
32488,
19866,
110486,
26762,
522980,
24279,
35571,
160368,
157370,
74435,
94250,
61066,
37884,
25284,
269393,
25170,
312854,
138189,
null,
334572,
null,
95310,
275474,
null,
309030,
25341,
14217,
null,
201268,
157977,
279535,
22764,
70143,
258159,
3394,
14828,
19408,
90624,
185544,
30663,
239230,
168421,
202864,
118208,
null,
57357,
176636,
78568,
175901,
3980,
null,
null,
8828,
650319,
63704,
85619,
62249,
97424,
32385,
526744,
38435,
66848,
29327,
185665,
284120,
188144,
66789,
9381,
36855,
100091,
43268,
94953,
27923,
248030,
170505,
314458,
30010,
103263,
41161,
245671,
240742,
21348,
31790,
82769,
43196,
5951,
150455,
20928,
52962,
39730,
32904,
30198,
307383,
5530,
null,
294771,
31159,
68277,
372260,
null,
26852,
193983,
126041,
90819,
5339,
200845,
40000,
151936,
28955,
253762,
162005,
5199,
118556,
224201,
170469,
21400,
5473,
108923,
303124,
13827,
309954,
109366,
88462,
43620,
57807,
18987,
363615,
12847,
174922,
116405,
null,
54636,
6801,
36066,
145611,
41183,
27989,
300949,
19189,
122265,
469709,
null,
288458,
11362,
33298,
null,
10810,
42838,
62204,
36563,
130387,
29319,
12972,
null,
277663,
51298,
52875,
56930,
65090,
21738,
230183,
24950,
874918,
46349,
285883,
15527,
16400,
17123,
12918,
273661,
163923,
54829,
11494,
120818,
4449,
4954,
null,
302486,
192679,
10698,
29783,
42626,
13939,
12895,
68799,
null,
426863,
90887,
192811,
24448,
1019,
188509,
26094,
123029,
68246,
432951,
9203,
415289,
169185,
268986,
320429,
292694,
310581,
105937,
211557,
39046,
376226,
273646,
237427,
32032,
null,
226422,
null,
4952,
144875,
360787,
null,
640343,
150034,
91113,
29185,
46573,
19296,
null,
234102,
24198,
82926,
11262,
510840,
339971,
113080,
71645,
41519,
603772,
68702,
236145,
303025,
61591,
428569,
27980,
762656,
50507,
23012,
137199,
142307,
105384,
191867,
38796,
290728,
23610,
22235,
null,
209658,
147254,
40060,
39201,
186773,
59636,
108631,
35302,
35734,
473813,
110607,
37847,
293817,
77516,
507066,
43215,
5862,
190336,
37790,
51299,
20118,
106779,
37687,
230114,
37881,
445828,
20747,
178216,
269015,
null,
null,
24964,
28370,
86263,
null,
163017,
35155,
66610,
67800,
65111,
4677,
183484,
145444,
51867,
297922,
66142,
28575,
368327,
127772,
null,
227071,
419418,
25385,
324351,
15669,
null,
190846,
64762,
40375,
29504,
7726,
1581,
537789,
204867,
206705,
69107,
86754,
305941,
109724,
205159,
111159,
503933,
141316,
56651,
19700,
25501,
null,
521905,
202352,
120486,
742028,
135250,
229526,
113394,
63622,
174759,
138913,
20180,
null,
null,
332658,
56004,
23987,
6077,
347817,
139268,
26023,
46185,
42351,
151256,
null,
null,
213606,
329356,
360258,
259080,
22797,
24868,
48970,
75722,
134921,
180291,
52320,
166401,
69015,
10451,
223326,
22711,
34124,
22945,
143257,
75273,
602592,
70682,
407684,
283059,
55492,
269292,
31102,
24046,
194728,
48451,
null,
47785,
71542,
24880,
49573,
209030,
169416,
16191,
49878,
41220,
218476,
160004,
4820,
30902,
173138,
93925,
276627,
null,
22593,
37068,
20718,
null,
62412,
44869,
171371,
32748,
76554,
234482,
7548,
102839,
83257,
70274,
23018,
246470,
566964,
126630,
37940,
86803,
9053,
42838,
564218,
46002,
93074,
214945,
156106,
165861,
112779,
218587,
11721,
17129,
251127,
25027,
80756,
46675,
101707,
45293,
315054,
33465,
37694,
115148,
40733,
33422,
51669,
174279,
30725,
280455,
27075,
20079,
8809,
49754,
77011,
4285,
147748,
41103,
11454,
396136,
79782,
98389,
41528,
146742,
26508,
379552,
28323,
null,
240212,
156180,
127969,
77287,
104429,
null,
22410,
209822,
18314,
57792,
119794,
30209,
168630,
null,
162933,
57489,
13582,
null,
245670,
75194,
943654,
250081,
117150,
166030,
172910,
30469,
24924,
21459,
185946,
23705,
70792,
351649,
8467,
107510,
19567,
421830,
485305,
33100,
7865,
91738,
null,
444152,
152475,
23561,
null,
19668,
523570,
null,
43025,
15650,
236077,
71944,
20914,
90417,
53384,
9305,
256582,
279405,
27757,
4486,
229916,
150190,
182601,
14376,
197305,
410657,
87185,
null,
35417,
125387,
88386,
42589,
14357,
95185,
18727,
59610,
32465,
null,
101616,
148372,
13226,
87215,
284688,
21823,
355264,
198457,
203232,
30638,
325047,
495417,
null,
198115,
4354,
24655,
19995,
142996,
null,
304122,
null,
217361,
null,
207336,
25189,
171905,
348478,
142801,
31661,
767219,
270460,
null,
5365,
57794,
167950,
198917,
571673,
56952,
24044,
20062,
34543,
63496,
72093,
41882,
59239,
259486,
12367,
243165,
9482,
359297,
34729,
31634,
497,
null,
null,
203365,
91993,
18871,
null,
71350,
52177,
21207,
319014,
39359,
8896,
410068,
252001,
237764,
10277,
145207,
219527,
59013,
127223,
112750,
54824,
8988,
11314,
1206312,
53747,
null,
286058,
56529,
161551,
26206,
7013,
68204,
null,
10797,
13484,
47422,
99807,
82131,
298872,
350790,
215818,
null,
25737,
8088,
307423,
263388,
118577,
438767,
242695,
47578,
46010,
414094,
256280,
202052,
160920,
19769,
242565,
null,
64888,
null,
304549,
24805,
230048,
34385,
218187,
54442,
null,
25843,
23111,
8373,
144137,
166526,
528870,
50386,
243847,
167450,
80379,
17254,
17102,
26884,
14884,
26447,
18654,
193321,
34005,
340835,
15570,
401877,
103178,
190601,
103617,
39235,
115628,
269396,
62114,
40322,
68256,
44386,
492320,
4257,
null,
110114,
25903,
199873,
61194,
175822,
137852,
181356,
222691,
258298,
33314,
297289,
65318,
72438,
18772,
214638,
null,
50754,
357553,
63652,
194819,
150054,
69544,
217489,
6733,
96243,
38865,
353632,
5537,
72955,
105509,
171811,
24696,
60136,
51550,
364524,
null,
null,
24505,
31524,
372505,
25664,
13807,
62827,
180416,
11994,
8781,
39914,
123935,
57322,
269164,
null,
112374,
128184,
380718,
14466,
null,
53653,
240882,
16094,
276576,
22921,
6540,
174522,
23394,
29014,
241059,
448214,
14733,
20957,
281471,
4701,
134443,
null,
36039,
94316,
319019,
226149,
337626,
570521,
113976,
385155,
118536,
146074,
4167,
18703,
34121,
337507,
227192,
10851,
50797,
144196,
37374,
18850,
34081,
null,
330958,
31950,
294346,
12864,
193087,
18883,
11620,
113769,
311166,
653612,
253619,
184176,
19933,
19597,
435087,
47144,
null,
212949,
13620,
22703,
276017,
85347,
17037,
228734,
220480,
132604,
43438,
71258,
49767,
52067,
50483,
2576,
237799,
46963,
42241,
187416,
282455,
196700,
55259,
13126,
11873,
172034,
53474,
127888,
36646,
229092,
102347,
198135,
67930,
37427,
204353,
null,
33813,
64758,
43318,
23502,
16104,
187292,
502616,
12907,
40436,
209001,
19851,
null,
299771,
107790,
106299,
108111,
46125,
null,
147997,
77623,
225726,
279976,
257077,
268643,
191558,
133192,
7111,
26124,
48744,
null,
35926,
null,
321630,
474584,
51932,
265241,
257343,
75735,
296168,
305253,
267258,
248546,
null,
217345,
10375,
5919,
238574,
225248,
120904,
456431,
26085,
225187,
null,
null,
null,
211010,
226934,
82357,
11370,
13847,
null,
24872,
66361,
111068,
12045,
124560,
39752,
127448,
377468,
64988,
427058,
48389,
92907,
227647,
339794,
178211,
14016,
195750,
400957,
66753,
17017,
190658,
27660,
111568,
39814,
53484,
23588,
111522,
28912,
21692,
113710,
419565,
91668,
69989,
194566,
20037,
43085,
47923,
14073,
18373,
null,
30821,
null,
7437,
94029,
53777,
32772,
207562,
24534,
504633,
424345,
982,
16219,
42588,
271644,
31528,
45715,
32492,
211012,
387748,
25839,
137160,
317496,
40356,
33476,
66472,
null,
null,
65714,
69612,
264190,
389931,
37966,
142110,
73796,
366133,
21072,
10973,
16444,
28217,
null,
59136,
269747,
2629,
3709,
11525,
340431,
29396,
366878,
180979,
432449,
178537,
14671,
446441,
102592,
93651,
50050,
18397,
25112,
361933,
299034,
142634,
670525,
28204,
437123,
7954,
null,
23963,
null,
47565,
31499,
24744,
29638,
75133,
20580,
217479,
447640,
154128,
193042,
24972,
150367,
44285,
597577,
19583,
42398,
303326,
19467,
316990,
221851,
11451,
4570,
6448,
330916,
176673,
72250,
199207,
196274,
72876,
null,
295213,
51455,
54437,
99046,
138705,
471634,
null,
200945,
206710,
127046,
354842,
220643,
26090,
26805,
74317,
74258,
137868,
46433,
207248,
734726,
142981,
35846,
112665,
47128,
null,
45892,
218537,
10587,
518558,
292717,
37854,
14869,
20770,
253275,
155610,
104721,
60658,
10757,
21395,
60157,
55085,
null,
7395,
null,
138574,
224981,
43253,
6780,
56011,
329620,
29447,
13215,
26868,
217393,
145953,
11876,
21911,
301850,
29665,
318063,
null,
330356,
null,
80163,
89666,
33084,
56527,
32413,
31153,
118846,
34711,
214907,
449962,
215537,
107094,
38437,
17635,
63215,
316314,
205377,
391759,
40774,
62356,
147587,
340196,
null,
178107,
376612,
13480,
38960,
217950,
35183,
239215,
29510,
62510,
14180,
104787,
17822,
376671,
389706,
184063,
null,
22121,
null,
61865,
42834,
136138,
40068,
134152,
326017,
20621,
494783,
57701,
63362,
198030,
7773,
968006,
5727,
324550,
309132,
133618,
9964,
217003,
64014,
56871,
54750,
241839,
301262,
20121,
81152,
15050,
178489,
81914,
80027,
136052,
181651,
127405,
27235,
null,
12910,
26453,
183920,
428957,
360557,
41299,
464033,
229864,
7575,
40646,
139494,
383939,
17776,
33884,
60865,
277391,
167873,
11265,
580802,
21671,
22108,
359533,
22205,
573769,
55605,
19452,
458489,
34120,
11267,
320846,
null,
64160,
143463,
7520,
215924,
1776628,
329607,
215046,
306306,
29791,
31243,
46465,
78420,
95696,
21277,
216758,
226828,
21137,
31743,
324836,
22012,
421673,
203692,
67523,
64682,
4950,
231478,
41217,
564818,
41550,
53719,
299477,
null,
34184,
null,
83796,
48059,
2933,
30016,
68305,
10879,
43192,
241974,
183465,
95879,
162155,
87366,
8100,
20151,
99975,
199914,
116370,
486053,
570029,
119466,
186572,
858946,
74106,
13148,
263165,
126899,
null,
10003,
52605,
38770,
163119,
35799,
17943,
33404,
143116,
null,
186368,
36510,
180104,
47108,
18891,
null,
79226,
28384,
68494,
16155,
48583,
167879,
75390,
38381,
12895,
3629,
34357,
84592,
17002,
12475,
26532,
30044,
26691,
33432,
49842,
38836,
46553,
96929,
77930,
87922,
70497,
null,
94446,
116327,
75315,
223114,
9547,
116899,
38394,
15556,
149736,
13060,
478258,
394905,
329697,
77792,
106429,
232931,
154918,
31211,
null,
31918,
232996,
39022,
103037,
51803,
42627,
10083,
400288,
6164,
54212,
40764,
268281,
584588,
188200,
344315,
null,
154602,
65949,
85005,
9420,
108841,
131669,
15810,
153139,
305968,
711052,
null,
32928,
110312,
25759,
26052,
212914,
675846,
108497,
38020,
158240,
13761,
201940,
8908,
58193,
269493,
179408,
null,
19179,
55569,
303634,
288608,
176337,
58060,
49940,
100862,
9228,
172460,
100509,
null,
97939,
22013,
26809,
18430,
null,
184929,
27601,
25496,
154377,
23743,
42562,
278187,
260029,
33283,
31685,
214186,
51256,
256555,
31101,
242748,
19725,
195155,
98148,
32142,
379303,
311748,
449580,
38405,
null,
59585,
224732,
170460,
64236,
174737,
202864,
318521,
9130,
259931,
40849,
28737,
36991,
185439,
32398,
160173,
266731,
212628,
131459,
157105,
477524,
28107,
3765,
123207,
134344,
100011,
4841,
8876,
85936,
182507,
43473,
30409,
153994,
321386,
331383,
155278,
25068,
28187,
292528,
196722,
226322,
241336,
108080,
17600,
72799,
null,
258180,
64438,
422333,
143150,
109469,
44808,
22791,
15732,
22110,
286872,
102158,
455455,
61444,
null,
207991,
44266,
264677,
null,
18938,
38650,
177606,
78734,
24763,
131065,
17595,
null,
180477,
3297,
211228,
null,
19055,
19551,
48247,
781,
246976,
149242,
12718,
61001,
73159,
22490,
73396,
237047,
61166,
175419,
493450,
49983,
124007,
22637,
5267,
171765,
34005,
49826,
163799,
434733,
41729,
267087,
16778,
28803,
910045,
11689,
270025,
30041,
null,
null,
19029,
422856,
38905,
25027,
29801,
243150,
31520,
282302,
131423,
50691,
338955,
50196,
190579,
117191,
99562,
8232,
36047,
31154,
183459,
82265,
null,
206648,
8277,
115000,
364318,
283655,
300927,
124835,
29345,
34022,
119750,
62941,
134587,
26647,
200985,
143697,
172437,
null,
352196,
46923,
19025,
28087,
251143,
8203,
16907,
465833,
77523,
27035,
18821,
634167,
129185,
109890,
null,
294841,
178779,
58860,
135962,
100988,
367159,
635213,
80179,
173920,
24261,
248890,
34948,
14085,
37125,
165909,
9330,
31554,
218807,
615691,
57719,
16925,
19651,
null,
13854,
372509,
247006,
17083,
119872,
65187,
21990,
137283,
31307,
119752,
637515,
295240,
709249,
394719,
252119,
26469,
332219,
191883,
368577,
21399,
197654,
35595,
25593,
220017,
null,
26114,
26726,
47824,
318270,
31204,
11148,
73263,
16722,
35528,
359876,
266444,
136022,
30559,
39652,
25102,
321387,
12554,
29838,
58143,
163798,
72069,
274235,
40850,
341114,
52733,
58987,
null,
22972,
380093,
31859,
669815,
198614,
29294,
274253,
138500,
28848,
32504,
218678,
20683,
613571,
48062,
93814,
92274,
231743,
82386,
43840,
174144,
160637,
55642,
144046,
225521,
189011,
138336,
35997,
226419,
null,
134727,
15163,
71245,
13116,
61505,
16488,
56557,
null,
112921,
30339,
43602,
185584,
458560,
11830,
null,
8000,
256450,
null,
23872,
74076,
140242,
59014,
213536,
39496,
206879,
447430,
35088,
63757,
8482,
159718,
185647,
251502,
292819,
24999,
80463,
28948,
68578,
129524,
391495,
4402,
54318,
464095,
12127,
70949,
261966,
336024,
72557,
212076,
101594,
217939,
155581,
39863,
289032,
23083,
90104,
5663,
69968,
117069,
null,
null,
409038,
20333,
29428,
521133,
250064,
154003,
11970,
44195,
53054,
115256,
27565,
362403,
44576,
19087,
15701,
12890,
20126,
36290,
341257,
17927,
null,
22482,
369912,
117596,
73890,
25433,
55913,
117851,
28674,
76225,
3277,
74724,
102125,
244553,
49636,
null,
24666,
309055,
244609,
63674,
195759,
19275,
15790,
24226,
132834,
73670,
164300,
159773,
59048,
323830,
22341,
197611,
65602,
15577,
28725,
26650,
265432,
349259,
33255,
230139,
277388,
null,
174537,
17771,
48256,
190222,
17441,
31443,
238650,
64993,
139863,
38527,
141648,
430225,
179666,
277709,
173094,
null,
161616,
9315,
null,
31777,
165153,
68648,
53901,
17941,
76392,
68858,
7598,
181464,
37065,
20121,
279816,
328981,
112371,
247418,
169128,
147598,
null,
136076,
null,
101054,
27251,
20351,
110515,
198240,
120584,
287259,
35105,
31558,
20811,
62784,
17255,
273437,
193002,
196430,
null,
16765,
141918,
46020,
440317,
237332,
156101,
47970,
18485,
3481,
622280,
33736,
28292,
34425,
12818,
157363,
39913,
90609,
247979,
9828,
65280,
424722,
135209,
40788,
160979,
20440,
399251,
null,
70820,
287496,
45575,
259812,
95696,
211505,
74427,
157518,
489056,
null,
294481,
307265,
12392,
360330,
23732,
16735,
256400,
33212,
238005,
22440,
894817,
57696,
762459,
117138,
null,
63643,
94335,
126606,
27578,
107213,
456942,
43568,
169806,
24602,
27527,
9440,
null,
null,
56150,
231963,
53631,
378510,
313882,
444537,
null,
null,
23883,
78990,
304459,
null,
53649,
null,
170595,
16145,
19291,
43401,
142113,
895389,
24690,
9232,
40087,
37939,
null,
61404,
25471,
34028,
49998,
36973,
99111,
124448,
27329,
5445,
23533,
659988,
156966,
343383,
74597,
34383,
219189,
320298,
89905,
99503,
181217,
126433,
20405,
6036,
null,
31664,
231726,
107309,
13815,
12969,
13236,
347943,
88654,
102574,
28338,
116851,
28016,
298488,
19960,
164848,
33163,
64659,
169031,
44415,
248807,
16040,
461010,
11160,
737898,
62355,
3838,
42358,
8770,
148277,
234525,
395138,
12457,
10824,
57977,
64053,
268534,
182447,
null,
249901,
12783,
45462,
15359,
327468,
357096,
141986,
310712,
11415,
null,
138266,
27785,
77739,
32746,
90845,
68636,
40823,
null,
418605,
13353,
117707,
392625,
null,
53057,
28262,
184817,
47141,
null,
157628,
null,
120529,
null,
18611,
456286,
null,
354366,
32936,
54101,
82263,
40814,
50476,
91962,
68650,
294896,
null,
182415,
84519,
11878,
238944,
49367,
151537,
412062,
62059,
280023,
15853,
294683,
194773,
null,
146204,
128499,
224001,
319543,
138916,
35696,
null,
204143,
93528,
11764,
557641,
110124,
37514,
381443,
29611,
439622,
192077,
18144,
147236,
260920,
179398,
50090,
325775,
27869,
364905,
127831,
23642,
19407,
153372,
1050877,
34638,
157014,
93297,
10826,
25371,
206383,
null,
456903,
298283,
37955,
57261,
407848,
115462,
null,
null,
null,
44583,
51889,
340059,
181774,
33645,
null,
195146,
138698,
44327,
406949,
200236,
160388,
null,
42409,
36831,
300675,
47737,
18899,
117462,
32090,
219826,
20118,
91009,
183436,
14389,
37326,
null,
144975,
null,
6201,
null,
136471,
47630,
756758,
302321,
184023,
180090,
67555,
212736,
46739,
145888,
9666,
116909,
237640,
177263,
63659,
223251,
6167,
144345,
48543,
12060,
138999,
38970,
42082,
382324,
18471,
11867,
64565,
86910,
17689,
8181,
19135,
34283,
21474,
null,
262668,
32674,
9215,
121073,
46575,
34873,
160575,
23373,
3185,
9441,
529008,
321422,
21709,
29316,
95864,
17901,
31666,
9951,
18211,
174527,
5578,
338739,
281648,
151223,
958,
24622,
null,
8424,
15037,
32470,
73934,
31175,
69301,
102064,
23671,
32706,
7747,
9389,
122341,
382780,
175773,
185687,
49362,
156413,
68062,
null,
null,
null,
39983,
16466,
433296,
36283,
151344,
4891,
56720,
249510,
132444,
6425,
102139,
21457,
110098,
611197,
231453,
296964,
98010,
121730,
64247,
155387,
264187,
null,
188710,
190534,
58219,
50660,
217186,
92167,
229003,
35234,
3598,
null,
22093,
189735,
49020,
16592,
244668,
76005,
2114,
93418,
15057,
17348,
98290,
37099,
27489,
126986,
34259,
340517,
167595,
240183,
55713,
14776,
209807,
38739,
41234,
15593,
156085,
158374,
null,
58187,
17613,
8113,
22493,
33956,
75677,
161515,
23296,
23935,
72103,
63842,
171518,
572614,
39568,
398638,
67184,
74550,
205667,
53476,
44235,
null,
360657,
95528,
3552,
8199,
82674,
68810,
524501,
33137,
386837,
10400,
26024,
28407,
87729,
54401,
77943,
41198,
31877,
70633,
120322,
472277,
56238,
58400,
null,
40823,
22792,
74310,
23683,
21348,
103643,
195987,
346894,
9235,
null,
49191,
83425,
49447,
247649,
65122,
372855,
20411,
365873,
36506,
30929,
94753,
17858,
19491,
40877,
41227,
null,
30056,
56738,
106965,
47401,
226700,
197654,
14422,
null,
109075,
55838,
299184,
26601,
12455,
115738,
41607,
11000,
49735,
167148,
42104,
null,
null,
76416,
163161,
133477,
25127,
null,
421485,
47300,
241494,
39738,
null,
34156,
71394,
5392,
55727,
197173,
202562,
141441,
126484,
266095,
39592,
398485,
6494,
null,
37779,
101821,
22744,
204523,
29655,
15331,
4637,
52908,
423857,
369445,
379535,
114261,
110137,
19820,
161693,
393251,
4502,
308479,
26937,
28072,
50981,
41924,
202398,
251496,
42470,
185486,
97756,
null,
20695,
137258,
66668,
50771,
10317,
160478,
null,
49728,
68029,
174833,
341422,
14902,
26818,
27582,
45463,
31578,
27628,
50817,
null,
null,
30437,
275669,
32331,
6480,
9032,
36028,
74657,
4789,
137272,
246882,
36300,
299576,
30323,
544926,
189935,
22663,
39295,
22184,
null,
160258,
17371,
null,
397543,
364139,
84628,
40351,
180464,
25163,
50809,
223552,
281480,
null,
299190,
null,
63584,
null,
31747,
22547,
60077,
136612,
33234,
255293,
407561,
101714,
254349,
null,
152935,
21544,
83448,
13678,
232660,
342698,
300458,
65407,
52198,
52124,
389274,
37660,
23713,
14302,
46710,
201992,
48872,
147463,
399091,
93709,
30302,
460456,
167232,
115671,
null,
70081,
113466,
41870,
152542,
65469,
262550,
34684,
315833,
153449,
17978,
40396,
12573,
676003,
170171,
26674,
7601,
19468,
53227,
34254,
13159,
217691,
132099,
32247,
36619,
579207,
82728,
333591,
188453,
250853,
null,
null,
6138,
49594,
83487,
224500,
268939,
49019,
18350,
2942,
null,
44947,
19371,
309631,
605232,
144842,
170289,
22401,
34907,
11599,
311969,
338245,
8272,
18630,
150327,
62018,
24165,
243053,
12774,
97421,
33761,
162104,
6754,
20525,
232767,
14249,
37989,
311556,
240648,
567888,
174501,
null,
93625,
107674,
328717,
80216,
95976,
328459,
27701,
55172,
439583,
150742,
51014,
174864,
16620,
260311,
17342,
31665,
14502,
278976,
10000,
175369,
12593,
185103,
226044,
35998,
153363,
39244,
174193,
20086,
2886,
459880,
13009,
null,
36083,
192889,
24724,
17838,
140934,
3732,
2746,
null,
3075,
222329,
332524,
116668,
37555,
209217,
254641,
128157,
19470,
54917,
378659,
77368,
null,
150657,
374867,
null,
98623,
72109,
35617,
77175,
37199,
371974,
135864,
1715,
16803,
209825,
null,
42508,
8142,
49850,
246292,
3839,
147663,
191327,
115059,
null,
405495,
196195,
276568,
91313,
157485,
3719,
29961,
277380,
56765,
16220,
269817,
27929,
74731,
203758,
75321,
46058,
200895,
284342,
179136,
20550,
69246,
249571,
132249,
769107,
170271,
null,
38708,
59979,
188684,
104417,
33950,
201857,
245597,
52059,
182025,
35556,
69421,
85274,
100871,
49693,
13859,
12800,
18128,
255903,
70882,
43019,
45712,
80110,
241821,
256124,
63483,
437781,
44315,
315918,
634376,
102181,
10615,
79514,
46264,
132123,
291024,
183219,
327641,
null,
37282,
null,
63101,
144359,
null,
380166,
171826,
null,
6023,
29218,
361423,
447134,
23117,
36084,
27664,
24281,
101234,
109355,
10406,
54402,
134607,
96535,
null,
92652,
94468,
55589,
32283,
27101,
58817,
192535,
48480,
19644,
180245,
5206,
100082,
429799,
28315,
147346,
46996,
215029,
null,
563610,
33975,
15397,
null,
164486,
248381,
43724,
74428,
555863,
295885,
215397,
141083,
52288,
283026,
238911,
null,
41397,
338539,
310407,
147400,
27089,
39634,
26344,
3848,
123695,
28552,
21562,
18911,
51938,
351734,
17704,
286099,
19800,
105440,
446846,
92766,
69089,
24081,
53478,
99787,
49553,
87285,
378775,
25690,
174492,
224678,
35566,
null,
375290,
111842,
145172,
127626,
230356,
607896,
null,
538143,
null,
21359,
56815,
195596,
47732,
281096,
334371,
194699,
98660,
null,
null,
100402,
334388,
67055,
16851,
157013,
744813,
174535,
119870,
20767,
34125,
23817,
28827,
93269,
null,
273712,
45283,
157141,
296940,
294013,
150815,
632686,
43946,
231063,
57125,
88497,
223720,
40418,
26144,
30253,
28156,
229007,
19572,
26926,
36695,
7891,
null,
null,
271843,
21772,
35430,
31906,
28561,
null,
34544,
21061,
3148
]
}
],
"layout": {
"barmode": "overlay",
"legend": {
"bgcolor": "#F5F6F9",
"font": {
"color": "#4D5663"
}
},
"paper_bgcolor": "#F5F6F9",
"plot_bgcolor": "#F5F6F9",
"template": {
"data": {
"bar": [
{
"error_x": {
"color": "#2a3f5f"
},
"error_y": {
"color": "#2a3f5f"
},
"marker": {
"line": {
"color": "#E5ECF6",
"width": 0.5
}
},
"type": "bar"
}
],
"barpolar": [
{
"marker": {
"line": {
"color": "#E5ECF6",
"width": 0.5
}
},
"type": "barpolar"
}
],
"carpet": [
{
"aaxis": {
"endlinecolor": "#2a3f5f",
"gridcolor": "white",
"linecolor": "white",
"minorgridcolor": "white",
"startlinecolor": "#2a3f5f"
},
"baxis": {
"endlinecolor": "#2a3f5f",
"gridcolor": "white",
"linecolor": "white",
"minorgridcolor": "white",
"startlinecolor": "#2a3f5f"
},
"type": "carpet"
}
],
"choropleth": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "choropleth"
}
],
"contour": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "contour"
}
],
"contourcarpet": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "contourcarpet"
}
],
"heatmap": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "heatmap"
}
],
"heatmapgl": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "heatmapgl"
}
],
"histogram": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "histogram"
}
],
"histogram2d": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "histogram2d"
}
],
"histogram2dcontour": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "histogram2dcontour"
}
],
"mesh3d": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "mesh3d"
}
],
"parcoords": [
{
"line": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "parcoords"
}
],
"pie": [
{
"automargin": true,
"type": "pie"
}
],
"scatter": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatter"
}
],
"scatter3d": [
{
"line": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatter3d"
}
],
"scattercarpet": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattercarpet"
}
],
"scattergeo": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattergeo"
}
],
"scattergl": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattergl"
}
],
"scattermapbox": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattermapbox"
}
],
"scatterpolar": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterpolar"
}
],
"scatterpolargl": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterpolargl"
}
],
"scatterternary": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterternary"
}
],
"surface": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "surface"
}
],
"table": [
{
"cells": {
"fill": {
"color": "#EBF0F8"
},
"line": {
"color": "white"
}
},
"header": {
"fill": {
"color": "#C8D4E3"
},
"line": {
"color": "white"
}
},
"type": "table"
}
]
},
"layout": {
"annotationdefaults": {
"arrowcolor": "#2a3f5f",
"arrowhead": 0,
"arrowwidth": 1
},
"coloraxis": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"colorscale": {
"diverging": [
[
0,
"#8e0152"
],
[
0.1,
"#c51b7d"
],
[
0.2,
"#de77ae"
],
[
0.3,
"#f1b6da"
],
[
0.4,
"#fde0ef"
],
[
0.5,
"#f7f7f7"
],
[
0.6,
"#e6f5d0"
],
[
0.7,
"#b8e186"
],
[
0.8,
"#7fbc41"
],
[
0.9,
"#4d9221"
],
[
1,
"#276419"
]
],
"sequential": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"sequentialminus": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
]
},
"colorway": [
"#636efa",
"#EF553B",
"#00cc96",
"#ab63fa",
"#FFA15A",
"#19d3f3",
"#FF6692",
"#B6E880",
"#FF97FF",
"#FECB52"
],
"font": {
"color": "#2a3f5f"
},
"geo": {
"bgcolor": "white",
"lakecolor": "white",
"landcolor": "#E5ECF6",
"showlakes": true,
"showland": true,
"subunitcolor": "white"
},
"hoverlabel": {
"align": "left"
},
"hovermode": "closest",
"mapbox": {
"style": "light"
},
"paper_bgcolor": "white",
"plot_bgcolor": "#E5ECF6",
"polar": {
"angularaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"bgcolor": "#E5ECF6",
"radialaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
}
},
"scene": {
"xaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
},
"yaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
},
"zaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
}
},
"shapedefaults": {
"line": {
"color": "#2a3f5f"
}
},
"ternary": {
"aaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"baxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"bgcolor": "#E5ECF6",
"caxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
}
},
"title": {
"x": 0.05
},
"xaxis": {
"automargin": true,
"gridcolor": "white",
"linecolor": "white",
"ticks": "",
"title": {
"standoff": 15
},
"zerolinecolor": "white",
"zerolinewidth": 2
},
"yaxis": {
"automargin": true,
"gridcolor": "white",
"linecolor": "white",
"ticks": "",
"title": {
"standoff": 15
},
"zerolinecolor": "white",
"zerolinewidth": 2
}
}
},
"title": {
"font": {
"color": "#4D5663"
},
"text": "tot_cur_bal Distribution"
},
"xaxis": {
"gridcolor": "#E1E5ED",
"showgrid": true,
"tickfont": {
"color": "#4D5663"
},
"title": {
"font": {
"color": "#4D5663"
},
"text": ""
},
"zerolinecolor": "#E1E5ED"
},
"yaxis": {
"gridcolor": "#E1E5ED",
"showgrid": true,
"tickfont": {
"color": "#4D5663"
},
"title": {
"font": {
"color": "#4D5663"
},
"text": ""
},
"zerolinecolor": "#E1E5ED"
}
}
},
"text/html": [
"\n",
" \n",
" \n",
" \n",
" \n",
" "
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"application/vnd.plotly.v1+json": {
"config": {
"linkText": "Export to plot.ly",
"plotlyServerURL": "https://plot.ly",
"showLink": true
},
"data": [
{
"boxpoints": false,
"line": {
"width": 1.3
},
"marker": {
"color": "rgba(255, 153, 51, 1.0)"
},
"name": "tot_cur_bal",
"orientation": "v",
"type": "box",
"y": [
28699,
9974,
38295,
55564,
47159,
350619,
13272,
272579,
281521,
76034,
72193,
39152,
194011,
165164,
39634,
48488,
71191,
221335,
34538,
125903,
66738,
null,
282808,
71697,
147448,
327930,
8589,
447388,
114298,
31445,
391749,
1385358,
68057,
6485,
23697,
4890,
5422,
176391,
10707,
141797,
53454,
229995,
13054,
42542,
624417,
38829,
28163,
null,
421664,
71646,
8312,
311014,
234697,
290962,
195008,
13166,
34752,
359326,
137019,
235231,
161107,
316510,
22198,
272177,
124248,
442155,
null,
null,
447154,
46867,
28862,
250586,
58396,
223151,
null,
103681,
123905,
405177,
77893,
22459,
174517,
244772,
23784,
28233,
27435,
275755,
142744,
37237,
15017,
408391,
106591,
35398,
24895,
null,
68650,
239603,
605585,
139788,
41237,
186934,
78372,
43807,
35449,
245928,
9943,
158699,
254138,
261143,
46625,
220405,
12172,
61294,
31225,
38746,
40749,
301791,
263725,
357941,
212529,
32825,
111460,
10163,
381787,
null,
618061,
58182,
23744,
105315,
31458,
14203,
null,
8328,
24353,
697738,
31254,
324254,
253332,
66287,
34248,
15736,
32296,
31773,
491917,
127882,
27519,
128115,
336159,
303569,
137534,
132687,
null,
57534,
null,
29284,
49328,
43998,
18955,
4161,
44318,
9687,
217361,
51448,
15567,
11346,
76398,
41374,
11900,
57897,
146182,
25315,
42886,
12743,
26807,
41719,
214384,
161474,
41019,
108745,
403512,
98749,
14677,
25608,
52348,
168733,
795423,
237669,
24110,
33335,
381762,
317022,
74344,
6557,
357373,
null,
207856,
null,
187785,
null,
45602,
20964,
23927,
74619,
18613,
36054,
28773,
2540,
209503,
null,
null,
189210,
12725,
67211,
31287,
141512,
17022,
38935,
397113,
268952,
30098,
null,
185010,
20974,
30163,
352644,
371710,
49447,
729286,
1275731,
369867,
10989,
142058,
109299,
419933,
236818,
230826,
197387,
38375,
21810,
null,
15550,
26955,
52359,
149955,
120660,
null,
59812,
21024,
130027,
10814,
315571,
2755,
null,
25885,
22363,
259654,
26566,
5713,
38691,
82172,
344169,
583364,
261450,
145255,
220734,
326635,
15925,
66547,
61199,
99488,
24981,
40106,
39636,
27105,
39497,
55926,
152124,
53692,
119007,
84473,
154943,
160755,
39752,
104546,
null,
35816,
32579,
61080,
329538,
33373,
178923,
37951,
256274,
162464,
347081,
216061,
295126,
null,
30235,
null,
13889,
351928,
300411,
38990,
null,
136956,
22720,
317207,
34706,
186750,
223548,
9657,
35975,
214793,
95565,
238017,
null,
50324,
394034,
20088,
20449,
130501,
164189,
13347,
179994,
17899,
39404,
287180,
56496,
41139,
10615,
658834,
63379,
68865,
354452,
30353,
null,
null,
411273,
46002,
55669,
53735,
99289,
180899,
18348,
747460,
25407,
43083,
236639,
29046,
35438,
34710,
14137,
23746,
146392,
214638,
312703,
28856,
56332,
6289,
9874,
93245,
null,
25218,
116274,
null,
144950,
13295,
43470,
81987,
198266,
41790,
null,
11304,
201921,
366823,
165886,
13288,
18299,
14262,
17403,
406681,
74413,
33086,
null,
61335,
60210,
35353,
null,
8183,
92860,
46894,
148501,
null,
57821,
170930,
15989,
233837,
244934,
240085,
211374,
103485,
139857,
22391,
184799,
264915,
57953,
129420,
111848,
327823,
26787,
64033,
254355,
101576,
556185,
23200,
null,
207625,
65485,
248611,
373534,
81863,
null,
14147,
null,
172831,
187073,
58250,
23287,
31369,
109651,
502944,
541157,
295656,
108124,
null,
33281,
216288,
106123,
34497,
41194,
56446,
19549,
180351,
40388,
70227,
258381,
27220,
24723,
22735,
14328,
151107,
468840,
4708,
122656,
19877,
263047,
71862,
124365,
21121,
148297,
32874,
75112,
376138,
5537,
24188,
69719,
159439,
40697,
8095,
366064,
213954,
210739,
null,
33582,
25085,
121160,
128656,
26913,
23672,
null,
203507,
163716,
165726,
183502,
15968,
54040,
278870,
92302,
152437,
16193,
230077,
131268,
135767,
154295,
48385,
210663,
124963,
34831,
null,
33079,
24878,
36930,
62949,
90030,
29880,
164515,
40347,
13177,
null,
447617,
177716,
12305,
null,
232601,
70078,
19900,
175950,
33874,
22444,
37039,
446278,
92948,
775376,
221904,
23696,
39890,
154730,
55151,
36726,
131678,
158221,
18632,
33280,
251220,
99581,
32863,
364241,
204018,
85343,
55869,
26448,
215033,
339858,
1234441,
141083,
15485,
102598,
158359,
24546,
180586,
58044,
17456,
50796,
20858,
16163,
372969,
64707,
271565,
185938,
null,
157226,
244426,
250201,
45336,
60407,
54924,
37839,
null,
18899,
202801,
null,
66981,
null,
27075,
60204,
175944,
32356,
212609,
161552,
17505,
null,
null,
15521,
215318,
76675,
20990,
31506,
15354,
null,
197356,
151870,
508277,
166089,
328730,
352961,
195109,
null,
null,
42394,
431407,
215895,
247430,
371149,
4185,
30496,
46613,
346859,
12438,
186158,
null,
195129,
45378,
255576,
14516,
98931,
77424,
301087,
204350,
20572,
43760,
230481,
64424,
35722,
130003,
569382,
129046,
100007,
338999,
34954,
179582,
15354,
31960,
43722,
53169,
47467,
277011,
39375,
70697,
459512,
10181,
288236,
40494,
1119620,
103771,
72539,
56368,
331686,
268631,
null,
21408,
18698,
160139,
751327,
61632,
25237,
144622,
11780,
1654,
177427,
null,
26847,
84876,
52458,
147071,
37677,
362232,
92482,
21099,
31232,
162622,
15685,
35217,
null,
13862,
171443,
40211,
47624,
17474,
41254,
69585,
4871,
262966,
33869,
2051680,
40168,
4780,
223359,
75802,
8822,
17695,
175182,
17870,
42759,
29655,
22696,
43035,
9621,
182034,
91870,
233656,
70569,
33436,
160967,
30480,
122956,
18235,
523816,
24449,
27678,
23189,
319370,
17448,
null,
143547,
165504,
331551,
16945,
145396,
7628,
16023,
334570,
27039,
300135,
null,
15441,
43020,
14267,
200947,
39517,
323104,
16238,
168329,
40044,
152851,
83950,
189558,
37026,
249444,
219679,
3917,
159744,
204239,
211916,
null,
649659,
248348,
13387,
61090,
39738,
108741,
183133,
28953,
2083,
null,
48858,
7641,
88149,
285279,
266350,
317918,
35547,
109845,
152573,
464373,
136494,
11589,
156615,
220896,
162212,
3455,
188825,
44121,
124109,
1332695,
257146,
332717,
532571,
99214,
null,
19856,
16862,
108141,
229954,
29900,
47451,
12041,
111218,
null,
18205,
73426,
8339,
238645,
269442,
55479,
353179,
50540,
48102,
103067,
39593,
35919,
31025,
97740,
159207,
111939,
149447,
7586,
25048,
74795,
null,
182475,
305232,
274663,
303129,
33624,
245780,
18149,
184455,
83420,
40938,
163459,
347024,
null,
33900,
11108,
24447,
null,
152177,
242499,
187876,
27377,
20078,
51845,
26433,
40217,
69090,
314302,
184109,
29714,
82175,
41940,
32048,
19750,
104870,
null,
177052,
12361,
130643,
39264,
120280,
24652,
104369,
141322,
27048,
74544,
157615,
229713,
102940,
283813,
20455,
24540,
200548,
30430,
453703,
40474,
1361016,
97388,
36910,
161786,
39954,
45661,
190690,
487234,
31397,
83891,
16998,
263086,
19968,
28757,
13052,
160096,
235173,
72132,
246771,
344875,
482448,
9398,
63337,
10688,
43421,
17370,
188555,
21189,
22481,
145197,
33175,
3926,
19542,
165551,
327709,
107965,
43369,
297064,
186147,
93547,
125549,
139951,
227205,
62735,
18094,
null,
416887,
46412,
125646,
null,
178347,
53034,
404034,
null,
293366,
29222,
8417,
260009,
7789,
44627,
89035,
195407,
293814,
53332,
79736,
195921,
106917,
441190,
41321,
198763,
241583,
6903,
44218,
215378,
221350,
736534,
199782,
179646,
21168,
220092,
72180,
285233,
null,
25505,
24617,
62296,
75364,
205002,
23046,
390172,
587516,
130805,
53443,
105006,
90903,
53434,
16338,
42889,
58161,
140595,
662752,
317097,
17831,
14924,
250749,
242372,
36937,
8246,
49249,
null,
13937,
190050,
39024,
null,
215143,
140054,
243071,
375143,
149073,
360615,
82230,
95921,
16222,
197496,
214187,
112820,
11707,
388146,
43745,
414011,
275721,
349168,
188142,
23505,
223350,
11279,
null,
121093,
38390,
39950,
25529,
4140,
35331,
135542,
44434,
189563,
156771,
390202,
null,
51434,
38587,
263842,
187006,
39707,
451200,
31468,
160563,
568085,
126705,
378709,
16774,
255080,
32348,
43492,
null,
45401,
183898,
294414,
839313,
null,
14519,
180375,
182819,
16927,
112677,
40710,
15706,
null,
19625,
12089,
53541,
null,
513741,
37126,
217490,
292718,
31749,
41969,
13425,
35085,
52898,
36175,
766037,
null,
13100,
185600,
29934,
372426,
32106,
69936,
35805,
null,
10770,
null,
24647,
178067,
65953,
322998,
null,
59736,
367936,
333261,
25027,
505867,
65182,
160399,
31577,
57566,
173610,
412881,
119411,
27884,
129321,
125016,
80937,
223263,
203705,
586647,
123495,
29786,
156212,
311958,
74497,
336577,
47861,
95506,
null,
38334,
280406,
14754,
17620,
39161,
123144,
361629,
347885,
213808,
124847,
46619,
528105,
9286,
21758,
55848,
117001,
36355,
30920,
29160,
173532,
17521,
30276,
10521,
414919,
252482,
157972,
89640,
65016,
53746,
217250,
52821,
119254,
133923,
187653,
215514,
28079,
24598,
191137,
37107,
55205,
156320,
null,
262786,
15650,
13148,
59362,
43873,
56882,
364366,
2951,
34868,
243513,
16285,
24372,
116276,
104112,
238341,
7971,
26043,
46525,
117800,
88498,
445227,
82287,
169664,
16378,
289657,
18637,
124490,
205685,
58759,
155187,
79634,
349560,
102449,
null,
39553,
37717,
3834,
162946,
209414,
42569,
161412,
15304,
58667,
76289,
24133,
null,
202599,
23320,
320292,
23866,
null,
385311,
122573,
20608,
319983,
null,
176240,
426261,
27852,
88451,
117411,
null,
36310,
8997,
576551,
267660,
14084,
341474,
66196,
34326,
null,
30589,
11373,
28241,
31879,
null,
101883,
12742,
1299833,
218018,
null,
44123,
30859,
357596,
14424,
5550,
29238,
139575,
5586,
53599,
null,
54459,
34634,
8951,
95828,
3068,
176068,
68241,
160416,
9583,
61841,
242955,
20408,
262383,
307991,
89473,
38055,
274980,
94191,
128468,
22540,
164164,
110677,
454209,
831171,
664011,
26766,
148132,
99391,
13366,
45624,
247677,
17151,
2054,
37908,
175814,
207044,
44825,
319276,
79233,
21395,
271011,
5498,
117477,
118844,
46116,
26437,
null,
293333,
224957,
null,
50096,
39734,
91806,
174888,
175085,
291528,
26258,
24889,
null,
220856,
null,
45196,
25625,
513291,
14181,
8501,
45642,
52658,
102677,
224552,
138025,
37736,
37288,
157472,
308045,
556906,
34662,
459505,
104325,
null,
234701,
27932,
56349,
57748,
104817,
17139,
2963,
272278,
null,
171835,
51680,
72649,
121215,
229613,
21493,
403165,
444914,
6856,
187261,
46013,
262923,
107379,
260335,
65038,
312245,
90268,
267052,
17676,
null,
5494,
27424,
102951,
9875,
424123,
176397,
23203,
54459,
67563,
106697,
23389,
9198,
33920,
34032,
103932,
185650,
129209,
97167,
null,
19299,
18332,
364168,
83437,
270092,
35769,
187305,
234095,
44392,
26364,
5619,
13095,
57182,
null,
null,
149090,
234080,
387297,
122672,
null,
82139,
264033,
16357,
804103,
168514,
29663,
24468,
84155,
70429,
192343,
24292,
69404,
52919,
234813,
387315,
45478,
null,
162380,
47648,
58390,
417928,
26485,
null,
21717,
202395,
75762,
null,
null,
62237,
28017,
206565,
359844,
17047,
null,
175620,
53940,
264836,
97845,
28124,
40233,
23859,
38349,
208745,
60489,
11852,
21366,
null,
45368,
null,
341561,
10238,
17176,
6643,
15162,
89264,
223596,
10241,
44838,
88258,
211338,
108213,
686794,
null,
178649,
335650,
24294,
null,
95096,
14741,
42209,
182366,
298929,
16862,
143117,
44064,
38384,
179761,
52351,
166311,
null,
291915,
40517,
99474,
455324,
8311,
109474,
100652,
73403,
31589,
163404,
null,
34623,
null,
49064,
218487,
60971,
349399,
191818,
137206,
17137,
20387,
341508,
356506,
16850,
126406,
35777,
44009,
15382,
null,
49889,
337240,
178172,
83087,
145334,
40584,
141749,
172682,
4296,
19605,
152319,
70369,
240658,
32280,
4595,
53430,
null,
201067,
16415,
32267,
32790,
408449,
198935,
403766,
23000,
7769,
63145,
53214,
232225,
null,
35481,
235408,
137246,
33368,
270069,
32240,
35143,
111602,
2982,
3258,
161352,
432949,
null,
18771,
35313,
22493,
187215,
569795,
31885,
360462,
47689,
10122,
475417,
445207,
66797,
34151,
33797,
33146,
211668,
34024,
null,
82279,
38433,
173726,
35478,
80550,
128762,
71736,
264016,
366882,
45453,
24199,
128111,
143073,
193880,
281967,
5032,
27566,
93031,
463860,
13530,
146633,
35252,
22585,
205560,
9374,
295344,
63503,
3437,
19906,
120133,
43435,
48595,
258284,
114869,
312731,
23541,
24092,
17511,
8093,
180805,
607673,
64746,
10005,
75671,
245623,
22723,
249170,
41661,
null,
85724,
106180,
411984,
55008,
250014,
88069,
13387,
217322,
239063,
149064,
19604,
89953,
24772,
41150,
172615,
377265,
22068,
48774,
46287,
405948,
41771,
234036,
89900,
27069,
38996,
45842,
218988,
17223,
16503,
null,
36960,
11194,
38185,
39166,
169984,
8630,
29369,
58396,
130734,
37248,
94562,
356299,
10112,
434862,
62696,
45710,
231330,
118221,
380990,
81845,
232212,
177204,
93032,
5113,
304632,
171628,
394150,
12911,
117003,
38560,
6310,
81696,
126067,
39064,
59522,
137647,
null,
100740,
38366,
null,
13460,
8678,
162780,
156847,
6471,
6064,
64169,
67493,
257173,
1167,
147027,
66755,
36013,
164454,
102165,
131125,
229172,
44094,
190750,
17261,
null,
81167,
15632,
222496,
210477,
80421,
183953,
208805,
253103,
10882,
39439,
442571,
157604,
121537,
30564,
20731,
238956,
326810,
416225,
56929,
295787,
null,
8170,
3357,
null,
405752,
82293,
null,
26325,
45819,
206121,
15867,
168705,
null,
61964,
433141,
49578,
182257,
158521,
8510,
629574,
37378,
26377,
120261,
87153,
8330,
321231,
43767,
null,
30171,
27146,
null,
126381,
22968,
304738,
495308,
163278,
40606,
15290,
30290,
25139,
11795,
null,
149849,
81651,
291641,
214563,
30031,
292038,
56415,
212243,
170208,
21491,
131867,
49872,
332464,
null,
102397,
26335,
48249,
122238,
null,
968125,
222822,
294971,
12770,
155016,
24979,
84125,
null,
65400,
241469,
34394,
165540,
18446,
44477,
56164,
250746,
31339,
6876,
65183,
22593,
54630,
538885,
16185,
352880,
10192,
175832,
126548,
200723,
42402,
22955,
269477,
362901,
470919,
51075,
19672,
163416,
33761,
49446,
53623,
214515,
484750,
185104,
451210,
731992,
234575,
null,
170461,
198520,
20669,
39989,
30928,
null,
33417,
5375,
24547,
388397,
25439,
23633,
57048,
376272,
36983,
113806,
29220,
17389,
83942,
131238,
392068,
254123,
52980,
24054,
6132,
980303,
28589,
22034,
254472,
100770,
15525,
null,
17751,
50934,
18115,
72219,
251142,
23685,
309298,
333386,
30462,
34028,
78060,
402250,
264969,
316581,
394245,
243030,
37667,
179121,
177912,
18413,
113166,
215831,
121835,
60434,
9883,
77925,
201308,
null,
12097,
283116,
142452,
37233,
172538,
467529,
9299,
201711,
210472,
64325,
157729,
37113,
188282,
538664,
89956,
46339,
17929,
260671,
283386,
13870,
105177,
254292,
313501,
343132,
53600,
156815,
7908,
414134,
390557,
3015,
470369,
59761,
139555,
152501,
121043,
324187,
10994,
12328,
null,
198708,
35139,
92846,
303010,
168090,
238734,
76009,
325499,
125555,
18310,
215660,
141000,
91448,
221476,
22142,
null,
283907,
158244,
85269,
58209,
324346,
8866,
56545,
129915,
45601,
58041,
482985,
48,
null,
337125,
197889,
138070,
130273,
16619,
18066,
153654,
458376,
42119,
78441,
259296,
209524,
35414,
160188,
1084326,
116035,
65064,
3848,
341365,
6417,
null,
91727,
106532,
37855,
225008,
6397,
132006,
225046,
54819,
null,
54587,
247424,
346819,
78450,
197933,
81052,
26678,
68622,
null,
null,
7078,
14626,
21978,
35059,
10195,
96531,
56502,
135637,
8283,
211335,
21696,
30608,
43797,
390085,
111519,
9639,
112937,
115485,
23294,
66833,
10291,
223730,
19454,
null,
null,
29567,
71118,
20104,
98280,
5765,
38547,
210355,
159793,
324151,
9409,
85607,
55878,
39199,
6311,
572434,
274477,
387876,
296683,
131135,
null,
101094,
null,
230588,
29682,
425774,
261176,
null,
211716,
11565,
21716,
386566,
42582,
141691,
131737,
196260,
188149,
2872,
204166,
198812,
8902,
50895,
109137,
8594,
339984,
25392,
45640,
368934,
196170,
211544,
195241,
96860,
104588,
48199,
17924,
344522,
717176,
13714,
null,
113964,
331514,
35226,
55692,
224252,
210875,
83186,
385993,
61091,
30571,
10831,
61242,
469787,
233600,
26903,
12113,
54356,
57296,
201289,
44216,
212442,
129417,
405277,
27397,
126177,
56944,
134854,
205914,
32620,
215936,
11190,
30137,
56335,
29466,
42498,
null,
39368,
184791,
6024,
252396,
25806,
null,
24192,
467700,
166000,
69541,
96198,
242582,
294141,
171366,
null,
72260,
163007,
155408,
291393,
209633,
107369,
20908,
121759,
190975,
58783,
161954,
72715,
293137,
null,
272909,
175440,
175530,
10563,
91801,
43687,
145497,
39518,
118090,
30421,
40606,
14894,
394342,
121656,
42623,
42422,
57098,
96355,
75289,
34624,
394894,
19350,
73401,
null,
194409,
212971,
7263,
34472,
6383,
15104,
156296,
33899,
196450,
null,
134310,
80385,
14163,
182726,
306792,
235773,
43143,
41714,
16403,
568845,
314293,
257401,
9066,
28293,
45704,
129161,
236646,
42997,
47301,
366365,
1303602,
283843,
36097,
68628,
46184,
null,
161430,
174295,
21056,
16652,
9312,
79549,
12989,
40137,
11928,
275922,
96614,
551318,
38910,
314926,
27965,
92293,
192801,
283662,
null,
98726,
238412,
24636,
208467,
284849,
84341,
249271,
39738,
54991,
345979,
null,
77555,
32171,
94692,
31427,
118928,
82920,
754414,
25733,
42456,
155332,
215553,
30150,
95117,
317765,
null,
38562,
436252,
226669,
25944,
22860,
12174,
57487,
113322,
189874,
52491,
41862,
null,
null,
null,
40275,
17755,
81518,
159950,
59699,
469053,
14153,
33832,
236699,
19800,
32343,
8115,
165760,
40136,
18212,
8233,
68619,
379952,
57374,
201205,
3608,
195767,
69833,
96771,
188727,
5919,
63034,
284610,
12252,
200626,
758189,
266569,
673419,
20743,
53068,
362147,
254705,
38934,
19881,
24244,
102326,
54135,
299011,
28788,
22709,
44260,
175207,
6422,
282736,
23519,
331651,
380681,
null,
237264,
213139,
25308,
7160,
191456,
31362,
187460,
3244,
null,
788382,
367577,
153979,
29752,
null,
183313,
9137,
61849,
213859,
215758,
211749,
265065,
189612,
171945,
null,
166535,
509708,
16911,
18418,
250087,
33279,
317034,
463385,
4740,
72620,
121266,
142013,
15759,
123088,
27361,
78998,
370612,
null,
13459,
null,
103157,
31378,
198672,
278376,
null,
79078,
null,
8470,
62515,
213463,
37632,
86183,
64638,
1826285,
null,
170438,
50579,
27665,
231941,
133545,
134858,
80185,
35496,
25119,
81007,
7190,
264260,
75340,
186164,
298938,
289560,
141733,
91626,
200277,
167584,
114121,
123917,
18761,
55569,
100588,
349028,
28482,
67472,
22570,
197665,
78342,
76541,
111399,
10411,
33697,
12862,
132552,
211105,
198590,
22458,
87842,
253479,
174456,
7000,
null,
158418,
319301,
280858,
36458,
125498,
31723,
329754,
null,
80325,
22231,
171550,
105643,
173796,
null,
8229,
330280,
71948,
106367,
8874,
362658,
177608,
39497,
128264,
33494,
110282,
null,
310434,
16128,
204188,
203458,
20162,
115455,
15558,
224654,
23723,
2780,
166975,
26147,
167992,
299056,
225522,
16793,
577172,
15057,
69159,
32305,
20029,
null,
23151,
null,
191416,
689956,
196115,
32851,
199438,
46711,
92286,
72536,
55119,
22304,
196324,
38363,
614368,
85680,
246340,
395264,
null,
null,
11676,
172703,
76226,
41701,
47667,
95830,
411457,
31445,
297988,
19799,
210829,
143576,
223450,
316448,
183477,
58692,
null,
15901,
332226,
394411,
21448,
331363,
42576,
470018,
18501,
6351,
189804,
136355,
193001,
56330,
43492,
30897,
278418,
336397,
22689,
29728,
132111,
21479,
11098,
34496,
43474,
256538,
24543,
17784,
210537,
null,
35769,
8801,
28182,
591644,
7689,
null,
2279,
368810,
13822,
null,
null,
4146,
207784,
27117,
34616,
48518,
134321,
260260,
746358,
244486,
80810,
254431,
121924,
null,
263495,
391729,
null,
203359,
15084,
72037,
378224,
251380,
171895,
40943,
146051,
147458,
126976,
12493,
117983,
32320,
null,
211401,
null,
72777,
5895,
533734,
23052,
350443,
45636,
20430,
439387,
33937,
null,
323610,
126367,
122399,
null,
628219,
null,
90720,
38642,
58988,
339878,
204449,
27286,
13870,
30044,
1042,
22532,
377861,
26479,
38754,
252269,
67395,
386016,
3431,
260145,
null,
22142,
14497,
63024,
41788,
321939,
null,
10028,
252647,
41359,
44403,
48945,
185887,
108102,
6929,
77574,
91415,
null,
12534,
63928,
22849,
45740,
87886,
35961,
224759,
367490,
154880,
334109,
198663,
154700,
47354,
139412,
94870,
171324,
120978,
31924,
168994,
128721,
43978,
46435,
131540,
65831,
34414,
40580,
199771,
107047,
39633,
218356,
26454,
23021,
36622,
310455,
45461,
13558,
18788,
91527,
null,
292879,
51127,
43140,
66066,
92389,
207447,
49313,
9250,
39642,
163465,
305620,
20795,
43057,
357477,
137104,
280422,
24349,
53574,
34568,
231788,
94305,
25154,
133195,
63881,
49095,
5551,
83173,
41320,
null,
30384,
29895,
18194,
236725,
402720,
145033,
133899,
10933,
null,
76918,
146441,
91640,
99500,
6315,
43865,
32831,
153525,
null,
59183,
356911,
19442,
9045,
null,
87950,
289056,
null,
69109,
null,
135972,
300548,
17403,
41716,
43910,
77022,
257338,
167989,
174814,
49830,
254707,
617363,
17195,
46548,
70950,
46618,
237326,
53624,
16907,
114717,
40920,
45076,
143051,
127990,
37385,
26636,
67145,
null,
140204,
163408,
230270,
11967,
159125,
57743,
18815,
369353,
194557,
170027,
323297,
79173,
318886,
53202,
12430,
null,
null,
35960,
94496,
33498,
207884,
53552,
134162,
169256,
null,
19433,
15284,
24444,
122182,
18907,
166058,
65787,
39910,
152435,
84199,
4014,
93547,
279562,
32752,
264236,
284462,
132000,
134405,
47508,
228780,
14265,
171645,
360160,
4859,
27292,
146256,
277431,
55470,
44981,
36795,
382802,
15678,
217205,
365770,
20473,
47199,
41213,
null,
null,
20373,
47344,
104135,
15973,
184154,
74905,
138322,
32818,
118836,
162308,
164530,
100357,
266195,
93821,
186819,
13238,
24235,
137167,
568141,
323160,
301293,
165507,
16717,
305320,
37279,
22148,
21723,
27950,
196911,
204374,
141033,
64443,
93024,
42674,
206850,
6476,
85602,
27631,
null,
174966,
92070,
38244,
240354,
132195,
20957,
22689,
119395,
295585,
6127,
113667,
214807,
310546,
161773,
33315,
164573,
390022,
73906,
195573,
205920,
8046,
51882,
49740,
58330,
32743,
209447,
15564,
28106,
152866,
51626,
183074,
61614,
59191,
261979,
6414,
78210,
439902,
25511,
13831,
58200,
33640,
241677,
5805,
91774,
336533,
21988,
38824,
190334,
71566,
379201,
15725,
162819,
594026,
545031,
123323,
338339,
71772,
28904,
226004,
33435,
65573,
62523,
8837,
186035,
52188,
11573,
90249,
261459,
41039,
116609,
385915,
6100,
49652,
13838,
13285,
78950,
null,
66344,
122942,
46432,
246197,
15308,
145789,
14536,
181273,
30462,
20641,
40305,
29354,
74140,
223624,
225071,
56406,
291405,
285644,
129075,
49340,
124692,
89279,
30842,
179109,
null,
110365,
34963,
178216,
null,
138736,
173881,
1718,
30599,
257269,
null,
88309,
226469,
30593,
null,
null,
24402,
136887,
72706,
null,
6702,
70046,
38370,
87756,
29620,
21419,
null,
112639,
369947,
22279,
21443,
69110,
7645,
18204,
347985,
32329,
4358,
25171,
null,
33144,
254218,
213630,
228339,
344979,
364449,
13158,
207373,
377128,
504441,
281198,
44409,
14150,
349386,
6702,
15156,
3938,
221251,
35873,
41643,
71389,
14518,
51906,
219145,
null,
null,
192525,
53016,
100117,
213535,
486757,
46611,
33276,
44690,
419006,
158704,
25543,
275286,
240909,
20185,
166283,
98601,
140532,
168605,
183672,
47555,
495423,
104278,
140928,
413188,
21419,
244781,
83575,
34348,
134708,
345050,
12230,
367907,
423946,
null,
59162,
393724,
26468,
17675,
74296,
305687,
124734,
205608,
157363,
252191,
27448,
369585,
224189,
14734,
315177,
12372,
298537,
129632,
8054,
null,
382701,
7511,
46666,
363291,
79322,
109705,
33122,
64187,
375777,
62007,
7311,
194947,
5862,
131819,
395676,
58225,
null,
190500,
465253,
29959,
283779,
167726,
189062,
337550,
108935,
29179,
14876,
400581,
129624,
4241,
42087,
155753,
237208,
null,
221140,
194586,
219563,
163701,
73044,
31700,
181481,
224335,
46746,
428522,
41875,
null,
224134,
39075,
41983,
22087,
36827,
209614,
135021,
30629,
343902,
40946,
65277,
184206,
50593,
55231,
35133,
350947,
302146,
18983,
40394,
87127,
26725,
182950,
279617,
21527,
277902,
11010,
164446,
303863,
43769,
185507,
32726,
253986,
28279,
246102,
298555,
311719,
null,
282661,
null,
null,
27573,
221429,
203646,
252406,
13207,
101395,
null,
420559,
140537,
34192,
56861,
9411,
73996,
338156,
13621,
47704,
392178,
22631,
27467,
16319,
18749,
36164,
200982,
null,
21076,
null,
23786,
null,
66576,
261270,
5954,
15456,
null,
215601,
null,
59015,
21000,
216134,
49909,
558723,
39428,
216000,
51579,
40203,
58437,
26226,
14487,
14571,
229562,
33787,
null,
487814,
30629,
17511,
32649,
99737,
43528,
354580,
62922,
24272,
338422,
165449,
43305,
null,
14176,
86242,
199901,
219311,
120251,
51468,
null,
78918,
3628,
37221,
150977,
366325,
28888,
15935,
340126,
41407,
185510,
78259,
37568,
96642,
36514,
45259,
259894,
null,
136029,
71306,
9698,
497222,
161516,
273093,
45024,
25119,
264498,
9057,
224222,
352980,
25193,
26029,
85640,
305410,
22768,
6589,
416103,
156239,
14656,
242922,
null,
14652,
175885,
107464,
47594,
160237,
null,
28944,
35379,
null,
321297,
null,
351228,
700336,
538256,
5633,
663937,
44218,
50919,
125950,
181617,
50368,
397625,
null,
40301,
191172,
null,
39082,
23925,
63842,
110289,
86092,
32036,
19137,
55665,
59003,
22402,
112662,
80895,
200792,
51434,
35875,
164658,
277228,
62200,
146539,
26204,
312208,
52352,
212366,
63022,
null,
105697,
124944,
24357,
10180,
45758,
55995,
170922,
null,
27033,
45546,
22713,
200179,
156212,
106832,
262327,
null,
501628,
160435,
660003,
1107,
210764,
37600,
68095,
42051,
66471,
null,
128710,
54505,
45996,
15844,
17204,
630340,
59901,
242717,
35262,
60790,
189237,
48785,
193893,
53675,
124114,
33629,
111384,
89445,
5088,
138396,
282176,
32952,
135225,
47283,
23776,
null,
161566,
432950,
4010,
213927,
null,
293144,
475197,
55532,
83782,
39006,
43676,
null,
11797,
null,
54294,
75528,
6001,
19865,
374264,
null,
23877,
8269,
45500,
545717,
428305,
136395,
36969,
226120,
30887,
15511,
314778,
4306,
172317,
178663,
16289,
51965,
null,
22907,
5132,
14165,
30611,
null,
null,
229078,
22676,
24547,
54925,
101914,
13456,
39481,
70449,
59448,
55667,
null,
9613,
244237,
null,
199809,
231907,
259334,
446611,
4204,
10061,
null,
19638,
117127,
449762,
36593,
113989,
9151,
39513,
28909,
114581,
228968,
14450,
155738,
227530,
200805,
260931,
22847,
22311,
null,
34946,
null,
20321,
144508,
321820,
172812,
423167,
201303,
547765,
30321,
11483,
null,
43230,
null,
278727,
162304,
153104,
86143,
444836,
212489,
136138,
176193,
null,
null,
63090,
125136,
664508,
325373,
170454,
286378,
26632,
22494,
56818,
73233,
254406,
null,
586934,
189210,
35634,
171622,
43447,
14413,
null,
7015,
151228,
24220,
170924,
52605,
226790,
null,
null,
161135,
219274,
30577,
183853,
272241,
null,
19033,
133501,
49966,
17045,
26927,
13210,
243454,
112949,
20458,
1393,
46910,
null,
369309,
25705,
16957,
1041916,
242012,
26994,
40128,
42975,
205820,
162233,
252462,
27166,
21477,
23467,
129487,
18984,
90687,
246224,
50448,
24209,
262925,
194886,
33360,
null,
27399,
104541,
87862,
290737,
401126,
81741,
123294,
222900,
109654,
372050,
17391,
181954,
15535,
19558,
66351,
54193,
178335,
131306,
127890,
244420,
18339,
178059,
84138,
271058,
159692,
77578,
75944,
178216,
404411,
438136,
4216,
270214,
49694,
21888,
723796,
null,
null,
54348,
48517,
135243,
53041,
null,
683078,
164696,
null,
null,
72271,
150053,
46556,
318675,
417746,
null,
68783,
64893,
98682,
30540,
57288,
44512,
875,
69440,
52096,
117689,
15750,
78102,
null,
63839,
64165,
389361,
17591,
28153,
482138,
225921,
73509,
null,
141355,
132399,
63097,
283427,
56790,
156532,
412800,
17054,
71658,
32416,
41692,
2643,
214958,
103828,
175148,
127867,
70942,
51837,
null,
39604,
137181,
32248,
null,
null,
97233,
96406,
10159,
13977,
118427,
10425,
71390,
116680,
168621,
322754,
28401,
17360,
12265,
342588,
30364,
57826,
114975,
31317,
177319,
175787,
159329,
22411,
4901,
98793,
318555,
162866,
8674,
null,
null,
9457,
null,
209165,
450574,
75503,
92036,
13861,
64217,
91663,
26474,
62944,
159888,
11529,
142925,
null,
210670,
63707,
458905,
69399,
114409,
4866,
181209,
91732,
97301,
116064,
112361,
114071,
156739,
165540,
null,
230306,
24857,
124422,
122903,
177550,
28736,
185289,
38444,
291673,
214551,
52892,
67163,
303878,
771664,
240971,
19406,
212015,
33028,
350719,
96205,
30233,
null,
75098,
22447,
201306,
12400,
64051,
null,
null,
17077,
15070,
null,
74833,
123969,
15497,
200314,
12813,
112191,
38943,
250522,
95149,
389790,
312236,
null,
18360,
78523,
137833,
288867,
234936,
13470,
748851,
null,
14809,
94815,
112075,
4415,
137207,
321104,
220316,
167327,
23670,
99012,
137664,
314518,
33562,
83186,
155247,
26571,
272348,
151687,
null,
5454,
292910,
13377,
333032,
13536,
71267,
15279,
22613,
86560,
490922,
152438,
21177,
34021,
87028,
27662,
25997,
27238,
138536,
108321,
300882,
33936,
23596,
126043,
27671,
158995,
294334,
15094,
8289,
42847,
null,
203259,
77765,
28093,
44863,
122458,
60717,
403122,
159180,
36079,
233129,
11694,
47125,
25413,
574594,
48705,
209291,
200280,
199612,
74410,
202752,
45217,
8098,
566959,
null,
46053,
48363,
337475,
256389,
9290,
466301,
61798,
168573,
null,
16829,
64995,
178226,
236626,
11720,
17404,
180222,
312198,
67257,
1010322,
311798,
null,
30065,
136131,
177566,
310748,
183149,
21915,
23884,
9003,
19462,
262371,
68173,
450736,
260261,
28973,
23669,
4909,
24603,
383631,
52231,
34689,
36075,
268285,
29104,
null,
251394,
15338,
132216,
37518,
134036,
31040,
386582,
262726,
356653,
154408,
132016,
22893,
28118,
349466,
244289,
13647,
8824,
107590,
159902,
10978,
8077,
112662,
32214,
31043,
8712,
12611,
32674,
125288,
27910,
179407,
530675,
21954,
null,
50047,
47996,
18809,
57982,
365072,
75521,
155485,
176521,
53865,
48647,
null,
55126,
41345,
null,
48408,
410422,
30008,
42119,
152385,
119414,
159259,
363890,
50259,
33369,
272306,
189232,
573300,
298776,
34642,
269301,
494167,
282374,
20714,
133163,
6262,
132882,
null,
253570,
341345,
163728,
42539,
307018,
null,
103344,
28451,
255828,
30055,
200722,
345780,
47400,
92926,
44983,
200311,
null,
37893,
46364,
298692,
282040,
84803,
13108,
135764,
280380,
141850,
720248,
435630,
159905,
31178,
251100,
19551,
271683,
159483,
37414,
246029,
407100,
166560,
185790,
90872,
11050,
182395,
72092,
144981,
463131,
27512,
36625,
null,
7530,
10239,
101140,
40119,
15439,
35701,
32306,
454547,
470814,
134646,
null,
48779,
8009,
464310,
10387,
189410,
272084,
57812,
145736,
164799,
25585,
5127,
18266,
363418,
null,
144765,
398427,
234664,
10596,
9303,
178297,
null,
12898,
24732,
54179,
426743,
13843,
387518,
317653,
219417,
237866,
226026,
null,
235349,
20327,
197020,
20747,
142758,
39619,
47202,
204145,
205875,
117882,
162151,
357144,
191042,
308369,
201361,
42246,
288683,
21982,
277271,
110179,
279011,
194964,
116523,
20532,
314873,
465156,
10977,
6624,
377383,
28824,
54375,
96425,
269898,
183709,
288408,
391757,
176367,
54366,
34755,
22418,
12396,
94712,
211442,
42470,
105965,
4817,
null,
24864,
181809,
28894,
146721,
3134,
26287,
22696,
9072,
7967,
34582,
62233,
17844,
101654,
342144,
27308,
361564,
589658,
23879,
59604,
45905,
14569,
102198,
28139,
105305,
254561,
null,
45854,
153039,
24618,
null,
37578,
70375,
401394,
110344,
60032,
136329,
247211,
318326,
59740,
85897,
50885,
273600,
73387,
37979,
null,
41791,
44311,
127394,
5483,
null,
428364,
9301,
31307,
103303,
24108,
209626,
117102,
263234,
22280,
236597,
3306,
59715,
264021,
354403,
31810,
31493,
348830,
167649,
377623,
32711,
26284,
24118,
83008,
90565,
24420,
4875,
null,
142432,
371175,
72936,
121664,
18920,
16017,
65744,
198850,
151858,
166794,
244372,
157395,
102672,
44071,
16605,
183739,
41790,
66571,
197798,
163085,
239734,
19074,
94238,
103212,
18876,
535847,
11033,
null,
30730,
207817,
68090,
157166,
8210,
654336,
97106,
null,
585824,
38384,
46596,
266568,
138427,
117370,
71620,
3246,
264659,
2742,
16962,
11057,
21065,
35580,
141953,
33617,
13373,
45911,
null,
104549,
31921,
46487,
13661,
45083,
20402,
359972,
84367,
164574,
335835,
76587,
7964,
556312,
207176,
50571,
522939,
207454,
320492,
33610,
null,
235846,
11424,
187804,
302417,
9692,
181959,
12074,
25131,
921640,
410156,
57250,
343079,
56201,
214391,
118438,
419082,
12243,
null,
219959,
162203,
null,
15951,
null,
55673,
305966,
170391,
61551,
375378,
175072,
34525,
14796,
311628,
171845,
112236,
36427,
356246,
92414,
358943,
15630,
292119,
38840,
402059,
7080,
189942,
599910,
5814,
115657,
252525,
123989,
null,
111586,
30191,
187741,
190044,
239548,
34487,
3031,
298384,
null,
218829,
29391,
8484,
24003,
7057,
16897,
160481,
56018,
402170,
76888,
33638,
51315,
170714,
55022,
null,
354466,
33952,
295879,
270006,
76073,
98224,
169334,
184720,
99383,
null,
197468,
103062,
25123,
357765,
186228,
62030,
null,
59656,
21227,
162790,
198040,
425734,
29502,
75203,
237273,
197199,
74047,
177883,
292439,
39595,
33364,
196414,
23368,
33959,
665264,
20410,
510968,
589272,
116226,
197043,
75465,
48537,
179251,
113566,
null,
20166,
292228,
null,
121453,
123626,
199594,
276618,
240437,
28460,
186766,
249909,
31406,
669956,
135402,
59441,
3616,
null,
90400,
264413,
120704,
5937,
208403,
46551,
24598,
206357,
417573,
24910,
69542,
267592,
258195,
346207,
257273,
53114,
4444,
423518,
147053,
183138,
19443,
23888,
361666,
216833,
154600,
89071,
237884,
28747,
92841,
31834,
76898,
115857,
20855,
63237,
292212,
14426,
148607,
9033,
291037,
4436,
null,
422373,
20221,
10442,
16461,
14400,
11603,
7875,
61439,
41042,
61205,
75838,
18151,
7887,
387996,
17276,
60180,
255052,
9144,
472675,
138071,
66108,
471787,
157676,
226085,
381154,
17402,
133182,
null,
309983,
14482,
52952,
433440,
8196,
50012,
24837,
null,
170087,
null,
617886,
31329,
23460,
20332,
162810,
33451,
120050,
138324,
162473,
257163,
18171,
157742,
24887,
null,
268462,
57513,
null,
null,
38955,
99267,
321911,
null,
224673,
238337,
108576,
430967,
371094,
9745,
258994,
9060,
122969,
395289,
298218,
77601,
132355,
243449,
34550,
28929,
52797,
228140,
225881,
42644,
null,
null,
292150,
95486,
179122,
null,
295042,
19304,
52056,
26987,
null,
33857,
41328,
null,
36967,
178871,
null,
201949,
485810,
null,
112875,
null,
234912,
7814,
385845,
200693,
27041,
84082,
2836,
182720,
67509,
742838,
120247,
97074,
69470,
8283,
28419,
60432,
253354,
204334,
22618,
34619,
24135,
23761,
485196,
null,
357950,
194181,
20115,
182825,
35010,
340594,
281065,
91584,
67050,
137444,
230533,
null,
287274,
207240,
6496,
23544,
27230,
254314,
644761,
209098,
121047,
17226,
111352,
31640,
241981,
25791,
703395,
312435,
38295,
209294,
23326,
8544,
147367,
1911,
83258,
163191,
17142,
275354,
496015,
null,
68265,
229145,
68411,
382822,
58159,
819319,
137880,
7707,
343426,
55163,
15254,
77250,
31457,
64623,
333774,
92787,
446584,
142603,
30360,
48581,
13357,
290621,
333382,
null,
null,
145611,
60466,
123776,
282340,
33108,
137781,
177450,
8773,
9790,
220697,
34901,
74533,
211805,
null,
61582,
308093,
14404,
27325,
466004,
289173,
878339,
189046,
175128,
23917,
11874,
137578,
null,
345012,
21716,
null,
34744,
26864,
null,
162671,
23550,
274228,
1537,
19034,
20939,
151126,
15604,
53865,
228520,
14511,
null,
73718,
98029,
null,
3540,
66045,
40317,
35670,
53314,
21807,
114517,
19729,
null,
1329807,
20835,
34952,
63001,
193582,
195037,
34736,
239798,
26532,
206540,
275255,
960818,
15169,
290429,
177262,
56673,
106404,
435469,
18199,
5727,
149795,
14926,
315280,
29599,
372031,
391914,
209844,
10135,
63727,
60982,
37443,
321980,
null,
12907,
22285,
172126,
42783,
186795,
28777,
226692,
27993,
6047,
14541,
170778,
98659,
20928,
57123,
9113,
232257,
198794,
47832,
63518,
43945,
24348,
51344,
17809,
null,
null,
null,
48929,
276795,
612298,
34975,
196303,
54226,
64748,
278944,
166432,
27972,
324490,
219063,
28805,
null,
361629,
65698,
26541,
282806,
53271,
127138,
33309,
46757,
113185,
90364,
17065,
192671,
23842,
22283,
280046,
null,
7784,
253373,
null,
61498,
361834,
134774,
13138,
217689,
309121,
50502,
131464,
301687,
229831,
147109,
235376,
233056,
39090,
20885,
36304,
12983,
192507,
67154,
null,
30206,
126607,
61495,
19369,
94424,
9262,
43847,
42809,
44914,
197961,
154604,
79534,
10712,
315761,
42108,
6195,
138599,
56724,
126379,
37541,
215836,
98491,
126922,
502915,
101104,
48996,
140214,
72305,
416272,
48813,
44933,
30845,
239907,
146547,
176739,
109488,
309294,
929860,
139642,
16025,
35036,
327910,
9772,
37388,
205143,
null,
45581,
23879,
187685,
108460,
374203,
null,
154684,
11443,
273546,
148866,
202877,
28802,
66005,
5959,
52096,
134091,
52012,
127959,
25104,
10755,
39950,
8988,
47939,
153842,
52084,
40475,
4573,
173634,
69081,
45894,
33040,
108720,
98278,
32838,
143490,
null,
708735,
21956,
45367,
27663,
20513,
153931,
230585,
7567,
37350,
176021,
7295,
57465,
38186,
241536,
15678,
172155,
27468,
6384,
79276,
null,
65092,
74578,
35722,
31828,
79306,
68660,
null,
443972,
26501,
24427,
266577,
15628,
33667,
314520,
54045,
146439,
18136,
42884,
121731,
308546,
308372,
152706,
46048,
569331,
40485,
82674,
217230,
31797,
18290,
1805,
30520,
21540,
25820,
31149,
3536,
47859,
55293,
33027,
241260,
69423,
180935,
41813,
465061,
174589,
148628,
48034,
30577,
313942,
428071,
320178,
527832,
69407,
19417,
23114,
39963,
110904,
168018,
38208,
null,
111949,
2274,
47393,
29624,
32447,
20765,
9482,
562627,
390053,
234319,
23790,
102263,
163898,
28028,
77282,
25298,
318888,
136240,
209556,
253209,
null,
167094,
471998,
5016,
16765,
130243,
140929,
28711,
292419,
37818,
286422,
232985,
55501,
102910,
16800,
188191,
622282,
249409,
170125,
191425,
18278,
null,
217805,
16041,
255946,
25804,
null,
109283,
null,
107458,
162402,
57397,
74400,
40721,
194693,
161198,
389663,
47232,
9769,
31012,
null,
15366,
255638,
131471,
null,
131471,
15354,
7482,
63541,
null,
234202,
77710,
212455,
21429,
161185,
301037,
401124,
18954,
19858,
553842,
192261,
410054,
109731,
168356,
546320,
20666,
213128,
48814,
79415,
39168,
211779,
61194,
483935,
226820,
5989,
13792,
235967,
null,
35422,
203267,
168996,
41987,
330177,
250484,
null,
304395,
132558,
55663,
223170,
18139,
32966,
174056,
71589,
21616,
16803,
199110,
610775,
null,
142447,
109492,
42286,
348903,
10118,
32812,
null,
91076,
125011,
55849,
169268,
97908,
230656,
755595,
92398,
16095,
5836,
22337,
90523,
122255,
41339,
156097,
null,
55975,
22723,
371359,
20674,
26700,
272214,
227005,
203905,
30033,
20962,
30683,
13409,
125503,
null,
189893,
30206,
70275,
319303,
92760,
62229,
18589,
278510,
146169,
327311,
391172,
null,
null,
101778,
15237,
406556,
53255,
20342,
89938,
286085,
167289,
59084,
11118,
41089,
117163,
244026,
248410,
15693,
23730,
263908,
38535,
33073,
133605,
27257,
29794,
null,
165206,
231406,
225828,
324912,
19030,
307713,
80154,
null,
579513,
23270,
22217,
46380,
41997,
65062,
95408,
37637,
11989,
33719,
62058,
null,
90005,
219950,
37028,
185514,
142250,
59003,
639918,
165806,
50202,
203827,
156714,
null,
27533,
297881,
null,
166190,
184998,
186501,
54009,
72821,
62613,
30317,
132493,
21100,
49140,
145197,
17219,
4397,
263094,
11906,
39883,
null,
160904,
30520,
295564,
49445,
487431,
233786,
23800,
586046,
279035,
26274,
51608,
null,
7652,
24024,
40229,
9577,
27539,
null,
16632,
82227,
507928,
134118,
49985,
186068,
44179,
28238,
7288,
202494,
44798,
208073,
140494,
237039,
50036,
20164,
413280,
19606,
21469,
70948,
255682,
3084,
157746,
330603,
340825,
70279,
54240,
36703,
141167,
147226,
null,
402012,
292396,
79074,
46804,
40256,
84239,
433796,
123244,
26564,
192490,
105466,
121708,
197470,
273001,
null,
48694,
null,
21592,
20673,
51255,
null,
6062,
23519,
29126,
119599,
35061,
270495,
181188,
154167,
null,
79241,
18820,
null,
417259,
87551,
130228,
430588,
8970,
131701,
40976,
null,
22709,
123897,
9540,
40477,
245664,
329033,
332221,
268725,
114959,
21551,
48537,
25618,
168877,
42709,
11915,
97700,
302021,
70719,
13859,
62604,
106834,
415050,
639211,
40720,
133244,
44964,
217813,
null,
15907,
null,
62866,
21018,
17890,
59251,
122722,
4726,
351755,
112068,
44532,
29723,
428498,
16725,
30146,
103201,
17441,
null,
85076,
42590,
399699,
307488,
22275,
232064,
69274,
51400,
null,
47179,
358529,
31799,
172993,
146749,
26922,
60212,
520225,
68813,
287943,
9842,
392270,
229860,
14029,
10928,
21362,
32109,
5435,
40758,
748170,
244439,
164908,
330492,
225314,
77532,
29610,
523282,
55374,
null,
185701,
227935,
86080,
12048,
40276,
25122,
160943,
49333,
153673,
9685,
null,
38253,
20,
16861,
273560,
29991,
78209,
81290,
193013,
140021,
53460,
47869,
67049,
130782,
385297,
38890,
143772,
15672,
23534,
37090,
103569,
72998,
15363,
425887,
22319,
49719,
9240,
17112,
73948,
11963,
16976,
591866,
77364,
null,
17214,
39654,
65154,
203519,
45923,
198094,
18051,
287671,
141752,
423294,
52121,
null,
68498,
196249,
20412,
371290,
512352,
17099,
20978,
46261,
16769,
43947,
101117,
21371,
26672,
null,
29031,
221269,
36047,
156996,
239891,
51427,
211152,
58603,
20556,
40083,
23027,
null,
88152,
29384,
14547,
48777,
26950,
40464,
182295,
384048,
288176,
78463,
10268,
null,
51625,
44808,
132935,
185859,
193323,
9751,
264756,
4896,
261318,
455855,
112050,
309246,
341353,
730276,
115435,
36250,
74797,
49652,
244767,
69922,
53013,
64270,
237326,
41757,
10899,
175390,
null,
31722,
null,
197396,
60154,
42489,
100267,
72929,
167461,
40288,
8792,
51209,
34093,
160690,
25762,
17393,
null,
20945,
47035,
186676,
30364,
null,
96663,
42113,
283976,
263336,
42572,
41835,
62927,
195204,
48224,
18746,
157953,
null,
3766,
53443,
324380,
20487,
74507,
19934,
51057,
77020,
234474,
36486,
175851,
6397,
null,
13720,
10132,
278062,
null,
27816,
88248,
14702,
216212,
null,
143016,
8921,
303922,
68898,
441571,
33274,
20029,
34213,
35358,
35267,
21482,
353248,
268054,
214270,
30984,
310649,
228861,
299962,
33232,
181744,
55849,
7452,
32860,
33230,
31100,
39057,
91607,
14292,
38209,
215128,
119933,
null,
201868,
59899,
null,
20004,
145048,
288304,
9506,
45584,
174315,
243723,
526048,
222758,
24083,
9081,
281251,
315249,
49983,
17437,
null,
541549,
372918,
493123,
196139,
30267,
null,
222608,
null,
22222,
32045,
8337,
44033,
56291,
10429,
101613,
220023,
26789,
13573,
112109,
132638,
23160,
24973,
null,
21483,
365899,
50372,
138434,
343952,
37497,
313044,
26882,
81328,
13619,
35917,
427731,
6832,
null,
78201,
33330,
53100,
4914,
109857,
258540,
null,
null,
60693,
null,
10079,
null,
380153,
14023,
382638,
513564,
15369,
94490,
300502,
null,
275466,
18652,
212775,
625580,
16064,
168314,
145703,
34888,
88779,
14848,
31925,
20854,
228116,
275725,
110407,
172116,
34628,
8756,
42838,
572512,
19941,
113624,
28520,
233763,
170216,
29554,
169065,
null,
82642,
114174,
118898,
260155,
3143,
768948,
173570,
12418,
31554,
null,
451209,
205147,
12734,
212786,
24635,
59104,
31967,
224635,
17854,
132953,
280088,
53654,
7868,
null,
166439,
22351,
527193,
296599,
17763,
24595,
31002,
760945,
149053,
44137,
70132,
40260,
76177,
6720,
162304,
66450,
659214,
24164,
275095,
null,
null,
10825,
22696,
108910,
49144,
128063,
37459,
49754,
120977,
61554,
140785,
187005,
14929,
29060,
null,
null,
59267,
98880,
7743,
null,
354632,
199151,
106643,
null,
214813,
214086,
198726,
422842,
224879,
12493,
48598,
204772,
279681,
57121,
154603,
100931,
242631,
189623,
177354,
108427,
16606,
315174,
565470,
4825,
63098,
125671,
11899,
47859,
10605,
371537,
130632,
246857,
194602,
138527,
7325,
138779,
76733,
32558,
4794,
9378,
null,
22023,
114661,
188910,
null,
39273,
15796,
214840,
292573,
36428,
39752,
305894,
39547,
26066,
378788,
158727,
111599,
171961,
594745,
63546,
521566,
65576,
25914,
166945,
45616,
52823,
448966,
100223,
35505,
136894,
20765,
320858,
258573,
23436,
60566,
76687,
158942,
12954,
79100,
4776,
267145,
195452,
216088,
35013,
119847,
115678,
null,
11128,
781456,
null,
null,
null,
15126,
null,
432679,
306403,
null,
233652,
286548,
9130,
14052,
34724,
19877,
13140,
27282,
null,
35075,
null,
253614,
174615,
53990,
196519,
145283,
267732,
142862,
327309,
83531,
699459,
14956,
11908,
111117,
426613,
null,
150657,
6006,
18597,
27594,
3845,
28443,
22191,
12429,
28563,
222130,
188229,
34351,
6816,
66307,
26651,
7120,
109245,
6707,
49840,
46691,
176861,
null,
75479,
328676,
7356,
275003,
34141,
271788,
193748,
150708,
213602,
136335,
306661,
63294,
56975,
54882,
208139,
183099,
112824,
287458,
10872,
309012,
32478,
null,
null,
null,
120182,
12708,
86110,
330121,
139653,
7461,
61626,
19205,
15843,
19696,
204243,
535756,
null,
20246,
145426,
23299,
144125,
249830,
213967,
16400,
254055,
292131,
741294,
252259,
218880,
22141,
9337,
25071,
66513,
null,
104022,
161400,
51534,
52697,
60562,
246481,
null,
15951,
19661,
75957,
392214,
282450,
22237,
384028,
30860,
544639,
20168,
6050,
989,
349126,
207475,
40615,
53289,
17004,
307151,
151422,
35219,
68428,
23366,
208579,
5956,
449193,
193155,
35800,
25128,
47260,
23340,
207090,
70900,
10054,
11045,
248688,
null,
null,
444429,
24615,
69982,
143875,
354289,
132430,
75274,
82577,
4024,
189038,
123800,
8982,
86717,
180951,
154615,
453602,
185823,
49572,
170851,
68891,
87829,
null,
132850,
59152,
318183,
248437,
62148,
737629,
24770,
69440,
229975,
136747,
615784,
443198,
28547,
19794,
166194,
159632,
107263,
14031,
58512,
223015,
15193,
44539,
341202,
265409,
262486,
223996,
147176,
131599,
46864,
371764,
584532,
null,
107974,
174607,
346852,
31966,
177122,
11526,
119968,
27057,
13959,
6513,
272341,
191402,
95092,
28035,
186706,
31088,
276363,
555807,
74938,
292342,
116538,
121524,
28124,
356286,
32048,
null,
6447,
315998,
null,
119734,
503448,
349183,
178110,
21004,
134017,
6800,
110034,
57238,
14194,
92642,
19510,
null,
73716,
21977,
153891,
31462,
321247,
109454,
49406,
345329,
null,
16882,
311967,
null,
292243,
133913,
121105,
14847,
27704,
269705,
335433,
9444,
42561,
111722,
585069,
21850,
246444,
28106,
12333,
38431,
420784,
9330,
246868,
null,
147254,
307795,
36741,
111290,
10728,
664776,
93105,
356934,
121599,
384544,
null,
5529,
null,
198717,
68326,
20926,
515632,
13258,
183052,
3333,
295335,
16146,
null,
28981,
13912,
28914,
26221,
371546,
272698,
24218,
212670,
9858,
42852,
327137,
220038,
115812,
344252,
43001,
null,
191181,
null,
77279,
34727,
390004,
null,
265034,
8743,
994739,
null,
14600,
null,
437974,
110334,
null,
null,
6049,
52416,
136300,
26052,
105329,
198712,
null,
78802,
8937,
39904,
181651,
63532,
null,
627549,
61170,
110731,
28977,
149265,
45227,
160354,
5053,
244986,
null,
36817,
131876,
132523,
39559,
null,
21451,
null,
null,
415590,
null,
null,
7397,
21113,
31550,
null,
243154,
30247,
165333,
261546,
null,
29259,
34010,
37340,
6116,
28328,
162609,
102758,
null,
167877,
2793,
22030,
114841,
107791,
179548,
null,
139487,
57680,
4498,
33940,
137287,
21364,
19942,
null,
419850,
578308,
145406,
260039,
106975,
4358,
35319,
267458,
null,
28850,
23518,
254371,
null,
null,
261022,
23074,
13699,
67650,
27537,
533992,
257600,
64977,
100465,
42365,
null,
68286,
null,
151733,
21703,
72430,
17563,
200951,
6355,
37538,
80415,
300833,
74020,
34132,
14403,
23771,
130430,
200989,
269809,
89321,
161458,
101170,
109573,
23135,
285497,
29407,
372662,
280525,
80427,
170707,
35763,
68317,
35545,
39903,
333627,
81191,
44939,
16501,
154083,
271885,
375927,
62834,
230444,
17596,
60890,
17889,
32713,
144622,
81444,
5500,
null,
40388,
41889,
46472,
74167,
333093,
38559,
28962,
98934,
244854,
99964,
75527,
294059,
254090,
13649,
306986,
null,
54908,
190772,
518560,
113031,
232046,
16391,
61389,
201092,
219010,
95871,
461564,
82909,
54115,
37887,
65472,
45006,
405338,
17272,
16266,
192073,
201529,
12879,
43471,
4856,
242237,
null,
238314,
55639,
40156,
331254,
42063,
18640,
null,
240432,
331044,
21678,
20425,
31686,
239605,
125288,
240751,
25541,
58392,
38941,
3776,
232784,
147045,
39556,
67168,
178732,
265677,
12291,
170823,
34021,
12234,
null,
30500,
234365,
287338,
563049,
24251,
95632,
44222,
284720,
12485,
183367,
23468,
null,
27248,
26763,
58991,
26337,
20516,
519706,
185713,
16623,
716836,
137436,
null,
559930,
440035,
145264,
65517,
138605,
449970,
218508,
193226,
23405,
138679,
213225,
52850,
2134998,
277356,
14777,
373708,
169987,
76694,
19717,
37454,
233281,
523640,
134100,
369532,
238096,
198740,
96777,
499760,
584204,
null,
138861,
54943,
31167,
null,
7006,
23576,
66354,
117509,
383750,
27982,
38203,
177193,
158694,
179632,
61750,
82353,
13709,
282244,
396257,
27061,
16409,
33163,
13218,
236550,
null,
149234,
51033,
373066,
96961,
68113,
261489,
49928,
121431,
39957,
153534,
305248,
19549,
254146,
118712,
195901,
5387,
336442,
267095,
185238,
61641,
159678,
208213,
26231,
219315,
307676,
null,
273822,
15876,
26277,
503511,
192625,
30500,
38288,
32274,
7270,
76654,
431952,
23866,
57953,
69189,
19289,
378638,
266930,
221768,
47451,
null,
49631,
15128,
7736,
135386,
246714,
55481,
113649,
169656,
126593,
17612,
27813,
43612,
83343,
66501,
304548,
140565,
91133,
289219,
15092,
19263,
null,
8891,
62606,
150702,
50072,
36055,
25395,
144676,
51233,
163301,
38566,
57544,
37853,
87164,
107503,
29675,
18522,
20684,
46352,
55209,
null,
183156,
23530,
31951,
17745,
34069,
47763,
48812,
84947,
47075,
17542,
223050,
53919,
334943,
370250,
335133,
69309,
24918,
83994,
null,
5157,
768976,
67414,
51390,
88427,
199200,
255628,
94191,
34259,
151242,
124572,
102794,
223774,
57977,
19603,
34006,
314800,
25894,
132790,
23302,
252752,
81867,
146180,
25413,
252668,
489096,
157533,
30253,
25424,
21272,
null,
8078,
323731,
31360,
57542,
92980,
50835,
45591,
457952,
304849,
358020,
185190,
62412,
142344,
221657,
46295,
27170,
25709,
11232,
13352,
39441,
100829,
8494,
118048,
77323,
304517,
224915,
55783,
32651,
205463,
27155,
120680,
18687,
157495,
606137,
28530,
225936,
100838,
null,
13237,
38987,
38607,
15592,
255390,
133458,
18430,
54228,
69580,
468950,
38806,
414671,
55819,
80992,
568245,
88903,
121504,
44647,
null,
161929,
23863,
820745,
34486,
114687,
11033,
145838,
12481,
7224,
48145,
735258,
null,
76720,
258147,
145210,
11103,
null,
35675,
202394,
83480,
460627,
17183,
68394,
158454,
85498,
64329,
135152,
79980,
14326,
168333,
15776,
null,
535395,
77144,
19048,
196454,
46762,
29657,
43791,
13677,
14417,
null,
148298,
151033,
53925,
12975,
334711,
75154,
104930,
14498,
null,
42788,
17940,
47589,
176315,
33103,
349206,
128262,
12708,
17499,
112382,
293100,
null,
161198,
154749,
4946,
60768,
46744,
36032,
453016,
319819,
152327,
47471,
59196,
34321,
23560,
22913,
214404,
99445,
174363,
243366,
30600,
203534,
173507,
81420,
32125,
16607,
26395,
19101,
30113,
80864,
52569,
63434,
null,
5748,
null,
25049,
174485,
26729,
259071,
69981,
162188,
120625,
294264,
61729,
198805,
439275,
44819,
195053,
25698,
423008,
198312,
26125,
254855,
7818,
80933,
272458,
86530,
165458,
null,
14803,
204222,
292762,
44543,
109006,
74986,
580866,
176800,
214321,
16158,
27372,
41174,
25744,
328280,
287711,
11683,
270441,
1620,
14757,
263198,
69423,
null,
37783,
129560,
528707,
38907,
112575,
14832,
35042,
233129,
200066,
125519,
240321,
107270,
4665,
17711,
419378,
null,
15988,
6674,
null,
142373,
426628,
179459,
39453,
175271,
217982,
36614,
18128,
null,
29690,
404596,
13848,
110992,
266959,
25129,
169691,
12430,
112383,
83824,
145257,
191689,
107568,
52478,
399475,
null,
199953,
10932,
100090,
10195,
138820,
260841,
313398,
45218,
176979,
158368,
25979,
353807,
4033,
24349,
226122,
4290,
331404,
17188,
37752,
17689,
51125,
50056,
207992,
722663,
189777,
67276,
314204,
113848,
null,
220204,
377020,
746402,
2739,
26958,
168870,
112499,
147090,
192886,
44137,
377688,
32662,
22342,
25130,
36716,
43996,
146729,
55399,
4191,
162961,
315816,
245690,
106687,
57164,
11430,
null,
123839,
72438,
139693,
92909,
25295,
41245,
32839,
18983,
24244,
172291,
177188,
239170,
43510,
57996,
34333,
188959,
208109,
6936,
43122,
null,
161914,
345298,
89006,
48894,
42818,
23550,
30519,
304408,
73150,
140013,
null,
26580,
67922,
null,
168527,
349896,
20187,
322598,
19635,
281071,
79744,
203673,
160321,
97968,
29371,
null,
null,
28175,
116657,
48110,
127132,
31968,
209886,
47477,
28058,
642004,
111925,
8833,
76803,
6335,
27965,
56866,
414407,
127342,
32243,
11329,
109965,
14580,
40650,
378770,
196342,
62739,
175049,
30670,
69744,
134463,
30755,
21301,
151190,
59201,
110929,
162632,
47652,
28488,
null,
55059,
21452,
28303,
31335,
null,
16994,
276462,
345336,
108414,
19630,
30402,
93089,
12651,
200311,
204551,
64115,
196622,
257753,
48371,
65090,
24738,
104389,
452644,
132526,
null,
27650,
33897,
172651,
31055,
31858,
24111,
138587,
null,
47643,
36937,
152766,
109808,
217073,
38334,
227668,
18186,
70626,
292848,
39923,
504628,
65260,
109424,
272569,
166637,
null,
138013,
76410,
225465,
360655,
321829,
62648,
28775,
106449,
168236,
10620,
42642,
16056,
40613,
43796,
null,
280689,
15196,
277516,
419070,
209704,
156893,
37575,
8348,
29297,
68100,
136416,
191039,
194645,
139689,
191238,
49965,
43162,
178097,
19289,
16784,
169473,
182429,
283880,
84978,
37822,
51571,
325114,
null,
25603,
29379,
458487,
23812,
null,
166396,
324551,
null,
88409,
34819,
384088,
243072,
66441,
253137,
131855,
116968,
35566,
421577,
27496,
34887,
26401,
118915,
22833,
42644,
36081,
354609,
47508,
157062,
270811,
7504,
6498,
75380,
29434,
41535,
null,
389723,
318271,
44043,
null,
11133,
null,
48633,
68943,
null,
221091,
344841,
122236,
12475,
140970,
29919,
60152,
5730,
null,
21540,
54120,
306956,
100332,
210861,
342581,
157383,
129757,
293089,
179158,
null,
81002,
272065,
164399,
30313,
234742,
82841,
223591,
211968,
188359,
344811,
304118,
37535,
320684,
35701,
37011,
36916,
10103,
7441,
39919,
259497,
23945,
3805,
13258,
18532,
31050,
94197,
12050,
270900,
364659,
84781,
15332,
296355,
54255,
113462,
null,
468677,
130489,
null,
37893,
null,
57776,
412901,
4814,
115408,
30317,
10447,
41046,
36712,
326925,
101117,
41005,
255609,
203527,
33268,
7364,
16732,
130926,
111233,
54595,
58726,
40734,
253999,
151115,
218588,
10629,
26512,
302389,
17952,
75971,
null,
31197,
15648,
7234,
289290,
180821,
20263,
43924,
63073,
283884,
6593,
null,
339238,
366921,
153258,
23191,
9023,
75891,
75883,
155992,
47010,
348128,
null,
148984,
84600,
338612,
341631,
134555,
115562,
325954,
154145,
43652,
156916,
27926,
44106,
214998,
234808,
33157,
21272,
183899,
305799,
439139,
264631,
102534,
157872,
23223,
76052,
244854,
126947,
217742,
680681,
31210,
379542,
null,
48983,
165251,
29012,
85383,
4551,
74937,
132432,
316258,
null,
38880,
208131,
200239,
184679,
175219,
191585,
18431,
108059,
26723,
1066302,
210119,
34873,
4425,
14459,
317477,
24090,
779859,
100307,
null,
39311,
223118,
16503,
161926,
null,
49659,
171019,
22884,
6836,
39837,
69600,
24616,
88099,
54507,
9275,
348808,
9123,
null,
22983,
null,
489138,
262751,
151685,
21178,
233723,
386286,
80076,
534969,
23001,
49792,
168389,
96890,
27705,
95697,
33972,
30292,
171998,
10815,
43154,
10520,
30338,
272714,
433144,
318161,
32284,
481172,
268190,
32734,
null,
325047,
20031,
null,
null,
240135,
149449,
242717,
421535,
5726,
236055,
null,
41291,
206235,
1765,
209598,
31540,
43416,
null,
70715,
211601,
194300,
null,
432768,
206462,
36048,
363960,
10994,
78655,
54712,
123116,
12142,
187096,
278586,
50603,
66973,
317434,
103436,
50201,
33444,
null,
null,
163244,
335891,
284191,
189438,
32754,
null,
452550,
621289,
26026,
221895,
39320,
37314,
290738,
null,
10576,
28413,
80425,
7938,
22482,
41241,
33036,
212098,
140633,
null,
112109,
275144,
13866,
85957,
250130,
234420,
298450,
null,
141781,
32759,
240899,
24189,
12687,
200165,
59602,
19031,
217888,
18377,
19745,
237776,
348564,
191258,
210890,
40204,
29431,
458904,
12802,
50548,
279104,
217750,
22370,
25663,
null,
null,
7086,
200154,
38088,
61387,
28491,
226959,
44755,
511253,
48215,
34914,
43440,
15824,
32685,
68536,
224099,
567894,
null,
104189,
63259,
null,
6018,
648725,
24021,
370739,
59997,
5915,
23444,
18214,
31594,
66960,
409442,
91350,
null,
509939,
69419,
17608,
357584,
435080,
101576,
38486,
176155,
193671,
17326,
208806,
255191,
79080,
136513,
39832,
45107,
30185,
243058,
9077,
7684,
327528,
86072,
25403,
13120,
150999,
28409,
239700,
166383,
8945,
16027,
84462,
160788,
200295,
189027,
54123,
146186,
17639,
18226,
32446,
230118,
null,
184166,
20774,
null,
223553,
67730,
400966,
6647,
30726,
86974,
21718,
120941,
164909,
208115,
34556,
67106,
null,
12122,
19661,
226542,
59344,
118740,
78460,
84691,
21111,
null,
79512,
130069,
36120,
52902,
57101,
30628,
130693,
64855,
3766,
801,
49668,
212779,
368922,
35294,
149280,
33570,
19568,
100295,
32572,
11064,
96398,
306431,
235682,
129162,
4439,
22384,
114165,
34081,
193959,
22114,
null,
179039,
115494,
null,
29671,
74953,
4897,
117759,
15242,
45255,
96842,
469458,
26641,
225924,
38672,
195933,
234062,
33110,
null,
52848,
13294,
430010,
332808,
232401,
16924,
241697,
143879,
381653,
431647,
257527,
56277,
null,
25811,
343806,
37037,
22573,
9509,
468691,
223013,
124154,
17708,
104229,
107261,
491984,
11642,
48254,
183689,
167673,
37198,
12247,
22077,
22581,
374153,
50234,
53560,
519513,
27536,
18706,
34267,
49972,
15471,
11103,
660012,
25788,
254978,
34673,
9344,
20124,
57066,
24767,
89117,
293275,
76147,
15976,
129523,
149280,
148919,
90779,
263547,
38926,
38097,
360022,
207067,
146657,
150772,
9346,
68139,
342965,
null,
328767,
216512,
13912,
325783,
264423,
25374,
56070,
269316,
23306,
116444,
null,
54035,
477725,
28190,
41543,
30615,
24225,
23972,
20760,
38012,
330707,
366858,
2815,
225205,
36224,
316421,
141481,
142442,
67466,
51676,
69752,
80857,
29649,
2599,
10761,
null,
28508,
9592,
30270,
23578,
15094,
166008,
179281,
42178,
38542,
27402,
109516,
112161,
56618,
7990,
621505,
17114,
281522,
531101,
11765,
1392,
36759,
212622,
21780,
233173,
48652,
101093,
311172,
19851,
null,
247971,
150363,
312243,
28640,
163821,
43863,
120899,
345604,
41685,
null,
52696,
null,
34910,
0,
18962,
42742,
69236,
25338,
162096,
108153,
27826,
47244,
226960,
14812,
61542,
44469,
76665,
72396,
null,
591017,
25482,
218343,
239078,
218573,
37716,
9993,
20317,
7461,
101355,
46265,
29853,
249207,
17251,
118839,
286062,
null,
292373,
326648,
105247,
null,
65498,
73254,
409318,
35665,
495216,
15354,
null,
45350,
46681,
26718,
11198,
174804,
14090,
52724,
3783,
193620,
320435,
29031,
139581,
141030,
19963,
91635,
97106,
96013,
80816,
24027,
343824,
32680,
130987,
135140,
28716,
315111,
347368,
40230,
58043,
52959,
293969,
661,
23512,
231695,
136464,
181563,
33910,
37943,
25935,
25119,
28926,
142470,
30851,
322740,
41080,
311888,
289910,
18092,
20654,
6938,
210437,
17286,
205747,
55482,
11488,
348824,
null,
178337,
299628,
84971,
259006,
190396,
null,
33171,
35781,
null,
200379,
133159,
null,
86874,
212290,
297117,
null,
25090,
131552,
5631,
null,
38811,
34851,
131780,
66048,
302908,
null,
225759,
159308,
124206,
38570,
27433,
99397,
19381,
189015,
336538,
16393,
106413,
127579,
292358,
104523,
161890,
162514,
48086,
278644,
null,
373293,
1787391,
249806,
29069,
19329,
32946,
445485,
205582,
214813,
8796,
21843,
27673,
null,
127143,
130943,
215609,
170461,
9820,
333292,
39139,
6130,
8912,
177568,
24158,
403221,
198389,
43012,
15019,
null,
95665,
89318,
31018,
821605,
245531,
131678,
187181,
180277,
343537,
36134,
109764,
29112,
13100,
17579,
234450,
11579,
50565,
64032,
2531,
2372,
155812,
98622,
468673,
270404,
37720,
80837,
30775,
19756,
199637,
49961,
78460,
13377,
126457,
16214,
177009,
24986,
129706,
13785,
18497,
211643,
23110,
68655,
30517,
372506,
24333,
518188,
129905,
13423,
583234,
264533,
null,
170765,
217940,
341906,
17015,
24224,
194754,
58652,
87783,
22209,
441460,
601146,
356216,
null,
205988,
108710,
60198,
438183,
59604,
null,
122488,
69087,
59899,
45437,
333521,
21731,
null,
44316,
56973,
3516,
2143,
141851,
5886,
225376,
6123,
222648,
230219,
178343,
448776,
155022,
42091,
353587,
24806,
32711,
32544,
22233,
27026,
89825,
190814,
39956,
10863,
197976,
196788,
125194,
145187,
23715,
null,
216807,
509534,
123894,
28191,
599198,
79273,
62319,
22349,
184059,
220467,
251839,
288852,
76419,
9631,
167580,
207117,
34984,
null,
null,
10396,
329306,
145986,
311603,
841012,
271662,
14764,
22661,
12508,
28282,
168458,
67907,
139998,
null,
null,
244081,
244229,
null,
223227,
208480,
null,
39741,
141643,
34482,
26377,
133051,
null,
174442,
140928,
206823,
25730,
null,
null,
38403,
53221,
29337,
91943,
91609,
52533,
90509,
1556,
53525,
185954,
60036,
147927,
28413,
16891,
38978,
305627,
148361,
133396,
287624,
37497,
129002,
12880,
30537,
349442,
19057,
203144,
264853,
null,
35665,
48944,
102483,
39733,
46060,
224115,
null,
277429,
208657,
26493,
36393,
215341,
16112,
355132,
7271,
35901,
3657,
null,
332568,
179584,
44576,
220594,
134998,
58296,
187380,
41326,
2308,
160550,
76027,
396271,
460038,
53579,
null,
null,
437724,
122600,
18052,
156280,
330926,
14065,
278220,
null,
150239,
122462,
24742,
18363,
69293,
192639,
35511,
45330,
154452,
266827,
28440,
null,
112875,
131606,
90299,
224188,
40557,
167923,
169896,
203955,
1273080,
93753,
336794,
22616,
208003,
60198,
219783,
null,
144405,
81748,
4914,
78239,
19714,
143505,
68731,
339675,
13683,
18070,
312915,
14989,
32274,
12808,
982076,
217582,
null,
72085,
153884,
219550,
18511,
99387,
7716,
9987,
246386,
174946,
30182,
96113,
191967,
251205,
278245,
57400,
156123,
36502,
60217,
180553,
25563,
10946,
123439,
219571,
7629,
64686,
12041,
253560,
54160,
7450,
221136,
30229,
38643,
122662,
317813,
125343,
79272,
40103,
9397,
38,
166435,
143073,
344131,
null,
null,
19862,
6184,
109470,
258526,
58168,
145007,
null,
170013,
290661,
154785,
30158,
67150,
11256,
21642,
378192,
123269,
8097,
22992,
124373,
9020,
202559,
44138,
19686,
218349,
110631,
12743,
5197,
615687,
265779,
64927,
171088,
343980,
9326,
201079,
6405,
33801,
161752,
35748,
77766,
207066,
69270,
33540,
187643,
95559,
63577,
null,
17499,
39201,
279008,
53924,
51982,
32821,
null,
20287,
64238,
132776,
37921,
78681,
null,
175042,
138989,
85020,
407421,
40701,
13751,
131583,
47807,
39516,
110237,
192455,
13459,
16650,
7754,
106944,
244119,
43941,
null,
228419,
27325,
208226,
269234,
32831,
100000,
256938,
146540,
null,
52415,
null,
166161,
39761,
21506,
54883,
null,
100379,
83871,
5346,
110255,
84149,
150711,
26558,
6735,
92344,
262707,
408136,
135040,
194001,
19079,
206447,
123367,
14837,
132343,
305229,
38040,
16979,
106377,
141030,
12768,
null,
358737,
958527,
30056,
46382,
5416,
214524,
168189,
436371,
8233,
103440,
204575,
178528,
22591,
176281,
49895,
14330,
63143,
207372,
30865,
243224,
71750,
674222,
46089,
68196,
111426,
226548,
276763,
null,
630539,
200325,
null,
22281,
263654,
null,
542565,
10382,
59606,
94167,
null,
62585,
100887,
null,
20000,
3125,
53331,
135469,
null,
81705,
209268,
184983,
81409,
23391,
20160,
30020,
430687,
23646,
40613,
13024,
204668,
null,
16398,
136966,
102783,
29957,
159206,
75237,
14812,
142142,
111493,
156869,
null,
417275,
291970,
52265,
44834,
3236,
null,
97744,
388785,
66723,
33138,
232760,
185485,
58663,
274741,
25112,
34152,
56782,
521659,
77206,
296588,
null,
200825,
22916,
92356,
24076,
171738,
20595,
140178,
8249,
null,
115557,
28318,
62388,
9593,
35204,
15517,
146929,
31413,
262518,
11409,
32491,
217658,
117882,
28785,
101077,
null,
342253,
null,
1063,
15948,
296698,
137366,
41719,
224308,
126434,
20499,
1080043,
188389,
30500,
50247,
247125,
374297,
12920,
73767,
346309,
null,
25873,
95111,
244817,
null,
null,
15049,
148100,
151948,
39018,
200853,
328987,
233854,
477666,
261998,
10648,
260285,
15557,
90566,
4301,
13156,
324773,
261763,
37739,
206538,
4966,
13223,
27571,
58875,
9934,
120659,
51573,
null,
53438,
34929,
48141,
43881,
420142,
46105,
269068,
73115,
424956,
140619,
39600,
8634,
21805,
8957,
39946,
64642,
97196,
354524,
252644,
150713,
10434,
680759,
90278,
148030,
165596,
73998,
191414,
44468,
141573,
141963,
213465,
361178,
47233,
41750,
null,
157051,
402620,
38249,
109664,
470984,
110668,
null,
244878,
168552,
825092,
149993,
214690,
151257,
92527,
9558,
80827,
44055,
31047,
204122,
103085,
259590,
84732,
328523,
758717,
149267,
238040,
null,
244693,
73881,
67297,
null,
27410,
175774,
32126,
14606,
501255,
13224,
32093,
397918,
127419,
49880,
133532,
126813,
90706,
106202,
8894,
165730,
30281,
161682,
373291,
484111,
214262,
364924,
null,
29201,
56962,
307116,
47774,
308718,
16118,
197487,
394719,
27230,
230304,
167878,
201387,
601523,
196818,
17299,
205157,
12111,
309317,
144864,
null,
197039,
null,
268270,
23440,
null,
147576,
155555,
90380,
150506,
44127,
50977,
190411,
20336,
30246,
266662,
46686,
219437,
149699,
30860,
31829,
18481,
180975,
19302,
24184,
527464,
28744,
86355,
129778,
130443,
387961,
141761,
192113,
201204,
63083,
15340,
68450,
15449,
43546,
15908,
30870,
178009,
11205,
64694,
53993,
299394,
null,
165900,
92773,
62208,
10256,
508052,
144671,
58577,
121317,
30539,
78986,
211548,
150626,
23169,
20628,
72912,
170301,
312333,
28585,
198042,
82162,
319489,
879838,
445062,
43508,
65117,
null,
67385,
375070,
1607,
409589,
76532,
25808,
222681,
287228,
17353,
115633,
21899,
29830,
166047,
247255,
null,
59751,
207753,
53653,
20415,
186857,
7631,
20031,
18444,
null,
16042,
218730,
181392,
6982,
280992,
54026,
56984,
null,
26848,
575314,
23467,
84439,
126248,
204316,
144071,
35552,
4089,
41374,
367016,
46171,
29165,
115110,
103669,
35678,
132550,
12499,
2307,
77401,
48784,
15806,
91909,
213766,
286547,
143250,
36699,
33167,
null,
null,
105825,
33249,
248350,
7463,
177758,
34061,
147570,
11586,
47657,
43989,
32891,
95002,
204305,
20699,
344159,
28509,
177778,
342970,
77569,
184292,
586196,
493205,
16264,
34869,
52690,
221555,
255994,
42941,
161021,
null,
32029,
null,
25362,
100906,
50701,
10603,
17001,
null,
211744,
68456,
62061,
52526,
296742,
42877,
542437,
20837,
374877,
59545,
19634,
241767,
22806,
433258,
36594,
29363,
798107,
60730,
257797,
307456,
18500,
18133,
null,
20940,
22902,
100638,
30556,
4258,
96512,
null,
56116,
47075,
42513,
109494,
null,
52972,
108534,
141171,
null,
176631,
150491,
15480,
5863,
14151,
28102,
83889,
15513,
357178,
131871,
32222,
316773,
50924,
83629,
74436,
577,
16468,
210271,
22995,
14878,
11833,
64169,
903,
4511,
7943,
73052,
131732,
50370,
3215,
32220,
240190,
3571,
128431,
124570,
432529,
25439,
127056,
25830,
54642,
140842,
383511,
881417,
60328,
262023,
263651,
53835,
160677,
31401,
23019,
null,
234511,
null,
223853,
342999,
154040,
277902,
48413,
195944,
198544,
11197,
25342,
121194,
151191,
84972,
26891,
null,
189437,
317831,
404433,
26327,
284890,
22034,
null,
1663,
46119,
15995,
185988,
36900,
149232,
33631,
153272,
47949,
50999,
null,
null,
null,
null,
144078,
595564,
8577,
112013,
35330,
37341,
3082,
143141,
35539,
23610,
170042,
null,
14186,
243905,
96564,
179915,
64959,
318554,
63348,
28640,
66931,
39527,
null,
551060,
51118,
22311,
43753,
38072,
63070,
null,
8250,
51467,
229635,
211712,
119386,
16999,
100591,
46290,
154822,
8014,
192810,
152507,
39073,
9779,
16196,
10151,
17262,
69992,
null,
6987,
196979,
null,
91152,
46069,
406753,
null,
52312,
99257,
5170,
25561,
161083,
null,
266654,
74330,
331152,
512994,
667730,
38073,
243258,
3744,
null,
12100,
236847,
80557,
17793,
303122,
null,
38642,
496126,
21105,
532839,
335356,
67116,
92443,
224397,
302065,
42838,
4904,
44499,
159758,
277591,
24439,
85166,
160811,
9008,
null,
12520,
241799,
102054,
69426,
15715,
265996,
27079,
326060,
147122,
8606,
31215,
100909,
184507,
88896,
18388,
405223,
286677,
4993,
317403,
24395,
172465,
48948,
706357,
21985,
42429,
24214,
17047,
41981,
10620,
124005,
30325,
17624,
36773,
731348,
null,
96428,
11232,
31805,
12633,
342418,
81047,
52213,
17776,
15302,
49062,
362662,
44590,
65433,
180015,
1110701,
49483,
null,
20022,
49009,
17939,
73712,
15048,
8407,
162171,
25527,
71295,
48387,
181449,
77726,
1191,
185544,
32933,
4354,
null,
191105,
160070,
22383,
198863,
9459,
7787,
453873,
149691,
31568,
31156,
122754,
null,
45391,
45077,
3291,
null,
177488,
6636,
52269,
30571,
24178,
21710,
157270,
175044,
8721,
42530,
48056,
null,
278837,
199652,
231357,
190429,
10464,
51737,
266136,
373228,
52623,
38674,
39227,
624896,
null,
16081,
71387,
51434,
147160,
16494,
414576,
5657,
42785,
41748,
19744,
57568,
492952,
129439,
19534,
27016,
48394,
177285,
60223,
275869,
80320,
53346,
179863,
8280,
145373,
null,
15084,
17710,
20505,
249120,
null,
53470,
115534,
108776,
35218,
170173,
116694,
250629,
30247,
6990,
143238,
63835,
6389,
null,
281723,
40704,
70440,
27192,
null,
284486,
29423,
61761,
168038,
72207,
109163,
47416,
334512,
144755,
261724,
179595,
null,
237487,
4213,
25490,
407985,
84658,
2318,
162967,
126032,
null,
215322,
240406,
708680,
548987,
21179,
118810,
10999,
19099,
730486,
11605,
39710,
288439,
33667,
28544,
35833,
null,
134361,
271672,
217064,
44727,
154535,
27527,
184034,
14333,
19222,
null,
191307,
37108,
54465,
74917,
118038,
43780,
176685,
269420,
null,
null,
54570,
618979,
28105,
104882,
67389,
255263,
370251,
161221,
19931,
14288,
247237,
24614,
6370,
81041,
112605,
51566,
56203,
194847,
5425,
270180,
13006,
126715,
383510,
161550,
201274,
127445,
272839,
34785,
37338,
368585,
28220,
31315,
226133,
5681,
196582,
126202,
67706,
141207,
311166,
299756,
104247,
376693,
97963,
28345,
169876,
194793,
1161200,
134432,
292515,
52232,
90055,
32588,
13751,
22644,
24903,
24353,
225925,
43502,
null,
301241,
214324,
93197,
275063,
281360,
81877,
null,
167214,
61534,
114474,
174652,
117129,
79672,
43615,
243663,
263165,
37672,
408928,
59713,
24636,
32329,
17688,
66903,
24917,
425405,
4428,
357189,
42981,
14137,
23957,
367963,
23498,
298846,
33789,
null,
31666,
15484,
249659,
114005,
null,
null,
49707,
262101,
112375,
662041,
134804,
null,
22535,
28940,
228483,
29149,
31891,
111610,
107938,
165581,
24094,
242949,
50999,
372984,
13190,
81115,
164121,
44861,
79392,
157388,
93455,
180226,
null,
40183,
9980,
320060,
177410,
43305,
2489,
28268,
122285,
9627,
null,
155713,
32016,
87423,
262356,
null,
16662,
123525,
128658,
97275,
5298,
49458,
24491,
29759,
107640,
163348,
null,
8806,
9203,
13176,
null,
163797,
28066,
320743,
17040,
29890,
156624,
500367,
65280,
192409,
107903,
250308,
322259,
305052,
141457,
70413,
128559,
227255,
365506,
300720,
989200,
240728,
634878,
288812,
null,
14649,
178581,
27948,
226135,
null,
115109,
null,
532415,
6577,
291098,
23414,
217164,
108803,
19824,
174466,
65997,
6816,
24177,
121502,
556429,
431404,
19018,
21915,
133029,
335697,
655046,
31160,
55956,
36262,
17783,
24528,
123570,
191121,
206816,
57465,
14146,
256446,
247784,
107941,
255197,
377306,
null,
76424,
43179,
232936,
428523,
383240,
165926,
14891,
213064,
107737,
96074,
360208,
264307,
253529,
24070,
267653,
47978,
57463,
240407,
76540,
26255,
null,
577568,
null,
20687,
null,
527786,
323933,
33756,
32373,
165103,
32766,
98530,
278028,
373679,
25330,
null,
null,
281788,
4423,
33439,
217397,
405573,
547036,
35098,
13416,
46971,
25109,
6694,
29771,
18994,
362207,
null,
66847,
295270,
278532,
366228,
65102,
73398,
45166,
222059,
146929,
33152,
437938,
108470,
234900,
183817,
402149,
null,
74528,
370142,
118051,
49460,
196913,
209491,
154118,
553926,
16335,
222416,
152710,
3808,
32391,
136311,
153314,
447925,
247103,
284717,
null,
51625,
350405,
104080,
11751,
140969,
28875,
56892,
267889,
225799,
612595,
79465,
19992,
41690,
47717,
259732,
118141,
263680,
36733,
267741,
150192,
282645,
200523,
83317,
7745,
19241,
11856,
18882,
9485,
39465,
572457,
21363,
null,
39684,
81463,
27916,
133551,
737989,
265998,
290464,
435418,
191741,
5414,
29329,
100881,
23504,
47250,
7401,
236009,
null,
180730,
null,
20501,
null,
68213,
null,
647323,
41160,
174230,
359660,
21605,
17143,
14209,
220382,
20105,
2018,
25388,
null,
null,
4074,
556428,
68349,
28375,
22913,
557890,
117725,
null,
23024,
61241,
79211,
68504,
74916,
219318,
181678,
100226,
242624,
80867,
43922,
132803,
285777,
107604,
36392,
34185,
433011,
114656,
4040,
5779,
41122,
14034,
74720,
34029,
5614,
33296,
16079,
171995,
522685,
60883,
98847,
6381,
166150,
222826,
20086,
353986,
264072,
322185,
null,
177441,
147926,
null,
null,
48391,
226704,
387726,
10497,
204393,
227580,
99461,
172126,
164036,
108830,
44773,
45413,
43307,
14575,
49605,
96336,
228160,
37026,
114655,
9591,
117041,
348502,
148923,
3461,
19857,
5715,
353872,
36630,
232696,
112981,
157919,
67597,
null,
47617,
17619,
18848,
null,
28231,
124336,
211098,
197506,
1348823,
236007,
78306,
334921,
54769,
17763,
43835,
20795,
null,
297361,
754500,
29284,
152262,
134618,
78732,
23836,
17793,
68224,
274916,
323343,
53495,
56947,
101558,
261356,
38264,
46845,
728964,
314028,
41552,
361818,
187664,
null,
65593,
64277,
8117,
39503,
331773,
46308,
24630,
149318,
53429,
null,
20364,
90241,
49847,
31723,
300568,
73485,
103653,
24576,
8319,
49156,
44664,
247918,
50221,
166275,
134321,
33290,
410189,
48712,
74769,
155048,
102572,
367696,
18400,
null,
50253,
6560,
68804,
598885,
22318,
23269,
267540,
18506,
118095,
17526,
null,
302520,
47923,
70191,
21628,
289810,
240933,
162218,
57166,
177811,
203338,
212496,
46561,
286510,
100760,
null,
74532,
null,
607002,
null,
283586,
34781,
207690,
134989,
7774,
22863,
463644,
27907,
214352,
165592,
32942,
429174,
24577,
219527,
493223,
254688,
66087,
158941,
25408,
24200,
18352,
157651,
38793,
null,
28416,
112819,
42248,
351829,
170525,
7115,
27885,
327705,
165449,
49593,
105672,
195495,
69087,
36835,
359284,
36971,
38755,
null,
12471,
684236,
14758,
33871,
92439,
112044,
57085,
null,
7188,
178093,
20460,
155893,
56844,
160836,
34826,
49544,
48215,
230535,
55574,
198659,
112682,
null,
null,
32764,
28530,
214049,
65560,
499758,
9985,
23875,
76341,
null,
291784,
241368,
null,
215700,
198088,
42753,
317104,
8448,
null,
149078,
25312,
312725,
33951,
144346,
5363,
449833,
29875,
75458,
323411,
103637,
38942,
56110,
154214,
1182474,
178109,
224250,
null,
419041,
187028,
31633,
101517,
47715,
210142,
39622,
100817,
48309,
487997,
28638,
351587,
15772,
160734,
20545,
151063,
303292,
51329,
208438,
285039,
327844,
184884,
554896,
31353,
null,
336155,
12762,
null,
92178,
68364,
20326,
43338,
123912,
13207,
121964,
150670,
341375,
105217,
296836,
251977,
298895,
31615,
315112,
55086,
5321,
238722,
47596,
284687,
5635,
26383,
164654,
201179,
182663,
35360,
221306,
74967,
227984,
390368,
69717,
5528,
null,
72615,
318185,
116131,
755579,
175017,
32690,
5097,
75089,
6449,
941851,
1247421,
null,
14650,
242866,
162140,
75878,
160069,
221920,
35852,
389327,
20485,
76482,
147173,
486937,
null,
109786,
78039,
2482331,
632725,
29712,
73412,
51916,
46693,
3594,
122078,
245648,
31435,
17823,
34658,
26422,
33404,
33449,
11403,
39856,
null,
31646,
35937,
490247,
23582,
28455,
null,
168857,
384828,
null,
14810,
8661,
25131,
60555,
240881,
116594,
166988,
254793,
38048,
88699,
126151,
14461,
100919,
130563,
251815,
146197,
126661,
59437,
278324,
13689,
null,
66077,
70074,
null,
407912,
169962,
116895,
27639,
202631,
12657,
137924,
30732,
121850,
null,
55553,
3779,
49931,
102969,
220121,
80927,
16994,
24341,
138718,
82386,
585365,
53118,
null,
null,
62243,
46392,
35948,
32647,
31364,
139546,
96921,
28532,
203619,
11410,
17194,
null,
231286,
18441,
231230,
39334,
35749,
204890,
32907,
30312,
130339,
74354,
65054,
21313,
298030,
148501,
45627,
473477,
null,
136114,
34619,
338103,
127489,
172177,
null,
91289,
575278,
null,
166555,
302760,
47254,
142498,
207210,
12147,
15887,
176207,
92718,
48450,
98318,
26055,
185766,
59820,
6272,
67024,
197109,
61436,
96322,
13907,
2823,
221542,
452544,
36255,
null,
39872,
76696,
230103,
406565,
88746,
null,
27047,
69530,
52062,
518338,
72652,
9791,
42588,
61049,
11409,
394307,
238180,
241764,
152095,
22661,
277174,
355081,
null,
383564,
9353,
185768,
33519,
294702,
75673,
391521,
68212,
null,
null,
1710232,
88782,
14373,
null,
50824,
22960,
44882,
92242,
225251,
187885,
146142,
22802,
26212,
52492,
null,
369531,
95907,
26749,
114949,
null,
41785,
329433,
35955,
11166,
48199,
65767,
46054,
313762,
180805,
57006,
39898,
87192,
null,
14264,
251345,
236818,
322310,
10901,
null,
11191,
33176,
49175,
55292,
337702,
108781,
null,
350620,
81211,
109945,
18244,
null,
55755,
8073,
130531,
18152,
371533,
25478,
138730,
36282,
413225,
129046,
75660,
6156,
15539,
23442,
62267,
26926,
null,
28140,
242362,
9801,
25357,
194192,
138764,
28142,
28907,
null,
321276,
189992,
14390,
359782,
190115,
588696,
56279,
6395,
22614,
196750,
163746,
181664,
221339,
362353,
154625,
357559,
34487,
null,
129786,
97113,
243948,
285989,
45549,
null,
403925,
2151,
208886,
93815,
519250,
45297,
92919,
406839,
15476,
1707,
233105,
189520,
116980,
24809,
24365,
162312,
2866,
891306,
151881,
176466,
15590,
37067,
205401,
28942,
null,
333529,
120894,
149624,
46102,
null,
497712,
null,
360031,
75367,
null,
182207,
291179,
null,
17644,
8124,
331019,
36164,
144728,
4157,
401534,
8930,
29921,
136139,
33594,
null,
45136,
28777,
28790,
174804,
30075,
null,
42962,
253631,
null,
365663,
189683,
61298,
166426,
40944,
null,
61443,
127345,
39679,
135942,
18577,
106784,
201074,
34530,
197147,
84760,
361382,
16732,
14222,
368773,
126124,
156390,
21598,
35491,
228800,
146395,
235156,
112466,
258812,
269781,
163536,
null,
null,
29808,
113128,
84490,
907858,
6397,
410365,
520017,
28019,
5007,
116669,
41361,
366556,
6714,
10549,
106240,
null,
104575,
75099,
52971,
432875,
258158,
256492,
7358,
103282,
91752,
177067,
34109,
15867,
59096,
null,
27299,
47561,
265113,
126798,
241309,
366679,
139859,
385274,
null,
747499,
272692,
372071,
95565,
null,
339816,
197713,
76522,
71028,
39312,
252816,
423970,
23629,
135724,
9980,
21478,
423664,
51006,
223183,
25268,
34684,
null,
123185,
5065,
37897,
26354,
37652,
63640,
35341,
95187,
134695,
243371,
28613,
183820,
22479,
40000,
21975,
149549,
297259,
362927,
19200,
31693,
158677,
71487,
34593,
167722,
52596,
258557,
215904,
177322,
8675,
null,
null,
122747,
33533,
163387,
270529,
49446,
339908,
93275,
340421,
685755,
181480,
216157,
4799,
50320,
4709,
317124,
7233,
237414,
128721,
42223,
33245,
33620,
71422,
50841,
33951,
280317,
36446,
217253,
13768,
200183,
364231,
149154,
1092523,
262440,
82641,
575328,
52140,
605550,
null,
712,
170055,
146374,
202278,
18296,
6182,
372510,
385745,
15057,
20324,
16342,
5957,
28623,
93104,
49508,
315702,
115724,
21111,
76485,
49737,
74143,
245940,
11530,
38344,
118524,
8067,
25586,
156739,
26347,
57919,
134287,
62593,
335416,
356611,
86749,
null,
220765,
344625,
92609,
51559,
183951,
39480,
176563,
20020,
null,
187741,
27783,
190373,
223673,
null,
72840,
262490,
417216,
137646,
374891,
17025,
267709,
103702,
84322,
29824,
15367,
57870,
29547,
18099,
303036,
22879,
400287,
49971,
302946,
51420,
5977,
154778,
13202,
null,
null,
7676,
17104,
264070,
424731,
70173,
363144,
69529,
34478,
61135,
236431,
279011,
15025,
25099,
23024,
161683,
26728,
25652,
198764,
753078,
94109,
44835,
146504,
526338,
null,
65585,
138142,
305208,
340222,
326362,
242664,
92066,
18317,
20209,
38247,
159104,
43121,
59610,
118085,
null,
6304,
295420,
20878,
13695,
148706,
93344,
46697,
10244,
32625,
45826,
null,
266401,
17366,
20996,
null,
287316,
15571,
162875,
30182,
25156,
35293,
108019,
44522,
268278,
41183,
171057,
35879,
315768,
272268,
null,
21097,
null,
250995,
216793,
36736,
254884,
37402,
398496,
123170,
13915,
88169,
198209,
254197,
21063,
null,
159942,
105270,
null,
7630,
21004,
257067,
63372,
40987,
162935,
144988,
21890,
74264,
125566,
null,
20562,
37834,
299936,
92181,
299643,
13480,
349908,
141544,
2881,
79700,
23918,
59803,
112031,
21530,
null,
55822,
184228,
29625,
270841,
215715,
21538,
349723,
30935,
263399,
74180,
62969,
170120,
293891,
197106,
189398,
371013,
30033,
192986,
40759,
6167,
50563,
55280,
13208,
58334,
229918,
160425,
58329,
81239,
85629,
27549,
99993,
311468,
56475,
15050,
174541,
89369,
12600,
318466,
295697,
29947,
10813,
195155,
18936,
39544,
485022,
25489,
370839,
18587,
200177,
4569,
65916,
22956,
7870,
3502,
258612,
265652,
null,
102123,
47610,
198833,
3031,
39288,
223011,
14914,
168642,
36193,
15608,
449220,
null,
28048,
714371,
273035,
88176,
188248,
180368,
17632,
324747,
75906,
63366,
29944,
228433,
36521,
303827,
174155,
21864,
70210,
44089,
122129,
5937,
439941,
73085,
26702,
43298,
38146,
207734,
150406,
37069,
126384,
12070,
158474,
null,
231712,
169903,
null,
138318,
694957,
280127,
359740,
95908,
null,
173782,
47561,
79331,
70048,
4986,
10936,
10460,
66889,
42421,
235952,
19894,
202093,
44823,
12066,
18173,
294880,
26785,
17115,
96723,
16962,
132477,
198182,
169307,
89142,
40096,
null,
51507,
220775,
250801,
19379,
205951,
150934,
19274,
null,
18119,
111356,
15973,
173302,
3008,
38175,
69363,
16950,
152568,
116940,
92880,
null,
null,
9946,
9438,
39233,
110922,
57536,
74087,
46358,
32362,
9865,
20817,
24562,
9420,
221281,
116767,
92423,
159041,
11211,
83293,
null,
192112,
16524,
12377,
107778,
23273,
79385,
20747,
88734,
39797,
41065,
13660,
64888,
25435,
190519,
215503,
73333,
122031,
54479,
24099,
100720,
64555,
223740,
6875,
230726,
59900,
209368,
16177,
100363,
10082,
39080,
99803,
573193,
109339,
141497,
159810,
52183,
21539,
27789,
9775,
25154,
332227,
11488,
null,
91186,
12045,
22664,
58449,
116531,
38986,
162705,
38066,
35431,
77534,
232932,
12931,
179519,
28380,
247169,
29548,
110873,
24428,
77290,
285578,
35330,
74545,
7448,
28877,
109057,
null,
193341,
null,
11734,
15022,
50676,
22451,
294867,
49101,
17929,
206785,
379275,
34594,
null,
14158,
1938,
284860,
73802,
74429,
5162,
8664,
56406,
121039,
null,
9715,
51783,
296858,
111430,
73299,
55544,
259057,
177385,
10406,
113120,
null,
209795,
158572,
368882,
125314,
6762,
42513,
null,
null,
155667,
281547,
34139,
41203,
106946,
56701,
null,
271635,
27691,
352845,
43865,
31949,
17920,
29440,
361749,
214868,
null,
234917,
13125,
311600,
103026,
259426,
192235,
158637,
37000,
19601,
38080,
369351,
172232,
81241,
11591,
305516,
84695,
166677,
75665,
43981,
164867,
14802,
null,
15205,
54971,
111179,
null,
441440,
427400,
350857,
83165,
null,
null,
236766,
160805,
41645,
167969,
16285,
null,
null,
367702,
38136,
67178,
176233,
11504,
313951,
214905,
181853,
126755,
11366,
64127,
null,
533159,
91063,
118544,
212952,
122208,
null,
77793,
153624,
null,
25134,
1859,
null,
39452,
16037,
362426,
68773,
null,
11592,
17008,
335295,
45612,
708475,
14526,
234866,
29898,
5797,
178397,
199495,
43223,
33884,
15874,
9039,
22111,
10624,
82587,
66456,
176199,
349435,
67097,
18934,
97689,
31632,
331079,
459123,
167225,
300255,
228413,
317300,
7962,
43294,
112214,
53190,
39179,
272358,
202022,
294227,
43348,
203004,
269123,
226147,
78054,
453989,
137243,
30521,
308711,
150816,
12726,
null,
132084,
108858,
76474,
14096,
273331,
105035,
124972,
18671,
379229,
60302,
73277,
143738,
280345,
147490,
38884,
28401,
null,
null,
155218,
475308,
34436,
355445,
109651,
416595,
351907,
188911,
37520,
36586,
51626,
61898,
3837,
149956,
174713,
425256,
15554,
214381,
257213,
116944,
null,
43083,
320499,
9938,
60439,
201776,
52386,
48511,
null,
27783,
99051,
355752,
248956,
248742,
607393,
43606,
16073,
22430,
22231,
123779,
165535,
212551,
336182,
117604,
365831,
11166,
null,
15218,
266330,
200717,
33990,
0,
2913,
41574,
8365,
56849,
40984,
234341,
350055,
62858,
null,
294285,
26778,
122311,
92657,
406379,
95744,
24633,
165111,
null,
337891,
7538,
27016,
28065,
47542,
74033,
null,
88705,
null,
162412,
201609,
201373,
152503,
84513,
10652,
37106,
6232,
154688,
387343,
31949,
null,
41737,
200067,
52178,
307568,
68218,
168090,
156224,
240969,
null,
250771,
69802,
32168,
199549,
27023,
null,
14059,
332500,
225032,
11758,
8023,
397661,
11980,
94724,
70545,
200521,
1286,
null,
92801,
56586,
148348,
35417,
104361,
415830,
15549,
43971,
176800,
244807,
172739,
21831,
48749,
196119,
29925,
42670,
5071,
12712,
156512,
363068,
38358,
236450,
30443,
3515,
112849,
null,
200832,
93430,
69857,
10438,
43703,
39316,
null,
16562,
null,
174938,
12661,
91,
4204,
269049,
241577,
225479,
11449,
46829,
397189,
18656,
18259,
13581,
92452,
190344,
184010,
147298,
6879,
25748,
64960,
44289,
null,
14498,
118916,
148694,
13923,
10368,
269281,
133037,
338336,
23020,
20857,
343181,
136306,
159068,
72963,
null,
133416,
227163,
132585,
22212,
284378,
354700,
41132,
61097,
254818,
null,
477692,
304634,
331836,
26006,
256894,
30775,
40949,
55929,
190811,
186107,
9847,
322775,
159773,
22318,
188488,
156764,
991484,
null,
12401,
null,
146323,
8803,
null,
27035,
5854,
348109,
97283,
123331,
224098,
191544,
205286,
366190,
15497,
83561,
303467,
null,
124145,
169701,
234057,
17109,
301909,
68501,
205305,
20120,
17670,
77700,
41090,
16826,
15024,
139883,
265687,
184641,
103960,
13943,
61973,
62210,
13154,
68205,
31710,
null,
65951,
202458,
46862,
252155,
null,
null,
null,
171462,
183292,
221938,
294611,
195402,
null,
38062,
13787,
192814,
63380,
108315,
9485,
98017,
122763,
159795,
128276,
6629,
26721,
189256,
187944,
421567,
38801,
281655,
9980,
null,
108551,
25910,
29180,
217991,
null,
3654,
95,
273305,
32026,
55995,
109216,
179312,
224645,
102487,
61161,
null,
215250,
100113,
31077,
57302,
42720,
148007,
15152,
196912,
85211,
440348,
789521,
222296,
4692,
122555,
10166,
null,
null,
null,
64612,
61594,
97734,
92080,
74414,
null,
238060,
null,
29338,
389743,
60456,
147238,
118382,
83863,
949,
81875,
69386,
205528,
18163,
51238,
42598,
70224,
127188,
114459,
84916,
112586,
null,
16067,
62794,
185978,
273847,
84861,
57364,
287131,
209841,
119591,
34106,
null,
10405,
128082,
12737,
54507,
9507,
31162,
67887,
12905,
263758,
146970,
283799,
92435,
130245,
49662,
199584,
187859,
14791,
180796,
192045,
167990,
132885,
14922,
300489,
39371,
20679,
80159,
10116,
9015,
361428,
33286,
173752,
71211,
585833,
130275,
321254,
12032,
518445,
328465,
114305,
null,
43808,
41324,
137079,
302586,
107160,
293733,
248883,
98454,
227966,
110720,
195559,
27735,
6420,
322617,
89981,
30063,
156833,
26817,
null,
317835,
48022,
14744,
245135,
15217,
76114,
179819,
370367,
53471,
32937,
167908,
133140,
23395,
24820,
16056,
150057,
309163,
5071,
63396,
395817,
22530,
29925,
192621,
200489,
252738,
null,
22217,
155070,
422071,
11952,
330037,
32716,
103770,
557315,
23233,
158553,
176969,
57208,
267448,
null,
41230,
197632,
71426,
480411,
42343,
26677,
45840,
56192,
452283,
null,
88363,
70074,
265021,
19748,
41063,
16516,
87230,
46618,
405642,
438822,
37094,
null,
19287,
16882,
414530,
14299,
311079,
65985,
39295,
151878,
null,
38532,
64309,
22358,
3333,
6810,
374493,
118765,
20297,
25818,
36356,
141737,
220077,
13751,
455627,
24109,
null,
386304,
null,
227435,
42161,
29867,
188902,
19423,
59098,
442732,
23807,
422096,
420223,
167023,
295018,
7676,
23629,
168478,
null,
343984,
225593,
310958,
218886,
228288,
459574,
33275,
55464,
231852,
31616,
139042,
21947,
21990,
304978,
null,
319248,
542086,
123895,
183481,
null,
280648,
168793,
415958,
40865,
30718,
null,
46162,
31399,
1172214,
null,
46269,
112473,
232888,
1362,
95132,
389440,
108333,
null,
38515,
31927,
107118,
12912,
290294,
155407,
null,
284333,
92535,
297872,
18150,
377786,
181162,
274508,
8258,
16983,
104277,
105060,
32014,
27696,
10481,
352295,
null,
301502,
146531,
380922,
12117,
82863,
26592,
16156,
31042,
20433,
null,
52269,
9896,
23558,
70406,
44882,
170556,
124940,
319827,
478290,
15281,
163080,
26061,
22702,
95071,
5654,
61358,
9975,
24937,
80880,
129298,
42506,
246780,
198186,
158224,
345543,
211142,
null,
174536,
6899,
67938,
100660,
199883,
337992,
59133,
141298,
3433,
29975,
204839,
35325,
246300,
25508,
49580,
25333,
17838,
62727,
14210,
28829,
276069,
12977,
276258,
13093,
59868,
137831,
264077,
23380,
156977,
209698,
217839,
null,
27509,
17488,
21117,
49722,
409195,
33554,
null,
91935,
29871,
170377,
18645,
328029,
62399,
158982,
25830,
262209,
495291,
53252,
107159,
27613,
176837,
35369,
292594,
561157,
42632,
4586,
35975,
190026,
135113,
88811,
null,
156487,
150296,
68025,
22683,
52979,
51857,
81178,
55091,
345110,
21376,
453905,
29678,
154508,
51963,
null,
16362,
null,
null,
6452,
188775,
229007,
230553,
76016,
207736,
34486,
50803,
196337,
48459,
155716,
748756,
null,
49873,
42449,
264689,
138753,
223388,
9028,
307368,
316923,
199659,
45933,
46566,
20371,
386703,
49122,
46952,
21000,
42219,
220848,
539868,
392846,
81638,
47189,
320172,
8839,
217783,
22557,
16652,
42655,
50123,
12704,
null,
71217,
465749,
64440,
64843,
255243,
213644,
183667,
38449,
null,
184243,
67199,
252431,
129408,
6710,
181964,
27135,
216132,
89087,
206476,
218715,
190475,
253778,
21359,
31024,
15233,
32924,
98835,
228428,
142276,
90728,
686857,
14305,
435092,
null,
61423,
204011,
235659,
51403,
13938,
36215,
247290,
103643,
162081,
120328,
27087,
170893,
44915,
null,
26505,
41361,
166599,
281571,
19750,
258694,
13778,
19674,
226547,
null,
8741,
26512,
18913,
290047,
41772,
40780,
null,
358858,
33913,
null,
326493,
75752,
86415,
52179,
null,
3005,
349441,
424118,
14878,
300537,
481922,
140155,
13312,
158436,
null,
null,
31589,
16545,
8263,
122290,
415733,
262646,
125523,
299916,
124824,
569245,
64345,
383496,
179572,
30080,
32649,
105520,
360583,
19982,
122405,
189426,
76925,
16291,
372771,
252102,
18514,
24002,
97215,
32306,
43664,
50312,
null,
7229,
null,
7562,
25017,
385738,
10408,
null,
127678,
null,
7033,
35178,
17153,
23235,
null,
232459,
15918,
77611,
26599,
13162,
169456,
37977,
49918,
141436,
155931,
null,
124248,
200627,
53102,
92575,
263752,
406061,
22993,
71913,
143714,
179956,
null,
null,
84205,
34373,
199161,
330398,
375634,
323225,
327640,
227582,
190951,
182011,
36873,
261349,
403435,
9204,
474697,
183090,
null,
57723,
22700,
167632,
302843,
32665,
189138,
null,
381537,
null,
89825,
42936,
230998,
139188,
123756,
166125,
62994,
35979,
36529,
44888,
56366,
233471,
106593,
330595,
353509,
14542,
139422,
47545,
31742,
48317,
139339,
11523,
79353,
5906,
null,
18489,
108069,
389113,
266556,
44042,
38850,
null,
15320,
3695,
52201,
558286,
null,
18188,
71719,
182729,
89425,
56225,
286599,
140050,
61744,
5605,
38941,
5437,
16486,
284815,
93056,
772341,
268146,
62268,
200459,
445209,
49465,
138788,
119643,
49595,
4201,
772475,
45866,
74983,
30593,
93769,
522410,
367097,
55235,
206796,
284245,
38051,
181139,
235683,
109446,
340225,
3874,
184503,
352002,
420969,
25218,
8001,
131938,
22167,
177975,
30117,
6581,
84063,
19567,
21079,
346484,
47343,
84895,
131263,
null,
106803,
null,
null,
145857,
125291,
24374,
69640,
43904,
66994,
null,
62928,
344054,
138610,
388470,
76411,
309871,
11159,
null,
36114,
389315,
77678,
182104,
37258,
3044,
18512,
246044,
396756,
31145,
5835,
41453,
167698,
3723,
210282,
18468,
15482,
270117,
3319,
219216,
356,
49659,
277404,
101489,
null,
381312,
20475,
2188,
12025,
69190,
202234,
37460,
91460,
212230,
186666,
42094,
646224,
9272,
23223,
397681,
20638,
60504,
37099,
23903,
293257,
13555,
262214,
82807,
21995,
215124,
32013,
7832,
23955,
184208,
27450,
13245,
18202,
25069,
null,
55306,
15733,
14301,
28053,
378915,
188819,
89770,
297474,
10605,
36932,
530376,
162975,
242271,
47954,
21281,
219196,
35700,
165146,
44147,
24846,
8850,
196389,
12892,
144094,
25880,
282569,
174642,
351757,
60264,
39353,
298863,
209542,
32857,
150921,
288345,
25565,
303425,
357700,
78938,
20628,
8922,
30539,
103683,
218981,
5017,
96236,
230085,
null,
7371,
132410,
8832,
332816,
null,
384026,
222345,
5410,
29752,
37830,
40550,
74619,
20155,
148451,
248300,
179354,
206160,
37342,
41006,
11257,
3198,
62982,
55653,
271114,
null,
461635,
8696,
223718,
241402,
null,
187668,
145558,
null,
73208,
272735,
241172,
58377,
47477,
30961,
9707,
38588,
34015,
9857,
349126,
140918,
151299,
142648,
34603,
240928,
287948,
14957,
9542,
270813,
41050,
29884,
43282,
10659,
35169,
8693,
219359,
null,
null,
169547,
443474,
390757,
15769,
691016,
372730,
134300,
null,
287652,
27372,
18273,
46618,
23861,
17559,
222717,
19206,
177265,
195697,
77035,
318344,
166836,
1386,
233068,
123695,
41052,
126843,
13784,
52289,
50369,
745510,
62310,
47402,
12828,
16580,
102197,
53686,
63776,
null,
21056,
49770,
null,
58058,
56504,
96909,
46647,
33011,
663911,
210239,
150076,
163586,
23136,
32378,
1926,
53886,
290257,
184280,
38943,
150368,
203384,
72998,
607283,
197595,
28187,
null,
364882,
40102,
null,
179742,
118729,
null,
131662,
115913,
35211,
50811,
475097,
107630,
13422,
408335,
44475,
13951,
46726,
19487,
42563,
12604,
218917,
23900,
34331,
21872,
36262,
144969,
233432,
6298,
2922,
204998,
324536,
160621,
444805,
304970,
147811,
237952,
88384,
14935,
23008,
64777,
104281,
4862,
294332,
15725,
27817,
170197,
23962,
224978,
45072,
192094,
221116,
4596,
57105,
433843,
127964,
47841,
40679,
330106,
81339,
29245,
279881,
913120,
93806,
51501,
367382,
169879,
11532,
141587,
44011,
701652,
33248,
13004,
10569,
76474,
58451,
49207,
70128,
26988,
526587,
44286,
145968,
115460,
266760,
994350,
25003,
15515,
18841,
34223,
426640,
59525,
10639,
51262,
27903,
351071,
22781,
110577,
61008,
59519,
280673,
27891,
28540,
237718,
156084,
97436,
96511,
191877,
72476,
57912,
304647,
212004,
78074,
767183,
70197,
100539,
26074,
103156,
8975,
165896,
90131,
249447,
127981,
152794,
126683,
159780,
61427,
747949,
161136,
14788,
21168,
233143,
34738,
91167,
null,
297771,
12040,
140368,
162727,
184991,
10464,
56821,
23783,
55449,
23501,
474695,
144988,
1800588,
192800,
69297,
149557,
null,
165688,
247962,
42162,
161834,
209547,
32870,
377833,
28831,
null,
6132,
20229,
283583,
16384,
47182,
20067,
205586,
104397,
128262,
null,
14580,
null,
343373,
74646,
23262,
339721,
53692,
24737,
93808,
19022,
63137,
13234,
3926,
354400,
36001,
83275,
316645,
59019,
339743,
16213,
704451,
null,
226296,
8609,
25915,
138919,
104140,
67434,
292009,
null,
21340,
18685,
72951,
7616,
114596,
19591,
27284,
220446,
255044,
313592,
19513,
23252,
221494,
107749,
75435,
8190,
3422,
167771,
328460,
90620,
165033,
134070,
31465,
331785,
null,
26227,
116393,
254046,
382912,
354244,
177831,
26741,
35775,
76171,
180596,
115360,
207196,
390302,
170585,
106718,
607205,
17488,
36520,
null,
36752,
21154,
79282,
504550,
230017,
77113,
182226,
38939,
21861,
282330,
28344,
53694,
25728,
18452,
7438,
265438,
224026,
null,
162610,
212702,
25269,
82441,
null,
200146,
245524,
315765,
293836,
12641,
33510,
159067,
13830,
171286,
null,
78368,
87187,
34044,
59385,
103747,
50274,
9722,
252856,
436916,
6957,
138671,
23700,
null,
198666,
165385,
3571,
323787,
20196,
367594,
46467,
80822,
329994,
84789,
157300,
389842,
27662,
8973,
21875,
187175,
9966,
69127,
124460,
27210,
202936,
null,
41589,
201752,
103867,
null,
null,
114811,
407761,
141632,
268069,
121948,
124918,
25134,
14191,
342132,
301497,
null,
null,
11234,
300859,
84236,
338119,
198673,
19362,
51379,
246323,
40437,
266645,
null,
null,
141821,
99039,
38484,
262527,
4352,
6835,
54690,
456229,
86327,
9181,
100864,
75794,
36178,
8189,
313853,
34618,
69325,
null,
163476,
66797,
4933,
79103,
157537,
138296,
208100,
58100,
20935,
232659,
16857,
126426,
152972,
null,
256758,
30376,
393622,
null,
29790,
25917,
22410,
319713,
96902,
29124,
80717,
94526,
98182,
232378,
null,
312788,
16307,
312373,
45248,
146814,
387310,
36129,
250969,
333882,
9156,
70307,
1557514,
151324,
508251,
15009,
171029,
380064,
185182,
96074,
12095,
177431,
11507,
55567,
145120,
216820,
141066,
185509,
6991,
17811,
17109,
null,
46981,
44139,
8230,
101678,
377267,
332526,
164968,
24868,
null,
41191,
77503,
226791,
31209,
179164,
null,
16813,
237899,
40524,
50621,
154379,
null,
null,
55179,
14942,
128374,
null,
115273,
39785,
16503,
135227,
90720,
27655,
89802,
440509,
742851,
81373,
207151,
30139,
154578,
139549,
171812,
24495,
118392,
201704,
66886,
209882,
314716,
322301,
23817,
20979,
209500,
45622,
212541,
119273,
311569,
230454,
26253,
377813,
22588,
313490,
310755,
124574,
4256,
302838,
51033,
120501,
70861,
301144,
null,
170234,
213050,
312901,
8270,
237296,
80874,
315622,
null,
null,
177226,
null,
67345,
146729,
78306,
181701,
64411,
930024,
25288,
72588,
11510,
383833,
499323,
411977,
303023,
37555,
50026,
32034,
245447,
645999,
61432,
61934,
23700,
26535,
363066,
193096,
null,
552725,
83669,
109193,
63961,
99852,
168937,
null,
14308,
388585,
238244,
344383,
56261,
6290,
45008,
143882,
27063,
133090,
98009,
6023,
91927,
50860,
141723,
35136,
10217,
204699,
92935,
20778,
null,
79904,
41662,
48322,
134298,
435234,
null,
38102,
31897,
262962,
352725,
221961,
122825,
49772,
153502,
360782,
101492,
27005,
95726,
166558,
312420,
271097,
38074,
144374,
19379,
268414,
99850,
348152,
63020,
31589,
29366,
24907,
24568,
44578,
489951,
238403,
null,
493938,
37665,
11753,
144157,
3440,
null,
170088,
396489,
19854,
257903,
103852,
70957,
71421,
57385,
197797,
56784,
null,
155996,
34770,
56649,
9134,
433604,
165830,
94796,
90687,
106025,
null,
64493,
null,
77286,
159436,
139851,
54740,
218322,
140288,
329014,
2024,
21942,
37069,
74415,
36434,
103046,
598694,
295277,
699798,
215228,
392273,
151841,
193798,
10456,
179355,
30402,
29650,
257499,
136677,
299546,
6477,
25639,
203660,
263344,
49337,
305382,
null,
119007,
60477,
18979,
346811,
33339,
38810,
75747,
26634,
6424,
39545,
41295,
null,
null,
155551,
42893,
null,
23901,
75436,
20408,
16406,
198982,
222143,
16334,
66841,
8216,
404742,
179222,
null,
269859,
null,
364129,
null,
278069,
310378,
178265,
58320,
8342,
125499,
735123,
63854,
40329,
24932,
null,
283950,
18761,
24198,
10361,
195095,
328562,
45710,
14751,
null,
23205,
22561,
156517,
271562,
52600,
31808,
16141,
10232,
63610,
377990,
302924,
105096,
78638,
135984,
214891,
527844,
null,
163146,
28567,
30443,
75864,
19359,
343466,
17856,
18379,
10603,
211184,
698801,
71124,
83723,
29480,
null,
73139,
47293,
29860,
22010,
82957,
137478,
26916,
null,
190499,
80343,
20649,
246872,
412207,
11468,
471954,
467019,
362103,
338160,
24923,
9637,
151859,
383398,
446381,
20699,
418654,
40453,
392453,
75386,
59218,
143155,
null,
146618,
30791,
null,
24240,
302015,
null,
18521,
426649,
12382,
null,
393776,
31721,
24277,
null,
293718,
29526,
100368,
53654,
16988,
89178,
78620,
34762,
null,
null,
24829,
245945,
78710,
null,
47561,
32832,
14965,
33767,
152535,
47118,
41519,
44371,
175458,
338551,
452158,
13257,
40928,
null,
350232,
14960,
24841,
13457,
184722,
55430,
308412,
8044,
60090,
66143,
null,
21281,
141879,
16041,
3549,
148515,
26150,
23286,
355758,
261925,
605012,
439865,
35520,
162597,
17621,
44803,
73450,
43382,
40657,
99804,
139257,
9470,
364549,
6991,
462000,
80321,
100734,
336927,
110652,
207259,
91704,
224640,
327492,
74832,
55493,
61128,
395948,
41311,
52001,
null,
50967,
122035,
260706,
366071,
12412,
11302,
114398,
11563,
33898,
490160,
494960,
99511,
318957,
19224,
75556,
58782,
173364,
337989,
268717,
29898,
81734,
200731,
6170,
10859,
130672,
331359,
730776,
null,
176059,
null,
null,
239695,
12262,
200035,
40535,
10180,
132862,
117703,
54229,
82578,
156093,
307141,
5772,
477103,
30013,
12505,
262338,
45592,
675544,
15790,
27086,
168120,
61237,
null,
60566,
35639,
44550,
264103,
94089,
30392,
435507,
11067,
44837,
208755,
12873,
19403,
33450,
22609,
440051,
97275,
197719,
41461,
202255,
307230,
51816,
312759,
745729,
11310,
11253,
341686,
18635,
265249,
39163,
null,
8019,
244850,
56511,
31596,
null,
90261,
260365,
197048,
547053,
196945,
51270,
319095,
32649,
183756,
554850,
511416,
null,
41219,
24778,
973451,
131318,
174087,
7522,
92958,
92013,
27954,
41811,
361061,
6655,
null,
42081,
187865,
45241,
224506,
95197,
112315,
1231,
168868,
289560,
123380,
25124,
null,
161465,
344684,
372681,
32107,
279504,
51687,
195402,
192681,
255607,
149148,
35877,
416681,
24020,
24918,
null,
172128,
246793,
158875,
31116,
37788,
149874,
84008,
123666,
50950,
null,
147052,
42530,
12121,
18399,
35313,
32776,
25208,
101707,
127190,
199382,
null,
null,
249463,
293747,
75682,
176977,
114237,
228230,
136007,
201190,
25149,
37545,
32194,
171811,
null,
80144,
270385,
337627,
154133,
370294,
172753,
null,
249296,
33786,
179650,
24966,
53283,
67321,
133232,
133106,
311312,
25199,
59066,
189850,
70802,
5667,
85776,
null,
47238,
185430,
357763,
184282,
73013,
14365,
222077,
9086,
124100,
15464,
null,
17143,
389152,
391979,
331274,
34135,
478205,
null,
45188,
130231,
479405,
61613,
296107,
26094,
6643,
197981,
16793,
17502,
489685,
90237,
null,
267239,
12914,
510739,
42245,
21214,
247830,
null,
39042,
17165,
81396,
45800,
180012,
54958,
285588,
6064,
21444,
34843,
437676,
276100,
7648,
14234,
null,
null,
7698,
92667,
255708,
134475,
null,
13000,
49825,
54933,
197255,
21285,
335062,
294489,
149686,
79529,
64311,
106677,
1263797,
60184,
null,
97433,
11584,
null,
61796,
257712,
145819,
45873,
326176,
null,
126393,
26296,
24170,
null,
42839,
344503,
18992,
85537,
null,
38073,
243212,
15793,
12622,
65604,
165943,
21198,
15138,
158753,
178311,
422052,
327564,
114020,
62589,
289956,
27682,
null,
36790,
46385,
30764,
314123,
369746,
17012,
395280,
78888,
193695,
null,
244699,
199199,
177430,
20927,
78348,
40554,
221516,
null,
30576,
387207,
24496,
72778,
254155,
239956,
517929,
10344,
374810,
3084,
56151,
42783,
31193,
116999,
300977,
6444,
200677,
16837,
358800,
48529,
172596,
17959,
310643,
121939,
20931,
38995,
274869,
179581,
38933,
914004,
24867,
139090,
106796,
147609,
178147,
297660,
177583,
37489,
26772,
31700,
30310,
17977,
121205,
11798,
31673,
105896,
305285,
197121,
17992,
173300,
38023,
198538,
108218,
null,
null,
28710,
54083,
28901,
41065,
null,
29930,
23257,
304794,
25968,
38323,
183367,
244203,
116765,
22827,
null,
null,
37143,
null,
137271,
281714,
106584,
60912,
null,
340057,
31733,
178224,
24773,
73722,
141228,
417699,
12175,
null,
171161,
371971,
147581,
16756,
453228,
15121,
277686,
9382,
33128,
35280,
53265,
79404,
53996,
15959,
240345,
35461,
33807,
4669,
248318,
12989,
17090,
28563,
44558,
111075,
41757,
127416,
30965,
196967,
32673,
86799,
297219,
384416,
219627,
171999,
null,
55267,
187027,
2402,
24909,
46486,
29004,
164466,
218456,
89388,
21013,
25193,
8175,
30549,
16101,
9749,
83195,
556130,
143114,
8735,
206847,
20336,
18408,
15478,
null,
30328,
363709,
21356,
176623,
3038,
30096,
148486,
89803,
198382,
21464,
90553,
36335,
5733,
379293,
93144,
234149,
null,
133630,
null,
50118,
17888,
31004,
76946,
147990,
75452,
253982,
13601,
6406,
37188,
41414,
36803,
180764,
159849,
85175,
30224,
71505,
38124,
23672,
4736,
195389,
null,
9710,
14511,
83041,
160696,
95856,
15972,
12703,
18047,
12443,
263942,
null,
96012,
90741,
349814,
77282,
7284,
44404,
44592,
56113,
171129,
176424,
47823,
18990,
22286,
29573,
23867,
35892,
200144,
26841,
192018,
213707,
166948,
29954,
8110,
160162,
29552,
18645,
60260,
89845,
227928,
71295,
17804,
227017,
138637,
32426,
40497,
38672,
null,
16774,
45530,
26593,
531508,
49073,
195412,
112112,
34453,
35433,
null,
207552,
62657,
173811,
18001,
166874,
90284,
217998,
8414,
null,
302391,
184309,
52327,
126135,
125061,
17918,
74335,
19885,
1092983,
18280,
50965,
40585,
351866,
45625,
263077,
35930,
245801,
6355,
222593,
null,
754474,
null,
null,
385865,
171430,
55127,
323702,
81906,
47666,
5868,
29164,
176409,
240290,
319704,
163546,
null,
233300,
18649,
3111,
180362,
43416,
37892,
422755,
26031,
202850,
219991,
257410,
34524,
217462,
159679,
26155,
27496,
17663,
164376,
30105,
90433,
263362,
9981,
17374,
25527,
296202,
7243,
13121,
81246,
289353,
37482,
13361,
14298,
233565,
10841,
85667,
296380,
164165,
45544,
76301,
23088,
362187,
232288,
22261,
12774,
166140,
36643,
83571,
null,
81645,
117908,
92925,
13309,
114781,
38446,
73177,
129428,
48702,
392988,
17039,
35649,
40596,
null,
225567,
133901,
null,
118653,
378765,
186121,
62204,
55503,
149107,
116096,
84365,
50305,
470734,
263851,
198245,
87235,
97940,
null,
187437,
151846,
null,
49079,
14086,
9297,
5684,
2919,
33345,
12598,
154068,
198024,
173044,
22666,
207253,
115792,
31242,
375702,
38152,
18350,
95581,
4837,
null,
null,
7691,
138745,
23175,
61353,
118946,
97168,
356001,
null,
65587,
72901,
27611,
21314,
6844,
515095,
229617,
148221,
256330,
37278,
292115,
171566,
null,
56327,
21422,
null,
252879,
177683,
600458,
57937,
9361,
74799,
79187,
186348,
344177,
78551,
239369,
39734,
223261,
19073,
266759,
11634,
191330,
21297,
13062,
48787,
250560,
26652,
326335,
193382,
15182,
262564,
20572,
82043,
11719,
28404,
57399,
8343,
25495,
49816,
292735,
23369,
50261,
41294,
42359,
54816,
3065,
224140,
null,
null,
null,
181388,
135952,
11264,
167877,
481022,
6778,
111060,
139501,
4417,
76805,
318075,
157898,
26355,
8964,
131700,
12498,
null,
157417,
12176,
31899,
4111,
27423,
null,
23373,
46852,
8523,
44444,
317529,
26886,
37794,
27439,
null,
351179,
206121,
28472,
19411,
48102,
74352,
null,
553484,
106805,
null,
265370,
56073,
127088,
46063,
81397,
62137,
21882,
83123,
null,
261154,
24633,
null,
27271,
386930,
196934,
140682,
20222,
8818,
1865,
161806,
177053,
27380,
null,
null,
97619,
39277,
59666,
null,
49656,
176216,
456283,
100587,
null,
35433,
11056,
8712,
315947,
40022,
94936,
26758,
476096,
380378,
null,
31759,
108777,
256032,
437149,
28918,
108914,
null,
293426,
404367,
9844,
null,
46883,
198831,
null,
167594,
26171,
29727,
null,
13951,
251883,
null,
17811,
259292,
159948,
191070,
118835,
195194,
179302,
null,
229333,
59372,
17793,
57287,
null,
283595,
269825,
46469,
10887,
99653,
12659,
377808,
null,
50656,
80253,
142042,
290901,
null,
44789,
307415,
38865,
89095,
288781,
8815,
359331,
310638,
254238,
230284,
289219,
59435,
113415,
25053,
218598,
14898,
266908,
52635,
172186,
214327,
457401,
237193,
231530,
112807,
348712,
81177,
59898,
null,
63774,
101933,
153641,
169047,
81048,
13504,
278871,
205520,
63437,
290874,
179344,
34144,
62217,
12366,
276515,
197152,
159652,
25965,
4897,
20485,
830130,
515844,
173537,
null,
107265,
null,
102189,
null,
58979,
126132,
29461,
146600,
331881,
277958,
199758,
45394,
24213,
19220,
139684,
20235,
6410,
225781,
262444,
20263,
161352,
21053,
145485,
350613,
368008,
178216,
6951,
162793,
34563,
273466,
54694,
217702,
23575,
149762,
40676,
358801,
27332,
358954,
50770,
32576,
150700,
null,
104639,
99551,
28295,
409799,
31991,
149594,
59022,
37804,
30889,
null,
7237,
220069,
163352,
280249,
59805,
30048,
318230,
null,
null,
361141,
389744,
207958,
17202,
188598,
244253,
294861,
61947,
52451,
470586,
322605,
null,
22486,
76888,
26417,
33614,
27399,
93591,
619563,
462390,
163772,
167935,
null,
23713,
318868,
123870,
56901,
5108,
52449,
282314,
18104,
null,
13214,
22955,
6683,
26652,
35569,
352478,
37128,
224386,
298888,
26765,
230343,
null,
63391,
226998,
27422,
240613,
null,
25297,
41583,
177867,
48824,
246957,
168990,
25169,
60843,
30281,
24733,
null,
215863,
2482,
407951,
180825,
33835,
152454,
22184,
47998,
16035,
96117,
249995,
38299,
278984,
1019644,
99484,
31357,
490875,
24655,
6853,
195933,
33841,
289424,
303598,
278598,
51673,
384458,
35621,
5457,
362949,
50999,
165914,
193766,
113901,
null,
16767,
334861,
50379,
37279,
33291,
45116,
132633,
22848,
106374,
214666,
231625,
6330,
null,
176093,
38030,
118948,
170985,
90792,
241045,
19261,
1087835,
152782,
103417,
134070,
60938,
99422,
280017,
48442,
11981,
529770,
149694,
120261,
310116,
36330,
189321,
3512,
21895,
24805,
395167,
25341,
60050,
null,
null,
52047,
267910,
50009,
13559,
30543,
316851,
217778,
30601,
23696,
6288,
358050,
63125,
138421,
297328,
69694,
111527,
204471,
null,
null,
226247,
null,
30561,
20068,
368656,
330933,
null,
42924,
548585,
323756,
20316,
17282,
281527,
938391,
6824,
39116,
58647,
113401,
15076,
248651,
281649,
39849,
null,
null,
398748,
755403,
6458,
null,
154741,
99753,
11626,
54031,
329978,
57553,
121744,
215002,
42513,
57289,
408664,
39598,
293223,
122283,
141648,
47823,
60905,
52948,
11488,
6679,
248347,
39210,
27353,
42778,
30601,
96523,
7526,
47127,
253891,
35553,
271084,
290630,
194651,
63109,
61542,
51532,
765950,
94379,
34060,
263729,
175337,
22303,
60590,
null,
8808,
38252,
386349,
120642,
212470,
407869,
140291,
null,
23285,
218271,
281474,
45171,
670509,
37817,
766371,
76613,
205109,
84760,
286512,
13600,
2645,
200235,
null,
285512,
326094,
417603,
513246,
126023,
291445,
22974,
436255,
65851,
47326,
5294,
24356,
24597,
null,
21366,
7367,
16830,
28846,
31846,
169527,
37059,
297535,
null,
254369,
231947,
148593,
28133,
37063,
339067,
29999,
95228,
56933,
30678,
57202,
13953,
null,
69494,
153982,
129325,
null,
76461,
302985,
53201,
58384,
37076,
444219,
63770,
307306,
125851,
224541,
244289,
206233,
99596,
832587,
86992,
370966,
272429,
70239,
62910,
250645,
370728,
231714,
64025,
150320,
195396,
54627,
397924,
420765,
66155,
703889,
242077,
218253,
7610,
20352,
27191,
205981,
175101,
32576,
null,
173320,
34032,
108232,
9937,
29531,
197546,
39782,
120493,
41891,
30142,
18077,
36096,
301959,
12087,
67583,
33068,
122111,
323113,
197126,
225828,
51580,
308094,
15919,
78410,
264997,
830972,
193547,
null,
25403,
154398,
15815,
266099,
235414,
73807,
33999,
25711,
236649,
24423,
217339,
154686,
346857,
64707,
109058,
116437,
70459,
227152,
74206,
143890,
16860,
19969,
39924,
174051,
null,
436143,
546966,
27218,
null,
227046,
153934,
412013,
44894,
34301,
29845,
14280,
33338,
177921,
446291,
null,
45333,
102052,
208567,
22312,
339909,
null,
76446,
235718,
181311,
9113,
50831,
13390,
18794,
351918,
268918,
237503,
51175,
91320,
114755,
null,
143477,
36641,
107707,
46065,
31184,
238189,
306489,
21590,
19659,
44035,
13866,
4914,
244386,
14014,
28026,
null,
9447,
86311,
109351,
null,
39171,
16061,
227839,
29871,
75813,
30214,
790616,
32693,
279979,
166490,
null,
13686,
30119,
283193,
179013,
212043,
12839,
22824,
923695,
34202,
18505,
143160,
23318,
216008,
34977,
null,
276816,
23277,
250807,
60259,
null,
122805,
184433,
27578,
null,
220117,
null,
30416,
433976,
24284,
192808,
395330,
15415,
207141,
null,
309701,
15125,
36927,
null,
98640,
120339,
17364,
9953,
287922,
314457,
47600,
11888,
null,
14464,
208820,
65760,
null,
35367,
19090,
268382,
164954,
16281,
81301,
29915,
54400,
267528,
70623,
131365,
33795,
25442,
39446,
108257,
245962,
390678,
91543,
1273619,
4755,
49821,
40679,
14245,
251208,
184456,
232705,
14354,
87362,
259771,
342079,
24381,
26840,
219229,
11567,
79504,
204177,
159512,
20856,
355726,
33760,
43462,
8435,
67126,
127847,
276109,
79988,
null,
426996,
268597,
53535,
26621,
106901,
21690,
294997,
21708,
115431,
20706,
254955,
129901,
62862,
15253,
37865,
15165,
227045,
31649,
325082,
3278,
null,
null,
43949,
430385,
238796,
166192,
210710,
127180,
178810,
9052,
510820,
null,
497802,
17375,
168225,
36375,
64034,
46126,
81877,
null,
164783,
13648,
163171,
42232,
72105,
7326,
51652,
146648,
291408,
5372,
210403,
52266,
263268,
4833,
185300,
197041,
346564,
null,
38246,
467569,
110721,
null,
262717,
43731,
23579,
32808,
31896,
207956,
47639,
19329,
212845,
68876,
12669,
82147,
26464,
73484,
361057,
52458,
65961,
322199,
86519,
73820,
null,
83130,
32370,
98102,
13802,
150425,
364006,
178179,
527428,
200792,
13430,
451063,
111399,
164319,
388157,
25716,
74396,
38006,
27675,
36875,
77871,
67164,
23338,
41060,
67422,
234963,
32102,
48993,
101294,
226214,
17643,
149179,
86016,
null,
32337,
108181,
346833,
null,
55684,
89764,
55450,
180181,
47648,
28190,
null,
38740,
24887,
121347,
31105,
99223,
10815,
17878,
45566,
null,
50607,
null,
11551,
297933,
70956,
12969,
37354,
23530,
39931,
192705,
52675,
114519,
4255,
61454,
38299,
34812,
36455,
41307,
25817,
318517,
274832,
43171,
344703,
92353,
186102,
1114,
15668,
181039,
418909,
280280,
147626,
13126,
263292,
27138,
912724,
29513,
34171,
12795,
32440,
14286,
130463,
null,
101915,
19526,
19015,
402580,
42371,
40837,
null,
319043,
12374,
null,
97347,
10136,
108979,
38270,
107772,
10822,
569871,
18389,
26098,
39435,
113631,
731689,
349703,
6492,
null,
194241,
17920,
533958,
114128,
13782,
116348,
44065,
169997,
304841,
28793,
506871,
33520,
193814,
198569,
148721,
21963,
18557,
260553,
325503,
24379,
40685,
17404,
19233,
440231,
157973,
320704,
46442,
402905,
301636,
407241,
16336,
318335,
103588,
10230,
195419,
22006,
46327,
140477,
427007,
245540,
598185,
154762,
11281,
null,
56384,
505996,
null,
453638,
41588,
17229,
56013,
52182,
91246,
43944,
13292,
29626,
null,
7885,
26869,
92161,
155021,
127261,
52789,
239381,
292085,
10827,
173510,
231923,
246246,
40737,
352694,
null,
147790,
98860,
82486,
115434,
7380,
12332,
305794,
24362,
70968,
30235,
203051,
32996,
20809,
3998,
4089,
89242,
null,
99754,
160288,
28979,
169218,
507525,
64044,
216431,
18260,
303393,
16531,
844969,
172685,
22750,
null,
68489,
null,
51289,
55090,
468122,
94945,
43433,
20190,
214866,
154683,
20030,
202855,
null,
257945,
144582,
117155,
164782,
41487,
null,
null,
133785,
32129,
34776,
151107,
435711,
22785,
null,
543072,
754095,
26371,
121550,
79794,
127299,
345435,
36721,
424147,
96755,
595168,
12179,
77890,
54629,
5319,
9868,
215152,
268077,
242156,
63679,
317190,
338549,
4265,
47424,
41051,
39442,
266563,
38010,
42976,
33779,
271897,
146994,
27408,
33764,
278813,
64446,
481816,
309044,
195392,
661354,
75423,
76479,
40258,
53657,
234911,
368411,
151584,
16159,
156554,
202077,
14628,
223249,
20026,
308090,
393453,
155740,
26386,
187833,
4952,
2689,
137814,
13052,
null,
66771,
339392,
179795,
54473,
143452,
17523,
27968,
136334,
1022,
null,
888738,
276262,
200758,
48528,
12714,
240744,
36083,
248100,
9267,
467917,
372024,
21415,
137793,
136746,
303383,
null,
57000,
146687,
42865,
197006,
54818,
50420,
193129,
149962,
193977,
null,
null,
270786,
142298,
59827,
354174,
226920,
672618,
null,
351343,
null,
32800,
211613,
25867,
383908,
19234,
158624,
163417,
66711,
1027321,
37023,
148164,
77531,
103947,
160965,
64202,
189338,
null,
29343,
15566,
null,
446790,
38737,
181461,
9179,
10901,
47805,
670265,
174164,
16760,
11910,
199341,
14994,
25209,
null,
401230,
18807,
31213,
27882,
26670,
41501,
null,
58759,
357741,
25637,
73292,
311133,
196787,
346548,
314949,
null,
212249,
null,
86085,
216261,
212708,
31067,
291380,
53680,
30011,
108051,
30225,
null,
36593,
60218,
null,
14994,
164901,
195069,
29495,
51436,
158902,
82563,
null,
null,
13860,
175147,
145514,
129182,
22634,
19203,
294989,
null,
68299,
25178,
74487,
67637,
218701,
null,
236668,
35568,
532034,
49523,
32623,
579600,
3517,
157415,
13671,
30959,
76709,
194704,
22653,
8750,
79016,
99214,
34344,
13537,
69475,
295751,
17152,
547369,
67114,
62073,
222446,
30568,
12103,
59209,
299926,
26264,
46366,
417086,
239613,
380926,
279715,
208215,
355082,
102604,
146537,
194595,
33158,
30875,
481492,
null,
31644,
24335,
371560,
12485,
129070,
39012,
14894,
8858,
20202,
null,
280668,
347244,
175544,
182132,
null,
4263,
271543,
374614,
null,
40955,
118996,
30761,
173557,
4338,
101855,
359988,
306823,
53618,
42442,
23937,
46779,
null,
null,
400957,
109867,
26721,
36506,
38460,
278472,
180298,
74045,
141745,
null,
145634,
22340,
32720,
33096,
49681,
125440,
116805,
426849,
187616,
332123,
null,
455170,
66142,
58670,
205463,
158465,
7934,
19359,
52155,
null,
46150,
9526,
212418,
154274,
143788,
203128,
48541,
219076,
120310,
453771,
284934,
53559,
279326,
972705,
37966,
438621,
8880,
264766,
84991,
48271,
null,
37976,
6493,
57482,
65294,
120658,
205036,
83812,
127250,
38293,
59782,
143715,
410074,
null,
39981,
null,
39543,
52997,
127755,
332043,
null,
496346,
null,
578219,
43693,
130697,
null,
111296,
98628,
11285,
9478,
17813,
119187,
283268,
101113,
1714681,
null,
234382,
28141,
707853,
269921,
24466,
35221,
47624,
32261,
36156,
48765,
35248,
10132,
16895,
9384,
66144,
136900,
12277,
189598,
22976,
104282,
15565,
86825,
null,
70535,
100502,
352919,
415119,
533259,
119844,
352988,
745191,
26607,
null,
254041,
74388,
10712,
18759,
252683,
58180,
238596,
null,
null,
91389,
17196,
34464,
329565,
21653,
260018,
179124,
395542,
10945,
33188,
34372,
18029,
null,
515482,
252884,
146066,
331934,
577138,
null,
36236,
266311,
27719,
null,
209988,
171467,
209145,
35613,
null,
25127,
138357,
28432,
30717,
217621,
26503,
208658,
122902,
211719,
49661,
60970,
234560,
18955,
39926,
70862,
448640,
33595,
47968,
12239,
39961,
27805,
157685,
289954,
null,
181460,
87113,
28476,
185283,
67948,
63699,
31883,
151655,
20255,
46540,
82779,
112464,
155177,
232910,
432073,
10454,
170830,
null,
95449,
108195,
33978,
54829,
210775,
16780,
7248,
null,
44241,
27892,
305578,
178270,
25623,
7865,
89197,
217671,
324164,
53291,
6135,
37350,
138673,
137036,
125060,
252269,
67998,
202066,
77140,
178428,
69674,
387939,
28742,
49706,
275606,
131244,
20112,
37084,
45871,
37594,
333001,
11934,
62749,
25081,
103290,
16213,
256417,
291275,
null,
404993,
89092,
31433,
null,
52489,
null,
188362,
null,
8124,
177011,
71000,
109086,
400909,
29985,
123259,
12941,
36463,
15723,
470057,
13107,
112597,
245195,
5249,
40824,
188737,
null,
21181,
6672,
27539,
11518,
1043178,
367979,
20706,
18707,
33370,
61388,
28664,
455637,
204736,
58657,
45149,
33365,
358888,
14259,
609758,
null,
49561,
null,
78055,
534788,
487671,
43965,
263543,
103237,
null,
24486,
35809,
281108,
17206,
226712,
95277,
27378,
93458,
222514,
null,
293446,
22183,
105696,
12289,
228325,
143989,
72861,
150769,
131335,
57194,
46217,
240953,
34436,
187190,
94269,
173366,
15058,
251903,
null,
568579,
388288,
null,
35171,
64364,
864809,
97005,
9765,
20862,
504944,
10320,
84064,
null,
218569,
null,
320493,
13823,
107879,
null,
279584,
77711,
146490,
27685,
20052,
144478,
132036,
249125,
150077,
120786,
null,
43586,
103590,
73948,
30435,
173081,
198498,
14534,
52323,
16378,
62211,
95964,
null,
null,
13488,
306523,
286230,
434605,
13826,
260788,
282773,
null,
41767,
212504,
25710,
191779,
80503,
114520,
206342,
281823,
135936,
12975,
72295,
195039,
206160,
240555,
22031,
null,
110597,
null,
169607,
20266,
253574,
61289,
29333,
184007,
216339,
13685,
123935,
11845,
46608,
141915,
22615,
null,
27380,
83117,
86773,
54312,
19648,
721440,
51344,
91345,
10920,
43479,
null,
157530,
89498,
22948,
106449,
415211,
269838,
null,
110980,
null,
403780,
143698,
249445,
322401,
21341,
23760,
49807,
21745,
65892,
229331,
20981,
7849,
260638,
153440,
31284,
11442,
229839,
301477,
36931,
19576,
19303,
210755,
null,
147423,
93642,
32983,
15480,
54168,
463458,
null,
433701,
null,
140309,
193651,
335000,
8930,
139660,
76795,
null,
305679,
57651,
97556,
54565,
71010,
220758,
412666,
101379,
113201,
411586,
22611,
165365,
26608,
585279,
162226,
40361,
null,
228742,
14351,
215129,
39413,
65660,
178270,
13335,
121480,
5944,
19634,
410161,
445532,
8747,
11335,
198059,
172061,
12662,
20444,
55924,
441068,
188136,
97135,
171424,
215733,
505701,
null,
24686,
13081,
null,
null,
454167,
null,
5463,
null,
299811,
186357,
37445,
15640,
258287,
44992,
28631,
355546,
296925,
10111,
101353,
11232,
210923,
43327,
null,
98395,
194146,
null,
590465,
null,
null,
43015,
22497,
401609,
147681,
56326,
103517,
35528,
261131,
178237,
35418,
3858,
368843,
null,
null,
300582,
67931,
175437,
31602,
113144,
44120,
null,
406436,
6539,
79751,
202918,
48917,
null,
163355,
null,
220056,
9746,
7386,
35419,
223080,
4195,
498040,
17350,
34605,
25443,
125697,
385363,
15182,
6302,
null,
55514,
336207,
32536,
426933,
273632,
62949,
95513,
39375,
4271,
38320,
336747,
45694,
218324,
73402,
499254,
14037,
28775,
32426,
312642,
57199,
114068,
62893,
237754,
30090,
49843,
203806,
43977,
21168,
44901,
407320,
16939,
151543,
213979,
23757,
71343,
368954,
28141,
21365,
80118,
39479,
4224,
9576,
89588,
40492,
5179,
14136,
15552,
5442,
456149,
317024,
167181,
123649,
316337,
154218,
14077,
57507,
91300,
37554,
31225,
4206,
41094,
263946,
6573,
327576,
37857,
59329,
176418,
19919,
210433,
17466,
3510,
113698,
104544,
810380,
158687,
72356,
null,
null,
43311,
null,
275501,
266360,
96218,
null,
72073,
59312,
393172,
10190,
243642,
72976,
10233,
22532,
254948,
230776,
172756,
45630,
112965,
42245,
64359,
23804,
43308,
null,
600651,
56107,
80143,
60297,
55407,
76497,
205447,
201168,
338897,
32736,
19299,
21300,
197474,
13222,
78544,
null,
188284,
null,
370051,
51517,
23195,
7811,
140452,
50275,
37994,
null,
163848,
66797,
42974,
522627,
216281,
27804,
25433,
437423,
244733,
null,
79857,
172250,
535832,
20865,
216366,
43010,
165678,
48950,
129773,
35588,
243614,
null,
230325,
349911,
243560,
180114,
23510,
777477,
282253,
176202,
482791,
289810,
144952,
18111,
13103,
92433,
189589,
24876,
217597,
13809,
34071,
26240,
48366,
152347,
48788,
46413,
6036,
706693,
55101,
32549,
174004,
62090,
66606,
162522,
172316,
360020,
152296,
141629,
140302,
null,
264736,
77661,
198676,
120365,
508423,
200697,
44059,
223684,
321610,
172452,
88006,
null,
14369,
5294,
339480,
108900,
20038,
21969,
172236,
263282,
14511,
55911,
17149,
23174,
9537,
153261,
52413,
289605,
22057,
61528,
null,
77090,
36203,
44088,
124683,
5636,
17378,
21431,
5496,
132106,
null,
4263,
163064,
155511,
11504,
563427,
135916,
83295,
44701,
null,
294593,
328745,
42222,
403178,
204528,
null,
342092,
46216,
null,
18229,
59690,
79083,
126316,
37378,
42605,
165039,
46148,
553173,
49614,
120762,
241675,
14224,
279873,
388074,
22496,
9889,
7436,
5125,
23901,
142490,
77983,
null,
null,
160907,
182698,
351959,
153384,
237464,
387199,
14469,
220725,
91114,
null,
127148,
400578,
100381,
45772,
44891,
null,
null,
123020,
null,
190722,
303979,
25238,
285154,
163787,
60558,
34092,
19839,
526699,
143198,
134789,
114448,
321617,
null,
261877,
12714,
108287,
null,
23688,
36569,
16002,
null,
351548,
null,
27526,
46488,
39197,
null,
94775,
null,
258596,
452811,
34719,
205370,
58484,
456571,
248161,
7075,
103990,
41830,
71287,
37758,
87343,
91817,
197573,
13402,
34924,
24569,
39942,
68110,
9575,
109234,
284936,
null,
241021,
null,
78118,
28897,
116057,
66409,
199580,
585917,
329600,
188944,
139669,
4083,
18523,
94427,
22156,
182112,
196261,
6017,
null,
112228,
71650,
37754,
211508,
47454,
201487,
null,
382176,
302484,
228625,
69323,
149723,
25267,
257779,
376437,
27692,
56094,
20938,
20704,
18434,
null,
362567,
13055,
56719,
86937,
56324,
51768,
26645,
102854,
30947,
287696,
null,
29526,
90225,
123743,
42880,
22764,
38679,
18431,
null,
129668,
14482,
224173,
170309,
787802,
103703,
70177,
null,
181744,
4301,
151386,
14003,
26389,
274071,
24772,
30055,
null,
180963,
42130,
48419,
151762,
343770,
28024,
null,
23297,
26720,
191807,
291510,
null,
443900,
46108,
36163,
3633,
86504,
39298,
224224,
373730,
148624,
75912,
96671,
2714,
15127,
306611,
720620,
420041,
null,
10173,
56888,
90686,
396842,
373578,
279319,
6978,
157992,
62485,
24219,
null,
221849,
null,
null,
231367,
69185,
11572,
27933,
56486,
232083,
238173,
38487,
43039,
19446,
12222,
46915,
11721,
26991,
23347,
37916,
28973,
23161,
27104,
10925,
518240,
129510,
197509,
50415,
57520,
212604,
null,
6442,
null,
24777,
null,
15941,
518403,
12720,
23715,
375583,
11482,
28135,
7525,
41246,
339173,
46706,
24704,
20386,
13639,
null,
94739,
308261,
250341,
133258,
162057,
null,
21557,
25006,
308467,
203837,
177014,
317971,
180569,
36815,
14633,
11580,
null,
99335,
404634,
27435,
null,
36933,
39596,
15335,
96659,
125932,
32640,
845854,
153808,
null,
24473,
null,
15705,
45804,
37135,
null,
323686,
51425,
215307,
202309,
null,
33449,
null,
111054,
4756,
206847,
236136,
321982,
39041,
27690,
18212,
314234,
71223,
387681,
125231,
234122,
83193,
213288,
31942,
112945,
77533,
null,
22652,
null,
294614,
228446,
27186,
46905,
44195,
23927,
31942,
137261,
null,
9141,
470800,
21168,
71372,
16784,
40310,
43614,
38041,
55700,
384172,
23097,
49880,
186102,
103959,
null,
150069,
293855,
null,
null,
49677,
16912,
41124,
18425,
82257,
30574,
158717,
82651,
181805,
157627,
167865,
21361,
26817,
89525,
183325,
6570,
10111,
27826,
106767,
122388,
33503,
44915,
53241,
100167,
23859,
426583,
170180,
12495,
null,
21855,
null,
407565,
141094,
19914,
181388,
null,
19017,
25992,
65160,
50684,
248492,
185186,
168586,
73920,
53606,
392194,
14756,
318609,
135251,
37971,
37583,
null,
31479,
48632,
558018,
390358,
52882,
121236,
8318,
260840,
175488,
41487,
16932,
476807,
135412,
51205,
8192,
147435,
null,
218451,
51711,
20317,
101790,
10708,
23314,
105414,
176124,
195628,
180777,
21657,
47277,
212973,
19762,
273165,
null,
null,
20242,
251344,
41954,
103918,
43131,
58612,
205626,
260747,
178090,
208253,
99623,
52304,
null,
496339,
null,
19625,
6475,
59855,
49803,
259924,
3010,
40365,
171010,
58373,
49305,
183451,
219015,
null,
8768,
265204,
286937,
77363,
51538,
17832,
793162,
115438,
null,
326008,
573393,
183912,
137854,
35192,
10419,
125768,
150814,
194933,
199535,
39591,
33378,
44368,
348875,
50884,
16552,
373254,
22846,
80438,
12055,
249451,
64139,
42073,
174290,
5240,
null,
212640,
25821,
616394,
92575,
30052,
498299,
459914,
8987,
301268,
null,
52505,
97376,
278729,
50991,
32635,
346281,
147786,
27821,
72924,
81046,
7516,
52491,
190907,
186862,
212035,
551642,
26226,
6601,
51233,
null,
43792,
194549,
122464,
75396,
57390,
20881,
39235,
332902,
26495,
10342,
6402,
52548,
null,
30587,
15316,
null,
46301,
14586,
54794,
51886,
279163,
118695,
140596,
32205,
211686,
46134,
103866,
160778,
57580,
119126,
206251,
59258,
320446,
51047,
269975,
321010,
275227,
234302,
76739,
null,
299201,
216336,
25911,
193207,
345390,
155918,
57746,
null,
443739,
22058,
47739,
null,
24011,
227619,
13927,
83704,
23793,
96339,
161708,
128688,
46663,
236294,
31359,
8121,
264584,
225853,
164234,
60648,
14544,
18962,
438216,
20615,
null,
131239,
406816,
332825,
130835,
203696,
21757,
3938,
155977,
508040,
49148,
219339,
180369,
20996,
663,
43697,
45547,
331145,
33394,
9793,
428,
302568,
15387,
null,
26264,
121643,
398843,
264065,
3690,
16473,
300310,
333237,
163704,
12377,
49510,
231283,
35856,
16044,
83144,
44698,
81572,
15060,
100776,
97795,
16134,
20436,
246026,
23553,
147157,
266039,
14619,
18672,
27657,
19419,
144114,
227063,
25361,
31612,
346386,
138901,
273643,
9843,
43705,
8910,
28002,
36802,
72487,
266614,
181002,
16115,
null,
127745,
25659,
10300,
303932,
198767,
20067,
49504,
34898,
15571,
21116,
30219,
109135,
482885,
11009,
61111,
198955,
298826,
22230,
9571,
49165,
36170,
198982,
136785,
61858,
32252,
39724,
204382,
40761,
122684,
34612,
196945,
369013,
313861,
163143,
null,
14132,
35507,
17317,
695603,
45377,
212685,
126500,
47738,
42914,
51610,
427117,
11718,
null,
102221,
249174,
25727,
239808,
null,
142413,
316450,
15307,
534297,
246401,
58617,
82451,
1246,
42361,
89272,
64613,
118159,
289230,
526698,
107241,
204307,
22471,
45710,
115785,
168488,
null,
121604,
314383,
22184,
148753,
265411,
102859,
4318,
342301,
28050,
null,
29069,
250864,
174359,
273234,
null,
null,
277969,
23600,
106121,
105767,
216840,
251846,
346686,
232948,
50312,
14395,
21504,
88148,
159359,
26253,
32345,
641633,
410022,
11644,
39240,
12080,
136003,
202246,
26407,
86388,
9967,
8772,
347915,
49471,
41449,
20069,
307670,
185439,
63508,
292464,
63810,
16887,
222861,
null,
158431,
316947,
135061,
57358,
null,
142211,
41001,
246861,
36008,
1153118,
5159,
292118,
410122,
7860,
18305,
35601,
101814,
81871,
261431,
35776,
84472,
17423,
null,
35844,
2168,
null,
382624,
441819,
351593,
289824,
35093,
351102,
29123,
159750,
24058,
235543,
76101,
208950,
null,
78030,
54842,
null,
null,
null,
16,
176260,
52618,
214048,
null,
175880,
176620,
447523,
385855,
22036,
null,
312143,
161598,
276985,
211878,
280692,
522834,
155450,
63098,
79931,
13652,
163617,
297458,
221556,
6682,
209884,
61645,
16560,
303081,
33352,
292036,
74041,
35667,
25069,
171981,
15910,
370336,
17825,
17493,
17432,
12273,
77018,
147093,
394950,
39333,
38017,
null,
23873,
21840,
141603,
5880,
null,
25491,
131056,
315432,
171307,
265447,
141828,
50959,
144329,
142548,
446634,
27431,
4541,
157676,
347894,
28832,
114668,
466918,
69946,
27901,
77551,
29336,
251919,
255879,
115308,
43109,
92279,
33130,
84230,
30789,
null,
39581,
null,
71922,
26902,
65208,
109598,
221020,
103228,
43421,
83168,
170067,
193004,
59214,
64129,
142979,
512257,
84666,
79656,
65417,
127745,
189648,
36607,
2266,
43566,
67386,
42642,
88685,
451127,
187788,
null,
75522,
71627,
149372,
260863,
223148,
178961,
43647,
222916,
123176,
326968,
6418,
124850,
null,
41920,
496261,
214722,
516090,
138384,
299480,
22740,
472257,
240427,
27717,
264701,
null,
24786,
549959,
345286,
74722,
14208,
30707,
49344,
99477,
214598,
null,
528033,
586572,
11929,
48644,
175330,
14868,
47135,
null,
19286,
140405,
103689,
170254,
180738,
453111,
40261,
null,
206690,
5402,
260212,
417525,
210938,
169682,
94694,
null,
33300,
91001,
21249,
6494,
56447,
37819,
567980,
310868,
44128,
40409,
222990,
10670,
35012,
335105,
129785,
138775,
29913,
141458,
66996,
39005,
180015,
29117,
14206,
40627,
22329,
63210,
290338,
643585,
9469,
127189,
null,
231014,
15290,
16266,
28098,
38586,
50979,
44727,
186396,
68124,
62481,
154373,
173516,
null,
17064,
54745,
443736,
16229,
43079,
312232,
124846,
33712,
190673,
254485,
289512,
null,
15114,
null,
153009,
null,
49521,
152562,
10828,
23963,
27214,
1181091,
58458,
15560,
43216,
403978,
250131,
10237,
34680,
46051,
522478,
14674,
30255,
101549,
null,
5003,
215062,
null,
null,
122310,
133519,
117292,
225672,
316589,
18791,
857304,
133996,
211594,
223694,
32143,
22029,
133089,
34802,
183847,
274455,
429987,
27766,
34284,
107685,
179200,
23822,
280723,
62044,
208517,
237762,
25122,
273326,
249459,
439308,
298797,
30290,
69874,
49844,
146660,
136900,
48679,
303547,
269735,
5673,
134720,
103329,
9410,
63142,
102416,
164561,
142688,
177587,
38301,
221138,
405264,
11151,
29269,
407279,
214574,
102289,
37953,
402364,
45684,
30998,
73675,
201281,
52907,
379869,
265392,
42253,
596894,
2138,
478772,
236013,
57539,
170076,
220517,
323278,
191782,
202038,
38045,
4587,
50525,
390951,
322531,
16620,
124099,
82215,
18768,
37500,
85909,
290987,
18569,
93350,
71787,
53043,
285608,
92231,
null,
290993,
null,
27155,
20004,
null,
66321,
23975,
162205,
106595,
271547,
247639,
23254,
153432,
39350,
112996,
25291,
156774,
208253,
null,
45994,
185055,
219740,
null,
163065,
153174,
211072,
32670,
309902,
19251,
null,
295969,
44317,
18985,
413295,
51332,
139130,
62584,
13262,
30826,
13305,
382015,
329971,
6405,
380464,
462513,
221983,
46076,
30969,
144385,
89065,
96841,
267175,
516473,
29622,
9925,
35099,
200558,
20270,
24692,
139036,
77284,
183465,
324799,
865398,
null,
8393,
267728,
66342,
302450,
null,
42851,
280548,
10245,
5631,
null,
284226,
43804,
194105,
36567,
22420,
194938,
145744,
86498,
320155,
94907,
31198,
413228,
6216,
192603,
13778,
139675,
53834,
null,
null,
51039,
218440,
127086,
null,
27928,
196203,
9142,
14038,
169002,
null,
9192,
264339,
143364,
null,
117721,
46517,
15556,
170932,
30021,
27633,
92363,
383152,
286321,
53509,
420242,
253033,
421096,
36542,
234020,
null,
381656,
107120,
13707,
39719,
37162,
119279,
null,
158733,
null,
225153,
130508,
132349,
23783,
6082,
81043,
null,
39613,
5799,
null,
1121630,
35430,
42847,
27481,
null,
23698,
471131,
7069,
3495,
161070,
21866,
115839,
null,
139816,
63075,
26485,
515171,
13904,
null,
185162,
35450,
46121,
42350,
null,
16940,
181669,
255318,
48617,
79097,
30108,
9175,
null,
285944,
193446,
null,
79529,
156742,
22628,
163319,
344156,
189494,
601355,
7571,
null,
null,
117469,
381977,
229989,
13706,
98692,
86123,
162399,
421709,
132553,
141534,
57458,
367323,
781553,
25551,
113775,
391867,
82579,
136969,
26755,
21035,
null,
38256,
348432,
44800,
33111,
514662,
15442,
404840,
263324,
49081,
27319,
114104,
140452,
14232,
167264,
18398,
212531,
16137,
35123,
363112,
223974,
159126,
630634,
113752,
40780,
27747,
null,
20480,
null,
381408,
399996,
248558,
13731,
177641,
201212,
436320,
191265,
7631,
50693,
null,
78590,
18503,
418279,
null,
48254,
117746,
276872,
16263,
null,
2736,
34418,
391030,
128525,
134581,
148797,
176202,
59553,
18672,
145383,
405248,
139158,
157330,
385839,
106269,
148807,
54916,
433911,
78218,
null,
null,
27885,
30501,
667175,
179850,
350453,
39174,
246093,
7922,
135339,
177345,
449149,
122180,
135301,
36314,
138155,
40226,
173479,
214905,
192458,
307492,
114896,
35823,
354819,
37346,
317073,
null,
74350,
null,
3709,
24928,
165522,
133909,
29913,
24518,
42065,
null,
61509,
294531,
146816,
231805,
205957,
57414,
116785,
141841,
27378,
206826,
47114,
147093,
5377,
121436,
6054,
20319,
14857,
126331,
435412,
101105,
56654,
322045,
49956,
397828,
72807,
32249,
80287,
44519,
224980,
144948,
142420,
null,
null,
71060,
100703,
12883,
98416,
43929,
null,
76762,
840845,
177241,
42149,
null,
26830,
87628,
409349,
49392,
36114,
78014,
null,
null,
482802,
null,
26578,
10934,
109599,
47423,
89444,
111441,
80450,
null,
87107,
139249,
19653,
240622,
43408,
44199,
10792,
380039,
111433,
172356,
355442,
178474,
304807,
68862,
284781,
39622,
null,
110305,
21865,
342923,
282669,
362469,
null,
8522,
278561,
54372,
63052,
4364,
null,
29087,
43791,
31885,
180658,
124475,
255922,
341446,
280056,
52451,
null,
55345,
21170,
29787,
91311,
170996,
40662,
18517,
222013,
29734,
37087,
36706,
89261,
null,
8021,
40535,
12410,
120818,
36541,
5525,
61016,
368998,
68854,
425770,
141342,
13479,
183773,
274278,
29891,
126338,
4564,
9812,
12400,
23170,
165563,
615821,
84412,
656906,
40552,
413849,
null,
137711,
48414,
null,
223117,
217506,
85091,
37850,
146667,
210222,
464234,
17179,
354810,
296138,
37816,
24735,
155566,
null,
298886,
138388,
68539,
28798,
18279,
294781,
33907,
44955,
7979,
null,
39996,
167103,
46156,
360507,
58146,
79220,
46008,
285754,
140801,
4889,
211609,
493641,
180875,
225773,
179140,
28557,
24109,
17080,
268130,
26215,
158328,
36062,
100779,
241322,
17728,
null,
15529,
34365,
278512,
773846,
117359,
38090,
467447,
98807,
334263,
32753,
313819,
61739,
40177,
null,
23444,
94506,
19136,
59269,
null,
74718,
79853,
null,
76231,
166855,
120443,
22104,
512662,
95884,
32401,
296336,
25583,
32508,
31293,
46243,
44927,
132033,
33050,
30436,
289711,
210619,
null,
34072,
null,
5763,
163325,
144532,
264306,
151507,
351842,
357236,
273288,
null,
186349,
12092,
420643,
80530,
352184,
152900,
228888,
6793,
93153,
241087,
119393,
168965,
27288,
67032,
365711,
146563,
387303,
501063,
60217,
156778,
14787,
30989,
151090,
10639,
null,
49366,
null,
15895,
121548,
210678,
19807,
16827,
481377,
82914,
203646,
174916,
7391,
165608,
null,
2556,
5547,
151825,
31953,
243736,
262319,
10702,
194579,
6688,
329058,
298782,
23143,
155753,
52779,
39930,
125452,
746460,
null,
98044,
229093,
398728,
76482,
34620,
12322,
9184,
337721,
102681,
411027,
117381,
31276,
71303,
210223,
12249,
15649,
18555,
31876,
246127,
248240,
248129,
9272,
32439,
27165,
243655,
75243,
202212,
227511,
25643,
2840,
46358,
92846,
null,
null,
13105,
6676,
89597,
191688,
266646,
371609,
113849,
44053,
346463,
8192,
633523,
37240,
120739,
null,
410564,
51784,
null,
19897,
76526,
257046,
56265,
178607,
514334,
378216,
43754,
98146,
20240,
217834,
235006,
106976,
28119,
29140,
91938,
202124,
null,
28742,
866133,
146645,
456376,
59954,
237657,
73726,
39755,
62766,
243885,
null,
14849,
375449,
233690,
283096,
242667,
227061,
414787,
51629,
31649,
15939,
19791,
101045,
241580,
335600,
28049,
476684,
326717,
59069,
255666,
339753,
95770,
34406,
null,
260852,
39396,
30183,
13481,
133782,
293885,
22193,
48753,
32300,
73221,
6449,
66401,
63859,
15566,
9869,
53448,
200035,
null,
67324,
57632,
95135,
19724,
32073,
41174,
null,
424699,
145204,
445491,
14608,
41844,
52532,
null,
85510,
157442,
130903,
46839,
35474,
125796,
199082,
203485,
21714,
30346,
57048,
65083,
207460,
10471,
32755,
13111,
6110,
1441,
306491,
330283,
212083,
30223,
14447,
69641,
null,
72048,
56432,
219200,
113201,
36964,
341668,
22100,
133412,
372327,
null,
70034,
270907,
181061,
1916,
172078,
null,
15322,
387051,
212382,
148535,
null,
117553,
16188,
236812,
60640,
33450,
302811,
65735,
4463,
121424,
75966,
21033,
119003,
19698,
27261,
12515,
19900,
52748,
31322,
291462,
108528,
59704,
9475,
183010,
68912,
58976,
100454,
2611,
542518,
null,
304510,
null,
322136,
17131,
115713,
93772,
91600,
232143,
309616,
111672,
685,
278565,
65694,
null,
15110,
48493,
360923,
197894,
346052,
115662,
26655,
10440,
376539,
316117,
118212,
41770,
null,
48951,
35946,
93743,
182550,
32857,
189009,
153411,
341376,
100891,
56025,
16377,
234099,
139998,
107858,
143211,
25054,
174507,
475669,
81185,
133888,
17782,
null,
215503,
209323,
7642,
102048,
44097,
126411,
284809,
67770,
32128,
43884,
51625,
null,
180910,
115839,
248190,
191413,
5269,
316953,
168239,
20766,
198186,
26523,
68616,
12560,
365178,
48852,
549699,
107730,
441737,
221459,
26291,
266943,
212931,
14323,
27846,
62066,
283660,
267780,
11811,
18685,
418919,
47761,
269284,
576989,
71648,
null,
43262,
null,
5939,
396048,
343914,
240727,
30059,
85407,
null,
10735,
661416,
9687,
171793,
null,
73516,
153921,
522992,
17226,
16638,
28474,
37942,
186318,
20277,
null,
2592,
31370,
130442,
169879,
171654,
17044,
22764,
223879,
101438,
608101,
null,
26861,
51105,
180173,
242342,
96934,
null,
29861,
135315,
237992,
277066,
35358,
46658,
27062,
47808,
630857,
77267,
29269,
158334,
157882,
234856,
205076,
59857,
26613,
8229,
388859,
66498,
165730,
55165,
91803,
153294,
30715,
53030,
309119,
390119,
16164,
22187,
null,
32009,
15847,
124684,
611600,
129825,
11216,
397547,
196899,
159517,
12547,
11951,
26048,
128220,
178934,
71944,
92353,
null,
11497,
405013,
308039,
22768,
197189,
238880,
87061,
236204,
7568,
23227,
173712,
91919,
71514,
6475,
null,
411103,
15067,
4518,
26940,
17185,
167500,
34922,
97354,
34635,
73313,
9988,
30181,
367775,
53428,
216879,
52809,
147895,
3472,
238143,
145811,
7191,
304691,
341299,
9035,
460186,
282572,
null,
185551,
233133,
378524,
21081,
15159,
260935,
245403,
153012,
25192,
658975,
443795,
60500,
309198,
160797,
null,
10841,
69937,
null,
46554,
34413,
241089,
414663,
131992,
109290,
117148,
94364,
97740,
141744,
null,
487934,
684136,
44632,
693499,
295489,
194798,
267692,
24749,
33273,
485988,
144596,
195348,
15690,
4477,
380136,
229975,
9907,
null,
253770,
272953,
18933,
288255,
65399,
94461,
179885,
27054,
809402,
218770,
173172,
256455,
215747,
228769,
45196,
64882,
93210,
7092,
28744,
22160,
151540,
231706,
41928,
null,
null,
25905,
256661,
403948,
19434,
2752,
26360,
79229,
4609,
29219,
30017,
7244,
253496,
210655,
1717,
158491,
247523,
17207,
284989,
24329,
91017,
158518,
103515,
519894,
352337,
455847,
15993,
315812,
25117,
17019,
207754,
248790,
194987,
null,
25153,
184323,
40127,
91075,
null,
48507,
null,
null,
47460,
38773,
37401,
11488,
107625,
291414,
29983,
486523,
90683,
32530,
72234,
253938,
40396,
43819,
330634,
50005,
null,
226954,
28881,
null,
456235,
12018,
97612,
17894,
39976,
243079,
95893,
34995,
68943,
52934,
153171,
86268,
163222,
198743,
22942,
232369,
340017,
43554,
681734,
20007,
56946,
201997,
38054,
8507,
32661,
42183,
302375,
null,
31321,
79273,
155582,
41245,
50566,
281224,
149831,
72402,
166964,
126531,
28710,
223623,
14677,
195194,
33753,
262910,
106763,
63956,
383916,
16338,
306370,
43070,
230504,
262521,
null,
6968,
337748,
53316,
17593,
304139,
151496,
253943,
439096,
38173,
15652,
77278,
null,
184659,
104583,
60058,
56732,
null,
20842,
263684,
151687,
149029,
191231,
245773,
33983,
null,
11333,
94943,
47497,
32329,
62649,
76464,
181860,
252988,
5082,
13599,
194410,
153899,
37595,
114567,
67992,
161078,
39757,
355801,
13765,
188139,
5440,
261787,
48903,
134656,
38306,
15644,
113370,
24805,
12775,
25058,
null,
381994,
50864,
41954,
503581,
39770,
16664,
171758,
19811,
null,
132325,
15838,
13694,
177572,
262411,
253076,
54069,
377837,
null,
27786,
13567,
139664,
680626,
null,
201338,
451338,
null,
254271,
208617,
5539,
129832,
19375,
55425,
null,
299666,
34394,
165167,
44278,
31990,
55393,
195256,
6303,
null,
98991,
224261,
451209,
229662,
91855,
674312,
24553,
281123,
408474,
14606,
79555,
26962,
42320,
57003,
5245,
233268,
135875,
368692,
45682,
4423,
50130,
291523,
223356,
259342,
62851,
null,
152148,
null,
253363,
229113,
45633,
18227,
103608,
40860,
41159,
210393,
26023,
null,
457612,
43148,
158779,
390403,
42702,
367585,
80735,
181764,
324157,
72932,
184937,
274372,
null,
217381,
17502,
474033,
101690,
18147,
23396,
34891,
289427,
103801,
30363,
21423,
503727,
19659,
52210,
22966,
242761,
25419,
255470,
27934,
10364,
4670,
29902,
27560,
284265,
279053,
183318,
46566,
34379,
40154,
38024,
13802,
276929,
18177,
16523,
32684,
433273,
369432,
292498,
566715,
3261,
279077,
97649,
310703,
146867,
62891,
214720,
33446,
134457,
59523,
261484,
null,
null,
179220,
null,
296448,
70726,
356571,
272227,
11538,
20842,
56313,
18008,
16700,
114924,
35694,
8004,
null,
117956,
null,
58195,
131302,
119164,
10772,
null,
29082,
297930,
162305,
13466,
45308,
null,
597185,
20916,
584674,
10128,
59992,
56803,
13494,
519654,
289674,
20031,
336577,
134099,
6860,
205987,
130277,
132006,
128555,
41365,
396724,
null,
9569,
null,
187199,
61732,
263503,
73049,
141070,
46840,
146737,
72525,
16582,
89694,
305388,
161649,
6235,
232850,
null,
158525,
37536,
null,
13912,
190821,
262433,
201633,
47745,
113825,
372151,
213918,
61847,
282220,
407879,
156988,
84090,
10825,
18716,
null,
222817,
26598,
383180,
179022,
285698,
42714,
40950,
48069,
48130,
47684,
null,
91489,
null,
262026,
211122,
65759,
40050,
null,
101215,
40261,
127163,
20073,
181811,
32375,
278107,
80589,
44987,
126071,
215834,
11712,
208166,
31351,
81542,
38085,
44352,
null,
29542,
32141,
52394,
209961,
128649,
196824,
65270,
461708,
209860,
500499,
114425,
282724,
387537,
258002,
9564,
37952,
335328,
178147,
33250,
26624,
454097,
47764,
31833,
32979,
35813,
18595,
8563,
null,
5433,
49665,
44865,
83001,
117922,
176239,
364535,
214672,
85480,
99327,
266224,
309281,
7481,
69887,
45364,
292298,
118370,
331687,
29441,
263211,
222162,
229808,
147622,
184226,
54039,
27806,
231253,
40442,
68009,
258310,
295996,
42433,
29098,
159236,
339605,
304727,
23035,
206871,
2150,
40561,
null,
469179,
314375,
28820,
21083,
273992,
176426,
5226,
304342,
34545,
16935,
82594,
36300,
42414,
760364,
43935,
149196,
302405,
6349,
60605,
56979,
null,
260320,
17658,
27850,
80142,
8100,
252277,
25019,
null,
107845,
26307,
127753,
20091,
266992,
275431,
1755,
222646,
173788,
232666,
247627,
197760,
null,
610775,
70222,
30296,
118318,
10099,
12257,
20335,
151063,
649928,
323982,
64073,
303308,
34772,
116180,
187392,
117735,
189834,
463955,
170326,
66212,
231471,
18058,
113395,
92736,
137663,
11956,
216861,
null,
64927,
412748,
20116,
332664,
370693,
85047,
19775,
19067,
297874,
22190,
263807,
37763,
46777,
23293,
235968,
98963,
8262,
170615,
775105,
180911,
45170,
162283,
87587,
192805,
112779,
246160,
null,
9421,
31315,
139443,
199883,
17669,
49422,
32502,
59359,
26978,
302690,
18235,
267446,
25542,
40830,
53821,
361886,
236155,
231529,
19788,
173580,
3841,
19314,
215712,
84223,
21934,
7062,
330529,
261370,
87788,
32446,
1584,
25997,
114926,
19156,
81323,
62121,
420843,
92294,
134934,
49171,
37214,
270135,
78936,
294070,
103692,
38029,
329445,
35578,
415002,
125954,
190763,
54338,
213946,
81179,
355834,
56459,
212062,
4537,
600969,
32301,
207207,
25640,
121665,
null,
25915,
20348,
102629,
45685,
20464,
null,
197792,
78188,
null,
5732,
321575,
27727,
101687,
44400,
177906,
37400,
133975,
24033,
124108,
135216,
25049,
32101,
166105,
228596,
70131,
null,
375436,
319697,
24387,
85877,
33983,
null,
724048,
62473,
95386,
33329,
221799,
166836,
20354,
42945,
13771,
37687,
44055,
21153,
3315,
201717,
148117,
null,
12985,
312315,
null,
47310,
140268,
286821,
null,
123768,
155696,
22870,
27061,
56492,
214387,
58416,
33043,
380205,
140889,
408128,
24924,
22441,
591480,
353550,
135142,
206688,
36554,
147445,
13958,
9923,
29693,
24395,
3633,
57366,
null,
140317,
30565,
416051,
56215,
416766,
41900,
93013,
241218,
334508,
173913,
206335,
72583,
17311,
300436,
43279,
25740,
91819,
136262,
58906,
42100,
null,
191830,
452589,
234678,
207793,
23867,
157051,
24545,
32549,
197183,
178545,
7820,
196017,
33981,
255711,
null,
131525,
27523,
195482,
123984,
138099,
44523,
null,
15,
68554,
46850,
280030,
161969,
24379,
null,
17355,
17287,
234067,
27245,
33568,
419181,
130215,
187179,
251283,
33637,
83646,
15239,
291072,
176400,
30542,
564700,
129806,
68730,
116313,
null,
15023,
31207,
120040,
54936,
138637,
29352,
76051,
192164,
164413,
136923,
73659,
53730,
null,
42697,
41748,
null,
360803,
154802,
578859,
235890,
9847,
null,
351650,
null,
161376,
6527,
196000,
61640,
157914,
12184,
315190,
37941,
175059,
78593,
63665,
64897,
270997,
10646,
23819,
91604,
83447,
17428,
344473,
43699,
183435,
45081,
137405,
76736,
239152,
153788,
318051,
428027,
null,
22566,
209715,
129406,
20353,
353306,
126928,
28527,
null,
274030,
178880,
13782,
7444,
83408,
237262,
18813,
36852,
28588,
59661,
420312,
71209,
365082,
116388,
56014,
32917,
30652,
24335,
9694,
219319,
123193,
19227,
null,
149965,
126659,
44877,
42535,
371372,
1242125,
805545,
178934,
244363,
28692,
337362,
302415,
null,
5584,
35389,
81956,
96067,
null,
272543,
164900,
375714,
27710,
209097,
328822,
45010,
39677,
56454,
662084,
null,
112620,
246182,
214795,
51528,
103865,
225151,
387926,
79819,
354631,
212966,
169668,
null,
180975,
163453,
61865,
221783,
93968,
319956,
147626,
102816,
32727,
69249,
623772,
35352,
223215,
137627,
null,
36369,
5015,
137805,
null,
36938,
594334,
13773,
105326,
123362,
61719,
null,
393810,
86651,
null,
23234,
32011,
18098,
30614,
270246,
195098,
11558,
307449,
169004,
47344,
154516,
150202,
null,
185586,
378786,
161661,
null,
68078,
3763,
15635,
18124,
150973,
299556,
46386,
260143,
25102,
146241,
16462,
55250,
29202,
21458,
84188,
null,
52144,
209617,
6504,
586379,
116753,
100537,
31187,
null,
174898,
328588,
87547,
48979,
10782,
66920,
77194,
382067,
471977,
38247,
94879,
17537,
217445,
48384,
328843,
379059,
148325,
42739,
26618,
247338,
22670,
471336,
null,
38302,
89119,
43523,
25524,
348124,
457196,
67975,
10686,
132805,
195490,
4775,
474667,
17151,
182981,
297978,
37404,
342996,
36755,
184999,
null,
209595,
259597,
257698,
152584,
333454,
356907,
22765,
84284,
99444,
6441,
28807,
431903,
149505,
41224,
8692,
178687,
79019,
175624,
null,
15891,
5764,
169259,
43951,
61804,
19963,
14367,
18427,
239791,
241015,
77205,
271376,
195041,
391209,
75962,
null,
114150,
31685,
484751,
11666,
317090,
365631,
210000,
18567,
174527,
120469,
42641,
229030,
250147,
29571,
362554,
468767,
290957,
37703,
179085,
null,
195185,
147989,
35060,
286649,
null,
8924,
170622,
322634,
30113,
65077,
129183,
272280,
103973,
17960,
289069,
115110,
101225,
128662,
277197,
31533,
99771,
null,
203921,
187799,
null,
185656,
409971,
115891,
23129,
128859,
75126,
12822,
186854,
329844,
40186,
476477,
16762,
72742,
12275,
null,
572941,
8116,
45865,
214280,
210995,
47281,
36284,
9185,
187646,
1318,
171558,
171927,
null,
194071,
15021,
6875,
306304,
33318,
13928,
509,
23846,
19977,
23611,
16082,
28566,
185594,
41319,
365885,
217179,
41464,
27292,
30581,
307342,
27100,
241606,
67454,
38350,
197227,
24440,
116324,
189147,
null,
308211,
25213,
185814,
378700,
11627,
20025,
687293,
74963,
3087,
213841,
530898,
118645,
167260,
243831,
305146,
14834,
23784,
167281,
218446,
52314,
34024,
16973,
39155,
7069,
53978,
214727,
63979,
213499,
158891,
83062,
19770,
13097,
3862,
293082,
22023,
94777,
74778,
7878,
31330,
56649,
159433,
67577,
202891,
146503,
18134,
22703,
517824,
33608,
150932,
34383,
364868,
57730,
23714,
206492,
14861,
117538,
2914,
30285,
285941,
112652,
311405,
17403,
325953,
2935,
24015,
49379,
157901,
179401,
null,
442621,
25273,
12221,
15172,
226467,
225474,
null,
236549,
12269,
131151,
31697,
22158,
null,
20116,
46635,
118640,
198994,
14089,
73215,
21853,
167986,
83224,
29741,
null,
56970,
26285,
38176,
45473,
46163,
null,
17725,
320746,
254038,
98537,
214388,
281349,
66441,
16473,
105756,
67680,
477838,
7370,
106973,
103277,
281844,
237408,
102151,
271990,
143479,
396186,
55092,
226831,
281083,
364943,
30267,
16072,
44178,
9624,
61326,
190195,
125983,
72062,
301109,
183991,
5741,
456545,
12747,
13647,
15743,
360883,
null,
280259,
64900,
48769,
328981,
1154,
420289,
268134,
58977,
64347,
18566,
65449,
105416,
41108,
39897,
42351,
25755,
323840,
28896,
44037,
90061,
68465,
242704,
370289,
15257,
74137,
24053,
57452,
110540,
15627,
29232,
76709,
42592,
387743,
null,
137652,
282981,
null,
420015,
16812,
526484,
20805,
119891,
30146,
2755,
7444,
6961,
301262,
95827,
60731,
399472,
56651,
25608,
482157,
203663,
null,
216567,
445612,
121268,
11109,
63366,
101804,
44410,
517803,
110518,
231050,
16171,
45132,
239551,
36517,
250875,
107503,
42192,
1086281,
165928,
211372,
167604,
25248,
430790,
null,
55845,
88122,
71886,
89863,
250637,
481258,
290287,
5259,
324754,
556945,
116523,
227956,
29884,
169084,
8936,
425128,
21780,
51380,
16605,
84497,
195389,
null,
24087,
47402,
8833,
14584,
379017,
15742,
337053,
null,
331284,
217824,
40391,
192018,
250089,
181449,
38325,
30024,
15398,
7312,
157008,
55208,
56142,
199725,
46198,
100232,
18855,
null,
690580,
52056,
30227,
23420,
45193,
144696,
31670,
398859,
25158,
11497,
193907,
115220,
362278,
17317,
286737,
211080,
496783,
43054,
201744,
284776,
46863,
286249,
290972,
65391,
246793,
49782,
327402,
37815,
252382,
33557,
94577,
698358,
46770,
108057,
58644,
25705,
28856,
178697,
140757,
129712,
57728,
95698,
65449,
757807,
115682,
178717,
null,
261124,
74395,
57519,
376527,
479304,
335398,
107813,
188339,
775958,
null,
38844,
23209,
185302,
69359,
177638,
323035,
37912,
338942,
474694,
27945,
51214,
67584,
1819,
33636,
394991,
54930,
45068,
10816,
15038,
null,
74277,
39475,
91864,
52467,
30153,
374709,
159504,
119349,
null,
null,
95387,
195531,
18008,
422759,
71790,
403606,
118665,
41888,
323527,
null,
44925,
30041,
313542,
31911,
6228,
149596,
null,
12223,
14353,
332571,
120064,
129903,
null,
368669,
193779,
21736,
37566,
31274,
11248,
30598,
60078,
201717,
141868,
160583,
14381,
125728,
null,
25849,
242119,
344871,
127154,
29282,
149719,
25841,
24624,
479302,
75723,
42276,
20944,
53158,
341817,
39552,
81587,
null,
35371,
196345,
268106,
74342,
393099,
87960,
40243,
272260,
121785,
542931,
87444,
133401,
69552,
69004,
286408,
20962,
31636,
282934,
77177,
439838,
33942,
63732,
50090,
30159,
11072,
40740,
285531,
240565,
302724,
18096,
192647,
6979,
30096,
8917,
69998,
96781,
null,
206830,
360020,
14465,
11751,
109199,
108141,
154762,
235086,
374411,
104053,
14543,
39469,
230269,
17181,
87709,
null,
38572,
388973,
54768,
18804,
35765,
23499,
44765,
6450,
null,
29745,
907,
74086,
25441,
42225,
24008,
151548,
57270,
4861,
89128,
100930,
273728,
94155,
281459,
405326,
95451,
88770,
58323,
13543,
6641,
28977,
143098,
403988,
276380,
630678,
134521,
18185,
200669,
89462,
9561,
197328,
55290,
12894,
15476,
18319,
280269,
435032,
12435,
57579,
91189,
null,
37358,
222158,
105486,
216628,
127627,
85302,
253262,
45439,
66079,
50052,
278631,
112335,
280245,
7076,
41663,
152558,
54870,
23257,
28381,
12236,
13560,
148260,
27712,
275328,
28463,
85809,
91445,
null,
14410,
41219,
40195,
221402,
40615,
35497,
132931,
358449,
51023,
null,
345844,
546935,
14765,
369365,
8800,
99587,
26141,
null,
129429,
4775,
33013,
6248,
178122,
19131,
196467,
127777,
470183,
183494,
89600,
828515,
241106,
296596,
13361,
125252,
null,
null,
634674,
210761,
39315,
126383,
164839,
212921,
44462,
387409,
null,
35132,
323859,
93542,
532476,
null,
36518,
213058,
607820,
107671,
183722,
111409,
20251,
142022,
null,
14326,
2128,
null,
24067,
179551,
103838,
null,
33832,
204203,
53535,
91818,
5868,
415211,
194145,
16777,
31770,
12897,
126681,
22165,
65296,
null,
2635,
252071,
25813,
19408,
49065,
37890,
67046,
337602,
34301,
217931,
167516,
526272,
268716,
5207,
358186,
90047,
62999,
null,
37151,
229013,
238048,
130456,
null,
202133,
8097,
38233,
277388,
101010,
449550,
175375,
613134,
22614,
125047,
118040,
null,
102448,
8241,
167684,
37919,
180246,
40212,
56469,
35627,
43765,
259060,
null,
44599,
null,
138764,
152124,
64116,
57985,
38360,
305198,
194352,
17706,
40696,
57383,
171358,
21824,
215226,
12278,
null,
null,
184783,
28362,
115113,
null,
11992,
42405,
310440,
619814,
18814,
373438,
254373,
181027,
5620,
null,
45864,
376975,
171260,
187679,
null,
22038,
464256,
15480,
null,
185726,
322378,
null,
160354,
226387,
81824,
33685,
25584,
133985,
46279,
104491,
24809,
205636,
389675,
null,
19121,
43209,
24602,
42086,
146460,
69440,
524723,
177133,
58489,
367997,
70795,
250735,
21118,
30679,
2285,
38532,
39691,
24673,
25354,
null,
4253,
38540,
43543,
311952,
126304,
36562,
14259,
218213,
156868,
338609,
296496,
269928,
212182,
170199,
37239,
182738,
163646,
452336,
37576,
36617,
42698,
12318,
11648,
null,
395862,
44414,
291261,
4572,
152885,
16865,
139530,
64220,
826111,
47365,
161842,
33009,
96496,
15429,
26264,
20050,
11176,
123391,
52325,
25182,
4710,
17249,
202129,
218088,
10853,
35857,
37920,
83069,
48117,
128370,
27991,
71209,
256799,
null,
295845,
354599,
143311,
18008,
69527,
null,
33186,
71567,
236303,
165906,
15952,
92049,
449,
72852,
218008,
35827,
69153,
58314,
200638,
75934,
16315,
null,
null,
14995,
282246,
12945,
75136,
29866,
269006,
51942,
49946,
134445,
209922,
9924,
null,
359551,
251195,
199426,
526344,
null,
29107,
27162,
null,
21993,
538269,
10148,
211008,
105910,
35084,
79119,
33871,
184736,
90951,
47946,
91196,
7856,
58686,
348923,
19564,
19248,
39264,
224069,
77511,
null,
343859,
16568,
78555,
162706,
39625,
null,
103172,
13495,
11812,
null,
259891,
null,
40268,
22013,
149545,
224669,
69194,
330227,
21890,
9216,
37342,
268214,
618366,
290579,
503557,
63770,
175227,
307789,
172467,
84713,
43714,
2136,
178671,
9870,
128785,
479339,
326896,
358745,
71600,
141740,
33890,
36343,
126657,
13012,
193479,
22174,
26394,
30511,
7622,
44200,
null,
121670,
38039,
169463,
167110,
null,
245218,
68981,
178849,
215980,
158018,
233555,
25625,
277082,
45722,
260538,
36337,
34130,
98256,
192842,
null,
212450,
118719,
46878,
3082,
176332,
194464,
46289,
null,
121120,
32472,
251523,
24256,
135628,
null,
315793,
18536,
null,
12328,
334576,
10011,
381217,
141643,
null,
680491,
294269,
218223,
30202,
217550,
8402,
12573,
401124,
102895,
23568,
12609,
73775,
32111,
379826,
null,
null,
126702,
80538,
369049,
64692,
39971,
326858,
72031,
379997,
152816,
128148,
26624,
7276,
444558,
344499,
45744,
21688,
46637,
45539,
35149,
18925,
44758,
85735,
26591,
357382,
13094,
178721,
195977,
27080,
393540,
229745,
403673,
213890,
340533,
null,
45917,
13406,
74203,
197991,
null,
387248,
null,
330678,
12311,
218507,
19388,
159477,
14425,
null,
39429,
174516,
260232,
70696,
70005,
36676,
381818,
397532,
37670,
null,
137028,
162971,
275445,
417028,
33649,
18164,
38763,
72916,
36966,
5174,
122816,
42762,
157023,
16740,
20556,
21233,
22405,
231503,
72910,
61246,
62992,
6274,
40876,
null,
393265,
362066,
39406,
null,
110776,
115983,
47647,
111296,
23656,
434462,
null,
24073,
null,
478253,
325051,
25260,
9432,
null,
32379,
18366,
94991,
46010,
167623,
39049,
93357,
277587,
70018,
229646,
223071,
309792,
17225,
33250,
43777,
402706,
286123,
77714,
49948,
293848,
11580,
548417,
null,
null,
119088,
15698,
null,
52098,
null,
668719,
23380,
79711,
117418,
47643,
274613,
72839,
41732,
30456,
24390,
211562,
60473,
106278,
22154,
109798,
379991,
9694,
55749,
7793,
18035,
132849,
519037,
142605,
45424,
62786,
254115,
7688,
218169,
198499,
160756,
496526,
null,
11055,
48132,
159567,
207407,
412209,
91710,
235544,
null,
453810,
163770,
54844,
161458,
85814,
118593,
159342,
58096,
257747,
297317,
null,
null,
261854,
583922,
178017,
14490,
101178,
22534,
223672,
324969,
211032,
33133,
604554,
39246,
35426,
7573,
262064,
13906,
219311,
72032,
26114,
283894,
311136,
294691,
376295,
33617,
53519,
82157,
63930,
199339,
19471,
33148,
33345,
16048,
50846,
201816,
null,
127753,
4337,
33343,
21145,
185834,
null,
213548,
230043,
null,
76230,
99366,
4190,
225724,
46595,
185697,
120162,
58289,
207250,
28353,
22902,
76756,
27895,
6289,
33240,
139254,
15798,
551581,
59437,
158718,
15734,
51667,
104398,
165564,
null,
83747,
4448,
null,
36869,
8029,
null,
null,
101254,
59640,
8672,
269686,
173944,
30945,
19466,
78949,
347747,
null,
296541,
28041,
33848,
40221,
68553,
6404,
13378,
58392,
8736,
null,
85901,
239199,
26270,
105873,
63989,
27920,
null,
43872,
78178,
83684,
113715,
6941,
254551,
6807,
16136,
7678,
21120,
null,
419918,
258618,
84664,
93900,
35986,
40951,
34247,
33499,
12057,
11350,
113417,
252272,
20567,
64074,
126567,
19723,
33087,
367627,
228960,
43424,
null,
7648,
33511,
105534,
56369,
167701,
29427,
16394,
86200,
92652,
null,
13739,
null,
243690,
7910,
47717,
311523,
80408,
25753,
36512,
39221,
101453,
169658,
35126,
42960,
76267,
39208,
245900,
118353,
58050,
212007,
117943,
49392,
328345,
62334,
211891,
34990,
17096,
454142,
66107,
89577,
42695,
101943,
118808,
391888,
81532,
200203,
120220,
195511,
null,
23478,
null,
198986,
27177,
339439,
null,
252019,
16189,
86753,
17474,
85712,
123108,
437948,
41603,
7280,
679390,
46174,
22735,
28890,
454248,
62450,
277092,
45902,
130123,
30962,
84238,
56431,
108555,
42939,
128775,
319165,
394631,
125320,
34908,
361899,
136401,
36560,
26169,
29193,
512580,
400640,
46717,
146202,
12220,
9991,
247188,
135652,
226374,
95711,
199035,
7304,
52836,
127056,
193358,
30753,
15122,
162438,
12007,
51353,
278991,
136608,
null,
530361,
2644,
4596,
84229,
140185,
10019,
null,
134696,
170969,
710392,
33705,
288264,
597573,
126996,
23077,
51668,
66576,
87871,
422948,
59754,
504748,
168866,
12413,
427503,
4610,
277014,
218301,
140732,
29075,
17660,
34800,
18985,
1716,
16956,
199733,
45909,
null,
22525,
144242,
71949,
497960,
84806,
142610,
135883,
10662,
12884,
null,
211413,
216680,
44847,
31172,
10892,
88868,
31844,
49074,
57800,
14364,
248350,
69140,
95042,
339472,
43697,
410022,
247575,
203800,
27595,
null,
24019,
35702,
70935,
59318,
18424,
111390,
141778,
19402,
63535,
37599,
243833,
253616,
193051,
71436,
12785,
67707,
44502,
29661,
178319,
null,
1843,
6190,
579225,
23639,
167997,
56862,
null,
102481,
9137,
28141,
59684,
169306,
229131,
95300,
512837,
41805,
20174,
31129,
175050,
165664,
48286,
386295,
null,
204872,
17445,
362916,
643024,
null,
null,
319609,
41817,
36432,
7970,
196864,
null,
10139,
41241,
null,
45981,
54101,
463694,
97683,
1036269,
55740,
166012,
116578,
712861,
null,
null,
222651,
12616,
259252,
323926,
42881,
415320,
2600,
4297,
25490,
231346,
12696,
254313,
107558,
188791,
15371,
13677,
485471,
266133,
189398,
61471,
290567,
73806,
26986,
49950,
55560,
226919,
null,
70683,
171539,
null,
4357,
72609,
150231,
1226768,
31279,
175688,
18374,
215073,
105595,
13102,
null,
26762,
300955,
302977,
null,
null,
51033,
194827,
238227,
107277,
38240,
320093,
45462,
73223,
null,
null,
12213,
174498,
39124,
351236,
77701,
227328,
421562,
502796,
13571,
null,
267454,
9045,
118693,
41000,
436808,
21766,
38259,
44841,
69059,
319155,
293864,
52864,
489795,
337710,
9847,
388358,
169662,
89428,
13471,
134135,
1745,
29470,
10950,
39575,
18704,
34102,
340403,
107902,
25829,
131965,
8720,
298660,
259751,
28250,
178657,
142977,
125527,
40189,
44555,
48610,
219829,
null,
140335,
290965,
111930,
35622,
62977,
3976,
93637,
264452,
53665,
23003,
null,
142169,
154983,
150303,
22110,
null,
52667,
33235,
null,
7844,
37097,
77422,
119722,
822589,
21245,
265265,
500796,
null,
6852,
73088,
31224,
164854,
399997,
13491,
55194,
41302,
695581,
208306,
18755,
220367,
11424,
205422,
null,
692275,
null,
31615,
212286,
327380,
18826,
187088,
44912,
24121,
94717,
31589,
529460,
15799,
23181,
145589,
368773,
20430,
43975,
52951,
267530,
388385,
84276,
24111,
68751,
164522,
598148,
467141,
230588,
147244,
169895,
72625,
533255,
27482,
29681,
40199,
259276,
242277,
13254,
18998,
274393,
60301,
null,
125270,
7837,
71294,
205005,
17693,
130793,
171998,
29481,
51497,
283330,
347836,
2145,
349331,
73127,
11097,
24880,
14030,
18360,
109938,
12537,
16473,
381704,
31615,
null,
236160,
128860,
46541,
46845,
null,
304749,
4841,
39752,
323803,
8042,
582279,
44904,
73871,
19511,
22016,
228646,
117610,
77819,
106591,
149903,
21850,
66885,
234618,
37380,
315395,
null,
25216,
214588,
15399,
48425,
328819,
127791,
176266,
null,
193333,
279847,
17543,
15341,
null,
12780,
133022,
139805,
238867,
33325,
11759,
210395,
50422,
79367,
31973,
182292,
null,
3583,
424680,
101563,
8546,
17610,
325939,
41026,
135579,
252344,
null,
25950,
33480,
408968,
14535,
7601,
67034,
112745,
38867,
7562,
886141,
14699,
48461,
342414,
72026,
null,
8844,
26323,
19035,
290775,
835,
39392,
176765,
78220,
17725,
430809,
250365,
699675,
31435,
140199,
331551,
55469,
null,
39474,
204067,
14224,
65506,
18628,
59365,
166116,
43821,
67058,
342719,
10993,
142218,
543168,
null,
69151,
269194,
165047,
27007,
null,
154317,
33919,
280608,
6989,
44117,
447067,
158984,
35975,
42538,
18083,
null,
81222,
null,
62715,
4998,
248165,
14854,
null,
74330,
421480,
33995,
424864,
null,
19707,
12921,
142010,
37263,
null,
44001,
null,
210717,
89534,
282645,
332258,
9193,
183217,
138373,
293317,
283361,
16930,
41430,
54201,
37880,
58693,
349005,
null,
65481,
2488,
127178,
124748,
443237,
60737,
26652,
301728,
29326,
845049,
22598,
33952,
49936,
322678,
523355,
182836,
64582,
320309,
10105,
308492,
265431,
null,
37236,
19392,
89926,
56077,
151752,
289149,
50855,
263761,
null,
99728,
168287,
45232,
null,
204495,
212945,
170556,
null,
299132,
160099,
21452,
null,
17379,
114233,
68444,
14594,
255689,
351293,
15193,
null,
59894,
46574,
311228,
null,
231858,
159692,
37557,
174465,
156586,
302426,
337930,
613808,
null,
8063,
952528,
265271,
25703,
16053,
170341,
272450,
73397,
46230,
1184,
292310,
175138,
219541,
11965,
177379,
9478,
55217,
41674,
36351,
5040,
42615,
6294,
132540,
52462,
16296,
112186,
301664,
198784,
null,
236575,
20181,
32922,
42404,
18417,
2750,
215439,
5899,
23357,
15455,
69457,
null,
195240,
3955,
268621,
443921,
null,
125355,
55998,
213451,
52280,
22205,
57761,
4185,
47318,
6436,
null,
null,
97144,
22881,
null,
355410,
14616,
133907,
234091,
86162,
417432,
71831,
6033,
372531,
37925,
11849,
487215,
61646,
388941,
73948,
90647,
9944,
34266,
2047,
9136,
188803,
9879,
109528,
97103,
298484,
180954,
368474,
112849,
239765,
45192,
37063,
328845,
103364,
347488,
13585,
326729,
4120,
679198,
359272,
356493,
null,
118973,
93080,
null,
7402,
86578,
220752,
44783,
167572,
138319,
94253,
401211,
10777,
282032,
29043,
null,
14606,
10436,
194351,
177595,
167062,
294812,
320590,
136941,
191477,
32297,
122137,
86593,
22103,
39284,
null,
247563,
315388,
121217,
null,
null,
20004,
null,
5497,
174585,
29688,
30113,
418538,
201698,
84130,
33521,
409612,
187468,
null,
51728,
225687,
330396,
167168,
37200,
null,
46140,
56551,
81890,
85799,
22177,
28865,
105073,
95363,
168230,
45754,
71412,
72478,
72764,
700880,
708222,
12692,
150675,
37009,
96630,
233617,
291500,
34611,
28189,
471938,
439005,
247309,
155187,
24246,
308091,
41633,
285468,
80847,
37974,
217462,
234824,
48346,
22604,
null,
41774,
149902,
242551,
154104,
411121,
59985,
57765,
10273,
16550,
473737,
113481,
366396,
220270,
155952,
29393,
346387,
9508,
29794,
287657,
242462,
170876,
103945,
null,
8543,
13973,
229666,
473579,
80039,
13604,
277749,
null,
47975,
27391,
230103,
19580,
60821,
112345,
26824,
null,
129216,
295391,
168789,
37572,
48730,
314620,
165186,
171813,
65005,
null,
325746,
69200,
299928,
20587,
4352,
54834,
470445,
424447,
359134,
19493,
180205,
2772,
13822,
165822,
null,
52665,
348442,
542044,
null,
111137,
null,
504836,
128221,
25466,
263636,
744007,
159279,
194768,
57329,
18968,
113684,
374235,
44969,
231876,
42427,
228542,
40430,
44993,
35398,
30305,
111101,
195352,
29834,
185126,
372123,
247734,
16319,
174222,
66898,
119786,
61194,
222788,
9277,
574277,
26490,
17382,
17709,
56996,
81572,
48776,
47809,
368302,
28361,
521432,
35096,
202224,
157308,
264201,
401190,
259270,
190399,
55088,
277023,
91675,
null,
32010,
176086,
132582,
118251,
386060,
14992,
24447,
240229,
134655,
6815,
104702,
34852,
116765,
32013,
151536,
28804,
369433,
182967,
48285,
null,
32379,
9816,
11034,
501293,
124564,
null,
null,
null,
312577,
41460,
20311,
158524,
null,
11559,
131306,
165663,
74692,
246583,
11107,
228128,
389004,
58085,
null,
48478,
141027,
308364,
235978,
165809,
75589,
15105,
80909,
81485,
46576,
207399,
21646,
437188,
19470,
null,
23218,
433021,
75262,
303761,
202362,
167784,
32652,
160963,
293619,
316951,
190407,
1568668,
91521,
3639,
2544,
null,
343756,
26855,
356651,
165419,
26860,
164387,
158729,
null,
48459,
203837,
35825,
29366,
62793,
36600,
null,
15797,
204176,
null,
124813,
44306,
358013,
33603,
367320,
26080,
39371,
165468,
24409,
350101,
333294,
null,
23000,
147480,
null,
345,
189554,
69087,
31583,
55799,
70232,
43447,
256347,
130944,
204849,
46690,
12392,
472835,
12847,
205037,
372627,
102516,
198493,
34246,
40047,
72148,
205505,
5175,
106122,
37001,
21921,
28607,
76575,
33356,
186388,
68248,
295643,
55164,
61375,
145738,
null,
238790,
280837,
117758,
20399,
189902,
395094,
285052,
13721,
811664,
162122,
11236,
133088,
231475,
231721,
23063,
114743,
21506,
29294,
18056,
272157,
357750,
129824,
27049,
32850,
427870,
17157,
21226,
6133,
38543,
22080,
28314,
358838,
194684,
283324,
67517,
170608,
37592,
null,
240566,
41377,
176849,
18693,
612831,
164631,
135506,
18943,
137650,
8827,
91637,
24028,
172871,
65974,
null,
162871,
262198,
78430,
337396,
32839,
10162,
null,
113898,
22864,
79445,
13710,
28167,
15863,
null,
164744,
25895,
47707,
45455,
214987,
21682,
200236,
279563,
23294,
11101,
28335,
609117,
403252,
19751,
null,
488263,
380931,
162355,
433943,
31489,
141865,
null,
32706,
232121,
98471,
142804,
137124,
163460,
null,
124026,
21469,
426130,
16073,
25555,
340966,
433958,
29942,
18727,
57902,
28634,
114896,
14270,
19813,
524857,
169043,
34028,
182526,
59971,
165224,
420003,
16217,
57914,
53680,
null,
2078,
46448,
190169,
24292,
353954,
null,
null,
26932,
155760,
20713,
16270,
137528,
52542,
6764,
17513,
145810,
18380,
278121,
132422,
327491,
79503,
39294,
144094,
66186,
null,
31410,
387805,
89571,
39941,
59826,
78123,
20362,
187197,
null,
33471,
63891,
1129,
3869,
241863,
37691,
404457,
99108,
12333,
65971,
397499,
15869,
27183,
202578,
151578,
217698,
33687,
126536,
89421,
117078,
51622,
76705,
null,
147231,
18337,
32344,
240683,
283020,
124946,
29178,
44157,
70662,
299451,
71849,
311351,
146652,
271144,
167359,
306496,
24654,
181590,
94256,
13237,
13115,
321536,
43648,
26536,
238426,
192214,
67599,
552793,
272677,
185434,
415936,
67677,
911561,
28035,
395175,
null,
459784,
52385,
null,
63564,
23489,
null,
13935,
45728,
434472,
33962,
141203,
303021,
31959,
55481,
29523,
24441,
368814,
116581,
61983,
145488,
3176,
279168,
168096,
315737,
46196,
136602,
89493,
181435,
35196,
null,
174968,
12083,
266018,
null,
313976,
36490,
null,
264132,
156884,
87053,
58046,
null,
39159,
26485,
399147,
32373,
432313,
187246,
16531,
52609,
659270,
782206,
13547,
7513,
69086,
null,
291028,
11646,
88459,
262072,
168990,
47699,
242591,
280561,
null,
9487,
117020,
191213,
442289,
299005,
44164,
356363,
205858,
117912,
105416,
89370,
null,
161310,
258715,
121337,
27735,
85254,
64978,
20917,
27959,
7831,
5247,
268532,
217337,
124186,
17253,
296091,
173339,
292041,
11457,
482789,
275351,
283812,
null,
271165,
269301,
215503,
null,
1580,
509021,
294692,
463027,
11438,
null,
31638,
286540,
12069,
274432,
43053,
492584,
81799,
115026,
39474,
18525,
334547,
28375,
37634,
429076,
null,
32516,
154091,
300637,
131014,
24629,
115826,
297135,
375203,
26755,
482632,
null,
422556,
null,
336125,
8183,
193503,
84391,
257216,
290632,
185759,
8262,
6309,
49679,
7025,
54932,
80194,
172953,
471211,
40824,
40482,
null,
265088,
118549,
null,
33518,
38695,
406634,
30345,
null,
24323,
221060,
220679,
475048,
137826,
57343,
141423,
228456,
27565,
21614,
null,
43036,
18079,
null,
53085,
45959,
216918,
299417,
13552,
81059,
59388,
151240,
467630,
17037,
11814,
24512,
null,
235082,
51636,
26882,
8945,
42251,
49838,
245877,
52037,
60075,
8844,
342882,
63711,
64644,
61758,
null,
27981,
43893,
94521,
29561,
53675,
15493,
75193,
18315,
172830,
19926,
43617,
28859,
25218,
23752,
102900,
183641,
123465,
142636,
151407,
107160,
174717,
35345,
150922,
110810,
287026,
50612,
11262,
31124,
123817,
21507,
431099,
null,
185820,
20350,
63130,
15418,
7454,
31966,
57659,
52438,
44958,
143493,
434238,
5626,
59038,
563050,
147247,
14270,
30704,
240502,
2708,
39503,
27799,
39175,
122973,
318562,
67047,
374826,
24355,
588744,
191557,
56999,
167563,
5266,
208061,
154809,
10879,
342728,
99191,
null,
99789,
237289,
112059,
299210,
161439,
4507,
372352,
14998,
87910,
null,
27865,
34788,
499350,
210124,
65166,
347225,
39065,
149660,
32038,
79481,
240019,
25790,
214921,
186714,
10951,
9859,
196722,
210468,
22942,
75493,
280717,
null,
null,
null,
23170,
50480,
73957,
3918,
98859,
75108,
149877,
null,
31134,
22363,
214329,
8962,
21488,
159846,
14365,
114684,
71638,
27020,
55859,
237180,
52852,
152369,
106657,
36475,
10692,
22583,
151103,
183747,
176138,
34851,
109179,
195929,
46639,
113268,
27748,
55223,
25276,
24421,
556098,
65241,
169752,
388737,
74255,
50455,
245861,
348938,
42084,
237730,
3061,
38034,
216691,
41149,
25438,
50053,
165696,
62919,
29345,
null,
563308,
185874,
275573,
74286,
212725,
139768,
19640,
22158,
285785,
371213,
657299,
28612,
17819,
144692,
195338,
29690,
57005,
183853,
53777,
64295,
8947,
49008,
64146,
321018,
127039,
229420,
39977,
278752,
468814,
55945,
118954,
120131,
25107,
186512,
55752,
25972,
27909,
118657,
255300,
2172,
17419,
289586,
44979,
208051,
61676,
87445,
null,
null,
309164,
15932,
71123,
449367,
121023,
67747,
55523,
51295,
882072,
308914,
115979,
98840,
39292,
88189,
175695,
57153,
25129,
101870,
39288,
15480,
404437,
113313,
24243,
289496,
757616,
400988,
325155,
52611,
43337,
569391,
28627,
234112,
48943,
42014,
38362,
18048,
94211,
36067,
61623,
220677,
220347,
414693,
379848,
30235,
153468,
328232,
71272,
null,
58039,
109670,
27073,
43948,
149205,
null,
399595,
1076751,
459261,
88752,
318690,
292598,
25402,
31156,
13885,
11391,
20282,
89149,
29434,
36039,
841214,
28048,
43270,
138668,
20904,
330187,
95404,
193372,
40169,
104907,
null,
29084,
344877,
196778,
470172,
174413,
33780,
19206,
81436,
37019,
245555,
null,
91703,
null,
8538,
20324,
254124,
44568,
17778,
20166,
215915,
10708,
189225,
76733,
14258,
100218,
76067,
null,
9417,
null,
61768,
307285,
341624,
44226,
115365,
63033,
83583,
13559,
627697,
48072,
400272,
121516,
35131,
22574,
38922,
105821,
295712,
21854,
59096,
356460,
33024,
34934,
36509,
77714,
444777,
178279,
null,
246725,
7329,
37082,
26419,
65240,
441030,
18688,
14844,
52084,
382670,
211783,
152139,
18445,
339323,
421260,
438467,
185976,
8782,
248476,
68084,
380074,
30031,
315461,
11989,
49421,
98165,
5282,
69198,
6804,
4139,
229369,
null,
12744,
356299,
null,
455065,
109386,
35625,
402406,
101367,
253353,
null,
139977,
17780,
92165,
303373,
50128,
42380,
null,
102982,
25378,
23970,
128566,
193980,
76621,
1863,
20997,
117392,
128362,
111380,
473919,
461002,
10387,
139270,
305383,
46558,
42794,
218488,
119383,
177717,
341598,
null,
423665,
44440,
14580,
222457,
134789,
null,
185749,
null,
null,
152134,
232058,
398861,
17360,
572571,
43437,
6418,
144464,
8759,
348441,
46591,
40896,
165679,
173126,
7114,
26816,
13338,
33799,
532737,
26762,
22836,
35927,
7663,
281393,
34026,
74656,
110346,
70644,
119690,
9280,
292147,
15594,
282849,
252152,
182857,
4214,
117335,
71623,
25556,
11624,
16314,
101914,
12145,
203650,
18485,
154457,
135306,
16755,
13483,
22607,
43677,
278450,
96866,
239,
19351,
34292,
36911,
19958,
518516,
49301,
15036,
170426,
61933,
78097,
492841,
158677,
260439,
166571,
10519,
64845,
87931,
168757,
27841,
385417,
101281,
295820,
28246,
35148,
450779,
212678,
46227,
5031,
9046,
209173,
12631,
11918,
40908,
132967,
39144,
33577,
207274,
null,
69036,
74117,
117264,
138427,
58602,
66635,
7756,
null,
368712,
235304,
47410,
9160,
197115,
8018,
null,
37955,
19914,
59616,
225916,
15323,
53883,
113415,
70084,
38923,
39263,
57168,
243809,
null,
75371,
215558,
91994,
7502,
31762,
34289,
34076,
125751,
116409,
88697,
null,
363127,
29332,
4020,
36151,
94241,
27703,
82796,
194819,
202395,
33284,
167859,
217436,
null,
35395,
33159,
12674,
51917,
380447,
174695,
140326,
10415,
395742,
28246,
146563,
16610,
38238,
272369,
175471,
16686,
45667,
21896,
114948,
124559,
22135,
59582,
216808,
196052,
58420,
null,
10421,
27778,
1893,
64514,
29903,
194448,
256799,
29517,
null,
9286,
134908,
390649,
26615,
222024,
119562,
19099,
49666,
418828,
424631,
141345,
283285,
46826,
111121,
null,
6644,
192477,
64727,
51677,
352008,
38322,
20522,
null,
20922,
341452,
14591,
43064,
14907,
352933,
38793,
20014,
340844,
41100,
174669,
256432,
31659,
47995,
203182,
24026,
6097,
208534,
79733,
42205,
33446,
82354,
144845,
null,
118815,
27296,
291332,
461012,
39221,
26489,
33037,
105961,
7476,
333566,
4230,
230171,
40098,
244145,
74647,
2670,
14461,
59662,
88773,
458096,
24520,
38306,
394294,
19765,
15284,
132406,
15502,
155555,
null,
409698,
26430,
310329,
15721,
20862,
43136,
89577,
30215,
495469,
32344,
25369,
43472,
null,
202062,
20951,
19830,
344285,
135317,
null,
7825,
136092,
null,
null,
null,
null,
231758,
40055,
32815,
null,
176798,
76213,
null,
10504,
10165,
25066,
132051,
47390,
39159,
215529,
196899,
61867,
27358,
590701,
332870,
null,
null,
312521,
371356,
1938,
19079,
333129,
26791,
510046,
275449,
9424,
174487,
380614,
308630,
24908,
41487,
49092,
92250,
54177,
207003,
16940,
14510,
63530,
63295,
357230,
5998,
25187,
219384,
null,
14090,
31281,
351466,
470463,
138006,
131233,
211852,
36991,
16662,
53281,
20031,
44716,
81011,
106744,
null,
30647,
null,
241730,
59618,
50456,
189723,
276709,
448612,
46509,
359600,
130685,
217221,
33811,
141494,
91188,
67555,
7399,
26065,
234035,
44199,
23418,
214823,
95991,
399672,
24719,
275317,
608364,
365915,
209765,
140918,
44136,
280655,
30561,
55064,
82128,
41154,
34581,
80065,
238215,
null,
170445,
34925,
81651,
12518,
79390,
179497,
21177,
34784,
20490,
29594,
346392,
29060,
22412,
272899,
40869,
44876,
14313,
283049,
227071,
235283,
390597,
5619,
240425,
259922,
12561,
600987,
37969,
273918,
148818,
11684,
184690,
32095,
123056,
270016,
69366,
14565,
48209,
136018,
null,
287263,
367843,
97776,
617,
4690,
37722,
198369,
120283,
191270,
502976,
197596,
26829,
200163,
null,
114949,
44079,
42336,
722659,
299248,
98840,
12094,
172100,
21749,
333103,
344238,
13606,
13368,
13221,
203988,
13296,
4252,
74376,
null,
64964,
109162,
57740,
126727,
198147,
7097,
231156,
34163,
122494,
227201,
91556,
58346,
21167,
67171,
30351,
292259,
338304,
11922,
74877,
24354,
null,
226929,
328998,
37628,
null,
194062,
144675,
34574,
29659,
19614,
181757,
null,
39120,
52757,
34857,
211548,
353913,
55766,
271572,
379455,
98904,
467849,
225740,
140402,
8083,
113868,
184045,
211238,
234522,
85762,
274805,
553627,
null,
null,
21738,
24680,
357909,
289001,
101030,
180511,
357400,
61107,
null,
19804,
35209,
121332,
null,
197004,
29958,
178632,
298972,
145704,
273542,
193349,
null,
46417,
144306,
null,
43445,
10171,
136740,
47593,
10896,
91960,
33699,
127243,
72476,
25862,
null,
120961,
156548,
27229,
109970,
296602,
312459,
207322,
33691,
83158,
31979,
325371,
null,
93374,
71876,
null,
115368,
207554,
237988,
264209,
258283,
158920,
226409,
39078,
68762,
122936,
10922,
null,
213095,
49153,
89313,
1105958,
null,
116910,
84276,
74910,
241133,
52796,
193900,
31955,
250825,
199841,
132425,
174653,
35803,
199917,
13165,
375805,
35166,
14056,
null,
53902,
80549,
35542,
null,
9317,
73152,
12155,
27426,
273430,
22034,
11086,
49571,
10161,
292893,
null,
34052,
216081,
10437,
57592,
189724,
26260,
216604,
328621,
435887,
282441,
378658,
27774,
7563,
36350,
12331,
299783,
104196,
126227,
372036,
null,
264375,
71764,
103176,
111832,
8352,
312323,
172826,
184124,
121823,
400683,
57353,
63470,
375571,
175274,
24765,
144833,
11656,
202048,
235634,
7933,
183044,
200393,
13449,
23845,
19847,
13821,
25625,
40234,
115582,
26209,
null,
139466,
null,
46404,
7928,
37967,
274344,
48352,
39482,
149918,
24627,
183890,
24289,
19341,
358976,
28601,
null,
69523,
77410,
35980,
260133,
47912,
6313,
437731,
38136,
323484,
23056,
32039,
44718,
9697,
null,
null,
55574,
59494,
19871,
83367,
162198,
17718,
80197,
18003,
88718,
180295,
275454,
451198,
213914,
13648,
221611,
96516,
566409,
473947,
123424,
6223,
219550,
289632,
42947,
40913,
15825,
29341,
243164,
177759,
73876,
7776,
24837,
31787,
33499,
131035,
187151,
57874,
244519,
76914,
94742,
null,
497242,
null,
211255,
20851,
506016,
120313,
109871,
276590,
30202,
170535,
36661,
147998,
380527,
31510,
115215,
515636,
57844,
180197,
9033,
18362,
112355,
14599,
173961,
38145,
175395,
24152,
6928,
null,
121347,
32943,
206624,
60344,
null,
185210,
10206,
272218,
148822,
17658,
444791,
null,
158213,
46500,
226918,
7585,
44471,
123742,
179480,
122629,
17446,
null,
347130,
191880,
95452,
85326,
104733,
26316,
41107,
57713,
7435,
432291,
46606,
10371,
56719,
111587,
205670,
173250,
22058,
224247,
296307,
8024,
5026,
41791,
18107,
null,
161533,
72004,
55279,
28386,
18170,
54078,
null,
43784,
133810,
178666,
160050,
null,
237379,
null,
null,
null,
162407,
8795,
183665,
201053,
148267,
228543,
7683,
291253,
22249,
247361,
136141,
38073,
44363,
306792,
118946,
348257,
54356,
46246,
603428,
425505,
41821,
13631,
217858,
285623,
253769,
135621,
23253,
16953,
44689,
514712,
30520,
35867,
79520,
1368650,
662606,
103579,
24607,
26860,
15328,
4479,
189853,
214319,
435048,
295380,
null,
12240,
12402,
null,
121437,
35047,
164766,
35506,
11848,
43119,
22049,
106511,
22351,
991025,
126565,
31837,
279274,
28865,
165226,
189970,
387590,
12165,
58580,
80871,
33359,
17887,
604388,
21346,
353799,
47729,
307034,
597555,
6861,
null,
20798,
30391,
32102,
74203,
158830,
57040,
7448,
197470,
135494,
124742,
568663,
8655,
25606,
332921,
309813,
71089,
null,
290918,
18441,
null,
50899,
9025,
36593,
55003,
400483,
8783,
216176,
187481,
39190,
201042,
85828,
186196,
34822,
455543,
31340,
144195,
116925,
54058,
266652,
null,
497312,
278931,
217274,
24334,
86174,
28821,
351271,
172693,
234958,
9220,
142180,
173234,
150121,
250494,
11267,
20176,
43835,
336704,
18997,
29311,
33057,
55628,
15793,
373773,
356557,
null,
18669,
12081,
172523,
141513,
342423,
99308,
172293,
11080,
444443,
176025,
7165,
137565,
23159,
15586,
181429,
27695,
114548,
42901,
13320,
42342,
39989,
20483,
325538,
50555,
136158,
150333,
318262,
30016,
319640,
31007,
91561,
318311,
31978,
762409,
94871,
48373,
17205,
155695,
61326,
200368,
9233,
107170,
20382,
246248,
409264,
4927,
203128,
32019,
null,
25810,
294643,
330755,
264126,
257554,
16424,
165857,
68005,
185731,
272983,
158793,
248457,
202256,
59963,
12963,
214426,
164733,
18185,
37710,
null,
174538,
30243,
291202,
764017,
3623,
29959,
38420,
351005,
50056,
null,
1667,
33824,
184568,
15353,
7751,
521078,
34554,
166318,
250800,
21021,
526202,
81607,
291585,
22065,
82141,
246032,
141003,
295889,
120667,
574461,
588091,
287870,
14018,
683993,
30462,
65609,
273724,
33444,
89617,
null,
190426,
205707,
343012,
41219,
56018,
19432,
10750,
null,
44036,
65794,
4427,
15061,
6761,
18029,
42027,
12762,
269198,
40734,
34016,
null,
565179,
323105,
13937,
149794,
91638,
567967,
null,
28241,
129567,
46305,
82760,
113263,
208827,
188202,
184007,
289999,
15362,
1526,
11452,
20918,
127101,
8614,
30784,
201404,
16182,
18302,
42473,
524912,
396657,
322077,
316109,
3015,
309340,
130441,
null,
13939,
458834,
4133,
37769,
267382,
279374,
357000,
null,
37064,
237115,
120943,
203435,
null,
null,
219935,
398103,
null,
29841,
330295,
24858,
96320,
15451,
2057,
13432,
34417,
214241,
29840,
44132,
34989,
94063,
46831,
187402,
183020,
29503,
71320,
27681,
47028,
18875,
9497,
3592,
471805,
499384,
10790,
17245,
50747,
39957,
255364,
117996,
177887,
null,
174780,
82619,
50464,
39755,
95754,
153443,
199728,
39599,
22414,
270352,
36502,
57638,
443360,
29584,
32759,
38705,
6637,
342270,
225841,
108462,
93328,
26969,
442942,
21020,
187756,
159203,
13455,
21398,
280989,
17884,
55081,
387154,
235199,
33198,
197686,
39259,
152635,
424062,
106989,
126836,
null,
157442,
null,
145741,
157364,
34409,
null,
42637,
325376,
45564,
421891,
206623,
50419,
47404,
15608,
318428,
360610,
352884,
212482,
11526,
63877,
12601,
33381,
77352,
121669,
163160,
40248,
129557,
374083,
712863,
307828,
25202,
29667,
38937,
36795,
53431,
38977,
40347,
61210,
81217,
22268,
252452,
41021,
9007,
null,
244021,
32932,
238174,
11895,
null,
null,
198534,
75257,
29542,
298309,
160602,
46816,
29913,
621591,
22823,
340542,
38493,
158144,
23460,
162630,
353355,
203378,
46390,
101115,
536105,
9074,
38864,
51024,
null,
13681,
26551,
null,
6624,
53689,
9706,
52171,
14225,
118136,
334282,
16211,
56842,
616041,
21361,
10662,
464925,
238268,
21907,
490860,
16946,
36764,
82132,
null,
26685,
null,
48147,
170482,
17389,
9571,
271402,
299408,
96529,
7251,
436652,
104374,
23888,
176391,
324138,
14206,
58375,
null,
17211,
13963,
631465,
null,
20090,
21076,
312895,
64977,
288736,
275614,
213827,
308147,
347734,
52591,
25693,
16697,
252931,
506589,
25477,
44060,
227085,
115652,
27511,
200956,
30312,
26871,
92976,
30239,
16136,
null,
51550,
132143,
38770,
31997,
17969,
119448,
407592,
8720,
23258,
51053,
191979,
64888,
95955,
108552,
19711,
416621,
181068,
344671,
250420,
23525,
78441,
null,
53731,
16624,
66111,
11396,
44267,
184172,
37379,
130253,
null,
209837,
248513,
35985,
282815,
194973,
193168,
70060,
null,
99251,
36266,
224014,
284914,
67993,
34135,
null,
254572,
21338,
14721,
146451,
104293,
24206,
9554,
155855,
5957,
121868,
31340,
60744,
36598,
119602,
259458,
345392,
262356,
null,
21674,
35499,
13524,
180351,
14616,
112765,
18470,
420484,
23213,
null,
128326,
28368,
29343,
281533,
184551,
60438,
298720,
176136,
93888,
57209,
14126,
221006,
38690,
38490,
233461,
196218,
26010,
35580,
7098,
157717,
73406,
62019,
5387,
43641,
267917,
22359,
135608,
179818,
61199,
574113,
389397,
62485,
29461,
16015,
21277,
22431,
116260,
121450,
368389,
32507,
150275,
19382,
16192,
5859,
175215,
239201,
39932,
13756,
305758,
304845,
416423,
47281,
232170,
314192,
492179,
238433,
100348,
20595,
214913,
35913,
null,
113203,
15742,
151953,
10378,
258195,
104999,
15958,
15909,
12950,
null,
19311,
58030,
146372,
41854,
148752,
79442,
16478,
23248,
54673,
294945,
42506,
130776,
316884,
165659,
126723,
null,
25869,
null,
371123,
26382,
86076,
140936,
null,
28840,
null,
31551,
164924,
187287,
194584,
21417,
61995,
22162,
25577,
7131,
null,
196717,
115336,
92336,
38966,
null,
5209,
14022,
7466,
29635,
316314,
21219,
null,
134321,
186806,
32377,
217501,
144502,
65606,
67797,
65757,
45525,
91751,
55685,
162703,
16821,
156532,
null,
8262,
30174,
32900,
4549,
455423,
14894,
83047,
182535,
111294,
137290,
15811,
180356,
377734,
180455,
87203,
580441,
428759,
43408,
350813,
154366,
5368,
100140,
74344,
17532,
38253,
60939,
556933,
27915,
null,
32867,
254358,
25790,
22374,
25381,
11982,
63131,
null,
201972,
44083,
83736,
284294,
433894,
148109,
278866,
65464,
34360,
null,
13145,
275678,
24719,
24884,
27219,
190781,
412130,
126392,
103480,
9338,
43469,
null,
146335,
9542,
39137,
64522,
null,
5538,
385098,
33006,
1207836,
307848,
309935,
null,
88134,
179164,
null,
178284,
201646,
1205797,
172058,
125831,
80845,
82381,
87958,
null,
457120,
298088,
85619,
144666,
37594,
26201,
231031,
56063,
73977,
17002,
60956,
9871,
176018,
282230,
240769,
4512,
183306,
97488,
65822,
44274,
98849,
156326,
56103,
110585,
29962,
137071,
null,
null,
189014,
236215,
308415,
null,
23778,
60057,
536428,
43624,
13146,
244074,
65128,
55938,
null,
46539,
197470,
2577,
66094,
null,
38118,
108832,
25619,
1015,
null,
262535,
235141,
16304,
139217,
253125,
167721,
96860,
null,
193576,
125669,
43730,
151388,
19285,
13605,
11763,
13903,
213714,
159899,
null,
322511,
199759,
null,
52251,
179360,
13509,
50884,
241005,
110734,
25837,
70431,
39966,
54348,
111705,
103694,
44690,
null,
114044,
212926,
315490,
22593,
75697,
205715,
299663,
30767,
290845,
303664,
165086,
null,
18997,
131953,
94535,
27226,
23972,
null,
18955,
28542,
null,
116968,
414877,
159431,
286602,
363912,
57822,
228199,
25409,
null,
290115,
49541,
327728,
75802,
39000,
40502,
7476,
28777,
48976,
47429,
53191,
48402,
null,
384232,
67423,
null,
null,
15179,
65087,
189973,
171748,
22993,
16256,
53168,
440590,
21962,
348454,
12100,
306700,
30746,
234218,
440987,
null,
104597,
null,
135122,
31093,
168135,
370536,
403154,
16485,
48857,
65803,
97167,
263744,
16260,
71532,
23806,
22954,
94880,
165556,
366404,
163429,
16490,
25242,
31785,
493939,
204168,
68527,
32084,
150047,
14649,
null,
40394,
1127,
null,
39406,
334843,
38096,
321607,
116803,
58674,
29597,
60982,
12315,
136357,
50445,
74936,
274474,
463301,
312784,
110645,
50215,
3780,
233302,
null,
61243,
318610,
87445,
269629,
17738,
67074,
21132,
513573,
null,
181754,
175794,
128216,
310523,
35924,
18452,
61733,
386429,
24268,
95147,
357962,
392614,
125770,
12459,
11159,
18071,
55731,
210826,
100957,
202245,
48536,
308928,
null,
798820,
2128434,
64348,
77711,
67732,
7768,
90654,
377097,
506020,
389969,
207721,
7858,
183436,
null,
5343,
30825,
null,
23180,
5549,
36331,
93966,
121915,
399446,
48190,
136332,
4094,
369057,
171144,
175437,
16568,
234468,
163931,
136151,
92385,
366092,
131961,
128536,
224634,
50678,
202868,
57996,
213674,
null,
26852,
129554,
11540,
46606,
20293,
278394,
8042,
163042,
385899,
331441,
355270,
228464,
53056,
143704,
36587,
412246,
218673,
36893,
312456,
38562,
134080,
447804,
36054,
null,
null,
10150,
23490,
161283,
70747,
251366,
12338,
243786,
172942,
null,
null,
203062,
45500,
41849,
50804,
37028,
433367,
247609,
55725,
119923,
300519,
591751,
130650,
17460,
81503,
221322,
37146,
null,
null,
179507,
28906,
345709,
45656,
65981,
194423,
16407,
83509,
51047,
248245,
170965,
23279,
36740,
326112,
131116,
23444,
104500,
32380,
28065,
74448,
150599,
310287,
5820,
61964,
21085,
52463,
59087,
154321,
150824,
126492,
63906,
22333,
144947,
217615,
300359,
49894,
312581,
128104,
32954,
16427,
477417,
44900,
13426,
null,
35903,
158113,
null,
358192,
598578,
44956,
134707,
6802,
24745,
9367,
13107,
72512,
136803,
36759,
118684,
23078,
10227,
468931,
397924,
19358,
49,
303898,
32416,
7042,
22958,
445498,
172455,
74801,
56524,
53521,
20376,
6391,
93465,
326529,
27511,
410228,
156528,
195263,
297172,
171786,
77359,
142317,
20632,
60070,
9990,
133195,
268367,
13163,
257404,
7101,
null,
118267,
422010,
174382,
42055,
18721,
166862,
216826,
534957,
122006,
null,
133108,
293324,
null,
183785,
297902,
261066,
null,
15877,
null,
91137,
null,
200570,
56307,
185882,
280043,
174558,
169139,
null,
45719,
172545,
71219,
33051,
7191,
409560,
46277,
45344,
99007,
268651,
192444,
110119,
28200,
15748,
26249,
49630,
205191,
13219,
13339,
69995,
37180,
216740,
27107,
null,
175224,
304693,
29067,
10767,
28628,
230134,
379757,
73382,
358731,
null,
498481,
21349,
337235,
634592,
7427,
17472,
null,
242920,
30109,
18253,
181737,
27354,
304951,
33756,
null,
94418,
244017,
53218,
169558,
42812,
493618,
37337,
513634,
70369,
19828,
97345,
275569,
29039,
873953,
16887,
249732,
210971,
81053,
245276,
311420,
217192,
82167,
84039,
473715,
310887,
257136,
53768,
89776,
467907,
11689,
651193,
23288,
432563,
141769,
86396,
49181,
250473,
30480,
null,
55613,
29184,
420658,
384384,
377830,
null,
287892,
281920,
39075,
44809,
null,
48738,
85079,
49015,
72166,
11748,
68055,
102701,
15106,
51969,
280513,
44745,
40064,
3562,
184285,
707939,
47885,
11769,
139173,
406293,
274014,
218871,
10779,
244930,
null,
115937,
140512,
1312,
1025728,
146577,
16595,
63446,
43110,
null,
21930,
83180,
202709,
null,
84323,
137149,
60088,
44074,
175686,
143739,
8442,
295970,
154175,
127379,
2491,
28452,
602838,
38534,
54762,
141975,
20052,
104175,
440300,
71814,
null,
27971,
49955,
143729,
426822,
201254,
null,
2847,
233406,
144905,
null,
39037,
61033,
20516,
null,
45167,
169417,
27489,
4790,
92638,
110271,
74245,
206735,
325487,
319636,
123329,
118887,
33524,
9424,
125671,
168022,
39428,
451872,
103026,
28260,
101838,
40844,
127714,
17376,
44240,
76247,
226922,
44970,
null,
320500,
237184,
223199,
18669,
282728,
45347,
173179,
19257,
166398,
236507,
168891,
99171,
680573,
153321,
176057,
44103,
68898,
351868,
48701,
34118,
173068,
16775,
3787,
131377,
74901,
133791,
17108,
28842,
36390,
54973,
26910,
295145,
234053,
19127,
21734,
null,
11798,
149097,
167197,
15400,
466071,
71971,
107135,
10318,
38104,
11135,
40124,
111824,
22005,
217332,
28057,
237944,
22304,
73980,
258060,
22380,
73721,
92908,
20255,
163780,
284427,
10096,
101648,
63086,
null,
220218,
50592,
24122,
51301,
603925,
62582,
97026,
117488,
9860,
58608,
null,
31347,
null,
271344,
415405,
400024,
113939,
60458,
29791,
107143,
29682,
14282,
98002,
30683,
169940,
103778,
39576,
35022,
199258,
105214,
33756,
null,
15148,
594954,
30069,
61349,
169323,
100130,
174161,
64751,
41784,
52173,
35448,
null,
561958,
49587,
107917,
32817,
293842,
439865,
41012,
247954,
35086,
79290,
394622,
336219,
306056,
57742,
262339,
122399,
47709,
162778,
177432,
146205,
633423,
339378,
168836,
456830,
75719,
380633,
24942,
266361,
43125,
104051,
null,
180930,
188954,
220924,
17846,
673615,
182431,
50784,
30002,
452932,
191989,
59392,
353563,
19229,
17942,
null,
131140,
21746,
44218,
31630,
42039,
35306,
14350,
3590,
297717,
24765,
53778,
182338,
null,
513265,
343017,
459552,
160047,
312918,
23196,
null,
15790,
19378,
481258,
66934,
29487,
70774,
224117,
211261,
352502,
235583,
null,
259463,
164745,
76177,
231486,
75846,
176987,
281297,
23989,
278820,
82299,
21963,
133442,
47008,
119654,
22900,
10240,
354014,
null,
16324,
39410,
246512,
186040,
77749,
403950,
101194,
135059,
219823,
112275,
23353,
58638,
161355,
168131,
20396,
90739,
24453,
86024,
25225,
137549,
12037,
60025,
null,
65619,
371733,
75227,
59297,
14624,
85011,
84582,
38225,
37723,
205398,
293097,
34477,
15871,
315899,
36559,
150571,
31444,
29668,
42191,
9669,
15356,
152190,
162234,
140418,
81464,
30289,
113291,
11784,
171692,
10000,
17350,
null,
115244,
20517,
393000,
122344,
210694,
20781,
97946,
276043,
15281,
170428,
156619,
null,
34920,
41628,
336304,
63068,
51311,
151131,
164259,
367016,
59463,
null,
137409,
28511,
136448,
204254,
32442,
5739,
20616,
25560,
309590,
81272,
240485,
80687,
120914,
47791,
40291,
21578,
40127,
122223,
172541,
88520,
28580,
5683,
51622,
537132,
6029,
264485,
38032,
26576,
55618,
45039,
150576,
null,
39452,
19632,
161650,
62510,
49398,
null,
120324,
269600,
181905,
423084,
73626,
13272,
39996,
10031,
68127,
41790,
56870,
123348,
94941,
null,
40133,
11430,
74201,
288927,
46057,
null,
146780,
27176,
262482,
406367,
29608,
307500,
70074,
48201,
56578,
263174,
51876,
6677,
null,
317847,
22018,
210737,
77752,
121640,
14518,
535570,
388266,
307348,
228418,
34373,
349033,
399928,
13290,
9287,
10316,
388435,
323986,
8613,
15119,
111927,
178546,
336014,
229179,
140959,
202837,
192515,
71157,
201740,
83506,
32304,
164688,
37713,
261055,
241593,
29019,
3762,
41724,
39380,
18724,
420462,
53606,
18876,
38695,
61547,
70273,
104370,
50319,
189828,
54917,
404759,
null,
122970,
238630,
22543,
313813,
51434,
47193,
76790,
656726,
306897,
147446,
31248,
271483,
null,
7931,
181885,
7153,
40561,
94617,
22452,
83537,
14992,
36017,
96562,
null,
64535,
258980,
9103,
17505,
11692,
6841,
1324818,
65522,
27170,
682618,
26880,
95557,
224565,
62817,
37335,
null,
8336,
37342,
16452,
33291,
51519,
110903,
317283,
291702,
348644,
236675,
138450,
186049,
25017,
29515,
16493,
6022,
140798,
99060,
20591,
54508,
41090,
240674,
152842,
358874,
40113,
null,
39675,
136140,
149652,
82756,
null,
286885,
315882,
30375,
18167,
10958,
96523,
79374,
31740,
23441,
153280,
154374,
58435,
321735,
299592,
58705,
13980,
24396,
8777,
32660,
155402,
49886,
14765,
19894,
52046,
37528,
null,
118758,
36142,
153922,
267206,
54544,
72584,
206628,
132037,
136314,
23361,
89258,
77894,
96402,
134009,
null,
374581,
775821,
263886,
308441,
159467,
21255,
22247,
39964,
26877,
25541,
151204,
null,
8288,
68506,
277799,
137373,
34573,
127274,
null,
272767,
182690,
42115,
32131,
314894,
23903,
45476,
240333,
31395,
106879,
25898,
249969,
226988,
193735,
35529,
272032,
null,
105767,
231624,
21392,
143458,
7505,
null,
12676,
38154,
26681,
11575,
495390,
135105,
31918,
45906,
654489,
26289,
24803,
183150,
42271,
11386,
192387,
null,
5803,
null,
180520,
212467,
197029,
189896,
144874,
null,
18762,
523919,
425472,
null,
96409,
20974,
44922,
69144,
36592,
105399,
84675,
87709,
12319,
15333,
14363,
39484,
65772,
270596,
239607,
42563,
182410,
20656,
5960,
117522,
80675,
33799,
23184,
71120,
13636,
186332,
61716,
29042,
56425,
63881,
257138,
240859,
180677,
148332,
43462,
18381,
4099,
52513,
124109,
338828,
90305,
136147,
null,
188588,
470568,
166205,
null,
39679,
103754,
17293,
130347,
208651,
753617,
504244,
2906,
31748,
231069,
199542,
7059,
394044,
null,
28266,
8805,
184888,
31907,
27425,
23747,
27265,
9041,
null,
117466,
57050,
71302,
9535,
56021,
100624,
444942,
46364,
299648,
421289,
288405,
80329,
17984,
50133,
53611,
null,
107876,
52276,
131138,
24897,
299344,
304748,
24092,
105426,
248857,
333935,
null,
244802,
null,
285325,
17003,
46721,
316802,
67186,
374926,
94571,
17006,
73976,
276829,
null,
22194,
238815,
211960,
38686,
38372,
21550,
223054,
292175,
40484,
232825,
18623,
248670,
345365,
174279,
307007,
34642,
93033,
50834,
53688,
180145,
27543,
29814,
43513,
185856,
23292,
548006,
52089,
94631,
76972,
186359,
null,
16590,
14558,
72204,
null,
5874,
132243,
6053,
307421,
47728,
237162,
15820,
360684,
43648,
9064,
227401,
null,
null,
40190,
16730,
50581,
183204,
198958,
58850,
25271,
352039,
32273,
122371,
80704,
77570,
44043,
79835,
25591,
611899,
33240,
9853,
595383,
25149,
null,
44084,
80741,
431561,
218891,
157794,
102339,
202020,
21231,
22487,
11623,
39607,
41414,
49697,
197529,
166451,
40804,
118297,
21622,
137025,
374146,
17724,
49140,
264777,
272283,
525030,
null,
33699,
null,
103386,
422732,
13359,
23806,
557847,
142735,
null,
226404,
337098,
21961,
191784,
32672,
68912,
280700,
51380,
115486,
332508,
15098,
123535,
24710,
26709,
183110,
89279,
33586,
61194,
9057,
null,
24211,
233287,
177885,
208969,
67791,
137285,
29321,
null,
27876,
17936,
42380,
75035,
163093,
10770,
38142,
63532,
15222,
14670,
null,
86452,
146514,
136684,
79819,
83281,
43364,
332264,
27302,
18348,
57864,
31023,
78680,
83630,
15739,
28796,
412974,
23779,
160198,
434844,
71631,
116196,
42467,
9928,
167511,
177115,
19590,
214629,
16859,
37395,
418043,
316453,
33941,
255327,
15598,
24572,
209799,
284227,
172947,
304054,
44501,
14389,
19299,
null,
132902,
266757,
44228,
null,
97461,
469649,
7094,
355893,
316800,
7679,
171045,
74080,
63032,
194170,
15934,
194469,
null,
14084,
199577,
26206,
245907,
252166,
108415,
267591,
156003,
231212,
null,
null,
14474,
484852,
104503,
null,
130815,
31106,
13102,
209030,
30214,
640526,
179717,
159499,
41536,
390680,
108835,
29639,
17232,
84513,
50274,
166951,
7453,
521944,
3183,
14732,
36738,
190028,
159517,
171011,
266810,
133838,
11237,
234156,
null,
588804,
174669,
32888,
41138,
103817,
15023,
40830,
17650,
21024,
22588,
50183,
80934,
5908,
40746,
5539,
196811,
230004,
52166,
19703,
308100,
14283,
135103,
null,
50729,
116126,
null,
260140,
56957,
28428,
66230,
139055,
24249,
23146,
7908,
409658,
319888,
209618,
24730,
357946,
152373,
237670,
null,
11702,
245687,
247983,
378054,
null,
312812,
261648,
243777,
45914,
15120,
41635,
143001,
158458,
35141,
68015,
null,
60130,
46886,
16954,
338917,
53709,
null,
798216,
null,
30296,
62356,
24463,
13884,
46963,
77489,
48991,
7120,
227697,
778056,
411219,
232616,
11620,
21945,
91088,
163542,
27650,
null,
142388,
3411,
131535,
163765,
null,
14583,
56852,
238455,
206441,
126738,
12707,
149179,
72753,
222101,
null,
null,
167388,
187965,
209971,
61244,
169390,
183682,
8772,
29296,
147221,
258011,
57165,
158072,
436670,
348455,
271836,
328507,
136655,
11200,
269511,
26944,
38843,
67497,
235352,
128215,
3139,
200388,
207925,
321430,
235666,
20761,
9780,
152335,
156241,
435423,
null,
72362,
43496,
null,
71978,
330319,
207836,
31440,
55987,
372811,
491278,
204283,
37678,
19468,
177104,
12939,
301153,
390879,
9199,
312082,
82685,
15621,
141539,
null,
53941,
37764,
31574,
323829,
166595,
61579,
143038,
40414,
111171,
399504,
5315,
14744,
51328,
38747,
233221,
32468,
134768,
15981,
523347,
null,
256837,
39597,
102522,
95794,
160671,
316426,
24445,
null,
null,
223175,
227732,
110955,
388152,
189370,
13537,
32982,
305330,
88350,
53071,
321304,
217267,
189162,
null,
375630,
4262,
140111,
null,
76116,
28142,
20039,
31988,
341833,
6813,
205467,
31567,
420096,
33457,
114641,
null,
232541,
327809,
152333,
123351,
23270,
291561,
75301,
314551,
3687,
456152,
null,
null,
227409,
21754,
39817,
19475,
200982,
26918,
247018,
86252,
14433,
38677,
18137,
272433,
14326,
18896,
186251,
1325807,
34166,
192990,
51786,
193543,
164249,
32539,
18017,
198324,
37880,
37085,
308482,
null,
79582,
33414,
32517,
31597,
28033,
null,
null,
44173,
295580,
134042,
466853,
181436,
54075,
110806,
null,
5089,
47427,
55878,
28520,
434695,
176775,
42129,
213551,
33501,
29027,
23895,
113701,
null,
null,
287458,
34025,
288723,
169144,
47415,
170142,
21783,
82062,
3377,
105037,
390655,
null,
51925,
65215,
25652,
92784,
10675,
72422,
207172,
347149,
23904,
22187,
36620,
308270,
18688,
171146,
53748,
7815,
27025,
151825,
171561,
29055,
166404,
null,
6235,
5157,
229560,
51992,
21154,
30450,
687470,
36030,
259694,
468251,
452396,
257165,
34480,
258503,
23591,
84992,
240109,
198503,
29539,
807885,
null,
424265,
294052,
17953,
250747,
20817,
163508,
49969,
21572,
394865,
1486126,
30777,
null,
null,
14007,
45383,
97200,
20946,
267492,
172811,
252221,
71522,
17002,
120502,
191321,
385091,
null,
44852,
516815,
279681,
9964,
17510,
42522,
251193,
37214,
21295,
336205,
24677,
290685,
442530,
35503,
77080,
null,
7462,
25853,
377176,
245417,
174748,
28588,
61746,
37032,
null,
67310,
92458,
632359,
44624,
272963,
30165,
32085,
415715,
68297,
253330,
863988,
60882,
145429,
null,
715576,
249430,
46977,
312245,
313071,
188349,
280590,
81643,
17971,
12782,
92272,
628560,
null,
23736,
66487,
364454,
163156,
72905,
9190,
25936,
91350,
106141,
15436,
465130,
9629,
157179,
451077,
112226,
68531,
244836,
43528,
23823,
551719,
53312,
119521,
4345,
247583,
null,
163705,
57533,
25502,
33196,
35950,
170113,
188928,
45718,
50785,
20716,
252258,
30664,
null,
null,
80206,
325209,
26118,
573076,
428588,
138808,
309439,
74134,
419862,
213768,
268321,
139291,
305649,
41659,
184767,
124860,
364347,
218834,
211725,
11269,
27444,
28230,
172489,
20933,
357635,
186508,
86496,
281674,
null,
155114,
78336,
18205,
16632,
120572,
11005,
11078,
532109,
null,
13412,
151075,
614417,
233682,
255532,
40536,
35811,
31084,
312514,
209961,
236585,
70572,
101011,
57307,
94292,
312630,
69668,
null,
217699,
89957,
116713,
277802,
232392,
336523,
7453,
108967,
34484,
15670,
null,
null,
262681,
53051,
182058,
null,
47603,
30925,
184272,
215490,
17666,
71064,
277521,
143096,
213173,
300229,
34693,
107349,
295449,
313761,
7277,
584602,
104366,
119783,
5389,
158293,
106663,
88368,
275173,
18193,
236964,
18285,
90406,
null,
651765,
null,
56038,
10921,
12595,
23337,
625413,
83073,
132826,
324880,
22148,
5574,
16302,
125524,
null,
854657,
160459,
96030,
28688,
282187,
47167,
19145,
null,
114885,
null,
74461,
122840,
175114,
155761,
null,
null,
53864,
9955,
164312,
206987,
167653,
165958,
647334,
229407,
14738,
297754,
42193,
9188,
223662,
50201,
192849,
229361,
17106,
221882,
20058,
37182,
198553,
332719,
677863,
6179,
null,
162971,
601299,
null,
11303,
229167,
231128,
42821,
35821,
30754,
33069,
135304,
6499,
231091,
123426,
426538,
81432,
null,
null,
68829,
55169,
12326,
72030,
173449,
18179,
31416,
25868,
23367,
9617,
43240,
532222,
38458,
41696,
7545,
null,
65431,
33688,
11409,
68658,
20976,
37483,
6403,
28781,
18267,
34479,
59226,
202079,
122138,
119812,
92796,
254163,
35173,
null,
26607,
null,
133612,
null,
8823,
150150,
93352,
280080,
40915,
308124,
295778,
64021,
39866,
21869,
161935,
128290,
239286,
3895,
12512,
149556,
51395,
38413,
193418,
424930,
203179,
41530,
null,
24704,
65846,
20470,
30104,
153641,
244541,
41214,
327521,
34502,
11166,
21448,
218556,
234227,
394299,
304493,
269090,
454818,
83997,
36379,
9378,
208926,
31359,
153541,
null,
10389,
393807,
25442,
10634,
43996,
28831,
26581,
144999,
412810,
28019,
null,
190625,
15400,
182516,
39364,
641383,
326309,
null,
134110,
151577,
98948,
348098,
28277,
125315,
24861,
46645,
79366,
154920,
25133,
38151,
379607,
88561,
50467,
30416,
51306,
117165,
223003,
null,
41794,
246931,
44232,
123532,
12617,
179292,
570342,
7758,
313343,
92641,
40738,
262230,
52450,
17928,
180223,
23348,
285153,
209545,
53838,
84962,
12026,
28674,
33904,
310987,
12290,
30865,
9638,
159891,
35178,
null,
235227,
61289,
15985,
null,
284364,
39656,
null,
295807,
31982,
39852,
null,
23420,
97881,
84410,
275759,
13143,
157280,
39643,
57422,
11099,
323865,
26435,
748357,
61192,
18807,
null,
317913,
277644,
507776,
890,
null,
8844,
132426,
20179,
32027,
94977,
5553,
195155,
440519,
null,
22985,
34764,
298714,
445573,
66417,
21954,
305470,
31693,
172744,
1114516,
20758,
401327,
229407,
209351,
null,
24092,
8424,
155165,
42186,
9161,
117004,
11411,
null,
13599,
24728,
152370,
485838,
240081,
162681,
182978,
19465,
38993,
21115,
40406,
525070,
null,
166614,
null,
3485,
139017,
37558,
null,
445821,
null,
351372,
236757,
247008,
212254,
64117,
72462,
10064,
160557,
10037,
5525,
8077,
97878,
147833,
146662,
null,
265148,
72937,
314700,
55002,
9991,
28842,
48482,
250384,
255971,
293777,
302975,
245854,
188502,
35733,
54956,
null,
18929,
78660,
49693,
117805,
242529,
22411,
354110,
3693,
100651,
361601,
523820,
199383,
74994,
52559,
13212,
62361,
38119,
247886,
254426,
null,
170583,
245932,
305662,
61773,
17449,
10339,
116486,
119003,
28716,
8201,
228774,
8499,
137635,
295131,
12543,
23148,
146692,
258828,
null,
153620,
258265,
18094,
49171,
284780,
18443,
159242,
348814,
28617,
16717,
329555,
18978,
40675,
175436,
21714,
515298,
218988,
251609,
325661,
391329,
null,
20965,
160558,
null,
225202,
17481,
208213,
14925,
153627,
32251,
170866,
73469,
144979,
138535,
120796,
602227,
54181,
81178,
36731,
17121,
259291,
169558,
187446,
69848,
2534,
24033,
52618,
123881,
534177,
168600,
162477,
18224,
null,
63648,
9108,
null,
552000,
237753,
186054,
24938,
26794,
100766,
221725,
174400,
125985,
3319,
null,
113775,
37186,
235979,
374614,
9736,
40496,
74089,
458599,
109714,
10021,
63326,
166079,
41840,
231441,
26820,
30061,
null,
100967,
27790,
65920,
4246,
323360,
90231,
157312,
83935,
27402,
98868,
28485,
31749,
27190,
186984,
null,
12973,
297939,
17459,
17309,
117818,
21354,
117095,
9187,
null,
202130,
266995,
100796,
479025,
56041,
109860,
48488,
17924,
50664,
118878,
null,
395019,
31930,
227311,
25189,
30780,
17583,
47524,
199671,
null,
383555,
29497,
8876,
5926,
92596,
35914,
299639,
12692,
154154,
161280,
32262,
319177,
204892,
134984,
330902,
50400,
235777,
114985,
133435,
138828,
191932,
307617,
null,
377961,
10306,
167510,
117053,
24325,
201384,
385377,
439907,
24038,
97994,
52358,
132377,
43773,
12533,
164088,
null,
326558,
null,
194286,
221461,
111600,
null,
52278,
19920,
14834,
78717,
16652,
577437,
236997,
37527,
null,
476739,
21573,
225580,
null,
3146,
228804,
305999,
49349,
87272,
394973,
168220,
179768,
127386,
16069,
251907,
222824,
32025,
480334,
6799,
141806,
null,
15996,
114732,
21247,
81880,
61320,
28509,
null,
239179,
130115,
16385,
190840,
521886,
84147,
112327,
null,
4238,
266433,
38866,
37052,
39361,
381386,
null,
167900,
44053,
461442,
null,
51071,
339144,
369998,
96613,
167282,
96324,
203045,
143007,
334404,
32369,
19964,
16405,
188584,
179189,
2806,
8021,
27347,
249014,
8637,
275744,
null,
119177,
199966,
55420,
266637,
33543,
62817,
33639,
178327,
292721,
34431,
39148,
28556,
144736,
385763,
37774,
2712,
null,
38677,
49467,
418427,
null,
32587,
null,
373944,
null,
65904,
42301,
38213,
179054,
131396,
30279,
222518,
20667,
105705,
14383,
null,
33714,
832125,
20349,
30032,
135394,
137801,
110852,
31283,
49936,
16080,
330651,
360682,
180986,
null,
73345,
159999,
207839,
92378,
10422,
186983,
30301,
81402,
22671,
185174,
18596,
9998,
21229,
124906,
122324,
23327,
189993,
207158,
115292,
43921,
13719,
214666,
24823,
20101,
51312,
85908,
55836,
129659,
null,
72132,
260821,
152605,
69284,
27391,
33710,
15866,
32854,
38812,
9245,
311503,
31209,
74707,
null,
33836,
414989,
122556,
95663,
416610,
7872,
50475,
108632,
36108,
29983,
187862,
31051,
144902,
199061,
81746,
58477,
33883,
256320,
14088,
28760,
227619,
31071,
null,
8985,
117362,
104907,
59946,
45786,
352317,
17848,
264637,
80908,
267850,
null,
214116,
133541,
null,
164659,
17396,
526397,
110845,
57712,
68002,
20598,
82406,
300409,
115361,
26606,
9202,
15899,
77255,
82383,
51391,
53818,
122857,
30512,
20565,
4518,
8753,
336360,
162408,
64663,
375373,
296251,
null,
33181,
49695,
84865,
418931,
878,
14908,
143112,
28484,
230879,
41073,
48795,
269690,
110467,
106914,
12979,
18174,
160859,
91055,
39270,
1533,
19721,
109018,
19899,
291532,
null,
13076,
186831,
188871,
15551,
15997,
null,
223419,
60576,
39136,
null,
281237,
365019,
47811,
60667,
319161,
46662,
221108,
41044,
152489,
18833,
62194,
395157,
156281,
335303,
7283,
33695,
17951,
198436,
278092,
18084,
40976,
61058,
49177,
9274,
null,
29561,
23160,
211758,
411242,
307272,
407704,
324977,
51205,
41080,
184541,
11226,
233910,
133135,
75125,
25487,
215448,
103884,
null,
8870,
41709,
22259,
23376,
400908,
189661,
null,
248561,
9735,
288759,
51689,
357313,
52127,
null,
315683,
356524,
23653,
6937,
32641,
33212,
46583,
176875,
387105,
39135,
186722,
161144,
52018,
22208,
20766,
107316,
344266,
63762,
11364,
494,
15177,
11440,
36707,
275790,
144899,
26541,
419414,
110628,
27884,
130375,
215836,
331665,
103339,
625125,
104150,
103322,
59739,
18917,
68786,
29291,
305631,
168319,
27800,
197563,
51951,
165324,
22780,
41527,
38717,
15272,
21790,
10510,
553354,
null,
170046,
93425,
90171,
434934,
null,
52527,
null,
102136,
null,
298266,
141045,
212175,
55863,
90476,
10458,
48698,
13070,
null,
298728,
641699,
7302,
131605,
77044,
38204,
18317,
224885,
62054,
116537,
48996,
166590,
46851,
14609,
292642,
193000,
360446,
null,
371433,
203279,
400194,
2109,
16482,
91287,
129456,
31267,
109985,
401446,
46290,
188945,
24475,
18280,
317525,
79652,
94254,
68640,
166104,
274170,
146166,
36799,
153944,
357569,
56137,
113185,
35297,
99689,
31490,
238991,
312352,
null,
133290,
289600,
195566,
303452,
167426,
95744,
63448,
310229,
267530,
45276,
33882,
10982,
211184,
17900,
277455,
33072,
184439,
23996,
20265,
20083,
20700,
54580,
30511,
128244,
324441,
null,
167882,
11,
40287,
24420,
92341,
151155,
3277,
49934,
30779,
18227,
147440,
176078,
90436,
148587,
null,
25861,
12307,
null,
63154,
343000,
83582,
24757,
62605,
35077,
18100,
25524,
21194,
20803,
2838,
220128,
97834,
165671,
1083902,
12413,
6746,
39029,
21143,
240262,
228915,
151291,
null,
138132,
23807,
438276,
99030,
237958,
152390,
114227,
64728,
163473,
170692,
41374,
222757,
23064,
78232,
10026,
28962,
282673,
205466,
73240,
18856,
9964,
135907,
486262,
31694,
330914,
12057,
106425,
301096,
158741,
152658,
111106,
null,
207847,
110582,
35190,
16269,
53938,
332264,
6509,
23784,
202904,
32501,
151941,
35274,
208331,
280864,
36907,
422908,
null,
5639,
412909,
441478,
11882,
332193,
38117,
354206,
223432,
524380,
494160,
289654,
145948,
20854,
77413,
184845,
183806,
19777,
24673,
221552,
740699,
23467,
17747,
182192,
18812,
32489,
36808,
57872,
37560,
130327,
254109,
165176,
440363,
15914,
166445,
21605,
null,
null,
225620,
67621,
111458,
94582,
383113,
316056,
58813,
null,
224147,
null,
351246,
53283,
287107,
644094,
191834,
83138,
38904,
null,
77353,
392250,
10584,
9364,
22022,
107412,
41048,
39426,
46639,
468698,
357922,
25253,
null,
309199,
205889,
43373,
116054,
224901,
210277,
428893,
60078,
49716,
3868,
122265,
179054,
32770,
52566,
279469,
12085,
13421,
132901,
58667,
467878,
13895,
167323,
null,
232811,
68891,
3454,
null,
6740,
38987,
53668,
214249,
null,
248188,
62688,
554512,
34522,
22877,
41227,
24002,
4693,
132719,
96531,
null,
248362,
444734,
642955,
22681,
36854,
21362,
86187,
26259,
28796,
690227,
8556,
190046,
271306,
13725,
70517,
455962,
19675,
33156,
338196,
44430,
96891,
66302,
105547,
35300,
265718,
20182,
59781,
88788,
103955,
49280,
154463,
null,
69107,
16322,
133567,
242016,
427540,
45127,
188122,
60044,
24568,
204726,
41888,
91804,
377414,
9695,
257312,
230684,
369355,
145890,
119703,
48483,
362675,
414285,
53318,
171042,
89312,
23265,
26275,
749079,
206995,
22930,
88423,
168487,
10838,
32478,
133669,
99227,
65719,
155237,
93521,
222000,
185682,
316697,
70649,
36140,
230675,
7058,
76707,
460965,
125887,
311237,
381294,
16715,
null,
36217,
260813,
8947,
11015,
null,
333934,
65958,
13277,
214266,
10544,
37081,
295340,
21930,
196686,
101349,
136520,
136235,
33619,
341173,
78802,
49385,
41699,
466647,
48435,
207033,
3910,
null,
223428,
418466,
359962,
31999,
45322,
110681,
45920,
47200,
42834,
131491,
474809,
12343,
330727,
null,
null,
479850,
38086,
128747,
8874,
67115,
31568,
38578,
438791,
140267,
3681,
19457,
46771,
558809,
259919,
23062,
175152,
468726,
null,
20253,
126135,
175508,
183869,
23872,
311388,
36469,
118679,
158500,
64751,
256491,
295896,
21359,
2961,
74444,
37483,
49752,
63140,
89307,
147504,
415995,
189316,
281817,
141103,
287569,
172137,
3515,
36941,
213617,
221013,
12816,
35474,
17779,
118626,
142493,
176722,
255241,
81574,
30985,
4470,
34610,
9372,
null,
338044,
43542,
30051,
107724,
13499,
285415,
9696,
203304,
100756,
29146,
227125,
173013,
268421,
133864,
177801,
35367,
5637,
6226,
616118,
36896,
477885,
327541,
14100,
13453,
25206,
25461,
14345,
22751,
781482,
87528,
43084,
18357,
76638,
17348,
245487,
68721,
156729,
97629,
8187,
12881,
111983,
74599,
42927,
250688,
74295,
null,
55020,
18474,
39058,
null,
3080,
22627,
182491,
340539,
545416,
377598,
86950,
58580,
63065,
62235,
224591,
12457,
78157,
54604,
14750,
221617,
20345,
50442,
550769,
115249,
15582,
39813,
265410,
290337,
73236,
457224,
11670,
8250,
76125,
null,
23574,
10398,
36667,
34104,
294665,
35901,
38847,
24563,
113446,
208098,
227422,
32968,
null,
null,
69891,
null,
null,
5301,
24363,
376417,
143491,
null,
346783,
256936,
68711,
72955,
1225,
7455,
67275,
108570,
9298,
251857,
247397,
7746,
163790,
308706,
58453,
196737,
210276,
421179,
19396,
207071,
null,
237171,
136834,
null,
79330,
null,
243892,
172699,
527535,
284658,
209844,
239938,
200942,
24209,
225087,
17118,
130768,
null,
578776,
4361,
400500,
111813,
36738,
321477,
26528,
233873,
327224,
122324,
14340,
91766,
264753,
6148,
19217,
212789,
467074,
5090,
12877,
12930,
53558,
252140,
33493,
48564,
219070,
365790,
299982,
167671,
123900,
null,
50469,
197645,
306431,
35873,
193326,
136330,
124697,
12916,
289832,
31945,
18812,
178457,
14676,
19173,
24740,
176045,
217118,
188057,
181168,
77621,
58553,
206539,
null,
39101,
25296,
null,
null,
290241,
599300,
19893,
160320,
40575,
null,
62731,
710495,
42930,
27667,
124911,
127936,
178793,
54930,
84313,
35022,
null,
137597,
10856,
18682,
29144,
null,
138921,
905596,
5213,
160365,
217805,
30208,
480673,
11164,
198542,
685918,
290030,
536396,
289749,
28369,
24126,
null,
85908,
308483,
null,
240795,
229154,
36739,
188189,
269846,
321460,
null,
241843,
44547,
15640,
15493,
229527,
49697,
263238,
221036,
332975,
12401,
60958,
34603,
202411,
13345,
249899,
7392,
137639,
52427,
189602,
239581,
280634,
32538,
420132,
293435,
72235,
400048,
219244,
6096,
376563,
167422,
420842,
87821,
33680,
43477,
417316,
22121,
345377,
116126,
18504,
null,
34863,
460750,
647520,
33044,
66374,
63646,
57059,
142654,
7517,
13988,
183716,
688729,
31124,
316009,
285192,
6522,
775070,
173653,
19530,
24949,
38460,
258630,
18046,
33049,
7928,
null,
258751,
8751,
8818,
202393,
21967,
13898,
185442,
99784,
14923,
19544,
84644,
638421,
10330,
16636,
217207,
19128,
226118,
45197,
21022,
58314,
null,
21300,
77546,
298085,
15292,
178011,
277878,
159380,
327367,
108266,
null,
51854,
16900,
106855,
39595,
76565,
95871,
12292,
28237,
7819,
216344,
28594,
2072,
200881,
41475,
30806,
81834,
63278,
349130,
19899,
260475,
261538,
97761,
137540,
233626,
23362,
23160,
42016,
49760,
25558,
20266,
28108,
310090,
228278,
null,
null,
30343,
165064,
232728,
null,
38897,
30871,
23718,
128731,
314396,
327336,
25841,
85921,
140977,
null,
10864,
90927,
29103,
24396,
5666,
null,
365831,
387180,
448238,
338909,
5916,
40719,
34414,
8191,
299840,
270261,
67006,
7837,
204046,
302349,
136993,
30828,
344398,
152080,
430474,
580246,
514118,
84646,
300005,
60133,
null,
32988,
58259,
100319,
29987,
93605,
134782,
null,
108889,
255175,
15824,
29985,
null,
92818,
78969,
null,
394441,
null,
114431,
null,
34691,
154606,
372297,
26023,
null,
null,
3038,
49143,
9098,
133326,
5724,
141691,
302326,
252895,
101254,
null,
null,
216493,
31716,
122155,
549702,
34627,
33691,
122330,
null,
257707,
179103,
null,
63932,
53795,
920517,
50921,
320780,
130524,
148292,
40538,
22473,
548547,
290413,
139375,
24362,
null,
111447,
34114,
217342,
null,
26418,
160102,
30804,
230567,
45328,
366804,
120136,
33792,
48462,
213001,
32349,
null,
149342,
null,
14053,
30899,
126130,
58282,
10180,
1894410,
null,
73665,
147435,
null,
14992,
126403,
51075,
251790,
37166,
66657,
26361,
298891,
171843,
133180,
192018,
243058,
5592,
54455,
45822,
77368,
121259,
25814,
31247,
33622,
25168,
218021,
250276,
24434,
436023,
91587,
7076,
239539,
18545,
40722,
347860,
172045,
164382,
null,
36279,
151769,
29279,
192071,
17189,
167672,
201719,
264924,
187150,
184654,
113632,
8774,
362094,
120310,
62395,
57809,
113267,
746503,
175785,
357486,
49422,
393562,
255144,
1641,
248064,
10694,
37211,
150100,
101621,
199940,
147137,
415537,
133879,
124856,
26718,
7839,
181805,
529068,
178193,
565661,
null,
15629,
119721,
51345,
314015,
239262,
205780,
140960,
90502,
48060,
514225,
46206,
7280,
12529,
343062,
294785,
null,
95226,
19024,
11658,
null,
115830,
null,
17224,
123412,
40855,
160581,
13818,
null,
57303,
129996,
27506,
49054,
25535,
1879,
31579,
115255,
20459,
281768,
237027,
80148,
49545,
35172,
163960,
433115,
419317,
18448,
315639,
461285,
185095,
604005,
null,
508570,
238893,
14488,
null,
318715,
14839,
55498,
32859,
null,
224677,
null,
23558,
70500,
294067,
137522,
144785,
289178,
198033,
78329,
36990,
17382,
78702,
63242,
25497,
56227,
459423,
375395,
178453,
46254,
72143,
79535,
290752,
29940,
288858,
765207,
53608,
323725,
165452,
375307,
83873,
175942,
22209,
11529,
318182,
261335,
140263,
66618,
26560,
34396,
229962,
null,
74084,
null,
257348,
20573,
501895,
154557,
41799,
225799,
9626,
11414,
9557,
null,
26317,
7076,
100165,
275673,
40961,
58786,
20065,
28900,
111141,
21835,
381507,
38911,
68338,
null,
53037,
159573,
123986,
18954,
31674,
154862,
15008,
null,
34273,
null,
226593,
300379,
136211,
241199,
132967,
20146,
35462,
35579,
105410,
39822,
111455,
161420,
null,
13872,
64333,
41497,
31616,
93613,
16122,
null,
308422,
506393,
7169,
16832,
null,
39446,
25708,
214488,
37454,
null,
23943,
66545,
19563,
707349,
229103,
504457,
26799,
null,
44709,
37164,
46620,
30732,
54492,
216530,
206509,
38301,
367964,
136491,
3965,
null,
485826,
94416,
12800,
42060,
58342,
126801,
275074,
52835,
228492,
19675,
26851,
187042,
328313,
21271,
28946,
43549,
18878,
31331,
427567,
460446,
94117,
102036,
8334,
null,
45194,
105067,
79552,
19694,
5031,
5915,
467666,
null,
191954,
54684,
24421,
30279,
189587,
29865,
10116,
149138,
102026,
null,
302911,
73723,
28797,
22239,
477744,
127568,
null,
19662,
74354,
72218,
152955,
62751,
105246,
184149,
37018,
237678,
10246,
22313,
47428,
43299,
54733,
106518,
220158,
11744,
24854,
166678,
15575,
16233,
321311,
47966,
29550,
40187,
47309,
93235,
299283,
50555,
46768,
278123,
74053,
8656,
25384,
null,
86813,
241082,
268671,
null,
244461,
152197,
12188,
362701,
59433,
200940,
22288,
null,
190142,
null,
30177,
42716,
169491,
6376,
31671,
622945,
72573,
301754,
null,
263208,
79744,
49043,
53152,
44156,
18906,
42441,
118149,
194653,
119248,
230540,
37542,
55619,
118831,
153669,
216137,
38914,
151996,
58173,
34568,
13139,
4761,
34273,
77237,
233871,
19438,
23161,
31163,
28492,
154567,
418081,
145615,
40988,
109862,
184637,
209399,
27912,
null,
150200,
null,
137518,
92589,
422405,
29843,
null,
240569,
62856,
133587,
34364,
56596,
210873,
8457,
13768,
138656,
196614,
628147,
null,
4288,
234380,
null,
null,
228479,
52984,
14769,
64061,
194643,
26408,
56483,
118710,
174362,
677571,
null,
104297,
null,
null,
195816,
174567,
125775,
null,
35175,
183516,
null,
167181,
6767,
null,
33997,
188174,
218557,
165002,
304332,
23210,
333738,
null,
240091,
75522,
204427,
267234,
288150,
345824,
3960,
12796,
null,
125181,
3389,
57564,
93716,
99871,
8317,
18818,
28301,
null,
12164,
9440,
127235,
55248,
103755,
127122,
null,
null,
6832,
37575,
137213,
null,
53030,
218819,
97966,
21762,
25394,
43142,
74335,
192810,
15083,
158328,
148604,
56053,
214380,
26489,
5589,
635,
49569,
45462,
105573,
191579,
26050,
372491,
278897,
131194,
34648,
55094,
23299,
8718,
162142,
119404,
132220,
23476,
109307,
null,
20978,
36149,
36680,
84933,
54693,
69262,
21073,
624229,
234927,
10915,
336638,
106124,
46781,
265378,
203781,
29505,
165464,
11067,
22918,
8599,
182902,
200225,
324258,
18930,
8497,
107022,
246775,
133814,
47750,
14154,
30293,
93415,
null,
197017,
34392,
17328,
134467,
104616,
139040,
48300,
116198,
70903,
23923,
19818,
247355,
null,
null,
9179,
172219,
26572,
164281,
48660,
null,
113661,
336986,
3140,
249413,
9387,
47471,
50345,
146815,
23893,
34845,
4067,
280559,
166098,
156498,
314249,
375374,
140238,
null,
151478,
154949,
520139,
1583,
319999,
3616,
26154,
3475,
34949,
32358,
156827,
290310,
224851,
135234,
27550,
142788,
477786,
247735,
84465,
386415,
126051,
280299,
818609,
13903,
13298,
909133,
211227,
38195,
3237,
218745,
294103,
76672,
31775,
115437,
137559,
21714,
25064,
9698,
33641,
57665,
268934,
33590,
57015,
290379,
118792,
16735,
50717,
112249,
293221,
7220,
37503,
23669,
219574,
159105,
34145,
51030,
38856,
24179,
154399,
19752,
161903,
12745,
22541,
7550,
276622,
null,
24803,
16167,
24619,
15704,
194791,
33104,
41675,
26060,
46128,
null,
472929,
88101,
458132,
null,
265058,
36618,
67330,
23238,
74334,
18938,
19578,
null,
28050,
233653,
null,
199245,
45985,
154070,
359694,
51621,
null,
183532,
65042,
216586,
41367,
45995,
18817,
32627,
172450,
147805,
null,
297136,
188051,
265657,
11126,
135434,
113686,
189862,
158384,
14368,
245657,
376392,
14985,
28695,
31089,
21016,
217055,
20333,
209723,
142668,
95388,
211872,
178867,
49798,
138805,
21046,
308887,
162215,
38958,
119432,
150287,
183072,
42245,
60268,
24784,
240728,
252856,
11645,
null,
36454,
88287,
null,
129087,
133718,
null,
36116,
32798,
176936,
13347,
40460,
63936,
648,
216432,
49301,
18957,
null,
231993,
336386,
311698,
172540,
47229,
34973,
172013,
91431,
111563,
7243,
121074,
233195,
25429,
18166,
32371,
11824,
44903,
null,
115053,
59804,
305177,
124469,
40247,
302955,
27656,
303908,
623483,
372272,
196430,
25146,
111664,
377664,
28398,
179674,
207644,
51846,
34668,
72261,
null,
169594,
142341,
null,
133024,
null,
3000,
null,
154184,
80287,
39084,
798541,
93165,
726757,
45400,
473115,
237951,
90771,
69004,
661104,
1791,
41268,
20855,
78411,
161075,
94615,
78644,
13137,
86128,
25475,
56295,
221330,
91484,
15559,
250194,
261965,
35361,
343339,
36869,
11672,
384253,
286315,
null,
193292,
217124,
8221,
null,
10384,
7734,
34271,
388138,
82146,
231006,
151614,
262156,
525806,
52838,
null,
1946,
null,
136056,
25671,
251580,
56709,
6775,
116489,
36522,
158371,
215224,
405747,
177679,
10906,
53985,
114500,
15921,
46045,
145679,
151887,
62225,
24572,
44396,
143619,
77373,
449060,
null,
66853,
133778,
48216,
182259,
115746,
436590,
654255,
313919,
27068,
null,
23858,
90941,
208472,
null,
7280,
88294,
9621,
79378,
68769,
33975,
181073,
103298,
40639,
46703,
null,
153663,
233387,
37010,
49030,
30070,
50021,
46078,
122376,
168363,
202828,
81606,
19524,
117439,
115795,
21994,
21851,
280640,
166057,
72246,
8276,
48354,
null,
365805,
344315,
21970,
164672,
null,
55156,
121578,
358843,
42722,
216050,
199543,
null,
229404,
138418,
3591,
255513,
226777,
24645,
1020895,
187876,
43815,
648169,
254317,
31287,
45774,
368902,
53003,
41521,
242311,
17465,
192558,
242091,
348116,
30428,
459333,
45979,
15567,
198221,
76180,
142274,
138034,
27478,
32440,
8784,
429073,
118762,
31188,
71910,
273455,
47277,
14712,
97434,
249369,
313737,
null,
327300,
151509,
57517,
100245,
170271,
39944,
36213,
41439,
12866,
61508,
192184,
null,
13058,
253427,
137977,
54222,
122343,
13875,
1064152,
222943,
2620,
12372,
null,
64814,
29328,
null,
98493,
8520,
213026,
390736,
371963,
117284,
75060,
354031,
321169,
null,
55080,
136816,
119553,
176096,
46551,
7170,
116819,
12148,
36191,
null,
271918,
17963,
16239,
210724,
270554,
239309,
552888,
152521,
21124,
27469,
179065,
19296,
5328,
20204,
7859,
null,
null,
90270,
40810,
35355,
null,
86359,
215603,
39779,
256812,
138084,
42003,
185888,
45379,
192604,
33407,
179998,
314914,
27407,
67096,
39537,
81049,
41401,
54621,
307986,
279760,
35224,
48684,
106837,
484744,
480363,
35092,
16899,
221129,
82677,
319155,
166638,
40817,
44541,
9992,
224733,
477285,
268827,
421856,
20122,
392042,
51389,
29307,
null,
null,
48676,
114902,
185526,
15984,
238105,
201417,
21477,
164443,
24091,
80291,
567006,
38382,
89107,
128203,
298615,
34527,
51123,
19904,
32122,
67228,
287256,
96542,
474487,
35787,
296444,
333736,
26761,
63529,
163324,
125087,
37692,
436747,
null,
72486,
27923,
23579,
262564,
60035,
112290,
6422,
317485,
178504,
63763,
163903,
38453,
187527,
185103,
17844,
248505,
218460,
60314,
22412,
303922,
102851,
8608,
11827,
11050,
40637,
347697,
32702,
7537,
16585,
202542,
82589,
12485,
325863,
309989,
41591,
127146,
467190,
339083,
63399,
333032,
27854,
12283,
51969,
39366,
134779,
426395,
126478,
368376,
115982,
71053,
null,
6809,
169929,
20899,
12283,
159712,
178676,
36797,
293080,
114816,
null,
56979,
35213,
261919,
234866,
40954,
255541,
410517,
46502,
25567,
282432,
247142,
182208,
90734,
null,
57930,
28656,
1026,
44693,
126830,
1135,
45599,
112676,
null,
25868,
203949,
38136,
858706,
128616,
485420,
32438,
214959,
null,
23956,
74675,
190429,
338097,
153416,
null,
184138,
45503,
76066,
6291,
null,
null,
91730,
160790,
51100,
283727,
31248,
422304,
28615,
154969,
143047,
346748,
31591,
94284,
9913,
29948,
null,
32107,
145592,
123081,
222129,
29426,
290290,
118964,
19605,
39740,
217226,
16109,
432688,
223658,
134676,
405009,
178527,
133426,
null,
162645,
14481,
388940,
11507,
42538,
397180,
78577,
33174,
206843,
93330,
31260,
132533,
242325,
166271,
7517,
null,
97851,
467616,
513862,
5194,
536761,
139023,
205122,
48683,
46980,
90818,
49623,
null,
265892,
119395,
115260,
23208,
20034,
826428,
18952,
68957,
160172,
206059,
null,
115242,
53767,
151778,
318328,
49664,
26783,
167434,
47895,
11641,
217614,
50105,
19444,
274353,
278963,
152138,
60761,
194198,
172134,
139860,
226234,
58560,
105693,
19755,
45915,
69809,
199262,
5786,
20994,
28391,
36370,
17772,
59334,
174079,
7271,
35811,
101502,
82256,
102564,
184572,
17177,
30970,
391542,
317748,
366875,
4248,
43080,
null,
9287,
144470,
10244,
270907,
347294,
28323,
53236,
156778,
1332,
309797,
229049,
10874,
225701,
47821,
15786,
329623,
258702,
17396,
191886,
4531,
14836,
84471,
129322,
7827,
323529,
1531324,
47305,
28172,
70628,
175043,
31374,
126742,
208996,
575032,
195074,
22492,
286897,
110329,
4615,
254715,
261829,
341501,
49105,
null,
28392,
107695,
13211,
176081,
382253,
149570,
272545,
37566,
43636,
16498,
264594,
304975,
119796,
null,
112620,
30286,
85349,
411164,
22093,
21594,
41911,
20963,
189856,
48669,
25830,
501653,
76140,
18709,
null,
37052,
389108,
130474,
36114,
290414,
406926,
288991,
27202,
180089,
null,
27432,
46025,
3081,
48269,
305720,
184990,
202912,
34510,
19746,
null,
40108,
29328,
85270,
31481,
412458,
117555,
74266,
25064,
40988,
null,
180100,
20416,
33245,
31688,
12079,
42141,
32923,
213335,
209476,
null,
8335,
128974,
5101,
27992,
44680,
361385,
44614,
null,
22112,
11167,
77602,
229866,
131780,
264415,
238224,
15672,
4689,
25123,
23890,
22188,
301865,
252095,
9584,
9285,
51961,
181498,
21279,
149731,
157608,
303019,
37631,
45780,
282289,
109406,
42575,
null,
null,
121798,
57417,
13705,
35084,
69381,
23871,
18564,
37105,
49169,
136637,
null,
289297,
52700,
219292,
29097,
null,
15218,
492226,
185416,
122897,
198698,
458391,
26237,
29621,
121619,
405974,
20088,
225877,
35829,
277514,
17832,
40571,
179778,
6100,
243192,
32602,
109389,
27906,
37158,
222607,
64378,
33337,
71468,
38647,
32424,
14100,
286928,
16065,
161125,
176271,
134831,
38391,
566094,
161966,
27095,
79646,
402841,
810472,
273634,
null,
390122,
95250,
158509,
19023,
37659,
159839,
226182,
13013,
30412,
89884,
null,
null,
113329,
307194,
272787,
143062,
270996,
17430,
77895,
47415,
176355,
104597,
159228,
315694,
null,
209692,
23413,
159356,
207387,
76163,
202201,
25392,
188672,
197973,
160599,
158275,
107900,
159380,
82817,
null,
493682,
47270,
243352,
198930,
504809,
325171,
24247,
11158,
236575,
43105,
14035,
166238,
152171,
null,
253938,
149387,
26775,
371734,
111125,
373753,
187682,
38082,
null,
240380,
18090,
18687,
304718,
50082,
311761,
8322,
23617,
70663,
30981,
18286,
154780,
291725,
161586,
245021,
375492,
24802,
196032,
275812,
67346,
293382,
171688,
42563,
296056,
6752,
188302,
233570,
6876,
327103,
26650,
480304,
51078,
225011,
null,
177069,
38830,
131856,
null,
43072,
82600,
107925,
33482,
11552,
38846,
139476,
19262,
60687,
140124,
290558,
8065,
95287,
58716,
262530,
184481,
282502,
235282,
25954,
363765,
16876,
22232,
160007,
24454,
121449,
35580,
12222,
103338,
37141,
50996,
86621,
21435,
36456,
null,
36852,
19854,
95121,
225734,
null,
100942,
392595,
437529,
192818,
10934,
23617,
250097,
280707,
143514,
233658,
145674,
12697,
191965,
29798,
24002,
60742,
34619,
108301,
190239,
408617,
179994,
null,
211279,
24529,
182649,
397123,
119737,
356961,
null,
19140,
296910,
147538,
164139,
22350,
40979,
60536,
204206,
10547,
72486,
null,
164668,
42003,
51977,
536130,
null,
1379,
null,
114298,
170954,
341173,
18814,
13530,
20460,
180730,
299799,
408706,
6141,
2331,
495939,
null,
145531,
157539,
621428,
null,
null,
194059,
85988,
null,
26422,
316795,
458380,
397832,
28404,
12571,
43012,
574806,
85827,
101782,
358872,
451892,
38723,
9547,
88900,
9844,
316889,
51825,
153427,
264562,
436297,
113626,
24289,
138910,
70634,
158943,
28536,
23656,
51344,
37554,
30194,
126160,
10000,
9283,
488064,
null,
33642,
52268,
11603,
25931,
991051,
73795,
64054,
163115,
243445,
165243,
82798,
133130,
18277,
31074,
103667,
503714,
168056,
642402,
10159,
169058,
47093,
93561,
null,
158400,
27524,
18852,
122179,
34801,
289986,
891296,
40925,
44781,
225141,
7272,
230614,
null,
32451,
25098,
35130,
null,
31675,
149961,
94159,
15895,
4767,
93748,
5353,
232975,
204720,
451868,
71724,
80646,
16689,
17510,
37828,
77470,
13815,
21263,
267869,
95229,
334687,
44882,
19419,
63109,
35300,
null,
363728,
149160,
9440,
238095,
268420,
183969,
9326,
119858,
65715,
50566,
19956,
296330,
143166,
330443,
197594,
243207,
163337,
166225,
289066,
10079,
71449,
45608,
17856,
77393,
null,
11483,
598300,
254568,
37458,
112489,
144209,
null,
10027,
168084,
167469,
58287,
23983,
182651,
154853,
136906,
808556,
46584,
262205,
857422,
69430,
32534,
48262,
345607,
53686,
202698,
79286,
257162,
382400,
148432,
187827,
295163,
191573,
1225,
10183,
29256,
45023,
4656,
58790,
22164,
22370,
34206,
62469,
15031,
83461,
56960,
449071,
72949,
227079,
10108,
33068,
555514,
185723,
152396,
253303,
null,
35842,
250853,
722094,
222682,
null,
16613,
null,
9654,
107816,
335893,
null,
181743,
67570,
363757,
248386,
42818,
40393,
276005,
59906,
25240,
30622,
215249,
302948,
30976,
208467,
152841,
31904,
626208,
22491,
45771,
410801,
9896,
40873,
258661,
47689,
258769,
205231,
52907,
null,
78885,
190232,
28408,
199959,
82629,
39079,
28927,
116577,
null,
274918,
null,
4720,
83449,
null,
492767,
null,
3806,
75280,
173100,
299657,
1179722,
322114,
31247,
42883,
12056,
null,
214469,
null,
41656,
318520,
197544,
365035,
271100,
6646,
127642,
250503,
19227,
48069,
11646,
17921,
214230,
300738,
20212,
429154,
172024,
27816,
55941,
300595,
4939,
110850,
350900,
17581,
33977,
15295,
343099,
617988,
10984,
20124,
10723,
71739,
198843,
37264,
237204,
364690,
53185,
16867,
12998,
171586,
20316,
230769,
526983,
44790,
203402,
112414,
18823,
null,
null,
383509,
12012,
null,
null,
4655,
67278,
30346,
206963,
56403,
35810,
190885,
300195,
144918,
56479,
166026,
34733,
37361,
358306,
28180,
23321,
95789,
87223,
29093,
161388,
null,
57788,
246149,
603184,
24542,
208717,
6072,
23290,
110962,
341243,
54841,
30929,
null,
58866,
29900,
7464,
13830,
272615,
31500,
12134,
5867,
44176,
11919,
null,
67537,
62262,
552631,
35820,
207793,
103221,
56398,
21314,
200945,
13058,
133399,
31365,
66767,
null,
null,
200082,
108099,
78873,
51967,
46712,
214179,
231699,
21715,
null,
19126,
29933,
26928,
1177,
7674,
115709,
218459,
13276,
458856,
33157,
283386,
209669,
329226,
364936,
296214,
90951,
36550,
47594,
333433,
31387,
163996,
44628,
254080,
239660,
9548,
null,
24661,
207014,
298539,
28249,
148647,
195493,
216873,
86148,
47399,
184701,
719676,
50171,
171574,
212506,
460763,
183856,
52383,
180078,
12632,
218337,
129572,
14531,
88991,
20644,
154566,
276277,
138414,
null,
115337,
91397,
81723,
154615,
369096,
190640,
363472,
11033,
188685,
8909,
54961,
119427,
136465,
361033,
385526,
18187,
23410,
61980,
57804,
206844,
288319,
32185,
227700,
223009,
356089,
25153,
21073,
166275,
13136,
105205,
8001,
13091,
322053,
null,
112419,
null,
141227,
276063,
8349,
240182,
285905,
28310,
32022,
390640,
136674,
null,
null,
132330,
60752,
null,
36652,
209755,
31785,
25525,
17392,
32706,
26378,
91912,
76517,
13039,
null,
205718,
53694,
69322,
9358,
23742,
139008,
30642,
90245,
104833,
31277,
173255,
198110,
208138,
39533,
105409,
121844,
29722,
261745,
38327,
160036,
160499,
222594,
11086,
86342,
2949,
40825,
398713,
702637,
168228,
28072,
42770,
42941,
135565,
28690,
264428,
18158,
9764,
509943,
87511,
168151,
6708,
31894,
87599,
188549,
38406,
null,
245126,
59254,
40525,
36307,
69261,
440927,
6043,
107151,
7763,
28361,
18350,
null,
206640,
null,
190567,
184514,
null,
21867,
481348,
124362,
233302,
735104,
74518,
11117,
185970,
626651,
37382,
null,
203839,
300011,
13569,
29638,
11518,
37009,
31193,
100470,
23304,
178572,
16024,
90360,
17628,
348927,
287932,
27876,
null,
149511,
80325,
105157,
213372,
216038,
287490,
353271,
18286,
530299,
9861,
null,
221873,
285808,
null,
70959,
358473,
8923,
35674,
11796,
322574,
35593,
null,
267664,
184227,
24199,
69723,
184017,
39360,
25202,
220150,
21854,
122635,
21136,
308128,
20924,
51031,
37937,
28175,
134991,
255098,
159272,
283916,
28118,
149653,
229404,
220948,
52368,
11684,
186201,
32502,
107982,
10613,
28488,
301685,
19305,
34979,
61676,
42913,
607411,
12763,
962183,
39147,
12407,
290989,
152891,
193174,
23050,
29272,
46810,
366958,
7582,
2043991,
450064,
60644,
237724,
null,
null,
236246,
58449,
51941,
59397,
171913,
null,
74008,
null,
34324,
46717,
204039,
null,
158986,
20637,
24841,
79029,
257724,
8443,
355888,
null,
140652,
97841,
324283,
22650,
241144,
274885,
344586,
null,
44030,
51832,
58110,
null,
210702,
30139,
120235,
18381,
26393,
253928,
79328,
256161,
200646,
365120,
97339,
3307,
null,
179966,
156695,
191826,
443433,
43235,
30610,
279954,
116019,
213339,
106847,
null,
164661,
10401,
118007,
16626,
78827,
214918,
181108,
622825,
38653,
259200,
77588,
212458,
54801,
31775,
361354,
21740,
188017,
25437,
null,
14431,
109081,
43156,
96746,
31674,
95594,
null,
254058,
4025,
115754,
12193,
4324,
10200,
194317,
130389,
4513,
256565,
364269,
8558,
18610,
null,
279078,
167881,
20848,
149097,
38268,
376716,
28296,
514692,
179341,
5069,
null,
265671,
61348,
317367,
92512,
6682,
13375,
43248,
11031,
10586,
61604,
11126,
73606,
23691,
null,
366548,
40167,
138691,
86886,
43791,
120117,
27589,
167269,
188239,
403249,
427900,
129294,
323021,
37610,
59845,
16881,
47810,
120363,
47935,
38945,
10459,
204919,
59644,
7513,
43025,
97334,
55998,
17640,
62358,
128463,
200773,
694698,
214828,
216781,
370534,
86650,
351773,
30484,
null,
243725,
56139,
24156,
9315,
138397,
352982,
325607,
579255,
16506,
34013,
251099,
41066,
7604,
49285,
10182,
280370,
323471,
11943,
294463,
258492,
4203,
252720,
41204,
330966,
18583,
13436,
45854,
48000,
639429,
20784,
163112,
44528,
427944,
18214,
39463,
null,
111753,
28915,
441962,
null,
85952,
153292,
22912,
68237,
160175,
399663,
103613,
96052,
14674,
252456,
6968,
22643,
12963,
189530,
409403,
null,
null,
55406,
60021,
null,
13885,
33601,
247855,
75855,
124917,
65821,
null,
32755,
237127,
86141,
7686,
null,
14697,
112138,
16323,
21991,
73042,
289701,
296103,
33548,
875664,
30480,
41884,
439778,
123020,
128783,
319195,
60757,
68509,
79749,
290902,
209569,
132019,
null,
25569,
57885,
272805,
50165,
114848,
5020,
38275,
102109,
73998,
null,
519897,
291244,
472365,
26119,
236057,
15454,
5396,
227451,
422331,
70053,
48088,
59443,
33075,
265554,
287740,
9995,
17916,
175067,
103056,
92950,
17255,
60872,
128195,
52863,
17888,
366830,
142159,
204162,
null,
271157,
141801,
102001,
27371,
142065,
273397,
33919,
256014,
33862,
17839,
107746,
358397,
477651,
17996,
262222,
null,
88551,
2127,
89385,
6362,
158073,
21021,
22493,
53405,
22904,
54694,
23865,
301737,
194162,
70151,
20976,
406776,
80735,
233646,
13785,
null,
115665,
308786,
10831,
13411,
243257,
5988,
35545,
41214,
null,
431282,
204353,
6938,
27927,
30797,
469091,
18539,
8507,
1158975,
47576,
null,
28089,
42830,
6016,
23220,
19658,
18887,
21905,
429739,
95339,
200437,
160267,
210103,
null,
null,
35765,
29639,
161968,
484041,
88139,
3599,
74531,
201940,
229749,
286511,
38874,
31144,
35564,
145456,
105553,
30679,
256315,
null,
7270,
260409,
38067,
33873,
105293,
145171,
340312,
94099,
133500,
34630,
24600,
22646,
16072,
371204,
155769,
323693,
267309,
240853,
9393,
268679,
39395,
236290,
46110,
60095,
34589,
7840,
198203,
178765,
null,
787933,
725616,
171893,
38184,
52891,
47580,
28206,
60705,
133225,
28471,
248297,
130169,
null,
31797,
156535,
23862,
403251,
612052,
33749,
23314,
120585,
237655,
null,
78130,
80471,
185572,
452903,
129846,
112798,
12004,
35468,
188507,
14425,
97023,
198204,
154402,
52474,
188030,
40802,
2873,
39805,
449252,
41711,
295625,
485735,
null,
110975,
49558,
24016,
43460,
35279,
67169,
192884,
36109,
48576,
161639,
193442,
null,
16881,
269792,
260654,
16162,
172737,
9722,
620670,
185448,
109484,
50506,
71133,
201403,
306007,
67936,
79657,
53490,
829578,
62095,
33587,
104945,
20912,
40296,
27406,
41907,
16114,
84833,
255467,
107198,
14999,
71960,
431646,
24320,
null,
324945,
81922,
17666,
314913,
28443,
68174,
4247,
16261,
243444,
400325,
49013,
null,
421562,
214441,
228129,
5573,
13345,
51688,
26380,
98006,
256490,
527739,
148124,
199128,
22255,
170331,
6686,
14785,
88905,
135199,
324859,
17998,
30903,
26131,
72839,
192391,
null,
28920,
66859,
45612,
43591,
361464,
41578,
24815,
18838,
17097,
321769,
158320,
null,
14977,
311121,
41424,
null,
76193,
86548,
28486,
108574,
142787,
30058,
38278,
15806,
133908,
19717,
4235,
141516,
160437,
212693,
7182,
309870,
224236,
222824,
224152,
301655,
39927,
177808,
14034,
43436,
59067,
112010,
153538,
40422,
17597,
null,
156838,
366771,
94290,
331366,
57349,
22058,
27740,
195924,
25701,
55999,
129774,
37742,
137841,
36987,
16125,
null,
null,
3737,
15942,
null,
43263,
12796,
5441,
14248,
180811,
17020,
12878,
154913,
71317,
291198,
441664,
221095,
47295,
280687,
343934,
19779,
46603,
417849,
36612,
48596,
256801,
262012,
24703,
23448,
41041,
323232,
431810,
null,
null,
184270,
76446,
14488,
36973,
153270,
31829,
7827,
181438,
168507,
469375,
29111,
96390,
40483,
103233,
17657,
35581,
253761,
208265,
10316,
68614,
null,
23179,
137857,
25523,
213110,
87496,
62147,
36538,
43722,
142817,
62944,
24998,
446710,
129715,
93756,
27962,
16455,
190680,
150102,
165558,
108813,
29857,
50420,
null,
531687,
83165,
143717,
48652,
358495,
348409,
374892,
30897,
464105,
72611,
null,
494595,
159409,
16804,
220530,
null,
364100,
28012,
82831,
9265,
136199,
308468,
206743,
null,
229459,
null,
325551,
360313,
126996,
27274,
83578,
23538,
581814,
109109,
38929,
259215,
25653,
36385,
300147,
21278,
67532,
138071,
59462,
68866,
null,
274891,
154320,
6807,
171270,
59002,
178439,
9365,
212082,
908655,
108642,
331759,
147382,
null,
64831,
29126,
258760,
1925,
126390,
182934,
231821,
null,
102736,
157497,
465710,
210156,
null,
279394,
264389,
137638,
29075,
24375,
55846,
192980,
233463,
151267,
363157,
null,
81149,
64634,
49163,
68389,
19740,
70937,
null,
null,
152246,
13856,
52128,
62094,
200614,
260600,
174210,
421308,
117057,
6696,
41107,
31093,
56840,
176419,
82893,
9664,
21683,
17276,
115973,
55872,
null,
210303,
19726,
108892,
5780,
324592,
71165,
240079,
26855,
99136,
77804,
204453,
68531,
14391,
138961,
27985,
40623,
326044,
2954,
124691,
37946,
156423,
161721,
68475,
349030,
40767,
48331,
41393,
210528,
211937,
279471,
45531,
147908,
121229,
175527,
162095,
167405,
365453,
9614,
21286,
122560,
86183,
22957,
193109,
162086,
197321,
14069,
5159,
19769,
149392,
196470,
34561,
28769,
9118,
22837,
30661,
196702,
10945,
203888,
681911,
null,
329528,
82883,
22133,
480070,
412503,
174947,
186689,
28662,
50884,
380783,
147113,
17214,
33402,
43333,
378356,
334100,
21335,
48305,
265642,
19620,
253843,
null,
21591,
22957,
37707,
157543,
11153,
52990,
55994,
19260,
205925,
431775,
120869,
291331,
23675,
37621,
892602,
17619,
59471,
13635,
120617,
243933,
10425,
null,
71927,
61268,
391009,
11026,
219390,
11823,
40157,
212175,
483122,
124549,
null,
312892,
156131,
38716,
29300,
63682,
15594,
122121,
192938,
374823,
16459,
259587,
140690,
14286,
86868,
27202,
473635,
null,
41258,
242897,
173706,
238525,
null,
268240,
9670,
64157,
93116,
20351,
322321,
13935,
null,
432149,
76175,
35881,
12919,
2700,
17805,
14457,
398402,
258751,
21771,
248001,
79587,
25701,
187021,
148174,
295784,
345037,
189309,
28588,
31850,
135397,
115225,
467607,
44778,
18605,
230549,
162469,
49193,
43547,
14272,
null,
171997,
13976,
21272,
70072,
77788,
5988,
92497,
399945,
67082,
431728,
42592,
125736,
20967,
310323,
null,
null,
10390,
32765,
627361,
139294,
25989,
10019,
136188,
39732,
25291,
15034,
8998,
30232,
109493,
5849,
50107,
24194,
225320,
100049,
251330,
null,
64969,
80496,
31792,
63418,
104595,
230658,
265994,
51022,
200461,
448679,
234588,
16100,
16512,
102114,
396470,
60836,
null,
48517,
426705,
78113,
321946,
176331,
268013,
317006,
32496,
null,
31100,
347954,
null,
null,
null,
12991,
154947,
241184,
46418,
772429,
null,
588207,
218499,
22840,
123553,
251939,
5379,
363063,
47397,
158942,
null,
86239,
28458,
null,
null,
23111,
24499,
78013,
67261,
207331,
null,
137869,
6132,
177720,
24769,
253747,
17524,
null,
37367,
48922,
null,
244085,
395739,
42321,
40073,
24545,
58113,
18047,
79277,
17698,
186607,
271984,
146957,
null,
38208,
301737,
14397,
312868,
106099,
3414,
31056,
305523,
49320,
null,
72482,
99567,
49850,
480495,
32264,
7899,
357902,
28237,
37291,
35966,
11485,
6624,
201206,
279328,
209618,
48614,
93008,
334184,
205425,
47590,
163066,
35516,
61506,
229635,
15419,
69687,
2393,
40327,
16084,
112578,
30698,
8502,
312701,
16743,
28268,
101242,
207335,
41945,
27934,
71628,
50490,
221986,
65563,
310738,
10238,
64770,
33466,
24887,
29390,
299265,
132301,
227825,
149535,
84415,
15103,
257955,
127379,
39050,
73436,
null,
225813,
264924,
null,
26160,
201270,
46845,
298928,
19801,
161408,
22894,
142762,
37823,
53653,
87242,
323587,
28413,
172698,
15683,
71268,
53949,
null,
17762,
412485,
181026,
200559,
275627,
121749,
305103,
44417,
6400,
49910,
37915,
30487,
25743,
240297,
241925,
45400,
355499,
1090199,
67489,
321432,
27359,
27604,
236269,
249011,
83921,
2408,
81552,
15344,
239125,
249324,
205751,
546178,
146598,
184862,
77051,
296234,
34067,
332694,
124163,
228907,
10524,
31270,
250334,
61500,
247415,
65349,
22968,
36861,
134375,
46262,
182962,
null,
304148,
33120,
337677,
null,
205002,
33625,
45624,
345779,
124787,
90114,
61722,
null,
16006,
4660,
27960,
63208,
221175,
42278,
486799,
259944,
365643,
408971,
195896,
212526,
31916,
7090,
7183,
19624,
17470,
11152,
25627,
81451,
30739,
420138,
14761,
192692,
null,
17171,
142190,
222139,
196977,
44847,
263503,
242268,
172329,
149799,
24061,
172513,
93730,
null,
251573,
174244,
145985,
10475,
424404,
null,
88830,
34500,
52126,
293255,
330365,
123386,
74017,
23223,
24591,
752026,
24803,
null,
26476,
295017,
17708,
291831,
26944,
55749,
141684,
98086,
272070,
27798,
174884,
419395,
null,
182398,
171355,
33004,
23796,
65600,
7049,
35655,
105918,
null,
65387,
65931,
null,
227504,
286902,
37055,
33891,
39134,
42295,
85559,
151105,
38611,
48696,
79839,
52415,
88835,
3630,
67599,
410026,
30432,
9277,
null,
78844,
549792,
120124,
115190,
112209,
449740,
19713,
71492,
null,
178791,
96224,
279558,
255792,
286823,
null,
4780,
60259,
31764,
253618,
10802,
339464,
42966,
4294,
10204,
64139,
62838,
235862,
80847,
21422,
44119,
3210,
92477,
228299,
38243,
24074,
18088,
304062,
153321,
40203,
55240,
43252,
null,
261529,
27515,
91427,
null,
5454,
33721,
247673,
101724,
43995,
66160,
124705,
54635,
68773,
44610,
38289,
62297,
381943,
null,
19054,
31874,
242202,
62197,
199602,
31506,
25928,
12854,
10713,
390918,
68207,
5884,
143269,
null,
9485,
72060,
97831,
215551,
227339,
8122,
72049,
303426,
22066,
248620,
51717,
42461,
83301,
31279,
178342,
32277,
33230,
25775,
203931,
23283,
17980,
324431,
101314,
null,
null,
106003,
null,
158834,
9736,
246104,
17953,
168211,
207116,
26709,
25736,
128163,
518370,
311160,
38298,
120566,
391619,
144688,
40148,
15853,
63811,
40063,
16178,
77338,
298006,
null,
34305,
96262,
339371,
252135,
14336,
null,
52401,
72777,
42179,
27588,
35544,
28125,
10686,
16062,
50610,
null,
46627,
64176,
54137,
75567,
30679,
183119,
40607,
43433,
190394,
224121,
53990,
114334,
249067,
67192,
12954,
49575,
1085912,
140760,
262666,
106583,
230731,
7204,
65944,
35704,
33752,
27192,
30945,
95537,
165707,
43584,
14285,
92556,
117643,
13285,
164611,
185263,
174286,
27100,
27138,
125838,
50009,
397655,
52627,
89005,
292743,
913925,
22964,
215585,
35069,
4104,
242942,
149838,
28696,
220751,
91352,
499564,
317943,
null,
3777,
203430,
58000,
145391,
38276,
287688,
30810,
388997,
220091,
26454,
96994,
218453,
95753,
30294,
234594,
null,
129997,
null,
340563,
44550,
51686,
70215,
null,
210515,
58565,
172049,
192971,
18779,
37425,
26375,
68849,
15206,
21729,
11860,
22482,
38458,
163926,
69887,
19049,
250500,
231080,
225127,
23986,
271194,
306669,
31408,
45372,
406900,
17528,
209310,
177332,
31367,
37367,
48194,
null,
null,
67736,
6251,
187039,
354311,
31544,
314869,
98274,
198400,
447953,
137505,
591919,
13129,
26959,
231530,
43406,
137545,
5656,
10573,
550404,
497889,
35666,
99085,
62549,
275690,
367743,
36393,
375189,
19096,
241001,
283124,
45527,
133919,
717036,
20925,
null,
418960,
21844,
null,
null,
291895,
1236650,
181690,
188895,
261171,
139236,
278189,
null,
356768,
47908,
1069743,
75671,
306718,
7900,
257864,
469971,
49714,
186010,
null,
23153,
52814,
181699,
32590,
199030,
144924,
11333,
87829,
2060,
190060,
13710,
279556,
199129,
null,
19033,
209827,
null,
71215,
65906,
35884,
10170,
30444,
342009,
248109,
98442,
36610,
115511,
191720,
233337,
200633,
289920,
58956,
290008,
197189,
19293,
24383,
null,
null,
151576,
6652,
null,
167615,
346460,
50586,
65942,
407473,
261671,
16771,
65974,
149216,
172584,
24599,
379202,
1727023,
24000,
448879,
null,
18847,
51766,
513530,
233460,
53077,
40748,
15648,
211275,
192971,
null,
34944,
32983,
null,
33509,
227199,
146594,
71178,
202339,
180957,
null,
78297,
null,
38935,
23188,
50192,
null,
55896,
6843,
null,
27199,
12205,
170420,
170217,
5667,
209905,
44518,
91991,
31825,
62544,
300641,
40470,
36235,
10589,
64240,
116188,
392394,
312137,
23346,
53693,
26835,
58508,
57331,
14151,
166378,
null,
278516,
182135,
null,
null,
241920,
24279,
50633,
137524,
209599,
831949,
13360,
40066,
2338,
17437,
10744,
244772,
48636,
22646,
74742,
140474,
123449,
null,
171643,
6678,
360650,
159249,
172494,
123936,
368990,
1217,
13906,
344875,
61446,
137380,
79504,
364515,
188467,
319961,
28223,
955426,
106017,
null,
21468,
27826,
100368,
431000,
155251,
13998,
16251,
null,
186667,
null,
62838,
160187,
14829,
6030,
272366,
166947,
3144,
112911,
null,
91182,
31524,
null,
225767,
324848,
40371,
51319,
292231,
null,
28060,
287452,
61146,
337075,
13320,
271303,
5633,
97195,
null,
70292,
12520,
18722,
7455,
null,
64445,
null,
157821,
4992,
3623,
13554,
32806,
51685,
5915,
51717,
34293,
51787,
70942,
401561,
51960,
61584,
null,
18494,
246798,
41136,
96377,
55286,
null,
106590,
901887,
28292,
null,
18395,
14014,
41560,
30705,
302592,
62817,
null,
5990,
36686,
null,
184141,
15905,
4033,
37390,
80160,
14409,
701862,
281024,
53625,
20764,
231807,
55238,
30765,
null,
37529,
7573,
11454,
196399,
36527,
231019,
7743,
40056,
66943,
62773,
20719,
146746,
17749,
24672,
121474,
151579,
null,
41140,
487315,
27223,
46755,
97086,
246595,
281263,
44806,
86363,
73576,
48865,
null,
49538,
433472,
133068,
39311,
31667,
45539,
217752,
52652,
70760,
50142,
137805,
300858,
350629,
354634,
266344,
29296,
5100,
4812,
50681,
200839,
238705,
50659,
5076,
21426,
57739,
25229,
239945,
34329,
3929,
367935,
114525,
79348,
39016,
84253,
8573,
24992,
59793,
62471,
null,
92011,
19137,
592283,
60192,
196423,
9703,
51354,
371395,
155683,
111097,
406376,
47712,
413531,
313269,
72038,
343851,
171356,
null,
105797,
26615,
28241,
385268,
24585,
57406,
185564,
462695,
31203,
25712,
null,
544037,
32567,
15258,
278247,
3321,
null,
59468,
325942,
17515,
274481,
123043,
20774,
134106,
25023,
70683,
23020,
52857,
154802,
null,
42112,
99763,
null,
26112,
29835,
48121,
111102,
15919,
13239,
83931,
22303,
370601,
30408,
487732,
326908,
36861,
null,
183481,
null,
22253,
null,
20023,
102639,
118506,
27790,
310507,
null,
35657,
43588,
329173,
28140,
302777,
217682,
4368,
32469,
29706,
598464,
69434,
108812,
25902,
160055,
349009,
131055,
20184,
43671,
20498,
214110,
252509,
53230,
23319,
148605,
29245,
52174,
null,
10525,
549700,
null,
33207,
56156,
36363,
77264,
14204,
54253,
510740,
214720,
292510,
35676,
null,
null,
17257,
37342,
null,
53847,
19999,
null,
90532,
20650,
23764,
671720,
142712,
3956,
230245,
697466,
130715,
28843,
53843,
48874,
146621,
428407,
355163,
129919,
341386,
21705,
20139,
38861,
307426,
303420,
57026,
156951,
null,
20604,
46951,
221898,
20870,
589479,
17891,
7507,
408625,
null,
138336,
59917,
null,
78902,
14010,
354927,
220044,
38314,
48961,
292492,
9670,
376788,
63359,
9483,
10794,
587691,
47145,
61395,
120473,
25436,
158062,
96255,
296472,
455778,
68545,
40219,
14359,
121974,
49936,
254385,
66447,
102197,
14737,
43736,
11146,
613119,
407876,
29551,
312262,
18622,
6922,
204667,
140436,
116078,
153286,
28613,
309518,
68870,
206976,
147361,
6194,
584365,
39418,
301598,
127751,
68112,
325651,
165040,
24729,
15530,
41387,
96518,
43447,
319032,
61455,
8962,
289002,
null,
203982,
665128,
null,
114602,
49876,
28940,
31374,
61763,
212107,
29720,
31332,
42100,
180587,
37370,
77777,
5040,
36950,
252005,
7881,
25612,
null,
73712,
247594,
null,
40655,
8524,
29081,
241001,
259349,
181399,
42800,
56103,
301178,
71138,
23846,
150142,
121472,
232387,
null,
225585,
12024,
10332,
15825,
14293,
128070,
null,
null,
55690,
100016,
10591,
26972,
null,
125851,
172926,
31590,
394086,
143211,
20513,
314227,
null,
46338,
47561,
4049,
24131,
135194,
28532,
39879,
242166,
null,
41966,
362279,
198926,
283287,
18917,
110543,
17246,
257458,
353998,
403081,
34460,
85834,
300465,
null,
263407,
4528,
59079,
217092,
18180,
49655,
208113,
10854,
50633,
330891,
178193,
114853,
null,
161511,
687429,
46811,
23782,
278223,
null,
291876,
17269,
157194,
38300,
203844,
166324,
58517,
8410,
4747,
612712,
42088,
168779,
70845,
236379,
17430,
11904,
140577,
188752,
185054,
353355,
25916,
586481,
194275,
214588,
105529,
75579,
14563,
206241,
237016,
null,
84572,
null,
154980,
null,
30478,
15442,
41099,
7016,
28151,
176441,
453695,
138554,
28990,
33851,
17342,
137734,
161012,
6682,
15820,
414981,
56328,
69803,
378185,
377214,
188534,
380834,
144791,
289426,
16897,
33392,
13847,
333979,
177033,
254346,
286559,
267803,
28394,
28281,
138943,
71155,
129734,
48524,
208929,
143930,
null,
42662,
17389,
19936,
28743,
null,
87989,
217391,
null,
19314,
46923,
344830,
null,
33159,
13519,
23496,
178592,
null,
24275,
108867,
null,
330662,
187783,
78516,
37078,
207418,
null,
40754,
53932,
259433,
162082,
239593,
null,
207990,
312393,
85844,
null,
16570,
39323,
235318,
391301,
340778,
205075,
25679,
null,
11782,
446087,
61941,
9178,
69039,
72566,
119870,
60201,
123112,
73747,
396131,
73894,
257949,
377279,
121051,
253057,
395751,
215164,
88904,
42714,
30991,
101797,
156659,
240498,
190572,
27305,
48785,
337746,
48055,
140977,
446918,
null,
2022,
277467,
null,
null,
515704,
39490,
340747,
92955,
13980,
37968,
303462,
45469,
184438,
37675,
210190,
57111,
19461,
35631,
566171,
86165,
16567,
206813,
8760,
2390,
36148,
76916,
45622,
192615,
267305,
47606,
10532,
20471,
80793,
3624,
1579,
9913,
24419,
169486,
591562,
118051,
148815,
171065,
140773,
null,
17874,
null,
5436,
208627,
77726,
426976,
1011,
291265,
657266,
15917,
587840,
16126,
385005,
225344,
220524,
21283,
77525,
7756,
23880,
212826,
348763,
273752,
97907,
104840,
30434,
null,
11891,
173940,
26415,
69407,
29984,
131521,
517002,
null,
102770,
241872,
222012,
11800,
207930,
20442,
72223,
22772,
65983,
null,
109981,
77692,
null,
23946,
242009,
19632,
25936,
49718,
474302,
167859,
56247,
97354,
187955,
8987,
479959,
187058,
173497,
486724,
14615,
294962,
126278,
null,
226321,
254121,
332360,
141026,
226663,
null,
7715,
null,
10342,
198942,
30392,
37216,
184852,
45990,
301393,
144642,
246074,
33534,
297264,
30794,
356629,
34089,
902750,
355591,
50418,
null,
42025,
354760,
198301,
5663,
86392,
61756,
28570,
64188,
117162,
48413,
198579,
13652,
238783,
null,
13852,
157437,
82513,
21781,
20061,
241803,
307451,
132621,
130117,
277762,
314325,
6254,
16609,
265791,
34089,
24155,
16286,
19532,
5496,
118794,
231849,
15724,
null,
22560,
76488,
126348,
51698,
263962,
8881,
216275,
null,
213561,
40914,
33059,
208206,
80845,
29426,
29982,
18443,
31051,
26049,
63820,
30885,
21388,
246476,
17997,
240854,
null,
195166,
125946,
13572,
81099,
20849,
260896,
3537,
19004,
31780,
72748,
565478,
167748,
236690,
266508,
24634,
33677,
147963,
21547,
334547,
259944,
91371,
null,
405490,
35949,
34559,
341480,
40786,
48833,
35988,
null,
17094,
77093,
30893,
474337,
13892,
166988,
1647,
4874,
276258,
175989,
null,
81555,
21031,
233207,
null,
1351,
38378,
47402,
141178,
14821,
89144,
261002,
189478,
14906,
228876,
241771,
33651,
174045,
206177,
49838,
null,
181147,
null,
8765,
26940,
88542,
178222,
11181,
33352,
null,
null,
144854,
283620,
47763,
14358,
700136,
85573,
13560,
127914,
2692,
76893,
4541,
26350,
48073,
42008,
321203,
50619,
225568,
79523,
60751,
215136,
29122,
213536,
28603,
363028,
17228,
null,
41536,
320770,
null,
3814,
null,
null,
23071,
212105,
66232,
19244,
202370,
242940,
379025,
25987,
86242,
10098,
43128,
100870,
189180,
69473,
250108,
404489,
224819,
40840,
6096,
129225,
59463,
137224,
314740,
42255,
null,
163076,
10904,
58607,
42946,
370333,
87481,
17902,
180599,
52057,
133464,
39159,
378746,
281556,
57310,
null,
193655,
241170,
325690,
47910,
27699,
50643,
403170,
null,
384342,
177810,
4570,
56655,
145199,
17478,
229554,
18170,
317001,
17231,
94684,
28528,
349903,
170775,
null,
4629,
18675,
79865,
172929,
95451,
151466,
150974,
178945,
null,
9652,
33977,
15725,
null,
34371,
45238,
57223,
287831,
186744,
17519,
219579,
379719,
null,
42952,
334378,
35876,
47473,
10424,
60468,
109071,
362364,
347497,
127841,
415482,
159897,
147526,
71105,
333237,
125437,
211486,
6679,
50384,
31265,
23391,
65866,
179923,
21477,
null,
225870,
280827,
651246,
45915,
39341,
502113,
2288155,
202482,
39024,
136562,
26870,
140952,
null,
23740,
337024,
170966,
49630,
26167,
172257,
279168,
38259,
39650,
374875,
43635,
140803,
30201,
239318,
30961,
30917,
28281,
56459,
124412,
443949,
172798,
20170,
29216,
null,
358595,
69793,
null,
498364,
178418,
27830,
null,
null,
115579,
39298,
33092,
21402,
93087,
35847,
45008,
197745,
11877,
142367,
99822,
142671,
null,
375279,
null,
142544,
null,
26233,
49720,
54087,
162411,
104997,
106703,
37268,
188447,
209500,
452353,
179582,
177489,
287096,
null,
16204,
104093,
49248,
177262,
30429,
19365,
75235,
184699,
173707,
26877,
52843,
283827,
169642,
397500,
89245,
128106,
44021,
6159,
18041,
445414,
65499,
203751,
29167,
58067,
202871,
177000,
61824,
214732,
20389,
17577,
186589,
31489,
353784,
141903,
5415,
294986,
22688,
38377,
43586,
46439,
54620,
309423,
579584,
45523,
6714,
null,
33262,
60914,
267869,
416052,
39748,
276640,
354430,
320894,
93598,
438779,
52725,
186382,
44217,
20681,
141700,
597718,
120307,
579795,
139100,
17759,
38672,
143800,
110209,
178341,
264578,
285419,
37995,
24530,
268026,
167318,
61761,
103425,
178539,
223093,
318019,
626677,
161934,
174528,
340052,
55182,
90811,
null,
351895,
231007,
247991,
638270,
13134,
33355,
18465,
null,
289722,
40611,
13495,
321040,
127905,
419475,
338833,
136994,
16932,
12502,
24367,
18396,
37312,
null,
345354,
63013,
235995,
64258,
7618,
null,
219593,
62081,
143819,
91962,
null,
null,
250900,
41805,
null,
27328,
30251,
77952,
2852,
null,
45129,
302276,
283899,
101696,
43192,
19090,
354806,
43184,
127944,
35365,
93447,
180891,
34971,
204856,
34962,
21941,
39799,
11406,
null,
116479,
230390,
90388,
156363,
61549,
17750,
427959,
11901,
23023,
163464,
315061,
3112,
null,
423367,
303228,
176155,
17070,
299808,
288259,
156649,
366361,
7576,
53102,
5288,
1332,
null,
81386,
277889,
426437,
44740,
4770,
26128,
13117,
85301,
29122,
null,
70909,
30913,
25564,
40742,
16552,
127728,
21144,
12596,
9499,
48253,
44208,
null,
38642,
169726,
66255,
426525,
29386,
306884,
95738,
252183,
208010,
34174,
196082,
205738,
308539,
6019,
null,
233342,
22588,
null,
286760,
280856,
16550,
169119,
8454,
339044,
29145,
308032,
265417,
169007,
49030,
108871,
12543,
867989,
306722,
300723,
47393,
578659,
37612,
23120,
32650,
249688,
216006,
16736,
252927,
204640,
34380,
274412,
25827,
113057,
281958,
26178,
162137,
15629,
173358,
44206,
31674,
20735,
41174,
8254,
17621,
142541,
85553,
22130,
65224,
85228,
30677,
10399,
302413,
45854,
200165,
null,
281572,
517837,
470102,
30370,
194178,
123709,
126399,
21064,
36342,
32976,
48397,
62833,
66122,
14477,
251805,
144725,
null,
26664,
230568,
25032,
429947,
143556,
null,
null,
150446,
608889,
144370,
154610,
436150,
255952,
null,
41885,
319872,
271546,
386417,
26739,
62771,
20781,
13189,
11511,
null,
null,
353496,
22325,
246454,
null,
null,
24989,
6810,
null,
120071,
144224,
528613,
181960,
223782,
215795,
15493,
668267,
33608,
24727,
61178,
39903,
151752,
12462,
54220,
206645,
17265,
null,
199302,
null,
37736,
126749,
69019,
19102,
361817,
247971,
54529,
33479,
23310,
37883,
155647,
19160,
344828,
224472,
524205,
363691,
40227,
20590,
108641,
null,
null,
5752,
21390,
14262,
35077,
62852,
25263,
301619,
54830,
29682,
371584,
83831,
52986,
16567,
56393,
355424,
383762,
313713,
251776,
110629,
270441,
421051,
32165,
11788,
430566,
953950,
172170,
26165,
419059,
null,
16652,
null,
276203,
87354,
12322,
276666,
null,
31914,
null,
53056,
267532,
143882,
11259,
37314,
73210,
21924,
381640,
219961,
50299,
null,
65712,
93708,
159684,
193990,
null,
22046,
18081,
null,
18619,
305052,
8999,
42866,
257432,
249550,
808833,
59629,
14275,
null,
null,
1212030,
166044,
191878,
117750,
460120,
333849,
29021,
18832,
79330,
42598,
295708,
18946,
null,
20436,
93872,
36440,
118412,
29743,
133286,
297249,
169553,
402010,
273535,
121850,
71787,
255101,
38766,
70287,
35621,
152640,
42805,
26339,
null,
386186,
183907,
196406,
10357,
39306,
8594,
130348,
11452,
17768,
301799,
943965,
null,
307238,
42116,
288261,
161802,
81575,
432577,
59107,
172287,
36834,
15288,
366619,
43804,
17337,
5685,
11207,
130547,
58069,
53504,
292248,
41504,
413469,
302803,
null,
40339,
null,
null,
152789,
160472,
331100,
201190,
237251,
24503,
497808,
138770,
6657,
5569,
236844,
74138,
null,
28122,
25027,
108781,
262754,
278822,
64710,
91127,
13197,
31071,
292185,
null,
49725,
31413,
271581,
161373,
176020,
268421,
184320,
null,
62695,
30242,
45705,
49399,
137573,
4988,
null,
48304,
172412,
45131,
352813,
26414,
36611,
26267,
49024,
62332,
42743,
null,
380315,
39402,
328260,
77743,
67655,
null,
null,
null,
521105,
48090,
570585,
85423,
67896,
236,
495507,
231620,
170684,
16198,
21100,
160444,
168950,
22820,
195613,
149281,
26487,
53233,
228956,
243420,
443662,
446434,
60537,
29663,
93676,
31640,
26874,
12782,
310681,
43586,
500657,
null,
251035,
295791,
348600,
null,
155720,
4466,
270587,
171312,
35577,
null,
173248,
null,
205379,
219677,
null,
1867,
44797,
31856,
7091,
278805,
56801,
14317,
null,
null,
25882,
39942,
240157,
18001,
47282,
263675,
155139,
21242,
27594,
77355,
246948,
null,
14401,
218195,
273756,
90734,
234087,
73117,
null,
null,
12754,
23898,
151190,
202144,
98153,
25123,
48850,
null,
38435,
42097,
201044,
18553,
14482,
66412,
273746,
47040,
21183,
28981,
51017,
309916,
15217,
37797,
20962,
137828,
109834,
14987,
22274,
41322,
40062,
10360,
188208,
222,
185663,
234554,
254784,
null,
279711,
76640,
321488,
76089,
238541,
37346,
24506,
94275,
37596,
46891,
32820,
54278,
36067,
null,
212546,
189131,
4049,
212537,
14323,
null,
215574,
286088,
96872,
122705,
53813,
163487,
35030,
29825,
14778,
201090,
254099,
32119,
null,
17959,
261940,
24025,
25836,
118021,
57360,
203627,
82887,
320298,
39449,
566847,
239296,
41782,
208600,
36439,
9188,
59736,
216488,
16642,
34359,
45905,
6091,
null,
14479,
36712,
509758,
null,
268508,
411167,
327514,
142164,
2443,
22166,
7139,
178465,
33173,
98287,
6597,
251438,
80674,
35288,
265678,
82671,
42111,
46189,
173486,
30510,
24897,
156522,
256340,
197301,
183101,
54527,
9877,
38486,
28424,
27674,
12001,
182202,
91976,
93839,
122646,
null,
13742,
142019,
189462,
135871,
45083,
116244,
24284,
49631,
5959,
303747,
33594,
573401,
39361,
418322,
null,
385985,
null,
37413,
3510,
77314,
72823,
null,
1477057,
387559,
23344,
172626,
338242,
102018,
null,
171167,
109620,
286434,
122543,
null,
157460,
75083,
79701,
28435,
114023,
34296,
31441,
44611,
93066,
31945,
33780,
132491,
562062,
48757,
292324,
340350,
74429,
33964,
null,
null,
266491,
101620,
93449,
231508,
28519,
32787,
118822,
626537,
299901,
null,
32798,
139670,
null,
117823,
null,
83180,
39331,
555965,
154189,
42659,
16516,
11333,
392945,
7809,
601954,
9719,
54047,
7771,
null,
24968,
88192,
183582,
10979,
35111,
51429,
35271,
404725,
127804,
null,
280210,
98533,
48148,
62966,
70554,
29581,
113949,
130328,
26556,
175787,
38034,
9731,
166779,
null,
280079,
null,
171463,
260569,
36401,
62634,
225679,
12655,
31114,
12618,
48165,
22859,
9465,
69154,
77524,
225757,
40222,
29829,
369343,
340793,
5457,
418621,
110580,
10148,
351701,
61970,
217816,
630226,
206485,
210481,
134221,
67932,
21138,
23889,
496816,
54851,
296824,
58518,
405339,
110042,
18968,
24008,
210250,
282152,
145353,
16769,
16075,
166909,
251368,
110820,
76093,
9877,
378072,
5289,
null,
24525,
88951,
16434,
35689,
265343,
36572,
15978,
null,
248251,
12976,
null,
491070,
104735,
503816,
30218,
170701,
8857,
103637,
28202,
66604,
3589,
7635,
47816,
377462,
36771,
null,
1004684,
50260,
149951,
42303,
8079,
8238,
null,
12136,
166225,
27894,
38739,
24860,
24514,
107467,
7146,
52550,
131231,
239559,
247772,
291702,
126808,
118826,
1810,
323391,
400558,
33558,
680045,
192198,
236102,
312106,
4038,
12434,
null,
49200,
725328,
107790,
251093,
null,
61631,
576293,
28717,
null,
178411,
333535,
143509,
63552,
37163,
44397,
22443,
65402,
21234,
16811,
32644,
37145,
21043,
13016,
8981,
62567,
70490,
187109,
null,
243721,
202730,
39138,
11579,
180601,
null,
146834,
264619,
37682,
12279,
77215,
41448,
81854,
91000,
null,
67859,
829762,
124459,
173732,
28774,
null,
29246,
119666,
null,
66439,
126224,
null,
8806,
19145,
null,
410345,
49532,
69697,
35079,
19482,
499207,
505,
16110,
171310,
283845,
37906,
223253,
81427,
191951,
446953,
62807,
11549,
null,
25100,
null,
8183,
null,
128174,
111568,
22135,
156248,
65024,
287295,
93544,
22001,
50686,
200102,
17365,
54396,
377631,
63491,
54223,
382863,
33651,
510904,
15621,
164616,
700259,
56229,
12595,
682324,
66363,
22307,
61153,
219622,
34405,
152292,
35204,
41324,
3866,
null,
null,
23293,
14867,
225537,
420162,
24013,
42097,
395102,
628260,
444712,
182219,
252714,
83635,
null,
23579,
182044,
164069,
46411,
23367,
17003,
45182,
505219,
170732,
36919,
9523,
12728,
353920,
33399,
163462,
159727,
329835,
248846,
18566,
334044,
45682,
378737,
null,
null,
9250,
158486,
429850,
88747,
424713,
33558,
76529,
59633,
223928,
null,
null,
116784,
96137,
25733,
38843,
23798,
359827,
837050,
23554,
5438,
232489,
108356,
57061,
12692,
null,
235928,
33298,
268238,
55268,
216246,
12104,
39451,
41264,
390059,
null,
248802,
39891,
134356,
34850,
241906,
54452,
null,
null,
67074,
99656,
23364,
57716,
18786,
18558,
254167,
508303,
15099,
42709,
52204,
218416,
201365,
284831,
31103,
26580,
28298,
289330,
30516,
75024,
62441,
23750,
345109,
25391,
37884,
174599,
80723,
263497,
32006,
42481,
122410,
14369,
15819,
75854,
195055,
305633,
26105,
15024,
8326,
37079,
29931,
14825,
156125,
7176,
52766,
459814,
27834,
42378,
null,
35308,
57866,
108808,
10453,
228899,
125079,
380459,
169902,
474215,
47204,
22872,
17911,
36032,
56898,
null,
25247,
41791,
45613,
47136,
43756,
null,
28570,
87149,
2954,
154842,
51906,
282206,
250349,
29954,
19677,
null,
184266,
226114,
4363,
2109,
20916,
150385,
113372,
47633,
185319,
null,
101880,
19647,
557647,
180484,
12833,
23113,
26573,
337049,
715277,
288601,
174227,
195204,
149800,
null,
40804,
346838,
196721,
27509,
157140,
20887,
11450,
70772,
144508,
101803,
265892,
43066,
2541,
241144,
30080,
14850,
35572,
9217,
240038,
51451,
93832,
40793,
18790,
30257,
107554,
326661,
68938,
19263,
67982,
100264,
20067,
85496,
318786,
55204,
19353,
38801,
90690,
20434,
null,
22959,
37408,
76245,
394536,
null,
null,
321277,
178098,
null,
217652,
38132,
370254,
22164,
466429,
355403,
13817,
129963,
16042,
47634,
519313,
56426,
237639,
126661,
50928,
216228,
null,
null,
136667,
14416,
436337,
null,
129010,
51534,
320477,
21930,
47816,
164649,
null,
41736,
202577,
null,
48027,
395283,
207601,
132306,
null,
148852,
6732,
34486,
22942,
325237,
64049,
317298,
6569,
17015,
167809,
246622,
237630,
293973,
149443,
null,
140104,
null,
15343,
45486,
28525,
154862,
7818,
18267,
201546,
282850,
320817,
15583,
190675,
null,
null,
7767,
35765,
456167,
294421,
323578,
null,
null,
361649,
25253,
325329,
65694,
26567,
112301,
495406,
323722,
324688,
58025,
105773,
52347,
57020,
198983,
26196,
88517,
null,
47974,
58133,
122595,
9774,
72292,
12025,
null,
138701,
null,
19190,
153455,
8211,
80212,
35767,
59044,
11656,
206765,
112599,
44350,
null,
581040,
113439,
21841,
18219,
40177,
157117,
5592,
253912,
39374,
8456,
309337,
null,
130945,
228493,
589573,
179064,
212144,
68750,
22642,
233740,
230,
52333,
71856,
32205,
168227,
207737,
null,
26692,
null,
16094,
521145,
null,
48839,
16895,
11196,
12369,
383595,
16901,
70814,
80062,
352831,
317179,
15775,
32445,
324248,
119920,
57353,
29133,
141035,
18659,
394025,
344760,
33608,
63479,
null,
4963,
203600,
36763,
233408,
21773,
null,
71773,
153350,
20272,
30768,
null,
25270,
222568,
23117,
30738,
29732,
317,
17699,
27047,
16786,
18009,
115440,
51860,
82042,
21131,
16060,
170860,
32793,
28663,
null,
26532,
359270,
20885,
238916,
4440,
209955,
283781,
null,
226026,
17987,
14068,
182951,
311725,
79019,
20354,
null,
274219,
47470,
366890,
10084,
64226,
270842,
44816,
null,
700335,
25111,
106441,
95715,
168251,
9514,
304999,
null,
80184,
22687,
40053,
181256,
234950,
450425,
226532,
9677,
442966,
82211,
269276,
40672,
713978,
121889,
22156,
197290,
48669,
67116,
null,
16589,
247963,
13131,
30839,
85991,
10910,
89229,
152890,
62186,
44681,
304052,
168557,
381518,
122344,
3501,
40078,
null,
260341,
67107,
11991,
273588,
null,
50287,
29724,
4774,
null,
31029,
223371,
62308,
177211,
154105,
858785,
386183,
203853,
49154,
170266,
84921,
698925,
235565,
177090,
100595,
277180,
252023,
105573,
null,
15336,
29649,
19674,
8197,
244098,
189180,
106174,
253193,
163195,
26746,
35453,
355148,
37318,
26016,
233444,
27619,
null,
160119,
35521,
46960,
23616,
472737,
11759,
160647,
null,
189235,
461421,
117869,
11277,
133375,
38867,
6758,
61316,
23665,
15050,
8779,
33744,
41882,
6140,
142506,
19689,
30677,
21192,
46031,
291510,
21121,
87672,
36143,
46689,
22023,
54793,
52427,
33963,
20862,
42538,
171312,
42167,
182527,
9310,
9042,
67318,
218443,
8350,
27909,
37131,
111453,
15710,
133749,
157219,
31467,
137096,
191038,
509729,
52611,
9999,
null,
null,
380957,
154951,
208146,
52268,
315366,
13535,
88514,
304844,
203881,
252447,
null,
284861,
200548,
159379,
303208,
9122,
110001,
14373,
166494,
360324,
236276,
273598,
206731,
20384,
10257,
null,
43501,
881284,
254064,
92367,
null,
81459,
16595,
290880,
null,
81886,
40323,
null,
null,
null,
46447,
171098,
133112,
null,
100146,
240727,
95160,
258779,
375536,
135566,
129984,
178284,
98777,
83873,
3830,
281791,
170058,
59894,
244675,
55699,
39686,
171410,
33527,
null,
95973,
51692,
60585,
28729,
180726,
null,
89098,
29685,
296981,
216408,
19007,
36366,
148998,
12586,
313656,
267467,
50961,
67987,
44714,
6757,
56010,
29244,
11551,
42894,
77677,
null,
null,
189529,
70604,
27086,
355226,
110279,
118929,
22390,
468978,
110060,
608145,
197716,
264430,
273298,
261161,
77735,
22949,
28701,
348426,
66545,
44231,
317058,
174324,
17265,
18274,
153347,
138256,
320422,
497706,
74505,
11874,
20366,
117720,
80826,
32780,
446419,
411512,
36234,
214265,
null,
34474,
31376,
287160,
38121,
210469,
231508,
156815,
340403,
null,
298482,
20392,
32756,
341918,
202083,
6896,
50602,
60296,
224353,
210702,
55584,
11440,
222689,
185811,
44489,
15545,
71024,
124506,
37280,
57133,
327012,
168171,
25990,
6462,
162854,
32808,
37196,
100756,
61932,
307948,
10051,
303353,
32765,
30052,
null,
35617,
114370,
31667,
null,
7453,
363230,
547924,
168738,
23695,
80610,
203802,
38141,
null,
216987,
52120,
35456,
32168,
32626,
23813,
166813,
17760,
127149,
103297,
94909,
247114,
127836,
366330,
10974,
61121,
238147,
188160,
286799,
null,
144689,
4711,
243520,
37245,
126966,
121945,
318692,
16774,
20903,
12227,
null,
31518,
163631,
51507,
6295,
null,
10733,
167837,
19815,
133048,
445544,
38058,
79229,
77982,
34161,
34264,
null,
null,
64607,
291737,
157819,
12662,
16337,
43942,
9230,
381792,
97117,
null,
6430,
8703,
128675,
39969,
49545,
12090,
251761,
23945,
141423,
91177,
387779,
null,
182793,
395524,
17415,
70371,
189323,
46563,
200962,
327013,
228477,
145860,
231681,
null,
285496,
38290,
26757,
47844,
48872,
286939,
221639,
261916,
315500,
92061,
49005,
102878,
223800,
376696,
30362,
200960,
148786,
392809,
39884,
32120,
121588,
null,
117243,
121821,
null,
177299,
89919,
27087,
38762,
14789,
211358,
null,
26839,
314643,
34648,
25572,
1222,
630413,
201255,
59935,
53428,
47423,
161597,
null,
452029,
99170,
7777,
28775,
126497,
15113,
268198,
40956,
456706,
75015,
430199,
184645,
166607,
null,
115500,
16390,
21075,
23547,
104763,
null,
15896,
19282,
28419,
278993,
null,
148706,
192561,
10198,
40876,
49367,
141678,
21174,
39771,
46218,
101397,
15968,
174808,
27280,
null,
366648,
336779,
9512,
67329,
33998,
242559,
41774,
75163,
164320,
134015,
11646,
244125,
55370,
19479,
40709,
78634,
229631,
323077,
109013,
59204,
9039,
16310,
21123,
244688,
94657,
233616,
192060,
14452,
262230,
16631,
12673,
null,
24989,
450293,
44976,
88775,
58889,
157241,
129037,
136950,
29268,
30004,
21508,
122836,
9323,
229977,
31065,
4047,
22885,
77007,
35059,
90911,
167615,
226511,
23455,
97723,
275042,
288126,
237851,
94448,
30443,
25628,
51451,
23977,
154554,
261121,
206239,
null,
38598,
5557,
395403,
23421,
250645,
61807,
128525,
3911,
13339,
10034,
375408,
183015,
153871,
null,
152217,
7547,
281804,
296249,
183339,
473118,
17652,
50340,
67467,
46020,
562128,
83244,
243216,
null,
32621,
null,
8218,
185988,
null,
30358,
287381,
274768,
32577,
138340,
287212,
175576,
64534,
12746,
81676,
41342,
14301,
51037,
271663,
47518,
49672,
248843,
623194,
25940,
11865,
7523,
36573,
25605,
148972,
259694,
418166,
167103,
153118,
234674,
263483,
170191,
261001,
37188,
12890,
25869,
172602,
242468,
273889,
246708,
23384,
213481,
34897,
27263,
7735,
12725,
6551,
15330,
238500,
97932,
50008,
30470,
null,
19702,
352395,
54490,
25139,
428703,
75059,
65457,
224978,
5520,
191855,
22343,
681608,
20057,
42096,
12042,
null,
36112,
361079,
12786,
262841,
385336,
73869,
75725,
43821,
228232,
69927,
5612,
10241,
18801,
351956,
24272,
158349,
43837,
null,
42458,
87772,
29588,
94722,
43051,
276766,
3437,
185578,
56060,
18349,
15719,
20686,
153891,
102644,
11390,
32603,
330956,
228255,
288558,
18392,
40336,
452932,
42322,
34830,
60447,
222635,
21677,
48848,
16599,
441397,
null,
178997,
238339,
39543,
105549,
49509,
59987,
null,
51334,
443653,
10357,
null,
32679,
64429,
33407,
341273,
42628,
62971,
235866,
101328,
13341,
12847,
null,
119699,
13818,
95426,
25857,
274663,
455124,
72282,
null,
159687,
7651,
245518,
304575,
87193,
40535,
520616,
23801,
121580,
132441,
262091,
10874,
23967,
231135,
54610,
17868,
277838,
25000,
74303,
72939,
237291,
15130,
250944,
10303,
207551,
50054,
null,
4416,
164877,
124397,
152691,
5904,
210248,
327698,
42251,
null,
34912,
21719,
72473,
70498,
28252,
210346,
228982,
103067,
317278,
null,
123550,
41682,
230758,
45183,
42112,
null,
239767,
188331,
30437,
61595,
100190,
7310,
137697,
88737,
108362,
35932,
180397,
35912,
71965,
163461,
36037,
57901,
90443,
281718,
59289,
57781,
40484,
33815,
20125,
21284,
10538,
7757,
15411,
27268,
137604,
null,
26741,
1129334,
262982,
38524,
369920,
null,
37500,
5023,
76575,
16938,
198515,
9271,
null,
307296,
184898,
218254,
92062,
358098,
10370,
506712,
259518,
168680,
700404,
505059,
15470,
14341,
517267,
null,
46422,
66246,
66727,
9567,
45771,
62004,
319170,
null,
76340,
93916,
148466,
14885,
138297,
364396,
50189,
242255,
765722,
60425,
38471,
142025,
50667,
79143,
299587,
86433,
298272,
7937,
326010,
12773,
41695,
35982,
251956,
31281,
198937,
99325,
55374,
484084,
222942,
444291,
9035,
35799,
null,
24256,
74699,
45702,
92245,
135609,
150256,
57081,
788,
615520,
73783,
127969,
286260,
172189,
144988,
144573,
7728,
13362,
2875,
165572,
155781,
176929,
9424,
10132,
110095,
18923,
380239,
15662,
19653,
480668,
201901,
37602,
17227,
6726,
141510,
565945,
null,
null,
248586,
190317,
103789,
370437,
4610,
290175,
399850,
14516,
205382,
232084,
194269,
33274,
449655,
241822,
20593,
212180,
16598,
38866,
338615,
7339,
43735,
283227,
null,
171488,
95911,
46126,
175801,
755824,
22944,
268878,
242181,
32310,
395591,
7003,
17744,
6248,
93381,
29378,
98004,
136550,
null,
55277,
28093,
78014,
212759,
null,
30592,
152351,
280902,
402386,
11854,
295927,
268095,
19194,
485174,
3787,
null,
58427,
8958,
842373,
682583,
18600,
85456,
39333,
217625,
11962,
344361,
365571,
137886,
43870,
36619,
8897,
21809,
195801,
120059,
27681,
261425,
67478,
230850,
243071,
119439,
188065,
161012,
37972,
186727,
45099,
41639,
null,
25780,
257267,
8582,
47367,
131286,
4842,
101523,
58227,
160245,
28926,
38075,
8267,
13032,
298065,
209523,
191743,
523793,
49092,
60698,
21396,
55341,
227995,
84688,
108220,
12705,
4783,
8546,
110448,
335454,
177502,
260484,
45286,
495453,
null,
203051,
18800,
10794,
115344,
null,
200551,
20257,
64260,
30404,
null,
33499,
23095,
25814,
39699,
98542,
408823,
46177,
65024,
11679,
48703,
200308,
157899,
255241,
219469,
5509,
182621,
172640,
50039,
32489,
973217,
24973,
108526,
133755,
9801,
null,
28702,
104919,
null,
247618,
445684,
997,
216487,
8703,
202870,
261783,
14676,
58231,
201465,
203186,
231188,
300517,
171003,
null,
null,
317951,
232088,
15295,
248283,
13201,
null,
201262,
495019,
2497,
17837,
117945,
343121,
11519,
63731,
null,
149091,
185647,
171357,
29728,
363696,
535445,
121919,
31907,
196187,
316147,
51516,
30676,
65422,
26717,
null,
65516,
38868,
58884,
9765,
37944,
194833,
321334,
254191,
43642,
281487,
38097,
11789,
391145,
16537,
53485,
41361,
16479,
60532,
28483,
666487,
721173,
19436,
654435,
214773,
null,
9730,
147706,
304110,
157476,
70089,
86895,
163459,
101418,
288962,
248241,
76691,
158585,
85087,
35401,
264271,
93073,
173282,
251864,
152262,
334399,
60097,
81565,
173911,
44293,
222696,
277707,
38716,
32995,
286395,
220290,
436161,
262294,
214562,
null,
153404,
79041,
56497,
277947,
null,
null,
217189,
107148,
84997,
8014,
24945,
416119,
null,
52498,
27000,
80905,
383036,
51014,
13952,
22158,
41508,
22931,
162842,
4875,
35469,
31594,
6421,
null,
132197,
27630,
26979,
649842,
7332,
138315,
223592,
182213,
15016,
224407,
464777,
844206,
null,
42827,
150487,
40646,
103329,
365195,
62028,
45572,
8666,
39377,
214054,
144527,
449165,
315345,
null,
15843,
null,
26035,
83914,
442978,
239828,
93117,
261054,
null,
null,
419361,
27931,
77500,
11411,
118858,
361108,
40855,
359356,
23666,
135711,
20508,
192189,
565490,
13170,
220176,
null,
264508,
6661,
69612,
288158,
null,
30920,
23991,
571504,
319548,
126371,
420353,
88923,
18568,
285359,
615394,
11319,
292365,
21735,
231668,
38911,
27659,
65767,
310163,
null,
13274,
34534,
105285,
40070,
null,
null,
9276,
319056,
418911,
221874,
220866,
199442,
13118,
29554,
12730,
138179,
24919,
257196,
178175,
null,
661566,
593463,
46909,
242831,
15101,
238708,
9873,
6745,
107442,
333885,
53881,
237093,
50080,
43389,
7571,
210032,
379762,
130492,
7263,
23903,
13876,
95636,
30773,
null,
64648,
24153,
199273,
24954,
227899,
94817,
null,
124189,
21030,
25492,
null,
21436,
231038,
29084,
255357,
41642,
13279,
13319,
327848,
8231,
135044,
26457,
11152,
42130,
29661,
142926,
249993,
26727,
215866,
750819,
26489,
496511,
280964,
463096,
76770,
143847,
17533,
154217,
154150,
10864,
494645,
245244,
47924,
322629,
null,
null,
56838,
278266,
17203,
278717,
292001,
218786,
17580,
27207,
361921,
null,
null,
397172,
241539,
null,
53926,
15784,
184638,
20894,
null,
439141,
64674,
22004,
31647,
278694,
68785,
301142,
8812,
71031,
212217,
45240,
511891,
21862,
303126,
null,
2774,
16401,
275783,
108483,
239090,
39315,
420297,
8104,
9764,
94417,
31236,
90415,
11296,
60854,
149992,
237109,
378899,
455206,
93181,
32064,
49110,
51659,
43360,
25703,
14887,
70057,
64436,
35827,
20071,
209616,
23214,
533284,
72950,
89626,
16495,
122960,
35355,
35945,
9817,
272351,
311992,
null,
204657,
14872,
18897,
48807,
31110,
116300,
5878,
263277,
14587,
412215,
392728,
15207,
null,
452387,
72791,
46934,
31977,
12160,
124167,
34926,
null,
181235,
23697,
182876,
145264,
10313,
8554,
26328,
332763,
44757,
66268,
195479,
145291,
195339,
192241,
225304,
113010,
168196,
null,
42051,
null,
22513,
61497,
50868,
null,
20504,
36249,
43305,
41045,
10272,
67376,
89611,
50486,
260421,
3155,
16413,
312735,
565901,
359168,
34718,
59529,
32275,
27889,
197809,
266503,
164050,
189483,
85209,
15433,
70481,
113714,
61705,
344905,
2742,
21394,
82088,
161722,
8411,
186057,
120662,
87176,
6372,
22269,
221400,
337014,
2517,
185538,
null,
22572,
123176,
683135,
46297,
356243,
214215,
286501,
305605,
10696,
28771,
432809,
223269,
9973,
197343,
7721,
21026,
63363,
50690,
27028,
251782,
53688,
57757,
425194,
16020,
134436,
51739,
346762,
5283,
9200,
250982,
48176,
58118,
null,
301936,
37459,
32709,
202911,
20564,
null,
144848,
75736,
355605,
126306,
38836,
305384,
49908,
151456,
127372,
36581,
386598,
74387,
34176,
20202,
181780,
100524,
83267,
308829,
558756,
null,
2685,
77434,
43568,
62837,
null,
180229,
119099,
75423,
203501,
294463,
null,
119872,
155460,
109073,
226455,
12201,
null,
4965,
2874,
null,
16772,
679058,
208574,
51000,
55929,
244083,
72274,
370597,
81185,
68511,
null,
158341,
26316,
90313,
423768,
337493,
34058,
111269,
476005,
1779,
333593,
146950,
null,
null,
216169,
null,
307236,
83955,
75229,
63029,
23401,
196087,
220118,
317801,
114692,
24778,
36627,
248611,
8845,
56589,
635168,
115604,
5902,
12631,
240063,
53953,
70143,
871810,
184560,
22583,
92341,
40990,
47466,
101541,
46526,
681502,
51487,
15722,
143764,
null,
20395,
280496,
21663,
21831,
265515,
66345,
262134,
null,
152953,
197623,
73535,
480530,
13101,
50307,
59436,
215291,
107027,
27343,
53049,
220236,
null,
65941,
7228,
299283,
283355,
211827,
37323,
50208,
61429,
26115,
67756,
57091,
5056,
374227,
186433,
56847,
227977,
196791,
411817,
7675,
18526,
108505,
34273,
289650,
33509,
null,
206529,
178006,
63266,
29199,
55224,
206288,
78318,
11593,
175062,
146703,
180637,
382424,
175367,
205502,
59945,
null,
308757,
291042,
37746,
89734,
149716,
60019,
null,
84928,
303863,
182502,
78836,
148740,
22918,
12694,
160462,
null,
441758,
27605,
209916,
11975,
176216,
7241,
53940,
22538,
59493,
39092,
163169,
5177,
161076,
44797,
40090,
39865,
32484,
282509,
273474,
147765,
231776,
362966,
20758,
206870,
null,
13302,
203131,
34283,
70637,
27163,
209287,
284906,
21327,
250039,
39940,
267029,
69113,
579717,
171851,
169536,
30747,
238868,
43101,
83151,
163701,
null,
271196,
37695,
44899,
56197,
null,
24124,
101174,
71091,
17146,
118646,
366913,
9362,
81034,
152900,
196841,
169536,
23843,
337411,
17545,
151038,
56399,
null,
28891,
null,
466108,
162884,
144195,
357099,
483569,
429429,
280368,
16911,
283323,
429401,
241121,
157982,
23402,
52897,
155677,
1303550,
205158,
6325,
22160,
null,
230352,
50164,
null,
13008,
12492,
null,
149028,
16385,
67640,
47408,
183563,
19317,
86302,
105118,
46993,
57718,
324305,
113176,
22401,
12889,
9799,
14908,
356531,
99456,
306559,
null,
205826,
195121,
29752,
16946,
null,
184672,
123769,
266251,
36134,
241562,
356443,
28356,
191752,
73199,
315766,
187180,
12601,
395174,
290204,
229351,
368347,
171543,
422643,
49340,
50410,
123461,
33184,
318684,
247991,
105867,
248324,
50344,
null,
360372,
141264,
11140,
42544,
148960,
157916,
216870,
42995,
113705,
106962,
686314,
18320,
112280,
428294,
25170,
33574,
17592,
324773,
9297,
21195,
20798,
46261,
77067,
35601,
39562,
62716,
13790,
1185111,
62665,
null,
28523,
392977,
52916,
89758,
108886,
654558,
111956,
90083,
342468,
23812,
179994,
null,
30763,
8828,
84942,
null,
26063,
34550,
26854,
198277,
42073,
17338,
94365,
342639,
16862,
61278,
225690,
183355,
24959,
15625,
248415,
null,
36093,
18976,
44479,
277022,
185807,
103479,
126653,
149551,
257072,
5470,
242897,
13296,
136748,
90740,
896,
55751,
null,
159586,
210143,
9302,
null,
12546,
11337,
37935,
77073,
106771,
301737,
79005,
12664,
null,
27669,
223573,
57145,
141420,
11940,
148425,
15594,
326276,
118870,
324090,
77723,
3787,
32014,
244301,
61870,
355299,
777538,
116218,
51563,
237762,
null,
14962,
37440,
426357,
74923,
31417,
89794,
5419,
249636,
51704,
46065,
136103,
493003,
null,
1138025,
199249,
743793,
4068,
114900,
28827,
374269,
null,
486949,
352172,
38212,
368266,
21453,
112755,
8286,
34944,
9065,
104567,
89969,
54424,
51046,
549117,
368478,
399963,
6839,
587999,
478988,
14254,
21303,
134980,
null,
180287,
26693,
15004,
36071,
null,
34357,
21152,
24516,
24227,
177721,
221533,
24471,
40430,
null,
30251,
250851,
10981,
30614,
null,
169388,
272055,
33966,
281040,
357571,
22218,
77055,
48059,
7496,
124446,
23197,
16693,
125407,
41581,
57515,
null,
52994,
254983,
10525,
71478,
22880,
378395,
7275,
28558,
42032,
56142,
85401,
null,
373996,
76000,
557765,
500570,
135564,
47306,
148092,
17568,
21033,
273586,
46391,
45467,
59064,
40003,
83011,
266153,
25826,
93964,
52846,
36808,
168084,
14198,
83520,
40490,
74350,
39166,
216805,
25062,
62153,
11619,
173563,
22978,
53292,
13181,
37905,
41145,
279232,
254,
401733,
331213,
28626,
35875,
133833,
25452,
10211,
411201,
29900,
4574,
18486,
null,
null,
17281,
25368,
84114,
37857,
15500,
49634,
null,
184696,
null,
57667,
null,
236856,
63815,
382827,
37507,
39985,
278572,
285425,
null,
32768,
246091,
143453,
81087,
20688,
23077,
118071,
144074,
29445,
47078,
361072,
10769,
52410,
24681,
291480,
123790,
167027,
256465,
5430,
11097,
null,
10632,
80877,
386023,
762669,
211839,
136167,
59409,
285220,
null,
40451,
86901,
50191,
22520,
57391,
134190,
38126,
169521,
132807,
101215,
345545,
18977,
122134,
140002,
null,
194161,
42502,
22163,
335894,
9207,
8827,
75692,
2992,
208619,
471138,
76550,
274646,
16616,
35483,
347481,
22760,
114346,
null,
57152,
1324144,
96643,
15818,
401540,
2198,
106801,
69846,
null,
248736,
321502,
29701,
27932,
18422,
62882,
298651,
null,
17585,
20136,
null,
2696,
null,
4942,
329230,
31429,
9465,
335258,
151748,
143852,
310911,
76344,
46898,
180443,
226681,
14838,
37296,
null,
125856,
105977,
28446,
28600,
6385,
243729,
167127,
38074,
156036,
18026,
35311,
469226,
78211,
40242,
42714,
21692,
6890,
410045,
53681,
57888,
129556,
87627,
67192,
null,
26055,
41569,
172272,
49937,
24958,
37416,
51445,
36770,
85212,
8980,
82481,
55852,
37648,
9249,
45140,
95440,
20021,
61514,
78421,
29671,
124328,
208212,
41666,
68280,
1765,
400396,
12006,
22784,
19142,
310538,
49435,
121852,
161945,
40383,
133823,
202866,
313342,
24165,
null,
null,
74840,
257096,
195530,
52998,
83230,
17201,
136235,
121492,
20394,
131119,
187251,
216613,
161602,
330058,
467725,
205601,
49280,
415294,
3941,
47697,
60299,
180897,
171289,
494724,
36640,
202559,
null,
19403,
28351,
469010,
null,
384325,
39104,
136875,
37367,
null,
26385,
74404,
180373,
359644,
8303,
212118,
229791,
15267,
327089,
323120,
344980,
20264,
245305,
133362,
10097,
35301,
4906,
33388,
5170,
null,
519576,
26626,
12277,
64193,
605383,
209464,
393851,
67401,
339847,
21544,
101760,
8451,
null,
null,
9722,
25817,
63335,
22453,
null,
36864,
251800,
868745,
197718,
52162,
16740,
12961,
40627,
148577,
18160,
61877,
152497,
72594,
22480,
353991,
196423,
34669,
38053,
230437,
37548,
276802,
101069,
467152,
104207,
365775,
219167,
68242,
554371,
22781,
116286,
197640,
29999,
180235,
254137,
2506,
73571,
11488,
72757,
22723,
207704,
null,
106480,
309719,
329915,
12818,
null,
98342,
81820,
20975,
null,
42418,
59991,
143713,
34641,
80538,
null,
null,
132950,
47558,
166156,
40927,
297412,
10407,
null,
27012,
22309,
72737,
null,
6373,
145422,
36971,
15380,
null,
207639,
281609,
null,
45297,
424695,
null,
3281,
90182,
33719,
402745,
363035,
40012,
321103,
362590,
22040,
null,
38665,
390496,
84282,
173797,
19761,
372912,
18133,
57719,
412635,
56766,
12183,
224543,
140526,
10276,
57272,
200342,
20122,
64697,
37194,
81735,
null,
217172,
69535,
39674,
null,
43777,
6255,
12002,
187650,
18152,
29615,
38838,
108623,
66707,
42976,
83656,
82270,
59557,
168044,
58948,
null,
182362,
150790,
40243,
22566,
184622,
179325,
34283,
104583,
16526,
10049,
333665,
176825,
77034,
210538,
33100,
203404,
23931,
null,
42599,
13017,
69492,
220339,
316403,
11975,
167741,
72759,
25669,
283279,
45600,
232366,
46166,
null,
51733,
82977,
191272,
172732,
192677,
null,
null,
229375,
30879,
145280,
null,
19567,
489776,
26571,
63106,
31172,
256195,
96145,
15521,
25455,
105673,
19383,
548340,
32251,
116652,
194294,
652224,
252059,
null,
61239,
12539,
19597,
373352,
161705,
258419,
20716,
46437,
167694,
56251,
137171,
28716,
24485,
22682,
420207,
76754,
40685,
174112,
53867,
391102,
45256,
29494,
25799,
240610,
37314,
62145,
214825,
11414,
44218,
36777,
null,
14572,
null,
133165,
10481,
15970,
28661,
34069,
303004,
135276,
265187,
44618,
6613,
31416,
36082,
40401,
281431,
26185,
138096,
41405,
54349,
203538,
43160,
210219,
null,
149729,
18891,
19225,
512315,
414452,
382804,
53414,
212627,
227261,
13352,
21380,
158812,
34035,
162217,
14860,
17821,
26463,
496248,
47239,
47794,
51321,
66917,
104750,
105889,
103750,
116337,
227619,
null,
17145,
44932,
23283,
28383,
135914,
70579,
9034,
null,
182852,
247800,
276501,
267258,
130319,
535811,
3451,
null,
58984,
10502,
82380,
62243,
12458,
373658,
143687,
17357,
100930,
466640,
153379,
32902,
14541,
50686,
200748,
168085,
72691,
35653,
80231,
null,
8448,
348046,
null,
null,
54817,
31698,
15760,
367343,
35431,
60513,
29631,
131236,
274126,
154856,
14634,
null,
20681,
null,
99655,
45243,
265511,
46569,
51461,
207705,
38144,
215884,
25660,
139920,
372967,
421722,
267022,
null,
317784,
181919,
26674,
17556,
274407,
28977,
404894,
14066,
80276,
24897,
null,
43117,
290484,
229424,
139521,
87883,
430246,
32437,
302444,
54785,
8586,
597521,
360227,
243992,
156284,
23238,
23355,
195012,
33101,
123424,
144300,
407029,
21534,
18718,
273485,
177717,
351838,
119299,
150589,
46484,
103532,
221732,
null,
40053,
null,
34047,
212124,
76092,
null,
37959,
43719,
105063,
230479,
null,
35528,
77743,
129918,
94577,
26801,
null,
62790,
23156,
77335,
99579,
46008,
31794,
68888,
279792,
272070,
7918,
423888,
30368,
119102,
null,
5394,
40165,
null,
295273,
9676,
11238,
374972,
41038,
30966,
196474,
5475,
124871,
null,
119163,
48724,
45629,
null,
188299,
57913,
61512,
43335,
52572,
285891,
312974,
91551,
145756,
242413,
784180,
51057,
null,
12636,
761166,
354545,
21171,
276730,
154399,
32149,
32038,
null,
15603,
203600,
47087,
33850,
33003,
87562,
null,
42681,
68261,
464338,
202637,
24107,
174047,
24347,
197533,
null,
572554,
187162,
135691,
33652,
127578,
51949,
325276,
138350,
29579,
170673,
376499,
54924,
324379,
116204,
158676,
296755,
245302,
201069,
181678,
133018,
92462,
49210,
null,
null,
204980,
null,
87303,
15364,
217086,
21935,
252067,
127264,
25728,
4412,
null,
264015,
16457,
444520,
171923,
154494,
292185,
135842,
22985,
72707,
16728,
305889,
13291,
22686,
11361,
17900,
283109,
43600,
164682,
43051,
27305,
50271,
34539,
23319,
2590,
244645,
44913,
79752,
20515,
93848,
154709,
110513,
37840,
16992,
232889,
257611,
null,
43001,
14068,
5114,
11312,
395394,
139934,
40488,
61015,
174726,
57137,
37227,
147426,
142640,
40068,
185017,
null,
82446,
15799,
219633,
16634,
7496,
15933,
31103,
null,
70115,
66364,
266127,
127426,
170860,
20896,
16120,
13712,
167848,
null,
181841,
10170,
266174,
294854,
16028,
234421,
null,
312778,
3960,
4350,
40231,
null,
146248,
35542,
63086,
118909,
148283,
156381,
544717,
142695,
15280,
138875,
39670,
328423,
null,
12813,
46826,
282619,
14294,
139361,
42197,
434955,
182280,
172947,
838923,
182375,
217972,
null,
15500,
103056,
166506,
181571,
132021,
54894,
230261,
null,
48519,
103478,
60975,
22933,
19270,
31309,
116460,
152864,
70492,
25399,
null,
null,
7277,
169033,
28399,
5239,
417075,
21976,
312627,
2343,
523468,
null,
18551,
110602,
170511,
35084,
65251,
122401,
155553,
22712,
133863,
335161,
452226,
256007,
31464,
12102,
214466,
103866,
20362,
6593,
306291,
81844,
51027,
718207,
125838,
96055,
52530,
116087,
42711,
215262,
203456,
189978,
148158,
199230,
24985,
184616,
5351,
246394,
112205,
7954,
36113,
28813,
21784,
264092,
57457,
195098,
40387,
null,
38617,
48036,
153981,
20254,
34450,
84442,
31042,
272590,
108610,
211553,
null,
null,
36783,
212392,
90713,
37945,
null,
28771,
185260,
276223,
285215,
14868,
573271,
407791,
null,
28668,
18871,
36911,
32355,
null,
53352,
70532,
264240,
35102,
232648,
237757,
68555,
296589,
54629,
18604,
338962,
27565,
308065,
29493,
91397,
53284,
14848,
195041,
41107,
215582,
84923,
119945,
233795,
108108,
61544,
147096,
135825,
2756,
4378,
186168,
216707,
279089,
79811,
47022,
null,
12978,
27261,
157121,
371229,
376591,
214587,
153753,
93217,
82806,
67831,
228415,
95732,
119862,
null,
104490,
76882,
644798,
8029,
47862,
91826,
59515,
375393,
null,
42444,
55168,
43188,
227910,
null,
33221,
275647,
56415,
8132,
109974,
2766,
92767,
75094,
168492,
263899,
48369,
36973,
266416,
null,
11781,
92783,
11995,
337839,
217058,
49563,
61646,
null,
114413,
178464,
259353,
null,
125035,
86303,
235061,
165720,
270294,
190794,
28052,
79849,
36431,
13814,
74003,
160351,
188995,
53929,
56173,
439241,
22260,
47830,
142017,
171087,
23570,
6606,
134512,
160703,
452383,
14822,
10065,
38863,
350537,
25521,
null,
108855,
58568,
115662,
80373,
23393,
17803,
null,
294289,
89186,
184335,
55824,
20594,
26525,
100149,
null,
null,
159942,
178145,
35315,
266454,
23616,
23469,
113299,
18479,
43820,
3960,
155591,
8990,
327561,
null,
37495,
23709,
27923,
14491,
323604,
145716,
18568,
55464,
62890,
3858,
47397,
511075,
40601,
null,
142538,
177632,
94396,
292952,
272097,
42920,
82587,
217323,
514077,
489229,
669993,
61931,
237945,
27271,
36877,
53257,
219511,
445265,
40380,
56528,
108174,
null,
427265,
26177,
59147,
157037,
264150,
12129,
49699,
245164,
150547,
null,
161833,
7758,
27639,
426234,
6051,
60161,
38921,
167188,
49311,
28882,
204112,
106893,
33168,
39807,
63301,
338195,
19446,
15045,
29920,
85944,
18197,
180688,
25240,
219648,
8468,
34380,
134604,
15552,
14994,
28013,
37937,
38152,
24351,
63856,
161341,
9270,
150692,
35653,
20350,
228458,
35690,
15827,
60083,
199056,
102882,
231815,
39113,
null,
353974,
106803,
22139,
165047,
145876,
null,
430466,
78557,
550651,
62657,
4680,
106793,
9976,
47704,
794972,
33434,
39874,
43380,
2267,
1354,
null,
20717,
36623,
58521,
19157,
8026,
60272,
null,
325074,
8731,
24054,
33977,
137400,
90476,
304275,
248169,
7619,
38281,
18165,
354538,
10199,
211417,
25812,
null,
null,
129448,
15776,
589189,
345724,
10719,
374451,
182268,
18487,
273886,
43136,
47307,
49170,
89346,
null,
43916,
9596,
57316,
40772,
16402,
36977,
100970,
213143,
39918,
null,
26096,
32087,
154983,
120185,
31544,
136857,
52634,
22584,
11138,
229670,
122375,
199842,
245651,
212386,
24679,
40524,
257485,
61135,
23194,
39338,
328910,
182708,
5931,
21915,
86063,
28632,
187513,
222444,
4790,
55932,
5086,
38241,
36754,
97266,
223741,
208217,
183980,
47787,
88594,
19101,
178193,
null,
null,
25160,
230102,
55493,
47286,
30147,
18833,
114723,
617190,
67099,
57401,
17709,
374307,
148878,
51755,
304482,
41161,
null,
382364,
175775,
45427,
35118,
null,
55296,
92576,
67519,
null,
25502,
57239,
71702,
32073,
85377,
101369,
339686,
36630,
63173,
21232,
227665,
40182,
288180,
28492,
175138,
243359,
85407,
101772,
213316,
166156,
22537,
51333,
340530,
21134,
19492,
851,
452478,
208300,
77259,
41764,
61304,
51734,
180267,
210969,
61567,
66120,
null,
63540,
44534,
266211,
151677,
142178,
101007,
null,
null,
132369,
334769,
238828,
279480,
10938,
18100,
null,
null,
120220,
41048,
137003,
258245,
55519,
23476,
156982,
21471,
361007,
243872,
389466,
127074,
9307,
57148,
343092,
157173,
91392,
215836,
28681,
19090,
45630,
102855,
31079,
161664,
15328,
372436,
60335,
1748,
18667,
15301,
null,
241978,
419159,
11649,
49430,
423286,
101915,
343009,
150692,
468481,
33350,
2128,
246146,
4759,
350087,
258917,
20139,
232041,
21405,
135049,
246913,
59785,
171098,
6618,
167699,
101926,
65389,
56417,
267220,
2154,
9912,
322827,
354223,
702988,
129776,
93822,
363823,
39099,
104913,
285269,
90836,
105724,
388668,
13095,
335433,
81630,
185775,
69112,
175361,
49926,
21618,
5627,
241547,
16655,
26732,
24061,
null,
227866,
176474,
10572,
260655,
39859,
32467,
24315,
410659,
37614,
10007,
93626,
35476,
40877,
48591,
29908,
232585,
81625,
12631,
217310,
14823,
89259,
34932,
395137,
20479,
596462,
118853,
23420,
198510,
411853,
99893,
72409,
238518,
null,
8459,
null,
16216,
294931,
126730,
119184,
null,
259438,
66428,
29811,
65220,
145769,
122511,
217770,
251088,
82872,
81720,
367886,
1109282,
143976,
19933,
50886,
359680,
31316,
9239,
129166,
154711,
104966,
230932,
161549,
null,
249002,
18847,
59765,
216415,
152502,
41484,
205229,
28284,
30956,
122972,
null,
39876,
94759,
null,
400455,
1650,
37746,
3929,
104130,
12189,
17273,
37371,
12929,
9849,
13473,
12772,
39280,
6439,
10938,
27631,
64524,
98343,
264471,
190103,
1871,
145512,
103533,
7802,
30491,
25908,
22986,
179426,
197797,
31165,
45002,
38216,
30199,
498181,
109755,
26676,
104474,
null,
16521,
24966,
null,
126193,
22740,
250765,
145106,
233836,
48069,
199675,
226577,
286079,
390490,
14358,
421626,
34172,
243350,
23181,
390637,
145238,
70730,
14747,
29234,
213351,
81180,
129282,
157285,
98442,
757512,
26088,
193782,
47021,
404184,
22133,
560749,
104162,
12629,
164156,
29769,
null,
172314,
null,
19134,
42935,
244142,
null,
null,
10849,
49293,
22140,
52032,
557664,
237733,
67850,
null,
12327,
32811,
6557,
87377,
95021,
262870,
null,
69606,
16723,
86943,
53810,
42442,
59912,
134638,
null,
13832,
199775,
73725,
38181,
38550,
null,
144177,
7432,
13169,
98288,
305687,
257157,
33206,
42995,
25387,
83429,
206210,
599703,
101815,
408925,
203869,
166177,
195397,
290499,
28247,
9337,
29128,
4965,
26598,
null,
116256,
152393,
27165,
94314,
11040,
27177,
129879,
54627,
140837,
403401,
362492,
41220,
null,
53398,
null,
13026,
202711,
191386,
47204,
23843,
48397,
384853,
558153,
62019,
172041,
62589,
49258,
24354,
326154,
37141,
30410,
489486,
242241,
null,
31119,
31433,
31560,
68678,
382431,
102498,
33648,
44244,
120417,
8419,
46146,
123482,
28910,
344147,
31264,
225026,
455643,
94311,
276391,
17883,
72993,
243176,
47090,
151624,
61365,
51025,
249876,
null,
29861,
5467,
228187,
260323,
48395,
113949,
34694,
294518,
103377,
170461,
125724,
32662,
null,
null,
null,
480820,
19090,
125598,
129845,
345206,
24500,
42252,
87237,
4217,
46358,
315743,
667844,
146148,
300606,
82351,
36099,
134679,
394592,
9703,
28686,
289711,
10401,
112458,
132337,
633392,
9166,
46374,
27525,
324759,
166799,
61998,
257788,
28099,
43916,
232257,
192577,
null,
288015,
90875,
577958,
193877,
171269,
8839,
47860,
null,
null,
283490,
206668,
253546,
310027,
316733,
22123,
27312,
165937,
27985,
12241,
119559,
9687,
10385,
368451,
250132,
111592,
17318,
41033,
49746,
91395,
28103,
7558,
13546,
228666,
32645,
163058,
7476,
129583,
439554,
101205,
45764,
172525,
496303,
308402,
539352,
75001,
107960,
192275,
109587,
146241,
32010,
33536,
55177,
103643,
259049,
299782,
12357,
6177,
103706,
134375,
28941,
284613,
61425,
null,
110740,
79607,
324627,
6282,
70482,
145339,
294544,
43678,
31965,
24183,
138034,
null,
150170,
null,
99875,
null,
50760,
null,
37727,
214927,
null,
242249,
167067,
65941,
256015,
273089,
40654,
193638,
129108,
24122,
67171,
8825,
46013,
76623,
32889,
133508,
42193,
15504,
31642,
254787,
62646,
32445,
null,
21455,
23085,
443714,
4741,
10807,
232084,
27795,
314823,
382897,
280057,
294739,
23006,
45887,
39032,
20456,
50632,
5694,
null,
50938,
89784,
100412,
399184,
9413,
324750,
21904,
null,
null,
null,
73145,
45991,
98601,
3334,
445091,
78765,
220645,
24136,
12792,
28726,
136161,
87510,
32392,
122213,
170885,
160462,
27963,
84534,
36073,
110944,
null,
null,
54367,
393670,
112020,
25702,
24875,
336879,
27881,
80761,
638994,
null,
10932,
165307,
21247,
355594,
157379,
565525,
233913,
342285,
41182,
115611,
173180,
317877,
33128,
51226,
null,
21938,
53021,
20935,
37219,
22116,
21007,
169566,
168623,
275219,
236210,
147285,
38394,
87914,
224048,
33149,
47033,
251087,
47841,
319599,
null,
41815,
117440,
21809,
50935,
37339,
263624,
28175,
273306,
59566,
103298,
37699,
74531,
97493,
73438,
20548,
232542,
14940,
13288,
239343,
24644,
220887,
129540,
242458,
33004,
11075,
94130,
105579,
32157,
16280,
25461,
16718,
109524,
24117,
628255,
127702,
163996,
17219,
81158,
17501,
163875,
8746,
23846,
168293,
151782,
88708,
26824,
null,
84888,
331540,
38561,
9100,
65282,
53240,
210192,
84320,
117446,
75247,
34124,
37607,
1016110,
352733,
243946,
31829,
21264,
160546,
129981,
150861,
61562,
32212,
62017,
36086,
40068,
320032,
305310,
292127,
58964,
22779,
12351,
88824,
59683,
37645,
120383,
37140,
129863,
53253,
244955,
246206,
241162,
240494,
515008,
null,
null,
35327,
87932,
510307,
4574,
403987,
37204,
35060,
659031,
162220,
null,
376156,
460761,
144337,
50416,
104766,
15015,
124231,
208403,
85668,
36826,
392016,
77696,
41339,
38759,
81270,
258360,
94724,
353272,
313976,
3905,
170564,
42570,
34334,
477263,
387067,
369910,
164799,
64561,
166944,
61176,
null,
39090,
35104,
433317,
31693,
33367,
184481,
32390,
8243,
152500,
25244,
91814,
34065,
null,
15411,
31366,
132016,
43250,
null,
8748,
19839,
18157,
56561,
9367,
35721,
198339,
16908,
43800,
12568,
56998,
440538,
23668,
211617,
94445,
56766,
60405,
164576,
26437,
177024,
393795,
17328,
841207,
24771,
42267,
48610,
null,
6181,
22362,
428362,
28709,
5183,
65116,
43701,
88073,
32439,
13722,
12409,
null,
376827,
268532,
33726,
20750,
141312,
11684,
34036,
null,
44161,
null,
null,
72602,
128612,
346701,
113163,
59009,
7246,
219225,
128363,
143292,
497119,
133306,
273565,
243642,
45478,
26884,
32998,
223564,
134088,
null,
23483,
191376,
18004,
257945,
31196,
3174,
46751,
93647,
32182,
270656,
27511,
39718,
474076,
62108,
459844,
217276,
115669,
208470,
157017,
59708,
97692,
96937,
14707,
455055,
315999,
24205,
null,
141495,
37675,
137542,
22682,
17444,
69388,
14669,
19664,
33035,
71514,
147092,
359718,
15661,
18355,
366635,
90875,
178426,
41226,
24613,
5290,
138736,
19860,
98050,
265886,
33956,
13587,
86462,
36300,
38308,
null,
18688,
68869,
33995,
null,
28975,
null,
30940,
null,
42886,
26672,
33640,
274623,
24803,
71567,
86171,
185106,
28146,
14746,
null,
50206,
75599,
477484,
null,
23734,
42396,
null,
182096,
151308,
349829,
206107,
183682,
13656,
34183,
200688,
222637,
263503,
359896,
268831,
260302,
9396,
52467,
394383,
209224,
467037,
407811,
79197,
332671,
54690,
28049,
15060,
18363,
24078,
32289,
89357,
96809,
435274,
125135,
197018,
341353,
17411,
6747,
55807,
73300,
232199,
44978,
null,
242690,
32549,
119165,
410617,
31125,
364316,
42462,
27817,
433703,
null,
482470,
191798,
56483,
138490,
20335,
191356,
123345,
41660,
25828,
264703,
51880,
82395,
2722,
30200,
77060,
14306,
318320,
44207,
1870,
22994,
39287,
58464,
265873,
37643,
117297,
361688,
null,
21996,
76596,
41103,
264887,
211012,
11942,
208868,
9077,
null,
3124,
87891,
108601,
455321,
70243,
28362,
209543,
416882,
21728,
28230,
22343,
129863,
46000,
144963,
248109,
319611,
154488,
461213,
17007,
164462,
null,
161439,
21123,
132540,
41397,
null,
549802,
null,
18532,
176069,
521954,
105471,
46985,
158692,
20689,
null,
272222,
316631,
89080,
null,
149368,
358199,
173517,
16516,
89609,
null,
87040,
328374,
284620,
99469,
13830,
26482,
189862,
224556,
288677,
28109,
null,
15922,
48295,
156010,
46414,
210635,
34279,
169255,
34388,
128405,
205420,
null,
147300,
53045,
214925,
19495,
201274,
23737,
2571,
12318,
1214,
16020,
143985,
547207,
27794,
473899,
139339,
153211,
null,
35422,
102697,
40025,
28583,
106916,
204869,
292549,
128458,
186355,
250640,
24176,
230403,
211909,
null,
23497,
7240,
378324,
167949,
223471,
14281,
41382,
103267,
21788,
72024,
86010,
26864,
146318,
521528,
11368,
212659,
226463,
14046,
null,
null,
17235,
217801,
459759,
47496,
null,
14920,
860702,
null,
7998,
62810,
87457,
57109,
150707,
331303,
94584,
110492,
43544,
9475,
409322,
186168,
146939,
50867,
44007,
39736,
51570,
34356,
288095,
375095,
299516,
null,
129492,
87961,
107401,
79977,
20145,
14363,
32668,
383404,
152618,
18227,
25382,
null,
126979,
20971,
263530,
5330,
220026,
45703,
53067,
4730,
97531,
null,
11264,
18438,
6412,
322655,
279748,
302551,
54695,
113897,
48068,
3978,
130036,
53383,
289119,
26074,
null,
8866,
56158,
null,
19077,
49251,
322768,
154249,
56507,
83356,
226778,
894728,
54557,
87774,
11123,
64685,
153016,
202206,
17955,
35071,
187625,
265047,
205257,
261997,
7628,
null,
35968,
65859,
93880,
null,
51711,
139164,
259434,
412835,
12288,
null,
null,
60090,
null,
380685,
444992,
null,
52526,
658879,
509027,
129896,
9787,
58041,
74998,
628119,
132771,
62840,
13895,
12037,
224388,
29068,
238453,
31646,
38339,
43726,
6803,
80677,
126080,
19643,
33330,
2647,
153235,
134592,
286242,
247295,
124102,
53131,
151764,
77236,
null,
null,
192117,
55586,
526044,
8657,
58130,
15510,
149013,
78905,
null,
61204,
105080,
21543,
59072,
106894,
20603,
159396,
14809,
139487,
197216,
38573,
356123,
31782,
168006,
326186,
null,
18766,
235244,
353515,
122905,
174867,
13543,
370258,
295701,
131937,
null,
325362,
156421,
175236,
82078,
26577,
221642,
23526,
12286,
311573,
68071,
16217,
224209,
76150,
21278,
116611,
97394,
41743,
24813,
44850,
429678,
129609,
19766,
37325,
null,
100397,
null,
92073,
35615,
273828,
101317,
376208,
null,
316020,
null,
113818,
159966,
138839,
null,
50552,
30878,
7589,
30641,
26963,
44978,
null,
null,
42638,
240558,
30563,
37503,
83006,
16307,
340967,
299154,
93428,
36436,
504723,
133745,
31943,
238504,
178052,
56554,
195967,
125528,
85390,
302016,
227166,
145541,
6751,
29898,
310771,
181689,
288989,
178908,
14786,
36767,
131744,
56587,
202907,
49787,
26843,
86020,
51466,
20483,
144123,
78804,
251754,
38541,
108940,
13514,
78899,
54607,
3174,
165328,
87907,
6238,
74143,
33866,
202774,
607412,
74825,
188304,
15725,
92267,
56711,
9522,
42279,
56810,
28714,
137608,
192389,
99276,
212744,
90039,
218072,
36020,
7847,
null,
168296,
12432,
318744,
15035,
32432,
149990,
252621,
83279,
39933,
259104,
51340,
137748,
322425,
25712,
57182,
64863,
27297,
53582,
25460,
null,
7817,
37605,
null,
67021,
47520,
342276,
301493,
389096,
162360,
null,
1020,
null,
41228,
256788,
165345,
null,
171172,
428143,
163203,
23346,
null,
297636,
448556,
null,
114054,
38824,
197469,
286281,
127522,
null,
5236,
28890,
44443,
147351,
null,
10607,
65861,
49163,
171568,
293788,
238692,
6356,
80218,
81298,
93897,
22441,
null,
28350,
45426,
117878,
21223,
33729,
39010,
26322,
50015,
48727,
106002,
null,
141475,
12376,
null,
27346,
408745,
286870,
31923,
203050,
169106,
54692,
12406,
219809,
15522,
14585,
74387,
687213,
67798,
308853,
7140,
66123,
90568,
333107,
35625,
43741,
2829,
214009,
292136,
184753,
126716,
59453,
378755,
184663,
15922,
288956,
9383,
174725,
52612,
182813,
128172,
240062,
null,
null,
93027,
1457,
15635,
9682,
null,
645050,
336269,
106814,
18520,
202091,
70505,
335837,
67948,
39151,
33046,
1053484,
101449,
439734,
61694,
41083,
66755,
19868,
13726,
133752,
177020,
333582,
20273,
193742,
157041,
587954,
15685,
231457,
40198,
35277,
189672,
137412,
95220,
54129,
28295,
33528,
161855,
280120,
277094,
109699,
38702,
236248,
320708,
null,
484581,
218396,
596153,
22835,
58669,
249016,
82973,
19475,
190016,
372539,
234276,
1239155,
351014,
137056,
null,
238425,
160667,
null,
51842,
16208,
203055,
23670,
216937,
147543,
22407,
10265,
49281,
186194,
null,
120790,
33213,
37536,
15269,
144371,
19430,
12325,
29284,
11401,
108249,
587179,
244550,
9368,
365816,
230819,
452539,
59240,
217326,
18376,
268716,
23173,
133383,
99039,
12874,
69638,
257914,
51467,
null,
null,
null,
37758,
271377,
198709,
50368,
29760,
138067,
20980,
119384,
39071,
206890,
44479,
211801,
11873,
35759,
null,
50833,
166954,
38045,
259769,
93724,
213785,
234432,
290623,
55408,
310346,
436120,
123925,
154675,
null,
null,
299319,
16419,
6405,
31787,
34194,
18432,
23315,
297121,
213322,
19463,
9476,
537890,
174718,
209199,
208783,
219101,
null,
224545,
305762,
null,
67154,
45324,
544861,
30441,
359646,
167133,
366723,
32314,
102255,
17169,
158030,
215631,
21896,
31403,
49638,
7089,
null,
36204,
19320,
43246,
431448,
34540,
307067,
null,
576048,
315008,
129979,
29798,
29187,
null,
46110,
34408,
101921,
11078,
298535,
6613,
235800,
37968,
208789,
292760,
197267,
280535,
17510,
41501,
184745,
36833,
66485,
24153,
181247,
135555,
33487,
502970,
287702,
47899,
40317,
25894,
42483,
34436,
250109,
108698,
32006,
44456,
419625,
55048,
22200,
120716,
null,
12890,
38801,
102678,
208579,
130137,
118774,
47300,
68782,
41426,
34063,
59833,
21277,
254499,
89884,
400017,
2170,
96997,
17027,
538191,
21498,
27671,
47640,
10218,
26587,
13613,
124182,
27714,
60589,
92660,
33629,
177294,
43224,
329804,
86340,
67965,
28945,
28130,
252932,
54538,
520243,
263462,
10744,
null,
35641,
284806,
36075,
357138,
217672,
139628,
69343,
26605,
114339,
327313,
18051,
318423,
184264,
null,
43401,
527773,
221930,
15964,
16291,
54720,
169054,
13898,
14096,
77739,
26600,
null,
21533,
34307,
null,
50359,
14348,
18492,
null,
338006,
211676,
80131,
31062,
72634,
87526,
34852,
8593,
86633,
null,
14164,
230001,
15787,
59476,
113952,
102360,
209677,
170494,
38503,
402149,
null,
9822,
148108,
5909,
160908,
179401,
null,
167660,
67925,
15873,
42126,
20285,
34070,
7697,
135619,
29306,
26690,
63909,
12140,
15888,
15709,
9293,
181763,
76911,
281988,
6625,
null,
48614,
7260,
34066,
293109,
241045,
46363,
187454,
2571,
172349,
171364,
null,
12181,
32872,
14731,
235687,
40804,
245461,
77617,
172376,
52395,
61238,
67212,
48823,
20027,
57954,
128763,
260542,
38805,
248678,
390469,
85896,
42360,
450270,
61207,
59262,
20539,
7110,
12395,
240073,
72818,
60402,
69422,
20052,
1825,
4862,
241288,
41292,
70889,
130103,
47650,
225312,
189324,
4351,
347692,
169400,
216113,
null,
174604,
26662,
52290,
69767,
28937,
16765,
22131,
57820,
33981,
32169,
52278,
null,
23663,
24968,
261897,
74181,
18155,
14931,
121855,
6641,
11325,
347688,
112629,
55790,
190815,
276217,
267647,
105938,
null,
29662,
23569,
5880,
133263,
411110,
248068,
264204,
56771,
39721,
9982,
187975,
50642,
15553,
109445,
111557,
192017,
34422,
162788,
null,
6692,
4403,
5665,
null,
256235,
155309,
58302,
352690,
481990,
23908,
219434,
539049,
234999,
18051,
214137,
80597,
5919,
20934,
154807,
258659,
7168,
188602,
43679,
31172,
null,
26635,
217781,
282155,
19619,
208182,
25374,
570199,
45032,
226737,
65748,
3783,
57607,
19291,
17299,
9813,
390747,
null,
75534,
348445,
172654,
25738,
310604,
168005,
18747,
326168,
88805,
35237,
147179,
324186,
15033,
10984,
52952,
25205,
11374,
null,
4798,
167828,
118061,
15405,
196917,
23124,
22960,
11066,
241931,
null,
null,
293350,
125436,
153711,
13208,
269121,
null,
385183,
25895,
312880,
null,
null,
159378,
584792,
275560,
253328,
136399,
15759,
71045,
304087,
204076,
16716,
12565,
76754,
153835,
131176,
259475,
36961,
24937,
315619,
3154,
468958,
582869,
236967,
12895,
26381,
298453,
93165,
352967,
179394,
27777,
27362,
194608,
138587,
224944,
134412,
211118,
519903,
205614,
163110,
16096,
21478,
256806,
401039,
40494,
44494,
null,
142477,
267941,
108654,
142719,
58708,
70526,
58290,
16151,
41165,
358186,
8911,
null,
220572,
84176,
517655,
81325,
14645,
80691,
121956,
51560,
28514,
12520,
15307,
167978,
94460,
140757,
212477,
66559,
380199,
131746,
199365,
18057,
196261,
19927,
54967,
null,
51481,
64686,
56657,
148085,
null,
180276,
144203,
148165,
426157,
237703,
null,
null,
269154,
57162,
161303,
275602,
27346,
18790,
80697,
29120,
3981,
17880,
89403,
250538,
37131,
21650,
17917,
15390,
157807,
28381,
101915,
156744,
null,
650180,
79187,
196069,
294737,
51794,
261902,
48939,
56037,
12975,
4010,
35616,
123866,
174281,
185362,
710543,
23450,
25106,
413308,
null,
58767,
26805,
34128,
267116,
18176,
37442,
171777,
69692,
null,
33541,
235590,
99335,
31086,
455199,
null,
612744,
208428,
347002,
184649,
917,
32640,
28860,
83612,
84906,
25747,
null,
30509,
19502,
160626,
212984,
495902,
14364,
27727,
11839,
171198,
49181,
33945,
469898,
207614,
38252,
39432,
255067,
null,
364717,
235376,
25139,
103255,
161440,
2546,
630054,
8977,
28514,
null,
500573,
21670,
41782,
40156,
16826,
240072,
245734,
299281,
383282,
5973,
265457,
null,
122232,
19071,
150564,
40242,
12180,
374617,
151558,
14576,
425635,
60978,
102573,
11087,
12491,
398045,
39802,
75187,
15930,
null,
59565,
260758,
7178,
149385,
53311,
43729,
172230,
27563,
295424,
49818,
48421,
162859,
42533,
50456,
22060,
329328,
30582,
87652,
61140,
3757,
9343,
45027,
177741,
261429,
432546,
167871,
50232,
74417,
70514,
372648,
23470,
92073,
178418,
167657,
42081,
24916,
37402,
12115,
null,
21536,
6450,
108938,
146252,
324808,
19585,
105501,
35163,
null,
123560,
65896,
18958,
null,
56017,
266589,
227530,
87506,
null,
22136,
232685,
143478,
20430,
null,
123817,
102193,
411637,
291476,
null,
23072,
147038,
26145,
209970,
14725,
44675,
581107,
146941,
45884,
41279,
null,
30000,
13076,
64376,
326287,
249294,
227252,
172353,
44156,
20982,
41528,
217923,
26012,
3032,
375226,
115269,
81333,
214724,
245757,
24508,
199279,
97443,
169517,
null,
19436,
188888,
7801,
41944,
39492,
81368,
40297,
59779,
140854,
29053,
139918,
131278,
28718,
421799,
5129,
39342,
41330,
95094,
5187,
101989,
96695,
342654,
442816,
null,
null,
234030,
129454,
141418,
348041,
412024,
149197,
30399,
10777,
151895,
150095,
38276,
10481,
249223,
null,
9583,
87267,
52135,
85868,
219179,
97284,
153511,
324435,
14041,
77094,
183077,
203714,
11580,
108418,
31427,
33581,
1832,
2108,
null,
143778,
81508,
73704,
null,
160851,
27634,
302016,
13323,
16748,
42467,
10343,
307686,
179015,
205405,
205038,
56274,
69713,
36109,
13731,
null,
9224,
21867,
null,
83576,
308063,
9819,
null,
8534,
49442,
506140,
176512,
562519,
51917,
84007,
21021,
211987,
66465,
75962,
958850,
38451,
23410,
154035,
17540,
null,
415777,
494163,
18087,
38914,
22111,
335938,
9902,
54064,
246100,
null,
87928,
187202,
5175,
222858,
78233,
199923,
169892,
16284,
191651,
73267,
264651,
468,
113495,
18441,
235830,
4902,
141646,
217778,
81012,
47574,
9833,
18769,
7623,
175890,
95764,
28811,
null,
18496,
149292,
341692,
194931,
129314,
26582,
304615,
474187,
549128,
57999,
null,
41519,
282770,
16944,
28978,
3189,
208826,
271273,
32713,
23801,
612171,
13970,
287565,
9122,
222495,
332526,
null,
20037,
14836,
20107,
65497,
28105,
3023,
46482,
160097,
71022,
26433,
136904,
71396,
274914,
223126,
178054,
306921,
47832,
null,
20099,
13016,
261642,
14136,
null,
365730,
null,
null,
175059,
865280,
812007,
27939,
168233,
null,
21083,
17736,
304462,
58675,
33993,
171306,
148369,
11105,
621936,
23082,
34529,
446218,
190531,
254804,
8375,
103000,
812487,
23446,
null,
165450,
141668,
102848,
402901,
17938,
36247,
18784,
22966,
30226,
399083,
39636,
188605,
50908,
13311,
51379,
284780,
165049,
null,
25166,
31733,
5460,
769817,
85686,
68078,
31259,
196713,
51337,
28114,
23122,
94834,
148147,
125316,
13789,
147275,
26586,
8727,
null,
201922,
132585,
160341,
371131,
20276,
124584,
39648,
55959,
40585,
118751,
135185,
null,
17847,
350610,
49279,
118763,
25317,
404906,
null,
563431,
47366,
19238,
18288,
59345,
28326,
91387,
260485,
149863,
36876,
23433,
349890,
9154,
24326,
234722,
173953,
117375,
26331,
261881,
255380,
68252,
340793,
481153,
295063,
433065,
55885,
745883,
65365,
10309,
194934,
4820,
182584,
90983,
202713,
193520,
277774,
21471,
128638,
244907,
3543,
215584,
null,
64567,
452934,
30802,
8446,
170906,
32772,
null,
42081,
8835,
79390,
20246,
164867,
60506,
22403,
88642,
119867,
221469,
null,
432742,
63561,
20682,
299008,
null,
416766,
null,
4781,
94676,
175828,
358982,
48153,
62608,
210471,
77040,
49904,
53274,
181627,
51323,
154511,
3338,
51950,
281945,
40515,
null,
214986,
256968,
832318,
83482,
37503,
20391,
851,
194806,
144712,
null,
14168,
395941,
35455,
463389,
25861,
200875,
308393,
67023,
28839,
172784,
270929,
null,
346714,
263511,
11451,
31270,
35535,
330372,
41643,
27672,
161518,
62716,
181630,
null,
46645,
null,
412519,
189241,
22053,
116398,
null,
27480,
12545,
21682,
160788,
632457,
127024,
218106,
413770,
77343,
198134,
null,
14033,
7635,
22786,
69156,
61218,
36294,
209700,
122568,
338708,
169902,
17730,
371554,
238911,
164242,
33851,
47178,
93817,
83997,
null,
22230,
14772,
63612,
540,
195767,
107998,
21399,
5537,
32737,
29315,
11178,
37606,
9198,
17586,
640945,
76452,
164479,
38866,
128502,
83945,
189644,
34617,
243246,
54370,
9041,
179900,
242295,
196701,
166630,
7554,
70775,
null,
73610,
9244,
null,
32724,
27756,
255242,
21650,
21339,
12064,
272743,
20509,
885735,
29631,
11402,
140612,
193391,
170739,
46473,
312173,
161847,
17925,
10200,
33394,
62930,
7419,
20713,
17272,
24251,
85522,
99034,
191758,
38893,
58716,
299736,
21607,
221010,
23108,
25228,
59099,
28310,
32598,
153617,
747628,
70941,
249723,
113343,
334198,
100405,
32460,
53480,
39894,
77939,
35959,
16832,
493148,
null,
83577,
6707,
14314,
143523,
57237,
22581,
205174,
263503,
153161,
9201,
6346,
194189,
338956,
null,
80500,
130684,
70755,
62436,
223348,
188198,
19186,
31455,
32758,
34136,
101195,
90095,
133204,
7329,
44593,
309356,
82080,
289910,
164025,
null,
272406,
71977,
22842,
85195,
131025,
67106,
450028,
60063,
38030,
27089,
37852,
31324,
49449,
222720,
348875,
11027,
241569,
50880,
21861,
127257,
332941,
184450,
30129,
81268,
34978,
152218,
42277,
33215,
26704,
374326,
169391,
102501,
130782,
29351,
37827,
153231,
16993,
377190,
52926,
82122,
177526,
419149,
62743,
12215,
187971,
324194,
186360,
89204,
45968,
640108,
34027,
null,
144480,
275738,
189154,
11402,
5479,
991366,
45105,
37098,
39405,
7882,
16475,
62116,
271437,
436490,
173176,
83959,
201444,
23966,
260794,
105506,
39750,
199997,
20393,
158600,
2187,
131910,
53614,
580473,
29894,
70326,
16091,
39520,
413349,
112621,
153092,
408900,
31937,
92344,
365478,
315585,
45549,
47005,
424944,
229424,
17763,
38697,
21539,
88882,
98282,
8274,
323910,
null,
13271,
139336,
43242,
109044,
2053,
786752,
97973,
18214,
124257,
484782,
292607,
null,
10227,
6403,
25769,
58135,
125602,
19014,
312872,
23975,
83085,
591976,
null,
null,
70918,
46108,
316337,
null,
56326,
407709,
61671,
209472,
null,
413316,
null,
28534,
null,
12616,
283637,
13929,
64893,
181236,
2185,
348598,
37128,
34789,
null,
123995,
180560,
270668,
275862,
134795,
12290,
34580,
198585,
27884,
161688,
null,
28192,
104721,
3776,
201899,
201290,
36029,
168257,
9689,
36445,
69003,
null,
343336,
4404,
83114,
20582,
8394,
121171,
19136,
497023,
113580,
231867,
null,
21864,
33828,
120768,
42553,
86427,
239154,
35601,
81671,
null,
182324,
19227,
91119,
25429,
173478,
24108,
50226,
1177682,
67525,
48351,
20097,
237068,
147345,
null,
73293,
null,
30733,
296626,
15302,
399794,
231171,
22875,
39208,
null,
406896,
211330,
175794,
74996,
197187,
24613,
126404,
15343,
133360,
45054,
328500,
145416,
31520,
400176,
166977,
341585,
125019,
61931,
15917,
109378,
32099,
299981,
675688,
192221,
null,
18068,
225781,
24370,
234457,
117916,
87145,
43123,
181960,
438883,
262107,
45553,
null,
224435,
375639,
24712,
199311,
null,
167140,
30939,
218766,
166951,
16273,
102297,
5766,
20112,
20591,
241741,
null,
7481,
15702,
33616,
30774,
48367,
null,
304897,
269947,
148361,
33627,
44055,
59074,
123512,
325302,
223496,
26971,
48335,
229576,
null,
18173,
69508,
227508,
105061,
77838,
201770,
37488,
44706,
16391,
182715,
null,
27471,
112555,
310432,
299939,
468199,
12970,
53787,
496886,
261225,
445763,
169680,
56636,
19332,
9624,
null,
31281,
25949,
230751,
793174,
120627,
322225,
485613,
206951,
185544,
10069,
null,
29024,
247241,
14632,
null,
185157,
41108,
18286,
8171,
162969,
97852,
160620,
236039,
5719,
51798,
304830,
55011,
96323,
180315,
28536,
315047,
151227,
259851,
16236,
294534,
58369,
null,
13089,
20866,
null,
5699,
6195,
50250,
14852,
208362,
155302,
281533,
49591,
14527,
168112,
93081,
null,
14961,
58259,
78009,
213898,
155329,
50555,
34420,
174030,
45843,
175185,
38704,
null,
61024,
108220,
45436,
97396,
33003,
null,
271508,
30295,
null,
30912,
150405,
46838,
13195,
197772,
null,
62443,
670654,
5943,
8054,
266348,
117945,
91240,
27298,
339622,
30306,
21000,
338617,
22480,
41098,
354173,
205334,
89528,
17728,
40637,
39780,
179413,
45688,
14483,
306809,
35077,
null,
191348,
289299,
114513,
13752,
109431,
6944,
128420,
29528,
129573,
3091,
142982,
52999,
19259,
70886,
75215,
1321,
201245,
345735,
219385,
144090,
20187,
11025,
89934,
44434,
110059,
331002,
38049,
78719,
352112,
36707,
15768,
53835,
61192,
50616,
null,
90610,
384405,
57235,
7946,
26657,
175615,
null,
52552,
14437,
329686,
368774,
363403,
41318,
233306,
11781,
25707,
1150307,
181635,
199881,
null,
28882,
27958,
329024,
48236,
13056,
154202,
46984,
null,
20175,
73438,
60149,
152696,
267534,
null,
19422,
130067,
86826,
112146,
35279,
18034,
726480,
13541,
37243,
22400,
46061,
64588,
305693,
501500,
194744,
593512,
226051,
218197,
324809,
172061,
null,
24768,
109856,
75919,
256191,
25566,
232098,
34348,
42965,
142398,
384218,
39058,
14748,
165580,
378382,
276598,
321772,
325436,
191103,
41896,
241890,
10601,
411794,
35492,
164501,
38784,
98663,
195691,
235828,
255907,
84715,
43317,
64800,
172817,
21342,
null,
206503,
299638,
28121,
52925,
125535,
467099,
68670,
274508,
236453,
161756,
242469,
111352,
166796,
179373,
14181,
491376,
408314,
181779,
261998,
41973,
37445,
33514,
174069,
186128,
150413,
29875,
null,
22506,
6339,
70045,
72947,
56260,
127014,
5074,
238729,
175865,
181363,
50072,
83512,
111720,
90395,
121133,
null,
249694,
188733,
34916,
227780,
304088,
19238,
163365,
106301,
225120,
43414,
339058,
88651,
379283,
36499,
58224,
309526,
36699,
61391,
17689,
192496,
43256,
null,
11715,
49967,
239408,
23412,
17100,
null,
null,
1684,
43675,
202378,
113863,
55484,
null,
50347,
108327,
35792,
76328,
227828,
null,
null,
222950,
266893,
375424,
201066,
206581,
174394,
8689,
101006,
286635,
17184,
30743,
138630,
129145,
138236,
209103,
231156,
331060,
257496,
590043,
353586,
91866,
32283,
363674,
124296,
27287,
313900,
144911,
null,
32722,
226313,
33015,
291057,
191866,
11220,
41822,
47588,
273607,
139656,
8593,
68066,
262902,
198750,
188134,
58382,
275858,
398124,
null,
287544,
27253,
35073,
2582,
7789,
118357,
220748,
28860,
31035,
88662,
259508,
265363,
1179,
535522,
234110,
91821,
339476,
210972,
48798,
153255,
35116,
27938,
207281,
260460,
22546,
13821,
null,
43874,
149415,
607787,
null,
296498,
95007,
null,
165871,
181368,
307787,
50826,
30009,
31278,
238130,
25021,
30294,
110735,
197453,
37510,
67796,
4572,
177810,
106659,
7712,
61301,
85069,
46916,
37542,
6744,
null,
47933,
null,
3537,
39578,
157995,
197513,
164566,
184803,
40619,
326039,
21221,
14964,
225529,
259865,
null,
163068,
19523,
null,
120223,
39083,
66465,
7648,
79525,
null,
153785,
109705,
21289,
39052,
97152,
10306,
4309,
118980,
97538,
246414,
46936,
78704,
34056,
11061,
170059,
null,
10357,
192586,
17561,
52262,
129657,
21831,
566332,
null,
11125,
143752,
37630,
131627,
30497,
245691,
null,
59043,
44323,
null,
115222,
146617,
1643,
null,
152348,
58453,
118655,
23550,
96954,
236002,
96672,
126669,
240392,
216917,
57590,
77063,
94026,
19120,
19115,
21832,
2836,
251882,
null,
135797,
77544,
82840,
72497,
5141,
258212,
116553,
34009,
166804,
182255,
59320,
272825,
33113,
447076,
50427,
107796,
802109,
75029,
60263,
95616,
163098,
37391,
88344,
247668,
88400,
389112,
7974,
180547,
null,
35469,
75532,
207868,
131062,
39731,
34669,
3823,
164458,
123381,
null,
7163,
215593,
18133,
38129,
204907,
34571,
85686,
null,
68195,
43818,
265655,
123164,
57099,
18779,
37307,
36202,
34644,
281757,
316415,
15684,
9439,
224161,
585925,
3978,
219431,
167488,
341467,
245000,
10927,
11983,
29883,
21670,
3827,
309800,
53407,
19243,
747919,
100990,
338813,
207975,
404580,
28320,
null,
48095,
15067,
201211,
111018,
7596,
null,
176236,
211692,
null,
45896,
49444,
59151,
48824,
43857,
21586,
null,
12539,
null,
4766,
59354,
201713,
217607,
139080,
15590,
195737,
70316,
16058,
13515,
17023,
327041,
93230,
342564,
40511,
36760,
38428,
52303,
610738,
13467,
50797,
154803,
4293,
162144,
null,
63313,
114765,
null,
21728,
780937,
26466,
10479,
14574,
19560,
111249,
21515,
203766,
61422,
71825,
10611,
150431,
34042,
null,
308295,
31368,
34082,
248497,
10936,
219095,
null,
112023,
452517,
343864,
null,
219839,
26348,
32755,
372919,
454179,
90172,
343159,
225287,
15176,
202393,
19193,
8038,
36942,
186161,
138500,
68759,
32169,
null,
13473,
206945,
null,
15830,
215748,
87427,
169519,
60644,
11005,
39436,
67326,
125071,
319878,
202978,
null,
78206,
48863,
8407,
null,
23809,
12106,
216678,
46549,
31791,
null,
60802,
492684,
null,
172725,
13149,
48691,
12614,
3537,
32519,
14360,
9510,
55055,
342226,
null,
189298,
502802,
167367,
46677,
144945,
11021,
16804,
155459,
9660,
220083,
69398,
240789,
55999,
44092,
72414,
215902,
28899,
29370,
177451,
7104,
12528,
34110,
9471,
16317,
58276,
11170,
285390,
316625,
13125,
420593,
239770,
168355,
105505,
null,
20565,
3451,
26908,
113501,
214523,
268976,
196334,
45692,
318684,
null,
293961,
416078,
297054,
12323,
39906,
229255,
13835,
207128,
14872,
33335,
98119,
35186,
null,
286873,
202638,
46841,
4897,
209614,
351168,
519299,
440531,
273093,
93914,
21610,
292191,
166662,
239295,
null,
null,
426516,
50271,
136989,
null,
346294,
245772,
144175,
197195,
89616,
29748,
21328,
316739,
158867,
23692,
99736,
54737,
439965,
253993,
143601,
61451,
128704,
36050,
139403,
344815,
333421,
19062,
99485,
76418,
23280,
18485,
null,
244489,
36589,
120886,
682328,
318801,
188065,
15611,
122220,
552645,
42799,
null,
331273,
184792,
206363,
13970,
158779,
100521,
98788,
457759,
310539,
157182,
32438,
239551,
125056,
null,
45355,
180487,
null,
211553,
127552,
272989,
48525,
265579,
98595,
36933,
79632,
348846,
28675,
48615,
183266,
101449,
null,
null,
null,
127390,
15707,
214911,
348893,
34226,
30892,
33596,
208388,
206991,
6407,
440339,
604219,
287965,
null,
16815,
null,
null,
38553,
133697,
124760,
114951,
435859,
67544,
58793,
152377,
358940,
26420,
11347,
412124,
46849,
15304,
30617,
187743,
387816,
394634,
15902,
512776,
null,
309950,
28549,
3152,
16669,
5087,
172467,
11593,
31930,
21356,
null,
205454,
80402,
37570,
16448,
40206,
138546,
82961,
406262,
240655,
212542,
137855,
321132,
201881,
490565,
25886,
65067,
179244,
139715,
321738,
25796,
225672,
null,
213994,
232779,
63388,
42369,
22785,
177954,
213654,
225646,
null,
5811,
363988,
229868,
null,
215623,
97697,
465716,
494754,
41780,
273392,
null,
null,
26772,
560786,
23528,
20015,
154948,
181339,
287156,
null,
142068,
11454,
92392,
301160,
60239,
58754,
97886,
110074,
459726,
160829,
378093,
11691,
156290,
16365,
233118,
177713,
137816,
381376,
25647,
37839,
195704,
196251,
50532,
null,
126595,
32873,
62149,
15558,
149861,
30770,
18752,
20036,
null,
90568,
85023,
91486,
284780,
42799,
153601,
94856,
144778,
null,
33794,
181798,
543845,
7654,
143911,
55924,
null,
49654,
21678,
24068,
24563,
42557,
5112,
78993,
210620,
54474,
37376,
800946,
179344,
301630,
37250,
107061,
265426,
28695,
34771,
22838,
27838,
null,
33211,
133438,
147628,
60389,
573142,
8742,
23001,
46777,
70812,
26420,
249174,
245370,
66377,
null,
32204,
5214,
291926,
17024,
55107,
30835,
100838,
121029,
156557,
96790,
1864,
30660,
33282,
43278,
59374,
26540,
462524,
28670,
174773,
214992,
394171,
90301,
19287,
38031,
286720,
41075,
61355,
29926,
null,
228827,
167756,
43230,
17579,
182237,
209200,
10537,
74485,
124107,
null,
423271,
67355,
22093,
150814,
98598,
16545,
1867,
64061,
29268,
91486,
57848,
272632,
26128,
15595,
52618,
2073,
448348,
30466,
26422,
317787,
null,
220798,
54302,
30500,
31895,
27860,
128918,
35347,
null,
48292,
40992,
60991,
305898,
33669,
364177,
289224,
121931,
145525,
40305,
122332,
90235,
198232,
526225,
299516,
119929,
187267,
319553,
16241,
28500,
214969,
210281,
668261,
492495,
5091,
236875,
251938,
78205,
199237,
272535,
212617,
179837,
22141,
855238,
59393,
74954,
91520,
121374,
356703,
322018,
43052,
54352,
23232,
100655,
5459,
11404,
16080,
22459,
387712,
75021,
21516,
475467,
38083,
29495,
100261,
82820,
30972,
163450,
5780,
null,
null,
41652,
24275,
20938,
182715,
278597,
214296,
78678,
null,
null,
40767,
36584,
182323,
77038,
null,
322953,
144998,
257148,
117987,
197067,
44548,
406035,
null,
11730,
13285,
335462,
220392,
190295,
177747,
301329,
400291,
195168,
31614,
14894,
29065,
145640,
405920,
16502,
21357,
21686,
37640,
31795,
245421,
157511,
166013,
75700,
51133,
5370,
202761,
24600,
103825,
12982,
10310,
155273,
239576,
31687,
42423,
38476,
25364,
328792,
149931,
17416,
321377,
251479,
19178,
10876,
35260,
null,
215064,
10199,
210525,
247845,
60019,
null,
493907,
9784,
212125,
241586,
139555,
288703,
3512,
198277,
195783,
26265,
248933,
23998,
76677,
507040,
95996,
277412,
287954,
262402,
242754,
152519,
34417,
14869,
318053,
170056,
57164,
12553,
51596,
22179,
517413,
42983,
null,
139623,
45777,
378361,
285073,
364585,
236222,
75158,
279079,
267523,
558382,
177368,
5686,
399072,
15386,
35915,
69160,
85465,
31324,
72462,
47164,
null,
268500,
143597,
61569,
306936,
42088,
88664,
75018,
144930,
25523,
698720,
25063,
99502,
10421,
325119,
10795,
28969,
221123,
140938,
72975,
323402,
198007,
262832,
281169,
155558,
312190,
19807,
null,
27473,
null,
375605,
null,
74152,
222604,
144146,
227386,
544777,
435656,
33277,
43295,
47475,
33139,
192537,
89312,
177990,
23209,
153666,
9386,
309961,
115000,
229099,
29374,
null,
36822,
null,
145535,
324550,
179354,
126562,
673448,
283569,
104937,
187565,
143324,
10588,
13649,
218226,
186915,
100926,
235739,
409797,
44721,
373100,
28275,
536103,
31854,
52388,
4947,
227007,
94141,
10912,
null,
111793,
87090,
2879,
181967,
164284,
61855,
55438,
72696,
702741,
288238,
80481,
567151,
10494,
48221,
7179,
207208,
27429,
349552,
4851,
133837,
82950,
64844,
13884,
27308,
72902,
214847,
203771,
148606,
632420,
256762,
42692,
46994,
286099,
null,
160412,
17225,
150550,
286229,
9740,
72654,
31924,
327335,
34550,
420405,
null,
110633,
17190,
267572,
140196,
116090,
28307,
444141,
null,
254827,
7305,
87285,
237635,
26652,
55545,
560505,
7840,
101567,
214471,
19505,
527980,
22859,
309098,
138014,
164205,
null,
null,
120995,
5485,
381517,
136136,
89526,
336017,
40033,
460896,
30173,
242281,
311206,
23932,
8289,
226102,
333874,
135350,
163088,
111735,
298886,
57293,
6184,
43260,
87120,
13914,
110208,
null,
46671,
109713,
40397,
165136,
70547,
16731,
197563,
59263,
75921,
190967,
76528,
null,
65573,
325217,
156625,
4317,
376448,
22601,
10527,
374868,
247799,
105561,
141699,
11094,
374461,
null,
49547,
78420,
null,
325169,
101134,
12983,
28847,
199990,
440974,
9189,
431724,
162203,
8745,
133611,
64195,
194831,
295288,
183591,
404193,
214986,
171839,
46601,
36033,
394142,
31175,
18800,
19869,
38556,
72881,
37122,
1157584,
264353,
153318,
387868,
188374,
164039,
38254,
191539,
30127,
207603,
20285,
96133,
62840,
98684,
17471,
116031,
170417,
30604,
50287,
237319,
272731,
4221,
170447,
207075,
10125,
5842,
4978,
13022,
519003,
90819,
11535,
106125,
20513,
135787,
89561,
490680,
32461,
486086,
49137,
179476,
11911,
56811,
192739,
61094,
36909,
162599,
229265,
177265,
358290,
655202,
82116,
170464,
24285,
108699,
85313,
36401,
237483,
150335,
17108,
24414,
397677,
102002,
588302,
73416,
120203,
108482,
30562,
153193,
41959,
46150,
50445,
179450,
213494,
15677,
53243,
29184,
275008,
35363,
123168,
67092,
50997,
null,
205817,
138035,
655905,
11717,
null,
null,
238506,
24832,
null,
20842,
255040,
43880,
23528,
10821,
36667,
121423,
136162,
86696,
34885,
42733,
72965,
241163,
13021,
210001,
227060,
822323,
132216,
253747,
152386,
25550,
24295,
61295,
16212,
205999,
1441,
36207,
185889,
42304,
204369,
39080,
126707,
212959,
null,
null,
68017,
11078,
104214,
70713,
232421,
3741,
128982,
29995,
19960,
398153,
21313,
409318,
50270,
485217,
208418,
23069,
14445,
175427,
140219,
41264,
88325,
null,
36180,
4549,
457011,
237260,
266650,
129717,
491431,
23218,
104658,
524579,
532419,
155760,
22901,
28989,
29016,
17821,
44018,
270600,
189617,
44985,
12754,
290670,
29092,
39583,
4341,
180978,
62052,
368293,
426483,
13316,
119840,
42010,
12757,
26658,
14293,
361039,
117915,
141522,
null,
52002,
270713,
370047,
407668,
241176,
null,
195032,
267861,
133678,
47518,
368805,
7736,
47443,
27316,
26993,
188492,
154333,
252276,
130478,
41998,
11732,
220603,
44724,
255474,
142029,
13427,
22907,
10422,
15369,
10085,
14293,
287897,
null,
483877,
338678,
101414,
122362,
29061,
74873,
13651,
137202,
17757,
33506,
19016,
142401,
43680,
14465,
820,
28838,
39947,
18464,
9085,
9472,
299703,
62529,
196342,
24494,
94834,
90751,
159108,
43415,
null,
234570,
35621,
33588,
null,
151929,
369360,
21853,
37162,
74646,
8454,
190955,
9752,
367585,
337422,
38367,
165364,
21830,
40941,
338280,
42235,
170905,
null,
230411,
422388,
null,
381402,
15365,
25247,
45973,
null,
33443,
256238,
72202,
135886,
250541,
22043,
77350,
231708,
195852,
176847,
186005,
32343,
932680,
12429,
178358,
48156,
20858,
null,
36623,
16011,
4002,
32199,
53182,
232541,
37434,
123561,
59102,
202787,
131431,
34858,
23184,
175325,
77565,
83860,
158437,
227980,
337874,
455039,
31577,
12289,
475336,
56036,
33668,
84576,
139037,
296287,
288958,
38839,
null,
12235,
null,
382770,
41389,
328850,
87787,
88993,
141226,
46243,
14649,
28255,
47702,
19165,
206928,
118615,
27356,
125229,
36278,
null,
195402,
273273,
322832,
52061,
415899,
46271,
166629,
210174,
null,
11232,
7190,
19395,
458806,
8315,
91345,
112484,
145461,
94961,
649152,
352751,
175430,
206326,
71646,
178942,
181591,
43103,
null,
35996,
18220,
28099,
17553,
364852,
239555,
321376,
49462,
236960,
null,
229962,
273396,
null,
520366,
159947,
284498,
543500,
250766,
251019,
134640,
6243,
69276,
217482,
166796,
530782,
488248,
28380,
11130,
11681,
46737,
4587,
280078,
69356,
null,
135660,
247749,
127823,
57612,
33442,
34879,
136684,
27484,
215705,
22184,
null,
51388,
189199,
19261,
18007,
null,
54123,
36109,
61066,
314273,
48217,
12759,
212583,
null,
144489,
315551,
null,
20136,
39999,
35931,
536675,
null,
58368,
146856,
299894,
27925,
126150,
337526,
66530,
94476,
32319,
225486,
63104,
99377,
320886,
546642,
null,
24034,
15009,
25341,
12802,
131554,
58909,
32556,
82228,
null,
16179,
14748,
125449,
null,
314524,
94140,
237342,
244140,
13775,
null,
33687,
410309,
219657,
116488,
64927,
25855,
40272,
83483,
189446,
13040,
16145,
null,
22462,
null,
322109,
140949,
9656,
291435,
62024,
null,
395425,
213474,
55088,
36947,
77497,
31684,
292416,
75453,
403328,
10341,
27955,
454892,
94959,
86208,
84121,
45234,
254639,
271517,
140121,
8008,
403107,
35673,
19393,
293871,
38699,
8739,
19417,
25492,
523453,
8366,
589303,
186081,
16707,
28576,
502564,
60178,
272005,
49131,
106508,
282240,
null,
143564,
232350,
206148,
776984,
395571,
166321,
32171,
19706,
34432,
409578,
310876,
307166,
26602,
196381,
247171,
null,
240246,
287421,
113378,
49112,
19923,
4690,
429186,
122083,
179400,
16388,
8518,
5290,
94075,
229394,
44362,
5515,
null,
191732,
122055,
null,
109388,
51386,
28642,
164972,
46288,
22362,
78066,
248412,
157792,
6748,
43418,
277796,
12294,
46837,
null,
175725,
10582,
null,
296768,
271170,
13880,
null,
129844,
155062,
374626,
141736,
9962,
22882,
207117,
361518,
60808,
3856,
127293,
50073,
75171,
79010,
19397,
447333,
null,
null,
32137,
47394,
87371,
28609,
274214,
53865,
20413,
182824,
21004,
40194,
73276,
83637,
158912,
72139,
35963,
195840,
221998,
14960,
42738,
18716,
36568,
null,
253265,
182877,
245545,
576471,
16096,
278754,
269481,
69725,
69931,
10560,
1061100,
263695,
93604,
43639,
232266,
8703,
554525,
44271,
510443,
249076,
145405,
48513,
34638,
161153,
22810,
9401,
7428,
134381,
36413,
226549,
173307,
142814,
80780,
36836,
6380,
15824,
202672,
7464,
278508,
17666,
91580,
null,
26092,
789224,
25925,
325262,
43671,
35190,
3938,
9652,
38377,
228345,
386895,
158803,
144213,
127547,
7678,
40368,
19746,
38331,
320174,
214461,
93501,
428612,
202481,
20328,
20386,
175802,
121891,
180375,
485292,
null,
null,
22211,
21753,
33773,
null,
null,
30761,
25909,
288190,
4541,
13311,
273462,
97819,
362834,
106208,
51168,
26127,
30559,
202503,
150653,
6861,
55052,
51959,
162510,
97219,
303824,
24039,
192337,
381792,
30838,
360773,
null,
141760,
48371,
14994,
7909,
212737,
374244,
138950,
22840,
50174,
143391,
17588,
176574,
41015,
16368,
34815,
37241,
89504,
245572,
197246,
null,
223704,
109626,
3468,
5947,
200920,
120389,
277899,
22349,
236712,
42863,
147200,
4031,
18535,
89562,
12552,
22575,
321938,
198900,
21406,
41424,
238024,
32157,
null,
97022,
144711,
97606,
11417,
54979,
20142,
2068,
104033,
59550,
81121,
114983,
146087,
58762,
195142,
108736,
7020,
16766,
196084,
null,
101889,
18221,
94791,
30753,
344975,
4086,
400741,
100862,
480442,
47345,
18317,
87305,
37936,
513925,
40702,
188315,
258425,
98889,
208117,
7708,
72432,
18776,
17246,
210044,
22087,
221537,
28555,
380233,
524240,
135478,
26796,
49662,
9943,
null,
47756,
121506,
512305,
60624,
193196,
26342,
24470,
73240,
3322,
21651,
38854,
140394,
137186,
68057,
44493,
42149,
10790,
257001,
64960,
null,
8607,
135256,
258795,
27694,
57257,
3951,
143171,
26615,
47005,
16227,
15830,
110873,
null,
244262,
100922,
505896,
39664,
375667,
28913,
null,
31640,
47225,
254462,
246933,
153926,
415546,
336537,
35848,
584890,
33313,
414117,
44737,
378179,
231006,
94622,
182646,
27728,
354544,
null,
127264,
245144,
180644,
10237,
268168,
259962,
null,
76569,
20988,
null,
45117,
101068,
198930,
7192,
null,
83737,
123334,
20179,
17253,
21477,
28836,
190497,
280296,
46313,
338033,
null,
11483,
85081,
88158,
44226,
23409,
611067,
33613,
815086,
436928,
491880,
125764,
null,
132410,
270330,
16508,
76272,
214795,
278719,
12285,
175283,
17902,
63001,
439164,
7170,
252977,
13838,
98697,
86837,
10579,
170098,
42364,
344560,
11346,
2956,
133904,
68603,
96621,
18320,
309731,
36993,
279359,
10322,
54419,
194722,
null,
48088,
17326,
22525,
30566,
47668,
11988,
null,
35982,
282483,
193641,
18146,
305569,
76150,
149222,
12228,
21407,
231244,
143297,
50479,
18041,
null,
18834,
19876,
481575,
40819,
16400,
399764,
292289,
35577,
24137,
39728,
null,
160602,
21782,
null,
48184,
13756,
15191,
235296,
19234,
121599,
40283,
463041,
null,
84299,
57845,
278603,
23053,
5478,
174585,
211000,
449602,
69331,
475212,
237498,
225055,
214905,
158275,
431446,
73963,
32593,
9805,
16764,
236034,
177165,
23655,
640149,
679908,
44399,
34827,
34873,
9657,
336833,
36432,
200013,
null,
421182,
17620,
231924,
316910,
5818,
269599,
10106,
89609,
44534,
null,
454663,
75995,
135860,
null,
21984,
null,
419183,
50012,
138559,
5311,
null,
159649,
218115,
72155,
203446,
22479,
52614,
241777,
66131,
218928,
null,
73730,
28191,
220989,
117053,
24198,
374873,
345401,
6729,
19334,
39763,
178774,
69630,
63803,
5753,
180064,
37460,
72169,
34558,
213326,
158838,
371514,
222531,
159203,
33404,
333540,
null,
256576,
17205,
null,
134576,
150198,
88507,
239501,
null,
222300,
63351,
212634,
12791,
163569,
190182,
11166,
20395,
38572,
45029,
212969,
6916,
33818,
90159,
29724,
21718,
20737,
179840,
125259,
168263,
14695,
132315,
26470,
49824,
347914,
31474,
295578,
122777,
7320,
70087,
null,
319808,
427114,
160595,
5,
41856,
1006121,
146635,
232127,
209484,
11328,
10411,
32098,
52724,
50311,
467086,
22320,
394278,
415926,
174861,
17865,
76924,
49400,
133543,
227185,
43150,
23674,
11465,
86806,
86761,
232627,
46522,
38216,
18296,
37127,
276657,
303040,
228537,
171485,
34219,
9419,
152441,
205504,
144392,
17278,
563844,
227979,
3120,
54893,
84820,
226413,
26989,
81259,
47488,
203547,
66298,
59413,
null,
32729,
234044,
445104,
18785,
7561,
null,
11132,
105254,
25413,
41485,
53752,
75051,
205291,
118,
424909,
52048,
24083,
54558,
127706,
25560,
7504,
387969,
2392,
23999,
20623,
224601,
11336,
153676,
58908,
310403,
21615,
173169,
21843,
115465,
568853,
134882,
25438,
245768,
365754,
290998,
212029,
27695,
86527,
null,
41350,
45336,
203983,
null,
207541,
276032,
57414,
180464,
228106,
277538,
414883,
98236,
317457,
30968,
38947,
218852,
148882,
88552,
30464,
115349,
27608,
null,
51676,
35939,
138880,
283669,
16982,
215717,
21741,
126131,
null,
33114,
null,
466550,
157250,
39065,
224369,
null,
46341,
123336,
null,
330245,
299098,
1942171,
150474,
92186,
15883,
null,
156065,
26158,
23178,
56404,
254736,
32194,
18107,
47908,
18286,
247606,
26752,
18473,
45692,
49603,
73848,
228782,
66115,
46199,
105803,
177078,
27803,
249898,
30659,
36711,
165306,
35816,
35259,
19287,
167884,
30514,
179690,
186470,
null,
80436,
51019,
47927,
93501,
206393,
295437,
141457,
130712,
2743,
302553,
11452,
27770,
275904,
null,
292047,
33408,
83305,
346034,
276397,
462097,
209210,
null,
21414,
84744,
51433,
90189,
39445,
100242,
79094,
266382,
8216,
57244,
141447,
360384,
66367,
247010,
333862,
null,
107374,
null,
148197,
61513,
93697,
52444,
326147,
128882,
93242,
542590,
277160,
47012,
86186,
66923,
130678,
180511,
165629,
195704,
35423,
191601,
22543,
459371,
68036,
59486,
21819,
323760,
7929,
null,
23189,
27816,
null,
60719,
184057,
47885,
230866,
375630,
23068,
66297,
153423,
32442,
39952,
25960,
19755,
null,
27806,
149570,
23717,
175879,
83626,
7065,
234605,
null,
280476,
18006,
123634,
null,
null,
331435,
26679,
null,
39784,
50079,
26689,
null,
842264,
260800,
74520,
16476,
290598,
262208,
316049,
106570,
363826,
9606,
null,
161371,
764451,
64593,
213795,
117145,
26992,
14975,
319286,
375809,
31098,
53830,
19236,
273210,
274529,
648329,
93168,
217827,
30855,
181100,
321651,
208057,
27506,
12918,
66701,
null,
299470,
20448,
499317,
411751,
45597,
21590,
92044,
null,
28821,
92970,
28874,
58229,
121843,
68547,
131283,
198070,
60661,
30280,
23701,
10415,
43117,
81798,
14951,
461422,
11421,
16921,
128285,
46316,
null,
35187,
95551,
33168,
53745,
133336,
4359,
464856,
24977,
179775,
117040,
null,
79306,
340688,
null,
142844,
88218,
135617,
576586,
21735,
15765,
154518,
269224,
3833,
73312,
25138,
111881,
222327,
382826,
2366,
64573,
53160,
161193,
138908,
198448,
4685,
245523,
null,
25704,
49507,
143760,
277260,
null,
null,
30455,
324057,
17053,
null,
3772,
31761,
380274,
null,
null,
546902,
12975,
null,
125597,
120668,
173360,
172092,
117638,
67143,
9086,
48782,
75862,
114739,
18506,
75454,
20366,
36003,
21468,
38779,
59589,
53174,
6792,
192519,
163061,
null,
31956,
197937,
228154,
25257,
336485,
18734,
213799,
21636,
6264,
27580,
288031,
88826,
312354,
236744,
9862,
null,
86787,
15235,
54767,
317755,
40035,
165009,
34276,
74720,
218580,
33128,
32696,
18381,
42226,
null,
304314,
53385,
46070,
19525,
17087,
32548,
154715,
27375,
15176,
164056,
11864,
13901,
140996,
224943,
323675,
null,
25707,
6455,
29479,
135873,
423901,
null,
91397,
414558,
54538,
30408,
172583,
37239,
373790,
46521,
478629,
92971,
null,
349953,
151994,
167804,
30184,
92421,
249491,
366417,
232856,
43139,
21716,
27133,
null,
22245,
31968,
337368,
335974,
167867,
87717,
333766,
148528,
30258,
62713,
384804,
220056,
49672,
231810,
376544,
505816,
39247,
137418,
13113,
245821,
487718,
22280,
23064,
6388,
15892,
273334,
21313,
54783,
66382,
60173,
18154,
439931,
228039,
40050,
440077,
208732,
350664,
270973,
57263,
56133,
19542,
52822,
94730,
null,
32809,
475642,
133942,
149577,
267105,
250243,
10703,
195721,
5348,
9436,
87390,
98465,
141791,
187534,
6300,
13966,
166695,
null,
119904,
35353,
277063,
12318,
8058,
183277,
364508,
205124,
259843,
154162,
102959,
26596,
59560,
174439,
134180,
275050,
181777,
null,
null,
251355,
313676,
4320,
110992,
87548,
265857,
52677,
88125,
71269,
475017,
13081,
16707,
273681,
15496,
134889,
28158,
66383,
181856,
93918,
13230,
176684,
21709,
323338,
null,
24915,
386109,
null,
236450,
14641,
33949,
68292,
333421,
56613,
95449,
154623,
95228,
74389,
209942,
37309,
170928,
13508,
135034,
155939,
127737,
30077,
506449,
32591,
368452,
13516,
null,
114466,
13153,
334919,
227613,
46912,
119814,
734106,
91103,
9517,
217880,
36477,
4466,
null,
121461,
30334,
106988,
31762,
176033,
633003,
0,
54639,
77816,
null,
640105,
43861,
45870,
51149,
43083,
18915,
127212,
91099,
93292,
160006,
42843,
34858,
34730,
47355,
20416,
671981,
104645,
12424,
296389,
27370,
28050,
203396,
11542,
223671,
36689,
66385,
358766,
42924,
195959,
146102,
118142,
166609,
165366,
47291,
43375,
74382,
111361,
null,
26930,
26932,
347202,
52625,
305755,
322460,
160676,
66405,
27711,
63524,
33948,
10465,
22426,
41223,
12150,
205050,
null,
56483,
14947,
193434,
75170,
37122,
36390,
110889,
217101,
22549,
27734,
58054,
34854,
154513,
133934,
241030,
16461,
332381,
196514,
30642,
356807,
19579,
72741,
134744,
24772,
337142,
146644,
60674,
86491,
22479,
339998,
39531,
253274,
210918,
9625,
11908,
122412,
31721,
328642,
266063,
11002,
42741,
null,
22939,
151065,
11999,
352038,
277285,
345401,
236915,
13656,
36308,
153618,
24653,
413240,
33316,
303608,
191774,
69426,
231895,
17545,
256287,
33935,
4680,
598165,
9459,
79155,
17164,
144494,
85031,
124893,
73119,
330975,
170016,
396512,
24615,
null,
23305,
208487,
29528,
28306,
41678,
12648,
3154,
348405,
1689,
55764,
15067,
22950,
247905,
288763,
331340,
14671,
39605,
3895,
25463,
39355,
116112,
67010,
69263,
227903,
43828,
217077,
109185,
219283,
18573,
207290,
122775,
172714,
null,
9919,
176625,
67541,
83947,
291268,
34985,
527849,
93065,
98360,
390006,
null,
77382,
13115,
326394,
31163,
null,
26670,
23692,
80285,
36295,
256738,
227590,
45686,
null,
281929,
196393,
420292,
209432,
2577,
7922,
37403,
null,
124639,
103885,
32611,
110321,
35308,
30893,
132156,
39175,
4785,
4225,
107347,
93483,
122525,
48860,
174810,
98206,
null,
205743,
9335,
135929,
72569,
3282,
801630,
22716,
61565,
82752,
153516,
4578,
51988,
24972,
29516,
108094,
36697,
27374,
160070,
null,
273371,
47218,
55415,
256953,
18031,
23678,
45869,
286154,
null,
389119,
75818,
37227,
39631,
64550,
30722,
11758,
76663,
22223,
127954,
165675,
64420,
41217,
23697,
144239,
45130,
290086,
98286,
13018,
248124,
null,
33486,
23656,
167290,
null,
8585,
58958,
102323,
165499,
234442,
19908,
379421,
78528,
211408,
504057,
300208,
377964,
183700,
204642,
16858,
185380,
14514,
74079,
17397,
51113,
195975,
19938,
null,
92674,
147914,
236339,
35161,
null,
34424,
21591,
31635,
84009,
289402,
298172,
17709,
87639,
25728,
51583,
29263,
147800,
7574,
40358,
155286,
144375,
436447,
12720,
22982,
512913,
27748,
97693,
26011,
null,
187098,
44224,
16877,
397817,
31310,
150516,
579989,
179894,
19625,
272467,
31681,
161628,
297438,
310904,
355421,
14051,
171973,
574148,
82587,
137595,
28909,
413873,
188633,
44765,
null,
11794,
2389,
12278,
32546,
115758,
66342,
336771,
27761,
19485,
204997,
70330,
16135,
124105,
181610,
null,
283144,
12959,
44857,
254042,
52732,
257082,
70851,
402777,
34192,
null,
45741,
253265,
333197,
null,
260345,
87982,
273998,
326786,
55133,
null,
75952,
13734,
12930,
204768,
162158,
211393,
45831,
115521,
38640,
123261,
212501,
288080,
59509,
41067,
63841,
223225,
140906,
144908,
486750,
38271,
26080,
152020,
31966,
70984,
34619,
147428,
159886,
39066,
11805,
31490,
23891,
13464,
67595,
16937,
62438,
null,
137413,
null,
73139,
160299,
10235,
28959,
166249,
17969,
88844,
160006,
167558,
111324,
141572,
110254,
207444,
165942,
201234,
286204,
207687,
159665,
166906,
193630,
256410,
246491,
392483,
27316,
419418,
5743,
348153,
73899,
40263,
93777,
286554,
19178,
13996,
24191,
null,
80320,
69447,
37393,
27960,
13869,
null,
119365,
221959,
168914,
91426,
15721,
11123,
126055,
39970,
464976,
61783,
59642,
76188,
216501,
27519,
64735,
null,
346472,
33663,
229247,
189631,
501121,
null,
11740,
46936,
108228,
183428,
104656,
121378,
62998,
235037,
139839,
11273,
22438,
39854,
48149,
6575,
32792,
73527,
16004,
9829,
354902,
299655,
244399,
59627,
null,
25843,
153969,
618236,
58071,
258422,
347263,
255634,
22625,
21084,
33818,
17162,
477646,
85179,
29744,
151765,
38075,
116797,
153678,
279849,
55841,
205378,
86247,
69329,
78919,
39188,
122612,
57230,
161115,
322169,
62524,
207363,
236772,
70011,
198703,
null,
417009,
224199,
272754,
300108,
304515,
41705,
10553,
11432,
34689,
158339,
11215,
null,
43429,
232579,
213845,
33049,
48390,
168422,
13415,
45131,
162655,
33633,
46502,
8514,
17867,
235331,
120327,
38039,
211702,
25035,
187230,
152030,
53892,
48718,
null,
44231,
27892,
47730,
63526,
240552,
277258,
null,
50232,
597042,
null,
26399,
103438,
55078,
278320,
83387,
59465,
752428,
393847,
null,
12277,
81786,
863497,
303095,
2018,
13226,
325972,
134836,
274092,
null,
172824,
10485,
18945,
23624,
null,
110924,
19836,
33823,
408871,
22771,
24885,
null,
208732,
11035,
25844,
490914,
40969,
256731,
228711,
13030,
35331,
146522,
35395,
29258,
66065,
23761,
312773,
68169,
1248,
342204,
72191,
26713,
161331,
26683,
14775,
138113,
163952,
45592,
214355,
30337,
11489,
572019,
51304,
null,
150553,
230542,
50564,
140794,
111005,
210367,
164626,
156457,
null,
145671,
170305,
223292,
null,
null,
43207,
102054,
261240,
27125,
19892,
8329,
5187,
33840,
82006,
null,
null,
22706,
12025,
546680,
null,
28067,
13701,
null,
327799,
9692,
232112,
null,
25641,
242348,
105331,
582627,
52609,
324801,
36351,
31534,
165859,
42520,
359720,
21846,
27857,
213896,
420784,
15764,
21269,
66313,
115821,
7889,
813,
244992,
null,
290172,
101665,
26407,
211210,
39254,
null,
24625,
43005,
209171,
362545,
73064,
86628,
13214,
111070,
240881,
59693,
57064,
114774,
32618,
217812,
66380,
80563,
8214,
172194,
62438,
384525,
18199,
43871,
229181,
35611,
51563,
null,
85825,
263247,
12322,
30489,
9614,
42284,
27429,
171044,
70352,
36745,
43852,
289734,
21689,
188302,
162710,
154991,
4362,
104434,
58436,
171249,
5414,
null,
43078,
60732,
16111,
null,
434348,
15615,
46090,
73925,
168073,
12270,
41603,
null,
70797,
54012,
11397,
null,
141743,
177335,
3986,
18270,
229032,
558652,
30296,
42931,
66999,
440144,
null,
81632,
27730,
41301,
28321,
63076,
585519,
101917,
225114,
133982,
120729,
293291,
null,
28525,
47380,
49553,
121370,
368520,
93765,
null,
69636,
32735,
63748,
9070,
85601,
null,
43594,
95312,
56700,
9859,
39648,
6164,
319883,
null,
null,
342156,
469455,
17434,
65619,
207040,
7194,
null,
33800,
283527,
162992,
35517,
14622,
null,
63240,
33672,
null,
21281,
38650,
146243,
8733,
136865,
62505,
null,
26441,
53522,
451563,
97469,
12109,
424214,
81571,
50130,
20707,
9284,
null,
185361,
267750,
147820,
230803,
null,
239936,
192192,
44201,
85336,
213818,
18061,
220542,
80526,
363088,
435854,
37441,
111436,
null,
458194,
null,
20296,
24166,
58434,
110073,
34521,
185326,
null,
63545,
139935,
513450,
59779,
274286,
null,
32137,
52981,
null,
61632,
null,
409826,
31833,
42576,
16281,
245389,
452712,
79555,
186560,
6786,
301488,
9796,
243963,
17755,
29147,
11474,
166263,
215261,
27563,
42504,
32306,
39792,
16689,
6050,
487603,
37938,
6025,
20694,
25640,
78490,
10192,
71264,
63231,
16746,
378858,
33921,
288417,
177287,
4361,
54993,
126895,
24620,
null,
225565,
92230,
19038,
100621,
74963,
346189,
null,
24189,
62166,
33026,
null,
299796,
124589,
null,
52127,
8396,
919563,
17621,
433383,
209074,
134572,
25963,
771805,
15665,
344653,
38719,
55218,
216435,
29409,
106677,
48538,
297273,
229781,
12737,
85715,
183607,
217320,
298047,
16246,
24491,
69701,
191835,
38645,
48584,
8045,
189174,
72288,
18583,
90892,
362196,
79663,
null,
14340,
12772,
62621,
23472,
31985,
18836,
19122,
46072,
44057,
68070,
null,
508983,
271194,
538310,
67616,
82911,
18558,
164146,
251229,
57891,
434833,
218671,
49340,
23667,
162607,
339819,
160202,
93880,
78805,
394260,
268931,
39950,
36306,
5451,
122145,
284810,
8721,
144169,
40283,
14182,
34577,
66407,
null,
182017,
null,
321167,
56580,
145130,
5255,
282341,
28830,
276413,
96161,
19275,
48261,
10874,
179324,
null,
29239,
143152,
17938,
4578,
419519,
62810,
146808,
180300,
null,
11819,
155040,
null,
45596,
309550,
66937,
null,
85528,
19660,
null,
117934,
50007,
136278,
538687,
50667,
41823,
19670,
66042,
65360,
167313,
57896,
206370,
159800,
115476,
224625,
77772,
229872,
23427,
18915,
null,
240844,
24710,
73434,
29075,
22767,
47568,
642921,
17436,
413564,
4964,
5097,
null,
20168,
279682,
17275,
184614,
113574,
330056,
97905,
351907,
174107,
829825,
50449,
30285,
164318,
132862,
36743,
17663,
38439,
162679,
12393,
7259,
11089,
204332,
153086,
77215,
190533,
61424,
8196,
57217,
75707,
231565,
31488,
274781,
20269,
197888,
271898,
35787,
28971,
62342,
440850,
18431,
384316,
51039,
15336,
47154,
7259,
387061,
16937,
82297,
434276,
23291,
37768,
null,
16719,
349162,
216633,
420169,
70745,
27682,
203180,
null,
362011,
228461,
79080,
15392,
223213,
191871,
390575,
177889,
null,
13624,
null,
null,
80647,
493966,
196027,
147624,
22076,
43456,
272615,
189260,
50665,
138697,
23541,
372271,
146848,
null,
22095,
null,
78937,
419282,
13271,
25942,
128597,
20272,
153072,
7946,
55532,
36376,
596918,
96952,
166252,
null,
14040,
26700,
171248,
54617,
10615,
15178,
32342,
28213,
107675,
287144,
311334,
70145,
null,
null,
34557,
8102,
137171,
7589,
328647,
159361,
13661,
122296,
125007,
190021,
388757,
19549,
60778,
32173,
210996,
16082,
72184,
null,
45421,
151774,
22244,
33532,
353468,
233112,
49949,
309500,
47973,
164376,
77006,
36850,
156165,
null,
102822,
27023,
143306,
138752,
147702,
17749,
140232,
null,
507679,
31318,
200902,
335552,
161391,
35877,
15796,
204086,
48498,
78652,
20002,
3860,
21238,
394102,
280516,
null,
55014,
112946,
9146,
319502,
null,
158147,
24615,
287430,
null,
251513,
5446,
11975,
42599,
134793,
41507,
null,
147720,
10210,
11181,
48695,
159427,
334694,
226521,
18053,
266167,
4026,
16736,
99444,
101450,
12387,
16233,
25896,
43360,
133216,
265564,
10382,
17121,
46319,
24317,
69653,
205290,
299028,
639604,
23623,
8679,
275541,
94101,
73916,
23117,
231427,
null,
91327,
null,
218253,
57902,
48941,
111636,
251136,
321950,
409407,
109465,
138904,
76290,
220646,
35962,
238922,
68048,
30796,
23021,
66555,
4279,
18110,
214913,
192847,
3989,
33434,
211796,
47493,
36900,
33508,
204744,
346203,
null,
49537,
176272,
362968,
35397,
501809,
31045,
21987,
5884,
190549,
664658,
null,
72865,
152447,
68386,
12512,
1130217,
33426,
46702,
112796,
5443,
7849,
251593,
43113,
248450,
122633,
null,
125684,
null,
18504,
342967,
10730,
4835,
22657,
276995,
51172,
133877,
8913,
550953,
219590,
134917,
404818,
89926,
21647,
99300,
39212,
63770,
412915,
5806,
184737,
50835,
25615,
27080,
291027,
27123,
77658,
19915,
442061,
36979,
26697,
8151,
61021,
7979,
250969,
347095,
62389,
208666,
232320,
null,
110055,
158232,
399057,
127169,
399462,
45094,
145830,
225692,
44361,
233750,
null,
100549,
313787,
29318,
46887,
6688,
23580,
null,
39152,
null,
199700,
349271,
189575,
60779,
17852,
59755,
232067,
17337,
null,
143734,
117065,
365929,
53012,
746647,
47084,
386739,
6592,
null,
31525,
647150,
121609,
6613,
205671,
23537,
477505,
210826,
10390,
34773,
50780,
103512,
29163,
12402,
11796,
119515,
null,
36229,
207393,
216254,
125947,
18061,
null,
17238,
110647,
248489,
165869,
133836,
168996,
257623,
null,
73576,
26163,
11346,
179397,
291662,
19247,
54067,
31266,
50226,
39296,
241897,
34246,
83098,
26815,
457,
33189,
72281,
154711,
135614,
25182,
26642,
57241,
108522,
20133,
49778,
143628,
54408,
535737,
319493,
174306,
23918,
65357,
60606,
22386,
59944,
12996,
199561,
50095,
148003,
191221,
228024,
32080,
40374,
144802,
34048,
4539,
467352,
392651,
285848,
29219,
12257,
102099,
null,
29924,
88393,
34059,
469214,
6699,
228784,
39825,
245486,
159778,
177623,
53569,
4074,
16557,
30330,
53370,
147727,
109765,
41432,
369065,
471587,
50926,
45911,
8143,
12543,
34753,
24725,
169516,
249316,
359670,
80775,
390243,
130040,
24569,
39814,
612156,
13971,
29700,
13515,
48043,
11113,
null,
111004,
12996,
36592,
17750,
94797,
119141,
null,
80843,
208045,
338594,
10202,
225195,
178108,
35563,
39558,
287559,
33861,
153545,
2524,
50695,
211360,
239459,
322479,
21890,
29654,
22931,
66154,
77744,
10214,
127656,
27909,
151047,
62628,
51925,
301056,
8038,
260191,
324106,
157310,
245347,
22578,
136513,
39496,
27781,
247806,
41153,
241685,
151521,
608705,
64380,
288342,
175088,
372618,
62947,
33224,
97189,
44904,
null,
72972,
null,
null,
22767,
16902,
47244,
320160,
443707,
29193,
178822,
314357,
12554,
319490,
58122,
null,
188415,
371631,
444192,
251234,
35139,
234682,
38385,
135676,
114643,
81302,
92474,
8274,
19229,
3881,
263171,
60315,
154591,
32184,
165791,
30940,
223706,
24102,
21226,
205802,
231058,
36673,
189333,
222743,
24166,
348786,
52424,
15493,
15371,
341056,
56059,
450438,
163160,
18042,
37989,
317543,
18105,
76248,
56955,
20930,
14091,
null,
16007,
186861,
25181,
null,
25567,
164193,
140166,
44862,
158206,
187066,
4356,
26957,
32532,
null,
127377,
21300,
82500,
79682,
437175,
142078,
64377,
221634,
164209,
23073,
12708,
129424,
70246,
null,
null,
43422,
107735,
456152,
122266,
177590,
179131,
37639,
12814,
63052,
null,
4980,
27226,
141672,
32255,
null,
146277,
412145,
null,
48395,
211706,
7142,
369276,
14395,
34676,
89180,
233908,
52695,
null,
25048,
51990,
9801,
45215,
4306,
142114,
159446,
186879,
59964,
676621,
null,
34443,
null,
188989,
215369,
233688,
8907,
145803,
116489,
9966,
80508,
71601,
190417,
87664,
null,
197044,
26470,
20209,
204774,
336044,
23420,
9766,
73073,
14232,
240595,
411,
73790,
376563,
65899,
378149,
126278,
121748,
null,
87579,
6869,
265944,
49684,
108463,
183648,
172351,
5907,
35429,
27828,
64455,
10652,
127601,
5980,
295407,
203627,
380794,
4394,
52245,
134230,
5356,
37278,
266083,
470925,
220637,
66553,
47738,
null,
86713,
14031,
251202,
13729,
null,
842241,
110039,
348589,
288712,
65780,
113849,
97878,
51313,
45941,
208042,
70536,
293112,
95783,
16070,
null,
81810,
34543,
156002,
102994,
143883,
194195,
67926,
47070,
296058,
48226,
176926,
null,
110602,
40106,
304490,
172692,
13268,
48808,
41165,
25874,
115787,
888029,
1801,
152689,
9753,
11663,
30920,
12656,
614213,
456180,
54745,
9873,
10786,
74494,
128435,
16903,
35832,
10903,
100817,
9900,
94971,
124780,
479833,
208234,
22088,
99410,
61967,
44043,
216167,
240457,
96387,
367322,
364346,
13163,
60077,
394286,
258688,
17021,
29836,
62007,
35147,
23568,
null,
184144,
9534,
21731,
14955,
278541,
19888,
220179,
143919,
77968,
15930,
44530,
null,
50253,
44994,
52247,
24978,
15157,
38841,
59137,
180392,
38556,
218439,
386869,
262639,
198796,
243464,
135435,
240192,
32585,
14392,
464467,
257208,
8972,
33108,
189581,
122913,
450298,
17223,
9772,
11676,
426399,
168627,
6686,
312841,
256586,
183911,
null,
30247,
null,
7515,
53480,
160052,
418119,
362823,
180613,
null,
17159,
61678,
333964,
269204,
547924,
65853,
221666,
22434,
43137,
329838,
32045,
243966,
95266,
25172,
48419,
9837,
null,
17790,
137035,
178519,
53062,
466907,
30901,
21353,
48253,
null,
null,
429189,
31854,
350864,
25203,
null,
267424,
46199,
10781,
261996,
184858,
15481,
315647,
162812,
12297,
202930,
26172,
null,
97231,
25953,
11229,
126870,
60116,
2056,
207412,
71700,
35883,
445283,
115875,
154720,
118686,
100303,
167017,
25003,
339546,
13100,
11289,
277373,
37211,
null,
17507,
18034,
null,
15156,
26202,
321842,
150419,
24134,
56779,
24309,
23730,
34629,
23313,
21969,
35888,
35564,
92734,
160530,
163057,
null,
41577,
31938,
7795,
50699,
50375,
null,
18012,
null,
41025,
306136,
13300,
450759,
240067,
108717,
30327,
54193,
38164,
118964,
164505,
479234,
33073,
176306,
15152,
134412,
161431,
null,
8304,
35829,
12219,
216713,
128357,
254733,
15397,
null,
221053,
968,
170274,
184676,
143663,
37540,
90283,
185711,
525530,
null,
75098,
50977,
38016,
7045,
295896,
232591,
126599,
null,
84454,
6166,
165714,
41598,
23242,
61241,
32040,
null,
137888,
14618,
null,
208953,
325042,
127582,
8497,
162791,
17066,
20853,
32419,
38293,
172789,
32172,
199282,
21239,
134716,
null,
255781,
71288,
36486,
236530,
43404,
null,
148865,
123086,
199377,
44735,
53978,
48662,
null,
16776,
274646,
10852,
51674,
311178,
25552,
299483,
286870,
235881,
12787,
8646,
56439,
143739,
330124,
19932,
24226,
18555,
44068,
131422,
362078,
32754,
335856,
43217,
1105509,
294628,
35444,
296389,
381071,
10076,
42445,
28734,
316763,
370157,
392028,
13771,
214891,
237625,
401760,
313652,
324360,
64742,
31143,
34808,
null,
112326,
126164,
286064,
18005,
30183,
339783,
null,
40560,
176814,
28618,
251039,
348126,
148309,
106688,
130998,
32953,
28233,
492524,
380177,
163547,
262530,
100842,
438980,
32933,
321631,
240116,
186782,
474440,
17979,
232857,
28974,
168653,
168285,
101781,
356100,
125989,
83515,
40829,
115571,
169858,
792818,
125264,
317134,
190079,
201572,
83044,
6996,
296466,
62240,
322850,
21605,
43896,
18396,
null,
89380,
156949,
434404,
172314,
277455,
316187,
18429,
145909,
32321,
30999,
null,
289647,
null,
102412,
58952,
243208,
111830,
28905,
295403,
142411,
24394,
65390,
4103,
18276,
null,
51811,
38866,
216108,
53541,
null,
3116,
310735,
107945,
13319,
218446,
121556,
250801,
281120,
288660,
10012,
540688,
349456,
41560,
9184,
15302,
140724,
247588,
null,
142650,
209422,
98475,
12903,
null,
87990,
125995,
56146,
7932,
350995,
13913,
119716,
239100,
10816,
34175,
391437,
44293,
25995,
null,
203050,
74496,
253418,
23083,
null,
282529,
29705,
406338,
54054,
128313,
9873,
85000,
58148,
208491,
404188,
221948,
100240,
548248,
140916,
123793,
670200,
595712,
331746,
34989,
17916,
264807,
6615,
28639,
44502,
89849,
504288,
9505,
22887,
151580,
29104,
38195,
51969,
173823,
107564,
49374,
49643,
216450,
149903,
null,
28309,
29584,
62269,
280182,
33378,
256209,
277464,
19218,
288160,
32839,
113781,
84407,
243360,
20184,
247545,
179562,
51757,
127035,
253219,
40917,
364976,
257787,
24668,
187373,
50861,
15884,
34345,
48223,
132807,
358518,
559952,
33159,
14107,
41269,
45336,
32200,
204637,
54582,
67571,
null,
321215,
281197,
123458,
350455,
72580,
243768,
408916,
32910,
171456,
757673,
62203,
22740,
24211,
387488,
253172,
835947,
83248,
null,
28103,
24485,
59783,
616829,
75661,
68790,
null,
247870,
324347,
129494,
10105,
43450,
49974,
null,
64460,
22584,
null,
217988,
419205,
9795,
166983,
218521,
16394,
10284,
44374,
29120,
25504,
147514,
7613,
154313,
92939,
83641,
20085,
null,
35533,
24466,
298955,
null,
61550,
7553,
32407,
284660,
67758,
138224,
57339,
408419,
44859,
392971,
null,
179949,
127392,
5781,
153141,
279416,
254287,
54810,
34775,
232880,
40765,
57075,
151624,
13958,
156806,
37306,
17220,
null,
390933,
252272,
17146,
120613,
7426,
26869,
null,
419099,
80412,
11956,
16079,
15652,
19391,
541955,
154261,
742153,
26589,
33981,
187097,
7274,
203800,
161363,
39478,
60257,
56456,
53785,
76392,
12349,
189519,
165913,
33177,
243597,
123168,
62472,
14306,
176681,
140921,
173280,
null,
335000,
282180,
4970,
28694,
22612,
282894,
212560,
134932,
8368,
76078,
19352,
187592,
638741,
227221,
null,
13252,
88423,
271558,
23626,
60238,
46771,
17752,
63310,
20291,
420182,
81663,
61507,
6651,
104633,
137795,
null,
6149,
283253,
14056,
12478,
12014,
252204,
97442,
155572,
24001,
46115,
548787,
108341,
141596,
124663,
null,
9414,
76043,
179265,
31067,
323494,
null,
77965,
437212,
15624,
315706,
148216,
null,
35670,
85048,
14813,
134890,
118397,
230799,
165748,
312399,
null,
24370,
13752,
21670,
352862,
47655,
10292,
61793,
227941,
64442,
27201,
20481,
21184,
82167,
199614,
411303,
19321,
99726,
97726,
null,
191585,
18491,
60899,
48497,
25288,
18012,
246600,
19554,
null,
40521,
226859,
358155,
49326,
59212,
7523,
7368,
277503,
56741,
66086,
123972,
15867,
305409,
348127,
314109,
30415,
159943,
18817,
298635,
161899,
301580,
15808,
87089,
15079,
325857,
null,
43578,
null,
26528,
10975,
30954,
193438,
86345,
60133,
50981,
93110,
167542,
12262,
79222,
12551,
84858,
null,
71968,
74681,
123281,
170056,
151328,
407860,
74960,
355436,
153068,
160918,
61967,
59227,
286995,
null,
86312,
30309,
129276,
59068,
18104,
960484,
186664,
306122,
79080,
32159,
21356,
13680,
42004,
43826,
21077,
34499,
236437,
631554,
129836,
28438,
290826,
106741,
27296,
15361,
90583,
19911,
308161,
24564,
154274,
15017,
16689,
47824,
324636,
112160,
511459,
43299,
null,
228271,
112861,
30551,
36260,
233972,
23363,
122915,
75778,
282657,
296025,
429666,
null,
24878,
344877,
405338,
null,
180780,
57473,
30572,
275769,
198772,
164914,
7586,
null,
286020,
null,
41567,
115132,
53357,
53169,
52594,
null,
109750,
302488,
38148,
9825,
66194,
89976,
null,
181774,
22698,
45242,
170454,
414960,
31091,
10449,
492378,
63971,
45966,
265726,
27547,
null,
19357,
156160,
31303,
37855,
36943,
null,
387281,
96784,
86591,
null,
188416,
94684,
255334,
null,
52103,
35551,
49900,
9210,
61074,
28203,
247639,
289575,
26868,
66084,
26849,
100618,
430406,
48341,
598839,
null,
290168,
12761,
109477,
177073,
775773,
155411,
10578,
null,
47151,
12122,
27846,
64330,
216301,
21352,
44306,
47241,
40959,
null,
241594,
18510,
21438,
374254,
null,
18206,
644130,
32972,
15944,
41941,
114708,
null,
45783,
33226,
190046,
30187,
59688,
38957,
670231,
null,
26796,
31366,
17690,
229770,
6831,
568444,
175622,
30613,
4383,
160933,
9118,
28334,
16825,
null,
14337,
417237,
4294,
348380,
7167,
95351,
null,
34867,
null,
16315,
33004,
28352,
16133,
35899,
16588,
42045,
515821,
36967,
294899,
33590,
null,
19327,
152204,
356876,
426594,
14251,
97958,
42546,
475841,
31869,
62741,
397615,
null,
49086,
20156,
15611,
329803,
37568,
283393,
110361,
78979,
118276,
258440,
417409,
49117,
23566,
15060,
57643,
32791,
37010,
null,
38774,
415201,
10837,
401533,
283334,
111550,
35120,
95860,
59484,
38219,
286242,
150774,
9801,
35889,
176235,
56719,
226525,
24083,
null,
130037,
21695,
270259,
null,
28835,
10805,
null,
122526,
40179,
182631,
6235,
23744,
78076,
null,
150155,
14503,
26097,
30860,
57965,
140549,
82444,
268373,
43758,
null,
15727,
121326,
180071,
79081,
37087,
233959,
null,
94784,
13084,
50281,
521050,
124088,
169820,
233892,
136115,
32464,
9285,
401510,
313667,
391716,
360329,
35183,
254242,
234494,
421901,
340751,
29605,
124873,
101000,
19805,
24900,
35560,
177704,
120600,
43889,
35513,
635837,
284670,
14753,
296405,
935931,
27466,
350435,
222955,
46216,
18878,
200092,
80119,
304791,
13965,
102663,
249476,
21455,
54942,
13611,
336010,
44771,
50653,
43519,
119213,
171892,
20205,
68658,
308563,
28284,
33287,
null,
41891,
13479,
223079,
193339,
17620,
null,
147707,
486435,
null,
null,
180782,
217014,
18367,
11327,
6507,
354217,
87863,
226339,
271110,
159674,
61150,
125909,
29884,
79412,
147351,
62396,
254711,
46661,
7567,
null,
27245,
83174,
null,
null,
35754,
null,
40861,
65971,
38705,
34573,
34786,
63061,
27980,
153727,
572316,
null,
102497,
210263,
23575,
320751,
17281,
43664,
34538,
11375,
21376,
24467,
17409,
177916,
30223,
null,
55033,
1119115,
20222,
395806,
479500,
51463,
214986,
15016,
159963,
90908,
328356,
158768,
7498,
16342,
22388,
51311,
127658,
33404,
73406,
35119,
64745,
45077,
509592,
283089,
255538,
null,
125729,
109415,
37459,
null,
16427,
40163,
24387,
310689,
192601,
400735,
61759,
309006,
29859,
299110,
67008,
null,
184632,
12418,
10781,
385849,
null,
67033,
18522,
217701,
261431,
166557,
88606,
55250,
28992,
null,
32234,
180087,
4545,
275532,
null,
52943,
null,
16711,
23794,
32232,
499783,
6988,
8377,
4439,
12147,
118818,
19018,
15925,
13003,
null,
156978,
373559,
213097,
34833,
53913,
33525,
57009,
530937,
359203,
114113,
333188,
172566,
34985,
167318,
4738,
12003,
115577,
220807,
77853,
357683,
19651,
588409,
116555,
211023,
291546,
326063,
47242,
399247,
null,
75847,
15147,
null,
55985,
35048,
null,
199649,
68232,
144127,
312588,
134211,
195212,
73565,
389625,
35289,
156879,
null,
14084,
359505,
202470,
306337,
124145,
261985,
284747,
110993,
6044,
550387,
79514,
null,
63992,
78324,
55130,
18782,
115859,
7678,
288329,
213046,
10654,
null,
28397,
61021,
169739,
172023,
279958,
260166,
56753,
26562,
176891,
35953,
392669,
89529,
179926,
196558,
80009,
410286,
53718,
122325,
272584,
774224,
158838,
23183,
38880,
47848,
48821,
18363,
235942,
null,
234636,
38113,
31652,
3336,
267993,
51977,
35399,
245146,
157984,
5720,
33621,
316405,
43297,
60023,
618679,
416262,
202525,
16801,
268820,
274389,
308161,
122535,
12644,
null,
121687,
null,
65939,
18757,
319204,
104731,
198652,
461426,
23300,
27835,
39446,
265700,
5481,
211343,
118891,
137952,
105362,
305027,
451762,
24742,
30332,
30167,
114462,
192235,
35614,
22410,
153699,
21315,
23746,
25770,
366482,
27363,
233206,
65448,
214792,
30202,
106733,
488637,
46522,
238579,
null,
346840,
89612,
84647,
245714,
243038,
234310,
151266,
64836,
31206,
21320,
381289,
19962,
30845,
173349,
41078,
161466,
320641,
159002,
null,
269907,
22085,
71194,
null,
5071,
120159,
329037,
220210,
306003,
63555,
335922,
143228,
34206,
290138,
505436,
null,
null,
null,
20711,
48448,
8845,
5410,
178271,
62822,
327160,
null,
6425,
233923,
131373,
null,
44658,
334557,
99284,
435707,
null,
16012,
426998,
6155,
43414,
151619,
79991,
185022,
190576,
86235,
254770,
12697,
106886,
11554,
148690,
12279,
78021,
12991,
155662,
28484,
70057,
284255,
74798,
432748,
7020,
275078,
255779,
11656,
55020,
141527,
505045,
29801,
27656,
350930,
87027,
5042,
7940,
324215,
95849,
42464,
67409,
117499,
14811,
303367,
5063,
196873,
5483,
560359,
null,
87800,
182836,
null,
301802,
213613,
25247,
38267,
43812,
50636,
44015,
139061,
206357,
31178,
125178,
191140,
64436,
26516,
11214,
57780,
158837,
null,
41043,
39336,
130799,
71685,
15377,
187817,
13423,
179326,
12822,
6948,
294874,
18790,
194861,
26896,
27750,
102923,
466263,
17809,
1100864,
80063,
202265,
240146,
11627,
124025,
148812,
333274,
38984,
157649,
null,
40865,
74244,
196006,
57062,
53083,
32983,
43845,
165714,
230118,
16186,
16837,
23947,
null,
23549,
null,
293461,
440547,
59555,
25240,
17221,
7539,
72838,
86655,
162459,
145723,
243847,
3830,
174184,
16104,
179481,
45791,
330650,
533906,
65751,
298473,
7923,
null,
69464,
65634,
7881,
56254,
43336,
14767,
279268,
28332,
194846,
303709,
38309,
116773,
28841,
36236,
26703,
176148,
null,
80461,
134311,
61341,
null,
213091,
512739,
229672,
284623,
180038,
null,
null,
166146,
171418,
175948,
88109,
340874,
37625,
35806,
356456,
274580,
139084,
34155,
27598,
null,
63661,
27503,
14435,
4907,
118308,
60682,
133790,
13607,
23619,
72191,
171045,
29119,
468149,
212919,
null,
29805,
31518,
280549,
464236,
87369,
44957,
582466,
46960,
43934,
164462,
239354,
33092,
111310,
419786,
20953,
27642,
100697,
58595,
40103,
11160,
27863,
31188,
179645,
62916,
null,
190444,
null,
42348,
61603,
92959,
70516,
304895,
12096,
431382,
17180,
301016,
67363,
385136,
31717,
35721,
198888,
145329,
137977,
93951,
125957,
344035,
46160,
null,
260314,
19280,
211986,
192456,
430666,
38183,
90876,
null,
153695,
136852,
401796,
null,
27095,
null,
67300,
113,
15541,
313326,
51993,
85907,
51698,
294209,
259945,
31162,
552779,
34136,
38278,
null,
195073,
26465,
107271,
125282,
271068,
29129,
26925,
438770,
72737,
123330,
472332,
134083,
163388,
170511,
84926,
254524,
17975,
868690,
45996,
552475,
201533,
23589,
6367,
29479,
309930,
818415,
336377,
406760,
265073,
303826,
49130,
7726,
70494,
786977,
120227,
8505,
157826,
41841,
35806,
203584,
35557,
202646,
154296,
35264,
402371,
12756,
7354,
66788,
381550,
93842,
187664,
288247,
14910,
25086,
273740,
32001,
261315,
20966,
434543,
1109,
null,
null,
61004,
29100,
77529,
17952,
306516,
18785,
2757,
31386,
244159,
252697,
37907,
261458,
291964,
39532,
610996,
null,
231112,
235500,
61771,
28965,
null,
null,
30705,
25059,
20623,
122783,
146441,
163576,
null,
23798,
122569,
11161,
60104,
342896,
21774,
null,
273174,
11234,
15584,
175743,
377287,
224969,
444647,
42795,
20969,
55256,
93137,
116040,
49281,
17142,
183135,
null,
28134,
69922,
26857,
40483,
30662,
155498,
140135,
18968,
330813,
272741,
61032,
149413,
469637,
30500,
25444,
null,
117870,
144995,
109164,
128076,
65115,
188349,
34157,
140468,
23714,
50504,
29961,
69786,
100064,
201283,
22406,
351045,
12355,
24386,
76269,
358383,
41597,
57987,
59730,
177761,
107058,
306732,
106673,
32178,
591111,
27814,
19530,
82564,
10412,
null,
274237,
18837,
176678,
134510,
342611,
35050,
340937,
268474,
12723,
17588,
244307,
30775,
728295,
188156,
24190,
19056,
null,
33922,
50536,
42337,
151496,
10021,
100080,
302162,
83083,
317859,
156984,
145601,
210104,
238905,
null,
137042,
95307,
26537,
20298,
67070,
146424,
484939,
32413,
10638,
108432,
85733,
3084,
56356,
114056,
23650,
26838,
358108,
256585,
135947,
69242,
217656,
null,
225405,
116467,
25942,
34884,
28664,
14385,
17781,
72081,
400127,
199175,
102885,
28064,
38378,
43304,
4802,
40701,
725132,
13618,
223181,
475332,
null,
271745,
60225,
159930,
40023,
4578,
66351,
59039,
79503,
138134,
150984,
241498,
39537,
3762,
84734,
103440,
68006,
26741,
90104,
192911,
17600,
31772,
39038,
306686,
11514,
277116,
87020,
43233,
87801,
null,
null,
147312,
34198,
46384,
24276,
null,
48361,
14232,
60236,
48299,
11556,
45979,
515773,
5651,
47689,
38791,
19998,
16026,
null,
34839,
219162,
20937,
32889,
null,
354844,
148702,
46834,
270109,
103336,
23144,
null,
69617,
214657,
311065,
70977,
122285,
93565,
31411,
null,
122456,
18689,
19565,
353551,
235508,
null,
null,
31488,
null,
298077,
333920,
39142,
146555,
null,
189365,
278187,
147511,
173878,
28731,
50340,
512660,
51793,
174175,
359125,
142950,
21990,
306437,
160060,
null,
213509,
164713,
86911,
349077,
null,
27282,
25430,
39138,
33196,
null,
79232,
null,
158307,
14419,
33502,
31590,
83660,
415261,
null,
17673,
65942,
140785,
271135,
177382,
398760,
359154,
140426,
549498,
null,
248407,
585905,
597000,
462344,
209477,
null,
126379,
337559,
350831,
25597,
null,
28199,
117212,
32741,
16928,
1457,
217900,
30863,
557755,
null,
21646,
656367,
227985,
251063,
17539,
25196,
33350,
25909,
179589,
34433,
93264,
206007,
268333,
203528,
43337,
191794,
18167,
4261,
236851,
48080,
221612,
64560,
31458,
201764,
null,
31954,
208733,
41317,
257223,
104989,
19377,
210092,
137610,
61363,
34297,
221325,
null,
53164,
177677,
307787,
68249,
null,
28888,
49924,
null,
6143,
318112,
370115,
164500,
4534,
53802,
22037,
159971,
41408,
100684,
351074,
313709,
55879,
66427,
18870,
140815,
null,
43564,
33557,
null,
278807,
3474,
131464,
239233,
null,
24746,
60367,
56466,
395742,
1020893,
12195,
482359,
430988,
86369,
95025,
327379,
157635,
16449,
200650,
112239,
142789,
null,
12070,
32717,
25164,
13731,
435128,
84540,
165748,
182238,
12961,
61834,
3577,
152875,
265580,
12842,
33327,
58353,
54305,
278909,
27584,
null,
null,
31782,
237353,
34932,
45400,
257522,
224276,
295195,
228718,
58036,
50591,
194968,
64106,
19536,
434628,
73303,
136352,
41721,
270952,
27354,
37402,
232405,
33779,
284834,
null,
29873,
82390,
197981,
73205,
19463,
146375,
54256,
16410,
115618,
66043,
139705,
118094,
415864,
785063,
232939,
302330,
149237,
17126,
308755,
92576,
21231,
null,
417579,
24899,
null,
318327,
25768,
34464,
299507,
403849,
317891,
5814,
15610,
59383,
137432,
7451,
29817,
89129,
13629,
11589,
96905,
8241,
12583,
299769,
210338,
49721,
538718,
186749,
118647,
86139,
46888,
250162,
117139,
116278,
288058,
240703,
281299,
578806,
45302,
296294,
552654,
null,
195091,
47377,
18951,
229916,
322865,
20993,
169256,
52035,
243263,
43379,
null,
130002,
null,
435550,
null,
23751,
9615,
273275,
239023,
7580,
18336,
1813,
98755,
14455,
205492,
12192,
13462,
13521,
39663,
269073,
91181,
41681,
null,
null,
24105,
38707,
10391,
205768,
13029,
9312,
7025,
38917,
316,
6099,
79227,
352157,
45907,
null,
null,
6934,
11564,
64629,
42093,
178791,
252451,
27851,
19757,
98933,
26255,
182712,
18881,
70104,
44882,
168896,
201481,
215588,
211944,
281790,
17431,
9902,
332015,
62594,
25419,
23860,
27280,
3787,
230103,
228870,
56886,
29706,
128620,
40173,
284833,
49058,
185448,
320327,
84952,
270212,
103165,
600215,
62320,
18470,
179510,
186198,
88051,
43959,
667596,
23943,
46394,
300255,
144681,
null,
185622,
144432,
69189,
205846,
242646,
47852,
41048,
null,
null,
413757,
null,
null,
28997,
96652,
127051,
33810,
264481,
243558,
20315,
316266,
117204,
315841,
257026,
169882,
163363,
26858,
22814,
20336,
377370,
33023,
225619,
109894,
68413,
null,
152934,
94009,
11206,
null,
21445,
17290,
27762,
32136,
216541,
263162,
313700,
231395,
18953,
67324,
388912,
8351,
326324,
160509,
30890,
199127,
501903,
348759,
89339,
29386,
30996,
9045,
177482,
113671,
141920,
137851,
8028,
18291,
38021,
52509,
25684,
38992,
657945,
59236,
36601,
16300,
21308,
24626,
96963,
null,
331433,
184773,
30493,
42952,
4092,
18283,
243424,
272344,
86117,
134926,
9506,
46339,
204668,
null,
110009,
25017,
232023,
2727,
98510,
261438,
71247,
20657,
18418,
193225,
60540,
45041,
49459,
187531,
88813,
28978,
159608,
67365,
260125,
11237,
39795,
7209,
84933,
17641,
176225,
273976,
null,
291612,
37421,
3229,
17632,
14728,
15323,
3404,
62344,
36218,
32612,
247809,
31487,
null,
118229,
11736,
309658,
294392,
41517,
43363,
49467,
14980,
317929,
36026,
157969,
41655,
527184,
71635,
286358,
null,
132555,
471407,
190545,
38887,
70944,
134789,
31931,
364568,
450856,
31013,
68182,
6419,
514534,
65623,
157719,
219727,
148313,
22529,
34670,
82543,
290333,
37034,
15730,
8743,
35580,
null,
546465,
186051,
53121,
28001,
36308,
168084,
184378,
665974,
57124,
3990,
null,
65659,
127738,
151978,
31949,
418395,
157596,
24011,
35155,
392090,
18200,
28510,
156490,
41247,
64089,
122662,
120539,
null,
52897,
175265,
null,
30282,
93111,
169590,
351506,
78749,
60177,
239721,
20462,
268316,
109176,
23593,
22430,
null,
22986,
null,
376006,
456043,
11043,
174456,
134235,
33512,
42642,
33863,
229252,
171189,
155961,
222468,
424118,
160853,
22322,
362741,
305571,
96851,
357849,
null,
26858,
26944,
134478,
186590,
468818,
134445,
233721,
33940,
265865,
461645,
84662,
79409,
348989,
126496,
345885,
444457,
40281,
173663,
52898,
159319,
394916,
43743,
270668,
163212,
222184,
12868,
174753,
171865,
18885,
680973,
295554,
287982,
168394,
283708,
19188,
471351,
170624,
8681,
33375,
137153,
269889,
149898,
25886,
213653,
77551,
34524,
53109,
29054,
86001,
182514,
37124,
19214,
89477,
72701,
130139,
null,
64364,
244598,
46391,
null,
152649,
42084,
170542,
17035,
21597,
null,
76453,
58498,
9399,
315425,
null,
142926,
80958,
116879,
18965,
114277,
373090,
33944,
173807,
175008,
13511,
204665,
84286,
71718,
null,
36989,
201497,
275507,
70896,
386605,
162994,
315155,
77094,
152548,
68372,
77697,
20110,
62772,
117812,
126436,
12820,
34424,
57275,
20980,
18327,
458914,
14096,
59833,
128666,
8364,
157619,
143811,
52560,
37723,
31192,
30929,
41888,
347277,
58705,
249706,
null,
null,
289592,
179016,
12617,
50882,
63630,
187121,
46685,
38376,
487848,
null,
95621,
66002,
12486,
26286,
50087,
31526,
null,
108608,
43727,
109662,
148631,
27997,
11409,
null,
128036,
10923,
53976,
44554,
86754,
220110,
194771,
10925,
null,
61358,
412321,
243174,
15590,
40107,
267058,
110524,
192755,
38940,
126555,
252656,
459309,
247007,
290444,
142632,
232431,
27927,
216923,
282415,
237651,
93787,
202096,
207311,
7535,
389113,
70695,
189806,
4532,
133635,
123476,
53884,
19869,
162684,
128306,
38330,
25925,
40826,
135348,
34096,
192470,
203061,
104289,
null,
211609,
28408,
52796,
32946,
34327,
59814,
391620,
218434,
25773,
172561,
19930,
62380,
273365,
14779,
88057,
184517,
8499,
null,
21737,
288053,
148514,
51456,
75500,
null,
278186,
25505,
35826,
241385,
59320,
190740,
12307,
34915,
41526,
19214,
48156,
16563,
4227,
36873,
284973,
267608,
166382,
219391,
16315,
41662,
38011,
164680,
null,
null,
297682,
30882,
9545,
26570,
642828,
31496,
25561,
113520,
204452,
22114,
460115,
47424,
286319,
22910,
81019,
390559,
27709,
null,
27565,
32362,
63230,
15826,
16501,
287602,
671550,
62547,
369703,
53399,
null,
51767,
null,
273868,
null,
171203,
279909,
10031,
13834,
45512,
149092,
236451,
277407,
137903,
42009,
440608,
46982,
null,
288398,
null,
41862,
9587,
11528,
25309,
66212,
null,
88353,
60263,
null,
782877,
157664,
61521,
null,
170254,
13508,
222117,
477433,
61338,
19384,
31120,
149499,
43171,
null,
265686,
63336,
222683,
30813,
30703,
15677,
272433,
354010,
22108,
177482,
308880,
264167,
49187,
526027,
52094,
119624,
null,
16272,
45472,
null,
41201,
293416,
71176,
40156,
36294,
146567,
2261,
168575,
236050,
194322,
39054,
37901,
61049,
44496,
163197,
174560,
23676,
72048,
29728,
116205,
265684,
148452,
2015,
345354,
707133,
147607,
103864,
305953,
112339,
39180,
558361,
66977,
433315,
12873,
16443,
27783,
17114,
12391,
28778,
41810,
186371,
190279,
70279,
314476,
57872,
527215,
2590,
411284,
161432,
149872,
17689,
655802,
11123,
123123,
261622,
169229,
39148,
104850,
18304,
null,
529185,
276017,
25609,
32565,
175047,
24340,
null,
30997,
84538,
49748,
365983,
43613,
123358,
23472,
25808,
41403,
35696,
179699,
96059,
23508,
169591,
26695,
28792,
9953,
9147,
null,
136452,
286261,
29678,
63850,
284351,
171461,
116064,
182321,
48607,
266942,
68834,
18700,
31443,
50412,
246487,
658,
null,
224256,
342862,
11052,
312663,
135816,
51168,
37722,
34016,
27731,
221433,
41622,
83938,
35973,
84076,
155195,
42155,
252055,
95913,
179014,
14211,
281144,
236577,
166883,
41557,
null,
null,
180469,
350679,
36392,
189081,
205404,
7876,
105506,
14186,
24562,
183903,
37395,
null,
156073,
null,
null,
29580,
90463,
94977,
340638,
3669,
53494,
368802,
184652,
254873,
185348,
48773,
36921,
1294903,
66982,
144955,
30060,
188966,
204657,
30372,
336710,
177950,
18763,
417861,
197585,
19386,
25881,
199222,
149274,
176968,
19980,
178341,
93246,
112810,
328588,
35864,
36410,
61827,
98856,
24178,
138367,
476582,
null,
319557,
134669,
501363,
56566,
181533,
26054,
373795,
30519,
49300,
41111,
143244,
217626,
644332,
231754,
null,
9582,
141499,
13366,
26690,
195190,
null,
257169,
24101,
51233,
196624,
603295,
13620,
115859,
158088,
null,
81262,
16631,
4714,
685496,
76468,
null,
209533,
null,
16123,
270869,
119530,
56806,
6838,
17829,
200248,
35540,
22935,
123455,
null,
null,
146440,
19281,
19726,
196131,
213776,
null,
80032,
null,
201502,
505541,
14932,
23434,
296953,
401432,
50510,
null,
82747,
null,
7767,
15902,
52121,
86393,
170315,
20787,
11910,
180661,
212442,
97204,
144444,
30962,
320829,
199706,
17018,
53948,
25191,
5732,
31269,
213723,
303128,
29386,
98345,
285857,
353419,
25414,
160567,
null,
19893,
20399,
474368,
465934,
27144,
412146,
null,
342305,
10368,
191049,
null,
81556,
73152,
37660,
460588,
25187,
14302,
15373,
455975,
112740,
219458,
138779,
null,
80876,
112264,
271086,
9762,
71404,
138505,
76784,
71124,
179031,
15137,
15684,
191464,
11378,
21039,
107160,
42506,
67212,
217214,
30216,
159233,
null,
null,
74895,
645838,
33363,
146804,
29210,
26112,
45425,
239901,
74413,
56694,
28866,
371889,
117259,
87307,
67882,
271286,
null,
182649,
29569,
241819,
12252,
59667,
368108,
null,
258533,
166017,
null,
290942,
79390,
52322,
60110,
14104,
8392,
31132,
431805,
42280,
89053,
null,
43770,
368583,
2152,
403687,
72230,
88070,
15684,
185623,
143526,
263315,
null,
210418,
137500,
167526,
470945,
51179,
41091,
332695,
158735,
281481,
37292,
42169,
23405,
273514,
19398,
null,
8581,
null,
21149,
42843,
12163,
878127,
463633,
10362,
107945,
279224,
120046,
563031,
281933,
101997,
null,
101318,
92102,
337737,
212966,
149711,
21823,
171507,
329689,
117600,
318191,
12391,
229079,
191293,
6493,
51535,
81695,
8979,
216666,
5815,
315109,
55208,
182289,
141561,
21783,
361836,
17042,
31490,
10684,
147874,
61353,
45116,
28161,
54992,
358891,
165809,
null,
49345,
30968,
29155,
null,
309129,
33525,
278111,
16824,
null,
4200,
47444,
23319,
11324,
134277,
null,
165140,
36571,
8061,
460000,
8875,
null,
60421,
22659,
2784,
24639,
null,
null,
57020,
27910,
228964,
null,
244393,
null,
155641,
47768,
19179,
36868,
19849,
175691,
60018,
66758,
44602,
274395,
415891,
136695,
95672,
38120,
124735,
17214,
22392,
13200,
301843,
207326,
27310,
207166,
529738,
471383,
8018,
418439,
279923,
107355,
21269,
242463,
27464,
15563,
209467,
401101,
26009,
24939,
31809,
177345,
31397,
4209,
22062,
133642,
null,
34561,
29182,
175052,
144446,
212204,
61749,
303338,
274176,
5293,
18495,
15430,
37326,
null,
66971,
37002,
28891,
76486,
222940,
354440,
197868,
null,
154917,
929765,
26836,
5912,
231640,
17968,
44570,
4763,
346691,
214531,
525424,
16769,
145991,
145903,
30190,
83584,
477034,
376008,
121843,
160141,
44609,
48220,
31964,
48472,
27088,
31512,
null,
47975,
21679,
50186,
223627,
257369,
4605,
189821,
40333,
null,
325856,
16162,
91009,
431968,
238815,
null,
82687,
19469,
412695,
396328,
75668,
79654,
24449,
null,
87465,
29987,
32231,
null,
29734,
29470,
null,
8434,
75380,
15591,
313733,
6910,
82740,
5171,
null,
55274,
38236,
69354,
264554,
763089,
35299,
353236,
178017,
85990,
7435,
32605,
null,
9544,
58308,
109443,
418069,
20653,
307958,
45238,
86823,
9907,
331240,
37049,
67152,
175732,
102991,
154218,
276204,
129401,
108443,
25555,
162519,
519684,
140756,
191853,
94027,
324819,
319122,
288226,
35865,
419583,
null,
19029,
4008,
113898,
49701,
21113,
542454,
13699,
611969,
473122,
24020,
210839,
null,
138530,
41684,
34739,
406022,
11311,
220023,
55045,
86685,
135552,
217460,
244312,
85756,
70509,
39597,
null,
null,
132933,
62750,
61033,
135864,
5525,
184944,
null,
134379,
221014,
287480,
57829,
null,
8201,
185044,
56602,
590803,
52827,
12727,
160740,
77460,
103554,
17422,
null,
null,
102425,
110819,
45160,
21918,
46015,
null,
16354,
32828,
114057,
43688,
86425,
82215,
33323,
57064,
4167,
null,
275588,
70686,
91397,
446738,
3384,
462631,
24700,
39876,
124312,
46562,
278207,
47440,
45737,
229439,
39412,
null,
822095,
73010,
261523,
19180,
334538,
45390,
68517,
43136,
null,
29059,
193167,
25804,
38041,
null,
187551,
null,
125355,
9701,
135853,
24478,
34216,
280754,
82604,
140956,
34494,
305863,
157653,
65124,
249409,
25437,
122415,
288643,
null,
248356,
238898,
123522,
548880,
230909,
278277,
49483,
315899,
22255,
39063,
191581,
124011,
238330,
185764,
63610,
213487,
172646,
38598,
49069,
4560,
392617,
112867,
137023,
30156,
29809,
157739,
974449,
316666,
18613,
27261,
326831,
240250,
284292,
30743,
24093,
111311,
45835,
26072,
118171,
189469,
164500,
194668,
443160,
48206,
17401,
15118,
118619,
34225,
211950,
384040,
33810,
123344,
283896,
100149,
173859,
167956,
null,
317951,
77530,
398322,
42214,
381151,
57163,
145940,
2007,
235788,
125676,
20051,
4598,
57139,
198787,
38164,
129382,
9378,
251277,
71484,
526028,
15188,
217832,
130493,
247181,
13470,
9018,
15494,
166797,
132411,
141123,
null,
null,
58329,
148161,
268662,
53840,
457310,
60420,
202263,
31198,
10169,
6841,
null,
282783,
167457,
null,
157120,
217145,
147300,
378467,
100701,
null,
70972,
143221,
302404,
228588,
26690,
8775,
80103,
null,
45677,
251432,
227948,
53687,
9786,
273428,
590420,
236908,
316139,
23860,
12234,
24326,
288552,
315953,
21115,
163578,
722392,
240418,
29435,
150487,
492197,
20685,
132018,
72200,
296617,
20712,
287692,
195471,
5576,
162777,
63882,
82609,
50328,
226932,
338019,
779972,
190074,
null,
364293,
547560,
null,
172182,
251709,
552587,
292508,
130619,
50112,
22446,
164192,
13559,
24701,
179321,
2686,
95322,
212115,
37510,
null,
861063,
162834,
12841,
54492,
115544,
193940,
10690,
62474,
253889,
251556,
363842,
null,
76734,
155509,
22761,
128847,
null,
66730,
26770,
20379,
133445,
236349,
10449,
160501,
7503,
53253,
192511,
83010,
204729,
20450,
164634,
45737,
150830,
9925,
111668,
37408,
13858,
319317,
171413,
139746,
14835,
543641,
null,
386082,
216877,
null,
23818,
8094,
11047,
34371,
199623,
null,
377800,
35536,
39774,
187508,
13287,
24785,
null,
null,
10240,
409268,
23253,
27027,
30677,
332521,
392611,
29909,
42941,
28901,
null,
144966,
39547,
33896,
83997,
null,
383426,
329788,
237710,
8046,
11756,
276169,
33074,
null,
19430,
687955,
35687,
null,
653655,
34034,
13331,
34922,
102069,
123627,
168377,
66633,
333501,
7374,
20219,
37809,
73657,
56968,
27184,
56831,
405381,
null,
87402,
70643,
20340,
8815,
240628,
39604,
326513,
190053,
38756,
234033,
15072,
557401,
98203,
273206,
66603,
441186,
182531,
174656,
22927,
20436,
251048,
40406,
342876,
15531,
144448,
221578,
400319,
42458,
983839,
254281,
3798,
167198,
73182,
53052,
30934,
16395,
359169,
54711,
null,
93238,
null,
16222,
184201,
323063,
75770,
232995,
155584,
null,
83876,
4015,
49965,
113082,
19564,
530074,
103781,
99493,
null,
null,
40021,
53422,
33604,
279973,
17149,
107871,
239629,
50223,
194722,
null,
null,
75643,
16292,
141504,
42616,
143112,
237181,
8659,
321021,
54250,
64568,
46096,
null,
15489,
80818,
15529,
209210,
216484,
34861,
66482,
212934,
35068,
140508,
105032,
110883,
152574,
168188,
74840,
397630,
5081,
234515,
154871,
191472,
217484,
39867,
24787,
39341,
175429,
88248,
null,
141221,
106639,
67067,
72431,
602762,
227133,
56972,
9129,
58236,
23465,
160405,
20960,
194058,
30286,
16072,
18118,
18391,
613657,
5453,
26390,
76028,
36474,
51214,
397647,
141509,
163930,
8401,
37822,
139177,
12527,
237517,
40737,
23147,
234422,
179723,
129820,
26021,
58520,
33124,
245017,
69129,
53077,
134033,
156800,
18754,
429728,
47449,
400550,
289344,
15956,
541465,
12809,
331327,
13660,
29058,
44677,
null,
18965,
31540,
389985,
201250,
333629,
12331,
32577,
441799,
146751,
303716,
6545,
210096,
162031,
null,
195846,
327264,
40076,
240364,
6991,
65267,
462441,
348648,
null,
42205,
43627,
62276,
339852,
null,
11871,
null,
193722,
95568,
7392,
59178,
126665,
18646,
88721,
44181,
null,
null,
null,
170689,
13611,
20131,
309625,
40430,
401227,
null,
122423,
10743,
87171,
317969,
40519,
177345,
624158,
29513,
81046,
12859,
196760,
null,
187620,
27563,
53029,
7040,
34834,
75278,
92499,
108263,
977415,
null,
74725,
3759,
198675,
66534,
109870,
32306,
39444,
500324,
4442,
58906,
369240,
14502,
102853,
75522,
null,
29919,
56753,
8160,
193792,
54965,
11018,
31827,
40081,
64529,
36963,
47585,
211683,
31542,
3231,
179187,
40689,
28059,
19236,
11290,
9636,
393945,
33502,
165093,
461542,
13481,
21472,
33860,
57049,
54920,
21042,
68326,
33640,
68028,
60058,
47769,
131742,
40550,
257350,
172657,
null,
435648,
276268,
23041,
155029,
29367,
null,
144908,
17643,
206520,
97727,
26207,
30557,
23503,
4770,
28498,
440415,
205785,
39075,
36674,
257154,
100554,
10687,
182917,
328136,
27429,
18920,
626685,
8990,
137510,
32950,
166973,
90326,
293704,
212225,
23235,
336125,
177116,
14975,
14975,
196092,
44082,
69482,
60999,
17072,
109631,
28990,
19017,
135710,
21071,
431107,
112232,
31078,
116624,
40435,
33643,
62533,
124103,
116604,
555875,
188094,
3238,
24214,
15034,
48239,
245758,
7816,
184653,
185123,
32986,
565934,
32295,
174332,
266483,
52147,
174753,
428310,
347880,
25337,
12914,
77543,
242216,
36321,
31988,
86249,
249232,
105194,
null,
188230,
16816,
null,
350077,
252720,
142812,
223155,
51232,
688108,
311155,
445036,
48380,
226279,
220994,
44399,
254685,
439927,
18975,
null,
25859,
120289,
166586,
168542,
353556,
285704,
14326,
81058,
32284,
241193,
307284,
44679,
13306,
264721,
279959,
null,
14597,
65429,
34982,
null,
276683,
342766,
28649,
25214,
273508,
82540,
59095,
28054,
15641,
181044,
161188,
30658,
40029,
28488,
211453,
12020,
19206,
126114,
25769,
60552,
140250,
529907,
303696,
260722,
null,
76272,
126226,
207512,
105357,
115245,
321958,
443589,
44723,
170351,
9450,
343442,
137907,
459588,
819257,
20064,
79502,
null,
187869,
106839,
null,
39161,
330700,
317097,
324448,
56523,
null,
209638,
11971,
38626,
54578,
null,
402170,
258975,
310620,
200326,
11163,
70070,
127544,
null,
31274,
26881,
null,
24374,
63795,
9201,
27370,
253894,
28517,
26308,
366373,
42416,
214757,
233849,
1154527,
222277,
155087,
18562,
null,
15110,
90149,
30719,
88177,
24830,
174705,
282732,
40428,
125667,
299696,
325428,
26696,
22011,
43907,
null,
223992,
232020,
5360,
240528,
286441,
11664,
213548,
187341,
7967,
185291,
20372,
51705,
null,
413949,
237897,
176792,
140996,
183928,
153773,
135261,
57042,
84087,
121578,
143105,
107950,
14700,
116374,
75635,
null,
18897,
207977,
221235,
23379,
43644,
526516,
24662,
233467,
422026,
86887,
108300,
277290,
125065,
140851,
474410,
17802,
32258,
124681,
112166,
169054,
250710,
117674,
90564,
154515,
2579,
10899,
320517,
91189,
26842,
30645,
247100,
4381,
null,
37597,
4783,
167082,
263835,
27998,
41885,
51747,
56487,
63924,
19082,
189699,
215814,
389615,
99824,
55652,
null,
116280,
47163,
19070,
26861,
286663,
70629,
11102,
166540,
116763,
122438,
133116,
63626,
12203,
66095,
214494,
439250,
357503,
62175,
575907,
198066,
27616,
29908,
268874,
209982,
166660,
24659,
191187,
10298,
79223,
23566,
25589,
30398,
403776,
619532,
59938,
null,
552878,
28941,
76365,
709217,
22346,
150042,
17965,
502264,
null,
354609,
74638,
87648,
86753,
246285,
60771,
5059,
195985,
36100,
20949,
139670,
63465,
146218,
241244,
8865,
14968,
232867,
8228,
16291,
40374,
269032,
35172,
341879,
43797,
37915,
14606,
332739,
372255,
414330,
29248,
6573,
164076,
146150,
31543,
46415,
26902,
29187,
381957,
22143,
18497,
27005,
191169,
null,
9436,
304637,
11972,
63364,
23971,
83481,
45086,
39741,
17119,
null,
417852,
24520,
52022,
73127,
776453,
672414,
39035,
7889,
255245,
517481,
45075,
39822,
9250,
243249,
76547,
17574,
35008,
239621,
284599,
37791,
289037,
17651,
12513,
4815,
19234,
34839,
null,
91919,
20266,
31080,
42921,
267879,
74855,
495228,
47813,
511572,
248810,
290588,
53370,
14980,
120051,
93713,
102555,
5527,
null,
20023,
37821,
914,
19242,
null,
129774,
null,
3680,
10147,
467424,
61102,
76677,
25331,
364447,
4383,
37709,
22445,
478989,
39720,
301671,
52335,
34123,
296948,
5181,
19185,
null,
39256,
18239,
245112,
41143,
29852,
92527,
28892,
107157,
217248,
282099,
138140,
39206,
null,
null,
36740,
30206,
172829,
146541,
22661,
20054,
65159,
34363,
29648,
104843,
null,
209598,
113869,
17950,
223584,
25266,
45573,
null,
null,
206151,
217587,
625273,
24704,
78083,
55007,
56107,
18944,
387365,
222066,
121781,
217214,
68608,
290200,
17240,
241099,
8507,
130341,
99323,
15644,
22502,
563248,
47785,
106973,
48554,
1802,
73772,
15055,
null,
144267,
27521,
null,
48426,
14180,
141143,
481528,
21192,
262495,
121780,
625,
22219,
330737,
217706,
97131,
33193,
288590,
null,
131388,
101017,
148342,
null,
196871,
20153,
394341,
286342,
181592,
null,
39182,
115608,
320705,
55229,
63579,
286839,
13887,
44712,
60030,
131721,
17220,
267111,
22299,
392723,
409013,
293527,
46787,
382551,
103496,
166963,
67705,
12241,
216705,
null,
19725,
180584,
30753,
283485,
34530,
186373,
245449,
315908,
183721,
177901,
70477,
55206,
410024,
311297,
145673,
6927,
36316,
254143,
8755,
null,
21394,
577941,
17488,
63118,
30898,
10353,
null,
24427,
null,
100571,
303610,
298208,
118636,
185065,
69013,
162735,
18091,
37157,
null,
3235,
313007,
12772,
25810,
null,
296566,
40658,
34280,
6544,
98936,
67620,
null,
25277,
64579,
363237,
82005,
181215,
284518,
null,
122726,
471310,
426585,
76124,
294722,
5855,
26714,
195543,
26853,
103634,
357494,
274153,
100936,
10392,
22664,
53467,
185205,
11315,
134333,
37714,
null,
223734,
74189,
121573,
265572,
216957,
117764,
null,
461086,
3716,
35157,
46881,
71222,
220416,
114995,
65191,
263084,
50323,
313156,
0,
26286,
199809,
340419,
74210,
12820,
77434,
495421,
null,
128434,
1630,
247743,
199402,
617055,
27186,
155415,
613013,
32214,
11935,
42225,
21631,
96075,
79896,
40674,
33958,
37812,
244431,
35021,
24546,
73387,
41531,
421756,
null,
null,
203568,
83191,
23453,
175892,
32828,
11893,
308182,
null,
48396,
44476,
56279,
18687,
null,
134662,
null,
10725,
29612,
89626,
9505,
48817,
116756,
17462,
187216,
224195,
192021,
null,
290672,
319344,
161794,
421927,
361866,
375147,
34753,
7537,
23823,
71231,
156220,
42805,
55137,
39607,
15302,
64418,
7738,
49186,
251239,
185230,
93580,
null,
170022,
null,
508256,
17637,
159165,
14848,
378299,
93440,
91908,
42653,
null,
10944,
146112,
11385,
264595,
94115,
134074,
43802,
63782,
11322,
27853,
210323,
30144,
272502,
null,
269652,
29056,
87236,
18147,
75431,
96772,
250518,
30260,
21096,
45402,
82985,
8447,
204531,
2970,
29901,
81216,
237741,
377652,
622133,
17540,
86638,
106807,
88550,
95197,
311477,
203812,
232090,
6940,
321106,
19812,
28668,
null,
130266,
7736,
183627,
28346,
5125,
1335,
401619,
23868,
102412,
165559,
46789,
43710,
206874,
9581,
246566,
67346,
215755,
152400,
76690,
12944,
161468,
15454,
21462,
526823,
35813,
154678,
80294,
560545,
91878,
394589,
45112,
150233,
54835,
83096,
25675,
97554,
59829,
43187,
29678,
3699,
268368,
16658,
15278,
249141,
102228,
50475,
null,
5597,
223186,
null,
88735,
342519,
6428,
104895,
21818,
null,
214943,
26545,
104358,
24901,
17128,
221571,
252065,
16356,
12987,
191308,
51244,
93581,
null,
58878,
null,
121649,
27593,
null,
null,
66150,
8437,
58033,
19343,
328810,
27505,
27807,
27497,
null,
203910,
208668,
null,
296628,
6079,
5704,
2247,
149099,
260009,
null,
314547,
31759,
41174,
null,
null,
47883,
96490,
162302,
12883,
234515,
498624,
33233,
31605,
237992,
24567,
46602,
178759,
137022,
137308,
397275,
39063,
421339,
86924,
155335,
335728,
15710,
41418,
81439,
36436,
null,
216415,
40951,
257428,
9998,
32981,
null,
14133,
115984,
778258,
21354,
96993,
63875,
267235,
52898,
372649,
142021,
270733,
272419,
346265,
21012,
215365,
24030,
39437,
55958,
44130,
32763,
47725,
189650,
79671,
71310,
119515,
160034,
49003,
30499,
403124,
76811,
318791,
207104,
69874,
45028,
17844,
60113,
321280,
21056,
39227,
43623,
15696,
247672,
119425,
106695,
199663,
21938,
508919,
868,
12051,
null,
2753,
430506,
236591,
29096,
297908,
null,
10951,
4297,
23443,
313671,
51316,
17337,
63279,
102435,
364621,
139052,
35254,
302785,
155860,
60355,
18788,
63328,
4224,
268741,
319499,
117381,
213326,
null,
43599,
288836,
222843,
17343,
81100,
7896,
41038,
25784,
288938,
319763,
64095,
null,
72229,
309180,
17509,
26396,
26950,
55840,
33373,
70773,
805611,
43218,
348986,
80192,
54623,
198650,
351839,
null,
490363,
42052,
365928,
290128,
23269,
317345,
47558,
92095,
24284,
null,
128428,
10676,
45309,
9990,
31695,
18701,
62550,
null,
172443,
9291,
317110,
10204,
18007,
764686,
11333,
87454,
108685,
167595,
176346,
null,
25675,
73046,
241236,
38072,
45250,
338140,
61458,
502292,
null,
50442,
18800,
219045,
124727,
8390,
152243,
328043,
75120,
404969,
74496,
63686,
61658,
94831,
137332,
14265,
315815,
196450,
64245,
145781,
17570,
110261,
11538,
16116,
214696,
203215,
542080,
6538,
62900,
189176,
161826,
115630,
239598,
57253,
147522,
17151,
262410,
37152,
30790,
76561,
17234,
49075,
23983,
16758,
10765,
66435,
17774,
106836,
25277,
184712,
54512,
167789,
23749,
28579,
141576,
334240,
338700,
198607,
35964,
48020,
10947,
78627,
383111,
66397,
15630,
436876,
201384,
166429,
50426,
29847,
62580,
48388,
94942,
355966,
12712,
136036,
396277,
89112,
107358,
287689,
22498,
129015,
19828,
275531,
72951,
null,
3302,
181597,
23719,
176377,
28190,
44809,
33967,
108338,
102365,
45148,
6733,
null,
272875,
8967,
22975,
237556,
33078,
30410,
5325,
16104,
79551,
352913,
115877,
215565,
37254,
135371,
null,
26040,
20625,
7573,
40428,
80046,
203244,
19687,
42573,
92203,
554318,
122155,
286415,
117804,
375626,
null,
120279,
null,
199023,
300486,
20698,
13466,
274720,
30009,
39577,
13502,
175732,
5083,
191312,
39663,
3637,
49274,
183141,
270097,
14740,
202041,
14290,
74244,
16844,
null,
null,
null,
63296,
null,
4076,
292054,
46212,
110076,
230042,
13742,
29260,
41772,
325086,
110455,
382001,
237782,
45471,
278811,
299357,
411014,
355119,
246095,
11256,
112955,
254511,
158050,
73806,
null,
108063,
214801,
215354,
281486,
57400,
38431,
334551,
376939,
306912,
186698,
55830,
419190,
779978,
59624,
36383,
270958,
38115,
551941,
48228,
178012,
33400,
88799,
237712,
17467,
280424,
174862,
141881,
162191,
61325,
15273,
3925,
286533,
442671,
114668,
21645,
189556,
51409,
219193,
73610,
529465,
51728,
20336,
52684,
124851,
32601,
175390,
19404,
50759,
316568,
213849,
43129,
6765,
75545,
38716,
297714,
102858,
190643,
131733,
217565,
42107,
138180,
42968,
83286,
8885,
28100,
644435,
2902,
18056,
9509,
null,
61134,
111659,
137479,
223565,
null,
171537,
382912,
134041,
43873,
62253,
44988,
3378,
null,
180012,
24562,
326725,
544533,
16555,
90109,
329164,
118858,
17103,
179600,
421756,
455987,
35936,
154180,
164380,
42633,
49016,
null,
418977,
251845,
300882,
115018,
59721,
289269,
367571,
484114,
51276,
198035,
null,
179802,
4842,
17038,
29903,
154930,
144136,
53988,
42517,
9376,
55043,
124168,
197007,
130868,
244595,
191696,
43322,
156529,
null,
173740,
16128,
710070,
null,
60697,
232173,
143271,
33225,
60161,
15263,
55209,
null,
97533,
197063,
37848,
null,
45194,
336447,
32352,
28715,
94636,
24561,
56361,
12412,
228608,
12519,
null,
211474,
230605,
32986,
36519,
35913,
134250,
11035,
22980,
null,
131663,
198219,
119527,
26552,
36133,
918956,
13927,
45316,
106411,
8310,
null,
12790,
220747,
313470,
52198,
7016,
251106,
293982,
144465,
4225,
32832,
18258,
24992,
null,
240105,
203177,
130343,
180892,
10707,
null,
8748,
132858,
24351,
75853,
17888,
435608,
8276,
4355,
382590,
21587,
null,
247490,
1162719,
295724,
13008,
140361,
110461,
540036,
216939,
113310,
53913,
190124,
95249,
222110,
20917,
14599,
54668,
105351,
150429,
34647,
42164,
33709,
241156,
44694,
null,
68873,
10886,
79894,
12134,
23865,
null,
21710,
133256,
303919,
196439,
39811,
154666,
76108,
14780,
41002,
363618,
439201,
null,
74010,
139003,
166975,
null,
58348,
469680,
49601,
312851,
131268,
55863,
83944,
28158,
14646,
254060,
66541,
25725,
null,
25910,
75869,
30190,
51098,
234491,
302332,
28842,
18703,
150398,
25078,
null,
15097,
118174,
210552,
57343,
32233,
50633,
9737,
107275,
null,
23047,
null,
33235,
19433,
64293,
16522,
3949,
32807,
null,
15369,
62585,
62038,
null,
36659,
304045,
498625,
99154,
80811,
192028,
28155,
248672,
16767,
23913,
241362,
88970,
89229,
23326,
186208,
45151,
4146,
308240,
42898,
11028,
326835,
3579,
null,
47101,
68295,
413646,
649227,
102709,
168873,
193064,
176426,
153425,
110489,
null,
234484,
null,
83227,
null,
150577,
9289,
186472,
606442,
null,
null,
5421,
18097,
30289,
29097,
90130,
195281,
1358606,
59905,
511103,
240247,
12877,
152925,
39677,
153802,
237915,
270054,
189174,
null,
420584,
9423,
135654,
24013,
16343,
105375,
279090,
31916,
null,
412342,
47138,
23453,
27411,
26061,
389727,
5296,
29033,
472358,
341168,
425201,
2264,
52318,
201737,
503199,
48696,
134827,
146464,
41181,
29374,
null,
20183,
124006,
18773,
91358,
95392,
null,
34551,
15869,
12781,
297155,
25271,
37443,
153111,
380221,
null,
18272,
null,
161822,
430276,
174444,
115952,
null,
35737,
null,
218110,
49066,
81625,
40447,
81784,
27718,
30469,
391193,
150733,
33455,
145007,
162739,
41084,
197884,
200841,
463888,
null,
58280,
74055,
210281,
31970,
null,
60428,
null,
11127,
279936,
198506,
null,
99644,
250032,
119113,
16021,
8886,
18212,
131558,
83183,
17103,
4215,
164921,
75601,
156519,
23880,
203500,
370103,
361595,
22378,
346741,
16935,
232820,
240495,
null,
7948,
377221,
null,
36666,
41581,
251904,
120243,
null,
477825,
null,
17163,
null,
54663,
187273,
41041,
100181,
124534,
47072,
385680,
16714,
null,
27474,
408857,
90178,
137311,
344964,
262449,
279124,
26942,
255591,
null,
363103,
334087,
null,
20281,
18608,
256260,
122099,
18487,
171646,
21486,
41492,
43591,
162739,
190362,
275460,
25256,
3242,
143328,
108555,
54382,
31177,
68487,
16545,
null,
382097,
211490,
168410,
199479,
null,
13263,
310507,
285179,
null,
123695,
3544,
56644,
49652,
242000,
30619,
58531,
28767,
28555,
306437,
93345,
58901,
370683,
39815,
36708,
55918,
20129,
51898,
71223,
225432,
31679,
177207,
3081,
6927,
null,
239504,
15985,
548403,
151808,
295304,
306693,
176871,
51740,
492587,
37070,
225814,
null,
466692,
27702,
3862,
8753,
162897,
145681,
44136,
36671,
null,
249513,
87431,
76700,
131620,
28156,
null,
92444,
250160,
6398,
212656,
null,
16552,
21965,
112995,
null,
23526,
null,
32762,
9582,
394008,
307494,
40658,
4424,
107621,
7611,
498306,
162239,
220331,
15763,
66175,
71043,
64060,
null,
499669,
259897,
63155,
15607,
178897,
385868,
121905,
55085,
324270,
null,
25019,
115148,
7411,
27597,
null,
271149,
70915,
28824,
361567,
null,
null,
13742,
17774,
318751,
32579,
21736,
94272,
22333,
12944,
85324,
54423,
293638,
279755,
null,
306911,
85034,
38507,
42896,
8117,
300950,
469775,
null,
67114,
122150,
24662,
333192,
null,
36785,
38862,
98149,
27370,
179322,
16602,
75391,
90849,
null,
null,
174116,
393276,
30867,
205817,
132379,
null,
755510,
8121,
102602,
401751,
143759,
34770,
197386,
153597,
64907,
119197,
42510,
203918,
230572,
215234,
202647,
189616,
365791,
15758,
76417,
26558,
41326,
267921,
59440,
130395,
113921,
289827,
null,
25303,
93219,
426506,
52775,
41204,
265035,
6323,
45555,
114883,
51792,
251242,
63814,
17438,
23532,
51811,
244038,
786030,
11045,
49982,
null,
134384,
27465,
8779,
266053,
72776,
55042,
15646,
25752,
63468,
null,
353372,
110976,
18003,
406674,
50570,
49643,
440531,
13142,
73492,
54175,
40476,
11911,
289435,
248808,
66568,
161245,
115612,
43762,
144512,
7397,
295752,
35604,
23085,
637603,
165747,
33446,
14058,
25829,
174890,
53531,
277917,
126326,
18893,
25289,
338997,
null,
173492,
36581,
31762,
26721,
13602,
211959,
41303,
41756,
null,
49696,
299278,
120306,
563888,
387807,
102664,
33568,
284339,
37517,
94865,
365495,
232840,
null,
9281,
24113,
11352,
null,
154773,
42472,
125776,
124892,
220843,
116921,
92233,
310189,
80242,
36527,
33059,
27467,
218991,
174228,
24638,
299971,
191361,
19316,
219477,
167650,
13644,
118060,
32382,
22746,
27399,
322314,
17504,
50129,
21643,
40126,
214720,
113433,
16761,
910509,
272252,
141237,
55986,
38661,
59449,
75750,
300051,
609966,
217937,
175737,
55603,
325881,
233540,
20817,
359587,
382687,
99452,
229371,
36239,
51050,
238203,
17934,
28100,
370110,
14912,
28397,
65341,
null,
34008,
195364,
259752,
9961,
266009,
149344,
23648,
null,
117065,
173538,
24643,
38455,
24711,
12504,
77359,
62132,
14412,
19762,
135930,
36317,
125946,
64227,
46096,
39413,
123434,
163825,
231106,
11950,
60618,
439794,
119470,
46491,
27129,
330216,
59965,
342452,
56881,
26867,
142417,
73722,
429439,
10305,
82672,
231685,
355543,
290684,
54279,
21854,
25869,
361059,
10545,
61891,
20212,
14139,
46047,
12189,
107449,
18443,
41299,
35034,
35634,
37487,
181172,
43264,
32913,
26904,
71479,
37876,
null,
111044,
297846,
null,
271862,
83598,
40170,
74604,
161296,
27833,
40081,
28683,
null,
198517,
93686,
4443,
156104,
405165,
31333,
577250,
null,
31549,
70339,
21272,
158064,
48605,
250741,
159662,
15541,
284039,
289744,
null,
60670,
43470,
76281,
19339,
492563,
156858,
116678,
34065,
230505,
38339,
8640,
188431,
94263,
32882,
67952,
20856,
315464,
5163,
168463,
105785,
17476,
314104,
95351,
57079,
15413,
163646,
254067,
91964,
17857,
72325,
null,
6223,
13995,
16859,
31675,
265224,
128500,
296372,
58174,
263968,
155951,
293339,
363189,
130292,
41179,
28101,
54729,
26364,
36319,
47354,
313986,
13343,
157467,
null,
627557,
350661,
7803,
52860,
382680,
17719,
389438,
null,
32952,
null,
518915,
3746,
162873,
432385,
62995,
39038,
18063,
143221,
30028,
417397,
276692,
null,
442603,
702371,
122127,
162109,
51195,
17367,
93551,
232118,
106848,
354004,
200174,
43539,
30723,
144865,
68382,
null,
177665,
28086,
144316,
33789,
33120,
54128,
83652,
215819,
8535,
135695,
500346,
241504,
24953,
328594,
66196,
14926,
null,
15124,
29329,
12919,
80766,
19000,
31951,
169132,
13476,
121477,
189863,
448710,
34491,
156405,
33098,
335025,
119211,
606082,
16820,
null,
338387,
17602,
null,
63454,
157912,
9934,
23148,
559022,
375802,
4419,
204788,
8921,
null,
338005,
17653,
38684,
82669,
7386,
142413,
27838,
17595,
36120,
89556,
214502,
47795,
72387,
18695,
5879,
214289,
51866,
5858,
69522,
31106,
209606,
271909,
156861,
102737,
464271,
417462,
80642,
396122,
35432,
372356,
40168,
5662,
305594,
30461,
19166,
228856,
15057,
398069,
34157,
57484,
38439,
55215,
46206,
68601,
6495,
182317,
49747,
139052,
95816,
37187,
222758,
222034,
3377,
20160,
62660,
297056,
21723,
824165,
37666,
215273,
104139,
31217,
42057,
615883,
93319,
252348,
278678,
36038,
292451,
82680,
256132,
102024,
3672,
88163,
7843,
262203,
655154,
93619,
797943,
25189,
58367,
null,
82308,
312123,
439471,
301165,
91979,
21438,
11363,
10040,
204618,
265220,
163910,
null,
67500,
153444,
31255,
510120,
260139,
157857,
253992,
null,
16711,
null,
247482,
25669,
359552,
336968,
137441,
283762,
null,
750468,
242129,
8515,
148766,
25655,
407690,
72839,
19442,
336774,
null,
142322,
215009,
25212,
25311,
33523,
47432,
43165,
293359,
294960,
401873,
263045,
14990,
188437,
123732,
161196,
437678,
6765,
158036,
20468,
279468,
55376,
62651,
49187,
286398,
162803,
265479,
66430,
21583,
467532,
521808,
42105,
17089,
31141,
35071,
null,
17795,
433981,
369608,
176481,
23145,
227938,
154023,
39560,
28587,
28210,
58962,
12703,
257135,
43432,
201438,
293761,
45921,
19673,
27027,
315498,
55036,
414863,
57799,
66156,
48079,
7010,
17785,
215091,
20511,
9230,
169910,
57039,
215264,
37175,
17611,
45840,
null,
null,
194447,
273998,
19522,
35236,
34073,
11972,
147676,
60297,
24008,
309536,
264166,
76792,
38370,
null,
10084,
118779,
58826,
33449,
70582,
null,
166981,
8559,
40982,
158119,
null,
78802,
16440,
359295,
null,
195197,
24912,
4301,
24512,
36958,
null,
108407,
115748,
41227,
43161,
null,
20528,
8962,
218485,
27705,
null,
75107,
242332,
187223,
null,
257395,
249338,
183274,
null,
221578,
16207,
205451,
null,
61869,
153781,
24207,
216046,
210143,
140390,
106131,
19180,
31269,
161874,
16134,
150266,
40435,
109411,
38279,
193487,
12630,
228218,
416879,
100756,
122916,
257712,
38145,
27414,
4285,
519107,
185766,
373657,
57871,
38391,
57212,
29733,
33985,
234903,
263774,
239336,
75287,
231054,
546864,
null,
22913,
226212,
25413,
2870,
1201215,
210773,
55546,
27865,
50688,
36680,
null,
38852,
95290,
186088,
128739,
285875,
505442,
212189,
9208,
198771,
281644,
62145,
131055,
542627,
25259,
173575,
90228,
11674,
53464,
46208,
612463,
279107,
10022,
null,
128422,
36566,
166510,
null,
26543,
9810,
181777,
29548,
26501,
394955,
52404,
98289,
310361,
9976,
34730,
null,
265647,
39135,
492017,
210693,
66332,
53719,
330880,
84381,
160991,
97779,
17131,
425773,
29269,
123664,
329095,
54786,
230250,
195803,
122206,
null,
117390,
45035,
276844,
131525,
298531,
16254,
null,
null,
751921,
61850,
204614,
435631,
348689,
600234,
189171,
64280,
null,
468043,
65142,
112168,
252493,
150010,
137016,
335122,
219494,
29969,
43046,
138672,
30174,
30505,
481366,
30107,
5304,
null,
117218,
279828,
88154,
122933,
9267,
312875,
622516,
11048,
45540,
158504,
2673,
178962,
175862,
4891,
193990,
104380,
336535,
3291,
39701,
327641,
180764,
36557,
110671,
24806,
37157,
628800,
237485,
29178,
3469,
43641,
129826,
46186,
56707,
307544,
89490,
176578,
16709,
91291,
26069,
13738,
146805,
398424,
42555,
45868,
null,
337620,
304572,
30725,
352121,
216283,
43075,
3706,
55042,
260232,
null,
185939,
82755,
214335,
61174,
6870,
75884,
77079,
null,
null,
348511,
229334,
574244,
43719,
16240,
null,
478349,
236697,
193581,
50430,
null,
102970,
20006,
349892,
80695,
19142,
12748,
17544,
86466,
28629,
25194,
234564,
9811,
201448,
20068,
null,
211341,
33464,
245207,
21924,
null,
96240,
null,
152464,
26293,
169890,
92566,
82414,
45689,
19238,
2885,
143005,
315558,
792145,
421030,
1761299,
222162,
33407,
19513,
null,
24309,
25420,
18300,
138944,
76536,
100044,
56820,
50296,
81106,
35656,
25678,
287700,
148728,
226131,
4978,
53670,
291905,
null,
77266,
124936,
26768,
11608,
197228,
26758,
42020,
21672,
133607,
15059,
22436,
16787,
329985,
62106,
18940,
22853,
339150,
null,
229438,
null,
54775,
199585,
null,
26659,
95094,
133700,
281499,
29930,
108053,
133954,
1064933,
98287,
97824,
16489,
9875,
172083,
194686,
197121,
null,
441457,
19860,
null,
112811,
203300,
97878,
72538,
469522,
24351,
273515,
29165,
120404,
8573,
19559,
418002,
7838,
188734,
58235,
227590,
309449,
null,
4156,
136066,
329635,
16550,
26918,
21930,
10772,
162144,
60231,
27692,
null,
329307,
8122,
7334,
191737,
71475,
57463,
42848,
123846,
165427,
17243,
163426,
258179,
22949,
348938,
201870,
10372,
152866,
97627,
42223,
343603,
277257,
40849,
101732,
9390,
8069,
3070,
25207,
null,
254428,
43987,
134974,
17625,
111688,
231904,
25255,
null,
35459,
26782,
12901,
30600,
72685,
29447,
26210,
532763,
286436,
54800,
35138,
33656,
54133,
421290,
239332,
45917,
3806,
94338,
21216,
255423,
27618,
425380,
149736,
null,
22068,
6161,
539560,
20985,
16592,
14720,
528647,
54145,
242045,
32443,
392685,
152780,
195678,
342064,
55507,
77612,
260285,
12816,
193393,
18357,
34259,
37509,
16559,
18642,
68207,
198084,
434698,
44068,
345727,
65296,
393848,
43632,
187417,
13434,
79282,
241837,
659530,
229884,
27457,
108825,
564881,
21835,
30262,
46396,
426530,
16801,
null,
29931,
265958,
281051,
27039,
24315,
93315,
527558,
540840,
141443,
508516,
24946,
265279,
10096,
19118,
96563,
103218,
9182,
146988,
212491,
18368,
531676,
606772,
386553,
150772,
183254,
30438,
142673,
63596,
160706,
562060,
16758,
14879,
368242,
596781,
14846,
82016,
8613,
306378,
69492,
115714,
34755,
null,
null,
214210,
19078,
458329,
8564,
18719,
20012,
264204,
45749,
152052,
14033,
29993,
43631,
268110,
511073,
152925,
275145,
138662,
null,
11825,
49719,
15316,
211861,
9567,
48560,
63246,
178677,
112028,
109896,
21387,
17648,
42210,
248464,
55688,
53904,
23828,
84189,
562404,
17908,
null,
42302,
69311,
20354,
209885,
142150,
39246,
58219,
null,
5815,
52120,
56405,
6444,
97072,
34794,
null,
13234,
58054,
166596,
5391,
9226,
286009,
89122,
null,
6276,
96245,
209779,
433159,
1042355,
369030,
49857,
212549,
488578,
19635,
18704,
9485,
49047,
172955,
69677,
15378,
26265,
335377,
172334,
25334,
14462,
15226,
171390,
27634,
null,
23885,
14674,
205134,
438240,
231442,
78946,
67593,
480,
31601,
66527,
237697,
317783,
null,
144910,
28958,
30567,
349283,
31401,
222502,
144937,
54796,
48647,
771955,
98747,
null,
6952,
113738,
49420,
58631,
147502,
12238,
96362,
521773,
26083,
11291,
149026,
45536,
25537,
58461,
54929,
10350,
23545,
204543,
null,
36563,
102083,
null,
33136,
227576,
160197,
277453,
83338,
19828,
157217,
21467,
322400,
null,
null,
30169,
22367,
37912,
95563,
101826,
186419,
29449,
274879,
198347,
15568,
23116,
48577,
27679,
21187,
587278,
356808,
51663,
39631,
21530,
43938,
33347,
null,
150986,
25633,
134043,
422689,
223829,
16036,
69308,
17047,
10898,
38427,
271998,
91825,
9902,
57224,
63659,
74248,
null,
170424,
10384,
null,
17286,
78945,
111513,
28960,
57416,
434048,
139692,
11339,
null,
258718,
71221,
235823,
213195,
59686,
756292,
217892,
378917,
null,
510,
null,
12375,
84803,
48093,
237875,
21343,
104844,
171409,
65797,
null,
221999,
10889,
100017,
275686,
27820,
258655,
120171,
104496,
343268,
2153,
931,
29165,
213428,
179437,
49864,
49624,
363988,
10045,
null,
323720,
216189,
146267,
141202,
142182,
16424,
112773,
113681,
150762,
68062,
19954,
null,
14334,
41358,
275177,
192743,
108510,
26082,
14792,
267530,
170468,
144066,
247826,
146313,
52268,
14033,
237363,
201297,
120262,
118866,
27857,
7669,
269871,
179868,
9169,
158619,
32141,
22093,
46894,
null,
34859,
102000,
37796,
43673,
236725,
14175,
42007,
270628,
314452,
101144,
211967,
94303,
203237,
348229,
null,
7069,
3595,
66609,
16448,
39900,
297505,
77059,
11151,
4066,
null,
85814,
238627,
423931,
223434,
7365,
345485,
4891,
387470,
651511,
45644,
null,
30410,
70959,
12292,
33073,
124839,
489844,
null,
145969,
191278,
211326,
286961,
61671,
378182,
437745,
79337,
148011,
153843,
38762,
113090,
28181,
47678,
null,
26582,
174644,
373318,
null,
37236,
23709,
118835,
172206,
229786,
121976,
225330,
null,
74846,
null,
189115,
667410,
26236,
334615,
405241,
18217,
302472,
32993,
106854,
20554,
18889,
27967,
33477,
40380,
161057,
6083,
73485,
35165,
131020,
185813,
224045,
98221,
25981,
251735,
14535,
341543,
null,
20458,
27197,
164200,
273218,
98044,
248418,
6580,
null,
370532,
201701,
253262,
167648,
76779,
13440,
null,
124286,
25165,
360599,
661539,
37935,
191096,
379991,
28176,
51425,
49059,
42448,
72192,
null,
376281,
13159,
556593,
712228,
18870,
127965,
112803,
132015,
259166,
128045,
39096,
21853,
9964,
86202,
25572,
62819,
18973,
209152,
298862,
null,
16527,
19495,
80695,
192792,
444016,
null,
20152,
287161,
252320,
31426,
null,
35211,
78490,
4675,
null,
126838,
204661,
39163,
105832,
314280,
28583,
141598,
33234,
41431,
178267,
15637,
14880,
8775,
23792,
781949,
174290,
46438,
124569,
132045,
30679,
24086,
25825,
77419,
83391,
419129,
79440,
9425,
373981,
25922,
14760,
202565,
16111,
305478,
289867,
26823,
511386,
295995,
34982,
181818,
283050,
174004,
7861,
7027,
215146,
18830,
35525,
26185,
300801,
null,
78202,
36142,
37886,
17293,
34555,
30314,
13629,
13688,
79421,
276343,
206101,
103494,
null,
63851,
320401,
573203,
null,
184856,
260142,
73553,
179800,
143795,
162585,
22461,
255287,
166127,
221913,
6917,
35176,
6112,
397178,
49131,
27930,
818308,
38846,
77773,
157518,
70689,
null,
38024,
17168,
28746,
null,
37673,
152878,
121248,
383155,
163628,
143593,
15402,
30721,
73658,
136597,
281365,
null,
null,
554181,
32787,
10730,
139795,
364383,
90394,
154236,
66941,
502109,
22878,
null,
360832,
170381,
210567,
13034,
101569,
17634,
4102,
94894,
null,
470032,
146855,
154151,
54057,
44047,
39724,
141276,
26945,
298100,
85963,
333,
756144,
31591,
70850,
23931,
68451,
26791,
187848,
105724,
44424,
34136,
321753,
71190,
34664,
175817,
5490,
230528,
57284,
141891,
133534,
270560,
142440,
null,
18955,
10162,
17654,
90138,
206867,
57727,
71038,
87936,
33743,
39921,
471935,
212424,
238434,
118169,
29141,
305101,
62396,
27790,
406510,
81095,
171926,
null,
679,
33742,
1034284,
null,
134311,
56571,
null,
27577,
null,
16401,
103357,
352438,
11585,
184765,
221538,
62661,
474463,
35129,
null,
null,
65354,
21364,
735462,
380263,
279892,
19066,
248853,
51219,
64679,
322580,
21432,
67604,
194476,
311165,
46347,
125697,
21807,
329429,
116630,
22859,
null,
136574,
259676,
140908,
433704,
42872,
70024,
231779,
447048,
11192,
22373,
9302,
605293,
556745,
293043,
39970,
null,
204209,
311447,
83543,
169502,
50556,
236900,
15556,
null,
24785,
49276,
109780,
58637,
178241,
16710,
60095,
77298,
179383,
82921,
52707,
176218,
270138,
15479,
51597,
79402,
41161,
479312,
202407,
null,
5610,
9397,
132162,
15802,
460750,
44727,
47110,
300408,
91664,
null,
423148,
111401,
138101,
277061,
191461,
84768,
37161,
95824,
308871,
32114,
42506,
141590,
71970,
27629,
null,
41828,
188534,
207710,
165521,
279732,
202755,
null,
345366,
1489,
62765,
null,
155981,
37719,
33425,
199601,
606672,
15312,
12838,
36938,
46926,
60842,
292525,
4398,
32798,
12857,
244446,
null,
4539,
52017,
215169,
20311,
147875,
166906,
295523,
57722,
97868,
100725,
23175,
13985,
611509,
109907,
346644,
10185,
43149,
44843,
212012,
106276,
null,
34751,
41472,
278767,
73110,
266449,
48337,
213181,
12076,
325415,
104940,
27913,
228902,
16114,
410303,
null,
35910,
25248,
61570,
315399,
222224,
18914,
null,
48811,
125427,
28275,
200289,
229855,
149020,
6284,
51134,
7321,
114511,
217751,
24497,
4881,
132984,
407402,
30945,
281494,
99690,
213510,
null,
249065,
288242,
99221,
null,
259052,
105810,
343010,
89690,
5711,
35373,
151385,
210607,
374391,
693660,
107413,
21509,
33717,
49732,
25512,
219579,
null,
94491,
35038,
369226,
47991,
155101,
52603,
269141,
107239,
37602,
null,
3711,
38466,
55988,
24050,
231773,
329705,
null,
345272,
255298,
138560,
1990,
161298,
321745,
540173,
19873,
142993,
null,
null,
24150,
34234,
93683,
93213,
124496,
null,
14325,
17529,
172077,
404119,
4549,
241013,
38866,
222439,
67814,
48254,
null,
67518,
49299,
40538,
347624,
349043,
15501,
231429,
170435,
354668,
55488,
158482,
112886,
142059,
603166,
null,
104845,
null,
625053,
90764,
115733,
310901,
30866,
59644,
null,
12684,
5113,
41768,
30366,
4190,
41917,
47926,
196771,
153950,
22244,
66242,
null,
56146,
3516,
330417,
6264,
325037,
165163,
187562,
null,
33643,
31386,
null,
14135,
6939,
1034998,
424481,
26536,
38972,
56559,
40684,
33818,
142377,
17595,
324890,
401006,
144893,
null,
186851,
475488,
15933,
511056,
36885,
24945,
17778,
131292,
null,
70252,
59532,
461858,
142249,
null,
71289,
55977,
20311,
156549,
255869,
5966,
26173,
12682,
null,
202839,
26814,
237621,
14099,
184293,
126519,
null,
291286,
20570,
11430,
5057,
null,
6580,
67040,
15709,
23167,
16824,
20180,
232285,
22430,
12664,
430615,
11257,
152769,
7172,
151136,
353109,
55904,
104697,
34612,
18139,
53918,
115506,
332125,
2716,
318856,
286629,
97410,
4580,
null,
263854,
167096,
56797,
141105,
127131,
150231,
24143,
579688,
506250,
27929,
29737,
217354,
29211,
178402,
372294,
10413,
35475,
378503,
null,
6624,
38664,
16504,
237309,
23456,
225109,
42540,
56693,
30004,
10372,
234313,
34872,
null,
75170,
30511,
10989,
13681,
186837,
307765,
372090,
68469,
40340,
77348,
267245,
742740,
242951,
364069,
2596,
315974,
182908,
41979,
6059,
25134,
45846,
210542,
46033,
192122,
10252,
38352,
null,
36345,
153663,
500744,
189117,
11996,
195998,
391014,
57646,
697813,
158645,
177600,
537050,
null,
245976,
129779,
19172,
36218,
11900,
5683,
34403,
119345,
223676,
null,
291796,
381961,
24712,
311634,
null,
null,
15077,
232404,
38166,
23640,
187873,
157530,
352173,
8246,
19759,
19884,
428870,
585778,
12327,
318282,
37884,
18832,
16329,
461525,
98108,
null,
71845,
55468,
43452,
218189,
19946,
31837,
36974,
null,
58245,
242179,
61360,
22156,
12826,
140608,
66071,
149903,
231621,
413954,
109696,
65784,
145039,
null,
13490,
29626,
7730,
985639,
167428,
547360,
29673,
89856,
49172,
193198,
453686,
null,
470428,
65326,
38030,
42713,
358395,
null,
null,
253491,
176604,
52326,
252238,
562714,
48927,
193151,
null,
43103,
132572,
102481,
22846,
18278,
101384,
2621,
347812,
69738,
239951,
290054,
9716,
165611,
416262,
30328,
15762,
10784,
34503,
31001,
56479,
103641,
39466,
153795,
null,
null,
14204,
5241,
84835,
30752,
59397,
507265,
29008,
23945,
null,
11567,
null,
367127,
133469,
264582,
313669,
216849,
120205,
103618,
454805,
63988,
456758,
null,
15344,
188308,
30441,
43662,
73615,
13490,
282511,
121265,
259649,
64156,
135223,
132149,
19436,
46479,
108610,
174275,
53619,
15201,
53026,
234671,
178973,
69867,
445120,
56048,
8293,
16964,
206094,
10330,
63221,
26762,
8710,
28893,
25243,
20069,
107969,
15480,
3674,
67270,
43703,
381273,
null,
129896,
5571,
11995,
203330,
298050,
32226,
32616,
688875,
221651,
23674,
67603,
28774,
37960,
221480,
288416,
133450,
121755,
341274,
80280,
38861,
null,
24550,
23868,
86324,
null,
106884,
44066,
194237,
164829,
11040,
178163,
null,
157436,
244607,
38056,
35682,
5829,
null,
190081,
240448,
19347,
178172,
18341,
23870,
19417,
72964,
227083,
307139,
203019,
15253,
581150,
39160,
45488,
90189,
22910,
43324,
68481,
53835,
120304,
19816,
null,
357883,
289803,
173467,
148677,
568814,
103890,
15834,
33433,
60224,
1855,
54833,
112592,
296019,
16656,
29801,
131702,
147499,
343448,
null,
243441,
25259,
null,
176602,
19010,
38231,
176375,
16938,
285543,
242301,
33531,
287409,
457075,
166115,
8341,
223386,
35975,
null,
273538,
null,
74369,
389410,
24517,
51960,
464381,
20525,
43199,
173631,
null,
47511,
26403,
62017,
26139,
109203,
79461,
163781,
113116,
92242,
331167,
262310,
967,
38580,
71593,
41499,
142004,
5146,
243126,
410235,
55016,
null,
259454,
10047,
408641,
102603,
145419,
98169,
33643,
119034,
4198,
202156,
null,
116528,
51408,
30390,
25787,
185300,
425217,
128786,
6221,
18302,
70070,
921885,
655372,
58532,
62535,
80142,
160641,
18940,
26144,
47450,
221182,
42824,
389974,
399436,
30415,
164959,
null,
20622,
69822,
85851,
66762,
null,
313883,
30247,
335023,
415614,
117160,
164926,
145076,
131028,
162544,
291759,
7352,
180313,
901113,
401761,
108941,
144026,
45416,
120112,
49314,
132043,
13409,
28760,
10366,
11171,
89591,
16036,
22511,
199832,
70054,
34234,
61292,
142964,
109391,
199498,
10465,
8057,
78520,
148200,
257865,
220942,
null,
16426,
378978,
null,
163736,
324345,
11881,
22407,
31797,
348061,
53793,
10649,
237682,
163995,
20636,
47422,
null,
351474,
113005,
21079,
116133,
79507,
391871,
169450,
249732,
185568,
165596,
18304,
95338,
385290,
198279,
null,
114059,
118866,
23691,
16188,
31811,
178989,
null,
187805,
316440,
675058,
74362,
145881,
null,
5449,
292579,
37319,
15327,
13094,
30709,
358754,
6579,
24471,
36418,
88995,
129817,
112373,
4043,
83805,
30799,
null,
319782,
10070,
32474,
65419,
113699,
81800,
23614,
267831,
21765,
null,
183041,
163976,
159625,
23503,
341825,
277417,
39266,
35128,
214360,
27897,
45207,
null,
44056,
433315,
24518,
null,
27729,
38817,
6479,
61219,
37970,
74361,
73413,
208283,
116939,
40557,
null,
469464,
211224,
267418,
186159,
34674,
46370,
3661,
45469,
261834,
null,
250895,
228486,
256352,
26500,
69564,
160035,
41611,
null,
255399,
55009,
9453,
27024,
19736,
35818,
null,
14432,
458681,
null,
283995,
null,
215887,
25910,
48397,
125642,
33846,
309709,
300298,
127333,
277959,
137917,
279131,
720201,
24828,
143320,
22894,
12263,
10466,
9490,
36252,
200103,
335150,
93397,
22429,
32747,
44353,
null,
46517,
278947,
284530,
93279,
193379,
17236,
154962,
95900,
14678,
75651,
255399,
541811,
13150,
55336,
5658,
147708,
249829,
99353,
418345,
39949,
261645,
423570,
186546,
null,
26829,
102676,
193857,
385676,
124478,
207512,
152941,
295009,
null,
122161,
null,
178732,
177646,
82628,
103643,
26825,
28341,
82097,
33893,
6410,
147256,
6137,
48891,
30461,
211835,
null,
8742,
181799,
76468,
53437,
207510,
null,
347032,
46118,
16095,
169290,
5598,
17039,
72449,
302955,
310714,
23884,
291003,
476439,
62709,
126958,
13591,
null,
20606,
42960,
36594,
82995,
108023,
89743,
331118,
null,
124608,
164974,
4535,
45846,
33476,
155262,
365322,
167542,
102110,
93988,
127436,
171071,
75546,
null,
35608,
39777,
25435,
51267,
null,
null,
375696,
62911,
246312,
395281,
null,
153346,
222037,
103808,
14856,
10856,
40220,
27030,
115838,
443374,
111419,
110979,
40491,
269108,
45867,
19709,
19727,
136841,
316132,
71235,
15639,
57439,
270273,
31701,
28067,
56772,
155830,
194803,
320154,
449285,
409867,
148187,
40171,
220850,
34860,
189663,
34695,
39539,
10168,
null,
244858,
17248,
26974,
144113,
120047,
34497,
61177,
178983,
43380,
null,
101188,
15910,
181286,
24408,
337041,
31440,
68816,
60327,
40422,
22598,
56760,
134091,
null,
46931,
50062,
102333,
354398,
389019,
21003,
null,
167685,
48870,
77011,
22885,
201795,
653630,
6779,
10105,
357843,
26885,
null,
6580,
86578,
197485,
56599,
29325,
84608,
null,
484417,
186204,
336160,
null,
30553,
6115,
117071,
null,
42793,
null,
null,
218860,
56545,
38270,
82400,
9630,
null,
333229,
595588,
198284,
null,
30659,
282983,
348253,
86161,
247622,
26026,
82904,
290634,
15771,
293913,
234998,
5056,
277961,
9948,
83503,
211097,
249751,
192774,
47495,
4637,
380449,
96401,
32407,
28768,
18145,
94626,
337373,
19905,
142397,
87199,
63617,
12657,
229705,
39147,
17264,
3847,
114856,
243447,
128983,
124976,
220717,
170943,
578521,
80387,
null,
8503,
null,
118022,
110851,
248685,
406870,
75274,
23071,
null,
27626,
270427,
48160,
12131,
null,
406923,
333363,
67337,
127763,
59731,
250181,
106981,
235830,
16945,
160114,
328265,
null,
299020,
51664,
83336,
225598,
276896,
208008,
18639,
18505,
27289,
33042,
null,
173949,
22618,
294857,
35419,
96489,
79508,
163499,
92639,
13805,
48238,
636154,
352299,
140008,
367153,
37849,
201909,
20764,
7947,
39007,
29414,
199928,
11535,
5406,
183364,
102970,
33027,
139528,
244311,
213481,
774532,
26988,
540072,
147810,
176683,
62224,
33377,
30392,
20496,
213615,
18261,
24382,
53683,
23293,
136644,
150219,
94272,
108950,
null,
173865,
14346,
26688,
37319,
142059,
1378,
226881,
306494,
19880,
117800,
52143,
51195,
337948,
8303,
363527,
14605,
44712,
null,
55190,
25954,
40230,
21403,
9035,
175516,
25645,
329802,
188914,
36255,
206257,
197597,
68520,
56639,
118155,
182314,
182068,
265480,
202722,
null,
null,
42565,
46782,
24898,
8053,
null,
113950,
297771,
596060,
107876,
90541,
140081,
784,
null,
137178,
118050,
139212,
706394,
237491,
38396,
13548,
37222,
122063,
111387,
1027562,
142383,
25076,
14906,
140323,
267843,
205851,
3286,
154757,
1153375,
150237,
47987,
143950,
240185,
102581,
14474,
66417,
235214,
86705,
152081,
44387,
74075,
3886,
19372,
9597,
75538,
99198,
215735,
8765,
12745,
328048,
77450,
140088,
460516,
265575,
186182,
214155,
144161,
63224,
17389,
32134,
16874,
576013,
87314,
491885,
140744,
594519,
28122,
266713,
96993,
76327,
13806,
176843,
313340,
95798,
19589,
7454,
75209,
166278,
205834,
33408,
718836,
37654,
906895,
36110,
533938,
416241,
25123,
39351,
57047,
26843,
100007,
12051,
538424,
132354,
43574,
null,
22015,
18165,
205838,
65583,
222242,
11432,
285416,
114955,
59272,
350951,
148298,
40865,
24525,
346199,
40183,
138646,
262295,
227982,
75527,
333418,
750820,
19966,
25889,
46875,
null,
214754,
34574,
80804,
288353,
99939,
null,
198756,
19198,
59808,
43773,
39646,
null,
386280,
2813,
204180,
41589,
null,
52534,
25066,
33089,
70964,
261830,
18471,
27178,
20119,
187145,
82480,
126177,
36471,
23471,
259557,
null,
53348,
27430,
17958,
null,
5911,
243908,
31187,
55871,
1587483,
143411,
143648,
24176,
29060,
167023,
null,
523014,
60342,
1223,
322686,
31431,
679983,
105704,
325785,
24042,
222562,
15058,
229611,
1191276,
282057,
207920,
36453,
1834,
324865,
114334,
35709,
null,
387137,
226861,
null,
259096,
178181,
37376,
162025,
89811,
42699,
453858,
104072,
481662,
160041,
32144,
45124,
36185,
336582,
91755,
154781,
93354,
7139,
null,
508544,
20172,
43258,
24891,
21539,
27376,
118825,
154603,
51375,
6196,
137452,
60417,
214466,
80610,
226582,
3611,
36086,
385020,
null,
14627,
29303,
89199,
7454,
213669,
18641,
23148,
8404,
27125,
97640,
40295,
39355,
223803,
190636,
55606,
366559,
null,
31603,
100874,
37300,
10917,
6276,
225457,
38364,
11478,
91746,
9204,
294219,
1950,
284554,
437118,
373890,
177360,
24848,
188142,
369812,
20468,
186618,
165018,
173391,
45406,
35792,
18823,
178722,
null,
8418,
null,
416785,
41804,
83188,
193882,
15668,
454633,
1138612,
59332,
29391,
null,
null,
305081,
114639,
109898,
10675,
26930,
10011,
4677,
14619,
null,
24949,
125790,
78456,
169562,
94357,
null,
174387,
43574,
431859,
222378,
247827,
294521,
262709,
21358,
61778,
177816,
68306,
null,
255620,
26139,
null,
26195,
null,
35330,
983,
105622,
261236,
146266,
61644,
47192,
26408,
23955,
53989,
8283,
3002,
56396,
13938,
15908,
23757,
128159,
null,
111399,
36580,
47708,
12613,
null,
16303,
null,
295711,
94360,
34495,
115527,
38509,
9045,
244745,
205574,
35567,
154369,
53330,
null,
52578,
47021,
null,
19372,
230753,
68322,
42424,
37383,
null,
322858,
26821,
121463,
125585,
71528,
41101,
7573,
58129,
58854,
68216,
322963,
18148,
233397,
3466,
15937,
103658,
227098,
357965,
23182,
11700,
26324,
29006,
115025,
100379,
4257,
168531,
28253,
262768,
226992,
82709,
9264,
21141,
181872,
14889,
215505,
84606,
null,
42309,
9312,
231455,
20364,
14985,
46882,
96615,
146458,
42419,
344032,
77488,
41046,
27932,
147195,
21958,
134263,
292009,
8467,
55500,
295775,
25943,
190137,
20118,
50694,
null,
221764,
11836,
199517,
95181,
32622,
64092,
340630,
4278,
66229,
433150,
269733,
218651,
10766,
158200,
15332,
182400,
55975,
735513,
19562,
325292,
9508,
102601,
115882,
159988,
null,
113067,
341827,
31130,
58369,
162314,
140866,
347724,
42777,
23455,
224610,
42771,
79993,
110587,
1289,
229828,
29926,
31167,
11657,
85035,
178722,
17861,
64302,
802250,
58137,
15456,
336001,
15044,
167639,
45184,
359065,
223439,
null,
225667,
303437,
285012,
51463,
419690,
27768,
41779,
362644,
56035,
19636,
717970,
164757,
76069,
5388,
13544,
63846,
36261,
185866,
147281,
24147,
10146,
17488,
56524,
52922,
192677,
68355,
19010,
238223,
35981,
76072,
458897,
19651,
15373,
277716,
48281,
169544,
178370,
172965,
564333,
437927,
419257,
264202,
30558,
7537,
33480,
20008,
21987,
53177,
null,
null,
227368,
49309,
70885,
null,
27923,
40802,
26030,
null,
57493,
114844,
12635,
55033,
20489,
40416,
5150,
55454,
28240,
190660,
263645,
50017,
15580,
49433,
22071,
36356,
54564,
96740,
14462,
38715,
97734,
215990,
75737,
null,
108858,
71229,
8689,
281422,
2487,
null,
234990,
12522,
null,
40521,
173324,
132508,
243757,
5745,
273458,
19988,
54108,
27642,
null,
62914,
62556,
506461,
160103,
74396,
85976,
83772,
null,
71672,
62475,
22631,
227947,
30265,
276004,
114147,
37428,
18723,
23894,
27363,
20098,
108741,
537529,
98412,
228300,
50325,
178731,
259168,
299375,
281586,
130399,
null,
31889,
181962,
149763,
26793,
289267,
14195,
267620,
335217,
238427,
null,
29534,
18296,
11969,
315381,
260449,
40489,
115968,
191934,
220566,
165346,
7447,
538391,
131640,
202998,
23861,
23962,
254704,
null,
32397,
null,
195143,
14522,
648024,
107075,
324087,
170999,
44067,
36662,
401950,
161835,
23578,
44030,
271629,
169502,
377532,
189524,
340020,
15762,
35229,
208192,
30630,
154001,
100681,
87242,
52673,
234356,
60045,
27498,
null,
null,
180115,
210687,
130729,
24165,
45643,
144009,
23111,
114562,
206549,
106844,
42219,
359871,
41941,
7502,
195591,
260084,
15983,
149719,
78177,
264673,
null,
50589,
null,
45227,
87458,
75043,
12901,
13846,
139572,
217279,
185835,
43579,
10221,
21710,
243935,
224569,
50433,
280166,
374321,
8997,
27962,
138777,
107112,
13564,
65272,
41145,
854422,
403134,
215741,
null,
210120,
220605,
null,
439128,
139089,
118357,
23336,
null,
86688,
13127,
229869,
3461,
53938,
40463,
336103,
193699,
6432,
238325,
205521,
59718,
430191,
11262,
36359,
176960,
null,
104557,
75384,
116729,
62690,
149819,
123599,
8694,
656458,
null,
68210,
72410,
24073,
43264,
8026,
332037,
360718,
36387,
33630,
109956,
445111,
278661,
259890,
133458,
195781,
131319,
null,
37185,
null,
131472,
53842,
85616,
45503,
10860,
487605,
433379,
70217,
11593,
218858,
35678,
238261,
70262,
37942,
401740,
238389,
28628,
14267,
29285,
37690,
84400,
197252,
20699,
128401,
33395,
45443,
113095,
129407,
213097,
317541,
25708,
null,
39583,
44748,
174563,
421315,
105833,
57704,
12175,
99177,
182944,
531076,
18403,
null,
358776,
243267,
131306,
8675,
102468,
298431,
7425,
125787,
474046,
124368,
39940,
115664,
8177,
30910,
81809,
8987,
4013,
96935,
211731,
385991,
204068,
47332,
31348,
12853,
64409,
17130,
156240,
35328,
null,
124352,
139306,
34879,
28966,
71878,
49577,
82971,
52153,
37970,
75898,
296153,
351847,
232634,
69530,
503350,
191553,
4579,
190953,
23649,
12791,
null,
296180,
39963,
53744,
427261,
29785,
37674,
4073,
454311,
79442,
118233,
18738,
22297,
79986,
240674,
145319,
100916,
178310,
29063,
356244,
54355,
null,
138986,
361727,
222534,
155798,
21103,
53852,
46878,
28918,
105352,
478365,
194530,
46782,
null,
170151,
5355,
138277,
68125,
284651,
164785,
418650,
14413,
105594,
17104,
313791,
43794,
234215,
142711,
null,
81689,
57214,
null,
42041,
null,
null,
45522,
8280,
185245,
351187,
32223,
172682,
23116,
363640,
54741,
null,
54134,
10012,
188136,
65563,
41772,
17417,
155858,
17497,
null,
45686,
46857,
147190,
95167,
56892,
26804,
285699,
21440,
154107,
224360,
74395,
5102,
389597,
642283,
58145,
7107,
22510,
72662,
29679,
94459,
358974,
null,
47243,
29268,
255752,
25639,
237277,
null,
null,
null,
269081,
232502,
20441,
331150,
24281,
170627,
395732,
114292,
38086,
215324,
77786,
176148,
22413,
27196,
20357,
45951,
28566,
36794,
111779,
136681,
213057,
38644,
151881,
83119,
null,
164306,
42558,
36644,
12119,
24010,
36977,
61499,
14700,
24416,
275725,
null,
12058,
216030,
74318,
13296,
null,
42014,
25305,
17332,
21404,
55571,
27267,
287326,
15238,
197206,
208840,
35324,
85956,
111342,
158592,
46260,
141387,
406800,
57659,
9357,
8882,
131628,
100833,
41602,
26187,
322322,
29184,
56255,
106782,
180039,
297513,
42245,
28730,
25941,
154690,
180077,
120613,
27446,
90430,
54713,
144736,
36055,
21432,
105064,
50596,
19958,
154199,
300146,
28012,
217248,
77869,
7131,
46741,
null,
17070,
201669,
21046,
496511,
56759,
113329,
25745,
106281,
346946,
44906,
55860,
189919,
9362,
317909,
199616,
547197,
35125,
130351,
48475,
98519,
360120,
36375,
285937,
89732,
91181,
334824,
38378,
13129,
26122,
204451,
162760,
445261,
29210,
10002,
274824,
16365,
317061,
139984,
83714,
128994,
34749,
7982,
172857,
28425,
439361,
96995,
74718,
350985,
65890,
316472,
83224,
143267,
308572,
17175,
456705,
10303,
340391,
null,
255776,
120876,
null,
328060,
129046,
null,
83917,
null,
11618,
298655,
24918,
40457,
33482,
15557,
17836,
52375,
5944,
77025,
41070,
360835,
33965,
99741,
288225,
86962,
81696,
114600,
25571,
257651,
220119,
182512,
9203,
19986,
288118,
105394,
243297,
1028190,
23552,
625680,
29342,
110098,
152338,
89924,
156476,
238035,
81252,
323314,
108381,
188768,
91194,
42728,
261085,
45899,
null,
46052,
274646,
null,
445972,
null,
226697,
47089,
null,
null,
8640,
46276,
264440,
51034,
126425,
21018,
13928,
28994,
32975,
null,
316571,
7285,
33299,
9236,
37161,
24768,
107372,
378661,
303957,
383926,
177409,
28163,
166830,
78655,
13424,
32832,
null,
107451,
49458,
153652,
168784,
75254,
19921,
48866,
50870,
31152,
552710,
12133,
37621,
34055,
21594,
403359,
8732,
308507,
285505,
40558,
33288,
713912,
34978,
205004,
155074,
28579,
820114,
20205,
49252,
9760,
37779,
null,
225467,
380254,
112644,
285774,
51903,
98872,
144882,
null,
null,
213063,
39353,
125243,
37992,
41308,
140203,
15823,
null,
190750,
78978,
137610,
72164,
582211,
80677,
234836,
14756,
37726,
25900,
94732,
194808,
31132,
null,
124971,
12585,
237689,
67581,
230093,
169873,
63448,
40770,
71672,
331964,
36595,
51904,
104998,
142149,
88985,
33167,
173356,
23911,
64702,
37113,
57186,
36182,
53957,
146804,
128236,
148176,
null,
21516,
110578,
2587,
9452,
82169,
372181,
267221,
174911,
24678,
52347,
169043,
203866,
187369,
30900,
19266,
null,
null,
4997,
241694,
306142,
14578,
216905,
441526,
31010,
19565,
55095,
28241,
7425,
322777,
null,
152063,
3084,
58906,
19096,
208522,
19570,
16417,
null,
147460,
213953,
216959,
17285,
248554,
246069,
411240,
232704,
356696,
494009,
320433,
118140,
254116,
266704,
11133,
27709,
54422,
null,
8657,
271562,
339341,
49874,
24008,
14898,
70779,
403544,
19894,
84685,
99628,
371368,
3304,
31471,
47197,
57758,
16280,
113622,
null,
17876,
null,
57758,
261749,
197889,
521007,
30792,
241640,
37631,
171782,
24786,
4186,
42361,
30252,
129260,
4269,
522470,
199053,
10482,
739969,
null,
150032,
164575,
398961,
210528,
60544,
196522,
175598,
117509,
20834,
76421,
116492,
24496,
32728,
46291,
54302,
null,
89134,
29546,
33723,
131822,
59430,
18195,
23417,
482156,
13818,
null,
127191,
60778,
651059,
117809,
442774,
47697,
537461,
147392,
32048,
4311,
231996,
434834,
null,
271056,
132363,
120456,
66855,
68628,
15216,
165839,
30125,
151190,
34896,
50610,
23909,
15704,
37951,
348968,
136108,
12613,
410691,
241029,
21342,
23420,
23984,
308928,
26146,
77095,
16464,
202925,
22565,
14992,
127499,
35672,
85729,
20936,
null,
28499,
null,
14251,
208892,
147510,
473728,
202760,
66706,
75797,
13821,
146628,
136394,
81166,
366824,
887579,
null,
7969,
228102,
126032,
165480,
43696,
303252,
30939,
129060,
30392,
33796,
139923,
49387,
153203,
53678,
43964,
null,
145390,
195174,
77960,
null,
216056,
323811,
534727,
null,
28654,
20968,
40187,
238486,
20295,
155141,
99575,
null,
256311,
334950,
507550,
157558,
564465,
29233,
356108,
73722,
13021,
309517,
252077,
55272,
226487,
79094,
209131,
10128,
9966,
148225,
93422,
26215,
36252,
52125,
179183,
220748,
170672,
169210,
282493,
32332,
null,
140980,
15862,
16278,
16516,
20812,
26656,
272202,
10730,
39142,
20557,
10859,
100013,
104413,
96370,
341059,
307619,
27410,
64781,
77828,
12712,
29645,
125013,
34202,
163377,
116584,
3853,
41771,
172703,
264683,
32504,
67453,
274829,
24957,
99499,
44936,
78364,
12537,
366381,
75825,
145220,
null,
28264,
24987,
17711,
324309,
84394,
null,
191438,
573054,
19077,
55487,
313047,
16126,
257676,
110615,
84372,
187195,
446347,
87796,
59822,
12655,
188144,
25818,
485199,
208235,
204854,
14976,
236825,
97947,
41449,
330657,
217933,
31290,
165789,
7160,
15778,
11497,
7825,
562340,
270618,
60441,
211804,
392737,
315677,
null,
268620,
null,
624699,
25173,
265392,
38420,
10116,
6413,
4615,
250168,
151771,
83343,
22697,
null,
null,
75462,
95365,
99331,
363022,
108808,
24491,
48103,
11349,
39849,
301742,
4670,
98011,
20999,
15199,
258658,
20452,
54303,
78262,
12787,
101358,
77286,
397025,
33031,
211221,
13213,
42769,
51293,
43834,
102639,
21756,
436667,
181023,
126199,
120310,
572843,
18732,
26641,
8315,
21286,
80550,
10581,
93139,
274264,
31951,
7956,
17073,
15570,
27643,
123824,
36016,
221936,
209089,
245941,
null,
70766,
444527,
36320,
318209,
null,
259050,
112926,
64904,
83409,
156321,
11911,
314241,
25946,
258979,
185916,
92773,
32522,
31823,
51674,
42967,
null,
492095,
11348,
338274,
12209,
177998,
22162,
null,
25729,
13966,
2741,
33382,
18894,
147833,
272941,
101306,
317793,
165924,
75178,
null,
48380,
84932,
417426,
182407,
278876,
37272,
113168,
88503,
184719,
272419,
null,
null,
164333,
19337,
88337,
null,
679763,
13991,
67130,
233579,
210370,
282862,
22523,
80050,
247804,
40981,
190635,
21120,
57082,
25037,
54814,
20413,
29011,
550891,
232313,
339110,
11488,
null,
249039,
9556,
273003,
43780,
25567,
194528,
null,
15393,
289424,
248395,
27402,
21003,
173040,
288328,
254737,
20281,
27919,
95703,
246214,
31370,
22154,
197141,
null,
44353,
294180,
365590,
12801,
59422,
25696,
null,
2312,
146415,
6214,
null,
22999,
258997,
13949,
14083,
438693,
134641,
190615,
315515,
30526,
6493,
23140,
46407,
382759,
49462,
12461,
218159,
269841,
60342,
null,
25043,
14563,
26372,
113817,
36618,
77927,
254026,
40854,
25991,
59090,
19076,
167592,
57536,
252547,
1072,
64948,
269961,
18925,
8483,
234056,
247376,
151293,
24904,
11667,
240749,
164265,
34274,
181205,
69676,
73682,
34532,
25051,
407007,
45007,
200423,
52524,
null,
202949,
5536,
397816,
46956,
3163,
401268,
66908,
38938,
26553,
9158,
356321,
null,
33647,
97841,
4723,
25898,
273661,
29315,
165943,
169709,
16917,
428352,
85767,
19498,
38232,
33799,
10099,
37052,
85467,
133392,
113570,
162706,
null,
264130,
277659,
193774,
21065,
197744,
13405,
443884,
59395,
149907,
41660,
225239,
156173,
171381,
177338,
96665,
34141,
18050,
39074,
5009,
14680,
51751,
267604,
5864,
209437,
55257,
196568,
42097,
72628,
9771,
30955,
240955,
18557,
34648,
30046,
244685,
269527,
132932,
2504,
30617,
135359,
14460,
180369,
311036,
10727,
49440,
null,
null,
52239,
31685,
23853,
302783,
2362,
null,
52523,
15619,
58544,
48996,
60666,
72796,
229861,
398535,
176512,
null,
124534,
null,
472553,
163033,
74429,
17127,
212357,
216309,
23864,
43688,
null,
279205,
283426,
269073,
259564,
424553,
13721,
6478,
323284,
35529,
515897,
209913,
28480,
274044,
null,
31250,
32521,
190709,
null,
64551,
33249,
null,
58711,
138752,
198106,
42348,
21635,
7469,
135713,
27965,
286599,
45672,
180695,
408952,
18347,
69032,
214699,
12087,
20361,
39765,
139681,
43697,
34277,
14758,
343772,
80470,
130859,
117801,
335101,
26793,
190266,
104504,
29173,
181134,
120988,
9676,
104842,
86616,
279583,
42925,
126592,
43820,
39452,
null,
153893,
83825,
431445,
136688,
49058,
44187,
230046,
328194,
96685,
26419,
42952,
20623,
31393,
74182,
41217,
null,
47940,
null,
20780,
214141,
77649,
421547,
28702,
null,
209020,
41178,
27485,
174522,
193655,
81227,
85146,
53473,
111251,
262349,
23950,
277014,
10107,
null,
111503,
251588,
0,
166127,
214776,
35737,
259244,
10463,
343093,
null,
116593,
64180,
26703,
20359,
218293,
25323,
29404,
238201,
61833,
67467,
200006,
108767,
77528,
150317,
400565,
316179,
23131,
10577,
38717,
120448,
133731,
38155,
208157,
31186,
24202,
290863,
104693,
12984,
5921,
25384,
56249,
82527,
140710,
99862,
null,
355729,
263970,
213115,
35300,
24289,
52746,
21095,
188942,
null,
190868,
250448,
78079,
167783,
628934,
187078,
15504,
27274,
47021,
185205,
370352,
30316,
null,
181649,
38965,
49683,
66371,
23902,
37647,
19328,
33443,
70585,
99738,
38585,
9309,
560908,
56826,
42556,
128868,
7614,
35533,
4115,
77489,
68191,
97220,
206364,
74485,
12075,
84190,
10196,
223867,
null,
92598,
18712,
28884,
88288,
12637,
382141,
145402,
68996,
95985,
5369,
136317,
6424,
195950,
13206,
null,
22030,
9657,
501783,
48865,
null,
387312,
46407,
28999,
null,
10307,
48809,
16252,
3312,
32115,
null,
364486,
33907,
232905,
40475,
22208,
56544,
26311,
19899,
236024,
317696,
70892,
114963,
49414,
215077,
null,
270417,
4823,
145774,
22400,
24179,
15373,
null,
277408,
13129,
48660,
45384,
245006,
198825,
146437,
119515,
11646,
128302,
34693,
556627,
28479,
50788,
23199,
52638,
null,
106529,
20237,
376742,
238719,
7157,
8958,
null,
178694,
null,
462660,
8124,
217177,
26052,
76319,
38486,
331276,
17216,
260945,
23197,
5866,
77141,
298395,
7448,
17058,
43043,
8622,
28773,
36471,
12748,
44236,
null,
333362,
347475,
114814,
163233,
28014,
209017,
13980,
38895,
103632,
null,
224527,
468477,
30899,
233439,
null,
545283,
33475,
41700,
282597,
27436,
321714,
21656,
61273,
57028,
30833,
26457,
248171,
118431,
null,
142071,
185664,
292524,
392980,
367235,
27618,
192593,
80285,
12986,
null,
58549,
107820,
233229,
264951,
49028,
159215,
550831,
246532,
73312,
113715,
388516,
8668,
422321,
167306,
47068,
45596,
null,
88306,
31223,
140524,
48792,
2838,
110610,
null,
209972,
30952,
null,
12724,
14319,
77063,
23367,
4273,
435222,
null,
185074,
62312,
192061,
157413,
16240,
34207,
324347,
59753,
41174,
81660,
110734,
20581,
null,
22489,
null,
98649,
46455,
45017,
173112,
581986,
25692,
227551,
30848,
41843,
569799,
60332,
null,
118985,
192840,
21872,
185715,
38085,
232340,
72748,
7620,
90625,
409782,
12549,
60953,
412672,
null,
22455,
56306,
288346,
390802,
34890,
18722,
3601,
20538,
119357,
161398,
5644,
48537,
42427,
34839,
231176,
15812,
null,
226699,
186143,
188117,
302386,
71948,
478049,
202,
142066,
242846,
12166,
39908,
5669,
262140,
69700,
11264,
22411,
350843,
51196,
29834,
227115,
38041,
20530,
85498,
212207,
60707,
27242,
38087,
11524,
144597,
59821,
181225,
154750,
157529,
41538,
284790,
272308,
123470,
278673,
null,
321572,
262023,
17213,
349327,
50581,
21707,
98563,
44548,
32049,
2420,
64573,
53578,
60058,
null,
null,
192710,
31594,
6343,
48711,
68472,
209180,
450758,
null,
54614,
36621,
217017,
212736,
181409,
93652,
47810,
74709,
362238,
204808,
46432,
72239,
43838,
19907,
39099,
21072,
208008,
90818,
218596,
23328,
27159,
124192,
107417,
355723,
36027,
179201,
80655,
33036,
95308,
214827,
287177,
96414,
20901,
462705,
129717,
1606,
56476,
45952,
55471,
17613,
35664,
61771,
203164,
121874,
84776,
57236,
3529,
null,
13025,
16832,
35624,
27856,
16034,
94419,
72451,
225431,
16324,
79847,
22872,
285255,
219337,
176990,
74010,
50562,
115662,
268975,
56584,
236326,
48247,
128142,
120671,
85432,
27661,
null,
3892,
28009,
49167,
91814,
null,
65871,
162673,
161242,
12832,
40583,
179859,
111035,
null,
321099,
184040,
283405,
39959,
44696,
19811,
14264,
192046,
127102,
192769,
54219,
47129,
203808,
49640,
33082,
743894,
13613,
298728,
null,
98080,
null,
47115,
119968,
63756,
null,
15495,
23086,
332663,
215127,
14188,
26788,
59141,
122542,
180215,
163809,
258351,
72223,
335007,
125449,
38692,
6694,
18690,
null,
186959,
20714,
4155,
52851,
70580,
265642,
null,
318446,
13493,
null,
378293,
124319,
null,
26085,
9050,
20568,
45128,
269435,
null,
48078,
256326,
69639,
10037,
61182,
33087,
788024,
188302,
null,
34320,
39027,
169371,
55151,
null,
310386,
47200,
81161,
79721,
25797,
731133,
9487,
21505,
393132,
9520,
44969,
295435,
189580,
null,
286199,
44170,
107321,
264765,
31924,
16461,
361740,
113694,
79399,
null,
107903,
19309,
167921,
458992,
24950,
24102,
7051,
58768,
null,
409271,
18023,
23415,
75057,
31624,
27934,
69056,
18933,
173989,
7176,
113443,
291748,
10779,
72841,
111635,
59272,
186453,
202998,
600905,
176690,
70841,
24225,
154435,
265995,
93524,
22203,
25833,
330153,
3242,
36767,
24972,
251566,
42310,
52748,
31977,
202519,
242994,
20605,
365388,
508912,
24844,
55028,
51523,
46493,
15621,
null,
840772,
126151,
202751,
234748,
516806,
143500,
120143,
56860,
362153,
29097,
44856,
31781,
207080,
301018,
null,
22823,
146886,
79289,
234958,
19920,
29776,
155965,
80863,
289442,
154330,
260294,
85784,
68334,
67007,
216494,
203633,
297109,
215239,
286291,
153968,
11953,
31856,
264078,
87862,
31545,
273102,
9566,
346901,
18692,
35217,
166980,
92486,
48375,
58777,
16609,
120280,
41604,
31540,
99101,
52019,
null,
453548,
491108,
535856,
null,
17384,
212568,
45639,
117657,
115480,
5220,
273106,
83552,
34097,
11898,
92582,
282117,
8971,
102262,
98400,
null,
96865,
208046,
75132,
629623,
4464,
null,
282448,
24834,
369198,
124811,
15083,
160185,
275872,
19367,
233246,
264878,
null,
52649,
127882,
358611,
33075,
175223,
16759,
65177,
184930,
36669,
null,
73867,
17384,
357079,
314633,
57688,
179156,
249587,
63228,
153769,
234539,
21552,
11298,
42688,
17172,
194187,
47169,
65498,
202030,
354516,
174776,
149771,
48472,
313044,
250163,
83278,
16834,
97987,
18712,
318229,
26974,
16525,
49008,
540190,
21424,
248929,
13418,
27450,
62361,
55508,
27487,
226421,
46478,
280023,
267290,
null,
20822,
74304,
23023,
158276,
189925,
37420,
38721,
225134,
189360,
170718,
54617,
15010,
111676,
9880,
482397,
145708,
36033,
81856,
43289,
291302,
36273,
65325,
25722,
13991,
108426,
308581,
9631,
17374,
17875,
20247,
27177,
52023,
68366,
3183,
182052,
77757,
39843,
255309,
22777,
222548,
69822,
null,
21676,
205529,
782108,
77202,
145413,
220470,
null,
284056,
219064,
257069,
44308,
67638,
182505,
382018,
58751,
18998,
359109,
null,
null,
72122,
null,
217517,
53236,
null,
8758,
82411,
52885,
59410,
107038,
154957,
232102,
67413,
186789,
38086,
176017,
177654,
340082,
381585,
216982,
277256,
7806,
165643,
121191,
492773,
27640,
22894,
32403,
319665,
null,
null,
27812,
37103,
155919,
433649,
203594,
217766,
500183,
20320,
216962,
105793,
197957,
4894,
120571,
49750,
24712,
167313,
88949,
null,
342161,
10782,
16832,
16240,
82328,
42015,
63718,
179496,
34715,
7860,
222034,
293405,
177116,
118327,
282719,
14944,
174035,
14830,
3717,
27042,
62730,
95493,
102127,
6401,
18465,
564461,
14807,
241813,
79284,
42939,
null,
31452,
null,
173663,
168037,
327195,
13349,
60118,
7805,
226598,
33629,
19639,
24021,
46055,
67690,
53199,
93692,
199873,
396407,
22772,
81758,
310760,
37892,
149102,
14031,
26265,
41745,
250813,
590731,
41831,
44430,
64155,
160817,
4568,
154002,
323301,
null,
null,
21503,
212842,
9067,
null,
139797,
745617,
320794,
null,
14900,
182697,
32769,
null,
24774,
305032,
51161,
303825,
23564,
378443,
38794,
74624,
318347,
119506,
345426,
184034,
null,
123553,
252389,
53465,
17420,
13673,
23630,
10884,
351395,
65356,
485726,
null,
10904,
476496,
108025,
22180,
20487,
255701,
409353,
7580,
532532,
32433,
73149,
35518,
41640,
144361,
null,
330599,
6521,
39028,
9993,
174643,
30227,
293237,
79656,
433405,
137999,
77025,
284859,
4070,
37622,
106673,
121469,
224017,
20103,
49859,
22878,
71022,
24100,
8829,
78552,
400399,
67924,
125026,
236716,
2513,
4177,
null,
32784,
22863,
164042,
84139,
246046,
186501,
44431,
29150,
15940,
31689,
63579,
793270,
54462,
169097,
342623,
147247,
5823,
19300,
13511,
86208,
41752,
98257,
null,
270867,
258699,
259454,
53828,
31279,
12124,
63226,
45081,
293458,
181069,
19300,
45935,
68993,
null,
20858,
86967,
24462,
40969,
null,
33515,
null,
298614,
265295,
629859,
477880,
75649,
66030,
4691,
190325,
263022,
748276,
11136,
28222,
305067,
35059,
172297,
12560,
66477,
3965,
11602,
289187,
39991,
29001,
49321,
12738,
138622,
48184,
432718,
24040,
159574,
33678,
141959,
36196,
75176,
12178,
24498,
198267,
347936,
100438,
null,
37939,
211243,
21345,
21367,
51354,
492441,
22013,
343364,
70324,
61690,
330510,
77284,
88419,
260156,
7902,
35002,
41630,
167818,
46070,
541305,
305616,
321438,
20426,
33990,
null,
6157,
16072,
40371,
206258,
25913,
365926,
44286,
16547,
1420912,
144903,
36569,
null,
24397,
9976,
217884,
226030,
237703,
316417,
null,
21547,
14023,
55965,
43816,
210709,
47700,
68191,
792357,
321711,
426650,
273508,
145038,
131709,
27532,
168225,
72037,
43357,
117850,
458633,
301355,
216204,
93206,
160630,
453946,
83932,
null,
57566,
103284,
21056,
276598,
27465,
144174,
221969,
32739,
453418,
296160,
47058,
520250,
18151,
322814,
186587,
22527,
47189,
7611,
452752,
343441,
90654,
3978,
72056,
33204,
56875,
46866,
41935,
358502,
null,
395568,
173726,
283855,
26743,
31136,
null,
113996,
null,
6957,
86452,
102620,
184481,
430452,
147668,
38659,
12325,
114819,
85903,
158303,
191746,
18393,
18229,
18444,
19220,
null,
63677,
4759,
415346,
57687,
278734,
875487,
20577,
244390,
300589,
54550,
338838,
12246,
46128,
31244,
295865,
346467,
36987,
6974,
36858,
168791,
173725,
347322,
11074,
39167,
165408,
83874,
335492,
170761,
1992,
40858,
244894,
240715,
57706,
16868,
187390,
66951,
null,
null,
125307,
4955,
294228,
332699,
null,
22920,
28317,
248294,
136299,
19891,
48737,
8678,
466481,
121611,
37171,
199545,
149050,
6150,
43274,
195578,
384089,
21183,
62691,
174839,
44785,
44239,
19905,
425048,
11364,
230121,
48716,
223238,
42453,
48507,
358421,
17635,
350707,
10826,
33332,
29318,
208896,
389535,
217214,
13268,
12640,
118533,
47385,
383542,
285406,
97913,
9973,
258113,
19274,
60995,
239780,
90194,
16917,
249399,
26571,
129101,
20161,
85599,
105239,
32835,
4294,
null,
35228,
26710,
16728,
447096,
4041,
155457,
226507,
76859,
30963,
172885,
51950,
166457,
127488,
102382,
145013,
42763,
31267,
16718,
8792,
37401,
204849,
null,
672236,
32975,
96731,
306553,
152244,
34445,
213748,
104022,
16847,
436908,
192851,
40714,
420422,
7378,
11229,
237278,
33268,
119429,
89418,
14041,
409073,
144974,
60657,
317668,
321028,
46782,
209580,
33868,
4458,
64800,
390689,
229634,
260482,
237273,
18676,
36727,
null,
688463,
38270,
411532,
122640,
null,
165573,
null,
64989,
573213,
44484,
39943,
188888,
13368,
null,
38613,
29612,
24318,
7986,
148657,
375958,
null,
370309,
17504,
259792,
202747,
null,
24373,
174640,
9022,
8575,
285290,
383191,
140609,
303136,
84910,
252076,
185185,
668681,
11031,
null,
35778,
34196,
18241,
133313,
27144,
56653,
582310,
35228,
null,
49266,
328734,
32655,
130647,
20477,
22477,
98746,
null,
42804,
382170,
198304,
19578,
11422,
53155,
361227,
158812,
null,
692763,
23733,
153315,
301791,
203441,
119760,
null,
187714,
240377,
43644,
null,
53560,
191927,
21498,
115839,
71136,
15400,
675709,
71552,
143699,
18907,
26505,
355672,
50329,
98395,
37900,
34713,
10410,
531222,
276238,
104869,
20784,
317703,
4991,
29260,
31185,
11419,
5632,
26632,
62777,
48322,
49039,
42658,
95627,
341523,
133002,
316015,
190660,
null,
323857,
11917,
31235,
35134,
386239,
243836,
274701,
15846,
30897,
23693,
208156,
287918,
192398,
171553,
115345,
155681,
34168,
41148,
null,
14200,
null,
81347,
83274,
62204,
21551,
51004,
41690,
158766,
37822,
176060,
46920,
67251,
71358,
71222,
10484,
212674,
26278,
52653,
77030,
68738,
253742,
94711,
123896,
28656,
12380,
43977,
412406,
21378,
45136,
37112,
null,
43177,
115782,
357827,
71338,
227960,
260559,
46447,
188308,
26424,
310230,
27533,
159360,
149089,
null,
56097,
null,
17055,
605251,
17016,
14788,
113801,
255003,
88879,
224739,
35601,
49555,
18269,
164571,
46535,
37351,
13146,
360405,
255517,
null,
36849,
524205,
130390,
276456,
null,
60890,
363214,
336139,
15202,
18835,
29393,
139352,
null,
326315,
10202,
141748,
152333,
26289,
7761,
null,
27312,
29267,
305568,
336414,
325579,
30704,
130877,
58165,
245390,
58175,
317888,
9032,
499265,
138117,
31144,
33669,
253211,
13556,
25017,
207343,
124625,
67124,
103216,
283348,
31819,
221313,
64401,
43163,
130827,
32510,
143864,
160078,
32599,
89837,
37802,
17832,
18329,
289671,
24562,
29750,
215954,
429390,
14880,
396254,
null,
417718,
50318,
113336,
1919,
182740,
209313,
191521,
null,
45349,
13047,
329940,
129166,
57154,
103133,
8124,
10807,
337519,
74856,
40773,
308636,
35880,
3633,
14033,
9306,
238134,
8767,
39031,
13166,
32298,
13061,
250449,
329061,
134619,
114530,
246586,
177240,
567649,
37660,
214871,
232748,
427937,
75474,
154228,
31120,
500519,
166318,
240356,
13862,
80971,
97374,
66130,
48398,
213342,
146461,
25150,
17958,
28024,
5850,
2471,
206847,
1433115,
96055,
210416,
129209,
645331,
366794,
181431,
54687,
17597,
18440,
30222,
58198,
13153,
null,
58522,
295608,
84331,
47245,
92024,
23471,
185537,
30131,
null,
175229,
107487,
275831,
44003,
171695,
null,
15845,
34402,
125508,
133141,
26939,
51066,
295788,
15991,
null,
356255,
134475,
430602,
166475,
113883,
30497,
null,
39133,
23223,
834566,
259776,
173753,
28016,
null,
72813,
3455,
217441,
31705,
9307,
381541,
120942,
5532,
null,
135675,
null,
14571,
228610,
852059,
234681,
236181,
null,
83924,
null,
451496,
82556,
12100,
50020,
25818,
15637,
null,
152419,
197028,
154453,
154777,
140320,
271995,
228999,
255755,
340368,
26026,
26905,
223789,
5199,
82030,
243947,
171280,
50322,
69584,
null,
12157,
276812,
null,
81344,
152101,
18788,
305141,
161519,
null,
9547,
6628,
7823,
54480,
49450,
304582,
34093,
373867,
79902,
58406,
163353,
32488,
19866,
110486,
26762,
522980,
24279,
35571,
160368,
157370,
74435,
94250,
61066,
37884,
25284,
269393,
25170,
312854,
138189,
null,
334572,
null,
95310,
275474,
null,
309030,
25341,
14217,
null,
201268,
157977,
279535,
22764,
70143,
258159,
3394,
14828,
19408,
90624,
185544,
30663,
239230,
168421,
202864,
118208,
null,
57357,
176636,
78568,
175901,
3980,
null,
null,
8828,
650319,
63704,
85619,
62249,
97424,
32385,
526744,
38435,
66848,
29327,
185665,
284120,
188144,
66789,
9381,
36855,
100091,
43268,
94953,
27923,
248030,
170505,
314458,
30010,
103263,
41161,
245671,
240742,
21348,
31790,
82769,
43196,
5951,
150455,
20928,
52962,
39730,
32904,
30198,
307383,
5530,
null,
294771,
31159,
68277,
372260,
null,
26852,
193983,
126041,
90819,
5339,
200845,
40000,
151936,
28955,
253762,
162005,
5199,
118556,
224201,
170469,
21400,
5473,
108923,
303124,
13827,
309954,
109366,
88462,
43620,
57807,
18987,
363615,
12847,
174922,
116405,
null,
54636,
6801,
36066,
145611,
41183,
27989,
300949,
19189,
122265,
469709,
null,
288458,
11362,
33298,
null,
10810,
42838,
62204,
36563,
130387,
29319,
12972,
null,
277663,
51298,
52875,
56930,
65090,
21738,
230183,
24950,
874918,
46349,
285883,
15527,
16400,
17123,
12918,
273661,
163923,
54829,
11494,
120818,
4449,
4954,
null,
302486,
192679,
10698,
29783,
42626,
13939,
12895,
68799,
null,
426863,
90887,
192811,
24448,
1019,
188509,
26094,
123029,
68246,
432951,
9203,
415289,
169185,
268986,
320429,
292694,
310581,
105937,
211557,
39046,
376226,
273646,
237427,
32032,
null,
226422,
null,
4952,
144875,
360787,
null,
640343,
150034,
91113,
29185,
46573,
19296,
null,
234102,
24198,
82926,
11262,
510840,
339971,
113080,
71645,
41519,
603772,
68702,
236145,
303025,
61591,
428569,
27980,
762656,
50507,
23012,
137199,
142307,
105384,
191867,
38796,
290728,
23610,
22235,
null,
209658,
147254,
40060,
39201,
186773,
59636,
108631,
35302,
35734,
473813,
110607,
37847,
293817,
77516,
507066,
43215,
5862,
190336,
37790,
51299,
20118,
106779,
37687,
230114,
37881,
445828,
20747,
178216,
269015,
null,
null,
24964,
28370,
86263,
null,
163017,
35155,
66610,
67800,
65111,
4677,
183484,
145444,
51867,
297922,
66142,
28575,
368327,
127772,
null,
227071,
419418,
25385,
324351,
15669,
null,
190846,
64762,
40375,
29504,
7726,
1581,
537789,
204867,
206705,
69107,
86754,
305941,
109724,
205159,
111159,
503933,
141316,
56651,
19700,
25501,
null,
521905,
202352,
120486,
742028,
135250,
229526,
113394,
63622,
174759,
138913,
20180,
null,
null,
332658,
56004,
23987,
6077,
347817,
139268,
26023,
46185,
42351,
151256,
null,
null,
213606,
329356,
360258,
259080,
22797,
24868,
48970,
75722,
134921,
180291,
52320,
166401,
69015,
10451,
223326,
22711,
34124,
22945,
143257,
75273,
602592,
70682,
407684,
283059,
55492,
269292,
31102,
24046,
194728,
48451,
null,
47785,
71542,
24880,
49573,
209030,
169416,
16191,
49878,
41220,
218476,
160004,
4820,
30902,
173138,
93925,
276627,
null,
22593,
37068,
20718,
null,
62412,
44869,
171371,
32748,
76554,
234482,
7548,
102839,
83257,
70274,
23018,
246470,
566964,
126630,
37940,
86803,
9053,
42838,
564218,
46002,
93074,
214945,
156106,
165861,
112779,
218587,
11721,
17129,
251127,
25027,
80756,
46675,
101707,
45293,
315054,
33465,
37694,
115148,
40733,
33422,
51669,
174279,
30725,
280455,
27075,
20079,
8809,
49754,
77011,
4285,
147748,
41103,
11454,
396136,
79782,
98389,
41528,
146742,
26508,
379552,
28323,
null,
240212,
156180,
127969,
77287,
104429,
null,
22410,
209822,
18314,
57792,
119794,
30209,
168630,
null,
162933,
57489,
13582,
null,
245670,
75194,
943654,
250081,
117150,
166030,
172910,
30469,
24924,
21459,
185946,
23705,
70792,
351649,
8467,
107510,
19567,
421830,
485305,
33100,
7865,
91738,
null,
444152,
152475,
23561,
null,
19668,
523570,
null,
43025,
15650,
236077,
71944,
20914,
90417,
53384,
9305,
256582,
279405,
27757,
4486,
229916,
150190,
182601,
14376,
197305,
410657,
87185,
null,
35417,
125387,
88386,
42589,
14357,
95185,
18727,
59610,
32465,
null,
101616,
148372,
13226,
87215,
284688,
21823,
355264,
198457,
203232,
30638,
325047,
495417,
null,
198115,
4354,
24655,
19995,
142996,
null,
304122,
null,
217361,
null,
207336,
25189,
171905,
348478,
142801,
31661,
767219,
270460,
null,
5365,
57794,
167950,
198917,
571673,
56952,
24044,
20062,
34543,
63496,
72093,
41882,
59239,
259486,
12367,
243165,
9482,
359297,
34729,
31634,
497,
null,
null,
203365,
91993,
18871,
null,
71350,
52177,
21207,
319014,
39359,
8896,
410068,
252001,
237764,
10277,
145207,
219527,
59013,
127223,
112750,
54824,
8988,
11314,
1206312,
53747,
null,
286058,
56529,
161551,
26206,
7013,
68204,
null,
10797,
13484,
47422,
99807,
82131,
298872,
350790,
215818,
null,
25737,
8088,
307423,
263388,
118577,
438767,
242695,
47578,
46010,
414094,
256280,
202052,
160920,
19769,
242565,
null,
64888,
null,
304549,
24805,
230048,
34385,
218187,
54442,
null,
25843,
23111,
8373,
144137,
166526,
528870,
50386,
243847,
167450,
80379,
17254,
17102,
26884,
14884,
26447,
18654,
193321,
34005,
340835,
15570,
401877,
103178,
190601,
103617,
39235,
115628,
269396,
62114,
40322,
68256,
44386,
492320,
4257,
null,
110114,
25903,
199873,
61194,
175822,
137852,
181356,
222691,
258298,
33314,
297289,
65318,
72438,
18772,
214638,
null,
50754,
357553,
63652,
194819,
150054,
69544,
217489,
6733,
96243,
38865,
353632,
5537,
72955,
105509,
171811,
24696,
60136,
51550,
364524,
null,
null,
24505,
31524,
372505,
25664,
13807,
62827,
180416,
11994,
8781,
39914,
123935,
57322,
269164,
null,
112374,
128184,
380718,
14466,
null,
53653,
240882,
16094,
276576,
22921,
6540,
174522,
23394,
29014,
241059,
448214,
14733,
20957,
281471,
4701,
134443,
null,
36039,
94316,
319019,
226149,
337626,
570521,
113976,
385155,
118536,
146074,
4167,
18703,
34121,
337507,
227192,
10851,
50797,
144196,
37374,
18850,
34081,
null,
330958,
31950,
294346,
12864,
193087,
18883,
11620,
113769,
311166,
653612,
253619,
184176,
19933,
19597,
435087,
47144,
null,
212949,
13620,
22703,
276017,
85347,
17037,
228734,
220480,
132604,
43438,
71258,
49767,
52067,
50483,
2576,
237799,
46963,
42241,
187416,
282455,
196700,
55259,
13126,
11873,
172034,
53474,
127888,
36646,
229092,
102347,
198135,
67930,
37427,
204353,
null,
33813,
64758,
43318,
23502,
16104,
187292,
502616,
12907,
40436,
209001,
19851,
null,
299771,
107790,
106299,
108111,
46125,
null,
147997,
77623,
225726,
279976,
257077,
268643,
191558,
133192,
7111,
26124,
48744,
null,
35926,
null,
321630,
474584,
51932,
265241,
257343,
75735,
296168,
305253,
267258,
248546,
null,
217345,
10375,
5919,
238574,
225248,
120904,
456431,
26085,
225187,
null,
null,
null,
211010,
226934,
82357,
11370,
13847,
null,
24872,
66361,
111068,
12045,
124560,
39752,
127448,
377468,
64988,
427058,
48389,
92907,
227647,
339794,
178211,
14016,
195750,
400957,
66753,
17017,
190658,
27660,
111568,
39814,
53484,
23588,
111522,
28912,
21692,
113710,
419565,
91668,
69989,
194566,
20037,
43085,
47923,
14073,
18373,
null,
30821,
null,
7437,
94029,
53777,
32772,
207562,
24534,
504633,
424345,
982,
16219,
42588,
271644,
31528,
45715,
32492,
211012,
387748,
25839,
137160,
317496,
40356,
33476,
66472,
null,
null,
65714,
69612,
264190,
389931,
37966,
142110,
73796,
366133,
21072,
10973,
16444,
28217,
null,
59136,
269747,
2629,
3709,
11525,
340431,
29396,
366878,
180979,
432449,
178537,
14671,
446441,
102592,
93651,
50050,
18397,
25112,
361933,
299034,
142634,
670525,
28204,
437123,
7954,
null,
23963,
null,
47565,
31499,
24744,
29638,
75133,
20580,
217479,
447640,
154128,
193042,
24972,
150367,
44285,
597577,
19583,
42398,
303326,
19467,
316990,
221851,
11451,
4570,
6448,
330916,
176673,
72250,
199207,
196274,
72876,
null,
295213,
51455,
54437,
99046,
138705,
471634,
null,
200945,
206710,
127046,
354842,
220643,
26090,
26805,
74317,
74258,
137868,
46433,
207248,
734726,
142981,
35846,
112665,
47128,
null,
45892,
218537,
10587,
518558,
292717,
37854,
14869,
20770,
253275,
155610,
104721,
60658,
10757,
21395,
60157,
55085,
null,
7395,
null,
138574,
224981,
43253,
6780,
56011,
329620,
29447,
13215,
26868,
217393,
145953,
11876,
21911,
301850,
29665,
318063,
null,
330356,
null,
80163,
89666,
33084,
56527,
32413,
31153,
118846,
34711,
214907,
449962,
215537,
107094,
38437,
17635,
63215,
316314,
205377,
391759,
40774,
62356,
147587,
340196,
null,
178107,
376612,
13480,
38960,
217950,
35183,
239215,
29510,
62510,
14180,
104787,
17822,
376671,
389706,
184063,
null,
22121,
null,
61865,
42834,
136138,
40068,
134152,
326017,
20621,
494783,
57701,
63362,
198030,
7773,
968006,
5727,
324550,
309132,
133618,
9964,
217003,
64014,
56871,
54750,
241839,
301262,
20121,
81152,
15050,
178489,
81914,
80027,
136052,
181651,
127405,
27235,
null,
12910,
26453,
183920,
428957,
360557,
41299,
464033,
229864,
7575,
40646,
139494,
383939,
17776,
33884,
60865,
277391,
167873,
11265,
580802,
21671,
22108,
359533,
22205,
573769,
55605,
19452,
458489,
34120,
11267,
320846,
null,
64160,
143463,
7520,
215924,
1776628,
329607,
215046,
306306,
29791,
31243,
46465,
78420,
95696,
21277,
216758,
226828,
21137,
31743,
324836,
22012,
421673,
203692,
67523,
64682,
4950,
231478,
41217,
564818,
41550,
53719,
299477,
null,
34184,
null,
83796,
48059,
2933,
30016,
68305,
10879,
43192,
241974,
183465,
95879,
162155,
87366,
8100,
20151,
99975,
199914,
116370,
486053,
570029,
119466,
186572,
858946,
74106,
13148,
263165,
126899,
null,
10003,
52605,
38770,
163119,
35799,
17943,
33404,
143116,
null,
186368,
36510,
180104,
47108,
18891,
null,
79226,
28384,
68494,
16155,
48583,
167879,
75390,
38381,
12895,
3629,
34357,
84592,
17002,
12475,
26532,
30044,
26691,
33432,
49842,
38836,
46553,
96929,
77930,
87922,
70497,
null,
94446,
116327,
75315,
223114,
9547,
116899,
38394,
15556,
149736,
13060,
478258,
394905,
329697,
77792,
106429,
232931,
154918,
31211,
null,
31918,
232996,
39022,
103037,
51803,
42627,
10083,
400288,
6164,
54212,
40764,
268281,
584588,
188200,
344315,
null,
154602,
65949,
85005,
9420,
108841,
131669,
15810,
153139,
305968,
711052,
null,
32928,
110312,
25759,
26052,
212914,
675846,
108497,
38020,
158240,
13761,
201940,
8908,
58193,
269493,
179408,
null,
19179,
55569,
303634,
288608,
176337,
58060,
49940,
100862,
9228,
172460,
100509,
null,
97939,
22013,
26809,
18430,
null,
184929,
27601,
25496,
154377,
23743,
42562,
278187,
260029,
33283,
31685,
214186,
51256,
256555,
31101,
242748,
19725,
195155,
98148,
32142,
379303,
311748,
449580,
38405,
null,
59585,
224732,
170460,
64236,
174737,
202864,
318521,
9130,
259931,
40849,
28737,
36991,
185439,
32398,
160173,
266731,
212628,
131459,
157105,
477524,
28107,
3765,
123207,
134344,
100011,
4841,
8876,
85936,
182507,
43473,
30409,
153994,
321386,
331383,
155278,
25068,
28187,
292528,
196722,
226322,
241336,
108080,
17600,
72799,
null,
258180,
64438,
422333,
143150,
109469,
44808,
22791,
15732,
22110,
286872,
102158,
455455,
61444,
null,
207991,
44266,
264677,
null,
18938,
38650,
177606,
78734,
24763,
131065,
17595,
null,
180477,
3297,
211228,
null,
19055,
19551,
48247,
781,
246976,
149242,
12718,
61001,
73159,
22490,
73396,
237047,
61166,
175419,
493450,
49983,
124007,
22637,
5267,
171765,
34005,
49826,
163799,
434733,
41729,
267087,
16778,
28803,
910045,
11689,
270025,
30041,
null,
null,
19029,
422856,
38905,
25027,
29801,
243150,
31520,
282302,
131423,
50691,
338955,
50196,
190579,
117191,
99562,
8232,
36047,
31154,
183459,
82265,
null,
206648,
8277,
115000,
364318,
283655,
300927,
124835,
29345,
34022,
119750,
62941,
134587,
26647,
200985,
143697,
172437,
null,
352196,
46923,
19025,
28087,
251143,
8203,
16907,
465833,
77523,
27035,
18821,
634167,
129185,
109890,
null,
294841,
178779,
58860,
135962,
100988,
367159,
635213,
80179,
173920,
24261,
248890,
34948,
14085,
37125,
165909,
9330,
31554,
218807,
615691,
57719,
16925,
19651,
null,
13854,
372509,
247006,
17083,
119872,
65187,
21990,
137283,
31307,
119752,
637515,
295240,
709249,
394719,
252119,
26469,
332219,
191883,
368577,
21399,
197654,
35595,
25593,
220017,
null,
26114,
26726,
47824,
318270,
31204,
11148,
73263,
16722,
35528,
359876,
266444,
136022,
30559,
39652,
25102,
321387,
12554,
29838,
58143,
163798,
72069,
274235,
40850,
341114,
52733,
58987,
null,
22972,
380093,
31859,
669815,
198614,
29294,
274253,
138500,
28848,
32504,
218678,
20683,
613571,
48062,
93814,
92274,
231743,
82386,
43840,
174144,
160637,
55642,
144046,
225521,
189011,
138336,
35997,
226419,
null,
134727,
15163,
71245,
13116,
61505,
16488,
56557,
null,
112921,
30339,
43602,
185584,
458560,
11830,
null,
8000,
256450,
null,
23872,
74076,
140242,
59014,
213536,
39496,
206879,
447430,
35088,
63757,
8482,
159718,
185647,
251502,
292819,
24999,
80463,
28948,
68578,
129524,
391495,
4402,
54318,
464095,
12127,
70949,
261966,
336024,
72557,
212076,
101594,
217939,
155581,
39863,
289032,
23083,
90104,
5663,
69968,
117069,
null,
null,
409038,
20333,
29428,
521133,
250064,
154003,
11970,
44195,
53054,
115256,
27565,
362403,
44576,
19087,
15701,
12890,
20126,
36290,
341257,
17927,
null,
22482,
369912,
117596,
73890,
25433,
55913,
117851,
28674,
76225,
3277,
74724,
102125,
244553,
49636,
null,
24666,
309055,
244609,
63674,
195759,
19275,
15790,
24226,
132834,
73670,
164300,
159773,
59048,
323830,
22341,
197611,
65602,
15577,
28725,
26650,
265432,
349259,
33255,
230139,
277388,
null,
174537,
17771,
48256,
190222,
17441,
31443,
238650,
64993,
139863,
38527,
141648,
430225,
179666,
277709,
173094,
null,
161616,
9315,
null,
31777,
165153,
68648,
53901,
17941,
76392,
68858,
7598,
181464,
37065,
20121,
279816,
328981,
112371,
247418,
169128,
147598,
null,
136076,
null,
101054,
27251,
20351,
110515,
198240,
120584,
287259,
35105,
31558,
20811,
62784,
17255,
273437,
193002,
196430,
null,
16765,
141918,
46020,
440317,
237332,
156101,
47970,
18485,
3481,
622280,
33736,
28292,
34425,
12818,
157363,
39913,
90609,
247979,
9828,
65280,
424722,
135209,
40788,
160979,
20440,
399251,
null,
70820,
287496,
45575,
259812,
95696,
211505,
74427,
157518,
489056,
null,
294481,
307265,
12392,
360330,
23732,
16735,
256400,
33212,
238005,
22440,
894817,
57696,
762459,
117138,
null,
63643,
94335,
126606,
27578,
107213,
456942,
43568,
169806,
24602,
27527,
9440,
null,
null,
56150,
231963,
53631,
378510,
313882,
444537,
null,
null,
23883,
78990,
304459,
null,
53649,
null,
170595,
16145,
19291,
43401,
142113,
895389,
24690,
9232,
40087,
37939,
null,
61404,
25471,
34028,
49998,
36973,
99111,
124448,
27329,
5445,
23533,
659988,
156966,
343383,
74597,
34383,
219189,
320298,
89905,
99503,
181217,
126433,
20405,
6036,
null,
31664,
231726,
107309,
13815,
12969,
13236,
347943,
88654,
102574,
28338,
116851,
28016,
298488,
19960,
164848,
33163,
64659,
169031,
44415,
248807,
16040,
461010,
11160,
737898,
62355,
3838,
42358,
8770,
148277,
234525,
395138,
12457,
10824,
57977,
64053,
268534,
182447,
null,
249901,
12783,
45462,
15359,
327468,
357096,
141986,
310712,
11415,
null,
138266,
27785,
77739,
32746,
90845,
68636,
40823,
null,
418605,
13353,
117707,
392625,
null,
53057,
28262,
184817,
47141,
null,
157628,
null,
120529,
null,
18611,
456286,
null,
354366,
32936,
54101,
82263,
40814,
50476,
91962,
68650,
294896,
null,
182415,
84519,
11878,
238944,
49367,
151537,
412062,
62059,
280023,
15853,
294683,
194773,
null,
146204,
128499,
224001,
319543,
138916,
35696,
null,
204143,
93528,
11764,
557641,
110124,
37514,
381443,
29611,
439622,
192077,
18144,
147236,
260920,
179398,
50090,
325775,
27869,
364905,
127831,
23642,
19407,
153372,
1050877,
34638,
157014,
93297,
10826,
25371,
206383,
null,
456903,
298283,
37955,
57261,
407848,
115462,
null,
null,
null,
44583,
51889,
340059,
181774,
33645,
null,
195146,
138698,
44327,
406949,
200236,
160388,
null,
42409,
36831,
300675,
47737,
18899,
117462,
32090,
219826,
20118,
91009,
183436,
14389,
37326,
null,
144975,
null,
6201,
null,
136471,
47630,
756758,
302321,
184023,
180090,
67555,
212736,
46739,
145888,
9666,
116909,
237640,
177263,
63659,
223251,
6167,
144345,
48543,
12060,
138999,
38970,
42082,
382324,
18471,
11867,
64565,
86910,
17689,
8181,
19135,
34283,
21474,
null,
262668,
32674,
9215,
121073,
46575,
34873,
160575,
23373,
3185,
9441,
529008,
321422,
21709,
29316,
95864,
17901,
31666,
9951,
18211,
174527,
5578,
338739,
281648,
151223,
958,
24622,
null,
8424,
15037,
32470,
73934,
31175,
69301,
102064,
23671,
32706,
7747,
9389,
122341,
382780,
175773,
185687,
49362,
156413,
68062,
null,
null,
null,
39983,
16466,
433296,
36283,
151344,
4891,
56720,
249510,
132444,
6425,
102139,
21457,
110098,
611197,
231453,
296964,
98010,
121730,
64247,
155387,
264187,
null,
188710,
190534,
58219,
50660,
217186,
92167,
229003,
35234,
3598,
null,
22093,
189735,
49020,
16592,
244668,
76005,
2114,
93418,
15057,
17348,
98290,
37099,
27489,
126986,
34259,
340517,
167595,
240183,
55713,
14776,
209807,
38739,
41234,
15593,
156085,
158374,
null,
58187,
17613,
8113,
22493,
33956,
75677,
161515,
23296,
23935,
72103,
63842,
171518,
572614,
39568,
398638,
67184,
74550,
205667,
53476,
44235,
null,
360657,
95528,
3552,
8199,
82674,
68810,
524501,
33137,
386837,
10400,
26024,
28407,
87729,
54401,
77943,
41198,
31877,
70633,
120322,
472277,
56238,
58400,
null,
40823,
22792,
74310,
23683,
21348,
103643,
195987,
346894,
9235,
null,
49191,
83425,
49447,
247649,
65122,
372855,
20411,
365873,
36506,
30929,
94753,
17858,
19491,
40877,
41227,
null,
30056,
56738,
106965,
47401,
226700,
197654,
14422,
null,
109075,
55838,
299184,
26601,
12455,
115738,
41607,
11000,
49735,
167148,
42104,
null,
null,
76416,
163161,
133477,
25127,
null,
421485,
47300,
241494,
39738,
null,
34156,
71394,
5392,
55727,
197173,
202562,
141441,
126484,
266095,
39592,
398485,
6494,
null,
37779,
101821,
22744,
204523,
29655,
15331,
4637,
52908,
423857,
369445,
379535,
114261,
110137,
19820,
161693,
393251,
4502,
308479,
26937,
28072,
50981,
41924,
202398,
251496,
42470,
185486,
97756,
null,
20695,
137258,
66668,
50771,
10317,
160478,
null,
49728,
68029,
174833,
341422,
14902,
26818,
27582,
45463,
31578,
27628,
50817,
null,
null,
30437,
275669,
32331,
6480,
9032,
36028,
74657,
4789,
137272,
246882,
36300,
299576,
30323,
544926,
189935,
22663,
39295,
22184,
null,
160258,
17371,
null,
397543,
364139,
84628,
40351,
180464,
25163,
50809,
223552,
281480,
null,
299190,
null,
63584,
null,
31747,
22547,
60077,
136612,
33234,
255293,
407561,
101714,
254349,
null,
152935,
21544,
83448,
13678,
232660,
342698,
300458,
65407,
52198,
52124,
389274,
37660,
23713,
14302,
46710,
201992,
48872,
147463,
399091,
93709,
30302,
460456,
167232,
115671,
null,
70081,
113466,
41870,
152542,
65469,
262550,
34684,
315833,
153449,
17978,
40396,
12573,
676003,
170171,
26674,
7601,
19468,
53227,
34254,
13159,
217691,
132099,
32247,
36619,
579207,
82728,
333591,
188453,
250853,
null,
null,
6138,
49594,
83487,
224500,
268939,
49019,
18350,
2942,
null,
44947,
19371,
309631,
605232,
144842,
170289,
22401,
34907,
11599,
311969,
338245,
8272,
18630,
150327,
62018,
24165,
243053,
12774,
97421,
33761,
162104,
6754,
20525,
232767,
14249,
37989,
311556,
240648,
567888,
174501,
null,
93625,
107674,
328717,
80216,
95976,
328459,
27701,
55172,
439583,
150742,
51014,
174864,
16620,
260311,
17342,
31665,
14502,
278976,
10000,
175369,
12593,
185103,
226044,
35998,
153363,
39244,
174193,
20086,
2886,
459880,
13009,
null,
36083,
192889,
24724,
17838,
140934,
3732,
2746,
null,
3075,
222329,
332524,
116668,
37555,
209217,
254641,
128157,
19470,
54917,
378659,
77368,
null,
150657,
374867,
null,
98623,
72109,
35617,
77175,
37199,
371974,
135864,
1715,
16803,
209825,
null,
42508,
8142,
49850,
246292,
3839,
147663,
191327,
115059,
null,
405495,
196195,
276568,
91313,
157485,
3719,
29961,
277380,
56765,
16220,
269817,
27929,
74731,
203758,
75321,
46058,
200895,
284342,
179136,
20550,
69246,
249571,
132249,
769107,
170271,
null,
38708,
59979,
188684,
104417,
33950,
201857,
245597,
52059,
182025,
35556,
69421,
85274,
100871,
49693,
13859,
12800,
18128,
255903,
70882,
43019,
45712,
80110,
241821,
256124,
63483,
437781,
44315,
315918,
634376,
102181,
10615,
79514,
46264,
132123,
291024,
183219,
327641,
null,
37282,
null,
63101,
144359,
null,
380166,
171826,
null,
6023,
29218,
361423,
447134,
23117,
36084,
27664,
24281,
101234,
109355,
10406,
54402,
134607,
96535,
null,
92652,
94468,
55589,
32283,
27101,
58817,
192535,
48480,
19644,
180245,
5206,
100082,
429799,
28315,
147346,
46996,
215029,
null,
563610,
33975,
15397,
null,
164486,
248381,
43724,
74428,
555863,
295885,
215397,
141083,
52288,
283026,
238911,
null,
41397,
338539,
310407,
147400,
27089,
39634,
26344,
3848,
123695,
28552,
21562,
18911,
51938,
351734,
17704,
286099,
19800,
105440,
446846,
92766,
69089,
24081,
53478,
99787,
49553,
87285,
378775,
25690,
174492,
224678,
35566,
null,
375290,
111842,
145172,
127626,
230356,
607896,
null,
538143,
null,
21359,
56815,
195596,
47732,
281096,
334371,
194699,
98660,
null,
null,
100402,
334388,
67055,
16851,
157013,
744813,
174535,
119870,
20767,
34125,
23817,
28827,
93269,
null,
273712,
45283,
157141,
296940,
294013,
150815,
632686,
43946,
231063,
57125,
88497,
223720,
40418,
26144,
30253,
28156,
229007,
19572,
26926,
36695,
7891,
null,
null,
271843,
21772,
35430,
31906,
28561,
null,
34544,
21061,
3148
]
}
],
"layout": {
"legend": {
"bgcolor": "#F5F6F9",
"font": {
"color": "#4D5663"
}
},
"paper_bgcolor": "#F5F6F9",
"plot_bgcolor": "#F5F6F9",
"template": {
"data": {
"bar": [
{
"error_x": {
"color": "#2a3f5f"
},
"error_y": {
"color": "#2a3f5f"
},
"marker": {
"line": {
"color": "#E5ECF6",
"width": 0.5
}
},
"type": "bar"
}
],
"barpolar": [
{
"marker": {
"line": {
"color": "#E5ECF6",
"width": 0.5
}
},
"type": "barpolar"
}
],
"carpet": [
{
"aaxis": {
"endlinecolor": "#2a3f5f",
"gridcolor": "white",
"linecolor": "white",
"minorgridcolor": "white",
"startlinecolor": "#2a3f5f"
},
"baxis": {
"endlinecolor": "#2a3f5f",
"gridcolor": "white",
"linecolor": "white",
"minorgridcolor": "white",
"startlinecolor": "#2a3f5f"
},
"type": "carpet"
}
],
"choropleth": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "choropleth"
}
],
"contour": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "contour"
}
],
"contourcarpet": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "contourcarpet"
}
],
"heatmap": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "heatmap"
}
],
"heatmapgl": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "heatmapgl"
}
],
"histogram": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "histogram"
}
],
"histogram2d": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "histogram2d"
}
],
"histogram2dcontour": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "histogram2dcontour"
}
],
"mesh3d": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "mesh3d"
}
],
"parcoords": [
{
"line": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "parcoords"
}
],
"pie": [
{
"automargin": true,
"type": "pie"
}
],
"scatter": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatter"
}
],
"scatter3d": [
{
"line": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatter3d"
}
],
"scattercarpet": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattercarpet"
}
],
"scattergeo": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattergeo"
}
],
"scattergl": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattergl"
}
],
"scattermapbox": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattermapbox"
}
],
"scatterpolar": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterpolar"
}
],
"scatterpolargl": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterpolargl"
}
],
"scatterternary": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterternary"
}
],
"surface": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "surface"
}
],
"table": [
{
"cells": {
"fill": {
"color": "#EBF0F8"
},
"line": {
"color": "white"
}
},
"header": {
"fill": {
"color": "#C8D4E3"
},
"line": {
"color": "white"
}
},
"type": "table"
}
]
},
"layout": {
"annotationdefaults": {
"arrowcolor": "#2a3f5f",
"arrowhead": 0,
"arrowwidth": 1
},
"coloraxis": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"colorscale": {
"diverging": [
[
0,
"#8e0152"
],
[
0.1,
"#c51b7d"
],
[
0.2,
"#de77ae"
],
[
0.3,
"#f1b6da"
],
[
0.4,
"#fde0ef"
],
[
0.5,
"#f7f7f7"
],
[
0.6,
"#e6f5d0"
],
[
0.7,
"#b8e186"
],
[
0.8,
"#7fbc41"
],
[
0.9,
"#4d9221"
],
[
1,
"#276419"
]
],
"sequential": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"sequentialminus": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
]
},
"colorway": [
"#636efa",
"#EF553B",
"#00cc96",
"#ab63fa",
"#FFA15A",
"#19d3f3",
"#FF6692",
"#B6E880",
"#FF97FF",
"#FECB52"
],
"font": {
"color": "#2a3f5f"
},
"geo": {
"bgcolor": "white",
"lakecolor": "white",
"landcolor": "#E5ECF6",
"showlakes": true,
"showland": true,
"subunitcolor": "white"
},
"hoverlabel": {
"align": "left"
},
"hovermode": "closest",
"mapbox": {
"style": "light"
},
"paper_bgcolor": "white",
"plot_bgcolor": "#E5ECF6",
"polar": {
"angularaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"bgcolor": "#E5ECF6",
"radialaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
}
},
"scene": {
"xaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
},
"yaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
},
"zaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
}
},
"shapedefaults": {
"line": {
"color": "#2a3f5f"
}
},
"ternary": {
"aaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"baxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"bgcolor": "#E5ECF6",
"caxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
}
},
"title": {
"x": 0.05
},
"xaxis": {
"automargin": true,
"gridcolor": "white",
"linecolor": "white",
"ticks": "",
"title": {
"standoff": 15
},
"zerolinecolor": "white",
"zerolinewidth": 2
},
"yaxis": {
"automargin": true,
"gridcolor": "white",
"linecolor": "white",
"ticks": "",
"title": {
"standoff": 15
},
"zerolinecolor": "white",
"zerolinewidth": 2
}
}
},
"title": {
"font": {
"color": "#4D5663"
},
"text": "tot_cur_bal Box plot"
},
"xaxis": {
"gridcolor": "#E1E5ED",
"showgrid": true,
"tickfont": {
"color": "#4D5663"
},
"title": {
"font": {
"color": "#4D5663"
},
"text": ""
},
"zerolinecolor": "#E1E5ED"
},
"yaxis": {
"gridcolor": "#E1E5ED",
"showgrid": true,
"tickfont": {
"color": "#4D5663"
},
"title": {
"font": {
"color": "#4D5663"
},
"text": ""
},
"zerolinecolor": "#E1E5ED"
}
}
},
"text/html": [
"\n",
" \n",
" \n",
" \n",
" \n",
" "
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"application/vnd.plotly.v1+json": {
"config": {
"linkText": "Export to plot.ly",
"plotlyServerURL": "https://plot.ly",
"showLink": true
},
"data": [
{
"histfunc": "count",
"histnorm": "",
"marker": {
"color": "rgba(255, 153, 51, 1.0)",
"line": {
"color": "#4D5663",
"width": 1.3
}
},
"name": "total_rev_hi_lim",
"opacity": 0.8,
"orientation": "v",
"type": "histogram",
"x": [
30800,
32900,
34900,
24700,
47033,
29500,
55500,
11800,
62100,
33200,
47000,
19600,
139900,
43000,
41200,
18500,
15900,
17400,
17000,
31000,
27200,
null,
25700,
14300,
41400,
43400,
19800,
33100,
49900,
10900,
94100,
69000,
4900,
12300,
30200,
8900,
6600,
37100,
16700,
62400,
5500,
46500,
26600,
32400,
57300,
9400,
72900,
null,
22500,
20100,
18200,
74000,
43300,
13000,
33600,
18800,
90600,
32900,
5600,
72600,
62800,
87000,
54500,
22100,
20000,
63700,
null,
null,
14400,
62200,
8300,
15700,
3000,
17300,
null,
33300,
10500,
40200,
34400,
26400,
15550,
118600,
23300,
27500,
43900,
12950,
16200,
23700,
23800,
8700,
46800,
19000,
0,
null,
44200,
5800,
22300,
16900,
84500,
31200,
14800,
31900,
67600,
71207,
6000,
6500,
23800,
130300,
24000,
31000,
48900,
64700,
54000,
5800,
43300,
70000,
34900,
7300,
45600,
15600,
22800,
12600,
92000,
null,
47400,
8800,
27500,
46000,
25300,
10800,
null,
8000,
7900,
46400,
67700,
13507,
60100,
33100,
31100,
15200,
19500,
37900,
33700,
22500,
7500,
12900,
57600,
38800,
95900,
59600,
null,
7800,
null,
14900,
37500,
12300,
46000,
41600,
27000,
12000,
18600,
19900,
28700,
11400,
46100,
26000,
5800,
49500,
25100,
19900,
14800,
21600,
110500,
48900,
143100,
17800,
47100,
62300,
11500,
31100,
11200,
15200,
22500,
22500,
28900,
19700,
16600,
16300,
47700,
4700,
68200,
13200,
29600,
null,
35800,
null,
38700,
null,
24500,
13500,
41100,
81300,
38050,
10700,
12700,
1000,
16200,
null,
null,
37000,
4850,
40800,
11500,
41300,
17400,
12700,
19100,
72300,
30800,
null,
50900,
8400,
25800,
25100,
17000,
3300,
149900,
16500,
95100,
28700,
18500,
5300,
60300,
99000,
28800,
47000,
38800,
18900,
null,
22800,
36400,
38900,
11700,
88197,
null,
5500,
20600,
36500,
10700,
33300,
9600,
null,
33500,
19000,
33000,
21300,
34900,
16100,
11610,
28500,
30900,
42600,
32500,
2600,
48600,
18800,
21900,
9300,
23900,
36000,
23000,
36800,
18600,
27500,
12900,
50200,
38600,
21100,
12400,
5700,
19600,
29500,
11500,
null,
37250,
18100,
32800,
7700,
19900,
24800,
6100,
75500,
19100,
56200,
81000,
12000,
null,
13500,
null,
17700,
58200,
78600,
5800,
null,
25100,
10300,
52200,
32800,
24800,
24900,
32500,
27900,
35800,
55400,
23500,
null,
25800,
241600,
32400,
39800,
184100,
53700,
6800,
23100,
32100,
32100,
26900,
14400,
23500,
4500,
47800,
44300,
15100,
45900,
24800,
null,
null,
31200,
3500,
27400,
49200,
27600,
13200,
62600,
54423,
15500,
22000,
70700,
22300,
20300,
7000,
11100,
12600,
28300,
31600,
37500,
10500,
74400,
23500,
14500,
64000,
null,
22200,
72600,
null,
20700,
5900,
33300,
11200,
41500,
32400,
null,
8800,
41400,
7500,
35500,
12600,
31400,
32300,
20000,
75000,
41245,
25500,
null,
21800,
26000,
24000,
null,
5900,
23500,
14000,
11800,
null,
24600,
46600,
20200,
1000,
81600,
19000,
1800,
11100,
11200,
18500,
44500,
24700,
13900,
56900,
3600,
27100,
13900,
26900,
65700,
41400,
66400,
30200,
null,
8400,
2300,
5300,
49700,
27300,
null,
2800,
null,
18500,
26000,
53800,
16600,
28000,
29600,
111400,
66100,
50100,
31600,
null,
11300,
51600,
21000,
27400,
14500,
20000,
19800,
27100,
10500,
29800,
57800,
12200,
8300,
23800,
14800,
12800,
28500,
17900,
16600,
16100,
35800,
24000,
62600,
16900,
86700,
33400,
44900,
30900,
20600,
6600,
13600,
43700,
43200,
6500,
25500,
30300,
45500,
null,
5700,
7600,
44000,
32400,
31400,
13300,
null,
13700,
31400,
19700,
15300,
26400,
30100,
48100,
11300,
27200,
12700,
16200,
79500,
35400,
30500,
4000,
8700,
20300,
4600,
null,
9700,
11300,
18900,
73400,
62100,
25300,
35200,
15200,
16900,
null,
11900,
16000,
28500,
null,
17700,
40800,
37900,
73800,
12500,
27700,
52200,
41500,
6300,
62100,
21200,
20600,
14800,
20600,
27400,
63700,
38500,
40300,
23500,
53100,
41700,
18100,
38500,
96300,
28500,
97700,
6800,
31600,
14500,
31700,
78200,
21500,
13100,
52800,
38000,
15100,
28700,
6400,
16800,
23400,
14700,
19000,
21500,
55300,
11900,
17000,
null,
68700,
46800,
22900,
18100,
9000,
56900,
26400,
null,
45000,
9800,
null,
20800,
null,
18400,
30500,
26800,
38400,
12800,
79700,
37000,
null,
null,
21200,
44000,
23800,
25100,
57800,
9700,
null,
26800,
18600,
27000,
14200,
26100,
21500,
90600,
null,
null,
49100,
17300,
9200,
22500,
76400,
32000,
10000,
9400,
20700,
16700,
30800,
null,
22300,
25000,
35600,
4500,
29000,
23000,
11900,
27400,
7000,
90000,
21200,
47400,
12500,
15300,
90300,
36900,
24100,
5100,
7800,
17900,
20500,
9100,
44200,
19700,
15300,
99800,
24600,
18900,
68000,
29000,
59300,
12900,
122400,
33200,
13750,
8100,
27400,
5751,
null,
33800,
15700,
21200,
51500,
53100,
6500,
53000,
20300,
5500,
52000,
null,
20600,
28400,
1700,
11200,
33500,
62000,
36200,
35400,
15200,
9500,
24000,
18300,
null,
24900,
23400,
68800,
28700,
48000,
26800,
35300,
21300,
2700,
48700,
371700,
8900,
5200,
10500,
15900,
8700,
23000,
17700,
16600,
3100,
15600,
13600,
17200,
17300,
21500,
13700,
50200,
25000,
35600,
25400,
49300,
9900,
50000,
50100,
15400,
34100,
13500,
28700,
31800,
null,
35100,
34600,
63400,
60900,
4800,
6750,
50800,
42000,
33000,
15100,
null,
30700,
22800,
20600,
32300,
23300,
60900,
53100,
23700,
22500,
15000,
20600,
25200,
34500,
28300,
76800,
4300,
63300,
25800,
14000,
null,
112900,
20800,
5200,
10300,
38300,
39200,
13700,
15200,
4200,
null,
44500,
3800,
22000,
70900,
42900,
53100,
31500,
36200,
41900,
78000,
21600,
10600,
10000,
32100,
31300,
6900,
12168,
10700,
30500,
188400,
25600,
100600,
34200,
20900,
null,
26400,
12100,
10400,
49600,
10500,
11200,
16400,
16000,
null,
10600,
45000,
12600,
139000,
26200,
17800,
22700,
14000,
12604,
7200,
23900,
8700,
27100,
16800,
7000,
27300,
30100,
6300,
12500,
35800,
null,
19100,
47700,
33900,
13800,
32000,
14300,
24100,
25200,
30800,
6500,
37500,
81000,
null,
19600,
13600,
34500,
null,
16000,
22800,
7500,
4600,
9100,
38700,
8300,
39800,
25100,
19500,
34900,
27000,
24300,
45700,
12500,
43500,
54400,
null,
36070,
5100,
14700,
41100,
18400,
11300,
29500,
50900,
14700,
21000,
63500,
55800,
4300,
35100,
8900,
18300,
16800,
13800,
59000,
18200,
41700,
23000,
28600,
25700,
0,
18100,
3200,
106000,
19300,
13500,
13200,
55300,
52922,
10200,
21800,
23900,
41600,
36300,
53700,
49600,
37500,
10300,
9900,
12000,
33700,
12200,
24800,
27000,
22800,
15300,
51100,
6900,
4500,
12000,
22700,
8000,
28800,
19100,
25000,
26800,
33700,
45500,
11600,
20600,
23800,
null,
122400,
41100,
6100,
null,
71100,
25600,
19700,
null,
51300,
15200,
14900,
33700,
11200,
25600,
74300,
30400,
21800,
20600,
33500,
47300,
43800,
53600,
28600,
31200,
56500,
9400,
10700,
69300,
23200,
71900,
37500,
49200,
26900,
15600,
8000,
41500,
null,
18700,
11500,
48100,
18000,
12900,
7400,
22000,
200100,
29200,
14500,
9300,
48700,
32100,
16700,
52900,
11100,
4500,
17500,
38300,
34500,
58900,
25100,
73525,
58700,
6800,
11500,
null,
15000,
33800,
14900,
null,
15200,
12800,
10500,
95300,
4800,
44400,
12600,
20000,
16500,
23300,
51400,
16950,
23800,
8100,
24900,
29500,
35000,
19800,
52100,
38300,
55500,
14800,
null,
24000,
37000,
45600,
31300,
5300,
26500,
97000,
10500,
27900,
20900,
27500,
null,
29700,
3700,
12840,
6900,
8200,
30000,
35400,
22300,
17600,
20100,
9600,
28000,
21300,
44100,
4800,
null,
35900,
31000,
9000,
10900,
null,
15200,
34600,
23700,
27500,
10400,
18300,
32700,
null,
27900,
25000,
7200,
null,
46900,
9500,
46400,
45000,
13500,
86000,
55700,
45800,
18200,
23800,
270900,
null,
21300,
29400,
9700,
30300,
18600,
29400,
28700,
null,
3700,
null,
22300,
16100,
25400,
29300,
null,
23700,
20400,
23900,
21100,
86700,
26300,
38200,
21500,
8000,
25700,
101900,
10100,
33200,
8500,
15900,
22400,
9100,
26800,
11000,
25100,
7900,
21000,
64600,
18800,
46000,
14600,
22200,
null,
25000,
13400,
7800,
15800,
29200,
39600,
51700,
43000,
27400,
36500,
24300,
62700,
3700,
20000,
27700,
19600,
35400,
18000,
31700,
10200,
17000,
41256,
18300,
52900,
72900,
51800,
11400,
43400,
37100,
15800,
51300,
75700,
20300,
56200,
7000,
13900,
19600,
23800,
52500,
22800,
31900,
null,
23600,
18800,
16400,
20100,
9500,
20200,
37700,
138300,
44405,
80500,
13000,
17300,
20700,
61600,
32000,
7300,
41500,
17700,
25000,
17600,
88300,
19700,
6900,
12900,
33000,
15200,
27100,
27200,
42100,
31700,
43700,
12000,
21500,
null,
76000,
7300,
8900,
97798,
22200,
6100,
37900,
24800,
12000,
48400,
15100,
null,
101100,
21700,
28900,
47900,
null,
41000,
25200,
49000,
32600,
null,
10110,
21200,
5400,
18600,
63400,
null,
11200,
35200,
14400,
19200,
14700,
66600,
56000,
17200,
null,
10200,
24900,
22700,
13200,
null,
27400,
16300,
165300,
35800,
null,
30119,
28042,
22300,
21800,
8500,
21600,
26100,
4300,
30000,
null,
12000,
24300,
4200,
27126,
9000,
35700,
22500,
29400,
10200,
22900,
61400,
15200,
14600,
19100,
37100,
26900,
23300,
18800,
9850,
22300,
7300,
13200,
40400,
111700,
113700,
21500,
36400,
24800,
26600,
25300,
16400,
17800,
14100,
28900,
31100,
4300,
13700,
72100,
33400,
12400,
53200,
14400,
30900,
22100,
15000,
31300,
null,
17000,
7300,
null,
67300,
28900,
8800,
30900,
19100,
17950,
17300,
8500,
null,
17700,
null,
17200,
7600,
24900,
36400,
12200,
32100,
48900,
12000,
20700,
246400,
8900,
31200,
13700,
19800,
30700,
11400,
127800,
14400,
null,
60500,
33600,
60100,
36100,
22200,
7500,
28100,
171600,
null,
19200,
16000,
18700,
11000,
166000,
12300,
51500,
84100,
20600,
17450,
6900,
66800,
34800,
29100,
26900,
68800,
23000,
42000,
21600,
null,
11600,
15100,
19100,
15700,
21700,
6000,
45300,
101500,
26800,
11500,
15300,
16900,
40700,
21200,
4650,
15100,
9900,
3100,
null,
28500,
17100,
33400,
24400,
78924,
36900,
40300,
71800,
40000,
102000,
14000,
29500,
13300,
null,
null,
17500,
17800,
85800,
42900,
null,
14800,
26400,
2900,
49500,
33500,
14500,
16900,
57800,
31100,
26800,
17500,
7000,
20700,
9000,
14300,
58500,
null,
34900,
37700,
52100,
122900,
9000,
null,
13800,
110000,
20500,
null,
null,
16100,
12200,
46400,
57000,
14700,
null,
33800,
38300,
20100,
7300,
23600,
34400,
6700,
80500,
41700,
9700,
10100,
10400,
null,
15500,
null,
30000,
7000,
10900,
12900,
18000,
27100,
18300,
40200,
5700,
34800,
11500,
30150,
64300,
null,
28500,
7100,
9900,
null,
106500,
22000,
20200,
106100,
10400,
37000,
30800,
15700,
21900,
16700,
78100,
20500,
null,
25700,
44900,
50600,
8800,
14000,
11500,
24500,
40800,
59500,
14100,
null,
57500,
null,
33800,
13000,
42800,
25700,
25100,
56600,
12600,
15200,
28800,
129900,
24700,
30300,
25500,
4900,
10800,
null,
61547,
24000,
42600,
17700,
48500,
59300,
42800,
15300,
16600,
11900,
9100,
2900,
60300,
13500,
40000,
38900,
null,
29000,
9900,
20500,
28000,
64000,
34000,
74635,
47900,
22400,
119900,
7100,
49100,
null,
40500,
24700,
22700,
7000,
12200,
18100,
5900,
34400,
86000,
14100,
38000,
72500,
null,
43189,
10010,
25200,
30000,
28700,
8300,
18400,
8700,
9000,
125900,
8700,
6700,
14400,
24300,
97800,
25222,
39200,
null,
22100,
39400,
41300,
17500,
45700,
48700,
15500,
7600,
27600,
25300,
5700,
15709,
21700,
23800,
34700,
10100,
14100,
21400,
69500,
18100,
42200,
28400,
21600,
13100,
14600,
11700,
15000,
6800,
23100,
9200,
17800,
15200,
11900,
21200,
73800,
29100,
25500,
20900,
97900,
25200,
28100,
11800,
10200,
26500,
40000,
16500,
23900,
17400,
null,
14700,
14500,
155700,
27000,
55700,
8300,
9800,
17100,
17700,
43500,
7700,
26900,
28700,
14600,
18700,
66000,
15300,
7900,
24400,
46600,
51500,
69400,
3500,
8700,
27600,
58500,
16900,
14600,
27345,
null,
19900,
29300,
33200,
33000,
15000,
2500,
34600,
17000,
77100,
22100,
32600,
158000,
8300,
20700,
144800,
41500,
24700,
26800,
38900,
22000,
64500,
33500,
35700,
3800,
6400,
18600,
18500,
12300,
21500,
9700,
5200,
13300,
8700,
34600,
114600,
23500,
null,
50000,
43400,
null,
16800,
23200,
8800,
21500,
12000,
10750,
18700,
43500,
26500,
17000,
144800,
22100,
53646,
14100,
26060,
79900,
204100,
43200,
13100,
38400,
null,
34800,
17200,
16300,
46700,
38800,
108100,
50400,
14400,
7100,
22300,
10700,
7000,
40100,
28900,
42400,
68500,
30100,
47100,
7400,
48800,
null,
41700,
4200,
null,
41500,
48000,
null,
13500,
25903,
29000,
6500,
32300,
null,
85700,
75300,
26400,
25400,
38800,
5000,
7400,
73000,
20625,
26600,
26000,
8200,
50800,
24000,
null,
41300,
38300,
null,
32200,
27500,
21400,
119700,
93700,
12700,
35300,
18400,
5100,
10300,
null,
57600,
19000,
17400,
17500,
5800,
54600,
45900,
43000,
19600,
36000,
36700,
21200,
32200,
null,
10800,
28400,
13400,
32400,
null,
133100,
71900,
78500,
12000,
36000,
25300,
19700,
null,
10900,
56200,
11100,
29400,
5800,
49700,
10600,
37300,
5900,
3000,
19600,
24000,
15400,
45300,
23300,
71100,
10800,
84500,
16900,
14800,
17300,
12600,
17700,
37700,
10300,
15000,
44800,
99200,
18700,
18200,
14800,
15800,
66247,
49900,
28300,
88100,
40000,
null,
16300,
53300,
13200,
15000,
12950,
null,
14400,
7900,
13500,
33700,
40600,
29000,
30000,
5100,
11500,
10800,
11500,
14700,
57400,
50900,
13000,
29800,
50700,
25167,
27800,
199200,
12300,
268100,
39900,
24200,
19700,
null,
66400,
14500,
13800,
19800,
45200,
9800,
67900,
52350,
28800,
15400,
19300,
22700,
26300,
62900,
44700,
54400,
8650,
56500,
7500,
28700,
37474,
39000,
9000,
10700,
21100,
17000,
41700,
null,
12300,
61800,
28200,
33000,
16700,
37600,
23000,
75500,
13400,
14000,
19000,
20000,
9000,
118850,
31200,
64800,
30400,
33800,
122400,
15600,
13400,
41700,
95100,
39100,
32000,
27300,
5700,
16300,
39300,
10600,
12000,
25800,
24500,
41900,
53000,
12000,
18600,
2800,
null,
43500,
21300,
43700,
44800,
12050,
21500,
10700,
35000,
9000,
28000,
51200,
43900,
27000,
35400,
35600,
null,
52500,
49500,
26900,
26300,
7000,
8200,
34000,
5700,
46900,
17500,
71000,
111100,
null,
39500,
34300,
62200,
51400,
18400,
19900,
40100,
66400,
68200,
37000,
30700,
40400,
12000,
35200,
44800,
5500,
22800,
13500,
57500,
24400,
null,
13000,
43400,
38000,
72500,
12900,
20500,
3000,
15300,
null,
54700,
43100,
25100,
17800,
22300,
13600,
7700,
8600,
null,
null,
13300,
12200,
3300,
37200,
11600,
17900,
32300,
31500,
25000,
92500,
2300,
9200,
34000,
55850,
34400,
33240,
31300,
15900,
23500,
43200,
26400,
26600,
23600,
null,
null,
12300,
12300,
9100,
20500,
16300,
39400,
1200,
8100,
42100,
10800,
25800,
19500,
20000,
23600,
24700,
24500,
65143,
58100,
14900,
null,
82800,
null,
52300,
38800,
42600,
110100,
null,
43500,
8600,
48000,
158300,
10000,
13800,
80100,
42800,
36500,
17600,
25700,
6000,
5100,
23300,
89600,
23600,
25500,
48290,
14600,
15300,
21600,
40900,
63100,
36400,
21200,
8100,
33800,
22500,
150160,
12100,
null,
61500,
27200,
62300,
20800,
47600,
22600,
13600,
49100,
25700,
9800,
6300,
14000,
23200,
20000,
26100,
18900,
43400,
18100,
27800,
36700,
60000,
39900,
62400,
25400,
24100,
3700,
27200,
9800,
12900,
17600,
14000,
12750,
19000,
11700,
28900,
null,
9900,
30500,
23800,
77100,
8100,
null,
19400,
90008,
11800,
22300,
6300,
69900,
73700,
36300,
null,
42700,
35400,
53800,
10500,
54300,
12100,
17800,
46400,
10800,
17200,
33900,
33400,
66500,
null,
36800,
49500,
10800,
25100,
34000,
48200,
6000,
29800,
14900,
22500,
43600,
12300,
56300,
9900,
40900,
25200,
28744,
24500,
34300,
2600,
16200,
5000,
29500,
null,
13200,
77400,
15500,
87600,
22900,
18100,
35000,
53600,
5500,
null,
18000,
6100,
13430,
14700,
22500,
13400,
44600,
7600,
29400,
111700,
10200,
83300,
17200,
22300,
39400,
9700,
58800,
40700,
11500,
14300,
769000,
60400,
14500,
64200,
26500,
null,
20800,
33900,
16400,
23100,
6800,
3100,
23100,
14800,
13900,
15100,
11500,
102700,
17100,
31600,
133400,
21200,
78200,
28428,
null,
9400,
73300,
29500,
91200,
18500,
8500,
36300,
87000,
32000,
143000,
null,
29300,
47300,
69100,
16400,
40700,
11200,
274560,
7800,
31100,
6400,
38400,
26700,
33800,
16400,
null,
18200,
17400,
17100,
6100,
5600,
21500,
20100,
11300,
117900,
18700,
12500,
null,
null,
null,
74400,
23400,
15800,
42900,
28200,
60900,
11500,
76244,
114100,
26600,
25000,
7200,
117900,
50300,
7500,
5500,
47200,
66000,
20800,
26800,
7700,
16700,
16200,
27200,
15500,
6000,
7500,
30800,
10500,
22500,
81200,
13000,
19700,
11200,
23000,
13200,
128400,
12000,
23600,
8800,
34800,
47888,
24500,
30800,
14600,
49600,
8900,
11300,
32600,
41500,
31600,
80300,
null,
37800,
50600,
34500,
5900,
46300,
4500,
23600,
4300,
null,
80500,
29900,
16200,
33200,
null,
24700,
10900,
21200,
30200,
9500,
16100,
44100,
42996,
16100,
null,
68500,
20100,
18400,
6700,
184200,
42600,
59100,
24100,
7200,
15900,
33800,
3100,
17200,
45800,
20600,
13300,
5900,
null,
9400,
null,
75200,
14400,
86300,
24500,
null,
39500,
null,
73815,
65700,
20800,
38200,
25900,
10400,
154700,
null,
51400,
61400,
38900,
48600,
5510,
24800,
14200,
17700,
15500,
40400,
14000,
30700,
46800,
64100,
35600,
5400,
59900,
16700,
45300,
43000,
21800,
41600,
48900,
11900,
11600,
50900,
37200,
50800,
16900,
51600,
77200,
28200,
374500,
11900,
22500,
21700,
15000,
28050,
52400,
5100,
86500,
18400,
10200,
13600,
null,
36700,
38300,
28400,
10600,
19700,
24600,
25800,
null,
70700,
7400,
29300,
7900,
58500,
null,
17000,
13500,
27600,
11600,
25700,
48800,
89000,
24200,
21400,
30500,
39200,
null,
32400,
38800,
122300,
12600,
14000,
7400,
32300,
17400,
49400,
128500,
64700,
8600,
38200,
55000,
38700,
10900,
44200,
27400,
4900,
41500,
16100,
null,
5200,
null,
26800,
3000,
46300,
25700,
24200,
22600,
32900,
12000,
33800,
5100,
52700,
40100,
109400,
11500,
12000,
39200,
null,
null,
16650,
16600,
3000,
42000,
1600,
27100,
38800,
17100,
16500,
80500,
29000,
39500,
27500,
49600,
21600,
57700,
null,
500,
48500,
17500,
18100,
34100,
10200,
28500,
41100,
56400,
4000,
8000,
67200,
40100,
11100,
21200,
43100,
23400,
14300,
8400,
6500,
32700,
20200,
22100,
23200,
36400,
13800,
30100,
27500,
null,
32800,
9500,
7200,
175700,
15200,
null,
5100,
41400,
10300,
null,
null,
3800,
17000,
1300,
14800,
10800,
6500,
56100,
93600,
106800,
66600,
77200,
23410,
null,
30600,
123900,
null,
12300,
34500,
52300,
61200,
7400,
83600,
13500,
24500,
9100,
8900,
13000,
50500,
14800,
null,
9000,
null,
17300,
10100,
69500,
9730,
73500,
19000,
8600,
61500,
20500,
null,
30300,
10400,
37700,
null,
40200,
null,
7000,
12300,
31400,
11500,
25500,
13200,
19600,
44400,
10500,
23700,
60000,
45400,
24800,
51500,
21800,
15800,
10400,
28200,
null,
32200,
59500,
8200,
17200,
51000,
null,
19700,
81300,
5500,
7600,
47300,
8400,
12800,
22500,
27200,
21200,
null,
23400,
44900,
21700,
22100,
56400,
10000,
38500,
100500,
32900,
22200,
16300,
9300,
21400,
30500,
5500,
63500,
35500,
17600,
46400,
20600,
30200,
35400,
33400,
7400,
15800,
17300,
27800,
24500,
10100,
39700,
13700,
21600,
30600,
7400,
45400,
13400,
12200,
16600,
null,
21000,
15600,
46900,
29000,
9200,
46000,
18400,
19600,
27900,
31900,
63600,
11200,
48700,
36300,
23900,
52600,
4900,
11500,
14900,
64300,
71700,
25100,
19700,
10200,
10600,
9300,
83000,
14000,
null,
9800,
65100,
9100,
30500,
44800,
21400,
11100,
6300,
null,
23700,
19200,
15600,
32800,
19900,
81900,
8400,
32200,
null,
7000,
51400,
12800,
14800,
null,
21300,
74100,
null,
10300,
null,
17700,
79100,
6100,
19500,
7400,
39900,
8800,
18400,
51400,
37000,
41100,
24100,
34600,
38200,
8400,
28200,
5900,
23800,
14000,
55900,
58100,
23200,
58000,
117400,
43100,
31800,
29500,
null,
17600,
30100,
29800,
11000,
63500,
47500,
14000,
16000,
30500,
10800,
21300,
9800,
19900,
29800,
12500,
null,
null,
11500,
7800,
20500,
47600,
25600,
66600,
12100,
null,
6200,
8700,
6000,
22200,
27100,
50300,
44700,
19000,
13700,
36500,
10100,
13200,
54800,
11100,
28600,
63100,
54600,
8400,
28800,
34900,
16800,
44400,
200500,
7500,
28600,
27300,
41200,
9400,
15600,
24600,
90100,
9200,
32700,
120700,
22100,
10400,
26200,
null,
null,
33100,
26000,
13100,
99300,
30000,
22000,
27200,
27400,
27900,
24500,
49800,
14300,
35500,
17500,
65800,
10500,
18200,
7800,
41700,
47800,
7300,
9500,
12000,
26900,
38500,
34200,
4600,
11000,
18100,
18400,
24100,
5200,
17500,
36200,
67000,
6000,
38300,
53300,
null,
18000,
37600,
31400,
21600,
25300,
15700,
8000,
108800,
56800,
8500,
14200,
20300,
26000,
30100,
9900,
21300,
30300,
6000,
7000,
13100,
5500,
9800,
6000,
53047,
42100,
9200,
41200,
18100,
3500,
11400,
26600,
4300,
23600,
20800,
12300,
30600,
28600,
16800,
40100,
62300,
20100,
46900,
10100,
15500,
51300,
11400,
5700,
23900,
14800,
41889,
14100,
26600,
156300,
55500,
4800,
34600,
6700,
9200,
97900,
9400,
53464,
20700,
7100,
8600,
21300,
12800,
31900,
19200,
9800,
22600,
33600,
6700,
50300,
29700,
18070,
7000,
null,
15800,
37200,
11300,
22800,
9700,
21600,
11700,
37400,
7500,
16500,
12500,
31800,
23000,
16800,
17800,
57600,
50300,
51400,
46000,
24400,
34500,
37700,
19500,
19600,
null,
51700,
23700,
32600,
null,
32900,
114300,
17000,
42350,
19300,
null,
8000,
54200,
37400,
null,
null,
11200,
33700,
24300,
null,
70400,
29300,
29800,
34400,
6900,
13000,
null,
29800,
23500,
56900,
8700,
8500,
8100,
3500,
102700,
22300,
7900,
137600,
null,
20500,
44000,
12700,
63300,
70300,
59400,
7800,
18100,
65300,
6500,
25800,
29300,
16900,
34500,
13100,
11400,
13900,
4100,
18900,
31100,
36000,
9300,
28300,
23300,
null,
null,
18600,
14800,
9600,
11100,
25700,
4300,
47400,
52100,
33100,
57400,
47200,
48700,
22800,
6600,
17300,
20100,
42500,
84200,
17500,
60000,
46600,
28600,
33800,
24300,
8700,
79200,
6200,
30300,
7000,
149500,
45100,
21200,
29400,
null,
31400,
21200,
7000,
25600,
8000,
32500,
38200,
10800,
10600,
34700,
8100,
103500,
9000,
37200,
20000,
28100,
30400,
12500,
5300,
null,
30500,
7400,
16000,
25200,
22400,
28800,
28800,
13900,
124100,
18200,
8800,
43800,
3100,
30000,
38137,
23200,
null,
22400,
33900,
32900,
39300,
89745,
23900,
80900,
15000,
4600,
30600,
24900,
25900,
9500,
12800,
32800,
51200,
null,
52400,
16900,
22700,
31800,
32800,
8600,
31500,
21200,
18300,
62800,
7000,
null,
37400,
48900,
33700,
22000,
3200,
15700,
19100,
47000,
38500,
16100,
24500,
20900,
9200,
51500,
46600,
44300,
53500,
19000,
18500,
36700,
16700,
15600,
59800,
9900,
25700,
15800,
4200,
51400,
5100,
28900,
35800,
21000,
4300,
33800,
92800,
29800,
null,
57300,
null,
null,
12700,
67200,
36900,
40900,
17200,
31900,
null,
40038,
32400,
13300,
28000,
5800,
34318,
84315,
10200,
10100,
15800,
21000,
7100,
21900,
10700,
26300,
56300,
null,
18200,
null,
9400,
null,
15400,
42850,
17400,
26500,
null,
15900,
null,
33000,
20900,
18900,
21600,
29600,
30800,
37900,
5100,
21500,
29400,
10000,
29000,
7200,
35200,
30100,
null,
54340,
10700,
5800,
19300,
17100,
8100,
78600,
43900,
13000,
69500,
9900,
67400,
null,
15000,
41600,
41200,
24900,
40300,
14300,
null,
53000,
6200,
16200,
39000,
25900,
17700,
13800,
94700,
33000,
9700,
50800,
23900,
17000,
39600,
43900,
16500,
null,
15900,
27600,
6300,
34700,
21700,
16400,
8000,
32300,
82200,
20800,
7600,
42400,
74500,
24300,
77500,
15500,
21800,
43100,
201800,
96000,
3250,
53200,
null,
3700,
17800,
46900,
28500,
51100,
null,
15600,
9200,
null,
78900,
null,
130400,
166100,
90300,
44100,
93100,
40700,
18300,
39600,
30900,
20600,
118400,
null,
3300,
34200,
null,
18800,
16400,
57500,
25300,
23800,
24000,
29117,
6300,
16800,
16500,
13900,
20100,
19000,
53000,
29000,
4500,
33800,
76800,
64700,
18100,
18700,
15300,
36300,
68400,
null,
126300,
29800,
67300,
20100,
36200,
49700,
54700,
null,
19300,
64200,
7500,
86700,
12600,
60700,
20200,
null,
23900,
6700,
102200,
5100,
39000,
21300,
69400,
17700,
13000,
null,
40500,
20500,
20200,
23700,
12000,
72400,
24900,
13100,
11400,
66500,
13700,
13300,
86600,
41300,
21600,
13800,
16900,
14500,
5300,
17100,
90100,
10100,
21500,
33000,
9900,
null,
33100,
33000,
9200,
38400,
null,
29950,
222600,
43300,
58300,
21500,
18000,
null,
11550,
null,
36700,
20200,
9300,
20300,
18400,
null,
7900,
13693,
12900,
19500,
31600,
34300,
7500,
9700,
11000,
49600,
101800,
6000,
23700,
52900,
25900,
25898,
null,
29200,
8400,
16400,
33600,
null,
null,
17300,
22400,
16100,
7100,
21800,
24100,
20900,
42000,
36800,
26200,
null,
8700,
15300,
null,
11700,
41700,
7800,
17500,
9600,
14000,
null,
35200,
11500,
36900,
6600,
16700,
13200,
74200,
15100,
16600,
21200,
11900,
39900,
10000,
65300,
50400,
18100,
8300,
null,
11400,
null,
20800,
12500,
49500,
8500,
49600,
10500,
25300,
18000,
5600,
null,
57400,
null,
64800,
9415,
23400,
28900,
38562,
45600,
45900,
15600,
null,
null,
5300,
30500,
124200,
99500,
8450,
11900,
11850,
8100,
26100,
26000,
43500,
null,
127300,
14100,
56400,
39000,
16500,
18100,
null,
10600,
54900,
41700,
132000,
7700,
13300,
null,
null,
100400,
72600,
11800,
13700,
42700,
null,
16100,
40900,
24800,
10500,
20500,
17300,
38000,
25900,
15700,
14300,
35400,
null,
20000,
30400,
23500,
112700,
14500,
6400,
18900,
25800,
33500,
50000,
38000,
2950,
17800,
1200,
34900,
20700,
48800,
30700,
77700,
25200,
44500,
9600,
19600,
null,
67600,
51800,
67200,
55300,
52900,
40300,
79100,
20300,
7950,
30600,
13500,
20500,
3900,
12900,
13300,
7500,
47800,
12400,
28400,
28700,
31400,
26300,
48500,
11200,
48100,
16500,
4500,
88750,
38300,
18100,
8200,
24300,
21900,
16000,
114500,
null,
null,
38000,
21600,
34800,
48000,
null,
47600,
8800,
null,
null,
31900,
20600,
30900,
40500,
37900,
null,
6700,
37400,
8300,
5700,
15600,
15317,
15000,
36800,
47000,
42200,
19500,
55600,
null,
9700,
33700,
99400,
6000,
1700,
41800,
15200,
12500,
null,
26700,
7800,
62900,
38296,
12900,
118200,
25400,
27100,
8100,
24400,
18300,
6800,
22000,
29174,
112900,
12900,
36000,
23000,
null,
52700,
58700,
12500,
null,
null,
19700,
10400,
31800,
16300,
6800,
23500,
49100,
8000,
15500,
18300,
43100,
9353,
8000,
113500,
51700,
27200,
5200,
26000,
28100,
25000,
30600,
44300,
15900,
8200,
27300,
63500,
13000,
null,
null,
23100,
null,
28100,
6000,
22000,
18300,
6000,
17500,
20400,
8200,
42400,
51100,
11200,
12800,
null,
8300,
14800,
54400,
13700,
34300,
9000,
27500,
26700,
32500,
8100,
12700,
49200,
19700,
8900,
null,
112000,
44400,
17000,
22800,
45000,
61600,
24400,
20000,
57000,
22500,
5600,
18000,
22200,
258700,
49900,
15600,
25700,
14900,
41500,
18800,
18700,
null,
29900,
24900,
16800,
12900,
27200,
null,
null,
60300,
15800,
null,
2600,
35300,
23400,
42300,
24000,
34400,
2100,
2700,
3390,
16700,
54300,
null,
3600,
33100,
25200,
57700,
28000,
4000,
47600,
null,
19800,
17700,
43300,
4500,
22200,
34000,
26400,
24400,
12100,
35700,
20000,
46200,
14800,
6400,
19600,
29100,
110700,
12300,
null,
11300,
33200,
11200,
38700,
11900,
26300,
26400,
35800,
71100,
26100,
180800,
17700,
28200,
62700,
12500,
34900,
15100,
45100,
42900,
29300,
15500,
13200,
36800,
11000,
15100,
33700,
4375,
28500,
12600,
null,
47400,
10500,
25450,
12700,
21000,
11400,
125800,
28900,
10450,
39600,
19500,
30900,
49900,
34400,
27500,
29100,
76300,
53400,
13800,
47000,
109100,
9245,
193700,
null,
10800,
17600,
7000,
32800,
18800,
40700,
89400,
5200,
null,
7800,
33200,
16100,
14350,
47700,
24600,
33200,
10900,
25400,
128400,
74300,
null,
15900,
7600,
26200,
14400,
55900,
27200,
20600,
9500,
24200,
44700,
42200,
32200,
37100,
7150,
14600,
12300,
29400,
8500,
27700,
28900,
18300,
43700,
105100,
null,
36800,
29900,
30200,
8300,
34000,
43600,
45100,
90100,
181600,
5800,
20300,
18400,
44500,
25600,
23500,
10100,
18000,
5000,
10400,
6200,
24100,
25300,
39000,
22000,
10700,
13600,
23300,
49800,
11700,
16400,
95800,
29100,
null,
31500,
28400,
17700,
39600,
5400,
33900,
25200,
23600,
13200,
600,
null,
20600,
36450,
null,
37700,
34000,
22200,
143500,
29000,
41900,
16700,
9300,
50600,
5900,
53400,
51455,
46000,
55400,
31400,
77900,
156900,
56800,
19200,
242400,
2000,
20200,
null,
44501,
21800,
33300,
27500,
40200,
null,
64400,
11200,
45200,
14000,
101500,
37700,
11000,
40900,
25500,
41500,
null,
54800,
42459,
36900,
67700,
124000,
19400,
36600,
23000,
14700,
75300,
21800,
30600,
13400,
9400,
15600,
3100,
91100,
17500,
68100,
8000,
29500,
31200,
54484,
12300,
38900,
9300,
78400,
22600,
24100,
20250,
null,
7850,
11800,
19900,
10800,
7000,
30700,
25700,
32000,
63200,
14900,
null,
49600,
9100,
158600,
12600,
43800,
28600,
19400,
21600,
14900,
64300,
6500,
10500,
4500,
null,
22600,
36700,
55400,
5300,
8600,
30600,
null,
11100,
15800,
30000,
51000,
31700,
110900,
22200,
38200,
17800,
42400,
null,
37400,
82500,
36000,
25000,
14600,
37400,
7800,
42100,
51300,
6300,
5400,
110800,
10700,
42500,
71400,
11700,
29676,
22900,
13350,
27700,
11460,
78700,
30000,
5000,
17000,
24200,
17000,
10600,
16700,
6200,
14600,
19300,
39100,
14100,
3600,
86800,
76100,
22100,
8800,
17800,
11500,
36600,
41700,
12200,
48122,
7200,
null,
34000,
110200,
13500,
23800,
17000,
64900,
5400,
14400,
13000,
17300,
34300,
18900,
32500,
34400,
4600,
58300,
194600,
22300,
43000,
13500,
12900,
81600,
10100,
4800,
9300,
null,
19500,
5700,
18100,
null,
40400,
27700,
66700,
26400,
60500,
4000,
19800,
171400,
28200,
26500,
126500,
14100,
41300,
27100,
null,
31600,
6000,
24700,
19300,
null,
76300,
31900,
52800,
22800,
38800,
36800,
14400,
16300,
23100,
55310,
8400,
9100,
8800,
31800,
21000,
18700,
55500,
10900,
112400,
43600,
18600,
23700,
23600,
18200,
14300,
8800,
null,
39700,
8600,
79500,
18400,
20400,
11500,
45000,
14900,
23400,
16400,
43400,
80900,
128900,
50500,
16000,
57800,
5500,
5400,
15100,
63400,
27200,
13000,
42300,
39600,
16700,
4900,
35300,
null,
14800,
45500,
34300,
36600,
5700,
114900,
6700,
null,
40500,
23100,
26100,
54800,
36800,
37200,
38800,
49700,
64171,
5400,
12500,
30500,
21100,
21100,
9400,
2300,
12400,
4200,
null,
27200,
40300,
37100,
33550,
30300,
18200,
28000,
55400,
11400,
77900,
40200,
22200,
54600,
13500,
43300,
48100,
22600,
38900,
13100,
null,
11500,
12400,
60100,
39700,
18500,
51000,
10900,
21700,
61000,
36100,
34400,
30100,
26100,
38800,
11700,
23000,
8900,
null,
229700,
53300,
null,
14300,
null,
16100,
19900,
43500,
50000,
21800,
21400,
30900,
23900,
81800,
15000,
23600,
5500,
111900,
24400,
57000,
8400,
65000,
21100,
63000,
18800,
12100,
206200,
14700,
69000,
32800,
31300,
null,
28700,
7860,
101767,
130900,
16100,
28810,
22400,
23800,
null,
6700,
23500,
6800,
14400,
11800,
3300,
22700,
16600,
74400,
11600,
32300,
46200,
22900,
19000,
null,
25800,
38100,
2800,
10400,
24700,
26200,
17800,
15500,
34700,
null,
48800,
80500,
30200,
88700,
44800,
9600,
null,
47300,
3500,
29000,
41300,
2500,
28300,
20400,
25700,
78000,
20500,
55500,
36100,
50358,
18400,
13500,
9200,
32000,
20700,
3160,
18000,
51800,
23300,
23000,
15586,
17000,
58200,
5050,
null,
48100,
42400,
null,
17700,
15900,
29000,
62000,
144800,
52658,
12100,
30800,
30700,
22500,
20700,
47700,
10700,
null,
12300,
24800,
23800,
25200,
17200,
32300,
4600,
13700,
58500,
52300,
27500,
9200,
18800,
10800,
56000,
28000,
9100,
53700,
32300,
12100,
10200,
24300,
42100,
53500,
22700,
60600,
156800,
24400,
21100,
16300,
48400,
28800,
16400,
42500,
186100,
51000,
17500,
20300,
9000,
23900,
null,
3500,
1000,
12000,
22400,
27600,
17600,
4800,
25000,
8500,
5300,
28100,
13900,
17700,
24700,
12900,
18800,
29100,
9500,
55700,
53800,
21349,
85400,
19900,
39100,
65000,
31000,
9000,
null,
43100,
16200,
60000,
13800,
15300,
49300,
8900,
null,
43200,
null,
64900,
28400,
29600,
8100,
16000,
7200,
10200,
31300,
11900,
39000,
4300,
33500,
25400,
null,
53900,
61900,
null,
null,
19600,
25200,
32400,
null,
14094,
37600,
13800,
60300,
26500,
16800,
45300,
10600,
61500,
97800,
47500,
14400,
9900,
68000,
5800,
51200,
17000,
71700,
37900,
10200,
null,
null,
19400,
44300,
12100,
null,
125400,
9600,
29500,
8000,
null,
21350,
124043,
null,
49800,
21300,
null,
69600,
201900,
null,
165500,
null,
20700,
15700,
58600,
50800,
14600,
13800,
9100,
37500,
16000,
81500,
9600,
22800,
23800,
41700,
50500,
83100,
9700,
36741,
21100,
9500,
27100,
14500,
80600,
null,
7950,
24900,
41800,
27404,
6900,
4500,
20000,
35000,
80200,
30900,
36800,
null,
101700,
16300,
12600,
7100,
50200,
19700,
17508,
95500,
32200,
9200,
44100,
30300,
28400,
32300,
41200,
53400,
26300,
15300,
11600,
15700,
28900,
47500,
25400,
26250,
4900,
99400,
39700,
null,
36200,
35000,
38800,
60487,
20000,
84500,
21600,
22500,
64600,
13500,
13100,
56900,
10200,
6200,
63400,
102300,
125800,
21400,
14400,
17500,
6669,
35600,
59250,
null,
null,
17300,
40700,
16700,
10800,
47400,
17700,
257200,
12200,
24000,
57200,
33700,
12700,
23800,
null,
30400,
50800,
24500,
21800,
182100,
86200,
51500,
23000,
29000,
25300,
11600,
17500,
null,
22200,
10900,
null,
32500,
48100,
null,
49000,
21700,
9100,
7900,
6900,
34100,
10900,
6000,
68400,
43200,
16300,
null,
34200,
71100,
null,
4200,
21700,
15800,
16160,
14000,
21400,
17700,
7900,
null,
57000,
45500,
41500,
16700,
29000,
33000,
4100,
45100,
46500,
34500,
39200,
291100,
19600,
95000,
20300,
48200,
10700,
21600,
13600,
1700,
13100,
15600,
6000,
76900,
12700,
27600,
63500,
56900,
16400,
57362,
52300,
32000,
null,
18400,
13300,
22000,
21300,
10500,
15800,
49900,
38200,
47400,
105500,
7700,
7100,
13900,
42700,
28700,
93400,
49800,
4200,
79200,
17400,
25200,
18794,
32100,
null,
null,
null,
38400,
95100,
29400,
16900,
28500,
53200,
27500,
53700,
36500,
42200,
34800,
38100,
26400,
null,
35000,
14800,
18800,
20900,
31200,
45600,
13900,
19300,
21700,
37000,
13300,
18600,
20100,
18500,
45900,
null,
7100,
31600,
null,
46400,
37100,
10500,
18900,
70600,
42700,
61700,
10200,
64100,
13500,
5100,
14000,
7800,
17900,
21200,
56700,
9800,
27800,
28200,
null,
40300,
42000,
105300,
11200,
28200,
33800,
34000,
25500,
28100,
10500,
76000,
26500,
6900,
33500,
22100,
14700,
40700,
38900,
29600,
27700,
12900,
21700,
39700,
409600,
96400,
35800,
62600,
39200,
19875,
67100,
2300,
1000,
32600,
24100,
19000,
7250,
54400,
86100,
13900,
8100,
14800,
48800,
8600,
36100,
42400,
null,
16700,
25000,
32700,
30900,
46100,
null,
5000,
5300,
62600,
9600,
14600,
6000,
12200,
57900,
19400,
37900,
27100,
8400,
18600,
18100,
56400,
10700,
21200,
22200,
37900,
20052,
5100,
77600,
52800,
18900,
63600,
53800,
19400,
21200,
34100,
null,
83400,
11000,
14200,
9800,
6800,
19800,
15500,
8400,
30500,
22700,
21500,
27000,
34700,
13200,
19600,
40300,
21700,
6600,
88500,
null,
4800,
28900,
36000,
13000,
2600,
500,
null,
95700,
12500,
53400,
37700,
7000,
39300,
21900,
32200,
33600,
8900,
12700,
28400,
42500,
23600,
20000,
13300,
57600,
46500,
10800,
23900,
7500,
20600,
6200,
49200,
21600,
8900,
66600,
4800,
29400,
19700,
18800,
30600,
74800,
11700,
3900,
48800,
19500,
29100,
24700,
34300,
64400,
99400,
115000,
6900,
28900,
54200,
21800,
21700,
33800,
28500,
24200,
null,
15900,
4200,
51100,
17200,
30500,
21300,
27900,
56200,
20000,
62500,
9300,
20900,
59100,
67500,
11200,
51600,
44300,
27200,
39700,
6900,
null,
19000,
37300,
36100,
41200,
19900,
78400,
32000,
23700,
8400,
18300,
12800,
38600,
55800,
41600,
16400,
73100,
54600,
11500,
38900,
22000,
null,
27700,
6300,
114800,
10500,
null,
10800,
null,
21800,
29500,
29900,
16900,
16000,
53500,
31900,
58300,
57100,
14800,
26600,
null,
10500,
30300,
9100,
null,
38100,
6000,
17100,
41700,
null,
37200,
16800,
54300,
4500,
17100,
119800,
34750,
18000,
26100,
32200,
52000,
46400,
18900,
10900,
33500,
37500,
5000,
15000,
8400,
27200,
58000,
14300,
7600,
26200,
19600,
13700,
61000,
null,
15200,
68800,
10500,
75000,
27500,
90300,
null,
18600,
41700,
29300,
31900,
17300,
13900,
40700,
41900,
13200,
46700,
26500,
12800,
null,
10000,
23500,
3600,
23600,
4990,
27000,
null,
13350,
23400,
7900,
75600,
24100,
29266,
68300,
20900,
38300,
10500,
14100,
11000,
43000,
16400,
153400,
null,
29700,
11400,
57805,
31800,
71800,
27800,
35000,
23700,
41400,
19900,
52200,
18300,
8700,
null,
17500,
66000,
9700,
8300,
6400,
3000,
17700,
26100,
60200,
28800,
57200,
null,
null,
118960,
22800,
38600,
32800,
6700,
25900,
19967,
40600,
31100,
9600,
43200,
32700,
9800,
26300,
12100,
58660,
93000,
33400,
23900,
24700,
9000,
19000,
null,
36600,
22600,
12300,
62100,
3100,
22200,
57900,
null,
230500,
59700,
10600,
12700,
26400,
7500,
65000,
36300,
14500,
19400,
19800,
null,
75262,
21700,
18400,
44400,
22100,
20224,
31500,
30300,
4500,
21300,
35500,
null,
9800,
65200,
null,
18000,
12300,
6000,
60200,
10100,
8200,
20800,
27800,
10300,
6600,
132600,
22600,
5500,
20600,
35000,
44000,
null,
4600,
27100,
57400,
30900,
26200,
60100,
13900,
37100,
35300,
22500,
36200,
null,
26900,
13800,
28800,
24400,
27300,
null,
16200,
15700,
48900,
10900,
16100,
32100,
28900,
29000,
32000,
34600,
12300,
72900,
1800,
8800,
11200,
6000,
101600,
26700,
12900,
35100,
18000,
6500,
15900,
30000,
16300,
51800,
9400,
18900,
61500,
41900,
null,
71900,
38800,
32200,
32300,
35800,
38600,
58400,
3900,
8600,
22200,
23200,
29800,
10900,
34800,
null,
22400,
null,
27600,
19100,
55800,
null,
11500,
12000,
38500,
38000,
22900,
23600,
29200,
3500,
null,
31400,
15500,
null,
225300,
18400,
64700,
37400,
16700,
22000,
22700,
null,
10700,
15600,
31600,
7300,
155413,
20500,
29900,
43800,
13400,
23700,
15900,
54900,
62970,
30000,
17690,
16900,
71400,
18300,
1000,
1500,
87900,
60000,
77400,
6600,
7900,
5300,
70900,
null,
17600,
null,
95600,
18600,
8700,
24600,
10000,
14400,
60700,
6500,
18700,
19000,
47900,
41000,
24800,
5000,
7600,
null,
117300,
9400,
22200,
30700,
30900,
5800,
18400,
38000,
null,
35800,
57400,
14200,
48900,
69200,
46400,
16000,
16700,
39000,
33600,
15900,
15800,
157000,
12000,
11400,
24500,
3950,
1850,
15700,
56200,
30700,
31000,
74400,
56000,
45700,
11400,
34200,
5600,
null,
23400,
15300,
74750,
19700,
30300,
25700,
18700,
23300,
17540,
72200,
null,
16400,
6500,
17000,
43600,
20000,
14900,
22300,
21900,
12300,
25600,
69000,
27300,
16000,
18800,
38800,
17600,
21000,
10100,
18800,
9900,
15300,
2700,
30200,
23400,
27700,
10900,
5000,
1500,
3800,
27100,
55000,
19800,
null,
10600,
14900,
16600,
30300,
16400,
76100,
5900,
6900,
25600,
60000,
9800,
null,
31800,
5500,
30000,
39800,
37300,
17300,
11000,
30400,
25300,
22800,
20500,
33400,
1800,
null,
42800,
54200,
19400,
12100,
23900,
13800,
12000,
7500,
17700,
22100,
36400,
null,
51900,
24900,
20800,
21800,
19550,
6200,
47500,
62000,
19700,
28400,
17600,
null,
11500,
37600,
300,
23900,
23900,
19000,
47500,
10100,
31000,
55700,
11000,
51600,
38600,
3400,
36200,
17100,
4900,
8400,
59200,
14900,
143200,
500,
20200,
8800,
38800,
38700,
null,
9700,
null,
17000,
30900,
23900,
24800,
21600,
10000,
24000,
13900,
38100,
22600,
15900,
15900,
33100,
null,
20700,
78500,
53800,
26200,
null,
19200,
57200,
10400,
19900,
10900,
37800,
53200,
15600,
13500,
26800,
13800,
null,
9800,
4400,
39900,
15400,
10200,
12800,
45000,
14350,
10300,
41200,
17000,
14400,
null,
32500,
11000,
35700,
null,
19500,
9400,
21000,
34000,
null,
9800,
15900,
31900,
39100,
34100,
24900,
8400,
6700,
48700,
40300,
10700,
7600,
40300,
85500,
29100,
21300,
64800,
42800,
33100,
23200,
18800,
18500,
4500,
40500,
79100,
1300,
19500,
14100,
13400,
43500,
41500,
null,
81200,
75800,
null,
30800,
21600,
38700,
7000,
19700,
10900,
37900,
23700,
33500,
31700,
18600,
34000,
18400,
25200,
19400,
null,
39500,
28000,
67000,
35200,
43100,
null,
21700,
null,
19600,
76500,
12500,
18500,
26500,
26600,
2800,
27500,
17500,
9900,
49200,
13800,
35500,
15200,
null,
22400,
50800,
8800,
5600,
116100,
26900,
22700,
17600,
19500,
13400,
27300,
16836,
12600,
null,
59800,
13600,
22100,
5700,
28500,
120200,
null,
null,
18500,
null,
28800,
null,
150657,
7818,
17400,
71600,
9500,
21200,
67300,
null,
40200,
18900,
15000,
245000,
17510,
26900,
30700,
52700,
15400,
4000,
21800,
16100,
111800,
34100,
86000,
97500,
22800,
11900,
9500,
14400,
15700,
25200,
37600,
40450,
132500,
16400,
34400,
null,
43700,
7600,
39500,
13400,
7800,
26100,
18500,
13100,
81900,
null,
94400,
42400,
18600,
54000,
16600,
4000,
50600,
22700,
23000,
50600,
38100,
57700,
16700,
null,
27200,
28200,
49800,
13200,
6600,
10000,
60000,
292600,
3800,
11700,
78000,
28700,
83400,
3800,
21400,
52261,
211100,
13800,
22900,
null,
null,
32800,
37600,
22400,
40700,
21300,
39200,
8500,
16600,
33600,
9000,
28300,
33400,
102400,
null,
null,
22400,
21700,
34800,
null,
40000,
28900,
37000,
null,
5700,
43500,
20500,
51800,
20600,
43500,
17400,
27700,
40650,
21140,
51100,
70000,
33000,
33000,
30000,
8700,
49700,
36500,
79400,
7100,
53500,
83700,
24500,
8800,
15800,
20000,
46200,
31800,
49100,
7900,
9200,
18500,
5800,
56700,
8100,
17600,
null,
32900,
8800,
39000,
null,
8700,
12800,
8900,
17900,
19000,
24500,
73800,
31000,
15300,
31900,
30400,
22100,
10600,
72700,
15500,
24400,
39000,
18900,
30700,
39200,
103200,
13100,
42700,
28500,
28500,
12300,
50800,
46600,
12300,
22400,
41500,
12600,
16800,
36100,
6600,
23600,
67500,
32600,
44900,
19400,
38300,
null,
37700,
155000,
null,
null,
null,
13600,
null,
18900,
17800,
null,
60300,
8600,
10000,
6100,
16400,
10300,
17700,
24300,
null,
27500,
null,
53500,
16100,
10100,
10500,
30900,
44200,
51600,
52000,
10700,
65200,
8700,
3500,
42800,
60000,
null,
25800,
14900,
15500,
22900,
4600,
21600,
24500,
5600,
11100,
8700,
32077,
13600,
24600,
10600,
7400,
15900,
39300,
9500,
25700,
118400,
4400,
null,
12900,
9200,
13200,
37000,
30000,
25400,
42000,
18700,
88300,
46300,
19800,
13800,
30500,
27200,
72900,
38800,
37900,
37400,
15800,
13200,
42480,
null,
null,
null,
12000,
12700,
8500,
25000,
18600,
7300,
38200,
65600,
46000,
16000,
16300,
14400,
null,
16100,
64200,
7100,
10000,
7700,
26700,
33500,
9800,
67500,
59100,
121825,
38300,
43016,
9630,
16800,
100700,
null,
17300,
22800,
25800,
26300,
41800,
5000,
null,
29300,
30300,
10400,
37000,
93600,
41200,
28700,
40100,
107330,
19900,
11800,
6100,
45600,
16600,
3900,
23200,
10100,
11500,
56800,
28600,
49100,
22700,
20700,
23000,
163574,
19900,
15600,
5300,
11400,
34700,
43400,
3800,
14300,
9100,
74300,
null,
null,
82100,
19200,
40800,
25300,
65200,
65400,
29900,
13800,
37900,
35000,
13400,
10935,
87000,
27500,
8550,
40400,
41600,
38300,
18500,
128600,
21200,
null,
6800,
77300,
70700,
73900,
3900,
14900,
25800,
63600,
27200,
18200,
49200,
94800,
22200,
25300,
50300,
6900,
31900,
10000,
7300,
16800,
22600,
39200,
36300,
132400,
48400,
60300,
21000,
40300,
10900,
16700,
60200,
null,
59300,
9600,
39300,
49700,
31900,
26000,
12400,
37400,
15400,
10600,
20000,
30100,
12100,
16900,
37700,
35400,
35100,
34600,
1000,
5900,
17200,
6000,
9700,
83500,
33900,
null,
9600,
24500,
null,
12000,
32600,
12900,
33100,
39300,
10800,
38100,
37700,
44300,
23300,
15200,
4900,
null,
20400,
18400,
4700,
31500,
26800,
14200,
45100,
43000,
null,
12400,
11975,
null,
39700,
35000,
48000,
20900,
16000,
21900,
50200,
26443,
39700,
10900,
238500,
9700,
34400,
20600,
61700,
18900,
148300,
22100,
31500,
null,
11500,
18200,
25600,
13300,
13200,
38400,
19200,
47500,
57000,
21500,
null,
10800,
null,
49300,
37500,
6300,
16100,
25800,
39200,
9200,
33100,
13600,
null,
3300,
16600,
22080,
22100,
19200,
48900,
19700,
39000,
8000,
6300,
24700,
36300,
43300,
68400,
7900,
null,
22500,
null,
38400,
20100,
46200,
null,
105100,
14100,
70511,
null,
2600,
null,
109300,
59300,
null,
null,
21900,
27900,
13500,
14700,
31500,
23500,
null,
3400,
11000,
36100,
25400,
23200,
null,
63600,
19100,
32400,
37600,
54200,
67200,
33100,
8100,
64200,
null,
8100,
26100,
35300,
14800,
null,
10100,
null,
null,
88700,
null,
null,
19500,
8100,
5200,
null,
16600,
32200,
25300,
31000,
null,
23200,
9000,
14800,
6100,
18650,
6500,
2200,
null,
37700,
21300,
9300,
26800,
50800,
18800,
null,
51400,
20300,
15550,
19500,
6320,
12300,
30100,
null,
53100,
111300,
11600,
25700,
57200,
8200,
11400,
18900,
null,
53700,
22700,
18274,
null,
null,
24600,
23200,
16100,
23500,
19700,
51670,
22500,
63800,
42500,
46800,
null,
43400,
null,
50100,
5400,
11000,
9500,
15500,
4400,
18100,
20800,
71700,
26400,
33600,
7600,
57300,
18000,
24800,
69685,
10600,
15700,
7150,
90900,
8200,
18100,
23400,
31000,
33000,
12200,
30000,
58600,
14600,
40100,
52800,
34000,
38200,
17800,
9150,
16600,
17000,
22200,
55700,
66700,
11700,
28200,
47400,
19200,
30900,
42500,
6100,
null,
55300,
22300,
21600,
22700,
13900,
16500,
32800,
13200,
22700,
6400,
3250,
34100,
61800,
19400,
75474,
null,
4800,
40200,
17400,
36700,
47100,
7500,
56100,
28700,
32500,
58000,
105800,
27000,
17300,
33000,
10800,
15800,
52500,
7400,
7100,
60500,
44500,
34200,
45600,
9400,
40400,
null,
23500,
27200,
124900,
3500,
42800,
9300,
null,
8500,
80100,
23300,
10500,
13500,
51600,
25400,
55000,
19300,
63200,
9000,
15700,
62600,
26700,
34400,
42600,
36700,
12900,
5900,
9900,
3600,
8600,
null,
32400,
41200,
38500,
71800,
28600,
4500,
13800,
29200,
8200,
37000,
23600,
null,
26400,
10900,
13400,
10200,
18700,
57100,
65600,
16800,
66900,
56400,
null,
67200,
17700,
23100,
61400,
89800,
121600,
20900,
19600,
10000,
39100,
41100,
62600,
260000,
72700,
16695,
14900,
27700,
35400,
9500,
54000,
59800,
205200,
39300,
87700,
35300,
17000,
11500,
118100,
292300,
null,
55300,
28300,
2900,
null,
8300,
32750,
34600,
28800,
51400,
17750,
4400,
14200,
23800,
66200,
10600,
70300,
17600,
31300,
36600,
30200,
8000,
39000,
5100,
12300,
null,
38500,
34200,
36300,
109600,
48050,
41900,
27200,
7500,
13900,
9400,
25800,
30900,
66100,
6900,
20900,
45400,
30800,
31200,
30400,
38800,
34000,
16700,
6800,
52900,
48700,
null,
35600,
21000,
27100,
25600,
45100,
15900,
21600,
13000,
7600,
62000,
30300,
5600,
67600,
8300,
57800,
31500,
41800,
6100,
17200,
null,
30900,
27300,
25100,
29800,
57100,
74800,
122500,
37000,
45900,
23300,
28600,
22400,
14400,
12800,
50800,
18800,
17300,
16300,
20800,
19300,
null,
16700,
25200,
13000,
25000,
23900,
23300,
42600,
18500,
9300,
25800,
53100,
4000,
12100,
3500,
35800,
44000,
7500,
13000,
17200,
null,
12400,
24200,
3800,
36400,
27700,
13500,
7200,
82900,
23900,
39100,
11000,
26700,
48800,
74200,
26300,
16900,
5000,
12100,
null,
6000,
79059,
27700,
20600,
5800,
15500,
30700,
22900,
33600,
19200,
28600,
22000,
14200,
51300,
12150,
19100,
10000,
19700,
16000,
25300,
50800,
47400,
15000,
7200,
21900,
18700,
33800,
24200,
10500,
27100,
null,
8600,
129815,
67600,
17500,
39300,
13800,
11800,
96500,
36000,
27500,
18800,
81600,
15850,
34400,
35400,
100500,
33500,
29300,
18100,
35500,
42000,
13500,
10500,
8100,
95400,
28000,
53200,
33400,
15500,
69500,
36200,
19200,
78153,
128800,
9600,
16700,
20100,
null,
15100,
29200,
40900,
4400,
201600,
13300,
35100,
22600,
52800,
42400,
5800,
22800,
43500,
4800,
90848,
43500,
23300,
23100,
null,
36200,
10100,
372000,
9900,
16200,
14000,
8200,
9000,
28500,
12400,
8800,
null,
22900,
34100,
22000,
15100,
null,
12100,
39600,
18700,
7200,
50800,
4000,
14600,
15200,
17100,
32600,
5800,
8100,
25098,
24400,
null,
36600,
29000,
4500,
26400,
11900,
28300,
41400,
8300,
9900,
null,
71400,
95500,
22700,
13600,
59600,
20100,
22300,
8300,
null,
55700,
33700,
58200,
22700,
54800,
20000,
25200,
22600,
3400,
40500,
46400,
null,
13500,
38400,
11900,
18000,
19200,
27000,
42800,
71900,
62300,
70600,
7400,
15800,
27000,
5700,
22000,
88600,
5500,
3000,
6800,
240598,
15600,
29000,
7400,
37700,
16000,
14800,
17300,
9800,
20400,
12900,
null,
14800,
null,
27400,
22700,
27000,
64000,
34100,
33500,
57300,
162000,
22100,
22900,
230010,
6900,
12600,
14600,
24900,
16000,
17000,
68900,
20200,
23300,
19400,
17000,
45200,
null,
12800,
35100,
26400,
8900,
14000,
29200,
24500,
19700,
5500,
12500,
42000,
7209,
33400,
59700,
10500,
18100,
28500,
9800,
17200,
44600,
41000,
null,
24600,
14600,
15900,
13300,
58400,
18800,
17400,
34400,
12600,
43800,
9200,
36800,
9800,
18700,
102200,
null,
25450,
15300,
null,
9300,
31800,
41600,
8600,
17000,
46500,
16400,
40100,
null,
7500,
44300,
14700,
8400,
67500,
13900,
28300,
12600,
12200,
72559,
12300,
48600,
49600,
17400,
4000,
null,
6800,
12650,
50800,
5900,
65800,
66400,
12000,
16300,
50200,
3900,
22000,
38800,
16000,
19400,
57900,
17200,
31900,
27500,
24200,
22300,
49100,
58100,
16000,
33800,
6450,
23000,
43100,
30100,
null,
18900,
66000,
286500,
4400,
11900,
42500,
29800,
9600,
26000,
12000,
86400,
20000,
34300,
19100,
44200,
31300,
9600,
22100,
8300,
34800,
47700,
25400,
37400,
29000,
24300,
null,
4200,
70100,
35600,
36600,
7000,
19800,
4200,
10000,
27900,
7100,
66100,
25500,
34300,
90100,
38300,
27600,
39300,
4600,
12300,
null,
138900,
23600,
14500,
32950,
8750,
48200,
14577,
36300,
8500,
50500,
null,
12800,
87600,
null,
45000,
106700,
3000,
29900,
27900,
49000,
21300,
11015,
17000,
37000,
30900,
null,
null,
31800,
32700,
12200,
11000,
20700,
8400,
18200,
37600,
10100,
26400,
23000,
60200,
17000,
18400,
72900,
46200,
24700,
15100,
6300,
17500,
40700,
40900,
23100,
45700,
17200,
39000,
7600,
14500,
92700,
13300,
19600,
29000,
20000,
37500,
19700,
5900,
16240,
null,
28300,
8300,
14900,
16700,
null,
11000,
98501,
71700,
20000,
13600,
9800,
23900,
12700,
28700,
61000,
6100,
56000,
46300,
21100,
47600,
14500,
19300,
94200,
37800,
null,
39200,
20800,
74400,
40300,
22100,
23600,
29200,
null,
53000,
17000,
73149,
21700,
17900,
4900,
48000,
90600,
12000,
32300,
19300,
22400,
24800,
6200,
36600,
42100,
null,
39800,
86700,
38200,
21400,
59357,
9200,
16000,
19700,
20800,
22900,
6100,
1800,
43000,
33200,
null,
28200,
11400,
74600,
43300,
37300,
140000,
17000,
18200,
33200,
45000,
109300,
19500,
38300,
84200,
88900,
17000,
15100,
41431,
13600,
12000,
29000,
47000,
25100,
47800,
39300,
81100,
52900,
null,
14800,
9700,
51000,
11100,
null,
18000,
29300,
null,
61100,
20700,
32700,
24400,
24800,
61500,
46400,
25900,
9800,
109900,
12000,
6300,
44600,
20200,
6500,
13100,
13600,
19800,
58800,
33500,
78600,
13500,
6000,
45100,
12300,
8500,
null,
49900,
61100,
9700,
null,
11400,
null,
14700,
41300,
null,
87900,
69000,
50600,
8300,
38300,
22500,
41800,
25500,
null,
40800,
27600,
14500,
11200,
41500,
6000,
89400,
27700,
32600,
55800,
null,
43900,
43900,
12800,
7300,
17500,
37900,
71100,
35400,
15700,
42200,
6500,
15800,
100300,
15700,
3300,
5900,
13100,
13900,
5000,
71200,
17800,
34300,
18400,
8800,
39800,
59400,
28400,
61900,
7300,
37600,
15000,
83800,
16600,
15200,
null,
16800,
66700,
null,
8500,
null,
12000,
3300,
19900,
44200,
17900,
30000,
22900,
130000,
57800,
2770,
67600,
38500,
33500,
15200,
15400,
21100,
60000,
3700,
8700,
24300,
15400,
39300,
13900,
19700,
23900,
17200,
42500,
40000,
16800,
null,
33200,
30200,
28760,
57400,
41200,
26700,
10300,
23600,
44800,
14900,
null,
24600,
62100,
78500,
17900,
26000,
28800,
18200,
25100,
28400,
49000,
null,
17900,
2600,
75100,
46424,
22000,
12300,
18400,
28100,
7050,
29500,
83600,
12200,
55000,
37300,
6700,
45100,
19400,
44900,
34700,
55600,
50700,
67000,
5900,
44300,
13200,
31100,
8600,
34000,
84300,
13300,
null,
14500,
17300,
18200,
45900,
12900,
10700,
38800,
93700,
null,
61400,
12000,
45700,
101600,
7900,
56900,
13900,
12500,
7400,
71000,
21000,
48100,
9800,
15600,
53800,
34800,
147200,
27900,
null,
47500,
30400,
13900,
26000,
null,
23700,
39900,
33300,
9900,
14400,
78300,
24100,
11100,
21500,
12400,
24800,
16900,
null,
19200,
null,
133500,
22400,
11700,
38500,
13200,
56700,
23800,
30500,
7000,
48500,
35600,
32500,
32000,
66100,
23900,
16300,
17800,
12900,
15100,
72900,
26700,
12800,
68608,
43800,
13800,
51700,
17300,
20000,
null,
50700,
8500,
null,
null,
30500,
13800,
37400,
49300,
11600,
133000,
null,
15300,
46400,
26800,
59000,
22800,
22400,
null,
13900,
4600,
33200,
null,
57000,
21800,
30200,
39200,
15700,
18900,
74500,
8500,
3500,
50300,
23300,
7500,
15100,
8700,
70700,
13900,
11100,
null,
null,
15600,
82000,
28900,
5400,
29400,
null,
44000,
82500,
20700,
27100,
15900,
11500,
21100,
null,
19300,
27900,
11300,
12900,
16400,
66300,
54400,
11700,
17500,
null,
21900,
34800,
20700,
73000,
40300,
13800,
72500,
null,
33100,
31900,
21900,
15200,
7900,
19700,
21600,
13700,
16500,
25300,
7800,
29500,
14600,
39000,
56300,
19100,
18200,
33600,
16100,
37300,
7500,
31700,
9900,
21800,
null,
null,
22100,
9300,
24600,
100900,
15800,
7400,
11200,
9400,
7600,
25200,
15900,
6200,
25900,
36500,
25800,
95200,
null,
40100,
17000,
null,
26000,
44300,
29100,
27800,
47400,
19900,
14700,
16000,
15100,
32550,
74900,
75900,
null,
48400,
38400,
12600,
32000,
70000,
21500,
45300,
35800,
16600,
27000,
12800,
4500,
14200,
18495,
7500,
59100,
41900,
49100,
12600,
15800,
11700,
76400,
16700,
23600,
30700,
13800,
46600,
42400,
42300,
31200,
2300,
18700,
47900,
33900,
32806,
52800,
30900,
15000,
18500,
45200,
null,
12000,
30400,
null,
41600,
29400,
124400,
19000,
6500,
29700,
14700,
9700,
66100,
6600,
10400,
10500,
null,
26000,
28000,
18900,
43200,
9500,
70000,
54400,
12100,
null,
33200,
27100,
26800,
18500,
66500,
32000,
39900,
14600,
25000,
6000,
20100,
34800,
84900,
28800,
26400,
7500,
19300,
48700,
41200,
17000,
28700,
6700,
30700,
53600,
6000,
66400,
13700,
14600,
31400,
31800,
null,
20400,
45844,
null,
31674,
20100,
12500,
230800,
21700,
43300,
14800,
18800,
28400,
32900,
19100,
68100,
36000,
40800,
null,
52700,
24500,
56800,
29700,
40000,
32800,
36900,
23545,
32700,
10400,
34700,
49200,
null,
35600,
18500,
19200,
13000,
14200,
28200,
45400,
24900,
19400,
33000,
35000,
24200,
16400,
19900,
11200,
11100,
25500,
15800,
46800,
10600,
7600,
32200,
12100,
85200,
3900,
21700,
41900,
15100,
11200,
14300,
109400,
19100,
22000,
19700,
6200,
10917,
53700,
22000,
16000,
42200,
10900,
22100,
12000,
4700,
20100,
8200,
69800,
26100,
12300,
45500,
66600,
46900,
75800,
12500,
30000,
59800,
null,
20300,
45000,
15600,
43000,
31300,
14500,
27200,
99600,
44900,
19000,
null,
11000,
67800,
18500,
16000,
33600,
5800,
6800,
40900,
16700,
11000,
17200,
7300,
20500,
22100,
39800,
16200,
19700,
16100,
7400,
14100,
15600,
22800,
25900,
19500,
null,
19200,
15600,
12800,
29200,
17000,
54900,
18300,
23600,
12800,
37600,
12700,
11500,
15800,
13900,
46200,
7300,
5900,
37300,
12100,
47800,
8500,
16500,
13100,
10700,
17100,
600,
14900,
13100,
null,
57000,
16300,
20100,
22000,
39100,
24000,
12900,
62100,
22900,
null,
27600,
null,
14100,
5300,
28000,
23300,
33200,
27000,
22800,
78600,
13800,
31700,
7300,
16800,
10600,
38000,
23800,
3300,
null,
71900,
15600,
21800,
25900,
19700,
9700,
12300,
41700,
12700,
27770,
7800,
14000,
45500,
16500,
25600,
77000,
null,
15300,
13400,
18300,
null,
13700,
78800,
43000,
16200,
34960,
17400,
null,
4400,
125300,
39000,
11700,
28400,
1600,
212400,
19400,
123691,
50100,
44300,
18900,
30600,
31200,
21000,
4700,
797,
11000,
33600,
11600,
20500,
14000,
48600,
5600,
22000,
31800,
16400,
8000,
10700,
20400,
16400,
13400,
18100,
60000,
10300,
16300,
23700,
10200,
20800,
29500,
19300,
5200,
35800,
12600,
31400,
71300,
6100,
18900,
13100,
23500,
24400,
11900,
9200,
6700,
16100,
null,
6000,
16700,
97500,
35600,
20000,
null,
55100,
29000,
null,
25000,
12000,
null,
10800,
11800,
33000,
null,
13700,
11200,
10400,
null,
61300,
14100,
10200,
25400,
20600,
null,
162100,
8100,
9900,
19500,
44800,
10700,
10000,
43300,
26400,
14100,
26700,
45600,
38500,
16900,
18500,
216800,
26100,
81740,
null,
19100,
193800,
5300,
12500,
16700,
16300,
41000,
83000,
31100,
16300,
18300,
16100,
null,
33000,
48400,
27400,
34200,
34000,
27900,
16000,
13300,
7700,
8900,
33800,
19100,
27600,
30300,
20200,
null,
42100,
69500,
13700,
158500,
57400,
20100,
37900,
17900,
35800,
53200,
48600,
11200,
4000,
35500,
23500,
12400,
41500,
22700,
18200,
4900,
10200,
47700,
9600,
37800,
13600,
4704,
21000,
17800,
25300,
73800,
26300,
17300,
24600,
15300,
32000,
3300,
24800,
20300,
6200,
24600,
6000,
14900,
11500,
79000,
7900,
66900,
47600,
3300,
43500,
60400,
null,
37900,
66825,
65700,
31400,
65100,
33400,
18600,
18600,
15400,
27800,
108400,
30100,
null,
8700,
38300,
87800,
52200,
15600,
null,
18250,
19800,
58700,
19300,
31800,
21850,
null,
26500,
10300,
8200,
32100,
46000,
42000,
33200,
11300,
18900,
37900,
55800,
22600,
15751,
12300,
52700,
25300,
13600,
25000,
18600,
92700,
26800,
32900,
19900,
16000,
7600,
29000,
36100,
27800,
4500,
null,
52100,
51600,
29200,
6900,
25700,
16000,
50300,
15900,
14100,
5300,
42800,
13600,
40800,
20600,
7200,
227600,
13900,
null,
null,
1800,
31000,
10900,
224150,
144400,
25700,
11600,
12600,
16700,
19200,
17500,
27400,
18100,
null,
null,
61800,
25900,
null,
10500,
65900,
null,
18800,
42400,
43100,
64900,
28700,
null,
59554,
40700,
22800,
66900,
null,
null,
5500,
45700,
16600,
52500,
23900,
31500,
65700,
4400,
9400,
48850,
73400,
131400,
30600,
20000,
59600,
18200,
17700,
16300,
20875,
42912,
16200,
12400,
25200,
2800,
45278,
54900,
18300,
null,
30300,
20100,
103600,
42200,
47400,
11000,
null,
43700,
34200,
13200,
35900,
32000,
5500,
32800,
11200,
17300,
7900,
null,
6300,
16600,
16800,
78700,
150200,
24200,
11300,
19000,
17800,
90693,
54200,
54300,
37400,
9500,
null,
null,
28800,
53600,
15800,
23600,
36800,
15100,
31500,
null,
20000,
10000,
11100,
22500,
37500,
55600,
7700,
7800,
85800,
22100,
23300,
null,
17200,
42200,
30500,
36500,
23500,
61300,
36168,
17300,
633200,
14100,
38100,
15100,
22300,
53100,
17700,
null,
23400,
17700,
8300,
5700,
13500,
6500,
41400,
39800,
13100,
7700,
13000,
19000,
26200,
8300,
40200,
31900,
null,
56595,
21000,
38800,
8000,
13000,
4000,
9600,
63500,
74000,
31600,
55123,
33000,
80200,
84500,
19900,
8000,
34400,
62000,
30700,
18800,
19000,
42900,
300500,
79700,
15500,
14500,
35500,
38200,
20700,
11300,
20000,
16400,
7300,
12000,
2800,
26900,
25700,
11400,
50000,
22450,
5300,
56400,
null,
null,
14600,
7600,
12300,
71000,
49600,
16700,
null,
68481,
41000,
25500,
13400,
45000,
13600,
17200,
99200,
9600,
7400,
9100,
26300,
11700,
33900,
18500,
21900,
66200,
20500,
25200,
7200,
131100,
23000,
29400,
34500,
117000,
11600,
8100,
8300,
4500,
15500,
47300,
49600,
23300,
47400,
30500,
67600,
25100,
33000,
null,
36000,
35600,
23700,
35400,
21700,
10100,
null,
16900,
25700,
38600,
25500,
23200,
null,
7750,
75030,
15000,
34600,
10500,
13300,
6500,
10600,
44500,
50200,
23200,
64000,
14600,
19900,
83900,
45300,
6400,
null,
17000,
17000,
13100,
81700,
3900,
27700,
34000,
15600,
null,
18300,
null,
17200,
19500,
15000,
6400,
null,
15900,
15200,
13200,
26000,
23700,
85300,
31200,
10300,
17500,
32500,
30900,
41800,
40900,
17600,
29400,
36500,
22900,
35600,
70200,
32500,
41800,
21100,
36000,
8000,
null,
6500,
162800,
9500,
22700,
2900,
36100,
34100,
34700,
11300,
7500,
90300,
18200,
28300,
28300,
7900,
16200,
14000,
44700,
13100,
34400,
17600,
246200,
21300,
47400,
17300,
10100,
24200,
null,
87500,
30000,
null,
33000,
73900,
null,
32300,
8100,
65500,
27800,
null,
9000,
27000,
null,
12500,
100700,
25700,
14500,
null,
14300,
24500,
32100,
25500,
76800,
22100,
43000,
6950,
11700,
29600,
6800,
4000,
null,
9900,
58600,
16600,
104300,
21100,
8100,
10900,
201500,
24000,
51000,
null,
101300,
59900,
79400,
18200,
5700,
null,
8000,
8000,
61500,
9300,
52700,
21100,
44200,
7600,
15000,
7200,
98300,
39400,
17400,
84100,
null,
17100,
3800,
46235,
10033,
18000,
25500,
4000,
11000,
null,
27200,
49300,
50200,
7000,
11700,
14800,
18400,
23500,
15400,
19800,
9000,
21400,
39900,
16800,
37000,
null,
26700,
null,
6000,
15000,
11700,
31300,
33400,
20100,
58600,
34200,
33400,
21300,
51300,
4500,
6000,
15700,
37800,
9200,
13600,
null,
19800,
6450,
39600,
null,
null,
28100,
9400,
64000,
29000,
42200,
39800,
39300,
93500,
33400,
13600,
46600,
5500,
40500,
8100,
15100,
29600,
56600,
47100,
48600,
20100,
8200,
41300,
32000,
11400,
26600,
14700,
null,
26700,
20200,
39400,
21000,
47900,
13300,
19900,
17700,
36500,
23500,
3500,
9800,
10400,
9800,
13700,
49800,
21400,
19000,
20000,
20900,
4100,
30900,
65800,
40300,
109900,
92900,
41700,
11300,
15200,
5900,
30500,
28800,
18400,
50000,
null,
21700,
25000,
13500,
13700,
34700,
62500,
null,
64600,
0,
117800,
24700,
22000,
31100,
20100,
19800,
37500,
9700,
37400,
43000,
10600,
21099,
44800,
36200,
27800,
28200,
21000,
null,
29400,
19900,
14100,
null,
15700,
29000,
13248,
25240,
88000,
6800,
15900,
169518,
32900,
46800,
23200,
21300,
54400,
42000,
57500,
10500,
116000,
112900,
74600,
50700,
53200,
28800,
null,
20600,
26500,
23500,
38000,
42900,
11000,
45100,
19700,
30000,
26000,
48900,
89600,
108400,
34100,
9500,
28000,
17700,
20000,
47800,
null,
65000,
null,
53500,
18900,
null,
23500,
38000,
91500,
29500,
3100,
67800,
13900,
21100,
16900,
163700,
16000,
26900,
8200,
12900,
30800,
19300,
8900,
39700,
47700,
208800,
11900,
24600,
33100,
13400,
28600,
26100,
17400,
6800,
44100,
57100,
26400,
22192,
8100,
24200,
17500,
53000,
36000,
44500,
29800,
32800,
null,
12600,
14500,
12000,
25900,
28600,
43200,
74800,
14500,
14100,
4100,
23000,
7000,
38400,
14100,
12200,
9200,
29700,
32400,
16900,
29900,
20500,
61900,
73500,
29100,
24000,
null,
25400,
84200,
19400,
55500,
36300,
23100,
91900,
81000,
31600,
19800,
40400,
11200,
17000,
11600,
null,
14600,
99800,
44100,
34300,
20000,
9200,
21200,
10200,
null,
7600,
52400,
48900,
8640,
53200,
17400,
25700,
null,
38000,
64300,
24300,
36500,
17400,
24600,
22900,
22500,
19100,
13900,
15700,
20500,
14600,
118700,
61700,
33100,
28100,
10600,
6600,
20100,
14200,
15700,
15600,
61000,
23600,
31900,
21200,
33200,
null,
null,
17300,
27300,
16700,
32100,
39000,
21600,
17800,
5200,
6400,
28600,
19300,
29300,
7100,
25100,
52500,
19300,
30900,
47200,
50200,
43300,
326700,
72000,
10300,
14500,
12400,
10000,
56000,
19000,
20200,
null,
11800,
null,
15000,
29200,
10900,
34100,
15500,
null,
62100,
14300,
30200,
7800,
22100,
58200,
35800,
20300,
53900,
49000,
35700,
23500,
28100,
23400,
31700,
13300,
65800,
67200,
39500,
35700,
16000,
6600,
null,
20800,
29300,
23500,
18100,
11000,
33700,
null,
9000,
46600,
6500,
17500,
null,
23000,
9000,
11700,
null,
8600,
10000,
4000,
16600,
33500,
47701,
33900,
19300,
29500,
13000,
21200,
31200,
25500,
19300,
8100,
7500,
6600,
23600,
23100,
24700,
4600,
17950,
7100,
11700,
27900,
12100,
46200,
27400,
17300,
13300,
17700,
6400,
28900,
90600,
58200,
11200,
16500,
21400,
29200,
18100,
80000,
267900,
40400,
4000,
12000,
74600,
99700,
22900,
13200,
null,
88600,
null,
33500,
23000,
20100,
63000,
13900,
22000,
47300,
9100,
13000,
42500,
90100,
38200,
36700,
null,
26100,
51100,
39500,
12200,
43700,
5600,
null,
2500,
6900,
5600,
18600,
7200,
21000,
11100,
26000,
16800,
31300,
null,
null,
null,
null,
16700,
9000,
17800,
19600,
16000,
27300,
7400,
22300,
37900,
27600,
19900,
null,
16300,
58900,
32500,
7500,
26000,
62207,
60600,
26800,
41500,
32600,
null,
38800,
1500,
30900,
23900,
40200,
22300,
null,
56700,
6000,
78500,
31200,
53300,
40400,
58905,
48500,
53800,
3200,
14500,
16100,
11300,
9250,
18600,
46100,
7200,
66600,
null,
5900,
15000,
null,
44600,
40964,
35000,
null,
60500,
11200,
8800,
80800,
50300,
null,
47600,
63600,
27900,
10800,
11800,
11000,
22000,
14400,
null,
4100,
8200,
18300,
17800,
15400,
null,
81700,
132500,
13800,
35800,
30300,
41700,
9000,
48100,
12400,
8000,
16300,
30200,
5900,
34100,
20700,
5400,
14000,
3600,
null,
7200,
63700,
6900,
12700,
15300,
87800,
11800,
73300,
30400,
23500,
61800,
73840,
14400,
34200,
4100,
22500,
20000,
7900,
29900,
24300,
2400,
1700,
23900,
20600,
16800,
11800,
18425,
6200,
32900,
8600,
51300,
74500,
14600,
178100,
null,
69200,
24700,
7600,
13800,
54900,
22300,
13500,
29500,
10200,
11200,
12000,
20100,
54200,
27800,
58600,
39300,
null,
25000,
14500,
2200,
32800,
19400,
7900,
59500,
18500,
28100,
12900,
49300,
18000,
9200,
45400,
10900,
16000,
null,
51900,
38000,
27700,
39000,
6900,
16100,
56400,
19700,
12100,
8800,
43300,
null,
13500,
34800,
6400,
null,
33900,
21200,
47000,
34000,
6800,
8400,
40100,
19000,
16500,
3500,
40400,
null,
17500,
39000,
100200,
53000,
23800,
36800,
69200,
48100,
9600,
9575,
18000,
6200,
null,
14500,
4400,
42400,
40700,
12500,
32000,
25900,
12800,
45900,
16400,
9800,
72600,
35800,
17500,
13300,
44600,
58500,
21400,
28000,
40900,
51900,
64200,
30700,
25400,
null,
20300,
21500,
19500,
50100,
null,
13800,
18600,
26900,
25200,
14300,
15200,
11500,
23400,
11400,
25300,
23000,
12500,
null,
63100,
19300,
33600,
16300,
null,
13500,
14700,
19200,
152400,
22100,
26700,
6100,
31700,
41900,
32600,
13800,
null,
36200,
2800,
8700,
19300,
47700,
5500,
35600,
23700,
null,
47500,
21900,
26000,
24500,
10100,
20700,
15700,
35100,
130209,
43600,
22100,
24400,
6800,
18500,
23600,
null,
66700,
150900,
34400,
54500,
36700,
79800,
18200,
38000,
16000,
null,
66100,
43100,
53300,
15700,
23950,
32100,
44400,
18200,
null,
null,
56400,
174600,
1100,
37000,
34700,
62700,
40800,
34900,
33100,
8700,
40600,
21100,
24300,
25100,
27100,
12600,
28900,
7800,
19100,
55700,
6100,
11500,
45119,
67400,
26700,
25900,
38200,
12500,
26100,
73300,
22000,
9700,
12000,
12700,
41100,
11200,
9000,
35300,
30600,
36400,
28900,
32500,
12300,
74700,
16100,
61000,
50800,
5700,
36600,
24200,
12100,
8100,
17800,
5400,
5900,
42700,
20600,
28500,
null,
27100,
59900,
13300,
12100,
16500,
94400,
null,
30600,
9600,
11300,
72400,
29400,
10900,
15100,
17300,
10100,
49000,
68700,
93400,
17300,
36600,
21700,
36700,
37900,
27600,
38700,
58600,
18200,
6700,
11100,
25700,
29100,
141100,
4000,
null,
66900,
9100,
0,
56700,
null,
null,
28900,
19100,
39700,
40700,
53400,
null,
18100,
25500,
6700,
25200,
23300,
39300,
13500,
16200,
14500,
68200,
23600,
41700,
36900,
31900,
47600,
14300,
22800,
16600,
58600,
25100,
null,
19300,
12100,
62600,
29500,
56400,
5900,
30200,
87100,
20100,
null,
15900,
37100,
42000,
76200,
null,
12400,
165500,
15300,
33100,
21300,
11900,
6600,
69500,
31800,
13900,
null,
78500,
21600,
11300,
null,
16500,
37800,
58250,
53300,
6500,
9100,
35200,
31700,
11600,
5500,
54300,
53600,
14400,
14400,
6300,
25600,
4800,
9600,
52500,
104474,
17300,
61200,
23300,
null,
19000,
18800,
27800,
38700,
null,
20000,
null,
13900,
14300,
44700,
20700,
64000,
17400,
39600,
43800,
9300,
11200,
41300,
15100,
44600,
8600,
11200,
23600,
16100,
40500,
75500,
5400,
38700,
800,
23100,
14000,
30800,
16300,
56900,
31500,
14800,
35400,
68800,
6700,
24200,
41200,
null,
29000,
44500,
17600,
76200,
10100,
7800,
14600,
33300,
24500,
19700,
40600,
37300,
64900,
38500,
13500,
16000,
28800,
31500,
18400,
5100,
null,
32800,
null,
45800,
null,
49400,
18000,
33600,
29900,
35600,
13100,
33500,
16700,
142500,
11900,
null,
null,
11400,
16800,
35400,
34900,
47000,
57100,
14000,
14400,
57500,
30600,
6600,
46200,
12900,
112500,
null,
11300,
15700,
67900,
113300,
32100,
46400,
30700,
49100,
22800,
74600,
19200,
144900,
59200,
2900,
73100,
null,
51700,
72100,
29200,
15800,
22800,
31600,
35500,
63800,
17100,
21600,
45800,
15600,
22900,
5000,
68200,
20900,
37500,
8800,
null,
8300,
44703,
12300,
12000,
20000,
48300,
47500,
23100,
25900,
7000,
77500,
10900,
14000,
47400,
32500,
26700,
38700,
21800,
79700,
16000,
41940,
23000,
77800,
16900,
16900,
17700,
20400,
7000,
41900,
8900,
22500,
null,
9492,
24600,
25300,
12500,
36600,
44900,
78500,
53383,
29100,
7900,
22000,
65900,
15100,
33700,
14600,
57300,
null,
45600,
null,
17300,
null,
26500,
null,
38400,
8600,
42700,
240700,
26700,
32520,
70800,
57700,
15600,
12780,
36200,
null,
null,
5800,
22000,
21500,
33200,
40700,
99000,
27900,
null,
30300,
37700,
12200,
75700,
65700,
19900,
30200,
22800,
4200,
23400,
32200,
79100,
28700,
37900,
25600,
24400,
189300,
7100,
5000,
11400,
30500,
29100,
79600,
47200,
20500,
26100,
17200,
16400,
43600,
21400,
13700,
10050,
37000,
48200,
20100,
41000,
12000,
5900,
null,
14300,
18500,
null,
null,
59900,
17450,
45300,
17000,
19800,
23000,
21400,
26400,
126500,
28700,
6500,
40000,
7700,
6600,
500,
27700,
44300,
14100,
27000,
9000,
24500,
120400,
46610,
7400,
16100,
6300,
81500,
15500,
28200,
39000,
34500,
9600,
null,
42000,
16600,
17500,
null,
13300,
16200,
10300,
19600,
39600,
10000,
15700,
63400,
18500,
37500,
25400,
19300,
null,
14000,
39700,
29500,
13600,
40500,
29000,
16700,
23700,
20800,
78700,
29400,
23600,
12600,
7000,
22800,
25400,
10400,
17200,
33100,
13000,
19400,
14100,
null,
52000,
56100,
1500,
27300,
32200,
3200,
28300,
11900,
74600,
null,
32400,
14400,
53200,
24514,
74600,
13100,
11300,
39400,
2200,
28200,
19000,
34400,
20600,
24700,
31600,
8200,
25500,
56100,
47500,
32400,
39100,
90000,
20300,
null,
27600,
7400,
40300,
115100,
35800,
18900,
30200,
21300,
50400,
7000,
null,
44300,
10200,
204900,
17500,
32000,
24455,
12500,
73900,
65400,
97400,
11400,
37100,
89900,
47200,
null,
47700,
null,
59700,
null,
1500,
52584,
46000,
59600,
16500,
15200,
29700,
10100,
39100,
34200,
14300,
107500,
8900,
19000,
36600,
22400,
18600,
9600,
41400,
73800,
8000,
12900,
33500,
null,
25700,
27800,
28400,
51000,
43300,
35100,
103900,
90100,
31800,
15100,
19700,
42754,
10400,
7100,
17600,
66600,
59500,
null,
16200,
98521,
14500,
10900,
25700,
64800,
30000,
null,
1600,
101400,
5500,
13900,
8300,
19800,
33500,
39280,
20000,
17600,
16900,
20600,
54600,
null,
null,
30100,
11800,
66100,
45300,
38500,
5200,
17900,
6200,
null,
23400,
55700,
null,
149400,
58200,
46900,
16000,
25700,
null,
51500,
40600,
102000,
20600,
26000,
12400,
75683,
13600,
54900,
35200,
25300,
21800,
13300,
32700,
76200,
31100,
29400,
null,
37800,
46100,
31200,
20800,
22810,
26900,
29500,
27600,
51900,
49000,
46100,
127200,
47800,
22500,
63200,
100900,
16200,
18500,
35700,
33600,
70400,
5700,
43600,
39400,
null,
74100,
14800,
null,
22700,
16900,
22800,
16200,
39900,
16100,
43400,
15800,
21400,
10800,
29400,
21500,
53200,
53800,
103000,
30700,
29900,
20500,
21400,
36000,
18500,
21100,
43200,
65800,
24700,
24800,
17800,
102800,
39700,
80600,
33900,
21400,
null,
25200,
46600,
2800,
54000,
95400,
26200,
8000,
34700,
16500,
65300,
367400,
null,
26600,
9600,
10800,
48000,
21000,
44700,
53100,
15000,
14500,
36700,
32900,
19400,
null,
33300,
19100,
678400,
10700,
31400,
8900,
25800,
48600,
9700,
9900,
32900,
20400,
10700,
5800,
91100,
6100,
15400,
1400,
14900,
null,
8600,
30900,
20300,
23400,
6700,
null,
24800,
41600,
null,
17500,
33100,
26100,
10500,
8500,
39300,
29200,
44700,
11600,
50300,
11800,
30500,
30800,
27400,
16000,
59700,
8600,
52400,
41500,
17900,
null,
57000,
22300,
null,
16300,
23400,
18700,
12500,
14300,
22800,
31900,
4250,
22400,
null,
13900,
16100,
64500,
5700,
22800,
28015,
33670,
8400,
14900,
9800,
20000,
27400,
null,
null,
94700,
16900,
37100,
20700,
15700,
32400,
13750,
12200,
54800,
64400,
29100,
null,
16000,
9200,
48700,
21700,
14600,
14000,
45100,
13500,
6600,
12200,
33000,
8300,
37700,
44800,
9500,
102300,
null,
30000,
32071,
116100,
28800,
13700,
null,
63800,
133000,
null,
22600,
34600,
90700,
120900,
22100,
17600,
25000,
68800,
27100,
48500,
15800,
34400,
21500,
40400,
8300,
32900,
32500,
59600,
144300,
10350,
32100,
17500,
57300,
35000,
null,
28000,
27100,
3400,
40400,
15700,
null,
46500,
28397,
42000,
60300,
13300,
10600,
13800,
53300,
11600,
86000,
53400,
19700,
21100,
9600,
17600,
68900,
null,
7400,
9200,
3500,
42700,
26200,
15600,
74600,
4900,
null,
null,
1314900,
33400,
13900,
null,
31000,
59100,
26300,
38100,
23500,
23500,
22900,
27500,
32300,
57900,
null,
17500,
25800,
14100,
17000,
null,
21400,
26000,
43100,
16000,
42600,
33000,
25400,
50900,
112400,
55100,
4400,
19900,
null,
42400,
86300,
45000,
77700,
12900,
null,
12700,
2000,
21400,
17700,
63800,
36900,
null,
49900,
6400,
31100,
8500,
null,
31000,
15200,
10300,
26500,
84800,
40200,
27100,
22300,
25600,
75800,
22000,
7300,
13500,
22700,
70200,
30100,
null,
29600,
35400,
12100,
19700,
38900,
9930,
23500,
21900,
null,
15800,
50300,
13400,
28700,
5800,
31500,
155400,
9600,
8600,
45151,
27400,
70600,
39600,
59260,
35300,
17700,
36100,
null,
10600,
13430,
5500,
26400,
39400,
null,
109800,
8600,
10900,
16200,
79800,
16300,
30100,
40400,
7400,
13000,
80400,
8300,
60700,
2400,
13100,
42000,
4900,
154500,
184185,
23000,
13600,
37600,
67700,
27400,
null,
18800,
6900,
13626,
1200,
null,
18900,
null,
29400,
26600,
null,
90000,
42600,
null,
8400,
24600,
36600,
9800,
25200,
3400,
64600,
15600,
22000,
15600,
14600,
null,
29800,
33600,
49800,
39300,
15000,
null,
2000,
15200,
null,
68400,
40400,
15900,
19500,
12600,
null,
8400,
11900,
21800,
41400,
27836,
27400,
24200,
31100,
11600,
24900,
65400,
9800,
16500,
62552,
47400,
32000,
16400,
11700,
104900,
22200,
15600,
51300,
8500,
20500,
38800,
null,
null,
36000,
37300,
78500,
328800,
17200,
59961,
385880,
76200,
19900,
22800,
60300,
21600,
10800,
14500,
59300,
null,
43700,
7300,
7800,
44400,
43200,
26500,
23400,
45100,
20000,
27032,
13800,
22200,
20200,
null,
11500,
54000,
30100,
11800,
8100,
49808,
5600,
39700,
null,
351000,
74771,
32600,
55200,
null,
19600,
16500,
31600,
22400,
16700,
15000,
13000,
72000,
17500,
24100,
20700,
51400,
50300,
30300,
31600,
9400,
null,
61500,
6000,
52100,
19800,
20700,
51700,
50500,
73600,
12500,
30700,
10700,
26500,
19700,
12700,
22200,
15100,
30200,
29800,
21000,
7200,
19300,
33300,
16500,
49300,
57400,
24300,
11100,
18600,
12400,
null,
null,
14900,
53000,
2500,
23500,
24700,
27100,
23100,
40900,
145900,
1600,
24700,
7200,
47600,
15800,
27200,
6500,
21300,
33300,
21400,
30919,
15000,
53000,
16600,
26300,
44400,
14800,
14000,
29500,
16700,
63000,
38300,
136200,
15500,
51900,
43400,
7300,
271000,
null,
18996,
18600,
13800,
39800,
21089,
8700,
98811,
6600,
82200,
22000,
17600,
8600,
25200,
57200,
36400,
39400,
12100,
42400,
31400,
25700,
27200,
40000,
15900,
15100,
56700,
14700,
15400,
40300,
36700,
12000,
35900,
49300,
31300,
53900,
9400,
null,
51000,
37200,
25600,
55300,
3100,
56100,
20600,
15900,
null,
64900,
30500,
20000,
45300,
null,
38800,
44000,
96000,
55600,
17700,
20400,
77000,
34800,
54700,
15100,
41500,
33900,
15500,
25000,
53000,
21300,
40000,
46200,
5500,
20000,
8600,
94600,
10200,
null,
null,
11400,
38600,
28600,
151900,
103600,
16000,
47200,
32900,
36600,
18700,
69900,
34300,
10700,
32800,
15800,
12500,
34600,
15400,
59500,
17700,
36300,
19300,
72900,
null,
27300,
8100,
22800,
15600,
21600,
17600,
16100,
34200,
28000,
15300,
12200,
48000,
50700,
48000,
null,
20000,
32700,
15600,
9700,
14900,
11400,
17200,
23950,
21900,
18900,
null,
48600,
8200,
11100,
null,
19100,
10800,
23521,
7700,
27800,
29100,
38600,
11200,
73800,
27000,
13200,
23600,
56900,
68114,
null,
26800,
null,
21200,
36300,
50900,
43800,
23300,
19600,
22950,
19800,
22300,
28200,
10200,
66000,
null,
50100,
30600,
null,
9000,
34400,
41200,
58200,
49300,
8300,
24500,
4900,
89400,
69100,
null,
15800,
11900,
23000,
29900,
26500,
6100,
56900,
18900,
21800,
93150,
16900,
13100,
20800,
11500,
null,
21700,
66232,
10800,
39100,
65100,
15500,
15500,
8500,
43500,
9900,
21400,
10300,
41700,
8800,
10900,
36900,
22000,
38000,
32500,
16800,
24400,
12200,
20500,
11700,
9200,
56500,
3000,
32300,
49200,
77000,
6400,
50400,
40800,
15800,
29201,
51000,
22000,
13000,
46500,
37800,
19600,
43500,
10800,
20600,
95300,
24554,
36200,
18800,
65600,
36700,
34100,
4200,
9400,
6900,
42600,
32000,
null,
54900,
30300,
22400,
5100,
25900,
39500,
11100,
47500,
45100,
16700,
53100,
null,
46500,
30100,
37050,
44200,
39700,
45800,
31100,
31500,
23900,
65500,
15000,
17600,
44300,
20700,
36100,
43400,
13600,
27400,
9200,
10200,
38700,
14900,
9500,
59700,
34100,
13600,
22100,
35800,
34600,
17100,
6400,
null,
81062,
57000,
null,
20300,
195600,
38900,
37600,
52300,
null,
55300,
37500,
58100,
62400,
10000,
10300,
34000,
27300,
8000,
20400,
21600,
16200,
34600,
15500,
48861,
37400,
13400,
16000,
32700,
19700,
17700,
25497,
27400,
25001,
54400,
null,
19800,
23500,
32200,
8600,
33603,
67900,
19000,
null,
30500,
16200,
26600,
4400,
4800,
34100,
18900,
25200,
28300,
28200,
31600,
null,
null,
14900,
17300,
17400,
20600,
32600,
23600,
57200,
22000,
34400,
17800,
12100,
14700,
102800,
46000,
36000,
53500,
17000,
9000,
null,
47300,
22200,
30600,
14400,
45000,
12900,
11200,
82900,
14700,
22800,
22860,
82400,
14700,
25500,
40100,
18900,
19500,
15300,
13900,
17800,
34000,
29800,
15200,
53400,
39700,
37300,
16400,
75000,
8900,
24600,
56100,
14200,
52500,
43700,
13300,
36500,
11200,
38900,
13100,
43500,
11200,
54000,
null,
29600,
15900,
24500,
31000,
43300,
45900,
22800,
28300,
30600,
21600,
64700,
24400,
67900,
30300,
33400,
10500,
49900,
7300,
74400,
19000,
35700,
27500,
33400,
32400,
13300,
null,
34000,
null,
4200,
21100,
27000,
11300,
50300,
5500,
19800,
62600,
4700,
13000,
null,
17700,
5700,
122500,
5500,
17400,
19200,
22600,
15800,
22300,
null,
26600,
33200,
12800,
6100,
5400,
42500,
35100,
8700,
13900,
9200,
null,
22300,
39400,
61300,
71300,
12600,
32000,
null,
null,
8000,
28800,
300500,
10200,
44222,
28900,
null,
23500,
19500,
38300,
15000,
19000,
6400,
11200,
47100,
37500,
null,
28000,
32800,
63300,
17900,
20200,
11100,
14700,
18700,
16100,
36800,
15000,
8500,
28800,
13100,
43900,
18500,
12400,
22200,
29600,
18700,
3000,
null,
109500,
42100,
15900,
null,
32000,
40100,
83700,
63100,
null,
null,
15600,
20900,
24600,
29900,
23100,
null,
null,
50200,
32000,
9400,
25000,
15200,
53200,
16300,
5900,
50800,
28400,
35000,
null,
56200,
25100,
52900,
30300,
8900,
null,
37400,
15400,
null,
89900,
15500,
null,
11100,
30800,
57600,
43000,
null,
34500,
24600,
10900,
46200,
85800,
800,
40500,
39800,
15200,
55400,
14700,
40700,
20600,
1000,
15800,
12000,
22100,
18600,
6300,
21100,
57200,
8500,
15800,
54800,
41200,
32400,
39700,
20500,
26000,
17300,
7800,
10600,
101300,
23100,
27800,
36900,
36000,
16000,
109300,
2500,
10300,
11500,
94500,
51000,
97600,
26500,
7000,
45500,
22400,
3000,
null,
5900,
44200,
8500,
10100,
49000,
7200,
31700,
11900,
44900,
37200,
107800,
52000,
6000,
19440,
18200,
8000,
null,
null,
37000,
72400,
3500,
41700,
14500,
112700,
52300,
26400,
36300,
27500,
17600,
36400,
13000,
40100,
18200,
46500,
13200,
6800,
69433,
32500,
null,
11200,
14200,
9900,
38500,
4500,
36200,
28400,
null,
9300,
40400,
24300,
26400,
50300,
31500,
35801,
12800,
23300,
12400,
14600,
29600,
57900,
50000,
46032,
100500,
61800,
null,
33400,
15600,
32800,
82300,
5000,
6500,
18800,
10300,
13800,
23200,
42200,
7700,
5600,
null,
91500,
39500,
8200,
18700,
54501,
7700,
16200,
33400,
null,
10700,
2700,
20600,
13400,
43100,
29100,
null,
8300,
null,
16200,
11800,
56900,
25200,
19000,
13300,
52300,
8100,
22800,
74300,
43600,
null,
9800,
63000,
29600,
19400,
150400,
12700,
27500,
44100,
null,
22100,
14400,
66900,
37700,
38800,
null,
12500,
34700,
50700,
28800,
5000,
92600,
32800,
27000,
18600,
57700,
3200,
null,
17900,
14300,
22700,
14900,
13200,
13000,
8600,
20700,
38400,
83900,
49900,
5900,
24700,
30100,
57178,
27000,
7300,
21300,
17900,
5500,
24400,
29000,
12400,
10000,
7250,
null,
47100,
10400,
44100,
19200,
42800,
20400,
null,
14600,
null,
48100,
15200,
7000,
6300,
26900,
63100,
53900,
13600,
24500,
27800,
66500,
12200,
19900,
28200,
16200,
19200,
19600,
25400,
14700,
116200,
9300,
null,
15900,
11200,
22400,
26800,
3350,
36000,
30000,
42965,
21025,
19700,
24000,
21600,
16700,
15700,
null,
64200,
57700,
5600,
17600,
17700,
20100,
3100,
86800,
18451,
null,
33000,
43200,
15100,
9000,
14800,
12100,
11800,
24200,
24300,
13900,
17600,
23000,
30500,
5400,
10600,
51700,
206449,
null,
17425,
null,
25500,
16500,
null,
76800,
28300,
24900,
64200,
20900,
21500,
32200,
48300,
3800,
38650,
10390,
80200,
null,
12500,
14000,
26500,
3500,
11700,
0,
26100,
26300,
18700,
10200,
9300,
19100,
22400,
18100,
124400,
17900,
28300,
9400,
9700,
7840,
9900,
35800,
50900,
null,
19000,
22100,
41800,
13000,
null,
null,
null,
45900,
10300,
46700,
20300,
12300,
null,
30800,
18200,
17700,
5150,
49300,
15000,
13900,
23100,
46800,
6850,
116700,
26845,
26000,
22300,
20300,
18400,
50200,
7400,
null,
66000,
15200,
21200,
7500,
null,
6400,
3400,
47100,
21600,
34800,
77735,
27200,
25500,
22600,
63000,
null,
32400,
9800,
26900,
41000,
34700,
15300,
10000,
29100,
15400,
53400,
234800,
19700,
21900,
6700,
17400,
null,
null,
null,
19200,
31000,
81300,
64400,
15300,
null,
28100,
null,
21600,
23500,
29300,
33400,
37600,
29900,
5100,
34200,
57200,
61900,
46000,
60500,
15000,
44300,
20500,
16600,
9700,
16000,
null,
22700,
19700,
53700,
88100,
30400,
21500,
102900,
14500,
17000,
68400,
null,
13400,
35700,
10050,
6200,
15100,
41400,
6600,
22500,
56700,
19197,
111700,
116920,
16100,
15300,
26200,
25100,
10424,
23700,
6900,
25800,
5700,
21400,
49200,
12000,
13800,
2100,
7300,
12700,
29000,
30300,
17300,
3100,
267100,
21900,
43300,
11000,
60000,
24900,
30300,
null,
10600,
44800,
19500,
14500,
13600,
45400,
51700,
20100,
4800,
73100,
153800,
26500,
9800,
56900,
70000,
25900,
3500,
13500,
null,
79800,
7500,
18400,
20600,
24000,
12900,
9800,
39700,
49702,
25500,
14100,
25923,
8200,
10100,
13000,
80900,
20900,
6500,
18700,
16900,
20800,
18600,
102400,
52900,
29200,
null,
23500,
23800,
55500,
28100,
61100,
10900,
17500,
67800,
24300,
33600,
44100,
37800,
53200,
null,
16200,
22500,
34500,
162000,
13700,
14800,
26700,
45600,
43500,
null,
31100,
70900,
48400,
44000,
16800,
19600,
45200,
14700,
48100,
26100,
9000,
null,
26000,
15100,
90000,
12100,
28400,
11900,
83800,
20856,
null,
35400,
43100,
3000,
11700,
20100,
38100,
47700,
30400,
56100,
28100,
21900,
50900,
9600,
33200,
40600,
null,
46800,
null,
18400,
11000,
18100,
19500,
22200,
6300,
67100,
53500,
70200,
33800,
5100,
7700,
1000,
37900,
18200,
null,
28100,
59200,
116200,
28800,
132000,
55300,
9300,
56000,
23000,
18600,
29400,
15200,
23900,
145900,
null,
28913,
82500,
2500,
12800,
null,
30800,
46200,
96200,
13750,
48300,
null,
15900,
15100,
309900,
null,
61100,
30800,
12200,
1900,
12200,
146100,
16900,
null,
14800,
25600,
88200,
11400,
54100,
31100,
null,
18800,
15100,
46200,
5100,
38200,
63300,
87373,
14900,
72000,
32200,
10500,
17100,
7600,
25000,
69200,
null,
12100,
20700,
21911,
22900,
49700,
17600,
16200,
11400,
24100,
null,
19900,
13800,
20900,
51500,
20400,
36200,
12100,
35100,
68300,
25800,
12100,
9850,
42100,
13900,
9400,
15500,
16200,
23700,
32600,
21000,
36200,
63700,
43700,
46873,
79300,
103305,
null,
19100,
11700,
47000,
52500,
48400,
132600,
42200,
23500,
25526,
18900,
13000,
28900,
28500,
21300,
18300,
8800,
19100,
27200,
18900,
14300,
42800,
14200,
4600,
25500,
21400,
16800,
28100,
14000,
31600,
123600,
4300,
null,
12100,
28000,
17300,
7300,
67200,
17400,
null,
26900,
8000,
5800,
17300,
37137,
7700,
184050,
24600,
50600,
60500,
16900,
20600,
22300,
27900,
16500,
42700,
62640,
17500,
15750,
8800,
8300,
4500,
11600,
null,
30600,
44900,
27500,
19500,
29600,
61600,
60800,
21900,
54000,
7900,
29300,
26000,
38300,
12600,
null,
34300,
null,
null,
12400,
16900,
55800,
18600,
7900,
22400,
13000,
20400,
40600,
13000,
12400,
42100,
null,
31400,
18000,
75500,
7100,
42300,
11200,
31500,
44400,
17000,
62644,
28700,
17100,
73000,
48400,
18500,
28100,
11200,
21500,
73000,
124750,
23400,
4900,
158100,
16500,
19500,
27800,
9900,
13700,
42100,
9100,
null,
12400,
57100,
56100,
29500,
60500,
60700,
14632,
17600,
null,
52900,
66500,
14900,
38500,
8800,
29200,
34200,
8900,
7700,
25000,
7236,
11000,
47400,
16700,
7800,
40100,
20300,
53620,
35700,
17700,
43300,
86300,
25400,
75100,
null,
165900,
50200,
18100,
8700,
19345,
10000,
35200,
19400,
46500,
74100,
48100,
32500,
55900,
null,
11600,
24600,
12600,
60900,
11000,
35600,
39600,
34400,
20900,
null,
13300,
6300,
15800,
36900,
16500,
41900,
null,
8700,
32800,
null,
29800,
40000,
19400,
27700,
null,
6000,
95400,
193500,
24300,
102100,
45000,
14800,
19300,
8300,
null,
null,
121200,
31900,
32900,
40600,
36700,
11200,
82200,
10700,
30000,
32200,
15200,
29200,
26200,
30300,
14100,
26200,
72100,
31417,
16200,
110200,
49286,
3700,
31500,
130400,
17600,
66700,
17000,
19700,
35700,
12800,
null,
3700,
null,
11100,
18900,
53600,
16000,
null,
32400,
null,
16700,
99200,
21900,
14300,
null,
63600,
6100,
69100,
14800,
22700,
13100,
8900,
34750,
29900,
5900,
null,
20500,
49100,
29600,
50500,
49600,
11000,
96095,
15200,
6400,
38500,
null,
null,
38600,
29900,
67600,
46400,
34000,
72800,
30800,
33500,
49600,
39800,
7300,
28000,
10700,
9400,
43000,
47100,
null,
33700,
28500,
72500,
31200,
35000,
5300,
null,
41900,
null,
14600,
17300,
38300,
26800,
39300,
4900,
6600,
75300,
15000,
17500,
17200,
38900,
20900,
35500,
202100,
12800,
15700,
22100,
13600,
20700,
14400,
18100,
4100,
12400,
null,
16000,
27500,
27300,
66650,
6300,
13800,
null,
19100,
6900,
17300,
10201,
null,
13100,
80400,
15100,
50700,
46200,
48600,
32700,
25742,
2700,
11000,
7600,
4900,
36900,
2200,
57800,
28500,
24100,
53400,
92100,
12200,
7800,
14500,
56100,
18600,
46900,
7200,
18000,
41300,
27900,
32800,
16500,
45200,
33100,
236200,
60900,
33000,
17600,
21900,
51700,
4300,
25700,
63300,
147000,
16000,
5700,
62300,
9700,
9500,
24400,
15900,
32900,
30000,
6300,
63500,
140200,
6800,
32000,
null,
10000,
null,
null,
83400,
53500,
35300,
39000,
35000,
56900,
null,
13500,
7900,
8600,
29700,
79700,
52000,
6500,
null,
47700,
38300,
61500,
43600,
17800,
7000,
14400,
19400,
27700,
2700,
8900,
6900,
25100,
8500,
28100,
26500,
28700,
90500,
11400,
51700,
29800,
49900,
77900,
30100,
null,
46100,
13100,
13900,
15700,
13000,
31900,
42200,
64700,
17300,
15200,
11900,
88700,
16900,
28600,
103200,
26700,
36600,
15100,
31700,
38000,
14200,
25000,
12300,
9400,
16700,
36940,
7100,
27700,
22400,
24100,
53100,
13900,
11100,
null,
60300,
9600,
49900,
78300,
36500,
11300,
14500,
19900,
15700,
10000,
48600,
36800,
56000,
55600,
28400,
8300,
15900,
18100,
20900,
26800,
15400,
23000,
16000,
20840,
25500,
117300,
16900,
23100,
33300,
31900,
30000,
6900,
33800,
2500,
53900,
18000,
18600,
16900,
12400,
17600,
10900,
6500,
15100,
33200,
18000,
12000,
139100,
null,
12100,
104200,
50400,
42800,
null,
24100,
26600,
35900,
7900,
21800,
10700,
169100,
36500,
30200,
25600,
38200,
27000,
20700,
12100,
29900,
10300,
14200,
14901,
87500,
null,
9800,
14030,
16000,
90350,
null,
46800,
16800,
null,
50300,
44700,
12700,
38700,
31100,
15600,
19100,
9500,
17300,
12300,
15200,
8500,
14400,
63500,
7400,
29700,
27900,
26800,
7700,
70200,
4200,
16300,
23000,
12600,
5600,
20900,
16800,
null,
null,
29200,
84700,
30200,
9000,
83300,
40400,
61300,
null,
56900,
13200,
14000,
48500,
8300,
21500,
900,
10100,
29000,
20600,
16000,
16600,
3700,
15000,
78300,
54600,
38700,
23700,
12900,
34300,
29400,
110000,
23500,
28200,
6100,
20700,
15900,
25800,
39800,
null,
54200,
19400,
null,
23900,
9900,
22600,
40300,
57100,
224800,
7000,
29300,
24700,
21500,
25900,
2500,
64400,
21600,
12500,
50500,
23100,
43500,
19500,
203500,
15900,
14500,
null,
67900,
25500,
null,
40700,
9600,
null,
28300,
9300,
35900,
23100,
107400,
24470,
18000,
52900,
17800,
7200,
21300,
36550,
56300,
24000,
12900,
24200,
25600,
15000,
24500,
27400,
21700,
10600,
3100,
52400,
31000,
8200,
137100,
137400,
21600,
43300,
18300,
12800,
7800,
47600,
14700,
8500,
23900,
21400,
8000,
14400,
29500,
29400,
23100,
5800,
50400,
8250,
6100,
61600,
19400,
14000,
38000,
39200,
7900,
38000,
17100,
2750,
11000,
11600,
54000,
53100,
11350,
38700,
17000,
28300,
3800,
17700,
37500,
22300,
47700,
21400,
43500,
38500,
69300,
48500,
29100,
32200,
97625,
103350,
49400,
25100,
20500,
35300,
33400,
19800,
17800,
51100,
21000,
28300,
39400,
31800,
47700,
15600,
7600,
64300,
10100,
16600,
58200,
11700,
11200,
26300,
47400,
15400,
36500,
13200,
8900,
25200,
11800,
34700,
26800,
47000,
18500,
7100,
8000,
9500,
74400,
8800,
40500,
19100,
96100,
14100,
53700,
36500,
41200,
5400,
16100,
21600,
null,
106100,
2900,
22600,
28800,
61100,
12700,
92585,
14200,
34900,
61900,
36900,
84500,
258000,
36600,
57600,
18300,
null,
10600,
42500,
29900,
40400,
23500,
22000,
16000,
31800,
null,
13200,
12000,
40050,
7600,
27200,
18900,
79900,
23400,
28800,
null,
16600,
null,
40400,
17000,
31300,
23100,
32900,
67100,
40500,
42300,
151000,
14005,
12700,
179100,
30200,
17300,
88400,
15100,
61500,
17500,
74500,
null,
36900,
13200,
8300,
48300,
18200,
88200,
40900,
null,
35000,
14000,
33500,
18600,
12200,
16800,
19900,
20700,
45800,
12800,
17200,
40600,
15600,
34300,
11000,
5600,
7200,
85200,
27700,
23400,
25100,
54500,
18600,
68400,
null,
18100,
59000,
73599,
69500,
35500,
21600,
40700,
38400,
12600,
22200,
1800,
46000,
55000,
36000,
12500,
41600,
79070,
12600,
null,
21300,
16100,
22600,
157800,
41300,
15000,
12600,
28800,
8800,
22700,
55500,
39700,
25400,
17301,
14500,
42500,
14000,
null,
39083,
38700,
4300,
11700,
null,
47800,
23000,
5000,
30000,
9000,
7400,
27700,
15300,
20800,
null,
29300,
11700,
29600,
4200,
43700,
26700,
7600,
52300,
37900,
11800,
16600,
22500,
null,
13800,
7900,
22000,
52700,
20400,
22000,
13200,
69200,
45800,
8100,
40100,
46600,
27900,
13300,
25400,
36600,
17000,
38700,
33400,
20800,
21900,
null,
41300,
17950,
6100,
null,
null,
24600,
44100,
27400,
23400,
24300,
18700,
1100,
21800,
51264,
18200,
null,
null,
5800,
16700,
19700,
34200,
18200,
15000,
23000,
23900,
14700,
17400,
null,
null,
34400,
23700,
11100,
17200,
8300,
12800,
57200,
42400,
29100,
12900,
20000,
87400,
38000,
14000,
45700,
46200,
24700,
null,
35400,
3400,
5900,
33400,
10900,
40000,
34400,
17300,
18800,
35400,
34900,
70496,
16200,
null,
32600,
15100,
17200,
null,
10900,
17100,
9300,
58200,
30400,
23000,
5000,
11400,
7700,
74100,
null,
21800,
9500,
31300,
20400,
15300,
80100,
33700,
11200,
115600,
12800,
47200,
202900,
38300,
31000,
136500,
46400,
44100,
22800,
12700,
16800,
38700,
11500,
53800,
18000,
19000,
49300,
31100,
24600,
23500,
24500,
null,
24500,
21000,
16600,
17450,
53100,
75800,
25300,
28600,
null,
58400,
18400,
31500,
16800,
38000,
null,
29200,
8200,
28640,
12600,
32000,
null,
null,
33400,
51500,
18600,
null,
6200,
13000,
13000,
8200,
166900,
23000,
64700,
9500,
125900,
33200,
11000,
30400,
13000,
93900,
23900,
14000,
15300,
43500,
14700,
4750,
51600,
43300,
11300,
33900,
10000,
7800,
62100,
53700,
19700,
12400,
9700,
39000,
29025,
39000,
101800,
27500,
51300,
120600,
23200,
18600,
17100,
40193,
null,
31900,
31500,
7000,
26600,
11200,
10700,
18500,
null,
null,
40537,
null,
18200,
4000,
31600,
33700,
31000,
69400,
4200,
24800,
17233,
2400,
20100,
47600,
30100,
32700,
4400,
16200,
110600,
45300,
16000,
8400,
7500,
26200,
105600,
73400,
null,
104100,
3000,
22900,
8700,
128900,
12100,
null,
26500,
50400,
17200,
77400,
6000,
27500,
49500,
3500,
22100,
20700,
28700,
22000,
10300,
43300,
6800,
8800,
9300,
38600,
36000,
9500,
null,
57300,
24050,
27200,
45200,
41800,
null,
28400,
25300,
55000,
16800,
18500,
18000,
56300,
11200,
23900,
23200,
19200,
49200,
64100,
32200,
76600,
24400,
36300,
10400,
29100,
10200,
12100,
33000,
16200,
19700,
32000,
21300,
14500,
48800,
190700,
null,
17400,
43800,
6700,
28500,
12600,
null,
19909,
49100,
8800,
49700,
22099,
30200,
13000,
36600,
19000,
13400,
null,
39400,
18000,
33800,
11100,
27400,
3800,
36700,
7300,
47663,
null,
61400,
null,
13700,
45400,
52000,
42200,
35800,
68900,
43600,
31379,
63100,
18000,
12200,
14500,
35500,
35200,
25600,
259500,
8900,
116100,
17800,
13500,
5200,
42100,
34000,
16300,
60400,
44800,
221300,
17300,
12600,
19900,
90500,
24600,
34500,
null,
11900,
59400,
114500,
25700,
52300,
56700,
76300,
10000,
5700,
17000,
17100,
null,
null,
36100,
12000,
null,
23300,
49600,
7500,
17500,
21900,
15000,
17400,
10600,
7500,
68900,
29100,
null,
51400,
null,
128100,
null,
34600,
38200,
14800,
21900,
22000,
45900,
87700,
42100,
18500,
18200,
null,
72900,
5500,
15200,
42300,
8600,
47800,
50300,
23900,
null,
24300,
8800,
13400,
69300,
43330,
74200,
20600,
19300,
22000,
147600,
35300,
9700,
17400,
42800,
38800,
14700,
null,
51600,
8900,
14600,
34100,
36000,
71500,
22300,
19900,
2800,
75400,
151860,
17000,
15900,
27400,
null,
10700,
31200,
80700,
20200,
27600,
37500,
32800,
null,
53800,
66600,
22200,
33000,
13600,
13600,
92100,
29900,
13400,
65100,
8900,
14600,
16100,
39400,
63200,
13900,
31800,
29800,
30090,
24000,
10400,
28800,
null,
39000,
9400,
null,
10500,
107600,
null,
19900,
22900,
15000,
null,
27300,
17700,
48400,
null,
20000,
26200,
37900,
29500,
11300,
6009,
56000,
19400,
null,
null,
27700,
9100,
18800,
null,
5700,
12900,
17100,
29100,
35300,
45200,
42400,
22500,
6900,
99700,
82000,
18600,
16900,
null,
41300,
13200,
43200,
10700,
41900,
8500,
37400,
2700,
6000,
57800,
null,
5050,
36600,
26100,
9100,
7400,
33000,
31100,
112000,
45800,
170700,
59000,
13400,
9800,
13700,
20700,
60000,
26300,
34000,
38600,
14500,
14300,
34900,
18100,
113500,
19600,
14500,
81400,
24100,
26700,
28400,
50600,
66800,
54800,
36400,
54700,
33400,
20500,
29900,
null,
46300,
10700,
19800,
60300,
3100,
17900,
50900,
12700,
47700,
58900,
26600,
15500,
4900,
5000,
41600,
14500,
56500,
45800,
18600,
28400,
23800,
61400,
11900,
31700,
9500,
30700,
71100,
null,
43200,
null,
null,
30300,
8500,
36100,
38300,
18300,
47900,
13200,
34800,
47300,
14800,
239800,
12400,
41000,
17700,
19500,
43700,
9300,
91200,
14600,
13100,
8900,
39500,
null,
50900,
31650,
40100,
30400,
11000,
35500,
50500,
12200,
29300,
55500,
50100,
12700,
30000,
13100,
31100,
20700,
46100,
7400,
11800,
40800,
31700,
37900,
85600,
20800,
25600,
12000,
21300,
7000,
6500,
null,
28800,
22900,
9800,
9000,
null,
31500,
29300,
58600,
57700,
22300,
5700,
63600,
28700,
12000,
73700,
18700,
null,
29500,
3800,
39000,
28000,
40200,
11600,
17600,
24380,
19400,
10300,
49500,
10900,
null,
21700,
128200,
27700,
10000,
57000,
19900,
18400,
41600,
85000,
50900,
10000,
null,
55000,
32400,
47900,
5400,
5900,
39000,
20800,
64900,
39600,
36200,
35900,
115100,
11700,
29400,
null,
31500,
19309,
78100,
36900,
19100,
37600,
16900,
10400,
10300,
null,
17800,
5300,
8100,
11100,
21000,
40900,
43200,
12200,
7600,
14300,
null,
null,
34900,
22400,
15400,
55000,
27200,
67100,
18200,
13500,
25500,
26100,
38600,
25500,
null,
30700,
47600,
20300,
38500,
21000,
53700,
null,
52600,
32300,
22400,
19400,
28400,
6100,
35800,
51500,
35000,
39800,
48700,
8500,
41900,
17200,
87900,
null,
32100,
43300,
12000,
17100,
23100,
7700,
27400,
8200,
17700,
11000,
null,
21600,
18000,
34900,
37300,
23100,
72400,
null,
23500,
151395,
92000,
18100,
31800,
18800,
8100,
48700,
8500,
3500,
68000,
58800,
null,
34300,
38700,
41000,
29000,
9300,
16700,
null,
10000,
13500,
12100,
23000,
3900,
10400,
41400,
13400,
18000,
25900,
100300,
6700,
3600,
28500,
null,
null,
17200,
13600,
69190,
27700,
null,
12900,
25300,
33200,
52500,
26600,
5400,
14400,
54000,
27100,
69100,
57400,
43000,
8000,
null,
3100,
14400,
null,
22100,
50300,
7300,
52900,
26700,
null,
10300,
26700,
10500,
null,
6600,
37000,
14800,
43800,
null,
14700,
13900,
20800,
31500,
19500,
23500,
22000,
16950,
21400,
55700,
20700,
12800,
12800,
38700,
30900,
40200,
null,
19600,
27300,
9475,
21000,
126500,
22200,
34700,
19800,
4400,
null,
14400,
39800,
29100,
19400,
28100,
15700,
42100,
null,
19100,
39600,
32400,
11200,
21600,
6500,
57400,
13500,
19000,
10400,
7700,
28000,
32900,
8500,
93100,
3000,
25700,
25000,
43600,
26400,
28400,
24900,
34800,
13200,
5400,
8800,
53200,
37000,
67300,
20100,
30800,
3100,
23600,
153800,
50400,
18900,
47700,
16500,
29500,
64600,
8700,
59200,
29000,
39800,
12900,
57964,
7900,
12300,
10400,
13700,
29500,
20500,
13800,
null,
null,
23100,
9600,
28200,
67700,
null,
28000,
52400,
62100,
8300,
34100,
13100,
6600,
38500,
12800,
null,
null,
18500,
null,
36800,
55800,
27100,
14300,
null,
20500,
22200,
35600,
31600,
18800,
13450,
57100,
31300,
null,
44400,
75300,
29700,
22600,
91400,
9000,
19200,
30500,
12900,
10000,
14600,
15800,
56300,
20400,
5900,
7700,
51200,
41800,
46900,
21500,
5400,
13100,
46200,
83400,
28570,
12300,
83000,
31000,
26700,
13700,
7800,
49000,
31900,
12500,
null,
24700,
45400,
3900,
66800,
5500,
16900,
103000,
22000,
15800,
10800,
11700,
12000,
33500,
44000,
15500,
14500,
41200,
30900,
6200,
15300,
11200,
8200,
24700,
null,
14100,
29600,
10700,
57900,
10500,
15700,
9700,
8100,
48100,
31100,
67600,
42700,
16600,
17000,
9600,
25300,
null,
25500,
null,
17800,
20000,
7600,
12000,
38700,
47200,
12000,
14800,
15300,
45200,
52400,
44100,
40200,
30500,
142500,
17900,
26600,
28100,
21400,
10100,
17100,
null,
27400,
22700,
15500,
38000,
15400,
13500,
5000,
3800,
13500,
35300,
null,
25200,
21800,
26400,
36100,
29500,
8800,
24600,
9600,
32900,
67300,
38200,
6000,
32400,
30331,
19100,
52700,
21600,
13700,
10900,
14800,
56700,
15600,
16500,
112000,
12200,
21000,
7500,
41200,
43200,
44700,
24700,
22800,
46300,
13700,
9000,
7000,
null,
17200,
24300,
24700,
95300,
49900,
19800,
12100,
21200,
20300,
null,
60700,
17000,
17600,
5150,
25000,
13300,
46900,
9200,
null,
10600,
56000,
27000,
28700,
13600,
25000,
41200,
45300,
377400,
17000,
36500,
11300,
7200,
13700,
30300,
9600,
69500,
6800,
59500,
null,
89450,
null,
null,
31700,
5400,
41000,
33600,
8800,
9300,
16200,
26900,
5500,
16900,
64600,
28400,
null,
11100,
20300,
8300,
59200,
51800,
36300,
14300,
17895,
31200,
21500,
55100,
37500,
57200,
52000,
12600,
16300,
9700,
35900,
3900,
26800,
58100,
21600,
26100,
10500,
47700,
8400,
33800,
16300,
38900,
42500,
36400,
13700,
122200,
15300,
20400,
22900,
71896,
26000,
6500,
14800,
46100,
11000,
24500,
8100,
41100,
11100,
19100,
null,
12700,
57900,
9000,
12000,
17100,
127200,
45900,
13500,
7400,
17800,
26300,
17800,
53700,
null,
39100,
49600,
null,
32400,
35500,
58500,
39700,
35200,
33500,
20900,
49800,
34500,
33700,
117700,
25000,
13700,
12900,
null,
13400,
42100,
null,
26463,
14800,
31300,
19200,
12500,
28400,
16600,
6300,
43200,
8600,
19500,
6000,
37800,
26500,
41000,
56500,
41800,
18600,
11100,
null,
null,
23800,
3800,
8400,
9800,
13300,
53200,
25400,
null,
34500,
55600,
17100,
56100,
21800,
29700,
27000,
64900,
44426,
45300,
26700,
35700,
null,
22200,
15000,
null,
17800,
16000,
54400,
21600,
1500,
26000,
46400,
19000,
24800,
16800,
31900,
40700,
64500,
16200,
19500,
50300,
19300,
26300,
8000,
10800,
14700,
27100,
19100,
35400,
39400,
21700,
6300,
36700,
7900,
17500,
8500,
18400,
32100,
4300,
48150,
13500,
54700,
15800,
72300,
77100,
5200,
22000,
null,
null,
null,
8000,
7100,
9800,
26800,
23800,
10500,
6300,
23000,
6900,
8800,
33000,
54100,
21600,
14900,
66200,
17100,
null,
13600,
11700,
33600,
9000,
9100,
null,
15500,
60000,
19800,
45100,
53400,
56100,
44600,
6800,
null,
66300,
48200,
15500,
17000,
8100,
7400,
null,
69300,
26900,
null,
5800,
68000,
11300,
56800,
14200,
22800,
45800,
22600,
null,
18100,
24700,
null,
13200,
97600,
6300,
14100,
44800,
20600,
11500,
14300,
22200,
86600,
null,
null,
11800,
11100,
40100,
null,
36200,
5600,
30300,
4300,
null,
23800,
37900,
40500,
11500,
35000,
48700,
14600,
20400,
58000,
null,
32400,
28400,
6800,
24100,
15400,
29900,
null,
84900,
13300,
69600,
null,
5600,
39200,
null,
17400,
7700,
62800,
null,
8200,
42500,
null,
13300,
8500,
13700,
35800,
1500,
27800,
6169,
null,
20600,
27300,
32600,
37200,
null,
74500,
39900,
11100,
12500,
6400,
14900,
65100,
null,
16800,
35700,
22100,
21600,
null,
42900,
71300,
87900,
23100,
8300,
13100,
11500,
18400,
72200,
20400,
24600,
41000,
26100,
9500,
52000,
11900,
12800,
30900,
54300,
30900,
34400,
22300,
71700,
14200,
17200,
35000,
64300,
null,
5500,
20800,
28200,
26300,
11400,
24800,
15100,
45283,
15900,
44200,
24400,
28300,
18100,
21000,
33300,
141400,
6400,
12400,
4300,
19600,
124900,
70000,
66251,
null,
72800,
null,
20800,
null,
5300,
16700,
32950,
27200,
22000,
84400,
25800,
32200,
18300,
7300,
54000,
8700,
6500,
20800,
15400,
17900,
37300,
22900,
5200,
35200,
95467,
62000,
11900,
8800,
74500,
17100,
92500,
6300,
42000,
64600,
15200,
44100,
19200,
23200,
35300,
41800,
18800,
null,
8700,
13100,
8500,
85500,
23400,
36800,
20800,
20800,
29700,
null,
18100,
79500,
18000,
30400,
13500,
19400,
37500,
null,
null,
5000,
82500,
6000,
7300,
32000,
48700,
18900,
21600,
22100,
44100,
55500,
null,
23500,
11600,
54200,
31200,
43300,
22600,
30400,
71000,
46900,
29000,
null,
48900,
71200,
29300,
15400,
5400,
43900,
45500,
9700,
null,
10600,
43100,
4600,
20200,
11800,
16700,
7800,
38800,
8900,
15000,
11200,
null,
47200,
14300,
7600,
9100,
null,
9700,
12800,
22100,
15000,
9200,
27400,
8300,
49100,
14600,
33500,
null,
73100,
23800,
34000,
27000,
46600,
30100,
1700,
4000,
6600,
49000,
53900,
60800,
44700,
69600,
22000,
25400,
361000,
8800,
14300,
19600,
35700,
37800,
27800,
10900,
5000,
98400,
12900,
5900,
50900,
9100,
21600,
29700,
3100,
null,
15500,
10000,
21700,
3300,
47400,
71400,
7600,
23400,
19500,
39200,
35900,
10900,
null,
12300,
27200,
27500,
15600,
1100,
41900,
20900,
16300,
11100,
35900,
17200,
37700,
23400,
40700,
11800,
14100,
148100,
13400,
111900,
60100,
10000,
71100,
6300,
19000,
7800,
22200,
35100,
73000,
null,
null,
32500,
31700,
22000,
18400,
32000,
28400,
59500,
34900,
17500,
13000,
25700,
62200,
75700,
15800,
3500,
3600,
22000,
null,
null,
30100,
null,
131300,
43500,
54900,
29700,
null,
42500,
20000,
30100,
7100,
33300,
19500,
84600,
10500,
7600,
49700,
17600,
9000,
12000,
29200,
13200,
null,
null,
28300,
17400,
8100,
null,
28700,
10000,
9900,
15300,
20700,
68200,
50300,
18700,
8005,
18900,
158000,
18700,
13200,
9150,
21162,
12500,
38700,
17700,
10500,
20400,
10500,
43800,
9400,
10900,
45300,
18100,
11500,
9200,
38500,
6100,
27700,
27100,
55100,
16800,
26500,
33650,
211100,
5350,
14200,
9700,
39500,
14100,
14000,
null,
13900,
40000,
130800,
23500,
46300,
21700,
18900,
null,
15100,
27700,
28600,
16900,
38400,
47600,
47600,
116600,
20200,
27400,
55400,
14000,
7500,
27800,
null,
22000,
8200,
39800,
10000,
22500,
9300,
36600,
107600,
58800,
22600,
11000,
21900,
32550,
null,
26400,
8400,
22400,
13200,
20500,
23800,
61000,
78300,
null,
49200,
24200,
29500,
31900,
16400,
45300,
41000,
20200,
9500,
26300,
12800,
13000,
null,
65900,
14200,
19700,
null,
14000,
30600,
18300,
37600,
19800,
27300,
31400,
85100,
10200,
39100,
14100,
16500,
46700,
69200,
16600,
9300,
27100,
30400,
63200,
17700,
32700,
42969,
41400,
23700,
57200,
11500,
1200,
46800,
17500,
105170,
48700,
48100,
12900,
19000,
19600,
40300,
6200,
23100,
null,
28700,
27200,
29800,
26800,
35600,
29800,
26200,
6190,
24600,
16200,
17700,
29800,
49100,
15200,
23800,
18800,
33900,
83500,
88900,
27500,
37500,
134300,
21000,
40600,
20800,
81100,
32800,
null,
11000,
21500,
10800,
40300,
18200,
13400,
152516,
36400,
16800,
38300,
11200,
11500,
6500,
16300,
57200,
5200,
17600,
31300,
40800,
12600,
22700,
18200,
35400,
6400,
null,
85700,
39200,
52800,
null,
27600,
33800,
41400,
28300,
56500,
4300,
6500,
13400,
16000,
38000,
null,
27000,
17400,
32100,
16300,
18200,
null,
8000,
26900,
131300,
13500,
28500,
9000,
14700,
36400,
5500,
20700,
96500,
22300,
16200,
null,
7500,
68700,
8400,
20400,
13900,
12200,
60900,
3500,
14100,
54700,
26400,
19500,
172100,
12500,
30700,
null,
11200,
32000,
12000,
null,
38900,
57300,
9400,
27300,
24100,
36900,
9900,
37700,
39600,
27400,
null,
24700,
6100,
17700,
101400,
7300,
23600,
8500,
147200,
18500,
4200,
17700,
14100,
28500,
21400,
null,
26600,
7600,
25000,
40400,
null,
28500,
9900,
19000,
null,
11600,
null,
22300,
31600,
34100,
15100,
21000,
9300,
8500,
null,
27500,
12600,
9000,
null,
9300,
53300,
12400,
14400,
59605,
53700,
53000,
13700,
null,
31600,
72700,
13300,
null,
36300,
16400,
21200,
65600,
8600,
23900,
18900,
30700,
10500,
13800,
45500,
16900,
53600,
16700,
25000,
64800,
91441,
54600,
128000,
7300,
35800,
51700,
14100,
28500,
24000,
42600,
37100,
26600,
7600,
44800,
18100,
25700,
122200,
14900,
24700,
74700,
41820,
1100,
62300,
35300,
7900,
12500,
37100,
73700,
45213,
52200,
null,
40141,
16400,
44300,
52500,
43032,
31800,
14400,
98700,
2600,
20300,
22500,
64400,
49000,
14800,
3000,
15500,
27700,
15900,
86600,
7700,
null,
null,
25800,
141800,
55100,
136900,
31800,
25500,
30500,
3600,
23300,
null,
84400,
15200,
47200,
27500,
16100,
11300,
10200,
null,
43500,
800,
13100,
27800,
13200,
9900,
53900,
24800,
27500,
8700,
69500,
38800,
91000,
13950,
19500,
15900,
29700,
null,
16700,
24600,
15000,
null,
45500,
20100,
23800,
25100,
142600,
12832,
24500,
4400,
94500,
61400,
7500,
28600,
34900,
17800,
52500,
46200,
35700,
25100,
25500,
9000,
null,
48600,
29800,
9450,
18900,
16000,
21500,
15200,
95000,
32300,
12900,
38000,
48100,
25200,
73200,
14500,
77200,
14700,
15500,
11000,
23100,
2300,
33964,
30300,
62290,
20700,
31800,
17400,
75700,
10100,
23700,
31400,
1200,
null,
17300,
32800,
15500,
null,
18500,
8200,
20900,
66100,
53900,
5000,
null,
24700,
21300,
15500,
16700,
8800,
22300,
7900,
26100,
null,
62500,
null,
12500,
22100,
24300,
17900,
16500,
14900,
27300,
23700,
18500,
4700,
5200,
27800,
8200,
26700,
12400,
24100,
19800,
55000,
33900,
33600,
14200,
85100,
19500,
5900,
14800,
25200,
63300,
11800,
11800,
46000,
118500,
6200,
46300,
6500,
22600,
20200,
62500,
25600,
15100,
null,
24900,
58800,
5400,
97305,
44700,
41600,
null,
24300,
7000,
null,
20700,
16700,
13000,
48400,
28900,
5900,
85400,
6600,
15200,
24000,
37500,
38700,
144300,
13800,
null,
13200,
44700,
144800,
111100,
26200,
10300,
14000,
39000,
12100,
20400,
19700,
43000,
40500,
85700,
38543,
37200,
25800,
21700,
64700,
30200,
32700,
73900,
7800,
210100,
19200,
14300,
25500,
123400,
11100,
54800,
12227,
35400,
86500,
21000,
53300,
7700,
31800,
21900,
59500,
1000,
33600,
30300,
17500,
null,
11200,
58400,
null,
27500,
41500,
12000,
12500,
50500,
36100,
7500,
33400,
32100,
null,
38400,
24100,
6900,
20700,
35200,
7600,
24800,
50100,
18100,
33800,
93900,
35500,
78800,
85800,
null,
9600,
9600,
43200,
21700,
11900,
13000,
32900,
76000,
56700,
9300,
22500,
36400,
92400,
4100,
11300,
18300,
null,
7800,
22000,
20200,
23000,
39900,
20800,
11400,
36800,
23500,
10369,
15800,
36900,
700,
null,
6500,
null,
30200,
44300,
28800,
46600,
30000,
6100,
26400,
11700,
6500,
62300,
null,
35400,
33400,
20500,
31300,
11300,
null,
null,
44400,
14200,
11200,
43900,
18900,
9700,
null,
24700,
177900,
9400,
10300,
11500,
71700,
48000,
24800,
41400,
31700,
232300,
54800,
22000,
10900,
9000,
13100,
39600,
71400,
42400,
14500,
30800,
6500,
11300,
6700,
22500,
60200,
50200,
15300,
20800,
20000,
17100,
20000,
17700,
12000,
34900,
10100,
40500,
40000,
21800,
137600,
32500,
24700,
1900,
11100,
39000,
42300,
23300,
13000,
22900,
7800,
26700,
12200,
14300,
101700,
59700,
11000,
16800,
29600,
14500,
4500,
18800,
11100,
null,
53500,
60800,
8145,
17100,
29400,
10990,
12600,
18300,
21900,
null,
283300,
35500,
13100,
35300,
12850,
55900,
22300,
43800,
12200,
47300,
14000,
27700,
18900,
4100,
133800,
null,
48000,
25300,
20600,
22100,
14800,
56900,
56500,
19800,
46200,
null,
null,
44400,
19700,
18400,
63800,
46500,
61100,
null,
103400,
null,
78100,
15700,
73900,
72400,
15800,
11300,
95300,
38100,
77500,
22700,
19500,
26000,
36400,
16100,
20800,
41800,
null,
11300,
5000,
null,
42800,
3900,
55800,
4000,
13800,
11900,
38800,
27100,
18600,
13200,
21400,
21700,
7200,
null,
15600,
21200,
54500,
22800,
31600,
58800,
null,
20800,
13000,
12500,
35400,
35600,
35900,
153100,
68300,
null,
23800,
null,
21600,
7300,
29600,
23600,
27400,
6200,
19500,
27100,
10500,
null,
13900,
15000,
null,
13900,
5400,
54100,
34400,
33600,
15700,
12400,
null,
null,
29200,
62600,
35300,
6800,
8400,
12600,
60400,
null,
70600,
15700,
63100,
20300,
19800,
null,
30300,
23300,
50200,
9500,
23900,
37700,
5000,
35500,
20500,
1000,
29800,
93600,
4400,
21200,
3800,
31400,
46600,
8750,
52500,
43100,
24200,
19300,
10500,
46100,
19800,
16300,
28400,
25600,
104900,
18000,
50600,
27700,
14100,
40700,
37500,
23900,
53200,
20000,
18200,
57900,
28800,
22700,
46000,
null,
13000,
6500,
60800,
21500,
40100,
21300,
105600,
10700,
17600,
null,
36500,
21500,
48500,
50100,
null,
1400,
42900,
25200,
null,
8000,
13200,
18500,
49900,
4900,
21300,
103500,
20200,
5300,
12700,
32900,
18200,
null,
null,
79900,
31100,
23700,
10700,
16400,
20100,
39300,
53500,
6000,
null,
4600,
17900,
75600,
14600,
16400,
15500,
16000,
64700,
16500,
102700,
null,
57300,
85600,
20409,
17300,
17800,
5200,
8200,
15100,
null,
9900,
11700,
62400,
27800,
72300,
57600,
14400,
46600,
9700,
121600,
7600,
21300,
40850,
89000,
38100,
44200,
15800,
23100,
2300,
20500,
null,
18300,
22500,
63900,
25100,
25800,
11400,
14900,
19000,
2900,
10900,
16300,
34400,
null,
16100,
null,
9200,
44000,
27300,
53900,
null,
119440,
null,
129200,
35000,
56200,
null,
42900,
21000,
44800,
4300,
13800,
7500,
34600,
11300,
132300,
null,
9500,
29000,
161300,
52700,
22700,
36500,
38600,
43800,
60600,
8900,
12100,
9500,
16100,
5500,
8300,
53600,
51300,
55500,
8900,
12300,
30000,
33100,
null,
29700,
89200,
68100,
22500,
16700,
35800,
109500,
114600,
45000,
null,
19600,
52100,
12000,
17800,
94100,
2800,
6500,
null,
null,
45800,
22200,
19800,
28200,
39300,
31400,
6200,
50300,
12800,
12150,
9900,
12900,
null,
6800,
31500,
3400,
24700,
41300,
null,
21700,
35300,
19100,
null,
12840,
66900,
31400,
33500,
null,
52000,
27300,
83800,
31900,
13500,
8000,
58600,
28000,
16600,
25300,
35300,
29900,
34400,
30100,
25500,
20000,
27400,
19600,
12600,
21500,
54300,
20500,
85200,
null,
58300,
19200,
16400,
34700,
26600,
27900,
10700,
39600,
4500,
11200,
19700,
12700,
28600,
32900,
27400,
5200,
22100,
null,
15500,
62500,
17100,
12800,
23433,
20000,
9800,
null,
39400,
61330,
109900,
38600,
3600,
16700,
52000,
28700,
12500,
20900,
6100,
80700,
20900,
7700,
1850,
57200,
8800,
29400,
30200,
37400,
35700,
1900,
13000,
38200,
51200,
35200,
11500,
18900,
10000,
39700,
30600,
16000,
15300,
19400,
9700,
13000,
21700,
54000,
null,
25600,
15900,
9700,
null,
53200,
null,
30200,
null,
4300,
42800,
17100,
14600,
44800,
35700,
13200,
21100,
24900,
9900,
67400,
16300,
44800,
90700,
11494,
6300,
25800,
null,
28100,
14800,
5500,
20200,
72100,
17700,
20600,
38100,
11700,
8500,
17555,
31200,
41300,
13800,
41000,
8200,
84000,
7800,
45400,
null,
45000,
null,
18900,
37600,
47500,
20800,
40800,
30300,
null,
23400,
22600,
20200,
14700,
7300,
53700,
74800,
17800,
20000,
null,
11500,
28400,
90500,
14200,
18200,
7700,
16600,
32400,
21700,
27300,
21100,
75000,
8050,
34300,
18600,
25200,
18600,
34000,
null,
33500,
44300,
null,
23600,
22800,
47000,
6100,
11551,
39400,
74100,
15000,
25100,
null,
19800,
null,
55000,
8300,
43300,
null,
36900,
11200,
5400,
26500,
11500,
7300,
85000,
36300,
10400,
23700,
null,
7100,
13100,
33800,
11700,
58700,
9000,
11700,
6800,
45800,
60300,
19800,
null,
null,
9000,
33700,
29700,
61600,
12150,
173600,
19700,
null,
91600,
10900,
12800,
41100,
27000,
14900,
13400,
36000,
28700,
8800,
34900,
22800,
39500,
39400,
24600,
null,
23000,
null,
22300,
29800,
25800,
13600,
18400,
31900,
25400,
12700,
21000,
13400,
22500,
31600,
13400,
null,
7600,
25000,
24700,
6000,
2600,
98600,
13400,
30400,
16800,
20300,
null,
17700,
11500,
21800,
40600,
76700,
63300,
null,
84500,
null,
71700,
15300,
31400,
38200,
6000,
11500,
31200,
13000,
18600,
45600,
65500,
9200,
129500,
10900,
35800,
9500,
81400,
30800,
23500,
11300,
13500,
28900,
null,
26500,
6200,
9350,
14000,
42200,
22100,
null,
24300,
null,
21800,
68500,
23100,
23000,
33400,
79000,
null,
25000,
52100,
3900,
29700,
80300,
31500,
31600,
12800,
27200,
6200,
17700,
40900,
15000,
50000,
8300,
27100,
null,
13200,
21700,
7000,
34900,
35500,
61000,
20200,
12300,
8900,
32000,
47700,
56400,
11500,
21100,
12300,
14800,
3700,
37100,
44500,
59500,
22200,
12000,
21300,
53400,
5800,
null,
12900,
14600,
null,
null,
60400,
null,
8000,
null,
16400,
12300,
17255,
4500,
12000,
55600,
23500,
103100,
900,
17800,
57700,
13400,
35700,
42200,
null,
35700,
9450,
null,
35400,
null,
null,
23600,
24500,
32000,
34300,
24100,
5700,
20200,
95700,
20100,
14200,
14000,
40000,
null,
null,
143000,
57200,
37100,
17400,
8300,
14700,
null,
6600,
16500,
131400,
31600,
14400,
null,
21500,
null,
41700,
9255,
10600,
34500,
56600,
15100,
55900,
17800,
16300,
26900,
16300,
93300,
11700,
14700,
null,
14400,
56710,
44500,
38300,
24200,
33900,
10700,
10300,
15600,
39800,
49700,
10900,
16100,
20600,
65900,
7200,
36200,
19800,
12800,
22800,
20000,
35500,
40400,
30400,
20400,
24000,
32300,
12250,
4300,
85700,
19400,
19600,
61900,
7300,
4550,
20000,
17300,
22400,
25000,
40500,
8500,
6000,
43800,
25700,
6600,
21600,
30400,
18800,
21500,
16000,
7200,
7800,
16600,
10800,
9000,
17000,
28900,
14800,
22900,
7500,
48500,
27500,
11600,
18100,
30400,
23800,
8000,
22500,
13900,
13300,
15300,
28200,
34700,
98400,
49500,
23900,
null,
null,
58800,
null,
19400,
88000,
52400,
null,
22200,
26800,
91100,
10600,
82800,
10500,
14200,
6300,
12000,
29100,
38900,
19800,
41700,
25800,
7500,
13400,
37600,
null,
35900,
5900,
112900,
78000,
18600,
41300,
17000,
28000,
42800,
6600,
24300,
26500,
22200,
26100,
68500,
null,
40000,
null,
3500,
18700,
5200,
8500,
18100,
32400,
14300,
null,
19600,
6500,
17500,
37100,
12900,
27400,
31500,
27700,
13800,
null,
40500,
55200,
252100,
18200,
41000,
16960,
1900,
5900,
4900,
21400,
12100,
null,
10600,
24900,
34300,
39300,
30900,
107300,
61000,
85600,
50000,
41800,
42200,
17200,
16500,
81300,
49700,
33100,
28000,
10000,
20000,
24100,
19300,
22700,
49400,
4100,
10800,
318300,
14000,
27400,
13800,
16800,
9700,
7500,
26500,
33050,
21000,
29800,
19700,
null,
72800,
46000,
49000,
42200,
43600,
42500,
48100,
11400,
21500,
24200,
29800,
null,
8100,
35500,
10200,
12700,
11900,
8700,
32200,
209800,
12900,
30600,
14850,
12800,
13900,
12300,
27200,
77500,
17800,
25900,
null,
28500,
15500,
23400,
44100,
7500,
15800,
3400,
6500,
30600,
null,
7600,
44800,
48400,
2900,
87900,
35300,
44800,
52100,
null,
22100,
57600,
20600,
67500,
97300,
null,
39500,
84000,
null,
202800,
11000,
52600,
8100,
17300,
13300,
54000,
33348,
2900,
7200,
44700,
53600,
13100,
70800,
44200,
27490,
9700,
15400,
14300,
4200,
62000,
7100,
null,
null,
42200,
24900,
111800,
20500,
30600,
83900,
14900,
50800,
32600,
null,
15000,
18500,
11200,
32500,
43100,
null,
null,
15100,
null,
75800,
58400,
15500,
19300,
19100,
39300,
4400,
14700,
22500,
67800,
6500,
3200,
37500,
null,
33600,
9000,
44400,
null,
4100,
9900,
23600,
null,
141600,
null,
8400,
7600,
31100,
null,
49900,
null,
23400,
61400,
13900,
54300,
43400,
77700,
112700,
6400,
9100,
37200,
18900,
13400,
5800,
69100,
32700,
6500,
6900,
13200,
16486,
48300,
23400,
42400,
72965,
null,
54300,
null,
15500,
54750,
37700,
27400,
11235,
83800,
67100,
13700,
32800,
24400,
54100,
5100,
28000,
33500,
3700,
29800,
null,
32100,
15900,
49900,
44200,
17600,
22700,
null,
27500,
33300,
25100,
69400,
51400,
7600,
17900,
21000,
16300,
19300,
7900,
7800,
17300,
null,
19000,
16800,
3100,
77800,
31100,
3000,
24900,
16400,
41200,
7500,
null,
24600,
15800,
19000,
5280,
19500,
45700,
21000,
null,
24200,
10600,
53800,
21300,
152200,
11700,
18900,
null,
21400,
6200,
5850,
17200,
13400,
21000,
62700,
7200,
null,
42800,
17600,
65300,
25100,
4600,
8000,
null,
33200,
35800,
61500,
9000,
null,
40700,
30000,
23600,
16500,
23900,
41500,
32200,
194000,
14000,
29250,
16500,
3800,
13300,
3300,
50400,
40900,
null,
21800,
22800,
13800,
62300,
49500,
31100,
15600,
56700,
7400,
21900,
null,
18800,
null,
null,
36700,
55400,
15400,
16100,
60000,
15000,
48500,
20200,
26200,
18900,
4500,
34300,
22500,
34100,
11400,
1700,
29200,
14300,
15390,
50200,
19300,
18900,
11600,
12200,
17500,
76800,
null,
8300,
null,
17700,
null,
15300,
71500,
16100,
26900,
11900,
6800,
66700,
26500,
6200,
32600,
3000,
9900,
34100,
17600,
null,
25400,
20600,
36300,
36100,
9000,
null,
13300,
28200,
58655,
31200,
18600,
27900,
7800,
27600,
9900,
47300,
null,
25700,
94200,
38900,
null,
18800,
24700,
4700,
26600,
33600,
9500,
78100,
19900,
null,
21100,
null,
31000,
28600,
88200,
null,
98900,
26000,
27600,
45900,
null,
26300,
null,
50200,
5500,
33300,
35400,
59100,
40200,
12100,
34100,
56600,
7000,
56200,
31500,
9000,
12600,
62000,
13000,
33100,
29500,
null,
62100,
null,
42800,
68000,
3400,
16300,
18500,
12200,
14600,
11400,
null,
32200,
31800,
9400,
71400,
7200,
38300,
10000,
8500,
4900,
20700,
18500,
44300,
55400,
43400,
null,
13000,
39800,
null,
null,
31600,
9600,
22600,
49100,
91600,
24500,
47000,
7400,
35400,
59200,
17500,
13700,
28500,
21100,
38200,
32800,
11200,
25200,
8000,
5300,
18000,
23400,
27700,
80710,
8600,
259900,
22600,
15400,
null,
13200,
null,
18200,
4300,
23800,
9900,
null,
18700,
22100,
25700,
29000,
10000,
16900,
17700,
4700,
12400,
21000,
14600,
19700,
68300,
18900,
34300,
null,
30800,
12800,
18700,
34800,
41400,
16500,
19100,
105100,
23600,
27400,
18500,
28000,
62900,
28200,
35000,
68900,
null,
22000,
58700,
24200,
41200,
12300,
6900,
9300,
49732,
20300,
37400,
6900,
27800,
121200,
8600,
18700,
null,
null,
3100,
50000,
32000,
37200,
8000,
57600,
21300,
13100,
33500,
16400,
34100,
32600,
null,
123800,
null,
24300,
6700,
20400,
26000,
18500,
9400,
18800,
32800,
16600,
13100,
45500,
22000,
null,
14200,
49600,
28800,
29400,
9200,
3300,
53800,
24600,
null,
50400,
10800,
24900,
42800,
12800,
15100,
51200,
22500,
34200,
6300,
86200,
19600,
5300,
113300,
45100,
15500,
40100,
25200,
5600,
62400,
16900,
33500,
21200,
15200,
6500,
null,
15500,
12900,
66500,
37600,
7000,
66100,
12400,
17200,
18900,
null,
13400,
27600,
18400,
32200,
15500,
40000,
24500,
18700,
2300,
45900,
17600,
30600,
38400,
22300,
50900,
66000,
13400,
8900,
24600,
null,
47810,
20500,
14700,
34400,
22200,
36500,
15800,
97900,
12300,
10200,
7000,
28400,
null,
25900,
15600,
null,
28200,
4300,
36900,
31200,
18500,
28588,
19900,
14500,
7300,
30890,
17400,
18900,
14200,
54300,
38200,
37000,
42800,
28100,
14500,
50400,
34500,
5100,
12200,
null,
29500,
57300,
14600,
19500,
43600,
20000,
7000,
null,
91300,
12800,
6000,
null,
30100,
14700,
14100,
36800,
25500,
25700,
17300,
41500,
88900,
15300,
6000,
17800,
7300,
41300,
21600,
39900,
20500,
10500,
86300,
24300,
null,
12400,
44700,
88300,
20800,
28200,
7700,
13100,
17100,
28300,
29400,
29000,
37086,
6800,
2900,
10900,
44300,
42100,
30500,
14700,
17100,
149800,
18500,
null,
6400,
25700,
32500,
27200,
7000,
16300,
44400,
21100,
14000,
18800,
25000,
11700,
6400,
45900,
3100,
42300,
51200,
46000,
39000,
7400,
36363,
11300,
48900,
9300,
9900,
25400,
8800,
35800,
44900,
39700,
55400,
38300,
31800,
7500,
57700,
10500,
23700,
34800,
65900,
9600,
8300,
15300,
39400,
36800,
27200,
25700,
null,
23400,
39400,
14300,
101300,
175500,
7000,
12000,
44900,
25200,
30200,
10600,
30600,
128300,
8100,
17500,
32100,
39900,
28000,
8000,
29900,
19700,
38000,
23160,
40700,
22800,
4100,
48400,
8900,
21800,
38900,
21100,
174400,
69800,
88500,
null,
22800,
26400,
33100,
92200,
14000,
21600,
10600,
57100,
16600,
13100,
9500,
13000,
null,
28700,
38200,
8500,
28800,
null,
22900,
47500,
2600,
40800,
103600,
35400,
30500,
3900,
5700,
7403,
11400,
26470,
55600,
23100,
41600,
85600,
10300,
8500,
79300,
14900,
null,
23200,
20000,
27200,
35200,
2800,
31400,
14600,
38100,
50500,
null,
9800,
63049,
79700,
8100,
null,
null,
16000,
8800,
53100,
13100,
43525,
197800,
25500,
9400,
13300,
15500,
15800,
29800,
43000,
16700,
27700,
116400,
35800,
4600,
57500,
18900,
84000,
14800,
34900,
90100,
86800,
8900,
103500,
16300,
10200,
20100,
44400,
34600,
11200,
13300,
22000,
22400,
12700,
null,
36770,
39000,
25716,
10200,
null,
33200,
82400,
299800,
55100,
383400,
29400,
22100,
17200,
13100,
4200,
45100,
32600,
21000,
42200,
45000,
12300,
34000,
null,
61500,
5900,
null,
40500,
76900,
31700,
57600,
29300,
139700,
17600,
19400,
10200,
10200,
3900,
13300,
null,
47000,
15300,
null,
null,
null,
6200,
56400,
41200,
28500,
null,
5000,
4600,
54400,
33500,
27700,
null,
54700,
18000,
29900,
72800,
67300,
78000,
11200,
12400,
30000,
24800,
31400,
21700,
18100,
6300,
10750,
5100,
22400,
203900,
28500,
8700,
22200,
16400,
34400,
33800,
27000,
41600,
16600,
29200,
47800,
26600,
13500,
25900,
51900,
31000,
8500,
null,
15900,
11900,
23600,
9900,
null,
14400,
52200,
71000,
4000,
45300,
40300,
14400,
29800,
20100,
97920,
7500,
6400,
16200,
58700,
26400,
19700,
9000,
21900,
18700,
40600,
38100,
23800,
30700,
39000,
5600,
19200,
237100,
75500,
23900,
null,
7700,
null,
10700,
16200,
30900,
14500,
72800,
63500,
23800,
26700,
43900,
17500,
28800,
15900,
42400,
35300,
24600,
13200,
25800,
8500,
43500,
21300,
5100,
22100,
7750,
73000,
2500,
49800,
16400,
null,
12500,
8100,
41900,
48100,
51500,
46900,
28300,
26000,
14800,
54700,
21800,
17300,
null,
3400,
25400,
8900,
70000,
21800,
13900,
16000,
45100,
52300,
16100,
19800,
null,
18400,
24500,
71400,
30900,
15000,
8000,
11400,
3800,
55400,
null,
52800,
10900,
8600,
26200,
100500,
22200,
25600,
null,
28200,
5600,
28900,
50300,
21800,
153600,
22500,
null,
12400,
2000,
47000,
13500,
34600,
18800,
21100,
null,
12800,
39700,
20800,
5600,
25400,
41900,
32700,
35700,
28400,
12400,
16400,
8600,
11600,
25100,
8700,
28500,
39300,
28100,
73500,
21900,
49300,
19000,
10700,
7300,
18900,
8500,
26700,
135600,
7100,
5000,
null,
38100,
15400,
10600,
7800,
27200,
66000,
18200,
76200,
51700,
38900,
22900,
12500,
null,
15000,
11800,
62800,
14200,
113400,
71300,
54500,
9200,
33900,
43850,
22700,
null,
11000,
null,
24500,
null,
19400,
37800,
23500,
12900,
47500,
5000,
18500,
14000,
46700,
77900,
15300,
30900,
37300,
25500,
106100,
23600,
19000,
21400,
null,
26300,
19100,
null,
null,
72700,
18100,
61400,
25200,
34700,
10700,
10500,
8700,
12600,
79300,
20500,
16900,
20300,
28100,
44700,
16100,
91200,
19500,
65700,
18200,
79700,
17900,
79200,
58900,
46500,
46500,
25900,
34600,
36400,
39700,
25400,
6000,
11300,
53900,
41800,
112200,
62400,
28700,
33900,
13800,
18400,
44800,
17400,
48800,
14800,
6900,
13100,
34900,
45000,
80387,
85500,
10600,
15300,
16200,
65500,
19200,
51400,
42400,
53300,
23600,
28700,
70300,
5900,
14200,
31600,
22600,
49800,
4150,
63000,
30400,
19400,
20200,
63000,
48500,
15900,
31200,
34700,
9600,
23200,
30700,
67200,
54700,
39850,
10200,
33900,
43000,
66400,
74900,
12600,
50700,
20000,
12900,
35700,
17900,
null,
20100,
null,
53700,
11082,
null,
12400,
32600,
106700,
10400,
24500,
158900,
16600,
47400,
11700,
17900,
29600,
8900,
8200,
null,
11800,
23000,
24000,
null,
38900,
52900,
23000,
26000,
15900,
15100,
null,
28200,
15200,
17000,
17000,
12700,
19500,
29700,
17200,
9780,
24000,
52700,
28700,
5900,
43300,
60600,
13900,
15300,
19900,
13600,
16900,
15400,
30200,
81700,
24300,
18000,
19000,
17600,
16400,
17400,
27000,
15900,
36100,
19700,
118100,
null,
13900,
69500,
15900,
9200,
null,
30400,
9900,
24200,
29500,
null,
25800,
29900,
29900,
14700,
11500,
70800,
7800,
24800,
29100,
11600,
13400,
8100,
18500,
44500,
14400,
32800,
27600,
null,
null,
8200,
13800,
19800,
null,
59400,
52700,
18000,
11500,
22049,
null,
14500,
61000,
31700,
null,
14400,
11900,
25700,
34300,
20600,
17100,
52700,
14600,
7500,
9200,
59100,
6550,
55600,
11500,
17700,
null,
59000,
26800,
7600,
19600,
37300,
16100,
null,
57000,
null,
24400,
35800,
14600,
21500,
13400,
23700,
null,
31500,
19800,
null,
137500,
15900,
14800,
39400,
null,
24100,
19300,
9600,
6500,
60220,
11440,
10500,
null,
38600,
43300,
8300,
236900,
26200,
null,
10900,
36000,
17100,
29300,
null,
2000,
20700,
64100,
21900,
15000,
35000,
6000,
null,
15800,
20800,
null,
81600,
31000,
10800,
42500,
27000,
17600,
17800,
14100,
null,
null,
17500,
61400,
56100,
17800,
61300,
12000,
48200,
33300,
37500,
35500,
30600,
66100,
38324,
16900,
38700,
18900,
23800,
117000,
34400,
14600,
null,
32700,
26100,
30500,
31000,
12900,
6600,
18500,
44100,
51700,
7100,
3500,
26100,
31500,
43500,
19200,
32700,
17800,
32500,
11600,
5500,
27100,
121800,
24800,
21400,
11900,
null,
16000,
null,
46300,
30700,
15700,
5400,
35300,
39500,
30900,
38500,
25300,
8300,
null,
78600,
37500,
34400,
null,
36400,
33400,
19180,
63100,
null,
8800,
4000,
43400,
13100,
16200,
11700,
42000,
73900,
24800,
18700,
31800,
10700,
20900,
24300,
15900,
31500,
29600,
26700,
36400,
null,
null,
38500,
13300,
49755,
55000,
28700,
34800,
71900,
6600,
40500,
2900,
5600,
8000,
42800,
45900,
14400,
27000,
30400,
30700,
20900,
33500,
13550,
6500,
43100,
21400,
135900,
null,
32100,
null,
23400,
15200,
5700,
13800,
9000,
21200,
19000,
null,
15200,
57500,
25200,
7300,
26000,
24100,
14100,
13600,
10630,
17700,
23300,
39800,
11900,
25900,
6400,
16600,
7400,
4500,
5900,
23600,
17000,
54700,
29500,
17000,
20300,
17900,
84400,
27500,
28100,
34800,
6600,
null,
null,
37700,
21300,
36500,
14700,
27400,
null,
49200,
485900,
3100,
64800,
null,
21200,
20900,
80400,
33000,
30800,
25700,
null,
null,
117800,
null,
8200,
68000,
17550,
49000,
47200,
13200,
24900,
null,
24100,
14400,
10500,
55000,
14400,
15000,
24700,
44700,
26500,
14000,
36500,
81700,
49700,
39400,
29700,
14550,
null,
31500,
36900,
121200,
38400,
62100,
null,
24800,
43100,
31100,
13900,
7100,
null,
28700,
9900,
15900,
15100,
16400,
32400,
74400,
24200,
20600,
null,
8400,
19700,
29200,
47500,
28400,
12600,
23000,
12300,
23200,
20000,
7700,
21300,
null,
27501,
33900,
20400,
18500,
34600,
6000,
12600,
66700,
16500,
19500,
41700,
7500,
39200,
74300,
33400,
49200,
6700,
7100,
9500,
31700,
100427,
74400,
51800,
99300,
38200,
58000,
null,
15500,
11900,
null,
44000,
26100,
10600,
18100,
19900,
46800,
121000,
32700,
44400,
83400,
19300,
52300,
119200,
null,
24500,
6400,
37100,
27900,
11000,
52200,
22500,
16000,
9811,
null,
24100,
22700,
12500,
15500,
28900,
21900,
22500,
13000,
19600,
25100,
58600,
32800,
18900,
22300,
72300,
14700,
36700,
18300,
30500,
10400,
30600,
31800,
29700,
52300,
34800,
null,
20400,
17500,
41100,
41500,
16400,
10000,
48300,
12100,
170500,
40600,
87000,
26100,
42700,
null,
22800,
23400,
1500,
10100,
null,
82708,
34800,
null,
24900,
2500,
35200,
39600,
52600,
57900,
10700,
16000,
12600,
65100,
30100,
64500,
12500,
11500,
11100,
14300,
41300,
16850,
null,
94900,
null,
10300,
7600,
24000,
13900,
9800,
46000,
31600,
65900,
null,
8600,
26500,
34100,
48600,
43000,
13300,
21400,
21000,
12000,
9400,
25600,
15800,
45800,
22400,
171500,
50600,
48300,
36800,
64600,
16600,
20600,
11100,
25900,
13700,
null,
25500,
null,
12200,
12900,
43700,
34700,
17000,
45600,
3800,
46700,
29400,
12700,
23800,
null,
8500,
33200,
28600,
87300,
41000,
26700,
13500,
55100,
16000,
63600,
13800,
30300,
15800,
21500,
50900,
12600,
41400,
null,
14200,
14300,
40100,
58400,
8500,
9000,
17000,
18500,
15900,
39300,
39300,
23400,
13800,
49600,
15000,
9700,
59200,
22000,
7800,
38900,
26900,
13800,
20600,
10600,
26000,
16300,
21500,
46000,
28300,
34500,
74550,
14200,
null,
null,
60400,
12300,
23000,
48600,
15000,
10700,
24200,
44400,
70700,
9800,
133300,
23500,
25200,
null,
69900,
12300,
null,
21000,
6900,
19400,
10500,
26300,
16700,
36100,
9000,
19000,
15500,
29600,
7750,
58400,
15800,
12600,
20700,
3400,
null,
13200,
173521,
8000,
25100,
78900,
48000,
19300,
58500,
124500,
34800,
null,
93500,
43200,
61600,
28000,
4200,
52200,
30100,
45000,
30200,
53114,
36300,
24900,
21000,
9500,
14000,
61300,
14300,
11000,
47100,
87000,
16700,
5400,
null,
38700,
18300,
16700,
22600,
39600,
12100,
34500,
38500,
10300,
10938,
6800,
5800,
20100,
13900,
16900,
40700,
10700,
null,
8400,
39100,
29100,
39400,
12000,
21300,
null,
8900,
42300,
8200,
14300,
39800,
37800,
null,
14100,
39600,
35900,
29500,
20400,
27500,
13200,
56400,
12900,
31600,
11900,
28700,
22000,
9900,
17500,
13400,
10200,
6500,
43800,
47700,
40000,
21150,
10500,
38400,
null,
49200,
30000,
17900,
39600,
21900,
47800,
26600,
20500,
39900,
null,
19400,
4600,
23700,
7800,
13800,
null,
13800,
15600,
77400,
11300,
null,
74400,
40000,
92800,
15900,
11500,
15100,
50100,
25900,
15900,
19400,
13100,
11600,
17800,
22300,
12300,
14200,
54800,
77788,
17800,
19000,
31500,
12500,
18200,
50900,
21200,
1300,
5600,
65300,
null,
78116,
null,
19900,
22200,
38300,
18100,
17200,
22200,
57300,
39800,
50500,
54200,
17700,
null,
19700,
63997,
64100,
26200,
21200,
3900,
18500,
9100,
20700,
38000,
7200,
19300,
null,
21600,
11600,
21200,
30200,
6700,
24800,
64100,
111600,
16200,
30700,
23700,
51500,
25600,
57300,
12900,
17000,
23900,
81000,
53200,
56900,
17300,
null,
92800,
10800,
17400,
14600,
27600,
30200,
32200,
37700,
17700,
34900,
21600,
null,
21600,
61300,
69300,
6600,
5100,
10900,
35600,
5800,
3600,
13000,
16000,
28500,
83400,
11600,
88000,
22800,
98200,
53200,
16300,
24500,
28700,
5800,
17100,
17000,
33800,
51300,
8400,
27000,
81500,
31600,
17200,
66900,
79800,
null,
12000,
null,
10300,
41500,
72900,
27600,
14700,
7650,
null,
17500,
144600,
19000,
33400,
null,
2000,
14500,
32800,
17100,
22000,
33900,
10000,
65900,
5400,
null,
31200,
18900,
10076,
45000,
42200,
61600,
40300,
12700,
4500,
9400,
null,
21700,
16000,
42600,
10100,
18400,
null,
10700,
70200,
67100,
34900,
13200,
26000,
18600,
31300,
184600,
165700,
27400,
28000,
65500,
33200,
26300,
28000,
26100,
15700,
14200,
43000,
18600,
44200,
29500,
26700,
56300,
21000,
53100,
48700,
53100,
16358,
null,
45300,
15500,
7400,
57000,
10200,
5400,
25500,
57000,
12900,
4000,
20400,
32800,
20200,
18900,
25700,
7700,
null,
16900,
18000,
81600,
18800,
4200,
24000,
28900,
20000,
15300,
36100,
38000,
63400,
40900,
26600,
null,
46400,
12300,
11000,
18300,
22100,
9500,
5500,
19300,
21600,
11200,
5800,
5700,
67500,
21500,
36100,
70300,
4300,
10300,
10400,
40800,
7370,
77700,
35200,
24700,
91500,
89000,
null,
102600,
115800,
26000,
18800,
10700,
38100,
18600,
86600,
13400,
94900,
42100,
44700,
12100,
27400,
null,
19200,
30500,
null,
11300,
21900,
26600,
22174,
29700,
25700,
24400,
46500,
6700,
16300,
null,
17100,
63700,
10400,
8600,
8100,
22800,
175400,
21900,
6900,
222800,
25800,
23500,
18500,
14700,
62700,
71700,
10900,
null,
39100,
48900,
16200,
49500,
26900,
8300,
29900,
6900,
5000,
19900,
63500,
37100,
22900,
16900,
15600,
57700,
43300,
9500,
22700,
6200,
34800,
19400,
6200,
null,
null,
9900,
21000,
20000,
6800,
3200,
9500,
1100,
20300,
15700,
22600,
15600,
31600,
12400,
9200,
130400,
59300,
3950,
39000,
23900,
14900,
10100,
19100,
256700,
30100,
48500,
13200,
65500,
57900,
8300,
19600,
26500,
91500,
null,
18400,
41500,
61900,
53700,
null,
23100,
null,
null,
23000,
28800,
29400,
27400,
8000,
9200,
21400,
70900,
6990,
3300,
14100,
50400,
58100,
21000,
29300,
6800,
null,
16000,
15300,
null,
30000,
45200,
19000,
18000,
16400,
13400,
41300,
81000,
2000,
50700,
41500,
19500,
13900,
30100,
20500,
56400,
60000,
23200,
45700,
18300,
36500,
9400,
20700,
9000,
23200,
9600,
24300,
null,
18700,
13700,
23200,
25000,
48400,
19800,
30600,
25731,
37800,
26200,
32800,
15400,
5200,
32700,
10700,
80800,
33800,
25900,
38100,
42000,
118800,
9500,
4300,
3500,
null,
7000,
175044,
35300,
20760,
35000,
5300,
66200,
69300,
41900,
16200,
11500,
null,
54700,
57400,
41000,
9400,
null,
18400,
10800,
36500,
23300,
7300,
11600,
13400,
null,
15900,
21500,
10800,
36700,
32800,
27600,
37700,
29000,
19800,
11500,
10300,
92900,
16400,
12700,
48500,
31100,
20500,
17500,
18800,
19000,
6400,
23300,
58365,
11000,
8200,
11200,
28500,
18800,
23700,
14300,
null,
62100,
16200,
22900,
131300,
55100,
11600,
16100,
39200,
null,
16700,
11100,
23700,
11200,
18200,
10700,
11100,
47400,
null,
6850,
12600,
26400,
159900,
null,
20900,
132700,
null,
8100,
51500,
19050,
53900,
40900,
24800,
null,
30700,
31400,
23400,
54200,
16100,
18700,
62500,
60300,
null,
11700,
28300,
39000,
17800,
38700,
12500,
12800,
69700,
59100,
24000,
12900,
18300,
48900,
7400,
12400,
13300,
79900,
10600,
35400,
16800,
12300,
31200,
31000,
61800,
33900,
null,
19500,
null,
60600,
19200,
28400,
14100,
16100,
49200,
24200,
15500,
50200,
null,
453500,
23800,
20000,
45500,
14900,
54200,
11500,
21000,
18100,
5300,
46900,
84000,
null,
10300,
55400,
47600,
15400,
10354,
12250,
26454,
36100,
11100,
10700,
94800,
23600,
9500,
10800,
27400,
5800,
17100,
123200,
29100,
6800,
8900,
21400,
4000,
33500,
20200,
32800,
34000,
45200,
13000,
23300,
17900,
34500,
38600,
9000,
25100,
125500,
23300,
9000,
68000,
8700,
74500,
17700,
22000,
52200,
36300,
22900,
18000,
83300,
54400,
18100,
null,
null,
11900,
null,
13800,
40500,
50300,
64300,
14000,
13700,
105600,
10700,
41900,
21200,
99100,
5300,
null,
15400,
null,
16600,
37400,
17000,
62200,
null,
11400,
101400,
22900,
17000,
43300,
null,
117900,
19600,
66600,
26100,
32000,
65800,
12700,
51000,
7800,
29800,
139900,
38500,
9500,
60400,
21000,
5500,
26100,
4600,
46300,
null,
12900,
null,
35900,
26000,
22100,
77200,
8000,
38998,
74280,
23300,
15900,
27600,
14700,
43739,
11100,
51800,
null,
16300,
39100,
null,
17600,
9300,
38900,
39100,
3550,
36700,
97900,
36600,
42600,
67600,
29400,
11000,
42100,
32500,
22000,
null,
33800,
21300,
35200,
11100,
51400,
70900,
11800,
27400,
13100,
32600,
null,
7200,
null,
30400,
21400,
32200,
42000,
null,
36300,
17400,
9800,
34000,
43600,
13700,
20800,
35600,
60800,
37800,
29100,
21500,
6600,
18400,
41700,
10700,
6700,
null,
21400,
31200,
49400,
110200,
23000,
53200,
77500,
63800,
51800,
31100,
14100,
37100,
11200,
26600,
17100,
5000,
49100,
15700,
62300,
35000,
27800,
60500,
42600,
6700,
12000,
9200,
54000,
null,
12700,
41400,
21000,
5100,
9000,
18300,
21800,
20000,
96400,
8000,
90800,
70200,
15300,
53000,
37800,
42300,
3100,
102400,
26600,
31200,
38200,
37200,
10300,
58300,
9600,
20100,
103900,
59100,
49600,
118600,
73000,
28300,
16700,
34400,
27500,
52400,
31000,
7500,
8900,
5300,
null,
12100,
3400,
5500,
16900,
12600,
13600,
7200,
52750,
28700,
17300,
11000,
29400,
16600,
90600,
34600,
17200,
42500,
26400,
51900,
40500,
null,
10100,
45300,
7100,
37600,
4400,
32700,
24300,
null,
44100,
16800,
20900,
17800,
23500,
11000,
5600,
16400,
19800,
27061,
16100,
59900,
null,
146400,
59200,
4200,
40700,
52500,
12000,
22000,
45000,
13700,
15000,
13400,
18100,
19100,
66500,
14300,
26800,
30400,
16900,
94200,
35200,
25500,
10100,
58800,
11800,
44600,
25625,
52900,
null,
31400,
38600,
14800,
49000,
130400,
14600,
5800,
15300,
76200,
33200,
9400,
41700,
46500,
24200,
75500,
51800,
9300,
53600,
75900,
27100,
44200,
64100,
33100,
61800,
5800,
21500,
null,
17000,
21400,
47000,
20100,
24200,
18500,
33500,
11500,
13800,
37600,
24100,
75400,
31900,
41000,
47100,
79300,
26100,
14100,
42000,
3700,
17500,
17500,
46000,
14000,
13100,
9100,
40300,
6800,
13600,
3000,
4400,
23100,
37700,
1500,
9400,
66500,
125800,
23600,
38900,
53770,
8200,
20600,
11500,
27100,
109900,
69500,
19500,
21200,
74800,
41300,
24200,
4100,
40900,
7700,
62900,
33200,
19700,
69100,
42500,
12000,
36700,
47100,
80900,
null,
6000,
22900,
29300,
47200,
45700,
null,
17000,
69200,
null,
11900,
38400,
26000,
34800,
14300,
55600,
25100,
22200,
64400,
15600,
17300,
16300,
37900,
17900,
42100,
41700,
null,
64200,
63400,
35500,
32600,
5200,
null,
85900,
40500,
11700,
31100,
55800,
11300,
17000,
21000,
19200,
7500,
38600,
38800,
3900,
182600,
32200,
null,
12500,
147800,
null,
4700,
5800,
30000,
null,
40700,
14700,
13000,
3800,
25400,
17200,
37200,
18100,
10400,
20200,
26900,
9200,
14700,
47500,
31900,
27700,
24900,
18300,
8500,
20400,
39300,
44700,
9300,
7800,
48200,
null,
52600,
30900,
50500,
13100,
27100,
21500,
53500,
53500,
13400,
38400,
9700,
21500,
24100,
57600,
102200,
6700,
3000,
22800,
6500,
59800,
null,
42800,
82300,
5700,
70300,
13100,
35800,
15700,
32500,
24400,
13600,
6500,
76800,
32400,
75500,
null,
25100,
36900,
5300,
17100,
16700,
46700,
null,
600,
6500,
6800,
31500,
39200,
24700,
null,
26200,
22400,
48000,
19600,
6300,
46300,
29800,
24150,
27300,
38000,
4400,
27000,
35100,
12800,
32800,
27200,
28300,
5100,
44700,
null,
12600,
14800,
31600,
25100,
83100,
4300,
31000,
44200,
51000,
48100,
12000,
23000,
null,
33200,
35000,
null,
58400,
3800,
91400,
16300,
23500,
null,
64700,
null,
23400,
31800,
36700,
31600,
45700,
11300,
9800,
14650,
12700,
168200,
10500,
22500,
37500,
5800,
26600,
29700,
34100,
49600,
19800,
9300,
100500,
23200,
22200,
37100,
7000,
43500,
75700,
21100,
null,
23700,
37000,
6900,
17600,
41800,
17300,
31000,
null,
55500,
43700,
45900,
4800,
16500,
19600,
9045,
29350,
41900,
16900,
37100,
12400,
78400,
41700,
40900,
58400,
15600,
78900,
5300,
47700,
34800,
34600,
null,
18400,
13600,
12900,
21600,
85500,
42200,
40500,
32700,
63400,
31600,
30700,
71000,
null,
8800,
16000,
81300,
24900,
null,
28400,
19200,
55900,
16500,
11800,
53700,
31000,
43600,
29300,
12100,
null,
20800,
9700,
14300,
21400,
12000,
32000,
13000,
44100,
39900,
20400,
43400,
null,
12800,
32600,
3200,
114200,
12100,
29100,
23500,
14900,
20800,
18500,
136400,
3400,
7000,
12300,
null,
28100,
27700,
33100,
null,
42900,
86300,
7400,
45400,
16900,
19700,
null,
69300,
22900,
null,
15500,
7000,
7500,
15900,
9100,
35300,
6000,
27800,
26700,
13300,
45000,
21900,
null,
13800,
106370,
64200,
null,
25900,
25400,
31900,
6700,
67300,
70500,
37800,
19500,
23100,
5000,
7900,
31500,
11300,
9600,
28500,
null,
51700,
51600,
32500,
46300,
118100,
26500,
11200,
null,
21500,
46000,
16000,
27600,
15500,
12900,
95200,
61400,
131200,
25400,
29100,
18500,
29200,
15400,
31200,
19100,
35900,
2700,
17000,
70500,
17400,
48000,
null,
32300,
79600,
42218,
25300,
24200,
91300,
10700,
6000,
58400,
12100,
3500,
61700,
8400,
20600,
23300,
48300,
42500,
1400,
20600,
null,
32800,
20300,
48100,
27300,
75000,
0,
18400,
57800,
8600,
19300,
19720,
79700,
29600,
14000,
34900,
15800,
8300,
20500,
null,
14700,
9600,
28200,
1900,
11900,
25450,
17600,
10500,
17200,
83600,
12300,
38900,
5200,
8000,
49669,
null,
24500,
13900,
151900,
43400,
20200,
29200,
13500,
6600,
41200,
8800,
37800,
197900,
40100,
17900,
23600,
60500,
51320,
23200,
17500,
null,
25600,
97300,
39900,
48100,
null,
11100,
25100,
37600,
11400,
16500,
33000,
8100,
18800,
8400,
15900,
29800,
15500,
18100,
60500,
17500,
47000,
null,
32900,
26600,
null,
91100,
101300,
116900,
11200,
8700,
10400,
36500,
18300,
62900,
16800,
40000,
4600,
25100,
13900,
null,
9900,
40300,
60400,
35800,
58300,
15800,
19500,
19400,
32600,
51100,
17000,
13200,
null,
12600,
22600,
20100,
55000,
12500,
14600,
12300,
6300,
12500,
11100,
31000,
32600,
14100,
19000,
58500,
23000,
64900,
34050,
13500,
10600,
11900,
32300,
47800,
41200,
40300,
23600,
38900,
18700,
null,
13000,
11300,
97000,
53500,
10100,
12200,
77600,
16100,
10900,
45200,
91500,
49700,
37100,
28800,
17000,
29600,
18800,
42900,
26700,
38200,
12100,
11700,
7761,
9000,
30600,
51200,
31600,
310200,
22500,
22000,
25000,
6400,
2700,
45300,
15500,
40100,
12500,
14700,
8900,
52500,
61700,
11700,
45900,
6900,
14600,
10100,
24000,
83800,
12600,
6500,
46700,
13400,
22200,
37100,
34400,
51300,
92700,
70000,
65000,
30400,
66500,
13900,
16400,
8100,
4650,
37800,
43600,
68400,
null,
22500,
38000,
24700,
31610,
50500,
94800,
null,
24300,
13400,
37200,
21800,
10100,
null,
14200,
56000,
18600,
18400,
26600,
13900,
15900,
11800,
70200,
8500,
null,
22400,
14600,
17000,
14800,
6500,
null,
26900,
27400,
36800,
20400,
36400,
28700,
27300,
19587,
8800,
54900,
24700,
26500,
55300,
26900,
35600,
19500,
37200,
13200,
7000,
158900,
28500,
8800,
25900,
78300,
16600,
29700,
40500,
20500,
31900,
66900,
25200,
38500,
9100,
86600,
7200,
134100,
13400,
13700,
11200,
54900,
null,
20900,
20600,
25400,
87800,
1400,
143200,
98500,
76400,
103900,
40200,
10400,
17800,
45000,
51900,
24600,
14100,
51600,
59400,
23200,
42000,
17200,
17400,
42300,
20200,
18700,
36300,
31000,
16300,
44900,
71500,
28600,
22400,
55770,
null,
34500,
29000,
null,
10700,
60600,
53200,
11100,
48800,
21900,
9600,
24900,
21800,
61000,
18700,
77800,
6700,
12700,
26700,
55300,
34500,
null,
19500,
4700,
111711,
19400,
30900,
16300,
37300,
115000,
13900,
26800,
20400,
54100,
68200,
1750,
141788,
20300,
17300,
55200,
85800,
63800,
17200,
30200,
129000,
null,
35000,
40200,
72800,
55250,
71000,
40500,
91800,
23900,
33900,
93900,
45100,
63400,
15800,
51800,
13100,
64300,
28100,
25000,
5500,
83000,
8600,
null,
33400,
63900,
18500,
29100,
62700,
24400,
18900,
null,
21900,
67300,
13200,
98500,
48500,
48600,
32700,
40300,
18400,
14900,
24900,
53085,
30600,
42506,
75800,
17100,
37500,
null,
59800,
37100,
24800,
26700,
29700,
14000,
15200,
30800,
22700,
14100,
13000,
117700,
72285,
27400,
56900,
51500,
17400,
14500,
41600,
254800,
18200,
57500,
53300,
39800,
78900,
75600,
111000,
28100,
39400,
28500,
41100,
229900,
45300,
40200,
48300,
27400,
34600,
70405,
9809,
50800,
7500,
46600,
26500,
24500,
16300,
25500,
null,
11200,
26400,
2100,
69800,
153300,
26800,
23900,
85500,
138800,
null,
67100,
11100,
197500,
79800,
17400,
65200,
9700,
236600,
83700,
31600,
29800,
29800,
24600,
15000,
50300,
23200,
13800,
8400,
29300,
null,
20600,
5200,
11400,
34600,
32300,
95430,
30600,
17900,
null,
null,
19400,
75600,
19900,
27800,
12500,
39000,
40100,
42900,
23100,
null,
11300,
31200,
35000,
38200,
8500,
76500,
null,
17800,
10900,
42000,
11200,
27500,
null,
30100,
42000,
20501,
25600,
16100,
12800,
13500,
28300,
51400,
20200,
38100,
35800,
36900,
null,
57700,
175900,
4600,
16000,
7700,
62600,
6900,
23000,
38700,
18500,
30000,
9500,
73700,
47400,
8000,
63600,
null,
12500,
32400,
23000,
27633,
97800,
45400,
38300,
125300,
41500,
24200,
27100,
33500,
41800,
37500,
48500,
37700,
19800,
125800,
49700,
89300,
24600,
3200,
77900,
35400,
15400,
11600,
22900,
45000,
16300,
36300,
17700,
15000,
9400,
17300,
99000,
11300,
null,
24900,
45100,
18500,
4400,
34700,
15000,
99800,
26600,
64550,
7800,
23100,
2100,
11200,
37200,
3500,
null,
34600,
17500,
25100,
13200,
15200,
8600,
11600,
7000,
null,
18000,
6800,
59800,
5500,
47600,
84000,
8600,
18600,
6500,
12200,
31600,
26000,
74600,
21700,
75500,
24400,
41800,
15900,
20300,
30000,
21300,
12600,
100900,
26300,
50700,
24300,
9600,
18500,
7900,
20000,
26500,
33500,
21000,
20500,
34800,
21400,
32900,
11700,
41000,
54400,
null,
34600,
72200,
52200,
42100,
46300,
16600,
22100,
39800,
6000,
24500,
39700,
33800,
103000,
27800,
41800,
45800,
81000,
29700,
42100,
29400,
15800,
53200,
30700,
15300,
8700,
27700,
25500,
null,
22000,
41300,
23100,
69300,
16700,
30100,
69300,
22600,
57800,
null,
42900,
115000,
28100,
18300,
13100,
27900,
32800,
null,
16400,
7500,
26100,
8600,
98000,
23600,
13000,
9100,
21600,
12400,
3800,
217600,
19900,
55500,
42700,
29500,
null,
null,
35200,
57600,
14600,
20700,
35300,
24900,
50200,
40900,
null,
40100,
81900,
55400,
38000,
null,
9600,
6900,
333400,
30100,
11100,
15600,
25830,
33200,
null,
7700,
22500,
null,
25400,
20800,
34100,
null,
9800,
30500,
22000,
40500,
20400,
67000,
141600,
11700,
21400,
12300,
23000,
1600,
24500,
null,
16500,
57800,
29100,
10400,
19100,
7300,
38900,
33500,
6700,
13100,
26000,
39500,
104700,
8950,
53400,
22100,
30700,
null,
28600,
15500,
21900,
26400,
null,
24700,
17000,
9900,
89300,
4500,
39000,
105420,
29000,
70200,
23100,
47100,
null,
63800,
9200,
88800,
22900,
78000,
28900,
34300,
12900,
56300,
16800,
null,
100400,
null,
13500,
4600,
25100,
75200,
21300,
21100,
21100,
6800,
34300,
88000,
13200,
2600,
27600,
29800,
null,
null,
42700,
16900,
28800,
null,
10600,
18700,
36100,
30400,
9000,
65900,
68700,
25700,
12200,
null,
3700,
45900,
17500,
9500,
null,
26200,
57900,
13600,
null,
16800,
98800,
null,
8300,
53600,
7700,
8900,
12900,
82600,
35200,
48600,
16500,
14200,
11000,
null,
10700,
23100,
132300,
31100,
174500,
38000,
43200,
15800,
10200,
12000,
18800,
30400,
14100,
35300,
4700,
30900,
22500,
17900,
6800,
null,
3600,
23200,
14600,
49400,
25400,
34900,
14000,
12400,
6400,
107700,
102400,
24100,
9300,
37600,
26300,
31600,
66400,
39300,
49700,
53600,
35900,
22100,
21800,
null,
32500,
55600,
36600,
6400,
15700,
8500,
34700,
41300,
12200,
52900,
13900,
35600,
29600,
8900,
26200,
66700,
5900,
18400,
16800,
31400,
17200,
2800,
81300,
28300,
36900,
19200,
53000,
11000,
12100,
37800,
29300,
18500,
19300,
null,
27200,
19600,
12700,
19000,
22400,
null,
24000,
26400,
19400,
23500,
35700,
12200,
2700,
44000,
26500,
22000,
18900,
8200,
115600,
34800,
32200,
null,
null,
9100,
22700,
14800,
13000,
74900,
6500,
18000,
28100,
11100,
21400,
10900,
null,
52500,
98700,
155900,
146700,
null,
4800,
27800,
null,
17200,
104000,
16800,
11800,
11000,
22300,
20000,
36000,
53232,
11000,
30300,
48400,
15700,
12800,
26800,
35900,
16000,
29400,
20600,
56700,
null,
40100,
16500,
30600,
57600,
18000,
null,
16700,
5700,
7300,
null,
28500,
null,
9000,
20432,
44200,
20200,
32300,
17300,
25300,
16300,
24700,
23400,
30200,
84800,
21500,
79500,
33200,
38700,
25000,
15200,
22000,
4400,
36800,
14700,
9750,
344500,
11400,
38800,
37300,
10300,
11200,
14500,
5400,
9000,
18900,
13500,
29400,
21400,
15100,
3000,
null,
22300,
56100,
26000,
43800,
null,
61400,
11300,
70800,
22100,
41100,
159200,
13800,
20100,
15800,
50200,
40400,
23131,
12300,
40000,
null,
27800,
12400,
24100,
2200,
7200,
31300,
8350,
null,
7500,
155400,
43100,
13300,
166800,
null,
10100,
121000,
null,
12952,
16600,
24400,
17200,
30500,
null,
201200,
68200,
87500,
32600,
89200,
24400,
3000,
41500,
47900,
10400,
9300,
18700,
20100,
111900,
null,
null,
12100,
9900,
28600,
5700,
19500,
84500,
6400,
51700,
16300,
18200,
22100,
19300,
42900,
34400,
43900,
9700,
42200,
19900,
62100,
32600,
14600,
6600,
10100,
15900,
18000,
29200,
37700,
31900,
24400,
78800,
55500,
30000,
56100,
null,
12500,
19400,
41100,
27100,
null,
37500,
null,
11000,
14500,
60800,
34900,
90000,
18000,
null,
59500,
59800,
19000,
24900,
39500,
27700,
70100,
53000,
27200,
null,
9400,
32200,
12200,
104900,
28700,
18500,
49400,
53500,
18900,
8200,
24000,
54800,
30100,
11300,
12300,
18300,
18100,
19500,
20000,
24300,
16400,
19300,
24700,
null,
12000,
174100,
14900,
null,
19400,
45200,
10600,
131100,
26800,
50900,
null,
16000,
null,
17400,
34700,
38900,
9300,
null,
22700,
33900,
38600,
6000,
29900,
15400,
78500,
54500,
47200,
77900,
50700,
9600,
16100,
41283,
43200,
34717,
50500,
28900,
71300,
83700,
14300,
24900,
null,
null,
10700,
14900,
null,
6500,
null,
6800,
21200,
1600,
11400,
28400,
42200,
60900,
19600,
44800,
22100,
57500,
78100,
16400,
27100,
58500,
33200,
19900,
5800,
9600,
37200,
52000,
81600,
30700,
21900,
31700,
16300,
10400,
26300,
31700,
47500,
28800,
null,
28600,
15600,
24100,
19100,
7700,
98200,
18300,
null,
17800,
9600,
5900,
24300,
26000,
26100,
20053,
19900,
10300,
27100,
null,
null,
66200,
31400,
15900,
1800,
24200,
28700,
58000,
60200,
59100,
16800,
32900,
38400,
26100,
23000,
40600,
20700,
51500,
38200,
38500,
29900,
47000,
67700,
31500,
13800,
11400,
22100,
9900,
22800,
5500,
12100,
15800,
38000,
6900,
31200,
null,
15300,
17600,
38400,
18400,
11100,
null,
40700,
40600,
null,
13200,
13500,
15700,
26500,
38200,
37500,
16100,
26100,
3500,
31600,
14800,
18700,
23000,
14500,
29300,
18000,
2500,
81200,
76300,
9700,
23500,
11900,
70300,
31150,
null,
16900,
19700,
null,
16600,
49700,
null,
null,
27250,
32300,
8800,
105500,
8300,
10000,
45200,
9700,
48000,
null,
24800,
27600,
15100,
19600,
11700,
16400,
21100,
17500,
10200,
null,
10000,
16800,
25100,
15100,
14900,
20400,
null,
8500,
42200,
13300,
11500,
13500,
47100,
13500,
11600,
13450,
7300,
null,
178400,
28300,
6700,
15500,
48500,
25800,
26600,
23300,
6600,
13500,
19900,
24600,
15800,
30800,
25600,
36900,
12700,
13700,
28800,
11800,
null,
21100,
45200,
9100,
3900,
80300,
8300,
4900,
14500,
30100,
null,
12500,
null,
20200,
13000,
48700,
91400,
14900,
118100,
22700,
8500,
40600,
28500,
42000,
19796,
15250,
16700,
40900,
8900,
28900,
12900,
58200,
28000,
21700,
15500,
22300,
3900,
29000,
28000,
45300,
23700,
19500,
63500,
10100,
24300,
48400,
20539,
68800,
47600,
null,
6300,
null,
14500,
36200,
44000,
null,
38800,
21300,
31700,
35600,
49100,
18300,
35500,
31500,
15010,
17000,
19000,
33000,
31550,
39300,
31500,
5500,
17100,
54800,
33500,
26500,
30700,
9300,
15400,
46800,
34100,
66200,
69700,
43400,
31400,
15700,
10400,
21900,
27100,
58400,
67900,
16400,
19200,
16400,
9600,
17300,
32200,
48900,
67600,
153300,
12000,
35500,
11800,
20800,
17400,
22300,
38500,
15600,
35500,
41400,
8800,
null,
54800,
2800,
5600,
40400,
9800,
14500,
null,
19000,
18400,
26100,
26400,
6500,
77300,
32900,
10500,
36400,
48300,
45200,
45900,
9800,
57100,
12700,
9400,
58900,
48000,
28000,
53700,
41600,
5100,
20950,
12000,
12000,
2400,
24500,
6500,
13600,
null,
24400,
14800,
4700,
45500,
7000,
12000,
38900,
13000,
37000,
null,
16500,
16100,
13000,
2200,
9400,
17200,
22100,
14454,
36800,
38800,
36000,
44300,
14400,
47800,
15200,
12600,
64700,
31000,
16000,
null,
5080,
25100,
3100,
69500,
18600,
29600,
19400,
34200,
8100,
21700,
119800,
31700,
13300,
15500,
3900,
22200,
46900,
17600,
9800,
null,
10700,
15500,
116700,
12500,
14000,
15200,
null,
37900,
11800,
25800,
16000,
34800,
51300,
54700,
24600,
53900,
21675,
6700,
31300,
82600,
25100,
73300,
null,
27900,
45400,
39700,
28279,
null,
null,
116700,
33200,
35500,
9300,
31200,
null,
25700,
21000,
null,
12400,
15100,
26500,
77500,
178000,
3775,
12000,
15000,
306600,
null,
null,
45400,
31300,
21700,
21600,
23100,
108800,
7300,
7400,
4800,
17700,
24600,
20200,
18600,
45400,
20300,
2000,
15300,
13100,
14700,
47600,
29400,
5900,
43000,
8100,
52700,
41701,
null,
20100,
25400,
null,
8300,
46000,
42900,
51800,
39600,
21700,
28700,
103200,
55900,
5000,
null,
17500,
27100,
24200,
null,
null,
203300,
42900,
23800,
21500,
22100,
89800,
38100,
7200,
null,
null,
5600,
40300,
23500,
39200,
4500,
49700,
2300,
27800,
14400,
null,
36800,
6200,
20000,
21500,
109400,
55600,
13000,
85000,
8500,
78200,
27700,
14900,
53200,
16600,
11100,
39200,
23900,
12700,
5400,
5500,
5500,
34400,
9400,
29200,
18400,
5500,
31100,
39100,
25700,
11700,
13500,
59600,
69000,
26600,
16800,
26100,
15900,
3300,
7500,
105500,
67300,
null,
9000,
37200,
25200,
14900,
17200,
5800,
15400,
60400,
40400,
18100,
null,
61900,
13800,
53800,
15000,
null,
18000,
13400,
null,
2600,
1900,
68000,
30079,
318800,
12700,
19800,
60000,
null,
5300,
50700,
10000,
8700,
37200,
15300,
15400,
23100,
253000,
20200,
10000,
87500,
30200,
34400,
null,
89400,
null,
42800,
17000,
107200,
25600,
34400,
14800,
25310,
24500,
14200,
107200,
30900,
27800,
28200,
32000,
16700,
19900,
41700,
63500,
39200,
22500,
23900,
66200,
29300,
9500,
44200,
30400,
68900,
22300,
57500,
50700,
19600,
81900,
53800,
35600,
6400,
21000,
17607,
27700,
16200,
null,
22100,
16500,
21200,
41000,
39700,
9900,
82159,
79750,
37600,
28300,
57100,
14200,
24700,
6500,
19500,
19800,
7200,
8400,
27200,
14300,
6500,
63400,
9800,
null,
25100,
22000,
8700,
55000,
null,
13900,
10800,
29800,
108200,
25100,
77800,
29500,
42500,
18600,
3700,
19900,
7000,
16501,
26900,
44900,
29800,
3600,
78700,
29500,
57200,
null,
40400,
10500,
39600,
34500,
9500,
8000,
21200,
null,
63000,
8018,
64300,
13200,
null,
10700,
10200,
7700,
54800,
19900,
8679,
10500,
53000,
15000,
35500,
50400,
null,
7800,
16500,
35100,
23100,
36500,
60200,
31300,
21700,
15400,
null,
11600,
26000,
44900,
11500,
8400,
19900,
107100,
11500,
3300,
53100,
17800,
66900,
1800,
3300,
null,
31800,
22700,
41900,
67500,
67300,
25700,
87500,
35700,
18700,
37000,
73200,
146100,
38200,
22500,
29900,
52500,
null,
27200,
63400,
16100,
47900,
27800,
9900,
46000,
21600,
76600,
117200,
15100,
28700,
231200,
null,
14700,
34400,
41200,
26000,
null,
39600,
8900,
5500,
17400,
11800,
15100,
59300,
14300,
16800,
11100,
null,
12250,
null,
51700,
12000,
10700,
19500,
null,
30200,
59100,
18000,
10300,
null,
53000,
38000,
49800,
12100,
null,
17500,
null,
24200,
21500,
14800,
67000,
28300,
16600,
19200,
64200,
172400,
24900,
32600,
21300,
35100,
33000,
101400,
null,
54300,
5600,
12000,
112800,
8600,
49610,
17800,
20200,
38000,
130000,
17500,
31100,
17200,
98100,
35200,
14600,
47800,
26700,
17700,
19500,
15800,
null,
43542,
4000,
18100,
13000,
34000,
40200,
163202,
46400,
null,
24900,
38700,
22200,
null,
12400,
24200,
34900,
null,
29102,
58000,
25400,
null,
32200,
29600,
12023,
8000,
48500,
58316,
11800,
null,
195592,
17900,
176300,
null,
25700,
80400,
14500,
57800,
65200,
15700,
43803,
80200,
null,
8600,
51300,
56800,
109000,
31600,
36200,
47700,
33600,
23300,
14900,
5100,
11700,
166600,
19900,
27500,
11000,
24400,
18500,
31200,
6500,
16650,
28900,
44200,
32800,
6920,
12900,
61900,
37700,
null,
22800,
17800,
28300,
13500,
18300,
7325,
33800,
19100,
45900,
26000,
34400,
null,
14300,
17100,
20700,
183400,
null,
9900,
20100,
9800,
54100,
9700,
38500,
4700,
53251,
7400,
null,
null,
66100,
27100,
null,
22200,
8800,
16900,
41600,
11600,
41100,
10000,
7795,
48900,
42800,
13100,
32500,
26100,
39200,
25700,
26100,
7800,
56100,
5100,
8500,
5400,
27400,
9200,
33400,
76600,
15200,
39700,
24700,
10600,
45300,
3900,
18200,
14200,
45700,
7300,
33100,
26400,
109100,
53800,
68600,
null,
13400,
18300,
null,
24700,
38500,
29300,
17300,
16200,
4700,
23300,
234800,
12800,
61200,
9400,
null,
6300,
12000,
47400,
6000,
27900,
14300,
77600,
35600,
35900,
26400,
4700,
14200,
29500,
5000,
null,
60000,
8700,
58300,
null,
null,
21200,
null,
12300,
9000,
26200,
9300,
31000,
12800,
19900,
23800,
3400,
5300,
null,
34301,
51800,
14300,
16000,
11400,
null,
5800,
43000,
6400,
2800,
41100,
10600,
51800,
33800,
24100,
23600,
13500,
31400,
42100,
131100,
134300,
13700,
54900,
15500,
187600,
57002,
14600,
17800,
40800,
53300,
25700,
24600,
31300,
7500,
22400,
50400,
79200,
59500,
28000,
75500,
82300,
11400,
13100,
null,
37100,
21000,
42750,
16300,
147100,
12800,
49200,
40000,
40100,
28300,
62000,
131100,
16500,
41800,
14700,
22000,
18400,
33700,
17500,
2400,
35700,
30000,
null,
7200,
14400,
14400,
32900,
26400,
22200,
31500,
null,
41100,
9000,
108100,
39600,
30900,
10200,
29100,
null,
21200,
25500,
29000,
42900,
28600,
71700,
61400,
58800,
15100,
null,
10300,
19100,
27600,
19700,
9200,
6800,
41900,
128500,
34100,
26600,
20300,
7200,
9700,
46900,
null,
21500,
49100,
54000,
null,
20900,
null,
94800,
37700,
10200,
25400,
143800,
43700,
29200,
13000,
19500,
76700,
60600,
35800,
23500,
10600,
109700,
85000,
51400,
71700,
8700,
26100,
45100,
7800,
28500,
6800,
22000,
24100,
42700,
18400,
34900,
7300,
55700,
5500,
56400,
25200,
33200,
18400,
62300,
17100,
74700,
53600,
39900,
34000,
47700,
20000,
24300,
44500,
43200,
67900,
47000,
51100,
13400,
22100,
13200,
null,
3800,
58200,
27800,
20100,
34000,
36300,
17600,
83700,
29600,
7500,
36300,
11800,
26600,
21300,
44500,
34800,
21800,
264600,
28700,
null,
40300,
36300,
25000,
46500,
15300,
null,
null,
null,
37300,
12600,
42900,
52500,
null,
6400,
13500,
15800,
79800,
18900,
15400,
41400,
43300,
27598,
null,
61900,
19600,
29000,
27800,
21300,
34600,
13400,
23900,
93400,
26800,
47800,
29300,
34250,
39000,
null,
9800,
150900,
24100,
18900,
22700,
22500,
29000,
35800,
46000,
42900,
42100,
148400,
27400,
5400,
21800,
null,
122600,
31600,
6300,
94700,
20400,
35919,
5900,
null,
31600,
19800,
59400,
45300,
34200,
29900,
null,
70200,
74000,
null,
24300,
30600,
38400,
33900,
7900,
15300,
52847,
25500,
17200,
61965,
44000,
null,
15200,
24600,
null,
16500,
18300,
10900,
35100,
9400,
38100,
15500,
27000,
64400,
10500,
12200,
10800,
4500,
18800,
41000,
50300,
16300,
65300,
10900,
43000,
10500,
64200,
11800,
32100,
19800,
41400,
27400,
23900,
24000,
22400,
10100,
30500,
31200,
6600,
39800,
null,
188200,
21200,
17100,
41766,
27700,
61400,
49500,
34300,
23300,
15900,
20200,
21200,
12900,
10100,
13800,
2400,
23400,
31600,
19500,
34300,
14800,
15700,
67800,
33700,
44900,
17700,
2850,
14100,
68800,
17400,
6300,
31500,
34800,
22000,
75400,
47400,
36000,
null,
21300,
11800,
17300,
13000,
64800,
8600,
38200,
10900,
700,
4700,
94200,
20500,
6100,
18200,
null,
37800,
87200,
32900,
12200,
34800,
26100,
null,
60200,
27000,
51000,
2500,
20100,
27800,
null,
11000,
12300,
24500,
108400,
37400,
20300,
19400,
15400,
26900,
11000,
14900,
107100,
40400,
23100,
null,
216000,
92200,
6500,
40100,
25800,
10000,
null,
38036,
24000,
10400,
19000,
17300,
27500,
null,
91000,
24200,
52800,
23800,
25100,
60400,
38018,
23900,
28900,
13200,
31600,
12900,
16000,
5200,
55900,
12100,
44100,
17300,
26500,
27700,
70900,
37500,
10300,
19500,
null,
14300,
31300,
46000,
32100,
44300,
null,
null,
22800,
26300,
37900,
21400,
27700,
21100,
24600,
14000,
19400,
30100,
75400,
13100,
27100,
54600,
15000,
56000,
40600,
null,
15000,
16300,
14800,
34000,
34500,
71500,
31100,
10300,
null,
15800,
19500,
2000,
7500,
33800,
11600,
131000,
42600,
12100,
61500,
13000,
14300,
72820,
20775,
25800,
30700,
25900,
7800,
14900,
49100,
28300,
60700,
null,
13300,
7500,
15800,
15500,
27100,
11900,
14700,
31300,
22700,
40400,
33800,
35100,
177350,
34800,
20800,
81800,
25800,
35800,
26500,
15377,
24600,
81400,
60800,
44200,
21100,
8300,
12300,
101000,
13800,
25000,
35800,
28600,
30400,
17150,
8700,
null,
22400,
85100,
null,
33400,
22700,
null,
21300,
18600,
46100,
6000,
15100,
49800,
7300,
23300,
24600,
40500,
16500,
27500,
25700,
12200,
11000,
25800,
66000,
61300,
22400,
6300,
18800,
55805,
12400,
null,
71000,
2600,
46600,
null,
12300,
24100,
null,
32241,
43300,
30200,
78500,
null,
4800,
65100,
36600,
8100,
18800,
23500,
19400,
13100,
155300,
323800,
6700,
12200,
66400,
null,
21100,
11300,
40700,
6300,
19900,
51900,
23600,
24600,
null,
10000,
6500,
18600,
43000,
33000,
9300,
41500,
110200,
188500,
10800,
13300,
null,
10500,
26600,
20300,
18200,
113500,
5000,
12200,
10900,
17500,
14400,
8100,
37100,
31200,
8100,
76700,
35000,
30200,
10300,
33900,
12800,
37000,
null,
32500,
11600,
28200,
null,
8700,
122500,
32600,
10200,
6600,
null,
13900,
82600,
18500,
21300,
15363,
90300,
20600,
35800,
20100,
22300,
71100,
19300,
35000,
68900,
null,
75700,
11300,
57500,
7900,
24800,
17000,
16300,
7300,
12200,
31200,
null,
51400,
null,
10800,
17800,
22500,
22800,
43100,
39500,
29000,
6500,
10800,
19000,
11300,
11500,
94500,
5900,
161000,
28700,
16300,
null,
43600,
7900,
null,
37600,
32700,
40900,
11500,
null,
25800,
45900,
29400,
62000,
169400,
13100,
55000,
9450,
32500,
28900,
null,
16400,
29400,
null,
77600,
37250,
36700,
57300,
16900,
16200,
28900,
5100,
116000,
20000,
29000,
8100,
null,
25900,
26900,
12700,
1000,
27900,
33400,
23100,
24300,
22760,
5200,
19200,
64600,
27000,
58300,
null,
8800,
28700,
51900,
59100,
11000,
21000,
33000,
7900,
104800,
17100,
15700,
15500,
27800,
19000,
18300,
34900,
21800,
89200,
12300,
44600,
26200,
76600,
37600,
7100,
40800,
34500,
26100,
21000,
13500,
45400,
85400,
null,
18500,
34400,
31200,
22100,
22500,
38500,
52500,
6300,
2400,
42600,
8600,
34100,
23300,
61800,
24500,
22900,
12400,
43000,
14000,
10500,
15400,
6900,
22500,
43400,
73200,
32800,
10800,
206000,
45500,
57800,
28300,
6000,
19300,
24100,
12500,
22900,
38500,
null,
19700,
91600,
35700,
53200,
12900,
5000,
61100,
22100,
20100,
null,
30300,
33200,
37900,
24800,
17600,
29000,
8100,
17600,
15500,
27200,
36450,
13500,
22700,
40200,
3500,
15400,
36900,
16300,
8500,
30300,
55400,
null,
null,
null,
26500,
33400,
40900,
11900,
17900,
62800,
51400,
null,
11600,
23300,
36300,
10100,
37100,
65700,
16100,
9000,
31700,
35300,
25100,
63900,
33990,
18200,
59500,
45200,
28100,
12500,
18300,
13800,
52597,
5600,
49500,
12500,
29600,
10500,
2600,
18400,
7500,
13800,
43000,
15300,
16700,
6500,
16900,
29600,
50100,
39100,
7100,
36600,
3900,
34700,
21400,
2400,
12800,
45800,
46400,
28900,
15600,
null,
31700,
1200,
44900,
17700,
62000,
23700,
20800,
12700,
24200,
19700,
73900,
25500,
23000,
48900,
18300,
17700,
32000,
52300,
28200,
30000,
15100,
16300,
4000,
34900,
22000,
18400,
42000,
41300,
36600,
34300,
15000,
65000,
11950,
17800,
20400,
6400,
26400,
25300,
53000,
5100,
17700,
10600,
12100,
23000,
40700,
12000,
null,
null,
35209,
27300,
21200,
69400,
22500,
39600,
18500,
17600,
20100,
23800,
8400,
28100,
16300,
45100,
49000,
11700,
5500,
7100,
36900,
10300,
52500,
7800,
5500,
26900,
149100,
37200,
29100,
59500,
8400,
29700,
35600,
16500,
42600,
14500,
6400,
9300,
23400,
26900,
111150,
46200,
2500,
72000,
39600,
22100,
23400,
8300,
8400,
null,
11600,
29900,
21600,
12600,
34700,
null,
153000,
106800,
54000,
10100,
76200,
39100,
29800,
4300,
8100,
6300,
16300,
10200,
22700,
15400,
283600,
6600,
45900,
5000,
47200,
41500,
67300,
26600,
8100,
50000,
null,
23800,
33000,
32600,
4350,
86800,
12500,
38900,
35800,
21600,
11800,
null,
5600,
null,
5500,
16300,
41400,
46300,
38200,
3300,
156900,
5500,
91600,
35900,
14200,
31600,
10300,
null,
8200,
null,
18100,
97000,
26500,
24200,
18400,
27700,
32700,
42100,
31500,
35200,
18000,
14200,
13100,
29100,
14900,
47100,
30600,
26000,
26900,
15400,
51000,
17500,
48000,
10300,
71600,
28100,
null,
33100,
7800,
3500,
51500,
62700,
52680,
10200,
31300,
56400,
51800,
32400,
29700,
29500,
27400,
25900,
12100,
58400,
25500,
62200,
61200,
103000,
9400,
86700,
8100,
17900,
65900,
15200,
18700,
17900,
22600,
15600,
null,
17700,
49300,
null,
75000,
37400,
9300,
42100,
28700,
13400,
null,
41300,
23900,
8600,
37900,
10500,
43200,
null,
45000,
32000,
18100,
18700,
69400,
5500,
6800,
26300,
44900,
250300,
24200,
188000,
19800,
14500,
31500,
25400,
2900,
22600,
13100,
33100,
44400,
21600,
null,
30000,
55000,
28100,
38900,
26900,
null,
26200,
null,
null,
45800,
59900,
92200,
17300,
49100,
4100,
10200,
29757,
13700,
43100,
13300,
59800,
34000,
81500,
8800,
6550,
35900,
9100,
84900,
40700,
8600,
49400,
9000,
24800,
28700,
38800,
55100,
21800,
34600,
5600,
45700,
25700,
13200,
12700,
26400,
67900,
21300,
14100,
22800,
16900,
12600,
11500,
19400,
28000,
17600,
29300,
15900,
13900,
14000,
15400,
31100,
55000,
55800,
9100,
15300,
8600,
9900,
25500,
286800,
15300,
16300,
41500,
8300,
20800,
46500,
18000,
18800,
93249,
7100,
38100,
7600,
6500,
21400,
46100,
9900,
16400,
21500,
7000,
107000,
46800,
23750,
7100,
11200,
5500,
65068,
23500,
19100,
18600,
26900,
23300,
18300,
null,
32900,
8100,
25900,
6500,
10900,
3000,
20800,
null,
58500,
26900,
9600,
5200,
77900,
28800,
null,
14500,
20850,
18700,
9800,
12100,
15500,
31300,
25700,
13700,
30500,
17900,
34200,
null,
34900,
49500,
73600,
11200,
24200,
12400,
16300,
12200,
24500,
13000,
null,
42900,
23500,
16700,
14200,
9200,
2300,
11100,
8900,
41200,
27000,
12800,
6600,
null,
3700,
9600,
2500,
42200,
82900,
68200,
7500,
18000,
48100,
16100,
19600,
13900,
20700,
32000,
31500,
43500,
30400,
39100,
13500,
8400,
12800,
10200,
47500,
20800,
13000,
null,
12300,
21800,
2800,
20500,
13000,
20500,
14200,
16100,
null,
10500,
9900,
74000,
18100,
25500,
21500,
6000,
16000,
107600,
19300,
21800,
34100,
5100,
62700,
null,
10300,
27500,
3500,
41600,
116700,
31800,
2900,
null,
33000,
13700,
16900,
32800,
22900,
38300,
23200,
35800,
26000,
19000,
36400,
52400,
8500,
15600,
10000,
5500,
6400,
6000,
35700,
20900,
14200,
8300,
14000,
null,
17600,
28600,
20700,
263500,
25600,
7000,
12500,
43600,
8400,
46600,
17100,
70800,
7400,
48800,
44700,
2500,
31400,
39500,
24300,
54500,
18700,
122700,
7200,
16300,
7300,
5300,
14300,
30400,
null,
20900,
21200,
50000,
4800,
23600,
38300,
28400,
28800,
105100,
46900,
10100,
21800,
null,
16800,
27600,
18400,
37300,
10000,
null,
12000,
25800,
null,
null,
null,
null,
19000,
27200,
27200,
null,
15000,
36900,
null,
12300,
12000,
21900,
14112,
5900,
26300,
43300,
53500,
36700,
30900,
6700,
27800,
null,
null,
40000,
4100,
21100,
35200,
26000,
9100,
107400,
15300,
10200,
159800,
41800,
21100,
24200,
12300,
24800,
1100,
30100,
52500,
12100,
22600,
54900,
11700,
5700,
16000,
16000,
110400,
null,
37100,
7600,
7600,
43100,
21900,
10800,
11000,
20200,
5200,
20100,
12100,
33100,
8500,
71400,
null,
11900,
null,
36700,
56900,
11900,
52700,
33600,
67200,
50300,
44200,
12610,
28100,
18400,
49200,
9100,
9600,
8500,
34800,
10700,
68300,
24900,
17600,
7900,
35100,
28200,
44100,
16300,
49000,
87700,
55900,
14400,
33500,
11500,
32000,
20400,
19500,
22200,
10600,
30600,
null,
31400,
19300,
34200,
21535,
60300,
43800,
10800,
21100,
10400,
23700,
21300,
15700,
27400,
57000,
6700,
37000,
4800,
10700,
61100,
34000,
22800,
9900,
51000,
8455,
16400,
72000,
13500,
75100,
52800,
46900,
46100,
17500,
9300,
22400,
15600,
14000,
25600,
16700,
null,
25600,
21900,
147700,
25300,
21600,
9900,
27300,
22200,
47600,
15200,
50725,
13600,
15700,
null,
18700,
7100,
18700,
25300,
43500,
15700,
6800,
14200,
33000,
27400,
53400,
14300,
20500,
7200,
18300,
7700,
11700,
21400,
null,
8600,
13100,
1800,
26600,
47500,
9900,
8700,
19200,
37400,
39600,
29800,
12300,
4100,
51100,
54200,
30500,
38500,
34700,
52500,
10200,
null,
42000,
21800,
16600,
null,
37200,
34400,
7600,
42511,
6700,
53000,
null,
22100,
11600,
7000,
30600,
50800,
59700,
29600,
41300,
20800,
83200,
30000,
10700,
26700,
9100,
16500,
12300,
176600,
32000,
25300,
107200,
null,
null,
28700,
27700,
48800,
125400,
17400,
15400,
33600,
63000,
null,
17900,
75700,
114800,
null,
21900,
28300,
21700,
24300,
41200,
38900,
20700,
null,
24300,
33700,
null,
38900,
24500,
67500,
27700,
10900,
45700,
28400,
7300,
10400,
40200,
null,
11600,
13300,
11900,
7000,
22300,
21300,
21500,
8300,
58700,
28400,
43900,
null,
26500,
13300,
null,
5800,
48000,
73600,
21400,
30150,
37400,
46600,
22100,
30400,
6700,
20000,
null,
19300,
36200,
56900,
105600,
null,
57200,
15100,
40200,
20300,
16100,
23800,
18000,
147600,
17500,
15600,
23800,
23000,
38700,
18700,
101200,
12600,
3700,
null,
14000,
6900,
16100,
null,
18200,
62700,
23600,
10600,
26800,
18600,
31000,
15300,
5300,
14950,
null,
26900,
20400,
13300,
32100,
41300,
52300,
13400,
28000,
105600,
33000,
31100,
27500,
19300,
83100,
13500,
22500,
4500,
6600,
47100,
null,
9300,
54700,
15600,
16500,
24500,
63282,
47300,
30376,
8900,
23900,
60200,
9300,
18800,
23500,
24100,
10500,
7500,
17400,
7400,
52700,
70900,
18800,
5600,
28900,
26700,
25810,
56900,
40600,
15600,
22050,
null,
2400,
null,
27400,
11700,
6400,
12300,
10200,
67000,
25600,
24300,
16900,
16300,
33100,
36200,
25300,
null,
37800,
31200,
18500,
15050,
15700,
6300,
36400,
5200,
23700,
21500,
31500,
9200,
33700,
null,
null,
30100,
44800,
24200,
15500,
34500,
10700,
26300,
5600,
103700,
37400,
30800,
49800,
2700,
7700,
22900,
44400,
191351,
54500,
26800,
18000,
37300,
36100,
37500,
21700,
31700,
9300,
24200,
27800,
21000,
12100,
35400,
35200,
18700,
15600,
18600,
5100,
56800,
7600,
55825,
null,
19100,
null,
31500,
10800,
24200,
15800,
40100,
42300,
46500,
84150,
14500,
49100,
45000,
24200,
22600,
45000,
30600,
27600,
10300,
23900,
22300,
7100,
10600,
7900,
25900,
7000,
11200,
null,
60300,
12300,
29800,
61700,
null,
74400,
7400,
41300,
73300,
14400,
59500,
null,
59500,
70600,
65900,
8100,
11600,
35100,
23800,
37500,
7400,
null,
15100,
17100,
26700,
8600,
19200,
15100,
22700,
1800,
31000,
46900,
18200,
13700,
24500,
14000,
10300,
18600,
29500,
18900,
41400,
10700,
11800,
35800,
12800,
null,
36600,
2000,
8000,
14500,
13800,
37000,
null,
34400,
43400,
55700,
70200,
null,
38000,
null,
null,
null,
132200,
8900,
33700,
20600,
26900,
10100,
18600,
6600,
41300,
98400,
7700,
31900,
17100,
68400,
4800,
24400,
14200,
13900,
53200,
95700,
18800,
37000,
39700,
30600,
62100,
7400,
23000,
15700,
23400,
34300,
7000,
22100,
39800,
237800,
140000,
10700,
17700,
4650,
26000,
9100,
40800,
41300,
147800,
34700,
null,
31900,
11200,
null,
0,
32100,
59000,
22700,
14100,
11200,
42400,
12600,
30500,
132599,
26500,
52900,
21200,
43600,
18200,
14600,
64500,
17500,
35400,
31900,
20100,
12000,
66800,
14500,
18300,
13200,
41700,
4000,
19700,
null,
33400,
12900,
13060,
62300,
63600,
19300,
39800,
64400,
9400,
19700,
87200,
26600,
4800,
3400,
13000,
15600,
null,
18200,
66900,
null,
5800,
14900,
85600,
97300,
29300,
12300,
6400,
32100,
27900,
43100,
17000,
46900,
20700,
102300,
12200,
121900,
12500,
27600,
36800,
null,
101400,
11100,
269399,
17400,
23000,
26500,
72700,
20900,
25700,
22600,
17800,
35600,
23500,
12600,
20200,
12700,
41200,
82800,
24700,
26500,
33100,
29000,
19000,
31800,
15000,
null,
3000,
9000,
72200,
48900,
14300,
15800,
18300,
13900,
26250,
40700,
16100,
33600,
24200,
47200,
33500,
30100,
19900,
10900,
19000,
11700,
8000,
16800,
47300,
108600,
38559,
28900,
24600,
10400,
100500,
12100,
44700,
81900,
19900,
125200,
18300,
32700,
50400,
15500,
27200,
40500,
19200,
6500,
36400,
14500,
66300,
23900,
15600,
22100,
null,
9500,
43300,
105700,
13300,
41700,
33200,
18700,
21300,
26800,
9400,
17300,
33800,
40600,
35600,
56200,
71186,
34000,
9300,
27200,
null,
47800,
31700,
35600,
315300,
39296,
27000,
68200,
123200,
22300,
null,
19200,
25400,
21400,
48400,
16800,
53300,
25500,
2000,
98100,
11800,
10000,
101300,
15000,
18500,
11700,
206700,
33300,
30300,
6000,
144900,
49300,
16700,
13200,
134800,
3100,
8000,
28600,
31300,
22500,
null,
31800,
17900,
55500,
24700,
46300,
23300,
15200,
null,
41100,
25900,
5700,
31800,
8600,
9600,
22100,
18600,
12600,
30700,
29400,
null,
40200,
50600,
23500,
21500,
21400,
3700,
null,
9000,
38200,
8700,
18900,
41500,
22100,
64500,
23100,
33300,
10000,
71500,
29200,
8050,
74700,
14500,
17400,
29700,
52400,
12300,
500,
69600,
55849,
12300,
50800,
8300,
59200,
24900,
null,
4900,
125800,
6700,
9800,
39200,
126000,
53158,
null,
41800,
25700,
45500,
26400,
null,
null,
29700,
4900,
null,
500,
36900,
11500,
18000,
6100,
6700,
14700,
9100,
54500,
17600,
6100,
35200,
51000,
8700,
14000,
15700,
53100,
15500,
34800,
18400,
6100,
49360,
3700,
39773,
106150,
19000,
7200,
47000,
24600,
28100,
34500,
34300,
null,
45000,
24600,
11900,
17600,
10700,
68500,
83500,
40500,
36600,
19100,
34700,
32100,
34000,
15500,
31000,
15600,
17500,
40800,
48300,
13900,
44100,
12800,
146300,
7900,
37200,
25600,
18500,
8800,
60900,
30800,
30200,
50300,
19900,
14400,
36300,
13900,
55500,
42500,
57900,
32900,
null,
18700,
null,
53700,
49800,
21400,
null,
5100,
17900,
46400,
40000,
18400,
30500,
46100,
18900,
37600,
9200,
31500,
53500,
12200,
29300,
9500,
25300,
21900,
40700,
30100,
17100,
32800,
21700,
27900,
90200,
12700,
7900,
43600,
21000,
60300,
23000,
19100,
54900,
28700,
1200,
25100,
31600,
11900,
null,
31500,
19600,
14000,
27800,
null,
null,
58100,
41700,
11200,
25400,
103800,
7800,
18100,
10600,
25200,
42900,
22500,
26500,
22000,
40890,
75900,
20200,
28600,
11000,
16600,
11200,
38100,
33700,
null,
9700,
57300,
null,
24300,
106600,
19400,
16500,
7300,
39000,
59300,
19500,
13400,
56200,
18100,
24000,
64400,
20800,
8400,
65300,
33200,
32000,
39300,
null,
5300,
null,
21900,
110100,
28400,
2400,
43200,
22000,
26100,
15000,
18900,
41200,
7200,
8600,
9400,
5900,
20900,
null,
20500,
8309,
49600,
null,
117500,
34300,
34400,
50500,
54900,
24600,
7800,
55700,
3300,
12600,
10100,
13100,
31400,
118200,
33800,
33400,
45600,
65900,
44200,
38300,
29400,
12400,
48300,
16450,
9700,
null,
73400,
14200,
21400,
19600,
27000,
10000,
46200,
13400,
8800,
8200,
22300,
35700,
18000,
23100,
14100,
45823,
22600,
70000,
25900,
14000,
18500,
null,
62700,
11650,
14000,
3400,
32500,
57200,
10500,
11100,
null,
16500,
51200,
15500,
27500,
28400,
37700,
15250,
null,
82100,
55300,
60700,
42900,
99600,
25100,
null,
15400,
35000,
13300,
37200,
25300,
28500,
13700,
5500,
11000,
70400,
21800,
36600,
24300,
21900,
50500,
37200,
12100,
null,
21800,
11500,
37400,
68500,
29700,
15800,
54600,
31100,
26400,
null,
17800,
12600,
25900,
44800,
28600,
51000,
40997,
79400,
7500,
29800,
27500,
22600,
14900,
34100,
25400,
7800,
24100,
63000,
19300,
23700,
20100,
81900,
11600,
27400,
63100,
21200,
63600,
24400,
41500,
87300,
75300,
17570,
16100,
1800,
21500,
25000,
21700,
13500,
49100,
20600,
33700,
8500,
26100,
22800,
21100,
9500,
7100,
9300,
68400,
53200,
45300,
28900,
13200,
22100,
41700,
9800,
104200,
12500,
65200,
86200,
null,
40500,
12700,
79000,
16100,
41500,
37500,
19200,
7300,
18400,
null,
14600,
26100,
81600,
36700,
19400,
22800,
12400,
10100,
22700,
50900,
20100,
31300,
30800,
99300,
20800,
null,
8500,
null,
14500,
66400,
98500,
9500,
null,
12200,
null,
8500,
26700,
45800,
38155,
18200,
24200,
9700,
27300,
9300,
null,
23800,
29700,
41800,
43600,
null,
18700,
8700,
23300,
17000,
19100,
27800,
null,
15600,
27100,
30800,
38100,
50600,
81764,
39300,
11800,
18900,
36400,
21500,
7500,
12300,
7400,
null,
21100,
32000,
38000,
11400,
161300,
30200,
9600,
8600,
19400,
36000,
21700,
64500,
60300,
34600,
17000,
64100,
23100,
47000,
21100,
28200,
5500,
14700,
46200,
71600,
34000,
34200,
5500,
23400,
null,
24500,
33500,
19400,
16400,
14000,
17800,
13220,
null,
7800,
46900,
20000,
29500,
91500,
36809,
63191,
28200,
22200,
null,
20100,
20000,
32100,
40500,
15800,
25900,
16500,
27200,
19000,
7700,
29700,
null,
27000,
5600,
24800,
42000,
null,
8600,
43200,
37600,
75300,
28800,
46500,
null,
29000,
155400,
null,
97300,
20000,
69200,
8400,
36100,
23300,
18800,
14800,
null,
126200,
37400,
32300,
23500,
24700,
27000,
35100,
30500,
15400,
24600,
8400,
4500,
9100,
66400,
77600,
25600,
41600,
7200,
12000,
15000,
31000,
45600,
3100,
4300,
36700,
21800,
null,
null,
16300,
35900,
97200,
null,
34700,
10900,
9200,
35800,
35200,
9000,
76600,
24000,
null,
7600,
19500,
14800,
42400,
null,
74380,
17500,
13200,
8500,
null,
2200,
38200,
3000,
33600,
55600,
70400,
51100,
null,
32000,
111500,
17900,
13500,
32900,
8100,
8700,
11500,
150100,
109800,
null,
63800,
21500,
null,
10800,
32000,
19700,
3000,
15100,
167300,
21100,
13000,
33600,
22700,
39600,
27100,
26100,
null,
22600,
50200,
67900,
12500,
19800,
16900,
20700,
70600,
47500,
19900,
45400,
null,
60200,
16300,
111500,
10600,
11900,
null,
34500,
15000,
null,
44700,
15500,
14300,
26700,
26300,
28600,
12100,
18900,
null,
154700,
9500,
13200,
56000,
36900,
20800,
8900,
29700,
43500,
16700,
60800,
18100,
null,
43700,
7400,
null,
null,
29800,
20400,
74000,
6200,
30200,
26000,
13700,
25200,
27400,
15300,
16600,
15400,
26200,
75700,
142600,
null,
11400,
null,
65700,
22600,
33700,
47500,
25200,
27000,
80700,
27100,
25900,
23200,
18100,
26600,
17500,
8200,
23500,
41000,
144800,
14700,
31200,
13300,
20600,
21400,
16200,
16000,
12100,
63500,
19100,
null,
20500,
20300,
null,
11300,
26900,
5900,
81800,
11500,
13900,
23100,
52700,
16000,
11700,
43600,
20300,
43100,
67400,
44400,
59000,
65700,
9500,
50900,
null,
900,
88600,
9400,
39400,
36600,
62100,
13900,
22700,
null,
26600,
9100,
11300,
42000,
15800,
11600,
27200,
60200,
20700,
52400,
175200,
51100,
26400,
13200,
13600,
31400,
21700,
25400,
3900,
31600,
23700,
18800,
null,
52100,
112000,
51600,
47000,
70225,
14800,
3500,
49800,
29400,
22100,
39600,
13700,
29800,
null,
8400,
20200,
null,
37900,
9300,
23300,
12800,
29100,
36400,
10700,
41200,
11200,
95900,
27400,
3000,
12400,
41400,
33300,
7500,
76000,
8900,
9300,
42900,
48800,
28600,
42700,
32000,
20800,
null,
10500,
26900,
17200,
20100,
12100,
27200,
3700,
22300,
157700,
35200,
46300,
19100,
24400,
71600,
18900,
15600,
21000,
20500,
100800,
57800,
9600,
194300,
21800,
null,
null,
10600,
4800,
12100,
44500,
8500,
3000,
29500,
35800,
null,
null,
34500,
27400,
32200,
13800,
22700,
39800,
16100,
17100,
33000,
50800,
125300,
24600,
3800,
23200,
24700,
41000,
null,
null,
16100,
15500,
37400,
9800,
15100,
147700,
11100,
12500,
13200,
29800,
43400,
3200,
15500,
33800,
14400,
11300,
116006,
27000,
26600,
24900,
54100,
17600,
11400,
21400,
11500,
23300,
23000,
53000,
17900,
22800,
19200,
11000,
46300,
60700,
42100,
18700,
43100,
18200,
13900,
2700,
30900,
22400,
22500,
null,
44600,
26500,
null,
83000,
160500,
18700,
36600,
21000,
6300,
15300,
18200,
15300,
16900,
18000,
18500,
44400,
8300,
33300,
138500,
19900,
12700,
18500,
30000,
11400,
19200,
94700,
41000,
15700,
59500,
43800,
18600,
9100,
61800,
81700,
38000,
8200,
25200,
38100,
74600,
5600,
39300,
64600,
53000,
22700,
27200,
9000,
33900,
18000,
68100,
19700,
null,
47300,
32400,
50010,
30900,
65400,
42400,
35900,
123400,
12500,
null,
23000,
21700,
null,
34400,
7000,
21000,
null,
56300,
null,
32600,
null,
51500,
27100,
25700,
69000,
41500,
27600,
null,
10600,
20300,
33500,
79900,
9600,
52800,
3200,
34500,
25300,
165100,
18000,
6000,
10800,
9200,
38400,
13200,
23100,
7900,
6900,
37200,
26700,
113400,
46200,
null,
28400,
31400,
84100,
14500,
22000,
27000,
65800,
51410,
31100,
null,
34900,
16400,
26000,
9900,
14000,
19300,
null,
90000,
3400,
28800,
103000,
25000,
18400,
36300,
null,
20400,
9100,
19600,
11600,
10700,
74100,
22100,
28700,
63900,
17700,
13500,
31200,
6400,
29500,
9800,
51800,
37200,
13600,
34383,
33100,
45000,
18500,
5500,
51900,
31400,
32700,
18000,
24100,
40600,
56500,
89300,
7500,
57700,
6500,
25000,
63300,
93700,
31000,
null,
20600,
21800,
46200,
17900,
42800,
null,
13300,
12600,
14800,
27300,
null,
43600,
17900,
17100,
11600,
11900,
59000,
18100,
13700,
32500,
49300,
43500,
23900,
4200,
25300,
21300,
28300,
15700,
24600,
143670,
24400,
72900,
38000,
52800,
null,
13200,
14700,
10800,
162100,
5800,
8400,
20500,
43900,
null,
16400,
67100,
70400,
null,
10800,
49300,
98800,
34500,
60300,
19500,
11800,
12100,
11500,
28700,
11500,
19200,
62200,
30500,
4700,
116700,
11370,
47000,
61450,
32700,
null,
4200,
11500,
16400,
66600,
39000,
null,
9800,
31600,
21100,
null,
25800,
19300,
35300,
null,
20600,
69700,
22800,
4900,
16700,
16400,
27200,
40000,
64100,
12500,
34400,
16700,
46400,
10700,
21200,
22800,
10900,
71900,
94000,
10200,
16000,
20600,
19400,
42100,
32700,
32000,
14800,
36200,
null,
112558,
53700,
23000,
11800,
213500,
6000,
20000,
16400,
20900,
48700,
16200,
30300,
17900,
28800,
42600,
17300,
90500,
33100,
49100,
28300,
262100,
51500,
12300,
30600,
16400,
35300,
10000,
25200,
6100,
4098,
16000,
27800,
12500,
3200,
10000,
null,
5700,
29600,
57700,
23000,
34700,
23900,
22400,
9500,
12100,
39000,
26700,
114600,
42900,
38000,
24100,
31000,
21300,
26000,
43000,
39900,
5300,
49700,
9850,
29200,
88200,
13800,
10500,
16500,
null,
43100,
6100,
11700,
53200,
80689,
24200,
14600,
16900,
14600,
27300,
null,
7100,
null,
22500,
74200,
13900,
15300,
8400,
76100,
14700,
13200,
13500,
10800,
19500,
18600,
11000,
33300,
46600,
41400,
19200,
24900,
null,
14200,
313000,
8700,
37000,
30000,
25800,
36000,
25000,
16900,
54900,
21100,
null,
7500,
8700,
16800,
14200,
35800,
17300,
46300,
10000,
10800,
16000,
23300,
83900,
14200,
10300,
28300,
17100,
17300,
18900,
42700,
4600,
54522,
52900,
107500,
42500,
16200,
98600,
13000,
37700,
20900,
26600,
null,
11300,
8400,
44500,
83000,
205700,
26100,
68700,
50700,
12700,
20500,
77500,
12500,
14000,
29600,
null,
55600,
30400,
23800,
30600,
14200,
36200,
7900,
5400,
38600,
31800,
5500,
27700,
null,
37800,
10400,
57800,
36300,
32300,
12800,
null,
19100,
2800,
35100,
14400,
9400,
9500,
37100,
26300,
50700,
19200,
null,
29300,
95400,
4700,
46300,
28100,
40000,
58500,
27300,
39000,
7945,
19700,
103000,
31900,
39300,
26700,
24700,
32800,
null,
15800,
37175,
12000,
6600,
32300,
38800,
6400,
10900,
14200,
12200,
19300,
32800,
60000,
5200,
10700,
66500,
10400,
21000,
53900,
12300,
33300,
8877,
null,
23900,
15300,
4500,
14700,
58300,
10500,
13500,
132300,
28700,
74900,
16600,
14700,
17500,
22197,
20300,
14300,
14900,
12900,
15300,
15800,
22800,
53300,
108700,
69400,
32200,
15800,
20000,
13300,
8600,
13600,
17900,
null,
22500,
9200,
52400,
3100,
10300,
6100,
113600,
78100,
10100,
5600,
44861,
null,
15600,
15500,
16800,
29000,
103400,
66700,
45800,
30900,
87100,
null,
32700,
16000,
18500,
38900,
38600,
10500,
14100,
15900,
57600,
41000,
118700,
22900,
34400,
11600,
21500,
27800,
15500,
20300,
43600,
12700,
33600,
6200,
34690,
43300,
14000,
22500,
20700,
30195,
17200,
57000,
22800,
null,
19400,
21100,
5200,
8600,
32400,
null,
18400,
63600,
6100,
46400,
13400,
8100,
16500,
5800,
17400,
12800,
39100,
34700,
48800,
null,
30900,
10600,
65600,
40624,
11700,
null,
16600,
18200,
100300,
70500,
33100,
52800,
31500,
102100,
15000,
33100,
21700,
11200,
null,
69800,
66338,
36200,
23600,
7000,
3500,
135900,
44300,
57935,
40500,
14400,
15600,
15800,
17500,
11400,
12400,
45800,
36035,
16300,
31600,
26750,
27300,
29000,
56200,
73700,
16600,
33000,
34000,
9000,
42100,
34100,
13900,
23500,
9200,
16000,
17500,
5900,
6600,
17900,
11400,
32000,
20500,
10800,
14400,
26000,
22100,
14300,
47200,
20000,
42000,
19700,
null,
21000,
15700,
11800,
66400,
37800,
3000,
40000,
26900,
44300,
31000,
7400,
36800,
null,
13200,
42700,
8600,
34700,
28800,
4500,
45069,
23900,
17400,
46200,
null,
7900,
26900,
19100,
23100,
19300,
4600,
93500,
15500,
16940,
20100,
46200,
14500,
39500,
13500,
32500,
null,
10300,
91600,
16600,
47500,
16700,
32900,
70400,
16000,
88300,
115100,
20900,
25600,
15300,
15500,
4500,
13600,
18300,
20000,
13800,
18300,
14400,
58400,
23200,
68400,
7200,
null,
21500,
15800,
54600,
35800,
null,
31900,
52900,
24200,
15800,
16200,
81900,
7000,
18100,
50800,
10000,
4500,
27700,
29200,
10000,
16500,
19100,
22800,
12000,
23700,
45700,
10800,
56000,
6400,
32900,
40900,
null,
13500,
17100,
9700,
32400,
60432,
16400,
12500,
11200,
22900,
14500,
33300,
10100,
18500,
23000,
null,
22200,
14600,
13600,
10900,
13600,
18700,
2600,
41100,
15900,
19900,
22400,
null,
15900,
62200,
30100,
23300,
15700,
11900,
null,
70700,
56600,
8900,
15000,
43000,
8300,
15300,
18800,
15400,
15100,
108600,
16300,
22700,
9100,
18700,
31000,
null,
22000,
22380,
16700,
12600,
29600,
null,
9250,
20100,
43200,
12900,
66386,
44700,
23400,
49200,
36600,
14000,
58716,
67400,
6500,
21200,
28000,
null,
21800,
null,
71400,
46100,
26400,
62800,
39300,
null,
15500,
11500,
21900,
null,
24100,
21400,
1900,
18300,
62357,
4500,
7100,
11700,
11200,
7300,
5000,
28600,
24800,
110700,
32900,
14000,
14800,
57300,
13200,
37200,
19400,
24700,
16400,
43000,
11000,
15000,
26800,
24500,
21200,
16000,
52500,
73000,
24000,
7600,
7900,
23800,
6962,
13500,
101700,
71200,
4300,
10200,
null,
30800,
237000,
29900,
null,
74000,
32600,
6000,
20100,
44100,
31100,
11500,
18900,
17000,
52100,
22600,
7200,
109800,
null,
15100,
28300,
24700,
13100,
19700,
18425,
22600,
19900,
null,
9200,
67600,
42200,
14200,
14300,
19700,
19900,
26400,
12900,
13800,
48300,
18000,
9800,
8100,
12300,
null,
170300,
36700,
48900,
17200,
8300,
23100,
26300,
43500,
31600,
27100,
null,
12300,
null,
27900,
6400,
42000,
16900,
16700,
102927,
21900,
41300,
9700,
37600,
null,
4500,
51800,
26500,
40000,
18400,
18200,
7000,
73850,
25400,
8700,
7600,
31700,
62400,
28400,
138100,
15300,
2300,
25300,
40800,
24100,
15800,
21600,
10700,
23000,
10600,
35700,
29700,
33900,
29100,
33100,
null,
24800,
20800,
6400,
null,
10400,
18300,
13400,
35300,
12000,
17400,
29400,
19300,
8200,
10900,
28200,
null,
null,
9200,
27300,
36300,
29100,
3500,
18700,
24500,
41200,
19510,
69500,
10700,
104300,
15100,
17000,
27500,
29300,
36500,
6400,
14000,
68000,
null,
35300,
56100,
25000,
3200,
17800,
37700,
20000,
10600,
19500,
12200,
28000,
23500,
40500,
70800,
25200,
22600,
13100,
19300,
38800,
16200,
14900,
26300,
50900,
46700,
61600,
null,
40500,
null,
11800,
82500,
33400,
13400,
28800,
18800,
null,
51600,
25300,
16300,
68800,
11800,
8570,
23000,
9050,
18600,
108800,
30500,
24700,
10600,
29300,
61800,
20800,
23600,
24600,
6000,
null,
19000,
23600,
28100,
51900,
26200,
35300,
5500,
null,
4700,
27500,
6300,
156500,
18000,
19700,
31810,
36000,
13000,
8600,
null,
19900,
27400,
8600,
20400,
76600,
31800,
15300,
17500,
20100,
25300,
38500,
11700,
52200,
19300,
16400,
46900,
13300,
13700,
83200,
29900,
23500,
18100,
41000,
7500,
25400,
24500,
5700,
18600,
26400,
163700,
6400,
20700,
3800,
24800,
31600,
41800,
35400,
42900,
22100,
93900,
8500,
36100,
null,
10000,
99100,
96700,
null,
38600,
22100,
13100,
19500,
46700,
20700,
23100,
5000,
47600,
20100,
36300,
14200,
null,
19900,
23500,
31200,
18900,
74700,
10300,
22500,
36770,
35200,
null,
null,
31684,
44200,
8800,
null,
66800,
34800,
23200,
75929,
14300,
114800,
26800,
57500,
27800,
35500,
26900,
21500,
38800,
44900,
20445,
14400,
8700,
42300,
6400,
26200,
28600,
18100,
34800,
11500,
25700,
52200,
29600,
15700,
null,
32200,
12450,
10600,
88300,
6600,
11400,
37600,
7700,
16800,
10000,
9800,
32500,
23600,
37800,
16400,
199600,
114600,
48500,
21500,
16600,
22300,
33800,
null,
45300,
7400,
null,
13800,
43800,
10000,
48500,
80100,
9000,
14500,
11700,
5000,
51600,
10800,
28200,
14500,
68900,
16000,
null,
11700,
88800,
67800,
1500,
null,
32600,
143500,
10500,
14600,
8600,
21900,
35200,
37601,
30100,
69000,
null,
36000,
49300,
18500,
38300,
57700,
null,
106700,
null,
6400,
13900,
15500,
13970,
33475,
17200,
52500,
18100,
57100,
35400,
21600,
26100,
12800,
5500,
26700,
16700,
23900,
null,
15300,
73900,
70100,
18200,
null,
24000,
30400,
47700,
108000,
18500,
6500,
34700,
31000,
39000,
null,
null,
19500,
79700,
20600,
61900,
11400,
8300,
9300,
7200,
5000,
12400,
125700,
10300,
22700,
21200,
25900,
25900,
14200,
12300,
47600,
16000,
22600,
33900,
42800,
25800,
13500,
65800,
28300,
63300,
13700,
9850,
14200,
24200,
16800,
30400,
null,
20700,
4300,
null,
5000,
49900,
26800,
16200,
64200,
11100,
12300,
84000,
42700,
10000,
23600,
13500,
51900,
42600,
12000,
46700,
45500,
6800,
17000,
null,
64300,
26300,
10600,
46900,
36900,
99100,
14500,
34400,
9200,
72100,
12800,
25500,
10800,
74140,
46900,
6300,
6000,
31900,
30600,
null,
313500,
30900,
32400,
81000,
43200,
33900,
27400,
null,
null,
27471,
6700,
5800,
23200,
25500,
21500,
9500,
26700,
14100,
12800,
30300,
27700,
35200,
null,
21400,
8300,
34100,
null,
17500,
24300,
12200,
23500,
24500,
21700,
6000,
4200,
9900,
59300,
102200,
null,
53900,
26000,
41600,
9600,
5500,
53600,
21700,
47700,
17350,
11800,
null,
null,
7500,
19900,
12500,
42700,
5800,
15500,
40900,
6500,
18000,
29400,
9400,
48400,
16000,
30000,
24000,
183800,
24900,
70200,
1500,
17700,
8700,
26100,
9300,
54700,
9200,
5100,
8900,
null,
19837,
23600,
39500,
12300,
14900,
null,
null,
14500,
23500,
37550,
55600,
18900,
36200,
18300,
null,
10500,
9500,
5900,
78400,
30900,
20600,
15200,
71300,
12000,
19600,
10700,
25300,
null,
null,
44400,
60200,
900,
15800,
48700,
45900,
15400,
85900,
10100,
138900,
37500,
null,
59800,
18800,
46300,
14600,
39400,
14300,
40900,
125900,
17300,
13700,
16800,
43200,
4400,
20400,
18000,
7800,
27600,
19400,
14800,
16900,
22800,
null,
28100,
30400,
19900,
55500,
7400,
41600,
97500,
29100,
32500,
25700,
11800,
37300,
16000,
29200,
32300,
58400,
10445,
36300,
6400,
45900,
null,
48000,
55100,
5500,
30612,
21300,
23800,
9500,
53900,
69700,
42600,
11580,
null,
null,
25200,
25100,
30700,
16600,
24680,
17600,
27600,
13200,
7050,
12400,
26900,
123700,
null,
15900,
28100,
30300,
7000,
17300,
30600,
30500,
27400,
11700,
15500,
24500,
87800,
52300,
23800,
33200,
null,
7500,
13700,
103600,
27400,
53700,
12900,
118500,
20200,
null,
30800,
6500,
135300,
11800,
23400,
37100,
15300,
15200,
35500,
20800,
26100,
42500,
12300,
null,
129800,
18100,
33600,
45500,
8600,
30300,
17100,
4500,
23800,
11500,
23800,
45900,
null,
14300,
45000,
29700,
40400,
117400,
8000,
17900,
40300,
1800,
30200,
195500,
12800,
17100,
83700,
23700,
41800,
10200,
12600,
26200,
50400,
10300,
40000,
12900,
28100,
null,
28400,
59100,
15100,
33800,
23100,
24700,
50300,
24100,
6900,
13100,
24700,
10500,
null,
null,
48100,
43200,
21100,
8000,
78100,
19300,
19100,
18200,
28300,
23300,
6300,
32600,
13400,
6175,
49100,
46700,
26500,
34600,
39900,
4000,
36700,
34400,
113300,
16000,
42400,
94200,
28500,
6200,
null,
85700,
23600,
19100,
15963,
29700,
25500,
21200,
1800,
null,
16000,
18500,
39200,
80800,
18500,
11900,
16700,
40600,
39200,
19700,
76600,
58700,
32300,
40000,
66700,
99800,
96300,
null,
54800,
3800,
122200,
18800,
38000,
11800,
8300,
15200,
4200,
24500,
null,
null,
5800,
62700,
25800,
null,
32700,
38200,
87430,
50200,
15100,
26200,
38100,
43100,
37340,
36400,
29300,
27300,
34400,
100200,
25100,
55300,
47300,
20800,
9600,
34400,
39300,
9600,
14100,
40400,
20700,
21400,
21600,
null,
20100,
null,
17200,
13300,
18200,
10600,
114900,
30000,
58800,
38500,
28700,
9500,
4300,
15200,
null,
8700,
20100,
29500,
15200,
75700,
68200,
14400,
null,
16000,
null,
27900,
75900,
15900,
9300,
null,
null,
25400,
12300,
53600,
8300,
36400,
33200,
51520,
24900,
7000,
53800,
8100,
3700,
14400,
8300,
6100,
53410,
15500,
9050,
23300,
40000,
15800,
79200,
345000,
24500,
null,
16800,
109600,
null,
18900,
27700,
32900,
35100,
20500,
53700,
35400,
23700,
7000,
21200,
50100,
73400,
54200,
null,
null,
28700,
22000,
11300,
27100,
46800,
16800,
21100,
19900,
10000,
11300,
15100,
37000,
10600,
2700,
16200,
null,
33000,
36800,
21300,
11600,
23900,
46400,
4000,
11300,
8500,
34200,
40300,
8100,
18900,
15600,
14800,
7600,
22300,
null,
72200,
null,
16200,
null,
24000,
5100,
11000,
12200,
25450,
30000,
52400,
15200,
20000,
34300,
42100,
28300,
9700,
4200,
17000,
17500,
42600,
17000,
50000,
57500,
31700,
18700,
null,
31200,
29500,
10400,
5700,
11200,
67400,
35900,
55600,
17700,
22300,
48300,
54600,
34300,
67300,
51300,
45800,
23500,
40000,
25900,
24600,
10500,
45500,
19900,
null,
12600,
59100,
36500,
5800,
25300,
19500,
7800,
10500,
139800,
32200,
null,
53900,
24800,
43300,
21300,
157400,
43100,
null,
27600,
16500,
19100,
83500,
19400,
2000,
6600,
8200,
17900,
15000,
30500,
21900,
61500,
11100,
17900,
44400,
16700,
24800,
11600,
null,
56700,
36000,
20700,
31700,
64300,
56100,
53700,
3800,
25000,
38500,
28600,
11750,
74000,
13200,
54900,
22900,
20800,
70653,
17900,
23600,
11700,
7100,
50000,
26300,
13200,
30162,
9800,
12400,
17500,
null,
13800,
29000,
12100,
null,
12500,
22100,
null,
12562,
33600,
23700,
null,
20900,
39500,
18900,
27000,
10200,
36500,
6300,
37500,
21200,
24600,
11300,
32800,
30100,
17500,
null,
19500,
68800,
248900,
4500,
null,
5200,
34200,
26500,
26100,
12400,
30900,
54100,
50000,
null,
10800,
25800,
50600,
39000,
73900,
35500,
24400,
84000,
13300,
105200,
9800,
14100,
5300,
11400,
null,
10100,
12100,
48400,
44734,
33000,
7000,
12700,
null,
7400,
16600,
120100,
46500,
30200,
35100,
27600,
11400,
17700,
4600,
9300,
111100,
null,
35200,
null,
4800,
15200,
30500,
null,
87300,
null,
78100,
19500,
29500,
64000,
47500,
19600,
15500,
25300,
33300,
7700,
13700,
41700,
8200,
122700,
null,
22800,
72600,
48100,
18100,
13100,
8600,
36900,
44900,
34100,
19500,
40800,
55800,
16500,
19800,
13000,
null,
8900,
71300,
11400,
16400,
57300,
9700,
31600,
17800,
44800,
43900,
58100,
18500,
9300,
15400,
15900,
18400,
41800,
29600,
99000,
null,
37500,
11900,
47400,
27400,
13500,
13000,
4800,
35900,
20600,
29500,
53800,
23800,
15000,
63300,
60900,
51300,
19400,
98400,
null,
26000,
32400,
32500,
1600,
44535,
20000,
66500,
9300,
4000,
8300,
60800,
25100,
24100,
23000,
3000,
75300,
44900,
28000,
90500,
21900,
null,
22600,
24200,
null,
17000,
13100,
24000,
33900,
29000,
97500,
11000,
73600,
51600,
16700,
29400,
23000,
51800,
7800,
28500,
16400,
3000,
94900,
25200,
70800,
18300,
22800,
9900,
17200,
19700,
18400,
171600,
13800,
null,
37000,
21400,
null,
75100,
22300,
21000,
26300,
14400,
31700,
57700,
22100,
50600,
5300,
null,
18300,
16100,
162200,
22500,
5000,
12700,
16500,
46000,
15500,
22900,
18800,
21100,
34200,
28800,
15300,
28505,
null,
15260,
5900,
28000,
6700,
53600,
19100,
64600,
19400,
52074,
20400,
7200,
14800,
10800,
8300,
null,
2150,
50700,
9400,
39900,
51900,
77600,
56000,
25200,
null,
12900,
52100,
13300,
21600,
20600,
37000,
10800,
14700,
19100,
71800,
null,
123400,
63000,
35000,
46400,
27100,
6300,
33200,
68500,
null,
31800,
31100,
9500,
21200,
26600,
13000,
42500,
19200,
33900,
29600,
24200,
42000,
47100,
32100,
61000,
17200,
63200,
54900,
27500,
68800,
26200,
54875,
null,
30400,
11100,
32500,
57500,
31100,
15500,
40300,
55100,
24000,
16100,
19600,
45200,
8100,
25100,
18700,
null,
166000,
null,
28500,
27100,
107000,
null,
7600,
14900,
17200,
41900,
27000,
36000,
49800,
2500,
null,
11200,
23500,
46900,
null,
8200,
18000,
37900,
12600,
69100,
23600,
18500,
67900,
28200,
16700,
39000,
44300,
16100,
25089,
16000,
26700,
null,
36500,
19700,
34400,
61100,
103100,
76874,
null,
36000,
38480,
26200,
6500,
126400,
30400,
84800,
null,
4300,
53500,
14450,
35900,
14100,
7800,
null,
22000,
4300,
19600,
null,
18600,
27600,
42900,
35800,
18700,
17600,
36700,
3500,
19000,
5600,
19600,
30400,
22100,
53800,
24100,
5700,
38500,
36800,
26200,
7500,
null,
29800,
51700,
51417,
33600,
30000,
69388,
33000,
8800,
19300,
22500,
21600,
30400,
36700,
160200,
10200,
1500,
null,
33600,
12800,
83300,
null,
22400,
null,
31600,
null,
79200,
24500,
18000,
10000,
52900,
9300,
86700,
96800,
14900,
7300,
null,
23600,
68200,
11300,
15700,
12800,
20000,
80200,
15300,
30200,
26800,
11000,
37300,
20100,
null,
32100,
47100,
32800,
39800,
14200,
48800,
16400,
11300,
8100,
32300,
20200,
9200,
8200,
37500,
11700,
30000,
56300,
7800,
58300,
22500,
7600,
32100,
32400,
20400,
43000,
12900,
23600,
12400,
null,
69700,
49700,
27800,
25300,
32100,
15200,
13400,
18200,
22500,
9600,
43600,
46600,
7400,
null,
12100,
41400,
14700,
16600,
69500,
15200,
30200,
41000,
22700,
35500,
23900,
21700,
84400,
25900,
12800,
63200,
7000,
29400,
17800,
14100,
43300,
26500,
null,
12500,
16000,
55700,
17000,
17300,
40500,
15200,
16300,
20600,
26100,
null,
25100,
15600,
null,
40100,
8800,
121300,
26300,
35800,
4300,
24800,
14500,
75300,
10100,
19200,
7566,
11100,
52500,
48000,
13700,
30700,
16600,
19800,
14300,
12200,
8200,
26400,
81600,
39500,
24200,
53600,
null,
52900,
1600,
8200,
44400,
19500,
15800,
36500,
35900,
51254,
51000,
29900,
12000,
49100,
23600,
14000,
20300,
19700,
29500,
18900,
20900,
4000,
18500,
24500,
12200,
null,
26100,
22000,
43600,
4300,
19000,
null,
46500,
83000,
19600,
null,
28600,
11600,
30800,
6500,
107700,
37900,
20200,
14200,
96700,
33000,
89300,
26700,
32200,
73700,
7100,
28600,
31000,
63300,
64600,
27700,
43600,
29600,
34900,
41300,
null,
7600,
26300,
7400,
23200,
95700,
42300,
11300,
9300,
24000,
8600,
11700,
47100,
39600,
37500,
17000,
15200,
7800,
null,
6800,
11200,
19900,
40000,
14200,
26480,
null,
74400,
17000,
24000,
24800,
123000,
29000,
null,
7300,
70800,
13700,
13000,
12100,
17400,
7500,
18000,
54000,
11300,
84100,
91800,
35300,
36500,
16000,
14450,
42600,
32900,
37900,
42600,
8050,
39700,
16400,
70800,
12600,
7300,
47500,
21700,
15700,
19900,
38500,
181400,
58800,
61380,
18100,
21600,
50900,
16000,
24600,
14800,
51400,
19100,
47000,
25400,
62100,
27100,
7900,
15100,
41900,
33000,
17100,
5000,
21400,
null,
26600,
43900,
30400,
16400,
null,
48800,
null,
22400,
null,
64600,
13690,
112500,
32000,
10500,
14700,
14400,
9600,
null,
26400,
198700,
11500,
14000,
21600,
11700,
14800,
11500,
11900,
37400,
53400,
17500,
33300,
9100,
99300,
121200,
95600,
null,
32300,
24200,
19500,
6200,
19400,
36100,
39000,
21400,
6300,
41900,
27800,
15200,
13100,
19700,
83900,
6400,
87600,
13800,
88800,
43500,
36100,
59400,
51600,
48400,
3800,
33300,
10900,
66200,
5300,
17600,
46900,
null,
36700,
70000,
8400,
26000,
30100,
50200,
46000,
12700,
45000,
14200,
68400,
21600,
74800,
12500,
43900,
17400,
60700,
21100,
17000,
30500,
10500,
16600,
12400,
12500,
64300,
null,
21300,
11000,
14600,
10300,
31000,
45400,
6400,
14500,
15100,
29500,
76400,
26800,
8900,
89300,
null,
41600,
14800,
null,
6000,
28800,
12300,
17100,
9500,
10700,
11700,
33577,
6500,
26400,
49700,
14800,
42300,
9400,
93200,
15100,
11300,
11700,
18300,
22600,
35900,
5200,
null,
29000,
8600,
44200,
38800,
40400,
23263,
22300,
26900,
25100,
28700,
18300,
40900,
14500,
14500,
8500,
34900,
37600,
22100,
30800,
13700,
17900,
15600,
43000,
33800,
58800,
21300,
23400,
17800,
24600,
23700,
35100,
null,
38100,
14800,
32600,
37300,
34100,
26300,
18700,
16200,
29600,
35500,
21900,
24400,
8300,
22500,
8500,
53100,
null,
10800,
23900,
89800,
6500,
49800,
25000,
13300,
22500,
30600,
42500,
54100,
34200,
23400,
54300,
51200,
111200,
8600,
23200,
26600,
91900,
44000,
31000,
15900,
18300,
10800,
26900,
19350,
7100,
7400,
38900,
21600,
9300,
27900,
24100,
37300,
null,
null,
26300,
75800,
49600,
10700,
439100,
35500,
10400,
null,
14700,
null,
29100,
48000,
6500,
80700,
14000,
13000,
9400,
null,
45000,
17200,
28800,
21250,
31500,
55500,
65200,
23100,
30900,
27400,
17600,
13700,
null,
9800,
31457,
15000,
117103,
100900,
4800,
48000,
6900,
16000,
26600,
22900,
29400,
31300,
26000,
12800,
7400,
69500,
31300,
10900,
54900,
31500,
14100,
null,
40700,
15600,
5100,
null,
20900,
35086,
36500,
11200,
null,
48100,
18000,
61300,
10000,
22000,
28300,
14600,
9800,
12200,
22800,
null,
8700,
122200,
106800,
1500,
14800,
30700,
20500,
3900,
21200,
121500,
9500,
44800,
20000,
16700,
15600,
144000,
36900,
25800,
23900,
48700,
50500,
66700,
22900,
28800,
12800,
35300,
32300,
17600,
18200,
41900,
9100,
null,
51600,
13600,
27700,
50800,
44600,
7500,
22100,
10500,
3300,
24700,
3900,
55900,
43000,
17200,
25800,
23500,
27600,
47300,
45100,
16400,
36700,
51100,
39800,
32100,
78800,
24300,
41200,
21800,
57400,
14600,
39500,
17000,
24600,
13800,
27500,
22400,
23200,
9100,
133400,
27500,
34700,
19200,
43700,
25300,
22450,
8300,
19100,
37900,
15500,
35300,
25200,
31700,
null,
35800,
36200,
16600,
25400,
null,
18300,
74995,
10100,
5400,
36700,
29600,
14900,
33200,
14000,
108200,
7500,
13300,
14200,
20300,
1300,
27800,
5500,
129900,
25300,
139000,
8800,
null,
16000,
23900,
60200,
22700,
36300,
142500,
41000,
19100,
60438,
6200,
10000,
15400,
149300,
null,
null,
57600,
28700,
20400,
72500,
9300,
22600,
17900,
55100,
12600,
6000,
3700,
18700,
181500,
47000,
20800,
12800,
9700,
null,
53000,
14600,
14700,
13000,
36800,
13600,
19300,
121100,
9500,
25400,
18400,
22000,
11900,
11800,
18400,
27700,
31800,
8300,
9100,
34600,
38300,
22100,
80500,
43100,
25400,
3600,
23200,
11500,
78000,
6400,
7500,
15000,
27000,
22100,
34200,
7800,
31012,
37900,
1000,
9500,
7200,
42800,
null,
36400,
22000,
37400,
19200,
9900,
35500,
21400,
21700,
5300,
28000,
79100,
59400,
35700,
52100,
2300,
39600,
7500,
9200,
26400,
28300,
36900,
14300,
11700,
8300,
10500,
53100,
4500,
5700,
23100,
88600,
51600,
6300,
7000,
11900,
81100,
14800,
113200,
58300,
23300,
4500,
43700,
35400,
15600,
49600,
35200,
null,
24900,
39800,
32100,
null,
4600,
26400,
33300,
11600,
10400,
28200,
24000,
32600,
21600,
55700,
15300,
14200,
14700,
19700,
42400,
5300,
27100,
36400,
11300,
28200,
34200,
19300,
44500,
16900,
14800,
23500,
19100,
20400,
36100,
null,
25500,
10900,
11000,
51400,
20900,
20900,
19900,
23300,
25500,
27800,
32000,
17400,
null,
null,
226400,
null,
null,
6600,
16500,
30000,
7500,
null,
20900,
23300,
44800,
7000,
1000,
4900,
20200,
32700,
31300,
16300,
17900,
6200,
6800,
55400,
19300,
40200,
39600,
34200,
13400,
39100,
null,
14500,
37200,
null,
8300,
null,
39300,
48500,
13100,
43400,
86200,
25000,
64800,
41900,
59800,
17400,
42100,
null,
26600,
5500,
111300,
26100,
30800,
79400,
19900,
114200,
48200,
22400,
18800,
110300,
47400,
22400,
30400,
25600,
5800,
9700,
22800,
13500,
10500,
37100,
20300,
14400,
48200,
35700,
24300,
26000,
1500,
null,
45800,
39000,
18100,
4300,
9700,
293500,
5000,
11500,
33550,
12800,
11400,
34500,
70200,
34000,
23600,
25900,
59300,
17600,
29300,
23500,
95900,
56300,
null,
33100,
5200,
null,
null,
14500,
4500,
7200,
11300,
19500,
null,
33000,
58600,
33600,
11300,
37400,
47500,
42300,
30100,
28317,
32100,
null,
91600,
11200,
14800,
34400,
null,
91000,
177870,
4400,
60000,
33900,
21913,
103100,
6500,
53123,
16800,
122900,
77000,
91200,
48000,
7600,
null,
12100,
43100,
null,
17400,
142900,
20100,
8100,
17100,
10800,
null,
16400,
17200,
22500,
8400,
50900,
13100,
41400,
5000,
26000,
15600,
24010,
22600,
40400,
30051,
23500,
20518,
29900,
51300,
82400,
21000,
37500,
23900,
68000,
33800,
19900,
41100,
14800,
8800,
37545,
171600,
26100,
26900,
18900,
44900,
5850,
10100,
68100,
65600,
13600,
null,
32100,
30600,
42300,
29300,
57800,
84900,
14700,
68528,
22900,
26700,
39100,
46800,
45400,
16700,
16700,
6400,
55500,
2900,
7547,
19000,
70200,
22200,
20800,
13200,
7700,
null,
32000,
20400,
20600,
43900,
37200,
4200,
20900,
6500,
23500,
7700,
7900,
119500,
44100,
11300,
144300,
8200,
28700,
14000,
7600,
40700,
null,
18300,
16100,
95100,
7400,
39500,
19400,
48400,
27700,
23200,
null,
14800,
14400,
11600,
4500,
23700,
94700,
5700,
8400,
133600,
24700,
22000,
5100,
14200,
110200,
16100,
26400,
36800,
24800,
5300,
39800,
39600,
17900,
5100,
28400,
37800,
29600,
96000,
21500,
29100,
26600,
19200,
21500,
19000,
null,
null,
11750,
22000,
39000,
null,
9500,
10300,
35200,
19800,
58400,
45600,
22300,
24950,
8200,
null,
12600,
27500,
6000,
25900,
9900,
null,
154000,
105900,
23700,
66300,
7200,
41600,
61500,
13000,
60000,
50300,
43000,
73800,
30462,
14100,
18400,
45100,
19100,
7600,
10600,
33200,
28300,
27500,
129600,
60700,
null,
37100,
39800,
36000,
24000,
9600,
15400,
null,
50100,
41674,
4100,
10100,
null,
30700,
33500,
null,
85900,
null,
2800,
null,
39500,
12700,
20000,
12000,
null,
null,
2000,
13430,
16400,
23400,
39500,
16200,
28300,
21900,
15100,
null,
null,
52300,
29000,
16200,
96000,
18300,
48900,
31200,
null,
35400,
55500,
null,
46800,
28300,
92200,
54500,
17100,
22300,
26700,
3200,
10957,
15300,
102125,
16700,
48500,
null,
21200,
43000,
20200,
null,
9700,
83900,
9600,
40100,
35800,
16900,
4300,
19300,
37100,
21600,
23400,
null,
14500,
null,
10100,
31100,
41800,
59300,
28300,
914900,
null,
19000,
16800,
null,
33000,
35120,
92400,
135000,
10800,
155800,
6500,
76000,
17900,
34200,
53100,
27700,
13900,
27800,
100940,
31600,
10000,
21200,
41300,
17300,
36500,
14000,
81400,
4500,
46200,
19200,
10100,
68701,
12000,
12100,
18100,
100500,
57200,
null,
77800,
9100,
8600,
7800,
25200,
26000,
13500,
26000,
45900,
12800,
11700,
9800,
78200,
13400,
34600,
35600,
5700,
157000,
36500,
8500,
38600,
38400,
13800,
2700,
31200,
36100,
101900,
127500,
11200,
37300,
29300,
33400,
21600,
18300,
52300,
12006,
30800,
59700,
10700,
119600,
null,
21300,
36900,
12600,
10400,
11000,
13400,
27900,
8600,
26600,
45900,
41000,
12500,
27800,
79200,
22800,
null,
26500,
37800,
9000,
null,
16300,
null,
18300,
24900,
34000,
40500,
7000,
null,
17300,
32900,
21900,
23500,
11800,
9100,
22200,
96700,
14300,
37500,
24000,
15600,
18660,
17400,
16600,
74000,
32500,
14800,
19700,
50400,
20100,
56600,
null,
86100,
41500,
9300,
null,
41000,
32800,
22700,
17500,
null,
27300,
null,
20500,
62300,
41700,
18400,
22454,
109300,
22100,
103200,
19100,
8500,
41700,
32900,
25400,
42200,
34300,
23500,
25000,
11600,
52200,
16200,
136600,
29500,
32500,
555800,
5000,
20600,
9500,
53900,
29200,
12900,
22600,
5600,
90100,
33200,
18600,
21000,
15550,
42700,
56200,
null,
17849,
null,
56075,
41900,
15100,
26200,
7500,
39300,
29900,
14000,
26000,
null,
26800,
10200,
40700,
10800,
17500,
18500,
15400,
19000,
3200,
21600,
98300,
3600,
26604,
null,
36000,
25500,
41500,
35400,
9800,
12300,
3600,
null,
27600,
null,
63300,
47300,
14900,
36500,
21000,
20700,
11100,
46000,
74000,
14700,
36700,
54500,
null,
6800,
25200,
26100,
51300,
57100,
15700,
null,
37808,
44600,
6600,
10900,
null,
35900,
25200,
12300,
40100,
null,
15900,
15600,
54900,
13500,
9000,
56800,
38400,
null,
15000,
15400,
12500,
22500,
18100,
67200,
17400,
85500,
53400,
3500,
24200,
null,
29800,
27200,
4600,
81400,
19900,
19200,
48900,
68500,
12700,
14900,
18100,
28600,
13600,
2900,
24100,
27600,
25000,
25100,
28400,
74600,
30500,
5105,
19300,
null,
11700,
7000,
15600,
12300,
11200,
11600,
23800,
null,
29900,
68500,
27000,
4500,
31000,
15700,
17900,
16000,
6300,
null,
74200,
15500,
6000,
12000,
15600,
35900,
null,
19500,
96100,
39900,
21100,
3000,
62500,
16500,
23400,
20600,
17500,
5300,
13100,
49300,
6100,
28800,
25400,
18700,
15000,
15700,
24400,
13600,
39200,
42000,
3400,
19600,
34100,
4500,
51100,
12100,
37000,
42000,
18100,
177900,
18800,
null,
6450,
12100,
36200,
null,
11200,
32100,
17000,
26000,
56130,
26800,
4350,
null,
9200,
null,
8400,
6700,
42600,
20900,
7600,
65000,
27000,
58700,
null,
16800,
32400,
51600,
64000,
20500,
10800,
28700,
20100,
20100,
20700,
76300,
36600,
21900,
22400,
14200,
44937,
3800,
42000,
23400,
6700,
49200,
5300,
24800,
93700,
7800,
29000,
53700,
16300,
34200,
19600,
4700,
13200,
28000,
8950,
27300,
25500,
36000,
null,
88500,
null,
5100,
39100,
7500,
44400,
null,
35800,
6100,
66800,
13200,
34200,
79600,
12500,
69900,
13500,
15800,
94900,
null,
6800,
12500,
null,
null,
176500,
15300,
1600,
11300,
30200,
86500,
22200,
39800,
23400,
131300,
null,
37900,
null,
null,
27200,
53103,
157200,
null,
36400,
25300,
null,
10500,
9700,
null,
23600,
14800,
15300,
124600,
18300,
17700,
67300,
null,
40000,
49200,
68600,
58000,
41700,
85100,
10900,
15500,
null,
42900,
5740,
25600,
59000,
9000,
18600,
35000,
50300,
null,
5700,
8300,
48000,
32400,
26700,
11300,
null,
null,
15800,
30300,
54200,
null,
4800,
33787,
29400,
14700,
18800,
68500,
32000,
22800,
8200,
7200,
21400,
45200,
39400,
50200,
31900,
4800,
7100,
179500,
31400,
13700,
34900,
57300,
71600,
146500,
28200,
56800,
33100,
19800,
21000,
18300,
27300,
55500,
7400,
null,
28700,
8800,
27300,
22700,
20100,
7400,
5600,
68500,
8300,
3300,
17000,
16700,
16000,
52800,
13600,
30100,
9000,
39700,
45600,
15600,
31300,
7000,
73700,
20400,
17800,
9000,
35100,
7100,
47500,
15400,
12800,
47900,
null,
19700,
28400,
31900,
144900,
31100,
56400,
23000,
3700,
35900,
8000,
7700,
14100,
null,
null,
41300,
28700,
67000,
5200,
18500,
null,
21800,
25200,
3700,
23500,
9200,
35900,
36300,
24700,
37060,
11700,
4700,
20300,
43500,
19300,
43200,
15600,
34000,
null,
36400,
54200,
41700,
40700,
23600,
4200,
19900,
13200,
28000,
11700,
79400,
100200,
35400,
21000,
7700,
4400,
23800,
19700,
17600,
41500,
24900,
60900,
28800,
8047,
17100,
12500,
25100,
2600,
17500,
61200,
27500,
3800,
63200,
19900,
8700,
20000,
9800,
22600,
15200,
87300,
128800,
26200,
12600,
42800,
37000,
18591,
58700,
30600,
34100,
11100,
11400,
6600,
37200,
24900,
12300,
24300,
8800,
18600,
24600,
88200,
52800,
13600,
12300,
7200,
39200,
null,
40700,
34900,
23400,
17600,
87300,
23700,
18900,
33400,
41400,
null,
24400,
20900,
26100,
null,
30200,
21600,
19900,
4100,
28500,
11200,
10500,
null,
12200,
119200,
null,
55500,
9800,
34400,
20200,
29400,
null,
68200,
55900,
23800,
11300,
88050,
25700,
13600,
11000,
17800,
null,
7300,
36700,
22800,
26000,
15100,
4100,
44700,
4600,
28100,
24400,
31700,
21400,
14300,
12500,
12800,
28500,
24200,
8100,
40100,
24000,
38800,
25800,
54300,
32700,
21300,
52500,
13800,
12275,
22700,
16500,
24500,
31200,
31995,
14800,
59000,
47900,
32500,
null,
24800,
34100,
null,
24400,
10300,
null,
19100,
47100,
73600,
15500,
48400,
13400,
27900,
10000,
28900,
16200,
null,
27500,
16600,
15400,
37300,
19200,
6300,
8300,
11650,
39700,
8000,
31900,
69200,
8100,
6200,
7800,
12500,
13300,
null,
14600,
17900,
116400,
15900,
89500,
29400,
24100,
27400,
65500,
29200,
82300,
3600,
31292,
72500,
25900,
48400,
44800,
53800,
32300,
30000,
null,
97400,
35300,
null,
60400,
null,
4600,
null,
14000,
24800,
4600,
23877,
30100,
105400,
25200,
61850,
27600,
39900,
9900,
10500,
4600,
19400,
27500,
15600,
19400,
17800,
10100,
7600,
56200,
29100,
32721,
39900,
50500,
19000,
21500,
37500,
20600,
27900,
2800,
33600,
26000,
31300,
null,
43900,
13400,
9700,
null,
10900,
21200,
25300,
118000,
24400,
45300,
22800,
39900,
244800,
41800,
null,
4900,
null,
88200,
32200,
12600,
35200,
19300,
81200,
29900,
22400,
58200,
7500,
40200,
6800,
27600,
15800,
40200,
39500,
25200,
4500,
24800,
24500,
29900,
9600,
13900,
13900,
null,
60800,
41700,
21000,
10900,
7700,
153600,
154500,
23900,
40700,
null,
3000,
20100,
91400,
null,
9700,
10200,
13400,
38100,
40300,
3150,
24300,
29600,
19000,
83700,
null,
27200,
31500,
20200,
34000,
25100,
11800,
9400,
21200,
15600,
25145,
41900,
41300,
2000,
18200,
28600,
15900,
37700,
31300,
14500,
35800,
24700,
null,
65500,
4200,
7000,
59100,
null,
7100,
17900,
19700,
12700,
35800,
22800,
null,
122900,
8500,
14800,
40100,
51268,
26400,
117200,
197800,
45100,
159900,
20600,
53600,
148100,
35900,
51300,
36900,
80900,
15000,
42600,
7200,
56400,
16700,
24000,
5000,
80600,
8200,
48900,
47000,
11500,
12600,
22800,
7700,
23900,
14200,
36000,
22500,
52350,
6500,
7300,
13400,
56000,
120900,
null,
22800,
34700,
34100,
15170,
26000,
42700,
11900,
50619,
18200,
39300,
27000,
null,
2700,
41500,
26500,
33900,
52500,
12400,
51700,
35200,
2700,
26000,
null,
58300,
33100,
null,
62400,
52300,
18200,
26400,
13000,
52200,
10700,
23100,
21500,
null,
18600,
23000,
46500,
43200,
14100,
7600,
10100,
12000,
28200,
null,
33600,
25000,
15400,
19300,
21300,
59100,
6800,
7700,
14100,
36800,
11250,
13500,
12900,
19000,
24800,
null,
null,
32200,
56334,
8200,
null,
18000,
20200,
6700,
6500,
5100,
10400,
41600,
23500,
48200,
13900,
47800,
16100,
2200,
18500,
42000,
28700,
26500,
111300,
13500,
17000,
27200,
21600,
13100,
18500,
15500,
10600,
57480,
53200,
4000,
32400,
6900,
17200,
43400,
17300,
36000,
68900,
72900,
48800,
19200,
27500,
4250,
42350,
null,
null,
27500,
16000,
41300,
12700,
16100,
26600,
59700,
26800,
37500,
51200,
48700,
12000,
29300,
2000,
7500,
1600,
11000,
6700,
12700,
6600,
33800,
48300,
23800,
27700,
53100,
39900,
31400,
35285,
26300,
19500,
11100,
23700,
null,
85500,
17300,
15300,
31400,
89700,
15100,
7300,
39909,
18200,
24600,
40000,
24800,
27900,
13900,
11300,
1500,
25400,
30800,
3600,
92600,
17000,
19400,
13000,
18800,
22300,
78000,
59500,
10400,
56200,
17000,
60000,
19000,
24500,
35300,
17800,
500,
88700,
44419,
33200,
20600,
11800,
10000,
27700,
7000,
4500,
62000,
13700,
74500,
12600,
22400,
null,
12300,
44100,
14100,
15900,
33400,
12000,
28300,
40300,
29600,
null,
41600,
22500,
125200,
38400,
9000,
94500,
26300,
15600,
18600,
15200,
12300,
3000,
13000,
null,
6200,
20700,
22600,
10500,
30900,
3000,
35900,
153400,
null,
7400,
12300,
19200,
391000,
9000,
87400,
27600,
21500,
null,
14000,
69200,
19384,
14600,
7000,
null,
75100,
88800,
76500,
14900,
null,
null,
31000,
30500,
40700,
23000,
24400,
104600,
27800,
21800,
27900,
54900,
25000,
42200,
44700,
16300,
null,
220200,
3800,
25000,
27200,
40700,
26000,
19600,
26300,
38200,
30700,
4450,
28600,
8300,
8100,
54600,
16000,
35300,
null,
133300,
15700,
11000,
11100,
14500,
26000,
26800,
53700,
36700,
37900,
34300,
25300,
53400,
15900,
18100,
null,
29200,
167700,
26400,
8300,
49800,
43900,
115200,
67800,
9700,
29300,
12400,
null,
15700,
10100,
36100,
20000,
9300,
138400,
45700,
15400,
16500,
16100,
null,
7500,
80600,
33000,
4300,
5900,
10300,
87000,
24400,
49200,
17800,
94200,
13700,
46400,
19400,
33700,
17400,
11200,
104400,
6400,
18800,
42700,
62100,
49000,
22100,
32032,
64000,
8800,
22000,
35300,
56700,
25600,
14700,
24000,
6500,
9000,
23600,
16200,
9000,
11400,
25300,
30400,
28200,
10100,
12700,
6400,
11500,
null,
6650,
4900,
3000,
13700,
34000,
29300,
20300,
20400,
17700,
81700,
38900,
12100,
15500,
34500,
21000,
38600,
27600,
21700,
44700,
5900,
7900,
15400,
54800,
11900,
58100,
291200,
15100,
89400,
26500,
44000,
46000,
13900,
13500,
21900,
44900,
5100,
28200,
17300,
18300,
12800,
130500,
20200,
38300,
null,
57200,
32900,
4700,
19200,
26200,
36000,
35800,
22000,
17100,
16700,
24400,
31900,
25600,
null,
37700,
43100,
23600,
118700,
16000,
13900,
11900,
13600,
22475,
24800,
11700,
35100,
4400,
4900,
null,
31400,
26900,
26000,
5200,
12000,
44600,
80000,
33900,
20900,
null,
31900,
61096,
3400,
30100,
14400,
108551,
24000,
20400,
11700,
null,
1500,
8300,
19600,
20000,
27300,
28000,
14100,
3400,
27100,
null,
28300,
25700,
39000,
19700,
14500,
13500,
15700,
43100,
36480,
null,
17500,
50668,
5300,
5900,
6400,
57900,
19000,
null,
11100,
31800,
23100,
12300,
62800,
43700,
34900,
9800,
29300,
27200,
26300,
20200,
56800,
12200,
9900,
11400,
42400,
16300,
3900,
42500,
28700,
91400,
12500,
14500,
33500,
27900,
11000,
null,
null,
81100,
19000,
15900,
11200,
27480,
31900,
13200,
20100,
34200,
4500,
null,
52800,
34200,
23375,
41303,
null,
76300,
183700,
47200,
32300,
60500,
125300,
29200,
26450,
12100,
29000,
15000,
40200,
33200,
43300,
11100,
16800,
23800,
7100,
35300,
30400,
45900,
10200,
13600,
23400,
12400,
5900,
38700,
20150,
35100,
19300,
140190,
5400,
22300,
98600,
16100,
36400,
33000,
50400,
21400,
29200,
18900,
30200,
2800,
null,
22600,
23700,
21800,
24600,
143800,
60200,
14700,
27300,
16200,
21200,
null,
null,
2400,
45200,
38900,
19300,
32200,
20100,
31300,
18100,
178025,
15700,
27300,
36700,
null,
67000,
8500,
17200,
17300,
28400,
25100,
22800,
15300,
8400,
15300,
58400,
18700,
13500,
18400,
null,
23500,
19800,
26100,
13500,
71800,
5700,
18200,
7500,
17300,
44900,
8900,
28800,
5500,
null,
11400,
10200,
19000,
41800,
61500,
57300,
54000,
6100,
null,
20900,
7300,
10800,
108572,
31862,
35300,
24500,
28700,
37300,
49300,
23900,
30100,
27900,
26100,
70500,
44500,
21200,
22000,
55200,
43800,
51400,
45300,
47900,
50000,
36700,
17100,
64000,
48900,
12100,
41500,
50200,
9700,
68100,
null,
12900,
18500,
6700,
null,
19600,
92500,
7900,
41100,
7800,
26200,
9100,
7200,
30700,
22400,
74900,
22200,
38100,
18600,
73950,
29400,
96700,
57100,
17700,
70400,
8800,
8800,
43500,
32000,
22300,
22900,
20700,
13300,
22900,
68800,
27900,
17700,
23900,
null,
25300,
33100,
23500,
30500,
null,
10800,
73000,
73600,
16300,
8600,
15300,
55800,
98200,
16000,
35600,
17200,
14700,
6700,
23000,
42700,
42300,
10300,
12800,
15000,
70024,
24800,
null,
48100,
9500,
32900,
32600,
53400,
23500,
null,
18500,
28900,
13700,
42500,
44900,
27200,
6000,
36100,
14000,
25500,
null,
54100,
27400,
15800,
48700,
null,
61500,
null,
29600,
19100,
23900,
18800,
10000,
23900,
48900,
346600,
47900,
6100,
3200,
67500,
null,
18400,
48200,
55000,
null,
null,
72300,
23200,
null,
64300,
41000,
18500,
40000,
42200,
12800,
197900,
18200,
10500,
15600,
40200,
44300,
14100,
13200,
53700,
18800,
65900,
9600,
13500,
42200,
37600,
12700,
11100,
59500,
23800,
71856,
53900,
37500,
27400,
7300,
22800,
177900,
11000,
16400,
22900,
null,
14700,
7500,
36000,
6000,
34400,
52100,
9000,
21600,
30700,
52900,
49110,
29200,
34500,
19100,
90600,
34600,
27100,
96800,
17400,
11200,
58400,
20200,
null,
28400,
15800,
14300,
39300,
16400,
12700,
151624,
14600,
17000,
39100,
22900,
53900,
null,
22300,
13400,
32800,
null,
9500,
41300,
11300,
19100,
13000,
23300,
14900,
33900,
5400,
55600,
32200,
45500,
10000,
21800,
31400,
43502,
14900,
53600,
7500,
66200,
41200,
24200,
11900,
53000,
8900,
null,
38200,
30000,
800,
41300,
51600,
17500,
2400,
97300,
27500,
15000,
25800,
32800,
6600,
44800,
37900,
21400,
12200,
46600,
77100,
10400,
22300,
23100,
32000,
46400,
null,
9800,
41700,
30300,
36300,
30100,
18100,
null,
13200,
40800,
8300,
19500,
14100,
18900,
24100,
31600,
32701,
22500,
25200,
119500,
28100,
14100,
29500,
47800,
32000,
45500,
97400,
34000,
32400,
55700,
27300,
17200,
12700,
16200,
9000,
10800,
16900,
23300,
19500,
8800,
18200,
35400,
19800,
12500,
5100,
14400,
94100,
87100,
23500,
10029,
13600,
32000,
13600,
6400,
23200,
null,
13300,
15700,
39400,
117300,
null,
20000,
null,
6050,
15500,
67600,
null,
17900,
6800,
34300,
11900,
9300,
6500,
38900,
20700,
17700,
16600,
16800,
28700,
15300,
24900,
42900,
15300,
183900,
29200,
58400,
69200,
19800,
33500,
44500,
22000,
15900,
44500,
9700,
null,
13600,
8800,
10688,
20100,
24900,
46200,
20300,
13800,
null,
10700,
null,
5400,
156200,
null,
17300,
null,
5100,
4300,
54870,
23400,
296700,
17500,
10600,
38100,
18900,
null,
18900,
null,
9600,
18500,
14100,
36700,
23200,
7100,
151700,
5300,
20300,
23800,
26100,
48800,
13000,
40000,
31000,
39100,
47800,
0,
11700,
11300,
6900,
300,
8700,
13700,
14100,
10400,
13300,
89100,
15300,
7500,
14500,
11800,
41900,
16300,
22300,
3500,
13400,
16900,
16000,
25000,
17700,
4800,
261500,
32689,
6900,
12900,
12800,
null,
null,
67800,
14500,
null,
null,
22900,
35300,
27300,
7400,
24100,
15900,
19400,
62900,
14900,
10900,
11300,
8300,
16800,
37200,
31800,
5200,
11400,
64100,
36700,
54000,
null,
69400,
4600,
29600,
5500,
37800,
10800,
13600,
73900,
69100,
14100,
17200,
null,
68100,
8500,
18700,
4600,
11700,
28300,
16500,
9200,
46600,
18200,
null,
21900,
19300,
68600,
17350,
17100,
11500,
20400,
8300,
2000,
20100,
8400,
42100,
38800,
null,
null,
22500,
74300,
10200,
43600,
3000,
107000,
47700,
16000,
null,
7800,
21900,
15600,
13400,
13400,
48000,
29400,
13900,
32300,
10900,
22200,
112500,
43700,
31500,
20500,
10800,
7700,
24100,
81127,
6500,
12400,
35600,
34300,
40100,
10400,
null,
13400,
30000,
7400,
27400,
13000,
13400,
30000,
18500,
25700,
14700,
93200,
54900,
26200,
18000,
14600,
76500,
6500,
24600,
1200,
66400,
24100,
4500,
25200,
20800,
17000,
48400,
20000,
null,
2400,
10200,
34500,
35100,
205553,
25200,
54600,
28300,
11200,
26000,
32700,
4500,
8100,
11750,
88400,
11100,
14500,
69900,
2000,
82300,
52600,
23400,
47500,
5500,
17400,
20000,
12600,
20900,
8200,
19200,
12600,
4100,
38000,
null,
45500,
null,
47300,
19900,
20800,
77600,
156150,
3900,
37700,
24100,
6800,
null,
null,
37769,
25800,
null,
11300,
13300,
25500,
21400,
50000,
7400,
27500,
4200,
35900,
18700,
null,
71700,
84800,
28175,
9800,
9600,
7000,
17000,
5100,
50600,
33400,
10900,
23250,
23300,
22100,
28900,
37287,
51000,
76400,
25100,
25000,
26300,
29400,
16100,
11500,
18000,
25300,
12700,
63300,
10900,
20900,
24000,
62400,
8000,
18400,
7800,
10000,
13900,
177811,
35700,
204900,
7600,
3800,
21300,
78000,
14400,
null,
25500,
76900,
16400,
25300,
44100,
63100,
10200,
845,
12000,
12900,
10800,
null,
4000,
null,
26800,
9400,
null,
13900,
86761,
48900,
34900,
145300,
7600,
10300,
41100,
46000,
45800,
null,
7700,
48200,
14011,
68100,
5700,
30100,
19000,
25900,
11600,
24200,
8900,
33000,
12200,
20300,
22200,
8900,
null,
13500,
16200,
7200,
4700,
27100,
54000,
35500,
22200,
27000,
15100,
null,
22500,
32600,
null,
6500,
19500,
5500,
41200,
42800,
150000,
13400,
null,
20600,
46700,
7500,
23800,
47500,
55500,
36529,
67800,
10100,
23400,
10400,
29900,
19300,
26900,
41600,
13100,
76727,
10050,
6300,
12700,
27100,
9000,
23900,
104300,
15400,
17200,
10500,
43500,
27600,
26000,
31900,
89668,
22600,
4500,
64001,
26500,
94600,
28000,
441100,
22200,
18100,
29600,
38400,
27800,
31300,
6000,
30000,
75000,
16100,
420500,
86950,
17400,
32400,
null,
null,
28500,
61200,
26200,
7000,
18800,
null,
31500,
null,
41000,
15300,
6500,
null,
52600,
6800,
8200,
16400,
34300,
20900,
29000,
null,
22700,
26800,
16700,
9400,
16500,
70700,
59400,
null,
25800,
22100,
40400,
null,
72200,
60500,
33800,
40900,
4300,
23500,
45400,
12000,
39200,
39300,
2800,
31200,
null,
57314,
101300,
27000,
32800,
16200,
20300,
18100,
40500,
92110,
19700,
null,
34000,
12400,
28000,
47600,
12900,
11600,
24300,
67500,
35000,
24900,
8200,
80100,
37600,
31400,
81600,
23500,
52100,
16300,
null,
21600,
14600,
18500,
26400,
46300,
64730,
null,
13500,
15800,
24900,
5800,
15200,
30900,
63300,
16650,
13200,
47850,
14100,
13000,
13400,
null,
36400,
22200,
20000,
5300,
18100,
56000,
24100,
289470,
94400,
6900,
null,
43600,
18600,
60500,
8100,
15200,
16900,
17600,
15800,
18300,
9700,
10700,
6700,
19100,
null,
12600,
63000,
27900,
8700,
81400,
16200,
14900,
41700,
19200,
47600,
61300,
20900,
26600,
45500,
28900,
69800,
54900,
9000,
27200,
6700,
12000,
24300,
9400,
35400,
26600,
113300,
15300,
22300,
13600,
40700,
60400,
71100,
13400,
37000,
11600,
9700,
11600,
18700,
null,
70200,
38900,
21200,
9300,
16500,
57700,
6700,
1350,
22600,
92600,
55600,
68400,
13500,
6700,
4100,
134500,
41300,
12300,
57000,
27939,
7300,
14200,
47000,
42700,
33600,
25500,
23400,
110200,
35400,
25800,
23400,
19900,
264000,
15500,
17400,
null,
101700,
37900,
63500,
null,
11700,
12200,
21500,
15700,
54500,
40500,
13000,
19800,
8300,
46000,
41300,
9800,
26000,
31700,
16700,
null,
null,
56500,
24900,
null,
11700,
27600,
7800,
23100,
23800,
19900,
null,
24300,
15000,
13900,
16200,
null,
19400,
2800,
38000,
12990,
27100,
25175,
32400,
24700,
182200,
33800,
52500,
23860,
31500,
24100,
21400,
24200,
7800,
17303,
25500,
64600,
11200,
null,
37100,
17300,
56200,
36100,
45200,
8100,
9500,
114900,
21200,
null,
80600,
47300,
80800,
18400,
34400,
16400,
10250,
24100,
96900,
7600,
57300,
28000,
35000,
52000,
20200,
21000,
36700,
33000,
47900,
29400,
19700,
35900,
20400,
23900,
28100,
3300,
10900,
45900,
null,
38400,
15500,
12900,
7400,
45600,
18800,
44000,
36000,
14400,
34800,
40700,
11100,
70600,
22100,
19700,
null,
64900,
2600,
37700,
9100,
27500,
12000,
28400,
52100,
30400,
5900,
51500,
48100,
20400,
33400,
5600,
77200,
29600,
15700,
4000,
null,
13600,
77100,
15200,
14500,
16100,
12000,
10500,
50225,
null,
37700,
40960,
7700,
6000,
9900,
5500,
10600,
5000,
30200,
33900,
null,
40300,
17400,
15300,
5300,
51300,
12300,
9700,
37300,
16400,
41300,
10700,
14300,
null,
null,
28500,
31000,
50200,
65900,
32800,
7300,
46400,
45200,
66700,
64100,
11900,
13500,
15200,
3000,
20500,
15000,
38600,
null,
15900,
32300,
5700,
56100,
22700,
5000,
61800,
21800,
75100,
33100,
41500,
53200,
17300,
9000,
47300,
23200,
36900,
178600,
23000,
64100,
21500,
18300,
16000,
13900,
10900,
14000,
27800,
17800,
null,
13900,
47300,
4600,
21300,
50300,
54300,
34600,
15500,
8100,
4600,
31800,
35200,
null,
17800,
21000,
7700,
53300,
17900,
14000,
21800,
83300,
34800,
null,
8900,
15600,
47900,
39700,
29300,
8000,
24800,
8200,
54400,
18600,
51600,
29300,
57300,
14100,
7300,
30400,
11200,
40000,
15000,
23800,
38600,
108900,
null,
23300,
48600,
35500,
13040,
21900,
59900,
41800,
5900,
30400,
25300,
11300,
null,
16200,
32300,
18300,
6200,
8200,
51600,
36200,
35000,
41900,
32200,
16000,
28700,
14400,
10500,
97070,
18400,
248900,
30700,
69900,
47500,
14300,
52600,
37800,
22700,
15000,
31000,
23600,
11200,
11100,
17800,
35973,
9300,
null,
13700,
22700,
8800,
54718,
4800,
35800,
46000,
21600,
2500,
57700,
22100,
null,
47400,
23600,
8400,
16000,
24500,
28100,
45000,
2816,
13000,
71100,
10500,
6500,
8537,
28300,
42000,
26600,
23000,
20200,
33700,
12700,
18500,
18600,
17400,
29700,
null,
26500,
29600,
33300,
53300,
63000,
15600,
28100,
17000,
22100,
14000,
32500,
null,
26000,
60000,
35400,
null,
25700,
26700,
29585,
22700,
46100,
22900,
16000,
3750,
17300,
3100,
7900,
13400,
10800,
50800,
5900,
39700,
85000,
18700,
18500,
24200,
22000,
27900,
7500,
106500,
15400,
46800,
71100,
61800,
76300,
null,
37600,
19400,
41200,
75000,
12000,
33600,
10000,
43000,
25500,
26400,
46600,
11900,
17800,
68100,
29500,
null,
null,
4400,
66100,
null,
25500,
19500,
8350,
30400,
50000,
4500,
25200,
57400,
43700,
23500,
16500,
57200,
28800,
41900,
33400,
21300,
21400,
92800,
27600,
22800,
30200,
42900,
20500,
15600,
18400,
136300,
30000,
null,
null,
28400,
8100,
11300,
2700,
63000,
52300,
9100,
38800,
21000,
89600,
35000,
12700,
11500,
41700,
15000,
52100,
91300,
32400,
55500,
35200,
null,
24100,
53140,
9000,
31900,
42800,
16400,
18900,
11800,
20500,
15700,
3600,
30500,
28900,
70600,
14200,
13000,
26300,
12500,
44300,
6000,
11400,
34400,
null,
21000,
19800,
53400,
11300,
13700,
12200,
46800,
60700,
35000,
28800,
null,
3100,
22900,
21100,
38000,
null,
47800,
45100,
28000,
10800,
10000,
12600,
23700,
null,
47100,
null,
23900,
23200,
16500,
38800,
13100,
12300,
50200,
66700,
13200,
71100,
17900,
6500,
36500,
4000,
28100,
23600,
26809,
27900,
null,
47800,
17200,
3000,
35500,
10700,
20400,
7500,
40400,
110600,
6400,
106800,
1500,
null,
8300,
33950,
41300,
10200,
15800,
22300,
18900,
null,
68800,
83000,
168400,
9100,
null,
19700,
32900,
6400,
17000,
85300,
37000,
16300,
49400,
27400,
41700,
null,
57500,
128500,
24500,
20300,
26200,
84300,
null,
null,
13800,
6100,
74500,
6100,
5700,
12800,
48600,
63100,
30600,
6100,
82000,
16900,
14700,
51500,
44100,
5500,
18700,
19300,
39600,
18100,
null,
14000,
16700,
65600,
6900,
33100,
34400,
41300,
9800,
35500,
16700,
70400,
20400,
23800,
67300,
30500,
12800,
91100,
4600,
56100,
42300,
25300,
58200,
71000,
26600,
43700,
14200,
53200,
25550,
6500,
4100,
33500,
15300,
25300,
3300,
29200,
22100,
58200,
24800,
22500,
10900,
19400,
64000,
86600,
19000,
14100,
41300,
3300,
23500,
13600,
20700,
56300,
32300,
15000,
11500,
35300,
86200,
12900,
23300,
131900,
null,
100100,
57000,
18400,
14300,
31300,
54400,
33500,
6200,
19300,
47400,
6300,
12000,
27100,
44900,
37100,
139900,
16500,
9300,
22100,
11300,
45700,
null,
31700,
12600,
17400,
10300,
48500,
32500,
29200,
9300,
20800,
40800,
53400,
9200,
11500,
20000,
16500,
66000,
20900,
25500,
20200,
45100,
13300,
null,
10300,
45600,
10100,
20800,
37000,
16300,
10200,
30100,
36500,
10000,
null,
40400,
6000,
20250,
28900,
24900,
7300,
22500,
18600,
107900,
12900,
42200,
19600,
28000,
85000,
30700,
89600,
null,
127400,
56600,
22550,
48000,
null,
106200,
1400,
41700,
15300,
53100,
34700,
10800,
null,
40400,
29300,
35900,
19700,
8600,
3950,
12100,
113600,
36800,
17000,
18200,
54200,
74200,
27100,
40100,
17200,
37100,
19500,
19900,
10500,
32900,
41300,
33700,
23286,
55800,
14900,
71800,
83888,
30000,
29900,
null,
28100,
10300,
46200,
11100,
78900,
6800,
67100,
137500,
6000,
12600,
20900,
16000,
16700,
73700,
null,
null,
27300,
12400,
55600,
6200,
6050,
14400,
12500,
8400,
49400,
24200,
18130,
27800,
39662,
27000,
20500,
7500,
48950,
34900,
34000,
null,
30000,
15900,
26700,
13800,
25600,
41000,
25200,
35000,
12500,
32800,
17600,
8300,
6500,
26700,
22000,
14700,
null,
22200,
91000,
44800,
27400,
42300,
43800,
15500,
11700,
null,
33700,
38700,
null,
null,
null,
24800,
5400,
41200,
3700,
72100,
null,
30500,
8500,
13500,
72600,
13000,
8400,
55300,
19100,
20000,
null,
65000,
39700,
null,
null,
14500,
1400,
48200,
6700,
24450,
null,
15600,
6800,
19800,
52300,
49700,
4600,
null,
22200,
49500,
null,
15900,
58100,
14500,
17400,
43900,
50100,
8300,
19300,
11500,
38200,
31000,
45400,
null,
23600,
70800,
18800,
74500,
50000,
4300,
24600,
8500,
11900,
null,
30300,
28200,
47200,
71500,
10400,
6600,
55000,
2600,
31000,
11400,
16100,
15900,
7700,
38700,
31900,
39700,
21000,
34000,
13800,
35500,
50200,
127800,
5900,
64100,
27200,
37300,
50800,
24500,
15300,
12300,
16600,
14000,
15700,
12100,
19500,
16400,
25400,
16500,
27200,
45200,
12600,
50700,
27700,
71600,
4400,
36400,
32800,
17500,
32700,
17700,
20800,
99800,
17800,
20600,
9700,
24000,
80300,
19100,
23500,
null,
9150,
48400,
null,
35700,
34400,
40700,
48000,
6010,
51300,
32900,
32400,
7100,
25000,
9400,
25100,
7500,
79500,
30983,
18900,
24400,
null,
15000,
8400,
81800,
2100,
39300,
65000,
12500,
16900,
6800,
18500,
13000,
35300,
6400,
19600,
110700,
15300,
95000,
629900,
59400,
20700,
29900,
16800,
39800,
19600,
17600,
11200,
37400,
16900,
65000,
53000,
11500,
24020,
9400,
51608,
73100,
48400,
26500,
40300,
17200,
62600,
14300,
49900,
21000,
13800,
14900,
49400,
25400,
9600,
31200,
27000,
11800,
null,
81600,
19200,
79800,
null,
42700,
16200,
17600,
13300,
27000,
42544,
22000,
null,
27000,
17200,
7900,
16000,
49100,
51100,
31700,
33500,
26900,
11400,
32600,
9100,
33900,
12900,
9200,
17150,
27600,
14300,
28300,
19500,
17600,
29200,
23500,
26300,
null,
5400,
13900,
58300,
71000,
67300,
53700,
58300,
18500,
17300,
5000,
14800,
36500,
null,
22800,
11200,
3900,
28800,
30600,
null,
15700,
51977,
15200,
74800,
26000,
53600,
63400,
18300,
5300,
25500,
13985,
null,
21400,
46900,
12500,
19000,
3100,
7100,
17700,
2300,
58200,
10600,
18700,
33500,
null,
12600,
58600,
22600,
30700,
53900,
13600,
68900,
2200,
null,
68000,
18200,
null,
27900,
57400,
20500,
22400,
38700,
14500,
26800,
18100,
37100,
28000,
39800,
21200,
18700,
4300,
23900,
51000,
7800,
13100,
null,
52000,
36800,
29800,
6200,
5050,
22400,
19700,
5400,
null,
19100,
47100,
12710,
61200,
38800,
null,
16700,
3300,
6400,
24800,
21000,
27800,
37700,
13600,
12200,
39500,
25500,
50600,
12800,
9400,
46200,
5800,
14500,
29500,
32300,
14200,
41021,
30900,
21400,
12800,
12300,
25000,
null,
66500,
45900,
17600,
null,
20100,
63600,
6700,
7100,
5400,
14700,
47200,
71400,
12300,
53309,
38200,
63100,
16500,
null,
20500,
62100,
15700,
6600,
49200,
25700,
7100,
17500,
54300,
47000,
98100,
11400,
40700,
null,
13000,
25000,
25200,
51500,
34600,
19700,
19500,
40860,
13026,
29828,
10200,
12100,
13000,
15900,
61100,
8100,
41600,
24900,
46400,
8300,
14900,
43400,
9500,
null,
null,
38400,
null,
50100,
22100,
56300,
8200,
34700,
17700,
18100,
30000,
18100,
41300,
55000,
26800,
49381,
34900,
10200,
44400,
12500,
17800,
4200,
27900,
12200,
38100,
null,
8200,
34900,
17200,
51000,
10500,
null,
26800,
10700,
11500,
11600,
35800,
23700,
9000,
5800,
13300,
null,
2800,
3000,
11200,
31700,
18400,
64400,
45100,
24800,
50100,
63300,
26300,
45200,
33400,
24800,
20200,
9600,
130300,
4100,
6200,
12800,
11400,
30900,
29600,
37700,
18800,
6200,
27600,
32500,
5100,
6000,
13800,
31000,
38800,
17900,
32500,
17400,
27300,
27100,
9200,
31000,
41000,
50900,
14300,
15100,
19000,
87200,
70000,
20300,
6600,
6700,
13100,
11250,
24300,
26200,
24200,
25600,
17300,
null,
7000,
62700,
9300,
4500,
31400,
29500,
51510,
62200,
34900,
27600,
6800,
63600,
8400,
97900,
52200,
null,
36200,
null,
65500,
16200,
15400,
6600,
null,
3600,
43300,
15100,
33400,
22800,
6200,
7000,
4800,
12900,
32600,
15500,
51600,
46800,
6600,
24800,
4650,
116000,
21600,
42700,
9700,
16890,
13600,
13600,
19000,
35000,
3600,
31000,
21100,
38900,
11000,
7500,
null,
null,
20400,
10000,
55300,
42200,
14700,
52600,
35100,
40400,
100100,
15700,
20100,
17400,
25300,
39700,
30500,
60100,
18000,
11700,
86000,
27200,
31900,
34000,
8800,
63300,
78000,
19000,
52200,
31800,
13400,
40000,
12400,
41500,
104700,
74900,
null,
1500,
19800,
null,
null,
20800,
5400,
3100,
26100,
3000,
24600,
53000,
null,
33500,
19825,
149500,
21900,
13600,
8500,
20000,
20700,
34900,
18433,
null,
28600,
11800,
47300,
66200,
15900,
33200,
26100,
109800,
43500,
41300,
21400,
14500,
68700,
null,
7500,
16400,
null,
16600,
123827,
15200,
11100,
8400,
44000,
41600,
47100,
42600,
118600,
13000,
52700,
20700,
15800,
20000,
54100,
29300,
10500,
105550,
null,
null,
28500,
10500,
null,
48600,
25200,
30700,
16100,
39800,
16600,
11300,
6000,
12700,
27500,
12600,
45400,
212000,
12700,
13600,
null,
75400,
21400,
236300,
56400,
36600,
14800,
17400,
11700,
26100,
null,
23800,
30000,
null,
42500,
27700,
36700,
9100,
26100,
22700,
null,
50700,
null,
13300,
72400,
17000,
null,
86800,
16600,
null,
28100,
25100,
30400,
30100,
6400,
31500,
32200,
24200,
96600,
36600,
87800,
4600,
7100,
14100,
22500,
40500,
56300,
44000,
98200,
12700,
20500,
22400,
45400,
21400,
34500,
null,
49300,
19400,
null,
null,
101000,
14500,
19600,
15200,
60600,
36200,
51700,
54900,
3200,
16300,
34300,
14000,
46100,
21200,
20000,
39200,
17800,
null,
7500,
11300,
24000,
5400,
10100,
15500,
69300,
2000,
12200,
31200,
21100,
35800,
17900,
26300,
15800,
48900,
7600,
281300,
69100,
null,
42700,
5300,
84500,
39100,
47200,
23900,
11000,
null,
52800,
null,
15400,
36000,
14100,
4700,
17800,
33000,
9500,
48900,
null,
21800,
21000,
null,
21000,
73200,
43000,
65000,
89300,
null,
141300,
112000,
43938,
62300,
12900,
9200,
14100,
18500,
null,
48100,
18300,
20600,
19200,
null,
44000,
null,
25400,
5900,
14000,
6200,
29900,
48400,
9900,
9900,
26400,
16000,
45300,
71000,
9600,
11700,
null,
20600,
143500,
18300,
5100,
55400,
null,
49800,
168400,
12500,
null,
19300,
43300,
15800,
26850,
43400,
17800,
null,
39700,
15300,
null,
27000,
37900,
10400,
23400,
74700,
36700,
100543,
13900,
44900,
10200,
283600,
14800,
11000,
null,
9600,
31900,
57400,
5500,
16400,
19900,
14600,
32000,
25700,
19900,
8500,
35500,
9800,
30700,
60300,
21700,
null,
22700,
32000,
14900,
44700,
31800,
8200,
21000,
29600,
24500,
6000,
11400,
null,
48000,
97300,
37300,
27100,
127886,
29200,
3000,
11900,
28200,
13500,
20700,
49300,
38100,
95400,
38800,
12100,
3800,
13200,
44300,
51900,
32600,
97100,
42400,
20600,
20200,
12300,
27300,
13700,
6100,
25800,
44600,
19500,
12300,
48300,
14300,
25300,
20900,
79800,
null,
37100,
9300,
71000,
18100,
129100,
9900,
11500,
39000,
9500,
79100,
51400,
33700,
73000,
43100,
8600,
17900,
21400,
null,
13700,
51500,
18900,
57800,
6900,
7800,
122000,
83400,
21900,
23400,
null,
70800,
3800,
11500,
33300,
5100,
null,
95000,
13200,
13800,
75500,
1000,
33900,
22600,
47600,
8500,
13100,
9300,
60000,
null,
21600,
31500,
null,
18100,
22100,
37800,
9600,
13796,
22537,
66900,
9900,
49400,
19700,
96600,
38300,
16400,
null,
7300,
null,
18300,
null,
7500,
87700,
4200,
55400,
38900,
null,
46900,
18500,
23600,
4750,
116600,
56300,
7500,
25000,
13400,
22300,
30700,
26300,
20100,
108800,
61800,
44000,
25300,
112500,
8000,
62000,
15700,
47400,
11700,
50366,
11200,
26600,
null,
20100,
16200,
null,
1400,
29000,
52800,
35600,
33728,
12700,
45500,
143600,
44800,
23300,
null,
null,
16000,
16600,
null,
16900,
14500,
null,
56600,
30700,
31100,
47000,
3700,
24400,
27900,
151600,
36600,
38700,
8800,
17200,
21400,
6400,
33000,
49100,
48100,
37800,
19900,
72200,
43000,
14000,
68500,
43100,
null,
10400,
12000,
25900,
24400,
51700,
20900,
8400,
29500,
null,
7100,
26700,
null,
8600,
4600,
77800,
124400,
16800,
8200,
20000,
19600,
25500,
46100,
12300,
13700,
66400,
19800,
5200,
27900,
12500,
50900,
27600,
3000,
52300,
22500,
43200,
24900,
80700,
17900,
67700,
14800,
11200,
5700,
25400,
38400,
18100,
27200,
43500,
166900,
23800,
19000,
26700,
9600,
25300,
28200,
34100,
40500,
21200,
5000,
24100,
9800,
51300,
12300,
5900,
29500,
54000,
33400,
2900,
19000,
11100,
77900,
30800,
18300,
5500,
9700,
13400,
59300,
null,
12500,
103500,
null,
18800,
7300,
17900,
12400,
44100,
13800,
23300,
6200,
19400,
12800,
45700,
18100,
61000,
28500,
65800,
7300,
25500,
null,
44600,
59600,
null,
18900,
12200,
6200,
55800,
28900,
14700,
26600,
55100,
59600,
34200,
8000,
48200,
49900,
21100,
null,
28800,
18200,
15200,
18100,
20500,
57300,
null,
null,
67700,
13500,
14700,
67800,
null,
23100,
7400,
6000,
106000,
44200,
1600,
74600,
null,
33600,
27300,
7600,
28600,
103400,
41000,
32500,
15500,
null,
47500,
96600,
47000,
17200,
14700,
19500,
27900,
45500,
47400,
21000,
13300,
46500,
79700,
null,
42600,
10600,
31900,
26100,
32300,
17100,
6600,
17600,
9300,
44500,
31600,
22900,
null,
17600,
88000,
104000,
25200,
39000,
null,
10100,
27200,
4700,
103100,
21800,
12800,
44800,
7800,
22900,
79300,
10400,
31100,
37100,
75400,
7100,
7200,
2700,
16300,
38100,
52300,
7900,
66700,
1400,
37000,
24000,
16100,
30300,
12900,
14500,
null,
12400,
null,
22400,
null,
8000,
18000,
22600,
16500,
12600,
64700,
34500,
30500,
39300,
13500,
35500,
6400,
23600,
12600,
6900,
36700,
11600,
20500,
37700,
24100,
4600,
56507,
30300,
13700,
14500,
6000,
4700,
45000,
79100,
35700,
3700,
13400,
7100,
41200,
16100,
25100,
27300,
21500,
12500,
4100,
null,
29500,
16900,
16400,
10400,
null,
20800,
1100,
null,
17500,
17700,
47400,
null,
28700,
17200,
65200,
34800,
null,
9200,
10000,
null,
17700,
22600,
12100,
36200,
62500,
null,
44200,
12741,
134400,
34400,
14900,
null,
9000,
19500,
22000,
null,
5000,
20800,
25900,
21000,
50100,
34800,
5500,
null,
24500,
12300,
13500,
18000,
29000,
21400,
16700,
38300,
15100,
7100,
48500,
22600,
32500,
36400,
37100,
41900,
34600,
186500,
29200,
15500,
9900,
33600,
17200,
26100,
28000,
29300,
6700,
37900,
24800,
52500,
24200,
null,
4900,
25900,
null,
null,
35800,
14800,
50300,
17000,
9300,
67200,
99500,
39500,
35300,
27200,
11800,
10000,
2900,
9700,
46300,
84000,
8600,
23600,
8900,
44100,
48600,
47100,
28000,
38400,
51800,
46300,
13800,
17850,
109200,
4000,
10900,
11200,
4800,
35000,
33700,
13900,
12000,
16900,
3500,
null,
16500,
null,
7300,
27200,
45300,
25700,
249400,
44000,
103570,
9700,
21600,
3400,
7890,
4200,
15200,
42200,
69200,
9900,
22500,
56300,
93500,
24900,
29000,
15300,
20100,
null,
11900,
36000,
19200,
29500,
3400,
43500,
49100,
null,
21600,
20800,
18100,
15900,
9700,
19100,
48800,
9000,
10200,
null,
39000,
7400,
null,
37900,
4300,
17100,
8600,
29900,
83600,
42600,
8900,
24000,
15500,
13400,
112100,
26500,
28000,
50900,
33900,
10800,
33600,
null,
31400,
32700,
26000,
18000,
42800,
null,
10000,
null,
11300,
58700,
30700,
48800,
32300,
33400,
21500,
32100,
143128,
27700,
15500,
9500,
23500,
16700,
104500,
21300,
27700,
null,
21700,
56300,
29800,
8800,
2500,
15200,
30600,
3000,
7550,
25500,
14200,
14200,
40500,
null,
12500,
33950,
11900,
13900,
30153,
16600,
18500,
16600,
31100,
49000,
101000,
14700,
18000,
45900,
2300,
15700,
18800,
24900,
9100,
35600,
10000,
14600,
null,
11500,
10600,
38500,
6800,
34700,
4300,
44000,
null,
64500,
18300,
36800,
30900,
35100,
6800,
23300,
1300,
4300,
38200,
30800,
17400,
15600,
6800,
18000,
14500,
null,
30200,
61251,
15200,
14900,
29600,
16500,
9500,
16800,
15900,
42400,
147160,
17900,
30900,
27800,
36200,
39600,
18300,
28300,
13200,
109800,
71000,
null,
59000,
19500,
8900,
24500,
35500,
11900,
74900,
null,
15700,
28800,
42100,
100100,
27700,
6900,
5000,
1300,
26100,
6700,
null,
13600,
12800,
54600,
null,
7500,
28782,
9300,
32000,
25100,
13000,
127200,
63000,
10700,
19400,
14400,
14900,
16300,
36300,
21500,
null,
20200,
null,
2600,
10000,
19000,
33900,
12100,
32000,
null,
null,
35200,
20500,
13100,
23000,
8500,
80000,
10500,
29100,
4400,
7300,
8300,
19800,
61000,
32300,
32200,
12300,
42600,
24300,
5000,
12600,
9800,
89800,
2900,
56300,
19400,
null,
28800,
43400,
null,
18300,
null,
null,
35400,
24000,
25400,
12200,
58700,
33900,
4300,
30800,
7600,
31700,
24400,
11000,
55400,
6300,
14900,
93900,
80300,
7600,
4300,
30900,
96800,
92100,
18600,
43500,
null,
44800,
20100,
42600,
61100,
13900,
22400,
9800,
38500,
11800,
21000,
7700,
17000,
217500,
17200,
null,
8000,
35900,
16400,
26900,
53200,
43100,
39500,
null,
99200,
15600,
28400,
10000,
19400,
24200,
15800,
10700,
11400,
16400,
67000,
38900,
81800,
22000,
null,
14400,
9100,
23800,
28100,
62300,
31300,
20400,
15500,
null,
10100,
27400,
21400,
null,
2100,
7700,
15600,
33700,
19000,
23800,
30000,
26400,
null,
106500,
71100,
27500,
31200,
9900,
16800,
12800,
53600,
7700,
17900,
22100,
31100,
16500,
9700,
27500,
16300,
9200,
17200,
16100,
14900,
21800,
32800,
14400,
30800,
null,
23700,
27300,
150600,
13800,
2600,
57800,
55000,
29600,
23000,
30700,
37000,
18000,
null,
13600,
97300,
4300,
13900,
12200,
54400,
76300,
38200,
38300,
13800,
45000,
14900,
24200,
58800,
31600,
17800,
16600,
50500,
21400,
14300,
44800,
24800,
25400,
null,
66900,
11500,
null,
25500,
52700,
41800,
null,
null,
22800,
55300,
16900,
2300,
75900,
39300,
14100,
20900,
20500,
38900,
11200,
14100,
null,
43100,
null,
31000,
null,
50800,
66200,
51600,
82300,
26300,
62300,
5500,
13100,
9200,
147400,
33800,
33500,
14300,
null,
8600,
22000,
14000,
110500,
15000,
50300,
23200,
14200,
122500,
27600,
7800,
23800,
5800,
53400,
27200,
14900,
11100,
12275,
6400,
47000,
24100,
47181,
12000,
56200,
42200,
37400,
12400,
13400,
19400,
21800,
44200,
17200,
48700,
22800,
7100,
23300,
14500,
14000,
43500,
24300,
9000,
23500,
22900,
21100,
6100,
null,
21000,
49300,
29300,
65100,
6400,
19300,
94200,
122500,
152100,
93500,
61500,
12400,
21400,
42300,
34300,
39200,
16200,
20500,
11300,
29600,
94800,
6750,
32400,
15800,
30100,
110100,
33800,
25500,
39600,
11300,
53300,
29800,
65400,
9250,
23850,
59100,
3100,
22040,
19300,
15900,
32300,
null,
33800,
79400,
57100,
65800,
10700,
19400,
12900,
null,
29600,
19700,
30700,
32800,
84300,
99700,
95200,
27500,
35000,
8400,
39000,
24000,
61800,
null,
34900,
38900,
33100,
42100,
14400,
null,
35531,
29000,
30600,
2400,
null,
null,
43700,
13400,
null,
11400,
30000,
21800,
33600,
null,
43800,
49400,
17900,
7600,
29400,
32200,
78600,
14100,
6750,
56300,
16600,
17000,
56700,
23400,
16500,
17500,
30100,
24200,
null,
35900,
7400,
9000,
48500,
19600,
17700,
22600,
8400,
15400,
18500,
56900,
11800,
null,
65000,
19700,
27500,
24300,
48100,
71300,
42600,
14300,
17900,
18100,
6000,
12600,
null,
37400,
39100,
91800,
38900,
12900,
4000,
23500,
3600,
12800,
null,
35200,
8500,
32000,
32800,
16300,
29100,
27700,
17300,
8200,
4100,
32600,
null,
21100,
9500,
75200,
51400,
11000,
51300,
17100,
13300,
11500,
2700,
13500,
55800,
25200,
19200,
null,
15900,
6400,
null,
62300,
14000,
26300,
4800,
9000,
38000,
11000,
38370,
7700,
13400,
21300,
69500,
23000,
64000,
19000,
64400,
18100,
1000,
46100,
14100,
12500,
6800,
56100,
13900,
6600,
12500,
28000,
39300,
84000,
8100,
113900,
19200,
18600,
7900,
29751,
29700,
6400,
47950,
13700,
13900,
35100,
14500,
12400,
10000,
31300,
7200,
17686,
22100,
39400,
25200,
47100,
null,
17200,
61900,
22700,
5700,
39900,
9800,
26400,
24000,
14300,
56600,
45600,
15200,
15200,
17200,
7300,
58500,
null,
86244,
17000,
16100,
38100,
13000,
null,
null,
58000,
50600,
13300,
19000,
57000,
76000,
null,
49400,
13800,
48200,
92200,
67300,
29400,
35100,
5400,
44600,
null,
null,
21100,
17400,
23700,
null,
null,
5600,
9500,
null,
15800,
8400,
40900,
25400,
32750,
179551,
18700,
13300,
3800,
7900,
18100,
29700,
21800,
17000,
38700,
29400,
13600,
null,
29700,
null,
28900,
66300,
21000,
48500,
42500,
41600,
21800,
35953,
21600,
28900,
33300,
10500,
12700,
42200,
157900,
15700,
15400,
6500,
26400,
null,
null,
18200,
11600,
16200,
83000,
23400,
24900,
16400,
6500,
20200,
69200,
41300,
66700,
23100,
7800,
70700,
23300,
43900,
25000,
17500,
28300,
18900,
31000,
12000,
44500,
195700,
56400,
7000,
37100,
null,
34300,
null,
26000,
7000,
3700,
106400,
null,
67940,
null,
21400,
24100,
64500,
55000,
16400,
6400,
8700,
65100,
130700,
20000,
null,
50600,
4600,
19600,
14500,
null,
38900,
14700,
null,
24030,
11100,
12700,
42500,
69600,
34100,
65700,
19700,
18200,
null,
null,
148200,
29100,
42600,
21500,
43100,
96300,
18200,
18300,
6800,
36400,
40300,
11900,
null,
39600,
21300,
10000,
54300,
62875,
17800,
45700,
8500,
82000,
33950,
23400,
36200,
64600,
34000,
21500,
31700,
29900,
34500,
23500,
null,
25700,
6800,
11200,
36200,
27900,
10600,
28300,
20000,
18300,
112200,
33995,
null,
37400,
31300,
28800,
21100,
49800,
108100,
11800,
24100,
45200,
42100,
12900,
36700,
26800,
13100,
5200,
15900,
7100,
63900,
52200,
32000,
82600,
33500,
null,
27100,
null,
null,
34600,
61500,
40194,
24700,
76900,
29500,
45000,
17800,
7500,
15600,
68330,
47500,
null,
15400,
4400,
54089,
53200,
5000,
6900,
35300,
4500,
38100,
16500,
null,
20900,
30600,
26000,
23200,
64200,
34200,
23400,
null,
35000,
9800,
37800,
3500,
37700,
15600,
null,
21100,
26400,
86200,
69000,
14000,
9600,
4300,
27500,
19000,
32900,
null,
39900,
29700,
21800,
6000,
22100,
null,
null,
null,
114300,
19200,
281700,
17500,
28100,
3000,
26500,
26400,
16200,
17500,
27700,
15800,
29200,
12050,
39100,
18400,
27400,
56600,
31800,
3100,
34000,
30000,
13100,
15200,
43400,
9900,
10100,
6600,
56500,
21600,
49500,
null,
34800,
22300,
42100,
null,
15400,
14900,
36100,
22700,
52400,
null,
12700,
null,
44500,
21933,
null,
6300,
73600,
17800,
8500,
25000,
24000,
15000,
null,
null,
8000,
23000,
5100,
16800,
33900,
23500,
17100,
12400,
18600,
19500,
56700,
null,
12100,
10300,
22100,
56500,
49200,
20900,
null,
null,
2000,
27700,
20200,
52900,
10400,
400,
18500,
null,
70400,
32100,
28600,
11800,
22700,
66500,
12100,
9800,
26400,
13000,
37600,
40800,
12400,
33800,
20600,
6500,
34000,
20500,
10100,
93100,
76000,
19400,
96200,
10900,
11600,
48500,
28200,
null,
28700,
89200,
30100,
6100,
34300,
12800,
18300,
3300,
13250,
8000,
10400,
3000,
21500,
null,
42100,
53200,
8000,
30500,
60100,
null,
15500,
49600,
56800,
19600,
13650,
48100,
36900,
73400,
14300,
60500,
45600,
17300,
null,
7400,
87500,
10800,
11700,
50900,
48100,
42968,
9600,
13300,
19700,
63400,
66000,
29700,
94300,
19200,
9400,
57900,
72800,
50300,
11100,
15100,
8700,
null,
18800,
27600,
202400,
null,
19500,
185600,
11100,
4000,
12700,
27900,
300,
47200,
15200,
21700,
12700,
43439,
21900,
10300,
3400,
52400,
47200,
64000,
15800,
26300,
29600,
17800,
9500,
13400,
21500,
52500,
17200,
42900,
29600,
22300,
5800,
26100,
23800,
6700,
12150,
null,
33700,
12500,
35300,
47200,
51200,
32500,
6900,
61800,
14500,
27600,
21800,
42200,
37000,
44500,
null,
11100,
null,
30100,
5600,
23100,
3600,
null,
66100,
35400,
40900,
32300,
13900,
53100,
null,
12200,
9000,
164200,
76400,
null,
4500,
41300,
10900,
10600,
17100,
27900,
41200,
11800,
15200,
27200,
25500,
21000,
31600,
40100,
16300,
43600,
29000,
26700,
null,
null,
43600,
43500,
16700,
9200,
33700,
52100,
40300,
206200,
79400,
null,
10100,
6000,
null,
39000,
null,
30200,
9800,
256300,
24100,
2000,
22400,
22800,
51100,
23500,
155300,
13500,
12300,
17200,
null,
24600,
13400,
37000,
22000,
20700,
14500,
21900,
44600,
18600,
null,
43664,
17200,
19600,
4400,
78455,
7200,
32900,
47000,
4500,
16300,
32500,
19900,
27100,
null,
22500,
null,
49088,
78900,
8500,
17700,
42400,
12500,
36600,
15400,
28866,
20500,
8500,
4000,
30500,
36400,
26000,
25200,
101000,
114200,
15100,
20500,
22700,
19500,
116000,
14200,
25000,
81200,
78100,
81400,
8000,
99900,
5475,
42100,
51600,
35200,
46100,
28100,
77100,
115600,
23500,
5700,
26200,
11000,
37500,
2200,
24000,
39000,
113300,
39500,
120100,
14600,
67000,
30200,
null,
12400,
19700,
13900,
33000,
54800,
88300,
13000,
null,
70400,
16500,
null,
58300,
38400,
45000,
5900,
29300,
12800,
12400,
28600,
49500,
7200,
8900,
14600,
47000,
32800,
null,
322000,
40200,
19700,
5600,
5000,
7300,
null,
24435,
20200,
15700,
0,
6300,
33900,
13100,
15500,
13100,
9500,
87900,
20900,
11020,
1600,
36100,
20600,
80800,
158800,
23400,
319300,
11700,
36800,
47200,
6800,
36400,
null,
9700,
146500,
13000,
51600,
null,
48700,
119600,
10400,
null,
6850,
121700,
20200,
12200,
8000,
19600,
24600,
8700,
19500,
65600,
19500,
5600,
22500,
18000,
11400,
47600,
14800,
12600,
null,
16000,
45100,
22100,
11900,
36200,
null,
33200,
59680,
45950,
36500,
28000,
56100,
9000,
17400,
null,
37300,
27400,
22500,
34100,
101700,
null,
24300,
11200,
null,
17700,
14300,
null,
6000,
15200,
null,
108500,
13800,
4600,
29100,
21500,
19450,
50000,
76500,
20600,
69100,
8200,
40100,
28800,
18700,
57500,
4300,
32000,
null,
62400,
null,
11300,
null,
19300,
18300,
15000,
26800,
27000,
29200,
14700,
22300,
15600,
70400,
44361,
11000,
5500,
35700,
38300,
16100,
21900,
89600,
13800,
38700,
194951,
6800,
20600,
178700,
34300,
28600,
4900,
8000,
19100,
1300,
34700,
39000,
4000,
null,
null,
9200,
5700,
5800,
92200,
29200,
44600,
42488,
152600,
26600,
3200,
31000,
41400,
null,
4400,
68900,
4200,
100600,
10500,
10600,
12500,
34000,
5900,
15200,
15400,
17600,
39000,
23600,
61700,
18000,
42300,
22400,
8400,
25600,
20900,
64600,
null,
null,
10800,
82000,
21700,
30900,
21700,
10400,
33600,
36400,
19800,
null,
null,
52800,
18100,
33200,
8800,
8000,
13600,
328800,
6700,
8900,
46000,
18000,
22200,
46500,
null,
92100,
25600,
45000,
30000,
41600,
20300,
15800,
37200,
21800,
null,
12800,
27600,
15700,
18300,
20200,
47800,
null,
null,
39400,
38800,
8700,
8500,
18100,
17800,
17100,
126200,
8600,
36200,
7800,
26200,
46200,
48000,
25000,
17300,
12400,
49300,
18000,
98100,
26000,
20600,
22900,
5900,
20200,
94400,
3300,
22100,
18500,
40700,
2000,
19600,
17700,
23600,
29000,
62000,
15500,
33050,
6700,
20100,
2200,
29000,
16300,
17200,
104700,
29800,
11600,
27700,
null,
19800,
7100,
27200,
22900,
65200,
38700,
79600,
44860,
105900,
74200,
11200,
27500,
8200,
10800,
null,
63000,
79923,
12200,
14100,
26200,
null,
12900,
13200,
12600,
28700,
36900,
8700,
21700,
11000,
21000,
null,
4800,
18100,
18600,
18900,
79900,
37300,
26300,
9900,
22800,
null,
65600,
25100,
37300,
300,
3300,
11500,
6800,
64000,
227500,
39200,
13400,
19200,
36000,
null,
17600,
26800,
12000,
6300,
16400,
15500,
10550,
22150,
31300,
35300,
100100,
62600,
4800,
39400,
29100,
14100,
25800,
10100,
19200,
24900,
95800,
5000,
17500,
35600,
15000,
46900,
13800,
9800,
89951,
16800,
30800,
15100,
88500,
26100,
4300,
6700,
48800,
43200,
null,
20700,
8000,
21400,
40194,
null,
null,
9000,
97700,
null,
9400,
24500,
41000,
14300,
11000,
74200,
4800,
20100,
21000,
46800,
20000,
31750,
8800,
54000,
21800,
55200,
null,
null,
13500,
26100,
96900,
null,
29900,
84200,
19900,
38600,
15300,
27700,
null,
9300,
24400,
null,
56300,
77200,
18400,
20000,
null,
26300,
31700,
28600,
15500,
47900,
24900,
15800,
10000,
27000,
29500,
37800,
101800,
50300,
26500,
null,
19900,
null,
16300,
26800,
21400,
8300,
8600,
6800,
15000,
26200,
37200,
7200,
23300,
null,
null,
26000,
91300,
32500,
30000,
49500,
null,
null,
27800,
43300,
55400,
26000,
4800,
6500,
88200,
48700,
21100,
9700,
34100,
68200,
63900,
6400,
5900,
22700,
null,
15300,
65900,
19800,
21700,
18600,
25200,
null,
14400,
null,
5800,
18200,
12600,
75800,
36300,
5500,
11500,
30000,
8200,
18900,
null,
69200,
22600,
15400,
19300,
12600,
29000,
10700,
141500,
13700,
27700,
38300,
null,
79400,
21000,
82000,
13100,
7700,
7400,
10700,
10000,
4000,
24700,
25200,
8700,
31800,
9500,
null,
12200,
null,
28000,
228200,
null,
52900,
3900,
16200,
19200,
44600,
118600,
10000,
7900,
59800,
58900,
13800,
4400,
46100,
48900,
48500,
25300,
51700,
17100,
75100,
54000,
6500,
59440,
null,
8600,
6400,
37000,
119000,
50200,
null,
33600,
15700,
15100,
13300,
null,
15100,
2200,
34400,
5800,
13500,
14200,
32400,
7300,
8200,
11700,
25600,
13000,
24500,
12600,
35800,
165600,
16400,
19400,
null,
7070,
26900,
14300,
27100,
6600,
10100,
30800,
null,
33000,
13900,
9300,
29000,
43300,
18200,
24100,
null,
98500,
3700,
41900,
9800,
15700,
49400,
48400,
null,
92000,
7100,
12900,
37000,
23600,
16200,
10400,
null,
41500,
31100,
40400,
16700,
26200,
16900,
52500,
22500,
14300,
21500,
24100,
35800,
284400,
18700,
6600,
16800,
13700,
34800,
null,
12700,
49300,
16300,
37000,
8300,
31300,
8300,
5500,
16400,
31600,
70600,
76300,
45600,
23400,
4200,
81300,
null,
29100,
31600,
15200,
35800,
null,
11600,
28000,
8250,
null,
4750,
37400,
20600,
25300,
82800,
100600,
30700,
28600,
21000,
14600,
14400,
66200,
29700,
2000,
45000,
19200,
29200,
37900,
null,
4200,
14900,
6600,
19200,
2500,
7400,
52900,
10400,
43000,
31800,
6600,
47100,
86200,
11900,
35200,
27400,
null,
58300,
30100,
74400,
10000,
43643,
25600,
9200,
null,
36600,
39300,
34700,
21100,
22100,
9500,
20200,
77800,
10400,
14600,
7800,
4500,
18800,
38500,
20700,
115600,
29900,
10400,
66100,
25800,
37400,
34900,
27500,
19100,
16900,
37900,
85900,
26100,
15900,
18400,
11600,
21400,
33700,
35200,
17000,
28745,
19700,
4600,
7300,
159500,
15600,
46700,
65234,
13500,
34800,
23500,
23753,
49500,
19000,
14500,
null,
null,
15500,
13200,
25200,
10500,
38400,
9700,
9500,
13400,
32000,
25900,
null,
7500,
14500,
10500,
13000,
9600,
32600,
22100,
5400,
46700,
96800,
85000,
19900,
4500,
6500,
null,
20100,
65900,
21150,
28800,
null,
13100,
87900,
14400,
null,
66600,
41100,
null,
null,
null,
29400,
29900,
21100,
null,
18300,
49200,
55000,
42200,
22000,
22800,
75600,
23100,
12600,
82000,
11400,
44800,
84800,
8800,
57928,
33805,
29400,
15700,
14900,
null,
12100,
20000,
15400,
12800,
43600,
null,
2050,
46500,
57200,
50800,
19800,
6750,
24600,
14500,
31300,
43300,
51100,
13000,
11600,
16500,
22800,
20400,
10500,
58900,
29000,
null,
null,
226300,
29900,
14000,
14900,
7500,
38500,
9800,
69200,
17700,
61400,
39500,
10900,
35200,
91500,
90600,
40200,
18100,
74500,
28500,
27100,
63700,
83300,
12800,
31500,
26800,
52000,
46000,
26400,
48800,
34900,
42400,
39000,
14900,
18000,
74400,
27900,
49860,
19100,
null,
50000,
21300,
18700,
41200,
77300,
14500,
8700,
8300,
null,
41100,
28000,
5900,
67900,
16300,
13800,
21100,
28900,
36700,
38500,
30300,
17800,
16300,
14300,
13800,
12200,
28300,
25800,
25600,
35800,
20500,
29600,
14000,
12500,
40600,
12900,
29100,
37000,
11700,
38800,
25100,
27800,
26400,
18000,
null,
6000,
18450,
13600,
null,
3200,
58100,
52100,
39200,
14000,
4300,
30500,
13900,
null,
37300,
26300,
29200,
37665,
7600,
12900,
41900,
8100,
45100,
88100,
39800,
52900,
36500,
26600,
14500,
13500,
51400,
40700,
43300,
null,
37900,
6000,
74400,
5300,
36400,
34500,
23200,
15000,
23000,
20400,
null,
24200,
19400,
52700,
31400,
null,
47700,
47700,
11900,
26500,
63900,
17000,
18300,
12800,
71900,
20600,
null,
null,
23700,
30100,
62500,
5300,
13200,
36200,
5000,
24500,
12400,
null,
19400,
9100,
41104,
33800,
30600,
29700,
62504,
20200,
16800,
33500,
92400,
null,
59600,
12500,
11300,
35400,
17100,
33000,
25300,
57700,
22100,
36600,
15250,
null,
63500,
52300,
16900,
30300,
22000,
19900,
102200,
39100,
43900,
87500,
15100,
16300,
20700,
56818,
25900,
8400,
25200,
18100,
3500,
600,
19900,
null,
13200,
19400,
null,
8400,
15000,
48600,
28200,
7200,
6800,
null,
15780,
43200,
24700,
17000,
5000,
109500,
38900,
27300,
33400,
11000,
6200,
null,
34400,
80300,
31400,
16100,
7300,
7300,
30200,
18100,
10000,
17300,
101300,
49000,
4500,
null,
17600,
17300,
11000,
26000,
15000,
null,
3300,
27300,
47200,
14100,
null,
37900,
13500,
14700,
30200,
31651,
29500,
37800,
27100,
21000,
8500,
16400,
40500,
36700,
null,
83500,
20600,
7000,
13200,
46200,
50300,
25600,
13900,
11200,
26800,
13800,
20300,
18300,
5100,
22200,
10700,
50200,
67700,
32700,
39700,
9700,
4600,
46400,
19500,
13400,
19400,
37400,
10700,
12300,
6000,
7400,
null,
23600,
52800,
15200,
37300,
32200,
8800,
25900,
39500,
66200,
22300,
14700,
17300,
35800,
146100,
17275,
11500,
23600,
8100,
10400,
22700,
33800,
37900,
11800,
3300,
10000,
38800,
22900,
14400,
11811,
12000,
39600,
9100,
50300,
6700,
33600,
null,
38400,
5700,
3500,
11700,
5800,
17100,
41988,
5600,
16300,
10300,
18400,
24900,
7800,
null,
77000,
64300,
35000,
116100,
14600,
20700,
7500,
7700,
17900,
15200,
49700,
30100,
55000,
null,
9800,
null,
10600,
32100,
null,
13800,
24500,
104500,
40500,
11500,
92500,
52300,
40400,
14800,
23000,
29900,
20800,
33600,
54700,
9800,
37600,
79500,
32200,
35900,
9400,
20500,
76800,
29600,
21900,
31100,
34000,
34600,
55500,
32800,
22200,
11200,
30000,
53500,
11000,
24700,
16800,
27700,
40800,
27400,
20300,
8700,
12600,
11900,
8000,
18600,
3800,
18000,
47300,
11400,
37900,
16100,
null,
28500,
14600,
6600,
13000,
89900,
4600,
9400,
14100,
7300,
56200,
31300,
46400,
41400,
11800,
13800,
null,
21100,
160700,
22200,
19700,
25200,
13300,
14200,
65100,
34500,
67700,
9400,
5700,
17400,
63700,
6700,
25500,
6700,
null,
25100,
63500,
1300,
36100,
21000,
25100,
17100,
54100,
23100,
27500,
21600,
28000,
40500,
63900,
15900,
2500,
10900,
10900,
5700,
20700,
61400,
27800,
34900,
13500,
33000,
86800,
17800,
16200,
22700,
52900,
null,
33200,
9500,
62900,
40500,
10100,
4000,
null,
6450,
41900,
5100,
null,
15900,
22100,
14100,
12300,
21300,
26100,
23100,
10300,
18500,
12900,
null,
13000,
49800,
149860,
8200,
24600,
49400,
158500,
null,
11100,
11600,
13900,
49800,
88000,
14500,
40900,
48400,
16300,
37600,
41200,
18600,
54400,
34600,
36200,
46200,
48200,
20000,
31500,
23800,
9700,
8700,
35300,
35100,
25100,
15300,
null,
4700,
5800,
37100,
10700,
14700,
30000,
36200,
31800,
null,
1300,
18100,
12000,
15900,
14300,
59300,
52500,
40000,
13310,
null,
16700,
24900,
39900,
25300,
50300,
null,
45800,
51800,
39400,
29200,
30000,
16100,
18500,
132200,
5700,
9800,
61400,
20500,
37100,
41000,
24800,
58710,
18500,
14200,
24100,
15800,
36500,
16600,
19100,
3700,
9600,
3800,
2500,
16700,
18200,
null,
16700,
69500,
16500,
27300,
48100,
null,
26900,
7700,
28500,
26800,
101700,
21300,
null,
25900,
45900,
14000,
1800,
26300,
13600,
71200,
18700,
8700,
21200,
133700,
5400,
31100,
123300,
null,
22400,
38700,
10100,
11300,
26200,
53200,
53700,
null,
11700,
45600,
48300,
2000,
13300,
30100,
6000,
15100,
29700,
19900,
16000,
31600,
23100,
36400,
23300,
8300,
7500,
11400,
117400,
12200,
43200,
27700,
83600,
18200,
30400,
19000,
13700,
25500,
14800,
72700,
16600,
45000,
null,
29600,
40200,
20500,
10500,
29900,
92600,
36200,
8700,
62100,
31500,
20300,
31300,
28700,
22900,
43700,
10500,
43500,
5000,
20900,
38500,
23500,
15000,
19400,
11900,
39800,
10000,
18600,
18400,
55300,
10500,
49400,
27000,
22600,
11900,
57100,
null,
null,
30100,
14200,
119898,
48000,
12600,
21300,
71100,
4600,
30000,
86000,
78300,
8500,
42500,
46900,
28900,
57800,
14600,
16700,
23200,
10900,
31900,
23600,
null,
35600,
30300,
35500,
23600,
15200,
37900,
46700,
20200,
21100,
30100,
26500,
19900,
6200,
19700,
33700,
11400,
18600,
null,
27200,
17200,
27700,
31500,
null,
76100,
54000,
25000,
136700,
17000,
23300,
33700,
26900,
17200,
9700,
null,
18800,
13500,
64600,
29600,
21600,
20400,
26600,
73500,
19800,
99700,
12100,
17400,
27900,
10300,
53200,
18100,
14400,
6000,
24600,
55000,
12100,
34700,
44500,
21100,
52800,
35400,
34400,
20200,
32900,
46800,
null,
39000,
39000,
5700,
55100,
37900,
8700,
31100,
45600,
45400,
53800,
16700,
15000,
16400,
48400,
28600,
48821,
46574,
25100,
17900,
28100,
34400,
32300,
41900,
46700,
21100,
10900,
12400,
54100,
42300,
23500,
12900,
11700,
102500,
null,
19200,
18500,
20700,
37500,
null,
14800,
6600,
35000,
16900,
null,
58700,
14700,
19100,
23000,
16400,
51200,
49200,
20500,
19600,
23400,
7045,
41400,
32300,
56000,
12300,
51000,
16800,
17300,
40200,
108500,
9800,
26000,
19000,
16500,
null,
36900,
36400,
null,
38200,
39400,
12200,
5500,
33800,
21300,
16300,
11800,
14800,
14400,
113400,
13000,
8400,
31690,
null,
null,
52000,
65500,
24500,
67700,
18900,
null,
23300,
47800,
7800,
24900,
9000,
18400,
12600,
63400,
null,
42400,
64000,
15300,
19200,
35300,
127600,
26800,
44114,
17100,
66600,
28200,
48900,
11600,
3800,
null,
6750,
12700,
15100,
13100,
6700,
7900,
72400,
22600,
30300,
45000,
43100,
11400,
62900,
21300,
3900,
4700,
10300,
21600,
17200,
59400,
15000,
52400,
112500,
84200,
null,
13400,
23200,
39100,
16200,
18700,
28100,
25000,
24300,
19400,
24900,
16400,
49300,
3750,
21100,
49400,
29600,
28500,
22400,
15000,
61300,
36900,
97500,
19100,
52600,
32500,
14500,
73900,
19300,
30300,
7000,
18800,
33100,
16100,
null,
14900,
36500,
64800,
20600,
null,
null,
19400,
17700,
37600,
9300,
11900,
28500,
null,
8600,
21600,
55000,
31700,
22600,
9800,
15900,
17300,
9300,
24400,
2700,
13300,
23100,
6500,
null,
12700,
12500,
15000,
20900,
8000,
57300,
22500,
20700,
19300,
37600,
58000,
38610,
null,
21900,
59800,
4000,
12100,
43500,
18500,
49000,
7200,
15600,
31300,
97621,
30100,
41600,
null,
26100,
null,
70800,
25000,
17100,
17000,
25200,
62397,
null,
null,
58600,
29400,
40209,
19700,
29100,
49000,
17700,
38300,
25700,
45300,
27500,
15100,
71100,
9700,
26500,
null,
6700,
6700,
86800,
35400,
null,
14600,
28600,
23500,
16000,
24900,
16900,
16600,
28100,
16600,
84800,
13100,
27500,
5100,
58900,
34700,
5000,
50400,
48094,
null,
10840,
5600,
16900,
64300,
null,
null,
9500,
64400,
20200,
25000,
42600,
21700,
35600,
8800,
17800,
6800,
9000,
27500,
21200,
null,
47000,
49300,
39900,
30200,
18000,
13368,
15500,
8200,
13400,
84500,
48800,
54300,
28500,
32300,
11900,
18500,
2800,
11500,
18100,
31900,
200,
10000,
15100,
null,
36000,
11500,
44000,
3525,
9400,
71100,
null,
15750,
2600,
18400,
null,
24200,
13500,
8000,
21700,
33500,
10500,
12700,
33100,
7900,
17100,
15700,
18400,
3800,
15500,
51800,
19100,
23000,
32400,
23500,
5800,
42000,
34900,
6600,
82100,
42500,
15800,
73200,
31100,
0,
130100,
23200,
19700,
68000,
null,
null,
18600,
24300,
26900,
12500,
40700,
29400,
8950,
59200,
18000,
null,
null,
91500,
15100,
null,
10000,
7500,
52700,
15900,
null,
56500,
8800,
15000,
20700,
38300,
12400,
19100,
10500,
2800,
28800,
24400,
25200,
13700,
18000,
null,
30000,
17200,
6500,
27400,
16500,
41200,
40900,
6700,
16900,
26100,
20500,
23600,
28400,
22500,
37400,
102600,
21700,
19537,
10200,
32300,
12400,
22600,
12100,
29100,
19700,
25300,
10900,
8000,
7900,
34300,
36400,
6500,
3300,
13500,
28500,
6500,
17800,
21600,
9100,
44400,
31600,
null,
83400,
10900,
7000,
27300,
36800,
24300,
7000,
22800,
13300,
65900,
24600,
19500,
null,
78800,
49100,
29900,
71400,
9200,
29500,
16700,
null,
119500,
27000,
18400,
43300,
10800,
13300,
44100,
91200,
62800,
12300,
32200,
9800,
36000,
25000,
87300,
7800,
12800,
null,
45900,
null,
10700,
24400,
27600,
null,
16600,
10600,
34800,
18900,
19700,
11800,
37900,
12900,
74700,
18300,
6500,
35000,
79000,
95900,
14400,
14700,
71200,
12300,
33700,
28500,
83500,
6200,
25900,
20700,
6500,
4200,
9500,
75700,
3800,
20900,
55500,
18800,
13100,
43200,
14100,
15400,
5400,
16700,
48400,
8800,
2600,
34800,
null,
24700,
76600,
46100,
27700,
89300,
68700,
32800,
32200,
49400,
17000,
7000,
31600,
4100,
48000,
15550,
20300,
27400,
19300,
6400,
22000,
69325,
42300,
19100,
44500,
19700,
2800,
31200,
8000,
16500,
88800,
21100,
55700,
null,
19300,
44900,
16700,
101200,
10500,
null,
105300,
60000,
47200,
72500,
23100,
46800,
16600,
15200,
6800,
17600,
37500,
45900,
37500,
34500,
11900,
29200,
31300,
13400,
60300,
null,
4400,
5400,
59400,
38100,
null,
14800,
2900,
13100,
22700,
47000,
null,
24100,
16300,
43400,
21800,
11500,
null,
10800,
13800,
null,
15000,
73000,
21300,
39800,
59800,
26700,
26300,
106300,
23600,
34800,
null,
10400,
25500,
14000,
44200,
12100,
37900,
5200,
27600,
3900,
25700,
17600,
null,
null,
55100,
null,
68500,
6100,
23400,
11300,
9900,
54700,
24900,
38100,
15000,
21100,
7300,
38000,
13700,
187300,
115600,
49500,
7300,
22800,
10300,
27000,
92400,
77500,
35700,
13500,
27200,
11400,
45200,
11400,
28100,
27800,
25900,
18600,
9100,
null,
20100,
36900,
25700,
21100,
42700,
24600,
33200,
null,
36400,
34000,
24700,
51400,
10800,
23900,
12800,
28500,
57500,
32300,
12900,
85700,
null,
61400,
26700,
44000,
68700,
71900,
23800,
22400,
26100,
19400,
23600,
21200,
8500,
40500,
4300,
52300,
54100,
21100,
27600,
15000,
51500,
30900,
17300,
51200,
29300,
null,
191100,
19100,
3500,
34200,
26500,
33200,
67900,
13500,
21800,
30000,
7000,
83400,
41300,
24214,
41500,
null,
37000,
93300,
13400,
50000,
52700,
21200,
null,
33000,
62600,
44800,
8300,
20800,
23600,
6000,
52100,
null,
27800,
14300,
20300,
19700,
24200,
5500,
26000,
12500,
9000,
29800,
16100,
9600,
10000,
14700,
5300,
5400,
31500,
61900,
37300,
34800,
52300,
8200,
26300,
23100,
null,
27200,
22100,
27300,
39200,
15300,
17400,
59500,
29300,
12700,
70300,
21500,
90905,
94700,
17500,
9500,
29100,
700,
7200,
30309,
20300,
null,
31600,
13400,
33300,
50200,
null,
7900,
60000,
71400,
13700,
33212,
34200,
5500,
16500,
28500,
18000,
28000,
56952,
105300,
6800,
79500,
153400,
null,
25600,
null,
49400,
12500,
21300,
28800,
17000,
69400,
59700,
97900,
53900,
54628,
11900,
20400,
17300,
30800,
24100,
3300,
15900,
87000,
30200,
null,
13000,
29300,
null,
17000,
15200,
null,
27100,
10300,
59500,
18650,
27100,
14300,
4800,
15000,
16200,
17000,
13800,
10100,
24800,
17800,
17400,
11900,
27600,
14400,
37100,
null,
26600,
15700,
24900,
19200,
null,
29400,
25400,
39600,
14800,
21000,
50200,
6000,
27400,
15500,
26800,
12500,
15500,
55600,
22000,
17600,
148300,
42000,
13200,
23700,
5500,
24900,
28300,
66900,
25600,
12400,
85460,
20600,
null,
20900,
14000,
4200,
22400,
20100,
47900,
12400,
5100,
16300,
26100,
54000,
22000,
17300,
42100,
27700,
13200,
14700,
32200,
11900,
45000,
1900,
24300,
49600,
32500,
12700,
13700,
11400,
51942,
60300,
null,
33900,
84600,
10000,
15400,
42900,
40200,
49800,
93700,
77900,
41500,
18200,
null,
27300,
26400,
20400,
null,
14200,
9000,
8000,
14100,
43100,
31700,
6100,
30100,
23100,
9700,
76500,
8400,
18000,
2550,
55000,
null,
29800,
18000,
21600,
34800,
62300,
58100,
22800,
18600,
21529,
8200,
27300,
14600,
2200,
30100,
16800,
44700,
null,
5100,
41900,
10200,
null,
5000,
15000,
19900,
22700,
10400,
24900,
37600,
14300,
null,
16200,
31200,
13600,
20100,
15900,
27400,
33200,
8100,
8800,
123300,
4000,
6100,
6600,
9500,
15500,
30300,
59300,
24700,
22700,
18900,
null,
24100,
32400,
51634,
17500,
9400,
16000,
46000,
16800,
23500,
6800,
42300,
73800,
null,
12900,
11400,
120500,
10600,
16100,
13500,
70100,
null,
108200,
53900,
54300,
51000,
17300,
27600,
15200,
8800,
12800,
18400,
24000,
75800,
19500,
175700,
12400,
62400,
12600,
49700,
53700,
27100,
8900,
26200,
null,
1000,
15400,
23300,
44400,
null,
29600,
31600,
34400,
9300,
35700,
7600,
29500,
17200,
null,
13400,
29400,
18500,
10800,
null,
67400,
38700,
27400,
16500,
10700,
38500,
31500,
32300,
19700,
14600,
25400,
10600,
19800,
27700,
43900,
null,
17000,
11700,
5100,
45400,
15600,
39300,
10500,
57400,
19300,
38400,
16000,
null,
106400,
6300,
85400,
47200,
25300,
47000,
49200,
24700,
11100,
2300,
26800,
11500,
33500,
30000,
4500,
44700,
9400,
21400,
9200,
38300,
24400,
8500,
87200,
36000,
18500,
16900,
28800,
32100,
26500,
16100,
15000,
6500,
23000,
16600,
22800,
5700,
25000,
17200,
86000,
10000,
7900,
15700,
13000,
11000,
24200,
20600,
31900,
15400,
7300,
null,
null,
17100,
47100,
69900,
53200,
16000,
17500,
null,
3900,
null,
4000,
null,
24700,
33000,
48700,
50700,
25400,
68700,
36400,
null,
14700,
57200,
64200,
13200,
12000,
9600,
21700,
13600,
29000,
24100,
27200,
13300,
15200,
16200,
32000,
10100,
23500,
63400,
9100,
14000,
null,
13600,
19800,
28000,
67700,
20200,
21000,
31200,
34500,
null,
15400,
39500,
10800,
10600,
19000,
23700,
31900,
18100,
3900,
28900,
52400,
7900,
10900,
54800,
null,
5600,
19700,
24600,
128512,
16750,
7850,
106300,
4300,
14000,
143300,
17700,
21000,
29400,
18500,
303900,
38100,
12700,
null,
7800,
334500,
15400,
16600,
102400,
40000,
22000,
26100,
null,
62600,
46200,
23900,
12600,
24600,
4100,
26900,
null,
18400,
6009,
null,
17200,
null,
13100,
24100,
13600,
17400,
45600,
40000,
69000,
63000,
13300,
15900,
2500,
32500,
12100,
13200,
null,
22300,
40800,
5600,
67900,
7400,
31400,
7800,
18700,
12400,
22200,
24900,
281400,
13500,
84300,
15500,
5900,
24700,
61600,
65200,
51100,
10100,
11900,
5900,
null,
26800,
66400,
19700,
16100,
20400,
50100,
37200,
56500,
28500,
14000,
34700,
29800,
36000,
19800,
50500,
6900,
13300,
9200,
27700,
63800,
20000,
44900,
16000,
80500,
13100,
60050,
49200,
18800,
21000,
27100,
5200,
17400,
3100,
33100,
9600,
35000,
112000,
15100,
null,
null,
52600,
46100,
20500,
6770,
31200,
16800,
33000,
17000,
20800,
100300,
78100,
37800,
45400,
26900,
2052,
9300,
10500,
119500,
5400,
20300,
7600,
5800,
36900,
48900,
8800,
6800,
null,
13000,
37600,
35100,
null,
12400,
61700,
93000,
37400,
null,
14600,
9350,
34800,
17400,
8600,
48989,
53500,
23600,
15500,
79900,
34500,
18700,
57000,
51300,
15500,
19000,
6800,
29600,
7100,
null,
29000,
22300,
36000,
20300,
16900,
17400,
96800,
5500,
10000,
13200,
32100,
34100,
null,
null,
20400,
27000,
20000,
22000,
null,
21700,
27300,
11000,
46700,
17000,
20600,
18200,
74300,
11200,
19100,
12100,
8900,
67300,
25800,
62500,
56700,
7900,
7500,
40100,
17300,
39000,
18500,
57100,
4000,
64200,
38600,
107500,
5500,
37400,
64100,
34300,
35500,
10500,
45931,
3100,
51100,
7000,
15000,
57500,
32100,
null,
69100,
14100,
16700,
17700,
null,
16900,
24300,
9600,
null,
7000,
32200,
55500,
7200,
9200,
null,
null,
25800,
35800,
24100,
36900,
27500,
8300,
null,
3600,
27300,
10100,
null,
17400,
28600,
16400,
17200,
null,
14300,
44900,
null,
46000,
25600,
null,
13250,
17000,
16600,
16800,
29500,
59700,
63800,
21700,
26600,
null,
23100,
45500,
20400,
32000,
6200,
35600,
18500,
31200,
45700,
26700,
10300,
26200,
28300,
37800,
22700,
6600,
8000,
17100,
10900,
78000,
null,
24800,
17700,
11000,
null,
13500,
22250,
23800,
44600,
9000,
44700,
14400,
11300,
19200,
36100,
36200,
21500,
24050,
40900,
25700,
null,
38200,
11500,
8300,
4500,
34900,
18100,
22000,
337400,
10600,
13300,
11200,
48300,
10100,
16000,
13700,
24900,
12200,
null,
37200,
25000,
31080,
112600,
10500,
9500,
71000,
22600,
8300,
108900,
38900,
27800,
10900,
null,
12400,
18600,
23500,
23100,
6700,
null,
null,
47900,
15500,
21100,
null,
10500,
46200,
7800,
49920,
5500,
6000,
45800,
7600,
23800,
25900,
11700,
192200,
23100,
10200,
6200,
116200,
7600,
null,
27700,
6300,
18700,
45000,
31300,
16600,
44450,
43800,
19300,
23300,
32200,
12100,
32100,
27300,
58300,
36400,
32200,
70500,
67100,
64100,
21000,
24800,
31000,
34300,
23000,
51800,
22349,
21900,
5000,
58000,
null,
41300,
null,
5700,
4700,
19000,
41600,
14400,
44300,
17900,
21100,
57100,
14500,
27000,
19100,
17000,
6000,
22500,
149200,
20500,
16900,
12900,
68900,
86200,
null,
19000,
20500,
26700,
140800,
51000,
15100,
22700,
18900,
32300,
25400,
34100,
10600,
22500,
29700,
71700,
49000,
45100,
48600,
29100,
14100,
24600,
8700,
26800,
10900,
19000,
14900,
55700,
null,
25400,
14700,
35490,
14600,
10000,
71500,
21600,
null,
36200,
15000,
22600,
24500,
28300,
50300,
31400,
null,
26400,
47400,
6900,
16300,
37700,
165500,
24200,
26100,
103200,
40200,
7200,
24400,
78400,
20000,
12200,
17500,
3500,
64100,
61500,
null,
15550,
32900,
null,
null,
15200,
21500,
13500,
31100,
54200,
16600,
29800,
175500,
39100,
24600,
6900,
null,
6500,
null,
12000,
40900,
50500,
42200,
45000,
30700,
41700,
13900,
38400,
30300,
21300,
17000,
92800,
null,
35100,
12200,
23100,
14200,
49100,
18500,
33000,
43900,
73500,
18500,
null,
26500,
33200,
58500,
21800,
23000,
38400,
24300,
66000,
13100,
13200,
73600,
58100,
26000,
62200,
6800,
19900,
22300,
19100,
65100,
20800,
54200,
65400,
6300,
33100,
62400,
18100,
14500,
11500,
20600,
25400,
34900,
null,
36700,
null,
11900,
18900,
45100,
null,
1900,
34400,
86700,
13400,
null,
29000,
9900,
21500,
41400,
26300,
null,
29500,
24200,
5900,
49200,
28500,
14000,
34200,
55800,
34100,
6600,
64800,
19800,
24800,
null,
16300,
86900,
null,
16300,
23900,
24200,
33000,
17900,
12900,
12500,
16800,
17800,
null,
12100,
12800,
22100,
null,
19100,
19100,
20400,
24900,
13300,
3300,
17900,
16000,
21500,
14000,
4800,
14200,
null,
17000,
69900,
17600,
8700,
36700,
15500,
60400,
21500,
null,
35500,
10900,
9900,
21800,
10000,
14400,
null,
12500,
29700,
12800,
26200,
15900,
14300,
43200,
24400,
null,
135200,
67700,
28400,
13300,
5000,
42500,
71300,
18800,
10600,
3500,
94800,
32000,
42000,
10500,
9200,
10400,
32100,
49600,
84500,
39700,
106800,
92300,
null,
null,
53600,
null,
21300,
19800,
44100,
8500,
29900,
24200,
14600,
21100,
null,
47600,
103800,
152900,
10700,
50600,
20800,
46900,
13000,
31500,
10700,
57600,
53800,
11000,
25500,
21100,
24900,
91600,
34000,
14000,
25800,
60100,
19300,
42500,
4700,
61300,
11100,
17800,
15200,
6100,
16400,
32500,
5500,
19400,
41400,
22200,
null,
30200,
47000,
14100,
12400,
39900,
21300,
42400,
53200,
15900,
42650,
55000,
21800,
60400,
25300,
36800,
null,
17500,
19400,
15900,
12700,
5600,
21000,
22600,
null,
16900,
27100,
22500,
9700,
16700,
1900,
11200,
38200,
7500,
null,
34200,
4700,
35000,
35700,
12100,
10800,
null,
85100,
12000,
7800,
23500,
null,
8400,
100200,
4300,
14100,
32300,
21700,
17600,
49700,
10100,
27900,
24800,
30700,
null,
38300,
24200,
168700,
13900,
44600,
15900,
47700,
41500,
63900,
27000,
32500,
24000,
null,
19200,
25900,
76400,
19600,
4700,
24505,
26000,
null,
39300,
10300,
14500,
10400,
23000,
14600,
18000,
23900,
32300,
34500,
null,
null,
5500,
32000,
22700,
6700,
64100,
25700,
29200,
12100,
17200,
null,
33300,
23000,
129700,
41200,
16000,
32500,
51800,
17300,
17400,
82200,
23300,
70200,
8800,
17200,
99600,
109200,
28100,
12800,
7400,
29900,
28300,
33300,
23200,
36300,
8000,
26800,
8100,
23600,
16900,
14600,
51000,
19600,
11300,
27800,
8100,
14700,
28400,
12500,
13500,
8100,
10000,
24200,
49700,
35300,
18100,
null,
16100,
41100,
40000,
26600,
10900,
23700,
8900,
19500,
31300,
26600,
null,
null,
8500,
43300,
14700,
16500,
null,
28000,
19900,
25100,
31800,
23700,
39000,
4300,
null,
21500,
21200,
38600,
28400,
null,
14800,
45300,
14800,
8400,
20900,
64800,
35200,
19400,
27600,
30000,
61600,
32700,
33300,
29700,
15300,
103000,
43300,
11600,
18700,
10200,
20500,
67100,
7300,
15800,
53100,
8000,
25900,
2200,
7300,
26700,
15200,
15400,
4900,
34500,
null,
12000,
43800,
71000,
17400,
32400,
17500,
7500,
5100,
50100,
34400,
38000,
30400,
11217,
null,
54300,
11200,
17300,
8000,
41600,
60700,
6100,
31092,
null,
8500,
18800,
35300,
34200,
null,
9300,
71660,
51000,
9100,
44200,
7600,
88900,
8900,
57400,
73700,
20200,
41800,
111700,
null,
29800,
42001,
22300,
42600,
52000,
12800,
105600,
null,
11500,
4000,
55900,
null,
30200,
4000,
53500,
84266,
4700,
64300,
11700,
14100,
13600,
4800,
20700,
6200,
6800,
23700,
18500,
55900,
15000,
51800,
17600,
18500,
10300,
8600,
20000,
10100,
94900,
22900,
30500,
32200,
51100,
48600,
null,
12500,
58900,
25500,
19800,
14900,
10100,
null,
19200,
13100,
21900,
46700,
22200,
13300,
28400,
null,
null,
10700,
8200,
9500,
19700,
11100,
26600,
17400,
26800,
25800,
4500,
41400,
15200,
50200,
null,
52550,
22800,
20700,
2800,
15500,
66500,
15000,
18900,
14500,
5800,
39500,
61000,
15200,
null,
6500,
39400,
50500,
43000,
9200,
18700,
47700,
18100,
48300,
38200,
31300,
25000,
3500,
3000,
53000,
18300,
17400,
33300,
26100,
13900,
26700,
null,
13900,
46800,
69500,
28300,
22700,
26201,
26600,
47300,
36000,
null,
38100,
15700,
135700,
181300,
39900,
18600,
19800,
17800,
29900,
20300,
82300,
94900,
13400,
37200,
23400,
45400,
22600,
37400,
38000,
27300,
20000,
22900,
18600,
21600,
13000,
12800,
10700,
17500,
19000,
24700,
9200,
10600,
27300,
24100,
19400,
10600,
32200,
11300,
23700,
26300,
40800,
27600,
18400,
41300,
16400,
9700,
17100,
null,
130060,
23000,
3900,
12500,
25100,
null,
17600,
22600,
25300,
20100,
6500,
17900,
11952,
19700,
62900,
14300,
63700,
13600,
30600,
25300,
null,
33000,
8400,
13100,
17900,
7200,
13600,
null,
14500,
15500,
11700,
24100,
137200,
7000,
42800,
48500,
28600,
48600,
14100,
327700,
13500,
10600,
41000,
null,
null,
26600,
15900,
86500,
50700,
16600,
73100,
28200,
22200,
40400,
13300,
30800,
37700,
57400,
null,
40100,
9600,
55000,
18000,
25000,
11400,
21800,
29900,
46200,
null,
26200,
23000,
17900,
11100,
3700,
8800,
30300,
31600,
50400,
27300,
19200,
58400,
39300,
21400,
21300,
15500,
11200,
14000,
3100,
22100,
56300,
29800,
10000,
10700,
29600,
22800,
41200,
64400,
9100,
39500,
8000,
25200,
30400,
59100,
22200,
63200,
26400,
23500,
19800,
52500,
42200,
null,
null,
17000,
14000,
60200,
14000,
23200,
29100,
24700,
48400,
44600,
31100,
6000,
23900,
30500,
40300,
37900,
13700,
null,
47200,
44300,
4400,
27000,
null,
16600,
33800,
27300,
null,
26400,
34400,
26500,
38700,
22400,
11200,
161000,
18000,
29500,
11500,
9100,
37328,
73200,
28100,
17200,
50600,
44800,
40300,
20900,
10300,
13500,
57900,
73300,
9200,
7700,
24100,
40100,
15400,
19900,
7500,
6700,
20200,
25600,
13300,
16500,
84000,
null,
31600,
37700,
12500,
74500,
14400,
16200,
null,
null,
21500,
32100,
52200,
48700,
13000,
50600,
null,
null,
37200,
35500,
22600,
93800,
30100,
8100,
29600,
32700,
27400,
26100,
30500,
55200,
18000,
41500,
21500,
16200,
7500,
36500,
7300,
16600,
55800,
36400,
41600,
22000,
14400,
112800,
24800,
6600,
37600,
16800,
null,
41100,
26800,
13800,
18700,
115100,
20400,
34275,
15800,
32600,
49500,
4500,
32400,
14100,
35200,
33500,
7400,
34100,
40100,
41300,
17345,
34300,
42400,
5500,
8500,
7900,
12500,
19200,
29800,
6050,
5800,
21700,
3300,
25000,
45600,
35400,
103800,
86000,
23100,
33600,
18700,
8100,
24200,
1500,
70100,
56300,
22800,
33400,
16400,
47600,
20400,
12700,
49100,
9900,
29000,
3500,
null,
111100,
39800,
36600,
11800,
33900,
29000,
17200,
32200,
30800,
31900,
9800,
27200,
35600,
6400,
37400,
26200,
13000,
12400,
15100,
31400,
21300,
24600,
70000,
6357,
153300,
25700,
14200,
14400,
15100,
32900,
11100,
14800,
null,
13800,
null,
15200,
59000,
29600,
21300,
null,
17600,
8800,
3000,
19700,
14500,
21800,
20000,
25600,
31200,
17000,
17100,
341900,
34200,
8900,
14800,
15600,
38100,
13700,
21700,
106500,
24700,
77956,
31500,
null,
59500,
46600,
11100,
10900,
12200,
37100,
170600,
20800,
18200,
15400,
null,
48400,
7200,
null,
9000,
5100,
19400,
5650,
12700,
11000,
21400,
37300,
10700,
35800,
31500,
12600,
23300,
18300,
38100,
30000,
10900,
41400,
30800,
42600,
9800,
13900,
12800,
12600,
35900,
41606,
30900,
90100,
9400,
25900,
55200,
39049,
25700,
37800,
44400,
7300,
46300,
null,
8000,
23600,
null,
29300,
23900,
29400,
56300,
13900,
31500,
15700,
44300,
38900,
23000,
18700,
115100,
9400,
34900,
32300,
46900,
50800,
23000,
18800,
8500,
15000,
18200,
35200,
31300,
7550,
68200,
24400,
29300,
34000,
69200,
72400,
276300,
5500,
2800,
33600,
30800,
null,
58200,
null,
19500,
8800,
75700,
null,
null,
19700,
63600,
46200,
37000,
41100,
8500,
8500,
null,
20600,
18700,
21700,
30900,
25500,
26900,
null,
40300,
13500,
7300,
23700,
73000,
10500,
52100,
null,
37600,
30200,
6600,
11700,
23700,
null,
8800,
14100,
6600,
79000,
107400,
30600,
57700,
35000,
9200,
46700,
15400,
180700,
46500,
82000,
48600,
76600,
50800,
31400,
31300,
16100,
25400,
22600,
3500,
null,
22800,
28200,
38700,
38300,
4200,
4200,
24800,
23000,
16100,
89600,
137300,
15500,
null,
50700,
null,
33000,
42900,
14600,
9700,
30900,
13600,
81600,
60550,
18800,
11800,
25200,
1900,
18696,
70869,
24900,
10900,
148700,
14500,
null,
37700,
56700,
22600,
3000,
21100,
42500,
27800,
42400,
43100,
6600,
2900,
32500,
20100,
27700,
40300,
67300,
48200,
18600,
160000,
10100,
7800,
38600,
36500,
91600,
20300,
11500,
19600,
null,
44100,
8100,
45400,
85400,
78900,
18400,
25900,
11400,
65800,
49200,
21300,
12900,
null,
null,
null,
36600,
15200,
32800,
111800,
40000,
32100,
20500,
30900,
5100,
21100,
43500,
30600,
14900,
66600,
18600,
13800,
34700,
30200,
6400,
75000,
152500,
5705,
19100,
6600,
38200,
44500,
19000,
29000,
49800,
78700,
26800,
74000,
5300,
12600,
20300,
51100,
null,
63500,
55200,
42900,
10300,
130100,
6600,
15700,
null,
null,
34600,
7100,
29000,
17900,
8500,
58000,
15000,
119500,
24800,
24900,
36800,
19300,
12600,
113930,
38800,
10600,
37800,
21600,
43600,
29100,
36900,
11400,
20600,
38400,
21500,
33400,
10700,
36400,
53600,
52800,
16400,
11400,
80500,
8100,
146400,
40700,
19800,
65700,
5300,
46500,
11100,
25600,
48400,
41456,
45700,
13500,
7400,
15400,
69500,
145800,
23000,
170900,
25500,
null,
14900,
41000,
41900,
15700,
15600,
10400,
8400,
7700,
19600,
11500,
81300,
null,
19200,
null,
67800,
null,
12000,
null,
20000,
17200,
null,
26500,
42000,
16800,
55700,
78422,
24800,
15200,
39000,
33200,
26000,
28100,
18300,
14500,
46300,
30000,
29000,
9100,
8500,
10400,
19300,
22600,
null,
7700,
43900,
29800,
6400,
3000,
43800,
27600,
92900,
43500,
65900,
34300,
6100,
27700,
15100,
4400,
13800,
20100,
null,
58900,
3600,
19900,
17200,
24100,
67400,
48300,
null,
null,
null,
8200,
42700,
13800,
2000,
16100,
56700,
33700,
46200,
47400,
22700,
20800,
6700,
15300,
55800,
10800,
40500,
30300,
12500,
25700,
5800,
null,
null,
15900,
26600,
30600,
21600,
14300,
42500,
31800,
0,
99500,
null,
15200,
11800,
7600,
114100,
31500,
2500,
5100,
7300,
50500,
21200,
110510,
34600,
50700,
38900,
null,
14400,
15800,
18900,
9400,
20600,
32700,
49500,
19100,
41900,
47200,
8300,
52800,
22100,
12300,
36600,
9500,
21600,
20600,
84400,
null,
9200,
24800,
20300,
13200,
13000,
12100,
38300,
8600,
27200,
136100,
24900,
12700,
36700,
23400,
7300,
9500,
18800,
16900,
15700,
32900,
70900,
32000,
230400,
5000,
14200,
5700,
51000,
76100,
7400,
17000,
17000,
19900,
19100,
17700,
32200,
9100,
11000,
14000,
5700,
81000,
20500,
28700,
33700,
11300,
6800,
55000,
null,
9400,
30400,
73800,
12500,
8400,
27600,
41800,
71400,
32800,
21900,
9800,
11200,
248100,
43300,
35500,
12000,
6200,
13200,
55600,
9900,
7000,
11700,
39100,
13800,
45400,
9200,
31900,
8500,
22300,
15900,
9200,
41600,
13600,
41500,
8100,
44000,
44000,
14500,
19000,
41500,
21500,
43000,
101700,
null,
null,
85500,
17500,
50100,
7300,
41500,
6900,
13100,
66900,
43400,
null,
43000,
1000,
21200,
19800,
47400,
64600,
42500,
12100,
9200,
23100,
40000,
8000,
25400,
19700,
13000,
32200,
5000,
15600,
53500,
6400,
29900,
16700,
27600,
25600,
27100,
71188,
16400,
18100,
32500,
26300,
null,
33100,
50900,
30900,
20100,
15800,
16000,
20500,
17500,
29100,
6900,
35800,
17200,
null,
2900,
5000,
9000,
23900,
null,
15600,
15600,
5500,
13800,
31600,
21700,
175700,
26300,
15000,
5600,
48350,
5900,
30500,
11300,
20700,
29800,
55500,
28000,
10200,
17800,
21600,
20100,
21700,
20600,
13000,
12000,
null,
15000,
33700,
20800,
14150,
17500,
24600,
29000,
22700,
24100,
11900,
21700,
null,
26900,
5500,
30000,
19800,
35800,
7200,
15000,
null,
10200,
null,
null,
10600,
94100,
67700,
28500,
27800,
2000,
38900,
40300,
57900,
23000,
10200,
23900,
70400,
52000,
34300,
30400,
10900,
33000,
null,
10600,
39500,
16800,
13100,
36600,
121600,
48700,
19400,
16000,
11800,
21300,
24500,
49700,
41800,
157600,
32600,
20995,
84000,
11800,
19900,
8200,
103500,
40000,
88800,
14600,
33300,
null,
34300,
32000,
13700,
19300,
16400,
63300,
19900,
16400,
15700,
25600,
14800,
17300,
42600,
58900,
23200,
10100,
7100,
33000,
27200,
6200,
91200,
7300,
25900,
52700,
46300,
19000,
21200,
15700,
35400,
null,
17200,
17369,
4000,
null,
41700,
null,
42400,
null,
57900,
28600,
5100,
24700,
19500,
34900,
26400,
59100,
29200,
13100,
null,
41800,
45800,
17500,
null,
8200,
10800,
null,
10500,
14400,
51900,
60300,
32500,
17500,
10300,
39900,
12900,
13300,
27000,
83700,
18300,
5800,
23800,
19600,
23580,
29300,
62800,
52400,
41700,
52400,
10400,
20600,
10900,
46000,
13000,
73900,
7500,
36600,
23700,
18200,
36000,
11600,
15500,
63700,
40100,
33500,
7900,
null,
25000,
27700,
10000,
28400,
19600,
19700,
19100,
15100,
42900,
null,
41100,
26900,
65400,
17100,
12800,
16800,
24200,
15700,
14200,
44100,
14700,
11200,
7500,
9200,
15100,
52700,
45200,
13100,
5700,
10000,
37800,
17700,
103200,
5000,
30800,
105000,
null,
38900,
17000,
27000,
29400,
94900,
7600,
42300,
14000,
null,
19390,
11000,
23700,
21200,
13900,
26200,
46600,
32600,
19200,
20700,
23800,
9300,
68900,
36500,
26500,
20500,
28000,
64800,
12200,
12000,
null,
45800,
1600,
34800,
14900,
null,
81200,
null,
30000,
97200,
53400,
106400,
28800,
83400,
7300,
null,
65900,
25300,
41600,
null,
30000,
94447,
35000,
5000,
79700,
null,
39100,
140800,
53400,
36900,
17600,
14300,
21000,
27800,
52900,
35100,
null,
55000,
27000,
21400,
10500,
66000,
28600,
24600,
14000,
6800,
46400,
null,
73800,
28900,
22900,
23700,
17700,
18700,
7500,
13800,
109100,
14300,
29500,
133600,
22200,
154900,
33800,
5700,
null,
32500,
34400,
48700,
8400,
40500,
12300,
20500,
24700,
16900,
64400,
10200,
26300,
17300,
null,
12700,
10500,
130600,
12500,
35800,
11000,
10200,
36100,
15000,
19625,
27000,
16700,
40100,
74500,
8800,
23700,
26600,
13000,
null,
null,
10500,
85600,
59400,
83200,
null,
18200,
24400,
null,
6500,
101400,
7000,
12500,
12200,
23600,
114700,
141550,
13500,
15200,
57600,
57000,
16500,
34200,
89800,
53705,
16200,
7800,
42600,
41600,
24900,
null,
18400,
14600,
22800,
66800,
30800,
28500,
6700,
32000,
11000,
16500,
11450,
null,
18000,
12700,
60200,
8500,
41100,
19700,
26500,
7300,
16000,
null,
34300,
22700,
7100,
58000,
55200,
76804,
32800,
65000,
48500,
6150,
5000,
10800,
79600,
13900,
null,
15800,
89500,
null,
22400,
12100,
24200,
15500,
31700,
22400,
31600,
104100,
77900,
27100,
26800,
10400,
61100,
29000,
48000,
41200,
25000,
30400,
70500,
38100,
11600,
null,
20100,
25200,
4200,
null,
127100,
11400,
67700,
64500,
10300,
null,
null,
5800,
null,
37400,
94600,
null,
12400,
48600,
56200,
20700,
16200,
80700,
51600,
194800,
17300,
120900,
15400,
6200,
19100,
13800,
23700,
9400,
10700,
27600,
24900,
9600,
18000,
6600,
23500,
3500,
12400,
19300,
23000,
33600,
3200,
44200,
56600,
39800,
null,
null,
23254,
71300,
252300,
7500,
47800,
27400,
34500,
22800,
null,
2500,
13500,
116100,
39800,
19000,
17100,
17500,
54600,
72900,
9200,
16700,
64900,
17000,
20100,
31400,
null,
25500,
75300,
42000,
9400,
9600,
15200,
22400,
79400,
82300,
null,
68500,
41300,
171300,
32900,
27000,
14900,
12400,
26300,
192100,
74400,
22600,
23100,
9000,
27300,
11200,
10500,
84500,
22300,
22100,
31200,
9600,
3300,
42100,
null,
26700,
null,
15000,
29200,
11300,
8100,
46800,
null,
84800,
null,
37700,
5500,
48100,
null,
39400,
14900,
13050,
7400,
28000,
20300,
null,
null,
84600,
31000,
17700,
3700,
15600,
11600,
26900,
120000,
33000,
11000,
29800,
19400,
36100,
78600,
16300,
8400,
7500,
8900,
34800,
29000,
8265,
25600,
10700,
52400,
73200,
28700,
16500,
24200,
8600,
10200,
95055,
13900,
11100,
21500,
11000,
29500,
72100,
18100,
117900,
6700,
48000,
12300,
66894,
28100,
9800,
23900,
17600,
27300,
48300,
9000,
18600,
2900,
61200,
42500,
21700,
26000,
16000,
14000,
79100,
19800,
62600,
27700,
34400,
14000,
52300,
41900,
17017,
13400,
23600,
24200,
21200,
null,
16500,
33000,
24500,
23500,
20200,
25300,
23600,
35600,
18200,
33800,
8600,
5100,
84200,
29800,
16000,
3100,
25600,
38200,
36500,
null,
23900,
47200,
null,
27100,
41600,
33200,
11300,
39800,
9000,
null,
41015,
null,
1500,
13500,
48000,
null,
11200,
49000,
7900,
33400,
null,
5000,
153900,
null,
15000,
35700,
25500,
17500,
48200,
null,
6100,
16600,
69900,
19300,
null,
16500,
40300,
19300,
16000,
17500,
42050,
14000,
60800,
10100,
11700,
26300,
null,
5600,
12400,
9800,
29600,
9500,
38200,
15800,
37900,
18900,
59500,
null,
28400,
15000,
null,
15400,
63000,
21500,
36900,
57600,
57900,
9600,
41200,
43200,
37400,
15700,
51600,
71300,
31400,
29100,
8700,
25800,
12800,
27500,
10100,
9700,
6950,
219700,
36000,
40000,
26400,
14000,
17100,
14900,
42000,
35500,
27800,
11300,
19200,
16200,
43700,
47726,
null,
null,
18500,
1800,
14700,
3500,
null,
94100,
31000,
33000,
32900,
6000,
96500,
34200,
47300,
15500,
9500,
211400,
9500,
25500,
30100,
30900,
15700,
16866,
22900,
12100,
37500,
28500,
13700,
38000,
14400,
54500,
21410,
45700,
28200,
27500,
17300,
15700,
17100,
10000,
8600,
20800,
42400,
29600,
26200,
39100,
15700,
8000,
18900,
null,
40000,
35400,
63200,
77300,
78400,
35200,
82200,
21800,
203100,
48700,
5100,
510200,
46100,
29100,
null,
52100,
26300,
null,
46400,
12300,
47700,
2300,
36300,
49900,
6600,
23200,
8000,
26100,
null,
43400,
6200,
18700,
7000,
9000,
13700,
16300,
18100,
16600,
49200,
69400,
101100,
17400,
21900,
38000,
19200,
10300,
36725,
6400,
5500,
32100,
61800,
9600,
11600,
24100,
10500,
29600,
null,
null,
null,
29200,
22800,
34700,
17100,
41900,
42700,
12800,
137800,
35000,
17900,
17100,
9900,
21000,
31900,
null,
54771,
19300,
11700,
20200,
49900,
31500,
51600,
21965,
46100,
72400,
18400,
32700,
90600,
null,
null,
36300,
23900,
9300,
22900,
10900,
21200,
20900,
55600,
27000,
26100,
11400,
132400,
42900,
43600,
62800,
41600,
null,
105700,
39100,
null,
53718,
51900,
72300,
27800,
42200,
17700,
31300,
34000,
64000,
12700,
18500,
22600,
25000,
66200,
12300,
12800,
null,
28400,
26400,
10400,
10500,
20200,
24700,
null,
46700,
36300,
11200,
6200,
25600,
null,
38500,
13800,
8200,
18500,
22900,
8000,
231400,
33300,
19800,
17800,
11900,
14400,
16700,
43400,
76600,
25700,
30100,
15900,
11500,
25800,
30200,
64900,
23700,
24400,
17300,
8300,
23500,
19500,
38000,
84500,
12500,
21000,
15829,
21700,
30400,
25000,
null,
6900,
57300,
170200,
2100,
13500,
10100,
61500,
20300,
23600,
33800,
2300,
15900,
33400,
12900,
8800,
5500,
32600,
7500,
61600,
16200,
41200,
9500,
8500,
37400,
6000,
10900,
13900,
22300,
41301,
9500,
33500,
21900,
41200,
25000,
23800,
22400,
53900,
7700,
11400,
53700,
60100,
27400,
null,
36400,
188800,
23900,
5000,
45800,
11200,
9500,
15700,
36100,
68000,
14700,
40100,
21400,
null,
39300,
81000,
31000,
11400,
22800,
13200,
106000,
25500,
25300,
11500,
19700,
null,
16300,
12500,
null,
9800,
26500,
23500,
null,
20900,
18300,
28800,
12700,
6100,
5000,
16100,
39800,
32300,
null,
18500,
22500,
7800,
28500,
26200,
21000,
95500,
37300,
31400,
21000,
null,
19800,
21500,
15200,
12900,
14100,
null,
16500,
47300,
3300,
12300,
22300,
14000,
14700,
6000,
37500,
10000,
69100,
23700,
32600,
26600,
9200,
20100,
4900,
5600,
15200,
null,
42300,
9400,
47700,
42200,
26800,
30600,
25800,
6600,
61000,
33200,
null,
27700,
44500,
14300,
36900,
4000,
20200,
89500,
47300,
12000,
19000,
41900,
29300,
28400,
118100,
43127,
68200,
16700,
45800,
49000,
39300,
19300,
48600,
15800,
17100,
5800,
15000,
31500,
1900,
12400,
8700,
17700,
17700,
15300,
3300,
55100,
8025,
38200,
18600,
128100,
99400,
20500,
47500,
24300,
53800,
32400,
null,
27900,
52600,
37500,
23100,
5600,
8400,
11400,
24200,
6000,
32600,
34700,
null,
61800,
22600,
4800,
27800,
4000,
32900,
29200,
12700,
14200,
10700,
29000,
15400,
33600,
30500,
58500,
12800,
null,
33200,
37800,
26650,
150400,
39900,
63500,
17800,
3600,
15200,
9900,
18300,
13500,
24300,
51600,
29300,
108800,
10100,
19215,
null,
22300,
21985,
25800,
null,
27800,
30000,
11200,
18500,
22700,
32600,
67700,
89800,
57000,
27300,
26900,
73700,
15300,
33500,
62700,
8700,
12200,
52500,
28700,
6200,
null,
7700,
11100,
20100,
15000,
35500,
33900,
53800,
10100,
34600,
27800,
5700,
64600,
8900,
6100,
9100,
225805,
null,
11200,
24900,
9700,
9700,
27900,
25300,
19000,
49200,
45630,
13200,
16700,
28900,
13300,
31400,
25500,
17700,
16900,
null,
900,
22800,
37000,
8900,
37000,
58400,
16000,
29500,
22400,
null,
null,
28000,
14900,
7500,
5500,
14200,
null,
50700,
15000,
15300,
null,
null,
74500,
44100,
24300,
15400,
5100,
11700,
18800,
33600,
37000,
19900,
15100,
24700,
3300,
7100,
36100,
40700,
30300,
18600,
5000,
18100,
71500,
19700,
14900,
33400,
43800,
13500,
23700,
24900,
27500,
9300,
25200,
16000,
39300,
25100,
21900,
29900,
18800,
24500,
31400,
17300,
37800,
8000,
9400,
28800,
null,
26200,
56600,
59500,
8100,
36100,
44300,
138800,
29000,
14507,
26100,
19400,
null,
49200,
20300,
70800,
21700,
20300,
18700,
30200,
62100,
31400,
14400,
35400,
36100,
5600,
20600,
24400,
77000,
64900,
19800,
135400,
5600,
21900,
10800,
22200,
null,
9600,
19300,
21500,
19300,
null,
28800,
32500,
6700,
75500,
59200,
null,
null,
52100,
29900,
14200,
65000,
24900,
16400,
18600,
22700,
10300,
21100,
24000,
110400,
10300,
38300,
19100,
11400,
27500,
31700,
16500,
15000,
null,
7400,
14200,
23800,
64500,
21000,
25800,
47800,
46700,
22300,
11800,
16500,
26700,
42000,
98100,
34600,
21200,
9100,
35620,
null,
43400,
31800,
30900,
20400,
21300,
15600,
70300,
39600,
null,
28220,
55100,
28100,
34300,
95900,
null,
34150,
3000,
17700,
33100,
10900,
46100,
14500,
36000,
12700,
8800,
null,
18600,
30400,
27000,
13200,
58500,
18200,
27000,
5200,
10500,
36000,
25100,
47900,
29400,
9600,
66300,
36700,
null,
36500,
33200,
57000,
72300,
23500,
13100,
248400,
9800,
15600,
null,
49439,
15600,
56701,
23600,
41800,
37400,
21400,
81100,
58100,
12300,
21600,
null,
27900,
14000,
8100,
24000,
9500,
10500,
12900,
5550,
51100,
22000,
7600,
14400,
20900,
15400,
7000,
25800,
9600,
null,
7500,
9200,
9800,
50900,
30500,
38800,
35800,
40300,
30900,
16400,
13700,
92100,
23900,
10200,
4000,
44400,
16300,
28800,
11300,
4400,
3700,
21980,
7700,
59600,
64600,
34100,
34700,
15300,
28400,
42200,
18200,
27600,
60200,
10000,
22000,
7750,
14700,
22600,
null,
4500,
7900,
67000,
70200,
33700,
25700,
132100,
16300,
null,
13150,
8200,
22800,
null,
30700,
46000,
36270,
22000,
null,
13200,
49200,
32200,
4300,
null,
21500,
25400,
77200,
20300,
null,
34300,
42600,
8600,
0,
17300,
35400,
53000,
32900,
19100,
42500,
null,
6500,
9300,
32100,
66900,
35300,
39700,
42100,
22700,
15000,
27800,
112800,
18800,
25400,
72806,
38500,
29200,
7800,
34800,
28100,
26500,
12100,
123600,
null,
15800,
81250,
11300,
17300,
23400,
64300,
12900,
7600,
4900,
9500,
16800,
32600,
47100,
110100,
20700,
2400,
10400,
36300,
15700,
11900,
15600,
7100,
70100,
null,
null,
11200,
30900,
10400,
17400,
37700,
31600,
6000,
28200,
16500,
24100,
15900,
46800,
35000,
null,
2600,
7500,
18500,
69300,
24400,
59700,
45600,
12500,
7900,
19700,
30000,
5500,
18800,
75400,
5500,
13100,
23800,
35100,
null,
10000,
5700,
15300,
null,
22300,
39300,
43700,
12000,
19500,
68100,
15500,
19600,
15700,
56000,
17400,
6600,
16600,
45000,
8450,
null,
16500,
30600,
null,
63100,
30000,
7200,
null,
3700,
22600,
56100,
117600,
40300,
59700,
41100,
19600,
18700,
14600,
18200,
25000,
28800,
27800,
68800,
23100,
null,
106800,
30500,
13200,
23600,
20500,
70300,
11300,
32100,
61000,
null,
64600,
50600,
11900,
46600,
30830,
27200,
21200,
23400,
6000,
16700,
5500,
30200,
11000,
56000,
26700,
13600,
102300,
36100,
138700,
14600,
6200,
13700,
9000,
19900,
10800,
19700,
null,
21400,
27900,
41100,
30100,
39800,
33250,
40400,
65800,
64400,
16900,
null,
27500,
98200,
29400,
11300,
10500,
34600,
15700,
19000,
18200,
91400,
20300,
80220,
11300,
14100,
65700,
null,
18100,
17000,
37500,
36000,
5900,
17000,
27600,
25700,
151600,
26800,
33400,
47800,
35500,
13900,
17300,
80800,
13300,
null,
20500,
8900,
53200,
24900,
null,
30900,
null,
null,
18600,
313000,
19800,
11200,
10600,
null,
3400,
26100,
38500,
30400,
25100,
16900,
2800,
27600,
15300,
50700,
17600,
77000,
42000,
43200,
13300,
30400,
17600,
19600,
null,
55300,
22000,
32000,
73300,
11200,
29200,
22200,
20700,
14600,
43600,
25400,
15900,
44800,
10900,
20000,
27600,
4600,
null,
13700,
48200,
6000,
58600,
11000,
36600,
7500,
56700,
34000,
19900,
32700,
10500,
21800,
21100,
13300,
27600,
89000,
8100,
null,
23100,
33830,
167500,
54200,
21300,
29100,
21800,
15300,
13000,
81200,
38900,
null,
7100,
41300,
24800,
65500,
10400,
16800,
null,
22300,
16700,
17300,
4200,
28900,
22300,
17500,
52200,
8250,
30200,
5700,
56500,
18900,
41000,
20200,
56200,
10800,
10500,
31100,
83800,
39500,
12400,
230200,
22100,
23300,
37600,
53000,
9600,
6950,
51100,
6500,
104500,
16400,
55500,
21100,
9200,
4100,
17700,
22000,
9200,
8500,
null,
25000,
47700,
26000,
19200,
34100,
2500,
null,
13500,
60300,
23400,
31900,
26000,
83124,
26400,
40200,
163000,
28000,
null,
18900,
9500,
12300,
22700,
null,
52800,
null,
4700,
7000,
19300,
28900,
12900,
10200,
19600,
47100,
22100,
22200,
8500,
17800,
35700,
16700,
39600,
53100,
16200,
null,
60300,
46800,
278200,
14100,
21700,
37100,
33500,
16900,
38385,
null,
50600,
45900,
15100,
53900,
14800,
72900,
21700,
40500,
37500,
22800,
61800,
null,
13700,
42400,
20100,
20600,
7637,
74300,
57400,
15700,
4450,
22200,
39274,
null,
25600,
null,
10700,
20100,
24500,
19400,
null,
36600,
6200,
12500,
9300,
132900,
23900,
22000,
22700,
40900,
52500,
null,
19400,
16200,
14000,
27700,
28800,
27300,
37700,
49700,
8600,
73100,
1500,
35600,
24400,
84000,
27100,
27700,
56600,
8500,
null,
30700,
10800,
18700,
5400,
23500,
16900,
41900,
17400,
39400,
8000,
14000,
50500,
13400,
29900,
17600,
7300,
23600,
28000,
25600,
92400,
197100,
4200,
37000,
7300,
6500,
32700,
6400,
11900,
18900,
4700,
12900,
null,
28000,
19300,
null,
27450,
24900,
13900,
17800,
13200,
18700,
21700,
2538,
53900,
35400,
11000,
21800,
22900,
23600,
44500,
15000,
8500,
24700,
42400,
21800,
4800,
8100,
5100,
25400,
9800,
1000,
28200,
146800,
52500,
20200,
41400,
12500,
32000,
9000,
5000,
66600,
31300,
26300,
13800,
68600,
38900,
71400,
38900,
88100,
35950,
43400,
26600,
15200,
15400,
20500,
8100,
68700,
null,
16800,
15100,
9800,
19500,
11300,
7300,
33600,
80600,
11100,
8700,
11100,
26400,
103500,
null,
96300,
18800,
65500,
37100,
52600,
10700,
7100,
30300,
40600,
29900,
34800,
23100,
85100,
12400,
43900,
5300,
11900,
16800,
15200,
null,
49600,
55200,
24000,
8800,
21000,
18000,
42900,
44400,
11100,
21300,
38200,
4400,
49400,
24500,
33400,
19200,
55300,
14100,
42900,
27300,
58020,
47600,
14700,
10800,
16000,
15700,
15400,
15500,
7400,
74850,
18300,
47000,
43400,
18700,
19100,
29000,
7800,
4000,
8200,
11800,
34700,
16500,
28000,
16000,
20800,
28200,
71100,
7200,
17100,
19000,
48500,
null,
156700,
47600,
17800,
7700,
19800,
41700,
67800,
13700,
14800,
12100,
13100,
13100,
8500,
15600,
39900,
53300,
29600,
36700,
46300,
122900,
28900,
22300,
19400,
6300,
14600,
21700,
20200,
48500,
36000,
17500,
52000,
55100,
94900,
68800,
33600,
44200,
40000,
3100,
60100,
35600,
25300,
23800,
52900,
45300,
68600,
16000,
14900,
29100,
17500,
22000,
17500,
null,
19100,
11500,
52100,
32700,
4200,
227150,
45000,
6100,
11400,
79800,
38700,
null,
7500,
57100,
3600,
39100,
8000,
57400,
62300,
33400,
10200,
80200,
null,
null,
28900,
19800,
55700,
null,
10100,
31300,
27500,
54100,
null,
17300,
null,
29800,
null,
42400,
43000,
17300,
47600,
20600,
7900,
64700,
11100,
44500,
null,
55600,
25200,
27100,
15400,
15800,
10900,
29300,
8200,
32900,
17800,
null,
33400,
16000,
15500,
18600,
15700,
45400,
25600,
16100,
6200,
46500,
null,
4600,
11400,
85000,
7500,
6300,
140700,
16500,
12200,
42900,
35700,
null,
6600,
14200,
8700,
19800,
11800,
42000,
13800,
40000,
null,
7100,
24900,
29000,
55600,
36200,
10800,
13200,
343500,
8700,
22200,
13100,
16700,
13000,
null,
14500,
null,
5400,
10800,
27900,
113168,
9200,
8600,
33356,
null,
33000,
24800,
9800,
14800,
19400,
29400,
147400,
10100,
22400,
27000,
39300,
101900,
14600,
21100,
33000,
44800,
35500,
68300,
17000,
27700,
17100,
41600,
85100,
50200,
null,
17600,
45600,
9500,
21200,
47500,
22000,
12300,
33500,
23600,
12100,
36800,
null,
59400,
28100,
22650,
27300,
null,
8850,
11800,
49300,
16100,
15200,
24700,
25600,
28700,
28800,
214100,
null,
8600,
12700,
11800,
11200,
21500,
null,
32800,
28100,
30500,
21400,
16100,
12300,
50800,
35900,
79300,
11700,
60800,
14500,
null,
10600,
7500,
112700,
13400,
16500,
26000,
56000,
8700,
51200,
28300,
null,
20500,
50600,
59700,
18000,
15700,
20300,
32700,
17700,
11200,
14900,
18500,
55500,
14600,
11000,
null,
14400,
12200,
64400,
103700,
42500,
19900,
170500,
23900,
118900,
37600,
null,
24900,
59500,
7300,
null,
13200,
126245,
7000,
20600,
29800,
38400,
11300,
12700,
16800,
17000,
25500,
21800,
23500,
17000,
43000,
86300,
15700,
62500,
9700,
115000,
16584,
null,
2500,
26100,
null,
9500,
10300,
19700,
6550,
35298,
24000,
33500,
18000,
15700,
11500,
22400,
null,
22000,
13600,
58700,
8300,
35500,
29000,
11200,
12300,
15500,
27500,
18400,
null,
42400,
15900,
54425,
13300,
13300,
null,
33700,
5300,
null,
27300,
4800,
22100,
6010,
21900,
null,
21400,
79100,
6900,
16100,
25100,
49100,
25172,
31700,
65200,
21700,
7400,
13200,
37800,
22900,
33800,
30600,
48500,
25000,
97600,
23700,
21780,
26600,
2900,
10000,
37000,
null,
32600,
25100,
19500,
17500,
58400,
17400,
10000,
12500,
37200,
11700,
48000,
48800,
19500,
13700,
68000,
11400,
36500,
10700,
84600,
8700,
19700,
11400,
18800,
16200,
52300,
8500,
13800,
15000,
59800,
23600,
25400,
27900,
25200,
29000,
null,
26300,
42300,
52000,
51300,
50800,
47100,
null,
15200,
8100,
63700,
36500,
4100,
47325,
25300,
23200,
14900,
231200,
44200,
54700,
null,
13500,
20400,
49200,
34700,
16800,
14000,
20500,
null,
22700,
9700,
52400,
7600,
3000,
null,
24800,
14300,
19300,
80951,
17900,
3500,
47600,
63100,
60100,
8300,
22700,
74200,
45200,
15700,
40300,
220000,
28400,
46100,
66700,
8800,
null,
3400,
15100,
23200,
42300,
27300,
21600,
33000,
46200,
11200,
89100,
23100,
10800,
9500,
7100,
43800,
42600,
14300,
47800,
1000,
42600,
14200,
58100,
8700,
24700,
26100,
24000,
12100,
18500,
18000,
11400,
26600,
30800,
29000,
6400,
null,
19900,
2400,
18600,
22400,
43100,
6600,
93700,
13900,
24700,
25300,
34300,
35600,
36100,
35300,
16500,
37400,
87000,
40500,
61850,
30700,
12400,
14900,
22400,
91400,
43000,
13400,
null,
17900,
9900,
47100,
18300,
11300,
37600,
6300,
33600,
35500,
101600,
15500,
39300,
61700,
42100,
48800,
null,
14900,
18500,
67400,
30700,
7400,
44200,
32400,
20400,
110200,
60200,
116300,
49500,
31400,
21600,
7800,
35700,
29900,
23200,
27300,
7300,
36500,
null,
34200,
56200,
25700,
5000,
26800,
null,
null,
6600,
40600,
10400,
70000,
51500,
null,
2700,
22300,
38100,
15500,
18300,
null,
null,
34400,
26100,
51600,
25800,
69400,
30300,
26200,
37800,
79000,
14000,
30600,
10928,
13600,
53500,
8400,
24700,
44900,
54200,
11600,
5300,
16000,
51181,
115600,
38400,
13300,
184200,
17800,
null,
35600,
24900,
20600,
32500,
35700,
20300,
8400,
29600,
47600,
4300,
53600,
7100,
21305,
157300,
69400,
54200,
61900,
10800,
null,
27600,
39900,
3000,
4900,
14700,
29300,
28900,
33400,
12400,
70000,
35300,
113000,
4300,
32400,
43600,
75300,
35400,
14500,
52400,
34300,
13500,
65200,
41100,
15800,
2000,
11200,
null,
3500,
27000,
163000,
null,
19800,
23400,
null,
53100,
12200,
28100,
9100,
7900,
9400,
42400,
34500,
12300,
56100,
51200,
25500,
11700,
9700,
35100,
32800,
13800,
41000,
19700,
33300,
22200,
17400,
null,
43900,
null,
4200,
2000,
13600,
37100,
16600,
27400,
75300,
27400,
6000,
10100,
38100,
20200,
null,
31400,
28700,
null,
6500,
18820,
21000,
18080,
57300,
null,
119700,
20400,
14300,
29400,
41300,
15100,
11700,
36100,
29000,
22700,
60300,
21600,
35500,
30400,
16300,
null,
28100,
30000,
7900,
24300,
6000,
13100,
104400,
null,
5200,
27200,
39500,
9600,
13300,
36800,
null,
22300,
12400,
null,
25500,
31500,
5800,
null,
12000,
44200,
10800,
25800,
26073,
70203,
13900,
43600,
65300,
21400,
43000,
83300,
7900,
12600,
36000,
16400,
5700,
16900,
null,
17400,
41100,
38000,
8200,
8100,
2000,
31500,
46700,
16700,
17000,
41500,
7800,
21000,
52900,
21300,
20800,
132300,
21200,
5300,
89400,
49400,
13100,
40600,
12000,
119300,
28700,
9300,
36700,
null,
32200,
15600,
11200,
15500,
75534,
20800,
31300,
1400,
13900,
null,
10800,
24800,
25500,
27890,
28100,
20000,
24100,
null,
38200,
3600,
59300,
17300,
6500,
23100,
29200,
45100,
13700,
23900,
36086,
25550,
7800,
26000,
38000,
11000,
48400,
37000,
57800,
9000,
26300,
25600,
6800,
30000,
12970,
87800,
1600,
16400,
24400,
19600,
38100,
20400,
22000,
16800,
null,
58200,
20800,
6000,
32500,
9900,
null,
24900,
59200,
null,
118900,
23400,
43900,
33400,
26200,
11200,
null,
24100,
null,
15200,
10100,
45400,
54500,
20800,
11800,
19200,
68300,
10300,
16100,
4600,
5700,
28100,
118400,
25300,
26600,
15400,
54500,
301800,
28500,
5400,
29600,
66100,
36500,
null,
36000,
18700,
null,
7300,
42400,
14100,
6300,
13600,
16200,
79800,
33500,
50700,
7100,
32700,
5100,
30900,
20500,
null,
39500,
29700,
12200,
35600,
5500,
10500,
null,
64500,
98730,
121400,
null,
7200,
27800,
42800,
83200,
84200,
11200,
43600,
15300,
7900,
37800,
26100,
27000,
47200,
61000,
22200,
32600,
17500,
null,
14800,
15900,
null,
26700,
23200,
13800,
78800,
39000,
13600,
22800,
24500,
23000,
35700,
31100,
null,
54800,
16100,
8676,
null,
11100,
15500,
24900,
2500,
16800,
null,
28700,
10600,
null,
60900,
16400,
21300,
25100,
11700,
19500,
14200,
32100,
20600,
15000,
null,
31900,
17500,
56400,
50400,
16200,
16300,
6800,
28400,
14500,
63900,
11000,
45200,
65400,
23700,
41900,
33200,
35600,
27900,
42300,
7000,
4100,
13300,
44300,
30600,
40400,
48200,
30500,
14100,
36300,
39900,
21800,
10400,
37100,
null,
5100,
5700,
15200,
8500,
10800,
81100,
74000,
21100,
20000,
null,
140700,
164400,
27400,
19400,
15300,
70700,
12000,
20500,
31800,
9000,
14000,
16800,
null,
49900,
67300,
6600,
12700,
31000,
5300,
27800,
20800,
119200,
26600,
22700,
44300,
16700,
71400,
null,
null,
3200,
26000,
13400,
null,
38000,
42100,
34400,
39700,
21200,
31500,
7200,
30700,
77850,
19700,
140270,
24800,
91600,
34800,
9500,
7900,
28200,
10500,
16500,
61700,
25100,
12400,
52800,
12400,
64700,
22400,
null,
15900,
21186,
48200,
116100,
12200,
46500,
19300,
24800,
12800,
6900,
null,
25400,
13800,
10800,
13600,
34700,
4300,
10200,
20000,
46700,
8500,
18600,
80503,
56000,
null,
31700,
55200,
null,
51800,
16700,
20800,
44600,
31500,
24500,
2200,
21600,
28000,
29100,
59100,
30600,
30100,
null,
null,
null,
9100,
13000,
40300,
31500,
16700,
34000,
28400,
29100,
24400,
21700,
95400,
71300,
25800,
null,
8100,
null,
null,
32600,
47000,
25100,
1300,
72200,
22300,
4400,
78900,
136200,
28200,
36200,
17600,
6700,
10200,
21300,
25300,
61800,
25100,
12100,
62500,
null,
14950,
23200,
12800,
37100,
15200,
26200,
22300,
14500,
5100,
null,
28100,
19150,
21500,
21400,
47500,
35300,
11400,
33100,
11200,
44100,
7000,
21300,
179800,
30000,
16400,
13500,
12800,
20600,
46700,
15200,
15400,
null,
53200,
35300,
9700,
26800,
9700,
47300,
33100,
9500,
null,
14100,
73000,
22300,
null,
39900,
4300,
27500,
13000,
13400,
8300,
null,
null,
24700,
88300,
18900,
28900,
10300,
36400,
60000,
null,
36700,
4000,
26000,
25500,
15800,
16100,
16800,
46100,
63300,
73200,
32000,
82500,
12700,
19500,
230000,
7300,
12200,
54600,
15800,
17600,
74500,
17900,
22500,
null,
26000,
36200,
16600,
13100,
22900,
21500,
13250,
14700,
null,
10700,
4900,
44400,
67100,
92800,
37200,
53200,
11000,
null,
13300,
34500,
48499,
10300,
44200,
26700,
null,
400,
3100,
12300,
21100,
7400,
5500,
23100,
37200,
28700,
27014,
181900,
12300,
6900,
41900,
12700,
29700,
24500,
44900,
10400,
14700,
null,
16600,
13500,
57700,
14300,
75150,
9500,
4300,
14500,
20300,
28300,
54700,
45300,
11000,
null,
10800,
4000,
50600,
21900,
55400,
31300,
50400,
13200,
9600,
16100,
8300,
22600,
35100,
32300,
29200,
18200,
69600,
9000,
26100,
18000,
1300,
27500,
56100,
8000,
6800,
9200,
22100,
11300,
null,
35000,
8000,
66600,
29700,
43500,
22600,
7300,
45300,
53800,
null,
24000,
32300,
17500,
17400,
2900,
700,
8100,
23600,
18700,
21200,
17200,
36700,
47000,
15900,
11000,
15900,
15100,
53130,
92000,
59800,
null,
23300,
39100,
14500,
4000,
3100,
21900,
29300,
null,
17100,
32000,
14600,
12200,
30640,
57000,
25200,
38000,
22600,
4900,
83100,
14200,
8400,
54400,
70000,
13400,
14300,
16500,
12500,
7600,
30900,
82300,
43200,
21600,
7400,
20500,
66500,
23500,
34100,
8100,
129400,
7000,
85200,
34000,
44700,
49100,
10700,
13400,
46400,
41000,
43500,
72700,
11100,
23300,
22800,
23100,
21300,
20500,
116425,
11600,
49500,
50100,
19700,
14500,
47500,
35600,
10400,
14500,
14700,
null,
null,
59100,
31100,
24100,
65533,
59600,
25800,
16300,
null,
null,
24300,
10000,
15800,
26900,
null,
15200,
66400,
19675,
6200,
47400,
30500,
15800,
null,
54200,
11400,
48600,
51300,
13200,
35300,
52000,
41200,
27600,
14900,
24700,
3500,
15900,
68400,
16700,
11100,
5000,
41200,
18200,
15200,
46100,
63000,
9800,
19600,
12600,
11100,
15300,
17300,
13400,
15200,
7825,
31500,
29000,
12700,
11300,
161100,
77920,
22900,
17800,
36200,
36500,
13900,
30700,
16600,
null,
17300,
16000,
43600,
15800,
7300,
null,
34900,
14000,
26400,
69929,
6400,
65000,
12200,
46000,
32000,
10000,
51000,
31000,
11800,
56600,
37600,
50800,
78300,
11500,
34800,
10200,
30000,
13600,
83300,
14600,
23200,
8900,
19600,
22400,
42400,
8500,
null,
73800,
18300,
5800,
36600,
30800,
16300,
4600,
54400,
88200,
84300,
16200,
33500,
25300,
9400,
11700,
41000,
6800,
19500,
12700,
14400,
null,
46300,
12300,
47200,
30100,
34300,
78700,
27000,
39000,
26100,
75700,
3300,
23500,
8300,
3800,
14900,
31900,
35900,
25200,
37500,
129500,
30600,
26000,
8500,
23700,
33600,
21000,
null,
24100,
null,
9700,
null,
62900,
25600,
48900,
42800,
64800,
15800,
23500,
15600,
41000,
34800,
52900,
40500,
16700,
42600,
15000,
9200,
20000,
23700,
27900,
44300,
null,
20400,
null,
37600,
10600,
18800,
14500,
76400,
16300,
7300,
70000,
26100,
21700,
20100,
26600,
24700,
15500,
43300,
88200,
83600,
63100,
7800,
178100,
20300,
15200,
6800,
23200,
7100,
34200,
null,
46300,
13700,
8800,
37400,
41600,
31800,
29500,
19300,
355000,
39400,
12802,
82800,
21600,
37200,
7400,
32900,
11900,
45500,
31000,
13500,
6200,
38600,
25800,
9000,
8900,
77100,
67500,
32000,
163700,
6400,
10700,
14500,
34700,
null,
115500,
70100,
26000,
19800,
20900,
39600,
20700,
72200,
6600,
10500,
null,
43700,
29800,
2600,
12200,
42700,
16800,
65400,
null,
23200,
17600,
12500,
27900,
16700,
17300,
200800,
9700,
30200,
24100,
62300,
10100,
14500,
105200,
42800,
13600,
null,
null,
92200,
10500,
69600,
12400,
151100,
15700,
50000,
24800,
24600,
47600,
48900,
33000,
14700,
14900,
17400,
48800,
40000,
40400,
24700,
12585,
6300,
22800,
94900,
31910,
14600,
null,
12600,
33100,
9900,
13300,
18300,
26300,
14300,
9800,
65400,
33200,
81700,
null,
23400,
63200,
31300,
7900,
59600,
18500,
31000,
52800,
54215,
90100,
74500,
18000,
68700,
null,
13200,
13500,
null,
37700,
75700,
8500,
51800,
9500,
110300,
14800,
45200,
8700,
5600,
11900,
15800,
55300,
32500,
6900,
19900,
11000,
13500,
3700,
35500,
110600,
69400,
17000,
44800,
16700,
4700,
12600,
160000,
17600,
87700,
53700,
52700,
51800,
6500,
58300,
17900,
5800,
29600,
7500,
15600,
28600,
11100,
7200,
58000,
36900,
44400,
30700,
28700,
5600,
32200,
15900,
15300,
13900,
26800,
11500,
46500,
40000,
7400,
10500,
34600,
5500,
50500,
67500,
25100,
128500,
2800,
8500,
28800,
24600,
23600,
39300,
7100,
5100,
26600,
24300,
58000,
40100,
12450,
16600,
16300,
20900,
9300,
8500,
26800,
161500,
16000,
8700,
33500,
8600,
60500,
8900,
47700,
108500,
56800,
17700,
16500,
56300,
98600,
36600,
24711,
9300,
24200,
22800,
16800,
16600,
35600,
133105,
72000,
null,
22900,
23900,
14800,
17000,
null,
null,
33100,
21300,
null,
37800,
29300,
110900,
26600,
26500,
16400,
24700,
16600,
41300,
20200,
21000,
30100,
38000,
21700,
26100,
17200,
41000,
22240,
22100,
25800,
10200,
23000,
34600,
36500,
19800,
11400,
19400,
71600,
25600,
31400,
63400,
16400,
11500,
null,
null,
35200,
4000,
22800,
21000,
24700,
5000,
9350,
4900,
7000,
10700,
9000,
62400,
15200,
59100,
14500,
28500,
12700,
67000,
13200,
20700,
19600,
null,
42000,
7500,
175600,
33200,
61200,
45600,
155600,
14400,
60000,
23500,
6900,
12700,
26300,
18500,
33700,
19100,
3200,
69500,
15500,
35300,
30800,
25400,
51000,
31800,
5400,
41500,
18900,
19000,
59900,
20400,
15900,
40500,
8100,
23500,
8200,
50682,
17000,
36000,
null,
12227,
18800,
106300,
28700,
40500,
null,
28000,
82000,
12300,
18300,
19900,
36500,
15400,
37200,
18800,
41100,
17000,
12800,
58700,
26100,
17800,
57000,
16500,
31100,
21900,
21700,
11600,
25800,
3300,
10700,
24000,
43500,
null,
118400,
55700,
30733,
32800,
9800,
71745,
8500,
4300,
26700,
83600,
13400,
78762,
12800,
19200,
5200,
30415,
2500,
20800,
11100,
5800,
47200,
11200,
6500,
7500,
30300,
156700,
28600,
12900,
null,
22100,
7300,
9800,
null,
20300,
32600,
10000,
46200,
69900,
20400,
53800,
11300,
51500,
33500,
22400,
7100,
30700,
9700,
32800,
22000,
11000,
null,
102100,
62100,
null,
54200,
8300,
28800,
28500,
null,
22600,
20500,
18400,
19700,
24400,
8300,
124900,
17800,
31600,
13300,
24700,
7200,
331000,
26700,
50400,
19200,
20700,
null,
10500,
6600,
8200,
6800,
40500,
27000,
26100,
24500,
9700,
35500,
95900,
15100,
12500,
33700,
119806,
8700,
19500,
16900,
65600,
8900,
30000,
25800,
16800,
30800,
9800,
24800,
13500,
86100,
10800,
1900,
null,
13700,
null,
98200,
11500,
44500,
42200,
31500,
18700,
29900,
15200,
12500,
31300,
10000,
22700,
30800,
18047,
7000,
14300,
null,
41300,
64100,
58000,
44101,
20600,
23400,
37000,
11300,
null,
25400,
10800,
70200,
46100,
7700,
29500,
25700,
19200,
60100,
80100,
35900,
67200,
39500,
16600,
44200,
8100,
25200,
null,
76600,
12200,
13900,
19300,
17500,
26400,
45400,
38100,
12200,
null,
19300,
16200,
null,
45600,
28000,
39700,
43200,
20300,
15100,
45000,
5700,
24100,
7800,
15100,
95800,
54800,
22300,
13600,
4800,
27000,
9600,
41600,
8500,
null,
12800,
31600,
52100,
14000,
36700,
66500,
26200,
28512,
14800,
5200,
null,
100400,
39000,
24800,
22177,
null,
21300,
26500,
53400,
42100,
39000,
5500,
43300,
null,
16300,
15900,
null,
55900,
11000,
16076,
79415,
null,
14900,
4900,
10700,
20600,
34600,
122000,
50300,
13000,
28800,
124300,
33900,
26400,
13700,
145500,
null,
17600,
31300,
6600,
11100,
49300,
31900,
14200,
2700,
null,
21100,
19600,
8500,
null,
21900,
51400,
27000,
13000,
17100,
null,
39800,
48900,
27700,
15000,
18200,
14200,
10800,
41200,
15300,
17700,
11600,
null,
14100,
null,
43200,
16600,
22100,
35500,
25200,
null,
94100,
48200,
22600,
22400,
83383,
19100,
11800,
46300,
41900,
17500,
20300,
38700,
26700,
5300,
10700,
35200,
30200,
45600,
11000,
15900,
10600,
18000,
25090,
19300,
14300,
7300,
22800,
16600,
60400,
6700,
67290,
33200,
32000,
17300,
67700,
11400,
103900,
13500,
17700,
33800,
null,
3300,
2800,
52700,
107000,
55400,
23100,
50300,
53500,
38300,
68000,
35400,
19300,
5000,
19600,
67000,
null,
19400,
5500,
58500,
22500,
27200,
17100,
37200,
54700,
34500,
9900,
26800,
12100,
25800,
36800,
40800,
8400,
null,
30800,
27000,
null,
24000,
24200,
8000,
14400,
21000,
5300,
45100,
19700,
20600,
21500,
20800,
19000,
22000,
15400,
null,
22700,
8500,
null,
92000,
12500,
17900,
null,
75300,
22100,
19700,
19300,
21200,
53700,
58300,
37000,
17000,
7500,
3000,
21600,
18900,
55800,
7300,
130600,
null,
null,
13100,
17300,
41800,
16600,
15600,
16500,
26300,
32900,
9000,
7200,
10800,
3600,
47800,
81500,
25000,
29800,
65400,
2800,
34500,
26000,
14200,
null,
31800,
22000,
52000,
32200,
26800,
4600,
34300,
73600,
27000,
17200,
170900,
22400,
6400,
46400,
21500,
23750,
56100,
10500,
96600,
97900,
42900,
15000,
57800,
22300,
24800,
9500,
12100,
47100,
17900,
56010,
6900,
27100,
18000,
5900,
9900,
4300,
35300,
18800,
52200,
8300,
28100,
null,
17200,
150000,
17600,
24300,
41100,
9800,
16300,
12700,
24800,
24100,
14900,
30000,
12600,
24400,
7000,
109200,
14700,
20100,
29000,
9000,
6900,
9100,
84500,
45300,
66300,
10200,
15500,
40900,
37900,
null,
null,
34900,
10100,
42700,
null,
null,
17200,
67500,
191875,
11100,
27000,
77000,
5400,
11200,
27800,
31500,
59300,
54000,
49600,
68700,
12100,
19600,
28700,
105100,
45500,
78200,
64800,
56800,
38600,
18500,
52200,
null,
6800,
44600,
27600,
12600,
31500,
29600,
45500,
5500,
26000,
30500,
21800,
25300,
80926,
25400,
67100,
57500,
6600,
125700,
16700,
null,
9900,
3500,
17300,
18200,
50000,
5700,
20600,
3700,
12000,
14000,
7100,
11100,
2300,
29500,
13300,
8600,
22800,
13100,
15300,
18800,
32300,
18600,
null,
27500,
57600,
57200,
20200,
18900,
20100,
30000,
39000,
12400,
20900,
77500,
55100,
18200,
16900,
12000,
14700,
7400,
15000,
null,
14700,
33300,
15700,
34400,
27400,
10900,
14800,
70300,
36600,
21400,
3100,
27600,
21000,
51800,
7200,
9300,
36400,
16000,
15400,
29300,
15400,
25100,
9000,
28000,
18200,
5400,
10000,
3100,
42900,
64100,
37700,
44478,
5400,
null,
38600,
29200,
56700,
12300,
12200,
49600,
68800,
117900,
6550,
22500,
18300,
20300,
34600,
10150,
17800,
18650,
5200,
32500,
59700,
null,
14600,
12800,
52100,
24300,
73700,
9100,
7100,
15500,
28300,
27100,
42000,
16100,
null,
32100,
6300,
61100,
16300,
34500,
33000,
null,
12800,
8600,
45700,
31400,
37300,
53800,
22000,
21900,
49500,
35700,
24700,
23200,
70000,
36300,
27200,
24800,
72100,
145200,
null,
13700,
41000,
34400,
8800,
31500,
35400,
null,
14932,
15700,
null,
12500,
42800,
24000,
16800,
null,
47400,
32700,
12100,
8000,
7950,
16300,
29600,
16900,
29000,
69900,
null,
14200,
1000,
101000,
18600,
36400,
200800,
33800,
23300,
57500,
46000,
15700,
null,
50500,
43200,
15900,
17400,
18000,
54700,
19900,
13700,
20300,
15400,
38500,
14600,
19100,
34600,
17600,
18000,
6300,
28700,
38300,
75900,
12000,
4800,
51400,
3300,
4600,
37900,
58400,
50100,
101992,
5900,
31900,
59000,
null,
18200,
12900,
17400,
6100,
48200,
43500,
null,
1700,
62400,
52400,
38000,
19200,
16900,
36000,
7300,
16300,
26100,
96400,
8800,
12300,
null,
11400,
7900,
18400,
28700,
11200,
18000,
29600,
21600,
9800,
6100,
null,
26300,
40100,
null,
22300,
12700,
22300,
13200,
9400,
31100,
33600,
120800,
null,
27100,
23200,
12800,
12600,
13800,
9800,
182300,
36600,
16500,
54920,
19400,
9850,
22100,
14000,
52000,
75100,
23000,
14100,
20100,
21400,
44900,
37700,
488400,
37600,
35800,
54300,
18800,
82000,
39050,
51300,
35300,
null,
38200,
7900,
103400,
16100,
44000,
49600,
16400,
7900,
34000,
null,
149300,
6400,
25800,
null,
39900,
null,
48000,
41000,
28300,
5600,
null,
46000,
98600,
54000,
95400,
21700,
30100,
2900,
48000,
49500,
null,
72400,
11400,
47800,
27900,
2500,
30600,
82500,
17100,
34400,
18400,
36000,
12700,
34500,
10200,
20600,
18100,
14700,
13400,
12000,
51500,
51400,
46500,
14000,
8300,
62000,
null,
87500,
27600,
null,
24100,
29600,
13200,
27300,
null,
10300,
26300,
38500,
46800,
102300,
10800,
8800,
52300,
23500,
31400,
38800,
13700,
21700,
20100,
30500,
15100,
16700,
59100,
48300,
68900,
6500,
25500,
10000,
19700,
60000,
7000,
57200,
14300,
24700,
31900,
null,
59800,
28700,
5000,
2800,
19800,
105600,
22100,
25500,
31800,
19000,
7800,
22500,
38600,
9700,
23700,
31700,
27900,
5500,
15900,
14000,
28100,
32600,
16400,
38000,
4400,
35400,
10000,
20300,
10150,
16500,
58500,
11700,
19500,
38100,
16800,
10000,
174175,
5600,
10900,
6900,
80400,
10100,
19700,
22700,
15000,
46600,
19200,
21400,
29500,
49000,
19300,
35645,
21400,
25400,
51789,
7300,
null,
34600,
18400,
21500,
16000,
11100,
null,
14900,
31400,
9900,
25000,
64400,
22200,
138500,
2800,
19600,
26000,
2000,
30900,
25000,
38700,
15500,
30600,
7600,
12600,
15300,
11800,
6500,
12000,
26900,
78500,
23900,
39000,
8900,
18600,
38600,
34200,
25200,
5800,
125100,
29900,
63400,
14200,
26000,
null,
12000,
27300,
26100,
null,
33700,
20500,
51600,
78300,
30600,
18500,
49900,
4000,
34800,
71900,
53200,
44600,
15700,
25200,
11600,
23600,
7500,
null,
45000,
26000,
10100,
10000,
21200,
52200,
13559,
6900,
null,
40200,
null,
64100,
30000,
5800,
4800,
null,
43500,
5500,
null,
28600,
70100,
607200,
2400,
27000,
35500,
null,
36400,
26500,
18300,
22100,
91600,
41000,
9800,
13100,
13300,
53500,
11800,
17300,
3400,
36500,
24500,
43800,
68100,
10100,
19700,
7500,
11240,
29200,
58800,
25400,
15800,
31900,
21200,
8500,
27800,
39200,
13700,
35600,
null,
9500,
29700,
13900,
15900,
79800,
64100,
49100,
38700,
17500,
23100,
13100,
75200,
19600,
null,
65900,
40100,
48700,
91800,
24700,
27700,
78500,
null,
25900,
22200,
36200,
17000,
20000,
15100,
38300,
32200,
5500,
40500,
17000,
114900,
50700,
26600,
19400,
null,
36500,
null,
19700,
9700,
11800,
18800,
131800,
12300,
22100,
16900,
63300,
19500,
57500,
18700,
24500,
19000,
54900,
56300,
23800,
53300,
9600,
96700,
28100,
95200,
10200,
22500,
47500,
null,
6900,
20700,
null,
9400,
22300,
35900,
16600,
59400,
48000,
2500,
23000,
16100,
23400,
21000,
21800,
null,
15300,
4700,
5800,
59300,
28500,
7800,
7500,
null,
27800,
23400,
7700,
null,
null,
55300,
19300,
null,
17800,
23700,
25500,
null,
178000,
40400,
19800,
35500,
3300,
36000,
46800,
23700,
57000,
20900,
null,
49200,
56200,
24000,
36600,
15500,
45100,
46601,
226500,
58100,
12100,
19300,
34300,
26800,
9900,
51100,
22400,
15500,
57800,
25900,
5500,
21200,
10900,
16600,
16300,
null,
51500,
42300,
17900,
37500,
39600,
24900,
60400,
null,
7900,
4700,
7200,
42100,
14100,
34900,
18200,
39000,
84000,
18300,
16800,
12600,
10200,
19600,
8400,
37700,
38600,
15100,
23200,
28900,
null,
25700,
35700,
3500,
106100,
14700,
14800,
67600,
34800,
21200,
7400,
null,
20300,
1000,
null,
77900,
16900,
11100,
19500,
32300,
8700,
19600,
41300,
13900,
28500,
9600,
9200,
11500,
72900,
15500,
15900,
47700,
22100,
10500,
7000,
13400,
33100,
null,
7100,
12800,
68986,
37000,
null,
null,
40700,
97900,
3400,
null,
4000,
15800,
24400,
null,
null,
53300,
8100,
null,
5300,
56000,
36500,
22200,
54400,
13500,
34000,
20800,
49100,
14900,
12900,
33800,
24300,
55900,
5000,
44100,
27600,
7500,
15800,
40600,
25100,
null,
7300,
14500,
22600,
66400,
23300,
34900,
21900,
17900,
21100,
23400,
50900,
22100,
41600,
47500,
4600,
null,
4600,
30100,
20600,
30000,
28000,
46100,
38900,
11600,
32171,
18300,
27200,
12000,
37600,
null,
69900,
34200,
52600,
22100,
12636,
19600,
15500,
8900,
13200,
5700,
13300,
17000,
5000,
52800,
48100,
null,
31600,
12700,
4200,
30000,
134800,
null,
10900,
35200,
32600,
17700,
58800,
18600,
68400,
8300,
195800,
27200,
null,
81000,
16900,
11500,
13600,
23800,
7000,
122600,
63700,
35800,
11400,
9100,
null,
18700,
17000,
29800,
5200,
51200,
40500,
59500,
32300,
35700,
16300,
41400,
15400,
28400,
3000,
75600,
63200,
8500,
29700,
12200,
23700,
89600,
9600,
21400,
20500,
12300,
33200,
27600,
8100,
27900,
38500,
8400,
32900,
22800,
28200,
134900,
1200,
101500,
20700,
7400,
22700,
59800,
44100,
12100,
null,
26500,
35800,
23700,
81700,
13600,
29200,
10300,
8300,
5500,
15800,
72600,
13100,
24000,
37500,
45700,
27400,
45500,
null,
82000,
6700,
54100,
15000,
13300,
34800,
84100,
12000,
49000,
19900,
33900,
6600,
48000,
81100,
6000,
13700,
20800,
null,
null,
52400,
20300,
5900,
16000,
4200,
48300,
23900,
27100,
15000,
56800,
30200,
35600,
56500,
13700,
11900,
10700,
54200,
13600,
45800,
17400,
47700,
40900,
16900,
null,
6800,
21300,
null,
37200,
6200,
13200,
38300,
44200,
25800,
14900,
57300,
40200,
39500,
30300,
42600,
94900,
14100,
8800,
19200,
9500,
7300,
16600,
15600,
28500,
4700,
null,
166200,
35900,
15400,
6700,
55400,
18700,
368900,
40500,
14200,
15700,
17200,
21700,
null,
5600,
36700,
26500,
22000,
14200,
22500,
2500,
58800,
47500,
null,
69000,
17200,
15500,
53800,
21300,
18000,
26100,
61800,
16700,
45100,
11600,
8600,
22700,
17100,
5950,
49700,
22500,
18500,
37900,
43200,
25400,
32200,
5500,
27200,
11100,
95800,
6400,
7300,
14600,
15400,
42200,
52200,
25500,
42300,
38700,
13500,
30100,
null,
14200,
24700,
124300,
26300,
51300,
40000,
21500,
31400,
20100,
10000,
8700,
5600,
5100,
4500,
22800,
39500,
null,
51100,
19300,
24700,
11000,
700,
12500,
37600,
18300,
52100,
11900,
26800,
19500,
16100,
113000,
55200,
7000,
29000,
84100,
11500,
37500,
55600,
63268,
5900,
68216,
29100,
16800,
23600,
11100,
16400,
44300,
28300,
17400,
27700,
21500,
16400,
25200,
20600,
38900,
18900,
13300,
39800,
null,
7500,
89742,
16900,
26000,
66300,
21200,
12300,
18400,
16700,
12800,
10100,
32800,
7700,
11900,
45300,
5900,
51300,
17500,
28800,
36800,
7700,
18500,
11600,
21400,
39000,
12100,
63200,
50100,
64100,
104500,
15400,
37700,
11100,
null,
23900,
41400,
10600,
25500,
15600,
10000,
5200,
85100,
1700,
64600,
14800,
20000,
35300,
44400,
30900,
23400,
29900,
17200,
19200,
26300,
19600,
49000,
37500,
71000,
9800,
34300,
32600,
17000,
24900,
49700,
45400,
19200,
null,
3500,
263100,
28500,
12200,
43500,
47000,
27650,
16500,
42400,
116700,
null,
11300,
29300,
17800,
13900,
null,
20800,
20500,
20900,
7200,
61500,
28500,
17800,
null,
32100,
100100,
181100,
8200,
16800,
4000,
42700,
null,
8000,
33200,
26300,
6600,
25200,
19800,
7600,
15500,
17500,
7400,
50762,
18900,
39600,
21600,
14500,
33720,
null,
28300,
22000,
181700,
60900,
7700,
77500,
11700,
29300,
6900,
22200,
9520,
37500,
28500,
35400,
24000,
21900,
7500,
18000,
null,
103700,
22100,
4500,
28200,
10900,
13300,
39500,
18600,
null,
24800,
42700,
23252,
19500,
74800,
22200,
20200,
7200,
21000,
23300,
27700,
14700,
58200,
40400,
34200,
33800,
16500,
11300,
59300,
24300,
null,
14629,
20600,
65100,
null,
9300,
150700,
29100,
34500,
33400,
6400,
24400,
40100,
59267,
80100,
22600,
28000,
52900,
14900,
18100,
13900,
23300,
11900,
32300,
7500,
38300,
15600,
null,
32500,
17600,
64900,
13000,
null,
34500,
900,
16100,
30500,
35000,
13200,
7500,
13400,
24600,
9600,
68000,
14400,
13600,
7100,
8600,
27700,
55900,
27300,
37500,
11700,
20800,
16300,
27900,
null,
39300,
58800,
27400,
14600,
25700,
11100,
224600,
145300,
9300,
31300,
23500,
14300,
51800,
17600,
19200,
15000,
24000,
29470,
28500,
37200,
12100,
30700,
21700,
77500,
null,
16000,
5200,
15500,
34300,
31900,
14300,
52400,
28500,
11800,
17000,
43500,
1400,
25400,
4200,
null,
48100,
14600,
10800,
36100,
25300,
54700,
13000,
17200,
50500,
null,
33200,
31300,
28900,
null,
48100,
49500,
6500,
48500,
23500,
null,
21300,
20000,
16500,
37700,
25900,
52600,
27500,
31300,
15500,
45800,
26000,
46200,
9000,
47600,
24100,
17400,
34200,
39200,
41300,
17000,
77900,
101100,
13800,
8200,
9300,
56200,
34300,
45800,
26400,
8100,
20200,
25200,
13900,
15200,
21300,
null,
42900,
null,
12000,
33000,
16500,
21300,
23100,
2600,
76700,
50600,
23200,
10800,
13000,
7900,
17800,
35300,
22100,
11500,
32800,
25300,
19000,
65700,
158400,
28300,
39800,
23300,
0,
15800,
70800,
11600,
25400,
30800,
8000,
14800,
10400,
18700,
null,
26400,
22100,
15800,
32400,
20200,
null,
6800,
10100,
36300,
14100,
56100,
23500,
55900,
60000,
56100,
8100,
27000,
1500,
4900,
36900,
23000,
null,
51800,
15100,
27900,
22000,
140500,
null,
11600,
38800,
48200,
49400,
47200,
25700,
10400,
18800,
1500,
21000,
14700,
46300,
16200,
28000,
12800,
1000,
24700,
19700,
88800,
34200,
44700,
24700,
null,
27000,
26500,
60300,
16900,
98200,
22600,
36500,
28300,
40900,
25400,
14500,
22600,
73400,
24300,
11100,
21800,
38700,
60000,
31300,
7500,
31100,
100400,
4500,
23200,
25300,
24100,
38800,
28000,
50700,
22100,
20200,
31600,
10400,
23900,
null,
53000,
16900,
114700,
26500,
17600,
10800,
8300,
25700,
7100,
32200,
18700,
null,
19600,
48000,
29800,
14200,
30200,
17100,
17300,
8700,
23900,
58300,
43873,
11100,
26600,
33000,
43800,
52300,
31000,
6300,
64700,
89258,
36500,
21600,
null,
9800,
20700,
27400,
12300,
19300,
57700,
null,
7200,
75100,
null,
10300,
20100,
40400,
87600,
27700,
2000,
357900,
38500,
null,
8900,
26900,
31300,
8400,
4700,
14300,
18400,
38200,
16200,
null,
40300,
6700,
63800,
17700,
null,
16100,
14400,
29800,
61000,
16100,
16200,
null,
41700,
19300,
14800,
73000,
6300,
45900,
25000,
8600,
33500,
42300,
13800,
59100,
22400,
18000,
45300,
18100,
12200,
38400,
147550,
9200,
25900,
14200,
23100,
30400,
60600,
25300,
27100,
14900,
6800,
24900,
28200,
null,
12400,
50200,
46600,
55500,
20400,
49000,
44806,
20710,
null,
4500,
20000,
14800,
null,
null,
3500,
32500,
106900,
12100,
37400,
12500,
15700,
23600,
22200,
null,
null,
800,
22600,
51100,
null,
35200,
29700,
null,
20000,
2850,
102400,
null,
30400,
38900,
45000,
26400,
50100,
28900,
22300,
34800,
29000,
33800,
87000,
23800,
18600,
41600,
54100,
13400,
69000,
10200,
56300,
44200,
9500,
77500,
null,
84500,
27100,
22100,
27000,
5800,
null,
23300,
42700,
71000,
38916,
16500,
75400,
10500,
7200,
19200,
11200,
26300,
16300,
40700,
83400,
19500,
17000,
16700,
8200,
42300,
27500,
5400,
6600,
16500,
15700,
42900,
null,
38500,
12300,
12700,
47400,
15400,
17500,
63700,
12100,
24100,
33100,
33600,
25000,
16700,
14400,
61000,
21000,
11300,
99600,
32900,
106300,
7500,
null,
14000,
73600,
25300,
null,
36600,
6900,
11300,
19100,
66500,
4200,
17800,
null,
46300,
19800,
24400,
null,
42900,
34800,
14200,
13100,
40300,
140800,
36100,
42900,
7500,
20300,
null,
49800,
10400,
24100,
35500,
23900,
110000,
56047,
44000,
28400,
15300,
51700,
null,
3600,
28200,
10500,
15800,
25500,
13500,
null,
18200,
26300,
18800,
17800,
21300,
null,
78600,
14750,
34200,
29700,
29900,
9350,
122300,
null,
null,
63900,
47300,
25700,
65700,
22400,
4900,
null,
31000,
147200,
28100,
7600,
21200,
null,
41700,
27800,
null,
7800,
29300,
47200,
17500,
35500,
52600,
null,
14100,
26500,
38100,
18100,
22900,
76300,
91900,
21500,
11600,
29500,
null,
5300,
13100,
63000,
48800,
null,
63400,
13600,
22100,
35300,
13300,
5600,
17500,
93000,
137600,
60600,
28000,
19300,
null,
26200,
null,
11700,
17500,
162900,
21200,
9200,
24000,
null,
9600,
60600,
61800,
50200,
120000,
null,
33900,
17900,
null,
12700,
null,
14200,
9200,
14500,
21100,
26100,
30700,
25000,
46100,
20000,
14500,
9400,
9000,
58100,
15400,
5600,
55800,
58300,
15600,
40800,
19500,
63300,
15100,
2100,
11500,
16000,
9200,
15900,
34700,
46800,
34500,
34300,
11700,
8200,
28500,
14200,
108000,
34700,
4600,
25600,
55900,
19700,
null,
4700,
15200,
18300,
30300,
35700,
58000,
null,
5600,
29400,
27200,
null,
91000,
21400,
null,
10600,
10700,
123300,
13600,
47100,
51300,
32100,
2700,
43100,
14800,
90250,
34600,
22300,
23300,
10600,
4500,
16100,
18300,
13500,
27000,
56300,
23200,
22000,
31100,
2500,
33300,
17300,
76300,
31300,
13400,
18200,
23700,
56300,
30100,
54200,
48600,
29400,
null,
18000,
15600,
30000,
14500,
11200,
16600,
16800,
11600,
86200,
36200,
null,
19500,
93950,
39600,
68400,
62500,
25300,
31500,
78000,
51300,
134300,
22800,
14100,
8200,
27300,
28500,
34600,
55100,
33000,
7725,
41900,
66573,
10500,
14200,
16100,
48600,
400,
12300,
32300,
300,
16300,
72526,
null,
46300,
null,
33900,
4900,
87000,
40000,
40200,
29000,
30100,
26700,
28900,
5900,
7500,
48700,
null,
26600,
9100,
15300,
9600,
27300,
18300,
21000,
83100,
null,
11900,
49000,
null,
24700,
9000,
10600,
null,
31700,
19400,
null,
65100,
28300,
21300,
39990,
52300,
24900,
14700,
13600,
8300,
55000,
37900,
6100,
33200,
125000,
19500,
10300,
29900,
53900,
9600,
null,
34300,
38600,
10732,
21800,
56100,
49000,
15000,
16800,
59600,
12600,
6800,
null,
22900,
26100,
41200,
35100,
34500,
72200,
41000,
19600,
11800,
40600,
47600,
21200,
3000,
14500,
39000,
18800,
10800,
26900,
19600,
86000,
31900,
28000,
41500,
40000,
66100,
22300,
15500,
24000,
20900,
27000,
14500,
55600,
11200,
42200,
126500,
19800,
25300,
24800,
58200,
8800,
20700,
10800,
37800,
75200,
12600,
118600,
35000,
49700,
22600,
22600,
43700,
null,
10100,
74100,
36000,
88200,
52000,
11300,
9000,
null,
166700,
54200,
13100,
7700,
21900,
28800,
39000,
87600,
null,
65900,
null,
null,
7600,
108100,
24200,
17500,
11600,
15200,
92400,
23000,
50000,
18500,
19600,
16400,
26900,
null,
25900,
null,
46200,
52100,
7800,
12000,
16300,
2300,
36900,
10800,
42900,
75200,
17000,
10900,
45100,
null,
21700,
75000,
60800,
25900,
14700,
22300,
43100,
69100,
17500,
57200,
32100,
12700,
null,
null,
5500,
6500,
29900,
13200,
57800,
34900,
17600,
2500,
4700,
41200,
49000,
6500,
51400,
16700,
37300,
11400,
13800,
null,
14700,
26800,
12400,
33306,
53000,
40700,
44100,
41000,
13900,
24400,
25500,
25800,
19700,
null,
7400,
23600,
8800,
16200,
12300,
55000,
31500,
null,
60700,
36700,
16800,
54200,
35000,
31200,
7200,
49700,
28200,
35300,
24680,
11600,
23400,
38900,
114800,
null,
13800,
15300,
17500,
57900,
null,
18100,
31000,
16300,
null,
5400,
7600,
25600,
9500,
48300,
18800,
null,
29400,
22100,
29200,
25100,
48200,
18400,
30900,
60100,
39700,
16200,
17600,
8250,
16800,
19000,
2400,
25706,
67800,
20700,
61200,
33400,
15000,
15500,
19500,
44000,
14300,
20700,
294600,
12000,
13900,
8000,
9700,
20800,
6600,
14700,
null,
87500,
null,
14500,
41800,
6800,
14700,
147200,
11600,
89100,
37100,
22500,
23100,
16400,
18800,
9800,
33900,
4300,
26300,
23900,
10500,
5800,
18100,
24400,
7100,
17100,
47100,
25700,
14600,
78500,
50200,
22800,
null,
6800,
34000,
38100,
13400,
24700,
45944,
5700,
11100,
21500,
9005,
null,
60400,
12100,
43400,
21400,
29000,
23100,
33000,
29622,
15600,
23600,
46200,
10400,
99200,
17400,
null,
26000,
null,
25200,
29500,
4100,
9700,
19400,
31700,
34000,
22200,
16000,
69800,
18400,
24200,
15100,
18070,
24425,
29400,
12500,
23700,
58200,
14700,
30400,
28300,
20830,
22800,
110800,
16100,
10900,
38700,
63200,
43700,
16000,
23600,
94300,
17200,
68700,
59800,
39600,
39400,
25100,
null,
19300,
6300,
11945,
18500,
9400,
6700,
14800,
47300,
60200,
38200,
null,
2400,
43500,
13100,
42500,
11100,
21500,
null,
17500,
null,
61000,
51700,
49600,
9300,
15200,
5900,
23000,
9400,
null,
14800,
41400,
12600,
27000,
96901,
19000,
32200,
15000,
null,
15000,
86200,
34600,
12900,
17200,
14500,
118450,
24100,
11800,
18300,
104100,
15300,
16900,
24600,
3400,
23700,
null,
9700,
16400,
57300,
32700,
17400,
null,
18800,
37000,
38700,
20800,
44400,
10000,
25600,
null,
6900,
13100,
29800,
134600,
46800,
11000,
28300,
7000,
11800,
29800,
29700,
14100,
22647,
48800,
17100,
105000,
12500,
34800,
64300,
13500,
61700,
52800,
50100,
32100,
55800,
12100,
25300,
77500,
33200,
30100,
29100,
21300,
1000,
28200,
58500,
13000,
49600,
42400,
91300,
39600,
60400,
59926,
18100,
11900,
35700,
12600,
12500,
18300,
49300,
32500,
18500,
85700,
null,
29800,
69800,
27400,
17100,
7800,
20900,
41800,
39400,
15200,
29600,
73000,
14000,
42048,
15700,
23542,
21200,
42900,
8300,
22200,
24700,
29900,
12500,
71500,
6600,
38000,
14600,
197700,
76200,
53300,
4900,
39600,
5600,
17900,
17700,
24600,
10800,
22700,
19700,
48100,
24200,
null,
11600,
27300,
23500,
21200,
75100,
26800,
null,
24100,
47000,
45800,
11900,
69400,
31700,
16700,
8600,
55404,
35950,
69000,
5100,
28000,
20300,
33250,
51600,
26800,
56500,
7300,
56800,
56800,
39500,
103000,
16600,
39600,
18100,
13800,
232500,
14500,
38900,
134900,
20500,
40200,
12000,
49723,
32900,
38600,
54300,
41500,
69600,
13100,
2000,
65100,
26100,
16800,
40200,
35300,
1600,
15300,
137800,
null,
30300,
null,
null,
7400,
17400,
13800,
3200,
52300,
5900,
104800,
72300,
25400,
43000,
24500,
null,
21300,
124700,
72000,
14400,
11900,
22800,
34100,
53300,
5100,
31700,
82000,
4600,
19900,
4600,
24400,
41600,
9200,
11600,
9300,
17500,
22300,
8100,
30500,
36100,
8800,
7600,
46579,
8900,
11500,
17800,
49400,
18500,
35100,
24600,
13000,
75500,
37200,
2800,
6500,
94900,
19500,
13000,
23200,
10200,
17900,
null,
9600,
42800,
13700,
null,
18000,
20300,
92900,
22500,
33400,
21700,
10200,
30400,
20400,
null,
87100,
22200,
15400,
22300,
58000,
119600,
8800,
61600,
24300,
20200,
24600,
34700,
46700,
null,
null,
7100,
13900,
6300,
9600,
15300,
25010,
6600,
2400,
7900,
null,
7500,
39000,
6600,
16000,
null,
14200,
62300,
null,
31600,
18200,
30400,
16100,
52100,
25400,
31500,
48000,
15800,
null,
11300,
9000,
14700,
8700,
8800,
21600,
20400,
40000,
45100,
27000,
null,
21500,
null,
21500,
13200,
216700,
32400,
30800,
55200,
27100,
26500,
11400,
12000,
31000,
null,
85047,
17200,
10700,
44300,
20700,
6900,
13700,
94500,
35200,
18800,
5200,
35600,
33700,
67500,
9000,
11200,
14900,
null,
28400,
5500,
40400,
43100,
24200,
29200,
28300,
10000,
19500,
33300,
27000,
8200,
22700,
15000,
58800,
20500,
48600,
5600,
24300,
38100,
12000,
9900,
53500,
26100,
32900,
30700,
11400,
null,
27600,
27100,
26900,
31900,
null,
3600,
16105,
30800,
13200,
6000,
18600,
13100,
16500,
22200,
7800,
68100,
59800,
14100,
4900,
null,
70167,
23200,
10300,
32750,
26700,
24600,
34600,
17100,
9400,
17300,
34100,
null,
18000,
13800,
52100,
24900,
16300,
19000,
51200,
18300,
15500,
31400,
18700,
52500,
8500,
8300,
9300,
16800,
9300,
38300,
19200,
7800,
57900,
64500,
49700,
29700,
5500,
23500,
8700,
9700,
71400,
29500,
78400,
31100,
24000,
26100,
52700,
5300,
23700,
13800,
22000,
58864,
4900,
14300,
42500,
117500,
42300,
6400,
12500,
20400,
28000,
19500,
null,
15000,
18500,
10800,
13700,
25800,
8900,
45500,
47100,
67200,
14100,
31900,
null,
22900,
30200,
16700,
3400,
6700,
15900,
7000,
17000,
31600,
6300,
56364,
136000,
63700,
24900,
11300,
19900,
55700,
3000,
54900,
23400,
15500,
6200,
37300,
60000,
81100,
38100,
25900,
19800,
91600,
10300,
13700,
43600,
34600,
44100,
null,
28600,
null,
7600,
56400,
11500,
54100,
9000,
12700,
null,
25900,
34000,
49593,
49000,
121900,
40200,
62900,
22800,
18500,
174700,
21800,
54900,
20200,
15200,
27600,
21800,
null,
29200,
20000,
44300,
17000,
15800,
32600,
14300,
21300,
null,
null,
23500,
27400,
16300,
19100,
null,
25500,
16300,
10300,
15200,
27600,
13000,
47200,
46900,
8820,
31900,
18400,
null,
59900,
9300,
14100,
14800,
77300,
21700,
21300,
16100,
18800,
45300,
26300,
21800,
6100,
36000,
44800,
35100,
27100,
16000,
11300,
19100,
16400,
null,
26600,
35300,
null,
17700,
13000,
20686,
8000,
9100,
37800,
16000,
14900,
4500,
11400,
33900,
13500,
13400,
30800,
23500,
10300,
null,
39400,
20200,
13000,
74200,
52000,
null,
21500,
null,
17900,
53600,
15900,
58300,
16900,
11800,
21350,
53300,
47600,
45000,
7800,
49100,
65800,
27400,
38700,
27900,
79400,
null,
25100,
32600,
19000,
9900,
16800,
13300,
18500,
null,
11200,
27350,
8200,
7700,
22000,
50400,
75000,
66600,
17000,
null,
65700,
9100,
17600,
21000,
40100,
36600,
11200,
null,
4000,
8200,
31800,
46500,
15100,
31800,
36000,
null,
12600,
20600,
null,
30200,
55400,
4700,
5000,
113020,
24700,
17400,
57000,
5600,
68000,
11900,
24200,
20600,
10300,
null,
22700,
11100,
16300,
11200,
42600,
null,
137800,
4300,
9000,
23700,
8000,
51700,
null,
23000,
38084,
3200,
25561,
108900,
33977,
36900,
39300,
56900,
14500,
9900,
16800,
48000,
38700,
24973,
23400,
67000,
23100,
32800,
28900,
54900,
19170,
296100,
55000,
76125,
7100,
17400,
111400,
11400,
22000,
20500,
96600,
42600,
93100,
9700,
80700,
70000,
67200,
6500,
110300,
12500,
19200,
70300,
null,
17200,
13200,
18700,
7500,
6400,
33600,
null,
30000,
13500,
7100,
30600,
44900,
25200,
6500,
31400,
16300,
42750,
19800,
45900,
33800,
51100,
24500,
98100,
22300,
46600,
39000,
87900,
14600,
33000,
12900,
14500,
36900,
3000,
4200,
45000,
49800,
6700,
16600,
29700,
22100,
95500,
15400,
58000,
11700,
51500,
15400,
10500,
21100,
48100,
21200,
7800,
13800,
4300,
null,
35900,
91100,
23400,
26000,
21300,
101200,
27300,
36300,
34300,
37800,
null,
20800,
null,
33000,
18800,
21500,
89600,
19976,
24500,
27300,
16300,
19100,
11100,
22600,
null,
28600,
31100,
26100,
20200,
null,
5400,
45300,
34100,
9900,
126800,
68300,
26600,
35600,
57250,
5300,
16000,
53500,
25500,
14300,
14900,
20900,
62100,
null,
29000,
17500,
12900,
6200,
null,
13500,
34100,
8500,
1800,
16500,
5900,
30000,
115200,
11300,
16400,
11500,
38100,
60500,
null,
49600,
7500,
20000,
11500,
null,
75600,
5800,
34600,
38900,
15500,
14100,
37200,
12500,
14700,
29100,
34800,
16100,
69000,
19100,
30000,
17500,
59100,
103700,
7300,
34000,
37981,
8100,
13500,
29061,
20400,
4300,
33000,
12000,
22600,
22400,
50800,
20500,
21900,
18500,
25100,
27700,
9000,
22400,
null,
20500,
30800,
42200,
330900,
17200,
29500,
88000,
34900,
22800,
4600,
14500,
11400,
25800,
33800,
62400,
23200,
54500,
12400,
20550,
6900,
128000,
30500,
6600,
6600,
55400,
15600,
22700,
10200,
92200,
26000,
42000,
13100,
29800,
9450,
30900,
44000,
20000,
48300,
119100,
null,
60000,
110000,
32300,
5400,
22000,
50400,
28600,
11000,
188800,
18600,
41700,
44900,
8900,
54600,
30400,
63200,
34000,
null,
52450,
17900,
24900,
17100,
31100,
78900,
null,
16050,
13600,
16500,
18500,
82500,
40100,
null,
6000,
3500,
null,
68200,
2000,
9500,
68700,
15200,
28600,
3700,
18500,
20600,
7800,
32500,
1300,
33100,
53000,
34400,
29200,
null,
43100,
14700,
45200,
null,
55300,
12900,
6200,
32700,
15800,
66000,
15200,
160500,
28600,
29800,
null,
20800,
42500,
21900,
174000,
63500,
76000,
20000,
6200,
60400,
35600,
24500,
24100,
19400,
50300,
7600,
20620,
null,
40100,
137000,
9400,
20900,
11100,
26600,
null,
37100,
17500,
11500,
19200,
13000,
11500,
24300,
31600,
63500,
4600,
8000,
19500,
17100,
28400,
25200,
16000,
40500,
7300,
45100,
4700,
8200,
52900,
75400,
6600,
44200,
9000,
12300,
29700,
16700,
38100,
40700,
null,
42400,
24100,
6600,
10500,
27800,
41900,
25500,
61500,
11300,
35900,
33100,
54700,
82900,
9900,
null,
14600,
37800,
53400,
51300,
22700,
2900,
33770,
90800,
4000,
44500,
22200,
37100,
10500,
10400,
86400,
null,
6500,
38637,
28800,
15300,
18300,
23700,
29600,
9700,
23500,
75100,
72500,
7200,
21000,
24500,
null,
11400,
35800,
110234,
16100,
19200,
null,
20700,
51300,
45900,
35100,
43300,
null,
17100,
28277,
24100,
65600,
14100,
55700,
27400,
31400,
null,
7300,
12500,
6000,
68000,
14700,
4600,
41500,
20400,
22200,
9400,
16400,
15300,
38000,
37500,
13400,
27900,
14300,
43700,
null,
60200,
17000,
22000,
26000,
20300,
19900,
30800,
38000,
null,
8500,
25400,
35900,
33200,
12600,
13500,
37900,
27400,
64800,
53000,
55800,
7400,
105300,
47900,
6400,
29600,
65934,
10800,
20100,
31800,
27100,
27100,
18400,
7700,
23900,
null,
44700,
null,
8800,
6000,
17400,
29300,
14700,
30000,
28100,
21900,
52000,
6700,
15800,
1600,
4500,
null,
21300,
43300,
25600,
20700,
20400,
31600,
12400,
26600,
75500,
7500,
19540,
69200,
59600,
null,
79000,
21100,
71300,
82700,
25000,
90200,
53900,
18100,
1000,
24000,
30000,
24600,
42200,
30000,
5400,
10300,
41100,
105900,
22200,
5400,
36400,
13800,
34100,
13800,
20200,
13500,
18600,
15900,
28900,
15900,
14500,
20500,
50800,
25300,
43100,
8200,
null,
26000,
39200,
14900,
27400,
39900,
7000,
28600,
13500,
22100,
12500,
50700,
null,
25900,
41800,
75900,
null,
42600,
28600,
15800,
43300,
17800,
33900,
22700,
null,
31300,
null,
8300,
45200,
33500,
55200,
30700,
null,
46600,
72900,
19200,
10600,
37600,
16000,
null,
8400,
16600,
7000,
22100,
45800,
40400,
77500,
12700,
56000,
27400,
100000,
15400,
null,
22900,
28300,
22800,
12900,
65000,
null,
28700,
16500,
13000,
null,
28500,
41600,
52400,
null,
116800,
7200,
10900,
15600,
17000,
14800,
28200,
11200,
16500,
68600,
37900,
27500,
90500,
13500,
22700,
null,
18600,
17700,
33800,
63304,
76600,
61300,
9800,
null,
85200,
9000,
9750,
15400,
6100,
22100,
31600,
41700,
47300,
null,
11400,
7500,
46700,
185100,
null,
12400,
145400,
17100,
35100,
25100,
35800,
null,
63200,
9400,
15844,
45700,
31700,
51500,
56700,
null,
68500,
32000,
15800,
28700,
8000,
151700,
5100,
37300,
9300,
46700,
7500,
26100,
23500,
null,
14300,
32000,
8700,
69000,
10200,
14600,
null,
6700,
null,
7000,
9500,
21000,
17100,
24800,
21700,
12600,
91800,
25800,
19700,
24300,
null,
7000,
27900,
32700,
92900,
39200,
21100,
12900,
24500,
7100,
45600,
9300,
null,
133100,
57400,
12400,
44600,
64400,
106900,
50900,
126850,
19100,
53500,
109600,
51000,
79300,
31300,
22100,
36090,
46700,
null,
24450,
22000,
2750,
27400,
30500,
13551,
5500,
69100,
25000,
15100,
43300,
36300,
21100,
35900,
26300,
8900,
18500,
19300,
null,
11500,
10500,
70200,
null,
19900,
13500,
null,
34374,
28100,
107500,
15600,
33800,
36300,
null,
21600,
15100,
23300,
11900,
27000,
18800,
27500,
22600,
3800,
null,
18200,
20500,
5800,
24000,
20800,
58000,
null,
7300,
15000,
72500,
100900,
9300,
54600,
22900,
73680,
31100,
22200,
56100,
17200,
30400,
24400,
27900,
18800,
34200,
19150,
97400,
46200,
34500,
27900,
6300,
10600,
38900,
39200,
39600,
28100,
10800,
49400,
66200,
8200,
45200,
28000,
12000,
30100,
28000,
47000,
24800,
35500,
14100,
70800,
9100,
9700,
11700,
6500,
13000,
15500,
69300,
45600,
10700,
12500,
22200,
34900,
13800,
18900,
52500,
26300,
29600,
null,
78500,
11100,
4000,
27500,
16500,
null,
35900,
14400,
null,
null,
111100,
34200,
25800,
14900,
7300,
127500,
74800,
96500,
7300,
24100,
23500,
29900,
63700,
25700,
9000,
6500,
24300,
25600,
8400,
null,
48400,
41800,
null,
null,
29674,
null,
46500,
89200,
12200,
3700,
34500,
10000,
20400,
4300,
100300,
null,
18000,
35500,
15800,
30500,
11100,
53300,
9700,
12300,
26800,
15300,
24300,
71800,
24400,
null,
17000,
367800,
40100,
47400,
96900,
16800,
19500,
19900,
43500,
43400,
23100,
22100,
12500,
25700,
6300,
13300,
19400,
34400,
8800,
12700,
16200,
36900,
31600,
11300,
132600,
null,
16500,
15800,
9100,
null,
10700,
10700,
41600,
13400,
67400,
15800,
25807,
17700,
18400,
93000,
12100,
null,
46700,
19800,
11200,
53900,
null,
7000,
36100,
79100,
8200,
26300,
21700,
22600,
20700,
null,
10700,
45200,
3900,
45800,
null,
11400,
null,
33900,
26200,
17900,
110800,
6800,
13850,
10400,
24700,
24100,
28300,
11300,
16800,
null,
16200,
31200,
86500,
5000,
13300,
40800,
46400,
49900,
61200,
13500,
17200,
35300,
300,
39800,
12000,
8900,
8900,
21500,
24200,
4600,
10100,
91800,
51200,
111800,
84900,
13400,
36500,
50600,
null,
45400,
12400,
null,
5800,
3000,
null,
12500,
26300,
15200,
2100,
17200,
11000,
33900,
104300,
22400,
25900,
null,
28200,
12500,
13000,
18300,
14500,
15300,
48400,
10720,
27100,
52000,
13800,
null,
18189,
14500,
12400,
34600,
10100,
8800,
13700,
10300,
16400,
null,
13700,
18000,
10300,
108900,
50300,
39300,
14700,
26500,
17300,
7900,
44200,
16900,
34800,
50300,
7000,
8696,
15200,
8200,
46400,
24700,
25500,
27000,
13700,
56100,
6400,
17400,
15200,
null,
45300,
14300,
21510,
7200,
10800,
28300,
37900,
13300,
56100,
26600,
40600,
189000,
47300,
34300,
37100,
21700,
33800,
17300,
73800,
47400,
61900,
33300,
29300,
null,
8800,
null,
16000,
7800,
13000,
42800,
48000,
39000,
17400,
13600,
20000,
36200,
21500,
34100,
60342,
23300,
19100,
43500,
52700,
15600,
35900,
57500,
26037,
15800,
26950,
10100,
23600,
14600,
20200,
18300,
152700,
11800,
24700,
10500,
16600,
18200,
35920,
185100,
25300,
14000,
null,
16600,
22400,
21800,
24100,
22500,
27500,
89300,
60200,
14500,
32700,
186200,
14200,
53100,
42900,
16200,
63800,
23200,
11650,
null,
49500,
23700,
23100,
null,
12500,
27600,
75000,
45100,
22400,
8500,
50100,
20700,
44200,
71000,
117800,
null,
null,
null,
13000,
28500,
19600,
12400,
28400,
22100,
64900,
null,
10400,
35700,
26400,
null,
8610,
27600,
18500,
58700,
null,
18500,
2700,
8100,
28400,
28500,
66600,
31700,
59000,
43300,
42300,
34800,
4300,
7500,
61000,
34550,
73900,
17100,
28100,
19700,
7500,
38700,
9900,
14700,
10600,
38700,
31900,
11900,
104400,
54300,
47300,
20100,
25100,
41200,
7700,
6600,
9000,
49500,
12500,
43800,
68300,
55900,
17300,
27300,
36100,
86700,
6300,
42100,
null,
65000,
41500,
null,
37700,
53600,
5500,
112900,
22400,
27600,
53500,
16800,
38968,
23100,
5400,
12200,
43400,
23600,
5500,
4100,
11900,
null,
22000,
36200,
45800,
8800,
59700,
40400,
19000,
28700,
9400,
19551,
56600,
204000,
11100,
46400,
41600,
19300,
105700,
29400,
140300,
4300,
22600,
17500,
3600,
13000,
74800,
30400,
16000,
27800,
null,
20300,
69800,
27300,
21700,
9000,
8500,
47500,
8000,
34100,
23400,
30700,
16900,
null,
46900,
null,
17750,
43000,
4200,
11500,
14500,
10900,
22200,
24800,
34700,
8700,
26700,
7600,
21100,
6400,
16200,
14100,
63400,
28600,
11800,
25400,
12700,
null,
23200,
51700,
17600,
39900,
18100,
8800,
17600,
20800,
21800,
32700,
28200,
22300,
12000,
30200,
20800,
54400,
null,
48600,
23200,
27500,
null,
12200,
16300,
89900,
79400,
110400,
null,
null,
102200,
23000,
30600,
46300,
11800,
9900,
27700,
145015,
43500,
14100,
37200,
13100,
null,
14800,
38143,
16600,
7500,
19500,
57200,
56300,
10300,
46351,
18900,
3000,
41100,
32000,
27800,
null,
87500,
41000,
94600,
55500,
53900,
20700,
41600,
45100,
25200,
59800,
23200,
11400,
105300,
93000,
22000,
13800,
36600,
31200,
68900,
18100,
29200,
12885,
32000,
15100,
null,
41100,
null,
51600,
22000,
11800,
16200,
28000,
24800,
27600,
43300,
12300,
23100,
13500,
18200,
15700,
28100,
32700,
13800,
23100,
11100,
39600,
12200,
null,
38300,
4350,
68600,
62800,
58900,
5300,
3900,
null,
36156,
24900,
77400,
null,
30170,
null,
33400,
3100,
20300,
22400,
18700,
12500,
16900,
17400,
27400,
49700,
52000,
13300,
28200,
null,
20400,
20400,
20200,
17300,
51700,
15900,
28000,
33700,
500,
82500,
30400,
31300,
23100,
57000,
2200,
23300,
20000,
49000,
31000,
28100,
47700,
3800,
8000,
18925,
59200,
121300,
79400,
82500,
20200,
39000,
6300,
14000,
11000,
55200,
29100,
20700,
33700,
36000,
48200,
3300,
6200,
53900,
22400,
19000,
21500,
14200,
10100,
25400,
44600,
16400,
15500,
52300,
3900,
22700,
16000,
8800,
16000,
31500,
42000,
6400,
null,
null,
47540,
26300,
78500,
25200,
45300,
7000,
26100,
29000,
29400,
20800,
10050,
70000,
92300,
70400,
59100,
null,
53300,
12500,
45900,
68500,
null,
null,
10800,
5600,
21400,
18900,
20300,
25800,
null,
46500,
14800,
9000,
41600,
22700,
5200,
null,
67200,
18900,
18100,
28327,
61800,
20700,
98300,
12000,
34700,
32100,
60900,
22100,
14800,
58300,
19500,
null,
10000,
22400,
31300,
4500,
43200,
7300,
8700,
41600,
20300,
12000,
7400,
16100,
63000,
25500,
14900,
null,
39000,
68200,
15400,
36400,
9300,
21300,
62400,
21300,
14100,
22100,
25500,
7800,
10600,
21400,
5600,
17600,
53500,
12600,
9000,
192400,
4800,
49900,
29900,
31500,
29000,
16900,
37800,
49200,
51700,
13900,
8600,
27300,
13500,
null,
16700,
11500,
57924,
81200,
14400,
33900,
39500,
12200,
12800,
6300,
44300,
43300,
307600,
71000,
13500,
18100,
null,
17300,
18600,
11900,
18600,
11900,
20500,
43210,
2300,
66300,
20800,
22100,
38700,
22000,
null,
15100,
64801,
23100,
4200,
29400,
28200,
46100,
30000,
12600,
77600,
22167,
4800,
5300,
45400,
10700,
17800,
68200,
26900,
48000,
30700,
28000,
null,
36700,
25500,
21700,
20400,
25300,
22100,
20300,
43400,
33300,
44000,
42100,
9450,
19600,
38600,
14700,
4000,
18800,
500,
59600,
45400,
null,
75500,
19600,
13600,
27550,
56500,
12200,
41700,
33600,
10800,
26600,
29600,
29200,
9800,
92800,
49400,
14600,
22200,
22800,
49400,
34700,
12400,
24500,
11200,
6600,
48400,
26700,
57400,
3200,
null,
null,
19300,
19300,
29800,
22000,
null,
15600,
16900,
63400,
30100,
13400,
31600,
13800,
5200,
59900,
25400,
29400,
8800,
null,
6600,
26600,
23400,
13800,
null,
9000,
12800,
44900,
10800,
29000,
25800,
null,
55700,
7900,
103700,
58000,
13200,
19600,
5900,
null,
104000,
25500,
15500,
38900,
30400,
null,
null,
24100,
null,
28200,
205400,
24500,
41700,
null,
33200,
70900,
39200,
11300,
10290,
3600,
93700,
11700,
34900,
26100,
21600,
14000,
14500,
8100,
null,
7700,
9100,
28400,
62900,
null,
38000,
14100,
74500,
23900,
null,
11700,
null,
19700,
6300,
19100,
15900,
23600,
32900,
null,
12500,
27000,
13500,
22400,
37300,
62000,
20600,
37700,
69800,
null,
50100,
44500,
65100,
55500,
28700,
null,
47900,
95700,
53641,
46200,
null,
34971,
29100,
10800,
17500,
17500,
14500,
31100,
27400,
null,
12000,
28100,
23000,
8600,
11600,
22400,
17300,
34200,
30700,
31600,
5000,
46800,
21500,
16400,
45100,
8400,
25500,
7700,
13050,
31600,
3200,
47300,
34000,
6600,
null,
12600,
19600,
13200,
34800,
16650,
5100,
28000,
64600,
4700,
7800,
20400,
null,
19700,
21700,
26100,
5800,
null,
20500,
55000,
null,
10200,
27900,
68000,
11400,
11000,
12200,
6200,
25900,
2500,
6700,
15300,
28000,
8700,
8700,
47700,
5700,
null,
40200,
13400,
null,
16400,
3500,
11700,
30000,
null,
16100,
14100,
9800,
56200,
14800,
25300,
41500,
26600,
29400,
16800,
91700,
68900,
8600,
2100,
14800,
42600,
null,
7000,
10150,
34500,
18400,
48700,
58400,
35900,
25800,
15300,
18200,
5800,
6800,
11200,
14600,
20700,
32900,
63200,
4550,
44100,
null,
null,
42100,
36400,
15800,
15500,
21800,
64900,
68093,
48100,
16200,
35500,
66700,
13200,
29200,
7000,
19100,
16100,
5400,
43500,
45200,
15800,
36500,
21800,
62000,
null,
13200,
126300,
46800,
11600,
25900,
18800,
13100,
23600,
24400,
28900,
194600,
14700,
13100,
45800,
48000,
71400,
17700,
1200,
102700,
10400,
24600,
null,
44600,
13100,
null,
68100,
8300,
4300,
8700,
65300,
28400,
16100,
37000,
10000,
22000,
8100,
17000,
24600,
43900,
11300,
12500,
13400,
18500,
42700,
19000,
44400,
37500,
131500,
49700,
31000,
15500,
43500,
8233,
16000,
44900,
36700,
46800,
50700,
17300,
65600,
45700,
null,
42900,
7800,
18100,
26300,
4600,
54500,
21000,
29300,
8400,
46900,
null,
33200,
null,
107100,
null,
24300,
22700,
70500,
77900,
49300,
18100,
25800,
33900,
19000,
22200,
10700,
14500,
15500,
27400,
37200,
8800,
13600,
null,
null,
28400,
24400,
5100,
13500,
14600,
10800,
26400,
42400,
9200,
19300,
4200,
23500,
600,
null,
null,
21400,
11900,
28000,
55100,
38500,
59539,
37200,
21900,
36600,
24000,
21600,
21000,
48200,
49800,
98900,
38400,
21600,
42300,
13100,
9600,
28400,
41300,
33900,
6100,
11200,
17450,
9600,
20400,
44100,
8900,
12100,
36900,
36600,
63900,
0,
25300,
66900,
47000,
35500,
28400,
195500,
24600,
27200,
46900,
28200,
26600,
36800,
40248,
74200,
37700,
213000,
3500,
null,
46700,
23300,
10400,
29500,
77900,
38600,
85800,
null,
null,
73500,
null,
null,
19700,
77500,
18900,
19900,
24400,
23700,
12400,
92000,
22600,
74800,
70300,
37100,
18800,
89300,
60600,
37800,
28900,
24600,
46100,
34700,
6200,
null,
21000,
65300,
11600,
null,
36800,
10300,
14300,
23000,
44100,
47600,
27200,
46900,
56300,
62400,
65100,
7900,
10200,
37900,
22400,
5400,
83900,
24000,
21500,
10100,
14300,
47600,
49100,
21500,
8600,
19800,
14200,
8900,
32300,
24800,
8700,
73800,
112700,
11700,
17800,
13100,
10900,
8200,
8500,
null,
23400,
39100,
10800,
7900,
22000,
17800,
5700,
15600,
15700,
26600,
31500,
73400,
2800,
null,
16500,
11700,
139600,
25500,
7600,
67300,
17400,
11000,
37900,
56500,
5300,
25100,
15500,
28700,
40841,
49400,
23300,
34900,
42600,
13800,
23800,
34700,
7900,
33600,
7300,
10300,
null,
45300,
8200,
10475,
15500,
26200,
71000,
32900,
23300,
23100,
14600,
83300,
37300,
null,
132560,
7900,
56700,
53900,
17100,
34300,
85100,
26100,
86200,
21100,
38700,
130300,
63000,
3500,
20800,
null,
35403,
76000,
18400,
22400,
30500,
175500,
29300,
29300,
141700,
30700,
8800,
20600,
56800,
129565,
9800,
68700,
63000,
15300,
34274,
11900,
47300,
6500,
49300,
28000,
37200,
null,
40300,
25700,
5800,
13300,
17000,
34800,
25300,
86900,
3900,
12700,
null,
21500,
23000,
8600,
50600,
50000,
33400,
25100,
56300,
50100,
22400,
8500,
10700,
28404,
33200,
8700,
15500,
null,
44900,
26300,
null,
53900,
17600,
14200,
36600,
16900,
72700,
89200,
69300,
56100,
24500,
8400,
21600,
null,
10800,
null,
55400,
19200,
14400,
16000,
18800,
25600,
14000,
37400,
42200,
28100,
44200,
30600,
11100,
74100,
22600,
5700,
102400,
9000,
25300,
null,
17500,
16700,
23100,
21600,
45000,
59300,
73300,
15100,
32800,
101200,
36700,
32000,
12500,
12500,
128700,
48300,
8600,
46200,
48400,
45176,
38500,
9800,
71800,
51900,
21800,
5700,
14600,
33300,
7000,
16600,
20800,
69400,
24300,
37600,
14050,
22900,
63200,
11600,
15100,
6000,
73650,
15000,
12000,
8500,
8000,
26400,
34300,
8500,
39300,
24700,
29600,
24200,
10300,
102200,
14200,
null,
26600,
12400,
51100,
null,
36800,
12300,
7000,
23300,
17500,
null,
21000,
11500,
11100,
32200,
null,
14000,
66500,
13500,
35400,
25900,
100000,
6200,
50600,
31100,
10300,
16600,
9300,
94000,
null,
22700,
29000,
17600,
106800,
129800,
50700,
44100,
67300,
24900,
12200,
4800,
16100,
64900,
15800,
27800,
24800,
28300,
18500,
28500,
12600,
36800,
14400,
8200,
19900,
20700,
15600,
12700,
12900,
14700,
42600,
7700,
2500,
21300,
14300,
15900,
null,
null,
38200,
17400,
5500,
28248,
77800,
15500,
58100,
4900,
19400,
null,
13800,
23000,
6300,
25100,
34200,
17300,
null,
23600,
47100,
30400,
28100,
10200,
19000,
null,
6500,
14500,
68800,
12900,
35500,
68700,
101240,
16700,
null,
26500,
25224,
30500,
10000,
162017,
42500,
25400,
48600,
38600,
34400,
100700,
35000,
12500,
23500,
14500,
23300,
15100,
14800,
29400,
84970,
7500,
54100,
97267,
21300,
10200,
12700,
38200,
7549,
25300,
32900,
64900,
6600,
42200,
37900,
45500,
32800,
16120,
20500,
15200,
61500,
22500,
21200,
null,
32200,
35200,
44600,
14900,
14100,
21300,
12300,
32000,
27700,
58700,
10900,
23400,
31800,
13300,
29600,
16000,
28700,
null,
6100,
14400,
14200,
19400,
78442,
null,
29600,
27000,
43600,
75000,
59300,
85100,
26900,
27000,
13600,
6800,
26600,
26300,
24800,
8500,
54200,
16600,
16400,
19700,
20700,
68548,
18300,
9500,
null,
null,
43400,
12200,
26500,
13000,
223800,
22500,
9950,
76600,
9600,
9600,
8500,
34300,
64000,
14700,
24200,
89600,
22100,
null,
22100,
15700,
62200,
34600,
7000,
134000,
48500,
40500,
31400,
61600,
null,
45100,
null,
30600,
null,
3300,
12200,
14100,
13500,
10700,
11300,
6700,
45500,
8400,
15000,
39300,
23300,
null,
55100,
null,
54500,
27500,
21500,
23600,
19500,
null,
57200,
88200,
null,
54100,
52300,
16900,
null,
60500,
41300,
37700,
16700,
18200,
29700,
19800,
13500,
5500,
null,
12400,
24300,
13900,
67600,
15400,
6800,
26680,
30200,
6600,
16300,
28250,
40100,
31800,
38700,
10030,
14000,
null,
13800,
72000,
null,
16700,
11500,
8500,
138900,
10000,
18500,
3900,
24600,
60700,
20800,
24100,
58800,
3900,
24400,
2200,
33796,
31400,
16800,
23000,
46900,
5800,
23900,
4000,
85900,
23300,
23000,
70797,
5300,
67900,
23700,
109900,
12000,
100800,
5600,
16200,
47800,
9200,
9700,
83700,
10500,
14800,
15900,
29300,
70100,
81100,
127800,
5300,
109200,
10300,
59100,
6000,
35300,
19000,
35300,
14500,
23600,
33000,
15700,
14700,
null,
43100,
82600,
24709,
7500,
5700,
42600,
null,
6900,
14900,
31900,
17500,
16200,
16700,
8400,
18400,
15200,
29200,
10200,
5800,
78800,
10250,
22600,
11800,
6600,
22500,
null,
8000,
56100,
56100,
40800,
29300,
26600,
1900,
31300,
26500,
6900,
59000,
18200,
14800,
27900,
44600,
32200,
null,
13600,
72200,
16600,
61300,
7600,
28000,
19900,
12100,
10500,
28600,
35400,
26200,
8400,
23300,
25000,
61300,
4400,
23500,
15800,
21800,
100509,
44700,
41100,
22200,
null,
null,
50700,
31481,
22100,
19700,
33000,
31500,
38100,
17300,
24300,
39390,
9800,
null,
28800,
null,
null,
41400,
10600,
37700,
57400,
8900,
18000,
56400,
8200,
42900,
33800,
29100,
3800,
182000,
9900,
56500,
26000,
26500,
52800,
9500,
12100,
37600,
33700,
87200,
15000,
21400,
7300,
95300,
56500,
24000,
4200,
32700,
7500,
7400,
52700,
20700,
19300,
4000,
54580,
22300,
34800,
27300,
null,
33700,
17300,
166100,
24000,
34600,
7700,
8200,
41200,
21700,
34600,
10800,
25523,
144800,
33600,
null,
7300,
15900,
10600,
21200,
82100,
null,
30500,
3400,
27000,
30500,
13600,
11100,
76500,
23900,
null,
60600,
15400,
16000,
31000,
18500,
null,
27000,
null,
5600,
29600,
35500,
17000,
39300,
39900,
27200,
13800,
14400,
54400,
null,
null,
19900,
10500,
14500,
22000,
33000,
null,
33900,
null,
14000,
56400,
27200,
14800,
29000,
93400,
14300,
null,
25900,
null,
28100,
20900,
28500,
17900,
22900,
17200,
6000,
38900,
18700,
45200,
14800,
17900,
42700,
53800,
47045,
15400,
4100,
2800,
34600,
80000,
14400,
41100,
35700,
23500,
46500,
20000,
39400,
null,
21700,
44000,
11800,
49100,
9600,
86700,
null,
28400,
25300,
25300,
null,
3900,
51400,
28400,
71000,
11000,
9500,
9300,
24600,
15900,
32400,
32100,
null,
14300,
27000,
46100,
13500,
54900,
16300,
33300,
40700,
10400,
6200,
57200,
25200,
13300,
100900,
57500,
11000,
27700,
13700,
26800,
13100,
null,
null,
22800,
20300,
46600,
20400,
15600,
10800,
11200,
18200,
17100,
25400,
26200,
63200,
7000,
48200,
33400,
6000,
null,
64400,
31700,
45100,
13500,
40100,
160100,
null,
3500,
33700,
null,
73000,
19200,
58900,
37700,
12700,
66700,
15900,
28800,
29400,
44500,
null,
18000,
31000,
5200,
87100,
19400,
46600,
11900,
24300,
25600,
70000,
null,
142500,
19000,
59400,
46700,
60300,
32400,
51800,
14000,
42100,
15900,
10000,
26300,
43200,
12600,
null,
10700,
null,
18800,
32900,
23300,
79000,
50200,
5200,
15900,
54600,
27200,
31700,
55400,
54900,
null,
19400,
62500,
127500,
60600,
14600,
13200,
7300,
41800,
21300,
19150,
1400,
12900,
22900,
33300,
39000,
40600,
7700,
27200,
11500,
42300,
43500,
24200,
19900,
5900,
137000,
10500,
13600,
1000,
27900,
42500,
29800,
8500,
33700,
50200,
17900,
null,
11500,
10600,
9800,
null,
14300,
15600,
18500,
26900,
null,
19700,
19200,
5000,
9700,
9400,
null,
11200,
10000,
5500,
43700,
13800,
null,
12500,
24100,
7300,
18300,
null,
null,
24900,
12000,
37000,
null,
10000,
null,
35600,
28700,
12800,
23900,
9500,
25600,
20400,
33800,
6500,
29400,
76500,
46100,
27000,
9600,
39100,
55500,
22600,
31500,
25500,
22300,
33900,
51700,
5500,
27700,
14000,
70100,
34500,
25300,
31700,
61500,
9100,
20500,
79500,
21100,
19900,
19500,
22000,
27200,
38200,
39000,
14700,
21700,
null,
14800,
26900,
11900,
26800,
43000,
7600,
14100,
16500,
17000,
25800,
23500,
13600,
null,
29000,
16000,
15100,
57100,
28900,
47545,
49300,
null,
20700,
218000,
5000,
15400,
32100,
47500,
14300,
8200,
31000,
7500,
137550,
10500,
52800,
25400,
34500,
32200,
144300,
33100,
35500,
63700,
37100,
3000,
20700,
15000,
14100,
17500,
null,
36300,
22200,
57900,
13300,
28500,
23300,
37900,
15500,
null,
29600,
10375,
40600,
10400,
25900,
null,
30900,
7700,
135200,
29600,
39000,
44800,
21300,
null,
17000,
38600,
23300,
null,
36200,
35800,
null,
12300,
24000,
24000,
22500,
15900,
104200,
5600,
null,
34000,
22400,
16000,
40500,
25900,
25700,
20800,
35400,
18100,
31867,
34800,
null,
14100,
15800,
12000,
154507,
29400,
72500,
18530,
6300,
33900,
35300,
45900,
8800,
26100,
11100,
23700,
36400,
44800,
64600,
10800,
10300,
49700,
22400,
27600,
22000,
19800,
37600,
8900,
19400,
65800,
null,
34200,
9000,
31676,
24600,
12300,
60900,
10800,
41900,
25700,
15100,
23800,
null,
35200,
28700,
9800,
45400,
26200,
42200,
14300,
52200,
8100,
12000,
9900,
47400,
24000,
14500,
null,
null,
21100,
14600,
28700,
34500,
15800,
20700,
null,
17500,
27200,
36600,
19300,
null,
19700,
13800,
31300,
48900,
48300,
9700,
37500,
8000,
46200,
14700,
null,
null,
17300,
22800,
77400,
42400,
48300,
null,
12300,
19200,
15700,
95100,
12100,
16970,
11400,
48500,
4700,
null,
30400,
14500,
29900,
12700,
5200,
39700,
23800,
12575,
31900,
19200,
60100,
41300,
10200,
20400,
28000,
null,
512600,
32600,
51400,
27600,
44200,
7750,
13700,
14100,
null,
12300,
11200,
13800,
8500,
null,
44745,
null,
42000,
14600,
23800,
45700,
9500,
85100,
17300,
29100,
48900,
52500,
3800,
26500,
24200,
20100,
48200,
19500,
null,
46900,
26000,
34700,
69100,
43200,
41500,
21800,
17400,
11900,
70300,
38000,
27456,
72000,
85300,
52100,
28800,
12000,
7500,
10900,
8400,
62300,
27600,
24700,
15200,
13600,
9500,
230142,
3500,
28200,
28200,
37600,
26700,
44600,
21100,
30500,
37300,
31900,
27700,
23700,
16800,
12500,
38600,
31600,
39900,
12200,
12300,
25995,
30900,
59200,
33500,
17900,
8400,
18200,
15500,
45299,
42800,
null,
22534,
57300,
69100,
10600,
49700,
6600,
17159,
7200,
37500,
41800,
17800,
1000,
18000,
29200,
25900,
76200,
23900,
9500,
14500,
88300,
11000,
39500,
22900,
65938,
49400,
14800,
21700,
16700,
6550,
15300,
null,
null,
13000,
24100,
41400,
9400,
33900,
43000,
52900,
14300,
8900,
12400,
null,
13700,
71800,
null,
35900,
81000,
39300,
41300,
17400,
null,
31500,
76200,
20000,
34000,
45000,
12200,
58700,
null,
26100,
83400,
28600,
37800,
20700,
62800,
61800,
32500,
55700,
18000,
30200,
8100,
37400,
27624,
12900,
13100,
33300,
48300,
20800,
17400,
24000,
9200,
35200,
54800,
27200,
1800,
65000,
10500,
14100,
28400,
82700,
8700,
51900,
33000,
16567,
397300,
12400,
null,
9200,
48400,
null,
37400,
107400,
8800,
46900,
46900,
62000,
14300,
11400,
34500,
13400,
45300,
12400,
27350,
29300,
26400,
null,
92400,
21600,
8300,
19900,
8300,
42800,
31620,
23400,
167000,
19800,
25000,
null,
66100,
84100,
38100,
45400,
null,
39700,
30600,
22700,
7800,
10300,
10600,
27820,
13800,
9700,
56100,
30500,
12600,
39700,
29300,
53200,
10200,
10900,
20000,
7000,
18800,
39900,
22900,
17300,
61200,
71500,
null,
89500,
34800,
null,
23200,
23700,
17400,
7800,
4000,
null,
16300,
47500,
10000,
47900,
9400,
21800,
null,
null,
32300,
40500,
15900,
10000,
9400,
141400,
68700,
42500,
15000,
29200,
null,
9100,
17800,
39000,
3800,
null,
47500,
82000,
14700,
19700,
20000,
28100,
37000,
null,
13300,
24800,
15700,
null,
7800,
48600,
14700,
33200,
10050,
20300,
60100,
50100,
29400,
18900,
15200,
40200,
15400,
34100,
13500,
26000,
59500,
null,
21000,
14800,
54400,
19000,
17400,
42400,
26100,
54700,
28300,
46200,
4400,
50500,
17600,
19500,
12100,
34100,
23700,
21900,
23900,
25600,
38900,
23500,
16200,
12100,
71700,
36400,
14000,
50100,
52800,
36400,
4000,
28000,
34300,
26100,
22100,
15900,
108600,
17900,
null,
38300,
null,
26900,
22900,
66700,
71900,
17300,
19300,
null,
31700,
6100,
18300,
2400,
22000,
124800,
11700,
27700,
null,
null,
37600,
10900,
11600,
45200,
36400,
4500,
15500,
12100,
32500,
null,
null,
33500,
20400,
34800,
10300,
14800,
39400,
20800,
44500,
33200,
8900,
19900,
null,
32800,
19100,
27800,
43400,
68700,
22000,
36700,
68100,
32400,
18100,
11800,
24000,
119000,
34600,
3200,
39300,
7800,
105500,
6600,
23300,
44500,
14800,
22200,
36700,
31600,
19000,
null,
15400,
12000,
5000,
19300,
29500,
40300,
11200,
18900,
28700,
28900,
33200,
3100,
30800,
7700,
16100,
49900,
62000,
19800,
9000,
20100,
87800,
18700,
26800,
20400,
23700,
44700,
7800,
47600,
13600,
6800,
51800,
12400,
9600,
19400,
62200,
21800,
18700,
40893,
33400,
44600,
34700,
16000,
12600,
40200,
24900,
42700,
15100,
18300,
6400,
15000,
83214,
20000,
57300,
14800,
27700,
47400,
null,
6700,
8600,
69300,
27500,
73300,
17800,
23800,
24900,
32200,
27600,
8100,
84000,
11600,
null,
42800,
16200,
19500,
35700,
7100,
15600,
28900,
22900,
null,
13500,
69600,
14400,
23500,
null,
15000,
null,
14000,
16300,
11200,
25900,
62000,
28800,
11900,
29700,
null,
null,
null,
24300,
9700,
14300,
54500,
38300,
151100,
null,
63400,
11200,
18900,
38200,
29400,
23331,
25600,
46200,
24780,
12200,
10000,
null,
48200,
33000,
29300,
9100,
9200,
500,
8200,
8300,
302700,
null,
48000,
9100,
33800,
82600,
13600,
36800,
28200,
74500,
60800,
2200,
23500,
12900,
23600,
1400,
null,
9100,
22900,
18900,
24100,
30400,
8900,
21500,
18000,
30300,
36500,
47900,
29700,
49200,
4600,
90000,
35600,
37700,
29300,
26800,
11800,
43000,
52700,
30900,
101500,
15500,
6200,
24200,
56100,
71400,
23500,
4800,
28600,
21000,
5600,
45000,
44700,
47400,
45400,
18400,
null,
29500,
33700,
49600,
32200,
21000,
null,
25600,
12000,
58600,
21900,
15500,
13700,
14100,
11000,
14900,
85100,
42700,
60900,
12900,
34800,
12800,
18500,
53100,
79200,
3000,
9500,
28200,
31300,
24800,
101900,
32400,
42000,
12700,
23200,
24200,
30300,
34300,
36600,
8200,
31600,
16500,
44600,
6300,
63800,
20200,
23400,
15900,
31500,
16400,
57307,
29800,
14400,
28400,
50400,
35100,
48300,
48500,
47600,
23900,
27200,
4400,
12700,
15000,
9000,
5200,
19900,
11400,
19600,
0,
80500,
38000,
20400,
36600,
45300,
32600,
13800,
71300,
17500,
18800,
33300,
32800,
24800,
5400,
45100,
33700,
28700,
null,
55000,
19900,
null,
31400,
16600,
19100,
18500,
12100,
30200,
102300,
44000,
37300,
19000,
38400,
19100,
34200,
175600,
16850,
null,
14500,
2800,
44000,
54500,
56700,
12700,
11700,
4000,
19400,
6800,
28300,
12400,
41300,
18800,
83100,
null,
12800,
16500,
13100,
null,
54800,
62000,
23300,
61700,
60000,
41400,
12100,
21500,
6400,
27500,
27600,
18000,
34100,
32900,
15000,
21100,
21300,
10900,
10500,
28700,
70000,
25700,
12600,
31400,
null,
5900,
25700,
75700,
20000,
5200,
56500,
49500,
21060,
30800,
48100,
29800,
9000,
45470,
231600,
95900,
19800,
null,
45100,
52100,
null,
26400,
52700,
23900,
48900,
17500,
null,
11000,
6000,
14000,
24500,
null,
16700,
78600,
13300,
203300,
16600,
28000,
139900,
null,
29600,
2000,
null,
10200,
18800,
15700,
7500,
4000,
27700,
22600,
13500,
32100,
48500,
32400,
183500,
33300,
15700,
56600,
null,
17200,
13600,
19300,
45600,
22200,
21300,
32400,
17800,
26300,
13000,
24200,
10700,
6900,
28300,
null,
33900,
21800,
4500,
20200,
35200,
25300,
15500,
34300,
12200,
11200,
28800,
18600,
null,
37650,
99400,
73100,
23400,
31100,
51400,
55900,
31900,
42681,
4300,
13200,
32200,
15800,
17600,
8520,
null,
27700,
30100,
108000,
45000,
7800,
77900,
5900,
15300,
4000,
57000,
12100,
41100,
59600,
21800,
23500,
19400,
18700,
68050,
27100,
5700,
76800,
9050,
36900,
62400,
10400,
13300,
51830,
25800,
28300,
10700,
3200,
9000,
null,
7500,
7600,
12600,
78800,
13000,
23200,
27400,
9700,
11700,
5300,
14000,
88900,
56300,
15800,
32000,
null,
39400,
1200,
9200,
14200,
61600,
6550,
21400,
117900,
15000,
12100,
21900,
43300,
13600,
36800,
75100,
46700,
41600,
11600,
211000,
19400,
23000,
7600,
16900,
18200,
39900,
3400,
15100,
21400,
38400,
20500,
11400,
17000,
65800,
66500,
7800,
null,
88700,
52600,
16400,
80300,
10300,
10700,
30500,
57800,
null,
26500,
4800,
16400,
19600,
24800,
25300,
5800,
33700,
26300,
17500,
26200,
43000,
24100,
25100,
16600,
26800,
58200,
21600,
11500,
32600,
36000,
36900,
10100,
7300,
24300,
11900,
31100,
74900,
329000,
9300,
26450,
32400,
54900,
49700,
13800,
18900,
43000,
30200,
21200,
10800,
27600,
16000,
null,
49600,
60900,
6400,
23300,
5300,
108230,
21900,
12400,
5200,
null,
14700,
26000,
24500,
36300,
251000,
21500,
8900,
14600,
16200,
17700,
2800,
21500,
12600,
41100,
22100,
18900,
9900,
18800,
29300,
22900,
126300,
28800,
24900,
8600,
16300,
81900,
null,
23800,
27100,
37500,
6500,
47900,
43600,
42100,
24400,
129020,
62700,
19300,
14300,
13000,
20400,
84600,
74600,
0,
null,
21700,
59400,
18500,
18598,
null,
16100,
null,
15500,
22300,
65500,
42500,
7500,
8900,
299100,
13000,
13400,
3600,
73400,
7000,
7800,
17600,
4700,
32500,
23900,
41700,
null,
28500,
13000,
48200,
17000,
59500,
27100,
12500,
35800,
52500,
19800,
45127,
26400,
null,
null,
22200,
23500,
31650,
35300,
10100,
9050,
17300,
20300,
12900,
21000,
null,
15000,
25000,
40400,
35500,
3500,
25200,
null,
null,
6200,
64700,
172198,
9900,
22400,
53300,
28400,
10800,
88900,
5000,
25500,
8000,
19300,
55800,
12500,
14800,
12500,
19600,
28300,
9100,
3600,
26200,
14600,
27200,
6700,
5000,
12700,
9000,
null,
79400,
15300,
null,
10600,
30700,
77800,
25400,
14600,
10250,
8700,
9200,
42200,
44700,
12700,
32000,
9300,
7600,
null,
20700,
19900,
69200,
null,
7500,
40700,
4600,
134900,
35800,
null,
33500,
46300,
11600,
20100,
27100,
7800,
21300,
16500,
18225,
21300,
27400,
32300,
25000,
21200,
32800,
31200,
17400,
13074,
32400,
46200,
17300,
49000,
14700,
null,
15200,
35200,
32400,
47600,
14000,
84800,
26700,
33600,
57700,
21300,
28000,
26600,
15400,
10000,
11700,
11100,
14200,
28600,
11500,
null,
19700,
69000,
23000,
8900,
30700,
15200,
null,
14000,
null,
54400,
22000,
19000,
71716,
18800,
42900,
23800,
28300,
24100,
null,
2900,
45300,
17200,
20250,
null,
2400,
14500,
24800,
17100,
24200,
13600,
null,
80400,
48100,
8600,
20600,
18700,
34200,
null,
20400,
7100,
85500,
20057,
28300,
7100,
15000,
11500,
14400,
72000,
33900,
32600,
18500,
34700,
6300,
19200,
69400,
13900,
22600,
10200,
null,
20600,
29000,
21500,
38600,
123100,
62400,
null,
123100,
12700,
10600,
29400,
153800,
7800,
29300,
9300,
12700,
34800,
65300,
2500,
29000,
49500,
100800,
11900,
34300,
32100,
45500,
null,
14400,
1700,
17300,
38500,
74800,
10900,
15400,
121300,
45000,
12200,
2700,
1800,
41900,
18470,
72900,
19900,
26500,
43700,
25300,
29800,
26500,
23300,
47200,
null,
null,
45400,
92800,
10600,
17800,
15200,
17900,
34100,
null,
5800,
1100,
41300,
11400,
null,
25600,
null,
46600,
30600,
7100,
18000,
39500,
32300,
30600,
31400,
11300,
5100,
null,
48900,
16800,
118600,
36462,
47800,
19100,
88700,
8600,
9200,
31100,
36900,
19200,
59900,
39200,
6800,
13600,
7600,
22500,
18100,
38200,
40500,
null,
19600,
null,
121300,
6600,
49300,
17500,
46100,
12400,
29500,
23900,
null,
16900,
51500,
18000,
12200,
12300,
49800,
16300,
15900,
111400,
101100,
10500,
16000,
51300,
null,
38600,
17700,
20300,
4500,
9800,
56900,
30600,
36400,
9300,
39675,
17000,
5300,
25200,
4100,
69700,
49600,
44500,
20500,
57000,
21900,
29600,
25770,
53800,
2400,
116400,
13000,
52800,
8450,
14800,
42900,
20700,
null,
17000,
8200,
32164,
30300,
19100,
5100,
37000,
15300,
25300,
23500,
12500,
51700,
33500,
5800,
33200,
0,
14200,
16500,
89100,
9000,
15500,
48300,
13000,
32200,
10300,
26200,
33100,
45300,
24700,
26000,
12100,
35000,
54300,
25200,
28000,
41700,
4400,
2000,
13700,
10900,
16000,
24000,
16400,
146100,
71800,
37300,
null,
8191,
18100,
null,
43338,
65900,
500,
52600,
34200,
null,
53300,
25800,
9000,
47500,
5900,
66280,
33700,
6200,
25600,
70900,
85500,
40500,
null,
27300,
null,
5200,
28000,
null,
null,
116100,
43400,
11000,
9750,
28900,
36900,
14200,
20885,
null,
13900,
16400,
null,
27600,
27500,
10700,
5800,
7200,
2960,
null,
31400,
19600,
44000,
null,
null,
27100,
16900,
42000,
12200,
58900,
15600,
28400,
20600,
11900,
14700,
40800,
40100,
27200,
68700,
26200,
20700,
37300,
73000,
4500,
38300,
16500,
52700,
27200,
16100,
null,
16000,
13600,
48300,
14600,
36200,
null,
49400,
30500,
18000,
8300,
12800,
29600,
32800,
5700,
41900,
45000,
28100,
53500,
27000,
13900,
5600,
15700,
25400,
5900,
9900,
22525,
21200,
35600,
26300,
17600,
7800,
10300,
9900,
29000,
106700,
27000,
17800,
92200,
0,
26200,
12700,
15300,
21000,
15000,
16300,
33100,
26600,
17100,
23200,
8900,
28600,
3800,
64900,
8700,
16600,
null,
5000,
35400,
22300,
26800,
37200,
null,
35000,
6800,
59500,
56400,
8800,
13000,
32300,
9700,
22700,
69900,
95800,
55700,
22400,
50800,
26800,
17100,
5800,
84500,
26300,
38000,
21500,
null,
15400,
54400,
85100,
34200,
6400,
8700,
24000,
37100,
13600,
48200,
39900,
null,
21880,
24900,
20100,
46621,
41600,
17200,
31500,
36300,
135400,
25400,
37700,
19800,
17800,
29600,
43500,
null,
3000,
15781,
83600,
20500,
24500,
38900,
17600,
11400,
18900,
null,
38789,
4300,
25900,
13200,
5300,
18100,
31000,
null,
26110,
19800,
115400,
3000,
23900,
19700,
10600,
8600,
7150,
81800,
31800,
null,
11000,
69500,
33800,
23200,
3900,
51900,
35500,
83600,
null,
45300,
9100,
43600,
21500,
6200,
12500,
37800,
6800,
23700,
40500,
19100,
11500,
33200,
13800,
11900,
39300,
52800,
10000,
20200,
22000,
8200,
12200,
27000,
58800,
34600,
41639,
12000,
8100,
38200,
18400,
34000,
18200,
3700,
5800,
20600,
92000,
31200,
12100,
8600,
18600,
41600,
32100,
33600,
36200,
16600,
22800,
20400,
17000,
22600,
3600,
36500,
16300,
38300,
16900,
83400,
79800,
17000,
51400,
45100,
17390,
45100,
6500,
13300,
9200,
105500,
34000,
29600,
74600,
20000,
30000,
47000,
39200,
54100,
8400,
9100,
127300,
27800,
28800,
54500,
32300,
18600,
9900,
80800,
29000,
null,
10100,
14600,
21000,
16000,
7400,
41900,
6000,
12100,
38100,
19000,
31600,
null,
3800,
14900,
3400,
26100,
16000,
11900,
12700,
18400,
41500,
28500,
20800,
15200,
20000,
32600,
null,
20800,
14000,
22500,
23900,
19100,
50600,
15500,
28000,
11500,
97900,
5800,
14100,
59500,
27800,
null,
55300,
null,
32400,
23000,
15700,
15600,
53800,
11900,
30500,
18600,
60300,
11100,
19700,
11800,
8400,
16800,
64000,
72500,
31500,
8800,
6500,
5200,
37039,
null,
null,
null,
15600,
null,
13100,
57300,
31500,
15400,
15200,
17900,
29100,
7600,
152500,
64103,
45700,
42900,
12900,
19700,
32700,
22200,
73500,
24600,
16300,
7400,
52500,
17800,
39500,
null,
163600,
42600,
16800,
93441,
32400,
24500,
8500,
17900,
64500,
22100,
18700,
12500,
35000,
36700,
23400,
82600,
89300,
87100,
17400,
61600,
28700,
106600,
41700,
25500,
35100,
19700,
8000,
106400,
30600,
20400,
5000,
13400,
4700,
7200,
23100,
83900,
23700,
33300,
28300,
22800,
16000,
30600,
17300,
7600,
22600,
58300,
8200,
91900,
14800,
17000,
50900,
17100,
13300,
43400,
49000,
31500,
28600,
27500,
42417,
19000,
10800,
24700,
21400,
15500,
27400,
194700,
28100,
1800,
14900,
null,
9900,
66500,
6000,
18700,
null,
27800,
22300,
13900,
17900,
8500,
14700,
8000,
null,
6000,
21700,
72800,
210500,
10300,
45500,
38100,
47600,
11000,
4700,
57200,
28200,
25100,
23400,
22700,
10200,
29946,
null,
99700,
43300,
120000,
20000,
16100,
34080,
106500,
54000,
11200,
55500,
null,
54400,
18300,
61366,
17000,
36200,
40200,
22700,
13900,
12300,
18200,
10200,
13500,
72100,
15900,
30000,
17900,
24400,
null,
51400,
16800,
43500,
null,
19900,
23300,
34500,
30900,
27800,
115100,
44300,
null,
24600,
45900,
11300,
null,
42400,
29300,
9300,
10100,
52400,
7300,
34500,
34500,
47800,
12200,
null,
15200,
28000,
49300,
21600,
53600,
37000,
28300,
24400,
null,
11400,
110600,
9400,
5000,
27300,
57800,
7200,
10800,
43800,
11700,
null,
11500,
25000,
30900,
28500,
16800,
49400,
28500,
35800,
26900,
17900,
26600,
43600,
null,
53600,
49100,
13800,
36000,
13700,
null,
7900,
45600,
14800,
21600,
41400,
31600,
17300,
11200,
14200,
2100,
null,
32400,
126100,
23300,
12100,
27100,
16900,
37000,
30400,
27000,
53612,
53900,
15200,
70500,
24300,
20900,
47200,
9000,
22000,
21800,
8300,
66500,
14000,
29000,
null,
45100,
9800,
17600,
30400,
10400,
null,
22800,
19700,
17700,
43400,
33100,
37911,
7800,
23900,
23600,
39500,
60800,
null,
6000,
17400,
19700,
null,
20100,
49600,
19900,
18500,
37400,
18000,
16400,
37800,
20700,
32200,
25000,
15400,
null,
23500,
27900,
27700,
66200,
61000,
51400,
54300,
4900,
31000,
33400,
null,
12400,
15100,
48300,
7700,
21548,
48900,
8100,
6500,
null,
25000,
null,
15300,
12400,
38300,
15600,
5000,
18900,
null,
22100,
58400,
11900,
null,
37400,
11500,
75500,
17600,
19400,
40700,
18400,
49700,
23200,
37500,
107100,
13700,
60600,
6800,
62000,
6400,
7300,
74400,
21000,
29100,
78100,
12700,
null,
40900,
8100,
5400,
121700,
15000,
30100,
8600,
34900,
15200,
20100,
null,
26900,
null,
163600,
null,
45900,
31900,
16300,
6100,
null,
null,
15300,
44600,
2100,
22800,
8000,
42450,
86000,
11700,
13600,
19400,
15100,
55300,
39000,
24500,
117800,
49400,
19200,
null,
65100,
12500,
139300,
30000,
6200,
2900,
7100,
3100,
null,
59080,
26700,
15032,
19700,
17500,
63100,
10300,
18100,
75600,
20700,
15494,
9800,
29700,
42800,
21600,
33700,
68500,
20000,
22900,
37000,
null,
35100,
26600,
20500,
15700,
44400,
null,
38600,
21800,
6800,
33100,
8100,
29200,
68100,
17100,
null,
21600,
null,
41600,
37600,
23200,
15700,
null,
32200,
null,
12200,
14400,
13300,
5900,
16700,
11100,
167600,
80100,
8800,
4000,
17000,
12700,
35300,
46400,
21000,
61500,
null,
208600,
12100,
17700,
16300,
null,
20500,
null,
20800,
48000,
9900,
null,
13600,
11500,
12700,
32800,
15300,
19100,
5800,
12700,
18900,
8800,
28300,
11100,
10100,
12900,
32300,
47900,
51000,
15800,
36000,
6700,
6600,
33160,
null,
12700,
58100,
null,
24000,
60500,
23100,
47500,
null,
56400,
null,
30600,
null,
46000,
89200,
63500,
14900,
88200,
5500,
37000,
20500,
null,
3810,
41100,
12600,
32800,
21200,
15500,
96800,
10200,
97500,
null,
74100,
28600,
null,
39500,
10000,
35200,
20700,
21600,
5700,
12000,
18100,
7800,
33300,
51200,
37900,
38500,
3700,
45500,
10300,
2100,
29100,
15700,
12900,
null,
32000,
31500,
24500,
27800,
null,
15100,
17800,
68400,
null,
19400,
14900,
11800,
10500,
6900,
27400,
6000,
42900,
30600,
36100,
15700,
23100,
187100,
12900,
45300,
6600,
15800,
38300,
24800,
44000,
29300,
22300,
15100,
56700,
null,
19425,
24500,
56900,
38300,
16200,
52200,
25300,
23000,
10300,
15500,
26100,
null,
108600,
13350,
8650,
13300,
14600,
8600,
29900,
25500,
null,
97500,
20200,
25100,
26100,
10500,
null,
48800,
61400,
11000,
13600,
null,
30400,
13300,
11450,
null,
21100,
null,
13400,
16600,
34400,
36200,
20000,
4100,
5300,
42900,
23400,
12000,
18500,
21500,
33900,
57900,
73600,
null,
53200,
19500,
26200,
18800,
44000,
66700,
29400,
11800,
33800,
null,
25500,
10100,
5800,
18800,
null,
35200,
12900,
19300,
12500,
null,
null,
17600,
20900,
19600,
7700,
50000,
12600,
20200,
14700,
71200,
47300,
12200,
22700,
null,
24900,
62200,
15500,
11300,
61300,
88200,
60100,
null,
39600,
11700,
36700,
27500,
null,
51200,
18600,
12200,
26300,
16100,
25900,
16300,
36200,
null,
null,
26300,
43800,
7300,
74300,
21600,
null,
61900,
29000,
44266,
161300,
19100,
21300,
19100,
11000,
17300,
31700,
20400,
44000,
39400,
59700,
57800,
37000,
23200,
26700,
19500,
22900,
13800,
14600,
14100,
3600,
29800,
19500,
null,
26200,
15700,
13800,
19100,
10300,
12600,
12300,
24800,
18200,
6600,
60900,
35600,
18500,
11700,
8200,
63380,
52096,
39100,
33700,
null,
14100,
25600,
14100,
52300,
11313,
5000,
18000,
52700,
5500,
null,
41200,
11800,
22500,
19500,
40900,
2100,
48500,
8400,
28000,
9100,
32300,
12700,
45700,
57400,
25400,
15800,
8400,
23200,
42700,
15100,
40700,
22500,
57600,
100700,
41100,
16900,
18600,
20700,
39300,
19700,
8700,
50700,
22200,
14400,
19900,
null,
42800,
20700,
28800,
10500,
17600,
83800,
14900,
1500,
null,
32100,
32700,
68100,
38500,
5800,
50000,
18200,
29800,
34586,
7100,
161300,
23500,
null,
14300,
9100,
14700,
null,
24000,
35400,
28600,
28500,
25500,
42400,
46900,
29400,
11700,
28600,
31100,
5000,
47000,
17000,
35400,
65100,
33600,
13250,
43600,
11100,
19400,
68100,
17300,
9500,
22000,
42500,
34200,
9200,
14800,
17800,
39700,
38100,
14000,
142300,
15700,
70000,
23800,
22700,
16800,
29000,
53900,
71300,
10200,
45600,
8600,
23300,
29100,
16000,
23800,
64600,
16100,
33100,
10000,
25700,
19000,
11500,
49200,
20000,
9200,
14800,
36200,
null,
5200,
41300,
28900,
18300,
12800,
5800,
5000,
null,
22200,
7200,
16000,
35500,
12500,
8700,
14600,
39900,
9800,
39700,
15000,
19400,
61500,
4700,
5900,
44200,
53900,
59900,
10800,
11300,
46100,
29800,
12700,
41500,
12300,
18650,
54800,
27500,
50400,
6500,
25300,
28000,
79300,
16300,
17700,
23700,
96600,
10600,
29300,
64200,
31400,
36500,
23032,
18500,
7100,
16800,
11650,
12900,
51400,
34400,
33600,
35100,
20100,
24500,
25800,
5300,
16600,
8900,
33500,
41200,
null,
37300,
9800,
null,
14500,
49300,
24231,
10000,
9800,
40900,
12000,
14200,
null,
52400,
19000,
11100,
40678,
12700,
34300,
74100,
null,
11900,
22700,
15000,
30900,
9500,
7100,
4700,
30900,
4300,
15100,
null,
13100,
25800,
43700,
39200,
120100,
62600,
43100,
6500,
47100,
16100,
17100,
195800,
7900,
7000,
15300,
13800,
38900,
22300,
45200,
29200,
1500,
72600,
65700,
9300,
17700,
23600,
50500,
7200,
1000,
27600,
null,
17100,
12300,
24500,
27600,
44000,
31400,
11900,
44530,
55500,
20600,
23400,
16200,
37600,
51700,
3200,
18300,
13700,
52600,
15700,
14600,
16500,
10000,
null,
159500,
31600,
3900,
4100,
33100,
36800,
92300,
null,
52600,
null,
28400,
6600,
7600,
37600,
28100,
16000,
8400,
17600,
19700,
41139,
76400,
null,
88600,
151900,
46229,
39100,
44100,
20731,
8500,
59400,
7800,
41900,
34900,
15000,
11453,
2500,
17000,
null,
36200,
14000,
32200,
23800,
9100,
6300,
22700,
22500,
24200,
27000,
131400,
29400,
19700,
4000,
26900,
23400,
null,
11300,
28100,
28474,
7700,
14000,
58900,
10500,
49500,
28900,
26600,
25700,
39400,
17400,
65900,
17000,
29000,
77500,
9200,
null,
24400,
5700,
null,
3800,
4300,
9600,
24600,
800,
13800,
34000,
31800,
22200,
null,
111300,
22800,
9500,
18200,
20500,
10300,
50400,
3500,
3000,
38300,
12000,
8900,
42300,
8100,
8500,
31100,
7500,
6300,
6600,
16400,
8000,
38700,
47700,
21000,
28200,
56100,
14300,
23200,
11700,
47800,
115145,
47100,
91667,
15981,
50800,
39396,
17400,
66900,
15900,
29600,
18400,
16100,
39300,
52100,
11100,
21800,
48500,
3900,
22300,
94000,
6200,
7000,
14800,
9600,
26200,
68700,
12400,
177800,
17400,
54700,
92300,
8000,
27000,
100000,
77600,
27400,
3300,
5500,
16100,
29500,
41200,
20200,
20500,
45400,
6200,
40000,
60000,
50000,
75600,
50400,
47100,
null,
48600,
49200,
28800,
19200,
22200,
16100,
21800,
4300,
11200,
31010,
49000,
null,
33200,
41500,
19500,
14800,
61800,
17100,
32200,
null,
22200,
null,
23000,
16600,
56700,
38800,
57300,
6800,
null,
36000,
143900,
14100,
25200,
21100,
30000,
30200,
18300,
24500,
null,
10200,
13700,
26100,
42700,
7300,
7600,
15700,
26700,
18700,
74600,
47200,
28000,
8500,
2000,
35700,
29700,
17500,
28500,
25500,
48750,
40000,
45900,
66500,
32800,
36800,
41300,
8600,
7300,
42600,
70900,
9800,
17400,
32600,
28300,
null,
21400,
18000,
16800,
22200,
33200,
86600,
20200,
12200,
13800,
24800,
118000,
9500,
77200,
12100,
42300,
56200,
36700,
34200,
16400,
48900,
3725,
25700,
10300,
15900,
6400,
8400,
17900,
52100,
11000,
24200,
24600,
11300,
39100,
24900,
25900,
32400,
null,
null,
31009,
15000,
4300,
67400,
34300,
1700,
10600,
17900,
13600,
47807,
14900,
15700,
15200,
null,
11800,
26500,
37600,
13000,
25000,
null,
38400,
43800,
3900,
10800,
null,
16000,
19150,
49800,
null,
2200,
22600,
11100,
17600,
65400,
null,
21600,
20400,
9000,
24300,
null,
5400,
10100,
8200,
48500,
null,
55400,
22700,
33400,
null,
13400,
16700,
24000,
null,
87900,
16100,
15200,
null,
48600,
26100,
38500,
114000,
27400,
18500,
16000,
20400,
30000,
13200,
12600,
55700,
12000,
55800,
35100,
27100,
9400,
22800,
15500,
22700,
5900,
13800,
3200,
55800,
7700,
25900,
56900,
57700,
20800,
7700,
44300,
19200,
18700,
57800,
30000,
42200,
8000,
29600,
48000,
null,
10100,
24300,
15200,
20700,
33600,
23400,
12000,
44100,
59500,
26400,
null,
21200,
17600,
23700,
29000,
13500,
17000,
21000,
7800,
27100,
19700,
14500,
18100,
84600,
28600,
40000,
13400,
8800,
22600,
38700,
77700,
14800,
42300,
null,
12800,
47400,
11300,
null,
25900,
3000,
46700,
55300,
4200,
73700,
46745,
6700,
39000,
18200,
14400,
null,
5068,
7300,
95100,
17400,
50800,
32300,
38800,
82400,
20700,
7400,
14000,
44900,
5200,
21200,
23200,
4000,
25900,
3600,
25200,
null,
30400,
32000,
20700,
39500,
84900,
8400,
null,
null,
50594,
31200,
65300,
21200,
70900,
78600,
54700,
12100,
null,
40900,
34900,
9800,
79900,
94800,
42200,
46100,
47400,
54600,
18100,
28400,
8500,
61500,
94000,
19000,
12900,
null,
4200,
54200,
39300,
25100,
5300,
36500,
28400,
16700,
31800,
29700,
2600,
16200,
82200,
54200,
80600,
40600,
25600,
9500,
9500,
72700,
26400,
17600,
34800,
32900,
8000,
26400,
29900,
52500,
8900,
42700,
10200,
7600,
14900,
27400,
24600,
27700,
8000,
38400,
32400,
15700,
68500,
17700,
12500,
14800,
null,
84300,
20200,
15500,
44100,
34821,
16400,
5200,
25100,
32500,
null,
29700,
48900,
27500,
18100,
13300,
37877,
37902,
null,
null,
127200,
44900,
28700,
16000,
8600,
null,
29500,
51800,
52800,
17300,
null,
18100,
10600,
31000,
27400,
30000,
18100,
8400,
20600,
28000,
12700,
16600,
41600,
24800,
12100,
null,
24400,
10800,
65000,
33400,
null,
12600,
null,
43000,
21700,
23410,
35000,
18900,
7500,
16200,
11510,
75900,
18200,
158000,
114300,
1119200,
16600,
43950,
16500,
null,
46500,
23400,
20000,
45200,
41900,
14000,
29650,
84600,
28900,
83400,
23000,
23100,
15500,
48200,
6800,
28600,
26900,
null,
18600,
40500,
5000,
13200,
47800,
22900,
34500,
6300,
74000,
27200,
14600,
37900,
31700,
28000,
56256,
35500,
72400,
null,
15700,
null,
13500,
26500,
null,
15500,
28800,
6900,
24600,
6600,
11800,
16100,
538900,
41900,
27400,
19600,
15700,
16400,
15000,
26700,
null,
87100,
22000,
null,
18180,
82200,
20200,
144400,
79300,
34400,
12500,
37000,
1500,
13700,
22200,
11000,
8100,
15400,
31500,
60800,
31300,
null,
8500,
9800,
36300,
14000,
20300,
10900,
2500,
87900,
28300,
46500,
null,
70600,
12700,
13100,
4500,
23200,
51300,
14600,
85800,
22300,
36500,
33300,
11300,
43700,
34900,
13500,
10400,
16012,
45900,
17600,
56700,
43600,
10900,
5000,
22700,
3300,
6900,
20600,
null,
500,
11200,
63000,
53000,
43400,
9600,
10100,
null,
7150,
18800,
38900,
1200,
48300,
37000,
17700,
94500,
56600,
57600,
5500,
90300,
28100,
91200,
11700,
23300,
32100,
35000,
8800,
66900,
15200,
73200,
27500,
null,
13350,
10500,
69600,
22300,
30300,
23400,
17400,
5700,
18100,
22200,
13400,
65000,
9200,
10000,
64800,
9900,
90600,
40300,
13300,
25150,
80000,
29500,
27200,
25900,
39200,
19300,
49400,
32400,
20700,
28400,
82400,
28400,
25900,
21000,
45900,
43000,
26700,
22964,
13000,
36300,
36900,
23500,
31700,
20100,
41700,
7800,
null,
10500,
70800,
61100,
11600,
17900,
11800,
102600,
58200,
38600,
87900,
17900,
19800,
42200,
12700,
29400,
13300,
20500,
10500,
48600,
16800,
55500,
27100,
27400,
14300,
40300,
24300,
24300,
35500,
8400,
38800,
17500,
28000,
92500,
19800,
6600,
17400,
10600,
24700,
7000,
15100,
13500,
null,
null,
12800,
15650,
16900,
6000,
7830,
28000,
79900,
4800,
11200,
16200,
24900,
42600,
97400,
135200,
48400,
65900,
18100,
null,
16600,
33900,
13900,
18500,
12100,
84100,
9900,
14900,
20400,
45200,
24400,
39300,
24700,
18800,
27900,
15300,
10800,
26200,
61700,
23400,
null,
21800,
23900,
15800,
231400,
26300,
89500,
11300,
null,
5300,
12800,
16700,
17800,
46200,
26700,
null,
8800,
19800,
13000,
26600,
6300,
32700,
9700,
null,
17800,
65900,
52700,
12400,
76480,
39900,
15200,
24600,
58700,
11700,
10300,
14500,
7600,
19600,
34100,
32400,
11000,
23600,
39300,
11400,
42400,
17900,
19550,
10600,
null,
18200,
34300,
19400,
40600,
22100,
77200,
20900,
15900,
31500,
41400,
15800,
44000,
null,
18700,
36300,
34300,
65600,
9500,
45000,
24600,
16800,
51600,
241700,
23700,
null,
36900,
19200,
72300,
30000,
22800,
9800,
44300,
78100,
10600,
6000,
13900,
37900,
8100,
30500,
2100,
12000,
24500,
40000,
null,
32200,
51100,
null,
21100,
55000,
37500,
257300,
26600,
38200,
23500,
9200,
22700,
null,
null,
35100,
38600,
23200,
21500,
89200,
21300,
27200,
21600,
37500,
45500,
21400,
20200,
10600,
4500,
66000,
17700,
36800,
6000,
23400,
53800,
15800,
null,
41300,
10000,
27800,
83500,
27200,
3500,
10900,
33300,
10200,
8300,
15900,
56100,
15400,
31500,
35800,
16400,
null,
5000,
8400,
null,
5500,
41100,
22900,
28700,
37000,
85000,
37500,
19300,
null,
70400,
12700,
9300,
5700,
17000,
35500,
45500,
68200,
null,
15400,
null,
26600,
17800,
12200,
88800,
25900,
8500,
106100,
6050,
null,
28300,
18100,
42100,
45900,
28100,
29500,
35800,
17800,
18300,
14800,
13300,
17800,
48300,
52700,
1700,
58900,
151800,
15200,
null,
21200,
44400,
20700,
49100,
23500,
26600,
35700,
18500,
44900,
5600,
33000,
null,
16600,
78500,
34500,
26900,
37800,
41600,
12300,
48200,
23400,
32900,
38600,
57600,
23300,
72300,
69600,
32600,
31500,
11000,
14500,
11300,
56700,
13600,
12950,
17300,
18700,
43200,
16400,
null,
7700,
26500,
15700,
10600,
20900,
26300,
16000,
93200,
25200,
6000,
40500,
15200,
29400,
16000,
null,
26950,
7600,
36500,
21700,
25500,
23800,
33300,
12200,
16100,
null,
18700,
47500,
63500,
22600,
36400,
43100,
18800,
27100,
45200,
45900,
null,
17400,
14000,
15100,
2700,
66300,
45300,
null,
45400,
51400,
36800,
33800,
45800,
16500,
52010,
19000,
71400,
48200,
58300,
28200,
10450,
15400,
null,
3300,
18200,
74500,
null,
49700,
9100,
32000,
49800,
68300,
72700,
15300,
null,
25900,
null,
24200,
14100,
19500,
18500,
23100,
18000,
24600,
22700,
25600,
8500,
5400,
16300,
5600,
14500,
10600,
31800,
23200,
53300,
16700,
22400,
100000,
8200,
9800,
97000,
38200,
34200,
null,
21000,
6800,
14900,
11500,
23900,
65100,
10400,
null,
48500,
44200,
55700,
60400,
49300,
11500,
null,
10400,
8200,
131300,
18000,
3600,
25300,
23400,
1900,
5400,
51000,
16800,
65900,
null,
89900,
10400,
27000,
32100,
31700,
21000,
48500,
26900,
69400,
41500,
10600,
17000,
8200,
57200,
47300,
5700,
5700,
116567,
102500,
null,
34000,
16500,
41500,
22600,
64300,
null,
20100,
15700,
14800,
37400,
null,
29600,
51900,
1700,
null,
9300,
34600,
15500,
16700,
159300,
4000,
35900,
23700,
41900,
14100,
24500,
24400,
23100,
66300,
151200,
79300,
38300,
17700,
36300,
27400,
20300,
14000,
11300,
88800,
63600,
46100,
8600,
42200,
22900,
19900,
21600,
16500,
28100,
25900,
18600,
31900,
12000,
63300,
34700,
22600,
8100,
5500,
8500,
23600,
22100,
4800,
19100,
30500,
null,
28000,
25200,
37400,
23600,
11900,
30100,
15600,
5100,
21500,
13000,
24200,
23600,
null,
61200,
20500,
36500,
null,
26600,
31600,
59800,
4700,
46000,
31700,
16400,
66200,
24500,
60800,
7552,
11400,
9000,
69900,
48100,
10400,
38400,
19800,
10000,
56500,
5900,
null,
31400,
9300,
12300,
null,
17800,
137400,
31600,
31800,
33400,
64700,
41100,
19300,
38600,
24800,
28100,
null,
null,
39800,
73900,
22000,
24000,
30300,
7300,
37400,
57300,
50300,
26800,
null,
80300,
42600,
34100,
7300,
13437,
23000,
9100,
15000,
null,
47900,
125895,
8700,
59200,
11000,
67000,
13800,
30000,
43800,
39900,
3800,
38000,
16300,
30200,
20000,
18900,
4200,
48300,
8900,
15600,
36800,
43564,
13100,
7000,
21900,
4300,
29300,
82400,
61800,
41600,
14100,
18600,
null,
13600,
44100,
24400,
44100,
55800,
43000,
27000,
45700,
16800,
6700,
83600,
28600,
55800,
13800,
32900,
13000,
16100,
10600,
54100,
15700,
4600,
null,
34800,
6600,
106069,
null,
56700,
35100,
null,
11300,
null,
39100,
5300,
89700,
18000,
13400,
40200,
22500,
43900,
18400,
null,
null,
13000,
45100,
105000,
56300,
16900,
14400,
81200,
19400,
40100,
58400,
6900,
23500,
26900,
46700,
19300,
21700,
9300,
38000,
39000,
9800,
null,
27700,
73500,
35800,
12300,
27800,
21400,
11200,
9800,
35100,
22500,
14700,
111300,
40200,
59500,
9200,
null,
122700,
32943,
44500,
26800,
23200,
55900,
13700,
null,
7100,
15800,
109426,
42800,
15200,
14800,
8000,
21200,
15300,
43764,
30800,
37800,
70600,
43000,
6400,
17500,
46700,
37500,
27900,
null,
3800,
11300,
18300,
11300,
29800,
17300,
9900,
54500,
3900,
null,
33200,
44300,
29800,
21200,
24200,
12500,
30100,
23000,
21600,
46300,
12300,
67300,
27000,
34100,
null,
8700,
50200,
41500,
26600,
4600,
60200,
null,
55300,
5400,
34300,
null,
40100,
12400,
14900,
41600,
60800,
19000,
12900,
17500,
20200,
15800,
12700,
59300,
65300,
14700,
10700,
null,
5500,
24200,
22200,
9500,
33000,
18800,
3000,
2050,
120300,
8400,
20000,
17200,
120250,
13962,
142800,
21200,
12200,
45000,
18300,
32300,
null,
17900,
52500,
7900,
4100,
81400,
38600,
18900,
9500,
17100,
37713,
7700,
30900,
34700,
25000,
null,
15100,
92900,
34400,
17900,
54300,
64500,
null,
44100,
6700,
64350,
39800,
49800,
16000,
21300,
37500,
8400,
10300,
47000,
26900,
21800,
28600,
84100,
11500,
44700,
4100,
25300,
null,
25300,
17000,
15700,
null,
39000,
61000,
13900,
18300,
12100,
21000,
12300,
54500,
64600,
60100,
13600,
17700,
22500,
60100,
19800,
4000,
null,
9100,
16800,
5200,
10400,
2600,
14300,
10500,
27500,
16900,
null,
15300,
35564,
22400,
18800,
33300,
16700,
null,
11100,
6000,
39100,
23900,
76300,
20500,
22000,
24500,
9800,
null,
null,
12100,
38600,
37200,
17100,
25087,
null,
15800,
39900,
89900,
84000,
10400,
41200,
22200,
46948,
33822,
15500,
null,
19200,
6100,
41000,
16400,
60100,
19200,
62400,
40700,
9900,
67400,
26200,
18900,
6900,
19500,
null,
22200,
null,
85100,
12300,
17400,
86000,
25098,
10100,
null,
12600,
23800,
23600,
41700,
14300,
80700,
30500,
82350,
28200,
33900,
15800,
null,
58100,
5800,
44900,
9800,
21200,
45100,
1700,
null,
13500,
22300,
null,
16500,
38400,
334100,
66500,
19100,
10800,
65700,
76200,
19100,
17200,
9300,
39600,
29000,
8900,
null,
56200,
138600,
8700,
86900,
51900,
26100,
11100,
54700,
null,
25500,
56200,
65400,
31200,
null,
41300,
63200,
20700,
45400,
38500,
16700,
3200,
27700,
null,
34210,
6000,
45400,
10600,
28000,
43700,
null,
29400,
16200,
33500,
7700,
null,
9700,
25100,
15300,
16200,
17900,
12200,
33300,
9100,
40300,
17900,
23400,
35400,
20300,
26500,
112900,
17400,
29600,
23500,
43050,
6500,
20200,
55600,
10700,
53000,
158400,
5100,
18700,
null,
15200,
15300,
25900,
7800,
28100,
15200,
33500,
50500,
26300,
48200,
17700,
91800,
14500,
15800,
24100,
14500,
40100,
55300,
null,
12200,
18900,
27400,
86200,
42500,
59900,
19900,
28300,
54000,
20600,
34500,
39100,
null,
27400,
21300,
8600,
15300,
38100,
57000,
205700,
64700,
89600,
64700,
88800,
72600,
20500,
72300,
16800,
110000,
40300,
23300,
36700,
68900,
13500,
48400,
27300,
40400,
18100,
19800,
null,
33100,
6800,
45500,
25500,
31000,
22573,
26000,
1500,
48900,
49600,
19313,
192700,
null,
6600,
11000,
10000,
32100,
36000,
23000,
22700,
82800,
14700,
null,
81000,
13000,
16400,
19900,
null,
null,
16300,
21300,
27200,
15500,
32100,
28700,
26560,
13100,
25800,
21200,
37900,
8900,
24700,
13300,
26500,
29500,
20500,
36300,
10300,
null,
51700,
3800,
16400,
49800,
13300,
5700,
8500,
null,
72900,
108100,
25000,
22800,
13800,
24700,
13500,
25181,
8200,
56400,
9800,
11700,
21600,
null,
15300,
13650,
9900,
231600,
17800,
126080,
9700,
31600,
18700,
3200,
19800,
null,
52437,
12100,
50600,
4800,
22600,
null,
null,
29500,
67000,
30800,
70500,
40500,
61300,
10400,
null,
26900,
16000,
6500,
41800,
17500,
21600,
8400,
20100,
34900,
18000,
6900,
14100,
39400,
56400,
50144,
17800,
13500,
11200,
13400,
28300,
31500,
28600,
53800,
null,
null,
15300,
36700,
52400,
10600,
62800,
77300,
18300,
9600,
null,
17500,
null,
42800,
214400,
43600,
26700,
42800,
45500,
23800,
66000,
37500,
43700,
null,
16600,
21900,
28300,
24000,
90600,
12000,
32400,
19000,
86700,
44400,
24900,
45000,
32600,
74553,
10100,
50700,
6000,
5000,
19200,
88500,
11400,
35200,
53900,
52500,
6100,
8600,
42300,
32900,
55900,
34200,
18100,
5500,
13200,
58100,
70000,
9400,
8000,
24700,
28300,
45100,
null,
44800,
10600,
17600,
10800,
4200,
28700,
9600,
72600,
13700,
9100,
24700,
17000,
7100,
55000,
57100,
65500,
47800,
6000,
43200,
7500,
null,
24600,
15700,
68800,
null,
20300,
12900,
18772,
24500,
10300,
16200,
null,
19500,
53400,
26600,
14100,
15500,
null,
32700,
16000,
15200,
26100,
36900,
20200,
16900,
20700,
30200,
43700,
11700,
17800,
281634,
11500,
29200,
97200,
28100,
25900,
17800,
21500,
26200,
8900,
null,
54100,
26000,
48200,
13000,
72300,
16800,
8500,
38800,
94800,
11500,
9400,
107100,
50100,
11700,
8700,
19100,
22500,
74900,
null,
190600,
21100,
null,
13400,
5800,
34300,
16800,
7300,
107600,
18800,
36100,
13500,
40300,
11700,
9000,
14700,
17500,
null,
28200,
null,
33100,
80100,
8000,
19300,
14800,
12500,
27900,
7800,
null,
27800,
13800,
28500,
49400,
121500,
18100,
14100,
38200,
21400,
73500,
8000,
6200,
31600,
32900,
16600,
8100,
14600,
7100,
8300,
18800,
null,
71800,
27300,
69900,
14100,
45700,
25500,
34800,
8200,
9700,
6200,
null,
21100,
23100,
20500,
31500,
6600,
59100,
27900,
10800,
52100,
40300,
237700,
41500,
104100,
20800,
15600,
78400,
19700,
10300,
21800,
47100,
17500,
73200,
44100,
9300,
26000,
null,
15100,
55900,
19300,
7400,
null,
14100,
12400,
56600,
28100,
15500,
34500,
65300,
114700,
79463,
19500,
56500,
17000,
34500,
66500,
34400,
43800,
17500,
35200,
12100,
12800,
6500,
5900,
15100,
20500,
39600,
26200,
34500,
17300,
10800,
79600,
16800,
41400,
16200,
32000,
7600,
14800,
40300,
37100,
68800,
35100,
null,
14000,
9500,
null,
45000,
15000,
25400,
17700,
10300,
22600,
25400,
10500,
70800,
49200,
10600,
25300,
null,
34500,
12300,
48700,
117100,
6800,
93200,
19700,
70200,
6900,
16700,
10300,
14800,
27600,
13600,
null,
7300,
84400,
8400,
32600,
5800,
16300,
null,
25600,
7500,
37800,
41100,
15400,
null,
24600,
48400,
23200,
30000,
28500,
51500,
18900,
9800,
15500,
5400,
18600,
122100,
16100,
13200,
19400,
15000,
null,
13800,
28300,
10000,
41300,
80500,
34100,
19400,
32200,
6100,
null,
56400,
27000,
21600,
9500,
7100,
52700,
48600,
6700,
22200,
29400,
14100,
null,
39500,
49600,
30000,
null,
12700,
29000,
11000,
134700,
19850,
12100,
24300,
27000,
22700,
53000,
null,
18900,
21600,
20600,
19200,
12300,
21900,
12800,
17900,
45100,
null,
45800,
15300,
44900,
16900,
8500,
39300,
9800,
null,
51800,
10800,
25800,
11800,
19600,
13100,
null,
6500,
29500,
null,
33600,
null,
67800,
74400,
42800,
44100,
28300,
13900,
32500,
24000,
15600,
8500,
15300,
8800,
39000,
28100,
8300,
26700,
13700,
48600,
12500,
24900,
63000,
21100,
11000,
48100,
24300,
null,
45200,
69100,
4500,
75400,
32100,
10500,
5300,
16900,
9400,
7200,
44500,
36000,
156900,
94800,
22975,
27000,
60800,
8000,
46000,
22200,
45300,
5700,
16800,
null,
23000,
16800,
18200,
80300,
14000,
26000,
39300,
56200,
null,
8500,
null,
27600,
73500,
28100,
85800,
25200,
25100,
31300,
23000,
71800,
22000,
15800,
73400,
16500,
11100,
null,
7200,
8300,
2800,
33200,
53600,
null,
21800,
11600,
12100,
15800,
14800,
13600,
22200,
36800,
58700,
21700,
38800,
15600,
22400,
57000,
6500,
null,
31900,
11500,
20200,
46890,
7300,
10000,
21000,
null,
8300,
11000,
11900,
10600,
28300,
28000,
36900,
30300,
47000,
65000,
32600,
7600,
61400,
null,
27200,
10500,
18900,
6000,
null,
null,
56700,
11600,
9200,
72800,
null,
6700,
10600,
33300,
16200,
9900,
13700,
37600,
5200,
30400,
73900,
5500,
52200,
11200,
29400,
21400,
10000,
26600,
97147,
61400,
15500,
15500,
49600,
27400,
22900,
30400,
72800,
60000,
47400,
19300,
56900,
34600,
36700,
67700,
36100,
57200,
45600,
14000,
3600,
null,
21200,
20000,
19200,
5100,
7200,
42600,
17800,
43400,
14000,
null,
23200,
14300,
28900,
22700,
39000,
37300,
17900,
5000,
16800,
40300,
41900,
12500,
null,
35900,
70924,
15900,
32500,
18200,
12000,
null,
20400,
18900,
40000,
28800,
25700,
42300,
7000,
19450,
46400,
4200,
null,
21400,
29700,
11000,
27700,
43200,
30400,
null,
14900,
25500,
24000,
null,
9200,
34200,
15900,
null,
23200,
null,
null,
7900,
12800,
21500,
14300,
22900,
null,
23000,
46000,
14400,
null,
29400,
46700,
40200,
47800,
29200,
33100,
20600,
103000,
21539,
39000,
44400,
21600,
15000,
9300,
14900,
20400,
37300,
31400,
35700,
16400,
51300,
20137,
8600,
9800,
12000,
10100,
24200,
8300,
16800,
10500,
10500,
4600,
68600,
36200,
8900,
5000,
45400,
29900,
16500,
17800,
42900,
46100,
83300,
32400,
null,
26100,
null,
22900,
16100,
11600,
14200,
59300,
4400,
null,
17500,
13200,
29800,
17800,
null,
22200,
6600,
26600,
33900,
55300,
12400,
49200,
74700,
27900,
54000,
8200,
null,
39700,
82700,
24400,
14100,
10000,
7500,
23100,
10900,
7300,
14700,
null,
46400,
33500,
52400,
22800,
60400,
16900,
15690,
13300,
11300,
5800,
24900,
29500,
23200,
32300,
13900,
6800,
8400,
10100,
26700,
33550,
16500,
53900,
11110,
17500,
19700,
12300,
700,
18400,
27700,
113400,
13100,
59600,
7500,
34000,
40100,
38800,
16700,
17200,
35200,
20200,
10200,
26800,
8300,
31400,
39400,
22500,
36200,
null,
11200,
14700,
26200,
10500,
28400,
1800,
20900,
53700,
38900,
65200,
7900,
7300,
27700,
13400,
4700,
8600,
3800,
null,
10800,
16800,
11000,
15600,
22900,
60500,
9000,
16300,
53700,
63500,
14200,
63700,
81650,
36800,
33900,
32500,
19500,
10200,
26000,
null,
null,
11500,
6300,
23300,
31100,
null,
26200,
33700,
257500,
17300,
7900,
42600,
6000,
null,
39100,
15900,
17300,
33300,
23200,
123300,
15600,
16200,
53100,
32800,
657000,
11500,
16100,
13800,
7200,
39200,
55300,
16000,
29600,
485300,
71700,
12400,
41260,
83600,
102400,
83400,
18300,
42800,
24400,
20100,
32400,
39000,
12800,
24400,
15690,
77000,
33100,
43700,
9900,
10200,
65800,
60094,
4600,
19800,
31000,
43300,
11700,
25300,
22100,
22300,
87300,
34000,
27100,
15900,
16600,
82200,
118500,
24400,
29200,
53600,
10000,
6399,
28900,
172100,
14800,
15600,
9600,
52200,
35000,
14200,
9000,
41000,
26000,
110500,
11600,
74600,
54200,
8000,
16500,
40400,
25900,
36500,
3250,
13500,
74900,
5200,
null,
26200,
13800,
34700,
20200,
27700,
20600,
38400,
30600,
47200,
17700,
71400,
13100,
29700,
44800,
11500,
34900,
41000,
43500,
1300,
57800,
47300,
9600,
11900,
31300,
null,
63200,
8200,
66200,
27100,
8200,
null,
26200,
20900,
11000,
37000,
13300,
null,
16300,
6100,
28200,
6600,
null,
7000,
82300,
34700,
17000,
38400,
31300,
15700,
10000,
25300,
5200,
19400,
25000,
28300,
86500,
null,
8200,
15300,
28200,
null,
10800,
76300,
19100,
24000,
83724,
40000,
10600,
41500,
63600,
29600,
null,
18200,
19800,
4500,
27400,
14300,
28550,
17800,
4700,
10900,
25800,
21800,
26800,
332300,
18700,
2000,
21400,
143500,
56100,
33500,
16600,
null,
15200,
79500,
null,
75300,
26700,
47000,
34900,
27000,
33800,
86000,
85800,
77100,
29100,
13000,
54300,
15500,
40200,
19700,
23800,
16700,
11500,
null,
49900,
20400,
28200,
27000,
26500,
17900,
26500,
30800,
37200,
19000,
34100,
20800,
25400,
53400,
35800,
15300,
6000,
44300,
null,
6700,
11700,
54500,
27800,
21800,
11900,
23800,
5500,
15200,
39400,
16300,
8500,
46300,
8300,
48800,
47800,
null,
23950,
20500,
23700,
8000,
7300,
12700,
33500,
5900,
25800,
12800,
44500,
2400,
34900,
158555,
109800,
39800,
28800,
20300,
83300,
15500,
41000,
10900,
17250,
9300,
26700,
27800,
53221,
null,
9800,
null,
41400,
36200,
53500,
22600,
18300,
75000,
43600,
65300,
62900,
null,
null,
50200,
66200,
63900,
11000,
13300,
12900,
11600,
11400,
null,
38300,
18800,
10800,
40700,
38200,
null,
76300,
8700,
13500,
6500,
28900,
8400,
56400,
21000,
3000,
15400,
7500,
null,
53000,
13600,
null,
14000,
null,
29400,
5900,
15800,
37000,
20500,
20400,
23600,
12800,
11700,
52000,
8300,
16200,
27800,
9900,
30900,
31700,
88900,
null,
26600,
21900,
27900,
12500,
null,
22500,
null,
31900,
13900,
13400,
30100,
45600,
40400,
38300,
11600,
68600,
20800,
10400,
null,
19900,
37400,
null,
8300,
25500,
89300,
0,
99500,
null,
6500,
25900,
27300,
8600,
34900,
21800,
13000,
40600,
45000,
11700,
99000,
43000,
100400,
19700,
44800,
31000,
31900,
50500,
20800,
10600,
23100,
22400,
19800,
27400,
17900,
39900,
14700,
18800,
6500,
17400,
36500,
18700,
9500,
10300,
72300,
64000,
null,
31200,
9500,
53400,
25100,
18525,
19100,
52800,
28900,
12100,
70400,
33700,
7775,
11800,
11300,
25200,
22400,
197300,
26400,
30200,
76300,
10600,
24400,
22800,
31300,
null,
50400,
6900,
53600,
39800,
26000,
56600,
51400,
8400,
16900,
9800,
81200,
23600,
11700,
25600,
20400,
34900,
15200,
23300,
13200,
60900,
22700,
71500,
16000,
23700,
null,
10500,
9400,
7700,
37400,
38000,
50000,
48200,
18900,
13100,
12400,
11500,
23800,
34400,
4600,
51300,
9000,
11900,
30200,
36300,
27100,
20000,
171000,
359000,
20600,
16000,
62400,
40000,
43700,
15000,
31000,
91600,
null,
33500,
29200,
15500,
28500,
6400,
21600,
33000,
109400,
24300,
24800,
166800,
76400,
20300,
6500,
11900,
30300,
18900,
37400,
18000,
23100,
10800,
4800,
38500,
32100,
30200,
91100,
13400,
59800,
5750,
13800,
58400,
47000,
8800,
22900,
7800,
31700,
17100,
50296,
319600,
33500,
68900,
34200,
38700,
26500,
15200,
8900,
53400,
23500,
null,
null,
32200,
3300,
23950,
null,
8300,
35400,
25600,
null,
31000,
8300,
16100,
85100,
40000,
61200,
10000,
24100,
34400,
24000,
12800,
14700,
16600,
38500,
30600,
14300,
40300,
49300,
13600,
54400,
13200,
37400,
17600,
null,
31900,
31200,
15000,
24300,
8900,
null,
30700,
4000,
null,
22200,
47300,
5600,
47800,
6800,
18800,
20500,
105000,
36400,
null,
75900,
27100,
34500,
67000,
10000,
4300,
22000,
null,
40200,
22200,
8900,
33500,
17000,
17300,
6500,
30000,
39600,
11800,
20100,
15800,
12300,
39600,
13500,
23900,
24900,
56900,
42500,
32783,
52600,
63400,
null,
35800,
79900,
27100,
26100,
39600,
26800,
28300,
4674,
25900,
null,
14800,
43500,
28900,
45200,
72300,
13700,
14300,
14700,
12700,
4800,
13300,
141500,
29600,
14500,
36600,
29400,
17700,
null,
8700,
null,
11600,
4700,
114000,
5700,
82000,
19900,
27900,
16800,
35900,
31800,
5900,
4200,
24200,
23200,
85700,
45900,
73700,
17400,
19100,
47500,
12900,
12300,
38600,
6300,
19800,
44000,
10700,
8700,
null,
null,
45800,
55100,
34653,
19700,
31300,
40070,
6000,
67400,
14700,
20800,
30880,
252000,
38900,
7600,
14000,
110300,
10000,
22200,
38600,
57800,
null,
14700,
null,
34700,
20400,
55100,
21500,
27100,
21100,
53500,
14100,
16000,
17400,
10900,
17600,
10500,
24500,
27300,
182100,
23700,
8800,
44300,
17200,
26000,
21300,
159900,
149550,
36900,
58800,
null,
26300,
21700,
null,
8000,
24000,
4900,
8400,
null,
23400,
26000,
58300,
6300,
30600,
33300,
20000,
10100,
13800,
31500,
59700,
38900,
44500,
20100,
71300,
7200,
null,
66800,
17100,
5600,
41000,
72400,
22700,
7600,
36100,
null,
9100,
13500,
5700,
56400,
15800,
31300,
92400,
24100,
21300,
21000,
66600,
36100,
37702,
11300,
19300,
16800,
null,
19500,
null,
68000,
20460,
11100,
9500,
7500,
49400,
90400,
18127,
12200,
34300,
21500,
5500,
9700,
31700,
42700,
31100,
11000,
17700,
4500,
73500,
73000,
55200,
16200,
61400,
17400,
11700,
7700,
24900,
28500,
22000,
17000,
null,
9900,
8200,
71800,
58900,
8400,
35100,
8400,
17300,
11200,
20300,
7300,
null,
11100,
41500,
28700,
1700,
61400,
37500,
3900,
27800,
46700,
17200,
17000,
38700,
9000,
11100,
37400,
6600,
11600,
14800,
13000,
67000,
19700,
25100,
4250,
23200,
38700,
22000,
38600,
59300,
null,
7250,
28700,
19800,
45600,
51600,
15800,
10850,
24200,
25100,
18400,
51800,
7050,
27800,
80000,
40800,
17100,
9700,
26400,
4600,
30500,
null,
27500,
79500,
1500,
32100,
21624,
22300,
4800,
31200,
78200,
36300,
24200,
17100,
8700,
116600,
22200,
51400,
31900,
43300,
30900,
24800,
null,
37950,
33900,
80800,
27600,
24000,
17100,
14000,
4500,
28200,
13400,
46100,
43700,
null,
22400,
2300,
29300,
37600,
14300,
25300,
53600,
9000,
39000,
16600,
7500,
15400,
36000,
9000,
null,
47600,
10600,
null,
4300,
null,
null,
34400,
15500,
15800,
24100,
17400,
48100,
26300,
110700,
52600,
null,
7300,
22900,
76300,
19000,
29500,
16500,
37100,
14500,
null,
4000,
17000,
37800,
49500,
77100,
25100,
46400,
800,
38500,
30700,
10600,
13200,
53000,
29300,
30600,
6800,
8200,
21000,
34900,
47000,
70500,
null,
116000,
11000,
26800,
5000,
43300,
null,
null,
null,
6100,
8700,
20400,
28400,
16900,
48800,
125200,
6300,
11400,
12500,
11800,
39300,
45600,
27300,
25150,
11600,
18100,
22600,
37524,
24400,
49700,
16100,
82200,
50500,
null,
29500,
13300,
46500,
21700,
13800,
40800,
30600,
10200,
13700,
35500,
null,
23800,
17600,
36500,
25100,
null,
19200,
26500,
8500,
54500,
11000,
13000,
14500,
14000,
22600,
13700,
57000,
12500,
30600,
7900,
20400,
17300,
13100,
27600,
10300,
13500,
29000,
63300,
66300,
19330,
37500,
10500,
49600,
11900,
10200,
2500,
24800,
21600,
24200,
30500,
34300,
4400,
30200,
71000,
11500,
59500,
24200,
40200,
46200,
16700,
12600,
68800,
4800,
39200,
20900,
8700,
12200,
50800,
null,
21200,
41700,
28600,
76300,
11100,
50600,
4900,
14400,
42800,
53100,
34200,
28000,
16900,
17600,
17700,
49600,
13500,
22900,
12600,
14200,
32700,
11400,
39700,
9500,
12400,
18400,
2500,
11500,
42400,
15900,
75300,
58900,
5300,
12200,
16600,
32700,
24900,
37200,
15100,
62900,
43600,
89500,
31200,
34300,
14400,
64000,
27900,
18000,
2500,
41652,
29100,
6500,
44500,
6500,
24300,
18400,
12100,
null,
56400,
29400,
null,
16100,
191000,
null,
49600,
null,
19700,
46600,
7600,
28000,
15400,
6700,
4800,
33500,
4900,
5000,
7400,
51900,
43900,
4900,
19100,
53700,
4400,
9700,
26700,
42400,
23300,
16000,
50100,
26300,
7900,
29500,
17700,
5600,
11100,
89400,
89400,
22300,
17900,
18500,
31000,
7500,
105300,
7900,
4700,
46800,
40100,
20800,
2000,
37800,
null,
32100,
34100,
null,
67700,
null,
4700,
21200,
null,
null,
33200,
23700,
40700,
25000,
91600,
13300,
20300,
21700,
13300,
null,
59800,
11900,
30000,
11700,
22300,
19100,
7200,
34300,
20200,
72100,
46600,
3500,
45100,
54800,
20750,
39100,
null,
34900,
15600,
16800,
18800,
29400,
21000,
49500,
14700,
24900,
84600,
13400,
26300,
15800,
61300,
42400,
58900,
144700,
46800,
31600,
27800,
28200,
24000,
31600,
26600,
16200,
73100,
31300,
13900,
33000,
56300,
null,
41400,
41700,
27100,
25400,
76600,
32300,
16500,
null,
null,
20000,
18500,
14700,
67800,
20500,
37900,
13000,
null,
54200,
10900,
58800,
38200,
20100,
41100,
173300,
7900,
25500,
12600,
13100,
47300,
41700,
null,
109900,
44400,
45300,
14800,
2300,
17500,
19300,
8500,
8700,
42000,
2500,
33500,
9800,
8900,
22700,
19700,
5800,
18800,
5400,
900,
9600,
16900,
19100,
120400,
17600,
59000,
null,
24500,
76700,
16000,
17800,
38700,
5300,
40800,
12500,
15200,
11200,
9300,
44100,
17900,
23000,
13600,
null,
null,
8400,
71500,
38700,
51100,
9600,
57300,
64000,
5150,
18600,
39400,
9800,
48400,
null,
18800,
9500,
13700,
8500,
66700,
20700,
40400,
null,
20200,
25500,
27100,
5200,
13800,
11500,
57400,
21500,
43500,
78600,
82700,
10100,
40200,
26600,
52400,
11800,
19200,
null,
9800,
24900,
54401,
24500,
26100,
9700,
32400,
23600,
34200,
204300,
65700,
80600,
5800,
23500,
25800,
37100,
29300,
9900,
null,
48100,
null,
79000,
45200,
71700,
195400,
11100,
28500,
19600,
60900,
6600,
8500,
40400,
8499,
50800,
5100,
53200,
59700,
13100,
45200,
null,
47600,
24100,
50000,
16500,
23000,
14800,
23800,
34700,
18800,
17500,
51700,
13000,
37200,
26400,
34600,
null,
16500,
13600,
88435,
42700,
23800,
3900,
12100,
31100,
18300,
null,
13800,
42100,
29800,
12200,
44200,
54100,
96300,
13100,
12700,
6700,
47200,
23700,
null,
29100,
8200,
17700,
12300,
26700,
17250,
20500,
39100,
9100,
12000,
2800,
34600,
11500,
21300,
69400,
21700,
21800,
29000,
20100,
26800,
42300,
20000,
49300,
44600,
26172,
20300,
46400,
16300,
25500,
48700,
18300,
5500,
10900,
null,
60400,
null,
19000,
50000,
10800,
22400,
13400,
54400,
16100,
57500,
3100,
36500,
24800,
7200,
24000,
null,
13500,
14900,
15700,
12205,
15700,
12400,
18400,
15100,
28900,
19300,
11700,
23800,
11700,
50200,
7600,
null,
15000,
19700,
60600,
null,
14200,
22800,
25100,
null,
76300,
13600,
81200,
9700,
24300,
12900,
20600,
null,
40500,
56300,
114700,
61300,
45700,
24800,
76400,
54800,
40200,
49400,
27200,
22800,
13700,
24900,
56200,
10700,
25600,
55000,
15000,
71400,
21200,
23100,
17700,
12700,
14800,
15500,
61100,
8000,
null,
37400,
20300,
7700,
22700,
23000,
33800,
5400,
13200,
25200,
8700,
10600,
108566,
27700,
22200,
31000,
42700,
19000,
17300,
8400,
10805,
20300,
8800,
32830,
23500,
18500,
19300,
41100,
38100,
10500,
51700,
11400,
9400,
9500,
21100,
39500,
10600,
16100,
42200,
35100,
12500,
null,
23800,
18100,
15000,
13300,
30800,
null,
21000,
71900,
18800,
24100,
37400,
31000,
94700,
50800,
107592,
45900,
66500,
56000,
46100,
15878,
126700,
34200,
24900,
31500,
11500,
8900,
12000,
16000,
14400,
13508,
35700,
71700,
21600,
11600,
11675,
9900,
39700,
24300,
24900,
39100,
9600,
25000,
37000,
null,
73400,
null,
13700,
31200,
33100,
24200,
5300,
7500,
11800,
23400,
6500,
30400,
33800,
null,
null,
3500,
57700,
45100,
19500,
11300,
19000,
18000,
6700,
11300,
29200,
7900,
13400,
10800,
4350,
41400,
12000,
12700,
31700,
9400,
18200,
31700,
24900,
17200,
16700,
9300,
76400,
33600,
71200,
13000,
23800,
45800,
22200,
16300,
19100,
105400,
33000,
15300,
20400,
48100,
13200,
9100,
12400,
6300,
67600,
7100,
38200,
9700,
49200,
4700,
27000,
9400,
38100,
37000,
null,
21500,
22200,
44900,
31400,
null,
26600,
13500,
9500,
21800,
16400,
25100,
56100,
15600,
27300,
29400,
27800,
11900,
10900,
29500,
21500,
null,
22700,
25100,
8800,
12000,
29800,
24026,
null,
24600,
7200,
5100,
31300,
7600,
6000,
20400,
52500,
22100,
30000,
45900,
null,
62800,
31600,
60200,
16900,
69100,
8300,
15500,
11500,
5900,
43100,
null,
null,
19300,
20100,
19400,
null,
128200,
32300,
45800,
24000,
64300,
32300,
6800,
12700,
51600,
6000,
22400,
78400,
9500,
18200,
18600,
9200,
17600,
31440,
39700,
18700,
11000,
null,
32300,
6300,
146000,
12400,
17300,
36104,
null,
21900,
26300,
63700,
16700,
9200,
44000,
29300,
38300,
41500,
37000,
15500,
20900,
16500,
20600,
22200,
null,
15000,
40800,
76700,
3300,
8000,
17900,
null,
12338,
14000,
11200,
null,
24700,
90600,
7300,
26300,
53800,
27000,
20300,
25700,
39300,
28600,
25000,
67100,
33100,
26800,
31600,
27600,
49900,
11300,
null,
38300,
16300,
44200,
42100,
43200,
12300,
61100,
9300,
12800,
16000,
24100,
24600,
48900,
92500,
23900,
18200,
34400,
19600,
10400,
14500,
26100,
42000,
24000,
15800,
32300,
19700,
24300,
17100,
14300,
12600,
13500,
29200,
41200,
29000,
62564,
51100,
null,
21000,
14200,
40600,
4000,
8700,
38800,
81800,
28400,
32200,
12200,
76400,
null,
10800,
13500,
6300,
27500,
80300,
24300,
27900,
35400,
19800,
43600,
6000,
23600,
44600,
17700,
22900,
58000,
29500,
28300,
7200,
14300,
null,
14800,
17200,
30900,
33100,
81700,
20100,
78500,
11400,
100600,
13000,
36300,
38400,
27500,
66800,
8000,
24300,
14300,
11200,
16300,
24618,
21900,
49500,
8600,
11500,
37800,
40300,
3200,
23100,
5400,
8500,
21400,
15100,
20300,
11800,
32700,
87800,
8400,
11800,
50100,
55001,
9100,
24300,
43600,
10300,
49200,
null,
null,
20600,
3000,
34100,
33300,
10700,
null,
42000,
22000,
58900,
17200,
33500,
83900,
56600,
33200,
76800,
null,
6900,
null,
45400,
19200,
70900,
10900,
36800,
46800,
26000,
42100,
null,
50900,
24800,
20000,
12900,
46500,
22400,
15500,
37600,
20100,
13200,
88700,
17700,
54800,
null,
18400,
22500,
17600,
null,
31100,
61600,
null,
38452,
16200,
33900,
26100,
23600,
17300,
30300,
12100,
34400,
6600,
53300,
63300,
24800,
38000,
46900,
9200,
23700,
4900,
16500,
7000,
45600,
19600,
16400,
31000,
800,
25600,
61200,
31800,
53200,
6400,
22600,
63100,
24300,
11200,
37900,
41500,
44800,
48610,
19000,
33000,
14100,
null,
5600,
12600,
46000,
36100,
17700,
15000,
3000,
42100,
39000,
17000,
9800,
10810,
9600,
40300,
22800,
null,
26800,
null,
18850,
66100,
22200,
41600,
22100,
null,
12100,
24900,
51900,
42900,
12800,
35800,
82490,
25900,
18900,
49300,
17100,
51800,
23700,
null,
24700,
28500,
10300,
21500,
14400,
31200,
7000,
36400,
62800,
null,
21500,
29500,
5900,
9900,
17100,
26700,
61500,
64500,
17700,
10200,
41800,
11200,
18250,
103500,
20000,
110600,
29900,
9400,
18800,
28900,
43200,
6100,
26313,
35055,
800,
13400,
12900,
19900,
26200,
4600,
87500,
33600,
45600,
72900,
null,
22400,
28500,
48300,
28400,
14900,
15100,
39300,
58900,
null,
40100,
27900,
11000,
129400,
65600,
41300,
26900,
17600,
25500,
40300,
61900,
18100,
null,
48800,
19900,
17400,
17600,
51100,
53900,
44800,
11900,
85200,
13500,
9600,
13300,
38200,
27700,
45700,
61800,
9200,
16100,
9700,
25400,
45700,
14580,
18500,
18700,
11000,
18500,
26600,
17200,
null,
14900,
12400,
33900,
16700,
16700,
42600,
15800,
21500,
101200,
21600,
29600,
6400,
33100,
11700,
null,
15100,
7500,
20200,
25100,
null,
36052,
22900,
14700,
null,
24200,
13600,
15800,
8000,
23400,
null,
40100,
14100,
14100,
37600,
18500,
8600,
3000,
27800,
129200,
28400,
13400,
14000,
62200,
58900,
null,
31700,
5200,
3800,
11800,
22600,
16400,
null,
44500,
21300,
17800,
19500,
15600,
4200,
27300,
27900,
11000,
36000,
8700,
63800,
18000,
11700,
11800,
25700,
null,
13300,
7900,
32750,
49500,
8800,
5200,
null,
42300,
null,
71237,
19800,
41500,
12700,
24200,
30300,
31700,
35500,
53300,
83800,
8900,
15900,
17500,
13800,
31900,
8000,
42900,
26600,
19300,
29400,
36400,
null,
18100,
66900,
20400,
35500,
24000,
14900,
16500,
500,
93700,
null,
51800,
55981,
94500,
28000,
null,
101400,
11900,
12100,
9000,
11200,
107100,
29600,
4200,
25900,
11700,
17900,
72300,
21500,
null,
26400,
17500,
44600,
30000,
43200,
8800,
20700,
41900,
16100,
null,
19900,
24200,
36300,
39100,
81800,
28100,
27900,
17900,
21000,
14200,
8300,
24900,
59200,
22900,
10800,
17200,
null,
9900,
23000,
40800,
76500,
4800,
16000,
null,
8300,
40900,
null,
45800,
16800,
12100,
32800,
13500,
71800,
null,
33000,
50800,
9700,
52000,
23000,
21700,
17700,
9200,
46400,
9800,
56100,
26000,
null,
8000,
null,
23400,
35100,
24400,
28500,
13100,
70900,
2500,
9800,
7500,
174400,
70600,
null,
63400,
37400,
27100,
7500,
20500,
72200,
49300,
3700,
3300,
6500,
13100,
3600,
25700,
null,
15800,
8000,
36000,
14600,
19100,
26250,
34200,
26800,
9400,
19200,
10900,
54100,
14600,
10000,
39700,
29500,
null,
68800,
29900,
128700,
111000,
81145,
5500,
5500,
30500,
45700,
22400,
11350,
7600,
14900,
15400,
10600,
7500,
203400,
6100,
27200,
27700,
38200,
25200,
30700,
16900,
15300,
3400,
16200,
10800,
71000,
14900,
17900,
35500,
74200,
17600,
22100,
25300,
38650,
5300,
null,
9100,
33600,
33800,
63900,
12500,
10100,
36300,
87400,
35200,
7400,
22500,
14500,
29200,
null,
null,
50100,
11200,
22400,
27500,
17100,
50300,
32000,
null,
30200,
17300,
47400,
50200,
55000,
13200,
25200,
29800,
185100,
8500,
8100,
21800,
25400,
13900,
32200,
13500,
18900,
23800,
15200,
15000,
30600,
23900,
127000,
12200,
40300,
46900,
77400,
11700,
30900,
35500,
41100,
78400,
10000,
41500,
19100,
11300,
40300,
45100,
44500,
14500,
31600,
24600,
39200,
77500,
116500,
25000,
7000,
null,
8300,
19700,
40100,
2300,
55400,
88500,
36500,
28600,
15100,
32700,
22900,
46900,
39400,
19000,
50400,
23600,
65700,
14700,
9800,
16300,
11800,
35500,
26500,
23400,
16400,
null,
28300,
11300,
12900,
21700,
null,
35000,
63800,
18700,
24400,
4300,
24300,
23500,
null,
95500,
34400,
23000,
9700,
49700,
29400,
19800,
84300,
21000,
17900,
17700,
36300,
40300,
5400,
16500,
38200,
13600,
20000,
null,
23900,
null,
3100,
25700,
102200,
null,
16800,
20200,
56200,
13600,
34100,
17150,
7100,
21600,
6600,
6700,
80100,
8600,
82100,
23300,
31400,
28500,
15500,
null,
44700,
18000,
10300,
11400,
28500,
30200,
null,
15000,
11800,
null,
39700,
32100,
null,
25500,
12000,
17800,
35400,
58100,
null,
23300,
97300,
18200,
7500,
16600,
25500,
39200,
57000,
null,
26600,
24800,
9100,
22100,
null,
74000,
44200,
52700,
19800,
21000,
351200,
18000,
23400,
58600,
11000,
7300,
15000,
28300,
null,
180400,
45000,
40100,
51951,
28500,
6800,
46400,
6100,
28300,
null,
129100,
25300,
4500,
10900,
14600,
13000,
13000,
13900,
null,
39600,
21100,
11800,
31800,
53400,
5000,
28400,
5000,
23000,
10900,
31100,
211600,
16200,
7400,
8700,
34500,
25200,
46000,
100800,
54800,
13140,
8100,
16600,
25900,
70800,
12400,
3200,
83500,
4500,
16600,
45600,
8800,
33600,
49700,
5750,
96800,
3400,
23200,
48300,
11200,
12100,
6400,
26000,
15400,
21300,
null,
53500,
49200,
15600,
76800,
51500,
21600,
17300,
43300,
66400,
4300,
38100,
11100,
33700,
121100,
null,
30300,
20900,
94600,
22400,
16800,
56200,
26500,
23200,
14400,
22700,
131558,
16800,
22000,
33900,
27700,
34400,
6300,
52300,
29400,
12300,
16900,
14300,
11600,
28500,
13400,
38100,
19900,
39085,
29300,
39600,
20200,
36300,
97100,
24100,
10800,
15000,
38500,
38300,
9500,
22700,
null,
53800,
71100,
128400,
null,
28200,
37700,
50800,
41800,
68000,
10930,
36700,
19400,
23500,
12000,
46900,
9200,
16300,
10700,
21300,
null,
22800,
27800,
37400,
26200,
12300,
null,
28200,
3800,
39000,
114300,
13100,
19700,
23500,
7000,
22400,
24600,
null,
23900,
63800,
61400,
19000,
20100,
5900,
12500,
37700,
29100,
null,
52533,
16900,
27500,
23700,
16500,
72400,
18100,
30600,
29700,
84800,
8100,
17400,
23700,
25800,
105500,
39100,
53600,
31500,
6700,
39700,
7200,
53300,
2000,
19100,
14600,
18500,
49600,
17500,
14100,
16500,
14000,
23500,
73300,
39600,
21000,
19200,
19100,
19700,
2100,
39900,
45300,
82400,
50200,
12000,
null,
15000,
29800,
24300,
26200,
76800,
20600,
8150,
21800,
28900,
18300,
15200,
22400,
14400,
10100,
150700,
11500,
22600,
32000,
19700,
52100,
20100,
56000,
29800,
56600,
71000,
4700,
13200,
12500,
15200,
5200,
13400,
28600,
111000,
12800,
34000,
15800,
6300,
29600,
13700,
102700,
27600,
null,
36300,
80900,
171800,
24000,
49100,
40100,
null,
55400,
39800,
33800,
2600,
34300,
92100,
48400,
34300,
3500,
26500,
null,
null,
18100,
null,
9900,
14300,
null,
18900,
26400,
7000,
26700,
38300,
19900,
41302,
33500,
24100,
17500,
21900,
14000,
54300,
7500,
10700,
77200,
10200,
40800,
12000,
66804,
57900,
11800,
12600,
69200,
null,
null,
13100,
28700,
18900,
29100,
36100,
51400,
63600,
10500,
109100,
19100,
45900,
15000,
65000,
24900,
11800,
26500,
24800,
null,
101100,
21800,
40000,
7500,
14800,
33400,
44100,
60000,
21700,
5100,
18400,
32300,
12700,
29300,
107900,
18400,
12600,
19700,
14100,
16100,
12500,
56900,
22500,
9400,
10800,
33600,
18200,
47900,
42700,
34000,
null,
61600,
null,
94200,
66100,
28800,
12900,
40200,
12200,
38500,
30000,
15200,
18700,
34900,
9000,
37500,
53500,
86700,
132900,
25000,
65000,
66400,
22400,
1600,
21200,
29400,
15700,
85000,
50400,
6600,
19600,
71700,
16800,
11000,
9400,
96500,
null,
null,
34400,
41200,
6100,
null,
13200,
14300,
55993,
null,
24000,
117900,
13600,
null,
45126,
40800,
17700,
81400,
33600,
75200,
50600,
25300,
39900,
28900,
8600,
59700,
null,
67400,
28300,
19300,
11100,
22200,
51900,
12500,
32200,
11500,
27600,
null,
13700,
105300,
71000,
7900,
18000,
63200,
40800,
12400,
48200,
21900,
5200,
11500,
27200,
27600,
null,
25900,
9600,
22575,
9500,
27000,
13300,
32500,
18700,
73600,
10400,
23477,
57810,
3000,
40848,
18900,
15000,
21300,
139800,
13300,
16200,
57500,
16200,
8700,
13000,
46500,
31500,
34700,
22800,
4400,
32013,
null,
31300,
16700,
56200,
35653,
25600,
52200,
4300,
20700,
12800,
22450,
14200,
62500,
5600,
14500,
52200,
42100,
10800,
6700,
13500,
29900,
36700,
9400,
null,
64700,
17700,
10400,
49600,
36500,
17000,
64100,
14100,
62500,
22900,
20800,
12400,
10400,
null,
24000,
15100,
17600,
53200,
null,
23800,
null,
14500,
18100,
92000,
187000,
40300,
12800,
13600,
12500,
10100,
89000,
11100,
38200,
40400,
31200,
24600,
8600,
31200,
9300,
8600,
40800,
44500,
20700,
22900,
33100,
6700,
28900,
32400,
14300,
24900,
29300,
20600,
16700,
36300,
17600,
41800,
18500,
12200,
20300,
null,
31950,
109200,
40300,
37800,
9800,
105800,
15600,
63900,
9800,
16700,
18500,
11900,
23500,
39600,
17100,
7000,
196400,
23200,
34100,
9100,
75208,
80500,
22800,
30500,
null,
18800,
34300,
23100,
39400,
8300,
66100,
35000,
31600,
112400,
21900,
50900,
null,
13600,
13646,
18100,
11200,
31000,
62600,
null,
16000,
16500,
10100,
67400,
55200,
39100,
55400,
160200,
7900,
40600,
29100,
11200,
33500,
20000,
26700,
26200,
43500,
18300,
58610,
32800,
39100,
7500,
55800,
55400,
41800,
null,
22700,
6600,
62900,
67780,
23700,
40900,
7500,
32600,
43500,
22000,
16300,
50800,
30800,
72800,
53000,
10400,
9400,
88100,
36900,
49100,
34000,
10000,
64900,
10800,
58100,
20200,
51400,
50702,
null,
166800,
155426,
35200,
19000,
16340,
null,
11400,
null,
5300,
46000,
10700,
23700,
53600,
17400,
20200,
3600,
14200,
100300,
37900,
31200,
20100,
20000,
17000,
20753,
null,
66500,
5200,
22200,
19100,
7300,
510100,
23500,
44300,
46400,
42300,
56400,
19400,
74400,
17800,
18700,
16000,
19600,
20300,
17300,
33700,
17500,
43900,
12500,
22300,
25700,
44100,
101200,
15000,
8900,
14000,
23500,
68300,
2900,
7500,
57200,
16700,
null,
null,
47600,
9160,
12300,
70318,
null,
15200,
31800,
17700,
35400,
4400,
41100,
16900,
7400,
8600,
66900,
55900,
50400,
3300,
26900,
14100,
132600,
5300,
25000,
50400,
26800,
19100,
19600,
37400,
21900,
12000,
19500,
13700,
8500,
14300,
82000,
73500,
112200,
9100,
16300,
9600,
20400,
23200,
8600,
19200,
20600,
49400,
45200,
28400,
43600,
70000,
7900,
20900,
11200,
20400,
1500,
11200,
25500,
62200,
20900,
54700,
7300,
33000,
18300,
10100,
5500,
null,
32600,
10100,
35200,
33200,
21700,
38000,
13000,
2000,
12100,
97100,
66800,
7450,
17600,
8300,
3500,
17900,
17800,
29100,
35600,
27003,
25800,
null,
112900,
22800,
18800,
28800,
21300,
25000,
7600,
86000,
22000,
13800,
32700,
29900,
51800,
13300,
23300,
18300,
39000,
31400,
14900,
16500,
67300,
10400,
45100,
18200,
22200,
10900,
58100,
19400,
7300,
14000,
259000,
27800,
7200,
13600,
17300,
12900,
null,
138900,
46900,
17600,
19900,
null,
25000,
null,
39800,
28200,
20300,
15600,
13000,
36800,
null,
32200,
2200,
21300,
7400,
26800,
19900,
null,
7000,
23300,
29800,
57900,
null,
25200,
17200,
8500,
13000,
29800,
26900,
22400,
25300,
44100,
103000,
20900,
63200,
8800,
null,
33100,
17800,
17900,
28200,
19474,
15900,
117800,
24800,
null,
40900,
50500,
9100,
15800,
23800,
12400,
12800,
null,
24400,
27300,
20600,
43100,
17900,
31000,
97700,
67200,
null,
96700,
12800,
46800,
33900,
48800,
28500,
null,
19000,
30700,
21600,
null,
28900,
9200,
4600,
19800,
48800,
20400,
61600,
40700,
42600,
24700,
11400,
104700,
13100,
22900,
27500,
16500,
25400,
32400,
21600,
13200,
10200,
34400,
8500,
15300,
9300,
43200,
9200,
27900,
17600,
6700,
100200,
40200,
50900,
13800,
13100,
15100,
19400,
null,
21900,
9500,
2800,
11600,
43100,
47100,
46000,
27000,
24500,
27200,
28500,
5300,
17800,
25600,
28300,
8100,
24600,
23500,
null,
67400,
null,
47600,
23100,
34400,
6800,
16200,
7200,
18300,
41700,
19200,
30400,
39500,
58800,
33000,
19500,
24400,
8200,
8910,
36100,
14900,
19100,
25100,
14500,
7400,
16300,
8100,
58900,
13300,
15800,
24500,
null,
30100,
17000,
23200,
15300,
35200,
53800,
5200,
61200,
28700,
21900,
15255,
18400,
6200,
null,
24700,
null,
26100,
65600,
6200,
26100,
23700,
36200,
48000,
11800,
11300,
23500,
15800,
27300,
49700,
10600,
16300,
38600,
35600,
null,
23700,
6300,
29200,
75400,
null,
19800,
62900,
26800,
11300,
20900,
12100,
21900,
null,
2600,
16300,
14700,
16300,
15000,
8400,
null,
20300,
19900,
17600,
24500,
56200,
30800,
63400,
53600,
42600,
14754,
101500,
15100,
70000,
55800,
36500,
11800,
81700,
9600,
9200,
29900,
21900,
35400,
7453,
33400,
55900,
40500,
71600,
63100,
45100,
14200,
53800,
43700,
13400,
11500,
9900,
22900,
16400,
7500,
43300,
34500,
15700,
68900,
3200,
38300,
null,
10830,
101100,
78100,
4300,
16300,
33400,
57500,
null,
19200,
6800,
10900,
18800,
24700,
6900,
7100,
16100,
127500,
18000,
14000,
6000,
60730,
8400,
7400,
15500,
68600,
23300,
19200,
4700,
86000,
16800,
2700,
41400,
8400,
6400,
36800,
13800,
202000,
11700,
33300,
6000,
97800,
25300,
29200,
101700,
32597,
20800,
1900,
6800,
64500,
82800,
93600,
16900,
21700,
12800,
9700,
42200,
24300,
16000,
9600,
50100,
260900,
31200,
80700,
25100,
51900,
27800,
6600,
13500,
2000,
44500,
8200,
25300,
9300,
null,
8100,
121300,
28000,
19700,
10900,
20100,
24700,
6800,
null,
17400,
19500,
34100,
36800,
13200,
null,
18100,
11500,
18300,
11000,
5800,
31800,
68400,
40000,
null,
12700,
47600,
37600,
14100,
17500,
16500,
null,
5400,
4800,
25500,
20500,
27500,
27000,
null,
14700,
5900,
19400,
16150,
19400,
26300,
27100,
22800,
null,
10900,
null,
14100,
19200,
114900,
78400,
35286,
null,
45900,
null,
45800,
2600,
22700,
5400,
40300,
13500,
null,
22303,
26000,
42300,
14500,
17500,
55500,
44000,
33000,
86500,
18800,
7700,
63795,
6000,
87900,
17200,
49500,
11800,
29100,
null,
25100,
10900,
null,
10700,
13600,
33000,
11600,
3100,
null,
36100,
20200,
9200,
36300,
9300,
48600,
19000,
49500,
37700,
21400,
38200,
23900,
16800,
22300,
26600,
4800,
19500,
28600,
17800,
16300,
17900,
5300,
50819,
16300,
10900,
15500,
50700,
86500,
6500,
null,
18900,
null,
37500,
26600,
null,
126300,
11200,
15400,
null,
55600,
33700,
52500,
30100,
41200,
30000,
200,
80915,
14400,
34600,
24900,
19400,
12100,
3800,
24700,
11000,
null,
23400,
31700,
29800,
15900,
13800,
null,
null,
18700,
25800,
17400,
7200,
13500,
46400,
31400,
20500,
34800,
31600,
15300,
28300,
36700,
7300,
6500,
26700,
31900,
4900,
52200,
12800,
11200,
54100,
15900,
10100,
14500,
98000,
9500,
80300,
38000,
44500,
9200,
78400,
44300,
14700,
11800,
13800,
15500,
26500,
35400,
43000,
43100,
5650,
null,
12300,
36100,
8600,
26100,
null,
1300,
8900,
73200,
12900,
10700,
90700,
19600,
62500,
18400,
54255,
14500,
9300,
21500,
45100,
16400,
11400,
13600,
12700,
22700,
17400,
23400,
31800,
19100,
25700,
12400,
10400,
54200,
14900,
13200,
107100,
null,
30500,
32000,
31900,
19400,
57500,
14100,
51200,
10900,
25000,
80500,
null,
21400,
16990,
40100,
null,
35200,
12200,
64100,
41800,
18700,
13400,
20200,
null,
24400,
9600,
34800,
74200,
2300,
24900,
13100,
17100,
677800,
7300,
39700,
24900,
12800,
14300,
15400,
61000,
31100,
13100,
13000,
23400,
1900,
7600,
null,
13000,
21100,
5100,
16900,
43700,
5900,
12900,
31400,
null,
51800,
35900,
70600,
7400,
1700,
28500,
13100,
22400,
44600,
74500,
13500,
24900,
19500,
88900,
50700,
47700,
55200,
11800,
37700,
9600,
18630,
48100,
10900,
35700,
null,
23500,
null,
12700,
15500,
34900,
null,
100800,
27300,
77400,
16200,
14050,
19800,
null,
109200,
18000,
59900,
55700,
31200,
10000,
76500,
17400,
41000,
142600,
6500,
54300,
117600,
19100,
38500,
7700,
116550,
35100,
7350,
18600,
28700,
12800,
40400,
34200,
49300,
26800,
21900,
null,
58100,
19800,
15800,
9300,
16800,
12800,
34900,
78600,
76200,
19600,
24400,
16300,
58500,
38700,
186955,
24000,
13100,
81700,
8400,
18000,
46800,
58200,
17680,
60300,
7500,
39200,
15900,
25100,
54000,
null,
null,
36600,
41900,
16400,
null,
18800,
16900,
53400,
60600,
54500,
14700,
41600,
12000,
17800,
41800,
24100,
61600,
54500,
29500,
null,
60600,
64000,
23900,
65500,
20400,
null,
22600,
27700,
25500,
50000,
12700,
56300,
291600,
35600,
30450,
13700,
217600,
113500,
10700,
71600,
54100,
53000,
17700,
30500,
12000,
28100,
null,
57300,
6300,
10300,
105200,
5800,
30000,
3700,
16700,
13500,
23700,
13700,
null,
null,
218100,
20400,
26500,
15200,
28700,
27500,
42300,
32500,
16600,
36900,
null,
null,
28700,
122900,
22500,
53600,
21000,
30800,
9500,
22400,
68574,
17300,
17500,
66200,
69200,
5900,
4900,
37400,
10500,
25700,
24100,
20000,
53500,
46600,
18400,
33000,
37100,
36400,
14800,
24900,
32217,
10600,
null,
19500,
27200,
16600,
10600,
13800,
103900,
20200,
41800,
10000,
27100,
21000,
13800,
12000,
32600,
44800,
49300,
null,
37000,
22500,
8300,
null,
34700,
100118,
68300,
21900,
13400,
21300,
10000,
14500,
14200,
17100,
14400,
36200,
34000,
23300,
33600,
84600,
12200,
11600,
345300,
18300,
14400,
27200,
25800,
73410,
9000,
20400,
90100,
23000,
29800,
5000,
1500,
42300,
43400,
23900,
38400,
6400,
18700,
44300,
22500,
13800,
5200,
6000,
22300,
31500,
11000,
15400,
14100,
14900,
28300,
1500,
117700,
42200,
36600,
69500,
28300,
6300,
21800,
9000,
12200,
17700,
6300,
null,
29900,
4300,
16430,
12800,
30800,
null,
6000,
12600,
10300,
34100,
39900,
8000,
12100,
null,
57700,
41500,
1200,
null,
49900,
30100,
176700,
56350,
16200,
16200,
4500,
20700,
16700,
20500,
27000,
6900,
9100,
74900,
17000,
30000,
7700,
47800,
22600,
2400,
12700,
15600,
null,
85400,
23000,
44100,
null,
44900,
124100,
null,
25700,
37500,
17100,
9600,
20800,
60300,
12100,
9500,
17600,
12000,
31200,
10800,
32900,
10100,
3100,
14900,
9700,
71300,
54400,
null,
53200,
15500,
33100,
27400,
42700,
40400,
22800,
23500,
15900,
null,
5000,
30800,
20100,
9800,
11400,
5300,
48100,
41800,
30800,
13800,
21300,
22400,
null,
20200,
7200,
13100,
30359,
25300,
null,
19000,
null,
14000,
null,
68600,
29100,
10200,
41700,
14000,
24700,
381900,
23400,
null,
8900,
28100,
29900,
47400,
52600,
19500,
6100,
18900,
7400,
9600,
8500,
26100,
44100,
29400,
33900,
40600,
12900,
12400,
20400,
7500,
3700,
null,
null,
63200,
32500,
72200,
null,
6150,
26000,
6000,
30300,
15300,
9100,
36300,
20600,
66338,
25200,
24600,
17100,
15600,
31000,
41300,
18500,
25600,
23400,
135000,
61900,
null,
29400,
37900,
58500,
31000,
7900,
35900,
null,
15800,
13200,
53700,
14600,
31700,
26000,
44500,
14200,
null,
28800,
20100,
57400,
13100,
27400,
75000,
21500,
3000,
1500,
93600,
26800,
45000,
7900,
21100,
23300,
null,
5800,
null,
15000,
31600,
26800,
10500,
62700,
38600,
null,
22000,
10200,
8300,
5700,
19200,
12800,
3800,
98900,
800,
71309,
27400,
11100,
29700,
18900,
5900,
12400,
49400,
13600,
49700,
62800,
63100,
67900,
18400,
50100,
21000,
9900,
36800,
4800,
42900,
11500,
43500,
44600,
4300,
null,
36200,
20900,
29200,
24800,
26500,
58000,
11900,
75000,
41900,
9600,
69400,
36900,
72800,
20400,
65300,
null,
7300,
23800,
24100,
109300,
43200,
33700,
31800,
12000,
40700,
25000,
17300,
8500,
24900,
9300,
21200,
62500,
40400,
33700,
25700,
null,
null,
21300,
31400,
105200,
24500,
31900,
2800,
24500,
12500,
7700,
37300,
13400,
27600,
34800,
null,
28200,
33900,
50100,
20300,
null,
35800,
40500,
8250,
39700,
0,
21100,
17500,
20500,
21200,
63600,
42000,
19100,
6800,
20900,
4500,
35300,
null,
8300,
16100,
46900,
600,
29100,
62900,
17200,
20900,
34100,
38200,
7300,
56900,
64800,
51000,
7500,
12800,
35400,
4800,
13500,
29200,
2850,
null,
12600,
31200,
6000,
33100,
22000,
29500,
5900,
36400,
40700,
34000,
21000,
21900,
13100,
16700,
68300,
53700,
null,
20700,
15200,
17800,
48600,
17100,
13500,
20400,
38900,
18100,
27800,
14100,
27500,
35548,
30900,
20900,
44800,
54900,
19600,
36500,
74900,
50600,
38600,
8500,
10000,
80900,
82500,
48500,
53300,
44400,
20500,
25500,
54466,
23900,
110100,
null,
12300,
50500,
6200,
13700,
5600,
26610,
210200,
22100,
30300,
9700,
17000,
null,
17200,
38000,
9800,
17600,
11500,
null,
22000,
26300,
16000,
42200,
6000,
27300,
13300,
7400,
5500,
32300,
3600,
null,
19600,
null,
22400,
51500,
10800,
37800,
77200,
36500,
30000,
70400,
32900,
43600,
null,
13000,
23500,
13500,
40100,
16600,
40300,
12600,
22600,
25000,
null,
null,
null,
20200,
11300,
40800,
11600,
15300,
null,
1800,
25800,
54200,
19900,
51000,
7000,
92097,
28400,
27900,
33400,
45200,
25800,
73700,
28900,
34200,
15700,
30400,
47200,
37500,
14600,
58000,
16200,
16800,
40300,
12600,
8820,
53600,
22900,
15300,
42600,
28900,
20900,
15400,
14300,
2900,
150400,
15400,
31900,
35700,
null,
94700,
null,
4400,
16200,
16800,
34400,
22200,
22900,
111900,
15600,
5000,
47600,
40500,
52600,
20600,
9600,
13600,
7300,
42300,
24700,
19900,
53700,
34400,
14500,
65400,
null,
null,
22000,
13100,
59100,
40800,
36300,
19100,
47100,
8700,
29100,
53800,
14700,
50200,
null,
23600,
40200,
15000,
11000,
12300,
38500,
22000,
62900,
22600,
18200,
36400,
35100,
36400,
48400,
30200,
19900,
32300,
27600,
37800,
31500,
15200,
46600,
35900,
96700,
9100,
null,
25400,
null,
40000,
14900,
3000,
1600,
13000,
23400,
71600,
43600,
21800,
38500,
35405,
42000,
61500,
84300,
17000,
15550,
34800,
4600,
107100,
24700,
17700,
17600,
9200,
43400,
11600,
11800,
34700,
30600,
22000,
null,
28500,
19000,
68771,
11900,
21000,
33300,
null,
15600,
32800,
18800,
14300,
33900,
206600,
40900,
5000,
37300,
18400,
25800,
3200,
70200,
41200,
11400,
28200,
15200,
null,
18900,
14000,
19800,
35100,
48000,
15600,
6100,
17400,
7200,
12800,
20900,
11500,
15500,
15100,
21200,
37800,
null,
10800,
null,
54300,
31600,
17600,
16900,
12000,
10200,
15300,
31100,
21700,
11300,
19600,
37600,
26700,
10400,
24600,
43800,
null,
47900,
null,
5800,
3900,
22600,
20800,
8100,
18400,
13000,
52500,
19500,
12900,
17000,
27900,
16100,
35000,
40100,
26900,
45800,
15400,
28500,
31800,
16200,
74000,
null,
15700,
10000,
16300,
23900,
13900,
10100,
16900,
40200,
11100,
13450,
78600,
13100,
86800,
60000,
43500,
null,
32200,
null,
17400,
39800,
55000,
8100,
38100,
135100,
24100,
80000,
8700,
26400,
31800,
11590,
4300,
18900,
42100,
39300,
21700,
3700,
9400,
8100,
10100,
33500,
34600,
67100,
4500,
42100,
15000,
11200,
14500,
19500,
27500,
25700,
100100,
118800,
null,
8000,
38000,
94000,
23900,
22200,
10800,
19600,
8500,
10100,
36200,
24500,
18400,
26800,
28700,
61500,
13600,
25100,
6500,
310800,
41200,
29900,
23900,
9700,
238800,
22100,
27700,
36076,
20300,
18800,
69500,
null,
45700,
33500,
14800,
12300,
888800,
57700,
78800,
32500,
32300,
68600,
23500,
47600,
12200,
86300,
56100,
89400,
21200,
46043,
17900,
14600,
47400,
40300,
31592,
19600,
9400,
24100,
77400,
14500,
25700,
16600,
46800,
null,
20000,
null,
10400,
60600,
12100,
7500,
23500,
26400,
18200,
28100,
34700,
16200,
133700,
27800,
11700,
18500,
17600,
32100,
62500,
79600,
69800,
55800,
67300,
98300,
15800,
25000,
48800,
27500,
null,
23100,
18300,
28300,
29600,
10200,
40000,
45400,
37800,
null,
23800,
19800,
28300,
80100,
20000,
null,
11500,
13000,
40200,
70800,
7700,
8400,
34200,
104535,
15700,
8700,
26600,
75700,
14500,
10500,
33200,
11300,
19500,
41800,
29000,
53300,
36400,
27300,
86400,
51900,
41000,
null,
19400,
23100,
3800,
100300,
15600,
9000,
49000,
14200,
18100,
27146,
28300,
12800,
19600,
102400,
7500,
31500,
27700,
11900,
null,
36300,
15900,
54600,
18300,
13600,
16700,
6100,
25200,
11900,
63000,
8800,
10000,
8800,
118688,
85500,
null,
17300,
20400,
12200,
22300,
45000,
23000,
24300,
40600,
47000,
262100,
null,
60900,
13000,
56800,
19900,
12700,
17000,
37400,
12500,
26200,
7600,
35600,
17700,
45500,
33300,
15800,
null,
16700,
10500,
36100,
17700,
29500,
44000,
14500,
12600,
7700,
20200,
41100,
null,
13400,
23200,
18700,
7200,
null,
57600,
5600,
25660,
24250,
62500,
7500,
41700,
50300,
16300,
33100,
68900,
19800,
33600,
61600,
8000,
16400,
27300,
14200,
43600,
14900,
12500,
159300,
24240,
null,
13700,
4400,
27900,
11300,
21200,
34200,
64800,
12000,
25700,
24300,
14800,
2200,
22900,
27000,
12500,
105900,
42200,
30000,
70400,
91300,
8200,
5500,
17400,
25900,
35000,
7200,
25125,
158400,
2800,
16500,
14800,
18000,
5500,
33900,
7700,
32300,
17600,
281000,
15900,
35900,
19500,
59800,
11100,
20200,
null,
27200,
30000,
47900,
33800,
9800,
11800,
34200,
14200,
34400,
50600,
83800,
31700,
20000,
null,
24400,
35600,
62500,
null,
11000,
11100,
13500,
53900,
21100,
14700,
25500,
null,
27300,
18200,
18200,
null,
5100,
12600,
47400,
17400,
20600,
14400,
4700,
5800,
24500,
14500,
5200,
84800,
32900,
28800,
58342,
40800,
26300,
9600,
5900,
22800,
22600,
21400,
16400,
55100,
28300,
34200,
10000,
6600,
92360,
9200,
22400,
4100,
null,
null,
15400,
58100,
10000,
9500,
52300,
24700,
42800,
19800,
6700,
31800,
59100,
34300,
92000,
18900,
6900,
21800,
29700,
77100,
53600,
53498,
null,
25600,
13900,
41300,
34100,
52300,
39800,
10000,
18500,
60600,
36899,
16000,
22800,
68600,
29600,
32300,
9800,
null,
17300,
4400,
25600,
21500,
14800,
17500,
14900,
45400,
47300,
5000,
10600,
206300,
9100,
26900,
null,
29800,
17900,
61700,
63200,
26400,
38900,
53400,
38800,
58100,
26100,
35200,
11200,
14400,
17100,
13600,
31100,
12800,
58500,
126800,
54900,
7600,
56700,
null,
17050,
84600,
28500,
8300,
17000,
27200,
18100,
14500,
51800,
37500,
46100,
40700,
53600,
6400,
20500,
15800,
23400,
6900,
76900,
26800,
21400,
8100,
14000,
42400,
null,
35400,
17900,
18500,
29300,
15800,
11100,
22500,
9800,
25000,
13300,
19700,
24900,
32100,
10000,
31000,
33400,
33800,
30300,
63000,
34800,
41200,
13100,
11900,
9600,
19000,
23600,
null,
14900,
42800,
21500,
126900,
43500,
12500,
26600,
18200,
48100,
26600,
34100,
20100,
21800,
62800,
20600,
33200,
33600,
43000,
39800,
27800,
30600,
43600,
7200,
6300,
109500,
50000,
25600,
46200,
null,
97800,
11700,
39600,
20500,
30100,
45000,
15800,
null,
10100,
8600,
15300,
68700,
52900,
24100,
null,
10500,
31400,
null,
9200,
34000,
11800,
31600,
7000,
17700,
16400,
40600,
14900,
39500,
9700,
32500,
23400,
10300,
69600,
22800,
34500,
19000,
36200,
13000,
18100,
46700,
10500,
25500,
20200,
39673,
44200,
27000,
37600,
46900,
28600,
22300,
10600,
50000,
47100,
36200,
34500,
7200,
13500,
23600,
null,
null,
14600,
18800,
8300,
18700,
120200,
28400,
24300,
12300,
56800,
15100,
43400,
19600,
44800,
16600,
11600,
44900,
4200,
36600,
19200,
30200,
null,
26200,
119300,
21100,
7900,
12500,
14400,
11400,
24900,
14400,
14900,
30800,
8900,
56400,
6100,
null,
13200,
16000,
51400,
22500,
52500,
21800,
27800,
12600,
58900,
21300,
25300,
16400,
6200,
33400,
16000,
53300,
34200,
11400,
32200,
29500,
15300,
96800,
32200,
15100,
26100,
null,
15100,
25400,
35000,
36200,
28400,
29100,
10200,
18700,
15300,
63800,
12900,
49700,
74900,
92450,
7800,
null,
33600,
17600,
null,
17100,
27200,
74900,
48000,
19500,
28700,
31600,
11900,
7400,
18700,
19700,
16000,
128431,
72500,
70800,
37000,
19600,
null,
15300,
null,
11000,
11200,
28000,
47600,
16200,
12100,
73800,
11900,
23700,
12400,
9000,
21100,
39100,
77800,
27000,
null,
22200,
16900,
10800,
115900,
24200,
11000,
9600,
23100,
9250,
28600,
50600,
51100,
2800,
11500,
25700,
46400,
14800,
20605,
7700,
20400,
3500,
35700,
40800,
26100,
32100,
8600,
null,
22000,
121000,
9100,
18100,
29800,
10100,
4800,
43600,
47400,
null,
12800,
44000,
15700,
16600,
29300,
22200,
56311,
54700,
12600,
18000,
9100,
50000,
29600,
6400,
null,
11700,
20200,
152700,
15300,
8200,
76600,
25200,
70500,
24100,
10600,
14500,
null,
null,
12000,
85900,
32670,
39700,
53200,
41000,
null,
null,
27200,
25000,
143800,
null,
57600,
null,
24500,
26600,
23600,
83400,
15800,
5000,
29600,
24800,
12600,
55500,
null,
44600,
9600,
20500,
29800,
61300,
41500,
37100,
23500,
8100,
28300,
35200,
12750,
12000,
16100,
10400,
58300,
29400,
18400,
12700,
44056,
18900,
34800,
12600,
null,
11200,
18300,
9000,
8400,
24400,
26200,
18100,
91200,
24500,
11300,
34300,
29100,
82000,
1200,
33400,
7400,
47506,
12100,
24100,
20900,
20500,
57800,
15500,
57300,
20900,
13400,
53600,
29100,
76700,
45000,
112600,
9200,
29500,
34000,
17600,
20900,
63800,
null,
48400,
16000,
57800,
23900,
32500,
26700,
43200,
74000,
6000,
null,
63200,
46400,
11900,
43500,
21800,
4500,
41200,
null,
34700,
12400,
102300,
13100,
null,
17400,
27500,
25300,
34700,
null,
22700,
null,
19000,
null,
14500,
29500,
null,
85600,
6900,
23000,
18900,
17000,
28000,
7000,
9700,
44600,
null,
25050,
33400,
23800,
22200,
23000,
55700,
36900,
9700,
21500,
500,
21700,
45800,
null,
28900,
12900,
7500,
43100,
37000,
12500,
null,
80800,
16500,
21850,
105200,
41000,
14500,
12100,
40137,
35500,
18300,
30500,
11300,
52500,
8300,
9000,
61500,
14850,
19100,
25600,
25900,
22600,
51800,
442736,
3800,
30100,
6900,
19900,
69400,
22100,
null,
208800,
25600,
48000,
8800,
13900,
17400,
null,
null,
null,
27700,
13900,
42700,
86600,
22400,
null,
20600,
26700,
20300,
6400,
13050,
19800,
null,
41100,
28100,
39900,
20656,
7800,
47000,
16500,
27600,
13900,
19900,
35700,
14600,
18100,
null,
25800,
null,
9500,
null,
13800,
47300,
20800,
120400,
9100,
15800,
30500,
37600,
31500,
18600,
22200,
43300,
29000,
2500,
29600,
40800,
17300,
19100,
7100,
5500,
18400,
34200,
16700,
14300,
6700,
16100,
27000,
18100,
31200,
3800,
7800,
25000,
39900,
null,
55500,
10000,
13900,
11500,
26600,
49800,
17900,
24700,
27900,
36500,
114400,
21700,
20400,
12600,
10600,
8700,
46800,
8600,
24400,
35500,
2400,
41100,
37400,
57400,
63900,
68100,
null,
17200,
21200,
57100,
67900,
77000,
12600,
32200,
8100,
50100,
5500,
20300,
108200,
18000,
57200,
25400,
23900,
3630,
9400,
null,
null,
null,
60200,
24598,
133000,
9700,
13500,
29900,
20100,
67300,
29300,
12800,
29500,
40700,
35500,
100100,
64600,
16900,
33200,
5800,
1300,
17300,
25700,
null,
110600,
17100,
81300,
62800,
7000,
17500,
22900,
25800,
3900,
null,
8600,
25500,
14100,
16300,
44100,
33200,
16500,
25200,
20100,
12100,
60300,
64400,
14200,
6100,
21300,
16700,
16000,
13600,
37600,
5200,
27400,
27900,
14200,
10100,
17000,
35400,
null,
24400,
33200,
6000,
3800,
45900,
27300,
36400,
7800,
19600,
65700,
60100,
21400,
33500,
52000,
8000,
28900,
4800,
26500,
87300,
14500,
null,
20100,
28500,
3900,
10100,
19300,
8700,
11500,
36600,
73900,
10900,
32100,
18300,
43300,
13300,
14800,
6800,
71733,
15900,
42200,
53500,
50300,
14900,
null,
38300,
13000,
18500,
9400,
17600,
25750,
24800,
10500,
12300,
null,
1000,
106900,
36100,
28200,
7600,
4500,
41100,
152000,
6200,
27300,
25000,
43400,
12700,
86561,
13000,
null,
8000,
30400,
6000,
9200,
42300,
27600,
13100,
null,
10400,
11700,
20300,
58800,
12800,
60100,
19600,
15300,
22900,
1000,
15300,
null,
null,
16900,
19600,
36100,
19100,
null,
30100,
43000,
27600,
8360,
null,
39400,
46900,
11000,
10400,
33900,
40400,
24700,
7000,
21600,
14300,
68300,
9000,
null,
39200,
29200,
32300,
28600,
4700,
51500,
7900,
18300,
8000,
24000,
106300,
39100,
21900,
27800,
42100,
70300,
40200,
20800,
22900,
26800,
43400,
20300,
13400,
51100,
21000,
103500,
45000,
null,
14600,
18900,
45200,
15700,
45200,
36336,
null,
9900,
40200,
56600,
6300,
37300,
13800,
12800,
30500,
20200,
15400,
20500,
null,
null,
14800,
11000,
6300,
10800,
16500,
32800,
107800,
6600,
6100,
3900,
25600,
40500,
55100,
117600,
51500,
6800,
19800,
12500,
null,
27000,
11600,
null,
17900,
30200,
17300,
9400,
44000,
17200,
24200,
24000,
37600,
null,
78400,
null,
15500,
null,
33200,
11000,
91100,
44600,
29500,
41000,
50100,
9000,
8500,
null,
18100,
4300,
47992,
48600,
30550,
55800,
15800,
37500,
2500,
32600,
40500,
13100,
21000,
15900,
47000,
70900,
14500,
35100,
31000,
9100,
24000,
22600,
26100,
16250,
null,
67100,
6800,
15200,
24000,
7600,
16400,
22000,
99600,
38000,
38700,
8900,
2500,
60500,
14000,
29900,
28600,
14000,
27700,
21500,
28300,
25200,
25900,
5000,
26600,
31100,
6200,
50700,
19400,
60500,
null,
null,
6700,
81100,
37100,
48600,
30900,
122300,
24800,
6900,
null,
6900,
6300,
60700,
19600,
14700,
39310,
35372,
27700,
15100,
44500,
14700,
10100,
44800,
18500,
26400,
25100,
27400,
20700,
27800,
7400,
20400,
6200,
6200,
21800,
27300,
21400,
16100,
96000,
47100,
36800,
null,
70900,
10000,
68570,
47600,
48100,
54800,
8200,
12900,
16800,
16300,
10200,
5300,
26500,
23800,
13000,
32200,
24200,
35300,
11000,
12979,
9900,
47800,
23100,
35300,
18100,
10800,
32900,
17700,
6100,
17300,
5300,
null,
13100,
19000,
14800,
76000,
8100,
4500,
81900,
null,
36500,
21100,
34500,
11300,
16400,
17300,
10500,
31700,
11400,
34200,
9200,
31407,
null,
28600,
25643,
null,
11900,
22000,
15600,
34100,
29900,
19300,
35380,
9500,
26300,
32600,
null,
5400,
16500,
10900,
51100,
4100,
22000,
6200,
18600,
null,
60300,
38900,
20200,
30500,
14900,
9600,
6800,
39300,
31900,
5100,
46400,
32700,
16200,
52300,
8700,
44800,
22400,
74437,
26800,
96300,
35200,
70100,
22100,
14000,
20500,
null,
22700,
68800,
33500,
6900,
52400,
56300,
35400,
10300,
61000,
31900,
45100,
17900,
8500,
12900,
4600,
5200,
37600,
45500,
8300,
23700,
22600,
7100,
29800,
36900,
2700,
218200,
5300,
76100,
107350,
17900,
13700,
14200,
7600,
29800,
19900,
32000,
43400,
null,
24000,
null,
25000,
26200,
null,
59800,
73551,
null,
3800,
37500,
64600,
154100,
3900,
64000,
44800,
27103,
5600,
40400,
17700,
2300,
83000,
120300,
null,
35300,
47500,
20100,
9400,
14000,
12941,
18500,
13900,
14100,
24200,
5300,
42400,
22500,
15600,
13500,
9000,
22600,
null,
205730,
39400,
11900,
null,
36200,
12600,
21700,
14500,
17400,
24300,
13100,
19900,
43300,
7000,
31400,
null,
9100,
59900,
33400,
52300,
13200,
24200,
30900,
10500,
23400,
9500,
23700,
3000,
67600,
90100,
11100,
9800,
6950,
27600,
54300,
27100,
27000,
15100,
22500,
34000,
30700,
38800,
58600,
11300,
35800,
50900,
21500,
null,
41200,
10300,
24800,
14300,
28100,
220860,
null,
27600,
null,
25700,
167418,
36700,
25500,
73900,
48000,
34100,
14100,
null,
null,
43100,
59300,
2600,
74500,
37200,
20200,
25400,
4900,
5250,
25600,
7100,
15100,
95300,
null,
38300,
16200,
47200,
7600,
67100,
29300,
32400,
46702,
24400,
9000,
11700,
20100,
23900,
8100,
47600,
20500,
40300,
39300,
48100,
16500,
6900,
null,
null,
42000,
12800,
31700,
2900,
39700,
null,
51200,
23500,
40988
]
}
],
"layout": {
"barmode": "overlay",
"legend": {
"bgcolor": "#F5F6F9",
"font": {
"color": "#4D5663"
}
},
"paper_bgcolor": "#F5F6F9",
"plot_bgcolor": "#F5F6F9",
"template": {
"data": {
"bar": [
{
"error_x": {
"color": "#2a3f5f"
},
"error_y": {
"color": "#2a3f5f"
},
"marker": {
"line": {
"color": "#E5ECF6",
"width": 0.5
}
},
"type": "bar"
}
],
"barpolar": [
{
"marker": {
"line": {
"color": "#E5ECF6",
"width": 0.5
}
},
"type": "barpolar"
}
],
"carpet": [
{
"aaxis": {
"endlinecolor": "#2a3f5f",
"gridcolor": "white",
"linecolor": "white",
"minorgridcolor": "white",
"startlinecolor": "#2a3f5f"
},
"baxis": {
"endlinecolor": "#2a3f5f",
"gridcolor": "white",
"linecolor": "white",
"minorgridcolor": "white",
"startlinecolor": "#2a3f5f"
},
"type": "carpet"
}
],
"choropleth": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "choropleth"
}
],
"contour": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "contour"
}
],
"contourcarpet": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "contourcarpet"
}
],
"heatmap": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "heatmap"
}
],
"heatmapgl": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "heatmapgl"
}
],
"histogram": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "histogram"
}
],
"histogram2d": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "histogram2d"
}
],
"histogram2dcontour": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "histogram2dcontour"
}
],
"mesh3d": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "mesh3d"
}
],
"parcoords": [
{
"line": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "parcoords"
}
],
"pie": [
{
"automargin": true,
"type": "pie"
}
],
"scatter": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatter"
}
],
"scatter3d": [
{
"line": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatter3d"
}
],
"scattercarpet": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattercarpet"
}
],
"scattergeo": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattergeo"
}
],
"scattergl": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattergl"
}
],
"scattermapbox": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattermapbox"
}
],
"scatterpolar": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterpolar"
}
],
"scatterpolargl": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterpolargl"
}
],
"scatterternary": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterternary"
}
],
"surface": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "surface"
}
],
"table": [
{
"cells": {
"fill": {
"color": "#EBF0F8"
},
"line": {
"color": "white"
}
},
"header": {
"fill": {
"color": "#C8D4E3"
},
"line": {
"color": "white"
}
},
"type": "table"
}
]
},
"layout": {
"annotationdefaults": {
"arrowcolor": "#2a3f5f",
"arrowhead": 0,
"arrowwidth": 1
},
"coloraxis": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"colorscale": {
"diverging": [
[
0,
"#8e0152"
],
[
0.1,
"#c51b7d"
],
[
0.2,
"#de77ae"
],
[
0.3,
"#f1b6da"
],
[
0.4,
"#fde0ef"
],
[
0.5,
"#f7f7f7"
],
[
0.6,
"#e6f5d0"
],
[
0.7,
"#b8e186"
],
[
0.8,
"#7fbc41"
],
[
0.9,
"#4d9221"
],
[
1,
"#276419"
]
],
"sequential": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"sequentialminus": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
]
},
"colorway": [
"#636efa",
"#EF553B",
"#00cc96",
"#ab63fa",
"#FFA15A",
"#19d3f3",
"#FF6692",
"#B6E880",
"#FF97FF",
"#FECB52"
],
"font": {
"color": "#2a3f5f"
},
"geo": {
"bgcolor": "white",
"lakecolor": "white",
"landcolor": "#E5ECF6",
"showlakes": true,
"showland": true,
"subunitcolor": "white"
},
"hoverlabel": {
"align": "left"
},
"hovermode": "closest",
"mapbox": {
"style": "light"
},
"paper_bgcolor": "white",
"plot_bgcolor": "#E5ECF6",
"polar": {
"angularaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"bgcolor": "#E5ECF6",
"radialaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
}
},
"scene": {
"xaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
},
"yaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
},
"zaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
}
},
"shapedefaults": {
"line": {
"color": "#2a3f5f"
}
},
"ternary": {
"aaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"baxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"bgcolor": "#E5ECF6",
"caxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
}
},
"title": {
"x": 0.05
},
"xaxis": {
"automargin": true,
"gridcolor": "white",
"linecolor": "white",
"ticks": "",
"title": {
"standoff": 15
},
"zerolinecolor": "white",
"zerolinewidth": 2
},
"yaxis": {
"automargin": true,
"gridcolor": "white",
"linecolor": "white",
"ticks": "",
"title": {
"standoff": 15
},
"zerolinecolor": "white",
"zerolinewidth": 2
}
}
},
"title": {
"font": {
"color": "#4D5663"
},
"text": "total_rev_hi_lim Distribution"
},
"xaxis": {
"gridcolor": "#E1E5ED",
"showgrid": true,
"tickfont": {
"color": "#4D5663"
},
"title": {
"font": {
"color": "#4D5663"
},
"text": ""
},
"zerolinecolor": "#E1E5ED"
},
"yaxis": {
"gridcolor": "#E1E5ED",
"showgrid": true,
"tickfont": {
"color": "#4D5663"
},
"title": {
"font": {
"color": "#4D5663"
},
"text": ""
},
"zerolinecolor": "#E1E5ED"
}
}
},
"text/html": [
"\n",
" \n",
" \n",
" \n",
" \n",
" "
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"application/vnd.plotly.v1+json": {
"config": {
"linkText": "Export to plot.ly",
"plotlyServerURL": "https://plot.ly",
"showLink": true
},
"data": [
{
"boxpoints": false,
"line": {
"width": 1.3
},
"marker": {
"color": "rgba(255, 153, 51, 1.0)"
},
"name": "total_rev_hi_lim",
"orientation": "v",
"type": "box",
"y": [
30800,
32900,
34900,
24700,
47033,
29500,
55500,
11800,
62100,
33200,
47000,
19600,
139900,
43000,
41200,
18500,
15900,
17400,
17000,
31000,
27200,
null,
25700,
14300,
41400,
43400,
19800,
33100,
49900,
10900,
94100,
69000,
4900,
12300,
30200,
8900,
6600,
37100,
16700,
62400,
5500,
46500,
26600,
32400,
57300,
9400,
72900,
null,
22500,
20100,
18200,
74000,
43300,
13000,
33600,
18800,
90600,
32900,
5600,
72600,
62800,
87000,
54500,
22100,
20000,
63700,
null,
null,
14400,
62200,
8300,
15700,
3000,
17300,
null,
33300,
10500,
40200,
34400,
26400,
15550,
118600,
23300,
27500,
43900,
12950,
16200,
23700,
23800,
8700,
46800,
19000,
0,
null,
44200,
5800,
22300,
16900,
84500,
31200,
14800,
31900,
67600,
71207,
6000,
6500,
23800,
130300,
24000,
31000,
48900,
64700,
54000,
5800,
43300,
70000,
34900,
7300,
45600,
15600,
22800,
12600,
92000,
null,
47400,
8800,
27500,
46000,
25300,
10800,
null,
8000,
7900,
46400,
67700,
13507,
60100,
33100,
31100,
15200,
19500,
37900,
33700,
22500,
7500,
12900,
57600,
38800,
95900,
59600,
null,
7800,
null,
14900,
37500,
12300,
46000,
41600,
27000,
12000,
18600,
19900,
28700,
11400,
46100,
26000,
5800,
49500,
25100,
19900,
14800,
21600,
110500,
48900,
143100,
17800,
47100,
62300,
11500,
31100,
11200,
15200,
22500,
22500,
28900,
19700,
16600,
16300,
47700,
4700,
68200,
13200,
29600,
null,
35800,
null,
38700,
null,
24500,
13500,
41100,
81300,
38050,
10700,
12700,
1000,
16200,
null,
null,
37000,
4850,
40800,
11500,
41300,
17400,
12700,
19100,
72300,
30800,
null,
50900,
8400,
25800,
25100,
17000,
3300,
149900,
16500,
95100,
28700,
18500,
5300,
60300,
99000,
28800,
47000,
38800,
18900,
null,
22800,
36400,
38900,
11700,
88197,
null,
5500,
20600,
36500,
10700,
33300,
9600,
null,
33500,
19000,
33000,
21300,
34900,
16100,
11610,
28500,
30900,
42600,
32500,
2600,
48600,
18800,
21900,
9300,
23900,
36000,
23000,
36800,
18600,
27500,
12900,
50200,
38600,
21100,
12400,
5700,
19600,
29500,
11500,
null,
37250,
18100,
32800,
7700,
19900,
24800,
6100,
75500,
19100,
56200,
81000,
12000,
null,
13500,
null,
17700,
58200,
78600,
5800,
null,
25100,
10300,
52200,
32800,
24800,
24900,
32500,
27900,
35800,
55400,
23500,
null,
25800,
241600,
32400,
39800,
184100,
53700,
6800,
23100,
32100,
32100,
26900,
14400,
23500,
4500,
47800,
44300,
15100,
45900,
24800,
null,
null,
31200,
3500,
27400,
49200,
27600,
13200,
62600,
54423,
15500,
22000,
70700,
22300,
20300,
7000,
11100,
12600,
28300,
31600,
37500,
10500,
74400,
23500,
14500,
64000,
null,
22200,
72600,
null,
20700,
5900,
33300,
11200,
41500,
32400,
null,
8800,
41400,
7500,
35500,
12600,
31400,
32300,
20000,
75000,
41245,
25500,
null,
21800,
26000,
24000,
null,
5900,
23500,
14000,
11800,
null,
24600,
46600,
20200,
1000,
81600,
19000,
1800,
11100,
11200,
18500,
44500,
24700,
13900,
56900,
3600,
27100,
13900,
26900,
65700,
41400,
66400,
30200,
null,
8400,
2300,
5300,
49700,
27300,
null,
2800,
null,
18500,
26000,
53800,
16600,
28000,
29600,
111400,
66100,
50100,
31600,
null,
11300,
51600,
21000,
27400,
14500,
20000,
19800,
27100,
10500,
29800,
57800,
12200,
8300,
23800,
14800,
12800,
28500,
17900,
16600,
16100,
35800,
24000,
62600,
16900,
86700,
33400,
44900,
30900,
20600,
6600,
13600,
43700,
43200,
6500,
25500,
30300,
45500,
null,
5700,
7600,
44000,
32400,
31400,
13300,
null,
13700,
31400,
19700,
15300,
26400,
30100,
48100,
11300,
27200,
12700,
16200,
79500,
35400,
30500,
4000,
8700,
20300,
4600,
null,
9700,
11300,
18900,
73400,
62100,
25300,
35200,
15200,
16900,
null,
11900,
16000,
28500,
null,
17700,
40800,
37900,
73800,
12500,
27700,
52200,
41500,
6300,
62100,
21200,
20600,
14800,
20600,
27400,
63700,
38500,
40300,
23500,
53100,
41700,
18100,
38500,
96300,
28500,
97700,
6800,
31600,
14500,
31700,
78200,
21500,
13100,
52800,
38000,
15100,
28700,
6400,
16800,
23400,
14700,
19000,
21500,
55300,
11900,
17000,
null,
68700,
46800,
22900,
18100,
9000,
56900,
26400,
null,
45000,
9800,
null,
20800,
null,
18400,
30500,
26800,
38400,
12800,
79700,
37000,
null,
null,
21200,
44000,
23800,
25100,
57800,
9700,
null,
26800,
18600,
27000,
14200,
26100,
21500,
90600,
null,
null,
49100,
17300,
9200,
22500,
76400,
32000,
10000,
9400,
20700,
16700,
30800,
null,
22300,
25000,
35600,
4500,
29000,
23000,
11900,
27400,
7000,
90000,
21200,
47400,
12500,
15300,
90300,
36900,
24100,
5100,
7800,
17900,
20500,
9100,
44200,
19700,
15300,
99800,
24600,
18900,
68000,
29000,
59300,
12900,
122400,
33200,
13750,
8100,
27400,
5751,
null,
33800,
15700,
21200,
51500,
53100,
6500,
53000,
20300,
5500,
52000,
null,
20600,
28400,
1700,
11200,
33500,
62000,
36200,
35400,
15200,
9500,
24000,
18300,
null,
24900,
23400,
68800,
28700,
48000,
26800,
35300,
21300,
2700,
48700,
371700,
8900,
5200,
10500,
15900,
8700,
23000,
17700,
16600,
3100,
15600,
13600,
17200,
17300,
21500,
13700,
50200,
25000,
35600,
25400,
49300,
9900,
50000,
50100,
15400,
34100,
13500,
28700,
31800,
null,
35100,
34600,
63400,
60900,
4800,
6750,
50800,
42000,
33000,
15100,
null,
30700,
22800,
20600,
32300,
23300,
60900,
53100,
23700,
22500,
15000,
20600,
25200,
34500,
28300,
76800,
4300,
63300,
25800,
14000,
null,
112900,
20800,
5200,
10300,
38300,
39200,
13700,
15200,
4200,
null,
44500,
3800,
22000,
70900,
42900,
53100,
31500,
36200,
41900,
78000,
21600,
10600,
10000,
32100,
31300,
6900,
12168,
10700,
30500,
188400,
25600,
100600,
34200,
20900,
null,
26400,
12100,
10400,
49600,
10500,
11200,
16400,
16000,
null,
10600,
45000,
12600,
139000,
26200,
17800,
22700,
14000,
12604,
7200,
23900,
8700,
27100,
16800,
7000,
27300,
30100,
6300,
12500,
35800,
null,
19100,
47700,
33900,
13800,
32000,
14300,
24100,
25200,
30800,
6500,
37500,
81000,
null,
19600,
13600,
34500,
null,
16000,
22800,
7500,
4600,
9100,
38700,
8300,
39800,
25100,
19500,
34900,
27000,
24300,
45700,
12500,
43500,
54400,
null,
36070,
5100,
14700,
41100,
18400,
11300,
29500,
50900,
14700,
21000,
63500,
55800,
4300,
35100,
8900,
18300,
16800,
13800,
59000,
18200,
41700,
23000,
28600,
25700,
0,
18100,
3200,
106000,
19300,
13500,
13200,
55300,
52922,
10200,
21800,
23900,
41600,
36300,
53700,
49600,
37500,
10300,
9900,
12000,
33700,
12200,
24800,
27000,
22800,
15300,
51100,
6900,
4500,
12000,
22700,
8000,
28800,
19100,
25000,
26800,
33700,
45500,
11600,
20600,
23800,
null,
122400,
41100,
6100,
null,
71100,
25600,
19700,
null,
51300,
15200,
14900,
33700,
11200,
25600,
74300,
30400,
21800,
20600,
33500,
47300,
43800,
53600,
28600,
31200,
56500,
9400,
10700,
69300,
23200,
71900,
37500,
49200,
26900,
15600,
8000,
41500,
null,
18700,
11500,
48100,
18000,
12900,
7400,
22000,
200100,
29200,
14500,
9300,
48700,
32100,
16700,
52900,
11100,
4500,
17500,
38300,
34500,
58900,
25100,
73525,
58700,
6800,
11500,
null,
15000,
33800,
14900,
null,
15200,
12800,
10500,
95300,
4800,
44400,
12600,
20000,
16500,
23300,
51400,
16950,
23800,
8100,
24900,
29500,
35000,
19800,
52100,
38300,
55500,
14800,
null,
24000,
37000,
45600,
31300,
5300,
26500,
97000,
10500,
27900,
20900,
27500,
null,
29700,
3700,
12840,
6900,
8200,
30000,
35400,
22300,
17600,
20100,
9600,
28000,
21300,
44100,
4800,
null,
35900,
31000,
9000,
10900,
null,
15200,
34600,
23700,
27500,
10400,
18300,
32700,
null,
27900,
25000,
7200,
null,
46900,
9500,
46400,
45000,
13500,
86000,
55700,
45800,
18200,
23800,
270900,
null,
21300,
29400,
9700,
30300,
18600,
29400,
28700,
null,
3700,
null,
22300,
16100,
25400,
29300,
null,
23700,
20400,
23900,
21100,
86700,
26300,
38200,
21500,
8000,
25700,
101900,
10100,
33200,
8500,
15900,
22400,
9100,
26800,
11000,
25100,
7900,
21000,
64600,
18800,
46000,
14600,
22200,
null,
25000,
13400,
7800,
15800,
29200,
39600,
51700,
43000,
27400,
36500,
24300,
62700,
3700,
20000,
27700,
19600,
35400,
18000,
31700,
10200,
17000,
41256,
18300,
52900,
72900,
51800,
11400,
43400,
37100,
15800,
51300,
75700,
20300,
56200,
7000,
13900,
19600,
23800,
52500,
22800,
31900,
null,
23600,
18800,
16400,
20100,
9500,
20200,
37700,
138300,
44405,
80500,
13000,
17300,
20700,
61600,
32000,
7300,
41500,
17700,
25000,
17600,
88300,
19700,
6900,
12900,
33000,
15200,
27100,
27200,
42100,
31700,
43700,
12000,
21500,
null,
76000,
7300,
8900,
97798,
22200,
6100,
37900,
24800,
12000,
48400,
15100,
null,
101100,
21700,
28900,
47900,
null,
41000,
25200,
49000,
32600,
null,
10110,
21200,
5400,
18600,
63400,
null,
11200,
35200,
14400,
19200,
14700,
66600,
56000,
17200,
null,
10200,
24900,
22700,
13200,
null,
27400,
16300,
165300,
35800,
null,
30119,
28042,
22300,
21800,
8500,
21600,
26100,
4300,
30000,
null,
12000,
24300,
4200,
27126,
9000,
35700,
22500,
29400,
10200,
22900,
61400,
15200,
14600,
19100,
37100,
26900,
23300,
18800,
9850,
22300,
7300,
13200,
40400,
111700,
113700,
21500,
36400,
24800,
26600,
25300,
16400,
17800,
14100,
28900,
31100,
4300,
13700,
72100,
33400,
12400,
53200,
14400,
30900,
22100,
15000,
31300,
null,
17000,
7300,
null,
67300,
28900,
8800,
30900,
19100,
17950,
17300,
8500,
null,
17700,
null,
17200,
7600,
24900,
36400,
12200,
32100,
48900,
12000,
20700,
246400,
8900,
31200,
13700,
19800,
30700,
11400,
127800,
14400,
null,
60500,
33600,
60100,
36100,
22200,
7500,
28100,
171600,
null,
19200,
16000,
18700,
11000,
166000,
12300,
51500,
84100,
20600,
17450,
6900,
66800,
34800,
29100,
26900,
68800,
23000,
42000,
21600,
null,
11600,
15100,
19100,
15700,
21700,
6000,
45300,
101500,
26800,
11500,
15300,
16900,
40700,
21200,
4650,
15100,
9900,
3100,
null,
28500,
17100,
33400,
24400,
78924,
36900,
40300,
71800,
40000,
102000,
14000,
29500,
13300,
null,
null,
17500,
17800,
85800,
42900,
null,
14800,
26400,
2900,
49500,
33500,
14500,
16900,
57800,
31100,
26800,
17500,
7000,
20700,
9000,
14300,
58500,
null,
34900,
37700,
52100,
122900,
9000,
null,
13800,
110000,
20500,
null,
null,
16100,
12200,
46400,
57000,
14700,
null,
33800,
38300,
20100,
7300,
23600,
34400,
6700,
80500,
41700,
9700,
10100,
10400,
null,
15500,
null,
30000,
7000,
10900,
12900,
18000,
27100,
18300,
40200,
5700,
34800,
11500,
30150,
64300,
null,
28500,
7100,
9900,
null,
106500,
22000,
20200,
106100,
10400,
37000,
30800,
15700,
21900,
16700,
78100,
20500,
null,
25700,
44900,
50600,
8800,
14000,
11500,
24500,
40800,
59500,
14100,
null,
57500,
null,
33800,
13000,
42800,
25700,
25100,
56600,
12600,
15200,
28800,
129900,
24700,
30300,
25500,
4900,
10800,
null,
61547,
24000,
42600,
17700,
48500,
59300,
42800,
15300,
16600,
11900,
9100,
2900,
60300,
13500,
40000,
38900,
null,
29000,
9900,
20500,
28000,
64000,
34000,
74635,
47900,
22400,
119900,
7100,
49100,
null,
40500,
24700,
22700,
7000,
12200,
18100,
5900,
34400,
86000,
14100,
38000,
72500,
null,
43189,
10010,
25200,
30000,
28700,
8300,
18400,
8700,
9000,
125900,
8700,
6700,
14400,
24300,
97800,
25222,
39200,
null,
22100,
39400,
41300,
17500,
45700,
48700,
15500,
7600,
27600,
25300,
5700,
15709,
21700,
23800,
34700,
10100,
14100,
21400,
69500,
18100,
42200,
28400,
21600,
13100,
14600,
11700,
15000,
6800,
23100,
9200,
17800,
15200,
11900,
21200,
73800,
29100,
25500,
20900,
97900,
25200,
28100,
11800,
10200,
26500,
40000,
16500,
23900,
17400,
null,
14700,
14500,
155700,
27000,
55700,
8300,
9800,
17100,
17700,
43500,
7700,
26900,
28700,
14600,
18700,
66000,
15300,
7900,
24400,
46600,
51500,
69400,
3500,
8700,
27600,
58500,
16900,
14600,
27345,
null,
19900,
29300,
33200,
33000,
15000,
2500,
34600,
17000,
77100,
22100,
32600,
158000,
8300,
20700,
144800,
41500,
24700,
26800,
38900,
22000,
64500,
33500,
35700,
3800,
6400,
18600,
18500,
12300,
21500,
9700,
5200,
13300,
8700,
34600,
114600,
23500,
null,
50000,
43400,
null,
16800,
23200,
8800,
21500,
12000,
10750,
18700,
43500,
26500,
17000,
144800,
22100,
53646,
14100,
26060,
79900,
204100,
43200,
13100,
38400,
null,
34800,
17200,
16300,
46700,
38800,
108100,
50400,
14400,
7100,
22300,
10700,
7000,
40100,
28900,
42400,
68500,
30100,
47100,
7400,
48800,
null,
41700,
4200,
null,
41500,
48000,
null,
13500,
25903,
29000,
6500,
32300,
null,
85700,
75300,
26400,
25400,
38800,
5000,
7400,
73000,
20625,
26600,
26000,
8200,
50800,
24000,
null,
41300,
38300,
null,
32200,
27500,
21400,
119700,
93700,
12700,
35300,
18400,
5100,
10300,
null,
57600,
19000,
17400,
17500,
5800,
54600,
45900,
43000,
19600,
36000,
36700,
21200,
32200,
null,
10800,
28400,
13400,
32400,
null,
133100,
71900,
78500,
12000,
36000,
25300,
19700,
null,
10900,
56200,
11100,
29400,
5800,
49700,
10600,
37300,
5900,
3000,
19600,
24000,
15400,
45300,
23300,
71100,
10800,
84500,
16900,
14800,
17300,
12600,
17700,
37700,
10300,
15000,
44800,
99200,
18700,
18200,
14800,
15800,
66247,
49900,
28300,
88100,
40000,
null,
16300,
53300,
13200,
15000,
12950,
null,
14400,
7900,
13500,
33700,
40600,
29000,
30000,
5100,
11500,
10800,
11500,
14700,
57400,
50900,
13000,
29800,
50700,
25167,
27800,
199200,
12300,
268100,
39900,
24200,
19700,
null,
66400,
14500,
13800,
19800,
45200,
9800,
67900,
52350,
28800,
15400,
19300,
22700,
26300,
62900,
44700,
54400,
8650,
56500,
7500,
28700,
37474,
39000,
9000,
10700,
21100,
17000,
41700,
null,
12300,
61800,
28200,
33000,
16700,
37600,
23000,
75500,
13400,
14000,
19000,
20000,
9000,
118850,
31200,
64800,
30400,
33800,
122400,
15600,
13400,
41700,
95100,
39100,
32000,
27300,
5700,
16300,
39300,
10600,
12000,
25800,
24500,
41900,
53000,
12000,
18600,
2800,
null,
43500,
21300,
43700,
44800,
12050,
21500,
10700,
35000,
9000,
28000,
51200,
43900,
27000,
35400,
35600,
null,
52500,
49500,
26900,
26300,
7000,
8200,
34000,
5700,
46900,
17500,
71000,
111100,
null,
39500,
34300,
62200,
51400,
18400,
19900,
40100,
66400,
68200,
37000,
30700,
40400,
12000,
35200,
44800,
5500,
22800,
13500,
57500,
24400,
null,
13000,
43400,
38000,
72500,
12900,
20500,
3000,
15300,
null,
54700,
43100,
25100,
17800,
22300,
13600,
7700,
8600,
null,
null,
13300,
12200,
3300,
37200,
11600,
17900,
32300,
31500,
25000,
92500,
2300,
9200,
34000,
55850,
34400,
33240,
31300,
15900,
23500,
43200,
26400,
26600,
23600,
null,
null,
12300,
12300,
9100,
20500,
16300,
39400,
1200,
8100,
42100,
10800,
25800,
19500,
20000,
23600,
24700,
24500,
65143,
58100,
14900,
null,
82800,
null,
52300,
38800,
42600,
110100,
null,
43500,
8600,
48000,
158300,
10000,
13800,
80100,
42800,
36500,
17600,
25700,
6000,
5100,
23300,
89600,
23600,
25500,
48290,
14600,
15300,
21600,
40900,
63100,
36400,
21200,
8100,
33800,
22500,
150160,
12100,
null,
61500,
27200,
62300,
20800,
47600,
22600,
13600,
49100,
25700,
9800,
6300,
14000,
23200,
20000,
26100,
18900,
43400,
18100,
27800,
36700,
60000,
39900,
62400,
25400,
24100,
3700,
27200,
9800,
12900,
17600,
14000,
12750,
19000,
11700,
28900,
null,
9900,
30500,
23800,
77100,
8100,
null,
19400,
90008,
11800,
22300,
6300,
69900,
73700,
36300,
null,
42700,
35400,
53800,
10500,
54300,
12100,
17800,
46400,
10800,
17200,
33900,
33400,
66500,
null,
36800,
49500,
10800,
25100,
34000,
48200,
6000,
29800,
14900,
22500,
43600,
12300,
56300,
9900,
40900,
25200,
28744,
24500,
34300,
2600,
16200,
5000,
29500,
null,
13200,
77400,
15500,
87600,
22900,
18100,
35000,
53600,
5500,
null,
18000,
6100,
13430,
14700,
22500,
13400,
44600,
7600,
29400,
111700,
10200,
83300,
17200,
22300,
39400,
9700,
58800,
40700,
11500,
14300,
769000,
60400,
14500,
64200,
26500,
null,
20800,
33900,
16400,
23100,
6800,
3100,
23100,
14800,
13900,
15100,
11500,
102700,
17100,
31600,
133400,
21200,
78200,
28428,
null,
9400,
73300,
29500,
91200,
18500,
8500,
36300,
87000,
32000,
143000,
null,
29300,
47300,
69100,
16400,
40700,
11200,
274560,
7800,
31100,
6400,
38400,
26700,
33800,
16400,
null,
18200,
17400,
17100,
6100,
5600,
21500,
20100,
11300,
117900,
18700,
12500,
null,
null,
null,
74400,
23400,
15800,
42900,
28200,
60900,
11500,
76244,
114100,
26600,
25000,
7200,
117900,
50300,
7500,
5500,
47200,
66000,
20800,
26800,
7700,
16700,
16200,
27200,
15500,
6000,
7500,
30800,
10500,
22500,
81200,
13000,
19700,
11200,
23000,
13200,
128400,
12000,
23600,
8800,
34800,
47888,
24500,
30800,
14600,
49600,
8900,
11300,
32600,
41500,
31600,
80300,
null,
37800,
50600,
34500,
5900,
46300,
4500,
23600,
4300,
null,
80500,
29900,
16200,
33200,
null,
24700,
10900,
21200,
30200,
9500,
16100,
44100,
42996,
16100,
null,
68500,
20100,
18400,
6700,
184200,
42600,
59100,
24100,
7200,
15900,
33800,
3100,
17200,
45800,
20600,
13300,
5900,
null,
9400,
null,
75200,
14400,
86300,
24500,
null,
39500,
null,
73815,
65700,
20800,
38200,
25900,
10400,
154700,
null,
51400,
61400,
38900,
48600,
5510,
24800,
14200,
17700,
15500,
40400,
14000,
30700,
46800,
64100,
35600,
5400,
59900,
16700,
45300,
43000,
21800,
41600,
48900,
11900,
11600,
50900,
37200,
50800,
16900,
51600,
77200,
28200,
374500,
11900,
22500,
21700,
15000,
28050,
52400,
5100,
86500,
18400,
10200,
13600,
null,
36700,
38300,
28400,
10600,
19700,
24600,
25800,
null,
70700,
7400,
29300,
7900,
58500,
null,
17000,
13500,
27600,
11600,
25700,
48800,
89000,
24200,
21400,
30500,
39200,
null,
32400,
38800,
122300,
12600,
14000,
7400,
32300,
17400,
49400,
128500,
64700,
8600,
38200,
55000,
38700,
10900,
44200,
27400,
4900,
41500,
16100,
null,
5200,
null,
26800,
3000,
46300,
25700,
24200,
22600,
32900,
12000,
33800,
5100,
52700,
40100,
109400,
11500,
12000,
39200,
null,
null,
16650,
16600,
3000,
42000,
1600,
27100,
38800,
17100,
16500,
80500,
29000,
39500,
27500,
49600,
21600,
57700,
null,
500,
48500,
17500,
18100,
34100,
10200,
28500,
41100,
56400,
4000,
8000,
67200,
40100,
11100,
21200,
43100,
23400,
14300,
8400,
6500,
32700,
20200,
22100,
23200,
36400,
13800,
30100,
27500,
null,
32800,
9500,
7200,
175700,
15200,
null,
5100,
41400,
10300,
null,
null,
3800,
17000,
1300,
14800,
10800,
6500,
56100,
93600,
106800,
66600,
77200,
23410,
null,
30600,
123900,
null,
12300,
34500,
52300,
61200,
7400,
83600,
13500,
24500,
9100,
8900,
13000,
50500,
14800,
null,
9000,
null,
17300,
10100,
69500,
9730,
73500,
19000,
8600,
61500,
20500,
null,
30300,
10400,
37700,
null,
40200,
null,
7000,
12300,
31400,
11500,
25500,
13200,
19600,
44400,
10500,
23700,
60000,
45400,
24800,
51500,
21800,
15800,
10400,
28200,
null,
32200,
59500,
8200,
17200,
51000,
null,
19700,
81300,
5500,
7600,
47300,
8400,
12800,
22500,
27200,
21200,
null,
23400,
44900,
21700,
22100,
56400,
10000,
38500,
100500,
32900,
22200,
16300,
9300,
21400,
30500,
5500,
63500,
35500,
17600,
46400,
20600,
30200,
35400,
33400,
7400,
15800,
17300,
27800,
24500,
10100,
39700,
13700,
21600,
30600,
7400,
45400,
13400,
12200,
16600,
null,
21000,
15600,
46900,
29000,
9200,
46000,
18400,
19600,
27900,
31900,
63600,
11200,
48700,
36300,
23900,
52600,
4900,
11500,
14900,
64300,
71700,
25100,
19700,
10200,
10600,
9300,
83000,
14000,
null,
9800,
65100,
9100,
30500,
44800,
21400,
11100,
6300,
null,
23700,
19200,
15600,
32800,
19900,
81900,
8400,
32200,
null,
7000,
51400,
12800,
14800,
null,
21300,
74100,
null,
10300,
null,
17700,
79100,
6100,
19500,
7400,
39900,
8800,
18400,
51400,
37000,
41100,
24100,
34600,
38200,
8400,
28200,
5900,
23800,
14000,
55900,
58100,
23200,
58000,
117400,
43100,
31800,
29500,
null,
17600,
30100,
29800,
11000,
63500,
47500,
14000,
16000,
30500,
10800,
21300,
9800,
19900,
29800,
12500,
null,
null,
11500,
7800,
20500,
47600,
25600,
66600,
12100,
null,
6200,
8700,
6000,
22200,
27100,
50300,
44700,
19000,
13700,
36500,
10100,
13200,
54800,
11100,
28600,
63100,
54600,
8400,
28800,
34900,
16800,
44400,
200500,
7500,
28600,
27300,
41200,
9400,
15600,
24600,
90100,
9200,
32700,
120700,
22100,
10400,
26200,
null,
null,
33100,
26000,
13100,
99300,
30000,
22000,
27200,
27400,
27900,
24500,
49800,
14300,
35500,
17500,
65800,
10500,
18200,
7800,
41700,
47800,
7300,
9500,
12000,
26900,
38500,
34200,
4600,
11000,
18100,
18400,
24100,
5200,
17500,
36200,
67000,
6000,
38300,
53300,
null,
18000,
37600,
31400,
21600,
25300,
15700,
8000,
108800,
56800,
8500,
14200,
20300,
26000,
30100,
9900,
21300,
30300,
6000,
7000,
13100,
5500,
9800,
6000,
53047,
42100,
9200,
41200,
18100,
3500,
11400,
26600,
4300,
23600,
20800,
12300,
30600,
28600,
16800,
40100,
62300,
20100,
46900,
10100,
15500,
51300,
11400,
5700,
23900,
14800,
41889,
14100,
26600,
156300,
55500,
4800,
34600,
6700,
9200,
97900,
9400,
53464,
20700,
7100,
8600,
21300,
12800,
31900,
19200,
9800,
22600,
33600,
6700,
50300,
29700,
18070,
7000,
null,
15800,
37200,
11300,
22800,
9700,
21600,
11700,
37400,
7500,
16500,
12500,
31800,
23000,
16800,
17800,
57600,
50300,
51400,
46000,
24400,
34500,
37700,
19500,
19600,
null,
51700,
23700,
32600,
null,
32900,
114300,
17000,
42350,
19300,
null,
8000,
54200,
37400,
null,
null,
11200,
33700,
24300,
null,
70400,
29300,
29800,
34400,
6900,
13000,
null,
29800,
23500,
56900,
8700,
8500,
8100,
3500,
102700,
22300,
7900,
137600,
null,
20500,
44000,
12700,
63300,
70300,
59400,
7800,
18100,
65300,
6500,
25800,
29300,
16900,
34500,
13100,
11400,
13900,
4100,
18900,
31100,
36000,
9300,
28300,
23300,
null,
null,
18600,
14800,
9600,
11100,
25700,
4300,
47400,
52100,
33100,
57400,
47200,
48700,
22800,
6600,
17300,
20100,
42500,
84200,
17500,
60000,
46600,
28600,
33800,
24300,
8700,
79200,
6200,
30300,
7000,
149500,
45100,
21200,
29400,
null,
31400,
21200,
7000,
25600,
8000,
32500,
38200,
10800,
10600,
34700,
8100,
103500,
9000,
37200,
20000,
28100,
30400,
12500,
5300,
null,
30500,
7400,
16000,
25200,
22400,
28800,
28800,
13900,
124100,
18200,
8800,
43800,
3100,
30000,
38137,
23200,
null,
22400,
33900,
32900,
39300,
89745,
23900,
80900,
15000,
4600,
30600,
24900,
25900,
9500,
12800,
32800,
51200,
null,
52400,
16900,
22700,
31800,
32800,
8600,
31500,
21200,
18300,
62800,
7000,
null,
37400,
48900,
33700,
22000,
3200,
15700,
19100,
47000,
38500,
16100,
24500,
20900,
9200,
51500,
46600,
44300,
53500,
19000,
18500,
36700,
16700,
15600,
59800,
9900,
25700,
15800,
4200,
51400,
5100,
28900,
35800,
21000,
4300,
33800,
92800,
29800,
null,
57300,
null,
null,
12700,
67200,
36900,
40900,
17200,
31900,
null,
40038,
32400,
13300,
28000,
5800,
34318,
84315,
10200,
10100,
15800,
21000,
7100,
21900,
10700,
26300,
56300,
null,
18200,
null,
9400,
null,
15400,
42850,
17400,
26500,
null,
15900,
null,
33000,
20900,
18900,
21600,
29600,
30800,
37900,
5100,
21500,
29400,
10000,
29000,
7200,
35200,
30100,
null,
54340,
10700,
5800,
19300,
17100,
8100,
78600,
43900,
13000,
69500,
9900,
67400,
null,
15000,
41600,
41200,
24900,
40300,
14300,
null,
53000,
6200,
16200,
39000,
25900,
17700,
13800,
94700,
33000,
9700,
50800,
23900,
17000,
39600,
43900,
16500,
null,
15900,
27600,
6300,
34700,
21700,
16400,
8000,
32300,
82200,
20800,
7600,
42400,
74500,
24300,
77500,
15500,
21800,
43100,
201800,
96000,
3250,
53200,
null,
3700,
17800,
46900,
28500,
51100,
null,
15600,
9200,
null,
78900,
null,
130400,
166100,
90300,
44100,
93100,
40700,
18300,
39600,
30900,
20600,
118400,
null,
3300,
34200,
null,
18800,
16400,
57500,
25300,
23800,
24000,
29117,
6300,
16800,
16500,
13900,
20100,
19000,
53000,
29000,
4500,
33800,
76800,
64700,
18100,
18700,
15300,
36300,
68400,
null,
126300,
29800,
67300,
20100,
36200,
49700,
54700,
null,
19300,
64200,
7500,
86700,
12600,
60700,
20200,
null,
23900,
6700,
102200,
5100,
39000,
21300,
69400,
17700,
13000,
null,
40500,
20500,
20200,
23700,
12000,
72400,
24900,
13100,
11400,
66500,
13700,
13300,
86600,
41300,
21600,
13800,
16900,
14500,
5300,
17100,
90100,
10100,
21500,
33000,
9900,
null,
33100,
33000,
9200,
38400,
null,
29950,
222600,
43300,
58300,
21500,
18000,
null,
11550,
null,
36700,
20200,
9300,
20300,
18400,
null,
7900,
13693,
12900,
19500,
31600,
34300,
7500,
9700,
11000,
49600,
101800,
6000,
23700,
52900,
25900,
25898,
null,
29200,
8400,
16400,
33600,
null,
null,
17300,
22400,
16100,
7100,
21800,
24100,
20900,
42000,
36800,
26200,
null,
8700,
15300,
null,
11700,
41700,
7800,
17500,
9600,
14000,
null,
35200,
11500,
36900,
6600,
16700,
13200,
74200,
15100,
16600,
21200,
11900,
39900,
10000,
65300,
50400,
18100,
8300,
null,
11400,
null,
20800,
12500,
49500,
8500,
49600,
10500,
25300,
18000,
5600,
null,
57400,
null,
64800,
9415,
23400,
28900,
38562,
45600,
45900,
15600,
null,
null,
5300,
30500,
124200,
99500,
8450,
11900,
11850,
8100,
26100,
26000,
43500,
null,
127300,
14100,
56400,
39000,
16500,
18100,
null,
10600,
54900,
41700,
132000,
7700,
13300,
null,
null,
100400,
72600,
11800,
13700,
42700,
null,
16100,
40900,
24800,
10500,
20500,
17300,
38000,
25900,
15700,
14300,
35400,
null,
20000,
30400,
23500,
112700,
14500,
6400,
18900,
25800,
33500,
50000,
38000,
2950,
17800,
1200,
34900,
20700,
48800,
30700,
77700,
25200,
44500,
9600,
19600,
null,
67600,
51800,
67200,
55300,
52900,
40300,
79100,
20300,
7950,
30600,
13500,
20500,
3900,
12900,
13300,
7500,
47800,
12400,
28400,
28700,
31400,
26300,
48500,
11200,
48100,
16500,
4500,
88750,
38300,
18100,
8200,
24300,
21900,
16000,
114500,
null,
null,
38000,
21600,
34800,
48000,
null,
47600,
8800,
null,
null,
31900,
20600,
30900,
40500,
37900,
null,
6700,
37400,
8300,
5700,
15600,
15317,
15000,
36800,
47000,
42200,
19500,
55600,
null,
9700,
33700,
99400,
6000,
1700,
41800,
15200,
12500,
null,
26700,
7800,
62900,
38296,
12900,
118200,
25400,
27100,
8100,
24400,
18300,
6800,
22000,
29174,
112900,
12900,
36000,
23000,
null,
52700,
58700,
12500,
null,
null,
19700,
10400,
31800,
16300,
6800,
23500,
49100,
8000,
15500,
18300,
43100,
9353,
8000,
113500,
51700,
27200,
5200,
26000,
28100,
25000,
30600,
44300,
15900,
8200,
27300,
63500,
13000,
null,
null,
23100,
null,
28100,
6000,
22000,
18300,
6000,
17500,
20400,
8200,
42400,
51100,
11200,
12800,
null,
8300,
14800,
54400,
13700,
34300,
9000,
27500,
26700,
32500,
8100,
12700,
49200,
19700,
8900,
null,
112000,
44400,
17000,
22800,
45000,
61600,
24400,
20000,
57000,
22500,
5600,
18000,
22200,
258700,
49900,
15600,
25700,
14900,
41500,
18800,
18700,
null,
29900,
24900,
16800,
12900,
27200,
null,
null,
60300,
15800,
null,
2600,
35300,
23400,
42300,
24000,
34400,
2100,
2700,
3390,
16700,
54300,
null,
3600,
33100,
25200,
57700,
28000,
4000,
47600,
null,
19800,
17700,
43300,
4500,
22200,
34000,
26400,
24400,
12100,
35700,
20000,
46200,
14800,
6400,
19600,
29100,
110700,
12300,
null,
11300,
33200,
11200,
38700,
11900,
26300,
26400,
35800,
71100,
26100,
180800,
17700,
28200,
62700,
12500,
34900,
15100,
45100,
42900,
29300,
15500,
13200,
36800,
11000,
15100,
33700,
4375,
28500,
12600,
null,
47400,
10500,
25450,
12700,
21000,
11400,
125800,
28900,
10450,
39600,
19500,
30900,
49900,
34400,
27500,
29100,
76300,
53400,
13800,
47000,
109100,
9245,
193700,
null,
10800,
17600,
7000,
32800,
18800,
40700,
89400,
5200,
null,
7800,
33200,
16100,
14350,
47700,
24600,
33200,
10900,
25400,
128400,
74300,
null,
15900,
7600,
26200,
14400,
55900,
27200,
20600,
9500,
24200,
44700,
42200,
32200,
37100,
7150,
14600,
12300,
29400,
8500,
27700,
28900,
18300,
43700,
105100,
null,
36800,
29900,
30200,
8300,
34000,
43600,
45100,
90100,
181600,
5800,
20300,
18400,
44500,
25600,
23500,
10100,
18000,
5000,
10400,
6200,
24100,
25300,
39000,
22000,
10700,
13600,
23300,
49800,
11700,
16400,
95800,
29100,
null,
31500,
28400,
17700,
39600,
5400,
33900,
25200,
23600,
13200,
600,
null,
20600,
36450,
null,
37700,
34000,
22200,
143500,
29000,
41900,
16700,
9300,
50600,
5900,
53400,
51455,
46000,
55400,
31400,
77900,
156900,
56800,
19200,
242400,
2000,
20200,
null,
44501,
21800,
33300,
27500,
40200,
null,
64400,
11200,
45200,
14000,
101500,
37700,
11000,
40900,
25500,
41500,
null,
54800,
42459,
36900,
67700,
124000,
19400,
36600,
23000,
14700,
75300,
21800,
30600,
13400,
9400,
15600,
3100,
91100,
17500,
68100,
8000,
29500,
31200,
54484,
12300,
38900,
9300,
78400,
22600,
24100,
20250,
null,
7850,
11800,
19900,
10800,
7000,
30700,
25700,
32000,
63200,
14900,
null,
49600,
9100,
158600,
12600,
43800,
28600,
19400,
21600,
14900,
64300,
6500,
10500,
4500,
null,
22600,
36700,
55400,
5300,
8600,
30600,
null,
11100,
15800,
30000,
51000,
31700,
110900,
22200,
38200,
17800,
42400,
null,
37400,
82500,
36000,
25000,
14600,
37400,
7800,
42100,
51300,
6300,
5400,
110800,
10700,
42500,
71400,
11700,
29676,
22900,
13350,
27700,
11460,
78700,
30000,
5000,
17000,
24200,
17000,
10600,
16700,
6200,
14600,
19300,
39100,
14100,
3600,
86800,
76100,
22100,
8800,
17800,
11500,
36600,
41700,
12200,
48122,
7200,
null,
34000,
110200,
13500,
23800,
17000,
64900,
5400,
14400,
13000,
17300,
34300,
18900,
32500,
34400,
4600,
58300,
194600,
22300,
43000,
13500,
12900,
81600,
10100,
4800,
9300,
null,
19500,
5700,
18100,
null,
40400,
27700,
66700,
26400,
60500,
4000,
19800,
171400,
28200,
26500,
126500,
14100,
41300,
27100,
null,
31600,
6000,
24700,
19300,
null,
76300,
31900,
52800,
22800,
38800,
36800,
14400,
16300,
23100,
55310,
8400,
9100,
8800,
31800,
21000,
18700,
55500,
10900,
112400,
43600,
18600,
23700,
23600,
18200,
14300,
8800,
null,
39700,
8600,
79500,
18400,
20400,
11500,
45000,
14900,
23400,
16400,
43400,
80900,
128900,
50500,
16000,
57800,
5500,
5400,
15100,
63400,
27200,
13000,
42300,
39600,
16700,
4900,
35300,
null,
14800,
45500,
34300,
36600,
5700,
114900,
6700,
null,
40500,
23100,
26100,
54800,
36800,
37200,
38800,
49700,
64171,
5400,
12500,
30500,
21100,
21100,
9400,
2300,
12400,
4200,
null,
27200,
40300,
37100,
33550,
30300,
18200,
28000,
55400,
11400,
77900,
40200,
22200,
54600,
13500,
43300,
48100,
22600,
38900,
13100,
null,
11500,
12400,
60100,
39700,
18500,
51000,
10900,
21700,
61000,
36100,
34400,
30100,
26100,
38800,
11700,
23000,
8900,
null,
229700,
53300,
null,
14300,
null,
16100,
19900,
43500,
50000,
21800,
21400,
30900,
23900,
81800,
15000,
23600,
5500,
111900,
24400,
57000,
8400,
65000,
21100,
63000,
18800,
12100,
206200,
14700,
69000,
32800,
31300,
null,
28700,
7860,
101767,
130900,
16100,
28810,
22400,
23800,
null,
6700,
23500,
6800,
14400,
11800,
3300,
22700,
16600,
74400,
11600,
32300,
46200,
22900,
19000,
null,
25800,
38100,
2800,
10400,
24700,
26200,
17800,
15500,
34700,
null,
48800,
80500,
30200,
88700,
44800,
9600,
null,
47300,
3500,
29000,
41300,
2500,
28300,
20400,
25700,
78000,
20500,
55500,
36100,
50358,
18400,
13500,
9200,
32000,
20700,
3160,
18000,
51800,
23300,
23000,
15586,
17000,
58200,
5050,
null,
48100,
42400,
null,
17700,
15900,
29000,
62000,
144800,
52658,
12100,
30800,
30700,
22500,
20700,
47700,
10700,
null,
12300,
24800,
23800,
25200,
17200,
32300,
4600,
13700,
58500,
52300,
27500,
9200,
18800,
10800,
56000,
28000,
9100,
53700,
32300,
12100,
10200,
24300,
42100,
53500,
22700,
60600,
156800,
24400,
21100,
16300,
48400,
28800,
16400,
42500,
186100,
51000,
17500,
20300,
9000,
23900,
null,
3500,
1000,
12000,
22400,
27600,
17600,
4800,
25000,
8500,
5300,
28100,
13900,
17700,
24700,
12900,
18800,
29100,
9500,
55700,
53800,
21349,
85400,
19900,
39100,
65000,
31000,
9000,
null,
43100,
16200,
60000,
13800,
15300,
49300,
8900,
null,
43200,
null,
64900,
28400,
29600,
8100,
16000,
7200,
10200,
31300,
11900,
39000,
4300,
33500,
25400,
null,
53900,
61900,
null,
null,
19600,
25200,
32400,
null,
14094,
37600,
13800,
60300,
26500,
16800,
45300,
10600,
61500,
97800,
47500,
14400,
9900,
68000,
5800,
51200,
17000,
71700,
37900,
10200,
null,
null,
19400,
44300,
12100,
null,
125400,
9600,
29500,
8000,
null,
21350,
124043,
null,
49800,
21300,
null,
69600,
201900,
null,
165500,
null,
20700,
15700,
58600,
50800,
14600,
13800,
9100,
37500,
16000,
81500,
9600,
22800,
23800,
41700,
50500,
83100,
9700,
36741,
21100,
9500,
27100,
14500,
80600,
null,
7950,
24900,
41800,
27404,
6900,
4500,
20000,
35000,
80200,
30900,
36800,
null,
101700,
16300,
12600,
7100,
50200,
19700,
17508,
95500,
32200,
9200,
44100,
30300,
28400,
32300,
41200,
53400,
26300,
15300,
11600,
15700,
28900,
47500,
25400,
26250,
4900,
99400,
39700,
null,
36200,
35000,
38800,
60487,
20000,
84500,
21600,
22500,
64600,
13500,
13100,
56900,
10200,
6200,
63400,
102300,
125800,
21400,
14400,
17500,
6669,
35600,
59250,
null,
null,
17300,
40700,
16700,
10800,
47400,
17700,
257200,
12200,
24000,
57200,
33700,
12700,
23800,
null,
30400,
50800,
24500,
21800,
182100,
86200,
51500,
23000,
29000,
25300,
11600,
17500,
null,
22200,
10900,
null,
32500,
48100,
null,
49000,
21700,
9100,
7900,
6900,
34100,
10900,
6000,
68400,
43200,
16300,
null,
34200,
71100,
null,
4200,
21700,
15800,
16160,
14000,
21400,
17700,
7900,
null,
57000,
45500,
41500,
16700,
29000,
33000,
4100,
45100,
46500,
34500,
39200,
291100,
19600,
95000,
20300,
48200,
10700,
21600,
13600,
1700,
13100,
15600,
6000,
76900,
12700,
27600,
63500,
56900,
16400,
57362,
52300,
32000,
null,
18400,
13300,
22000,
21300,
10500,
15800,
49900,
38200,
47400,
105500,
7700,
7100,
13900,
42700,
28700,
93400,
49800,
4200,
79200,
17400,
25200,
18794,
32100,
null,
null,
null,
38400,
95100,
29400,
16900,
28500,
53200,
27500,
53700,
36500,
42200,
34800,
38100,
26400,
null,
35000,
14800,
18800,
20900,
31200,
45600,
13900,
19300,
21700,
37000,
13300,
18600,
20100,
18500,
45900,
null,
7100,
31600,
null,
46400,
37100,
10500,
18900,
70600,
42700,
61700,
10200,
64100,
13500,
5100,
14000,
7800,
17900,
21200,
56700,
9800,
27800,
28200,
null,
40300,
42000,
105300,
11200,
28200,
33800,
34000,
25500,
28100,
10500,
76000,
26500,
6900,
33500,
22100,
14700,
40700,
38900,
29600,
27700,
12900,
21700,
39700,
409600,
96400,
35800,
62600,
39200,
19875,
67100,
2300,
1000,
32600,
24100,
19000,
7250,
54400,
86100,
13900,
8100,
14800,
48800,
8600,
36100,
42400,
null,
16700,
25000,
32700,
30900,
46100,
null,
5000,
5300,
62600,
9600,
14600,
6000,
12200,
57900,
19400,
37900,
27100,
8400,
18600,
18100,
56400,
10700,
21200,
22200,
37900,
20052,
5100,
77600,
52800,
18900,
63600,
53800,
19400,
21200,
34100,
null,
83400,
11000,
14200,
9800,
6800,
19800,
15500,
8400,
30500,
22700,
21500,
27000,
34700,
13200,
19600,
40300,
21700,
6600,
88500,
null,
4800,
28900,
36000,
13000,
2600,
500,
null,
95700,
12500,
53400,
37700,
7000,
39300,
21900,
32200,
33600,
8900,
12700,
28400,
42500,
23600,
20000,
13300,
57600,
46500,
10800,
23900,
7500,
20600,
6200,
49200,
21600,
8900,
66600,
4800,
29400,
19700,
18800,
30600,
74800,
11700,
3900,
48800,
19500,
29100,
24700,
34300,
64400,
99400,
115000,
6900,
28900,
54200,
21800,
21700,
33800,
28500,
24200,
null,
15900,
4200,
51100,
17200,
30500,
21300,
27900,
56200,
20000,
62500,
9300,
20900,
59100,
67500,
11200,
51600,
44300,
27200,
39700,
6900,
null,
19000,
37300,
36100,
41200,
19900,
78400,
32000,
23700,
8400,
18300,
12800,
38600,
55800,
41600,
16400,
73100,
54600,
11500,
38900,
22000,
null,
27700,
6300,
114800,
10500,
null,
10800,
null,
21800,
29500,
29900,
16900,
16000,
53500,
31900,
58300,
57100,
14800,
26600,
null,
10500,
30300,
9100,
null,
38100,
6000,
17100,
41700,
null,
37200,
16800,
54300,
4500,
17100,
119800,
34750,
18000,
26100,
32200,
52000,
46400,
18900,
10900,
33500,
37500,
5000,
15000,
8400,
27200,
58000,
14300,
7600,
26200,
19600,
13700,
61000,
null,
15200,
68800,
10500,
75000,
27500,
90300,
null,
18600,
41700,
29300,
31900,
17300,
13900,
40700,
41900,
13200,
46700,
26500,
12800,
null,
10000,
23500,
3600,
23600,
4990,
27000,
null,
13350,
23400,
7900,
75600,
24100,
29266,
68300,
20900,
38300,
10500,
14100,
11000,
43000,
16400,
153400,
null,
29700,
11400,
57805,
31800,
71800,
27800,
35000,
23700,
41400,
19900,
52200,
18300,
8700,
null,
17500,
66000,
9700,
8300,
6400,
3000,
17700,
26100,
60200,
28800,
57200,
null,
null,
118960,
22800,
38600,
32800,
6700,
25900,
19967,
40600,
31100,
9600,
43200,
32700,
9800,
26300,
12100,
58660,
93000,
33400,
23900,
24700,
9000,
19000,
null,
36600,
22600,
12300,
62100,
3100,
22200,
57900,
null,
230500,
59700,
10600,
12700,
26400,
7500,
65000,
36300,
14500,
19400,
19800,
null,
75262,
21700,
18400,
44400,
22100,
20224,
31500,
30300,
4500,
21300,
35500,
null,
9800,
65200,
null,
18000,
12300,
6000,
60200,
10100,
8200,
20800,
27800,
10300,
6600,
132600,
22600,
5500,
20600,
35000,
44000,
null,
4600,
27100,
57400,
30900,
26200,
60100,
13900,
37100,
35300,
22500,
36200,
null,
26900,
13800,
28800,
24400,
27300,
null,
16200,
15700,
48900,
10900,
16100,
32100,
28900,
29000,
32000,
34600,
12300,
72900,
1800,
8800,
11200,
6000,
101600,
26700,
12900,
35100,
18000,
6500,
15900,
30000,
16300,
51800,
9400,
18900,
61500,
41900,
null,
71900,
38800,
32200,
32300,
35800,
38600,
58400,
3900,
8600,
22200,
23200,
29800,
10900,
34800,
null,
22400,
null,
27600,
19100,
55800,
null,
11500,
12000,
38500,
38000,
22900,
23600,
29200,
3500,
null,
31400,
15500,
null,
225300,
18400,
64700,
37400,
16700,
22000,
22700,
null,
10700,
15600,
31600,
7300,
155413,
20500,
29900,
43800,
13400,
23700,
15900,
54900,
62970,
30000,
17690,
16900,
71400,
18300,
1000,
1500,
87900,
60000,
77400,
6600,
7900,
5300,
70900,
null,
17600,
null,
95600,
18600,
8700,
24600,
10000,
14400,
60700,
6500,
18700,
19000,
47900,
41000,
24800,
5000,
7600,
null,
117300,
9400,
22200,
30700,
30900,
5800,
18400,
38000,
null,
35800,
57400,
14200,
48900,
69200,
46400,
16000,
16700,
39000,
33600,
15900,
15800,
157000,
12000,
11400,
24500,
3950,
1850,
15700,
56200,
30700,
31000,
74400,
56000,
45700,
11400,
34200,
5600,
null,
23400,
15300,
74750,
19700,
30300,
25700,
18700,
23300,
17540,
72200,
null,
16400,
6500,
17000,
43600,
20000,
14900,
22300,
21900,
12300,
25600,
69000,
27300,
16000,
18800,
38800,
17600,
21000,
10100,
18800,
9900,
15300,
2700,
30200,
23400,
27700,
10900,
5000,
1500,
3800,
27100,
55000,
19800,
null,
10600,
14900,
16600,
30300,
16400,
76100,
5900,
6900,
25600,
60000,
9800,
null,
31800,
5500,
30000,
39800,
37300,
17300,
11000,
30400,
25300,
22800,
20500,
33400,
1800,
null,
42800,
54200,
19400,
12100,
23900,
13800,
12000,
7500,
17700,
22100,
36400,
null,
51900,
24900,
20800,
21800,
19550,
6200,
47500,
62000,
19700,
28400,
17600,
null,
11500,
37600,
300,
23900,
23900,
19000,
47500,
10100,
31000,
55700,
11000,
51600,
38600,
3400,
36200,
17100,
4900,
8400,
59200,
14900,
143200,
500,
20200,
8800,
38800,
38700,
null,
9700,
null,
17000,
30900,
23900,
24800,
21600,
10000,
24000,
13900,
38100,
22600,
15900,
15900,
33100,
null,
20700,
78500,
53800,
26200,
null,
19200,
57200,
10400,
19900,
10900,
37800,
53200,
15600,
13500,
26800,
13800,
null,
9800,
4400,
39900,
15400,
10200,
12800,
45000,
14350,
10300,
41200,
17000,
14400,
null,
32500,
11000,
35700,
null,
19500,
9400,
21000,
34000,
null,
9800,
15900,
31900,
39100,
34100,
24900,
8400,
6700,
48700,
40300,
10700,
7600,
40300,
85500,
29100,
21300,
64800,
42800,
33100,
23200,
18800,
18500,
4500,
40500,
79100,
1300,
19500,
14100,
13400,
43500,
41500,
null,
81200,
75800,
null,
30800,
21600,
38700,
7000,
19700,
10900,
37900,
23700,
33500,
31700,
18600,
34000,
18400,
25200,
19400,
null,
39500,
28000,
67000,
35200,
43100,
null,
21700,
null,
19600,
76500,
12500,
18500,
26500,
26600,
2800,
27500,
17500,
9900,
49200,
13800,
35500,
15200,
null,
22400,
50800,
8800,
5600,
116100,
26900,
22700,
17600,
19500,
13400,
27300,
16836,
12600,
null,
59800,
13600,
22100,
5700,
28500,
120200,
null,
null,
18500,
null,
28800,
null,
150657,
7818,
17400,
71600,
9500,
21200,
67300,
null,
40200,
18900,
15000,
245000,
17510,
26900,
30700,
52700,
15400,
4000,
21800,
16100,
111800,
34100,
86000,
97500,
22800,
11900,
9500,
14400,
15700,
25200,
37600,
40450,
132500,
16400,
34400,
null,
43700,
7600,
39500,
13400,
7800,
26100,
18500,
13100,
81900,
null,
94400,
42400,
18600,
54000,
16600,
4000,
50600,
22700,
23000,
50600,
38100,
57700,
16700,
null,
27200,
28200,
49800,
13200,
6600,
10000,
60000,
292600,
3800,
11700,
78000,
28700,
83400,
3800,
21400,
52261,
211100,
13800,
22900,
null,
null,
32800,
37600,
22400,
40700,
21300,
39200,
8500,
16600,
33600,
9000,
28300,
33400,
102400,
null,
null,
22400,
21700,
34800,
null,
40000,
28900,
37000,
null,
5700,
43500,
20500,
51800,
20600,
43500,
17400,
27700,
40650,
21140,
51100,
70000,
33000,
33000,
30000,
8700,
49700,
36500,
79400,
7100,
53500,
83700,
24500,
8800,
15800,
20000,
46200,
31800,
49100,
7900,
9200,
18500,
5800,
56700,
8100,
17600,
null,
32900,
8800,
39000,
null,
8700,
12800,
8900,
17900,
19000,
24500,
73800,
31000,
15300,
31900,
30400,
22100,
10600,
72700,
15500,
24400,
39000,
18900,
30700,
39200,
103200,
13100,
42700,
28500,
28500,
12300,
50800,
46600,
12300,
22400,
41500,
12600,
16800,
36100,
6600,
23600,
67500,
32600,
44900,
19400,
38300,
null,
37700,
155000,
null,
null,
null,
13600,
null,
18900,
17800,
null,
60300,
8600,
10000,
6100,
16400,
10300,
17700,
24300,
null,
27500,
null,
53500,
16100,
10100,
10500,
30900,
44200,
51600,
52000,
10700,
65200,
8700,
3500,
42800,
60000,
null,
25800,
14900,
15500,
22900,
4600,
21600,
24500,
5600,
11100,
8700,
32077,
13600,
24600,
10600,
7400,
15900,
39300,
9500,
25700,
118400,
4400,
null,
12900,
9200,
13200,
37000,
30000,
25400,
42000,
18700,
88300,
46300,
19800,
13800,
30500,
27200,
72900,
38800,
37900,
37400,
15800,
13200,
42480,
null,
null,
null,
12000,
12700,
8500,
25000,
18600,
7300,
38200,
65600,
46000,
16000,
16300,
14400,
null,
16100,
64200,
7100,
10000,
7700,
26700,
33500,
9800,
67500,
59100,
121825,
38300,
43016,
9630,
16800,
100700,
null,
17300,
22800,
25800,
26300,
41800,
5000,
null,
29300,
30300,
10400,
37000,
93600,
41200,
28700,
40100,
107330,
19900,
11800,
6100,
45600,
16600,
3900,
23200,
10100,
11500,
56800,
28600,
49100,
22700,
20700,
23000,
163574,
19900,
15600,
5300,
11400,
34700,
43400,
3800,
14300,
9100,
74300,
null,
null,
82100,
19200,
40800,
25300,
65200,
65400,
29900,
13800,
37900,
35000,
13400,
10935,
87000,
27500,
8550,
40400,
41600,
38300,
18500,
128600,
21200,
null,
6800,
77300,
70700,
73900,
3900,
14900,
25800,
63600,
27200,
18200,
49200,
94800,
22200,
25300,
50300,
6900,
31900,
10000,
7300,
16800,
22600,
39200,
36300,
132400,
48400,
60300,
21000,
40300,
10900,
16700,
60200,
null,
59300,
9600,
39300,
49700,
31900,
26000,
12400,
37400,
15400,
10600,
20000,
30100,
12100,
16900,
37700,
35400,
35100,
34600,
1000,
5900,
17200,
6000,
9700,
83500,
33900,
null,
9600,
24500,
null,
12000,
32600,
12900,
33100,
39300,
10800,
38100,
37700,
44300,
23300,
15200,
4900,
null,
20400,
18400,
4700,
31500,
26800,
14200,
45100,
43000,
null,
12400,
11975,
null,
39700,
35000,
48000,
20900,
16000,
21900,
50200,
26443,
39700,
10900,
238500,
9700,
34400,
20600,
61700,
18900,
148300,
22100,
31500,
null,
11500,
18200,
25600,
13300,
13200,
38400,
19200,
47500,
57000,
21500,
null,
10800,
null,
49300,
37500,
6300,
16100,
25800,
39200,
9200,
33100,
13600,
null,
3300,
16600,
22080,
22100,
19200,
48900,
19700,
39000,
8000,
6300,
24700,
36300,
43300,
68400,
7900,
null,
22500,
null,
38400,
20100,
46200,
null,
105100,
14100,
70511,
null,
2600,
null,
109300,
59300,
null,
null,
21900,
27900,
13500,
14700,
31500,
23500,
null,
3400,
11000,
36100,
25400,
23200,
null,
63600,
19100,
32400,
37600,
54200,
67200,
33100,
8100,
64200,
null,
8100,
26100,
35300,
14800,
null,
10100,
null,
null,
88700,
null,
null,
19500,
8100,
5200,
null,
16600,
32200,
25300,
31000,
null,
23200,
9000,
14800,
6100,
18650,
6500,
2200,
null,
37700,
21300,
9300,
26800,
50800,
18800,
null,
51400,
20300,
15550,
19500,
6320,
12300,
30100,
null,
53100,
111300,
11600,
25700,
57200,
8200,
11400,
18900,
null,
53700,
22700,
18274,
null,
null,
24600,
23200,
16100,
23500,
19700,
51670,
22500,
63800,
42500,
46800,
null,
43400,
null,
50100,
5400,
11000,
9500,
15500,
4400,
18100,
20800,
71700,
26400,
33600,
7600,
57300,
18000,
24800,
69685,
10600,
15700,
7150,
90900,
8200,
18100,
23400,
31000,
33000,
12200,
30000,
58600,
14600,
40100,
52800,
34000,
38200,
17800,
9150,
16600,
17000,
22200,
55700,
66700,
11700,
28200,
47400,
19200,
30900,
42500,
6100,
null,
55300,
22300,
21600,
22700,
13900,
16500,
32800,
13200,
22700,
6400,
3250,
34100,
61800,
19400,
75474,
null,
4800,
40200,
17400,
36700,
47100,
7500,
56100,
28700,
32500,
58000,
105800,
27000,
17300,
33000,
10800,
15800,
52500,
7400,
7100,
60500,
44500,
34200,
45600,
9400,
40400,
null,
23500,
27200,
124900,
3500,
42800,
9300,
null,
8500,
80100,
23300,
10500,
13500,
51600,
25400,
55000,
19300,
63200,
9000,
15700,
62600,
26700,
34400,
42600,
36700,
12900,
5900,
9900,
3600,
8600,
null,
32400,
41200,
38500,
71800,
28600,
4500,
13800,
29200,
8200,
37000,
23600,
null,
26400,
10900,
13400,
10200,
18700,
57100,
65600,
16800,
66900,
56400,
null,
67200,
17700,
23100,
61400,
89800,
121600,
20900,
19600,
10000,
39100,
41100,
62600,
260000,
72700,
16695,
14900,
27700,
35400,
9500,
54000,
59800,
205200,
39300,
87700,
35300,
17000,
11500,
118100,
292300,
null,
55300,
28300,
2900,
null,
8300,
32750,
34600,
28800,
51400,
17750,
4400,
14200,
23800,
66200,
10600,
70300,
17600,
31300,
36600,
30200,
8000,
39000,
5100,
12300,
null,
38500,
34200,
36300,
109600,
48050,
41900,
27200,
7500,
13900,
9400,
25800,
30900,
66100,
6900,
20900,
45400,
30800,
31200,
30400,
38800,
34000,
16700,
6800,
52900,
48700,
null,
35600,
21000,
27100,
25600,
45100,
15900,
21600,
13000,
7600,
62000,
30300,
5600,
67600,
8300,
57800,
31500,
41800,
6100,
17200,
null,
30900,
27300,
25100,
29800,
57100,
74800,
122500,
37000,
45900,
23300,
28600,
22400,
14400,
12800,
50800,
18800,
17300,
16300,
20800,
19300,
null,
16700,
25200,
13000,
25000,
23900,
23300,
42600,
18500,
9300,
25800,
53100,
4000,
12100,
3500,
35800,
44000,
7500,
13000,
17200,
null,
12400,
24200,
3800,
36400,
27700,
13500,
7200,
82900,
23900,
39100,
11000,
26700,
48800,
74200,
26300,
16900,
5000,
12100,
null,
6000,
79059,
27700,
20600,
5800,
15500,
30700,
22900,
33600,
19200,
28600,
22000,
14200,
51300,
12150,
19100,
10000,
19700,
16000,
25300,
50800,
47400,
15000,
7200,
21900,
18700,
33800,
24200,
10500,
27100,
null,
8600,
129815,
67600,
17500,
39300,
13800,
11800,
96500,
36000,
27500,
18800,
81600,
15850,
34400,
35400,
100500,
33500,
29300,
18100,
35500,
42000,
13500,
10500,
8100,
95400,
28000,
53200,
33400,
15500,
69500,
36200,
19200,
78153,
128800,
9600,
16700,
20100,
null,
15100,
29200,
40900,
4400,
201600,
13300,
35100,
22600,
52800,
42400,
5800,
22800,
43500,
4800,
90848,
43500,
23300,
23100,
null,
36200,
10100,
372000,
9900,
16200,
14000,
8200,
9000,
28500,
12400,
8800,
null,
22900,
34100,
22000,
15100,
null,
12100,
39600,
18700,
7200,
50800,
4000,
14600,
15200,
17100,
32600,
5800,
8100,
25098,
24400,
null,
36600,
29000,
4500,
26400,
11900,
28300,
41400,
8300,
9900,
null,
71400,
95500,
22700,
13600,
59600,
20100,
22300,
8300,
null,
55700,
33700,
58200,
22700,
54800,
20000,
25200,
22600,
3400,
40500,
46400,
null,
13500,
38400,
11900,
18000,
19200,
27000,
42800,
71900,
62300,
70600,
7400,
15800,
27000,
5700,
22000,
88600,
5500,
3000,
6800,
240598,
15600,
29000,
7400,
37700,
16000,
14800,
17300,
9800,
20400,
12900,
null,
14800,
null,
27400,
22700,
27000,
64000,
34100,
33500,
57300,
162000,
22100,
22900,
230010,
6900,
12600,
14600,
24900,
16000,
17000,
68900,
20200,
23300,
19400,
17000,
45200,
null,
12800,
35100,
26400,
8900,
14000,
29200,
24500,
19700,
5500,
12500,
42000,
7209,
33400,
59700,
10500,
18100,
28500,
9800,
17200,
44600,
41000,
null,
24600,
14600,
15900,
13300,
58400,
18800,
17400,
34400,
12600,
43800,
9200,
36800,
9800,
18700,
102200,
null,
25450,
15300,
null,
9300,
31800,
41600,
8600,
17000,
46500,
16400,
40100,
null,
7500,
44300,
14700,
8400,
67500,
13900,
28300,
12600,
12200,
72559,
12300,
48600,
49600,
17400,
4000,
null,
6800,
12650,
50800,
5900,
65800,
66400,
12000,
16300,
50200,
3900,
22000,
38800,
16000,
19400,
57900,
17200,
31900,
27500,
24200,
22300,
49100,
58100,
16000,
33800,
6450,
23000,
43100,
30100,
null,
18900,
66000,
286500,
4400,
11900,
42500,
29800,
9600,
26000,
12000,
86400,
20000,
34300,
19100,
44200,
31300,
9600,
22100,
8300,
34800,
47700,
25400,
37400,
29000,
24300,
null,
4200,
70100,
35600,
36600,
7000,
19800,
4200,
10000,
27900,
7100,
66100,
25500,
34300,
90100,
38300,
27600,
39300,
4600,
12300,
null,
138900,
23600,
14500,
32950,
8750,
48200,
14577,
36300,
8500,
50500,
null,
12800,
87600,
null,
45000,
106700,
3000,
29900,
27900,
49000,
21300,
11015,
17000,
37000,
30900,
null,
null,
31800,
32700,
12200,
11000,
20700,
8400,
18200,
37600,
10100,
26400,
23000,
60200,
17000,
18400,
72900,
46200,
24700,
15100,
6300,
17500,
40700,
40900,
23100,
45700,
17200,
39000,
7600,
14500,
92700,
13300,
19600,
29000,
20000,
37500,
19700,
5900,
16240,
null,
28300,
8300,
14900,
16700,
null,
11000,
98501,
71700,
20000,
13600,
9800,
23900,
12700,
28700,
61000,
6100,
56000,
46300,
21100,
47600,
14500,
19300,
94200,
37800,
null,
39200,
20800,
74400,
40300,
22100,
23600,
29200,
null,
53000,
17000,
73149,
21700,
17900,
4900,
48000,
90600,
12000,
32300,
19300,
22400,
24800,
6200,
36600,
42100,
null,
39800,
86700,
38200,
21400,
59357,
9200,
16000,
19700,
20800,
22900,
6100,
1800,
43000,
33200,
null,
28200,
11400,
74600,
43300,
37300,
140000,
17000,
18200,
33200,
45000,
109300,
19500,
38300,
84200,
88900,
17000,
15100,
41431,
13600,
12000,
29000,
47000,
25100,
47800,
39300,
81100,
52900,
null,
14800,
9700,
51000,
11100,
null,
18000,
29300,
null,
61100,
20700,
32700,
24400,
24800,
61500,
46400,
25900,
9800,
109900,
12000,
6300,
44600,
20200,
6500,
13100,
13600,
19800,
58800,
33500,
78600,
13500,
6000,
45100,
12300,
8500,
null,
49900,
61100,
9700,
null,
11400,
null,
14700,
41300,
null,
87900,
69000,
50600,
8300,
38300,
22500,
41800,
25500,
null,
40800,
27600,
14500,
11200,
41500,
6000,
89400,
27700,
32600,
55800,
null,
43900,
43900,
12800,
7300,
17500,
37900,
71100,
35400,
15700,
42200,
6500,
15800,
100300,
15700,
3300,
5900,
13100,
13900,
5000,
71200,
17800,
34300,
18400,
8800,
39800,
59400,
28400,
61900,
7300,
37600,
15000,
83800,
16600,
15200,
null,
16800,
66700,
null,
8500,
null,
12000,
3300,
19900,
44200,
17900,
30000,
22900,
130000,
57800,
2770,
67600,
38500,
33500,
15200,
15400,
21100,
60000,
3700,
8700,
24300,
15400,
39300,
13900,
19700,
23900,
17200,
42500,
40000,
16800,
null,
33200,
30200,
28760,
57400,
41200,
26700,
10300,
23600,
44800,
14900,
null,
24600,
62100,
78500,
17900,
26000,
28800,
18200,
25100,
28400,
49000,
null,
17900,
2600,
75100,
46424,
22000,
12300,
18400,
28100,
7050,
29500,
83600,
12200,
55000,
37300,
6700,
45100,
19400,
44900,
34700,
55600,
50700,
67000,
5900,
44300,
13200,
31100,
8600,
34000,
84300,
13300,
null,
14500,
17300,
18200,
45900,
12900,
10700,
38800,
93700,
null,
61400,
12000,
45700,
101600,
7900,
56900,
13900,
12500,
7400,
71000,
21000,
48100,
9800,
15600,
53800,
34800,
147200,
27900,
null,
47500,
30400,
13900,
26000,
null,
23700,
39900,
33300,
9900,
14400,
78300,
24100,
11100,
21500,
12400,
24800,
16900,
null,
19200,
null,
133500,
22400,
11700,
38500,
13200,
56700,
23800,
30500,
7000,
48500,
35600,
32500,
32000,
66100,
23900,
16300,
17800,
12900,
15100,
72900,
26700,
12800,
68608,
43800,
13800,
51700,
17300,
20000,
null,
50700,
8500,
null,
null,
30500,
13800,
37400,
49300,
11600,
133000,
null,
15300,
46400,
26800,
59000,
22800,
22400,
null,
13900,
4600,
33200,
null,
57000,
21800,
30200,
39200,
15700,
18900,
74500,
8500,
3500,
50300,
23300,
7500,
15100,
8700,
70700,
13900,
11100,
null,
null,
15600,
82000,
28900,
5400,
29400,
null,
44000,
82500,
20700,
27100,
15900,
11500,
21100,
null,
19300,
27900,
11300,
12900,
16400,
66300,
54400,
11700,
17500,
null,
21900,
34800,
20700,
73000,
40300,
13800,
72500,
null,
33100,
31900,
21900,
15200,
7900,
19700,
21600,
13700,
16500,
25300,
7800,
29500,
14600,
39000,
56300,
19100,
18200,
33600,
16100,
37300,
7500,
31700,
9900,
21800,
null,
null,
22100,
9300,
24600,
100900,
15800,
7400,
11200,
9400,
7600,
25200,
15900,
6200,
25900,
36500,
25800,
95200,
null,
40100,
17000,
null,
26000,
44300,
29100,
27800,
47400,
19900,
14700,
16000,
15100,
32550,
74900,
75900,
null,
48400,
38400,
12600,
32000,
70000,
21500,
45300,
35800,
16600,
27000,
12800,
4500,
14200,
18495,
7500,
59100,
41900,
49100,
12600,
15800,
11700,
76400,
16700,
23600,
30700,
13800,
46600,
42400,
42300,
31200,
2300,
18700,
47900,
33900,
32806,
52800,
30900,
15000,
18500,
45200,
null,
12000,
30400,
null,
41600,
29400,
124400,
19000,
6500,
29700,
14700,
9700,
66100,
6600,
10400,
10500,
null,
26000,
28000,
18900,
43200,
9500,
70000,
54400,
12100,
null,
33200,
27100,
26800,
18500,
66500,
32000,
39900,
14600,
25000,
6000,
20100,
34800,
84900,
28800,
26400,
7500,
19300,
48700,
41200,
17000,
28700,
6700,
30700,
53600,
6000,
66400,
13700,
14600,
31400,
31800,
null,
20400,
45844,
null,
31674,
20100,
12500,
230800,
21700,
43300,
14800,
18800,
28400,
32900,
19100,
68100,
36000,
40800,
null,
52700,
24500,
56800,
29700,
40000,
32800,
36900,
23545,
32700,
10400,
34700,
49200,
null,
35600,
18500,
19200,
13000,
14200,
28200,
45400,
24900,
19400,
33000,
35000,
24200,
16400,
19900,
11200,
11100,
25500,
15800,
46800,
10600,
7600,
32200,
12100,
85200,
3900,
21700,
41900,
15100,
11200,
14300,
109400,
19100,
22000,
19700,
6200,
10917,
53700,
22000,
16000,
42200,
10900,
22100,
12000,
4700,
20100,
8200,
69800,
26100,
12300,
45500,
66600,
46900,
75800,
12500,
30000,
59800,
null,
20300,
45000,
15600,
43000,
31300,
14500,
27200,
99600,
44900,
19000,
null,
11000,
67800,
18500,
16000,
33600,
5800,
6800,
40900,
16700,
11000,
17200,
7300,
20500,
22100,
39800,
16200,
19700,
16100,
7400,
14100,
15600,
22800,
25900,
19500,
null,
19200,
15600,
12800,
29200,
17000,
54900,
18300,
23600,
12800,
37600,
12700,
11500,
15800,
13900,
46200,
7300,
5900,
37300,
12100,
47800,
8500,
16500,
13100,
10700,
17100,
600,
14900,
13100,
null,
57000,
16300,
20100,
22000,
39100,
24000,
12900,
62100,
22900,
null,
27600,
null,
14100,
5300,
28000,
23300,
33200,
27000,
22800,
78600,
13800,
31700,
7300,
16800,
10600,
38000,
23800,
3300,
null,
71900,
15600,
21800,
25900,
19700,
9700,
12300,
41700,
12700,
27770,
7800,
14000,
45500,
16500,
25600,
77000,
null,
15300,
13400,
18300,
null,
13700,
78800,
43000,
16200,
34960,
17400,
null,
4400,
125300,
39000,
11700,
28400,
1600,
212400,
19400,
123691,
50100,
44300,
18900,
30600,
31200,
21000,
4700,
797,
11000,
33600,
11600,
20500,
14000,
48600,
5600,
22000,
31800,
16400,
8000,
10700,
20400,
16400,
13400,
18100,
60000,
10300,
16300,
23700,
10200,
20800,
29500,
19300,
5200,
35800,
12600,
31400,
71300,
6100,
18900,
13100,
23500,
24400,
11900,
9200,
6700,
16100,
null,
6000,
16700,
97500,
35600,
20000,
null,
55100,
29000,
null,
25000,
12000,
null,
10800,
11800,
33000,
null,
13700,
11200,
10400,
null,
61300,
14100,
10200,
25400,
20600,
null,
162100,
8100,
9900,
19500,
44800,
10700,
10000,
43300,
26400,
14100,
26700,
45600,
38500,
16900,
18500,
216800,
26100,
81740,
null,
19100,
193800,
5300,
12500,
16700,
16300,
41000,
83000,
31100,
16300,
18300,
16100,
null,
33000,
48400,
27400,
34200,
34000,
27900,
16000,
13300,
7700,
8900,
33800,
19100,
27600,
30300,
20200,
null,
42100,
69500,
13700,
158500,
57400,
20100,
37900,
17900,
35800,
53200,
48600,
11200,
4000,
35500,
23500,
12400,
41500,
22700,
18200,
4900,
10200,
47700,
9600,
37800,
13600,
4704,
21000,
17800,
25300,
73800,
26300,
17300,
24600,
15300,
32000,
3300,
24800,
20300,
6200,
24600,
6000,
14900,
11500,
79000,
7900,
66900,
47600,
3300,
43500,
60400,
null,
37900,
66825,
65700,
31400,
65100,
33400,
18600,
18600,
15400,
27800,
108400,
30100,
null,
8700,
38300,
87800,
52200,
15600,
null,
18250,
19800,
58700,
19300,
31800,
21850,
null,
26500,
10300,
8200,
32100,
46000,
42000,
33200,
11300,
18900,
37900,
55800,
22600,
15751,
12300,
52700,
25300,
13600,
25000,
18600,
92700,
26800,
32900,
19900,
16000,
7600,
29000,
36100,
27800,
4500,
null,
52100,
51600,
29200,
6900,
25700,
16000,
50300,
15900,
14100,
5300,
42800,
13600,
40800,
20600,
7200,
227600,
13900,
null,
null,
1800,
31000,
10900,
224150,
144400,
25700,
11600,
12600,
16700,
19200,
17500,
27400,
18100,
null,
null,
61800,
25900,
null,
10500,
65900,
null,
18800,
42400,
43100,
64900,
28700,
null,
59554,
40700,
22800,
66900,
null,
null,
5500,
45700,
16600,
52500,
23900,
31500,
65700,
4400,
9400,
48850,
73400,
131400,
30600,
20000,
59600,
18200,
17700,
16300,
20875,
42912,
16200,
12400,
25200,
2800,
45278,
54900,
18300,
null,
30300,
20100,
103600,
42200,
47400,
11000,
null,
43700,
34200,
13200,
35900,
32000,
5500,
32800,
11200,
17300,
7900,
null,
6300,
16600,
16800,
78700,
150200,
24200,
11300,
19000,
17800,
90693,
54200,
54300,
37400,
9500,
null,
null,
28800,
53600,
15800,
23600,
36800,
15100,
31500,
null,
20000,
10000,
11100,
22500,
37500,
55600,
7700,
7800,
85800,
22100,
23300,
null,
17200,
42200,
30500,
36500,
23500,
61300,
36168,
17300,
633200,
14100,
38100,
15100,
22300,
53100,
17700,
null,
23400,
17700,
8300,
5700,
13500,
6500,
41400,
39800,
13100,
7700,
13000,
19000,
26200,
8300,
40200,
31900,
null,
56595,
21000,
38800,
8000,
13000,
4000,
9600,
63500,
74000,
31600,
55123,
33000,
80200,
84500,
19900,
8000,
34400,
62000,
30700,
18800,
19000,
42900,
300500,
79700,
15500,
14500,
35500,
38200,
20700,
11300,
20000,
16400,
7300,
12000,
2800,
26900,
25700,
11400,
50000,
22450,
5300,
56400,
null,
null,
14600,
7600,
12300,
71000,
49600,
16700,
null,
68481,
41000,
25500,
13400,
45000,
13600,
17200,
99200,
9600,
7400,
9100,
26300,
11700,
33900,
18500,
21900,
66200,
20500,
25200,
7200,
131100,
23000,
29400,
34500,
117000,
11600,
8100,
8300,
4500,
15500,
47300,
49600,
23300,
47400,
30500,
67600,
25100,
33000,
null,
36000,
35600,
23700,
35400,
21700,
10100,
null,
16900,
25700,
38600,
25500,
23200,
null,
7750,
75030,
15000,
34600,
10500,
13300,
6500,
10600,
44500,
50200,
23200,
64000,
14600,
19900,
83900,
45300,
6400,
null,
17000,
17000,
13100,
81700,
3900,
27700,
34000,
15600,
null,
18300,
null,
17200,
19500,
15000,
6400,
null,
15900,
15200,
13200,
26000,
23700,
85300,
31200,
10300,
17500,
32500,
30900,
41800,
40900,
17600,
29400,
36500,
22900,
35600,
70200,
32500,
41800,
21100,
36000,
8000,
null,
6500,
162800,
9500,
22700,
2900,
36100,
34100,
34700,
11300,
7500,
90300,
18200,
28300,
28300,
7900,
16200,
14000,
44700,
13100,
34400,
17600,
246200,
21300,
47400,
17300,
10100,
24200,
null,
87500,
30000,
null,
33000,
73900,
null,
32300,
8100,
65500,
27800,
null,
9000,
27000,
null,
12500,
100700,
25700,
14500,
null,
14300,
24500,
32100,
25500,
76800,
22100,
43000,
6950,
11700,
29600,
6800,
4000,
null,
9900,
58600,
16600,
104300,
21100,
8100,
10900,
201500,
24000,
51000,
null,
101300,
59900,
79400,
18200,
5700,
null,
8000,
8000,
61500,
9300,
52700,
21100,
44200,
7600,
15000,
7200,
98300,
39400,
17400,
84100,
null,
17100,
3800,
46235,
10033,
18000,
25500,
4000,
11000,
null,
27200,
49300,
50200,
7000,
11700,
14800,
18400,
23500,
15400,
19800,
9000,
21400,
39900,
16800,
37000,
null,
26700,
null,
6000,
15000,
11700,
31300,
33400,
20100,
58600,
34200,
33400,
21300,
51300,
4500,
6000,
15700,
37800,
9200,
13600,
null,
19800,
6450,
39600,
null,
null,
28100,
9400,
64000,
29000,
42200,
39800,
39300,
93500,
33400,
13600,
46600,
5500,
40500,
8100,
15100,
29600,
56600,
47100,
48600,
20100,
8200,
41300,
32000,
11400,
26600,
14700,
null,
26700,
20200,
39400,
21000,
47900,
13300,
19900,
17700,
36500,
23500,
3500,
9800,
10400,
9800,
13700,
49800,
21400,
19000,
20000,
20900,
4100,
30900,
65800,
40300,
109900,
92900,
41700,
11300,
15200,
5900,
30500,
28800,
18400,
50000,
null,
21700,
25000,
13500,
13700,
34700,
62500,
null,
64600,
0,
117800,
24700,
22000,
31100,
20100,
19800,
37500,
9700,
37400,
43000,
10600,
21099,
44800,
36200,
27800,
28200,
21000,
null,
29400,
19900,
14100,
null,
15700,
29000,
13248,
25240,
88000,
6800,
15900,
169518,
32900,
46800,
23200,
21300,
54400,
42000,
57500,
10500,
116000,
112900,
74600,
50700,
53200,
28800,
null,
20600,
26500,
23500,
38000,
42900,
11000,
45100,
19700,
30000,
26000,
48900,
89600,
108400,
34100,
9500,
28000,
17700,
20000,
47800,
null,
65000,
null,
53500,
18900,
null,
23500,
38000,
91500,
29500,
3100,
67800,
13900,
21100,
16900,
163700,
16000,
26900,
8200,
12900,
30800,
19300,
8900,
39700,
47700,
208800,
11900,
24600,
33100,
13400,
28600,
26100,
17400,
6800,
44100,
57100,
26400,
22192,
8100,
24200,
17500,
53000,
36000,
44500,
29800,
32800,
null,
12600,
14500,
12000,
25900,
28600,
43200,
74800,
14500,
14100,
4100,
23000,
7000,
38400,
14100,
12200,
9200,
29700,
32400,
16900,
29900,
20500,
61900,
73500,
29100,
24000,
null,
25400,
84200,
19400,
55500,
36300,
23100,
91900,
81000,
31600,
19800,
40400,
11200,
17000,
11600,
null,
14600,
99800,
44100,
34300,
20000,
9200,
21200,
10200,
null,
7600,
52400,
48900,
8640,
53200,
17400,
25700,
null,
38000,
64300,
24300,
36500,
17400,
24600,
22900,
22500,
19100,
13900,
15700,
20500,
14600,
118700,
61700,
33100,
28100,
10600,
6600,
20100,
14200,
15700,
15600,
61000,
23600,
31900,
21200,
33200,
null,
null,
17300,
27300,
16700,
32100,
39000,
21600,
17800,
5200,
6400,
28600,
19300,
29300,
7100,
25100,
52500,
19300,
30900,
47200,
50200,
43300,
326700,
72000,
10300,
14500,
12400,
10000,
56000,
19000,
20200,
null,
11800,
null,
15000,
29200,
10900,
34100,
15500,
null,
62100,
14300,
30200,
7800,
22100,
58200,
35800,
20300,
53900,
49000,
35700,
23500,
28100,
23400,
31700,
13300,
65800,
67200,
39500,
35700,
16000,
6600,
null,
20800,
29300,
23500,
18100,
11000,
33700,
null,
9000,
46600,
6500,
17500,
null,
23000,
9000,
11700,
null,
8600,
10000,
4000,
16600,
33500,
47701,
33900,
19300,
29500,
13000,
21200,
31200,
25500,
19300,
8100,
7500,
6600,
23600,
23100,
24700,
4600,
17950,
7100,
11700,
27900,
12100,
46200,
27400,
17300,
13300,
17700,
6400,
28900,
90600,
58200,
11200,
16500,
21400,
29200,
18100,
80000,
267900,
40400,
4000,
12000,
74600,
99700,
22900,
13200,
null,
88600,
null,
33500,
23000,
20100,
63000,
13900,
22000,
47300,
9100,
13000,
42500,
90100,
38200,
36700,
null,
26100,
51100,
39500,
12200,
43700,
5600,
null,
2500,
6900,
5600,
18600,
7200,
21000,
11100,
26000,
16800,
31300,
null,
null,
null,
null,
16700,
9000,
17800,
19600,
16000,
27300,
7400,
22300,
37900,
27600,
19900,
null,
16300,
58900,
32500,
7500,
26000,
62207,
60600,
26800,
41500,
32600,
null,
38800,
1500,
30900,
23900,
40200,
22300,
null,
56700,
6000,
78500,
31200,
53300,
40400,
58905,
48500,
53800,
3200,
14500,
16100,
11300,
9250,
18600,
46100,
7200,
66600,
null,
5900,
15000,
null,
44600,
40964,
35000,
null,
60500,
11200,
8800,
80800,
50300,
null,
47600,
63600,
27900,
10800,
11800,
11000,
22000,
14400,
null,
4100,
8200,
18300,
17800,
15400,
null,
81700,
132500,
13800,
35800,
30300,
41700,
9000,
48100,
12400,
8000,
16300,
30200,
5900,
34100,
20700,
5400,
14000,
3600,
null,
7200,
63700,
6900,
12700,
15300,
87800,
11800,
73300,
30400,
23500,
61800,
73840,
14400,
34200,
4100,
22500,
20000,
7900,
29900,
24300,
2400,
1700,
23900,
20600,
16800,
11800,
18425,
6200,
32900,
8600,
51300,
74500,
14600,
178100,
null,
69200,
24700,
7600,
13800,
54900,
22300,
13500,
29500,
10200,
11200,
12000,
20100,
54200,
27800,
58600,
39300,
null,
25000,
14500,
2200,
32800,
19400,
7900,
59500,
18500,
28100,
12900,
49300,
18000,
9200,
45400,
10900,
16000,
null,
51900,
38000,
27700,
39000,
6900,
16100,
56400,
19700,
12100,
8800,
43300,
null,
13500,
34800,
6400,
null,
33900,
21200,
47000,
34000,
6800,
8400,
40100,
19000,
16500,
3500,
40400,
null,
17500,
39000,
100200,
53000,
23800,
36800,
69200,
48100,
9600,
9575,
18000,
6200,
null,
14500,
4400,
42400,
40700,
12500,
32000,
25900,
12800,
45900,
16400,
9800,
72600,
35800,
17500,
13300,
44600,
58500,
21400,
28000,
40900,
51900,
64200,
30700,
25400,
null,
20300,
21500,
19500,
50100,
null,
13800,
18600,
26900,
25200,
14300,
15200,
11500,
23400,
11400,
25300,
23000,
12500,
null,
63100,
19300,
33600,
16300,
null,
13500,
14700,
19200,
152400,
22100,
26700,
6100,
31700,
41900,
32600,
13800,
null,
36200,
2800,
8700,
19300,
47700,
5500,
35600,
23700,
null,
47500,
21900,
26000,
24500,
10100,
20700,
15700,
35100,
130209,
43600,
22100,
24400,
6800,
18500,
23600,
null,
66700,
150900,
34400,
54500,
36700,
79800,
18200,
38000,
16000,
null,
66100,
43100,
53300,
15700,
23950,
32100,
44400,
18200,
null,
null,
56400,
174600,
1100,
37000,
34700,
62700,
40800,
34900,
33100,
8700,
40600,
21100,
24300,
25100,
27100,
12600,
28900,
7800,
19100,
55700,
6100,
11500,
45119,
67400,
26700,
25900,
38200,
12500,
26100,
73300,
22000,
9700,
12000,
12700,
41100,
11200,
9000,
35300,
30600,
36400,
28900,
32500,
12300,
74700,
16100,
61000,
50800,
5700,
36600,
24200,
12100,
8100,
17800,
5400,
5900,
42700,
20600,
28500,
null,
27100,
59900,
13300,
12100,
16500,
94400,
null,
30600,
9600,
11300,
72400,
29400,
10900,
15100,
17300,
10100,
49000,
68700,
93400,
17300,
36600,
21700,
36700,
37900,
27600,
38700,
58600,
18200,
6700,
11100,
25700,
29100,
141100,
4000,
null,
66900,
9100,
0,
56700,
null,
null,
28900,
19100,
39700,
40700,
53400,
null,
18100,
25500,
6700,
25200,
23300,
39300,
13500,
16200,
14500,
68200,
23600,
41700,
36900,
31900,
47600,
14300,
22800,
16600,
58600,
25100,
null,
19300,
12100,
62600,
29500,
56400,
5900,
30200,
87100,
20100,
null,
15900,
37100,
42000,
76200,
null,
12400,
165500,
15300,
33100,
21300,
11900,
6600,
69500,
31800,
13900,
null,
78500,
21600,
11300,
null,
16500,
37800,
58250,
53300,
6500,
9100,
35200,
31700,
11600,
5500,
54300,
53600,
14400,
14400,
6300,
25600,
4800,
9600,
52500,
104474,
17300,
61200,
23300,
null,
19000,
18800,
27800,
38700,
null,
20000,
null,
13900,
14300,
44700,
20700,
64000,
17400,
39600,
43800,
9300,
11200,
41300,
15100,
44600,
8600,
11200,
23600,
16100,
40500,
75500,
5400,
38700,
800,
23100,
14000,
30800,
16300,
56900,
31500,
14800,
35400,
68800,
6700,
24200,
41200,
null,
29000,
44500,
17600,
76200,
10100,
7800,
14600,
33300,
24500,
19700,
40600,
37300,
64900,
38500,
13500,
16000,
28800,
31500,
18400,
5100,
null,
32800,
null,
45800,
null,
49400,
18000,
33600,
29900,
35600,
13100,
33500,
16700,
142500,
11900,
null,
null,
11400,
16800,
35400,
34900,
47000,
57100,
14000,
14400,
57500,
30600,
6600,
46200,
12900,
112500,
null,
11300,
15700,
67900,
113300,
32100,
46400,
30700,
49100,
22800,
74600,
19200,
144900,
59200,
2900,
73100,
null,
51700,
72100,
29200,
15800,
22800,
31600,
35500,
63800,
17100,
21600,
45800,
15600,
22900,
5000,
68200,
20900,
37500,
8800,
null,
8300,
44703,
12300,
12000,
20000,
48300,
47500,
23100,
25900,
7000,
77500,
10900,
14000,
47400,
32500,
26700,
38700,
21800,
79700,
16000,
41940,
23000,
77800,
16900,
16900,
17700,
20400,
7000,
41900,
8900,
22500,
null,
9492,
24600,
25300,
12500,
36600,
44900,
78500,
53383,
29100,
7900,
22000,
65900,
15100,
33700,
14600,
57300,
null,
45600,
null,
17300,
null,
26500,
null,
38400,
8600,
42700,
240700,
26700,
32520,
70800,
57700,
15600,
12780,
36200,
null,
null,
5800,
22000,
21500,
33200,
40700,
99000,
27900,
null,
30300,
37700,
12200,
75700,
65700,
19900,
30200,
22800,
4200,
23400,
32200,
79100,
28700,
37900,
25600,
24400,
189300,
7100,
5000,
11400,
30500,
29100,
79600,
47200,
20500,
26100,
17200,
16400,
43600,
21400,
13700,
10050,
37000,
48200,
20100,
41000,
12000,
5900,
null,
14300,
18500,
null,
null,
59900,
17450,
45300,
17000,
19800,
23000,
21400,
26400,
126500,
28700,
6500,
40000,
7700,
6600,
500,
27700,
44300,
14100,
27000,
9000,
24500,
120400,
46610,
7400,
16100,
6300,
81500,
15500,
28200,
39000,
34500,
9600,
null,
42000,
16600,
17500,
null,
13300,
16200,
10300,
19600,
39600,
10000,
15700,
63400,
18500,
37500,
25400,
19300,
null,
14000,
39700,
29500,
13600,
40500,
29000,
16700,
23700,
20800,
78700,
29400,
23600,
12600,
7000,
22800,
25400,
10400,
17200,
33100,
13000,
19400,
14100,
null,
52000,
56100,
1500,
27300,
32200,
3200,
28300,
11900,
74600,
null,
32400,
14400,
53200,
24514,
74600,
13100,
11300,
39400,
2200,
28200,
19000,
34400,
20600,
24700,
31600,
8200,
25500,
56100,
47500,
32400,
39100,
90000,
20300,
null,
27600,
7400,
40300,
115100,
35800,
18900,
30200,
21300,
50400,
7000,
null,
44300,
10200,
204900,
17500,
32000,
24455,
12500,
73900,
65400,
97400,
11400,
37100,
89900,
47200,
null,
47700,
null,
59700,
null,
1500,
52584,
46000,
59600,
16500,
15200,
29700,
10100,
39100,
34200,
14300,
107500,
8900,
19000,
36600,
22400,
18600,
9600,
41400,
73800,
8000,
12900,
33500,
null,
25700,
27800,
28400,
51000,
43300,
35100,
103900,
90100,
31800,
15100,
19700,
42754,
10400,
7100,
17600,
66600,
59500,
null,
16200,
98521,
14500,
10900,
25700,
64800,
30000,
null,
1600,
101400,
5500,
13900,
8300,
19800,
33500,
39280,
20000,
17600,
16900,
20600,
54600,
null,
null,
30100,
11800,
66100,
45300,
38500,
5200,
17900,
6200,
null,
23400,
55700,
null,
149400,
58200,
46900,
16000,
25700,
null,
51500,
40600,
102000,
20600,
26000,
12400,
75683,
13600,
54900,
35200,
25300,
21800,
13300,
32700,
76200,
31100,
29400,
null,
37800,
46100,
31200,
20800,
22810,
26900,
29500,
27600,
51900,
49000,
46100,
127200,
47800,
22500,
63200,
100900,
16200,
18500,
35700,
33600,
70400,
5700,
43600,
39400,
null,
74100,
14800,
null,
22700,
16900,
22800,
16200,
39900,
16100,
43400,
15800,
21400,
10800,
29400,
21500,
53200,
53800,
103000,
30700,
29900,
20500,
21400,
36000,
18500,
21100,
43200,
65800,
24700,
24800,
17800,
102800,
39700,
80600,
33900,
21400,
null,
25200,
46600,
2800,
54000,
95400,
26200,
8000,
34700,
16500,
65300,
367400,
null,
26600,
9600,
10800,
48000,
21000,
44700,
53100,
15000,
14500,
36700,
32900,
19400,
null,
33300,
19100,
678400,
10700,
31400,
8900,
25800,
48600,
9700,
9900,
32900,
20400,
10700,
5800,
91100,
6100,
15400,
1400,
14900,
null,
8600,
30900,
20300,
23400,
6700,
null,
24800,
41600,
null,
17500,
33100,
26100,
10500,
8500,
39300,
29200,
44700,
11600,
50300,
11800,
30500,
30800,
27400,
16000,
59700,
8600,
52400,
41500,
17900,
null,
57000,
22300,
null,
16300,
23400,
18700,
12500,
14300,
22800,
31900,
4250,
22400,
null,
13900,
16100,
64500,
5700,
22800,
28015,
33670,
8400,
14900,
9800,
20000,
27400,
null,
null,
94700,
16900,
37100,
20700,
15700,
32400,
13750,
12200,
54800,
64400,
29100,
null,
16000,
9200,
48700,
21700,
14600,
14000,
45100,
13500,
6600,
12200,
33000,
8300,
37700,
44800,
9500,
102300,
null,
30000,
32071,
116100,
28800,
13700,
null,
63800,
133000,
null,
22600,
34600,
90700,
120900,
22100,
17600,
25000,
68800,
27100,
48500,
15800,
34400,
21500,
40400,
8300,
32900,
32500,
59600,
144300,
10350,
32100,
17500,
57300,
35000,
null,
28000,
27100,
3400,
40400,
15700,
null,
46500,
28397,
42000,
60300,
13300,
10600,
13800,
53300,
11600,
86000,
53400,
19700,
21100,
9600,
17600,
68900,
null,
7400,
9200,
3500,
42700,
26200,
15600,
74600,
4900,
null,
null,
1314900,
33400,
13900,
null,
31000,
59100,
26300,
38100,
23500,
23500,
22900,
27500,
32300,
57900,
null,
17500,
25800,
14100,
17000,
null,
21400,
26000,
43100,
16000,
42600,
33000,
25400,
50900,
112400,
55100,
4400,
19900,
null,
42400,
86300,
45000,
77700,
12900,
null,
12700,
2000,
21400,
17700,
63800,
36900,
null,
49900,
6400,
31100,
8500,
null,
31000,
15200,
10300,
26500,
84800,
40200,
27100,
22300,
25600,
75800,
22000,
7300,
13500,
22700,
70200,
30100,
null,
29600,
35400,
12100,
19700,
38900,
9930,
23500,
21900,
null,
15800,
50300,
13400,
28700,
5800,
31500,
155400,
9600,
8600,
45151,
27400,
70600,
39600,
59260,
35300,
17700,
36100,
null,
10600,
13430,
5500,
26400,
39400,
null,
109800,
8600,
10900,
16200,
79800,
16300,
30100,
40400,
7400,
13000,
80400,
8300,
60700,
2400,
13100,
42000,
4900,
154500,
184185,
23000,
13600,
37600,
67700,
27400,
null,
18800,
6900,
13626,
1200,
null,
18900,
null,
29400,
26600,
null,
90000,
42600,
null,
8400,
24600,
36600,
9800,
25200,
3400,
64600,
15600,
22000,
15600,
14600,
null,
29800,
33600,
49800,
39300,
15000,
null,
2000,
15200,
null,
68400,
40400,
15900,
19500,
12600,
null,
8400,
11900,
21800,
41400,
27836,
27400,
24200,
31100,
11600,
24900,
65400,
9800,
16500,
62552,
47400,
32000,
16400,
11700,
104900,
22200,
15600,
51300,
8500,
20500,
38800,
null,
null,
36000,
37300,
78500,
328800,
17200,
59961,
385880,
76200,
19900,
22800,
60300,
21600,
10800,
14500,
59300,
null,
43700,
7300,
7800,
44400,
43200,
26500,
23400,
45100,
20000,
27032,
13800,
22200,
20200,
null,
11500,
54000,
30100,
11800,
8100,
49808,
5600,
39700,
null,
351000,
74771,
32600,
55200,
null,
19600,
16500,
31600,
22400,
16700,
15000,
13000,
72000,
17500,
24100,
20700,
51400,
50300,
30300,
31600,
9400,
null,
61500,
6000,
52100,
19800,
20700,
51700,
50500,
73600,
12500,
30700,
10700,
26500,
19700,
12700,
22200,
15100,
30200,
29800,
21000,
7200,
19300,
33300,
16500,
49300,
57400,
24300,
11100,
18600,
12400,
null,
null,
14900,
53000,
2500,
23500,
24700,
27100,
23100,
40900,
145900,
1600,
24700,
7200,
47600,
15800,
27200,
6500,
21300,
33300,
21400,
30919,
15000,
53000,
16600,
26300,
44400,
14800,
14000,
29500,
16700,
63000,
38300,
136200,
15500,
51900,
43400,
7300,
271000,
null,
18996,
18600,
13800,
39800,
21089,
8700,
98811,
6600,
82200,
22000,
17600,
8600,
25200,
57200,
36400,
39400,
12100,
42400,
31400,
25700,
27200,
40000,
15900,
15100,
56700,
14700,
15400,
40300,
36700,
12000,
35900,
49300,
31300,
53900,
9400,
null,
51000,
37200,
25600,
55300,
3100,
56100,
20600,
15900,
null,
64900,
30500,
20000,
45300,
null,
38800,
44000,
96000,
55600,
17700,
20400,
77000,
34800,
54700,
15100,
41500,
33900,
15500,
25000,
53000,
21300,
40000,
46200,
5500,
20000,
8600,
94600,
10200,
null,
null,
11400,
38600,
28600,
151900,
103600,
16000,
47200,
32900,
36600,
18700,
69900,
34300,
10700,
32800,
15800,
12500,
34600,
15400,
59500,
17700,
36300,
19300,
72900,
null,
27300,
8100,
22800,
15600,
21600,
17600,
16100,
34200,
28000,
15300,
12200,
48000,
50700,
48000,
null,
20000,
32700,
15600,
9700,
14900,
11400,
17200,
23950,
21900,
18900,
null,
48600,
8200,
11100,
null,
19100,
10800,
23521,
7700,
27800,
29100,
38600,
11200,
73800,
27000,
13200,
23600,
56900,
68114,
null,
26800,
null,
21200,
36300,
50900,
43800,
23300,
19600,
22950,
19800,
22300,
28200,
10200,
66000,
null,
50100,
30600,
null,
9000,
34400,
41200,
58200,
49300,
8300,
24500,
4900,
89400,
69100,
null,
15800,
11900,
23000,
29900,
26500,
6100,
56900,
18900,
21800,
93150,
16900,
13100,
20800,
11500,
null,
21700,
66232,
10800,
39100,
65100,
15500,
15500,
8500,
43500,
9900,
21400,
10300,
41700,
8800,
10900,
36900,
22000,
38000,
32500,
16800,
24400,
12200,
20500,
11700,
9200,
56500,
3000,
32300,
49200,
77000,
6400,
50400,
40800,
15800,
29201,
51000,
22000,
13000,
46500,
37800,
19600,
43500,
10800,
20600,
95300,
24554,
36200,
18800,
65600,
36700,
34100,
4200,
9400,
6900,
42600,
32000,
null,
54900,
30300,
22400,
5100,
25900,
39500,
11100,
47500,
45100,
16700,
53100,
null,
46500,
30100,
37050,
44200,
39700,
45800,
31100,
31500,
23900,
65500,
15000,
17600,
44300,
20700,
36100,
43400,
13600,
27400,
9200,
10200,
38700,
14900,
9500,
59700,
34100,
13600,
22100,
35800,
34600,
17100,
6400,
null,
81062,
57000,
null,
20300,
195600,
38900,
37600,
52300,
null,
55300,
37500,
58100,
62400,
10000,
10300,
34000,
27300,
8000,
20400,
21600,
16200,
34600,
15500,
48861,
37400,
13400,
16000,
32700,
19700,
17700,
25497,
27400,
25001,
54400,
null,
19800,
23500,
32200,
8600,
33603,
67900,
19000,
null,
30500,
16200,
26600,
4400,
4800,
34100,
18900,
25200,
28300,
28200,
31600,
null,
null,
14900,
17300,
17400,
20600,
32600,
23600,
57200,
22000,
34400,
17800,
12100,
14700,
102800,
46000,
36000,
53500,
17000,
9000,
null,
47300,
22200,
30600,
14400,
45000,
12900,
11200,
82900,
14700,
22800,
22860,
82400,
14700,
25500,
40100,
18900,
19500,
15300,
13900,
17800,
34000,
29800,
15200,
53400,
39700,
37300,
16400,
75000,
8900,
24600,
56100,
14200,
52500,
43700,
13300,
36500,
11200,
38900,
13100,
43500,
11200,
54000,
null,
29600,
15900,
24500,
31000,
43300,
45900,
22800,
28300,
30600,
21600,
64700,
24400,
67900,
30300,
33400,
10500,
49900,
7300,
74400,
19000,
35700,
27500,
33400,
32400,
13300,
null,
34000,
null,
4200,
21100,
27000,
11300,
50300,
5500,
19800,
62600,
4700,
13000,
null,
17700,
5700,
122500,
5500,
17400,
19200,
22600,
15800,
22300,
null,
26600,
33200,
12800,
6100,
5400,
42500,
35100,
8700,
13900,
9200,
null,
22300,
39400,
61300,
71300,
12600,
32000,
null,
null,
8000,
28800,
300500,
10200,
44222,
28900,
null,
23500,
19500,
38300,
15000,
19000,
6400,
11200,
47100,
37500,
null,
28000,
32800,
63300,
17900,
20200,
11100,
14700,
18700,
16100,
36800,
15000,
8500,
28800,
13100,
43900,
18500,
12400,
22200,
29600,
18700,
3000,
null,
109500,
42100,
15900,
null,
32000,
40100,
83700,
63100,
null,
null,
15600,
20900,
24600,
29900,
23100,
null,
null,
50200,
32000,
9400,
25000,
15200,
53200,
16300,
5900,
50800,
28400,
35000,
null,
56200,
25100,
52900,
30300,
8900,
null,
37400,
15400,
null,
89900,
15500,
null,
11100,
30800,
57600,
43000,
null,
34500,
24600,
10900,
46200,
85800,
800,
40500,
39800,
15200,
55400,
14700,
40700,
20600,
1000,
15800,
12000,
22100,
18600,
6300,
21100,
57200,
8500,
15800,
54800,
41200,
32400,
39700,
20500,
26000,
17300,
7800,
10600,
101300,
23100,
27800,
36900,
36000,
16000,
109300,
2500,
10300,
11500,
94500,
51000,
97600,
26500,
7000,
45500,
22400,
3000,
null,
5900,
44200,
8500,
10100,
49000,
7200,
31700,
11900,
44900,
37200,
107800,
52000,
6000,
19440,
18200,
8000,
null,
null,
37000,
72400,
3500,
41700,
14500,
112700,
52300,
26400,
36300,
27500,
17600,
36400,
13000,
40100,
18200,
46500,
13200,
6800,
69433,
32500,
null,
11200,
14200,
9900,
38500,
4500,
36200,
28400,
null,
9300,
40400,
24300,
26400,
50300,
31500,
35801,
12800,
23300,
12400,
14600,
29600,
57900,
50000,
46032,
100500,
61800,
null,
33400,
15600,
32800,
82300,
5000,
6500,
18800,
10300,
13800,
23200,
42200,
7700,
5600,
null,
91500,
39500,
8200,
18700,
54501,
7700,
16200,
33400,
null,
10700,
2700,
20600,
13400,
43100,
29100,
null,
8300,
null,
16200,
11800,
56900,
25200,
19000,
13300,
52300,
8100,
22800,
74300,
43600,
null,
9800,
63000,
29600,
19400,
150400,
12700,
27500,
44100,
null,
22100,
14400,
66900,
37700,
38800,
null,
12500,
34700,
50700,
28800,
5000,
92600,
32800,
27000,
18600,
57700,
3200,
null,
17900,
14300,
22700,
14900,
13200,
13000,
8600,
20700,
38400,
83900,
49900,
5900,
24700,
30100,
57178,
27000,
7300,
21300,
17900,
5500,
24400,
29000,
12400,
10000,
7250,
null,
47100,
10400,
44100,
19200,
42800,
20400,
null,
14600,
null,
48100,
15200,
7000,
6300,
26900,
63100,
53900,
13600,
24500,
27800,
66500,
12200,
19900,
28200,
16200,
19200,
19600,
25400,
14700,
116200,
9300,
null,
15900,
11200,
22400,
26800,
3350,
36000,
30000,
42965,
21025,
19700,
24000,
21600,
16700,
15700,
null,
64200,
57700,
5600,
17600,
17700,
20100,
3100,
86800,
18451,
null,
33000,
43200,
15100,
9000,
14800,
12100,
11800,
24200,
24300,
13900,
17600,
23000,
30500,
5400,
10600,
51700,
206449,
null,
17425,
null,
25500,
16500,
null,
76800,
28300,
24900,
64200,
20900,
21500,
32200,
48300,
3800,
38650,
10390,
80200,
null,
12500,
14000,
26500,
3500,
11700,
0,
26100,
26300,
18700,
10200,
9300,
19100,
22400,
18100,
124400,
17900,
28300,
9400,
9700,
7840,
9900,
35800,
50900,
null,
19000,
22100,
41800,
13000,
null,
null,
null,
45900,
10300,
46700,
20300,
12300,
null,
30800,
18200,
17700,
5150,
49300,
15000,
13900,
23100,
46800,
6850,
116700,
26845,
26000,
22300,
20300,
18400,
50200,
7400,
null,
66000,
15200,
21200,
7500,
null,
6400,
3400,
47100,
21600,
34800,
77735,
27200,
25500,
22600,
63000,
null,
32400,
9800,
26900,
41000,
34700,
15300,
10000,
29100,
15400,
53400,
234800,
19700,
21900,
6700,
17400,
null,
null,
null,
19200,
31000,
81300,
64400,
15300,
null,
28100,
null,
21600,
23500,
29300,
33400,
37600,
29900,
5100,
34200,
57200,
61900,
46000,
60500,
15000,
44300,
20500,
16600,
9700,
16000,
null,
22700,
19700,
53700,
88100,
30400,
21500,
102900,
14500,
17000,
68400,
null,
13400,
35700,
10050,
6200,
15100,
41400,
6600,
22500,
56700,
19197,
111700,
116920,
16100,
15300,
26200,
25100,
10424,
23700,
6900,
25800,
5700,
21400,
49200,
12000,
13800,
2100,
7300,
12700,
29000,
30300,
17300,
3100,
267100,
21900,
43300,
11000,
60000,
24900,
30300,
null,
10600,
44800,
19500,
14500,
13600,
45400,
51700,
20100,
4800,
73100,
153800,
26500,
9800,
56900,
70000,
25900,
3500,
13500,
null,
79800,
7500,
18400,
20600,
24000,
12900,
9800,
39700,
49702,
25500,
14100,
25923,
8200,
10100,
13000,
80900,
20900,
6500,
18700,
16900,
20800,
18600,
102400,
52900,
29200,
null,
23500,
23800,
55500,
28100,
61100,
10900,
17500,
67800,
24300,
33600,
44100,
37800,
53200,
null,
16200,
22500,
34500,
162000,
13700,
14800,
26700,
45600,
43500,
null,
31100,
70900,
48400,
44000,
16800,
19600,
45200,
14700,
48100,
26100,
9000,
null,
26000,
15100,
90000,
12100,
28400,
11900,
83800,
20856,
null,
35400,
43100,
3000,
11700,
20100,
38100,
47700,
30400,
56100,
28100,
21900,
50900,
9600,
33200,
40600,
null,
46800,
null,
18400,
11000,
18100,
19500,
22200,
6300,
67100,
53500,
70200,
33800,
5100,
7700,
1000,
37900,
18200,
null,
28100,
59200,
116200,
28800,
132000,
55300,
9300,
56000,
23000,
18600,
29400,
15200,
23900,
145900,
null,
28913,
82500,
2500,
12800,
null,
30800,
46200,
96200,
13750,
48300,
null,
15900,
15100,
309900,
null,
61100,
30800,
12200,
1900,
12200,
146100,
16900,
null,
14800,
25600,
88200,
11400,
54100,
31100,
null,
18800,
15100,
46200,
5100,
38200,
63300,
87373,
14900,
72000,
32200,
10500,
17100,
7600,
25000,
69200,
null,
12100,
20700,
21911,
22900,
49700,
17600,
16200,
11400,
24100,
null,
19900,
13800,
20900,
51500,
20400,
36200,
12100,
35100,
68300,
25800,
12100,
9850,
42100,
13900,
9400,
15500,
16200,
23700,
32600,
21000,
36200,
63700,
43700,
46873,
79300,
103305,
null,
19100,
11700,
47000,
52500,
48400,
132600,
42200,
23500,
25526,
18900,
13000,
28900,
28500,
21300,
18300,
8800,
19100,
27200,
18900,
14300,
42800,
14200,
4600,
25500,
21400,
16800,
28100,
14000,
31600,
123600,
4300,
null,
12100,
28000,
17300,
7300,
67200,
17400,
null,
26900,
8000,
5800,
17300,
37137,
7700,
184050,
24600,
50600,
60500,
16900,
20600,
22300,
27900,
16500,
42700,
62640,
17500,
15750,
8800,
8300,
4500,
11600,
null,
30600,
44900,
27500,
19500,
29600,
61600,
60800,
21900,
54000,
7900,
29300,
26000,
38300,
12600,
null,
34300,
null,
null,
12400,
16900,
55800,
18600,
7900,
22400,
13000,
20400,
40600,
13000,
12400,
42100,
null,
31400,
18000,
75500,
7100,
42300,
11200,
31500,
44400,
17000,
62644,
28700,
17100,
73000,
48400,
18500,
28100,
11200,
21500,
73000,
124750,
23400,
4900,
158100,
16500,
19500,
27800,
9900,
13700,
42100,
9100,
null,
12400,
57100,
56100,
29500,
60500,
60700,
14632,
17600,
null,
52900,
66500,
14900,
38500,
8800,
29200,
34200,
8900,
7700,
25000,
7236,
11000,
47400,
16700,
7800,
40100,
20300,
53620,
35700,
17700,
43300,
86300,
25400,
75100,
null,
165900,
50200,
18100,
8700,
19345,
10000,
35200,
19400,
46500,
74100,
48100,
32500,
55900,
null,
11600,
24600,
12600,
60900,
11000,
35600,
39600,
34400,
20900,
null,
13300,
6300,
15800,
36900,
16500,
41900,
null,
8700,
32800,
null,
29800,
40000,
19400,
27700,
null,
6000,
95400,
193500,
24300,
102100,
45000,
14800,
19300,
8300,
null,
null,
121200,
31900,
32900,
40600,
36700,
11200,
82200,
10700,
30000,
32200,
15200,
29200,
26200,
30300,
14100,
26200,
72100,
31417,
16200,
110200,
49286,
3700,
31500,
130400,
17600,
66700,
17000,
19700,
35700,
12800,
null,
3700,
null,
11100,
18900,
53600,
16000,
null,
32400,
null,
16700,
99200,
21900,
14300,
null,
63600,
6100,
69100,
14800,
22700,
13100,
8900,
34750,
29900,
5900,
null,
20500,
49100,
29600,
50500,
49600,
11000,
96095,
15200,
6400,
38500,
null,
null,
38600,
29900,
67600,
46400,
34000,
72800,
30800,
33500,
49600,
39800,
7300,
28000,
10700,
9400,
43000,
47100,
null,
33700,
28500,
72500,
31200,
35000,
5300,
null,
41900,
null,
14600,
17300,
38300,
26800,
39300,
4900,
6600,
75300,
15000,
17500,
17200,
38900,
20900,
35500,
202100,
12800,
15700,
22100,
13600,
20700,
14400,
18100,
4100,
12400,
null,
16000,
27500,
27300,
66650,
6300,
13800,
null,
19100,
6900,
17300,
10201,
null,
13100,
80400,
15100,
50700,
46200,
48600,
32700,
25742,
2700,
11000,
7600,
4900,
36900,
2200,
57800,
28500,
24100,
53400,
92100,
12200,
7800,
14500,
56100,
18600,
46900,
7200,
18000,
41300,
27900,
32800,
16500,
45200,
33100,
236200,
60900,
33000,
17600,
21900,
51700,
4300,
25700,
63300,
147000,
16000,
5700,
62300,
9700,
9500,
24400,
15900,
32900,
30000,
6300,
63500,
140200,
6800,
32000,
null,
10000,
null,
null,
83400,
53500,
35300,
39000,
35000,
56900,
null,
13500,
7900,
8600,
29700,
79700,
52000,
6500,
null,
47700,
38300,
61500,
43600,
17800,
7000,
14400,
19400,
27700,
2700,
8900,
6900,
25100,
8500,
28100,
26500,
28700,
90500,
11400,
51700,
29800,
49900,
77900,
30100,
null,
46100,
13100,
13900,
15700,
13000,
31900,
42200,
64700,
17300,
15200,
11900,
88700,
16900,
28600,
103200,
26700,
36600,
15100,
31700,
38000,
14200,
25000,
12300,
9400,
16700,
36940,
7100,
27700,
22400,
24100,
53100,
13900,
11100,
null,
60300,
9600,
49900,
78300,
36500,
11300,
14500,
19900,
15700,
10000,
48600,
36800,
56000,
55600,
28400,
8300,
15900,
18100,
20900,
26800,
15400,
23000,
16000,
20840,
25500,
117300,
16900,
23100,
33300,
31900,
30000,
6900,
33800,
2500,
53900,
18000,
18600,
16900,
12400,
17600,
10900,
6500,
15100,
33200,
18000,
12000,
139100,
null,
12100,
104200,
50400,
42800,
null,
24100,
26600,
35900,
7900,
21800,
10700,
169100,
36500,
30200,
25600,
38200,
27000,
20700,
12100,
29900,
10300,
14200,
14901,
87500,
null,
9800,
14030,
16000,
90350,
null,
46800,
16800,
null,
50300,
44700,
12700,
38700,
31100,
15600,
19100,
9500,
17300,
12300,
15200,
8500,
14400,
63500,
7400,
29700,
27900,
26800,
7700,
70200,
4200,
16300,
23000,
12600,
5600,
20900,
16800,
null,
null,
29200,
84700,
30200,
9000,
83300,
40400,
61300,
null,
56900,
13200,
14000,
48500,
8300,
21500,
900,
10100,
29000,
20600,
16000,
16600,
3700,
15000,
78300,
54600,
38700,
23700,
12900,
34300,
29400,
110000,
23500,
28200,
6100,
20700,
15900,
25800,
39800,
null,
54200,
19400,
null,
23900,
9900,
22600,
40300,
57100,
224800,
7000,
29300,
24700,
21500,
25900,
2500,
64400,
21600,
12500,
50500,
23100,
43500,
19500,
203500,
15900,
14500,
null,
67900,
25500,
null,
40700,
9600,
null,
28300,
9300,
35900,
23100,
107400,
24470,
18000,
52900,
17800,
7200,
21300,
36550,
56300,
24000,
12900,
24200,
25600,
15000,
24500,
27400,
21700,
10600,
3100,
52400,
31000,
8200,
137100,
137400,
21600,
43300,
18300,
12800,
7800,
47600,
14700,
8500,
23900,
21400,
8000,
14400,
29500,
29400,
23100,
5800,
50400,
8250,
6100,
61600,
19400,
14000,
38000,
39200,
7900,
38000,
17100,
2750,
11000,
11600,
54000,
53100,
11350,
38700,
17000,
28300,
3800,
17700,
37500,
22300,
47700,
21400,
43500,
38500,
69300,
48500,
29100,
32200,
97625,
103350,
49400,
25100,
20500,
35300,
33400,
19800,
17800,
51100,
21000,
28300,
39400,
31800,
47700,
15600,
7600,
64300,
10100,
16600,
58200,
11700,
11200,
26300,
47400,
15400,
36500,
13200,
8900,
25200,
11800,
34700,
26800,
47000,
18500,
7100,
8000,
9500,
74400,
8800,
40500,
19100,
96100,
14100,
53700,
36500,
41200,
5400,
16100,
21600,
null,
106100,
2900,
22600,
28800,
61100,
12700,
92585,
14200,
34900,
61900,
36900,
84500,
258000,
36600,
57600,
18300,
null,
10600,
42500,
29900,
40400,
23500,
22000,
16000,
31800,
null,
13200,
12000,
40050,
7600,
27200,
18900,
79900,
23400,
28800,
null,
16600,
null,
40400,
17000,
31300,
23100,
32900,
67100,
40500,
42300,
151000,
14005,
12700,
179100,
30200,
17300,
88400,
15100,
61500,
17500,
74500,
null,
36900,
13200,
8300,
48300,
18200,
88200,
40900,
null,
35000,
14000,
33500,
18600,
12200,
16800,
19900,
20700,
45800,
12800,
17200,
40600,
15600,
34300,
11000,
5600,
7200,
85200,
27700,
23400,
25100,
54500,
18600,
68400,
null,
18100,
59000,
73599,
69500,
35500,
21600,
40700,
38400,
12600,
22200,
1800,
46000,
55000,
36000,
12500,
41600,
79070,
12600,
null,
21300,
16100,
22600,
157800,
41300,
15000,
12600,
28800,
8800,
22700,
55500,
39700,
25400,
17301,
14500,
42500,
14000,
null,
39083,
38700,
4300,
11700,
null,
47800,
23000,
5000,
30000,
9000,
7400,
27700,
15300,
20800,
null,
29300,
11700,
29600,
4200,
43700,
26700,
7600,
52300,
37900,
11800,
16600,
22500,
null,
13800,
7900,
22000,
52700,
20400,
22000,
13200,
69200,
45800,
8100,
40100,
46600,
27900,
13300,
25400,
36600,
17000,
38700,
33400,
20800,
21900,
null,
41300,
17950,
6100,
null,
null,
24600,
44100,
27400,
23400,
24300,
18700,
1100,
21800,
51264,
18200,
null,
null,
5800,
16700,
19700,
34200,
18200,
15000,
23000,
23900,
14700,
17400,
null,
null,
34400,
23700,
11100,
17200,
8300,
12800,
57200,
42400,
29100,
12900,
20000,
87400,
38000,
14000,
45700,
46200,
24700,
null,
35400,
3400,
5900,
33400,
10900,
40000,
34400,
17300,
18800,
35400,
34900,
70496,
16200,
null,
32600,
15100,
17200,
null,
10900,
17100,
9300,
58200,
30400,
23000,
5000,
11400,
7700,
74100,
null,
21800,
9500,
31300,
20400,
15300,
80100,
33700,
11200,
115600,
12800,
47200,
202900,
38300,
31000,
136500,
46400,
44100,
22800,
12700,
16800,
38700,
11500,
53800,
18000,
19000,
49300,
31100,
24600,
23500,
24500,
null,
24500,
21000,
16600,
17450,
53100,
75800,
25300,
28600,
null,
58400,
18400,
31500,
16800,
38000,
null,
29200,
8200,
28640,
12600,
32000,
null,
null,
33400,
51500,
18600,
null,
6200,
13000,
13000,
8200,
166900,
23000,
64700,
9500,
125900,
33200,
11000,
30400,
13000,
93900,
23900,
14000,
15300,
43500,
14700,
4750,
51600,
43300,
11300,
33900,
10000,
7800,
62100,
53700,
19700,
12400,
9700,
39000,
29025,
39000,
101800,
27500,
51300,
120600,
23200,
18600,
17100,
40193,
null,
31900,
31500,
7000,
26600,
11200,
10700,
18500,
null,
null,
40537,
null,
18200,
4000,
31600,
33700,
31000,
69400,
4200,
24800,
17233,
2400,
20100,
47600,
30100,
32700,
4400,
16200,
110600,
45300,
16000,
8400,
7500,
26200,
105600,
73400,
null,
104100,
3000,
22900,
8700,
128900,
12100,
null,
26500,
50400,
17200,
77400,
6000,
27500,
49500,
3500,
22100,
20700,
28700,
22000,
10300,
43300,
6800,
8800,
9300,
38600,
36000,
9500,
null,
57300,
24050,
27200,
45200,
41800,
null,
28400,
25300,
55000,
16800,
18500,
18000,
56300,
11200,
23900,
23200,
19200,
49200,
64100,
32200,
76600,
24400,
36300,
10400,
29100,
10200,
12100,
33000,
16200,
19700,
32000,
21300,
14500,
48800,
190700,
null,
17400,
43800,
6700,
28500,
12600,
null,
19909,
49100,
8800,
49700,
22099,
30200,
13000,
36600,
19000,
13400,
null,
39400,
18000,
33800,
11100,
27400,
3800,
36700,
7300,
47663,
null,
61400,
null,
13700,
45400,
52000,
42200,
35800,
68900,
43600,
31379,
63100,
18000,
12200,
14500,
35500,
35200,
25600,
259500,
8900,
116100,
17800,
13500,
5200,
42100,
34000,
16300,
60400,
44800,
221300,
17300,
12600,
19900,
90500,
24600,
34500,
null,
11900,
59400,
114500,
25700,
52300,
56700,
76300,
10000,
5700,
17000,
17100,
null,
null,
36100,
12000,
null,
23300,
49600,
7500,
17500,
21900,
15000,
17400,
10600,
7500,
68900,
29100,
null,
51400,
null,
128100,
null,
34600,
38200,
14800,
21900,
22000,
45900,
87700,
42100,
18500,
18200,
null,
72900,
5500,
15200,
42300,
8600,
47800,
50300,
23900,
null,
24300,
8800,
13400,
69300,
43330,
74200,
20600,
19300,
22000,
147600,
35300,
9700,
17400,
42800,
38800,
14700,
null,
51600,
8900,
14600,
34100,
36000,
71500,
22300,
19900,
2800,
75400,
151860,
17000,
15900,
27400,
null,
10700,
31200,
80700,
20200,
27600,
37500,
32800,
null,
53800,
66600,
22200,
33000,
13600,
13600,
92100,
29900,
13400,
65100,
8900,
14600,
16100,
39400,
63200,
13900,
31800,
29800,
30090,
24000,
10400,
28800,
null,
39000,
9400,
null,
10500,
107600,
null,
19900,
22900,
15000,
null,
27300,
17700,
48400,
null,
20000,
26200,
37900,
29500,
11300,
6009,
56000,
19400,
null,
null,
27700,
9100,
18800,
null,
5700,
12900,
17100,
29100,
35300,
45200,
42400,
22500,
6900,
99700,
82000,
18600,
16900,
null,
41300,
13200,
43200,
10700,
41900,
8500,
37400,
2700,
6000,
57800,
null,
5050,
36600,
26100,
9100,
7400,
33000,
31100,
112000,
45800,
170700,
59000,
13400,
9800,
13700,
20700,
60000,
26300,
34000,
38600,
14500,
14300,
34900,
18100,
113500,
19600,
14500,
81400,
24100,
26700,
28400,
50600,
66800,
54800,
36400,
54700,
33400,
20500,
29900,
null,
46300,
10700,
19800,
60300,
3100,
17900,
50900,
12700,
47700,
58900,
26600,
15500,
4900,
5000,
41600,
14500,
56500,
45800,
18600,
28400,
23800,
61400,
11900,
31700,
9500,
30700,
71100,
null,
43200,
null,
null,
30300,
8500,
36100,
38300,
18300,
47900,
13200,
34800,
47300,
14800,
239800,
12400,
41000,
17700,
19500,
43700,
9300,
91200,
14600,
13100,
8900,
39500,
null,
50900,
31650,
40100,
30400,
11000,
35500,
50500,
12200,
29300,
55500,
50100,
12700,
30000,
13100,
31100,
20700,
46100,
7400,
11800,
40800,
31700,
37900,
85600,
20800,
25600,
12000,
21300,
7000,
6500,
null,
28800,
22900,
9800,
9000,
null,
31500,
29300,
58600,
57700,
22300,
5700,
63600,
28700,
12000,
73700,
18700,
null,
29500,
3800,
39000,
28000,
40200,
11600,
17600,
24380,
19400,
10300,
49500,
10900,
null,
21700,
128200,
27700,
10000,
57000,
19900,
18400,
41600,
85000,
50900,
10000,
null,
55000,
32400,
47900,
5400,
5900,
39000,
20800,
64900,
39600,
36200,
35900,
115100,
11700,
29400,
null,
31500,
19309,
78100,
36900,
19100,
37600,
16900,
10400,
10300,
null,
17800,
5300,
8100,
11100,
21000,
40900,
43200,
12200,
7600,
14300,
null,
null,
34900,
22400,
15400,
55000,
27200,
67100,
18200,
13500,
25500,
26100,
38600,
25500,
null,
30700,
47600,
20300,
38500,
21000,
53700,
null,
52600,
32300,
22400,
19400,
28400,
6100,
35800,
51500,
35000,
39800,
48700,
8500,
41900,
17200,
87900,
null,
32100,
43300,
12000,
17100,
23100,
7700,
27400,
8200,
17700,
11000,
null,
21600,
18000,
34900,
37300,
23100,
72400,
null,
23500,
151395,
92000,
18100,
31800,
18800,
8100,
48700,
8500,
3500,
68000,
58800,
null,
34300,
38700,
41000,
29000,
9300,
16700,
null,
10000,
13500,
12100,
23000,
3900,
10400,
41400,
13400,
18000,
25900,
100300,
6700,
3600,
28500,
null,
null,
17200,
13600,
69190,
27700,
null,
12900,
25300,
33200,
52500,
26600,
5400,
14400,
54000,
27100,
69100,
57400,
43000,
8000,
null,
3100,
14400,
null,
22100,
50300,
7300,
52900,
26700,
null,
10300,
26700,
10500,
null,
6600,
37000,
14800,
43800,
null,
14700,
13900,
20800,
31500,
19500,
23500,
22000,
16950,
21400,
55700,
20700,
12800,
12800,
38700,
30900,
40200,
null,
19600,
27300,
9475,
21000,
126500,
22200,
34700,
19800,
4400,
null,
14400,
39800,
29100,
19400,
28100,
15700,
42100,
null,
19100,
39600,
32400,
11200,
21600,
6500,
57400,
13500,
19000,
10400,
7700,
28000,
32900,
8500,
93100,
3000,
25700,
25000,
43600,
26400,
28400,
24900,
34800,
13200,
5400,
8800,
53200,
37000,
67300,
20100,
30800,
3100,
23600,
153800,
50400,
18900,
47700,
16500,
29500,
64600,
8700,
59200,
29000,
39800,
12900,
57964,
7900,
12300,
10400,
13700,
29500,
20500,
13800,
null,
null,
23100,
9600,
28200,
67700,
null,
28000,
52400,
62100,
8300,
34100,
13100,
6600,
38500,
12800,
null,
null,
18500,
null,
36800,
55800,
27100,
14300,
null,
20500,
22200,
35600,
31600,
18800,
13450,
57100,
31300,
null,
44400,
75300,
29700,
22600,
91400,
9000,
19200,
30500,
12900,
10000,
14600,
15800,
56300,
20400,
5900,
7700,
51200,
41800,
46900,
21500,
5400,
13100,
46200,
83400,
28570,
12300,
83000,
31000,
26700,
13700,
7800,
49000,
31900,
12500,
null,
24700,
45400,
3900,
66800,
5500,
16900,
103000,
22000,
15800,
10800,
11700,
12000,
33500,
44000,
15500,
14500,
41200,
30900,
6200,
15300,
11200,
8200,
24700,
null,
14100,
29600,
10700,
57900,
10500,
15700,
9700,
8100,
48100,
31100,
67600,
42700,
16600,
17000,
9600,
25300,
null,
25500,
null,
17800,
20000,
7600,
12000,
38700,
47200,
12000,
14800,
15300,
45200,
52400,
44100,
40200,
30500,
142500,
17900,
26600,
28100,
21400,
10100,
17100,
null,
27400,
22700,
15500,
38000,
15400,
13500,
5000,
3800,
13500,
35300,
null,
25200,
21800,
26400,
36100,
29500,
8800,
24600,
9600,
32900,
67300,
38200,
6000,
32400,
30331,
19100,
52700,
21600,
13700,
10900,
14800,
56700,
15600,
16500,
112000,
12200,
21000,
7500,
41200,
43200,
44700,
24700,
22800,
46300,
13700,
9000,
7000,
null,
17200,
24300,
24700,
95300,
49900,
19800,
12100,
21200,
20300,
null,
60700,
17000,
17600,
5150,
25000,
13300,
46900,
9200,
null,
10600,
56000,
27000,
28700,
13600,
25000,
41200,
45300,
377400,
17000,
36500,
11300,
7200,
13700,
30300,
9600,
69500,
6800,
59500,
null,
89450,
null,
null,
31700,
5400,
41000,
33600,
8800,
9300,
16200,
26900,
5500,
16900,
64600,
28400,
null,
11100,
20300,
8300,
59200,
51800,
36300,
14300,
17895,
31200,
21500,
55100,
37500,
57200,
52000,
12600,
16300,
9700,
35900,
3900,
26800,
58100,
21600,
26100,
10500,
47700,
8400,
33800,
16300,
38900,
42500,
36400,
13700,
122200,
15300,
20400,
22900,
71896,
26000,
6500,
14800,
46100,
11000,
24500,
8100,
41100,
11100,
19100,
null,
12700,
57900,
9000,
12000,
17100,
127200,
45900,
13500,
7400,
17800,
26300,
17800,
53700,
null,
39100,
49600,
null,
32400,
35500,
58500,
39700,
35200,
33500,
20900,
49800,
34500,
33700,
117700,
25000,
13700,
12900,
null,
13400,
42100,
null,
26463,
14800,
31300,
19200,
12500,
28400,
16600,
6300,
43200,
8600,
19500,
6000,
37800,
26500,
41000,
56500,
41800,
18600,
11100,
null,
null,
23800,
3800,
8400,
9800,
13300,
53200,
25400,
null,
34500,
55600,
17100,
56100,
21800,
29700,
27000,
64900,
44426,
45300,
26700,
35700,
null,
22200,
15000,
null,
17800,
16000,
54400,
21600,
1500,
26000,
46400,
19000,
24800,
16800,
31900,
40700,
64500,
16200,
19500,
50300,
19300,
26300,
8000,
10800,
14700,
27100,
19100,
35400,
39400,
21700,
6300,
36700,
7900,
17500,
8500,
18400,
32100,
4300,
48150,
13500,
54700,
15800,
72300,
77100,
5200,
22000,
null,
null,
null,
8000,
7100,
9800,
26800,
23800,
10500,
6300,
23000,
6900,
8800,
33000,
54100,
21600,
14900,
66200,
17100,
null,
13600,
11700,
33600,
9000,
9100,
null,
15500,
60000,
19800,
45100,
53400,
56100,
44600,
6800,
null,
66300,
48200,
15500,
17000,
8100,
7400,
null,
69300,
26900,
null,
5800,
68000,
11300,
56800,
14200,
22800,
45800,
22600,
null,
18100,
24700,
null,
13200,
97600,
6300,
14100,
44800,
20600,
11500,
14300,
22200,
86600,
null,
null,
11800,
11100,
40100,
null,
36200,
5600,
30300,
4300,
null,
23800,
37900,
40500,
11500,
35000,
48700,
14600,
20400,
58000,
null,
32400,
28400,
6800,
24100,
15400,
29900,
null,
84900,
13300,
69600,
null,
5600,
39200,
null,
17400,
7700,
62800,
null,
8200,
42500,
null,
13300,
8500,
13700,
35800,
1500,
27800,
6169,
null,
20600,
27300,
32600,
37200,
null,
74500,
39900,
11100,
12500,
6400,
14900,
65100,
null,
16800,
35700,
22100,
21600,
null,
42900,
71300,
87900,
23100,
8300,
13100,
11500,
18400,
72200,
20400,
24600,
41000,
26100,
9500,
52000,
11900,
12800,
30900,
54300,
30900,
34400,
22300,
71700,
14200,
17200,
35000,
64300,
null,
5500,
20800,
28200,
26300,
11400,
24800,
15100,
45283,
15900,
44200,
24400,
28300,
18100,
21000,
33300,
141400,
6400,
12400,
4300,
19600,
124900,
70000,
66251,
null,
72800,
null,
20800,
null,
5300,
16700,
32950,
27200,
22000,
84400,
25800,
32200,
18300,
7300,
54000,
8700,
6500,
20800,
15400,
17900,
37300,
22900,
5200,
35200,
95467,
62000,
11900,
8800,
74500,
17100,
92500,
6300,
42000,
64600,
15200,
44100,
19200,
23200,
35300,
41800,
18800,
null,
8700,
13100,
8500,
85500,
23400,
36800,
20800,
20800,
29700,
null,
18100,
79500,
18000,
30400,
13500,
19400,
37500,
null,
null,
5000,
82500,
6000,
7300,
32000,
48700,
18900,
21600,
22100,
44100,
55500,
null,
23500,
11600,
54200,
31200,
43300,
22600,
30400,
71000,
46900,
29000,
null,
48900,
71200,
29300,
15400,
5400,
43900,
45500,
9700,
null,
10600,
43100,
4600,
20200,
11800,
16700,
7800,
38800,
8900,
15000,
11200,
null,
47200,
14300,
7600,
9100,
null,
9700,
12800,
22100,
15000,
9200,
27400,
8300,
49100,
14600,
33500,
null,
73100,
23800,
34000,
27000,
46600,
30100,
1700,
4000,
6600,
49000,
53900,
60800,
44700,
69600,
22000,
25400,
361000,
8800,
14300,
19600,
35700,
37800,
27800,
10900,
5000,
98400,
12900,
5900,
50900,
9100,
21600,
29700,
3100,
null,
15500,
10000,
21700,
3300,
47400,
71400,
7600,
23400,
19500,
39200,
35900,
10900,
null,
12300,
27200,
27500,
15600,
1100,
41900,
20900,
16300,
11100,
35900,
17200,
37700,
23400,
40700,
11800,
14100,
148100,
13400,
111900,
60100,
10000,
71100,
6300,
19000,
7800,
22200,
35100,
73000,
null,
null,
32500,
31700,
22000,
18400,
32000,
28400,
59500,
34900,
17500,
13000,
25700,
62200,
75700,
15800,
3500,
3600,
22000,
null,
null,
30100,
null,
131300,
43500,
54900,
29700,
null,
42500,
20000,
30100,
7100,
33300,
19500,
84600,
10500,
7600,
49700,
17600,
9000,
12000,
29200,
13200,
null,
null,
28300,
17400,
8100,
null,
28700,
10000,
9900,
15300,
20700,
68200,
50300,
18700,
8005,
18900,
158000,
18700,
13200,
9150,
21162,
12500,
38700,
17700,
10500,
20400,
10500,
43800,
9400,
10900,
45300,
18100,
11500,
9200,
38500,
6100,
27700,
27100,
55100,
16800,
26500,
33650,
211100,
5350,
14200,
9700,
39500,
14100,
14000,
null,
13900,
40000,
130800,
23500,
46300,
21700,
18900,
null,
15100,
27700,
28600,
16900,
38400,
47600,
47600,
116600,
20200,
27400,
55400,
14000,
7500,
27800,
null,
22000,
8200,
39800,
10000,
22500,
9300,
36600,
107600,
58800,
22600,
11000,
21900,
32550,
null,
26400,
8400,
22400,
13200,
20500,
23800,
61000,
78300,
null,
49200,
24200,
29500,
31900,
16400,
45300,
41000,
20200,
9500,
26300,
12800,
13000,
null,
65900,
14200,
19700,
null,
14000,
30600,
18300,
37600,
19800,
27300,
31400,
85100,
10200,
39100,
14100,
16500,
46700,
69200,
16600,
9300,
27100,
30400,
63200,
17700,
32700,
42969,
41400,
23700,
57200,
11500,
1200,
46800,
17500,
105170,
48700,
48100,
12900,
19000,
19600,
40300,
6200,
23100,
null,
28700,
27200,
29800,
26800,
35600,
29800,
26200,
6190,
24600,
16200,
17700,
29800,
49100,
15200,
23800,
18800,
33900,
83500,
88900,
27500,
37500,
134300,
21000,
40600,
20800,
81100,
32800,
null,
11000,
21500,
10800,
40300,
18200,
13400,
152516,
36400,
16800,
38300,
11200,
11500,
6500,
16300,
57200,
5200,
17600,
31300,
40800,
12600,
22700,
18200,
35400,
6400,
null,
85700,
39200,
52800,
null,
27600,
33800,
41400,
28300,
56500,
4300,
6500,
13400,
16000,
38000,
null,
27000,
17400,
32100,
16300,
18200,
null,
8000,
26900,
131300,
13500,
28500,
9000,
14700,
36400,
5500,
20700,
96500,
22300,
16200,
null,
7500,
68700,
8400,
20400,
13900,
12200,
60900,
3500,
14100,
54700,
26400,
19500,
172100,
12500,
30700,
null,
11200,
32000,
12000,
null,
38900,
57300,
9400,
27300,
24100,
36900,
9900,
37700,
39600,
27400,
null,
24700,
6100,
17700,
101400,
7300,
23600,
8500,
147200,
18500,
4200,
17700,
14100,
28500,
21400,
null,
26600,
7600,
25000,
40400,
null,
28500,
9900,
19000,
null,
11600,
null,
22300,
31600,
34100,
15100,
21000,
9300,
8500,
null,
27500,
12600,
9000,
null,
9300,
53300,
12400,
14400,
59605,
53700,
53000,
13700,
null,
31600,
72700,
13300,
null,
36300,
16400,
21200,
65600,
8600,
23900,
18900,
30700,
10500,
13800,
45500,
16900,
53600,
16700,
25000,
64800,
91441,
54600,
128000,
7300,
35800,
51700,
14100,
28500,
24000,
42600,
37100,
26600,
7600,
44800,
18100,
25700,
122200,
14900,
24700,
74700,
41820,
1100,
62300,
35300,
7900,
12500,
37100,
73700,
45213,
52200,
null,
40141,
16400,
44300,
52500,
43032,
31800,
14400,
98700,
2600,
20300,
22500,
64400,
49000,
14800,
3000,
15500,
27700,
15900,
86600,
7700,
null,
null,
25800,
141800,
55100,
136900,
31800,
25500,
30500,
3600,
23300,
null,
84400,
15200,
47200,
27500,
16100,
11300,
10200,
null,
43500,
800,
13100,
27800,
13200,
9900,
53900,
24800,
27500,
8700,
69500,
38800,
91000,
13950,
19500,
15900,
29700,
null,
16700,
24600,
15000,
null,
45500,
20100,
23800,
25100,
142600,
12832,
24500,
4400,
94500,
61400,
7500,
28600,
34900,
17800,
52500,
46200,
35700,
25100,
25500,
9000,
null,
48600,
29800,
9450,
18900,
16000,
21500,
15200,
95000,
32300,
12900,
38000,
48100,
25200,
73200,
14500,
77200,
14700,
15500,
11000,
23100,
2300,
33964,
30300,
62290,
20700,
31800,
17400,
75700,
10100,
23700,
31400,
1200,
null,
17300,
32800,
15500,
null,
18500,
8200,
20900,
66100,
53900,
5000,
null,
24700,
21300,
15500,
16700,
8800,
22300,
7900,
26100,
null,
62500,
null,
12500,
22100,
24300,
17900,
16500,
14900,
27300,
23700,
18500,
4700,
5200,
27800,
8200,
26700,
12400,
24100,
19800,
55000,
33900,
33600,
14200,
85100,
19500,
5900,
14800,
25200,
63300,
11800,
11800,
46000,
118500,
6200,
46300,
6500,
22600,
20200,
62500,
25600,
15100,
null,
24900,
58800,
5400,
97305,
44700,
41600,
null,
24300,
7000,
null,
20700,
16700,
13000,
48400,
28900,
5900,
85400,
6600,
15200,
24000,
37500,
38700,
144300,
13800,
null,
13200,
44700,
144800,
111100,
26200,
10300,
14000,
39000,
12100,
20400,
19700,
43000,
40500,
85700,
38543,
37200,
25800,
21700,
64700,
30200,
32700,
73900,
7800,
210100,
19200,
14300,
25500,
123400,
11100,
54800,
12227,
35400,
86500,
21000,
53300,
7700,
31800,
21900,
59500,
1000,
33600,
30300,
17500,
null,
11200,
58400,
null,
27500,
41500,
12000,
12500,
50500,
36100,
7500,
33400,
32100,
null,
38400,
24100,
6900,
20700,
35200,
7600,
24800,
50100,
18100,
33800,
93900,
35500,
78800,
85800,
null,
9600,
9600,
43200,
21700,
11900,
13000,
32900,
76000,
56700,
9300,
22500,
36400,
92400,
4100,
11300,
18300,
null,
7800,
22000,
20200,
23000,
39900,
20800,
11400,
36800,
23500,
10369,
15800,
36900,
700,
null,
6500,
null,
30200,
44300,
28800,
46600,
30000,
6100,
26400,
11700,
6500,
62300,
null,
35400,
33400,
20500,
31300,
11300,
null,
null,
44400,
14200,
11200,
43900,
18900,
9700,
null,
24700,
177900,
9400,
10300,
11500,
71700,
48000,
24800,
41400,
31700,
232300,
54800,
22000,
10900,
9000,
13100,
39600,
71400,
42400,
14500,
30800,
6500,
11300,
6700,
22500,
60200,
50200,
15300,
20800,
20000,
17100,
20000,
17700,
12000,
34900,
10100,
40500,
40000,
21800,
137600,
32500,
24700,
1900,
11100,
39000,
42300,
23300,
13000,
22900,
7800,
26700,
12200,
14300,
101700,
59700,
11000,
16800,
29600,
14500,
4500,
18800,
11100,
null,
53500,
60800,
8145,
17100,
29400,
10990,
12600,
18300,
21900,
null,
283300,
35500,
13100,
35300,
12850,
55900,
22300,
43800,
12200,
47300,
14000,
27700,
18900,
4100,
133800,
null,
48000,
25300,
20600,
22100,
14800,
56900,
56500,
19800,
46200,
null,
null,
44400,
19700,
18400,
63800,
46500,
61100,
null,
103400,
null,
78100,
15700,
73900,
72400,
15800,
11300,
95300,
38100,
77500,
22700,
19500,
26000,
36400,
16100,
20800,
41800,
null,
11300,
5000,
null,
42800,
3900,
55800,
4000,
13800,
11900,
38800,
27100,
18600,
13200,
21400,
21700,
7200,
null,
15600,
21200,
54500,
22800,
31600,
58800,
null,
20800,
13000,
12500,
35400,
35600,
35900,
153100,
68300,
null,
23800,
null,
21600,
7300,
29600,
23600,
27400,
6200,
19500,
27100,
10500,
null,
13900,
15000,
null,
13900,
5400,
54100,
34400,
33600,
15700,
12400,
null,
null,
29200,
62600,
35300,
6800,
8400,
12600,
60400,
null,
70600,
15700,
63100,
20300,
19800,
null,
30300,
23300,
50200,
9500,
23900,
37700,
5000,
35500,
20500,
1000,
29800,
93600,
4400,
21200,
3800,
31400,
46600,
8750,
52500,
43100,
24200,
19300,
10500,
46100,
19800,
16300,
28400,
25600,
104900,
18000,
50600,
27700,
14100,
40700,
37500,
23900,
53200,
20000,
18200,
57900,
28800,
22700,
46000,
null,
13000,
6500,
60800,
21500,
40100,
21300,
105600,
10700,
17600,
null,
36500,
21500,
48500,
50100,
null,
1400,
42900,
25200,
null,
8000,
13200,
18500,
49900,
4900,
21300,
103500,
20200,
5300,
12700,
32900,
18200,
null,
null,
79900,
31100,
23700,
10700,
16400,
20100,
39300,
53500,
6000,
null,
4600,
17900,
75600,
14600,
16400,
15500,
16000,
64700,
16500,
102700,
null,
57300,
85600,
20409,
17300,
17800,
5200,
8200,
15100,
null,
9900,
11700,
62400,
27800,
72300,
57600,
14400,
46600,
9700,
121600,
7600,
21300,
40850,
89000,
38100,
44200,
15800,
23100,
2300,
20500,
null,
18300,
22500,
63900,
25100,
25800,
11400,
14900,
19000,
2900,
10900,
16300,
34400,
null,
16100,
null,
9200,
44000,
27300,
53900,
null,
119440,
null,
129200,
35000,
56200,
null,
42900,
21000,
44800,
4300,
13800,
7500,
34600,
11300,
132300,
null,
9500,
29000,
161300,
52700,
22700,
36500,
38600,
43800,
60600,
8900,
12100,
9500,
16100,
5500,
8300,
53600,
51300,
55500,
8900,
12300,
30000,
33100,
null,
29700,
89200,
68100,
22500,
16700,
35800,
109500,
114600,
45000,
null,
19600,
52100,
12000,
17800,
94100,
2800,
6500,
null,
null,
45800,
22200,
19800,
28200,
39300,
31400,
6200,
50300,
12800,
12150,
9900,
12900,
null,
6800,
31500,
3400,
24700,
41300,
null,
21700,
35300,
19100,
null,
12840,
66900,
31400,
33500,
null,
52000,
27300,
83800,
31900,
13500,
8000,
58600,
28000,
16600,
25300,
35300,
29900,
34400,
30100,
25500,
20000,
27400,
19600,
12600,
21500,
54300,
20500,
85200,
null,
58300,
19200,
16400,
34700,
26600,
27900,
10700,
39600,
4500,
11200,
19700,
12700,
28600,
32900,
27400,
5200,
22100,
null,
15500,
62500,
17100,
12800,
23433,
20000,
9800,
null,
39400,
61330,
109900,
38600,
3600,
16700,
52000,
28700,
12500,
20900,
6100,
80700,
20900,
7700,
1850,
57200,
8800,
29400,
30200,
37400,
35700,
1900,
13000,
38200,
51200,
35200,
11500,
18900,
10000,
39700,
30600,
16000,
15300,
19400,
9700,
13000,
21700,
54000,
null,
25600,
15900,
9700,
null,
53200,
null,
30200,
null,
4300,
42800,
17100,
14600,
44800,
35700,
13200,
21100,
24900,
9900,
67400,
16300,
44800,
90700,
11494,
6300,
25800,
null,
28100,
14800,
5500,
20200,
72100,
17700,
20600,
38100,
11700,
8500,
17555,
31200,
41300,
13800,
41000,
8200,
84000,
7800,
45400,
null,
45000,
null,
18900,
37600,
47500,
20800,
40800,
30300,
null,
23400,
22600,
20200,
14700,
7300,
53700,
74800,
17800,
20000,
null,
11500,
28400,
90500,
14200,
18200,
7700,
16600,
32400,
21700,
27300,
21100,
75000,
8050,
34300,
18600,
25200,
18600,
34000,
null,
33500,
44300,
null,
23600,
22800,
47000,
6100,
11551,
39400,
74100,
15000,
25100,
null,
19800,
null,
55000,
8300,
43300,
null,
36900,
11200,
5400,
26500,
11500,
7300,
85000,
36300,
10400,
23700,
null,
7100,
13100,
33800,
11700,
58700,
9000,
11700,
6800,
45800,
60300,
19800,
null,
null,
9000,
33700,
29700,
61600,
12150,
173600,
19700,
null,
91600,
10900,
12800,
41100,
27000,
14900,
13400,
36000,
28700,
8800,
34900,
22800,
39500,
39400,
24600,
null,
23000,
null,
22300,
29800,
25800,
13600,
18400,
31900,
25400,
12700,
21000,
13400,
22500,
31600,
13400,
null,
7600,
25000,
24700,
6000,
2600,
98600,
13400,
30400,
16800,
20300,
null,
17700,
11500,
21800,
40600,
76700,
63300,
null,
84500,
null,
71700,
15300,
31400,
38200,
6000,
11500,
31200,
13000,
18600,
45600,
65500,
9200,
129500,
10900,
35800,
9500,
81400,
30800,
23500,
11300,
13500,
28900,
null,
26500,
6200,
9350,
14000,
42200,
22100,
null,
24300,
null,
21800,
68500,
23100,
23000,
33400,
79000,
null,
25000,
52100,
3900,
29700,
80300,
31500,
31600,
12800,
27200,
6200,
17700,
40900,
15000,
50000,
8300,
27100,
null,
13200,
21700,
7000,
34900,
35500,
61000,
20200,
12300,
8900,
32000,
47700,
56400,
11500,
21100,
12300,
14800,
3700,
37100,
44500,
59500,
22200,
12000,
21300,
53400,
5800,
null,
12900,
14600,
null,
null,
60400,
null,
8000,
null,
16400,
12300,
17255,
4500,
12000,
55600,
23500,
103100,
900,
17800,
57700,
13400,
35700,
42200,
null,
35700,
9450,
null,
35400,
null,
null,
23600,
24500,
32000,
34300,
24100,
5700,
20200,
95700,
20100,
14200,
14000,
40000,
null,
null,
143000,
57200,
37100,
17400,
8300,
14700,
null,
6600,
16500,
131400,
31600,
14400,
null,
21500,
null,
41700,
9255,
10600,
34500,
56600,
15100,
55900,
17800,
16300,
26900,
16300,
93300,
11700,
14700,
null,
14400,
56710,
44500,
38300,
24200,
33900,
10700,
10300,
15600,
39800,
49700,
10900,
16100,
20600,
65900,
7200,
36200,
19800,
12800,
22800,
20000,
35500,
40400,
30400,
20400,
24000,
32300,
12250,
4300,
85700,
19400,
19600,
61900,
7300,
4550,
20000,
17300,
22400,
25000,
40500,
8500,
6000,
43800,
25700,
6600,
21600,
30400,
18800,
21500,
16000,
7200,
7800,
16600,
10800,
9000,
17000,
28900,
14800,
22900,
7500,
48500,
27500,
11600,
18100,
30400,
23800,
8000,
22500,
13900,
13300,
15300,
28200,
34700,
98400,
49500,
23900,
null,
null,
58800,
null,
19400,
88000,
52400,
null,
22200,
26800,
91100,
10600,
82800,
10500,
14200,
6300,
12000,
29100,
38900,
19800,
41700,
25800,
7500,
13400,
37600,
null,
35900,
5900,
112900,
78000,
18600,
41300,
17000,
28000,
42800,
6600,
24300,
26500,
22200,
26100,
68500,
null,
40000,
null,
3500,
18700,
5200,
8500,
18100,
32400,
14300,
null,
19600,
6500,
17500,
37100,
12900,
27400,
31500,
27700,
13800,
null,
40500,
55200,
252100,
18200,
41000,
16960,
1900,
5900,
4900,
21400,
12100,
null,
10600,
24900,
34300,
39300,
30900,
107300,
61000,
85600,
50000,
41800,
42200,
17200,
16500,
81300,
49700,
33100,
28000,
10000,
20000,
24100,
19300,
22700,
49400,
4100,
10800,
318300,
14000,
27400,
13800,
16800,
9700,
7500,
26500,
33050,
21000,
29800,
19700,
null,
72800,
46000,
49000,
42200,
43600,
42500,
48100,
11400,
21500,
24200,
29800,
null,
8100,
35500,
10200,
12700,
11900,
8700,
32200,
209800,
12900,
30600,
14850,
12800,
13900,
12300,
27200,
77500,
17800,
25900,
null,
28500,
15500,
23400,
44100,
7500,
15800,
3400,
6500,
30600,
null,
7600,
44800,
48400,
2900,
87900,
35300,
44800,
52100,
null,
22100,
57600,
20600,
67500,
97300,
null,
39500,
84000,
null,
202800,
11000,
52600,
8100,
17300,
13300,
54000,
33348,
2900,
7200,
44700,
53600,
13100,
70800,
44200,
27490,
9700,
15400,
14300,
4200,
62000,
7100,
null,
null,
42200,
24900,
111800,
20500,
30600,
83900,
14900,
50800,
32600,
null,
15000,
18500,
11200,
32500,
43100,
null,
null,
15100,
null,
75800,
58400,
15500,
19300,
19100,
39300,
4400,
14700,
22500,
67800,
6500,
3200,
37500,
null,
33600,
9000,
44400,
null,
4100,
9900,
23600,
null,
141600,
null,
8400,
7600,
31100,
null,
49900,
null,
23400,
61400,
13900,
54300,
43400,
77700,
112700,
6400,
9100,
37200,
18900,
13400,
5800,
69100,
32700,
6500,
6900,
13200,
16486,
48300,
23400,
42400,
72965,
null,
54300,
null,
15500,
54750,
37700,
27400,
11235,
83800,
67100,
13700,
32800,
24400,
54100,
5100,
28000,
33500,
3700,
29800,
null,
32100,
15900,
49900,
44200,
17600,
22700,
null,
27500,
33300,
25100,
69400,
51400,
7600,
17900,
21000,
16300,
19300,
7900,
7800,
17300,
null,
19000,
16800,
3100,
77800,
31100,
3000,
24900,
16400,
41200,
7500,
null,
24600,
15800,
19000,
5280,
19500,
45700,
21000,
null,
24200,
10600,
53800,
21300,
152200,
11700,
18900,
null,
21400,
6200,
5850,
17200,
13400,
21000,
62700,
7200,
null,
42800,
17600,
65300,
25100,
4600,
8000,
null,
33200,
35800,
61500,
9000,
null,
40700,
30000,
23600,
16500,
23900,
41500,
32200,
194000,
14000,
29250,
16500,
3800,
13300,
3300,
50400,
40900,
null,
21800,
22800,
13800,
62300,
49500,
31100,
15600,
56700,
7400,
21900,
null,
18800,
null,
null,
36700,
55400,
15400,
16100,
60000,
15000,
48500,
20200,
26200,
18900,
4500,
34300,
22500,
34100,
11400,
1700,
29200,
14300,
15390,
50200,
19300,
18900,
11600,
12200,
17500,
76800,
null,
8300,
null,
17700,
null,
15300,
71500,
16100,
26900,
11900,
6800,
66700,
26500,
6200,
32600,
3000,
9900,
34100,
17600,
null,
25400,
20600,
36300,
36100,
9000,
null,
13300,
28200,
58655,
31200,
18600,
27900,
7800,
27600,
9900,
47300,
null,
25700,
94200,
38900,
null,
18800,
24700,
4700,
26600,
33600,
9500,
78100,
19900,
null,
21100,
null,
31000,
28600,
88200,
null,
98900,
26000,
27600,
45900,
null,
26300,
null,
50200,
5500,
33300,
35400,
59100,
40200,
12100,
34100,
56600,
7000,
56200,
31500,
9000,
12600,
62000,
13000,
33100,
29500,
null,
62100,
null,
42800,
68000,
3400,
16300,
18500,
12200,
14600,
11400,
null,
32200,
31800,
9400,
71400,
7200,
38300,
10000,
8500,
4900,
20700,
18500,
44300,
55400,
43400,
null,
13000,
39800,
null,
null,
31600,
9600,
22600,
49100,
91600,
24500,
47000,
7400,
35400,
59200,
17500,
13700,
28500,
21100,
38200,
32800,
11200,
25200,
8000,
5300,
18000,
23400,
27700,
80710,
8600,
259900,
22600,
15400,
null,
13200,
null,
18200,
4300,
23800,
9900,
null,
18700,
22100,
25700,
29000,
10000,
16900,
17700,
4700,
12400,
21000,
14600,
19700,
68300,
18900,
34300,
null,
30800,
12800,
18700,
34800,
41400,
16500,
19100,
105100,
23600,
27400,
18500,
28000,
62900,
28200,
35000,
68900,
null,
22000,
58700,
24200,
41200,
12300,
6900,
9300,
49732,
20300,
37400,
6900,
27800,
121200,
8600,
18700,
null,
null,
3100,
50000,
32000,
37200,
8000,
57600,
21300,
13100,
33500,
16400,
34100,
32600,
null,
123800,
null,
24300,
6700,
20400,
26000,
18500,
9400,
18800,
32800,
16600,
13100,
45500,
22000,
null,
14200,
49600,
28800,
29400,
9200,
3300,
53800,
24600,
null,
50400,
10800,
24900,
42800,
12800,
15100,
51200,
22500,
34200,
6300,
86200,
19600,
5300,
113300,
45100,
15500,
40100,
25200,
5600,
62400,
16900,
33500,
21200,
15200,
6500,
null,
15500,
12900,
66500,
37600,
7000,
66100,
12400,
17200,
18900,
null,
13400,
27600,
18400,
32200,
15500,
40000,
24500,
18700,
2300,
45900,
17600,
30600,
38400,
22300,
50900,
66000,
13400,
8900,
24600,
null,
47810,
20500,
14700,
34400,
22200,
36500,
15800,
97900,
12300,
10200,
7000,
28400,
null,
25900,
15600,
null,
28200,
4300,
36900,
31200,
18500,
28588,
19900,
14500,
7300,
30890,
17400,
18900,
14200,
54300,
38200,
37000,
42800,
28100,
14500,
50400,
34500,
5100,
12200,
null,
29500,
57300,
14600,
19500,
43600,
20000,
7000,
null,
91300,
12800,
6000,
null,
30100,
14700,
14100,
36800,
25500,
25700,
17300,
41500,
88900,
15300,
6000,
17800,
7300,
41300,
21600,
39900,
20500,
10500,
86300,
24300,
null,
12400,
44700,
88300,
20800,
28200,
7700,
13100,
17100,
28300,
29400,
29000,
37086,
6800,
2900,
10900,
44300,
42100,
30500,
14700,
17100,
149800,
18500,
null,
6400,
25700,
32500,
27200,
7000,
16300,
44400,
21100,
14000,
18800,
25000,
11700,
6400,
45900,
3100,
42300,
51200,
46000,
39000,
7400,
36363,
11300,
48900,
9300,
9900,
25400,
8800,
35800,
44900,
39700,
55400,
38300,
31800,
7500,
57700,
10500,
23700,
34800,
65900,
9600,
8300,
15300,
39400,
36800,
27200,
25700,
null,
23400,
39400,
14300,
101300,
175500,
7000,
12000,
44900,
25200,
30200,
10600,
30600,
128300,
8100,
17500,
32100,
39900,
28000,
8000,
29900,
19700,
38000,
23160,
40700,
22800,
4100,
48400,
8900,
21800,
38900,
21100,
174400,
69800,
88500,
null,
22800,
26400,
33100,
92200,
14000,
21600,
10600,
57100,
16600,
13100,
9500,
13000,
null,
28700,
38200,
8500,
28800,
null,
22900,
47500,
2600,
40800,
103600,
35400,
30500,
3900,
5700,
7403,
11400,
26470,
55600,
23100,
41600,
85600,
10300,
8500,
79300,
14900,
null,
23200,
20000,
27200,
35200,
2800,
31400,
14600,
38100,
50500,
null,
9800,
63049,
79700,
8100,
null,
null,
16000,
8800,
53100,
13100,
43525,
197800,
25500,
9400,
13300,
15500,
15800,
29800,
43000,
16700,
27700,
116400,
35800,
4600,
57500,
18900,
84000,
14800,
34900,
90100,
86800,
8900,
103500,
16300,
10200,
20100,
44400,
34600,
11200,
13300,
22000,
22400,
12700,
null,
36770,
39000,
25716,
10200,
null,
33200,
82400,
299800,
55100,
383400,
29400,
22100,
17200,
13100,
4200,
45100,
32600,
21000,
42200,
45000,
12300,
34000,
null,
61500,
5900,
null,
40500,
76900,
31700,
57600,
29300,
139700,
17600,
19400,
10200,
10200,
3900,
13300,
null,
47000,
15300,
null,
null,
null,
6200,
56400,
41200,
28500,
null,
5000,
4600,
54400,
33500,
27700,
null,
54700,
18000,
29900,
72800,
67300,
78000,
11200,
12400,
30000,
24800,
31400,
21700,
18100,
6300,
10750,
5100,
22400,
203900,
28500,
8700,
22200,
16400,
34400,
33800,
27000,
41600,
16600,
29200,
47800,
26600,
13500,
25900,
51900,
31000,
8500,
null,
15900,
11900,
23600,
9900,
null,
14400,
52200,
71000,
4000,
45300,
40300,
14400,
29800,
20100,
97920,
7500,
6400,
16200,
58700,
26400,
19700,
9000,
21900,
18700,
40600,
38100,
23800,
30700,
39000,
5600,
19200,
237100,
75500,
23900,
null,
7700,
null,
10700,
16200,
30900,
14500,
72800,
63500,
23800,
26700,
43900,
17500,
28800,
15900,
42400,
35300,
24600,
13200,
25800,
8500,
43500,
21300,
5100,
22100,
7750,
73000,
2500,
49800,
16400,
null,
12500,
8100,
41900,
48100,
51500,
46900,
28300,
26000,
14800,
54700,
21800,
17300,
null,
3400,
25400,
8900,
70000,
21800,
13900,
16000,
45100,
52300,
16100,
19800,
null,
18400,
24500,
71400,
30900,
15000,
8000,
11400,
3800,
55400,
null,
52800,
10900,
8600,
26200,
100500,
22200,
25600,
null,
28200,
5600,
28900,
50300,
21800,
153600,
22500,
null,
12400,
2000,
47000,
13500,
34600,
18800,
21100,
null,
12800,
39700,
20800,
5600,
25400,
41900,
32700,
35700,
28400,
12400,
16400,
8600,
11600,
25100,
8700,
28500,
39300,
28100,
73500,
21900,
49300,
19000,
10700,
7300,
18900,
8500,
26700,
135600,
7100,
5000,
null,
38100,
15400,
10600,
7800,
27200,
66000,
18200,
76200,
51700,
38900,
22900,
12500,
null,
15000,
11800,
62800,
14200,
113400,
71300,
54500,
9200,
33900,
43850,
22700,
null,
11000,
null,
24500,
null,
19400,
37800,
23500,
12900,
47500,
5000,
18500,
14000,
46700,
77900,
15300,
30900,
37300,
25500,
106100,
23600,
19000,
21400,
null,
26300,
19100,
null,
null,
72700,
18100,
61400,
25200,
34700,
10700,
10500,
8700,
12600,
79300,
20500,
16900,
20300,
28100,
44700,
16100,
91200,
19500,
65700,
18200,
79700,
17900,
79200,
58900,
46500,
46500,
25900,
34600,
36400,
39700,
25400,
6000,
11300,
53900,
41800,
112200,
62400,
28700,
33900,
13800,
18400,
44800,
17400,
48800,
14800,
6900,
13100,
34900,
45000,
80387,
85500,
10600,
15300,
16200,
65500,
19200,
51400,
42400,
53300,
23600,
28700,
70300,
5900,
14200,
31600,
22600,
49800,
4150,
63000,
30400,
19400,
20200,
63000,
48500,
15900,
31200,
34700,
9600,
23200,
30700,
67200,
54700,
39850,
10200,
33900,
43000,
66400,
74900,
12600,
50700,
20000,
12900,
35700,
17900,
null,
20100,
null,
53700,
11082,
null,
12400,
32600,
106700,
10400,
24500,
158900,
16600,
47400,
11700,
17900,
29600,
8900,
8200,
null,
11800,
23000,
24000,
null,
38900,
52900,
23000,
26000,
15900,
15100,
null,
28200,
15200,
17000,
17000,
12700,
19500,
29700,
17200,
9780,
24000,
52700,
28700,
5900,
43300,
60600,
13900,
15300,
19900,
13600,
16900,
15400,
30200,
81700,
24300,
18000,
19000,
17600,
16400,
17400,
27000,
15900,
36100,
19700,
118100,
null,
13900,
69500,
15900,
9200,
null,
30400,
9900,
24200,
29500,
null,
25800,
29900,
29900,
14700,
11500,
70800,
7800,
24800,
29100,
11600,
13400,
8100,
18500,
44500,
14400,
32800,
27600,
null,
null,
8200,
13800,
19800,
null,
59400,
52700,
18000,
11500,
22049,
null,
14500,
61000,
31700,
null,
14400,
11900,
25700,
34300,
20600,
17100,
52700,
14600,
7500,
9200,
59100,
6550,
55600,
11500,
17700,
null,
59000,
26800,
7600,
19600,
37300,
16100,
null,
57000,
null,
24400,
35800,
14600,
21500,
13400,
23700,
null,
31500,
19800,
null,
137500,
15900,
14800,
39400,
null,
24100,
19300,
9600,
6500,
60220,
11440,
10500,
null,
38600,
43300,
8300,
236900,
26200,
null,
10900,
36000,
17100,
29300,
null,
2000,
20700,
64100,
21900,
15000,
35000,
6000,
null,
15800,
20800,
null,
81600,
31000,
10800,
42500,
27000,
17600,
17800,
14100,
null,
null,
17500,
61400,
56100,
17800,
61300,
12000,
48200,
33300,
37500,
35500,
30600,
66100,
38324,
16900,
38700,
18900,
23800,
117000,
34400,
14600,
null,
32700,
26100,
30500,
31000,
12900,
6600,
18500,
44100,
51700,
7100,
3500,
26100,
31500,
43500,
19200,
32700,
17800,
32500,
11600,
5500,
27100,
121800,
24800,
21400,
11900,
null,
16000,
null,
46300,
30700,
15700,
5400,
35300,
39500,
30900,
38500,
25300,
8300,
null,
78600,
37500,
34400,
null,
36400,
33400,
19180,
63100,
null,
8800,
4000,
43400,
13100,
16200,
11700,
42000,
73900,
24800,
18700,
31800,
10700,
20900,
24300,
15900,
31500,
29600,
26700,
36400,
null,
null,
38500,
13300,
49755,
55000,
28700,
34800,
71900,
6600,
40500,
2900,
5600,
8000,
42800,
45900,
14400,
27000,
30400,
30700,
20900,
33500,
13550,
6500,
43100,
21400,
135900,
null,
32100,
null,
23400,
15200,
5700,
13800,
9000,
21200,
19000,
null,
15200,
57500,
25200,
7300,
26000,
24100,
14100,
13600,
10630,
17700,
23300,
39800,
11900,
25900,
6400,
16600,
7400,
4500,
5900,
23600,
17000,
54700,
29500,
17000,
20300,
17900,
84400,
27500,
28100,
34800,
6600,
null,
null,
37700,
21300,
36500,
14700,
27400,
null,
49200,
485900,
3100,
64800,
null,
21200,
20900,
80400,
33000,
30800,
25700,
null,
null,
117800,
null,
8200,
68000,
17550,
49000,
47200,
13200,
24900,
null,
24100,
14400,
10500,
55000,
14400,
15000,
24700,
44700,
26500,
14000,
36500,
81700,
49700,
39400,
29700,
14550,
null,
31500,
36900,
121200,
38400,
62100,
null,
24800,
43100,
31100,
13900,
7100,
null,
28700,
9900,
15900,
15100,
16400,
32400,
74400,
24200,
20600,
null,
8400,
19700,
29200,
47500,
28400,
12600,
23000,
12300,
23200,
20000,
7700,
21300,
null,
27501,
33900,
20400,
18500,
34600,
6000,
12600,
66700,
16500,
19500,
41700,
7500,
39200,
74300,
33400,
49200,
6700,
7100,
9500,
31700,
100427,
74400,
51800,
99300,
38200,
58000,
null,
15500,
11900,
null,
44000,
26100,
10600,
18100,
19900,
46800,
121000,
32700,
44400,
83400,
19300,
52300,
119200,
null,
24500,
6400,
37100,
27900,
11000,
52200,
22500,
16000,
9811,
null,
24100,
22700,
12500,
15500,
28900,
21900,
22500,
13000,
19600,
25100,
58600,
32800,
18900,
22300,
72300,
14700,
36700,
18300,
30500,
10400,
30600,
31800,
29700,
52300,
34800,
null,
20400,
17500,
41100,
41500,
16400,
10000,
48300,
12100,
170500,
40600,
87000,
26100,
42700,
null,
22800,
23400,
1500,
10100,
null,
82708,
34800,
null,
24900,
2500,
35200,
39600,
52600,
57900,
10700,
16000,
12600,
65100,
30100,
64500,
12500,
11500,
11100,
14300,
41300,
16850,
null,
94900,
null,
10300,
7600,
24000,
13900,
9800,
46000,
31600,
65900,
null,
8600,
26500,
34100,
48600,
43000,
13300,
21400,
21000,
12000,
9400,
25600,
15800,
45800,
22400,
171500,
50600,
48300,
36800,
64600,
16600,
20600,
11100,
25900,
13700,
null,
25500,
null,
12200,
12900,
43700,
34700,
17000,
45600,
3800,
46700,
29400,
12700,
23800,
null,
8500,
33200,
28600,
87300,
41000,
26700,
13500,
55100,
16000,
63600,
13800,
30300,
15800,
21500,
50900,
12600,
41400,
null,
14200,
14300,
40100,
58400,
8500,
9000,
17000,
18500,
15900,
39300,
39300,
23400,
13800,
49600,
15000,
9700,
59200,
22000,
7800,
38900,
26900,
13800,
20600,
10600,
26000,
16300,
21500,
46000,
28300,
34500,
74550,
14200,
null,
null,
60400,
12300,
23000,
48600,
15000,
10700,
24200,
44400,
70700,
9800,
133300,
23500,
25200,
null,
69900,
12300,
null,
21000,
6900,
19400,
10500,
26300,
16700,
36100,
9000,
19000,
15500,
29600,
7750,
58400,
15800,
12600,
20700,
3400,
null,
13200,
173521,
8000,
25100,
78900,
48000,
19300,
58500,
124500,
34800,
null,
93500,
43200,
61600,
28000,
4200,
52200,
30100,
45000,
30200,
53114,
36300,
24900,
21000,
9500,
14000,
61300,
14300,
11000,
47100,
87000,
16700,
5400,
null,
38700,
18300,
16700,
22600,
39600,
12100,
34500,
38500,
10300,
10938,
6800,
5800,
20100,
13900,
16900,
40700,
10700,
null,
8400,
39100,
29100,
39400,
12000,
21300,
null,
8900,
42300,
8200,
14300,
39800,
37800,
null,
14100,
39600,
35900,
29500,
20400,
27500,
13200,
56400,
12900,
31600,
11900,
28700,
22000,
9900,
17500,
13400,
10200,
6500,
43800,
47700,
40000,
21150,
10500,
38400,
null,
49200,
30000,
17900,
39600,
21900,
47800,
26600,
20500,
39900,
null,
19400,
4600,
23700,
7800,
13800,
null,
13800,
15600,
77400,
11300,
null,
74400,
40000,
92800,
15900,
11500,
15100,
50100,
25900,
15900,
19400,
13100,
11600,
17800,
22300,
12300,
14200,
54800,
77788,
17800,
19000,
31500,
12500,
18200,
50900,
21200,
1300,
5600,
65300,
null,
78116,
null,
19900,
22200,
38300,
18100,
17200,
22200,
57300,
39800,
50500,
54200,
17700,
null,
19700,
63997,
64100,
26200,
21200,
3900,
18500,
9100,
20700,
38000,
7200,
19300,
null,
21600,
11600,
21200,
30200,
6700,
24800,
64100,
111600,
16200,
30700,
23700,
51500,
25600,
57300,
12900,
17000,
23900,
81000,
53200,
56900,
17300,
null,
92800,
10800,
17400,
14600,
27600,
30200,
32200,
37700,
17700,
34900,
21600,
null,
21600,
61300,
69300,
6600,
5100,
10900,
35600,
5800,
3600,
13000,
16000,
28500,
83400,
11600,
88000,
22800,
98200,
53200,
16300,
24500,
28700,
5800,
17100,
17000,
33800,
51300,
8400,
27000,
81500,
31600,
17200,
66900,
79800,
null,
12000,
null,
10300,
41500,
72900,
27600,
14700,
7650,
null,
17500,
144600,
19000,
33400,
null,
2000,
14500,
32800,
17100,
22000,
33900,
10000,
65900,
5400,
null,
31200,
18900,
10076,
45000,
42200,
61600,
40300,
12700,
4500,
9400,
null,
21700,
16000,
42600,
10100,
18400,
null,
10700,
70200,
67100,
34900,
13200,
26000,
18600,
31300,
184600,
165700,
27400,
28000,
65500,
33200,
26300,
28000,
26100,
15700,
14200,
43000,
18600,
44200,
29500,
26700,
56300,
21000,
53100,
48700,
53100,
16358,
null,
45300,
15500,
7400,
57000,
10200,
5400,
25500,
57000,
12900,
4000,
20400,
32800,
20200,
18900,
25700,
7700,
null,
16900,
18000,
81600,
18800,
4200,
24000,
28900,
20000,
15300,
36100,
38000,
63400,
40900,
26600,
null,
46400,
12300,
11000,
18300,
22100,
9500,
5500,
19300,
21600,
11200,
5800,
5700,
67500,
21500,
36100,
70300,
4300,
10300,
10400,
40800,
7370,
77700,
35200,
24700,
91500,
89000,
null,
102600,
115800,
26000,
18800,
10700,
38100,
18600,
86600,
13400,
94900,
42100,
44700,
12100,
27400,
null,
19200,
30500,
null,
11300,
21900,
26600,
22174,
29700,
25700,
24400,
46500,
6700,
16300,
null,
17100,
63700,
10400,
8600,
8100,
22800,
175400,
21900,
6900,
222800,
25800,
23500,
18500,
14700,
62700,
71700,
10900,
null,
39100,
48900,
16200,
49500,
26900,
8300,
29900,
6900,
5000,
19900,
63500,
37100,
22900,
16900,
15600,
57700,
43300,
9500,
22700,
6200,
34800,
19400,
6200,
null,
null,
9900,
21000,
20000,
6800,
3200,
9500,
1100,
20300,
15700,
22600,
15600,
31600,
12400,
9200,
130400,
59300,
3950,
39000,
23900,
14900,
10100,
19100,
256700,
30100,
48500,
13200,
65500,
57900,
8300,
19600,
26500,
91500,
null,
18400,
41500,
61900,
53700,
null,
23100,
null,
null,
23000,
28800,
29400,
27400,
8000,
9200,
21400,
70900,
6990,
3300,
14100,
50400,
58100,
21000,
29300,
6800,
null,
16000,
15300,
null,
30000,
45200,
19000,
18000,
16400,
13400,
41300,
81000,
2000,
50700,
41500,
19500,
13900,
30100,
20500,
56400,
60000,
23200,
45700,
18300,
36500,
9400,
20700,
9000,
23200,
9600,
24300,
null,
18700,
13700,
23200,
25000,
48400,
19800,
30600,
25731,
37800,
26200,
32800,
15400,
5200,
32700,
10700,
80800,
33800,
25900,
38100,
42000,
118800,
9500,
4300,
3500,
null,
7000,
175044,
35300,
20760,
35000,
5300,
66200,
69300,
41900,
16200,
11500,
null,
54700,
57400,
41000,
9400,
null,
18400,
10800,
36500,
23300,
7300,
11600,
13400,
null,
15900,
21500,
10800,
36700,
32800,
27600,
37700,
29000,
19800,
11500,
10300,
92900,
16400,
12700,
48500,
31100,
20500,
17500,
18800,
19000,
6400,
23300,
58365,
11000,
8200,
11200,
28500,
18800,
23700,
14300,
null,
62100,
16200,
22900,
131300,
55100,
11600,
16100,
39200,
null,
16700,
11100,
23700,
11200,
18200,
10700,
11100,
47400,
null,
6850,
12600,
26400,
159900,
null,
20900,
132700,
null,
8100,
51500,
19050,
53900,
40900,
24800,
null,
30700,
31400,
23400,
54200,
16100,
18700,
62500,
60300,
null,
11700,
28300,
39000,
17800,
38700,
12500,
12800,
69700,
59100,
24000,
12900,
18300,
48900,
7400,
12400,
13300,
79900,
10600,
35400,
16800,
12300,
31200,
31000,
61800,
33900,
null,
19500,
null,
60600,
19200,
28400,
14100,
16100,
49200,
24200,
15500,
50200,
null,
453500,
23800,
20000,
45500,
14900,
54200,
11500,
21000,
18100,
5300,
46900,
84000,
null,
10300,
55400,
47600,
15400,
10354,
12250,
26454,
36100,
11100,
10700,
94800,
23600,
9500,
10800,
27400,
5800,
17100,
123200,
29100,
6800,
8900,
21400,
4000,
33500,
20200,
32800,
34000,
45200,
13000,
23300,
17900,
34500,
38600,
9000,
25100,
125500,
23300,
9000,
68000,
8700,
74500,
17700,
22000,
52200,
36300,
22900,
18000,
83300,
54400,
18100,
null,
null,
11900,
null,
13800,
40500,
50300,
64300,
14000,
13700,
105600,
10700,
41900,
21200,
99100,
5300,
null,
15400,
null,
16600,
37400,
17000,
62200,
null,
11400,
101400,
22900,
17000,
43300,
null,
117900,
19600,
66600,
26100,
32000,
65800,
12700,
51000,
7800,
29800,
139900,
38500,
9500,
60400,
21000,
5500,
26100,
4600,
46300,
null,
12900,
null,
35900,
26000,
22100,
77200,
8000,
38998,
74280,
23300,
15900,
27600,
14700,
43739,
11100,
51800,
null,
16300,
39100,
null,
17600,
9300,
38900,
39100,
3550,
36700,
97900,
36600,
42600,
67600,
29400,
11000,
42100,
32500,
22000,
null,
33800,
21300,
35200,
11100,
51400,
70900,
11800,
27400,
13100,
32600,
null,
7200,
null,
30400,
21400,
32200,
42000,
null,
36300,
17400,
9800,
34000,
43600,
13700,
20800,
35600,
60800,
37800,
29100,
21500,
6600,
18400,
41700,
10700,
6700,
null,
21400,
31200,
49400,
110200,
23000,
53200,
77500,
63800,
51800,
31100,
14100,
37100,
11200,
26600,
17100,
5000,
49100,
15700,
62300,
35000,
27800,
60500,
42600,
6700,
12000,
9200,
54000,
null,
12700,
41400,
21000,
5100,
9000,
18300,
21800,
20000,
96400,
8000,
90800,
70200,
15300,
53000,
37800,
42300,
3100,
102400,
26600,
31200,
38200,
37200,
10300,
58300,
9600,
20100,
103900,
59100,
49600,
118600,
73000,
28300,
16700,
34400,
27500,
52400,
31000,
7500,
8900,
5300,
null,
12100,
3400,
5500,
16900,
12600,
13600,
7200,
52750,
28700,
17300,
11000,
29400,
16600,
90600,
34600,
17200,
42500,
26400,
51900,
40500,
null,
10100,
45300,
7100,
37600,
4400,
32700,
24300,
null,
44100,
16800,
20900,
17800,
23500,
11000,
5600,
16400,
19800,
27061,
16100,
59900,
null,
146400,
59200,
4200,
40700,
52500,
12000,
22000,
45000,
13700,
15000,
13400,
18100,
19100,
66500,
14300,
26800,
30400,
16900,
94200,
35200,
25500,
10100,
58800,
11800,
44600,
25625,
52900,
null,
31400,
38600,
14800,
49000,
130400,
14600,
5800,
15300,
76200,
33200,
9400,
41700,
46500,
24200,
75500,
51800,
9300,
53600,
75900,
27100,
44200,
64100,
33100,
61800,
5800,
21500,
null,
17000,
21400,
47000,
20100,
24200,
18500,
33500,
11500,
13800,
37600,
24100,
75400,
31900,
41000,
47100,
79300,
26100,
14100,
42000,
3700,
17500,
17500,
46000,
14000,
13100,
9100,
40300,
6800,
13600,
3000,
4400,
23100,
37700,
1500,
9400,
66500,
125800,
23600,
38900,
53770,
8200,
20600,
11500,
27100,
109900,
69500,
19500,
21200,
74800,
41300,
24200,
4100,
40900,
7700,
62900,
33200,
19700,
69100,
42500,
12000,
36700,
47100,
80900,
null,
6000,
22900,
29300,
47200,
45700,
null,
17000,
69200,
null,
11900,
38400,
26000,
34800,
14300,
55600,
25100,
22200,
64400,
15600,
17300,
16300,
37900,
17900,
42100,
41700,
null,
64200,
63400,
35500,
32600,
5200,
null,
85900,
40500,
11700,
31100,
55800,
11300,
17000,
21000,
19200,
7500,
38600,
38800,
3900,
182600,
32200,
null,
12500,
147800,
null,
4700,
5800,
30000,
null,
40700,
14700,
13000,
3800,
25400,
17200,
37200,
18100,
10400,
20200,
26900,
9200,
14700,
47500,
31900,
27700,
24900,
18300,
8500,
20400,
39300,
44700,
9300,
7800,
48200,
null,
52600,
30900,
50500,
13100,
27100,
21500,
53500,
53500,
13400,
38400,
9700,
21500,
24100,
57600,
102200,
6700,
3000,
22800,
6500,
59800,
null,
42800,
82300,
5700,
70300,
13100,
35800,
15700,
32500,
24400,
13600,
6500,
76800,
32400,
75500,
null,
25100,
36900,
5300,
17100,
16700,
46700,
null,
600,
6500,
6800,
31500,
39200,
24700,
null,
26200,
22400,
48000,
19600,
6300,
46300,
29800,
24150,
27300,
38000,
4400,
27000,
35100,
12800,
32800,
27200,
28300,
5100,
44700,
null,
12600,
14800,
31600,
25100,
83100,
4300,
31000,
44200,
51000,
48100,
12000,
23000,
null,
33200,
35000,
null,
58400,
3800,
91400,
16300,
23500,
null,
64700,
null,
23400,
31800,
36700,
31600,
45700,
11300,
9800,
14650,
12700,
168200,
10500,
22500,
37500,
5800,
26600,
29700,
34100,
49600,
19800,
9300,
100500,
23200,
22200,
37100,
7000,
43500,
75700,
21100,
null,
23700,
37000,
6900,
17600,
41800,
17300,
31000,
null,
55500,
43700,
45900,
4800,
16500,
19600,
9045,
29350,
41900,
16900,
37100,
12400,
78400,
41700,
40900,
58400,
15600,
78900,
5300,
47700,
34800,
34600,
null,
18400,
13600,
12900,
21600,
85500,
42200,
40500,
32700,
63400,
31600,
30700,
71000,
null,
8800,
16000,
81300,
24900,
null,
28400,
19200,
55900,
16500,
11800,
53700,
31000,
43600,
29300,
12100,
null,
20800,
9700,
14300,
21400,
12000,
32000,
13000,
44100,
39900,
20400,
43400,
null,
12800,
32600,
3200,
114200,
12100,
29100,
23500,
14900,
20800,
18500,
136400,
3400,
7000,
12300,
null,
28100,
27700,
33100,
null,
42900,
86300,
7400,
45400,
16900,
19700,
null,
69300,
22900,
null,
15500,
7000,
7500,
15900,
9100,
35300,
6000,
27800,
26700,
13300,
45000,
21900,
null,
13800,
106370,
64200,
null,
25900,
25400,
31900,
6700,
67300,
70500,
37800,
19500,
23100,
5000,
7900,
31500,
11300,
9600,
28500,
null,
51700,
51600,
32500,
46300,
118100,
26500,
11200,
null,
21500,
46000,
16000,
27600,
15500,
12900,
95200,
61400,
131200,
25400,
29100,
18500,
29200,
15400,
31200,
19100,
35900,
2700,
17000,
70500,
17400,
48000,
null,
32300,
79600,
42218,
25300,
24200,
91300,
10700,
6000,
58400,
12100,
3500,
61700,
8400,
20600,
23300,
48300,
42500,
1400,
20600,
null,
32800,
20300,
48100,
27300,
75000,
0,
18400,
57800,
8600,
19300,
19720,
79700,
29600,
14000,
34900,
15800,
8300,
20500,
null,
14700,
9600,
28200,
1900,
11900,
25450,
17600,
10500,
17200,
83600,
12300,
38900,
5200,
8000,
49669,
null,
24500,
13900,
151900,
43400,
20200,
29200,
13500,
6600,
41200,
8800,
37800,
197900,
40100,
17900,
23600,
60500,
51320,
23200,
17500,
null,
25600,
97300,
39900,
48100,
null,
11100,
25100,
37600,
11400,
16500,
33000,
8100,
18800,
8400,
15900,
29800,
15500,
18100,
60500,
17500,
47000,
null,
32900,
26600,
null,
91100,
101300,
116900,
11200,
8700,
10400,
36500,
18300,
62900,
16800,
40000,
4600,
25100,
13900,
null,
9900,
40300,
60400,
35800,
58300,
15800,
19500,
19400,
32600,
51100,
17000,
13200,
null,
12600,
22600,
20100,
55000,
12500,
14600,
12300,
6300,
12500,
11100,
31000,
32600,
14100,
19000,
58500,
23000,
64900,
34050,
13500,
10600,
11900,
32300,
47800,
41200,
40300,
23600,
38900,
18700,
null,
13000,
11300,
97000,
53500,
10100,
12200,
77600,
16100,
10900,
45200,
91500,
49700,
37100,
28800,
17000,
29600,
18800,
42900,
26700,
38200,
12100,
11700,
7761,
9000,
30600,
51200,
31600,
310200,
22500,
22000,
25000,
6400,
2700,
45300,
15500,
40100,
12500,
14700,
8900,
52500,
61700,
11700,
45900,
6900,
14600,
10100,
24000,
83800,
12600,
6500,
46700,
13400,
22200,
37100,
34400,
51300,
92700,
70000,
65000,
30400,
66500,
13900,
16400,
8100,
4650,
37800,
43600,
68400,
null,
22500,
38000,
24700,
31610,
50500,
94800,
null,
24300,
13400,
37200,
21800,
10100,
null,
14200,
56000,
18600,
18400,
26600,
13900,
15900,
11800,
70200,
8500,
null,
22400,
14600,
17000,
14800,
6500,
null,
26900,
27400,
36800,
20400,
36400,
28700,
27300,
19587,
8800,
54900,
24700,
26500,
55300,
26900,
35600,
19500,
37200,
13200,
7000,
158900,
28500,
8800,
25900,
78300,
16600,
29700,
40500,
20500,
31900,
66900,
25200,
38500,
9100,
86600,
7200,
134100,
13400,
13700,
11200,
54900,
null,
20900,
20600,
25400,
87800,
1400,
143200,
98500,
76400,
103900,
40200,
10400,
17800,
45000,
51900,
24600,
14100,
51600,
59400,
23200,
42000,
17200,
17400,
42300,
20200,
18700,
36300,
31000,
16300,
44900,
71500,
28600,
22400,
55770,
null,
34500,
29000,
null,
10700,
60600,
53200,
11100,
48800,
21900,
9600,
24900,
21800,
61000,
18700,
77800,
6700,
12700,
26700,
55300,
34500,
null,
19500,
4700,
111711,
19400,
30900,
16300,
37300,
115000,
13900,
26800,
20400,
54100,
68200,
1750,
141788,
20300,
17300,
55200,
85800,
63800,
17200,
30200,
129000,
null,
35000,
40200,
72800,
55250,
71000,
40500,
91800,
23900,
33900,
93900,
45100,
63400,
15800,
51800,
13100,
64300,
28100,
25000,
5500,
83000,
8600,
null,
33400,
63900,
18500,
29100,
62700,
24400,
18900,
null,
21900,
67300,
13200,
98500,
48500,
48600,
32700,
40300,
18400,
14900,
24900,
53085,
30600,
42506,
75800,
17100,
37500,
null,
59800,
37100,
24800,
26700,
29700,
14000,
15200,
30800,
22700,
14100,
13000,
117700,
72285,
27400,
56900,
51500,
17400,
14500,
41600,
254800,
18200,
57500,
53300,
39800,
78900,
75600,
111000,
28100,
39400,
28500,
41100,
229900,
45300,
40200,
48300,
27400,
34600,
70405,
9809,
50800,
7500,
46600,
26500,
24500,
16300,
25500,
null,
11200,
26400,
2100,
69800,
153300,
26800,
23900,
85500,
138800,
null,
67100,
11100,
197500,
79800,
17400,
65200,
9700,
236600,
83700,
31600,
29800,
29800,
24600,
15000,
50300,
23200,
13800,
8400,
29300,
null,
20600,
5200,
11400,
34600,
32300,
95430,
30600,
17900,
null,
null,
19400,
75600,
19900,
27800,
12500,
39000,
40100,
42900,
23100,
null,
11300,
31200,
35000,
38200,
8500,
76500,
null,
17800,
10900,
42000,
11200,
27500,
null,
30100,
42000,
20501,
25600,
16100,
12800,
13500,
28300,
51400,
20200,
38100,
35800,
36900,
null,
57700,
175900,
4600,
16000,
7700,
62600,
6900,
23000,
38700,
18500,
30000,
9500,
73700,
47400,
8000,
63600,
null,
12500,
32400,
23000,
27633,
97800,
45400,
38300,
125300,
41500,
24200,
27100,
33500,
41800,
37500,
48500,
37700,
19800,
125800,
49700,
89300,
24600,
3200,
77900,
35400,
15400,
11600,
22900,
45000,
16300,
36300,
17700,
15000,
9400,
17300,
99000,
11300,
null,
24900,
45100,
18500,
4400,
34700,
15000,
99800,
26600,
64550,
7800,
23100,
2100,
11200,
37200,
3500,
null,
34600,
17500,
25100,
13200,
15200,
8600,
11600,
7000,
null,
18000,
6800,
59800,
5500,
47600,
84000,
8600,
18600,
6500,
12200,
31600,
26000,
74600,
21700,
75500,
24400,
41800,
15900,
20300,
30000,
21300,
12600,
100900,
26300,
50700,
24300,
9600,
18500,
7900,
20000,
26500,
33500,
21000,
20500,
34800,
21400,
32900,
11700,
41000,
54400,
null,
34600,
72200,
52200,
42100,
46300,
16600,
22100,
39800,
6000,
24500,
39700,
33800,
103000,
27800,
41800,
45800,
81000,
29700,
42100,
29400,
15800,
53200,
30700,
15300,
8700,
27700,
25500,
null,
22000,
41300,
23100,
69300,
16700,
30100,
69300,
22600,
57800,
null,
42900,
115000,
28100,
18300,
13100,
27900,
32800,
null,
16400,
7500,
26100,
8600,
98000,
23600,
13000,
9100,
21600,
12400,
3800,
217600,
19900,
55500,
42700,
29500,
null,
null,
35200,
57600,
14600,
20700,
35300,
24900,
50200,
40900,
null,
40100,
81900,
55400,
38000,
null,
9600,
6900,
333400,
30100,
11100,
15600,
25830,
33200,
null,
7700,
22500,
null,
25400,
20800,
34100,
null,
9800,
30500,
22000,
40500,
20400,
67000,
141600,
11700,
21400,
12300,
23000,
1600,
24500,
null,
16500,
57800,
29100,
10400,
19100,
7300,
38900,
33500,
6700,
13100,
26000,
39500,
104700,
8950,
53400,
22100,
30700,
null,
28600,
15500,
21900,
26400,
null,
24700,
17000,
9900,
89300,
4500,
39000,
105420,
29000,
70200,
23100,
47100,
null,
63800,
9200,
88800,
22900,
78000,
28900,
34300,
12900,
56300,
16800,
null,
100400,
null,
13500,
4600,
25100,
75200,
21300,
21100,
21100,
6800,
34300,
88000,
13200,
2600,
27600,
29800,
null,
null,
42700,
16900,
28800,
null,
10600,
18700,
36100,
30400,
9000,
65900,
68700,
25700,
12200,
null,
3700,
45900,
17500,
9500,
null,
26200,
57900,
13600,
null,
16800,
98800,
null,
8300,
53600,
7700,
8900,
12900,
82600,
35200,
48600,
16500,
14200,
11000,
null,
10700,
23100,
132300,
31100,
174500,
38000,
43200,
15800,
10200,
12000,
18800,
30400,
14100,
35300,
4700,
30900,
22500,
17900,
6800,
null,
3600,
23200,
14600,
49400,
25400,
34900,
14000,
12400,
6400,
107700,
102400,
24100,
9300,
37600,
26300,
31600,
66400,
39300,
49700,
53600,
35900,
22100,
21800,
null,
32500,
55600,
36600,
6400,
15700,
8500,
34700,
41300,
12200,
52900,
13900,
35600,
29600,
8900,
26200,
66700,
5900,
18400,
16800,
31400,
17200,
2800,
81300,
28300,
36900,
19200,
53000,
11000,
12100,
37800,
29300,
18500,
19300,
null,
27200,
19600,
12700,
19000,
22400,
null,
24000,
26400,
19400,
23500,
35700,
12200,
2700,
44000,
26500,
22000,
18900,
8200,
115600,
34800,
32200,
null,
null,
9100,
22700,
14800,
13000,
74900,
6500,
18000,
28100,
11100,
21400,
10900,
null,
52500,
98700,
155900,
146700,
null,
4800,
27800,
null,
17200,
104000,
16800,
11800,
11000,
22300,
20000,
36000,
53232,
11000,
30300,
48400,
15700,
12800,
26800,
35900,
16000,
29400,
20600,
56700,
null,
40100,
16500,
30600,
57600,
18000,
null,
16700,
5700,
7300,
null,
28500,
null,
9000,
20432,
44200,
20200,
32300,
17300,
25300,
16300,
24700,
23400,
30200,
84800,
21500,
79500,
33200,
38700,
25000,
15200,
22000,
4400,
36800,
14700,
9750,
344500,
11400,
38800,
37300,
10300,
11200,
14500,
5400,
9000,
18900,
13500,
29400,
21400,
15100,
3000,
null,
22300,
56100,
26000,
43800,
null,
61400,
11300,
70800,
22100,
41100,
159200,
13800,
20100,
15800,
50200,
40400,
23131,
12300,
40000,
null,
27800,
12400,
24100,
2200,
7200,
31300,
8350,
null,
7500,
155400,
43100,
13300,
166800,
null,
10100,
121000,
null,
12952,
16600,
24400,
17200,
30500,
null,
201200,
68200,
87500,
32600,
89200,
24400,
3000,
41500,
47900,
10400,
9300,
18700,
20100,
111900,
null,
null,
12100,
9900,
28600,
5700,
19500,
84500,
6400,
51700,
16300,
18200,
22100,
19300,
42900,
34400,
43900,
9700,
42200,
19900,
62100,
32600,
14600,
6600,
10100,
15900,
18000,
29200,
37700,
31900,
24400,
78800,
55500,
30000,
56100,
null,
12500,
19400,
41100,
27100,
null,
37500,
null,
11000,
14500,
60800,
34900,
90000,
18000,
null,
59500,
59800,
19000,
24900,
39500,
27700,
70100,
53000,
27200,
null,
9400,
32200,
12200,
104900,
28700,
18500,
49400,
53500,
18900,
8200,
24000,
54800,
30100,
11300,
12300,
18300,
18100,
19500,
20000,
24300,
16400,
19300,
24700,
null,
12000,
174100,
14900,
null,
19400,
45200,
10600,
131100,
26800,
50900,
null,
16000,
null,
17400,
34700,
38900,
9300,
null,
22700,
33900,
38600,
6000,
29900,
15400,
78500,
54500,
47200,
77900,
50700,
9600,
16100,
41283,
43200,
34717,
50500,
28900,
71300,
83700,
14300,
24900,
null,
null,
10700,
14900,
null,
6500,
null,
6800,
21200,
1600,
11400,
28400,
42200,
60900,
19600,
44800,
22100,
57500,
78100,
16400,
27100,
58500,
33200,
19900,
5800,
9600,
37200,
52000,
81600,
30700,
21900,
31700,
16300,
10400,
26300,
31700,
47500,
28800,
null,
28600,
15600,
24100,
19100,
7700,
98200,
18300,
null,
17800,
9600,
5900,
24300,
26000,
26100,
20053,
19900,
10300,
27100,
null,
null,
66200,
31400,
15900,
1800,
24200,
28700,
58000,
60200,
59100,
16800,
32900,
38400,
26100,
23000,
40600,
20700,
51500,
38200,
38500,
29900,
47000,
67700,
31500,
13800,
11400,
22100,
9900,
22800,
5500,
12100,
15800,
38000,
6900,
31200,
null,
15300,
17600,
38400,
18400,
11100,
null,
40700,
40600,
null,
13200,
13500,
15700,
26500,
38200,
37500,
16100,
26100,
3500,
31600,
14800,
18700,
23000,
14500,
29300,
18000,
2500,
81200,
76300,
9700,
23500,
11900,
70300,
31150,
null,
16900,
19700,
null,
16600,
49700,
null,
null,
27250,
32300,
8800,
105500,
8300,
10000,
45200,
9700,
48000,
null,
24800,
27600,
15100,
19600,
11700,
16400,
21100,
17500,
10200,
null,
10000,
16800,
25100,
15100,
14900,
20400,
null,
8500,
42200,
13300,
11500,
13500,
47100,
13500,
11600,
13450,
7300,
null,
178400,
28300,
6700,
15500,
48500,
25800,
26600,
23300,
6600,
13500,
19900,
24600,
15800,
30800,
25600,
36900,
12700,
13700,
28800,
11800,
null,
21100,
45200,
9100,
3900,
80300,
8300,
4900,
14500,
30100,
null,
12500,
null,
20200,
13000,
48700,
91400,
14900,
118100,
22700,
8500,
40600,
28500,
42000,
19796,
15250,
16700,
40900,
8900,
28900,
12900,
58200,
28000,
21700,
15500,
22300,
3900,
29000,
28000,
45300,
23700,
19500,
63500,
10100,
24300,
48400,
20539,
68800,
47600,
null,
6300,
null,
14500,
36200,
44000,
null,
38800,
21300,
31700,
35600,
49100,
18300,
35500,
31500,
15010,
17000,
19000,
33000,
31550,
39300,
31500,
5500,
17100,
54800,
33500,
26500,
30700,
9300,
15400,
46800,
34100,
66200,
69700,
43400,
31400,
15700,
10400,
21900,
27100,
58400,
67900,
16400,
19200,
16400,
9600,
17300,
32200,
48900,
67600,
153300,
12000,
35500,
11800,
20800,
17400,
22300,
38500,
15600,
35500,
41400,
8800,
null,
54800,
2800,
5600,
40400,
9800,
14500,
null,
19000,
18400,
26100,
26400,
6500,
77300,
32900,
10500,
36400,
48300,
45200,
45900,
9800,
57100,
12700,
9400,
58900,
48000,
28000,
53700,
41600,
5100,
20950,
12000,
12000,
2400,
24500,
6500,
13600,
null,
24400,
14800,
4700,
45500,
7000,
12000,
38900,
13000,
37000,
null,
16500,
16100,
13000,
2200,
9400,
17200,
22100,
14454,
36800,
38800,
36000,
44300,
14400,
47800,
15200,
12600,
64700,
31000,
16000,
null,
5080,
25100,
3100,
69500,
18600,
29600,
19400,
34200,
8100,
21700,
119800,
31700,
13300,
15500,
3900,
22200,
46900,
17600,
9800,
null,
10700,
15500,
116700,
12500,
14000,
15200,
null,
37900,
11800,
25800,
16000,
34800,
51300,
54700,
24600,
53900,
21675,
6700,
31300,
82600,
25100,
73300,
null,
27900,
45400,
39700,
28279,
null,
null,
116700,
33200,
35500,
9300,
31200,
null,
25700,
21000,
null,
12400,
15100,
26500,
77500,
178000,
3775,
12000,
15000,
306600,
null,
null,
45400,
31300,
21700,
21600,
23100,
108800,
7300,
7400,
4800,
17700,
24600,
20200,
18600,
45400,
20300,
2000,
15300,
13100,
14700,
47600,
29400,
5900,
43000,
8100,
52700,
41701,
null,
20100,
25400,
null,
8300,
46000,
42900,
51800,
39600,
21700,
28700,
103200,
55900,
5000,
null,
17500,
27100,
24200,
null,
null,
203300,
42900,
23800,
21500,
22100,
89800,
38100,
7200,
null,
null,
5600,
40300,
23500,
39200,
4500,
49700,
2300,
27800,
14400,
null,
36800,
6200,
20000,
21500,
109400,
55600,
13000,
85000,
8500,
78200,
27700,
14900,
53200,
16600,
11100,
39200,
23900,
12700,
5400,
5500,
5500,
34400,
9400,
29200,
18400,
5500,
31100,
39100,
25700,
11700,
13500,
59600,
69000,
26600,
16800,
26100,
15900,
3300,
7500,
105500,
67300,
null,
9000,
37200,
25200,
14900,
17200,
5800,
15400,
60400,
40400,
18100,
null,
61900,
13800,
53800,
15000,
null,
18000,
13400,
null,
2600,
1900,
68000,
30079,
318800,
12700,
19800,
60000,
null,
5300,
50700,
10000,
8700,
37200,
15300,
15400,
23100,
253000,
20200,
10000,
87500,
30200,
34400,
null,
89400,
null,
42800,
17000,
107200,
25600,
34400,
14800,
25310,
24500,
14200,
107200,
30900,
27800,
28200,
32000,
16700,
19900,
41700,
63500,
39200,
22500,
23900,
66200,
29300,
9500,
44200,
30400,
68900,
22300,
57500,
50700,
19600,
81900,
53800,
35600,
6400,
21000,
17607,
27700,
16200,
null,
22100,
16500,
21200,
41000,
39700,
9900,
82159,
79750,
37600,
28300,
57100,
14200,
24700,
6500,
19500,
19800,
7200,
8400,
27200,
14300,
6500,
63400,
9800,
null,
25100,
22000,
8700,
55000,
null,
13900,
10800,
29800,
108200,
25100,
77800,
29500,
42500,
18600,
3700,
19900,
7000,
16501,
26900,
44900,
29800,
3600,
78700,
29500,
57200,
null,
40400,
10500,
39600,
34500,
9500,
8000,
21200,
null,
63000,
8018,
64300,
13200,
null,
10700,
10200,
7700,
54800,
19900,
8679,
10500,
53000,
15000,
35500,
50400,
null,
7800,
16500,
35100,
23100,
36500,
60200,
31300,
21700,
15400,
null,
11600,
26000,
44900,
11500,
8400,
19900,
107100,
11500,
3300,
53100,
17800,
66900,
1800,
3300,
null,
31800,
22700,
41900,
67500,
67300,
25700,
87500,
35700,
18700,
37000,
73200,
146100,
38200,
22500,
29900,
52500,
null,
27200,
63400,
16100,
47900,
27800,
9900,
46000,
21600,
76600,
117200,
15100,
28700,
231200,
null,
14700,
34400,
41200,
26000,
null,
39600,
8900,
5500,
17400,
11800,
15100,
59300,
14300,
16800,
11100,
null,
12250,
null,
51700,
12000,
10700,
19500,
null,
30200,
59100,
18000,
10300,
null,
53000,
38000,
49800,
12100,
null,
17500,
null,
24200,
21500,
14800,
67000,
28300,
16600,
19200,
64200,
172400,
24900,
32600,
21300,
35100,
33000,
101400,
null,
54300,
5600,
12000,
112800,
8600,
49610,
17800,
20200,
38000,
130000,
17500,
31100,
17200,
98100,
35200,
14600,
47800,
26700,
17700,
19500,
15800,
null,
43542,
4000,
18100,
13000,
34000,
40200,
163202,
46400,
null,
24900,
38700,
22200,
null,
12400,
24200,
34900,
null,
29102,
58000,
25400,
null,
32200,
29600,
12023,
8000,
48500,
58316,
11800,
null,
195592,
17900,
176300,
null,
25700,
80400,
14500,
57800,
65200,
15700,
43803,
80200,
null,
8600,
51300,
56800,
109000,
31600,
36200,
47700,
33600,
23300,
14900,
5100,
11700,
166600,
19900,
27500,
11000,
24400,
18500,
31200,
6500,
16650,
28900,
44200,
32800,
6920,
12900,
61900,
37700,
null,
22800,
17800,
28300,
13500,
18300,
7325,
33800,
19100,
45900,
26000,
34400,
null,
14300,
17100,
20700,
183400,
null,
9900,
20100,
9800,
54100,
9700,
38500,
4700,
53251,
7400,
null,
null,
66100,
27100,
null,
22200,
8800,
16900,
41600,
11600,
41100,
10000,
7795,
48900,
42800,
13100,
32500,
26100,
39200,
25700,
26100,
7800,
56100,
5100,
8500,
5400,
27400,
9200,
33400,
76600,
15200,
39700,
24700,
10600,
45300,
3900,
18200,
14200,
45700,
7300,
33100,
26400,
109100,
53800,
68600,
null,
13400,
18300,
null,
24700,
38500,
29300,
17300,
16200,
4700,
23300,
234800,
12800,
61200,
9400,
null,
6300,
12000,
47400,
6000,
27900,
14300,
77600,
35600,
35900,
26400,
4700,
14200,
29500,
5000,
null,
60000,
8700,
58300,
null,
null,
21200,
null,
12300,
9000,
26200,
9300,
31000,
12800,
19900,
23800,
3400,
5300,
null,
34301,
51800,
14300,
16000,
11400,
null,
5800,
43000,
6400,
2800,
41100,
10600,
51800,
33800,
24100,
23600,
13500,
31400,
42100,
131100,
134300,
13700,
54900,
15500,
187600,
57002,
14600,
17800,
40800,
53300,
25700,
24600,
31300,
7500,
22400,
50400,
79200,
59500,
28000,
75500,
82300,
11400,
13100,
null,
37100,
21000,
42750,
16300,
147100,
12800,
49200,
40000,
40100,
28300,
62000,
131100,
16500,
41800,
14700,
22000,
18400,
33700,
17500,
2400,
35700,
30000,
null,
7200,
14400,
14400,
32900,
26400,
22200,
31500,
null,
41100,
9000,
108100,
39600,
30900,
10200,
29100,
null,
21200,
25500,
29000,
42900,
28600,
71700,
61400,
58800,
15100,
null,
10300,
19100,
27600,
19700,
9200,
6800,
41900,
128500,
34100,
26600,
20300,
7200,
9700,
46900,
null,
21500,
49100,
54000,
null,
20900,
null,
94800,
37700,
10200,
25400,
143800,
43700,
29200,
13000,
19500,
76700,
60600,
35800,
23500,
10600,
109700,
85000,
51400,
71700,
8700,
26100,
45100,
7800,
28500,
6800,
22000,
24100,
42700,
18400,
34900,
7300,
55700,
5500,
56400,
25200,
33200,
18400,
62300,
17100,
74700,
53600,
39900,
34000,
47700,
20000,
24300,
44500,
43200,
67900,
47000,
51100,
13400,
22100,
13200,
null,
3800,
58200,
27800,
20100,
34000,
36300,
17600,
83700,
29600,
7500,
36300,
11800,
26600,
21300,
44500,
34800,
21800,
264600,
28700,
null,
40300,
36300,
25000,
46500,
15300,
null,
null,
null,
37300,
12600,
42900,
52500,
null,
6400,
13500,
15800,
79800,
18900,
15400,
41400,
43300,
27598,
null,
61900,
19600,
29000,
27800,
21300,
34600,
13400,
23900,
93400,
26800,
47800,
29300,
34250,
39000,
null,
9800,
150900,
24100,
18900,
22700,
22500,
29000,
35800,
46000,
42900,
42100,
148400,
27400,
5400,
21800,
null,
122600,
31600,
6300,
94700,
20400,
35919,
5900,
null,
31600,
19800,
59400,
45300,
34200,
29900,
null,
70200,
74000,
null,
24300,
30600,
38400,
33900,
7900,
15300,
52847,
25500,
17200,
61965,
44000,
null,
15200,
24600,
null,
16500,
18300,
10900,
35100,
9400,
38100,
15500,
27000,
64400,
10500,
12200,
10800,
4500,
18800,
41000,
50300,
16300,
65300,
10900,
43000,
10500,
64200,
11800,
32100,
19800,
41400,
27400,
23900,
24000,
22400,
10100,
30500,
31200,
6600,
39800,
null,
188200,
21200,
17100,
41766,
27700,
61400,
49500,
34300,
23300,
15900,
20200,
21200,
12900,
10100,
13800,
2400,
23400,
31600,
19500,
34300,
14800,
15700,
67800,
33700,
44900,
17700,
2850,
14100,
68800,
17400,
6300,
31500,
34800,
22000,
75400,
47400,
36000,
null,
21300,
11800,
17300,
13000,
64800,
8600,
38200,
10900,
700,
4700,
94200,
20500,
6100,
18200,
null,
37800,
87200,
32900,
12200,
34800,
26100,
null,
60200,
27000,
51000,
2500,
20100,
27800,
null,
11000,
12300,
24500,
108400,
37400,
20300,
19400,
15400,
26900,
11000,
14900,
107100,
40400,
23100,
null,
216000,
92200,
6500,
40100,
25800,
10000,
null,
38036,
24000,
10400,
19000,
17300,
27500,
null,
91000,
24200,
52800,
23800,
25100,
60400,
38018,
23900,
28900,
13200,
31600,
12900,
16000,
5200,
55900,
12100,
44100,
17300,
26500,
27700,
70900,
37500,
10300,
19500,
null,
14300,
31300,
46000,
32100,
44300,
null,
null,
22800,
26300,
37900,
21400,
27700,
21100,
24600,
14000,
19400,
30100,
75400,
13100,
27100,
54600,
15000,
56000,
40600,
null,
15000,
16300,
14800,
34000,
34500,
71500,
31100,
10300,
null,
15800,
19500,
2000,
7500,
33800,
11600,
131000,
42600,
12100,
61500,
13000,
14300,
72820,
20775,
25800,
30700,
25900,
7800,
14900,
49100,
28300,
60700,
null,
13300,
7500,
15800,
15500,
27100,
11900,
14700,
31300,
22700,
40400,
33800,
35100,
177350,
34800,
20800,
81800,
25800,
35800,
26500,
15377,
24600,
81400,
60800,
44200,
21100,
8300,
12300,
101000,
13800,
25000,
35800,
28600,
30400,
17150,
8700,
null,
22400,
85100,
null,
33400,
22700,
null,
21300,
18600,
46100,
6000,
15100,
49800,
7300,
23300,
24600,
40500,
16500,
27500,
25700,
12200,
11000,
25800,
66000,
61300,
22400,
6300,
18800,
55805,
12400,
null,
71000,
2600,
46600,
null,
12300,
24100,
null,
32241,
43300,
30200,
78500,
null,
4800,
65100,
36600,
8100,
18800,
23500,
19400,
13100,
155300,
323800,
6700,
12200,
66400,
null,
21100,
11300,
40700,
6300,
19900,
51900,
23600,
24600,
null,
10000,
6500,
18600,
43000,
33000,
9300,
41500,
110200,
188500,
10800,
13300,
null,
10500,
26600,
20300,
18200,
113500,
5000,
12200,
10900,
17500,
14400,
8100,
37100,
31200,
8100,
76700,
35000,
30200,
10300,
33900,
12800,
37000,
null,
32500,
11600,
28200,
null,
8700,
122500,
32600,
10200,
6600,
null,
13900,
82600,
18500,
21300,
15363,
90300,
20600,
35800,
20100,
22300,
71100,
19300,
35000,
68900,
null,
75700,
11300,
57500,
7900,
24800,
17000,
16300,
7300,
12200,
31200,
null,
51400,
null,
10800,
17800,
22500,
22800,
43100,
39500,
29000,
6500,
10800,
19000,
11300,
11500,
94500,
5900,
161000,
28700,
16300,
null,
43600,
7900,
null,
37600,
32700,
40900,
11500,
null,
25800,
45900,
29400,
62000,
169400,
13100,
55000,
9450,
32500,
28900,
null,
16400,
29400,
null,
77600,
37250,
36700,
57300,
16900,
16200,
28900,
5100,
116000,
20000,
29000,
8100,
null,
25900,
26900,
12700,
1000,
27900,
33400,
23100,
24300,
22760,
5200,
19200,
64600,
27000,
58300,
null,
8800,
28700,
51900,
59100,
11000,
21000,
33000,
7900,
104800,
17100,
15700,
15500,
27800,
19000,
18300,
34900,
21800,
89200,
12300,
44600,
26200,
76600,
37600,
7100,
40800,
34500,
26100,
21000,
13500,
45400,
85400,
null,
18500,
34400,
31200,
22100,
22500,
38500,
52500,
6300,
2400,
42600,
8600,
34100,
23300,
61800,
24500,
22900,
12400,
43000,
14000,
10500,
15400,
6900,
22500,
43400,
73200,
32800,
10800,
206000,
45500,
57800,
28300,
6000,
19300,
24100,
12500,
22900,
38500,
null,
19700,
91600,
35700,
53200,
12900,
5000,
61100,
22100,
20100,
null,
30300,
33200,
37900,
24800,
17600,
29000,
8100,
17600,
15500,
27200,
36450,
13500,
22700,
40200,
3500,
15400,
36900,
16300,
8500,
30300,
55400,
null,
null,
null,
26500,
33400,
40900,
11900,
17900,
62800,
51400,
null,
11600,
23300,
36300,
10100,
37100,
65700,
16100,
9000,
31700,
35300,
25100,
63900,
33990,
18200,
59500,
45200,
28100,
12500,
18300,
13800,
52597,
5600,
49500,
12500,
29600,
10500,
2600,
18400,
7500,
13800,
43000,
15300,
16700,
6500,
16900,
29600,
50100,
39100,
7100,
36600,
3900,
34700,
21400,
2400,
12800,
45800,
46400,
28900,
15600,
null,
31700,
1200,
44900,
17700,
62000,
23700,
20800,
12700,
24200,
19700,
73900,
25500,
23000,
48900,
18300,
17700,
32000,
52300,
28200,
30000,
15100,
16300,
4000,
34900,
22000,
18400,
42000,
41300,
36600,
34300,
15000,
65000,
11950,
17800,
20400,
6400,
26400,
25300,
53000,
5100,
17700,
10600,
12100,
23000,
40700,
12000,
null,
null,
35209,
27300,
21200,
69400,
22500,
39600,
18500,
17600,
20100,
23800,
8400,
28100,
16300,
45100,
49000,
11700,
5500,
7100,
36900,
10300,
52500,
7800,
5500,
26900,
149100,
37200,
29100,
59500,
8400,
29700,
35600,
16500,
42600,
14500,
6400,
9300,
23400,
26900,
111150,
46200,
2500,
72000,
39600,
22100,
23400,
8300,
8400,
null,
11600,
29900,
21600,
12600,
34700,
null,
153000,
106800,
54000,
10100,
76200,
39100,
29800,
4300,
8100,
6300,
16300,
10200,
22700,
15400,
283600,
6600,
45900,
5000,
47200,
41500,
67300,
26600,
8100,
50000,
null,
23800,
33000,
32600,
4350,
86800,
12500,
38900,
35800,
21600,
11800,
null,
5600,
null,
5500,
16300,
41400,
46300,
38200,
3300,
156900,
5500,
91600,
35900,
14200,
31600,
10300,
null,
8200,
null,
18100,
97000,
26500,
24200,
18400,
27700,
32700,
42100,
31500,
35200,
18000,
14200,
13100,
29100,
14900,
47100,
30600,
26000,
26900,
15400,
51000,
17500,
48000,
10300,
71600,
28100,
null,
33100,
7800,
3500,
51500,
62700,
52680,
10200,
31300,
56400,
51800,
32400,
29700,
29500,
27400,
25900,
12100,
58400,
25500,
62200,
61200,
103000,
9400,
86700,
8100,
17900,
65900,
15200,
18700,
17900,
22600,
15600,
null,
17700,
49300,
null,
75000,
37400,
9300,
42100,
28700,
13400,
null,
41300,
23900,
8600,
37900,
10500,
43200,
null,
45000,
32000,
18100,
18700,
69400,
5500,
6800,
26300,
44900,
250300,
24200,
188000,
19800,
14500,
31500,
25400,
2900,
22600,
13100,
33100,
44400,
21600,
null,
30000,
55000,
28100,
38900,
26900,
null,
26200,
null,
null,
45800,
59900,
92200,
17300,
49100,
4100,
10200,
29757,
13700,
43100,
13300,
59800,
34000,
81500,
8800,
6550,
35900,
9100,
84900,
40700,
8600,
49400,
9000,
24800,
28700,
38800,
55100,
21800,
34600,
5600,
45700,
25700,
13200,
12700,
26400,
67900,
21300,
14100,
22800,
16900,
12600,
11500,
19400,
28000,
17600,
29300,
15900,
13900,
14000,
15400,
31100,
55000,
55800,
9100,
15300,
8600,
9900,
25500,
286800,
15300,
16300,
41500,
8300,
20800,
46500,
18000,
18800,
93249,
7100,
38100,
7600,
6500,
21400,
46100,
9900,
16400,
21500,
7000,
107000,
46800,
23750,
7100,
11200,
5500,
65068,
23500,
19100,
18600,
26900,
23300,
18300,
null,
32900,
8100,
25900,
6500,
10900,
3000,
20800,
null,
58500,
26900,
9600,
5200,
77900,
28800,
null,
14500,
20850,
18700,
9800,
12100,
15500,
31300,
25700,
13700,
30500,
17900,
34200,
null,
34900,
49500,
73600,
11200,
24200,
12400,
16300,
12200,
24500,
13000,
null,
42900,
23500,
16700,
14200,
9200,
2300,
11100,
8900,
41200,
27000,
12800,
6600,
null,
3700,
9600,
2500,
42200,
82900,
68200,
7500,
18000,
48100,
16100,
19600,
13900,
20700,
32000,
31500,
43500,
30400,
39100,
13500,
8400,
12800,
10200,
47500,
20800,
13000,
null,
12300,
21800,
2800,
20500,
13000,
20500,
14200,
16100,
null,
10500,
9900,
74000,
18100,
25500,
21500,
6000,
16000,
107600,
19300,
21800,
34100,
5100,
62700,
null,
10300,
27500,
3500,
41600,
116700,
31800,
2900,
null,
33000,
13700,
16900,
32800,
22900,
38300,
23200,
35800,
26000,
19000,
36400,
52400,
8500,
15600,
10000,
5500,
6400,
6000,
35700,
20900,
14200,
8300,
14000,
null,
17600,
28600,
20700,
263500,
25600,
7000,
12500,
43600,
8400,
46600,
17100,
70800,
7400,
48800,
44700,
2500,
31400,
39500,
24300,
54500,
18700,
122700,
7200,
16300,
7300,
5300,
14300,
30400,
null,
20900,
21200,
50000,
4800,
23600,
38300,
28400,
28800,
105100,
46900,
10100,
21800,
null,
16800,
27600,
18400,
37300,
10000,
null,
12000,
25800,
null,
null,
null,
null,
19000,
27200,
27200,
null,
15000,
36900,
null,
12300,
12000,
21900,
14112,
5900,
26300,
43300,
53500,
36700,
30900,
6700,
27800,
null,
null,
40000,
4100,
21100,
35200,
26000,
9100,
107400,
15300,
10200,
159800,
41800,
21100,
24200,
12300,
24800,
1100,
30100,
52500,
12100,
22600,
54900,
11700,
5700,
16000,
16000,
110400,
null,
37100,
7600,
7600,
43100,
21900,
10800,
11000,
20200,
5200,
20100,
12100,
33100,
8500,
71400,
null,
11900,
null,
36700,
56900,
11900,
52700,
33600,
67200,
50300,
44200,
12610,
28100,
18400,
49200,
9100,
9600,
8500,
34800,
10700,
68300,
24900,
17600,
7900,
35100,
28200,
44100,
16300,
49000,
87700,
55900,
14400,
33500,
11500,
32000,
20400,
19500,
22200,
10600,
30600,
null,
31400,
19300,
34200,
21535,
60300,
43800,
10800,
21100,
10400,
23700,
21300,
15700,
27400,
57000,
6700,
37000,
4800,
10700,
61100,
34000,
22800,
9900,
51000,
8455,
16400,
72000,
13500,
75100,
52800,
46900,
46100,
17500,
9300,
22400,
15600,
14000,
25600,
16700,
null,
25600,
21900,
147700,
25300,
21600,
9900,
27300,
22200,
47600,
15200,
50725,
13600,
15700,
null,
18700,
7100,
18700,
25300,
43500,
15700,
6800,
14200,
33000,
27400,
53400,
14300,
20500,
7200,
18300,
7700,
11700,
21400,
null,
8600,
13100,
1800,
26600,
47500,
9900,
8700,
19200,
37400,
39600,
29800,
12300,
4100,
51100,
54200,
30500,
38500,
34700,
52500,
10200,
null,
42000,
21800,
16600,
null,
37200,
34400,
7600,
42511,
6700,
53000,
null,
22100,
11600,
7000,
30600,
50800,
59700,
29600,
41300,
20800,
83200,
30000,
10700,
26700,
9100,
16500,
12300,
176600,
32000,
25300,
107200,
null,
null,
28700,
27700,
48800,
125400,
17400,
15400,
33600,
63000,
null,
17900,
75700,
114800,
null,
21900,
28300,
21700,
24300,
41200,
38900,
20700,
null,
24300,
33700,
null,
38900,
24500,
67500,
27700,
10900,
45700,
28400,
7300,
10400,
40200,
null,
11600,
13300,
11900,
7000,
22300,
21300,
21500,
8300,
58700,
28400,
43900,
null,
26500,
13300,
null,
5800,
48000,
73600,
21400,
30150,
37400,
46600,
22100,
30400,
6700,
20000,
null,
19300,
36200,
56900,
105600,
null,
57200,
15100,
40200,
20300,
16100,
23800,
18000,
147600,
17500,
15600,
23800,
23000,
38700,
18700,
101200,
12600,
3700,
null,
14000,
6900,
16100,
null,
18200,
62700,
23600,
10600,
26800,
18600,
31000,
15300,
5300,
14950,
null,
26900,
20400,
13300,
32100,
41300,
52300,
13400,
28000,
105600,
33000,
31100,
27500,
19300,
83100,
13500,
22500,
4500,
6600,
47100,
null,
9300,
54700,
15600,
16500,
24500,
63282,
47300,
30376,
8900,
23900,
60200,
9300,
18800,
23500,
24100,
10500,
7500,
17400,
7400,
52700,
70900,
18800,
5600,
28900,
26700,
25810,
56900,
40600,
15600,
22050,
null,
2400,
null,
27400,
11700,
6400,
12300,
10200,
67000,
25600,
24300,
16900,
16300,
33100,
36200,
25300,
null,
37800,
31200,
18500,
15050,
15700,
6300,
36400,
5200,
23700,
21500,
31500,
9200,
33700,
null,
null,
30100,
44800,
24200,
15500,
34500,
10700,
26300,
5600,
103700,
37400,
30800,
49800,
2700,
7700,
22900,
44400,
191351,
54500,
26800,
18000,
37300,
36100,
37500,
21700,
31700,
9300,
24200,
27800,
21000,
12100,
35400,
35200,
18700,
15600,
18600,
5100,
56800,
7600,
55825,
null,
19100,
null,
31500,
10800,
24200,
15800,
40100,
42300,
46500,
84150,
14500,
49100,
45000,
24200,
22600,
45000,
30600,
27600,
10300,
23900,
22300,
7100,
10600,
7900,
25900,
7000,
11200,
null,
60300,
12300,
29800,
61700,
null,
74400,
7400,
41300,
73300,
14400,
59500,
null,
59500,
70600,
65900,
8100,
11600,
35100,
23800,
37500,
7400,
null,
15100,
17100,
26700,
8600,
19200,
15100,
22700,
1800,
31000,
46900,
18200,
13700,
24500,
14000,
10300,
18600,
29500,
18900,
41400,
10700,
11800,
35800,
12800,
null,
36600,
2000,
8000,
14500,
13800,
37000,
null,
34400,
43400,
55700,
70200,
null,
38000,
null,
null,
null,
132200,
8900,
33700,
20600,
26900,
10100,
18600,
6600,
41300,
98400,
7700,
31900,
17100,
68400,
4800,
24400,
14200,
13900,
53200,
95700,
18800,
37000,
39700,
30600,
62100,
7400,
23000,
15700,
23400,
34300,
7000,
22100,
39800,
237800,
140000,
10700,
17700,
4650,
26000,
9100,
40800,
41300,
147800,
34700,
null,
31900,
11200,
null,
0,
32100,
59000,
22700,
14100,
11200,
42400,
12600,
30500,
132599,
26500,
52900,
21200,
43600,
18200,
14600,
64500,
17500,
35400,
31900,
20100,
12000,
66800,
14500,
18300,
13200,
41700,
4000,
19700,
null,
33400,
12900,
13060,
62300,
63600,
19300,
39800,
64400,
9400,
19700,
87200,
26600,
4800,
3400,
13000,
15600,
null,
18200,
66900,
null,
5800,
14900,
85600,
97300,
29300,
12300,
6400,
32100,
27900,
43100,
17000,
46900,
20700,
102300,
12200,
121900,
12500,
27600,
36800,
null,
101400,
11100,
269399,
17400,
23000,
26500,
72700,
20900,
25700,
22600,
17800,
35600,
23500,
12600,
20200,
12700,
41200,
82800,
24700,
26500,
33100,
29000,
19000,
31800,
15000,
null,
3000,
9000,
72200,
48900,
14300,
15800,
18300,
13900,
26250,
40700,
16100,
33600,
24200,
47200,
33500,
30100,
19900,
10900,
19000,
11700,
8000,
16800,
47300,
108600,
38559,
28900,
24600,
10400,
100500,
12100,
44700,
81900,
19900,
125200,
18300,
32700,
50400,
15500,
27200,
40500,
19200,
6500,
36400,
14500,
66300,
23900,
15600,
22100,
null,
9500,
43300,
105700,
13300,
41700,
33200,
18700,
21300,
26800,
9400,
17300,
33800,
40600,
35600,
56200,
71186,
34000,
9300,
27200,
null,
47800,
31700,
35600,
315300,
39296,
27000,
68200,
123200,
22300,
null,
19200,
25400,
21400,
48400,
16800,
53300,
25500,
2000,
98100,
11800,
10000,
101300,
15000,
18500,
11700,
206700,
33300,
30300,
6000,
144900,
49300,
16700,
13200,
134800,
3100,
8000,
28600,
31300,
22500,
null,
31800,
17900,
55500,
24700,
46300,
23300,
15200,
null,
41100,
25900,
5700,
31800,
8600,
9600,
22100,
18600,
12600,
30700,
29400,
null,
40200,
50600,
23500,
21500,
21400,
3700,
null,
9000,
38200,
8700,
18900,
41500,
22100,
64500,
23100,
33300,
10000,
71500,
29200,
8050,
74700,
14500,
17400,
29700,
52400,
12300,
500,
69600,
55849,
12300,
50800,
8300,
59200,
24900,
null,
4900,
125800,
6700,
9800,
39200,
126000,
53158,
null,
41800,
25700,
45500,
26400,
null,
null,
29700,
4900,
null,
500,
36900,
11500,
18000,
6100,
6700,
14700,
9100,
54500,
17600,
6100,
35200,
51000,
8700,
14000,
15700,
53100,
15500,
34800,
18400,
6100,
49360,
3700,
39773,
106150,
19000,
7200,
47000,
24600,
28100,
34500,
34300,
null,
45000,
24600,
11900,
17600,
10700,
68500,
83500,
40500,
36600,
19100,
34700,
32100,
34000,
15500,
31000,
15600,
17500,
40800,
48300,
13900,
44100,
12800,
146300,
7900,
37200,
25600,
18500,
8800,
60900,
30800,
30200,
50300,
19900,
14400,
36300,
13900,
55500,
42500,
57900,
32900,
null,
18700,
null,
53700,
49800,
21400,
null,
5100,
17900,
46400,
40000,
18400,
30500,
46100,
18900,
37600,
9200,
31500,
53500,
12200,
29300,
9500,
25300,
21900,
40700,
30100,
17100,
32800,
21700,
27900,
90200,
12700,
7900,
43600,
21000,
60300,
23000,
19100,
54900,
28700,
1200,
25100,
31600,
11900,
null,
31500,
19600,
14000,
27800,
null,
null,
58100,
41700,
11200,
25400,
103800,
7800,
18100,
10600,
25200,
42900,
22500,
26500,
22000,
40890,
75900,
20200,
28600,
11000,
16600,
11200,
38100,
33700,
null,
9700,
57300,
null,
24300,
106600,
19400,
16500,
7300,
39000,
59300,
19500,
13400,
56200,
18100,
24000,
64400,
20800,
8400,
65300,
33200,
32000,
39300,
null,
5300,
null,
21900,
110100,
28400,
2400,
43200,
22000,
26100,
15000,
18900,
41200,
7200,
8600,
9400,
5900,
20900,
null,
20500,
8309,
49600,
null,
117500,
34300,
34400,
50500,
54900,
24600,
7800,
55700,
3300,
12600,
10100,
13100,
31400,
118200,
33800,
33400,
45600,
65900,
44200,
38300,
29400,
12400,
48300,
16450,
9700,
null,
73400,
14200,
21400,
19600,
27000,
10000,
46200,
13400,
8800,
8200,
22300,
35700,
18000,
23100,
14100,
45823,
22600,
70000,
25900,
14000,
18500,
null,
62700,
11650,
14000,
3400,
32500,
57200,
10500,
11100,
null,
16500,
51200,
15500,
27500,
28400,
37700,
15250,
null,
82100,
55300,
60700,
42900,
99600,
25100,
null,
15400,
35000,
13300,
37200,
25300,
28500,
13700,
5500,
11000,
70400,
21800,
36600,
24300,
21900,
50500,
37200,
12100,
null,
21800,
11500,
37400,
68500,
29700,
15800,
54600,
31100,
26400,
null,
17800,
12600,
25900,
44800,
28600,
51000,
40997,
79400,
7500,
29800,
27500,
22600,
14900,
34100,
25400,
7800,
24100,
63000,
19300,
23700,
20100,
81900,
11600,
27400,
63100,
21200,
63600,
24400,
41500,
87300,
75300,
17570,
16100,
1800,
21500,
25000,
21700,
13500,
49100,
20600,
33700,
8500,
26100,
22800,
21100,
9500,
7100,
9300,
68400,
53200,
45300,
28900,
13200,
22100,
41700,
9800,
104200,
12500,
65200,
86200,
null,
40500,
12700,
79000,
16100,
41500,
37500,
19200,
7300,
18400,
null,
14600,
26100,
81600,
36700,
19400,
22800,
12400,
10100,
22700,
50900,
20100,
31300,
30800,
99300,
20800,
null,
8500,
null,
14500,
66400,
98500,
9500,
null,
12200,
null,
8500,
26700,
45800,
38155,
18200,
24200,
9700,
27300,
9300,
null,
23800,
29700,
41800,
43600,
null,
18700,
8700,
23300,
17000,
19100,
27800,
null,
15600,
27100,
30800,
38100,
50600,
81764,
39300,
11800,
18900,
36400,
21500,
7500,
12300,
7400,
null,
21100,
32000,
38000,
11400,
161300,
30200,
9600,
8600,
19400,
36000,
21700,
64500,
60300,
34600,
17000,
64100,
23100,
47000,
21100,
28200,
5500,
14700,
46200,
71600,
34000,
34200,
5500,
23400,
null,
24500,
33500,
19400,
16400,
14000,
17800,
13220,
null,
7800,
46900,
20000,
29500,
91500,
36809,
63191,
28200,
22200,
null,
20100,
20000,
32100,
40500,
15800,
25900,
16500,
27200,
19000,
7700,
29700,
null,
27000,
5600,
24800,
42000,
null,
8600,
43200,
37600,
75300,
28800,
46500,
null,
29000,
155400,
null,
97300,
20000,
69200,
8400,
36100,
23300,
18800,
14800,
null,
126200,
37400,
32300,
23500,
24700,
27000,
35100,
30500,
15400,
24600,
8400,
4500,
9100,
66400,
77600,
25600,
41600,
7200,
12000,
15000,
31000,
45600,
3100,
4300,
36700,
21800,
null,
null,
16300,
35900,
97200,
null,
34700,
10900,
9200,
35800,
35200,
9000,
76600,
24000,
null,
7600,
19500,
14800,
42400,
null,
74380,
17500,
13200,
8500,
null,
2200,
38200,
3000,
33600,
55600,
70400,
51100,
null,
32000,
111500,
17900,
13500,
32900,
8100,
8700,
11500,
150100,
109800,
null,
63800,
21500,
null,
10800,
32000,
19700,
3000,
15100,
167300,
21100,
13000,
33600,
22700,
39600,
27100,
26100,
null,
22600,
50200,
67900,
12500,
19800,
16900,
20700,
70600,
47500,
19900,
45400,
null,
60200,
16300,
111500,
10600,
11900,
null,
34500,
15000,
null,
44700,
15500,
14300,
26700,
26300,
28600,
12100,
18900,
null,
154700,
9500,
13200,
56000,
36900,
20800,
8900,
29700,
43500,
16700,
60800,
18100,
null,
43700,
7400,
null,
null,
29800,
20400,
74000,
6200,
30200,
26000,
13700,
25200,
27400,
15300,
16600,
15400,
26200,
75700,
142600,
null,
11400,
null,
65700,
22600,
33700,
47500,
25200,
27000,
80700,
27100,
25900,
23200,
18100,
26600,
17500,
8200,
23500,
41000,
144800,
14700,
31200,
13300,
20600,
21400,
16200,
16000,
12100,
63500,
19100,
null,
20500,
20300,
null,
11300,
26900,
5900,
81800,
11500,
13900,
23100,
52700,
16000,
11700,
43600,
20300,
43100,
67400,
44400,
59000,
65700,
9500,
50900,
null,
900,
88600,
9400,
39400,
36600,
62100,
13900,
22700,
null,
26600,
9100,
11300,
42000,
15800,
11600,
27200,
60200,
20700,
52400,
175200,
51100,
26400,
13200,
13600,
31400,
21700,
25400,
3900,
31600,
23700,
18800,
null,
52100,
112000,
51600,
47000,
70225,
14800,
3500,
49800,
29400,
22100,
39600,
13700,
29800,
null,
8400,
20200,
null,
37900,
9300,
23300,
12800,
29100,
36400,
10700,
41200,
11200,
95900,
27400,
3000,
12400,
41400,
33300,
7500,
76000,
8900,
9300,
42900,
48800,
28600,
42700,
32000,
20800,
null,
10500,
26900,
17200,
20100,
12100,
27200,
3700,
22300,
157700,
35200,
46300,
19100,
24400,
71600,
18900,
15600,
21000,
20500,
100800,
57800,
9600,
194300,
21800,
null,
null,
10600,
4800,
12100,
44500,
8500,
3000,
29500,
35800,
null,
null,
34500,
27400,
32200,
13800,
22700,
39800,
16100,
17100,
33000,
50800,
125300,
24600,
3800,
23200,
24700,
41000,
null,
null,
16100,
15500,
37400,
9800,
15100,
147700,
11100,
12500,
13200,
29800,
43400,
3200,
15500,
33800,
14400,
11300,
116006,
27000,
26600,
24900,
54100,
17600,
11400,
21400,
11500,
23300,
23000,
53000,
17900,
22800,
19200,
11000,
46300,
60700,
42100,
18700,
43100,
18200,
13900,
2700,
30900,
22400,
22500,
null,
44600,
26500,
null,
83000,
160500,
18700,
36600,
21000,
6300,
15300,
18200,
15300,
16900,
18000,
18500,
44400,
8300,
33300,
138500,
19900,
12700,
18500,
30000,
11400,
19200,
94700,
41000,
15700,
59500,
43800,
18600,
9100,
61800,
81700,
38000,
8200,
25200,
38100,
74600,
5600,
39300,
64600,
53000,
22700,
27200,
9000,
33900,
18000,
68100,
19700,
null,
47300,
32400,
50010,
30900,
65400,
42400,
35900,
123400,
12500,
null,
23000,
21700,
null,
34400,
7000,
21000,
null,
56300,
null,
32600,
null,
51500,
27100,
25700,
69000,
41500,
27600,
null,
10600,
20300,
33500,
79900,
9600,
52800,
3200,
34500,
25300,
165100,
18000,
6000,
10800,
9200,
38400,
13200,
23100,
7900,
6900,
37200,
26700,
113400,
46200,
null,
28400,
31400,
84100,
14500,
22000,
27000,
65800,
51410,
31100,
null,
34900,
16400,
26000,
9900,
14000,
19300,
null,
90000,
3400,
28800,
103000,
25000,
18400,
36300,
null,
20400,
9100,
19600,
11600,
10700,
74100,
22100,
28700,
63900,
17700,
13500,
31200,
6400,
29500,
9800,
51800,
37200,
13600,
34383,
33100,
45000,
18500,
5500,
51900,
31400,
32700,
18000,
24100,
40600,
56500,
89300,
7500,
57700,
6500,
25000,
63300,
93700,
31000,
null,
20600,
21800,
46200,
17900,
42800,
null,
13300,
12600,
14800,
27300,
null,
43600,
17900,
17100,
11600,
11900,
59000,
18100,
13700,
32500,
49300,
43500,
23900,
4200,
25300,
21300,
28300,
15700,
24600,
143670,
24400,
72900,
38000,
52800,
null,
13200,
14700,
10800,
162100,
5800,
8400,
20500,
43900,
null,
16400,
67100,
70400,
null,
10800,
49300,
98800,
34500,
60300,
19500,
11800,
12100,
11500,
28700,
11500,
19200,
62200,
30500,
4700,
116700,
11370,
47000,
61450,
32700,
null,
4200,
11500,
16400,
66600,
39000,
null,
9800,
31600,
21100,
null,
25800,
19300,
35300,
null,
20600,
69700,
22800,
4900,
16700,
16400,
27200,
40000,
64100,
12500,
34400,
16700,
46400,
10700,
21200,
22800,
10900,
71900,
94000,
10200,
16000,
20600,
19400,
42100,
32700,
32000,
14800,
36200,
null,
112558,
53700,
23000,
11800,
213500,
6000,
20000,
16400,
20900,
48700,
16200,
30300,
17900,
28800,
42600,
17300,
90500,
33100,
49100,
28300,
262100,
51500,
12300,
30600,
16400,
35300,
10000,
25200,
6100,
4098,
16000,
27800,
12500,
3200,
10000,
null,
5700,
29600,
57700,
23000,
34700,
23900,
22400,
9500,
12100,
39000,
26700,
114600,
42900,
38000,
24100,
31000,
21300,
26000,
43000,
39900,
5300,
49700,
9850,
29200,
88200,
13800,
10500,
16500,
null,
43100,
6100,
11700,
53200,
80689,
24200,
14600,
16900,
14600,
27300,
null,
7100,
null,
22500,
74200,
13900,
15300,
8400,
76100,
14700,
13200,
13500,
10800,
19500,
18600,
11000,
33300,
46600,
41400,
19200,
24900,
null,
14200,
313000,
8700,
37000,
30000,
25800,
36000,
25000,
16900,
54900,
21100,
null,
7500,
8700,
16800,
14200,
35800,
17300,
46300,
10000,
10800,
16000,
23300,
83900,
14200,
10300,
28300,
17100,
17300,
18900,
42700,
4600,
54522,
52900,
107500,
42500,
16200,
98600,
13000,
37700,
20900,
26600,
null,
11300,
8400,
44500,
83000,
205700,
26100,
68700,
50700,
12700,
20500,
77500,
12500,
14000,
29600,
null,
55600,
30400,
23800,
30600,
14200,
36200,
7900,
5400,
38600,
31800,
5500,
27700,
null,
37800,
10400,
57800,
36300,
32300,
12800,
null,
19100,
2800,
35100,
14400,
9400,
9500,
37100,
26300,
50700,
19200,
null,
29300,
95400,
4700,
46300,
28100,
40000,
58500,
27300,
39000,
7945,
19700,
103000,
31900,
39300,
26700,
24700,
32800,
null,
15800,
37175,
12000,
6600,
32300,
38800,
6400,
10900,
14200,
12200,
19300,
32800,
60000,
5200,
10700,
66500,
10400,
21000,
53900,
12300,
33300,
8877,
null,
23900,
15300,
4500,
14700,
58300,
10500,
13500,
132300,
28700,
74900,
16600,
14700,
17500,
22197,
20300,
14300,
14900,
12900,
15300,
15800,
22800,
53300,
108700,
69400,
32200,
15800,
20000,
13300,
8600,
13600,
17900,
null,
22500,
9200,
52400,
3100,
10300,
6100,
113600,
78100,
10100,
5600,
44861,
null,
15600,
15500,
16800,
29000,
103400,
66700,
45800,
30900,
87100,
null,
32700,
16000,
18500,
38900,
38600,
10500,
14100,
15900,
57600,
41000,
118700,
22900,
34400,
11600,
21500,
27800,
15500,
20300,
43600,
12700,
33600,
6200,
34690,
43300,
14000,
22500,
20700,
30195,
17200,
57000,
22800,
null,
19400,
21100,
5200,
8600,
32400,
null,
18400,
63600,
6100,
46400,
13400,
8100,
16500,
5800,
17400,
12800,
39100,
34700,
48800,
null,
30900,
10600,
65600,
40624,
11700,
null,
16600,
18200,
100300,
70500,
33100,
52800,
31500,
102100,
15000,
33100,
21700,
11200,
null,
69800,
66338,
36200,
23600,
7000,
3500,
135900,
44300,
57935,
40500,
14400,
15600,
15800,
17500,
11400,
12400,
45800,
36035,
16300,
31600,
26750,
27300,
29000,
56200,
73700,
16600,
33000,
34000,
9000,
42100,
34100,
13900,
23500,
9200,
16000,
17500,
5900,
6600,
17900,
11400,
32000,
20500,
10800,
14400,
26000,
22100,
14300,
47200,
20000,
42000,
19700,
null,
21000,
15700,
11800,
66400,
37800,
3000,
40000,
26900,
44300,
31000,
7400,
36800,
null,
13200,
42700,
8600,
34700,
28800,
4500,
45069,
23900,
17400,
46200,
null,
7900,
26900,
19100,
23100,
19300,
4600,
93500,
15500,
16940,
20100,
46200,
14500,
39500,
13500,
32500,
null,
10300,
91600,
16600,
47500,
16700,
32900,
70400,
16000,
88300,
115100,
20900,
25600,
15300,
15500,
4500,
13600,
18300,
20000,
13800,
18300,
14400,
58400,
23200,
68400,
7200,
null,
21500,
15800,
54600,
35800,
null,
31900,
52900,
24200,
15800,
16200,
81900,
7000,
18100,
50800,
10000,
4500,
27700,
29200,
10000,
16500,
19100,
22800,
12000,
23700,
45700,
10800,
56000,
6400,
32900,
40900,
null,
13500,
17100,
9700,
32400,
60432,
16400,
12500,
11200,
22900,
14500,
33300,
10100,
18500,
23000,
null,
22200,
14600,
13600,
10900,
13600,
18700,
2600,
41100,
15900,
19900,
22400,
null,
15900,
62200,
30100,
23300,
15700,
11900,
null,
70700,
56600,
8900,
15000,
43000,
8300,
15300,
18800,
15400,
15100,
108600,
16300,
22700,
9100,
18700,
31000,
null,
22000,
22380,
16700,
12600,
29600,
null,
9250,
20100,
43200,
12900,
66386,
44700,
23400,
49200,
36600,
14000,
58716,
67400,
6500,
21200,
28000,
null,
21800,
null,
71400,
46100,
26400,
62800,
39300,
null,
15500,
11500,
21900,
null,
24100,
21400,
1900,
18300,
62357,
4500,
7100,
11700,
11200,
7300,
5000,
28600,
24800,
110700,
32900,
14000,
14800,
57300,
13200,
37200,
19400,
24700,
16400,
43000,
11000,
15000,
26800,
24500,
21200,
16000,
52500,
73000,
24000,
7600,
7900,
23800,
6962,
13500,
101700,
71200,
4300,
10200,
null,
30800,
237000,
29900,
null,
74000,
32600,
6000,
20100,
44100,
31100,
11500,
18900,
17000,
52100,
22600,
7200,
109800,
null,
15100,
28300,
24700,
13100,
19700,
18425,
22600,
19900,
null,
9200,
67600,
42200,
14200,
14300,
19700,
19900,
26400,
12900,
13800,
48300,
18000,
9800,
8100,
12300,
null,
170300,
36700,
48900,
17200,
8300,
23100,
26300,
43500,
31600,
27100,
null,
12300,
null,
27900,
6400,
42000,
16900,
16700,
102927,
21900,
41300,
9700,
37600,
null,
4500,
51800,
26500,
40000,
18400,
18200,
7000,
73850,
25400,
8700,
7600,
31700,
62400,
28400,
138100,
15300,
2300,
25300,
40800,
24100,
15800,
21600,
10700,
23000,
10600,
35700,
29700,
33900,
29100,
33100,
null,
24800,
20800,
6400,
null,
10400,
18300,
13400,
35300,
12000,
17400,
29400,
19300,
8200,
10900,
28200,
null,
null,
9200,
27300,
36300,
29100,
3500,
18700,
24500,
41200,
19510,
69500,
10700,
104300,
15100,
17000,
27500,
29300,
36500,
6400,
14000,
68000,
null,
35300,
56100,
25000,
3200,
17800,
37700,
20000,
10600,
19500,
12200,
28000,
23500,
40500,
70800,
25200,
22600,
13100,
19300,
38800,
16200,
14900,
26300,
50900,
46700,
61600,
null,
40500,
null,
11800,
82500,
33400,
13400,
28800,
18800,
null,
51600,
25300,
16300,
68800,
11800,
8570,
23000,
9050,
18600,
108800,
30500,
24700,
10600,
29300,
61800,
20800,
23600,
24600,
6000,
null,
19000,
23600,
28100,
51900,
26200,
35300,
5500,
null,
4700,
27500,
6300,
156500,
18000,
19700,
31810,
36000,
13000,
8600,
null,
19900,
27400,
8600,
20400,
76600,
31800,
15300,
17500,
20100,
25300,
38500,
11700,
52200,
19300,
16400,
46900,
13300,
13700,
83200,
29900,
23500,
18100,
41000,
7500,
25400,
24500,
5700,
18600,
26400,
163700,
6400,
20700,
3800,
24800,
31600,
41800,
35400,
42900,
22100,
93900,
8500,
36100,
null,
10000,
99100,
96700,
null,
38600,
22100,
13100,
19500,
46700,
20700,
23100,
5000,
47600,
20100,
36300,
14200,
null,
19900,
23500,
31200,
18900,
74700,
10300,
22500,
36770,
35200,
null,
null,
31684,
44200,
8800,
null,
66800,
34800,
23200,
75929,
14300,
114800,
26800,
57500,
27800,
35500,
26900,
21500,
38800,
44900,
20445,
14400,
8700,
42300,
6400,
26200,
28600,
18100,
34800,
11500,
25700,
52200,
29600,
15700,
null,
32200,
12450,
10600,
88300,
6600,
11400,
37600,
7700,
16800,
10000,
9800,
32500,
23600,
37800,
16400,
199600,
114600,
48500,
21500,
16600,
22300,
33800,
null,
45300,
7400,
null,
13800,
43800,
10000,
48500,
80100,
9000,
14500,
11700,
5000,
51600,
10800,
28200,
14500,
68900,
16000,
null,
11700,
88800,
67800,
1500,
null,
32600,
143500,
10500,
14600,
8600,
21900,
35200,
37601,
30100,
69000,
null,
36000,
49300,
18500,
38300,
57700,
null,
106700,
null,
6400,
13900,
15500,
13970,
33475,
17200,
52500,
18100,
57100,
35400,
21600,
26100,
12800,
5500,
26700,
16700,
23900,
null,
15300,
73900,
70100,
18200,
null,
24000,
30400,
47700,
108000,
18500,
6500,
34700,
31000,
39000,
null,
null,
19500,
79700,
20600,
61900,
11400,
8300,
9300,
7200,
5000,
12400,
125700,
10300,
22700,
21200,
25900,
25900,
14200,
12300,
47600,
16000,
22600,
33900,
42800,
25800,
13500,
65800,
28300,
63300,
13700,
9850,
14200,
24200,
16800,
30400,
null,
20700,
4300,
null,
5000,
49900,
26800,
16200,
64200,
11100,
12300,
84000,
42700,
10000,
23600,
13500,
51900,
42600,
12000,
46700,
45500,
6800,
17000,
null,
64300,
26300,
10600,
46900,
36900,
99100,
14500,
34400,
9200,
72100,
12800,
25500,
10800,
74140,
46900,
6300,
6000,
31900,
30600,
null,
313500,
30900,
32400,
81000,
43200,
33900,
27400,
null,
null,
27471,
6700,
5800,
23200,
25500,
21500,
9500,
26700,
14100,
12800,
30300,
27700,
35200,
null,
21400,
8300,
34100,
null,
17500,
24300,
12200,
23500,
24500,
21700,
6000,
4200,
9900,
59300,
102200,
null,
53900,
26000,
41600,
9600,
5500,
53600,
21700,
47700,
17350,
11800,
null,
null,
7500,
19900,
12500,
42700,
5800,
15500,
40900,
6500,
18000,
29400,
9400,
48400,
16000,
30000,
24000,
183800,
24900,
70200,
1500,
17700,
8700,
26100,
9300,
54700,
9200,
5100,
8900,
null,
19837,
23600,
39500,
12300,
14900,
null,
null,
14500,
23500,
37550,
55600,
18900,
36200,
18300,
null,
10500,
9500,
5900,
78400,
30900,
20600,
15200,
71300,
12000,
19600,
10700,
25300,
null,
null,
44400,
60200,
900,
15800,
48700,
45900,
15400,
85900,
10100,
138900,
37500,
null,
59800,
18800,
46300,
14600,
39400,
14300,
40900,
125900,
17300,
13700,
16800,
43200,
4400,
20400,
18000,
7800,
27600,
19400,
14800,
16900,
22800,
null,
28100,
30400,
19900,
55500,
7400,
41600,
97500,
29100,
32500,
25700,
11800,
37300,
16000,
29200,
32300,
58400,
10445,
36300,
6400,
45900,
null,
48000,
55100,
5500,
30612,
21300,
23800,
9500,
53900,
69700,
42600,
11580,
null,
null,
25200,
25100,
30700,
16600,
24680,
17600,
27600,
13200,
7050,
12400,
26900,
123700,
null,
15900,
28100,
30300,
7000,
17300,
30600,
30500,
27400,
11700,
15500,
24500,
87800,
52300,
23800,
33200,
null,
7500,
13700,
103600,
27400,
53700,
12900,
118500,
20200,
null,
30800,
6500,
135300,
11800,
23400,
37100,
15300,
15200,
35500,
20800,
26100,
42500,
12300,
null,
129800,
18100,
33600,
45500,
8600,
30300,
17100,
4500,
23800,
11500,
23800,
45900,
null,
14300,
45000,
29700,
40400,
117400,
8000,
17900,
40300,
1800,
30200,
195500,
12800,
17100,
83700,
23700,
41800,
10200,
12600,
26200,
50400,
10300,
40000,
12900,
28100,
null,
28400,
59100,
15100,
33800,
23100,
24700,
50300,
24100,
6900,
13100,
24700,
10500,
null,
null,
48100,
43200,
21100,
8000,
78100,
19300,
19100,
18200,
28300,
23300,
6300,
32600,
13400,
6175,
49100,
46700,
26500,
34600,
39900,
4000,
36700,
34400,
113300,
16000,
42400,
94200,
28500,
6200,
null,
85700,
23600,
19100,
15963,
29700,
25500,
21200,
1800,
null,
16000,
18500,
39200,
80800,
18500,
11900,
16700,
40600,
39200,
19700,
76600,
58700,
32300,
40000,
66700,
99800,
96300,
null,
54800,
3800,
122200,
18800,
38000,
11800,
8300,
15200,
4200,
24500,
null,
null,
5800,
62700,
25800,
null,
32700,
38200,
87430,
50200,
15100,
26200,
38100,
43100,
37340,
36400,
29300,
27300,
34400,
100200,
25100,
55300,
47300,
20800,
9600,
34400,
39300,
9600,
14100,
40400,
20700,
21400,
21600,
null,
20100,
null,
17200,
13300,
18200,
10600,
114900,
30000,
58800,
38500,
28700,
9500,
4300,
15200,
null,
8700,
20100,
29500,
15200,
75700,
68200,
14400,
null,
16000,
null,
27900,
75900,
15900,
9300,
null,
null,
25400,
12300,
53600,
8300,
36400,
33200,
51520,
24900,
7000,
53800,
8100,
3700,
14400,
8300,
6100,
53410,
15500,
9050,
23300,
40000,
15800,
79200,
345000,
24500,
null,
16800,
109600,
null,
18900,
27700,
32900,
35100,
20500,
53700,
35400,
23700,
7000,
21200,
50100,
73400,
54200,
null,
null,
28700,
22000,
11300,
27100,
46800,
16800,
21100,
19900,
10000,
11300,
15100,
37000,
10600,
2700,
16200,
null,
33000,
36800,
21300,
11600,
23900,
46400,
4000,
11300,
8500,
34200,
40300,
8100,
18900,
15600,
14800,
7600,
22300,
null,
72200,
null,
16200,
null,
24000,
5100,
11000,
12200,
25450,
30000,
52400,
15200,
20000,
34300,
42100,
28300,
9700,
4200,
17000,
17500,
42600,
17000,
50000,
57500,
31700,
18700,
null,
31200,
29500,
10400,
5700,
11200,
67400,
35900,
55600,
17700,
22300,
48300,
54600,
34300,
67300,
51300,
45800,
23500,
40000,
25900,
24600,
10500,
45500,
19900,
null,
12600,
59100,
36500,
5800,
25300,
19500,
7800,
10500,
139800,
32200,
null,
53900,
24800,
43300,
21300,
157400,
43100,
null,
27600,
16500,
19100,
83500,
19400,
2000,
6600,
8200,
17900,
15000,
30500,
21900,
61500,
11100,
17900,
44400,
16700,
24800,
11600,
null,
56700,
36000,
20700,
31700,
64300,
56100,
53700,
3800,
25000,
38500,
28600,
11750,
74000,
13200,
54900,
22900,
20800,
70653,
17900,
23600,
11700,
7100,
50000,
26300,
13200,
30162,
9800,
12400,
17500,
null,
13800,
29000,
12100,
null,
12500,
22100,
null,
12562,
33600,
23700,
null,
20900,
39500,
18900,
27000,
10200,
36500,
6300,
37500,
21200,
24600,
11300,
32800,
30100,
17500,
null,
19500,
68800,
248900,
4500,
null,
5200,
34200,
26500,
26100,
12400,
30900,
54100,
50000,
null,
10800,
25800,
50600,
39000,
73900,
35500,
24400,
84000,
13300,
105200,
9800,
14100,
5300,
11400,
null,
10100,
12100,
48400,
44734,
33000,
7000,
12700,
null,
7400,
16600,
120100,
46500,
30200,
35100,
27600,
11400,
17700,
4600,
9300,
111100,
null,
35200,
null,
4800,
15200,
30500,
null,
87300,
null,
78100,
19500,
29500,
64000,
47500,
19600,
15500,
25300,
33300,
7700,
13700,
41700,
8200,
122700,
null,
22800,
72600,
48100,
18100,
13100,
8600,
36900,
44900,
34100,
19500,
40800,
55800,
16500,
19800,
13000,
null,
8900,
71300,
11400,
16400,
57300,
9700,
31600,
17800,
44800,
43900,
58100,
18500,
9300,
15400,
15900,
18400,
41800,
29600,
99000,
null,
37500,
11900,
47400,
27400,
13500,
13000,
4800,
35900,
20600,
29500,
53800,
23800,
15000,
63300,
60900,
51300,
19400,
98400,
null,
26000,
32400,
32500,
1600,
44535,
20000,
66500,
9300,
4000,
8300,
60800,
25100,
24100,
23000,
3000,
75300,
44900,
28000,
90500,
21900,
null,
22600,
24200,
null,
17000,
13100,
24000,
33900,
29000,
97500,
11000,
73600,
51600,
16700,
29400,
23000,
51800,
7800,
28500,
16400,
3000,
94900,
25200,
70800,
18300,
22800,
9900,
17200,
19700,
18400,
171600,
13800,
null,
37000,
21400,
null,
75100,
22300,
21000,
26300,
14400,
31700,
57700,
22100,
50600,
5300,
null,
18300,
16100,
162200,
22500,
5000,
12700,
16500,
46000,
15500,
22900,
18800,
21100,
34200,
28800,
15300,
28505,
null,
15260,
5900,
28000,
6700,
53600,
19100,
64600,
19400,
52074,
20400,
7200,
14800,
10800,
8300,
null,
2150,
50700,
9400,
39900,
51900,
77600,
56000,
25200,
null,
12900,
52100,
13300,
21600,
20600,
37000,
10800,
14700,
19100,
71800,
null,
123400,
63000,
35000,
46400,
27100,
6300,
33200,
68500,
null,
31800,
31100,
9500,
21200,
26600,
13000,
42500,
19200,
33900,
29600,
24200,
42000,
47100,
32100,
61000,
17200,
63200,
54900,
27500,
68800,
26200,
54875,
null,
30400,
11100,
32500,
57500,
31100,
15500,
40300,
55100,
24000,
16100,
19600,
45200,
8100,
25100,
18700,
null,
166000,
null,
28500,
27100,
107000,
null,
7600,
14900,
17200,
41900,
27000,
36000,
49800,
2500,
null,
11200,
23500,
46900,
null,
8200,
18000,
37900,
12600,
69100,
23600,
18500,
67900,
28200,
16700,
39000,
44300,
16100,
25089,
16000,
26700,
null,
36500,
19700,
34400,
61100,
103100,
76874,
null,
36000,
38480,
26200,
6500,
126400,
30400,
84800,
null,
4300,
53500,
14450,
35900,
14100,
7800,
null,
22000,
4300,
19600,
null,
18600,
27600,
42900,
35800,
18700,
17600,
36700,
3500,
19000,
5600,
19600,
30400,
22100,
53800,
24100,
5700,
38500,
36800,
26200,
7500,
null,
29800,
51700,
51417,
33600,
30000,
69388,
33000,
8800,
19300,
22500,
21600,
30400,
36700,
160200,
10200,
1500,
null,
33600,
12800,
83300,
null,
22400,
null,
31600,
null,
79200,
24500,
18000,
10000,
52900,
9300,
86700,
96800,
14900,
7300,
null,
23600,
68200,
11300,
15700,
12800,
20000,
80200,
15300,
30200,
26800,
11000,
37300,
20100,
null,
32100,
47100,
32800,
39800,
14200,
48800,
16400,
11300,
8100,
32300,
20200,
9200,
8200,
37500,
11700,
30000,
56300,
7800,
58300,
22500,
7600,
32100,
32400,
20400,
43000,
12900,
23600,
12400,
null,
69700,
49700,
27800,
25300,
32100,
15200,
13400,
18200,
22500,
9600,
43600,
46600,
7400,
null,
12100,
41400,
14700,
16600,
69500,
15200,
30200,
41000,
22700,
35500,
23900,
21700,
84400,
25900,
12800,
63200,
7000,
29400,
17800,
14100,
43300,
26500,
null,
12500,
16000,
55700,
17000,
17300,
40500,
15200,
16300,
20600,
26100,
null,
25100,
15600,
null,
40100,
8800,
121300,
26300,
35800,
4300,
24800,
14500,
75300,
10100,
19200,
7566,
11100,
52500,
48000,
13700,
30700,
16600,
19800,
14300,
12200,
8200,
26400,
81600,
39500,
24200,
53600,
null,
52900,
1600,
8200,
44400,
19500,
15800,
36500,
35900,
51254,
51000,
29900,
12000,
49100,
23600,
14000,
20300,
19700,
29500,
18900,
20900,
4000,
18500,
24500,
12200,
null,
26100,
22000,
43600,
4300,
19000,
null,
46500,
83000,
19600,
null,
28600,
11600,
30800,
6500,
107700,
37900,
20200,
14200,
96700,
33000,
89300,
26700,
32200,
73700,
7100,
28600,
31000,
63300,
64600,
27700,
43600,
29600,
34900,
41300,
null,
7600,
26300,
7400,
23200,
95700,
42300,
11300,
9300,
24000,
8600,
11700,
47100,
39600,
37500,
17000,
15200,
7800,
null,
6800,
11200,
19900,
40000,
14200,
26480,
null,
74400,
17000,
24000,
24800,
123000,
29000,
null,
7300,
70800,
13700,
13000,
12100,
17400,
7500,
18000,
54000,
11300,
84100,
91800,
35300,
36500,
16000,
14450,
42600,
32900,
37900,
42600,
8050,
39700,
16400,
70800,
12600,
7300,
47500,
21700,
15700,
19900,
38500,
181400,
58800,
61380,
18100,
21600,
50900,
16000,
24600,
14800,
51400,
19100,
47000,
25400,
62100,
27100,
7900,
15100,
41900,
33000,
17100,
5000,
21400,
null,
26600,
43900,
30400,
16400,
null,
48800,
null,
22400,
null,
64600,
13690,
112500,
32000,
10500,
14700,
14400,
9600,
null,
26400,
198700,
11500,
14000,
21600,
11700,
14800,
11500,
11900,
37400,
53400,
17500,
33300,
9100,
99300,
121200,
95600,
null,
32300,
24200,
19500,
6200,
19400,
36100,
39000,
21400,
6300,
41900,
27800,
15200,
13100,
19700,
83900,
6400,
87600,
13800,
88800,
43500,
36100,
59400,
51600,
48400,
3800,
33300,
10900,
66200,
5300,
17600,
46900,
null,
36700,
70000,
8400,
26000,
30100,
50200,
46000,
12700,
45000,
14200,
68400,
21600,
74800,
12500,
43900,
17400,
60700,
21100,
17000,
30500,
10500,
16600,
12400,
12500,
64300,
null,
21300,
11000,
14600,
10300,
31000,
45400,
6400,
14500,
15100,
29500,
76400,
26800,
8900,
89300,
null,
41600,
14800,
null,
6000,
28800,
12300,
17100,
9500,
10700,
11700,
33577,
6500,
26400,
49700,
14800,
42300,
9400,
93200,
15100,
11300,
11700,
18300,
22600,
35900,
5200,
null,
29000,
8600,
44200,
38800,
40400,
23263,
22300,
26900,
25100,
28700,
18300,
40900,
14500,
14500,
8500,
34900,
37600,
22100,
30800,
13700,
17900,
15600,
43000,
33800,
58800,
21300,
23400,
17800,
24600,
23700,
35100,
null,
38100,
14800,
32600,
37300,
34100,
26300,
18700,
16200,
29600,
35500,
21900,
24400,
8300,
22500,
8500,
53100,
null,
10800,
23900,
89800,
6500,
49800,
25000,
13300,
22500,
30600,
42500,
54100,
34200,
23400,
54300,
51200,
111200,
8600,
23200,
26600,
91900,
44000,
31000,
15900,
18300,
10800,
26900,
19350,
7100,
7400,
38900,
21600,
9300,
27900,
24100,
37300,
null,
null,
26300,
75800,
49600,
10700,
439100,
35500,
10400,
null,
14700,
null,
29100,
48000,
6500,
80700,
14000,
13000,
9400,
null,
45000,
17200,
28800,
21250,
31500,
55500,
65200,
23100,
30900,
27400,
17600,
13700,
null,
9800,
31457,
15000,
117103,
100900,
4800,
48000,
6900,
16000,
26600,
22900,
29400,
31300,
26000,
12800,
7400,
69500,
31300,
10900,
54900,
31500,
14100,
null,
40700,
15600,
5100,
null,
20900,
35086,
36500,
11200,
null,
48100,
18000,
61300,
10000,
22000,
28300,
14600,
9800,
12200,
22800,
null,
8700,
122200,
106800,
1500,
14800,
30700,
20500,
3900,
21200,
121500,
9500,
44800,
20000,
16700,
15600,
144000,
36900,
25800,
23900,
48700,
50500,
66700,
22900,
28800,
12800,
35300,
32300,
17600,
18200,
41900,
9100,
null,
51600,
13600,
27700,
50800,
44600,
7500,
22100,
10500,
3300,
24700,
3900,
55900,
43000,
17200,
25800,
23500,
27600,
47300,
45100,
16400,
36700,
51100,
39800,
32100,
78800,
24300,
41200,
21800,
57400,
14600,
39500,
17000,
24600,
13800,
27500,
22400,
23200,
9100,
133400,
27500,
34700,
19200,
43700,
25300,
22450,
8300,
19100,
37900,
15500,
35300,
25200,
31700,
null,
35800,
36200,
16600,
25400,
null,
18300,
74995,
10100,
5400,
36700,
29600,
14900,
33200,
14000,
108200,
7500,
13300,
14200,
20300,
1300,
27800,
5500,
129900,
25300,
139000,
8800,
null,
16000,
23900,
60200,
22700,
36300,
142500,
41000,
19100,
60438,
6200,
10000,
15400,
149300,
null,
null,
57600,
28700,
20400,
72500,
9300,
22600,
17900,
55100,
12600,
6000,
3700,
18700,
181500,
47000,
20800,
12800,
9700,
null,
53000,
14600,
14700,
13000,
36800,
13600,
19300,
121100,
9500,
25400,
18400,
22000,
11900,
11800,
18400,
27700,
31800,
8300,
9100,
34600,
38300,
22100,
80500,
43100,
25400,
3600,
23200,
11500,
78000,
6400,
7500,
15000,
27000,
22100,
34200,
7800,
31012,
37900,
1000,
9500,
7200,
42800,
null,
36400,
22000,
37400,
19200,
9900,
35500,
21400,
21700,
5300,
28000,
79100,
59400,
35700,
52100,
2300,
39600,
7500,
9200,
26400,
28300,
36900,
14300,
11700,
8300,
10500,
53100,
4500,
5700,
23100,
88600,
51600,
6300,
7000,
11900,
81100,
14800,
113200,
58300,
23300,
4500,
43700,
35400,
15600,
49600,
35200,
null,
24900,
39800,
32100,
null,
4600,
26400,
33300,
11600,
10400,
28200,
24000,
32600,
21600,
55700,
15300,
14200,
14700,
19700,
42400,
5300,
27100,
36400,
11300,
28200,
34200,
19300,
44500,
16900,
14800,
23500,
19100,
20400,
36100,
null,
25500,
10900,
11000,
51400,
20900,
20900,
19900,
23300,
25500,
27800,
32000,
17400,
null,
null,
226400,
null,
null,
6600,
16500,
30000,
7500,
null,
20900,
23300,
44800,
7000,
1000,
4900,
20200,
32700,
31300,
16300,
17900,
6200,
6800,
55400,
19300,
40200,
39600,
34200,
13400,
39100,
null,
14500,
37200,
null,
8300,
null,
39300,
48500,
13100,
43400,
86200,
25000,
64800,
41900,
59800,
17400,
42100,
null,
26600,
5500,
111300,
26100,
30800,
79400,
19900,
114200,
48200,
22400,
18800,
110300,
47400,
22400,
30400,
25600,
5800,
9700,
22800,
13500,
10500,
37100,
20300,
14400,
48200,
35700,
24300,
26000,
1500,
null,
45800,
39000,
18100,
4300,
9700,
293500,
5000,
11500,
33550,
12800,
11400,
34500,
70200,
34000,
23600,
25900,
59300,
17600,
29300,
23500,
95900,
56300,
null,
33100,
5200,
null,
null,
14500,
4500,
7200,
11300,
19500,
null,
33000,
58600,
33600,
11300,
37400,
47500,
42300,
30100,
28317,
32100,
null,
91600,
11200,
14800,
34400,
null,
91000,
177870,
4400,
60000,
33900,
21913,
103100,
6500,
53123,
16800,
122900,
77000,
91200,
48000,
7600,
null,
12100,
43100,
null,
17400,
142900,
20100,
8100,
17100,
10800,
null,
16400,
17200,
22500,
8400,
50900,
13100,
41400,
5000,
26000,
15600,
24010,
22600,
40400,
30051,
23500,
20518,
29900,
51300,
82400,
21000,
37500,
23900,
68000,
33800,
19900,
41100,
14800,
8800,
37545,
171600,
26100,
26900,
18900,
44900,
5850,
10100,
68100,
65600,
13600,
null,
32100,
30600,
42300,
29300,
57800,
84900,
14700,
68528,
22900,
26700,
39100,
46800,
45400,
16700,
16700,
6400,
55500,
2900,
7547,
19000,
70200,
22200,
20800,
13200,
7700,
null,
32000,
20400,
20600,
43900,
37200,
4200,
20900,
6500,
23500,
7700,
7900,
119500,
44100,
11300,
144300,
8200,
28700,
14000,
7600,
40700,
null,
18300,
16100,
95100,
7400,
39500,
19400,
48400,
27700,
23200,
null,
14800,
14400,
11600,
4500,
23700,
94700,
5700,
8400,
133600,
24700,
22000,
5100,
14200,
110200,
16100,
26400,
36800,
24800,
5300,
39800,
39600,
17900,
5100,
28400,
37800,
29600,
96000,
21500,
29100,
26600,
19200,
21500,
19000,
null,
null,
11750,
22000,
39000,
null,
9500,
10300,
35200,
19800,
58400,
45600,
22300,
24950,
8200,
null,
12600,
27500,
6000,
25900,
9900,
null,
154000,
105900,
23700,
66300,
7200,
41600,
61500,
13000,
60000,
50300,
43000,
73800,
30462,
14100,
18400,
45100,
19100,
7600,
10600,
33200,
28300,
27500,
129600,
60700,
null,
37100,
39800,
36000,
24000,
9600,
15400,
null,
50100,
41674,
4100,
10100,
null,
30700,
33500,
null,
85900,
null,
2800,
null,
39500,
12700,
20000,
12000,
null,
null,
2000,
13430,
16400,
23400,
39500,
16200,
28300,
21900,
15100,
null,
null,
52300,
29000,
16200,
96000,
18300,
48900,
31200,
null,
35400,
55500,
null,
46800,
28300,
92200,
54500,
17100,
22300,
26700,
3200,
10957,
15300,
102125,
16700,
48500,
null,
21200,
43000,
20200,
null,
9700,
83900,
9600,
40100,
35800,
16900,
4300,
19300,
37100,
21600,
23400,
null,
14500,
null,
10100,
31100,
41800,
59300,
28300,
914900,
null,
19000,
16800,
null,
33000,
35120,
92400,
135000,
10800,
155800,
6500,
76000,
17900,
34200,
53100,
27700,
13900,
27800,
100940,
31600,
10000,
21200,
41300,
17300,
36500,
14000,
81400,
4500,
46200,
19200,
10100,
68701,
12000,
12100,
18100,
100500,
57200,
null,
77800,
9100,
8600,
7800,
25200,
26000,
13500,
26000,
45900,
12800,
11700,
9800,
78200,
13400,
34600,
35600,
5700,
157000,
36500,
8500,
38600,
38400,
13800,
2700,
31200,
36100,
101900,
127500,
11200,
37300,
29300,
33400,
21600,
18300,
52300,
12006,
30800,
59700,
10700,
119600,
null,
21300,
36900,
12600,
10400,
11000,
13400,
27900,
8600,
26600,
45900,
41000,
12500,
27800,
79200,
22800,
null,
26500,
37800,
9000,
null,
16300,
null,
18300,
24900,
34000,
40500,
7000,
null,
17300,
32900,
21900,
23500,
11800,
9100,
22200,
96700,
14300,
37500,
24000,
15600,
18660,
17400,
16600,
74000,
32500,
14800,
19700,
50400,
20100,
56600,
null,
86100,
41500,
9300,
null,
41000,
32800,
22700,
17500,
null,
27300,
null,
20500,
62300,
41700,
18400,
22454,
109300,
22100,
103200,
19100,
8500,
41700,
32900,
25400,
42200,
34300,
23500,
25000,
11600,
52200,
16200,
136600,
29500,
32500,
555800,
5000,
20600,
9500,
53900,
29200,
12900,
22600,
5600,
90100,
33200,
18600,
21000,
15550,
42700,
56200,
null,
17849,
null,
56075,
41900,
15100,
26200,
7500,
39300,
29900,
14000,
26000,
null,
26800,
10200,
40700,
10800,
17500,
18500,
15400,
19000,
3200,
21600,
98300,
3600,
26604,
null,
36000,
25500,
41500,
35400,
9800,
12300,
3600,
null,
27600,
null,
63300,
47300,
14900,
36500,
21000,
20700,
11100,
46000,
74000,
14700,
36700,
54500,
null,
6800,
25200,
26100,
51300,
57100,
15700,
null,
37808,
44600,
6600,
10900,
null,
35900,
25200,
12300,
40100,
null,
15900,
15600,
54900,
13500,
9000,
56800,
38400,
null,
15000,
15400,
12500,
22500,
18100,
67200,
17400,
85500,
53400,
3500,
24200,
null,
29800,
27200,
4600,
81400,
19900,
19200,
48900,
68500,
12700,
14900,
18100,
28600,
13600,
2900,
24100,
27600,
25000,
25100,
28400,
74600,
30500,
5105,
19300,
null,
11700,
7000,
15600,
12300,
11200,
11600,
23800,
null,
29900,
68500,
27000,
4500,
31000,
15700,
17900,
16000,
6300,
null,
74200,
15500,
6000,
12000,
15600,
35900,
null,
19500,
96100,
39900,
21100,
3000,
62500,
16500,
23400,
20600,
17500,
5300,
13100,
49300,
6100,
28800,
25400,
18700,
15000,
15700,
24400,
13600,
39200,
42000,
3400,
19600,
34100,
4500,
51100,
12100,
37000,
42000,
18100,
177900,
18800,
null,
6450,
12100,
36200,
null,
11200,
32100,
17000,
26000,
56130,
26800,
4350,
null,
9200,
null,
8400,
6700,
42600,
20900,
7600,
65000,
27000,
58700,
null,
16800,
32400,
51600,
64000,
20500,
10800,
28700,
20100,
20100,
20700,
76300,
36600,
21900,
22400,
14200,
44937,
3800,
42000,
23400,
6700,
49200,
5300,
24800,
93700,
7800,
29000,
53700,
16300,
34200,
19600,
4700,
13200,
28000,
8950,
27300,
25500,
36000,
null,
88500,
null,
5100,
39100,
7500,
44400,
null,
35800,
6100,
66800,
13200,
34200,
79600,
12500,
69900,
13500,
15800,
94900,
null,
6800,
12500,
null,
null,
176500,
15300,
1600,
11300,
30200,
86500,
22200,
39800,
23400,
131300,
null,
37900,
null,
null,
27200,
53103,
157200,
null,
36400,
25300,
null,
10500,
9700,
null,
23600,
14800,
15300,
124600,
18300,
17700,
67300,
null,
40000,
49200,
68600,
58000,
41700,
85100,
10900,
15500,
null,
42900,
5740,
25600,
59000,
9000,
18600,
35000,
50300,
null,
5700,
8300,
48000,
32400,
26700,
11300,
null,
null,
15800,
30300,
54200,
null,
4800,
33787,
29400,
14700,
18800,
68500,
32000,
22800,
8200,
7200,
21400,
45200,
39400,
50200,
31900,
4800,
7100,
179500,
31400,
13700,
34900,
57300,
71600,
146500,
28200,
56800,
33100,
19800,
21000,
18300,
27300,
55500,
7400,
null,
28700,
8800,
27300,
22700,
20100,
7400,
5600,
68500,
8300,
3300,
17000,
16700,
16000,
52800,
13600,
30100,
9000,
39700,
45600,
15600,
31300,
7000,
73700,
20400,
17800,
9000,
35100,
7100,
47500,
15400,
12800,
47900,
null,
19700,
28400,
31900,
144900,
31100,
56400,
23000,
3700,
35900,
8000,
7700,
14100,
null,
null,
41300,
28700,
67000,
5200,
18500,
null,
21800,
25200,
3700,
23500,
9200,
35900,
36300,
24700,
37060,
11700,
4700,
20300,
43500,
19300,
43200,
15600,
34000,
null,
36400,
54200,
41700,
40700,
23600,
4200,
19900,
13200,
28000,
11700,
79400,
100200,
35400,
21000,
7700,
4400,
23800,
19700,
17600,
41500,
24900,
60900,
28800,
8047,
17100,
12500,
25100,
2600,
17500,
61200,
27500,
3800,
63200,
19900,
8700,
20000,
9800,
22600,
15200,
87300,
128800,
26200,
12600,
42800,
37000,
18591,
58700,
30600,
34100,
11100,
11400,
6600,
37200,
24900,
12300,
24300,
8800,
18600,
24600,
88200,
52800,
13600,
12300,
7200,
39200,
null,
40700,
34900,
23400,
17600,
87300,
23700,
18900,
33400,
41400,
null,
24400,
20900,
26100,
null,
30200,
21600,
19900,
4100,
28500,
11200,
10500,
null,
12200,
119200,
null,
55500,
9800,
34400,
20200,
29400,
null,
68200,
55900,
23800,
11300,
88050,
25700,
13600,
11000,
17800,
null,
7300,
36700,
22800,
26000,
15100,
4100,
44700,
4600,
28100,
24400,
31700,
21400,
14300,
12500,
12800,
28500,
24200,
8100,
40100,
24000,
38800,
25800,
54300,
32700,
21300,
52500,
13800,
12275,
22700,
16500,
24500,
31200,
31995,
14800,
59000,
47900,
32500,
null,
24800,
34100,
null,
24400,
10300,
null,
19100,
47100,
73600,
15500,
48400,
13400,
27900,
10000,
28900,
16200,
null,
27500,
16600,
15400,
37300,
19200,
6300,
8300,
11650,
39700,
8000,
31900,
69200,
8100,
6200,
7800,
12500,
13300,
null,
14600,
17900,
116400,
15900,
89500,
29400,
24100,
27400,
65500,
29200,
82300,
3600,
31292,
72500,
25900,
48400,
44800,
53800,
32300,
30000,
null,
97400,
35300,
null,
60400,
null,
4600,
null,
14000,
24800,
4600,
23877,
30100,
105400,
25200,
61850,
27600,
39900,
9900,
10500,
4600,
19400,
27500,
15600,
19400,
17800,
10100,
7600,
56200,
29100,
32721,
39900,
50500,
19000,
21500,
37500,
20600,
27900,
2800,
33600,
26000,
31300,
null,
43900,
13400,
9700,
null,
10900,
21200,
25300,
118000,
24400,
45300,
22800,
39900,
244800,
41800,
null,
4900,
null,
88200,
32200,
12600,
35200,
19300,
81200,
29900,
22400,
58200,
7500,
40200,
6800,
27600,
15800,
40200,
39500,
25200,
4500,
24800,
24500,
29900,
9600,
13900,
13900,
null,
60800,
41700,
21000,
10900,
7700,
153600,
154500,
23900,
40700,
null,
3000,
20100,
91400,
null,
9700,
10200,
13400,
38100,
40300,
3150,
24300,
29600,
19000,
83700,
null,
27200,
31500,
20200,
34000,
25100,
11800,
9400,
21200,
15600,
25145,
41900,
41300,
2000,
18200,
28600,
15900,
37700,
31300,
14500,
35800,
24700,
null,
65500,
4200,
7000,
59100,
null,
7100,
17900,
19700,
12700,
35800,
22800,
null,
122900,
8500,
14800,
40100,
51268,
26400,
117200,
197800,
45100,
159900,
20600,
53600,
148100,
35900,
51300,
36900,
80900,
15000,
42600,
7200,
56400,
16700,
24000,
5000,
80600,
8200,
48900,
47000,
11500,
12600,
22800,
7700,
23900,
14200,
36000,
22500,
52350,
6500,
7300,
13400,
56000,
120900,
null,
22800,
34700,
34100,
15170,
26000,
42700,
11900,
50619,
18200,
39300,
27000,
null,
2700,
41500,
26500,
33900,
52500,
12400,
51700,
35200,
2700,
26000,
null,
58300,
33100,
null,
62400,
52300,
18200,
26400,
13000,
52200,
10700,
23100,
21500,
null,
18600,
23000,
46500,
43200,
14100,
7600,
10100,
12000,
28200,
null,
33600,
25000,
15400,
19300,
21300,
59100,
6800,
7700,
14100,
36800,
11250,
13500,
12900,
19000,
24800,
null,
null,
32200,
56334,
8200,
null,
18000,
20200,
6700,
6500,
5100,
10400,
41600,
23500,
48200,
13900,
47800,
16100,
2200,
18500,
42000,
28700,
26500,
111300,
13500,
17000,
27200,
21600,
13100,
18500,
15500,
10600,
57480,
53200,
4000,
32400,
6900,
17200,
43400,
17300,
36000,
68900,
72900,
48800,
19200,
27500,
4250,
42350,
null,
null,
27500,
16000,
41300,
12700,
16100,
26600,
59700,
26800,
37500,
51200,
48700,
12000,
29300,
2000,
7500,
1600,
11000,
6700,
12700,
6600,
33800,
48300,
23800,
27700,
53100,
39900,
31400,
35285,
26300,
19500,
11100,
23700,
null,
85500,
17300,
15300,
31400,
89700,
15100,
7300,
39909,
18200,
24600,
40000,
24800,
27900,
13900,
11300,
1500,
25400,
30800,
3600,
92600,
17000,
19400,
13000,
18800,
22300,
78000,
59500,
10400,
56200,
17000,
60000,
19000,
24500,
35300,
17800,
500,
88700,
44419,
33200,
20600,
11800,
10000,
27700,
7000,
4500,
62000,
13700,
74500,
12600,
22400,
null,
12300,
44100,
14100,
15900,
33400,
12000,
28300,
40300,
29600,
null,
41600,
22500,
125200,
38400,
9000,
94500,
26300,
15600,
18600,
15200,
12300,
3000,
13000,
null,
6200,
20700,
22600,
10500,
30900,
3000,
35900,
153400,
null,
7400,
12300,
19200,
391000,
9000,
87400,
27600,
21500,
null,
14000,
69200,
19384,
14600,
7000,
null,
75100,
88800,
76500,
14900,
null,
null,
31000,
30500,
40700,
23000,
24400,
104600,
27800,
21800,
27900,
54900,
25000,
42200,
44700,
16300,
null,
220200,
3800,
25000,
27200,
40700,
26000,
19600,
26300,
38200,
30700,
4450,
28600,
8300,
8100,
54600,
16000,
35300,
null,
133300,
15700,
11000,
11100,
14500,
26000,
26800,
53700,
36700,
37900,
34300,
25300,
53400,
15900,
18100,
null,
29200,
167700,
26400,
8300,
49800,
43900,
115200,
67800,
9700,
29300,
12400,
null,
15700,
10100,
36100,
20000,
9300,
138400,
45700,
15400,
16500,
16100,
null,
7500,
80600,
33000,
4300,
5900,
10300,
87000,
24400,
49200,
17800,
94200,
13700,
46400,
19400,
33700,
17400,
11200,
104400,
6400,
18800,
42700,
62100,
49000,
22100,
32032,
64000,
8800,
22000,
35300,
56700,
25600,
14700,
24000,
6500,
9000,
23600,
16200,
9000,
11400,
25300,
30400,
28200,
10100,
12700,
6400,
11500,
null,
6650,
4900,
3000,
13700,
34000,
29300,
20300,
20400,
17700,
81700,
38900,
12100,
15500,
34500,
21000,
38600,
27600,
21700,
44700,
5900,
7900,
15400,
54800,
11900,
58100,
291200,
15100,
89400,
26500,
44000,
46000,
13900,
13500,
21900,
44900,
5100,
28200,
17300,
18300,
12800,
130500,
20200,
38300,
null,
57200,
32900,
4700,
19200,
26200,
36000,
35800,
22000,
17100,
16700,
24400,
31900,
25600,
null,
37700,
43100,
23600,
118700,
16000,
13900,
11900,
13600,
22475,
24800,
11700,
35100,
4400,
4900,
null,
31400,
26900,
26000,
5200,
12000,
44600,
80000,
33900,
20900,
null,
31900,
61096,
3400,
30100,
14400,
108551,
24000,
20400,
11700,
null,
1500,
8300,
19600,
20000,
27300,
28000,
14100,
3400,
27100,
null,
28300,
25700,
39000,
19700,
14500,
13500,
15700,
43100,
36480,
null,
17500,
50668,
5300,
5900,
6400,
57900,
19000,
null,
11100,
31800,
23100,
12300,
62800,
43700,
34900,
9800,
29300,
27200,
26300,
20200,
56800,
12200,
9900,
11400,
42400,
16300,
3900,
42500,
28700,
91400,
12500,
14500,
33500,
27900,
11000,
null,
null,
81100,
19000,
15900,
11200,
27480,
31900,
13200,
20100,
34200,
4500,
null,
52800,
34200,
23375,
41303,
null,
76300,
183700,
47200,
32300,
60500,
125300,
29200,
26450,
12100,
29000,
15000,
40200,
33200,
43300,
11100,
16800,
23800,
7100,
35300,
30400,
45900,
10200,
13600,
23400,
12400,
5900,
38700,
20150,
35100,
19300,
140190,
5400,
22300,
98600,
16100,
36400,
33000,
50400,
21400,
29200,
18900,
30200,
2800,
null,
22600,
23700,
21800,
24600,
143800,
60200,
14700,
27300,
16200,
21200,
null,
null,
2400,
45200,
38900,
19300,
32200,
20100,
31300,
18100,
178025,
15700,
27300,
36700,
null,
67000,
8500,
17200,
17300,
28400,
25100,
22800,
15300,
8400,
15300,
58400,
18700,
13500,
18400,
null,
23500,
19800,
26100,
13500,
71800,
5700,
18200,
7500,
17300,
44900,
8900,
28800,
5500,
null,
11400,
10200,
19000,
41800,
61500,
57300,
54000,
6100,
null,
20900,
7300,
10800,
108572,
31862,
35300,
24500,
28700,
37300,
49300,
23900,
30100,
27900,
26100,
70500,
44500,
21200,
22000,
55200,
43800,
51400,
45300,
47900,
50000,
36700,
17100,
64000,
48900,
12100,
41500,
50200,
9700,
68100,
null,
12900,
18500,
6700,
null,
19600,
92500,
7900,
41100,
7800,
26200,
9100,
7200,
30700,
22400,
74900,
22200,
38100,
18600,
73950,
29400,
96700,
57100,
17700,
70400,
8800,
8800,
43500,
32000,
22300,
22900,
20700,
13300,
22900,
68800,
27900,
17700,
23900,
null,
25300,
33100,
23500,
30500,
null,
10800,
73000,
73600,
16300,
8600,
15300,
55800,
98200,
16000,
35600,
17200,
14700,
6700,
23000,
42700,
42300,
10300,
12800,
15000,
70024,
24800,
null,
48100,
9500,
32900,
32600,
53400,
23500,
null,
18500,
28900,
13700,
42500,
44900,
27200,
6000,
36100,
14000,
25500,
null,
54100,
27400,
15800,
48700,
null,
61500,
null,
29600,
19100,
23900,
18800,
10000,
23900,
48900,
346600,
47900,
6100,
3200,
67500,
null,
18400,
48200,
55000,
null,
null,
72300,
23200,
null,
64300,
41000,
18500,
40000,
42200,
12800,
197900,
18200,
10500,
15600,
40200,
44300,
14100,
13200,
53700,
18800,
65900,
9600,
13500,
42200,
37600,
12700,
11100,
59500,
23800,
71856,
53900,
37500,
27400,
7300,
22800,
177900,
11000,
16400,
22900,
null,
14700,
7500,
36000,
6000,
34400,
52100,
9000,
21600,
30700,
52900,
49110,
29200,
34500,
19100,
90600,
34600,
27100,
96800,
17400,
11200,
58400,
20200,
null,
28400,
15800,
14300,
39300,
16400,
12700,
151624,
14600,
17000,
39100,
22900,
53900,
null,
22300,
13400,
32800,
null,
9500,
41300,
11300,
19100,
13000,
23300,
14900,
33900,
5400,
55600,
32200,
45500,
10000,
21800,
31400,
43502,
14900,
53600,
7500,
66200,
41200,
24200,
11900,
53000,
8900,
null,
38200,
30000,
800,
41300,
51600,
17500,
2400,
97300,
27500,
15000,
25800,
32800,
6600,
44800,
37900,
21400,
12200,
46600,
77100,
10400,
22300,
23100,
32000,
46400,
null,
9800,
41700,
30300,
36300,
30100,
18100,
null,
13200,
40800,
8300,
19500,
14100,
18900,
24100,
31600,
32701,
22500,
25200,
119500,
28100,
14100,
29500,
47800,
32000,
45500,
97400,
34000,
32400,
55700,
27300,
17200,
12700,
16200,
9000,
10800,
16900,
23300,
19500,
8800,
18200,
35400,
19800,
12500,
5100,
14400,
94100,
87100,
23500,
10029,
13600,
32000,
13600,
6400,
23200,
null,
13300,
15700,
39400,
117300,
null,
20000,
null,
6050,
15500,
67600,
null,
17900,
6800,
34300,
11900,
9300,
6500,
38900,
20700,
17700,
16600,
16800,
28700,
15300,
24900,
42900,
15300,
183900,
29200,
58400,
69200,
19800,
33500,
44500,
22000,
15900,
44500,
9700,
null,
13600,
8800,
10688,
20100,
24900,
46200,
20300,
13800,
null,
10700,
null,
5400,
156200,
null,
17300,
null,
5100,
4300,
54870,
23400,
296700,
17500,
10600,
38100,
18900,
null,
18900,
null,
9600,
18500,
14100,
36700,
23200,
7100,
151700,
5300,
20300,
23800,
26100,
48800,
13000,
40000,
31000,
39100,
47800,
0,
11700,
11300,
6900,
300,
8700,
13700,
14100,
10400,
13300,
89100,
15300,
7500,
14500,
11800,
41900,
16300,
22300,
3500,
13400,
16900,
16000,
25000,
17700,
4800,
261500,
32689,
6900,
12900,
12800,
null,
null,
67800,
14500,
null,
null,
22900,
35300,
27300,
7400,
24100,
15900,
19400,
62900,
14900,
10900,
11300,
8300,
16800,
37200,
31800,
5200,
11400,
64100,
36700,
54000,
null,
69400,
4600,
29600,
5500,
37800,
10800,
13600,
73900,
69100,
14100,
17200,
null,
68100,
8500,
18700,
4600,
11700,
28300,
16500,
9200,
46600,
18200,
null,
21900,
19300,
68600,
17350,
17100,
11500,
20400,
8300,
2000,
20100,
8400,
42100,
38800,
null,
null,
22500,
74300,
10200,
43600,
3000,
107000,
47700,
16000,
null,
7800,
21900,
15600,
13400,
13400,
48000,
29400,
13900,
32300,
10900,
22200,
112500,
43700,
31500,
20500,
10800,
7700,
24100,
81127,
6500,
12400,
35600,
34300,
40100,
10400,
null,
13400,
30000,
7400,
27400,
13000,
13400,
30000,
18500,
25700,
14700,
93200,
54900,
26200,
18000,
14600,
76500,
6500,
24600,
1200,
66400,
24100,
4500,
25200,
20800,
17000,
48400,
20000,
null,
2400,
10200,
34500,
35100,
205553,
25200,
54600,
28300,
11200,
26000,
32700,
4500,
8100,
11750,
88400,
11100,
14500,
69900,
2000,
82300,
52600,
23400,
47500,
5500,
17400,
20000,
12600,
20900,
8200,
19200,
12600,
4100,
38000,
null,
45500,
null,
47300,
19900,
20800,
77600,
156150,
3900,
37700,
24100,
6800,
null,
null,
37769,
25800,
null,
11300,
13300,
25500,
21400,
50000,
7400,
27500,
4200,
35900,
18700,
null,
71700,
84800,
28175,
9800,
9600,
7000,
17000,
5100,
50600,
33400,
10900,
23250,
23300,
22100,
28900,
37287,
51000,
76400,
25100,
25000,
26300,
29400,
16100,
11500,
18000,
25300,
12700,
63300,
10900,
20900,
24000,
62400,
8000,
18400,
7800,
10000,
13900,
177811,
35700,
204900,
7600,
3800,
21300,
78000,
14400,
null,
25500,
76900,
16400,
25300,
44100,
63100,
10200,
845,
12000,
12900,
10800,
null,
4000,
null,
26800,
9400,
null,
13900,
86761,
48900,
34900,
145300,
7600,
10300,
41100,
46000,
45800,
null,
7700,
48200,
14011,
68100,
5700,
30100,
19000,
25900,
11600,
24200,
8900,
33000,
12200,
20300,
22200,
8900,
null,
13500,
16200,
7200,
4700,
27100,
54000,
35500,
22200,
27000,
15100,
null,
22500,
32600,
null,
6500,
19500,
5500,
41200,
42800,
150000,
13400,
null,
20600,
46700,
7500,
23800,
47500,
55500,
36529,
67800,
10100,
23400,
10400,
29900,
19300,
26900,
41600,
13100,
76727,
10050,
6300,
12700,
27100,
9000,
23900,
104300,
15400,
17200,
10500,
43500,
27600,
26000,
31900,
89668,
22600,
4500,
64001,
26500,
94600,
28000,
441100,
22200,
18100,
29600,
38400,
27800,
31300,
6000,
30000,
75000,
16100,
420500,
86950,
17400,
32400,
null,
null,
28500,
61200,
26200,
7000,
18800,
null,
31500,
null,
41000,
15300,
6500,
null,
52600,
6800,
8200,
16400,
34300,
20900,
29000,
null,
22700,
26800,
16700,
9400,
16500,
70700,
59400,
null,
25800,
22100,
40400,
null,
72200,
60500,
33800,
40900,
4300,
23500,
45400,
12000,
39200,
39300,
2800,
31200,
null,
57314,
101300,
27000,
32800,
16200,
20300,
18100,
40500,
92110,
19700,
null,
34000,
12400,
28000,
47600,
12900,
11600,
24300,
67500,
35000,
24900,
8200,
80100,
37600,
31400,
81600,
23500,
52100,
16300,
null,
21600,
14600,
18500,
26400,
46300,
64730,
null,
13500,
15800,
24900,
5800,
15200,
30900,
63300,
16650,
13200,
47850,
14100,
13000,
13400,
null,
36400,
22200,
20000,
5300,
18100,
56000,
24100,
289470,
94400,
6900,
null,
43600,
18600,
60500,
8100,
15200,
16900,
17600,
15800,
18300,
9700,
10700,
6700,
19100,
null,
12600,
63000,
27900,
8700,
81400,
16200,
14900,
41700,
19200,
47600,
61300,
20900,
26600,
45500,
28900,
69800,
54900,
9000,
27200,
6700,
12000,
24300,
9400,
35400,
26600,
113300,
15300,
22300,
13600,
40700,
60400,
71100,
13400,
37000,
11600,
9700,
11600,
18700,
null,
70200,
38900,
21200,
9300,
16500,
57700,
6700,
1350,
22600,
92600,
55600,
68400,
13500,
6700,
4100,
134500,
41300,
12300,
57000,
27939,
7300,
14200,
47000,
42700,
33600,
25500,
23400,
110200,
35400,
25800,
23400,
19900,
264000,
15500,
17400,
null,
101700,
37900,
63500,
null,
11700,
12200,
21500,
15700,
54500,
40500,
13000,
19800,
8300,
46000,
41300,
9800,
26000,
31700,
16700,
null,
null,
56500,
24900,
null,
11700,
27600,
7800,
23100,
23800,
19900,
null,
24300,
15000,
13900,
16200,
null,
19400,
2800,
38000,
12990,
27100,
25175,
32400,
24700,
182200,
33800,
52500,
23860,
31500,
24100,
21400,
24200,
7800,
17303,
25500,
64600,
11200,
null,
37100,
17300,
56200,
36100,
45200,
8100,
9500,
114900,
21200,
null,
80600,
47300,
80800,
18400,
34400,
16400,
10250,
24100,
96900,
7600,
57300,
28000,
35000,
52000,
20200,
21000,
36700,
33000,
47900,
29400,
19700,
35900,
20400,
23900,
28100,
3300,
10900,
45900,
null,
38400,
15500,
12900,
7400,
45600,
18800,
44000,
36000,
14400,
34800,
40700,
11100,
70600,
22100,
19700,
null,
64900,
2600,
37700,
9100,
27500,
12000,
28400,
52100,
30400,
5900,
51500,
48100,
20400,
33400,
5600,
77200,
29600,
15700,
4000,
null,
13600,
77100,
15200,
14500,
16100,
12000,
10500,
50225,
null,
37700,
40960,
7700,
6000,
9900,
5500,
10600,
5000,
30200,
33900,
null,
40300,
17400,
15300,
5300,
51300,
12300,
9700,
37300,
16400,
41300,
10700,
14300,
null,
null,
28500,
31000,
50200,
65900,
32800,
7300,
46400,
45200,
66700,
64100,
11900,
13500,
15200,
3000,
20500,
15000,
38600,
null,
15900,
32300,
5700,
56100,
22700,
5000,
61800,
21800,
75100,
33100,
41500,
53200,
17300,
9000,
47300,
23200,
36900,
178600,
23000,
64100,
21500,
18300,
16000,
13900,
10900,
14000,
27800,
17800,
null,
13900,
47300,
4600,
21300,
50300,
54300,
34600,
15500,
8100,
4600,
31800,
35200,
null,
17800,
21000,
7700,
53300,
17900,
14000,
21800,
83300,
34800,
null,
8900,
15600,
47900,
39700,
29300,
8000,
24800,
8200,
54400,
18600,
51600,
29300,
57300,
14100,
7300,
30400,
11200,
40000,
15000,
23800,
38600,
108900,
null,
23300,
48600,
35500,
13040,
21900,
59900,
41800,
5900,
30400,
25300,
11300,
null,
16200,
32300,
18300,
6200,
8200,
51600,
36200,
35000,
41900,
32200,
16000,
28700,
14400,
10500,
97070,
18400,
248900,
30700,
69900,
47500,
14300,
52600,
37800,
22700,
15000,
31000,
23600,
11200,
11100,
17800,
35973,
9300,
null,
13700,
22700,
8800,
54718,
4800,
35800,
46000,
21600,
2500,
57700,
22100,
null,
47400,
23600,
8400,
16000,
24500,
28100,
45000,
2816,
13000,
71100,
10500,
6500,
8537,
28300,
42000,
26600,
23000,
20200,
33700,
12700,
18500,
18600,
17400,
29700,
null,
26500,
29600,
33300,
53300,
63000,
15600,
28100,
17000,
22100,
14000,
32500,
null,
26000,
60000,
35400,
null,
25700,
26700,
29585,
22700,
46100,
22900,
16000,
3750,
17300,
3100,
7900,
13400,
10800,
50800,
5900,
39700,
85000,
18700,
18500,
24200,
22000,
27900,
7500,
106500,
15400,
46800,
71100,
61800,
76300,
null,
37600,
19400,
41200,
75000,
12000,
33600,
10000,
43000,
25500,
26400,
46600,
11900,
17800,
68100,
29500,
null,
null,
4400,
66100,
null,
25500,
19500,
8350,
30400,
50000,
4500,
25200,
57400,
43700,
23500,
16500,
57200,
28800,
41900,
33400,
21300,
21400,
92800,
27600,
22800,
30200,
42900,
20500,
15600,
18400,
136300,
30000,
null,
null,
28400,
8100,
11300,
2700,
63000,
52300,
9100,
38800,
21000,
89600,
35000,
12700,
11500,
41700,
15000,
52100,
91300,
32400,
55500,
35200,
null,
24100,
53140,
9000,
31900,
42800,
16400,
18900,
11800,
20500,
15700,
3600,
30500,
28900,
70600,
14200,
13000,
26300,
12500,
44300,
6000,
11400,
34400,
null,
21000,
19800,
53400,
11300,
13700,
12200,
46800,
60700,
35000,
28800,
null,
3100,
22900,
21100,
38000,
null,
47800,
45100,
28000,
10800,
10000,
12600,
23700,
null,
47100,
null,
23900,
23200,
16500,
38800,
13100,
12300,
50200,
66700,
13200,
71100,
17900,
6500,
36500,
4000,
28100,
23600,
26809,
27900,
null,
47800,
17200,
3000,
35500,
10700,
20400,
7500,
40400,
110600,
6400,
106800,
1500,
null,
8300,
33950,
41300,
10200,
15800,
22300,
18900,
null,
68800,
83000,
168400,
9100,
null,
19700,
32900,
6400,
17000,
85300,
37000,
16300,
49400,
27400,
41700,
null,
57500,
128500,
24500,
20300,
26200,
84300,
null,
null,
13800,
6100,
74500,
6100,
5700,
12800,
48600,
63100,
30600,
6100,
82000,
16900,
14700,
51500,
44100,
5500,
18700,
19300,
39600,
18100,
null,
14000,
16700,
65600,
6900,
33100,
34400,
41300,
9800,
35500,
16700,
70400,
20400,
23800,
67300,
30500,
12800,
91100,
4600,
56100,
42300,
25300,
58200,
71000,
26600,
43700,
14200,
53200,
25550,
6500,
4100,
33500,
15300,
25300,
3300,
29200,
22100,
58200,
24800,
22500,
10900,
19400,
64000,
86600,
19000,
14100,
41300,
3300,
23500,
13600,
20700,
56300,
32300,
15000,
11500,
35300,
86200,
12900,
23300,
131900,
null,
100100,
57000,
18400,
14300,
31300,
54400,
33500,
6200,
19300,
47400,
6300,
12000,
27100,
44900,
37100,
139900,
16500,
9300,
22100,
11300,
45700,
null,
31700,
12600,
17400,
10300,
48500,
32500,
29200,
9300,
20800,
40800,
53400,
9200,
11500,
20000,
16500,
66000,
20900,
25500,
20200,
45100,
13300,
null,
10300,
45600,
10100,
20800,
37000,
16300,
10200,
30100,
36500,
10000,
null,
40400,
6000,
20250,
28900,
24900,
7300,
22500,
18600,
107900,
12900,
42200,
19600,
28000,
85000,
30700,
89600,
null,
127400,
56600,
22550,
48000,
null,
106200,
1400,
41700,
15300,
53100,
34700,
10800,
null,
40400,
29300,
35900,
19700,
8600,
3950,
12100,
113600,
36800,
17000,
18200,
54200,
74200,
27100,
40100,
17200,
37100,
19500,
19900,
10500,
32900,
41300,
33700,
23286,
55800,
14900,
71800,
83888,
30000,
29900,
null,
28100,
10300,
46200,
11100,
78900,
6800,
67100,
137500,
6000,
12600,
20900,
16000,
16700,
73700,
null,
null,
27300,
12400,
55600,
6200,
6050,
14400,
12500,
8400,
49400,
24200,
18130,
27800,
39662,
27000,
20500,
7500,
48950,
34900,
34000,
null,
30000,
15900,
26700,
13800,
25600,
41000,
25200,
35000,
12500,
32800,
17600,
8300,
6500,
26700,
22000,
14700,
null,
22200,
91000,
44800,
27400,
42300,
43800,
15500,
11700,
null,
33700,
38700,
null,
null,
null,
24800,
5400,
41200,
3700,
72100,
null,
30500,
8500,
13500,
72600,
13000,
8400,
55300,
19100,
20000,
null,
65000,
39700,
null,
null,
14500,
1400,
48200,
6700,
24450,
null,
15600,
6800,
19800,
52300,
49700,
4600,
null,
22200,
49500,
null,
15900,
58100,
14500,
17400,
43900,
50100,
8300,
19300,
11500,
38200,
31000,
45400,
null,
23600,
70800,
18800,
74500,
50000,
4300,
24600,
8500,
11900,
null,
30300,
28200,
47200,
71500,
10400,
6600,
55000,
2600,
31000,
11400,
16100,
15900,
7700,
38700,
31900,
39700,
21000,
34000,
13800,
35500,
50200,
127800,
5900,
64100,
27200,
37300,
50800,
24500,
15300,
12300,
16600,
14000,
15700,
12100,
19500,
16400,
25400,
16500,
27200,
45200,
12600,
50700,
27700,
71600,
4400,
36400,
32800,
17500,
32700,
17700,
20800,
99800,
17800,
20600,
9700,
24000,
80300,
19100,
23500,
null,
9150,
48400,
null,
35700,
34400,
40700,
48000,
6010,
51300,
32900,
32400,
7100,
25000,
9400,
25100,
7500,
79500,
30983,
18900,
24400,
null,
15000,
8400,
81800,
2100,
39300,
65000,
12500,
16900,
6800,
18500,
13000,
35300,
6400,
19600,
110700,
15300,
95000,
629900,
59400,
20700,
29900,
16800,
39800,
19600,
17600,
11200,
37400,
16900,
65000,
53000,
11500,
24020,
9400,
51608,
73100,
48400,
26500,
40300,
17200,
62600,
14300,
49900,
21000,
13800,
14900,
49400,
25400,
9600,
31200,
27000,
11800,
null,
81600,
19200,
79800,
null,
42700,
16200,
17600,
13300,
27000,
42544,
22000,
null,
27000,
17200,
7900,
16000,
49100,
51100,
31700,
33500,
26900,
11400,
32600,
9100,
33900,
12900,
9200,
17150,
27600,
14300,
28300,
19500,
17600,
29200,
23500,
26300,
null,
5400,
13900,
58300,
71000,
67300,
53700,
58300,
18500,
17300,
5000,
14800,
36500,
null,
22800,
11200,
3900,
28800,
30600,
null,
15700,
51977,
15200,
74800,
26000,
53600,
63400,
18300,
5300,
25500,
13985,
null,
21400,
46900,
12500,
19000,
3100,
7100,
17700,
2300,
58200,
10600,
18700,
33500,
null,
12600,
58600,
22600,
30700,
53900,
13600,
68900,
2200,
null,
68000,
18200,
null,
27900,
57400,
20500,
22400,
38700,
14500,
26800,
18100,
37100,
28000,
39800,
21200,
18700,
4300,
23900,
51000,
7800,
13100,
null,
52000,
36800,
29800,
6200,
5050,
22400,
19700,
5400,
null,
19100,
47100,
12710,
61200,
38800,
null,
16700,
3300,
6400,
24800,
21000,
27800,
37700,
13600,
12200,
39500,
25500,
50600,
12800,
9400,
46200,
5800,
14500,
29500,
32300,
14200,
41021,
30900,
21400,
12800,
12300,
25000,
null,
66500,
45900,
17600,
null,
20100,
63600,
6700,
7100,
5400,
14700,
47200,
71400,
12300,
53309,
38200,
63100,
16500,
null,
20500,
62100,
15700,
6600,
49200,
25700,
7100,
17500,
54300,
47000,
98100,
11400,
40700,
null,
13000,
25000,
25200,
51500,
34600,
19700,
19500,
40860,
13026,
29828,
10200,
12100,
13000,
15900,
61100,
8100,
41600,
24900,
46400,
8300,
14900,
43400,
9500,
null,
null,
38400,
null,
50100,
22100,
56300,
8200,
34700,
17700,
18100,
30000,
18100,
41300,
55000,
26800,
49381,
34900,
10200,
44400,
12500,
17800,
4200,
27900,
12200,
38100,
null,
8200,
34900,
17200,
51000,
10500,
null,
26800,
10700,
11500,
11600,
35800,
23700,
9000,
5800,
13300,
null,
2800,
3000,
11200,
31700,
18400,
64400,
45100,
24800,
50100,
63300,
26300,
45200,
33400,
24800,
20200,
9600,
130300,
4100,
6200,
12800,
11400,
30900,
29600,
37700,
18800,
6200,
27600,
32500,
5100,
6000,
13800,
31000,
38800,
17900,
32500,
17400,
27300,
27100,
9200,
31000,
41000,
50900,
14300,
15100,
19000,
87200,
70000,
20300,
6600,
6700,
13100,
11250,
24300,
26200,
24200,
25600,
17300,
null,
7000,
62700,
9300,
4500,
31400,
29500,
51510,
62200,
34900,
27600,
6800,
63600,
8400,
97900,
52200,
null,
36200,
null,
65500,
16200,
15400,
6600,
null,
3600,
43300,
15100,
33400,
22800,
6200,
7000,
4800,
12900,
32600,
15500,
51600,
46800,
6600,
24800,
4650,
116000,
21600,
42700,
9700,
16890,
13600,
13600,
19000,
35000,
3600,
31000,
21100,
38900,
11000,
7500,
null,
null,
20400,
10000,
55300,
42200,
14700,
52600,
35100,
40400,
100100,
15700,
20100,
17400,
25300,
39700,
30500,
60100,
18000,
11700,
86000,
27200,
31900,
34000,
8800,
63300,
78000,
19000,
52200,
31800,
13400,
40000,
12400,
41500,
104700,
74900,
null,
1500,
19800,
null,
null,
20800,
5400,
3100,
26100,
3000,
24600,
53000,
null,
33500,
19825,
149500,
21900,
13600,
8500,
20000,
20700,
34900,
18433,
null,
28600,
11800,
47300,
66200,
15900,
33200,
26100,
109800,
43500,
41300,
21400,
14500,
68700,
null,
7500,
16400,
null,
16600,
123827,
15200,
11100,
8400,
44000,
41600,
47100,
42600,
118600,
13000,
52700,
20700,
15800,
20000,
54100,
29300,
10500,
105550,
null,
null,
28500,
10500,
null,
48600,
25200,
30700,
16100,
39800,
16600,
11300,
6000,
12700,
27500,
12600,
45400,
212000,
12700,
13600,
null,
75400,
21400,
236300,
56400,
36600,
14800,
17400,
11700,
26100,
null,
23800,
30000,
null,
42500,
27700,
36700,
9100,
26100,
22700,
null,
50700,
null,
13300,
72400,
17000,
null,
86800,
16600,
null,
28100,
25100,
30400,
30100,
6400,
31500,
32200,
24200,
96600,
36600,
87800,
4600,
7100,
14100,
22500,
40500,
56300,
44000,
98200,
12700,
20500,
22400,
45400,
21400,
34500,
null,
49300,
19400,
null,
null,
101000,
14500,
19600,
15200,
60600,
36200,
51700,
54900,
3200,
16300,
34300,
14000,
46100,
21200,
20000,
39200,
17800,
null,
7500,
11300,
24000,
5400,
10100,
15500,
69300,
2000,
12200,
31200,
21100,
35800,
17900,
26300,
15800,
48900,
7600,
281300,
69100,
null,
42700,
5300,
84500,
39100,
47200,
23900,
11000,
null,
52800,
null,
15400,
36000,
14100,
4700,
17800,
33000,
9500,
48900,
null,
21800,
21000,
null,
21000,
73200,
43000,
65000,
89300,
null,
141300,
112000,
43938,
62300,
12900,
9200,
14100,
18500,
null,
48100,
18300,
20600,
19200,
null,
44000,
null,
25400,
5900,
14000,
6200,
29900,
48400,
9900,
9900,
26400,
16000,
45300,
71000,
9600,
11700,
null,
20600,
143500,
18300,
5100,
55400,
null,
49800,
168400,
12500,
null,
19300,
43300,
15800,
26850,
43400,
17800,
null,
39700,
15300,
null,
27000,
37900,
10400,
23400,
74700,
36700,
100543,
13900,
44900,
10200,
283600,
14800,
11000,
null,
9600,
31900,
57400,
5500,
16400,
19900,
14600,
32000,
25700,
19900,
8500,
35500,
9800,
30700,
60300,
21700,
null,
22700,
32000,
14900,
44700,
31800,
8200,
21000,
29600,
24500,
6000,
11400,
null,
48000,
97300,
37300,
27100,
127886,
29200,
3000,
11900,
28200,
13500,
20700,
49300,
38100,
95400,
38800,
12100,
3800,
13200,
44300,
51900,
32600,
97100,
42400,
20600,
20200,
12300,
27300,
13700,
6100,
25800,
44600,
19500,
12300,
48300,
14300,
25300,
20900,
79800,
null,
37100,
9300,
71000,
18100,
129100,
9900,
11500,
39000,
9500,
79100,
51400,
33700,
73000,
43100,
8600,
17900,
21400,
null,
13700,
51500,
18900,
57800,
6900,
7800,
122000,
83400,
21900,
23400,
null,
70800,
3800,
11500,
33300,
5100,
null,
95000,
13200,
13800,
75500,
1000,
33900,
22600,
47600,
8500,
13100,
9300,
60000,
null,
21600,
31500,
null,
18100,
22100,
37800,
9600,
13796,
22537,
66900,
9900,
49400,
19700,
96600,
38300,
16400,
null,
7300,
null,
18300,
null,
7500,
87700,
4200,
55400,
38900,
null,
46900,
18500,
23600,
4750,
116600,
56300,
7500,
25000,
13400,
22300,
30700,
26300,
20100,
108800,
61800,
44000,
25300,
112500,
8000,
62000,
15700,
47400,
11700,
50366,
11200,
26600,
null,
20100,
16200,
null,
1400,
29000,
52800,
35600,
33728,
12700,
45500,
143600,
44800,
23300,
null,
null,
16000,
16600,
null,
16900,
14500,
null,
56600,
30700,
31100,
47000,
3700,
24400,
27900,
151600,
36600,
38700,
8800,
17200,
21400,
6400,
33000,
49100,
48100,
37800,
19900,
72200,
43000,
14000,
68500,
43100,
null,
10400,
12000,
25900,
24400,
51700,
20900,
8400,
29500,
null,
7100,
26700,
null,
8600,
4600,
77800,
124400,
16800,
8200,
20000,
19600,
25500,
46100,
12300,
13700,
66400,
19800,
5200,
27900,
12500,
50900,
27600,
3000,
52300,
22500,
43200,
24900,
80700,
17900,
67700,
14800,
11200,
5700,
25400,
38400,
18100,
27200,
43500,
166900,
23800,
19000,
26700,
9600,
25300,
28200,
34100,
40500,
21200,
5000,
24100,
9800,
51300,
12300,
5900,
29500,
54000,
33400,
2900,
19000,
11100,
77900,
30800,
18300,
5500,
9700,
13400,
59300,
null,
12500,
103500,
null,
18800,
7300,
17900,
12400,
44100,
13800,
23300,
6200,
19400,
12800,
45700,
18100,
61000,
28500,
65800,
7300,
25500,
null,
44600,
59600,
null,
18900,
12200,
6200,
55800,
28900,
14700,
26600,
55100,
59600,
34200,
8000,
48200,
49900,
21100,
null,
28800,
18200,
15200,
18100,
20500,
57300,
null,
null,
67700,
13500,
14700,
67800,
null,
23100,
7400,
6000,
106000,
44200,
1600,
74600,
null,
33600,
27300,
7600,
28600,
103400,
41000,
32500,
15500,
null,
47500,
96600,
47000,
17200,
14700,
19500,
27900,
45500,
47400,
21000,
13300,
46500,
79700,
null,
42600,
10600,
31900,
26100,
32300,
17100,
6600,
17600,
9300,
44500,
31600,
22900,
null,
17600,
88000,
104000,
25200,
39000,
null,
10100,
27200,
4700,
103100,
21800,
12800,
44800,
7800,
22900,
79300,
10400,
31100,
37100,
75400,
7100,
7200,
2700,
16300,
38100,
52300,
7900,
66700,
1400,
37000,
24000,
16100,
30300,
12900,
14500,
null,
12400,
null,
22400,
null,
8000,
18000,
22600,
16500,
12600,
64700,
34500,
30500,
39300,
13500,
35500,
6400,
23600,
12600,
6900,
36700,
11600,
20500,
37700,
24100,
4600,
56507,
30300,
13700,
14500,
6000,
4700,
45000,
79100,
35700,
3700,
13400,
7100,
41200,
16100,
25100,
27300,
21500,
12500,
4100,
null,
29500,
16900,
16400,
10400,
null,
20800,
1100,
null,
17500,
17700,
47400,
null,
28700,
17200,
65200,
34800,
null,
9200,
10000,
null,
17700,
22600,
12100,
36200,
62500,
null,
44200,
12741,
134400,
34400,
14900,
null,
9000,
19500,
22000,
null,
5000,
20800,
25900,
21000,
50100,
34800,
5500,
null,
24500,
12300,
13500,
18000,
29000,
21400,
16700,
38300,
15100,
7100,
48500,
22600,
32500,
36400,
37100,
41900,
34600,
186500,
29200,
15500,
9900,
33600,
17200,
26100,
28000,
29300,
6700,
37900,
24800,
52500,
24200,
null,
4900,
25900,
null,
null,
35800,
14800,
50300,
17000,
9300,
67200,
99500,
39500,
35300,
27200,
11800,
10000,
2900,
9700,
46300,
84000,
8600,
23600,
8900,
44100,
48600,
47100,
28000,
38400,
51800,
46300,
13800,
17850,
109200,
4000,
10900,
11200,
4800,
35000,
33700,
13900,
12000,
16900,
3500,
null,
16500,
null,
7300,
27200,
45300,
25700,
249400,
44000,
103570,
9700,
21600,
3400,
7890,
4200,
15200,
42200,
69200,
9900,
22500,
56300,
93500,
24900,
29000,
15300,
20100,
null,
11900,
36000,
19200,
29500,
3400,
43500,
49100,
null,
21600,
20800,
18100,
15900,
9700,
19100,
48800,
9000,
10200,
null,
39000,
7400,
null,
37900,
4300,
17100,
8600,
29900,
83600,
42600,
8900,
24000,
15500,
13400,
112100,
26500,
28000,
50900,
33900,
10800,
33600,
null,
31400,
32700,
26000,
18000,
42800,
null,
10000,
null,
11300,
58700,
30700,
48800,
32300,
33400,
21500,
32100,
143128,
27700,
15500,
9500,
23500,
16700,
104500,
21300,
27700,
null,
21700,
56300,
29800,
8800,
2500,
15200,
30600,
3000,
7550,
25500,
14200,
14200,
40500,
null,
12500,
33950,
11900,
13900,
30153,
16600,
18500,
16600,
31100,
49000,
101000,
14700,
18000,
45900,
2300,
15700,
18800,
24900,
9100,
35600,
10000,
14600,
null,
11500,
10600,
38500,
6800,
34700,
4300,
44000,
null,
64500,
18300,
36800,
30900,
35100,
6800,
23300,
1300,
4300,
38200,
30800,
17400,
15600,
6800,
18000,
14500,
null,
30200,
61251,
15200,
14900,
29600,
16500,
9500,
16800,
15900,
42400,
147160,
17900,
30900,
27800,
36200,
39600,
18300,
28300,
13200,
109800,
71000,
null,
59000,
19500,
8900,
24500,
35500,
11900,
74900,
null,
15700,
28800,
42100,
100100,
27700,
6900,
5000,
1300,
26100,
6700,
null,
13600,
12800,
54600,
null,
7500,
28782,
9300,
32000,
25100,
13000,
127200,
63000,
10700,
19400,
14400,
14900,
16300,
36300,
21500,
null,
20200,
null,
2600,
10000,
19000,
33900,
12100,
32000,
null,
null,
35200,
20500,
13100,
23000,
8500,
80000,
10500,
29100,
4400,
7300,
8300,
19800,
61000,
32300,
32200,
12300,
42600,
24300,
5000,
12600,
9800,
89800,
2900,
56300,
19400,
null,
28800,
43400,
null,
18300,
null,
null,
35400,
24000,
25400,
12200,
58700,
33900,
4300,
30800,
7600,
31700,
24400,
11000,
55400,
6300,
14900,
93900,
80300,
7600,
4300,
30900,
96800,
92100,
18600,
43500,
null,
44800,
20100,
42600,
61100,
13900,
22400,
9800,
38500,
11800,
21000,
7700,
17000,
217500,
17200,
null,
8000,
35900,
16400,
26900,
53200,
43100,
39500,
null,
99200,
15600,
28400,
10000,
19400,
24200,
15800,
10700,
11400,
16400,
67000,
38900,
81800,
22000,
null,
14400,
9100,
23800,
28100,
62300,
31300,
20400,
15500,
null,
10100,
27400,
21400,
null,
2100,
7700,
15600,
33700,
19000,
23800,
30000,
26400,
null,
106500,
71100,
27500,
31200,
9900,
16800,
12800,
53600,
7700,
17900,
22100,
31100,
16500,
9700,
27500,
16300,
9200,
17200,
16100,
14900,
21800,
32800,
14400,
30800,
null,
23700,
27300,
150600,
13800,
2600,
57800,
55000,
29600,
23000,
30700,
37000,
18000,
null,
13600,
97300,
4300,
13900,
12200,
54400,
76300,
38200,
38300,
13800,
45000,
14900,
24200,
58800,
31600,
17800,
16600,
50500,
21400,
14300,
44800,
24800,
25400,
null,
66900,
11500,
null,
25500,
52700,
41800,
null,
null,
22800,
55300,
16900,
2300,
75900,
39300,
14100,
20900,
20500,
38900,
11200,
14100,
null,
43100,
null,
31000,
null,
50800,
66200,
51600,
82300,
26300,
62300,
5500,
13100,
9200,
147400,
33800,
33500,
14300,
null,
8600,
22000,
14000,
110500,
15000,
50300,
23200,
14200,
122500,
27600,
7800,
23800,
5800,
53400,
27200,
14900,
11100,
12275,
6400,
47000,
24100,
47181,
12000,
56200,
42200,
37400,
12400,
13400,
19400,
21800,
44200,
17200,
48700,
22800,
7100,
23300,
14500,
14000,
43500,
24300,
9000,
23500,
22900,
21100,
6100,
null,
21000,
49300,
29300,
65100,
6400,
19300,
94200,
122500,
152100,
93500,
61500,
12400,
21400,
42300,
34300,
39200,
16200,
20500,
11300,
29600,
94800,
6750,
32400,
15800,
30100,
110100,
33800,
25500,
39600,
11300,
53300,
29800,
65400,
9250,
23850,
59100,
3100,
22040,
19300,
15900,
32300,
null,
33800,
79400,
57100,
65800,
10700,
19400,
12900,
null,
29600,
19700,
30700,
32800,
84300,
99700,
95200,
27500,
35000,
8400,
39000,
24000,
61800,
null,
34900,
38900,
33100,
42100,
14400,
null,
35531,
29000,
30600,
2400,
null,
null,
43700,
13400,
null,
11400,
30000,
21800,
33600,
null,
43800,
49400,
17900,
7600,
29400,
32200,
78600,
14100,
6750,
56300,
16600,
17000,
56700,
23400,
16500,
17500,
30100,
24200,
null,
35900,
7400,
9000,
48500,
19600,
17700,
22600,
8400,
15400,
18500,
56900,
11800,
null,
65000,
19700,
27500,
24300,
48100,
71300,
42600,
14300,
17900,
18100,
6000,
12600,
null,
37400,
39100,
91800,
38900,
12900,
4000,
23500,
3600,
12800,
null,
35200,
8500,
32000,
32800,
16300,
29100,
27700,
17300,
8200,
4100,
32600,
null,
21100,
9500,
75200,
51400,
11000,
51300,
17100,
13300,
11500,
2700,
13500,
55800,
25200,
19200,
null,
15900,
6400,
null,
62300,
14000,
26300,
4800,
9000,
38000,
11000,
38370,
7700,
13400,
21300,
69500,
23000,
64000,
19000,
64400,
18100,
1000,
46100,
14100,
12500,
6800,
56100,
13900,
6600,
12500,
28000,
39300,
84000,
8100,
113900,
19200,
18600,
7900,
29751,
29700,
6400,
47950,
13700,
13900,
35100,
14500,
12400,
10000,
31300,
7200,
17686,
22100,
39400,
25200,
47100,
null,
17200,
61900,
22700,
5700,
39900,
9800,
26400,
24000,
14300,
56600,
45600,
15200,
15200,
17200,
7300,
58500,
null,
86244,
17000,
16100,
38100,
13000,
null,
null,
58000,
50600,
13300,
19000,
57000,
76000,
null,
49400,
13800,
48200,
92200,
67300,
29400,
35100,
5400,
44600,
null,
null,
21100,
17400,
23700,
null,
null,
5600,
9500,
null,
15800,
8400,
40900,
25400,
32750,
179551,
18700,
13300,
3800,
7900,
18100,
29700,
21800,
17000,
38700,
29400,
13600,
null,
29700,
null,
28900,
66300,
21000,
48500,
42500,
41600,
21800,
35953,
21600,
28900,
33300,
10500,
12700,
42200,
157900,
15700,
15400,
6500,
26400,
null,
null,
18200,
11600,
16200,
83000,
23400,
24900,
16400,
6500,
20200,
69200,
41300,
66700,
23100,
7800,
70700,
23300,
43900,
25000,
17500,
28300,
18900,
31000,
12000,
44500,
195700,
56400,
7000,
37100,
null,
34300,
null,
26000,
7000,
3700,
106400,
null,
67940,
null,
21400,
24100,
64500,
55000,
16400,
6400,
8700,
65100,
130700,
20000,
null,
50600,
4600,
19600,
14500,
null,
38900,
14700,
null,
24030,
11100,
12700,
42500,
69600,
34100,
65700,
19700,
18200,
null,
null,
148200,
29100,
42600,
21500,
43100,
96300,
18200,
18300,
6800,
36400,
40300,
11900,
null,
39600,
21300,
10000,
54300,
62875,
17800,
45700,
8500,
82000,
33950,
23400,
36200,
64600,
34000,
21500,
31700,
29900,
34500,
23500,
null,
25700,
6800,
11200,
36200,
27900,
10600,
28300,
20000,
18300,
112200,
33995,
null,
37400,
31300,
28800,
21100,
49800,
108100,
11800,
24100,
45200,
42100,
12900,
36700,
26800,
13100,
5200,
15900,
7100,
63900,
52200,
32000,
82600,
33500,
null,
27100,
null,
null,
34600,
61500,
40194,
24700,
76900,
29500,
45000,
17800,
7500,
15600,
68330,
47500,
null,
15400,
4400,
54089,
53200,
5000,
6900,
35300,
4500,
38100,
16500,
null,
20900,
30600,
26000,
23200,
64200,
34200,
23400,
null,
35000,
9800,
37800,
3500,
37700,
15600,
null,
21100,
26400,
86200,
69000,
14000,
9600,
4300,
27500,
19000,
32900,
null,
39900,
29700,
21800,
6000,
22100,
null,
null,
null,
114300,
19200,
281700,
17500,
28100,
3000,
26500,
26400,
16200,
17500,
27700,
15800,
29200,
12050,
39100,
18400,
27400,
56600,
31800,
3100,
34000,
30000,
13100,
15200,
43400,
9900,
10100,
6600,
56500,
21600,
49500,
null,
34800,
22300,
42100,
null,
15400,
14900,
36100,
22700,
52400,
null,
12700,
null,
44500,
21933,
null,
6300,
73600,
17800,
8500,
25000,
24000,
15000,
null,
null,
8000,
23000,
5100,
16800,
33900,
23500,
17100,
12400,
18600,
19500,
56700,
null,
12100,
10300,
22100,
56500,
49200,
20900,
null,
null,
2000,
27700,
20200,
52900,
10400,
400,
18500,
null,
70400,
32100,
28600,
11800,
22700,
66500,
12100,
9800,
26400,
13000,
37600,
40800,
12400,
33800,
20600,
6500,
34000,
20500,
10100,
93100,
76000,
19400,
96200,
10900,
11600,
48500,
28200,
null,
28700,
89200,
30100,
6100,
34300,
12800,
18300,
3300,
13250,
8000,
10400,
3000,
21500,
null,
42100,
53200,
8000,
30500,
60100,
null,
15500,
49600,
56800,
19600,
13650,
48100,
36900,
73400,
14300,
60500,
45600,
17300,
null,
7400,
87500,
10800,
11700,
50900,
48100,
42968,
9600,
13300,
19700,
63400,
66000,
29700,
94300,
19200,
9400,
57900,
72800,
50300,
11100,
15100,
8700,
null,
18800,
27600,
202400,
null,
19500,
185600,
11100,
4000,
12700,
27900,
300,
47200,
15200,
21700,
12700,
43439,
21900,
10300,
3400,
52400,
47200,
64000,
15800,
26300,
29600,
17800,
9500,
13400,
21500,
52500,
17200,
42900,
29600,
22300,
5800,
26100,
23800,
6700,
12150,
null,
33700,
12500,
35300,
47200,
51200,
32500,
6900,
61800,
14500,
27600,
21800,
42200,
37000,
44500,
null,
11100,
null,
30100,
5600,
23100,
3600,
null,
66100,
35400,
40900,
32300,
13900,
53100,
null,
12200,
9000,
164200,
76400,
null,
4500,
41300,
10900,
10600,
17100,
27900,
41200,
11800,
15200,
27200,
25500,
21000,
31600,
40100,
16300,
43600,
29000,
26700,
null,
null,
43600,
43500,
16700,
9200,
33700,
52100,
40300,
206200,
79400,
null,
10100,
6000,
null,
39000,
null,
30200,
9800,
256300,
24100,
2000,
22400,
22800,
51100,
23500,
155300,
13500,
12300,
17200,
null,
24600,
13400,
37000,
22000,
20700,
14500,
21900,
44600,
18600,
null,
43664,
17200,
19600,
4400,
78455,
7200,
32900,
47000,
4500,
16300,
32500,
19900,
27100,
null,
22500,
null,
49088,
78900,
8500,
17700,
42400,
12500,
36600,
15400,
28866,
20500,
8500,
4000,
30500,
36400,
26000,
25200,
101000,
114200,
15100,
20500,
22700,
19500,
116000,
14200,
25000,
81200,
78100,
81400,
8000,
99900,
5475,
42100,
51600,
35200,
46100,
28100,
77100,
115600,
23500,
5700,
26200,
11000,
37500,
2200,
24000,
39000,
113300,
39500,
120100,
14600,
67000,
30200,
null,
12400,
19700,
13900,
33000,
54800,
88300,
13000,
null,
70400,
16500,
null,
58300,
38400,
45000,
5900,
29300,
12800,
12400,
28600,
49500,
7200,
8900,
14600,
47000,
32800,
null,
322000,
40200,
19700,
5600,
5000,
7300,
null,
24435,
20200,
15700,
0,
6300,
33900,
13100,
15500,
13100,
9500,
87900,
20900,
11020,
1600,
36100,
20600,
80800,
158800,
23400,
319300,
11700,
36800,
47200,
6800,
36400,
null,
9700,
146500,
13000,
51600,
null,
48700,
119600,
10400,
null,
6850,
121700,
20200,
12200,
8000,
19600,
24600,
8700,
19500,
65600,
19500,
5600,
22500,
18000,
11400,
47600,
14800,
12600,
null,
16000,
45100,
22100,
11900,
36200,
null,
33200,
59680,
45950,
36500,
28000,
56100,
9000,
17400,
null,
37300,
27400,
22500,
34100,
101700,
null,
24300,
11200,
null,
17700,
14300,
null,
6000,
15200,
null,
108500,
13800,
4600,
29100,
21500,
19450,
50000,
76500,
20600,
69100,
8200,
40100,
28800,
18700,
57500,
4300,
32000,
null,
62400,
null,
11300,
null,
19300,
18300,
15000,
26800,
27000,
29200,
14700,
22300,
15600,
70400,
44361,
11000,
5500,
35700,
38300,
16100,
21900,
89600,
13800,
38700,
194951,
6800,
20600,
178700,
34300,
28600,
4900,
8000,
19100,
1300,
34700,
39000,
4000,
null,
null,
9200,
5700,
5800,
92200,
29200,
44600,
42488,
152600,
26600,
3200,
31000,
41400,
null,
4400,
68900,
4200,
100600,
10500,
10600,
12500,
34000,
5900,
15200,
15400,
17600,
39000,
23600,
61700,
18000,
42300,
22400,
8400,
25600,
20900,
64600,
null,
null,
10800,
82000,
21700,
30900,
21700,
10400,
33600,
36400,
19800,
null,
null,
52800,
18100,
33200,
8800,
8000,
13600,
328800,
6700,
8900,
46000,
18000,
22200,
46500,
null,
92100,
25600,
45000,
30000,
41600,
20300,
15800,
37200,
21800,
null,
12800,
27600,
15700,
18300,
20200,
47800,
null,
null,
39400,
38800,
8700,
8500,
18100,
17800,
17100,
126200,
8600,
36200,
7800,
26200,
46200,
48000,
25000,
17300,
12400,
49300,
18000,
98100,
26000,
20600,
22900,
5900,
20200,
94400,
3300,
22100,
18500,
40700,
2000,
19600,
17700,
23600,
29000,
62000,
15500,
33050,
6700,
20100,
2200,
29000,
16300,
17200,
104700,
29800,
11600,
27700,
null,
19800,
7100,
27200,
22900,
65200,
38700,
79600,
44860,
105900,
74200,
11200,
27500,
8200,
10800,
null,
63000,
79923,
12200,
14100,
26200,
null,
12900,
13200,
12600,
28700,
36900,
8700,
21700,
11000,
21000,
null,
4800,
18100,
18600,
18900,
79900,
37300,
26300,
9900,
22800,
null,
65600,
25100,
37300,
300,
3300,
11500,
6800,
64000,
227500,
39200,
13400,
19200,
36000,
null,
17600,
26800,
12000,
6300,
16400,
15500,
10550,
22150,
31300,
35300,
100100,
62600,
4800,
39400,
29100,
14100,
25800,
10100,
19200,
24900,
95800,
5000,
17500,
35600,
15000,
46900,
13800,
9800,
89951,
16800,
30800,
15100,
88500,
26100,
4300,
6700,
48800,
43200,
null,
20700,
8000,
21400,
40194,
null,
null,
9000,
97700,
null,
9400,
24500,
41000,
14300,
11000,
74200,
4800,
20100,
21000,
46800,
20000,
31750,
8800,
54000,
21800,
55200,
null,
null,
13500,
26100,
96900,
null,
29900,
84200,
19900,
38600,
15300,
27700,
null,
9300,
24400,
null,
56300,
77200,
18400,
20000,
null,
26300,
31700,
28600,
15500,
47900,
24900,
15800,
10000,
27000,
29500,
37800,
101800,
50300,
26500,
null,
19900,
null,
16300,
26800,
21400,
8300,
8600,
6800,
15000,
26200,
37200,
7200,
23300,
null,
null,
26000,
91300,
32500,
30000,
49500,
null,
null,
27800,
43300,
55400,
26000,
4800,
6500,
88200,
48700,
21100,
9700,
34100,
68200,
63900,
6400,
5900,
22700,
null,
15300,
65900,
19800,
21700,
18600,
25200,
null,
14400,
null,
5800,
18200,
12600,
75800,
36300,
5500,
11500,
30000,
8200,
18900,
null,
69200,
22600,
15400,
19300,
12600,
29000,
10700,
141500,
13700,
27700,
38300,
null,
79400,
21000,
82000,
13100,
7700,
7400,
10700,
10000,
4000,
24700,
25200,
8700,
31800,
9500,
null,
12200,
null,
28000,
228200,
null,
52900,
3900,
16200,
19200,
44600,
118600,
10000,
7900,
59800,
58900,
13800,
4400,
46100,
48900,
48500,
25300,
51700,
17100,
75100,
54000,
6500,
59440,
null,
8600,
6400,
37000,
119000,
50200,
null,
33600,
15700,
15100,
13300,
null,
15100,
2200,
34400,
5800,
13500,
14200,
32400,
7300,
8200,
11700,
25600,
13000,
24500,
12600,
35800,
165600,
16400,
19400,
null,
7070,
26900,
14300,
27100,
6600,
10100,
30800,
null,
33000,
13900,
9300,
29000,
43300,
18200,
24100,
null,
98500,
3700,
41900,
9800,
15700,
49400,
48400,
null,
92000,
7100,
12900,
37000,
23600,
16200,
10400,
null,
41500,
31100,
40400,
16700,
26200,
16900,
52500,
22500,
14300,
21500,
24100,
35800,
284400,
18700,
6600,
16800,
13700,
34800,
null,
12700,
49300,
16300,
37000,
8300,
31300,
8300,
5500,
16400,
31600,
70600,
76300,
45600,
23400,
4200,
81300,
null,
29100,
31600,
15200,
35800,
null,
11600,
28000,
8250,
null,
4750,
37400,
20600,
25300,
82800,
100600,
30700,
28600,
21000,
14600,
14400,
66200,
29700,
2000,
45000,
19200,
29200,
37900,
null,
4200,
14900,
6600,
19200,
2500,
7400,
52900,
10400,
43000,
31800,
6600,
47100,
86200,
11900,
35200,
27400,
null,
58300,
30100,
74400,
10000,
43643,
25600,
9200,
null,
36600,
39300,
34700,
21100,
22100,
9500,
20200,
77800,
10400,
14600,
7800,
4500,
18800,
38500,
20700,
115600,
29900,
10400,
66100,
25800,
37400,
34900,
27500,
19100,
16900,
37900,
85900,
26100,
15900,
18400,
11600,
21400,
33700,
35200,
17000,
28745,
19700,
4600,
7300,
159500,
15600,
46700,
65234,
13500,
34800,
23500,
23753,
49500,
19000,
14500,
null,
null,
15500,
13200,
25200,
10500,
38400,
9700,
9500,
13400,
32000,
25900,
null,
7500,
14500,
10500,
13000,
9600,
32600,
22100,
5400,
46700,
96800,
85000,
19900,
4500,
6500,
null,
20100,
65900,
21150,
28800,
null,
13100,
87900,
14400,
null,
66600,
41100,
null,
null,
null,
29400,
29900,
21100,
null,
18300,
49200,
55000,
42200,
22000,
22800,
75600,
23100,
12600,
82000,
11400,
44800,
84800,
8800,
57928,
33805,
29400,
15700,
14900,
null,
12100,
20000,
15400,
12800,
43600,
null,
2050,
46500,
57200,
50800,
19800,
6750,
24600,
14500,
31300,
43300,
51100,
13000,
11600,
16500,
22800,
20400,
10500,
58900,
29000,
null,
null,
226300,
29900,
14000,
14900,
7500,
38500,
9800,
69200,
17700,
61400,
39500,
10900,
35200,
91500,
90600,
40200,
18100,
74500,
28500,
27100,
63700,
83300,
12800,
31500,
26800,
52000,
46000,
26400,
48800,
34900,
42400,
39000,
14900,
18000,
74400,
27900,
49860,
19100,
null,
50000,
21300,
18700,
41200,
77300,
14500,
8700,
8300,
null,
41100,
28000,
5900,
67900,
16300,
13800,
21100,
28900,
36700,
38500,
30300,
17800,
16300,
14300,
13800,
12200,
28300,
25800,
25600,
35800,
20500,
29600,
14000,
12500,
40600,
12900,
29100,
37000,
11700,
38800,
25100,
27800,
26400,
18000,
null,
6000,
18450,
13600,
null,
3200,
58100,
52100,
39200,
14000,
4300,
30500,
13900,
null,
37300,
26300,
29200,
37665,
7600,
12900,
41900,
8100,
45100,
88100,
39800,
52900,
36500,
26600,
14500,
13500,
51400,
40700,
43300,
null,
37900,
6000,
74400,
5300,
36400,
34500,
23200,
15000,
23000,
20400,
null,
24200,
19400,
52700,
31400,
null,
47700,
47700,
11900,
26500,
63900,
17000,
18300,
12800,
71900,
20600,
null,
null,
23700,
30100,
62500,
5300,
13200,
36200,
5000,
24500,
12400,
null,
19400,
9100,
41104,
33800,
30600,
29700,
62504,
20200,
16800,
33500,
92400,
null,
59600,
12500,
11300,
35400,
17100,
33000,
25300,
57700,
22100,
36600,
15250,
null,
63500,
52300,
16900,
30300,
22000,
19900,
102200,
39100,
43900,
87500,
15100,
16300,
20700,
56818,
25900,
8400,
25200,
18100,
3500,
600,
19900,
null,
13200,
19400,
null,
8400,
15000,
48600,
28200,
7200,
6800,
null,
15780,
43200,
24700,
17000,
5000,
109500,
38900,
27300,
33400,
11000,
6200,
null,
34400,
80300,
31400,
16100,
7300,
7300,
30200,
18100,
10000,
17300,
101300,
49000,
4500,
null,
17600,
17300,
11000,
26000,
15000,
null,
3300,
27300,
47200,
14100,
null,
37900,
13500,
14700,
30200,
31651,
29500,
37800,
27100,
21000,
8500,
16400,
40500,
36700,
null,
83500,
20600,
7000,
13200,
46200,
50300,
25600,
13900,
11200,
26800,
13800,
20300,
18300,
5100,
22200,
10700,
50200,
67700,
32700,
39700,
9700,
4600,
46400,
19500,
13400,
19400,
37400,
10700,
12300,
6000,
7400,
null,
23600,
52800,
15200,
37300,
32200,
8800,
25900,
39500,
66200,
22300,
14700,
17300,
35800,
146100,
17275,
11500,
23600,
8100,
10400,
22700,
33800,
37900,
11800,
3300,
10000,
38800,
22900,
14400,
11811,
12000,
39600,
9100,
50300,
6700,
33600,
null,
38400,
5700,
3500,
11700,
5800,
17100,
41988,
5600,
16300,
10300,
18400,
24900,
7800,
null,
77000,
64300,
35000,
116100,
14600,
20700,
7500,
7700,
17900,
15200,
49700,
30100,
55000,
null,
9800,
null,
10600,
32100,
null,
13800,
24500,
104500,
40500,
11500,
92500,
52300,
40400,
14800,
23000,
29900,
20800,
33600,
54700,
9800,
37600,
79500,
32200,
35900,
9400,
20500,
76800,
29600,
21900,
31100,
34000,
34600,
55500,
32800,
22200,
11200,
30000,
53500,
11000,
24700,
16800,
27700,
40800,
27400,
20300,
8700,
12600,
11900,
8000,
18600,
3800,
18000,
47300,
11400,
37900,
16100,
null,
28500,
14600,
6600,
13000,
89900,
4600,
9400,
14100,
7300,
56200,
31300,
46400,
41400,
11800,
13800,
null,
21100,
160700,
22200,
19700,
25200,
13300,
14200,
65100,
34500,
67700,
9400,
5700,
17400,
63700,
6700,
25500,
6700,
null,
25100,
63500,
1300,
36100,
21000,
25100,
17100,
54100,
23100,
27500,
21600,
28000,
40500,
63900,
15900,
2500,
10900,
10900,
5700,
20700,
61400,
27800,
34900,
13500,
33000,
86800,
17800,
16200,
22700,
52900,
null,
33200,
9500,
62900,
40500,
10100,
4000,
null,
6450,
41900,
5100,
null,
15900,
22100,
14100,
12300,
21300,
26100,
23100,
10300,
18500,
12900,
null,
13000,
49800,
149860,
8200,
24600,
49400,
158500,
null,
11100,
11600,
13900,
49800,
88000,
14500,
40900,
48400,
16300,
37600,
41200,
18600,
54400,
34600,
36200,
46200,
48200,
20000,
31500,
23800,
9700,
8700,
35300,
35100,
25100,
15300,
null,
4700,
5800,
37100,
10700,
14700,
30000,
36200,
31800,
null,
1300,
18100,
12000,
15900,
14300,
59300,
52500,
40000,
13310,
null,
16700,
24900,
39900,
25300,
50300,
null,
45800,
51800,
39400,
29200,
30000,
16100,
18500,
132200,
5700,
9800,
61400,
20500,
37100,
41000,
24800,
58710,
18500,
14200,
24100,
15800,
36500,
16600,
19100,
3700,
9600,
3800,
2500,
16700,
18200,
null,
16700,
69500,
16500,
27300,
48100,
null,
26900,
7700,
28500,
26800,
101700,
21300,
null,
25900,
45900,
14000,
1800,
26300,
13600,
71200,
18700,
8700,
21200,
133700,
5400,
31100,
123300,
null,
22400,
38700,
10100,
11300,
26200,
53200,
53700,
null,
11700,
45600,
48300,
2000,
13300,
30100,
6000,
15100,
29700,
19900,
16000,
31600,
23100,
36400,
23300,
8300,
7500,
11400,
117400,
12200,
43200,
27700,
83600,
18200,
30400,
19000,
13700,
25500,
14800,
72700,
16600,
45000,
null,
29600,
40200,
20500,
10500,
29900,
92600,
36200,
8700,
62100,
31500,
20300,
31300,
28700,
22900,
43700,
10500,
43500,
5000,
20900,
38500,
23500,
15000,
19400,
11900,
39800,
10000,
18600,
18400,
55300,
10500,
49400,
27000,
22600,
11900,
57100,
null,
null,
30100,
14200,
119898,
48000,
12600,
21300,
71100,
4600,
30000,
86000,
78300,
8500,
42500,
46900,
28900,
57800,
14600,
16700,
23200,
10900,
31900,
23600,
null,
35600,
30300,
35500,
23600,
15200,
37900,
46700,
20200,
21100,
30100,
26500,
19900,
6200,
19700,
33700,
11400,
18600,
null,
27200,
17200,
27700,
31500,
null,
76100,
54000,
25000,
136700,
17000,
23300,
33700,
26900,
17200,
9700,
null,
18800,
13500,
64600,
29600,
21600,
20400,
26600,
73500,
19800,
99700,
12100,
17400,
27900,
10300,
53200,
18100,
14400,
6000,
24600,
55000,
12100,
34700,
44500,
21100,
52800,
35400,
34400,
20200,
32900,
46800,
null,
39000,
39000,
5700,
55100,
37900,
8700,
31100,
45600,
45400,
53800,
16700,
15000,
16400,
48400,
28600,
48821,
46574,
25100,
17900,
28100,
34400,
32300,
41900,
46700,
21100,
10900,
12400,
54100,
42300,
23500,
12900,
11700,
102500,
null,
19200,
18500,
20700,
37500,
null,
14800,
6600,
35000,
16900,
null,
58700,
14700,
19100,
23000,
16400,
51200,
49200,
20500,
19600,
23400,
7045,
41400,
32300,
56000,
12300,
51000,
16800,
17300,
40200,
108500,
9800,
26000,
19000,
16500,
null,
36900,
36400,
null,
38200,
39400,
12200,
5500,
33800,
21300,
16300,
11800,
14800,
14400,
113400,
13000,
8400,
31690,
null,
null,
52000,
65500,
24500,
67700,
18900,
null,
23300,
47800,
7800,
24900,
9000,
18400,
12600,
63400,
null,
42400,
64000,
15300,
19200,
35300,
127600,
26800,
44114,
17100,
66600,
28200,
48900,
11600,
3800,
null,
6750,
12700,
15100,
13100,
6700,
7900,
72400,
22600,
30300,
45000,
43100,
11400,
62900,
21300,
3900,
4700,
10300,
21600,
17200,
59400,
15000,
52400,
112500,
84200,
null,
13400,
23200,
39100,
16200,
18700,
28100,
25000,
24300,
19400,
24900,
16400,
49300,
3750,
21100,
49400,
29600,
28500,
22400,
15000,
61300,
36900,
97500,
19100,
52600,
32500,
14500,
73900,
19300,
30300,
7000,
18800,
33100,
16100,
null,
14900,
36500,
64800,
20600,
null,
null,
19400,
17700,
37600,
9300,
11900,
28500,
null,
8600,
21600,
55000,
31700,
22600,
9800,
15900,
17300,
9300,
24400,
2700,
13300,
23100,
6500,
null,
12700,
12500,
15000,
20900,
8000,
57300,
22500,
20700,
19300,
37600,
58000,
38610,
null,
21900,
59800,
4000,
12100,
43500,
18500,
49000,
7200,
15600,
31300,
97621,
30100,
41600,
null,
26100,
null,
70800,
25000,
17100,
17000,
25200,
62397,
null,
null,
58600,
29400,
40209,
19700,
29100,
49000,
17700,
38300,
25700,
45300,
27500,
15100,
71100,
9700,
26500,
null,
6700,
6700,
86800,
35400,
null,
14600,
28600,
23500,
16000,
24900,
16900,
16600,
28100,
16600,
84800,
13100,
27500,
5100,
58900,
34700,
5000,
50400,
48094,
null,
10840,
5600,
16900,
64300,
null,
null,
9500,
64400,
20200,
25000,
42600,
21700,
35600,
8800,
17800,
6800,
9000,
27500,
21200,
null,
47000,
49300,
39900,
30200,
18000,
13368,
15500,
8200,
13400,
84500,
48800,
54300,
28500,
32300,
11900,
18500,
2800,
11500,
18100,
31900,
200,
10000,
15100,
null,
36000,
11500,
44000,
3525,
9400,
71100,
null,
15750,
2600,
18400,
null,
24200,
13500,
8000,
21700,
33500,
10500,
12700,
33100,
7900,
17100,
15700,
18400,
3800,
15500,
51800,
19100,
23000,
32400,
23500,
5800,
42000,
34900,
6600,
82100,
42500,
15800,
73200,
31100,
0,
130100,
23200,
19700,
68000,
null,
null,
18600,
24300,
26900,
12500,
40700,
29400,
8950,
59200,
18000,
null,
null,
91500,
15100,
null,
10000,
7500,
52700,
15900,
null,
56500,
8800,
15000,
20700,
38300,
12400,
19100,
10500,
2800,
28800,
24400,
25200,
13700,
18000,
null,
30000,
17200,
6500,
27400,
16500,
41200,
40900,
6700,
16900,
26100,
20500,
23600,
28400,
22500,
37400,
102600,
21700,
19537,
10200,
32300,
12400,
22600,
12100,
29100,
19700,
25300,
10900,
8000,
7900,
34300,
36400,
6500,
3300,
13500,
28500,
6500,
17800,
21600,
9100,
44400,
31600,
null,
83400,
10900,
7000,
27300,
36800,
24300,
7000,
22800,
13300,
65900,
24600,
19500,
null,
78800,
49100,
29900,
71400,
9200,
29500,
16700,
null,
119500,
27000,
18400,
43300,
10800,
13300,
44100,
91200,
62800,
12300,
32200,
9800,
36000,
25000,
87300,
7800,
12800,
null,
45900,
null,
10700,
24400,
27600,
null,
16600,
10600,
34800,
18900,
19700,
11800,
37900,
12900,
74700,
18300,
6500,
35000,
79000,
95900,
14400,
14700,
71200,
12300,
33700,
28500,
83500,
6200,
25900,
20700,
6500,
4200,
9500,
75700,
3800,
20900,
55500,
18800,
13100,
43200,
14100,
15400,
5400,
16700,
48400,
8800,
2600,
34800,
null,
24700,
76600,
46100,
27700,
89300,
68700,
32800,
32200,
49400,
17000,
7000,
31600,
4100,
48000,
15550,
20300,
27400,
19300,
6400,
22000,
69325,
42300,
19100,
44500,
19700,
2800,
31200,
8000,
16500,
88800,
21100,
55700,
null,
19300,
44900,
16700,
101200,
10500,
null,
105300,
60000,
47200,
72500,
23100,
46800,
16600,
15200,
6800,
17600,
37500,
45900,
37500,
34500,
11900,
29200,
31300,
13400,
60300,
null,
4400,
5400,
59400,
38100,
null,
14800,
2900,
13100,
22700,
47000,
null,
24100,
16300,
43400,
21800,
11500,
null,
10800,
13800,
null,
15000,
73000,
21300,
39800,
59800,
26700,
26300,
106300,
23600,
34800,
null,
10400,
25500,
14000,
44200,
12100,
37900,
5200,
27600,
3900,
25700,
17600,
null,
null,
55100,
null,
68500,
6100,
23400,
11300,
9900,
54700,
24900,
38100,
15000,
21100,
7300,
38000,
13700,
187300,
115600,
49500,
7300,
22800,
10300,
27000,
92400,
77500,
35700,
13500,
27200,
11400,
45200,
11400,
28100,
27800,
25900,
18600,
9100,
null,
20100,
36900,
25700,
21100,
42700,
24600,
33200,
null,
36400,
34000,
24700,
51400,
10800,
23900,
12800,
28500,
57500,
32300,
12900,
85700,
null,
61400,
26700,
44000,
68700,
71900,
23800,
22400,
26100,
19400,
23600,
21200,
8500,
40500,
4300,
52300,
54100,
21100,
27600,
15000,
51500,
30900,
17300,
51200,
29300,
null,
191100,
19100,
3500,
34200,
26500,
33200,
67900,
13500,
21800,
30000,
7000,
83400,
41300,
24214,
41500,
null,
37000,
93300,
13400,
50000,
52700,
21200,
null,
33000,
62600,
44800,
8300,
20800,
23600,
6000,
52100,
null,
27800,
14300,
20300,
19700,
24200,
5500,
26000,
12500,
9000,
29800,
16100,
9600,
10000,
14700,
5300,
5400,
31500,
61900,
37300,
34800,
52300,
8200,
26300,
23100,
null,
27200,
22100,
27300,
39200,
15300,
17400,
59500,
29300,
12700,
70300,
21500,
90905,
94700,
17500,
9500,
29100,
700,
7200,
30309,
20300,
null,
31600,
13400,
33300,
50200,
null,
7900,
60000,
71400,
13700,
33212,
34200,
5500,
16500,
28500,
18000,
28000,
56952,
105300,
6800,
79500,
153400,
null,
25600,
null,
49400,
12500,
21300,
28800,
17000,
69400,
59700,
97900,
53900,
54628,
11900,
20400,
17300,
30800,
24100,
3300,
15900,
87000,
30200,
null,
13000,
29300,
null,
17000,
15200,
null,
27100,
10300,
59500,
18650,
27100,
14300,
4800,
15000,
16200,
17000,
13800,
10100,
24800,
17800,
17400,
11900,
27600,
14400,
37100,
null,
26600,
15700,
24900,
19200,
null,
29400,
25400,
39600,
14800,
21000,
50200,
6000,
27400,
15500,
26800,
12500,
15500,
55600,
22000,
17600,
148300,
42000,
13200,
23700,
5500,
24900,
28300,
66900,
25600,
12400,
85460,
20600,
null,
20900,
14000,
4200,
22400,
20100,
47900,
12400,
5100,
16300,
26100,
54000,
22000,
17300,
42100,
27700,
13200,
14700,
32200,
11900,
45000,
1900,
24300,
49600,
32500,
12700,
13700,
11400,
51942,
60300,
null,
33900,
84600,
10000,
15400,
42900,
40200,
49800,
93700,
77900,
41500,
18200,
null,
27300,
26400,
20400,
null,
14200,
9000,
8000,
14100,
43100,
31700,
6100,
30100,
23100,
9700,
76500,
8400,
18000,
2550,
55000,
null,
29800,
18000,
21600,
34800,
62300,
58100,
22800,
18600,
21529,
8200,
27300,
14600,
2200,
30100,
16800,
44700,
null,
5100,
41900,
10200,
null,
5000,
15000,
19900,
22700,
10400,
24900,
37600,
14300,
null,
16200,
31200,
13600,
20100,
15900,
27400,
33200,
8100,
8800,
123300,
4000,
6100,
6600,
9500,
15500,
30300,
59300,
24700,
22700,
18900,
null,
24100,
32400,
51634,
17500,
9400,
16000,
46000,
16800,
23500,
6800,
42300,
73800,
null,
12900,
11400,
120500,
10600,
16100,
13500,
70100,
null,
108200,
53900,
54300,
51000,
17300,
27600,
15200,
8800,
12800,
18400,
24000,
75800,
19500,
175700,
12400,
62400,
12600,
49700,
53700,
27100,
8900,
26200,
null,
1000,
15400,
23300,
44400,
null,
29600,
31600,
34400,
9300,
35700,
7600,
29500,
17200,
null,
13400,
29400,
18500,
10800,
null,
67400,
38700,
27400,
16500,
10700,
38500,
31500,
32300,
19700,
14600,
25400,
10600,
19800,
27700,
43900,
null,
17000,
11700,
5100,
45400,
15600,
39300,
10500,
57400,
19300,
38400,
16000,
null,
106400,
6300,
85400,
47200,
25300,
47000,
49200,
24700,
11100,
2300,
26800,
11500,
33500,
30000,
4500,
44700,
9400,
21400,
9200,
38300,
24400,
8500,
87200,
36000,
18500,
16900,
28800,
32100,
26500,
16100,
15000,
6500,
23000,
16600,
22800,
5700,
25000,
17200,
86000,
10000,
7900,
15700,
13000,
11000,
24200,
20600,
31900,
15400,
7300,
null,
null,
17100,
47100,
69900,
53200,
16000,
17500,
null,
3900,
null,
4000,
null,
24700,
33000,
48700,
50700,
25400,
68700,
36400,
null,
14700,
57200,
64200,
13200,
12000,
9600,
21700,
13600,
29000,
24100,
27200,
13300,
15200,
16200,
32000,
10100,
23500,
63400,
9100,
14000,
null,
13600,
19800,
28000,
67700,
20200,
21000,
31200,
34500,
null,
15400,
39500,
10800,
10600,
19000,
23700,
31900,
18100,
3900,
28900,
52400,
7900,
10900,
54800,
null,
5600,
19700,
24600,
128512,
16750,
7850,
106300,
4300,
14000,
143300,
17700,
21000,
29400,
18500,
303900,
38100,
12700,
null,
7800,
334500,
15400,
16600,
102400,
40000,
22000,
26100,
null,
62600,
46200,
23900,
12600,
24600,
4100,
26900,
null,
18400,
6009,
null,
17200,
null,
13100,
24100,
13600,
17400,
45600,
40000,
69000,
63000,
13300,
15900,
2500,
32500,
12100,
13200,
null,
22300,
40800,
5600,
67900,
7400,
31400,
7800,
18700,
12400,
22200,
24900,
281400,
13500,
84300,
15500,
5900,
24700,
61600,
65200,
51100,
10100,
11900,
5900,
null,
26800,
66400,
19700,
16100,
20400,
50100,
37200,
56500,
28500,
14000,
34700,
29800,
36000,
19800,
50500,
6900,
13300,
9200,
27700,
63800,
20000,
44900,
16000,
80500,
13100,
60050,
49200,
18800,
21000,
27100,
5200,
17400,
3100,
33100,
9600,
35000,
112000,
15100,
null,
null,
52600,
46100,
20500,
6770,
31200,
16800,
33000,
17000,
20800,
100300,
78100,
37800,
45400,
26900,
2052,
9300,
10500,
119500,
5400,
20300,
7600,
5800,
36900,
48900,
8800,
6800,
null,
13000,
37600,
35100,
null,
12400,
61700,
93000,
37400,
null,
14600,
9350,
34800,
17400,
8600,
48989,
53500,
23600,
15500,
79900,
34500,
18700,
57000,
51300,
15500,
19000,
6800,
29600,
7100,
null,
29000,
22300,
36000,
20300,
16900,
17400,
96800,
5500,
10000,
13200,
32100,
34100,
null,
null,
20400,
27000,
20000,
22000,
null,
21700,
27300,
11000,
46700,
17000,
20600,
18200,
74300,
11200,
19100,
12100,
8900,
67300,
25800,
62500,
56700,
7900,
7500,
40100,
17300,
39000,
18500,
57100,
4000,
64200,
38600,
107500,
5500,
37400,
64100,
34300,
35500,
10500,
45931,
3100,
51100,
7000,
15000,
57500,
32100,
null,
69100,
14100,
16700,
17700,
null,
16900,
24300,
9600,
null,
7000,
32200,
55500,
7200,
9200,
null,
null,
25800,
35800,
24100,
36900,
27500,
8300,
null,
3600,
27300,
10100,
null,
17400,
28600,
16400,
17200,
null,
14300,
44900,
null,
46000,
25600,
null,
13250,
17000,
16600,
16800,
29500,
59700,
63800,
21700,
26600,
null,
23100,
45500,
20400,
32000,
6200,
35600,
18500,
31200,
45700,
26700,
10300,
26200,
28300,
37800,
22700,
6600,
8000,
17100,
10900,
78000,
null,
24800,
17700,
11000,
null,
13500,
22250,
23800,
44600,
9000,
44700,
14400,
11300,
19200,
36100,
36200,
21500,
24050,
40900,
25700,
null,
38200,
11500,
8300,
4500,
34900,
18100,
22000,
337400,
10600,
13300,
11200,
48300,
10100,
16000,
13700,
24900,
12200,
null,
37200,
25000,
31080,
112600,
10500,
9500,
71000,
22600,
8300,
108900,
38900,
27800,
10900,
null,
12400,
18600,
23500,
23100,
6700,
null,
null,
47900,
15500,
21100,
null,
10500,
46200,
7800,
49920,
5500,
6000,
45800,
7600,
23800,
25900,
11700,
192200,
23100,
10200,
6200,
116200,
7600,
null,
27700,
6300,
18700,
45000,
31300,
16600,
44450,
43800,
19300,
23300,
32200,
12100,
32100,
27300,
58300,
36400,
32200,
70500,
67100,
64100,
21000,
24800,
31000,
34300,
23000,
51800,
22349,
21900,
5000,
58000,
null,
41300,
null,
5700,
4700,
19000,
41600,
14400,
44300,
17900,
21100,
57100,
14500,
27000,
19100,
17000,
6000,
22500,
149200,
20500,
16900,
12900,
68900,
86200,
null,
19000,
20500,
26700,
140800,
51000,
15100,
22700,
18900,
32300,
25400,
34100,
10600,
22500,
29700,
71700,
49000,
45100,
48600,
29100,
14100,
24600,
8700,
26800,
10900,
19000,
14900,
55700,
null,
25400,
14700,
35490,
14600,
10000,
71500,
21600,
null,
36200,
15000,
22600,
24500,
28300,
50300,
31400,
null,
26400,
47400,
6900,
16300,
37700,
165500,
24200,
26100,
103200,
40200,
7200,
24400,
78400,
20000,
12200,
17500,
3500,
64100,
61500,
null,
15550,
32900,
null,
null,
15200,
21500,
13500,
31100,
54200,
16600,
29800,
175500,
39100,
24600,
6900,
null,
6500,
null,
12000,
40900,
50500,
42200,
45000,
30700,
41700,
13900,
38400,
30300,
21300,
17000,
92800,
null,
35100,
12200,
23100,
14200,
49100,
18500,
33000,
43900,
73500,
18500,
null,
26500,
33200,
58500,
21800,
23000,
38400,
24300,
66000,
13100,
13200,
73600,
58100,
26000,
62200,
6800,
19900,
22300,
19100,
65100,
20800,
54200,
65400,
6300,
33100,
62400,
18100,
14500,
11500,
20600,
25400,
34900,
null,
36700,
null,
11900,
18900,
45100,
null,
1900,
34400,
86700,
13400,
null,
29000,
9900,
21500,
41400,
26300,
null,
29500,
24200,
5900,
49200,
28500,
14000,
34200,
55800,
34100,
6600,
64800,
19800,
24800,
null,
16300,
86900,
null,
16300,
23900,
24200,
33000,
17900,
12900,
12500,
16800,
17800,
null,
12100,
12800,
22100,
null,
19100,
19100,
20400,
24900,
13300,
3300,
17900,
16000,
21500,
14000,
4800,
14200,
null,
17000,
69900,
17600,
8700,
36700,
15500,
60400,
21500,
null,
35500,
10900,
9900,
21800,
10000,
14400,
null,
12500,
29700,
12800,
26200,
15900,
14300,
43200,
24400,
null,
135200,
67700,
28400,
13300,
5000,
42500,
71300,
18800,
10600,
3500,
94800,
32000,
42000,
10500,
9200,
10400,
32100,
49600,
84500,
39700,
106800,
92300,
null,
null,
53600,
null,
21300,
19800,
44100,
8500,
29900,
24200,
14600,
21100,
null,
47600,
103800,
152900,
10700,
50600,
20800,
46900,
13000,
31500,
10700,
57600,
53800,
11000,
25500,
21100,
24900,
91600,
34000,
14000,
25800,
60100,
19300,
42500,
4700,
61300,
11100,
17800,
15200,
6100,
16400,
32500,
5500,
19400,
41400,
22200,
null,
30200,
47000,
14100,
12400,
39900,
21300,
42400,
53200,
15900,
42650,
55000,
21800,
60400,
25300,
36800,
null,
17500,
19400,
15900,
12700,
5600,
21000,
22600,
null,
16900,
27100,
22500,
9700,
16700,
1900,
11200,
38200,
7500,
null,
34200,
4700,
35000,
35700,
12100,
10800,
null,
85100,
12000,
7800,
23500,
null,
8400,
100200,
4300,
14100,
32300,
21700,
17600,
49700,
10100,
27900,
24800,
30700,
null,
38300,
24200,
168700,
13900,
44600,
15900,
47700,
41500,
63900,
27000,
32500,
24000,
null,
19200,
25900,
76400,
19600,
4700,
24505,
26000,
null,
39300,
10300,
14500,
10400,
23000,
14600,
18000,
23900,
32300,
34500,
null,
null,
5500,
32000,
22700,
6700,
64100,
25700,
29200,
12100,
17200,
null,
33300,
23000,
129700,
41200,
16000,
32500,
51800,
17300,
17400,
82200,
23300,
70200,
8800,
17200,
99600,
109200,
28100,
12800,
7400,
29900,
28300,
33300,
23200,
36300,
8000,
26800,
8100,
23600,
16900,
14600,
51000,
19600,
11300,
27800,
8100,
14700,
28400,
12500,
13500,
8100,
10000,
24200,
49700,
35300,
18100,
null,
16100,
41100,
40000,
26600,
10900,
23700,
8900,
19500,
31300,
26600,
null,
null,
8500,
43300,
14700,
16500,
null,
28000,
19900,
25100,
31800,
23700,
39000,
4300,
null,
21500,
21200,
38600,
28400,
null,
14800,
45300,
14800,
8400,
20900,
64800,
35200,
19400,
27600,
30000,
61600,
32700,
33300,
29700,
15300,
103000,
43300,
11600,
18700,
10200,
20500,
67100,
7300,
15800,
53100,
8000,
25900,
2200,
7300,
26700,
15200,
15400,
4900,
34500,
null,
12000,
43800,
71000,
17400,
32400,
17500,
7500,
5100,
50100,
34400,
38000,
30400,
11217,
null,
54300,
11200,
17300,
8000,
41600,
60700,
6100,
31092,
null,
8500,
18800,
35300,
34200,
null,
9300,
71660,
51000,
9100,
44200,
7600,
88900,
8900,
57400,
73700,
20200,
41800,
111700,
null,
29800,
42001,
22300,
42600,
52000,
12800,
105600,
null,
11500,
4000,
55900,
null,
30200,
4000,
53500,
84266,
4700,
64300,
11700,
14100,
13600,
4800,
20700,
6200,
6800,
23700,
18500,
55900,
15000,
51800,
17600,
18500,
10300,
8600,
20000,
10100,
94900,
22900,
30500,
32200,
51100,
48600,
null,
12500,
58900,
25500,
19800,
14900,
10100,
null,
19200,
13100,
21900,
46700,
22200,
13300,
28400,
null,
null,
10700,
8200,
9500,
19700,
11100,
26600,
17400,
26800,
25800,
4500,
41400,
15200,
50200,
null,
52550,
22800,
20700,
2800,
15500,
66500,
15000,
18900,
14500,
5800,
39500,
61000,
15200,
null,
6500,
39400,
50500,
43000,
9200,
18700,
47700,
18100,
48300,
38200,
31300,
25000,
3500,
3000,
53000,
18300,
17400,
33300,
26100,
13900,
26700,
null,
13900,
46800,
69500,
28300,
22700,
26201,
26600,
47300,
36000,
null,
38100,
15700,
135700,
181300,
39900,
18600,
19800,
17800,
29900,
20300,
82300,
94900,
13400,
37200,
23400,
45400,
22600,
37400,
38000,
27300,
20000,
22900,
18600,
21600,
13000,
12800,
10700,
17500,
19000,
24700,
9200,
10600,
27300,
24100,
19400,
10600,
32200,
11300,
23700,
26300,
40800,
27600,
18400,
41300,
16400,
9700,
17100,
null,
130060,
23000,
3900,
12500,
25100,
null,
17600,
22600,
25300,
20100,
6500,
17900,
11952,
19700,
62900,
14300,
63700,
13600,
30600,
25300,
null,
33000,
8400,
13100,
17900,
7200,
13600,
null,
14500,
15500,
11700,
24100,
137200,
7000,
42800,
48500,
28600,
48600,
14100,
327700,
13500,
10600,
41000,
null,
null,
26600,
15900,
86500,
50700,
16600,
73100,
28200,
22200,
40400,
13300,
30800,
37700,
57400,
null,
40100,
9600,
55000,
18000,
25000,
11400,
21800,
29900,
46200,
null,
26200,
23000,
17900,
11100,
3700,
8800,
30300,
31600,
50400,
27300,
19200,
58400,
39300,
21400,
21300,
15500,
11200,
14000,
3100,
22100,
56300,
29800,
10000,
10700,
29600,
22800,
41200,
64400,
9100,
39500,
8000,
25200,
30400,
59100,
22200,
63200,
26400,
23500,
19800,
52500,
42200,
null,
null,
17000,
14000,
60200,
14000,
23200,
29100,
24700,
48400,
44600,
31100,
6000,
23900,
30500,
40300,
37900,
13700,
null,
47200,
44300,
4400,
27000,
null,
16600,
33800,
27300,
null,
26400,
34400,
26500,
38700,
22400,
11200,
161000,
18000,
29500,
11500,
9100,
37328,
73200,
28100,
17200,
50600,
44800,
40300,
20900,
10300,
13500,
57900,
73300,
9200,
7700,
24100,
40100,
15400,
19900,
7500,
6700,
20200,
25600,
13300,
16500,
84000,
null,
31600,
37700,
12500,
74500,
14400,
16200,
null,
null,
21500,
32100,
52200,
48700,
13000,
50600,
null,
null,
37200,
35500,
22600,
93800,
30100,
8100,
29600,
32700,
27400,
26100,
30500,
55200,
18000,
41500,
21500,
16200,
7500,
36500,
7300,
16600,
55800,
36400,
41600,
22000,
14400,
112800,
24800,
6600,
37600,
16800,
null,
41100,
26800,
13800,
18700,
115100,
20400,
34275,
15800,
32600,
49500,
4500,
32400,
14100,
35200,
33500,
7400,
34100,
40100,
41300,
17345,
34300,
42400,
5500,
8500,
7900,
12500,
19200,
29800,
6050,
5800,
21700,
3300,
25000,
45600,
35400,
103800,
86000,
23100,
33600,
18700,
8100,
24200,
1500,
70100,
56300,
22800,
33400,
16400,
47600,
20400,
12700,
49100,
9900,
29000,
3500,
null,
111100,
39800,
36600,
11800,
33900,
29000,
17200,
32200,
30800,
31900,
9800,
27200,
35600,
6400,
37400,
26200,
13000,
12400,
15100,
31400,
21300,
24600,
70000,
6357,
153300,
25700,
14200,
14400,
15100,
32900,
11100,
14800,
null,
13800,
null,
15200,
59000,
29600,
21300,
null,
17600,
8800,
3000,
19700,
14500,
21800,
20000,
25600,
31200,
17000,
17100,
341900,
34200,
8900,
14800,
15600,
38100,
13700,
21700,
106500,
24700,
77956,
31500,
null,
59500,
46600,
11100,
10900,
12200,
37100,
170600,
20800,
18200,
15400,
null,
48400,
7200,
null,
9000,
5100,
19400,
5650,
12700,
11000,
21400,
37300,
10700,
35800,
31500,
12600,
23300,
18300,
38100,
30000,
10900,
41400,
30800,
42600,
9800,
13900,
12800,
12600,
35900,
41606,
30900,
90100,
9400,
25900,
55200,
39049,
25700,
37800,
44400,
7300,
46300,
null,
8000,
23600,
null,
29300,
23900,
29400,
56300,
13900,
31500,
15700,
44300,
38900,
23000,
18700,
115100,
9400,
34900,
32300,
46900,
50800,
23000,
18800,
8500,
15000,
18200,
35200,
31300,
7550,
68200,
24400,
29300,
34000,
69200,
72400,
276300,
5500,
2800,
33600,
30800,
null,
58200,
null,
19500,
8800,
75700,
null,
null,
19700,
63600,
46200,
37000,
41100,
8500,
8500,
null,
20600,
18700,
21700,
30900,
25500,
26900,
null,
40300,
13500,
7300,
23700,
73000,
10500,
52100,
null,
37600,
30200,
6600,
11700,
23700,
null,
8800,
14100,
6600,
79000,
107400,
30600,
57700,
35000,
9200,
46700,
15400,
180700,
46500,
82000,
48600,
76600,
50800,
31400,
31300,
16100,
25400,
22600,
3500,
null,
22800,
28200,
38700,
38300,
4200,
4200,
24800,
23000,
16100,
89600,
137300,
15500,
null,
50700,
null,
33000,
42900,
14600,
9700,
30900,
13600,
81600,
60550,
18800,
11800,
25200,
1900,
18696,
70869,
24900,
10900,
148700,
14500,
null,
37700,
56700,
22600,
3000,
21100,
42500,
27800,
42400,
43100,
6600,
2900,
32500,
20100,
27700,
40300,
67300,
48200,
18600,
160000,
10100,
7800,
38600,
36500,
91600,
20300,
11500,
19600,
null,
44100,
8100,
45400,
85400,
78900,
18400,
25900,
11400,
65800,
49200,
21300,
12900,
null,
null,
null,
36600,
15200,
32800,
111800,
40000,
32100,
20500,
30900,
5100,
21100,
43500,
30600,
14900,
66600,
18600,
13800,
34700,
30200,
6400,
75000,
152500,
5705,
19100,
6600,
38200,
44500,
19000,
29000,
49800,
78700,
26800,
74000,
5300,
12600,
20300,
51100,
null,
63500,
55200,
42900,
10300,
130100,
6600,
15700,
null,
null,
34600,
7100,
29000,
17900,
8500,
58000,
15000,
119500,
24800,
24900,
36800,
19300,
12600,
113930,
38800,
10600,
37800,
21600,
43600,
29100,
36900,
11400,
20600,
38400,
21500,
33400,
10700,
36400,
53600,
52800,
16400,
11400,
80500,
8100,
146400,
40700,
19800,
65700,
5300,
46500,
11100,
25600,
48400,
41456,
45700,
13500,
7400,
15400,
69500,
145800,
23000,
170900,
25500,
null,
14900,
41000,
41900,
15700,
15600,
10400,
8400,
7700,
19600,
11500,
81300,
null,
19200,
null,
67800,
null,
12000,
null,
20000,
17200,
null,
26500,
42000,
16800,
55700,
78422,
24800,
15200,
39000,
33200,
26000,
28100,
18300,
14500,
46300,
30000,
29000,
9100,
8500,
10400,
19300,
22600,
null,
7700,
43900,
29800,
6400,
3000,
43800,
27600,
92900,
43500,
65900,
34300,
6100,
27700,
15100,
4400,
13800,
20100,
null,
58900,
3600,
19900,
17200,
24100,
67400,
48300,
null,
null,
null,
8200,
42700,
13800,
2000,
16100,
56700,
33700,
46200,
47400,
22700,
20800,
6700,
15300,
55800,
10800,
40500,
30300,
12500,
25700,
5800,
null,
null,
15900,
26600,
30600,
21600,
14300,
42500,
31800,
0,
99500,
null,
15200,
11800,
7600,
114100,
31500,
2500,
5100,
7300,
50500,
21200,
110510,
34600,
50700,
38900,
null,
14400,
15800,
18900,
9400,
20600,
32700,
49500,
19100,
41900,
47200,
8300,
52800,
22100,
12300,
36600,
9500,
21600,
20600,
84400,
null,
9200,
24800,
20300,
13200,
13000,
12100,
38300,
8600,
27200,
136100,
24900,
12700,
36700,
23400,
7300,
9500,
18800,
16900,
15700,
32900,
70900,
32000,
230400,
5000,
14200,
5700,
51000,
76100,
7400,
17000,
17000,
19900,
19100,
17700,
32200,
9100,
11000,
14000,
5700,
81000,
20500,
28700,
33700,
11300,
6800,
55000,
null,
9400,
30400,
73800,
12500,
8400,
27600,
41800,
71400,
32800,
21900,
9800,
11200,
248100,
43300,
35500,
12000,
6200,
13200,
55600,
9900,
7000,
11700,
39100,
13800,
45400,
9200,
31900,
8500,
22300,
15900,
9200,
41600,
13600,
41500,
8100,
44000,
44000,
14500,
19000,
41500,
21500,
43000,
101700,
null,
null,
85500,
17500,
50100,
7300,
41500,
6900,
13100,
66900,
43400,
null,
43000,
1000,
21200,
19800,
47400,
64600,
42500,
12100,
9200,
23100,
40000,
8000,
25400,
19700,
13000,
32200,
5000,
15600,
53500,
6400,
29900,
16700,
27600,
25600,
27100,
71188,
16400,
18100,
32500,
26300,
null,
33100,
50900,
30900,
20100,
15800,
16000,
20500,
17500,
29100,
6900,
35800,
17200,
null,
2900,
5000,
9000,
23900,
null,
15600,
15600,
5500,
13800,
31600,
21700,
175700,
26300,
15000,
5600,
48350,
5900,
30500,
11300,
20700,
29800,
55500,
28000,
10200,
17800,
21600,
20100,
21700,
20600,
13000,
12000,
null,
15000,
33700,
20800,
14150,
17500,
24600,
29000,
22700,
24100,
11900,
21700,
null,
26900,
5500,
30000,
19800,
35800,
7200,
15000,
null,
10200,
null,
null,
10600,
94100,
67700,
28500,
27800,
2000,
38900,
40300,
57900,
23000,
10200,
23900,
70400,
52000,
34300,
30400,
10900,
33000,
null,
10600,
39500,
16800,
13100,
36600,
121600,
48700,
19400,
16000,
11800,
21300,
24500,
49700,
41800,
157600,
32600,
20995,
84000,
11800,
19900,
8200,
103500,
40000,
88800,
14600,
33300,
null,
34300,
32000,
13700,
19300,
16400,
63300,
19900,
16400,
15700,
25600,
14800,
17300,
42600,
58900,
23200,
10100,
7100,
33000,
27200,
6200,
91200,
7300,
25900,
52700,
46300,
19000,
21200,
15700,
35400,
null,
17200,
17369,
4000,
null,
41700,
null,
42400,
null,
57900,
28600,
5100,
24700,
19500,
34900,
26400,
59100,
29200,
13100,
null,
41800,
45800,
17500,
null,
8200,
10800,
null,
10500,
14400,
51900,
60300,
32500,
17500,
10300,
39900,
12900,
13300,
27000,
83700,
18300,
5800,
23800,
19600,
23580,
29300,
62800,
52400,
41700,
52400,
10400,
20600,
10900,
46000,
13000,
73900,
7500,
36600,
23700,
18200,
36000,
11600,
15500,
63700,
40100,
33500,
7900,
null,
25000,
27700,
10000,
28400,
19600,
19700,
19100,
15100,
42900,
null,
41100,
26900,
65400,
17100,
12800,
16800,
24200,
15700,
14200,
44100,
14700,
11200,
7500,
9200,
15100,
52700,
45200,
13100,
5700,
10000,
37800,
17700,
103200,
5000,
30800,
105000,
null,
38900,
17000,
27000,
29400,
94900,
7600,
42300,
14000,
null,
19390,
11000,
23700,
21200,
13900,
26200,
46600,
32600,
19200,
20700,
23800,
9300,
68900,
36500,
26500,
20500,
28000,
64800,
12200,
12000,
null,
45800,
1600,
34800,
14900,
null,
81200,
null,
30000,
97200,
53400,
106400,
28800,
83400,
7300,
null,
65900,
25300,
41600,
null,
30000,
94447,
35000,
5000,
79700,
null,
39100,
140800,
53400,
36900,
17600,
14300,
21000,
27800,
52900,
35100,
null,
55000,
27000,
21400,
10500,
66000,
28600,
24600,
14000,
6800,
46400,
null,
73800,
28900,
22900,
23700,
17700,
18700,
7500,
13800,
109100,
14300,
29500,
133600,
22200,
154900,
33800,
5700,
null,
32500,
34400,
48700,
8400,
40500,
12300,
20500,
24700,
16900,
64400,
10200,
26300,
17300,
null,
12700,
10500,
130600,
12500,
35800,
11000,
10200,
36100,
15000,
19625,
27000,
16700,
40100,
74500,
8800,
23700,
26600,
13000,
null,
null,
10500,
85600,
59400,
83200,
null,
18200,
24400,
null,
6500,
101400,
7000,
12500,
12200,
23600,
114700,
141550,
13500,
15200,
57600,
57000,
16500,
34200,
89800,
53705,
16200,
7800,
42600,
41600,
24900,
null,
18400,
14600,
22800,
66800,
30800,
28500,
6700,
32000,
11000,
16500,
11450,
null,
18000,
12700,
60200,
8500,
41100,
19700,
26500,
7300,
16000,
null,
34300,
22700,
7100,
58000,
55200,
76804,
32800,
65000,
48500,
6150,
5000,
10800,
79600,
13900,
null,
15800,
89500,
null,
22400,
12100,
24200,
15500,
31700,
22400,
31600,
104100,
77900,
27100,
26800,
10400,
61100,
29000,
48000,
41200,
25000,
30400,
70500,
38100,
11600,
null,
20100,
25200,
4200,
null,
127100,
11400,
67700,
64500,
10300,
null,
null,
5800,
null,
37400,
94600,
null,
12400,
48600,
56200,
20700,
16200,
80700,
51600,
194800,
17300,
120900,
15400,
6200,
19100,
13800,
23700,
9400,
10700,
27600,
24900,
9600,
18000,
6600,
23500,
3500,
12400,
19300,
23000,
33600,
3200,
44200,
56600,
39800,
null,
null,
23254,
71300,
252300,
7500,
47800,
27400,
34500,
22800,
null,
2500,
13500,
116100,
39800,
19000,
17100,
17500,
54600,
72900,
9200,
16700,
64900,
17000,
20100,
31400,
null,
25500,
75300,
42000,
9400,
9600,
15200,
22400,
79400,
82300,
null,
68500,
41300,
171300,
32900,
27000,
14900,
12400,
26300,
192100,
74400,
22600,
23100,
9000,
27300,
11200,
10500,
84500,
22300,
22100,
31200,
9600,
3300,
42100,
null,
26700,
null,
15000,
29200,
11300,
8100,
46800,
null,
84800,
null,
37700,
5500,
48100,
null,
39400,
14900,
13050,
7400,
28000,
20300,
null,
null,
84600,
31000,
17700,
3700,
15600,
11600,
26900,
120000,
33000,
11000,
29800,
19400,
36100,
78600,
16300,
8400,
7500,
8900,
34800,
29000,
8265,
25600,
10700,
52400,
73200,
28700,
16500,
24200,
8600,
10200,
95055,
13900,
11100,
21500,
11000,
29500,
72100,
18100,
117900,
6700,
48000,
12300,
66894,
28100,
9800,
23900,
17600,
27300,
48300,
9000,
18600,
2900,
61200,
42500,
21700,
26000,
16000,
14000,
79100,
19800,
62600,
27700,
34400,
14000,
52300,
41900,
17017,
13400,
23600,
24200,
21200,
null,
16500,
33000,
24500,
23500,
20200,
25300,
23600,
35600,
18200,
33800,
8600,
5100,
84200,
29800,
16000,
3100,
25600,
38200,
36500,
null,
23900,
47200,
null,
27100,
41600,
33200,
11300,
39800,
9000,
null,
41015,
null,
1500,
13500,
48000,
null,
11200,
49000,
7900,
33400,
null,
5000,
153900,
null,
15000,
35700,
25500,
17500,
48200,
null,
6100,
16600,
69900,
19300,
null,
16500,
40300,
19300,
16000,
17500,
42050,
14000,
60800,
10100,
11700,
26300,
null,
5600,
12400,
9800,
29600,
9500,
38200,
15800,
37900,
18900,
59500,
null,
28400,
15000,
null,
15400,
63000,
21500,
36900,
57600,
57900,
9600,
41200,
43200,
37400,
15700,
51600,
71300,
31400,
29100,
8700,
25800,
12800,
27500,
10100,
9700,
6950,
219700,
36000,
40000,
26400,
14000,
17100,
14900,
42000,
35500,
27800,
11300,
19200,
16200,
43700,
47726,
null,
null,
18500,
1800,
14700,
3500,
null,
94100,
31000,
33000,
32900,
6000,
96500,
34200,
47300,
15500,
9500,
211400,
9500,
25500,
30100,
30900,
15700,
16866,
22900,
12100,
37500,
28500,
13700,
38000,
14400,
54500,
21410,
45700,
28200,
27500,
17300,
15700,
17100,
10000,
8600,
20800,
42400,
29600,
26200,
39100,
15700,
8000,
18900,
null,
40000,
35400,
63200,
77300,
78400,
35200,
82200,
21800,
203100,
48700,
5100,
510200,
46100,
29100,
null,
52100,
26300,
null,
46400,
12300,
47700,
2300,
36300,
49900,
6600,
23200,
8000,
26100,
null,
43400,
6200,
18700,
7000,
9000,
13700,
16300,
18100,
16600,
49200,
69400,
101100,
17400,
21900,
38000,
19200,
10300,
36725,
6400,
5500,
32100,
61800,
9600,
11600,
24100,
10500,
29600,
null,
null,
null,
29200,
22800,
34700,
17100,
41900,
42700,
12800,
137800,
35000,
17900,
17100,
9900,
21000,
31900,
null,
54771,
19300,
11700,
20200,
49900,
31500,
51600,
21965,
46100,
72400,
18400,
32700,
90600,
null,
null,
36300,
23900,
9300,
22900,
10900,
21200,
20900,
55600,
27000,
26100,
11400,
132400,
42900,
43600,
62800,
41600,
null,
105700,
39100,
null,
53718,
51900,
72300,
27800,
42200,
17700,
31300,
34000,
64000,
12700,
18500,
22600,
25000,
66200,
12300,
12800,
null,
28400,
26400,
10400,
10500,
20200,
24700,
null,
46700,
36300,
11200,
6200,
25600,
null,
38500,
13800,
8200,
18500,
22900,
8000,
231400,
33300,
19800,
17800,
11900,
14400,
16700,
43400,
76600,
25700,
30100,
15900,
11500,
25800,
30200,
64900,
23700,
24400,
17300,
8300,
23500,
19500,
38000,
84500,
12500,
21000,
15829,
21700,
30400,
25000,
null,
6900,
57300,
170200,
2100,
13500,
10100,
61500,
20300,
23600,
33800,
2300,
15900,
33400,
12900,
8800,
5500,
32600,
7500,
61600,
16200,
41200,
9500,
8500,
37400,
6000,
10900,
13900,
22300,
41301,
9500,
33500,
21900,
41200,
25000,
23800,
22400,
53900,
7700,
11400,
53700,
60100,
27400,
null,
36400,
188800,
23900,
5000,
45800,
11200,
9500,
15700,
36100,
68000,
14700,
40100,
21400,
null,
39300,
81000,
31000,
11400,
22800,
13200,
106000,
25500,
25300,
11500,
19700,
null,
16300,
12500,
null,
9800,
26500,
23500,
null,
20900,
18300,
28800,
12700,
6100,
5000,
16100,
39800,
32300,
null,
18500,
22500,
7800,
28500,
26200,
21000,
95500,
37300,
31400,
21000,
null,
19800,
21500,
15200,
12900,
14100,
null,
16500,
47300,
3300,
12300,
22300,
14000,
14700,
6000,
37500,
10000,
69100,
23700,
32600,
26600,
9200,
20100,
4900,
5600,
15200,
null,
42300,
9400,
47700,
42200,
26800,
30600,
25800,
6600,
61000,
33200,
null,
27700,
44500,
14300,
36900,
4000,
20200,
89500,
47300,
12000,
19000,
41900,
29300,
28400,
118100,
43127,
68200,
16700,
45800,
49000,
39300,
19300,
48600,
15800,
17100,
5800,
15000,
31500,
1900,
12400,
8700,
17700,
17700,
15300,
3300,
55100,
8025,
38200,
18600,
128100,
99400,
20500,
47500,
24300,
53800,
32400,
null,
27900,
52600,
37500,
23100,
5600,
8400,
11400,
24200,
6000,
32600,
34700,
null,
61800,
22600,
4800,
27800,
4000,
32900,
29200,
12700,
14200,
10700,
29000,
15400,
33600,
30500,
58500,
12800,
null,
33200,
37800,
26650,
150400,
39900,
63500,
17800,
3600,
15200,
9900,
18300,
13500,
24300,
51600,
29300,
108800,
10100,
19215,
null,
22300,
21985,
25800,
null,
27800,
30000,
11200,
18500,
22700,
32600,
67700,
89800,
57000,
27300,
26900,
73700,
15300,
33500,
62700,
8700,
12200,
52500,
28700,
6200,
null,
7700,
11100,
20100,
15000,
35500,
33900,
53800,
10100,
34600,
27800,
5700,
64600,
8900,
6100,
9100,
225805,
null,
11200,
24900,
9700,
9700,
27900,
25300,
19000,
49200,
45630,
13200,
16700,
28900,
13300,
31400,
25500,
17700,
16900,
null,
900,
22800,
37000,
8900,
37000,
58400,
16000,
29500,
22400,
null,
null,
28000,
14900,
7500,
5500,
14200,
null,
50700,
15000,
15300,
null,
null,
74500,
44100,
24300,
15400,
5100,
11700,
18800,
33600,
37000,
19900,
15100,
24700,
3300,
7100,
36100,
40700,
30300,
18600,
5000,
18100,
71500,
19700,
14900,
33400,
43800,
13500,
23700,
24900,
27500,
9300,
25200,
16000,
39300,
25100,
21900,
29900,
18800,
24500,
31400,
17300,
37800,
8000,
9400,
28800,
null,
26200,
56600,
59500,
8100,
36100,
44300,
138800,
29000,
14507,
26100,
19400,
null,
49200,
20300,
70800,
21700,
20300,
18700,
30200,
62100,
31400,
14400,
35400,
36100,
5600,
20600,
24400,
77000,
64900,
19800,
135400,
5600,
21900,
10800,
22200,
null,
9600,
19300,
21500,
19300,
null,
28800,
32500,
6700,
75500,
59200,
null,
null,
52100,
29900,
14200,
65000,
24900,
16400,
18600,
22700,
10300,
21100,
24000,
110400,
10300,
38300,
19100,
11400,
27500,
31700,
16500,
15000,
null,
7400,
14200,
23800,
64500,
21000,
25800,
47800,
46700,
22300,
11800,
16500,
26700,
42000,
98100,
34600,
21200,
9100,
35620,
null,
43400,
31800,
30900,
20400,
21300,
15600,
70300,
39600,
null,
28220,
55100,
28100,
34300,
95900,
null,
34150,
3000,
17700,
33100,
10900,
46100,
14500,
36000,
12700,
8800,
null,
18600,
30400,
27000,
13200,
58500,
18200,
27000,
5200,
10500,
36000,
25100,
47900,
29400,
9600,
66300,
36700,
null,
36500,
33200,
57000,
72300,
23500,
13100,
248400,
9800,
15600,
null,
49439,
15600,
56701,
23600,
41800,
37400,
21400,
81100,
58100,
12300,
21600,
null,
27900,
14000,
8100,
24000,
9500,
10500,
12900,
5550,
51100,
22000,
7600,
14400,
20900,
15400,
7000,
25800,
9600,
null,
7500,
9200,
9800,
50900,
30500,
38800,
35800,
40300,
30900,
16400,
13700,
92100,
23900,
10200,
4000,
44400,
16300,
28800,
11300,
4400,
3700,
21980,
7700,
59600,
64600,
34100,
34700,
15300,
28400,
42200,
18200,
27600,
60200,
10000,
22000,
7750,
14700,
22600,
null,
4500,
7900,
67000,
70200,
33700,
25700,
132100,
16300,
null,
13150,
8200,
22800,
null,
30700,
46000,
36270,
22000,
null,
13200,
49200,
32200,
4300,
null,
21500,
25400,
77200,
20300,
null,
34300,
42600,
8600,
0,
17300,
35400,
53000,
32900,
19100,
42500,
null,
6500,
9300,
32100,
66900,
35300,
39700,
42100,
22700,
15000,
27800,
112800,
18800,
25400,
72806,
38500,
29200,
7800,
34800,
28100,
26500,
12100,
123600,
null,
15800,
81250,
11300,
17300,
23400,
64300,
12900,
7600,
4900,
9500,
16800,
32600,
47100,
110100,
20700,
2400,
10400,
36300,
15700,
11900,
15600,
7100,
70100,
null,
null,
11200,
30900,
10400,
17400,
37700,
31600,
6000,
28200,
16500,
24100,
15900,
46800,
35000,
null,
2600,
7500,
18500,
69300,
24400,
59700,
45600,
12500,
7900,
19700,
30000,
5500,
18800,
75400,
5500,
13100,
23800,
35100,
null,
10000,
5700,
15300,
null,
22300,
39300,
43700,
12000,
19500,
68100,
15500,
19600,
15700,
56000,
17400,
6600,
16600,
45000,
8450,
null,
16500,
30600,
null,
63100,
30000,
7200,
null,
3700,
22600,
56100,
117600,
40300,
59700,
41100,
19600,
18700,
14600,
18200,
25000,
28800,
27800,
68800,
23100,
null,
106800,
30500,
13200,
23600,
20500,
70300,
11300,
32100,
61000,
null,
64600,
50600,
11900,
46600,
30830,
27200,
21200,
23400,
6000,
16700,
5500,
30200,
11000,
56000,
26700,
13600,
102300,
36100,
138700,
14600,
6200,
13700,
9000,
19900,
10800,
19700,
null,
21400,
27900,
41100,
30100,
39800,
33250,
40400,
65800,
64400,
16900,
null,
27500,
98200,
29400,
11300,
10500,
34600,
15700,
19000,
18200,
91400,
20300,
80220,
11300,
14100,
65700,
null,
18100,
17000,
37500,
36000,
5900,
17000,
27600,
25700,
151600,
26800,
33400,
47800,
35500,
13900,
17300,
80800,
13300,
null,
20500,
8900,
53200,
24900,
null,
30900,
null,
null,
18600,
313000,
19800,
11200,
10600,
null,
3400,
26100,
38500,
30400,
25100,
16900,
2800,
27600,
15300,
50700,
17600,
77000,
42000,
43200,
13300,
30400,
17600,
19600,
null,
55300,
22000,
32000,
73300,
11200,
29200,
22200,
20700,
14600,
43600,
25400,
15900,
44800,
10900,
20000,
27600,
4600,
null,
13700,
48200,
6000,
58600,
11000,
36600,
7500,
56700,
34000,
19900,
32700,
10500,
21800,
21100,
13300,
27600,
89000,
8100,
null,
23100,
33830,
167500,
54200,
21300,
29100,
21800,
15300,
13000,
81200,
38900,
null,
7100,
41300,
24800,
65500,
10400,
16800,
null,
22300,
16700,
17300,
4200,
28900,
22300,
17500,
52200,
8250,
30200,
5700,
56500,
18900,
41000,
20200,
56200,
10800,
10500,
31100,
83800,
39500,
12400,
230200,
22100,
23300,
37600,
53000,
9600,
6950,
51100,
6500,
104500,
16400,
55500,
21100,
9200,
4100,
17700,
22000,
9200,
8500,
null,
25000,
47700,
26000,
19200,
34100,
2500,
null,
13500,
60300,
23400,
31900,
26000,
83124,
26400,
40200,
163000,
28000,
null,
18900,
9500,
12300,
22700,
null,
52800,
null,
4700,
7000,
19300,
28900,
12900,
10200,
19600,
47100,
22100,
22200,
8500,
17800,
35700,
16700,
39600,
53100,
16200,
null,
60300,
46800,
278200,
14100,
21700,
37100,
33500,
16900,
38385,
null,
50600,
45900,
15100,
53900,
14800,
72900,
21700,
40500,
37500,
22800,
61800,
null,
13700,
42400,
20100,
20600,
7637,
74300,
57400,
15700,
4450,
22200,
39274,
null,
25600,
null,
10700,
20100,
24500,
19400,
null,
36600,
6200,
12500,
9300,
132900,
23900,
22000,
22700,
40900,
52500,
null,
19400,
16200,
14000,
27700,
28800,
27300,
37700,
49700,
8600,
73100,
1500,
35600,
24400,
84000,
27100,
27700,
56600,
8500,
null,
30700,
10800,
18700,
5400,
23500,
16900,
41900,
17400,
39400,
8000,
14000,
50500,
13400,
29900,
17600,
7300,
23600,
28000,
25600,
92400,
197100,
4200,
37000,
7300,
6500,
32700,
6400,
11900,
18900,
4700,
12900,
null,
28000,
19300,
null,
27450,
24900,
13900,
17800,
13200,
18700,
21700,
2538,
53900,
35400,
11000,
21800,
22900,
23600,
44500,
15000,
8500,
24700,
42400,
21800,
4800,
8100,
5100,
25400,
9800,
1000,
28200,
146800,
52500,
20200,
41400,
12500,
32000,
9000,
5000,
66600,
31300,
26300,
13800,
68600,
38900,
71400,
38900,
88100,
35950,
43400,
26600,
15200,
15400,
20500,
8100,
68700,
null,
16800,
15100,
9800,
19500,
11300,
7300,
33600,
80600,
11100,
8700,
11100,
26400,
103500,
null,
96300,
18800,
65500,
37100,
52600,
10700,
7100,
30300,
40600,
29900,
34800,
23100,
85100,
12400,
43900,
5300,
11900,
16800,
15200,
null,
49600,
55200,
24000,
8800,
21000,
18000,
42900,
44400,
11100,
21300,
38200,
4400,
49400,
24500,
33400,
19200,
55300,
14100,
42900,
27300,
58020,
47600,
14700,
10800,
16000,
15700,
15400,
15500,
7400,
74850,
18300,
47000,
43400,
18700,
19100,
29000,
7800,
4000,
8200,
11800,
34700,
16500,
28000,
16000,
20800,
28200,
71100,
7200,
17100,
19000,
48500,
null,
156700,
47600,
17800,
7700,
19800,
41700,
67800,
13700,
14800,
12100,
13100,
13100,
8500,
15600,
39900,
53300,
29600,
36700,
46300,
122900,
28900,
22300,
19400,
6300,
14600,
21700,
20200,
48500,
36000,
17500,
52000,
55100,
94900,
68800,
33600,
44200,
40000,
3100,
60100,
35600,
25300,
23800,
52900,
45300,
68600,
16000,
14900,
29100,
17500,
22000,
17500,
null,
19100,
11500,
52100,
32700,
4200,
227150,
45000,
6100,
11400,
79800,
38700,
null,
7500,
57100,
3600,
39100,
8000,
57400,
62300,
33400,
10200,
80200,
null,
null,
28900,
19800,
55700,
null,
10100,
31300,
27500,
54100,
null,
17300,
null,
29800,
null,
42400,
43000,
17300,
47600,
20600,
7900,
64700,
11100,
44500,
null,
55600,
25200,
27100,
15400,
15800,
10900,
29300,
8200,
32900,
17800,
null,
33400,
16000,
15500,
18600,
15700,
45400,
25600,
16100,
6200,
46500,
null,
4600,
11400,
85000,
7500,
6300,
140700,
16500,
12200,
42900,
35700,
null,
6600,
14200,
8700,
19800,
11800,
42000,
13800,
40000,
null,
7100,
24900,
29000,
55600,
36200,
10800,
13200,
343500,
8700,
22200,
13100,
16700,
13000,
null,
14500,
null,
5400,
10800,
27900,
113168,
9200,
8600,
33356,
null,
33000,
24800,
9800,
14800,
19400,
29400,
147400,
10100,
22400,
27000,
39300,
101900,
14600,
21100,
33000,
44800,
35500,
68300,
17000,
27700,
17100,
41600,
85100,
50200,
null,
17600,
45600,
9500,
21200,
47500,
22000,
12300,
33500,
23600,
12100,
36800,
null,
59400,
28100,
22650,
27300,
null,
8850,
11800,
49300,
16100,
15200,
24700,
25600,
28700,
28800,
214100,
null,
8600,
12700,
11800,
11200,
21500,
null,
32800,
28100,
30500,
21400,
16100,
12300,
50800,
35900,
79300,
11700,
60800,
14500,
null,
10600,
7500,
112700,
13400,
16500,
26000,
56000,
8700,
51200,
28300,
null,
20500,
50600,
59700,
18000,
15700,
20300,
32700,
17700,
11200,
14900,
18500,
55500,
14600,
11000,
null,
14400,
12200,
64400,
103700,
42500,
19900,
170500,
23900,
118900,
37600,
null,
24900,
59500,
7300,
null,
13200,
126245,
7000,
20600,
29800,
38400,
11300,
12700,
16800,
17000,
25500,
21800,
23500,
17000,
43000,
86300,
15700,
62500,
9700,
115000,
16584,
null,
2500,
26100,
null,
9500,
10300,
19700,
6550,
35298,
24000,
33500,
18000,
15700,
11500,
22400,
null,
22000,
13600,
58700,
8300,
35500,
29000,
11200,
12300,
15500,
27500,
18400,
null,
42400,
15900,
54425,
13300,
13300,
null,
33700,
5300,
null,
27300,
4800,
22100,
6010,
21900,
null,
21400,
79100,
6900,
16100,
25100,
49100,
25172,
31700,
65200,
21700,
7400,
13200,
37800,
22900,
33800,
30600,
48500,
25000,
97600,
23700,
21780,
26600,
2900,
10000,
37000,
null,
32600,
25100,
19500,
17500,
58400,
17400,
10000,
12500,
37200,
11700,
48000,
48800,
19500,
13700,
68000,
11400,
36500,
10700,
84600,
8700,
19700,
11400,
18800,
16200,
52300,
8500,
13800,
15000,
59800,
23600,
25400,
27900,
25200,
29000,
null,
26300,
42300,
52000,
51300,
50800,
47100,
null,
15200,
8100,
63700,
36500,
4100,
47325,
25300,
23200,
14900,
231200,
44200,
54700,
null,
13500,
20400,
49200,
34700,
16800,
14000,
20500,
null,
22700,
9700,
52400,
7600,
3000,
null,
24800,
14300,
19300,
80951,
17900,
3500,
47600,
63100,
60100,
8300,
22700,
74200,
45200,
15700,
40300,
220000,
28400,
46100,
66700,
8800,
null,
3400,
15100,
23200,
42300,
27300,
21600,
33000,
46200,
11200,
89100,
23100,
10800,
9500,
7100,
43800,
42600,
14300,
47800,
1000,
42600,
14200,
58100,
8700,
24700,
26100,
24000,
12100,
18500,
18000,
11400,
26600,
30800,
29000,
6400,
null,
19900,
2400,
18600,
22400,
43100,
6600,
93700,
13900,
24700,
25300,
34300,
35600,
36100,
35300,
16500,
37400,
87000,
40500,
61850,
30700,
12400,
14900,
22400,
91400,
43000,
13400,
null,
17900,
9900,
47100,
18300,
11300,
37600,
6300,
33600,
35500,
101600,
15500,
39300,
61700,
42100,
48800,
null,
14900,
18500,
67400,
30700,
7400,
44200,
32400,
20400,
110200,
60200,
116300,
49500,
31400,
21600,
7800,
35700,
29900,
23200,
27300,
7300,
36500,
null,
34200,
56200,
25700,
5000,
26800,
null,
null,
6600,
40600,
10400,
70000,
51500,
null,
2700,
22300,
38100,
15500,
18300,
null,
null,
34400,
26100,
51600,
25800,
69400,
30300,
26200,
37800,
79000,
14000,
30600,
10928,
13600,
53500,
8400,
24700,
44900,
54200,
11600,
5300,
16000,
51181,
115600,
38400,
13300,
184200,
17800,
null,
35600,
24900,
20600,
32500,
35700,
20300,
8400,
29600,
47600,
4300,
53600,
7100,
21305,
157300,
69400,
54200,
61900,
10800,
null,
27600,
39900,
3000,
4900,
14700,
29300,
28900,
33400,
12400,
70000,
35300,
113000,
4300,
32400,
43600,
75300,
35400,
14500,
52400,
34300,
13500,
65200,
41100,
15800,
2000,
11200,
null,
3500,
27000,
163000,
null,
19800,
23400,
null,
53100,
12200,
28100,
9100,
7900,
9400,
42400,
34500,
12300,
56100,
51200,
25500,
11700,
9700,
35100,
32800,
13800,
41000,
19700,
33300,
22200,
17400,
null,
43900,
null,
4200,
2000,
13600,
37100,
16600,
27400,
75300,
27400,
6000,
10100,
38100,
20200,
null,
31400,
28700,
null,
6500,
18820,
21000,
18080,
57300,
null,
119700,
20400,
14300,
29400,
41300,
15100,
11700,
36100,
29000,
22700,
60300,
21600,
35500,
30400,
16300,
null,
28100,
30000,
7900,
24300,
6000,
13100,
104400,
null,
5200,
27200,
39500,
9600,
13300,
36800,
null,
22300,
12400,
null,
25500,
31500,
5800,
null,
12000,
44200,
10800,
25800,
26073,
70203,
13900,
43600,
65300,
21400,
43000,
83300,
7900,
12600,
36000,
16400,
5700,
16900,
null,
17400,
41100,
38000,
8200,
8100,
2000,
31500,
46700,
16700,
17000,
41500,
7800,
21000,
52900,
21300,
20800,
132300,
21200,
5300,
89400,
49400,
13100,
40600,
12000,
119300,
28700,
9300,
36700,
null,
32200,
15600,
11200,
15500,
75534,
20800,
31300,
1400,
13900,
null,
10800,
24800,
25500,
27890,
28100,
20000,
24100,
null,
38200,
3600,
59300,
17300,
6500,
23100,
29200,
45100,
13700,
23900,
36086,
25550,
7800,
26000,
38000,
11000,
48400,
37000,
57800,
9000,
26300,
25600,
6800,
30000,
12970,
87800,
1600,
16400,
24400,
19600,
38100,
20400,
22000,
16800,
null,
58200,
20800,
6000,
32500,
9900,
null,
24900,
59200,
null,
118900,
23400,
43900,
33400,
26200,
11200,
null,
24100,
null,
15200,
10100,
45400,
54500,
20800,
11800,
19200,
68300,
10300,
16100,
4600,
5700,
28100,
118400,
25300,
26600,
15400,
54500,
301800,
28500,
5400,
29600,
66100,
36500,
null,
36000,
18700,
null,
7300,
42400,
14100,
6300,
13600,
16200,
79800,
33500,
50700,
7100,
32700,
5100,
30900,
20500,
null,
39500,
29700,
12200,
35600,
5500,
10500,
null,
64500,
98730,
121400,
null,
7200,
27800,
42800,
83200,
84200,
11200,
43600,
15300,
7900,
37800,
26100,
27000,
47200,
61000,
22200,
32600,
17500,
null,
14800,
15900,
null,
26700,
23200,
13800,
78800,
39000,
13600,
22800,
24500,
23000,
35700,
31100,
null,
54800,
16100,
8676,
null,
11100,
15500,
24900,
2500,
16800,
null,
28700,
10600,
null,
60900,
16400,
21300,
25100,
11700,
19500,
14200,
32100,
20600,
15000,
null,
31900,
17500,
56400,
50400,
16200,
16300,
6800,
28400,
14500,
63900,
11000,
45200,
65400,
23700,
41900,
33200,
35600,
27900,
42300,
7000,
4100,
13300,
44300,
30600,
40400,
48200,
30500,
14100,
36300,
39900,
21800,
10400,
37100,
null,
5100,
5700,
15200,
8500,
10800,
81100,
74000,
21100,
20000,
null,
140700,
164400,
27400,
19400,
15300,
70700,
12000,
20500,
31800,
9000,
14000,
16800,
null,
49900,
67300,
6600,
12700,
31000,
5300,
27800,
20800,
119200,
26600,
22700,
44300,
16700,
71400,
null,
null,
3200,
26000,
13400,
null,
38000,
42100,
34400,
39700,
21200,
31500,
7200,
30700,
77850,
19700,
140270,
24800,
91600,
34800,
9500,
7900,
28200,
10500,
16500,
61700,
25100,
12400,
52800,
12400,
64700,
22400,
null,
15900,
21186,
48200,
116100,
12200,
46500,
19300,
24800,
12800,
6900,
null,
25400,
13800,
10800,
13600,
34700,
4300,
10200,
20000,
46700,
8500,
18600,
80503,
56000,
null,
31700,
55200,
null,
51800,
16700,
20800,
44600,
31500,
24500,
2200,
21600,
28000,
29100,
59100,
30600,
30100,
null,
null,
null,
9100,
13000,
40300,
31500,
16700,
34000,
28400,
29100,
24400,
21700,
95400,
71300,
25800,
null,
8100,
null,
null,
32600,
47000,
25100,
1300,
72200,
22300,
4400,
78900,
136200,
28200,
36200,
17600,
6700,
10200,
21300,
25300,
61800,
25100,
12100,
62500,
null,
14950,
23200,
12800,
37100,
15200,
26200,
22300,
14500,
5100,
null,
28100,
19150,
21500,
21400,
47500,
35300,
11400,
33100,
11200,
44100,
7000,
21300,
179800,
30000,
16400,
13500,
12800,
20600,
46700,
15200,
15400,
null,
53200,
35300,
9700,
26800,
9700,
47300,
33100,
9500,
null,
14100,
73000,
22300,
null,
39900,
4300,
27500,
13000,
13400,
8300,
null,
null,
24700,
88300,
18900,
28900,
10300,
36400,
60000,
null,
36700,
4000,
26000,
25500,
15800,
16100,
16800,
46100,
63300,
73200,
32000,
82500,
12700,
19500,
230000,
7300,
12200,
54600,
15800,
17600,
74500,
17900,
22500,
null,
26000,
36200,
16600,
13100,
22900,
21500,
13250,
14700,
null,
10700,
4900,
44400,
67100,
92800,
37200,
53200,
11000,
null,
13300,
34500,
48499,
10300,
44200,
26700,
null,
400,
3100,
12300,
21100,
7400,
5500,
23100,
37200,
28700,
27014,
181900,
12300,
6900,
41900,
12700,
29700,
24500,
44900,
10400,
14700,
null,
16600,
13500,
57700,
14300,
75150,
9500,
4300,
14500,
20300,
28300,
54700,
45300,
11000,
null,
10800,
4000,
50600,
21900,
55400,
31300,
50400,
13200,
9600,
16100,
8300,
22600,
35100,
32300,
29200,
18200,
69600,
9000,
26100,
18000,
1300,
27500,
56100,
8000,
6800,
9200,
22100,
11300,
null,
35000,
8000,
66600,
29700,
43500,
22600,
7300,
45300,
53800,
null,
24000,
32300,
17500,
17400,
2900,
700,
8100,
23600,
18700,
21200,
17200,
36700,
47000,
15900,
11000,
15900,
15100,
53130,
92000,
59800,
null,
23300,
39100,
14500,
4000,
3100,
21900,
29300,
null,
17100,
32000,
14600,
12200,
30640,
57000,
25200,
38000,
22600,
4900,
83100,
14200,
8400,
54400,
70000,
13400,
14300,
16500,
12500,
7600,
30900,
82300,
43200,
21600,
7400,
20500,
66500,
23500,
34100,
8100,
129400,
7000,
85200,
34000,
44700,
49100,
10700,
13400,
46400,
41000,
43500,
72700,
11100,
23300,
22800,
23100,
21300,
20500,
116425,
11600,
49500,
50100,
19700,
14500,
47500,
35600,
10400,
14500,
14700,
null,
null,
59100,
31100,
24100,
65533,
59600,
25800,
16300,
null,
null,
24300,
10000,
15800,
26900,
null,
15200,
66400,
19675,
6200,
47400,
30500,
15800,
null,
54200,
11400,
48600,
51300,
13200,
35300,
52000,
41200,
27600,
14900,
24700,
3500,
15900,
68400,
16700,
11100,
5000,
41200,
18200,
15200,
46100,
63000,
9800,
19600,
12600,
11100,
15300,
17300,
13400,
15200,
7825,
31500,
29000,
12700,
11300,
161100,
77920,
22900,
17800,
36200,
36500,
13900,
30700,
16600,
null,
17300,
16000,
43600,
15800,
7300,
null,
34900,
14000,
26400,
69929,
6400,
65000,
12200,
46000,
32000,
10000,
51000,
31000,
11800,
56600,
37600,
50800,
78300,
11500,
34800,
10200,
30000,
13600,
83300,
14600,
23200,
8900,
19600,
22400,
42400,
8500,
null,
73800,
18300,
5800,
36600,
30800,
16300,
4600,
54400,
88200,
84300,
16200,
33500,
25300,
9400,
11700,
41000,
6800,
19500,
12700,
14400,
null,
46300,
12300,
47200,
30100,
34300,
78700,
27000,
39000,
26100,
75700,
3300,
23500,
8300,
3800,
14900,
31900,
35900,
25200,
37500,
129500,
30600,
26000,
8500,
23700,
33600,
21000,
null,
24100,
null,
9700,
null,
62900,
25600,
48900,
42800,
64800,
15800,
23500,
15600,
41000,
34800,
52900,
40500,
16700,
42600,
15000,
9200,
20000,
23700,
27900,
44300,
null,
20400,
null,
37600,
10600,
18800,
14500,
76400,
16300,
7300,
70000,
26100,
21700,
20100,
26600,
24700,
15500,
43300,
88200,
83600,
63100,
7800,
178100,
20300,
15200,
6800,
23200,
7100,
34200,
null,
46300,
13700,
8800,
37400,
41600,
31800,
29500,
19300,
355000,
39400,
12802,
82800,
21600,
37200,
7400,
32900,
11900,
45500,
31000,
13500,
6200,
38600,
25800,
9000,
8900,
77100,
67500,
32000,
163700,
6400,
10700,
14500,
34700,
null,
115500,
70100,
26000,
19800,
20900,
39600,
20700,
72200,
6600,
10500,
null,
43700,
29800,
2600,
12200,
42700,
16800,
65400,
null,
23200,
17600,
12500,
27900,
16700,
17300,
200800,
9700,
30200,
24100,
62300,
10100,
14500,
105200,
42800,
13600,
null,
null,
92200,
10500,
69600,
12400,
151100,
15700,
50000,
24800,
24600,
47600,
48900,
33000,
14700,
14900,
17400,
48800,
40000,
40400,
24700,
12585,
6300,
22800,
94900,
31910,
14600,
null,
12600,
33100,
9900,
13300,
18300,
26300,
14300,
9800,
65400,
33200,
81700,
null,
23400,
63200,
31300,
7900,
59600,
18500,
31000,
52800,
54215,
90100,
74500,
18000,
68700,
null,
13200,
13500,
null,
37700,
75700,
8500,
51800,
9500,
110300,
14800,
45200,
8700,
5600,
11900,
15800,
55300,
32500,
6900,
19900,
11000,
13500,
3700,
35500,
110600,
69400,
17000,
44800,
16700,
4700,
12600,
160000,
17600,
87700,
53700,
52700,
51800,
6500,
58300,
17900,
5800,
29600,
7500,
15600,
28600,
11100,
7200,
58000,
36900,
44400,
30700,
28700,
5600,
32200,
15900,
15300,
13900,
26800,
11500,
46500,
40000,
7400,
10500,
34600,
5500,
50500,
67500,
25100,
128500,
2800,
8500,
28800,
24600,
23600,
39300,
7100,
5100,
26600,
24300,
58000,
40100,
12450,
16600,
16300,
20900,
9300,
8500,
26800,
161500,
16000,
8700,
33500,
8600,
60500,
8900,
47700,
108500,
56800,
17700,
16500,
56300,
98600,
36600,
24711,
9300,
24200,
22800,
16800,
16600,
35600,
133105,
72000,
null,
22900,
23900,
14800,
17000,
null,
null,
33100,
21300,
null,
37800,
29300,
110900,
26600,
26500,
16400,
24700,
16600,
41300,
20200,
21000,
30100,
38000,
21700,
26100,
17200,
41000,
22240,
22100,
25800,
10200,
23000,
34600,
36500,
19800,
11400,
19400,
71600,
25600,
31400,
63400,
16400,
11500,
null,
null,
35200,
4000,
22800,
21000,
24700,
5000,
9350,
4900,
7000,
10700,
9000,
62400,
15200,
59100,
14500,
28500,
12700,
67000,
13200,
20700,
19600,
null,
42000,
7500,
175600,
33200,
61200,
45600,
155600,
14400,
60000,
23500,
6900,
12700,
26300,
18500,
33700,
19100,
3200,
69500,
15500,
35300,
30800,
25400,
51000,
31800,
5400,
41500,
18900,
19000,
59900,
20400,
15900,
40500,
8100,
23500,
8200,
50682,
17000,
36000,
null,
12227,
18800,
106300,
28700,
40500,
null,
28000,
82000,
12300,
18300,
19900,
36500,
15400,
37200,
18800,
41100,
17000,
12800,
58700,
26100,
17800,
57000,
16500,
31100,
21900,
21700,
11600,
25800,
3300,
10700,
24000,
43500,
null,
118400,
55700,
30733,
32800,
9800,
71745,
8500,
4300,
26700,
83600,
13400,
78762,
12800,
19200,
5200,
30415,
2500,
20800,
11100,
5800,
47200,
11200,
6500,
7500,
30300,
156700,
28600,
12900,
null,
22100,
7300,
9800,
null,
20300,
32600,
10000,
46200,
69900,
20400,
53800,
11300,
51500,
33500,
22400,
7100,
30700,
9700,
32800,
22000,
11000,
null,
102100,
62100,
null,
54200,
8300,
28800,
28500,
null,
22600,
20500,
18400,
19700,
24400,
8300,
124900,
17800,
31600,
13300,
24700,
7200,
331000,
26700,
50400,
19200,
20700,
null,
10500,
6600,
8200,
6800,
40500,
27000,
26100,
24500,
9700,
35500,
95900,
15100,
12500,
33700,
119806,
8700,
19500,
16900,
65600,
8900,
30000,
25800,
16800,
30800,
9800,
24800,
13500,
86100,
10800,
1900,
null,
13700,
null,
98200,
11500,
44500,
42200,
31500,
18700,
29900,
15200,
12500,
31300,
10000,
22700,
30800,
18047,
7000,
14300,
null,
41300,
64100,
58000,
44101,
20600,
23400,
37000,
11300,
null,
25400,
10800,
70200,
46100,
7700,
29500,
25700,
19200,
60100,
80100,
35900,
67200,
39500,
16600,
44200,
8100,
25200,
null,
76600,
12200,
13900,
19300,
17500,
26400,
45400,
38100,
12200,
null,
19300,
16200,
null,
45600,
28000,
39700,
43200,
20300,
15100,
45000,
5700,
24100,
7800,
15100,
95800,
54800,
22300,
13600,
4800,
27000,
9600,
41600,
8500,
null,
12800,
31600,
52100,
14000,
36700,
66500,
26200,
28512,
14800,
5200,
null,
100400,
39000,
24800,
22177,
null,
21300,
26500,
53400,
42100,
39000,
5500,
43300,
null,
16300,
15900,
null,
55900,
11000,
16076,
79415,
null,
14900,
4900,
10700,
20600,
34600,
122000,
50300,
13000,
28800,
124300,
33900,
26400,
13700,
145500,
null,
17600,
31300,
6600,
11100,
49300,
31900,
14200,
2700,
null,
21100,
19600,
8500,
null,
21900,
51400,
27000,
13000,
17100,
null,
39800,
48900,
27700,
15000,
18200,
14200,
10800,
41200,
15300,
17700,
11600,
null,
14100,
null,
43200,
16600,
22100,
35500,
25200,
null,
94100,
48200,
22600,
22400,
83383,
19100,
11800,
46300,
41900,
17500,
20300,
38700,
26700,
5300,
10700,
35200,
30200,
45600,
11000,
15900,
10600,
18000,
25090,
19300,
14300,
7300,
22800,
16600,
60400,
6700,
67290,
33200,
32000,
17300,
67700,
11400,
103900,
13500,
17700,
33800,
null,
3300,
2800,
52700,
107000,
55400,
23100,
50300,
53500,
38300,
68000,
35400,
19300,
5000,
19600,
67000,
null,
19400,
5500,
58500,
22500,
27200,
17100,
37200,
54700,
34500,
9900,
26800,
12100,
25800,
36800,
40800,
8400,
null,
30800,
27000,
null,
24000,
24200,
8000,
14400,
21000,
5300,
45100,
19700,
20600,
21500,
20800,
19000,
22000,
15400,
null,
22700,
8500,
null,
92000,
12500,
17900,
null,
75300,
22100,
19700,
19300,
21200,
53700,
58300,
37000,
17000,
7500,
3000,
21600,
18900,
55800,
7300,
130600,
null,
null,
13100,
17300,
41800,
16600,
15600,
16500,
26300,
32900,
9000,
7200,
10800,
3600,
47800,
81500,
25000,
29800,
65400,
2800,
34500,
26000,
14200,
null,
31800,
22000,
52000,
32200,
26800,
4600,
34300,
73600,
27000,
17200,
170900,
22400,
6400,
46400,
21500,
23750,
56100,
10500,
96600,
97900,
42900,
15000,
57800,
22300,
24800,
9500,
12100,
47100,
17900,
56010,
6900,
27100,
18000,
5900,
9900,
4300,
35300,
18800,
52200,
8300,
28100,
null,
17200,
150000,
17600,
24300,
41100,
9800,
16300,
12700,
24800,
24100,
14900,
30000,
12600,
24400,
7000,
109200,
14700,
20100,
29000,
9000,
6900,
9100,
84500,
45300,
66300,
10200,
15500,
40900,
37900,
null,
null,
34900,
10100,
42700,
null,
null,
17200,
67500,
191875,
11100,
27000,
77000,
5400,
11200,
27800,
31500,
59300,
54000,
49600,
68700,
12100,
19600,
28700,
105100,
45500,
78200,
64800,
56800,
38600,
18500,
52200,
null,
6800,
44600,
27600,
12600,
31500,
29600,
45500,
5500,
26000,
30500,
21800,
25300,
80926,
25400,
67100,
57500,
6600,
125700,
16700,
null,
9900,
3500,
17300,
18200,
50000,
5700,
20600,
3700,
12000,
14000,
7100,
11100,
2300,
29500,
13300,
8600,
22800,
13100,
15300,
18800,
32300,
18600,
null,
27500,
57600,
57200,
20200,
18900,
20100,
30000,
39000,
12400,
20900,
77500,
55100,
18200,
16900,
12000,
14700,
7400,
15000,
null,
14700,
33300,
15700,
34400,
27400,
10900,
14800,
70300,
36600,
21400,
3100,
27600,
21000,
51800,
7200,
9300,
36400,
16000,
15400,
29300,
15400,
25100,
9000,
28000,
18200,
5400,
10000,
3100,
42900,
64100,
37700,
44478,
5400,
null,
38600,
29200,
56700,
12300,
12200,
49600,
68800,
117900,
6550,
22500,
18300,
20300,
34600,
10150,
17800,
18650,
5200,
32500,
59700,
null,
14600,
12800,
52100,
24300,
73700,
9100,
7100,
15500,
28300,
27100,
42000,
16100,
null,
32100,
6300,
61100,
16300,
34500,
33000,
null,
12800,
8600,
45700,
31400,
37300,
53800,
22000,
21900,
49500,
35700,
24700,
23200,
70000,
36300,
27200,
24800,
72100,
145200,
null,
13700,
41000,
34400,
8800,
31500,
35400,
null,
14932,
15700,
null,
12500,
42800,
24000,
16800,
null,
47400,
32700,
12100,
8000,
7950,
16300,
29600,
16900,
29000,
69900,
null,
14200,
1000,
101000,
18600,
36400,
200800,
33800,
23300,
57500,
46000,
15700,
null,
50500,
43200,
15900,
17400,
18000,
54700,
19900,
13700,
20300,
15400,
38500,
14600,
19100,
34600,
17600,
18000,
6300,
28700,
38300,
75900,
12000,
4800,
51400,
3300,
4600,
37900,
58400,
50100,
101992,
5900,
31900,
59000,
null,
18200,
12900,
17400,
6100,
48200,
43500,
null,
1700,
62400,
52400,
38000,
19200,
16900,
36000,
7300,
16300,
26100,
96400,
8800,
12300,
null,
11400,
7900,
18400,
28700,
11200,
18000,
29600,
21600,
9800,
6100,
null,
26300,
40100,
null,
22300,
12700,
22300,
13200,
9400,
31100,
33600,
120800,
null,
27100,
23200,
12800,
12600,
13800,
9800,
182300,
36600,
16500,
54920,
19400,
9850,
22100,
14000,
52000,
75100,
23000,
14100,
20100,
21400,
44900,
37700,
488400,
37600,
35800,
54300,
18800,
82000,
39050,
51300,
35300,
null,
38200,
7900,
103400,
16100,
44000,
49600,
16400,
7900,
34000,
null,
149300,
6400,
25800,
null,
39900,
null,
48000,
41000,
28300,
5600,
null,
46000,
98600,
54000,
95400,
21700,
30100,
2900,
48000,
49500,
null,
72400,
11400,
47800,
27900,
2500,
30600,
82500,
17100,
34400,
18400,
36000,
12700,
34500,
10200,
20600,
18100,
14700,
13400,
12000,
51500,
51400,
46500,
14000,
8300,
62000,
null,
87500,
27600,
null,
24100,
29600,
13200,
27300,
null,
10300,
26300,
38500,
46800,
102300,
10800,
8800,
52300,
23500,
31400,
38800,
13700,
21700,
20100,
30500,
15100,
16700,
59100,
48300,
68900,
6500,
25500,
10000,
19700,
60000,
7000,
57200,
14300,
24700,
31900,
null,
59800,
28700,
5000,
2800,
19800,
105600,
22100,
25500,
31800,
19000,
7800,
22500,
38600,
9700,
23700,
31700,
27900,
5500,
15900,
14000,
28100,
32600,
16400,
38000,
4400,
35400,
10000,
20300,
10150,
16500,
58500,
11700,
19500,
38100,
16800,
10000,
174175,
5600,
10900,
6900,
80400,
10100,
19700,
22700,
15000,
46600,
19200,
21400,
29500,
49000,
19300,
35645,
21400,
25400,
51789,
7300,
null,
34600,
18400,
21500,
16000,
11100,
null,
14900,
31400,
9900,
25000,
64400,
22200,
138500,
2800,
19600,
26000,
2000,
30900,
25000,
38700,
15500,
30600,
7600,
12600,
15300,
11800,
6500,
12000,
26900,
78500,
23900,
39000,
8900,
18600,
38600,
34200,
25200,
5800,
125100,
29900,
63400,
14200,
26000,
null,
12000,
27300,
26100,
null,
33700,
20500,
51600,
78300,
30600,
18500,
49900,
4000,
34800,
71900,
53200,
44600,
15700,
25200,
11600,
23600,
7500,
null,
45000,
26000,
10100,
10000,
21200,
52200,
13559,
6900,
null,
40200,
null,
64100,
30000,
5800,
4800,
null,
43500,
5500,
null,
28600,
70100,
607200,
2400,
27000,
35500,
null,
36400,
26500,
18300,
22100,
91600,
41000,
9800,
13100,
13300,
53500,
11800,
17300,
3400,
36500,
24500,
43800,
68100,
10100,
19700,
7500,
11240,
29200,
58800,
25400,
15800,
31900,
21200,
8500,
27800,
39200,
13700,
35600,
null,
9500,
29700,
13900,
15900,
79800,
64100,
49100,
38700,
17500,
23100,
13100,
75200,
19600,
null,
65900,
40100,
48700,
91800,
24700,
27700,
78500,
null,
25900,
22200,
36200,
17000,
20000,
15100,
38300,
32200,
5500,
40500,
17000,
114900,
50700,
26600,
19400,
null,
36500,
null,
19700,
9700,
11800,
18800,
131800,
12300,
22100,
16900,
63300,
19500,
57500,
18700,
24500,
19000,
54900,
56300,
23800,
53300,
9600,
96700,
28100,
95200,
10200,
22500,
47500,
null,
6900,
20700,
null,
9400,
22300,
35900,
16600,
59400,
48000,
2500,
23000,
16100,
23400,
21000,
21800,
null,
15300,
4700,
5800,
59300,
28500,
7800,
7500,
null,
27800,
23400,
7700,
null,
null,
55300,
19300,
null,
17800,
23700,
25500,
null,
178000,
40400,
19800,
35500,
3300,
36000,
46800,
23700,
57000,
20900,
null,
49200,
56200,
24000,
36600,
15500,
45100,
46601,
226500,
58100,
12100,
19300,
34300,
26800,
9900,
51100,
22400,
15500,
57800,
25900,
5500,
21200,
10900,
16600,
16300,
null,
51500,
42300,
17900,
37500,
39600,
24900,
60400,
null,
7900,
4700,
7200,
42100,
14100,
34900,
18200,
39000,
84000,
18300,
16800,
12600,
10200,
19600,
8400,
37700,
38600,
15100,
23200,
28900,
null,
25700,
35700,
3500,
106100,
14700,
14800,
67600,
34800,
21200,
7400,
null,
20300,
1000,
null,
77900,
16900,
11100,
19500,
32300,
8700,
19600,
41300,
13900,
28500,
9600,
9200,
11500,
72900,
15500,
15900,
47700,
22100,
10500,
7000,
13400,
33100,
null,
7100,
12800,
68986,
37000,
null,
null,
40700,
97900,
3400,
null,
4000,
15800,
24400,
null,
null,
53300,
8100,
null,
5300,
56000,
36500,
22200,
54400,
13500,
34000,
20800,
49100,
14900,
12900,
33800,
24300,
55900,
5000,
44100,
27600,
7500,
15800,
40600,
25100,
null,
7300,
14500,
22600,
66400,
23300,
34900,
21900,
17900,
21100,
23400,
50900,
22100,
41600,
47500,
4600,
null,
4600,
30100,
20600,
30000,
28000,
46100,
38900,
11600,
32171,
18300,
27200,
12000,
37600,
null,
69900,
34200,
52600,
22100,
12636,
19600,
15500,
8900,
13200,
5700,
13300,
17000,
5000,
52800,
48100,
null,
31600,
12700,
4200,
30000,
134800,
null,
10900,
35200,
32600,
17700,
58800,
18600,
68400,
8300,
195800,
27200,
null,
81000,
16900,
11500,
13600,
23800,
7000,
122600,
63700,
35800,
11400,
9100,
null,
18700,
17000,
29800,
5200,
51200,
40500,
59500,
32300,
35700,
16300,
41400,
15400,
28400,
3000,
75600,
63200,
8500,
29700,
12200,
23700,
89600,
9600,
21400,
20500,
12300,
33200,
27600,
8100,
27900,
38500,
8400,
32900,
22800,
28200,
134900,
1200,
101500,
20700,
7400,
22700,
59800,
44100,
12100,
null,
26500,
35800,
23700,
81700,
13600,
29200,
10300,
8300,
5500,
15800,
72600,
13100,
24000,
37500,
45700,
27400,
45500,
null,
82000,
6700,
54100,
15000,
13300,
34800,
84100,
12000,
49000,
19900,
33900,
6600,
48000,
81100,
6000,
13700,
20800,
null,
null,
52400,
20300,
5900,
16000,
4200,
48300,
23900,
27100,
15000,
56800,
30200,
35600,
56500,
13700,
11900,
10700,
54200,
13600,
45800,
17400,
47700,
40900,
16900,
null,
6800,
21300,
null,
37200,
6200,
13200,
38300,
44200,
25800,
14900,
57300,
40200,
39500,
30300,
42600,
94900,
14100,
8800,
19200,
9500,
7300,
16600,
15600,
28500,
4700,
null,
166200,
35900,
15400,
6700,
55400,
18700,
368900,
40500,
14200,
15700,
17200,
21700,
null,
5600,
36700,
26500,
22000,
14200,
22500,
2500,
58800,
47500,
null,
69000,
17200,
15500,
53800,
21300,
18000,
26100,
61800,
16700,
45100,
11600,
8600,
22700,
17100,
5950,
49700,
22500,
18500,
37900,
43200,
25400,
32200,
5500,
27200,
11100,
95800,
6400,
7300,
14600,
15400,
42200,
52200,
25500,
42300,
38700,
13500,
30100,
null,
14200,
24700,
124300,
26300,
51300,
40000,
21500,
31400,
20100,
10000,
8700,
5600,
5100,
4500,
22800,
39500,
null,
51100,
19300,
24700,
11000,
700,
12500,
37600,
18300,
52100,
11900,
26800,
19500,
16100,
113000,
55200,
7000,
29000,
84100,
11500,
37500,
55600,
63268,
5900,
68216,
29100,
16800,
23600,
11100,
16400,
44300,
28300,
17400,
27700,
21500,
16400,
25200,
20600,
38900,
18900,
13300,
39800,
null,
7500,
89742,
16900,
26000,
66300,
21200,
12300,
18400,
16700,
12800,
10100,
32800,
7700,
11900,
45300,
5900,
51300,
17500,
28800,
36800,
7700,
18500,
11600,
21400,
39000,
12100,
63200,
50100,
64100,
104500,
15400,
37700,
11100,
null,
23900,
41400,
10600,
25500,
15600,
10000,
5200,
85100,
1700,
64600,
14800,
20000,
35300,
44400,
30900,
23400,
29900,
17200,
19200,
26300,
19600,
49000,
37500,
71000,
9800,
34300,
32600,
17000,
24900,
49700,
45400,
19200,
null,
3500,
263100,
28500,
12200,
43500,
47000,
27650,
16500,
42400,
116700,
null,
11300,
29300,
17800,
13900,
null,
20800,
20500,
20900,
7200,
61500,
28500,
17800,
null,
32100,
100100,
181100,
8200,
16800,
4000,
42700,
null,
8000,
33200,
26300,
6600,
25200,
19800,
7600,
15500,
17500,
7400,
50762,
18900,
39600,
21600,
14500,
33720,
null,
28300,
22000,
181700,
60900,
7700,
77500,
11700,
29300,
6900,
22200,
9520,
37500,
28500,
35400,
24000,
21900,
7500,
18000,
null,
103700,
22100,
4500,
28200,
10900,
13300,
39500,
18600,
null,
24800,
42700,
23252,
19500,
74800,
22200,
20200,
7200,
21000,
23300,
27700,
14700,
58200,
40400,
34200,
33800,
16500,
11300,
59300,
24300,
null,
14629,
20600,
65100,
null,
9300,
150700,
29100,
34500,
33400,
6400,
24400,
40100,
59267,
80100,
22600,
28000,
52900,
14900,
18100,
13900,
23300,
11900,
32300,
7500,
38300,
15600,
null,
32500,
17600,
64900,
13000,
null,
34500,
900,
16100,
30500,
35000,
13200,
7500,
13400,
24600,
9600,
68000,
14400,
13600,
7100,
8600,
27700,
55900,
27300,
37500,
11700,
20800,
16300,
27900,
null,
39300,
58800,
27400,
14600,
25700,
11100,
224600,
145300,
9300,
31300,
23500,
14300,
51800,
17600,
19200,
15000,
24000,
29470,
28500,
37200,
12100,
30700,
21700,
77500,
null,
16000,
5200,
15500,
34300,
31900,
14300,
52400,
28500,
11800,
17000,
43500,
1400,
25400,
4200,
null,
48100,
14600,
10800,
36100,
25300,
54700,
13000,
17200,
50500,
null,
33200,
31300,
28900,
null,
48100,
49500,
6500,
48500,
23500,
null,
21300,
20000,
16500,
37700,
25900,
52600,
27500,
31300,
15500,
45800,
26000,
46200,
9000,
47600,
24100,
17400,
34200,
39200,
41300,
17000,
77900,
101100,
13800,
8200,
9300,
56200,
34300,
45800,
26400,
8100,
20200,
25200,
13900,
15200,
21300,
null,
42900,
null,
12000,
33000,
16500,
21300,
23100,
2600,
76700,
50600,
23200,
10800,
13000,
7900,
17800,
35300,
22100,
11500,
32800,
25300,
19000,
65700,
158400,
28300,
39800,
23300,
0,
15800,
70800,
11600,
25400,
30800,
8000,
14800,
10400,
18700,
null,
26400,
22100,
15800,
32400,
20200,
null,
6800,
10100,
36300,
14100,
56100,
23500,
55900,
60000,
56100,
8100,
27000,
1500,
4900,
36900,
23000,
null,
51800,
15100,
27900,
22000,
140500,
null,
11600,
38800,
48200,
49400,
47200,
25700,
10400,
18800,
1500,
21000,
14700,
46300,
16200,
28000,
12800,
1000,
24700,
19700,
88800,
34200,
44700,
24700,
null,
27000,
26500,
60300,
16900,
98200,
22600,
36500,
28300,
40900,
25400,
14500,
22600,
73400,
24300,
11100,
21800,
38700,
60000,
31300,
7500,
31100,
100400,
4500,
23200,
25300,
24100,
38800,
28000,
50700,
22100,
20200,
31600,
10400,
23900,
null,
53000,
16900,
114700,
26500,
17600,
10800,
8300,
25700,
7100,
32200,
18700,
null,
19600,
48000,
29800,
14200,
30200,
17100,
17300,
8700,
23900,
58300,
43873,
11100,
26600,
33000,
43800,
52300,
31000,
6300,
64700,
89258,
36500,
21600,
null,
9800,
20700,
27400,
12300,
19300,
57700,
null,
7200,
75100,
null,
10300,
20100,
40400,
87600,
27700,
2000,
357900,
38500,
null,
8900,
26900,
31300,
8400,
4700,
14300,
18400,
38200,
16200,
null,
40300,
6700,
63800,
17700,
null,
16100,
14400,
29800,
61000,
16100,
16200,
null,
41700,
19300,
14800,
73000,
6300,
45900,
25000,
8600,
33500,
42300,
13800,
59100,
22400,
18000,
45300,
18100,
12200,
38400,
147550,
9200,
25900,
14200,
23100,
30400,
60600,
25300,
27100,
14900,
6800,
24900,
28200,
null,
12400,
50200,
46600,
55500,
20400,
49000,
44806,
20710,
null,
4500,
20000,
14800,
null,
null,
3500,
32500,
106900,
12100,
37400,
12500,
15700,
23600,
22200,
null,
null,
800,
22600,
51100,
null,
35200,
29700,
null,
20000,
2850,
102400,
null,
30400,
38900,
45000,
26400,
50100,
28900,
22300,
34800,
29000,
33800,
87000,
23800,
18600,
41600,
54100,
13400,
69000,
10200,
56300,
44200,
9500,
77500,
null,
84500,
27100,
22100,
27000,
5800,
null,
23300,
42700,
71000,
38916,
16500,
75400,
10500,
7200,
19200,
11200,
26300,
16300,
40700,
83400,
19500,
17000,
16700,
8200,
42300,
27500,
5400,
6600,
16500,
15700,
42900,
null,
38500,
12300,
12700,
47400,
15400,
17500,
63700,
12100,
24100,
33100,
33600,
25000,
16700,
14400,
61000,
21000,
11300,
99600,
32900,
106300,
7500,
null,
14000,
73600,
25300,
null,
36600,
6900,
11300,
19100,
66500,
4200,
17800,
null,
46300,
19800,
24400,
null,
42900,
34800,
14200,
13100,
40300,
140800,
36100,
42900,
7500,
20300,
null,
49800,
10400,
24100,
35500,
23900,
110000,
56047,
44000,
28400,
15300,
51700,
null,
3600,
28200,
10500,
15800,
25500,
13500,
null,
18200,
26300,
18800,
17800,
21300,
null,
78600,
14750,
34200,
29700,
29900,
9350,
122300,
null,
null,
63900,
47300,
25700,
65700,
22400,
4900,
null,
31000,
147200,
28100,
7600,
21200,
null,
41700,
27800,
null,
7800,
29300,
47200,
17500,
35500,
52600,
null,
14100,
26500,
38100,
18100,
22900,
76300,
91900,
21500,
11600,
29500,
null,
5300,
13100,
63000,
48800,
null,
63400,
13600,
22100,
35300,
13300,
5600,
17500,
93000,
137600,
60600,
28000,
19300,
null,
26200,
null,
11700,
17500,
162900,
21200,
9200,
24000,
null,
9600,
60600,
61800,
50200,
120000,
null,
33900,
17900,
null,
12700,
null,
14200,
9200,
14500,
21100,
26100,
30700,
25000,
46100,
20000,
14500,
9400,
9000,
58100,
15400,
5600,
55800,
58300,
15600,
40800,
19500,
63300,
15100,
2100,
11500,
16000,
9200,
15900,
34700,
46800,
34500,
34300,
11700,
8200,
28500,
14200,
108000,
34700,
4600,
25600,
55900,
19700,
null,
4700,
15200,
18300,
30300,
35700,
58000,
null,
5600,
29400,
27200,
null,
91000,
21400,
null,
10600,
10700,
123300,
13600,
47100,
51300,
32100,
2700,
43100,
14800,
90250,
34600,
22300,
23300,
10600,
4500,
16100,
18300,
13500,
27000,
56300,
23200,
22000,
31100,
2500,
33300,
17300,
76300,
31300,
13400,
18200,
23700,
56300,
30100,
54200,
48600,
29400,
null,
18000,
15600,
30000,
14500,
11200,
16600,
16800,
11600,
86200,
36200,
null,
19500,
93950,
39600,
68400,
62500,
25300,
31500,
78000,
51300,
134300,
22800,
14100,
8200,
27300,
28500,
34600,
55100,
33000,
7725,
41900,
66573,
10500,
14200,
16100,
48600,
400,
12300,
32300,
300,
16300,
72526,
null,
46300,
null,
33900,
4900,
87000,
40000,
40200,
29000,
30100,
26700,
28900,
5900,
7500,
48700,
null,
26600,
9100,
15300,
9600,
27300,
18300,
21000,
83100,
null,
11900,
49000,
null,
24700,
9000,
10600,
null,
31700,
19400,
null,
65100,
28300,
21300,
39990,
52300,
24900,
14700,
13600,
8300,
55000,
37900,
6100,
33200,
125000,
19500,
10300,
29900,
53900,
9600,
null,
34300,
38600,
10732,
21800,
56100,
49000,
15000,
16800,
59600,
12600,
6800,
null,
22900,
26100,
41200,
35100,
34500,
72200,
41000,
19600,
11800,
40600,
47600,
21200,
3000,
14500,
39000,
18800,
10800,
26900,
19600,
86000,
31900,
28000,
41500,
40000,
66100,
22300,
15500,
24000,
20900,
27000,
14500,
55600,
11200,
42200,
126500,
19800,
25300,
24800,
58200,
8800,
20700,
10800,
37800,
75200,
12600,
118600,
35000,
49700,
22600,
22600,
43700,
null,
10100,
74100,
36000,
88200,
52000,
11300,
9000,
null,
166700,
54200,
13100,
7700,
21900,
28800,
39000,
87600,
null,
65900,
null,
null,
7600,
108100,
24200,
17500,
11600,
15200,
92400,
23000,
50000,
18500,
19600,
16400,
26900,
null,
25900,
null,
46200,
52100,
7800,
12000,
16300,
2300,
36900,
10800,
42900,
75200,
17000,
10900,
45100,
null,
21700,
75000,
60800,
25900,
14700,
22300,
43100,
69100,
17500,
57200,
32100,
12700,
null,
null,
5500,
6500,
29900,
13200,
57800,
34900,
17600,
2500,
4700,
41200,
49000,
6500,
51400,
16700,
37300,
11400,
13800,
null,
14700,
26800,
12400,
33306,
53000,
40700,
44100,
41000,
13900,
24400,
25500,
25800,
19700,
null,
7400,
23600,
8800,
16200,
12300,
55000,
31500,
null,
60700,
36700,
16800,
54200,
35000,
31200,
7200,
49700,
28200,
35300,
24680,
11600,
23400,
38900,
114800,
null,
13800,
15300,
17500,
57900,
null,
18100,
31000,
16300,
null,
5400,
7600,
25600,
9500,
48300,
18800,
null,
29400,
22100,
29200,
25100,
48200,
18400,
30900,
60100,
39700,
16200,
17600,
8250,
16800,
19000,
2400,
25706,
67800,
20700,
61200,
33400,
15000,
15500,
19500,
44000,
14300,
20700,
294600,
12000,
13900,
8000,
9700,
20800,
6600,
14700,
null,
87500,
null,
14500,
41800,
6800,
14700,
147200,
11600,
89100,
37100,
22500,
23100,
16400,
18800,
9800,
33900,
4300,
26300,
23900,
10500,
5800,
18100,
24400,
7100,
17100,
47100,
25700,
14600,
78500,
50200,
22800,
null,
6800,
34000,
38100,
13400,
24700,
45944,
5700,
11100,
21500,
9005,
null,
60400,
12100,
43400,
21400,
29000,
23100,
33000,
29622,
15600,
23600,
46200,
10400,
99200,
17400,
null,
26000,
null,
25200,
29500,
4100,
9700,
19400,
31700,
34000,
22200,
16000,
69800,
18400,
24200,
15100,
18070,
24425,
29400,
12500,
23700,
58200,
14700,
30400,
28300,
20830,
22800,
110800,
16100,
10900,
38700,
63200,
43700,
16000,
23600,
94300,
17200,
68700,
59800,
39600,
39400,
25100,
null,
19300,
6300,
11945,
18500,
9400,
6700,
14800,
47300,
60200,
38200,
null,
2400,
43500,
13100,
42500,
11100,
21500,
null,
17500,
null,
61000,
51700,
49600,
9300,
15200,
5900,
23000,
9400,
null,
14800,
41400,
12600,
27000,
96901,
19000,
32200,
15000,
null,
15000,
86200,
34600,
12900,
17200,
14500,
118450,
24100,
11800,
18300,
104100,
15300,
16900,
24600,
3400,
23700,
null,
9700,
16400,
57300,
32700,
17400,
null,
18800,
37000,
38700,
20800,
44400,
10000,
25600,
null,
6900,
13100,
29800,
134600,
46800,
11000,
28300,
7000,
11800,
29800,
29700,
14100,
22647,
48800,
17100,
105000,
12500,
34800,
64300,
13500,
61700,
52800,
50100,
32100,
55800,
12100,
25300,
77500,
33200,
30100,
29100,
21300,
1000,
28200,
58500,
13000,
49600,
42400,
91300,
39600,
60400,
59926,
18100,
11900,
35700,
12600,
12500,
18300,
49300,
32500,
18500,
85700,
null,
29800,
69800,
27400,
17100,
7800,
20900,
41800,
39400,
15200,
29600,
73000,
14000,
42048,
15700,
23542,
21200,
42900,
8300,
22200,
24700,
29900,
12500,
71500,
6600,
38000,
14600,
197700,
76200,
53300,
4900,
39600,
5600,
17900,
17700,
24600,
10800,
22700,
19700,
48100,
24200,
null,
11600,
27300,
23500,
21200,
75100,
26800,
null,
24100,
47000,
45800,
11900,
69400,
31700,
16700,
8600,
55404,
35950,
69000,
5100,
28000,
20300,
33250,
51600,
26800,
56500,
7300,
56800,
56800,
39500,
103000,
16600,
39600,
18100,
13800,
232500,
14500,
38900,
134900,
20500,
40200,
12000,
49723,
32900,
38600,
54300,
41500,
69600,
13100,
2000,
65100,
26100,
16800,
40200,
35300,
1600,
15300,
137800,
null,
30300,
null,
null,
7400,
17400,
13800,
3200,
52300,
5900,
104800,
72300,
25400,
43000,
24500,
null,
21300,
124700,
72000,
14400,
11900,
22800,
34100,
53300,
5100,
31700,
82000,
4600,
19900,
4600,
24400,
41600,
9200,
11600,
9300,
17500,
22300,
8100,
30500,
36100,
8800,
7600,
46579,
8900,
11500,
17800,
49400,
18500,
35100,
24600,
13000,
75500,
37200,
2800,
6500,
94900,
19500,
13000,
23200,
10200,
17900,
null,
9600,
42800,
13700,
null,
18000,
20300,
92900,
22500,
33400,
21700,
10200,
30400,
20400,
null,
87100,
22200,
15400,
22300,
58000,
119600,
8800,
61600,
24300,
20200,
24600,
34700,
46700,
null,
null,
7100,
13900,
6300,
9600,
15300,
25010,
6600,
2400,
7900,
null,
7500,
39000,
6600,
16000,
null,
14200,
62300,
null,
31600,
18200,
30400,
16100,
52100,
25400,
31500,
48000,
15800,
null,
11300,
9000,
14700,
8700,
8800,
21600,
20400,
40000,
45100,
27000,
null,
21500,
null,
21500,
13200,
216700,
32400,
30800,
55200,
27100,
26500,
11400,
12000,
31000,
null,
85047,
17200,
10700,
44300,
20700,
6900,
13700,
94500,
35200,
18800,
5200,
35600,
33700,
67500,
9000,
11200,
14900,
null,
28400,
5500,
40400,
43100,
24200,
29200,
28300,
10000,
19500,
33300,
27000,
8200,
22700,
15000,
58800,
20500,
48600,
5600,
24300,
38100,
12000,
9900,
53500,
26100,
32900,
30700,
11400,
null,
27600,
27100,
26900,
31900,
null,
3600,
16105,
30800,
13200,
6000,
18600,
13100,
16500,
22200,
7800,
68100,
59800,
14100,
4900,
null,
70167,
23200,
10300,
32750,
26700,
24600,
34600,
17100,
9400,
17300,
34100,
null,
18000,
13800,
52100,
24900,
16300,
19000,
51200,
18300,
15500,
31400,
18700,
52500,
8500,
8300,
9300,
16800,
9300,
38300,
19200,
7800,
57900,
64500,
49700,
29700,
5500,
23500,
8700,
9700,
71400,
29500,
78400,
31100,
24000,
26100,
52700,
5300,
23700,
13800,
22000,
58864,
4900,
14300,
42500,
117500,
42300,
6400,
12500,
20400,
28000,
19500,
null,
15000,
18500,
10800,
13700,
25800,
8900,
45500,
47100,
67200,
14100,
31900,
null,
22900,
30200,
16700,
3400,
6700,
15900,
7000,
17000,
31600,
6300,
56364,
136000,
63700,
24900,
11300,
19900,
55700,
3000,
54900,
23400,
15500,
6200,
37300,
60000,
81100,
38100,
25900,
19800,
91600,
10300,
13700,
43600,
34600,
44100,
null,
28600,
null,
7600,
56400,
11500,
54100,
9000,
12700,
null,
25900,
34000,
49593,
49000,
121900,
40200,
62900,
22800,
18500,
174700,
21800,
54900,
20200,
15200,
27600,
21800,
null,
29200,
20000,
44300,
17000,
15800,
32600,
14300,
21300,
null,
null,
23500,
27400,
16300,
19100,
null,
25500,
16300,
10300,
15200,
27600,
13000,
47200,
46900,
8820,
31900,
18400,
null,
59900,
9300,
14100,
14800,
77300,
21700,
21300,
16100,
18800,
45300,
26300,
21800,
6100,
36000,
44800,
35100,
27100,
16000,
11300,
19100,
16400,
null,
26600,
35300,
null,
17700,
13000,
20686,
8000,
9100,
37800,
16000,
14900,
4500,
11400,
33900,
13500,
13400,
30800,
23500,
10300,
null,
39400,
20200,
13000,
74200,
52000,
null,
21500,
null,
17900,
53600,
15900,
58300,
16900,
11800,
21350,
53300,
47600,
45000,
7800,
49100,
65800,
27400,
38700,
27900,
79400,
null,
25100,
32600,
19000,
9900,
16800,
13300,
18500,
null,
11200,
27350,
8200,
7700,
22000,
50400,
75000,
66600,
17000,
null,
65700,
9100,
17600,
21000,
40100,
36600,
11200,
null,
4000,
8200,
31800,
46500,
15100,
31800,
36000,
null,
12600,
20600,
null,
30200,
55400,
4700,
5000,
113020,
24700,
17400,
57000,
5600,
68000,
11900,
24200,
20600,
10300,
null,
22700,
11100,
16300,
11200,
42600,
null,
137800,
4300,
9000,
23700,
8000,
51700,
null,
23000,
38084,
3200,
25561,
108900,
33977,
36900,
39300,
56900,
14500,
9900,
16800,
48000,
38700,
24973,
23400,
67000,
23100,
32800,
28900,
54900,
19170,
296100,
55000,
76125,
7100,
17400,
111400,
11400,
22000,
20500,
96600,
42600,
93100,
9700,
80700,
70000,
67200,
6500,
110300,
12500,
19200,
70300,
null,
17200,
13200,
18700,
7500,
6400,
33600,
null,
30000,
13500,
7100,
30600,
44900,
25200,
6500,
31400,
16300,
42750,
19800,
45900,
33800,
51100,
24500,
98100,
22300,
46600,
39000,
87900,
14600,
33000,
12900,
14500,
36900,
3000,
4200,
45000,
49800,
6700,
16600,
29700,
22100,
95500,
15400,
58000,
11700,
51500,
15400,
10500,
21100,
48100,
21200,
7800,
13800,
4300,
null,
35900,
91100,
23400,
26000,
21300,
101200,
27300,
36300,
34300,
37800,
null,
20800,
null,
33000,
18800,
21500,
89600,
19976,
24500,
27300,
16300,
19100,
11100,
22600,
null,
28600,
31100,
26100,
20200,
null,
5400,
45300,
34100,
9900,
126800,
68300,
26600,
35600,
57250,
5300,
16000,
53500,
25500,
14300,
14900,
20900,
62100,
null,
29000,
17500,
12900,
6200,
null,
13500,
34100,
8500,
1800,
16500,
5900,
30000,
115200,
11300,
16400,
11500,
38100,
60500,
null,
49600,
7500,
20000,
11500,
null,
75600,
5800,
34600,
38900,
15500,
14100,
37200,
12500,
14700,
29100,
34800,
16100,
69000,
19100,
30000,
17500,
59100,
103700,
7300,
34000,
37981,
8100,
13500,
29061,
20400,
4300,
33000,
12000,
22600,
22400,
50800,
20500,
21900,
18500,
25100,
27700,
9000,
22400,
null,
20500,
30800,
42200,
330900,
17200,
29500,
88000,
34900,
22800,
4600,
14500,
11400,
25800,
33800,
62400,
23200,
54500,
12400,
20550,
6900,
128000,
30500,
6600,
6600,
55400,
15600,
22700,
10200,
92200,
26000,
42000,
13100,
29800,
9450,
30900,
44000,
20000,
48300,
119100,
null,
60000,
110000,
32300,
5400,
22000,
50400,
28600,
11000,
188800,
18600,
41700,
44900,
8900,
54600,
30400,
63200,
34000,
null,
52450,
17900,
24900,
17100,
31100,
78900,
null,
16050,
13600,
16500,
18500,
82500,
40100,
null,
6000,
3500,
null,
68200,
2000,
9500,
68700,
15200,
28600,
3700,
18500,
20600,
7800,
32500,
1300,
33100,
53000,
34400,
29200,
null,
43100,
14700,
45200,
null,
55300,
12900,
6200,
32700,
15800,
66000,
15200,
160500,
28600,
29800,
null,
20800,
42500,
21900,
174000,
63500,
76000,
20000,
6200,
60400,
35600,
24500,
24100,
19400,
50300,
7600,
20620,
null,
40100,
137000,
9400,
20900,
11100,
26600,
null,
37100,
17500,
11500,
19200,
13000,
11500,
24300,
31600,
63500,
4600,
8000,
19500,
17100,
28400,
25200,
16000,
40500,
7300,
45100,
4700,
8200,
52900,
75400,
6600,
44200,
9000,
12300,
29700,
16700,
38100,
40700,
null,
42400,
24100,
6600,
10500,
27800,
41900,
25500,
61500,
11300,
35900,
33100,
54700,
82900,
9900,
null,
14600,
37800,
53400,
51300,
22700,
2900,
33770,
90800,
4000,
44500,
22200,
37100,
10500,
10400,
86400,
null,
6500,
38637,
28800,
15300,
18300,
23700,
29600,
9700,
23500,
75100,
72500,
7200,
21000,
24500,
null,
11400,
35800,
110234,
16100,
19200,
null,
20700,
51300,
45900,
35100,
43300,
null,
17100,
28277,
24100,
65600,
14100,
55700,
27400,
31400,
null,
7300,
12500,
6000,
68000,
14700,
4600,
41500,
20400,
22200,
9400,
16400,
15300,
38000,
37500,
13400,
27900,
14300,
43700,
null,
60200,
17000,
22000,
26000,
20300,
19900,
30800,
38000,
null,
8500,
25400,
35900,
33200,
12600,
13500,
37900,
27400,
64800,
53000,
55800,
7400,
105300,
47900,
6400,
29600,
65934,
10800,
20100,
31800,
27100,
27100,
18400,
7700,
23900,
null,
44700,
null,
8800,
6000,
17400,
29300,
14700,
30000,
28100,
21900,
52000,
6700,
15800,
1600,
4500,
null,
21300,
43300,
25600,
20700,
20400,
31600,
12400,
26600,
75500,
7500,
19540,
69200,
59600,
null,
79000,
21100,
71300,
82700,
25000,
90200,
53900,
18100,
1000,
24000,
30000,
24600,
42200,
30000,
5400,
10300,
41100,
105900,
22200,
5400,
36400,
13800,
34100,
13800,
20200,
13500,
18600,
15900,
28900,
15900,
14500,
20500,
50800,
25300,
43100,
8200,
null,
26000,
39200,
14900,
27400,
39900,
7000,
28600,
13500,
22100,
12500,
50700,
null,
25900,
41800,
75900,
null,
42600,
28600,
15800,
43300,
17800,
33900,
22700,
null,
31300,
null,
8300,
45200,
33500,
55200,
30700,
null,
46600,
72900,
19200,
10600,
37600,
16000,
null,
8400,
16600,
7000,
22100,
45800,
40400,
77500,
12700,
56000,
27400,
100000,
15400,
null,
22900,
28300,
22800,
12900,
65000,
null,
28700,
16500,
13000,
null,
28500,
41600,
52400,
null,
116800,
7200,
10900,
15600,
17000,
14800,
28200,
11200,
16500,
68600,
37900,
27500,
90500,
13500,
22700,
null,
18600,
17700,
33800,
63304,
76600,
61300,
9800,
null,
85200,
9000,
9750,
15400,
6100,
22100,
31600,
41700,
47300,
null,
11400,
7500,
46700,
185100,
null,
12400,
145400,
17100,
35100,
25100,
35800,
null,
63200,
9400,
15844,
45700,
31700,
51500,
56700,
null,
68500,
32000,
15800,
28700,
8000,
151700,
5100,
37300,
9300,
46700,
7500,
26100,
23500,
null,
14300,
32000,
8700,
69000,
10200,
14600,
null,
6700,
null,
7000,
9500,
21000,
17100,
24800,
21700,
12600,
91800,
25800,
19700,
24300,
null,
7000,
27900,
32700,
92900,
39200,
21100,
12900,
24500,
7100,
45600,
9300,
null,
133100,
57400,
12400,
44600,
64400,
106900,
50900,
126850,
19100,
53500,
109600,
51000,
79300,
31300,
22100,
36090,
46700,
null,
24450,
22000,
2750,
27400,
30500,
13551,
5500,
69100,
25000,
15100,
43300,
36300,
21100,
35900,
26300,
8900,
18500,
19300,
null,
11500,
10500,
70200,
null,
19900,
13500,
null,
34374,
28100,
107500,
15600,
33800,
36300,
null,
21600,
15100,
23300,
11900,
27000,
18800,
27500,
22600,
3800,
null,
18200,
20500,
5800,
24000,
20800,
58000,
null,
7300,
15000,
72500,
100900,
9300,
54600,
22900,
73680,
31100,
22200,
56100,
17200,
30400,
24400,
27900,
18800,
34200,
19150,
97400,
46200,
34500,
27900,
6300,
10600,
38900,
39200,
39600,
28100,
10800,
49400,
66200,
8200,
45200,
28000,
12000,
30100,
28000,
47000,
24800,
35500,
14100,
70800,
9100,
9700,
11700,
6500,
13000,
15500,
69300,
45600,
10700,
12500,
22200,
34900,
13800,
18900,
52500,
26300,
29600,
null,
78500,
11100,
4000,
27500,
16500,
null,
35900,
14400,
null,
null,
111100,
34200,
25800,
14900,
7300,
127500,
74800,
96500,
7300,
24100,
23500,
29900,
63700,
25700,
9000,
6500,
24300,
25600,
8400,
null,
48400,
41800,
null,
null,
29674,
null,
46500,
89200,
12200,
3700,
34500,
10000,
20400,
4300,
100300,
null,
18000,
35500,
15800,
30500,
11100,
53300,
9700,
12300,
26800,
15300,
24300,
71800,
24400,
null,
17000,
367800,
40100,
47400,
96900,
16800,
19500,
19900,
43500,
43400,
23100,
22100,
12500,
25700,
6300,
13300,
19400,
34400,
8800,
12700,
16200,
36900,
31600,
11300,
132600,
null,
16500,
15800,
9100,
null,
10700,
10700,
41600,
13400,
67400,
15800,
25807,
17700,
18400,
93000,
12100,
null,
46700,
19800,
11200,
53900,
null,
7000,
36100,
79100,
8200,
26300,
21700,
22600,
20700,
null,
10700,
45200,
3900,
45800,
null,
11400,
null,
33900,
26200,
17900,
110800,
6800,
13850,
10400,
24700,
24100,
28300,
11300,
16800,
null,
16200,
31200,
86500,
5000,
13300,
40800,
46400,
49900,
61200,
13500,
17200,
35300,
300,
39800,
12000,
8900,
8900,
21500,
24200,
4600,
10100,
91800,
51200,
111800,
84900,
13400,
36500,
50600,
null,
45400,
12400,
null,
5800,
3000,
null,
12500,
26300,
15200,
2100,
17200,
11000,
33900,
104300,
22400,
25900,
null,
28200,
12500,
13000,
18300,
14500,
15300,
48400,
10720,
27100,
52000,
13800,
null,
18189,
14500,
12400,
34600,
10100,
8800,
13700,
10300,
16400,
null,
13700,
18000,
10300,
108900,
50300,
39300,
14700,
26500,
17300,
7900,
44200,
16900,
34800,
50300,
7000,
8696,
15200,
8200,
46400,
24700,
25500,
27000,
13700,
56100,
6400,
17400,
15200,
null,
45300,
14300,
21510,
7200,
10800,
28300,
37900,
13300,
56100,
26600,
40600,
189000,
47300,
34300,
37100,
21700,
33800,
17300,
73800,
47400,
61900,
33300,
29300,
null,
8800,
null,
16000,
7800,
13000,
42800,
48000,
39000,
17400,
13600,
20000,
36200,
21500,
34100,
60342,
23300,
19100,
43500,
52700,
15600,
35900,
57500,
26037,
15800,
26950,
10100,
23600,
14600,
20200,
18300,
152700,
11800,
24700,
10500,
16600,
18200,
35920,
185100,
25300,
14000,
null,
16600,
22400,
21800,
24100,
22500,
27500,
89300,
60200,
14500,
32700,
186200,
14200,
53100,
42900,
16200,
63800,
23200,
11650,
null,
49500,
23700,
23100,
null,
12500,
27600,
75000,
45100,
22400,
8500,
50100,
20700,
44200,
71000,
117800,
null,
null,
null,
13000,
28500,
19600,
12400,
28400,
22100,
64900,
null,
10400,
35700,
26400,
null,
8610,
27600,
18500,
58700,
null,
18500,
2700,
8100,
28400,
28500,
66600,
31700,
59000,
43300,
42300,
34800,
4300,
7500,
61000,
34550,
73900,
17100,
28100,
19700,
7500,
38700,
9900,
14700,
10600,
38700,
31900,
11900,
104400,
54300,
47300,
20100,
25100,
41200,
7700,
6600,
9000,
49500,
12500,
43800,
68300,
55900,
17300,
27300,
36100,
86700,
6300,
42100,
null,
65000,
41500,
null,
37700,
53600,
5500,
112900,
22400,
27600,
53500,
16800,
38968,
23100,
5400,
12200,
43400,
23600,
5500,
4100,
11900,
null,
22000,
36200,
45800,
8800,
59700,
40400,
19000,
28700,
9400,
19551,
56600,
204000,
11100,
46400,
41600,
19300,
105700,
29400,
140300,
4300,
22600,
17500,
3600,
13000,
74800,
30400,
16000,
27800,
null,
20300,
69800,
27300,
21700,
9000,
8500,
47500,
8000,
34100,
23400,
30700,
16900,
null,
46900,
null,
17750,
43000,
4200,
11500,
14500,
10900,
22200,
24800,
34700,
8700,
26700,
7600,
21100,
6400,
16200,
14100,
63400,
28600,
11800,
25400,
12700,
null,
23200,
51700,
17600,
39900,
18100,
8800,
17600,
20800,
21800,
32700,
28200,
22300,
12000,
30200,
20800,
54400,
null,
48600,
23200,
27500,
null,
12200,
16300,
89900,
79400,
110400,
null,
null,
102200,
23000,
30600,
46300,
11800,
9900,
27700,
145015,
43500,
14100,
37200,
13100,
null,
14800,
38143,
16600,
7500,
19500,
57200,
56300,
10300,
46351,
18900,
3000,
41100,
32000,
27800,
null,
87500,
41000,
94600,
55500,
53900,
20700,
41600,
45100,
25200,
59800,
23200,
11400,
105300,
93000,
22000,
13800,
36600,
31200,
68900,
18100,
29200,
12885,
32000,
15100,
null,
41100,
null,
51600,
22000,
11800,
16200,
28000,
24800,
27600,
43300,
12300,
23100,
13500,
18200,
15700,
28100,
32700,
13800,
23100,
11100,
39600,
12200,
null,
38300,
4350,
68600,
62800,
58900,
5300,
3900,
null,
36156,
24900,
77400,
null,
30170,
null,
33400,
3100,
20300,
22400,
18700,
12500,
16900,
17400,
27400,
49700,
52000,
13300,
28200,
null,
20400,
20400,
20200,
17300,
51700,
15900,
28000,
33700,
500,
82500,
30400,
31300,
23100,
57000,
2200,
23300,
20000,
49000,
31000,
28100,
47700,
3800,
8000,
18925,
59200,
121300,
79400,
82500,
20200,
39000,
6300,
14000,
11000,
55200,
29100,
20700,
33700,
36000,
48200,
3300,
6200,
53900,
22400,
19000,
21500,
14200,
10100,
25400,
44600,
16400,
15500,
52300,
3900,
22700,
16000,
8800,
16000,
31500,
42000,
6400,
null,
null,
47540,
26300,
78500,
25200,
45300,
7000,
26100,
29000,
29400,
20800,
10050,
70000,
92300,
70400,
59100,
null,
53300,
12500,
45900,
68500,
null,
null,
10800,
5600,
21400,
18900,
20300,
25800,
null,
46500,
14800,
9000,
41600,
22700,
5200,
null,
67200,
18900,
18100,
28327,
61800,
20700,
98300,
12000,
34700,
32100,
60900,
22100,
14800,
58300,
19500,
null,
10000,
22400,
31300,
4500,
43200,
7300,
8700,
41600,
20300,
12000,
7400,
16100,
63000,
25500,
14900,
null,
39000,
68200,
15400,
36400,
9300,
21300,
62400,
21300,
14100,
22100,
25500,
7800,
10600,
21400,
5600,
17600,
53500,
12600,
9000,
192400,
4800,
49900,
29900,
31500,
29000,
16900,
37800,
49200,
51700,
13900,
8600,
27300,
13500,
null,
16700,
11500,
57924,
81200,
14400,
33900,
39500,
12200,
12800,
6300,
44300,
43300,
307600,
71000,
13500,
18100,
null,
17300,
18600,
11900,
18600,
11900,
20500,
43210,
2300,
66300,
20800,
22100,
38700,
22000,
null,
15100,
64801,
23100,
4200,
29400,
28200,
46100,
30000,
12600,
77600,
22167,
4800,
5300,
45400,
10700,
17800,
68200,
26900,
48000,
30700,
28000,
null,
36700,
25500,
21700,
20400,
25300,
22100,
20300,
43400,
33300,
44000,
42100,
9450,
19600,
38600,
14700,
4000,
18800,
500,
59600,
45400,
null,
75500,
19600,
13600,
27550,
56500,
12200,
41700,
33600,
10800,
26600,
29600,
29200,
9800,
92800,
49400,
14600,
22200,
22800,
49400,
34700,
12400,
24500,
11200,
6600,
48400,
26700,
57400,
3200,
null,
null,
19300,
19300,
29800,
22000,
null,
15600,
16900,
63400,
30100,
13400,
31600,
13800,
5200,
59900,
25400,
29400,
8800,
null,
6600,
26600,
23400,
13800,
null,
9000,
12800,
44900,
10800,
29000,
25800,
null,
55700,
7900,
103700,
58000,
13200,
19600,
5900,
null,
104000,
25500,
15500,
38900,
30400,
null,
null,
24100,
null,
28200,
205400,
24500,
41700,
null,
33200,
70900,
39200,
11300,
10290,
3600,
93700,
11700,
34900,
26100,
21600,
14000,
14500,
8100,
null,
7700,
9100,
28400,
62900,
null,
38000,
14100,
74500,
23900,
null,
11700,
null,
19700,
6300,
19100,
15900,
23600,
32900,
null,
12500,
27000,
13500,
22400,
37300,
62000,
20600,
37700,
69800,
null,
50100,
44500,
65100,
55500,
28700,
null,
47900,
95700,
53641,
46200,
null,
34971,
29100,
10800,
17500,
17500,
14500,
31100,
27400,
null,
12000,
28100,
23000,
8600,
11600,
22400,
17300,
34200,
30700,
31600,
5000,
46800,
21500,
16400,
45100,
8400,
25500,
7700,
13050,
31600,
3200,
47300,
34000,
6600,
null,
12600,
19600,
13200,
34800,
16650,
5100,
28000,
64600,
4700,
7800,
20400,
null,
19700,
21700,
26100,
5800,
null,
20500,
55000,
null,
10200,
27900,
68000,
11400,
11000,
12200,
6200,
25900,
2500,
6700,
15300,
28000,
8700,
8700,
47700,
5700,
null,
40200,
13400,
null,
16400,
3500,
11700,
30000,
null,
16100,
14100,
9800,
56200,
14800,
25300,
41500,
26600,
29400,
16800,
91700,
68900,
8600,
2100,
14800,
42600,
null,
7000,
10150,
34500,
18400,
48700,
58400,
35900,
25800,
15300,
18200,
5800,
6800,
11200,
14600,
20700,
32900,
63200,
4550,
44100,
null,
null,
42100,
36400,
15800,
15500,
21800,
64900,
68093,
48100,
16200,
35500,
66700,
13200,
29200,
7000,
19100,
16100,
5400,
43500,
45200,
15800,
36500,
21800,
62000,
null,
13200,
126300,
46800,
11600,
25900,
18800,
13100,
23600,
24400,
28900,
194600,
14700,
13100,
45800,
48000,
71400,
17700,
1200,
102700,
10400,
24600,
null,
44600,
13100,
null,
68100,
8300,
4300,
8700,
65300,
28400,
16100,
37000,
10000,
22000,
8100,
17000,
24600,
43900,
11300,
12500,
13400,
18500,
42700,
19000,
44400,
37500,
131500,
49700,
31000,
15500,
43500,
8233,
16000,
44900,
36700,
46800,
50700,
17300,
65600,
45700,
null,
42900,
7800,
18100,
26300,
4600,
54500,
21000,
29300,
8400,
46900,
null,
33200,
null,
107100,
null,
24300,
22700,
70500,
77900,
49300,
18100,
25800,
33900,
19000,
22200,
10700,
14500,
15500,
27400,
37200,
8800,
13600,
null,
null,
28400,
24400,
5100,
13500,
14600,
10800,
26400,
42400,
9200,
19300,
4200,
23500,
600,
null,
null,
21400,
11900,
28000,
55100,
38500,
59539,
37200,
21900,
36600,
24000,
21600,
21000,
48200,
49800,
98900,
38400,
21600,
42300,
13100,
9600,
28400,
41300,
33900,
6100,
11200,
17450,
9600,
20400,
44100,
8900,
12100,
36900,
36600,
63900,
0,
25300,
66900,
47000,
35500,
28400,
195500,
24600,
27200,
46900,
28200,
26600,
36800,
40248,
74200,
37700,
213000,
3500,
null,
46700,
23300,
10400,
29500,
77900,
38600,
85800,
null,
null,
73500,
null,
null,
19700,
77500,
18900,
19900,
24400,
23700,
12400,
92000,
22600,
74800,
70300,
37100,
18800,
89300,
60600,
37800,
28900,
24600,
46100,
34700,
6200,
null,
21000,
65300,
11600,
null,
36800,
10300,
14300,
23000,
44100,
47600,
27200,
46900,
56300,
62400,
65100,
7900,
10200,
37900,
22400,
5400,
83900,
24000,
21500,
10100,
14300,
47600,
49100,
21500,
8600,
19800,
14200,
8900,
32300,
24800,
8700,
73800,
112700,
11700,
17800,
13100,
10900,
8200,
8500,
null,
23400,
39100,
10800,
7900,
22000,
17800,
5700,
15600,
15700,
26600,
31500,
73400,
2800,
null,
16500,
11700,
139600,
25500,
7600,
67300,
17400,
11000,
37900,
56500,
5300,
25100,
15500,
28700,
40841,
49400,
23300,
34900,
42600,
13800,
23800,
34700,
7900,
33600,
7300,
10300,
null,
45300,
8200,
10475,
15500,
26200,
71000,
32900,
23300,
23100,
14600,
83300,
37300,
null,
132560,
7900,
56700,
53900,
17100,
34300,
85100,
26100,
86200,
21100,
38700,
130300,
63000,
3500,
20800,
null,
35403,
76000,
18400,
22400,
30500,
175500,
29300,
29300,
141700,
30700,
8800,
20600,
56800,
129565,
9800,
68700,
63000,
15300,
34274,
11900,
47300,
6500,
49300,
28000,
37200,
null,
40300,
25700,
5800,
13300,
17000,
34800,
25300,
86900,
3900,
12700,
null,
21500,
23000,
8600,
50600,
50000,
33400,
25100,
56300,
50100,
22400,
8500,
10700,
28404,
33200,
8700,
15500,
null,
44900,
26300,
null,
53900,
17600,
14200,
36600,
16900,
72700,
89200,
69300,
56100,
24500,
8400,
21600,
null,
10800,
null,
55400,
19200,
14400,
16000,
18800,
25600,
14000,
37400,
42200,
28100,
44200,
30600,
11100,
74100,
22600,
5700,
102400,
9000,
25300,
null,
17500,
16700,
23100,
21600,
45000,
59300,
73300,
15100,
32800,
101200,
36700,
32000,
12500,
12500,
128700,
48300,
8600,
46200,
48400,
45176,
38500,
9800,
71800,
51900,
21800,
5700,
14600,
33300,
7000,
16600,
20800,
69400,
24300,
37600,
14050,
22900,
63200,
11600,
15100,
6000,
73650,
15000,
12000,
8500,
8000,
26400,
34300,
8500,
39300,
24700,
29600,
24200,
10300,
102200,
14200,
null,
26600,
12400,
51100,
null,
36800,
12300,
7000,
23300,
17500,
null,
21000,
11500,
11100,
32200,
null,
14000,
66500,
13500,
35400,
25900,
100000,
6200,
50600,
31100,
10300,
16600,
9300,
94000,
null,
22700,
29000,
17600,
106800,
129800,
50700,
44100,
67300,
24900,
12200,
4800,
16100,
64900,
15800,
27800,
24800,
28300,
18500,
28500,
12600,
36800,
14400,
8200,
19900,
20700,
15600,
12700,
12900,
14700,
42600,
7700,
2500,
21300,
14300,
15900,
null,
null,
38200,
17400,
5500,
28248,
77800,
15500,
58100,
4900,
19400,
null,
13800,
23000,
6300,
25100,
34200,
17300,
null,
23600,
47100,
30400,
28100,
10200,
19000,
null,
6500,
14500,
68800,
12900,
35500,
68700,
101240,
16700,
null,
26500,
25224,
30500,
10000,
162017,
42500,
25400,
48600,
38600,
34400,
100700,
35000,
12500,
23500,
14500,
23300,
15100,
14800,
29400,
84970,
7500,
54100,
97267,
21300,
10200,
12700,
38200,
7549,
25300,
32900,
64900,
6600,
42200,
37900,
45500,
32800,
16120,
20500,
15200,
61500,
22500,
21200,
null,
32200,
35200,
44600,
14900,
14100,
21300,
12300,
32000,
27700,
58700,
10900,
23400,
31800,
13300,
29600,
16000,
28700,
null,
6100,
14400,
14200,
19400,
78442,
null,
29600,
27000,
43600,
75000,
59300,
85100,
26900,
27000,
13600,
6800,
26600,
26300,
24800,
8500,
54200,
16600,
16400,
19700,
20700,
68548,
18300,
9500,
null,
null,
43400,
12200,
26500,
13000,
223800,
22500,
9950,
76600,
9600,
9600,
8500,
34300,
64000,
14700,
24200,
89600,
22100,
null,
22100,
15700,
62200,
34600,
7000,
134000,
48500,
40500,
31400,
61600,
null,
45100,
null,
30600,
null,
3300,
12200,
14100,
13500,
10700,
11300,
6700,
45500,
8400,
15000,
39300,
23300,
null,
55100,
null,
54500,
27500,
21500,
23600,
19500,
null,
57200,
88200,
null,
54100,
52300,
16900,
null,
60500,
41300,
37700,
16700,
18200,
29700,
19800,
13500,
5500,
null,
12400,
24300,
13900,
67600,
15400,
6800,
26680,
30200,
6600,
16300,
28250,
40100,
31800,
38700,
10030,
14000,
null,
13800,
72000,
null,
16700,
11500,
8500,
138900,
10000,
18500,
3900,
24600,
60700,
20800,
24100,
58800,
3900,
24400,
2200,
33796,
31400,
16800,
23000,
46900,
5800,
23900,
4000,
85900,
23300,
23000,
70797,
5300,
67900,
23700,
109900,
12000,
100800,
5600,
16200,
47800,
9200,
9700,
83700,
10500,
14800,
15900,
29300,
70100,
81100,
127800,
5300,
109200,
10300,
59100,
6000,
35300,
19000,
35300,
14500,
23600,
33000,
15700,
14700,
null,
43100,
82600,
24709,
7500,
5700,
42600,
null,
6900,
14900,
31900,
17500,
16200,
16700,
8400,
18400,
15200,
29200,
10200,
5800,
78800,
10250,
22600,
11800,
6600,
22500,
null,
8000,
56100,
56100,
40800,
29300,
26600,
1900,
31300,
26500,
6900,
59000,
18200,
14800,
27900,
44600,
32200,
null,
13600,
72200,
16600,
61300,
7600,
28000,
19900,
12100,
10500,
28600,
35400,
26200,
8400,
23300,
25000,
61300,
4400,
23500,
15800,
21800,
100509,
44700,
41100,
22200,
null,
null,
50700,
31481,
22100,
19700,
33000,
31500,
38100,
17300,
24300,
39390,
9800,
null,
28800,
null,
null,
41400,
10600,
37700,
57400,
8900,
18000,
56400,
8200,
42900,
33800,
29100,
3800,
182000,
9900,
56500,
26000,
26500,
52800,
9500,
12100,
37600,
33700,
87200,
15000,
21400,
7300,
95300,
56500,
24000,
4200,
32700,
7500,
7400,
52700,
20700,
19300,
4000,
54580,
22300,
34800,
27300,
null,
33700,
17300,
166100,
24000,
34600,
7700,
8200,
41200,
21700,
34600,
10800,
25523,
144800,
33600,
null,
7300,
15900,
10600,
21200,
82100,
null,
30500,
3400,
27000,
30500,
13600,
11100,
76500,
23900,
null,
60600,
15400,
16000,
31000,
18500,
null,
27000,
null,
5600,
29600,
35500,
17000,
39300,
39900,
27200,
13800,
14400,
54400,
null,
null,
19900,
10500,
14500,
22000,
33000,
null,
33900,
null,
14000,
56400,
27200,
14800,
29000,
93400,
14300,
null,
25900,
null,
28100,
20900,
28500,
17900,
22900,
17200,
6000,
38900,
18700,
45200,
14800,
17900,
42700,
53800,
47045,
15400,
4100,
2800,
34600,
80000,
14400,
41100,
35700,
23500,
46500,
20000,
39400,
null,
21700,
44000,
11800,
49100,
9600,
86700,
null,
28400,
25300,
25300,
null,
3900,
51400,
28400,
71000,
11000,
9500,
9300,
24600,
15900,
32400,
32100,
null,
14300,
27000,
46100,
13500,
54900,
16300,
33300,
40700,
10400,
6200,
57200,
25200,
13300,
100900,
57500,
11000,
27700,
13700,
26800,
13100,
null,
null,
22800,
20300,
46600,
20400,
15600,
10800,
11200,
18200,
17100,
25400,
26200,
63200,
7000,
48200,
33400,
6000,
null,
64400,
31700,
45100,
13500,
40100,
160100,
null,
3500,
33700,
null,
73000,
19200,
58900,
37700,
12700,
66700,
15900,
28800,
29400,
44500,
null,
18000,
31000,
5200,
87100,
19400,
46600,
11900,
24300,
25600,
70000,
null,
142500,
19000,
59400,
46700,
60300,
32400,
51800,
14000,
42100,
15900,
10000,
26300,
43200,
12600,
null,
10700,
null,
18800,
32900,
23300,
79000,
50200,
5200,
15900,
54600,
27200,
31700,
55400,
54900,
null,
19400,
62500,
127500,
60600,
14600,
13200,
7300,
41800,
21300,
19150,
1400,
12900,
22900,
33300,
39000,
40600,
7700,
27200,
11500,
42300,
43500,
24200,
19900,
5900,
137000,
10500,
13600,
1000,
27900,
42500,
29800,
8500,
33700,
50200,
17900,
null,
11500,
10600,
9800,
null,
14300,
15600,
18500,
26900,
null,
19700,
19200,
5000,
9700,
9400,
null,
11200,
10000,
5500,
43700,
13800,
null,
12500,
24100,
7300,
18300,
null,
null,
24900,
12000,
37000,
null,
10000,
null,
35600,
28700,
12800,
23900,
9500,
25600,
20400,
33800,
6500,
29400,
76500,
46100,
27000,
9600,
39100,
55500,
22600,
31500,
25500,
22300,
33900,
51700,
5500,
27700,
14000,
70100,
34500,
25300,
31700,
61500,
9100,
20500,
79500,
21100,
19900,
19500,
22000,
27200,
38200,
39000,
14700,
21700,
null,
14800,
26900,
11900,
26800,
43000,
7600,
14100,
16500,
17000,
25800,
23500,
13600,
null,
29000,
16000,
15100,
57100,
28900,
47545,
49300,
null,
20700,
218000,
5000,
15400,
32100,
47500,
14300,
8200,
31000,
7500,
137550,
10500,
52800,
25400,
34500,
32200,
144300,
33100,
35500,
63700,
37100,
3000,
20700,
15000,
14100,
17500,
null,
36300,
22200,
57900,
13300,
28500,
23300,
37900,
15500,
null,
29600,
10375,
40600,
10400,
25900,
null,
30900,
7700,
135200,
29600,
39000,
44800,
21300,
null,
17000,
38600,
23300,
null,
36200,
35800,
null,
12300,
24000,
24000,
22500,
15900,
104200,
5600,
null,
34000,
22400,
16000,
40500,
25900,
25700,
20800,
35400,
18100,
31867,
34800,
null,
14100,
15800,
12000,
154507,
29400,
72500,
18530,
6300,
33900,
35300,
45900,
8800,
26100,
11100,
23700,
36400,
44800,
64600,
10800,
10300,
49700,
22400,
27600,
22000,
19800,
37600,
8900,
19400,
65800,
null,
34200,
9000,
31676,
24600,
12300,
60900,
10800,
41900,
25700,
15100,
23800,
null,
35200,
28700,
9800,
45400,
26200,
42200,
14300,
52200,
8100,
12000,
9900,
47400,
24000,
14500,
null,
null,
21100,
14600,
28700,
34500,
15800,
20700,
null,
17500,
27200,
36600,
19300,
null,
19700,
13800,
31300,
48900,
48300,
9700,
37500,
8000,
46200,
14700,
null,
null,
17300,
22800,
77400,
42400,
48300,
null,
12300,
19200,
15700,
95100,
12100,
16970,
11400,
48500,
4700,
null,
30400,
14500,
29900,
12700,
5200,
39700,
23800,
12575,
31900,
19200,
60100,
41300,
10200,
20400,
28000,
null,
512600,
32600,
51400,
27600,
44200,
7750,
13700,
14100,
null,
12300,
11200,
13800,
8500,
null,
44745,
null,
42000,
14600,
23800,
45700,
9500,
85100,
17300,
29100,
48900,
52500,
3800,
26500,
24200,
20100,
48200,
19500,
null,
46900,
26000,
34700,
69100,
43200,
41500,
21800,
17400,
11900,
70300,
38000,
27456,
72000,
85300,
52100,
28800,
12000,
7500,
10900,
8400,
62300,
27600,
24700,
15200,
13600,
9500,
230142,
3500,
28200,
28200,
37600,
26700,
44600,
21100,
30500,
37300,
31900,
27700,
23700,
16800,
12500,
38600,
31600,
39900,
12200,
12300,
25995,
30900,
59200,
33500,
17900,
8400,
18200,
15500,
45299,
42800,
null,
22534,
57300,
69100,
10600,
49700,
6600,
17159,
7200,
37500,
41800,
17800,
1000,
18000,
29200,
25900,
76200,
23900,
9500,
14500,
88300,
11000,
39500,
22900,
65938,
49400,
14800,
21700,
16700,
6550,
15300,
null,
null,
13000,
24100,
41400,
9400,
33900,
43000,
52900,
14300,
8900,
12400,
null,
13700,
71800,
null,
35900,
81000,
39300,
41300,
17400,
null,
31500,
76200,
20000,
34000,
45000,
12200,
58700,
null,
26100,
83400,
28600,
37800,
20700,
62800,
61800,
32500,
55700,
18000,
30200,
8100,
37400,
27624,
12900,
13100,
33300,
48300,
20800,
17400,
24000,
9200,
35200,
54800,
27200,
1800,
65000,
10500,
14100,
28400,
82700,
8700,
51900,
33000,
16567,
397300,
12400,
null,
9200,
48400,
null,
37400,
107400,
8800,
46900,
46900,
62000,
14300,
11400,
34500,
13400,
45300,
12400,
27350,
29300,
26400,
null,
92400,
21600,
8300,
19900,
8300,
42800,
31620,
23400,
167000,
19800,
25000,
null,
66100,
84100,
38100,
45400,
null,
39700,
30600,
22700,
7800,
10300,
10600,
27820,
13800,
9700,
56100,
30500,
12600,
39700,
29300,
53200,
10200,
10900,
20000,
7000,
18800,
39900,
22900,
17300,
61200,
71500,
null,
89500,
34800,
null,
23200,
23700,
17400,
7800,
4000,
null,
16300,
47500,
10000,
47900,
9400,
21800,
null,
null,
32300,
40500,
15900,
10000,
9400,
141400,
68700,
42500,
15000,
29200,
null,
9100,
17800,
39000,
3800,
null,
47500,
82000,
14700,
19700,
20000,
28100,
37000,
null,
13300,
24800,
15700,
null,
7800,
48600,
14700,
33200,
10050,
20300,
60100,
50100,
29400,
18900,
15200,
40200,
15400,
34100,
13500,
26000,
59500,
null,
21000,
14800,
54400,
19000,
17400,
42400,
26100,
54700,
28300,
46200,
4400,
50500,
17600,
19500,
12100,
34100,
23700,
21900,
23900,
25600,
38900,
23500,
16200,
12100,
71700,
36400,
14000,
50100,
52800,
36400,
4000,
28000,
34300,
26100,
22100,
15900,
108600,
17900,
null,
38300,
null,
26900,
22900,
66700,
71900,
17300,
19300,
null,
31700,
6100,
18300,
2400,
22000,
124800,
11700,
27700,
null,
null,
37600,
10900,
11600,
45200,
36400,
4500,
15500,
12100,
32500,
null,
null,
33500,
20400,
34800,
10300,
14800,
39400,
20800,
44500,
33200,
8900,
19900,
null,
32800,
19100,
27800,
43400,
68700,
22000,
36700,
68100,
32400,
18100,
11800,
24000,
119000,
34600,
3200,
39300,
7800,
105500,
6600,
23300,
44500,
14800,
22200,
36700,
31600,
19000,
null,
15400,
12000,
5000,
19300,
29500,
40300,
11200,
18900,
28700,
28900,
33200,
3100,
30800,
7700,
16100,
49900,
62000,
19800,
9000,
20100,
87800,
18700,
26800,
20400,
23700,
44700,
7800,
47600,
13600,
6800,
51800,
12400,
9600,
19400,
62200,
21800,
18700,
40893,
33400,
44600,
34700,
16000,
12600,
40200,
24900,
42700,
15100,
18300,
6400,
15000,
83214,
20000,
57300,
14800,
27700,
47400,
null,
6700,
8600,
69300,
27500,
73300,
17800,
23800,
24900,
32200,
27600,
8100,
84000,
11600,
null,
42800,
16200,
19500,
35700,
7100,
15600,
28900,
22900,
null,
13500,
69600,
14400,
23500,
null,
15000,
null,
14000,
16300,
11200,
25900,
62000,
28800,
11900,
29700,
null,
null,
null,
24300,
9700,
14300,
54500,
38300,
151100,
null,
63400,
11200,
18900,
38200,
29400,
23331,
25600,
46200,
24780,
12200,
10000,
null,
48200,
33000,
29300,
9100,
9200,
500,
8200,
8300,
302700,
null,
48000,
9100,
33800,
82600,
13600,
36800,
28200,
74500,
60800,
2200,
23500,
12900,
23600,
1400,
null,
9100,
22900,
18900,
24100,
30400,
8900,
21500,
18000,
30300,
36500,
47900,
29700,
49200,
4600,
90000,
35600,
37700,
29300,
26800,
11800,
43000,
52700,
30900,
101500,
15500,
6200,
24200,
56100,
71400,
23500,
4800,
28600,
21000,
5600,
45000,
44700,
47400,
45400,
18400,
null,
29500,
33700,
49600,
32200,
21000,
null,
25600,
12000,
58600,
21900,
15500,
13700,
14100,
11000,
14900,
85100,
42700,
60900,
12900,
34800,
12800,
18500,
53100,
79200,
3000,
9500,
28200,
31300,
24800,
101900,
32400,
42000,
12700,
23200,
24200,
30300,
34300,
36600,
8200,
31600,
16500,
44600,
6300,
63800,
20200,
23400,
15900,
31500,
16400,
57307,
29800,
14400,
28400,
50400,
35100,
48300,
48500,
47600,
23900,
27200,
4400,
12700,
15000,
9000,
5200,
19900,
11400,
19600,
0,
80500,
38000,
20400,
36600,
45300,
32600,
13800,
71300,
17500,
18800,
33300,
32800,
24800,
5400,
45100,
33700,
28700,
null,
55000,
19900,
null,
31400,
16600,
19100,
18500,
12100,
30200,
102300,
44000,
37300,
19000,
38400,
19100,
34200,
175600,
16850,
null,
14500,
2800,
44000,
54500,
56700,
12700,
11700,
4000,
19400,
6800,
28300,
12400,
41300,
18800,
83100,
null,
12800,
16500,
13100,
null,
54800,
62000,
23300,
61700,
60000,
41400,
12100,
21500,
6400,
27500,
27600,
18000,
34100,
32900,
15000,
21100,
21300,
10900,
10500,
28700,
70000,
25700,
12600,
31400,
null,
5900,
25700,
75700,
20000,
5200,
56500,
49500,
21060,
30800,
48100,
29800,
9000,
45470,
231600,
95900,
19800,
null,
45100,
52100,
null,
26400,
52700,
23900,
48900,
17500,
null,
11000,
6000,
14000,
24500,
null,
16700,
78600,
13300,
203300,
16600,
28000,
139900,
null,
29600,
2000,
null,
10200,
18800,
15700,
7500,
4000,
27700,
22600,
13500,
32100,
48500,
32400,
183500,
33300,
15700,
56600,
null,
17200,
13600,
19300,
45600,
22200,
21300,
32400,
17800,
26300,
13000,
24200,
10700,
6900,
28300,
null,
33900,
21800,
4500,
20200,
35200,
25300,
15500,
34300,
12200,
11200,
28800,
18600,
null,
37650,
99400,
73100,
23400,
31100,
51400,
55900,
31900,
42681,
4300,
13200,
32200,
15800,
17600,
8520,
null,
27700,
30100,
108000,
45000,
7800,
77900,
5900,
15300,
4000,
57000,
12100,
41100,
59600,
21800,
23500,
19400,
18700,
68050,
27100,
5700,
76800,
9050,
36900,
62400,
10400,
13300,
51830,
25800,
28300,
10700,
3200,
9000,
null,
7500,
7600,
12600,
78800,
13000,
23200,
27400,
9700,
11700,
5300,
14000,
88900,
56300,
15800,
32000,
null,
39400,
1200,
9200,
14200,
61600,
6550,
21400,
117900,
15000,
12100,
21900,
43300,
13600,
36800,
75100,
46700,
41600,
11600,
211000,
19400,
23000,
7600,
16900,
18200,
39900,
3400,
15100,
21400,
38400,
20500,
11400,
17000,
65800,
66500,
7800,
null,
88700,
52600,
16400,
80300,
10300,
10700,
30500,
57800,
null,
26500,
4800,
16400,
19600,
24800,
25300,
5800,
33700,
26300,
17500,
26200,
43000,
24100,
25100,
16600,
26800,
58200,
21600,
11500,
32600,
36000,
36900,
10100,
7300,
24300,
11900,
31100,
74900,
329000,
9300,
26450,
32400,
54900,
49700,
13800,
18900,
43000,
30200,
21200,
10800,
27600,
16000,
null,
49600,
60900,
6400,
23300,
5300,
108230,
21900,
12400,
5200,
null,
14700,
26000,
24500,
36300,
251000,
21500,
8900,
14600,
16200,
17700,
2800,
21500,
12600,
41100,
22100,
18900,
9900,
18800,
29300,
22900,
126300,
28800,
24900,
8600,
16300,
81900,
null,
23800,
27100,
37500,
6500,
47900,
43600,
42100,
24400,
129020,
62700,
19300,
14300,
13000,
20400,
84600,
74600,
0,
null,
21700,
59400,
18500,
18598,
null,
16100,
null,
15500,
22300,
65500,
42500,
7500,
8900,
299100,
13000,
13400,
3600,
73400,
7000,
7800,
17600,
4700,
32500,
23900,
41700,
null,
28500,
13000,
48200,
17000,
59500,
27100,
12500,
35800,
52500,
19800,
45127,
26400,
null,
null,
22200,
23500,
31650,
35300,
10100,
9050,
17300,
20300,
12900,
21000,
null,
15000,
25000,
40400,
35500,
3500,
25200,
null,
null,
6200,
64700,
172198,
9900,
22400,
53300,
28400,
10800,
88900,
5000,
25500,
8000,
19300,
55800,
12500,
14800,
12500,
19600,
28300,
9100,
3600,
26200,
14600,
27200,
6700,
5000,
12700,
9000,
null,
79400,
15300,
null,
10600,
30700,
77800,
25400,
14600,
10250,
8700,
9200,
42200,
44700,
12700,
32000,
9300,
7600,
null,
20700,
19900,
69200,
null,
7500,
40700,
4600,
134900,
35800,
null,
33500,
46300,
11600,
20100,
27100,
7800,
21300,
16500,
18225,
21300,
27400,
32300,
25000,
21200,
32800,
31200,
17400,
13074,
32400,
46200,
17300,
49000,
14700,
null,
15200,
35200,
32400,
47600,
14000,
84800,
26700,
33600,
57700,
21300,
28000,
26600,
15400,
10000,
11700,
11100,
14200,
28600,
11500,
null,
19700,
69000,
23000,
8900,
30700,
15200,
null,
14000,
null,
54400,
22000,
19000,
71716,
18800,
42900,
23800,
28300,
24100,
null,
2900,
45300,
17200,
20250,
null,
2400,
14500,
24800,
17100,
24200,
13600,
null,
80400,
48100,
8600,
20600,
18700,
34200,
null,
20400,
7100,
85500,
20057,
28300,
7100,
15000,
11500,
14400,
72000,
33900,
32600,
18500,
34700,
6300,
19200,
69400,
13900,
22600,
10200,
null,
20600,
29000,
21500,
38600,
123100,
62400,
null,
123100,
12700,
10600,
29400,
153800,
7800,
29300,
9300,
12700,
34800,
65300,
2500,
29000,
49500,
100800,
11900,
34300,
32100,
45500,
null,
14400,
1700,
17300,
38500,
74800,
10900,
15400,
121300,
45000,
12200,
2700,
1800,
41900,
18470,
72900,
19900,
26500,
43700,
25300,
29800,
26500,
23300,
47200,
null,
null,
45400,
92800,
10600,
17800,
15200,
17900,
34100,
null,
5800,
1100,
41300,
11400,
null,
25600,
null,
46600,
30600,
7100,
18000,
39500,
32300,
30600,
31400,
11300,
5100,
null,
48900,
16800,
118600,
36462,
47800,
19100,
88700,
8600,
9200,
31100,
36900,
19200,
59900,
39200,
6800,
13600,
7600,
22500,
18100,
38200,
40500,
null,
19600,
null,
121300,
6600,
49300,
17500,
46100,
12400,
29500,
23900,
null,
16900,
51500,
18000,
12200,
12300,
49800,
16300,
15900,
111400,
101100,
10500,
16000,
51300,
null,
38600,
17700,
20300,
4500,
9800,
56900,
30600,
36400,
9300,
39675,
17000,
5300,
25200,
4100,
69700,
49600,
44500,
20500,
57000,
21900,
29600,
25770,
53800,
2400,
116400,
13000,
52800,
8450,
14800,
42900,
20700,
null,
17000,
8200,
32164,
30300,
19100,
5100,
37000,
15300,
25300,
23500,
12500,
51700,
33500,
5800,
33200,
0,
14200,
16500,
89100,
9000,
15500,
48300,
13000,
32200,
10300,
26200,
33100,
45300,
24700,
26000,
12100,
35000,
54300,
25200,
28000,
41700,
4400,
2000,
13700,
10900,
16000,
24000,
16400,
146100,
71800,
37300,
null,
8191,
18100,
null,
43338,
65900,
500,
52600,
34200,
null,
53300,
25800,
9000,
47500,
5900,
66280,
33700,
6200,
25600,
70900,
85500,
40500,
null,
27300,
null,
5200,
28000,
null,
null,
116100,
43400,
11000,
9750,
28900,
36900,
14200,
20885,
null,
13900,
16400,
null,
27600,
27500,
10700,
5800,
7200,
2960,
null,
31400,
19600,
44000,
null,
null,
27100,
16900,
42000,
12200,
58900,
15600,
28400,
20600,
11900,
14700,
40800,
40100,
27200,
68700,
26200,
20700,
37300,
73000,
4500,
38300,
16500,
52700,
27200,
16100,
null,
16000,
13600,
48300,
14600,
36200,
null,
49400,
30500,
18000,
8300,
12800,
29600,
32800,
5700,
41900,
45000,
28100,
53500,
27000,
13900,
5600,
15700,
25400,
5900,
9900,
22525,
21200,
35600,
26300,
17600,
7800,
10300,
9900,
29000,
106700,
27000,
17800,
92200,
0,
26200,
12700,
15300,
21000,
15000,
16300,
33100,
26600,
17100,
23200,
8900,
28600,
3800,
64900,
8700,
16600,
null,
5000,
35400,
22300,
26800,
37200,
null,
35000,
6800,
59500,
56400,
8800,
13000,
32300,
9700,
22700,
69900,
95800,
55700,
22400,
50800,
26800,
17100,
5800,
84500,
26300,
38000,
21500,
null,
15400,
54400,
85100,
34200,
6400,
8700,
24000,
37100,
13600,
48200,
39900,
null,
21880,
24900,
20100,
46621,
41600,
17200,
31500,
36300,
135400,
25400,
37700,
19800,
17800,
29600,
43500,
null,
3000,
15781,
83600,
20500,
24500,
38900,
17600,
11400,
18900,
null,
38789,
4300,
25900,
13200,
5300,
18100,
31000,
null,
26110,
19800,
115400,
3000,
23900,
19700,
10600,
8600,
7150,
81800,
31800,
null,
11000,
69500,
33800,
23200,
3900,
51900,
35500,
83600,
null,
45300,
9100,
43600,
21500,
6200,
12500,
37800,
6800,
23700,
40500,
19100,
11500,
33200,
13800,
11900,
39300,
52800,
10000,
20200,
22000,
8200,
12200,
27000,
58800,
34600,
41639,
12000,
8100,
38200,
18400,
34000,
18200,
3700,
5800,
20600,
92000,
31200,
12100,
8600,
18600,
41600,
32100,
33600,
36200,
16600,
22800,
20400,
17000,
22600,
3600,
36500,
16300,
38300,
16900,
83400,
79800,
17000,
51400,
45100,
17390,
45100,
6500,
13300,
9200,
105500,
34000,
29600,
74600,
20000,
30000,
47000,
39200,
54100,
8400,
9100,
127300,
27800,
28800,
54500,
32300,
18600,
9900,
80800,
29000,
null,
10100,
14600,
21000,
16000,
7400,
41900,
6000,
12100,
38100,
19000,
31600,
null,
3800,
14900,
3400,
26100,
16000,
11900,
12700,
18400,
41500,
28500,
20800,
15200,
20000,
32600,
null,
20800,
14000,
22500,
23900,
19100,
50600,
15500,
28000,
11500,
97900,
5800,
14100,
59500,
27800,
null,
55300,
null,
32400,
23000,
15700,
15600,
53800,
11900,
30500,
18600,
60300,
11100,
19700,
11800,
8400,
16800,
64000,
72500,
31500,
8800,
6500,
5200,
37039,
null,
null,
null,
15600,
null,
13100,
57300,
31500,
15400,
15200,
17900,
29100,
7600,
152500,
64103,
45700,
42900,
12900,
19700,
32700,
22200,
73500,
24600,
16300,
7400,
52500,
17800,
39500,
null,
163600,
42600,
16800,
93441,
32400,
24500,
8500,
17900,
64500,
22100,
18700,
12500,
35000,
36700,
23400,
82600,
89300,
87100,
17400,
61600,
28700,
106600,
41700,
25500,
35100,
19700,
8000,
106400,
30600,
20400,
5000,
13400,
4700,
7200,
23100,
83900,
23700,
33300,
28300,
22800,
16000,
30600,
17300,
7600,
22600,
58300,
8200,
91900,
14800,
17000,
50900,
17100,
13300,
43400,
49000,
31500,
28600,
27500,
42417,
19000,
10800,
24700,
21400,
15500,
27400,
194700,
28100,
1800,
14900,
null,
9900,
66500,
6000,
18700,
null,
27800,
22300,
13900,
17900,
8500,
14700,
8000,
null,
6000,
21700,
72800,
210500,
10300,
45500,
38100,
47600,
11000,
4700,
57200,
28200,
25100,
23400,
22700,
10200,
29946,
null,
99700,
43300,
120000,
20000,
16100,
34080,
106500,
54000,
11200,
55500,
null,
54400,
18300,
61366,
17000,
36200,
40200,
22700,
13900,
12300,
18200,
10200,
13500,
72100,
15900,
30000,
17900,
24400,
null,
51400,
16800,
43500,
null,
19900,
23300,
34500,
30900,
27800,
115100,
44300,
null,
24600,
45900,
11300,
null,
42400,
29300,
9300,
10100,
52400,
7300,
34500,
34500,
47800,
12200,
null,
15200,
28000,
49300,
21600,
53600,
37000,
28300,
24400,
null,
11400,
110600,
9400,
5000,
27300,
57800,
7200,
10800,
43800,
11700,
null,
11500,
25000,
30900,
28500,
16800,
49400,
28500,
35800,
26900,
17900,
26600,
43600,
null,
53600,
49100,
13800,
36000,
13700,
null,
7900,
45600,
14800,
21600,
41400,
31600,
17300,
11200,
14200,
2100,
null,
32400,
126100,
23300,
12100,
27100,
16900,
37000,
30400,
27000,
53612,
53900,
15200,
70500,
24300,
20900,
47200,
9000,
22000,
21800,
8300,
66500,
14000,
29000,
null,
45100,
9800,
17600,
30400,
10400,
null,
22800,
19700,
17700,
43400,
33100,
37911,
7800,
23900,
23600,
39500,
60800,
null,
6000,
17400,
19700,
null,
20100,
49600,
19900,
18500,
37400,
18000,
16400,
37800,
20700,
32200,
25000,
15400,
null,
23500,
27900,
27700,
66200,
61000,
51400,
54300,
4900,
31000,
33400,
null,
12400,
15100,
48300,
7700,
21548,
48900,
8100,
6500,
null,
25000,
null,
15300,
12400,
38300,
15600,
5000,
18900,
null,
22100,
58400,
11900,
null,
37400,
11500,
75500,
17600,
19400,
40700,
18400,
49700,
23200,
37500,
107100,
13700,
60600,
6800,
62000,
6400,
7300,
74400,
21000,
29100,
78100,
12700,
null,
40900,
8100,
5400,
121700,
15000,
30100,
8600,
34900,
15200,
20100,
null,
26900,
null,
163600,
null,
45900,
31900,
16300,
6100,
null,
null,
15300,
44600,
2100,
22800,
8000,
42450,
86000,
11700,
13600,
19400,
15100,
55300,
39000,
24500,
117800,
49400,
19200,
null,
65100,
12500,
139300,
30000,
6200,
2900,
7100,
3100,
null,
59080,
26700,
15032,
19700,
17500,
63100,
10300,
18100,
75600,
20700,
15494,
9800,
29700,
42800,
21600,
33700,
68500,
20000,
22900,
37000,
null,
35100,
26600,
20500,
15700,
44400,
null,
38600,
21800,
6800,
33100,
8100,
29200,
68100,
17100,
null,
21600,
null,
41600,
37600,
23200,
15700,
null,
32200,
null,
12200,
14400,
13300,
5900,
16700,
11100,
167600,
80100,
8800,
4000,
17000,
12700,
35300,
46400,
21000,
61500,
null,
208600,
12100,
17700,
16300,
null,
20500,
null,
20800,
48000,
9900,
null,
13600,
11500,
12700,
32800,
15300,
19100,
5800,
12700,
18900,
8800,
28300,
11100,
10100,
12900,
32300,
47900,
51000,
15800,
36000,
6700,
6600,
33160,
null,
12700,
58100,
null,
24000,
60500,
23100,
47500,
null,
56400,
null,
30600,
null,
46000,
89200,
63500,
14900,
88200,
5500,
37000,
20500,
null,
3810,
41100,
12600,
32800,
21200,
15500,
96800,
10200,
97500,
null,
74100,
28600,
null,
39500,
10000,
35200,
20700,
21600,
5700,
12000,
18100,
7800,
33300,
51200,
37900,
38500,
3700,
45500,
10300,
2100,
29100,
15700,
12900,
null,
32000,
31500,
24500,
27800,
null,
15100,
17800,
68400,
null,
19400,
14900,
11800,
10500,
6900,
27400,
6000,
42900,
30600,
36100,
15700,
23100,
187100,
12900,
45300,
6600,
15800,
38300,
24800,
44000,
29300,
22300,
15100,
56700,
null,
19425,
24500,
56900,
38300,
16200,
52200,
25300,
23000,
10300,
15500,
26100,
null,
108600,
13350,
8650,
13300,
14600,
8600,
29900,
25500,
null,
97500,
20200,
25100,
26100,
10500,
null,
48800,
61400,
11000,
13600,
null,
30400,
13300,
11450,
null,
21100,
null,
13400,
16600,
34400,
36200,
20000,
4100,
5300,
42900,
23400,
12000,
18500,
21500,
33900,
57900,
73600,
null,
53200,
19500,
26200,
18800,
44000,
66700,
29400,
11800,
33800,
null,
25500,
10100,
5800,
18800,
null,
35200,
12900,
19300,
12500,
null,
null,
17600,
20900,
19600,
7700,
50000,
12600,
20200,
14700,
71200,
47300,
12200,
22700,
null,
24900,
62200,
15500,
11300,
61300,
88200,
60100,
null,
39600,
11700,
36700,
27500,
null,
51200,
18600,
12200,
26300,
16100,
25900,
16300,
36200,
null,
null,
26300,
43800,
7300,
74300,
21600,
null,
61900,
29000,
44266,
161300,
19100,
21300,
19100,
11000,
17300,
31700,
20400,
44000,
39400,
59700,
57800,
37000,
23200,
26700,
19500,
22900,
13800,
14600,
14100,
3600,
29800,
19500,
null,
26200,
15700,
13800,
19100,
10300,
12600,
12300,
24800,
18200,
6600,
60900,
35600,
18500,
11700,
8200,
63380,
52096,
39100,
33700,
null,
14100,
25600,
14100,
52300,
11313,
5000,
18000,
52700,
5500,
null,
41200,
11800,
22500,
19500,
40900,
2100,
48500,
8400,
28000,
9100,
32300,
12700,
45700,
57400,
25400,
15800,
8400,
23200,
42700,
15100,
40700,
22500,
57600,
100700,
41100,
16900,
18600,
20700,
39300,
19700,
8700,
50700,
22200,
14400,
19900,
null,
42800,
20700,
28800,
10500,
17600,
83800,
14900,
1500,
null,
32100,
32700,
68100,
38500,
5800,
50000,
18200,
29800,
34586,
7100,
161300,
23500,
null,
14300,
9100,
14700,
null,
24000,
35400,
28600,
28500,
25500,
42400,
46900,
29400,
11700,
28600,
31100,
5000,
47000,
17000,
35400,
65100,
33600,
13250,
43600,
11100,
19400,
68100,
17300,
9500,
22000,
42500,
34200,
9200,
14800,
17800,
39700,
38100,
14000,
142300,
15700,
70000,
23800,
22700,
16800,
29000,
53900,
71300,
10200,
45600,
8600,
23300,
29100,
16000,
23800,
64600,
16100,
33100,
10000,
25700,
19000,
11500,
49200,
20000,
9200,
14800,
36200,
null,
5200,
41300,
28900,
18300,
12800,
5800,
5000,
null,
22200,
7200,
16000,
35500,
12500,
8700,
14600,
39900,
9800,
39700,
15000,
19400,
61500,
4700,
5900,
44200,
53900,
59900,
10800,
11300,
46100,
29800,
12700,
41500,
12300,
18650,
54800,
27500,
50400,
6500,
25300,
28000,
79300,
16300,
17700,
23700,
96600,
10600,
29300,
64200,
31400,
36500,
23032,
18500,
7100,
16800,
11650,
12900,
51400,
34400,
33600,
35100,
20100,
24500,
25800,
5300,
16600,
8900,
33500,
41200,
null,
37300,
9800,
null,
14500,
49300,
24231,
10000,
9800,
40900,
12000,
14200,
null,
52400,
19000,
11100,
40678,
12700,
34300,
74100,
null,
11900,
22700,
15000,
30900,
9500,
7100,
4700,
30900,
4300,
15100,
null,
13100,
25800,
43700,
39200,
120100,
62600,
43100,
6500,
47100,
16100,
17100,
195800,
7900,
7000,
15300,
13800,
38900,
22300,
45200,
29200,
1500,
72600,
65700,
9300,
17700,
23600,
50500,
7200,
1000,
27600,
null,
17100,
12300,
24500,
27600,
44000,
31400,
11900,
44530,
55500,
20600,
23400,
16200,
37600,
51700,
3200,
18300,
13700,
52600,
15700,
14600,
16500,
10000,
null,
159500,
31600,
3900,
4100,
33100,
36800,
92300,
null,
52600,
null,
28400,
6600,
7600,
37600,
28100,
16000,
8400,
17600,
19700,
41139,
76400,
null,
88600,
151900,
46229,
39100,
44100,
20731,
8500,
59400,
7800,
41900,
34900,
15000,
11453,
2500,
17000,
null,
36200,
14000,
32200,
23800,
9100,
6300,
22700,
22500,
24200,
27000,
131400,
29400,
19700,
4000,
26900,
23400,
null,
11300,
28100,
28474,
7700,
14000,
58900,
10500,
49500,
28900,
26600,
25700,
39400,
17400,
65900,
17000,
29000,
77500,
9200,
null,
24400,
5700,
null,
3800,
4300,
9600,
24600,
800,
13800,
34000,
31800,
22200,
null,
111300,
22800,
9500,
18200,
20500,
10300,
50400,
3500,
3000,
38300,
12000,
8900,
42300,
8100,
8500,
31100,
7500,
6300,
6600,
16400,
8000,
38700,
47700,
21000,
28200,
56100,
14300,
23200,
11700,
47800,
115145,
47100,
91667,
15981,
50800,
39396,
17400,
66900,
15900,
29600,
18400,
16100,
39300,
52100,
11100,
21800,
48500,
3900,
22300,
94000,
6200,
7000,
14800,
9600,
26200,
68700,
12400,
177800,
17400,
54700,
92300,
8000,
27000,
100000,
77600,
27400,
3300,
5500,
16100,
29500,
41200,
20200,
20500,
45400,
6200,
40000,
60000,
50000,
75600,
50400,
47100,
null,
48600,
49200,
28800,
19200,
22200,
16100,
21800,
4300,
11200,
31010,
49000,
null,
33200,
41500,
19500,
14800,
61800,
17100,
32200,
null,
22200,
null,
23000,
16600,
56700,
38800,
57300,
6800,
null,
36000,
143900,
14100,
25200,
21100,
30000,
30200,
18300,
24500,
null,
10200,
13700,
26100,
42700,
7300,
7600,
15700,
26700,
18700,
74600,
47200,
28000,
8500,
2000,
35700,
29700,
17500,
28500,
25500,
48750,
40000,
45900,
66500,
32800,
36800,
41300,
8600,
7300,
42600,
70900,
9800,
17400,
32600,
28300,
null,
21400,
18000,
16800,
22200,
33200,
86600,
20200,
12200,
13800,
24800,
118000,
9500,
77200,
12100,
42300,
56200,
36700,
34200,
16400,
48900,
3725,
25700,
10300,
15900,
6400,
8400,
17900,
52100,
11000,
24200,
24600,
11300,
39100,
24900,
25900,
32400,
null,
null,
31009,
15000,
4300,
67400,
34300,
1700,
10600,
17900,
13600,
47807,
14900,
15700,
15200,
null,
11800,
26500,
37600,
13000,
25000,
null,
38400,
43800,
3900,
10800,
null,
16000,
19150,
49800,
null,
2200,
22600,
11100,
17600,
65400,
null,
21600,
20400,
9000,
24300,
null,
5400,
10100,
8200,
48500,
null,
55400,
22700,
33400,
null,
13400,
16700,
24000,
null,
87900,
16100,
15200,
null,
48600,
26100,
38500,
114000,
27400,
18500,
16000,
20400,
30000,
13200,
12600,
55700,
12000,
55800,
35100,
27100,
9400,
22800,
15500,
22700,
5900,
13800,
3200,
55800,
7700,
25900,
56900,
57700,
20800,
7700,
44300,
19200,
18700,
57800,
30000,
42200,
8000,
29600,
48000,
null,
10100,
24300,
15200,
20700,
33600,
23400,
12000,
44100,
59500,
26400,
null,
21200,
17600,
23700,
29000,
13500,
17000,
21000,
7800,
27100,
19700,
14500,
18100,
84600,
28600,
40000,
13400,
8800,
22600,
38700,
77700,
14800,
42300,
null,
12800,
47400,
11300,
null,
25900,
3000,
46700,
55300,
4200,
73700,
46745,
6700,
39000,
18200,
14400,
null,
5068,
7300,
95100,
17400,
50800,
32300,
38800,
82400,
20700,
7400,
14000,
44900,
5200,
21200,
23200,
4000,
25900,
3600,
25200,
null,
30400,
32000,
20700,
39500,
84900,
8400,
null,
null,
50594,
31200,
65300,
21200,
70900,
78600,
54700,
12100,
null,
40900,
34900,
9800,
79900,
94800,
42200,
46100,
47400,
54600,
18100,
28400,
8500,
61500,
94000,
19000,
12900,
null,
4200,
54200,
39300,
25100,
5300,
36500,
28400,
16700,
31800,
29700,
2600,
16200,
82200,
54200,
80600,
40600,
25600,
9500,
9500,
72700,
26400,
17600,
34800,
32900,
8000,
26400,
29900,
52500,
8900,
42700,
10200,
7600,
14900,
27400,
24600,
27700,
8000,
38400,
32400,
15700,
68500,
17700,
12500,
14800,
null,
84300,
20200,
15500,
44100,
34821,
16400,
5200,
25100,
32500,
null,
29700,
48900,
27500,
18100,
13300,
37877,
37902,
null,
null,
127200,
44900,
28700,
16000,
8600,
null,
29500,
51800,
52800,
17300,
null,
18100,
10600,
31000,
27400,
30000,
18100,
8400,
20600,
28000,
12700,
16600,
41600,
24800,
12100,
null,
24400,
10800,
65000,
33400,
null,
12600,
null,
43000,
21700,
23410,
35000,
18900,
7500,
16200,
11510,
75900,
18200,
158000,
114300,
1119200,
16600,
43950,
16500,
null,
46500,
23400,
20000,
45200,
41900,
14000,
29650,
84600,
28900,
83400,
23000,
23100,
15500,
48200,
6800,
28600,
26900,
null,
18600,
40500,
5000,
13200,
47800,
22900,
34500,
6300,
74000,
27200,
14600,
37900,
31700,
28000,
56256,
35500,
72400,
null,
15700,
null,
13500,
26500,
null,
15500,
28800,
6900,
24600,
6600,
11800,
16100,
538900,
41900,
27400,
19600,
15700,
16400,
15000,
26700,
null,
87100,
22000,
null,
18180,
82200,
20200,
144400,
79300,
34400,
12500,
37000,
1500,
13700,
22200,
11000,
8100,
15400,
31500,
60800,
31300,
null,
8500,
9800,
36300,
14000,
20300,
10900,
2500,
87900,
28300,
46500,
null,
70600,
12700,
13100,
4500,
23200,
51300,
14600,
85800,
22300,
36500,
33300,
11300,
43700,
34900,
13500,
10400,
16012,
45900,
17600,
56700,
43600,
10900,
5000,
22700,
3300,
6900,
20600,
null,
500,
11200,
63000,
53000,
43400,
9600,
10100,
null,
7150,
18800,
38900,
1200,
48300,
37000,
17700,
94500,
56600,
57600,
5500,
90300,
28100,
91200,
11700,
23300,
32100,
35000,
8800,
66900,
15200,
73200,
27500,
null,
13350,
10500,
69600,
22300,
30300,
23400,
17400,
5700,
18100,
22200,
13400,
65000,
9200,
10000,
64800,
9900,
90600,
40300,
13300,
25150,
80000,
29500,
27200,
25900,
39200,
19300,
49400,
32400,
20700,
28400,
82400,
28400,
25900,
21000,
45900,
43000,
26700,
22964,
13000,
36300,
36900,
23500,
31700,
20100,
41700,
7800,
null,
10500,
70800,
61100,
11600,
17900,
11800,
102600,
58200,
38600,
87900,
17900,
19800,
42200,
12700,
29400,
13300,
20500,
10500,
48600,
16800,
55500,
27100,
27400,
14300,
40300,
24300,
24300,
35500,
8400,
38800,
17500,
28000,
92500,
19800,
6600,
17400,
10600,
24700,
7000,
15100,
13500,
null,
null,
12800,
15650,
16900,
6000,
7830,
28000,
79900,
4800,
11200,
16200,
24900,
42600,
97400,
135200,
48400,
65900,
18100,
null,
16600,
33900,
13900,
18500,
12100,
84100,
9900,
14900,
20400,
45200,
24400,
39300,
24700,
18800,
27900,
15300,
10800,
26200,
61700,
23400,
null,
21800,
23900,
15800,
231400,
26300,
89500,
11300,
null,
5300,
12800,
16700,
17800,
46200,
26700,
null,
8800,
19800,
13000,
26600,
6300,
32700,
9700,
null,
17800,
65900,
52700,
12400,
76480,
39900,
15200,
24600,
58700,
11700,
10300,
14500,
7600,
19600,
34100,
32400,
11000,
23600,
39300,
11400,
42400,
17900,
19550,
10600,
null,
18200,
34300,
19400,
40600,
22100,
77200,
20900,
15900,
31500,
41400,
15800,
44000,
null,
18700,
36300,
34300,
65600,
9500,
45000,
24600,
16800,
51600,
241700,
23700,
null,
36900,
19200,
72300,
30000,
22800,
9800,
44300,
78100,
10600,
6000,
13900,
37900,
8100,
30500,
2100,
12000,
24500,
40000,
null,
32200,
51100,
null,
21100,
55000,
37500,
257300,
26600,
38200,
23500,
9200,
22700,
null,
null,
35100,
38600,
23200,
21500,
89200,
21300,
27200,
21600,
37500,
45500,
21400,
20200,
10600,
4500,
66000,
17700,
36800,
6000,
23400,
53800,
15800,
null,
41300,
10000,
27800,
83500,
27200,
3500,
10900,
33300,
10200,
8300,
15900,
56100,
15400,
31500,
35800,
16400,
null,
5000,
8400,
null,
5500,
41100,
22900,
28700,
37000,
85000,
37500,
19300,
null,
70400,
12700,
9300,
5700,
17000,
35500,
45500,
68200,
null,
15400,
null,
26600,
17800,
12200,
88800,
25900,
8500,
106100,
6050,
null,
28300,
18100,
42100,
45900,
28100,
29500,
35800,
17800,
18300,
14800,
13300,
17800,
48300,
52700,
1700,
58900,
151800,
15200,
null,
21200,
44400,
20700,
49100,
23500,
26600,
35700,
18500,
44900,
5600,
33000,
null,
16600,
78500,
34500,
26900,
37800,
41600,
12300,
48200,
23400,
32900,
38600,
57600,
23300,
72300,
69600,
32600,
31500,
11000,
14500,
11300,
56700,
13600,
12950,
17300,
18700,
43200,
16400,
null,
7700,
26500,
15700,
10600,
20900,
26300,
16000,
93200,
25200,
6000,
40500,
15200,
29400,
16000,
null,
26950,
7600,
36500,
21700,
25500,
23800,
33300,
12200,
16100,
null,
18700,
47500,
63500,
22600,
36400,
43100,
18800,
27100,
45200,
45900,
null,
17400,
14000,
15100,
2700,
66300,
45300,
null,
45400,
51400,
36800,
33800,
45800,
16500,
52010,
19000,
71400,
48200,
58300,
28200,
10450,
15400,
null,
3300,
18200,
74500,
null,
49700,
9100,
32000,
49800,
68300,
72700,
15300,
null,
25900,
null,
24200,
14100,
19500,
18500,
23100,
18000,
24600,
22700,
25600,
8500,
5400,
16300,
5600,
14500,
10600,
31800,
23200,
53300,
16700,
22400,
100000,
8200,
9800,
97000,
38200,
34200,
null,
21000,
6800,
14900,
11500,
23900,
65100,
10400,
null,
48500,
44200,
55700,
60400,
49300,
11500,
null,
10400,
8200,
131300,
18000,
3600,
25300,
23400,
1900,
5400,
51000,
16800,
65900,
null,
89900,
10400,
27000,
32100,
31700,
21000,
48500,
26900,
69400,
41500,
10600,
17000,
8200,
57200,
47300,
5700,
5700,
116567,
102500,
null,
34000,
16500,
41500,
22600,
64300,
null,
20100,
15700,
14800,
37400,
null,
29600,
51900,
1700,
null,
9300,
34600,
15500,
16700,
159300,
4000,
35900,
23700,
41900,
14100,
24500,
24400,
23100,
66300,
151200,
79300,
38300,
17700,
36300,
27400,
20300,
14000,
11300,
88800,
63600,
46100,
8600,
42200,
22900,
19900,
21600,
16500,
28100,
25900,
18600,
31900,
12000,
63300,
34700,
22600,
8100,
5500,
8500,
23600,
22100,
4800,
19100,
30500,
null,
28000,
25200,
37400,
23600,
11900,
30100,
15600,
5100,
21500,
13000,
24200,
23600,
null,
61200,
20500,
36500,
null,
26600,
31600,
59800,
4700,
46000,
31700,
16400,
66200,
24500,
60800,
7552,
11400,
9000,
69900,
48100,
10400,
38400,
19800,
10000,
56500,
5900,
null,
31400,
9300,
12300,
null,
17800,
137400,
31600,
31800,
33400,
64700,
41100,
19300,
38600,
24800,
28100,
null,
null,
39800,
73900,
22000,
24000,
30300,
7300,
37400,
57300,
50300,
26800,
null,
80300,
42600,
34100,
7300,
13437,
23000,
9100,
15000,
null,
47900,
125895,
8700,
59200,
11000,
67000,
13800,
30000,
43800,
39900,
3800,
38000,
16300,
30200,
20000,
18900,
4200,
48300,
8900,
15600,
36800,
43564,
13100,
7000,
21900,
4300,
29300,
82400,
61800,
41600,
14100,
18600,
null,
13600,
44100,
24400,
44100,
55800,
43000,
27000,
45700,
16800,
6700,
83600,
28600,
55800,
13800,
32900,
13000,
16100,
10600,
54100,
15700,
4600,
null,
34800,
6600,
106069,
null,
56700,
35100,
null,
11300,
null,
39100,
5300,
89700,
18000,
13400,
40200,
22500,
43900,
18400,
null,
null,
13000,
45100,
105000,
56300,
16900,
14400,
81200,
19400,
40100,
58400,
6900,
23500,
26900,
46700,
19300,
21700,
9300,
38000,
39000,
9800,
null,
27700,
73500,
35800,
12300,
27800,
21400,
11200,
9800,
35100,
22500,
14700,
111300,
40200,
59500,
9200,
null,
122700,
32943,
44500,
26800,
23200,
55900,
13700,
null,
7100,
15800,
109426,
42800,
15200,
14800,
8000,
21200,
15300,
43764,
30800,
37800,
70600,
43000,
6400,
17500,
46700,
37500,
27900,
null,
3800,
11300,
18300,
11300,
29800,
17300,
9900,
54500,
3900,
null,
33200,
44300,
29800,
21200,
24200,
12500,
30100,
23000,
21600,
46300,
12300,
67300,
27000,
34100,
null,
8700,
50200,
41500,
26600,
4600,
60200,
null,
55300,
5400,
34300,
null,
40100,
12400,
14900,
41600,
60800,
19000,
12900,
17500,
20200,
15800,
12700,
59300,
65300,
14700,
10700,
null,
5500,
24200,
22200,
9500,
33000,
18800,
3000,
2050,
120300,
8400,
20000,
17200,
120250,
13962,
142800,
21200,
12200,
45000,
18300,
32300,
null,
17900,
52500,
7900,
4100,
81400,
38600,
18900,
9500,
17100,
37713,
7700,
30900,
34700,
25000,
null,
15100,
92900,
34400,
17900,
54300,
64500,
null,
44100,
6700,
64350,
39800,
49800,
16000,
21300,
37500,
8400,
10300,
47000,
26900,
21800,
28600,
84100,
11500,
44700,
4100,
25300,
null,
25300,
17000,
15700,
null,
39000,
61000,
13900,
18300,
12100,
21000,
12300,
54500,
64600,
60100,
13600,
17700,
22500,
60100,
19800,
4000,
null,
9100,
16800,
5200,
10400,
2600,
14300,
10500,
27500,
16900,
null,
15300,
35564,
22400,
18800,
33300,
16700,
null,
11100,
6000,
39100,
23900,
76300,
20500,
22000,
24500,
9800,
null,
null,
12100,
38600,
37200,
17100,
25087,
null,
15800,
39900,
89900,
84000,
10400,
41200,
22200,
46948,
33822,
15500,
null,
19200,
6100,
41000,
16400,
60100,
19200,
62400,
40700,
9900,
67400,
26200,
18900,
6900,
19500,
null,
22200,
null,
85100,
12300,
17400,
86000,
25098,
10100,
null,
12600,
23800,
23600,
41700,
14300,
80700,
30500,
82350,
28200,
33900,
15800,
null,
58100,
5800,
44900,
9800,
21200,
45100,
1700,
null,
13500,
22300,
null,
16500,
38400,
334100,
66500,
19100,
10800,
65700,
76200,
19100,
17200,
9300,
39600,
29000,
8900,
null,
56200,
138600,
8700,
86900,
51900,
26100,
11100,
54700,
null,
25500,
56200,
65400,
31200,
null,
41300,
63200,
20700,
45400,
38500,
16700,
3200,
27700,
null,
34210,
6000,
45400,
10600,
28000,
43700,
null,
29400,
16200,
33500,
7700,
null,
9700,
25100,
15300,
16200,
17900,
12200,
33300,
9100,
40300,
17900,
23400,
35400,
20300,
26500,
112900,
17400,
29600,
23500,
43050,
6500,
20200,
55600,
10700,
53000,
158400,
5100,
18700,
null,
15200,
15300,
25900,
7800,
28100,
15200,
33500,
50500,
26300,
48200,
17700,
91800,
14500,
15800,
24100,
14500,
40100,
55300,
null,
12200,
18900,
27400,
86200,
42500,
59900,
19900,
28300,
54000,
20600,
34500,
39100,
null,
27400,
21300,
8600,
15300,
38100,
57000,
205700,
64700,
89600,
64700,
88800,
72600,
20500,
72300,
16800,
110000,
40300,
23300,
36700,
68900,
13500,
48400,
27300,
40400,
18100,
19800,
null,
33100,
6800,
45500,
25500,
31000,
22573,
26000,
1500,
48900,
49600,
19313,
192700,
null,
6600,
11000,
10000,
32100,
36000,
23000,
22700,
82800,
14700,
null,
81000,
13000,
16400,
19900,
null,
null,
16300,
21300,
27200,
15500,
32100,
28700,
26560,
13100,
25800,
21200,
37900,
8900,
24700,
13300,
26500,
29500,
20500,
36300,
10300,
null,
51700,
3800,
16400,
49800,
13300,
5700,
8500,
null,
72900,
108100,
25000,
22800,
13800,
24700,
13500,
25181,
8200,
56400,
9800,
11700,
21600,
null,
15300,
13650,
9900,
231600,
17800,
126080,
9700,
31600,
18700,
3200,
19800,
null,
52437,
12100,
50600,
4800,
22600,
null,
null,
29500,
67000,
30800,
70500,
40500,
61300,
10400,
null,
26900,
16000,
6500,
41800,
17500,
21600,
8400,
20100,
34900,
18000,
6900,
14100,
39400,
56400,
50144,
17800,
13500,
11200,
13400,
28300,
31500,
28600,
53800,
null,
null,
15300,
36700,
52400,
10600,
62800,
77300,
18300,
9600,
null,
17500,
null,
42800,
214400,
43600,
26700,
42800,
45500,
23800,
66000,
37500,
43700,
null,
16600,
21900,
28300,
24000,
90600,
12000,
32400,
19000,
86700,
44400,
24900,
45000,
32600,
74553,
10100,
50700,
6000,
5000,
19200,
88500,
11400,
35200,
53900,
52500,
6100,
8600,
42300,
32900,
55900,
34200,
18100,
5500,
13200,
58100,
70000,
9400,
8000,
24700,
28300,
45100,
null,
44800,
10600,
17600,
10800,
4200,
28700,
9600,
72600,
13700,
9100,
24700,
17000,
7100,
55000,
57100,
65500,
47800,
6000,
43200,
7500,
null,
24600,
15700,
68800,
null,
20300,
12900,
18772,
24500,
10300,
16200,
null,
19500,
53400,
26600,
14100,
15500,
null,
32700,
16000,
15200,
26100,
36900,
20200,
16900,
20700,
30200,
43700,
11700,
17800,
281634,
11500,
29200,
97200,
28100,
25900,
17800,
21500,
26200,
8900,
null,
54100,
26000,
48200,
13000,
72300,
16800,
8500,
38800,
94800,
11500,
9400,
107100,
50100,
11700,
8700,
19100,
22500,
74900,
null,
190600,
21100,
null,
13400,
5800,
34300,
16800,
7300,
107600,
18800,
36100,
13500,
40300,
11700,
9000,
14700,
17500,
null,
28200,
null,
33100,
80100,
8000,
19300,
14800,
12500,
27900,
7800,
null,
27800,
13800,
28500,
49400,
121500,
18100,
14100,
38200,
21400,
73500,
8000,
6200,
31600,
32900,
16600,
8100,
14600,
7100,
8300,
18800,
null,
71800,
27300,
69900,
14100,
45700,
25500,
34800,
8200,
9700,
6200,
null,
21100,
23100,
20500,
31500,
6600,
59100,
27900,
10800,
52100,
40300,
237700,
41500,
104100,
20800,
15600,
78400,
19700,
10300,
21800,
47100,
17500,
73200,
44100,
9300,
26000,
null,
15100,
55900,
19300,
7400,
null,
14100,
12400,
56600,
28100,
15500,
34500,
65300,
114700,
79463,
19500,
56500,
17000,
34500,
66500,
34400,
43800,
17500,
35200,
12100,
12800,
6500,
5900,
15100,
20500,
39600,
26200,
34500,
17300,
10800,
79600,
16800,
41400,
16200,
32000,
7600,
14800,
40300,
37100,
68800,
35100,
null,
14000,
9500,
null,
45000,
15000,
25400,
17700,
10300,
22600,
25400,
10500,
70800,
49200,
10600,
25300,
null,
34500,
12300,
48700,
117100,
6800,
93200,
19700,
70200,
6900,
16700,
10300,
14800,
27600,
13600,
null,
7300,
84400,
8400,
32600,
5800,
16300,
null,
25600,
7500,
37800,
41100,
15400,
null,
24600,
48400,
23200,
30000,
28500,
51500,
18900,
9800,
15500,
5400,
18600,
122100,
16100,
13200,
19400,
15000,
null,
13800,
28300,
10000,
41300,
80500,
34100,
19400,
32200,
6100,
null,
56400,
27000,
21600,
9500,
7100,
52700,
48600,
6700,
22200,
29400,
14100,
null,
39500,
49600,
30000,
null,
12700,
29000,
11000,
134700,
19850,
12100,
24300,
27000,
22700,
53000,
null,
18900,
21600,
20600,
19200,
12300,
21900,
12800,
17900,
45100,
null,
45800,
15300,
44900,
16900,
8500,
39300,
9800,
null,
51800,
10800,
25800,
11800,
19600,
13100,
null,
6500,
29500,
null,
33600,
null,
67800,
74400,
42800,
44100,
28300,
13900,
32500,
24000,
15600,
8500,
15300,
8800,
39000,
28100,
8300,
26700,
13700,
48600,
12500,
24900,
63000,
21100,
11000,
48100,
24300,
null,
45200,
69100,
4500,
75400,
32100,
10500,
5300,
16900,
9400,
7200,
44500,
36000,
156900,
94800,
22975,
27000,
60800,
8000,
46000,
22200,
45300,
5700,
16800,
null,
23000,
16800,
18200,
80300,
14000,
26000,
39300,
56200,
null,
8500,
null,
27600,
73500,
28100,
85800,
25200,
25100,
31300,
23000,
71800,
22000,
15800,
73400,
16500,
11100,
null,
7200,
8300,
2800,
33200,
53600,
null,
21800,
11600,
12100,
15800,
14800,
13600,
22200,
36800,
58700,
21700,
38800,
15600,
22400,
57000,
6500,
null,
31900,
11500,
20200,
46890,
7300,
10000,
21000,
null,
8300,
11000,
11900,
10600,
28300,
28000,
36900,
30300,
47000,
65000,
32600,
7600,
61400,
null,
27200,
10500,
18900,
6000,
null,
null,
56700,
11600,
9200,
72800,
null,
6700,
10600,
33300,
16200,
9900,
13700,
37600,
5200,
30400,
73900,
5500,
52200,
11200,
29400,
21400,
10000,
26600,
97147,
61400,
15500,
15500,
49600,
27400,
22900,
30400,
72800,
60000,
47400,
19300,
56900,
34600,
36700,
67700,
36100,
57200,
45600,
14000,
3600,
null,
21200,
20000,
19200,
5100,
7200,
42600,
17800,
43400,
14000,
null,
23200,
14300,
28900,
22700,
39000,
37300,
17900,
5000,
16800,
40300,
41900,
12500,
null,
35900,
70924,
15900,
32500,
18200,
12000,
null,
20400,
18900,
40000,
28800,
25700,
42300,
7000,
19450,
46400,
4200,
null,
21400,
29700,
11000,
27700,
43200,
30400,
null,
14900,
25500,
24000,
null,
9200,
34200,
15900,
null,
23200,
null,
null,
7900,
12800,
21500,
14300,
22900,
null,
23000,
46000,
14400,
null,
29400,
46700,
40200,
47800,
29200,
33100,
20600,
103000,
21539,
39000,
44400,
21600,
15000,
9300,
14900,
20400,
37300,
31400,
35700,
16400,
51300,
20137,
8600,
9800,
12000,
10100,
24200,
8300,
16800,
10500,
10500,
4600,
68600,
36200,
8900,
5000,
45400,
29900,
16500,
17800,
42900,
46100,
83300,
32400,
null,
26100,
null,
22900,
16100,
11600,
14200,
59300,
4400,
null,
17500,
13200,
29800,
17800,
null,
22200,
6600,
26600,
33900,
55300,
12400,
49200,
74700,
27900,
54000,
8200,
null,
39700,
82700,
24400,
14100,
10000,
7500,
23100,
10900,
7300,
14700,
null,
46400,
33500,
52400,
22800,
60400,
16900,
15690,
13300,
11300,
5800,
24900,
29500,
23200,
32300,
13900,
6800,
8400,
10100,
26700,
33550,
16500,
53900,
11110,
17500,
19700,
12300,
700,
18400,
27700,
113400,
13100,
59600,
7500,
34000,
40100,
38800,
16700,
17200,
35200,
20200,
10200,
26800,
8300,
31400,
39400,
22500,
36200,
null,
11200,
14700,
26200,
10500,
28400,
1800,
20900,
53700,
38900,
65200,
7900,
7300,
27700,
13400,
4700,
8600,
3800,
null,
10800,
16800,
11000,
15600,
22900,
60500,
9000,
16300,
53700,
63500,
14200,
63700,
81650,
36800,
33900,
32500,
19500,
10200,
26000,
null,
null,
11500,
6300,
23300,
31100,
null,
26200,
33700,
257500,
17300,
7900,
42600,
6000,
null,
39100,
15900,
17300,
33300,
23200,
123300,
15600,
16200,
53100,
32800,
657000,
11500,
16100,
13800,
7200,
39200,
55300,
16000,
29600,
485300,
71700,
12400,
41260,
83600,
102400,
83400,
18300,
42800,
24400,
20100,
32400,
39000,
12800,
24400,
15690,
77000,
33100,
43700,
9900,
10200,
65800,
60094,
4600,
19800,
31000,
43300,
11700,
25300,
22100,
22300,
87300,
34000,
27100,
15900,
16600,
82200,
118500,
24400,
29200,
53600,
10000,
6399,
28900,
172100,
14800,
15600,
9600,
52200,
35000,
14200,
9000,
41000,
26000,
110500,
11600,
74600,
54200,
8000,
16500,
40400,
25900,
36500,
3250,
13500,
74900,
5200,
null,
26200,
13800,
34700,
20200,
27700,
20600,
38400,
30600,
47200,
17700,
71400,
13100,
29700,
44800,
11500,
34900,
41000,
43500,
1300,
57800,
47300,
9600,
11900,
31300,
null,
63200,
8200,
66200,
27100,
8200,
null,
26200,
20900,
11000,
37000,
13300,
null,
16300,
6100,
28200,
6600,
null,
7000,
82300,
34700,
17000,
38400,
31300,
15700,
10000,
25300,
5200,
19400,
25000,
28300,
86500,
null,
8200,
15300,
28200,
null,
10800,
76300,
19100,
24000,
83724,
40000,
10600,
41500,
63600,
29600,
null,
18200,
19800,
4500,
27400,
14300,
28550,
17800,
4700,
10900,
25800,
21800,
26800,
332300,
18700,
2000,
21400,
143500,
56100,
33500,
16600,
null,
15200,
79500,
null,
75300,
26700,
47000,
34900,
27000,
33800,
86000,
85800,
77100,
29100,
13000,
54300,
15500,
40200,
19700,
23800,
16700,
11500,
null,
49900,
20400,
28200,
27000,
26500,
17900,
26500,
30800,
37200,
19000,
34100,
20800,
25400,
53400,
35800,
15300,
6000,
44300,
null,
6700,
11700,
54500,
27800,
21800,
11900,
23800,
5500,
15200,
39400,
16300,
8500,
46300,
8300,
48800,
47800,
null,
23950,
20500,
23700,
8000,
7300,
12700,
33500,
5900,
25800,
12800,
44500,
2400,
34900,
158555,
109800,
39800,
28800,
20300,
83300,
15500,
41000,
10900,
17250,
9300,
26700,
27800,
53221,
null,
9800,
null,
41400,
36200,
53500,
22600,
18300,
75000,
43600,
65300,
62900,
null,
null,
50200,
66200,
63900,
11000,
13300,
12900,
11600,
11400,
null,
38300,
18800,
10800,
40700,
38200,
null,
76300,
8700,
13500,
6500,
28900,
8400,
56400,
21000,
3000,
15400,
7500,
null,
53000,
13600,
null,
14000,
null,
29400,
5900,
15800,
37000,
20500,
20400,
23600,
12800,
11700,
52000,
8300,
16200,
27800,
9900,
30900,
31700,
88900,
null,
26600,
21900,
27900,
12500,
null,
22500,
null,
31900,
13900,
13400,
30100,
45600,
40400,
38300,
11600,
68600,
20800,
10400,
null,
19900,
37400,
null,
8300,
25500,
89300,
0,
99500,
null,
6500,
25900,
27300,
8600,
34900,
21800,
13000,
40600,
45000,
11700,
99000,
43000,
100400,
19700,
44800,
31000,
31900,
50500,
20800,
10600,
23100,
22400,
19800,
27400,
17900,
39900,
14700,
18800,
6500,
17400,
36500,
18700,
9500,
10300,
72300,
64000,
null,
31200,
9500,
53400,
25100,
18525,
19100,
52800,
28900,
12100,
70400,
33700,
7775,
11800,
11300,
25200,
22400,
197300,
26400,
30200,
76300,
10600,
24400,
22800,
31300,
null,
50400,
6900,
53600,
39800,
26000,
56600,
51400,
8400,
16900,
9800,
81200,
23600,
11700,
25600,
20400,
34900,
15200,
23300,
13200,
60900,
22700,
71500,
16000,
23700,
null,
10500,
9400,
7700,
37400,
38000,
50000,
48200,
18900,
13100,
12400,
11500,
23800,
34400,
4600,
51300,
9000,
11900,
30200,
36300,
27100,
20000,
171000,
359000,
20600,
16000,
62400,
40000,
43700,
15000,
31000,
91600,
null,
33500,
29200,
15500,
28500,
6400,
21600,
33000,
109400,
24300,
24800,
166800,
76400,
20300,
6500,
11900,
30300,
18900,
37400,
18000,
23100,
10800,
4800,
38500,
32100,
30200,
91100,
13400,
59800,
5750,
13800,
58400,
47000,
8800,
22900,
7800,
31700,
17100,
50296,
319600,
33500,
68900,
34200,
38700,
26500,
15200,
8900,
53400,
23500,
null,
null,
32200,
3300,
23950,
null,
8300,
35400,
25600,
null,
31000,
8300,
16100,
85100,
40000,
61200,
10000,
24100,
34400,
24000,
12800,
14700,
16600,
38500,
30600,
14300,
40300,
49300,
13600,
54400,
13200,
37400,
17600,
null,
31900,
31200,
15000,
24300,
8900,
null,
30700,
4000,
null,
22200,
47300,
5600,
47800,
6800,
18800,
20500,
105000,
36400,
null,
75900,
27100,
34500,
67000,
10000,
4300,
22000,
null,
40200,
22200,
8900,
33500,
17000,
17300,
6500,
30000,
39600,
11800,
20100,
15800,
12300,
39600,
13500,
23900,
24900,
56900,
42500,
32783,
52600,
63400,
null,
35800,
79900,
27100,
26100,
39600,
26800,
28300,
4674,
25900,
null,
14800,
43500,
28900,
45200,
72300,
13700,
14300,
14700,
12700,
4800,
13300,
141500,
29600,
14500,
36600,
29400,
17700,
null,
8700,
null,
11600,
4700,
114000,
5700,
82000,
19900,
27900,
16800,
35900,
31800,
5900,
4200,
24200,
23200,
85700,
45900,
73700,
17400,
19100,
47500,
12900,
12300,
38600,
6300,
19800,
44000,
10700,
8700,
null,
null,
45800,
55100,
34653,
19700,
31300,
40070,
6000,
67400,
14700,
20800,
30880,
252000,
38900,
7600,
14000,
110300,
10000,
22200,
38600,
57800,
null,
14700,
null,
34700,
20400,
55100,
21500,
27100,
21100,
53500,
14100,
16000,
17400,
10900,
17600,
10500,
24500,
27300,
182100,
23700,
8800,
44300,
17200,
26000,
21300,
159900,
149550,
36900,
58800,
null,
26300,
21700,
null,
8000,
24000,
4900,
8400,
null,
23400,
26000,
58300,
6300,
30600,
33300,
20000,
10100,
13800,
31500,
59700,
38900,
44500,
20100,
71300,
7200,
null,
66800,
17100,
5600,
41000,
72400,
22700,
7600,
36100,
null,
9100,
13500,
5700,
56400,
15800,
31300,
92400,
24100,
21300,
21000,
66600,
36100,
37702,
11300,
19300,
16800,
null,
19500,
null,
68000,
20460,
11100,
9500,
7500,
49400,
90400,
18127,
12200,
34300,
21500,
5500,
9700,
31700,
42700,
31100,
11000,
17700,
4500,
73500,
73000,
55200,
16200,
61400,
17400,
11700,
7700,
24900,
28500,
22000,
17000,
null,
9900,
8200,
71800,
58900,
8400,
35100,
8400,
17300,
11200,
20300,
7300,
null,
11100,
41500,
28700,
1700,
61400,
37500,
3900,
27800,
46700,
17200,
17000,
38700,
9000,
11100,
37400,
6600,
11600,
14800,
13000,
67000,
19700,
25100,
4250,
23200,
38700,
22000,
38600,
59300,
null,
7250,
28700,
19800,
45600,
51600,
15800,
10850,
24200,
25100,
18400,
51800,
7050,
27800,
80000,
40800,
17100,
9700,
26400,
4600,
30500,
null,
27500,
79500,
1500,
32100,
21624,
22300,
4800,
31200,
78200,
36300,
24200,
17100,
8700,
116600,
22200,
51400,
31900,
43300,
30900,
24800,
null,
37950,
33900,
80800,
27600,
24000,
17100,
14000,
4500,
28200,
13400,
46100,
43700,
null,
22400,
2300,
29300,
37600,
14300,
25300,
53600,
9000,
39000,
16600,
7500,
15400,
36000,
9000,
null,
47600,
10600,
null,
4300,
null,
null,
34400,
15500,
15800,
24100,
17400,
48100,
26300,
110700,
52600,
null,
7300,
22900,
76300,
19000,
29500,
16500,
37100,
14500,
null,
4000,
17000,
37800,
49500,
77100,
25100,
46400,
800,
38500,
30700,
10600,
13200,
53000,
29300,
30600,
6800,
8200,
21000,
34900,
47000,
70500,
null,
116000,
11000,
26800,
5000,
43300,
null,
null,
null,
6100,
8700,
20400,
28400,
16900,
48800,
125200,
6300,
11400,
12500,
11800,
39300,
45600,
27300,
25150,
11600,
18100,
22600,
37524,
24400,
49700,
16100,
82200,
50500,
null,
29500,
13300,
46500,
21700,
13800,
40800,
30600,
10200,
13700,
35500,
null,
23800,
17600,
36500,
25100,
null,
19200,
26500,
8500,
54500,
11000,
13000,
14500,
14000,
22600,
13700,
57000,
12500,
30600,
7900,
20400,
17300,
13100,
27600,
10300,
13500,
29000,
63300,
66300,
19330,
37500,
10500,
49600,
11900,
10200,
2500,
24800,
21600,
24200,
30500,
34300,
4400,
30200,
71000,
11500,
59500,
24200,
40200,
46200,
16700,
12600,
68800,
4800,
39200,
20900,
8700,
12200,
50800,
null,
21200,
41700,
28600,
76300,
11100,
50600,
4900,
14400,
42800,
53100,
34200,
28000,
16900,
17600,
17700,
49600,
13500,
22900,
12600,
14200,
32700,
11400,
39700,
9500,
12400,
18400,
2500,
11500,
42400,
15900,
75300,
58900,
5300,
12200,
16600,
32700,
24900,
37200,
15100,
62900,
43600,
89500,
31200,
34300,
14400,
64000,
27900,
18000,
2500,
41652,
29100,
6500,
44500,
6500,
24300,
18400,
12100,
null,
56400,
29400,
null,
16100,
191000,
null,
49600,
null,
19700,
46600,
7600,
28000,
15400,
6700,
4800,
33500,
4900,
5000,
7400,
51900,
43900,
4900,
19100,
53700,
4400,
9700,
26700,
42400,
23300,
16000,
50100,
26300,
7900,
29500,
17700,
5600,
11100,
89400,
89400,
22300,
17900,
18500,
31000,
7500,
105300,
7900,
4700,
46800,
40100,
20800,
2000,
37800,
null,
32100,
34100,
null,
67700,
null,
4700,
21200,
null,
null,
33200,
23700,
40700,
25000,
91600,
13300,
20300,
21700,
13300,
null,
59800,
11900,
30000,
11700,
22300,
19100,
7200,
34300,
20200,
72100,
46600,
3500,
45100,
54800,
20750,
39100,
null,
34900,
15600,
16800,
18800,
29400,
21000,
49500,
14700,
24900,
84600,
13400,
26300,
15800,
61300,
42400,
58900,
144700,
46800,
31600,
27800,
28200,
24000,
31600,
26600,
16200,
73100,
31300,
13900,
33000,
56300,
null,
41400,
41700,
27100,
25400,
76600,
32300,
16500,
null,
null,
20000,
18500,
14700,
67800,
20500,
37900,
13000,
null,
54200,
10900,
58800,
38200,
20100,
41100,
173300,
7900,
25500,
12600,
13100,
47300,
41700,
null,
109900,
44400,
45300,
14800,
2300,
17500,
19300,
8500,
8700,
42000,
2500,
33500,
9800,
8900,
22700,
19700,
5800,
18800,
5400,
900,
9600,
16900,
19100,
120400,
17600,
59000,
null,
24500,
76700,
16000,
17800,
38700,
5300,
40800,
12500,
15200,
11200,
9300,
44100,
17900,
23000,
13600,
null,
null,
8400,
71500,
38700,
51100,
9600,
57300,
64000,
5150,
18600,
39400,
9800,
48400,
null,
18800,
9500,
13700,
8500,
66700,
20700,
40400,
null,
20200,
25500,
27100,
5200,
13800,
11500,
57400,
21500,
43500,
78600,
82700,
10100,
40200,
26600,
52400,
11800,
19200,
null,
9800,
24900,
54401,
24500,
26100,
9700,
32400,
23600,
34200,
204300,
65700,
80600,
5800,
23500,
25800,
37100,
29300,
9900,
null,
48100,
null,
79000,
45200,
71700,
195400,
11100,
28500,
19600,
60900,
6600,
8500,
40400,
8499,
50800,
5100,
53200,
59700,
13100,
45200,
null,
47600,
24100,
50000,
16500,
23000,
14800,
23800,
34700,
18800,
17500,
51700,
13000,
37200,
26400,
34600,
null,
16500,
13600,
88435,
42700,
23800,
3900,
12100,
31100,
18300,
null,
13800,
42100,
29800,
12200,
44200,
54100,
96300,
13100,
12700,
6700,
47200,
23700,
null,
29100,
8200,
17700,
12300,
26700,
17250,
20500,
39100,
9100,
12000,
2800,
34600,
11500,
21300,
69400,
21700,
21800,
29000,
20100,
26800,
42300,
20000,
49300,
44600,
26172,
20300,
46400,
16300,
25500,
48700,
18300,
5500,
10900,
null,
60400,
null,
19000,
50000,
10800,
22400,
13400,
54400,
16100,
57500,
3100,
36500,
24800,
7200,
24000,
null,
13500,
14900,
15700,
12205,
15700,
12400,
18400,
15100,
28900,
19300,
11700,
23800,
11700,
50200,
7600,
null,
15000,
19700,
60600,
null,
14200,
22800,
25100,
null,
76300,
13600,
81200,
9700,
24300,
12900,
20600,
null,
40500,
56300,
114700,
61300,
45700,
24800,
76400,
54800,
40200,
49400,
27200,
22800,
13700,
24900,
56200,
10700,
25600,
55000,
15000,
71400,
21200,
23100,
17700,
12700,
14800,
15500,
61100,
8000,
null,
37400,
20300,
7700,
22700,
23000,
33800,
5400,
13200,
25200,
8700,
10600,
108566,
27700,
22200,
31000,
42700,
19000,
17300,
8400,
10805,
20300,
8800,
32830,
23500,
18500,
19300,
41100,
38100,
10500,
51700,
11400,
9400,
9500,
21100,
39500,
10600,
16100,
42200,
35100,
12500,
null,
23800,
18100,
15000,
13300,
30800,
null,
21000,
71900,
18800,
24100,
37400,
31000,
94700,
50800,
107592,
45900,
66500,
56000,
46100,
15878,
126700,
34200,
24900,
31500,
11500,
8900,
12000,
16000,
14400,
13508,
35700,
71700,
21600,
11600,
11675,
9900,
39700,
24300,
24900,
39100,
9600,
25000,
37000,
null,
73400,
null,
13700,
31200,
33100,
24200,
5300,
7500,
11800,
23400,
6500,
30400,
33800,
null,
null,
3500,
57700,
45100,
19500,
11300,
19000,
18000,
6700,
11300,
29200,
7900,
13400,
10800,
4350,
41400,
12000,
12700,
31700,
9400,
18200,
31700,
24900,
17200,
16700,
9300,
76400,
33600,
71200,
13000,
23800,
45800,
22200,
16300,
19100,
105400,
33000,
15300,
20400,
48100,
13200,
9100,
12400,
6300,
67600,
7100,
38200,
9700,
49200,
4700,
27000,
9400,
38100,
37000,
null,
21500,
22200,
44900,
31400,
null,
26600,
13500,
9500,
21800,
16400,
25100,
56100,
15600,
27300,
29400,
27800,
11900,
10900,
29500,
21500,
null,
22700,
25100,
8800,
12000,
29800,
24026,
null,
24600,
7200,
5100,
31300,
7600,
6000,
20400,
52500,
22100,
30000,
45900,
null,
62800,
31600,
60200,
16900,
69100,
8300,
15500,
11500,
5900,
43100,
null,
null,
19300,
20100,
19400,
null,
128200,
32300,
45800,
24000,
64300,
32300,
6800,
12700,
51600,
6000,
22400,
78400,
9500,
18200,
18600,
9200,
17600,
31440,
39700,
18700,
11000,
null,
32300,
6300,
146000,
12400,
17300,
36104,
null,
21900,
26300,
63700,
16700,
9200,
44000,
29300,
38300,
41500,
37000,
15500,
20900,
16500,
20600,
22200,
null,
15000,
40800,
76700,
3300,
8000,
17900,
null,
12338,
14000,
11200,
null,
24700,
90600,
7300,
26300,
53800,
27000,
20300,
25700,
39300,
28600,
25000,
67100,
33100,
26800,
31600,
27600,
49900,
11300,
null,
38300,
16300,
44200,
42100,
43200,
12300,
61100,
9300,
12800,
16000,
24100,
24600,
48900,
92500,
23900,
18200,
34400,
19600,
10400,
14500,
26100,
42000,
24000,
15800,
32300,
19700,
24300,
17100,
14300,
12600,
13500,
29200,
41200,
29000,
62564,
51100,
null,
21000,
14200,
40600,
4000,
8700,
38800,
81800,
28400,
32200,
12200,
76400,
null,
10800,
13500,
6300,
27500,
80300,
24300,
27900,
35400,
19800,
43600,
6000,
23600,
44600,
17700,
22900,
58000,
29500,
28300,
7200,
14300,
null,
14800,
17200,
30900,
33100,
81700,
20100,
78500,
11400,
100600,
13000,
36300,
38400,
27500,
66800,
8000,
24300,
14300,
11200,
16300,
24618,
21900,
49500,
8600,
11500,
37800,
40300,
3200,
23100,
5400,
8500,
21400,
15100,
20300,
11800,
32700,
87800,
8400,
11800,
50100,
55001,
9100,
24300,
43600,
10300,
49200,
null,
null,
20600,
3000,
34100,
33300,
10700,
null,
42000,
22000,
58900,
17200,
33500,
83900,
56600,
33200,
76800,
null,
6900,
null,
45400,
19200,
70900,
10900,
36800,
46800,
26000,
42100,
null,
50900,
24800,
20000,
12900,
46500,
22400,
15500,
37600,
20100,
13200,
88700,
17700,
54800,
null,
18400,
22500,
17600,
null,
31100,
61600,
null,
38452,
16200,
33900,
26100,
23600,
17300,
30300,
12100,
34400,
6600,
53300,
63300,
24800,
38000,
46900,
9200,
23700,
4900,
16500,
7000,
45600,
19600,
16400,
31000,
800,
25600,
61200,
31800,
53200,
6400,
22600,
63100,
24300,
11200,
37900,
41500,
44800,
48610,
19000,
33000,
14100,
null,
5600,
12600,
46000,
36100,
17700,
15000,
3000,
42100,
39000,
17000,
9800,
10810,
9600,
40300,
22800,
null,
26800,
null,
18850,
66100,
22200,
41600,
22100,
null,
12100,
24900,
51900,
42900,
12800,
35800,
82490,
25900,
18900,
49300,
17100,
51800,
23700,
null,
24700,
28500,
10300,
21500,
14400,
31200,
7000,
36400,
62800,
null,
21500,
29500,
5900,
9900,
17100,
26700,
61500,
64500,
17700,
10200,
41800,
11200,
18250,
103500,
20000,
110600,
29900,
9400,
18800,
28900,
43200,
6100,
26313,
35055,
800,
13400,
12900,
19900,
26200,
4600,
87500,
33600,
45600,
72900,
null,
22400,
28500,
48300,
28400,
14900,
15100,
39300,
58900,
null,
40100,
27900,
11000,
129400,
65600,
41300,
26900,
17600,
25500,
40300,
61900,
18100,
null,
48800,
19900,
17400,
17600,
51100,
53900,
44800,
11900,
85200,
13500,
9600,
13300,
38200,
27700,
45700,
61800,
9200,
16100,
9700,
25400,
45700,
14580,
18500,
18700,
11000,
18500,
26600,
17200,
null,
14900,
12400,
33900,
16700,
16700,
42600,
15800,
21500,
101200,
21600,
29600,
6400,
33100,
11700,
null,
15100,
7500,
20200,
25100,
null,
36052,
22900,
14700,
null,
24200,
13600,
15800,
8000,
23400,
null,
40100,
14100,
14100,
37600,
18500,
8600,
3000,
27800,
129200,
28400,
13400,
14000,
62200,
58900,
null,
31700,
5200,
3800,
11800,
22600,
16400,
null,
44500,
21300,
17800,
19500,
15600,
4200,
27300,
27900,
11000,
36000,
8700,
63800,
18000,
11700,
11800,
25700,
null,
13300,
7900,
32750,
49500,
8800,
5200,
null,
42300,
null,
71237,
19800,
41500,
12700,
24200,
30300,
31700,
35500,
53300,
83800,
8900,
15900,
17500,
13800,
31900,
8000,
42900,
26600,
19300,
29400,
36400,
null,
18100,
66900,
20400,
35500,
24000,
14900,
16500,
500,
93700,
null,
51800,
55981,
94500,
28000,
null,
101400,
11900,
12100,
9000,
11200,
107100,
29600,
4200,
25900,
11700,
17900,
72300,
21500,
null,
26400,
17500,
44600,
30000,
43200,
8800,
20700,
41900,
16100,
null,
19900,
24200,
36300,
39100,
81800,
28100,
27900,
17900,
21000,
14200,
8300,
24900,
59200,
22900,
10800,
17200,
null,
9900,
23000,
40800,
76500,
4800,
16000,
null,
8300,
40900,
null,
45800,
16800,
12100,
32800,
13500,
71800,
null,
33000,
50800,
9700,
52000,
23000,
21700,
17700,
9200,
46400,
9800,
56100,
26000,
null,
8000,
null,
23400,
35100,
24400,
28500,
13100,
70900,
2500,
9800,
7500,
174400,
70600,
null,
63400,
37400,
27100,
7500,
20500,
72200,
49300,
3700,
3300,
6500,
13100,
3600,
25700,
null,
15800,
8000,
36000,
14600,
19100,
26250,
34200,
26800,
9400,
19200,
10900,
54100,
14600,
10000,
39700,
29500,
null,
68800,
29900,
128700,
111000,
81145,
5500,
5500,
30500,
45700,
22400,
11350,
7600,
14900,
15400,
10600,
7500,
203400,
6100,
27200,
27700,
38200,
25200,
30700,
16900,
15300,
3400,
16200,
10800,
71000,
14900,
17900,
35500,
74200,
17600,
22100,
25300,
38650,
5300,
null,
9100,
33600,
33800,
63900,
12500,
10100,
36300,
87400,
35200,
7400,
22500,
14500,
29200,
null,
null,
50100,
11200,
22400,
27500,
17100,
50300,
32000,
null,
30200,
17300,
47400,
50200,
55000,
13200,
25200,
29800,
185100,
8500,
8100,
21800,
25400,
13900,
32200,
13500,
18900,
23800,
15200,
15000,
30600,
23900,
127000,
12200,
40300,
46900,
77400,
11700,
30900,
35500,
41100,
78400,
10000,
41500,
19100,
11300,
40300,
45100,
44500,
14500,
31600,
24600,
39200,
77500,
116500,
25000,
7000,
null,
8300,
19700,
40100,
2300,
55400,
88500,
36500,
28600,
15100,
32700,
22900,
46900,
39400,
19000,
50400,
23600,
65700,
14700,
9800,
16300,
11800,
35500,
26500,
23400,
16400,
null,
28300,
11300,
12900,
21700,
null,
35000,
63800,
18700,
24400,
4300,
24300,
23500,
null,
95500,
34400,
23000,
9700,
49700,
29400,
19800,
84300,
21000,
17900,
17700,
36300,
40300,
5400,
16500,
38200,
13600,
20000,
null,
23900,
null,
3100,
25700,
102200,
null,
16800,
20200,
56200,
13600,
34100,
17150,
7100,
21600,
6600,
6700,
80100,
8600,
82100,
23300,
31400,
28500,
15500,
null,
44700,
18000,
10300,
11400,
28500,
30200,
null,
15000,
11800,
null,
39700,
32100,
null,
25500,
12000,
17800,
35400,
58100,
null,
23300,
97300,
18200,
7500,
16600,
25500,
39200,
57000,
null,
26600,
24800,
9100,
22100,
null,
74000,
44200,
52700,
19800,
21000,
351200,
18000,
23400,
58600,
11000,
7300,
15000,
28300,
null,
180400,
45000,
40100,
51951,
28500,
6800,
46400,
6100,
28300,
null,
129100,
25300,
4500,
10900,
14600,
13000,
13000,
13900,
null,
39600,
21100,
11800,
31800,
53400,
5000,
28400,
5000,
23000,
10900,
31100,
211600,
16200,
7400,
8700,
34500,
25200,
46000,
100800,
54800,
13140,
8100,
16600,
25900,
70800,
12400,
3200,
83500,
4500,
16600,
45600,
8800,
33600,
49700,
5750,
96800,
3400,
23200,
48300,
11200,
12100,
6400,
26000,
15400,
21300,
null,
53500,
49200,
15600,
76800,
51500,
21600,
17300,
43300,
66400,
4300,
38100,
11100,
33700,
121100,
null,
30300,
20900,
94600,
22400,
16800,
56200,
26500,
23200,
14400,
22700,
131558,
16800,
22000,
33900,
27700,
34400,
6300,
52300,
29400,
12300,
16900,
14300,
11600,
28500,
13400,
38100,
19900,
39085,
29300,
39600,
20200,
36300,
97100,
24100,
10800,
15000,
38500,
38300,
9500,
22700,
null,
53800,
71100,
128400,
null,
28200,
37700,
50800,
41800,
68000,
10930,
36700,
19400,
23500,
12000,
46900,
9200,
16300,
10700,
21300,
null,
22800,
27800,
37400,
26200,
12300,
null,
28200,
3800,
39000,
114300,
13100,
19700,
23500,
7000,
22400,
24600,
null,
23900,
63800,
61400,
19000,
20100,
5900,
12500,
37700,
29100,
null,
52533,
16900,
27500,
23700,
16500,
72400,
18100,
30600,
29700,
84800,
8100,
17400,
23700,
25800,
105500,
39100,
53600,
31500,
6700,
39700,
7200,
53300,
2000,
19100,
14600,
18500,
49600,
17500,
14100,
16500,
14000,
23500,
73300,
39600,
21000,
19200,
19100,
19700,
2100,
39900,
45300,
82400,
50200,
12000,
null,
15000,
29800,
24300,
26200,
76800,
20600,
8150,
21800,
28900,
18300,
15200,
22400,
14400,
10100,
150700,
11500,
22600,
32000,
19700,
52100,
20100,
56000,
29800,
56600,
71000,
4700,
13200,
12500,
15200,
5200,
13400,
28600,
111000,
12800,
34000,
15800,
6300,
29600,
13700,
102700,
27600,
null,
36300,
80900,
171800,
24000,
49100,
40100,
null,
55400,
39800,
33800,
2600,
34300,
92100,
48400,
34300,
3500,
26500,
null,
null,
18100,
null,
9900,
14300,
null,
18900,
26400,
7000,
26700,
38300,
19900,
41302,
33500,
24100,
17500,
21900,
14000,
54300,
7500,
10700,
77200,
10200,
40800,
12000,
66804,
57900,
11800,
12600,
69200,
null,
null,
13100,
28700,
18900,
29100,
36100,
51400,
63600,
10500,
109100,
19100,
45900,
15000,
65000,
24900,
11800,
26500,
24800,
null,
101100,
21800,
40000,
7500,
14800,
33400,
44100,
60000,
21700,
5100,
18400,
32300,
12700,
29300,
107900,
18400,
12600,
19700,
14100,
16100,
12500,
56900,
22500,
9400,
10800,
33600,
18200,
47900,
42700,
34000,
null,
61600,
null,
94200,
66100,
28800,
12900,
40200,
12200,
38500,
30000,
15200,
18700,
34900,
9000,
37500,
53500,
86700,
132900,
25000,
65000,
66400,
22400,
1600,
21200,
29400,
15700,
85000,
50400,
6600,
19600,
71700,
16800,
11000,
9400,
96500,
null,
null,
34400,
41200,
6100,
null,
13200,
14300,
55993,
null,
24000,
117900,
13600,
null,
45126,
40800,
17700,
81400,
33600,
75200,
50600,
25300,
39900,
28900,
8600,
59700,
null,
67400,
28300,
19300,
11100,
22200,
51900,
12500,
32200,
11500,
27600,
null,
13700,
105300,
71000,
7900,
18000,
63200,
40800,
12400,
48200,
21900,
5200,
11500,
27200,
27600,
null,
25900,
9600,
22575,
9500,
27000,
13300,
32500,
18700,
73600,
10400,
23477,
57810,
3000,
40848,
18900,
15000,
21300,
139800,
13300,
16200,
57500,
16200,
8700,
13000,
46500,
31500,
34700,
22800,
4400,
32013,
null,
31300,
16700,
56200,
35653,
25600,
52200,
4300,
20700,
12800,
22450,
14200,
62500,
5600,
14500,
52200,
42100,
10800,
6700,
13500,
29900,
36700,
9400,
null,
64700,
17700,
10400,
49600,
36500,
17000,
64100,
14100,
62500,
22900,
20800,
12400,
10400,
null,
24000,
15100,
17600,
53200,
null,
23800,
null,
14500,
18100,
92000,
187000,
40300,
12800,
13600,
12500,
10100,
89000,
11100,
38200,
40400,
31200,
24600,
8600,
31200,
9300,
8600,
40800,
44500,
20700,
22900,
33100,
6700,
28900,
32400,
14300,
24900,
29300,
20600,
16700,
36300,
17600,
41800,
18500,
12200,
20300,
null,
31950,
109200,
40300,
37800,
9800,
105800,
15600,
63900,
9800,
16700,
18500,
11900,
23500,
39600,
17100,
7000,
196400,
23200,
34100,
9100,
75208,
80500,
22800,
30500,
null,
18800,
34300,
23100,
39400,
8300,
66100,
35000,
31600,
112400,
21900,
50900,
null,
13600,
13646,
18100,
11200,
31000,
62600,
null,
16000,
16500,
10100,
67400,
55200,
39100,
55400,
160200,
7900,
40600,
29100,
11200,
33500,
20000,
26700,
26200,
43500,
18300,
58610,
32800,
39100,
7500,
55800,
55400,
41800,
null,
22700,
6600,
62900,
67780,
23700,
40900,
7500,
32600,
43500,
22000,
16300,
50800,
30800,
72800,
53000,
10400,
9400,
88100,
36900,
49100,
34000,
10000,
64900,
10800,
58100,
20200,
51400,
50702,
null,
166800,
155426,
35200,
19000,
16340,
null,
11400,
null,
5300,
46000,
10700,
23700,
53600,
17400,
20200,
3600,
14200,
100300,
37900,
31200,
20100,
20000,
17000,
20753,
null,
66500,
5200,
22200,
19100,
7300,
510100,
23500,
44300,
46400,
42300,
56400,
19400,
74400,
17800,
18700,
16000,
19600,
20300,
17300,
33700,
17500,
43900,
12500,
22300,
25700,
44100,
101200,
15000,
8900,
14000,
23500,
68300,
2900,
7500,
57200,
16700,
null,
null,
47600,
9160,
12300,
70318,
null,
15200,
31800,
17700,
35400,
4400,
41100,
16900,
7400,
8600,
66900,
55900,
50400,
3300,
26900,
14100,
132600,
5300,
25000,
50400,
26800,
19100,
19600,
37400,
21900,
12000,
19500,
13700,
8500,
14300,
82000,
73500,
112200,
9100,
16300,
9600,
20400,
23200,
8600,
19200,
20600,
49400,
45200,
28400,
43600,
70000,
7900,
20900,
11200,
20400,
1500,
11200,
25500,
62200,
20900,
54700,
7300,
33000,
18300,
10100,
5500,
null,
32600,
10100,
35200,
33200,
21700,
38000,
13000,
2000,
12100,
97100,
66800,
7450,
17600,
8300,
3500,
17900,
17800,
29100,
35600,
27003,
25800,
null,
112900,
22800,
18800,
28800,
21300,
25000,
7600,
86000,
22000,
13800,
32700,
29900,
51800,
13300,
23300,
18300,
39000,
31400,
14900,
16500,
67300,
10400,
45100,
18200,
22200,
10900,
58100,
19400,
7300,
14000,
259000,
27800,
7200,
13600,
17300,
12900,
null,
138900,
46900,
17600,
19900,
null,
25000,
null,
39800,
28200,
20300,
15600,
13000,
36800,
null,
32200,
2200,
21300,
7400,
26800,
19900,
null,
7000,
23300,
29800,
57900,
null,
25200,
17200,
8500,
13000,
29800,
26900,
22400,
25300,
44100,
103000,
20900,
63200,
8800,
null,
33100,
17800,
17900,
28200,
19474,
15900,
117800,
24800,
null,
40900,
50500,
9100,
15800,
23800,
12400,
12800,
null,
24400,
27300,
20600,
43100,
17900,
31000,
97700,
67200,
null,
96700,
12800,
46800,
33900,
48800,
28500,
null,
19000,
30700,
21600,
null,
28900,
9200,
4600,
19800,
48800,
20400,
61600,
40700,
42600,
24700,
11400,
104700,
13100,
22900,
27500,
16500,
25400,
32400,
21600,
13200,
10200,
34400,
8500,
15300,
9300,
43200,
9200,
27900,
17600,
6700,
100200,
40200,
50900,
13800,
13100,
15100,
19400,
null,
21900,
9500,
2800,
11600,
43100,
47100,
46000,
27000,
24500,
27200,
28500,
5300,
17800,
25600,
28300,
8100,
24600,
23500,
null,
67400,
null,
47600,
23100,
34400,
6800,
16200,
7200,
18300,
41700,
19200,
30400,
39500,
58800,
33000,
19500,
24400,
8200,
8910,
36100,
14900,
19100,
25100,
14500,
7400,
16300,
8100,
58900,
13300,
15800,
24500,
null,
30100,
17000,
23200,
15300,
35200,
53800,
5200,
61200,
28700,
21900,
15255,
18400,
6200,
null,
24700,
null,
26100,
65600,
6200,
26100,
23700,
36200,
48000,
11800,
11300,
23500,
15800,
27300,
49700,
10600,
16300,
38600,
35600,
null,
23700,
6300,
29200,
75400,
null,
19800,
62900,
26800,
11300,
20900,
12100,
21900,
null,
2600,
16300,
14700,
16300,
15000,
8400,
null,
20300,
19900,
17600,
24500,
56200,
30800,
63400,
53600,
42600,
14754,
101500,
15100,
70000,
55800,
36500,
11800,
81700,
9600,
9200,
29900,
21900,
35400,
7453,
33400,
55900,
40500,
71600,
63100,
45100,
14200,
53800,
43700,
13400,
11500,
9900,
22900,
16400,
7500,
43300,
34500,
15700,
68900,
3200,
38300,
null,
10830,
101100,
78100,
4300,
16300,
33400,
57500,
null,
19200,
6800,
10900,
18800,
24700,
6900,
7100,
16100,
127500,
18000,
14000,
6000,
60730,
8400,
7400,
15500,
68600,
23300,
19200,
4700,
86000,
16800,
2700,
41400,
8400,
6400,
36800,
13800,
202000,
11700,
33300,
6000,
97800,
25300,
29200,
101700,
32597,
20800,
1900,
6800,
64500,
82800,
93600,
16900,
21700,
12800,
9700,
42200,
24300,
16000,
9600,
50100,
260900,
31200,
80700,
25100,
51900,
27800,
6600,
13500,
2000,
44500,
8200,
25300,
9300,
null,
8100,
121300,
28000,
19700,
10900,
20100,
24700,
6800,
null,
17400,
19500,
34100,
36800,
13200,
null,
18100,
11500,
18300,
11000,
5800,
31800,
68400,
40000,
null,
12700,
47600,
37600,
14100,
17500,
16500,
null,
5400,
4800,
25500,
20500,
27500,
27000,
null,
14700,
5900,
19400,
16150,
19400,
26300,
27100,
22800,
null,
10900,
null,
14100,
19200,
114900,
78400,
35286,
null,
45900,
null,
45800,
2600,
22700,
5400,
40300,
13500,
null,
22303,
26000,
42300,
14500,
17500,
55500,
44000,
33000,
86500,
18800,
7700,
63795,
6000,
87900,
17200,
49500,
11800,
29100,
null,
25100,
10900,
null,
10700,
13600,
33000,
11600,
3100,
null,
36100,
20200,
9200,
36300,
9300,
48600,
19000,
49500,
37700,
21400,
38200,
23900,
16800,
22300,
26600,
4800,
19500,
28600,
17800,
16300,
17900,
5300,
50819,
16300,
10900,
15500,
50700,
86500,
6500,
null,
18900,
null,
37500,
26600,
null,
126300,
11200,
15400,
null,
55600,
33700,
52500,
30100,
41200,
30000,
200,
80915,
14400,
34600,
24900,
19400,
12100,
3800,
24700,
11000,
null,
23400,
31700,
29800,
15900,
13800,
null,
null,
18700,
25800,
17400,
7200,
13500,
46400,
31400,
20500,
34800,
31600,
15300,
28300,
36700,
7300,
6500,
26700,
31900,
4900,
52200,
12800,
11200,
54100,
15900,
10100,
14500,
98000,
9500,
80300,
38000,
44500,
9200,
78400,
44300,
14700,
11800,
13800,
15500,
26500,
35400,
43000,
43100,
5650,
null,
12300,
36100,
8600,
26100,
null,
1300,
8900,
73200,
12900,
10700,
90700,
19600,
62500,
18400,
54255,
14500,
9300,
21500,
45100,
16400,
11400,
13600,
12700,
22700,
17400,
23400,
31800,
19100,
25700,
12400,
10400,
54200,
14900,
13200,
107100,
null,
30500,
32000,
31900,
19400,
57500,
14100,
51200,
10900,
25000,
80500,
null,
21400,
16990,
40100,
null,
35200,
12200,
64100,
41800,
18700,
13400,
20200,
null,
24400,
9600,
34800,
74200,
2300,
24900,
13100,
17100,
677800,
7300,
39700,
24900,
12800,
14300,
15400,
61000,
31100,
13100,
13000,
23400,
1900,
7600,
null,
13000,
21100,
5100,
16900,
43700,
5900,
12900,
31400,
null,
51800,
35900,
70600,
7400,
1700,
28500,
13100,
22400,
44600,
74500,
13500,
24900,
19500,
88900,
50700,
47700,
55200,
11800,
37700,
9600,
18630,
48100,
10900,
35700,
null,
23500,
null,
12700,
15500,
34900,
null,
100800,
27300,
77400,
16200,
14050,
19800,
null,
109200,
18000,
59900,
55700,
31200,
10000,
76500,
17400,
41000,
142600,
6500,
54300,
117600,
19100,
38500,
7700,
116550,
35100,
7350,
18600,
28700,
12800,
40400,
34200,
49300,
26800,
21900,
null,
58100,
19800,
15800,
9300,
16800,
12800,
34900,
78600,
76200,
19600,
24400,
16300,
58500,
38700,
186955,
24000,
13100,
81700,
8400,
18000,
46800,
58200,
17680,
60300,
7500,
39200,
15900,
25100,
54000,
null,
null,
36600,
41900,
16400,
null,
18800,
16900,
53400,
60600,
54500,
14700,
41600,
12000,
17800,
41800,
24100,
61600,
54500,
29500,
null,
60600,
64000,
23900,
65500,
20400,
null,
22600,
27700,
25500,
50000,
12700,
56300,
291600,
35600,
30450,
13700,
217600,
113500,
10700,
71600,
54100,
53000,
17700,
30500,
12000,
28100,
null,
57300,
6300,
10300,
105200,
5800,
30000,
3700,
16700,
13500,
23700,
13700,
null,
null,
218100,
20400,
26500,
15200,
28700,
27500,
42300,
32500,
16600,
36900,
null,
null,
28700,
122900,
22500,
53600,
21000,
30800,
9500,
22400,
68574,
17300,
17500,
66200,
69200,
5900,
4900,
37400,
10500,
25700,
24100,
20000,
53500,
46600,
18400,
33000,
37100,
36400,
14800,
24900,
32217,
10600,
null,
19500,
27200,
16600,
10600,
13800,
103900,
20200,
41800,
10000,
27100,
21000,
13800,
12000,
32600,
44800,
49300,
null,
37000,
22500,
8300,
null,
34700,
100118,
68300,
21900,
13400,
21300,
10000,
14500,
14200,
17100,
14400,
36200,
34000,
23300,
33600,
84600,
12200,
11600,
345300,
18300,
14400,
27200,
25800,
73410,
9000,
20400,
90100,
23000,
29800,
5000,
1500,
42300,
43400,
23900,
38400,
6400,
18700,
44300,
22500,
13800,
5200,
6000,
22300,
31500,
11000,
15400,
14100,
14900,
28300,
1500,
117700,
42200,
36600,
69500,
28300,
6300,
21800,
9000,
12200,
17700,
6300,
null,
29900,
4300,
16430,
12800,
30800,
null,
6000,
12600,
10300,
34100,
39900,
8000,
12100,
null,
57700,
41500,
1200,
null,
49900,
30100,
176700,
56350,
16200,
16200,
4500,
20700,
16700,
20500,
27000,
6900,
9100,
74900,
17000,
30000,
7700,
47800,
22600,
2400,
12700,
15600,
null,
85400,
23000,
44100,
null,
44900,
124100,
null,
25700,
37500,
17100,
9600,
20800,
60300,
12100,
9500,
17600,
12000,
31200,
10800,
32900,
10100,
3100,
14900,
9700,
71300,
54400,
null,
53200,
15500,
33100,
27400,
42700,
40400,
22800,
23500,
15900,
null,
5000,
30800,
20100,
9800,
11400,
5300,
48100,
41800,
30800,
13800,
21300,
22400,
null,
20200,
7200,
13100,
30359,
25300,
null,
19000,
null,
14000,
null,
68600,
29100,
10200,
41700,
14000,
24700,
381900,
23400,
null,
8900,
28100,
29900,
47400,
52600,
19500,
6100,
18900,
7400,
9600,
8500,
26100,
44100,
29400,
33900,
40600,
12900,
12400,
20400,
7500,
3700,
null,
null,
63200,
32500,
72200,
null,
6150,
26000,
6000,
30300,
15300,
9100,
36300,
20600,
66338,
25200,
24600,
17100,
15600,
31000,
41300,
18500,
25600,
23400,
135000,
61900,
null,
29400,
37900,
58500,
31000,
7900,
35900,
null,
15800,
13200,
53700,
14600,
31700,
26000,
44500,
14200,
null,
28800,
20100,
57400,
13100,
27400,
75000,
21500,
3000,
1500,
93600,
26800,
45000,
7900,
21100,
23300,
null,
5800,
null,
15000,
31600,
26800,
10500,
62700,
38600,
null,
22000,
10200,
8300,
5700,
19200,
12800,
3800,
98900,
800,
71309,
27400,
11100,
29700,
18900,
5900,
12400,
49400,
13600,
49700,
62800,
63100,
67900,
18400,
50100,
21000,
9900,
36800,
4800,
42900,
11500,
43500,
44600,
4300,
null,
36200,
20900,
29200,
24800,
26500,
58000,
11900,
75000,
41900,
9600,
69400,
36900,
72800,
20400,
65300,
null,
7300,
23800,
24100,
109300,
43200,
33700,
31800,
12000,
40700,
25000,
17300,
8500,
24900,
9300,
21200,
62500,
40400,
33700,
25700,
null,
null,
21300,
31400,
105200,
24500,
31900,
2800,
24500,
12500,
7700,
37300,
13400,
27600,
34800,
null,
28200,
33900,
50100,
20300,
null,
35800,
40500,
8250,
39700,
0,
21100,
17500,
20500,
21200,
63600,
42000,
19100,
6800,
20900,
4500,
35300,
null,
8300,
16100,
46900,
600,
29100,
62900,
17200,
20900,
34100,
38200,
7300,
56900,
64800,
51000,
7500,
12800,
35400,
4800,
13500,
29200,
2850,
null,
12600,
31200,
6000,
33100,
22000,
29500,
5900,
36400,
40700,
34000,
21000,
21900,
13100,
16700,
68300,
53700,
null,
20700,
15200,
17800,
48600,
17100,
13500,
20400,
38900,
18100,
27800,
14100,
27500,
35548,
30900,
20900,
44800,
54900,
19600,
36500,
74900,
50600,
38600,
8500,
10000,
80900,
82500,
48500,
53300,
44400,
20500,
25500,
54466,
23900,
110100,
null,
12300,
50500,
6200,
13700,
5600,
26610,
210200,
22100,
30300,
9700,
17000,
null,
17200,
38000,
9800,
17600,
11500,
null,
22000,
26300,
16000,
42200,
6000,
27300,
13300,
7400,
5500,
32300,
3600,
null,
19600,
null,
22400,
51500,
10800,
37800,
77200,
36500,
30000,
70400,
32900,
43600,
null,
13000,
23500,
13500,
40100,
16600,
40300,
12600,
22600,
25000,
null,
null,
null,
20200,
11300,
40800,
11600,
15300,
null,
1800,
25800,
54200,
19900,
51000,
7000,
92097,
28400,
27900,
33400,
45200,
25800,
73700,
28900,
34200,
15700,
30400,
47200,
37500,
14600,
58000,
16200,
16800,
40300,
12600,
8820,
53600,
22900,
15300,
42600,
28900,
20900,
15400,
14300,
2900,
150400,
15400,
31900,
35700,
null,
94700,
null,
4400,
16200,
16800,
34400,
22200,
22900,
111900,
15600,
5000,
47600,
40500,
52600,
20600,
9600,
13600,
7300,
42300,
24700,
19900,
53700,
34400,
14500,
65400,
null,
null,
22000,
13100,
59100,
40800,
36300,
19100,
47100,
8700,
29100,
53800,
14700,
50200,
null,
23600,
40200,
15000,
11000,
12300,
38500,
22000,
62900,
22600,
18200,
36400,
35100,
36400,
48400,
30200,
19900,
32300,
27600,
37800,
31500,
15200,
46600,
35900,
96700,
9100,
null,
25400,
null,
40000,
14900,
3000,
1600,
13000,
23400,
71600,
43600,
21800,
38500,
35405,
42000,
61500,
84300,
17000,
15550,
34800,
4600,
107100,
24700,
17700,
17600,
9200,
43400,
11600,
11800,
34700,
30600,
22000,
null,
28500,
19000,
68771,
11900,
21000,
33300,
null,
15600,
32800,
18800,
14300,
33900,
206600,
40900,
5000,
37300,
18400,
25800,
3200,
70200,
41200,
11400,
28200,
15200,
null,
18900,
14000,
19800,
35100,
48000,
15600,
6100,
17400,
7200,
12800,
20900,
11500,
15500,
15100,
21200,
37800,
null,
10800,
null,
54300,
31600,
17600,
16900,
12000,
10200,
15300,
31100,
21700,
11300,
19600,
37600,
26700,
10400,
24600,
43800,
null,
47900,
null,
5800,
3900,
22600,
20800,
8100,
18400,
13000,
52500,
19500,
12900,
17000,
27900,
16100,
35000,
40100,
26900,
45800,
15400,
28500,
31800,
16200,
74000,
null,
15700,
10000,
16300,
23900,
13900,
10100,
16900,
40200,
11100,
13450,
78600,
13100,
86800,
60000,
43500,
null,
32200,
null,
17400,
39800,
55000,
8100,
38100,
135100,
24100,
80000,
8700,
26400,
31800,
11590,
4300,
18900,
42100,
39300,
21700,
3700,
9400,
8100,
10100,
33500,
34600,
67100,
4500,
42100,
15000,
11200,
14500,
19500,
27500,
25700,
100100,
118800,
null,
8000,
38000,
94000,
23900,
22200,
10800,
19600,
8500,
10100,
36200,
24500,
18400,
26800,
28700,
61500,
13600,
25100,
6500,
310800,
41200,
29900,
23900,
9700,
238800,
22100,
27700,
36076,
20300,
18800,
69500,
null,
45700,
33500,
14800,
12300,
888800,
57700,
78800,
32500,
32300,
68600,
23500,
47600,
12200,
86300,
56100,
89400,
21200,
46043,
17900,
14600,
47400,
40300,
31592,
19600,
9400,
24100,
77400,
14500,
25700,
16600,
46800,
null,
20000,
null,
10400,
60600,
12100,
7500,
23500,
26400,
18200,
28100,
34700,
16200,
133700,
27800,
11700,
18500,
17600,
32100,
62500,
79600,
69800,
55800,
67300,
98300,
15800,
25000,
48800,
27500,
null,
23100,
18300,
28300,
29600,
10200,
40000,
45400,
37800,
null,
23800,
19800,
28300,
80100,
20000,
null,
11500,
13000,
40200,
70800,
7700,
8400,
34200,
104535,
15700,
8700,
26600,
75700,
14500,
10500,
33200,
11300,
19500,
41800,
29000,
53300,
36400,
27300,
86400,
51900,
41000,
null,
19400,
23100,
3800,
100300,
15600,
9000,
49000,
14200,
18100,
27146,
28300,
12800,
19600,
102400,
7500,
31500,
27700,
11900,
null,
36300,
15900,
54600,
18300,
13600,
16700,
6100,
25200,
11900,
63000,
8800,
10000,
8800,
118688,
85500,
null,
17300,
20400,
12200,
22300,
45000,
23000,
24300,
40600,
47000,
262100,
null,
60900,
13000,
56800,
19900,
12700,
17000,
37400,
12500,
26200,
7600,
35600,
17700,
45500,
33300,
15800,
null,
16700,
10500,
36100,
17700,
29500,
44000,
14500,
12600,
7700,
20200,
41100,
null,
13400,
23200,
18700,
7200,
null,
57600,
5600,
25660,
24250,
62500,
7500,
41700,
50300,
16300,
33100,
68900,
19800,
33600,
61600,
8000,
16400,
27300,
14200,
43600,
14900,
12500,
159300,
24240,
null,
13700,
4400,
27900,
11300,
21200,
34200,
64800,
12000,
25700,
24300,
14800,
2200,
22900,
27000,
12500,
105900,
42200,
30000,
70400,
91300,
8200,
5500,
17400,
25900,
35000,
7200,
25125,
158400,
2800,
16500,
14800,
18000,
5500,
33900,
7700,
32300,
17600,
281000,
15900,
35900,
19500,
59800,
11100,
20200,
null,
27200,
30000,
47900,
33800,
9800,
11800,
34200,
14200,
34400,
50600,
83800,
31700,
20000,
null,
24400,
35600,
62500,
null,
11000,
11100,
13500,
53900,
21100,
14700,
25500,
null,
27300,
18200,
18200,
null,
5100,
12600,
47400,
17400,
20600,
14400,
4700,
5800,
24500,
14500,
5200,
84800,
32900,
28800,
58342,
40800,
26300,
9600,
5900,
22800,
22600,
21400,
16400,
55100,
28300,
34200,
10000,
6600,
92360,
9200,
22400,
4100,
null,
null,
15400,
58100,
10000,
9500,
52300,
24700,
42800,
19800,
6700,
31800,
59100,
34300,
92000,
18900,
6900,
21800,
29700,
77100,
53600,
53498,
null,
25600,
13900,
41300,
34100,
52300,
39800,
10000,
18500,
60600,
36899,
16000,
22800,
68600,
29600,
32300,
9800,
null,
17300,
4400,
25600,
21500,
14800,
17500,
14900,
45400,
47300,
5000,
10600,
206300,
9100,
26900,
null,
29800,
17900,
61700,
63200,
26400,
38900,
53400,
38800,
58100,
26100,
35200,
11200,
14400,
17100,
13600,
31100,
12800,
58500,
126800,
54900,
7600,
56700,
null,
17050,
84600,
28500,
8300,
17000,
27200,
18100,
14500,
51800,
37500,
46100,
40700,
53600,
6400,
20500,
15800,
23400,
6900,
76900,
26800,
21400,
8100,
14000,
42400,
null,
35400,
17900,
18500,
29300,
15800,
11100,
22500,
9800,
25000,
13300,
19700,
24900,
32100,
10000,
31000,
33400,
33800,
30300,
63000,
34800,
41200,
13100,
11900,
9600,
19000,
23600,
null,
14900,
42800,
21500,
126900,
43500,
12500,
26600,
18200,
48100,
26600,
34100,
20100,
21800,
62800,
20600,
33200,
33600,
43000,
39800,
27800,
30600,
43600,
7200,
6300,
109500,
50000,
25600,
46200,
null,
97800,
11700,
39600,
20500,
30100,
45000,
15800,
null,
10100,
8600,
15300,
68700,
52900,
24100,
null,
10500,
31400,
null,
9200,
34000,
11800,
31600,
7000,
17700,
16400,
40600,
14900,
39500,
9700,
32500,
23400,
10300,
69600,
22800,
34500,
19000,
36200,
13000,
18100,
46700,
10500,
25500,
20200,
39673,
44200,
27000,
37600,
46900,
28600,
22300,
10600,
50000,
47100,
36200,
34500,
7200,
13500,
23600,
null,
null,
14600,
18800,
8300,
18700,
120200,
28400,
24300,
12300,
56800,
15100,
43400,
19600,
44800,
16600,
11600,
44900,
4200,
36600,
19200,
30200,
null,
26200,
119300,
21100,
7900,
12500,
14400,
11400,
24900,
14400,
14900,
30800,
8900,
56400,
6100,
null,
13200,
16000,
51400,
22500,
52500,
21800,
27800,
12600,
58900,
21300,
25300,
16400,
6200,
33400,
16000,
53300,
34200,
11400,
32200,
29500,
15300,
96800,
32200,
15100,
26100,
null,
15100,
25400,
35000,
36200,
28400,
29100,
10200,
18700,
15300,
63800,
12900,
49700,
74900,
92450,
7800,
null,
33600,
17600,
null,
17100,
27200,
74900,
48000,
19500,
28700,
31600,
11900,
7400,
18700,
19700,
16000,
128431,
72500,
70800,
37000,
19600,
null,
15300,
null,
11000,
11200,
28000,
47600,
16200,
12100,
73800,
11900,
23700,
12400,
9000,
21100,
39100,
77800,
27000,
null,
22200,
16900,
10800,
115900,
24200,
11000,
9600,
23100,
9250,
28600,
50600,
51100,
2800,
11500,
25700,
46400,
14800,
20605,
7700,
20400,
3500,
35700,
40800,
26100,
32100,
8600,
null,
22000,
121000,
9100,
18100,
29800,
10100,
4800,
43600,
47400,
null,
12800,
44000,
15700,
16600,
29300,
22200,
56311,
54700,
12600,
18000,
9100,
50000,
29600,
6400,
null,
11700,
20200,
152700,
15300,
8200,
76600,
25200,
70500,
24100,
10600,
14500,
null,
null,
12000,
85900,
32670,
39700,
53200,
41000,
null,
null,
27200,
25000,
143800,
null,
57600,
null,
24500,
26600,
23600,
83400,
15800,
5000,
29600,
24800,
12600,
55500,
null,
44600,
9600,
20500,
29800,
61300,
41500,
37100,
23500,
8100,
28300,
35200,
12750,
12000,
16100,
10400,
58300,
29400,
18400,
12700,
44056,
18900,
34800,
12600,
null,
11200,
18300,
9000,
8400,
24400,
26200,
18100,
91200,
24500,
11300,
34300,
29100,
82000,
1200,
33400,
7400,
47506,
12100,
24100,
20900,
20500,
57800,
15500,
57300,
20900,
13400,
53600,
29100,
76700,
45000,
112600,
9200,
29500,
34000,
17600,
20900,
63800,
null,
48400,
16000,
57800,
23900,
32500,
26700,
43200,
74000,
6000,
null,
63200,
46400,
11900,
43500,
21800,
4500,
41200,
null,
34700,
12400,
102300,
13100,
null,
17400,
27500,
25300,
34700,
null,
22700,
null,
19000,
null,
14500,
29500,
null,
85600,
6900,
23000,
18900,
17000,
28000,
7000,
9700,
44600,
null,
25050,
33400,
23800,
22200,
23000,
55700,
36900,
9700,
21500,
500,
21700,
45800,
null,
28900,
12900,
7500,
43100,
37000,
12500,
null,
80800,
16500,
21850,
105200,
41000,
14500,
12100,
40137,
35500,
18300,
30500,
11300,
52500,
8300,
9000,
61500,
14850,
19100,
25600,
25900,
22600,
51800,
442736,
3800,
30100,
6900,
19900,
69400,
22100,
null,
208800,
25600,
48000,
8800,
13900,
17400,
null,
null,
null,
27700,
13900,
42700,
86600,
22400,
null,
20600,
26700,
20300,
6400,
13050,
19800,
null,
41100,
28100,
39900,
20656,
7800,
47000,
16500,
27600,
13900,
19900,
35700,
14600,
18100,
null,
25800,
null,
9500,
null,
13800,
47300,
20800,
120400,
9100,
15800,
30500,
37600,
31500,
18600,
22200,
43300,
29000,
2500,
29600,
40800,
17300,
19100,
7100,
5500,
18400,
34200,
16700,
14300,
6700,
16100,
27000,
18100,
31200,
3800,
7800,
25000,
39900,
null,
55500,
10000,
13900,
11500,
26600,
49800,
17900,
24700,
27900,
36500,
114400,
21700,
20400,
12600,
10600,
8700,
46800,
8600,
24400,
35500,
2400,
41100,
37400,
57400,
63900,
68100,
null,
17200,
21200,
57100,
67900,
77000,
12600,
32200,
8100,
50100,
5500,
20300,
108200,
18000,
57200,
25400,
23900,
3630,
9400,
null,
null,
null,
60200,
24598,
133000,
9700,
13500,
29900,
20100,
67300,
29300,
12800,
29500,
40700,
35500,
100100,
64600,
16900,
33200,
5800,
1300,
17300,
25700,
null,
110600,
17100,
81300,
62800,
7000,
17500,
22900,
25800,
3900,
null,
8600,
25500,
14100,
16300,
44100,
33200,
16500,
25200,
20100,
12100,
60300,
64400,
14200,
6100,
21300,
16700,
16000,
13600,
37600,
5200,
27400,
27900,
14200,
10100,
17000,
35400,
null,
24400,
33200,
6000,
3800,
45900,
27300,
36400,
7800,
19600,
65700,
60100,
21400,
33500,
52000,
8000,
28900,
4800,
26500,
87300,
14500,
null,
20100,
28500,
3900,
10100,
19300,
8700,
11500,
36600,
73900,
10900,
32100,
18300,
43300,
13300,
14800,
6800,
71733,
15900,
42200,
53500,
50300,
14900,
null,
38300,
13000,
18500,
9400,
17600,
25750,
24800,
10500,
12300,
null,
1000,
106900,
36100,
28200,
7600,
4500,
41100,
152000,
6200,
27300,
25000,
43400,
12700,
86561,
13000,
null,
8000,
30400,
6000,
9200,
42300,
27600,
13100,
null,
10400,
11700,
20300,
58800,
12800,
60100,
19600,
15300,
22900,
1000,
15300,
null,
null,
16900,
19600,
36100,
19100,
null,
30100,
43000,
27600,
8360,
null,
39400,
46900,
11000,
10400,
33900,
40400,
24700,
7000,
21600,
14300,
68300,
9000,
null,
39200,
29200,
32300,
28600,
4700,
51500,
7900,
18300,
8000,
24000,
106300,
39100,
21900,
27800,
42100,
70300,
40200,
20800,
22900,
26800,
43400,
20300,
13400,
51100,
21000,
103500,
45000,
null,
14600,
18900,
45200,
15700,
45200,
36336,
null,
9900,
40200,
56600,
6300,
37300,
13800,
12800,
30500,
20200,
15400,
20500,
null,
null,
14800,
11000,
6300,
10800,
16500,
32800,
107800,
6600,
6100,
3900,
25600,
40500,
55100,
117600,
51500,
6800,
19800,
12500,
null,
27000,
11600,
null,
17900,
30200,
17300,
9400,
44000,
17200,
24200,
24000,
37600,
null,
78400,
null,
15500,
null,
33200,
11000,
91100,
44600,
29500,
41000,
50100,
9000,
8500,
null,
18100,
4300,
47992,
48600,
30550,
55800,
15800,
37500,
2500,
32600,
40500,
13100,
21000,
15900,
47000,
70900,
14500,
35100,
31000,
9100,
24000,
22600,
26100,
16250,
null,
67100,
6800,
15200,
24000,
7600,
16400,
22000,
99600,
38000,
38700,
8900,
2500,
60500,
14000,
29900,
28600,
14000,
27700,
21500,
28300,
25200,
25900,
5000,
26600,
31100,
6200,
50700,
19400,
60500,
null,
null,
6700,
81100,
37100,
48600,
30900,
122300,
24800,
6900,
null,
6900,
6300,
60700,
19600,
14700,
39310,
35372,
27700,
15100,
44500,
14700,
10100,
44800,
18500,
26400,
25100,
27400,
20700,
27800,
7400,
20400,
6200,
6200,
21800,
27300,
21400,
16100,
96000,
47100,
36800,
null,
70900,
10000,
68570,
47600,
48100,
54800,
8200,
12900,
16800,
16300,
10200,
5300,
26500,
23800,
13000,
32200,
24200,
35300,
11000,
12979,
9900,
47800,
23100,
35300,
18100,
10800,
32900,
17700,
6100,
17300,
5300,
null,
13100,
19000,
14800,
76000,
8100,
4500,
81900,
null,
36500,
21100,
34500,
11300,
16400,
17300,
10500,
31700,
11400,
34200,
9200,
31407,
null,
28600,
25643,
null,
11900,
22000,
15600,
34100,
29900,
19300,
35380,
9500,
26300,
32600,
null,
5400,
16500,
10900,
51100,
4100,
22000,
6200,
18600,
null,
60300,
38900,
20200,
30500,
14900,
9600,
6800,
39300,
31900,
5100,
46400,
32700,
16200,
52300,
8700,
44800,
22400,
74437,
26800,
96300,
35200,
70100,
22100,
14000,
20500,
null,
22700,
68800,
33500,
6900,
52400,
56300,
35400,
10300,
61000,
31900,
45100,
17900,
8500,
12900,
4600,
5200,
37600,
45500,
8300,
23700,
22600,
7100,
29800,
36900,
2700,
218200,
5300,
76100,
107350,
17900,
13700,
14200,
7600,
29800,
19900,
32000,
43400,
null,
24000,
null,
25000,
26200,
null,
59800,
73551,
null,
3800,
37500,
64600,
154100,
3900,
64000,
44800,
27103,
5600,
40400,
17700,
2300,
83000,
120300,
null,
35300,
47500,
20100,
9400,
14000,
12941,
18500,
13900,
14100,
24200,
5300,
42400,
22500,
15600,
13500,
9000,
22600,
null,
205730,
39400,
11900,
null,
36200,
12600,
21700,
14500,
17400,
24300,
13100,
19900,
43300,
7000,
31400,
null,
9100,
59900,
33400,
52300,
13200,
24200,
30900,
10500,
23400,
9500,
23700,
3000,
67600,
90100,
11100,
9800,
6950,
27600,
54300,
27100,
27000,
15100,
22500,
34000,
30700,
38800,
58600,
11300,
35800,
50900,
21500,
null,
41200,
10300,
24800,
14300,
28100,
220860,
null,
27600,
null,
25700,
167418,
36700,
25500,
73900,
48000,
34100,
14100,
null,
null,
43100,
59300,
2600,
74500,
37200,
20200,
25400,
4900,
5250,
25600,
7100,
15100,
95300,
null,
38300,
16200,
47200,
7600,
67100,
29300,
32400,
46702,
24400,
9000,
11700,
20100,
23900,
8100,
47600,
20500,
40300,
39300,
48100,
16500,
6900,
null,
null,
42000,
12800,
31700,
2900,
39700,
null,
51200,
23500,
40988
]
}
],
"layout": {
"legend": {
"bgcolor": "#F5F6F9",
"font": {
"color": "#4D5663"
}
},
"paper_bgcolor": "#F5F6F9",
"plot_bgcolor": "#F5F6F9",
"template": {
"data": {
"bar": [
{
"error_x": {
"color": "#2a3f5f"
},
"error_y": {
"color": "#2a3f5f"
},
"marker": {
"line": {
"color": "#E5ECF6",
"width": 0.5
}
},
"type": "bar"
}
],
"barpolar": [
{
"marker": {
"line": {
"color": "#E5ECF6",
"width": 0.5
}
},
"type": "barpolar"
}
],
"carpet": [
{
"aaxis": {
"endlinecolor": "#2a3f5f",
"gridcolor": "white",
"linecolor": "white",
"minorgridcolor": "white",
"startlinecolor": "#2a3f5f"
},
"baxis": {
"endlinecolor": "#2a3f5f",
"gridcolor": "white",
"linecolor": "white",
"minorgridcolor": "white",
"startlinecolor": "#2a3f5f"
},
"type": "carpet"
}
],
"choropleth": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "choropleth"
}
],
"contour": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "contour"
}
],
"contourcarpet": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "contourcarpet"
}
],
"heatmap": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "heatmap"
}
],
"heatmapgl": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "heatmapgl"
}
],
"histogram": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "histogram"
}
],
"histogram2d": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "histogram2d"
}
],
"histogram2dcontour": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "histogram2dcontour"
}
],
"mesh3d": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "mesh3d"
}
],
"parcoords": [
{
"line": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "parcoords"
}
],
"pie": [
{
"automargin": true,
"type": "pie"
}
],
"scatter": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatter"
}
],
"scatter3d": [
{
"line": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatter3d"
}
],
"scattercarpet": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattercarpet"
}
],
"scattergeo": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattergeo"
}
],
"scattergl": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattergl"
}
],
"scattermapbox": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattermapbox"
}
],
"scatterpolar": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterpolar"
}
],
"scatterpolargl": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterpolargl"
}
],
"scatterternary": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterternary"
}
],
"surface": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "surface"
}
],
"table": [
{
"cells": {
"fill": {
"color": "#EBF0F8"
},
"line": {
"color": "white"
}
},
"header": {
"fill": {
"color": "#C8D4E3"
},
"line": {
"color": "white"
}
},
"type": "table"
}
]
},
"layout": {
"annotationdefaults": {
"arrowcolor": "#2a3f5f",
"arrowhead": 0,
"arrowwidth": 1
},
"coloraxis": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"colorscale": {
"diverging": [
[
0,
"#8e0152"
],
[
0.1,
"#c51b7d"
],
[
0.2,
"#de77ae"
],
[
0.3,
"#f1b6da"
],
[
0.4,
"#fde0ef"
],
[
0.5,
"#f7f7f7"
],
[
0.6,
"#e6f5d0"
],
[
0.7,
"#b8e186"
],
[
0.8,
"#7fbc41"
],
[
0.9,
"#4d9221"
],
[
1,
"#276419"
]
],
"sequential": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"sequentialminus": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
]
},
"colorway": [
"#636efa",
"#EF553B",
"#00cc96",
"#ab63fa",
"#FFA15A",
"#19d3f3",
"#FF6692",
"#B6E880",
"#FF97FF",
"#FECB52"
],
"font": {
"color": "#2a3f5f"
},
"geo": {
"bgcolor": "white",
"lakecolor": "white",
"landcolor": "#E5ECF6",
"showlakes": true,
"showland": true,
"subunitcolor": "white"
},
"hoverlabel": {
"align": "left"
},
"hovermode": "closest",
"mapbox": {
"style": "light"
},
"paper_bgcolor": "white",
"plot_bgcolor": "#E5ECF6",
"polar": {
"angularaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"bgcolor": "#E5ECF6",
"radialaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
}
},
"scene": {
"xaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
},
"yaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
},
"zaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
}
},
"shapedefaults": {
"line": {
"color": "#2a3f5f"
}
},
"ternary": {
"aaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"baxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"bgcolor": "#E5ECF6",
"caxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
}
},
"title": {
"x": 0.05
},
"xaxis": {
"automargin": true,
"gridcolor": "white",
"linecolor": "white",
"ticks": "",
"title": {
"standoff": 15
},
"zerolinecolor": "white",
"zerolinewidth": 2
},
"yaxis": {
"automargin": true,
"gridcolor": "white",
"linecolor": "white",
"ticks": "",
"title": {
"standoff": 15
},
"zerolinecolor": "white",
"zerolinewidth": 2
}
}
},
"title": {
"font": {
"color": "#4D5663"
},
"text": "total_rev_hi_lim Box plot"
},
"xaxis": {
"gridcolor": "#E1E5ED",
"showgrid": true,
"tickfont": {
"color": "#4D5663"
},
"title": {
"font": {
"color": "#4D5663"
},
"text": ""
},
"zerolinecolor": "#E1E5ED"
},
"yaxis": {
"gridcolor": "#E1E5ED",
"showgrid": true,
"tickfont": {
"color": "#4D5663"
},
"title": {
"font": {
"color": "#4D5663"
},
"text": ""
},
"zerolinecolor": "#E1E5ED"
}
}
},
"text/html": [
"\n",
" \n",
" \n",
" \n",
" \n",
" "
]
},
"metadata": {},
"output_type": "display_data"
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"\n",
"columns inputed with : mean are ['revol_util', 'tot_cur_bal', 'total_rev_hi_lim']\n",
"revol_util filled with: 55.045863060809744\n",
"tot_cur_bal filled with: 139812.53492993632\n",
"total_rev_hi_lim filled with: 32223.922038216562\n",
"\n",
"columns label encoded\n",
" Index(['term', 'grade', 'sub_grade', 'emp_title', 'emp_length',\n",
" 'home_ownership', 'verification_status', 'purpose', 'title', 'zip_code',\n",
" 'addr_state', 'initial_list_status', 'application_type',\n",
" 'last_week_pay'],\n",
" dtype='object')\n"
]
},
{
"data": {
"application/vnd.plotly.v1+json": {
"config": {
"plotlyServerURL": "https://plot.ly"
},
"data": [
{
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"reversescale": false,
"showscale": true,
"type": "heatmap",
"x": [
"loan_amnt",
"funded_amnt",
"funded_amnt_inv",
"term",
"int_rate",
"grade",
"sub_grade",
"emp_title",
"emp_length",
"home_ownership",
"annual_inc",
"verification_status",
"purpose",
"title",
"zip_code",
"addr_state",
"dti",
"delinq_2yrs",
"inq_last_6mths",
"open_acc",
"pub_rec",
"revol_bal",
"revol_util",
"total_acc",
"initial_list_status",
"total_rec_int",
"total_rec_late_fee",
"recoveries",
"collection_recovery_fee",
"collections_12_mths_ex_med",
"application_type",
"last_week_pay",
"acc_now_delinq",
"tot_cur_bal",
"total_rev_hi_lim",
"loan_status"
],
"y": [
"loan_amnt",
"funded_amnt",
"funded_amnt_inv",
"term",
"int_rate",
"grade",
"sub_grade",
"emp_title",
"emp_length",
"home_ownership",
"annual_inc",
"verification_status",
"purpose",
"title",
"zip_code",
"addr_state",
"dti",
"delinq_2yrs",
"inq_last_6mths",
"open_acc",
"pub_rec",
"revol_bal",
"revol_util",
"total_acc",
"initial_list_status",
"total_rec_int",
"total_rec_late_fee",
"recoveries",
"collection_recovery_fee",
"collections_12_mths_ex_med",
"application_type",
"last_week_pay",
"acc_now_delinq",
"tot_cur_bal",
"total_rev_hi_lim",
"loan_status"
],
"z": [
[
1,
0.9993673107070573,
0.9973949825265475,
0.41311371953604037,
0.14366943710400248,
0.15123445239190716,
0.15536725259812714,
-0.05673961933312235,
-0.06308131688329331,
-0.2019158715910581,
0.40108540920753716,
0.2737970376550767,
-0.16068862997246122,
-0.13425640681305548,
-0.00507487327949772,
0.014357096225740723,
0.04160853225294765,
0.0007415367106552037,
-0.03400768276149403,
0.19332376596788578,
-0.0816999635971703,
0.34149699703986486,
0.1230515269517587,
0.22199995958283308,
0.08229056535555854,
0.5323758319755684,
0.03039699981128343,
0.0755662292629318,
0.05456576387485704,
-0.015887925632336142,
0.00537034555863025,
0.022006609114648416,
0.0004827152903769945,
0.3214379296704683,
0.3469448299096464,
-0.09806066158604641
],
[
0.9993673107070573,
1,
0.9981704288031574,
0.412339652004089,
0.14379252375822307,
0.15107359569631804,
0.15509596609179319,
-0.056446660003662,
-0.06291062598972043,
-0.2018326352785139,
0.40087176939356634,
0.2731419955737419,
-0.16138750772421034,
-0.13500421435162355,
-0.00517543484882429,
0.01446970373805114,
0.04232391258958052,
0.0010547673276096636,
-0.03452233482826037,
0.1935251707354553,
-0.0814461770879756,
0.3413116909130855,
0.12341263209434497,
0.22157396955347955,
0.08378860902113754,
0.5314657533019836,
0.030269633683367422,
0.07543904480895032,
0.054488650595454505,
-0.015726918732288136,
0.005404500361503288,
0.022646819725312677,
0.0005841390999188,
0.321611053068661,
0.3471316910806371,
-0.09974063517361584
],
[
0.9973949825265475,
0.9981704288031574,
1,
0.41290376483488955,
0.14394478670358515,
0.14940628867128436,
0.15339121987627705,
-0.05538084917111292,
-0.061882506224260926,
-0.2015453711610762,
0.39994608406008947,
0.2741103680435304,
-0.16352652242173563,
-0.13749931253022543,
-0.005417715817851578,
0.014472860465228195,
0.04439172279281363,
0.0015324685071629318,
-0.03866603173524088,
0.1941822791080103,
-0.08061178508457131,
0.339649030440468,
0.12392080589216109,
0.22173133490096522,
0.08787930617565409,
0.5292283263940617,
0.026987296260350367,
0.0734694212367801,
0.051602719267371436,
-0.015296932487366122,
0.0054739591017863775,
0.02449943082066455,
0.0004408390208968079,
0.3210757354942176,
0.3465968857344195,
-0.10368158647050939
],
[
0.41311371953604037,
0.412339652004089,
0.41290376483488955,
1,
0.4277873334938889,
0.4423558955036647,
0.45202147295116846,
-0.026528122521823187,
-0.033802765736630484,
-0.10380357604396363,
0.07558694303098122,
0.16758167815281758,
-0.05839364427570224,
-0.0632057798737132,
-0.029624717714176636,
0.02436666095721477,
0.10730932533245617,
0.0007659632105278963,
-0.0007276146170709287,
0.08853665094524413,
-0.023698233348671688,
0.09521153970092615,
0.0882227390403947,
0.10510958357225778,
0.12848024309665088,
0.38653366117227445,
0.005894751256496635,
0.06230716598495562,
0.039043197714352496,
-0.0013881705983337703,
0.012339505523841695,
0.03296842706856984,
0.005923374315533706,
0.10989707632923694,
0.07583482299734122,
-0.1314544468506384
],
[
0.14366943710400248,
0.14379252375822307,
0.14394478670358515,
0.4277873334938889,
1,
0.9535737112910263,
0.9769146297008081,
0.02169564790117714,
0.013380584294397252,
0.06633301052504133,
-0.07568113658436114,
0.2499537419998286,
0.15113729552332306,
0.09364436618277527,
0.0007001602988473001,
0.008100369802086492,
0.15789622187463925,
0.05506105904294921,
0.23028709311292908,
-0.0077782473446677694,
0.05702890617850652,
-0.03542229297624434,
0.2713516886712768,
-0.033447633685265134,
-0.11415670051317652,
0.44807241953966465,
0.05059996085209665,
0.11253201737516652,
0.0694149647782059,
0.013964592160664847,
0.007174505406334653,
-0.023394941410067434,
0.02531738684242965,
-0.08760582484385757,
-0.18303223766351773,
0.001315715105046892
],
[
0.15123445239190716,
0.15107359569631804,
0.14940628867128436,
0.4423558955036647,
0.9535737112910263,
1,
0.9764644961761394,
0.022024054326508734,
0.009289495708890953,
0.06537746822995874,
-0.06549187393939643,
0.22903340191862673,
0.15171332806631785,
0.053369691121970986,
-0.002022135809065368,
0.009447616977660677,
0.16554426481598802,
0.060681948093255916,
0.21859411405363868,
0.004608563914233126,
0.06639976104248572,
-0.02810499380157885,
0.24839279175837192,
-0.026212002732536065,
-0.0714167395414081,
0.3778210686601146,
0.04587727350190705,
0.09522884945324374,
0.06395382244989364,
0.02200069409636774,
0.010719897959057688,
0.025224964290838536,
0.0262133129357894,
-0.07927942053537479,
-0.16346685445001832,
-0.05842830898633616
],
[
0.15536725259812714,
0.15509596609179319,
0.15339121987627705,
0.45202147295116846,
0.9769146297008081,
0.9764644961761394,
1,
0.02240755755220031,
0.009626479243445736,
0.06814367868219676,
-0.06853616970854917,
0.24063454524081382,
0.15545522292123395,
0.05471932554746991,
-0.0022399910656615857,
0.009516955532873407,
0.1716199024286485,
0.06183474618339236,
0.22460573730587255,
0.0031617682901269196,
0.0670626523143616,
-0.028723472772034003,
0.2590168538347546,
-0.028710384582010504,
-0.06682686863767658,
0.3888325382656363,
0.04631111290164317,
0.09759050588479604,
0.0653599491919464,
0.021704450136974866,
0.010804005313944208,
0.025549773424498573,
0.027855172810561185,
-0.08300776878706932,
-0.17099740460608218,
-0.05729791014263772
],
[
-0.05673961933312235,
-0.056446660003662,
-0.05538084917111292,
-0.026528122521823187,
0.02169564790117714,
0.022024054326508734,
0.02240755755220031,
1,
0.18144202307584517,
-0.008263794158526726,
-0.06209924217529195,
0.05846964248451429,
0.020798856679962313,
0.08029298153311334,
-0.006686383150673372,
0.0075940206348329995,
0.015824119915088496,
0.0001333279948853352,
0.0015097664673913243,
-0.0515308210974667,
0.04137749167349271,
-0.03623594058065723,
-0.027383105883524696,
-0.036178856247907724,
-0.0010246656340571671,
-0.026362634357548657,
0.005936576934344635,
0.0036308115645922335,
0.007072288972627666,
0.013407638485743775,
-0.003331560851945194,
0.0067456219276319,
0.0015094721747491195,
-0.05026705594493313,
-0.03272903963528642,
-0.036046910279810475
],
[
-0.06308131688329331,
-0.06291062598972043,
-0.061882506224260926,
-0.033802765736630484,
0.013380584294397252,
0.009289495708890953,
0.009626479243445736,
0.18144202307584517,
1,
-0.0006562355291177585,
-0.06803881613030116,
0.08334061150694358,
0.007907050977030938,
0.01814969911058476,
0.0016449886098510234,
-0.003741104513591542,
0.026991125089876163,
-0.026786863693399318,
-0.0032947760836769986,
-0.04146233602712595,
0.030841454907430236,
-0.04252827491856082,
-0.023925010310720883,
-0.04337915466801065,
-0.013676609292509388,
-0.026182606822821832,
-0.0033834219667489523,
0.006559616342723415,
0.0038612858505641225,
-3.638296436917112e-05,
0.00029247265744294747,
-0.002723463176442134,
-0.010314795530514705,
-0.04104551735009645,
-0.03920916331672977,
-0.006294912291385543
],
[
-0.2019158715910581,
-0.2018326352785139,
-0.2015453711610762,
-0.10380357604396363,
0.06633301052504133,
0.06537746822995874,
0.06814367868219676,
-0.008263794158526726,
-0.0006562355291177585,
1,
-0.18483117718102926,
-0.0345023641605532,
0.0337984861944795,
0.0036708446150360246,
0.01529191761546139,
-0.06740060904395742,
0.014071761469811669,
-0.05255823619001008,
-0.036371871475244434,
-0.13106315818290842,
0.010074780311283886,
-0.16784768447422393,
-0.018615295017250816,
-0.21471441255940335,
-0.026552318247412224,
-0.10295309187685193,
-0.0043236572276293414,
-0.00875991306974773,
-0.008606677552553283,
0.004395076043852439,
-0.00010662964918016358,
0.00582070910628204,
-0.01682702954559417,
-0.4938532067528801,
-0.17435976358907318,
-0.008417080510053349
],
[
0.40108540920753716,
0.40087176939356634,
0.39994608406008947,
0.07558694303098122,
-0.07568113658436114,
-0.06549187393939643,
-0.06853616970854917,
-0.06209924217529195,
-0.06803881613030116,
-0.18483117718102926,
1,
0.08192131136654758,
0.006430029735015196,
-0.031234879280442707,
-0.015439174112058827,
-0.003952337172149827,
-0.20860517481450574,
0.05586758573498273,
0.039720857750799234,
0.1561661847581233,
-0.009555280504687002,
0.3529061023310094,
0.041811059093469424,
0.2193065184763861,
0.04575758892406839,
0.1606931503806069,
0.01417862241455744,
0.006552077985370611,
0.006751696947288823,
-0.005112151418505477,
-0.006289245567748207,
0.017414227537550456,
0.02230982529097467,
0.4768413759531402,
0.34182754393774584,
-0.005600004657288227
],
[
0.2737970376550767,
0.2731419955737419,
0.2741103680435304,
0.16758167815281758,
0.2499537419998286,
0.22903340191862673,
0.24063454524081382,
0.05846964248451429,
0.08334061150694358,
-0.0345023641605532,
0.08192131136654758,
1,
0.012701615229108211,
0.007900988943574362,
0.001166926419317222,
-0.003009362948922437,
0.09837099957973558,
0.0033209380373541457,
0.0729302811147864,
0.04603212753302003,
0.039724424930923784,
0.08989391307183653,
0.08462927510827067,
0.06406415580219664,
-0.034538559231869326,
0.26760334159587096,
0.013422384867226342,
0.05006620059727212,
0.02938127689085275,
0.012941042166460179,
0.004872166169305358,
-0.04295672830300664,
0.007586400642540934,
0.06139975588774038,
0.05116657756902476,
-0.02661784839361224
],
[
-0.16068862997246122,
-0.16138750772421034,
-0.16352652242173563,
-0.05839364427570224,
0.15113729552332306,
0.15171332806631785,
0.15545522292123395,
0.020798856679962313,
0.007907050977030938,
0.0337984861944795,
0.006430029735015196,
0.012701615229108211,
1,
0.41751295336363037,
-0.011285153016651232,
-0.0040111077904582985,
-0.08990901398991973,
0.017449799245961788,
0.05189253323562731,
-0.07852834685162759,
0.019167439718075406,
-0.07800272081085825,
-0.1067868440081956,
-0.061511148758259554,
-0.06914102669124954,
-0.034450076060040746,
0.025660757149675535,
0.017536225346724128,
0.011132642431576807,
0.00678373092690319,
0.0010118822324284358,
-0.0214607567958376,
0.008531885664845716,
-0.027290053564699837,
-0.05936139744964515,
0.05696551253971207
],
[
-0.13425640681305548,
-0.13500421435162355,
-0.13749931253022543,
-0.0632057798737132,
0.09364436618277527,
0.053369691121970986,
0.05471932554746991,
0.08029298153311334,
0.01814969911058476,
0.0036708446150360246,
-0.031234879280442707,
0.007900988943574362,
0.41751295336363037,
1,
-0.006805577445327398,
-0.0047158148873595925,
-0.07645939273115507,
-0.018143656921564236,
0.05604090676832486,
-0.07787494493535581,
-0.01883872075323851,
-0.06471104835823145,
-0.04328088508219377,
-0.05940083429340112,
-0.15550183125608844,
0.06749152386272105,
0.029753084053691675,
0.04076494881688665,
0.024636053362644045,
-0.01811070084174997,
-0.0021504504245727753,
-0.1735758892551564,
0.0008111386605700343,
-0.028545090351875455,
-0.055351025295872214,
0.1710336867954722
],
[
-0.00507487327949772,
-0.00517543484882429,
-0.005417715817851578,
-0.029624717714176636,
0.0007001602988473001,
-0.002022135809065368,
-0.0022399910656615857,
-0.006686383150673372,
0.0016449886098510234,
0.01529191761546139,
-0.015439174112058827,
0.001166926419317222,
-0.011285153016651232,
-0.006805577445327398,
1,
-0.2637121981089354,
0.0021985731510732807,
-0.03246170020848946,
0.00014251621358845064,
-0.05459778777075654,
-0.0012874684195429982,
-0.027087322901021522,
0.01817575740524541,
-0.02378191562538043,
-0.01012453949849028,
-0.00808468034770711,
-0.003279678719922463,
0.0028110682936848155,
0.006795583967923758,
-0.0005492985501828694,
0.0007560843314131327,
-0.008318446541552485,
-0.0026600218666307527,
-0.004858219884591405,
-0.03594356420102614,
0.018249726101813062
],
[
0.014357096225740723,
0.01446970373805114,
0.014472860465228195,
0.02436666095721477,
0.008100369802086492,
0.009447616977660677,
0.009516955532873407,
0.0075940206348329995,
-0.003741104513591542,
-0.06740060904395742,
-0.003952337172149827,
-0.003009362948922437,
-0.0040111077904582985,
-0.0047158148873595925,
-0.2637121981089354,
1,
0.03843233639050731,
0.019538735058602343,
0.0053724801882894585,
0.036955421535015215,
-0.009460322071780942,
-0.00641658612807751,
0.0029847625607689744,
0.04594385517357497,
0.01701193489995595,
0.0093732114563079,
-0.00031587719371388944,
-0.005739695653081888,
-0.001773515467238366,
0.007243743988879271,
0.0027959414778755886,
0.011460765823582738,
0.009037407873233157,
-0.005982905081269974,
-0.0005637893461752431,
-0.020198474342035685
],
[
0.04160853225294765,
0.04232391258958052,
0.04439172279281363,
0.10730932533245617,
0.15789622187463925,
0.16554426481598802,
0.1716199024286485,
0.015824119915088496,
0.026991125089876163,
0.014071761469811669,
-0.20860517481450574,
0.09837099957973558,
-0.08990901398991973,
-0.07645939273115507,
0.0021985731510732807,
0.03843233639050731,
1,
-0.004306565723081028,
-0.01647472597217059,
0.2985305829222179,
-0.04459167911769544,
0.13991221742431906,
0.17132147035400355,
0.22204282167014028,
0.05110386522772334,
0.01671088814410185,
-0.006292770123648165,
0.0034653042211982617,
0.0036727057841006226,
0.0033788540311453833,
0.025256662744338958,
0.0407586315913094,
0.013712516532054077,
-0.01818752150691596,
0.0824519602024066,
-0.1343557063926868
],
[
0.0007415367106552037,
0.0010547673276096636,
0.0015324685071629318,
0.0007659632105278963,
0.05506105904294921,
0.060681948093255916,
0.06183474618339236,
0.0001333279948853352,
-0.026786863693399318,
-0.05255823619001008,
0.05586758573498273,
0.0033209380373541457,
0.017449799245961788,
-0.018143656921564236,
-0.03246170020848946,
0.019538735058602343,
-0.004306565723081028,
1,
0.020384034504745612,
0.05550346075276047,
-0.01067849965464546,
-0.03243883558798766,
-0.011997274915568491,
0.12489130033898062,
0.015743819721073016,
-0.0021257926522072128,
0.01798692632914995,
-0.0023232066061796572,
-0.0008419453977416289,
0.0658318099856898,
-0.0007549075432580317,
0.027770547906924115,
0.13013020308737916,
0.06509155070255052,
-0.045356838682710184,
-0.04467080853930925
],
[
-0.03400768276149403,
-0.03452233482826037,
-0.03866603173524088,
-0.0007276146170709287,
0.23028709311292908,
0.21859411405363868,
0.22460573730587255,
0.0015097664673913243,
-0.0032947760836769986,
-0.036371871475244434,
0.039720857750799234,
0.0729302811147864,
0.05189253323562731,
0.05604090676832486,
0.00014251621358845064,
0.0053724801882894585,
-0.01647472597217059,
0.020384034504745612,
1,
0.11339725191786394,
0.050194605668322706,
-0.02391365988845393,
-0.09094808528856578,
0.13622335666530158,
-0.08677399964492707,
0.08725949814981891,
0.02098680794852601,
0.04480882234369649,
0.03640581684262851,
0.006046808767780671,
-0.006416705957685335,
-0.010084465041148372,
-0.005410403954381636,
0.029620923728497763,
0.004312386499570435,
0.08851260689281325
],
[
0.19332376596788578,
0.1935251707354553,
0.1941822791080103,
0.08853665094524413,
-0.0077782473446677694,
0.004608563914233126,
0.0031617682901269196,
-0.0515308210974667,
-0.04146233602712595,
-0.13106315818290842,
0.1561661847581233,
0.04603212753302003,
-0.07852834685162759,
-0.07787494493535581,
-0.05459778777075654,
0.036955421535015215,
0.2985305829222179,
0.05550346075276047,
0.11339725191786394,
1,
-0.03423327020670189,
0.2196085500870657,
-0.1515926659905363,
0.6980956657110625,
0.06495306513072319,
0.06446598079600936,
-0.007397402362062316,
-0.00025758601801110094,
0.0015986210424646448,
0.011836146009475114,
-0.004514816219778578,
0.037521371007512364,
0.017524817385453865,
0.23600303267186948,
0.35866222790091923,
-0.06503025859446773
],
[
-0.0816999635971703,
-0.0814461770879756,
-0.08061178508457131,
-0.023698233348671688,
0.05702890617850652,
0.06639976104248572,
0.0670626523143616,
0.04137749167349271,
0.030841454907430236,
0.010074780311283886,
-0.009555280504687002,
0.039724424930923784,
0.019167439718075406,
-0.01883872075323851,
-0.0012874684195429982,
-0.009460322071780942,
-0.04459167911769544,
-0.01067849965464546,
0.050194605668322706,
-0.03423327020670189,
1,
-0.10333969996810113,
-0.07789160638163083,
0.008906053136261595,
0.021823003590788845,
-0.05560786537046778,
-0.01438426181210534,
-0.014396798491525835,
-0.006055711509509304,
0.027307640924854687,
0.003649835399042438,
0.05220987126693662,
0.007607311659102293,
-0.07610300243421696,
-0.11896927858944512,
-0.047414324415988945
],
[
0.34149699703986486,
0.3413116909130855,
0.339649030440468,
0.09521153970092615,
-0.03542229297624434,
-0.02810499380157885,
-0.028723472772034003,
-0.03623594058065723,
-0.04252827491856082,
-0.16784768447422393,
0.3529061023310094,
0.08989391307183653,
-0.07800272081085825,
-0.06471104835823145,
-0.027087322901021522,
-0.00641658612807751,
0.13991221742431906,
-0.03243883558798766,
-0.02391365988845393,
0.2196085500870657,
-0.10333969996810113,
1,
0.21728161263631166,
0.18215744606752643,
0.04107106988798885,
0.1449897777501001,
0.003473770726778378,
0.00977871689914861,
0.006674213517660574,
-0.02688637728505219,
-0.0013534661309447867,
0.0035753748752334075,
0.00018477323219028436,
0.43869659815013035,
0.8217569136566378,
-0.04166450720175678
],
[
0.1230515269517587,
0.12341263209434497,
0.12392080589216109,
0.0882227390403947,
0.2713516886712768,
0.24839279175837192,
0.2590168538347546,
-0.027383105883524696,
-0.023925010310720883,
-0.018615295017250816,
0.041811059093469424,
0.08462927510827067,
-0.1067868440081956,
-0.04328088508219377,
0.01817575740524541,
0.0029847625607689744,
0.17132147035400355,
-0.011997274915568491,
-0.09094808528856578,
-0.1515926659905363,
-0.07789160638163083,
0.21728161263631166,
1,
-0.1182951904571059,
-0.03594143376279657,
0.18295627318848992,
0.01690915539961196,
0.0332996326637299,
0.021104638711206016,
-0.03833373650277318,
0.009465679760186837,
-0.02071095807745041,
-0.028518925798846892,
0.07892105439026302,
-0.13194931484096498,
-0.04767002019513653
],
[
0.22199995958283308,
0.22157396955347955,
0.22173133490096522,
0.10510958357225778,
-0.033447633685265134,
-0.026212002732536065,
-0.028710384582010504,
-0.036178856247907724,
-0.04337915466801065,
-0.21471441255940335,
0.2193065184763861,
0.06406415580219664,
-0.061511148758259554,
-0.05940083429340112,
-0.02378191562538043,
0.04594385517357497,
0.22204282167014028,
0.12489130033898062,
0.13622335666530158,
0.6980956657110625,
0.008906053136261595,
0.18215744606752643,
-0.1182951904571059,
1,
0.04964627996646787,
0.09451252723266558,
-0.004425509244874343,
0.008567785983567751,
0.007105454883750359,
0.010017137747474446,
-0.0049636867294269825,
0.034853511246596795,
0.02429861728758495,
0.2979801075033031,
0.27875469771835226,
-0.0022069144086347145
],
[
0.08229056535555854,
0.08378860902113754,
0.08787930617565409,
0.12848024309665088,
-0.11415670051317652,
-0.0714167395414081,
-0.06682686863767658,
-0.0010246656340571671,
-0.013676609292509388,
-0.026552318247412224,
0.04575758892406839,
-0.034538559231869326,
-0.06914102669124954,
-0.15550183125608844,
-0.01012453949849028,
0.01701193489995595,
0.05110386522772334,
0.015743819721073016,
-0.08677399964492707,
0.06495306513072319,
0.021823003590788845,
0.04107106988798885,
-0.03594143376279657,
0.04964627996646787,
1,
-0.1621818346204736,
-0.03269411815607662,
-0.06470581516264627,
-0.046648226131306744,
0.02698604874907086,
0.014030351773278445,
0.17460355812768374,
0.005386865361166284,
0.02967428849718705,
0.06462589394318119,
-0.2263849321958786
],
[
0.5323758319755684,
0.5314657533019836,
0.5292283263940617,
0.38653366117227445,
0.44807241953966465,
0.3778210686601146,
0.3888325382656363,
-0.026362634357548657,
-0.026182606822821832,
-0.10295309187685193,
0.1606931503806069,
0.26760334159587096,
-0.034450076060040746,
0.06749152386272105,
-0.00808468034770711,
0.0093732114563079,
0.01671088814410185,
-0.0021257926522072128,
0.08725949814981891,
0.06446598079600936,
-0.05560786537046778,
0.1449897777501001,
0.18295627318848992,
0.09451252723266558,
-0.1621818346204736,
1,
0.0852835608756438,
0.07280709975574022,
0.05849546777900835,
-0.029296428214199727,
-0.015166449011570104,
-0.1709003017123901,
0.00015138319789988005,
0.12931663184671807,
0.08087666752344008,
0.03804778658884139
],
[
0.03039699981128343,
0.030269633683367422,
0.026987296260350367,
0.005894751256496635,
0.05059996085209665,
0.04587727350190705,
0.04631111290164317,
0.005936576934344635,
-0.0033834219667489523,
-0.0043236572276293414,
0.01417862241455744,
0.013422384867226342,
0.025660757149675535,
0.029753084053691675,
-0.003279678719922463,
-0.00031587719371388944,
-0.006292770123648165,
0.01798692632914995,
0.02098680794852601,
-0.007397402362062316,
-0.01438426181210534,
0.003473770726778378,
0.01690915539961196,
-0.004425509244874343,
-0.03269411815607662,
0.0852835608756438,
1,
0.08606644247307588,
0.06398867272896556,
-0.006113794354628054,
0.0007952716495211405,
-0.023818356347927644,
0.0048827428487531275,
0.007895156726208084,
-0.0031219181236287357,
-0.002616490770933299
],
[
0.0755662292629318,
0.07543904480895032,
0.0734694212367801,
0.06230716598495562,
0.11253201737516652,
0.09522884945324374,
0.09759050588479604,
0.0036308115645922335,
0.006559616342723415,
-0.00875991306974773,
0.006552077985370611,
0.05006620059727212,
0.017536225346724128,
0.04076494881688665,
0.0028110682936848155,
-0.005739695653081888,
0.0034653042211982617,
-0.0023232066061796572,
0.04480882234369649,
-0.00025758601801110094,
-0.014396798491525835,
0.00977871689914861,
0.0332996326637299,
0.008567785983567751,
-0.06470581516264627,
0.07280709975574022,
0.08606644247307588,
1,
0.7980052100207572,
-0.0016024388724498715,
-0.0024309625494929373,
0.014068203826042265,
-0.0002289659087295931,
-0.001887419417588788,
0.0016162289829809635,
-0.0648411851145522
],
[
0.05456576387485704,
0.054488650595454505,
0.051602719267371436,
0.039043197714352496,
0.0694149647782059,
0.06395382244989364,
0.0653599491919464,
0.007072288972627666,
0.0038612858505641225,
-0.008606677552553283,
0.006751696947288823,
0.02938127689085275,
0.011132642431576807,
0.024636053362644045,
0.006795583967923758,
-0.001773515467238366,
0.0036727057841006226,
-0.0008419453977416289,
0.03640581684262851,
0.0015986210424646448,
-0.006055711509509304,
0.006674213517660574,
0.021104638711206016,
0.007105454883750359,
-0.046648226131306744,
0.05849546777900835,
0.06398867272896556,
0.7980052100207572,
1,
0.002665874005773007,
-0.0015445884852588862,
0.0058878558864206305,
-0.0020990966362222055,
0.0015573305013247298,
0.002716171101254757,
-0.04119888556874379
],
[
-0.015887925632336142,
-0.015726918732288136,
-0.015296932487366122,
-0.0013881705983337703,
0.013964592160664847,
0.02200069409636774,
0.021704450136974866,
0.013407638485743775,
-3.638296436917112e-05,
0.004395076043852439,
-0.005112151418505477,
0.012941042166460179,
0.00678373092690319,
-0.01811070084174997,
-0.0005492985501828694,
0.007243743988879271,
0.0033788540311453833,
0.0658318099856898,
0.006046808767780671,
0.011836146009475114,
0.027307640924854687,
-0.02688637728505219,
-0.03833373650277318,
0.010017137747474446,
0.02698604874907086,
-0.029296428214199727,
-0.006113794354628054,
-0.0016024388724498715,
0.002665874005773007,
1,
-0.0023738717767656514,
0.01955040770797248,
0.017389460249368206,
-0.015476179404925185,
-0.02340160057083718,
-0.036778701612293505
],
[
0.00537034555863025,
0.005404500361503288,
0.0054739591017863775,
0.012339505523841695,
0.007174505406334653,
0.010719897959057688,
0.010804005313944208,
-0.003331560851945194,
0.00029247265744294747,
-0.00010662964918016358,
-0.006289245567748207,
0.004872166169305358,
0.0010118822324284358,
-0.0021504504245727753,
0.0007560843314131327,
0.0027959414778755886,
0.025256662744338958,
-0.0007549075432580317,
-0.006416705957685335,
-0.004514816219778578,
0.003649835399042438,
-0.0013534661309447867,
0.009465679760186837,
-0.0049636867294269825,
0.014030351773278445,
-0.015166449011570104,
0.0007952716495211405,
-0.0024309625494929373,
-0.0015445884852588862,
-0.0023738717767656514,
1,
0.017579517381095262,
-0.0014163741952864593,
-0.0009449880330908882,
-0.0055088770832310546,
-0.011674749402946619
],
[
0.022006609114648416,
0.022646819725312677,
0.02449943082066455,
0.03296842706856984,
-0.023394941410067434,
0.025224964290838536,
0.025549773424498573,
0.0067456219276319,
-0.002723463176442134,
0.00582070910628204,
0.017414227537550456,
-0.04295672830300664,
-0.0214607567958376,
-0.1735758892551564,
-0.008318446541552485,
0.011460765823582738,
0.0407586315913094,
0.027770547906924115,
-0.010084465041148372,
0.037521371007512364,
0.05220987126693662,
0.0035753748752334075,
-0.02071095807745041,
0.034853511246596795,
0.17460355812768374,
-0.1709003017123901,
-0.023818356347927644,
0.014068203826042265,
0.0058878558864206305,
0.01955040770797248,
0.017579517381095262,
1,
0.006485493601996285,
-0.004241175184069997,
0.004339542182509757,
-0.11455446404926434
],
[
0.0004827152903769945,
0.0005841390999188,
0.0004408390208968079,
0.005923374315533706,
0.02531738684242965,
0.0262133129357894,
0.027855172810561185,
0.0015094721747491195,
-0.010314795530514705,
-0.01682702954559417,
0.02230982529097467,
0.007586400642540934,
0.008531885664845716,
0.0008111386605700343,
-0.0026600218666307527,
0.009037407873233157,
0.013712516532054077,
0.13013020308737916,
-0.005410403954381636,
0.017524817385453865,
0.007607311659102293,
0.00018477323219028436,
-0.028518925798846892,
0.02429861728758495,
0.005386865361166284,
0.00015138319789988005,
0.0048827428487531275,
-0.0002289659087295931,
-0.0020990966362222055,
0.017389460249368206,
-0.0014163741952864593,
0.006485493601996285,
1,
0.025502908944671734,
0.009807676666848494,
-0.013868266555449984
],
[
0.3214379296704683,
0.321611053068661,
0.3210757354942176,
0.10989707632923694,
-0.08760582484385757,
-0.07927942053537479,
-0.08300776878706932,
-0.05026705594493313,
-0.04104551735009645,
-0.4938532067528801,
0.4768413759531402,
0.06139975588774038,
-0.027290053564699837,
-0.028545090351875455,
-0.004858219884591405,
-0.005982905081269974,
-0.01818752150691596,
0.06509155070255052,
0.029620923728497763,
0.23600303267186948,
-0.07610300243421696,
0.43869659815013035,
0.07892105439026302,
0.2979801075033031,
0.02967428849718705,
0.12931663184671807,
0.007895156726208084,
-0.001887419417588788,
0.0015573305013247298,
-0.015476179404925185,
-0.0009449880330908882,
-0.004241175184069997,
0.025502908944671734,
1,
0.42756299169797507,
0.016235464993980004
],
[
0.3469448299096464,
0.3471316910806371,
0.3465968857344195,
0.07583482299734122,
-0.18303223766351773,
-0.16346685445001832,
-0.17099740460608218,
-0.03272903963528642,
-0.03920916331672977,
-0.17435976358907318,
0.34182754393774584,
0.05116657756902476,
-0.05936139744964515,
-0.055351025295872214,
-0.03594356420102614,
-0.0005637893461752431,
0.0824519602024066,
-0.045356838682710184,
0.004312386499570435,
0.35866222790091923,
-0.11896927858944512,
0.8217569136566378,
-0.13194931484096498,
0.27875469771835226,
0.06462589394318119,
0.08087666752344008,
-0.0031219181236287357,
0.0016162289829809635,
0.002716171101254757,
-0.02340160057083718,
-0.0055088770832310546,
0.004339542182509757,
0.009807676666848494,
0.42756299169797507,
1,
-0.023938271700324212
],
[
-0.09806066158604641,
-0.09974063517361584,
-0.10368158647050939,
-0.1314544468506384,
0.001315715105046892,
-0.05842830898633616,
-0.05729791014263772,
-0.036046910279810475,
-0.006294912291385543,
-0.008417080510053349,
-0.005600004657288227,
-0.02661784839361224,
0.05696551253971207,
0.1710336867954722,
0.018249726101813062,
-0.020198474342035685,
-0.1343557063926868,
-0.04467080853930925,
0.08851260689281325,
-0.06503025859446773,
-0.047414324415988945,
-0.04166450720175678,
-0.04767002019513653,
-0.0022069144086347145,
-0.2263849321958786,
0.03804778658884139,
-0.002616490770933299,
-0.0648411851145522,
-0.04119888556874379,
-0.036778701612293505,
-0.011674749402946619,
-0.11455446404926434,
-0.013868266555449984,
0.016235464993980004,
-0.023938271700324212,
1
]
]
}
],
"layout": {
"annotations": [
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "loan_amnt",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "funded_amnt",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "funded_amnt_inv",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.41",
"x": "term",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.14",
"x": "int_rate",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.15",
"x": "grade",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.16",
"x": "sub_grade",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "emp_title",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "emp_length",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.2",
"x": "home_ownership",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.4",
"x": "annual_inc",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.27",
"x": "verification_status",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.16",
"x": "purpose",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.13",
"x": "title",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "zip_code",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "addr_state",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "dti",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "delinq_2yrs",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "inq_last_6mths",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.19",
"x": "open_acc",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "pub_rec",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.34",
"x": "revol_bal",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "revol_util",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.22",
"x": "total_acc",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "initial_list_status",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.53",
"x": "total_rec_int",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "total_rec_late_fee",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "recoveries",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "collection_recovery_fee",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "application_type",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "last_week_pay",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "acc_now_delinq",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.32",
"x": "tot_cur_bal",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.35",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "loan_status",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "loan_amnt",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "funded_amnt",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "funded_amnt_inv",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.41",
"x": "term",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.14",
"x": "int_rate",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.15",
"x": "grade",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.16",
"x": "sub_grade",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "emp_title",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "emp_length",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.2",
"x": "home_ownership",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.4",
"x": "annual_inc",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.27",
"x": "verification_status",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.16",
"x": "purpose",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.14",
"x": "title",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "zip_code",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "addr_state",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "dti",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "delinq_2yrs",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "inq_last_6mths",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.19",
"x": "open_acc",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "pub_rec",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.34",
"x": "revol_bal",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "revol_util",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.22",
"x": "total_acc",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "initial_list_status",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.53",
"x": "total_rec_int",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "total_rec_late_fee",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "recoveries",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "collection_recovery_fee",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "application_type",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "last_week_pay",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "acc_now_delinq",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.32",
"x": "tot_cur_bal",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.35",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "loan_status",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "loan_amnt",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "funded_amnt",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "funded_amnt_inv",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.41",
"x": "term",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.14",
"x": "int_rate",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.15",
"x": "grade",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.15",
"x": "sub_grade",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "emp_title",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "emp_length",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.2",
"x": "home_ownership",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.4",
"x": "annual_inc",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.27",
"x": "verification_status",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.16",
"x": "purpose",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.14",
"x": "title",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "zip_code",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "addr_state",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "dti",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "delinq_2yrs",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "inq_last_6mths",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.19",
"x": "open_acc",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "pub_rec",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.34",
"x": "revol_bal",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "revol_util",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.22",
"x": "total_acc",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "initial_list_status",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.53",
"x": "total_rec_int",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "total_rec_late_fee",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "recoveries",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "collection_recovery_fee",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "application_type",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "last_week_pay",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "acc_now_delinq",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.32",
"x": "tot_cur_bal",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.35",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "loan_status",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.41",
"x": "loan_amnt",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.41",
"x": "funded_amnt",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.41",
"x": "funded_amnt_inv",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "term",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.43",
"x": "int_rate",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.44",
"x": "grade",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.45",
"x": "sub_grade",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "emp_title",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "emp_length",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "home_ownership",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "annual_inc",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.17",
"x": "verification_status",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "purpose",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "title",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "zip_code",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "addr_state",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.11",
"x": "dti",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "delinq_2yrs",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "inq_last_6mths",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "open_acc",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "pub_rec",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "revol_bal",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "revol_util",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.11",
"x": "total_acc",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.13",
"x": "initial_list_status",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.39",
"x": "total_rec_int",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "total_rec_late_fee",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "recoveries",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "collection_recovery_fee",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "application_type",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "last_week_pay",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "acc_now_delinq",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.11",
"x": "tot_cur_bal",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.13",
"x": "loan_status",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.14",
"x": "loan_amnt",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.14",
"x": "funded_amnt",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.14",
"x": "funded_amnt_inv",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.43",
"x": "term",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "int_rate",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.95",
"x": "grade",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.98",
"x": "sub_grade",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "emp_title",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "emp_length",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "home_ownership",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "annual_inc",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.25",
"x": "verification_status",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.15",
"x": "purpose",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "title",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "zip_code",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "addr_state",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.16",
"x": "dti",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "delinq_2yrs",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.23",
"x": "inq_last_6mths",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "open_acc",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "pub_rec",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "revol_bal",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.27",
"x": "revol_util",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "total_acc",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.11",
"x": "initial_list_status",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.45",
"x": "total_rec_int",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "total_rec_late_fee",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.11",
"x": "recoveries",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "collection_recovery_fee",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "application_type",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "last_week_pay",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "acc_now_delinq",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.09",
"x": "tot_cur_bal",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.18",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "loan_status",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.15",
"x": "loan_amnt",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.15",
"x": "funded_amnt",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.15",
"x": "funded_amnt_inv",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.44",
"x": "term",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.95",
"x": "int_rate",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "grade",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.98",
"x": "sub_grade",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "emp_title",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "emp_length",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "home_ownership",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "annual_inc",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.23",
"x": "verification_status",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.15",
"x": "purpose",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "title",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "zip_code",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "addr_state",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.17",
"x": "dti",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "delinq_2yrs",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.22",
"x": "inq_last_6mths",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "open_acc",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "pub_rec",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "revol_bal",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.25",
"x": "revol_util",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "total_acc",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "initial_list_status",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.38",
"x": "total_rec_int",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "total_rec_late_fee",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "recoveries",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "collection_recovery_fee",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "application_type",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "last_week_pay",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "acc_now_delinq",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "tot_cur_bal",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.16",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "loan_status",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.16",
"x": "loan_amnt",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.16",
"x": "funded_amnt",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.15",
"x": "funded_amnt_inv",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.45",
"x": "term",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.98",
"x": "int_rate",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.98",
"x": "grade",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "sub_grade",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "emp_title",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "emp_length",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "home_ownership",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "annual_inc",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.24",
"x": "verification_status",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.16",
"x": "purpose",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "title",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "zip_code",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "addr_state",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.17",
"x": "dti",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "delinq_2yrs",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.22",
"x": "inq_last_6mths",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "open_acc",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "pub_rec",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "revol_bal",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.26",
"x": "revol_util",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "total_acc",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "initial_list_status",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.39",
"x": "total_rec_int",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "total_rec_late_fee",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "recoveries",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "collection_recovery_fee",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "application_type",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "last_week_pay",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "acc_now_delinq",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "tot_cur_bal",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.17",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "loan_status",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "loan_amnt",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "funded_amnt",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "funded_amnt_inv",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "term",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "int_rate",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "grade",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "sub_grade",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "emp_title",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.18",
"x": "emp_length",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "home_ownership",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "annual_inc",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "verification_status",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "purpose",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "title",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "zip_code",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "addr_state",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "dti",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "delinq_2yrs",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "inq_last_6mths",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "open_acc",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "pub_rec",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "revol_bal",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "revol_util",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "total_acc",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "initial_list_status",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "total_rec_int",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "total_rec_late_fee",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "recoveries",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "collection_recovery_fee",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "application_type",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "last_week_pay",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "acc_now_delinq",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "tot_cur_bal",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "loan_status",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "loan_amnt",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "funded_amnt",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "funded_amnt_inv",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "term",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "int_rate",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "grade",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "sub_grade",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.18",
"x": "emp_title",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "emp_length",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "home_ownership",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "annual_inc",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "verification_status",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "purpose",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "title",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "zip_code",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "addr_state",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "dti",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "delinq_2yrs",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "inq_last_6mths",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "open_acc",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "pub_rec",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "revol_bal",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "revol_util",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "total_acc",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "initial_list_status",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "total_rec_int",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "total_rec_late_fee",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "recoveries",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "collection_recovery_fee",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "application_type",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "last_week_pay",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "acc_now_delinq",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "tot_cur_bal",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "loan_status",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.2",
"x": "loan_amnt",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.2",
"x": "funded_amnt",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.2",
"x": "funded_amnt_inv",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "term",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "int_rate",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "grade",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "sub_grade",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "emp_title",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "emp_length",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "home_ownership",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.18",
"x": "annual_inc",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "verification_status",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "purpose",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "title",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "zip_code",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "addr_state",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "dti",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "delinq_2yrs",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "inq_last_6mths",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.13",
"x": "open_acc",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "pub_rec",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.17",
"x": "revol_bal",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "revol_util",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.21",
"x": "total_acc",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "initial_list_status",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "total_rec_int",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "total_rec_late_fee",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "recoveries",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "collection_recovery_fee",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "application_type",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "last_week_pay",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "acc_now_delinq",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.49",
"x": "tot_cur_bal",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.17",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "loan_status",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.4",
"x": "loan_amnt",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.4",
"x": "funded_amnt",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.4",
"x": "funded_amnt_inv",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "term",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "int_rate",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "grade",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "sub_grade",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "emp_title",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "emp_length",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.18",
"x": "home_ownership",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "annual_inc",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "verification_status",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "purpose",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "title",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "zip_code",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "addr_state",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.21",
"x": "dti",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "delinq_2yrs",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "inq_last_6mths",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.16",
"x": "open_acc",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "pub_rec",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.35",
"x": "revol_bal",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "revol_util",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.22",
"x": "total_acc",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "initial_list_status",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.16",
"x": "total_rec_int",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "total_rec_late_fee",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "recoveries",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "collection_recovery_fee",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "application_type",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "last_week_pay",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "acc_now_delinq",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.48",
"x": "tot_cur_bal",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.34",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "loan_status",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.27",
"x": "loan_amnt",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.27",
"x": "funded_amnt",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.27",
"x": "funded_amnt_inv",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.17",
"x": "term",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.25",
"x": "int_rate",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.23",
"x": "grade",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.24",
"x": "sub_grade",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "emp_title",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "emp_length",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "home_ownership",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "annual_inc",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "verification_status",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "purpose",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "title",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "zip_code",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "addr_state",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "dti",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "delinq_2yrs",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "inq_last_6mths",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "open_acc",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "pub_rec",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "revol_bal",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "revol_util",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "total_acc",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "initial_list_status",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.27",
"x": "total_rec_int",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "total_rec_late_fee",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "recoveries",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "collection_recovery_fee",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "application_type",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "last_week_pay",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "acc_now_delinq",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "tot_cur_bal",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "loan_status",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.16",
"x": "loan_amnt",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.16",
"x": "funded_amnt",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.16",
"x": "funded_amnt_inv",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "term",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.15",
"x": "int_rate",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.15",
"x": "grade",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.16",
"x": "sub_grade",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "emp_title",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "emp_length",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "home_ownership",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "annual_inc",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "verification_status",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "purpose",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.42",
"x": "title",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "zip_code",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "addr_state",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.09",
"x": "dti",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "delinq_2yrs",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "inq_last_6mths",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "open_acc",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "pub_rec",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "revol_bal",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.11",
"x": "revol_util",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "total_acc",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "initial_list_status",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "total_rec_int",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "total_rec_late_fee",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "recoveries",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "collection_recovery_fee",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "application_type",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "last_week_pay",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "acc_now_delinq",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "tot_cur_bal",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "loan_status",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.13",
"x": "loan_amnt",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.14",
"x": "funded_amnt",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.14",
"x": "funded_amnt_inv",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "term",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "int_rate",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "grade",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "sub_grade",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "emp_title",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "emp_length",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "home_ownership",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "annual_inc",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "verification_status",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.42",
"x": "purpose",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "title",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "zip_code",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "addr_state",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "dti",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "delinq_2yrs",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "inq_last_6mths",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "open_acc",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "pub_rec",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "revol_bal",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "revol_util",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "total_acc",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.16",
"x": "initial_list_status",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "total_rec_int",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "total_rec_late_fee",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "recoveries",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "collection_recovery_fee",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "application_type",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.17",
"x": "last_week_pay",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "acc_now_delinq",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "tot_cur_bal",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.17",
"x": "loan_status",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "loan_amnt",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "funded_amnt",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "funded_amnt_inv",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "term",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "int_rate",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "grade",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "sub_grade",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "emp_title",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "emp_length",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "home_ownership",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "annual_inc",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "verification_status",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "purpose",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "title",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "zip_code",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.26",
"x": "addr_state",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "dti",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "delinq_2yrs",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "inq_last_6mths",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "open_acc",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "pub_rec",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "revol_bal",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "revol_util",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "total_acc",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "initial_list_status",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "total_rec_int",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "total_rec_late_fee",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "recoveries",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "collection_recovery_fee",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "application_type",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "last_week_pay",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "acc_now_delinq",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "tot_cur_bal",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "loan_status",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "loan_amnt",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "funded_amnt",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "funded_amnt_inv",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "term",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "int_rate",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "grade",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "sub_grade",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "emp_title",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "emp_length",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "home_ownership",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "annual_inc",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "verification_status",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "purpose",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "title",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.26",
"x": "zip_code",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "addr_state",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "dti",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "delinq_2yrs",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "inq_last_6mths",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "open_acc",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "pub_rec",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "revol_bal",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "revol_util",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "total_acc",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "initial_list_status",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "total_rec_int",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "total_rec_late_fee",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "recoveries",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "collection_recovery_fee",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "application_type",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "last_week_pay",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "acc_now_delinq",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "tot_cur_bal",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "loan_status",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "loan_amnt",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "funded_amnt",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "funded_amnt_inv",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.11",
"x": "term",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.16",
"x": "int_rate",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.17",
"x": "grade",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.17",
"x": "sub_grade",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "emp_title",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "emp_length",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "home_ownership",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.21",
"x": "annual_inc",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "verification_status",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.09",
"x": "purpose",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "title",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "zip_code",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "addr_state",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "dti",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "delinq_2yrs",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "inq_last_6mths",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.3",
"x": "open_acc",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "pub_rec",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.14",
"x": "revol_bal",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.17",
"x": "revol_util",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.22",
"x": "total_acc",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "initial_list_status",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "total_rec_int",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "total_rec_late_fee",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "recoveries",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "collection_recovery_fee",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "application_type",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "last_week_pay",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "acc_now_delinq",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "tot_cur_bal",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.13",
"x": "loan_status",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "loan_amnt",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "funded_amnt",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "funded_amnt_inv",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "term",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "int_rate",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "grade",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "sub_grade",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "emp_title",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "emp_length",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "home_ownership",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "annual_inc",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "verification_status",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "purpose",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "title",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "zip_code",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "addr_state",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "dti",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "delinq_2yrs",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "inq_last_6mths",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "open_acc",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "pub_rec",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "revol_bal",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "revol_util",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "total_acc",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "initial_list_status",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "total_rec_int",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "total_rec_late_fee",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "recoveries",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "collection_recovery_fee",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "application_type",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "last_week_pay",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.13",
"x": "acc_now_delinq",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "tot_cur_bal",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "loan_status",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "loan_amnt",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "funded_amnt",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "funded_amnt_inv",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "term",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.23",
"x": "int_rate",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.22",
"x": "grade",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.22",
"x": "sub_grade",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "emp_title",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "emp_length",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "home_ownership",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "annual_inc",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "verification_status",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "purpose",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "title",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "zip_code",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "addr_state",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "dti",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "delinq_2yrs",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "inq_last_6mths",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.11",
"x": "open_acc",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "pub_rec",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "revol_bal",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.09",
"x": "revol_util",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.14",
"x": "total_acc",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.09",
"x": "initial_list_status",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "total_rec_int",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "total_rec_late_fee",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "recoveries",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "collection_recovery_fee",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "application_type",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "last_week_pay",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "acc_now_delinq",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "tot_cur_bal",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "loan_status",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.19",
"x": "loan_amnt",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.19",
"x": "funded_amnt",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.19",
"x": "funded_amnt_inv",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "term",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "int_rate",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "grade",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "sub_grade",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "emp_title",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "emp_length",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.13",
"x": "home_ownership",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.16",
"x": "annual_inc",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "verification_status",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "purpose",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "title",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "zip_code",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "addr_state",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.3",
"x": "dti",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "delinq_2yrs",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.11",
"x": "inq_last_6mths",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "open_acc",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "pub_rec",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.22",
"x": "revol_bal",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.15",
"x": "revol_util",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.7",
"x": "total_acc",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "initial_list_status",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "total_rec_int",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "total_rec_late_fee",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "recoveries",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "collection_recovery_fee",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "application_type",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "last_week_pay",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "acc_now_delinq",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.24",
"x": "tot_cur_bal",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.36",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "loan_status",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "loan_amnt",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "funded_amnt",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "funded_amnt_inv",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "term",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "int_rate",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "grade",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "sub_grade",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "emp_title",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "emp_length",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "home_ownership",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "annual_inc",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "verification_status",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "purpose",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "title",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "zip_code",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "addr_state",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "dti",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "delinq_2yrs",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "inq_last_6mths",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "open_acc",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "pub_rec",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "revol_bal",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "revol_util",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "total_acc",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "initial_list_status",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "total_rec_int",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "total_rec_late_fee",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "recoveries",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "collection_recovery_fee",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "application_type",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "last_week_pay",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "acc_now_delinq",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "tot_cur_bal",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.12",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "loan_status",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.34",
"x": "loan_amnt",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.34",
"x": "funded_amnt",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.34",
"x": "funded_amnt_inv",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "term",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "int_rate",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "grade",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "sub_grade",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "emp_title",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "emp_length",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.17",
"x": "home_ownership",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.35",
"x": "annual_inc",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "verification_status",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "purpose",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "title",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "zip_code",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "addr_state",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.14",
"x": "dti",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "delinq_2yrs",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "inq_last_6mths",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.22",
"x": "open_acc",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "pub_rec",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "revol_bal",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.22",
"x": "revol_util",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.18",
"x": "total_acc",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "initial_list_status",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.14",
"x": "total_rec_int",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "total_rec_late_fee",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "recoveries",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "collection_recovery_fee",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "application_type",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "last_week_pay",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "acc_now_delinq",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.44",
"x": "tot_cur_bal",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.82",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "loan_status",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "loan_amnt",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "funded_amnt",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "funded_amnt_inv",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "term",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.27",
"x": "int_rate",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.25",
"x": "grade",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.26",
"x": "sub_grade",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "emp_title",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "emp_length",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "home_ownership",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "annual_inc",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "verification_status",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.11",
"x": "purpose",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "title",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "zip_code",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "addr_state",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.17",
"x": "dti",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "delinq_2yrs",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.09",
"x": "inq_last_6mths",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.15",
"x": "open_acc",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "pub_rec",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.22",
"x": "revol_bal",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "revol_util",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.12",
"x": "total_acc",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "initial_list_status",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.18",
"x": "total_rec_int",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "total_rec_late_fee",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "recoveries",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "collection_recovery_fee",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "application_type",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "last_week_pay",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "acc_now_delinq",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "tot_cur_bal",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.13",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "loan_status",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.22",
"x": "loan_amnt",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.22",
"x": "funded_amnt",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.22",
"x": "funded_amnt_inv",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.11",
"x": "term",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "int_rate",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "grade",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "sub_grade",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "emp_title",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "emp_length",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.21",
"x": "home_ownership",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.22",
"x": "annual_inc",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "verification_status",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "purpose",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "title",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "zip_code",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "addr_state",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.22",
"x": "dti",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "delinq_2yrs",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.14",
"x": "inq_last_6mths",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.7",
"x": "open_acc",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "pub_rec",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.18",
"x": "revol_bal",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.12",
"x": "revol_util",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "total_acc",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "initial_list_status",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "total_rec_int",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "total_rec_late_fee",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "recoveries",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "collection_recovery_fee",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "application_type",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "last_week_pay",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "acc_now_delinq",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.3",
"x": "tot_cur_bal",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.28",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "loan_status",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "loan_amnt",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "funded_amnt",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "funded_amnt_inv",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.13",
"x": "term",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.11",
"x": "int_rate",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "grade",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "sub_grade",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "emp_title",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "emp_length",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "home_ownership",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "annual_inc",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "verification_status",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "purpose",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.16",
"x": "title",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "zip_code",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "addr_state",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "dti",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "delinq_2yrs",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.09",
"x": "inq_last_6mths",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "open_acc",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "pub_rec",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "revol_bal",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "revol_util",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "total_acc",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "initial_list_status",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.16",
"x": "total_rec_int",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "total_rec_late_fee",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "recoveries",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "collection_recovery_fee",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "application_type",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.17",
"x": "last_week_pay",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "acc_now_delinq",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "tot_cur_bal",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.23",
"x": "loan_status",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.53",
"x": "loan_amnt",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.53",
"x": "funded_amnt",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.53",
"x": "funded_amnt_inv",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.39",
"x": "term",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.45",
"x": "int_rate",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.38",
"x": "grade",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.39",
"x": "sub_grade",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "emp_title",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "emp_length",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "home_ownership",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.16",
"x": "annual_inc",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.27",
"x": "verification_status",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "purpose",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "title",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "zip_code",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "addr_state",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "dti",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "delinq_2yrs",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "inq_last_6mths",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "open_acc",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "pub_rec",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.14",
"x": "revol_bal",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.18",
"x": "revol_util",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "total_acc",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.16",
"x": "initial_list_status",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "total_rec_int",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "total_rec_late_fee",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "recoveries",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "collection_recovery_fee",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "application_type",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.17",
"x": "last_week_pay",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "acc_now_delinq",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.13",
"x": "tot_cur_bal",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "loan_status",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "loan_amnt",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "funded_amnt",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "funded_amnt_inv",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "term",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "int_rate",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "grade",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "sub_grade",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "emp_title",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "emp_length",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "home_ownership",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "annual_inc",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "verification_status",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "purpose",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "title",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "zip_code",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "addr_state",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "dti",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "delinq_2yrs",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "inq_last_6mths",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "open_acc",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "pub_rec",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "revol_bal",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "revol_util",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "total_acc",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "initial_list_status",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "total_rec_int",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "total_rec_late_fee",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "recoveries",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "collection_recovery_fee",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "application_type",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "last_week_pay",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "acc_now_delinq",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "tot_cur_bal",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "loan_status",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "loan_amnt",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "funded_amnt",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "funded_amnt_inv",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "term",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.11",
"x": "int_rate",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "grade",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "sub_grade",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "emp_title",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "emp_length",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "home_ownership",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "annual_inc",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "verification_status",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "purpose",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "title",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "zip_code",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "addr_state",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "dti",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "delinq_2yrs",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "inq_last_6mths",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "open_acc",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "pub_rec",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "revol_bal",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "revol_util",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "total_acc",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "initial_list_status",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "total_rec_int",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "total_rec_late_fee",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "recoveries",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.8",
"x": "collection_recovery_fee",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "application_type",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "last_week_pay",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "acc_now_delinq",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "tot_cur_bal",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "loan_status",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "loan_amnt",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "funded_amnt",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "funded_amnt_inv",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "term",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "int_rate",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "grade",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "sub_grade",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "emp_title",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "emp_length",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "home_ownership",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "annual_inc",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "verification_status",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "purpose",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "title",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "zip_code",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "addr_state",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "dti",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "delinq_2yrs",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "inq_last_6mths",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "open_acc",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "pub_rec",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "revol_bal",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "revol_util",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "total_acc",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "initial_list_status",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "total_rec_int",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "total_rec_late_fee",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.8",
"x": "recoveries",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "collection_recovery_fee",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "application_type",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "last_week_pay",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "acc_now_delinq",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "tot_cur_bal",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "loan_status",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "loan_amnt",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "funded_amnt",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "funded_amnt_inv",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "term",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "int_rate",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "grade",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "sub_grade",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "emp_title",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "emp_length",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "home_ownership",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "annual_inc",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "verification_status",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "purpose",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "title",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "zip_code",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "addr_state",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "dti",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "delinq_2yrs",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "inq_last_6mths",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "open_acc",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "pub_rec",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "revol_bal",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "revol_util",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "total_acc",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "initial_list_status",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "total_rec_int",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "total_rec_late_fee",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "recoveries",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "collection_recovery_fee",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "application_type",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "last_week_pay",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "acc_now_delinq",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "tot_cur_bal",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "loan_status",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "loan_amnt",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "funded_amnt",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "funded_amnt_inv",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "term",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "int_rate",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "grade",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "sub_grade",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "emp_title",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "emp_length",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "home_ownership",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "annual_inc",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "verification_status",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "purpose",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "title",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "zip_code",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "addr_state",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "dti",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "delinq_2yrs",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "inq_last_6mths",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "open_acc",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "pub_rec",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "revol_bal",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "revol_util",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "total_acc",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "initial_list_status",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "total_rec_int",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "total_rec_late_fee",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "recoveries",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "collection_recovery_fee",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "application_type",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "last_week_pay",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "acc_now_delinq",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "tot_cur_bal",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "loan_status",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "loan_amnt",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "funded_amnt",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "funded_amnt_inv",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "term",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "int_rate",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "grade",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "sub_grade",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "emp_title",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "emp_length",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "home_ownership",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "annual_inc",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "verification_status",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "purpose",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.17",
"x": "title",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "zip_code",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "addr_state",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "dti",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "delinq_2yrs",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "inq_last_6mths",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "open_acc",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "pub_rec",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "revol_bal",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "revol_util",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "total_acc",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.17",
"x": "initial_list_status",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.17",
"x": "total_rec_int",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "total_rec_late_fee",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "recoveries",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "collection_recovery_fee",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "application_type",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "last_week_pay",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "acc_now_delinq",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "tot_cur_bal",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.11",
"x": "loan_status",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "loan_amnt",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "funded_amnt",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "funded_amnt_inv",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "term",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "int_rate",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "grade",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "sub_grade",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "emp_title",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "emp_length",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "home_ownership",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "annual_inc",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "verification_status",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "purpose",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "title",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "zip_code",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "addr_state",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "dti",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.13",
"x": "delinq_2yrs",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "inq_last_6mths",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "open_acc",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "pub_rec",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "revol_bal",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "revol_util",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "total_acc",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "initial_list_status",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "total_rec_int",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "total_rec_late_fee",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "recoveries",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "collection_recovery_fee",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "application_type",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "last_week_pay",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "acc_now_delinq",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "tot_cur_bal",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "loan_status",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.32",
"x": "loan_amnt",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.32",
"x": "funded_amnt",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.32",
"x": "funded_amnt_inv",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.11",
"x": "term",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.09",
"x": "int_rate",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "grade",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "sub_grade",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "emp_title",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "emp_length",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.49",
"x": "home_ownership",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.48",
"x": "annual_inc",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "verification_status",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "purpose",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "title",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "zip_code",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "addr_state",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "dti",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "delinq_2yrs",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "inq_last_6mths",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.24",
"x": "open_acc",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "pub_rec",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.44",
"x": "revol_bal",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "revol_util",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.3",
"x": "total_acc",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "initial_list_status",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.13",
"x": "total_rec_int",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "total_rec_late_fee",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "recoveries",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "collection_recovery_fee",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "application_type",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "last_week_pay",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "acc_now_delinq",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "tot_cur_bal",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.43",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "loan_status",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.35",
"x": "loan_amnt",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.35",
"x": "funded_amnt",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.35",
"x": "funded_amnt_inv",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "term",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.18",
"x": "int_rate",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.16",
"x": "grade",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.17",
"x": "sub_grade",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "emp_title",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "emp_length",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.17",
"x": "home_ownership",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.34",
"x": "annual_inc",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "verification_status",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "purpose",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "title",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "zip_code",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "addr_state",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "dti",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "delinq_2yrs",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "inq_last_6mths",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.36",
"x": "open_acc",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.12",
"x": "pub_rec",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.82",
"x": "revol_bal",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.13",
"x": "revol_util",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.28",
"x": "total_acc",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "initial_list_status",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "total_rec_int",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "total_rec_late_fee",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "recoveries",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "collection_recovery_fee",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "application_type",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "last_week_pay",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "acc_now_delinq",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.43",
"x": "tot_cur_bal",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "loan_status",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "loan_amnt",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "funded_amnt",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "funded_amnt_inv",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.13",
"x": "term",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "int_rate",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "grade",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "sub_grade",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "emp_title",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "emp_length",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "home_ownership",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "annual_inc",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "verification_status",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "purpose",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.17",
"x": "title",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "zip_code",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "addr_state",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.13",
"x": "dti",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "delinq_2yrs",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "inq_last_6mths",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "open_acc",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "pub_rec",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "revol_bal",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "revol_util",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "total_acc",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.23",
"x": "initial_list_status",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "total_rec_int",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "total_rec_late_fee",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "recoveries",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "collection_recovery_fee",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "application_type",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.11",
"x": "last_week_pay",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "acc_now_delinq",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "tot_cur_bal",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "loan_status",
"xref": "x",
"y": "loan_status",
"yref": "y"
}
],
"template": {
"data": {
"bar": [
{
"error_x": {
"color": "#2a3f5f"
},
"error_y": {
"color": "#2a3f5f"
},
"marker": {
"line": {
"color": "#E5ECF6",
"width": 0.5
}
},
"type": "bar"
}
],
"barpolar": [
{
"marker": {
"line": {
"color": "#E5ECF6",
"width": 0.5
}
},
"type": "barpolar"
}
],
"carpet": [
{
"aaxis": {
"endlinecolor": "#2a3f5f",
"gridcolor": "white",
"linecolor": "white",
"minorgridcolor": "white",
"startlinecolor": "#2a3f5f"
},
"baxis": {
"endlinecolor": "#2a3f5f",
"gridcolor": "white",
"linecolor": "white",
"minorgridcolor": "white",
"startlinecolor": "#2a3f5f"
},
"type": "carpet"
}
],
"choropleth": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "choropleth"
}
],
"contour": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "contour"
}
],
"contourcarpet": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "contourcarpet"
}
],
"heatmap": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "heatmap"
}
],
"heatmapgl": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "heatmapgl"
}
],
"histogram": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "histogram"
}
],
"histogram2d": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "histogram2d"
}
],
"histogram2dcontour": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "histogram2dcontour"
}
],
"mesh3d": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "mesh3d"
}
],
"parcoords": [
{
"line": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "parcoords"
}
],
"pie": [
{
"automargin": true,
"type": "pie"
}
],
"scatter": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatter"
}
],
"scatter3d": [
{
"line": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatter3d"
}
],
"scattercarpet": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattercarpet"
}
],
"scattergeo": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattergeo"
}
],
"scattergl": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattergl"
}
],
"scattermapbox": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattermapbox"
}
],
"scatterpolar": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterpolar"
}
],
"scatterpolargl": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterpolargl"
}
],
"scatterternary": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterternary"
}
],
"surface": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "surface"
}
],
"table": [
{
"cells": {
"fill": {
"color": "#EBF0F8"
},
"line": {
"color": "white"
}
},
"header": {
"fill": {
"color": "#C8D4E3"
},
"line": {
"color": "white"
}
},
"type": "table"
}
]
},
"layout": {
"annotationdefaults": {
"arrowcolor": "#2a3f5f",
"arrowhead": 0,
"arrowwidth": 1
},
"coloraxis": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"colorscale": {
"diverging": [
[
0,
"#8e0152"
],
[
0.1,
"#c51b7d"
],
[
0.2,
"#de77ae"
],
[
0.3,
"#f1b6da"
],
[
0.4,
"#fde0ef"
],
[
0.5,
"#f7f7f7"
],
[
0.6,
"#e6f5d0"
],
[
0.7,
"#b8e186"
],
[
0.8,
"#7fbc41"
],
[
0.9,
"#4d9221"
],
[
1,
"#276419"
]
],
"sequential": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"sequentialminus": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
]
},
"colorway": [
"#636efa",
"#EF553B",
"#00cc96",
"#ab63fa",
"#FFA15A",
"#19d3f3",
"#FF6692",
"#B6E880",
"#FF97FF",
"#FECB52"
],
"font": {
"color": "#2a3f5f"
},
"geo": {
"bgcolor": "white",
"lakecolor": "white",
"landcolor": "#E5ECF6",
"showlakes": true,
"showland": true,
"subunitcolor": "white"
},
"hoverlabel": {
"align": "left"
},
"hovermode": "closest",
"mapbox": {
"style": "light"
},
"paper_bgcolor": "white",
"plot_bgcolor": "#E5ECF6",
"polar": {
"angularaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"bgcolor": "#E5ECF6",
"radialaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
}
},
"scene": {
"xaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
},
"yaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
},
"zaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
}
},
"shapedefaults": {
"line": {
"color": "#2a3f5f"
}
},
"ternary": {
"aaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"baxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"bgcolor": "#E5ECF6",
"caxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
}
},
"title": {
"x": 0.05
},
"xaxis": {
"automargin": true,
"gridcolor": "white",
"linecolor": "white",
"ticks": "",
"title": {
"standoff": 15
},
"zerolinecolor": "white",
"zerolinewidth": 2
},
"yaxis": {
"automargin": true,
"gridcolor": "white",
"linecolor": "white",
"ticks": "",
"title": {
"standoff": 15
},
"zerolinecolor": "white",
"zerolinewidth": 2
}
}
},
"xaxis": {
"dtick": 1,
"gridcolor": "rgb(0, 0, 0)",
"side": "top",
"ticks": ""
},
"yaxis": {
"dtick": 1,
"ticks": "",
"ticksuffix": " "
}
}
},
"text/html": [
"\n",
" \n",
" \n",
" \n",
" \n",
" "
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"application/vnd.plotly.v1+json": {
"config": {
"plotlyServerURL": "https://plot.ly"
},
"data": [
{
"domain": {
"x": [
0,
1
],
"y": [
0,
1
]
},
"hole": 0.4,
"hoverinfo": "label+percent+name",
"hoverlabel": {
"namelength": 0
},
"hovertemplate": "label=%{label}
value=%{value}",
"labels": [
0,
1
],
"legendgroup": "",
"name": "",
"showlegend": true,
"type": "pie",
"values": [
48802,
15197
]
}
],
"layout": {
"legend": {
"tracegroupgap": 0
},
"template": {
"data": {
"bar": [
{
"error_x": {
"color": "#2a3f5f"
},
"error_y": {
"color": "#2a3f5f"
},
"marker": {
"line": {
"color": "#E5ECF6",
"width": 0.5
}
},
"type": "bar"
}
],
"barpolar": [
{
"marker": {
"line": {
"color": "#E5ECF6",
"width": 0.5
}
},
"type": "barpolar"
}
],
"carpet": [
{
"aaxis": {
"endlinecolor": "#2a3f5f",
"gridcolor": "white",
"linecolor": "white",
"minorgridcolor": "white",
"startlinecolor": "#2a3f5f"
},
"baxis": {
"endlinecolor": "#2a3f5f",
"gridcolor": "white",
"linecolor": "white",
"minorgridcolor": "white",
"startlinecolor": "#2a3f5f"
},
"type": "carpet"
}
],
"choropleth": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "choropleth"
}
],
"contour": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "contour"
}
],
"contourcarpet": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "contourcarpet"
}
],
"heatmap": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "heatmap"
}
],
"heatmapgl": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "heatmapgl"
}
],
"histogram": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "histogram"
}
],
"histogram2d": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "histogram2d"
}
],
"histogram2dcontour": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "histogram2dcontour"
}
],
"mesh3d": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "mesh3d"
}
],
"parcoords": [
{
"line": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "parcoords"
}
],
"pie": [
{
"automargin": true,
"type": "pie"
}
],
"scatter": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatter"
}
],
"scatter3d": [
{
"line": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatter3d"
}
],
"scattercarpet": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattercarpet"
}
],
"scattergeo": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattergeo"
}
],
"scattergl": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattergl"
}
],
"scattermapbox": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattermapbox"
}
],
"scatterpolar": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterpolar"
}
],
"scatterpolargl": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterpolargl"
}
],
"scatterternary": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterternary"
}
],
"surface": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "surface"
}
],
"table": [
{
"cells": {
"fill": {
"color": "#EBF0F8"
},
"line": {
"color": "white"
}
},
"header": {
"fill": {
"color": "#C8D4E3"
},
"line": {
"color": "white"
}
},
"type": "table"
}
]
},
"layout": {
"annotationdefaults": {
"arrowcolor": "#2a3f5f",
"arrowhead": 0,
"arrowwidth": 1
},
"coloraxis": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"colorscale": {
"diverging": [
[
0,
"#8e0152"
],
[
0.1,
"#c51b7d"
],
[
0.2,
"#de77ae"
],
[
0.3,
"#f1b6da"
],
[
0.4,
"#fde0ef"
],
[
0.5,
"#f7f7f7"
],
[
0.6,
"#e6f5d0"
],
[
0.7,
"#b8e186"
],
[
0.8,
"#7fbc41"
],
[
0.9,
"#4d9221"
],
[
1,
"#276419"
]
],
"sequential": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"sequentialminus": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
]
},
"colorway": [
"#636efa",
"#EF553B",
"#00cc96",
"#ab63fa",
"#FFA15A",
"#19d3f3",
"#FF6692",
"#B6E880",
"#FF97FF",
"#FECB52"
],
"font": {
"color": "#2a3f5f"
},
"geo": {
"bgcolor": "white",
"lakecolor": "white",
"landcolor": "#E5ECF6",
"showlakes": true,
"showland": true,
"subunitcolor": "white"
},
"hoverlabel": {
"align": "left"
},
"hovermode": "closest",
"mapbox": {
"style": "light"
},
"paper_bgcolor": "white",
"plot_bgcolor": "#E5ECF6",
"polar": {
"angularaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"bgcolor": "#E5ECF6",
"radialaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
}
},
"scene": {
"xaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
},
"yaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
},
"zaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
}
},
"shapedefaults": {
"line": {
"color": "#2a3f5f"
}
},
"ternary": {
"aaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"baxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"bgcolor": "#E5ECF6",
"caxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
}
},
"title": {
"x": 0.05
},
"xaxis": {
"automargin": true,
"gridcolor": "white",
"linecolor": "white",
"ticks": "",
"title": {
"standoff": 15
},
"zerolinecolor": "white",
"zerolinewidth": 2
},
"yaxis": {
"automargin": true,
"gridcolor": "white",
"linecolor": "white",
"ticks": "",
"title": {
"standoff": 15
},
"zerolinecolor": "white",
"zerolinewidth": 2
}
}
},
"title": {
"text": "Percentage data of loan_status"
}
}
},
"text/html": [
"\n",
" \n",
" \n",
" \n",
" \n",
" "
]
},
"metadata": {},
"output_type": "display_data"
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"************************************************************\n",
"\n",
"\n",
" OLS Regression Results \n",
"=======================================================================================\n",
"Dep. Variable: loan_status R-squared (uncentered): 0.357\n",
"Model: OLS Adj. R-squared (uncentered): 0.357\n",
"Method: Least Squares F-statistic: 1110.\n",
"Date: Tue, 17 Mar 2020 Prob (F-statistic): 0.00\n",
"Time: 15:52:24 Log-Likelihood: -30665.\n",
"No. Observations: 63999 AIC: 6.139e+04\n",
"Df Residuals: 63967 BIC: 6.168e+04\n",
"Df Model: 32 \n",
"Covariance Type: nonrobust \n",
"===========================================================================================\n",
" coef std err t P>|t| [0.025 0.975]\n",
"-------------------------------------------------------------------------------------------\n",
"loan_amnt -2.078e-06 2.67e-07 -7.784 0.000 -2.6e-06 -1.55e-06\n",
"term -0.0601 0.004 -14.037 0.000 -0.069 -0.052\n",
"int_rate 0.0846 0.001 64.946 0.000 0.082 0.087\n",
"grade -0.0181 0.005 -3.321 0.001 -0.029 -0.007\n",
"sub_grade -0.0515 0.001 -34.544 0.000 -0.054 -0.049\n",
"emp_title -2.238e-06 1.65e-07 -13.588 0.000 -2.56e-06 -1.92e-06\n",
"emp_length -0.0013 0.001 -2.548 0.011 -0.002 -0.000\n",
"home_ownership -0.0027 0.001 -2.926 0.003 -0.004 -0.001\n",
"annual_inc -1.405e-07 3.62e-08 -3.884 0.000 -2.11e-07 -6.96e-08\n",
"verification_status -0.0059 0.002 -2.805 0.005 -0.010 -0.002\n",
"purpose -0.0040 0.001 -5.099 0.000 -0.005 -0.002\n",
"title 3.48e-05 1.56e-06 22.313 0.000 3.17e-05 3.79e-05\n",
"zip_code -3.354e-06 5.81e-06 -0.577 0.564 -1.47e-05 8.04e-06\n",
"addr_state -0.0005 0.000 -4.756 0.000 -0.001 -0.000\n",
"dti -0.0051 0.000 -23.481 0.000 -0.005 -0.005\n",
"delinq_2yrs -0.0229 0.002 -12.517 0.000 -0.027 -0.019\n",
"inq_last_6mths 0.0232 0.002 14.117 0.000 0.020 0.026\n",
"open_acc -0.0076 0.000 -17.411 0.000 -0.008 -0.007\n",
"pub_rec -0.0394 0.003 -13.728 0.000 -0.045 -0.034\n",
"revol_bal -2.196e-07 1.51e-07 -1.451 0.147 -5.16e-07 7.71e-08\n",
"revol_util -0.0009 8.26e-05 -10.311 0.000 -0.001 -0.001\n",
"total_acc 0.0033 0.000 17.411 0.000 0.003 0.004\n",
"initial_list_status -0.1331 0.003 -40.528 0.000 -0.140 -0.127\n",
"total_rec_int -2.848e-06 1.04e-06 -2.740 0.006 -4.89e-06 -8.11e-07\n",
"total_rec_late_fee -0.0006 0.000 -1.704 0.088 -0.001 9.44e-05\n",
"recoveries -0.0001 6.84e-06 -20.976 0.000 -0.000 -0.000\n",
"collection_recovery_fee 0.0004 4.18e-05 8.410 0.000 0.000 0.000\n",
"application_type -0.0415 0.074 -0.561 0.575 -0.186 0.103\n",
"last_week_pay -0.0004 6.09e-05 -7.363 0.000 -0.001 -0.000\n",
"acc_now_delinq -0.0310 0.020 -1.588 0.112 -0.069 0.007\n",
"tot_cur_bal 1.139e-07 1.46e-08 7.819 0.000 8.54e-08 1.43e-07\n",
"total_rev_hi_lim 2.649e-07 1.11e-07 2.381 0.017 4.68e-08 4.83e-07\n",
"==============================================================================\n",
"Omnibus: 7448.626 Durbin-Watson: 2.001\n",
"Prob(Omnibus): 0.000 Jarque-Bera (JB): 10200.031\n",
"Skew: 0.970 Prob(JB): 0.00\n",
"Kurtosis: 2.750 Cond. No. 1.05e+07\n",
"==============================================================================\n",
"\n",
"Warnings:\n",
"[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.\n",
"[2] The condition number is large, 1.05e+07. This might indicate that there are\n",
"strong multicollinearity or other numerical problems.\n",
"\n",
"\n",
"******** VIF *********\n",
"\n",
" feature vif\n",
"4 sub_grade 153.09\n",
"2 int_rate 147.28\n",
"3 grade 61.36\n",
"17 open_acc 12.90\n",
"21 total_acc 11.97\n",
"31 total_rev_hi_lim 10.39\n",
"20 revol_util 10.31\n",
"0 loan_amnt 8.65\n",
"14 dti 7.85\n",
"19 revol_bal 7.45\n",
"11 title 5.76\n",
"28 last_week_pay 5.39\n",
"8 annual_inc 4.71\n",
"5 emp_title 4.33\n",
"7 home_ownership 4.27\n",
"12 zip_code 3.89\n",
"30 tot_cur_bal 3.65\n",
"13 addr_state 3.49\n",
"23 total_rec_int 3.40\n",
"9 verification_status 3.15\n",
"10 purpose 3.00\n",
"25 recoveries 2.87\n",
"26 collection_recovery_fee 2.78\n",
"1 term 2.32\n",
"22 initial_list_status 2.25\n",
"6 emp_length 2.19\n",
"16 inq_last_6mths 1.72\n",
"32 loan_status 1.56\n",
"15 delinq_2yrs 1.20\n",
"18 pub_rec 1.18\n",
"24 total_rec_late_fee 1.03\n",
"29 acc_now_delinq 1.03\n",
"27 application_type 1.00\n"
]
},
{
"data": {
"application/javascript": [
"\n",
" if (window._pyforest_update_imports_cell) { window._pyforest_update_imports_cell('from sklearn.model_selection import train_test_split'); }\n",
" "
],
"text/plain": [
""
]
},
"metadata": {},
"output_type": "display_data"
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"\n",
" *************** Random Forest ***************\n",
"\n"
]
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAqQAAAGwCAYAAAB/6Xe5AAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADt0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjByYzEsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy/xvVyzAAAgAElEQVR4nO3de7yv9Zz//8dTpVJbWwoV2Qkl0Wk7hFSEGYMwyGGwGRNjlMwvpi/fIWOMjDP9jNkTGuRUGcJ0cOgkUnvXrl1oHIoomorOpb17ff+4rqVPnz5rrc86Xmut/bjfbp/b+qz39b6u6/V5f671Wc91nVaqCkmSJKkr9+i6AEmSJK3bDKSSJEnqlIFUkiRJnTKQSpIkqVMGUkmSJHXKQCpJkqROGUgl/UmSZUkqybKua5EkrTsMpNIMaYNd72NtkmuTnNYGv3Rd43yX5PAB49z7uKzrGiejrf20Scx39DjjMeFlTlZPLUtma53TJck+sz1eXfGPUM0V63ddgLQOeGf7dQPgocDzgL2BpcAbuipqgTkdOG1A+x9muY654mvAqgHtl81yHZI0FAOpNMOq6vDe75M8ETgDeH2SD1TVpZ0UtrCc1j/O67ivVtXRXRchScPykL00y6rqLOAnQIA9eqcl2SPJR5Jc0B7evzXJT5N8IMl9+pfVe7gtyb7t6QA3JLk+yTeTPGJQDUkemuTYJL9PclOS7yf5i7Hqbms7PslVSW5L8sskH0+y1YC+I4drt0vyhiQ/al/LZUneOnK6QpIXJjmnreGqJEcm2WgCwzkhk3wND0lyUJILk9zSexg3yeZJ3pPkx+2065J8J8nTByzvnkkOTnJeO+43t+PxtST7tX2WJRn5f8579x1uP3wGxuMlSU5t67m1fR3/N8mGA/o+N8nnkvxP+37dmGRl+5ru0de3gFe231466BSK9rVfxgC581SMffqX227jD0hyVJLfpDkVZllPn8clOS7Jb5P8McnlSf49ydaTHaeeZff+vD0tyZntOPxvkk8nWdz22y3JN9pxvTHJCRlw6kL7WirJhkn+Ocml7Xb58yTvSHLPUep4apKTcudnxP8kOSLJZmOs455J3p7kknYdR7fb8qfbrp/u296WtPNv3c53Vs+YXpHk8xnw+ZJkSTv/0e3zLya5uq1zRZJnjTG+B7Q/PyOv67IkX0iydEDfobddzQ/uIZW6MXL+6O197X9Dc0j/dODbwHrA7sDfA3+e5HFVdcOA5T0L2B84EfgEsBPwTOAxSXaqqqv/tOLkYcAPgPu2/VfRnErw1fb7uxfb/BI5vq37OOCXNGH6b4H9kzyxqi4bMOv7gX2ArwOnAM8B3g3cM8m1wBHtes8Engb8Xfua/3ZQHVMxhdfwEWAv4JvAfwNr2+U9mOY0gSVt/ScBm9C8FycleW1V/UfPco4GXgJcBHwGuAXYGngS8Gc07/cqmlM83tHWd3TP/KdN9rUPkuSTwKuBXwNfoTm94fHAu4CnJnlaVa3pmeUI4A7gh8BvgM2Ap9CMz2OAl/f0fSfwXGCXdvrIqRPTcQrF5sDZwI1t3XcAv2tf06uA/wBuA04ALgceBrwGeHaSx1fVr6ahhufQvM/foPl5ewKwDNguyWHAd2i2iU8CjwKeDWyf5FFVdceA5X2ZZgyPo/lM2B84HFia5DlVNfJHCkleC/wbcBNwLHAVzc/YP7Sv8YlVNWicj2/XcSLNz9xVNNvUH9r19Z/mMbKMJwOHAae2y7iRZkxfADynXd8FA9b3YOAc4BfAZ2netwOAryXZr6pO7XlNoQnGrwSupnlf/xd4ILAvcAmwoqf/RLddzQdV5cOHjxl4ANX8iN2t/ck0oeY2YKu+aQ8G1hswz1+3y/uHvvZlbfsa4Kl9097TTntLX/spbfsb+9r3H6kZWNbTvinNL4m1wF598/xD2/+Uvvaj2/bLgG162he3y7qJ5hfOI3qmbQj8qB2X+w05xoe36zmtfd7/WDINr+E3wHYD1n0aTRh6cV/7Yppf7LcA92/bNmv7rhjl/b3vgG3ntElscyM1f3WU8Vjct918Bdh4lDHt3z62H7C+ewD/2fZ/3Ci1LBml1suAy8Z5X/cZ9DNFE+jX75v2cOCPwM96t7l22lPa9/6/hhzHfQa9B9z1523vvnH4VjvtWuBlffN9sp22/4BtqID/Ae7T074RzR+NBby8p/3BND8f1wM79i3r423/5aOs40JgiwGvdeQ1LRtlLO4HLBrQvgtNOD2xr31Jz/v0jr5pz2jb/7uv/cC2/Rxgs75p69HzOTmZbdfH/Hh0XoAPHwv10fOhfHj7eDfwpfaX5h3AQRNYVoDrgO/2tY98OH9uwDzbtdOO62l7YNv2CwYHo5FfXst62l7Wtn1+QP/1gUvb6dv2tB/dtv31gHk+1U77pwHT3tFO23vIcRn5BTTaY59peA13++XW/jIu4NhR6hoJ969vv793+/1ZQIbcdk6bxDY3UvNojyVtv/Np9sQtHrCM9WjC+zlDrnP3dtlvH6WWJaPMdxmTC6QD/2ABPtRO/4tRlvlfNEHybuFqQN99Br0H3Pnz9tkB87yinXbGgGl7MzignUZf6BxQw6k9bW9r2/5lQP/70ATVW4ANB6xj//55+l7TskHTxxmnE4BbgQ162pZw5x+jgz5jfglc3de2up1ntyHWOW3bro+59fCQvTTz3tH3/UhQ+3R/xyQbAK8FXkxz2H0z7nqu9zajrGPFgLbL26+9557u1n79XlWtHTDPaTS/PHvt3n79bn/nqlqT5AyaX0K7Af2HQwfVdUX7deWAab9pvz5wwLSxvLPGvqhpKq/hnAHL27P9ulkGn9u5Zfv1Ee06rk/ydZpDt6uSHE9zSPeHVXXzGHVP1qtqlIuaktyLJlBfDRySwXcfu22k9p757gu8meZUkIfQnJ7Qa7Rtc7pdVlVXDWgfeU/2TvKYAdPvRxNYHs7gbW8ipnu7Pn1A25k0AXq3nraxtuPfJzmf5gjMjkD/YfRB2/FQ0pxf/jqaO4Nswd1P99sCuLKvbdUonzGXc+d7RZJNgJ2B31XV+ePUMaltV/ODgVSaYVU1cgHPJjQfxJ8EPpHkl1XV/4vlSzTnkP6C5pyu39J8wAIcQnNYe5C7nTPWBi1ofgmPGLno4XejLOe3A9pG5un/hUNf++IB064b0LZmiGkbjLKuyZrKaxg0Jvdtvz6tfYxm057nB9CcHvBS7rwV2K1JjgMOrarR3pPpdh+aPe5bcvc/lgZqL9Y5l2av+zk0h8yvpXm/FgNvZPRtc7oNej/gzvfkzePMv+k404cx3dv13d77qlqb5BqaID1iurfjcSU5mOY84N/TnJbwK+Bmmj+sR84THvTej3a+8Bru+kf2SK2/GdC334S3Xc0fBlJpllTVTcC3kzwbOA/4zyQ7jOwha68kfR7NxS3PrKo/XfCU5irmt0xDGSO/LO8/yvQHjDHPoGkAW/X1m4um8hpqjOW9sao+OkwBVXUL7ekbSR5EsydrGfBXNHtn9xpmOdNgpPbzq2r3MXve6TU0YfRue6KT7EkTSCfqDmDgVeQMDlQjBr0fcOfr2qyqrp9EPV26P3175pOsRxOye19L73Z88YDljLodV9Vo4zaqJOvT/PH0W2D3qrqyb/qeA2ecmJHgOswe9slsu5onvO2TNMuq6kKaK4EfCLypZ9JD268n9IbR1mOBjadh9SOHxJ7U/sLrt88Y89xtWvsL60ntt+dNtbgZNN2v4ez266RCZFVdXlXH0Fzk8VOa9+O+PV3u4K57tqdNVd1IE2YemWTzIWcb2TaPHzCt/xSPESOHa0d7Hb8H7t+eptLvbrf5GcKU3pOODRrDvWh2GvUexh5rO14M7EpzTuePJ7Dusd6nLWj+OPj+gDC6KXeeQjBp7R/qF9FsC7uN03cy267mCQOp1I1/pvnFcWjuvL/oZe3XfXo7Jrkf8P9Px0qr6tc0h922o++/RCXZn8G/GL9Kc3j2JUke3zftEJrzCb9d03M7nZkyra+hqlbQnOP3/CSvHtQnyaPa944kWyZ53IBumwCLaA5j/rGn/RrgQcPUMkkfpNk7+ak2yNxFkvsk6Q0bl7Vf9+nrtxvwf0ZZxzXt121HmX4OTeB6Vd8ylwFPHL30UR1Jc7HLh5I8vH9iex/OuRpW/7Hnc4A09+J9T/tt77nmn6N5jQcleSh39S6ai+c+V1W3Mbyx3qeraA7P79EG0JH6NqA5jL/FBNYzlpGjDP+evnupJrlH7nqf4Iluu5onPGQvdaCqfpPk32kOdb6F5pf6uTRXYT8/yfeB79EcyvtzmvvwXTHK4ibq72huKfPhNDdwv4A7/6XpyIU3vbXe2IauY4HTkxxLc3hxD+DpNIfzXjtNtc2IGXoNL6W5uOST7Xl2P6Q5/PhA4NE0F2rsSfNLfRvg7CQ/ptkLezlNeHgWzeHXj9Zd7y/7HeDF7YVQK2kC6xlVdcZEX/sgVfWpJHsArwd+nuRkmvHYnOaPlSfTBKHXtbN8hubczA8n2Zdmr+7D2vq/QnN+bL/vtPP8R3ue7I3AH6rqyHb6x2jC6L8leSrNmOxCc0/Pb7TLnshr+kn7Hn8KuDjJSTS3U9qAJmztRXOrsR0nstxZ8mOamnvvQ7o9zb1vPzvSqaouS3IIzR+o5yX5Ms1r2ptmW/sJzXnKE/EDmtB5SLvXceR81o9V1XVJPkpzH9LVSb5GEwb3pdlWTm2fT9VRNEcpXgH8tF3P/9Lcp/cpNO/p4TCpbVfzRdeX+fvwsVAfjHIf0p7p96e5H+dN3Hm/ys1p7id4Gc0e1J8D/wLciwG3yWH8ewgOvH0QTQA9jiZA3UTzS+kvxloezU21/4vmF8UfaX4J/Buw9YC+RzPKLX8Y5ZY+w7yeMZZ1+JD9p+U19PRZBLyVJjTeSHPLnUtpgsSBwCZtv8XA22kC7G9oLlS7kuauBi+h71ZQNBeyfJ4mHKwd9jX21Dzs+I3c3P2qdjx+S7Pn8p+5+30ud6K5zc9V7Tazkubc0iXtOo8esPy/pwlbt7V9+rffJ9H8G92bac6V/CZNmB+4jYy2Pff1eVQ7Dr9s13stzSHhfweeMuS47DNoXWNtnz3z3O19Gm2MuPOWTBu2Y35pW/MvaC7a2XCU+p5Ocz/h37f9fwb8K4NvhXQaY3wOtX3+jOYz4Ebufouw9dv38Uc02/dvaULygxnwMzLW9jBePTS3Zzud5lzRW9vxOIbm/NVJb7s+5scj7RsrSZJmUZp/3bl3tXfikNZlnkMqSZKkThlIJUmS1CkDqSRJkjrlOaSSJEnqlLd9mue22GKLWrJkSddlSJIkjWvlypVXV9WW/e0G0nluyZIlrFixousyJEmSxpXkl4PaPYdUkiRJnTKQSpIkqVMesp/nfvzra9jjzZ/pugxJkjRPrXzfK7ouwT2kkiRJ6paBVJIkSZ0ykEqSJKlTBlJJkiR1ykAqSZKkThlIJUmS1CkDqSRJkjplIJUkSVKnDKSSJEnqlIFUkiRJnTKQSpIkqVMGUkmSJHVqxgJpku8P0eeoJDu1z986iflvHGPakiQXtc+XJvnoOH1fOt76Bsy3OMnrp6ufJEnSumjGAmlVPWGIPq+pqh+13761b9q480+glhVVdfAYXZYAEw6kwGJgmKA5bD9JkqR1zkzuIb2x/bpPktOSHJfkJ0mOSZJ22mnt3ssjgI2TrEpyTN/8myb5TpLzkqxOsv8katknyTfa53u361mV5Pwki4AjgL3atjeNsoxHJjmn7XNhkoe1823ftr1vjFr7+/2pnnbZRyZZ1j4/IsmP2nW8f5RaDkyyIsmKNTffMNHhkCRJmlPWn6X17AY8ErgCOAt4IvC9kYlVdViSN1TVrgPmvRV4XlVdn2QL4OwkJ1RVTbKWQ4G/q6qzkmzaLv8w4NCqetYY870O+EhVHZPknsB67Xw7j9SdZP1BtQ7ot8+gFSTZHHgesGNVVZLFg/pV1XJgOcAmD9husuMgSZI0J8zWRU3nVNWvq+oOYBXNIfJhBfiXJBcC3wa2Ae4/hVrOAj6Y5GBgcVWtGXK+HwBvTfIPwIOr6pYZqPV6moB8VJLnAzdPYF5JkqR5abYC6W09z9cysT2zLwO2BPZo9zD+DthosoVU1RHAa4CNafZg7jjkfJ8HngPcApyc5ClTqHUNdx37jdp1rAEeCxwPPBc4aZjaJEmS5rPZOmQ/jNuTbFBVt/e1bwZcVVW3J9kXePBUVpJk+6paDaxOsiewI3A5sGic+R4C/KKqPto+fzRwQd98o9V6Q1+/XwI7JdmQJow+FfheewrBvarqv5OcDfxsKq9VkiRpPphLgXQ5cGGS86rqZT3txwBfT7KC5nD/T6a4nkPasLgW+BFwInAHsCbJBcDRVfWhAfMdAPxVktuB3wL/VFXXJjmrvb3UicB7B9VaVdf09quqNyf5MnAh8FPg/HYdi4CvJdmI5vD/wAusJEmSFpJM/togzQWbPGC72vHl7+y6DEmSNE+tfN8rZm1dSVZW1dL+dv9TkyRJkjo1lw7ZT0qSRwGf7Wu+raoeN8nlPYPm0HuvS6vqeZNZniRJksY27wNpe4HSoPuXTnZ5JwMnT9fyJEmSNDYP2UuSJKlTBlJJkiR1ykAqSZKkThlIJUmS1CkDqSRJkjplIJUkSVKn5v1tn9Z1j3jgfVkxi/9hQZIkabq5h1SSJEmdMpBKkiSpUwZSSZIkdcpAKkmSpE4ZSCVJktQpA6kkSZI65W2f5rk/Xnkxv/qnR3VdhiRJArZ9++quS5iX3EMqSZKkThlIJUmS1CkDqSRJkjplIJUkSVKnDKSSJEnqlIFUkiRJnTKQSpIkqVMGUkmSJHXKQCpJkqROGUglSZLUKQOpJEmSOmUgnQFJFid5fft86yTHtc93TfLMnn7LkhzZVZ2SJElzgYF0ZiwGXg9QVVdU1Qva9l2BZ446lyRJ0jpo/a4LWKCOALZPsgr4KfAIYHfgn4CNkzwJeE/vDEm2BD4BbNs2HVJVZ81eyZIkSd1wD+nMOAz4eVXtCrwZoKr+CLwd+FJV7VpVX+qb5yPAh6rqMcBfAkeNtvAkByZZkWTFtTetnZlXIEmSNEvcQzp37AfslGTk+3snWVRVN/R3rKrlwHKAR2+zcc1eiZIkSdPPQDp33APYs6pu6boQSZKk2eQh+5lxA7BoAu0ApwBvGPkmya4zUJckSdKcYyCdAVV1DXBWkouA9/VMOpXmsPyqJAf0zXYwsDTJhUl+BLxulsqVJEnqlIfsZ0hVvXRA27XAY/qaj26nXQ30h1RJkqQFzz2kkiRJ6pSBVJIkSZ0ykEqSJKlTBlJJkiR1ykAqSZKkThlIJUmS1CkDqSRJkjplIJUkSVKnDKSSJEnqlIFUkiRJnfJfh85z99zqkWz79hVdlyFJkjRp7iGVJElSpwykkiRJ6pSBVJIkSZ0ykEqSJKlTBlJJkiR1ykAqSZKkTnnbp3nuJ1f9hCd+7IldlyFJ0qw666Czui5B08g9pJIkSeqUgVSSJEmdMpBKkiSpUwZSSZIkdcpAKkmSpE4ZSCVJktQpA6kkSZI6ZSCVJElSpwykkiRJ6pSBVJIkSZ0ykEqSJKlTBlJJkiR1asEE0iSLk7x+nD5Lkrx0tmrqWe+yJEdOcJ7LkmwxUzVJkiTNFQsmkAKLgTEDKbAEmLFAmmT9mVq2JEnSQrWQAukRwPZJViV5X/u4KMnqJAf09Nmr7fOmQQtJsl6S97fzXZjkoLb9T3sskyxNclr7/PAky5OcAnxmjPoelOSkJJckeUfP+r6aZGWSi5McOMwLTXJgkhVJVtx+4+3DzCJJkjRnLaQ9eocBO1fVrkn+EngdsAuwBXBukjPaPodW1bPGWM6BwHbAblW1JsnmQ6x7D+BJVXXLGH0eC+wM3NzW882qWgG8uqquTbJx2358VV0z1sqqajmwHGDTbTetIeqTJEmasxbSHtJeTwK+UFVrq+p3wOnAY4acdz/gE1W1BqCqrh1inhPGCaMA36qqa9p+X2lrBDg4yQXA2cCDgIcNWackSdKCsJD2kPbKFOcdtNdxDXcG+I36pt00xHL7l1lJ9qEJwHtW1c3taQD9y5YkSVrQFtIe0huARe3zM4AD2vNBtwSeDJzT12c0pwCvG7lAqeeQ/WU0h+YB/nIS9T0tyebtofnnAmcBmwG/b8PojsDjJ7FcSZKkeW3BBNL2vMuzklwE7AlcCFwAfBd4S1X9tm1bk+SC0S5qAo4CfgVc2B5KH7kq/53AR5KcCaydRInfAz4LrAKOb88fPQlYP8mFwLtoDttLkiStU1LlNTHz2abbblq7vHmXrsuQJGlWnXXQWV2XoElIsrKqlva3L5g9pJIkSZqfFupFTeNK8gzgvX3Nl1bV8+bSMiVJkha6dTaQVtXJwMlzfZmSJEkLnYfsJUmS1CkDqSRJkjplIJUkSVKnDKSSJEnqlIFUkiRJnTKQSpIkqVPr7G2fFood77ej/61CkiTNa+4hlSRJUqcMpJIkSeqUgVSSJEmdMpBKkiSpUwZSSZIkdcpAKkmSpE5526d57oZLLuH0J+/ddRmSpBmw9xmnd12CNCvcQypJkqROGUglSZLUKQOpJEmSOmUglSRJUqcMpJIkSeqUgVSSJEmdMpBKkiSpUwZSSZIkdcpAKkmSpE4ZSCVJktQpA6kkSZI6ZSCVJElSp+ZEIE1y4yTnOyTJvaa7nnHWeXSSF8zmOiVJkhayORFIp+AQYFYDqSRJkqbXnAqkSTZN8p0k5yVZnWT/tn2TJN9MckGSi5IckORgYGvg1CSnjrK8FyX5YPv8jUl+0T7fPsn32ud7JDk9ycokJyfZqqfPSW37mUl2HLD8d7V7TAeOY5LLkrw3yTnt46Ft+7OT/DDJ+Um+neT+Se6R5KdJtmz73CPJz5JsMWC5ByZZkWTFdbffPvGBliRJmkPmVCAFbgWeV1W7A/sCH0gS4M+AK6pql6raGTipqj4KXAHsW1X7jrK8M4C92ud7Adck2QZ4EnBmkg2AjwEvqKo9gE8B7277LwcOatsPBT7eu+Ak/wrcD3hVVd0xxmu6vqoeCxwJfLht+x7w+KraDfgi8JZ2GZ8DXtb22Q+4oKqu7l9gVS2vqqVVtXSzDTYYY9WSJElz3/pdF9AnwL8keTJwB7ANcH9gNfD+JO8FvlFVZw6zsKr6bbvXdRHwIODzwJNpwulXgB2AnYFvNbmX9YArk2wKPAE4tm0H2LBn0f8I/LCqDhyijC/0fP1Q+/yBwJfavbH3BC5t2z8FfI0muL4a+PQwr1OSJGk+m2t7SF8GbAnsUVW7Ar8DNqqq/wH2oAmm70ny9gks8wfAq4BLgDNpwuiewFk0Afjiqtq1fTyqqp5OMy5/6Gnftaoe0bPMc4E9kmw+xPprwPOPAUdW1aOA1wIbAVTV5cDvkjwFeBxw4gRepyRJ0rw01wLpZsBVVXV7kn2BBwMk2Rq4uao+B7wf2L3tfwOwaJxlnkFzyP0M4HyaUwFuq6rraELqlkn2bNezQZJHVtX1wKVJXti2J8kuPcs8CTgC+Ga793UsB/R8/UHP6/xN+/yVff2Pojl0/+WqWjvOsiVJkua9uXbI/hjg60lWAKuAn7TtjwLel+QO4Hbgb9v25cCJSa4c4zzSM2kO159RVWuTXD6y3Kr6Y3sLp48m2YxmPD4MXEyzt/bfkvxfYAOacz0vGFloVR3bhtETkjyzqm4ZZf0bJvkhTfh/Sdt2OM3pAL8Bzga26+l/As2heg/XS5KkdUKqavxempQklwFLB12YNMY8S4EPVdVe43YGdli0qJbvtvv4HSVJ887eZ5zedQnStEqysqqW9rfPtT2k67Qkh9Hs/X3ZeH0lSZIWigUTSNvD4hv2Nb+8qlbPwrr/i7sedgf4h6paMpHlVNURNOemSpIkrTMWTCCtqsd1uO7ndbVuSZKk+W6uXWUvSZKkdYyBVJIkSZ0ykEqSJKlTBlJJkiR1ykAqSZKkThlIJUmS1KkFc9unddWiHXbwP3lIkqR5zT2kkiRJ6pSBVJIkSZ0ykEqSJKlTBlJJkiR1ykAqSZKkThlIJUmS1Clv+zTPXfXr6zjy//t612VI0qx4wwee3XUJkmaAe0glSZLUKQOpJEmSOmUglSRJUqcMpJIkSeqUgVSSJEmdMpBKkiSpUwZSSZIkdcpAKkmSpE4ZSCVJktQpA6kkSZI6ZSCVJElSpwykkiRJ6tSsBtIki5O8fpw+S5K8dIhlLUly0fRVN74khyc5dJRp3x9jvj/VmmRpko/OVI2SJEnzzWzvIV0MjBlIgSXAuIF0IpKsP53LG6SqnjBkvxVVdfBM1yNJkjRfzHYgPQLYPsmqJO9rHxclWZ3kgJ4+e7V93tTuXTwzyXntY6jgl2RZkmOTfB04JckmST6V5Nwk5yfZv+33wySP7JnvtCR7jLHondo+v0hycM98Nw5Z1z5JvtE+PzzJfyY5JcllSZ6f5F/b8TgpyQbDLFOSJGk+GyqQJtk+yYbt832SHJxk8STWdxjw86raFTgb2BXYBdgPeF+Srdo+Z1bVrlX1IeAq4GlVtTtwADCRw917Aq+sqqcAbwO+W1WPAfZt17cJ8EXgRe1r2wrYuqpWjrHMHYFnAI8F3jENoXF74C+A/YHPAadW1aOAW9r2u0lyYJIVSVbcePN1U1y9JElSt4bdQ3o8sDbJQ4FPAtsBn5/iup8EfKGq1lbV74DTgccM6LcB8B9JVgPHAjtNYB3fqqpr2+dPBw5Lsgo4DdgI2Bb4MvDCts+L2nWM5ZtVdVtVXU0Tlu8/gXoGObGqbgdWA+sBJ7Xtq2lOX7ibqlpeVUuraumm99psiquXJEnq1rDnVt5RVWuSPA/4cFV9LMn5U1x3huz3JuB3NHtS7wHcOoF13NS3vr+sqkvuVkhyTZJH0+yBfe04y7yt5/lahh/DMZdXVXckub2qqm2/YxqWLUmSNOcNu4f09iQvAV4JfKNtm8yh6huARe3zM4ADkqyXZEvgycA5fX0ANgOurKo7gJfT7EWcjJOBg5IEIMluPdO+CLwF2KyqVk9y+ZIkSZqEYQPpq2jOx3x3VV2aZDua8x0npKquAc5qb4G0J3AhcAHwXeAtVfXbtm1NkguSvAn4OPDKJIk4Rr0AABVpSURBVGcDD+euez0n4l00IfrCdv3v6pl2HPBimsP3kiRJmkW58wjxOB2TjYFtBx3yVne2fcDD6i0v+2DXZUjSrHjDB57ddQmSpiDJyqpa2t8+7FX2zwZW0V5wk2TXJCdMb4mSJElaFw170czhNLc5Og2gqla1h+07l+QZwHv7mi+tqudNYZmvAt7Y13xWVf3dOPM9CvhsX/NtVfW4ydYiSZK00A0bSNdU1XXt9UAjhjvWP8Oq6mSaC5amc5mfBj49iflW09xbVZIkSUMaNpBe1P5/+fWSPAw4GBj1f7dLkiRJwxr2KvuDgEfS3DPz88B1wCEzVZQkSZLWHePuIU2yHnBCVe1H8+83JUmSpGkz7h7SqloL3JzE/1EpSZKkaTfsOaS3AquTfIueG9NX1cEzUpUkSZLWGcMG0m+2D0mSJGlaDf2fmjQ3LV26tFasWNF1GZIkSeMa7T81DbWHNMmlDLjvaFU9ZBpqkyRJ0jps2EP2vUl2I+CFwObTX44kSZLWNUPdh7Sqrul5/KaqPgw8ZYZrkyRJ0jpg2EP2u/d8ew+aPaaLZqQiSZIkrVOGPWT/gZ7na4BLgRdNfzmSJEla1wwbSP+6qn7R25BkuxmoR5IkSeuYoW77lOS8qtq9r21lVe0xY5VpKNvc9z71+j9/atdlSNPubZ87rusSJEnTbFK3fUqyI/BIYLMkz++ZdG+aq+0lSZKkKRnvkP0OwLOAxcCze9pvAP5mpoqSJEnSumPMQFpVXwO+lmTPqvrBLNUkSZKkdciwFzWdn+TvaA7f/+lQfVW9ekaqkiRJ0jpjqBvjA58FHgA8AzgdeCDNYXtJkiRpSoYNpA+tqn8Ebqqq/wT+AnjUzJUlSZKkdcWwgfT29usfkuwMbAYsmZGKJEmStE4Z9hzS5UnuA/wjcAKwKfD2GatKkiRJ64yhAmlVHdU+PR14yMyVI0mSpHXNUIfsk9w/ySeTnNh+v1OSv57Z0iRJkrQuGPYc0qOBk4Gt2+//BzhkJgqSJEnSumXYQLpFVX0ZuAOgqtYAa2esqnVIksOTHJpkWZKte9qPSrJTl7VJkiTNhmEvaropyX2BAkjyeOC6Gatq3bQMuAi4AqCqXtNpNZIkSbNk2D2kf09zdf32Sc4CPgMcNGNVLXBJ3pbkkiTfBnZom5cCxyRZlWTjJKclWdphmZIkSbNizD2kSbatql9V1XlJ9qYJTwEuqarbx5pXgyXZA3gxsBvN+J8HrARWAIdW1Yq2X2c1SpIkzabx9pB+tef5l6rq4qq6yDA6JXsB/1VVN1fV9TR7nickyYFJViRZcdOtt01/hZIkSbNovEDau5vO+49On5rSzFXLq2ppVS3dZKMNp6smSZKkTowXSGuU55q8M4DnteeJLgKe3bbfACzqrixJkqRujHeV/S5JrqfZU7px+5z2+6qqe89odQtQez7ul4BVwC+BM9tJRwOfSHILsGdH5UmSJM26MQNpVa03W4WsS6rq3cC7B0w6vuf5PrNTjSRJUreGve2TJEmSNCMMpJIkSeqUgVSSJEmdMpBKkiSpUwZSSZIkdcpAKkmSpE4ZSCVJktQpA6kkSZI6ZSCVJElSpwykkiRJ6tR4/8tec9xW223P2z53XNdlSJIkTZp7SCVJktQpA6kkSZI6ZSCVJElSpwykkiRJ6pSBVJIkSZ0ykEqSJKlT3vZpnrv1yhv48bu/23UZ0lAe8bandF2CJGkOcg+pJEmSOmUglSRJUqcMpJIkSeqUgVSSJEmdMpBKkiSpUwZSSZIkdcpAKkmSpE4ZSCVJktQpA6kkSZI6ZSCVJElSpwykkiRJ6pSBVJIkSZ2ad4E0yeIkrx+nz5IkLx1iWUuSXDR91Y0vyVFJdhqnz3PH6yNJkrRQzLtACiwGxgykwBJg3EA6EUnWn47lVNVrqupH43R7LmAglSRJ64T5GEiPALZPsirJ+9rHRUlWJzmgp89ebZ83tXtCz0xyXvt4wjArSrIsybFJvg6ckmSTJJ9Kcm6S85Ps3/ZbL8n72xouTHLQGMs8LcnS9vmNSd6d5IIkZye5f1vbc4D3tfVvP5XBkiRJmuumZa/fLDsM2Lmqdk3yl8DrgF2ALYBzk5zR9jm0qp4FkORewNOq6tYkDwO+ACwdcn17Ao+uqmuT/Avw3ap6dZLFwDlJvg28AtgO2K2q1iTZfMhlbwKcXVVvS/KvwN9U1T8nOQH4RlUdN2imJAcCBwJstdn9hlyVJEnS3DQfA2mvJwFfqKq1wO+SnA48Bri+r98GwJFJdgXWAg+fwDq+VVXXts+fDjwnyaHt9xsB2wL7AZ+oqjUAPf3H80fgG+3zlcDThpmpqpYDywF23maHGnJdkiRJc9J8D6QZst+bgN/R7Em9B3DrBNZxU9/6/rKqLrlLEUmAyQTD26tqZL61zP/3Q5IkacLm4zmkNwCL2udnAAe053BuCTwZOKevD8BmwJVVdQfwcmC9Sa77ZOCgNoCSZLe2/RTgdSMXPk3gkP1o+uuXJElasOZdIK2qa4Cz2ts17QlcCFwAfBd4S1X9tm1b014s9Cbg48Ark5xNc7j+psFLH9e7aA7/X9iu/11t+1HAr9r2C5j6Ff5fBN7cXjjlRU2SJGlBy51HjDUf7bzNDnXs6/+t6zKkoTzibU/pugRJUoeSrKyqu11YPu/2kEqSJGlh8SIaIMkzgPf2NV9aVc+bwjL/i+ZWUL3+oapOnuwyJUmSFiIDKdCGxGkNilMJs5IkSesSD9lLkiSpUwZSSZIkdcpAKkmSpE4ZSCVJktQpA6kkSZI6ZSCVJElSp7zt0zy30VaL/O83kiRpXnMPqSRJkjplIJUkSVKnDKSSJEnqlIFUkiRJnTKQSpIkqVMGUkmSJHXK2z7Nc1dccQWHH35412VIAG6LkqRJcQ+pJEmSOmUglSRJUqcMpJIkSeqUgVSSJEmdMpBKkiSpUwZSSZIkdcpAKkmSpE4ZSCVJktQpA6kkSZI6ZSCVJElSpwykkiRJ6pSBVJIkSZ0ykE6DJIuTvL7rOiRJkuYjA+n0WAwMHUjTcOwlSZIwkE6XI4Dtk6xK8r4kb05ybpILk7wTIMmSJD9O8nHgPGCvJD9JclSSi5Ick2S/JGcl+WmSx3b6iiRJkmaJgXR6HAb8vKp2Bb4FPAx4LLArsEeSJ7f9dgA+U1W7Ab8EHgp8BHg0sCPwUuBJwKHAW0dbWZIDk6xIsuLmm2+eoZckSZI0O9bvuoAF6Ont4/z2+01pAuqvgF9W1dk9fS+tqtUASS4GvlNVlWQ1sGS0FVTVcmA5wNZbb13T/gokSZJmkYF0+gV4T1X9+10akyXATX19b+t5fkfP93fgeyNJktYRHrKfHjcAi9rnJwOvTrIpQJJtktyvs8okSZLmOPfCTYOquqa9GOki4ETg88APkgDcCPwVsLbDEiVJkuYsA+k0qaqX9jV9ZEC3nXv6X9b3/bLRpkmSJC1kHrKXJElSpwykkiRJ6pSBVJIkSZ0ykEqSJKlTBlJJkiR1ykAqSZKkThlIJUmS1CkDqSRJkjplIJUkSVKnUlVd16ApWLp0aa1YsaLrMiRJksaVZGVVLe1vdw+pJEmSOmUglSRJUqcMpJIkSeqUgVSSJEmdMpBKkiSpUwZSSZIkdcpAKkmSpE6t33UBmprf//7HfPnYx3ZdhuapF73wnK5LkCTJPaSSJEnqloFUkiRJnTKQSpIkqVMGUkmSJHXKQCpJkqROGUglSZLUKQOpJEmSOmUglSRJUqcMpJIkSeqUgVSSJEmdMpBKkiSpUwbSWZTkOUkO67oOSZKkuWT9rguYDUkCpKru6LCG9avqBOCErmqQJEmaixbsHtIkS5L8OMnHgfOAf0xybpILk7yzp98r2rYLkny2bXtwku+07d9Jsm2SzZJcluQebZ97Jbk8yQZJtk9yUpKVSc5MsmPb5+gkH0xyKvDeJMuSHNlO2zLJ8W1N5yZ5Ytu+d5JV7eP8JItmeegkSZJm1ULfQ7oD8Crgq8ALgMcCAU5I8mTgGuBtwBOr6uokm7fzHQl8pqr+M8mrgY9W1XOTXADsDZwKPBs4uapuT7IceF1V/TTJ44CPA09pl/VwYL+qWptkWU9tHwE+VFXfS7ItcDLwCOBQ4O+q6qwkmwK39r+oJAcCBwJsscU9p2OcJEmSOrPQA+kvq+rsJO8Hng6c37ZvCjwM2AU4rqquBqiqa9vpewLPb59/FvjX9vmXgANoAumLgY+3ofEJwLHNmQEAbNhTw7FVtXZAbfsBO/XMc+92b+hZwAeTHAN8pap+3T9jVS0HlgNsv/0mNcxASJIkzVULPZDe1H4N8J6q+vfeiUkOBoYJdCN9TgDe0+5J3QP4LrAJ8Ieq2nWcGvrdA9izqm7paz8iyTeBZwJnJ9mvqn4yRI2SJEnz0oI9h7TPycCr272ZJNkmyf2A7wAvSnLftn3kkP33afaAArwM+B5AVd0InENzuP0bVbW2qq4HLk3ywnYZSbLLEDWdArxh5Jsku7Zft6+q1VX1XmAFsOMUXrckSdKct04E0qo6Bfg88IMkq4HjgEVVdTHwbuD09vzQD7azHAy8KsmFwMuBN/Ys7kvAX7VfR7wM+Ot2GRcD+w9R1sHA0vbCqR8Br2vbD0lyUbusW4ATJ/6KJUmS5o9UeQrifLb99pvUe454ZNdlaJ560QvP6boESdI6JMnKqlra375O7CGVJEnS3GUglSRJUqcMpJIkSeqUgVSSJEmdMpBKkiSpUwZSSZIkdcpAKkmSpE4ZSCVJktQpA6kkSZI6tX7XBWhq7nOfR/jfdiRJ0rzmHlJJkiR1ykAqSZKkThlIJUmS1CkDqSRJkjplIJUkSVKnDKSSJEnqlIFUkiRJnfI+pPPcj35/Pbscd3LXZWiOueAFz+i6BEmShuYeUkmSJHXKQCpJkqROGUglSZLUKQOpJEmSOmUglSRJUqcMpJIkSeqUgVSSJEmdMpBKkiSpUwZSSZIkdcpAKkmSpE4ZSCVJktQpA6kkSZI6ZSDtkeT7Q/Q5JMm9pml9y5JsPR3LkiRJmq8MpD2q6glDdDsEGDqQJllvjMnLAAOpJElapxlIeyS5sf26T5LTkhyX5CdJjknjYJoAeWqSU8daTpJ/SvJDYM8kb09ybpKLkixvl/UCYClwTJJVSTZOskeS05OsTHJykq1GWf6BSVYkWbHm+utmYCQkSZJmj4F0dLvR7A3dCXgI8MSq+ihwBbBvVe07xrybABdV1eOq6nvAkVX1mKraGdgYeFZVHQesAF5WVbsCa4CPAS+oqj2ATwHvHrTwqlpeVUuraun6995sel6tJElSR9bvuoA57Jyq+jVAklXAEuB7Q867Fji+5/t9k7yF5lD/5sDFwNf75tkB2Bn4VhKA9YArJ1u8JEnSfGEgHd1tPc/XMrGxurWq1gIk2Qj4OLC0qi5Pcjiw0YB5AlxcVXtOsl5JkqR5yUP2E3cDsGgC/UfC59VJNgVeMMqyLgG2TLInQJINkjxyqsVKkiTNdQbSiVsOnDjWRU29quoPwH8Aq4GvAuf2TD4a+ER7SsB6NGH1vUkuAFYBw1z1L0mSNK+lqrquQVNwr+0fXg9778e6LkNzzAUveEbXJUiSdDdJVlbV0v5295BKkiSpU17UNAXtfUY37Gt+eVWt7qIeSZKk+chAOgVV9biua5AkSZrvPGQvSZKkThlIJUmS1CkDqSRJkjplIJUkSVKnDKSSJEnqlFfZz3M73eferPAm6JIkaR5zD6kkSZI6ZSCVJElSpwykkiRJ6lSqqusaNAVJbgAu6bqOOWwL4Oqui5jjHKPxOUbjc4zG5xiNzfEZ30IYowdX1Zb9jV7UNP9dUlVLuy5irkqywvEZm2M0PsdofI7R+ByjsTk+41vIY+Qhe0mSJHXKQCpJkqROGUjnv+VdFzDHOT7jc4zG5xiNzzEan2M0NsdnfAt2jLyoSZIkSZ1yD6kkSZI6ZSCVJElSpwykc1SSP0tySZKfJTlswPQk+Wg7/cIkuw8770Ix2TFK8qAkpyb5cZKLk7xx9qufHVPZjtrp6yU5P8k3Zq/q2TPFn7PFSY5L8pN2W9pzdqufHVMcoze1P2MXJflCko1mt/rZMcQY7ZjkB0luS3LoROZdKCY7Rn5e32X6qNtRO31+f15XlY859gDWA34OPAS4J3ABsFNfn2cCJwIBHg/8cNh5F8JjimO0FbB7+3wR8D+O0V3HqGf63wOfB77R9euZa+MD/Cfwmvb5PYHFXb+muTRGwDbApcDG7fdfBpZ1/Zo6GqP7AY8B3g0cOpF5F8JjimPk5/U4Y9QzfV5/XruHdG56LPCzqvpFVf0R+CKwf1+f/YHPVONsYHGSrYacdyGY9BhV1ZVVdR5AVd0A/Jjml+dCM5XtiCQPBP4COGo2i55Fkx6fJPcGngx8EqCq/lhVf5jN4mfJlLYhmn++snGS9YF7AVfMVuGzaNwxqqqrqupc4PaJzrtATHqM/Ly+0xjb0YL4vDaQzk3bAJf3fP9r7v4DOFqfYeZdCKYyRn+SZAmwG/DDaa+we1Mdow8DbwHumKkCOzaV8XkI8L/Ap9tDZEcl2WQmi+3IpMeoqn4DvB/4FXAlcF1VnTKDtXZlKp+5fl5PgJ/XY5r3n9cG0rkpA9r67881Wp9h5l0IpjJGzcRkU+B44JCqun4aa5srJj1GSZ4FXFVVK6e/rDljKtvQ+sDuwL9V1W7ATcBCPP9vKtvQfWj28GwHbA1skuSvprm+uWAqn7l+Xg+7AD+vR59xgXxeG0jnpl8DD+r5/oHc/VDXaH2GmXchmMoYkWQDmg+3Y6rqKzNYZ5emMkZPBJ6T5DKaQ0dPSfK5mSu1E1P9Oft1VY3sqTmOJqAuNFMZo/2AS6vqf6vqduArwBNmsNauTOUz18/rIfh5Pa4F8XltIJ2bzgUelmS7JPcEXgyc0NfnBOAV7RWuj6c5HHblkPMuBJMeoyShOffvx1X1wdkte1ZNeoyq6v9U1QOrakk733eraqHt3ZrK+PwWuDzJDm2/pwI/mrXKZ89UPot+BTw+yb3an7mn0pz/t9BM5TPXz+tx+Hk9voXyeb1+1wXo7qpqTZI3ACfTXHn3qaq6OMnr2umfAP6b5urWnwE3A68aa94OXsaMmsoY0fw1+XJgdZJVbdtbq+q/Z/M1zLQpjtGCNw3jcxBwTPvL4xcswLGb4mfRD5McB5wHrAHOZwH+28NhxijJA4AVwL2BO5IcQnMF9fV+Xo89RsCj8fN63O2os8Knkf86VJIkSZ3ykL0kSZI6ZSCVJElSpwykkiRJ6pSBVJIkSZ0ykEqSJKlTBlJJkiR1ykAqSZKkTv0/Idn/yEbr2E8AAAAASUVORK5CYII=\n",
"text/plain": [
""
]
},
"metadata": {
"needs_background": "light"
},
"output_type": "display_data"
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"-----------------------------------------\n",
"************* Model Results *************\n",
"-----------------------------------------\n",
"F1 Score : 0.781688137529659\n",
"Report:\n",
" precision recall f1-score support\n",
"\n",
" 0 0.87 0.82 0.85 14622\n",
" 1 0.52 0.62 0.57 4578\n",
"\n",
" accuracy 0.78 19200\n",
" macro avg 0.70 0.72 0.71 19200\n",
"weighted avg 0.79 0.78 0.78 19200\n",
"\n"
]
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAW0AAAENCAYAAADE9TR4AAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADt0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjByYzEsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy/xvVyzAAAgAElEQVR4nO3dd3wVVdrA8d+ThNBCQksCEhR8ZaWKFUEQEFRCE+yoCCqKsq4FUfoKFrCurrorLljAiqhIkI7UlY6VvqC0UJIgkASQkMTn/WMm4RJuKiHhDs+Xz3zuvWfmnDm38NxznzkzEVXFGGNMYAgq7Q4YY4wpOAvaxhgTQCxoG2NMALGgbYwxAcSCtjHGBBAL2sYYE0AsaHuIiDwqIutF5A8RURF5vAT2uU1Etp3u/ZwN3PdsYWn3w5zZLGgXgYjUF5G3RGStiCSLyDER2S0i00Wkj4iUK4U+9QDeAI4C/wSeAZaXdD/OBO4XibrLNXls94HPdiNPcZ9ti6MdY/ITUtodCDQi8jQwAucLbzkwATgERANtgXeBfsDlJdy1Llm3qrq7BPfbvgT3VVgZwAPAgpwrRCQcuM3d5kz5f9AAOFLanTBntjPlwxoQRGQozgh2J3Crqq7ws00XYEBJ9w04B6CEAzaq+mtJ7q+QpgE3iUg1Vf09x7q7gArA18CNJd4zP1R1Y2n3wZz5LD1SQCJSBxgJpAOd/AVsAFWdBsT6qX+biCx20yl/iMgaERkiImX9bLvNXSqIyCsiskNE0kRki4gMEhHx2XakiChwjfs46+e+ZvXbfTw+l+e1MGtbnzIRkd4islREkkTkqIjsFJHZInK7v776abesiAwWkV9E5IiIpIjIf0XkNj/bZvfRvT9RRPa5+13tfhEWxTigLHC3n3UP4Hz5zvJXUUT+IiIvuvtPcl//7SIyVkRicmw7nuOj+RG+74GItHW3ucd9fI+IxLqve7Lva58zpy0idUXkoIjsF5HzcuyzoohsEJFMEWlT2BfGBC4baRfcvUAZYKKqrs1rQ1VN830sIqOBIcA+4FOcdEpHYDTQQUSuU9X0HM2UAebgjKBn4vyM7w68CJTDGfEDLHRv7wHO8yk/FaPc/m4FJgHJQE3gCuBW4PO8KotIKDAbaANsBP6NM6q9BfhcRC5W1aF+qp4HrAR+Az4CqgK3A3Eicq2qnpTmyMdcYBtwP06eP6t/lwGX4LxWf+ZS9ybgIZxgvBQ4BjRy2+oqIper6i532ynubW9gEcffE9z9+7oF50t9JvAOUCe3zqvqVhG5H/gC+ExEWqtqhrv6baA+MFJVF+XWhvEgVbWlAAswD1Dg/kLWa+HW2wHU8CkPAb5x1w3NUWebWz4DKO9THgUcdJcyOeosdN7Ok/Zfx21rfC79O6ke8DsQD1Tws311P33dlqNsiE//Q3L0P+u5XeWnjwqMyNFWh6y2CvGaZ+0jBBju3m/hs/4dIBM4FycIK07w822jFlDWT9vXu3XH5Chv668dn/X3uOv/BGJz2UaBhX7K33bXveA+7uU+XgAElfb/DVtKdrH0SMHVdG/jC1nvPvf2eVXdm1WozohpAM5/4vtzqfuoqv7hUycRiAMigAsL2Y/CSscJTidQ1X0FqHsfTlB5Qo+PDLP6/5z70N9z3g48n2N/s3G+8JoVrNsneR/neTwATloBuBOYrao7cqukqrs0xy8mt3wOsA7ny6Qo4lTVb0omD08APwODRORvOEE8CbhLVXP7pWA8yoJ2wWXlkQt7LdtL3dv5OVeo6v9wvgTqikjlHKuTVXWLn/Z2urdVCtmPwvgEZ/S7TkRecHOwEQWpKCKVgAuA3er/wFrW63CJn3U/qepJXxQ4z7lIz1edA7MzgNvcGSM9gEo4+e5cuXn9niLyrZvTzvA5VtAEZyReFCsLW0FVj+KkiQ4Db+GkmnppCR90NmcGC9oFl/UfJCbPrU6WFez25LJ+T47tshzMZfuskWtwIftRGP2Bx3GCxGCc/Os+EYkTkQvyqVvQ55vzSwryfs6n8lkdB1QE7sAZce/FSU3l5TWcvHpDnPz8P3By4M/g/CIILWJf9ua/iV//A35x76/HOd5hzkIWtAvuO/e2sPOSk93bGrmsr5lju+KW9fM5t4POJwVPVc1U1TdUtSnO/PObcabG3QDM8jfjxUdpP19/ZgC7cPLbVwIf+KZtchKRKOBRYC1woar2VNVBqjpSVUcCJ6VNCqGof3VkMHAVzsHsRjjHDcxZyIJ2wX2Ak+e9WUQa5rVhjqD2o3vb1s92F+CM3Leqam6jzFN1wL2t7Wf/4cBf8qqsqomqOllVb8NJbfwf0DiP7VOBX4FaIlLPzyZZZyj+UIC+Fws35fI+zmutwHv5VDkf5//GHPf5ZHOn+53vp05WWqfYfwGJyFXAs8AmnNd+E/CMiLQq7n2ZM58F7QJS1W0487RDgeki4veMRxHJms6V5X33driIRPpsFwy8ivMe5BdEiswNOhuBlr5fNu7+XwPK+27vzq9u7zsX3C0vgzMFD/I/a+99nGMAr7j7yWqjOvB3n21K0ps4J9F00PxPCNrm3rbK0f8wnFSLv18tWSfvnHuK/TyBiFQBPsP5Uuihqgk4+e0MnGmA1Ypzf+bMZ/O0C0FVR4tICM5p7KtEZCmwmuOnsbcG6rllWXWWisjLwEBgrYh8iZMr7ogzavoOeOU0d/0VnC+GJSLyBc71Sa7BmQv+M9DUZ9vywLfANhFZgZO/LQdch3Oa9VRV3ZDP/l7FeX7dgJ9FZAbOwbNbcab9vayq3+VRv9i5s16m5Luhs+1eEZmIc9DyJxGZg5Orvw7ntfsJuDhHtU04KZgeInIMZ8aLAh+p6vZT6Pr7OF8Ej6rqT27/fhaRAcC/cH4B3nAK7ZtAU9pzDgNxwQleb+HkPFNwTrzYgzPC7oP/+b09cAJ0Ks5//HXAMKCcn223kWPus8+6kTjBoG2O8oX4mafts76Pu880nINh/wGq5ayHE8gHus9lh9vXJJzrrDwEhBakrziBfqj7Gv3hPu/vgDv8bFuHQs4lz+f92ea2F1KAbXObp10B5ySjLe5rsBPnJKGTXjOfOlfgzOdPxjmWkP0+cXye9j159OWEedrAI25ZXC7bT3bX9y/t/xO2lNwi7ptvjDEmAFhO2xhjAogFbWOMCSAWtI0xJhci8r6IJIrIWp+yV0Rko3sFy699z2YW58qdW0Rkk4h08Cm/TJwre24RkTezZme5s7U+d8tXiHM10TxZ0DbGmNyN5+RLLc8FGqvqRThnqg4BcKfU9sA5+SkWeNtnyugYoC/O7LJ6Pm32AQ6o6gXA68BL+XXotE/5aytP25FOc5JpKcNKuwvmDBRWqazkv1XeChNzFuqzee5PVRfnHP2qc9GwLMtxLrcLzhTXiepcaGyriGwBmolzvflwVV0GICIf4lxmeaZbZ6Rb/0vgXyIimscMERtpG2POWiLSV5w/dJG19C1kE/dx/GS6Why/oBs4F4Or5S7xfspPqKPOpRWScaaV5spOrjHGeEqOk3nzpH/qWGBsEfczDOfM1E+yivztIo/yvOrkyoK2McZTJPiUMyz570OkN84f027vk8qI58Rr/MTgXB00nhOvDppV7lsn3j3bOgLYn9e+LT1ijPEUkYIvRWtfYoFBwA2q6nsdnqk4lzEoKyJ1cQ44rlTVPUCqiDR3Z430wvljJll1erv3bwHm55XPBhtpG2O8pqjR2G9T8hnOFTqri0g8znWHhuD8wei5bipmuao+pKrrRGQSzvXOM4CH9fgf9eiHMxOlPE4OPCsP/h7wkXvQcj/O7JM8WdA2xnhKMcZsVPUOP8W5XpVTVUfhXLMmZ/lq/FzSWJ2/SnRrYfpkQdsY4ykSdPpz2qXJgrYxxluKc6h9BrKgbYzxlCAbaRtjTADxdsy2oG2M8RbLaRtjTADxeErbgrYxxmM8HrUtaBtjPCWoBE5jL00WtI0x3mIjbWOMCRwej9kWtI0x3lKYS7MGIgvaxhhv8XbMtqBtjPEWm6dtjDEBxIK2McYEEMtpG2NMIPH43+OyoG2M8RQbaRtjTADxeMy2oG2M8RY7EGmMMQHEgrYxxgQSj+dHLGgbYzzF4zHbgrYxxlts9ogxxgQSm6dtjDGBIyjI21HbgrYxxlPE2zHbgrYxxmMsp22MMYHD4zHbgrYxxlvs5BpjjAkkHh9qW9A2xnhKULAFbWOMCRw20jbGmMDh8Zjt9XOHjDFnGwmSAi/5tiXyvogkishan7KqIjJXRDa7t1V81g0RkS0isklEOviUXyYia9x1b4p7rr2IlBWRz93yFSJSJ78+WdA2xniLFGLJ33ggNkfZYGCeqtYD5rmPEZGGQA+gkVvnbREJduuMAfoC9dwlq80+wAFVvQB4HXgpvw5Z0DbGeEpQcFCBl/yo6mJgf47ibsAE9/4EoLtP+URVTVPVrcAWoJmI1ATCVXWZqirwYY46WW19CbSXfK54ZUHbGOMpIoVZpK+IrPZZ+hZgF9GqugfAvY1yy2sBO322i3fLarn3c5afUEdVM4BkoFpeO7cDkcYYbynEkUhVHQuMLa49+9tFHuV51cmVjbSNMZ5SnAcic5HgpjxwbxPd8nigts92McButzzGT/kJdUQkBIjg5HTMCSxoG2M8pTDpkSKaCvR27/cG4nzKe7gzQuriHHBc6aZQUkWkuZuv7pWjTlZbtwDz3bx3riw9YozxlmKcqC0inwFtgeoiEg+MAF4EJolIH2AHcCuAqq4TkUnAeiADeFhVM92m+uHMRCkPzHQXgPeAj0RkC84Iu0d+fbKgbYzxlOI8jV1V78hlVftcth8FjPJTvhpo7Kf8KG7QLygL2sYYb/H4KZEWtI0xnuLxmO39oD3wve606PIXDiYe5t4m/wbgoZev56quF5J+LJPdv+7npXuncCj5KAB3Dr6azn0uJTNTeevRGayaswWAl2feTdWalQgOCWLNf7fzz4en8eefSlTtCIZMuImwyuUIChbGDp7LipmbT+rHXy6tyeDxN1G2fAjLZ2zmrcdmAFAmNJghH97EhZedQ/Lvf/Ds7ZPYu/0gAB16Xczdw9sA8NHzi5j94U8A1KhTmacn3kZ41fL874fdjL57MhnpTurskTc60bxTPY4eSefFe75m8497AGjW4QL+9kYngoOF6e/+wKcv/fd0veQBZe/evTw9Yhi//76PoKAgbrzxZu68oyf/+c/bfD1lMlWqOGcoP/zXR2nV6mrSM9J57rmRbNy4gczMTDp37sp9995/Qpv9+z/Crl3xTJr0td99vv/Bu8TFfU1wUBBPPjWYq1q0BGDDhvWMGDmctLQ0Wra8mqeeHISIcOzYMZ4eMYwNG9YTERHBiy+8wjnnONN8v5kWx3vvjQOgT58H6NqlGwC7dsUzZOhAUlJSqF+/Ac89O5oyZcqgqrzy6kssWfJfypUrx8iRz9GgfsPT8tqWFq9fT9vzs0dmjf+RgbEfnVC2eu6v3Nv43/Rp+jY7//c7dw65GoDzGkTSrkcT7mn0LwbGfsjjb3chyP0AjLxtEvdf/Db3Nv4XEZEVaHtrIwDuHt6GBZPW8sClY3i2xxf0f7uL3370H9OVV/tO5a56bxBTrxrNYusB0KnPpRw6cJS76r3Bl68vpe9L1wFQqUp5eo9oS78rx/JQs//Qe0RbwiqXA+DBl67ny9eX0vMvb3DowFE69bkUgCs71iOmXjXuqvcG/+g7lf5jugIQFCQ89u8uDOr4Eb0b/ot2dzThvAaRxfkyB6zgkGD69x/AV1/GMf6Dj/nii8/57bdfAbjzzp589ukXfPbpF7Rq5XxGvv12DunH0pn0+WQ+/ngikyd/ye7du7Lbmz//W8pXqJDr/n777VfmzJnFF5O+5q23xvDii6PIzHS+cF944XmGDxvBlK+nsXPndpYu/Q6AKXGTCa8UTtyU6dx15928+dY/AUhOTmbcuHeYMP4TPpzwKePGvUNKSgoAb771T+66826mfD2N8ErhTImbDMCSJd+xc+d2pnw9jeHDnuaFF54v5lf0DFAC00dKU75BW0Tqi8gg9yInb7j3G5RE54rDL//dTur+P04oWz33VzIz/wRg/fJ4ImPCAWjZrT7zJ64h/Vgme7cdZNeW/dRv5kyvPJKaBkBwSBBlQkPImpSjqlQMLwtAxYhy7NudelIfqtYIo2J4WdYvd06Wmv3hT7TqXt/dZwNmTXBG0Iu+XM9l7c8H4IoOF7B67q+kHviDQwePsnrur9mB/tJ2dVn05XoAZk34iVbdG2T3P2s0vn5FPGGVy1G1Rhj1m8Wwa8t+9mw9QEZ6JvMnrqFlt/qn9Lp6RWT1yOyRZsWKFalbpy6JiYm5bi8Ifxw9QkZGBmlH0yhTpgwVK4YBcOTIET7+5CPu75P7SXULFy3g+utjCQ0NpVatGGrXPpd169aStC+JQ4cPcdFFTREROnfqysKFCwBYtGghXbrcAED79texcuUKVJVly5ZwZbMWREREEB4ezpXNWrB06XeoKqtWraR9e2cA0KXLDT5tLaBzp66ICE2aNOVQaipJ+5JO/YU8g3g8ZucdtEVkEDAR56ydlcAq9/5nIjL49Hfv9Ot036WsdNMZkbXCSdqZnL0uKT6ZyFqVsh+/PKsXUxIHcSQ1jUVfrgNg/MgFXNezKV/sHMBLM3ry5iPTT9pHZK1wkuJTfNpNIbJWuLuuUvY+MzP/5FByGhHVKrh9OblORLUKHDp4NPtLx7ePJ/ffqeO7j5z7N8ft3r2LjZs20rhxEwAmTZrI7T1u5plnns4ewba/9jrKl6tAh9j2dO5yPXf37E1ERAQAY8b8i549e1GuXLlc95GUmEiN6BrZj6OjoklMTCApMZHo6Ojj5dHRJCYlunUSsteFhIQQFhbGweSDJCYlEu3TVpRb52DyQSpVqkRIiJP9jIqKJikxAcCpU+PEOkl5fEkFIgkOKvASiPLrdR/gClV9UVU/dpcXgWbuOr98z+ffzQ/F2d9i1XNoazIzMpn7yS9OgZ9vXt9p7gNjP+Tmmq9Qpmwwl7RzRsTt77iIWeN/5Nba/2BQp48Z+tHNnHS9l7za9fN1r6q51MmtPL+2cik32Y4cOcJTA5/gyQEDCQsL45ZbbiduynQ++/QLqlevzuuvvwrAurVrCQoOYtasb/lm6kw+/ngC8fHxbNq0kZ3xO2h3jd+ZYNnUzxnKIuL3/ch62/y9U4Kc+OH0actfeVZj/vcToEPOXJzVI23gT+AcP+U13XV+qepYVb1cVS8/h0tPpX+nTYdeF9Oiy4U8f9dX2WVJ8SlE1o7IfhwZE3FSuuNYWgZLp26ilZte6NTnUhZMci61u375TkLLhRBR/cScZlJ8SnYKxmk3nH27U07aZ3BwEGERZUnZ/4dbnrNOKsn7jhBWuRzB7ijBt49J8ck5+u/UOfl5hftN45yt0jPSeWrgE3SM7Uy7dtcCUK1aNYKDg7MPTq5btwaAWbNncFWLlpQJKUPVqtVo2vQS1m9Yxy9rfmbDhg106RpLn/t7s33Hdvr2ve+kfUVFRbM3YW/244TEBCIjo4iKjiYhIeF4eUICkdWjsutkrcvIyODQoUNERES45cfbSkxIILJ6JJUrVyE1NZWMjAyn3N0HOCP7hL0n1qke6a3jGyVwGnupyi9oPw7ME5GZIjLWXWbhXEP2sdPfvdOjWYcLuGNQK4be8Alpf6Rnly+dupF2PZpQJjSYGnUqE1OvKhtXxlO+YihVazh5y+DgIK7sVI8dG508YOKO5Ow89Ln1qxNaLoSDSYdP2N/+vYc4knqMhlc6+fEOvS5mSdzG7H3G9r4YgDa3NOSH+VsBWDV7C1dcfwFhlcsRVrkcV1x/AatmOzNZflywlTa3OHnY2N4XsyRug9vWJjr0ctpqeGUMh5OPsn/vITat2kVMvarUqFOZkDLBtOvRhKVTNxbzqxqYVJXnnh1B3bp16dmzV3a5b553wYL5/N//OccTakTXZNXqlagqf/xxhDVrf6FunbrcesvtzJ41j2nfzOK9dydw3rnnMXbs+yftr03rtsyZM4tjx46xa1c8O3dup1GjxkRWj6RixYqsWfMzqsr0Gd/Qps012XWmTZsKwLx5c7niimaICC1atGT5iqWkpKSQkpLC8hVLadGiJSLC5Zdfwbx5cwGYNm0qbdq0BaB1m7ZMn/ENqsqaNT8TFlaJyOoeC9oiBV4CkeT3M1lEgnDSIbVwfpzHA6t8Ts/MU1t5ulR/h//901u4uG1dIqpX4EDCIT4YsYC7hlxNmbIhpPx+BHAORr7W7xvASZl0vO9SMjP+5F+Pz2TlrM1UiarIC9N6UqZsMEHBQfw4/zf+3X8WmZl/cl6DSJ4c143yYaGgyjsD57B6rjP74N0f+3H/JWMAuPCycxg8/kZCy5dh5czNvOHmvkPLhjD0o5uod0lNUvb/wbM9vmDP1gMAdLz3EnoObQ3AR6MWM2v8jwDUrFuFpyfeSnjV8mz+cQ+jen5F+jHn7XjsX51pFluPtCPpvHTv12z63rkuzZUd6/G3f3YkKDiIme//wMejF5fEy5+raSnDSnX/WX786Qfuv/8eLrigHkFBzhjm4b8+yuzZM9n0v42ICOfUPIehw54msnokR44cYeQzf2fr1t9QVW7o2o1eve49oc3du3fx+ON/y57yt2jRAtZvWE+/hx4G4L33xhI3dQohwcEMGDCQli2dmSnr169j5MjhHE1Lo+VVrRg4cAgiQlpaGn9/eiibNm0kIjyC0aNfJibGGQDExX3N+x+8C0Cf+x7ghhucyzTHx8czdOhAklOSufDC+jz/3AuEhoaiqrz08miWLl3iTPkb8RwNGzY6/S90AYVVKnvKkfSR2z4tcMx5a9KdARe58w3ap6q0g7Y5M50pQducWYojaD92x8QCx5w3PusRcEHb8yfXGGPOMgGaqy4oC9rGGE8J0FR1gVnQNsZ4SqAeYCwoC9rGGG+x9IgxxgQOjw+0LWgbY7wlUE9PLygL2sYYT7GctjHGBBDx9kDbgrYxxltspG2MMYHEgrYxxgQOS48YY0wAsdkjxhgTQCynbYwxAcTjMduCtjHGY+w0dmOMCRyWHjHGmAAiwRa0jTEmYNhI2xhjAkig/pX1grKgbYzxFm/HbAvaxhhvsfSIMcYEEK+nR7x9vqcx5qwjQVLgJd+2RPqLyDoRWSsin4lIORGpKiJzRWSze1vFZ/shIrJFRDaJSAef8stEZI277k05hZ8DFrSNMZ4iIgVe8mmnFvAocLmqNgaCgR7AYGCeqtYD5rmPEZGG7vpGQCzwtogEu82NAfoC9dwltqjPz4K2McZTRAq+FEAIUF5EQoAKwG6gGzDBXT8B6O7e7wZMVNU0Vd0KbAGaiUhNIFxVl6mqAh/61Ck0C9rGGE8prqCtqruAV4EdwB4gWVXnANGqusfdZg8Q5VapBez0aSLeLavl3s9ZXiQWtI0xnlKY9IiI9BWR1T5LX592quCMnusC5wAVRaRnXrv2U6Z5lBeJzR4xxnhKUCFmj6jqWGBsLquvBbaqahKAiEwGrgISRKSmqu5xUx+J7vbxQG2f+jE46ZR4937O8iKxkbYxxlOKMae9A2guIhXc2R7tgQ3AVKC3u01vIM69PxXoISJlRaQuzgHHlW4KJVVEmrvt9PKpU2g20jbGeEpxnVyjqitE5EvgByAD+BFnVB4GTBKRPjiB/VZ3+3UiMglY727/sKpmus31A8YD5YGZ7lIkFrSNMZ5SnCdEquoIYESO4jScUbe/7UcBo/yUrwYaF0efLGgbYzxFPH7xEQvaxhhP8filRyxoG2O8pTCzRwKRBW1jjKfYSNsYYwKJx6O2BW1jjKd4PGZb0DbGeIv9EQRjjAkgHo/ZFrSNMd5is0eMMSaAeDtkW9A2xniM5bSNMSaAeDxmW9A2xniLjbSNMSaA2IFIY4wJIB4faFvQNsZ4iwVtY4wJIJbTNsaYAOLxmH36g/a89JGnexcmAB0+lFbaXTAeZSNtY4wJIGKzR4wxJnDYSNsYYwKIx2O2BW1jjLfYSNsYYwKIx2O2BW1jjLfYSNsYYwKIXXvEGGMCiI20jTEmgNg8bWOMCSAeH2hb0DbGeIulR4wxJoDYgUhjjAkgNtI2xpgA4vGYbUHbGOMxHo/aQaXdAWOMKU4iUuClAG1VFpEvRWSjiGwQkRYiUlVE5orIZve2is/2Q0Rki4hsEpEOPuWXicgad92bcgo5HAvaxhhPESn4UgBvALNUtT7QFNgADAbmqWo9YJ77GBFpCPQAGgGxwNsiEuy2MwboC9Rzl9iiPj8L2sYYTwkKlgIveRGRcKA18B6Aqh5T1YNAN2CCu9kEoLt7vxswUVXTVHUrsAVoJiI1gXBVXaaqCnzoU6fwz6+oFY0x5kxUmPSIiPQVkdU+S1+fps4HkoAPRORHEXlXRCoC0aq6B8C9jXK3rwXs9Kkf75bVcu/nLC8SOxBpjPGUwqSLVXUsMDaX1SHApcAjqrpCRN7ATYXktmt/u8ijvEhspG2M8ZRizGnHA/GqusJ9/CVOEE9wUx64t4k+29f2qR8D7HbLY/yUF4kFbWOMpxTX7BFV3QvsFJEL3aL2wHpgKtDbLesNxLn3pwI9RKSsiNTFOeC40k2hpIpIc3fWSC+fOoVm6RFjjKcU8xmRjwCfiEgo8BtwL85gd5KI9AF2ALcCqOo6EZmEE9gzgIdVNdNtpx8wHigPzHSXIhHnYObpk5nx5+ndgQlIhw+llXYXzBkovHL5U464c+ZsLnDMuf76egF3Jo6NtI0xnmLXHjHGmADi8ZhtQdsY4y32l2uMMSaA2EjbGGMCiOW0jTEmgFjQNsaYAOLxmG1B2xjjLTbSNsaYAOLxmG1B2xjjLTbSNsaYABJk87SNMSZweHygbUHbGOMtFrSNMSaAiN8/FOMdFrSNMZ5iI21jjAkgdiDSGGMCiE35M8aYAOLxmG1B2xjjLTbSNsaYQOLtmG1B2xjjLTbSNsaYAGKzR4wxJoB4O2Rb0DbGeIylR4wxJoB4PGafXUF72PBhLFq0kKpVqzI17hsAnhjQn61btwGQmppCpUrhfD35a5YuXcJrr79Geno6ZcqU4ckBT9G8eXMOHz5Mz7t7ZreZkLCXrl26Mgc69AIAABAtSURBVGTI0JP2N3bcWL766iuCg4MYOmQYrVq1AmDdunUMHTaEo0fTaN26NUOHDEVEOHbsGIOHDGLduvVUrlyZ1/7xGrVq1QJgypQpvPOfMQA89GA/unfvDkB8fDwDnhxAcvJBGjZsyIsvvERoaCiqyugXRrN48WLKly/H6FGjadiw0Wl7bQPV3oS9jBw5nN/3/46IcGP3m7mjx11s+t9GXnxxFGnH0ggJDmHQwCE0atSE3bt3cVuPmzj33PMAaNL4IoYMHg7A22PeYvqMaaSmprB44bJc9/nB+PeY+s0UgoKCeHLAIFo0vwqADRvW88xzT5OWlkbLq1ox4ImB2Z+LEc8MZ+PGDURERDD6+Zc45xznczFt+lTef38cAPfd9wBdOt8AwK7duxg2fBApyclcWL8Bz44cRZkyZVBV/vHayyxZ+h3lypVjxN+fpX79Bqft9S0NXh9po6qndclIz9QzZVm+bLn+8vMv2qlTJ7/rR40arW++8aZmpGfqL7+s0d279mhGeqZuWL9BW7Vq5bdO9+7ddfmy5SeVb9ywSbt26apHDv+h27Zu1/bt22va0WOakZ6pN990s65etVrTj2Xofff10fnzF2hGeqZ+9OFHOnz43zUjPVOnxk3VRx99VDPSM3Vf0u/arl073Zf0u/6+b7+2a9dOf9+3XzPSM/WRRx7VqXFTNSM9U4cP/7t+/NHHmpGeqfPmzdf77uuj6ccy9PvV3+vNN99S6q+/75J84MgZsfy6ebuuWPa9Jh84orvjk/Ta9tfqj9+v0bt79tIZ0+do8oEjOmPabO3R4w5NPnBEN6zbrLGxHf229d3i5frr5u3atGnTXPf34/drtHOnLpqUcFDXr9us11zTTvfvS9XkA0e0e/cb9b+Ll+nB/Ye1d+97s/f/7rgPdPCgoZp84Ih+8flk/etf/6bJB47ojm17tG3ba3THtj26c/tebdv2Gt25fa8mHziif+33sH7x+WRNPnBEBw8aqu+9Oz77ufTufa8e3H9Yv1u8XG+88aZSfw98l+KIOevXJ2hBl9Md/07HElTaXxol6fLLryAiorLfdarK7Nmz6NS5MwANGzQkKioKgAsuqEdaWhrHjh07oc627dvYv38/l112+UntzV8wn46dOhEaGkpMTAzn1j6XNWt+ISkpkUOHD3HxxZcgInS7oRvz5s1z6syfT/du3QC4/voOLF++HFVlyZIltGhxFZUrVyYiIoIWLa7iu+++Q1VZsWI511/fAYDu3U5sq9sN3RARmja9mNTUFJKSEovhVfSW6tUjs0eaFStWpE6d80lKSkREOHz4MACHDh0isnpkvm01aXIR1fPZbtHihVx3XQdCQ0OpdU4tasfUZt36tezbl8Thw4e5qElTRITOHbuwaNECABYvXkjnzl0BaNfuWlatWomqsnz5Uq5s1pyIiAjCw8O5sllzli1bgqqyavUq2rW7FoDOnbtmt7Vo8UI6d+yCiNCkyUWkpqayb19S0V68M1RQkBR4CURnVXokL99/v5pq1apR57w6J62bM2cODRo0IDQ09ITyGdOnExvb0e/PscSEBC5q2jT7cXSNaBISEgkJKUN0dPQJ5YmJCQAkJCZQo0ZNAEJCQqhUqRIHDx4kITGBmjVqZNepER1NQmICBw8epFKlcEJCnLcxOroGCW5biYkJ1PCpEx1dg4SERCIjowr70pw1du/exab/baRRoyY80f8pHnnsr7zx5muo/sl74yacsN1dd99OxYph9HvwYS655NIC7yMpKZHGjS/KfhwVFU1SYiIhISFERUWfWO5+ySYmJRId5byXISEhhIWFkZx80CmPrnFCncSkRJKTD1KpUqXsz0VWedb+/dXJ78smkHg9O1LkkbaI3JvHur4islpEVo8bN7aouyhR02dMp1OnzieVb96ymdde/wcjRzxz0roZM2fS2U8dcEbuOYmI/3J3kpL/OoVsS/Jqy+Of5lNw5MgRBg1+kif6P0VYWBhfTf6CJx5/kunfzKb/40/y3Cjn/a9ePZJvps7ik48+p/9jAxj+9BAOHTpU4P0U5r0kj/fS/WAUuK08PxcemyQnIgVeAtGppEdOjmIuVR2rqper6uUPPND3FHZRMjIyMvj222/pGNvxhPK9e/fy6KOP8MLoFzn33HNPWLdx40YyMzNo1Mj/wb3oGjXYu3dv9uOEvQlERUVSo0Y0CQkJJ5RHummYGtE12Lt3T3afUlNTiYioTI3oGuzxaWtvQgJRkVFUqVKF1NQUMjIynLYS9hLljqSjo3PsP2EvUVHeGU0Vp4yMdAYNHkBsbCfaXdMegGnTv+Ea9/617a9n/bq1AISGhlLZTbE1aNCQmJgYduzcXuB9RUVFk5Bw/H1JTEygemQk0VHHf3FllWelZKKjoklI3Ov2NYNDhw4RER7ht63I6pFUrlyF1NTU7M+Fb1t+60Ta5yKQ5Bm0ReSXXJY1QHRedQPJsmXLqFu37gnphJSUFPr1e4j+jz/BpZee/PN3Ri4j8yzXXHMNM2fM4NixY8THx7N9x3aaNLmIyMgoKlaoyM8//4SqEjc1jnbt2mXXmRIXB8CcObO58srmiAgtW7Zk6dIlJCcnk5yczNKlS2jZsiUiQrNmVzJnzmwApsQdb6vdNdcQNzUOVeXnn3+iUlglS434oao89/wz1KlTl7vuvDu7PDIykh9+WA3AqtUrqV3b+dI+cGA/mZmZAMTvimfnzh3UOiemwPtr3boNc+fO5tixY+zavYsdO3fQqGFjqlePpEKFCqxZ8wuqyvSZ02jTui0AV1/dhunTndlO8+d/yxWXX4GI0Lz5VaxYsYyUlBRSUlJYsWIZzZtfhYhw+WWXM3/+twBMn/4Nrd22Wl/dhukzp6GqrFnzC2FhYZ5KjYD3R9ri96dX1kqRBKADcCDnKmCpqp6T3w4yM/7MfQcl7MknB7By1UoOHjxItWrV+NvDf+Pmm29h6NAhXNS0KT1u75G97TvvjGHcu+Oyp3YBvDvuXapVqwbA9R2u450x/+H888/PXj9//nzWrVvLI4886rTxn3f4+uvJBAcHM3jwEFpf3RqAtWvXMnTYENLS0ri61dUMGzYcESEtLY1BgwexYcMGKkdE8Oqr/6B27doAfDX5K8aOdVJNDz74IDfdeBMAO3fu5MknB3AwOZkGDRrw8ksvZ0/5e/755/huiTO1a9Tzo2ncuPFpfHUL5/ChtNLuAgA//fQjDzx4LxdcUC/7P/HD/R6hYsUw/vHay2RmZhJaNpRBTw2lQYOGzJ//Le+MfZuQ4BCCgoPo+0A/Wl/dBoA333qd2bNnkrQvicjqkXTrdiN9H+jHosUL2bBhPQ89+FcA3v9gHFO/iSM4OJgn+j9Fy6ucqaDrN6zjmWedKX9XtWjJU08Ozv5cjBg5jE3/20R4eDijnn+JmFrOF8XUqVP4YMJ7ANx7Tx9u6OpOBd0V70z5S0nhwr9cyLPPjM7+XLz8ygssW76UcuXK8fTfn6FhgzNnKmh45fKnHEl//fX3Asec//u/agEXufML2u8BH6jqd37Wfaqqd+a3gzMpaJszx5kStM2ZpTiC9m+/FTxon39+/kFbRIKB1cAuVe0iIlWBz4E6wDbgNlU94G47BOgDZAKPqupst/wyYDxQHpgBPKZ5Bd885JkeUdU+/gK2uy7fgG2MMSVNCvGvgB4DNvg8HgzMU9V6wDz3MSLSEOgBNAJigbfdgA8wBugL1HOX2KI+v7NqnrYx5iwghVjya0okBugMvOtT3A3ImgM6AejuUz5RVdNUdSuwBWgmIjWBcFVd5o6uP/SpU2gWtI0xniJSmOX49GR3yTnd7Z/AQOBPn7JoVd0D4N5mHeGvBez02S7eLavl3s9ZXiR2co0xxlMKM+9cVccCfk8mEZEuQKKqfi8ibQu0az+7yKO8SCxoG2M8pRhn8rUEbhCRTkA5IFxEPgYSRKSmqu5xUx9Z14eIB2r71I8BdrvlMX7Ki8TSI8YYTymuedqqOkRVY1S1Ds4Bxvmq2hOYCvR2N+sNxLn3pwI9RKSsiNTFOeC40k2hpIpIc3F22sunTqHZSNsY4y2nf+b1i8AkEekD7ABuBVDVdSIyCVgPZAAPq2qmW6cfx6f8zXSXIslznnZxsHnaxh+bp238KY552vE7DxY45sTUrhxwJ9fYSNsY4ymBenp6QVlO2xhjAoiNtI0xnhKof9ygoGykbYwxAcRG2sYYT/F4StuCtjHGW7z2l3hysqBtjPEWb8dsC9rGGG/x+HFIC9rGGI/xeFLbgrYxxlO8HbItaBtjPMbjA20L2sYYj/F41LagbYzxFG+HbAvaxhiP8foFoyxoG2M8xeMx2649YowxgcRG2sYYT/H6SNuCtjHGY7wdtS1oG2M8xUbaxhgTSCxoG2NM4PD6pVlt9ogxxgQQG2kbYzzF6zltG2kbY0wAsZG2McZT7DR2Y4wJJN6O2Ra0jTHe4vGYbUHbGOMxHk+P2IFIY4wJIDbSNsZ4irfH2Ra0jTEeY7NHjDEmkHg7ZlvQNsZ4i8djth2INMZ4jBRiyasZkdoiskBENojIOhF5zC2vKiJzRWSze1vFp84QEdkiIptEpINP+WUissZd96acQg7HgrYxxmOKKWpDBjBAVRsAzYGHRaQhMBiYp6r1gHnuY9x1PYBGQCzwtogEu22NAfoC9dwltqjPzoK2McZTiitkq+oeVf3BvZ8KbABqAd2ACe5mE4Du7v1uwERVTVPVrcAWoJmI1ATCVXWZqirwoU+dQrOgbYzxFJHCLNJXRFb7LH39tyl1gEuAFUC0qu4BJ7ADUe5mtYCdPtXi3bJa7v2c5UViByKNMd5SiHSxqo4FxubdnIQBXwGPq2pKHulofys0j/IisZG2McbkQkTK4ATsT1R1sluc4KY8cG8T3fJ4oLZP9Rhgt1se46e8SCxoG2M8pTDpkbzbEQHeAzao6ms+q6YCvd37vYE4n/IeIlJWROriHHBc6aZQUkWkudtmL586hWbpEWOM8a8lcDewRkR+csuGAi8Ck0SkD7ADuBVAVdeJyCRgPc7Mk4dVNdOt1w8YD5QHZrpLkYhzMPP0ycz48/TuwASkw4fSSrsL5gwUXrn8KZ8bU5iYExwSFHDn4pz2oG2OE5G+7oEPY7LZ58IUhuW0S5bf6UTmrGefC1NgFrSNMSaAWNA2xpgAYkG7ZFne0vhjnwtTYHYg0hhjAoiNtI0xJoBY0DbGmABiQbuEiEise2H0LSIyuLT7Y0qfiLwvIokisra0+2IChwXtEuBeCP3fQEegIXCHe8F0c3YbzylcDN+cnSxol4xmwBZV/U1VjwETcS6Ybs5iqroY2F/a/TCBxYJ2ycjt4ujGGFMoFrRLRrFeBN0Yc/ayoF0ycrs4ujHGFIoF7ZKxCqgnInVFJBTnLzZPLeU+GWMCkAXtEqCqGcDfgNk4f9F5kqquK91emdImIp8By4ALRSTevai+MXmy09iNMSaA2EjbGGMCiAVtY4wJIBa0jTEmgFjQNsaYAGJB2xhjAogFbWOMCSAWtI0xJoD8Px4ZOOHKTyysAAAAAElFTkSuQmCC\n",
"text/plain": [
""
]
},
"metadata": {
"needs_background": "light"
},
"output_type": "display_data"
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"-----------------------------------------\n"
]
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAYoAAAEWCAYAAAB42tAoAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADt0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjByYzEsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy/xvVyzAAAgAElEQVR4nO3dd5gUVdbA4d+RDCIoIEoSVERAkgxJBVFWRRxEV8WwBlz9EANm1xxWdNddw4IREV2MoGIEVFCRIIgIokgWkTCCSpYgwgzn++PUMM3sTE8zTHd195z3efphurq66nQNU6fr1r3niqrinHPOFWafsANwzjmX3DxROOeci8oThXPOuag8UTjnnIvKE4VzzrmoPFE455yLyhOF2yMiMldEuoYdR7IQkTtEZGhI+x4mIg+Ese+SJiJ/EZFxxXyv/5+MM08UKUxElorI7yKyWUR+Dk4c+8Zzn6raXFUnxHMfuUSkgoj8U0SWB5/zexG5RUQkEfsvIJ6uIpIVuUxV/6Gql8dpfyIi14rIHBHZIiJZIvKmiLSIx/6KS0TuE5FX9mYbqvqqqp4cw77+Jzkm8v9kaeWJIvX1VNV9gdZAG+D2kOPZYyJStpCX3gS6AT2AqsBFQF9gUBxiEBFJtr+HQcB1wLXAAcARwLvAaSW9oyi/g7gLc98uRqrqjxR9AEuBP0U8/zcwJuJ5R2AqsAH4Fuga8doBwH+BlcB64N2I1zKBb4L3TQVa5t8nUAf4HTgg4rU2wBqgXPD8r8D8YPtjgUMi1lXgauB74McCPls3YBtQP9/yDkAOcHjwfALwT2A6sBF4L19M0Y7BBOBBYErwWQ4HLg1i3gQsAa4I1q0SrLMT2Bw86gD3Aa8E6zQMPtclwPLgWNwZsb9KwIvB8ZgP/A3IKuR32zj4nO2j/P6HAU8BY4J4vwQOi3h9ELAC+A2YCXSOeO0+YCTwSvD65UB74IvgWK0CngTKR7ynOfAxsA74BbgD6A5sB3YEx+TbYN1qwPPBdn4CHgDKBK/1CY75f4JtPRAs+zx4XYLXfg1+p7OBo7AvCTuC/W0GRuX/OwDKBHH9EByTmeT7P+SPYpxrwg7AH3vxy9v9D6Qe8B0wKHheF1iLfRvfBzgpeF4reH0M8DqwP1AOOD5YfnTwB9oh+KO7JNhPhQL2OR74v4h4HgYGBz+fASwGmgJlgbuAqRHranDSOQCoVMBnewiYWMjnXkbeCXxCcCI6CjuZv0XeibuoYzABO6E3D2Ish31bPyw4WR0PbAWODtbvSr4TOwUniuewpNAK+ANoGvmZgmNeLzgBFpYo+gHLivj9D8NOtO2D+F8FRkS8fiFQI3jtJuBnoGJE3DuC39M+QbxtscRaNvgs84Hrg/WrYif9m4CKwfMO+Y9BxL7fBZ4NficHYok893fWB8gG+gf7qsTuieIU7ARfPfg9NAUOjvjMD0T5O7gF+ztoEry3FVAj7L/VVH+EHoA/9uKXZ38gm7FvTgp8ClQPXrsVeDnf+mOxE//B2Dfj/QvY5jPAgHzLFpKXSCL/KC8Hxgc/C/bttUvw/EPgsoht7IOddA8JnitwYpTPNjTypJfvtWkE39Sxk/1DEa81w75xlol2DCLee38Rx/hd4Lrg567ElijqRbw+HTgv+HkJcErEa5fn317Ea3cC04qIbRgwNOJ5D2BBlPXXA60i4p5UxPavB94Jfj4fmFXIeruOQfC8NpYgK0UsOx/4LPi5D7A83zb6kJcoTgQWYUlrnwI+c7REsRDoFY+/t9L8SLY2WbfnzlDVqthJ7EigZrD8EOAcEdmQ+wCOw5JEfWCdqq4vYHuHADfle199rJklv5FAJxGpA3TBTpKTI7YzKGIb67BkUjfi/SuifK41QawFOTh4vaDtLMOuDGoS/RgUGIOInCoi00RkXbB+D/KOaax+jvh5K5DbwaBOvv1F+/xrKfzzx7IvROQmEZkvIhuDz1KN3T9L/s9+hIiMDjpG/Ab8I2L9+lhzTiwOwX4HqyKO+7PYlUWB+46kquOxZq+ngF9EZIiI7BfjvvckThcjTxRpQlUnYt+2HgkWrcC+TVePeFRR1YeC1w4QkeoFbGoF8GC+91VW1eEF7HMDMA7oDVwADNfga12wnSvybaeSqk6N3ESUj/QJ0EFE6kcuFJH22MlgfMTiyHUaYE0qa4o4Bv8Tg4hUwJquHgFqq2p14AMswRUVbyxWYU1OBcWd36dAPRHJKM6ORKQzdkXVG7tyrI6190f2GMv/eZ4BFgCNVXU/rK0/d/0VWJNcQfJvZwV2RVEz4rjvp6rNo7xn9w2qPq6qbbFmwSOwJqUi31dEnK6YPFGkl4HASSLSGrtJ2VNEThGRMiJSMejeWU9VV2FNQ0+LyP4iUk5EugTbeA7oJyIdgp5AVUTkNBGpWsg+XwMuBs4Kfs41GLhdRJoDiEg1ETkn1g+iqp9gJ8u3RKR58Bk6Yu3wz6jq9xGrXygizUSkMnA/MFJVc6Idg0J2Wx6oAKwGskXkVCCyy+YvQA0RqRbr58jnDeyY7C8idYFrClsx+HxPA8ODmMsH8Z8nIrfFsK+q2H2A1UBZEbkHKOpbeVXsxvZmETkSuDLitdHAQSJyfdBtuaqIdAhe+wVomNtrLPj/NQ54VET2E5F9ROQwETk+hrgRkXbB/79ywBasU0NOxL4OjfL2ocAAEWkc/P9tKSI1YtmvK5wnijSiqquBl4C7VXUF0Av7Vrga+6Z1C3m/84uwb94LsJvX1wfbmAH8H3bpvx67Id0nym7fx3ro/KKq30bE8g7wL2BE0IwxBzh1Dz/SWcBnwEfYvZhXsJ40/fOt9zJ2NfUzdqP12iCGoo7BblR1U/DeN7DPfkHw+XJfXwAMB5YETSoFNcdFcz+QBfyIXTGNxL55F+Za8ppgNmBNKmcCo2LY11jsy8AirDluG9GbugBuxj7zJuwLw+u5LwTH5iSgJ3acvwdOCF5+M/h3rYh8Hfx8MZZ452HHciSxNaWBJbTngvctw5rhcq+UnweaBcf/3QLe+xj2+xuHJb3nsZvlbi9IXkuBc6lHRCZgN1JDGR29N0TkSuxGd0zftJ0Li19ROJcgInKwiBwbNMU0wbqavhN2XM4VJW6JQkReEJFfRWROIa+LiDwuIotFZLaIHB2vWJxLEuWx3j+bsJvx72H3IZxLanFregpujm4GXlLVowp4vQfW1twDG9w1SFU75F/POedcuOJ2RaGqk7C+84XphSURVdVpQHURifVml3POuQQJsxhXXXbvhZEVLFuVf0UR6YvVeaFKlSptjzzyyIQE6JxzqWjHDti40R6VNq7iIP2ZWexco6q1irO9MBNFQaWiC2wHU9UhwBCAjIwMnTFjRjzjcs65lKIK33wDo0bB6NEwezaAUr++cHvH9zm17DgajX5qWXG3H2aiyGL3kan1sEqmzjnnirB1K3z6qSWG0aNh5UoQgZMy1jOr7c0c1OlQaj9+JyKnA6eDPFXsfYWZKN4HrhGREdjN7I3BiE7nnHMFWLECxoyxxPDpp7BtG1StCqecApmZ0EvfofrtV8Hq1ZB5V8HtNsUQt0QhIsOxQnU1xWYFuxcrFIaqDsZq6PTARv5uxeYBcM45F9i5E6ZPz7tq+DaofXDooXDFFdCzJ3TuDOXX/wL9+8Obb0Lr1pZNji65EQdxSxSqen4Rr+dOXOOccy7w22/w8ceWGMaMsYuDMmXguOPg4YftyqFJE2tm2iX3UuPBB+GWW6BcuRKNyacgdM65kC1ZYolh1CiYONF6Le2/P5x6qiWG7t3t+W6WLbM3XHMNZGTA8uVQIz71Dz1ROOdcgmVnw9SpeU1K8+fb8qZN4YYbLDl06gRlCzpD79wJzzwDtwVFhM86Cw4+OG5JAjxROOdcQqxfDx99ZInhww/tebly0LUr9OsHp50GhxU1k8bChXD55fD553YH+9lnLUnEmScK55yLA1U7r+eObZgyBXJyoFYt6NXLrhpOPtl6LcVk61a7UZGTA8OGwcUX57tRET+eKJxzroRs3w6TJuU1Kf0QTMraujXcfrslh3btYJ89KZ60aBE0bgyVK8PLL9vGDjooLvEXxhOFc87thV9/taak0aNh7FjYtAkqVoRu3eDmm61JqX60SW8Ls20bDBgA//qXXUFceKHd1Q6BJwrnnNsDqlYiI/eq4csvbVmdOnD++Ta24cQT7QKg2KZMgcsus7arSy+1bBMiTxTOOVeE33+Hzz7LSw4rgnKm7dvD3/9uTUqtW5fQLYMBA+Dee6FBA7tEOfnkot8TZ54onHOuACtX5iWGTz6xZFGlip2377sPevQo4VsFqpZpWre2UdYPPgj77luCOyg+TxTOOYcNT5g5My85fP21LW/Y0HqkZmbC8cdDhQolvON162zwxOGHw913W9tVz54lvJO944nCOVdqbd5sVwu55TJ+/tl6JB1zDDz0kCWHZs3i2At15Ei4+mpLFnffHaed7D1PFM65UmXp0ryrhs8+sy6t1apZh6LMTCubEcdBzmbVKiu98fbb0LYtjBsHrVrFeafF54nCOZfWcnJg2rS85DBnji0/4gi7FZCZCcceW+J19KJbudJuVP/rX3DjjYXU6kgeyR2dc84Vw8aNdh4eNcrGOKxda+fiLl3gscest+kRRyQ4qKVLLaD+/e0qYsWKAir9JSdPFM65tLBoUd5Vw+TJVnivRg3rnZSZaaWRqlULIbCcHHjqKbjjDrsBcs451l0qRZIEeKJwzqWoHTusNl5uee7vv7flLVrYlAyZmdChg83lEJr5863L1NSpdhPk2WcTXn6jJHiicM6ljDVr8splfPSRTfJTvryNhL7uOmtSatgw7CgDW7daW9fOnfDSS1aCI0FF/EqaJwrnXNJShblz85qUvvjCzrsHHWQtOD17Wk2lJBmXZhYssCnoKleGV1+13ky1a4cd1V7xROGcSyrbttksb7nJYelSW962rQ01yMy06aD3qAJrIvz+uw3ZfuQRePFFu4JIgvIbJcEThXMudKtWwQcfWGL4+GPYsgUqVYKTTrJ7wD16QN26YUcZxaRJdi/i++/zhnGnEU8UzrmEU4VZs/KuGr76ypbXrw+XXGLn2a5dLVkkvb//3a4kGjWyYd7duoUdUYnzROGcS4itW+HTT62H0pgxNuZMBDp2tPp3mZnWYyll7vfmFvHLyLBaTQMGWNXANOSJwjkXN8uXW1IYPRrGj7f7D1Wr2piGzExrUqpVK+wo99CaNZYYGjeGe+6xrlYhzxcRb54onHMlJifHmpFym5S+/daWH3YY9OtnyaFzZ+vSmnJU4c03rUbT+vU2Z0Qp4YnCObdXfvvNatqNHm03pFevtkFuxx0HDz9syaFJkxRqUirIypVw1VXw3nvW1PTJJ9CyZdhRJYwnCufcHvvhh7yrhokTbZT0/vtb5dWePa1pKYUqVBTt55+t7ezhh+H665O+iF9JK12f1jlXLNnZVoUit1zGggW2vFkza67PzIROndLs/LlkCbz/viWGo4+2Gy7Vq4cdVSjS6dfqnCtB69ZZmYzRo61sxoYNVoq7a1e48kq7f3vYYWFHGQc5OfD443DnnfaBzzvPhoKX0iQBniiccwFVu1LIbVKaMsXOmbVqwRlnWJPSSSdZr6W0NXcuXHYZfPmlZcLBg1OyiF9J80ThXCm2fbsNKh41ypLDkiW2vHVruP12a1Jq1y4Jy2XEw9atNim2CLz2ml1JpPQd+JLjicK5UubXX/PKZYwbB5s2QcWKNqD4llvsi3T9+mFHmUDz5kHTplbEb8QIK+KXcoM74ssThXNpThVmz85rUvryS1tWty5ccIFdNZx4op0nS5WtW20sxGOPwbBhcNFF8Kc/hR1VUvJE4Vwa+v13682Zmxyysmx5+/ZWmigz05qXSm3LyoQJ8H//B4sXwxVXwOmnhx1RUvNE4Vya+OmnvHIZn3xiyaJKFat0/fe/W7kMvy+LXUXcf7912Ro/Hk44IeyIkp4nCudS1M6dMHNm3tiGWbNsecOGeZWujz8eKlQINczkkVvEr317uOkmSxalrr2teOKaKESkOzAIKAMMVdWH8r1eDXgFaBDE8oiq/jeeMTmXyjZvtvkaRo+2q4dffrEeScccAw89ZMmhWbNS3KRUkNWrbZ7UJk3saqIUFPEraXFLFCJSBngKOAnIAr4SkfdVdV7EalcD81S1p4jUAhaKyKuquj1ecTmXapYuzbtqmDDBurRWq2blMjIzoXt3qFEj7CiTkCoMHw7XXmsFqf7+97AjSlnxvKJoDyxW1SUAIjIC6AVEJgoFqoqIAPsC64DsOMbkXNLLybG5oXNvRM+da8ubNIH+/S05HHusDRp2hcjKsuHjo0dDhw7w/PPQvHnYUaWseCaKusCKiOdZQId86zwJvA+sBKoC56rqzvwbEpG+QF+ABg0axCVY58K0YQOMHZtXgXXdOqub1KWLDRTOzLTpD1yMVq+2kYSPPWZXFGXKhB1RSotnoiiolVTzPT8F+AY4ETgM+FhEJqvqb7u9SXUIMAQgIyMj/zacS0mLFuU1KU2ebFcSNWpY83nPntZbqVq1sKNMIYsX28G84QZo0wZWrID99gs7qrQQz0SRBUSO76yHXTlEuhR4SFUVWCwiPwJHAtPjGJdzodixwxJCbpPS99/b8hYt4G9/s6uGDh38y+8ey86GgQPh7ruti9cFF0Dt2p4kSlA8E8VXQGMRaQT8BJwHXJBvneVAN2CyiNQGmgBL4hiTcwm1Zo1VXh092iqx/vabze524olWvfq00+CQQ8KOMoV99521zX31lQ2ae/ppSxKuRMUtUahqtohcA4zFuse+oKpzRaRf8PpgYAAwTES+w5qqblXVNfGKybl4U7Wbz7lF9r74wpYddBD07m1XDd26wb77hh1pGti61QbL7bOP1Wjq3dv7BceJWKtP6sjIyNAZM2aEHYZzu2zbZt1Wc5uUli2z5W3bWmLIzLR5b0pFBdZEmDPHejCJwKefWhG/mjXDjirpichMVc0oznt9ZLZzxbBqVV4F1o8/hi1boFIlm6/hzjutSalOnbCjTDNbtth9iIED4cUXrYhft25hR1UqeKJwLgaq8PXXeVcNuRe19evDJZfYVUPXrpYsXBx8+qkV8fvxR7jqKujVK+yIShVPFM4VYssWOz/llstYudJaOzp2hAcftC6sRx3lzeJxd/fd8MADNpBk4kQbXOISyhOFcxGWL7ekMGqUFRb94w+b+rN7d7tqOPVUn9MmYXbuzCtk9be/wX33+SVbSDxRuFItJwemT89rUpo925YfdphVgMjMhM6drUurS5Bff7XR1E2aWH2mU0+1hwuNJwpX6vz2m00BmlsuY/VqG+R23HHw8MPWpHTEEd6klHCq8OqrVul182YrA+6SgicKVyr88EPe2IZJk2yU9P7722Q+mZlwyin23IVkxQro188yd6dOMHSo1Ut3ScEThUtL2dkwZUpek9KCBba8WTMrBZSZaeejsv4XkBzWrrVf2KBBcPXVXsckyfifiUsb69ZZmYzRo61sxoYNVoq7a1frUXnaaXDooWFH6XZZtAjefx9uvtkm8F6xwnoOuKTjicKlLFWYPz/vqmHKFOsoc+CBcOaZdtVw0kl+7kk62dnw6KM221ylSjZwrnZt/0UlMU8ULqX88YfdY8hNDkuCEpKtW8Mdd1hyaNfOy2UkrW+/hb/+1UYvnnkmPPWUF/FLAZ4oXNL79Ve7xzlqlPVW2rwZKlaEP/3Jutf36GEjpF2S27rVSm6ULQsjR8JZZ4UdkYuRJwqXdFTti2fuVcP06basbl34y1/squHEE6Fy5bAjdTGZPdsm3ahcGd5804r4HXBA2FG5PeCJwiWF33+3kdCjRtnI6KwsW96+vY256tnTzi8+tiGFbN5sFRKfeAKGDYOLL7ay4C7leKJwofnpp7yrhk8/tWSx7742Bej999tg3IMOCjtKVywffwx9+8LSpXDNNXY/wqUsTxQuYXbutKqruclh1ixb3rAhXH65NSkdf7zNZulS2J13wj/+YSU4Jk+2Ie8upcWcKESkiqpuiWcwLv1s2gSffGJNSh98AL/8klfn7V//suTQtKk3KaWF3CJ+xx0Ht98O99xjvQ5cyisyUYjIMcBQYF+ggYi0Aq5Q1aviHZxLTT/+mHfVMGECbN8O1apZU1JmplVirVEj7Chdifn5Z2teatYsr83Qi/illViuKP4DnAK8D6Cq34qIF4R3u2Rnw7RplhhGjYJ582x5kybQv78lh2OPtVHSLo2o2kxzN95oXV87dgw7IhcnMTU9qeoK2b1tICc+4bhUsWHD7uUy1q2z7vFduthEZKedZvPMuDS1bJndrB43zpqahg61bwYuLcWSKFYEzU8qIuWBa4H58Q3LJaOFC/OalCZPtrkcata0K4bMTOutVK1a2FG6hNiwAb76Cp580ibu8KHwaS2WRNEPGATUBbKAcYDfnygFtm+Hzz/PSw7ff2/LW7SwEdGZmdChgxf6LDUWLrQifrfcYoNali+3/swu7cWSKJqo6l8iF4jIscCU+ITkwrR6tTUljR4NY8faJD8VKthI6OuvtyalQw4JO0qXUDt2wCOP2MjHKlXgkkus8qIniVIjlkTxBHB0DMtcClKFOXPyrhq++MKWHXQQ9O5tVw3duvk5odSaNQsuu8z+Pftsa2o68MCwo3IJVmiiEJFOwDFALRG5MeKl/QBvbEhh27ZZt9XcGd+WL7flbdta1/eePaFNG292LvW2brU67eXKwVtvwZ//HHZELiTRrijKY2MnygKRheJ/A86OZ1Cu5K1aZTWURo+26gpbt1qNtpNOgrvvtgqsdeqEHaVLCrNmWd32ypWtymurVj5PbClXaKJQ1YnARBEZpqrLEhiTKwE7d9rfe+7YhpkzbXmDBtCnjzUpde1q88Y4B9gw+ttvtzkiXnzRivh17Rp2VC4JxHKPYquIPAw0B3aNx1fVE+MWlSuWLVusXMbo0Xb1sGqVlcbo2NFK72RmwlFHebkMV4CPPoIrrrDpSK+7zpuZ3G5iSRSvAq8DmVhX2UuA1fEMysVu2bK8JqXx420GuKpVrUxGZqZVUqhVK+woXVK7/XZ46CErujVlCnTqFHZELsnEkihqqOrzInJdRHPUxHgH5gqWk2MT+eQ2KX33nS0/7DAb95SZCZ07Q/ny4cbpUkBOjg2C6drVhtXfdZeX7nUFiiVR7Aj+XSUipwErgXrxC8nlt3GjVUoYPdoqsK5ZY3/fxx1n3dszM+GII7xJycVo1Sq4+mpo3hwGDIBTTrGHc4WIJVE8ICLVgJuw8RP7AdfHNSrH9u0weLANhJ040Qrv7b+/9U7KzLS/a++I4vaIqs00d+ON1kfa54lwMSoyUajq6ODHjcAJsGtktoujBx+0is3Nmtnfdc+edlO6rE815Ypj6VKr1vjJJ9Y2OXSoXYY6F4NoA+7KAL2xGk8fqeocEckE7gAqAW0SE2Lps20bPPOMXTmMGhV2NC4tbNwIX38NTz9tvZt8NKXbA9H+tzwPXA7UAB4Xkf8CjwD/VtWYkoSIdBeRhSKyWERuK2SdriLyjYjM9ZvkZvhwq7l0vTfwub0xb571ZoK8In5e6dUVg6hqwS+IzAFaqupOEakIrAEOV9WfY9qwXZEsAk7Cqs5+BZyvqvMi1qkOTAW6q+pyETlQVX+Ntt2MjAydMWNGLCGkJFUrn5GTA7Nn+w1qVwzbt8O//203qqtWtYTh9ZlKPRGZqaoZxXlvtK8W21V1J4CqbgMWxZokAu2Bxaq6RFW3AyOAXvnWuQB4W1WXB/uJmiRKg4kT4dtv7WrCk4TbYzNmQLt2Vpflz3/2JOFKRLRbo0eKyOzgZwEOC54LoKrasoht1wVWRDzPAjrkW+cIoJyITMDqSQ1S1Zfyb0hE+gJ9ARo0aFDEblPbwIE2GdAFF4QdiUs5W7ZYd7iKFeG99+D008OOyKWJaImi6V5uu6Dvw/nbucoCbYFu2A3yL0Rkmqou2u1NqkOAIWBNT3sZV9L64QfrDnvnnV6Dye2Br7+2In5VqsA770DLllC9ethRuTRSaNOTqi6L9ohh21lA/Yjn9bDBevnX+UhVt6jqGmAS0GpPP0S6eOIJ6/565ZVhR+JSwm+/wVVXWX34V16xZV26eJJwJS6e3R++AhqLSKNgru3zgPfzrfMe0FlEyopIZaxpqlTOx/3bb/DCCzZZkJf7dkX64AMbWf3sszbQ5qyzwo7IpbG4Dd9S1WwRuQYYi0109IKqzhWRfsHrg1V1voh8BMwGdgJDVXVOvGJKZi+8YFWevUusK9Ktt1qvpmbNbL6IDvlv/TlXsgrtHrvbSiKVgAaqujD+IUWXjt1jc3JskOzBB8Pnn4cdjUtKqjbJSJkyVvhryhS44w4v4udiFq/usbkb7wl8A3wUPG8tIvmbkNxeGD0alizxqwlXiJ9+gjPOgHvvtecnnwx//7snCZcwsdyjuA8bE7EBQFW/ARrGL6TSZ+BAm3nujDPCjsQlFVV47jlrYho3zvpNOxeCWO5RZKvqRvHRX3HxzTcwYQI8/LAX/HMRfvwRLrsMPvvM5ot47jk4/PCwo3KlVCynpjkicgFQRkQaA9diZTdcCRg0yLq/X3ZZ2JG4pLJ5s9VwefZZuPxyr8/kQhXL/77+2HzZfwCvYeXGvTW9BPzyC7z2GvTp43NLOGDOHJvcHKBFCyvi17evJwkXulj+BzZR1TtVtV3wuCuo/eT20uDBVr+tf/+wI3Gh2r7dbk4ffTT85z/wa1DyrHLlcONyLhBLonhMRBaIyAARaR73iEqJP/6wOSd69IAmTcKOxoXmq69sZPV998E553gRP5eUYpnh7gQROQibxGiIiOwHvK6qD8Q9ujT2+uvW9ORdYkuxLVuge3cr7PX++zaNoXNJKKYBd7tWFmkB/A04V1XLxy2qKNJhwJ2qfYn84w9rlvYOZaXMjBnWzLTPPjbCskULqFYt7Khcmov3gLumInJfMJHRk1iPp3rF2ZkzkyfDrFk+50Sps3GjTUParl1eEb/jjvMk4ZJeLN1j/wsMB05W1fzVX10xDBwINWrAhReGHYlLmFGjoF8/+PlnuPlmOPvssCNyLmax3KPomIhASoslS+Ddd7EepOUAAB8fSURBVOH2233OiVLjllvgkUesiendd+2KwrkUUmiiEJE3VLW3iHzH7hMOxTrDnSvAk09aXberrgo7EhdXqlbtsWxZq820335W9bV8KLf2nNsr0a4orgv+zUxEIKXBpk3w/PPWC7Ju3bCjcXGTlWWzT7VsCQ8+CCedZA/nUlS0Ge5WBT9eVcDsdv59uBiGDbMJirxLbJraudNKbjRrBuPHw0EHhR2RcyUilgF3BX0VOrWkA0l3O3daXadOnaB9+7CjcSVuyRI48US7Yd2+PXz3nQ+5d2kj2j2KK7Erh0NFZHbES1WBKfEOLN2MGQM//JBXyselmS1bbFT10KHw1796v2eXVqLdo3gN+BD4J3BbxPJNqrourlGloYEDoX59+POfw47ElZjvvoP33oO77rIeTcuWeVc2l5aiNT2pqi4FrgY2RTwQkQPiH1r6mD3bmqyvucbnnEgLf/wB99xjo6sffzyviJ8nCZemirqiyARmYt1jI6+lFTg0jnGllUGD7Bxy+eVhR+L22rRpNnnIvHlw0UVW7bVGjbCjci6uCk0UqpoZ/NsoceGkn9Wr4dVX4dJL4QC/DkttW7bAaafZTFMffACnep8OVzrEUuvpWBGpEvx8oYg8JiIN4h9aenj2WWupuPbasCNxxfbll9ZtrUoVK8Uxd64nCVeqxNI99hlgq4i0wirHLgNejmtUaWL7dnjqKask3bRp2NG4PbZhg7UXduyYV8TvmGOgatVw43IuwWJJFNlqtch7AYNUdRDWRdYV4Y03rAacD7BLQe++awPnhg2z0hvnnBN2RM6FJpY+OJtE5HbgIqCziJQBysU3rNSnavc5mza1Uj8uhdx4o/3yWrWypqa2bcOOyLlQxZIozgUuAP6qqj8H9ycejm9YqW/KFPj6a5sX28depYDIIn49elhPpr/9Dcr5dyLnYprhTkRqA7m1kaer6q9xjSqKVJnh7uyzbexEVhZUrhx2NC6q5cut9EabNlbEz7k0FO8Z7noD04FzsHmzvxQRn3UlimXL4J13oG9fTxJJbedOePppaN4cJk6EOnXCjsi5pBRL09OdQLvcqwgRqQV8AoyMZ2Cp7Mknrbnp6qvDjsQVavFiq8k0ebKVAB8yBBo2DDsq55JSLIlin3xNTWuJrbdUqbR5Mzz3nDU91a8fdjSuUNu2waJF8N//wiWX+I0k56KIJVF8JCJjsXmzwW5ufxC/kFLbiy/Cxo3eJTYpffONFfG791446ihYuhQqVgw7KueSXpFXBqp6C/As0BJoBQxR1VvjHVgqyp1zokMHG6PlksS2bXDnnZCRAc88k1fEz5OEczGJNh9FY+AR4DDgO+BmVf0pUYGlog8/hO+/h+HDi17XJcjUqVbEb8ECa2J67DEvuuXcHop2RfECMBo4C6sg+0RCIkphAwfaXNhnnRV2JA6wIn49e8LWrfDRRzbK2pOEc3ss2j2Kqqr6XPDzQhH5OhEBpaq5c+GTT2wGOx+jFbIvvrD2vypVYPRoux/h9ZmcK7ZoVxQVRaSNiBwtIkcDlfI9L5KIdBeRhSKyWERui7JeOxHJSeXxGYMGWZN3375hR1KKrV9vXV6POQZeDupWdurkScK5vRTtimIV8FjE858jnitwYrQNBzWhngJOArKAr0TkfVWdV8B6/wLG7lnoyWPNGjsvXXyxz2ETmrfftoErq1fD7bfDueeGHZFzaSPaxEUn7OW22wOLVXUJgIiMwCrQzsu3Xn/gLfJKhKScIUOsY81114UdSSl1ww12g6h1a5tQqE2bsCNyLq3EcwbnusCKiOdZQIfIFUSkLnAmdnVSaKIQkb5AX4AGDZJrzqTcOSdOPtmqUrsEiSzil5kJBx4IN9/sN4ici4N4jrAuaKhr/gqEA4FbVTUn2oZUdYiqZqhqRq1atUoswJIwciSsXOkD7BJq6VKbDeruu+15t27W3ORJwrm4iGeiyAIii1jUA1bmWycDGCEiS4GzgadF5Iw4xlSiVK3F44gj4JRTwo6mFNi5E554wnoxTZ0KhxwSdkTOlQpFNj2JiAB/AQ5V1fuD+SgOUtXpRbz1K6CxiDQCfgLOw+a12EVVG0XsZxgwWlXf3bOPEJ5p0+Crr6zpaR+vfhVf338Pl15qE310724TfXiicC4hYjm9PQ10As4Pnm/CejNFparZwDVYb6b5wBuqOldE+olIv2LGm1QGDoTq1a23k4uz7dvhhx/gpZfshrUnCecSJpab2R1U9WgRmQWgqutFpHwsG1fVD8hXQFBVBxeybp9Ytpksli+Ht96yWTP33TfsaNLUrFlWxO+++2zOiKVLoUKFsKNyrtSJ5YpiRzDWQWHXfBQ74xpVCngquKa65ppw40hL27bZzel27eDZZ21sBHiScC4ksSSKx4F3gANF5EHgc+AfcY0qyW3ZYmMn/vxnSLLeuqnv88+hVSt46CFr05s3D5Ksp5tzpU2RTU+q+qqIzAS6YV1ez1DV+XGPLIm99BJs2OBdYkvc5s3Qqxfstx+MG2czzznnQhdLr6cGwFZgVOQyVV0ez8CSVe6cExkZVkbIlYDPP7f6TPvuC2PGWPdXv/HjXNKIpelpDFZufAzwKbAE+DCeQSWzceNg4UK7mvDZM/fS2rXWvNS5c14Rv44dPUk4l2RiaXpqEfk8qBx7RdwiSnIDB8LBB8M554QdSQpTtSHt11wD69bZCOvzzgs7KudcIfa41pOqfi0iKVvAb2/Mmwdjx8IDD0D5mDoIuwLdcIO137Vta5dorVqFHZFzLopY7lHcGPF0H+BoYHXcIkpijz/uc04UmypkZ1s9ptNPhzp1bBBK2XjWpXTOlYRY7lFUjXhUwO5V9IpnUMlo7Vrr7XThhd5bc4/9+KOV180t4nfiifC3v3mScC5FRP1LDQba7auqtyQonqT13HPw++8+58QeycmBJ5+EO+6AMmX8xo5zKarQRCEiZVU1O9ZpT9PZjh12vuvWzXpuuhgsWgR9+tj81aeeaiOs69cv8m3OueQT7YpiOnY/4hsReR94E9iS+6Kqvh3n2JLG22/DTz9ZwVIXo+xsWLYMXnkFLrjA+xI7l8JiaSQ+AFiLzUKn2OhsBUpNohg4EA4/HHr0CDuSJDdjhhXxGzDApvtbssTrMzmXBqIligODHk9zyEsQufLPVJe2pk2zxxNP+JwThfr9d7j3Xnj0UTjoILj2Wrvj70nCubQQ7dRXBtg3eFSN+Dn3USoMGgTVqllzuyvAxInQsiU8/DBcdhnMnevdwpxLM9GuKFap6v0JiyQJZWXBm29auQ6vKlGAzZuthG716vDpp9bt1TmXdqIlilJ/9/Gpp2ycmM85kc/kyXDssZY9P/zQJhWqUiXsqJxzcRKt6albwqJIQlu3Wo/OM86Ahg3DjiZJrFljIw67dMkr4te+vScJ59JcoVcUqroukYEkm1degfXrfc4JwC6r3ngD+ve3g3LvvV7Ez7lSxGsoFEDVusQefTQcd1zY0SSB666zbl/t2tm9iBYtin6Pcy5teKIowMcfw/z5Vtup1I4TU7Uh6eXLw5lnwiGH2OVVmTJhR+acSzAfGVCAgQNtOEDv3mFHEpIffrB6JXfdZc9POAFuusmThHOllCeKfBYssI48V11VCseL5eTAY49Z09LMmdCkSdgROeeSgDc95fP445Ygrihtc/gtWACXXALTp0PPnvDMM1C3bthROeeSgCeKCOvXw4svWg27Aw8MO5oE27kTVq6E4cPh3HNL8c0Z51x+nigiDB1q4ydKzZwT06dbEb8HH7Qifj/84HO8Ouf+h9+jCGRnWw/QE04oBVM4b90KN98MnTrZJdTqYGZbTxLOuQJ4ogi88w6sWFEKBth99pndrH70Ufi///Mifs65InnTU2DgQDjsMDjttLAjiaPNm2060urVLWF07Rp2RM65FOBXFFhT/dSpNo1CWg4VmDDBblbnFvGbPduThHMuZp4osDkn9tsPLr007EhK2OrVcP75duPllVdsWbt2ULlyuHE551JKqU8UP/1k9e7++leoWjXsaEqIKrz2GjRtahN+DxjgRfycc8VW6u9RPPOMDUju3z/sSEpQ//42mUbHjvD889b11TnniqlUJ4rff4fBg6FXLzj00LCj2Us7d1of3/Ll4eyz4fDDLWGk5U0X51wixbXpSUS6i8hCEVksIrcV8PpfRGR28JgqIgkdwfDqq7B2bRp0if3+e5uG9M477XnXrl7p1TlXYuKWKESkDPAUcCrQDDhfRPK3gfwIHK+qLYEBwJB4xZNf7pwTrVvbhG0pKTsbHnkEWraEb76xexLOOVfC4tn01B5YrKpLAERkBNALmJe7gqpOjVh/GlAvjvHs5tNPbazZsGEpWtZo/ny4+GKYMcPazp5+GurUCTsq51waimfTU11gRcTzrGBZYS4DPizoBRHpKyIzRGTG6txyE3tp4EAr/JfSnYF++QVef92GlXuScM7FSTwTRUHf07XAFUVOwBLFrQW9rqpDVDVDVTNqlUC5iUWLYMwYuPLKFJtzYto0uP12+7lpUyvi17t3il4SOedSRTwTRRZQP+J5PWBl/pVEpCUwFOilqmvjGM8uTzxhnYP69UvE3krAli1www1wzDF2Bz73qqpcuXDjcs6VCvFMFF8BjUWkkYiUB84D3o9cQUQaAG8DF6nqojjGssuGDfDf/9qA5YMOSsQe99Inn8BRR1lb2VVXeRE/51zCxe1mtqpmi8g1wFigDPCCqs4VkX7B64OBe4AawNNizSfZqpoRr5jAxp9t2ZIic05s3mw3UQ44ACZNgs6dw47IOVcKiWqBtw2SVkZGhs6YMaNY783OtnFoDRtanbykNX48HH+8jYOYOdNGVleqFHZUzrkUJiIzi/tFvFTVenrvPVi2LIkH2P3yi92c7tYtr4hf27aeJJxzoSpViWLgQGjUCHr2DDuSfFTh5ZftyiF3atILLgg7KuecA0pRraeZM+Hzz+Gxx5KwssXVV1t1wk6d7CaKj7B2ziWRUpMoBg2yeXv++tewIwns3Ak7dthAjnPPteRw1VVJmMWcc6VdqWh6WrUKRoywJFGtWtjRAAsX2s3q3CJ+xx/vlV6dc0mrVCSKZ56xHk+hzzmxYwc89BC0agVz5kCLFiEH5JxzRUv7pqdt2yxR9OxpXWNDM3cuXHQRzJoFf/6zTSyUEiP+nHOlXdonitdegzVrkqBLbJkysG4djBwJZ50VcjDOORe7tG56yp1zomVLm8sn4aZOhVuDOodHHgmLF3uScM6lnLROFJ99Bt99Z+U6ElpgdfNmuPZaOO44KwO+Zo0tL5v2F3DOuTSU1oli0CCoWTPBY9fGjbMifk8+CddcYzeta9ZMYADOOVey0vYr7uLFMGoU3HUXVKyYoJ1u3gx/+QvUqAGTJ8OxxyZox845Fz9pe0XxxBPW0nPllQnY2ccfQ06OjegbN87mr/Yk4ZxLE2mZKDZuhBdesArdBx8cxx2tWmU3p08+2SYUAmjTJoGXMM45F39pmSheeMFageI254QqDBtmRfzGjLFBdF7EzzmXptLuHkVODjz+uM3x07ZtnHZy5ZXw7LPWq2noUGjSJE47ci617dixg6ysLLZt2xZ2KKVGxYoVqVevHuVKcKrktEsU778PS5fCI4+U8IYji/hdcIENzujXD/ZJy4sy50pEVlYWVatWpWHDhkhC+6iXTqrK2rVrycrKolGjRiW23bQ7yw0aBIccAr16leBG58+3S5Q77rDnXbpYpVdPEs5FtW3bNmrUqOFJIkFEhBo1apT4FVxanelmzYKJE634X4mMbduxA/7xD2jdGhYssBvVzrk94kkiseJxvNOq6WnQIKhSBS67rAQ2NncuXHihdXU95xzrb1u7dgls2DnnUkvaXFH8/DMMHw6XXgrVq5fABsuWtX62b78Nb7zhScK5FPbOO+8gIixYsGDXsgkTJpCZmbnben369GHkyJGA3Yi/7bbbaNy4MUcddRTt27fnww8/3OtY/vnPf3L44YfTpEkTxo4dW+A65557Lq1bt6Z169Y0bNiQ1q1bA/Dxxx/Ttm1bWrRoQdu2bRk/fvxexxOLtLmiGDwYtm+3EkvFNnmyzVn9yCPWk2nRIq/P5FwaGD58OMcddxwjRozgvvvui+k9d999N6tWrWLOnDlUqFCBX375hYkTJ+5VHPPmzWPEiBHMnTuXlStX8qc//YlFixZRJt+kZa+//vqun2+66SaqBTOu1axZk1GjRlGnTh3mzJnDKaecwk8//bRXMcUiLc6CuXNOZGZC48bF2MCmTXDbbfD009Cokf1cs6YnCedK0PXXW0tuSWrd2ipER7N582amTJnCZ599xumnnx5Toti6dSvPPfccP/74IxUqVACgdu3a9O7de6/ife+99zjvvPOoUKECjRo14vDDD2f69Ol06tSpwPVVlTfeeGPXlUObiPukzZs3Z9u2bfzxxx+7YoyXtGh6GjECfv21mAPsPvwQmje3THP99VZu1ov4OZc23n33Xbp3784RRxzBAQccwNdff13kexYvXkyDBg3Yb7/9ilz3hhtu2NVMFPl46KGH/mfdn376ifr16+96Xq9evahXBJMnT6Z27do0LuAb8FtvvUWbNm3iniQgDa4oVO0mdvPm0K3bHr550ya4+GI48ECbO6Jjx7jE6Jwr+pt/vAwfPpzrg5nLzjvvPIYPH87RRx9daO+gPe019J///CfmdVV1j/Y3fPhwzj///P9ZPnfuXG699VbGjRsX8773RsonikmT7HL2uedinHNCFcaOhZNOgqpV4ZNPbFKhBGRl51xirV27lvHjxzNnzhxEhJycHESEf//739SoUYP169fvtv66deuoWbMmhx9+OMuXL2fTpk1UrVo16j5uuOEGPvvss/9Zft5553HbbbfttqxevXqsWLFi1/OsrCzq1KlT4Hazs7N5++23mTlz5m7Ls7KyOPPMM3nppZc47LDDosZWYlQ1pR5t27bVSGecoVqjhurWrVq0lSvtDaD64osxvME5tzfmzZsX6v4HDx6sffv23W1Zly5ddNKkSbpt2zZt2LDhrhiXLl2qDRo00A0bNqiq6i233KJ9+vTRP/74Q1VVV65cqS+//PJexTNnzhxt2bKlbtu2TZcsWaKNGjXS7OzsAtf98MMPtUuXLrstW79+vbZs2VJHjhwZdT8FHXdghhbzvJvS9yiWLLFOSv36QaVKUVZUtUqBTZvCRx/Bv//tRfycKwWGDx/OmWeeuduys846i9dee40KFSrwyiuvcOmll9K6dWvOPvtshg4duquH0QMPPECtWrVo1qwZRx11FGeccQa1atXaq3iaN29O7969adasGd27d+epp57a1ePp8ssvZ8aMGbvWHTFixP80Oz355JMsXryYAQMG7LoX8uuvv+5VTLEQLaDNLJllZGRo7sG84QabSG7ZMijk6s1ccQUMGWKlN4YOLWbXKOfcnpo/fz5NmzYNO4xSp6DjLiIzVTWjONtL2XsUv/0Gzz8P555bSJLIybESHBUr2gjrNm2gb1+vz+Scc3soZc+a//2vdVoqsEvs3Lk2w1xuEb/Onb3Sq3POFVNKnjlzcqz00jHHQLt2ES9s3w4DBtjVw+LF+V50zoUh1Zq3U108jndKJooxY+CHH2x83C7ffQcZGXDPPTY96fz5UED/Y+dc4lSsWJG1a9d6skgQDeajqFjC0zGn5D2KgQOhfn3YrTND+fKwdat1gzr99NBic87lqVevHllZWaxevTrsUEqN3BnuSlLKJYrff4eZM62Ha9kpE21Ku0cftSJ+CxdCvuJazrnwlCtXrkRnWnPhiGvTk4h0F5GFIrJYRG4r4HURkceD12eLyNFFbfOXX6B2pd+4dv6V0LUrvPsurFljL3qScM65Ehe3RCEiZYCngFOBZsD5ItIs32qnAo2DR1/gmaK2m712I/P3aU6FF4fAjTd6ET/nnIuzeF5RtAcWq+oSVd0OjADyz2TdC3gpGGE+DaguIgdH22hDllK5TjUr4vfoo1C5cnyid845B8T3HkVdYEXE8yygQwzr1AVWRa4kIn2xKw6APyp+P3eOV3oFoCawJuwgkoQfizx+LPL4scjTpLhvjGeiKKiWa/4+crGsg6oOAYYAiMiM4g5DTzd+LPL4scjjxyKPH4s8IjKj6LUKFs+mpyygfsTzesDKYqzjnHMuRPFMFF8BjUWkkYiUB84D3s+3zvvAxUHvp47ARlVdlX9DzjnnwhO3pidVzRaRa4CxQBngBVWdKyL9gtcHAx8APYDFwFbg0hg2PSROIaciPxZ5/Fjk8WORx49FnmIfi5QrM+6ccy6xUrLWk3POucTxROGccy6qpE0U8Sj/kapiOBZ/CY7BbBGZKiKtwogzEYo6FhHrtRORHBE5O5HxJVIsx0JEuorINyIyV0QmJjrGRInhb6SaiIwSkW+DYxHL/dCUIyIviMivIjKnkNeLd94s7mTb8XxgN79/AA4FygPfAs3yrdMD+BAbi9ER+DLsuEM8FscA+wc/n1qaj0XEeuOxzhJnhx13iP8vqgPzgAbB8wPDjjvEY3EH8K/g51rAOqB82LHH4Vh0AY4G5hTyerHOm8l6RRGX8h8pqshjoapTVXV98HQaNh4lHcXy/wKgP/AWEP9Z58MTy7G4AHhbVZcDqGq6Ho9YjoUCVUVEgH2xRJGd2DDjT1UnYZ+tMMU6byZroiistMeerpMO9vRzXoZ9Y0hHRR4LEakLnAkMTmBcYYjl/8URwP4iMkFEZorIxQmLLrFiORZPAk2xAb3fAdep6s7EhJdUinXeTNb5KEqs/EcaiPlzisgJWKI4Lq4RhSeWYzEQuFVVc+zLY9qK5ViUBdoC3YBKwBciMk1VF8U7uASL5VicAnwDnAgcBnwsIpNV9bd4B5dkinXeTNZE4eU/8sT0OUWkJTAUOFVV1yYotkSL5VhkACOCJFET6CEi2ar6bmJCTJhY/0bWqOoWYIuITAJaAemWKGI5FpcCD6k11C8WkR+BI4HpiQkxaRTrvJmsTU9e/iNPkcdCRBoAbwMXpeG3xUhFHgtVbaSqDVW1ITASuCoNkwTE9jfyHtBZRMqKSGWsevP8BMeZCLEci+XYlRUiUhurpLokoVEmh2KdN5PyikLjV/4j5cR4LO4BagBPB9+kszUNK2bGeCxKhViOharOF5GPgNnATmCoqhbYbTKVxfj/YgAwTES+w5pfblXVtCs/LiLDga5ATRHJAu4FysHenTe9hIdzzrmokrXpyTnnXJLwROGccy4qTxTOOeei8kThnHMuKk8UzjnnovJE4ZJSUPn1m4hHwyjrbi6B/Q0TkR+DfX0tIp2KsY2hItIs+PmOfK9N3dsYg+3kHpc5QTXU6kWs31pEepTEvl3p5d1jXVISkc2qum9JrxtlG8OA0ao6UkROBh5R1ZZ7sb29jqmo7YrIi8AiVX0wyvp9gAxVvaakY3Glh19RuJQgIvuKyKfBt/3vROR/qsaKyMEiMiniG3fnYPnJIvJF8N43RaSoE/gk4PDgvTcG25ojItcHy6qIyJhgboM5InJusHyCiGSIyENApSCOV4PXNgf/vh75DT+4kjlLRMqIyMMi8pXYPAFXxHBYviAo6CYi7cXmIpkV/NskGKV8P3BuEMu5QewvBPuZVdBxdO5/hF0/3R/+KOgB5GBF3L4B3sGqCOwXvFYTG1mae0W8Ofj3JuDO4OcyQNVg3UlAlWD5rcA9BexvGMHcFcA5wJdYQb3vgCpYaeq5QBvgLOC5iPdWC/6dgH173xVTxDq5MZ4JvBj8XB6r5FkJ6AvcFSyvAMwAGhUQ5+aIz/cm0D14vh9QNvj5T8Bbwc99gCcj3v8P4MLg5+pY3acqYf++/ZHcj6Qs4eEc8Luqts59IiLlgH+ISBesHEVdoDbwc8R7vgJeCNZ9V1W/EZHjgWbAlKC8SXnsm3hBHhaRu4DVWBXebsA7akX1EJG3gc7AR8AjIvIvrLlq8h58rg+Bx0WkAtAdmKSqvwfNXS0lb0a+akBj4Md8768kIt8ADYGZwMcR678oIo2xaqDlCtn/ycDpInJz8Lwi0ID0rAHlSognCpcq/oLNTNZWVXeIyFLsJLeLqk4KEslpwMsi8jCwHvhYVc+PYR+3qOrI3Cci8qeCVlLVRSLSFquZ808RGaeq98fyIVR1m4hMwMpenwsMz90d0F9Vxxaxid9VtbWIVANGA1cDj2O1jD5T1TODG/8TCnm/AGep6sJY4nUO/B6FSx3VgF+DJHECcEj+FUTkkGCd54DnsSkhpwHHikjuPYfKInJEjPucBJwRvKcK1mw0WUTqAFtV9RXgkWA/+e0IrmwKMgIrxtYZK2RH8O+Vue8RkSOCfRZIVTcC1wI3B++pBvwUvNwnYtVNWBNcrrFAfwkur0SkTWH7cC6XJwqXKl4FMkRkBnZ1saCAdboC34jILOw+wiBVXY2dOIeLyGwscRwZyw5V9Wvs3sV07J7FUFWdBbQApgdNQHcCDxTw9iHA7Nyb2fmMw+Y2/kRt6k6wuUTmAV+LyBzgWYq44g9i+RYrq/1v7OpmCnb/ItdnQLPcm9nYlUe5ILY5wXPnovLusc4556LyKwrnnHNReaJwzjkXlScK55xzUXmicM45F5UnCuecc1F5onDOOReVJwrnnHNR/T9cbAREBPhNogAAAABJRU5ErkJggg==\n",
"text/plain": [
""
]
},
"metadata": {
"needs_background": "light"
},
"output_type": "display_data"
}
],
"source": [
"df1 = es.importdata('train_split.csv')\n",
"es.info(df1)\n",
"es.box_hist_plot(df1,'emp_length')\n",
"df1 = es.drop_columns(df1,20,'member_id','pymnt_plan','batch_enrolled')\n",
"es.missingdata(df1)\n",
"es.extract_number(df1,'emp_length')\n",
"df1 = es.fillnulls(df1,'unknown','emp_title','title')\n",
"es.box_hist_plot(df1,'revol_util','tot_cur_bal','total_rev_hi_lim')\n",
"df1 = es.dropcolumns(df1,'tot_coll_amt')\n",
"df1 = es.fillnulls(df1,'mean','revol_util','tot_cur_bal','total_rev_hi_lim')\n",
"df2 = es.label_encode(df1)\n",
"es.corr_heatmap(df2,'interactive')\n",
"es.dropcolumns(df2,'funded_amnt_inv','funded_amnt','collections_12_mths_ex_med')\n",
"es.showbias(df1,'loan_status')\n",
"X = df2.drop('loan_status',axis=1)\n",
"y = df2['loan_status']\n",
"es.stat_models(y,X)\n",
"es.VIF(df2)\n",
"X_train,X_test,y_train,y_test = train_test_split(X,y,train_size=.7,random_state=101)\n",
"print('\\n *************** Random Forest ***************\\n')\n",
"y_pred, rfc = es.randomforest_classifier(X_train,y_train,X_test,y_test)\n",
"es.classification_result(y_test,y_pred)\n",
"es.roc_curve_graph(y_test, y_pred)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### menu based classification available and All models results"
]
},
{
"cell_type": "code",
"execution_count": 11,
"metadata": {
"ExecuteTime": {
"end_time": "2020-03-17T10:24:50.376260Z",
"start_time": "2020-03-17T10:23:45.601856Z"
}
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"########## MENU ##############\n",
"\n",
"1. Logisitic Regression \n",
"2. Random Forest \n",
"3. XGB Classifier \n",
"4. LGB CLassifier \n",
"5. Gradient Boosting Classifier \n",
"6. AdaBoost Classifier \n",
"99. For all models\n",
"\n",
"Input No, which you want:6\n",
"Predicting with Ada Boost CLassifier\n"
]
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAqQAAAGwCAYAAAB/6Xe5AAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADt0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjByYzEsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy/xvVyzAAAgAElEQVR4nO3deZwlVX3//9ebAWSVEUEFFAdRQUFBGBcUENyIJgZQlCgxoDFIiBDIDw3RaCbxq4IYTdRoMlGDcd+iokbAqKzKMgMzDKjgwhgVhAjKDrJ8fn9UtXO93O6+08tUL6/n43EfXX3q1KlTdatvv7tOVXWqCkmSJKkr63XdAUmSJM1vBlJJkiR1ykAqSZKkThlIJUmS1CkDqSRJkjplIJUkSVKnDKSSBkpyapJKsqjrvkiS5jYDqTQHJXljGyYryU4d9+XUnr6MvO5NckOSbyY5rMv+jSfJorbPp05g2bMGbHvva63bnKiRvqyr9U2lJEes6/3VlSRL2m3dr+u+SOvS+l13QNLUShLgT4ECAvwZcEKnnWp8CVjRTm8IPAr4Q2D/JI+vqjd21rPp9xFg9YDyFQPKJGneMZBKc8/zgB2AU4HnA4cneUNV/abTXsEXq+rU3oIkewLLgL9K8paqurOTnk2/U6vqrK47IUkzlUP20tzzZ+3Xfwc+DmwFHDxa5STPSXJuktuS3Jjki0l2HqP+EUk+n+THSe5IcnOS85P88dp2tKqWAzcCGwGbD1jXs5Oc3vbrziRXJTkpyRaj9O0xSf4zyc+T/CbJNe33jxlQd/Mkb0pyebsNtyT5UZJPt0GZJEuAq9tFDu8bbj9ibbd3LEnWT3J0kgva/tye5NIkr01yv8/qYd+HkUsOgGe23/duw1k99X7n+7427nc9ce+lDEke2+6365Pc1zvcnOSAJP+d5JdJ7mr38SlJFk5uj/3u8HaSlyVZ3u63a5K8K8kD2nrPai9ZuDnJr5J8NMmDB7S3un1tkeR97XF0Z5LvJjm2HX0Y1I+XJjknyU3te7Eqyd+MrH+UdTyw7ePqJHe327Ia+Lu26rd636ue5R/b/gwsS/J/7T79SZKlSR4+YH37tW0sSbJ7kq8m+XW7n85O8vRRtmlBkqPaY2pku36Y5IP9P09re+xKg3iGVJpDkjyUZhj8qqr6dpKbgb8CjgQ+PaD+IW35b9qv1wJ7A98BLhtlNR8Avguc09Z/MPAC4KNJdqqqN61Ff/cAtgR+UlX/1zfvNe26bgM+C1wP7Af8NfDCJM+oql/31H8y8D80wfa0to87A4cBByZ5dlUta+sGOB14erutHwTuAR7RruNcYDlwFrAQ+EtgJfDFni5O2XB7kg2ALwMHAFcCnwDuBPYH3gs8FXhF32LDvg+/Bv4eOAJ4ZDs9YvUUdH9H4ELgKpo/gDYGbm63683t+m4EvkLzHj6R5hKSFyTZq6punoI+HEMzGvBFmvfsecDxwJZJvgR8CvgqsJTmPf9jmj/Unj+grQ1pjqOF7XIbAi8G/hnYCfiL3spJ3gb8DfBLmvft1rbdtwEHJHluVd09YB3fpDn2z6TZX1cD/wQcRPPHw2iXebwIOAr4FvBtmp/dXYBX0/xcLK6qnw9YbjHwetYc79u32/WNJLtX1ZU927Rhu7+eA/y03a6bgUU0f9yeB/ygrTuRY1e6v6ry5cvXHHkBJ9JcO/o3PWXLgfuAR/fV3Qy4AbgbWNw3791tOwUs6pu344D1bgh8o21ru755p7btfBFY0r7exppf3j8F9ulb5pHAXTS/BHfum/f+tr2lPWUBvteWH9ZX/9C2/PvAem3ZE9qyLwzYlvWAB/V8v6ite+oE3o+zRpbt2fbfvnrqLWnrvRdY0FO+APhQO+/ASb4PZzUf+aP2tYCzRpk38h4u6ikb2S8FvG3AMvu3874NLOybd0Q7791D7seR+qf2lY/st5uAx/WUPwC4AriX5hh/Zt/7+/V2ud372lvdlp8HPKCnfEvgR+28fXvK92rL/hd4WE/5+jQhrYA3jLKO/wE2HbCtI9u03yj7YrvevvWUP6/d3g/0le/X8z4d0TfvNW35+/vK39aWn9a/rnbfbj2ZY9eXr0Gvzjvgy5evqXnRhLIftr+UtuspP6b9pXBSX/3D2vKPDGhrC5oza/cLpGOs/0Vt/T/pKz+15xdi/+t24GTuH1jeyOhB50E0QfWOkV+WwDPa+t8epW/n9oYJ1gTSTwyxXYuYfCAd+GrrrEdzdu1aYP0BbSyk+YPiM5N8H84aWecoy000kP6iP7S087/Qzt9llDYvBa4fcpuOGPQe9IShtwxY5s3tvP8cMO/wdt7hfeWr2/J9xujDf/SU/XtbduSA+o+l+Vn88Sjr2G2UbR3Zpv0mcLxdNmB9+7XtnTeg/gY0f7ws6ylbQPOzfzuw7Tjrm9Jj19f8fjlkL80dz6IZPj2jfnfI7hPAO4Ejkryp1gwf7tF+Pbu/oaq6KckK2usOeyXZnmbY/Nk0w34b91XZbpT+vbLam5qSLAAeThMMltAMqS+uqlv7+vbNAX37VZJLgX1phuRXjlW/p3xv4Ek0Q9zfpRlyf1mSR9I8AeA8ml/M03Hz1/41+k1Nj6UZbv8B8LejXKZ4B/C43oJJvA9TbWVV3TWgfC+asPOSJC8ZMH9DYOskD66qGybZh2UDyq5pvy4fMG/k5+N+11zSXLrx7QHlZ7Vfn9RTNtZxelWSnwE7JFlYPZeX0Axpj3ZJzJjay00OownIu9H8gbagp8pox+/99lFV3Z3kuraNETvT/EF6YVVd079Mnwkdu9IgBlJp7jiy/Xpqb2FV3ZDkyzTXix0IfK6dNXJj0HWjtPeL/oIkjwIuovkFdi7N9W830ZwJWkQTMO93I0e/qroX+AnwD0keS/ML9hjg7X19u3aUJkbKR26MWav6VXVvkmfRnEU7hOYsLcAtST5Cc8nDrfdvZlqM3FzzGNbc0DLIZiMTU/U+TJH7HSetB9P8jhlrm2DNpSOTcdOAsnuGmLfBgHm/bI/PfiPb2XtD3TDH3fasGXEYcX1V1SjLjOddwHFt22fQhOs72nlH0FzuMsivRym/h98NtCM/U4OuQ+231seuNBoDqTQHJNma5mYIgE8m+eQoVY9kTSAd+UX90FHqPmxA2V/R/BL67dnOnj68jCYIra0LaQLpU3rKRvr2MJprAftt01evt/4g/fWpql/R3PhyfJJH05wNfg3wWppfyuvqRoyRPn2hql405DLT8T4Uo/9OGOuO+NGC1U001+xuOYG+dGmrJAsGhNKRY6s34PYedz8a0Nb9jrvWhMJokocAxwKXA0+vqlv65r9sIu32GQmuw5xhn8ixKw3k4xikueFwmiHQ5TQ3Egx6/R/wnCQ7tMtc0n4dNCy/BbD7gPU8uv36+QHz7tfOkEaGC3s/jy5tv+43oG8L277dSXMj05j1+8ovGTSzqn5YVR+i2YZbac4kjxgJJgvut+DU+D5NCHhae8fyMCbyPtwLv71cYpBf0Txl4He09QcdC+O5AHhQkl0msGyX1qe5E7/ffu3XS3vKxjpOH01zScDVfcP14xnreHsUzc/JmQPC6MPb+ZM1cjw+Mcm2Q9Zdm2NXGshAKs0Nr26/Hl1Vrx70Av6N5sankbpfogkhL0+yuK+9Jfzu0OSI1e3X/XoLkxzQ0+7QkjwIeGX77Vk9sz5Gc/3hMe0v9l5vAR4IfKzn2sXzaR45s3f7KKvedRxCc73pVTTXiZJkh1GC0oNohrrv6Cn7Fc0Zre3XauOGVFX30NyhvA3wniT914KSZJskj+8pWt1+3a+v3ljvw8iw+GjbcRGwfZLn9ZX/LaMPA4/l3e3Xfx8UbJJsmuRpE2h3XXh7ep4hmmRLmv0A8B899T7cfv3bdpRipP4Cmuu216P5Y3BtjPU+rW6/7t37h0WSzWhusJr0qGd7Zvj9NNck/2v6nqWaZMORbZ3gsSsN5JC9NMuleQj5TsCqqrpojKoforl7/ZVJ/q6qbk0y8nzSc5P0Pod0V5qbf/bta+P9NAHys0k+T3Od2a7A7wGfoXnE0mgOypoHq4/c1PRCmqHni4F/HalYVauTHAf8C3BJks/QnOF9Js3NMt+nuaFnpH4lOZzmcT6fbp89+f12vxwE3EJz1/l97SK7AV9Ispxm+PMaYGuaM6MbsOaaUtr9dCGwT5KP0wTbe4HTqmpCN6YM8Ja2T0fRPEvymzT79iE01+c9g+a9+25bfyLvwzeAlwD/leS/aUL3T6rqo+38d9I8S/JL7bFwI82Zwh1o/ljYb202qKq+keREmuuCf9Cu82qa6wkfSfNentf2eSa5luaPksuTnEZzPBxCE7reX1XnjFSs5lm/76B5vuflST5H89zc59O8H+cBp6zl+r9Fc2f625PsSvMHEVX1/6rqF0k+BfwRsCLJmTR/OD6XZsRgBRM7m93v72meH/pC4KokX6H5GXoEzeOlXseaa9XX9tiVBuv6Nn9fvnxN7kXzMPICjh2i7plt3YN7yp5L84vzdppffl+iudP2VAY/h/TpNHcV/4rml9R5NKFvv7b+kr76I+30v26mOSv3OmCjUfr7vLbPv6J5LukPgXfQ95ionvo7AR+lCRV3t18/BuzUV+/hNM9aPJ/mZpW7gJ8BXwOeP6DdR9M8V/IGmrBQ9D3TcZT+nMWQj/ChOXv9CprgeCPN3dI/b/fvG4BHTPJ9WNBu84/bfXO/xzzR/FOFZTTh5gaaB8M/ctCxwJCPw6L5A+czNKH/NzR/WKyguTln8Xj7pW3jiEHrYoxHJPUsc7/3aYx9tLp9bUHzx9DP22PjezTXbmaU/v1Ru/9vaffdFTQh7H7H9cg6xtneP2730R30PCKsnbcJ8Faan4U7aZ7j+y80f9id1Vt3rG0drz80J6xeS/MzeitN0P4BzT8X6H+m8Vodu758DXqlaqI3+kmSNHek+dedVNWibnsizT9eQypJkqROGUglSZLUKQOpJEmSOuU1pJIkSeqUj32a5bbaaqtatGhR192QJEka1/Lly39ZVVv3lxtIZ7lFixaxbNmyrrshSZI0riQ/GVTuNaSSJEnqlIFUkiRJnXLIfpb73s9uYM/X/WfX3ZAkSbPU8lP+pOsueIZUkiRJ3TKQSpIkqVMGUkmSJHXKQCpJkqROGUglSZLUKQOpJEmSOmUglSRJUqcMpJIkSeqUgVSSJEmdMpBKkiSpUwZSSZIkdcpAKkmSpE4ZSHsk+fYQdY5LsskUre+IJNtORVuSJEmzlYG0R1U9fYhqxwFDB9IkC8aYfQRgIJUkSfOagbRHklvbr/slOSvJ55J8P8nH0ziWJkB+K8m3xmonyT8kuRDYK8mbk1yc5PIkS9u2DgEWAx9PsiLJxkn2THJ2kuVJzkiyzSjtH5lkWZJl99x+yzTsCUmSpHXHQDq6J9GcDX088CjgGVX1HuAaYP+q2n+MZTcFLq+qp1bVecD7qurJVbUrsDHwB1X1OWAZcFhV7Q7cA7wXOKSq9gQ+DLx1UONVtbSqFlfV4vU32XxqtlaSJKkj63fdgRnsoqr6GUCSFcAi4Lwhl70X+HzP9/sneT3NUP+WwBXAl/uW2QnYFfh6EoAFwLUT7bwkSdJsYSAd3V090/eydvvqzqq6FyDJRsD7gcVV9dMkS4CNBiwT4Iqq2muC/ZUkSZqVHLJfe7cAazNOPhI+f5lkM+CQUdq6Etg6yV4ASTZIsstkOytJkjTTGUjX3lLga2Pd1NSrqn4N/DuwCvgicHHP7FOBf20vCVhAE1ZPTrISWAEMc9e/JEnSrJaq6roPmoRNH7ZD7fyKv++6G5IkaZZafsqfrLN1JVleVYv7yz1DKkmSpE55U9MktM8ZfUBf8SuqalUX/ZEkSZqNDKSTUFVP7boPkiRJs51D9pIkSeqUgVSSJEmdMpBKkiSpUwZSSZIkdcpAKkmSpE4ZSCVJktQpH/s0yz3u4Q9m2Tr8DwuSJElTzTOkkiRJ6pSBVJIkSZ0ykEqSJKlTBlJJkiR1ykAqSZKkThlIJUmS1Ckf+zTL/ebaK/jff3hC192QJElTYPs3r+q6C53wDKkkSZI6ZSCVJElSpwykkiRJ6pSBVJIkSZ0ykEqSJKlTBlJJkiR1ykAqSZKkThlIJUmS1CkDqSRJkjplIJUkSVKnDKSSJEnqlIFUkiRJnZoRgTTJrRNc7rgkm0x1f8ZZ56lJDlmX65QkSZrLZkQgnYTjgHUaSCVJkjS1ZlQgTbJZkm8kuSTJqiQHtuWbJvlqkpVJLk9yaJJjgW2BbyX51ijtvTTJu9rpv0zy43Z6xyTntdN7Jjk7yfIkZyTZpqfO6W35uUl2HtD+W9ozpgP3Y5LVSU5OclH7enRb/sIkFya5NMn/JHlokvWS/CDJ1m2d9ZL8MMlWA9o9MsmyJMtuvO3etd/RkiRJM8iMCqTAncDBVbUHsD/wj0kC/B5wTVXtVlW7AqdX1XuAa4D9q2r/Udo7B9innd4HuCHJdsDewLlJNgDeCxxSVXsCHwbe2tZfChzTlp8AvL+34STvAB4CvLKq7htjm26uqqcA7wP+qS07D3haVT0J+BTw+raNjwGHtXWeA6ysql/2N1hVS6tqcVUt3nLTBWOsWpIkaeZbv+sO9AnwtiT7AvcB2wEPBVYB70xyMvCVqjp3mMaq6hftWdfNgUcAnwD2pQmn/wXsBOwKfL3JvSwArk2yGfB04LNtOcADepp+E3BhVR05RDc+2fP13e30w4FPt2djNwSubss/DHyJJri+CviPYbZTkiRpNptpZ0gPA7YG9qyq3YHrgI2q6ipgT5pg+vYkb16LNr8DvBK4EjiXJozuBZxPE4CvqKrd29cTqup5NPvl1z3lu1fV43ravBjYM8mWQ6y/Bky/F3hfVT0BeA2wEUBV/RS4LsmzgKcCX1uL7ZQkSZqVZlog3QK4vqruTrI/8EiAJNsCt1fVx4B3Anu09W8BNh+nzXNohtzPAS6luRTgrqq6iSakbp1kr3Y9GyTZpapuBq5O8pK2PEl262nzdOAk4Kvt2dexHNrz9Ts92/nzdvrwvvofpBm6/0xVeYGoJEma82bakP3HgS8nWQasAL7flj8BOCXJfcDdwJ+35UuBryW5dozrSM+lGa4/p6ruTfLTkXar6jftI5zek2QLmv3xT8AVNGdrP5Dkb4ENaK71XDnSaFV9tg2jpyV5QVXdMcr6H5DkQprw/7K2bAnN5QA/By4AduipfxrNUL3D9ZIkaV5IVY1fSxOSZDWweNCNSWMssxh4d1XtM25l4InbbVxfec2jJ9hDSZI0k2z/5lVdd2FaJVleVYv7y2faGdJ5LcmJNGd/DxuvriRJ0lwxZwJpOyz+gL7iV1TVtP+pkeQL/O6wO8BfV9WitWmnqk6iuTZVkiRp3pgzgbSqntrhug/uat2SJEmz3Uy7y16SJEnzjIFUkiRJnTKQSpIkqVMGUkmSJHXKQCpJkqROGUglSZLUqTnz2Kf5asNtdmH7Ny/ruhuSJEkT5hlSSZIkdcpAKkmSpE4ZSCVJktQpA6kkSZI6ZSCVJElSpwykkiRJ6pSPfZrlvn/993nGe5/RdTckad46/5jzu+6CNOt5hlSSJEmdMpBKkiSpUwZSSZIkdcpAKkmSpE4ZSCVJktQpA6kkSZI6ZSCVJElSpwykkiRJ6pSBVJIkSZ0ykEqSJKlTBlJJkiR1ykAqSZKkTs37QJpkSZITOlz/rV2tW5IkaSaY94F0OiRZ0HUfJEmSZos5GUiTbJrkq0lWJrk8yaFJVifZqp2/OMlZPYvsluSbSX6Q5M/GaHe9JO9PckWSryT57ySHtPNWJ3lzkvOAlyT5syQXt334fJJN2no7JPlOO+8tfe2/ri2/LMnfj9GPI5MsS7Ls7lvvnsSekiRJ6t6cDKTA7wHXVNVuVbUrcPo49Z8I/D6wF/DmJNuOUu9FwCLgCcCr2/q97qyqvavqU8B/VdWTq2o34HvAn7Z1/hn4QFU9GfjFyIJJngc8BngKsDuwZ5J9B3WiqpZW1eKqWrzBZhuMs2mSJEkz21wNpKuA5yQ5Ock+VXXTOPW/VFV3VNUvgW/RhMJB9gY+W1X3VdUv2rq9Pt0zvWuSc5OsAg4DdmnLnwF8sp3+aE/957WvS4FLgJ1pAqokSdKctn7XHZgOVXVVkj2BFwBvT3ImcA9rAvhG/YuM8/2IjLPq23qmTwUOqqqVSY4A9hun/QBvr6p/G2cdkiRJc8qcPEPaDrnfXlUfA94J7AGsBvZsq7y4b5EDk2yU5ME0wfHiUZo+D3hxey3pQ/ndkNlvc+DaJBvQnCEdcT7wR+10b/kZwKuSbNZuw3ZJHjJG+5IkSXPCnDxDSnON5ylJ7gPuBv4c2Bj4UJI3ABf21b8I+CqwPfCWqrpmlHY/DzwbuBy4qm1ntMsB3tTO/wnNJQSbt+V/CXwiyV+27QFQVWcmeRzwnSQAtwJ/DFw/5DZLkiTNSqkabXRagyTZrKpubc+mXgQ8o72etBObbb9Z7fa63bpavSTNe+cfc37XXZBmjSTLq2pxf/lcPUM6nb6SZCGwIc3Z1M7CqCRJ0lxgIB0gyRP43TvgAe6qqqdW1X4ddEmSJGnOMpAOUFWraJ4FKkmSpGk2J++ylyRJ0uxhIJUkSVKnDKSSJEnqlIFUkiRJnTKQSpIkqVMGUkmSJHXKxz7Ncjs/ZGf/S4gkSZrVPEMqSZKkThlIJUmS1CkDqSRJkjplIJUkSVKnDKSSJEnqlIFUkiRJnfKxT7PcLVdeydn7PrPrbkhS5555ztldd0HSBHmGVJIkSZ0ykEqSJKlTBlJJkiR1ykAqSZKkThlIJUmS1CkDqSRJkjplIJUkSVKnDKSSJEnqlIFUkiRJnTKQSpIkqVMGUkmSJHXKQDoNkixMcnQ7vW2Sz7XTuyd5QU+9I5K8r6t+SpIkzQQG0umxEDgaoKquqapD2vLdgReMupQkSdI8tH7XHZijTgJ2TLIC+AHwOGAP4B+AjZPsDby9d4EkWwP/CmzfFh1XVeevuy5LkiR1wzOk0+NE4EdVtTvwOoCq+g3wZuDTVbV7VX26b5l/Bt5dVU8GXgx8cLTGkxyZZFmSZTfdfff0bIEkSdI64hnSmeM5wOOTjHz/wCSbV9Ut/RWraimwFGCnzTevdddFSZKkqWcgnTnWA/aqqju67ogkSdK65JD99LgF2HwtygHOBF478k2S3aehX5IkSTOOgXQaVNUNwPlJLgdO6Zn1LZph+RVJDu1b7FhgcZLLknwXOGoddVeSJKlTDtlPk6p6+YCyG4En9xWf2s77JdAfUiVJkuY8z5BKkiSpUwZSSZIkdcpAKkmSpE4ZSCVJktQpA6kkSZI6ZSCVJElSpwykkiRJ6pSBVJIkSZ0ykEqSJKlTBlJJkiR1yn8dOsttvtNOPPOcs7vuhiRJ0oR5hlSSJEmdMpBKkiSpUwZSSZIkdcpAKkmSpE4ZSCVJktQpA6kkSZI65WOfZrnrf3YT7/v/vtx1N6RZ5bX/+MKuuyBJ6uEZUkmSJHXKQCpJkqROGUglSZLUKQOpJEmSOmUglSRJUqcMpJIkSeqUgVSSJEmdMpBKkiSpUwZSSZIkdcpAKkmSpE4ZSCVJktQpA6kkSZI6tU4DaZKFSY4ep86iJC8foq1FSS6fut6NL8mSJCeMMu/bYyz3274mWZzkPdPVR0mSpNlmXZ8hXQiMGUiBRcC4gXRtJFl/KtsbpKqePmS9ZVV17HT3R5IkabZY14H0JGDHJCuSnNK+Lk+yKsmhPXX2aesc355dPDfJJe1rqOCX5Igkn03yZeDMJJsm+XCSi5NcmuTAtt6FSXbpWe6sJHuO0fTj2zo/TnJsz3K3Dtmv/ZJ8pZ1ekuQjSc5MsjrJi5K8o90fpyfZYJg2JUmSZrOhAmmSHZM8oJ3eL8mxSRZOYH0nAj+qqt2BC4Ddgd2A5wCnJNmmrXNuVe1eVe8GrgeeW1V7AIcCazPcvRdweFU9C3gj8M2qejKwf7u+TYFPAS9tt20bYNuqWj5GmzsDBwBPAf5uCkLjjsDvAwcCHwO+VVVPAO5oy+8nyZFJliVZduvtN01y9ZIkSd0a9gzp54F7kzwa+BCwA/CJSa57b+CTVXVvVV0HnA08eUC9DYB/T7IK+Czw+LVYx9er6sZ2+nnAiUlWAGcBGwHbA58BXtLWeWm7jrF8taruqqpf0oTlh65Ffwb5WlXdDawCFgCnt+WraC5fuJ+qWlpVi6tq8WabbDHJ1UuSJHVr2Gsr76uqe5IcDPxTVb03yaWTXHeGrHc8cB3NmdT1gDvXYh239a3vxVV15f06ktyQ5Ik0Z2BfM06bd/VM38vw+3DM9qrqviR3V1W15fdNQduSJEkz3rBnSO9O8jLgcOArbdlEhqpvATZvp88BDk2yIMnWwL7ARX11ALYArq2q+4BX0JxFnIgzgGOSBCDJk3rmfQp4PbBFVa2aYPuSJEmagGED6Stprsd8a1VdnWQHmusd10pV3QCc3z4CaS/gMmAl8E3g9VX1i7bsniQrkxwPvB84PMkFwGP53bOea+MtNCH6snb9b+mZ9zngj2iG7yVJkrQOZc0I8TgVk42B7QcNeas72z/sMfX6w97VdTekWeW1//jCrrsgSfNSkuVVtbi/fNi77F8IrKC94SbJ7klOm9ouSpIkaT4a9qaZJTSPOToLoKpWtMP2nUtyAHByX/HVVXXwJNp8JfCXfcXnV9VfjLPcE4CP9hXfVVVPnWhfJEmS5rphA+k9VXVTez/QiOHG+qdZVZ1Bc8PSVLb5H8B/TGC5VTTPVpUkSdKQhg2kl7f/X35BkscAxwKj/u92SZIkaVjD3mV/DLALzTMzPwHcBBw3XZ2SJEnS/DHuGdIkC4DTquo5NP9+U5IkSZoy454hrap7gduT+D8qJUmSNOWGvYb0TmBVkq/T82D6qjp2WnolSZKkeWPYQPrV9iVJkiRNqaH/U5NmpsWLF9eyZcu67oYkSdK4RvtPTUOdIU1yNQOeO1pVj5qCvkmSJGkeG3bIvjfJbgS8BNhy6rsjSZKk+Wao55BW1Q09r59X1T8Bz5rmvkmSJGkeGHbIfo+eb9ejOWO6+bT0SJIkSfPKsEP2/9gzfQ9wNfDSqe+OJEmS5pthA+mfVtqrwsgAABZsSURBVNWPewuS7DAN/ZEkSdI8M9Rjn5JcUlV79JUtr6o9p61nGsp2D35QHf38Z3fdDWnC3vixz3XdBUnSOjKhxz4l2RnYBdgiyYt6Zj2Q5m57SZIkaVLGG7LfCfgDYCHwwp7yW4A/m65OSZIkaf4YM5BW1ZeALyXZq6q+s476JEmSpHlk2JuaLk3yFzTD978dqq+qV01LryRJkjRvDPVgfOCjwMOAA4CzgYfTDNtLkiRJkzJsIH10Vb0JuK2qPgL8PvCE6euWJEmS5othA+nd7ddfJ9kV2AJYNC09kiRJ0rwy7DWkS5M8CHgTcBqwGfDmaeuVJEmS5o2hAmlVfbCdPBt41PR1R5IkSfPNUEP2SR6a5ENJvtZ+//gkfzq9XZMkSdJ8MOw1pKcCZwDbtt9fBRw3HR2SJEnS/DJsIN2qqj4D3AdQVfcA905bryRJkjRvDBtIb0vyYKAAkjwNuGnaejUBSRYmOXqcOouSvHxd9alnvUcked9aLrM6yVbT1SdJkqSZYthA+lc0d9fvmOR84D+BY6atVxOzEBgzkNI8qmraAmmSYZ9aIEmSpNaYgTTJ9gBVdQnwTODpwGuAXarqsunv3lo5iSYwr0hySvu6PMmqJIf21NmnrXP8oEaSLEjyzna5y5Ic05b/9oxlksVJzmqnlyRZmuRMmqA+mkckOT3JlUn+rmd9X0yyPMkVSY6c/G6QJEmaXcY7o/dFYI92+tNV9eJp7s9knAjsWlW7J3kxcBSwG7AVcHGSc9o6J1TVH4zRzpHADsCTquqeJFsOse49gb2r6o4x6jwF2BW4ve3PV6tqGfCqqroxycZt+eer6oaxVtYG1yMBtthk4yG6J0mSNHONN2SfnunZ9PzRvYFPVtW9VXUdzfNTnzzkss8B/rW9cYuqunGIZU4bJ4wCfL2qbmjr/VfbR4Bjk6wELgAeATxmvJVV1dKqWlxVizfd6AFDdE+SJGnmGu8MaY0yPdNl/CpjLjtoW+9hTYDfqG/ebUO0299mJdmPJgDvVVW3t5cB9LctSZI0p413hnS3JDcnuQV4Yjt9c5Jbkty8Ljq4Fm4BNm+nzwEOba8H3RrYF7ior85ozgSOGrlBqWfIfjXN0DzARC5deG6SLduh+YOA84EtgF+1YXRn4GkTaFeSJGlWGzOQVtWCqnpgVW1eVeu30yPfP3BddXIY7XWX5ye5HNgLuAxYCXwTeH1V/aItuyfJytFuagI+CPwvcFk7lD5yV/7fA/+c5Fwm9gzW84CPAiuAz7fXj54OrJ/kMuAtNMP2kiRJ80qqZtNIvPpt9+AH1dHPf3bX3ZAm7I0f+1zXXZAkrSNJllfV4v7yYZ9DKkmSJE2Lefsg9yQHACf3FV9dVQfPpDYlSZLmunkbSKvqDOCMmd6mJEnSXOeQvSRJkjplIJUkSVKnDKSSJEnqlIFUkiRJnTKQSpIkqVMGUkmSJHVq3j72aa7YZocd/U83kiRpVvMMqSRJkjplIJUkSVKnDKSSJEnqlIFUkiRJnTKQSpIkqVMGUkmSJHXKxz7Ncndeewvfe+s3u+6Gptjj3visrrsgSdI64xlSSZIkdcpAKkmSpE4ZSCVJktQpA6kkSZI6ZSCVJElSpwykkiRJ6pSBVJIkSZ0ykEqSJKlTBlJJkiR1ykAqSZKkThlIJUmS1CkDqSRJkjo16wJpkoVJjh6nzqIkLx+irUVJLp+63o0vyQeTPH6cOgeNV0eSJGmumHWBFFgIjBlIgUXAuIF0bSRZfyraqapXV9V3x6l2EGAglSRJ88JsDKQnATsmWZHklPZ1eZJVSQ7tqbNPW+f49kzouUkuaV9PH2ZFSY5I8tkkXwbOTLJpkg8nuTjJpUkObOstSPLOtg+XJTlmjDbPSrK4nb41yVuTrExyQZKHtn37Q+CUtv87TmZnSZIkzXRTctZvHTsR2LWqdk/yYuAoYDdgK+DiJOe0dU6oqj8ASLIJ8NyqujPJY4BPAouHXN9ewBOr6sYkbwO+WVWvSrIQuCjJ/wB/AuwAPKmq7kmy5ZBtbwpcUFVvTPIO4M+q6v8lOQ34SlV9btBCSY4EjgTYZouHDLkqSZKkmWk2BtJeewOfrKp7geuSnA08Gbi5r94GwPuS7A7cCzx2Ldbx9aq6sZ1+HvCHSU5ov98I2B54DvCvVXUPQE/98fwG+Eo7vRx47jALVdVSYCnArtvtVEOuS5IkaUaa7YE0Q9Y7HriO5kzqesCda7GO2/rW9+KquvJ3OpEEmEgwvLuqRpa7l9n/fkiSJK212XgN6S3A5u30OcCh7TWcWwP7Ahf11QHYAri2qu4DXgEsmOC6zwCOaQMoSZ7Ulp8JHDVy49NaDNmPpr//kiRJc9asC6RVdQNwfvu4pr2Ay4CVwDeB11fVL9qye9qbhY4H3g8cnuQCmuH62wa3Pq630Az/X9au/y1t+QeB/23LVzL5O/w/BbyuvXHKm5okSdKcljUjxpqNdt1up/rs0R/ouhuaYo9747O67oIkSVMuyfKqut+N5bPuDKkkSZLmFm+iAZIcAJzcV3x1VR08iTa/QPMoqF5/XVVnTLRNSZKkuchACrQhcUqD4mTCrCRJ0nzikL0kSZI6ZSCVJElSpwykkiRJ6pSBVJIkSZ0ykEqSJKlTBlJJkiR1ysc+zXIbbbO5/9VHkiTNap4hlSRJUqcMpJIkSeqUgVSSJEmdMpBKkiSpUwZSSZIkdcpAKkmSpE752KdZ7pprrmHJkiVdd2POct9KkjT9PEMqSZKkThlIJUmS1CkDqSRJkjplIJUkSVKnDKSSJEnqlIFUkiRJnTKQSpIkqVMGUkmSJHXKQCpJkqROGUglSZLUKQOpJEmSOmUglSRJUqfmXSBNsjDJ0ePUWZTk5UO0tSjJ5VPXO0mSpPln3gVSYCEwZiAFFgHjBlJJkiRN3nwMpCcBOyZZkeSU9nV5klVJDu2ps09b5/j2TOi5SS5pX08fZkVjLZfk9e06VyY5qS17dJL/acsuSbLjlG+9JEnSDLN+1x3owInArlW1e5IXA0cBuwFbARcnOaetc0JV/QFAkk2A51bVnUkeA3wSWDzEuq4ftFyS5wMHAU+tqtuTbNnW/zhwUlV9IclGjPIHQ5IjgSMBtthii4nsA0mSpBljPgbSXnsDn6yqe4HrkpwNPBm4ua/eBsD7kuwO3As8dsj2R1vuOcB/VNXtAFV1Y5LNge2q6gtt2Z2jNVpVS4GlANtuu20N2RdJkqQZab4H0gxZ73jgOpozqesBo4bFIZcL0B8kh+2LJEnSnDIfryG9Bdi8nT4HODTJgiRbA/sCF/XVAdgCuLaq7gNeASwYcl2jLXcm8Kr2UgCSbFlVNwM/S3JQW/aAkfmSJElz2bwLpFV1A3B++7imvYDLgJXAN4HXV9Uv2rJ72puLjgfeDxye5AKaYffbhlzdwOWq6nTgNGBZkhXACW39VwDHJrkM+DbwsElvsCRJ0gyXKi9BnM223XbbOvLII7vuxpy1ZMmSrrsgSdKckWR5Vd3vxvB5d4ZUkiRJM8t8v6lpSiQ5ADi5r/jqqjq4i/5IkiTNJgbSKVBVZwBndN0PSZKk2cghe0mSJHXKQCpJkqROGUglSZLUKQOpJEmSOmUglSRJUqcMpJIkSeqU/6lpllu8eHEtW7as625IkiSNy//UJEmSpBnJQCpJkqROGUglSZLUKQOpJEmSOmUglSRJUqcMpJIkSeqUgVSSJEmdWr/rDmhyfvWr7/GZzz6l627MWS99yUVdd0GSpDnPM6SSJEnqlIFUkiRJnTKQSpIkqVMGUkmSJHXKQCpJkqROGUglSZLUKQOpJEmSOmUglSRJUqcMpJIkSeqUgVSSJEmdMpBKkiSpUwZSSZIkdcpAOklJ1u+6D5IkSbOZgRRIsijJ95N8JMllST6XZJMkq5Ns1dZZnOSsdnpJkqVJzgT+M8kRSb6U5PQkVyb5u562/yrJ5e3ruLZs0yRfTbKyLT+0Ld8zydlJlic5I8k2635vSJIkrVue3VtjJ+BPq+r8JB8Gjh6n/p7A3lV1R5IjgKcAuwK3Axcn+SpQwCuBpwIBLkxyNvAo4Jqq+n2AJFsk2QB4L3BgVf1fG1LfCryqf8VJjgSOBNhqqw0nudmSJEndMpCu8dOqOr+d/hhw7Dj1T6uqO3q+/3pV3QCQ5L+AvWkC6Req6rae8n2A04F3JjkZ+EpVnZtkV5pA+/UkAAuAawetuKqWAksBdtxx01rrLZUkSZpBDKRr9Ae7Au5hzWUNG/XNv22I5TNwRVVXJdkTeAHw9nbo/wvAFVW119p2XJIkaTbzGtI1tk8yEgZfBpwHrKYZmgd48TjLPzfJlkk2Bg4CzgfOAQ5qr0fdFDgYODfJtsDtVfUx4J3AHsCVwNYjfUiyQZJdpm7zJEmSZibPkK7xPeDwJP8G/AD4AHAR8KEkbwAuHGf584CPAo8GPlFVywCSnNq2A/DBqro0yQHAKUnuA+4G/ryqfpPkEOA9SbageW/+CbhiKjdSkiRppjGQrnFfVR3VV3Yu8Nj+ilW1ZMDy11fVawfUfRfwrr6yM4AzBtRdAey7Fn2WJEma9RyylyRJUqc8QwpU1WqaO9wnuvypwKlT1B1JkqR5xTOkkiRJ6pSBVJIkSZ0ykEqSJKlTBlJJkiR1ykAqSZKkThlIJUmS1CkDqSRJkjrlc0hnuQc96HG89CUXjV9RkiRphvIMqSRJkjplIJUkSVKnDKSSJEnqlIFUkiRJnTKQSpIkqVMGUkmSJHXKQCpJkqRO+RzSWe67v7qZ3T53RtfdmLNWHnJA112QJGnO8wypJEmSOmUglSRJUqcMpJIkSeqUgVSSJEmdMpBKkiSpUwZSSZIkdcpAKkmSpE4ZSCVJktQpA6kkSZI6ZSCVJElSpwykkiRJ6pSBVJIkSZ2atkCa5NtD1Plgkse302+YwPK3jjFvUZLL2+nFSd4zTt2Xj7e+AcstTHL0VNWTJEmaj6YtkFbV04eo8+qq+m777Rv65o27/Fr0ZVlVHTtGlUXAWgdSYCEwTNActp4kSdK8M51nSG9tv+6X5Kwkn0vy/SQfT5J23lnt2cuTgI2TrEjy8b7lN0vyjSSXJFmV5MAJ9GW/JF9pp5/ZrmdFkkuTbA6cBOzTlh0/Shu7JLmorXNZkse0y+3Ylp0yRl/76/22P23b70tyRDt9UpLvtut45yh9OTLJsiTL7rn5prXdHZIkSTPK+utoPU8CdgGuAc4HngGcNzKzqk5M8tqq2n3AsncCB1fVzUm2Ai5IclpV1QT7cgLwF1V1fpLN2vZPBE6oqj8YY7mjgH+uqo8n2RBY0C6360i/k6w/qK8D6u03aAVJtgQOBnauqkqycFC9qloKLAXYZMfHTnQ/SJIkzQjr6qami6rqZ1V1H7CCZoh8WAHeluQy4H+A7YCHTqIv5wPvSnIssLCq7hlyue8Ab0jy18Ajq+qOaejrzTQB+YNJXgTcvhbLSpIkzUrrKpDe1TN9L2t3ZvYwYGtgz/YM43XARhPtSFWdBLwa2JjmDObOQy73CeAPgTuAM5I8axJ9vYff3fcbteu4B3gK8HngIOD0YfomSZI0m62rIfth3J1kg6q6u698C+D6qro7yf7AIyezkiQ7VtUqYFWSvYCdgZ8Cm4+z3KOAH1fVe9rpJwIr+5Ybra+39NX7CfD4JA+gCaPPBs5rLyHYpKr+O8kFwA8ns62SJEmzwUwKpEuBy5JcUlWH9ZR/HPhykmU0w/3fn+R6jmvD4r3Ad4GvAfcB9yRZCZxaVe8esNyhwB8nuRv4BfAPVXVjkvPbx0t9DTh5UF+r6obeelX1uiSfAS4DfgBc2q5jc+BLSTaiGf4feIOVJEnSXJKJ3xukmWCTHR9bjzn5vV13Y85aecgBXXdBkqQ5I8nyqlrcX+5/apIkSVKnZtKQ/YQkeQLw0b7iu6rqqRNs7wCaofdeV1fVwRNpT5IkSWOb9YG0vUFp0PNLJ9reGcAZU9WeJEmSxuaQvSRJkjplIJUkSVKnDKSSJEnqlIFUkiRJnTKQSpIkqVOz/i77+e7xD3ogy3x4uyRJmsU8QypJkqROGUglSZLUKQOpJEmSOpWq6roPmoQktwBXdt2PWWAr4Jddd2KGcx8Nx/00HPfTcNxPw3E/jW+27KNHVtXW/YXe1DT7XVlVi7vuxEyXZJn7aWzuo+G4n4bjfhqO+2k47qfxzfZ95JC9JEmSOmUglSRJUqcMpLPf0q47MEu4n8bnPhqO+2k47qfhuJ+G434a36zeR97UJEmSpE55hlSSJEmdMpBKkiSpUwbSGSTJ7yW5MskPk5w4YH6SvKedf1mSPcZbNsmWSb6e5Aft1wetq+2ZLhPdT0kekeRbSb6X5Iokf9mzzJIkP0+yon29YF1u03SY5PG0Osmqdl8s6ymfU8fTJI6lnXqOlRVJbk5yXDtvPh5LOyf5TpK7kpwwzLJz7ViCie8nP5vuN3+s42lefDbBpI6n2fn5VFW+ZsALWAD8CHgUsCGwEnh8X50XAF8DAjwNuHC8ZYF3ACe20ycCJ3e9rR3up22APdrpzYGrevbTEuCErrdvJuyndt5qYKsB7c6Z42my+6ivnV/QPOx5vh5LDwGeDLy1d9v9bBp6P/nZNMR+aufN+c+mqdhPfe3Mis8nz5DOHE8BflhVP66q3wCfAg7sq3Mg8J/VuABYmGSbcZY9EPhIO/0R4KDp3pBpNuH9VFXXVtUlAFV1C/A9YLt12fl1aDLH01jm0vE0Vfvo2cCPquon09/lToy7n6rq+qq6GLh7LZadS8cSTGI/+dk09PE0Fo+nwWbN55OBdObYDvhpz/c/4/4fSKPVGWvZh1bVtdB86NH8RTWbTWY//VaSRcCTgAt7il/bDst+eA4M90x2PxVwZpLlSY7sqTOXjqcpOZaAPwI+2Vc2346liSw7l44lmNx++i0/m8Y1Hz6bYIqOJ2bR55OBdObIgLL+Z3KNVmeYZeeKyeynZmayGfB54Liqurkt/gCwI7A7cC3wj5Pvaqcmu5+eUVV7AM8H/iLJvlPZuRliKo6lDYE/BD7bM38+HkvTsexsM+lt9bNpKPPhswmm5niaVZ9PBtKZ42fAI3q+fzhwzZB1xlr2upEhxvbr9VPY5y5MZj+RZAOaD/yPV9V/jVSoquuq6t6qug/4d5rhktlsUvupqka+Xg98gTX7Yy4dT5PaR63nA5dU1XUjBfP0WJrIsnPpWILJ7Sc/m4Y0Tz6bYJL7qTWrPp8MpDPHxcBjkuzQ/lXzR8BpfXVOA/4kjacBN7VDE2MtexpweDt9OPCl6d6QaTbh/ZQkwIeA71XVu3oX6Lsu8GDg8unbhHViMvtp0ySbAyTZFHgea/bHXDqeJvMzN+Jl9A2HzdNjaSLLzqVjCSaxn/xsGno/zZfPJpjcz92I2fX51PVdVb7WvGju6L2K5s66N7ZlRwFHtdMB/qWdvwpYPNaybfmDgW8AP2i/btn1dna1n4C9aYY8LgNWtK8XtPM+2ta9jOaHfpuut7PD/fQomjs6VwJXzOXjaZI/c5sANwBb9LU5H4+lh9Gc0bkZ+HU7/cDRlp2Lx9Jk9pOfTUPvp3nz2TSZ/dTOm3WfT/7rUEmSJHXKIXtJkiR1ykAqSZKkThlIJUmS1CkDqSRJkjplIJUkSVKnDKSSJEnqlIFUkiRJnfr/AW32BOlhzBrwAAAAAElFTkSuQmCC\n",
"text/plain": [
""
]
},
"metadata": {
"needs_background": "light"
},
"output_type": "display_data"
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"\n",
"Model used: AdaBoostClassifier(algorithm='SAMME.R', base_estimator=None, learning_rate=1.0,\n",
" n_estimators=100, random_state=None) \n",
" Done.\n",
"-----------------------------------------\n",
"************* Model Results *************\n",
"-----------------------------------------\n",
"F1 Score : 0.6576365174253705\n",
"Report:\n",
" precision recall f1-score support\n",
"\n",
" 0 0.76 0.87 0.81 14622\n",
" 1 0.23 0.12 0.16 4578\n",
"\n",
" accuracy 0.69 19200\n",
" macro avg 0.50 0.50 0.49 19200\n",
"weighted avg 0.63 0.69 0.66 19200\n",
"\n"
]
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAW0AAAENCAYAAADE9TR4AAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADt0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjByYzEsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy/xvVyzAAAgAElEQVR4nO3dd3wVVfrH8c+ThCaQBEIoElz1BypFBQtFFFFUUFHctWEDFURx3bUvxQauBV2VRVAUFFERkQUErIggunQQC4LigiKEklBDAKXE8/tjJuEmuamEMuP3zWte994z55w5d2547rlnzsyYcw4REQmGmEPdABERKT4FbRGRAFHQFhEJEAVtEZEAUdAWEQkQBW0RkQBR0A4RM/u7mS01s1/NzJnZXQdhmyvNbOWB3s4fgf+ZzTjU7ZDDm4J2KZjZCWY22My+M7MMM9ttZmvN7AMz62ZmFQ9BmzoDg4DfgH8D/YG5B7sdhwP/i8T5yzmF5HstIl+//dxm27KoR6QocYe6AUFjZg8Dj+B94c0FXge2A7WAtsArQE/gtIPctI7Zj865tQdxu+0O4rZKai9wC/BZ3hVmFg9c5ec5XP4fNAR2HupGyOHtcPljDQQz64vXg10NXOmcmxclT0fg3oPdNuBIgIMcsHHOrTiY2yuh94G/mFmSc25TnnXXAUcA7wJ/Pugti8I598OhboMc/jQ8UkxmdjTQD9gDXBQtYAM4594HOkQpf5WZfeEPp/xqZovNrI+ZVYiSd6W/HGFm/zKzVWa2y8yWm1kvM7OIvP3MzAHn+K+zf+677Hb7r0cW8L5mZOeNSDMz62pms81sg5n9ZmarzWyKmV0dra1R6q1gZr3N7Fsz22lm28zsv2Z2VZS8OW30n48xs43+dhf6X4SlMRyoANwQZd0teF++H0craGbHmdkAf/sb/P3/i5kNM7OUPHlHsq83/0jkZ2Bmbf08N/qvbzSzDv5+z4jc93nHtM3sGDPbamabzexPebZZ2cy+N7MsMzu7pDtGgks97eK7CSgHjHHOfVdYRufcrsjXZvYE0AfYCIzGG065EHgCaG9m5zvn9uSpphzwCV4P+iO8n/GXAQOAing9foAZ/uONwJ8i0vfH4357fwbGAhlAHeB04ErgncIKm1l5YApwNvAD8AJer/YK4B0za+qc6xul6J+A+cBPwJtAdeBqYJKZneecyzfMUYSpwEqgO944f3b7TgWa4e2r3wso+xfgNrxgPBvYDTT267rEzE5zzq3x8070H7sCn7PvM8HffqQr8L7UPwJeAo4uqPHOuZ/NrDvwH+BtM2vjnNvrr34ROAHo55z7vKA6JIScc1qKsQDTAAd0L2G5Vn65VUDtiPQ44D1/Xd88ZVb66R8ClSLSawJb/aVcnjIzvI8z3/aP9usaWUD78pUDNgGpwBFR8teI0taVedL6RLQ/Lk/7s9/bGVHa6IBH8tTVPruuEuzz7G3EAQ/6z1tFrH8JyAKOwgvCDi/4RdZRF6gQpe4L/LJD86S3jVZPxPob/fW/Ax0KyOOAGVHSX/TXPem/7uK//gyIOdT/N7Qc3EXDI8VXx39MLWG5m/3Hx5xz67MTnddjuhfvP3H3Asr+3Tn3a0SZdGASkAAcX8J2lNQevOCUi3NuYzHK3owXVO5x+3qG2e3/p/8y2nv+BXgsz/am4H3hNS9es/MZgfc+bgFvWAG4FpjinFtVUCHn3BqX5xeTn/4JsATvy6Q0Jjnnog7JFOIe4Bugl5ndgRfENwDXOecK+qUgIaWgXXzZ48glvZbtKf7j9LwrnHM/4n0JHGNmiXlWZzjnlkepb7X/WK2E7SiJt/B6v0vM7El/DDahOAXNrCpQH1jroh9Yy94PzaKs+9o5l++LAu89l+r9Ou/A7IfAVf6Mkc5AVbzx7gL54/rXm9mn/pj23ohjBSfi9cRLY35JCzjnfsMbJtoBDMYbauriDvJBZzk8KGgXX/Z/kJRCc+WXHezWFbB+XZ582bYWkD+75xpbwnaUxN3AXXhBojfe+OtGM5tkZvWLKFvc95v3SwoKf8/787c6HKgMXIPX416PNzRVmOfwxtUb4Y3PP4s3Bt4f7xdB+VK2ZX3RWaL6EfjWf74U73iH/AEpaBffTP+xpPOSM/zH2gWsr5MnX1nL/vlc0EHnfMHTOZflnBvknDsZb/755XhT4y4FPo424yXCoX6/0XwIrMEb324BvBY5bJOXmdUE/g58BxzvnLveOdfLOdfPOdcPyDdsUgKlvetIb+AMvIPZjfGOG8gfkIJ28b2GN857uZk1KixjnqD2lf/YNkq++ng995+dcwX1MvfXFv+xXpTtxwPHFVbYOZfunJvgnLsKb2jj/4AmheTPBFYAdc2sQZQs2WcoLipG28uEP+QyAm9fO+DVIooci/d/4xP//eTwp/sdG6VM9rBOmf8CMrMzgEeBZXj7fhnQ38zOLOttyeFPQbuYnHMr8eZplwc+MLOoZzyaWfZ0rmwj/McHzSw5Il8s8AzeZ1BUECk1P+j8ALSO/LLxt/8cUCkyvz+/ul3kXHA/vRzeFDwo+qy9EXjHAP7lbye7jhrAQxF5Dqbn8U6iae+KPiFopf94Zp72V8Ebaon2qyX75J2j9rOduZhZNeBtvC+Fzs65NLzx7b140wCTynJ7cvjTPO0ScM49YWZxeKexLzCz2cBC9p3G3gZo4Kdll5ltZk8D/wC+M7NxeGPFF+L1mmYC/zrATf8X3hfDLDP7D971Sc7Bmwv+DXByRN5KwKfASjObhzd+WxE4H+8068nOue+L2N4zeO+vE/CNmX2Id/DsSrxpf08752YWUr7M+bNeJhaZ0cu73szG4B20/NrMPsEbqz8fb999DTTNU2wZ3hBMZzPbjTfjxQFvOud+2Y+mj8D7Ivi7c+5rv33fmNm9wBC8X4CX7kf9EjSHes5hEBe84DUYb8xzG96JF+vwetjdiD6/tzNegM7E+4+/BHgAqBgl70ryzH2OWNcPLxi0zZM+gyjztCPWd/O3uQvvYNjLQFLecniB/B/+e1nlt3UD3nVWbgPKF6eteIG+r7+PfvXf90zgmih5j6aEc8mL+HxW+vXFFSNvQfO0j8A7yWi5vw9W450klG+fRZQ5HW8+fwbesYScz4l987RvLKQtueZpA3/z0yYVkH+Cv/7uQ/1/QsvBW8z/8EVEJAA0pi0iEiAK2iIiAaKgLSISIAraIiIBcsCn/LW1h3WkU/KZvEUn9El+8YmVrOhchStJzJnhHt3v7R1s6mmLiASIgraIhIqZFXspRl0jzCzdzL6LSPuXmf1g3l2Z3s2+Qqd/16Vfzexrf3kposyp5t2tarmZPZ99xrF/BvI7fvo88+6QVSgFbREJFYu1Yi/FMJL8tw+cCjRxzp2Ed/XFyLG+Fc65pv5yW0T6UKAH3hnTDSLq7AZscc7VBwYCTxXVIAVtEQkVs+IvRXHOfQFszpP2idt3lci5FHG5ZjOrA8Q75+Y472zGN/BuHQjepR5e95+PA/Jd9ycvBW0RCZcSRG0z62HezZuzlx4l3NrN5L5A3DFm9pWZfW5mZ/lpdcl9x6tU9t1Eoy7+jU38L4IMvEslFEgXjBKRUClODzqbc24YMKx027EH8K62+JaftA44yjm3yb959EQza8y+u17l2nR2NYWsi0pBW0RCxWIO/Cw+M+sKdATa+UMeOO+eorv851+a2Qq869WnknsIJYV9d8JKxbvWfap/BdEE8gzH5KXhEREJl7Ic1I5avXUAegGXOud2RqQnZ19/3cyOxTvg+JNzbh2QaWYt/fHqLng36AaYDHT1n18BTHdFXMVPPW0RCZWYMuxpm9nbeHedqmFmqXjX0u8DVACm+scM5/ozRdoAj5rZXrybVtzmnMvuNffEm4lSCW8MPHsc/FXgTTNbjtfD7lxUmxS0RSRcynB0xDl3TZTkqHeacs6NB8YXsG4hUW7T55z7De/mIMWmoC0ioXIwxrQPJQVtEQmVUg5VB4aCtoiES8ijtoK2iIRKTPFOTw8sBW0RCRf1tEVEgiPkMVtBW0TCpTiXXA0yBW0RCZdwx2wFbREJF83TFhEJEAVtEZEA0Zi2iEiQhPzapQraIhIq6mmLiARIyGO2graIhIsORIqIBIiCtohIkIR8fERBW0RCJeQxW0FbRMJFs0dERIJE87RFRIIjJibcUVtBW0RCxcIdsxW0RSRkNKYtIhIcIY/ZCtoiEi46uUZEJEhC3tVW0BaRUImJVdAWEQkO9bRFRIIj5DFbQVtEwkUHIkVEgiTcMVtBW0TCJSY23KdEKmiLSKhoTFtEJEhCHrUVtEUkVMJ+IDLcgz8i8odjVvyl6LpshJmlm9l3EWnVzWyqmf3Pf6wWsa6PmS03s2Vm1j4i/VQzW+yve978OzWYWQUze8dPn2dmRxfVJgVtEQmXsozaMBLokCetNzDNOdcAmOa/xswaAZ2Bxn6ZF80s1i8zFOgBNPCX7Dq7AVucc/WBgcBTRTVIQVtEQiUm1oq9FMU59wWwOU9yJ+B1//nrwGUR6WOcc7uccz8Dy4HmZlYHiHfOzXHOOeCNPGWy6xoHtLMi7pemoC0i4VK2Pe1oajnn1gH4jzX99LrA6oh8qX5aXf953vRcZZxze4EMIKmwjStoi0iolCRmm1kPM1sYsfTYn01HSXOFpBdWpkChnz3yj1cvo1XH49iavoObTnwBgNuevoAzLjmePbuzWLtiM0/dNJHtGb9x3rUn0fn+1jlljz2pFj1OeYnl36wnrlwsdw65mKZtj8b97njlgWl8MWEpAG2vbMyN/c7BOVjxzXoeu25cvnYcd0odeo/8CxUqxTH3w/8x+M4PAShXPpY+b/yF4089koxNv/Lo1WNZ/8tWANp3acoND54NwJuPfc6UN74GoPbRiTw85iriq1fix0VreeKGCezdkwXA3wZdRMuLGvDbzj0MuPFd/vfVOgCat6/PHYMuIjbW+OCVRYx+6r8HYncH0qP/fISZs76gWrXqvPP2eACW/fgDAwY8zq7du4iLjaPXP/rQuPGJrF27hqs6/4WjjvoTACc2OYk+vR8EYM+ePTz9rydZtGghFhPD7bfdwbnnnpdve6+NfJXJ700kJiaG++7tRauWZwDw/fdL6f/Ph9m1axetzziTe+/5B2bG7t27eaT/g/zww/ckJCTwxGNPceSRXkft/Q8mM2LEcABuvvkWOl58KQBr1q7hgQd7sS0jg+NPaMij/R6nXLlyOOd49rmnmTV7JhUrVuSRhx7lhBMaHtgdfJCVZPaIc24YMKyEm0gzszrOuXX+0Ee6n54K1IvIlwKs9dNToqRHlkk1szgggfzDMbmEvqf98civ+EeHN3OlLZy6gpuavEC3k19k9Y+buLbPWQB8OvpbujcbSvdmQ3n8hvGsX7mV5d+sB+D6B9qwNX0HNxz/PF0bDeGbz1cCULd+da7r04Y7Wr/CTU2GMOSuj6K24+6hl/BMj8lc12AQKQ2SaN6hAQAXdTuF7Vt+47oGgxg3cDY9njofgKrVKtH1kbb0bDGM25q/TNdH2lIlsSIAtz51AeMGzub64waxfctvXNTtFABaXNiAlAZJXNdgEM/2mMzdQy8BICbGuPOFjvS68E26NhrCudecyJ8aJpfhXg62jh0v5fl/v5grbfDgf9O9+62MHjWWW3v05Pkh/85ZV7duCqNHjWX0qLE5ARtgxGvDqV69OuPHTWbsmAmccsqp+bb1008rmDp1Cu+8PZ7nB73IU08/QVaW94U74OnH6dvnISaMm8yq1auYPWcWAJMmv0t81XjeHf8e13a+nsEvDAIgIyOD4a+8zGsjRjHytbcY/srLbNu2DYAhQ/7NtZ2vZ8L494ivGs+kye8CMHv2TFatXsWEcZPp2/shBjz9eBnuycPEgR8emQx09Z93BSZFpHf2Z4Qcg3fAcb4/hJJpZi398eouecpk13UFMN0f9y5QkUHbzE4ws17+NJVB/vPAfDV/+99fyNz8a660hVNXkJX1OwBL56aSnBKfr1y7a05i2tuLc15fdPMpvPXkFwA458jYtBOAjrecxsQX5rF9628AbN2wI19d1WtXoXJ8BZbO9Ya7przxNWdedgIArTs15OPXvR705+OWcmq7YwE4vX19Fk5dQeaWX9m+9TcWTl2RE+hPOfcYPh/n9fI/fv1rzrysoV/XCTm98aXzUqmSWJHqtatwQvMU1izfzLqft7B3TxbTxyymdacTSrYjQ+yUZqcSH5/7b8DM2LHD+yy3b99Oco2iv+QmvzeJG7t2A7w7gicmVsuX5/MvZnD++e0pX748dY+sS72UeixZ+h0bN25gx44dnHTiyZgZF1/Ykc8//wyAL76YwcUXe1/A5557HgsWzMc5x9y5s2nRvCUJCQnEx8fTonlL5syZhXOOBQsX5PTyL774kpy6Pv9iBhdf2BEz48QTTyIzM5ONGzeUcs8dnsp4yt/bwBzgeDNLNbNuwADgfDP7H3C+/xrn3BJgLLAU+Bj4q3Muy6+qJ/AK3sHJFUB27+5VIMnMlgP34M9EKUyhwyNm1gu4BhgDzPeTU4C3zWyMc25A0W/78HbRzafw2TuL86Wfc3UTHuw0GoAqCV4P9+Z/tqNp26NZu2Izg+74gC3pO6h3nHfMYPDM7sTGGiP7fcb8Kctz1ZVcN54NqdtyXm9I3UZy3Xh/XVU2rM4AICvrd7Zn7CIh6QivzOr8ZRKSjmD71t9yvnQ2pGaQXLfqvu34dUWWidxGdnqjFpG/1iSve+6+n7/deTuDnn8O537n1eGv56xbu3YN191wNZUrV6HnrX+lWbNTyMz0PquXXn6BLxctJKVuCvff14ekpNzHlDZsSKdJk5NyXtesWYsN6enExcVRs2at3OkbvF/d6RvSqVWzNgBxcXFUqVKFjIytXnqt2rnKpG9IJyNjK1WrViUuLi5Xevb2o5WpUYwvpaCwMrz2iHPumgJWtSsg/+NAvp8vzrmFQJMo6b8BV5akTUW9u27A6c65Ac65Uf4yAGjur4sqcnB/LYtK0p6D6vq+bcjam8XUt77Nld6weQq7du7h5yXeH3psXAw16yXw3axV9Dj1JZbMSaXnM+1z1qU0qM5dbUfw6DX/4f5XOuUE+RxRvtFzfgBF+bp3zhVQpqD0ouoqIF0KNH7Cf7jnrvv44L0p3H3Xffzz8f4A1KiRzHuTP+atN9/h7jvv5cGH+7B9+3aysrJIT0/j5JOaMuqNMZx44skMev65fPVG2+9mFv3z8D+3AteVoC4rpC4L2WXxDvzoyKFVVND+HTgySnodf11UzrlhzrnTnHOnHckp+9O+A6Z9l6a06ng8j103Pt+6czs3yTU0krFpJ7/u2M1/3/0egBn/+Y4Gp3i7ZUPqNmZN+oGsvb+zfuVWVi3bRN0G1XPVtyF1W64hmOSUeDau3bZvXb0EAGJjY6iSUIFtm3/10/OWySRj406qJFYk1u9NJKcksHFtpl9XRk5dkWUitxGZLgV7/4P3OOccrzN1XrsLWLrEOyGufPnyJCYkAtCwYSNSUlJYtfoXEhISqVixIm3bngtAu3bn88Oy7/PVW7NmLdLS1ue8Tk9Po0ZyMrVq1iI9PS1XevaQTK2atUhL98rs3buX7du3kxCfELWu5BrJJCZWIzMzk7179+arK2qZ5PD0ssE7EFncJYiKCtp3AdPM7CMzG+YvH+OdBXTngW/egdG8fX2u6XUmfS99i12/7sm1zsxoe2Vjpo/JPWQy571lNG17NACntjuWX5Z6vfCZE7+n6TnHAJCQdAT1jkti3U9bcpXdvH47OzN35wxJtO/SlFmTfgBg9uQf6NC1KQBnX9GIRdN/BmDBlOWcfkF9qiRWpEpiRU6/oD4L/GGXrz77mbOvaARAh65NmTXpe7+uZbTv4tXVqEUKOzJ+Y/P67SxbsIaUBtWpfXQiceViObfzicye/MN+7sVwS05OZtGihQAsWDifevWOAmDLls05Bw5T16SyevUq6h6Zgplx1pln82V2mQXzOPaYY/PV26bN2UydOoXdu3ezZu0aVq1eReNGTahRI5kjjjiCxYu/xTnHBx+9z9lt2gJw1lln88EH7wEwffqnnH7a6ZgZLVuewbx5c9i2bRvbtm1j3rw5tGx5BmbGaaeexvTpnwLwwQfv0cavq81ZZ/PBR+/jnGPx4m+pUqVKqIZGwPs/XNwliKyon8lmFoM3HFIX78d5KrAgYoC9UG3t4UP6O/yh0VfQtO0xJNQ4gi1p23ntkc+4rs9ZlKsQxzb/YOLSuak819P7T9H07KPpMeB8bm81PFc9tY5KoO+bl1MlsSJbN+zkqZveJd0fJ7792Q4071Cf37Mcox7/nOnveL2yV77qSfdmQwE4/tQj6T3yz5SvVI75H/2PQX/7AIDyFeLo++ZfaNCsDts2/8qjnf/Dup+9oH/hTc24vm8bAN58/As+HvkVAHWOqcbDY64kvnol/vfVOh6/fjx7dnsfx51DLqZ5hwbs2rmHp256l2VfejOLWlzYgDv+fSExsTF8NGIRo5744sDs8GKavKXPId1+pAce7M2XixaydetWkqpXp0ePnvzpqKN59rmnycrKonyF8vS6vy8NGzZi+vRPeWnYi8TFxhETG0OPW3rS5ixvWua6dWt5pN+DZG7PJDGxGo881J/atevw+Rcz+P77pdx26+2AN8tk8nuTiI2N5Z6776f1GWcCsPT7JfR/1Jvyd0ar1tx/X2/MjF27dvFIvwdY9uMy4uPjefyxp0ip63UAJk+eyGuvvwrATTd249JLvBPtUtekelP+tm3j+OOO59H+T1C+fHmcczz9ryeZM3c2FStW5OGH+tOoYeODvcsLFJ9Yab8j6d+uGl3smDN47LWBi9xFBu39daiDthyeDqegLYePsgjad14zptgxZ9DbnQMXtEN/co2I/MEEdKy6uBS0RSRUAjpUXWwK2iISKkE9wFhcCtoiEi4aHhERCY6Qd7QVtEUkXMryNPbDkYK2iISKxrRFRALEwt3RVtAWkXBRT1tEJEgUtEVEgkPDIyIiAaLZIyIiAaIxbRGRAAl5zFbQFpGQ0WnsIiLBoeEREZEAsVgFbRGRwFBPW0QkQIJ6l/XiUtAWkXAJd8xW0BaRcNHwiIhIgGh4REQkQBS0RUQCRMMjIiIBEvKYraAtIuGioC0iEiAaHhERCZAYHYgUEQmOkHe0FbRFJFw0PCIiEiAhj9mE+2ZqIvKHYyX4V2g9Zseb2dcRyzYzu8vM+pnZmoj0iyLK9DGz5Wa2zMzaR6SfamaL/XXP2378HFDQFpFQMSv+Uhjn3DLnXFPnXFPgVGAn8K6/emD2Oufch952rRHQGWgMdABeNLNYP/9QoAfQwF86lPb9KWiLSKjExFixlxJoB6xwzv1SSJ5OwBjn3C7n3M/AcqC5mdUB4p1zc5xzDngDuKzU76+0BUVEDkcl6WmbWQ8zWxix9Cig2s7A2xGv7zCzb81shJlV89PqAqsj8qT6aXX953nTS0VBW0TCpQRR2zk3zDl3WsQyLH91Vh64FPiPnzQU+D+gKbAOeDY7a5TWuELSS0WzR0QkVA7A7JELgUXOuTSA7EdvWzYceN9/mQrUiyiXAqz101OipJeKetoiEipmVuylmK4hYmjEH6PO9mfgO//5ZKCzmVUws2PwDjjOd86tAzLNrKU/a6QLMKm07089bREJlbLsaZvZEcD5wK0RyU+bWVO8IY6V2eucc0vMbCywFNgL/NU5l+WX6QmMBCoBH/lLqShoi0iolOW1R5xzO4GkPGk3FJL/ceDxKOkLgSZl0SYFbREJlZCfEKmgLSLhomuPiIgESMhjtoK2iISLetoiIgGimyCIiARIyDvaCtoiEi4K2iIiAaIxbRGRAAl5zD7wQXvwt7cf6E1IAFWuUuFQN0FCSj1tEZEAMc0eEREJDvW0RUQCJOQxW0FbRMJFPW0RkQAJecxW0BaRcFFPW0QkQHTtERGRAFFPW0QkQDRPW0QkQELe0VbQFpFw0fCIiEiA6ECkiEiAqKctIhIgIY/ZCtoiEjIhj9oK2iISKhoeEREJkJDHbAVtEQmXmNhwR20FbREJFQ2PiIgEiIK2iEiAhDxmK2iLSLiopy0iEiAK2iIiAaJrj4iIBIh62iIiARLymE3MoW6AiEhZshgr9lJkXWYrzWyxmX1tZgv9tOpmNtXM/uc/VovI38fMlpvZMjNrH5F+ql/PcjN73vbj54CCtoiEilnxl2I6xznX1Dl3mv+6NzDNOdcAmOa/xswaAZ2BxkAH4EUzi/XLDAV6AA38pUNp35+CtoiEipkVeymlTsDr/vPXgcsi0sc453Y5534GlgPNzawOEO+cm+Occ8AbEWVKTEFbREKlJEHbzHqY2cKIpUee6hzwiZl9GbGulnNuHYD/WNNPrwusjiib6qfV9Z/nTS8VHYgUkVApSQfaOTcMGFZIltbOubVmVhOYamY/FLbpaJsoJL1U1NMWkVApy+ER59xa/zEdeBdoDqT5Qx74j+l+9lSgXkTxFGCtn54SJb1UFLRFJFTK6kCkmVU2s6rZz4ELgO+AyUBXP1tXYJL/fDLQ2cwqmNkxeAcc5/tDKJlm1tKfNdIlokyJaXhEREKlDE+uqQW869cXB4x2zn1sZguAsWbWDVgFXAngnFtiZmOBpcBe4K/OuSy/rp7ASKAS8JG/lIp5BzMPnMWL1x/YDUggNWpYs+hM8ocTG7f/56DPnrOq2DHnjFZHBe5UHPW0RSRUwn5GpIK2iISKgraISIBY1Bl24aGgLSKhop62iEiA6HraIiIBoutpi4gESMhjtoK2iISLetoiIkES7pitoC0i4aKetohIgGj2iIhIgIQ7ZCtoi0jIaHhERCRAQh6z/3hBOysri169elC9ejJ9+w4gM3MbAwf2Iz19PTVr1uaee/pTpUpVMjMzeOaZh1mxYhlt23age/e78tU1YEAf0tLWMXDgyKjbmjBhFNOnf0hMTAw33/x3mjZtDsCKFct44YUn2b17N82ateDmm/+OmbFnz24GD36Cn376kSpV4rnnnkeoWbMOADNmfMy4cW8AcMUVXWjb1ruZs7f9/mzfvo1jjz2Ov/3tAcqVK4dzjhEjnuerr+ZRvnwF7rijD8cee9wB2Gnhkf8AAA3dSURBVKPhc9757ahcuTIxMbHExcXyn7HjABj11ihGj36L2NhYzm5zNvfdd39OmbVr13LJpZfw17/+lZtvujlfnVu3buXe++5hzZo11K1bl+eeHUhCQgIAw4YPY/z48cTGxtC3zwOceeaZACxZsoS+D/Tht9920aZNG/r26YuZsXv3bnr36cWSJUtJTEzkuWefo25d75aDEydO5KWXhwJw2609uewy7/6xqamp3HvfvWRkbKVRo0YMePIpypcvf+B24iEU9p72H+7ONR9+OI6UlD/lvJ448S1OPPFUhgwZzYknnsq7774FQLly5encuRs33NAzaj1z535BxYqVCtzO6tUrmTVrOgMHjuSBB/7F8OEDycryroc+fPhz3HrrfQwe/Bbr1qXy1VfzAJg27QMqV67KkCGj6djxSkaNehmAzMxtjB07kieffIkBA15m7NiRbN+eCcCoUS/RseOVDBkymsqVqzJ9+gcAfPXVPNatS2Xw4Le47bb7GDbsuf3cc38sI197nXcnvJsTsOfNm8f06dOY+O4k3pv8PjflCcxPPTWAs846q8D6XnllOC1btOLjj6bQskUrXnllOADLly/now8/5L3J7zHs5eH887FHc/5OHn20P/379efjjz7ml19+4b8z/wvA+PHjiI9PYMrHU+japQvPPvcM4H0xvDj0Bca8/Q7vjBnLi0NfICMjA4Bnn3uWrl268PFHU4iPT2DChPFlu8MOI2V155rD1R8qaG/alM6XX86lXbuOOWkLFszK6bW2bduBBQtmAlCxYiUaNjwpam/k11938v77Y7n88i4FbmvBgpm0bn0u5cqVp1atOtSuXZfly79ny5ZN7Ny5k+OPb4KZ0bZt+5xtem1pD0CrVmezePEinHN88818Tj75NKpWjadKlaqcfPJpfP31PJxzfPfdV7Rqdbbf/vbMnz8zZ/tt27bHzDjuuMbs3LmdLVs2lcFe/GMa884Yune/JefvISkpKWfdp9M+JaVePerXr19g+emfTeeyyzoBcNllnZg2fVpO+oUXXUT58uVJSUnhqHpHsXjxt2zYkM72Hdtp2rQZZkanSzsxbZpfZvp0Luvk1XXBBe2ZO3cuzjlmzZpFq1ZnkJiYSEJCAq1ancHMmTNxzjFv3lwuuMD727qs0766wigmxoq9BNEfKmi/9toQbrjhtlw/n7Zu3UK1at5/wGrVksjI2FJkPWPGjOCSS66iQoUKBebZvHkjNWrsuztLUlIymzdvZNOmDSQlJeekV6+ezKZNG/OViY2N44gjKpOZmcGmTRtJSqqZr0xmZgaVK1chNjbO30ZNNm/26opeZkOR7028n9fdb+nGFVdeztixYwFYuXIlX375JVd3vpouXW9g8eLFAOzcuZNXX32F23veXmidmzZtIjnZ+zySk2uyefNmANLT0qhdu3ZOvlq1a5GWlk5aWjq1atXKlZ6engZAWnoatWt7w2ZxcXFUrVqVrVu3kpaeRp2IumrXqkVaehpbt26latV44uK8v5NatWqT5tcVRuppF8DMbipkXQ8zW2hmC8eNe7O0myhTCxfOJiEhkf/7v+P3q56ff/4f69en0qJFm0LzRbuNm/dlES29NGWMaHeK2/eHWFBdUpS3Ro1m/LgJvPzSMN5+ezQLFy4gK2sv27ZtY8zbY7jv3vu55967cc4x5IUhdOnSlcqVK5dqWwV95lHT/cls0cuUsK4Q/y2U5d3YD0f7cyCyP/BatBXOuWHAMDh87hG5bNl3LFgwm0WL5rFnz2527tzBoEGPkZhYjS1bNlGtWhJbtmwiIaFaofX8+OMSfvrpR3r2vJqsrCy2bdvCww/fyaOPDsqVLykpmY0b03Neb9q0gWrVkkhKqpmrx7t58waqV6+Rq0xSUk2ysvayc+cOqlSJJykpmSVLvs5VpnHjpsTHJ7Bjx3aysvYSGxvHpk3pVKu2r65Nm9KjbkcKV7Om1yNOSkqi3Xnn8e3ixdSuVZvzzzsfM+Okk04iJiaGLVu28O233/LJJ1N49tlnyMzMxCyGCuUrcN111+WqMykpiQ0b0klOrsmGDelUr14dgFq1a7N+/fqcfGnr06hZM5natWuRlpaWKz3Zb1ftWrVZv34dtWvXZu/evWRmZpKQkEjtWrWZv2B+Tpn1aWk0P7051apVIzNzG3v37iUuLo60tPXUTNY9OoOq0J62mX1bwLIY707FgXHddT0YNmwcQ4e+w113PUyTJqdw550PctpprZkx42PAm6Fx+umtC62nffvLGD58AkOHvsNjjw2mTp16+QI2wOmnt2bWrOns2bObtLR1rFuXSv36DalWLYlKlSrx449LcM4xY8YUTj/dmy3gtWUKAHPmfE6TJt545sknN+ebbxawfXsm27dn8s03Czj55OaYGY0bN2XOnM/99k/JaX92Xc45fvxxCUccUTlnGEgKtnPnTnbs2JHzfPbsWTSo34Bz27Vj3ry5AKxc+TN79uyhWrVqjHpzFJ9OncanU6dxww1d6NGjR76ADXDOOecyceIkACZOnMS555zrp5/DRx9+yO7du0lNTeWXVb9w4oknkZxck8pHVOabb77GOcekyZM499x9ZSZO8ur65JMptGjREjOjdevWzJ49i4yMDDIyMpg9exatW7fGzGjevAWffOL9bU2ctK+uMPqj97RrAe2BvAO9Bsw+IC06yP7852t59tl+TJv2ATVq1OLee/vnrOvZ82p+/XUHe/fuZf78mTz00DPUq3d0gXUtWDCLFSt+oHPnbtSrdwxnnHEOd93VldjYWLp3v4vY2FgAbrnlHl54YQC7d++iWbMWNGvWAoB27S7i+ecf5447rqVKlarcffcjAFStGs/ll3ehd+9bAbjiiq5UrRoPwA033MbAgf0ZM+ZVjj66Pu3aXQzAKae0ZNGiudxxx7VUqFCB22/vXeb7Low2bdrE3//+NwD2Zu3l4os7ctZZZ7F7924efOhBLu10CeXKleOJx58s8j/9Qw8/yNVXdaZJkybc0r07d99zD+MnjKNOnSMZ+NxAABrUb0D7Dh245NKOxMbG8uCDD+X8nTz88CP0faAPu3bt4qwzz6LNWd6Q3OWXX0Gv3r1o36E9iQkJPPPMswAkJiZy2209uerqqwDo2fN2EhMTAbj3nnu57757GfT88zRs2JDLL7+i7HfeYSKgsbjYLNp4V85Ks1eB15xzM6OsG+2cu7aoDRwuwyNyeGnUUD/PJb/YuP2f0vHTT5uKHXOOPTYpcCG+0J62c65bIeuKDNgiIgebbuwrIhIk4Y7ZCtoiEi5hH9NW0BaRUNHwiIhIgKinLSISIEGdf11cCtoiEi7hjtkK2iISLiGP2QraIhIuYR8e+UNdmlVEJOjU0xaRUAnqzQ2KSz1tEZEAUdAWkVApqzvXmFk9M/vMzL43syVmdqef3s/M1pjZ1/5yUUSZPma23MyWmVn7iPRTzWyxv+5524+Bdw2PiEiolOEZkXuBe51zi8ysKvClmU311w10zj2Ta7tmjYDOQGPgSOBTMzvOOZcFDAV6AHOBD4EOwEelaZR62iISLlaCpRDOuXXOuUX+80zge6BuIUU6AWOcc7uccz8Dy4HmZlYHiHfOzXHetbDfAC4r7dtT0BaRUImx4i+R97P1lx7R6jSzo4FmwDw/6Q7/Ll4jzCz7HoV1gdURxVL9tLr+87zppXt/pS0oInJYKsGgtnNumHPutIhlWP7qrAowHrjLObcNb6jj/4CmwDrg2eysUVrjCkkvFQVtEQmVMhod8eoyK4cXsN9yzk0AcM6lOeeynHO/A8OB5n72VKBeRPEUYK2fnhIlvVQUtEUkVMpw9ogBrwLfO+eei0ivE5Htz8B3/vPJQGczq2BmxwANgPnOuXVAppm19OvsAkwq7fvT7BERCZeyO429NXADsNjMvvbT+gLXmFlTvCGOlcCtAM65JWY2FliKN/Pkr/7MEYCewEigEt6skVLNHIEibuxbFnRjX4lGN/aVaMrixr6bN+4odsypXqNy4E6fVE9bREIl7BeMUtAWkVAJeczWgUgRkSBRT1tEQiXsPW0FbREJmXBHbQVtEQkV9bRFRIJEQVtEJDjK8NKshyXNHhERCRD1tEUkVMI+pq2etohIgKinLSKhotPYRUSCJNwxW0FbRMIl5DFbQVtEQibkwyM6ECkiEiDqaYtIqIS7n62gLSIho9kjIiJBEu6YraAtIuES8pitoC0iIRPyqK2gLSIhE+6oraAtIqES7pCtoC0iIRPyySMK2iISMiGP2jojUkQkQNTTFpFQCXlHWz1tEZEgUU9bREIl7Kexm3PuULfhD8PMejjnhh3qdsjhRX8XUhIaHjm4ehzqBshhSX8XUmwK2iIiAaKgLSISIAraB5fGLSUa/V1IselApIhIgKinLSISIAraIiIBoqB9kJhZBzNbZmbLzaz3oW6PHHpmNsLM0s3su0PdFgkOBe2DwMxigReAC4FGwDVm1ujQtkoOAyOBDoe6ERIsCtoHR3NguXPuJ+fcbmAM0OkQt0kOMefcF8DmQ90OCRYF7YOjLrA64nWqnyYiUiIK2gdHtCvYaK6liJSYgvbBkQrUi3idAqw9RG0RkQBT0D44FgANzOwYMysPdAYmH+I2iUgAKWgfBM65vcAdwBTge2Csc27JoW2VHGpm9jYwBzjezFLNrNuhbpMc/nQau4hIgKinLSISIAraIiIBoqAtIhIgCtoiIgGioC0iEiAK2iIiAaKgLSISIP8PUScTMbQslV8AAAAASUVORK5CYII=\n",
"text/plain": [
""
]
},
"metadata": {
"needs_background": "light"
},
"output_type": "display_data"
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"-----------------------------------------\n"
]
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAYoAAAEWCAYAAAB42tAoAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADt0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjByYzEsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy/xvVyzAAAgAElEQVR4nO3deZxN9RvA8c9j7GMLkZ0i2ZXJUoSkEPWTFmmTLSpFESktJIqKIrtkV2RJtspWISRhxpKsYxCSfZjl+f1xjtymWa4xd+6dmef9et3X3HPP95zznO+de577/Z5zv0dUFWOMMSYhmfwdgDHGmMBmicIYY0yiLFEYY4xJlCUKY4wxibJEYYwxJlGWKIwxxiTKEoW5IiISKiIN/B1HoBCRPiIyzk/bnigi7/hj2ylNRB4TkaXJXNb+J33MEkUaJiJ7ReS8iJwRkcPugSOXL7epqpVUdYUvt3GJiGQTkYEist/dz99FpKeISGpsP554GohIuOdrqvquqnbw0fZERF4Qka0iclZEwkXkSxGp4ovtJZeIvCUiU65mHao6VVXv9mJb/0mOqfk/mVFZokj7WqhqLqA6cDPwqp/juWIikjmBWV8CjYBmQG7gCaATMMwHMYiIBNrnYRjwIvACkB+4EZgL3JvSG0rkPfA5f27beElV7ZFGH8Be4C6P6feBbzymawOrgb+B34AGHvPyA58BEcAJYK7HvObAJne51UDVuNsEigLngfwe824GjgFZ3Ol2wDZ3/UuAUh5lFXgO+B3YE8++NQIigRJxXq8FxABl3ekVwEBgHXASmBcnpsTqYAUwAPjJ3ZeywNNuzKeB3cAzbtlgt0wscMZ9FAXeAqa4ZUq7+/UUsN+ti9c8tpcD+Nytj23AK0B4Au9tOXc/ayby/k8ERgDfuPH+DNzgMX8YcAA4BfwC1POY9xYwC5jizu8A1ATWuHV1CBgOZPVYphLwLfAXcAToAzQBLgJRbp385pbNC4x313MQeAcIcue1dev8I3dd77iv/ejOF3fen+57uhmojPMlIcrd3hng67ifAyDIjesPt05+Ic7/kD2ScazxdwD2uIo3798fkOLAFmCYO10MOI7zbTwT0Nidvtad/w0wE7gGyALUd1+/xf2A1nI/dE+528kWzzaXAR094hkMjHKf/w/YBVQAMgOvA6s9yqp70MkP5Ihn3wYBKxPY731cPoCvcA9ElXEO5rO5fOBOqg5W4BzQK7kxZsH5tn6De7CqD5wDbnHLNyDOgZ34E8VYnKRQDbgAVPDcJ7fOi7sHwIQSRWdgXxLv/0ScA21NN/6pwAyP+Y8DBdx5LwOHgewecUe571MmN94aOIk1s7sv24BubvncOAf9l4Hs7nStuHXgse25wGj3PSmEk8gvvWdtgWigq7utHPw7UdyDc4DP574PFYAiHvv8TiKfg544n4Py7rLVgAL+/qym9YffA7DHVbx5zgfkDM43JwW+B/K583oBk+OUX4Jz4C+C8834mnjWORLoH+e1HVxOJJ4fyg7AMve54Hx7vcOdXgS091hHJpyDbil3WoE7E9m3cZ4HvTjz1uJ+U8c52A/ymFcR5xtnUGJ14LFsvyTqeC7wovu8Ad4liuIe89cBrd3nu4F7POZ1iLs+j3mvAWuTiG0iMM5juhmwPZHyJ4BqHnGvSmL93YA57vNHgV8TKPdPHbjThXESZA6P1x4FlrvP2wL746yjLZcTxZ3ATpyklSmefU4sUewA7vfF5y0jPwKtT9Zcuf+pam6cg9hNQEH39VLAQyLy96UHUBcnSZQA/lLVE/GsrxTwcpzlSuB0s8Q1C6gjIkWBO3AOkj94rGeYxzr+wkkmxTyWP5DIfh1zY41PEXd+fOvZh9MyKEjidRBvDCLSVETWishfbvlmXK5Tbx32eH4OuHSBQdE420ts/4+T8P57sy1E5GUR2SYiJ919ycu/9yXuvt8oIgvcCyNOAe96lC+B053jjVI478Ehj3ofjdOyiHfbnlR1GU631wjgiIiMEZE8Xm77SuI0XrJEkU6o6kqcb1tD3JcO4HybzufxCFbVQe68/CKSL55VHQAGxFkup6pOj2ebfwNLgYeBNsB0db/Wuet5Js56cqjqas9VJLJL3wG1RKSE54siUhPnYLDM42XPMiVxulSOJVEH/4lBRLLhdF0NAQqraj5gIU6CSypebxzC6XKKL+64vgeKi0hIcjYkIvVwWlQP47Qc8+H093teMRZ3f0YC24FyqpoHp6//UvkDOF1y8Ym7ngM4LYqCHvWeR1UrJbLMv1eo+rGq1sDpFrwRp0spyeWSiNMkkyWK9GUo0FhEquOcpGwhIveISJCIZHcv7yyuqodwuoY+FZFrRCSLiNzhrmMs0FlEarlXAgWLyL0ikjuBbU4DngRauc8vGQW8KiKVAEQkr4g85O2OqOp3OAfL2SJSyd2H2jj98CNV9XeP4o+LSEURyQn0A2apakxidZDAZrMC2YCjQLSINAU8L9k8AhQQkbze7kccX+DUyTUiUgx4PqGC7v59Ckx3Y87qxt9aRHp7sa3cOOcBjgKZReQNIKlv5blxTmyfEZGbgC4e8xYA14lIN/ey5dwiUsuddwQofemqMff/aynwgYjkEZFMInKDiNT3Im5E5Fb3/y8LcBbnooYYj21dn8ji44D+IlLO/f+tKiIFvNmuSZglinREVY8Ck4C+qnoAuB/nW+FRnG9aPbn8nj+B8817O87J627uOjYAHXGa/idwTki3TWSz83Gu0Dmiqr95xDIHeA+Y4XZjbAWaXuEutQKWA4txzsVMwbmSpmuccpNxWlOHcU60vuDGkFQd/IuqnnaX/QJn39u4+3dp/nZgOrDb7VKJrzsuMf2AcGAPTotpFs4374S8wOUumL9xulRaAl97sa0lOF8GduJ0x0WSeFcXQA+cfT6N84Vh5qUZbt00Blrg1PPvQEN39pfu3+MistF9/iRO4g3DqctZeNeVBk5CG+sutw+nG+5SS3k8UNGt/7nxLPshzvu3FCfpjcc5WW6uglzuKTAm7RGRFTgnUv3y6+irISJdcE50e/VN2xh/sRaFMalERIqIyO1uV0x5nEtN5/g7LmOS4rNEISITRORPEdmawHwRkY9FZJeIbBaRW3wVizEBIivO1T+ncU7Gz8M5D2FMQPNZ15N7cvQMMElVK8czvxlOX3MznB93DVPVWnHLGWOM8S+ftShUdRXOtfMJuR8niaiqrgXyiYi3J7uMMcakEn8OxlWMf1+FEe6+dihuQRHphDPOC8HBwTVuuummVAnQGGPSsthYOL3zELnPHuZXYo+p6rXJWY8/E0V8Q0XH2w+mqmOAMQAhISG6YcMGX8ZljDFp3vffKR07CZXPzuflKktpsGXEvuSuy59XPYXz71+mFscZydQYY0wyndx3gh/Lt2dZ43fJnBl6rrqP+puHX9U6/Zko5gNPulc/1QZOur/oNMYYkwzr+8wh8vqK1N75OQ1ui+K336Bevatfr8+6nkRkOs5AdQXFuSvYmzgDhaGqo3DG0GmG88vfczj3ATDGGHOFjoUeYVfTrtQ+8CXbslfn+NhvaPx4yv3iwGeJQlUfTWL+pRvXGGOMSQZVmDkTxnU+wLyT37Cs0QDqzutJ1uAsKbod+2W2McakQUfW7WNMteE8+iicLh/C/h/2c+d3fVI8SYB/r3oyxhhzhTQmljVPjqTKtN60AfSNVnR8owhBQb4bJNcShTHGpBHh3+/gxIMduO3vH1l3zT0UmjOazvV9/ztl63oyxpgAFxsLnw45R7a76lL871CWPTmRkKOLKF2/VKps31oUxhgTwP5YtJMn+5dj9ZqcHAqZTOdR1bmzxnWpGoO1KIwxJgBFnY7kp4avUapZRapsnsqkSdBvXROKpXKSAGtRGGNMwPl94k9k7tye2y/sYFnpp+m3+F4KlfdfPNaiMMaYAHHhAnxXvz83PF2PzFGR/Nh3CXfumUCh8tf4NS5rURhjTABYs1pp30G4YVt1tEJXaiweQN2SufwdFmAtCmOM8auzB/5ifcWnWHT7O5w9C88vbkHjsGHkD5AkAZYojDHGb7a8OYvzZSpQfds0atZUtm6Fe+7xd1T/ZV1PxhiTyk7tOMSuJs9zy96v2JKtBvvGLKV5u2r+DitB1qIwxphUtGABPFIvghv3LmFh/fcoe3QtNQI4SYAlCmOMSRV/bdzL5yGf0KIFHLyuBr9/f4BmK14hR+7A79gJ/AiNMSYN0+gYNnYYwU2f96ElmTjW4yG6DriOrFn9e8nrlbBEYYwxPvLnym0cb9mBGidWszpvEwp8OZqXG6f+L6uvlnU9GWNMClOFiZ+eI1PDOyh0YjsLH51ErWMLKd+4pL9DSxZLFMYYk4LCv9vO3Y2Vp5/LyaDKUzm1Joxm054gKLP4O7Rks0RhjDEpIPbseTbc1YsijStR+qepjBwJ72+6mzK1C/s7tKtm5yiMMeYq7Zu8CunUgZDI31lcvANvLmpO8cr+jirlWIvCGGOSKSoKfrjrbUo9WZ/Yi9F82+s77tk/luKV8/k7tBRlLQpjjEmGTb8q7doLRX4N4WS57ty6uD+Nrw/2d1g+YS0KY4y5AhcOHmNTlSeYG9KfiAhoP/temu/8kMLpNEmAJQpjjPGOKjvf+YIzpSpSaesMqlTNRFgYPPCAvwPzPet6MsaYJJzbFcEf9zxLld3z+C1LCKc/+Y5WXar6O6xUYy0KY4xJxLJl0LrBYUrtXsZXdQZz/ZE11M1ASQIsURhjTLxO/babmXWG0qgRbMtxC1sW7OeB1T3IfU3G64ixRGGMMZ5iYgjt8BFZbq5Mk7Vv8naXw2zeDLffm74ueb0SGS81GmNMAk78GMrx/7Wn0vGfWZn7XvJOG8UbzdPeIH4pzVoUxpgMTxVmTTpH7B31yXv8D2a3mkado19TvXlxf4cWECxRGGMytD9XhNHyf8pDT+XkjXIzOLYyjFazHiVrtrQ7iF9Ks0RhjMmQ9Ow5tjTpSYGGVci/aAqDB8Ow0LuocMe1/g4t4Ng5CmNMhnN4xgpi2nWkyvldzCvyDK8tuI8bbvF3VIHLWhTGmAwjNhbWNX2T6x5tSGSkMu/FZbQIH8UNt+T1d2gBzVoUxpgMYcd2pX0HIe9PNWlX+mVqLu7H/eVz+jusNMGnLQoRaSIiO0Rkl4j0jmd+XhH5WkR+E5FQEXnal/EYYzKe6ENHCa3ehi8q9yMsDB75/F4e2D2EEpYkvOazRCEiQcAIoClQEXhURCrGKfYcEKaq1YAGwAciktVXMRljMhBV9g6cxpkSFSj32yyuvykrYWHw5JMgdkHTFfFl11NNYJeq7gYQkRnA/UCYRxkFcouIALmAv4BoH8ZkjMkALvwRzp4mXbhp1wJ+yVKL40PG81i3Sv4OK83yZddTMeCAx3S4+5qn4UAFIALYAryoqrFxVyQinURkg4hsOHr0qK/iNcakA2vXQpvGRymyaxXTQj6kzMGfuNuSxFXxZaKIr3GncabvATYBRYHqwHARyfOfhVTHqGqIqoZce61d42yM+a9zm3cxt/5H3HYbrI++mXWzDtBmfXfyXxvk79DSPF8minCghMd0cZyWg6enga/UsQvYA9zkw5iMMelNdDS/dx5CpupVaLDqbV556gihodC41X++c5pk8mWiWA+UE5Ey7gnq1sD8OGX2A40ARKQwUB7Y7cOYjDHpyOnVW9hT9DbKje7JjznvZvusUAZ9Vpjcuf0dWfris5PZqhotIs8DS4AgYIKqhopIZ3f+KKA/MFFEtuB0VfVS1WO+iskYk34snHWO2o80JDg2E1NbzOCBGQ+TI6ddzuQLohr3tEFgCwkJ0Q0bNvg7DGOMn5z4YSvPj6zEtOlC+9Lf89yYatzcuKC/wwp4IvKLqoYkZ1kbwsMYkybombPsuPcl8t5RlaxfTOGtt+DTHY0sSaQCG8LDGBPwjs38nuh2HSl/bg9fFnqWHnPvp1Idf0eVcViLwhgTsFRhU4u+FGx9F6fPZ2ZGl5W0PDiCSnXsiqbUZC0KY0xA2rs7lk6dMxH07W08UfwVai58i9ZVcvg7rAzJWhTGmIASe/hPdtZozfSb3mbNGrjv06a03vceZS1J+I0lCmNMYFDl0OApnC5RgVIb51C4TE5CQ6FLF8hkRyq/sq4nY4zfRe85wN6mnSm7YyHrgupw6N1xPN27oo3yGiAsTxtj/Oq33+CJZscpuOMnJlQbRsl9P3D/q5YkAoklCmOMX1zcupPFdw0hJASWn6jOyskHaLfpBa4rZoP4BRpLFMaY1BUdzf7n3kOrVqXW9wPo3PIIYWFw/+M2QFOgsnMUxphUc37tbxy7vx0l/9zIohwtyTZ2BJ88VtjfYZkkWKIwxqSKlYvOUaV5I7LEZmbM3bNo/WUr8tjv5tIE63oyxvjU6Z8280wnpUGznLxw3Zf8MT+MTkssSaQlliiMMb5x5gx77nuR4LrVuTBuMj16wJjfG3J7i/z+jsxcIet6MsakuJOzvuVC206UObuXafmfp+vsltRo4O+oTHJZi8IYk2JUIeyB18j70N2cOJuNCU//wIOHPqFGA7uiKS3zukUhIsGqetaXwRhj0q6I8Fie65qJyLl1efi6V7n16zdoF5Ld32GZFJBki0JEbhORMGCbO11NRD71eWTGmDRBDx1mT8iDTCn7FosXQ6PBTXniwLtUtiSRbnjT9fQRcA9wHEBVfwPu8GVQxpg0QJVjQyZyumRFivyygFxF87B5M/ToAZnt7Ge64tXbqaoH5N8Dr8T4JhxjTFoQu2cfB5p1otT2pazOVJd9b46j8xvlbZTXdMqbt/WAiNwGqIhkFZEeuN1QxpiMZ8cOaPfA3+Tevp4RFYZT/I+VPPqWJYn0zJsWRWdgGFAMCAeWAs/6MihjTOCJDt3Bqp7zabasJzlzVqPxqP082ymXjfKaAXjzHaC8qj6mqoVVtZCqPg5U8HVgxpgAERXFoRcGElOlGtUWDeLRRn8SFgaPPWNJIqPwJlF84uVrxph05uLPvxJRshZFPunDkqwtWD02jM++KcR11/k7MpOaEux6EpE6wG3AtSLyksesPIANGG9MOrduxTnK3dUYicnCx/Vn89jsByhQwN9RGX9IrEWRFciFk0xyezxOAQ/6PjRjjD+cX/0rL3VXat+Zk07XzGLrzDBeWGFJIiNLsEWhqiuBlSIyUVX3pWJMxhh/OH2a8Cdepfi8ERzjczp3eZJBgxrYKK/Gq6uezonIYKAS8M9PLVX1Tp9FZYxJVWdnLyay7TMUPXOAiXlfpOP0B6jX1N9RmUDhzcnsqcB2oAzwNrAXWO/DmIwxqWjXQ68S/GBTjpwJ5tM2P/FwxFDqNc3l77BMAPGmRVFAVceLyIse3VErfR2YMca3jh2JodvLQRyd1YCWBTNTY87rPF83m7/DMgHIm0QR5f49JCL3AhFAcd+FZIzxJY04xMH/PcfM0ErMvNif1968h3Z97iFrVn9HZgKVN4niHRHJC7yM8/uJPEA3n0ZljEl5qvw9dCKZe71EgahIMhWvy8aFUKWKvwMzgS7JRKGqC9ynJ4GGACJyuy+DMsakLN2zl4jmHSkW9h0/Sj229xxH13dvtFFejVcSPJktIkEi8qiI9BCRyu5rzUVkNTA81SI0xlyVvXuhS5uTZA/byAc3fEqhsBV0eN+ShPFeYv8q44ESwDrgYxHZB9QBeqvqXG9WLiJNcAYUDALGqeqgeMo0AIYCWYBjqlr/ivbAGBOv2K1hrO0zn7uX9UakGrd8uJ/uLwbbKK/miiWWKEKAqqoaKyLZgWNAWVU97M2KRSQIGAE0xhl1dr2IzFfVMI8y+YBPgSaqul9ECiV3R4wxrosXOfrK++T9uD83am7ubdCO9ycWolSpYH9HZtKoxBLFRVWNBVDVSBHZ6W2ScNUEdqnqbgARmQHcD4R5lGkDfKWq+93t/HlF0Rtj/iV67Qb+atmeQoc3MztLa6I/GMaM5wvZKK/mqiSWKG4Skc3ucwFucKcFUFWtmsS6iwEHPKbDgVpxytwIZBGRFTjjSA1T1UlxVyQinYBOACVLlkxis8ZkTFvWnqVE3XuIisnOwNrzeHrOfTbKq0kRiSWKq73nRHzfYTSe7dcAGgE5gDUislZVd/5rIdUxwBiAkJCQuOswJkO7uHYj7yyozsD3gmmWew7thlbl1afy+Tssk44kNijg1Q4EGI5zMvyS4jg/1otb5piqngXOisgqoBqwE2NM4k6d4sjTvSn81Uj28jmPPvEkH310h43yalKcL69/WA+UE5EyIpIVaA3Mj1NmHlBPRDKLSE6crim7H7cxSYj8aiEnilWi4FejGZPrJR6b3YpJk7AkYXzCZ1dSq2q0iDwPLMG5PHaCqoaKSGd3/ihV3SYii4HNQCzOJbRbfRWTMenBvkd7UWrG+/xBRca0nEWXibVsKHDjU6KadJe/iOQASqrqDt+HlLiQkBDdsGGDv8MwJnWpcvJELK+8GsSeMUtpcc1PVJ3Rh/p32yB+xjsi8ouqhiRn2SS7nkSkBbAJWOxOVxeRuF1IxhhfOXiQw3X+x8TSbzJuHFR9+W7ah79tScKkGm/OUbyF85uIvwFUdRNQ2nchGWMAUOX0R2M5V6YieX9eyvnggqxZA0OGQM6c/g7OZCTenKOIVtWTYr/YMSbV6O49/HlfewqHLmeFNOC358fSfUhZslkjwviBNy2KrSLSBggSkXIi8gmw2sdxGZNhHToE3TqcISh0MwNKjib/xu958RNLEsZ/vEkUXXHul30BmIYz3Ljdj8KYFKZbtvJLq3epWBHGrKnC5Hf20+uPTlStbqP4Gf/ypuupvKq+Brzm62CMyZAuXuREr4HkGjaAkpqXerU6MGRSIW680U5EmMDgTaL4UESKAF8CM1Q11McxGZNhxP68nhMt21Hg0FZmZm7D2XeGMrfntTYUuAko3tzhrqGIXAc8DIwRkTzATFV9x+fRGZOO7fz1LIXrNuF8dA7evHk+7ea0oFQpf0dlzH959b1FVQ+r6sdAZ5zfVLzh06iMScei127gvYGxVK0TTOvs81j1aShv/WJJwgQub35wV0FE3hKRrTi3QF2NM8CfMeZKnDzJ8QefIXOdWwntM4V774XPfq9Lmy557X4RJqB5c47iM2A6cLeqxh391RjjhaivvuZ8287kO32YETl70HLMg7R8zN9RGeMdb85R1E6NQIxJryIe70nRqUPYRhVmN53LC5NvtVFeTZqSYKIQkS9U9WER2cK/bzjk7R3ujMm4VDl3Ooa+b2dm67S7aZwnD5Um9eLt+7P6OzJjrlhiLYoX3b/NUyMQY9KN8HCOPdyFL7ZV5cO/B9C5c2M6vdfYhgI3aVaCJ7NV9ZD79FlV3ef5AJ5NnfCMSUNiYzk/dDTnr69IjjXLOJr5OpYvh5EjsSRh0jRvLo9tHM9rTVM6EGPStN27OV79TnJ078xPUTUZ1n4LPfd1pUEDfwdmzNVLMFGISBf3/ER5Edns8diDc0c6Ywxw/Dj07nqWmC1hvFF0HHnWfkufcdfbUOAm3UjsHMU0YBEwEOjt8fppVf3Lp1EZkwbo5i1sHTCPRstf58SJKgS/uo/X3sxho7yadCexRKGquldEnos7Q0TyW7IwGdaFC5zuPYAcwwZSWK+hWtVOfPBdIapWzeHvyIzxiaRaFM2BX3Auj/X87agC1/swLmMCkq5Zy98PtueaiDCmZnqC430/YlHfAmT25qerxqRRCf57q2pz92+Z1AvHmMC1f9tZ8tW/l9NRwQyouJBOc5py443+jsoY3/NmrKfbRSTYff64iHwoIiV9H5oxgSF2zc8M/ziWircG0zLoaxYPCeX9LZYkTMbhzeWxI4FzIlINeAXYB0z2aVTGBIK//+bkQx3IdFtt1r04hdtvhwnbb6PTy7ntfhEmQ/Hm3z1aVRW4HximqsOA3L4Nyxj/ipk9l9MlKxI8ayJDs/Wi8eiHWLwYGwrcZEjenII7LSKvAk8A9UQkCMji27CM8Z+jT7zEtVM+4g+qMaXB17w8rQZFivg7KmP8x5tE8QjQBminqofd8xODfRuWMalMlQvnYhjwXmZ+ntaMBsEFKDf2FQa3zmL3ijAZXpJdT6p6GJgK5BWR5kCkqk7yeWTGpJb9+/n79nuZWPpN+veHQm3uotO+13jwUUsSxoB3Vz09DKwDHsK5b/bPIvKgrwMzxudiY7k49FMiy1Yiy5qVHIguyjffwOTJ2P0ijPHgTdfTa8CtqvongIhcC3wHzPJlYMb41K5d/N2qHfk2/8BSGrOyzRh6jSxto7waEw9vrnrKdClJuI57uZwxAenUKejXJ5LIzTt55drPyLpsCQOmWpIwJiHetCgWi8gSnPtmg3Nye6HvQjLGRzZtYueQeTRa+SYREZU5+8Je3hqY3UZ5NSYJ3twzu6eIPADUxRnvaYyqzvF5ZMaklMhIzvXpT7ah75FHC1L6xi7MWl2IWrWy+zsyY9KExO6ZXQ4YAtwAbAF6qOrB1ArMmJSgP63m9CPtyXNwO5PkKQ72+JDv3slvQ4EbcwUSO9cwAVgAtMIZQfaTVInImBRy+I+znGnYghMHz/F82cVU+3Uirw62JGHMlUqs6ym3qo51n+8QkY2pEZAxV0tXr+Hz7bXo/nIwVVlAy36VGfpqbhsK3JhkSqxFkV1EbhaRW0TkFiBHnOkkiUgTEdkhIrtEpHci5W4VkRj7fYa5KidOcObhdsjtt7G8/WQqV4axW+vQra8lCWOuRmIfn0PAhx7Thz2mFbgzsRW7Y0KNABoD4cB6EZmvqmHxlHsPWHJloRtzWeysrzjf/jmynzrK4CyvUuf9R/jsBWyUV2NSQGI3Lmp4leuuCexS1d0AIjIDZwTasDjlugKzgVuvcnsmgzrRtjvXfD6UnVRnbO2F9Jpxs43yakwK8mWDvBhwwGM6HKjlWUBEigEtcVonCSYKEekEdAIoWdLumWQAVaIvxPDhx5lZPq05dbIXotQnPRjR3sZnMial+bJhHt/HVeNMDwV6qWpMYitS1TGqGqKqIddee22KBWjSqL17OX17EyaX6UuvXpCjeSM67n6VpzpYkjDGF3zZoggHSnhMFwci4pQJAWaI8+kuCDQTkWhVnevDuExaFRtL1D5tIZ8AABg8SURBVLARxPZ6FaKEsNwt+eILePBBLEEY40NJJgpxjuKPAderaj/3fhTXqeq6JBZdD5QTkTLAQaA1zn0t/qGqZTy2MxFYYEnCxOv33zn94NPk3vwTi2jCkv+Nou+4UjbKqzGpwJuup0+BOsCj7vRpnKuZEqWq0cDzOFczbQO+UNVQEeksIp2TGa/JgM6dg8EDLnJm8x+8eM0kYr9eyNA5liSMSS3edD3VUtVbRORXAFU9ISJZvVm5qi4kzgCCqjoqgbJtvVmnyUB+/ZW9w+Zx149v8ccfldjXYS/vfpDNRnk1JpV506KIcn/roPDP/ShifRqVydgiI7nw0qvE1LiVbJ+PJn/MUZYtg+FjLUkY4w/etCg+BuYAhURkAPAg8LpPozIZ148/cqZ1e3Id3MlnPM0fz37AisHX2FDgxviRN8OMTxWRX4BGOJe8/k9Vt/k8MpPhHN93hmyN7ufoxTx0K7mUjl805ulaSS9njPEtb656KgmcA772fE1V9/syMJOB/PgjsyJu47muuSgX8w1NelVmxNu5bJRXYwKEN11P3+CcnxAgO1AG2AFU8mFcJiM4fpxznbuTc9ZkvmYiJWo8xYiltalWzd+BGWM8edP1VMVz2h059hmfRWTSP1X0y1lEdnyeLKf+4t2gvlR5uzXje2GjvBoTgK74Y6mqG0XEBvAzyXaqfXfyfDaMUGowvPpSXp1RjfLl/R2VMSYh3pyjeMljMhNwC3DUZxGZ9EmV2IvRjByXhYXT7+PmLEUpMvglJnTNbEOBGxPgvGlR5PZ4Ho1zzmK2b8Ix6dKePZx9vBNz99fg+fBBNG58Jx3G3Enp0v4OzBjjjUQThftDu1yq2jOV4jHpSUwMMcOGE9O7DzFRQazP8RATJkDbtjaInzFpSYKJQkQyq2q0t7c9NeZfdu7k7MNtCf5tDUtoyld3j6b/xBIUKeLvwIwxVyqxFsU6nPMRm0RkPvAlcPbSTFX9ysexmTTq4kUYMzSalr/to0fuKdw5rg1jHxJrRRiTRnlzjiI/cBznLnSXfk+hgCUK828bNnDw03ncs64/oaEV+eXR3Qz+OBsFC/o7MGPM1UgsURRyr3jayuUEcUncO9WZjOz8eaL6vEnQsA9AryPTdS+wYMG13Huv/bTamPQgsUQRBOTCu1uamoxq5UrOPdaBnAd3MYaObGv7Pj8MzUfevP4OzBiTUhJLFIdUtV+qRWLSnFMRZ8h0zwMcuZCPN4t8T/upd9Kpob+jMsaktMQShZ16NPH74QcWnbqdZ7rkosiFRTR8vhKjBwUTHOzvwIwxvpBYomiUalGYtOHYMS506Ua2WVOZwURyV3yKYWtqUru2vwMzxvhSgoMnqOpfqRmICWCqMHMmkTdUJNOsmfSTNynTuzUbN2JJwpgMwMbqNEk62/FFgsd/wmZu5YMK39NnehUbCtyYDMQShYmfKnoxikkzsjJ7ZksqBJWiQP9uTO0ZZEOBG5PB2Efe/NcffxD5REe+PhRC273vc/vtDWk3vqENBW5MBmUDPJvLYmKI/eBDoipU4cKaX1geUZ5PPoFVq7AkYUwGZi0K49i+nfOPPEWOzetYQAum1xvJwEnFbChwY4y1KAxER8OEcbEc3xxB+5zTOT5+HtNWWpIwxjisRZGRrVvHn2Pnce+mAWzYUJEH7/uDYSOzUrSovwMzxgQSa1FkROfOEdO9B7G163Bx3Oec2XOUmTPhi7mWJIwx/2Utioxm+XIin+hA9oO7GcUz/PLQe/zwaV4bCtwYkyBrUWQg5/48w9lmDxF+UHio4HJKLBjF2C8sSRhjEmctioxgxQpW6h106JSLfJGLqNWuEuM+zGlDgRtjvGItivTs6FGiHnwUGjZk/J1TiI2F95fdyvDxliSMMd6zFkV6pArTp3OxywvoqdP0pT+FX2jN5nexocCNMVfMEkU6FNmxK9nHj+AXavPu9eN5bWpFG+XVGJNslijSi9hYiI5m1vysTJ39INdnKktw767MeiOIbHbramPMVfDpOQoRaSIiO0Rkl4j0jmf+YyKy2X2sFhEbvDo5fv+di3XvZF7l13joIdh/fQOe3NiNfgMsSRhjrp7PEoWIBAEjgKZAReBREakYp9geoL6qVgX6A2N8FU+6FB2NDh5CdKWqnF+7iYV7KjBwIPz8M3a/CGNMivFl11NNYJeq7gYQkRnA/UDYpQKqutqj/FqguA/jSV+2beNC6yfJtnkDC7ifz0I+5f0pRW2UV2NMivNl11Mx4IDHdLj7WkLaA4vimyEinURkg4hsOHr0aAqGmDbFxsL06fDnliM8mW0mB4bNYc7PliSMMb7hyxaFxPOaxltQpCFOoqgb33xVHYPbLRUSEhLvOjKEtWv567N5tNw+kFWrKnDPnX8wanwWG+XVGONTvmxRhAMlPKaLAxFxC4lIVWAccL+qHvdhPGnX2bPEvtgdve02zo6ZSvivRxk/HhZ9Z0nCGON7vmxRrAfKiUgZ4CDQGmjjWUBESgJfAU+o6k4fxpJ2ffcdF5/qSNaIvQznOX5sNpAfxua2UV6NManGZ4lCVaNF5HlgCRAETFDVUBHp7M4fBbwBFAA+FRGAaFUN8VVMac3Fv84QfV9rDp7Pz0t5V/H46HpMfxgkvk49Y4zxEVFNW13+ISEhumHDBn+H4VvLlrE+Z33adQwi69ZfqPpIRQYPz2GjvBpjkk1EfknuF3EbFDCQHDlCdKuHoVEjPr1tCidOwNtf1+CzGZYkjDH+Y0N4BAJVmDKFqOe7oafO0IcBZG/fhtAh2Civxhi/sxZFALjY8Tl48knWnypP8+KbuOv7Powcm8WShDEmIFiLwl9iYyEqikXLsjFh/iMUoQJZXnyWOQOCbChwY0xAsUThDzt2ENW2A9+eqsW9YUOoUKE+L8+vb0OBG2MCknU9paaoKBg0iJgq1Tj781Zmba/C66/Dr79iScIYE7CsRZFaQkOJav0EWbb+ylweYHSVEbw/6TqqV/d3YMYYkzhrUaQCVZgzP4hDYX/ROvMsfh84m4UbLUkYY9IGa1H40urVnJo8j0f2vsfixTdxx227GD0+Mzfd5O/AjDHGe9ai8IUzZ9CuL6B163Ji9EzCVh3j449h+Q+WJIwxaY+1KFLa0qVEPd2JoIj9DOd5vm3wLis/y2WjvBpj0ixrUaSgC8fPcLblY+yOyE6zXD+Qa/zHzF9mScIYk7ZZiyIlfPstP2S5k05dcpH93FKqPFSBiR9n57rr/B2YMcZcPWtRXI1Dh7jYohXcfTdjG07l/Hl4d+HNTPrCkoQxJv2wFkVyqKITPyeqa3diz57nVRlEke5tCO2HDb9hjEl3LFEkw+nHu5B72mh+pi5DK43j9cnluflmf0dlTOCJiooiPDycyMhIf4eSYWTPnp3ixYuTJUuWFFunJQpvxcYSfT6KoSOzsXR2GyplrUrpQZ354oVMBAX5OzhjAlN4eDi5c+emdOnSiN2a0edUlePHjxMeHk6ZMmVSbL12jsIb27Zx5uZ6TC/Th549Ifvdd9D992d5sbslCWMSExkZSYECBSxJpBIRoUCBAinegrNEkZioKC68+S7RVapzYfN2fr54M7Nmwbx5ULKkv4MzJm2wJJG6fFHf1vWUkNBQTrZ4nLx7NvEFD/HLU58wYFhhu5mQMSbDsRZFPCIi4IWXMnN8z0leLPEVxX/6gvcmWpIwJq2aM2cOIsL27dv/eW3FihU0b978X+Xatm3LrFmzAOdEfO/evSlXrhyVK1emZs2aLFq06KpjGThwIGXLlqV8+fIsWbIk3jJvvfUWxYoVo3r16lSvXp2FCxde0fIpzVoUHmJX/sDm/vOov34IFy6Up0i/nQzulZmsWf0dmTHmakyfPp26desyY8YM3nrrLa+W6du3L4cOHWLr1q1ky5aNI0eOsHLlyquKIywsjBkzZhAaGkpERAR33XUXO3fuJCiek53du3enR48eyV4+JVmiADh9muMde1Ng5qfkoQx31u3N+xMKUq6cVY8xKaVbN9i0KWXXWb06DB2aeJkzZ87w008/sXz5cu677z6vEsW5c+cYO3Yse/bsIVu2bAAULlyYhx9++KrinTdvHq1btyZbtmyUKVOGsmXLsm7dOurUqZMqyydXhu96ujB3EX8Xr8Q1M0cyKns31o7ZwlerClKunL8jM8akhLlz59KkSRNuvPFG8ufPz8aNG5NcZteuXZQsWZI8efIkWbZ79+7/dBF5PgYNGvSfsgcPHqREiRL/TBcvXpyDBw/Gu97hw4dTtWpV2rVrx4kTJ654+ZSUob8yr1xwmiqtnuRQbCE+brqaZyfVpmBBf0dlTPqU1Dd/X5k+fTrdunUDoHXr1kyfPp1bbrklwauDrvSqoY8++sjrsqrq1fa6dOlC3759ERH69u3Lyy+/zIQJE7xePqVlvEShyskvltDtm8ZMnJyb5iW+o/vom3ijaTZ/R2aMSWHHjx9n2bJlbN26FREhJiYGEeH999+nQIEC/3xTv+Svv/6iYMGClC1blv3793P69Gly586d6Da6d+/O8uXL//N669at6d27979eK168OAcOHPhnOjw8nKJFi/5n2cKFC//zvGPHjv+cdPd2+RSnqmnqUaNGDU2u2IMRuu+W/6mCts30ufbpo3ruXLJXZ4xJQlhYmF+3P2rUKO3UqdO/Xrvjjjt01apVGhkZqaVLl/4nxr1792rJkiX177//VlXVnj17atu2bfXChQuqqhoREaGTJ0++qni2bt2qVatW1cjISN29e7eWKVNGo6Oj/1MuIiLin+cffvihPvLII1e0fHz1DmzQZB53M0aLQpUjgz4j+I2XuDb6AsNLvs/L89pQ2e5ZbUy6Nn369P98q2/VqhXTpk2jXr16TJkyhaeffprIyEiyZMnCuHHjyOteB//OO+/w+uuvU7FiRbJnz05wcDD9+vW7qngqVarEww8/TMWKFcmcOTMjRoz454qlDh060LlzZ0JCQnjllVfYtGkTIkLp0qUZPXp0ksv7kmg8fV6BLCQkRDds2OB1+YsXIbTuM9y8fgw/Bt3B/r7jaN23HJky/Gl8Y3xv27ZtVKhQwd9hZDjx1buI/KKqIclZX/ptUcTEsPaHKDp2zU6+rY/zxM0303x+J+oWtwxhjDFXIl0eNU+vDWVP0dtZ07APJ0/CK/Pr0WljZ4pakjDGmCuWro6ceuEioa37k63OzeT+cxcFmtxKaCi0aOHvyIzJuNJa93Za54v6TjddT4e/3UJkq8eodHoLi/O15rovPubJxtf6OyxjMrTs2bNz/PhxG2o8lah7P4rs2bOn6HrTfKKIiYHhw+HzPln58vw55rSdR4ux95E5ze+ZMWlf8eLFCQ8P5+jRo/4OJcO4dIe7lJSmD6e/j1vJutfn0+3IBzRpUp5Mn+ygZVm7k5AxgSJLliwpeqc14x8+PUchIk1EZIeI7BKR3vHMFxH52J2/WURu8Wa9Zw+dYk31LpTr2IDbj85l9uhjLFwIZSxJGGNMivNZi0JEgoARQGMgHFgvIvNVNcyjWFOgnPuoBYx0/ybo3KGTnCxRiZoxESyt/BIhi/rzQPGcvtkJY4wxPm1R1AR2qepuVb0IzADuj1PmfmCS+wvztUA+ESmS2EqzRuzlTFBeNo9czd1bPiC/JQljjPEpX56jKAYc8JgO57+thfjKFAMOeRYSkU5AJ3fyQvmLoVvpUhu6pGzAaVBB4Ji/gwgQVheXWV1cZnVxWfnkLujLRBHftXBxL/D1pgyqOgYYAyAiG5L7M/T0xuriMquLy6wuLrO6uExEvB/7KA5fdj2FAyU8posDEckoY4wxxo98mSjWA+VEpIyIZAVaA/PjlJkPPOle/VQbOKmqh+KuyBhjjP/4rOtJVaNF5HlgCRAETFDVUBHp7M4fBSwEmgG7gHPA016seoyPQk6LrC4us7q4zOriMquLy5JdF2lumHFjjDGpK10NCmiMMSblWaIwxhiTqIBNFL4a/iMt8qIuHnPrYLOIrBaRav6IMzUkVRce5W4VkRgReTA140tN3tSFiDQQkU0iEioiK1M7xtTixWckr4h8LSK/uXXhzfnQNEdEJojInyKyNYH5yTtuJvdm27584Jz8/gO4HsgK/AZUjFOmGbAI57cYtYGf/R23H+viNuAa93nTjFwXHuWW4Vws8aC/4/bj/0U+IAwo6U4X8nfcfqyLPsB77vNrgb+ArP6O3Qd1cQdwC7A1gfnJOm4GaovCJ8N/pFFJ1oWqrlbVE+7kWpzfo6RH3vxfAHQFZgN/pmZwqcybumgDfKWq+wFUNb3Whzd1oUBucW6KkQsnUUSnbpi+p6qrcPYtIck6bgZqokhoaI8rLZMeXOl+tsf5xpAeJVkXIlIMaAmMSsW4/MGb/4sbgWtEZIWI/CIiT6ZadKnLm7oYDlTA+UHvFuBFVY1NnfACSrKOm4F6P4oUG/4jHfB6P0WkIU6iqOvTiPzHm7oYCvRS1Zh0fkc1b+oiM1ADaATkANaIyFpV3enr4FKZN3VxD7AJuBO4AfhWRH5Q1VO+Di7AJOu4GaiJwob/uMyr/RSRqsA4oKmqHk+l2FKbN3URAsxwk0RBoJmIRKvq3NQJMdV4+xk5pqpngbMisgqoBqS3ROFNXTwNDFKno36XiOwBbgLWpU6IASNZx81A7Xqy4T8uS7IuRKQk8BXwRDr8tugpybpQ1TKqWlpVSwOzgGfTYZIA7z4j84B6IpJZRHLijN68LZXjTA3e1MV+nJYVIlIYZyTV3akaZWBI1nEzIFsU6rvhP9IcL+viDaAA8Kn7TTpa0+GImV7WRYbgTV2o6jYRWQxsBmKBcaoa72WTaZmX/xf9gYkisgWn+6WXqqa74cdFZDrQACgoIuHAm0AWuLrjpg3hYYwxJlGB2vVkjDEmQFiiMMYYkyhLFMYYYxJlicIYY0yiLFEYY4xJlCUKE5DckV83eTxKJ1L2TApsb6KI7HG3tVFE6iRjHeNEpKL7vE+ceauvNkZ3PZfqZas7Gmq+JMpXF5FmKbFtk3HZ5bEmIInIGVXNldJlE1nHRGCBqs4SkbuBIapa9SrWd9UxJbVeEfkc2KmqAxIp3xYIUdXnUzoWk3FYi8KkCSKSS0S+d7/tbxGR/4waKyJFRGSVxzfueu7rd4vIGnfZL0UkqQP4KqCsu+xL7rq2ikg397VgEfnGvbfBVhF5xH19hYiEiMggIIcbx1R33hn370zPb/huS6aViASJyGARWS/OfQKe8aJa1uAO6CYiNcW5F8mv7t/y7q+U+wGPuLE84sY+wd3Or/HVozH/4e/x0+1hj/geQAzOIG6bgDk4owjkcecVxPll6aUW8Rn378vAa+7zICC3W3YVEOy+3gt4I57tTcS9dwXwEPAzzoB6W4BgnKGpQ4GbgVbAWI9l87p/V+B8e/8nJo8yl2JsCXzuPs+KM5JnDqAT8Lr7ejZgA1AmnjjPeOzfl0ATdzoPkNl9fhcw233eFhjusfy7wOPu83w44z4F+/v9tkdgPwJyCA9jgPOqWv3ShIhkAd4VkTtwhqMoBhQGDnsssx6Y4Jadq6qbRKQ+UBH4yR3eJCvON/H4DBaR14GjOKPwNgLmqDOoHiLyFVAPWAwMEZH3cLqrfriC/VoEfCwi2YAmwCpVPe92d1WVy3fkywuUA/bEWT6HiGwCSgO/AN96lP9cRMrhjAaaJYHt3w3cJyI93OnsQEnS5xhQJoVYojBpxWM4dyaroapRIrIX5yD3D1Vd5SaSe4HJIjIYOAF8q6qPerGNnqo669KEiNwVXyFV3SkiNXDGzBkoIktVtZ83O6GqkSKyAmfY60eA6Zc2B3RV1SVJrOK8qlYXkbzAAuA54GOcsYyWq2pL98T/igSWF6CVqu7wJl5jwM5RmLQjL/CnmyQaAqXiFhCRUm6ZscB4nFtCrgVuF5FL5xxyisiNXm5zFfA/d5lgnG6jH0SkKHBOVacAQ9ztxBXltmziMwNnMLZ6OAPZ4f7tcmkZEbnR3Wa8VPUk8ALQw10mL3DQnd3Wo+hpnC64S5YAXcVtXonIzQltw5hLLFGYtGIqECIiG3BaF9vjKdMA2CQiv+KcRximqkdxDpzTRWQzTuK4yZsNqupGnHMX63DOWYxT1V+BKsA6twvoNeCdeBYfA2y+dDI7jqU49zb+Tp1bd4JzL5EwYKOIbAVGk0SL343lN5xhtd/Had38hHP+4pLlQMVLJ7NxWh5Z3Ni2utPGJMoujzXGGJMoa1EYY4xJlCUKY4wxibJEYYwxJlGWKIwxxiTKEoUxxphEWaIwxhiTKEsUxhhjEvV/XskSRH3VGpAAAAAASUVORK5CYII=\n",
"text/plain": [
""
]
},
"metadata": {
"needs_background": "light"
},
"output_type": "display_data"
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"\n",
"Please wait Training-Testing with all models..\n",
"\n",
"Done with LogisticRegression\n",
"Done with RandomForestClassifier\n",
"Done with XGBoost Classifier\n",
"Done with LGBoost Classifier\n",
"Done with AdaBoost Classifier\n",
"Done with GradientBoostingClassifier\n"
]
},
{
"data": {
"text/html": [
" Model F1 score AUC-ROC score Accuracy Confustion-Matrix \n",
" \n",
" 3 \n",
" LGBoost Classifier \n",
" 0.926282 \n",
" 0.8 \n",
" 0.933333 \n",
" [[25 0]\n",
" [ 2 3]] \n",
" \n",
" \n",
" 5 \n",
" GradientBoostingClassifier \n",
" 0.926282 \n",
" 0.8 \n",
" 0.933333 \n",
" [[25 0]\n",
" [ 2 3]] \n",
" \n",
" \n",
" 2 \n",
" XGBoost Classifier \n",
" 0.881402 \n",
" 0.7 \n",
" 0.9 \n",
" [[25 0]\n",
" [ 3 2]] \n",
" \n",
" \n",
" 4 \n",
" AdaBoost Classifier \n",
" 0.881402 \n",
" 0.7 \n",
" 0.9 \n",
" [[25 0]\n",
" [ 3 2]] \n",
" \n",
" \n",
" 1 \n",
" RandomForestClassifier \n",
" 0.852564 \n",
" 0.68 \n",
" 0.866667 \n",
" [[24 1]\n",
" [ 3 2]] \n",
" \n",
" \n",
" 0 \n",
" LogisticRegression \n",
" 0.757576 \n",
" 0.5 \n",
" 0.833333 \n",
" [[25 0]\n",
" [ 5 0]] \n",
" \n",
"
"
],
"text/plain": [
""
]
},
"execution_count": 11,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"y_pred, model = es.classification(X,y)\n",
"es.classification_result(y_test,y_pred)\n",
"es.roc_curve_graph(y_test, y_pred)\n",
"es.quick_pred(X,y,'c')"
]
},
{
"cell_type": "code",
"execution_count": 3,
"metadata": {
"ExecuteTime": {
"end_time": "2020-04-26T19:50:56.925457Z",
"start_time": "2020-04-26T19:50:02.506420Z"
}
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Dataframe Imported Successfully\n",
"*** Dataset Infomarion ***\n",
"##################################################\n",
"No of Rows : 1302\n",
"No of columns : 7\n",
"No of Numerical columns: 7\n",
"No of Categorical columns: 0\n",
"##################################################\n",
"\n",
" Total Missing values : 0 \n",
"\n",
"##################################################\n",
"Summary of DataFrame:\n",
"\n",
" Column Name Nulls/NaN outof Unique Type of Columns\n",
"0 buying_price 0 1302 4 Numerical\n",
"1 maintainence_cost 0 1302 4 Numerical\n",
"2 number_of_doors 0 1302 4 Numerical\n",
"3 number_of_seats 0 1302 3 Numerical\n",
"4 luggage_boot_size 0 1302 3 Numerical\n",
"5 safety_rating 0 1302 3 Numerical\n",
"6 popularity 0 1302 4 Numerical\n"
]
},
{
"data": {
"application/javascript": [
"\n",
" if (window._pyforest_update_imports_cell) { window._pyforest_update_imports_cell('from sklearn.model_selection import train_test_split'); }\n",
" "
],
"text/plain": [
""
]
},
"metadata": {},
"output_type": "display_data"
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"************************************************************\n",
"\n",
"\n",
" OLS Regression Results \n",
"=======================================================================================\n",
"Dep. Variable: popularity R-squared (uncentered): 0.894\n",
"Model: OLS Adj. R-squared (uncentered): 0.894\n",
"Method: Least Squares F-statistic: 1825.\n",
"Date: Mon, 27 Apr 2020 Prob (F-statistic): 0.00\n",
"Time: 01:20:02 Log-Likelihood: -915.04\n",
"No. Observations: 1302 AIC: 1842.\n",
"Df Residuals: 1296 BIC: 1873.\n",
"Df Model: 6 \n",
"Covariance Type: nonrobust \n",
"=====================================================================================\n",
" coef std err t P>|t| [0.025 0.975]\n",
"-------------------------------------------------------------------------------------\n",
"buying_price -0.1362 0.012 -11.721 0.000 -0.159 -0.113\n",
"maintainence_cost -0.1092 0.011 -9.546 0.000 -0.132 -0.087\n",
"number_of_doors 0.0537 0.011 5.102 0.000 0.033 0.074\n",
"number_of_seats 0.2138 0.009 22.528 0.000 0.195 0.232\n",
"luggage_boot_size 0.1288 0.015 8.385 0.000 0.099 0.159\n",
"safety_rating 0.3725 0.015 24.433 0.000 0.343 0.402\n",
"==============================================================================\n",
"Omnibus: 281.511 Durbin-Watson: 2.017\n",
"Prob(Omnibus): 0.000 Jarque-Bera (JB): 701.940\n",
"Skew: 1.150 Prob(JB): 3.76e-153\n",
"Kurtosis: 5.766 Cond. No. 8.35\n",
"==============================================================================\n",
"\n",
"Warnings:\n",
"[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.\n",
"\n",
"\n",
"******** VIF *********\n",
"\n",
" feature vif\n",
"3 number_of_seats 10.14\n",
"6 popularity 9.45\n",
"5 safety_rating 8.54\n",
"2 number_of_doors 8.28\n",
"4 luggage_boot_size 6.26\n",
"0 buying_price 6.20\n",
"1 maintainence_cost 5.73\n",
"########## MENU ##############\n",
"\n",
"1. Logisitic Regression \n",
"2. Random Forest \n",
"3. XGB Classifier \n",
"4. LGB CLassifier \n",
"5. Gradient Boosting Classifier \n",
"6. AdaBoost Classifier\n",
"\n",
"Input No, which you want:3\n",
"Predicting with XGB boost Classifier\n",
"--------------------------------------------------------\n",
"********************* Model Results ********************\n",
"--------------------------------------------------------\n",
"F1 Score : 0.9770320347121912\n",
"AUC-ROC Score : 0.9707396672414965\n",
"Report:\n",
" precision recall f1-score support\n",
"\n",
" 1 0.99 0.99 0.99 277\n",
" 2 0.96 0.95 0.95 94\n",
" 3 0.86 1.00 0.92 12\n",
" 4 1.00 0.88 0.93 8\n",
"\n",
" accuracy 0.98 391\n",
" macro avg 0.95 0.95 0.95 391\n",
"weighted avg 0.98 0.98 0.98 391\n",
"\n"
]
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAYEAAAEgCAYAAABSGc9vAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADt0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjByYzEsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy/xvVyzAAAgAElEQVR4nO3de5xVdb3/8ddbxlEBL6UxY0ogAcdCjpi3hEKlDBOSjiChdbwk8vP36yeVnLx1QqFTnuO1k6csUrH6laaZUqCVQYpl3lFSUTMdxcsMeUO8AM7w+f2x1uA47Blmhj17zZr1fj4e+7Fn3T/znT37vdd3XbYiAjMzK6atsi7AzMyy4xAwMyswh4CZWYE5BMzMCswhYGZWYA4BM7MCcwhYjyZppqRHJL0lKSR9pQLbrJNU193bKYL0b3Zr1nVY2xwCBoCkPSVdKukhSaslrZf0vKRFkk6StG0GNU0D/htYC3wHmAPcWek6eoI0mCJ9HNrOfPNbzHfuFm7zkHKsx3q2qqwLsOxJmg2cQ/Kh4E7gx8DrQA1wCHA58L+B/Spc2sTm54h4voLb/UQFt9VZjcDJwB9bT5C0AzA1naen/G9/CHgz6yKsbT3lhWIZkXQ2ySfslcDREXFXiXkmArMqXRvwfoAKBwAR8fdKbq+TFgJHSdo5Il5qNe3zQF/gBuBfKl5ZCRHxaNY1WPvcHVRgkgYD5wJvA0eUCgCAiFgIHF5i+amSlqbdR29J+quksyRtU2LeuvTRV9IFkp6RtE7SE5LOkKQW854rKYBD0+Hm7o1orjsdvqqN3+vW5nlbjJOk4yXdIekfktZKWinpd5I+V6rWEuvdRtKZkpZLelPSa5JulzS1xLwba0x/vkbSi+l2702DtSt+BGwD/GuJaSeThPlvSy0oabik/0y3/4+0/Z+WNE/S7q3mvYp39jbOafk3kHRIOs8J6fAJkg5P2311y7ZvfUxA0h6SXpX0sqRBrbbZT9IKSU2SDu5sw1jXeE+g2E4EtgauiYiH2psxIta1HJb0beAs4EXg5yTdR58Gvg2Ml3RYRLzdajVbA78n+YR/M0m3xWeB/wS2JdkjAbg1fT4BGNRi/Jb4VlrvU8C1wGpgV2B/4GjgF+0tLKka+B1wMPAo8D2ST91TgF9IGhURZ5dYdBBwN/Ak8FPgvcDngAWSPhkRm3TrbMYtQB0wneQ4SXN9+wL7kLTVhjaWPQo4heTN/Q5gPTAiXddnJO0XEc+l896YPh8P3MY7fxPS7bc0heRDws3AD4DBbRUfEU9Jmg5cB1wtaWxENKaTvw/sCZwbEbe1tQ4rs4jwo6APYDEQwPROLndQutwzQG2L8VXAb9JpZ7dapi4dfxOwXYvxA4BX08fWrZa5NXmJbrL9wem6rmqjvk2WA14CngX6lph/lxK11rUad1aL+qta1d/8u40uUWMA57Ra1/jmdXWizZu3UQX8e/rzQS2m/wBoAj5A8qYeJG+mLdexG7BNiXV/Kl32slbjDym1nhbTT0inbwAOb2OeAG4tMf776bTz0uHj0uE/Altl/b9RpIe7g4pt1/T52U4u98X0+T8ior55ZCSf6GaRvClMb2PZmRHxVotlVgELgB2Bf+pkHZ31Nsmb3btExIsdWPaLJG9Sp8U7n1yb6/9mOljqd34a+I9W2/sdSYAe0LGyN3Elye9xMiTdKMCxwO8i4pm2FoqI56LVHl06/vfAwyTh1BULIqJkF1Q7TgMeBM6Q9H9JQuEfwOcjoq09GesGDoFia+6H7+z9xD+SPi9pPSEiHicJlT0k7dRq8uqIeKLE+lamz+/pZB2d8TOST+cPSzov7cPesSMLStoeGAo8H6UPdDa3wz4lpj0QEZsED8nv3KXfN5ID5TcBU9MzgqYB25McL2hTelzkC5L+kB4TaGxxrGUkyZ5CV9zd2QUiYi1Jt9gbwKUkXWvHRYVPAjCHQNE1/8Pt3u5cm2p+83yhjekvtJqv2attzN/8ybpPJ+vojK8CXyF50zmTpP/6RUkLJA3dzLId/X1bhx60/ztvyf/fj4B+wDEkewT1JF1x7bmY5LjEh0mOb1xEcgxhDskeS3UXa6nf/CwlPQ4sT39+hOR4kVWYQ6DY/pQ+d/a8+NXpc20b03dtNV+5NXcXtHViwyZvxhHRFBH/HRF7k1z/MJnkVMojgd+WOqOphax/31JuAp4jOT5wIDC/ZTdVa5IGADOBh4B/iogvRMQZEXFuRJwLbNJN1Ald/WaqM4HRJCcXjCA57mIV5hAotvkk/eSTJX24vRlbvUkuS58PKTHfUJI9i6cioq1PwVvqlfR5YInt7wAMb2/hiFgVEb+KiKkkXTkfBPZqZ/41wN+B3SQNKzFL8xW893eg9rJIu5iuJGnrAK7YzCJDSP7ff5/+Phulp4cOKbFMczdW2ffQJI0G5gKPkbT9Y8AcSR8r97asfQ6BAouIOpLrBKqBRZJKXhEsqfn0v2ZXps//Lul9LebrA1xI8rra3JtSl6VvYo8CY1qGV7r9i4HtWs6fnt//iZbXIqTjtyY5ZRM2f1XrlSTHUC5It9O8jl2Ab7SYp5K+S3JR2PjY/AVudenzx1rV35+ka6nUXlXzxWgf2MI630XSe4CrSUJmWkQ0kBwfaCQ5bXTncm7P2ufrBAouIr4tqYrkthH3SLoDuJd3bhsxFhiWjmte5g5J5wOnAw9J+iVJX/unST7V/Qm4oJtLv4AkaP4s6TqS+wsdSnItwoPA3i3m3Q74A1An6S6S/u9tgcNIbmvw64hYsZntXUjy+00CHpR0E8nBzKNJThM9PyL+1M7yZZee1XTjZmdM5q2XdA3JQeQHJP2e5FjHYSRt9wAwqtVij5F0OU2TtJ7kjKYAfhoRT29B6VeSBMvMiHggre9BSbOA/yHZQz1yC9ZvnZH1Oap+9IwHyZvhpSR9xq+RXEj0AskewEmUPr98Gskb/hqSN5KHga8D25aYt45W5963mHYuyZvLIa3G30qJ6wRaTD8p3eY6koOTPwR2br0cSTCcnv4uz6S1/oPkPkmnANUdqZUkOM5O2+it9Pf+E3BMiXkH08lrGTbz96lL11fVgXnbuk6gL8lFc0+kbbCS5KK3TdqsxTL7k1xPsprkWMzGvxPvXCdwQju1vOs6AeDUdNyCNub/VTr9q1n/TxTlobThzcysgHxMwMyswBwCZmYF5hAwMyswh4CZWYHl6hRRtbpHvJmZbV5EqK1puQoBKy/fq6t8pPfjM+3KR5Lbs0xaXSO5CXcHmZkVmEPAzKzAHAJmZgXmEDAzKzCHgJlZgTkEzMwKzCFgZlZgDgEzswJzCJiZFZhDwMyswBwCZmYF5hAwMyswh4CZWYE5BMzMCswhYGZWYA4BM7MCcwiYmRWYQ8DMrMAcAmZmBeYQMDMrMIeAmVmBOQQ6affdd2fJkiU88sgjPPTQQ8ycOROAa665hmXLlrFs2TKeeuopli1b9q7lBg4cyJo1a5g1a1YWZefOunXrmDLlFI488iQmTDiB7353ftYl5d7SpUsZP348hx12GPPmzcu6nNzrLe1ZlXUBedPY2MisWbNYtmwZ/fv357777uOWW25h2rRpG+e58MILWb169buWu+SSS7j55psrXW5uVVdX8+MfX0y/fn15++1Gjj32VMaOPYBRo0ZkXVouNTU1MXfuXObPn09NTQ1Tpkxh3LhxDB06NOvScqk3taf3BDqpvr5+46f8119/nRUrVrDbbru9a56pU6dy9dVXbxyeNGkSTz75JA8//HBFa80zSfTr1xdIgrexsRFJGVeVX8uXL2fQoEEMHDiQ6upqJkyYwOLFi7MuK7d6U3s6BLbAoEGD2Geffbjrrrs2jvv4xz9OQ0MDTzzxBAB9+/bljDPOYM6cOVmVmVtNTU1MmnQSo0d/ltGj92PvvT+cdUm51dDQQG1t7cbhmpoaGhoaMqwo33pTe/aIEJB0YtY1dFa/fv24/vrr+cpXvsKaNWs2jj/mmGPetRcwZ84cLrnkEt54440sysy1Pn36sGDBFdx223UsX76Cxx9/MuuScisiNhnnPauu603t2VOOCcwBSh75kzQDmFHZctpXVVXF9ddfz89+9jNuuOGGjeP79OnDUUcdxb777rtx3IEHHsiUKVM4//zz2WmnndiwYQNr167le9/7Xhal59IOO2zPgQeO4vbb72b48CFZl5NLtbW11NfXbxxuaGhgwIABGVaUb72pPSsWApKWtzUJqGlruYiYB8xL17Fp/GbgiiuuYMWKFVxyySXvGv/JT36SRx99lOeee27juLFjx278+ZxzzuH11193AHTAyy+/SlVVH3bYYXvWrl3HHXfcx8knH5N1Wbk1cuRI6urqWLlyJTU1NSxatIiLLroo67Jyqze1ZyX3BGqA8cArrcYLuKOCdWyRMWPGcNxxx7F8+fKNB4jPPvtsbr75ZqZNm/auriDrulWrXuLMM8+jqWkDERs4/PBDOfTQ0VmXlVtVVVXMnj2b6dOn09TUxOTJkxk2bFjWZeVWb2pPlerb6pYNSVcA8yPiTyWm/Twiju3AOnrEnkBvEfF81iX0GtL7S/YTW9dIcnuWSdqWbR6wqFgIlINDoLwcAuXjECgvh0D5bC4EesTZQWZmlg2HgJlZgTkEzMwKzCFgZlZgDgEzswJzCJiZFZhDwMyswBwCZmYF5hAwMyswh4CZWYE5BMzMCswhYGZWYA4BM7MCcwiYmRWYQ8DMrMAcAmZmBeYQMDMrMIeAmVmBOQTMzArMIWBmVmAOATOzAlNEZF1Dh0nKT7FmZj1ERKitaVWVLKQcIp7PuoReQXo/MfcbWZfRa2j2N4lYk3UZvYa0PXn6gNqTSW2+/wPuDjIzKzSHgJlZgTkEzMwKzCFgZlZgDgEzswJzCJiZFZhDwMyswBwCZmYF5hAwMyswh4CZWYE5BMzMCswhYGZWYA4BM7MCcwiYmRWYQ8DMrMAcAmZmBeYQMDMrMIeAmVmBOQTMzArMIWBmVmAOATOzAnMImJkVWFXWBfQm69at4/Of/zLr179NU1MT48cfzMyZJ2ZdVr4ceBDssy9EwKoG+PWNsMvOcMSRUF0Nr74KN/wS1q/LutJceeGFek4/fTYvvvgSW221FVOn/gvHH39s1mXl2tKlS/nWt77Fhg0bOProo5kxY0bWJXWJQ6CMqqur+fGPL6Zfv768/XYjxx57KmPHHsCoUSOyLi0ftt8e9v8o/OBSaGyEyVNhxF6w/4Fwy+/gmTrYex8YPQZuXZJ1tbnSp08fzjzzq4wY8SFef/0NJk/+AmPGfJShQ4dkXVouNTU1MXfuXObPn09NTQ1Tpkxh3LhxDB06NOvSOq2i3UGS9pT0CUn9W40/vJJ1dBdJ9OvXF4DGxkYaGxuRlHFVObPVVlC1NSh9fn0N7LxzEgAAT/0d9vxwpiXm0YAB72PEiA8B0L9/P4YM2YOGhlUZV5Vfy5cvZ9CgQQwcOJDq6momTJjA4sWLsy6rSyoWApJmAguAU4GHJE1qMfnblaqjuzU1NTFp0kmMHv1ZRo/ej7339htWh61ZA3f+Gb58Gnz1a7BuLTz5d1i1Cobvmczzob1ghx2zrTPnnn32eVaseJS9994r61Jyq6Ghgdra2o3DNTU1NDQ0ZFhR11VyT+BkYN+I+CxwCPANSV9Op7X5cVnSDEn3Srq3AjVusT59+rBgwRXcdtt1LF++gscffzLrkvJj222TN/tLL4HvXJAcAxj5z/CbG2G/A2D6KbBNNTQ1ZV1pbr3xxpvMnPk1zj773+jfv//mF7CSImKTcXnd66/kMYE+EfE6QETUSToE+KWkQbQTAhExD5gHIGnTlu+hdthhew48cBS33343w4e737VD9vggvPoKvPlmMvzoI7D7B+Cvy+HnP0nGvXdnGDo8uxpz7O2332bmzK/xmc98mk99alzW5eRabW0t9fX1G4cbGhoYMGBAhhV1XSX3BOoljWoeSANhIrALMLKCdXSbl19+lddeWwPA2rXruOOO+xgy5AMZV5Ujq1fD7gOTYwEAg4fAi/+Avv3SGQQfPxjuuyezEvMqIvj617/JkCF7cOKJX8i6nNwbOXIkdXV1rFy5kvXr17No0SLGjctnsFZyT+A4oLHliIhoBI6T9MMK1tFtVq16iTPPPI+mpg1EbODwww/l0ENHZ11Wfjz/LKx4GE4+BTZsgPoX4P57Yd/9k+4ggEdXwIPLsq0zh+677wEWLFjE8OFDmTTpGABOO+1LHHzwxzKuLJ+qqqqYPXs206dPp6mpicmTJzNs2LCsy+oSlerb6qkkRcTzWZfRK0jvJ+Z+I+syeg3N/iYRa7Iuo9eQti/Z726dJ4mIaLPL3VcMm5kVmEPAzKzA2jwmIOnaTqwnIuJzZajHzMwqqL0Dw++rWBVmZpaJNkMgIg6tZCFmZlZ5PiZgZlZgHb5OQNL2wCRgOLBt6+kRcXoZ6zIzswroUAhI+iDwZ6Av0A/4B/DedPlXgNWAQ8DMLGc62h10CXAvUENyn58jgO2ALwCvAz4zyMwshzraHXQAMB1o/jqn6ohoAn4uaRfgvwHfH8HMLGc6uiewLfBaRGwAXgbe32LaQ8De5S7MzMy6X0dD4HFgUPrzMuAUSdtK2ho4CfANfczMcqij3UHXAKOAnwLfAH4HvAZsSNdxQncUZ2Zm3atDIRARF7f4+U5JewGfJukmWhIRD3VTfWZm1o269H0CEbGS9Nu+zMwsvzp6ncARm5snIm7a8nLMzKySOronsBAINv0u4Jbf+tCnLBWZmVnFdDQE9igx7r3Ap0gOCp9YroLMzKxyOnpg+OkSo58GlklqAs4GjixnYWZm1v3KcRfRZcC4MqzHzMwqbItCQFI1SXfQC2WpxszMKkoRsfmZpHt490FggGpgMLA9cGJE/KTs1W1ax+aLNTOzd4mI1if1bNTRA8MPs2kIrAWuA26MiIe7WJuZmWWoQ3sCPYWkyFO9PZkk3Jblk7Snv1KjXKTz/fosk/R/vc09gQ4dE5C0RNKebUwbLmlJVws0M7PsdPTA8CHADm1M2wEYW5ZqzMysojpzdtAm+2bp2UHjgPqyVWRmZhXT5oFhSecAs9PBAO6U2uxWuqDMdZmZWQW0d3bQTcCLJPcL+i5wEVDXap71wKMRcXu3VGdmZt2qzRCIiHuAewAkrQEWRsRLlSrMzMy6X0ePCTwAHFhqgqQjJP1z+UoyM7NK6WgIXEIbIQDsn043M7Oc6WgIfAT4cxvT/gLsU55yzMyskjoaAn2Afm1M60dyHyEzM8uZjobAPcCMNqbNAO4tTzlmZlZJHb2B3LnAHyTdBfyY5OKwXYHjgFHAJ7ulOjMz61Yd/WaxpZI+BZwHXEpy7cAG4C7gE+mzmZnlTEf3BIiIW4GDJPUF3gO8AhwEHA8sAHbujgLNzKz7dDgEWhgJHANMBWqAl4FrylmUmZlVRodCQNJeJG/800i+TWw9yRlBs4D/iYjG7irQzMy6T5tnB0kaIulsSX8FHgT+DVhBcjB4GMlxgfsdAGZm+dXensATJHcPvQv4X8D1EfEKgKQdK1CbmZl1s/auE3ia5NP+XiRfKjNaUleOIZiZWQ/VZghExB7AGJLrAj4B/AZokPSjdNhfAGpmlnPtXjEcEX+JiFOB3YDxJKeCTgZ+mc5ysqT9urdEMzPrLh26bUREbIiIWyLii0AtcBRwHfAvwF2SVnRjjbmxdOlSxo8fz2GHHca8efOyLif33J5b5qyz7uegg25i4sTFG8f91389xOGH/4HPfGYJX/rSXbz22voMK8y33vL67Mx3DAMQEesj4saImEZyncBxJAeRC62pqYm5c+dy+eWXs2jRIhYuXMgTTxS+WbrM7bnljjrqA1x++eh3jRszZgALF47jN78Zx+DB/fnhD/+WUXX51pten50OgZYi4o2I+FlEfKYj80s6QNL+6c8flnSapCO2pIaeYvny5QwaNIiBAwdSXV3NhAkTWLx48eYXtJLcnltu//13Yccdt37XuI99bABVVcm//ahR76G+/q0sSsu93vT63KIQ6Iz0i+u/C1wm6Tzgf4D+wJmSvl6pOrpLQ0MDtbW1G4drampoaGjIsKJ8c3t2v+uvf5qxY2uyLiOXetPrs5KnfE4huePoNiR3Id09Il6TdAHJtQjfKrWQpBm0fRvrHiNi05OlJGVQSe/g9uxel132GH36bMWRR+6edSm51Jten5UMgcaIaALelPT3iHgNICLekrShrYUiYh4wD0BSjz0ttba2lvr6+o3DDQ0NDBgwIMOK8s3t2X1uuOEZbr21nquuGpPbN66s9abXZ8W6g4D16R1IAfZtHplefdxmCOTFyJEjqaurY+XKlaxfv55FixYxbty4rMvKLbdn91i6tIEf/ehvXHbZR9luO1/72VW96fVZyVfB2IhYB8kppy3Gb01yO+pcq6qqYvbs2UyfPp2mpiYmT57MsGHDsi4rt9yeW+600+7h7rtf5JVX1jN27G859dQ9mTfvb6xfv4ETT0y+Mnzvvd/L3LmjMq40f3rT61Ol+rZ6KkmRp3p7Mkkl+zWta5L2PD3rMnoN6Xy/Pssk/V9vs9+vkt1BZmbWwzgEzMwKzCFgZlZgDgEzswJzCJiZFZhDwMyswBwCZmYF5hAwMyswh4CZWYE5BMzMCswhYGZWYA4BM7MCcwiYmRWYQ8DMrMAcAmZmBeYQMDMrMIeAmVmBOQTMzArMIWBmVmAOATOzAnMImJkVmEPAzKzAFBFZ19BhkvJTrJlZDxERamtaVSULKYc8hVZPJsltWUZuz/JK2nNh1mX0CtLEdqe7O8jMrMAcAmZmBeYQMDMrMIeAmVmBOQTMzArMIWBmVmAOATOzAnMImJkVmEPAzKzAHAJmZgXmEDAzKzCHgJlZgTkEzMwKzCFgZlZgDgEzswJzCJiZFZhDwMyswBwCZmYF5hAwMyswh4CZWYE5BMzMCswhUEZLly5l/PjxHHbYYcybNy/rcnLvrLPO4qCDDmLixIlZl9Ir+PVZPk8+uYpJky7c+PjIR87iqqtuy7qsLlFEZF1Dh0mKnlpvU1MT48ePZ/78+dTU1DBlyhQuvvhihg4dmnVpJUmip7Zls3vuuYe+fftyxhlnsHDhwqzLaVdPb898vj579t+8WVPTBsaOncO1136Z3XZ7b9blbEKaSESoreneEyiT5cuXM2jQIAYOHEh1dTUTJkxg8eLFWZeVa/vvvz877rhj1mX0Cn59dp+//OVvDBy4c48MgI7INAQk/STL7ZdTQ0MDtbW1G4drampoaGjIsCKzd/j12X0WLVrGxIn7ZF1Gl1VVakOSft16FHCopJ0AIuLIStXSHUp1BUht7oGZVZRfn91j/fpGlix5mFmzJmRdSpdVLASA3YFHgMuBIAmB/YCL2ltI0gxgRrdXt4Vqa2upr6/fONzQ0MCAAQMyrMjsHX59do+lSx9lxIjd2GWX7bMupcsq2R20H3Af8HVgdUTcCrwVEbdFRJuH1SNiXkTsFxH7VajOLhk5ciR1dXWsXLmS9evXs2jRIsaNG5d1WWaAX5/dZdGi+5kw4SNZl7FFKrYnEBEbgEskXZc+N1Ry+92tqqqK2bNnM336dJqampg8eTLDhg3LuqxcO+2007j77rt55ZVXGDt2LKeeeipHH3101mXlkl+f5ffWW+u5447HmTs336/JzE4RlTQBGBMRZ3dimR57imje9PRTGvPG7VleeTpFtKfb3CmimX0Sj4hFwKKstm9mZr5OwMys0BwCZmYF5hAwMyswh4CZWYE5BMzMCswhYGZWYA4BM7MCcwiYmRWYQ8DMrMAcAmZmBeYQMDMrMIeAmVmBOQTMzArMIWBmVmAOATOzAnMImJkVmEPAzKzAHAJmZgXmEDAzKzCHgJlZgTkEzMwKTBGRdQ0dJik/xZqZ9RARobam5SoE8kLSjIiYl3UdvYXbs3zcluXVG9rT3UHdY0bWBfQybs/ycVuWV+7b0yFgZlZgDgEzswJzCHSPXPcR9kBuz/JxW5ZX7tvTB4bNzArMewJmZgXmEDAzKzCHQBlJulLSKkkPZV1L3kkaKOmPklZIeljSl7OuKc8kbSvpbkkPpu05J+ua8k5SH0nLJC3MupYt4RAor6uAw7MuopdoBGZFxIeAjwJfkvThjGvKs3XAuIjYGxgFHC7poxnXlHdfBlZkXcSWcgiUUUQsBV7Ouo7eICJeiIj705/XkPyz7ZZtVfkVidfTwa3Th88K6SJJuwMTgMuzrmVLOQSsx5M0GNgHuCvbSvIt7b54AFgF3BIRbs+u+w5wOrAh60K2lEPAejRJ/YHrga9ExGtZ15NnEdEUEaOA3YEDJO2VdU15JGkisCoi7su6lnJwCFiPJWlrkgD4WUT8Kut6eouIeBW4FR+/6qoxwJGS6oBrgHGS/l+2JXWdQ8B6JEkCrgBWRMTFWdeTd5LeJ2mn9OftgE8Cj2ZbVT5FxFkRsXtEDAamAUsi4gsZl9VlDoEyknQ18BfgnyQ9K+mkrGvKsTHAv5J8ynogfRyRdVE5tivwR0nLgXtIjgnk+tRGKw/fNsLMrMC8J2BmVmAOATOzAnMImJkVmEPAzKzAHAJmZgXmELDck3SupGjxeF7S9ZI+2E3bm5huZ3A6PDgdntiJdUyVdEIZa+qf1lC2dVoxVGVdgFmZrOadK2CHAN8EFksaERFvdPO2XwAOonMXX00FdiG586xZZhwC1ls0RsSd6c93SnoGuB04Ariu5YyStouIt8q14YhYB9y52RnNeiB3B1lv1Xxzr8GS6iRdJOkbkp4FXgOQtJWkMyU9IWmdpMclHd9yJUqcm35Z0BpJPwF2aDVPye4gSSdL+quktZIaJP1S0o6SrgImAwe36MI6t8VykyTdmy5XL+n89D5KLdc9Oa33LUlLgT3L02xWNN4TsN5qcPpcnz4fCzwM/B/eed1fChwPzAXuBw4DrpT0UotbKswEZgPfJtmzOAo4f3Mbl/Tv6Xq/D3wN6Ety//n+JF1VHwB2SusBeDZdbipwNfBD4Gzgg8B5JB/Y/i2d5yPAL4AbSL7YZARwbQfaxGxTEeGHH7l+AOcCL5K8uVcBw4E/knzi3xWoI+m337bFMkNJ7gV/fKt1/QS4J/25D/A8cFmreZlxweUAAAJiSURBVG4h+UKWwenw4HR4Yjq8E/AmcHE7Nf8SuLXVOAFPA/Nbjf8i8Bawczp8LfAI6W1f0nFfT2s4Ieu/hx/5erg7yHqLnYG308djJAeHPxcRL6TTF0fE2hbzf4IkBG6QVNX8ABYDoyT1AQaShMiCVtva3G2tDwK2A+Z38ncYTrKHcG2rmpYA2wLN9/8/APh1RLS88ZdvtW1d4u4g6y1Wk9weOUi6gJ5v9SbZ0Gr+XUg+6a9uY327ArXpz6taTWs93NrO6fML7c61qV3S55vamD4wfa7tQk1mJTkErLdojIh725ne+na5L5N8mf0YSn9F4Cre+f8Y0Gpa6+HWXkqfdyXppuqo5u+nngEsKzH9qfS5vgs1mZXkELCiWkKyJ7BjRNxSagZJK0necCcBv20x6ajNrPsvJH34x5MezC1hPUkXT0uPAc+RHGv4UTvrv4fkm63OarG3s7mazEpyCFghRcRjkn4AXCPpfOBekjflEcDwiJgeEU3ptAslvUhydtBk4EObWferkr4JfEtSNUn3zjYkZwfNiYjnSC4smyTpsyRnBj0fEc9LmgX8VNIOwM0kYTEE+CwwJSLeBP4LuIvk2MEVJMcK/AVG1iU+MGxF9iWS0zWPI3mjvorkjXppi3m+Q3J66Ckk33fcHzh9cyuOiPOA/01ynGIBySmfOwFr0lm+D/weuJLkk/2MdLlfkOx5jCK5yO1XJKeR3k8SCKTdXtOAfYAbSQLic5395c3A3yxmZlZo3hMwMyswh4CZWYE5BMzMCswhYGZWYA4BM7MCcwiYmRWYQ8DMrMAcAmZmBfb/AVxyUmlOGxkqAAAAAElFTkSuQmCC\n",
"text/plain": [
""
]
},
"metadata": {
"needs_background": "light"
},
"output_type": "display_data"
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"--------------------------------------------------------\n",
"\n",
"Model used: XGBClassifier(base_score=0.5, booster='gbtree', class_weight='balanced',\n",
" colsample_bylevel=1, colsample_bynode=1, colsample_bytree=1,\n",
" gamma=0, learning_rate=0.1, max_delta_step=0, max_depth=8,\n",
" min_child_weight=1, missing=None, n_estimator=100,\n",
" n_estimators=100, n_jobs=1, nthread=None,\n",
" objective='multi:softprob', random_state=0, refit='AUC',\n",
" reg_alpha=0, reg_lambda=1, scale_pos_weight=1, seed=None,\n",
" silent=None, subsample=1, verbosity=1) \n",
" Done.\n",
"\n",
"\n",
"*** Start Hypertuning ***\n",
"\n",
"Performing GridSearchCV \n",
"Please wait............\n",
"Done ¯\\_(ツ)_/¯\n",
"\n",
"best parameters: \n",
" XGBClassifier(base_score=0.5, booster='gbtree', class_weight='balanced',\n",
" colsample_bylevel=1, colsample_bynode=1, colsample_bytree=1,\n",
" gamma=0, learning_rate=0.1, max_delta_step=0, max_depth=80,\n",
" min_child_weight=1, min_samples_leaf=3, min_samples_split=8,\n",
" missing=None, n_estimator=100, n_estimators=40, n_jobs=1,\n",
" nthread=None, objective='multi:softprob', random_state=0,\n",
" refit='AUC', reg_alpha=0, reg_lambda=1, scale_pos_weight=1,\n",
" seed=None, silent=None, subsample=1, verbosity=1)\n",
"\n",
"\n",
"*** Grid Search CV Result ***\n",
"\n",
"--------------------------------------------------------\n",
"********************* Model Results ********************\n",
"--------------------------------------------------------\n",
"F1 Score : 0.9618660674598313\n",
"AUC-ROC Score : 0.959293573399994\n",
"Report:\n",
" precision recall f1-score support\n",
"\n",
" 1 0.99 0.97 0.98 277\n",
" 2 0.92 0.94 0.93 94\n",
" 3 0.91 0.83 0.87 12\n",
" 4 0.80 1.00 0.89 8\n",
"\n",
" accuracy 0.96 391\n",
" macro avg 0.90 0.94 0.92 391\n",
"weighted avg 0.96 0.96 0.96 391\n",
"\n"
]
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAYEAAAEgCAYAAABSGc9vAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADt0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjByYzEsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy/xvVyzAAAgAElEQVR4nO3dfZyVdZ3/8ddbR8RbTFhAgSBvKFNSU9zI1lUUMaEw8Abb1ruUrZ8/zcW2FXczpV3bX5nWtltJeJP9TNIsMUZLBZEtFTRRUkAjHQORIRURFRwZPvvHdQ0OZ86ZO86ca85c7+fjcR5nrvvP+c7MeZ/re90cRQRmZpZPO2RdgJmZZcchYGaWYw4BM7MccwiYmeWYQ8DMLMccAmZmOeYQsG5N0sWSlkraKCkkXVKBbdZJquvq7eRB+jubn3UdVppDwACQ9CFJ35P0tKT1khokrZZUK+nzknpnUNNk4LvAJuA7wFXAo5WuoztIgynSx3GtzHdTs/mu3M5tHluO9Vj3VpN1AZY9SVcAXyP5UPAo8GPgTWAAcCwwE/gicGSFSxvf9BwRqyu43eMruK2O2gxcADxYOEHSnsDp6Tzd5X/7IODtrIuw0rrLH4plRNLlJJ+wVwKnRcTCIvOMBy6tdG3AvgAVDgAi4k+V3F4HzQEmSuobEa8WTPs7YFfgl8BnKl5ZERGxPOsarHXuDsoxScOAK4F3gZOLBQBARMwBTiqy/OmSFqTdRxsl/UHSNEk7F5m3Ln3sKulbkv4s6R1JKyT9syQ1m/dKSQEclw43dW9EU93p8M0lXtf8pnmbjZOksyU9LOkvkjZJWinpN5LOKFZrkfXuLOkySUskvS3pDUn/I+n0IvNurTH9eZakV9LtPp4Ga2f8CNgZ+Psi0y4gCfNfF1tQ0nBJ/5Fu/y9p+78oaYakwQXz3sx7extfa/47kHRsOs856fA5kk5K231987YvPCYg6QOSXpf0mqShBdvcTdIySY2S/rajDWOd4z2BfDsX2AmYFRFPtzZjRLzTfFjS1cA04BXgpyTdR58ErgbGShoTEe8WrGYn4D6ST/j3knRbnAL8B9CbZI8EYH76fA4wtNn47fHvab0vALcD64F9gJHAacDPWltYUi/gN8DfAsuB/yb51H0q8DNJh0XE5UUWHQosAp4HfgLsDZwBzJZ0QkS06NZpw/1AHXA+yXGSpvqOAA4naastJZadCHyB5M39YaABODhd16ckHRkRL6Xz3pU+nw08xHu/E9LtN3cqyYeEe4EfAsNKFR8RL0g6H7gDuE3SMRGxOZ38feBDwJUR8VCpdViZRYQfOX0Ac4EAzu/gcqPS5f4MDGw2vgb4VTrt8oJl6tLx9wC7NBvfH3g9fexUsMz85E+0xfaHpeu6uUR9LZYDXgVWAbsWmb9fkVrrCsZNa1Z/TUH9Ta/t40VqDOBrBesa27SuDrR50zZqgH9Nfx7VbPoPgUbg/SRv6kHyZtp8HYOAnYus+8R02R8UjD+22HqaTT8nnb4FOKnEPAHMLzL+++m0b6TDZ6XDDwI7ZP2/kaeHu4PybZ/0eVUHlzsvff63iFjTNDKST3SXkrwpnF9i2YsjYmOzZdYCs4E+wAc7WEdHvUvyZreNiHilHcueR/ImNTXe++TaVP/X08Fir/lF4N8KtvcbkgA9qn1lt3Ajyeu4AJJuFOCzwG8i4s+lFoqIl6Jgjy4dfx/wDEk4dcbsiCjaBdWKqcBTwD9L+r8kofAX4O8iotSejHUBh0C+NfXDd/R+4h9Nn+cVToiI50hC5QOS9iqYvD4iVhRZ38r0+X0drKMjbiX5dP6MpG+kfdh92rOgpD2AA4DVUfxAZ1M7HF5k2pMR0SJ4SF5zp15vJAfK7wFOT88ImgzsQXK8oKT0uMjnJD2QHhPY3OxYywiSPYXOWNTRBSJiE0m32FvA90i61s6KCp8EYA6BvGv6hxvc6lwtNb15vlxi+ssF8zV5vcT8TZ+sd+xgHR3xj8AlJG86l5H0X78iabakA9pYtr2vtzD0oPXXvD3/fz8CdgPOJNkjWEPSFdeaa0mOS3yY5PjGt0mOIVxFssfSq5O1rGl7lqKeA5akPy8lOV5kFeYQyLffps8dPS9+ffo8sMT0fQrmK7em7oJSJza0eDOOiMaI+G5EHEpy/cMkklMpPw38utgZTc1k/XqLuQd4ieT4wF8DNzXvpiokqT9wMfA08MGI+FxE/HNEXBkRVwItuok6oLPfTHUZ8HGSkwsOJjnuYhXmEMi3m0j6ySdJ+nBrMxa8SS5On48tMt8BJHsWL0REqU/B22td+jykyPb3BIa3tnBErI2IX0TE6SRdOfsDh7Qy/wbgT8AgSQcWmaXpCt4n2lF7WaRdTDeStHUAN7SxyH4k/+/3pa9nq/T00P2KLNPUjVX2PTRJHwemA8+StP2zwFWSPlHubVnrHAI5FhF1JNcJ9AJqJRW9IlhS0+l/TW5Mn/9V0l81m29H4BqSv6u23pQ6LX0TWw4c3Ty80u1fC+zSfP70/P7jm1+LkI7fieSUTWj7qtYbSY6hfCvdTtM6+gFfbTZPJf0nyUVhY6PtC9zq0udPFNS/O0nXUrG9qqaL0d6/nXVuQ9L7gNtIQmZyRNSTHB/YTHLaaN9ybs9a5+sEci4irpZUQ3LbiMckPQw8znu3jTgGODAd17TMw5K+CXwFeFrSz0n62j9J8qnut8C3urj0b5EEze8k3UFyf6HjSK5FeAo4tNm8uwAPAHWSFpL0f/cGxpDc1uDuiFjWxvauIXl9E4CnJN1DcjDzNJLTRL8ZEb9tZfmyS89quqvNGZN510iaRXIQ+UlJ95Ec6xhD0nZPAocVLPYsSZfTZEkNJGc0BfCTiHhxO0q/kSRYLo6IJ9P6npJ0KfBfJHuon96O9VtHZH2Oqh/d40HyZvg9kj7jN0guJHqZZA/g8xQ/v3wyyRv+BpI3kmeAfwF6F5m3joJz75tNu5LkzeXYgvHzKXKdQLPpn0+3+Q7Jwcnrgb6Fy5EEw1fS1/LntNa/kNwn6QtAr/bUShIcl6dttDF93b8Fziwy7zA6eC1DG7+funR9Ne2Yt9R1AruSXDS3Im2DlSQXvbVos2bLjCS5nmQ9ybGYrb8n3rtO4JxWatnmOgHgonTc7BLz/yKd/o9Z/0/k5aG04c3MLId8TMDMLMccAmZmOeYQMDPLMYeAmVmOVdUpoiq4R7yZmbUtIlRqWlWFgJVX8l0xVg7SeHymXflIcnuWScE1ki24O8jMLMccAmZmOeYQMDPLMYeAmVmOOQTMzHLMIWBmlmMOATOzHHMImJnlmEPAzCzHHAJmZjnmEDAzyzGHgJlZjjkEzMxyzCFgZpZjDgEzsxxzCJiZ5ZhDwMwsxxwCZmY55hAwM8sxh4CZWY45BMzMcswh0EGDBw9m3rx5LF26lKeffpqLL74YgFmzZrF48WIWL17MCy+8wOLFi7cuc9lll/HHP/6R5cuXc+KJJ2ZVelV5/vm1TJhwzdbHRz86jZtvfijrsqraggULGDt2LGPGjGHGjBlZl1P1ekp71mRdQLXZvHkzl156KYsXL2b33Xfn97//Pffffz+TJ0/eOs8111zD+vXrATjooIOYPHkyBx98MPvuuy8PPPAAw4cPZ8uWLVm9hKqw3379mT37ywA0Nm7hmGOuYsyYERlXVb0aGxuZPn06N910EwMGDODUU09l9OjRHHDAAVmXVpV6Unt6T6CD1qxZs/VT/ptvvsmyZcsYNGjQNvOcfvrp3HbbbQBMmDCBWbNm0dDQQF1dHStWrOCoo46qeN3V7JFH/siQIX0ZNGjvrEupWkuWLGHo0KEMGTKEXr16MW7cOObOnZt1WVWrJ7WnQ2A7DB06lMMPP5yFCxduHfc3f/M31NfXs2LFCgAGDRrEypUrt05ftWpVi9Cw1tXWLmb8+MOzLqOq1dfXM3DgwK3DAwYMoL6+PsOKqltPas9uEQKSzs26ho7abbfduPPOO7nkkkvYsGHD1vFnnnnm1r0AAEktlo2IitTYEzQ0bGbevGc46aTDsi6lqhX7myv2t2nt05Pas7scE7gKuKnYBElTgCmVLad1NTU13Hnnndx666388pe/3Dp+xx13ZOLEiRxxxBFbx61atYohQ4ZsHR48eDCrV6+uaL3VbMGC5Rx88CD69dsj61Kq2sCBA1mzZs3W4fr6evr3759hRdWtJ7VnxfYEJC0p8fgDMKDUchExIyKOjIgjK1VrW2644QaWLVvGddddt834E044geXLl/PSSy9tHXf33XczefJkevXqxbBhwzjwwANZtGhRpUuuWrW1TzBu3EezLqPqjRgxgrq6OlauXElDQwO1tbWMHj0667KqVk9qz0ruCQwAxgLrCsYLeLiCdWyXo48+mrPOOoslS5ZsPUB8+eWXc++99zJ58uRtuoIAli5dyu23387SpUvZvHkzF154oc8MaqeNGxt4+OHnmD79tKxLqXo1NTVcccUVnH/++TQ2NjJp0iQOPPDArMuqWj2pPVWp/mlJNwA3RcRvi0z7aUR8th3rcGd6GUXMybqEHkMa72M9ZSTJ7VkmaVuWPGBRsRAoB4dAeTkEyschUF4OgfJpKwS6xdlBZmaWDYeAmVmOOQTMzHLMIWBmlmMOATOzHHMImJnlmEPAzCzHHAJmZjnmEDAzyzGHgJlZjjkEzMxyzCFgZpZjDgEzsxxzCJiZ5ZhDwMwsxxwCZmY55hAwM8sxh4CZWY45BMzMcswhYGaWYw4BM7McU0RkXUO7SaqeYs3MuomIUKlpNZUspBwinsu6hB5BGk5M/2rWZfQYuuLrVNMHqu5OktuzTKSS7/+Au4PMzHLNIWBmlmMOATOzHHMImJnlmEPAzCzHHAJmZjnmEDAzyzGHgJlZjjkEzMxyzCFgZpZjDgEzsxxzCJiZ5ZhDwMwsxxwCZmY55hAwM8sxh4CZWY45BMzMcswhYGaWYw4BM7MccwiYmeWYQ8DMLMccAmZmOVaTdQE9TWNjI5Mm/SMDBvTl+uu/lnU51eevR8HhR0AErK2Hu++Cfv3g5E9BTQ1s2QL3zoHVL2VdaVWZNm0a8+fPp2/fvsyZMyfrcqpeT2pP7wmU2S233M3++w/JuozqtMceMPJjMPOHcP1/ww47wMGHwPEnwoL58KMfwEPzkmHrkIkTJzJz5sysy+gxelJ7VjQEJH1I0vGSdi8Yf1Il6+gqa9a8wvz5j3HqqX6T6rQddoCanUDp85sbkvE775w+935vnLXbyJEj6dOnT9Zl9Bg9qT0r1h0k6WLgQmAZcIOkL0XE7HTy1cCvK1VLV7n66hn80z+dx1tvvZ11KdVpwwZ49Hfwpanw7mZ4fgU8/yd4Yz189iw4YSxIcPOPsq7UrMeo5DGBC4AjIuJNScOAn0saFhHfBVRqIUlTgCmVKbHzHnxwEXvvvReHHHIACxcuybqc6tS7Nwz/EHzvOti0CU49A0Z8BPYdDPf9GpYvhQ8fDONPgVt/nHW1Zj1CJUNgx4h4EyAi6iQdSxIEQ2klBCJiBjADQFJUotDOeOKJpcybt5AFCx7nnXcaePPNjXz5y9dwzTVfzrq06vGB/eH1dfB2uie1fCkMfj8c8hH4zT3JuKXPwPgJ2dVo1sNU8pjAGkmHNQ2kgTAe6AeMqGAdXeLSS89hwYIfM2/ejVx77Vf42Mc+4gDoqPXrYfCQ5FgAwLD94JW/JMcAhg57b9xrr2VWollPU8k9gbOAzc1HRMRm4CxJ11ewDuuuVq+CZc/ABV9ITgVd8zI88XjyPPbk5KDx5s0wZ3bb67JtTJ06lUWLFrFu3TqOOeYYLrroIk477bSsy6paPak9FdFte1hakBQRz2VdRo8gDSemfzXrMnoMXfF1qul/qbuT5PYsk7QtS3a5+zoBM7MccwiYmeVYyWMCkm7vwHoiIs4oQz1mZlZBrR0Y/quKVWFmZpkoGQIRcVwlCzEzs8rzMQEzsxxr93UCkvYAJgDDgd6F0yPiK2Wsy8zMKqBdISBpf+B3wK7AbsBfgL3T5dcB6wGHgJlZlWlvd9B1wOPAAJL7/JwM7AJ8DngT8JlBZmZVqL3dQUcB5wPvpMO9IqIR+KmkfsB3gY93QX1mZtaF2rsn0Bt4IyK2AK8B+zab9jRwaLkLMzOzrtfeEHgOGJr+vBj4gqTeknYCPg+s7orizMysa7W3O2gWcBjwE+CrwG+AN4At6TrO6YrizMysa7UrBCLi2mY/PyrpEOCTJN1E8yLi6S6qz8zMulCnvk8gIlaSftuXmZlVr/ZeJ3ByW/NExD3bX46ZmVVSe/cE5gBBy+8Cbv6tDzuWpSIzM6uY9obAB4qM2xs4keSg8LnlKsjMzCqnvQeGXywy+kVgsaRG4HLg0+UszMzMul457iK6GBhdhvWYmVmFbVcISOpF0h30clmqMTOzilJEtD2T9BjbHgQG6AUMA/YAzo2IW8peXcs62i7WzMy2ERGFJ/Vs1d4Dw8/QMgQ2AXcAd0XEM52szczMMtSuPYHuQlJUU73dmSTcluWTtOe1bc9o7SJN9d9nmaT/6yX3BNp1TEDSPEkfKjFtuKR5nS3QzMyy094Dw8cCe5aYtidwTFmqMTOziurI2UEt9s3Ss4NGA2vKVpGZmVVMyQPDkr4GXJEOBvCoVLJb6VtlrsvMzCqgtbOD7gFeIblf0H8C3wbqCuZpAJZHxP90SXVmZtalSoZARDwGPAYgaQMwJyJerVRhZmbW9dp7TOBJ4K+LTZB0sqSPlK8kMzOrlPaGwHWUCAFgZDrdzMyqTHtD4KPA70pMewQ4vDzlmJlZJbU3BHYEdisxbTeS+wiZmVmVaW8IPAZMKTFtCvB4ecoxM7NKau8N5K4EHpC0EPgxycVh+wBnAYcBJ3RJdWZm1qXa+81iCySdCHwD+B7JtQNbgIXA8emzmZlVmfbuCRAR84FRknYF3gesA0YBZwOzgb5dUaCZmXWddodAMyOAM4HTgQHAa8CschZlZmaV0a4QkHQIyRv/ZJJvE2sgOSPoUuC/ImJzVxVoZmZdp+TZQZL2k3S5pD8ATwFfBpaRHAw+kOS4wBMOADOz6tXansAKkruHLgT+AbgzItYBSOpTgdrMzKyLtXadwIskn/YPIflSmY9L6swxBDMz66ZKhkBEfAA4muS6gOOBXwH1kn6UDvsLQM3MqlyrVwxHxCMRcREwCBhLciroJODn6SwXSDqya0s0M7Ou0q7bRkTEloi4PyLOAwYCE4E7gM8ACyUt68Iaq8aCBQsYO3YsY8aMYcaMGVmXU/WmTZvGqFGjGD9+fNalVKVp0x5k1KibGT/+Z1vHvf76Js4991eceOJPOffcX7F+/TsZVli9etLfZke+YxiAiGiIiLsiYjLJdQJnkRxEzrXGxkamT5/OzJkzqa2tZc6cOaxYkftm2S4TJ05k5syZWZdRtSZO/CAzZ47bZtyMGYsZNWow9933WUaNGsyMGYszqq669aS/zQ6HQHMR8VZE3BoRn2rP/JKOkjQy/fnDkqZKOnl7augulixZwtChQxkyZAi9evVi3LhxzJ07N+uyqtrIkSPp08cnonXWyJH70qfPztuMmzu3jlNOGQ7AKacM54EHXsiitKrXk/42K3a2T/rF9Z8EaiTdT/IlNfOByyQdHhH/XqlaukJ9fT0DBw7cOjxgwACWLFmSYUVmLb366kb690/uCt+//2689trGjCuyrFXylM9TSe44ujPJXUgHR8Qbkr5Fci1C0RCQNIXSt7HuNiJaniwlKYNKzMzab7u6gzpoc0Q0RsTbwJ8i4g2AiNhIckfSoiJiRkQcGRHd+iykgQMHsmbNmq3D9fX19O/fP8OKzFrq23cX1q59C4C1a99i7713ybgiy1olQ6AhvQMpwBFNI9Orj0uGQLUYMWIEdXV1rFy5koaGBmpraxk9enTWZZltY/ToYdx113MA3HXXcxx//LBsC7LMqVg3RpdsSNo5IlqcjyapH7BPRPyhHeuIStXbGQ899BBXX301jY2NTJo0iS9+8YtZl1SSpKJdWN3J1KlTWbRoEevWraNv375cdNFFnHbaaVmXVVTSntdmXcY2pk59gEWLVrNu3Sb69t2Fiy46khNO+ACXXHI/L7+8gX322YPvfncMe+3VO+tSW5Cmduu/z+r724ySfdMVC4Fy6O4hUE2qIQSqSXcMgWrW3UOgmrQVApXsDjIzs27GIWBmlmMOATOzHHMImJnlmEPAzCzHHAJmZjnmEDAzyzGHgJlZjjkEzMxyzCFgZpZjDgEzsxxzCJiZ5ZhDwMwsxxwCZmY55hAwM8sxh4CZWY45BMzMcswhYGaWYw4BM7MccwiYmeWYQ8DMLMccAmZmOaaIyLqGdpNUPcWamXUTEaFS02oqWUg5VFNodWeS3JZl5PYsr6Q9b8u6jB5BOrPV6e4OMjPLMYeAmVmOOQTMzHLMIWBmlmMOATOzHHMImJnlmEPAzCzHHAJmZjnmEDAzyzGHgJlZjjkEzMxyzCFgZpZjDgEzsxxzCJiZ5ZhDwMwsxxwCZmY55hAwM8sxh4CZWY45BMzMcswhYGaWYw4BM7MccwiU0YIFCxg7dixjxoxhxowZWZdT9dye5eX2LK+bb36YceP+i/Hj/5upU+/gnXfezbqkTnEIlEljYyPTp09n5syZ1NbWMmfOHFasWJF1WVXL7Vlebs/yqq9/g1tuWcidd/4Dc+ZcSGNjUFv7dNZldYpDoEyWLFnC0KFDGTJkCL169WLcuHHMnTs367KqltuzvNye5dfYuIVNm95l8+ZGNm16l/7998i6pE7JNAQk3ZLl9supvr6egQMHbh0eMGAA9fX1GVZU3dye5eX2LK8BA/bkvPM+znHHXccnPnENu+++M5/4xAFZl9UpNZXakKS7C0cBx0naCyAiPl2pWrpCRLQYJymDSnoGt2d5uT3La/36jcyd+yxz517CHnv05ktfup3Zs59iwoRDsy6twyoWAsBgYCkwEwiSEDgS+HZrC0maAkzp8uq208CBA1mzZs3W4fr6evr3759hRdXN7Vlebs/yevjh5xk8eC/23ns3AE488SAWL15ZlSFQye6gI4HfA/8CrI+I+cDGiHgoIh4qtVBEzIiIIyPiyArV2SkjRoygrq6OlStX0tDQQG1tLaNHj866rKrl9iwvt2d57btvH556ahUbNzYQETzyyPPsv3+/rMvqlIrtCUTEFuA6SXekz/WV3H5Xq6mp4YorruD888+nsbGRSZMmceCBB2ZdVtVye5aX27O8Dj10MGPHfpjPfOZ6amp24KCDBnLGGd36c2pJKtZXWJENS+OAoyPi8g4sE1nV29NIKtpPbJ3j9iyvpD1vy7qMHkE6k4goeQAos0/iEVEL1Ga1fTMz83UCZma55hAwM8sxh4CZWY45BMzMcswhYGaWYw4BM7MccwiYmeWYQ8DMLMccAmZmOeYQMDPLMYeAmVmOOQTMzHLMIWBmlmMOATOzHHMImJnlmEPAzCzHHAJmZjnmEDAzyzGHgJlZjjkEzMxyzCFgZpZjioisa2g3SdVTrJlZNxERKjWtqkKgWkiaEhEzsq6jp3B7lo/bsrx6Qnu6O6hrTMm6gB7G7Vk+bsvyqvr2dAiYmeWYQ8DMLMccAl2jqvsIuyG3Z/m4Lcur6tvTB4bNzHLMewJmZjnmEDAzyzGHQBlJulHSWklPZ11LtZM0RNKDkpZJekbSl7KuqZpJ6i1pkaSn0va8Kuuaqp2kHSUtljQn61q2h0OgvG4GTsq6iB5iM3BpRBwEfAy4UNKHM66pmr0DjI6IQ4HDgJMkfSzjmqrdl4BlWRexvRwCZRQRC4DXsq6jJ4iIlyPiifTnDST/bIOyrap6ReLNdHCn9OGzQjpJ0mBgHDAz61q2l0PAuj1Jw4DDgYXZVlLd0u6LJ4G1wP0R4fbsvO8AXwG2ZF3I9nIIWLcmaXfgTuCSiHgj63qqWUQ0RsRhwGDgKEmHZF1TNZI0HlgbEb/PupZycAhYtyVpJ5IAuDUifpF1PT1FRLwOzMfHrzrraODTkuqAWcBoSf8/25I6zyFg3ZIkATcAyyLi2qzrqXaS/krSXunPuwAnAMuzrao6RcS0iBgcEcOAycC8iPhcxmV1mkOgjCTdBjwCfFDSKkmfz7qmKnY08Pckn7KeTB8nZ11UFdsHeFDSEuAxkmMCVX1qo5WHbxthZpZj3hMwM8sxh4CZWY45BMzMcswhYGaWYw4BM7MccwhY1ZN0paRo9lgt6U5J+3fR9san2xmWDg9Lh8d3YB2nSzqnjDXtntZQtnVaPtRkXYBZmaznvStg9wO+DsyVdHBEvNXF234ZGEXHLr46HehHcudZs8w4BKyn2BwRj6Y/Pyrpz8D/ACcDdzSfUdIuEbGxXBuOiHeAR9uc0awbcneQ9VRNN/caJqlO0rclfVXSKuANAEk7SLpM0gpJ70h6TtLZzVeixJXplwVtkHQLsGfBPEW7gyRdIOkPkjZJqpf0c0l9JN0MTAL+tlkX1pXNlpsg6fF0uTWSvpneR6n5uiel9W6UtAD4UHmazfLGewLWUw1Ln9ekz58FngH+D+/93X8POBuYDjwBjAFulPRqs1sqXAxcAVxNsmcxEfhmWxuX9K/per8P/BOwK8n953cn6ap6P7BXWg/AqnS504HbgOuBy4H9gW+QfGD7cjrPR4GfAb8k+WKTg4Hb29EmZi1FhB9+VPUDuBJ4heTNvQYYDjxI8ol/H6COpN++d7NlDiC5F/zZBeu6BXgs/XlHYDXwg4J57if5QpZh6fCwdHh8OrwX8DZwbSs1/xyYXzBOwIvATQXjzwM2An3T4duBpaS3fUnH/UtawzlZ/z78qK6Hu4Osp+gLvJs+niU5OHxGRLycTp8bEZuazX88SQj8UlJN0wOYCxwmaUdgCEmIzC7YVlu3tR4F7ALc1MHXMJxkD+H2gprmAb2Bpvv/HwXcHRHNb/zlW21bp7g7yHqK9SS3Rw6SLqDVBW+S9QXz9yP5pL++xPr2AQamP68tmFY4XKhv+vxyq3O11C99vqfE9CHp88BO1GRWlEPAeorNEfF4K9MLb5f7GsmX2R9N8a8IXMt7/x/9C6YVDhd6NX3eh6Sbqr2avp96CrC4yPQX0uc1najJrCiHgOXVPFZEJDkAAAFJSURBVJI9gT4RcX+xGSStJHnDnQD8utmkiW2s+xGSPvyzSQ/mFtFA0sXT3LPASyTHGn7UyvofI/lmq2nN9nbaqsmsKIeA5VJEPCvph8AsSd8EHid5Uz4YGB4R50dEYzrtGkmvkJwdNAk4qI11vy7p68C/S+pF0r2zM8nZQVdFxEskF5ZNkHQKyZlBqyNitaRLgZ9I2hO4lyQs9gNOAU6NiLeB/wcsJDl2cAPJsQJ/gZF1ig8MW55dSHK65lkkb9Q3k7xRL2g2z3dITg/9Asn3He8OfKWtFUfEN4AvkhynmE1yyudewIZ0lu8D9wE3knyyn5Iu9zOSPY/DSC5y+wXJaaRPkAQCabfXZOBw4C6SgDijoy/eDPzNYmZmueY9ATOzHHMImJnlmEPAzCzHHAJmZjnmEDAzyzGHgJlZjjkEzMxyzCFgZpZj/wsu8RxfA/apqgAAAABJRU5ErkJggg==\n",
"text/plain": [
""
]
},
"metadata": {
"needs_background": "light"
},
"output_type": "display_data"
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"--------------------------------------------------------\n"
]
}
],
"source": [
"## car popularity dataset\n",
"df = es.importdata('TrainDataset.csv')\n",
"es.info(df)\n",
"X = df.drop('popularity',axis=1)\n",
"y = df['popularity']\n",
"X_train,X_test,y_train,y_test = train_test_split(X,y,train_size=0.7,random_state=42)\n",
"es.stat_models(y,X)\n",
"es.VIF(df)\n",
"y_pred , model = es.classification(X,y)\n",
"print('\\n\\n*** Start Hypertuning ***\\n')\n",
"y_pred,grid = es.grid_search(model,'quick',X_train,y_train,X_test,y_test)\n",
"print('\\n\\n*** Grid Search CV Result ***\\n')\n",
"es.classification_result(y_test,y_pred)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Deployment\n",
"#### Deploying Model from above prediction"
]
},
{
"cell_type": "code",
"execution_count": 8,
"metadata": {
"ExecuteTime": {
"end_time": "2020-04-26T19:53:04.171870Z",
"start_time": "2020-04-26T19:53:04.156859Z"
}
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"All Deployment Files Created Successfully\n",
"\n",
"Files Created and stored in : /deployment-files named Folder\n",
"\n",
"Open deployment-files folder and open command prompt and run \"python app.py\" copy link and paste in browser to run app, enjoy.\n",
"\n",
"Files created:\n",
" 1. model.pkl - Model file using pickle\n",
" 2.app.py - Flask server file\n",
"3.index.html - User Interface file.\n"
]
}
],
"source": [
"# it will create a folder deployment-files containing all flask files\n",
"es.deploy_one(model,X_train.columns,'Cars 3 Rocks')"
]
},
{
"cell_type": "code",
"execution_count": 13,
"metadata": {
"ExecuteTime": {
"end_time": "2020-03-17T10:30:47.566234Z",
"start_time": "2020-03-17T10:30:46.336101Z"
}
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"\n",
"Please wait Training-Testing with all models..\n",
"\n",
"Done with LogisticRegression\n",
"Done with RandomForestClassifier\n",
"Done with XGBoost Classifier\n",
"Done with LGBoost Classifier\n",
"Done with AdaBoost Classifier\n",
"Done with GradientBoostingClassifier\n"
]
},
{
"data": {
"text/html": [
" Model F1 score AUC-ROC score Accuracy Confustion-Matrix \n",
" \n",
" 1 \n",
" RandomForestClassifier \n",
" 1 \n",
" 1 \n",
" 1 \n",
" [[21 0]\n",
" [ 0 9]] \n",
" \n",
" \n",
" 3 \n",
" LGBoost Classifier \n",
" 1 \n",
" 1 \n",
" 1 \n",
" [[21 0]\n",
" [ 0 9]] \n",
" \n",
" \n",
" 2 \n",
" XGBoost Classifier \n",
" 0.967137 \n",
" 0.97619 \n",
" 0.966667 \n",
" [[20 1]\n",
" [ 0 9]] \n",
" \n",
" \n",
" 5 \n",
" GradientBoostingClassifier \n",
" 0.967137 \n",
" 0.97619 \n",
" 0.966667 \n",
" [[20 1]\n",
" [ 0 9]] \n",
" \n",
" \n",
" 4 \n",
" AdaBoost Classifier \n",
" 0.898222 \n",
" 0.865079 \n",
" 0.9 \n",
" [[20 1]\n",
" [ 2 7]] \n",
" \n",
" \n",
" 0 \n",
" LogisticRegression \n",
" 0.822222 \n",
" 0.753968 \n",
" 0.833333 \n",
" [[20 1]\n",
" [ 4 5]] \n",
" \n",
"
"
],
"text/plain": [
""
]
},
"execution_count": 13,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"## just again using quick_pred\n",
"es.quick_pred(X,y,'c') ## use quick pred instantly on clean data to get immidate result"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## thank you"
]
}
],
"metadata": {
"hide_input": false,
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.7.4"
}
},
"nbformat": 4,
"nbformat_minor": 2
}
�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������Chintan99-eazeml-468f933/usage-example/eazeml-testfile-mini.ipynb�����������������������������������0000664�0000000�0000000�00000530402�13704552311�0024654�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������{
"cells": [
{
"cell_type": "code",
"execution_count": 632,
"metadata": {
"ExecuteTime": {
"end_time": "2020-03-29T19:57:08.575971Z",
"start_time": "2020-03-29T19:57:08.572970Z"
}
},
"outputs": [],
"source": [
"import eazeml as ez"
]
},
{
"cell_type": "code",
"execution_count": 633,
"metadata": {
"ExecuteTime": {
"end_time": "2020-03-29T19:57:18.286583Z",
"start_time": "2020-03-29T19:57:10.350946Z"
}
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Dataframe Imported Successfully\n",
"########## MENU ##############\n",
"\n",
"1. Logisitic Regression \n",
"2. Random Forest \n",
"3. XGB Classifier \n",
"4. LGB CLassifier \n",
"5. Gradient Boosting Classifier \n",
"6. AdaBoost Classifier\n",
"\n",
"Input No, which you want:4\n",
"Predicting with Light GBM Classifier\n"
]
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAx8AAAHyCAYAAACK4XPQAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADt0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjByYzEsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy/xvVyzAAAgAElEQVR4nOzdebxVdb3/8dcHEBxQykBF0UhFUUQPQphZOd7SyMqcUiuHzDS9Djczf2lKeU1Mu+pVM61MzQKncshrDiBCzoAo6lXsCiWamiMKKoOf3x9rHdoczwRy1sbD6/l47Ad7f9d3re9n7XN8uN/n+11rR2YiSZIkSR2tS70LkCRJkrRiMHxIkiRJqoThQ5IkSVIlDB+SJEmSKmH4kCRJklQJw4ckSZKkShg+JGkZiYiREfFSK9t3iIiMiC2W8LgHlfv1bKPfYRHx5Ra29YiI4yLiwYh4IyLejoinIuKciPhYTb/+5ViNj4UR8feI+GVE9GlyzPFln182M976EfFuuX2HJTnfVs5vfJPaGh8nL4vj14yzT0QctCyPubSW9nemXiJik/K/gw/VuxZJy6du9S5AklYgU4Btgf/roOMfBjwKXF/bGBGrArcBg4HzgZOBecAWwLeAvYD1mxzreOBuoCuwGXA68FHgs036vQnsGRHfycz5Ne1fBeYArQampXAn8IMmbc8s4zH2AXoDly3j464INgFOpXjvXqtvKZKWR4YPSapIZs4G7qvD0KcDDcA2mflYTfudEXEh8M1m9nkyMxtrvTsiugMXRETPzHyzpt9dwKeBzwF/qmn/KnAjsP+yOonSKzV1fSBExCqZ+Va96+hIERFAj3rXIWn557IrSapIc0toIuLDETEmIuZExHMR8f2IODsiZjZziI9FxO1l3yci4is1xxkPDAUOrFmOdFA563EY8PMmwQOAzHw3M9+zbKoZbwBBMRNS623gBoqw0VjLAGAIMKYdx11mImLliPhpRDwTEe9ExMMR8fkmfb4REX+JiFci4tWIuDMihtVsvwzYE9i+5n0cWW6bGRFnNzneYkvian7Gn4uIGyPiTeCCctsG5c/6lYiYGxG3RsSmS3GeWS6h+1lEvBwRL0XE8eW2AyPi6Yh4LSIujYiVm6n14xExMSLeiojpEbFHM2McVS7Leyci/hoRxzXZPrIc91MR8SDF78HewE1llxnlWDPL/n3Lep6uGfc/y1DbeMzGJX/7RMTFEfF6RMyKiB9FRJcm428ZETeV5/lmRDwQEf9Ws33N8hgvRLHE8J6I2GZJ32tJy54zH5JUX5cBnwKOAZ4HjqNYurKwmb6/By4BzgL+HRgTERtm5izgO8B1wNPAaWX//6MIJI3LrpZEl4joRhE2BgLfA+7MzNeb6TsauLrmL/z7AQ8AM5ZwzPaIsq5FMnNB+fRaYDjFsp//o1g+dWNEDMvMqWWf/sAV5fbuFDMzEyJii8xsfO82AD5E8Z4CzFqKOn8N/AY4F3g7ItYE/gK8DBwOzAVOBO6IiE2WYmbku8DNFO/1F4CzImIt4OPA0eU5nANMB0Y12fcq4OfAT4BDgWsiYmhmPgwQEd+iWJ73X8CtwI7AzyKiR2bWHmtV4HLgp+U4r1As1zsb+ArwD+Cdsm/vcvt/AK9S/I6PBPoA325S308pfpf3AnYGTgEeA64u6xtIsSTwSYr38mVgGOXSwYjoAdxB8TP8HvAicATFez0gM59v/a2V1KEy04cPHz58LIMHxYepl1rZvgOQwBbl6y3K13vX9FkFeAmYWdN2UNnvkJq2jwALgMNr2iYBlzUZc99y302btHeh+ANUN6BbTXv/sn/Tx2PAek2OMZ7iA3+3sua9y/bHgGNrzm+HZfT+jm+htm4UH1IT2L7JPhOAa1o4XuN78ARwSk37tcD4ZvrPBM5u0tb4s+nZ5Gd8TpN+p1F8SF6zpu3DwOvAke39nSnbkiII1p7HPyg+1K9R0341cH8ztf6gyb5PAGNqXj8L/KZJHT8va1255nc9gS816feFsr1/Gz/LbhTB722ge5PfvSua9J3aWF/5ejRFIFylhWN/k+KapgFNxvs/4Kxl8bvow4ePpX+47EqS6qdxuU/jUhWy+Av4HS30v62m38sUf9Ht18YY0bhLk/YbgfmNj3jv3ZSOo/gr+nBgD2A2cEs0c8etLGYergO+GhFbUsyUXN1GXUVxEV0jolvNI9rYZVxZ16JHOf4uFDNHd9ceDxjLv95nImKziPhjRLxAMbs0H9iU4i/xy9LNTV7vAtwOzK6p7Q1gcm19S2Bs45PMfJdilmlyFtcVNforsF4z+/6xyb43UPycofh9Whe4psk+VwFrUNy0YNHuwC3tKTYKx0bE4xHxFsX7/juK60Q2aNK96Szd4yz+e74TcFW2PFu0C8X7OqPmvYbi+qSlea8lLUMuu5Kk+lkHeCMz327S/s8W+je9e9A8YOXmOtZ4tvy3H8XSmEbHUvz1eijwi2b2+2tmTiqfPxgRd1N8uD+I8hqGJsYA/0PxF/iJmflcudSoLWOB7Wte70gxw9GSV2vqqtWb4v2c38y2hQARsTrFB9sXKJb//I3iL++/ou33cUm90Ex9n6CYiWpqbDNtbWnud6G9vx8vNvO6b/m88d+m9Te+rv2ZvpqZ89ouFSh+386mWAJ2F8UszceBC5upsa3z+AjF71lLGt/r5n4XOupOc5LayfAhSfXzPLB6RKzcJID0aWmHpTCZ4vqCz1LMGgCQmX8FaG4mozmZ+c8ovsNksxa6NH6gPAI4cgnq+zawes3rJ5dg31qvUAStZr/npLQtRQj7t8x8orExInq1c4y3Ka4TqdVSwGo60/QKxWzTac30faOd4y8ra1EsAat93fhh/h81bbXWLv99paat6Tm2Zm+K5W8nNTZExOZLsH+tl/lXSGrOKxRLEI9oZts7zbRJqpDhQ5Lqp/Ev+F/kXxfTrgL8G0v3gfQ9f+nOzLkRcQlwZERcnpn/uzSFRsTaFH9RbvY7NTLz3Yj4CcWSl2vbe9zMXNqw0dRYiouw36wNFk2sUv676ANoRHyS4lqDyTX9WpoxmMV7w9e/NdOvpfr2AR5rZblQVfYA/hegvIvUlyhuEADFOT5HERZql1TtQ7H0blobx26cCWn6/q3Cez/4H7BEVf/LWGCfiDipmVnDxu2fBf6emU1neSTVmeFDkpat7hGxVzPtdzVtyMxHI+Im4KJySdDzFMuB5gLvLsXYTwCfi4jPUfx1eEZ5bchJFGv6742IC4CJFH/FXw84kGJZUtMPcZuWMx1R9vsexRcKjm5p8My8gOaXZFXhdoo7M90eEWdSXPS+BsX3m6ycmf+P4jtW3gR+GRE/pZgFGcm/lqY1egL4UhTfFj8LeC4zn6O4VuL8iPgB8CDFHZ0GtbO+/wK+BoyLiPPLMdemWHL2l8xs8X3tAIdGxDyKL6T8FrAxxV2zGkPkSODiiHiZ4n3dnmIW4QctfNiv1Rgmvx0RY4C5mTmtPM7REXE/xdKnA8pxl8aPKN7/CRHxM4rf9SHAy5l5KcXdzA4Hxkdxa+SnKZZqDQeez8xzlnJcScuA4UOSlq3Vee/FulBcy9Ccg4CLgP+m+GB8IcWHpY8vxdj/SXHx7tUUH7wPprj71dyI2IliOdT+FOvvu1HMYowFtmpchlWj9vssXqCYpfl2Zv5tKerqcJmZUXzvyQ8ozm8DiuU3UyluG0tmvhARe1Oc2w3AUxQfUk9ocrifU3yYvZTijlQ/oggplwAbUdzKtgfFh9z/BC5uR30vRcQnKL7w8RyK28D+g+L2u48s5Wkvra+WNfwnRbjaNzMfqqn1l+Xtao+luAX0LOC77fnQnpl/i+I7R46muB30LIqZpR9TLCf8z7LrH8o+NzVzmLbGeDIiPkVx/civyubHKX72ZObbEbFjOeaPKELeixSzOzcu6XiSlq3IXJIlm5KkjlTemedRilukHljvetR5RMRBFN89snou/i31klQZZz4kqY7Kv8SvS7GWfg2KZTADgG/Usy5JkjqC4UOS6msOxfKojSm+TXwasHtmPtDqXpIkfQC57EqSJElSJfyGc0mSJEmVMHxIkiRJqoTXfKwgevfunf379693GZIkSerkJk+e/FJm9mlum+FjBdG/f38mTZrUdkdJkiTpfYiIFr8TymVXkiRJkiph+JAkSZJUCcOHJEmSpEoYPiRJkiRVwvAhSZIkqRKGD0mSJEmVMHxIkiRJqoThQ5IkSVIlDB+SJEmSKmH4kCRJklQJw4ckSZKkShg+JEmSJFXC8CFJkiSpEoYPSZIkSZUwfEiSJEmqhOFDkiRJUiUMH5IkSZIqYfiQJEmSVAnDhyRJkqRKGD4kSZIkVcLwIUmSJKkShg9JkiRJlTB8SJIkSaqE4UOSJElSJQwfkiRJkiph+JAkSZJUCcOHJEmSpEoYPiRJkiRVwvAhSZIkqRKGD0mSJEmVMHxIkiRJqoThQ5IkSVIlDB+SJEmSKmH4kCRJklQJw4ckSZKkSnSrdwGqxrRnX6f/iTfXuwxJkqQVysxRI+pdwnLFmQ9JkiRJlTB8SJIkSaqE4UOSJElSJQwfkiRJkiph+JAkSZJUCcOHJEmSpEoYPiRJkiRVwvAhSZIkqRKGD0mSJEmVMHxIkiRJqoThQ5IkSVIlDB+SJEmSKmH4kCRJklQJw4ckSZKkShg+JEmSJFXC8CFJkiSpEoYPSZIkSZUwfEiSJEmqhOFDkiRJUiUMH5IkSVIHevLJJ2loaFj0WGONNTj33HMBOP/889l0000ZNGgQJ5xwwqJ9zjjjDDbeeGM23XRTbr311kXtkydPZvDgwWy88cYcffTRZGbl5/N+dKt3AZIkSVJntummmzJ16lQAFi5cyHrrrccee+zBnXfeyQ033MAjjzxCjx49ePHFFwF4/PHHGTNmDI899hjPPfccu+yyC9OnT6dr164cccQRXHLJJXziE5/g85//PH/+85/Zbbfd6nl6S2S5nPmIiGER8d9t9PlQRHynnce7Z9lUtvyJiB/UuwZJkiS1z9ixY9loo4346Ec/ykUXXcSJJ55Ijx49AFhrrbUAuOGGG/jqV79Kjx49+NjHPsbGG2/MAw88wD/+8Q9mz57NtttuS0TwjW98g+uvv76ep7PElsvwkZmTMvPoNrp9CGhX+MjMT77/qpZbhg9JkqQPiDFjxrDffvsBMH36dCZOnMg222zD9ttvz4MPPgjAs88+y/rrr79on379+vHss8/y7LPP0q9fv/e0f5B0WPiIiP4R8URE/CoiHo2I30XELhFxd0Q8FRHDy8c9EfFQ+e+m5b47RMSfyucjI+LSiBgfEU9HRGMoGQVsFBFTI+KsiOgZEWMjYkpETIuIL9XU8mbNccdHxLVlbb+LiCi3DY2IuyJickTcGhF9y/bxEXFmRDwQEdMj4tNle9eIOLsc65GI+PfWjtPCe7RxRNwREQ+XdW8UhbPK92xaROxb9u0bERPK8300Ij4dEaOAVcq23y3jH6EkSZKWoXnz5nHjjTey9957A7BgwQJeffVV7rvvPs466yz22WcfMrPZ6zgiosX2D5KOvuZjY2Bv4DDgQWB/4FPAFyn+Yv8N4DOZuSAidgF+AuzZzHEGAjsCqwNPRsRFwInAFpnZABAR3YA9MnN2RPQG7ouIG/O9P6UhwCDgOeBuYLuIuB84H/hSZv6z/MB/OnBIuU+3zBweEZ8HTgV2Kc/pY8CQsv41I2KlNo7T1O+AUZn5x4hYmSIMfgVoALYCegMPRsSE8r27NTNPj4iuwKqZOTEijmp8D5qKiMPKOum6Rp8WSpAkSVIVbrnlFrbeemvWXnttoJi5+MpXvkJEMHz4cLp06cJLL71Ev379eOaZZxbtN2vWLNZdd1369evHrFmz3tP+QdLRy65mZOa0zHwXeAwYW4aBaUB/oBdwTUQ8CpxDEQqac3NmvpOZLwEvAms30yeAn0TEI8AdwHot9HsgM2eVNU0t69gU2AK4PSKmAicD/Wr2+UP57+SyPxQB5BeZuQAgM19px3H+VWzE6sB6mfnHcv+3M3MuRTgbnZkLM/MF4C7g4xTh7eCIGAkMzsw3WnivFsnMSzJzWGYO67pqr7a6S5IkqQONHj160ZIrgC9/+cuMGzcOKJZgzZs3j969e/PFL36RMWPG8M477zBjxgyeeuophg8fTt++fVl99dW57777yEyuuOIKvvSlL7U03HKpo2c+3ql5/m7N63fLsU8D7szMPSKiPzC+HcdZSPN1HwD0AYZm5vyImAms3M5jBfBYZm7bxvi1YwfQdFalreM07dvu9sycEBGfAUYAv42IszLzinaMI0mSpDqbO3cut99+OxdffPGitkMOOYRDDjmELbbYgu7du3P55ZcTEQwaNIh99tmHzTffnG7dunHhhRfStWtXAC666CIOOugg3nrrLXbbbbcP1J2uoP632u0FNF4lc9AS7vsGxTKs2mO9WAaPHYGPLsGxngT6RMS2mXlvuXxqk8x8rJV9bgMOj4jxjcuuluQ45fKwWRHx5cy8PiJ6AF2BCcC3I+JyYE3gM8D3IuKjwLOZ+cuIWA3YGrgCmB8RK2Xm/CU4X0mSJFVo1VVX5eWXX16srXv37lx55ZXN9j/ppJM46aST3tM+bNgwHn300Q6psQr1vtvVT4EzIuJuig/e7ZaZLwN3lxdfn0Vx/cSwiJhEMQvyxBIcax6wF3BmRDxMsRyrrTtk/Qr4O/BIuc/+S3GcrwNHl0vF7gHWAf4IPAI8DIwDTsjM54EdgKkR8RDFdTHnlce4pKzBC84lSZK0XIsP2rciaun06Dsg+x54br3LkCRJWqHMHDWi3iVULiImZ+aw5rbVe+ZDkiRJ0gqi3td8rBAi4kJguybN52Xmb+pRjyRJklQPho8KZOaR9a5BkiRJqjeXXUmSJEmqhOFDkiRJUiUMH5IkSZIqYfiQJEmSVAnDhyRJkqRKGD4kSZIkVcLwIUmSJKkShg9JkiRJlTB8SJIkSaqE4UOSJElSJQwfkiRJkiph+JAkSZJUCcOHJEmSpEoYPiRJkiRVwvAhSZIkqRKGD0mSJEmV6FbvAlSNwev1YtKoEfUuQ5IkSSswZz4kSZIkVcLwIUmSJKkShg9JkiRJlTB8SJIkSaqE4UOSJElSJQwfkiRJkiph+JAkSZJUCcOHJEmSpEoYPiRJkiRVwvAhSZIkqRKGD0mSJEmV6FbvAlSNac++Tv8Tb653GZIkaQUxc9SIepeg5ZAzH5IkSZIqYfiQJEmSVAnDhyRJkqRKGD4kSZIkVcLwIUmSJKkShg9JkiRJlTB8SJIkSaqE4UOSJElSJQwfkiRJkiph+JAkSZJUCcOHJEmSpEoYPiRJkiRVwvAhSZIkqRKGD0mSJEmVMHxIkiRJqoThQ5IkSVIlDB+SJEmSKmH4kCRJklQJw4ckSZKkShg+JEmS1GFee+019tprLwYOHMhmm23Gvffey7777ktDQwMNDQ3079+fhoYGAObPn8+BBx7I4MGD2WyzzTjjjDMAmDt3LiNGjGDgwIEMGjSIE088sZ6npPehW70LkCRJUud1zDHHsOuuu3Lttdcyb9485s6dy1VXXbVo+3e/+1169eoFwDXXXMM777zDtGnTmDt3Lptvvjn77bcfa621Fscffzw77rgj8+bNY+edd+aWW25ht912q9dpaSl1uvAREf2BP2XmFu/zOIcDczPzimVR1wdlbEmSpGVl9uzZTJgwgcsuuwyA7t27071790XbM5Orr76acePGARARzJkzhwULFvDWW2/RvXt31lhjDVZddVV23HHHRcfYeuutmTVrVuXno/fPZVctyMxf1Cl4dKvX2JIkScvS008/TZ8+fTj44IMZMmQIhx56KHPmzFm0feLEiay99toMGDAAgL322ovVVluNvn37ssEGG3D88cez5pprLnbM1157jZtuuomdd9650nPRstFZw0e3iLg8Ih6JiGsjYtWImBkRvQEiYlhEjI+ILhHxVET0Kdu7RMRfI6J3RIyMiOPL9vERcWZEPBAR0yPi02X7qhFxdTnOVRFxf0QMa6moiHgzIn4WEVMiYmzNuOMj4icRcRdwTJOxN46IOyLi4XK/jcr270XEg+XYP+rQd1OSJGkpLFiwgClTpnDEEUfw0EMPsdpqqzFq1KhF20ePHs1+++236PUDDzxA165dee6555gxYwY/+9nPePrppxc73n777cfRRx/NhhtuWOm5aNnorOFjU+CSzNwSmA18p7lOmfkucCVwQNm0C/BwZr7UTPdumTkcOBY4tWz7DvBqOc5pwNA26loNmJKZWwN31RwH4EOZuX1m/qzJPr8DLszMrYBPAv+IiM8CA4DhQAMwNCI+03SwiDgsIiZFxKSFc19vozRJkqRlq1+/fvTr149tttkGKGY2pkyZAhRB4g9/+AP77rvvov6///3v2XXXXVlppZVYa6212G677Zg0adKi7YcddhgDBgzg2GOPrfZEtMx01vDxTGbeXT6/EvhUK30vBb5RPj8E+E0L/f5Q/jsZ6F8+/xQwBiAzHwUeaaOud4HGK6ya1nVV084RsTqwXmb+sRzj7cycC3y2fDwETAEGUoSRxWTmJZk5LDOHdV21VxulSZIkLVvrrLMO66+/Pk8++SQAY8eOZfPNNwfgjjvuYODAgfTr129R/w022IBx48aRmcyZM4f77ruPgQMHAnDyySfz+uuvc+6551Z/IlpmOt0F56Vs5vUC/hW2Vl60IfOZiHghInYCtuFfsyBNvVP+u5B/vW+xDOuc08z2lo4fwBmZefH7HF+SJKlDnX/++RxwwAHMmzePDTfckN/8pvg775gxYxZbcgVw5JFHcvDBB7PFFluQmRx88MFsueWWzJo1i9NPP52BAwey9dZbA3DUUUdx6KGHVn4+en86a/jYICK2zcx7gf2AvwCrUyyLugXYs0n/X1HMRPw2MxcuwTh/AfYB7oyIzYHBbfTvAuxFMVuyf7l/izJzdkTMiogvZ+b1EdED6ArcCpwWEb/LzDcjYj1gfma+uAS1S5IkdbiGhobFlk41arwDVq2ePXtyzTXXvKe9X79+ZDb927I+iDrrsqv/BQ6MiEeANYGLgB8B50XERIrZi1o3Aj1peclVS34O9CnH+T7FsqvWLq6YAwyKiMnATsCP2zHG14GjyzHuAdbJzNuA3wP3RsQ04FqKcCVJkiQtt8IUWdz9CjgnMz+9hPt1BVbKzLfLu1CNBTbJzHkt9H8zM3u+/4qXXI++A7Lvga6RlCRJ1Zg5akS9S1CdRMTkzGz2DrCdddlVu0XEicARtHytR2tWpVhytRLFdRhHtBQ8JEmSpBXdCh8+MnMUMKrNjs3v+wbwnlQXEfcDPZo0f71esx6SJEnS8mCFDx8dITO3qXcNkiRJ0vKms15wLkmSJGk5Y/iQJEmSVAnDhyRJkqRKGD4kSZIkVcLwIUmSJKkShg9JkiRJlTB8SJIkSaqE4UOSJElSJQwfkiRJkiph+JAkSZJUCcOHJEmSpEoYPiRJkiRVwvAhSZIkqRKGD0mSJEmVMHxIkiRJqoThQ5IkSVIlutW7AFVj8Hq9mDRqRL3LkCRJ0grMmQ9JkiRJlTB8SJIkSaqE4UOSJElSJQwfkiRJkiph+JAkSZJUCcOHJEmSpEoYPiRJkiRVwvAhSZIkqRKGD0mSJEmVMHxIkiRJqoThQ5IkSVIlutW7AFVj2rOv0//Em+tdhiRJqpOZo0bUuwTJmQ9JkiRJ1TB8SJIkSaqE4UOSJElSJQwfkiRJkiph+JAkSZJUCcOHJEmSpEoYPiRJkiRVwvAhSZIkqRKGD0mSJEmVMHxIkiRJqoThQ5IkSVIlDB+SJEmSKmH4kCRJklQJw4ckSZKkShg+JEmSJFXC8CFJkiSpEoYPSZIkSZUwfEiSJEmqhOFDkiRJUiUMH5IkSZIqYfiQJElagbz22mvstddeDBw4kM0224x777130bazzz6biOCll14C4Pbbb2fo0KEMHjyYoUOHMm7cuEV9R48ezeDBg9lyyy3ZddddF+0jtabThY+IGB8Rwyoc76yIeCwizmpn/zc7uiZJkqSWHHPMMey666488cQTPPzww2y22WYAPPPMM9x+++1ssMEGi/r27t2bm266iWnTpnH55Zfz9a9/HYAFCxZwzDHHcOedd/LII4+w5ZZbcsEFF9TlfPTB0unCx/sREd2WYrdvA1tn5veWdT0tiYiuVY0lSZI6j9mzZzNhwgS++c1vAtC9e3c+9KEPAXDcccfx05/+lIhY1H/IkCGsu+66AAwaNIi3336bd955h8wkM5kzZw6ZyezZsxf1k1pTt/AREf0j4n8j4pflzMFtEbFK7cxFRPSOiJnl84Mi4vqIuCkiZkTEURHxHxHxUETcFxFr1hz+axFxT0Q8GhHDy/1Xi4hLI+LBcp8v1Rz3moi4CbithVqjnOF4NCKmRcS+ZfuNwGrA/Y1tzez7sYi4txz3tHYcs6X2HSLizoj4PTCtPJ+bI+Lhsm+z40uSJDV6+umn6dOnDwcffDBDhgzh0EMPZc6cOdx4442st956bLXVVi3ue9111zFkyBB69OjBSiutxEUXXcTgwYNZd911efzxxxcFGqk19Z75GABcmJmDgNeAPdvovwWwPzAcOB2Ym5lDgHuBb9T0Wy0zPwl8B7i0bDsJGJeZHwd2BM6KiNXKbdsCB2bmTi2M+xWgAdgK2KXct29mfhF4KzMbMvOqFvY9D7ioHPf5to7ZSjvleZ+UmZsDuwLPZeZWmbkF8OemA0fEYRExKSImLZz7egvlSZKkFcWCBQuYMmUKRxxxBA899BCrrbYaI0eO5PTTT+fHP/5xi/s99thjfP/73+fiiy8GYP78+Vx00UU89NBDPPfcc2y55ZacccYZVZ2GPsDqHT5mZObU8vlkoH8b/e/MzDcy85/A68BNZfu0JvuOBsjMCcAaEfEh4LPAiRExFRgPrAw0Lmq8PTNfaWXcTwGjM3NhZr4A3AV8vO3TA2C7xnqA37bjmK2N9UBmzqg5510i4syI+HRmviddZOYlmTksM4d1XbVXO8uVJEmdVb9+/ejXrx/bbLMNAHvttRdTpkxhxowZbLXVVvTv359Zs2ax9dZb8/zzxd9MZ3H77+UAACAASURBVM2axR577MEVV1zBRhttBMDUqcXHt4022oiIYJ999uGee+6pz0npA6Xe4eOdmucLgW7AAv5V18qt9H+35vW75b6Nssl+CQSwZzlL0ZCZG2Tm/5bb57RRZ7SxvS1N62ntmK2NtajOzJwODKUIIWdExClLX54kSVoRrLPOOqy//vo8+eSTAIwdO5att96aF198kZkzZzJz5kz69evHlClTWGeddXjttdcYMWIEZ5xxBtttt92i46y33no8/vjj/POf/wSKu2I1Xrgutabe4aM5Myk+VAPstZTHaLxO4lPA6+WswK3Av0d5FVVEDFmC400A9o2IrhHRB/gM8EA7970b+Gr5/IB2HLNdY0XEuhTLzq4Ezga2XoLzkSRJK6jzzz+fAw44gC233JKpU6fygx/8oMW+F1xwAX/961857bTTaGhooKGhgRdffJF1112XU089lc985jPtOo7UaGnu7tTRzgaujoivA+Pa6tyCVyPiHmAN4JCy7TTgXOCRMoDMBL7QzuP9keK6kIcpZjFOyMznW99lkWOA30fEMcB1bR0zIlpqH9jkuIMprgd5F5gPHNHOeiRJ0gqsoaGBSZMmtbh95syZi56ffPLJnHzyyc32O/zwwzn88MOXdXnq5CKzuRVB6mx69B2QfQ88t95lSJKkOpk5akS9S9AKIiImZ2az37u3PC67kiRJktQJLY/LruomIgaz+B2pAN7JzG3ase9JwN5Nmq/JzNOXVX2SJEnSB5nho0ZmTqP4jo2l2fd0iu8ekSRJktQMl11JkiRJqoThQ5IkSVIlDB+SJEmSKtGu8BERG0VEj/L5DhFxdER8qGNLkyRJktSZtHfm4zpgYURsDPwa+Bjw+w6rSpIkSVKn097w8W5mLgD2AM7NzOOAvh1XliRJkqTOpr3hY35E7AccCPypbFupY0qSJEmS1Bm1N3wcDGwLnJ6ZMyLiY8CVHVeWJEmSpM6mXV8ymJmPR8T3gQ3K1zOAUR1ZmCRJkqTOpb13u9odmAr8uXzdEBE3dmRhkiRJkjqX9i67GgkMB14DyMypFHe8kiRJkqR2aW/4WJCZrzdpy2VdjCRJkqTOq13XfACPRsT+QNeIGAAcDdzTcWVJkiRJ6mzaO/Px78Ag4B2KLxd8HTi2o4qSJEmS1Pm0OfMREV2BGzNzF+Ckji9JkiRJUmfU5sxHZi4E5kZErwrqkSRJktRJtfeaj7eBaRFxOzCnsTEzj+6QqrTMDV6vF5NGjah3GZIkSVqBtTd83Fw+JEmSJGmptPcbzi/v6EIkSZIkdW7tCh8RMYNmvtcjMzdc5hVJkiRJ6pTau+xqWM3zlYG9gTWXfTmSJEmSOqt2fc9HZr5c83g2M88Fdurg2iRJkiR1Iu1ddrV1zcsuFDMhq3dIRZIkSZI6pfYuu/pZzfMFwAxgn2VfjiRJkqTOqr3h45uZ+XRtQ0R8rAPqkSRJktRJteuaD+DadrZJkiRJUrNanfmIiIHAIKBXRHylZtMaFHe9kiRJkqR2aWvZ1abAF4APAbvXtL8BfKujipIkSZLU+bQaPjLzBuCGiNg2M++tqCZJkiRJnVB7Lzh/KCKOpFiCtWi5VWYe0iFVaZmb9uzr9D/x5nqXIUlSXc0cNaLeJUgrtPZecP5bYB3gc8BdQD+KpVeSJEmS1C7tDR8bZ+YPgTmZeTkwAhjccWVJkiRJ6mzaGz7ml/++FhFbAL2A/h1SkSRJkqROqb3XfFwSER8GfgjcCPQETumwqiRJkiR1Ou0KH5n5q/LpXcCGHVeOJEmSpM6qXcuuImLtiPh1RNxSvt48Ir7ZsaVJkiRJ6kzae83HZcCtwLrl6+nAsR1RkCRJkqTOqb3ho3dmXg28C5CZC4CFHVaVJEmSpE6nveFjTkR8BEiAiPgE8HqHVSVJkiSp02nv3a7+g+IuVxtFxN1AH2CvDqtKkiRJUqfTaviIiA0y8++ZOSUitgc2BQJ4MjPnt7avJEmSJNVqa9nV9TXPr8rMxzLzUYOHJEmSpCXVVviImud+v4ckSZKkpdZW+MgWnkuSJEnSEmnrgvOtImI2xQzIKuVzyteZmWt0aHWSJEmSOo1Ww0dmdq2qEEmSJEmdW3u/50OSJEmS3hfDhyRJkqRKGD4kSZIkVcLwIUmSVjj9+/dn8ODBNDQ0MGzYsEXt559/PptuuimDBg3ihBNOWGyfv//97/Ts2ZOzzz57Udu8efM47LDD2GSTTRg4cCDXXXddZecgfRC1dbcrSZKkTunOO++kd+/ei72+4YYbeOSRR+jRowcvvvjiYv2PO+44dtttt8XaTj/9dNZaay2mT5/Ou+++yyuvvFJJ7dIHVYeHj4h4MzN7dvQ4y1JEjATezMyz2+rbxnH6A5/MzN8vxb73ZOYn38/4kiSp/S666CJOPPFEevToAcBaa621aNv111/PhhtuyGqrrbbYPpdeeilPPPEEAF26dFkszEh6L5dddaz+wP5Ls6PBQ5KkjhMRfPazn2Xo0KFccsklAEyfPp2JEyeyzTbbsP322/Pggw8CMGfOHM4880xOPfXUxY7x2muvAfDDH/6Qrbfemr333psXXnih2hORPmAqCx8RsUNE/Knm9QURcVD5/PMR8URE/CUi/ruxX0T0iYjbI2JKRFwcEX+LiN7ltusjYnJEPBYRh9Uc95sRMT0ixkfELyPigppjXRcRD5aP7dooeauIGBcRT0XEt8pjREScFRGPRsS0iNi3tXZgFPDpiJgaEce18L4MiogHyj6PRMSAsv3N8t8fl9umRsSzEfGbsv1rNftdHBHv+U6WiDgsIiZFxKSFc19v60ckSdIK4+6772bKlCnccsstXHjhhUyYMIEFCxbw6quvct9993HWWWexzz77kJmceuqpHHfccfTsufhCjgULFjBr1iy22247pkyZwrbbbsvxxx9fpzOSPhjqfs1HRKwMXAx8JjNnRMToms2nAuMy84yI2BU4rGbbIZn5SkSsAjwYEdcBPYAfAlsDbwDjgIfL/ucB52TmXyJiA+BWYLNWStsS+ASwGvBQRNwMbAs0AFsBvctxJwCfbKH9ROD4zPxCK+McDpyXmb+LiO7AYiEiM08BTomIXsBE4IKI2AzYF9guM+dHxM+BA4Armux7CXAJQI++A7KVGiRJWqGsu+66QLG0ao899uCBBx6gX79+fOUrXyEiGD58OF26dOGll17i/vvv59prr+WEE07gtddeo0uXLqy88soceeSRrLrqquyxxx4A7L333vz617+u52lJy726hw9gIPB0Zs4oX4/mXyHjU8AeAJn554h4tWa/oyNij/L5+sAAYB3grsx8BSAirgE2KfvsAmweEY37rxERq2fmGy3UdUNmvgW8FRF3AsPLekZn5kLghYi4C/h4K+2z23H+9wInRUQ/4A+Z+VTTDlEU/TuK8DQ5Io4ChlKEHIBVgBeb7idJkt5rzpw5vPvuu6y++urMmTOH2267jVNOOYWePXsybtw4dthhB6ZPn868efPo3bs3EydOXLTvyJEj6dmzJ0cddRQAu+++O+PHj2ennXZi7NixbL755vU6LekDocrwsYDFl3mtXP4bzfSltW0RsQNFmNg2M+dGxPjyeK0dq0vZ/6121tt0piBbOX5r47Y+SObvI+J+YARwa0QcmpnjmnQbCczKzN/UjHd5Zv6/pR1XkqQV1QsvvLBotmLBggXsv//+7LrrrsybN49DDjmELbbYgu7du3P55ZdT80fLZp155pl8/etf59hjj6VPnz785je/abW/tKKrMnz8jWLmoQdFUNgZ+AvwBLBhRPTPzJkUy4ka/QXYBzgzIj4LfLhs7wW8WgaPgRTLowAeAM6JiA9TLLvaE5hWbrsNOAo4CyAiGjJzaiv1fikizqBYdrUDxRKqrsC3I+JyYE3gM8D3KN7H5trXA1Zv7U2JiA0pZn7+u3y+JcVyscbtXwD+rayh0Vjghog4JzNfjIg1gdUz82+tjSVJkmDDDTfk4Ycffk979+7dufLKK1vdd+TIkYu9/uhHP8qECROWZXlSp1ZZ+MjMZyLiauAR4CngobL9rYj4DvDniHiJIkA0+hEwuryA+y7gHxSh4s/A4RHxCPAkcF95rGcj4ifA/cBzwONA45XWRwMXlvt0AyZQXG/RkgeAm4ENgNMy87mI+CPFdR8PU8yEnJCZz7fS/jKwICIeBi7LzHOaGWdf4GsRMR94Hvhxk+3fBdYFHij/+nJjZp4SEScDt0VEF2A+cCRFwJMkSZKWS5FZ/+uQI6JnZr5ZXttwIfBUZp5TzpIszMwFEbEtcFFmNrTzWN2APwKXZuYfO/4slm89+g7IvgeeW+8yJEmqq5mjRtS7BKnTi4jJmTmsuW3LwwXnAN+KiAOB7hQzIheX7RsAV5d/3Z8HfKsdxxoZEbtQLO26Dbi+A+qVJEmStISWi/BRLkd6z5Kk8s5PQ5bwWO2+wXZEHAwc06T57sw8cknGbOdYnwPObNI8IzP3aK6/JEmS1NksF+GjXsq7R1VyW4rMvJXiu0UkSZKkFVJl33AuSZIkacVm+JAkSZJUCcOHJEmSpEoYPiRJkiRVwvAhSZIkqRKGD0mSJEmVMHxIkiRJqoThQ5IkSVIlDB+SJEmSKmH4kCRJklQJw4ckSZKkShg+JEmSJFXC8CFJkiSpEoYPSZIkSZUwfEiSJEmqRLd6F6BqDF6vF5NGjah3GZIkSVqBOfMhSZIkqRKGD0mSJEmVMHxIkiRJqoThQ5IkSVIlDB+SJEmSKmH4kCRJklQJw4ckSZKkShg+JEmSJFXC8CFJkiSpEoYPSZIkSZUwfEiSJEmqhOFDkiRJUiW61bsAVWPas6/T/8Sb612GJKkCM0eNqHcJktQsZz4kSZIkVcLwIUmSJKkShg9JkiRJlTB8SJIkSaqE4UOSJElSJQwfkiRJkiph+JAkSZJUCcOHJEmSpEoYPiRJkiRVwvAhSZIkqRKGD0mSJEmVMHxIkiRJqoThQ5IkSVIlDB+SJEmSKmH4kCRJklQJw4ckSZKkShg+JEmSJFXC8CFJkiSpEoYPSZIkSZUwfEiS1IktXLiQIUOG8IUvfAGAfffdl4aGBhoaGujfvz8NDQ0AzJw5k1VWWWXRtsMPP3zRMa666iq23HJLBg0axAknnFCX85DUOXSrdwGSJKnjnHfeeWy22WbMnj0bKIJEo+9+97v06tVr0euNNtqIqVOnLrb/yy+/zPe+9z0mT55Mnz59OPDAAxk7diw777xzNScgqVNZIWc+ImJgREyNiIciYqNW+v2gglp+0OT1PR09piRpxTBr1ixuvvlmDj300Pdsy0yuvvpq9ttvv1aP8fTTT7PJJpvQp08fAHbZZReuu+66DqlXUue3QoYP4MvADZk5JDP/r5V+7zt8RETXNrosNkZmfvL9jilJEsCxxx7LT3/6U7p0ee//7idOnMjaa6/NgAEDFrXNmDGDIUOGsP322zNx4kQANt54Y5544glmzpzJggULuP7663nmmWcqOwdJnUunWXYVEasBVwP9gK7AacCmwO7AKsA9wLeB3YBjgYUR8ZnM3DEivgYcDXQH7ge+A5wOrBIRU4HHgKeBlzLzvHK804EXMvO/m6llB+BU4B9AA7B5RFwPrA+sDJyXmZdExKjaMTLzgIh4MzN7lscYCbwEbAFMBr6WmRkRnwf+q9w2BdgwM7+wjN5KSVIn8Kc//Ym11lqLoUOHMn78+PdsHz169GKzHn379uXvf/87H/nIR5g8eTJf/vKXeeyxx/jwhz/MRRddxL777kuXLl345Cc/ydNPP13hmUjqTDpN+AB2BZ7LzBEAEdELuD0zf1y+/i3whcy8KSJ+AbyZmWdHxGbAvsB2mTk/In4OHJCZJ0bEUZnZUO7fH/gDcF5EdAG+CgxvpZ7hwBaZOaN8fUhmvhIRqwAPRsR1TcdoxhBgEPAccDewXURMAi4GPpOZMyJidEsFRMRhwGEAXdfo00qpkqTO5u677+bGG2/kf/7nf3j77beZPXs2X/va17jyyitZsGABf/jDH5g8efKi/j169KBHjx4ADB06lI022ojp06czbNgwdt99d3bffXcALrnkErp2bWtSX5Ka15mWXU0DdomIMyPi05n5OrBjRNwfEdOAnSg+yDe1MzCUIhBMLV9v2LRTZs4EXo6IIcBngYcy8+VW6nmgJngAHB0RDwP3UcyADGh+t/ccY1ZmvgtMBfoDA4Gna47dYvjIzEsyc1hmDuu6aq+WukmSOqEzzjiDWbNmMXPmTMaMGcNOO+3ElVdeCcAdd9zBwIED6dev36L+//znP1m4cCFQXOfx1FNPseGGxf8OX3zxRQBeffVVfv7znzd7DYkktUenmfnIzOkRMRT4PHBGRNwGHAkMy8xnImIkxZKnpgK4PDP/XzuG+RVwELAOcGkbfecsGqBYQrULsG1mzo2I8S3U0tQ7Nc8XUvy8oh37SZLUojFjxrznQvMJEyZwyimn0K1bN7p27covfvEL1lxzTQCOOeYYHn74YQBOOeUUNtlkk8prltQ5dJrwERHrAq9k5pUR8SZFSAB4KSJ6AnsB1zaz61jghog4JzNfjIg1gdUz82/A/IhYKTPnl33/CPwYWAnYfwnK6wW8WgaPgcAnarY1HaMtTwAbRkT/cjZm3yWoQ5K0Atphhx3YYYcdFr2+7LLL3tNnzz33ZM8992x2/9GjW5xkl6Ql0mnCBzAYOCsi3gXmA0dQ3NVqGjATeLC5nTLz8Yg4GbitvJZjPsWMyd+AS4BHImJKZh6QmfMi4k7gtcxcuAS1/Rk4PCIeAZ6kWHrVaLEx2jpQZr4VEd8B/hwRLwEPLEEdkiRJUt1EZta7hg+MMpxMAfbOzKfqWEfPzHwzIgK4EHgqM89pbZ8efQdk3wPPraZASVJdzRw1ot4lSFqBRcTkzBzW3LbOdMF5h4qIzYG/AmPrGTxK36q5BXAvirtfSZIkScu1zrTsqkNl5uM0uQtWRAwGftuk6zuZuU0H13IO0OpMhyRJkrS8MXy8D5k5jeJLBCVJkiS1wWVXkiRJkiph+JAkSZJUCcOHJEmSpEoYPiRJkiRVwvAhSZIkqRKGD0mSJEmVMHxIkiRJqoThQ5IkSVIlDB+SJEmSKmH4kCRJklQJw4ckSZKkShg+JEmSJFXC8CFJkiSpEoYPSZIkSZUwfEiSJEmqRLd6F6BqDF6vF5NGjah3GZIkSVqBOfMhSZIkqRKGD0mSJEmVMHxIkiRJqoThQ5IkSVIlDB+SJEmSKmH4kCRJklQJw4ckSZKkShg+JEmSJFXC8CFJkiSpEoYPSZIkSZUwfEiSJEmqhOFDkiRJUiW61bsAVWPas6/T/8Sb612GJC1m5qgR9S5BklQhZz4kSZIkVcLwIUmSJKkShg9JkiRJlTB8SJIkSaqE4UOSJElSJQwfkiRJkiph+JAkSZJUCcOHJEmSpEoYPiRJkiRVwvAhSZIkqRKGD0mSJEmVMHxIkiRJqoThQ5IkSVIlDB+SJEmSKmH4kCRJklQJw4ckSZKkShg+JEmSJFXC8CFJkiSpEoYPSZIkSZUwfEiS6urtt99m+PDhbLXVVgwaNIhTTz110bbzzz+f/9/evQfbVdZpHv8+JiRgQogRQ6VBLloMEUI6XBrkMkjjhaBMSGsacMYxgKPSo9b0WMjQZU2XjuOlRXuosbuc0m6mUVtsYtMClm24BDqWCiGQEGIjKIbpRiKXFhBCOjd+88d+EzfHk3CSQ9Y5Sb6fql177Xetd613PZCzz++8a+19xBFHcNRRR3HppZcCsGHDBubPn8/RRx/N6173Oj796U9v2X727Nlb9nPxxRezadOmzs9HkrR1Y0d6AJKkPdv48eNZtGgREydOZMOGDZx66qmcddZZrF27luuuu44VK1Ywfvx4HnvsMQAWLFjAunXruPfee3nuuec48sgjeec738mhhx7KNddcw6RJk6gq5s2bx4IFCzj//PNH+AwlSZvtljMfSW5LcnyHx7s8yY+SXL4TjzE5yX/eWfuXpJGShIkTJwK9WY0NGzaQhC9+8YtcdtlljB8/HoCpU6du2X7NmjVs3LiRtWvXMm7cOCZNmgSw5Xnjxo2sX7+eJCNwRpKkrdkti4/hSLIjs0HvB46tqo+81OPpMxmw+JC0W9q0aROzZs1i6tSpvPnNb+bEE0/kgQce4Hvf+x4nnngib3jDG7jzzjsBmDdvHhMmTGDatGkcfPDBXHLJJUyZMmXLvs4880ymTp3Kvvvuy7x580bqlCRJgxjR4iPJoUnuS/LlNnNwY5J9+mcukuyf5KG2fEGSbyW5IcmqJB9M8uEky5LcnmRK3+7fleQHSVYmOaH1n5DkyiR3tj7n9O13QZIbgBu3Mta0GY6VSe5Ncl5rvx6YANyxuW2Qvr/f+t2TZHFrG9P2d2eSFUne39onJrklyd3tOOe03XwGeG2S5a3ftCSL2+uVSf7tsP5jSNIIGjNmDMuXL+fhhx9myZIlrFy5ko0bN/Lkk09y++23c/nll3PuuedSVSxZsoQxY8bwyCOPsGrVKj7/+c/zs5/9bMu+Fi5cyOrVq1m3bh2LFi0awbOSJA00GmY+Dgf+vKqOAp4C3vEi288A/j1wAvBJ4LmqOgb4IfDuvu0mVNXJ9GYLrmxtHwUWVdXvAL8LXJ5kQlt3EjC/qs7YynHfDswCfht4U+s7rarmAGuralZV/c1W+v4xcGZV/TYwp7W9B3i6jeV3gPcmOQz4V+D3qurYNsbPp3fdwGXAg+04H2kZLKyqzWNaPvCgSd6XZGmSpZuee3orQ5Ok0WPy5MmcfvrpfPe73+Wggw7i7W9/O0k44YQTeNnLXsYTTzzB17/+dWbPns1ee+3F1KlTOeWUU1i6dOkL9rP33nszZ84crrvuuhE6E0nSYEZD8bGqqjb/4nwXcOiLbH9rVT1TVY8DTwM3tPZ7B/S9GqCqFgOTkkwG3gJclmQ5cBuwN3Bw2/6mqvrlNo57KnB1VW2qqkeBf6BXNAzF94G/SvJeYExrewvw7jaWO4BX0ivEAnwqyQrgZuBA4IBB9nkncGGSjwFHV9UzAzeoqi9V1fFVdfyYl+83xKFKUrcef/xxnnrqKQDWrl3LzTffzPTp05k7d+6WmYsHHniA9evXs//++3PwwQezaNEiqoo1a9Zw++23M336dJ599llWr14N9O75+M53vsP06dNH7LwkSb9pNHza1bq+5U3APsBGfl0Y7b2N7Z/ve/08LzyfGtCv6P1i/46qur9/RZITgTUvMs4dvmuxqi5ux3gbsDzJrLa/D1XVwgFjuQB4FXBcVW1ol5wNzICqWpzktLbPrya5vKq+sqNjlKSRsnr1aubPn8+mTZt4/vnnOffcczn77LNZv349F110ETNmzGDcuHFcddVVJOEDH/gAF154ITNmzKCquPDCC5k5cyaPPvooc+bMYd26dWzatIkzzjiDiy++eKRPT5LUZzQUH4N5CDgOWALs6N2C5wG3JjmV3uVNTydZCHwoyYeqqpIcU1XLhri/xcD7k1wFTAFOA4Z0g3mS11bVHfTuC/l3wKuBhcAfJFnUiox/A/wc2A94rLX9LnBI280zwL59+zwE+HlVfbldOnYsYPEhaZczc+ZMli37zR/F48aN42tf+9pvtE+cOJEFCxb8RvsBBxyw5aZ0SdLoNFqLj88B1yT5j8CO3i34ZJIfAJOAi1rbJ4ArgBXtPoqHgLOHuL+/o3dfyD30ZlEurapfDLHv5Uk2X1J1S9vHCnqXid3dxvI4MBf4a+CGJEvp3cfxY4Cq+pck30+yEvh7YCXwkSQbgGd54f0ukiRJ0qiTqoFXJ2l3NH7a4TVt/hUjPQxJeoGHPvO2kR6CJOklluSuqhr0O/dGww3nkiRJkvYAo/WyqxGT5GjgqwOa11XViUPo+1Hg9wc0L6iqT75U45MkSZJ2VRYfA1TVvfS+z2NH+n6S3nePSJIkSRrAy64kSZIkdcLiQ5IkSVInLD4kSZIkdcLiQ5IkSVInLD4kSZIkdcLiQ5IkSVInLD4kSZIkdcLiQ5IkSVInLD4kSZIkdcLiQ5IkSVInLD4kSZIkdcLiQ5IkSVInLD4kSZIkdcLiQ5IkSVInLD4kSZIkdcLiQ5IkSVInxo70ANSNow/cj6WfedtID0OSJEl7MGc+JEmSJHXC4kOSJElSJyw+JEmSJHXC4kOSJElSJyw+JEmSJHXC4kOSJElSJyw+JEmSJHXC4kOSJElSJyw+JEmSJHXC4kOSJElSJyw+JEmSJHXC4kOSJElSJyw+JEmSJHXC4kOSJElSJyw+JEmSJHXC4kOSJElSJyw+JEmSJHXC4kOSJElSJyw+JEmSJHXC4kOSJElSJyw+JEmSJHXC4kOSJElSJyw+JEmSJHXC4kOSJElSJyw+JEmSJHXC4kOSJElSJyw+JEmSJHXC4kOSJElSJyw+JEmSJHXC4kOSJElSJyw+JEmSJHXC4kOSJElSJyw+JEmSJHXC4kOSJElSJyw+JEmSJHXC4kOSJElSJ1JVIz0GdSDJM8D9Iz2OXdj+wBMjPYhdmPkNj/kNnxkOj/kNj/kNj/kNz0jkd0hVvWqwFWM7HohGzv1VdfxID2JXlWSp+e048xse8xs+Mxwe8xse8xse8xue0Zafl11JkiRJ6oTFhyRJkqROWHzsOb400gPYxZnf8Jjf8Jjf8Jnh8Jjf8Jjf8Jjf8Iyq/LzhXJIkSVInnPmQJEmS1AmLjz1AktlJ7k/y0ySXjfR4RoskVyZ5LMnKvrYpSW5K8pP2/Iq+dX/UMrw/yZl97cclubet+99J0vW5dC3Jq5PcmuS+JD9K8l9au/kNQZK9kyxJck/L7+Ot3fy2Q5IxSZYl+XZ7bX7bIclD7dyXJ1na2sxwiJJMTvLNJD9uPwtPMr+hSXJE+/9u8+NXSf7Q/IYuyX9t7x8rk1zd3ld2jfyqysdu/ADGAA8CrwHGAfcAN7Yx5AAAB+tJREFUR470uEbDAzgNOBZY2df2WeCytnwZ8Cdt+ciW3XjgsJbpmLZuCXASEODvgbNG+tw6yG4acGxb3hd4oGVkfkPLL8DEtrwXcAfwevPb7hw/DHwd+HZ7bX7bl99DwP4D2sxw6PldBfyntjwOmGx+O5TjGOAXwCHmN+TMDgRWAfu019cAF+wq+Tnzsfs7AfhpVf2sqtYD3wDOGeExjQpVtRj45YDmc+i9odCe5/a1f6Oq1lXVKuCnwAlJpgGTquqH1ftX/JW+PrutqlpdVXe35WeA++j9MDS/IaieZ9vLvdqjML8hS3IQ8DbgL/qazW/4zHAIkkyi9wesvwSoqvVV9RTmtyPeCDxYVf8P89seY4F9kowFXg48wi6Sn8XH7u9A4J/7Xj/c2jS4A6pqNfR+wQamtvat5XhgWx7YvsdIcihwDL2/3pvfELVLhpYDjwE3VZX5bZ8rgEuB5/vazG/7FHBjkruSvK+1meHQvAZ4HPi/7dK/v0gyAfPbEecDV7dl8xuCqvo58Dngn4DVwNNVdSO7SH4WH7u/wa7d8yPOtt/Wctyj800yEfhb4A+r6lfb2nSQtj06v6raVFWzgIPo/QVqxjY2N78+Sc4GHququ4baZZC2PTa/PqdU1bHAWcAHkpy2jW3N8IXG0rts94tVdQywht5lLltjfoNIMg6YAyx4sU0Hadtj82v3cpxD7xKq3wImJHnXtroM0jZi+Vl87P4eBl7d9/ogelNzGtyjbRqS9vxYa99ajg+35YHtu70ke9ErPP66qq5tzea3ndqlGrcBszG/oToFmJPkIXqXkp6R5GuY33apqkfa82PA39G7TNcMh+Zh4OE2YwnwTXrFiPltn7OAu6vq0fba/IbmTcCqqnq8qjYA1wIns4vkZ/Gx+7sTODzJYe0vDOcD14/wmEaz64H5bXk+cF1f+/lJxic5DDgcWNKmNZ9J8vr2CRHv7uuz22rn+pfAfVX1p32rzG8IkrwqyeS2vA+9N5IfY35DUlV/VFUHVdWh9H6mLaqqd2F+Q5ZkQpJ9Ny8DbwFWYoZDUlW/AP45yRGt6Y3AP2J+2+ud/PqSKzC/ofon4PVJXt7O+4307r3cNfLb2Xe0+xj5B/BWep9G9CDw0ZEez2h50PuBtxrYQK/6fw/wSuAW4CfteUrf9h9tGd5P36dBAMfTe9N+EPgz2pd37s4P4FR6U7MrgOXt8VbzG3J+M4FlLb+VwB+3dvPb/ixP59efdmV+Q8/tNfQ+/eYe4Eeb3xvMcLsynAUsbf+OvwW8wvy2K7+XA/8C7NfXZn5Dz+/j9P5otRL4Kr1Pstol8vMbziVJkiR1wsuuJEmSJHXC4kOSJElSJyw+JEmSJHXC4kOSJElSJyw+JEmSJHXC4kOStNMk2ZRked/j0B3Yx9wkR770o4Mkv5Xkmztj39s45qwkb+3ymJI0Wowd6QFIknZra6tq1jD3MRf4Nr0vcRuSJGOrauOLbVe9b/meN4yxbZckY+l9P8TxwHe6Oq4kjRbOfEiSOpXkuCT/kOSuJAuTTGvt701yZ5J7kvxt+/bek4E5wOVt5uS1SW5Lcnzrs3+Sh9ryBUkWJLkBuLF9i/eVbZ/LkpwzyFgOTbKyr/+3ktyQZFWSDyb5cOt7e5IpbbvbklyR5AdJViY5obVPaf1XtO1ntvaPJflSkhuBrwD/Azivnc95SU5o+1rWno/oG8+1Sb6b5CdJPts37tlJ7m5Z3dLaXvR8JWmkOfMhSdqZ9kmyvC2vAs4FvgCcU1WPJzkP+CRwEXBtVX0ZIMn/BN5TVV9Icj29bzH/Zlu3reOdBMysql8m+RSwqKouSjIZWJLk5qpas43+M4BjgL2BnwL/raqOSfK/gHcDV7TtJlTVyUlOA65s/T4OLKuquUnOoFdobJ71OQ44tarWJrkAOL6qPtjOZxJwWlVtTPIm4FPAO1q/WW0864D7k3wB+Ffgy63Pqs1FEb1vMN7e85WkTll8SJJ2phdcdpVkBr1f1G9qRcQYYHVbPaMVHZOBicDCHTjeTVX1y7b8FmBOkkva672Bg4H7ttH/1qp6BngmydPADa39XmBm33ZXA1TV4iST2i/7p9KKhqpalOSVSfZr219fVWu3csz9gKuSHA4UsFffuluq6mmAJP8IHAK8AlhcVavasYZzvpLUKYsPSVKXAvyoqk4aZN1fAXOr6p42O3D6VvaxkV9fNrz3gHX9f+UP8I6qun87xreub/n5vtfP88L3zBrQr9rxBtq83bZmHz5Br+j5vXZD/m1bGc+mNoYMcnzYsfOVpE55z4ckqUv3A69KchJAkr2SHNXW7QusTrIX8B/6+jzT1m32EL3LmGDbN4svBD6UNsWS5JjhD3+L89o+TwWebrMTi2njTnI68ERV/WqQvgPPZz/g5235giEc+4fAG5Ic1o61+bKrnXm+kvSSsPiQJHWmqtbTKxj+JMk9wHLg5Lb6vwN3ADcBP+7r9g3gI+0m6tcCnwP+IMkPgP23cbhP0LuEaUW7qfwTL+GpPNmO/3+A97S2jwHHJ1kBfAaYv5W+twJHbr7hHPgs8Okk36d3Gdo2VdXjwPuAa1uGf9NW7czzlaSXRKoGm7mVJEmDSXIbcElVLR3psUjSrsaZD0mSJEmdcOZDkiRJUiec+ZAkSZLUCYsPSZIkSZ2w+JAkSZLUCYsPSZIkSZ2w+JAkSZLUCYsPSZIkSZ34/7KD14RCBIXpAAAAAElFTkSuQmCC\n",
"text/plain": [
""
]
},
"metadata": {
"needs_background": "light"
},
"output_type": "display_data"
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"--------------------------------------------------------\n",
"********************* Model Results ********************\n",
"--------------------------------------------------------\n",
"F1 Score : 0.9847625713245376\n",
"AUC-ROC Score : 0.9916415441328472\n",
"Report:\n",
" precision recall f1-score support\n",
"\n",
" 1 1.00 0.99 0.99 277\n",
" 2 0.97 0.97 0.97 94\n",
" 3 0.92 1.00 0.96 12\n",
" 4 0.89 1.00 0.94 8\n",
"\n",
" accuracy 0.98 391\n",
" macro avg 0.94 0.99 0.97 391\n",
"weighted avg 0.99 0.98 0.98 391\n",
"\n"
]
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAYEAAAEgCAYAAABSGc9vAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADt0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjByYzEsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy/xvVyzAAAgAElEQVR4nO3de5yUdf338dc7VlRAMCVYE4JUzEPeYnlIMVKUMDEpMEQrD4n86u7O/MnvzkOFQL/yl2l0thAP1V1aREaBVoYhlUkeUELRIl3Dw65n0OIgy+f+47oWh2Fm2V1m59rZ6/18POYxM9fxM9+dnfdc3+swigjMzCyf3pB1AWZmlh2HgJlZjjkEzMxyzCFgZpZjDgEzsxxzCJiZ5ZhDwLo0SRdIeljSOkkh6cIqrLNBUkNnrycP0r/Z4qzrsPIcAgaApAMkfVPSCklrJG2U9LSkhZLOk7RLBjVNAr4OrAe+BswA7q52HV1BGkyR3o5vZbobCqabvoPrPK4Sy7GurS7rAix7kqYBl5N8Kbgb+D7wKjAQOA6YA3wCOLzKpZ3Sch8RT1dxvSdUcV3ttQk4H/h98QhJfYGJ6TRd5X/7QODfWRdh5XWVN4plRNJlJN+wVwMfioilJaY5BZha7dqANwNUOQCIiH9Uc33ttAAYL2nPiHihaNyHgV7ALcAHq15ZCRHxSNY1WOvcHZRjkoYC04HXgJNLBQBARCwATiox/0RJS9Luo3WS/irpUkk7l5i2Ib31kvQVSf+UtEHSKkkXS1LBtNMlBXB8+ryleyNa6k6f31jmdS1umbZgmCSdLekuSc9JWi9ptaTfSDq9VK0llruzpEskLZf0b0lrJf1B0sQS026pMX18s6Tn0/XemwZrR1wL7Ax8tMS480nC/NelZpS0v6T/Sdf/XNr+T0iaLWlQ0bQ38vrWxuWFfwNJx6XTnJM+P0fSSWm7ryls++J9ApLeKullSS9KGlK0zt6SVkpqlvSe9jaMdYy3BPLtXGAn4OaIWNHahBGxofC5pC8BlwLPAz8m6T56H/AlYIyk0RHxWtFidgJ+S/IN/zaSbosPAP8D7EKyRQKwOL0/BxhSMHxHfDGt93Hgp8AaYC/gCOBDwE9am1lST+A3wHuAR4Bvk3zrPg34iaThEXFZiVmHAH8BHgN+COwBnA7Ml3RiRGzTrbMdtwMNwGSS/SQt9b0TOIykrTaXmXc88HGSD/e7gI3Awemy3i/p8Ih4Kp32F+n92cCdvP43IV1/odNIviTcBnwXGFqu+Ih4XNJkYC5wk6SREbEpHf0d4ABgekTcWW4ZVmER4VtOb8AiIIDJ7Zzv6HS+fwL1BcPrgF+l4y4rmqchHX4rsGvB8AHAy+ltp6J5Fidv0W3WPzRd1o1l6ttmPuAF4EmgV4np+5eotaFo2KUF9dcV1d/y2o4pUWMAlxcta0zLstrR5i3rqAM+lz4+umD8d4Fm4C0kH+pB8mFauIy9gZ1LLPu96bzXFA0/rtRyCsafk47fDJxUZpoAFpcY/p103BXp87PS578H3pD1/0aebu4Oyre90vsn2znfx9L7/46IxpaBkXyjm0ryoTC5zLwXRMS6gnmeBeYD/YC3tbOO9nqN5MNuKxHxfBvm/RjJh9RF8fo315b6v5A+LfWanwD+u2h9vyEJ0CPbVvY2rid5HedD0o0CnAn8JiL+WW6miHgqirbo0uG/BR4iCaeOmB8RJbugWnER8CBwsaT/QxIKzwEfjohyWzLWCRwC+dbSD9/e64m/I72/o3hERPyNJFTeKmn3otFrImJVieWtTu/f2M462uNHJN/OH5J0RdqH3a8tM0raDdgPeDpK7+hsaYfDSox7ICK2CR6S19yh1xvJjvJbgYnpEUGTgN1I9heUle4X+Yik36X7BDYV7Gs5hGRLoSP+0t4ZImI9SbfYv4BvknStnRVVPgjAHAJ51/IPN6jVqbbV8uH5TJnxzxRN1+LlMtO3fLPu0c462uM/gQtJPnQuIem/fl7SfEn7bWfetr7e4tCD1l/zjvz/XQv0Bs4g2SJoJOmKa81XSfZLHESyf+Nqkn0IM0i2WHp2sJbG7U9S0t+A5enjh0n2F1mVOQTy7Y/pfXuPi1+T3teXGb9X0XSV1tJdUO7Ahm0+jCOiOSK+HhGHkpz/MIHkUMpTgV+XOqKpQNavt5RbgadI9g8cBdxQ2E1VTNIA4AJgBfC2iPhIRFwcEdMjYjqwTTdRO3T0l6kuAY4hObjgYJL9LlZlDoF8u4Gkn3yCpINam7DoQ3JZen9cien2I9myeDwiyn0L3lEvpfeDS6y/L7B/azNHxLMR8fOImEjSlbMv8PZWpn8F+Aewt6RhJSZpOYP3/jbUXhFpF9P1JG0dwHXbmWUfkv/336avZ4v08NB9SszT0o1V8S00SccAM4FHSdr+UWCGpGMrvS5rnUMgxyKigeQ8gZ7AQkklzwiW1HL4X4vr0/vPSXpTwXQ9gKtI3lfb+1DqsPRD7BFgRGF4pev/KrBr4fTp8f0nFJ6LkA7fieSQTdj+Wa3Xk+xD+Uq6npZl9Ac+XzBNNX2D5KSwMbH9E9wa0vtji+rvQ9K1VGqrquVktLfsYJ1bkfRG4CaSkJkUEU0k+wc2kRw2umcl12et83kCORcRX5JUR3LZiHsk3QXcy+uXjRgJDEuHtcxzl6Qrgc8AKyT9jKSv/X0k3+r+CHylk0v/CknQ/EnSXJLrCx1Pci7Cg8ChBdPuCvwOaJC0lKT/exdgNMllDX4ZESu3s76rSF7fOOBBSbeS7Mz8EMlholdGxB9bmb/i0qOafrHdCZNpGyXdTLIT+QFJvyXZ1zGapO0eAIYXzfYoSZfTJEkbSY5oCuCHEfHEDpR+PUmwXBARD6T1PShpKvAtki3UU3dg+dYeWR+j6lvXuJF8GH6TpM94LcmJRM+QbAGcR+njyyeRfOC/QvJB8hDwWWCXEtM2UHTsfcG46SQfLscVDV9MifMECsafl65zA8nOye8BexbPRxIMn0lfyz/TWp8juU7Sx4GebamVJDguS9toXfq6/wicUWLaobTzXIbt/H0a0uXVtWHacucJ9CI5aW5V2garSU5626bNCuY5guR8kjUk+2K2/J14/TyBc1qpZavzBIBPpcPml5n+5+n4/8z6fyIvN6UNb2ZmOeR9AmZmOeYQMDPLMYeAmVmOOQTMzHKspg4RVdE14s3MbPsiQuXG1VQIWGX5Wl2VI70ZH2lXOZLcnhVSdI7kNtwdZGaWYw4BM7MccwiYmeWYQ8DMLMccAmZmOeYQMDPLMYeAmVmOOQTMzHLMIWBmlmMOATOzHHMImJnlmEPAzCzHHAJmZjnmEDAzyzGHgJlZjjkEzMxyzCFgZpZjDgEzsxxzCJiZ5ZhDwMwsxxwCZmY55hBop0GDBnHHHXfw8MMPs2LFCi644AIAbr75ZpYtW8ayZct4/PHHWbZs2VbzDR48mFdeeYWpU6dmUXbN2bBhA6ed9nFOPfU8xo49h29844asS6p5S5YsYcyYMYwePZrZs2dnXU7N6y7tWZd1AbVm06ZNTJ06lWXLltGnTx/uu+8+br/9diZNmrRlmquuuoo1a9ZsNd+sWbO47bbbql1uzerZsyff//5X6d27F6+9tokzz/wUI0ceyfDhB2ddWk1qbm5m5syZ3HDDDQwcOJDTTjuNUaNGsd9++2VdWk3qTu3pLYF2amxs3PIt/9VXX2XlypXsvffeW00zceJEbrrppi3Px40bx2OPPcZDDz1U1VprmSR69+4FJMG7adMmJGVcVe1avnw5Q4YMYfDgwfTs2ZOxY8eyaNGirMuqWd2pPR0CO2DIkCEcdthhLF26dMuwd7/73TQ1NbFq1SoAevXqxcUXX8yMGTOyKrNmNTc3M27ceRxzzAc45pjDOfTQg7IuqWY1NTVRX1+/5fnAgQNpamrKsKLa1p3as0uEgKRzs66hvXr37s28efO48MILeeWVV7YMP+OMM7baCpgxYwazZs3iX//6VxZl1rQePXowf/513HnnXJYvX8nf/vZY1iXVrIjYZpi3rDquO7VnV9knMAMouedP0hRgSnXLaV1dXR3z5s3jRz/6EbfccsuW4T169GD8+PG8853v3DLsqKOO4rTTTuPKK69k9913Z/Pmzaxfv55vf/vbWZRek/r23Y2jjhrOH/7wF/bff5+sy6lJ9fX1NDY2bnne1NTEgAEDMqyotnWn9qxaCEhaXm4UMLDcfBExG5idLmPb+M3Addddx8qVK5k1a9ZWw0888UQeeeQRnnrqqS3DRo4cueXx5ZdfzquvvuoAaIMXX3yZuroe9O27G+vXb+Cuu+7j/PPPyLqsmnXIIYfQ0NDA6tWrGThwIAsXLuTqq6/Ouqya1Z3as5pbAgOBMcBLRcMF3FXFOnbIiBEjOOuss1i+fPmWHcSXXXYZt912G5MmTdqqK8g67tlnX+CSS66guXkzEZs56aTjOf74Y7Iuq2bV1dUxbdo0Jk+eTHNzMxMmTGDYsGFZl1WzulN7qlTfVqesSLoOuCEi/lhi3I8j4sw2LKNLbAl0FxFPZ11CtyG9uWQ/sXWMJLdnhaRtWXaHRdVCoBIcApXlEKgch0BlOQQqZ3sh0CWODjIzs2w4BMzMcswhYGaWYw4BM7MccwiYmeWYQ8DMLMccAmZmOeYQMDPLMYeAmVmOOQTMzHLMIWBmlmMOATOzHHMImJnlmEPAzCzHHAJmZjnmEDAzyzGHgJlZjjkEzMxyzCFgZpZjDgEzsxxzCJiZ5ZgiIusa2kxS7RRrZtZFRITKjaurZiGVUEuh1ZVJIqbNyLqMbkMzL/d7s4IkuT0rRCr7+Q+4O8jMLNccAmZmOeYQMDPLMYeAmVmOOQTMzHLMIWBmlmMOATOzHHMImJnlmEPAzCzHHAJmZjnmEDAzyzGHgJlZjjkEzMxyzCFgZpZjDgEzsxxzCJiZ5ZhDwMwsxxwCZmY55hAwM8sxh4CZWY45BMzMcswhYGaWY3VZF9CdXHrppSxevJg999yTBQsWZF1ObXrXkfCOd4CA+5bB3UvhoAPh+PdA/zfBtXPg6WeyrrLm+L1ZWd2pPb0lUEHjx49nzpw5WZdRuwa8KQmAa+fANd+D/YfBHnvAs8/BzXPhiSeyrrBm+b1ZWd2pPasaApIOkHSCpD5Fw0+qZh2d5YgjjqBfv35Zl1G7+veHJ5+E1zbB5kg+9A88AJ5/Hl54Ievqaprfm5XVndqzaiEg6QJgPvApYIWkcQWjv1StOqwLe/Y5GDIEdt0VdqqDYcOgX9+sqzLr1qq5T+B84J0R8aqkocDPJA2NiK+T9ACXJGkKMKU6JVqmnn8e/vQnOOsjsHEjNDbC5s1ZV2XWrVUzBHpExKsAEdEg6TiSIBhCKyEQEbOB2QCSohqFWobufyC5AZwwCtauzbYes26umvsEGiUNb3mSBsIpQH/gkCrWYV1Z717Jfb++yf6Av67Ith6zbq6aIXAW0Fg4ICI2RcRZwMgq1tFpLrroIiZNmsTjjz/OyJEjmTt3btYl1Z7TJ8InPwFnToKFt8H69XDA2+CiC2HwIPjwGfDRD2ddZc3xe7OyulN7KqJ2elgkRS3V25VJIqbNyLqMbkMzL8fvzcqR5PaskLQty3a5+zwBM7MccwiYmeVY2aODJP20HcuJiDi9AvWYmVkVtXaI6JuqVoWZmWWibAhExPHVLMTMzKrP+wTMzHKszWcMS9oNGAfsD+xSPD4iPlPBuszMrAraFAKS9gX+BPQCegPPAXuk878ErAEcAmZmNaat3UGzgHuBgSTX+TkZ2BX4CPAq4CODzMxqUFu7g44EJgMb0uc9I6IZ+LGk/sDXgWM6oT4zM+tEbd0S2AVYGxGbgReBNxeMWwEcWunCzMys87U1BP4GDEkfLwM+LmkXSTsB5wFPd0ZxZmbWudraHXQzMBz4IfB54DfAWmBzuoxzOqM4MzPrXG0KgYj4asHjuyW9HXgfSTfRHRHhi76bmdWgDv2yWESsJv21LzMzq11tPU/g5O1NExG37ng5ZmZWTW3dElgABNv+FnDhrz70qEhFZmZWNW0NgbeWGLYH8F6SncLnVqogMzOrnrbuGH6ixOAngGWSmoHLgFMrWZiZmXW+SlxFdBkwqgLLMTOzKtuhEJDUk6Q76JmKVGNmZlWliNj+RNI9bL0TGKAnMBTYDTg3In5Q8eq2rWP7xZqZ2VYiovigni3aumP4IbYNgfXAXOAXEfFQB2szM7MMtWlLoKuQFLVUb1cmCbdl5STt6Z/UqBTpSr8/KyT9Xy+7JdCmfQKS7pB0QJlx+0u6o6MFmplZdtq6Y/g4oG+ZcX2BkRWpxszMqqo9Rwdts22WHh00CmisWEVmZlY1ZXcMS7ocmJY+DeBuqWy30lcqXJeZmVVBa0cH3Qo8T3K9oG8AVwMNRdNsBB6JiD90SnVmZtapyoZARNwD3AMg6RVgQUS8UK3CzMys87V1n8ADwFGlRkg6WdL/qlxJZmZWLW0NgVmUCQHgiHS8mZnVmLaGwDuAP5UZ92fgsMqUY2Zm1dTWEOgB9C4zrjfJdYTMzKzGtDUE7gGmlBk3Bbi3MuWYmVk1tfUCctOB30laCnyf5OSwvYCzgOHAiZ1SnZmZdaq2/rLYEknvBa4Avkly7sBmYClwQnpvZmY1pq1bAkTEYuBoSb2ANwIvAUcDZwPzgT07o0AzM+s8bQ6BAocAZwATgYHAi8DNlSzKzMyqo00hIOntJB/8k0h+TWwjyRFBU4FvRcSmzirQzMw6T9mjgyTtI+kySX8FHgT+C1hJsjN4GMl+gfsdAGZmtau1LYFVJFcPXQr8BzAvIl4CkNSvCrWZmVkna+08gSdIvu2/neRHZY6R1JF9CGZm1kWVDYGIeCswguS8gBOAXwFNkq5Nn/sHQM3MalyrZwxHxJ8j4lPA3sAYkkNBJwA/Syc5X9LhnVuimZl1ljZdNiIiNkfE7RHxMaAeGA/MBT4ILJW0shNrrBlLlixhzJgxjB49mtmzZ2ddTs1ze+6YSy+9n6OPvpVTTlm0ZdiXv7yCk076He9//x188pNLWbt2Y4YV1rbu8v5sz28MAxARGyPiFxExieQ8gbNIdiLnWnNzMzNnzmTOnDksXLiQBQsWsGpV7pulw9yeO278+LcwZ84xWw0bMWIACxaM4le/GsXQoX343vf+nlF1ta07vT/bHQKFIuJfEfGjiHh/W6aXdKSkI9LHB0m6SNLJO1JDV7F8+XKGDBnC4MGD6dmzJ2PHjmXRokXbn9FKcnvuuCOO6E+/fjttNezYYwdQV5f82w8f/kYaG9dlUVrN607vzx0KgfZIf7j+G8A1kq4AvgX0AS6R9Nlq1dFZmpqaqK+v3/J84MCBNDU1ZVhRbXN7dr55855g5MiBWZdRk7rT+7Oah3yeRnLF0Z1JrkI6KCLWSvoKybkIXyw1k6QplL+MdZcRse3BUpIyqKR7cHt2rmuueZQePd7AqacOyrqUmtSd3p/VDIFNEdEM/FvSPyJiLUBErJO0udxMETEbmA0gqcsellpfX09jY+OW501NTQwYMCDDimqb27Pz3HLLP1m8uJEbbxxRsx9cWetO78+qdQcBG9MrkAK8s2VgevZx2RCoFYcccggNDQ2sXr2ajRs3snDhQkaNGpV1WTXL7dk5lixp4tpr/84117yLXXf1uZ8d1Z3en9V8F4yMiA2QHHJaMHwnkstR17S6ujqmTZvG5MmTaW5uZsKECQwbNizrsmqW23PHXXTRPfzlL8/z0ksbGTny13zqUwcwe/bf2bhxM+eem/xk+KGH7sHMmcMzrrT2dKf3p0r1bXVVkqKW6u3KJJXs17SOSdrzM1mX0W1IV/r9WSHp/3rZfr9qdgeZmVkX4xAwM8sxh4CZWY45BMzMcswhYGaWYw4BM7MccwiYmeWYQ8DMLMccAmZmOeYQMDPLMYeAmVmOOQTMzHLMIWBmlmMOATOzHHMImJnlmEPAzCzHHAJmZjnmEDAzyzGHgJlZjjkEzMxyzCFgZpZjDgEzsxxTRGRdQ5tJqp1izcy6iIhQuXF11SykEmoptLoySW7LCnJ7VlbSnjdlXUa3IJ3R6nh3B5mZ5ZhDwMwsxxwCZmY55hAwM8sxh4CZWY45BMzMcswhYGaWYw4BM7MccwiYmeWYQ8DMLMccAmZmOeYQMDPLMYeAmVmOOQTMzHLMIWBmlmMOATOzHHMImJnlmEPAzCzHHAJmZjnmEDAzyzGHgJlZjjkEKmjJkiWMGTOG0aNHM3v27KzLqXluz8pye1bWjTfexdix3+KUU77NRRfNZcOG17IuqUMcAhXS3NzMzJkzmTNnDgsXLmTBggWsWrUq67JqltuzstyeldXUtJYf/GAp8+b9BwsWfJLm5mDhwhVZl9UhDoEKWb58OUOGDGHw4MH07NmTsWPHsmjRoqzLqlluz8pye1Zec/Nm1q9/jU2bmlm//jUGDNgt65I6JNMQkPSDLNdfSU1NTdTX1295PnDgQJqamjKsqLa5PSvL7VlZAwf25WMfO4bjj5/FscdeRZ8+O3PssftlXVaH1FVrRZJ+WTwIOF7S7gARcWq1aukMEbHNMEkZVNI9uD0ry+1ZWWvWrGPRokdZtOhCdtttFz796Z8yf/6DjBt3aNaltVvVQgAYBDwMzAGCJAQOB65ubSZJU4ApnV7dDqqvr6exsXHL86amJgYMGJBhRbXN7VlZbs/Kuuuuxxg0aHf22KM3AO9974EsW7a6JkOgmt1BhwP3AZ8F1kTEYmBdRNwZEXeWmykiZkfE4RFxeJXq7JBDDjmEhoYGVq9ezcaNG1m4cCGjRo3Kuqya5fasLLdnZb35zf148MEnWbduIxHBn//8GPvu2z/rsjqkalsCEbEZmCVpbnrfVM31d7a6ujqmTZvG5MmTaW5uZsKECQwbNizrsmqW27Oy3J6Vdeihgxgz5iA++MHvUVf3Bg48sJ7TT+/S31PLUqm+wqqsWBoLjIiIy9oxT2RVb3cjqWQ/sXWM27Oykva8KesyugXpDCKi7A6gzL6JR8RCYGFW6zczM58nYGaWaw4BM7MccwiYmeWYQ8DMLMccAmZmOeYQMDPLMYeAmVmOOQTMzHLMIWBmlmMOATOzHHMImJnlmEPAzCzHHAJmZjnmEDAzyzGHgJlZjjkEzMxyzCFgZpZjDgEzsxxzCJiZ5ZhDwMwsxxwCZmY5pojIuoY2k1Q7xZqZdRERoXLjaioEaoWkKRExO+s6ugu3Z+W4LSurO7Snu4M6x5SsC+hm3J6V47asrJpvT4eAmVmOOQTMzHLMIdA5arqPsAtye1aO27Kyar49vWPYzCzHvCVgZpZjDgEzsxxzCFSQpOslPStpRda11DpJgyX9XtJKSQ9J+nTWNdUySbtI+oukB9P2nJF1TbVOUg9JyyQtyLqWHeEQqKwbgZOyLqKb2ARMjYgDgXcBn5R0UMY11bINwKiIOBQYDpwk6V0Z11TrPg2szLqIHeUQqKCIWAK8mHUd3UFEPBMR96ePXyH5Z9s726pqVyReTZ/ulN58VEgHSRoEjAXmZF3LjnIIWJcnaShwGLA020pqW9p98QDwLHB7RLg9O+5rwGeAzVkXsqMcAtalSeoDzAMujIi1WddTyyKiOSKGA4OAIyW9PeuaapGkU4BnI+K+rGupBIeAdVmSdiIJgB9FxM+zrqe7iIiXgcV4/1VHjQBOldQA3AyMkvT/si2p4xwC1iVJEnAdsDIivpp1PbVO0psk7Z4+3hU4EXgk26pqU0RcGhGDImIoMAm4IyI+knFZHeYQqCBJNwF/Bt4m6UlJ52VdUw0bAXyU5FvWA+nt5KyLqmF7Ab+XtBy4h2SfQE0f2miV4ctGmJnlmLcEzMxyzCFgZpZjDgEzsxxzCJiZ5ZhDwMwsxxwCVvMkTZcUBbenJc2TtG8nre+UdD1D0+dD0+entGMZEyWdU8Ga+qQ1VGyZlg91WRdgViFreP0M2H2ALwCLJB0cEf/q5HU/AxxN+06+mgj0J7nyrFlmHALWXWyKiLvTx3dL+ifwB+BkYG7hhJJ2jYh1lVpxRGwA7t7uhGZdkLuDrLtqubjXUEkNkq6W9HlJTwJrASS9QdIlklZJ2iDpb5LOLlyIEtPTHwt6RdIPgL5F05TsDpJ0vqS/SlovqUnSzyT1k3QjMAF4T0EX1vSC+cZJujedr1HSlel1lAqXPSGtd52kJcABlWk2yxtvCVh3NTS9b0zvzwQeAv43r7/vvwmcDcwE7gdGA9dLeqHgkgoXANOAL5FsWYwHrtzeyiV9Ll3ud4D/C/Qiuf58H5KuqrcAu6f1ADyZzjcRuAn4HnAZsC9wBckXtv9Kp3kH8BPgFpIfNjkY+Gkb2sRsWxHhm281fQOmA8+TfLjXAfsDvyf5xr8X0EDSb79LwTz7kVwL/uyiZf0AuCd93AN4GrimaJrbSX6QZWj6fGj6/JT0+e7Av4GvtlLzz4DFRcMEPAHcUDT8Y8A6YM/0+U+Bh0kv+5IO+2xawzlZ/z18q62bu4Osu9gTeC29PUqyc/j0iHgmHb8oItYXTH8CSQjcIqmu5QYsAoZL6gEMJgmR+UXr2t5lrY8GdgVuaOdr2J9kC+GnRTXdAewCtFz//0jglxFReOEvX2rbOsTdQdZdrCG5PHKQdAE9XfQh2VQ0fX+Sb/pryixvL6A+ffxs0bji58X2TO+faXWqbfVP728tM35wel/fgZrMSnIIWHexKSLubWV88eVyXyT5MfsRlP6JwGd5/f9jQNG44ufFXkjv9yLppmqrlt+nngIsKzH+8fS+sQM1mZXkELC8uoNkS6BfRNxeagJJq0k+cMcBvy4YNX47y/4zSR/+2aQ7c0vYSNLFU+hR4CmSfQ3XtrL8e0h+2erSgq2d7dVkVpJDwHIpIh6V9F3gZklXAveSfCgfDOwfEZMjojkdd5Wk50mODpoAHLidZb8s6QvAFyX1JOne2Znk6KAZEfEUyYll4yR9gOTIoKcj4mlJU4EfSuoL3EYSFvsAHwBOi4h/A18GlpLsO7iOZF+Bf8DIOsQ7hi3PPklyuOZZJB/UN5J8UC8pmOZrJIeHfpzk9477AJ/Z3oIj4grgEyT7KeaTHPK5O/BKOsl3gN8C15N8s5+SzvcTki2P4T9PjDsAAABUSURBVCQnuf2c5DDS+0kCgbTbaxJwGPALkoA4vb0v3gz8y2JmZrnmLQEzsxxzCJiZ5ZhDwMwsxxwCZmY55hAwM8sxh4CZWY45BMzMcswhYGaWY/8fnjUD7taE1g8AAAAASUVORK5CYII=\n",
"text/plain": [
""
]
},
"metadata": {
"needs_background": "light"
},
"output_type": "display_data"
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"--------------------------------------------------------\n",
"\n",
"Model used: LGBMClassifier(boosting_type='gbdt', class_weight='balanced',\n",
" colsample_bytree=1.0, learning_rate=0.1, max_depth=8,\n",
" min_child_samples=20, min_child_weight=0.001, min_split_gain=0.0,\n",
" n_estimators=600, n_jobs=-1, num_leaves=31, objective=None,\n",
" random_state=101, reg_alpha=0.0, reg_lambda=0.0, silent=True,\n",
" subsample=1.0, subsample_for_bin=200000, subsample_freq=1,\n",
" verbose=1) \n",
" Done.\n"
]
}
],
"source": [
"df = ez.importdata('TrainDataset.csv')\n",
"X = df.drop('popularity',axis=1)\n",
"y = df.popularity\n",
"y_pred, model = ez.classification(X,y)"
]
},
{
"cell_type": "code",
"execution_count": 634,
"metadata": {
"ExecuteTime": {
"end_time": "2020-03-29T19:57:43.217847Z",
"start_time": "2020-03-29T19:57:33.057699Z"
}
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"*** Dataset Infomarion ***\n",
"##################################################\n",
"No of Rows : 1302\n",
"No of columns : 7\n",
"No of Numerical columns: 7\n",
"No of Categorical columns: 0\n",
"##################################################\n",
"\n",
" Total Missing values : 0 \n",
"\n",
"##################################################\n",
"Summary of DataFrame:\n",
"\n",
" Column Name Nulls/NaN outof Unique Type of Columns\n",
"0 buying_price 0 1302 4 Numerical\n",
"1 maintainence_cost 0 1302 4 Numerical\n",
"2 number_of_doors 0 1302 4 Numerical\n",
"3 number_of_seats 0 1302 3 Numerical\n",
"4 luggage_boot_size 0 1302 3 Numerical\n",
"5 safety_rating 0 1302 3 Numerical\n",
"6 popularity 0 1302 4 Numerical\n"
]
},
{
"data": {
"application/vnd.plotly.v1+json": {
"config": {
"plotlyServerURL": "https://plot.ly"
},
"data": [
{
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"reversescale": false,
"showscale": true,
"type": "heatmap",
"x": [
"buying_price",
"maintainence_cost",
"number_of_doors",
"number_of_seats",
"luggage_boot_size",
"safety_rating",
"popularity"
],
"y": [
"buying_price",
"maintainence_cost",
"number_of_doors",
"number_of_seats",
"luggage_boot_size",
"safety_rating",
"popularity"
],
"z": [
[
1,
-0.00601914794363575,
0.01431989962017954,
0.022869684564446633,
0.016355250728557667,
0.04381300694020507,
-0.2148840997128597
],
[
-0.00601914794363575,
1,
0.015885336815707744,
0.003790665852549147,
0.026792686209264383,
0.0004764712883163013,
-0.19645299365239596
],
[
0.01431989962017954,
0.015885336815707744,
1,
-0.025651392354451002,
0.01158000083312545,
-0.010466524889640786,
0.047387829407119234
],
[
0.022869684564446633,
0.003790665852549147,
-0.025651392354451002,
1,
-0.013527576547962002,
-0.03534956734726059,
0.36157273687024777
],
[
0.016355250728557667,
0.026792686209264383,
0.01158000083312545,
-0.013527576547962002,
1,
-0.011534135355788986,
0.12351538896214398
],
[
0.04381300694020507,
0.0004764712883163013,
-0.010466524889640786,
-0.03534956734726059,
-0.011534135355788986,
1,
0.42076893798445325
],
[
-0.2148840997128597,
-0.19645299365239596,
0.047387829407119234,
0.36157273687024777,
0.12351538896214398,
0.42076893798445325,
1
]
]
}
],
"layout": {
"annotations": [
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "buying_price",
"xref": "x",
"y": "buying_price",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "maintainence_cost",
"xref": "x",
"y": "buying_price",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "number_of_doors",
"xref": "x",
"y": "buying_price",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "number_of_seats",
"xref": "x",
"y": "buying_price",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "luggage_boot_size",
"xref": "x",
"y": "buying_price",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "safety_rating",
"xref": "x",
"y": "buying_price",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.21",
"x": "popularity",
"xref": "x",
"y": "buying_price",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "buying_price",
"xref": "x",
"y": "maintainence_cost",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "maintainence_cost",
"xref": "x",
"y": "maintainence_cost",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "number_of_doors",
"xref": "x",
"y": "maintainence_cost",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "number_of_seats",
"xref": "x",
"y": "maintainence_cost",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "luggage_boot_size",
"xref": "x",
"y": "maintainence_cost",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "safety_rating",
"xref": "x",
"y": "maintainence_cost",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.2",
"x": "popularity",
"xref": "x",
"y": "maintainence_cost",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "buying_price",
"xref": "x",
"y": "number_of_doors",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "maintainence_cost",
"xref": "x",
"y": "number_of_doors",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "number_of_doors",
"xref": "x",
"y": "number_of_doors",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "number_of_seats",
"xref": "x",
"y": "number_of_doors",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "luggage_boot_size",
"xref": "x",
"y": "number_of_doors",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "safety_rating",
"xref": "x",
"y": "number_of_doors",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "popularity",
"xref": "x",
"y": "number_of_doors",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "buying_price",
"xref": "x",
"y": "number_of_seats",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "maintainence_cost",
"xref": "x",
"y": "number_of_seats",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "number_of_doors",
"xref": "x",
"y": "number_of_seats",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "number_of_seats",
"xref": "x",
"y": "number_of_seats",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "luggage_boot_size",
"xref": "x",
"y": "number_of_seats",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "safety_rating",
"xref": "x",
"y": "number_of_seats",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.36",
"x": "popularity",
"xref": "x",
"y": "number_of_seats",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "buying_price",
"xref": "x",
"y": "luggage_boot_size",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "maintainence_cost",
"xref": "x",
"y": "luggage_boot_size",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "number_of_doors",
"xref": "x",
"y": "luggage_boot_size",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "number_of_seats",
"xref": "x",
"y": "luggage_boot_size",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "luggage_boot_size",
"xref": "x",
"y": "luggage_boot_size",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "safety_rating",
"xref": "x",
"y": "luggage_boot_size",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "popularity",
"xref": "x",
"y": "luggage_boot_size",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "buying_price",
"xref": "x",
"y": "safety_rating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "maintainence_cost",
"xref": "x",
"y": "safety_rating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "number_of_doors",
"xref": "x",
"y": "safety_rating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "number_of_seats",
"xref": "x",
"y": "safety_rating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "luggage_boot_size",
"xref": "x",
"y": "safety_rating",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "safety_rating",
"xref": "x",
"y": "safety_rating",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.42",
"x": "popularity",
"xref": "x",
"y": "safety_rating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.21",
"x": "buying_price",
"xref": "x",
"y": "popularity",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.2",
"x": "maintainence_cost",
"xref": "x",
"y": "popularity",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "number_of_doors",
"xref": "x",
"y": "popularity",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.36",
"x": "number_of_seats",
"xref": "x",
"y": "popularity",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "luggage_boot_size",
"xref": "x",
"y": "popularity",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.42",
"x": "safety_rating",
"xref": "x",
"y": "popularity",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "popularity",
"xref": "x",
"y": "popularity",
"yref": "y"
}
],
"template": {
"data": {
"bar": [
{
"error_x": {
"color": "#2a3f5f"
},
"error_y": {
"color": "#2a3f5f"
},
"marker": {
"line": {
"color": "#E5ECF6",
"width": 0.5
}
},
"type": "bar"
}
],
"barpolar": [
{
"marker": {
"line": {
"color": "#E5ECF6",
"width": 0.5
}
},
"type": "barpolar"
}
],
"carpet": [
{
"aaxis": {
"endlinecolor": "#2a3f5f",
"gridcolor": "white",
"linecolor": "white",
"minorgridcolor": "white",
"startlinecolor": "#2a3f5f"
},
"baxis": {
"endlinecolor": "#2a3f5f",
"gridcolor": "white",
"linecolor": "white",
"minorgridcolor": "white",
"startlinecolor": "#2a3f5f"
},
"type": "carpet"
}
],
"choropleth": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "choropleth"
}
],
"contour": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "contour"
}
],
"contourcarpet": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "contourcarpet"
}
],
"heatmap": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "heatmap"
}
],
"heatmapgl": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "heatmapgl"
}
],
"histogram": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "histogram"
}
],
"histogram2d": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "histogram2d"
}
],
"histogram2dcontour": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "histogram2dcontour"
}
],
"mesh3d": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "mesh3d"
}
],
"parcoords": [
{
"line": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "parcoords"
}
],
"pie": [
{
"automargin": true,
"type": "pie"
}
],
"scatter": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatter"
}
],
"scatter3d": [
{
"line": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatter3d"
}
],
"scattercarpet": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattercarpet"
}
],
"scattergeo": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattergeo"
}
],
"scattergl": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattergl"
}
],
"scattermapbox": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattermapbox"
}
],
"scatterpolar": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterpolar"
}
],
"scatterpolargl": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterpolargl"
}
],
"scatterternary": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterternary"
}
],
"surface": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "surface"
}
],
"table": [
{
"cells": {
"fill": {
"color": "#EBF0F8"
},
"line": {
"color": "white"
}
},
"header": {
"fill": {
"color": "#C8D4E3"
},
"line": {
"color": "white"
}
},
"type": "table"
}
]
},
"layout": {
"annotationdefaults": {
"arrowcolor": "#2a3f5f",
"arrowhead": 0,
"arrowwidth": 1
},
"coloraxis": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"colorscale": {
"diverging": [
[
0,
"#8e0152"
],
[
0.1,
"#c51b7d"
],
[
0.2,
"#de77ae"
],
[
0.3,
"#f1b6da"
],
[
0.4,
"#fde0ef"
],
[
0.5,
"#f7f7f7"
],
[
0.6,
"#e6f5d0"
],
[
0.7,
"#b8e186"
],
[
0.8,
"#7fbc41"
],
[
0.9,
"#4d9221"
],
[
1,
"#276419"
]
],
"sequential": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"sequentialminus": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
]
},
"colorway": [
"#636efa",
"#EF553B",
"#00cc96",
"#ab63fa",
"#FFA15A",
"#19d3f3",
"#FF6692",
"#B6E880",
"#FF97FF",
"#FECB52"
],
"font": {
"color": "#2a3f5f"
},
"geo": {
"bgcolor": "white",
"lakecolor": "white",
"landcolor": "#E5ECF6",
"showlakes": true,
"showland": true,
"subunitcolor": "white"
},
"hoverlabel": {
"align": "left"
},
"hovermode": "closest",
"mapbox": {
"style": "light"
},
"paper_bgcolor": "white",
"plot_bgcolor": "#E5ECF6",
"polar": {
"angularaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"bgcolor": "#E5ECF6",
"radialaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
}
},
"scene": {
"xaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
},
"yaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
},
"zaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
}
},
"shapedefaults": {
"line": {
"color": "#2a3f5f"
}
},
"ternary": {
"aaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"baxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"bgcolor": "#E5ECF6",
"caxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
}
},
"title": {
"x": 0.05
},
"xaxis": {
"automargin": true,
"gridcolor": "white",
"linecolor": "white",
"ticks": "",
"title": {
"standoff": 15
},
"zerolinecolor": "white",
"zerolinewidth": 2
},
"yaxis": {
"automargin": true,
"gridcolor": "white",
"linecolor": "white",
"ticks": "",
"title": {
"standoff": 15
},
"zerolinecolor": "white",
"zerolinewidth": 2
}
}
},
"xaxis": {
"dtick": 1,
"gridcolor": "rgb(0, 0, 0)",
"side": "top",
"ticks": ""
},
"yaxis": {
"dtick": 1,
"ticks": "",
"ticksuffix": " "
}
}
},
"text/html": [
"\n",
" \n",
" \n",
" \n",
" \n",
" "
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"application/vnd.plotly.v1+json": {
"config": {
"plotlyServerURL": "https://plot.ly"
},
"data": [
{
"domain": {
"x": [
0,
1
],
"y": [
0,
1
]
},
"hole": 0.4,
"hoverinfo": "label+percent+name",
"hoverlabel": {
"namelength": 0
},
"hovertemplate": "label=%{label}
value=%{value}",
"labels": [
1,
2,
3,
4
],
"legendgroup": "",
"name": "",
"showlegend": true,
"type": "pie",
"values": [
941,
294,
36,
31
]
}
],
"layout": {
"legend": {
"tracegroupgap": 0
},
"template": {
"data": {
"bar": [
{
"error_x": {
"color": "#2a3f5f"
},
"error_y": {
"color": "#2a3f5f"
},
"marker": {
"line": {
"color": "#E5ECF6",
"width": 0.5
}
},
"type": "bar"
}
],
"barpolar": [
{
"marker": {
"line": {
"color": "#E5ECF6",
"width": 0.5
}
},
"type": "barpolar"
}
],
"carpet": [
{
"aaxis": {
"endlinecolor": "#2a3f5f",
"gridcolor": "white",
"linecolor": "white",
"minorgridcolor": "white",
"startlinecolor": "#2a3f5f"
},
"baxis": {
"endlinecolor": "#2a3f5f",
"gridcolor": "white",
"linecolor": "white",
"minorgridcolor": "white",
"startlinecolor": "#2a3f5f"
},
"type": "carpet"
}
],
"choropleth": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "choropleth"
}
],
"contour": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "contour"
}
],
"contourcarpet": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "contourcarpet"
}
],
"heatmap": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "heatmap"
}
],
"heatmapgl": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "heatmapgl"
}
],
"histogram": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "histogram"
}
],
"histogram2d": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "histogram2d"
}
],
"histogram2dcontour": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "histogram2dcontour"
}
],
"mesh3d": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "mesh3d"
}
],
"parcoords": [
{
"line": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "parcoords"
}
],
"pie": [
{
"automargin": true,
"type": "pie"
}
],
"scatter": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatter"
}
],
"scatter3d": [
{
"line": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatter3d"
}
],
"scattercarpet": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattercarpet"
}
],
"scattergeo": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattergeo"
}
],
"scattergl": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattergl"
}
],
"scattermapbox": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattermapbox"
}
],
"scatterpolar": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterpolar"
}
],
"scatterpolargl": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterpolargl"
}
],
"scatterternary": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterternary"
}
],
"surface": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "surface"
}
],
"table": [
{
"cells": {
"fill": {
"color": "#EBF0F8"
},
"line": {
"color": "white"
}
},
"header": {
"fill": {
"color": "#C8D4E3"
},
"line": {
"color": "white"
}
},
"type": "table"
}
]
},
"layout": {
"annotationdefaults": {
"arrowcolor": "#2a3f5f",
"arrowhead": 0,
"arrowwidth": 1
},
"coloraxis": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"colorscale": {
"diverging": [
[
0,
"#8e0152"
],
[
0.1,
"#c51b7d"
],
[
0.2,
"#de77ae"
],
[
0.3,
"#f1b6da"
],
[
0.4,
"#fde0ef"
],
[
0.5,
"#f7f7f7"
],
[
0.6,
"#e6f5d0"
],
[
0.7,
"#b8e186"
],
[
0.8,
"#7fbc41"
],
[
0.9,
"#4d9221"
],
[
1,
"#276419"
]
],
"sequential": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"sequentialminus": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
]
},
"colorway": [
"#636efa",
"#EF553B",
"#00cc96",
"#ab63fa",
"#FFA15A",
"#19d3f3",
"#FF6692",
"#B6E880",
"#FF97FF",
"#FECB52"
],
"font": {
"color": "#2a3f5f"
},
"geo": {
"bgcolor": "white",
"lakecolor": "white",
"landcolor": "#E5ECF6",
"showlakes": true,
"showland": true,
"subunitcolor": "white"
},
"hoverlabel": {
"align": "left"
},
"hovermode": "closest",
"mapbox": {
"style": "light"
},
"paper_bgcolor": "white",
"plot_bgcolor": "#E5ECF6",
"polar": {
"angularaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"bgcolor": "#E5ECF6",
"radialaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
}
},
"scene": {
"xaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
},
"yaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
},
"zaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
}
},
"shapedefaults": {
"line": {
"color": "#2a3f5f"
}
},
"ternary": {
"aaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"baxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"bgcolor": "#E5ECF6",
"caxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
}
},
"title": {
"x": 0.05
},
"xaxis": {
"automargin": true,
"gridcolor": "white",
"linecolor": "white",
"ticks": "",
"title": {
"standoff": 15
},
"zerolinecolor": "white",
"zerolinewidth": 2
},
"yaxis": {
"automargin": true,
"gridcolor": "white",
"linecolor": "white",
"ticks": "",
"title": {
"standoff": 15
},
"zerolinecolor": "white",
"zerolinewidth": 2
}
}
},
"title": {
"text": "Percentage data of popularity"
}
}
},
"text/html": [
"\n",
" \n",
" \n",
" \n",
" \n",
" "
]
},
"metadata": {},
"output_type": "display_data"
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"Detailed Executing with RandomForest ..\n"
]
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAq8AAAGwCAYAAACHCYxOAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADt0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjByYzEsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy/xvVyzAAAgAElEQVR4nO3deZgkZZmu8fuRRkBAFhtFUWhEFBdkFUVWlXFm3HAd3AdxxA3RmXGb8QyiDooHPS7jBiqioo6KgqijoEiDgtJ0Q7MprrQDKCKCrIos7/kjouwkO6sqq7qrs6L6/l1XXpX5xRcRb0RkVj4V+WVUqgpJkiSpC+426gIkSZKkYRleJUmS1BmGV0mSJHWG4VWSJEmdYXiVJElSZxheJUmS1BmGV0nTkuTAJJXkwFHXIklacxhepVmgDYG9tzuSXJtkYRsSM+oauy7J4QP2c+9t2ahrnI629oXTmO+4SfbHlJc5XT21LFhd61xVkuy7uvfXqPgHq2aLeaMuQNJdvK39uTbwIOAZwD7ArsAhoypqjjkDWDig/Y+ruY7Z4mvA0gHty1ZzHZI0FMOrNItU1eG9j5PsAZwJvCrJe6vqspEUNrcs7N/Pa7iTquq4URchScNy2IA0i1XVWcClQIBdeqcl2SXJB5Jc0A4x+HOSnyd5b5JN+pfV+5Ffkse1QxJuTHJDkm8meeigGpI8KMmXk1yX5OYkZyd58kR1t7V9JcnVSW5N8uskH0ly3wF9xz4y3jrJIUl+3G7LsiT/PjZkIslzkixqa7g6yYeSrDuF3Tkl09yGByZ5TZILk/yp96PkJJsmeVeSn7TTrk9yWpInDlje3ZMcmuS8dr/f0u6PryXZr+1zYJKx/++9T99H/ofPwP54XpLT23r+3G7H/0myzoC+T09yfJKftcfrpiRL2m26W1/fAv6xfXjZoGEc7bYvY4AsHw6yb/9y2+f45kk+keTKNMNxDuzp8+gkJyS5Kslfklye5Ogk95vufupZdu/r7W+SfL/dD79P8qkkG7f9dkryjXa/3pTk5AwYPtFuSyVZJ8l/JrmsfV7+Mslbk9x9nDqekOTbWf474mdJjkyy0QTruHuSw5L8tF3Hce1z+VNt10/1Pd8WtPPfr53vrJ59+pskn8+A3y9JFrTzH9fe/+8k17R1Lk7ylAn27wHt62dsu5Yl+UKSXQf0Hfq5q27wzKs0+42Nd72tr/1lNMMKzgC+C6wF7Az8C/D3SR5dVTcOWN5TgP2BbwEfAx4GPAl4VJKHVdU1f11xsi3wQ+Bebf+lNMMZTmofr1hs84bzlbbuE4Bf0wTvVwL7J9mjqpYNmPU9wL7A14FTgacBRwB3T3ItcGS73u8DfwO8ut3mVw6qY2WsxDZ8ANgL+CbwP8Ad7fK2ohmqsKCt/9vA+jTH4ttJXl5VH+9ZznHA84CLgc8AfwLuB+wJ/B3N8V5KM8zkrW19x/XMv3C62z5Ikk8CBwFXAF+lGWLxGOAdwBOS/E1V3d4zy5HAncA5wJXARsDjafbPo4AX9fR9G/B0YId2+tjwjVUxjGNT4EfATW3ddwK/a7fpJcDHgVuBk4HLgW2BfwKemuQxVfW/q6CGp9Ec52/QvN4eCxwIbJ3kzcBpNM+JTwLbA08FtkmyfVXdOWB5X6LZhyfQ/E7YHzgc2DXJ06pq7A8akrwc+ChwM/Bl4Gqa19ib2m3co6oG7eevtOv4Fs1r7mqa59Qf2/X1DzUZW8bewJuB09tl3ESzT58NPK1d3wUD1rcVsAj4FfBZmuN2APC1JPtV1ek92xSaEP2PwDU0x/X3wP2BxwE/BRb39J/qc1ddUFXevHkb8Q2o5uW4QvveNAHoVuC+fdO2AtYaMM9L2+W9qa/9wLb9duAJfdPe1U57Y1/7qW37a/va9x+rGTiwp30DmjeUO4C9+uZ5U9v/1L7249r2ZcAWPe0bt8u6mebN6aE909YBftzul3sPuY8Pb9ezsL3ff1uwCrbhSmDrAeteSBOcntvXvjFNCPgTcJ+2baO27+Jxju+9Bjx3Fk7jOTdW80nj7I+N+543XwXWG2ef9j8/thmwvrsBn277P3qcWhaMU+syYNkkx3XfQa8pmvA/r2/ag4G/AL/ofc610x7fHvsTh9yP+w46Btz19bZP3374TjvtWuAFffN9sp22/4DnUAE/AzbpaV+X5g/MAl7U074VzevjBmC7vmV9pO1/zDjruBCYP2Bbx7bpwHH2xb2BDQe070ATZL/V176g5zi9tW/a37bt/9PXfnDbvgjYqG/aWvT8npzOc9dbN24jL8CbN293eaM9vL0dAXyxfYO9E3jNFJYV4Hrge33tY7/Ijx8wz9bttBN62u7ftv2KwSFq7I3uwJ62F7Rtnx/Qfx5wWTt9y57249q2lw6Y59h22tsHTHtrO22fIffL2JvVeLd9V8E2rPBG2L5xF/Dlceoa+0PgVe3je7aPzwIy5HNn4TSec2M1j3db0PY7n+YM38YDlrEWTdBfNOQ6d26Xfdg4tSwYZ75lTC+8DvzjBnhfO/3J4yzzRJrQuUIQG9B330HHgOWvt88OmOfF7bQzB0zbh8FhbiF9AXVADaf3tL2lbXvngP6b0ITaPwHrDFjH/v3z9G3TgYOmT7KfTgb+DKzd07aA5X+4Dvod82vgmr62i9p5dhpinavsuettdt0cNiDNLm/tezwW6j7V3zHJ2sDLgefSfPS/EXcdx77FOOtYPKDt8vZn71jZndqfP6iqOwbMs5DmjbbXzu3P7/V3rqrbk5xJ84a1E9D/keygun7T/lwyYNqV7c/7D5g2kbfVxF/YWpltWDRgebu3PzfK4LGom7U/H9qu44YkX6f5+Hhpkq/QfKx8TlXdMkHd0/WSGucLW0nuQRO+rwFel8FXbLt1rPae+e4FvIFmOMoDaYZI9BrvubmqLauqqwe0jx2TfZI8asD0e9OEmwcz+Lk3Fav6eX3GgLbv04TtnXraJnoeX5fkfJpPdrYD+j/KH/Q8Hkqa8fCvoLlCynxWHJ44H/htX9vScX7HXM7yY0WS9YFHAL+rqvMnqWNaz111g+FVmkWqauzLSevT/NL+JPCxJL+uqv43oS/SjHn9Fc0YtKtofhkDvI7mo/VBVhjj1oYyaN6wx4x9oeN34yznqgFtY/P0vznR177xgGnXD2i7fYhpa4+zrulamW0YtE/u1f78m/Y2ng167h9AM0Th+Sy/fNqfk5wAvL6qxjsmq9omNGfyN2PFP6wGar+IdC7N2fxFNB/bX0tzvDYGXsv4z81VbdDxgOXH5A2TzL/BJNOHsaqf1ysc+6q6I8kfaEL3mFX9PJ5UkkNpxi1fRzM04n+BW2j+CB8b1zzo2I83vvl27voH+VitVw7o22/Kz111h+FVmoWq6mbgu0meCpwHfDrJQ8bOvLXfqH0GzRd3nlRVf/0yV5pvc79xFZQx9sZ6n3Gmbz7BPIOmAdy3r99stDLbUBMs77VV9cFhCqiqP9EOIUnyAJozZAcCL6Q567vXMMtZBcZqP7+qdp6w53L/RBNcVzjDnWR3mvA6VXcCA79Nz+DwNWbQ8YDl27VRVd0wjXpG6T70nfFPshZNIO/dlt7n8SUDljPu87iqxttv40oyj+YPrauAnavqt33Tdx8449SMhdxhztxP57mrjvBSWdIsVlUX0nwj+v7AP/dMelD78+Te4NraDVhvFax+7GO5Pds3x377TjDPCtPaN7c924fnrWxxM2hVb8OP2p/TCpxVdXlVfY7mCyw/pzke9+rpcid3PWO+ylTVTTTB5+FJNh1ytrHn5lcGTOsfZjJm7CPj8bbjOuA+7VCZfitcGmkIK3VMRmzQPtyL5mRU70fpEz2PNwZ2pBmD+pMprHui4zSf5g+JswcE1w1YPoxh2to/6i+meS7sNEnf6Tx31RGGV2n2+0+aN5nXZ/n1W5e1P/ft7Zjk3sCHV8VKq+oKmo/+tqbvv3sl2Z/Bb6In0XxE/Lwkj+mb9jqa8Y/frVVzCaKZskq3oaoW04xJfGaSgwb1SbJ9e+xIslmSRw/otj6wIc1HqX/paf8D8IBhapmm/0dz1vPYNvTcRZJNkvQGk2Xtz337+u0E/Ns46/hD+3PLcaYvoglnL+lb5oHAHuOXPq4P0XyR531JHtw/sb3O6WwNtv/R83uANNc6flf7sHds/PE02/iaJA/irt5B88XA46vqVoY30XG6mmaIwC5tWB2rb22aoQTzp7CeiYx9enF0+q5Vm+Ruuet1mKf63FVHOGxAmuWq6sokR9N83PpGmgBwLs230Z+Z5GzgBzQfJ/49zXUOfzPO4qbq1TSX4Xl/movpX8Dyf1s79qWi3lpvagPal4EzknyZ5iPOXYAn0nyk+PJVVNuMmKFteD7NF2c+2Y4LPIfmI9D7A4+k+RLK7jQBYAvgR0l+QnN293KaoPEUmo+AP1h3vX7vacBz2y95LaEJt2dW1ZlT3fZBqurYJLsArwJ+meQUmv2xKc0fNnvThKZXtLN8hmYs6fuTPI7mbPG2bf1fpRnP2++0dp6Pt+N6bwL+WFUfaqf/F01w/WiSJ9Dskx1orpn6jXbZU9mmS9tjfCxwSZJv01yCam2aYLYXzeXZtpvKcleTn9DU3Hud121ori382bFOVbUsyeto/pg9L8mXaLZpH5rn2qU046qn4oc0AfV17dnMsfG3/1VV1yf5IM11Xi9K8jWa4Pg4mufK6e39lfUJmk8/Xgz8vF3P72mug/x4mmN6OEzruauuGPXlDrx587b8UlkTTL8PzfVOb2b59UA3pble4zKaM7O/BN4J3IMBlxZi8ms0DrzkEk1YPYEmbN1M8wb25ImWR3OB8xNp3lT+QvOG8VHgfgP6Hsc4l0linMsgDbM9Eyzr8CH7r5Jt6OmzIfDvNAHzJprLFF1GEzoOBtZv+20MHEYTdq+k+RLeb2mu7vA8+i6fRfMlnc/TBIk7ht3GnpqH3X9jF9q/ut0fV9GcEf1PVryO6MNoLo10dfucWUIzFnZBu87jBiz/X2iC2a1tn/7n7540/yr5Fpqxnd+kCf4DnyPjPZ/7+mzf7odft+u9luZj6aOBxw+5X/YdtK6Jnp8986xwnMbbRyy/jNU67T6/rK35VzRfSFpnnPqeSHO95uva/r8A/i+DLx+1kAl+D7V9/o7md8BNrHhZtXntcfwxzfP7KppAvRUDXiMTPR8mq4fmknZn0Ixt/XO7Pz5HM9522s9db924pT2wkiRplkrz71n3qfaKJNKazDGvkiRJ6gzDqyRJkjrD8CpJkqTOcMyrJEmSOsNLZa0h5s+fXwsWLBh1GZIkSZNasmTJNVW12aBphtc1xIIFC1i8ePGoy5AkSZpUkl+PN80xr5IkSeoMw6skSZI6w/AqSZKkzjC8SpIkqTMMr5IkSeoMrzawhvjJFX9glzd8ZtRlSJKkDlty1ItHXYJnXiVJktQdhldJkiR1huFVkiRJnWF4lSRJUmcYXiVJktQZhldJkiR1huFVkiRJnWF4lSRJUmcYXiVJktQZhldJkiR1huFVkiRJnWF4lSRJUmcYXiVJktQZhldJkiR1huFVkiRJnWF4lSRJUmcYXiVJktQZhldJkiR1huFVkiRJnWF4lSRJUmcYXiVJktQZhldJkiR1xhoZXpNsl2RpkvOTbDNBv39fDbX8e9/js2d6nZIkSV21RoZX4OnA16pqp6r65QT9Vjq8Jllrki53WUdVPXZl1ylJkjRXzZnwmmT9JN9MckGSi5MckOSwJOe2j49J40nA64B/SnJ6O+8Lkyxqz8YenWStJEcC67Vtn0vyjiSv7VnfEUkOHaeWfZOcnuTzwEVt20lJliS5JMnBbdtd1tG23dSzjIVJTkhyaVtD2mlPatt+kOSDSb4xTh0HJ1mcZPHtt9y4iva0JEnS6MwbdQGr0N8Bv6mqJwMk2Qj4TlW9vX38WeApVfX1JB8Dbqqq9yR5KHAAsEdV3ZbkI8ALqurNSQ6pqh3b+RcAXwU+kORuwHOB3SaoZzfgEVV1Wfv4oKq6Nsl6wLlJvtK/jgF2Ah4O/AY4C9gjyWLgaGDvqrosyRfGK6CqjgGOAVh/861rglolSZI6Yc6ceaU5w7lfkncn2auqrgcel+ScJBcBj6cJgv2eAOxCEyiXto8f2N+pqpYBf0iyE/BE4Pyq+sME9SzqCa4Ahya5APgR8ABg2yG2aVFVXVFVdwJLgQXAdsCvepY9bniVJEmaa+bMmdeq+lmSXYAnAe9KcirwamDXqro8yeHAugNmDfDpqvq3IVbzCeBAYHPg2En63vzXFST7AvsBu1fVLUkWjlNLv1t77t9Bc7wyxHySJElz0pw585rkfsAtVXU88B5g53bSNUk2AJ49zqynAc9Ocu92OZsm2aqddluStXv6nkgzPOFRwClTKG8j4Lo2uG4HPKZnWv86JnMp8MB2GAM0Qx4kSZLWCHPmzCuwPXBUkjuB24BX0lxV4CJgGXDuoJmq6sdJ/g9wajuW9TaaM7a/phkvemGS86rqBVX1l/ZLXn+sqjumUNu3gVckuRD4Kc3QgTF3WcdkC6qqPyV5FfDtJNcAi6ZQhyRJUqelyu/xDKsNt+cBz6mqn4+wjg2q6qb26gMfBn5eVe+baJ71N9+6tnvR21ZPgZIkaU5actSLV8t6kiypql0HTZszwwZmWpKHAb8AThtlcG29rP1y2SU0QxKOHnE9kiRJq8VcGjYwo6rqx/RdhSDJ9sBn+7reWlWPnuFa3gdMeKZVkiRpLjK8roSquggY7xqtkiRJWsUcNiBJkqTOMLxKkiSpMwyvkiRJ6gzDqyRJkjrD8CpJkqTOMLxKkiSpMwyvkiRJ6gzDqyRJkjrD8CpJkqTOMLxKkiSpMwyvkiRJ6gzDqyRJkjrD8CpJkqTOMLxKkiSpMwyvkiRJ6ox5oy5Aq8dD738vFh/14lGXIUmStFI88ypJkqTOMLxKkiSpMwyvkiRJ6gzDqyRJkjrD8CpJkqTOMLxKkiSpMwyvkiRJ6gzDqyRJkjrD8CpJkqTOMLxKkiSpMwyvkiRJ6gzDqyRJkjpj3qgL0Orxl99ewv++fftRlyFJmsW2POyiUZcgTcozr5IkSeoMw6skSZI6w/AqSZKkzjC8SpIkqTMMr5IkSeoMw6skSZI6w/AqSZKkzjC8SpIkqTMMr5IkSeoMw6skSZI6w/AqSZKkzjC8SpIkqTMMr5IkSeoMw6skSZI6w/AqSZKkzjC8SpIkqTMMr5IkSeoMw6skSZI6w/AqSZKkzjC8SpIkqTMMr5IkSeoMw6skSZI6Y86F1yQLkly8CpbziiQvXhU1dWndkiRJs9m8URcwW1XVx0ax3iTzRrVuSZKk2W7OnXltzUvy6SQXJjkhyT2SLEsyHyDJrkkWJrlbkp8n2axtv1uSXySZn+TwJK9v2xcmeXeSRUl+lmSvtv0eSb7UrueLSc5Jsut4RSW5Kcl7k5yX5LSe9S5M8s4kZwCv7Vv3g5J8N8kF7XzbtO1vSHJuu+63jbO+g5MsTrL42pvvWIW7V5IkaTTmanh9CHBMVT0SuAF41aBOVXUncDzwgrZpP+CCqrpmQPd5VbUb8DrgrW3bq4Dr2vW8A9hlkrrWB86rqp2BM3qWA7BxVe1TVe/tm+dzwIeragfgscBvkzwR2BbYDdgR2CXJ3gO275iq2rWqdt10/bUmKU2SJGn2m6vh9fKqOqu9fzyw5wR9jwXGxpceBHxqnH5fbX8uARa09/cE/hugqi4GLpykrjuBL45T1xf7OyfZENiiqk5s1/HnqroFeGJ7Ox84D9iOJsxKkiTNaXN1zGsNeHw7y8P6un+dUHV5kt8leTzwaJafhe13a/vzDpbvt6zCOm8eMH285Qd4V1UdvZLrlyRJ6pS5euZ1yyS7t/efB/wAWMbyj/Wf1df/EzRnQr9UVVMZHPoD4B8AkjwM2H6S/ncDnt3ef347/7iq6gbgiiRPb9exTpJ7AKcAByXZoG3fIsm9p1C3JElSJ83V8PoT4B+TXAhsCnwUeBvwgSTfpzl72utkYAPGHzIwno8Am7XreRPNsIHrJ+h/M/DwJEuAxwNvH2IdLwIObddxNrB5VZ0KfB74YZKLgBOADadYuyRJUuekqv8T9jVPe4WA91XVXlOcby1g7ar6c3sVgNOAB1fVX8bpf1NVbbDyFU/dI7dYr77x8geNYtWSpI7Y8rCLRl2CBECSJVU18ApOc3XM69CSvBl4JeOPdZ3IPYDTk6xNMw71leMFV0mSJK28NT68VtWRwJHTnPdGYIW/CpKcA6zT1/yiUZ11lSRJmivW+PA6E6rq0aOuQZIkaS6aq1/YkiRJ0hxkeJUkSVJnGF4lSZLUGYZXSZIkdYbhVZIkSZ1heJUkSVJnGF4lSZLUGYZXSZIkdYbhVZIkSZ1heJUkSVJnGF4lSZLUGYZXSZIkdYbhVZIkSZ1heJUkSVJnGF4lSZLUGYZXSZIkdca8UReg1ePu9304Wx62eNRlSJIkrRTPvEqSJKkzDK+SJEnqDMOrJEmSOsPwKkmSpM4wvEqSJKkzDK+SJEnqDMOrJEmSOsPwKkmSpM4wvEqSJKkzDK+SJEnqDMOrJEmSOmPeqAvQ6nHp1Zeyx3/tMeoyJElDOOs1Z426BGnW8syrJEmSOsPwKkmSpM4wvEqSJKkzDK+SJEnqDMOrJEmSOsPwKkmSpM4wvEqSJKkzDK+SJEnqDMOrJEmSOsPwKkmSpM4wvEqSJKkzDK+SJEnqDMOrJEmSOsPwKkmSpM4wvEqSJKkzDK+SJEnqDMOrJEmSOsPwKkmSpM4wvEqSJKkzDK+SJEnqDMOrJEmSOsPwKkmSpM4wvEqSJKkzZmV4TbJrkg9O0mfjJK8acnlnr5rKZp8k/z7qGiRJklaXWRleq2pxVR06SbeNgaHCa1U9duWrmrUMr5IkaY0xY+E1yYIklyb5RJKLk3wuyX5Jzkry8yS7tbezk5zf/nxIO+++Sb7R3j88ybFJFib5VZKxUHsksE2SpUmOSrJBktOSnJfkoiT799RyU89yFyY5oa3tc0nSTtslyRlJliQ5Jcl92/aFSd6dZFGSnyXZq21fK8l72nVdmOQ1Ey1nnH30oCTfTXJBW/c2aRzV7rOLkhzQ9r1vkjPb7b04yV5JjgTWa9s+N2D5BydZnGTxbTfdttLHVJIkadTmzfDyHwQ8BzgYOBd4PrAn8DSaM4YvBvauqtuT7Ae8E3jWgOVsBzwO2BD4aZKPAm8GHlFVOwIkmQc8o6puSDIf+FGSk6uq+pa1E/Bw4DfAWcAeSc4B/gvYv6p+3wbGI4CD2nnmVdVuSZ4EvBXYr92mrYGd2vo3TbL2JMvp9zngyKo6Mcm6NH9MPBPYEdgBmA+cm+TMdt+dUlVHJFkLuEdVfT/JIWP7oF9VHQMcA7DBlhv07wdJkqTOmenwellVXQSQ5BLgtKqqJBcBC4CNgE8n2RYoYO1xlvPNqroVuDXJ1cB9BvQJ8M4kewN3Alu0/a7q67eoqq5oa1ra1vFH4BHAd9oTsWsBv+2Z56vtzyVtf2gC7Meq6naAqro2ySMmWc7yYpMNgS2q6sR2/j+37XsCX6iqO4DfJTkDeBRN+D+2DcgnVdXScfaVJEnSnDXT4fXWnvt39jy+s133O4DTq+oZSRYAC4dYzh0MrvsFwGbALlV1W5JlwLpDLivAJVW1+yTr7113aAJ3r8mW09936PaqOrMN5k8GPpvkqKr6zBDrkSRJmjNG/YWtjYAr2/sHTnHeG2mGEfQu6+o2uD4O2GoKy/opsFmS3QGSrJ3k4ZPMcyrwina4Akk2ncpyquoG4IokT2/7rpPkHsCZwAHtmNrNgL2BRUm2arfv48AngZ3bRd3Wno2VJEma80YdXv8v8K4kZ9F8xD60qvoDcFb75aWjaMaP7ppkMc1Z2EunsKy/AM8G3p3kAmApMNkVCj4B/C9wYTvP86exnBcBhya5EDgb2Bw4EbgQuAD4HvDGqroK2BdYmuR8mnHBH2iXcUxbwwpf2JIkSZprsuL3mTQXbbDlBrXDG3YYdRmSpCGc9ZqzRl2CNFJJllTVroOmjfrMqyRJkjS0mf7CloAkHwb26Gv+QFV9ahT1SJIkdZXhdTWoqlePugZJkqS5wGEDkiRJ6gzDqyRJkjrD8CpJkqTOGCq8JtkmyTrt/X2THJpk45ktTZIkSbqrYc+8fgW4I8mDaP6709bA52esKkmSJGmAYcPrnVV1O/AM4P1V9c/AfWeuLEmSJGlFw4bX25I8D/hH4Btt29ozU5IkSZI02LDh9SXA7sARVXVZkq2B42euLEmSJGlFQ/2Tgqr6cZI3AVu2jy8DjpzJwiRJkqR+w15t4KnAUuDb7eMdk5w8k4VJkiRJ/YYdNnA4sBvwR4CqWkpzxQFJkiRptRk2vN5eVdf3tdWqLkaSJEmayFBjXoGLkzwfWCvJtsChwNkzV5YkSZK0omHPvL4GeDhwK80/J7geeN1MFSVJkiQNMumZ1yRrASdX1X7AW2a+JEmSJGmwScNrVd2R5JYkGw0Y96qO2O7e23HWa84adRmSJEkrZdgxr38GLkryHeDmscaqOnRGqpIkSZIGGDa8frO9SZIkSSMz7H/Y+vRMFyJJkiRNZqjwmuQyBlzXtaoeuMorkiRJksYx7LCBXXvurws8B9h01ZcjSZIkjW+o67xW1R96bldW1fuBx89wbZIkSdJdDDtsYOeeh3ejORO74YxUJEmSJI1j2GED7+25fztwGfAPq74cSZIkaXzDhteXVtWvehuSbD0D9UiSJEnjGmrMK3DCkG2SJEnSjJnwzGuS7YCHAxsleWbPpHvSXHVAkiRJWm0mGzbwEOApwMbAU3vabwReNlNFSZIkSYOkaoX/PbBip2T3qvrhaqhHM+QhG25Yx+y08+QdJWkO2+fMM0ZdgqQhJFlSVbsOmjbsF7bOT/JqmiEEfx0uUFUHrYL6JEmSpKEM+4WtzwKbA38LnAHcn2bogCRJkrTaDBteH1RV/wHcXFWfBp4MbD9zZUmSJEkrGja83tb+/GOSRwAbAQtmpCJJkiRpHMOOeT0mySbAfwAnAxsAh81YVZIkSdIAQ4XXqvpEe/cM4IEzV44kSZI0vqGGDSS5T5JPJvlW+/hhSV46s793kl4AABNbSURBVKVJkiRJdzXsmNfjgFOA+7WPfwa8biYKkiRJksYzbHidX1VfAu4EqKrbgTtmrCpJkiRpgGHD681J7gUUQJLHANfPWFWSJEnSAMNebeBfaK4ysE2Ss4DNgGfPWFWSJEnSABOG1yRbVtX/VtV5SfYBHgIE+GlV3TbRvJIkSdKqNtmwgZN67n+xqi6pqosNrpIkSRqFycJreu57fVdJkiSN1GThtca5L0mSJK12k31ha4ckN9CcgV2vvU/7uKrqnjNanSRJktRjwvBaVWutrkIkSZKkyQx7nVdJkiRp5AyvkiRJ6gzDqyRJkjrD8CpJkqTOMLxKkiSpM+ZkeE2yMMmuq3F9RyW5JMlRM7iOjZO8aqaWL0mS1AWTXed1jZNkXlXdPsXZXg5sVlW3zkRNrY2BVwEfmcF1SJIkzWojPfOaZEGSnyT5eHvm8tQk6/WeOU0yP8my9v6BSU5K8vUklyU5JMm/JDk/yY+SbNqz+BcmOTvJxUl2a+dfP8mxSc5t59m/Z7lfTvJ14NRxak17hvXiJBclOaBtPxlYHzhnrG3AvM9p57sgyZlt21rt8s5NcmGSl7ftGyQ5Lcl57Xr2bxdzJLBNkqXtfPdNcmb7+OIkew1Y78FJFidZfP1tt03x6EiSJM0+s+HM67bA86rqZUm+BDxrkv6PAHYC1gV+AbypqnZK8j7gxcD7237rV9Vjk+wNHNvO9xbge1V1UJKNgUVJvtv23x14ZFVdO856nwnsCOwAzAfOTXJmVT0tyU1VteMENR8G/G1VXdmuF+ClwPVV9agk6wBnJTkVuBx4RlXdkGQ+8KM2IL8ZeMTYepL8K3BKVR2RZC3gHv0rrapjgGMAHrLhhv57X0mS1HmzIbxeVlVL2/tLgAWT9D+9qm4EbkxyPfD1tv0i4JE9/b4AUFVnJrlnGxqfCDwtyevbPusCW7b3vzNBcAXYE/hCVd0B/C7JGcCjgJMn3UI4CziuDedfbdueCDwyybPbxxvRBPkrgHe2oftOYAvgPgOWeS5wbJK1gZN69qEkSdKcNRvCa+840TuA9YDbWT6kYd0J+t/Z8/hO7ro9/WcaCwjwrKr6ae+EJI8Gbp6kzkwyfVxV9Yp2HU8GlibZsV3ea6rqlL5aDgQ2A3apqtvaIRP9+2AslO/dLvOzSY6qqs9Mt0ZJkqQumK1XG1gG7NLef/YE/SYyNiZ1T5qP568HTgFekyTttJ2msLwzgQPasaqbAXsDi4aZMck2VXVOVR0GXAM8oK3lle2ZU5I8OMn6NGdgr26D6+OArdrF3Ahs2LPMrdp+Hwc+Cew8hW2RJEnqpNlw5nWQ9wBfSvIi4HvTXMZ1Sc4G7gkc1La9g2ZM7IVtgF0GPGXI5Z1IMy72ApqzuG+sqquGnPeoJNvSnG09rV3GhTRDJM5ra/k98HTgc8DXkywGlgKXAlTVH5KcleRi4FvAxcAbktwG3EQz3leSJGlOS5Xf41kTPGTDDeuYnTw5K2nNts+ZZ4y6BElDSLKkqgZes3+2DhuQJEmSVjBbhw2MTJLtgc/2Nd9aVY8eYt63AM/pa/5yVR2xquqTJElakxle+1TVRTTXc53OvEcABlVJkqQZ4rABSZIkdYbhVZIkSZ1heJUkSVJnGF4lSZLUGYZXSZIkdYbhVZIkSZ1heJUkSVJnGF4lSZLUGYZXSZIkdYbhVZIkSZ1heJUkSVJnGF4lSZLUGYZXSZIkdYbhVZIkSZ1heJUkSVJnGF4lSZLUGfNGXYBWjw0f8hD2OfOMUZchSZK0UjzzKkmSpM4wvEqSJKkzDK+SJEnqDMOrJEmSOsPwKkmSpM4wvEqSJKkzDK+SJEnqDMOrJEmSOsPwKkmSpM4wvEqSJKkzDK+SJEnqjHmjLkCrx9VXXM+H/vXroy5DUkcd8t6njroESQI88ypJkqQOMbxKkiSpMwyvkiRJ6gzDqyRJkjrD8CpJkqTOMLxKkiSpMwyvkiRJ6gzDqyRJkjrD8CpJkqTOMLxKkiSpMwyvkiRJ6gzDqyRJkjrD8CpJkqTOMLxKkiSpMwyvkiRJ6gzDqyRJkjrD8CpJkqTOMLxKkiSpMwyvkiRJ6gzDqyRJkjrD8CpJkqTOMLxKkiSpM2Y8vCa5aabXsaolOTzJ61fBchYkef405z17ZdcvSZI013jmdWYtAKYVXqvqsau2FEmSpO5bbeE1yb5JvtHz+ENJDmzvPynJpUl+kOSDY/2SbJbkO0nOS3J0kl8nmd9OOynJkiSXJDm4Z7kvTfKzJAuTfDzJh3qW9ZUk57a3PSYpeYck30vy8yQva5eRJEcluTjJRUkOmKgdOBLYK8nSJP88zn55eJJFbZ8Lk2zbtt/U/nx7O21pkiuTfKptf2HPfEcnWWtqR0SSJKl75o26gCTrAkcDe1fVZUm+0DP5rcD3qupdSf4OOLhn2kFVdW2S9YBzk3wFWAf4D2Bn4Ebge8AFbf8PAO+rqh8k2RI4BXjoBKU9EngMsD5wfpJvArsDOwI7APPb9Z4JPHac9jcDr6+qp0ywnlcAH6iqzyW5O3CXEFpVhwGHJdkI+D7woSQPBQ4A9qiq25J8BHgB8JneedtQfzDAJhtuNkEJkiRJ3TDy8ApsB/yqqi5rH3+B5SF1T+AZAFX17STX9cx3aJJntPcfAGwLbA6cUVXXAiT5MvDgts9+wMOSjM1/zyQbVtWN49T1tar6E/CnJKcDu7X1fKGq7gB+l+QM4FETtN8wxPb/EHhLkvsDX62qn/d3SFP052jC95IkhwC70IRkgPWAq/vnq6pjgGMAttx82xqiFkmSpFltdYbX27nrMIV1258Z0JeJpiXZlyaM7l5VtyRZ2C5vomXdre3/pyHr7Q97NcHyJ1rvxCup+nySc4AnA6ck+aeq+l5ft8OBK6rqUz3r+3RV/dt01ytJktRFq/MLW7+mOfO5TvsR+BPa9kuBByZZ0D4+oGeeHwD/AJDkicAmbftGwHVtcN2O5uN9gEXAPkk2STIPeFbPsk4FDhl7kGTHSerdP8m6Se4F7AucC5wJHJBkrSSbAXu36xyv/UZgw4lWkuSBNGeePwicTDNcoXf6U4C/AQ7taT4NeHaSe7d9Nk2y1STbI0mS1Hmr7cxrVV2e5EvAhcDPgfPb9j8leRXw7STX0IS+MW8DvtB+AeoM4Lc0gfDbwCuSXAj8FPhRu6wrk7wTOAf4DfBj4Pp2WYcCH27nmUcTOF8xQcmLgG8CWwLvqKrfJDmRZtzrBTRnYt9YVVdN0P4H4PYkFwDHVdX7BqznAOCFSW4DrgLe3jf9X4H7AYvaIQInV9VhSf4PcGqSuwG3Aa+m+QNBkiRpzkrV6IdCJtmgqm5qx3Z+GPh5Vb0vyTrAHVV1e5LdgY9W1YRnTHuWNQ84ETi2qk6c+a2Y3bbcfNt64wv+36jLkNRRh7z3qaMuQdIaJMmSqtp10LTZ8IUtgJcl+Ufg7jRnZI9u27cEvtSeXfwL8LIhlnV4kv1oxsCeCpw0A/VKkiRpBGZFeG0/Tl/hI/X2m/c7TXFZQ/9nrCQvAV7b13xWVb16Kusccl1/C7y7r/myqnrGoP6SJEla0awIr6PSfnv/U5N2XDXrOoXm2rKSJEmaJv89rCRJkjrD8CpJkqTOMLxKkiSpMwyvkiRJ6gzDqyRJkjrD8CpJkqTOMLxKkiSpMwyvkiRJ6gzDqyRJkjrD8CpJkqTOMLxKkiSpMwyvkiRJ6gzDqyRJkjrD8CpJkqTOMLxKkiSpMwyvkiRJ6ox5oy5Aq8e9778Rh7z3qaMuQ5IkaaV45lWSJEmdYXiVJElSZxheJUmS1BmGV0mSJHWG4VWSJEmdYXiVJElSZxheJUmS1BmGV0mSJHWG4VWSJEmdYXiVJElSZxheJUmS1BmGV0mSJHXGvFEXoNXjt5f9kiNe+OxRl6E1xFuOP2HUJUiS5ijPvEqSJKkzDK+SJEnqDMOrJEmSOsPwKkmSpM4wvEqSJKkzDK+SJEnqDMOrJEmSOsPwKkmSpM4wvEqSJKkzDK+SJEnqDMOrJEmSOsPwKkmSpM4wvEqSJKkzDK+SJEnqDMOrJEmSOsPwKkmSpM4wvEqSJKkzDK+SJEnqDMOrJEmSOsPwKkmSpM4wvEqSJKkzDK+SJEnqjDkXXpMsTLLralzfUUkuSXLUkP1vmumaJEmS5qp5oy5gNkkyr6pun+JsLwc2q6pbZ6KmQZKsVVV3rK71SZIkzRYjO/OaZEGSnyT5eHvm8tQk6/WeOU0yP8my9v6BSU5K8vUklyU5JMm/JDk/yY+SbNqz+BcmOTvJxUl2a+dfP8mxSc5t59m/Z7lfTvJ14NRxak17hvXiJBclOaBtPxlYHzhnrG3AvFsn+WG73ncMsczx2vdNcnqSzwMXtdvzzSQXtH1XWH+Sg5MsTrL45j+vtmwtSZI0Y0Z95nVb4HlV9bIkXwKeNUn/RwA7AesCvwDeVFU7JXkf8GLg/W2/9avqsUn2Bo5t53sL8L2qOijJxsCiJN9t++8OPLKqrh1nvc8EdgR2AOYD5yY5s6qeluSmqtpxgpo/AHy0qj6T5NWTLRN47DjtALsBj6iqy5I8C/hNVT0ZIMlG/SuuqmOAYwC2uNcmNUGNkiRJnTDqMa+XVdXS9v4SYMEk/U+vqhur6vfA9cDX2/aL+ub9AkBVnQncsw2rTwTenGQpsJAmAG/Z9v/OBMEVYE/gC1V1R1X9DjgDeNTkmwfAHmP1AJ8dYpkTrWtRVV3Ws837JXl3kr2q6voh65EkSeqsUYfX3s+y76A5E3w7y+tad4L+d/Y8vpO7nkXuP8tYQIBnVdWO7W3LqvpJO/3mSerMJNMnM+is53jLnGhdf62zqn4G7EITYt+V5LDplydJktQNow6vgyyjCWUAz57mMsbGie4JXN+elTwFeE2StNN2msLyzgQOSLJWks2AvYFFQ857FvDc9v4LhljmUOtKcj/glqo6HngPsPMUtkeSJKmTRj3mdZD3AF9K8iLge9NcxnVJzgbuCRzUtr2DZkzshW2AXQY8ZcjlnUgzLvYCmrOob6yqq4ac97XA55O8FvjKZMtMMl77dn3L3R44KsmdwG3AK4esR5IkqbNS5fd41gRb3GuTetXfP2HUZWgN8ZbjTxh1CZKkDkuypKoGXrd/Ng4bkCRJkgaajcMGRibJ9tz1igAAt1bVo4eY9y3Ac/qav1xVR6yq+iRJktZ0htceVXURzTVWpzPvEYBBVZIkaQY5bECSJEmdYXiVJElSZxheJUmS1BmGV0mSJHWG4VWSJEmdYXiVJElSZxheJUmS1BmGV0mSJHWG4VWSJEmdYXiVJElSZxheJUmS1BmGV0mSJHWG4VWSJEmdYXiVJElSZxheJUmS1BnzRl2AVo/7br0Nbzn+hFGXIUmStFI88ypJkqTOMLxKkiSpMwyvkiRJ6gzDqyRJkjrD8CpJkqTOMLxKkiSpM1JVo65Bq0GSG4GfjroOrWA+cM2oi9AKPC6zl8dmdvK4zE5dPi5bVdVmgyZ4ndc1x0+ratdRF6G7SrLY4zL7eFxmL4/N7ORxmZ3m6nFx2IAkSZI6w/AqSZKkzjC8rjmOGXUBGsjjMjt5XGYvj83s5HGZnebkcfELW5IkSeoMz7xKkiSpMwyvkiRJ6gzD6xyQ5O+S/DTJL5K8ecD0JPlgO/3CJDsPO6+mbyWPy7IkFyVZmmTx6q18bhviuGyX5IdJbk3y+qnMq+lbyePi62WGDHFcXtD+/rowydlJdhh2Xk3fSh6X7r9eqspbh2/AWsAvgQcCdwcuAB7W1+dJwLeAAI8Bzhl2Xm+r/7i005YB80e9HXPtNuRxuTfwKOAI4PVTmdfb6j8u7TRfL6M7Lo8FNmnv/73vL7P7uLSPO/968cxr9+0G/KKqflVVfwH+G9i/r8/+wGeq8SNg4yT3HXJeTc/KHBfNnEmPS1VdXVXnArdNdV5N28ocF82cYY7L2VV1XfvwR8D9h51X07Yyx2VOMLx23xbA5T2Pr2jbhukzzLyanpU5LgAFnJpkSZKDZ6zKNc/KPOd9vcycld23vl5mxlSPy0tpPk2azrwa3socF5gDrxf/PWz3ZUBb//XPxuszzLyanpU5LgB7VNVvktwb+E6SS6vqzFVa4ZppZZ7zvl5mzsruW18vM2Po45LkcTQhac+pzqspW5njAnPg9eKZ1+67AnhAz+P7A78Zss8w82p6Vua4UFVjP68GTqT5mEgrb2We875eZs5K7VtfLzNmqOOS5JHAJ4D9q+oPU5lX07Iyx2VOvF4Mr913LrBtkq2T3B14LnByX5+TgRe3325/DHB9Vf12yHk1PdM+LknWT7IhQJL1gScCF6/O4uewlXnO+3qZOdPet75eZtSkxyXJlsBXgRdV1c+mMq+mbdrHZa68Xhw20HFVdXuSQ4BTaL6BeGxVXZLkFe30jwH/Q/PN9l8AtwAvmWjeEWzGnLMyxwW4D3BiEmheo5+vqm+v5k2Yk4Y5Lkk2BxYD9wTuTPI6mm/y3uDrZWaszHEB5uPrZUYM+XvsMOBewEfaY3B7Ve3q+8vMWZnjwhx5f/Hfw0qSJKkzHDYgSZKkzjC8SpIkqTMMr5IkSeoMw6skSZI6w/AqSZKkzjC8SpIkqTMMr5IkSeqM/w8hweiE6cqA8wAAAABJRU5ErkJggg==\n",
"text/plain": [
""
]
},
"metadata": {
"needs_background": "light"
},
"output_type": "display_data"
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"--------------------------------------------------------\n",
"********************* Model Results ********************\n",
"--------------------------------------------------------\n",
"F1 Score : 0.9541854384201013\n",
"AUC-ROC Score : 0.9439188867749603\n",
"Report:\n",
" precision recall f1-score support\n",
"\n",
" 1 0.98 0.97 0.98 277\n",
" 2 0.91 0.91 0.91 94\n",
" 3 0.86 1.00 0.92 12\n",
" 4 0.75 0.75 0.75 8\n",
"\n",
" accuracy 0.95 391\n",
" macro avg 0.87 0.91 0.89 391\n",
"weighted avg 0.95 0.95 0.95 391\n",
"\n"
]
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAYEAAAEgCAYAAABSGc9vAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADt0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjByYzEsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy/xvVyzAAAgAElEQVR4nO3dfZxUdf338dcHFgJBSbnZNSEQgVJEUKEkDA1DUFAMvC28S+TKy6R+WCpYhvpLy8rus1BB7arM8oYCzQxC8g5RUUTxtlZB2BUMuRF03eVz/fE9u67DzN7Oztmz5/18POYxO+f2M2dn5j3n+z3njLk7IiKSTu3iLkBEROKjEBARSTGFgIhIiikERERSTCEgIpJiCgERkRRTCEirZmYzzOx5M9tpZm5mXy/AOkvNrLSl15MG0f9sadx1SG4KAQHAzD5pZj83s9VmtsXMKsxsvZktMrPzzKxTDDWdDvwUeBf4CXAl8Fih62gNomDy6Pa5OqabX2u6Oc1c59H5WI60bkVxFyDxM7MrgO8QvhQ8BtwKbAeKgaOBm4ALgOEFLm1i9b27ry/geo8p4LoaqxI4H/hn5ggz2ws4NZqmtby3DwR2xF2E5NZaXigSEzObTfiGvRY4xd2XZ5lmInBxoWsDPgZQ4ADA3V8t5PoaaSEw2cy6u/tbGeO+BOwB3A18oeCVZeHuL8Rdg9RNzUEpZmb9gDnA+8Dx2QIAwN0XAuOzzH+qmS2Lmo92mtmzZjbLzD6SZdrS6LaHmf3AzF43s/fM7BUzu9TMrNa0c8zMgc9Fj6ubN7y67ujxLTme19LqaWsNMzM728weMbONZvauma01s/vN7LRstWZZ7kfM7DIzW2VmO8xsq5n9y8xOzTJtTY3R37eb2aZovU9EwdoUNwIfAc7MMu58Qpj/LduMZjbIzL4XrX9jtP1fM7O5ZtY7Y9pb+GBv4zu1/wdmdnQ0zTnR43PMbHy03bfU3vaZfQJmtr+ZvW1m/zWzvhnr7GJma8ysysyOauyGkabRnkC6nQt0AG5399V1Teju79V+bGbXALOATcDvCc1HxwHXAOPMbKy7v5+xmA7A3wnf8O8jNFucBHwP6ETYIwFYGt2fA/StNbw5vhvV+x/gDmALsC8wAjgF+GNdM5tZR+B+4CjgBeCXhG/dJwN/NLNh7j47y6x9gceBfwO/BfYBTgMWmNnn3X23Zp16PACUAtMI/STV9R0OHErYVrtyzDsZ+Arhw/0RoAIYHC3rBDMb7u5vRNPeE92fDTzIB/8TovXXdjLhS8J9wK+BfrmKd/f/mNk04E/AH8xstLtXRqN/BXwSmOPuD+ZahuSZu+uW0huwGHBgWiPnGxnN9zpQUmt4EfDXaNzsjHlKo+H3Ap1rDe8FvB3dOmTMszS8RHdbf79oWbfkqG+3+YC3gHXAHlmm75Gl1tKMYbNq1V+UUX/1c/tMlhod+E7GssZVL6sR27x6HUXAt6K/R9Ya/2ugCvg44UPdCR+mtZexH/CRLMs+Npr3hozhR2dbTq3x50TjdwHjc0zjwNIsw38Vjbs2enxW9PifQLu43xtpuqk5KN32je7XNXK+L0f3/+vuZdUDPXyju5jwoTAtx7wz3H1nrXneBBYA3YBPNLKOxnqf8GH3Ie6+qQHzfpnwITXTP/jmWl3/1dHDbM/5NeB/M9Z3PyFAP9Wwsnczj/A8zofQjAJ8Ebjf3V/PNZO7v+EZe3TR8L8DzxHCqSkWuHvWJqg6zASeAS41s68SQmEj8CV3z7UnIy1AIZBu1e3wjb2e+GHR/ZLMEe7+EiFU9jezj2aM3uLur2RZ3trofu9G1tEYvyN8O3/OzK6N2rC7NWRGM9sTGACs9+wdndXb4dAs4552992Ch/Ccm/R8PXSU3wucGh0RdDqwJ6G/IKeoX2Sqmf0j6hOorNXXMoSwp9AUjzd2Bnd/l9As9g7wc0LT2lle4IMARCGQdtVvuN51TrW76g/PDTnGb8iYrtrbOaav/mbdvpF1NMb/AF8nfOhcRmi/3mRmC8xsQD3zNvT5ZoYe1P2cm/P+uxHoApxB2CMoIzTF1eV6Qr/EQYT+jR8R+hCuJOyxdGxiLWX1T5LVS8Cq6O/nCf1FUmAKgXR7KLpv7HHxW6L7khzj982YLt+qmwtyHdiw24exu1e5+0/dfSjh/IcphEMpTwT+lu2Iplrifr7Z3Au8Qegf+DQwv3YzVSYz6wXMAFYDn3D3qe5+qbvPcfc5wG7NRI3Q1F+mugz4DOHggsGEfhcpMIVAus0ntJNPMbOD6pow40NyZXR/dJbpBhD2LP7j7rm+BTfX5ui+T5b17wUMqmtmd3/T3e9y91MJTTkHAAfXMf024FVgPzMbmGWS6jN4n2pA7XkRNTHNI2xrB26uZ5b+hPf736PnUyM6PLR/lnmqm7HyvodmZp8BrgJeJGz7F4ErzezIfK9L6qYQSDF3LyWcJ9ARWGRmWc8INrPqw/+qzYvuv2VmPWtN1x74IeF1Vd+HUpNFH2IvAKNqh1e0/uuBzrWnj47vP6b2uQjR8A6EQzah/rNa5xH6UH4Qrad6GT2Ab9eappB+RjgpbJzXf4JbaXR/ZEb9XQlNS9n2qqpPRvt4M+v8EDPbG/gDIWROd/dyQv9AJeGw0e75XJ/UTecJpJy7X2NmRYTLRqwws0eAJ/jgshGjgYHRsOp5HjGz64BLgNVm9mdCW/txhG91DwE/aOHSf0AImofN7E+E6wt9jnAuwjPA0FrTdgb+AZSa2XJC+3cnYCzhsgZ/cfc19azvh4TnNwl4xszuJXRmnkI4TPQ6d3+ojvnzLjqq6Z56JwzTlpnZ7YRO5KfN7O+Evo6xhG33NDAsY7YXCU1Op5tZBeGIJgd+6+6vNaP0eYRgmeHuT0f1PWNmFwO/IOyhntiM5UtjxH2Mqm6t40b4MPw5oc14K+FEog2EPYDzyH58+emED/xthA+S54DLgU5Zpi0l49j7WuPmED5cjs4YvpQs5wnUGn9etM73CJ2TvwG6Z85HCIZLoufyelTrRsJ1kr4CdGxIrYTgmB1to53R834IOCPLtP1o5LkM9fx/SqPlFTVg2lznCexBOGnulWgbrCWc9LbbNqs1zwjC+SRbCH0xNf8nPjhP4Jw6avnQeQLARdGwBTmmvysa/z9xvyfScrNow4uISAqpT0BEJMUUAiIiKaYQEBFJMYWAiEiKJeoQUcu4RryIiNTP3S3XuESFgORX+K0YyQeziehIu/wxM23PPMk4R3I3ag4SEUkxhYCISIopBEREUkwhICKSYgoBEZEUUwiIiKSYQkBEJMUUAiIiKaYQEBFJMYWAiEiKKQRERFJMISAikmIKARGRFFMIiIikmEJARCTFFAIiIimmEBARSTGFgIhIiikERERSTCEgIpJiCgERkRRTCDRS7969WbJkCc8//zyrV69mxowZNeO++tWv8sILL7B69Wq+//3vA9ChQwfmzZvHqlWrePrppznqqKPiKj1R/v3vN5k06Yc1t8MOm8UttzwYd1mJNWvWLEaOHMnEiRPjLqXNWLZsGePGjWPs2LHMnTs37nKarCjuApKmsrKSiy++mJUrV9K1a1eefPJJHnjgAYqLi5k0aRKHHHIIFRUV9OzZE4Dzzz8fgEMOOYSePXty3333MWLECNw9zqfR6vXv34sFC74BQFXVLkaPvpKxY4fEXFVyTZ48malTp3LppZfGXUqbUFVVxVVXXcX8+fMpLi7m5JNPZsyYMQwYMCDu0hpNewKNVFZWxsqVKwHYvn07a9asYb/99uOCCy7ge9/7HhUVFQBs3LgRgIMOOojFixfXDHv77bcZPnx4PMUn1KOPvkyfPt3Zb7994i4lsUaMGEG3bt3iLqPNWLVqFX379qVPnz507NiRCRMm1LzPk0Yh0Ax9+/bl0EMPZfny5QwaNIjPfvazPPbYYyxdurTmg/6ZZ55h0qRJtG/fnn79+nH44YfTp0+fmCtPlkWLVjJx4qFxlyFSo7y8nJKSkprHxcXFlJeXx1hR07WK5iAzO9fd58ddR2N06dKFO++8k69//ets27aNoqIi9t57b4444ghGjBjBHXfcQf/+/Zk3bx4HHnggTzzxBK+99hqPPPIIlZWVcZefGBUVlSxZ8hwXXzwh7lJEamRrzjWzGCppvlYRAsCVQNYQMLPpwPTCllO3oqIi7rzzTn73u99x9913A7Bu3TruuusuAFasWMGuXbvo0aMHmzZtYubMmTXzPvzww7z88sux1J1Ey5a9wODB+9Gjx55xlyJSo6SkhLKysprH5eXl9OrVK8aKmq5gzUFmtirH7VmgONd87j7X3Ye7e6tpSL/55ptZs2YNP/7xj2uG3XPPPYwZMwaAgQMH0rFjRzZt2kTnzp3ZY489APj85z9PZWUla9asiaXuJFq06CkmTDgs7jJEPmTIkCGUlpaydu1aKioqWLRoUc37P2kKuSdQDIwDNmcMN+CRAtbRLKNGjeKss85i1apVNR3Es2fPZt68ecybN49nn32WiooKzj77bAB69erF/fffz65du3jjjTc488wz4yw/UXburOCRR17iqqtOibuUxJs5cyaPP/44mzdvZvTo0Vx00UWccoq2a1MVFRVxxRVXMG3aNKqqqpgyZQoDBw6Mu6wmsUIdqmhmNwPz3f2hLON+7+5fbMAydFxlHrkvjLuENsNsog77zSMz0/bMk2hb5uywKFgI5INCIL8UAvmjEMgvhUD+1BcCOkRURCTFFAIiIimmEBARSTGFgIhIiikERERSTCEgIpJiCgERkRRTCIiIpJhCQEQkxRQCIiIpphAQEUkxhYCISIopBEREUkwhICKSYgoBEZEUUwiIiKSYQkBEJMUUAiIiKaYQEBFJMYWAiEiKKQRERFLM3D3uGhrMzJJTrIhIK+HulmtcUSELyQf3J+MuoU0wOxy/ZlbcZbQZNvtakvSFqrUzM9y3xV1Gm2C2Z53j1RwkIpJiCgERkRRTCIiIpJhCQEQkxRQCIiIpphAQEUkxhYCISIopBEREUkwhICKSYgoBEZEUUwiIiKSYQkBEJMUUAiIiKaYQEBFJMYWAiEiKKQRERFJMISAikmIKARGRFFMIiIikmEJARCTFFAIiIimmEBARSbGiuAtoa8aMuYguXTrTrl072rdvx113XRN3SckyYhQMHR7+3lgGC++Eqko4fCQcfgTs2gWvvgj//Fu8dSbMrFmzWLp0Kd27d2fhwoVxl5N4GzaUccklV7Bp01u0a9eOU0/9Amef/cW4y2oShUALuPXWb7HPPnvFXUbydN0Lho+EG38ClZVw0hlw0CGw5W0YeCDc/DOoqoI9usRdaeJMnjyZqVOncumll8ZdSpvQvn17Lrvsfxg8+EC2b3+HKVOmMmrUEQwY0D/u0hqtoM1BZvZJMzvGzLpmDB9fyDqkFWvXDoo6gLWDDh1g+1Y47NPw2IMhAAB2vBNvjQk0YsQIunXrFncZbUavXj0ZPPhAALp27UL//vtTXv5mzFU1TcH2BMxsBnAhsAa42cy+5u4LotHXAG1k/94477xrMTNOO+0YTjvtmLgLSo7tW2H5Q3DhJWFP4D8vw39egc+Nhz794Khjw/Al98KGN+KuVgSAdevWs2bNCwwdenDcpTRJIZuDzgcOd/ftZtYP+LOZ9XP3nwKWayYzmw5ML0yJzfeHP8yhuHgf3nprC+eeew39+3+MESMOjLusZOjUKTT7/OqH8N5O+MIXYfAwaNceOnWGW2+AfXuHZqIbfhh3tSK8884OZsz4JrNnf4OuXbvWP0MrVMjmoPbuvh3A3UuBo4HjzOx66ggBd5/r7sPdfXhBqmym4uJ9AOjevRtjx45g1apXY64oQfoNgC2bYec7oQP4xeeg98dh25bwN8CGdeAOndUvIPF6//33mTHjm5xwwnEce+yYuMtpskKGQJmZDat+EAXCRKAHMKSAdbSYHTveZfv2nTV/P/zwKgYO7B1zVQmy9W34WJ/QJwDQ7wDYtBFeeh76HhCG7dMd2rcPQSESE3fn8suvpn///Tn33Klxl9MshWwOOguorD3A3SuBs8zsNwWso8W89dYWLrzwegCqqqqYOHEUo0cPq2cuqbF+Hby4Gr781bAnUL4enn4cHJgwGaZ9LRwuuvDPcVeaODNnzuTxxx9n8+bNjB49mosuuohTTjkl7rIS68knn2bBgkUMGjSASZPOAGDmzAs56qgjY66s8czd466hwczM3Z+Mu4w2wexw/JpZcZfRZtjsa0nSe6m1MzPct8VdRptgtifunrPJXWcMi4ikmEJARCTFcvYJmNkdjViOu/tpeahHREQKqK6O4Z4Fq0JERGKRMwTc/XOFLERERApPfQIiIinW4PMEzGxPYBIwCOiUOd7dL8ljXSIiUgANCgEzOwB4GNgD6AJsBPaJ5t8MbAEUAiIiCdPQ5qAfA08AxYTr/BwPdAamAtsBHRkkIpJADW0O+hQwDXgvetzR3auA35tZD+CnwGdaoD4REWlBDd0T6ARsdfddwH+Bj9UatxoYmu/CRESk5TU0BF4C+kZ/rwS+YmadzKwDcB6wviWKExGRltXQ5qDbgWHAb4FvA/cDW4Fd0TLOaYniRESkZTUoBNz9+lp/P2ZmBwPHEZqJlrj76haqT0REWlCTfk/A3dcCc/Nci4iIFFhDzxM4vr5p3P3e5pcjIiKF1NA9gYWE33fK/GGC2r+i0T4vFYmISME0NAT2zzJsH+BYQqfwufkqSERECqehHcOvZRn8GrDSzKqA2cCJ+SxMRERaXj6uIroSGJOH5YiISIE1KwTMrCOhOWhDXqoREZGCMnevfyKzFXy4ExigI9AP2BM4191vy3t1u9dRf7EiIvIh7p55UE+NhnYMP8fuIfAu8CfgHnd/rom1iYhIjBq0J9BamJknqd7WzMzQtsyfsD31kxr5YnadXp95Er3Xc+4JNKhPwMyWmNknc4wbZGZLmlqgiIjEp6Edw0cDe+UYtxcwOi/ViIhIQTXm6KDd9s2io4PGAGV5q0hERAomZ8ewmX0HuCJ66MBjZjmblX6Q57pERKQA6jo66F5gE+F6QT8DfgSUZkxTAbzg7v9qkepERKRF5QwBd18BrAAws23AQnd/q1CFiYhIy2ton8DTwKezjTCz483skPyVJCIihdLQEPgxOUIAGBGNFxGRhGloCBwGPJxj3KPAofkpR0RECqmhIdAe6JJjXBfCdYRERCRhGhoCK4DpOcZNB57ITzkiIlJIDb2A3BzgH2a2HLiVcHLYvsBZwDDg8y1SnYiItKiG/rLYMjM7FrgW+Dnh3IFdwHLgmOheREQSpqF7Arj7UmCkme0B7A1sBkYCZwMLgO4tUaCIiLScBodALUOAM4BTgWLgv8Dt+SxKREQKo0EhYGYHEz74Tyf8mlgF4Yigi4FfuHtlSxUoIiItJ+fRQWbW38xmm9mzwDPAN4A1hM7ggYR+gacUACIiyVXXnsArhKuHLgf+D3Cnu28GMLNuBahNRERaWF3nCbxG+LZ/MOFHZT5jZk3pQxARkVYqZwi4+/7AKMJ5AccAfwXKzezG6LF+AFREJOHqPGPY3R9194uA/YBxhENBpwB/jiY538yGt2yJIiLSUhp02Qh33+XuD7j7l4ESYDLwJ+ALwHIzW9OCNSbGsmXLGDduHGPHjmXu3Llxl5N42p7NM2vWU4wceS8TJy6uGfb9769m/Ph/cMIJS7jwwuVs3VoRY4XJ1lZen435jWEA3L3C3e9x99MJ5wmcRehETrWqqiquuuoqbrrpJhYtWsTChQt55ZXUb5Ym0/ZsvsmTP85NN33mQ8NGjerFwoVj+Otfx9CvX1d+85uXY6ou2drS67PRIVCbu7/j7r9z9xMaMr2ZfcrMRkR/H2RmM83s+ObU0FqsWrWKvn370qdPHzp27MiECRNYvHhx/TNKVtqezTdiRA+6devwoWFHHtmLoqLwth82bG/KynbGUVritaXXZ7NCoDGiH67/GXCDmV0L/ALoClxmZpcXqo6WUl5eTklJSc3j4uJiysvLY6wo2bQ9W96dd77G6NHFcZeRSG3p9VnIQz5PJlxx9COEq5D2dvetZvYDwrkI3802k5lNJ/dlrFsN990PljKzGCppG7Q9W9YNN7xI+/btOPHE3nGXkkht6fVZyBCodPcqYIeZveruWwHcfaeZ7co1k7vPBeYCmFmrPSy1pKSEsrKymsfl5eX06tUrxoqSTduz5dx99+ssXVrGLbeMSuwHV9za0uuzYM1BQEV0BVKAw6sHRmcf5wyBpBgyZAilpaWsXbuWiooKFi1axJgxY+IuK7G0PVvGsmXl3Hjjy9xwwxF07qxzP5uqLb0+C/kqGO3u70E45LTW8A6Ey1EnWlFREVdccQXTpk2jqqqKKVOmMHDgwLjLSixtz+abOXMFjz++ic2bKxg9+m9cdNEnmTv3ZSoqdnHuueEnw4cO3YerrhoWc6XJ05Zen5atbau1MjNPUr2tmZllbdeUpgnb85K4y2gzzK7T6zNPovd6zna/QjYHiYhIK6MQEBFJMYWAiEiKKQRERFJMISAikmIKARGRFFMIiIikmEJARCTFFAIiIimmEBARSTGFgIhIiikERERSTCEgIpJiCgERkRRTCIiIpJhCQEQkxRQCIiIpphAQEUkxhYCISIopBEREUkwhICKSYgoBEZEUM3ePu4YGM7PkFCsi0kq4u+UaV1TIQvIhSaHVmpkZ7tviLqPNMNtTr808Cq/PpXGX0SaYHV3neDUHiYikmEJARCTFFAIiIimmEBARSTGFgIhIiikERERSTCEgIpJiCgERkRRTCIiIpJhCQEQkxRQCIiIpphAQEUkxhYCISIopBEREUkwhICKSYgoBEZEUUwiIiKSYQkBEJMUUAiIiKaYQEBFJMYWAiEiKKQTyaNmyZYwbN46xY8cyd+7cuMtJtA0byjjzzOkcd9wUJkw4hVtv/X3cJSWeXp/5tXXrDmbM+DXjx3+b4467gpUrX427pCYxd4+7hgYzM2+t9VZVVTFu3Djmz59PcXExJ598Mtdffz0DBgyIu7SszAz3bXGXkdObb25k48ZNDB58INu3v8OUKVP55S9/xIAB/eMuLSuzPWmtr01I6utzadxl1OnSS+czfPgATjnls1RUVPLuuxXstdcecZe1G7OjcXfLNV57AnmyatUq+vbtS58+fejYsSMTJkxg8eLFcZeVWL169WTw4AMB6Nq1C/377095+ZsxV5Vcen3m1/btO1mx4iVOPvlIADp2LGqVAdAQsYaAmd0W5/rzqby8nJKSkprHxcXFlJeXx1hR27Fu3XrWrHmBoUMPjruUxNLrM7/Wrt3EPvvsyaxZt3DSSVdz+eW3sWPHe3GX1SQFCwEz+0vG7a/A5OrHhaqjpWRrCjDLuQcmDfTOOzuYMeObzJ79Dbp27Rp3OYml12d+VVZW8fzzr3PGGUdxzz3fpnPnjsyd+7e4y2qSogKuqzfwPHAT4IABw4Ef1TWTmU0Hprd4dc1UUlJCWVlZzePy8nJ69eoVY0XJ9/777zNjxjc54YTjOPbYMXGXk2h6feZXScnelJTszdChoY9q/PjDmTv3vpirappCNgcNB54ELge2eOj12enuD7r7g7lmcve57j7c3YcXqM4mGTJkCKWlpaxdu5aKigoWLVrEmDH64Goqd+fyy6+mf//9OffcqXGXk3h6feZXz57dKCnZm3//OwTro4+u4YADPhZzVU1T8KODzKw38GOgHDjR3T/eiHlb7dFBAA8++CDXXHMNVVVVTJkyhQsuuCDuknJq7UcHPfHESr70pWkMGjSAdu3Cd5WZMy/kqKOOjLmy7Fr70UGQxNfn0rjLqNOaNWu5/PLbeP/9Svr06cG1155Dt25d4i5rN/UdHRTbIaJmNgEY5e6zGzFPqw6BJGntIZA0SQiBJElCCCRFfSFQyD6BD3H3RcCiuNYvIiI6T0BEJNUUAiIiKaYQEBFJMYWAiEiKKQRERFJMISAikmIKARGRFFMIiIikmEJARCTFFAIiIimmEBARSTGFgIhIiikERERSTCEgIpJiCgERkRRTCIiIpJhCQEQkxRQCIiIpphAQEUkxhYCISIopBEREUszcPe4aGszMklOsiEgr4e6Wa1yiQiApzGy6u8+Nu462Qtszf7Qt86stbE81B7WM6XEX0MZoe+aPtmV+JX57KgRERFJMISAikmIKgZaR6DbCVkjbM3+0LfMr8dtTHcMiIimmPQERkRRTCIiIpJhCII/MbJ6ZvWlmq+OuJenMrI+Z/dPM1pjZc2b2tbhrSjIz62Rmj5vZM9H2vDLumpLOzNqb2UozWxh3Lc2hEMivW4DxcRfRRlQCF7v7gcARwIVmdlDMNSXZe8AYdx8KDAPGm9kRMdeUdF8D1sRdRHMpBPLI3ZcB/427jrbA3Te4+1PR39sIb7b94q0quTzYHj3sEN10VEgTmVlvYAJwU9y1NJdCQFo9M+sHHAosj7eSZIuaL54G3gQecHdtz6b7CXAJsCvuQppLISCtmpl1Be4Evu7uW+OuJ8ncvcrdhwG9gU+Z2cFx15REZjYReNPdn4y7lnxQCEirZWYdCAHwO3e/K+562gp3fxtYivqvmmoUcKKZlQK3A2PM7P/FW1LTKQSkVTIzA24G1rj79XHXk3Rm1tPMPhr93Rn4PPBCvFUlk7vPcvfe7t4POB1Y4u5TYy6ryRQCeWRmfwAeBT5hZuvM7Ly4a0qwUcCZhG9ZT0e34+MuKsH2Bf5pZquAFYQ+gUQf2ij5octGiIikmPYERERSTCEgIpJiCgERkRRTCIiIpJhCQEQkxRQCknhmNsfMvNZtvZndaWYHtND6Jkbr6Rc97hc9ntiIZZxqZufksaauUQ15W6akQ1HcBYjkyRY+OAO2P3A1sNjMBrv7Oy287g3ASBp38tWpQA/ClWdFYqMQkLai0t0fi/5+zMxeB/4FHA/8qfaEZtbZ3Xfma8Xu/h7wWL0TirRCag6Stqr64l79zKzUzH5kZt82s3XAVgAza2dml5nZK2b2npm9ZGZn116IBXOiHwvaZma3AXtlTJO1OcjMzjezZ83sXTMrN7M/m1k3M7sFmAIcVasJa06t+SaZ2RPRfGVmdl10HaXay54S1QHSr/0AAAMKSURBVLvTzJYBn8zPZpO00Z6AtFX9ovuy6P6LwHPA/+WD1/3PgbOBq4CngLHAPDN7q9YlFWYAVwDXEPYsJgPX1bdyM/tWtNxfAd8E9iBcf74roanq48BHo3oA1kXznQr8AfgNMBs4ALiW8IXtG9E0hwF/BO4m/LDJYOCOBmwTkd25u266JfoGzAE2ET7ci4BBwD8J3/j3BUoJ7fadas0zgHAt+LMzlnUbsCL6uz2wHrghY5oHCD/I0i963C96PDF6/FFgB3B9HTX/GViaMcyA14D5GcO/DOwEukeP7wCeJ7rsSzTs8qiGc+L+f+iWrJuag6St6A68H91eJHQOn+buG6Lxi9393VrTH0MIgbvNrKj6BiwGhplZe6APIUQWZKyrvstajwQ6A/Mb+RwGEfYQ7sioaQnQCai+/v+ngL+4e+0Lf+lS29Ikag6StmIL4fLITmgCWp/xIVmeMX0Pwjf9LTmWty9QEv39Zsa4zMeZukf3G+qcanc9ovt7c4zvE92XNKEmkawUAtJWVLr7E3WMz7xc7n8JP2Y/iuw/EfgmH7w/emWMy3yc6a3ofl9CM1VDVf8+9XRgZZbx/4nuy5pQk0hWCgFJqyWEPYFu7v5AtgnMbC3hA3cS8LdaoybXs+xHCW34ZxN15mZRQWjiqe1F4A1CX8ONdSx/BeGXrWbV2tupryaRrBQCkkru/qKZ/Rq43cyuA54gfCgPBga5+zR3r4rG/dDMNhGODpoCHFjPst82s6uB75pZR0LzzkcIRwdd6e5vEE4sm2RmJxGODFrv7uvN7GLgt2a2F3AfISz6AycBJ7v7DuD7wHJC38HNhL4C/YCRNIk6hiXNLiQcrnkW4YP6FsIH9bJa0/yEcHjoVwi/d9wVuKS+Bbv7tcAFhH6KBYRDPj8KbIsm+RXwd2Ae4Zv99Gi+PxL2PIYRTnK7i3AY6VOEQCBq9jodOBS4hxAQpzX2yYuAfllMRCTVtCcgIpJiCgERkRRTCIiIpJhCQEQkxRQCIiIpphAQEUkxhYCISIopBEREUuz/AwKdeyKpQuf0AAAAAElFTkSuQmCC\n",
"text/plain": [
""
]
},
"metadata": {
"needs_background": "light"
},
"output_type": "display_data"
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"--------------------------------------------------------\n",
"\n",
" please wait while performing prediction using RFE...\n",
"\n",
"Executing RFE\n",
"Please wait.........\n",
"### RFE selected columns:\n",
" Index(['buying_price', 'maintainence_cost', 'safety_rating'], dtype='object')\n",
"RFE Selected Features Index(['buying_price', 'maintainence_cost', 'safety_rating'], dtype='object')\n"
]
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAq8AAAGwCAYAAACHCYxOAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADt0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjByYzEsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy/xvVyzAAAgAElEQVR4nO3deZhkdX3v8fdHBlHBgDjggoFBMEFRkUUUkUUlXqOJaIKXqNGgJu4gyaPR671B1KjkmlyXJCpEENdERVGjcSUMRFBgBgYQBRcYBVwIqOCAbMP3/nFOOzU11d3V093T85t5v56nnu466/f86tddnz71O6dTVUiSJEktuNtCFyBJkiSNy/AqSZKkZhheJUmS1AzDqyRJkppheJUkSVIzDK+SJElqhuFV0npJclSSSnLUQtciSdp8GF6ljUAfAgcfq5P8PMnSPiRmoWtsXZLjR7Tz4GPlQte4Pvral67HeqdO0x4z3ub6GqhlyYba51xJcuiGbq+F4h+s2lgsWugCJK3ljf3XLYHdgWcChwD7Aa9cqKI2MWcBS0dM/+UGrmNj8VlgxYjpKzdwHZI0FsOrtBGpquMHnyc5EDgbeHmSf6iqqxaksE3L0uF23sx9pqpOXegiJGlcDhuQNmJVdQ5wORBg38F5SfZN8q4kF/dDDG5N8r0k/5DkPsPbGvzIL8kT+iEJv0pyU5IvJHnoqBqS7J7kk0l+keTmJOcmedpUdfe1fSrJdUluS/LDJO9J8oARy058ZLxrklcm+XZ/LCuTvH5iyESSZyU5v6/huiT/lOQeM2jOGVnPY3hwkqOTXJLk14MfJSfZPsnbknynn3djkjOSPHnE9u6e5JgkF/btfkvfHp9Ncli/zFFJJv6/9yFDH/kfPw/t8ewkZ/b13Nofx/9JstWIZZ+R5CNJvtu/XquSLO+P6W5DyxbwZ/3Tq0YN4+iPfSUjZM1wkEOHt9v38fsneX+Sa9MNxzlqYJnHJDktyU+T3J7k6iQnJnng+rbTwLYHf95+L8l/9e3w30k+kGS7frm9k3y+b9dVST6XEcMn+mOpJFsl+dskV/X98gdJ3pDk7pPU8aQkX8qa3xHfTXJCkm2n2MfdkxyX5Ip+H6f2ffkD/aIfGOpvS/r1H9ivd85Am/44yccy4vdLkiX9+qf23/9bkuv7Opcl+YMp2vfI/udn4rhWJvnXJPuNWHbsvqs2eOZV2vhNjHe9Y2j6X9ANKzgL+BqwBbAP8FfA7yd5TFX9asT2/gA4HPgi8D7gYcBTgUcneVhVXf+bHScPAb4B3LdffgXdcIbP9M/XLbZ7w/lUX/dpwA/pgvfLgMOTHFhVK0es+vfAocC/A18Bng68Bbh7kp8DJ/T7/S/g94BX9Mf8slF1zMYsjuFdwEHAF4D/AFb329uFbqjCkr7+LwFb070WX0rykqr6l4HtnAo8G/gW8CHg18ADgccDT6F7vVfQDTN5Q1/fqQPrL13fYx8lycnAC4FrgE/TDbF4LPBm4ElJfq+q7hxY5QTgLuA84FpgW+CJdO3zaOB5A8u+EXgGsFc/f2L4xlwM49ge+Cawqq/7LuBn/TG9APgX4Dbgc8DVwEOAPwf+MMljq+pHc1DD0+le58/T/bw9DjgK2DXJ64Az6PrEycAjgD8EdkvyiKq6a8T2PkHXhqfR/U44HDge2C/J06tq4g8akrwEeC9wM/BJ4Dq6n7HX9sd4YFWNaudP9fv4It3P3HV0feqX/f6Gh5pMbONg4HXAmf02VtG16RHA0/v9XTxif7sA5wNXAh+me92OBD6b5LCqOnPgmEIXov8MuJ7udf1v4EHAE4ArgGUDy8+076oFVeXDh48FfgDV/TiuM/1gugB0G/CAoXm7AFuMWOdF/fZeOzT9qH76ncCThua9rZ/310PTv9JPf9XQ9MMnagaOGpi+Dd0bymrgoKF1Xtsv/5Wh6af201cCOw1M367f1s10b04PHZi3FfDtvl12HLONj+/3s7T/fvixZA6O4Vpg1xH7XkoXnP5kaPp2dCHg18D9+mnb9ssum+T1ve+IvrN0PfrcRM2fmaQ9thvqN58G7jlJmw73j91G7O9uwAf75R8zSS1LJql1JbBymtf10FE/U3Thf9HQvN8Bbge+P9jn+nlP7F/708dsx0NHvQas/fN2yFA7fLWf93PguUPrndzPO3xEHyrgu8B9Bqbfg+4PzAKeNzB9F7qfj5uAPYa29Z5++ZMm2cclwOIRxzpxTEdN0hY7AvceMX0vuiD7xaHpSwZepzcMzfsf/fT/GJr+4n76+cC2Q/O2YOD35Pr0XR9tPBa8AB8+fKz1Rnt8/3gL8PH+DfYu4OgZbCvAjcB/Dk2f+EX+kRHr7NrPO21g2oP6aVcyOkRNvNEdNTDtuf20j41YfhFwVT9/54Hpp/bTXjRinVP6eW8aMe8N/bxDxmyXiTeryR6HzsExrPNG2L9xF/DJSeqa+EPg5f3z3+qfnwNkzL6zdD363ETNkz2W9MtdRHeGb7sR29iCLuifP+Y+9+m3fdwktSyZZL2VrF94HfnHDfCOfv7TJtnm6XShc50gNmLZQ0e9Bqz5efvwiHWe3887e8S8Qxgd5pYyFFBH1HDmwLT/3U9764jl70MXan8NbDViH4cPrzN0TEeNmj9NO30OuBXYcmDaEtb84Trqd8wPgeuHpl3ar7P3GPucs77rY+N6OGxA2ri8Yej5RKj7wPCCSbYEXgL8Cd1H/9uy9jj2nSbZx7IR067uvw6Old27//r1qlo9Yp2ldG+0g/bpv/7n8MJVdWeSs+nesPYGhj+SHVXXj/uvy0fMu7b/+qAR86byxpr6gq3ZHMP5I7Z3QP9124wei7pD//Wh/T5uSvLvdB8fr0jyKbqPlc+rqlumqHt9vaAmuWAryb3owvf1wLEZfce22yZqH1jvvsBr6IajPJhuiMSgyfrmXFtZVdeNmD7xmhyS5NEj5u9IF25+h9F9bybmul+fNWLaf9GF7b0Hpk3Vj3+R5CK6T3b2AIY/yh/Vj8eSbjz8S+nukLKYdYcnLgZ+MjRtxSS/Y65mzWtFkq2BhwM/q6qLpqljvfqu2mB4lTYiVTVxcdLWdL+0Twbel+SHVTX8JvRxujGvV9KNQfsp3S9jgGPpPlofZZ0xbn0og+4Ne8LEBR0/m2Q7Px0xbWKd4TcnhqZvN2LejSOm3TnGvC0n2df6ms0xjGqT+/Zff69/TGabge+PpBui8BzW3D7t1iSnAa+uqslek7l2H7oz+Tuw7h9WI/UXIl1Adzb/fLqP7X9O93ptB7yKyfvmXBv1esCa1+Q106y/zTTzxzHX/Xqd176qVie5gS50T5jrfjytJMfQjVv+Bd3QiB8Bt9D9ET4xrnnUaz/Z+OY7WfsP8olarx2x7LAZ9121w/AqbYSq6mbga0n+ELgQ+GCS350489ZfUftMugt3nlpVv7mYK93V3H89B2VMvLHeb5L5959inVHzAB4wtNzGaDbHUFNs71VV9e5xCqiqX9MPIUny23RnyI4C/pTurO9B42xnDkzUflFV7TPlkmv8OV1wXecMd5ID6MLrTN0FjLyantHha8Ko1wPWHNe2VXXTetSzkO7H0Bn/JFvQBfLBYxnsx5eN2M6k/biqJmu3SSVZRPeH1k+BfarqJ0PzDxi54sxMhNxxztyvT99VI7xVlrQRq6pL6K6IfhDwlwOzdu+/fm4wuPb2B+45B7uf+Fju8f2b47BDp1hnnXn9m9vj+6cXzra4eTTXx/DN/ut6Bc6qurqqPkp3Acv36F6P+w4schdrnzGfM1W1ii747Jlk+zFXm+ibnxoxb3iYyYSJj4wnO45fAPfrh8oMW+fWSGOY1WuywEa14UF0J6MGP0qfqh9vBzyKbgzqd2aw76lep8V0f0icOyK4bsOaYQzrrf+j/lt0fWHvaZZdn76rRhhepY3f39K9ybw6a+7furL/eujggkl2BP55LnZaVdfQffS3K0P/3SvJ4Yx+E/0M3UfEz07y2KF5x9KNf/xazc0tiObLnB5DVS2jG5P4R0leOGqZJI/oXzuS7JDkMSMW2xq4N91HqbcPTL8B+O1xallP/4/urOcpfehZS5L7JBkMJiv7r4cOLbc38L8m2ccN/dedJ5l/Pl04e8HQNo8CDpy89En9E92FPO9I8jvDM/v7nG6swfZvBn4PkO5ex2/rnw6Ojf8I3TEenWR31vZmugsDP1JVtzG+qV6n6+iGCOzbh9WJ+rakG0qweAb7mcrEpxcnZuhetUnulrXvwzzTvqtGOGxA2shV1bVJTqT7uPWv6QLABXRXo/9RknOBr9N9nPj7dPc5/PEkm5upV9Ddhued6W6mfzFr/m3txEVFg7Wu6gPaJ4GzknyS7iPOfYEn032k+JI5qm1ezNMxPIfuwpmT+3GB59F9BPog4JF0F6EcQBcAdgK+meQ7dGd3r6YLGn9A9xHwu2vt+/eeAfxJf5HXcrpwe3ZVnT3TYx+lqk5Jsi/wcuAHSb5M1x7b0/1hczBdaHppv8qH6MaSvjPJE+jOFj+kr//TdON5h53Rr/Mv/bjeVcAvq+qf+vn/SBdc35vkSXRtshfdPVM/3297Jsd0ef8anwJcluRLdLeg2pIumB1Ed3u2PWay3Q3kO3Q1D97ndTe6ewt/eGKhqlqZ5Fi6P2YvTPIJumM6hK6vXU43rnomvkEXUI/tz2ZOjL/9x6q6Mcm76e7zemmSz9IFxyfQ9ZUz++9n6/10n348H/hev5//prsP8hPpXtPjYb36rlqx0Lc78OHDx5pbZU0x/3509zu9mTX3A92e7n6NK+nOzP4AeCtwL0bcWojp79E48pZLdGH1NLqwdTPdG9jTptoe3Q3OT6d7U7md7g3jvcADRyx7KpPcJolJboM0zvFMsa3jx1x+To5hYJl7A6+nC5ir6G5TdBVd6HgxsHW/3HbAcXRh91q6i/B+Qnd3h2czdPssuot0PkYXJFaPe4wDNY/bfhM32r+ub4+f0p0R/VvWvY/ow+hujXRd32eW042FXdLv89QR2/8rumB2W7/McP99PN2/Sr6FbmznF+iC/8g+Mll/HlrmEX07/LDf78/pPpY+EXjimO1y6Kh9TdU/B9ZZ53WarI1Ycxurrfo2v6qv+Uq6C5K2mqS+J9Pdr/kX/fLfB/4vo28ftZQpfg/1yzyF7nfAKta9rdqi/nX8Nl3//ildoN6FET8jU/WH6eqhu6XdWXRjW2/t2+OjdONt17vv+mjjkf6FlSRJG6l0/571kOrvSCJtzhzzKkmSpGYYXiVJktQMw6skSZKa4ZhXSZIkNcNbZW0mFi9eXEuWLFnoMiRJkqa1fPny66tqh1HzDK+biSVLlrBs2bKFLkOSJGlaSX442TzHvEqSJKkZhldJkiQ1w/AqSZKkZhheJUmS1AzDqyRJkppheJUkSVIzDK+SJElqhuFVkiRJzTC8SpIkqRmGV0mSJDXD8CpJkqRmLFroArRhfOeaG9j3NR9a6DIkSVLDlr/9+QtdgmdeJUmS1A7DqyRJkppheJUkSVIzDK+SJElqhuFVkiRJzTC8SpIkqRmGV0mSJDXD8CpJkqRmGF4lSZLUDMOrJEmSmmF4lSRJUjMMr5IkSWqG4VWSJEnNMLxKkiSpGYZXSZIkNcPwKkmSpGYYXiVJktQMw6skSZKaYXiVJElSMwyvkiRJaobhVZIkSc0wvEqSJKkZhldJkiQ1w/AqSZKkZhheJUmS1AzDqyRJkppheJUkSVIzDK+SJElqhuFVkiRJzTC8SpIkqRmGV0mSJDXD8CpJkqRmGF4lSZLUDMOrJEmSmmF4lSRJUjMMr5IkSWqG4VWSJEnNMLxKkiSpGYZXSZIkNcPwKkmSpGYYXiVJktQMw6skSZKaYXiVJElSMwyvkiRJaobhVZIkSc0wvEqSJKkZhldJkiQ1w/AqSZKkZmyW4TXJHklWJLkoyW5TLPf6DVDL64eenzvf+5QkSWrVZhlegWcAn62qvavqB1MsN+vwmmSLaRZZax9V9bjZ7lOSJGlTtcmE1yRbJ/lCkouTfCvJkUmOS3JB//ykdJ4KHAv8eZIz+3X/NMn5/dnYE5NskeQE4J79tI8meXOSVw3s7y1JjpmklkOTnJnkY8Cl/bTPJFme5LIkL+6nrbWPftqqgW0sTXJaksv7GtLPe2o/7etJ3p3k85PU8eIky5Isu/OWX81RS0uSJC2cRQtdwBx6CvDjqnoaQJJtga9W1Zv65x8G/qCq/j3J+4BVVfX3SR4KHAkcWFV3JHkP8Nyqel2SV1bVo/r1lwCfBt6V5G7AnwD7T1HP/sDDq+qq/vkLq+rnSe4JXJDkU8P7GGFvYE/gx8A5wIFJlgEnAgdX1VVJ/nWyAqrqJOAkgK3vv2tNUaskSVITNpkzr3RnOA9L8ndJDqqqG4EnJDkvyaXAE+mC4LAnAfvSBcoV/fMHDy9UVSuBG5LsDTwZuKiqbpiinvMHgivAMUkuBr4J/DbwkDGO6fyquqaq7gJWAEuAPYArB7Y9aXiVJEna1GwyZ16r6rtJ9gWeCrwtyVeAVwD7VdXVSY4H7jFi1QAfrKr/NcZu3g8cBdwfOGWaZW/+zQ6SQ4HDgAOq6pYkSyepZdhtA9+vpnu9MsZ6kiRJm6RN5sxrkgcCt1TVR4C/B/bpZ12fZBvgiElWPQM4IsmO/Xa2T7JLP++OJFsOLHs63fCERwNfnkF52wK/6IPrHsBjB+YN72M6lwMP7ocxQDfkQZIkabOwyZx5BR4BvD3JXcAdwMvo7ipwKbASuGDUSlX17ST/B/hKP5b1Droztj+kGy96SZILq+q5VXV7f5HXL6tq9Qxq+xLw0iSXAFfQDR2YsNY+pttQVf06ycuBLyW5Hjh/BnVIkiQ1LVVexzOuPtxeCDyrqr63gHVsU1Wr+rsP/DPwvap6x1TrbH3/XWuP571xwxQoSZI2Scvf/vwNsp8ky6tqv1HzNplhA/MtycOA7wNnLGRw7f1Ff3HZZXRDEk5c4HokSZI2iE1p2MC8qqpvM3QXgiSPAD48tOhtVfWYea7lHcCUZ1olSZI2RYbXWaiqS4HJ7tEqSZKkOeawAUmSJDXD8CpJkqRmGF4lSZLUDMOrJEmSmmF4lSRJUjMMr5IkSWqG4VWSJEnNMLxKkiSpGYZXSZIkNcPwKkmSpGYYXiVJktQMw6skSZKaYXiVJElSMwyvkiRJaobhVZIkSc0wvEqSJKkZhldJkiQ1w/AqSZKkZhheJUmS1AzDqyRJkppheJUkSVIzDK+SJElqhuFVkiRJzTC8SpIkqRmGV0mSJDXD8CpJkqRmGF4lSZLUDMOrJEmSmmF4lSRJUjMMr5IkSWqG4VWSJEnNMLxKkiSpGYZXSZIkNcPwKkmSpGYYXiVJktQMw6skSZKaYXiVJElSMwyvkiRJaobhVZIkSc0wvEqSJKkZixa6AG0YD33QfVn29ucvdBmSJEmz4plXSZIkNcPwKkmSpGYYXiVJktQMw6skSZKaYXiVJElSMwyvkiRJaobhVZIkSc0wvEqSJKkZhldJkiQ1w/AqSZKkZhheJUmS1AzDqyRJkppheJUkSVIzDK+SJElqhuFVkiRJzTC8SpIkqRmGV0mSJDXD8CpJkqRmGF4lSZLUDMOrJEmSmmF4lSRJUjMMr5IkSWqG4VWSJEnNMLxKkiSpGYZXSZIkNWPRQhegDeP2n1zGj970iIUuQ5KkDW7n4y5d6BI0hzzzKkmSpGYYXiVJktQMw6skSZKaYXiVJElSMwyvkiRJaobhVZIkSc0wvEqSJKkZhldJkiQ1w/AqSZKkZhheJUmS1AzDqyRJkppheJUkSVIzDK+SJElqhuFVkiRJzTC8SpIkqRmGV0mSJDXD8CpJkqRmGF4lSZLUDMOrJEmSmmF4lSRJUjMMr5IkSWqG4VWSJEnNMLxKkiSpGYZXSZIkNcPwKkmSpGYYXiVJktQMw6skSZKaYXiVJElSMwyvkiRJaobhVZIkSc0wvEqSJKkZY4XXJLsl2ar//tAkxyTZbn5LkyRJktY27pnXTwGrk+wOnAzsCnxs3qqSJEmSRhg3vN5VVXcCzwTeWVV/CTxg/sqSJEmS1jVueL0jybOBPwM+30/bcn5KkiRJkkYbN7y+ADgAeEtVXZVkV+Aj81eWJEmStK5F4yxUVd9O8lpg5/75VcAJ81mYJEmSNGzcuw38IbAC+FL//FFJPjefhUmSJEnDxh02cDywP/BLgKpaQXfHAUmSJGmDGTe83llVNw5Nq7kuRpIkSZrKWGNegW8leQ6wRZKHAMcA585fWZIkSdK6xj3zejSwJ3Ab3T8nuBE4dr6KkiRJkkaZ9sxrki2Az1XVYcD/nv+SJEmSpNGmPfNaVauBW5JsuwHqkSRJkiY17pjXW4FLk3wVuHliYlUdMy9VSZIkSSOMG16/0D8kSZKkBTPuf9j64HwXIkmSJE1nrPCa5CpG3Ne1qh485xXNUpIlwOer6uGz3M5LgVuq6kNzUVcr+5YkSdqYjTtsYL+B7+8BPAvYfu7L2XhU1fsWYr9JFi3UviVJkjZ2Y93ntapuGHhcW1XvBJ44z7XNxqIkH0xySZLTktwrycokiwGS7JdkaZK7Jflekh366XdL8v0ki5Mcn+TV/fSlSf4uyflJvpvkoH76vZJ8ot/Px5Ocl2S/yYpKsirJPyS5MMkZA/tdmuStSc4CXjW0792TfC3Jxf16u/XTX5Pkgn7fb5zX1pQkSdpIjBVek+wz8Niv/1j73vNc22z8LnBSVT0SuAl4+aiFquou4CPAc/tJhwEXV9X1IxZfVFX70/1zhjf0014O/KLfz5uBfaepa2vgwqraBzhrYDsA21XVIVX1D0PrfBT456raC3gc8JMkTwYeAuwPPArYN8nBwztL8uIky5Is+/nNq6cpTZIkaeM37rCBwUB1J3AV8D/nvpw5c3VVndN//xG6f2c7mVOAzwLvBF4IfGCS5T7df10OLOm/fzzwLoCq+laSS6ap6y7g4wN1fXpg3seHF05yb2Cnqjq938et/fQnA08GLuoX3YYuzJ49uH5VnQScBPDIne65zphlSZKk1owbXl9UVVcOTkiy6zzUM1eGg1rRhe6JM833+M2MqquT/CzJE4HHsOYs7LDb+q+rWdNumcM6bx4xf7LtB3hbVZ04y/1LkiQ1ZaxhA8BpY07bWOyc5ID++2cDXwdWsuZj/T8eWv79dGdCP9H/R7FxfZ3+DHSShwGPmGb5uwFH9N8/p19/UlV1E3BNkmf0+9gqyb2ALwMvTLJNP32nJDvOoG5JkqQmTXnmNckewJ7Atkn+aGDWbzFw9nIj9B3gz5KcCHwPeC9wPnByktcD5w0t/zm64QKTDRmYzHuAD/bDBS4CLgFunGL5m4E9kyzvlztyjH08DzgxyZuAO4BnVdVXkjwU+EYSgFXAnwLXzbB+SZKkpqRq8qGQSQ4HngE8nS7gTfgV8G9Vde78lrdh9HcIeEdVHTTD9bYAtqyqW/u7AJwB/E5V3T7J8quqapvZVzxzj9zpnvX5l+y+ELuWJGlB7XzcpQtdgmYoyfKqGnkHpynPvFbVZ4HPJjmgqr4xL9UtsCSvA17G5GNdp3Iv4MwkW9KNQ33ZZMFVkiRJszfuBVsXJXkF3RCCwYudXjgvVW1AVXUCcMJ6rvsr1v4HDgAkOQ/Yamjy8xbqrKskSdKmYtzw+mHgcuB/AG+iO0v5nfkqqnVV9ZiFrkGSJGlTNO7dBnavqr8Bbq6qDwJPY/or6yVJkqQ5NW54vaP/+sskDwe2Zc2N+iVJkqQNYtxhAycluQ/wN3R3HdgGOG7eqpIkSZJGGCu8VtX7+2/PAh48f+VIkiRJkxtr2ECS+yU5OckX++cPS/Ki+S1NkiRJWtu4Y15PpfuXpA/sn38XOHY+CpIkSZImM254XVxVnwDuAqiqO4HV81aVJEmSNMK44fXmJPcFCiDJY4Eb560qSZIkaYRx7zbwV3R3GdgtyTnADsAR81aVJEmSNMKU4TXJzlX1o6q6MMkhwO8CAa6oqjumWleSJEmaa9MNG/jMwPcfr6rLqupbBldJkiQthOnCawa+9/6ukiRJWlDThdea5HtJkiRpg5vugq29ktxEdwb2nv339M+rqn5rXquTJEmSBkwZXqtqiw1ViCRJkjSdce/zKkmSJC04w6skSZKaYXiVJElSMwyvkiRJaobhVZIkSc0wvEqSJKkZhldJkiQ1w/AqSZKkZhheJUmS1AzDqyRJkppheJUkSVIzDK+SJElqhuFVkiRJzTC8SpIkqRmGV0mSJDXD8CpJkqRmGF4lSZLUDMOrJEmSmmF4lSRJUjMMr5IkSWqG4VWSJEnNMLxKkiSpGYZXSZIkNcPwKkmSpGYYXiVJktQMw6skSZKasWihC9CGcfcH7MnOxy1b6DIkSZJmxTOvkiRJaobhVZIkSc0wvEqSJKkZhldJkiQ1w/AqSZKkZhheJUmS1AzDqyRJkppheJUkSVIzDK+SJElqhuFVkiRJzTC8SpIkqRmGV0mSJDXD8CpJkqRmGF4lSZLUDMOrJEmSmmF4lSRJUjMMr5IkSWqG4VWSJEnNMLxKkiSpGYZXSZIkNcPwKkmSpGYYXiVJktQMw6skSZKaYXiVJElSMwyvkiRJasaihS5AG8bl113Ogf944EKXIUlaYOccfc5ClyDNimdeJUmS1AzDqyRJkppheJUkSVIzDK+SJElqhuFVkiRJzTC8SpIkqRmGV0mSJDXD8CpJkqRmGF4lSZLUDMOrJEmSmmF4lSRJUjMMr5IkSWqG4VWSJEnNMLxKkiSpGYZXSZIkNcPwKkmSpGYYXiVJktQMw6skSZKaYXiVJElSMwyvkiRJaobhVZIkSc0wvEqSJKkZhldJkiQ1w/AqSZKkZhheJUmS1AzDqyRJkppheJUkSVIzDK+SJElqhuFVkiRJzTC8SpIkqRmGV0mSJDXD8CpJkqRmGF4lSZLUDMOrJEmSmmF4lSRJUjMMr5IkSWqG4VWSJEnNMLxKkiSpGYZXSZIkNcPwKkmSpGYYXiVJktQMw6skSZKaYXiVJElSMwyvkiRJaobhVZIkSc0wvEqSJKkZhldJkiQ1Y6MMr0n2S/LuaZbZLsnLx9zeuXNT2cYnyesXugZJksej6WYAAAl9SURBVKQNZaMMr1W1rKqOmWax7YCxwmtVPW72VW20DK+SJGmzMW/hNcmSJJcneX+SbyX5aJLDkpyT5HtJ9u8f5ya5qP/6u/26hyb5fP/98UlOSbI0yZVJJkLtCcBuSVYkeXuSbZKckeTCJJcmOXygllUD212a5LS+to8mST9v3yRnJVme5MtJHtBPX5rk75Kcn+S7SQ7qp2+R5O/7fV2S5OiptjNJG+2e5GtJLu7r3i2dt/dtdmmSI/tlH5Dk7P54v5XkoCQnAPfsp310xPZfnGRZkmV3rLpj1q+pJEnSQls0z9vfHXgW8GLgAuA5wOOBp9OdMXw+cHBV3ZnkMOCtwB+P2M4ewBOAewNXJHkv8Drg4VX1KIAki4BnVtVNSRYD30zyuaqqoW3tDewJ/Bg4BzgwyXnAPwKHV9V/94HxLcAL+3UWVdX+SZ4KvAE4rD+mXYG9+/q3T7LlNNsZ9lHghKo6Pck96P6Y+CPgUcBewGLggiRn92335ap6S5ItgHtV1X8leeVEGwyrqpOAkwC22Xmb4XaQJElqznyH16uq6lKAJJcBZ1RVJbkUWAJsC3wwyUOAAracZDtfqKrbgNuSXAfcb8QyAd6a5GDgLmCnfrmfDi13flVd09e0oq/jl8DDga/2J2K3AH4ysM6n+6/L++WhC7Dvq6o7Aarq50kePs121hSb3BvYqapO79e/tZ/+eOBfq2o18LMkZwGPpgv/p/QB+TNVtWKStpIkSdpkzXd4vW3g+7sGnt/V7/vNwJlV9cwkS4ClY2xnNaPrfi6wA7BvVd2RZCVwjzG3FeCyqjpgmv0P7jt0gXvQdNsZXnbs6VV1dh/MnwZ8OMnbq+pDY+xHkiRpk7HQF2xtC1zbf3/UDNf9Fd0wgsFtXdcH1ycAu8xgW1cAOyQ5ACDJlkn2nGadrwAv7YcrkGT7mWynqm4CrknyjH7ZrZLcCzgbOLIfU7sDcDBwfpJd+uP7F+BkYJ9+U3f0Z2MlSZI2eQsdXv8v8LYk59B9xD62qroBOKe/eOntdONH90uyjO4s7OUz2NbtwBHA3yW5GFgBTHeHgvcDPwIu6dd5znps53nAMUkuAc4F7g+cDlwCXAz8J/DXVfVT4FBgRZKL6MYFv6vfxkl9DetcsCVJkrSpybrXM2lTtM3O29Rer9lrocuQJC2wc44+Z6FLkKaVZHlV7Tdq3kKfeZUkSZLGNt8XbAlI8s/AgUOT31VVH1iIeiRJklpleN0AquoVC12DJEnSpsBhA5IkSWqG4VWSJEnNMLxKkiSpGYZXSZIkNcPwKkmSpGYYXiVJktQMw6skSZKaYXiVJElSMwyvkiRJaobhVZIkSc0wvEqSJKkZhldJkiQ1w/AqSZKkZhheJUmS1AzDqyRJkppheJUkSVIzDK+SJElqhuFVkiRJzTC8SpIkqRmGV0mSJDXD8CpJkqRmGF4lSZLUDMOrJEmSmmF4lSRJUjMMr5IkSWqG4VWSJEnNMLxKkiSpGYZXSZIkNcPwKkmSpGYYXiVJktQMw6skSZKaYXiVJElSMwyvkiRJaobhVZIkSc0wvEqSJKkZhldJkiQ1w/AqSZKkZhheJUmS1AzDqyRJkppheJUkSVIzDK+SJElqxqKFLkAbxh477sE5R5+z0GVIkiTNimdeJUmS1AzDqyRJkppheJUkSVIzDK+SJElqhuFVkiRJzTC8SpIkqRmGV0mSJDXD8CpJkqRmGF4lSZLUDMOrJEmSmmF4lSRJUjMMr5IkSWpGqmqha9AGkORXwBULXcdGZjFw/UIXsRGxPdZme6zLNlmb7bEu22Rttse6xm2TXapqh1EzFs1tPdqIXVFV+y10ERuTJMtskzVsj7XZHuuyTdZme6zLNlmb7bGuuWgThw1IkiSpGYZXSZIkNcPwuvk4aaEL2AjZJmuzPdZme6zLNlmb7bEu22Rttse6Zt0mXrAlSZKkZnjmVZIkSc0wvEqSJKkZhtdNQJKnJLkiyfeTvG7E/CR5dz//kiT7jLtui2bZHiuTXJpkRZJlG7by+TFGe+yR5BtJbkvy6pms26pZtsnm2Eee2/+sXJLk3CR7jbtuq2bZJptjHzm8b4sVSZYlefy467Zqlm2y2fWRgeUenWR1kiNmuu5vVJWPhh/AFsAPgAcDdwcuBh42tMxTgS8CAR4LnDfuuq09ZtMe/byVwOKFPo4N3B47Ao8G3gK8eibrtviYTZtsxn3kccB9+u9/f1P+HTLbNtmM+8g2rLmO5pHA5faR0W2yufaRgeX+E/gP4Ij17SOeeW3f/sD3q+rKqrod+Dfg8KFlDgc+VJ1vAtslecCY67ZmNu2xKZq2Parquqq6ALhjpus2ajZtsikapz3Orapf9E+/CTxo3HUbNZs22RSN0x6rqk8iwNZAjbtuo2bTJpuicV/no4FPAdetx7q/YXht307A1QPPr+mnjbPMOOu2ZjbtAd0vl68kWZ7kxfNW5YYzm9d4U+wfMPvj2tz7yIvoPrlYn3VbMZs2gc20jyR5ZpLLgS8AL5zJug2aTZvAZthHkuwEPBN430zXHea/h21fRkwb/utusmXGWbc1s2kPgAOr6sdJdgS+muTyqjp7TivcsGbzGm+K/QNmf1ybbR9J8gS6oDYxdm+z7yMj2gQ20z5SVacDpyc5GHgzcNi46zZoNm0Cm2cfeSfw2qpanay1+Iz7iGde23cN8NsDzx8E/HjMZcZZtzWzaQ+qauLrdcDpdB9ntGw2r/Gm2D9glse1ufaRJI8E3g8cXlU3zGTdBs2mTTbbPjKhD2G7JVk803UbMps22Vz7yH7AvyVZCRwBvCfJM8Zcd20LPcjXx6wHSS8CrgR2Zc1A5z2Hlnkaa1+gdP6467b2mGV7bA3ce+D7c4GnLPQxzXd7DCx7PGtfsLXJ9Y85aJPNso8AOwPfBx63vm3Z0mOWbbK59pHdWXNx0j7Atf3v2M25j0zWJptlHxla/lTWXLA14z7isIHGVdWdSV4JfJnuir1TquqyJC/t57+P7qq+p9L9or0FeMFU6y7AYcyZ2bQHcD+6j3eg+2H6WFV9aQMfwpwapz2S3B9YBvwWcFeSY+mu9LxpU+sfMLs2ARazGfYR4DjgvnRnSgDurKr9NsXfITC7NmEz/T0C/DHw/CR3AL8GjqwumWzOfWRkmyTZXPvIjNadan/+e1hJkiQ1wzGvkiRJaobhVZIkSc0wvEqSJKkZhldJkiQ1w/AqSZKkZhheJUmS1AzDqyRJkprx/wHOwhcq6CPDBwAAAABJRU5ErkJggg==\n",
"text/plain": [
""
]
},
"metadata": {
"needs_background": "light"
},
"output_type": "display_data"
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"Features used for prediction\n",
" Index(['buying_price', 'maintainence_cost', 'safety_rating'], dtype='object')\n",
"\n",
"Please wait Training-Testing with all models..\n",
"\n"
]
},
{
"data": {
"application/vnd.jupyter.widget-view+json": {
"model_id": "78d5ed200cbf4c54884739c77b0023cb",
"version_major": 2,
"version_minor": 0
},
"text/plain": [
"HBox(children=(FloatProgress(value=0.0, max=6.0), HTML(value='')))"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"Done with LogisticRegression\n",
"Done with RandomForestClassifier\n",
"Done with XGBoost Classifier\n",
"Done with LGBoost Classifier\n",
"Done with AdaBoost Classifier\n",
"Done with GradientBoostingClassifier\n",
"\n",
" Model F1 score AUC-ROC score Accuracy \\\n",
"1 RandomForestClassifier 1.000000 1.000000 1.000000 \n",
"3 LGBoost Classifier 1.000000 1.000000 1.000000 \n",
"2 XGBoost Classifier 0.967137 0.976190 0.966667 \n",
"5 GradientBoostingClassifier 0.967137 0.976190 0.966667 \n",
"4 AdaBoost Classifier 0.898222 0.865079 0.900000 \n",
"0 LogisticRegression 0.861364 0.809524 0.866667 \n",
"\n",
" Balanced Accuracy Score \n",
"1 1.000000 \n",
"3 1.000000 \n",
"2 0.976190 \n",
"5 0.976190 \n",
"4 0.865079 \n",
"0 0.809524 \n",
"\n",
"Check returned table\n",
"\n"
]
}
],
"source": [
"result, model = ez.quick_ml(df,'popularity','c',3)"
]
},
{
"cell_type": "code",
"execution_count": 7,
"metadata": {
"ExecuteTime": {
"end_time": "2020-03-26T21:21:59.877676Z",
"start_time": "2020-03-26T21:21:59.872675Z"
}
},
"outputs": [
{
"data": {
"text/plain": [
"RandomForestClassifier(bootstrap=True, class_weight='balanced',\n",
" criterion='gini', max_depth=None, max_features='auto',\n",
" max_leaf_nodes=None, min_impurity_decrease=0.0,\n",
" min_impurity_split=None, min_samples_leaf=1,\n",
" min_samples_split=2, min_weight_fraction_leaf=0.0,\n",
" n_estimators=200, n_jobs=None, oob_score=False,\n",
" random_state=101, verbose=0, warm_start=False)"
]
},
"execution_count": 7,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"model"
]
},
{
"cell_type": "code",
"execution_count": 13,
"metadata": {
"ExecuteTime": {
"end_time": "2020-03-26T21:23:22.971760Z",
"start_time": "2020-03-26T21:23:22.967757Z"
}
},
"outputs": [
{
"data": {
"text/plain": [
"3"
]
},
"execution_count": 13,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"model.n_features_"
]
},
{
"cell_type": "code",
"execution_count": 14,
"metadata": {
"ExecuteTime": {
"end_time": "2020-03-26T21:23:53.042435Z",
"start_time": "2020-03-26T21:23:53.039434Z"
}
},
"outputs": [],
"source": [
"features = ['buying_price', 'maintainence_cost', 'safety_rating']"
]
},
{
"cell_type": "code",
"execution_count": 15,
"metadata": {
"ExecuteTime": {
"end_time": "2020-03-26T21:24:12.962507Z",
"start_time": "2020-03-26T21:24:12.942493Z"
}
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"All Deployment Files Created Successfully\n",
"\n",
"Files Created and stored in : /deployment-files named Folder\n",
"\n",
"Open deployment-files folder and open command prompt and run \"python app.py\" copy link and paste in browser to run app, enjoy.\n",
"\n",
"Files created:\n",
" 1. model.pkl - Model file using pickle\n",
" 2.app.py - Flask server file\n",
"3.index.html - User Interface file.\n"
]
}
],
"source": [
"ez.deploy_one(model,features,'Chintan Fucks RUles')"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": []
}
],
"metadata": {
"hide_input": false,
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.7.4"
}
},
"nbformat": 4,
"nbformat_minor": 2
}
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������
"
]
},
"metadata": {
"needs_background": "light"
},
"output_type": "display_data"
},
{
"data": {
"application/vnd.plotly.v1+json": {
"config": {
"linkText": "Export to plot.ly",
"plotlyServerURL": "https://plot.ly",
"showLink": true
},
"data": [
{
"histfunc": "count",
"histnorm": "",
"marker": {
"color": "rgba(255, 153, 51, 1.0)",
"line": {
"color": "#4D5663",
"width": 1.3
}
},
"name": "emp_length",
"opacity": 0.8,
"orientation": "v",
"type": "histogram",
"x": [
"9 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"8 years",
"7 years",
"2 years",
"10+ years",
"4 years",
"7 years",
"10+ years",
"10+ years",
"4 years",
"9 years",
null,
"7 years",
"7 years",
"9 years",
"2 years",
"10+ years",
"7 years",
"< 1 year",
"4 years",
"2 years",
"1 year",
"3 years",
"2 years",
"10+ years",
"8 years",
"2 years",
"9 years",
"10+ years",
null,
null,
"10+ years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"3 years",
"10+ years",
"9 years",
"4 years",
"7 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"6 years",
"2 years",
"10+ years",
"2 years",
"< 1 year",
"4 years",
"1 year",
"9 years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"< 1 year",
"2 years",
"9 years",
"8 years",
"3 years",
"3 years",
"8 years",
"2 years",
"7 years",
"10+ years",
"7 years",
"1 year",
"10+ years",
null,
"10+ years",
"8 years",
"5 years",
"6 years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"4 years",
null,
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"1 year",
"10+ years",
"5 years",
"8 years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"8 years",
"2 years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"4 years",
"1 year",
"3 years",
"8 years",
"3 years",
"2 years",
null,
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"1 year",
"2 years",
"8 years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"3 years",
"9 years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"3 years",
"4 years",
"4 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
null,
"4 years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"< 1 year",
"10+ years",
"2 years",
"4 years",
"2 years",
"< 1 year",
"4 years",
"2 years",
"1 year",
"5 years",
"4 years",
"3 years",
"9 years",
"5 years",
null,
"10+ years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"6 years",
"10+ years",
"1 year",
"7 years",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"5 years",
"10+ years",
"3 years",
null,
"10+ years",
null,
"10+ years",
"8 years",
"2 years",
"7 years",
"7 years",
"10+ years",
"8 years",
"6 years",
"9 years",
"3 years",
"4 years",
"5 years",
"< 1 year",
"< 1 year",
"7 years",
"7 years",
"< 1 year",
"1 year",
"< 1 year",
null,
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"6 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"8 years",
"1 year",
"< 1 year",
"4 years",
"1 year",
"7 years",
"< 1 year",
"3 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"6 years",
null,
"< 1 year",
"2 years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"9 years",
"4 years",
"3 years",
"10+ years",
"7 years",
null,
null,
"10+ years",
"2 years",
null,
"5 years",
"< 1 year",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"< 1 year",
"10+ years",
"2 years",
null,
"7 years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"5 years",
"< 1 year",
"< 1 year",
"4 years",
"3 years",
"3 years",
"8 years",
"2 years",
"1 year",
"10+ years",
"3 years",
"3 years",
"4 years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"1 year",
null,
"5 years",
"< 1 year",
"4 years",
"3 years",
"2 years",
"3 years",
"1 year",
"9 years",
"7 years",
"1 year",
"10+ years",
"10+ years",
"2 years",
null,
"3 years",
"3 years",
"< 1 year",
"2 years",
"1 year",
"10+ years",
"10+ years",
null,
"10+ years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
null,
null,
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
null,
"4 years",
"10+ years",
"7 years",
"2 years",
"6 years",
"10+ years",
"2 years",
"2 years",
"4 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"6 years",
"6 years",
"8 years",
"1 year",
"3 years",
"5 years",
"6 years",
"9 years",
"3 years",
null,
"7 years",
"5 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"9 years",
"3 years",
"2 years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"6 years",
"< 1 year",
"8 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"6 years",
"2 years",
"9 years",
"3 years",
"8 years",
"8 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"4 years",
"7 years",
"3 years",
"8 years",
"2 years",
"9 years",
"6 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"7 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"< 1 year",
"2 years",
"9 years",
"8 years",
"3 years",
"10+ years",
"8 years",
"10+ years",
"6 years",
"7 years",
"10+ years",
"5 years",
"10+ years",
"1 year",
"1 year",
null,
"3 years",
"10+ years",
"3 years",
"4 years",
"4 years",
"2 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"7 years",
"10+ years",
null,
"2 years",
"< 1 year",
"2 years",
"1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"8 years",
"7 years",
"5 years",
"2 years",
"10+ years",
"1 year",
"7 years",
"10+ years",
null,
"10+ years",
"8 years",
"10+ years",
"4 years",
"8 years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"7 years",
"3 years",
"5 years",
"1 year",
"10+ years",
"6 years",
"10+ years",
null,
"9 years",
"5 years",
"7 years",
"6 years",
"3 years",
"8 years",
"10+ years",
"7 years",
"5 years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"10+ years",
"6 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"1 year",
"8 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"7 years",
"5 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"4 years",
"3 years",
"8 years",
"1 year",
null,
"5 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"4 years",
"10+ years",
"5 years",
"< 1 year",
"2 years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"6 years",
null,
"10+ years",
"5 years",
"4 years",
"9 years",
"6 years",
"4 years",
"4 years",
"< 1 year",
"4 years",
"8 years",
"10+ years",
null,
"1 year",
"7 years",
"9 years",
"1 year",
"8 years",
"8 years",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"9 years",
"10+ years",
"6 years",
"10+ years",
"6 years",
"5 years",
null,
"2 years",
"3 years",
null,
"10+ years",
"3 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"6 years",
"< 1 year",
"10+ years",
null,
"9 years",
"3 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"7 years",
"7 years",
"1 year",
"10+ years",
"7 years",
"10+ years",
"< 1 year",
"8 years",
"2 years",
"8 years",
"4 years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"7 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"8 years",
"3 years",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"8 years",
"5 years",
"10+ years",
"5 years",
"5 years",
"3 years",
"< 1 year",
"10+ years",
"1 year",
"4 years",
"10+ years",
"3 years",
null,
"5 years",
"6 years",
"2 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"3 years",
null,
"< 1 year",
"9 years",
"10+ years",
"10+ years",
"7 years",
"1 year",
"7 years",
"5 years",
"8 years",
"10+ years",
"5 years",
"4 years",
"4 years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"9 years",
"2 years",
"3 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"4 years",
"4 years",
"5 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"1 year",
"2 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"9 years",
"2 years",
"10+ years",
null,
"6 years",
"3 years",
"3 years",
null,
null,
"7 years",
"2 years",
"4 years",
"1 year",
"< 1 year",
"6 years",
"9 years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"2 years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"5 years",
"< 1 year",
"9 years",
"8 years",
"10+ years",
"7 years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"6 years",
"8 years",
"10+ years",
"7 years",
"10+ years",
"5 years",
"3 years",
null,
"6 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
null,
"2 years",
"3 years",
"4 years",
"2 years",
"10+ years",
"5 years",
"9 years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"7 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"7 years",
"3 years",
"5 years",
null,
"10+ years",
"10+ years",
"2 years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"8 years",
"1 year",
"6 years",
"7 years",
"10+ years",
null,
"5 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"3 years",
"< 1 year",
"< 1 year",
"3 years",
"9 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"1 year",
"10+ years",
"4 years",
"6 years",
"10+ years",
"3 years",
"< 1 year",
null,
"10+ years",
"1 year",
"5 years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"8 years",
"10+ years",
"< 1 year",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"4 years",
"< 1 year",
"1 year",
"8 years",
"9 years",
"< 1 year",
"6 years",
"8 years",
"10+ years",
"10+ years",
"9 years",
"6 years",
null,
"< 1 year",
"10+ years",
"5 years",
"5 years",
"10+ years",
"8 years",
"5 years",
"1 year",
"2 years",
"5 years",
"7 years",
"4 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"4 years",
"10+ years",
"3 years",
"7 years",
"4 years",
"9 years",
"3 years",
"9 years",
"7 years",
"10+ years",
"1 year",
"5 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"< 1 year",
"1 year",
"8 years",
"8 years",
"10+ years",
"7 years",
"4 years",
"6 years",
"8 years",
"< 1 year",
"4 years",
"4 years",
"7 years",
"1 year",
"1 year",
"10+ years",
"5 years",
"8 years",
"5 years",
"10+ years",
"7 years",
"8 years",
"5 years",
"2 years",
"10+ years",
"4 years",
null,
null,
"8 years",
"2 years",
"5 years",
"10+ years",
"5 years",
null,
"3 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"3 years",
"3 years",
"9 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"4 years",
"10+ years",
"< 1 year",
"5 years",
null,
"2 years",
"10+ years",
"4 years",
"< 1 year",
"8 years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"4 years",
null,
"9 years",
null,
"7 years",
"7 years",
"2 years",
"1 year",
"1 year",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"6 years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
null,
"5 years",
"< 1 year",
"6 years",
"3 years",
"7 years",
"< 1 year",
"10+ years",
"5 years",
"8 years",
"10+ years",
"7 years",
"1 year",
"4 years",
"10+ years",
"10+ years",
"5 years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"6 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"9 years",
"7 years",
"10+ years",
"6 years",
"8 years",
"2 years",
"3 years",
"3 years",
"10+ years",
"2 years",
"8 years",
"9 years",
"2 years",
"10+ years",
"4 years",
"1 year",
"2 years",
"7 years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
null,
"10+ years",
"6 years",
null,
"10+ years",
"7 years",
null,
"10+ years",
"6 years",
"3 years",
"4 years",
"5 years",
"7 years",
"3 years",
"10+ years",
"6 years",
null,
"< 1 year",
"8 years",
"3 years",
"7 years",
"2 years",
"9 years",
"10+ years",
"2 years",
"7 years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"5 years",
null,
"2 years",
"4 years",
"6 years",
"6 years",
"6 years",
"6 years",
"1 year",
"10+ years",
"3 years",
null,
"10+ years",
"7 years",
"2 years",
"< 1 year",
"4 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
null,
"6 years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
"8 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"1 year",
"10+ years",
"7 years",
"7 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"1 year",
"7 years",
"< 1 year",
"3 years",
"5 years",
"2 years",
"3 years",
"10+ years",
null,
"2 years",
null,
"< 1 year",
"10+ years",
null,
"2 years",
"7 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"5 years",
"1 year",
"1 year",
"3 years",
"4 years",
"6 years",
"3 years",
"2 years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"9 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"1 year",
"< 1 year",
"< 1 year",
"7 years",
"8 years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"8 years",
"3 years",
"4 years",
"< 1 year",
"< 1 year",
"2 years",
"9 years",
"5 years",
"6 years",
"5 years",
"< 1 year",
"10+ years",
"< 1 year",
"1 year",
"7 years",
"1 year",
"10+ years",
"5 years",
"10+ years",
"1 year",
"10+ years",
"2 years",
"2 years",
"2 years",
"3 years",
"7 years",
"7 years",
"8 years",
"10+ years",
null,
null,
null,
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"9 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"6 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"1 year",
"< 1 year",
"10+ years",
"2 years",
"5 years",
"4 years",
"9 years",
"10+ years",
"10+ years",
"3 years",
"9 years",
null,
"8 years",
"1 year",
"10+ years",
"4 years",
"10+ years",
"7 years",
"10+ years",
"1 year",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"3 years",
null,
"5 years",
"1 year",
"1 year",
"10+ years",
"10+ years",
null,
"4 years",
"9 years",
null,
"10+ years",
"10+ years",
"7 years",
"5 years",
null,
"< 1 year",
"2 years",
"2 years",
"1 year",
"10+ years",
"4 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"4 years",
"2 years",
"2 years",
"3 years",
"1 year",
"9 years",
"2 years",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"6 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"4 years",
"6 years",
"9 years",
"1 year",
"2 years",
"2 years",
"6 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"7 years",
"5 years",
"1 year",
"3 years",
"6 years",
"4 years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
null,
"10+ years",
"7 years",
"2 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"3 years",
null,
"10+ years",
"8 years",
"5 years",
"1 year",
"3 years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"7 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"< 1 year",
"6 years",
"8 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"1 year",
"< 1 year",
"< 1 year",
"6 years",
"9 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"8 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"7 years",
"4 years",
"7 years",
"9 years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"8 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"5 years",
"6 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"9 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"8 years",
"6 years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"3 years",
"3 years",
"7 years",
"10+ years",
"6 years",
"7 years",
"4 years",
"4 years",
"2 years",
"< 1 year",
"1 year",
"10+ years",
"2 years",
"10+ years",
"8 years",
null,
"10+ years",
"10+ years",
"2 years",
"3 years",
"1 year",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"3 years",
"7 years",
"6 years",
null,
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
null,
null,
"4 years",
"4 years",
"7 years",
"3 years",
"1 year",
null,
"8 years",
"6 years",
"2 years",
"10+ years",
"2 years",
"< 1 year",
"2 years",
"9 years",
"5 years",
"8 years",
"5 years",
"6 years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
null,
"2 years",
"6 years",
null,
"10+ years",
"3 years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"1 year",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"8 years",
"2 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"5 years",
"7 years",
null,
"1 year",
"10+ years",
"2 years",
"3 years",
"< 1 year",
null,
"10+ years",
"10+ years",
"2 years",
"< 1 year",
null,
"3 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"2 years",
"4 years",
"10+ years",
"< 1 year",
"6 years",
"8 years",
"4 years",
"10+ years",
"1 year",
"5 years",
"9 years",
"10+ years",
null,
"1 year",
"10+ years",
"4 years",
"3 years",
"9 years",
"< 1 year",
"3 years",
"7 years",
"5 years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"8 years",
"< 1 year",
"10+ years",
"7 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"1 year",
"6 years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"7 years",
"10+ years",
"3 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"< 1 year",
"4 years",
"3 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"9 years",
null,
"< 1 year",
"6 years",
"4 years",
"8 years",
"3 years",
"5 years",
"1 year",
"8 years",
"5 years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"2 years",
"3 years",
"< 1 year",
"5 years",
"10+ years",
"5 years",
"9 years",
"2 years",
"4 years",
"5 years",
"6 years",
null,
"7 years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"6 years",
"8 years",
"2 years",
null,
"7 years",
"7 years",
"10+ years",
"7 years",
"< 1 year",
"6 years",
"8 years",
"1 year",
"6 years",
"2 years",
"3 years",
"4 years",
"6 years",
"10+ years",
"8 years",
"6 years",
null,
"5 years",
"7 years",
"3 years",
"2 years",
"10+ years",
"9 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"4 years",
"1 year",
"10+ years",
"5 years",
null,
"10+ years",
"10+ years",
"6 years",
"10+ years",
null,
"6 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"7 years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"2 years",
null,
"10+ years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"10+ years",
"4 years",
"10+ years",
"8 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
null,
"1 year",
"10+ years",
"1 year",
"2 years",
"10+ years",
"< 1 year",
"1 year",
"3 years",
"2 years",
null,
"10+ years",
"10+ years",
"4 years",
null,
"3 years",
"3 years",
"< 1 year",
"9 years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
null,
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"3 years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
null,
"< 1 year",
null,
"3 years",
"3 years",
"4 years",
"2 years",
"10+ years",
"2 years",
"< 1 year",
null,
"10+ years",
"4 years",
"7 years",
"< 1 year",
"9 years",
"2 years",
"4 years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"< 1 year",
"8 years",
"8 years",
"5 years",
"10+ years",
null,
"9 years",
"1 year",
"10+ years",
"5 years",
null,
"7 years",
null,
"6 years",
null,
"5 years",
"5 years",
"3 years",
"9 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"4 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"4 years",
"10+ years",
"8 years",
"7 years",
"< 1 year",
null,
"6 years",
"1 year",
"10+ years",
"5 years",
"5 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"10+ years",
null,
"2 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
null,
"< 1 year",
"< 1 year",
"10+ years",
"2 years",
"4 years",
"1 year",
"2 years",
"10+ years",
"2 years",
"7 years",
"2 years",
"3 years",
"2 years",
"10+ years",
"6 years",
"10+ years",
"7 years",
"3 years",
"4 years",
"7 years",
"2 years",
"1 year",
"6 years",
"1 year",
"10+ years",
"< 1 year",
"4 years",
"5 years",
"5 years",
"7 years",
"< 1 year",
null,
"10+ years",
"9 years",
"4 years",
"3 years",
"9 years",
null,
"10+ years",
"10+ years",
"7 years",
"4 years",
"2 years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"4 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"4 years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"3 years",
"8 years",
"10+ years",
"1 year",
"4 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"8 years",
"1 year",
"8 years",
"6 years",
"4 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
null,
"1 year",
"10+ years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"6 years",
"1 year",
"9 years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"7 years",
"3 years",
"3 years",
"10+ years",
"5 years",
"1 year",
"1 year",
null,
"5 years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"3 years",
"< 1 year",
"7 years",
"3 years",
"5 years",
"10+ years",
null,
"10+ years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"8 years",
"9 years",
"4 years",
"10+ years",
"5 years",
"7 years",
"10+ years",
"10+ years",
"9 years",
"1 year",
"10+ years",
"1 year",
"1 year",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"9 years",
"2 years",
"2 years",
"< 1 year",
"2 years",
"3 years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"4 years",
"9 years",
"3 years",
"3 years",
"10+ years",
"1 year",
"6 years",
"10+ years",
"7 years",
"1 year",
"6 years",
"9 years",
"8 years",
"4 years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"10+ years",
null,
"5 years",
"10+ years",
"10+ years",
"8 years",
"1 year",
"6 years",
null,
null,
"6 years",
"3 years",
"1 year",
"< 1 year",
"7 years",
"2 years",
null,
"2 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"4 years",
"10+ years",
null,
"4 years",
"4 years",
"6 years",
"4 years",
"10+ years",
"10+ years",
"4 years",
null,
"10+ years",
"4 years",
"3 years",
"2 years",
"3 years",
"4 years",
"8 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
null,
"4 years",
"2 years",
"7 years",
"4 years",
"10+ years",
"2 years",
"9 years",
"2 years",
"2 years",
"< 1 year",
"10+ years",
"4 years",
"9 years",
"1 year",
"10+ years",
"3 years",
"3 years",
"10+ years",
"5 years",
"6 years",
"7 years",
"3 years",
"10+ years",
"3 years",
null,
"1 year",
"2 years",
"10+ years",
"7 years",
"8 years",
"10+ years",
"8 years",
"3 years",
"9 years",
"< 1 year",
"9 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
null,
"6 years",
"10+ years",
"3 years",
"8 years",
"6 years",
"5 years",
"< 1 year",
"2 years",
"10+ years",
"2 years",
"10+ years",
null,
"10+ years",
"5 years",
"7 years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"3 years",
"2 years",
"1 year",
"2 years",
"< 1 year",
"2 years",
"3 years",
"3 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"3 years",
null,
"< 1 year",
"3 years",
"< 1 year",
"< 1 year",
"10+ years",
"3 years",
"7 years",
"10+ years",
"2 years",
"4 years",
"2 years",
"10+ years",
"6 years",
"6 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"< 1 year",
"8 years",
"10+ years",
"5 years",
"3 years",
"1 year",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"8 years",
"4 years",
"2 years",
"2 years",
"9 years",
"10+ years",
"7 years",
"10+ years",
"< 1 year",
"9 years",
"2 years",
"< 1 year",
null,
"6 years",
"2 years",
"2 years",
"10+ years",
"4 years",
null,
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"7 years",
"10+ years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"2 years",
"10+ years",
"9 years",
"6 years",
null,
null,
"3 years",
"5 years",
"10+ years",
"8 years",
"5 years",
"6 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"5 years",
"6 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"1 year",
"2 years",
"10+ years",
"6 years",
"9 years",
"9 years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"9 years",
"2 years",
null,
"10+ years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"< 1 year",
null,
"4 years",
null,
"10+ years",
null,
"10+ years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"6 years",
"8 years",
"8 years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"3 years",
"10+ years",
"5 years",
null,
"< 1 year",
"10+ years",
"< 1 year",
"2 years",
"1 year",
"10+ years",
"9 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"3 years",
"9 years",
"5 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"3 years",
"1 year",
"7 years",
"7 years",
"8 years",
"2 years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"< 1 year",
"3 years",
"5 years",
"3 years",
"2 years",
"10+ years",
"3 years",
"8 years",
"5 years",
"7 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
null,
"3 years",
"5 years",
"7 years",
"10+ years",
"2 years",
"2 years",
null,
"3 years",
"4 years",
"8 years",
"10+ years",
"1 year",
"1 year",
"9 years",
"8 years",
"5 years",
"2 years",
"8 years",
"< 1 year",
"6 years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"7 years",
null,
"7 years",
"5 years",
"1 year",
"10+ years",
"10+ years",
"8 years",
"4 years",
"10+ years",
"10+ years",
null,
"10+ years",
"8 years",
"8 years",
"10+ years",
"5 years",
"7 years",
"9 years",
"8 years",
"10+ years",
"4 years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"6 years",
"10+ years",
"10+ years",
null,
"10+ years",
"1 year",
"< 1 year",
null,
"2 years",
"8 years",
"7 years",
"4 years",
"10+ years",
"2 years",
"4 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"7 years",
"10+ years",
"4 years",
"< 1 year",
"2 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"4 years",
"3 years",
"10+ years",
"8 years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"8 years",
"9 years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"2 years",
"9 years",
"10+ years",
"2 years",
"10+ years",
"9 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
null,
"10+ years",
"10+ years",
"1 year",
"3 years",
"5 years",
"8 years",
"7 years",
"6 years",
"2 years",
"5 years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"2 years",
"10+ years",
"1 year",
"3 years",
"2 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"8 years",
"10+ years",
"4 years",
"2 years",
"< 1 year",
"6 years",
"4 years",
"3 years",
"< 1 year",
"10+ years",
"1 year",
"4 years",
"7 years",
"3 years",
"1 year",
"5 years",
"3 years",
"7 years",
"10+ years",
"2 years",
"1 year",
"4 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"1 year",
"2 years",
null,
"7 years",
"10+ years",
null,
"10+ years",
"10+ years",
"3 years",
"5 years",
"1 year",
"10+ years",
"10+ years",
"8 years",
"1 year",
"10+ years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"10+ years",
null,
"10+ years",
"< 1 year",
null,
"2 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"3 years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"2 years",
"3 years",
"2 years",
"10+ years",
"3 years",
"1 year",
"9 years",
"1 year",
"9 years",
"10+ years",
null,
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
null,
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
null,
"7 years",
"3 years",
"1 year",
"4 years",
"9 years",
"1 year",
"5 years",
"10+ years",
"2 years",
"10+ years",
null,
null,
"10+ years",
"2 years",
"10+ years",
"7 years",
"2 years",
"2 years",
null,
"2 years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"9 years",
"3 years",
"2 years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"1 year",
"2 years",
"10+ years",
"1 year",
"2 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"6 years",
"2 years",
"2 years",
"6 years",
"5 years",
"< 1 year",
"3 years",
"7 years",
"8 years",
"8 years",
"4 years",
"9 years",
"7 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"3 years",
null,
"1 year",
"10+ years",
"1 year",
"10+ years",
"5 years",
"5 years",
"2 years",
"9 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"1 year",
"1 year",
"2 years",
"< 1 year",
"10+ years",
null,
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"4 years",
"9 years",
"10+ years",
"9 years",
"3 years",
"6 years",
"6 years",
"3 years",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"2 years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"5 years",
"10+ years",
"3 years",
"6 years",
"10+ years",
"7 years",
"< 1 year",
"9 years",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"6 years",
"< 1 year",
"1 year",
"2 years",
"9 years",
"1 year",
"1 year",
"6 years",
"6 years",
"8 years",
"7 years",
"6 years",
"4 years",
"4 years",
"10+ years",
null,
"9 years",
"4 years",
null,
"3 years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"2 years",
"6 years",
"6 years",
"5 years",
"5 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"3 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"6 years",
"10+ years",
"4 years",
"3 years",
"9 years",
"10+ years",
"10+ years",
"6 years",
"5 years",
"5 years",
"10+ years",
"10+ years",
"4 years",
null,
"< 1 year",
"5 years",
"6 years",
"1 year",
"< 1 year",
"2 years",
"10+ years",
null,
"10+ years",
"< 1 year",
"1 year",
"8 years",
"< 1 year",
"10+ years",
"2 years",
"9 years",
"10+ years",
"1 year",
"< 1 year",
"< 1 year",
"4 years",
"5 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"3 years",
"7 years",
"2 years",
"< 1 year",
"9 years",
"1 year",
"3 years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"8 years",
"7 years",
"7 years",
null,
"10+ years",
"5 years",
"6 years",
"1 year",
"7 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
null,
"2 years",
"5 years",
"9 years",
"3 years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"6 years",
null,
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"5 years",
"10+ years",
"7 years",
"1 year",
null,
"2 years",
"10+ years",
"4 years",
"10+ years",
null,
null,
"10+ years",
"3 years",
"< 1 year",
"6 years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
null,
"2 years",
"2 years",
"2 years",
"8 years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"1 year",
"3 years",
"7 years",
"7 years",
"5 years",
"< 1 year",
"8 years",
"7 years",
"7 years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"1 year",
"4 years",
null,
"10+ years",
"8 years",
"9 years",
"1 year",
null,
"< 1 year",
"1 year",
"1 year",
null,
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"9 years",
null,
"2 years",
"10+ years",
"6 years",
"2 years",
"10+ years",
null,
"10+ years",
"8 years",
"3 years",
"5 years",
null,
"3 years",
"4 years",
"5 years",
"2 years",
"9 years",
"2 years",
"1 year",
"5 years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"3 years",
"5 years",
"1 year",
"7 years",
"10+ years",
"8 years",
"1 year",
"2 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"6 years",
"7 years",
"10+ years",
"8 years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"5 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"4 years",
"8 years",
"10+ years",
"6 years",
"1 year",
"6 years",
"3 years",
"9 years",
"5 years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"1 year",
"6 years",
"2 years",
"1 year",
"1 year",
"10+ years",
"1 year",
"10+ years",
"8 years",
"10+ years",
null,
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"3 years",
null,
"10+ years",
"9 years",
"10+ years",
"6 years",
"9 years",
"1 year",
"< 1 year",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"5 years",
"4 years",
"8 years",
null,
"10+ years",
"4 years",
null,
"2 years",
"10+ years",
"6 years",
"< 1 year",
"10+ years",
null,
"2 years",
null,
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"6 years",
"< 1 year",
"4 years",
"9 years",
"7 years",
"3 years",
"9 years",
"4 years",
"10+ years",
"2 years",
"3 years",
null,
"3 years",
null,
"4 years",
"4 years",
"< 1 year",
"5 years",
"2 years",
"3 years",
"10+ years",
"2 years",
"8 years",
"2 years",
"10+ years",
"9 years",
"1 year",
"7 years",
"7 years",
"9 years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"8 years",
"2 years",
"2 years",
null,
"5 years",
"6 years",
"< 1 year",
"4 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"6 years",
"4 years",
"7 years",
null,
"1 year",
"3 years",
"8 years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"7 years",
"3 years",
"7 years",
"< 1 year",
"8 years",
"2 years",
"2 years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"9 years",
"4 years",
"< 1 year",
"2 years",
"< 1 year",
"8 years",
"7 years",
"10+ years",
"< 1 year",
"< 1 year",
"9 years",
"4 years",
"3 years",
"< 1 year",
"4 years",
"< 1 year",
"9 years",
"10+ years",
"6 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"6 years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"2 years",
"10+ years",
"7 years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
null,
"10+ years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"1 year",
"6 years",
"4 years",
"5 years",
"3 years",
"10+ years",
"9 years",
"8 years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"1 year",
"10+ years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"8 years",
null,
"10+ years",
"10+ years",
"10+ years",
"8 years",
"2 years",
"6 years",
"10+ years",
null,
"7 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"9 years",
"5 years",
"6 years",
"5 years",
"1 year",
"5 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"7 years",
"2 years",
"5 years",
"6 years",
"10+ years",
"< 1 year",
"3 years",
"4 years",
"2 years",
"8 years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"1 year",
"7 years",
"7 years",
"10+ years",
"10+ years",
"7 years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"6 years",
"5 years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"7 years",
"10+ years",
null,
"7 years",
"5 years",
"5 years",
"3 years",
"10+ years",
"9 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"1 year",
"1 year",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"3 years",
null,
"3 years",
"6 years",
"8 years",
"7 years",
"2 years",
"7 years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"< 1 year",
"1 year",
"3 years",
"9 years",
"10+ years",
"2 years",
"10+ years",
"4 years",
"2 years",
"4 years",
"10+ years",
"6 years",
"10+ years",
null,
"9 years",
"7 years",
"7 years",
"1 year",
"1 year",
"5 years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"2 years",
"9 years",
"5 years",
"6 years",
"2 years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"7 years",
"10+ years",
"6 years",
"6 years",
"6 years",
"10+ years",
"6 years",
null,
"10+ years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"2 years",
null,
"10+ years",
"10+ years",
null,
"8 years",
"1 year",
"4 years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"8 years",
"10+ years",
"6 years",
"7 years",
"1 year",
"2 years",
"8 years",
"10+ years",
"1 year",
"3 years",
"< 1 year",
"< 1 year",
null,
"10+ years",
"10+ years",
"3 years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"6 years",
"10+ years",
"10+ years",
"6 years",
"6 years",
"< 1 year",
"5 years",
"5 years",
"1 year",
"4 years",
"8 years",
"10+ years",
"8 years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"3 years",
"7 years",
"4 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"8 years",
"4 years",
"3 years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"8 years",
"9 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"9 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"2 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"3 years",
"4 years",
"9 years",
"10+ years",
"9 years",
"4 years",
"10+ years",
"1 year",
"6 years",
"< 1 year",
null,
"10+ years",
"2 years",
"10+ years",
"9 years",
"4 years",
"< 1 year",
"10+ years",
"1 year",
"2 years",
"10+ years",
"2 years",
null,
"< 1 year",
"10+ years",
"1 year",
"3 years",
"2 years",
"8 years",
null,
"9 years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"9 years",
"6 years",
"< 1 year",
"2 years",
"5 years",
"9 years",
"1 year",
"4 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"4 years",
"3 years",
"10+ years",
"10+ years",
null,
"1 year",
null,
"< 1 year",
"3 years",
"5 years",
"3 years",
"7 years",
null,
"10+ years",
"9 years",
"2 years",
null,
"10+ years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"7 years",
"< 1 year",
null,
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"1 year",
"10+ years",
"2 years",
"9 years",
"3 years",
"3 years",
"< 1 year",
"1 year",
"2 years",
"2 years",
"6 years",
"7 years",
"10+ years",
"< 1 year",
"1 year",
"3 years",
"2 years",
"10+ years",
"5 years",
"2 years",
"7 years",
"3 years",
"1 year",
"8 years",
"2 years",
"6 years",
"2 years",
"4 years",
"3 years",
"8 years",
"1 year",
"10+ years",
"5 years",
"< 1 year",
"4 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"2 years",
"2 years",
"3 years",
"10+ years",
"7 years",
"10+ years",
null,
"2 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"< 1 year",
"3 years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"2 years",
"9 years",
"3 years",
"1 year",
"6 years",
"1 year",
"1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"3 years",
null,
"7 years",
"1 year",
"8 years",
"< 1 year",
"4 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"7 years",
"10+ years",
"< 1 year",
null,
"4 years",
"9 years",
"10+ years",
"2 years",
null,
"7 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"4 years",
"6 years",
"10+ years",
"8 years",
"< 1 year",
"2 years",
"6 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"6 years",
"7 years",
"1 year",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"5 years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"4 years",
"< 1 year",
"10+ years",
null,
"7 years",
"3 years",
"9 years",
"6 years",
null,
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"< 1 year",
"10+ years",
"8 years",
null,
"1 year",
null,
"5 years",
null,
"10+ years",
null,
"10+ years",
"5 years",
"< 1 year",
"4 years",
"5 years",
"10+ years",
"1 year",
"1 year",
"8 years",
"7 years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"4 years",
"4 years",
"2 years",
"7 years",
null,
"10+ years",
"5 years",
null,
"10+ years",
"10+ years",
"10+ years",
"1 year",
"7 years",
"8 years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"6 years",
"10+ years",
"9 years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"6 years",
"6 years",
"2 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
null,
"2 years",
"10+ years",
"3 years",
"8 years",
"< 1 year",
"6 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"4 years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
null,
"10+ years",
null,
"9 years",
"4 years",
"5 years",
"4 years",
"10+ years",
null,
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"10+ years",
"1 year",
"10+ years",
"8 years",
"10+ years",
null,
"3 years",
"8 years",
"3 years",
"3 years",
"2 years",
"2 years",
"6 years",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"9 years",
"< 1 year",
"< 1 year",
"4 years",
"< 1 year",
"1 year",
"3 years",
null,
"3 years",
"6 years",
"8 years",
"6 years",
"7 years",
"10+ years",
"8 years",
null,
"10+ years",
"9 years",
"7 years",
"2 years",
"10+ years",
"2 years",
"2 years",
null,
"10+ years",
"7 years",
"2 years",
"2 years",
"10+ years",
"9 years",
"< 1 year",
"8 years",
"8 years",
"< 1 year",
"10+ years",
"8 years",
"3 years",
"4 years",
null,
"10+ years",
"6 years",
"4 years",
"7 years",
"5 years",
"2 years",
"3 years",
"1 year",
"< 1 year",
"5 years",
"1 year",
null,
"10+ years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"4 years",
"8 years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"1 year",
"2 years",
null,
"10+ years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"7 years",
"3 years",
"10+ years",
"4 years",
"1 year",
"7 years",
"10+ years",
"3 years",
"2 years",
"9 years",
"10+ years",
"8 years",
null,
"2 years",
"2 years",
"7 years",
"10+ years",
"3 years",
null,
"4 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"1 year",
"< 1 year",
"2 years",
"< 1 year",
"10+ years",
"9 years",
"6 years",
"8 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"9 years",
"10+ years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"4 years",
"< 1 year",
"3 years",
"3 years",
"8 years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"6 years",
"< 1 year",
"7 years",
"5 years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"7 years",
"5 years",
"10+ years",
"10+ years",
null,
null,
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"1 year",
"10+ years",
"10+ years",
"8 years",
"9 years",
"10+ years",
"1 year",
"3 years",
"5 years",
"5 years",
"2 years",
"8 years",
"10+ years",
"3 years",
"3 years",
"4 years",
null,
"10+ years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"5 years",
"< 1 year",
"3 years",
"8 years",
"6 years",
"6 years",
"5 years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"6 years",
"10+ years",
"2 years",
"3 years",
"6 years",
"10+ years",
"8 years",
"7 years",
null,
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"8 years",
"3 years",
"< 1 year",
"4 years",
"< 1 year",
"10+ years",
"6 years",
"3 years",
"8 years",
"< 1 year",
"1 year",
"10+ years",
"4 years",
"9 years",
"1 year",
"3 years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
null,
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"6 years",
"3 years",
"10+ years",
"< 1 year",
null,
"10+ years",
"4 years",
"10+ years",
"3 years",
"1 year",
"10+ years",
"2 years",
null,
"< 1 year",
"3 years",
"2 years",
"3 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"6 years",
"9 years",
"5 years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"< 1 year",
"7 years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
null,
"2 years",
"5 years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"2 years",
"10+ years",
"9 years",
"2 years",
"5 years",
"6 years",
"3 years",
"10+ years",
"5 years",
"2 years",
"8 years",
"10+ years",
"< 1 year",
"6 years",
"< 1 year",
"5 years",
"5 years",
"10+ years",
"10+ years",
null,
"1 year",
"2 years",
"2 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"6 years",
"5 years",
"9 years",
"1 year",
"2 years",
"10+ years",
"3 years",
"< 1 year",
"8 years",
"7 years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"8 years",
null,
null,
"10+ years",
"5 years",
"2 years",
"2 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"9 years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"2 years",
"8 years",
"< 1 year",
"8 years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"8 years",
null,
"3 years",
"10+ years",
"2 years",
"10+ years",
"6 years",
"1 year",
"10+ years",
"7 years",
"10+ years",
"7 years",
"3 years",
"1 year",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"2 years",
"10+ years",
"5 years",
"4 years",
"6 years",
"5 years",
"9 years",
"1 year",
"8 years",
"< 1 year",
"10+ years",
"9 years",
"< 1 year",
"7 years",
null,
null,
"10+ years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"2 years",
"2 years",
"4 years",
"< 1 year",
"9 years",
"9 years",
"7 years",
null,
"2 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
null,
"10+ years",
"3 years",
"< 1 year",
"7 years",
"8 years",
"3 years",
"3 years",
"10+ years",
"3 years",
"9 years",
"5 years",
"7 years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"3 years",
"3 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
null,
"3 years",
"3 years",
"1 year",
"< 1 year",
"2 years",
null,
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"7 years",
"10+ years",
"1 year",
"1 year",
"5 years",
"< 1 year",
"3 years",
"3 years",
"4 years",
"8 years",
"< 1 year",
"7 years",
"2 years",
"10+ years",
null,
"4 years",
"5 years",
"1 year",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"6 years",
"5 years",
"8 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"8 years",
null,
"< 1 year",
"6 years",
"10+ years",
"7 years",
"3 years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"8 years",
"2 years",
"< 1 year",
"4 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"4 years",
"3 years",
"10+ years",
"5 years",
"< 1 year",
"9 years",
"4 years",
null,
"3 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"7 years",
"1 year",
"3 years",
"10+ years",
"5 years",
"2 years",
"1 year",
"5 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"7 years",
"5 years",
"7 years",
"5 years",
"2 years",
"10+ years",
"4 years",
"8 years",
"10+ years",
"2 years",
"5 years",
null,
null,
"10+ years",
"10+ years",
"8 years",
"5 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"8 years",
"2 years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"4 years",
"5 years",
"5 years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"1 year",
"8 years",
"10+ years",
"5 years",
"8 years",
null,
"10+ years",
"< 1 year",
"8 years",
"4 years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"2 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"4 years",
"< 1 year",
"8 years",
null,
"10+ years",
"9 years",
"1 year",
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"9 years",
"5 years",
"2 years",
"6 years",
"< 1 year",
"10+ years",
"9 years",
"6 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"4 years",
"7 years",
"5 years",
"10+ years",
"3 years",
"4 years",
null,
"10+ years",
"7 years",
"9 years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"< 1 year",
"10+ years",
"7 years",
"7 years",
"3 years",
"10+ years",
"3 years",
"< 1 year",
"6 years",
"< 1 year",
"10+ years",
"2 years",
"7 years",
"10+ years",
"< 1 year",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"2 years",
"1 year",
"8 years",
null,
"1 year",
"2 years",
"10+ years",
"5 years",
"10+ years",
null,
"1 year",
"2 years",
"10+ years",
"5 years",
"2 years",
"1 year",
"3 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"1 year",
null,
"10+ years",
"7 years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"8 years",
"2 years",
"2 years",
"8 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
null,
"10+ years",
"2 years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"4 years",
"5 years",
"8 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"3 years",
"2 years",
null,
"3 years",
"2 years",
"10+ years",
"3 years",
null,
"8 years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"10+ years",
"8 years",
"2 years",
"6 years",
"4 years",
"6 years",
"7 years",
"9 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"3 years",
"9 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"4 years",
"8 years",
"< 1 year",
"10+ years",
"6 years",
"9 years",
"2 years",
"3 years",
"10+ years",
"4 years",
"10+ years",
"8 years",
"7 years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"1 year",
"5 years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"3 years",
"3 years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"1 year",
"8 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"6 years",
"< 1 year",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"8 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"5 years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"2 years",
"7 years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"4 years",
"8 years",
null,
"5 years",
"2 years",
null,
"10+ years",
"10+ years",
"1 year",
"4 years",
null,
"9 years",
"1 year",
"2 years",
"9 years",
"6 years",
"3 years",
"4 years",
"1 year",
"4 years",
"10+ years",
"3 years",
"6 years",
"10+ years",
"4 years",
"2 years",
"3 years",
"2 years",
"10+ years",
"6 years",
"8 years",
"8 years",
"2 years",
"9 years",
"4 years",
"3 years",
"9 years",
"4 years",
"7 years",
"5 years",
"5 years",
"7 years",
"6 years",
"1 year",
"9 years",
"< 1 year",
"< 1 year",
"< 1 year",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"8 years",
"8 years",
"< 1 year",
"9 years",
"3 years",
"9 years",
"9 years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"7 years",
"5 years",
"6 years",
"10+ years",
null,
"10+ years",
"3 years",
"9 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"5 years",
null,
"3 years",
"10+ years",
"8 years",
"7 years",
"8 years",
"1 year",
"2 years",
"3 years",
"10+ years",
"8 years",
"1 year",
"1 year",
"10+ years",
"4 years",
null,
"3 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
null,
"3 years",
"9 years",
"2 years",
"2 years",
"6 years",
"4 years",
"3 years",
"1 year",
"< 1 year",
"6 years",
"2 years",
"9 years",
"4 years",
"2 years",
"10+ years",
"4 years",
"2 years",
"7 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"10+ years",
null,
"2 years",
"1 year",
"4 years",
"2 years",
"4 years",
"2 years",
"4 years",
"10+ years",
"6 years",
"1 year",
null,
"10+ years",
"4 years",
"10+ years",
"1 year",
"2 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"8 years",
"3 years",
"10+ years",
"8 years",
"5 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"4 years",
"< 1 year",
"2 years",
"10+ years",
"1 year",
"9 years",
"1 year",
"3 years",
"1 year",
"6 years",
"6 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
null,
"1 year",
"10+ years",
null,
"7 years",
"10+ years",
"6 years",
"10+ years",
null,
"10+ years",
"5 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"9 years",
"< 1 year",
"7 years",
"5 years",
"10+ years",
"2 years",
"9 years",
"10+ years",
"3 years",
"9 years",
"5 years",
"10+ years",
"10+ years",
"9 years",
"7 years",
"10+ years",
"5 years",
"1 year",
"5 years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"3 years",
"10+ years",
null,
"5 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"3 years",
"3 years",
"2 years",
"6 years",
"10+ years",
"3 years",
"7 years",
"8 years",
"5 years",
null,
"10+ years",
"10+ years",
"5 years",
"1 year",
"3 years",
"10+ years",
"4 years",
"6 years",
"5 years",
"1 year",
"10+ years",
"6 years",
null,
"2 years",
"7 years",
"10+ years",
"1 year",
"< 1 year",
"9 years",
"10+ years",
"7 years",
"4 years",
"7 years",
"3 years",
"1 year",
"8 years",
"3 years",
"2 years",
"8 years",
"10+ years",
"5 years",
"7 years",
null,
"10+ years",
"4 years",
"7 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"8 years",
"10+ years",
"7 years",
"9 years",
"8 years",
"3 years",
"7 years",
"2 years",
"5 years",
"10+ years",
"5 years",
"4 years",
"9 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"9 years",
"2 years",
"4 years",
"1 year",
"2 years",
"2 years",
"< 1 year",
"4 years",
"10+ years",
"3 years",
"8 years",
"8 years",
"< 1 year",
"3 years",
"4 years",
"4 years",
"5 years",
"10+ years",
"5 years",
"4 years",
"7 years",
"2 years",
"3 years",
null,
"8 years",
"2 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
null,
"3 years",
"4 years",
"10+ years",
"6 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"3 years",
null,
"5 years",
"5 years",
"2 years",
"4 years",
"2 years",
"< 1 year",
"< 1 year",
"< 1 year",
null,
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"< 1 year",
"1 year",
"6 years",
null,
null,
"10+ years",
"5 years",
"10+ years",
"6 years",
"10+ years",
"7 years",
"6 years",
"10+ years",
"5 years",
"7 years",
"3 years",
"10+ years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"5 years",
"< 1 year",
"7 years",
"5 years",
"5 years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"1 year",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"3 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"2 years",
"10+ years",
"2 years",
"2 years",
"3 years",
"< 1 year",
"8 years",
"10+ years",
"5 years",
"3 years",
"4 years",
"2 years",
"9 years",
"9 years",
"6 years",
"4 years",
"2 years",
"10+ years",
"1 year",
"8 years",
"5 years",
"5 years",
"5 years",
"3 years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"1 year",
"3 years",
null,
null,
"2 years",
"10+ years",
"9 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"7 years",
"2 years",
"5 years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"8 years",
"5 years",
"< 1 year",
"3 years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"10+ years",
null,
"4 years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"3 years",
"10+ years",
"6 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
null,
"3 years",
"8 years",
"2 years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"7 years",
"4 years",
null,
"10+ years",
"10+ years",
"2 years",
"5 years",
"9 years",
"1 year",
"10+ years",
"10+ years",
"4 years",
null,
"10+ years",
"10+ years",
"7 years",
"3 years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"< 1 year",
"6 years",
"2 years",
"6 years",
"9 years",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"4 years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"4 years",
"3 years",
"4 years",
"1 year",
"10+ years",
"5 years",
"3 years",
"3 years",
"< 1 year",
"10+ years",
"< 1 year",
"1 year",
"1 year",
"5 years",
"1 year",
"10+ years",
"2 years",
"8 years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"1 year",
"3 years",
"6 years",
"1 year",
"7 years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"8 years",
"5 years",
"< 1 year",
"10+ years",
"3 years",
"1 year",
"6 years",
"10+ years",
"< 1 year",
"1 year",
"3 years",
"5 years",
"3 years",
"8 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"7 years",
"10+ years",
"10+ years",
"10+ years",
null,
"6 years",
"3 years",
"10+ years",
"5 years",
"6 years",
null,
"2 years",
"2 years",
"10+ years",
"< 1 year",
null,
"9 years",
"6 years",
"2 years",
"< 1 year",
"< 1 year",
"10+ years",
"6 years",
"5 years",
"6 years",
"< 1 year",
"4 years",
"6 years",
"1 year",
"3 years",
"10+ years",
"9 years",
"2 years",
"8 years",
"8 years",
"7 years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"3 years",
"9 years",
"2 years",
"< 1 year",
"3 years",
"4 years",
"3 years",
"8 years",
"3 years",
"2 years",
"3 years",
"10+ years",
"2 years",
"9 years",
"10+ years",
"6 years",
"3 years",
"6 years",
"9 years",
"7 years",
"1 year",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"4 years",
"7 years",
"10+ years",
"1 year",
"3 years",
"1 year",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"< 1 year",
"< 1 year",
"3 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"1 year",
"4 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"5 years",
"2 years",
"10+ years",
"4 years",
"7 years",
"7 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"8 years",
"4 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
null,
null,
"9 years",
null,
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"5 years",
"8 years",
"6 years",
"7 years",
"1 year",
"2 years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"8 years",
"1 year",
"1 year",
"10+ years",
"2 years",
"3 years",
"10+ years",
"4 years",
"8 years",
"10+ years",
"1 year",
"4 years",
"10+ years",
"8 years",
"2 years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
"9 years",
"6 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
null,
"4 years",
null,
"7 years",
"2 years",
"2 years",
"6 years",
"6 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"8 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
null,
"10+ years",
"5 years",
"3 years",
"6 years",
"3 years",
"9 years",
"5 years",
"1 year",
"4 years",
"10+ years",
"< 1 year",
"1 year",
"< 1 year",
"6 years",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"2 years",
"1 year",
"10+ years",
"5 years",
"10+ years",
"2 years",
"10+ years",
null,
"9 years",
"10+ years",
"6 years",
"3 years",
"< 1 year",
"10+ years",
"7 years",
"5 years",
"10+ years",
"5 years",
"2 years",
"6 years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"3 years",
"< 1 year",
"1 year",
"< 1 year",
"5 years",
"3 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"2 years",
"8 years",
"2 years",
null,
"10+ years",
"8 years",
"< 1 year",
"< 1 year",
"5 years",
"10+ years",
"1 year",
"8 years",
null,
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"9 years",
"10+ years",
"3 years",
null,
"5 years",
"1 year",
"1 year",
"3 years",
"4 years",
null,
"5 years",
"10+ years",
"8 years",
"4 years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
null,
"10+ years",
"5 years",
null,
"1 year",
"4 years",
"2 years",
"10+ years",
"4 years",
"3 years",
"2 years",
"10+ years",
"3 years",
"3 years",
"8 years",
"4 years",
"8 years",
"5 years",
"2 years",
"10+ years",
"7 years",
"4 years",
"2 years",
"3 years",
"6 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
null,
"4 years",
"10+ years",
"9 years",
null,
"8 years",
"9 years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"6 years",
"8 years",
"10+ years",
"10+ years",
"6 years",
"9 years",
"< 1 year",
"3 years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"1 year",
"9 years",
null,
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"6 years",
"5 years",
null,
"3 years",
"2 years",
"6 years",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"2 years",
"< 1 year",
"< 1 year",
"7 years",
"10+ years",
"1 year",
"2 years",
"4 years",
"6 years",
"4 years",
"10+ years",
"1 year",
"< 1 year",
"2 years",
"8 years",
"10+ years",
"< 1 year",
"9 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"4 years",
"5 years",
"4 years",
null,
"10+ years",
"10+ years",
"4 years",
"3 years",
"< 1 year",
"10+ years",
"1 year",
"7 years",
null,
"4 years",
"5 years",
"6 years",
"3 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"3 years",
null,
"1 year",
"1 year",
"5 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"9 years",
"10+ years",
"5 years",
"2 years",
"5 years",
"10+ years",
"< 1 year",
"1 year",
"4 years",
"< 1 year",
"< 1 year",
"8 years",
"4 years",
"2 years",
"4 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"7 years",
"6 years",
"< 1 year",
"8 years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"8 years",
"3 years",
"2 years",
"10+ years",
"9 years",
"10+ years",
"2 years",
"4 years",
"7 years",
"9 years",
"3 years",
"< 1 year",
"2 years",
"6 years",
"< 1 year",
"5 years",
"2 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
null,
"6 years",
"4 years",
"1 year",
"3 years",
"4 years",
"1 year",
"1 year",
"< 1 year",
"1 year",
"10+ years",
"7 years",
"8 years",
"9 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"5 years",
"9 years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"8 years",
"8 years",
"8 years",
"8 years",
"6 years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"< 1 year",
"< 1 year",
"7 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"2 years",
"8 years",
"1 year",
"1 year",
null,
"10+ years",
"10+ years",
"2 years",
"5 years",
"< 1 year",
"5 years",
"2 years",
"10+ years",
null,
"10+ years",
"7 years",
"6 years",
"6 years",
"5 years",
"5 years",
"4 years",
"10+ years",
"1 year",
"5 years",
"9 years",
"2 years",
"9 years",
"5 years",
"8 years",
"2 years",
"10+ years",
"< 1 year",
"< 1 year",
"2 years",
null,
"7 years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"7 years",
"7 years",
null,
"2 years",
"8 years",
"5 years",
"9 years",
"10+ years",
"9 years",
"8 years",
"9 years",
"10+ years",
null,
"10+ years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"5 years",
"7 years",
"10+ years",
"6 years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"8 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"4 years",
"10+ years",
"1 year",
"8 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"6 years",
"8 years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"7 years",
"3 years",
"5 years",
"1 year",
"< 1 year",
"2 years",
"4 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"9 years",
"9 years",
"7 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"< 1 year",
"10+ years",
null,
"8 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"< 1 year",
"4 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"7 years",
"10+ years",
"5 years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
null,
"2 years",
"8 years",
"9 years",
null,
"< 1 year",
"10+ years",
"< 1 year",
"< 1 year",
"1 year",
"2 years",
"1 year",
"3 years",
"2 years",
"1 year",
"4 years",
"< 1 year",
"1 year",
"10+ years",
"< 1 year",
"3 years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"9 years",
"< 1 year",
null,
"2 years",
"3 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"6 years",
"9 years",
"2 years",
"3 years",
"4 years",
"10+ years",
"1 year",
"5 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"4 years",
"8 years",
"2 years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"5 years",
"1 year",
"9 years",
"7 years",
"1 year",
"8 years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"3 years",
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"6 years",
"4 years",
"10+ years",
"10+ years",
"7 years",
"7 years",
"3 years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"< 1 year",
"3 years",
"2 years",
"2 years",
"10+ years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"6 years",
"10+ years",
"3 years",
"10+ years",
null,
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"8 years",
"7 years",
"9 years",
"3 years",
"3 years",
"2 years",
"4 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"6 years",
"5 years",
"10+ years",
"8 years",
"9 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"9 years",
null,
"6 years",
"9 years",
"5 years",
"4 years",
"10+ years",
"10+ years",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"9 years",
"3 years",
"3 years",
"2 years",
"2 years",
"5 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"2 years",
"8 years",
"8 years",
"3 years",
null,
"3 years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"3 years",
"8 years",
"4 years",
"4 years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"1 year",
"4 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"7 years",
"< 1 year",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"3 years",
null,
"3 years",
"10+ years",
"7 years",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
null,
"8 years",
"10+ years",
"< 1 year",
"8 years",
"3 years",
"10+ years",
"10+ years",
null,
"1 year",
"7 years",
"< 1 year",
"3 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"8 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"5 years",
"10+ years",
null,
"1 year",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"9 years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
null,
"3 years",
"2 years",
"8 years",
"2 years",
"10+ years",
"< 1 year",
"3 years",
"< 1 year",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"5 years",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"5 years",
null,
"2 years",
"8 years",
"1 year",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"5 years",
"3 years",
"10+ years",
"5 years",
"4 years",
"8 years",
"5 years",
null,
"5 years",
"10+ years",
"2 years",
"2 years",
"< 1 year",
"10+ years",
"7 years",
"3 years",
"2 years",
"< 1 year",
"1 year",
"7 years",
"2 years",
"10+ years",
"4 years",
"3 years",
"8 years",
"3 years",
"8 years",
"< 1 year",
"2 years",
"1 year",
"2 years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"2 years",
"5 years",
"< 1 year",
"< 1 year",
"6 years",
"10+ years",
"3 years",
"7 years",
null,
"3 years",
null,
"5 years",
"2 years",
"10+ years",
"7 years",
"3 years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"1 year",
"8 years",
"7 years",
"6 years",
"10+ years",
"7 years",
"10+ years",
"9 years",
"< 1 year",
"3 years",
"5 years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"8 years",
"5 years",
"3 years",
"9 years",
"1 year",
"10+ years",
null,
"3 years",
"5 years",
"8 years",
"3 years",
"7 years",
"3 years",
"7 years",
"3 years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"4 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"8 years",
"8 years",
"1 year",
"4 years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"< 1 year",
"1 year",
"7 years",
"6 years",
"3 years",
"< 1 year",
"3 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"< 1 year",
"9 years",
"2 years",
"9 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
null,
"2 years",
"< 1 year",
"< 1 year",
"4 years",
"7 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"1 year",
"1 year",
"10+ years",
"4 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"7 years",
"< 1 year",
"2 years",
"10+ years",
"5 years",
"8 years",
"2 years",
"3 years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"1 year",
"6 years",
"6 years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"6 years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"3 years",
"8 years",
null,
"7 years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"4 years",
"3 years",
"10+ years",
"3 years",
"7 years",
"9 years",
"10+ years",
"10+ years",
"8 years",
"3 years",
"2 years",
"10+ years",
"9 years",
"8 years",
"< 1 year",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"< 1 year",
"5 years",
"10+ years",
"5 years",
"8 years",
"10+ years",
"9 years",
"10+ years",
"5 years",
"10+ years",
"3 years",
"1 year",
"3 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"6 years",
"3 years",
"10+ years",
"8 years",
"5 years",
"7 years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"1 year",
"8 years",
"10+ years",
"2 years",
"7 years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
null,
"10+ years",
"9 years",
"9 years",
"< 1 year",
"2 years",
"4 years",
"< 1 year",
"5 years",
"5 years",
"3 years",
"10+ years",
"< 1 year",
null,
"10+ years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"7 years",
"10+ years",
"< 1 year",
"9 years",
"9 years",
"2 years",
"9 years",
"8 years",
null,
null,
"10+ years",
"5 years",
"6 years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"9 years",
"4 years",
"2 years",
"3 years",
"1 year",
"10+ years",
"6 years",
"< 1 year",
"8 years",
"3 years",
"5 years",
"10+ years",
"10+ years",
null,
"< 1 year",
null,
"10+ years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"4 years",
"1 year",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
null,
"1 year",
"5 years",
"4 years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"8 years",
"8 years",
"6 years",
"8 years",
"3 years",
"2 years",
"10+ years",
"8 years",
"1 year",
"10+ years",
null,
"4 years",
"4 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"1 year",
"5 years",
"6 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"3 years",
"5 years",
"3 years",
"2 years",
"6 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"7 years",
"2 years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"3 years",
"9 years",
"< 1 year",
"10+ years",
"9 years",
"< 1 year",
"3 years",
"< 1 year",
"4 years",
"2 years",
"5 years",
"7 years",
"10+ years",
"< 1 year",
"2 years",
"4 years",
"1 year",
"6 years",
"1 year",
"10+ years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"3 years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"1 year",
"8 years",
"< 1 year",
"< 1 year",
"4 years",
"10+ years",
null,
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"8 years",
null,
"2 years",
"9 years",
"2 years",
"10+ years",
"8 years",
"3 years",
"8 years",
"10+ years",
"9 years",
"8 years",
"10+ years",
"4 years",
null,
"2 years",
"< 1 year",
"8 years",
"4 years",
"4 years",
"10+ years",
"3 years",
"3 years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"5 years",
"9 years",
"9 years",
"2 years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"2 years",
"6 years",
"5 years",
null,
"5 years",
"< 1 year",
"2 years",
null,
"3 years",
"3 years",
"5 years",
"8 years",
"8 years",
"5 years",
"2 years",
"10+ years",
"7 years",
"8 years",
"2 years",
"5 years",
"10+ years",
"7 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
null,
"7 years",
"3 years",
"7 years",
"6 years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"1 year",
"4 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"3 years",
"7 years",
"2 years",
"7 years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"8 years",
"2 years",
"4 years",
"1 year",
"4 years",
null,
"4 years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"9 years",
"7 years",
"< 1 year",
null,
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"< 1 year",
"4 years",
"5 years",
"< 1 year",
"6 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
null,
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"7 years",
null,
"4 years",
"10+ years",
"9 years",
null,
"9 years",
"10+ years",
"< 1 year",
null,
"3 years",
"8 years",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"7 years",
"9 years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"7 years",
"4 years",
"8 years",
"7 years",
"6 years",
"3 years",
"1 year",
"< 1 year",
"10+ years",
"4 years",
"3 years",
"< 1 year",
"3 years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"9 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
null,
"2 years",
"< 1 year",
"< 1 year",
"4 years",
"8 years",
"4 years",
null,
"10+ years",
"1 year",
"< 1 year",
"1 year",
"< 1 year",
"< 1 year",
"5 years",
"2 years",
"8 years",
"10+ years",
"6 years",
"6 years",
"7 years",
"10+ years",
"4 years",
"2 years",
null,
"< 1 year",
"3 years",
"3 years",
"10+ years",
null,
"2 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"1 year",
"10+ years",
"4 years",
"7 years",
"1 year",
null,
"10+ years",
"4 years",
"2 years",
"2 years",
"5 years",
"9 years",
"2 years",
"5 years",
"10+ years",
"9 years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"3 years",
"1 year",
"8 years",
"5 years",
"4 years",
"9 years",
"2 years",
"10+ years",
"10+ years",
null,
"5 years",
"2 years",
"7 years",
"10+ years",
"1 year",
"8 years",
"5 years",
"9 years",
"7 years",
"6 years",
"7 years",
"4 years",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
null,
"10+ years",
"5 years",
"10+ years",
"9 years",
"8 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"7 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"4 years",
"8 years",
"10+ years",
"10+ years",
"6 years",
"4 years",
"2 years",
"9 years",
"6 years",
"3 years",
"10+ years",
"5 years",
"7 years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"7 years",
null,
"< 1 year",
"10+ years",
"2 years",
"5 years",
"2 years",
"2 years",
"2 years",
null,
"10+ years",
"10+ years",
"8 years",
"2 years",
"3 years",
"3 years",
"4 years",
"6 years",
"8 years",
"10+ years",
"2 years",
null,
"2 years",
"1 year",
"10+ years",
null,
"10+ years",
null,
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"6 years",
"5 years",
"10+ years",
null,
"10+ years",
"10+ years",
"3 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"< 1 year",
"9 years",
null,
"10+ years",
"8 years",
"10+ years",
"10+ years",
"6 years",
null,
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"6 years",
"7 years",
"1 year",
"8 years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"6 years",
"10+ years",
null,
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"3 years",
null,
"10+ years",
"4 years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"< 1 year",
"4 years",
"5 years",
"3 years",
null,
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"9 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"8 years",
null,
"1 year",
"6 years",
"2 years",
"< 1 year",
"6 years",
"9 years",
"10+ years",
"5 years",
"2 years",
"4 years",
"3 years",
"6 years",
"2 years",
"2 years",
"3 years",
null,
"3 years",
null,
"9 years",
"< 1 year",
"1 year",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"9 years",
"2 years",
"5 years",
"4 years",
"7 years",
"9 years",
"10+ years",
"3 years",
"1 year",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"1 year",
"3 years",
"6 years",
"10+ years",
"7 years",
"10+ years",
"7 years",
"3 years",
"6 years",
"10+ years",
"3 years",
"4 years",
null,
"2 years",
"< 1 year",
"3 years",
"10+ years",
"5 years",
null,
"< 1 year",
"6 years",
"1 year",
"4 years",
"3 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
null,
"10+ years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"5 years",
"5 years",
"4 years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"7 years",
"10+ years",
"2 years",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"8 years",
"7 years",
"10+ years",
null,
"< 1 year",
"8 years",
"7 years",
"6 years",
"10+ years",
"9 years",
"2 years",
"5 years",
"1 year",
"5 years",
"10+ years",
"2 years",
"10+ years",
"6 years",
"9 years",
"1 year",
"9 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"5 years",
"5 years",
"10+ years",
"9 years",
"10+ years",
"3 years",
"2 years",
"1 year",
"9 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"5 years",
null,
"5 years",
"10+ years",
"10+ years",
"2 years",
"7 years",
null,
"5 years",
"8 years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"7 years",
"4 years",
"5 years",
"4 years",
"< 1 year",
"5 years",
"10+ years",
"3 years",
"6 years",
"4 years",
null,
null,
"10+ years",
null,
null,
"5 years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"7 years",
"2 years",
"7 years",
"1 year",
"< 1 year",
"3 years",
"1 year",
"10+ years",
"8 years",
"5 years",
"2 years",
"7 years",
"5 years",
"9 years",
"8 years",
"10+ years",
"2 years",
"< 1 year",
"8 years",
"2 years",
"2 years",
"1 year",
"< 1 year",
"5 years",
"2 years",
"5 years",
"10+ years",
"8 years",
"6 years",
"4 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"4 years",
"5 years",
"2 years",
"5 years",
"10+ years",
"1 year",
"4 years",
"6 years",
"3 years",
"8 years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"7 years",
"1 year",
"10+ years",
"6 years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"5 years",
"10+ years",
null,
"3 years",
"8 years",
"8 years",
"10+ years",
"3 years",
"5 years",
"< 1 year",
"10+ years",
"2 years",
"3 years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
null,
"< 1 year",
"6 years",
"3 years",
"5 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"3 years",
"10+ years",
"< 1 year",
"2 years",
"2 years",
"6 years",
"9 years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"4 years",
"2 years",
"2 years",
null,
"10+ years",
"< 1 year",
null,
"1 year",
null,
"10+ years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"9 years",
"1 year",
"7 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"6 years",
"5 years",
"2 years",
"4 years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"4 years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"8 years",
"< 1 year",
"4 years",
"1 year",
null,
"10+ years",
"10+ years",
"10+ years",
"3 years",
null,
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"1 year",
"2 years",
null,
"7 years",
"2 years",
"10+ years",
null,
null,
"2 years",
"1 year",
"7 years",
"10+ years",
"< 1 year",
"5 years",
"5 years",
null,
"10+ years",
"6 years",
null,
"10+ years",
"2 years",
"6 years",
"9 years",
"< 1 year",
"9 years",
"10+ years",
"2 years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"2 years",
"6 years",
"10+ years",
"4 years",
"4 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"5 years",
"5 years",
null,
"4 years",
"5 years",
"2 years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"3 years",
"5 years",
"4 years",
"7 years",
"10+ years",
"7 years",
"10+ years",
"< 1 year",
"2 years",
"9 years",
"1 year",
"3 years",
"10+ years",
"2 years",
"7 years",
"9 years",
"10+ years",
null,
"9 years",
"4 years",
"2 years",
"6 years",
null,
"10+ years",
"1 year",
"3 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"9 years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"8 years",
"8 years",
"1 year",
"10+ years",
"10+ years",
"9 years",
"4 years",
"3 years",
"4 years",
"10+ years",
"2 years",
"1 year",
"7 years",
null,
"1 year",
"10+ years",
"7 years",
"7 years",
"7 years",
"2 years",
"< 1 year",
"9 years",
"4 years",
"2 years",
"10+ years",
"2 years",
"4 years",
"10+ years",
"2 years",
"8 years",
"1 year",
"8 years",
"10+ years",
"3 years",
"9 years",
"8 years",
null,
"10+ years",
"3 years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"1 year",
"2 years",
"5 years",
"2 years",
"5 years",
"5 years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"3 years",
null,
"8 years",
null,
"10+ years",
"5 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"9 years",
"2 years",
"3 years",
"10+ years",
"4 years",
"< 1 year",
"1 year",
"5 years",
"4 years",
"10+ years",
"10+ years",
null,
"4 years",
"10+ years",
"10+ years",
null,
"3 years",
"1 year",
"2 years",
"7 years",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
null,
"10+ years",
"1 year",
"3 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"7 years",
"6 years",
"2 years",
"10+ years",
"6 years",
"4 years",
"10+ years",
"9 years",
"3 years",
"2 years",
"10+ years",
"2 years",
"1 year",
"8 years",
"< 1 year",
"3 years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"4 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"1 year",
"4 years",
"8 years",
"10+ years",
"6 years",
"10+ years",
"5 years",
"10+ years",
"8 years",
"1 year",
"1 year",
"7 years",
"7 years",
"< 1 year",
"8 years",
"10+ years",
null,
"< 1 year",
"8 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
null,
"2 years",
"3 years",
"10+ years",
"3 years",
"4 years",
"8 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"8 years",
"< 1 year",
"4 years",
"5 years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"9 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"3 years",
"5 years",
"1 year",
"8 years",
"10+ years",
"< 1 year",
"8 years",
"2 years",
"1 year",
null,
"10+ years",
"10+ years",
"2 years",
"5 years",
null,
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"8 years",
"10+ years",
"6 years",
"6 years",
"3 years",
"8 years",
"7 years",
null,
null,
"10+ years",
"2 years",
"10+ years",
"2 years",
"1 year",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"9 years",
"4 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"8 years",
"2 years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"6 years",
"7 years",
"5 years",
"8 years",
"10+ years",
"< 1 year",
"< 1 year",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"9 years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"7 years",
"10+ years",
"8 years",
null,
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"5 years",
null,
"10+ years",
null,
"1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"< 1 year",
"1 year",
"5 years",
"4 years",
"2 years",
"10+ years",
"2 years",
"2 years",
"3 years",
null,
"10+ years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"6 years",
"6 years",
"10+ years",
"2 years",
"< 1 year",
"8 years",
"10+ years",
"5 years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
null,
"5 years",
"1 year",
"1 year",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"8 years",
"8 years",
"10+ years",
"4 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"< 1 year",
"8 years",
"1 year",
"4 years",
"8 years",
"2 years",
"10+ years",
"< 1 year",
"2 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
null,
"1 year",
"4 years",
"3 years",
"< 1 year",
"9 years",
"6 years",
"6 years",
null,
"10+ years",
"7 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"8 years",
"8 years",
"8 years",
"4 years",
"4 years",
"< 1 year",
"1 year",
"1 year",
"7 years",
"7 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"4 years",
"3 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"7 years",
"< 1 year",
"5 years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"2 years",
"7 years",
null,
"10+ years",
"10+ years",
"9 years",
"5 years",
"2 years",
"10+ years",
"6 years",
"7 years",
"10+ years",
"4 years",
"3 years",
null,
"10+ years",
"9 years",
"2 years",
"5 years",
"< 1 year",
"7 years",
"4 years",
"2 years",
"2 years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"1 year",
"9 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"4 years",
"10+ years",
null,
"2 years",
"10+ years",
"8 years",
"3 years",
"< 1 year",
"4 years",
"10+ years",
"8 years",
"1 year",
"3 years",
"10+ years",
"1 year",
"10+ years",
"2 years",
"6 years",
"10+ years",
"3 years",
"3 years",
"9 years",
"7 years",
"10+ years",
"3 years",
"1 year",
null,
"2 years",
"6 years",
"6 years",
"< 1 year",
"8 years",
"10+ years",
"2 years",
"6 years",
"5 years",
"6 years",
"3 years",
"6 years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"8 years",
"3 years",
"5 years",
"9 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
null,
"< 1 year",
"10+ years",
"7 years",
"2 years",
"1 year",
"1 year",
"3 years",
"4 years",
"10+ years",
"7 years",
"2 years",
"< 1 year",
"1 year",
"10+ years",
"3 years",
"< 1 year",
"2 years",
"9 years",
"8 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"6 years",
"< 1 year",
"4 years",
"6 years",
"6 years",
"6 years",
"2 years",
"5 years",
"8 years",
null,
"< 1 year",
"6 years",
"6 years",
"4 years",
"7 years",
"7 years",
"7 years",
"7 years",
"10+ years",
null,
"6 years",
"8 years",
"3 years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"4 years",
"9 years",
"9 years",
"8 years",
"3 years",
"1 year",
"9 years",
null,
"< 1 year",
null,
"1 year",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"2 years",
"8 years",
"2 years",
"5 years",
"1 year",
"10+ years",
"7 years",
"2 years",
"8 years",
null,
"6 years",
"< 1 year",
"10+ years",
"7 years",
"9 years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"7 years",
"10+ years",
null,
"10+ years",
"9 years",
"< 1 year",
null,
"10+ years",
"10+ years",
"7 years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"3 years",
"< 1 year",
null,
"5 years",
"10+ years",
"10+ years",
"1 year",
"8 years",
"10+ years",
"6 years",
"8 years",
"2 years",
"10+ years",
"6 years",
"10+ years",
"7 years",
"5 years",
"4 years",
"10+ years",
"1 year",
"7 years",
"1 year",
"< 1 year",
"3 years",
"5 years",
"7 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"2 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"4 years",
"2 years",
"5 years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"< 1 year",
"< 1 year",
"2 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"4 years",
"1 year",
"10+ years",
"10+ years",
"1 year",
"4 years",
"5 years",
"3 years",
"7 years",
"3 years",
"3 years",
"1 year",
"10+ years",
null,
"10+ years",
"3 years",
"9 years",
"< 1 year",
"10+ years",
"7 years",
"1 year",
"2 years",
"< 1 year",
"2 years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"4 years",
null,
"4 years",
"3 years",
"< 1 year",
"5 years",
"5 years",
"5 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"1 year",
"3 years",
"9 years",
"3 years",
"10+ years",
"3 years",
null,
null,
"6 years",
"< 1 year",
"6 years",
"10+ years",
"4 years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"5 years",
"6 years",
"4 years",
"10+ years",
"< 1 year",
null,
"10+ years",
"8 years",
"5 years",
null,
"3 years",
"< 1 year",
"7 years",
"9 years",
"2 years",
"4 years",
"10+ years",
"5 years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"1 year",
"7 years",
"7 years",
"< 1 year",
"6 years",
"5 years",
"7 years",
"10+ years",
"2 years",
null,
"2 years",
"3 years",
"9 years",
"10+ years",
"10+ years",
"8 years",
"6 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"7 years",
"9 years",
"1 year",
null,
"10+ years",
"1 year",
"1 year",
"3 years",
"10+ years",
"5 years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
null,
"< 1 year",
"7 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"6 years",
"10+ years",
null,
"4 years",
"2 years",
"8 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"1 year",
"< 1 year",
"4 years",
"1 year",
"< 1 year",
"8 years",
"10+ years",
"3 years",
"3 years",
"4 years",
"10+ years",
"< 1 year",
"2 years",
"4 years",
"5 years",
"5 years",
"10+ years",
"9 years",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"1 year",
"5 years",
"10+ years",
"5 years",
"5 years",
null,
"6 years",
"10+ years",
"< 1 year",
"6 years",
"7 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"1 year",
"3 years",
"3 years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"< 1 year",
"8 years",
"6 years",
"< 1 year",
"< 1 year",
"1 year",
"1 year",
"7 years",
"4 years",
"1 year",
"2 years",
"6 years",
"< 1 year",
"7 years",
"1 year",
"2 years",
"10+ years",
"6 years",
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"3 years",
"5 years",
"10+ years",
"6 years",
"3 years",
"4 years",
"4 years",
null,
"7 years",
"7 years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"7 years",
"10+ years",
"8 years",
"< 1 year",
"6 years",
"< 1 year",
"9 years",
"1 year",
"10+ years",
"2 years",
"5 years",
null,
"1 year",
"2 years",
"2 years",
"10+ years",
"< 1 year",
"5 years",
"< 1 year",
"9 years",
"10+ years",
"3 years",
"1 year",
"2 years",
"10+ years",
"7 years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"5 years",
null,
"1 year",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
null,
"10+ years",
"9 years",
"7 years",
"1 year",
null,
"10+ years",
"< 1 year",
null,
"10+ years",
null,
"10+ years",
"2 years",
"7 years",
"< 1 year",
null,
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"8 years",
"7 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"8 years",
"10+ years",
null,
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"9 years",
"< 1 year",
"10+ years",
"2 years",
"4 years",
"6 years",
"4 years",
"5 years",
null,
"10+ years",
"5 years",
"8 years",
"8 years",
"3 years",
"8 years",
"1 year",
"2 years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"6 years",
"8 years",
"8 years",
"10+ years",
"6 years",
"1 year",
"10+ years",
"6 years",
"< 1 year",
"9 years",
"7 years",
"< 1 year",
"8 years",
"4 years",
null,
null,
"3 years",
"10+ years",
"3 years",
"5 years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"9 years",
"< 1 year",
"< 1 year",
"3 years",
"8 years",
"4 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"8 years",
"7 years",
"10+ years",
"5 years",
"2 years",
"8 years",
"7 years",
"10+ years",
"2 years",
null,
"8 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"7 years",
"7 years",
"7 years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"6 years",
"7 years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"6 years",
"3 years",
"10+ years",
"5 years",
"2 years",
"4 years",
"5 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
null,
"9 years",
"10+ years",
"7 years",
"2 years",
"2 years",
"1 year",
"8 years",
"8 years",
null,
"10+ years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"6 years",
"10+ years",
"6 years",
"9 years",
null,
"3 years",
"10+ years",
"1 year",
"3 years",
"1 year",
"5 years",
"10+ years",
"7 years",
"< 1 year",
"5 years",
null,
"10+ years",
"10+ years",
"9 years",
null,
"10+ years",
"2 years",
"3 years",
"1 year",
"10+ years",
"5 years",
"6 years",
"4 years",
"3 years",
"3 years",
"2 years",
"10+ years",
"4 years",
"2 years",
"3 years",
null,
null,
"10+ years",
"10+ years",
"10+ years",
"4 years",
"9 years",
null,
"9 years",
"3 years",
"1 year",
"10+ years",
"3 years",
"4 years",
"10+ years",
"5 years",
null,
"2 years",
"9 years",
"10+ years",
"5 years",
"8 years",
"2 years",
"2 years",
"10+ years",
"2 years",
"8 years",
"6 years",
"< 1 year",
"4 years",
"3 years",
"10+ years",
"2 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"2 years",
null,
"4 years",
"3 years",
"10+ years",
"4 years",
"2 years",
"5 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"5 years",
"7 years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"5 years",
"8 years",
"10+ years",
"10+ years",
"8 years",
null,
"7 years",
"5 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"2 years",
"4 years",
"6 years",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"< 1 year",
"5 years",
"3 years",
"2 years",
"6 years",
"8 years",
"4 years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"< 1 year",
"2 years",
"2 years",
"4 years",
"< 1 year",
null,
"6 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"6 years",
"8 years",
"5 years",
"5 years",
"4 years",
"4 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
null,
"2 years",
"10+ years",
"4 years",
null,
"10+ years",
"1 year",
"10+ years",
"10+ years",
"7 years",
"9 years",
"5 years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"6 years",
"3 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"4 years",
"4 years",
"10+ years",
"9 years",
"2 years",
"10+ years",
null,
null,
"1 year",
"< 1 year",
"3 years",
"5 years",
null,
"1 year",
"7 years",
"10+ years",
"1 year",
"4 years",
"10+ years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"4 years",
"2 years",
"3 years",
"6 years",
"2 years",
"6 years",
"3 years",
"9 years",
"3 years",
"3 years",
"8 years",
"1 year",
"9 years",
"1 year",
null,
"4 years",
"2 years",
"< 1 year",
"8 years",
"3 years",
"10+ years",
"7 years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"4 years",
"3 years",
"6 years",
"2 years",
"3 years",
"10+ years",
null,
"10+ years",
"10+ years",
"8 years",
"7 years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
null,
"3 years",
"9 years",
null,
"5 years",
"10+ years",
null,
"2 years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"8 years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"9 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"3 years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"5 years",
"3 years",
null,
"9 years",
"< 1 year",
"< 1 year",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"2 years",
"10+ years",
null,
"7 years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"8 years",
"9 years",
"7 years",
"9 years",
"1 year",
"10+ years",
"1 year",
"9 years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"1 year",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"8 years",
"2 years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"8 years",
"3 years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"4 years",
"10+ years",
"8 years",
null,
"< 1 year",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"8 years",
"< 1 year",
"4 years",
"2 years",
"6 years",
"4 years",
"1 year",
"< 1 year",
"10+ years",
"9 years",
"9 years",
"3 years",
null,
null,
"10+ years",
"< 1 year",
"5 years",
"9 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"5 years",
null,
"< 1 year",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"3 years",
null,
"6 years",
"2 years",
"5 years",
"10+ years",
"8 years",
"9 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"5 years",
"2 years",
"4 years",
"10+ years",
"2 years",
"5 years",
"1 year",
"8 years",
"< 1 year",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"8 years",
"2 years",
"10+ years",
"1 year",
null,
"10+ years",
"5 years",
"2 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
null,
null,
"9 years",
"7 years",
null,
"5 years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"2 years",
"< 1 year",
"2 years",
"5 years",
"7 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"1 year",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"7 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"8 years",
"8 years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"3 years",
"1 year",
"8 years",
"10+ years",
"8 years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"4 years",
"6 years",
"10+ years",
"4 years",
"10+ years",
"1 year",
"10+ years",
"6 years",
"9 years",
"10+ years",
"3 years",
"5 years",
null,
"10+ years",
null,
"6 years",
"9 years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"7 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
null,
"1 year",
"3 years",
"< 1 year",
"5 years",
"7 years",
"5 years",
"1 year",
"7 years",
"2 years",
"10+ years",
null,
"3 years",
"4 years",
"10+ years",
"8 years",
"< 1 year",
null,
"3 years",
"3 years",
"1 year",
"5 years",
"6 years",
"9 years",
"5 years",
"6 years",
"5 years",
"3 years",
"8 years",
"3 years",
"3 years",
"2 years",
"10+ years",
"< 1 year",
"4 years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"5 years",
"5 years",
"10+ years",
"4 years",
"5 years",
"1 year",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"4 years",
"9 years",
"3 years",
"6 years",
"4 years",
"9 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"1 year",
null,
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"7 years",
"2 years",
"1 year",
"9 years",
"4 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"4 years",
"< 1 year",
"10+ years",
"9 years",
null,
"7 years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"3 years",
"3 years",
"4 years",
"1 year",
"1 year",
null,
"4 years",
"2 years",
"4 years",
"4 years",
"10+ years",
"3 years",
"< 1 year",
"9 years",
"1 year",
"1 year",
"< 1 year",
"3 years",
"2 years",
"5 years",
"3 years",
"10+ years",
"3 years",
"5 years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
null,
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"2 years",
"< 1 year",
"2 years",
"6 years",
"10+ years",
null,
"6 years",
"2 years",
"1 year",
null,
"10+ years",
null,
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"6 years",
"7 years",
"9 years",
"6 years",
"2 years",
null,
"2 years",
"10+ years",
"5 years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"< 1 year",
"4 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"7 years",
"10+ years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"3 years",
"8 years",
"5 years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"1 year",
"1 year",
"4 years",
"5 years",
null,
"< 1 year",
"1 year",
"10+ years",
null,
"10+ years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"3 years",
"8 years",
null,
"10+ years",
"< 1 year",
"6 years",
"10+ years",
null,
"8 years",
"2 years",
"10+ years",
"6 years",
"7 years",
"2 years",
"6 years",
"4 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"5 years",
"5 years",
"10+ years",
"7 years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"1 year",
"10+ years",
null,
"1 year",
"5 years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"8 years",
"8 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"3 years",
"9 years",
"5 years",
"10+ years",
"1 year",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"7 years",
"4 years",
"4 years",
"8 years",
"4 years",
"10+ years",
"3 years",
"3 years",
"6 years",
"3 years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"1 year",
"3 years",
"10+ years",
null,
"2 years",
"10+ years",
"8 years",
"10+ years",
"7 years",
"5 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"7 years",
"5 years",
"4 years",
"7 years",
"7 years",
"< 1 year",
"3 years",
"10+ years",
"< 1 year",
"2 years",
"7 years",
"8 years",
"10+ years",
null,
"10+ years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"2 years",
"7 years",
"8 years",
"8 years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"3 years",
"5 years",
"5 years",
"9 years",
"2 years",
"10+ years",
"1 year",
"6 years",
"4 years",
"10+ years",
"< 1 year",
"8 years",
"5 years",
"10+ years",
null,
"4 years",
"3 years",
"1 year",
"4 years",
"10+ years",
"3 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"9 years",
"4 years",
"8 years",
"5 years",
"3 years",
"10+ years",
"7 years",
"4 years",
null,
null,
"10+ years",
"4 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"4 years",
"10+ years",
"7 years",
"8 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
null,
"7 years",
"6 years",
"1 year",
"4 years",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"4 years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"4 years",
"3 years",
"7 years",
null,
"5 years",
"< 1 year",
"1 year",
"10+ years",
"6 years",
"4 years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"6 years",
"5 years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"1 year",
"3 years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"10+ years",
"2 years",
null,
"10+ years",
"9 years",
"10+ years",
"10+ years",
"9 years",
"8 years",
"5 years",
"10+ years",
"< 1 year",
"7 years",
"2 years",
"3 years",
"5 years",
"10+ years",
null,
"3 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"2 years",
"8 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"4 years",
"1 year",
"5 years",
"3 years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"5 years",
"2 years",
null,
"6 years",
"1 year",
"1 year",
"7 years",
"5 years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"5 years",
"2 years",
"10+ years",
"1 year",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"5 years",
"2 years",
"3 years",
"2 years",
"< 1 year",
"6 years",
"3 years",
"2 years",
"7 years",
"5 years",
"7 years",
"4 years",
"10+ years",
"< 1 year",
"< 1 year",
"4 years",
"8 years",
null,
"10+ years",
"10+ years",
"6 years",
"2 years",
"10+ years",
null,
"1 year",
"1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"4 years",
"< 1 year",
"3 years",
"8 years",
"10+ years",
"8 years",
"2 years",
"9 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"5 years",
"2 years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"6 years",
"8 years",
"4 years",
"7 years",
"5 years",
"4 years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"5 years",
"5 years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"3 years",
"10+ years",
"6 years",
"4 years",
"10+ years",
"1 year",
"6 years",
"10+ years",
"5 years",
"4 years",
"5 years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"6 years",
"< 1 year",
"10+ years",
"2 years",
"1 year",
"10+ years",
"2 years",
"8 years",
"4 years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"6 years",
"3 years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"7 years",
"7 years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
null,
"6 years",
"< 1 year",
"< 1 year",
"10+ years",
"4 years",
"9 years",
"< 1 year",
null,
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
"5 years",
"6 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"1 year",
"9 years",
"4 years",
"3 years",
"2 years",
"9 years",
"10+ years",
"2 years",
"4 years",
"1 year",
"3 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
null,
"10+ years",
"< 1 year",
"3 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"8 years",
"9 years",
"10+ years",
"1 year",
"10+ years",
"4 years",
"2 years",
"5 years",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"6 years",
"10+ years",
null,
"10+ years",
"< 1 year",
"8 years",
"6 years",
"5 years",
"1 year",
"3 years",
"1 year",
"7 years",
"9 years",
"2 years",
"8 years",
"9 years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
null,
"10+ years",
"10+ years",
"9 years",
"8 years",
"5 years",
"10+ years",
"4 years",
"8 years",
"10+ years",
"5 years",
"1 year",
"7 years",
"10+ years",
"1 year",
"8 years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"1 year",
"< 1 year",
"9 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"4 years",
"8 years",
"4 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"8 years",
null,
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"3 years",
"10+ years",
"7 years",
"6 years",
"8 years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"7 years",
"10+ years",
"6 years",
"5 years",
"3 years",
"1 year",
"10+ years",
"4 years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"4 years",
"2 years",
null,
"10+ years",
"1 year",
"6 years",
"10+ years",
"6 years",
"5 years",
"10+ years",
"2 years",
"5 years",
"7 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"1 year",
"2 years",
"8 years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"5 years",
"5 years",
"3 years",
"9 years",
"2 years",
"2 years",
"2 years",
"< 1 year",
"2 years",
"10+ years",
"9 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"9 years",
"1 year",
"7 years",
"5 years",
"10+ years",
"10+ years",
"6 years",
"9 years",
"< 1 year",
"5 years",
"6 years",
null,
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"7 years",
null,
"1 year",
"10+ years",
"10+ years",
"8 years",
"2 years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"9 years",
null,
"10+ years",
"3 years",
"10+ years",
"4 years",
"10+ years",
"9 years",
"5 years",
"10+ years",
null,
"< 1 year",
"6 years",
"6 years",
"4 years",
"4 years",
"1 year",
"10+ years",
"< 1 year",
"< 1 year",
"8 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"5 years",
"< 1 year",
"6 years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"10+ years",
"6 years",
null,
"6 years",
"6 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"< 1 year",
"< 1 year",
"7 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"8 years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"< 1 year",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"3 years",
null,
"10+ years",
"1 year",
"8 years",
"7 years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"1 year",
null,
"< 1 year",
"4 years",
"4 years",
"4 years",
"5 years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"5 years",
"10+ years",
"4 years",
"10+ years",
"4 years",
"3 years",
"9 years",
"< 1 year",
"1 year",
"5 years",
"9 years",
"6 years",
null,
"2 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"7 years",
"6 years",
"5 years",
"5 years",
"8 years",
null,
"< 1 year",
"6 years",
"6 years",
"3 years",
"4 years",
"10+ years",
"8 years",
"< 1 year",
"< 1 year",
"6 years",
"10+ years",
"10+ years",
null,
"< 1 year",
"2 years",
"9 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"4 years",
"4 years",
"< 1 year",
"9 years",
"10+ years",
"10+ years",
"1 year",
"6 years",
"8 years",
"9 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"3 years",
"2 years",
"< 1 year",
"3 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"6 years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"1 year",
null,
"3 years",
"2 years",
"4 years",
"10+ years",
"4 years",
"8 years",
"5 years",
"2 years",
"4 years",
"3 years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"2 years",
"< 1 year",
"5 years",
"8 years",
"9 years",
"10+ years",
"10+ years",
"3 years",
null,
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"4 years",
"1 year",
"5 years",
"2 years",
"6 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"6 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"9 years",
"6 years",
"8 years",
"1 year",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"6 years",
null,
"6 years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"2 years",
"1 year",
"10+ years",
"7 years",
"3 years",
"< 1 year",
"10+ years",
"4 years",
"3 years",
"< 1 year",
"5 years",
"7 years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"5 years",
"9 years",
"1 year",
"3 years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"6 years",
null,
"8 years",
"10+ years",
"5 years",
"< 1 year",
"2 years",
"6 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"10+ years",
"7 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"6 years",
null,
"< 1 year",
"< 1 year",
"10+ years",
"3 years",
"7 years",
"< 1 year",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"4 years",
"3 years",
"10+ years",
"9 years",
"10+ years",
"4 years",
"8 years",
"10+ years",
"6 years",
"< 1 year",
null,
"10+ years",
"8 years",
"7 years",
"4 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"3 years",
"< 1 year",
"4 years",
"9 years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"8 years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"9 years",
"2 years",
"6 years",
"10+ years",
"< 1 year",
"3 years",
"9 years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"5 years",
"9 years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"6 years",
"10+ years",
"3 years",
null,
null,
"10+ years",
null,
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"4 years",
"5 years",
"4 years",
"1 year",
null,
"6 years",
"10+ years",
"6 years",
"4 years",
"10+ years",
"< 1 year",
"2 years",
"9 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"8 years",
"3 years",
"5 years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"7 years",
"4 years",
"10+ years",
null,
"7 years",
"2 years",
"6 years",
"9 years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"8 years",
"< 1 year",
"3 years",
"1 year",
"2 years",
"9 years",
"9 years",
"2 years",
"8 years",
"10+ years",
"7 years",
"6 years",
"9 years",
"5 years",
null,
null,
"2 years",
"7 years",
"9 years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"6 years",
"9 years",
"10+ years",
"10+ years",
"2 years",
null,
"3 years",
"5 years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"3 years",
"7 years",
"6 years",
null,
"< 1 year",
"4 years",
"6 years",
"7 years",
"< 1 year",
"< 1 year",
"3 years",
"2 years",
"3 years",
"1 year",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"9 years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"7 years",
"3 years",
"3 years",
"8 years",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"8 years",
"6 years",
"6 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"1 year",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"5 years",
"2 years",
"1 year",
"2 years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"4 years",
"10+ years",
"1 year",
"< 1 year",
"6 years",
"10+ years",
"2 years",
"4 years",
"4 years",
"1 year",
"9 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"7 years",
"5 years",
"6 years",
"3 years",
"10+ years",
null,
null,
"10+ years",
"< 1 year",
"1 year",
"8 years",
"7 years",
"< 1 year",
"10+ years",
null,
"5 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"3 years",
"6 years",
"2 years",
"2 years",
null,
null,
"10+ years",
"7 years",
"10+ years",
"7 years",
"5 years",
"7 years",
"10+ years",
null,
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
null,
"< 1 year",
"3 years",
"4 years",
"10+ years",
"6 years",
"9 years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"9 years",
"10+ years",
"7 years",
"4 years",
"5 years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"7 years",
"9 years",
"8 years",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
"2 years",
"2 years",
"4 years",
"< 1 year",
"1 year",
"4 years",
"10+ years",
"2 years",
"< 1 year",
"6 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"2 years",
"4 years",
"8 years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"3 years",
"< 1 year",
"< 1 year",
"6 years",
"2 years",
"5 years",
"7 years",
"< 1 year",
"6 years",
"2 years",
"2 years",
"9 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"8 years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"7 years",
"5 years",
"10+ years",
"4 years",
"1 year",
null,
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"6 years",
"7 years",
"5 years",
"8 years",
"4 years",
"8 years",
"4 years",
null,
"7 years",
"1 year",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
null,
"7 years",
"< 1 year",
"10+ years",
"8 years",
"5 years",
"10+ years",
"5 years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
null,
"5 years",
"2 years",
null,
"3 years",
"7 years",
"2 years",
"1 year",
"10+ years",
"4 years",
"7 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"1 year",
"2 years",
"1 year",
"8 years",
"5 years",
"8 years",
"9 years",
"< 1 year",
"9 years",
"10+ years",
"1 year",
"9 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"7 years",
"4 years",
"10+ years",
"< 1 year",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"2 years",
"10+ years",
"8 years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
null,
"< 1 year",
"10+ years",
"3 years",
null,
"1 year",
"6 years",
"5 years",
"8 years",
"2 years",
"2 years",
"4 years",
null,
"5 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"3 years",
null,
"10+ years",
"8 years",
"< 1 year",
"1 year",
"10+ years",
"2 years",
"4 years",
"1 year",
"< 1 year",
"2 years",
"10+ years",
"< 1 year",
"2 years",
"6 years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"10+ years",
null,
"10+ years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"5 years",
"5 years",
"2 years",
"1 year",
"< 1 year",
"3 years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"1 year",
"1 year",
"10+ years",
"1 year",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
null,
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
null,
"3 years",
"3 years",
"< 1 year",
"< 1 year",
"10+ years",
"1 year",
"7 years",
"2 years",
"9 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
null,
"10+ years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"4 years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"8 years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"7 years",
"10+ years",
null,
"10+ years",
"10+ years",
"3 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"9 years",
"10+ years",
"10+ years",
"5 years",
"8 years",
"10+ years",
"10+ years",
null,
"1 year",
"< 1 year",
"4 years",
"10+ years",
"7 years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"5 years",
"3 years",
"5 years",
"5 years",
"8 years",
"8 years",
"4 years",
"3 years",
"3 years",
"8 years",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
null,
"10+ years",
"4 years",
"5 years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"6 years",
"2 years",
"1 year",
"1 year",
"9 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"1 year",
"< 1 year",
"1 year",
"3 years",
"4 years",
"2 years",
"7 years",
"5 years",
"1 year",
"10+ years",
"< 1 year",
"4 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
null,
"3 years",
"10+ years",
"2 years",
null,
"3 years",
"4 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
null,
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"4 years",
"2 years",
"5 years",
"2 years",
"8 years",
"4 years",
"2 years",
"10+ years",
"5 years",
null,
"2 years",
"< 1 year",
"9 years",
"5 years",
"3 years",
"10+ years",
"10+ years",
null,
"2 years",
"6 years",
"10+ years",
"2 years",
"9 years",
"6 years",
"2 years",
"< 1 year",
"6 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
null,
"7 years",
"1 year",
"10+ years",
"1 year",
"5 years",
null,
"2 years",
null,
"10+ years",
"1 year",
"5 years",
"10+ years",
"10+ years",
"5 years",
null,
"10+ years",
"10+ years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"2 years",
"1 year",
"3 years",
"8 years",
"< 1 year",
"10+ years",
"6 years",
"2 years",
"9 years",
"2 years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"6 years",
"3 years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"8 years",
"10+ years",
"4 years",
"1 year",
"1 year",
"10+ years",
"6 years",
"2 years",
"1 year",
"7 years",
"8 years",
"5 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"8 years",
"4 years",
"1 year",
"2 years",
"2 years",
"8 years",
"10+ years",
"< 1 year",
"1 year",
"8 years",
"3 years",
"5 years",
"5 years",
"1 year",
"10+ years",
"3 years",
"4 years",
"2 years",
"9 years",
"< 1 year",
"8 years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
null,
"6 years",
null,
"6 years",
"5 years",
"9 years",
null,
"< 1 year",
"5 years",
"8 years",
"4 years",
"9 years",
null,
"1 year",
"10+ years",
"3 years",
"< 1 year",
"5 years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"1 year",
"1 year",
"10+ years",
"8 years",
null,
"3 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"9 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"8 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"1 year",
"4 years",
"8 years",
"3 years",
"6 years",
"10+ years",
"10+ years",
"8 years",
"7 years",
"10+ years",
"2 years",
"5 years",
"6 years",
null,
"< 1 year",
"7 years",
"5 years",
"5 years",
"10+ years",
"< 1 year",
"8 years",
"< 1 year",
"10+ years",
"7 years",
"9 years",
"1 year",
"3 years",
"2 years",
"3 years",
"< 1 year",
"8 years",
null,
"10+ years",
"8 years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
null,
"< 1 year",
"9 years",
"7 years",
"10+ years",
"3 years",
"7 years",
null,
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"6 years",
"7 years",
"6 years",
"10+ years",
null,
"4 years",
"2 years",
"< 1 year",
"6 years",
"10+ years",
"10+ years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"6 years",
"10+ years",
"2 years",
"4 years",
"5 years",
"6 years",
null,
"2 years",
"7 years",
"1 year",
"2 years",
"8 years",
"7 years",
"8 years",
"10+ years",
"< 1 year",
null,
"10+ years",
"3 years",
"4 years",
"10+ years",
"6 years",
"7 years",
"2 years",
"4 years",
"3 years",
"7 years",
"8 years",
"4 years",
"4 years",
"5 years",
"4 years",
"5 years",
"< 1 year",
null,
"3 years",
"4 years",
"10+ years",
"8 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"1 year",
"6 years",
"1 year",
"3 years",
"< 1 year",
"< 1 year",
"2 years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"6 years",
"1 year",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
null,
"3 years",
"6 years",
"< 1 year",
"< 1 year",
"10+ years",
"8 years",
"< 1 year",
"2 years",
"10+ years",
"< 1 year",
"6 years",
null,
"< 1 year",
"4 years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
null,
"< 1 year",
"6 years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"5 years",
"6 years",
"2 years",
"2 years",
"10+ years",
"6 years",
"7 years",
"4 years",
"7 years",
"< 1 year",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
null,
"5 years",
"< 1 year",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"8 years",
"< 1 year",
"1 year",
"5 years",
"2 years",
"1 year",
"7 years",
"7 years",
"4 years",
"3 years",
"2 years",
"7 years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"1 year",
"3 years",
"10+ years",
"4 years",
"3 years",
"10+ years",
"9 years",
"1 year",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
null,
"4 years",
"3 years",
null,
"< 1 year",
"5 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"3 years",
"6 years",
"< 1 year",
"2 years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"5 years",
"4 years",
"10+ years",
"10+ years",
null,
"1 year",
"10+ years",
"5 years",
"5 years",
"1 year",
"3 years",
"2 years",
"9 years",
"9 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"7 years",
"10+ years",
"6 years",
"2 years",
null,
"7 years",
"2 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
null,
null,
"2 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"6 years",
"2 years",
null,
"4 years",
"8 years",
"3 years",
"< 1 year",
"2 years",
"3 years",
"2 years",
"2 years",
"9 years",
"6 years",
"9 years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"5 years",
"10+ years",
"< 1 year",
"4 years",
"2 years",
null,
"8 years",
"8 years",
"< 1 year",
"4 years",
"< 1 year",
null,
"10+ years",
"2 years",
null,
null,
"8 years",
"8 years",
"4 years",
"4 years",
"10+ years",
"5 years",
"2 years",
"1 year",
"3 years",
"10+ years",
"2 years",
"2 years",
"8 years",
"6 years",
"4 years",
"5 years",
"5 years",
"10+ years",
"2 years",
"2 years",
"5 years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"< 1 year",
"8 years",
"10+ years",
"7 years",
"7 years",
"5 years",
"10+ years",
"10+ years",
null,
"2 years",
"2 years",
"4 years",
"5 years",
"10+ years",
null,
"3 years",
"2 years",
"10+ years",
"10+ years",
null,
"2 years",
"8 years",
"10+ years",
"5 years",
"3 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"9 years",
"6 years",
"8 years",
"8 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
null,
"10+ years",
"5 years",
"10+ years",
"4 years",
"7 years",
"10+ years",
"6 years",
"6 years",
null,
"8 years",
"3 years",
"10+ years",
"6 years",
"10+ years",
"6 years",
"< 1 year",
"1 year",
"6 years",
null,
"3 years",
"5 years",
"2 years",
"9 years",
"10+ years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"4 years",
"5 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
null,
"10+ years",
"10+ years",
"8 years",
"7 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"9 years",
null,
"< 1 year",
"2 years",
"10+ years",
"6 years",
"< 1 year",
"9 years",
"9 years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"4 years",
"4 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"1 year",
"4 years",
"7 years",
"5 years",
"10+ years",
"3 years",
"2 years",
null,
"3 years",
"10+ years",
"9 years",
"< 1 year",
"1 year",
"5 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"2 years",
"4 years",
"9 years",
"1 year",
"10+ years",
"10+ years",
"4 years",
"9 years",
"7 years",
"7 years",
"< 1 year",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"1 year",
"7 years",
null,
"4 years",
"6 years",
"< 1 year",
"1 year",
"7 years",
"5 years",
"2 years",
"8 years",
"5 years",
"10+ years",
"6 years",
"10+ years",
null,
"10+ years",
"6 years",
"4 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"2 years",
"3 years",
"4 years",
"5 years",
"6 years",
"10+ years",
"7 years",
"5 years",
"2 years",
"< 1 year",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"7 years",
"9 years",
"10+ years",
"10+ years",
"5 years",
"5 years",
"5 years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"3 years",
"8 years",
"4 years",
"2 years",
"1 year",
"< 1 year",
"6 years",
"7 years",
"3 years",
"6 years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"5 years",
"7 years",
"10+ years",
"7 years",
"10+ years",
"7 years",
"4 years",
"6 years",
"2 years",
"10+ years",
"8 years",
"9 years",
"8 years",
"10+ years",
"5 years",
"9 years",
"5 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"5 years",
"9 years",
"9 years",
"2 years",
"3 years",
"4 years",
"10+ years",
"7 years",
"< 1 year",
"2 years",
"2 years",
"3 years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"9 years",
"4 years",
"6 years",
"8 years",
"5 years",
"6 years",
"2 years",
"10+ years",
"3 years",
"3 years",
"8 years",
"4 years",
null,
"5 years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"< 1 year",
"7 years",
"10+ years",
"7 years",
"10+ years",
"4 years",
"7 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"9 years",
"4 years",
"< 1 year",
"3 years",
"3 years",
"6 years",
"8 years",
"9 years",
"2 years",
"10+ years",
"2 years",
"5 years",
"9 years",
"5 years",
"10+ years",
"8 years",
null,
"2 years",
"6 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"5 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"4 years",
"10+ years",
"7 years",
"10+ years",
"< 1 year",
null,
"1 year",
"10+ years",
"8 years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"8 years",
"< 1 year",
"2 years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"1 year",
"6 years",
"6 years",
"7 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"4 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
null,
"< 1 year",
"1 year",
"9 years",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"3 years",
"3 years",
"5 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
null,
"2 years",
"10+ years",
"2 years",
"2 years",
"7 years",
"7 years",
"9 years",
"5 years",
"< 1 year",
"10+ years",
"5 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"4 years",
"8 years",
"3 years",
"10+ years",
"5 years",
"9 years",
"10+ years",
"7 years",
"8 years",
"5 years",
"4 years",
"8 years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
null,
"< 1 year",
null,
"2 years",
null,
"10+ years",
null,
"2 years",
"3 years",
"10+ years",
"1 year",
"7 years",
"5 years",
"< 1 year",
"< 1 year",
"10+ years",
"5 years",
"2 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"6 years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"8 years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"4 years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"2 years",
null,
"10+ years",
"10+ years",
"6 years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
null,
"10+ years",
"6 years",
"10+ years",
"1 year",
"2 years",
"4 years",
null,
"2 years",
"8 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"1 year",
null,
"1 year",
null,
"5 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"4 years",
"< 1 year",
"5 years",
"2 years",
"3 years",
"6 years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"9 years",
"3 years",
"5 years",
"1 year",
"< 1 year",
"10+ years",
"1 year",
"2 years",
"1 year",
"4 years",
"9 years",
"3 years",
null,
"2 years",
"8 years",
"10+ years",
null,
"10+ years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"4 years",
"4 years",
null,
"10+ years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"5 years",
"8 years",
"< 1 year",
"2 years",
"4 years",
"2 years",
"7 years",
"6 years",
"3 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"9 years",
"3 years",
"7 years",
"8 years",
null,
"1 year",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
null,
"8 years",
"1 year",
"10+ years",
"5 years",
"< 1 year",
null,
"9 years",
"10+ years",
"7 years",
"10+ years",
"1 year",
"2 years",
"2 years",
"1 year",
"5 years",
"2 years",
"10+ years",
"10+ years",
"8 years",
null,
"1 year",
"10+ years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"6 years",
"7 years",
"10+ years",
"9 years",
"9 years",
"10+ years",
"8 years",
"2 years",
"5 years",
null,
"< 1 year",
"10+ years",
"1 year",
"9 years",
"3 years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"< 1 year",
null,
"4 years",
"2 years",
"8 years",
"6 years",
"3 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"5 years",
"1 year",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"< 1 year",
"1 year",
"9 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"7 years",
"6 years",
"1 year",
"1 year",
null,
null,
"6 years",
"4 years",
"3 years",
"< 1 year",
"7 years",
null,
"5 years",
"6 years",
"1 year",
"6 years",
"7 years",
"3 years",
"10+ years",
"9 years",
"3 years",
"5 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"6 years",
"1 year",
"10+ years",
"1 year",
"2 years",
"3 years",
"1 year",
"10+ years",
"2 years",
"4 years",
"8 years",
"< 1 year",
"6 years",
"8 years",
"10+ years",
"2 years",
"10+ years",
null,
"6 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"< 1 year",
"4 years",
"8 years",
"4 years",
"10+ years",
null,
"2 years",
"5 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"3 years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"< 1 year",
"5 years",
"5 years",
"< 1 year",
"< 1 year",
"10+ years",
"1 year",
"6 years",
"10+ years",
"7 years",
"3 years",
"< 1 year",
"2 years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"7 years",
"3 years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"8 years",
"10+ years",
"6 years",
"10+ years",
"1 year",
"6 years",
"10+ years",
"2 years",
"9 years",
"5 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"1 year",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"< 1 year",
"6 years",
"10+ years",
"6 years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"9 years",
"3 years",
"5 years",
"4 years",
"10+ years",
"5 years",
"3 years",
null,
"10+ years",
"7 years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"8 years",
"6 years",
"2 years",
"< 1 year",
"3 years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"9 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"8 years",
"1 year",
"3 years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"1 year",
"6 years",
null,
"10+ years",
"1 year",
"2 years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"7 years",
"2 years",
"1 year",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"4 years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"4 years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"7 years",
"< 1 year",
"< 1 year",
"6 years",
"8 years",
"2 years",
"10+ years",
"1 year",
"7 years",
"10+ years",
"2 years",
"3 years",
"4 years",
"1 year",
"5 years",
"2 years",
"1 year",
"< 1 year",
"4 years",
"10+ years",
"6 years",
"8 years",
"10+ years",
"< 1 year",
"9 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"3 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"6 years",
null,
"8 years",
"3 years",
"5 years",
"1 year",
"3 years",
"2 years",
"10+ years",
null,
"6 years",
"7 years",
"10+ years",
"10+ years",
"8 years",
"6 years",
"4 years",
"3 years",
"7 years",
"< 1 year",
"6 years",
"5 years",
"8 years",
"7 years",
"4 years",
"5 years",
null,
"< 1 year",
null,
"8 years",
"5 years",
"6 years",
"10+ years",
null,
"3 years",
"4 years",
"4 years",
"5 years",
"1 year",
null,
"1 year",
"7 years",
"5 years",
null,
"8 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"1 year",
"< 1 year",
"8 years",
"< 1 year",
"10+ years",
"6 years",
"9 years",
"3 years",
"5 years",
"2 years",
"8 years",
"3 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"9 years",
null,
"7 years",
"3 years",
null,
"6 years",
"10+ years",
"2 years",
"4 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"10+ years",
"5 years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"7 years",
"10+ years",
"10+ years",
null,
"10+ years",
"5 years",
"10+ years",
"9 years",
"< 1 year",
null,
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
null,
"1 year",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"6 years",
null,
"10+ years",
"10+ years",
"9 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"1 year",
null,
"< 1 year",
"< 1 year",
"4 years",
"6 years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"5 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"4 years",
"< 1 year",
"2 years",
"3 years",
"7 years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"7 years",
"10+ years",
"9 years",
"10+ years",
"5 years",
"1 year",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"3 years",
"< 1 year",
"2 years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"8 years",
"8 years",
"6 years",
"< 1 year",
"3 years",
"1 year",
"10+ years",
"5 years",
"10+ years",
"9 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"3 years",
"8 years",
null,
"10+ years",
null,
"2 years",
"8 years",
"5 years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"6 years",
"10+ years",
null,
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"7 years",
"8 years",
"7 years",
null,
"8 years",
"8 years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"7 years",
"1 year",
"7 years",
"10+ years",
null,
"7 years",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"5 years",
"2 years",
"9 years",
"< 1 year",
null,
"3 years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"4 years",
"3 years",
"10+ years",
"1 year",
"3 years",
"1 year",
"5 years",
"10+ years",
null,
"8 years",
"3 years",
null,
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"1 year",
"6 years",
"5 years",
null,
"< 1 year",
"2 years",
"2 years",
"9 years",
"10+ years",
"3 years",
"2 years",
"< 1 year",
"2 years",
"< 1 year",
"3 years",
"1 year",
"10+ years",
"3 years",
"6 years",
"7 years",
"10+ years",
"7 years",
"10+ years",
null,
"8 years",
"2 years",
"2 years",
"5 years",
"10+ years",
"5 years",
"5 years",
"10+ years",
"3 years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"1 year",
"10+ years",
"6 years",
"6 years",
"7 years",
"4 years",
"1 year",
"10+ years",
"7 years",
"2 years",
"4 years",
"8 years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"8 years",
"10+ years",
"3 years",
"6 years",
"10+ years",
"5 years",
"< 1 year",
"1 year",
"7 years",
"6 years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"2 years",
"5 years",
null,
"10+ years",
"7 years",
"4 years",
"3 years",
"6 years",
"9 years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"4 years",
"2 years",
"5 years",
"3 years",
null,
"10+ years",
"5 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
null,
"10+ years",
"4 years",
"1 year",
"10+ years",
"6 years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"6 years",
null,
"3 years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"8 years",
"7 years",
"7 years",
null,
"< 1 year",
"10+ years",
"2 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"2 years",
"3 years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"< 1 year",
"7 years",
"7 years",
"9 years",
"9 years",
"9 years",
"8 years",
"2 years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"< 1 year",
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
null,
"10+ years",
"5 years",
"8 years",
"7 years",
"10+ years",
"4 years",
"9 years",
"3 years",
"7 years",
"4 years",
"5 years",
"4 years",
"4 years",
"10+ years",
"2 years",
"< 1 year",
"2 years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"8 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"9 years",
"1 year",
"3 years",
null,
"10+ years",
"6 years",
"< 1 year",
"5 years",
"2 years",
"10+ years",
"9 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"5 years",
"< 1 year",
"3 years",
"6 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"6 years",
"5 years",
"10+ years",
"10+ years",
null,
"10+ years",
"1 year",
"5 years",
"4 years",
"2 years",
"4 years",
"1 year",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"7 years",
"8 years",
"10+ years",
"1 year",
"6 years",
"7 years",
"10+ years",
"3 years",
"4 years",
"4 years",
"4 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"7 years",
"3 years",
"2 years",
"2 years",
"10+ years",
"3 years",
"3 years",
"< 1 year",
"3 years",
"10+ years",
"3 years",
"6 years",
"7 years",
"5 years",
"5 years",
"< 1 year",
"10+ years",
"3 years",
"5 years",
"8 years",
null,
"1 year",
null,
null,
"1 year",
"4 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"< 1 year",
"2 years",
"1 year",
"10+ years",
"9 years",
"10+ years",
"8 years",
"2 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"2 years",
"5 years",
"2 years",
"4 years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"9 years",
"10+ years",
"3 years",
null,
"< 1 year",
"10+ years",
"10+ years",
"4 years",
null,
"< 1 year",
"2 years",
"10+ years",
"7 years",
"9 years",
"3 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"3 years",
null,
"10+ years",
"7 years",
"3 years",
"10+ years",
"7 years",
"1 year",
"2 years",
"10+ years",
"8 years",
"1 year",
"10+ years",
"3 years",
"7 years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
null,
"10+ years",
"10+ years",
"4 years",
"7 years",
"2 years",
"1 year",
"8 years",
"7 years",
"5 years",
"6 years",
null,
"10+ years",
"3 years",
"< 1 year",
"2 years",
"10+ years",
"3 years",
"1 year",
"5 years",
"10+ years",
"9 years",
"10+ years",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"4 years",
null,
"10+ years",
"9 years",
"3 years",
"1 year",
"4 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"6 years",
"5 years",
null,
"3 years",
"7 years",
"5 years",
"6 years",
"7 years",
"10+ years",
"10+ years",
"9 years",
"4 years",
"5 years",
"1 year",
"3 years",
"9 years",
"7 years",
"10+ years",
"10+ years",
"4 years",
"6 years",
"8 years",
"8 years",
"4 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"7 years",
"< 1 year",
"10+ years",
"9 years",
"5 years",
"10+ years",
"7 years",
"< 1 year",
"2 years",
"2 years",
"5 years",
"7 years",
"3 years",
"2 years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"8 years",
"7 years",
"3 years",
null,
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"1 year",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"< 1 year",
"6 years",
"10+ years",
null,
"5 years",
"5 years",
"7 years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"7 years",
"< 1 year",
"1 year",
"< 1 year",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
null,
"10+ years",
"< 1 year",
"10+ years",
"9 years",
"1 year",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"9 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"1 year",
"10+ years",
"4 years",
"7 years",
"< 1 year",
"7 years",
"5 years",
"6 years",
"< 1 year",
"< 1 year",
"10+ years",
"2 years",
"< 1 year",
"6 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"5 years",
"4 years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"1 year",
"8 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"6 years",
"10+ years",
"7 years",
"2 years",
"4 years",
"7 years",
"7 years",
"4 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"5 years",
"7 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"5 years",
"9 years",
"2 years",
"10+ years",
"3 years",
"4 years",
"1 year",
"8 years",
"4 years",
"10+ years",
"4 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"2 years",
"1 year",
"1 year",
"10+ years",
"< 1 year",
"8 years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"7 years",
"5 years",
"10+ years",
"5 years",
"10+ years",
null,
"2 years",
"3 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"8 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"7 years",
"< 1 year",
"3 years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"7 years",
"10+ years",
"8 years",
"7 years",
"9 years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"4 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"2 years",
"10+ years",
"8 years",
"< 1 year",
"1 year",
"8 years",
"10+ years",
"4 years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"1 year",
"9 years",
"3 years",
"7 years",
"9 years",
"10+ years",
"10+ years",
"5 years",
"7 years",
"< 1 year",
"5 years",
"8 years",
"10+ years",
"< 1 year",
"5 years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"3 years",
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"8 years",
"6 years",
"7 years",
"3 years",
"2 years",
"2 years",
"5 years",
"2 years",
"2 years",
"10+ years",
"6 years",
"10+ years",
"2 years",
null,
"10+ years",
"6 years",
"3 years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"5 years",
"7 years",
"6 years",
null,
"8 years",
null,
"10+ years",
"4 years",
"10+ years",
"5 years",
"2 years",
"8 years",
"5 years",
"7 years",
null,
"1 year",
"10+ years",
"10+ years",
"1 year",
"2 years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"7 years",
"< 1 year",
null,
null,
"6 years",
"10+ years",
"2 years",
"10+ years",
"7 years",
"9 years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"10+ years",
"7 years",
"4 years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"1 year",
"5 years",
null,
"10+ years",
"< 1 year",
"3 years",
null,
"10+ years",
"10+ years",
"6 years",
"5 years",
"2 years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
null,
"6 years",
"1 year",
"5 years",
"9 years",
null,
"10+ years",
"10+ years",
"2 years",
"6 years",
"4 years",
"1 year",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"6 years",
null,
"6 years",
"2 years",
"8 years",
"1 year",
"10+ years",
"< 1 year",
null,
"10+ years",
"10+ years",
"10+ years",
"4 years",
"8 years",
"10+ years",
"6 years",
"3 years",
"6 years",
"< 1 year",
"10+ years",
null,
null,
"10+ years",
"2 years",
"10+ years",
"5 years",
"5 years",
"3 years",
"8 years",
"10+ years",
"5 years",
"6 years",
"8 years",
"10+ years",
"2 years",
"1 year",
"7 years",
"3 years",
"3 years",
"10+ years",
"4 years",
"6 years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"4 years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"< 1 year",
"9 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"8 years",
"10+ years",
null,
"< 1 year",
"< 1 year",
"10+ years",
"1 year",
"2 years",
"7 years",
"9 years",
"10+ years",
"4 years",
"4 years",
"7 years",
"10+ years",
"< 1 year",
null,
"4 years",
"3 years",
"3 years",
null,
"1 year",
"8 years",
"3 years",
"2 years",
"< 1 year",
"< 1 year",
"2 years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"8 years",
"1 year",
"7 years",
"2 years",
"7 years",
"2 years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"9 years",
"5 years",
"10+ years",
"9 years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"3 years",
"6 years",
"< 1 year",
"2 years",
"7 years",
null,
"< 1 year",
"< 1 year",
"7 years",
"7 years",
"6 years",
"2 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"6 years",
"< 1 year",
"8 years",
"10+ years",
"6 years",
"10+ years",
"8 years",
"9 years",
"1 year",
"10+ years",
null,
"10+ years",
"3 years",
"2 years",
"5 years",
"4 years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"1 year",
"1 year",
"10+ years",
"8 years",
"10+ years",
"8 years",
"4 years",
"< 1 year",
"8 years",
"10+ years",
"< 1 year",
"1 year",
"7 years",
null,
"3 years",
"< 1 year",
"6 years",
"10+ years",
"8 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"9 years",
"5 years",
"10+ years",
"7 years",
"< 1 year",
"6 years",
"10+ years",
"5 years",
"< 1 year",
"< 1 year",
"< 1 year",
"3 years",
"6 years",
"10+ years",
"9 years",
"7 years",
"2 years",
null,
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
null,
"10+ years",
"< 1 year",
null,
"< 1 year",
"< 1 year",
"< 1 year",
"10+ years",
"9 years",
"5 years",
"< 1 year",
"10+ years",
"< 1 year",
"8 years",
null,
"5 years",
"10+ years",
"10+ years",
"6 years",
null,
"3 years",
"10+ years",
"7 years",
"10+ years",
"5 years",
"1 year",
"2 years",
"< 1 year",
"10+ years",
"4 years",
"1 year",
"4 years",
"5 years",
"10+ years",
"9 years",
"3 years",
"5 years",
"2 years",
"10+ years",
"1 year",
"5 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
null,
"4 years",
"10+ years",
"9 years",
"1 year",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"4 years",
"< 1 year",
"8 years",
"3 years",
"3 years",
"7 years",
"4 years",
"10+ years",
"5 years",
"10+ years",
"6 years",
"4 years",
"8 years",
"3 years",
"9 years",
"3 years",
"4 years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"10+ years",
null,
"10+ years",
"1 year",
"10+ years",
"10+ years",
null,
"10+ years",
"6 years",
"9 years",
"8 years",
"< 1 year",
"7 years",
"2 years",
"6 years",
"3 years",
"7 years",
null,
"3 years",
"7 years",
"3 years",
"3 years",
"5 years",
"10+ years",
"8 years",
"< 1 year",
"1 year",
"10+ years",
"4 years",
"2 years",
"10+ years",
"1 year",
"8 years",
"10+ years",
"8 years",
"3 years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"9 years",
"< 1 year",
"2 years",
"5 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"6 years",
"6 years",
"8 years",
"10+ years",
"7 years",
"8 years",
"3 years",
"10+ years",
"4 years",
"7 years",
"8 years",
"< 1 year",
"2 years",
"4 years",
"8 years",
"9 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"4 years",
"9 years",
"1 year",
"2 years",
"6 years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"4 years",
"8 years",
"10+ years",
"5 years",
"7 years",
"5 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"8 years",
"4 years",
"8 years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"9 years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"4 years",
"8 years",
"4 years",
"8 years",
"10+ years",
"9 years",
"3 years",
"10+ years",
"3 years",
"2 years",
"6 years",
"3 years",
null,
"10+ years",
"7 years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"9 years",
null,
"4 years",
"4 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"9 years",
"3 years",
"4 years",
"4 years",
"7 years",
"5 years",
"10+ years",
"< 1 year",
"< 1 year",
"4 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"6 years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"6 years",
"4 years",
"8 years",
"< 1 year",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"< 1 year",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"6 years",
"8 years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
null,
"10+ years",
"3 years",
"7 years",
null,
"10+ years",
"5 years",
"10+ years",
"3 years",
"3 years",
"6 years",
"5 years",
"5 years",
"< 1 year",
"< 1 year",
"4 years",
"3 years",
"< 1 year",
"10+ years",
null,
"10+ years",
"10+ years",
"7 years",
"3 years",
"5 years",
"6 years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
null,
"10+ years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"6 years",
"10+ years",
"< 1 year",
"4 years",
"6 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"< 1 year",
"9 years",
"< 1 year",
"6 years",
"< 1 year",
"< 1 year",
"4 years",
"1 year",
"6 years",
"10+ years",
"10+ years",
null,
"10+ years",
"1 year",
null,
"10+ years",
"8 years",
"6 years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"10+ years",
"1 year",
"7 years",
"1 year",
"2 years",
"9 years",
"9 years",
"8 years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"6 years",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"5 years",
"2 years",
"9 years",
"10+ years",
"< 1 year",
"5 years",
"4 years",
"7 years",
"8 years",
"< 1 year",
"1 year",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"1 year",
"9 years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"8 years",
"3 years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"10+ years",
null,
"5 years",
"2 years",
"6 years",
"10+ years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"2 years",
"1 year",
"2 years",
"10+ years",
null,
"10+ years",
"10+ years",
"9 years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"9 years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"7 years",
"7 years",
"10+ years",
null,
"4 years",
"10+ years",
null,
null,
"4 years",
"5 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"6 years",
"< 1 year",
"10+ years",
"2 years",
"2 years",
"5 years",
"6 years",
"4 years",
"6 years",
"4 years",
"< 1 year",
"10+ years",
"8 years",
"4 years",
"9 years",
"10+ years",
"5 years",
"< 1 year",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"3 years",
"2 years",
"1 year",
"4 years",
"3 years",
"10+ years",
"8 years",
"7 years",
"6 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"4 years",
"2 years",
"6 years",
"10+ years",
null,
"4 years",
"10+ years",
null,
"3 years",
"3 years",
"10+ years",
"10+ years",
"6 years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"9 years",
"5 years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"9 years",
"< 1 year",
"2 years",
"10+ years",
"3 years",
"4 years",
"8 years",
"4 years",
"2 years",
"6 years",
"< 1 year",
"10+ years",
"7 years",
"3 years",
"8 years",
"4 years",
"9 years",
"1 year",
"8 years",
"9 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"5 years",
"4 years",
"4 years",
"7 years",
"10+ years",
"10+ years",
"5 years",
"1 year",
"2 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
null,
"10+ years",
"3 years",
"< 1 year",
"1 year",
"< 1 year",
"< 1 year",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"2 years",
"< 1 year",
"5 years",
"9 years",
"2 years",
"10+ years",
"3 years",
null,
"4 years",
null,
null,
"5 years",
"4 years",
"3 years",
"9 years",
"10+ years",
"2 years",
"5 years",
"9 years",
"8 years",
"4 years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"9 years",
"2 years",
"10+ years",
"4 years",
null,
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
null,
"1 year",
"10+ years",
"10+ years",
null,
"5 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"< 1 year",
"5 years",
"< 1 year",
"5 years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"6 years",
null,
"10+ years",
"4 years",
"4 years",
"5 years",
"10+ years",
null,
"2 years",
null,
"8 years",
"1 year",
"10+ years",
"6 years",
"7 years",
"4 years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"2 years",
"4 years",
"4 years",
"7 years",
"1 year",
"3 years",
"2 years",
"2 years",
"8 years",
"9 years",
"10+ years",
"9 years",
"7 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"6 years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"4 years",
null,
"4 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"3 years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"4 years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"9 years",
"3 years",
null,
"7 years",
"2 years",
"6 years",
"10+ years",
"1 year",
"10+ years",
"8 years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"3 years",
"9 years",
"10+ years",
"10+ years",
"2 years",
"7 years",
"< 1 year",
"1 year",
"3 years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"8 years",
"1 year",
"8 years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"8 years",
"2 years",
"3 years",
"3 years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"3 years",
null,
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"< 1 year",
"4 years",
"1 year",
"2 years",
"6 years",
"8 years",
null,
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"1 year",
"1 year",
"4 years",
"6 years",
"7 years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"3 years",
null,
"10+ years",
"6 years",
"< 1 year",
"6 years",
"10+ years",
null,
"1 year",
"10+ years",
"9 years",
"2 years",
"4 years",
"2 years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"7 years",
"9 years",
"8 years",
null,
"< 1 year",
"4 years",
"< 1 year",
"< 1 year",
"8 years",
"2 years",
"3 years",
"10+ years",
"4 years",
"10+ years",
"9 years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
null,
"3 years",
null,
"1 year",
"1 year",
"10+ years",
"8 years",
"6 years",
"10+ years",
"1 year",
"10+ years",
"2 years",
"1 year",
"5 years",
"5 years",
"5 years",
"4 years",
"10+ years",
"10+ years",
"6 years",
"1 year",
"< 1 year",
null,
"4 years",
"10+ years",
"3 years",
null,
"10+ years",
"10+ years",
null,
"1 year",
"2 years",
"6 years",
"10+ years",
"< 1 year",
null,
"2 years",
"7 years",
"3 years",
"10+ years",
"3 years",
null,
"3 years",
null,
"8 years",
"7 years",
"1 year",
"3 years",
null,
"10+ years",
"5 years",
"3 years",
"5 years",
"2 years",
"9 years",
"7 years",
"5 years",
"10+ years",
"2 years",
"9 years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"6 years",
"< 1 year",
"4 years",
null,
"3 years",
"10+ years",
"2 years",
"7 years",
"5 years",
"10+ years",
"9 years",
"8 years",
"10+ years",
"10+ years",
"6 years",
"5 years",
"10+ years",
"5 years",
"7 years",
"8 years",
"5 years",
"2 years",
"< 1 year",
"2 years",
"6 years",
"6 years",
"10+ years",
null,
"7 years",
"8 years",
"10+ years",
null,
"10+ years",
"3 years",
"7 years",
"8 years",
"5 years",
"7 years",
"10+ years",
"8 years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"1 year",
"4 years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"8 years",
"2 years",
"10+ years",
"7 years",
null,
"9 years",
"10+ years",
"5 years",
"< 1 year",
"9 years",
"10+ years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"3 years",
"8 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"7 years",
"3 years",
"9 years",
"< 1 year",
"10+ years",
"2 years",
"1 year",
"9 years",
"7 years",
"5 years",
"10+ years",
"< 1 year",
"6 years",
"3 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"4 years",
"< 1 year",
"10+ years",
"< 1 year",
"5 years",
"3 years",
"< 1 year",
"3 years",
"10+ years",
"2 years",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"2 years",
"1 year",
"2 years",
"7 years",
"6 years",
"9 years",
"5 years",
"7 years",
"10+ years",
"2 years",
"3 years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
null,
"2 years",
"3 years",
"9 years",
"7 years",
"10+ years",
"9 years",
"2 years",
"5 years",
"7 years",
"9 years",
"< 1 year",
"< 1 year",
"3 years",
"10+ years",
null,
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"5 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"8 years",
"10+ years",
"8 years",
"5 years",
"7 years",
"1 year",
"10+ years",
null,
"10+ years",
"10+ years",
"5 years",
"10+ years",
null,
"10+ years",
"4 years",
"2 years",
null,
null,
"10+ years",
"3 years",
"10+ years",
null,
"6 years",
"2 years",
"5 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
null,
"2 years",
"1 year",
"10+ years",
"< 1 year",
"8 years",
"8 years",
"1 year",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"6 years",
"6 years",
"3 years",
"5 years",
"10+ years",
"9 years",
"1 year",
"< 1 year",
null,
"10+ years",
"1 year",
"4 years",
"2 years",
"8 years",
"8 years",
"5 years",
"3 years",
"5 years",
"< 1 year",
"8 years",
"9 years",
"4 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"8 years",
"6 years",
"< 1 year",
"10+ years",
"7 years",
"9 years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"10+ years",
"4 years",
"9 years",
"10+ years",
"10+ years",
null,
"10+ years",
"5 years",
null,
"9 years",
"8 years",
"4 years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"7 years",
"< 1 year",
"3 years",
"2 years",
"10+ years",
"4 years",
"1 year",
"1 year",
"10+ years",
"5 years",
"3 years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"9 years",
"4 years",
"5 years",
"8 years",
"10+ years",
"< 1 year",
"3 years",
"4 years",
"10+ years",
"9 years",
"10+ years",
"8 years",
"8 years",
null,
"2 years",
"4 years",
"6 years",
"2 years",
"7 years",
"5 years",
"4 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"10+ years",
"6 years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"7 years",
"10+ years",
"4 years",
"8 years",
"2 years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"6 years",
"3 years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"4 years",
"10+ years",
"4 years",
null,
"9 years",
"4 years",
"5 years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"< 1 year",
"4 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"3 years",
"5 years",
"10+ years",
null,
"< 1 year",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"1 year",
"2 years",
null,
null,
"10+ years",
null,
"3 years",
"1 year",
"2 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"4 years",
"3 years",
"2 years",
"< 1 year",
"5 years",
"3 years",
"9 years",
"< 1 year",
"10+ years",
"5 years",
null,
"8 years",
null,
"10+ years",
"9 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"6 years",
"< 1 year",
"1 year",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
null,
"10+ years",
"7 years",
"< 1 year",
"6 years",
"< 1 year",
"< 1 year",
"10+ years",
null,
"10+ years",
"10+ years",
null,
"4 years",
"4 years",
"10+ years",
"3 years",
"7 years",
"8 years",
"2 years",
null,
"10+ years",
"< 1 year",
"8 years",
"2 years",
"< 1 year",
"4 years",
"3 years",
"5 years",
"10+ years",
"4 years",
"< 1 year",
"9 years",
"10+ years",
"9 years",
"3 years",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"8 years",
"4 years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"7 years",
"< 1 year",
"1 year",
"8 years",
"8 years",
"10+ years",
"7 years",
"3 years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"9 years",
"4 years",
"4 years",
"8 years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"9 years",
null,
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"6 years",
"2 years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"3 years",
"2 years",
"< 1 year",
"< 1 year",
"< 1 year",
"10+ years",
"7 years",
"< 1 year",
null,
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"3 years",
"3 years",
"3 years",
"4 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"8 years",
"7 years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"6 years",
"10+ years",
null,
"6 years",
"9 years",
"2 years",
"1 year",
"6 years",
"1 year",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"9 years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"2 years",
"5 years",
"3 years",
"2 years",
"10+ years",
"9 years",
"6 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"2 years",
"6 years",
"5 years",
null,
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"1 year",
"9 years",
"10+ years",
"1 year",
"9 years",
"3 years",
"3 years",
"3 years",
"< 1 year",
"< 1 year",
"4 years",
"9 years",
"5 years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
null,
"5 years",
"4 years",
"5 years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"8 years",
"7 years",
"7 years",
"10+ years",
"6 years",
"10+ years",
"9 years",
"2 years",
"10+ years",
"2 years",
"9 years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
null,
"10+ years",
"8 years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"1 year",
"3 years",
"2 years",
"< 1 year",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"6 years",
null,
"< 1 year",
"2 years",
"1 year",
"10+ years",
null,
"6 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"8 years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"9 years",
"9 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"4 years",
"10+ years",
"7 years",
"9 years",
"3 years",
"10+ years",
"8 years",
"3 years",
"3 years",
"3 years",
"< 1 year",
"< 1 year",
"10+ years",
"4 years",
"3 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"6 years",
"8 years",
"1 year",
"4 years",
"9 years",
null,
"1 year",
"4 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"3 years",
"2 years",
"1 year",
"5 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"1 year",
"2 years",
"10+ years",
"7 years",
"4 years",
"7 years",
"6 years",
null,
"< 1 year",
"1 year",
"3 years",
"2 years",
"10+ years",
"1 year",
"2 years",
"5 years",
"4 years",
"6 years",
"< 1 year",
"10+ years",
null,
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"2 years",
"10+ years",
"4 years",
"4 years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"1 year",
"7 years",
"9 years",
"4 years",
"4 years",
"1 year",
"10+ years",
"2 years",
"< 1 year",
"6 years",
"1 year",
null,
"7 years",
"10+ years",
null,
"< 1 year",
"3 years",
"10+ years",
"3 years",
"1 year",
"< 1 year",
"10+ years",
"8 years",
"< 1 year",
"3 years",
null,
"2 years",
"10+ years",
"8 years",
null,
"4 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
null,
"7 years",
"< 1 year",
"3 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"8 years",
"9 years",
"6 years",
null,
"10+ years",
"< 1 year",
null,
"10+ years",
"5 years",
"6 years",
"2 years",
"10+ years",
"6 years",
null,
"7 years",
"10+ years",
"4 years",
null,
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"5 years",
"3 years",
"8 years",
"8 years",
"1 year",
null,
"10+ years",
"7 years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"10+ years",
null,
"2 years",
"5 years",
"10+ years",
"6 years",
"< 1 year",
"5 years",
"5 years",
"4 years",
"3 years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
null,
"1 year",
"8 years",
"6 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"7 years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"9 years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"10+ years",
"4 years",
"3 years",
"10+ years",
null,
"10+ years",
"7 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"6 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"2 years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"5 years",
"5 years",
"10+ years",
"5 years",
"7 years",
"2 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"4 years",
"8 years",
"5 years",
"3 years",
null,
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"3 years",
"5 years",
null,
"9 years",
"10+ years",
"10+ years",
"7 years",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"9 years",
"1 year",
"1 year",
"5 years",
"2 years",
"2 years",
"7 years",
null,
"8 years",
"5 years",
"7 years",
null,
"1 year",
"8 years",
"3 years",
"10+ years",
"8 years",
"10+ years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"2 years",
"3 years",
"4 years",
"2 years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"2 years",
"3 years",
"10+ years",
"9 years",
"< 1 year",
null,
"10+ years",
"8 years",
"4 years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"4 years",
"3 years",
"10+ years",
null,
"7 years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"4 years",
"5 years",
"10+ years",
"3 years",
"8 years",
"3 years",
null,
"3 years",
"7 years",
"2 years",
"< 1 year",
"5 years",
"3 years",
"< 1 year",
"1 year",
"5 years",
"5 years",
"7 years",
"< 1 year",
"5 years",
"< 1 year",
"1 year",
"4 years",
"5 years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"7 years",
"2 years",
"10+ years",
"1 year",
"7 years",
"2 years",
"2 years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"8 years",
"1 year",
"2 years",
"< 1 year",
"< 1 year",
"5 years",
"8 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"2 years",
"10+ years",
"9 years",
"< 1 year",
"6 years",
"1 year",
"< 1 year",
"< 1 year",
"9 years",
"< 1 year",
"6 years",
"< 1 year",
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"2 years",
"4 years",
"< 1 year",
"8 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"4 years",
"7 years",
"5 years",
"5 years",
"7 years",
"5 years",
"4 years",
"3 years",
"10+ years",
"7 years",
"10+ years",
"5 years",
"9 years",
"3 years",
"4 years",
"10+ years",
null,
"9 years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"2 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"1 year",
"6 years",
"9 years",
"10+ years",
"9 years",
"< 1 year",
null,
"8 years",
"2 years",
"6 years",
"2 years",
"10+ years",
"9 years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"8 years",
"6 years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
null,
"1 year",
"10+ years",
"5 years",
"2 years",
"6 years",
"3 years",
"10+ years",
"5 years",
"3 years",
"1 year",
"3 years",
"8 years",
"8 years",
"1 year",
"5 years",
"8 years",
"5 years",
"1 year",
"8 years",
"< 1 year",
"2 years",
"< 1 year",
null,
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"2 years",
null,
"3 years",
"< 1 year",
"2 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"5 years",
"10+ years",
null,
"8 years",
"5 years",
"3 years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"4 years",
"10+ years",
"1 year",
"4 years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"7 years",
"< 1 year",
"< 1 year",
"1 year",
"1 year",
"8 years",
"4 years",
"3 years",
"3 years",
"6 years",
"4 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"6 years",
"3 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
null,
"5 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"6 years",
"6 years",
"5 years",
null,
"5 years",
"7 years",
"7 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"< 1 year",
"3 years",
"10+ years",
"9 years",
"5 years",
"10+ years",
"7 years",
"3 years",
"8 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"1 year",
"< 1 year",
"1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"7 years",
"10+ years",
"7 years",
"2 years",
"< 1 year",
"10+ years",
null,
"5 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"< 1 year",
"1 year",
"4 years",
"1 year",
"4 years",
null,
"3 years",
"3 years",
"5 years",
"5 years",
"10+ years",
null,
null,
"< 1 year",
"2 years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"5 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"2 years",
"5 years",
"9 years",
"7 years",
"1 year",
"5 years",
"2 years",
"10+ years",
"1 year",
"4 years",
"2 years",
"2 years",
"< 1 year",
"6 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"< 1 year",
"< 1 year",
"10+ years",
"1 year",
"< 1 year",
"7 years",
null,
"10+ years",
"10+ years",
"4 years",
"1 year",
"< 1 year",
"2 years",
"5 years",
"1 year",
"3 years",
"1 year",
"10+ years",
"5 years",
"4 years",
"8 years",
"1 year",
"10+ years",
"9 years",
"10+ years",
"2 years",
"3 years",
"5 years",
"4 years",
"3 years",
"2 years",
"1 year",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"8 years",
"7 years",
null,
"4 years",
"< 1 year",
"10+ years",
"2 years",
null,
"10+ years",
"7 years",
"4 years",
"6 years",
"10+ years",
"5 years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"4 years",
null,
null,
"< 1 year",
"10+ years",
"2 years",
"1 year",
"10+ years",
null,
"1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"6 years",
"4 years",
"2 years",
"2 years",
"10+ years",
"5 years",
"7 years",
"3 years",
"10+ years",
null,
"7 years",
"10+ years",
"10+ years",
null,
"1 year",
"10+ years",
"8 years",
null,
"< 1 year",
"< 1 year",
"1 year",
"10+ years",
"2 years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"7 years",
null,
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"1 year",
null,
"8 years",
"6 years",
"10+ years",
"2 years",
"8 years",
"< 1 year",
"3 years",
"5 years",
"4 years",
"3 years",
"8 years",
"9 years",
"4 years",
"4 years",
"3 years",
"3 years",
"5 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"3 years",
"6 years",
"1 year",
"6 years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"10+ years",
null,
"2 years",
"10+ years",
"6 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"< 1 year",
"4 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"3 years",
"9 years",
"1 year",
"7 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"6 years",
"2 years",
"1 year",
"8 years",
"< 1 year",
"7 years",
"3 years",
"9 years",
"8 years",
"1 year",
"10+ years",
"6 years",
"4 years",
"10+ years",
null,
"5 years",
"6 years",
"7 years",
"5 years",
"< 1 year",
"6 years",
"10+ years",
"8 years",
"< 1 year",
"3 years",
"3 years",
"10+ years",
"1 year",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"8 years",
"7 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"8 years",
"8 years",
"1 year",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"3 years",
"8 years",
"9 years",
"6 years",
"7 years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"9 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
null,
"10+ years",
"8 years",
"10+ years",
"9 years",
"3 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"8 years",
"10+ years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"2 years",
"2 years",
"5 years",
"6 years",
"8 years",
"10+ years",
"3 years",
"7 years",
null,
"2 years",
"5 years",
"10+ years",
"8 years",
"10+ years",
"4 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"1 year",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"5 years",
"1 year",
"4 years",
"< 1 year",
"4 years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"2 years",
"10+ years",
"5 years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"2 years",
null,
"5 years",
"1 year",
"10+ years",
"2 years",
"6 years",
"3 years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"1 year",
"9 years",
"6 years",
"1 year",
"8 years",
"8 years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"1 year",
null,
null,
"7 years",
"6 years",
"4 years",
"2 years",
"3 years",
"8 years",
null,
"10+ years",
"6 years",
"2 years",
"10+ years",
"< 1 year",
"< 1 year",
"1 year",
"1 year",
"5 years",
"2 years",
"2 years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"2 years",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"9 years",
null,
"10+ years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"9 years",
"10+ years",
"5 years",
"1 year",
null,
"10+ years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"3 years",
"4 years",
null,
"7 years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"< 1 year",
null,
"5 years",
"1 year",
"1 year",
"10+ years",
"4 years",
"10+ years",
"2 years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"8 years",
"4 years",
"5 years",
"2 years",
null,
"10+ years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"7 years",
"1 year",
"3 years",
"5 years",
"5 years",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"10+ years",
"8 years",
"2 years",
"8 years",
"10+ years",
null,
"10+ years",
"< 1 year",
"10+ years",
null,
"3 years",
"< 1 year",
"< 1 year",
"6 years",
null,
"10+ years",
"10+ years",
"2 years",
"6 years",
"< 1 year",
"7 years",
"< 1 year",
"7 years",
"3 years",
"7 years",
"3 years",
"1 year",
"10+ years",
"2 years",
"7 years",
"3 years",
"1 year",
"10+ years",
"2 years",
"5 years",
"4 years",
"10+ years",
"1 year",
"10+ years",
"6 years",
"3 years",
"10+ years",
null,
"10+ years",
"10+ years",
null,
"6 years",
"8 years",
"7 years",
"9 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"6 years",
"4 years",
"2 years",
"6 years",
"5 years",
null,
"3 years",
"3 years",
"5 years",
"8 years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"6 years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"3 years",
"1 year",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"7 years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"6 years",
"4 years",
null,
null,
"1 year",
"< 1 year",
"7 years",
"10+ years",
null,
"6 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"1 year",
"5 years",
"5 years",
"1 year",
"8 years",
"10+ years",
null,
"1 year",
null,
"1 year",
"3 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"1 year",
"< 1 year",
"1 year",
"< 1 year",
"2 years",
"3 years",
"6 years",
"1 year",
"10+ years",
"8 years",
"9 years",
"10+ years",
"7 years",
"10+ years",
"3 years",
null,
"5 years",
"6 years",
"5 years",
"3 years",
"10+ years",
null,
"9 years",
"8 years",
"10+ years",
"6 years",
"7 years",
"8 years",
"6 years",
"4 years",
"4 years",
"3 years",
"6 years",
"7 years",
"10+ years",
"4 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"1 year",
"9 years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
null,
"10+ years",
"2 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"< 1 year",
"5 years",
"10+ years",
null,
"1 year",
"3 years",
"1 year",
"10+ years",
"2 years",
"8 years",
"6 years",
"< 1 year",
"7 years",
"2 years",
"6 years",
"< 1 year",
"2 years",
"4 years",
"8 years",
"8 years",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"3 years",
null,
"10+ years",
"2 years",
"7 years",
"4 years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"1 year",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
null,
"3 years",
"8 years",
"4 years",
"4 years",
"6 years",
"1 year",
"10+ years",
"2 years",
"4 years",
null,
"7 years",
"9 years",
"5 years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"3 years",
"6 years",
"9 years",
"< 1 year",
"10+ years",
"4 years",
"1 year",
"< 1 year",
"10+ years",
"4 years",
"3 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"9 years",
"4 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"1 year",
"5 years",
"3 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"1 year",
null,
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"6 years",
"1 year",
"10+ years",
"6 years",
"10+ years",
"8 years",
"10+ years",
"8 years",
"10+ years",
null,
"2 years",
null,
"1 year",
"2 years",
"10+ years",
"5 years",
"1 year",
"3 years",
"3 years",
"< 1 year",
"2 years",
"10+ years",
"6 years",
"7 years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"5 years",
"1 year",
"5 years",
"10+ years",
"9 years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"5 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
null,
"6 years",
"10+ years",
"1 year",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"8 years",
"3 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"10+ years",
"4 years",
"< 1 year",
"3 years",
"10+ years",
null,
null,
"10+ years",
"5 years",
"9 years",
null,
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"4 years",
"3 years",
"4 years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"1 year",
null,
"9 years",
"< 1 year",
"5 years",
null,
"< 1 year",
"5 years",
"4 years",
"3 years",
"3 years",
"1 year",
"5 years",
"10+ years",
null,
"10+ years",
"1 year",
"2 years",
null,
"8 years",
"3 years",
"3 years",
"10+ years",
"1 year",
"5 years",
"5 years",
"10+ years",
"4 years",
"6 years",
"3 years",
"2 years",
"5 years",
"6 years",
"< 1 year",
"3 years",
"2 years",
"6 years",
"9 years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"4 years",
"2 years",
"< 1 year",
"9 years",
"10+ years",
"9 years",
"10+ years",
"6 years",
"3 years",
"2 years",
"8 years",
"10+ years",
null,
"10+ years",
"6 years",
"4 years",
"10+ years",
null,
"10+ years",
"5 years",
null,
"10+ years",
"10+ years",
"4 years",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"< 1 year",
"4 years",
"< 1 year",
"4 years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"8 years",
"2 years",
"10+ years",
"< 1 year",
"5 years",
"6 years",
"6 years",
"10+ years",
"2 years",
"4 years",
"10+ years",
"6 years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"2 years",
"4 years",
null,
null,
"2 years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"9 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"6 years",
"7 years",
"10+ years",
null,
"10+ years",
"10+ years",
"7 years",
"2 years",
"< 1 year",
"5 years",
"10+ years",
"5 years",
"7 years",
"3 years",
"10+ years",
"5 years",
null,
"< 1 year",
"3 years",
"4 years",
"10+ years",
"5 years",
"< 1 year",
"4 years",
"3 years",
"2 years",
"4 years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"3 years",
"5 years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"2 years",
"10+ years",
"8 years",
"< 1 year",
"8 years",
null,
"7 years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"7 years",
"4 years",
"10+ years",
"10+ years",
"9 years",
"1 year",
"10+ years",
"3 years",
"9 years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"1 year",
null,
"10+ years",
"3 years",
"6 years",
"9 years",
"4 years",
"10+ years",
"9 years",
"10+ years",
"8 years",
"10+ years",
"9 years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"< 1 year",
null,
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"< 1 year",
"3 years",
"5 years",
"10+ years",
"7 years",
"8 years",
"3 years",
"2 years",
"2 years",
"1 year",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"7 years",
"3 years",
"4 years",
"6 years",
null,
"2 years",
"< 1 year",
"7 years",
"1 year",
null,
"< 1 year",
"8 years",
"10+ years",
"7 years",
"2 years",
null,
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"6 years",
"1 year",
"3 years",
"10+ years",
"3 years",
"2 years",
"1 year",
"9 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"3 years",
null,
"4 years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
null,
"10+ years",
"10+ years",
"5 years",
"3 years",
"1 year",
"10+ years",
null,
"10+ years",
"9 years",
"4 years",
"4 years",
"6 years",
"10+ years",
"3 years",
"5 years",
"2 years",
"10+ years",
"8 years",
"4 years",
null,
"10+ years",
"3 years",
"< 1 year",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"7 years",
"6 years",
"10+ years",
"< 1 year",
"9 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"6 years",
"8 years",
"8 years",
"10+ years",
"< 1 year",
"2 years",
"< 1 year",
"4 years",
"6 years",
"3 years",
"< 1 year",
"8 years",
"10+ years",
"1 year",
"< 1 year",
"8 years",
"4 years",
"1 year",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"< 1 year",
"2 years",
"1 year",
"9 years",
"7 years",
"10+ years",
"1 year",
"10+ years",
null,
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"5 years",
"6 years",
"10+ years",
"1 year",
"3 years",
"5 years",
"7 years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"8 years",
"3 years",
"10+ years",
"10+ years",
null,
"< 1 year",
"8 years",
"1 year",
null,
"10+ years",
"10+ years",
"3 years",
"6 years",
"2 years",
"7 years",
"10+ years",
"1 year",
"9 years",
"3 years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"< 1 year",
"10+ years",
"6 years",
"4 years",
null,
"7 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"4 years",
"9 years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"3 years",
"2 years",
"1 year",
"4 years",
"9 years",
"10+ years",
"7 years",
"2 years",
"< 1 year",
"5 years",
"9 years",
"10+ years",
"9 years",
"4 years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"3 years",
"< 1 year",
"8 years",
"10+ years",
"1 year",
"2 years",
"3 years",
"3 years",
"2 years",
"5 years",
"6 years",
"6 years",
"5 years",
null,
"4 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"1 year",
"4 years",
"4 years",
"3 years",
"10+ years",
"6 years",
"1 year",
"3 years",
"2 years",
"1 year",
null,
null,
"1 year",
"< 1 year",
null,
"1 year",
"10+ years",
"10+ years",
null,
"10+ years",
"5 years",
null,
null,
"2 years",
"8 years",
"5 years",
"10+ years",
"5 years",
"1 year",
"10+ years",
null,
"10+ years",
"7 years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"10+ years",
null,
"< 1 year",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"5 years",
"9 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
null,
"10+ years",
"1 year",
"2 years",
"4 years",
"10+ years",
"1 year",
null,
"10+ years",
"9 years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"8 years",
"< 1 year",
null,
"7 years",
"5 years",
"4 years",
"7 years",
"10+ years",
"7 years",
"3 years",
"6 years",
"10+ years",
"< 1 year",
null,
"5 years",
"6 years",
"3 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"9 years",
"10+ years",
"7 years",
"9 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"4 years",
"8 years",
"8 years",
"7 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"3 years",
"< 1 year",
"2 years",
"< 1 year",
"5 years",
"2 years",
"1 year",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"6 years",
"5 years",
"10+ years",
"8 years",
"10+ years",
"6 years",
"3 years",
"6 years",
"2 years",
"< 1 year",
"10+ years",
"2 years",
"2 years",
"< 1 year",
"10+ years",
"8 years",
"1 year",
"7 years",
"6 years",
"6 years",
"1 year",
"< 1 year",
"1 year",
"10+ years",
"2 years",
"9 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"1 year",
"10+ years",
"3 years",
"3 years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"5 years",
"6 years",
"4 years",
null,
"10+ years",
"1 year",
"8 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"4 years",
"1 year",
"7 years",
"5 years",
"4 years",
"2 years",
"3 years",
"6 years",
"4 years",
"10+ years",
"9 years",
"6 years",
"4 years",
"10+ years",
"< 1 year",
"4 years",
"3 years",
null,
"10+ years",
"10+ years",
"8 years",
"10+ years",
"1 year",
"4 years",
"7 years",
"4 years",
"2 years",
"7 years",
"10+ years",
"4 years",
"8 years",
"2 years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"9 years",
"10+ years",
"1 year",
"10+ years",
"7 years",
"1 year",
"4 years",
"1 year",
"8 years",
"3 years",
"6 years",
"7 years",
"2 years",
"8 years",
"9 years",
"2 years",
"< 1 year",
null,
"10+ years",
"2 years",
"3 years",
"10+ years",
"6 years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"7 years",
"< 1 year",
"< 1 year",
"3 years",
"9 years",
"< 1 year",
"6 years",
"5 years",
"3 years",
"10+ years",
"6 years",
"6 years",
"9 years",
"4 years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"9 years",
"4 years",
"3 years",
"6 years",
"10+ years",
"10+ years",
"7 years",
"6 years",
"1 year",
"< 1 year",
"10+ years",
"9 years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"6 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"7 years",
"4 years",
"10+ years",
"10+ years",
"1 year",
null,
"10+ years",
"10+ years",
"2 years",
"10+ years",
"6 years",
"< 1 year",
"5 years",
"5 years",
"10+ years",
"10+ years",
null,
"3 years",
"3 years",
"6 years",
"8 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"2 years",
"3 years",
"7 years",
"8 years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
null,
"< 1 year",
"< 1 year",
"5 years",
"5 years",
"8 years",
"9 years",
"7 years",
null,
"4 years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"6 years",
"< 1 year",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"4 years",
"10+ years",
"2 years",
null,
"1 year",
"8 years",
"8 years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"5 years",
"10+ years",
"5 years",
"8 years",
"1 year",
"9 years",
null,
null,
"10+ years",
"5 years",
"8 years",
"10+ years",
"9 years",
"5 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"6 years",
null,
"3 years",
"< 1 year",
"10+ years",
"7 years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"< 1 year",
"10+ years",
null,
"5 years",
"6 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"2 years",
"4 years",
"2 years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"7 years",
"10+ years",
"7 years",
"< 1 year",
"2 years",
"3 years",
"1 year",
"1 year",
"5 years",
"10+ years",
"10+ years",
"10+ years",
null,
"3 years",
"5 years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"7 years",
"3 years",
"10+ years",
"4 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"3 years",
"3 years",
"10+ years",
null,
"7 years",
"2 years",
"10+ years",
"9 years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"9 years",
"10+ years",
"2 years",
"9 years",
"7 years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"4 years",
"1 year",
"3 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"5 years",
"< 1 year",
"3 years",
"< 1 year",
"< 1 year",
"2 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"4 years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"9 years",
"8 years",
"4 years",
"4 years",
"7 years",
null,
"10+ years",
"2 years",
"9 years",
"10+ years",
"2 years",
"10+ years",
"6 years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"5 years",
"2 years",
"8 years",
"4 years",
"10+ years",
"< 1 year",
"5 years",
null,
"4 years",
"1 year",
"1 year",
"5 years",
null,
"2 years",
"9 years",
"9 years",
"5 years",
"8 years",
"3 years",
"8 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"5 years",
"10+ years",
"5 years",
"3 years",
"5 years",
"9 years",
"4 years",
"1 year",
"8 years",
"8 years",
"1 year",
"7 years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"3 years",
"8 years",
"10+ years",
"5 years",
"< 1 year",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"7 years",
"10+ years",
null,
"1 year",
null,
"9 years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"7 years",
"6 years",
"10+ years",
"1 year",
null,
"10+ years",
"4 years",
"< 1 year",
"7 years",
"8 years",
"10+ years",
"3 years",
"7 years",
"5 years",
null,
null,
"7 years",
"< 1 year",
"6 years",
"10+ years",
"4 years",
"< 1 year",
"4 years",
"10+ years",
"9 years",
"4 years",
"< 1 year",
"8 years",
"10+ years",
"< 1 year",
"< 1 year",
null,
"8 years",
"< 1 year",
"1 year",
"2 years",
"8 years",
"8 years",
"6 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"8 years",
"9 years",
"< 1 year",
"7 years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"3 years",
"3 years",
"7 years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"6 years",
"5 years",
"3 years",
"1 year",
"3 years",
"7 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"7 years",
null,
"10+ years",
"9 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"4 years",
"8 years",
"8 years",
"4 years",
"3 years",
"1 year",
"2 years",
"9 years",
"9 years",
"10+ years",
"1 year",
"2 years",
"10+ years",
"7 years",
"3 years",
"9 years",
null,
"5 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
null,
"1 year",
"2 years",
"5 years",
"6 years",
"3 years",
"7 years",
"10+ years",
"8 years",
"8 years",
"5 years",
"1 year",
null,
"10+ years",
null,
"4 years",
"8 years",
"1 year",
"10+ years",
"6 years",
"8 years",
"8 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"8 years",
"2 years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"8 years",
"7 years",
"10+ years",
"5 years",
"8 years",
"< 1 year",
"10+ years",
"3 years",
"8 years",
"7 years",
"4 years",
"5 years",
"9 years",
"3 years",
"1 year",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"7 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
null,
"5 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"8 years",
"6 years",
"3 years",
"5 years",
"6 years",
"< 1 year",
"7 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"3 years",
"4 years",
"7 years",
"2 years",
"2 years",
"10+ years",
"6 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
null,
"6 years",
"1 year",
"10+ years",
"6 years",
"10+ years",
"3 years",
"2 years",
null,
"10+ years",
"9 years",
"< 1 year",
"1 year",
null,
"5 years",
"5 years",
"5 years",
"5 years",
"10+ years",
null,
"2 years",
"10+ years",
"8 years",
"10+ years",
"6 years",
"3 years",
"< 1 year",
"4 years",
"4 years",
"3 years",
"4 years",
"10+ years",
"9 years",
"7 years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"4 years",
"8 years",
"4 years",
"10+ years",
"1 year",
"10+ years",
"8 years",
"3 years",
"2 years",
null,
"< 1 year",
"8 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"3 years",
null,
"10+ years",
"4 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
null,
"10+ years",
"9 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
null,
"4 years",
"7 years",
"8 years",
"8 years",
"9 years",
"2 years",
"1 year",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"5 years",
"3 years",
"5 years",
"10+ years",
"< 1 year",
"5 years",
"6 years",
"4 years",
"3 years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
null,
"1 year",
"10+ years",
"10+ years",
"2 years",
"9 years",
"2 years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"4 years",
"10+ years",
"7 years",
"1 year",
"2 years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"1 year",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"6 years",
null,
"9 years",
"4 years",
"2 years",
null,
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"3 years",
"1 year",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
null,
"4 years",
"10+ years",
"10+ years",
"9 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"9 years",
"9 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"8 years",
"3 years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"4 years",
"2 years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
null,
"10+ years",
"6 years",
"10+ years",
"7 years",
"7 years",
"1 year",
"5 years",
"8 years",
null,
"6 years",
null,
"10+ years",
"4 years",
"6 years",
null,
"10+ years",
"7 years",
"9 years",
"4 years",
"5 years",
"2 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"6 years",
"10+ years",
null,
"8 years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"4 years",
"4 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"2 years",
"2 years",
"9 years",
"3 years",
null,
"2 years",
"9 years",
"8 years",
"10+ years",
"4 years",
"10+ years",
"6 years",
"4 years",
"10+ years",
"1 year",
"2 years",
"< 1 year",
"5 years",
"2 years",
"10+ years",
"4 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"3 years",
"10+ years",
null,
"10+ years",
"8 years",
"< 1 year",
"8 years",
"1 year",
"10+ years",
"2 years",
"5 years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"3 years",
"< 1 year",
"6 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
null,
"8 years",
"2 years",
"9 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
null,
"8 years",
"10+ years",
"4 years",
"10+ years",
"6 years",
"6 years",
"1 year",
"2 years",
"6 years",
"10+ years",
"< 1 year",
"< 1 year",
"2 years",
"2 years",
"< 1 year",
"5 years",
"7 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"10+ years",
"7 years",
"< 1 year",
"4 years",
"6 years",
"6 years",
"10+ years",
"3 years",
"10+ years",
null,
"4 years",
"7 years",
"5 years",
"2 years",
"4 years",
null,
"10+ years",
"< 1 year",
"7 years",
"4 years",
null,
"1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"7 years",
null,
null,
"1 year",
"< 1 year",
"5 years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"7 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"2 years",
"< 1 year",
"4 years",
"6 years",
"10+ years",
"7 years",
"2 years",
"1 year",
"4 years",
"10+ years",
"7 years",
"< 1 year",
"1 year",
"10+ years",
"3 years",
"6 years",
"9 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"1 year",
"6 years",
"1 year",
"9 years",
"9 years",
"10+ years",
"8 years",
"9 years",
"6 years",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"< 1 year",
"8 years",
"10+ years",
"4 years",
"10+ years",
null,
"2 years",
"2 years",
"< 1 year",
null,
"9 years",
"8 years",
"3 years",
"< 1 year",
"5 years",
"10+ years",
"6 years",
"6 years",
"10+ years",
"5 years",
"7 years",
"3 years",
"2 years",
"1 year",
"10+ years",
"2 years",
"9 years",
"10+ years",
"4 years",
"< 1 year",
"8 years",
"9 years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"3 years",
"< 1 year",
"4 years",
"1 year",
"< 1 year",
"2 years",
"3 years",
"8 years",
"10+ years",
null,
"10+ years",
"5 years",
null,
"9 years",
"5 years",
"5 years",
"10+ years",
"3 years",
"3 years",
null,
"< 1 year",
"7 years",
"5 years",
"10+ years",
"8 years",
"3 years",
"2 years",
null,
"6 years",
"< 1 year",
"< 1 year",
"5 years",
"< 1 year",
"10+ years",
"3 years",
"5 years",
"2 years",
"2 years",
"7 years",
"9 years",
"7 years",
"9 years",
null,
"9 years",
"< 1 year",
"10+ years",
"9 years",
"9 years",
"2 years",
"8 years",
"3 years",
"4 years",
"8 years",
"5 years",
"10+ years",
"3 years",
"4 years",
"8 years",
"3 years",
"3 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"3 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"7 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"2 years",
"< 1 year",
"10+ years",
"9 years",
"9 years",
"4 years",
"4 years",
"3 years",
null,
"3 years",
"5 years",
"7 years",
null,
null,
"6 years",
null,
"10+ years",
"10+ years",
"6 years",
"1 year",
"5 years",
"3 years",
null,
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"2 years",
"4 years",
"10+ years",
"9 years",
"6 years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"9 years",
"10+ years",
"10+ years",
"9 years",
"4 years",
"5 years",
"1 year",
"4 years",
"7 years",
"9 years",
"10+ years",
"9 years",
"8 years",
null,
"4 years",
"< 1 year",
"1 year",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"9 years",
"10+ years",
"3 years",
null,
null,
"10+ years",
"3 years",
"1 year",
"7 years",
"4 years",
"10+ years",
"3 years",
"1 year",
"7 years",
"10+ years",
"3 years",
"10+ years",
null,
"2 years",
"10+ years",
"10+ years",
"5 years",
"9 years",
"5 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"5 years",
"5 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"7 years",
"3 years",
"10+ years",
"10+ years",
null,
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"9 years",
"2 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"2 years",
"< 1 year",
"10+ years",
null,
null,
"9 years",
"10+ years",
null,
"10+ years",
"4 years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"4 years",
"2 years",
"10+ years",
"3 years",
"< 1 year",
"1 year",
"3 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"4 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"8 years",
"5 years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"2 years",
"3 years",
"10+ years",
"6 years",
"1 year",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"1 year",
"9 years",
"4 years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"6 years",
"< 1 year",
"1 year",
"3 years",
"2 years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"6 years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"10+ years",
"2 years",
"6 years",
"3 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"5 years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"3 years",
"8 years",
"10+ years",
"6 years",
"3 years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"5 years",
null,
"2 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"8 years",
"9 years",
"3 years",
null,
"2 years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"6 years",
"3 years",
"2 years",
"< 1 year",
"4 years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"2 years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"6 years",
"2 years",
"< 1 year",
"5 years",
"3 years",
"< 1 year",
"< 1 year",
"< 1 year",
"4 years",
"4 years",
"3 years",
"10+ years",
null,
"4 years",
"3 years",
"< 1 year",
"2 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"6 years",
"10+ years",
"< 1 year",
"2 years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
null,
"7 years",
"7 years",
"5 years",
"10+ years",
"6 years",
null,
"2 years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
null,
"10+ years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"6 years",
"3 years",
null,
"8 years",
"5 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"4 years",
"< 1 year",
"9 years",
"1 year",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"4 years",
"10+ years",
"1 year",
"10+ years",
"5 years",
"3 years",
"2 years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"8 years",
"< 1 year",
"9 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"4 years",
"3 years",
"10+ years",
"< 1 year",
"7 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"1 year",
"< 1 year",
"3 years",
"10+ years",
"1 year",
"4 years",
"2 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"7 years",
"4 years",
"3 years",
"1 year",
"4 years",
"2 years",
"7 years",
"1 year",
"8 years",
"10+ years",
null,
"5 years",
"4 years",
"10+ years",
"7 years",
"8 years",
"3 years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
"8 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"7 years",
null,
"4 years",
"< 1 year",
"10+ years",
"5 years",
"1 year",
"2 years",
"7 years",
"7 years",
"6 years",
"4 years",
"10+ years",
"6 years",
"10+ years",
"8 years",
"< 1 year",
"5 years",
"2 years",
"4 years",
"9 years",
"4 years",
null,
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"8 years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"1 year",
"3 years",
"3 years",
"10+ years",
"10+ years",
null,
"9 years",
"10+ years",
"10+ years",
"9 years",
"3 years",
null,
"10+ years",
"10+ years",
"4 years",
"4 years",
"8 years",
"1 year",
"2 years",
"8 years",
"10+ years",
"10+ years",
"6 years",
"< 1 year",
"10+ years",
null,
"4 years",
"4 years",
"9 years",
"4 years",
"10+ years",
"4 years",
"2 years",
"< 1 year",
"10+ years",
null,
"3 years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"< 1 year",
"7 years",
"4 years",
"10+ years",
null,
"10+ years",
"6 years",
"9 years",
"9 years",
"< 1 year",
"2 years",
"8 years",
"< 1 year",
"1 year",
"4 years",
"2 years",
null,
"6 years",
"2 years",
"3 years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"8 years",
"1 year",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"7 years",
"6 years",
"3 years",
"5 years",
"10+ years",
"7 years",
"10+ years",
"1 year",
"10+ years",
"5 years",
"3 years",
"7 years",
"8 years",
"10+ years",
"10+ years",
"5 years",
"4 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"2 years",
null,
"7 years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"2 years",
"10+ years",
"7 years",
"5 years",
"5 years",
"10+ years",
"7 years",
"< 1 year",
"5 years",
"2 years",
"10+ years",
"8 years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"2 years",
"4 years",
"10+ years",
"1 year",
"6 years",
"4 years",
"7 years",
"9 years",
"3 years",
"8 years",
"10+ years",
"< 1 year",
"5 years",
"< 1 year",
"8 years",
"10+ years",
"1 year",
"10+ years",
"7 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"2 years",
"9 years",
"3 years",
"10+ years",
"2 years",
"1 year",
"8 years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"8 years",
"3 years",
"7 years",
"9 years",
"3 years",
"2 years",
"10+ years",
"1 year",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"8 years",
"3 years",
null,
"10+ years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"1 year",
"10+ years",
"5 years",
"3 years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"8 years",
"8 years",
"1 year",
"10+ years",
"3 years",
null,
"10+ years",
"8 years",
"1 year",
"3 years",
"2 years",
null,
"1 year",
"3 years",
"10+ years",
"6 years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"2 years",
"< 1 year",
"10+ years",
null,
"6 years",
"< 1 year",
"10+ years",
"2 years",
"3 years",
"5 years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"7 years",
"1 year",
"3 years",
"1 year",
"< 1 year",
"9 years",
"3 years",
"7 years",
"2 years",
"< 1 year",
"2 years",
"7 years",
"8 years",
"10+ years",
"< 1 year",
"3 years",
"2 years",
"2 years",
"1 year",
"10+ years",
"5 years",
"< 1 year",
"3 years",
"2 years",
"10+ years",
"1 year",
"2 years",
"5 years",
"5 years",
"4 years",
"5 years",
"8 years",
"7 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"9 years",
"< 1 year",
"5 years",
"2 years",
"3 years",
"9 years",
"7 years",
"10+ years",
"6 years",
"2 years",
null,
"2 years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"3 years",
null,
"3 years",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"1 year",
null,
"9 years",
"8 years",
"3 years",
null,
"4 years",
"10+ years",
"2 years",
"5 years",
"5 years",
"3 years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"4 years",
"1 year",
"10+ years",
null,
"3 years",
"2 years",
"10+ years",
null,
"10+ years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"8 years",
"8 years",
"10+ years",
"1 year",
"8 years",
null,
"10+ years",
"4 years",
"< 1 year",
"5 years",
"5 years",
"10+ years",
"6 years",
"10+ years",
"9 years",
"2 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"< 1 year",
"3 years",
"4 years",
"4 years",
"9 years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"2 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"1 year",
"4 years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"3 years",
"1 year",
"9 years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"1 year",
"10+ years",
"9 years",
null,
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"9 years",
"7 years",
"10+ years",
"8 years",
"3 years",
"7 years",
"10+ years",
"5 years",
"< 1 year",
"< 1 year",
"3 years",
"10+ years",
"5 years",
"7 years",
"1 year",
"10+ years",
"3 years",
"6 years",
"1 year",
"10+ years",
"2 years",
"2 years",
"5 years",
"6 years",
"7 years",
"4 years",
"10+ years",
"< 1 year",
"5 years",
"< 1 year",
"6 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"9 years",
"10+ years",
"10+ years",
"4 years",
"6 years",
"4 years",
"10+ years",
"1 year",
"10+ years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"5 years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"2 years",
"< 1 year",
"< 1 year",
"4 years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
null,
"1 year",
"10+ years",
"2 years",
"5 years",
"8 years",
"2 years",
"< 1 year",
"10+ years",
"1 year",
"9 years",
"< 1 year",
"7 years",
"4 years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"2 years",
"3 years",
"9 years",
"1 year",
"3 years",
"5 years",
"3 years",
"5 years",
"10+ years",
"1 year",
"< 1 year",
"1 year",
null,
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"5 years",
"4 years",
"8 years",
"4 years",
"5 years",
"6 years",
"10+ years",
"6 years",
"1 year",
"1 year",
null,
"3 years",
"2 years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"8 years",
"9 years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"9 years",
"10+ years",
"< 1 year",
"3 years",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"7 years",
"6 years",
"10+ years",
"9 years",
"2 years",
"7 years",
"5 years",
"1 year",
"7 years",
"10+ years",
"< 1 year",
null,
"10+ years",
"9 years",
"5 years",
"7 years",
"< 1 year",
"10+ years",
"2 years",
"4 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"6 years",
null,
"< 1 year",
"1 year",
"2 years",
"9 years",
"7 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
null,
"10+ years",
null,
"7 years",
"3 years",
"2 years",
"< 1 year",
"3 years",
"5 years",
"2 years",
"4 years",
"10+ years",
null,
"< 1 year",
"< 1 year",
"4 years",
"4 years",
"2 years",
"10+ years",
"3 years",
"9 years",
"10+ years",
"< 1 year",
"9 years",
"4 years",
"7 years",
null,
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"4 years",
"5 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"8 years",
"< 1 year",
null,
"5 years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"7 years",
"3 years",
"2 years",
"10+ years",
"2 years",
"6 years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"6 years",
"7 years",
"10+ years",
null,
"2 years",
"3 years",
"2 years",
null,
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"6 years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"10+ years",
null,
"2 years",
"10+ years",
"7 years",
"10+ years",
"9 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"1 year",
"10+ years",
"5 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"3 years",
null,
"2 years",
"8 years",
"< 1 year",
"10+ years",
"1 year",
null,
"7 years",
"1 year",
"4 years",
null,
"5 years",
"10+ years",
null,
"8 years",
"1 year",
"< 1 year",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"3 years",
"3 years",
"< 1 year",
"10+ years",
"< 1 year",
"2 years",
"8 years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"1 year",
"8 years",
"4 years",
"10+ years",
"1 year",
"9 years",
"5 years",
"7 years",
"1 year",
"6 years",
"3 years",
"7 years",
"2 years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"1 year",
"3 years",
"9 years",
"< 1 year",
"2 years",
"10+ years",
"8 years",
"7 years",
"2 years",
"6 years",
"< 1 year",
"< 1 year",
"1 year",
"10+ years",
"5 years",
"10+ years",
"4 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"8 years",
"1 year",
"10+ years",
null,
"3 years",
"4 years",
"6 years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"1 year",
"5 years",
"2 years",
"6 years",
"6 years",
"7 years",
"3 years",
"8 years",
"10+ years",
"10+ years",
"4 years",
"7 years",
"9 years",
"10+ years",
"4 years",
"9 years",
"< 1 year",
"3 years",
"9 years",
"< 1 year",
"10+ years",
"2 years",
"1 year",
"3 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"7 years",
null,
"10+ years",
"10+ years",
null,
"7 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"5 years",
"< 1 year",
"6 years",
"3 years",
"< 1 year",
"2 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"9 years",
"10+ years",
"6 years",
"1 year",
"< 1 year",
"2 years",
"9 years",
"10+ years",
"< 1 year",
null,
"10+ years",
"< 1 year",
"5 years",
"9 years",
"6 years",
"10+ years",
"1 year",
"4 years",
"3 years",
"3 years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"6 years",
"3 years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"2 years",
"7 years",
"8 years",
"10+ years",
"10+ years",
null,
"1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"7 years",
"10+ years",
"10+ years",
null,
"6 years",
"5 years",
"< 1 year",
"5 years",
"7 years",
"1 year",
"3 years",
"8 years",
"7 years",
null,
null,
"10+ years",
"2 years",
"< 1 year",
null,
"10+ years",
"5 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"8 years",
"5 years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"2 years",
null,
"10+ years",
"8 years",
"6 years",
"9 years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
null,
"4 years",
"7 years",
null,
"8 years",
"10+ years",
"7 years",
"7 years",
"1 year",
"1 year",
"10+ years",
"5 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"3 years",
"3 years",
"9 years",
"4 years",
"1 year",
null,
"3 years",
"2 years",
"3 years",
"4 years",
"10+ years",
"9 years",
"10+ years",
"8 years",
"1 year",
"7 years",
"1 year",
"< 1 year",
"10+ years",
"1 year",
"8 years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"1 year",
null,
"< 1 year",
"2 years",
"2 years",
"10+ years",
null,
"4 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"5 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"7 years",
"2 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"< 1 year",
"8 years",
"6 years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"1 year",
"2 years",
"8 years",
"2 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"10+ years",
"6 years",
"5 years",
"< 1 year",
"3 years",
"4 years",
"1 year",
"8 years",
"6 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"6 years",
"4 years",
"10+ years",
"5 years",
"10+ years",
"6 years",
"4 years",
"10+ years",
"7 years",
"10+ years",
null,
"< 1 year",
"4 years",
"< 1 year",
"4 years",
"2 years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"4 years",
"< 1 year",
"1 year",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"4 years",
"9 years",
"< 1 year",
"10+ years",
"9 years",
"5 years",
"2 years",
"3 years",
"4 years",
"10+ years",
"7 years",
"4 years",
"< 1 year",
"10+ years",
"< 1 year",
"4 years",
"3 years",
"2 years",
"8 years",
"7 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
null,
"10+ years",
"8 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"9 years",
"4 years",
"9 years",
"5 years",
"1 year",
"10+ years",
null,
"3 years",
"10+ years",
"< 1 year",
"4 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"9 years",
"9 years",
"7 years",
"10+ years",
"4 years",
"5 years",
"5 years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
null,
"4 years",
"< 1 year",
"8 years",
"4 years",
"10+ years",
"3 years",
"5 years",
null,
"6 years",
"10+ years",
"10+ years",
"1 year",
"9 years",
"5 years",
"10+ years",
"< 1 year",
null,
"10+ years",
"2 years",
"10+ years",
null,
"5 years",
"4 years",
"5 years",
"9 years",
"< 1 year",
null,
"1 year",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"1 year",
"9 years",
"7 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
null,
"10+ years",
"2 years",
"6 years",
"6 years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"4 years",
null,
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
null,
"6 years",
null,
"10+ years",
"4 years",
"10+ years",
"1 year",
"2 years",
"2 years",
"7 years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"7 years",
"4 years",
"8 years",
"9 years",
"10+ years",
"10+ years",
"8 years",
"1 year",
"3 years",
"6 years",
"3 years",
"1 year",
"1 year",
"4 years",
"5 years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"4 years",
"6 years",
"3 years",
"10+ years",
null,
"10+ years",
"10+ years",
"1 year",
"9 years",
"2 years",
"6 years",
"10+ years",
"9 years",
"10+ years",
"4 years",
"7 years",
"10+ years",
"1 year",
"10+ years",
"5 years",
null,
"10+ years",
"7 years",
"10+ years",
"6 years",
"8 years",
"1 year",
"4 years",
"5 years",
"7 years",
"4 years",
"10+ years",
"1 year",
"< 1 year",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"5 years",
"7 years",
"2 years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"4 years",
null,
"3 years",
"2 years",
"7 years",
"7 years",
"5 years",
"10+ years",
"1 year",
null,
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"6 years",
"10+ years",
"4 years",
"9 years",
"10+ years",
"< 1 year",
"8 years",
"2 years",
"10+ years",
"8 years",
"1 year",
"10+ years",
"3 years",
"6 years",
"10+ years",
"3 years",
"9 years",
"8 years",
"4 years",
"3 years",
"10+ years",
"4 years",
"5 years",
"2 years",
"2 years",
"8 years",
"10+ years",
"10+ years",
null,
"3 years",
"7 years",
"8 years",
"4 years",
"10+ years",
"< 1 year",
"9 years",
"3 years",
"10+ years",
"5 years",
"3 years",
"8 years",
"10+ years",
"3 years",
"5 years",
"8 years",
"1 year",
"1 year",
"10+ years",
"8 years",
"< 1 year",
"2 years",
"2 years",
"3 years",
"2 years",
"8 years",
"10+ years",
"< 1 year",
"8 years",
"3 years",
"4 years",
null,
"10+ years",
"10+ years",
"8 years",
null,
"10+ years",
"6 years",
"9 years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"5 years",
"3 years",
"10+ years",
"7 years",
"10+ years",
"7 years",
"7 years",
"4 years",
"8 years",
"10+ years",
null,
"10+ years",
"10+ years",
"2 years",
"9 years",
"1 year",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"8 years",
"< 1 year",
"< 1 year",
"10+ years",
null,
"10+ years",
"7 years",
"6 years",
"9 years",
"10+ years",
"10+ years",
"9 years",
"4 years",
"2 years",
"2 years",
"10+ years",
"2 years",
"1 year",
"5 years",
null,
"2 years",
"4 years",
"10+ years",
"9 years",
"3 years",
"< 1 year",
"1 year",
"10+ years",
"7 years",
"6 years",
"4 years",
"4 years",
"3 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
null,
"10+ years",
"9 years",
"< 1 year",
"3 years",
"3 years",
"4 years",
"4 years",
"4 years",
"9 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"< 1 year",
"4 years",
"5 years",
"< 1 year",
"2 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"4 years",
"< 1 year",
"10+ years",
"6 years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"8 years",
"3 years",
null,
"5 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"8 years",
"9 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"8 years",
"4 years",
"4 years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"7 years",
"5 years",
"3 years",
"4 years",
"5 years",
"9 years",
"3 years",
"9 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"9 years",
"10+ years",
"4 years",
"7 years",
"6 years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"6 years",
"4 years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"1 year",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"< 1 year",
"< 1 year",
"5 years",
"8 years",
"2 years",
"10+ years",
"5 years",
null,
null,
"1 year",
null,
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"3 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"7 years",
"9 years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"8 years",
"9 years",
"1 year",
"8 years",
"2 years",
"10+ years",
"6 years",
"3 years",
"10+ years",
"2 years",
"6 years",
"9 years",
"2 years",
"10+ years",
null,
null,
"2 years",
"9 years",
"3 years",
"10+ years",
"3 years",
"4 years",
"1 year",
"1 year",
"< 1 year",
"6 years",
"1 year",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"2 years",
"9 years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"8 years",
"4 years",
"6 years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"7 years",
"10+ years",
"2 years",
"< 1 year",
"7 years",
"10+ years",
"2 years",
"3 years",
"1 year",
"4 years",
"3 years",
"3 years",
"9 years",
"1 year",
"4 years",
"2 years",
"7 years",
"3 years",
"9 years",
"1 year",
"10+ years",
null,
"7 years",
"5 years",
"6 years",
"< 1 year",
"10+ years",
"< 1 year",
"7 years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"1 year",
"5 years",
"1 year",
"3 years",
"4 years",
"< 1 year",
"6 years",
"10+ years",
"3 years",
"10+ years",
null,
"10+ years",
"9 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"9 years",
"5 years",
"2 years",
"< 1 year",
"10+ years",
"1 year",
"7 years",
"10+ years",
"10+ years",
"9 years",
"7 years",
"7 years",
"8 years",
"10+ years",
"5 years",
"10+ years",
"1 year",
"4 years",
"10+ years",
"6 years",
"10+ years",
"9 years",
"1 year",
"6 years",
"< 1 year",
"10+ years",
null,
null,
"10+ years",
"< 1 year",
"3 years",
"3 years",
"1 year",
"4 years",
null,
"5 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
null,
"7 years",
"1 year",
"7 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
null,
"5 years",
"6 years",
"8 years",
null,
"4 years",
"1 year",
"2 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"8 years",
"6 years",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"3 years",
"9 years",
"5 years",
"9 years",
"2 years",
null,
"10+ years",
"5 years",
"9 years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"2 years",
"< 1 year",
"3 years",
"7 years",
"10+ years",
"5 years",
"2 years",
"2 years",
"3 years",
"< 1 year",
"10+ years",
"2 years",
"3 years",
"2 years",
"4 years",
"10+ years",
"4 years",
"5 years",
"6 years",
"10+ years",
"7 years",
"3 years",
"2 years",
"5 years",
"4 years",
"< 1 year",
"3 years",
null,
"10+ years",
null,
"10+ years",
"9 years",
"2 years",
"< 1 year",
"3 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"10+ years",
null,
"1 year",
null,
"2 years",
"4 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"7 years",
"3 years",
"4 years",
"4 years",
null,
"10+ years",
"2 years",
"2 years",
"8 years",
"9 years",
"1 year",
"4 years",
"< 1 year",
"4 years",
"10+ years",
"< 1 year",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"8 years",
"10+ years",
"10+ years",
null,
"5 years",
"2 years",
"7 years",
"10+ years",
"7 years",
"5 years",
"5 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"6 years",
"5 years",
"< 1 year",
"10+ years",
"4 years",
"4 years",
"7 years",
"8 years",
"2 years",
"7 years",
"8 years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"2 years",
null,
"4 years",
"2 years",
"< 1 year",
"2 years",
"9 years",
"2 years",
"10+ years",
"9 years",
null,
"1 year",
"7 years",
"4 years",
"9 years",
"5 years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"< 1 year",
"3 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"6 years",
"10+ years",
"< 1 year",
"< 1 year",
"9 years",
"5 years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
null,
"3 years",
"10+ years",
"< 1 year",
"2 years",
null,
"6 years",
"8 years",
"1 year",
"< 1 year",
"3 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
null,
"10+ years",
"5 years",
"4 years",
"8 years",
"2 years",
"10+ years",
"9 years",
null,
"5 years",
"9 years",
"2 years",
"7 years",
"10+ years",
"5 years",
"2 years",
"7 years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"4 years",
"5 years",
"10+ years",
"< 1 year",
"1 year",
"2 years",
"10+ years",
null,
"10+ years",
"10+ years",
"6 years",
null,
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"2 years",
null,
"3 years",
"10+ years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"8 years",
"9 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"2 years",
"3 years",
"8 years",
"10+ years",
"8 years",
"6 years",
"3 years",
"1 year",
"10+ years",
"4 years",
"2 years",
"3 years",
"5 years",
"5 years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"3 years",
"8 years",
null,
"10+ years",
"< 1 year",
"3 years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"2 years",
"2 years",
"6 years",
"9 years",
"10+ years",
"3 years",
"8 years",
null,
"2 years",
"10+ years",
"10+ years",
"4 years",
"9 years",
"2 years",
"1 year",
"10+ years",
"6 years",
"3 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"6 years",
"7 years",
"4 years",
"10+ years",
"10+ years",
"3 years",
null,
"2 years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"4 years",
"4 years",
"< 1 year",
"10+ years",
null,
"8 years",
"10+ years",
"8 years",
"3 years",
"< 1 year",
"10+ years",
"1 year",
"5 years",
"3 years",
"10+ years",
"1 year",
"2 years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"9 years",
"10+ years",
"1 year",
"4 years",
"3 years",
"1 year",
"10+ years",
"< 1 year",
"8 years",
"4 years",
"5 years",
"8 years",
"10+ years",
null,
"10+ years",
"10+ years",
"2 years",
"4 years",
"3 years",
null,
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"3 years",
"10+ years",
"< 1 year",
"6 years",
"5 years",
"3 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"1 year",
"2 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"6 years",
"6 years",
"10+ years",
"6 years",
"7 years",
"1 year",
"10+ years",
"10+ years",
"9 years",
null,
"4 years",
"9 years",
"3 years",
"6 years",
"< 1 year",
null,
"2 years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"4 years",
"2 years",
"< 1 year",
"5 years",
"2 years",
"2 years",
null,
"8 years",
"< 1 year",
null,
"3 years",
"1 year",
"1 year",
"9 years",
"< 1 year",
"8 years",
"1 year",
"< 1 year",
"10+ years",
"8 years",
"7 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
null,
"< 1 year",
"5 years",
"3 years",
"10+ years",
"3 years",
"4 years",
"2 years",
"4 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"1 year",
"2 years",
"7 years",
"7 years",
"2 years",
"5 years",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"5 years",
"4 years",
"4 years",
"< 1 year",
"10+ years",
"1 year",
"6 years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"6 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"< 1 year",
"4 years",
"7 years",
"2 years",
"3 years",
"3 years",
"7 years",
"10+ years",
"2 years",
"5 years",
"8 years",
"1 year",
"4 years",
"1 year",
"10+ years",
"6 years",
"4 years",
"< 1 year",
"3 years",
"8 years",
"3 years",
"< 1 year",
"1 year",
"1 year",
"10+ years",
"3 years",
"10+ years",
"5 years",
"6 years",
null,
"10+ years",
"7 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"2 years",
"1 year",
"4 years",
"10+ years",
"7 years",
"10+ years",
"7 years",
"7 years",
"10+ years",
"8 years",
null,
"10+ years",
"4 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"5 years",
"10+ years",
"2 years",
"< 1 year",
null,
"7 years",
null,
"6 years",
"< 1 year",
"10+ years",
"3 years",
null,
"5 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"8 years",
"6 years",
"< 1 year",
"10+ years",
"7 years",
"6 years",
null,
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"4 years",
"8 years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"3 years",
"5 years",
"6 years",
"< 1 year",
"1 year",
"10+ years",
"< 1 year",
"5 years",
"8 years",
"10+ years",
"2 years",
"< 1 year",
null,
"8 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"3 years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"4 years",
"3 years",
"10+ years",
"9 years",
"6 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
null,
"2 years",
"8 years",
"9 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"3 years",
null,
"10+ years",
"8 years",
null,
"5 years",
null,
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"3 years",
"10+ years",
"9 years",
"5 years",
"5 years",
"2 years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"5 years",
"6 years",
"8 years",
"2 years",
"9 years",
"5 years",
null,
"7 years",
"7 years",
"3 years",
"5 years",
"9 years",
"6 years",
"2 years",
"7 years",
"10+ years",
null,
"3 years",
"10+ years",
"7 years",
"4 years",
"7 years",
"5 years",
"2 years",
"< 1 year",
"2 years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"8 years",
"< 1 year",
"5 years",
null,
"10+ years",
"5 years",
"4 years",
"2 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"6 years",
"3 years",
"10+ years",
"6 years",
"4 years",
"10+ years",
"8 years",
"5 years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"10+ years",
"< 1 year",
"8 years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"7 years",
"< 1 year",
"8 years",
"1 year",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"< 1 year",
"5 years",
"4 years",
"1 year",
"10+ years",
"3 years",
"8 years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
null,
"< 1 year",
"10+ years",
null,
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"5 years",
"2 years",
"5 years",
"10+ years",
"3 years",
"3 years",
"1 year",
"4 years",
"1 year",
"4 years",
null,
null,
"3 years",
"< 1 year",
"3 years",
"< 1 year",
"5 years",
"10+ years",
"4 years",
"2 years",
"5 years",
"7 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"1 year",
"5 years",
"5 years",
"10+ years",
null,
"< 1 year",
"4 years",
"2 years",
null,
"10+ years",
"10+ years",
"4 years",
"6 years",
"3 years",
null,
"10+ years",
"10+ years",
"4 years",
"1 year",
"4 years",
null,
"1 year",
"9 years",
"5 years",
"9 years",
"4 years",
"< 1 year",
"2 years",
"8 years",
"3 years",
"1 year",
"2 years",
"3 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"< 1 year",
"5 years",
"< 1 year",
null,
"3 years",
"10+ years",
"8 years",
"7 years",
"8 years",
"8 years",
"7 years",
"9 years",
"5 years",
"6 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"9 years",
"10+ years",
null,
"2 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
null,
"8 years",
"4 years",
"10+ years",
"10+ years",
"9 years",
null,
"< 1 year",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"4 years",
"8 years",
"10+ years",
null,
"< 1 year",
"3 years",
"< 1 year",
"6 years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"1 year",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"6 years",
"1 year",
"4 years",
"10+ years",
"3 years",
"7 years",
"4 years",
null,
"10+ years",
"6 years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"7 years",
"1 year",
"< 1 year",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"2 years",
"2 years",
"4 years",
"< 1 year",
"1 year",
"4 years",
"7 years",
"1 year",
"2 years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"2 years",
"7 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"8 years",
"< 1 year",
"3 years",
"10+ years",
"< 1 year",
"1 year",
"5 years",
"< 1 year",
"1 year",
"8 years",
"4 years",
null,
"10+ years",
"7 years",
"4 years",
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"2 years",
"8 years",
"< 1 year",
"2 years",
"9 years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"7 years",
null,
"10+ years",
"2 years",
"3 years",
"7 years",
"10+ years",
null,
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"4 years",
"3 years",
"10+ years",
"9 years",
"10+ years",
"9 years",
"8 years",
"10+ years",
"9 years",
"4 years",
"6 years",
"5 years",
"8 years",
null,
"9 years",
"3 years",
"2 years",
"1 year",
"8 years",
"7 years",
"2 years",
"10+ years",
"4 years",
"< 1 year",
null,
"6 years",
"7 years",
"10+ years",
"8 years",
"3 years",
"7 years",
"10+ years",
null,
"3 years",
"7 years",
"10+ years",
"7 years",
"10+ years",
"5 years",
"10+ years",
"1 year",
"9 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"5 years",
"10+ years",
"4 years",
"2 years",
"4 years",
"5 years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"2 years",
"7 years",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
"9 years",
"4 years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"8 years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"4 years",
"6 years",
"2 years",
"< 1 year",
"10+ years",
"5 years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"5 years",
"10+ years",
"8 years",
"6 years",
"< 1 year",
"3 years",
"4 years",
"10+ years",
"1 year",
"7 years",
"2 years",
"6 years",
"4 years",
"7 years",
"10+ years",
null,
"< 1 year",
"3 years",
"< 1 year",
"9 years",
"5 years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"6 years",
"10+ years",
"2 years",
"7 years",
"1 year",
"10+ years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
null,
"7 years",
"10+ years",
"2 years",
"4 years",
"2 years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"9 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"< 1 year",
"3 years",
"5 years",
"9 years",
"5 years",
"< 1 year",
"1 year",
"8 years",
"10+ years",
"5 years",
null,
"2 years",
null,
"8 years",
"6 years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"4 years",
"5 years",
"3 years",
"10+ years",
"1 year",
"1 year",
"6 years",
"10+ years",
"4 years",
"1 year",
"9 years",
"< 1 year",
"10+ years",
"9 years",
"10+ years",
"10+ years",
null,
"10+ years",
"6 years",
"10+ years",
"7 years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
null,
"6 years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"3 years",
"10+ years",
null,
null,
"10+ years",
"9 years",
"2 years",
"10+ years",
"2 years",
"7 years",
null,
"2 years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
null,
"10+ years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"5 years",
"6 years",
"4 years",
"< 1 year",
"1 year",
"10+ years",
"1 year",
"8 years",
"3 years",
"9 years",
"6 years",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"7 years",
"10+ years",
"6 years",
"3 years",
"8 years",
"1 year",
"10+ years",
"7 years",
"3 years",
"4 years",
"6 years",
"2 years",
"< 1 year",
"10+ years",
"3 years",
"4 years",
"10+ years",
"1 year",
"9 years",
null,
"7 years",
"8 years",
"6 years",
"10+ years",
"10+ years",
"9 years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"6 years",
"5 years",
"6 years",
"< 1 year",
"10+ years",
"5 years",
"8 years",
"3 years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"< 1 year",
"< 1 year",
null,
"4 years",
"10+ years",
"9 years",
"3 years",
"2 years",
"< 1 year",
"10+ years",
"5 years",
"3 years",
"9 years",
"4 years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"2 years",
"10+ years",
"9 years",
"7 years",
"10+ years",
null,
"10+ years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"1 year",
"8 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"4 years",
"6 years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"3 years",
"6 years",
"< 1 year",
"2 years",
"6 years",
"2 years",
"3 years",
"10+ years",
null,
"10+ years",
"10+ years",
"6 years",
"7 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"4 years",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"6 years",
"4 years",
"10+ years",
"7 years",
"9 years",
"5 years",
"10+ years",
"7 years",
"10+ years",
null,
"10+ years",
"1 year",
null,
"< 1 year",
"1 year",
"3 years",
"10+ years",
"6 years",
"9 years",
"10+ years",
"2 years",
"5 years",
"7 years",
"10+ years",
"2 years",
"3 years",
null,
"3 years",
"6 years",
"2 years",
"2 years",
"6 years",
"1 year",
"3 years",
"< 1 year",
null,
"4 years",
"5 years",
"< 1 year",
"6 years",
"5 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"5 years",
"4 years",
null,
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"2 years",
"10+ years",
null,
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"9 years",
"8 years",
null,
"< 1 year",
"6 years",
"1 year",
"2 years",
null,
"2 years",
"8 years",
"10+ years",
"2 years",
"10+ years",
"9 years",
"2 years",
"2 years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"9 years",
"4 years",
"< 1 year",
"2 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"1 year",
"< 1 year",
"10+ years",
"7 years",
"1 year",
"5 years",
"1 year",
"10+ years",
"6 years",
"10+ years",
"3 years",
"< 1 year",
"2 years",
"< 1 year",
"4 years",
"2 years",
"2 years",
"2 years",
"8 years",
"4 years",
"10+ years",
"8 years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
null,
"9 years",
"2 years",
"3 years",
"< 1 year",
"3 years",
"2 years",
"8 years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"5 years",
"6 years",
"1 year",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"< 1 year",
"2 years",
"10+ years",
"2 years",
"5 years",
"4 years",
"10+ years",
"2 years",
"< 1 year",
"< 1 year",
"5 years",
"< 1 year",
"10+ years",
"4 years",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"5 years",
"9 years",
"2 years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"1 year",
"2 years",
null,
"10+ years",
"10+ years",
"7 years",
"10+ years",
"5 years",
"< 1 year",
"8 years",
"2 years",
"10+ years",
"10+ years",
"1 year",
"9 years",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"9 years",
"3 years",
null,
"7 years",
"7 years",
"10+ years",
null,
"7 years",
"2 years",
"4 years",
"2 years",
"4 years",
"8 years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"6 years",
"8 years",
"7 years",
"8 years",
"1 year",
"10+ years",
"2 years",
"1 year",
"1 year",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"6 years",
null,
"6 years",
"10+ years",
"10+ years",
"8 years",
"6 years",
"1 year",
"4 years",
"3 years",
"10+ years",
"< 1 year",
"4 years",
"2 years",
"10+ years",
"5 years",
"2 years",
"9 years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"1 year",
"6 years",
"8 years",
"6 years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"10+ years",
null,
"5 years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"4 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"1 year",
"2 years",
"1 year",
"10+ years",
"4 years",
"< 1 year",
null,
"10+ years",
"7 years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"3 years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"4 years",
"7 years",
"8 years",
"10+ years",
"3 years",
"5 years",
"4 years",
"1 year",
"4 years",
"9 years",
"3 years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"4 years",
"4 years",
"10+ years",
"1 year",
"9 years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"3 years",
"7 years",
"4 years",
"2 years",
"1 year",
"1 year",
"< 1 year",
"< 1 year",
"2 years",
"8 years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"5 years",
"3 years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"9 years",
"4 years",
"10+ years",
"4 years",
"2 years",
"2 years",
"10+ years",
"4 years",
"7 years",
"3 years",
"10+ years",
"9 years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
null,
"10+ years",
"6 years",
"8 years",
"2 years",
"10+ years",
"2 years",
"6 years",
"< 1 year",
"9 years",
"1 year",
"4 years",
null,
"2 years",
null,
"10+ years",
null,
"5 years",
"4 years",
"10+ years",
"7 years",
"6 years",
"1 year",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"9 years",
"10+ years",
null,
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"1 year",
"10+ years",
null,
"9 years",
"3 years",
"3 years",
"4 years",
"4 years",
"8 years",
"4 years",
"9 years",
"5 years",
"9 years",
"1 year",
"2 years",
"4 years",
"4 years",
"10+ years",
null,
"< 1 year",
"5 years",
"5 years",
"2 years",
"< 1 year",
"5 years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"3 years",
"5 years",
"8 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
null,
"< 1 year",
"1 year",
"8 years",
"7 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"2 years",
"4 years",
"8 years",
"2 years",
"7 years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"2 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"7 years",
"3 years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"9 years",
"6 years",
"10+ years",
"4 years",
"1 year",
"9 years",
"7 years",
"8 years",
"1 year",
"8 years",
"10+ years",
"4 years",
"3 years",
"5 years",
"3 years",
"< 1 year",
"4 years",
"10+ years",
null,
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"4 years",
null,
"7 years",
null,
"10+ years",
"6 years",
null,
"5 years",
"8 years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"2 years",
null,
"10+ years",
"10+ years",
"5 years",
"2 years",
"7 years",
"< 1 year",
"3 years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"6 years",
"6 years",
"10+ years",
"1 year",
"7 years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"4 years",
"1 year",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"2 years",
"5 years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"6 years",
"10+ years",
"5 years",
"10+ years",
"1 year",
"3 years",
"8 years",
"3 years",
"10+ years",
"8 years",
"7 years",
"10+ years",
"1 year",
"5 years",
"8 years",
"3 years",
"7 years",
"5 years",
"2 years",
"< 1 year",
"10+ years",
"< 1 year",
"7 years",
"1 year",
"5 years",
"5 years",
"10+ years",
"3 years",
"6 years",
"10+ years",
"6 years",
"8 years",
"8 years",
"< 1 year",
"3 years",
"4 years",
"4 years",
"3 years",
"3 years",
"< 1 year",
"9 years",
"10+ years",
"3 years",
null,
"3 years",
"1 year",
"5 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
null,
"10+ years",
"10+ years",
"2 years",
"2 years",
"2 years",
"8 years",
"2 years",
"6 years",
"10+ years",
"1 year",
"6 years",
"2 years",
"7 years",
"< 1 year",
"10+ years",
"< 1 year",
"2 years",
"9 years",
"10+ years",
"7 years",
"3 years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"2 years",
"4 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"3 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"4 years",
null,
"6 years",
"2 years",
"8 years",
"< 1 year",
"3 years",
"< 1 year",
null,
"< 1 year",
"6 years",
"4 years",
"1 year",
"10+ years",
"1 year",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"< 1 year",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"9 years",
"5 years",
null,
"9 years",
"10+ years",
"2 years",
"8 years",
"3 years",
null,
"2 years",
"10+ years",
"1 year",
"10+ years",
"7 years",
"3 years",
"2 years",
"8 years",
"9 years",
"6 years",
"10+ years",
"10+ years",
"1 year",
"7 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"2 years",
"< 1 year",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
"9 years",
"6 years",
"10+ years",
"10+ years",
"7 years",
"9 years",
"1 year",
"2 years",
"7 years",
"10+ years",
null,
"10+ years",
"1 year",
"10+ years",
"< 1 year",
null,
"2 years",
"10+ years",
"9 years",
"10+ years",
"3 years",
"3 years",
"< 1 year",
"9 years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
null,
"3 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"7 years",
"6 years",
"4 years",
"5 years",
"4 years",
"5 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"< 1 year",
"10+ years",
"5 years",
"5 years",
"< 1 year",
"3 years",
"10+ years",
"7 years",
"10+ years",
"< 1 year",
"8 years",
"5 years",
"10+ years",
"< 1 year",
"9 years",
"9 years",
"4 years",
"5 years",
"10+ years",
"< 1 year",
"2 years",
null,
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"1 year",
"< 1 year",
"4 years",
"< 1 year",
"1 year",
"8 years",
"8 years",
"3 years",
"7 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"3 years",
"< 1 year",
null,
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"1 year",
"1 year",
"1 year",
"8 years",
"7 years",
"10+ years",
"2 years",
"1 year",
"3 years",
"4 years",
"7 years",
"< 1 year",
null,
"9 years",
"5 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"8 years",
"10+ years",
"10+ years",
"3 years",
null,
"10+ years",
"< 1 year",
"1 year",
"1 year",
"2 years",
"10+ years",
"10+ years",
"1 year",
"8 years",
null,
null,
"< 1 year",
"1 year",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"3 years",
"10+ years",
"6 years",
"< 1 year",
null,
"2 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"5 years",
"2 years",
"2 years",
"3 years",
"3 years",
"10+ years",
"3 years",
"1 year",
"6 years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"2 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"1 year",
"3 years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"3 years",
"2 years",
"9 years",
"10+ years",
"< 1 year",
null,
"8 years",
"10+ years",
"5 years",
"9 years",
null,
"5 years",
"2 years",
"10+ years",
"2 years",
"1 year",
"6 years",
"4 years",
"3 years",
"7 years",
"6 years",
"1 year",
"4 years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"8 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"1 year",
null,
"2 years",
"5 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"2 years",
"9 years",
"10+ years",
"10+ years",
"4 years",
"7 years",
"7 years",
null,
"7 years",
"1 year",
"9 years",
"4 years",
"10+ years",
null,
"10+ years",
"5 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
null,
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"3 years",
"4 years",
"1 year",
"10+ years",
"4 years",
"10+ years",
"7 years",
"10+ years",
"9 years",
"5 years",
"< 1 year",
"10+ years",
"1 year",
"8 years",
"9 years",
"1 year",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"2 years",
"1 year",
"10+ years",
"5 years",
"8 years",
"< 1 year",
"1 year",
"< 1 year",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"2 years",
"< 1 year",
"< 1 year",
"3 years",
"7 years",
"10+ years",
"2 years",
"< 1 year",
"9 years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"7 years",
"5 years",
"10+ years",
"2 years",
"< 1 year",
"9 years",
"< 1 year",
"7 years",
"5 years",
null,
"1 year",
"10+ years",
"1 year",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"9 years",
"6 years",
"10+ years",
null,
"1 year",
"8 years",
"7 years",
"10+ years",
"8 years",
"4 years",
"10+ years",
"5 years",
"6 years",
"6 years",
"6 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"10+ years",
null,
"3 years",
"10+ years",
"2 years",
"6 years",
"8 years",
"6 years",
"3 years",
"5 years",
"7 years",
"7 years",
"10+ years",
null,
"10+ years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"3 years",
null,
"5 years",
"10+ years",
"< 1 year",
"6 years",
"1 year",
"4 years",
"10+ years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"2 years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"8 years",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"2 years",
null,
"3 years",
"7 years",
"7 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"10+ years",
"1 year",
"< 1 year",
"5 years",
"< 1 year",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"5 years",
"8 years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
null,
"< 1 year",
"2 years",
"10+ years",
"9 years",
"3 years",
"4 years",
"2 years",
"2 years",
"10+ years",
"1 year",
"< 1 year",
"< 1 year",
"9 years",
"< 1 year",
"8 years",
"10+ years",
null,
"3 years",
"8 years",
"6 years",
"9 years",
"7 years",
"6 years",
"2 years",
"4 years",
"9 years",
"3 years",
null,
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"6 years",
"10+ years",
"8 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"3 years",
"< 1 year",
"2 years",
"2 years",
"10+ years",
"8 years",
"3 years",
"2 years",
"10+ years",
"1 year",
"5 years",
"4 years",
"1 year",
"9 years",
"10+ years",
"7 years",
"7 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"1 year",
"9 years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"1 year",
"6 years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"3 years",
null,
null,
"10+ years",
"4 years",
"7 years",
"8 years",
null,
"10+ years",
"3 years",
"7 years",
"1 year",
"6 years",
"10+ years",
"< 1 year",
"< 1 year",
"7 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"3 years",
"9 years",
"8 years",
"1 year",
"< 1 year",
"7 years",
null,
"1 year",
"10+ years",
"5 years",
"8 years",
"8 years",
"< 1 year",
"6 years",
"< 1 year",
"2 years",
"1 year",
"10+ years",
"5 years",
"4 years",
"3 years",
"4 years",
"10+ years",
"3 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"7 years",
"7 years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"3 years",
"9 years",
"< 1 year",
"2 years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"8 years",
"2 years",
"9 years",
null,
"4 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"6 years",
"5 years",
"2 years",
"7 years",
"2 years",
"10+ years",
"5 years",
"4 years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"9 years",
"5 years",
"6 years",
"3 years",
"10+ years",
"3 years",
"3 years",
"2 years",
"10+ years",
null,
"10+ years",
"3 years",
"2 years",
"2 years",
"1 year",
"7 years",
"2 years",
"2 years",
"4 years",
"8 years",
"8 years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"9 years",
"4 years",
"< 1 year",
"10+ years",
"1 year",
"2 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"1 year",
"< 1 year",
"4 years",
"3 years",
"3 years",
"4 years",
null,
"10+ years",
"1 year",
"8 years",
"2 years",
"2 years",
"9 years",
"3 years",
"1 year",
"< 1 year",
"10+ years",
"8 years",
"6 years",
"< 1 year",
"10+ years",
"7 years",
"2 years",
"2 years",
null,
"9 years",
"2 years",
"6 years",
"10+ years",
"7 years",
"3 years",
"5 years",
"5 years",
"1 year",
"10+ years",
null,
"2 years",
"5 years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"8 years",
"4 years",
"< 1 year",
"8 years",
"2 years",
"10+ years",
"4 years",
"< 1 year",
"5 years",
"1 year",
"5 years",
"3 years",
"4 years",
"10+ years",
"10+ years",
null,
"< 1 year",
"< 1 year",
"8 years",
"4 years",
"10+ years",
null,
"< 1 year",
"9 years",
"< 1 year",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"2 years",
"9 years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"5 years",
"5 years",
"10+ years",
"6 years",
"4 years",
"3 years",
"1 year",
"5 years",
"2 years",
"5 years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"1 year",
"2 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"6 years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"7 years",
"4 years",
"6 years",
"10+ years",
"10+ years",
"5 years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
null,
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"< 1 year",
"6 years",
"4 years",
"10+ years",
"5 years",
"4 years",
"10+ years",
"6 years",
"1 year",
"10+ years",
"10+ years",
"9 years",
"2 years",
"5 years",
"5 years",
"9 years",
"2 years",
"10+ years",
"2 years",
"2 years",
"< 1 year",
"4 years",
"7 years",
"< 1 year",
"< 1 year",
"5 years",
"< 1 year",
"8 years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"2 years",
"5 years",
"5 years",
"4 years",
"4 years",
"7 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"4 years",
"< 1 year",
"4 years",
"3 years",
"5 years",
null,
null,
"3 years",
"5 years",
"4 years",
"1 year",
"10+ years",
"5 years",
"10+ years",
"9 years",
"10+ years",
"7 years",
"7 years",
"10+ years",
"8 years",
"9 years",
"1 year",
"2 years",
"1 year",
"8 years",
"10+ years",
"10+ years",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"4 years",
null,
"< 1 year",
"10+ years",
"< 1 year",
"2 years",
null,
"2 years",
"4 years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"1 year",
"4 years",
"4 years",
"7 years",
"3 years",
"6 years",
"10+ years",
"7 years",
"4 years",
"4 years",
"10+ years",
null,
"6 years",
"< 1 year",
"< 1 year",
"10+ years",
"3 years",
"< 1 year",
"3 years",
null,
"8 years",
"2 years",
"1 year",
"10+ years",
"10+ years",
null,
"5 years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"< 1 year",
"9 years",
"8 years",
"10+ years",
"6 years",
"2 years",
"1 year",
"6 years",
"< 1 year",
"7 years",
"7 years",
"3 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"< 1 year",
"1 year",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"5 years",
"2 years",
null,
"8 years",
"10+ years",
"< 1 year",
null,
"2 years",
"8 years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"6 years",
"< 1 year",
null,
"3 years",
null,
"< 1 year",
"4 years",
"6 years",
"6 years",
"1 year",
"2 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"8 years",
"< 1 year",
"10+ years",
"8 years",
"6 years",
"2 years",
"3 years",
"4 years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"7 years",
"1 year",
"7 years",
null,
"10+ years",
"2 years",
"1 year",
"10+ years",
"8 years",
"6 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"8 years",
"7 years",
"< 1 year",
"2 years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"8 years",
null,
"9 years",
null,
"2 years",
"< 1 year",
"9 years",
"< 1 year",
"10+ years",
"7 years",
"3 years",
"1 year",
"3 years",
"8 years",
"3 years",
"10+ years",
"5 years",
"7 years",
"10+ years",
"9 years",
"4 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"4 years",
null,
"10+ years",
"3 years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"1 year",
"2 years",
"7 years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"8 years",
"8 years",
"3 years",
"5 years",
"10+ years",
"3 years",
"8 years",
"4 years",
"< 1 year",
"8 years",
"4 years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"5 years",
"8 years",
"4 years",
"10+ years",
"5 years",
"8 years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"6 years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"8 years",
"2 years",
"3 years",
"4 years",
"< 1 year",
"< 1 year",
"4 years",
null,
"1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"5 years",
"9 years",
"< 1 year",
"2 years",
"2 years",
"6 years",
"1 year",
"3 years",
"3 years",
"10+ years",
"< 1 year",
null,
"3 years",
"10+ years",
"5 years",
"10+ years",
"1 year",
"< 1 year",
null,
"9 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
null,
"10+ years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
null,
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"4 years",
"10+ years",
"3 years",
"< 1 year",
"3 years",
null,
"5 years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"2 years",
null,
"< 1 year",
"4 years",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"4 years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"7 years",
"6 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"8 years",
"8 years",
"4 years",
"10+ years",
"9 years",
null,
"6 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"7 years",
"9 years",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
null,
"4 years",
"3 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"5 years",
null,
"10+ years",
"7 years",
null,
"10+ years",
"4 years",
"4 years",
"5 years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"7 years",
null,
"8 years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"3 years",
null,
"< 1 year",
null,
"3 years",
"2 years",
null,
"10+ years",
"6 years",
"10+ years",
"< 1 year",
null,
"10+ years",
null,
"4 years",
"2 years",
"5 years",
"10+ years",
"8 years",
"5 years",
"3 years",
"7 years",
"7 years",
"10+ years",
"5 years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"4 years",
"6 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"1 year",
"9 years",
"2 years",
"< 1 year",
"10+ years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"7 years",
"5 years",
"10+ years",
null,
"10+ years",
"10+ years",
"9 years",
"8 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"< 1 year",
"5 years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"10+ years",
null,
"10+ years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"3 years",
"8 years",
"10+ years",
"6 years",
"4 years",
"< 1 year",
"5 years",
"6 years",
"4 years",
"2 years",
"10+ years",
"8 years",
"5 years",
"3 years",
"5 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"3 years",
"5 years",
"9 years",
"2 years",
"2 years",
"5 years",
"2 years",
"7 years",
"10+ years",
"< 1 year",
"5 years",
"7 years",
"8 years",
"2 years",
"10+ years",
"5 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"8 years",
"8 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"5 years",
"2 years",
"< 1 year",
"6 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"6 years",
"4 years",
"6 years",
"10+ years",
"2 years",
"10+ years",
"6 years",
"2 years",
"1 year",
null,
"7 years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"8 years",
"9 years",
"7 years",
"10+ years",
"3 years",
"8 years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"8 years",
"7 years",
"6 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
null,
"3 years",
"6 years",
"< 1 year",
"2 years",
null,
"4 years",
"3 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"5 years",
"< 1 year",
"6 years",
"2 years",
"< 1 year",
"< 1 year",
null,
"10+ years",
"1 year",
"5 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"9 years",
"10+ years",
"9 years",
"2 years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"5 years",
"10+ years",
null,
"2 years",
"5 years",
"8 years",
"10+ years",
"1 year",
"2 years",
"10+ years",
"8 years",
"< 1 year",
"2 years",
"3 years",
null,
"10+ years",
null,
"10+ years",
"10+ years",
"8 years",
"1 year",
"6 years",
"4 years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"5 years",
"1 year",
"< 1 year",
"4 years",
null,
"1 year",
null,
"10+ years",
"9 years",
"9 years",
null,
"10+ years",
"10+ years",
"5 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"< 1 year",
"9 years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"5 years",
"< 1 year",
"3 years",
"4 years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"3 years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"3 years",
"< 1 year",
"10+ years",
"2 years",
"7 years",
"10+ years",
"8 years",
"6 years",
"8 years",
"10+ years",
"2 years",
"5 years",
null,
"10+ years",
"4 years",
"5 years",
null,
"4 years",
"10+ years",
null,
"10+ years",
"3 years",
"9 years",
"5 years",
"8 years",
"3 years",
"2 years",
"3 years",
"6 years",
"< 1 year",
"1 year",
"3 years",
"3 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"6 years",
"7 years",
"10+ years",
"2 years",
null,
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"4 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
null,
"10+ years",
"10+ years",
"6 years",
"8 years",
"5 years",
"2 years",
"4 years",
"2 years",
"1 year",
"6 years",
"9 years",
"3 years",
"1 year",
"9 years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"5 years",
"10+ years",
"9 years",
"10+ years",
"7 years",
"3 years",
null,
"6 years",
"1 year",
"2 years",
"< 1 year",
"1 year",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
null,
"10+ years",
"6 years",
"3 years",
"3 years",
"10+ years",
"1 year",
"3 years",
"1 year",
"10+ years",
"10+ years",
"9 years",
"7 years",
"6 years",
"6 years",
"8 years",
"10+ years",
"8 years",
"3 years",
"9 years",
"10+ years",
"7 years",
null,
null,
"6 years",
"4 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"8 years",
"5 years",
"5 years",
"2 years",
"9 years",
"< 1 year",
"4 years",
"5 years",
"10+ years",
"9 years",
"10+ years",
"2 years",
"2 years",
"9 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"3 years",
"4 years",
"6 years",
"10+ years",
"9 years",
"8 years",
"7 years",
"4 years",
"10+ years",
"< 1 year",
"5 years",
"4 years",
"10+ years",
"7 years",
"7 years",
"3 years",
"< 1 year",
"10+ years",
"3 years",
"3 years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"4 years",
"< 1 year",
"6 years",
"10+ years",
"5 years",
null,
"1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
null,
"5 years",
"5 years",
"2 years",
"8 years",
"1 year",
"5 years",
"10+ years",
"1 year",
"10+ years",
"9 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"6 years",
null,
null,
"2 years",
"7 years",
"5 years",
"10+ years",
"5 years",
"1 year",
"3 years",
"5 years",
"10+ years",
"2 years",
"6 years",
"7 years",
"< 1 year",
"7 years",
"7 years",
"10+ years",
"< 1 year",
"9 years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"3 years",
"1 year",
"7 years",
"5 years",
null,
"10+ years",
"9 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"9 years",
"2 years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"9 years",
"3 years",
null,
"6 years",
"2 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"5 years",
"10+ years",
"1 year",
"6 years",
"1 year",
"5 years",
"1 year",
"6 years",
"< 1 year",
"2 years",
"3 years",
"10+ years",
"1 year",
"2 years",
"4 years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"5 years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"6 years",
"5 years",
"10+ years",
"4 years",
"9 years",
"1 year",
"1 year",
"10+ years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"8 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"3 years",
"10+ years",
"3 years",
"1 year",
"< 1 year",
"4 years",
"10+ years",
null,
"8 years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"4 years",
"4 years",
"3 years",
"5 years",
"2 years",
"< 1 year",
"1 year",
"< 1 year",
"2 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
null,
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"5 years",
null,
"10+ years",
"2 years",
"10+ years",
"5 years",
"2 years",
"8 years",
"7 years",
"8 years",
"10+ years",
"1 year",
"5 years",
"10+ years",
"8 years",
"10+ years",
"1 year",
"2 years",
"9 years",
"7 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"9 years",
"9 years",
"< 1 year",
"8 years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"7 years",
"10+ years",
"5 years",
"8 years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"8 years",
"10+ years",
null,
"4 years",
"2 years",
"10+ years",
"1 year",
null,
"1 year",
"3 years",
"10+ years",
"1 year",
"6 years",
"5 years",
"4 years",
"< 1 year",
"2 years",
"1 year",
"1 year",
"5 years",
"5 years",
"< 1 year",
"< 1 year",
"10+ years",
"6 years",
"1 year",
"4 years",
"10+ years",
"10+ years",
"4 years",
"7 years",
null,
"10+ years",
"2 years",
"6 years",
"1 year",
"10+ years",
"< 1 year",
"1 year",
"1 year",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"1 year",
"2 years",
"7 years",
"1 year",
"10+ years",
"< 1 year",
"2 years",
"3 years",
"5 years",
"10+ years",
"8 years",
"2 years",
"3 years",
"10+ years",
null,
"8 years",
"< 1 year",
"2 years",
"4 years",
null,
"4 years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
null,
"2 years",
"3 years",
"7 years",
"10+ years",
"< 1 year",
"1 year",
"2 years",
"1 year",
"10+ years",
"7 years",
"< 1 year",
"8 years",
"2 years",
"10+ years",
"5 years",
"1 year",
null,
"< 1 year",
"2 years",
"10+ years",
"9 years",
"< 1 year",
"8 years",
"10+ years",
"1 year",
"4 years",
"3 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"3 years",
null,
"10+ years",
"10+ years",
"6 years",
"2 years",
"4 years",
"10+ years",
"10+ years",
"7 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"1 year",
"< 1 year",
"10+ years",
"1 year",
"7 years",
null,
"< 1 year",
"2 years",
"10+ years",
"2 years",
"9 years",
"6 years",
"7 years",
"3 years",
"10+ years",
"4 years",
"10+ years",
"9 years",
"10+ years",
"3 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
null,
null,
"10+ years",
"4 years",
"10+ years",
"< 1 year",
null,
"2 years",
"4 years",
"< 1 year",
"5 years",
"2 years",
"10+ years",
null,
"9 years",
"< 1 year",
"3 years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"5 years",
"10+ years",
null,
"5 years",
"2 years",
"10+ years",
"7 years",
"9 years",
"1 year",
"5 years",
"2 years",
"3 years",
"3 years",
"8 years",
null,
"8 years",
"2 years",
"7 years",
"1 year",
"3 years",
"1 year",
"3 years",
"5 years",
"1 year",
"5 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"8 years",
"8 years",
"10+ years",
"6 years",
"4 years",
"6 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"1 year",
"3 years",
"2 years",
"< 1 year",
"4 years",
"6 years",
"4 years",
"1 year",
"8 years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"6 years",
"1 year",
null,
"8 years",
"10+ years",
"9 years",
"5 years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"9 years",
"7 years",
"10+ years",
"2 years",
"3 years",
"7 years",
"3 years",
"2 years",
"3 years",
"7 years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"2 years",
"8 years",
"2 years",
"3 years",
"8 years",
null,
"10+ years",
"10+ years",
"10+ years",
"7 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"< 1 year",
"6 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"2 years",
null,
"10+ years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
null,
"3 years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"7 years",
"7 years",
null,
"2 years",
"10+ years",
"4 years",
null,
"3 years",
"3 years",
"8 years",
"5 years",
"10+ years",
"10+ years",
"6 years",
"< 1 year",
"1 year",
"1 year",
"4 years",
"7 years",
"4 years",
"10+ years",
"10+ years",
"8 years",
null,
"10+ years",
null,
"3 years",
"< 1 year",
"2 years",
"10+ years",
null,
"10+ years",
"8 years",
"10+ years",
"8 years",
"5 years",
"9 years",
"10+ years",
null,
"10+ years",
"3 years",
"6 years",
"5 years",
null,
"< 1 year",
"10+ years",
null,
"< 1 year",
"3 years",
"< 1 year",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"2 years",
"6 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"4 years",
"7 years",
"3 years",
"10+ years",
"1 year",
"5 years",
"10+ years",
"< 1 year",
null,
"10+ years",
null,
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"9 years",
null,
"3 years",
"< 1 year",
"6 years",
"2 years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
null,
"< 1 year",
"7 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
null,
"5 years",
null,
"10+ years",
"7 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
null,
"10+ years",
"9 years",
"7 years",
"4 years",
null,
"1 year",
"10+ years",
"10+ years",
"1 year",
"8 years",
"2 years",
"10+ years",
"7 years",
"7 years",
"2 years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"5 years",
"8 years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"7 years",
"4 years",
null,
"10+ years",
"7 years",
"2 years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
null,
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"8 years",
"3 years",
"< 1 year",
"2 years",
"1 year",
"10+ years",
"7 years",
"4 years",
"7 years",
"10+ years",
"10+ years",
null,
"5 years",
"10+ years",
"6 years",
"10+ years",
"9 years",
"1 year",
null,
"< 1 year",
"10+ years",
"5 years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"3 years",
"9 years",
"1 year",
"6 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"3 years",
"2 years",
null,
"10+ years",
"10+ years",
"10+ years",
"1 year",
"7 years",
"10+ years",
null,
"2 years",
null,
"10+ years",
null,
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"9 years",
"2 years",
"4 years",
null,
"7 years",
"3 years",
"1 year",
"1 year",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"8 years",
"< 1 year",
"6 years",
"8 years",
"10+ years",
"< 1 year",
"1 year",
"1 year",
"< 1 year",
"5 years",
"4 years",
"9 years",
"5 years",
"< 1 year",
"3 years",
"10+ years",
"6 years",
"5 years",
"2 years",
"8 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"5 years",
"4 years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
null,
"10+ years",
"4 years",
"3 years",
"< 1 year",
"10+ years",
null,
"2 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"1 year",
"2 years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"6 years",
"9 years",
"10+ years",
"< 1 year",
"3 years",
"2 years",
"10+ years",
"2 years",
"1 year",
"4 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"10+ years",
"3 years",
"3 years",
"7 years",
"4 years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"4 years",
"7 years",
"9 years",
"3 years",
"1 year",
"1 year",
"8 years",
"3 years",
"< 1 year",
"10+ years",
"7 years",
"1 year",
"10+ years",
"8 years",
"2 years",
"10+ years",
"1 year",
null,
"7 years",
"10+ years",
"7 years",
"3 years",
"10+ years",
"10+ years",
"6 years",
"< 1 year",
"< 1 year",
"5 years",
"6 years",
"4 years",
"10+ years",
"7 years",
"10+ years",
"1 year",
null,
"6 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"3 years",
"6 years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"4 years",
"7 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
null,
"2 years",
"10+ years",
"8 years",
"1 year",
"1 year",
null,
"5 years",
"10+ years",
"8 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"7 years",
null,
"< 1 year",
"2 years",
"9 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"2 years",
"1 year",
"10+ years",
"4 years",
"2 years",
"3 years",
"5 years",
"4 years",
null,
"10+ years",
"4 years",
"10+ years",
"1 year",
"6 years",
"< 1 year",
"< 1 year",
"10+ years",
"1 year",
"< 1 year",
"1 year",
"4 years",
"5 years",
"4 years",
"< 1 year",
null,
"10+ years",
"2 years",
"3 years",
"1 year",
"1 year",
"7 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"6 years",
"1 year",
"< 1 year",
"10+ years",
"7 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"4 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"8 years",
null,
"< 1 year",
null,
"10+ years",
"2 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"4 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
null,
"< 1 year",
"2 years",
"6 years",
"8 years",
"1 year",
"10+ years",
"3 years",
"2 years",
"10+ years",
"2 years",
null,
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"3 years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"7 years",
null,
"5 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"4 years",
"2 years",
"2 years",
"3 years",
"9 years",
"6 years",
null,
"10+ years",
"10+ years",
"2 years",
"10+ years",
null,
"3 years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"2 years",
"3 years",
"7 years",
"2 years",
"< 1 year",
"10+ years",
"9 years",
"10+ years",
"4 years",
"5 years",
"3 years",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
"9 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
null,
"5 years",
"10+ years",
"< 1 year",
"4 years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"8 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"8 years",
"5 years",
null,
"3 years",
"4 years",
"7 years",
"2 years",
"3 years",
"10+ years",
"10+ years",
null,
"10+ years",
"6 years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"4 years",
"9 years",
"2 years",
"4 years",
"2 years",
"2 years",
"2 years",
"1 year",
"2 years",
"6 years",
"10+ years",
"< 1 year",
"5 years",
"< 1 year",
null,
"2 years",
"7 years",
null,
"1 year",
"3 years",
"2 years",
"5 years",
"1 year",
"10+ years",
"8 years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"7 years",
"< 1 year",
"6 years",
"7 years",
"2 years",
"9 years",
"< 1 year",
"8 years",
"10+ years",
"3 years",
"< 1 year",
"3 years",
"10+ years",
"7 years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"8 years",
"2 years",
"< 1 year",
"5 years",
"7 years",
"10+ years",
"10+ years",
"6 years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"8 years",
"2 years",
"3 years",
"5 years",
null,
"10+ years",
"6 years",
"10+ years",
"2 years",
"2 years",
"4 years",
"10+ years",
"1 year",
"2 years",
"1 year",
"4 years",
"< 1 year",
"7 years",
"7 years",
"10+ years",
null,
"8 years",
"3 years",
"2 years",
"< 1 year",
"1 year",
"2 years",
"3 years",
"10+ years",
"5 years",
null,
"6 years",
"10+ years",
"3 years",
"7 years",
"< 1 year",
"3 years",
"4 years",
"3 years",
"10+ years",
"8 years",
"5 years",
"9 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"8 years",
"8 years",
"9 years",
"3 years",
"< 1 year",
"9 years",
"5 years",
"10+ years",
"2 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
null,
"6 years",
"10+ years",
null,
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"7 years",
"5 years",
"2 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"10+ years",
"1 year",
"5 years",
"7 years",
"1 year",
"8 years",
"10+ years",
"4 years",
"10+ years",
null,
"5 years",
"1 year",
"8 years",
"< 1 year",
"4 years",
"7 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
null,
"3 years",
"1 year",
"4 years",
"2 years",
"7 years",
"1 year",
"8 years",
"8 years",
null,
"1 year",
"10+ years",
"1 year",
"10+ years",
"8 years",
"5 years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"3 years",
"7 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"4 years",
null,
"10+ years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"5 years",
null,
"1 year",
"10+ years",
"7 years",
"4 years",
"6 years",
"10+ years",
"< 1 year",
"1 year",
"9 years",
"10+ years",
"2 years",
"3 years",
"5 years",
"3 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
null,
"1 year",
null,
"9 years",
"3 years",
null,
"1 year",
"1 year",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"2 years",
"6 years",
"5 years",
"5 years",
"10+ years",
"< 1 year",
"4 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"3 years",
"9 years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"5 years",
"7 years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"2 years",
"4 years",
"4 years",
"< 1 year",
"4 years",
"5 years",
null,
"7 years",
"2 years",
"1 year",
"2 years",
"2 years",
"5 years",
null,
"3 years",
"2 years",
"10+ years",
"2 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"6 years",
"3 years",
"4 years",
"9 years",
"10+ years",
"2 years",
"2 years",
"1 year",
"6 years",
"7 years",
null,
"10+ years",
"6 years",
"5 years",
"4 years",
"10+ years",
"3 years",
"3 years",
"8 years",
"10+ years",
"3 years",
"2 years",
"7 years",
"3 years",
"4 years",
null,
"3 years",
"10+ years",
"7 years",
"6 years",
"1 year",
"9 years",
"4 years",
"2 years",
"2 years",
"6 years",
"< 1 year",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"9 years",
"6 years",
"3 years",
"10+ years",
"4 years",
"8 years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"8 years",
"7 years",
null,
"< 1 year",
"< 1 year",
"10+ years",
"5 years",
"9 years",
null,
"10+ years",
"7 years",
"6 years",
"10+ years",
"< 1 year",
null,
"10+ years",
"6 years",
"10+ years",
"8 years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"2 years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"9 years",
"3 years",
"6 years",
"1 year",
null,
"5 years",
"7 years",
"10+ years",
"2 years",
"5 years",
"10+ years",
null,
"10+ years",
null,
"6 years",
"7 years",
"10+ years",
null,
"3 years",
"5 years",
"< 1 year",
"< 1 year",
"3 years",
"10+ years",
"2 years",
"3 years",
"7 years",
"5 years",
"9 years",
"4 years",
"1 year",
"2 years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"4 years",
null,
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"4 years",
"2 years",
"< 1 year",
"8 years",
null,
"10+ years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"7 years",
"2 years",
"10+ years",
"2 years",
"9 years",
"10+ years",
"7 years",
"6 years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"1 year",
"7 years",
"2 years",
"4 years",
null,
"2 years",
"8 years",
"3 years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"4 years",
"2 years",
"3 years",
"< 1 year",
"2 years",
"6 years",
"10+ years",
"5 years",
"7 years",
"3 years",
"8 years",
"3 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"1 year",
"10+ years",
null,
"6 years",
"3 years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"1 year",
"6 years",
null,
"10+ years",
null,
"< 1 year",
"7 years",
"3 years",
"10+ years",
"5 years",
"7 years",
null,
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
null,
"6 years",
"1 year",
"< 1 year",
"< 1 year",
"10+ years",
"2 years",
"1 year",
null,
"10+ years",
"7 years",
"1 year",
"8 years",
"3 years",
"5 years",
"1 year",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"3 years",
null,
"10+ years",
"6 years",
"8 years",
"10+ years",
"10+ years",
"1 year",
"6 years",
"6 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"2 years",
"8 years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"3 years",
"2 years",
null,
"10+ years",
"< 1 year",
"6 years",
"8 years",
"< 1 year",
"< 1 year",
"3 years",
"4 years",
"< 1 year",
"2 years",
"10+ years",
"6 years",
"8 years",
"6 years",
"10+ years",
"2 years",
"6 years",
"5 years",
"8 years",
"3 years",
"10+ years",
"4 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"< 1 year",
"7 years",
"2 years",
"4 years",
"10+ years",
"5 years",
"10+ years",
"3 years",
null,
null,
"1 year",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"1 year",
"4 years",
null,
"10+ years",
"3 years",
"2 years",
"10+ years",
null,
"10+ years",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"7 years",
"2 years",
"8 years",
"8 years",
"4 years",
"3 years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"7 years",
"7 years",
"10+ years",
"10+ years",
"1 year",
"4 years",
"7 years",
"6 years",
null,
"3 years",
"1 year",
"10+ years",
"3 years",
"6 years",
"7 years",
"3 years",
"< 1 year",
"< 1 year",
"10+ years",
"< 1 year",
null,
"10+ years",
"6 years",
"1 year",
"4 years",
"6 years",
"< 1 year",
"4 years",
"3 years",
"10+ years",
"1 year",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"< 1 year",
"8 years",
"5 years",
"7 years",
"2 years",
"3 years",
"1 year",
"5 years",
"5 years",
"2 years",
"2 years",
"5 years",
"10+ years",
null,
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"5 years",
"5 years",
"2 years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"4 years",
"2 years",
"10+ years",
null,
"< 1 year",
null,
"4 years",
"2 years",
"6 years",
"8 years",
"3 years",
null,
"1 year",
null,
"2 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"4 years",
"5 years",
"5 years",
"9 years",
"2 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"9 years",
"10+ years",
"2 years",
"7 years",
"3 years",
"3 years",
"7 years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"3 years",
"6 years",
"8 years",
"10+ years",
"8 years",
null,
"10+ years",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
null,
"8 years",
"< 1 year",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"6 years",
"5 years",
"4 years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"3 years",
"10+ years",
null,
"9 years",
"10+ years",
"9 years",
"10+ years",
"2 years",
null,
"10+ years",
"10+ years",
"9 years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"1 year",
"7 years",
"10+ years",
"8 years",
"2 years",
"< 1 year",
"7 years",
"5 years",
"7 years",
"5 years",
null,
"< 1 year",
"< 1 year",
"4 years",
"8 years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"9 years",
"6 years",
"7 years",
"7 years",
"8 years",
"10+ years",
"10+ years",
"2 years",
null,
"10+ years",
"7 years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"4 years",
"10+ years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"8 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"6 years",
"< 1 year",
"5 years",
"10+ years",
null,
"9 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"8 years",
"8 years",
"4 years",
"2 years",
"8 years",
"10+ years",
"4 years",
"4 years",
"< 1 year",
"7 years",
"10+ years",
"9 years",
"8 years",
"9 years",
"< 1 year",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"7 years",
"8 years",
"8 years",
"< 1 year",
"6 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
null,
"1 year",
"2 years",
"2 years",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"9 years",
"8 years",
"10+ years",
"6 years",
"3 years",
"10+ years",
"10+ years",
"9 years",
"1 year",
"10+ years",
"2 years",
"4 years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"< 1 year",
"10+ years",
"4 years",
"2 years",
"5 years",
"1 year",
"10+ years",
"3 years",
"6 years",
"2 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"2 years",
"4 years",
"10+ years",
"10+ years",
"1 year",
"9 years",
"3 years",
null,
"1 year",
"7 years",
"10+ years",
"3 years",
"2 years",
"< 1 year",
"4 years",
"1 year",
"10+ years",
"1 year",
"2 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"< 1 year",
"1 year",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"5 years",
"4 years",
"2 years",
"< 1 year",
"1 year",
"7 years",
"7 years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"< 1 year",
"8 years",
"3 years",
"3 years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"7 years",
"1 year",
"10+ years",
"4 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"2 years",
"8 years",
"9 years",
"6 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"6 years",
"2 years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"9 years",
"10+ years",
"1 year",
"6 years",
"3 years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
null,
"2 years",
"5 years",
"4 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
null,
"9 years",
"10+ years",
"9 years",
"2 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
null,
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"6 years",
"2 years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"9 years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"7 years",
"4 years",
"9 years",
"7 years",
null,
"10+ years",
"5 years",
"10+ years",
"3 years",
"7 years",
"6 years",
"6 years",
"10+ years",
"10+ years",
"8 years",
"6 years",
"8 years",
"< 1 year",
"3 years",
"9 years",
"9 years",
"7 years",
"2 years",
"5 years",
"10+ years",
"< 1 year",
"4 years",
"5 years",
"7 years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"4 years",
"10+ years",
null,
"1 year",
"2 years",
"9 years",
"3 years",
"8 years",
"10+ years",
"5 years",
"6 years",
"6 years",
"3 years",
"1 year",
null,
"2 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"4 years",
"8 years",
"5 years",
"6 years",
"8 years",
"5 years",
"10+ years",
"10+ years",
"7 years",
"6 years",
"10+ years",
"2 years",
"2 years",
"4 years",
"3 years",
"10+ years",
"8 years",
"5 years",
"10+ years",
null,
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"9 years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"6 years",
"10+ years",
"7 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"7 years",
"5 years",
"6 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"4 years",
"10+ years",
"9 years",
"3 years",
"7 years",
"1 year",
"1 year",
"10+ years",
"5 years",
"9 years",
"2 years",
"10+ years",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"2 years",
"< 1 year",
"3 years",
"5 years",
"1 year",
"6 years",
"5 years",
"3 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"5 years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"4 years",
"7 years",
"8 years",
"1 year",
"10+ years",
"3 years",
"7 years",
"3 years",
"10+ years",
"9 years",
"1 year",
"< 1 year",
"< 1 year",
"8 years",
"2 years",
"9 years",
null,
"10+ years",
"< 1 year",
"7 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"2 years",
"7 years",
"5 years",
"9 years",
"3 years",
"< 1 year",
"3 years",
"9 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"8 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"4 years",
"4 years",
"9 years",
"4 years",
"10+ years",
null,
"10+ years",
"10+ years",
"2 years",
"3 years",
"2 years",
"10+ years",
"2 years",
"8 years",
"6 years",
"5 years",
"10+ years",
"6 years",
"10+ years",
"4 years",
"8 years",
null,
"3 years",
"2 years",
"10+ years",
"10+ years",
"9 years",
"7 years",
"3 years",
"2 years",
"< 1 year",
"< 1 year",
"10+ years",
"2 years",
"8 years",
"1 year",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"8 years",
"10+ years",
null,
"2 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"7 years",
null,
"10+ years",
"9 years",
"5 years",
"1 year",
"2 years",
"10+ years",
"< 1 year",
"4 years",
"5 years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"4 years",
"10+ years",
null,
"9 years",
"5 years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"8 years",
"1 year",
"10+ years",
"6 years",
"3 years",
"10+ years",
"1 year",
"5 years",
"8 years",
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"2 years",
"2 years",
"7 years",
"10+ years",
"8 years",
"< 1 year",
"4 years",
"10+ years",
null,
"2 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"8 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"3 years",
"3 years",
null,
null,
"10+ years",
"5 years",
"3 years",
"4 years",
"8 years",
"2 years",
null,
"3 years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"10+ years",
"9 years",
"1 year",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"1 year",
"6 years",
"6 years",
"10+ years",
"10+ years",
"8 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"5 years",
"6 years",
"1 year",
"8 years",
"2 years",
"8 years",
"3 years",
"2 years",
"1 year",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"2 years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"9 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"1 year",
"4 years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"5 years",
"10+ years",
"1 year",
"8 years",
"7 years",
"10+ years",
"10+ years",
"3 years",
null,
"2 years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"4 years",
"5 years",
"8 years",
"10+ years",
"10+ years",
null,
"3 years",
"< 1 year",
"10+ years",
"7 years",
"6 years",
"3 years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
null,
"8 years",
"< 1 year",
"7 years",
"10+ years",
null,
"2 years",
"5 years",
"1 year",
null,
"9 years",
"4 years",
"6 years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"6 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"5 years",
"6 years",
"10+ years",
"1 year",
"10+ years",
"2 years",
null,
"10+ years",
"5 years",
"9 years",
"6 years",
"10+ years",
"3 years",
"< 1 year",
"1 year",
"2 years",
"< 1 year",
null,
"10+ years",
"4 years",
"3 years",
"5 years",
"10+ years",
"4 years",
"8 years",
"< 1 year",
"10+ years",
"1 year",
"4 years",
"2 years",
null,
"3 years",
"3 years",
"10+ years",
"8 years",
"5 years",
"8 years",
"6 years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"1 year",
"7 years",
"4 years",
"7 years",
"7 years",
"7 years",
"6 years",
"10+ years",
"7 years",
"8 years",
null,
"1 year",
"3 years",
"4 years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"3 years",
"9 years",
"7 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"1 year",
"1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"< 1 year",
"< 1 year",
"10+ years",
"2 years",
"2 years",
"5 years",
"3 years",
"3 years",
"8 years",
"5 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"< 1 year",
"< 1 year",
"10+ years",
"1 year",
"1 year",
"4 years",
"1 year",
"9 years",
"4 years",
"10+ years",
"7 years",
"5 years",
"8 years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"2 years",
null,
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"9 years",
"< 1 year",
"8 years",
"3 years",
"2 years",
"2 years",
"6 years",
"10+ years",
"1 year",
"4 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"4 years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"6 years",
"7 years",
"4 years",
"2 years",
null,
"7 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"5 years",
"10+ years",
"2 years",
"4 years",
"10+ years",
null,
null,
"7 years",
"3 years",
"4 years",
"< 1 year",
"9 years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"5 years",
"3 years",
"3 years",
"2 years",
"10+ years",
"8 years",
"9 years",
null,
null,
"3 years",
"2 years",
"4 years",
"1 year",
"7 years",
"10+ years",
"8 years",
"8 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"7 years",
"7 years",
"2 years",
"2 years",
"10+ years",
"9 years",
"3 years",
"2 years",
"4 years",
"3 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"9 years",
null,
null,
"6 years",
"7 years",
"10+ years",
null,
"7 years",
"5 years",
"10+ years",
"< 1 year",
"1 year",
"9 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"2 years",
"10+ years",
null,
"10+ years",
"7 years",
"3 years",
"10+ years",
null,
"4 years",
"7 years",
"10+ years",
"6 years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"2 years",
"1 year",
"3 years",
null,
"9 years",
"10+ years",
"2 years",
"5 years",
"7 years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"3 years",
"< 1 year",
"8 years",
"4 years",
"8 years",
"10+ years",
"5 years",
"7 years",
"10+ years",
"10+ years",
"3 years",
null,
"2 years",
"10+ years",
null,
"4 years",
"10+ years",
"6 years",
"6 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"10+ years",
null,
"5 years",
"3 years",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"9 years",
"1 year",
null,
"1 year",
"10+ years",
"7 years",
"10+ years",
"9 years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"2 years",
"1 year",
"2 years",
"9 years",
"1 year",
"< 1 year",
"9 years",
"5 years",
"10+ years",
"9 years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
null,
"7 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"8 years",
"9 years",
"9 years",
"10+ years",
"1 year",
"2 years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"1 year",
"10+ years",
"9 years",
"5 years",
"7 years",
"2 years",
"2 years",
"10+ years",
"6 years",
"3 years",
"1 year",
"5 years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"9 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"9 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"7 years",
"9 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"7 years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"3 years",
"< 1 year",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"4 years",
"10+ years",
"8 years",
"1 year",
"4 years",
"10+ years",
"2 years",
"2 years",
"4 years",
"5 years",
"< 1 year",
"10+ years",
"7 years",
"3 years",
"6 years",
"8 years",
"3 years",
"< 1 year",
"1 year",
"1 year",
"1 year",
"8 years",
"10+ years",
"6 years",
"4 years",
"10+ years",
"6 years",
"2 years",
"3 years",
null,
"8 years",
"10+ years",
"8 years",
"< 1 year",
"4 years",
"< 1 year",
"6 years",
"10+ years",
"6 years",
"10+ years",
"7 years",
"5 years",
"5 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"9 years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"8 years",
"3 years",
"4 years",
"10+ years",
"4 years",
"10+ years",
"4 years",
"8 years",
"6 years",
"10+ years",
"< 1 year",
"1 year",
"7 years",
"5 years",
"6 years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"5 years",
"5 years",
"2 years",
"7 years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"3 years",
"2 years",
"7 years",
"10+ years",
"6 years",
"5 years",
null,
"< 1 year",
"10+ years",
"7 years",
"8 years",
null,
"< 1 year",
"3 years",
"4 years",
"4 years",
null,
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"9 years",
null,
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"1 year",
"2 years",
"1 year",
"7 years",
"10+ years",
"10+ years",
"5 years",
"8 years",
"2 years",
null,
"7 years",
"2 years",
"< 1 year",
"10+ years",
"3 years",
"9 years",
null,
"< 1 year",
null,
"< 1 year",
"4 years",
"10+ years",
"2 years",
"8 years",
"< 1 year",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"3 years",
"6 years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"9 years",
"6 years",
"10+ years",
"6 years",
"3 years",
"10+ years",
"9 years",
"8 years",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"< 1 year",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"3 years",
"2 years",
"1 year",
"6 years",
"5 years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
null,
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"2 years",
"8 years",
"6 years",
"2 years",
"1 year",
"2 years",
"< 1 year",
"1 year",
"1 year",
"1 year",
"8 years",
"4 years",
"10+ years",
"1 year",
"6 years",
null,
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"8 years",
"1 year",
"10+ years",
"7 years",
"5 years",
"2 years",
"9 years",
"5 years",
"9 years",
"8 years",
"3 years",
"5 years",
"3 years",
"10+ years",
"8 years",
"< 1 year",
"3 years",
null,
"6 years",
"2 years",
"3 years",
"9 years",
"8 years",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"1 year",
"4 years",
"1 year",
null,
"4 years",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
null,
"2 years",
"5 years",
"2 years",
"10+ years",
"7 years",
"7 years",
"4 years",
"7 years",
"7 years",
"4 years",
"5 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"1 year",
"3 years",
"9 years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"6 years",
"2 years",
"2 years",
"1 year",
"5 years",
null,
"10+ years",
"1 year",
"8 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"3 years",
"7 years",
"3 years",
"6 years",
"9 years",
"3 years",
null,
"2 years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"2 years",
"8 years",
null,
"10+ years",
"8 years",
"4 years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"< 1 year",
"6 years",
"8 years",
"7 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
null,
"4 years",
"8 years",
"10+ years",
"4 years",
"7 years",
"6 years",
"10+ years",
"1 year",
"9 years",
"10+ years",
"6 years",
"7 years",
"9 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"8 years",
null,
"8 years",
"4 years",
"7 years",
"8 years",
"< 1 year",
"8 years",
null,
"10+ years",
"3 years",
"2 years",
"1 year",
"1 year",
"10+ years",
"5 years",
null,
"3 years",
"10+ years",
"1 year",
"6 years",
"2 years",
"7 years",
"4 years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"2 years",
"4 years",
"10+ years",
"9 years",
"6 years",
"10+ years",
"8 years",
null,
"10+ years",
"10+ years",
"2 years",
"10+ years",
"9 years",
"4 years",
"3 years",
"10+ years",
"7 years",
"2 years",
"8 years",
"< 1 year",
"6 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"6 years",
"2 years",
"5 years",
"5 years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"6 years",
"2 years",
"9 years",
"3 years",
"6 years",
"9 years",
"10+ years",
"< 1 year",
"4 years",
"< 1 year",
"4 years",
"10+ years",
null,
"10+ years",
"7 years",
null,
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"< 1 year",
"9 years",
"2 years",
"2 years",
"3 years",
"4 years",
"6 years",
"9 years",
"9 years",
"4 years",
"6 years",
null,
"10+ years",
"2 years",
"< 1 year",
null,
"10+ years",
"3 years",
"3 years",
"10+ years",
"5 years",
"9 years",
"9 years",
"10+ years",
"3 years",
"< 1 year",
"1 year",
"3 years",
"10+ years",
"1 year",
"10+ years",
"2 years",
"4 years",
"9 years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"3 years",
"1 year",
"7 years",
null,
"10+ years",
"10+ years",
"6 years",
"2 years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"1 year",
"4 years",
"< 1 year",
"9 years",
"10+ years",
"2 years",
"6 years",
"2 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
null,
null,
"7 years",
"10+ years",
"2 years",
"5 years",
"6 years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"5 years",
"1 year",
"2 years",
"5 years",
"8 years",
"10+ years",
"2 years",
"2 years",
"5 years",
"1 year",
"10+ years",
"2 years",
"2 years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
null,
"2 years",
"10+ years",
"1 year",
"10+ years",
"9 years",
"10+ years",
"7 years",
"8 years",
"4 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"5 years",
"1 year",
"1 year",
"8 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"7 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"3 years",
"7 years",
"6 years",
null,
"10+ years",
"9 years",
"1 year",
"10+ years",
"9 years",
"9 years",
"10+ years",
"1 year",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"6 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"6 years",
"< 1 year",
"6 years",
"10+ years",
"1 year",
"< 1 year",
"4 years",
"8 years",
"< 1 year",
null,
"10+ years",
"7 years",
"6 years",
"10+ years",
"3 years",
"3 years",
"4 years",
"3 years",
"< 1 year",
"10+ years",
"8 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"6 years",
"7 years",
"7 years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"7 years",
"4 years",
"9 years",
"4 years",
"< 1 year",
"10+ years",
"9 years",
"2 years",
"8 years",
"5 years",
"3 years",
"2 years",
"9 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"3 years",
"< 1 year",
"8 years",
"< 1 year",
"3 years",
"8 years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"5 years",
"< 1 year",
"3 years",
"7 years",
"10+ years",
"6 years",
"6 years",
"4 years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"5 years",
"2 years",
"2 years",
"8 years",
"7 years",
"6 years",
"3 years",
"7 years",
"6 years",
"4 years",
"8 years",
"7 years",
"10+ years",
"1 year",
"4 years",
null,
"7 years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"1 year",
"< 1 year",
"10+ years",
"7 years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
null,
"4 years",
"6 years",
"< 1 year",
"10+ years",
"5 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"6 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"5 years",
"< 1 year",
"3 years",
"10+ years",
"6 years",
"5 years",
"1 year",
"10+ years",
"7 years",
"8 years",
"8 years",
null,
"3 years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"2 years",
"3 years",
"< 1 year",
"5 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"9 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"7 years",
null,
"10+ years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
null,
"10+ years",
"7 years",
null,
"2 years",
"3 years",
"5 years",
"5 years",
"10+ years",
"5 years",
"9 years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"7 years",
"6 years",
"7 years",
"10+ years",
"4 years",
"7 years",
null,
"< 1 year",
"< 1 year",
"1 year",
"7 years",
"3 years",
"1 year",
"< 1 year",
"2 years",
"3 years",
"10+ years",
"5 years",
null,
"10+ years",
"10+ years",
"9 years",
"4 years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"3 years",
"3 years",
null,
"1 year",
null,
"1 year",
"10+ years",
"3 years",
"8 years",
"5 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"7 years",
"2 years",
"4 years",
"10+ years",
"3 years",
"2 years",
"2 years",
"5 years",
"10+ years",
"9 years",
"6 years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"6 years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
null,
"3 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"7 years",
"6 years",
"1 year",
"< 1 year",
"< 1 year",
"10+ years",
"2 years",
"5 years",
"2 years",
"1 year",
"9 years",
"10+ years",
"10+ years",
"5 years",
"1 year",
"1 year",
"< 1 year",
"10+ years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"3 years",
"9 years",
"< 1 year",
"10+ years",
"4 years",
"8 years",
"10+ years",
"1 year",
"5 years",
"10+ years",
"10+ years",
"10+ years",
null,
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
null,
"8 years",
"3 years",
"< 1 year",
"6 years",
"< 1 year",
"< 1 year",
null,
"5 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"8 years",
"2 years",
"10+ years",
"10+ years",
null,
"7 years",
"< 1 year",
"3 years",
"3 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"3 years",
"8 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"1 year",
null,
"10+ years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"7 years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"7 years",
"10+ years",
"7 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"4 years",
"10+ years",
"4 years",
"5 years",
null,
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"3 years",
"1 year",
"10+ years",
"9 years",
"10+ years",
"2 years",
"3 years",
"< 1 year",
"5 years",
"< 1 year",
"7 years",
"5 years",
"7 years",
"3 years",
"10+ years",
"2 years",
"1 year",
null,
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"7 years",
"2 years",
"4 years",
"8 years",
"4 years",
"< 1 year",
"10+ years",
"4 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"4 years",
"2 years",
"10+ years",
"10+ years",
null,
"4 years",
"< 1 year",
"10+ years",
"9 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"10+ years",
"5 years",
"1 year",
"3 years",
"< 1 year",
"9 years",
"5 years",
"2 years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"7 years",
"4 years",
"10+ years",
"< 1 year",
"2 years",
"7 years",
"10+ years",
"2 years",
"8 years",
"< 1 year",
"10+ years",
"9 years",
"6 years",
"10+ years",
"6 years",
null,
"8 years",
"2 years",
"4 years",
"< 1 year",
"< 1 year",
"4 years",
"1 year",
"6 years",
"10+ years",
"3 years",
"6 years",
"8 years",
"10+ years",
"4 years",
"2 years",
"2 years",
"9 years",
"1 year",
"7 years",
"< 1 year",
"4 years",
"4 years",
"9 years",
"10+ years",
"4 years",
"9 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
null,
"3 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"7 years",
"2 years",
null,
"7 years",
"3 years",
"9 years",
"4 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"6 years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
null,
"10+ years",
"4 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"6 years",
"10+ years",
"9 years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"< 1 year",
"8 years",
"1 year",
"2 years",
"2 years",
"6 years",
"10+ years",
null,
"10+ years",
null,
null,
"9 years",
"10+ years",
"9 years",
"4 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"1 year",
"7 years",
null,
"10+ years",
"7 years",
"2 years",
"6 years",
"8 years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"7 years",
"5 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"2 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"2 years",
null,
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"< 1 year",
"1 year",
"4 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"9 years",
"7 years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"1 year",
"1 year",
"4 years",
"3 years",
"7 years",
"1 year",
"3 years",
"3 years",
"4 years",
"10+ years",
"1 year",
"8 years",
"10+ years",
"1 year",
"10+ years",
"8 years",
"2 years",
"10+ years",
"< 1 year",
null,
"6 years",
"3 years",
"10+ years",
"9 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"1 year",
"7 years",
"3 years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"1 year",
"5 years",
"4 years",
"4 years",
"1 year",
"2 years",
"5 years",
"10+ years",
"2 years",
null,
"3 years",
"4 years",
"2 years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"6 years",
"2 years",
"10+ years",
"1 year",
"2 years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"2 years",
"4 years",
"3 years",
"5 years",
"10+ years",
null,
"2 years",
null,
"9 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"10+ years",
null,
"2 years",
"3 years",
"4 years",
"6 years",
"9 years",
"< 1 year",
"3 years",
"10+ years",
"2 years",
"8 years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"7 years",
"6 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"9 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
null,
"10+ years",
"1 year",
"10+ years",
"1 year",
"6 years",
"2 years",
"10+ years",
"2 years",
"9 years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"6 years",
"2 years",
"10+ years",
"5 years",
"< 1 year",
"5 years",
"6 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"7 years",
"10+ years",
"6 years",
"10+ years",
null,
"10+ years",
"5 years",
"5 years",
"6 years",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
null,
"10+ years",
"9 years",
"5 years",
"7 years",
"10+ years",
"10+ years",
"5 years",
"5 years",
"5 years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"9 years",
"6 years",
"< 1 year",
"4 years",
"4 years",
"10+ years",
"10+ years",
"1 year",
"6 years",
"3 years",
"5 years",
"10+ years",
"6 years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"1 year",
"8 years",
"1 year",
"7 years",
null,
"5 years",
"9 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"4 years",
"3 years",
"6 years",
"4 years",
"10+ years",
"10+ years",
"7 years",
"6 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"5 years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"7 years",
"9 years",
"10+ years",
"8 years",
"2 years",
"2 years",
"7 years",
"6 years",
"10+ years",
"2 years",
"1 year",
"7 years",
"10+ years",
"9 years",
"1 year",
"< 1 year",
"6 years",
null,
"10+ years",
"8 years",
"< 1 year",
"2 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"8 years",
"10+ years",
"2 years",
null,
"3 years",
"10+ years",
"8 years",
"5 years",
"< 1 year",
"6 years",
null,
"5 years",
null,
"4 years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"6 years",
"3 years",
"4 years",
"9 years",
"5 years",
"2 years",
"7 years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"6 years",
"10+ years",
"7 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"3 years",
"8 years",
"2 years",
"4 years",
"10+ years",
"1 year",
"2 years",
"10+ years",
"10+ years",
null,
"6 years",
"8 years",
"3 years",
"3 years",
"10+ years",
"9 years",
"2 years",
"7 years",
"10+ years",
"4 years",
"8 years",
"5 years",
null,
"10+ years",
"< 1 year",
"3 years",
"6 years",
"4 years",
"7 years",
"< 1 year",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"4 years",
"2 years",
"7 years",
"10+ years",
"3 years",
"1 year",
"7 years",
"10+ years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"4 years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"9 years",
"4 years",
"8 years",
"10+ years",
"< 1 year",
"< 1 year",
"5 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"< 1 year",
"10+ years",
"5 years",
"3 years",
"8 years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"5 years",
"3 years",
"1 year",
null,
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"3 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"3 years",
"2 years",
"4 years",
"4 years",
"10+ years",
"8 years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"5 years",
"2 years",
"2 years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"10+ years",
"9 years",
"7 years",
"5 years",
"9 years",
"6 years",
"5 years",
"10+ years",
"9 years",
"2 years",
"10+ years",
"< 1 year",
"1 year",
"3 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"9 years",
"10+ years",
"1 year",
"7 years",
"< 1 year",
"7 years",
"8 years",
"6 years",
"3 years",
"9 years",
"10+ years",
"6 years",
"1 year",
"10+ years",
"7 years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"9 years",
"5 years",
"< 1 year",
"3 years",
"1 year",
"< 1 year",
"10+ years",
"4 years",
"3 years",
"10+ years",
"5 years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"3 years",
"9 years",
null,
"< 1 year",
"10+ years",
"2 years",
"5 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"1 year",
"7 years",
"< 1 year",
"10+ years",
"6 years",
null,
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"9 years",
"3 years",
"9 years",
"3 years",
"8 years",
null,
null,
"7 years",
"5 years",
"10+ years",
"1 year",
"1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"9 years",
"10+ years",
"10+ years",
"8 years",
"7 years",
"2 years",
"10+ years",
"8 years",
"8 years",
"1 year",
"5 years",
"3 years",
"< 1 year",
"9 years",
null,
"10+ years",
"< 1 year",
"4 years",
"< 1 year",
"6 years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"7 years",
"2 years",
"1 year",
"2 years",
"1 year",
"10+ years",
"10+ years",
null,
"10+ years",
"6 years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"< 1 year",
"8 years",
"4 years",
null,
"5 years",
"10+ years",
"5 years",
"2 years",
"6 years",
"4 years",
"1 year",
"9 years",
"8 years",
"2 years",
"6 years",
"3 years",
"6 years",
"10+ years",
null,
"7 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"< 1 year",
"6 years",
"4 years",
"6 years",
null,
"3 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"2 years",
"10+ years",
null,
"3 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"3 years",
"10+ years",
null,
"8 years",
"6 years",
"3 years",
"9 years",
"10+ years",
"8 years",
"2 years",
"4 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"6 years",
"< 1 year",
"8 years",
"5 years",
"2 years",
null,
"< 1 year",
"1 year",
"9 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
null,
"10+ years",
"4 years",
null,
"10+ years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"2 years",
"1 year",
null,
"2 years",
"9 years",
"2 years",
"9 years",
"10+ years",
"2 years",
"4 years",
"< 1 year",
"8 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"4 years",
"10+ years",
null,
"3 years",
"< 1 year",
"3 years",
"10+ years",
"7 years",
"3 years",
null,
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"8 years",
"4 years",
"9 years",
"3 years",
"8 years",
"4 years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"1 year",
"3 years",
"10+ years",
"< 1 year",
"3 years",
"4 years",
"< 1 year",
"10+ years",
"3 years",
"< 1 year",
"1 year",
"10+ years",
"2 years",
"9 years",
"3 years",
"3 years",
"3 years",
"4 years",
"9 years",
"< 1 year",
"4 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"2 years",
"1 year",
"8 years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"8 years",
"9 years",
"4 years",
"1 year",
null,
"10+ years",
"10+ years",
"8 years",
"8 years",
"9 years",
"10+ years",
"< 1 year",
"< 1 year",
"4 years",
"4 years",
"6 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"2 years",
"< 1 year",
"2 years",
"5 years",
"5 years",
"10+ years",
"< 1 year",
"1 year",
"7 years",
"4 years",
null,
"10+ years",
"2 years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"4 years",
"4 years",
"2 years",
"2 years",
"10+ years",
"9 years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"7 years",
"2 years",
"10+ years",
"5 years",
"4 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"2 years",
"10+ years",
null,
"7 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
null,
"10+ years",
"< 1 year",
"10+ years",
null,
"10+ years",
"8 years",
"6 years",
"2 years",
"9 years",
"6 years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
null,
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"< 1 year",
"8 years",
"7 years",
"2 years",
"3 years",
"5 years",
"5 years",
"2 years",
"10+ years",
"3 years",
"2 years",
"4 years",
"< 1 year",
"4 years",
"1 year",
"9 years",
"3 years",
"10+ years",
"2 years",
"3 years",
"1 year",
"7 years",
"10+ years",
"1 year",
"10+ years",
"2 years",
"2 years",
"4 years",
"3 years",
"9 years",
"10+ years",
null,
"10+ years",
"1 year",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"1 year",
"4 years",
"7 years",
"6 years",
"< 1 year",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
null,
"4 years",
"2 years",
"10+ years",
"10+ years",
"6 years",
null,
"< 1 year",
"5 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"7 years",
"1 year",
"3 years",
"5 years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"8 years",
"1 year",
"< 1 year",
"2 years",
"3 years",
"4 years",
"8 years",
"1 year",
"4 years",
"3 years",
"10+ years",
null,
"1 year",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"4 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"1 year",
"4 years",
"7 years",
"7 years",
"7 years",
"10+ years",
"9 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"10+ years",
null,
"5 years",
"9 years",
"6 years",
"7 years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"9 years",
"6 years",
"5 years",
"10+ years",
"2 years",
null,
"3 years",
"2 years",
"9 years",
"1 year",
"4 years",
"4 years",
"4 years",
"3 years",
null,
"7 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"9 years",
"9 years",
"5 years",
"10+ years",
"< 1 year",
"3 years",
"9 years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"7 years",
"10+ years",
"7 years",
"< 1 year",
"3 years",
"5 years",
"8 years",
null,
null,
"1 year",
"5 years",
"5 years",
"6 years",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"3 years",
"5 years",
"7 years",
"9 years",
"10+ years",
"1 year",
"4 years",
"10+ years",
"< 1 year",
"9 years",
"6 years",
"3 years",
"2 years",
"3 years",
"3 years",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"9 years",
"< 1 year",
"6 years",
"4 years",
"10+ years",
"9 years",
null,
"10+ years",
"2 years",
"10+ years",
null,
"7 years",
null,
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"6 years",
"3 years",
"5 years",
"1 year",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"9 years",
"4 years",
"1 year",
"1 year",
"9 years",
"7 years",
"8 years",
null,
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"2 years",
"8 years",
null,
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"3 years",
null,
"1 year",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"9 years",
"9 years",
"3 years",
"5 years",
null,
"1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
null,
"2 years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"< 1 year",
"5 years",
"8 years",
"6 years",
"10+ years",
"10+ years",
"7 years",
"< 1 year",
"8 years",
"10+ years",
"3 years",
"2 years",
"5 years",
"10+ years",
"< 1 year",
"5 years",
"3 years",
"< 1 year",
"9 years",
"10+ years",
"6 years",
"8 years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"6 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"3 years",
null,
"4 years",
"10+ years",
"5 years",
"4 years",
"2 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"8 years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"9 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"7 years",
"3 years",
"4 years",
"6 years",
"9 years",
"10+ years",
"10+ years",
"6 years",
"5 years",
"9 years",
"< 1 year",
"7 years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
null,
"< 1 year",
"9 years",
"10+ years",
"2 years",
"2 years",
"1 year",
"6 years",
"2 years",
"< 1 year",
"10+ years",
"6 years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"2 years",
null,
"10+ years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"2 years",
"8 years",
"5 years",
"4 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"2 years",
"2 years",
null,
"6 years",
"3 years",
"7 years",
"7 years",
"8 years",
"10+ years",
"4 years",
"2 years",
"10+ years",
"7 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"4 years",
"9 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"3 years",
"4 years",
"4 years",
"3 years",
"2 years",
"10+ years",
"1 year",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"7 years",
"4 years",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"4 years",
"< 1 year",
"6 years",
"5 years",
"7 years",
"6 years",
"1 year",
null,
"2 years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"1 year",
"9 years",
"< 1 year",
"3 years",
"1 year",
"10+ years",
"1 year",
"6 years",
"5 years",
"4 years",
null,
"10+ years",
"6 years",
"6 years",
"10+ years",
"10+ years",
"5 years",
"6 years",
"10+ years",
"7 years",
"9 years",
"< 1 year",
"9 years",
"8 years",
"9 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"4 years",
"6 years",
"2 years",
"10+ years",
"5 years",
"6 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"7 years",
"10+ years",
null,
"2 years",
"3 years",
"10+ years",
null,
"4 years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
null,
"4 years",
"2 years",
"1 year",
"2 years",
"8 years",
"4 years",
"2 years",
"< 1 year",
"10+ years",
"7 years",
"< 1 year",
"3 years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"2 years",
"3 years",
"5 years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"6 years",
"6 years",
"7 years",
"7 years",
"< 1 year",
null,
"1 year",
"9 years",
"2 years",
"9 years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"8 years",
"3 years",
"10+ years",
"5 years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"2 years",
"10+ years",
"1 year",
"3 years",
"8 years",
"9 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
null,
"2 years",
"7 years",
"10+ years",
"4 years",
"9 years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"1 year",
"2 years",
null,
"10+ years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"3 years",
"5 years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"6 years",
"2 years",
"3 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"9 years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"10+ years",
"5 years",
"6 years",
"10+ years",
"4 years",
"6 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"8 years",
"< 1 year",
"2 years",
null,
"4 years",
"< 1 year",
"5 years",
"< 1 year",
"4 years",
"8 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"4 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"2 years",
"< 1 year",
"2 years",
"5 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"4 years",
"8 years",
"10+ years",
"1 year",
"9 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"3 years",
"7 years",
"5 years",
"3 years",
"10+ years",
"4 years",
"2 years",
"6 years",
"8 years",
"3 years",
"6 years",
"8 years",
"10+ years",
"1 year",
null,
"10+ years",
"< 1 year",
"2 years",
"8 years",
"1 year",
"3 years",
"10+ years",
"3 years",
"6 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"2 years",
"< 1 year",
"5 years",
null,
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"4 years",
null,
null,
"6 years",
"5 years",
"1 year",
"4 years",
"5 years",
"4 years",
"3 years",
"2 years",
"4 years",
"3 years",
"7 years",
null,
"2 years",
"3 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"< 1 year",
"3 years",
"< 1 year",
"7 years",
"3 years",
"10+ years",
"8 years",
"3 years",
"2 years",
"4 years",
"4 years",
"10+ years",
"8 years",
"6 years",
"2 years",
"8 years",
null,
"9 years",
"9 years",
"8 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
null,
"5 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"4 years",
"1 year",
null,
"7 years",
"< 1 year",
"9 years",
"8 years",
"2 years",
null,
"1 year",
"< 1 year",
"1 year",
"5 years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"3 years",
"< 1 year",
"8 years",
"1 year",
"10+ years",
"4 years",
"3 years",
"5 years",
"10+ years",
"< 1 year",
"1 year",
null,
"2 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"7 years",
"10+ years",
"9 years",
"4 years",
"7 years",
"6 years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
null,
"10+ years",
"7 years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
null,
"3 years",
"10+ years",
"5 years",
"8 years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"9 years",
"10+ years",
"1 year",
"10+ years",
"5 years",
"3 years",
"10+ years",
"9 years",
"2 years",
null,
"3 years",
"3 years",
"6 years",
"9 years",
"10+ years",
"1 year",
"10+ years",
"8 years",
"3 years",
"10+ years",
"9 years",
null,
"1 year",
"6 years",
"10+ years",
"1 year",
"1 year",
"1 year",
"10+ years",
"10+ years",
"1 year",
"8 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"3 years",
"8 years",
"10+ years",
"10+ years",
null,
"5 years",
"1 year",
"6 years",
"3 years",
"10+ years",
"1 year",
"1 year",
"2 years",
"4 years",
"10+ years",
"4 years",
"8 years",
"6 years",
"9 years",
"5 years",
"4 years",
"< 1 year",
"6 years",
"2 years",
"5 years",
"9 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"1 year",
null,
"10+ years",
"7 years",
"2 years",
"5 years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
null,
"10+ years",
"5 years",
"3 years",
"3 years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"2 years",
"10+ years",
"2 years",
"2 years",
"1 year",
"10+ years",
"3 years",
"9 years",
"3 years",
"< 1 year",
"10+ years",
"8 years",
"5 years",
"9 years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"9 years",
"2 years",
"7 years",
"10+ years",
"2 years",
"4 years",
"8 years",
"10+ years",
"4 years",
"1 year",
"8 years",
"10+ years",
"8 years",
"7 years",
"10+ years",
"10+ years",
"8 years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"9 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"4 years",
"1 year",
"9 years",
null,
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
null,
"5 years",
"10+ years",
null,
"6 years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"5 years",
"7 years",
"7 years",
"9 years",
"10+ years",
"1 year",
"8 years",
"4 years",
null,
null,
"5 years",
null,
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"9 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
null,
"1 year",
"6 years",
null,
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"2 years",
"6 years",
"8 years",
"10+ years",
"7 years",
"9 years",
"7 years",
"5 years",
"1 year",
"5 years",
"9 years",
"10+ years",
"2 years",
"2 years",
"8 years",
"5 years",
"6 years",
"10+ years",
"8 years",
"10+ years",
null,
"7 years",
"10+ years",
null,
"4 years",
"4 years",
"10+ years",
"4 years",
"3 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"6 years",
"7 years",
"4 years",
"5 years",
"5 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"4 years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"< 1 year",
"3 years",
"4 years",
"5 years",
"9 years",
"2 years",
"10+ years",
"3 years",
"5 years",
"1 year",
"10+ years",
"3 years",
"2 years",
"10+ years",
"2 years",
"5 years",
"1 year",
"8 years",
"< 1 year",
"10+ years",
"5 years",
"7 years",
"2 years",
"10+ years",
"6 years",
"8 years",
"< 1 year",
"2 years",
"1 year",
null,
"10+ years",
"3 years",
"2 years",
"< 1 year",
"3 years",
"1 year",
"4 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"8 years",
"5 years",
"10+ years",
"6 years",
"4 years",
"10+ years",
"7 years",
null,
"8 years",
"3 years",
null,
"10+ years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
null,
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"7 years",
"< 1 year",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"8 years",
null,
"10+ years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"6 years",
"2 years",
"10+ years",
"3 years",
"9 years",
"2 years",
"5 years",
"2 years",
"5 years",
"10+ years",
"3 years",
null,
"3 years",
"5 years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"4 years",
"4 years",
"2 years",
"< 1 year",
"< 1 year",
"< 1 year",
"7 years",
"< 1 year",
"2 years",
null,
"10+ years",
"3 years",
"10+ years",
"6 years",
"2 years",
null,
"10+ years",
"7 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"3 years",
"7 years",
"3 years",
"10+ years",
"7 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"7 years",
"3 years",
"10+ years",
"7 years",
"7 years",
"2 years",
"10+ years",
"7 years",
"3 years",
"5 years",
"3 years",
"10+ years",
"9 years",
"8 years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"5 years",
"5 years",
"10+ years",
null,
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"2 years",
"3 years",
"< 1 year",
"< 1 year",
"2 years",
"2 years",
"10+ years",
"10+ years",
"9 years",
"8 years",
"2 years",
"1 year",
"5 years",
null,
"2 years",
"7 years",
"5 years",
null,
"10+ years",
"4 years",
"10+ years",
"1 year",
"3 years",
"< 1 year",
"8 years",
"< 1 year",
null,
"2 years",
"10+ years",
"1 year",
"8 years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"9 years",
"10+ years",
"5 years",
"5 years",
"10+ years",
"2 years",
"< 1 year",
"9 years",
"5 years",
"3 years",
"1 year",
"3 years",
"10+ years",
"5 years",
"5 years",
"5 years",
"8 years",
"10+ years",
"10+ years",
null,
"1 year",
"10+ years",
"2 years",
"3 years",
"10+ years",
"5 years",
"8 years",
"10+ years",
"5 years",
"7 years",
"7 years",
"8 years",
"10+ years",
null,
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"< 1 year",
"7 years",
"< 1 year",
null,
"3 years",
"4 years",
null,
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"10+ years",
"5 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"8 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"5 years",
"2 years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"2 years",
"9 years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"3 years",
"1 year",
"4 years",
"10+ years",
"10+ years",
"7 years",
"9 years",
"5 years",
"< 1 year",
"< 1 year",
"1 year",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"5 years",
"8 years",
"9 years",
"2 years",
"< 1 year",
"8 years",
"9 years",
"5 years",
"9 years",
"< 1 year",
"8 years",
"7 years",
"10+ years",
null,
"5 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"8 years",
"2 years",
"2 years",
"10+ years",
"9 years",
"5 years",
"10+ years",
"6 years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"6 years",
"8 years",
"6 years",
null,
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"8 years",
"6 years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"7 years",
"1 year",
"< 1 year",
"7 years",
"8 years",
null,
"10+ years",
"7 years",
"1 year",
"8 years",
"2 years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"8 years",
"8 years",
"5 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"4 years",
null,
"10+ years",
null,
"3 years",
"8 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"1 year",
"2 years",
"2 years",
"1 year",
null,
"10+ years",
null,
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"5 years",
"10+ years",
null,
"9 years",
"1 year",
"7 years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"8 years",
"6 years",
"10+ years",
"6 years",
"7 years",
"10+ years",
"7 years",
"5 years",
"4 years",
"8 years",
"7 years",
"3 years",
"10+ years",
"4 years",
"4 years",
null,
"10+ years",
"1 year",
"10+ years",
"3 years",
"3 years",
"6 years",
"10+ years",
"10+ years",
"5 years",
null,
"5 years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"2 years",
"1 year",
"7 years",
"3 years",
"2 years",
"1 year",
"2 years",
"2 years",
"3 years",
"10+ years",
"6 years",
"4 years",
"7 years",
"8 years",
"10+ years",
"10+ years",
"6 years",
"1 year",
"3 years",
"4 years",
"7 years",
"4 years",
"9 years",
"10+ years",
"1 year",
"4 years",
"3 years",
null,
"10+ years",
null,
"10+ years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"4 years",
null,
"4 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"5 years",
null,
"10+ years",
"5 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"9 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"6 years",
"< 1 year",
"8 years",
"6 years",
"10+ years",
null,
"6 years",
"1 year",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"8 years",
null,
"9 years",
"10+ years",
"7 years",
"10+ years",
"< 1 year",
"< 1 year",
"6 years",
"1 year",
"6 years",
"9 years",
"9 years",
"10+ years",
"5 years",
"8 years",
"4 years",
"10+ years",
"8 years",
"3 years",
"10+ years",
null,
"5 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"1 year",
"1 year",
"4 years",
"5 years",
"2 years",
"2 years",
"8 years",
"4 years",
"3 years",
"7 years",
"6 years",
"6 years",
"1 year",
"10+ years",
"7 years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"1 year",
"3 years",
"1 year",
"5 years",
"5 years",
"5 years",
"10+ years",
"5 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"4 years",
"10+ years",
"< 1 year",
"9 years",
"< 1 year",
"10+ years",
null,
"2 years",
"7 years",
"4 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"1 year",
"2 years",
"10+ years",
"< 1 year",
"4 years",
"4 years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"5 years",
"9 years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"1 year",
"10+ years",
"8 years",
"< 1 year",
"6 years",
"4 years",
"2 years",
"4 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"1 year",
null,
"10+ years",
"10+ years",
"4 years",
"7 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"4 years",
null,
"3 years",
"1 year",
"3 years",
"10+ years",
"7 years",
"9 years",
null,
"< 1 year",
"10+ years",
"6 years",
"2 years",
null,
"2 years",
"< 1 year",
"< 1 year",
"3 years",
"3 years",
"< 1 year",
"4 years",
"10+ years",
"6 years",
"4 years",
"5 years",
"5 years",
"6 years",
"5 years",
"< 1 year",
"10+ years",
"3 years",
"2 years",
"< 1 year",
"10+ years",
"9 years",
"< 1 year",
"7 years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"2 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"9 years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"4 years",
"9 years",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"6 years",
"1 year",
"10+ years",
"< 1 year",
"4 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"9 years",
"10+ years",
"9 years",
"8 years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"1 year",
"8 years",
"2 years",
"10+ years",
"1 year",
null,
"< 1 year",
"8 years",
"1 year",
"10+ years",
"3 years",
"7 years",
"< 1 year",
"3 years",
"10+ years",
"9 years",
"2 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"8 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"2 years",
"2 years",
"4 years",
"< 1 year",
"4 years",
null,
"6 years",
null,
"2 years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"9 years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"2 years",
null,
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"8 years",
"7 years",
"2 years",
"1 year",
"6 years",
"2 years",
"3 years",
"2 years",
"3 years",
"10+ years",
"3 years",
"4 years",
"10+ years",
null,
"10+ years",
"2 years",
"3 years",
"7 years",
"< 1 year",
"4 years",
"2 years",
"7 years",
"10+ years",
"9 years",
"3 years",
"4 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"9 years",
null,
"5 years",
"1 year",
"8 years",
"6 years",
"9 years",
"6 years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"5 years",
"5 years",
"3 years",
"5 years",
"2 years",
"5 years",
"< 1 year",
"10+ years",
"3 years",
"< 1 year",
"1 year",
"6 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"7 years",
"6 years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
null,
"8 years",
"10+ years",
"7 years",
"10+ years",
"6 years",
"10+ years",
"4 years",
"5 years",
null,
"6 years",
"2 years",
"3 years",
"3 years",
"10+ years",
null,
"5 years",
"3 years",
"2 years",
"2 years",
"10+ years",
"5 years",
"7 years",
"8 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"2 years",
"3 years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"6 years",
"6 years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"7 years",
"6 years",
"< 1 year",
"3 years",
"5 years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"9 years",
"4 years",
"3 years",
"10+ years",
"3 years",
"6 years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"8 years",
"1 year",
"3 years",
"10+ years",
"1 year",
"5 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"9 years",
"7 years",
"< 1 year",
"8 years",
"1 year",
"10+ years",
"5 years",
"10+ years",
"1 year",
"< 1 year",
"2 years",
null,
"5 years",
"10+ years",
"2 years",
"1 year",
"2 years",
"7 years",
"4 years",
"4 years",
"3 years",
"2 years",
"10+ years",
null,
"8 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"4 years",
"1 year",
"8 years",
"10+ years",
"7 years",
"4 years",
"10+ years",
"6 years",
"10+ years",
"8 years",
"9 years",
"10+ years",
"10+ years",
"8 years",
null,
"6 years",
"4 years",
"3 years",
"10+ years",
"2 years",
"1 year",
"1 year",
"< 1 year",
"10+ years",
"< 1 year",
null,
"4 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"7 years",
"< 1 year",
"3 years",
"4 years",
"< 1 year",
"1 year",
"5 years",
"10+ years",
"1 year",
"6 years",
"10+ years",
"7 years",
"5 years",
"9 years",
"9 years",
"10+ years",
"10+ years",
"6 years",
"< 1 year",
"< 1 year",
"2 years",
"9 years",
"10+ years",
"10+ years",
"5 years",
"5 years",
"10+ years",
"1 year",
"9 years",
"7 years",
"8 years",
"5 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
null,
"9 years",
"5 years",
"3 years",
"4 years",
"8 years",
"3 years",
"9 years",
"< 1 year",
"10+ years",
"8 years",
"9 years",
"2 years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"6 years",
"5 years",
"8 years",
"10+ years",
"1 year",
null,
"4 years",
"4 years",
"5 years",
"10+ years",
"9 years",
"1 year",
"10+ years",
"1 year",
"1 year",
"6 years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"5 years",
"1 year",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"8 years",
"7 years",
"10+ years",
"4 years",
"5 years",
"10+ years",
null,
"10+ years",
"6 years",
null,
"7 years",
"7 years",
"10+ years",
"8 years",
"6 years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"7 years",
"< 1 year",
"10+ years",
"6 years",
"1 year",
"2 years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"8 years",
"4 years",
"2 years",
"2 years",
"3 years",
"8 years",
"5 years",
"10+ years",
"3 years",
"2 years",
"8 years",
"5 years",
"1 year",
"9 years",
"10+ years",
"8 years",
"6 years",
"1 year",
"1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"1 year",
"9 years",
"3 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"9 years",
"10+ years",
null,
"10+ years",
"7 years",
"5 years",
"9 years",
null,
"10+ years",
"10+ years",
"4 years",
"1 year",
"8 years",
"2 years",
"10+ years",
"2 years",
"9 years",
"1 year",
"10+ years",
"1 year",
"5 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"3 years",
"6 years",
"2 years",
"8 years",
"2 years",
"7 years",
"2 years",
"8 years",
null,
"3 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"1 year",
"6 years",
"2 years",
"10+ years",
"8 years",
"4 years",
"10+ years",
"6 years",
"3 years",
"6 years",
"< 1 year",
"7 years",
"4 years",
"8 years",
"10+ years",
null,
"10+ years",
"6 years",
"10+ years",
"4 years",
"4 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"6 years",
"4 years",
"7 years",
"5 years",
null,
"10+ years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"10+ years",
null,
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"3 years",
"10+ years",
"2 years",
"< 1 year",
"3 years",
"5 years",
"10+ years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"< 1 year",
null,
"4 years",
null,
"3 years",
"3 years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"4 years",
"< 1 year",
"10+ years",
"5 years",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
null,
null,
"9 years",
"2 years",
"2 years",
"1 year",
"1 year",
"3 years",
null,
"1 year",
"8 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"8 years",
"7 years",
"7 years",
"4 years",
"1 year",
"1 year",
"8 years",
"7 years",
"10+ years",
"3 years",
"5 years",
"3 years",
"2 years",
"9 years",
"10+ years",
"3 years",
null,
"3 years",
"3 years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"2 years",
null,
"< 1 year",
"7 years",
"10+ years",
"6 years",
"7 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"5 years",
"2 years",
"7 years",
"2 years",
null,
"3 years",
"8 years",
"5 years",
"6 years",
"10+ years",
"1 year",
"6 years",
"3 years",
"5 years",
"10+ years",
null,
"1 year",
"10+ years",
"4 years",
"3 years",
"1 year",
"2 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"5 years",
"4 years",
"9 years",
"3 years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"3 years",
"10+ years",
null,
"1 year",
"3 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"7 years",
"10+ years",
"8 years",
"3 years",
"< 1 year",
"5 years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"2 years",
null,
"8 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"2 years",
"< 1 year",
"5 years",
"5 years",
"2 years",
"7 years",
"< 1 year",
"10+ years",
null,
"10+ years",
"5 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"9 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
null,
"6 years",
"5 years",
"8 years",
"6 years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"6 years",
"4 years",
"1 year",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"8 years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"7 years",
"1 year",
"5 years",
"10+ years",
null,
"10+ years",
"2 years",
"6 years",
"4 years",
"< 1 year",
"3 years",
"8 years",
"10+ years",
"10+ years",
"4 years",
"4 years",
"6 years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"7 years",
"8 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"6 years",
"8 years",
"10+ years",
"9 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"3 years",
null,
"10+ years",
"< 1 year",
null,
"10+ years",
"10+ years",
"7 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"< 1 year",
"3 years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"7 years",
"1 year",
"5 years",
"2 years",
"7 years",
"8 years",
"10+ years",
"2 years",
"5 years",
"3 years",
"1 year",
"< 1 year",
"2 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"7 years",
"1 year",
"10+ years",
"< 1 year",
"2 years",
"8 years",
"10+ years",
"8 years",
"2 years",
"5 years",
"< 1 year",
"2 years",
"1 year",
"2 years",
"1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"2 years",
"9 years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"4 years",
"3 years",
"2 years",
"5 years",
null,
"4 years",
"10+ years",
"< 1 year",
"9 years",
"1 year",
"2 years",
"4 years",
"< 1 year",
"1 year",
"9 years",
"1 year",
"10+ years",
"10+ years",
"7 years",
"1 year",
"3 years",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"6 years",
null,
"5 years",
"1 year",
"7 years",
"2 years",
"5 years",
"1 year",
"< 1 year",
"8 years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"1 year",
"< 1 year",
"8 years",
"2 years",
"5 years",
"10+ years",
"3 years",
"< 1 year",
"3 years",
"10+ years",
"6 years",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"5 years",
"10+ years",
"< 1 year",
null,
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"< 1 year",
"2 years",
"3 years",
"< 1 year",
"6 years",
"3 years",
"10+ years",
"2 years",
null,
"4 years",
"3 years",
"1 year",
"7 years",
"10+ years",
"10+ years",
"8 years",
"1 year",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"5 years",
"1 year",
"4 years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"7 years",
"6 years",
"7 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"< 1 year",
"< 1 year",
"3 years",
"3 years",
"9 years",
"10+ years",
"2 years",
"4 years",
"1 year",
"3 years",
"< 1 year",
"< 1 year",
"7 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"< 1 year",
"< 1 year",
"5 years",
"10+ years",
"< 1 year",
"< 1 year",
"1 year",
"< 1 year",
"8 years",
"10+ years",
"9 years",
"9 years",
"6 years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"6 years",
"1 year",
"2 years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"9 years",
"10+ years",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"8 years",
"8 years",
null,
"10+ years",
"< 1 year",
"10+ years",
null,
"1 year",
"10+ years",
"1 year",
"2 years",
"10+ years",
"8 years",
"2 years",
"2 years",
"1 year",
"3 years",
"< 1 year",
"5 years",
"8 years",
"1 year",
"10+ years",
null,
"9 years",
"3 years",
"8 years",
"2 years",
"< 1 year",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"3 years",
"< 1 year",
"4 years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"4 years",
"5 years",
"10+ years",
null,
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"2 years",
"4 years",
"2 years",
"10+ years",
null,
"5 years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"7 years",
"10+ years",
null,
"< 1 year",
"8 years",
"1 year",
"10+ years",
"1 year",
"3 years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"< 1 year",
"10+ years",
"5 years",
"7 years",
"10+ years",
null,
"5 years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"9 years",
"8 years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"9 years",
"8 years",
"10+ years",
"9 years",
"4 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
null,
null,
"5 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"10+ years",
null,
"10+ years",
"7 years",
"3 years",
"1 year",
"5 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"9 years",
"< 1 year",
"6 years",
"10+ years",
"1 year",
"9 years",
"2 years",
"< 1 year",
"1 year",
"2 years",
"< 1 year",
"10+ years",
"7 years",
"5 years",
"4 years",
"3 years",
"1 year",
"< 1 year",
"5 years",
"1 year",
"8 years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"7 years",
"3 years",
"10+ years",
"1 year",
"2 years",
"4 years",
"5 years",
"10+ years",
"8 years",
"< 1 year",
"< 1 year",
"< 1 year",
"1 year",
"10+ years",
"5 years",
"10+ years",
"7 years",
"10+ years",
"6 years",
"4 years",
"2 years",
"2 years",
null,
"5 years",
"7 years",
"10+ years",
"4 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"7 years",
"3 years",
"< 1 year",
null,
"10+ years",
"7 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"10+ years",
"8 years",
"10+ years",
"6 years",
"1 year",
"10+ years",
"< 1 year",
"7 years",
"8 years",
"10+ years",
"8 years",
"7 years",
"6 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"7 years",
"10+ years",
"1 year",
"7 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
null,
"9 years",
"8 years",
"7 years",
"5 years",
"6 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"9 years",
"7 years",
"7 years",
null,
"1 year",
"10+ years",
"4 years",
null,
"1 year",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"7 years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"3 years",
"10+ years",
null,
"9 years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"9 years",
"5 years",
null,
"10+ years",
"6 years",
"9 years",
"10+ years",
"6 years",
"10+ years",
null,
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"2 years",
"6 years",
"5 years",
"10+ years",
null,
"3 years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"1 year",
"10+ years",
null,
"3 years",
"8 years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"1 year",
"10+ years",
"7 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"5 years",
"2 years",
"1 year",
"< 1 year",
"4 years",
null,
"7 years",
"4 years",
"4 years",
"7 years",
"6 years",
"3 years",
"8 years",
"8 years",
"5 years",
"1 year",
"3 years",
"4 years",
"4 years",
"2 years",
"1 year",
"10+ years",
"2 years",
"5 years",
"8 years",
"< 1 year",
"< 1 year",
"9 years",
"10+ years",
"6 years",
"1 year",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
null,
"9 years",
"< 1 year",
"8 years",
"8 years",
"2 years",
"2 years",
"4 years",
"1 year",
"10+ years",
null,
"5 years",
"< 1 year",
"10+ years",
"5 years",
"3 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"8 years",
"1 year",
"2 years",
"9 years",
"10+ years",
"2 years",
"5 years",
"4 years",
"2 years",
"3 years",
"8 years",
null,
"2 years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"7 years",
"5 years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"1 year",
"4 years",
"10+ years",
"2 years",
"3 years",
"3 years",
"1 year",
"10+ years",
"10+ years",
null,
"10+ years",
"8 years",
"1 year",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"< 1 year",
"4 years",
"5 years",
"3 years",
"4 years",
"7 years",
"5 years",
"3 years",
"8 years",
"1 year",
"10+ years",
"7 years",
"8 years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"7 years",
"3 years",
"5 years",
"8 years",
"7 years",
"4 years",
"6 years",
"7 years",
"3 years",
"4 years",
"10+ years",
"3 years",
"7 years",
"2 years",
"8 years",
"5 years",
"< 1 year",
"4 years",
"< 1 year",
"3 years",
"1 year",
"10+ years",
"3 years",
"9 years",
"8 years",
"3 years",
"10+ years",
"< 1 year",
"1 year",
null,
"10+ years",
"6 years",
"10+ years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"9 years",
"4 years",
"10+ years",
"6 years",
"1 year",
"8 years",
"2 years",
"10+ years",
"1 year",
"6 years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"2 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"5 years",
"3 years",
"6 years",
"9 years",
"2 years",
null,
"10+ years",
"10+ years",
"6 years",
null,
"6 years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
null,
"9 years",
"8 years",
"5 years",
"3 years",
"9 years",
null,
"9 years",
null,
"1 year",
"9 years",
"10+ years",
"< 1 year",
"< 1 year",
"2 years",
"< 1 year",
"10+ years",
"3 years",
"2 years",
"9 years",
"6 years",
"4 years",
"6 years",
"4 years",
"3 years",
"6 years",
"2 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"8 years",
"7 years",
"5 years",
"4 years",
"4 years",
"< 1 year",
"10+ years",
"4 years",
"9 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"7 years",
"4 years",
"3 years",
"< 1 year",
"4 years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"7 years",
"6 years",
"4 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"5 years",
"6 years",
"4 years",
"4 years",
"7 years",
"10+ years",
"7 years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"2 years",
"8 years",
"1 year",
"2 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
null,
"8 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"6 years",
"10+ years",
"2 years",
"2 years",
"5 years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"9 years",
null,
"6 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"6 years",
"10+ years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"10+ years",
"9 years",
"10+ years",
"7 years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
null,
"6 years",
"9 years",
"8 years",
"2 years",
"2 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
null,
"5 years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"4 years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"7 years",
"9 years",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
null,
"6 years",
"10+ years",
"10+ years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"10+ years",
"8 years",
"10+ years",
"6 years",
"4 years",
"10+ years",
"10+ years",
"9 years",
"5 years",
"10+ years",
"7 years",
"8 years",
"6 years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"4 years",
"6 years",
"< 1 year",
"3 years",
null,
"5 years",
"2 years",
"10+ years",
"1 year",
null,
"2 years",
"2 years",
"6 years",
"2 years",
"2 years",
"10+ years",
"6 years",
"8 years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"1 year",
"2 years",
"8 years",
"1 year",
"6 years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"6 years",
"< 1 year",
"2 years",
"8 years",
null,
"4 years",
"6 years",
"5 years",
"7 years",
"2 years",
"7 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"8 years",
null,
"10+ years",
"< 1 year",
"10+ years",
"9 years",
"10+ years",
"5 years",
"4 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"5 years",
"2 years",
"1 year",
"10+ years",
null,
"2 years",
"10+ years",
"7 years",
"6 years",
"7 years",
"10+ years",
"< 1 year",
"6 years",
"7 years",
"3 years",
"7 years",
"1 year",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"6 years",
"5 years",
"4 years",
"8 years",
"2 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"4 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"1 year",
"10+ years",
"2 years",
"7 years",
"10+ years",
null,
"< 1 year",
"3 years",
null,
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"< 1 year",
"8 years",
"7 years",
"6 years",
"< 1 year",
"7 years",
"1 year",
"6 years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
null,
"5 years",
null,
"< 1 year",
"9 years",
"4 years",
"4 years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"8 years",
"10+ years",
"9 years",
"7 years",
"10+ years",
"4 years",
"5 years",
null,
"8 years",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"2 years",
"5 years",
"8 years",
"5 years",
"9 years",
"3 years",
"< 1 year",
"1 year",
"4 years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
null,
"10+ years",
"8 years",
null,
"1 year",
"6 years",
"8 years",
"5 years",
"10+ years",
"1 year",
"7 years",
"< 1 year",
"3 years",
"2 years",
"10+ years",
"10+ years",
null,
"10+ years",
"8 years",
null,
"10+ years",
"4 years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"2 years",
"4 years",
"6 years",
"7 years",
null,
"10+ years",
"3 years",
"10+ years",
"7 years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"1 year",
"10+ years",
"6 years",
"3 years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"< 1 year",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"1 year",
"10+ years",
"5 years",
"6 years",
"8 years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"5 years",
"4 years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"8 years",
"4 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"1 year",
"8 years",
null,
"9 years",
"9 years",
"2 years",
"6 years",
"7 years",
"< 1 year",
"5 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"< 1 year",
"4 years",
"8 years",
"2 years",
"6 years",
"6 years",
null,
"2 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"4 years",
"< 1 year",
"3 years",
"10+ years",
"1 year",
"5 years",
"1 year",
"2 years",
"7 years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"9 years",
"1 year",
"9 years",
"< 1 year",
"5 years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
null,
"10+ years",
"5 years",
null,
"10+ years",
"4 years",
"10+ years",
"7 years",
"10+ years",
"5 years",
"1 year",
"5 years",
"5 years",
"< 1 year",
"5 years",
"6 years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"3 years",
"2 years",
"4 years",
"5 years",
"4 years",
null,
"10+ years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"2 years",
"10+ years",
"2 years",
"1 year",
"9 years",
"2 years",
"8 years",
"< 1 year",
null,
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"2 years",
"7 years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"8 years",
"3 years",
"4 years",
"7 years",
"< 1 year",
"10+ years",
"1 year",
"4 years",
"3 years",
"10+ years",
"5 years",
"3 years",
"< 1 year",
"< 1 year",
"1 year",
"1 year",
"7 years",
"10+ years",
"3 years",
"6 years",
"5 years",
"4 years",
"4 years",
"1 year",
"4 years",
null,
"10+ years",
"7 years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"5 years",
"1 year",
"10+ years",
"10+ years",
"1 year",
"9 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
null,
"8 years",
null,
"8 years",
"1 year",
"2 years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"9 years",
"1 year",
"6 years",
"10+ years",
"1 year",
"7 years",
"2 years",
"10+ years",
"5 years",
"5 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
null,
"10+ years",
"1 year",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"7 years",
"2 years",
"5 years",
null,
"10+ years",
"6 years",
"3 years",
"10+ years",
"< 1 year",
"6 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"4 years",
"8 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"1 year",
"6 years",
"4 years",
"1 year",
"10+ years",
"10+ years",
"7 years",
"6 years",
"7 years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"1 year",
"3 years",
"7 years",
"5 years",
"5 years",
"1 year",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"9 years",
null,
"< 1 year",
"2 years",
"6 years",
"< 1 year",
"3 years",
"10+ years",
"4 years",
"3 years",
"6 years",
"10+ years",
null,
"6 years",
"8 years",
"2 years",
"5 years",
"6 years",
"2 years",
"10+ years",
"3 years",
"8 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"6 years",
"4 years",
"5 years",
"10+ years",
"< 1 year",
"2 years",
"4 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"9 years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"1 year",
"6 years",
"10+ years",
"1 year",
"10+ years",
"8 years",
"1 year",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"5 years",
"4 years",
"10+ years",
"5 years",
"5 years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"6 years",
"10+ years",
"3 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
null,
"7 years",
"3 years",
"2 years",
"6 years",
"10+ years",
null,
"3 years",
"3 years",
"10+ years",
"5 years",
"3 years",
"5 years",
"10+ years",
"8 years",
"10+ years",
"9 years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"4 years",
"3 years",
"2 years",
"1 year",
"3 years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"5 years",
"10+ years",
"4 years",
"10+ years",
"2 years",
null,
"3 years",
"10+ years",
"10+ years",
"7 years",
"< 1 year",
"7 years",
"< 1 year",
null,
"10+ years",
"4 years",
null,
"2 years",
"10+ years",
"2 years",
null,
"5 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"10+ years",
"7 years",
null,
"8 years",
"3 years",
"4 years",
"1 year",
"1 year",
"5 years",
"6 years",
"3 years",
"10+ years",
"5 years",
"5 years",
"9 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"7 years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"7 years",
"2 years",
"< 1 year",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"8 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"< 1 year",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"5 years",
"< 1 year",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"10+ years",
null,
"10+ years",
"3 years",
"2 years",
"9 years",
"< 1 year",
"10+ years",
null,
"10+ years",
"4 years",
"7 years",
"1 year",
"7 years",
"2 years",
"2 years",
"5 years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"9 years",
"3 years",
"< 1 year",
"8 years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"6 years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"3 years",
"4 years",
"2 years",
"2 years",
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"< 1 year",
"3 years",
"1 year",
"4 years",
"8 years",
"4 years",
"4 years",
"8 years",
"3 years",
"8 years",
null,
"1 year",
"10+ years",
"6 years",
"7 years",
"10+ years",
"4 years",
"10+ years",
null,
"10+ years",
"8 years",
"4 years",
null,
"9 years",
"4 years",
"3 years",
"10+ years",
"< 1 year",
"1 year",
"7 years",
"6 years",
"5 years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"3 years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"< 1 year",
"1 year",
"2 years",
"3 years",
"10+ years",
"3 years",
"3 years",
"2 years",
"< 1 year",
"10+ years",
"< 1 year",
"< 1 year",
"5 years",
"6 years",
"6 years",
null,
"10+ years",
"2 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"3 years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"2 years",
"3 years",
"5 years",
"8 years",
"4 years",
"10+ years",
"< 1 year",
"5 years",
null,
"5 years",
"5 years",
"9 years",
"10+ years",
"10+ years",
null,
"7 years",
"10+ years",
null,
"10+ years",
"7 years",
"10+ years",
"6 years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
null,
"7 years",
"5 years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"10+ years",
"1 year",
"4 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"5 years",
"5 years",
"7 years",
null,
"10+ years",
"6 years",
"10+ years",
"7 years",
"3 years",
"1 year",
"5 years",
"10+ years",
"2 years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"8 years",
"2 years",
"10+ years",
"2 years",
"2 years",
"8 years",
"7 years",
"3 years",
null,
"10+ years",
"7 years",
"1 year",
"7 years",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"2 years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"1 year",
"3 years",
"7 years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"6 years",
"4 years",
"2 years",
"6 years",
"9 years",
"3 years",
"10+ years",
null,
"10+ years",
"1 year",
null,
"10+ years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"10+ years",
"2 years",
"4 years",
"10+ years",
null,
"5 years",
"10+ years",
null,
"< 1 year",
"3 years",
"3 years",
null,
"1 year",
"10+ years",
"7 years",
"1 year",
"10+ years",
"4 years",
"4 years",
"5 years",
"< 1 year",
"3 years",
"3 years",
"10+ years",
null,
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
null,
"8 years",
"3 years",
"3 years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"1 year",
"10+ years",
"5 years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"5 years",
"10+ years",
null,
"7 years",
"8 years",
"10+ years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"7 years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"9 years",
"2 years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"3 years",
"2 years",
"8 years",
"1 year",
"10+ years",
null,
"2 years",
"8 years",
"7 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"3 years",
"4 years",
"1 year",
"2 years",
"2 years",
"4 years",
"4 years",
"4 years",
"3 years",
"10+ years",
"6 years",
"3 years",
"9 years",
"4 years",
"9 years",
"10+ years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"2 years",
"1 year",
"< 1 year",
"7 years",
"7 years",
"10+ years",
"9 years",
"10+ years",
"5 years",
"9 years",
"5 years",
"1 year",
"10+ years",
"3 years",
"1 year",
"< 1 year",
"5 years",
"2 years",
"5 years",
"8 years",
"7 years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"< 1 year",
"8 years",
"10+ years",
"2 years",
"< 1 year",
"2 years",
"4 years",
"< 1 year",
"6 years",
"10+ years",
null,
"10+ years",
null,
"1 year",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"7 years",
"5 years",
null,
"3 years",
"10+ years",
"5 years",
"9 years",
"10+ years",
"3 years",
"4 years",
"9 years",
"5 years",
"10+ years",
"10+ years",
"8 years",
"9 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"2 years",
"9 years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"8 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
null,
"< 1 year",
"10+ years",
"9 years",
"6 years",
"3 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"3 years",
"2 years",
"1 year",
"< 1 year",
"< 1 year",
"7 years",
"5 years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"1 year",
"6 years",
"10+ years",
"2 years",
"10+ years",
"8 years",
"7 years",
"1 year",
"10+ years",
"3 years",
"5 years",
"1 year",
"10+ years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"2 years",
"5 years",
"5 years",
"7 years",
"10+ years",
"2 years",
null,
"6 years",
"5 years",
"< 1 year",
"2 years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"< 1 year",
"3 years",
"5 years",
"10+ years",
"< 1 year",
null,
"3 years",
"5 years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"1 year",
"7 years",
"3 years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"4 years",
"4 years",
null,
"10+ years",
"6 years",
"7 years",
"10+ years",
"3 years",
"2 years",
"1 year",
"< 1 year",
"5 years",
"< 1 year",
"8 years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"8 years",
"6 years",
"10+ years",
"1 year",
"7 years",
"< 1 year",
"10+ years",
"3 years",
"4 years",
"5 years",
"2 years",
"10+ years",
"2 years",
"1 year",
"4 years",
"< 1 year",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"6 years",
"9 years",
"10+ years",
"5 years",
"8 years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
null,
"9 years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"4 years",
null,
"8 years",
"10+ years",
"9 years",
"7 years",
"1 year",
null,
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"8 years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"< 1 year",
"7 years",
"2 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"5 years",
"5 years",
"< 1 year",
"10+ years",
"3 years",
"4 years",
"10+ years",
"6 years",
"1 year",
"10+ years",
"4 years",
null,
"10+ years",
"1 year",
"2 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"1 year",
"10+ years",
"2 years",
"4 years",
"8 years",
"4 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"1 year",
"10+ years",
"7 years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"6 years",
"10+ years",
"6 years",
"10+ years",
"4 years",
"9 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"1 year",
"9 years",
"5 years",
"5 years",
"6 years",
"10+ years",
"9 years",
"9 years",
"6 years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"9 years",
"4 years",
null,
"10+ years",
"9 years",
"3 years",
"< 1 year",
"6 years",
"10+ years",
"6 years",
"7 years",
"2 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"3 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"8 years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"3 years",
"5 years",
null,
"5 years",
"10+ years",
"1 year",
"3 years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"4 years",
"9 years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"3 years",
"1 year",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"2 years",
"9 years",
"< 1 year",
"10+ years",
"4 years",
null,
"10+ years",
"6 years",
"7 years",
"2 years",
"10+ years",
"2 years",
"1 year",
"< 1 year",
"8 years",
"2 years",
"7 years",
"10+ years",
"3 years",
"2 years",
null,
"< 1 year",
"1 year",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"5 years",
"3 years",
"5 years",
"7 years",
"7 years",
"3 years",
"5 years",
"8 years",
"7 years",
"1 year",
"5 years",
"< 1 year",
"2 years",
"7 years",
"1 year",
"7 years",
"3 years",
"7 years",
"5 years",
"1 year",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"4 years",
"< 1 year",
"2 years",
"< 1 year",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"4 years",
"6 years",
"9 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"9 years",
"5 years",
"8 years",
null,
"10+ years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"3 years",
"1 year",
"8 years",
"5 years",
"10+ years",
"3 years",
"3 years",
"< 1 year",
"1 year",
"10+ years",
null,
"4 years",
null,
null,
"3 years",
"7 years",
"2 years",
"10+ years",
"2 years",
null,
"6 years",
"2 years",
"9 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
null,
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"2 years",
"10+ years",
"3 years",
"3 years",
"6 years",
"2 years",
"< 1 year",
"3 years",
"2 years",
"3 years",
"10+ years",
"6 years",
"< 1 year",
"< 1 year",
"3 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
null,
"10+ years",
"4 years",
"10+ years",
"7 years",
"10+ years",
null,
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"8 years",
"10+ years",
null,
"10+ years",
"10+ years",
"6 years",
null,
"10+ years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"5 years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"3 years",
"4 years",
null,
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"< 1 year",
"1 year",
"7 years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"4 years",
"8 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"2 years",
"4 years",
"< 1 year",
"10+ years",
"8 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"2 years",
"5 years",
"3 years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"2 years",
"2 years",
null,
null,
"2 years",
"10+ years",
"7 years",
"8 years",
"3 years",
"9 years",
"10+ years",
"7 years",
null,
"2 years",
"5 years",
"1 year",
"9 years",
"5 years",
"7 years",
"10+ years",
"< 1 year",
"9 years",
"8 years",
"9 years",
"10+ years",
"10+ years",
null,
"2 years",
"8 years",
"9 years",
"2 years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"9 years",
null,
"10+ years",
null,
"3 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"8 years",
"5 years",
"10+ years",
"10+ years",
"9 years",
"6 years",
"3 years",
"5 years",
"10+ years",
"5 years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"3 years",
"3 years",
"4 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"3 years",
"5 years",
"2 years",
"7 years",
"3 years",
"2 years",
"9 years",
"6 years",
null,
"2 years",
"4 years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"2 years",
"10+ years",
null,
"10+ years",
"6 years",
"5 years",
"3 years",
"6 years",
"10+ years",
"5 years",
"8 years",
"2 years",
"3 years",
"10+ years",
"3 years",
"9 years",
"4 years",
"10+ years",
"1 year",
"4 years",
"1 year",
"10+ years",
"5 years",
"2 years",
"3 years",
"1 year",
"4 years",
"5 years",
null,
"6 years",
"9 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"7 years",
"1 year",
"7 years",
"10+ years",
"8 years",
"< 1 year",
null,
"5 years",
"5 years",
"10+ years",
"10+ years",
"8 years",
"1 year",
"5 years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
null,
"3 years",
"5 years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"1 year",
null,
"1 year",
"< 1 year",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
null,
"3 years",
null,
"1 year",
"6 years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"2 years",
"< 1 year",
"2 years",
"2 years",
"2 years",
null,
"4 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"5 years",
"10+ years",
"7 years",
"10+ years",
"1 year",
"10+ years",
"8 years",
"2 years",
"9 years",
"5 years",
"5 years",
"10+ years",
"9 years",
"7 years",
"5 years",
"3 years",
"10+ years",
"< 1 year",
null,
"8 years",
"6 years",
"2 years",
"9 years",
"2 years",
"7 years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"8 years",
"1 year",
"2 years",
null,
"2 years",
"1 year",
"4 years",
"6 years",
"2 years",
null,
"6 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"4 years",
"2 years",
"6 years",
"< 1 year",
"< 1 year",
"6 years",
"2 years",
"7 years",
"5 years",
"< 1 year",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"3 years",
"8 years",
"10+ years",
"3 years",
"< 1 year",
"6 years",
"10+ years",
"8 years",
"3 years",
"3 years",
"3 years",
"< 1 year",
"2 years",
"9 years",
"10+ years",
"8 years",
"< 1 year",
"6 years",
"1 year",
"1 year",
"6 years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"5 years",
"6 years",
"5 years",
"10+ years",
"4 years",
"10+ years",
"4 years",
"2 years",
"1 year",
"5 years",
null,
null,
"10+ years",
"10+ years",
null,
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"6 years",
"10+ years",
"5 years",
"7 years",
"3 years",
"10+ years",
"2 years",
"10+ years",
null,
"10+ years",
"4 years",
"10+ years",
"5 years",
"< 1 year",
"6 years",
"7 years",
"1 year",
"< 1 year",
"8 years",
"< 1 year",
"5 years",
"4 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
null,
"10+ years",
"10+ years",
"10+ years",
"7 years",
"5 years",
"4 years",
"9 years",
"4 years",
"8 years",
"9 years",
"10+ years",
"2 years",
"1 year",
"9 years",
"10+ years",
"< 1 year",
"1 year",
"3 years",
"3 years",
"< 1 year",
"2 years",
"6 years",
"10+ years",
"10+ years",
"4 years",
"6 years",
"4 years",
"10+ years",
"10+ years",
null,
"3 years",
"2 years",
"4 years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"< 1 year",
"< 1 year",
"6 years",
"7 years",
"10+ years",
"4 years",
"7 years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"2 years",
"6 years",
"< 1 year",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"6 years",
"10+ years",
"4 years",
"< 1 year",
"9 years",
"5 years",
"10+ years",
null,
"< 1 year",
"3 years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"6 years",
"5 years",
"4 years",
"3 years",
"8 years",
"10+ years",
"2 years",
"1 year",
"1 year",
null,
"8 years",
"10+ years",
"4 years",
null,
null,
"2 years",
"10+ years",
null,
"7 years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"4 years",
"10+ years",
"4 years",
"8 years",
"7 years",
"8 years",
"6 years",
"10+ years",
"7 years",
"4 years",
"3 years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"7 years",
"1 year",
"9 years",
"3 years",
null,
null,
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"1 year",
"10+ years",
"5 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"7 years",
"4 years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"6 years",
"7 years",
"10+ years",
"< 1 year",
"3 years",
"5 years",
"8 years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"10+ years",
"< 1 year",
null,
"4 years",
"10+ years",
"10+ years",
"10+ years",
null,
"6 years",
"9 years",
"7 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"2 years",
"7 years",
"3 years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"3 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"8 years",
"3 years",
"< 1 year",
"4 years",
"< 1 year",
"1 year",
"< 1 year",
null,
"7 years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"4 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"2 years",
"1 year",
"3 years",
"7 years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"8 years",
"3 years",
"6 years",
"10+ years",
"2 years",
"3 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"2 years",
"7 years",
"< 1 year",
"3 years",
null,
"< 1 year",
"3 years",
"4 years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
null,
"10+ years",
"4 years",
"< 1 year",
"3 years",
"4 years",
"2 years",
"10+ years",
null,
"5 years",
"1 year",
"10+ years",
"5 years",
"1 year",
"9 years",
"4 years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"3 years",
"6 years",
"10+ years",
null,
"1 year",
"10+ years",
"2 years",
"3 years",
"< 1 year",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"10+ years",
null,
"3 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"5 years",
"< 1 year",
"2 years",
"10+ years",
"4 years",
"8 years",
"8 years",
"10+ years",
"< 1 year",
"2 years",
"5 years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"10+ years",
null,
"10+ years",
"6 years",
"6 years",
"6 years",
"< 1 year",
null,
"10+ years",
null,
"2 years",
"4 years",
"4 years",
"5 years",
"5 years",
"2 years",
"6 years",
"2 years",
"5 years",
"2 years",
"1 year",
"1 year",
"< 1 year",
"10+ years",
"1 year",
"9 years",
"5 years",
null,
"5 years",
"5 years",
"10+ years",
"7 years",
"1 year",
"7 years",
"4 years",
"< 1 year",
"10+ years",
"2 years",
"3 years",
"< 1 year",
"5 years",
"< 1 year",
"10+ years",
"5 years",
"4 years",
null,
"4 years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"5 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
null,
"10+ years",
"1 year",
"10+ years",
"2 years",
"3 years",
"4 years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"1 year",
"2 years",
"< 1 year",
"2 years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"6 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"8 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"1 year",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"6 years",
"10+ years",
"< 1 year",
"< 1 year",
"< 1 year",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"7 years",
"4 years",
null,
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"9 years",
"3 years",
"10+ years",
"5 years",
"4 years",
"5 years",
null,
"4 years",
"1 year",
"8 years",
"6 years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"6 years",
"3 years",
"10+ years",
"9 years",
"3 years",
"2 years",
"8 years",
"2 years",
"10+ years",
"4 years",
"6 years",
"5 years",
null,
"2 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"3 years",
"2 years",
"4 years",
"10+ years",
"1 year",
"1 year",
"2 years",
"10+ years",
"3 years",
"2 years",
"4 years",
"3 years",
"< 1 year",
"7 years",
null,
"1 year",
"3 years",
"2 years",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"9 years",
"10+ years",
"7 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"6 years",
"< 1 year",
"10+ years",
null,
"1 year",
"7 years",
"6 years",
"9 years",
"3 years",
"5 years",
"4 years",
"8 years",
"8 years",
"9 years",
"2 years",
"< 1 year",
"10+ years",
"6 years",
"1 year",
"10+ years",
"6 years",
"2 years",
"10+ years",
"4 years",
"5 years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"8 years",
"3 years",
"8 years",
"9 years",
"4 years",
"1 year",
null,
"10+ years",
"2 years",
"10+ years",
null,
"2 years",
"3 years",
"< 1 year",
"1 year",
"3 years",
"10+ years",
"4 years",
"1 year",
"1 year",
"8 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"< 1 year",
"2 years",
"5 years",
"10+ years",
"1 year",
"1 year",
"6 years",
"10+ years",
"8 years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
null,
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"3 years",
"6 years",
"1 year",
"10+ years",
"< 1 year",
"8 years",
"8 years",
"2 years",
"9 years",
"9 years",
"8 years",
"10+ years",
"3 years",
"9 years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"7 years",
"7 years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"1 year",
"2 years",
"< 1 year",
"10+ years",
"7 years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"4 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"7 years",
"2 years",
"2 years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"4 years",
"6 years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"9 years",
"5 years",
"6 years",
"5 years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"5 years",
"5 years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"5 years",
"3 years",
"8 years",
"9 years",
"< 1 year",
"7 years",
"10+ years",
"2 years",
"4 years",
"10+ years",
"8 years",
"3 years",
null,
"7 years",
"9 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"3 years",
null,
"4 years",
"9 years",
"10+ years",
"3 years",
"9 years",
"1 year",
"4 years",
"1 year",
"10+ years",
"9 years",
"< 1 year",
"5 years",
"1 year",
"9 years",
"1 year",
"10+ years",
"4 years",
"3 years",
"10+ years",
null,
null,
"7 years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"3 years",
null,
"< 1 year",
"< 1 year",
null,
"1 year",
"7 years",
null,
"5 years",
"10+ years",
"2 years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"2 years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"2 years",
"1 year",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"< 1 year",
"5 years",
"3 years",
"3 years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"1 year",
"6 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
null,
"5 years",
"10+ years",
"10+ years",
"1 year",
"8 years",
"2 years",
"2 years",
"< 1 year",
"6 years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"1 year",
"6 years",
"5 years",
"5 years",
"9 years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"6 years",
"8 years",
"10+ years",
"4 years",
"10+ years",
"1 year",
"2 years",
"2 years",
"< 1 year",
"2 years",
"7 years",
null,
"5 years",
"4 years",
null,
"2 years",
"1 year",
"8 years",
"10+ years",
"10+ years",
"9 years",
"8 years",
"4 years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
"5 years",
"4 years",
null,
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
null,
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"3 years",
"8 years",
"10+ years",
"7 years",
"3 years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"4 years",
"3 years",
"8 years",
null,
"10+ years",
"8 years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"9 years",
null,
"6 years",
"4 years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"3 years",
"8 years",
"9 years",
"< 1 year",
null,
"4 years",
"< 1 year",
"3 years",
"10+ years",
"4 years",
"10+ years",
null,
"2 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"3 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"6 years",
"9 years",
"7 years",
null,
"< 1 year",
"10+ years",
"1 year",
"5 years",
"4 years",
"7 years",
"1 year",
"7 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"< 1 year",
"1 year",
"9 years",
"9 years",
"< 1 year",
"5 years",
"9 years",
"7 years",
"3 years",
"10+ years",
"9 years",
"5 years",
"2 years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"< 1 year",
"8 years",
"1 year",
"2 years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"2 years",
"10+ years",
"5 years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"1 year",
"2 years",
"5 years",
"10+ years",
"5 years",
"10+ years",
null,
"3 years",
"5 years",
"2 years",
"6 years",
"6 years",
"10+ years",
"10+ years",
"8 years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"6 years",
"7 years",
"5 years",
"10+ years",
"7 years",
"1 year",
"9 years",
"5 years",
"10+ years",
"2 years",
"1 year",
"8 years",
"2 years",
"8 years",
"7 years",
"7 years",
"< 1 year",
"1 year",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"1 year",
"9 years",
"4 years",
"10+ years",
null,
"2 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"3 years",
"4 years",
"6 years",
"5 years",
"4 years",
"10+ years",
"9 years",
"3 years",
"5 years",
"10+ years",
"4 years",
"4 years",
"10+ years",
"5 years",
"1 year",
"7 years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"1 year",
"10+ years",
null,
"2 years",
"2 years",
null,
"3 years",
"10+ years",
"9 years",
"4 years",
"1 year",
"10+ years",
"5 years",
"10+ years",
null,
"< 1 year",
"10+ years",
"8 years",
"7 years",
"2 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"6 years",
"2 years",
"6 years",
"6 years",
"8 years",
"10+ years",
"7 years",
"1 year",
"4 years",
"4 years",
null,
"6 years",
"5 years",
"9 years",
"2 years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"1 year",
"2 years",
"9 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"2 years",
"2 years",
"< 1 year",
"10+ years",
"9 years",
"5 years",
"1 year",
"1 year",
"1 year",
null,
"1 year",
null,
"10+ years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"6 years",
"5 years",
"8 years",
"8 years",
"6 years",
"9 years",
"3 years",
null,
"10+ years",
"5 years",
null,
"2 years",
"< 1 year",
"10+ years",
"1 year",
"6 years",
null,
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"4 years",
"9 years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"4 years",
null,
"1 year",
"5 years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"< 1 year",
"6 years",
"4 years",
"7 years",
"3 years",
"2 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
"3 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"7 years",
"3 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"5 years",
"10+ years",
"6 years",
"< 1 year",
"< 1 year",
"9 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"6 years",
"10+ years",
"4 years",
null,
"10+ years",
"5 years",
"< 1 year",
"8 years",
"1 year",
"6 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"4 years",
null,
"7 years",
"1 year",
"8 years",
"4 years",
"10+ years",
"5 years",
"3 years",
"8 years",
"5 years",
"3 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"2 years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"2 years",
"6 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"8 years",
"3 years",
"7 years",
"7 years",
"9 years",
"5 years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"4 years",
"10+ years",
"2 years",
"1 year",
"4 years",
"2 years",
"8 years",
"10+ years",
"7 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"7 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"< 1 year",
"10+ years",
"3 years",
"5 years",
"7 years",
null,
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"9 years",
null,
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"7 years",
"7 years",
"5 years",
"3 years",
"1 year",
"10+ years",
"2 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
null,
"3 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"2 years",
"2 years",
"4 years",
"8 years",
"< 1 year",
"< 1 year",
"1 year",
"2 years",
"5 years",
"5 years",
"10+ years",
"3 years",
null,
"10+ years",
"10+ years",
"4 years",
"8 years",
"6 years",
"4 years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"3 years",
"2 years",
"1 year",
"7 years",
"9 years",
"1 year",
"2 years",
"9 years",
"< 1 year",
"2 years",
"1 year",
"4 years",
null,
"6 years",
"10+ years",
"10+ years",
null,
"5 years",
"4 years",
"6 years",
null,
"1 year",
null,
"10+ years",
"2 years",
"1 year",
"2 years",
"3 years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"2 years",
"7 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
null,
"4 years",
"6 years",
"1 year",
"2 years",
"10+ years",
"4 years",
"5 years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"6 years",
"2 years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"6 years",
"5 years",
"5 years",
"3 years",
"5 years",
"3 years",
null,
null,
null,
"1 year",
"10+ years",
"9 years",
"10+ years",
"8 years",
"3 years",
"9 years",
"< 1 year",
"5 years",
null,
"2 years",
"3 years",
"7 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"8 years",
"8 years",
"< 1 year",
"2 years",
"2 years",
"< 1 year",
"10+ years",
"5 years",
"8 years",
"4 years",
"8 years",
"7 years",
"10+ years",
"8 years",
null,
"4 years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"5 years",
"2 years",
"5 years",
"2 years",
"9 years",
"5 years",
"< 1 year",
"9 years",
"< 1 year",
"1 year",
"2 years",
"1 year",
"8 years",
"8 years",
"10+ years",
"5 years",
"7 years",
"10+ years",
"8 years",
"5 years",
"< 1 year",
"< 1 year",
"1 year",
"9 years",
"10+ years",
"1 year",
"5 years",
"7 years",
"9 years",
"10+ years",
"4 years",
"< 1 year",
"8 years",
"1 year",
"2 years",
"9 years",
"5 years",
"< 1 year",
"5 years",
"10+ years",
"1 year",
"< 1 year",
"2 years",
"8 years",
"4 years",
"2 years",
"4 years",
"1 year",
"10+ years",
"10+ years",
null,
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
null,
"3 years",
"1 year",
"6 years",
"10+ years",
"5 years",
"6 years",
"5 years",
"1 year",
"1 year",
"< 1 year",
"10+ years",
null,
"10+ years",
"4 years",
"2 years",
"10+ years",
"2 years",
"3 years",
"3 years",
"5 years",
"3 years",
"4 years",
"10+ years",
"4 years",
"10+ years",
"2 years",
null,
"1 year",
"7 years",
"2 years",
"2 years",
"10+ years",
"2 years",
null,
"10+ years",
"10+ years",
"6 years",
"5 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"8 years",
null,
"< 1 year",
"< 1 year",
"3 years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"3 years",
"< 1 year",
"1 year",
"2 years",
"6 years",
"5 years",
"1 year",
"10+ years",
"3 years",
"7 years",
"2 years",
"< 1 year",
"< 1 year",
"4 years",
"5 years",
"< 1 year",
"2 years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"4 years",
"8 years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"2 years",
"< 1 year",
"2 years",
"< 1 year",
"1 year",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"8 years",
"10+ years",
"1 year",
"4 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"3 years",
null,
"3 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"1 year",
"10+ years",
"5 years",
"3 years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"6 years",
"6 years",
"2 years",
null,
"4 years",
"5 years",
"4 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"1 year",
"8 years",
"3 years",
"4 years",
"10+ years",
"5 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
null,
"2 years",
"4 years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"6 years",
"3 years",
"5 years",
"2 years",
"8 years",
"3 years",
"10+ years",
"9 years",
"1 year",
"2 years",
"7 years",
"9 years",
"8 years",
null,
"2 years",
"2 years",
null,
"4 years",
"10+ years",
"1 year",
"1 year",
"8 years",
"3 years",
"6 years",
"1 year",
"3 years",
"5 years",
"1 year",
"10+ years",
"2 years",
"9 years",
"3 years",
"9 years",
"9 years",
"10+ years",
"7 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"1 year",
"1 year",
null,
"10+ years",
"10+ years",
"6 years",
"4 years",
"6 years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"4 years",
null,
"1 year",
"1 year",
"3 years",
"10+ years",
"2 years",
"2 years",
"3 years",
"6 years",
"2 years",
"4 years",
"9 years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"5 years",
"1 year",
"4 years",
"5 years",
"3 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"7 years",
"10+ years",
"2 years",
null,
"1 year",
"8 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"6 years",
"8 years",
"< 1 year",
null,
"10+ years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"5 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"9 years",
"1 year",
"6 years",
"10+ years",
null,
"5 years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"4 years",
null,
"7 years",
"4 years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"8 years",
"7 years",
"5 years",
"< 1 year",
"10+ years",
"2 years",
"6 years",
null,
"10+ years",
"8 years",
"10+ years",
"10+ years",
"5 years",
"6 years",
null,
"10+ years",
"7 years",
"8 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"< 1 year",
"6 years",
"3 years",
"6 years",
"10+ years",
"4 years",
"10+ years",
"6 years",
"8 years",
"10+ years",
"5 years",
"1 year",
"9 years",
"10+ years",
"2 years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"< 1 year",
"5 years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"6 years",
"6 years",
"8 years",
"1 year",
"3 years",
"< 1 year",
"6 years",
"< 1 year",
"8 years",
"3 years",
"1 year",
null,
"2 years",
"2 years",
"7 years",
"5 years",
"< 1 year",
"2 years",
"10+ years",
"1 year",
"3 years",
"3 years",
"4 years",
"8 years",
"1 year",
"5 years",
"10+ years",
"9 years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"4 years",
"4 years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"3 years",
"6 years",
"< 1 year",
"8 years",
"3 years",
"9 years",
"3 years",
"10+ years",
"3 years",
"1 year",
"< 1 year",
"3 years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"9 years",
"2 years",
"1 year",
"1 year",
"10+ years",
null,
"5 years",
"10+ years",
"10+ years",
"3 years",
"6 years",
"10+ years",
"1 year",
null,
"10+ years",
"4 years",
"10+ years",
"2 years",
"2 years",
null,
"3 years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"2 years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
null,
"5 years",
null,
"2 years",
"2 years",
null,
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"2 years",
"2 years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"4 years",
"10+ years",
"1 year",
"2 years",
"10+ years",
null,
"< 1 year",
"< 1 year",
"2 years",
"5 years",
"10+ years",
"1 year",
"9 years",
"10+ years",
"7 years",
"2 years",
"9 years",
"10+ years",
"1 year",
"5 years",
"3 years",
"10+ years",
"10+ years",
null,
"< 1 year",
"9 years",
"10+ years",
"6 years",
"9 years",
"10+ years",
"8 years",
"6 years",
"1 year",
"< 1 year",
"3 years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"1 year",
"8 years",
"10+ years",
"4 years",
"1 year",
null,
"2 years",
"8 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
null,
"1 year",
"8 years",
"2 years",
null,
null,
"10+ years",
"10+ years",
null,
"1 year",
"3 years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"7 years",
"9 years",
"7 years",
"< 1 year",
"< 1 year",
"10+ years",
"< 1 year",
null,
"2 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"4 years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"6 years",
"5 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"9 years",
"9 years",
"1 year",
"2 years",
null,
"1 year",
"10+ years",
"10+ years",
"5 years",
"8 years",
"3 years",
"5 years",
"7 years",
"1 year",
"2 years",
null,
"9 years",
"10+ years",
"7 years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"5 years",
"10+ years",
null,
"8 years",
"2 years",
null,
"< 1 year",
null,
"10+ years",
"5 years",
"< 1 year",
"7 years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"9 years",
"1 year",
"5 years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"10+ years",
"6 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
null,
"1 year",
"2 years",
"2 years",
"4 years",
"10+ years",
"2 years",
"6 years",
"10+ years",
null,
null,
"5 years",
null,
"2 years",
null,
"5 years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"6 years",
"4 years",
"10+ years",
"8 years",
"10+ years",
"6 years",
"1 year",
"9 years",
"8 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"5 years",
"4 years",
"5 years",
"6 years",
"1 year",
"6 years",
"3 years",
"2 years",
"8 years",
"2 years",
"< 1 year",
"10+ years",
"9 years",
"1 year",
"7 years",
"10+ years",
"6 years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"1 year",
"8 years",
"2 years",
"7 years",
"3 years",
"6 years",
"3 years",
"2 years",
null,
"7 years",
"10+ years",
"8 years",
"10+ years",
"4 years",
"5 years",
"8 years",
"1 year",
"3 years",
"6 years",
"2 years",
"3 years",
"4 years",
null,
"10+ years",
"4 years",
"10+ years",
"10+ years",
"5 years",
"7 years",
"6 years",
"10+ years",
"3 years",
null,
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"10+ years",
"< 1 year",
"< 1 year",
"3 years",
"9 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"7 years",
"3 years",
"5 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
null,
"2 years",
"10+ years",
"7 years",
"10+ years",
"5 years",
"7 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"3 years",
"2 years",
"2 years",
"10+ years",
"< 1 year",
"5 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"5 years",
"10+ years",
"< 1 year",
"4 years",
"4 years",
"10+ years",
"3 years",
"3 years",
"3 years",
null,
"2 years",
"1 year",
"5 years",
"10+ years",
"1 year",
"2 years",
"3 years",
"10+ years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"2 years",
"4 years",
"7 years",
"8 years",
"3 years",
"8 years",
null,
"8 years",
null,
"10+ years",
"2 years",
"7 years",
"9 years",
"7 years",
"7 years",
"3 years",
"< 1 year",
"8 years",
"1 year",
null,
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"1 year",
"6 years",
"2 years",
"< 1 year",
"9 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"10+ years",
"4 years",
"10+ years",
null,
"10+ years",
"3 years",
"3 years",
"10+ years",
"9 years",
"2 years",
"< 1 year",
"2 years",
"3 years",
"< 1 year",
null,
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"2 years",
"< 1 year",
"1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
null,
"3 years",
"8 years",
"3 years",
"< 1 year",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"5 years",
"8 years",
null,
"10+ years",
"< 1 year",
"9 years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"5 years",
"2 years",
"10+ years",
"7 years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"9 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"7 years",
"6 years",
"5 years",
"3 years",
"9 years",
"9 years",
"3 years",
"10+ years",
"4 years",
"2 years",
"10+ years",
"1 year",
null,
"9 years",
null,
"< 1 year",
"< 1 year",
"10+ years",
"5 years",
"1 year",
null,
"10+ years",
"10+ years",
"7 years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
null,
"5 years",
"2 years",
"9 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"4 years",
null,
"8 years",
"6 years",
"10+ years",
"8 years",
"3 years",
"4 years",
"10+ years",
"4 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"9 years",
"7 years",
"< 1 year",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"1 year",
"7 years",
"6 years",
"10+ years",
"2 years",
"5 years",
"3 years",
null,
"2 years",
"6 years",
"1 year",
"10+ years",
"10+ years",
"6 years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"6 years",
"< 1 year",
"10+ years",
"3 years",
"8 years",
"10+ years",
"< 1 year",
"7 years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"2 years",
"9 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"5 years",
"2 years",
"< 1 year",
"9 years",
"10+ years",
"9 years",
"4 years",
"8 years",
"10+ years",
"8 years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"5 years",
"8 years",
"6 years",
"1 year",
"10+ years",
"9 years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"4 years",
"10+ years",
"5 years",
"1 year",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"9 years",
"10+ years",
"4 years",
"5 years",
"1 year",
"10+ years",
null,
"10+ years",
"< 1 year",
"5 years",
"2 years",
"< 1 year",
"3 years",
"7 years",
"10+ years",
null,
"5 years",
"10+ years",
"9 years",
"10+ years",
"5 years",
"2 years",
"2 years",
"10+ years",
"8 years",
"7 years",
"2 years",
"10+ years",
"9 years",
"9 years",
"4 years",
"2 years",
"9 years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"2 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"3 years",
"9 years",
"6 years",
"2 years",
"5 years",
"8 years",
"6 years",
"2 years",
"7 years",
"2 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"2 years",
"1 year",
"3 years",
"2 years",
"4 years",
"7 years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"6 years",
null,
"< 1 year",
null,
"10+ years",
"2 years",
"6 years",
"5 years",
"< 1 year",
"2 years",
"2 years",
"2 years",
"5 years",
null,
"1 year",
"1 year",
"7 years",
"6 years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
null,
"< 1 year",
"2 years",
"2 years",
"2 years",
"7 years",
null,
"2 years",
"10+ years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"5 years",
"5 years",
"2 years",
"5 years",
null,
"6 years",
"< 1 year",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"2 years",
"3 years",
"5 years",
"2 years",
null,
"2 years",
"5 years",
"9 years",
"3 years",
null,
"< 1 year",
"10+ years",
"7 years",
null,
null,
"1 year",
"5 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"7 years",
"8 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"3 years",
"10+ years",
"10+ years",
null,
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"5 years",
"5 years",
"10+ years",
"8 years",
"10+ years",
"9 years",
"10+ years",
"2 years",
"< 1 year",
"< 1 year",
"2 years",
null,
"10+ years",
"1 year",
"10+ years",
"8 years",
"7 years",
"5 years",
"3 years",
"3 years",
"7 years",
"2 years",
"6 years",
"< 1 year",
"7 years",
"5 years",
"7 years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"6 years",
"2 years",
"7 years",
"10+ years",
"3 years",
"9 years",
"2 years",
"10+ years",
null,
"4 years",
"5 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"3 years",
"8 years",
"3 years",
null,
null,
"1 year",
"< 1 year",
"10+ years",
"7 years",
"4 years",
"2 years",
"10+ years",
"4 years",
"5 years",
"2 years",
null,
"10+ years",
"1 year",
"3 years",
"2 years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"9 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"3 years",
"9 years",
"4 years",
"2 years",
"7 years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"2 years",
null,
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"9 years",
"5 years",
"< 1 year",
"7 years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"6 years",
"2 years",
"1 year",
"1 year",
"4 years",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"10+ years",
"7 years",
"2 years",
"2 years",
"1 year",
"6 years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"6 years",
"6 years",
"1 year",
"10+ years",
"10+ years",
"8 years",
"7 years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"4 years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"8 years",
"4 years",
"7 years",
"2 years",
"3 years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"2 years",
"3 years",
null,
"3 years",
"7 years",
"3 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"7 years",
"7 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"3 years",
"1 year",
"8 years",
"7 years",
"6 years",
"7 years",
"5 years",
"5 years",
"1 year",
"4 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"6 years",
"8 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"6 years",
"10+ years",
"7 years",
null,
"10+ years",
"4 years",
"5 years",
"8 years",
null,
"10+ years",
"3 years",
"3 years",
"5 years",
null,
"10+ years",
"10+ years",
"2 years",
null,
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"9 years",
"10+ years",
"2 years",
"7 years",
"7 years",
"8 years",
"10+ years",
null,
"2 years",
"4 years",
"10+ years",
null,
"2 years",
"1 year",
"1 year",
"3 years",
"4 years",
"10+ years",
"6 years",
"7 years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"7 years",
null,
null,
"5 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"1 year",
"8 years",
"4 years",
"5 years",
"7 years",
"5 years",
"10+ years",
"< 1 year",
"7 years",
null,
"< 1 year",
"1 year",
"10+ years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"6 years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"8 years",
"2 years",
null,
"4 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"2 years",
"7 years",
"2 years",
"8 years",
"6 years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"1 year",
"9 years",
"< 1 year",
"< 1 year",
"10+ years",
null,
"3 years",
"3 years",
"10+ years",
"1 year",
"4 years",
"5 years",
"2 years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"6 years",
"8 years",
"1 year",
"4 years",
"< 1 year",
"7 years",
null,
"< 1 year",
"10+ years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"1 year",
"2 years",
"4 years",
"10+ years",
"8 years",
"< 1 year",
null,
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"6 years",
"10+ years",
null,
"10+ years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"7 years",
"6 years",
"10+ years",
"4 years",
"< 1 year",
"2 years",
"5 years",
"9 years",
"10+ years",
"3 years",
"5 years",
"7 years",
null,
"3 years",
"4 years",
"< 1 year",
"5 years",
"6 years",
"4 years",
null,
"4 years",
"6 years",
"< 1 year",
"9 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"6 years",
"10+ years",
"7 years",
"3 years",
"10+ years",
"6 years",
"3 years",
"< 1 year",
"2 years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"6 years",
"10+ years",
"6 years",
"3 years",
"< 1 year",
"5 years",
"6 years",
"1 year",
"10+ years",
"10+ years",
"9 years",
"4 years",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"1 year",
"7 years",
"5 years",
"5 years",
"6 years",
"< 1 year",
null,
"10+ years",
"9 years",
"10+ years",
null,
"10+ years",
null,
"< 1 year",
"10+ years",
"4 years",
"4 years",
"6 years",
"10+ years",
"7 years",
"6 years",
"10+ years",
"9 years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"1 year",
"2 years",
"1 year",
null,
"9 years",
"5 years",
"5 years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"4 years",
"8 years",
"10+ years",
"7 years",
null,
"6 years",
"2 years",
"2 years",
"3 years",
null,
"6 years",
"2 years",
"5 years",
"8 years",
"10+ years",
"2 years",
"2 years",
"6 years",
"2 years",
null,
"1 year",
"1 year",
null,
"2 years",
"< 1 year",
"8 years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"5 years",
null,
"8 years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"7 years",
"8 years",
null,
"10+ years",
"1 year",
"5 years",
"2 years",
"10+ years",
"2 years",
"3 years",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"5 years",
"3 years",
"6 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"8 years",
"3 years",
"8 years",
null,
"10+ years",
"9 years",
"5 years",
"4 years",
"< 1 year",
"9 years",
"10+ years",
"10+ years",
null,
"7 years",
"10+ years",
"5 years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
null,
"7 years",
"4 years",
"7 years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"< 1 year",
"< 1 year",
"10+ years",
"4 years",
"2 years",
"5 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"2 years",
"2 years",
"3 years",
"1 year",
"10+ years",
null,
"8 years",
"5 years",
"10+ years",
"5 years",
"8 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"7 years",
"< 1 year",
"3 years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"2 years",
"1 year",
"1 year",
null,
"2 years",
"8 years",
"10+ years",
"10+ years",
null,
"6 years",
"7 years",
"10+ years",
"7 years",
"3 years",
"10+ years",
"7 years",
"10+ years",
"4 years",
"6 years",
"10+ years",
"3 years",
"10+ years",
null,
"2 years",
"10+ years",
"3 years",
"1 year",
"3 years",
"2 years",
"6 years",
"8 years",
"10+ years",
"5 years",
"1 year",
"2 years",
"5 years",
"4 years",
"10+ years",
"7 years",
"< 1 year",
"7 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"6 years",
"1 year",
"2 years",
"10+ years",
"9 years",
"10+ years",
"2 years",
"7 years",
null,
"10+ years",
"2 years",
"10+ years",
"4 years",
null,
"5 years",
"6 years",
"10+ years",
"< 1 year",
"< 1 year",
null,
"2 years",
null,
"10+ years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"< 1 year",
"3 years",
"8 years",
"10+ years",
"6 years",
"3 years",
"6 years",
"< 1 year",
"2 years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"6 years",
"9 years",
"7 years",
"2 years",
"3 years",
"2 years",
"7 years",
"10+ years",
"5 years",
"2 years",
null,
"2 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"4 years",
"< 1 year",
"10+ years",
"9 years",
"< 1 year",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"2 years",
"8 years",
"5 years",
"10+ years",
"6 years",
"8 years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"3 years",
null,
"10+ years",
"10+ years",
"8 years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"< 1 year",
"3 years",
"4 years",
"10+ years",
"< 1 year",
"< 1 year",
"4 years",
"10+ years",
"< 1 year",
"< 1 year",
"3 years",
"6 years",
"8 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"6 years",
"< 1 year",
"7 years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"9 years",
null,
"10+ years",
"10+ years",
null,
"9 years",
"< 1 year",
"6 years",
"2 years",
"8 years",
"7 years",
"10+ years",
"10+ years",
null,
"2 years",
"7 years",
null,
"4 years",
"10+ years",
null,
"10+ years",
null,
"2 years",
"8 years",
"10+ years",
"2 years",
"1 year",
null,
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"6 years",
"5 years",
"3 years",
"1 year",
"10+ years",
"7 years",
null,
"3 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"8 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"2 years",
"7 years",
"2 years",
"7 years",
"4 years",
"4 years",
"9 years",
"9 years",
"6 years",
"10+ years",
"7 years",
"8 years",
"10+ years",
"6 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"2 years",
"9 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"1 year",
"8 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"2 years",
"5 years",
"1 year",
"3 years",
"10+ years",
"1 year",
null,
"3 years",
"10+ years",
"4 years",
"5 years",
"2 years",
null,
"10+ years",
"4 years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"1 year",
"< 1 year",
"1 year",
"5 years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"8 years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"2 years",
"< 1 year",
"2 years",
"9 years",
"9 years",
"10+ years",
"3 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"7 years",
"4 years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"7 years",
"6 years",
"7 years",
"< 1 year",
"10+ years",
"4 years",
"3 years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
null,
"8 years",
"1 year",
"1 year",
"6 years",
"3 years",
"2 years",
"10+ years",
"< 1 year",
"1 year",
"4 years",
"9 years",
"10+ years",
"5 years",
"3 years",
"3 years",
"5 years",
"4 years",
"10+ years",
"8 years",
"9 years",
"7 years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"< 1 year",
"6 years",
"10+ years",
null,
"7 years",
"3 years",
"6 years",
"7 years",
"10+ years",
"3 years",
"< 1 year",
"4 years",
"1 year",
"1 year",
"7 years",
"4 years",
"5 years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"3 years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"9 years",
null,
"5 years",
"7 years",
"2 years",
"6 years",
"4 years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"8 years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"3 years",
"1 year",
"< 1 year",
"10+ years",
"2 years",
"1 year",
"3 years",
"10+ years",
"9 years",
"3 years",
"1 year",
"10+ years",
"7 years",
"2 years",
"9 years",
"6 years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"7 years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"4 years",
"4 years",
"5 years",
"9 years",
"4 years",
"10+ years",
"< 1 year",
"2 years",
"3 years",
null,
"10+ years",
null,
"6 years",
null,
"10+ years",
"10+ years",
null,
"10+ years",
"6 years",
"7 years",
"3 years",
"< 1 year",
"9 years",
"2 years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"9 years",
"10+ years",
"7 years",
"3 years",
"< 1 year",
null,
"4 years",
null,
"2 years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"4 years",
"5 years",
null,
"3 years",
"7 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"< 1 year",
"6 years",
"8 years",
"5 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"2 years",
"5 years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"4 years",
"10+ years",
"10+ years",
null,
"3 years",
"2 years",
"< 1 year",
"6 years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"3 years",
"8 years",
"4 years",
"9 years",
"7 years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"3 years",
"8 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
null,
"2 years",
"6 years",
"10+ years",
"7 years",
"8 years",
"< 1 year",
"10+ years",
"2 years",
"2 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"6 years",
"8 years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"1 year",
"10+ years",
null,
null,
"10+ years",
"1 year",
"4 years",
"1 year",
"3 years",
"3 years",
"10+ years",
"2 years",
"5 years",
"3 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
null,
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"6 years",
"8 years",
"7 years",
null,
"5 years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"1 year",
"10+ years",
"4 years",
"3 years",
"< 1 year",
"10+ years",
"< 1 year",
"4 years",
"1 year",
"1 year",
"5 years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"3 years",
"2 years",
"10+ years",
"1 year",
"8 years",
"10+ years",
"8 years",
"10+ years",
null,
"2 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"5 years",
"10+ years",
"6 years",
null,
"3 years",
"8 years",
"2 years",
"6 years",
null,
"3 years",
"5 years",
"4 years",
"5 years",
"2 years",
null,
"< 1 year",
"< 1 year",
"10+ years",
"3 years",
"7 years",
"2 years",
"< 1 year",
"3 years",
"10+ years",
"3 years",
"2 years",
null,
"4 years",
"< 1 year",
"8 years",
"7 years",
"6 years",
"8 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"8 years",
"8 years",
"9 years",
"10+ years",
"8 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"< 1 year",
"10+ years",
"9 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"7 years",
"2 years",
"6 years",
"1 year",
"2 years",
"10+ years",
"4 years",
"3 years",
"5 years",
"2 years",
"2 years",
null,
"10+ years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"6 years",
"10+ years",
"6 years",
"< 1 year",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"3 years",
"< 1 year",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"7 years",
null,
"10+ years",
"7 years",
"10+ years",
"2 years",
"3 years",
"< 1 year",
"9 years",
null,
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"2 years",
"8 years",
"6 years",
"< 1 year",
"2 years",
"1 year",
"2 years",
"2 years",
null,
"10+ years",
"5 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"1 year",
"2 years",
"8 years",
"10+ years",
"10+ years",
"1 year",
"9 years",
"1 year",
"< 1 year",
"5 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"4 years",
null,
"10+ years",
"6 years",
"7 years",
"< 1 year",
"1 year",
"6 years",
"6 years",
"5 years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"7 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"4 years",
"7 years",
"4 years",
"10+ years",
"5 years",
"7 years",
"6 years",
"8 years",
"2 years",
"10+ years",
"6 years",
"8 years",
"4 years",
null,
"4 years",
"4 years",
"3 years",
"1 year",
"4 years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"4 years",
"7 years",
"1 year",
null,
"10+ years",
"2 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"6 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"4 years",
"< 1 year",
"7 years",
"3 years",
"2 years",
"4 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"8 years",
"4 years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"8 years",
"1 year",
"3 years",
"1 year",
"2 years",
"4 years",
"10+ years",
"5 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
null,
"1 year",
"3 years",
"8 years",
"6 years",
"< 1 year",
"2 years",
"7 years",
"4 years",
"5 years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"2 years",
"7 years",
"3 years",
"10+ years",
"3 years",
"7 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"6 years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"4 years",
"9 years",
"10+ years",
"2 years",
"10+ years",
"4 years",
"2 years",
"1 year",
"9 years",
"10+ years",
"< 1 year",
"< 1 year",
"8 years",
"10+ years",
"2 years",
"10+ years",
null,
"3 years",
"1 year",
"< 1 year",
"7 years",
"1 year",
"6 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"3 years",
"4 years",
"8 years",
"< 1 year",
"6 years",
"7 years",
"10+ years",
"8 years",
null,
"7 years",
"10+ years",
"3 years",
"10+ years",
null,
"5 years",
"6 years",
"< 1 year",
"10+ years",
"4 years",
"2 years",
null,
"10+ years",
"2 years",
"8 years",
"9 years",
"2 years",
"4 years",
"5 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"8 years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"4 years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
null,
"2 years",
"3 years",
"10+ years",
"1 year",
"5 years",
"1 year",
"5 years",
"10+ years",
"7 years",
"10+ years",
"1 year",
"3 years",
"9 years",
"5 years",
"6 years",
"10+ years",
"4 years",
"2 years",
"7 years",
"2 years",
"7 years",
"10+ years",
"7 years",
"8 years",
"10+ years",
"6 years",
"5 years",
"10+ years",
"6 years",
"8 years",
"6 years",
"3 years",
"10+ years",
"8 years",
"7 years",
"10+ years",
"< 1 year",
null,
"7 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"3 years",
"1 year",
"9 years",
"10+ years",
"10+ years",
null,
"3 years",
"10+ years",
null,
"2 years",
"10+ years",
"5 years",
"1 year",
"5 years",
"< 1 year",
"8 years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"6 years",
null,
"7 years",
"1 year",
"10+ years",
"6 years",
"8 years",
"6 years",
"8 years",
"5 years",
"8 years",
"< 1 year",
"10+ years",
"1 year",
"8 years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"1 year",
"4 years",
"4 years",
null,
"6 years",
"10+ years",
"10+ years",
"6 years",
"5 years",
"1 year",
"6 years",
"1 year",
"8 years",
"7 years",
"4 years",
"< 1 year",
"5 years",
"5 years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"1 year",
"4 years",
"7 years",
"2 years",
"5 years",
"4 years",
"1 year",
"10+ years",
"5 years",
null,
"4 years",
"1 year",
"10+ years",
"1 year",
"1 year",
null,
"10+ years",
"6 years",
"7 years",
"3 years",
"2 years",
"8 years",
"1 year",
"3 years",
"3 years",
"< 1 year",
"10+ years",
"5 years",
"5 years",
"10+ years",
"< 1 year",
"4 years",
"3 years",
"4 years",
"10+ years",
"4 years",
"10+ years",
null,
"2 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
null,
"5 years",
"7 years",
null,
"3 years",
"2 years",
"1 year",
"7 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"4 years",
"1 year",
"5 years",
"10+ years",
"6 years",
"10+ years",
"3 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"7 years",
"< 1 year",
"9 years",
"4 years",
"2 years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"8 years",
"2 years",
"3 years",
"10+ years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"2 years",
null,
"6 years",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"3 years",
"7 years",
"10+ years",
null,
"6 years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"8 years",
null,
"3 years",
"1 year",
"6 years",
"10+ years",
"1 year",
"2 years",
"2 years",
null,
"10+ years",
"10+ years",
"6 years",
"< 1 year",
"6 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
null,
"7 years",
"10+ years",
"6 years",
"7 years",
"10+ years",
"10+ years",
null,
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"7 years",
"7 years",
"< 1 year",
"3 years",
"1 year",
"8 years",
"3 years",
"6 years",
"4 years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
null,
"10+ years",
"2 years",
"3 years",
"4 years",
"10+ years",
"7 years",
"< 1 year",
"6 years",
"5 years",
"4 years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"5 years",
"< 1 year",
null,
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"1 year",
"2 years",
"1 year",
"1 year",
"< 1 year",
"10+ years",
"8 years",
null,
null,
"6 years",
"4 years",
"5 years",
"10+ years",
"4 years",
"< 1 year",
"< 1 year",
"2 years",
"3 years",
"10+ years",
"9 years",
"4 years",
"2 years",
"6 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"9 years",
"9 years",
"7 years",
"9 years",
"2 years",
"5 years",
"2 years",
"1 year",
null,
"< 1 year",
"8 years",
"2 years",
null,
"7 years",
"7 years",
"3 years",
"8 years",
"10+ years",
"9 years",
"6 years",
"10+ years",
"8 years",
"9 years",
"10+ years",
"10+ years",
"7 years",
null,
"10+ years",
"9 years",
"1 year",
"2 years",
"< 1 year",
"6 years",
"10+ years",
"8 years",
"< 1 year",
"3 years",
"10+ years",
"4 years",
"1 year",
"3 years",
"9 years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"6 years",
"1 year",
"10+ years",
"3 years",
"8 years",
"10+ years",
"3 years",
"7 years",
"3 years",
"3 years",
null,
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"4 years",
"10+ years",
"10+ years",
"8 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"8 years",
"8 years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"10+ years",
"9 years",
"1 year",
null,
"5 years",
"< 1 year",
"10+ years",
"< 1 year",
"4 years",
null,
"< 1 year",
"1 year",
"10+ years",
"3 years",
"7 years",
"8 years",
"9 years",
"3 years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"2 years",
"5 years",
"1 year",
"2 years",
"3 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"8 years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"4 years",
"7 years",
"10+ years",
"10+ years",
null,
null,
null,
"< 1 year",
"10+ years",
"4 years",
"3 years",
"10+ years",
"5 years",
"< 1 year",
"2 years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"9 years",
null,
"10+ years",
"6 years",
"9 years",
"5 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
null,
"5 years",
"5 years",
"2 years",
"10+ years",
null,
"10+ years",
"9 years",
"10+ years",
"2 years",
"10+ years",
"8 years",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"1 year",
"3 years",
"7 years",
"2 years",
"3 years",
"7 years",
"5 years",
"2 years",
"10+ years",
"10+ years",
null,
"5 years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"2 years",
"6 years",
"9 years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"3 years",
"9 years",
"3 years",
"9 years",
"4 years",
"8 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
null,
"4 years",
"9 years",
"5 years",
"9 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
null,
"< 1 year",
"1 year",
"9 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"7 years",
"< 1 year",
"9 years",
"8 years",
"4 years",
null,
"10+ years",
"1 year",
"4 years",
"9 years",
"10+ years",
"10+ years",
"6 years",
null,
"3 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"1 year",
"10+ years",
"1 year",
"6 years",
"10+ years",
"7 years",
"5 years",
"8 years",
"7 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"8 years",
"< 1 year",
"6 years",
"6 years",
"10+ years",
"1 year",
"3 years",
"2 years",
null,
"< 1 year",
"5 years",
"10+ years",
"6 years",
"5 years",
"10+ years",
"3 years",
"10+ years",
null,
"10+ years",
"7 years",
"10+ years",
"5 years",
"7 years",
null,
"3 years",
"< 1 year",
"2 years",
"10+ years",
"2 years",
"10+ years",
"6 years",
"4 years",
"7 years",
"7 years",
"8 years",
"2 years",
"10+ years",
"3 years",
"3 years",
"4 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
null,
"10+ years",
"5 years",
"6 years",
"10+ years",
"1 year",
"1 year",
"7 years",
"8 years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"1 year",
"9 years",
null,
"2 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"3 years",
"6 years",
"10+ years",
"7 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"10+ years",
"9 years",
"5 years",
"1 year",
"10+ years",
"2 years",
null,
"1 year",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"4 years",
"10+ years",
"8 years",
"6 years",
"3 years",
"2 years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"1 year",
"2 years",
"4 years",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"1 year",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"8 years",
"2 years",
"2 years",
"6 years",
"10+ years",
"6 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"1 year",
"10+ years",
"2 years",
"< 1 year",
"3 years",
"2 years",
"10+ years",
"7 years",
"4 years",
null,
"10+ years",
"10+ years",
"8 years",
null,
"10+ years",
"10+ years",
"4 years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"2 years",
null,
"< 1 year",
"5 years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"7 years",
"4 years",
null,
"8 years",
"2 years",
"1 year",
"10+ years",
"2 years",
"1 year",
"7 years",
"3 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"10+ years",
"5 years",
"3 years",
"9 years",
"3 years",
"1 year",
"10+ years",
"9 years",
"5 years",
"3 years",
"4 years",
"3 years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
null,
"9 years",
"10+ years",
"10+ years",
"8 years",
null,
"5 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"7 years",
"10+ years",
"4 years",
null,
null,
"10+ years",
"10+ years",
"6 years",
"2 years",
"2 years",
"4 years",
"8 years",
"4 years",
null,
"6 years",
"1 year",
null,
"2 years",
"4 years",
"10+ years",
"10+ years",
"1 year",
"3 years",
null,
"10+ years",
"4 years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"6 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"< 1 year",
"1 year",
"5 years",
"8 years",
"6 years",
"10+ years",
"3 years",
"2 years",
"4 years",
"1 year",
"2 years",
"3 years",
"7 years",
"5 years",
"1 year",
"10+ years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"6 years",
"5 years",
"6 years",
null,
"3 years",
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"4 years",
"6 years",
"4 years",
"< 1 year",
"1 year",
"10+ years",
"9 years",
"10+ years",
"3 years",
"3 years",
"< 1 year",
"< 1 year",
"1 year",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"6 years",
"5 years",
"< 1 year",
"6 years",
"10+ years",
"7 years",
"4 years",
"2 years",
"5 years",
"1 year",
"7 years",
"8 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"8 years",
"6 years",
null,
"4 years",
"10+ years",
"4 years",
"9 years",
"10+ years",
"2 years",
"7 years",
"8 years",
"10+ years",
"10+ years",
null,
null,
"10+ years",
"2 years",
"1 year",
"10+ years",
"2 years",
null,
"6 years",
null,
"2 years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"5 years",
"4 years",
"10+ years",
"6 years",
"8 years",
"5 years",
"1 year",
"8 years",
"7 years",
"3 years",
"3 years",
"10+ years",
"4 years",
"3 years",
null,
"9 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"4 years",
"1 year",
null,
"10+ years",
"3 years",
"10+ years",
"2 years",
"7 years",
"5 years",
"3 years",
"5 years",
"1 year",
"10+ years",
null,
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"3 years",
"10+ years",
"7 years",
"5 years",
"10+ years",
"10+ years",
"6 years",
"9 years",
"4 years",
"10+ years",
"6 years",
"9 years",
"< 1 year",
"< 1 year",
"10+ years",
"2 years",
"4 years",
"10+ years",
"1 year",
"2 years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"2 years",
"3 years",
"10+ years",
"10+ years",
null,
"10+ years",
"4 years",
"< 1 year",
"3 years",
null,
"2 years",
"2 years",
"2 years",
"10+ years",
"< 1 year",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"6 years",
"7 years",
"7 years",
"10+ years",
"9 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"6 years",
"2 years",
"7 years",
"8 years",
"5 years",
"3 years",
"10+ years",
"7 years",
"2 years",
"8 years",
"2 years",
"4 years",
"4 years",
"2 years",
"10+ years",
"4 years",
"7 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"2 years",
"< 1 year",
"6 years",
"7 years",
"3 years",
"1 year",
null,
"1 year",
"10+ years",
"2 years",
"< 1 year",
"9 years",
"9 years",
"10+ years",
"9 years",
"2 years",
"10+ years",
"10+ years",
"1 year",
null,
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"5 years",
"1 year",
"1 year",
"2 years",
"10+ years",
"9 years",
"4 years",
"8 years",
"< 1 year",
"9 years",
null,
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"8 years",
"1 year",
"4 years",
"3 years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"6 years",
"2 years",
"4 years",
"6 years",
"1 year",
"1 year",
"10+ years",
null,
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"9 years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"4 years",
"10+ years",
null,
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"2 years",
"5 years",
"< 1 year",
"10+ years",
"< 1 year",
"1 year",
"5 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"1 year",
"1 year",
null,
"10+ years",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"8 years",
"8 years",
"4 years",
null,
"10+ years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
null,
"4 years",
"10+ years",
"5 years",
"2 years",
"4 years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"9 years",
"4 years",
"3 years",
"5 years",
"2 years",
"10+ years",
"3 years",
"5 years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"1 year",
"4 years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"7 years",
"< 1 year",
"2 years",
"10+ years",
"8 years",
"8 years",
"6 years",
"3 years",
"7 years",
"7 years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"5 years",
"8 years",
"8 years",
"8 years",
"9 years",
"8 years",
"4 years",
"4 years",
"8 years",
"10+ years",
null,
"6 years",
"10+ years",
"< 1 year",
"5 years",
"2 years",
"8 years",
null,
"4 years",
"4 years",
"5 years",
"3 years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
null,
"< 1 year",
"2 years",
null,
"10+ years",
"6 years",
"4 years",
"2 years",
"4 years",
"10+ years",
"8 years",
"1 year",
"10+ years",
"4 years",
"1 year",
"4 years",
"7 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"4 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"9 years",
"3 years",
"9 years",
"1 year",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"< 1 year",
"5 years",
"7 years",
"< 1 year",
"8 years",
"< 1 year",
"8 years",
"1 year",
"5 years",
"10+ years",
"5 years",
"< 1 year",
"5 years",
"10+ years",
null,
"1 year",
"10+ years",
"6 years",
"7 years",
"6 years",
"< 1 year",
"5 years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"9 years",
"< 1 year",
"4 years",
"9 years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
null,
"9 years",
"10+ years",
"8 years",
"8 years",
"6 years",
"< 1 year",
"7 years",
"8 years",
"8 years",
"7 years",
"6 years",
"2 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"1 year",
"10+ years",
"7 years",
"6 years",
"7 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"9 years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"7 years",
"3 years",
"6 years",
"10+ years",
"2 years",
"2 years",
"2 years",
"7 years",
"9 years",
"1 year",
"10+ years",
"5 years",
"< 1 year",
"2 years",
"2 years",
"< 1 year",
"2 years",
"3 years",
"6 years",
"9 years",
"6 years",
"3 years",
"10+ years",
"1 year",
null,
null,
"9 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"4 years",
"3 years",
"10+ years",
"< 1 year",
"8 years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"8 years",
"2 years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"4 years",
"2 years",
"3 years",
"< 1 year",
null,
"10+ years",
null,
"10+ years",
"10+ years",
"2 years",
"2 years",
"4 years",
"4 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"2 years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"9 years",
"4 years",
"1 year",
"5 years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"10+ years",
"6 years",
"4 years",
"7 years",
"10+ years",
"9 years",
"6 years",
"6 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"7 years",
"7 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"7 years",
"< 1 year",
"4 years",
"10+ years",
"7 years",
"7 years",
"10+ years",
"8 years",
"4 years",
"2 years",
"2 years",
"4 years",
null,
"10+ years",
"1 year",
"1 year",
"< 1 year",
"5 years",
"1 year",
"8 years",
"8 years",
"< 1 year",
"1 year",
"8 years",
"7 years",
"8 years",
"4 years",
"4 years",
null,
"2 years",
"< 1 year",
"< 1 year",
"3 years",
"1 year",
"5 years",
"2 years",
"2 years",
"4 years",
"9 years",
null,
"1 year",
"8 years",
"4 years",
"10+ years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"6 years",
"4 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"< 1 year",
null,
"10+ years",
"5 years",
"10+ years",
null,
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"9 years",
"7 years",
"6 years",
"4 years",
"3 years",
"< 1 year",
"10+ years",
"< 1 year",
"6 years",
"6 years",
"7 years",
"10+ years",
"3 years",
"3 years",
"8 years",
"2 years",
"9 years",
"< 1 year",
"1 year",
"< 1 year",
"1 year",
"< 1 year",
null,
"10+ years",
"6 years",
"5 years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
null,
"2 years",
"10+ years",
"6 years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"10+ years",
null,
"3 years",
"10+ years",
"10+ years",
null,
"5 years",
"2 years",
"10+ years",
"10+ years",
"9 years",
"5 years",
"2 years",
"10+ years",
"2 years",
"4 years",
"< 1 year",
"3 years",
"5 years",
"5 years",
"10+ years",
"5 years",
"1 year",
"< 1 year",
"10+ years",
"< 1 year",
"2 years",
"< 1 year",
"9 years",
"10+ years",
"2 years",
"4 years",
"9 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
null,
"5 years",
null,
"8 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"2 years",
"3 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"8 years",
"3 years",
"< 1 year",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"3 years",
"2 years",
"4 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"3 years",
null,
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"6 years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"6 years",
"10+ years",
"3 years",
"< 1 year",
"5 years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"5 years",
"8 years",
"2 years",
"6 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"6 years",
"7 years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"10+ years",
"3 years",
"< 1 year",
"7 years",
"5 years",
"4 years",
"< 1 year",
"6 years",
"10+ years",
"1 year",
"3 years",
"9 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"4 years",
"< 1 year",
null,
"8 years",
"4 years",
"3 years",
"10+ years",
"6 years",
"4 years",
"10+ years",
"10+ years",
"3 years",
"1 year",
null,
"10+ years",
"10+ years",
"1 year",
"5 years",
null,
"10+ years",
"9 years",
"5 years",
null,
"3 years",
"10+ years",
"10+ years",
null,
"10+ years",
"6 years",
"10+ years",
"7 years",
null,
"1 year",
"10+ years",
"2 years",
"7 years",
"4 years",
"5 years",
"4 years",
"9 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"1 year",
"2 years",
"9 years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"6 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"2 years",
"8 years",
"2 years",
"5 years",
"1 year",
"2 years",
"6 years",
null,
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"1 year",
"< 1 year",
"< 1 year",
"6 years",
"10+ years",
"1 year",
"8 years",
"2 years",
"6 years",
"6 years",
"5 years",
"2 years",
"8 years",
"1 year",
null,
"9 years",
"3 years",
"7 years",
"3 years",
"10+ years",
"1 year",
null,
"10+ years",
"7 years",
"10+ years",
"1 year",
"6 years",
"2 years",
"10+ years",
"7 years",
"< 1 year",
"4 years",
"6 years",
"2 years",
"10+ years",
"6 years",
"3 years",
"2 years",
"3 years",
"10+ years",
"6 years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"5 years",
"2 years",
"10+ years",
"9 years",
null,
"< 1 year",
"1 year",
"5 years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"8 years",
"9 years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"1 year",
null,
"10+ years",
"1 year",
"< 1 year",
"4 years",
"2 years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"4 years",
"7 years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"< 1 year",
"3 years",
"5 years",
"10+ years",
"< 1 year",
"4 years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"9 years",
"4 years",
"2 years",
"3 years",
"10+ years",
"8 years",
"4 years",
"10+ years",
"1 year",
"4 years",
"3 years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"7 years",
"< 1 year",
null,
"3 years",
"2 years",
null,
"10+ years",
"8 years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
null,
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"7 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"3 years",
"1 year",
"< 1 year",
"4 years",
"10+ years",
"< 1 year",
"2 years",
"< 1 year",
"< 1 year",
"8 years",
"10+ years",
"8 years",
"6 years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"1 year",
"3 years",
"1 year",
"1 year",
"5 years",
"10+ years",
"5 years",
"2 years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"1 year",
"2 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
null,
"2 years",
"1 year",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"3 years",
null,
"1 year",
"10+ years",
"9 years",
"7 years",
"8 years",
"4 years",
"7 years",
"10+ years",
"1 year",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"4 years",
"1 year",
"4 years",
"2 years",
"2 years",
null,
"< 1 year",
"10+ years",
"4 years",
"8 years",
"10+ years",
"9 years",
"3 years",
"7 years",
"5 years",
"< 1 year",
"10+ years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"8 years",
"6 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"7 years",
"7 years",
"9 years",
"1 year",
"2 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"< 1 year",
null,
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
null,
"< 1 year",
"2 years",
null,
"8 years",
"1 year",
"6 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"9 years",
"< 1 year",
"10+ years",
"2 years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
null,
"1 year",
"8 years",
"2 years",
"1 year",
"10+ years",
"4 years",
"8 years",
"1 year",
"1 year",
"9 years",
"10+ years",
"10+ years",
"4 years",
"7 years",
null,
"10+ years",
"1 year",
"2 years",
"6 years",
"4 years",
"3 years",
"5 years",
"8 years",
"3 years",
"1 year",
"7 years",
"5 years",
"10+ years",
"3 years",
"1 year",
"10+ years",
"5 years",
"10+ years",
"2 years",
"4 years",
"10+ years",
"7 years",
"10+ years",
"5 years",
"8 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"7 years",
"1 year",
"9 years",
"7 years",
"8 years",
"4 years",
"8 years",
"10+ years",
"10+ years",
"1 year",
"9 years",
"5 years",
"< 1 year",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"6 years",
"4 years",
"2 years",
"2 years",
"8 years",
"6 years",
"1 year",
"3 years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"7 years",
null,
"10+ years",
"< 1 year",
"6 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"3 years",
"2 years",
"2 years",
"10+ years",
"9 years",
"6 years",
"4 years",
"8 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"2 years",
"7 years",
"10+ years",
"9 years",
"3 years",
"< 1 year",
"2 years",
"10+ years",
"1 year",
"3 years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"7 years",
"3 years",
"< 1 year",
"6 years",
null,
"10+ years",
"< 1 year",
null,
"2 years",
null,
"1 year",
"< 1 year",
"7 years",
"1 year",
"3 years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"2 years",
"5 years",
"1 year",
"5 years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"3 years",
"< 1 year",
"3 years",
"4 years",
"2 years",
"10+ years",
"3 years",
"1 year",
"4 years",
null,
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"9 years",
"10+ years",
"5 years",
"6 years",
"10+ years",
"6 years",
null,
"5 years",
null,
"4 years",
"2 years",
"4 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"4 years",
"6 years",
"6 years",
"1 year",
"< 1 year",
"6 years",
"2 years",
"4 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"3 years",
"6 years",
"2 years",
"10+ years",
"6 years",
"6 years",
"10+ years",
"6 years",
"8 years",
"2 years",
"10+ years",
"1 year",
"2 years",
"2 years",
"7 years",
"1 year",
"4 years",
"10+ years",
"6 years",
"9 years",
"1 year",
"7 years",
"< 1 year",
"6 years",
"< 1 year",
"8 years",
"3 years",
"6 years",
"1 year",
"6 years",
"4 years",
"2 years",
"10+ years",
"6 years",
"6 years",
"10+ years",
"9 years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"7 years",
"1 year",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"9 years",
null,
"10+ years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"2 years",
"6 years",
"8 years",
"8 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"6 years",
"8 years",
"2 years",
null,
"8 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"< 1 year",
"1 year",
"< 1 year",
"6 years",
"10+ years",
"2 years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"4 years",
"5 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"8 years",
"10+ years",
null,
"10+ years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"5 years",
"9 years",
"6 years",
"10+ years",
"3 years",
"9 years",
"10+ years",
"10+ years",
"9 years",
null,
"< 1 year",
"5 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"5 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
null,
null,
"5 years",
"7 years",
"3 years",
"5 years",
"< 1 year",
"8 years",
"10+ years",
"3 years",
null,
"10+ years",
"4 years",
"10+ years",
null,
"3 years",
"9 years",
"3 years",
"1 year",
"10+ years",
"1 year",
"5 years",
"3 years",
"10+ years",
"6 years",
"9 years",
null,
"4 years",
null,
"5 years",
"10+ years",
"3 years",
"5 years",
"5 years",
"6 years",
"2 years",
"9 years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"6 years",
"5 years",
"10+ years",
"1 year",
"8 years",
"2 years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"2 years",
"9 years",
"10+ years",
null,
"10+ years",
"< 1 year",
"< 1 year",
"4 years",
"10+ years",
"2 years",
"1 year",
"5 years",
"1 year",
"2 years",
"9 years",
"8 years",
null,
"2 years",
"10+ years",
"< 1 year",
"2 years",
"6 years",
"< 1 year",
"7 years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"9 years",
"1 year",
"7 years",
"7 years",
"8 years",
"5 years",
"4 years",
"10+ years",
"8 years",
"4 years",
"2 years",
"5 years",
"10+ years",
"2 years",
"4 years",
"4 years",
"< 1 year",
"10+ years",
"7 years",
"< 1 year",
"2 years",
"10+ years",
"< 1 year",
"< 1 year",
"2 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
null,
"3 years",
"7 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"4 years",
"1 year",
"8 years",
"2 years",
"3 years",
"5 years",
"9 years",
"5 years",
"1 year",
"5 years",
"10+ years",
"8 years",
"< 1 year",
"< 1 year",
"3 years",
"5 years",
"2 years",
"10+ years",
null,
"6 years",
null,
null,
"2 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"< 1 year",
null,
"2 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"7 years",
"2 years",
"1 year",
"4 years",
"6 years",
"7 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"9 years",
"1 year",
"9 years",
"4 years",
"1 year",
"4 years",
"5 years",
"10+ years",
"8 years",
"6 years",
"3 years",
"10+ years",
"2 years",
null,
"10+ years",
"< 1 year",
"2 years",
"3 years",
"7 years",
"10+ years",
"4 years",
"1 year",
"2 years",
"1 year",
"< 1 year",
"10+ years",
"7 years",
"8 years",
"9 years",
"2 years",
"10+ years",
"9 years",
"2 years",
"4 years",
"4 years",
null,
"10+ years",
"3 years",
"10+ years",
"2 years",
"4 years",
"< 1 year",
"< 1 year",
"10+ years",
"< 1 year",
"2 years",
"< 1 year",
null,
"1 year",
"10+ years",
"10+ years",
null,
"2 years",
"< 1 year",
"7 years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"1 year",
"< 1 year",
"3 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"4 years",
"3 years",
"2 years",
"10+ years",
"1 year",
"9 years",
"1 year",
"1 year",
"10+ years",
"1 year",
"5 years",
"10+ years",
"1 year",
"10+ years",
"4 years",
"7 years",
"2 years",
"2 years",
"10+ years",
"6 years",
"5 years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"8 years",
"5 years",
"4 years",
"2 years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"8 years",
"5 years",
"2 years",
"2 years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"4 years",
"10+ years",
"4 years",
"10+ years",
"4 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"9 years",
"3 years",
"< 1 year",
"10+ years",
"1 year",
"3 years",
"1 year",
"< 1 year",
"2 years",
"8 years",
null,
"4 years",
"2 years",
"6 years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"5 years",
"10+ years",
null,
"8 years",
"7 years",
"5 years",
"10+ years",
null,
"1 year",
"8 years",
null,
"8 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"7 years",
"8 years",
"9 years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"7 years",
"5 years",
"10+ years",
"< 1 year",
"2 years",
"3 years",
"10+ years",
"6 years",
null,
"2 years",
"8 years",
"1 year",
"10+ years",
"3 years",
"6 years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"4 years",
"10+ years",
"7 years",
"4 years",
"< 1 year",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"2 years",
"3 years",
"7 years",
"7 years",
"4 years",
"< 1 year",
null,
"1 year",
"1 year",
"8 years",
"6 years",
"2 years",
"3 years",
"< 1 year",
"4 years",
"1 year",
"4 years",
"4 years",
"5 years",
"10+ years",
"< 1 year",
"1 year",
"4 years",
"4 years",
"3 years",
"4 years",
"6 years",
"4 years",
"4 years",
"10+ years",
"8 years",
"2 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"< 1 year",
"5 years",
"< 1 year",
"3 years",
"3 years",
null,
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"5 years",
"10+ years",
null,
"1 year",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"5 years",
"7 years",
"2 years",
"9 years",
"10+ years",
"4 years",
null,
"10+ years",
null,
"10+ years",
"< 1 year",
null,
"3 years",
"8 years",
"< 1 year",
"8 years",
"9 years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"5 years",
"7 years",
"6 years",
"10+ years",
"3 years",
"4 years",
"1 year",
"10+ years",
"10+ years",
"7 years",
"3 years",
"8 years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"7 years",
"1 year",
"1 year",
null,
"2 years",
"9 years",
"< 1 year",
"5 years",
"10+ years",
null,
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"2 years",
"3 years",
"1 year",
"6 years",
"6 years",
"< 1 year",
"4 years",
"3 years",
"3 years",
"10+ years",
"6 years",
null,
"10+ years",
"3 years",
"10+ years",
"5 years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"6 years",
"2 years",
"2 years",
null,
null,
"10+ years",
"10+ years",
"4 years",
"9 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"8 years",
"2 years",
"9 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"4 years",
"< 1 year",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"8 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"6 years",
"4 years",
"10+ years",
"3 years",
null,
"8 years",
"10+ years",
"6 years",
"< 1 year",
"3 years",
"5 years",
"10+ years",
"2 years",
"2 years",
"2 years",
"4 years",
"2 years",
"9 years",
"3 years",
"7 years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"< 1 year",
"8 years",
"3 years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"9 years",
"6 years",
"10+ years",
"7 years",
"5 years",
"5 years",
"7 years",
"< 1 year",
"10+ years",
null,
"1 year",
"10+ years",
"1 year",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"4 years",
"< 1 year",
"6 years",
null,
"4 years",
"9 years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"9 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"5 years",
"3 years",
"2 years",
"10+ years",
"8 years",
"3 years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"8 years",
"< 1 year",
"1 year",
"10+ years",
"8 years",
"4 years",
"10+ years",
null,
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"< 1 year",
"< 1 year",
null,
null,
"3 years",
"4 years",
"7 years",
"< 1 year",
"8 years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"7 years",
"9 years",
"7 years",
"2 years",
"10+ years",
null,
"10+ years",
"10+ years",
"9 years",
"< 1 year",
null,
"10+ years",
"10+ years",
"9 years",
"3 years",
"9 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"7 years",
"10+ years",
"10+ years",
"6 years",
"4 years",
"5 years",
"5 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
null,
"1 year",
null,
"4 years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"6 years",
"1 year",
"8 years",
"8 years",
"7 years",
null,
"8 years",
"3 years",
"10+ years",
"5 years",
"7 years",
"5 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"9 years",
"8 years",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"< 1 year",
"6 years",
"4 years",
"7 years",
"1 year",
null,
"6 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"6 years",
null,
"10+ years",
"3 years",
"5 years",
"7 years",
"7 years",
"9 years",
"< 1 year",
"8 years",
"2 years",
"5 years",
"2 years",
"5 years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"5 years",
"3 years",
"2 years",
"9 years",
"< 1 year",
"7 years",
"5 years",
"4 years",
"3 years",
"10+ years",
"9 years",
"2 years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
null,
"< 1 year",
"< 1 year",
"8 years",
"10+ years",
"7 years",
"3 years",
"8 years",
"4 years",
"7 years",
"< 1 year",
"4 years",
"7 years",
"1 year",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"4 years",
"3 years",
null,
"4 years",
"4 years",
null,
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"9 years",
"3 years",
"1 year",
"5 years",
"< 1 year",
"2 years",
null,
"3 years",
"6 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"6 years",
"2 years",
"7 years",
"2 years",
"2 years",
"10+ years",
"2 years",
"2 years",
"6 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
null,
"5 years",
"1 year",
"5 years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"4 years",
"1 year",
"8 years",
"10+ years",
"10+ years",
null,
"4 years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"5 years",
"3 years",
"< 1 year",
"7 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
null,
"3 years",
"4 years",
"1 year",
"6 years",
"5 years",
"8 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
null,
"< 1 year",
"5 years",
"4 years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"< 1 year",
"1 year",
"7 years",
"3 years",
"3 years",
"10+ years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"6 years",
"1 year",
"1 year",
"9 years",
"9 years",
null,
"< 1 year",
"4 years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
null,
"10+ years",
"8 years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"6 years",
"4 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"< 1 year",
"1 year",
"2 years",
"< 1 year",
"5 years",
"< 1 year",
"4 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"2 years",
"9 years",
"6 years",
"6 years",
"< 1 year",
"7 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"6 years",
"1 year",
"10+ years",
"5 years",
"8 years",
"1 year",
"10+ years",
"3 years",
"8 years",
"10+ years",
"10+ years",
"7 years",
"< 1 year",
"< 1 year",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"3 years",
"2 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"1 year",
"4 years",
"10+ years",
"4 years",
"7 years",
"2 years",
"10+ years",
"8 years",
"7 years",
"10+ years",
"2 years",
null,
null,
"9 years",
"1 year",
"2 years",
"< 1 year",
null,
"10+ years",
"2 years",
"9 years",
"5 years",
"8 years",
"2 years",
"9 years",
null,
"10+ years",
"1 year",
"10+ years",
"2 years",
"6 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"8 years",
"5 years",
"5 years",
"10+ years",
"8 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
null,
"4 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"3 years",
null,
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"5 years",
"7 years",
"5 years",
"1 year",
null,
"3 years",
"8 years",
"1 year",
"4 years",
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"6 years",
"2 years",
"10+ years",
"3 years",
"3 years",
"9 years",
"9 years",
"3 years",
"5 years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
null,
"2 years",
"2 years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"5 years",
"7 years",
"1 year",
"10+ years",
"< 1 year",
"2 years",
"4 years",
"< 1 year",
"10+ years",
"< 1 year",
"3 years",
"5 years",
"4 years",
"10+ years",
null,
"10+ years",
"2 years",
"10+ years",
"8 years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"2 years",
"< 1 year",
"3 years",
"2 years",
"10+ years",
"10+ years",
null,
"4 years",
"1 year",
"10+ years",
"2 years",
"< 1 year",
"3 years",
"1 year",
"10+ years",
null,
"10+ years",
"5 years",
"10+ years",
"3 years",
"1 year",
"8 years",
"1 year",
"10+ years",
"6 years",
"2 years",
"1 year",
"3 years",
"1 year",
null,
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"6 years",
"10+ years",
"2 years",
"6 years",
"9 years",
"< 1 year",
"9 years",
"7 years",
"7 years",
"10+ years",
null,
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"5 years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"1 year",
"3 years",
"< 1 year",
"10+ years",
null,
null,
"10+ years",
"< 1 year",
"4 years",
"8 years",
"2 years",
"3 years",
"10+ years",
"2 years",
null,
"7 years",
"2 years",
"< 1 year",
"< 1 year",
null,
"4 years",
"7 years",
null,
"9 years",
"8 years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"7 years",
"10+ years",
"2 years",
"1 year",
"3 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"< 1 year",
"1 year",
"< 1 year",
"< 1 year",
"8 years",
"10+ years",
"1 year",
"7 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"6 years",
"< 1 year",
"2 years",
"10+ years",
"2 years",
"2 years",
"< 1 year",
"4 years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"3 years",
"5 years",
"1 year",
"10+ years",
"6 years",
"8 years",
"6 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"6 years",
"10+ years",
"10+ years",
"5 years",
"8 years",
"10+ years",
"< 1 year",
"5 years",
"8 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"9 years",
"10+ years",
"8 years",
"4 years",
"8 years",
"8 years",
"2 years",
null,
"10+ years",
"7 years",
"10+ years",
null,
"4 years",
null,
"10+ years",
"9 years",
"10+ years",
"2 years",
"3 years",
"< 1 year",
"4 years",
"4 years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"7 years",
"1 year",
"4 years",
"10+ years",
"2 years",
"9 years",
"10+ years",
"< 1 year",
"2 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"6 years",
"< 1 year",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"7 years",
"6 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"2 years",
null,
"4 years",
"7 years",
"2 years",
"5 years",
null,
"10+ years",
"7 years",
"5 years",
null,
"5 years",
"6 years",
"< 1 year",
"10+ years",
"2 years",
"1 year",
"5 years",
"3 years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"4 years",
"3 years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"1 year",
null,
"5 years",
"10+ years",
"10+ years",
"5 years",
"9 years",
"4 years",
"4 years",
"8 years",
"6 years",
"< 1 year",
"10+ years",
"9 years",
"5 years",
"10+ years",
null,
"6 years",
null,
"2 years",
"3 years",
"5 years",
null,
"10+ years",
"10+ years",
"10+ years",
null,
"2 years",
"3 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"7 years",
"1 year",
"9 years",
"9 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"6 years",
"< 1 year",
"3 years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"8 years",
"3 years",
"10+ years",
null,
"10+ years",
null,
"7 years",
"2 years",
"10+ years",
null,
"< 1 year",
null,
"8 years",
null,
null,
"2 years",
"2 years",
null,
"1 year",
"2 years",
"1 year",
null,
"10+ years",
"8 years",
"8 years",
null,
"7 years",
"3 years",
"5 years",
"5 years",
"< 1 year",
"8 years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
null,
"6 years",
"6 years",
"10+ years",
"< 1 year",
"7 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"2 years",
"1 year",
"10+ years",
"1 year",
"2 years",
"10+ years",
null,
"10+ years",
"10+ years",
"2 years",
"4 years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"9 years",
"10+ years",
"3 years",
"2 years",
"< 1 year",
null,
"9 years",
"7 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"1 year",
"3 years",
"9 years",
"7 years",
"9 years",
null,
"10+ years",
"7 years",
"2 years",
null,
"5 years",
"2 years",
"1 year",
"10+ years",
"8 years",
"5 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"1 year",
"8 years",
"10+ years",
"9 years",
"6 years",
"< 1 year",
"4 years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"1 year",
"9 years",
"3 years",
"2 years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"5 years",
"5 years",
"6 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
null,
"2 years",
"1 year",
"2 years",
"10+ years",
"1 year",
null,
"10+ years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"1 year",
"3 years",
null,
"8 years",
null,
"10+ years",
"4 years",
"10+ years",
"9 years",
"10+ years",
"7 years",
"5 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"1 year",
"2 years",
"4 years",
"2 years",
"10+ years",
"3 years",
"1 year",
"10+ years",
"2 years",
"3 years",
"10+ years",
"5 years",
null,
"3 years",
"8 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
null,
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
null,
"2 years",
"8 years",
"8 years",
"7 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"1 year",
null,
"7 years",
"10+ years",
"4 years",
null,
"3 years",
"10+ years",
"1 year",
"2 years",
"6 years",
"10+ years",
"2 years",
"3 years",
"< 1 year",
"2 years",
null,
"3 years",
"8 years",
"7 years",
"6 years",
"3 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"2 years",
"< 1 year",
"5 years",
"6 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
null,
"1 year",
"8 years",
"4 years",
"2 years",
null,
"< 1 year",
"10+ years",
"6 years",
"7 years",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"2 years",
"3 years",
null,
"4 years",
"10+ years",
"10+ years",
"7 years",
"5 years",
"10+ years",
"4 years",
"2 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"8 years",
"10+ years",
"2 years",
null,
"6 years",
null,
"8 years",
"10+ years",
"10+ years",
null,
"4 years",
"4 years",
"8 years",
"3 years",
"< 1 year",
"2 years",
"2 years",
"2 years",
"6 years",
"1 year",
"< 1 year",
"1 year",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"3 years",
"2 years",
"6 years",
null,
"< 1 year",
"2 years",
"10+ years",
null,
"< 1 year",
"5 years",
"< 1 year",
"10+ years",
"3 years",
"4 years",
"5 years",
"7 years",
"10+ years",
"3 years",
"8 years",
"2 years",
"9 years",
"8 years",
"< 1 year",
"< 1 year",
"5 years",
"2 years",
"3 years",
"6 years",
"3 years",
"< 1 year",
"7 years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"3 years",
"3 years",
"10+ years",
"9 years",
"10+ years",
"7 years",
"6 years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"2 years",
"9 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"6 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"7 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"6 years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"2 years",
"7 years",
"< 1 year",
"1 year",
"2 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"4 years",
"4 years",
"6 years",
"2 years",
"2 years",
"7 years",
"2 years",
"1 year",
"10+ years",
null,
"10+ years",
"3 years",
"10+ years",
"1 year",
"9 years",
"1 year",
"4 years",
"6 years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"4 years",
"8 years",
"7 years",
"8 years",
"8 years",
"8 years",
"3 years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"8 years",
"< 1 year",
null,
"5 years",
"3 years",
"10+ years",
"3 years",
"1 year",
"4 years",
"10+ years",
"9 years",
"3 years",
"9 years",
"2 years",
"1 year",
"2 years",
null,
"3 years",
"1 year",
"< 1 year",
"3 years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"9 years",
"5 years",
null,
"9 years",
"< 1 year",
"3 years",
"4 years",
"5 years",
"8 years",
"6 years",
null,
"1 year",
"1 year",
"9 years",
"2 years",
"10+ years",
"2 years",
"8 years",
"1 year",
"< 1 year",
"3 years",
"4 years",
"6 years",
"9 years",
"3 years",
"1 year",
"2 years",
"2 years",
null,
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"3 years",
"7 years",
"10+ years",
null,
"10+ years",
null,
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
null,
"4 years",
"10+ years",
null,
"2 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"7 years",
"2 years",
"4 years",
null,
null,
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"1 year",
"10+ years",
"7 years",
null,
"10+ years",
"7 years",
"6 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"2 years",
"1 year",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"10+ years",
"6 years",
"2 years",
"4 years",
"10+ years",
"10+ years",
null,
"10+ years",
"5 years",
"4 years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"1 year",
null,
"6 years",
"6 years",
"8 years",
"5 years",
"< 1 year",
"4 years",
"1 year",
"2 years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"4 years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"6 years",
"8 years",
"9 years",
"5 years",
"5 years",
null,
"2 years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"9 years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"4 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"2 years",
"6 years",
"1 year",
"10+ years",
"2 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"1 year",
"< 1 year",
null,
"2 years",
"3 years",
"9 years",
"< 1 year",
null,
"2 years",
"< 1 year",
"6 years",
"1 year",
null,
"10+ years",
"7 years",
"9 years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"9 years",
"1 year",
"5 years",
"7 years",
"1 year",
"2 years",
"6 years",
"10+ years",
"2 years",
"5 years",
"6 years",
"3 years",
null,
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"2 years",
"3 years",
"< 1 year",
"5 years",
"1 year",
"1 year",
"6 years",
"1 year",
"4 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"5 years",
"2 years",
"9 years",
"2 years",
"5 years",
"10+ years",
"9 years",
"2 years",
"10+ years",
"4 years",
"3 years",
"10+ years",
"1 year",
"7 years",
"9 years",
"10+ years",
"7 years",
"5 years",
null,
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"3 years",
"1 year",
"< 1 year",
"7 years",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"9 years",
"10+ years",
"6 years",
"10+ years",
"8 years",
"< 1 year",
"2 years",
"< 1 year",
"4 years",
"3 years",
"7 years",
"10+ years",
"10+ years",
null,
"5 years",
"< 1 year",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"< 1 year",
"7 years",
"10+ years",
null,
"10+ years",
"3 years",
"10+ years",
"4 years",
"4 years",
null,
"2 years",
"5 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"5 years",
"8 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"3 years",
"3 years",
"7 years",
"< 1 year",
"2 years",
"< 1 year",
"5 years",
"5 years",
"1 year",
"3 years",
"2 years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"9 years",
"10+ years",
"8 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"8 years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"7 years",
"6 years",
"2 years",
"2 years",
"10+ years",
"9 years",
"7 years",
null,
"8 years",
null,
"10+ years",
"5 years",
"5 years",
"2 years",
"10+ years",
"2 years",
"1 year",
"2 years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"9 years",
"5 years",
"6 years",
"2 years",
"7 years",
"7 years",
"1 year",
"7 years",
"10+ years",
"1 year",
"9 years",
"4 years",
"10+ years",
"8 years",
"6 years",
"10+ years",
"9 years",
"6 years",
null,
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"6 years",
null,
"3 years",
"10+ years",
"6 years",
"3 years",
"5 years",
"10+ years",
"< 1 year",
"3 years",
null,
"2 years",
"2 years",
"9 years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"2 years",
null,
"6 years",
"8 years",
"4 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"10+ years",
null,
"10+ years",
"6 years",
"10+ years",
"2 years",
"3 years",
"< 1 year",
"10+ years",
"2 years",
"6 years",
"3 years",
"10+ years",
"5 years",
"6 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"6 years",
"5 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
null,
null,
"10+ years",
"8 years",
"10+ years",
"2 years",
"< 1 year",
"2 years",
"10+ years",
"3 years",
null,
"10+ years",
"1 year",
"< 1 year",
"8 years",
"9 years",
"8 years",
"5 years",
"< 1 year",
"< 1 year",
"10+ years",
"5 years",
"2 years",
null,
"5 years",
"2 years",
"< 1 year",
"4 years",
"9 years",
"8 years",
"2 years",
"6 years",
"7 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"8 years",
"< 1 year",
"1 year",
null,
"10+ years",
"5 years",
"2 years",
"4 years",
"< 1 year",
"2 years",
"10+ years",
"4 years",
"2 years",
"10+ years",
"6 years",
"4 years",
"10+ years",
"3 years",
"10+ years",
null,
"7 years",
"6 years",
"10+ years",
"4 years",
"10+ years",
"1 year",
"7 years",
"9 years",
"10+ years",
"6 years",
"6 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"3 years",
"9 years",
"10+ years",
"< 1 year",
"6 years",
"3 years",
null,
"2 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"6 years",
"< 1 year",
"7 years",
"9 years",
null,
"< 1 year",
"3 years",
"10+ years",
"1 year",
"8 years",
null,
"10+ years",
"8 years",
"9 years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"8 years",
"4 years",
"10+ years",
"3 years",
null,
"10+ years",
"6 years",
"1 year",
"< 1 year",
"3 years",
"2 years",
"10+ years",
"9 years",
"10+ years",
null,
"4 years",
"2 years",
"6 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"8 years",
"10+ years",
"3 years",
"5 years",
"< 1 year",
"10+ years",
null,
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"5 years",
"< 1 year",
"1 year",
"5 years",
"4 years",
"10+ years",
"2 years",
null,
"< 1 year",
null,
"7 years",
"4 years",
null,
"5 years",
"9 years",
"7 years",
"1 year",
"3 years",
"6 years",
"1 year",
"1 year",
"3 years",
null,
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
null,
"9 years",
"10+ years",
"8 years",
"9 years",
"2 years",
"5 years",
"5 years",
null,
"8 years",
"1 year",
"10+ years",
"9 years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"7 years",
"10+ years",
"2 years",
"7 years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"6 years",
"9 years",
"4 years",
"< 1 year",
"8 years",
null,
"2 years",
"6 years",
"6 years",
"8 years",
"2 years",
"2 years",
"5 years",
"3 years",
"9 years",
"2 years",
"1 year",
"< 1 year",
"6 years",
"10+ years",
null,
"10+ years",
"6 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
null,
null,
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"4 years",
"9 years",
"2 years",
"4 years",
"10+ years",
"10+ years",
"5 years",
"8 years",
"3 years",
"1 year",
"1 year",
"5 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"9 years",
"3 years",
"10+ years",
"1 year",
"2 years",
"8 years",
"2 years",
"10+ years",
null,
"10+ years",
"6 years",
"9 years",
"5 years",
"8 years",
"10+ years",
"7 years",
"3 years",
"6 years",
"10+ years",
"5 years",
"8 years",
"9 years",
"1 year",
"< 1 year",
"9 years",
null,
"5 years",
"2 years",
null,
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"2 years",
"3 years",
"10+ years",
"4 years",
null,
"10+ years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"4 years",
"4 years",
null,
"10+ years",
null,
"5 years",
"8 years",
"4 years",
"8 years",
"10+ years",
null,
"10+ years",
"2 years",
"7 years",
"< 1 year",
null,
"9 years",
"3 years",
"2 years",
"5 years",
"10+ years",
"8 years",
"10+ years",
"8 years",
"9 years",
"8 years",
"10+ years",
"4 years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"< 1 year",
"3 years",
"10+ years",
"3 years",
null,
"2 years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"< 1 year",
"6 years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"7 years",
null,
"10+ years",
"5 years",
"7 years",
"10+ years",
"3 years",
"< 1 year",
"9 years",
"8 years",
"7 years",
"10+ years",
"5 years",
"10+ years",
"6 years",
"2 years",
"1 year",
"1 year",
"4 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"2 years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"6 years",
null,
"10+ years",
"5 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
null,
"10+ years",
"9 years",
"10+ years",
"1 year",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"7 years",
"5 years",
"< 1 year",
"9 years",
"10+ years",
"6 years",
"9 years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"< 1 year",
"5 years",
"6 years",
"1 year",
"7 years",
"8 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"5 years",
"4 years",
"< 1 year",
"10+ years",
"2 years",
"6 years",
"8 years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"4 years",
"7 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"5 years",
"9 years",
"8 years",
"8 years",
"10+ years",
null,
"5 years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"1 year",
"4 years",
"10+ years",
"5 years",
"2 years",
"7 years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"5 years",
"1 year",
"10+ years",
"< 1 year",
null,
"< 1 year",
"10+ years",
"6 years",
"3 years",
"1 year",
"2 years",
"9 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"4 years",
"10+ years",
"1 year",
"7 years",
"10+ years",
null,
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"1 year",
"6 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"9 years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"9 years",
"10+ years",
"10+ years",
"4 years",
"5 years",
"5 years",
"10+ years",
"10+ years",
"7 years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
null,
"10+ years",
"< 1 year",
"1 year",
"1 year",
"10+ years",
"< 1 year",
"7 years",
"5 years",
"6 years",
"< 1 year",
"10+ years",
"5 years",
"2 years",
"9 years",
null,
"10+ years",
"10+ years",
null,
null,
"< 1 year",
"3 years",
"< 1 year",
"1 year",
"10+ years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"< 1 year",
"2 years",
"2 years",
"1 year",
"3 years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"9 years",
"7 years",
"2 years",
null,
"2 years",
"9 years",
"5 years",
null,
null,
"6 years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"2 years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"4 years",
"6 years",
"5 years",
"10+ years",
"1 year",
"1 year",
"1 year",
"1 year",
"4 years",
"8 years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"9 years",
null,
"5 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"1 year",
"3 years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"3 years",
"3 years",
null,
"9 years",
null,
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"9 years",
"10+ years",
"3 years",
null,
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"4 years",
"5 years",
"3 years",
"10+ years",
"4 years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"6 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"6 years",
"9 years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"< 1 year",
"< 1 year",
"10+ years",
"6 years",
"5 years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"9 years",
"1 year",
"3 years",
"4 years",
"3 years",
"5 years",
"2 years",
"4 years",
"2 years",
"4 years",
"4 years",
"3 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"9 years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"< 1 year",
"6 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"6 years",
"1 year",
"10+ years",
"9 years",
"2 years",
"6 years",
"10+ years",
"6 years",
"10+ years",
null,
"5 years",
"1 year",
"10+ years",
"8 years",
"2 years",
"4 years",
"6 years",
"10+ years",
"2 years",
null,
"8 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"7 years",
"10+ years",
"5 years",
"5 years",
"5 years",
"10+ years",
null,
"10+ years",
"2 years",
"2 years",
"10+ years",
"5 years",
"1 year",
null,
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
"2 years",
"4 years",
"6 years",
"5 years",
"10+ years",
"< 1 year",
"9 years",
"10+ years",
"5 years",
"5 years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"1 year",
"2 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
null,
"1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"7 years",
null,
"2 years",
"3 years",
"9 years",
"7 years",
"4 years",
"< 1 year",
"2 years",
"2 years",
"2 years",
"10+ years",
"4 years",
"< 1 year",
null,
"10+ years",
"3 years",
"2 years",
"10+ years",
"< 1 year",
"4 years",
null,
"10+ years",
"10+ years",
"10+ years",
"7 years",
"4 years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"9 years",
"10+ years",
"10+ years",
null,
"10+ years",
"7 years",
"9 years",
"< 1 year",
"< 1 year",
"7 years",
"5 years",
"4 years",
"8 years",
"1 year",
"6 years",
"6 years",
"< 1 year",
"5 years",
"2 years",
"9 years",
"1 year",
"9 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"9 years",
"10+ years",
"10+ years",
"8 years",
null,
"4 years",
"2 years",
"8 years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"1 year",
"2 years",
"4 years",
"6 years",
"3 years",
"2 years",
"1 year",
"10+ years",
"1 year",
"< 1 year",
"5 years",
"8 years",
"10+ years",
"5 years",
"4 years",
"10+ years",
"10+ years",
"6 years",
"9 years",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"8 years",
"8 years",
null,
"< 1 year",
"4 years",
null,
"10+ years",
"5 years",
"10+ years",
"7 years",
null,
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"9 years",
null,
null,
"< 1 year",
"< 1 year",
"5 years",
"7 years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"9 years",
"2 years",
"< 1 year",
"2 years",
"2 years",
"10+ years",
"3 years",
"9 years",
"10+ years",
"9 years",
"10+ years",
"7 years",
"6 years",
"10+ years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"6 years",
"< 1 year",
"5 years",
"5 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"4 years",
"7 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"1 year",
"10+ years",
"9 years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"6 years",
"4 years",
"10+ years",
"10+ years",
"4 years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"5 years",
"< 1 year",
"10+ years",
null,
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"1 year",
"< 1 year",
"1 year",
"5 years",
"2 years",
"10+ years",
"5 years",
null,
"5 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"5 years",
"6 years",
"2 years",
"10+ years",
"2 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
null,
"6 years",
"1 year",
"2 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"2 years",
"1 year",
"1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"1 year",
"3 years",
"4 years",
"6 years",
"4 years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"5 years",
"10+ years",
null,
"10+ years",
"7 years",
"2 years",
"2 years",
"2 years",
"10+ years",
"8 years",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"< 1 year",
"6 years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"2 years",
"9 years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"1 year",
"3 years",
"10+ years",
"5 years",
"8 years",
"2 years",
"7 years",
"3 years",
"10+ years",
"10+ years",
"3 years",
null,
"6 years",
"2 years",
"3 years",
"2 years",
"10+ years",
"3 years",
"2 years",
"5 years",
"4 years",
"2 years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"5 years",
"6 years",
"< 1 year",
"6 years",
"7 years",
"10+ years",
"5 years",
"2 years",
"8 years",
"10+ years",
"2 years",
"6 years",
"8 years",
"< 1 year",
"1 year",
"10+ years",
"6 years",
"1 year",
"10+ years",
null,
"< 1 year",
"1 year",
"6 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"6 years",
null,
"10+ years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"6 years",
"< 1 year",
"10+ years",
null,
"7 years",
"10+ years",
"10+ years",
null,
"10+ years",
"4 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"4 years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"4 years",
"6 years",
"3 years",
"3 years",
"10+ years",
"7 years",
"3 years",
"4 years",
"10+ years",
"9 years",
"1 year",
"10+ years",
"5 years",
"2 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"3 years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"9 years",
"4 years",
"2 years",
"6 years",
"7 years",
"9 years",
"< 1 year",
"10+ years",
"< 1 year",
"6 years",
"4 years",
"4 years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"5 years",
"3 years",
"< 1 year",
"10+ years",
"2 years",
"< 1 year",
"7 years",
"1 year",
"7 years",
"10+ years",
null,
null,
"8 years",
"6 years",
"10+ years",
"8 years",
"4 years",
"10+ years",
"10+ years",
"4 years",
"4 years",
"10+ years",
null,
"4 years",
"10+ years",
"7 years",
"< 1 year",
null,
"10+ years",
null,
"7 years",
"8 years",
"3 years",
"2 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"9 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"10+ years",
null,
"6 years",
"3 years",
"2 years",
"5 years",
"5 years",
"6 years",
"2 years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"9 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"4 years",
"9 years",
"2 years",
"10+ years",
"10+ years",
"9 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"9 years",
"3 years",
"9 years",
"4 years",
"5 years",
"3 years",
"4 years",
"1 year",
"2 years",
null,
"3 years",
"7 years",
"2 years",
"< 1 year",
"6 years",
null,
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"1 year",
"6 years",
"7 years",
"6 years",
"< 1 year",
"10+ years",
"9 years",
null,
"10+ years",
"8 years",
"5 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"8 years",
"4 years",
"2 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"5 years",
"< 1 year",
"< 1 year",
"10+ years",
"2 years",
"9 years",
"2 years",
"6 years",
"10+ years",
"9 years",
"< 1 year",
"2 years",
"2 years",
"10+ years",
null,
"1 year",
"10+ years",
"8 years",
"< 1 year",
"5 years",
null,
"3 years",
"2 years",
"3 years",
"10+ years",
"9 years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
null,
null,
"10+ years",
"5 years",
"4 years",
"9 years",
"2 years",
"< 1 year",
"3 years",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"6 years",
"3 years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"3 years",
null,
"10+ years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"4 years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
null,
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"8 years",
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"8 years",
"4 years",
"2 years",
"10+ years",
"6 years",
"1 year",
"2 years",
"< 1 year",
null,
"10+ years",
"6 years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"6 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
null,
"4 years",
"10+ years",
"4 years",
"2 years",
"4 years",
"4 years",
"8 years",
"10+ years",
null,
"5 years",
"9 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"6 years",
"2 years",
"9 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"< 1 year",
"2 years",
"5 years",
"2 years",
"1 year",
"3 years",
"10+ years",
null,
"3 years",
"10+ years",
null,
"10+ years",
"2 years",
"< 1 year",
"9 years",
"7 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
null,
"< 1 year",
null,
"9 years",
"1 year",
"7 years",
"3 years",
"10+ years",
"4 years",
null,
"2 years",
"4 years",
"1 year",
null,
"4 years",
"9 years",
"< 1 year",
"4 years",
"9 years",
"< 1 year",
"7 years",
"3 years",
"10+ years",
"5 years",
"3 years",
"9 years",
"8 years",
"4 years",
"< 1 year",
"1 year",
"4 years",
"7 years",
null,
"2 years",
"2 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"5 years",
"10+ years",
"9 years",
"2 years",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"9 years",
"1 year",
"< 1 year",
"10+ years",
"2 years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"3 years",
"< 1 year",
"6 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"1 year",
"2 years",
"10+ years",
"10+ years",
null,
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"3 years",
null,
"5 years",
"2 years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"5 years",
null,
"10+ years",
"6 years",
"2 years",
"< 1 year",
null,
null,
"1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"5 years",
"1 year",
"6 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
null,
"< 1 year",
"8 years",
"1 year",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"7 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"9 years",
null,
"2 years",
"< 1 year",
"2 years",
"2 years",
"3 years",
"4 years",
"4 years",
"10+ years",
"2 years",
"2 years",
"5 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"6 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"7 years",
"6 years",
"3 years",
"1 year",
"10+ years",
"4 years",
"8 years",
"7 years",
"4 years",
"3 years",
"10+ years",
"5 years",
"5 years",
"2 years",
"10+ years",
"8 years",
"1 year",
"5 years",
"5 years",
"3 years",
"10+ years",
"7 years",
"10+ years",
"1 year",
"2 years",
"6 years",
"2 years",
"2 years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"2 years",
null,
"< 1 year",
"1 year",
null,
"10+ years",
"6 years",
"10+ years",
"5 years",
"2 years",
"6 years",
"4 years",
"10+ years",
"4 years",
null,
"5 years",
"10+ years",
"10+ years",
"5 years",
"1 year",
"7 years",
"5 years",
"1 year",
"< 1 year",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"9 years",
"8 years",
"2 years",
"1 year",
"2 years",
"10+ years",
"5 years",
"3 years",
"6 years",
"1 year",
"4 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"2 years",
"6 years",
"< 1 year",
null,
"3 years",
"5 years",
"10+ years",
"8 years",
"10+ years",
"6 years",
"< 1 year",
null,
"6 years",
"10+ years",
"2 years",
"2 years",
"8 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"7 years",
"6 years",
"5 years",
"6 years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
null,
"2 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"6 years",
"1 year",
"10+ years",
"1 year",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"9 years",
"2 years",
"7 years",
"9 years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"6 years",
"10+ years",
"7 years",
"3 years",
"10+ years",
null,
"< 1 year",
"10+ years",
"9 years",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
null,
"10+ years",
"2 years",
null,
"10+ years",
"4 years",
"5 years",
"3 years",
"8 years",
"< 1 year",
"2 years",
"10+ years",
"7 years",
"7 years",
"4 years",
"5 years",
"1 year",
"4 years",
"< 1 year",
"2 years",
"1 year",
"1 year",
"4 years",
"< 1 year",
"7 years",
"10+ years",
null,
"10+ years",
"4 years",
"8 years",
"10+ years",
"7 years",
"7 years",
"1 year",
"10+ years",
null,
"2 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"5 years",
"5 years",
"4 years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"2 years",
"4 years",
"10+ years",
"8 years",
"2 years",
"7 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"6 years",
"4 years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"10+ years",
null,
"10+ years",
"7 years",
"7 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"4 years",
"1 year",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"5 years",
"3 years",
"6 years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"7 years",
null,
"7 years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"2 years",
"8 years",
null,
"< 1 year",
null,
"3 years",
"7 years",
"2 years",
"9 years",
"2 years",
"3 years",
"10+ years",
"5 years",
"3 years",
"4 years",
"3 years",
"8 years",
"4 years",
"10+ years",
"3 years",
"8 years",
"2 years",
"10+ years",
"3 years",
null,
"10+ years",
"< 1 year",
null,
"1 year",
"1 year",
"2 years",
"10+ years",
"1 year",
"1 year",
"8 years",
"9 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
null,
null,
"10+ years",
"4 years",
"10+ years",
"5 years",
null,
"1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"3 years",
"7 years",
"8 years",
"5 years",
"3 years",
"10+ years",
"1 year",
"3 years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"9 years",
"2 years",
"2 years",
null,
"< 1 year",
null,
"10+ years",
"< 1 year",
"7 years",
"1 year",
"7 years",
"< 1 year",
"3 years",
"10+ years",
"1 year",
null,
"1 year",
"10+ years",
"4 years",
"10+ years",
"7 years",
"6 years",
"3 years",
"1 year",
"10+ years",
null,
"3 years",
"3 years",
"1 year",
"2 years",
"4 years",
"10+ years",
"9 years",
"2 years",
"6 years",
"10+ years",
"10+ years",
"8 years",
"3 years",
null,
"8 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"2 years",
"6 years",
null,
"10+ years",
"1 year",
"< 1 year",
"3 years",
"8 years",
"1 year",
null,
"10+ years",
"9 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"8 years",
"7 years",
"9 years",
null,
"10+ years",
"10+ years",
"2 years",
"3 years",
"7 years",
"9 years",
"7 years",
"4 years",
"10+ years",
"8 years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"4 years",
"8 years",
"1 year",
"3 years",
"10+ years",
"1 year",
"4 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"8 years",
"2 years",
"2 years",
"3 years",
"2 years",
"7 years",
"8 years",
"10+ years",
"4 years",
"5 years",
"6 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"8 years",
"4 years",
"3 years",
"2 years",
"1 year",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"1 year",
"7 years",
"7 years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"5 years",
"10+ years",
"1 year",
"2 years",
"4 years",
"1 year",
"2 years",
null,
"8 years",
"10+ years",
"4 years",
"< 1 year",
"6 years",
"8 years",
"7 years",
"1 year",
"5 years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"1 year",
"4 years",
"3 years",
"4 years",
"< 1 year",
"5 years",
"3 years",
"2 years",
"5 years",
"4 years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"3 years",
null,
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"5 years",
"8 years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"7 years",
"2 years",
"6 years",
"3 years",
"4 years",
"2 years",
"6 years",
"8 years",
"10+ years",
"10+ years",
"7 years",
"5 years",
"1 year",
"10+ years",
"7 years",
null,
"3 years",
"4 years",
"< 1 year",
"10+ years",
"2 years",
"9 years",
"2 years",
"1 year",
"10+ years",
"3 years",
"< 1 year",
"8 years",
"< 1 year",
"2 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
null,
"5 years",
"9 years",
"10+ years",
"5 years",
"4 years",
"10+ years",
"1 year",
"4 years",
"8 years",
"10+ years",
"8 years",
null,
"10+ years",
"10+ years",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
null,
"6 years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"3 years",
"6 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"3 years",
"< 1 year",
"10+ years",
"< 1 year",
"1 year",
"3 years",
"6 years",
"3 years",
"4 years",
"6 years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"6 years",
"10+ years",
"5 years",
"10+ years",
"8 years",
"1 year",
"3 years",
null,
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"< 1 year",
"8 years",
"< 1 year",
"10+ years",
"4 years",
"9 years",
null,
"3 years",
"< 1 year",
"5 years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"7 years",
"3 years",
"6 years",
"10+ years",
"10+ years",
"8 years",
"2 years",
"7 years",
"3 years",
"9 years",
"7 years",
"< 1 year",
"4 years",
"5 years",
"7 years",
"6 years",
"10+ years",
"2 years",
"10+ years",
"8 years",
"6 years",
"< 1 year",
"2 years",
"< 1 year",
"6 years",
null,
"< 1 year",
"< 1 year",
"8 years",
"9 years",
"10+ years",
"1 year",
"< 1 year",
"9 years",
"3 years",
"10+ years",
null,
"8 years",
"10+ years",
"6 years",
"2 years",
null,
"10+ years",
"4 years",
"8 years",
"< 1 year",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
null,
"4 years",
"2 years",
"4 years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"4 years",
"9 years",
null,
"2 years",
"10+ years",
null,
"5 years",
"7 years",
"1 year",
"10+ years",
"< 1 year",
"< 1 year",
"2 years",
"3 years",
"2 years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
null,
"10+ years",
"5 years",
null,
"10+ years",
"7 years",
"< 1 year",
"2 years",
"5 years",
null,
"7 years",
"5 years",
"3 years",
"1 year",
"1 year",
"7 years",
"7 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"5 years",
"< 1 year",
"10+ years",
"2 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"5 years",
"2 years",
"6 years",
"4 years",
"1 year",
"3 years",
"10+ years",
"3 years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"2 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"7 years",
"6 years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
null,
"< 1 year",
null,
"2 years",
"5 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"2 years",
"10+ years",
"2 years",
"5 years",
null,
"8 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
null,
"5 years",
"2 years",
"6 years",
"10+ years",
"1 year",
"2 years",
"9 years",
"7 years",
"3 years",
"5 years",
"4 years",
"5 years",
"3 years",
"5 years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"9 years",
"7 years",
"10+ years",
"10+ years",
"8 years",
"7 years",
"10+ years",
null,
"6 years",
null,
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"1 year",
null,
"10+ years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"2 years",
"< 1 year",
"5 years",
"1 year",
"4 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"7 years",
"< 1 year",
"< 1 year",
"10+ years",
"7 years",
"< 1 year",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
null,
"3 years",
"5 years",
null,
"7 years",
"3 years",
"< 1 year",
"4 years",
"1 year",
"5 years",
"< 1 year",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"6 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
null,
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"2 years",
"10+ years",
"1 year",
"4 years",
"10+ years",
"4 years",
null,
"3 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"9 years",
"1 year",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"2 years",
"3 years",
null,
"10+ years",
"10+ years",
"1 year",
"4 years",
"4 years",
"5 years",
null,
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"7 years",
null,
"2 years",
"< 1 year",
"6 years",
"2 years",
"10+ years",
"< 1 year",
"4 years",
"3 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
null,
null,
"6 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"6 years",
"4 years",
"10+ years",
null,
"< 1 year",
"8 years",
null,
"1 year",
"10+ years",
null,
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"3 years",
"4 years",
"9 years",
"10+ years",
"9 years",
"2 years",
"1 year",
"7 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
null,
"10+ years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
null,
"6 years",
"10+ years",
"10+ years",
"2 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
null,
"9 years",
"1 year",
"8 years",
"< 1 year",
"2 years",
"1 year",
"4 years",
"2 years",
null,
"< 1 year",
"10+ years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
null,
"5 years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"2 years",
"3 years",
"10+ years",
"1 year",
"2 years",
"2 years",
"8 years",
"3 years",
"4 years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"4 years",
"1 year",
"6 years",
"9 years",
"6 years",
"1 year",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"< 1 year",
"2 years",
"5 years",
"8 years",
"7 years",
"10+ years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"9 years",
"3 years",
"9 years",
"1 year",
"3 years",
"< 1 year",
"6 years",
"6 years",
"5 years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"2 years",
"7 years",
"10+ years",
"3 years",
"2 years",
"2 years",
"8 years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"1 year",
"1 year",
null,
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"4 years",
null,
"7 years",
"6 years",
"10+ years",
"2 years",
"7 years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"7 years",
"4 years",
"5 years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"6 years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"8 years",
"6 years",
null,
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"< 1 year",
"4 years",
"2 years",
"5 years",
"4 years",
"7 years",
"1 year",
"10+ years",
"7 years",
null,
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
null,
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"7 years",
"4 years",
"10+ years",
"< 1 year",
"3 years",
"4 years",
"< 1 year",
"4 years",
"10+ years",
"9 years",
"< 1 year",
"1 year",
"1 year",
"3 years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"8 years",
"2 years",
"9 years",
"10+ years",
"10+ years",
"9 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"4 years",
"10+ years",
"9 years",
"10+ years",
"4 years",
"1 year",
"3 years",
"10+ years",
"8 years",
"10+ years",
"4 years",
"6 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"< 1 year",
"3 years",
"2 years",
"7 years",
"5 years",
"8 years",
"1 year",
"10+ years",
"10+ years",
null,
"2 years",
null,
"5 years",
"5 years",
"3 years",
"10+ years",
"4 years",
"1 year",
"9 years",
"4 years",
"2 years",
"10+ years",
"1 year",
"1 year",
"< 1 year",
"10+ years",
"2 years",
"4 years",
"10+ years",
"< 1 year",
"3 years",
"9 years",
null,
"7 years",
"2 years",
"1 year",
"3 years",
"2 years",
"10+ years",
null,
null,
"5 years",
"1 year",
"6 years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"8 years",
null,
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"3 years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"2 years",
"6 years",
"2 years",
"1 year",
"3 years",
"2 years",
"7 years",
"2 years",
"4 years",
"3 years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"1 year",
"4 years",
"1 year",
"10+ years",
"2 years",
"5 years",
"10+ years",
null,
"1 year",
"7 years",
"3 years",
"< 1 year",
"9 years",
"10+ years",
"8 years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"7 years",
"5 years",
"4 years",
"10+ years",
"1 year",
"4 years",
"3 years",
"4 years",
null,
"4 years",
"4 years",
"10+ years",
null,
"7 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"6 years",
"4 years",
"4 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"1 year",
"7 years",
"10+ years",
"6 years",
"1 year",
"< 1 year",
"8 years",
"10+ years",
"1 year",
"10+ years",
"5 years",
"10+ years",
"6 years",
"3 years",
"6 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"7 years",
"7 years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"10+ years",
"7 years",
"10+ years",
"8 years",
null,
"7 years",
"2 years",
"4 years",
"9 years",
"10+ years",
"3 years",
"< 1 year",
"4 years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"3 years",
"2 years",
"2 years",
"3 years",
"9 years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"8 years",
"2 years",
"10+ years",
"8 years",
"9 years",
null,
"5 years",
"2 years",
"< 1 year",
"< 1 year",
"10+ years",
"2 years",
"2 years",
"3 years",
"6 years",
"10+ years",
null,
"10+ years",
"10+ years",
"4 years",
"2 years",
"8 years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"5 years",
"6 years",
"3 years",
"7 years",
"3 years",
"10+ years",
"1 year",
"7 years",
"3 years",
"5 years",
"10+ years",
"1 year",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"9 years",
"10+ years",
"9 years",
"10+ years",
"5 years",
"9 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"6 years",
"8 years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"6 years",
"10+ years",
"1 year",
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"2 years",
"< 1 year",
"2 years",
"9 years",
"< 1 year",
"8 years",
"5 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"< 1 year",
"6 years",
"10+ years",
"7 years",
"7 years",
"2 years",
"5 years",
"8 years",
"10+ years",
"7 years",
"1 year",
"9 years",
"3 years",
"2 years",
"3 years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"4 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
null,
"< 1 year",
"10+ years",
"6 years",
"4 years",
"2 years",
"8 years",
"< 1 year",
"3 years",
"7 years",
"2 years",
"10+ years",
"5 years",
"2 years",
"1 year",
"5 years",
"8 years",
"8 years",
"7 years",
"10+ years",
"< 1 year",
"3 years",
"< 1 year",
"4 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"7 years",
"7 years",
"6 years",
"10+ years",
"< 1 year",
"4 years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"7 years",
"< 1 year",
"10+ years",
"2 years",
"3 years",
"< 1 year",
"9 years",
"< 1 year",
"5 years",
"3 years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"3 years",
"8 years",
"10+ years",
"10+ years",
null,
"5 years",
"9 years",
"10+ years",
"8 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"< 1 year",
"8 years",
"7 years",
"9 years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"5 years",
"1 year",
"10+ years",
"9 years",
"6 years",
"< 1 year",
"7 years",
"7 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
null,
null,
"6 years",
"2 years",
"4 years",
"10+ years",
"4 years",
"2 years",
"8 years",
"8 years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
"3 years",
"< 1 year",
"3 years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"5 years",
"< 1 year",
"10+ years",
"< 1 year",
"8 years",
"2 years",
"7 years",
"< 1 year",
"3 years",
"5 years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"1 year",
"9 years",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"2 years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"8 years",
"< 1 year",
"5 years",
"10+ years",
"9 years",
"4 years",
"4 years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"8 years",
"4 years",
"5 years",
"7 years",
"< 1 year",
"7 years",
"< 1 year",
"3 years",
null,
"2 years",
"7 years",
"6 years",
"10+ years",
"5 years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"5 years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
null,
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"2 years",
"6 years",
"5 years",
"10+ years",
"5 years",
"< 1 year",
"1 year",
"10+ years",
"7 years",
"1 year",
"2 years",
"6 years",
"7 years",
"4 years",
"8 years",
"1 year",
"10+ years",
"8 years",
"4 years",
"7 years",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"8 years",
"5 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"7 years",
"3 years",
"9 years",
"9 years",
"6 years",
"1 year",
"2 years",
"4 years",
"2 years",
"< 1 year",
"9 years",
"10+ years",
"3 years",
"1 year",
null,
"8 years",
"6 years",
"2 years",
"7 years",
"10+ years",
null,
"1 year",
"10+ years",
"5 years",
"5 years",
"7 years",
"6 years",
"5 years",
"7 years",
"< 1 year",
"7 years",
"1 year",
"9 years",
null,
"3 years",
"< 1 year",
"3 years",
"3 years",
null,
"10+ years",
"10+ years",
"4 years",
"10+ years",
"7 years",
"2 years",
"< 1 year",
"5 years",
"8 years",
"2 years",
"10+ years",
null,
"10+ years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"2 years",
"< 1 year",
"5 years",
"5 years",
"4 years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"6 years",
"1 year",
null,
"10+ years",
"6 years",
"3 years",
"10+ years",
"9 years",
"9 years",
"3 years",
"7 years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"6 years",
"2 years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"< 1 year",
"10+ years",
"3 years",
"1 year",
"6 years",
"4 years",
"9 years",
"1 year",
"10+ years",
"4 years",
"5 years",
"8 years",
"3 years",
"9 years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"4 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"8 years",
"9 years",
"4 years",
"3 years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"8 years",
"5 years",
"9 years",
"10+ years",
"10+ years",
"1 year",
"7 years",
"10+ years",
"2 years",
"< 1 year",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"2 years",
"3 years",
"9 years",
"2 years",
"2 years",
"3 years",
"1 year",
null,
null,
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"< 1 year",
"10+ years",
"5 years",
"6 years",
"5 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"10+ years",
null,
"5 years",
"< 1 year",
"10+ years",
"2 years",
"3 years",
"5 years",
"< 1 year",
"2 years",
"6 years",
"5 years",
"1 year",
"8 years",
"6 years",
"2 years",
"4 years",
"9 years",
"10+ years",
"10+ years",
null,
"< 1 year",
"3 years",
"< 1 year",
"5 years",
"2 years",
"5 years",
"8 years",
null,
null,
"10+ years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"8 years",
"5 years",
"6 years",
"4 years",
"2 years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"5 years",
"3 years",
"10+ years",
"5 years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
null,
"8 years",
"4 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"6 years",
"2 years",
"2 years",
"< 1 year",
"9 years",
"2 years",
"10+ years",
"8 years",
null,
"5 years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"1 year",
"1 year",
null,
"10+ years",
"3 years",
"1 year",
"7 years",
"8 years",
"< 1 year",
"10+ years",
"2 years",
"2 years",
"4 years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"5 years",
"2 years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"7 years",
"10+ years",
"4 years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"9 years",
null,
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"7 years",
"7 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"6 years",
"< 1 year",
"8 years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"4 years",
"7 years",
"7 years",
"< 1 year",
"10+ years",
"3 years",
"8 years",
"2 years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"10+ years",
"8 years",
"2 years",
"2 years",
"6 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"2 years",
null,
"2 years",
"5 years",
"9 years",
"7 years",
"5 years",
"2 years",
"9 years",
"3 years",
"3 years",
null,
"10+ years",
"< 1 year",
"3 years",
null,
"10+ years",
"10+ years",
"6 years",
"4 years",
"10+ years",
"9 years",
"10+ years",
"7 years",
"6 years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"< 1 year",
"< 1 year",
"5 years",
"5 years",
"3 years",
"10+ years",
null,
"5 years",
null,
"5 years",
"6 years",
"< 1 year",
"< 1 year",
"9 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"1 year",
"3 years",
"10+ years",
"5 years",
"5 years",
"7 years",
null,
"9 years",
"7 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"2 years",
"9 years",
"9 years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"5 years",
"10+ years",
null,
null,
"10+ years",
"6 years",
"< 1 year",
"7 years",
"8 years",
"3 years",
"8 years",
"3 years",
null,
"10+ years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"10+ years",
"3 years",
"8 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"1 year",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"7 years",
null,
"9 years",
"1 year",
"10+ years",
"2 years",
"< 1 year",
null,
"6 years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"6 years",
"6 years",
"10+ years",
"3 years",
"2 years",
"1 year",
"10+ years",
"1 year",
"2 years",
"1 year",
"9 years",
"10+ years",
"10+ years",
null,
"4 years",
"10+ years",
"10+ years",
null,
"5 years",
null,
"6 years",
"8 years",
"7 years",
"6 years",
"9 years",
"10+ years",
"6 years",
"10+ years",
"9 years",
"4 years",
"2 years",
"2 years",
"< 1 year",
"2 years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"8 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"9 years",
"4 years",
"8 years",
"< 1 year",
null,
"9 years",
"9 years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"4 years",
"5 years",
"6 years",
"8 years",
"5 years",
"2 years",
"1 year",
"10+ years",
null,
"9 years",
"6 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"2 years",
"2 years",
"1 year",
"4 years",
"6 years",
"10+ years",
"10+ years",
"9 years",
null,
"2 years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"6 years",
"1 year",
"2 years",
"1 year",
"5 years",
"3 years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
null,
"10+ years",
"7 years",
"9 years",
"2 years",
"1 year",
"< 1 year",
null,
"5 years",
"2 years",
null,
"10+ years",
"10+ years",
"8 years",
"1 year",
"3 years",
"1 year",
"< 1 year",
"6 years",
"4 years",
"< 1 year",
"8 years",
"10+ years",
"5 years",
"10+ years",
"1 year",
null,
"10+ years",
"< 1 year",
"3 years",
"< 1 year",
"2 years",
"8 years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"5 years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"7 years",
"5 years",
"7 years",
"10+ years",
null,
"5 years",
"2 years",
"6 years",
"7 years",
"2 years",
"10+ years",
"1 year",
"8 years",
"4 years",
"< 1 year",
null,
"9 years",
"8 years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"7 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"8 years",
"1 year",
"6 years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"5 years",
"10+ years",
"4 years",
"8 years",
"< 1 year",
"4 years",
"2 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
null,
"3 years",
"8 years",
"10+ years",
"9 years",
"5 years",
"8 years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"2 years",
"4 years",
"7 years",
"1 year",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"5 years",
"5 years",
"10+ years",
"6 years",
"1 year",
"10+ years",
null,
"10+ years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"3 years",
"4 years",
"2 years",
"1 year",
"5 years",
"2 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"1 year",
"10+ years",
"8 years",
"2 years",
"10+ years",
"4 years",
"5 years",
"4 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"8 years",
"8 years",
"4 years",
"10+ years",
"10+ years",
"6 years",
"5 years",
"3 years",
"10+ years",
"1 year",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"2 years",
"1 year",
"8 years",
"10+ years",
"1 year",
"3 years",
"7 years",
"10+ years",
"6 years",
"3 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"2 years",
"< 1 year",
"10+ years",
null,
"< 1 year",
"10+ years",
null,
"10+ years",
"10+ years",
null,
"10+ years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"10+ years",
null,
"10+ years",
"10+ years",
"3 years",
"5 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"7 years",
"3 years",
"< 1 year",
"< 1 year",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"5 years",
"3 years",
null,
"6 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
null,
"8 years",
"10+ years",
"4 years",
"4 years",
"7 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"1 year",
"4 years",
"5 years",
"< 1 year",
"7 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"9 years",
"2 years",
"8 years",
"< 1 year",
"< 1 year",
"< 1 year",
"1 year",
"2 years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"4 years",
"4 years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"8 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"1 year",
"7 years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"2 years",
"10+ years",
"1 year",
"2 years",
"3 years",
"6 years",
"9 years",
"10+ years",
"8 years",
"3 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"8 years",
"9 years",
"9 years",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
null,
"8 years",
"7 years",
"2 years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"< 1 year",
"< 1 year",
"4 years",
"< 1 year",
"7 years",
"2 years",
"< 1 year",
"10+ years",
"9 years",
"4 years",
"3 years",
"3 years",
"10+ years",
"2 years",
"5 years",
"7 years",
"3 years",
"2 years",
null,
"5 years",
"4 years",
"4 years",
"9 years",
"5 years",
null,
"2 years",
"10+ years",
null,
"10+ years",
"5 years",
null,
"4 years",
"5 years",
"10+ years",
null,
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"10+ years",
null,
"10+ years",
"< 1 year",
"4 years",
null,
"2 years",
"7 years",
"2 years",
"10+ years",
"6 years",
"8 years",
"10+ years",
"8 years",
"10+ years",
"1 year",
"< 1 year",
null,
"10+ years",
"6 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"2 years",
null,
null,
"7 years",
"1 year",
"< 1 year",
"8 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"4 years",
"< 1 year",
"10+ years",
"3 years",
"8 years",
"2 years",
"6 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"1 year",
"8 years",
"8 years",
"10+ years",
"2 years",
"8 years",
"9 years",
"2 years",
"7 years",
"3 years",
"2 years",
"< 1 year",
"7 years",
"10+ years",
"9 years",
"2 years",
"5 years",
null,
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
null,
"7 years",
"10+ years",
null,
null,
"7 years",
"3 years",
"2 years",
"10+ years",
"< 1 year",
"< 1 year",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"< 1 year",
"10+ years",
"5 years",
"9 years",
"1 year",
"10+ years",
"7 years",
"4 years",
"1 year",
"10+ years",
"5 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"4 years",
"1 year",
"< 1 year",
"3 years",
null,
"1 year",
"7 years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"10+ years",
"4 years",
"3 years",
"10+ years",
"8 years",
"2 years",
"1 year",
"4 years",
"2 years",
"10+ years",
"6 years",
"< 1 year",
"8 years",
"10+ years",
"3 years",
"5 years",
"2 years",
"4 years",
"6 years",
"5 years",
"8 years",
"< 1 year",
"10+ years",
"3 years",
"3 years",
"3 years",
"10+ years",
"4 years",
"4 years",
"10+ years",
"2 years",
"8 years",
"9 years",
"8 years",
"10+ years",
"4 years",
null,
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
null,
"1 year",
"10+ years",
"4 years",
"3 years",
"5 years",
"1 year",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"5 years",
"6 years",
"7 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"1 year",
"5 years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
null,
"3 years",
"10+ years",
"10+ years",
"9 years",
"2 years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
null,
null,
null,
"7 years",
"7 years",
"10+ years",
"6 years",
"3 years",
"4 years",
"< 1 year",
"2 years",
"2 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"3 years",
"2 years",
"4 years",
"8 years",
"4 years",
"< 1 year",
null,
null,
"10+ years",
"3 years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"7 years",
"4 years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"3 years",
"7 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"10+ years",
null,
"9 years",
"10+ years",
"6 years",
"10+ years",
null,
null,
"5 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"7 years",
"6 years",
"1 year",
"3 years",
"2 years",
"2 years",
"10+ years",
"5 years",
"6 years",
"10+ years",
"1 year",
"10+ years",
"6 years",
"< 1 year",
"4 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"5 years",
"1 year",
"< 1 year",
"10+ years",
"1 year",
"1 year",
"10+ years",
"7 years",
"3 years",
"< 1 year",
"10+ years",
"4 years",
null,
"< 1 year",
"6 years",
null,
"2 years",
"4 years",
"1 year",
"7 years",
"10+ years",
null,
"5 years",
"2 years",
"8 years",
"8 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"10+ years",
null,
"4 years",
"5 years",
"5 years",
"9 years",
"10+ years",
"3 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"9 years",
"4 years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
null,
"9 years",
"2 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"< 1 year",
"4 years",
"5 years",
"10+ years",
"7 years",
"5 years",
"6 years",
"6 years",
"2 years",
"< 1 year",
"3 years",
"8 years",
"8 years",
"5 years",
"10+ years",
"3 years",
"< 1 year",
"4 years",
"4 years",
"2 years",
"8 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"9 years",
"10+ years",
"7 years",
"3 years",
"5 years",
"6 years",
"4 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"6 years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"< 1 year",
"4 years",
"7 years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"5 years",
"1 year",
"1 year",
"4 years",
"3 years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"10+ years",
null,
"3 years",
"3 years",
"10+ years",
"1 year",
"4 years",
"1 year",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"2 years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"6 years",
"7 years",
"2 years",
null,
"9 years",
null,
"2 years",
"< 1 year",
"9 years",
"2 years",
"8 years",
"2 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"2 years",
"9 years",
"6 years",
"10+ years",
"1 year",
"4 years",
"9 years",
"5 years",
"9 years",
"< 1 year",
"9 years",
"2 years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"5 years",
null,
"4 years",
"6 years",
"6 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"3 years",
"7 years",
"1 year",
"3 years",
"3 years",
"4 years",
"3 years",
"2 years",
"1 year",
"3 years",
null,
"7 years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"6 years",
"3 years",
"8 years",
"1 year",
null,
"10+ years",
"8 years",
"10+ years",
"6 years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"5 years",
"9 years",
"3 years",
"5 years",
null,
"10+ years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"2 years",
"10+ years",
"2 years",
"< 1 year",
"1 year",
"1 year",
"2 years",
"3 years",
"< 1 year",
"5 years",
"2 years",
"10+ years",
"3 years",
"9 years",
"10+ years",
"8 years",
"6 years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"9 years",
null,
"7 years",
"1 year",
"7 years",
"7 years",
"8 years",
"5 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"< 1 year",
"< 1 year",
"3 years",
"< 1 year",
"5 years",
"8 years",
"5 years",
"1 year",
"5 years",
"< 1 year",
"8 years",
"4 years",
"6 years",
"1 year",
"2 years",
"5 years",
"10+ years",
"6 years",
"3 years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
null,
"5 years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"2 years",
"4 years",
"2 years",
"10+ years",
"2 years",
"7 years",
"2 years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"< 1 year",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"5 years",
"6 years",
"5 years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"8 years",
"6 years",
"7 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"1 year",
"4 years",
"9 years",
"10+ years",
"< 1 year",
null,
"6 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"6 years",
"2 years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"3 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
null,
"1 year",
"7 years",
null,
null,
"2 years",
"10+ years",
"5 years",
"6 years",
"3 years",
"10+ years",
"3 years",
"6 years",
"1 year",
"7 years",
"1 year",
"2 years",
"8 years",
"2 years",
"4 years",
"10+ years",
"10+ years",
null,
null,
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"8 years",
"6 years",
"3 years",
"2 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
null,
null,
"9 years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"6 years",
"2 years",
"10+ years",
"2 years",
"7 years",
"5 years",
"10+ years",
"1 year",
"9 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"8 years",
"9 years",
"2 years",
"6 years",
"< 1 year",
"5 years",
null,
"6 years",
"10+ years",
"8 years",
"8 years",
"2 years",
"10+ years",
"4 years",
"2 years",
"3 years",
"1 year",
"2 years",
"< 1 year",
"9 years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"1 year",
null,
"1 year",
"2 years",
"10+ years",
"10+ years",
"8 years",
"2 years",
"8 years",
"8 years",
"10+ years",
"6 years",
"3 years",
"< 1 year",
"7 years",
"3 years",
"2 years",
"8 years",
"2 years",
"10+ years",
"2 years",
"3 years",
"4 years",
"10+ years",
"2 years",
"4 years",
"9 years",
"7 years",
"2 years",
"< 1 year",
"< 1 year",
"10+ years",
"< 1 year",
"1 year",
"2 years",
"10+ years",
"8 years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"6 years",
"3 years",
null,
"6 years",
"4 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"6 years",
"6 years",
"7 years",
"10+ years",
"3 years",
null,
"5 years",
"10+ years",
"6 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"7 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"5 years",
"6 years",
"2 years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"2 years",
"7 years",
"3 years",
"3 years",
"4 years",
"4 years",
"7 years",
"5 years",
"10+ years",
"9 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"7 years",
"4 years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"9 years",
null,
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"9 years",
"7 years",
"1 year",
"< 1 year",
"5 years",
"6 years",
"5 years",
"9 years",
"5 years",
"5 years",
null,
"5 years",
"10+ years",
"1 year",
"3 years",
"6 years",
"7 years",
"2 years",
"10+ years",
"< 1 year",
"3 years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"< 1 year",
"3 years",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"3 years",
"9 years",
"10+ years",
null,
"3 years",
"8 years",
"10+ years",
"6 years",
null,
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"4 years",
"3 years",
"6 years",
"10+ years",
"2 years",
"9 years",
"5 years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
null,
"8 years",
"1 year",
"3 years",
"1 year",
"3 years",
"6 years",
"10+ years",
"4 years",
null,
"4 years",
"10+ years",
"10+ years",
"6 years",
"4 years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"8 years",
null,
"1 year",
"4 years",
"10+ years",
"3 years",
"< 1 year",
"7 years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"6 years",
"5 years",
"2 years",
"10+ years",
"6 years",
"1 year",
"2 years",
null,
"10+ years",
"3 years",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"8 years",
"10+ years",
"4 years",
null,
"10+ years",
null,
"10+ years",
null,
"4 years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"4 years",
"6 years",
"4 years",
"8 years",
"1 year",
"7 years",
"< 1 year",
"7 years",
"6 years",
"9 years",
"10+ years",
"2 years",
"1 year",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"7 years",
"10+ years",
"6 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"8 years",
null,
"10+ years",
"1 year",
"3 years",
"10+ years",
"1 year",
"7 years",
"10+ years",
"1 year",
"5 years",
"10+ years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"1 year",
"8 years",
"7 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"7 years",
"2 years",
"< 1 year",
"1 year",
"1 year",
"5 years",
"4 years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"8 years",
"2 years",
"1 year",
"10+ years",
"1 year",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"9 years",
"2 years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"5 years",
"7 years",
"9 years",
"6 years",
"5 years",
"< 1 year",
"2 years",
"< 1 year",
"9 years",
"4 years",
"10+ years",
"2 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"2 years",
"7 years",
"7 years",
null,
"< 1 year",
"6 years",
"10+ years",
"7 years",
"3 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"9 years",
"2 years",
"< 1 year",
"1 year",
"5 years",
"< 1 year",
"9 years",
"2 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"1 year",
"3 years",
"10+ years",
"5 years",
"4 years",
"5 years",
"8 years",
"10+ years",
null,
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"4 years",
null,
"3 years",
"10+ years",
null,
null,
"6 years",
"< 1 year",
"8 years",
"10+ years",
"1 year",
"< 1 year",
null,
"10+ years",
null,
"10+ years",
"3 years",
"10+ years",
"1 year",
"5 years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"3 years",
"6 years",
"< 1 year",
"1 year",
"7 years",
"10+ years",
"2 years",
"< 1 year",
"3 years",
"< 1 year",
"3 years",
"2 years",
"3 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"5 years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"5 years",
"9 years",
"4 years",
"1 year",
"10+ years",
"8 years",
"10+ years",
"1 year",
null,
"10+ years",
"2 years",
"10+ years",
"4 years",
"2 years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"9 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"4 years",
"10+ years",
"1 year",
"10+ years",
null,
"10+ years",
"4 years",
"10+ years",
"5 years",
"10+ years",
"9 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"2 years",
"3 years",
"< 1 year",
"< 1 year",
"10+ years",
"5 years",
null,
"6 years",
"1 year",
"5 years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"9 years",
"8 years",
"8 years",
"6 years",
null,
"6 years",
"7 years",
"< 1 year",
null,
"10+ years",
"10+ years",
"3 years",
"10+ years",
null,
"8 years",
"9 years",
"8 years",
"5 years",
"5 years",
null,
"2 years",
"2 years",
"5 years",
"10+ years",
"2 years",
"2 years",
"1 year",
"8 years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"3 years",
"3 years",
null,
"10+ years",
"4 years",
null,
"10+ years",
"10+ years",
null,
"10+ years",
"6 years",
"10+ years",
"9 years",
"< 1 year",
"5 years",
"8 years",
"1 year",
"9 years",
"8 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"1 year",
"4 years",
"< 1 year",
"10+ years",
"2 years",
"3 years",
"10+ years",
"3 years",
"3 years",
"1 year",
"8 years",
"< 1 year",
"< 1 year",
"5 years",
null,
"10+ years",
"1 year",
"3 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"< 1 year",
"6 years",
"7 years",
"3 years",
"9 years",
"10+ years",
"9 years",
"2 years",
"6 years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"2 years",
"4 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
null,
"< 1 year",
"4 years",
"1 year",
"1 year",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"7 years",
"10+ years",
null,
"7 years",
"10+ years",
"9 years",
"5 years",
"5 years",
"1 year",
"< 1 year",
"< 1 year",
"5 years",
"2 years",
"6 years",
"2 years",
null,
"6 years",
"4 years",
"7 years",
"3 years",
"2 years",
"4 years",
"10+ years",
"5 years",
"3 years",
"4 years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"6 years",
"< 1 year",
"9 years",
"4 years",
"3 years",
"3 years",
"< 1 year",
"8 years",
"3 years",
"5 years",
"5 years",
"10+ years",
"10+ years",
null,
null,
"10+ years",
"8 years",
"10+ years",
"8 years",
"9 years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"7 years",
"6 years",
"2 years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
null,
"2 years",
"7 years",
"3 years",
"1 year",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"7 years",
"6 years",
"10+ years",
"< 1 year",
null,
"4 years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
null,
"1 year",
"10+ years",
"10+ years",
"2 years",
null,
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
null,
"10+ years",
"7 years",
"2 years",
"2 years",
"7 years",
"2 years",
"1 year",
null,
"10+ years",
"10+ years",
"4 years",
"4 years",
"5 years",
"< 1 year",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"6 years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"7 years",
"2 years",
null,
"10+ years",
"9 years",
"1 year",
"2 years",
"2 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"8 years",
"3 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"5 years",
"2 years",
"6 years",
"4 years",
"1 year",
"10+ years",
"6 years",
"10+ years",
"5 years",
"< 1 year",
"3 years",
null,
"2 years",
"7 years",
"1 year",
"5 years",
"3 years",
"10+ years",
"5 years",
null,
"8 years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"10+ years",
"7 years",
"< 1 year",
"3 years",
"4 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
null,
"7 years",
"1 year",
"9 years",
"8 years",
"9 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"5 years",
"7 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
null,
"10+ years",
"8 years",
"7 years",
null,
"7 years",
"7 years",
"1 year",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"5 years",
"4 years",
"9 years",
"1 year",
"< 1 year",
"8 years",
"8 years",
"5 years",
"10+ years",
"6 years",
"3 years",
"8 years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"6 years",
"8 years",
"6 years",
"10+ years",
"4 years",
"< 1 year",
"< 1 year",
"8 years",
"10+ years",
"4 years",
"1 year",
"3 years",
"1 year",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"3 years",
"9 years",
"< 1 year",
"10+ years",
"1 year",
"5 years",
"7 years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"3 years",
"3 years",
"5 years",
"< 1 year",
"8 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"4 years",
"6 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"6 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"9 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"6 years",
"5 years",
"5 years",
"3 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"9 years",
"10+ years",
"1 year",
"2 years",
null,
"2 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"1 year",
"9 years",
"5 years",
"< 1 year",
"3 years",
"3 years",
"< 1 year",
"9 years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"6 years",
"5 years",
"9 years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"5 years",
"9 years",
"7 years",
"1 year",
"10+ years",
null,
"10+ years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"7 years",
"10+ years",
"5 years",
"6 years",
"< 1 year",
"9 years",
"6 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"1 year",
"3 years",
"1 year",
"10+ years",
null,
"3 years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
null,
"7 years",
"6 years",
"8 years",
"10+ years",
"8 years",
"10+ years",
"7 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"10+ years",
"9 years",
"< 1 year",
null,
null,
"10+ years",
"2 years",
"10+ years",
"1 year",
"10+ years",
null,
null,
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"2 years",
"10+ years",
"5 years",
"9 years",
"4 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"7 years",
"2 years",
"10+ years",
null,
"10+ years",
"10+ years",
"1 year",
"6 years",
"7 years",
"4 years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"1 year",
"2 years",
"3 years",
"10+ years",
"2 years",
"2 years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"3 years",
"< 1 year",
"1 year",
"4 years",
"6 years",
"7 years",
"10+ years",
"10+ years",
"3 years",
"9 years",
"10+ years",
"6 years",
"6 years",
"< 1 year",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
null,
"10+ years",
"3 years",
"1 year",
"10+ years",
"5 years",
"10+ years",
"6 years",
"< 1 year",
"10+ years",
null,
null,
"5 years",
"3 years",
"10+ years",
"7 years",
"2 years",
"3 years",
"1 year",
"3 years",
"10+ years",
null,
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"5 years",
"5 years",
"5 years",
"7 years",
"8 years",
"9 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"1 year",
"3 years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"4 years",
"2 years",
null,
"10+ years",
"6 years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"1 year",
"9 years",
"10+ years",
null,
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"6 years",
"3 years",
"10+ years",
"6 years",
null,
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"9 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"7 years",
null,
"10+ years",
"6 years",
"2 years",
"10+ years",
"9 years",
"9 years",
"< 1 year",
null,
"9 years",
"10+ years",
null,
"1 year",
"10+ years",
"4 years",
"1 year",
"5 years",
"4 years",
"6 years",
null,
"2 years",
"5 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
null,
"7 years",
"1 year",
"4 years",
"< 1 year",
"10+ years",
"1 year",
"2 years",
"4 years",
"7 years",
"7 years",
"1 year",
"8 years",
"7 years",
"2 years",
"9 years",
"8 years",
"2 years",
"3 years",
"9 years",
"1 year",
null,
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"1 year",
"3 years",
"7 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"2 years",
"2 years",
"10+ years",
"8 years",
"7 years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"7 years",
"3 years",
"5 years",
"10+ years",
null,
"10+ years",
"6 years",
"7 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"1 year",
"10+ years",
"2 years",
"4 years",
"8 years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"8 years",
"1 year",
"10+ years",
"10+ years",
"7 years",
"2 years",
"6 years",
"7 years",
"3 years",
"2 years",
"< 1 year",
"5 years",
"7 years",
"7 years",
"10+ years",
"5 years",
"9 years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
null,
"1 year",
"< 1 year",
"10+ years",
null,
"4 years",
"9 years",
"7 years",
"5 years",
"10+ years",
"10+ years",
null,
"7 years",
"10+ years",
"< 1 year",
"2 years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"6 years",
"2 years",
"< 1 year",
"10+ years",
null,
"2 years",
"1 year",
"7 years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"10+ years",
"4 years",
"7 years",
null,
"10+ years",
"6 years",
"6 years",
"3 years",
"8 years",
"< 1 year",
null,
"3 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
null,
null,
"4 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"6 years",
"10+ years",
"7 years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"1 year",
"4 years",
"10+ years",
"10+ years",
"6 years",
"< 1 year",
"3 years",
"7 years",
"9 years",
"8 years",
null,
"6 years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"1 year",
"5 years",
null,
"< 1 year",
"7 years",
null,
"10+ years",
"3 years",
null,
"10+ years",
"4 years",
"2 years",
null,
"< 1 year",
"2 years",
"< 1 year",
"9 years",
"3 years",
"1 year",
null,
"5 years",
"8 years",
"1 year",
"2 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"6 years",
"3 years",
"6 years",
"< 1 year",
"5 years",
"5 years",
"5 years",
"6 years",
"2 years",
"4 years",
"10+ years",
"1 year",
"8 years",
"< 1 year",
null,
"4 years",
"9 years",
"< 1 year",
"3 years",
"1 year",
"2 years",
"1 year",
"10+ years",
"10+ years",
"5 years",
null,
"6 years",
"3 years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"2 years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"8 years",
"5 years",
"5 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"5 years",
"5 years",
"9 years",
"5 years",
"< 1 year",
"1 year",
"10+ years",
"2 years",
"8 years",
"1 year",
"< 1 year",
"1 year",
"4 years",
"< 1 year",
"5 years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
null,
"6 years",
"< 1 year",
null,
"< 1 year",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"6 years",
"4 years",
"2 years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"8 years",
"10+ years",
"10+ years",
"5 years",
null,
"5 years",
"5 years",
"6 years",
"10+ years",
"10+ years",
"9 years",
"3 years",
"5 years",
"< 1 year",
"10+ years",
"6 years",
"1 year",
"2 years",
"8 years",
"< 1 year",
"3 years",
"< 1 year",
"7 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"3 years",
"10+ years",
"8 years",
"2 years",
"6 years",
"9 years",
"1 year",
"9 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"7 years",
"4 years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"5 years",
"6 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"6 years",
"4 years",
"3 years",
"8 years",
"4 years",
"10+ years",
"6 years",
"< 1 year",
"10+ years",
"9 years",
"9 years",
"< 1 year",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"< 1 year",
null,
null,
null,
"2 years",
"6 years",
"3 years",
"4 years",
"1 year",
"3 years",
"10+ years",
"7 years",
"5 years",
"2 years",
"3 years",
"8 years",
null,
"10+ years",
"< 1 year",
"1 year",
"9 years",
"10+ years",
"8 years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"7 years",
"7 years",
"10+ years",
"< 1 year",
"9 years",
"5 years",
"6 years",
"6 years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"7 years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"4 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"10+ years",
"3 years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"2 years",
"5 years",
"9 years",
"3 years",
"10+ years",
"3 years",
"1 year",
"3 years",
"2 years",
"9 years",
"10+ years",
null,
"10+ years",
"7 years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"4 years",
"1 year",
"9 years",
"< 1 year",
"3 years",
null,
"< 1 year",
"10+ years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"5 years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"8 years",
"10+ years",
"8 years",
"10+ years",
"4 years",
"6 years",
null,
"4 years",
"2 years",
"< 1 year",
"3 years",
"10+ years",
"2 years",
"4 years",
"6 years",
null,
"3 years",
"9 years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"1 year",
"2 years",
"4 years",
"4 years",
"10+ years",
"8 years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"1 year",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"6 years",
"3 years",
"10+ years",
"3 years",
"5 years",
"5 years",
"1 year",
"10+ years",
"6 years",
"2 years",
"2 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"6 years",
null,
"10+ years",
"5 years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"1 year",
null,
"4 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"9 years",
"7 years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"5 years",
"10+ years",
"3 years",
"1 year",
"6 years",
"10+ years",
"9 years",
"4 years",
null,
"2 years",
"10+ years",
"7 years",
"4 years",
"3 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"4 years",
"6 years",
"9 years",
"10+ years",
"1 year",
"2 years",
"2 years",
"10+ years",
"2 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"3 years",
"3 years",
"9 years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"8 years",
"3 years",
"3 years",
"< 1 year",
"3 years",
"7 years",
"< 1 year",
"6 years",
"3 years",
"< 1 year",
"10+ years",
"2 years",
null,
"1 year",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"2 years",
"7 years",
"8 years",
"10+ years",
"7 years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"6 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"7 years",
null,
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"1 year",
"7 years",
"9 years",
"6 years",
"5 years",
"9 years",
"6 years",
"10+ years",
"2 years",
"< 1 year",
"3 years",
"6 years",
"4 years",
"4 years",
"6 years",
"2 years",
"4 years",
"8 years",
"2 years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"< 1 year",
"< 1 year",
"7 years",
"10+ years",
"1 year",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"2 years",
"3 years",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"9 years",
"2 years",
"9 years",
"4 years",
"4 years",
"10+ years",
"8 years",
"8 years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"2 years",
"2 years",
"1 year",
"2 years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"3 years",
null,
"10+ years",
"10+ years",
"8 years",
"5 years",
"< 1 year",
"3 years",
"3 years",
null,
"10+ years",
"6 years",
"10+ years",
null,
"3 years",
null,
"10+ years",
"6 years",
"9 years",
"< 1 year",
"9 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"2 years",
"9 years",
"2 years",
"3 years",
"1 year",
"3 years",
"8 years",
"2 years",
"5 years",
"10+ years",
null,
"2 years",
"10+ years",
"8 years",
"9 years",
"9 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"4 years",
"2 years",
"1 year",
"5 years",
null,
"10+ years",
"10+ years",
"9 years",
"1 year",
"2 years",
"10+ years",
"6 years",
"1 year",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"2 years",
null,
"< 1 year",
null,
"10+ years",
"5 years",
"10+ years",
"4 years",
null,
"< 1 year",
"3 years",
"2 years",
"10+ years",
"5 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"6 years",
"10+ years",
"10+ years",
"2 years",
"7 years",
"1 year",
"4 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"9 years",
"6 years",
null,
"10+ years",
"6 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"4 years",
"8 years",
"8 years",
"10+ years",
"7 years",
"9 years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"9 years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"9 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"3 years",
"4 years",
"5 years",
"6 years",
"9 years",
"8 years",
"10+ years",
"10+ years",
null,
"8 years",
"< 1 year",
"2 years",
"10+ years",
"2 years",
"9 years",
null,
"10+ years",
"< 1 year",
null,
"3 years",
"9 years",
"10+ years",
"7 years",
"8 years",
null,
"7 years",
"10+ years",
"10+ years",
"1 year",
"4 years",
"9 years",
"10+ years",
"4 years",
"3 years",
"< 1 year",
"10+ years",
null,
"10+ years",
"7 years",
"10+ years",
"1 year",
"10+ years",
"4 years",
"4 years",
"< 1 year",
"2 years",
"10+ years",
"2 years",
"3 years",
"< 1 year",
"10+ years",
"2 years",
"8 years",
"10+ years",
"9 years",
"< 1 year",
"8 years",
"7 years",
"3 years",
"4 years",
"10+ years",
"9 years",
null,
"4 years",
"5 years",
"< 1 year",
"10+ years",
"6 years",
"5 years",
"6 years",
"3 years",
"2 years",
"2 years",
"10+ years",
"3 years",
"6 years",
"6 years",
"10+ years",
"1 year",
"9 years",
"3 years",
"< 1 year",
"6 years",
"10+ years",
null,
"10+ years",
"5 years",
null,
"10+ years",
"6 years",
"10+ years",
null,
"1 year",
"7 years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"9 years",
"9 years",
"10+ years",
"10+ years",
"5 years",
"6 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"7 years",
"3 years",
"4 years",
"7 years",
null,
"< 1 year",
"< 1 year",
"10+ years",
"4 years",
"2 years",
"2 years",
"8 years",
"10+ years",
"4 years",
"2 years",
"4 years",
"10+ years",
"1 year",
"10+ years",
"8 years",
"1 year",
"5 years",
"8 years",
"10+ years",
"3 years",
"4 years",
"7 years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
null,
null,
"9 years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"9 years",
null,
"6 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"2 years",
null,
"10+ years",
"5 years",
"10+ years",
"4 years",
"7 years",
"6 years",
null,
"10+ years",
"4 years",
"3 years",
"1 year",
"7 years",
"< 1 year",
"3 years",
"10+ years",
"7 years",
"< 1 year",
"8 years",
"2 years",
"10+ years",
null,
"6 years",
"3 years",
"1 year",
"3 years",
"8 years",
"< 1 year",
"1 year",
"8 years",
"10+ years",
"8 years",
"9 years",
"3 years",
"8 years",
"2 years",
"2 years",
"2 years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"1 year",
null,
"10+ years",
"1 year",
"3 years",
"1 year",
"< 1 year",
"10+ years",
"1 year",
null,
"7 years",
"10+ years",
"< 1 year",
null,
"2 years",
"10+ years",
"9 years",
"< 1 year",
"1 year",
"8 years",
"5 years",
"10+ years",
"7 years",
null,
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"6 years",
"1 year",
"9 years",
"7 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"2 years",
"3 years",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"7 years",
"10+ years",
"7 years",
"4 years",
"3 years",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"9 years",
"1 year",
"8 years",
"10+ years",
"1 year",
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
null,
"< 1 year",
"10+ years",
"6 years",
"< 1 year",
"10+ years",
"< 1 year",
"2 years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
null,
"5 years",
"3 years",
"2 years",
"10+ years",
"5 years",
"5 years",
"10+ years",
"3 years",
"5 years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
null,
"< 1 year",
"3 years",
"6 years",
"6 years",
"8 years",
"8 years",
"6 years",
"7 years",
null,
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"< 1 year",
"2 years",
"4 years",
"3 years",
"5 years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"6 years",
"< 1 year",
"8 years",
"< 1 year",
"1 year",
null,
"2 years",
"< 1 year",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"4 years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"2 years",
"< 1 year",
"4 years",
"6 years",
"8 years",
"10+ years",
"1 year",
"3 years",
"2 years",
"10+ years",
"8 years",
"5 years",
"4 years",
"< 1 year",
"5 years",
"4 years",
"1 year",
"1 year",
"10+ years",
"8 years",
"4 years",
"3 years",
"1 year",
null,
"1 year",
"3 years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"10+ years",
"1 year",
"5 years",
"10+ years",
"6 years",
"8 years",
"10+ years",
"10+ years",
"8 years",
"9 years",
"7 years",
"4 years",
"10+ years",
"7 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"4 years",
"9 years",
"10+ years",
"10+ years",
"6 years",
"8 years",
"2 years",
null,
"9 years",
"10+ years",
"5 years",
"8 years",
"10+ years",
"2 years",
"2 years",
"4 years",
"3 years",
"2 years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"6 years",
"10+ years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"4 years",
"1 year",
"6 years",
"8 years",
"4 years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
null,
"4 years",
"3 years",
"10+ years",
"7 years",
"4 years",
"5 years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"< 1 year",
"8 years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"1 year",
null,
"5 years",
"10+ years",
"< 1 year",
"< 1 year",
"6 years",
"< 1 year",
"7 years",
"3 years",
"7 years",
"3 years",
"10+ years",
"7 years",
"5 years",
"1 year",
"7 years",
null,
"3 years",
"10+ years",
null,
"8 years",
"10+ years",
"10+ years",
null,
"2 years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"2 years",
"1 year",
"8 years",
"9 years",
"10+ years",
"7 years",
"3 years",
"2 years",
"8 years",
"1 year",
"10+ years",
"1 year",
"4 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"2 years",
"3 years",
"5 years",
"3 years",
"9 years",
"10+ years",
"3 years",
"7 years",
"9 years",
"< 1 year",
"3 years",
"10+ years",
"2 years",
"2 years",
"< 1 year",
"10+ years",
null,
"10+ years",
"5 years",
"5 years",
"10+ years",
"1 year",
"3 years",
"6 years",
"10+ years",
"10+ years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"7 years",
"5 years",
"8 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"9 years",
"5 years",
"10+ years",
"3 years",
"3 years",
"< 1 year",
"10+ years",
"1 year",
"8 years",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"4 years",
"1 year",
"1 year",
"3 years",
"8 years",
"6 years",
"2 years",
"4 years",
"10+ years",
"3 years",
"5 years",
"4 years",
null,
"2 years",
"7 years",
"3 years",
"6 years",
"4 years",
"10+ years",
"10+ years",
null,
"1 year",
"10+ years",
"7 years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"7 years",
"6 years",
"7 years",
"4 years",
"4 years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
null,
"5 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"9 years",
"2 years",
"1 year",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"1 year",
"5 years",
"7 years",
"10+ years",
"8 years",
"7 years",
"8 years",
"9 years",
"8 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"7 years",
"8 years",
"5 years",
"10+ years",
"2 years",
"2 years",
null,
"5 years",
"2 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"3 years",
null,
"10+ years",
"10+ years",
"3 years",
"2 years",
"8 years",
"8 years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"5 years",
"8 years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"9 years",
"3 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"3 years",
"4 years",
"2 years",
"10+ years",
"6 years",
"6 years",
"4 years",
"10+ years",
"6 years",
"1 year",
"10+ years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"7 years",
null,
"7 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"7 years",
"4 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"4 years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"3 years",
null,
"3 years",
"1 year",
"1 year",
"10+ years",
null,
"1 year",
"4 years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
null,
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"3 years",
"7 years",
"4 years",
"10+ years",
"2 years",
"2 years",
"6 years",
null,
"1 year",
"8 years",
"3 years",
"9 years",
"10+ years",
"10+ years",
"6 years",
"< 1 year",
null,
"10+ years",
null,
"8 years",
null,
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"10+ years",
"1 year",
"3 years",
null,
"10+ years",
"6 years",
"2 years",
null,
"2 years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"5 years",
"2 years",
"2 years",
"8 years",
"6 years",
"10+ years",
"1 year",
"5 years",
"2 years",
"8 years",
"6 years",
"5 years",
"10+ years",
"< 1 year",
"3 years",
null,
"< 1 year",
null,
"10+ years",
"< 1 year",
"8 years",
"7 years",
"< 1 year",
"9 years",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"< 1 year",
"1 year",
"3 years",
"< 1 year",
"2 years",
"4 years",
"7 years",
"9 years",
"6 years",
"10+ years",
"9 years",
null,
"9 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"6 years",
"4 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"2 years",
"2 years",
"3 years",
"< 1 year",
"10+ years",
"9 years",
null,
"10+ years",
"9 years",
"10+ years",
"3 years",
null,
"2 years",
"7 years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
null,
"5 years",
"6 years",
"3 years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"< 1 year",
"1 year",
"5 years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"7 years",
"3 years",
"9 years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"1 year",
"4 years",
"5 years",
"1 year",
"3 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
null,
"6 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"6 years",
"2 years",
"5 years",
"8 years",
null,
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"6 years",
"1 year",
"3 years",
null,
"3 years",
null,
null,
"1 year",
"10+ years",
"10+ years",
"3 years",
"5 years",
"5 years",
"5 years",
"1 year",
"7 years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"1 year",
"5 years",
"3 years",
"10+ years",
"1 year",
"9 years",
"10+ years",
"10+ years",
"8 years",
"1 year",
"10+ years",
"4 years",
"10+ years",
"5 years",
"2 years",
"4 years",
"8 years",
"3 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"5 years",
"1 year",
"1 year",
"1 year",
"3 years",
"9 years",
"7 years",
"< 1 year",
"7 years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"10+ years",
null,
"5 years",
null,
"10+ years",
"3 years",
"5 years",
"6 years",
"< 1 year",
"3 years",
"10+ years",
"6 years",
"5 years",
"1 year",
"< 1 year",
"10+ years",
"8 years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
null,
"3 years",
"5 years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"< 1 year",
null,
"10+ years",
null,
"7 years",
"10+ years",
null,
"7 years",
"4 years",
"3 years",
"5 years",
"10+ years",
"1 year",
"2 years",
"< 1 year",
"< 1 year",
"3 years",
"7 years",
"10+ years",
"7 years",
"4 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"2 years",
"3 years",
null,
"10+ years",
"2 years",
"10+ years",
"9 years",
"2 years",
"4 years",
"< 1 year",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"8 years",
"5 years",
"3 years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"1 year",
"< 1 year",
null,
"3 years",
"10+ years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"10+ years",
"6 years",
"1 year",
null,
"10+ years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"2 years",
"10+ years",
"9 years",
"10+ years",
"1 year",
"6 years",
"< 1 year",
"5 years",
"< 1 year",
"10+ years",
"6 years",
"7 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"3 years",
null,
"10+ years",
"8 years",
"1 year",
"6 years",
"10+ years",
"9 years",
"10+ years",
"2 years",
null,
"3 years",
"1 year",
"2 years",
"7 years",
"10+ years",
"8 years",
"3 years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"2 years",
"< 1 year",
"10+ years",
"9 years",
null,
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
null,
"2 years",
"5 years",
"10+ years",
"6 years",
null,
"6 years",
"3 years",
"6 years",
"10+ years",
"10+ years",
"4 years",
null,
"10+ years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"6 years",
"3 years",
"< 1 year",
"2 years",
"6 years",
"7 years",
"1 year",
"3 years",
"2 years",
"10+ years",
"2 years",
"4 years",
"10+ years",
"< 1 year",
"3 years",
"4 years",
"10+ years",
null,
"5 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"4 years",
"10+ years",
null,
"10+ years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"2 years",
"4 years",
"7 years",
"3 years",
"< 1 year",
null,
"7 years",
"< 1 year",
"5 years",
"10+ years",
"9 years",
"4 years",
"4 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
null,
"10+ years",
"7 years",
"5 years",
"7 years",
"2 years",
"4 years",
"< 1 year",
"2 years",
"10+ years",
"1 year",
"10+ years",
"4 years",
"3 years",
"3 years",
"2 years",
"10+ years",
"5 years",
null,
"1 year",
"10+ years",
"10+ years",
"4 years",
"3 years",
null,
"9 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"6 years",
"1 year",
"2 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"2 years",
"2 years",
"4 years",
"3 years",
"10+ years",
"9 years",
"7 years",
"< 1 year",
"2 years",
"< 1 year",
"5 years",
"5 years",
"10+ years",
"9 years",
"3 years",
"5 years",
"4 years",
"6 years",
"4 years",
"2 years",
"3 years",
"< 1 year",
"9 years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"4 years",
null,
"4 years",
"5 years",
"8 years",
"9 years",
"10+ years",
"9 years",
"3 years",
"10+ years",
"1 year",
"2 years",
"4 years",
"2 years",
"7 years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"5 years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"9 years",
"10+ years",
"7 years",
"5 years",
"1 year",
"10+ years",
"9 years",
"10+ years",
null,
"9 years",
"5 years",
"10+ years",
"< 1 year",
"9 years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"9 years",
"10+ years",
"3 years",
"< 1 year",
"9 years",
"< 1 year",
"10+ years",
"5 years",
"< 1 year",
"6 years",
"1 year",
"2 years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"9 years",
"< 1 year",
"2 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"9 years",
"7 years",
"7 years",
"10+ years",
"3 years",
"8 years",
"1 year",
"2 years",
"< 1 year",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"3 years",
"3 years",
"5 years",
null,
"10+ years",
null,
"10+ years",
"10+ years",
"7 years",
"6 years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"10+ years",
null,
"3 years",
"7 years",
null,
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"5 years",
"10+ years",
"8 years",
"9 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"9 years",
"10+ years",
"6 years",
"8 years",
"5 years",
"6 years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"2 years",
"3 years",
"10+ years",
"5 years",
null,
"5 years",
"2 years",
"3 years",
"10+ years",
"2 years",
"< 1 year",
"6 years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"5 years",
"9 years",
"9 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"5 years",
"3 years",
"10+ years",
"9 years",
null,
"10+ years",
"8 years",
"10+ years",
"4 years",
"3 years",
"8 years",
"6 years",
null,
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"9 years",
"7 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"7 years",
"6 years",
"9 years",
"10+ years",
"8 years",
"6 years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"8 years",
"9 years",
"3 years",
"10+ years",
"8 years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"7 years",
"10+ years",
"< 1 year",
"9 years",
"10+ years",
"4 years",
"8 years",
"10+ years",
"5 years",
"< 1 year",
"6 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"8 years",
"2 years",
"8 years",
"10+ years",
"6 years",
"9 years",
"3 years",
"10+ years",
"< 1 year",
"6 years",
"2 years",
"6 years",
"5 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"3 years",
"2 years",
"4 years",
"6 years",
"3 years",
"< 1 year",
"3 years",
"1 year",
"2 years",
null,
"3 years",
null,
"10+ years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"< 1 year",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"5 years",
null,
"10+ years",
null,
"10+ years",
"4 years",
"10+ years",
"4 years",
"< 1 year",
"9 years",
"7 years",
"10+ years",
"10+ years",
"8 years",
"7 years",
"10+ years",
"3 years",
"< 1 year",
"3 years",
"6 years",
null,
"5 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"< 1 year",
"5 years",
null,
"10+ years",
"2 years",
"2 years",
"1 year",
null,
"10+ years",
"7 years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"9 years",
"5 years",
"4 years",
"8 years",
"1 year",
"6 years",
"10+ years",
"< 1 year",
null,
null,
"9 years",
null,
"1 year",
"10+ years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"4 years",
"8 years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"5 years",
"7 years",
"10+ years",
"6 years",
"5 years",
"5 years",
"10+ years",
"10+ years",
null,
"3 years",
"1 year",
"1 year",
"2 years",
"10+ years",
"< 1 year",
"5 years",
"3 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"5 years",
null,
"10+ years",
"7 years",
"10+ years",
"9 years",
"7 years",
"7 years",
"10+ years",
"1 year",
"10+ years",
"2 years",
"5 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"8 years",
"10+ years",
"2 years",
"6 years",
"2 years",
"1 year",
"4 years",
null,
"2 years",
"< 1 year",
"10+ years",
"2 years",
"1 year",
"7 years",
"7 years",
"5 years",
"2 years",
"2 years",
"8 years",
null,
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"9 years",
"6 years",
"5 years",
"10+ years",
"4 years",
null,
"3 years",
"5 years",
"2 years",
"10+ years",
null,
"5 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"4 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"9 years",
"< 1 year",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"7 years",
"< 1 year",
"4 years",
"2 years",
"8 years",
"< 1 year",
"9 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"5 years",
"10+ years",
"8 years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"6 years",
"4 years",
"1 year",
"5 years",
"2 years",
"2 years",
"5 years",
"1 year",
"5 years",
"2 years",
"10+ years",
"2 years",
"3 years",
"5 years",
"4 years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"8 years",
"1 year",
"1 year",
"< 1 year",
"10+ years",
"8 years",
"9 years",
"5 years",
"3 years",
"10+ years",
"8 years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"2 years",
"< 1 year",
"7 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"3 years",
"6 years",
"4 years",
"6 years",
"4 years",
null,
null,
"9 years",
"3 years",
"4 years",
"2 years",
"10+ years",
"6 years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"9 years",
"4 years",
null,
"2 years",
"1 year",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"5 years",
null,
"1 year",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"8 years",
"7 years",
"5 years",
null,
"3 years",
"6 years",
"7 years",
"4 years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"4 years",
"5 years",
"7 years",
"6 years",
"5 years",
"5 years",
"7 years",
"< 1 year",
"3 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"8 years",
"7 years",
"7 years",
"3 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"6 years",
"1 year",
"7 years",
"4 years",
"2 years",
"< 1 year",
"4 years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"6 years",
"2 years",
"4 years",
"4 years",
"< 1 year",
"3 years",
"10+ years",
"8 years",
"5 years",
"5 years",
"8 years",
"7 years",
"6 years",
"2 years",
"10+ years",
"8 years",
"4 years",
"10+ years",
"4 years",
null,
"7 years",
"10+ years",
"3 years",
"5 years",
"5 years",
"6 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"9 years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"9 years",
null,
"2 years",
"< 1 year",
"10+ years",
"< 1 year",
"4 years",
"8 years",
"7 years",
"4 years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"3 years",
"9 years",
"7 years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"5 years",
"10+ years",
"< 1 year",
"2 years",
"5 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"9 years",
"10+ years",
"8 years",
"5 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"4 years",
"< 1 year",
"4 years",
null,
"4 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"< 1 year",
"2 years",
"7 years",
"5 years",
"4 years",
"< 1 year",
"6 years",
"2 years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"8 years",
null,
"3 years",
"5 years",
"9 years",
"8 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"10+ years",
"5 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"5 years",
"2 years",
"2 years",
"< 1 year",
null,
"2 years",
"< 1 year",
null,
"1 year",
"10+ years",
"2 years",
"8 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"2 years",
"10+ years",
"10+ years",
"10+ years",
null,
"7 years",
null,
"10+ years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"8 years",
"10+ years",
"3 years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"2 years",
null,
"10+ years",
"4 years",
"4 years",
"9 years",
"4 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"10+ years",
null,
"1 year",
"10+ years",
"2 years",
"4 years",
"10+ years",
"1 year",
"2 years",
"1 year",
"10+ years",
"7 years",
"10+ years",
"< 1 year",
"5 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"6 years",
"3 years",
"5 years",
"5 years",
"7 years",
"10+ years",
null,
"3 years",
"4 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"8 years",
"10+ years",
"6 years",
"< 1 year",
"4 years",
"6 years",
"< 1 year",
"8 years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"8 years",
"< 1 year",
"8 years",
"7 years",
"8 years",
"10+ years",
"1 year",
"2 years",
"4 years",
"< 1 year",
"7 years",
"10+ years",
"< 1 year",
"4 years",
"3 years",
"10+ years",
"2 years",
"7 years",
"4 years",
"10+ years",
"5 years",
"7 years",
"7 years",
"6 years",
"10+ years",
"8 years",
null,
"10+ years",
"3 years",
"< 1 year",
"2 years",
"5 years",
"9 years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"9 years",
"2 years",
"10+ years",
"6 years",
"8 years",
"5 years",
"< 1 year",
"5 years",
"10+ years",
"6 years",
"10+ years",
"1 year",
"4 years",
"< 1 year",
null,
"4 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"4 years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"5 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"4 years",
"5 years",
"5 years",
"5 years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"1 year",
"2 years",
"2 years",
null,
"10+ years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"4 years",
"4 years",
"6 years",
"10+ years",
"10+ years",
"7 years",
null,
"10+ years",
"5 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"2 years",
"9 years",
"3 years",
"10+ years",
null,
"4 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"6 years",
"7 years",
"3 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"8 years",
"< 1 year",
"1 year",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"< 1 year",
"< 1 year",
"1 year",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"6 years",
"10+ years",
null,
"10+ years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"4 years",
"10+ years",
"4 years",
"9 years",
null,
"9 years",
"3 years",
"10+ years",
"3 years",
"5 years",
"4 years",
"8 years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"2 years",
"< 1 year",
"9 years",
"3 years",
"4 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"9 years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"5 years",
"10+ years",
"10+ years",
"8 years",
"2 years",
"< 1 year",
"< 1 year",
"3 years",
null,
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"7 years",
"10+ years",
"7 years",
"1 year",
null,
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"3 years",
"< 1 year",
"< 1 year",
"10+ years",
"8 years",
"8 years",
"1 year",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"8 years",
"7 years",
"10+ years",
"< 1 year",
"7 years",
null,
"10+ years",
"2 years",
"10+ years",
"7 years",
"< 1 year",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"8 years",
"2 years",
"10+ years",
"4 years",
"8 years",
"10+ years",
"9 years",
"< 1 year",
"2 years",
"8 years",
"6 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"1 year",
"10+ years",
"10+ years",
"9 years",
"4 years",
"4 years",
"3 years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"1 year",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"1 year",
null,
"3 years",
"7 years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
null,
"5 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
null,
null,
"10+ years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"4 years",
"9 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"3 years",
"< 1 year",
"6 years",
"1 year",
"4 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"3 years",
"3 years",
"10+ years",
"4 years",
"10+ years",
"7 years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"< 1 year",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"9 years",
"< 1 year",
null,
"3 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"2 years",
"10+ years",
"4 years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"5 years",
"1 year",
"5 years",
"10+ years",
"3 years",
"5 years",
"7 years",
"1 year",
"3 years",
"10+ years",
"6 years",
"3 years",
"8 years",
"10+ years",
"4 years",
"8 years",
"< 1 year",
"6 years",
"10+ years",
"6 years",
"6 years",
"5 years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
null,
null,
"10+ years",
null,
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"9 years",
"6 years",
"10+ years",
"6 years",
"8 years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
null,
null,
"9 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"1 year",
"2 years",
"< 1 year",
"1 year",
"10+ years",
"9 years",
"5 years",
"< 1 year",
"7 years",
"1 year",
"< 1 year",
"1 year",
null,
"10+ years",
"10+ years",
"1 year",
"10+ years",
"4 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"1 year",
"3 years",
"4 years",
"6 years",
"1 year",
"2 years",
"7 years",
"10+ years",
"6 years",
"6 years",
"< 1 year",
"10+ years",
"4 years",
null,
"5 years",
"2 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"1 year",
null,
"10+ years",
null,
"< 1 year",
"4 years",
"< 1 year",
null,
"5 years",
"10+ years",
"9 years",
"8 years",
"9 years",
null,
null,
"4 years",
"< 1 year",
"< 1 year",
"< 1 year",
"8 years",
null,
"10+ years",
"8 years",
"1 year",
"8 years",
"9 years",
"8 years",
"5 years",
"10+ years",
"5 years",
"4 years",
"10+ years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"5 years",
"3 years",
"1 year",
null,
"4 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"3 years",
"10+ years",
"6 years",
"3 years",
"6 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"1 year",
"10+ years",
"7 years",
"10+ years",
"8 years",
"1 year",
"3 years",
"4 years",
"10+ years",
"7 years",
"5 years",
"< 1 year",
"9 years",
"4 years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"2 years",
"2 years",
"9 years",
"3 years",
"3 years",
"2 years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"8 years",
"10+ years",
"1 year",
null,
"8 years",
"7 years",
"7 years",
"10+ years",
"10+ years",
null,
"< 1 year",
"8 years",
"9 years",
"5 years",
"4 years",
"10+ years",
"10+ years",
"5 years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"3 years",
"2 years",
"1 year",
null,
"10+ years",
"8 years",
"10+ years",
null,
"10+ years",
"2 years",
"10+ years",
"6 years",
null,
"6 years",
"2 years",
"5 years",
"7 years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"1 year",
"7 years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"8 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
null,
"< 1 year",
"3 years",
null,
"6 years",
"6 years",
null,
"8 years",
"9 years",
"8 years",
null,
"9 years",
"3 years",
"1 year",
"8 years",
"8 years",
"7 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"5 years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"6 years",
"5 years",
"7 years",
"8 years",
"7 years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"6 years",
"3 years",
"7 years",
null,
"10+ years",
"2 years",
"9 years",
"< 1 year",
"7 years",
"5 years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"1 year",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"9 years",
"10+ years",
"6 years",
"1 year",
null,
"7 years",
"10+ years",
null,
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"3 years",
"< 1 year",
"7 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"< 1 year",
"2 years",
"10+ years",
"6 years",
"6 years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"4 years",
"4 years",
"3 years",
"2 years",
"6 years",
"4 years",
"3 years",
null,
null,
"5 years",
"4 years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"8 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"4 years",
"10+ years",
"10+ years",
"7 years",
"5 years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"3 years",
"9 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"2 years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"7 years",
"< 1 year",
"5 years",
"7 years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"9 years",
"5 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"3 years",
"6 years",
"< 1 year",
"8 years",
"10+ years",
"6 years",
"1 year",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"9 years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"3 years",
"< 1 year",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"7 years",
"10+ years",
"4 years",
"3 years",
"7 years",
"5 years",
"2 years",
"5 years",
"10+ years",
"2 years",
null,
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"1 year",
"2 years",
"3 years",
"9 years",
"< 1 year",
"4 years",
"6 years",
"< 1 year",
"1 year",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
null,
"5 years",
"6 years",
"< 1 year",
"5 years",
"10+ years",
"2 years",
"8 years",
"7 years",
"4 years",
"10+ years",
"< 1 year",
"6 years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"1 year",
"< 1 year",
"7 years",
"7 years",
"10+ years",
"1 year",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"8 years",
"10+ years",
"9 years",
"4 years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"1 year",
"4 years",
"9 years",
"2 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"9 years",
"10+ years",
"5 years",
"7 years",
null,
"2 years",
"10+ years",
"7 years",
"5 years",
"10+ years",
"< 1 year",
null,
"5 years",
"7 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"10+ years",
null,
"1 year",
"10+ years",
"3 years",
"3 years",
"7 years",
"3 years",
"2 years",
"6 years",
"10+ years",
"8 years",
"10+ years",
"1 year",
"7 years",
"1 year",
null,
"5 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"9 years",
"1 year",
"9 years",
"1 year",
"1 year",
"7 years",
"1 year",
null,
"10+ years",
"3 years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"< 1 year",
"< 1 year",
"1 year",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"1 year",
"2 years",
"7 years",
"8 years",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"2 years",
"< 1 year",
"10+ years",
"4 years",
"8 years",
"10+ years",
"10+ years",
"6 years",
"4 years",
"1 year",
"1 year",
"3 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"5 years",
"9 years",
"4 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"4 years",
"< 1 year",
"10+ years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"4 years",
"4 years",
"< 1 year",
"6 years",
"5 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
null,
"10+ years",
"< 1 year",
"5 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"8 years",
"< 1 year",
"5 years",
"10+ years",
"8 years",
"10+ years",
"8 years",
"1 year",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"8 years",
"3 years",
"5 years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"1 year",
"4 years",
"2 years",
"1 year",
"7 years",
"8 years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"5 years",
"3 years",
"8 years",
"10+ years",
"6 years",
null,
"5 years",
"10+ years",
"5 years",
"5 years",
"1 year",
"4 years",
"2 years",
"9 years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"6 years",
"9 years",
"1 year",
"7 years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"9 years",
"9 years",
"2 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"7 years",
"9 years",
"5 years",
"9 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"9 years",
"3 years",
"2 years",
"< 1 year",
"10+ years",
"2 years",
"4 years",
"4 years",
"10+ years",
"2 years",
"7 years",
"5 years",
"10+ years",
"10+ years",
"7 years",
"3 years",
null,
"4 years",
"6 years",
"7 years",
"1 year",
"3 years",
"3 years",
"3 years",
null,
"4 years",
"5 years",
"2 years",
"3 years",
"10+ years",
"7 years",
"3 years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"1 year",
"7 years",
"3 years",
null,
null,
"8 years",
"< 1 year",
"< 1 year",
"5 years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"1 year",
"2 years",
"10+ years",
"2 years",
"6 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"5 years",
"4 years",
"10+ years",
"10+ years",
"4 years",
null,
"1 year",
"10+ years",
"3 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"7 years",
null,
"10+ years",
null,
"2 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"6 years",
"10+ years",
"3 years",
"7 years",
"4 years",
"3 years",
"10+ years",
"7 years",
"1 year",
"1 year",
"8 years",
"10+ years",
"3 years",
"6 years",
"9 years",
"2 years",
"5 years",
"7 years",
"10+ years",
"3 years",
"3 years",
"5 years",
"3 years",
"2 years",
"10+ years",
"2 years",
"2 years",
"7 years",
"2 years",
"2 years",
"1 year",
"1 year",
"8 years",
"6 years",
"1 year",
"3 years",
"3 years",
"3 years",
"4 years",
"2 years",
"4 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"9 years",
"10+ years",
null,
"10+ years",
"10+ years",
"7 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"6 years",
"4 years",
null,
"4 years",
null,
"8 years",
"10+ years",
"10+ years",
"7 years",
"3 years",
"< 1 year",
null,
"2 years",
"< 1 year",
null,
null,
"10+ years",
"10+ years",
"3 years",
"5 years",
"5 years",
"5 years",
"< 1 year",
"1 year",
"10+ years",
null,
"2 years",
"4 years",
"7 years",
"10+ years",
"5 years",
"9 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"1 year",
"4 years",
"10+ years",
"1 year",
"< 1 year",
"2 years",
"4 years",
"10+ years",
"1 year",
"5 years",
"10+ years",
"7 years",
"7 years",
"10+ years",
"7 years",
"10+ years",
"2 years",
null,
null,
null,
"10+ years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"1 year",
"4 years",
null,
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"3 years",
"8 years",
"9 years",
"7 years",
null,
"5 years",
"4 years",
"< 1 year",
null,
"10+ years",
"6 years",
"10+ years",
"4 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"2 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"1 year",
"8 years",
"5 years",
"5 years",
"5 years",
"7 years",
"< 1 year",
"6 years",
"8 years",
"10+ years",
"3 years",
null,
"9 years",
"< 1 year",
"1 year",
"2 years",
"2 years",
"2 years",
"5 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"4 years",
"9 years",
"8 years",
"2 years",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"8 years",
"9 years",
"10+ years",
null,
"2 years",
"10+ years",
"9 years",
"2 years",
"3 years",
"3 years",
"4 years",
null,
"2 years",
"10+ years",
"10+ years",
"5 years",
"9 years",
"8 years",
"8 years",
"6 years",
"10+ years",
"8 years",
"9 years",
"< 1 year",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"3 years",
"4 years",
"3 years",
"< 1 year",
"4 years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"7 years",
"5 years",
"7 years",
"3 years",
"2 years",
"5 years",
"8 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"7 years",
"< 1 year",
"3 years",
null,
"< 1 year",
"3 years",
"10+ years",
"5 years",
"10+ years",
null,
"10+ years",
"2 years",
"5 years",
"7 years",
"6 years",
"8 years",
"8 years",
null,
"10+ years",
null,
"8 years",
"10+ years",
"8 years",
"5 years",
"4 years",
"1 year",
"3 years",
"6 years",
"10+ years",
"5 years",
"7 years",
"4 years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"3 years",
"< 1 year",
"3 years",
null,
"10+ years",
"10+ years",
"10+ years",
"8 years",
"6 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"1 year",
"2 years",
"< 1 year",
"4 years",
"9 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"7 years",
"3 years",
"1 year",
"10+ years",
"2 years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"6 years",
null,
"2 years",
"2 years",
"10+ years",
"2 years",
"2 years",
"1 year",
"10+ years",
"5 years",
"3 years",
"< 1 year",
null,
"5 years",
"8 years",
"4 years",
"10+ years",
"7 years",
"1 year",
"2 years",
"10+ years",
"5 years",
"10+ years",
null,
"10+ years",
"10+ years",
"2 years",
"8 years",
"8 years",
"2 years",
"< 1 year",
"3 years",
"2 years",
"4 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"9 years",
"9 years",
"7 years",
"10+ years",
null,
"7 years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"9 years",
"9 years",
"4 years",
"< 1 year",
"< 1 year",
"5 years",
"10+ years",
"5 years",
"7 years",
null,
"3 years",
"2 years",
"7 years",
"7 years",
"< 1 year",
"10+ years",
"< 1 year",
"1 year",
"1 year",
"7 years",
"9 years",
"1 year",
"7 years",
"6 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
null,
"3 years",
"8 years",
"5 years",
"5 years",
"5 years",
"10+ years",
"1 year",
"8 years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
null,
"10+ years",
null,
"6 years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"1 year",
null,
"< 1 year",
"8 years",
"2 years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"8 years",
null,
"10+ years",
"10+ years",
"10+ years",
"4 years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"6 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"9 years",
null,
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"7 years",
"6 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"4 years",
"9 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
null,
"7 years",
"2 years",
"5 years",
"2 years",
"4 years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"1 year",
"1 year",
"7 years",
"10+ years",
"1 year",
"9 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"3 years",
"< 1 year",
"3 years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"4 years",
"2 years",
"10+ years",
"9 years",
"8 years",
"< 1 year",
"10+ years",
null,
"9 years",
"10+ years",
null,
"3 years",
"7 years",
"4 years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"5 years",
"3 years",
"< 1 year",
"2 years",
"10+ years",
"8 years",
"5 years",
"1 year",
"10+ years",
"10+ years",
null,
"< 1 year",
"< 1 year",
"< 1 year",
"10+ years",
"7 years",
"< 1 year",
"< 1 year",
"4 years",
"5 years",
"10+ years",
null,
"8 years",
"3 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"3 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"6 years",
"1 year",
"10+ years",
"6 years",
"10+ years",
"6 years",
"10+ years",
"8 years",
"8 years",
null,
"7 years",
"< 1 year",
"4 years",
"8 years",
"10+ years",
null,
"5 years",
"3 years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"8 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"7 years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
null,
"2 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"8 years",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"5 years",
"10+ years",
null,
"< 1 year",
"2 years",
"< 1 year",
"< 1 year",
null,
"7 years",
"3 years",
"10+ years",
"1 year",
"9 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"5 years",
"7 years",
"3 years",
"2 years",
"9 years",
"10+ years",
"10+ years",
"7 years",
null,
"5 years",
"10+ years",
"1 year",
"< 1 year",
"1 year",
"9 years",
"< 1 year",
"10+ years",
"3 years",
"3 years",
"2 years",
"9 years",
"4 years",
"4 years",
"7 years",
"2 years",
"5 years",
null,
"5 years",
"< 1 year",
"3 years",
"10+ years",
"4 years",
"2 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
null,
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"2 years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"9 years",
"6 years",
"5 years",
"4 years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"9 years",
null,
"3 years",
"4 years",
"5 years",
"6 years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"2 years",
"5 years",
"4 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"5 years",
"4 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"6 years",
"< 1 year",
"5 years",
"2 years",
"< 1 year",
"5 years",
"9 years",
null,
"< 1 year",
null,
"10+ years",
"10+ years",
"2 years",
"5 years",
"3 years",
"4 years",
"6 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"4 years",
"4 years",
"10+ years",
null,
"3 years",
"6 years",
"10+ years",
"4 years",
"5 years",
"3 years",
"5 years",
"10+ years",
"6 years",
"6 years",
"10+ years",
"2 years",
"10+ years",
"7 years",
"8 years",
"8 years",
"3 years",
"6 years",
"< 1 year",
"7 years",
"1 year",
"1 year",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"10+ years",
"1 year",
"10+ years",
null,
"10+ years",
"8 years",
"10+ years",
"6 years",
"10+ years",
"6 years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"2 years",
"7 years",
"5 years",
"4 years",
"5 years",
"8 years",
"8 years",
"10+ years",
"7 years",
"2 years",
"1 year",
"5 years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"6 years",
"4 years",
"< 1 year",
"3 years",
"2 years",
"2 years",
"10+ years",
"1 year",
"6 years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"7 years",
"9 years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"5 years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"3 years",
"9 years",
"4 years",
"10+ years",
"2 years",
null,
"4 years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
null,
"3 years",
"10+ years",
"10+ years",
null,
"2 years",
"8 years",
"8 years",
"10+ years",
"5 years",
"5 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"9 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"1 year",
"7 years",
"5 years",
"5 years",
"6 years",
"5 years",
"10+ years",
"5 years",
"2 years",
"10+ years",
null,
"< 1 year",
"1 year",
"10+ years",
"7 years",
"10+ years",
"8 years",
"2 years",
"10+ years",
"10+ years",
null,
"1 year",
"5 years",
"10+ years",
"4 years",
"2 years",
"7 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"6 years",
"9 years",
"< 1 year",
null,
"8 years",
"3 years",
"6 years",
"6 years",
"8 years",
"6 years",
"7 years",
"2 years",
"9 years",
"< 1 year",
"7 years",
"1 year",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"5 years",
"9 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"2 years",
"< 1 year",
"4 years",
"7 years",
"5 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"3 years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"9 years",
"10+ years",
null,
"5 years",
"8 years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"1 year",
null,
"3 years",
"10+ years",
"4 years",
"2 years",
"10+ years",
"6 years",
"2 years",
"2 years",
"4 years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"9 years",
null,
"2 years",
"2 years",
"9 years",
"3 years",
"10+ years",
"1 year",
"6 years",
"4 years",
"< 1 year",
"2 years",
"8 years",
"10+ years",
"10+ years",
"6 years",
"8 years",
null,
"10+ years",
"10+ years",
"3 years",
"5 years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"7 years",
"7 years",
"7 years",
"6 years",
"6 years",
"2 years",
"10+ years",
"1 year",
null,
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"9 years",
"1 year",
"9 years",
"8 years",
"3 years",
"2 years",
"10+ years",
"4 years",
"2 years",
"7 years",
"2 years",
"9 years",
"2 years",
"10+ years",
"6 years",
"5 years",
"1 year",
"2 years",
"< 1 year",
"10+ years",
"9 years",
"6 years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"9 years",
null,
"9 years",
"9 years",
"2 years",
"1 year",
"< 1 year",
"8 years",
"7 years",
"8 years",
"5 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"4 years",
"4 years",
"10+ years",
"7 years",
"7 years",
"< 1 year",
"8 years",
"2 years",
"3 years",
"5 years",
"3 years",
"4 years",
"10+ years",
"1 year",
"10+ years",
"8 years",
"8 years",
"3 years",
"9 years",
"2 years",
"7 years",
"< 1 year",
"10+ years",
"5 years",
"5 years",
"1 year",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
null,
null,
"6 years",
"5 years",
"10+ years",
null,
"10+ years",
"2 years",
"7 years",
null,
"10+ years",
"7 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"2 years",
"2 years",
"4 years",
"10+ years",
"2 years",
"9 years",
null,
"2 years",
"8 years",
"10+ years",
"6 years",
"3 years",
"5 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
null,
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"2 years",
"6 years",
"5 years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"< 1 year",
"4 years",
"8 years",
"8 years",
"10+ years",
"5 years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"9 years",
"2 years",
"10+ years",
null,
"1 year",
"1 year",
"4 years",
"8 years",
"3 years",
"4 years",
"< 1 year",
"4 years",
"3 years",
"10+ years",
"2 years",
"7 years",
"< 1 year",
"7 years",
"10+ years",
"4 years",
"3 years",
"10+ years",
"10+ years",
null,
"5 years",
"9 years",
"8 years",
"5 years",
"5 years",
null,
"5 years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"8 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"1 year",
"3 years",
"3 years",
"< 1 year",
"8 years",
"2 years",
"9 years",
"8 years",
"10+ years",
"10+ years",
"1 year",
"4 years",
"2 years",
"10+ years",
"2 years",
"1 year",
"1 year",
"10+ years",
"3 years",
"1 year",
"2 years",
"10+ years",
"2 years",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"3 years",
"3 years",
"10+ years",
"3 years",
"6 years",
"10+ years",
null,
"10+ years",
"7 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"4 years",
"5 years",
"2 years",
"5 years",
"4 years",
"10+ years",
"6 years",
"7 years",
"7 years",
"10+ years",
"10+ years",
"8 years",
"6 years",
"10+ years",
"7 years",
"5 years",
"7 years",
null,
"5 years",
"2 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"4 years",
"9 years",
"10+ years",
null,
null,
"< 1 year",
"4 years",
"6 years",
"10+ years",
"5 years",
"6 years",
"< 1 year",
"8 years",
"10+ years",
null,
"5 years",
"10+ years",
"3 years",
"9 years",
"10+ years",
"5 years",
"8 years",
"4 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"5 years",
"3 years",
"10+ years",
"3 years",
"2 years",
"4 years",
"8 years",
"6 years",
"4 years",
"4 years",
"3 years",
"1 year",
"1 year",
"10+ years",
"2 years",
"9 years",
"1 year",
"10+ years",
"1 year",
null,
null,
"6 years",
"6 years",
"10+ years",
"10+ years",
null,
"6 years",
"2 years",
"5 years",
"< 1 year",
null,
null,
"10+ years",
"< 1 year",
"3 years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
null,
"6 years",
"5 years",
null,
"2 years",
"4 years",
"10+ years",
"1 year",
"7 years",
null,
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"2 years",
"10+ years",
null,
"3 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"5 years",
"5 years",
"6 years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"3 years",
"9 years",
"4 years",
"5 years",
"1 year",
"3 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"3 years",
"2 years",
"2 years",
"5 years",
"5 years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"5 years",
"10+ years",
"2 years",
"4 years",
"4 years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"< 1 year",
"6 years",
"7 years",
"10+ years",
"4 years",
"5 years",
"2 years",
"10+ years",
null,
"2 years",
"4 years",
null,
"4 years",
"1 year",
"9 years",
"2 years",
"10+ years",
"2 years",
null,
"< 1 year",
"9 years",
"2 years",
"3 years",
"5 years",
null,
"5 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"8 years",
null,
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
null,
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"7 years",
"< 1 year",
"4 years",
"2 years",
"10+ years",
"4 years",
"3 years",
"2 years",
"8 years",
"1 year",
"6 years",
"< 1 year",
null,
"10+ years",
"1 year",
"9 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"2 years",
"2 years",
"10+ years",
"1 year",
"5 years",
"9 years",
"3 years",
"10+ years",
null,
"2 years",
null,
"5 years",
"10+ years",
"< 1 year",
"2 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"< 1 year",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"2 years",
"7 years",
"3 years",
"< 1 year",
"10+ years",
null,
"4 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
null,
"5 years",
"9 years",
"10+ years",
"< 1 year",
"6 years",
null,
"6 years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"4 years",
"7 years",
"4 years",
"10+ years",
"1 year",
"10+ years",
"6 years",
"10+ years",
"9 years",
"3 years",
"5 years",
"2 years",
"< 1 year",
"1 year",
"9 years",
"9 years",
"2 years",
"10+ years",
"6 years",
"5 years",
"7 years",
null,
"4 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"3 years",
"2 years",
"10+ years",
"2 years",
"2 years",
"1 year",
"8 years",
"10+ years",
null,
"5 years",
"6 years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
null,
"4 years",
"8 years",
"10+ years",
"8 years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"< 1 year",
"7 years",
"1 year",
"6 years",
"7 years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"2 years",
"8 years",
"< 1 year",
"1 year",
"10+ years",
"7 years",
"< 1 year",
"< 1 year",
"3 years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
null,
"10+ years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"9 years",
"3 years",
"2 years",
"10+ years",
null,
"4 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"5 years",
"6 years",
"5 years",
"5 years",
"10+ years",
null,
"9 years",
"2 years",
"4 years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"7 years",
"9 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"6 years",
null,
"2 years",
"< 1 year",
"10+ years",
"6 years",
"4 years",
"3 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"1 year",
"4 years",
"4 years",
"10+ years",
"2 years",
"7 years",
"2 years",
"3 years",
"2 years",
"9 years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"4 years",
"2 years",
"2 years",
"3 years",
"10+ years",
"9 years",
"4 years",
"5 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"5 years",
"5 years",
"10+ years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"5 years",
"6 years",
"10+ years",
"4 years",
"4 years",
"10+ years",
"8 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"7 years",
"3 years",
"9 years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"7 years",
"6 years",
"10+ years",
null,
"10+ years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"1 year",
"8 years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"6 years",
"8 years",
"7 years",
"6 years",
"10+ years",
"8 years",
"7 years",
"10+ years",
"3 years",
null,
"10+ years",
"7 years",
"< 1 year",
"3 years",
"6 years",
"4 years",
"2 years",
"10+ years",
"4 years",
"< 1 year",
"2 years",
"10+ years",
"8 years",
"6 years",
"< 1 year",
"9 years",
"7 years",
"1 year",
"5 years",
null,
"6 years",
"5 years",
"3 years",
null,
"10+ years",
"3 years",
"3 years",
"10+ years",
"7 years",
"< 1 year",
"9 years",
"5 years",
"5 years",
"3 years",
"< 1 year",
"8 years",
"8 years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
null,
"3 years",
"8 years",
"2 years",
"2 years",
null,
"3 years",
"6 years",
"10+ years",
"6 years",
"9 years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"< 1 year",
"6 years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"9 years",
"10+ years",
"5 years",
"8 years",
"7 years",
"10+ years",
"10+ years",
"9 years",
"7 years",
null,
"8 years",
"10+ years",
"5 years",
"< 1 year",
"6 years",
"4 years",
"10+ years",
"8 years",
"7 years",
"7 years",
"10+ years",
"4 years",
null,
"10+ years",
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"5 years",
"4 years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"7 years",
"10+ years",
"10+ years",
"1 year",
null,
"2 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"3 years",
"10+ years",
"7 years",
"4 years",
"7 years",
"10+ years",
"6 years",
null,
"< 1 year",
"10+ years",
"4 years",
"8 years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"4 years",
"5 years",
"6 years",
null,
"10+ years",
"1 year",
"1 year",
"10+ years",
"1 year",
"9 years",
"10+ years",
"10+ years",
"6 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"1 year",
"6 years",
"8 years",
"10+ years",
"10+ years",
"7 years",
"8 years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"1 year",
"4 years",
"< 1 year",
"6 years",
"2 years",
"10+ years",
"5 years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"6 years",
"10+ years",
"3 years",
"1 year",
"6 years",
"8 years",
"6 years",
"7 years",
"2 years",
"9 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"2 years",
"10+ years",
null,
null,
"10+ years",
"5 years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"2 years",
"2 years",
"5 years",
"1 year",
"2 years",
"4 years",
"< 1 year",
"8 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
null,
"8 years",
null,
"10+ years",
"10+ years",
"4 years",
"10+ years",
null,
"7 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
null,
null,
"6 years",
"< 1 year",
"< 1 year",
"< 1 year",
"7 years",
"6 years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"4 years",
null,
"10+ years",
"5 years",
"< 1 year",
"5 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"6 years",
"6 years",
"8 years",
"5 years",
null,
"4 years",
"7 years",
"3 years",
"9 years",
"5 years",
"< 1 year",
"10+ years",
"7 years",
"5 years",
"4 years",
"8 years",
"10+ years",
"7 years",
"10+ years",
"5 years",
"4 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"< 1 year",
"9 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"7 years",
"1 year",
"6 years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"3 years",
null,
"5 years",
"4 years",
"1 year",
"2 years",
"2 years",
"6 years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"3 years",
"2 years",
"5 years",
"< 1 year",
"8 years",
"< 1 year",
"2 years",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"< 1 year",
"10+ years",
"9 years",
"10+ years",
"7 years",
"8 years",
"10+ years",
"10+ years",
"8 years",
"8 years",
"4 years",
null,
"3 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
null,
"2 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"4 years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"5 years",
"10+ years",
"2 years",
"4 years",
"5 years",
"10+ years",
"10+ years",
"6 years",
"< 1 year",
"2 years",
"2 years",
"< 1 year",
"2 years",
"6 years",
"2 years",
"9 years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"3 years",
"2 years",
"3 years",
"3 years",
"8 years",
"9 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
null,
"4 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
null,
"4 years",
null,
"10+ years",
"< 1 year",
"1 year",
"2 years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"2 years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"8 years",
"7 years",
"10+ years",
null,
"6 years",
null,
"8 years",
"10+ years",
"10+ years",
"8 years",
"8 years",
"< 1 year",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"9 years",
null,
"10+ years",
"7 years",
"10+ years",
"10+ years",
"4 years",
"4 years",
"10+ years",
null,
"< 1 year",
"10+ years",
"5 years",
"4 years",
"10+ years",
"4 years",
"1 year",
"6 years",
"3 years",
"< 1 year",
"4 years",
"10+ years",
null,
null,
"2 years",
"3 years",
"4 years",
"1 year",
"6 years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"9 years",
"9 years",
"4 years",
"3 years",
"10+ years",
"10+ years",
null,
"2 years",
"10+ years",
null,
"7 years",
"1 year",
"4 years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"4 years",
"6 years",
"2 years",
"4 years",
"3 years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"1 year",
"2 years",
"4 years",
"9 years",
"10+ years",
"5 years",
"< 1 year",
"6 years",
"4 years",
"10+ years",
"5 years",
"3 years",
"8 years",
"1 year",
null,
"10+ years",
null,
"2 years",
"2 years",
"7 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"2 years",
"4 years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"< 1 year",
"8 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"4 years",
null,
"10+ years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"7 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"9 years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"5 years",
"8 years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"2 years",
"3 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"6 years",
"6 years",
"< 1 year",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"5 years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"8 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"2 years",
"4 years",
"4 years",
"2 years",
"10+ years",
"10+ years",
null,
"1 year",
"3 years",
null,
"2 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"5 years",
"4 years",
null,
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"3 years",
"10+ years",
"4 years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"6 years",
"9 years",
"10+ years",
"4 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"5 years",
"7 years",
"4 years",
"< 1 year",
"8 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"5 years",
"2 years",
"5 years",
"4 years",
"9 years",
"5 years",
"< 1 year",
"3 years",
"2 years",
"6 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"7 years",
"8 years",
"< 1 year",
"8 years",
"10+ years",
"5 years",
"5 years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"3 years",
"10+ years",
null,
"5 years",
"10+ years",
"10+ years",
"5 years",
"5 years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"4 years",
"10+ years",
"2 years",
"3 years",
"< 1 year",
"7 years",
"9 years",
"1 year",
"1 year",
"9 years",
"< 1 year",
"2 years",
"2 years",
"8 years",
"10+ years",
"4 years",
"2 years",
"8 years",
null,
"8 years",
"8 years",
"6 years",
"1 year",
"2 years",
"7 years",
"10+ years",
"< 1 year",
"< 1 year",
"< 1 year",
"< 1 year",
"3 years",
"7 years",
"2 years",
"10+ years",
"3 years",
"9 years",
"8 years",
"3 years",
"3 years",
"3 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
null,
"8 years",
"5 years",
null,
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"3 years",
"4 years",
"5 years",
"2 years",
"4 years",
"5 years",
"3 years",
"7 years",
"3 years",
"10+ years",
null,
"< 1 year",
"10+ years",
"4 years",
"3 years",
"< 1 year",
"10+ years",
"9 years",
"3 years",
"10+ years",
"5 years",
"4 years",
"10+ years",
"10+ years",
"1 year",
"6 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"3 years",
"2 years",
"10+ years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"6 years",
"2 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"1 year",
"3 years",
"5 years",
"8 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"5 years",
"10+ years",
"2 years",
"9 years",
"8 years",
"< 1 year",
"10+ years",
"5 years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"1 year",
null,
"10+ years",
"2 years",
"< 1 year",
"3 years",
"6 years",
null,
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"9 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"3 years",
"7 years",
"5 years",
"3 years",
"8 years",
"6 years",
"9 years",
"7 years",
"< 1 year",
"1 year",
"1 year",
"9 years",
"8 years",
"10+ years",
"4 years",
"2 years",
"2 years",
"5 years",
"6 years",
"3 years",
"7 years",
null,
"1 year",
"10+ years",
"5 years",
"9 years",
"8 years",
"2 years",
"6 years",
"1 year",
"3 years",
"7 years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"2 years",
null,
"2 years",
"4 years",
"6 years",
"9 years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"1 year",
"6 years",
"< 1 year",
"8 years",
"1 year",
"3 years",
"7 years",
"10+ years",
"2 years",
"< 1 year",
"2 years",
"6 years",
"7 years",
"3 years",
"1 year",
"7 years",
"2 years",
"< 1 year",
"9 years",
"1 year",
"2 years",
"1 year",
"1 year",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"4 years",
"6 years",
"10+ years",
"8 years",
"7 years",
"10+ years",
"10+ years",
"6 years",
"5 years",
"10+ years",
"7 years",
null,
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"9 years",
"7 years",
"9 years",
"1 year",
"8 years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"3 years",
"8 years",
"8 years",
"2 years",
"3 years",
"6 years",
"8 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"6 years",
null,
"10+ years",
"< 1 year",
"4 years",
"8 years",
"7 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"9 years",
"10+ years",
"3 years",
"2 years",
null,
"< 1 year",
"9 years",
"10+ years",
"3 years",
"4 years",
"5 years",
"10+ years",
"10+ years",
null,
"1 year",
"9 years",
"10+ years",
"6 years",
"2 years",
"10+ years",
null,
"< 1 year",
"7 years",
"10+ years",
"10+ years",
null,
"7 years",
"1 year",
"7 years",
"3 years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"9 years",
"3 years",
"10+ years",
null,
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"< 1 year",
"10+ years",
"2 years",
"7 years",
"4 years",
"8 years",
"7 years",
"2 years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"9 years",
"6 years",
"10+ years",
"6 years",
"3 years",
"4 years",
"3 years",
"10+ years",
"7 years",
"5 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"2 years",
"< 1 year",
"6 years",
"2 years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"2 years",
"3 years",
"5 years",
"3 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"6 years",
"9 years",
"< 1 year",
"1 year",
"< 1 year",
"5 years",
"10+ years",
"5 years",
"5 years",
"10+ years",
"9 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"2 years",
"1 year",
"8 years",
"4 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"5 years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"3 years",
"< 1 year",
"6 years",
null,
"8 years",
"2 years",
"9 years",
"5 years",
"1 year",
"8 years",
"10+ years",
"5 years",
"4 years",
"1 year",
"< 1 year",
"< 1 year",
null,
"10+ years",
"10+ years",
"< 1 year",
null,
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"9 years",
"10+ years",
"< 1 year",
null,
"5 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"1 year",
"< 1 year",
"3 years",
"4 years",
"10+ years",
"3 years",
"1 year",
"1 year",
"2 years",
"10+ years",
"7 years",
"3 years",
"5 years",
"1 year",
"10+ years",
"2 years",
"8 years",
"10+ years",
"3 years",
"2 years",
"4 years",
"10+ years",
"3 years",
"5 years",
"7 years",
"5 years",
"10+ years",
"4 years",
"< 1 year",
"6 years",
"3 years",
null,
"5 years",
"2 years",
"4 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"7 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"1 year",
"1 year",
"4 years",
"7 years",
"10+ years",
"4 years",
"< 1 year",
"1 year",
"10+ years",
"7 years",
"4 years",
"< 1 year",
"7 years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"4 years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"2 years",
"10+ years",
null,
"10+ years",
null,
"< 1 year",
"10+ years",
null,
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"7 years",
"8 years",
"< 1 year",
"8 years",
"< 1 year",
"5 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"9 years",
null,
"< 1 year",
"6 years",
"10+ years",
"< 1 year",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"1 year",
"8 years",
"8 years",
"7 years",
null,
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"5 years",
"8 years",
"10+ years",
"5 years",
"8 years",
null,
"10+ years",
"1 year",
"10+ years",
null,
"2 years",
"7 years",
"4 years",
"2 years",
"2 years",
"< 1 year",
"1 year",
"10+ years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"8 years",
"< 1 year",
"7 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"1 year",
"6 years",
null,
"4 years",
"10+ years",
null,
"10+ years",
"6 years",
"7 years",
"3 years",
"6 years",
null,
"9 years",
"7 years",
"10+ years",
"10+ years",
"5 years",
"4 years",
"4 years",
"10+ years",
"6 years",
"< 1 year",
"10+ years",
"7 years",
"1 year",
null,
"10+ years",
"5 years",
"8 years",
"10+ years",
"1 year",
"< 1 year",
"4 years",
"7 years",
"5 years",
"3 years",
"10+ years",
"6 years",
"9 years",
"8 years",
"10+ years",
"3 years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
null,
"10+ years",
"3 years",
"3 years",
"10+ years",
"< 1 year",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"10+ years",
null,
"10+ years",
"7 years",
"7 years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"1 year",
"7 years",
"5 years",
"4 years",
"10+ years",
"4 years",
"6 years",
"2 years",
"4 years",
"10+ years",
"8 years",
"6 years",
"10+ years",
"2 years",
"3 years",
"5 years",
"10+ years",
"2 years",
null,
"10+ years",
"8 years",
"10+ years",
"8 years",
"5 years",
"< 1 year",
"8 years",
"8 years",
"< 1 year",
"2 years",
"4 years",
"3 years",
"5 years",
"10+ years",
null,
"10+ years",
"< 1 year",
null,
"10+ years",
"10+ years",
"1 year",
"2 years",
"2 years",
"2 years",
"7 years",
"10+ years",
"1 year",
"1 year",
"10+ years",
null,
"2 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
null,
"8 years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"9 years",
"2 years",
"1 year",
"5 years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"3 years",
"< 1 year",
"3 years",
"3 years",
"10+ years",
"7 years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"4 years",
"2 years",
"5 years",
"10+ years",
"7 years",
"1 year",
"4 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"1 year",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"8 years",
"5 years",
null,
"9 years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
null,
"10+ years",
"7 years",
"4 years",
"9 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"9 years",
"6 years",
"6 years",
"4 years",
"1 year",
"10+ years",
null,
"9 years",
"3 years",
"10+ years",
"< 1 year",
null,
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
null,
"< 1 year",
"3 years",
"2 years",
"10+ years",
"< 1 year",
"3 years",
"2 years",
"9 years",
"10+ years",
"< 1 year",
"2 years",
"3 years",
null,
null,
"7 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"5 years",
"5 years",
"2 years",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"3 years",
"7 years",
null,
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"9 years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"6 years",
"< 1 year",
"10+ years",
null,
"2 years",
"2 years",
"1 year",
"10+ years",
"1 year",
"1 year",
"8 years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"< 1 year",
"1 year",
"3 years",
"1 year",
"10+ years",
null,
"2 years",
"9 years",
"10+ years",
null,
"< 1 year",
"10+ years",
null,
"10+ years",
"3 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"2 years",
"2 years",
"2 years",
"4 years",
"< 1 year",
"8 years",
"10+ years",
"5 years",
"< 1 year",
"4 years",
"1 year",
"5 years",
"1 year",
"9 years",
"4 years",
"6 years",
"5 years",
"8 years",
"9 years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"2 years",
"< 1 year",
"10+ years",
"9 years",
"1 year",
"4 years",
"10+ years",
"< 1 year",
"2 years",
"2 years",
"7 years",
null,
"5 years",
"10+ years",
"3 years",
"1 year",
"3 years",
"3 years",
null,
"10+ years",
"8 years",
"10+ years",
"10+ years",
"6 years",
null,
"3 years",
"3 years",
"2 years",
"10+ years",
"2 years",
"4 years",
"3 years",
"< 1 year",
"10+ years",
"3 years",
"7 years",
"2 years",
"2 years",
"10+ years",
"2 years",
"3 years",
"1 year",
"3 years",
"< 1 year",
"1 year",
"< 1 year",
"10+ years",
"3 years",
"4 years",
"2 years",
null,
"< 1 year",
"10+ years",
"5 years",
"2 years",
"10+ years",
null,
"3 years",
"9 years",
"4 years",
"1 year",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"9 years",
"3 years",
null,
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"4 years",
"8 years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"1 year",
"4 years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
null,
"< 1 year",
"3 years",
"3 years",
"3 years",
"< 1 year",
"4 years",
"10+ years",
"< 1 year",
"5 years",
"< 1 year",
"5 years",
"4 years",
null,
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"6 years",
"9 years",
"3 years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"< 1 year",
"5 years",
"7 years",
"5 years",
"6 years",
"1 year",
"2 years",
"< 1 year",
"< 1 year",
"10+ years",
null,
"10+ years",
"2 years",
"10+ years",
"1 year",
"7 years",
"7 years",
"4 years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"8 years",
"9 years",
"5 years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"4 years",
"1 year",
"< 1 year",
"9 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"9 years",
"8 years",
"10+ years",
"2 years",
"4 years",
"7 years",
"10+ years",
"5 years",
"1 year",
"< 1 year",
"5 years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"6 years",
"< 1 year",
"7 years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"3 years",
"7 years",
"5 years",
"< 1 year",
"8 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"2 years",
"< 1 year",
"2 years",
"3 years",
"< 1 year",
"1 year",
"1 year",
"8 years",
null,
null,
"10+ years",
"7 years",
null,
"9 years",
"2 years",
"7 years",
"10+ years",
"5 years",
null,
"2 years",
"10+ years",
"10+ years",
"4 years",
null,
"10+ years",
"10+ years",
null,
"7 years",
"4 years",
"7 years",
"2 years",
null,
"2 years",
"7 years",
null,
"5 years",
"10+ years",
"1 year",
"10+ years",
"5 years",
null,
"10+ years",
"1 year",
"10+ years",
"3 years",
"8 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"5 years",
"2 years",
"< 1 year",
"7 years",
"5 years",
"10+ years",
"1 year",
"10+ years",
"5 years",
null,
"1 year",
"10+ years",
null,
"9 years",
"< 1 year",
"< 1 year",
"3 years",
"1 year",
"10+ years",
"10+ years",
"2 years",
null,
"8 years",
"5 years",
"9 years",
"< 1 year",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"1 year",
"10+ years",
"3 years",
"10+ years",
"8 years",
"10+ years",
"3 years",
null,
"5 years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"2 years",
"3 years",
"< 1 year",
"4 years",
null,
"< 1 year",
"< 1 year",
"8 years",
"8 years",
"4 years",
"5 years",
null,
"3 years",
"5 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"3 years",
"3 years",
"7 years",
"4 years",
"< 1 year",
"2 years",
"6 years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"6 years",
"2 years",
"1 year",
"3 years",
"1 year",
"2 years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"9 years",
"2 years",
null,
"10+ years",
"2 years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"< 1 year",
"9 years",
"2 years",
"10+ years",
"6 years",
"3 years",
null,
"10+ years",
"9 years",
"9 years",
"10+ years",
"5 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
null,
"8 years",
"10+ years",
"6 years",
"< 1 year",
"8 years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"6 years",
"5 years",
"10+ years",
"1 year",
"2 years",
"10+ years",
"7 years",
"7 years",
"10+ years",
"5 years",
"3 years",
"1 year",
"5 years",
"10+ years",
"6 years",
"3 years",
"1 year",
"7 years",
"4 years",
"10+ years",
"7 years",
"1 year",
"5 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"2 years",
"< 1 year",
"10+ years",
"4 years",
"1 year",
"4 years",
"10+ years",
null,
"5 years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"< 1 year",
"6 years",
"4 years",
"1 year",
"10+ years",
"10+ years",
"6 years",
"2 years",
"9 years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"2 years",
"4 years",
"7 years",
"8 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"7 years",
"7 years",
"1 year",
"10+ years",
"1 year",
"1 year",
"1 year",
"7 years",
null,
"3 years",
"7 years",
"10+ years",
"10+ years",
"6 years",
"6 years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
null,
"< 1 year",
"10+ years",
"5 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"4 years",
null,
"10+ years",
"4 years",
"10+ years",
null,
"10+ years",
"8 years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"1 year",
"1 year",
"2 years",
"10+ years",
"4 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"1 year",
"2 years",
"8 years",
"10+ years",
"5 years",
"2 years",
"2 years",
"6 years",
"5 years",
"3 years",
"< 1 year",
"10+ years",
"8 years",
"3 years",
"10+ years",
"7 years",
"2 years",
"8 years",
"10+ years",
"8 years",
"4 years",
"4 years",
null,
"< 1 year",
"1 year",
"6 years",
"9 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"< 1 year",
"2 years",
"2 years",
"3 years",
"5 years"
]
}
],
"layout": {
"barmode": "overlay",
"legend": {
"bgcolor": "#F5F6F9",
"font": {
"color": "#4D5663"
}
},
"paper_bgcolor": "#F5F6F9",
"plot_bgcolor": "#F5F6F9",
"template": {
"data": {
"bar": [
{
"error_x": {
"color": "#2a3f5f"
},
"error_y": {
"color": "#2a3f5f"
},
"marker": {
"line": {
"color": "#E5ECF6",
"width": 0.5
}
},
"type": "bar"
}
],
"barpolar": [
{
"marker": {
"line": {
"color": "#E5ECF6",
"width": 0.5
}
},
"type": "barpolar"
}
],
"carpet": [
{
"aaxis": {
"endlinecolor": "#2a3f5f",
"gridcolor": "white",
"linecolor": "white",
"minorgridcolor": "white",
"startlinecolor": "#2a3f5f"
},
"baxis": {
"endlinecolor": "#2a3f5f",
"gridcolor": "white",
"linecolor": "white",
"minorgridcolor": "white",
"startlinecolor": "#2a3f5f"
},
"type": "carpet"
}
],
"choropleth": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "choropleth"
}
],
"contour": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "contour"
}
],
"contourcarpet": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "contourcarpet"
}
],
"heatmap": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "heatmap"
}
],
"heatmapgl": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "heatmapgl"
}
],
"histogram": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "histogram"
}
],
"histogram2d": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "histogram2d"
}
],
"histogram2dcontour": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "histogram2dcontour"
}
],
"mesh3d": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "mesh3d"
}
],
"parcoords": [
{
"line": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "parcoords"
}
],
"pie": [
{
"automargin": true,
"type": "pie"
}
],
"scatter": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatter"
}
],
"scatter3d": [
{
"line": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatter3d"
}
],
"scattercarpet": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattercarpet"
}
],
"scattergeo": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattergeo"
}
],
"scattergl": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattergl"
}
],
"scattermapbox": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattermapbox"
}
],
"scatterpolar": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterpolar"
}
],
"scatterpolargl": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterpolargl"
}
],
"scatterternary": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterternary"
}
],
"surface": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "surface"
}
],
"table": [
{
"cells": {
"fill": {
"color": "#EBF0F8"
},
"line": {
"color": "white"
}
},
"header": {
"fill": {
"color": "#C8D4E3"
},
"line": {
"color": "white"
}
},
"type": "table"
}
]
},
"layout": {
"annotationdefaults": {
"arrowcolor": "#2a3f5f",
"arrowhead": 0,
"arrowwidth": 1
},
"coloraxis": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"colorscale": {
"diverging": [
[
0,
"#8e0152"
],
[
0.1,
"#c51b7d"
],
[
0.2,
"#de77ae"
],
[
0.3,
"#f1b6da"
],
[
0.4,
"#fde0ef"
],
[
0.5,
"#f7f7f7"
],
[
0.6,
"#e6f5d0"
],
[
0.7,
"#b8e186"
],
[
0.8,
"#7fbc41"
],
[
0.9,
"#4d9221"
],
[
1,
"#276419"
]
],
"sequential": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"sequentialminus": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
]
},
"colorway": [
"#636efa",
"#EF553B",
"#00cc96",
"#ab63fa",
"#FFA15A",
"#19d3f3",
"#FF6692",
"#B6E880",
"#FF97FF",
"#FECB52"
],
"font": {
"color": "#2a3f5f"
},
"geo": {
"bgcolor": "white",
"lakecolor": "white",
"landcolor": "#E5ECF6",
"showlakes": true,
"showland": true,
"subunitcolor": "white"
},
"hoverlabel": {
"align": "left"
},
"hovermode": "closest",
"mapbox": {
"style": "light"
},
"paper_bgcolor": "white",
"plot_bgcolor": "#E5ECF6",
"polar": {
"angularaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"bgcolor": "#E5ECF6",
"radialaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
}
},
"scene": {
"xaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
},
"yaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
},
"zaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
}
},
"shapedefaults": {
"line": {
"color": "#2a3f5f"
}
},
"ternary": {
"aaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"baxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"bgcolor": "#E5ECF6",
"caxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
}
},
"title": {
"x": 0.05
},
"xaxis": {
"automargin": true,
"gridcolor": "white",
"linecolor": "white",
"ticks": "",
"title": {
"standoff": 15
},
"zerolinecolor": "white",
"zerolinewidth": 2
},
"yaxis": {
"automargin": true,
"gridcolor": "white",
"linecolor": "white",
"ticks": "",
"title": {
"standoff": 15
},
"zerolinecolor": "white",
"zerolinewidth": 2
}
}
},
"title": {
"font": {
"color": "#4D5663"
},
"text": "emp_length Distribution"
},
"xaxis": {
"gridcolor": "#E1E5ED",
"showgrid": true,
"tickfont": {
"color": "#4D5663"
},
"title": {
"font": {
"color": "#4D5663"
},
"text": ""
},
"zerolinecolor": "#E1E5ED"
},
"yaxis": {
"gridcolor": "#E1E5ED",
"showgrid": true,
"tickfont": {
"color": "#4D5663"
},
"title": {
"font": {
"color": "#4D5663"
},
"text": ""
},
"zerolinecolor": "#E1E5ED"
}
}
},
"text/html": [
"
\n",
" \n",
" \n",
" \n",
" \n",
"
"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"application/vnd.plotly.v1+json": {
"config": {
"linkText": "Export to plot.ly",
"plotlyServerURL": "https://plot.ly",
"showLink": true
},
"data": [
{
"boxpoints": false,
"line": {
"width": 1.3
},
"marker": {
"color": "rgba(255, 153, 51, 1.0)"
},
"name": "emp_length",
"orientation": "v",
"type": "box",
"y": [
"9 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"8 years",
"7 years",
"2 years",
"10+ years",
"4 years",
"7 years",
"10+ years",
"10+ years",
"4 years",
"9 years",
null,
"7 years",
"7 years",
"9 years",
"2 years",
"10+ years",
"7 years",
"< 1 year",
"4 years",
"2 years",
"1 year",
"3 years",
"2 years",
"10+ years",
"8 years",
"2 years",
"9 years",
"10+ years",
null,
null,
"10+ years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"3 years",
"10+ years",
"9 years",
"4 years",
"7 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"6 years",
"2 years",
"10+ years",
"2 years",
"< 1 year",
"4 years",
"1 year",
"9 years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"< 1 year",
"2 years",
"9 years",
"8 years",
"3 years",
"3 years",
"8 years",
"2 years",
"7 years",
"10+ years",
"7 years",
"1 year",
"10+ years",
null,
"10+ years",
"8 years",
"5 years",
"6 years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"4 years",
null,
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"1 year",
"10+ years",
"5 years",
"8 years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"8 years",
"2 years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"4 years",
"1 year",
"3 years",
"8 years",
"3 years",
"2 years",
null,
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"1 year",
"2 years",
"8 years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"3 years",
"9 years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"3 years",
"4 years",
"4 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
null,
"4 years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"< 1 year",
"10+ years",
"2 years",
"4 years",
"2 years",
"< 1 year",
"4 years",
"2 years",
"1 year",
"5 years",
"4 years",
"3 years",
"9 years",
"5 years",
null,
"10+ years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"6 years",
"10+ years",
"1 year",
"7 years",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"5 years",
"10+ years",
"3 years",
null,
"10+ years",
null,
"10+ years",
"8 years",
"2 years",
"7 years",
"7 years",
"10+ years",
"8 years",
"6 years",
"9 years",
"3 years",
"4 years",
"5 years",
"< 1 year",
"< 1 year",
"7 years",
"7 years",
"< 1 year",
"1 year",
"< 1 year",
null,
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"6 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"8 years",
"1 year",
"< 1 year",
"4 years",
"1 year",
"7 years",
"< 1 year",
"3 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"6 years",
null,
"< 1 year",
"2 years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"9 years",
"4 years",
"3 years",
"10+ years",
"7 years",
null,
null,
"10+ years",
"2 years",
null,
"5 years",
"< 1 year",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"< 1 year",
"10+ years",
"2 years",
null,
"7 years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"5 years",
"< 1 year",
"< 1 year",
"4 years",
"3 years",
"3 years",
"8 years",
"2 years",
"1 year",
"10+ years",
"3 years",
"3 years",
"4 years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"1 year",
null,
"5 years",
"< 1 year",
"4 years",
"3 years",
"2 years",
"3 years",
"1 year",
"9 years",
"7 years",
"1 year",
"10+ years",
"10+ years",
"2 years",
null,
"3 years",
"3 years",
"< 1 year",
"2 years",
"1 year",
"10+ years",
"10+ years",
null,
"10+ years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
null,
null,
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
null,
"4 years",
"10+ years",
"7 years",
"2 years",
"6 years",
"10+ years",
"2 years",
"2 years",
"4 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"6 years",
"6 years",
"8 years",
"1 year",
"3 years",
"5 years",
"6 years",
"9 years",
"3 years",
null,
"7 years",
"5 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"9 years",
"3 years",
"2 years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"6 years",
"< 1 year",
"8 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"6 years",
"2 years",
"9 years",
"3 years",
"8 years",
"8 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"4 years",
"7 years",
"3 years",
"8 years",
"2 years",
"9 years",
"6 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"7 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"< 1 year",
"2 years",
"9 years",
"8 years",
"3 years",
"10+ years",
"8 years",
"10+ years",
"6 years",
"7 years",
"10+ years",
"5 years",
"10+ years",
"1 year",
"1 year",
null,
"3 years",
"10+ years",
"3 years",
"4 years",
"4 years",
"2 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"7 years",
"10+ years",
null,
"2 years",
"< 1 year",
"2 years",
"1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"8 years",
"7 years",
"5 years",
"2 years",
"10+ years",
"1 year",
"7 years",
"10+ years",
null,
"10+ years",
"8 years",
"10+ years",
"4 years",
"8 years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"7 years",
"3 years",
"5 years",
"1 year",
"10+ years",
"6 years",
"10+ years",
null,
"9 years",
"5 years",
"7 years",
"6 years",
"3 years",
"8 years",
"10+ years",
"7 years",
"5 years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"10+ years",
"6 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"1 year",
"8 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"7 years",
"5 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"4 years",
"3 years",
"8 years",
"1 year",
null,
"5 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"4 years",
"10+ years",
"5 years",
"< 1 year",
"2 years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"6 years",
null,
"10+ years",
"5 years",
"4 years",
"9 years",
"6 years",
"4 years",
"4 years",
"< 1 year",
"4 years",
"8 years",
"10+ years",
null,
"1 year",
"7 years",
"9 years",
"1 year",
"8 years",
"8 years",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"9 years",
"10+ years",
"6 years",
"10+ years",
"6 years",
"5 years",
null,
"2 years",
"3 years",
null,
"10+ years",
"3 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"6 years",
"< 1 year",
"10+ years",
null,
"9 years",
"3 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"7 years",
"7 years",
"1 year",
"10+ years",
"7 years",
"10+ years",
"< 1 year",
"8 years",
"2 years",
"8 years",
"4 years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"7 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"8 years",
"3 years",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"8 years",
"5 years",
"10+ years",
"5 years",
"5 years",
"3 years",
"< 1 year",
"10+ years",
"1 year",
"4 years",
"10+ years",
"3 years",
null,
"5 years",
"6 years",
"2 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"3 years",
null,
"< 1 year",
"9 years",
"10+ years",
"10+ years",
"7 years",
"1 year",
"7 years",
"5 years",
"8 years",
"10+ years",
"5 years",
"4 years",
"4 years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"9 years",
"2 years",
"3 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"4 years",
"4 years",
"5 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"1 year",
"2 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"9 years",
"2 years",
"10+ years",
null,
"6 years",
"3 years",
"3 years",
null,
null,
"7 years",
"2 years",
"4 years",
"1 year",
"< 1 year",
"6 years",
"9 years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"2 years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"5 years",
"< 1 year",
"9 years",
"8 years",
"10+ years",
"7 years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"6 years",
"8 years",
"10+ years",
"7 years",
"10+ years",
"5 years",
"3 years",
null,
"6 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
null,
"2 years",
"3 years",
"4 years",
"2 years",
"10+ years",
"5 years",
"9 years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"7 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"7 years",
"3 years",
"5 years",
null,
"10+ years",
"10+ years",
"2 years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"8 years",
"1 year",
"6 years",
"7 years",
"10+ years",
null,
"5 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"3 years",
"< 1 year",
"< 1 year",
"3 years",
"9 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"1 year",
"10+ years",
"4 years",
"6 years",
"10+ years",
"3 years",
"< 1 year",
null,
"10+ years",
"1 year",
"5 years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"8 years",
"10+ years",
"< 1 year",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"4 years",
"< 1 year",
"1 year",
"8 years",
"9 years",
"< 1 year",
"6 years",
"8 years",
"10+ years",
"10+ years",
"9 years",
"6 years",
null,
"< 1 year",
"10+ years",
"5 years",
"5 years",
"10+ years",
"8 years",
"5 years",
"1 year",
"2 years",
"5 years",
"7 years",
"4 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"4 years",
"10+ years",
"3 years",
"7 years",
"4 years",
"9 years",
"3 years",
"9 years",
"7 years",
"10+ years",
"1 year",
"5 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"< 1 year",
"1 year",
"8 years",
"8 years",
"10+ years",
"7 years",
"4 years",
"6 years",
"8 years",
"< 1 year",
"4 years",
"4 years",
"7 years",
"1 year",
"1 year",
"10+ years",
"5 years",
"8 years",
"5 years",
"10+ years",
"7 years",
"8 years",
"5 years",
"2 years",
"10+ years",
"4 years",
null,
null,
"8 years",
"2 years",
"5 years",
"10+ years",
"5 years",
null,
"3 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"3 years",
"3 years",
"9 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"4 years",
"10+ years",
"< 1 year",
"5 years",
null,
"2 years",
"10+ years",
"4 years",
"< 1 year",
"8 years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"4 years",
null,
"9 years",
null,
"7 years",
"7 years",
"2 years",
"1 year",
"1 year",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"6 years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
null,
"5 years",
"< 1 year",
"6 years",
"3 years",
"7 years",
"< 1 year",
"10+ years",
"5 years",
"8 years",
"10+ years",
"7 years",
"1 year",
"4 years",
"10+ years",
"10+ years",
"5 years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"6 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"9 years",
"7 years",
"10+ years",
"6 years",
"8 years",
"2 years",
"3 years",
"3 years",
"10+ years",
"2 years",
"8 years",
"9 years",
"2 years",
"10+ years",
"4 years",
"1 year",
"2 years",
"7 years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
null,
"10+ years",
"6 years",
null,
"10+ years",
"7 years",
null,
"10+ years",
"6 years",
"3 years",
"4 years",
"5 years",
"7 years",
"3 years",
"10+ years",
"6 years",
null,
"< 1 year",
"8 years",
"3 years",
"7 years",
"2 years",
"9 years",
"10+ years",
"2 years",
"7 years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"5 years",
null,
"2 years",
"4 years",
"6 years",
"6 years",
"6 years",
"6 years",
"1 year",
"10+ years",
"3 years",
null,
"10+ years",
"7 years",
"2 years",
"< 1 year",
"4 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
null,
"6 years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
"8 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"1 year",
"10+ years",
"7 years",
"7 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"1 year",
"7 years",
"< 1 year",
"3 years",
"5 years",
"2 years",
"3 years",
"10+ years",
null,
"2 years",
null,
"< 1 year",
"10+ years",
null,
"2 years",
"7 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"5 years",
"1 year",
"1 year",
"3 years",
"4 years",
"6 years",
"3 years",
"2 years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"9 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"1 year",
"< 1 year",
"< 1 year",
"7 years",
"8 years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"8 years",
"3 years",
"4 years",
"< 1 year",
"< 1 year",
"2 years",
"9 years",
"5 years",
"6 years",
"5 years",
"< 1 year",
"10+ years",
"< 1 year",
"1 year",
"7 years",
"1 year",
"10+ years",
"5 years",
"10+ years",
"1 year",
"10+ years",
"2 years",
"2 years",
"2 years",
"3 years",
"7 years",
"7 years",
"8 years",
"10+ years",
null,
null,
null,
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"9 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"6 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"1 year",
"< 1 year",
"10+ years",
"2 years",
"5 years",
"4 years",
"9 years",
"10+ years",
"10+ years",
"3 years",
"9 years",
null,
"8 years",
"1 year",
"10+ years",
"4 years",
"10+ years",
"7 years",
"10+ years",
"1 year",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"3 years",
null,
"5 years",
"1 year",
"1 year",
"10+ years",
"10+ years",
null,
"4 years",
"9 years",
null,
"10+ years",
"10+ years",
"7 years",
"5 years",
null,
"< 1 year",
"2 years",
"2 years",
"1 year",
"10+ years",
"4 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"4 years",
"2 years",
"2 years",
"3 years",
"1 year",
"9 years",
"2 years",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"6 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"4 years",
"6 years",
"9 years",
"1 year",
"2 years",
"2 years",
"6 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"7 years",
"5 years",
"1 year",
"3 years",
"6 years",
"4 years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
null,
"10+ years",
"7 years",
"2 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"3 years",
null,
"10+ years",
"8 years",
"5 years",
"1 year",
"3 years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"7 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"< 1 year",
"6 years",
"8 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"1 year",
"< 1 year",
"< 1 year",
"6 years",
"9 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"8 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"7 years",
"4 years",
"7 years",
"9 years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"8 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"5 years",
"6 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"9 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"8 years",
"6 years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"3 years",
"3 years",
"7 years",
"10+ years",
"6 years",
"7 years",
"4 years",
"4 years",
"2 years",
"< 1 year",
"1 year",
"10+ years",
"2 years",
"10+ years",
"8 years",
null,
"10+ years",
"10+ years",
"2 years",
"3 years",
"1 year",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"3 years",
"7 years",
"6 years",
null,
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
null,
null,
"4 years",
"4 years",
"7 years",
"3 years",
"1 year",
null,
"8 years",
"6 years",
"2 years",
"10+ years",
"2 years",
"< 1 year",
"2 years",
"9 years",
"5 years",
"8 years",
"5 years",
"6 years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
null,
"2 years",
"6 years",
null,
"10+ years",
"3 years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"1 year",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"8 years",
"2 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"5 years",
"7 years",
null,
"1 year",
"10+ years",
"2 years",
"3 years",
"< 1 year",
null,
"10+ years",
"10+ years",
"2 years",
"< 1 year",
null,
"3 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"2 years",
"4 years",
"10+ years",
"< 1 year",
"6 years",
"8 years",
"4 years",
"10+ years",
"1 year",
"5 years",
"9 years",
"10+ years",
null,
"1 year",
"10+ years",
"4 years",
"3 years",
"9 years",
"< 1 year",
"3 years",
"7 years",
"5 years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"8 years",
"< 1 year",
"10+ years",
"7 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"1 year",
"6 years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"7 years",
"10+ years",
"3 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"< 1 year",
"4 years",
"3 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"9 years",
null,
"< 1 year",
"6 years",
"4 years",
"8 years",
"3 years",
"5 years",
"1 year",
"8 years",
"5 years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"2 years",
"3 years",
"< 1 year",
"5 years",
"10+ years",
"5 years",
"9 years",
"2 years",
"4 years",
"5 years",
"6 years",
null,
"7 years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"6 years",
"8 years",
"2 years",
null,
"7 years",
"7 years",
"10+ years",
"7 years",
"< 1 year",
"6 years",
"8 years",
"1 year",
"6 years",
"2 years",
"3 years",
"4 years",
"6 years",
"10+ years",
"8 years",
"6 years",
null,
"5 years",
"7 years",
"3 years",
"2 years",
"10+ years",
"9 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"4 years",
"1 year",
"10+ years",
"5 years",
null,
"10+ years",
"10+ years",
"6 years",
"10+ years",
null,
"6 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"7 years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"2 years",
null,
"10+ years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"10+ years",
"4 years",
"10+ years",
"8 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
null,
"1 year",
"10+ years",
"1 year",
"2 years",
"10+ years",
"< 1 year",
"1 year",
"3 years",
"2 years",
null,
"10+ years",
"10+ years",
"4 years",
null,
"3 years",
"3 years",
"< 1 year",
"9 years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
null,
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"3 years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
null,
"< 1 year",
null,
"3 years",
"3 years",
"4 years",
"2 years",
"10+ years",
"2 years",
"< 1 year",
null,
"10+ years",
"4 years",
"7 years",
"< 1 year",
"9 years",
"2 years",
"4 years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"< 1 year",
"8 years",
"8 years",
"5 years",
"10+ years",
null,
"9 years",
"1 year",
"10+ years",
"5 years",
null,
"7 years",
null,
"6 years",
null,
"5 years",
"5 years",
"3 years",
"9 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"4 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"4 years",
"10+ years",
"8 years",
"7 years",
"< 1 year",
null,
"6 years",
"1 year",
"10+ years",
"5 years",
"5 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"10+ years",
null,
"2 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
null,
"< 1 year",
"< 1 year",
"10+ years",
"2 years",
"4 years",
"1 year",
"2 years",
"10+ years",
"2 years",
"7 years",
"2 years",
"3 years",
"2 years",
"10+ years",
"6 years",
"10+ years",
"7 years",
"3 years",
"4 years",
"7 years",
"2 years",
"1 year",
"6 years",
"1 year",
"10+ years",
"< 1 year",
"4 years",
"5 years",
"5 years",
"7 years",
"< 1 year",
null,
"10+ years",
"9 years",
"4 years",
"3 years",
"9 years",
null,
"10+ years",
"10+ years",
"7 years",
"4 years",
"2 years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"4 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"4 years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"3 years",
"8 years",
"10+ years",
"1 year",
"4 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"8 years",
"1 year",
"8 years",
"6 years",
"4 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
null,
"1 year",
"10+ years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"6 years",
"1 year",
"9 years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"7 years",
"3 years",
"3 years",
"10+ years",
"5 years",
"1 year",
"1 year",
null,
"5 years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"3 years",
"< 1 year",
"7 years",
"3 years",
"5 years",
"10+ years",
null,
"10+ years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"8 years",
"9 years",
"4 years",
"10+ years",
"5 years",
"7 years",
"10+ years",
"10+ years",
"9 years",
"1 year",
"10+ years",
"1 year",
"1 year",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"9 years",
"2 years",
"2 years",
"< 1 year",
"2 years",
"3 years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"4 years",
"9 years",
"3 years",
"3 years",
"10+ years",
"1 year",
"6 years",
"10+ years",
"7 years",
"1 year",
"6 years",
"9 years",
"8 years",
"4 years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"10+ years",
null,
"5 years",
"10+ years",
"10+ years",
"8 years",
"1 year",
"6 years",
null,
null,
"6 years",
"3 years",
"1 year",
"< 1 year",
"7 years",
"2 years",
null,
"2 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"4 years",
"10+ years",
null,
"4 years",
"4 years",
"6 years",
"4 years",
"10+ years",
"10+ years",
"4 years",
null,
"10+ years",
"4 years",
"3 years",
"2 years",
"3 years",
"4 years",
"8 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
null,
"4 years",
"2 years",
"7 years",
"4 years",
"10+ years",
"2 years",
"9 years",
"2 years",
"2 years",
"< 1 year",
"10+ years",
"4 years",
"9 years",
"1 year",
"10+ years",
"3 years",
"3 years",
"10+ years",
"5 years",
"6 years",
"7 years",
"3 years",
"10+ years",
"3 years",
null,
"1 year",
"2 years",
"10+ years",
"7 years",
"8 years",
"10+ years",
"8 years",
"3 years",
"9 years",
"< 1 year",
"9 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
null,
"6 years",
"10+ years",
"3 years",
"8 years",
"6 years",
"5 years",
"< 1 year",
"2 years",
"10+ years",
"2 years",
"10+ years",
null,
"10+ years",
"5 years",
"7 years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"3 years",
"2 years",
"1 year",
"2 years",
"< 1 year",
"2 years",
"3 years",
"3 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"3 years",
null,
"< 1 year",
"3 years",
"< 1 year",
"< 1 year",
"10+ years",
"3 years",
"7 years",
"10+ years",
"2 years",
"4 years",
"2 years",
"10+ years",
"6 years",
"6 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"< 1 year",
"8 years",
"10+ years",
"5 years",
"3 years",
"1 year",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"8 years",
"4 years",
"2 years",
"2 years",
"9 years",
"10+ years",
"7 years",
"10+ years",
"< 1 year",
"9 years",
"2 years",
"< 1 year",
null,
"6 years",
"2 years",
"2 years",
"10+ years",
"4 years",
null,
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"7 years",
"10+ years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"2 years",
"10+ years",
"9 years",
"6 years",
null,
null,
"3 years",
"5 years",
"10+ years",
"8 years",
"5 years",
"6 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"5 years",
"6 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"1 year",
"2 years",
"10+ years",
"6 years",
"9 years",
"9 years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"9 years",
"2 years",
null,
"10+ years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"< 1 year",
null,
"4 years",
null,
"10+ years",
null,
"10+ years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"6 years",
"8 years",
"8 years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"3 years",
"10+ years",
"5 years",
null,
"< 1 year",
"10+ years",
"< 1 year",
"2 years",
"1 year",
"10+ years",
"9 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"3 years",
"9 years",
"5 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"3 years",
"1 year",
"7 years",
"7 years",
"8 years",
"2 years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"< 1 year",
"3 years",
"5 years",
"3 years",
"2 years",
"10+ years",
"3 years",
"8 years",
"5 years",
"7 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
null,
"3 years",
"5 years",
"7 years",
"10+ years",
"2 years",
"2 years",
null,
"3 years",
"4 years",
"8 years",
"10+ years",
"1 year",
"1 year",
"9 years",
"8 years",
"5 years",
"2 years",
"8 years",
"< 1 year",
"6 years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"7 years",
null,
"7 years",
"5 years",
"1 year",
"10+ years",
"10+ years",
"8 years",
"4 years",
"10+ years",
"10+ years",
null,
"10+ years",
"8 years",
"8 years",
"10+ years",
"5 years",
"7 years",
"9 years",
"8 years",
"10+ years",
"4 years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"6 years",
"10+ years",
"10+ years",
null,
"10+ years",
"1 year",
"< 1 year",
null,
"2 years",
"8 years",
"7 years",
"4 years",
"10+ years",
"2 years",
"4 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"7 years",
"10+ years",
"4 years",
"< 1 year",
"2 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"4 years",
"3 years",
"10+ years",
"8 years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"8 years",
"9 years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"2 years",
"9 years",
"10+ years",
"2 years",
"10+ years",
"9 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
null,
"10+ years",
"10+ years",
"1 year",
"3 years",
"5 years",
"8 years",
"7 years",
"6 years",
"2 years",
"5 years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"2 years",
"10+ years",
"1 year",
"3 years",
"2 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"8 years",
"10+ years",
"4 years",
"2 years",
"< 1 year",
"6 years",
"4 years",
"3 years",
"< 1 year",
"10+ years",
"1 year",
"4 years",
"7 years",
"3 years",
"1 year",
"5 years",
"3 years",
"7 years",
"10+ years",
"2 years",
"1 year",
"4 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"1 year",
"2 years",
null,
"7 years",
"10+ years",
null,
"10+ years",
"10+ years",
"3 years",
"5 years",
"1 year",
"10+ years",
"10+ years",
"8 years",
"1 year",
"10+ years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"10+ years",
null,
"10+ years",
"< 1 year",
null,
"2 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"3 years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"2 years",
"3 years",
"2 years",
"10+ years",
"3 years",
"1 year",
"9 years",
"1 year",
"9 years",
"10+ years",
null,
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
null,
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
null,
"7 years",
"3 years",
"1 year",
"4 years",
"9 years",
"1 year",
"5 years",
"10+ years",
"2 years",
"10+ years",
null,
null,
"10+ years",
"2 years",
"10+ years",
"7 years",
"2 years",
"2 years",
null,
"2 years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"9 years",
"3 years",
"2 years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"1 year",
"2 years",
"10+ years",
"1 year",
"2 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"6 years",
"2 years",
"2 years",
"6 years",
"5 years",
"< 1 year",
"3 years",
"7 years",
"8 years",
"8 years",
"4 years",
"9 years",
"7 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"3 years",
null,
"1 year",
"10+ years",
"1 year",
"10+ years",
"5 years",
"5 years",
"2 years",
"9 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"1 year",
"1 year",
"2 years",
"< 1 year",
"10+ years",
null,
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"4 years",
"9 years",
"10+ years",
"9 years",
"3 years",
"6 years",
"6 years",
"3 years",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"2 years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"5 years",
"10+ years",
"3 years",
"6 years",
"10+ years",
"7 years",
"< 1 year",
"9 years",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"6 years",
"< 1 year",
"1 year",
"2 years",
"9 years",
"1 year",
"1 year",
"6 years",
"6 years",
"8 years",
"7 years",
"6 years",
"4 years",
"4 years",
"10+ years",
null,
"9 years",
"4 years",
null,
"3 years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"2 years",
"6 years",
"6 years",
"5 years",
"5 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"3 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"6 years",
"10+ years",
"4 years",
"3 years",
"9 years",
"10+ years",
"10+ years",
"6 years",
"5 years",
"5 years",
"10+ years",
"10+ years",
"4 years",
null,
"< 1 year",
"5 years",
"6 years",
"1 year",
"< 1 year",
"2 years",
"10+ years",
null,
"10+ years",
"< 1 year",
"1 year",
"8 years",
"< 1 year",
"10+ years",
"2 years",
"9 years",
"10+ years",
"1 year",
"< 1 year",
"< 1 year",
"4 years",
"5 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"3 years",
"7 years",
"2 years",
"< 1 year",
"9 years",
"1 year",
"3 years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"8 years",
"7 years",
"7 years",
null,
"10+ years",
"5 years",
"6 years",
"1 year",
"7 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
null,
"2 years",
"5 years",
"9 years",
"3 years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"6 years",
null,
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"5 years",
"10+ years",
"7 years",
"1 year",
null,
"2 years",
"10+ years",
"4 years",
"10+ years",
null,
null,
"10+ years",
"3 years",
"< 1 year",
"6 years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
null,
"2 years",
"2 years",
"2 years",
"8 years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"1 year",
"3 years",
"7 years",
"7 years",
"5 years",
"< 1 year",
"8 years",
"7 years",
"7 years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"1 year",
"4 years",
null,
"10+ years",
"8 years",
"9 years",
"1 year",
null,
"< 1 year",
"1 year",
"1 year",
null,
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"9 years",
null,
"2 years",
"10+ years",
"6 years",
"2 years",
"10+ years",
null,
"10+ years",
"8 years",
"3 years",
"5 years",
null,
"3 years",
"4 years",
"5 years",
"2 years",
"9 years",
"2 years",
"1 year",
"5 years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"3 years",
"5 years",
"1 year",
"7 years",
"10+ years",
"8 years",
"1 year",
"2 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"6 years",
"7 years",
"10+ years",
"8 years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"5 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"4 years",
"8 years",
"10+ years",
"6 years",
"1 year",
"6 years",
"3 years",
"9 years",
"5 years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"1 year",
"6 years",
"2 years",
"1 year",
"1 year",
"10+ years",
"1 year",
"10+ years",
"8 years",
"10+ years",
null,
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"3 years",
null,
"10+ years",
"9 years",
"10+ years",
"6 years",
"9 years",
"1 year",
"< 1 year",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"5 years",
"4 years",
"8 years",
null,
"10+ years",
"4 years",
null,
"2 years",
"10+ years",
"6 years",
"< 1 year",
"10+ years",
null,
"2 years",
null,
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"6 years",
"< 1 year",
"4 years",
"9 years",
"7 years",
"3 years",
"9 years",
"4 years",
"10+ years",
"2 years",
"3 years",
null,
"3 years",
null,
"4 years",
"4 years",
"< 1 year",
"5 years",
"2 years",
"3 years",
"10+ years",
"2 years",
"8 years",
"2 years",
"10+ years",
"9 years",
"1 year",
"7 years",
"7 years",
"9 years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"8 years",
"2 years",
"2 years",
null,
"5 years",
"6 years",
"< 1 year",
"4 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"6 years",
"4 years",
"7 years",
null,
"1 year",
"3 years",
"8 years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"7 years",
"3 years",
"7 years",
"< 1 year",
"8 years",
"2 years",
"2 years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"9 years",
"4 years",
"< 1 year",
"2 years",
"< 1 year",
"8 years",
"7 years",
"10+ years",
"< 1 year",
"< 1 year",
"9 years",
"4 years",
"3 years",
"< 1 year",
"4 years",
"< 1 year",
"9 years",
"10+ years",
"6 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"6 years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"2 years",
"10+ years",
"7 years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
null,
"10+ years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"1 year",
"6 years",
"4 years",
"5 years",
"3 years",
"10+ years",
"9 years",
"8 years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"1 year",
"10+ years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"8 years",
null,
"10+ years",
"10+ years",
"10+ years",
"8 years",
"2 years",
"6 years",
"10+ years",
null,
"7 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"9 years",
"5 years",
"6 years",
"5 years",
"1 year",
"5 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"7 years",
"2 years",
"5 years",
"6 years",
"10+ years",
"< 1 year",
"3 years",
"4 years",
"2 years",
"8 years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"1 year",
"7 years",
"7 years",
"10+ years",
"10+ years",
"7 years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"6 years",
"5 years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"7 years",
"10+ years",
null,
"7 years",
"5 years",
"5 years",
"3 years",
"10+ years",
"9 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"1 year",
"1 year",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"3 years",
null,
"3 years",
"6 years",
"8 years",
"7 years",
"2 years",
"7 years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"< 1 year",
"1 year",
"3 years",
"9 years",
"10+ years",
"2 years",
"10+ years",
"4 years",
"2 years",
"4 years",
"10+ years",
"6 years",
"10+ years",
null,
"9 years",
"7 years",
"7 years",
"1 year",
"1 year",
"5 years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"2 years",
"9 years",
"5 years",
"6 years",
"2 years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"7 years",
"10+ years",
"6 years",
"6 years",
"6 years",
"10+ years",
"6 years",
null,
"10+ years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"2 years",
null,
"10+ years",
"10+ years",
null,
"8 years",
"1 year",
"4 years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"8 years",
"10+ years",
"6 years",
"7 years",
"1 year",
"2 years",
"8 years",
"10+ years",
"1 year",
"3 years",
"< 1 year",
"< 1 year",
null,
"10+ years",
"10+ years",
"3 years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"6 years",
"10+ years",
"10+ years",
"6 years",
"6 years",
"< 1 year",
"5 years",
"5 years",
"1 year",
"4 years",
"8 years",
"10+ years",
"8 years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"3 years",
"7 years",
"4 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"8 years",
"4 years",
"3 years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"8 years",
"9 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"9 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"2 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"3 years",
"4 years",
"9 years",
"10+ years",
"9 years",
"4 years",
"10+ years",
"1 year",
"6 years",
"< 1 year",
null,
"10+ years",
"2 years",
"10+ years",
"9 years",
"4 years",
"< 1 year",
"10+ years",
"1 year",
"2 years",
"10+ years",
"2 years",
null,
"< 1 year",
"10+ years",
"1 year",
"3 years",
"2 years",
"8 years",
null,
"9 years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"9 years",
"6 years",
"< 1 year",
"2 years",
"5 years",
"9 years",
"1 year",
"4 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"4 years",
"3 years",
"10+ years",
"10+ years",
null,
"1 year",
null,
"< 1 year",
"3 years",
"5 years",
"3 years",
"7 years",
null,
"10+ years",
"9 years",
"2 years",
null,
"10+ years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"7 years",
"< 1 year",
null,
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"1 year",
"10+ years",
"2 years",
"9 years",
"3 years",
"3 years",
"< 1 year",
"1 year",
"2 years",
"2 years",
"6 years",
"7 years",
"10+ years",
"< 1 year",
"1 year",
"3 years",
"2 years",
"10+ years",
"5 years",
"2 years",
"7 years",
"3 years",
"1 year",
"8 years",
"2 years",
"6 years",
"2 years",
"4 years",
"3 years",
"8 years",
"1 year",
"10+ years",
"5 years",
"< 1 year",
"4 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"2 years",
"2 years",
"3 years",
"10+ years",
"7 years",
"10+ years",
null,
"2 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"< 1 year",
"3 years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"2 years",
"9 years",
"3 years",
"1 year",
"6 years",
"1 year",
"1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"3 years",
null,
"7 years",
"1 year",
"8 years",
"< 1 year",
"4 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"7 years",
"10+ years",
"< 1 year",
null,
"4 years",
"9 years",
"10+ years",
"2 years",
null,
"7 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"4 years",
"6 years",
"10+ years",
"8 years",
"< 1 year",
"2 years",
"6 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"6 years",
"7 years",
"1 year",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"5 years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"4 years",
"< 1 year",
"10+ years",
null,
"7 years",
"3 years",
"9 years",
"6 years",
null,
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"< 1 year",
"10+ years",
"8 years",
null,
"1 year",
null,
"5 years",
null,
"10+ years",
null,
"10+ years",
"5 years",
"< 1 year",
"4 years",
"5 years",
"10+ years",
"1 year",
"1 year",
"8 years",
"7 years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"4 years",
"4 years",
"2 years",
"7 years",
null,
"10+ years",
"5 years",
null,
"10+ years",
"10+ years",
"10+ years",
"1 year",
"7 years",
"8 years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"6 years",
"10+ years",
"9 years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"6 years",
"6 years",
"2 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
null,
"2 years",
"10+ years",
"3 years",
"8 years",
"< 1 year",
"6 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"4 years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
null,
"10+ years",
null,
"9 years",
"4 years",
"5 years",
"4 years",
"10+ years",
null,
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"10+ years",
"1 year",
"10+ years",
"8 years",
"10+ years",
null,
"3 years",
"8 years",
"3 years",
"3 years",
"2 years",
"2 years",
"6 years",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"9 years",
"< 1 year",
"< 1 year",
"4 years",
"< 1 year",
"1 year",
"3 years",
null,
"3 years",
"6 years",
"8 years",
"6 years",
"7 years",
"10+ years",
"8 years",
null,
"10+ years",
"9 years",
"7 years",
"2 years",
"10+ years",
"2 years",
"2 years",
null,
"10+ years",
"7 years",
"2 years",
"2 years",
"10+ years",
"9 years",
"< 1 year",
"8 years",
"8 years",
"< 1 year",
"10+ years",
"8 years",
"3 years",
"4 years",
null,
"10+ years",
"6 years",
"4 years",
"7 years",
"5 years",
"2 years",
"3 years",
"1 year",
"< 1 year",
"5 years",
"1 year",
null,
"10+ years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"4 years",
"8 years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"1 year",
"2 years",
null,
"10+ years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"7 years",
"3 years",
"10+ years",
"4 years",
"1 year",
"7 years",
"10+ years",
"3 years",
"2 years",
"9 years",
"10+ years",
"8 years",
null,
"2 years",
"2 years",
"7 years",
"10+ years",
"3 years",
null,
"4 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"1 year",
"< 1 year",
"2 years",
"< 1 year",
"10+ years",
"9 years",
"6 years",
"8 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"9 years",
"10+ years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"4 years",
"< 1 year",
"3 years",
"3 years",
"8 years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"6 years",
"< 1 year",
"7 years",
"5 years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"7 years",
"5 years",
"10+ years",
"10+ years",
null,
null,
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"1 year",
"10+ years",
"10+ years",
"8 years",
"9 years",
"10+ years",
"1 year",
"3 years",
"5 years",
"5 years",
"2 years",
"8 years",
"10+ years",
"3 years",
"3 years",
"4 years",
null,
"10+ years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"5 years",
"< 1 year",
"3 years",
"8 years",
"6 years",
"6 years",
"5 years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"6 years",
"10+ years",
"2 years",
"3 years",
"6 years",
"10+ years",
"8 years",
"7 years",
null,
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"8 years",
"3 years",
"< 1 year",
"4 years",
"< 1 year",
"10+ years",
"6 years",
"3 years",
"8 years",
"< 1 year",
"1 year",
"10+ years",
"4 years",
"9 years",
"1 year",
"3 years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
null,
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"6 years",
"3 years",
"10+ years",
"< 1 year",
null,
"10+ years",
"4 years",
"10+ years",
"3 years",
"1 year",
"10+ years",
"2 years",
null,
"< 1 year",
"3 years",
"2 years",
"3 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"6 years",
"9 years",
"5 years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"< 1 year",
"7 years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
null,
"2 years",
"5 years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"2 years",
"10+ years",
"9 years",
"2 years",
"5 years",
"6 years",
"3 years",
"10+ years",
"5 years",
"2 years",
"8 years",
"10+ years",
"< 1 year",
"6 years",
"< 1 year",
"5 years",
"5 years",
"10+ years",
"10+ years",
null,
"1 year",
"2 years",
"2 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"6 years",
"5 years",
"9 years",
"1 year",
"2 years",
"10+ years",
"3 years",
"< 1 year",
"8 years",
"7 years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"8 years",
null,
null,
"10+ years",
"5 years",
"2 years",
"2 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"9 years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"2 years",
"8 years",
"< 1 year",
"8 years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"8 years",
null,
"3 years",
"10+ years",
"2 years",
"10+ years",
"6 years",
"1 year",
"10+ years",
"7 years",
"10+ years",
"7 years",
"3 years",
"1 year",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"2 years",
"10+ years",
"5 years",
"4 years",
"6 years",
"5 years",
"9 years",
"1 year",
"8 years",
"< 1 year",
"10+ years",
"9 years",
"< 1 year",
"7 years",
null,
null,
"10+ years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"2 years",
"2 years",
"4 years",
"< 1 year",
"9 years",
"9 years",
"7 years",
null,
"2 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
null,
"10+ years",
"3 years",
"< 1 year",
"7 years",
"8 years",
"3 years",
"3 years",
"10+ years",
"3 years",
"9 years",
"5 years",
"7 years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"3 years",
"3 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
null,
"3 years",
"3 years",
"1 year",
"< 1 year",
"2 years",
null,
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"7 years",
"10+ years",
"1 year",
"1 year",
"5 years",
"< 1 year",
"3 years",
"3 years",
"4 years",
"8 years",
"< 1 year",
"7 years",
"2 years",
"10+ years",
null,
"4 years",
"5 years",
"1 year",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"6 years",
"5 years",
"8 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"8 years",
null,
"< 1 year",
"6 years",
"10+ years",
"7 years",
"3 years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"8 years",
"2 years",
"< 1 year",
"4 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"4 years",
"3 years",
"10+ years",
"5 years",
"< 1 year",
"9 years",
"4 years",
null,
"3 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"7 years",
"1 year",
"3 years",
"10+ years",
"5 years",
"2 years",
"1 year",
"5 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"7 years",
"5 years",
"7 years",
"5 years",
"2 years",
"10+ years",
"4 years",
"8 years",
"10+ years",
"2 years",
"5 years",
null,
null,
"10+ years",
"10+ years",
"8 years",
"5 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"8 years",
"2 years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"4 years",
"5 years",
"5 years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"1 year",
"8 years",
"10+ years",
"5 years",
"8 years",
null,
"10+ years",
"< 1 year",
"8 years",
"4 years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"2 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"4 years",
"< 1 year",
"8 years",
null,
"10+ years",
"9 years",
"1 year",
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"9 years",
"5 years",
"2 years",
"6 years",
"< 1 year",
"10+ years",
"9 years",
"6 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"4 years",
"7 years",
"5 years",
"10+ years",
"3 years",
"4 years",
null,
"10+ years",
"7 years",
"9 years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"< 1 year",
"10+ years",
"7 years",
"7 years",
"3 years",
"10+ years",
"3 years",
"< 1 year",
"6 years",
"< 1 year",
"10+ years",
"2 years",
"7 years",
"10+ years",
"< 1 year",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"2 years",
"1 year",
"8 years",
null,
"1 year",
"2 years",
"10+ years",
"5 years",
"10+ years",
null,
"1 year",
"2 years",
"10+ years",
"5 years",
"2 years",
"1 year",
"3 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"1 year",
null,
"10+ years",
"7 years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"8 years",
"2 years",
"2 years",
"8 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
null,
"10+ years",
"2 years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"4 years",
"5 years",
"8 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"3 years",
"2 years",
null,
"3 years",
"2 years",
"10+ years",
"3 years",
null,
"8 years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"10+ years",
"8 years",
"2 years",
"6 years",
"4 years",
"6 years",
"7 years",
"9 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"3 years",
"9 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"4 years",
"8 years",
"< 1 year",
"10+ years",
"6 years",
"9 years",
"2 years",
"3 years",
"10+ years",
"4 years",
"10+ years",
"8 years",
"7 years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"1 year",
"5 years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"3 years",
"3 years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"1 year",
"8 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"6 years",
"< 1 year",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"8 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"5 years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"2 years",
"7 years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"4 years",
"8 years",
null,
"5 years",
"2 years",
null,
"10+ years",
"10+ years",
"1 year",
"4 years",
null,
"9 years",
"1 year",
"2 years",
"9 years",
"6 years",
"3 years",
"4 years",
"1 year",
"4 years",
"10+ years",
"3 years",
"6 years",
"10+ years",
"4 years",
"2 years",
"3 years",
"2 years",
"10+ years",
"6 years",
"8 years",
"8 years",
"2 years",
"9 years",
"4 years",
"3 years",
"9 years",
"4 years",
"7 years",
"5 years",
"5 years",
"7 years",
"6 years",
"1 year",
"9 years",
"< 1 year",
"< 1 year",
"< 1 year",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"8 years",
"8 years",
"< 1 year",
"9 years",
"3 years",
"9 years",
"9 years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"7 years",
"5 years",
"6 years",
"10+ years",
null,
"10+ years",
"3 years",
"9 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"5 years",
null,
"3 years",
"10+ years",
"8 years",
"7 years",
"8 years",
"1 year",
"2 years",
"3 years",
"10+ years",
"8 years",
"1 year",
"1 year",
"10+ years",
"4 years",
null,
"3 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
null,
"3 years",
"9 years",
"2 years",
"2 years",
"6 years",
"4 years",
"3 years",
"1 year",
"< 1 year",
"6 years",
"2 years",
"9 years",
"4 years",
"2 years",
"10+ years",
"4 years",
"2 years",
"7 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"10+ years",
null,
"2 years",
"1 year",
"4 years",
"2 years",
"4 years",
"2 years",
"4 years",
"10+ years",
"6 years",
"1 year",
null,
"10+ years",
"4 years",
"10+ years",
"1 year",
"2 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"8 years",
"3 years",
"10+ years",
"8 years",
"5 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"4 years",
"< 1 year",
"2 years",
"10+ years",
"1 year",
"9 years",
"1 year",
"3 years",
"1 year",
"6 years",
"6 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
null,
"1 year",
"10+ years",
null,
"7 years",
"10+ years",
"6 years",
"10+ years",
null,
"10+ years",
"5 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"9 years",
"< 1 year",
"7 years",
"5 years",
"10+ years",
"2 years",
"9 years",
"10+ years",
"3 years",
"9 years",
"5 years",
"10+ years",
"10+ years",
"9 years",
"7 years",
"10+ years",
"5 years",
"1 year",
"5 years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"3 years",
"10+ years",
null,
"5 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"3 years",
"3 years",
"2 years",
"6 years",
"10+ years",
"3 years",
"7 years",
"8 years",
"5 years",
null,
"10+ years",
"10+ years",
"5 years",
"1 year",
"3 years",
"10+ years",
"4 years",
"6 years",
"5 years",
"1 year",
"10+ years",
"6 years",
null,
"2 years",
"7 years",
"10+ years",
"1 year",
"< 1 year",
"9 years",
"10+ years",
"7 years",
"4 years",
"7 years",
"3 years",
"1 year",
"8 years",
"3 years",
"2 years",
"8 years",
"10+ years",
"5 years",
"7 years",
null,
"10+ years",
"4 years",
"7 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"8 years",
"10+ years",
"7 years",
"9 years",
"8 years",
"3 years",
"7 years",
"2 years",
"5 years",
"10+ years",
"5 years",
"4 years",
"9 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"9 years",
"2 years",
"4 years",
"1 year",
"2 years",
"2 years",
"< 1 year",
"4 years",
"10+ years",
"3 years",
"8 years",
"8 years",
"< 1 year",
"3 years",
"4 years",
"4 years",
"5 years",
"10+ years",
"5 years",
"4 years",
"7 years",
"2 years",
"3 years",
null,
"8 years",
"2 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
null,
"3 years",
"4 years",
"10+ years",
"6 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"3 years",
null,
"5 years",
"5 years",
"2 years",
"4 years",
"2 years",
"< 1 year",
"< 1 year",
"< 1 year",
null,
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"< 1 year",
"1 year",
"6 years",
null,
null,
"10+ years",
"5 years",
"10+ years",
"6 years",
"10+ years",
"7 years",
"6 years",
"10+ years",
"5 years",
"7 years",
"3 years",
"10+ years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"5 years",
"< 1 year",
"7 years",
"5 years",
"5 years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"1 year",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"3 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"2 years",
"10+ years",
"2 years",
"2 years",
"3 years",
"< 1 year",
"8 years",
"10+ years",
"5 years",
"3 years",
"4 years",
"2 years",
"9 years",
"9 years",
"6 years",
"4 years",
"2 years",
"10+ years",
"1 year",
"8 years",
"5 years",
"5 years",
"5 years",
"3 years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"1 year",
"3 years",
null,
null,
"2 years",
"10+ years",
"9 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"7 years",
"2 years",
"5 years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"8 years",
"5 years",
"< 1 year",
"3 years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"10+ years",
null,
"4 years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"3 years",
"10+ years",
"6 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
null,
"3 years",
"8 years",
"2 years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"7 years",
"4 years",
null,
"10+ years",
"10+ years",
"2 years",
"5 years",
"9 years",
"1 year",
"10+ years",
"10+ years",
"4 years",
null,
"10+ years",
"10+ years",
"7 years",
"3 years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"< 1 year",
"6 years",
"2 years",
"6 years",
"9 years",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"4 years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"4 years",
"3 years",
"4 years",
"1 year",
"10+ years",
"5 years",
"3 years",
"3 years",
"< 1 year",
"10+ years",
"< 1 year",
"1 year",
"1 year",
"5 years",
"1 year",
"10+ years",
"2 years",
"8 years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"1 year",
"3 years",
"6 years",
"1 year",
"7 years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"8 years",
"5 years",
"< 1 year",
"10+ years",
"3 years",
"1 year",
"6 years",
"10+ years",
"< 1 year",
"1 year",
"3 years",
"5 years",
"3 years",
"8 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"7 years",
"10+ years",
"10+ years",
"10+ years",
null,
"6 years",
"3 years",
"10+ years",
"5 years",
"6 years",
null,
"2 years",
"2 years",
"10+ years",
"< 1 year",
null,
"9 years",
"6 years",
"2 years",
"< 1 year",
"< 1 year",
"10+ years",
"6 years",
"5 years",
"6 years",
"< 1 year",
"4 years",
"6 years",
"1 year",
"3 years",
"10+ years",
"9 years",
"2 years",
"8 years",
"8 years",
"7 years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"3 years",
"9 years",
"2 years",
"< 1 year",
"3 years",
"4 years",
"3 years",
"8 years",
"3 years",
"2 years",
"3 years",
"10+ years",
"2 years",
"9 years",
"10+ years",
"6 years",
"3 years",
"6 years",
"9 years",
"7 years",
"1 year",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"4 years",
"7 years",
"10+ years",
"1 year",
"3 years",
"1 year",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"< 1 year",
"< 1 year",
"3 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"1 year",
"4 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"5 years",
"2 years",
"10+ years",
"4 years",
"7 years",
"7 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"8 years",
"4 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
null,
null,
"9 years",
null,
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"5 years",
"8 years",
"6 years",
"7 years",
"1 year",
"2 years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"8 years",
"1 year",
"1 year",
"10+ years",
"2 years",
"3 years",
"10+ years",
"4 years",
"8 years",
"10+ years",
"1 year",
"4 years",
"10+ years",
"8 years",
"2 years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
"9 years",
"6 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
null,
"4 years",
null,
"7 years",
"2 years",
"2 years",
"6 years",
"6 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"8 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
null,
"10+ years",
"5 years",
"3 years",
"6 years",
"3 years",
"9 years",
"5 years",
"1 year",
"4 years",
"10+ years",
"< 1 year",
"1 year",
"< 1 year",
"6 years",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"2 years",
"1 year",
"10+ years",
"5 years",
"10+ years",
"2 years",
"10+ years",
null,
"9 years",
"10+ years",
"6 years",
"3 years",
"< 1 year",
"10+ years",
"7 years",
"5 years",
"10+ years",
"5 years",
"2 years",
"6 years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"3 years",
"< 1 year",
"1 year",
"< 1 year",
"5 years",
"3 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"2 years",
"8 years",
"2 years",
null,
"10+ years",
"8 years",
"< 1 year",
"< 1 year",
"5 years",
"10+ years",
"1 year",
"8 years",
null,
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"9 years",
"10+ years",
"3 years",
null,
"5 years",
"1 year",
"1 year",
"3 years",
"4 years",
null,
"5 years",
"10+ years",
"8 years",
"4 years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
null,
"10+ years",
"5 years",
null,
"1 year",
"4 years",
"2 years",
"10+ years",
"4 years",
"3 years",
"2 years",
"10+ years",
"3 years",
"3 years",
"8 years",
"4 years",
"8 years",
"5 years",
"2 years",
"10+ years",
"7 years",
"4 years",
"2 years",
"3 years",
"6 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
null,
"4 years",
"10+ years",
"9 years",
null,
"8 years",
"9 years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"6 years",
"8 years",
"10+ years",
"10+ years",
"6 years",
"9 years",
"< 1 year",
"3 years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"1 year",
"9 years",
null,
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"6 years",
"5 years",
null,
"3 years",
"2 years",
"6 years",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"2 years",
"< 1 year",
"< 1 year",
"7 years",
"10+ years",
"1 year",
"2 years",
"4 years",
"6 years",
"4 years",
"10+ years",
"1 year",
"< 1 year",
"2 years",
"8 years",
"10+ years",
"< 1 year",
"9 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"4 years",
"5 years",
"4 years",
null,
"10+ years",
"10+ years",
"4 years",
"3 years",
"< 1 year",
"10+ years",
"1 year",
"7 years",
null,
"4 years",
"5 years",
"6 years",
"3 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"3 years",
null,
"1 year",
"1 year",
"5 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"9 years",
"10+ years",
"5 years",
"2 years",
"5 years",
"10+ years",
"< 1 year",
"1 year",
"4 years",
"< 1 year",
"< 1 year",
"8 years",
"4 years",
"2 years",
"4 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"7 years",
"6 years",
"< 1 year",
"8 years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"8 years",
"3 years",
"2 years",
"10+ years",
"9 years",
"10+ years",
"2 years",
"4 years",
"7 years",
"9 years",
"3 years",
"< 1 year",
"2 years",
"6 years",
"< 1 year",
"5 years",
"2 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
null,
"6 years",
"4 years",
"1 year",
"3 years",
"4 years",
"1 year",
"1 year",
"< 1 year",
"1 year",
"10+ years",
"7 years",
"8 years",
"9 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"5 years",
"9 years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"8 years",
"8 years",
"8 years",
"8 years",
"6 years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"< 1 year",
"< 1 year",
"7 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"2 years",
"8 years",
"1 year",
"1 year",
null,
"10+ years",
"10+ years",
"2 years",
"5 years",
"< 1 year",
"5 years",
"2 years",
"10+ years",
null,
"10+ years",
"7 years",
"6 years",
"6 years",
"5 years",
"5 years",
"4 years",
"10+ years",
"1 year",
"5 years",
"9 years",
"2 years",
"9 years",
"5 years",
"8 years",
"2 years",
"10+ years",
"< 1 year",
"< 1 year",
"2 years",
null,
"7 years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"7 years",
"7 years",
null,
"2 years",
"8 years",
"5 years",
"9 years",
"10+ years",
"9 years",
"8 years",
"9 years",
"10+ years",
null,
"10+ years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"5 years",
"7 years",
"10+ years",
"6 years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"8 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"4 years",
"10+ years",
"1 year",
"8 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"6 years",
"8 years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"7 years",
"3 years",
"5 years",
"1 year",
"< 1 year",
"2 years",
"4 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"9 years",
"9 years",
"7 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"< 1 year",
"10+ years",
null,
"8 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"< 1 year",
"4 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"7 years",
"10+ years",
"5 years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
null,
"2 years",
"8 years",
"9 years",
null,
"< 1 year",
"10+ years",
"< 1 year",
"< 1 year",
"1 year",
"2 years",
"1 year",
"3 years",
"2 years",
"1 year",
"4 years",
"< 1 year",
"1 year",
"10+ years",
"< 1 year",
"3 years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"9 years",
"< 1 year",
null,
"2 years",
"3 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"6 years",
"9 years",
"2 years",
"3 years",
"4 years",
"10+ years",
"1 year",
"5 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"4 years",
"8 years",
"2 years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"5 years",
"1 year",
"9 years",
"7 years",
"1 year",
"8 years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"3 years",
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"6 years",
"4 years",
"10+ years",
"10+ years",
"7 years",
"7 years",
"3 years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"< 1 year",
"3 years",
"2 years",
"2 years",
"10+ years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"6 years",
"10+ years",
"3 years",
"10+ years",
null,
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"8 years",
"7 years",
"9 years",
"3 years",
"3 years",
"2 years",
"4 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"6 years",
"5 years",
"10+ years",
"8 years",
"9 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"9 years",
null,
"6 years",
"9 years",
"5 years",
"4 years",
"10+ years",
"10+ years",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"9 years",
"3 years",
"3 years",
"2 years",
"2 years",
"5 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"2 years",
"8 years",
"8 years",
"3 years",
null,
"3 years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"3 years",
"8 years",
"4 years",
"4 years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"1 year",
"4 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"7 years",
"< 1 year",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"3 years",
null,
"3 years",
"10+ years",
"7 years",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
null,
"8 years",
"10+ years",
"< 1 year",
"8 years",
"3 years",
"10+ years",
"10+ years",
null,
"1 year",
"7 years",
"< 1 year",
"3 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"8 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"5 years",
"10+ years",
null,
"1 year",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"9 years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
null,
"3 years",
"2 years",
"8 years",
"2 years",
"10+ years",
"< 1 year",
"3 years",
"< 1 year",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"5 years",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"5 years",
null,
"2 years",
"8 years",
"1 year",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"5 years",
"3 years",
"10+ years",
"5 years",
"4 years",
"8 years",
"5 years",
null,
"5 years",
"10+ years",
"2 years",
"2 years",
"< 1 year",
"10+ years",
"7 years",
"3 years",
"2 years",
"< 1 year",
"1 year",
"7 years",
"2 years",
"10+ years",
"4 years",
"3 years",
"8 years",
"3 years",
"8 years",
"< 1 year",
"2 years",
"1 year",
"2 years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"2 years",
"5 years",
"< 1 year",
"< 1 year",
"6 years",
"10+ years",
"3 years",
"7 years",
null,
"3 years",
null,
"5 years",
"2 years",
"10+ years",
"7 years",
"3 years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"1 year",
"8 years",
"7 years",
"6 years",
"10+ years",
"7 years",
"10+ years",
"9 years",
"< 1 year",
"3 years",
"5 years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"8 years",
"5 years",
"3 years",
"9 years",
"1 year",
"10+ years",
null,
"3 years",
"5 years",
"8 years",
"3 years",
"7 years",
"3 years",
"7 years",
"3 years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"4 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"8 years",
"8 years",
"1 year",
"4 years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"< 1 year",
"1 year",
"7 years",
"6 years",
"3 years",
"< 1 year",
"3 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"< 1 year",
"9 years",
"2 years",
"9 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
null,
"2 years",
"< 1 year",
"< 1 year",
"4 years",
"7 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"1 year",
"1 year",
"10+ years",
"4 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"7 years",
"< 1 year",
"2 years",
"10+ years",
"5 years",
"8 years",
"2 years",
"3 years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"1 year",
"6 years",
"6 years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"6 years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"3 years",
"8 years",
null,
"7 years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"4 years",
"3 years",
"10+ years",
"3 years",
"7 years",
"9 years",
"10+ years",
"10+ years",
"8 years",
"3 years",
"2 years",
"10+ years",
"9 years",
"8 years",
"< 1 year",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"< 1 year",
"5 years",
"10+ years",
"5 years",
"8 years",
"10+ years",
"9 years",
"10+ years",
"5 years",
"10+ years",
"3 years",
"1 year",
"3 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"6 years",
"3 years",
"10+ years",
"8 years",
"5 years",
"7 years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"1 year",
"8 years",
"10+ years",
"2 years",
"7 years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
null,
"10+ years",
"9 years",
"9 years",
"< 1 year",
"2 years",
"4 years",
"< 1 year",
"5 years",
"5 years",
"3 years",
"10+ years",
"< 1 year",
null,
"10+ years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"7 years",
"10+ years",
"< 1 year",
"9 years",
"9 years",
"2 years",
"9 years",
"8 years",
null,
null,
"10+ years",
"5 years",
"6 years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"9 years",
"4 years",
"2 years",
"3 years",
"1 year",
"10+ years",
"6 years",
"< 1 year",
"8 years",
"3 years",
"5 years",
"10+ years",
"10+ years",
null,
"< 1 year",
null,
"10+ years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"4 years",
"1 year",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
null,
"1 year",
"5 years",
"4 years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"8 years",
"8 years",
"6 years",
"8 years",
"3 years",
"2 years",
"10+ years",
"8 years",
"1 year",
"10+ years",
null,
"4 years",
"4 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"1 year",
"5 years",
"6 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"3 years",
"5 years",
"3 years",
"2 years",
"6 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"7 years",
"2 years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"3 years",
"9 years",
"< 1 year",
"10+ years",
"9 years",
"< 1 year",
"3 years",
"< 1 year",
"4 years",
"2 years",
"5 years",
"7 years",
"10+ years",
"< 1 year",
"2 years",
"4 years",
"1 year",
"6 years",
"1 year",
"10+ years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"3 years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"1 year",
"8 years",
"< 1 year",
"< 1 year",
"4 years",
"10+ years",
null,
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"8 years",
null,
"2 years",
"9 years",
"2 years",
"10+ years",
"8 years",
"3 years",
"8 years",
"10+ years",
"9 years",
"8 years",
"10+ years",
"4 years",
null,
"2 years",
"< 1 year",
"8 years",
"4 years",
"4 years",
"10+ years",
"3 years",
"3 years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"5 years",
"9 years",
"9 years",
"2 years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"2 years",
"6 years",
"5 years",
null,
"5 years",
"< 1 year",
"2 years",
null,
"3 years",
"3 years",
"5 years",
"8 years",
"8 years",
"5 years",
"2 years",
"10+ years",
"7 years",
"8 years",
"2 years",
"5 years",
"10+ years",
"7 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
null,
"7 years",
"3 years",
"7 years",
"6 years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"1 year",
"4 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"3 years",
"7 years",
"2 years",
"7 years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"8 years",
"2 years",
"4 years",
"1 year",
"4 years",
null,
"4 years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"9 years",
"7 years",
"< 1 year",
null,
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"< 1 year",
"4 years",
"5 years",
"< 1 year",
"6 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
null,
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"7 years",
null,
"4 years",
"10+ years",
"9 years",
null,
"9 years",
"10+ years",
"< 1 year",
null,
"3 years",
"8 years",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"7 years",
"9 years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"7 years",
"4 years",
"8 years",
"7 years",
"6 years",
"3 years",
"1 year",
"< 1 year",
"10+ years",
"4 years",
"3 years",
"< 1 year",
"3 years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"9 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
null,
"2 years",
"< 1 year",
"< 1 year",
"4 years",
"8 years",
"4 years",
null,
"10+ years",
"1 year",
"< 1 year",
"1 year",
"< 1 year",
"< 1 year",
"5 years",
"2 years",
"8 years",
"10+ years",
"6 years",
"6 years",
"7 years",
"10+ years",
"4 years",
"2 years",
null,
"< 1 year",
"3 years",
"3 years",
"10+ years",
null,
"2 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"1 year",
"10+ years",
"4 years",
"7 years",
"1 year",
null,
"10+ years",
"4 years",
"2 years",
"2 years",
"5 years",
"9 years",
"2 years",
"5 years",
"10+ years",
"9 years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"3 years",
"1 year",
"8 years",
"5 years",
"4 years",
"9 years",
"2 years",
"10+ years",
"10+ years",
null,
"5 years",
"2 years",
"7 years",
"10+ years",
"1 year",
"8 years",
"5 years",
"9 years",
"7 years",
"6 years",
"7 years",
"4 years",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
null,
"10+ years",
"5 years",
"10+ years",
"9 years",
"8 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"7 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"4 years",
"8 years",
"10+ years",
"10+ years",
"6 years",
"4 years",
"2 years",
"9 years",
"6 years",
"3 years",
"10+ years",
"5 years",
"7 years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"7 years",
null,
"< 1 year",
"10+ years",
"2 years",
"5 years",
"2 years",
"2 years",
"2 years",
null,
"10+ years",
"10+ years",
"8 years",
"2 years",
"3 years",
"3 years",
"4 years",
"6 years",
"8 years",
"10+ years",
"2 years",
null,
"2 years",
"1 year",
"10+ years",
null,
"10+ years",
null,
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"6 years",
"5 years",
"10+ years",
null,
"10+ years",
"10+ years",
"3 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"< 1 year",
"9 years",
null,
"10+ years",
"8 years",
"10+ years",
"10+ years",
"6 years",
null,
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"6 years",
"7 years",
"1 year",
"8 years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"6 years",
"10+ years",
null,
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"3 years",
null,
"10+ years",
"4 years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"< 1 year",
"4 years",
"5 years",
"3 years",
null,
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"9 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"8 years",
null,
"1 year",
"6 years",
"2 years",
"< 1 year",
"6 years",
"9 years",
"10+ years",
"5 years",
"2 years",
"4 years",
"3 years",
"6 years",
"2 years",
"2 years",
"3 years",
null,
"3 years",
null,
"9 years",
"< 1 year",
"1 year",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"9 years",
"2 years",
"5 years",
"4 years",
"7 years",
"9 years",
"10+ years",
"3 years",
"1 year",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"1 year",
"3 years",
"6 years",
"10+ years",
"7 years",
"10+ years",
"7 years",
"3 years",
"6 years",
"10+ years",
"3 years",
"4 years",
null,
"2 years",
"< 1 year",
"3 years",
"10+ years",
"5 years",
null,
"< 1 year",
"6 years",
"1 year",
"4 years",
"3 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
null,
"10+ years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"5 years",
"5 years",
"4 years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"7 years",
"10+ years",
"2 years",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"8 years",
"7 years",
"10+ years",
null,
"< 1 year",
"8 years",
"7 years",
"6 years",
"10+ years",
"9 years",
"2 years",
"5 years",
"1 year",
"5 years",
"10+ years",
"2 years",
"10+ years",
"6 years",
"9 years",
"1 year",
"9 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"5 years",
"5 years",
"10+ years",
"9 years",
"10+ years",
"3 years",
"2 years",
"1 year",
"9 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"5 years",
null,
"5 years",
"10+ years",
"10+ years",
"2 years",
"7 years",
null,
"5 years",
"8 years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"7 years",
"4 years",
"5 years",
"4 years",
"< 1 year",
"5 years",
"10+ years",
"3 years",
"6 years",
"4 years",
null,
null,
"10+ years",
null,
null,
"5 years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"7 years",
"2 years",
"7 years",
"1 year",
"< 1 year",
"3 years",
"1 year",
"10+ years",
"8 years",
"5 years",
"2 years",
"7 years",
"5 years",
"9 years",
"8 years",
"10+ years",
"2 years",
"< 1 year",
"8 years",
"2 years",
"2 years",
"1 year",
"< 1 year",
"5 years",
"2 years",
"5 years",
"10+ years",
"8 years",
"6 years",
"4 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"4 years",
"5 years",
"2 years",
"5 years",
"10+ years",
"1 year",
"4 years",
"6 years",
"3 years",
"8 years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"7 years",
"1 year",
"10+ years",
"6 years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"5 years",
"10+ years",
null,
"3 years",
"8 years",
"8 years",
"10+ years",
"3 years",
"5 years",
"< 1 year",
"10+ years",
"2 years",
"3 years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
null,
"< 1 year",
"6 years",
"3 years",
"5 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"3 years",
"10+ years",
"< 1 year",
"2 years",
"2 years",
"6 years",
"9 years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"4 years",
"2 years",
"2 years",
null,
"10+ years",
"< 1 year",
null,
"1 year",
null,
"10+ years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"9 years",
"1 year",
"7 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"6 years",
"5 years",
"2 years",
"4 years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"4 years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"8 years",
"< 1 year",
"4 years",
"1 year",
null,
"10+ years",
"10+ years",
"10+ years",
"3 years",
null,
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"1 year",
"2 years",
null,
"7 years",
"2 years",
"10+ years",
null,
null,
"2 years",
"1 year",
"7 years",
"10+ years",
"< 1 year",
"5 years",
"5 years",
null,
"10+ years",
"6 years",
null,
"10+ years",
"2 years",
"6 years",
"9 years",
"< 1 year",
"9 years",
"10+ years",
"2 years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"2 years",
"6 years",
"10+ years",
"4 years",
"4 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"5 years",
"5 years",
null,
"4 years",
"5 years",
"2 years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"3 years",
"5 years",
"4 years",
"7 years",
"10+ years",
"7 years",
"10+ years",
"< 1 year",
"2 years",
"9 years",
"1 year",
"3 years",
"10+ years",
"2 years",
"7 years",
"9 years",
"10+ years",
null,
"9 years",
"4 years",
"2 years",
"6 years",
null,
"10+ years",
"1 year",
"3 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"9 years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"8 years",
"8 years",
"1 year",
"10+ years",
"10+ years",
"9 years",
"4 years",
"3 years",
"4 years",
"10+ years",
"2 years",
"1 year",
"7 years",
null,
"1 year",
"10+ years",
"7 years",
"7 years",
"7 years",
"2 years",
"< 1 year",
"9 years",
"4 years",
"2 years",
"10+ years",
"2 years",
"4 years",
"10+ years",
"2 years",
"8 years",
"1 year",
"8 years",
"10+ years",
"3 years",
"9 years",
"8 years",
null,
"10+ years",
"3 years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"1 year",
"2 years",
"5 years",
"2 years",
"5 years",
"5 years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"3 years",
null,
"8 years",
null,
"10+ years",
"5 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"9 years",
"2 years",
"3 years",
"10+ years",
"4 years",
"< 1 year",
"1 year",
"5 years",
"4 years",
"10+ years",
"10+ years",
null,
"4 years",
"10+ years",
"10+ years",
null,
"3 years",
"1 year",
"2 years",
"7 years",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
null,
"10+ years",
"1 year",
"3 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"7 years",
"6 years",
"2 years",
"10+ years",
"6 years",
"4 years",
"10+ years",
"9 years",
"3 years",
"2 years",
"10+ years",
"2 years",
"1 year",
"8 years",
"< 1 year",
"3 years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"4 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"1 year",
"4 years",
"8 years",
"10+ years",
"6 years",
"10+ years",
"5 years",
"10+ years",
"8 years",
"1 year",
"1 year",
"7 years",
"7 years",
"< 1 year",
"8 years",
"10+ years",
null,
"< 1 year",
"8 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
null,
"2 years",
"3 years",
"10+ years",
"3 years",
"4 years",
"8 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"8 years",
"< 1 year",
"4 years",
"5 years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"9 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"3 years",
"5 years",
"1 year",
"8 years",
"10+ years",
"< 1 year",
"8 years",
"2 years",
"1 year",
null,
"10+ years",
"10+ years",
"2 years",
"5 years",
null,
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"8 years",
"10+ years",
"6 years",
"6 years",
"3 years",
"8 years",
"7 years",
null,
null,
"10+ years",
"2 years",
"10+ years",
"2 years",
"1 year",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"9 years",
"4 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"8 years",
"2 years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"6 years",
"7 years",
"5 years",
"8 years",
"10+ years",
"< 1 year",
"< 1 year",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"9 years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"7 years",
"10+ years",
"8 years",
null,
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"5 years",
null,
"10+ years",
null,
"1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"< 1 year",
"1 year",
"5 years",
"4 years",
"2 years",
"10+ years",
"2 years",
"2 years",
"3 years",
null,
"10+ years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"6 years",
"6 years",
"10+ years",
"2 years",
"< 1 year",
"8 years",
"10+ years",
"5 years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
null,
"5 years",
"1 year",
"1 year",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"8 years",
"8 years",
"10+ years",
"4 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"< 1 year",
"8 years",
"1 year",
"4 years",
"8 years",
"2 years",
"10+ years",
"< 1 year",
"2 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
null,
"1 year",
"4 years",
"3 years",
"< 1 year",
"9 years",
"6 years",
"6 years",
null,
"10+ years",
"7 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"8 years",
"8 years",
"8 years",
"4 years",
"4 years",
"< 1 year",
"1 year",
"1 year",
"7 years",
"7 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"4 years",
"3 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"7 years",
"< 1 year",
"5 years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"2 years",
"7 years",
null,
"10+ years",
"10+ years",
"9 years",
"5 years",
"2 years",
"10+ years",
"6 years",
"7 years",
"10+ years",
"4 years",
"3 years",
null,
"10+ years",
"9 years",
"2 years",
"5 years",
"< 1 year",
"7 years",
"4 years",
"2 years",
"2 years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"1 year",
"9 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"4 years",
"10+ years",
null,
"2 years",
"10+ years",
"8 years",
"3 years",
"< 1 year",
"4 years",
"10+ years",
"8 years",
"1 year",
"3 years",
"10+ years",
"1 year",
"10+ years",
"2 years",
"6 years",
"10+ years",
"3 years",
"3 years",
"9 years",
"7 years",
"10+ years",
"3 years",
"1 year",
null,
"2 years",
"6 years",
"6 years",
"< 1 year",
"8 years",
"10+ years",
"2 years",
"6 years",
"5 years",
"6 years",
"3 years",
"6 years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"8 years",
"3 years",
"5 years",
"9 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
null,
"< 1 year",
"10+ years",
"7 years",
"2 years",
"1 year",
"1 year",
"3 years",
"4 years",
"10+ years",
"7 years",
"2 years",
"< 1 year",
"1 year",
"10+ years",
"3 years",
"< 1 year",
"2 years",
"9 years",
"8 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"6 years",
"< 1 year",
"4 years",
"6 years",
"6 years",
"6 years",
"2 years",
"5 years",
"8 years",
null,
"< 1 year",
"6 years",
"6 years",
"4 years",
"7 years",
"7 years",
"7 years",
"7 years",
"10+ years",
null,
"6 years",
"8 years",
"3 years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"4 years",
"9 years",
"9 years",
"8 years",
"3 years",
"1 year",
"9 years",
null,
"< 1 year",
null,
"1 year",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"2 years",
"8 years",
"2 years",
"5 years",
"1 year",
"10+ years",
"7 years",
"2 years",
"8 years",
null,
"6 years",
"< 1 year",
"10+ years",
"7 years",
"9 years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"7 years",
"10+ years",
null,
"10+ years",
"9 years",
"< 1 year",
null,
"10+ years",
"10+ years",
"7 years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"3 years",
"< 1 year",
null,
"5 years",
"10+ years",
"10+ years",
"1 year",
"8 years",
"10+ years",
"6 years",
"8 years",
"2 years",
"10+ years",
"6 years",
"10+ years",
"7 years",
"5 years",
"4 years",
"10+ years",
"1 year",
"7 years",
"1 year",
"< 1 year",
"3 years",
"5 years",
"7 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"2 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"4 years",
"2 years",
"5 years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"< 1 year",
"< 1 year",
"2 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"4 years",
"1 year",
"10+ years",
"10+ years",
"1 year",
"4 years",
"5 years",
"3 years",
"7 years",
"3 years",
"3 years",
"1 year",
"10+ years",
null,
"10+ years",
"3 years",
"9 years",
"< 1 year",
"10+ years",
"7 years",
"1 year",
"2 years",
"< 1 year",
"2 years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"4 years",
null,
"4 years",
"3 years",
"< 1 year",
"5 years",
"5 years",
"5 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"1 year",
"3 years",
"9 years",
"3 years",
"10+ years",
"3 years",
null,
null,
"6 years",
"< 1 year",
"6 years",
"10+ years",
"4 years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"5 years",
"6 years",
"4 years",
"10+ years",
"< 1 year",
null,
"10+ years",
"8 years",
"5 years",
null,
"3 years",
"< 1 year",
"7 years",
"9 years",
"2 years",
"4 years",
"10+ years",
"5 years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"1 year",
"7 years",
"7 years",
"< 1 year",
"6 years",
"5 years",
"7 years",
"10+ years",
"2 years",
null,
"2 years",
"3 years",
"9 years",
"10+ years",
"10+ years",
"8 years",
"6 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"7 years",
"9 years",
"1 year",
null,
"10+ years",
"1 year",
"1 year",
"3 years",
"10+ years",
"5 years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
null,
"< 1 year",
"7 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"6 years",
"10+ years",
null,
"4 years",
"2 years",
"8 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"1 year",
"< 1 year",
"4 years",
"1 year",
"< 1 year",
"8 years",
"10+ years",
"3 years",
"3 years",
"4 years",
"10+ years",
"< 1 year",
"2 years",
"4 years",
"5 years",
"5 years",
"10+ years",
"9 years",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"1 year",
"5 years",
"10+ years",
"5 years",
"5 years",
null,
"6 years",
"10+ years",
"< 1 year",
"6 years",
"7 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"1 year",
"3 years",
"3 years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"< 1 year",
"8 years",
"6 years",
"< 1 year",
"< 1 year",
"1 year",
"1 year",
"7 years",
"4 years",
"1 year",
"2 years",
"6 years",
"< 1 year",
"7 years",
"1 year",
"2 years",
"10+ years",
"6 years",
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"3 years",
"5 years",
"10+ years",
"6 years",
"3 years",
"4 years",
"4 years",
null,
"7 years",
"7 years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"7 years",
"10+ years",
"8 years",
"< 1 year",
"6 years",
"< 1 year",
"9 years",
"1 year",
"10+ years",
"2 years",
"5 years",
null,
"1 year",
"2 years",
"2 years",
"10+ years",
"< 1 year",
"5 years",
"< 1 year",
"9 years",
"10+ years",
"3 years",
"1 year",
"2 years",
"10+ years",
"7 years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"5 years",
null,
"1 year",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
null,
"10+ years",
"9 years",
"7 years",
"1 year",
null,
"10+ years",
"< 1 year",
null,
"10+ years",
null,
"10+ years",
"2 years",
"7 years",
"< 1 year",
null,
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"8 years",
"7 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"8 years",
"10+ years",
null,
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"9 years",
"< 1 year",
"10+ years",
"2 years",
"4 years",
"6 years",
"4 years",
"5 years",
null,
"10+ years",
"5 years",
"8 years",
"8 years",
"3 years",
"8 years",
"1 year",
"2 years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"6 years",
"8 years",
"8 years",
"10+ years",
"6 years",
"1 year",
"10+ years",
"6 years",
"< 1 year",
"9 years",
"7 years",
"< 1 year",
"8 years",
"4 years",
null,
null,
"3 years",
"10+ years",
"3 years",
"5 years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"9 years",
"< 1 year",
"< 1 year",
"3 years",
"8 years",
"4 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"8 years",
"7 years",
"10+ years",
"5 years",
"2 years",
"8 years",
"7 years",
"10+ years",
"2 years",
null,
"8 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"7 years",
"7 years",
"7 years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"6 years",
"7 years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"6 years",
"3 years",
"10+ years",
"5 years",
"2 years",
"4 years",
"5 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
null,
"9 years",
"10+ years",
"7 years",
"2 years",
"2 years",
"1 year",
"8 years",
"8 years",
null,
"10+ years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"6 years",
"10+ years",
"6 years",
"9 years",
null,
"3 years",
"10+ years",
"1 year",
"3 years",
"1 year",
"5 years",
"10+ years",
"7 years",
"< 1 year",
"5 years",
null,
"10+ years",
"10+ years",
"9 years",
null,
"10+ years",
"2 years",
"3 years",
"1 year",
"10+ years",
"5 years",
"6 years",
"4 years",
"3 years",
"3 years",
"2 years",
"10+ years",
"4 years",
"2 years",
"3 years",
null,
null,
"10+ years",
"10+ years",
"10+ years",
"4 years",
"9 years",
null,
"9 years",
"3 years",
"1 year",
"10+ years",
"3 years",
"4 years",
"10+ years",
"5 years",
null,
"2 years",
"9 years",
"10+ years",
"5 years",
"8 years",
"2 years",
"2 years",
"10+ years",
"2 years",
"8 years",
"6 years",
"< 1 year",
"4 years",
"3 years",
"10+ years",
"2 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"2 years",
null,
"4 years",
"3 years",
"10+ years",
"4 years",
"2 years",
"5 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"5 years",
"7 years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"5 years",
"8 years",
"10+ years",
"10+ years",
"8 years",
null,
"7 years",
"5 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"2 years",
"4 years",
"6 years",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"< 1 year",
"5 years",
"3 years",
"2 years",
"6 years",
"8 years",
"4 years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"< 1 year",
"2 years",
"2 years",
"4 years",
"< 1 year",
null,
"6 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"6 years",
"8 years",
"5 years",
"5 years",
"4 years",
"4 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
null,
"2 years",
"10+ years",
"4 years",
null,
"10+ years",
"1 year",
"10+ years",
"10+ years",
"7 years",
"9 years",
"5 years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"6 years",
"3 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"4 years",
"4 years",
"10+ years",
"9 years",
"2 years",
"10+ years",
null,
null,
"1 year",
"< 1 year",
"3 years",
"5 years",
null,
"1 year",
"7 years",
"10+ years",
"1 year",
"4 years",
"10+ years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"4 years",
"2 years",
"3 years",
"6 years",
"2 years",
"6 years",
"3 years",
"9 years",
"3 years",
"3 years",
"8 years",
"1 year",
"9 years",
"1 year",
null,
"4 years",
"2 years",
"< 1 year",
"8 years",
"3 years",
"10+ years",
"7 years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"4 years",
"3 years",
"6 years",
"2 years",
"3 years",
"10+ years",
null,
"10+ years",
"10+ years",
"8 years",
"7 years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
null,
"3 years",
"9 years",
null,
"5 years",
"10+ years",
null,
"2 years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"8 years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"9 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"3 years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"5 years",
"3 years",
null,
"9 years",
"< 1 year",
"< 1 year",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"2 years",
"10+ years",
null,
"7 years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"8 years",
"9 years",
"7 years",
"9 years",
"1 year",
"10+ years",
"1 year",
"9 years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"1 year",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"8 years",
"2 years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"8 years",
"3 years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"4 years",
"10+ years",
"8 years",
null,
"< 1 year",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"8 years",
"< 1 year",
"4 years",
"2 years",
"6 years",
"4 years",
"1 year",
"< 1 year",
"10+ years",
"9 years",
"9 years",
"3 years",
null,
null,
"10+ years",
"< 1 year",
"5 years",
"9 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"5 years",
null,
"< 1 year",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"3 years",
null,
"6 years",
"2 years",
"5 years",
"10+ years",
"8 years",
"9 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"5 years",
"2 years",
"4 years",
"10+ years",
"2 years",
"5 years",
"1 year",
"8 years",
"< 1 year",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"8 years",
"2 years",
"10+ years",
"1 year",
null,
"10+ years",
"5 years",
"2 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
null,
null,
"9 years",
"7 years",
null,
"5 years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"2 years",
"< 1 year",
"2 years",
"5 years",
"7 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"1 year",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"7 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"8 years",
"8 years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"3 years",
"1 year",
"8 years",
"10+ years",
"8 years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"4 years",
"6 years",
"10+ years",
"4 years",
"10+ years",
"1 year",
"10+ years",
"6 years",
"9 years",
"10+ years",
"3 years",
"5 years",
null,
"10+ years",
null,
"6 years",
"9 years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"7 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
null,
"1 year",
"3 years",
"< 1 year",
"5 years",
"7 years",
"5 years",
"1 year",
"7 years",
"2 years",
"10+ years",
null,
"3 years",
"4 years",
"10+ years",
"8 years",
"< 1 year",
null,
"3 years",
"3 years",
"1 year",
"5 years",
"6 years",
"9 years",
"5 years",
"6 years",
"5 years",
"3 years",
"8 years",
"3 years",
"3 years",
"2 years",
"10+ years",
"< 1 year",
"4 years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"5 years",
"5 years",
"10+ years",
"4 years",
"5 years",
"1 year",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"4 years",
"9 years",
"3 years",
"6 years",
"4 years",
"9 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"1 year",
null,
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"7 years",
"2 years",
"1 year",
"9 years",
"4 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"4 years",
"< 1 year",
"10+ years",
"9 years",
null,
"7 years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"3 years",
"3 years",
"4 years",
"1 year",
"1 year",
null,
"4 years",
"2 years",
"4 years",
"4 years",
"10+ years",
"3 years",
"< 1 year",
"9 years",
"1 year",
"1 year",
"< 1 year",
"3 years",
"2 years",
"5 years",
"3 years",
"10+ years",
"3 years",
"5 years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
null,
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"2 years",
"< 1 year",
"2 years",
"6 years",
"10+ years",
null,
"6 years",
"2 years",
"1 year",
null,
"10+ years",
null,
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"6 years",
"7 years",
"9 years",
"6 years",
"2 years",
null,
"2 years",
"10+ years",
"5 years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"< 1 year",
"4 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"7 years",
"10+ years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"3 years",
"8 years",
"5 years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"1 year",
"1 year",
"4 years",
"5 years",
null,
"< 1 year",
"1 year",
"10+ years",
null,
"10+ years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"3 years",
"8 years",
null,
"10+ years",
"< 1 year",
"6 years",
"10+ years",
null,
"8 years",
"2 years",
"10+ years",
"6 years",
"7 years",
"2 years",
"6 years",
"4 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"5 years",
"5 years",
"10+ years",
"7 years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"1 year",
"10+ years",
null,
"1 year",
"5 years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"8 years",
"8 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"3 years",
"9 years",
"5 years",
"10+ years",
"1 year",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"7 years",
"4 years",
"4 years",
"8 years",
"4 years",
"10+ years",
"3 years",
"3 years",
"6 years",
"3 years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"1 year",
"3 years",
"10+ years",
null,
"2 years",
"10+ years",
"8 years",
"10+ years",
"7 years",
"5 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"7 years",
"5 years",
"4 years",
"7 years",
"7 years",
"< 1 year",
"3 years",
"10+ years",
"< 1 year",
"2 years",
"7 years",
"8 years",
"10+ years",
null,
"10+ years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"2 years",
"7 years",
"8 years",
"8 years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"3 years",
"5 years",
"5 years",
"9 years",
"2 years",
"10+ years",
"1 year",
"6 years",
"4 years",
"10+ years",
"< 1 year",
"8 years",
"5 years",
"10+ years",
null,
"4 years",
"3 years",
"1 year",
"4 years",
"10+ years",
"3 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"9 years",
"4 years",
"8 years",
"5 years",
"3 years",
"10+ years",
"7 years",
"4 years",
null,
null,
"10+ years",
"4 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"4 years",
"10+ years",
"7 years",
"8 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
null,
"7 years",
"6 years",
"1 year",
"4 years",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"4 years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"4 years",
"3 years",
"7 years",
null,
"5 years",
"< 1 year",
"1 year",
"10+ years",
"6 years",
"4 years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"6 years",
"5 years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"1 year",
"3 years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"10+ years",
"2 years",
null,
"10+ years",
"9 years",
"10+ years",
"10+ years",
"9 years",
"8 years",
"5 years",
"10+ years",
"< 1 year",
"7 years",
"2 years",
"3 years",
"5 years",
"10+ years",
null,
"3 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"2 years",
"8 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"4 years",
"1 year",
"5 years",
"3 years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"5 years",
"2 years",
null,
"6 years",
"1 year",
"1 year",
"7 years",
"5 years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"5 years",
"2 years",
"10+ years",
"1 year",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"5 years",
"2 years",
"3 years",
"2 years",
"< 1 year",
"6 years",
"3 years",
"2 years",
"7 years",
"5 years",
"7 years",
"4 years",
"10+ years",
"< 1 year",
"< 1 year",
"4 years",
"8 years",
null,
"10+ years",
"10+ years",
"6 years",
"2 years",
"10+ years",
null,
"1 year",
"1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"4 years",
"< 1 year",
"3 years",
"8 years",
"10+ years",
"8 years",
"2 years",
"9 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"5 years",
"2 years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"6 years",
"8 years",
"4 years",
"7 years",
"5 years",
"4 years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"5 years",
"5 years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"3 years",
"10+ years",
"6 years",
"4 years",
"10+ years",
"1 year",
"6 years",
"10+ years",
"5 years",
"4 years",
"5 years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"6 years",
"< 1 year",
"10+ years",
"2 years",
"1 year",
"10+ years",
"2 years",
"8 years",
"4 years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"6 years",
"3 years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"7 years",
"7 years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
null,
"6 years",
"< 1 year",
"< 1 year",
"10+ years",
"4 years",
"9 years",
"< 1 year",
null,
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
"5 years",
"6 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"1 year",
"9 years",
"4 years",
"3 years",
"2 years",
"9 years",
"10+ years",
"2 years",
"4 years",
"1 year",
"3 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
null,
"10+ years",
"< 1 year",
"3 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"8 years",
"9 years",
"10+ years",
"1 year",
"10+ years",
"4 years",
"2 years",
"5 years",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"6 years",
"10+ years",
null,
"10+ years",
"< 1 year",
"8 years",
"6 years",
"5 years",
"1 year",
"3 years",
"1 year",
"7 years",
"9 years",
"2 years",
"8 years",
"9 years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
null,
"10+ years",
"10+ years",
"9 years",
"8 years",
"5 years",
"10+ years",
"4 years",
"8 years",
"10+ years",
"5 years",
"1 year",
"7 years",
"10+ years",
"1 year",
"8 years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"1 year",
"< 1 year",
"9 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"4 years",
"8 years",
"4 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"8 years",
null,
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"3 years",
"10+ years",
"7 years",
"6 years",
"8 years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"7 years",
"10+ years",
"6 years",
"5 years",
"3 years",
"1 year",
"10+ years",
"4 years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"4 years",
"2 years",
null,
"10+ years",
"1 year",
"6 years",
"10+ years",
"6 years",
"5 years",
"10+ years",
"2 years",
"5 years",
"7 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"1 year",
"2 years",
"8 years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"5 years",
"5 years",
"3 years",
"9 years",
"2 years",
"2 years",
"2 years",
"< 1 year",
"2 years",
"10+ years",
"9 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"9 years",
"1 year",
"7 years",
"5 years",
"10+ years",
"10+ years",
"6 years",
"9 years",
"< 1 year",
"5 years",
"6 years",
null,
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"7 years",
null,
"1 year",
"10+ years",
"10+ years",
"8 years",
"2 years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"9 years",
null,
"10+ years",
"3 years",
"10+ years",
"4 years",
"10+ years",
"9 years",
"5 years",
"10+ years",
null,
"< 1 year",
"6 years",
"6 years",
"4 years",
"4 years",
"1 year",
"10+ years",
"< 1 year",
"< 1 year",
"8 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"5 years",
"< 1 year",
"6 years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"10+ years",
"6 years",
null,
"6 years",
"6 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"< 1 year",
"< 1 year",
"7 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"8 years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"< 1 year",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"3 years",
null,
"10+ years",
"1 year",
"8 years",
"7 years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"1 year",
null,
"< 1 year",
"4 years",
"4 years",
"4 years",
"5 years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"5 years",
"10+ years",
"4 years",
"10+ years",
"4 years",
"3 years",
"9 years",
"< 1 year",
"1 year",
"5 years",
"9 years",
"6 years",
null,
"2 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"7 years",
"6 years",
"5 years",
"5 years",
"8 years",
null,
"< 1 year",
"6 years",
"6 years",
"3 years",
"4 years",
"10+ years",
"8 years",
"< 1 year",
"< 1 year",
"6 years",
"10+ years",
"10+ years",
null,
"< 1 year",
"2 years",
"9 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"4 years",
"4 years",
"< 1 year",
"9 years",
"10+ years",
"10+ years",
"1 year",
"6 years",
"8 years",
"9 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"3 years",
"2 years",
"< 1 year",
"3 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"6 years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"1 year",
null,
"3 years",
"2 years",
"4 years",
"10+ years",
"4 years",
"8 years",
"5 years",
"2 years",
"4 years",
"3 years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"2 years",
"< 1 year",
"5 years",
"8 years",
"9 years",
"10+ years",
"10+ years",
"3 years",
null,
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"4 years",
"1 year",
"5 years",
"2 years",
"6 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"6 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"9 years",
"6 years",
"8 years",
"1 year",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"6 years",
null,
"6 years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"2 years",
"1 year",
"10+ years",
"7 years",
"3 years",
"< 1 year",
"10+ years",
"4 years",
"3 years",
"< 1 year",
"5 years",
"7 years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"5 years",
"9 years",
"1 year",
"3 years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"6 years",
null,
"8 years",
"10+ years",
"5 years",
"< 1 year",
"2 years",
"6 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"10+ years",
"7 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"6 years",
null,
"< 1 year",
"< 1 year",
"10+ years",
"3 years",
"7 years",
"< 1 year",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"4 years",
"3 years",
"10+ years",
"9 years",
"10+ years",
"4 years",
"8 years",
"10+ years",
"6 years",
"< 1 year",
null,
"10+ years",
"8 years",
"7 years",
"4 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"3 years",
"< 1 year",
"4 years",
"9 years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"8 years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"9 years",
"2 years",
"6 years",
"10+ years",
"< 1 year",
"3 years",
"9 years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"5 years",
"9 years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"6 years",
"10+ years",
"3 years",
null,
null,
"10+ years",
null,
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"4 years",
"5 years",
"4 years",
"1 year",
null,
"6 years",
"10+ years",
"6 years",
"4 years",
"10+ years",
"< 1 year",
"2 years",
"9 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"8 years",
"3 years",
"5 years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"7 years",
"4 years",
"10+ years",
null,
"7 years",
"2 years",
"6 years",
"9 years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"8 years",
"< 1 year",
"3 years",
"1 year",
"2 years",
"9 years",
"9 years",
"2 years",
"8 years",
"10+ years",
"7 years",
"6 years",
"9 years",
"5 years",
null,
null,
"2 years",
"7 years",
"9 years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"6 years",
"9 years",
"10+ years",
"10+ years",
"2 years",
null,
"3 years",
"5 years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"3 years",
"7 years",
"6 years",
null,
"< 1 year",
"4 years",
"6 years",
"7 years",
"< 1 year",
"< 1 year",
"3 years",
"2 years",
"3 years",
"1 year",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"9 years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"7 years",
"3 years",
"3 years",
"8 years",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"8 years",
"6 years",
"6 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"1 year",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"5 years",
"2 years",
"1 year",
"2 years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"4 years",
"10+ years",
"1 year",
"< 1 year",
"6 years",
"10+ years",
"2 years",
"4 years",
"4 years",
"1 year",
"9 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"7 years",
"5 years",
"6 years",
"3 years",
"10+ years",
null,
null,
"10+ years",
"< 1 year",
"1 year",
"8 years",
"7 years",
"< 1 year",
"10+ years",
null,
"5 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"3 years",
"6 years",
"2 years",
"2 years",
null,
null,
"10+ years",
"7 years",
"10+ years",
"7 years",
"5 years",
"7 years",
"10+ years",
null,
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
null,
"< 1 year",
"3 years",
"4 years",
"10+ years",
"6 years",
"9 years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"9 years",
"10+ years",
"7 years",
"4 years",
"5 years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"7 years",
"9 years",
"8 years",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
"2 years",
"2 years",
"4 years",
"< 1 year",
"1 year",
"4 years",
"10+ years",
"2 years",
"< 1 year",
"6 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"2 years",
"4 years",
"8 years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"3 years",
"< 1 year",
"< 1 year",
"6 years",
"2 years",
"5 years",
"7 years",
"< 1 year",
"6 years",
"2 years",
"2 years",
"9 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"8 years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"7 years",
"5 years",
"10+ years",
"4 years",
"1 year",
null,
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"6 years",
"7 years",
"5 years",
"8 years",
"4 years",
"8 years",
"4 years",
null,
"7 years",
"1 year",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
null,
"7 years",
"< 1 year",
"10+ years",
"8 years",
"5 years",
"10+ years",
"5 years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
null,
"5 years",
"2 years",
null,
"3 years",
"7 years",
"2 years",
"1 year",
"10+ years",
"4 years",
"7 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"1 year",
"2 years",
"1 year",
"8 years",
"5 years",
"8 years",
"9 years",
"< 1 year",
"9 years",
"10+ years",
"1 year",
"9 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"7 years",
"4 years",
"10+ years",
"< 1 year",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"2 years",
"10+ years",
"8 years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
null,
"< 1 year",
"10+ years",
"3 years",
null,
"1 year",
"6 years",
"5 years",
"8 years",
"2 years",
"2 years",
"4 years",
null,
"5 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"3 years",
null,
"10+ years",
"8 years",
"< 1 year",
"1 year",
"10+ years",
"2 years",
"4 years",
"1 year",
"< 1 year",
"2 years",
"10+ years",
"< 1 year",
"2 years",
"6 years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"10+ years",
null,
"10+ years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"5 years",
"5 years",
"2 years",
"1 year",
"< 1 year",
"3 years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"1 year",
"1 year",
"10+ years",
"1 year",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
null,
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
null,
"3 years",
"3 years",
"< 1 year",
"< 1 year",
"10+ years",
"1 year",
"7 years",
"2 years",
"9 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
null,
"10+ years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"4 years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"8 years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"7 years",
"10+ years",
null,
"10+ years",
"10+ years",
"3 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"9 years",
"10+ years",
"10+ years",
"5 years",
"8 years",
"10+ years",
"10+ years",
null,
"1 year",
"< 1 year",
"4 years",
"10+ years",
"7 years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"5 years",
"3 years",
"5 years",
"5 years",
"8 years",
"8 years",
"4 years",
"3 years",
"3 years",
"8 years",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
null,
"10+ years",
"4 years",
"5 years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"6 years",
"2 years",
"1 year",
"1 year",
"9 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"1 year",
"< 1 year",
"1 year",
"3 years",
"4 years",
"2 years",
"7 years",
"5 years",
"1 year",
"10+ years",
"< 1 year",
"4 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
null,
"3 years",
"10+ years",
"2 years",
null,
"3 years",
"4 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
null,
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"4 years",
"2 years",
"5 years",
"2 years",
"8 years",
"4 years",
"2 years",
"10+ years",
"5 years",
null,
"2 years",
"< 1 year",
"9 years",
"5 years",
"3 years",
"10+ years",
"10+ years",
null,
"2 years",
"6 years",
"10+ years",
"2 years",
"9 years",
"6 years",
"2 years",
"< 1 year",
"6 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
null,
"7 years",
"1 year",
"10+ years",
"1 year",
"5 years",
null,
"2 years",
null,
"10+ years",
"1 year",
"5 years",
"10+ years",
"10+ years",
"5 years",
null,
"10+ years",
"10+ years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"2 years",
"1 year",
"3 years",
"8 years",
"< 1 year",
"10+ years",
"6 years",
"2 years",
"9 years",
"2 years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"6 years",
"3 years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"8 years",
"10+ years",
"4 years",
"1 year",
"1 year",
"10+ years",
"6 years",
"2 years",
"1 year",
"7 years",
"8 years",
"5 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"8 years",
"4 years",
"1 year",
"2 years",
"2 years",
"8 years",
"10+ years",
"< 1 year",
"1 year",
"8 years",
"3 years",
"5 years",
"5 years",
"1 year",
"10+ years",
"3 years",
"4 years",
"2 years",
"9 years",
"< 1 year",
"8 years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
null,
"6 years",
null,
"6 years",
"5 years",
"9 years",
null,
"< 1 year",
"5 years",
"8 years",
"4 years",
"9 years",
null,
"1 year",
"10+ years",
"3 years",
"< 1 year",
"5 years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"1 year",
"1 year",
"10+ years",
"8 years",
null,
"3 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"9 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"8 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"1 year",
"4 years",
"8 years",
"3 years",
"6 years",
"10+ years",
"10+ years",
"8 years",
"7 years",
"10+ years",
"2 years",
"5 years",
"6 years",
null,
"< 1 year",
"7 years",
"5 years",
"5 years",
"10+ years",
"< 1 year",
"8 years",
"< 1 year",
"10+ years",
"7 years",
"9 years",
"1 year",
"3 years",
"2 years",
"3 years",
"< 1 year",
"8 years",
null,
"10+ years",
"8 years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
null,
"< 1 year",
"9 years",
"7 years",
"10+ years",
"3 years",
"7 years",
null,
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"6 years",
"7 years",
"6 years",
"10+ years",
null,
"4 years",
"2 years",
"< 1 year",
"6 years",
"10+ years",
"10+ years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"6 years",
"10+ years",
"2 years",
"4 years",
"5 years",
"6 years",
null,
"2 years",
"7 years",
"1 year",
"2 years",
"8 years",
"7 years",
"8 years",
"10+ years",
"< 1 year",
null,
"10+ years",
"3 years",
"4 years",
"10+ years",
"6 years",
"7 years",
"2 years",
"4 years",
"3 years",
"7 years",
"8 years",
"4 years",
"4 years",
"5 years",
"4 years",
"5 years",
"< 1 year",
null,
"3 years",
"4 years",
"10+ years",
"8 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"1 year",
"6 years",
"1 year",
"3 years",
"< 1 year",
"< 1 year",
"2 years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"6 years",
"1 year",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
null,
"3 years",
"6 years",
"< 1 year",
"< 1 year",
"10+ years",
"8 years",
"< 1 year",
"2 years",
"10+ years",
"< 1 year",
"6 years",
null,
"< 1 year",
"4 years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
null,
"< 1 year",
"6 years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"5 years",
"6 years",
"2 years",
"2 years",
"10+ years",
"6 years",
"7 years",
"4 years",
"7 years",
"< 1 year",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
null,
"5 years",
"< 1 year",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"8 years",
"< 1 year",
"1 year",
"5 years",
"2 years",
"1 year",
"7 years",
"7 years",
"4 years",
"3 years",
"2 years",
"7 years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"1 year",
"3 years",
"10+ years",
"4 years",
"3 years",
"10+ years",
"9 years",
"1 year",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
null,
"4 years",
"3 years",
null,
"< 1 year",
"5 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"3 years",
"6 years",
"< 1 year",
"2 years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"5 years",
"4 years",
"10+ years",
"10+ years",
null,
"1 year",
"10+ years",
"5 years",
"5 years",
"1 year",
"3 years",
"2 years",
"9 years",
"9 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"7 years",
"10+ years",
"6 years",
"2 years",
null,
"7 years",
"2 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
null,
null,
"2 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"6 years",
"2 years",
null,
"4 years",
"8 years",
"3 years",
"< 1 year",
"2 years",
"3 years",
"2 years",
"2 years",
"9 years",
"6 years",
"9 years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"5 years",
"10+ years",
"< 1 year",
"4 years",
"2 years",
null,
"8 years",
"8 years",
"< 1 year",
"4 years",
"< 1 year",
null,
"10+ years",
"2 years",
null,
null,
"8 years",
"8 years",
"4 years",
"4 years",
"10+ years",
"5 years",
"2 years",
"1 year",
"3 years",
"10+ years",
"2 years",
"2 years",
"8 years",
"6 years",
"4 years",
"5 years",
"5 years",
"10+ years",
"2 years",
"2 years",
"5 years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"< 1 year",
"8 years",
"10+ years",
"7 years",
"7 years",
"5 years",
"10+ years",
"10+ years",
null,
"2 years",
"2 years",
"4 years",
"5 years",
"10+ years",
null,
"3 years",
"2 years",
"10+ years",
"10+ years",
null,
"2 years",
"8 years",
"10+ years",
"5 years",
"3 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"9 years",
"6 years",
"8 years",
"8 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
null,
"10+ years",
"5 years",
"10+ years",
"4 years",
"7 years",
"10+ years",
"6 years",
"6 years",
null,
"8 years",
"3 years",
"10+ years",
"6 years",
"10+ years",
"6 years",
"< 1 year",
"1 year",
"6 years",
null,
"3 years",
"5 years",
"2 years",
"9 years",
"10+ years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"4 years",
"5 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
null,
"10+ years",
"10+ years",
"8 years",
"7 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"9 years",
null,
"< 1 year",
"2 years",
"10+ years",
"6 years",
"< 1 year",
"9 years",
"9 years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"4 years",
"4 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"1 year",
"4 years",
"7 years",
"5 years",
"10+ years",
"3 years",
"2 years",
null,
"3 years",
"10+ years",
"9 years",
"< 1 year",
"1 year",
"5 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"2 years",
"4 years",
"9 years",
"1 year",
"10+ years",
"10+ years",
"4 years",
"9 years",
"7 years",
"7 years",
"< 1 year",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"1 year",
"7 years",
null,
"4 years",
"6 years",
"< 1 year",
"1 year",
"7 years",
"5 years",
"2 years",
"8 years",
"5 years",
"10+ years",
"6 years",
"10+ years",
null,
"10+ years",
"6 years",
"4 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"2 years",
"3 years",
"4 years",
"5 years",
"6 years",
"10+ years",
"7 years",
"5 years",
"2 years",
"< 1 year",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"7 years",
"9 years",
"10+ years",
"10+ years",
"5 years",
"5 years",
"5 years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"3 years",
"8 years",
"4 years",
"2 years",
"1 year",
"< 1 year",
"6 years",
"7 years",
"3 years",
"6 years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"5 years",
"7 years",
"10+ years",
"7 years",
"10+ years",
"7 years",
"4 years",
"6 years",
"2 years",
"10+ years",
"8 years",
"9 years",
"8 years",
"10+ years",
"5 years",
"9 years",
"5 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"5 years",
"9 years",
"9 years",
"2 years",
"3 years",
"4 years",
"10+ years",
"7 years",
"< 1 year",
"2 years",
"2 years",
"3 years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"9 years",
"4 years",
"6 years",
"8 years",
"5 years",
"6 years",
"2 years",
"10+ years",
"3 years",
"3 years",
"8 years",
"4 years",
null,
"5 years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"< 1 year",
"7 years",
"10+ years",
"7 years",
"10+ years",
"4 years",
"7 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"9 years",
"4 years",
"< 1 year",
"3 years",
"3 years",
"6 years",
"8 years",
"9 years",
"2 years",
"10+ years",
"2 years",
"5 years",
"9 years",
"5 years",
"10+ years",
"8 years",
null,
"2 years",
"6 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"5 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"4 years",
"10+ years",
"7 years",
"10+ years",
"< 1 year",
null,
"1 year",
"10+ years",
"8 years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"8 years",
"< 1 year",
"2 years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"1 year",
"6 years",
"6 years",
"7 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"4 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
null,
"< 1 year",
"1 year",
"9 years",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"3 years",
"3 years",
"5 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
null,
"2 years",
"10+ years",
"2 years",
"2 years",
"7 years",
"7 years",
"9 years",
"5 years",
"< 1 year",
"10+ years",
"5 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"4 years",
"8 years",
"3 years",
"10+ years",
"5 years",
"9 years",
"10+ years",
"7 years",
"8 years",
"5 years",
"4 years",
"8 years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
null,
"< 1 year",
null,
"2 years",
null,
"10+ years",
null,
"2 years",
"3 years",
"10+ years",
"1 year",
"7 years",
"5 years",
"< 1 year",
"< 1 year",
"10+ years",
"5 years",
"2 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"6 years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"8 years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"4 years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"2 years",
null,
"10+ years",
"10+ years",
"6 years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
null,
"10+ years",
"6 years",
"10+ years",
"1 year",
"2 years",
"4 years",
null,
"2 years",
"8 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"1 year",
null,
"1 year",
null,
"5 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"4 years",
"< 1 year",
"5 years",
"2 years",
"3 years",
"6 years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"9 years",
"3 years",
"5 years",
"1 year",
"< 1 year",
"10+ years",
"1 year",
"2 years",
"1 year",
"4 years",
"9 years",
"3 years",
null,
"2 years",
"8 years",
"10+ years",
null,
"10+ years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"4 years",
"4 years",
null,
"10+ years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"5 years",
"8 years",
"< 1 year",
"2 years",
"4 years",
"2 years",
"7 years",
"6 years",
"3 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"9 years",
"3 years",
"7 years",
"8 years",
null,
"1 year",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
null,
"8 years",
"1 year",
"10+ years",
"5 years",
"< 1 year",
null,
"9 years",
"10+ years",
"7 years",
"10+ years",
"1 year",
"2 years",
"2 years",
"1 year",
"5 years",
"2 years",
"10+ years",
"10+ years",
"8 years",
null,
"1 year",
"10+ years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"6 years",
"7 years",
"10+ years",
"9 years",
"9 years",
"10+ years",
"8 years",
"2 years",
"5 years",
null,
"< 1 year",
"10+ years",
"1 year",
"9 years",
"3 years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"< 1 year",
null,
"4 years",
"2 years",
"8 years",
"6 years",
"3 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"5 years",
"1 year",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"< 1 year",
"1 year",
"9 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"7 years",
"6 years",
"1 year",
"1 year",
null,
null,
"6 years",
"4 years",
"3 years",
"< 1 year",
"7 years",
null,
"5 years",
"6 years",
"1 year",
"6 years",
"7 years",
"3 years",
"10+ years",
"9 years",
"3 years",
"5 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"6 years",
"1 year",
"10+ years",
"1 year",
"2 years",
"3 years",
"1 year",
"10+ years",
"2 years",
"4 years",
"8 years",
"< 1 year",
"6 years",
"8 years",
"10+ years",
"2 years",
"10+ years",
null,
"6 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"< 1 year",
"4 years",
"8 years",
"4 years",
"10+ years",
null,
"2 years",
"5 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"3 years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"< 1 year",
"5 years",
"5 years",
"< 1 year",
"< 1 year",
"10+ years",
"1 year",
"6 years",
"10+ years",
"7 years",
"3 years",
"< 1 year",
"2 years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"7 years",
"3 years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"8 years",
"10+ years",
"6 years",
"10+ years",
"1 year",
"6 years",
"10+ years",
"2 years",
"9 years",
"5 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"1 year",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"< 1 year",
"6 years",
"10+ years",
"6 years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"9 years",
"3 years",
"5 years",
"4 years",
"10+ years",
"5 years",
"3 years",
null,
"10+ years",
"7 years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"8 years",
"6 years",
"2 years",
"< 1 year",
"3 years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"9 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"8 years",
"1 year",
"3 years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"1 year",
"6 years",
null,
"10+ years",
"1 year",
"2 years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"7 years",
"2 years",
"1 year",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"4 years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"4 years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"7 years",
"< 1 year",
"< 1 year",
"6 years",
"8 years",
"2 years",
"10+ years",
"1 year",
"7 years",
"10+ years",
"2 years",
"3 years",
"4 years",
"1 year",
"5 years",
"2 years",
"1 year",
"< 1 year",
"4 years",
"10+ years",
"6 years",
"8 years",
"10+ years",
"< 1 year",
"9 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"3 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"6 years",
null,
"8 years",
"3 years",
"5 years",
"1 year",
"3 years",
"2 years",
"10+ years",
null,
"6 years",
"7 years",
"10+ years",
"10+ years",
"8 years",
"6 years",
"4 years",
"3 years",
"7 years",
"< 1 year",
"6 years",
"5 years",
"8 years",
"7 years",
"4 years",
"5 years",
null,
"< 1 year",
null,
"8 years",
"5 years",
"6 years",
"10+ years",
null,
"3 years",
"4 years",
"4 years",
"5 years",
"1 year",
null,
"1 year",
"7 years",
"5 years",
null,
"8 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"1 year",
"< 1 year",
"8 years",
"< 1 year",
"10+ years",
"6 years",
"9 years",
"3 years",
"5 years",
"2 years",
"8 years",
"3 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"9 years",
null,
"7 years",
"3 years",
null,
"6 years",
"10+ years",
"2 years",
"4 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"10+ years",
"5 years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"7 years",
"10+ years",
"10+ years",
null,
"10+ years",
"5 years",
"10+ years",
"9 years",
"< 1 year",
null,
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
null,
"1 year",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"6 years",
null,
"10+ years",
"10+ years",
"9 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"1 year",
null,
"< 1 year",
"< 1 year",
"4 years",
"6 years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"5 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"4 years",
"< 1 year",
"2 years",
"3 years",
"7 years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"7 years",
"10+ years",
"9 years",
"10+ years",
"5 years",
"1 year",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"3 years",
"< 1 year",
"2 years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"8 years",
"8 years",
"6 years",
"< 1 year",
"3 years",
"1 year",
"10+ years",
"5 years",
"10+ years",
"9 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"3 years",
"8 years",
null,
"10+ years",
null,
"2 years",
"8 years",
"5 years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"6 years",
"10+ years",
null,
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"7 years",
"8 years",
"7 years",
null,
"8 years",
"8 years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"7 years",
"1 year",
"7 years",
"10+ years",
null,
"7 years",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"5 years",
"2 years",
"9 years",
"< 1 year",
null,
"3 years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"4 years",
"3 years",
"10+ years",
"1 year",
"3 years",
"1 year",
"5 years",
"10+ years",
null,
"8 years",
"3 years",
null,
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"1 year",
"6 years",
"5 years",
null,
"< 1 year",
"2 years",
"2 years",
"9 years",
"10+ years",
"3 years",
"2 years",
"< 1 year",
"2 years",
"< 1 year",
"3 years",
"1 year",
"10+ years",
"3 years",
"6 years",
"7 years",
"10+ years",
"7 years",
"10+ years",
null,
"8 years",
"2 years",
"2 years",
"5 years",
"10+ years",
"5 years",
"5 years",
"10+ years",
"3 years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"1 year",
"10+ years",
"6 years",
"6 years",
"7 years",
"4 years",
"1 year",
"10+ years",
"7 years",
"2 years",
"4 years",
"8 years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"8 years",
"10+ years",
"3 years",
"6 years",
"10+ years",
"5 years",
"< 1 year",
"1 year",
"7 years",
"6 years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"2 years",
"5 years",
null,
"10+ years",
"7 years",
"4 years",
"3 years",
"6 years",
"9 years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"4 years",
"2 years",
"5 years",
"3 years",
null,
"10+ years",
"5 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
null,
"10+ years",
"4 years",
"1 year",
"10+ years",
"6 years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"6 years",
null,
"3 years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"8 years",
"7 years",
"7 years",
null,
"< 1 year",
"10+ years",
"2 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"2 years",
"3 years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"< 1 year",
"7 years",
"7 years",
"9 years",
"9 years",
"9 years",
"8 years",
"2 years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"< 1 year",
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
null,
"10+ years",
"5 years",
"8 years",
"7 years",
"10+ years",
"4 years",
"9 years",
"3 years",
"7 years",
"4 years",
"5 years",
"4 years",
"4 years",
"10+ years",
"2 years",
"< 1 year",
"2 years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"8 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"9 years",
"1 year",
"3 years",
null,
"10+ years",
"6 years",
"< 1 year",
"5 years",
"2 years",
"10+ years",
"9 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"5 years",
"< 1 year",
"3 years",
"6 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"6 years",
"5 years",
"10+ years",
"10+ years",
null,
"10+ years",
"1 year",
"5 years",
"4 years",
"2 years",
"4 years",
"1 year",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"7 years",
"8 years",
"10+ years",
"1 year",
"6 years",
"7 years",
"10+ years",
"3 years",
"4 years",
"4 years",
"4 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"7 years",
"3 years",
"2 years",
"2 years",
"10+ years",
"3 years",
"3 years",
"< 1 year",
"3 years",
"10+ years",
"3 years",
"6 years",
"7 years",
"5 years",
"5 years",
"< 1 year",
"10+ years",
"3 years",
"5 years",
"8 years",
null,
"1 year",
null,
null,
"1 year",
"4 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"< 1 year",
"2 years",
"1 year",
"10+ years",
"9 years",
"10+ years",
"8 years",
"2 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"2 years",
"5 years",
"2 years",
"4 years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"9 years",
"10+ years",
"3 years",
null,
"< 1 year",
"10+ years",
"10+ years",
"4 years",
null,
"< 1 year",
"2 years",
"10+ years",
"7 years",
"9 years",
"3 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"3 years",
null,
"10+ years",
"7 years",
"3 years",
"10+ years",
"7 years",
"1 year",
"2 years",
"10+ years",
"8 years",
"1 year",
"10+ years",
"3 years",
"7 years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
null,
"10+ years",
"10+ years",
"4 years",
"7 years",
"2 years",
"1 year",
"8 years",
"7 years",
"5 years",
"6 years",
null,
"10+ years",
"3 years",
"< 1 year",
"2 years",
"10+ years",
"3 years",
"1 year",
"5 years",
"10+ years",
"9 years",
"10+ years",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"4 years",
null,
"10+ years",
"9 years",
"3 years",
"1 year",
"4 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"6 years",
"5 years",
null,
"3 years",
"7 years",
"5 years",
"6 years",
"7 years",
"10+ years",
"10+ years",
"9 years",
"4 years",
"5 years",
"1 year",
"3 years",
"9 years",
"7 years",
"10+ years",
"10+ years",
"4 years",
"6 years",
"8 years",
"8 years",
"4 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"7 years",
"< 1 year",
"10+ years",
"9 years",
"5 years",
"10+ years",
"7 years",
"< 1 year",
"2 years",
"2 years",
"5 years",
"7 years",
"3 years",
"2 years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"8 years",
"7 years",
"3 years",
null,
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"1 year",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"< 1 year",
"6 years",
"10+ years",
null,
"5 years",
"5 years",
"7 years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"7 years",
"< 1 year",
"1 year",
"< 1 year",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
null,
"10+ years",
"< 1 year",
"10+ years",
"9 years",
"1 year",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"9 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"1 year",
"10+ years",
"4 years",
"7 years",
"< 1 year",
"7 years",
"5 years",
"6 years",
"< 1 year",
"< 1 year",
"10+ years",
"2 years",
"< 1 year",
"6 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"5 years",
"4 years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"1 year",
"8 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"6 years",
"10+ years",
"7 years",
"2 years",
"4 years",
"7 years",
"7 years",
"4 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"5 years",
"7 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"5 years",
"9 years",
"2 years",
"10+ years",
"3 years",
"4 years",
"1 year",
"8 years",
"4 years",
"10+ years",
"4 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"2 years",
"1 year",
"1 year",
"10+ years",
"< 1 year",
"8 years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"7 years",
"5 years",
"10+ years",
"5 years",
"10+ years",
null,
"2 years",
"3 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"8 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"7 years",
"< 1 year",
"3 years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"7 years",
"10+ years",
"8 years",
"7 years",
"9 years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"4 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"2 years",
"10+ years",
"8 years",
"< 1 year",
"1 year",
"8 years",
"10+ years",
"4 years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"1 year",
"9 years",
"3 years",
"7 years",
"9 years",
"10+ years",
"10+ years",
"5 years",
"7 years",
"< 1 year",
"5 years",
"8 years",
"10+ years",
"< 1 year",
"5 years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"3 years",
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"8 years",
"6 years",
"7 years",
"3 years",
"2 years",
"2 years",
"5 years",
"2 years",
"2 years",
"10+ years",
"6 years",
"10+ years",
"2 years",
null,
"10+ years",
"6 years",
"3 years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"5 years",
"7 years",
"6 years",
null,
"8 years",
null,
"10+ years",
"4 years",
"10+ years",
"5 years",
"2 years",
"8 years",
"5 years",
"7 years",
null,
"1 year",
"10+ years",
"10+ years",
"1 year",
"2 years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"7 years",
"< 1 year",
null,
null,
"6 years",
"10+ years",
"2 years",
"10+ years",
"7 years",
"9 years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"10+ years",
"7 years",
"4 years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"1 year",
"5 years",
null,
"10+ years",
"< 1 year",
"3 years",
null,
"10+ years",
"10+ years",
"6 years",
"5 years",
"2 years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
null,
"6 years",
"1 year",
"5 years",
"9 years",
null,
"10+ years",
"10+ years",
"2 years",
"6 years",
"4 years",
"1 year",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"6 years",
null,
"6 years",
"2 years",
"8 years",
"1 year",
"10+ years",
"< 1 year",
null,
"10+ years",
"10+ years",
"10+ years",
"4 years",
"8 years",
"10+ years",
"6 years",
"3 years",
"6 years",
"< 1 year",
"10+ years",
null,
null,
"10+ years",
"2 years",
"10+ years",
"5 years",
"5 years",
"3 years",
"8 years",
"10+ years",
"5 years",
"6 years",
"8 years",
"10+ years",
"2 years",
"1 year",
"7 years",
"3 years",
"3 years",
"10+ years",
"4 years",
"6 years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"4 years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"< 1 year",
"9 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"8 years",
"10+ years",
null,
"< 1 year",
"< 1 year",
"10+ years",
"1 year",
"2 years",
"7 years",
"9 years",
"10+ years",
"4 years",
"4 years",
"7 years",
"10+ years",
"< 1 year",
null,
"4 years",
"3 years",
"3 years",
null,
"1 year",
"8 years",
"3 years",
"2 years",
"< 1 year",
"< 1 year",
"2 years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"8 years",
"1 year",
"7 years",
"2 years",
"7 years",
"2 years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"9 years",
"5 years",
"10+ years",
"9 years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"3 years",
"6 years",
"< 1 year",
"2 years",
"7 years",
null,
"< 1 year",
"< 1 year",
"7 years",
"7 years",
"6 years",
"2 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"6 years",
"< 1 year",
"8 years",
"10+ years",
"6 years",
"10+ years",
"8 years",
"9 years",
"1 year",
"10+ years",
null,
"10+ years",
"3 years",
"2 years",
"5 years",
"4 years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"1 year",
"1 year",
"10+ years",
"8 years",
"10+ years",
"8 years",
"4 years",
"< 1 year",
"8 years",
"10+ years",
"< 1 year",
"1 year",
"7 years",
null,
"3 years",
"< 1 year",
"6 years",
"10+ years",
"8 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"9 years",
"5 years",
"10+ years",
"7 years",
"< 1 year",
"6 years",
"10+ years",
"5 years",
"< 1 year",
"< 1 year",
"< 1 year",
"3 years",
"6 years",
"10+ years",
"9 years",
"7 years",
"2 years",
null,
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
null,
"10+ years",
"< 1 year",
null,
"< 1 year",
"< 1 year",
"< 1 year",
"10+ years",
"9 years",
"5 years",
"< 1 year",
"10+ years",
"< 1 year",
"8 years",
null,
"5 years",
"10+ years",
"10+ years",
"6 years",
null,
"3 years",
"10+ years",
"7 years",
"10+ years",
"5 years",
"1 year",
"2 years",
"< 1 year",
"10+ years",
"4 years",
"1 year",
"4 years",
"5 years",
"10+ years",
"9 years",
"3 years",
"5 years",
"2 years",
"10+ years",
"1 year",
"5 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
null,
"4 years",
"10+ years",
"9 years",
"1 year",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"4 years",
"< 1 year",
"8 years",
"3 years",
"3 years",
"7 years",
"4 years",
"10+ years",
"5 years",
"10+ years",
"6 years",
"4 years",
"8 years",
"3 years",
"9 years",
"3 years",
"4 years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"10+ years",
null,
"10+ years",
"1 year",
"10+ years",
"10+ years",
null,
"10+ years",
"6 years",
"9 years",
"8 years",
"< 1 year",
"7 years",
"2 years",
"6 years",
"3 years",
"7 years",
null,
"3 years",
"7 years",
"3 years",
"3 years",
"5 years",
"10+ years",
"8 years",
"< 1 year",
"1 year",
"10+ years",
"4 years",
"2 years",
"10+ years",
"1 year",
"8 years",
"10+ years",
"8 years",
"3 years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"9 years",
"< 1 year",
"2 years",
"5 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"6 years",
"6 years",
"8 years",
"10+ years",
"7 years",
"8 years",
"3 years",
"10+ years",
"4 years",
"7 years",
"8 years",
"< 1 year",
"2 years",
"4 years",
"8 years",
"9 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"4 years",
"9 years",
"1 year",
"2 years",
"6 years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"4 years",
"8 years",
"10+ years",
"5 years",
"7 years",
"5 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"8 years",
"4 years",
"8 years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"9 years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"4 years",
"8 years",
"4 years",
"8 years",
"10+ years",
"9 years",
"3 years",
"10+ years",
"3 years",
"2 years",
"6 years",
"3 years",
null,
"10+ years",
"7 years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"9 years",
null,
"4 years",
"4 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"9 years",
"3 years",
"4 years",
"4 years",
"7 years",
"5 years",
"10+ years",
"< 1 year",
"< 1 year",
"4 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"6 years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"6 years",
"4 years",
"8 years",
"< 1 year",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"< 1 year",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"6 years",
"8 years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
null,
"10+ years",
"3 years",
"7 years",
null,
"10+ years",
"5 years",
"10+ years",
"3 years",
"3 years",
"6 years",
"5 years",
"5 years",
"< 1 year",
"< 1 year",
"4 years",
"3 years",
"< 1 year",
"10+ years",
null,
"10+ years",
"10+ years",
"7 years",
"3 years",
"5 years",
"6 years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
null,
"10+ years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"6 years",
"10+ years",
"< 1 year",
"4 years",
"6 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"< 1 year",
"9 years",
"< 1 year",
"6 years",
"< 1 year",
"< 1 year",
"4 years",
"1 year",
"6 years",
"10+ years",
"10+ years",
null,
"10+ years",
"1 year",
null,
"10+ years",
"8 years",
"6 years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"10+ years",
"1 year",
"7 years",
"1 year",
"2 years",
"9 years",
"9 years",
"8 years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"6 years",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"5 years",
"2 years",
"9 years",
"10+ years",
"< 1 year",
"5 years",
"4 years",
"7 years",
"8 years",
"< 1 year",
"1 year",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"1 year",
"9 years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"8 years",
"3 years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"10+ years",
null,
"5 years",
"2 years",
"6 years",
"10+ years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"2 years",
"1 year",
"2 years",
"10+ years",
null,
"10+ years",
"10+ years",
"9 years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"9 years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"7 years",
"7 years",
"10+ years",
null,
"4 years",
"10+ years",
null,
null,
"4 years",
"5 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"6 years",
"< 1 year",
"10+ years",
"2 years",
"2 years",
"5 years",
"6 years",
"4 years",
"6 years",
"4 years",
"< 1 year",
"10+ years",
"8 years",
"4 years",
"9 years",
"10+ years",
"5 years",
"< 1 year",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"3 years",
"2 years",
"1 year",
"4 years",
"3 years",
"10+ years",
"8 years",
"7 years",
"6 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"4 years",
"2 years",
"6 years",
"10+ years",
null,
"4 years",
"10+ years",
null,
"3 years",
"3 years",
"10+ years",
"10+ years",
"6 years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"9 years",
"5 years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"9 years",
"< 1 year",
"2 years",
"10+ years",
"3 years",
"4 years",
"8 years",
"4 years",
"2 years",
"6 years",
"< 1 year",
"10+ years",
"7 years",
"3 years",
"8 years",
"4 years",
"9 years",
"1 year",
"8 years",
"9 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"5 years",
"4 years",
"4 years",
"7 years",
"10+ years",
"10+ years",
"5 years",
"1 year",
"2 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
null,
"10+ years",
"3 years",
"< 1 year",
"1 year",
"< 1 year",
"< 1 year",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"2 years",
"< 1 year",
"5 years",
"9 years",
"2 years",
"10+ years",
"3 years",
null,
"4 years",
null,
null,
"5 years",
"4 years",
"3 years",
"9 years",
"10+ years",
"2 years",
"5 years",
"9 years",
"8 years",
"4 years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"9 years",
"2 years",
"10+ years",
"4 years",
null,
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
null,
"1 year",
"10+ years",
"10+ years",
null,
"5 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"< 1 year",
"5 years",
"< 1 year",
"5 years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"6 years",
null,
"10+ years",
"4 years",
"4 years",
"5 years",
"10+ years",
null,
"2 years",
null,
"8 years",
"1 year",
"10+ years",
"6 years",
"7 years",
"4 years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"2 years",
"4 years",
"4 years",
"7 years",
"1 year",
"3 years",
"2 years",
"2 years",
"8 years",
"9 years",
"10+ years",
"9 years",
"7 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"6 years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"4 years",
null,
"4 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"3 years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"4 years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"9 years",
"3 years",
null,
"7 years",
"2 years",
"6 years",
"10+ years",
"1 year",
"10+ years",
"8 years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"3 years",
"9 years",
"10+ years",
"10+ years",
"2 years",
"7 years",
"< 1 year",
"1 year",
"3 years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"8 years",
"1 year",
"8 years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"8 years",
"2 years",
"3 years",
"3 years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"3 years",
null,
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"< 1 year",
"4 years",
"1 year",
"2 years",
"6 years",
"8 years",
null,
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"1 year",
"1 year",
"4 years",
"6 years",
"7 years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"3 years",
null,
"10+ years",
"6 years",
"< 1 year",
"6 years",
"10+ years",
null,
"1 year",
"10+ years",
"9 years",
"2 years",
"4 years",
"2 years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"7 years",
"9 years",
"8 years",
null,
"< 1 year",
"4 years",
"< 1 year",
"< 1 year",
"8 years",
"2 years",
"3 years",
"10+ years",
"4 years",
"10+ years",
"9 years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
null,
"3 years",
null,
"1 year",
"1 year",
"10+ years",
"8 years",
"6 years",
"10+ years",
"1 year",
"10+ years",
"2 years",
"1 year",
"5 years",
"5 years",
"5 years",
"4 years",
"10+ years",
"10+ years",
"6 years",
"1 year",
"< 1 year",
null,
"4 years",
"10+ years",
"3 years",
null,
"10+ years",
"10+ years",
null,
"1 year",
"2 years",
"6 years",
"10+ years",
"< 1 year",
null,
"2 years",
"7 years",
"3 years",
"10+ years",
"3 years",
null,
"3 years",
null,
"8 years",
"7 years",
"1 year",
"3 years",
null,
"10+ years",
"5 years",
"3 years",
"5 years",
"2 years",
"9 years",
"7 years",
"5 years",
"10+ years",
"2 years",
"9 years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"6 years",
"< 1 year",
"4 years",
null,
"3 years",
"10+ years",
"2 years",
"7 years",
"5 years",
"10+ years",
"9 years",
"8 years",
"10+ years",
"10+ years",
"6 years",
"5 years",
"10+ years",
"5 years",
"7 years",
"8 years",
"5 years",
"2 years",
"< 1 year",
"2 years",
"6 years",
"6 years",
"10+ years",
null,
"7 years",
"8 years",
"10+ years",
null,
"10+ years",
"3 years",
"7 years",
"8 years",
"5 years",
"7 years",
"10+ years",
"8 years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"1 year",
"4 years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"8 years",
"2 years",
"10+ years",
"7 years",
null,
"9 years",
"10+ years",
"5 years",
"< 1 year",
"9 years",
"10+ years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"3 years",
"8 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"7 years",
"3 years",
"9 years",
"< 1 year",
"10+ years",
"2 years",
"1 year",
"9 years",
"7 years",
"5 years",
"10+ years",
"< 1 year",
"6 years",
"3 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"4 years",
"< 1 year",
"10+ years",
"< 1 year",
"5 years",
"3 years",
"< 1 year",
"3 years",
"10+ years",
"2 years",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"2 years",
"1 year",
"2 years",
"7 years",
"6 years",
"9 years",
"5 years",
"7 years",
"10+ years",
"2 years",
"3 years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
null,
"2 years",
"3 years",
"9 years",
"7 years",
"10+ years",
"9 years",
"2 years",
"5 years",
"7 years",
"9 years",
"< 1 year",
"< 1 year",
"3 years",
"10+ years",
null,
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"5 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"8 years",
"10+ years",
"8 years",
"5 years",
"7 years",
"1 year",
"10+ years",
null,
"10+ years",
"10+ years",
"5 years",
"10+ years",
null,
"10+ years",
"4 years",
"2 years",
null,
null,
"10+ years",
"3 years",
"10+ years",
null,
"6 years",
"2 years",
"5 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
null,
"2 years",
"1 year",
"10+ years",
"< 1 year",
"8 years",
"8 years",
"1 year",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"6 years",
"6 years",
"3 years",
"5 years",
"10+ years",
"9 years",
"1 year",
"< 1 year",
null,
"10+ years",
"1 year",
"4 years",
"2 years",
"8 years",
"8 years",
"5 years",
"3 years",
"5 years",
"< 1 year",
"8 years",
"9 years",
"4 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"8 years",
"6 years",
"< 1 year",
"10+ years",
"7 years",
"9 years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"10+ years",
"4 years",
"9 years",
"10+ years",
"10+ years",
null,
"10+ years",
"5 years",
null,
"9 years",
"8 years",
"4 years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"7 years",
"< 1 year",
"3 years",
"2 years",
"10+ years",
"4 years",
"1 year",
"1 year",
"10+ years",
"5 years",
"3 years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"9 years",
"4 years",
"5 years",
"8 years",
"10+ years",
"< 1 year",
"3 years",
"4 years",
"10+ years",
"9 years",
"10+ years",
"8 years",
"8 years",
null,
"2 years",
"4 years",
"6 years",
"2 years",
"7 years",
"5 years",
"4 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"10+ years",
"6 years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"7 years",
"10+ years",
"4 years",
"8 years",
"2 years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"6 years",
"3 years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"4 years",
"10+ years",
"4 years",
null,
"9 years",
"4 years",
"5 years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"< 1 year",
"4 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"3 years",
"5 years",
"10+ years",
null,
"< 1 year",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"1 year",
"2 years",
null,
null,
"10+ years",
null,
"3 years",
"1 year",
"2 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"4 years",
"3 years",
"2 years",
"< 1 year",
"5 years",
"3 years",
"9 years",
"< 1 year",
"10+ years",
"5 years",
null,
"8 years",
null,
"10+ years",
"9 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"6 years",
"< 1 year",
"1 year",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
null,
"10+ years",
"7 years",
"< 1 year",
"6 years",
"< 1 year",
"< 1 year",
"10+ years",
null,
"10+ years",
"10+ years",
null,
"4 years",
"4 years",
"10+ years",
"3 years",
"7 years",
"8 years",
"2 years",
null,
"10+ years",
"< 1 year",
"8 years",
"2 years",
"< 1 year",
"4 years",
"3 years",
"5 years",
"10+ years",
"4 years",
"< 1 year",
"9 years",
"10+ years",
"9 years",
"3 years",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"8 years",
"4 years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"7 years",
"< 1 year",
"1 year",
"8 years",
"8 years",
"10+ years",
"7 years",
"3 years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"9 years",
"4 years",
"4 years",
"8 years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"9 years",
null,
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"6 years",
"2 years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"3 years",
"2 years",
"< 1 year",
"< 1 year",
"< 1 year",
"10+ years",
"7 years",
"< 1 year",
null,
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"3 years",
"3 years",
"3 years",
"4 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"8 years",
"7 years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"6 years",
"10+ years",
null,
"6 years",
"9 years",
"2 years",
"1 year",
"6 years",
"1 year",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"9 years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"2 years",
"5 years",
"3 years",
"2 years",
"10+ years",
"9 years",
"6 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"2 years",
"6 years",
"5 years",
null,
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"1 year",
"9 years",
"10+ years",
"1 year",
"9 years",
"3 years",
"3 years",
"3 years",
"< 1 year",
"< 1 year",
"4 years",
"9 years",
"5 years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
null,
"5 years",
"4 years",
"5 years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"8 years",
"7 years",
"7 years",
"10+ years",
"6 years",
"10+ years",
"9 years",
"2 years",
"10+ years",
"2 years",
"9 years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
null,
"10+ years",
"8 years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"1 year",
"3 years",
"2 years",
"< 1 year",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"6 years",
null,
"< 1 year",
"2 years",
"1 year",
"10+ years",
null,
"6 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"8 years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"9 years",
"9 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"4 years",
"10+ years",
"7 years",
"9 years",
"3 years",
"10+ years",
"8 years",
"3 years",
"3 years",
"3 years",
"< 1 year",
"< 1 year",
"10+ years",
"4 years",
"3 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"6 years",
"8 years",
"1 year",
"4 years",
"9 years",
null,
"1 year",
"4 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"3 years",
"2 years",
"1 year",
"5 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"1 year",
"2 years",
"10+ years",
"7 years",
"4 years",
"7 years",
"6 years",
null,
"< 1 year",
"1 year",
"3 years",
"2 years",
"10+ years",
"1 year",
"2 years",
"5 years",
"4 years",
"6 years",
"< 1 year",
"10+ years",
null,
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"2 years",
"10+ years",
"4 years",
"4 years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"1 year",
"7 years",
"9 years",
"4 years",
"4 years",
"1 year",
"10+ years",
"2 years",
"< 1 year",
"6 years",
"1 year",
null,
"7 years",
"10+ years",
null,
"< 1 year",
"3 years",
"10+ years",
"3 years",
"1 year",
"< 1 year",
"10+ years",
"8 years",
"< 1 year",
"3 years",
null,
"2 years",
"10+ years",
"8 years",
null,
"4 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
null,
"7 years",
"< 1 year",
"3 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"8 years",
"9 years",
"6 years",
null,
"10+ years",
"< 1 year",
null,
"10+ years",
"5 years",
"6 years",
"2 years",
"10+ years",
"6 years",
null,
"7 years",
"10+ years",
"4 years",
null,
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"5 years",
"3 years",
"8 years",
"8 years",
"1 year",
null,
"10+ years",
"7 years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"10+ years",
null,
"2 years",
"5 years",
"10+ years",
"6 years",
"< 1 year",
"5 years",
"5 years",
"4 years",
"3 years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
null,
"1 year",
"8 years",
"6 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"7 years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"9 years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"10+ years",
"4 years",
"3 years",
"10+ years",
null,
"10+ years",
"7 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"6 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"2 years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"5 years",
"5 years",
"10+ years",
"5 years",
"7 years",
"2 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"4 years",
"8 years",
"5 years",
"3 years",
null,
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"3 years",
"5 years",
null,
"9 years",
"10+ years",
"10+ years",
"7 years",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"9 years",
"1 year",
"1 year",
"5 years",
"2 years",
"2 years",
"7 years",
null,
"8 years",
"5 years",
"7 years",
null,
"1 year",
"8 years",
"3 years",
"10+ years",
"8 years",
"10+ years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"2 years",
"3 years",
"4 years",
"2 years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"2 years",
"3 years",
"10+ years",
"9 years",
"< 1 year",
null,
"10+ years",
"8 years",
"4 years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"4 years",
"3 years",
"10+ years",
null,
"7 years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"4 years",
"5 years",
"10+ years",
"3 years",
"8 years",
"3 years",
null,
"3 years",
"7 years",
"2 years",
"< 1 year",
"5 years",
"3 years",
"< 1 year",
"1 year",
"5 years",
"5 years",
"7 years",
"< 1 year",
"5 years",
"< 1 year",
"1 year",
"4 years",
"5 years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"7 years",
"2 years",
"10+ years",
"1 year",
"7 years",
"2 years",
"2 years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"8 years",
"1 year",
"2 years",
"< 1 year",
"< 1 year",
"5 years",
"8 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"2 years",
"10+ years",
"9 years",
"< 1 year",
"6 years",
"1 year",
"< 1 year",
"< 1 year",
"9 years",
"< 1 year",
"6 years",
"< 1 year",
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"2 years",
"4 years",
"< 1 year",
"8 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"4 years",
"7 years",
"5 years",
"5 years",
"7 years",
"5 years",
"4 years",
"3 years",
"10+ years",
"7 years",
"10+ years",
"5 years",
"9 years",
"3 years",
"4 years",
"10+ years",
null,
"9 years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"2 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"1 year",
"6 years",
"9 years",
"10+ years",
"9 years",
"< 1 year",
null,
"8 years",
"2 years",
"6 years",
"2 years",
"10+ years",
"9 years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"8 years",
"6 years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
null,
"1 year",
"10+ years",
"5 years",
"2 years",
"6 years",
"3 years",
"10+ years",
"5 years",
"3 years",
"1 year",
"3 years",
"8 years",
"8 years",
"1 year",
"5 years",
"8 years",
"5 years",
"1 year",
"8 years",
"< 1 year",
"2 years",
"< 1 year",
null,
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"2 years",
null,
"3 years",
"< 1 year",
"2 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"5 years",
"10+ years",
null,
"8 years",
"5 years",
"3 years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"4 years",
"10+ years",
"1 year",
"4 years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"7 years",
"< 1 year",
"< 1 year",
"1 year",
"1 year",
"8 years",
"4 years",
"3 years",
"3 years",
"6 years",
"4 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"6 years",
"3 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
null,
"5 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"6 years",
"6 years",
"5 years",
null,
"5 years",
"7 years",
"7 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"< 1 year",
"3 years",
"10+ years",
"9 years",
"5 years",
"10+ years",
"7 years",
"3 years",
"8 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"1 year",
"< 1 year",
"1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"7 years",
"10+ years",
"7 years",
"2 years",
"< 1 year",
"10+ years",
null,
"5 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"< 1 year",
"1 year",
"4 years",
"1 year",
"4 years",
null,
"3 years",
"3 years",
"5 years",
"5 years",
"10+ years",
null,
null,
"< 1 year",
"2 years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"5 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"2 years",
"5 years",
"9 years",
"7 years",
"1 year",
"5 years",
"2 years",
"10+ years",
"1 year",
"4 years",
"2 years",
"2 years",
"< 1 year",
"6 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"< 1 year",
"< 1 year",
"10+ years",
"1 year",
"< 1 year",
"7 years",
null,
"10+ years",
"10+ years",
"4 years",
"1 year",
"< 1 year",
"2 years",
"5 years",
"1 year",
"3 years",
"1 year",
"10+ years",
"5 years",
"4 years",
"8 years",
"1 year",
"10+ years",
"9 years",
"10+ years",
"2 years",
"3 years",
"5 years",
"4 years",
"3 years",
"2 years",
"1 year",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"8 years",
"7 years",
null,
"4 years",
"< 1 year",
"10+ years",
"2 years",
null,
"10+ years",
"7 years",
"4 years",
"6 years",
"10+ years",
"5 years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"4 years",
null,
null,
"< 1 year",
"10+ years",
"2 years",
"1 year",
"10+ years",
null,
"1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"6 years",
"4 years",
"2 years",
"2 years",
"10+ years",
"5 years",
"7 years",
"3 years",
"10+ years",
null,
"7 years",
"10+ years",
"10+ years",
null,
"1 year",
"10+ years",
"8 years",
null,
"< 1 year",
"< 1 year",
"1 year",
"10+ years",
"2 years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"7 years",
null,
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"1 year",
null,
"8 years",
"6 years",
"10+ years",
"2 years",
"8 years",
"< 1 year",
"3 years",
"5 years",
"4 years",
"3 years",
"8 years",
"9 years",
"4 years",
"4 years",
"3 years",
"3 years",
"5 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"3 years",
"6 years",
"1 year",
"6 years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"10+ years",
null,
"2 years",
"10+ years",
"6 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"< 1 year",
"4 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"3 years",
"9 years",
"1 year",
"7 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"6 years",
"2 years",
"1 year",
"8 years",
"< 1 year",
"7 years",
"3 years",
"9 years",
"8 years",
"1 year",
"10+ years",
"6 years",
"4 years",
"10+ years",
null,
"5 years",
"6 years",
"7 years",
"5 years",
"< 1 year",
"6 years",
"10+ years",
"8 years",
"< 1 year",
"3 years",
"3 years",
"10+ years",
"1 year",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"8 years",
"7 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"8 years",
"8 years",
"1 year",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"3 years",
"8 years",
"9 years",
"6 years",
"7 years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"9 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
null,
"10+ years",
"8 years",
"10+ years",
"9 years",
"3 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"8 years",
"10+ years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"2 years",
"2 years",
"5 years",
"6 years",
"8 years",
"10+ years",
"3 years",
"7 years",
null,
"2 years",
"5 years",
"10+ years",
"8 years",
"10+ years",
"4 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"1 year",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"5 years",
"1 year",
"4 years",
"< 1 year",
"4 years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"2 years",
"10+ years",
"5 years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"2 years",
null,
"5 years",
"1 year",
"10+ years",
"2 years",
"6 years",
"3 years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"1 year",
"9 years",
"6 years",
"1 year",
"8 years",
"8 years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"1 year",
null,
null,
"7 years",
"6 years",
"4 years",
"2 years",
"3 years",
"8 years",
null,
"10+ years",
"6 years",
"2 years",
"10+ years",
"< 1 year",
"< 1 year",
"1 year",
"1 year",
"5 years",
"2 years",
"2 years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"2 years",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"9 years",
null,
"10+ years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"9 years",
"10+ years",
"5 years",
"1 year",
null,
"10+ years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"3 years",
"4 years",
null,
"7 years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"< 1 year",
null,
"5 years",
"1 year",
"1 year",
"10+ years",
"4 years",
"10+ years",
"2 years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"8 years",
"4 years",
"5 years",
"2 years",
null,
"10+ years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"7 years",
"1 year",
"3 years",
"5 years",
"5 years",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"10+ years",
"8 years",
"2 years",
"8 years",
"10+ years",
null,
"10+ years",
"< 1 year",
"10+ years",
null,
"3 years",
"< 1 year",
"< 1 year",
"6 years",
null,
"10+ years",
"10+ years",
"2 years",
"6 years",
"< 1 year",
"7 years",
"< 1 year",
"7 years",
"3 years",
"7 years",
"3 years",
"1 year",
"10+ years",
"2 years",
"7 years",
"3 years",
"1 year",
"10+ years",
"2 years",
"5 years",
"4 years",
"10+ years",
"1 year",
"10+ years",
"6 years",
"3 years",
"10+ years",
null,
"10+ years",
"10+ years",
null,
"6 years",
"8 years",
"7 years",
"9 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"6 years",
"4 years",
"2 years",
"6 years",
"5 years",
null,
"3 years",
"3 years",
"5 years",
"8 years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"6 years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"3 years",
"1 year",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"7 years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"6 years",
"4 years",
null,
null,
"1 year",
"< 1 year",
"7 years",
"10+ years",
null,
"6 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"1 year",
"5 years",
"5 years",
"1 year",
"8 years",
"10+ years",
null,
"1 year",
null,
"1 year",
"3 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"1 year",
"< 1 year",
"1 year",
"< 1 year",
"2 years",
"3 years",
"6 years",
"1 year",
"10+ years",
"8 years",
"9 years",
"10+ years",
"7 years",
"10+ years",
"3 years",
null,
"5 years",
"6 years",
"5 years",
"3 years",
"10+ years",
null,
"9 years",
"8 years",
"10+ years",
"6 years",
"7 years",
"8 years",
"6 years",
"4 years",
"4 years",
"3 years",
"6 years",
"7 years",
"10+ years",
"4 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"1 year",
"9 years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
null,
"10+ years",
"2 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"< 1 year",
"5 years",
"10+ years",
null,
"1 year",
"3 years",
"1 year",
"10+ years",
"2 years",
"8 years",
"6 years",
"< 1 year",
"7 years",
"2 years",
"6 years",
"< 1 year",
"2 years",
"4 years",
"8 years",
"8 years",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"3 years",
null,
"10+ years",
"2 years",
"7 years",
"4 years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"1 year",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
null,
"3 years",
"8 years",
"4 years",
"4 years",
"6 years",
"1 year",
"10+ years",
"2 years",
"4 years",
null,
"7 years",
"9 years",
"5 years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"3 years",
"6 years",
"9 years",
"< 1 year",
"10+ years",
"4 years",
"1 year",
"< 1 year",
"10+ years",
"4 years",
"3 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"9 years",
"4 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"1 year",
"5 years",
"3 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"1 year",
null,
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"6 years",
"1 year",
"10+ years",
"6 years",
"10+ years",
"8 years",
"10+ years",
"8 years",
"10+ years",
null,
"2 years",
null,
"1 year",
"2 years",
"10+ years",
"5 years",
"1 year",
"3 years",
"3 years",
"< 1 year",
"2 years",
"10+ years",
"6 years",
"7 years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"5 years",
"1 year",
"5 years",
"10+ years",
"9 years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"5 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
null,
"6 years",
"10+ years",
"1 year",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"8 years",
"3 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"10+ years",
"4 years",
"< 1 year",
"3 years",
"10+ years",
null,
null,
"10+ years",
"5 years",
"9 years",
null,
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"4 years",
"3 years",
"4 years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"1 year",
null,
"9 years",
"< 1 year",
"5 years",
null,
"< 1 year",
"5 years",
"4 years",
"3 years",
"3 years",
"1 year",
"5 years",
"10+ years",
null,
"10+ years",
"1 year",
"2 years",
null,
"8 years",
"3 years",
"3 years",
"10+ years",
"1 year",
"5 years",
"5 years",
"10+ years",
"4 years",
"6 years",
"3 years",
"2 years",
"5 years",
"6 years",
"< 1 year",
"3 years",
"2 years",
"6 years",
"9 years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"4 years",
"2 years",
"< 1 year",
"9 years",
"10+ years",
"9 years",
"10+ years",
"6 years",
"3 years",
"2 years",
"8 years",
"10+ years",
null,
"10+ years",
"6 years",
"4 years",
"10+ years",
null,
"10+ years",
"5 years",
null,
"10+ years",
"10+ years",
"4 years",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"< 1 year",
"4 years",
"< 1 year",
"4 years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"8 years",
"2 years",
"10+ years",
"< 1 year",
"5 years",
"6 years",
"6 years",
"10+ years",
"2 years",
"4 years",
"10+ years",
"6 years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"2 years",
"4 years",
null,
null,
"2 years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"9 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"6 years",
"7 years",
"10+ years",
null,
"10+ years",
"10+ years",
"7 years",
"2 years",
"< 1 year",
"5 years",
"10+ years",
"5 years",
"7 years",
"3 years",
"10+ years",
"5 years",
null,
"< 1 year",
"3 years",
"4 years",
"10+ years",
"5 years",
"< 1 year",
"4 years",
"3 years",
"2 years",
"4 years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"3 years",
"5 years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"2 years",
"10+ years",
"8 years",
"< 1 year",
"8 years",
null,
"7 years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"7 years",
"4 years",
"10+ years",
"10+ years",
"9 years",
"1 year",
"10+ years",
"3 years",
"9 years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"1 year",
null,
"10+ years",
"3 years",
"6 years",
"9 years",
"4 years",
"10+ years",
"9 years",
"10+ years",
"8 years",
"10+ years",
"9 years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"< 1 year",
null,
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"< 1 year",
"3 years",
"5 years",
"10+ years",
"7 years",
"8 years",
"3 years",
"2 years",
"2 years",
"1 year",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"7 years",
"3 years",
"4 years",
"6 years",
null,
"2 years",
"< 1 year",
"7 years",
"1 year",
null,
"< 1 year",
"8 years",
"10+ years",
"7 years",
"2 years",
null,
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"6 years",
"1 year",
"3 years",
"10+ years",
"3 years",
"2 years",
"1 year",
"9 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"3 years",
null,
"4 years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
null,
"10+ years",
"10+ years",
"5 years",
"3 years",
"1 year",
"10+ years",
null,
"10+ years",
"9 years",
"4 years",
"4 years",
"6 years",
"10+ years",
"3 years",
"5 years",
"2 years",
"10+ years",
"8 years",
"4 years",
null,
"10+ years",
"3 years",
"< 1 year",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"7 years",
"6 years",
"10+ years",
"< 1 year",
"9 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"6 years",
"8 years",
"8 years",
"10+ years",
"< 1 year",
"2 years",
"< 1 year",
"4 years",
"6 years",
"3 years",
"< 1 year",
"8 years",
"10+ years",
"1 year",
"< 1 year",
"8 years",
"4 years",
"1 year",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"< 1 year",
"2 years",
"1 year",
"9 years",
"7 years",
"10+ years",
"1 year",
"10+ years",
null,
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"5 years",
"6 years",
"10+ years",
"1 year",
"3 years",
"5 years",
"7 years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"8 years",
"3 years",
"10+ years",
"10+ years",
null,
"< 1 year",
"8 years",
"1 year",
null,
"10+ years",
"10+ years",
"3 years",
"6 years",
"2 years",
"7 years",
"10+ years",
"1 year",
"9 years",
"3 years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"< 1 year",
"10+ years",
"6 years",
"4 years",
null,
"7 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"4 years",
"9 years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"3 years",
"2 years",
"1 year",
"4 years",
"9 years",
"10+ years",
"7 years",
"2 years",
"< 1 year",
"5 years",
"9 years",
"10+ years",
"9 years",
"4 years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"3 years",
"< 1 year",
"8 years",
"10+ years",
"1 year",
"2 years",
"3 years",
"3 years",
"2 years",
"5 years",
"6 years",
"6 years",
"5 years",
null,
"4 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"1 year",
"4 years",
"4 years",
"3 years",
"10+ years",
"6 years",
"1 year",
"3 years",
"2 years",
"1 year",
null,
null,
"1 year",
"< 1 year",
null,
"1 year",
"10+ years",
"10+ years",
null,
"10+ years",
"5 years",
null,
null,
"2 years",
"8 years",
"5 years",
"10+ years",
"5 years",
"1 year",
"10+ years",
null,
"10+ years",
"7 years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"10+ years",
null,
"< 1 year",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"5 years",
"9 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
null,
"10+ years",
"1 year",
"2 years",
"4 years",
"10+ years",
"1 year",
null,
"10+ years",
"9 years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"8 years",
"< 1 year",
null,
"7 years",
"5 years",
"4 years",
"7 years",
"10+ years",
"7 years",
"3 years",
"6 years",
"10+ years",
"< 1 year",
null,
"5 years",
"6 years",
"3 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"9 years",
"10+ years",
"7 years",
"9 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"4 years",
"8 years",
"8 years",
"7 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"3 years",
"< 1 year",
"2 years",
"< 1 year",
"5 years",
"2 years",
"1 year",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"6 years",
"5 years",
"10+ years",
"8 years",
"10+ years",
"6 years",
"3 years",
"6 years",
"2 years",
"< 1 year",
"10+ years",
"2 years",
"2 years",
"< 1 year",
"10+ years",
"8 years",
"1 year",
"7 years",
"6 years",
"6 years",
"1 year",
"< 1 year",
"1 year",
"10+ years",
"2 years",
"9 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"1 year",
"10+ years",
"3 years",
"3 years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"5 years",
"6 years",
"4 years",
null,
"10+ years",
"1 year",
"8 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"4 years",
"1 year",
"7 years",
"5 years",
"4 years",
"2 years",
"3 years",
"6 years",
"4 years",
"10+ years",
"9 years",
"6 years",
"4 years",
"10+ years",
"< 1 year",
"4 years",
"3 years",
null,
"10+ years",
"10+ years",
"8 years",
"10+ years",
"1 year",
"4 years",
"7 years",
"4 years",
"2 years",
"7 years",
"10+ years",
"4 years",
"8 years",
"2 years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"9 years",
"10+ years",
"1 year",
"10+ years",
"7 years",
"1 year",
"4 years",
"1 year",
"8 years",
"3 years",
"6 years",
"7 years",
"2 years",
"8 years",
"9 years",
"2 years",
"< 1 year",
null,
"10+ years",
"2 years",
"3 years",
"10+ years",
"6 years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"7 years",
"< 1 year",
"< 1 year",
"3 years",
"9 years",
"< 1 year",
"6 years",
"5 years",
"3 years",
"10+ years",
"6 years",
"6 years",
"9 years",
"4 years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"9 years",
"4 years",
"3 years",
"6 years",
"10+ years",
"10+ years",
"7 years",
"6 years",
"1 year",
"< 1 year",
"10+ years",
"9 years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"6 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"7 years",
"4 years",
"10+ years",
"10+ years",
"1 year",
null,
"10+ years",
"10+ years",
"2 years",
"10+ years",
"6 years",
"< 1 year",
"5 years",
"5 years",
"10+ years",
"10+ years",
null,
"3 years",
"3 years",
"6 years",
"8 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"2 years",
"3 years",
"7 years",
"8 years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
null,
"< 1 year",
"< 1 year",
"5 years",
"5 years",
"8 years",
"9 years",
"7 years",
null,
"4 years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"6 years",
"< 1 year",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"4 years",
"10+ years",
"2 years",
null,
"1 year",
"8 years",
"8 years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"5 years",
"10+ years",
"5 years",
"8 years",
"1 year",
"9 years",
null,
null,
"10+ years",
"5 years",
"8 years",
"10+ years",
"9 years",
"5 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"6 years",
null,
"3 years",
"< 1 year",
"10+ years",
"7 years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"< 1 year",
"10+ years",
null,
"5 years",
"6 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"2 years",
"4 years",
"2 years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"7 years",
"10+ years",
"7 years",
"< 1 year",
"2 years",
"3 years",
"1 year",
"1 year",
"5 years",
"10+ years",
"10+ years",
"10+ years",
null,
"3 years",
"5 years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"7 years",
"3 years",
"10+ years",
"4 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"3 years",
"3 years",
"10+ years",
null,
"7 years",
"2 years",
"10+ years",
"9 years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"9 years",
"10+ years",
"2 years",
"9 years",
"7 years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"4 years",
"1 year",
"3 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"5 years",
"< 1 year",
"3 years",
"< 1 year",
"< 1 year",
"2 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"4 years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"9 years",
"8 years",
"4 years",
"4 years",
"7 years",
null,
"10+ years",
"2 years",
"9 years",
"10+ years",
"2 years",
"10+ years",
"6 years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"5 years",
"2 years",
"8 years",
"4 years",
"10+ years",
"< 1 year",
"5 years",
null,
"4 years",
"1 year",
"1 year",
"5 years",
null,
"2 years",
"9 years",
"9 years",
"5 years",
"8 years",
"3 years",
"8 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"5 years",
"10+ years",
"5 years",
"3 years",
"5 years",
"9 years",
"4 years",
"1 year",
"8 years",
"8 years",
"1 year",
"7 years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"3 years",
"8 years",
"10+ years",
"5 years",
"< 1 year",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"7 years",
"10+ years",
null,
"1 year",
null,
"9 years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"7 years",
"6 years",
"10+ years",
"1 year",
null,
"10+ years",
"4 years",
"< 1 year",
"7 years",
"8 years",
"10+ years",
"3 years",
"7 years",
"5 years",
null,
null,
"7 years",
"< 1 year",
"6 years",
"10+ years",
"4 years",
"< 1 year",
"4 years",
"10+ years",
"9 years",
"4 years",
"< 1 year",
"8 years",
"10+ years",
"< 1 year",
"< 1 year",
null,
"8 years",
"< 1 year",
"1 year",
"2 years",
"8 years",
"8 years",
"6 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"8 years",
"9 years",
"< 1 year",
"7 years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"3 years",
"3 years",
"7 years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"6 years",
"5 years",
"3 years",
"1 year",
"3 years",
"7 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"7 years",
null,
"10+ years",
"9 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"4 years",
"8 years",
"8 years",
"4 years",
"3 years",
"1 year",
"2 years",
"9 years",
"9 years",
"10+ years",
"1 year",
"2 years",
"10+ years",
"7 years",
"3 years",
"9 years",
null,
"5 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
null,
"1 year",
"2 years",
"5 years",
"6 years",
"3 years",
"7 years",
"10+ years",
"8 years",
"8 years",
"5 years",
"1 year",
null,
"10+ years",
null,
"4 years",
"8 years",
"1 year",
"10+ years",
"6 years",
"8 years",
"8 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"8 years",
"2 years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"8 years",
"7 years",
"10+ years",
"5 years",
"8 years",
"< 1 year",
"10+ years",
"3 years",
"8 years",
"7 years",
"4 years",
"5 years",
"9 years",
"3 years",
"1 year",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"7 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
null,
"5 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"8 years",
"6 years",
"3 years",
"5 years",
"6 years",
"< 1 year",
"7 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"3 years",
"4 years",
"7 years",
"2 years",
"2 years",
"10+ years",
"6 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
null,
"6 years",
"1 year",
"10+ years",
"6 years",
"10+ years",
"3 years",
"2 years",
null,
"10+ years",
"9 years",
"< 1 year",
"1 year",
null,
"5 years",
"5 years",
"5 years",
"5 years",
"10+ years",
null,
"2 years",
"10+ years",
"8 years",
"10+ years",
"6 years",
"3 years",
"< 1 year",
"4 years",
"4 years",
"3 years",
"4 years",
"10+ years",
"9 years",
"7 years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"4 years",
"8 years",
"4 years",
"10+ years",
"1 year",
"10+ years",
"8 years",
"3 years",
"2 years",
null,
"< 1 year",
"8 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"3 years",
null,
"10+ years",
"4 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
null,
"10+ years",
"9 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
null,
"4 years",
"7 years",
"8 years",
"8 years",
"9 years",
"2 years",
"1 year",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"5 years",
"3 years",
"5 years",
"10+ years",
"< 1 year",
"5 years",
"6 years",
"4 years",
"3 years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
null,
"1 year",
"10+ years",
"10+ years",
"2 years",
"9 years",
"2 years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"4 years",
"10+ years",
"7 years",
"1 year",
"2 years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"1 year",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"6 years",
null,
"9 years",
"4 years",
"2 years",
null,
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"3 years",
"1 year",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
null,
"4 years",
"10+ years",
"10+ years",
"9 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"9 years",
"9 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"8 years",
"3 years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"4 years",
"2 years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
null,
"10+ years",
"6 years",
"10+ years",
"7 years",
"7 years",
"1 year",
"5 years",
"8 years",
null,
"6 years",
null,
"10+ years",
"4 years",
"6 years",
null,
"10+ years",
"7 years",
"9 years",
"4 years",
"5 years",
"2 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"6 years",
"10+ years",
null,
"8 years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"4 years",
"4 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"2 years",
"2 years",
"9 years",
"3 years",
null,
"2 years",
"9 years",
"8 years",
"10+ years",
"4 years",
"10+ years",
"6 years",
"4 years",
"10+ years",
"1 year",
"2 years",
"< 1 year",
"5 years",
"2 years",
"10+ years",
"4 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"3 years",
"10+ years",
null,
"10+ years",
"8 years",
"< 1 year",
"8 years",
"1 year",
"10+ years",
"2 years",
"5 years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"3 years",
"< 1 year",
"6 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
null,
"8 years",
"2 years",
"9 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
null,
"8 years",
"10+ years",
"4 years",
"10+ years",
"6 years",
"6 years",
"1 year",
"2 years",
"6 years",
"10+ years",
"< 1 year",
"< 1 year",
"2 years",
"2 years",
"< 1 year",
"5 years",
"7 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"10+ years",
"7 years",
"< 1 year",
"4 years",
"6 years",
"6 years",
"10+ years",
"3 years",
"10+ years",
null,
"4 years",
"7 years",
"5 years",
"2 years",
"4 years",
null,
"10+ years",
"< 1 year",
"7 years",
"4 years",
null,
"1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"7 years",
null,
null,
"1 year",
"< 1 year",
"5 years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"7 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"2 years",
"< 1 year",
"4 years",
"6 years",
"10+ years",
"7 years",
"2 years",
"1 year",
"4 years",
"10+ years",
"7 years",
"< 1 year",
"1 year",
"10+ years",
"3 years",
"6 years",
"9 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"1 year",
"6 years",
"1 year",
"9 years",
"9 years",
"10+ years",
"8 years",
"9 years",
"6 years",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"< 1 year",
"8 years",
"10+ years",
"4 years",
"10+ years",
null,
"2 years",
"2 years",
"< 1 year",
null,
"9 years",
"8 years",
"3 years",
"< 1 year",
"5 years",
"10+ years",
"6 years",
"6 years",
"10+ years",
"5 years",
"7 years",
"3 years",
"2 years",
"1 year",
"10+ years",
"2 years",
"9 years",
"10+ years",
"4 years",
"< 1 year",
"8 years",
"9 years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"3 years",
"< 1 year",
"4 years",
"1 year",
"< 1 year",
"2 years",
"3 years",
"8 years",
"10+ years",
null,
"10+ years",
"5 years",
null,
"9 years",
"5 years",
"5 years",
"10+ years",
"3 years",
"3 years",
null,
"< 1 year",
"7 years",
"5 years",
"10+ years",
"8 years",
"3 years",
"2 years",
null,
"6 years",
"< 1 year",
"< 1 year",
"5 years",
"< 1 year",
"10+ years",
"3 years",
"5 years",
"2 years",
"2 years",
"7 years",
"9 years",
"7 years",
"9 years",
null,
"9 years",
"< 1 year",
"10+ years",
"9 years",
"9 years",
"2 years",
"8 years",
"3 years",
"4 years",
"8 years",
"5 years",
"10+ years",
"3 years",
"4 years",
"8 years",
"3 years",
"3 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"3 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"7 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"2 years",
"< 1 year",
"10+ years",
"9 years",
"9 years",
"4 years",
"4 years",
"3 years",
null,
"3 years",
"5 years",
"7 years",
null,
null,
"6 years",
null,
"10+ years",
"10+ years",
"6 years",
"1 year",
"5 years",
"3 years",
null,
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"2 years",
"4 years",
"10+ years",
"9 years",
"6 years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"9 years",
"10+ years",
"10+ years",
"9 years",
"4 years",
"5 years",
"1 year",
"4 years",
"7 years",
"9 years",
"10+ years",
"9 years",
"8 years",
null,
"4 years",
"< 1 year",
"1 year",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"9 years",
"10+ years",
"3 years",
null,
null,
"10+ years",
"3 years",
"1 year",
"7 years",
"4 years",
"10+ years",
"3 years",
"1 year",
"7 years",
"10+ years",
"3 years",
"10+ years",
null,
"2 years",
"10+ years",
"10+ years",
"5 years",
"9 years",
"5 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"5 years",
"5 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"7 years",
"3 years",
"10+ years",
"10+ years",
null,
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"9 years",
"2 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"2 years",
"< 1 year",
"10+ years",
null,
null,
"9 years",
"10+ years",
null,
"10+ years",
"4 years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"4 years",
"2 years",
"10+ years",
"3 years",
"< 1 year",
"1 year",
"3 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"4 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"8 years",
"5 years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"2 years",
"3 years",
"10+ years",
"6 years",
"1 year",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"1 year",
"9 years",
"4 years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"6 years",
"< 1 year",
"1 year",
"3 years",
"2 years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"6 years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"10+ years",
"2 years",
"6 years",
"3 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"5 years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"3 years",
"8 years",
"10+ years",
"6 years",
"3 years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"5 years",
null,
"2 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"8 years",
"9 years",
"3 years",
null,
"2 years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"6 years",
"3 years",
"2 years",
"< 1 year",
"4 years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"2 years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"6 years",
"2 years",
"< 1 year",
"5 years",
"3 years",
"< 1 year",
"< 1 year",
"< 1 year",
"4 years",
"4 years",
"3 years",
"10+ years",
null,
"4 years",
"3 years",
"< 1 year",
"2 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"6 years",
"10+ years",
"< 1 year",
"2 years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
null,
"7 years",
"7 years",
"5 years",
"10+ years",
"6 years",
null,
"2 years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
null,
"10+ years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"6 years",
"3 years",
null,
"8 years",
"5 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"4 years",
"< 1 year",
"9 years",
"1 year",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"4 years",
"10+ years",
"1 year",
"10+ years",
"5 years",
"3 years",
"2 years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"8 years",
"< 1 year",
"9 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"4 years",
"3 years",
"10+ years",
"< 1 year",
"7 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"1 year",
"< 1 year",
"3 years",
"10+ years",
"1 year",
"4 years",
"2 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"7 years",
"4 years",
"3 years",
"1 year",
"4 years",
"2 years",
"7 years",
"1 year",
"8 years",
"10+ years",
null,
"5 years",
"4 years",
"10+ years",
"7 years",
"8 years",
"3 years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
"8 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"7 years",
null,
"4 years",
"< 1 year",
"10+ years",
"5 years",
"1 year",
"2 years",
"7 years",
"7 years",
"6 years",
"4 years",
"10+ years",
"6 years",
"10+ years",
"8 years",
"< 1 year",
"5 years",
"2 years",
"4 years",
"9 years",
"4 years",
null,
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"8 years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"1 year",
"3 years",
"3 years",
"10+ years",
"10+ years",
null,
"9 years",
"10+ years",
"10+ years",
"9 years",
"3 years",
null,
"10+ years",
"10+ years",
"4 years",
"4 years",
"8 years",
"1 year",
"2 years",
"8 years",
"10+ years",
"10+ years",
"6 years",
"< 1 year",
"10+ years",
null,
"4 years",
"4 years",
"9 years",
"4 years",
"10+ years",
"4 years",
"2 years",
"< 1 year",
"10+ years",
null,
"3 years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"< 1 year",
"7 years",
"4 years",
"10+ years",
null,
"10+ years",
"6 years",
"9 years",
"9 years",
"< 1 year",
"2 years",
"8 years",
"< 1 year",
"1 year",
"4 years",
"2 years",
null,
"6 years",
"2 years",
"3 years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"8 years",
"1 year",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"7 years",
"6 years",
"3 years",
"5 years",
"10+ years",
"7 years",
"10+ years",
"1 year",
"10+ years",
"5 years",
"3 years",
"7 years",
"8 years",
"10+ years",
"10+ years",
"5 years",
"4 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"2 years",
null,
"7 years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"2 years",
"10+ years",
"7 years",
"5 years",
"5 years",
"10+ years",
"7 years",
"< 1 year",
"5 years",
"2 years",
"10+ years",
"8 years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"2 years",
"4 years",
"10+ years",
"1 year",
"6 years",
"4 years",
"7 years",
"9 years",
"3 years",
"8 years",
"10+ years",
"< 1 year",
"5 years",
"< 1 year",
"8 years",
"10+ years",
"1 year",
"10+ years",
"7 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"2 years",
"9 years",
"3 years",
"10+ years",
"2 years",
"1 year",
"8 years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"8 years",
"3 years",
"7 years",
"9 years",
"3 years",
"2 years",
"10+ years",
"1 year",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"8 years",
"3 years",
null,
"10+ years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"1 year",
"10+ years",
"5 years",
"3 years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"8 years",
"8 years",
"1 year",
"10+ years",
"3 years",
null,
"10+ years",
"8 years",
"1 year",
"3 years",
"2 years",
null,
"1 year",
"3 years",
"10+ years",
"6 years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"2 years",
"< 1 year",
"10+ years",
null,
"6 years",
"< 1 year",
"10+ years",
"2 years",
"3 years",
"5 years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"7 years",
"1 year",
"3 years",
"1 year",
"< 1 year",
"9 years",
"3 years",
"7 years",
"2 years",
"< 1 year",
"2 years",
"7 years",
"8 years",
"10+ years",
"< 1 year",
"3 years",
"2 years",
"2 years",
"1 year",
"10+ years",
"5 years",
"< 1 year",
"3 years",
"2 years",
"10+ years",
"1 year",
"2 years",
"5 years",
"5 years",
"4 years",
"5 years",
"8 years",
"7 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"9 years",
"< 1 year",
"5 years",
"2 years",
"3 years",
"9 years",
"7 years",
"10+ years",
"6 years",
"2 years",
null,
"2 years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"3 years",
null,
"3 years",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"1 year",
null,
"9 years",
"8 years",
"3 years",
null,
"4 years",
"10+ years",
"2 years",
"5 years",
"5 years",
"3 years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"4 years",
"1 year",
"10+ years",
null,
"3 years",
"2 years",
"10+ years",
null,
"10+ years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"8 years",
"8 years",
"10+ years",
"1 year",
"8 years",
null,
"10+ years",
"4 years",
"< 1 year",
"5 years",
"5 years",
"10+ years",
"6 years",
"10+ years",
"9 years",
"2 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"< 1 year",
"3 years",
"4 years",
"4 years",
"9 years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"2 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"1 year",
"4 years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"3 years",
"1 year",
"9 years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"1 year",
"10+ years",
"9 years",
null,
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"9 years",
"7 years",
"10+ years",
"8 years",
"3 years",
"7 years",
"10+ years",
"5 years",
"< 1 year",
"< 1 year",
"3 years",
"10+ years",
"5 years",
"7 years",
"1 year",
"10+ years",
"3 years",
"6 years",
"1 year",
"10+ years",
"2 years",
"2 years",
"5 years",
"6 years",
"7 years",
"4 years",
"10+ years",
"< 1 year",
"5 years",
"< 1 year",
"6 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"9 years",
"10+ years",
"10+ years",
"4 years",
"6 years",
"4 years",
"10+ years",
"1 year",
"10+ years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"5 years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"2 years",
"< 1 year",
"< 1 year",
"4 years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
null,
"1 year",
"10+ years",
"2 years",
"5 years",
"8 years",
"2 years",
"< 1 year",
"10+ years",
"1 year",
"9 years",
"< 1 year",
"7 years",
"4 years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"2 years",
"3 years",
"9 years",
"1 year",
"3 years",
"5 years",
"3 years",
"5 years",
"10+ years",
"1 year",
"< 1 year",
"1 year",
null,
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"5 years",
"4 years",
"8 years",
"4 years",
"5 years",
"6 years",
"10+ years",
"6 years",
"1 year",
"1 year",
null,
"3 years",
"2 years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"8 years",
"9 years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"9 years",
"10+ years",
"< 1 year",
"3 years",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"7 years",
"6 years",
"10+ years",
"9 years",
"2 years",
"7 years",
"5 years",
"1 year",
"7 years",
"10+ years",
"< 1 year",
null,
"10+ years",
"9 years",
"5 years",
"7 years",
"< 1 year",
"10+ years",
"2 years",
"4 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"6 years",
null,
"< 1 year",
"1 year",
"2 years",
"9 years",
"7 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
null,
"10+ years",
null,
"7 years",
"3 years",
"2 years",
"< 1 year",
"3 years",
"5 years",
"2 years",
"4 years",
"10+ years",
null,
"< 1 year",
"< 1 year",
"4 years",
"4 years",
"2 years",
"10+ years",
"3 years",
"9 years",
"10+ years",
"< 1 year",
"9 years",
"4 years",
"7 years",
null,
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"4 years",
"5 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"8 years",
"< 1 year",
null,
"5 years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"7 years",
"3 years",
"2 years",
"10+ years",
"2 years",
"6 years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"6 years",
"7 years",
"10+ years",
null,
"2 years",
"3 years",
"2 years",
null,
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"6 years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"10+ years",
null,
"2 years",
"10+ years",
"7 years",
"10+ years",
"9 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"1 year",
"10+ years",
"5 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"3 years",
null,
"2 years",
"8 years",
"< 1 year",
"10+ years",
"1 year",
null,
"7 years",
"1 year",
"4 years",
null,
"5 years",
"10+ years",
null,
"8 years",
"1 year",
"< 1 year",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"3 years",
"3 years",
"< 1 year",
"10+ years",
"< 1 year",
"2 years",
"8 years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"1 year",
"8 years",
"4 years",
"10+ years",
"1 year",
"9 years",
"5 years",
"7 years",
"1 year",
"6 years",
"3 years",
"7 years",
"2 years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"1 year",
"3 years",
"9 years",
"< 1 year",
"2 years",
"10+ years",
"8 years",
"7 years",
"2 years",
"6 years",
"< 1 year",
"< 1 year",
"1 year",
"10+ years",
"5 years",
"10+ years",
"4 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"8 years",
"1 year",
"10+ years",
null,
"3 years",
"4 years",
"6 years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"1 year",
"5 years",
"2 years",
"6 years",
"6 years",
"7 years",
"3 years",
"8 years",
"10+ years",
"10+ years",
"4 years",
"7 years",
"9 years",
"10+ years",
"4 years",
"9 years",
"< 1 year",
"3 years",
"9 years",
"< 1 year",
"10+ years",
"2 years",
"1 year",
"3 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"7 years",
null,
"10+ years",
"10+ years",
null,
"7 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"5 years",
"< 1 year",
"6 years",
"3 years",
"< 1 year",
"2 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"9 years",
"10+ years",
"6 years",
"1 year",
"< 1 year",
"2 years",
"9 years",
"10+ years",
"< 1 year",
null,
"10+ years",
"< 1 year",
"5 years",
"9 years",
"6 years",
"10+ years",
"1 year",
"4 years",
"3 years",
"3 years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"6 years",
"3 years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"2 years",
"7 years",
"8 years",
"10+ years",
"10+ years",
null,
"1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"7 years",
"10+ years",
"10+ years",
null,
"6 years",
"5 years",
"< 1 year",
"5 years",
"7 years",
"1 year",
"3 years",
"8 years",
"7 years",
null,
null,
"10+ years",
"2 years",
"< 1 year",
null,
"10+ years",
"5 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"8 years",
"5 years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"2 years",
null,
"10+ years",
"8 years",
"6 years",
"9 years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
null,
"4 years",
"7 years",
null,
"8 years",
"10+ years",
"7 years",
"7 years",
"1 year",
"1 year",
"10+ years",
"5 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"3 years",
"3 years",
"9 years",
"4 years",
"1 year",
null,
"3 years",
"2 years",
"3 years",
"4 years",
"10+ years",
"9 years",
"10+ years",
"8 years",
"1 year",
"7 years",
"1 year",
"< 1 year",
"10+ years",
"1 year",
"8 years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"1 year",
null,
"< 1 year",
"2 years",
"2 years",
"10+ years",
null,
"4 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"5 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"7 years",
"2 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"< 1 year",
"8 years",
"6 years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"1 year",
"2 years",
"8 years",
"2 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"10+ years",
"6 years",
"5 years",
"< 1 year",
"3 years",
"4 years",
"1 year",
"8 years",
"6 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"6 years",
"4 years",
"10+ years",
"5 years",
"10+ years",
"6 years",
"4 years",
"10+ years",
"7 years",
"10+ years",
null,
"< 1 year",
"4 years",
"< 1 year",
"4 years",
"2 years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"4 years",
"< 1 year",
"1 year",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"4 years",
"9 years",
"< 1 year",
"10+ years",
"9 years",
"5 years",
"2 years",
"3 years",
"4 years",
"10+ years",
"7 years",
"4 years",
"< 1 year",
"10+ years",
"< 1 year",
"4 years",
"3 years",
"2 years",
"8 years",
"7 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
null,
"10+ years",
"8 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"9 years",
"4 years",
"9 years",
"5 years",
"1 year",
"10+ years",
null,
"3 years",
"10+ years",
"< 1 year",
"4 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"9 years",
"9 years",
"7 years",
"10+ years",
"4 years",
"5 years",
"5 years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
null,
"4 years",
"< 1 year",
"8 years",
"4 years",
"10+ years",
"3 years",
"5 years",
null,
"6 years",
"10+ years",
"10+ years",
"1 year",
"9 years",
"5 years",
"10+ years",
"< 1 year",
null,
"10+ years",
"2 years",
"10+ years",
null,
"5 years",
"4 years",
"5 years",
"9 years",
"< 1 year",
null,
"1 year",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"1 year",
"9 years",
"7 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
null,
"10+ years",
"2 years",
"6 years",
"6 years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"4 years",
null,
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
null,
"6 years",
null,
"10+ years",
"4 years",
"10+ years",
"1 year",
"2 years",
"2 years",
"7 years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"7 years",
"4 years",
"8 years",
"9 years",
"10+ years",
"10+ years",
"8 years",
"1 year",
"3 years",
"6 years",
"3 years",
"1 year",
"1 year",
"4 years",
"5 years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"4 years",
"6 years",
"3 years",
"10+ years",
null,
"10+ years",
"10+ years",
"1 year",
"9 years",
"2 years",
"6 years",
"10+ years",
"9 years",
"10+ years",
"4 years",
"7 years",
"10+ years",
"1 year",
"10+ years",
"5 years",
null,
"10+ years",
"7 years",
"10+ years",
"6 years",
"8 years",
"1 year",
"4 years",
"5 years",
"7 years",
"4 years",
"10+ years",
"1 year",
"< 1 year",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"5 years",
"7 years",
"2 years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"4 years",
null,
"3 years",
"2 years",
"7 years",
"7 years",
"5 years",
"10+ years",
"1 year",
null,
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"6 years",
"10+ years",
"4 years",
"9 years",
"10+ years",
"< 1 year",
"8 years",
"2 years",
"10+ years",
"8 years",
"1 year",
"10+ years",
"3 years",
"6 years",
"10+ years",
"3 years",
"9 years",
"8 years",
"4 years",
"3 years",
"10+ years",
"4 years",
"5 years",
"2 years",
"2 years",
"8 years",
"10+ years",
"10+ years",
null,
"3 years",
"7 years",
"8 years",
"4 years",
"10+ years",
"< 1 year",
"9 years",
"3 years",
"10+ years",
"5 years",
"3 years",
"8 years",
"10+ years",
"3 years",
"5 years",
"8 years",
"1 year",
"1 year",
"10+ years",
"8 years",
"< 1 year",
"2 years",
"2 years",
"3 years",
"2 years",
"8 years",
"10+ years",
"< 1 year",
"8 years",
"3 years",
"4 years",
null,
"10+ years",
"10+ years",
"8 years",
null,
"10+ years",
"6 years",
"9 years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"5 years",
"3 years",
"10+ years",
"7 years",
"10+ years",
"7 years",
"7 years",
"4 years",
"8 years",
"10+ years",
null,
"10+ years",
"10+ years",
"2 years",
"9 years",
"1 year",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"8 years",
"< 1 year",
"< 1 year",
"10+ years",
null,
"10+ years",
"7 years",
"6 years",
"9 years",
"10+ years",
"10+ years",
"9 years",
"4 years",
"2 years",
"2 years",
"10+ years",
"2 years",
"1 year",
"5 years",
null,
"2 years",
"4 years",
"10+ years",
"9 years",
"3 years",
"< 1 year",
"1 year",
"10+ years",
"7 years",
"6 years",
"4 years",
"4 years",
"3 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
null,
"10+ years",
"9 years",
"< 1 year",
"3 years",
"3 years",
"4 years",
"4 years",
"4 years",
"9 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"< 1 year",
"4 years",
"5 years",
"< 1 year",
"2 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"4 years",
"< 1 year",
"10+ years",
"6 years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"8 years",
"3 years",
null,
"5 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"8 years",
"9 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"8 years",
"4 years",
"4 years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"7 years",
"5 years",
"3 years",
"4 years",
"5 years",
"9 years",
"3 years",
"9 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"9 years",
"10+ years",
"4 years",
"7 years",
"6 years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"6 years",
"4 years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"1 year",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"< 1 year",
"< 1 year",
"5 years",
"8 years",
"2 years",
"10+ years",
"5 years",
null,
null,
"1 year",
null,
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"3 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"7 years",
"9 years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"8 years",
"9 years",
"1 year",
"8 years",
"2 years",
"10+ years",
"6 years",
"3 years",
"10+ years",
"2 years",
"6 years",
"9 years",
"2 years",
"10+ years",
null,
null,
"2 years",
"9 years",
"3 years",
"10+ years",
"3 years",
"4 years",
"1 year",
"1 year",
"< 1 year",
"6 years",
"1 year",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"2 years",
"9 years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"8 years",
"4 years",
"6 years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"7 years",
"10+ years",
"2 years",
"< 1 year",
"7 years",
"10+ years",
"2 years",
"3 years",
"1 year",
"4 years",
"3 years",
"3 years",
"9 years",
"1 year",
"4 years",
"2 years",
"7 years",
"3 years",
"9 years",
"1 year",
"10+ years",
null,
"7 years",
"5 years",
"6 years",
"< 1 year",
"10+ years",
"< 1 year",
"7 years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"1 year",
"5 years",
"1 year",
"3 years",
"4 years",
"< 1 year",
"6 years",
"10+ years",
"3 years",
"10+ years",
null,
"10+ years",
"9 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"9 years",
"5 years",
"2 years",
"< 1 year",
"10+ years",
"1 year",
"7 years",
"10+ years",
"10+ years",
"9 years",
"7 years",
"7 years",
"8 years",
"10+ years",
"5 years",
"10+ years",
"1 year",
"4 years",
"10+ years",
"6 years",
"10+ years",
"9 years",
"1 year",
"6 years",
"< 1 year",
"10+ years",
null,
null,
"10+ years",
"< 1 year",
"3 years",
"3 years",
"1 year",
"4 years",
null,
"5 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
null,
"7 years",
"1 year",
"7 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
null,
"5 years",
"6 years",
"8 years",
null,
"4 years",
"1 year",
"2 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"8 years",
"6 years",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"3 years",
"9 years",
"5 years",
"9 years",
"2 years",
null,
"10+ years",
"5 years",
"9 years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"2 years",
"< 1 year",
"3 years",
"7 years",
"10+ years",
"5 years",
"2 years",
"2 years",
"3 years",
"< 1 year",
"10+ years",
"2 years",
"3 years",
"2 years",
"4 years",
"10+ years",
"4 years",
"5 years",
"6 years",
"10+ years",
"7 years",
"3 years",
"2 years",
"5 years",
"4 years",
"< 1 year",
"3 years",
null,
"10+ years",
null,
"10+ years",
"9 years",
"2 years",
"< 1 year",
"3 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"10+ years",
null,
"1 year",
null,
"2 years",
"4 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"7 years",
"3 years",
"4 years",
"4 years",
null,
"10+ years",
"2 years",
"2 years",
"8 years",
"9 years",
"1 year",
"4 years",
"< 1 year",
"4 years",
"10+ years",
"< 1 year",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"8 years",
"10+ years",
"10+ years",
null,
"5 years",
"2 years",
"7 years",
"10+ years",
"7 years",
"5 years",
"5 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"6 years",
"5 years",
"< 1 year",
"10+ years",
"4 years",
"4 years",
"7 years",
"8 years",
"2 years",
"7 years",
"8 years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"2 years",
null,
"4 years",
"2 years",
"< 1 year",
"2 years",
"9 years",
"2 years",
"10+ years",
"9 years",
null,
"1 year",
"7 years",
"4 years",
"9 years",
"5 years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"< 1 year",
"3 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"6 years",
"10+ years",
"< 1 year",
"< 1 year",
"9 years",
"5 years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
null,
"3 years",
"10+ years",
"< 1 year",
"2 years",
null,
"6 years",
"8 years",
"1 year",
"< 1 year",
"3 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
null,
"10+ years",
"5 years",
"4 years",
"8 years",
"2 years",
"10+ years",
"9 years",
null,
"5 years",
"9 years",
"2 years",
"7 years",
"10+ years",
"5 years",
"2 years",
"7 years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"4 years",
"5 years",
"10+ years",
"< 1 year",
"1 year",
"2 years",
"10+ years",
null,
"10+ years",
"10+ years",
"6 years",
null,
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"2 years",
null,
"3 years",
"10+ years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"8 years",
"9 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"2 years",
"3 years",
"8 years",
"10+ years",
"8 years",
"6 years",
"3 years",
"1 year",
"10+ years",
"4 years",
"2 years",
"3 years",
"5 years",
"5 years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"3 years",
"8 years",
null,
"10+ years",
"< 1 year",
"3 years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"2 years",
"2 years",
"6 years",
"9 years",
"10+ years",
"3 years",
"8 years",
null,
"2 years",
"10+ years",
"10+ years",
"4 years",
"9 years",
"2 years",
"1 year",
"10+ years",
"6 years",
"3 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"6 years",
"7 years",
"4 years",
"10+ years",
"10+ years",
"3 years",
null,
"2 years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"4 years",
"4 years",
"< 1 year",
"10+ years",
null,
"8 years",
"10+ years",
"8 years",
"3 years",
"< 1 year",
"10+ years",
"1 year",
"5 years",
"3 years",
"10+ years",
"1 year",
"2 years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"9 years",
"10+ years",
"1 year",
"4 years",
"3 years",
"1 year",
"10+ years",
"< 1 year",
"8 years",
"4 years",
"5 years",
"8 years",
"10+ years",
null,
"10+ years",
"10+ years",
"2 years",
"4 years",
"3 years",
null,
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"3 years",
"10+ years",
"< 1 year",
"6 years",
"5 years",
"3 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"1 year",
"2 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"6 years",
"6 years",
"10+ years",
"6 years",
"7 years",
"1 year",
"10+ years",
"10+ years",
"9 years",
null,
"4 years",
"9 years",
"3 years",
"6 years",
"< 1 year",
null,
"2 years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"4 years",
"2 years",
"< 1 year",
"5 years",
"2 years",
"2 years",
null,
"8 years",
"< 1 year",
null,
"3 years",
"1 year",
"1 year",
"9 years",
"< 1 year",
"8 years",
"1 year",
"< 1 year",
"10+ years",
"8 years",
"7 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
null,
"< 1 year",
"5 years",
"3 years",
"10+ years",
"3 years",
"4 years",
"2 years",
"4 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"1 year",
"2 years",
"7 years",
"7 years",
"2 years",
"5 years",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"5 years",
"4 years",
"4 years",
"< 1 year",
"10+ years",
"1 year",
"6 years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"6 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"< 1 year",
"4 years",
"7 years",
"2 years",
"3 years",
"3 years",
"7 years",
"10+ years",
"2 years",
"5 years",
"8 years",
"1 year",
"4 years",
"1 year",
"10+ years",
"6 years",
"4 years",
"< 1 year",
"3 years",
"8 years",
"3 years",
"< 1 year",
"1 year",
"1 year",
"10+ years",
"3 years",
"10+ years",
"5 years",
"6 years",
null,
"10+ years",
"7 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"2 years",
"1 year",
"4 years",
"10+ years",
"7 years",
"10+ years",
"7 years",
"7 years",
"10+ years",
"8 years",
null,
"10+ years",
"4 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"5 years",
"10+ years",
"2 years",
"< 1 year",
null,
"7 years",
null,
"6 years",
"< 1 year",
"10+ years",
"3 years",
null,
"5 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"8 years",
"6 years",
"< 1 year",
"10+ years",
"7 years",
"6 years",
null,
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"4 years",
"8 years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"3 years",
"5 years",
"6 years",
"< 1 year",
"1 year",
"10+ years",
"< 1 year",
"5 years",
"8 years",
"10+ years",
"2 years",
"< 1 year",
null,
"8 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"3 years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"4 years",
"3 years",
"10+ years",
"9 years",
"6 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
null,
"2 years",
"8 years",
"9 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"3 years",
null,
"10+ years",
"8 years",
null,
"5 years",
null,
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"3 years",
"10+ years",
"9 years",
"5 years",
"5 years",
"2 years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"5 years",
"6 years",
"8 years",
"2 years",
"9 years",
"5 years",
null,
"7 years",
"7 years",
"3 years",
"5 years",
"9 years",
"6 years",
"2 years",
"7 years",
"10+ years",
null,
"3 years",
"10+ years",
"7 years",
"4 years",
"7 years",
"5 years",
"2 years",
"< 1 year",
"2 years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"8 years",
"< 1 year",
"5 years",
null,
"10+ years",
"5 years",
"4 years",
"2 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"6 years",
"3 years",
"10+ years",
"6 years",
"4 years",
"10+ years",
"8 years",
"5 years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"10+ years",
"< 1 year",
"8 years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"7 years",
"< 1 year",
"8 years",
"1 year",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"< 1 year",
"5 years",
"4 years",
"1 year",
"10+ years",
"3 years",
"8 years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
null,
"< 1 year",
"10+ years",
null,
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"5 years",
"2 years",
"5 years",
"10+ years",
"3 years",
"3 years",
"1 year",
"4 years",
"1 year",
"4 years",
null,
null,
"3 years",
"< 1 year",
"3 years",
"< 1 year",
"5 years",
"10+ years",
"4 years",
"2 years",
"5 years",
"7 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"1 year",
"5 years",
"5 years",
"10+ years",
null,
"< 1 year",
"4 years",
"2 years",
null,
"10+ years",
"10+ years",
"4 years",
"6 years",
"3 years",
null,
"10+ years",
"10+ years",
"4 years",
"1 year",
"4 years",
null,
"1 year",
"9 years",
"5 years",
"9 years",
"4 years",
"< 1 year",
"2 years",
"8 years",
"3 years",
"1 year",
"2 years",
"3 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"< 1 year",
"5 years",
"< 1 year",
null,
"3 years",
"10+ years",
"8 years",
"7 years",
"8 years",
"8 years",
"7 years",
"9 years",
"5 years",
"6 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"9 years",
"10+ years",
null,
"2 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
null,
"8 years",
"4 years",
"10+ years",
"10+ years",
"9 years",
null,
"< 1 year",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"4 years",
"8 years",
"10+ years",
null,
"< 1 year",
"3 years",
"< 1 year",
"6 years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"1 year",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"6 years",
"1 year",
"4 years",
"10+ years",
"3 years",
"7 years",
"4 years",
null,
"10+ years",
"6 years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"7 years",
"1 year",
"< 1 year",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"2 years",
"2 years",
"4 years",
"< 1 year",
"1 year",
"4 years",
"7 years",
"1 year",
"2 years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"2 years",
"7 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"8 years",
"< 1 year",
"3 years",
"10+ years",
"< 1 year",
"1 year",
"5 years",
"< 1 year",
"1 year",
"8 years",
"4 years",
null,
"10+ years",
"7 years",
"4 years",
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"2 years",
"8 years",
"< 1 year",
"2 years",
"9 years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"7 years",
null,
"10+ years",
"2 years",
"3 years",
"7 years",
"10+ years",
null,
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"4 years",
"3 years",
"10+ years",
"9 years",
"10+ years",
"9 years",
"8 years",
"10+ years",
"9 years",
"4 years",
"6 years",
"5 years",
"8 years",
null,
"9 years",
"3 years",
"2 years",
"1 year",
"8 years",
"7 years",
"2 years",
"10+ years",
"4 years",
"< 1 year",
null,
"6 years",
"7 years",
"10+ years",
"8 years",
"3 years",
"7 years",
"10+ years",
null,
"3 years",
"7 years",
"10+ years",
"7 years",
"10+ years",
"5 years",
"10+ years",
"1 year",
"9 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"5 years",
"10+ years",
"4 years",
"2 years",
"4 years",
"5 years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"2 years",
"7 years",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
"9 years",
"4 years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"8 years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"4 years",
"6 years",
"2 years",
"< 1 year",
"10+ years",
"5 years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"5 years",
"10+ years",
"8 years",
"6 years",
"< 1 year",
"3 years",
"4 years",
"10+ years",
"1 year",
"7 years",
"2 years",
"6 years",
"4 years",
"7 years",
"10+ years",
null,
"< 1 year",
"3 years",
"< 1 year",
"9 years",
"5 years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"6 years",
"10+ years",
"2 years",
"7 years",
"1 year",
"10+ years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
null,
"7 years",
"10+ years",
"2 years",
"4 years",
"2 years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"9 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"< 1 year",
"3 years",
"5 years",
"9 years",
"5 years",
"< 1 year",
"1 year",
"8 years",
"10+ years",
"5 years",
null,
"2 years",
null,
"8 years",
"6 years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"4 years",
"5 years",
"3 years",
"10+ years",
"1 year",
"1 year",
"6 years",
"10+ years",
"4 years",
"1 year",
"9 years",
"< 1 year",
"10+ years",
"9 years",
"10+ years",
"10+ years",
null,
"10+ years",
"6 years",
"10+ years",
"7 years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
null,
"6 years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"3 years",
"10+ years",
null,
null,
"10+ years",
"9 years",
"2 years",
"10+ years",
"2 years",
"7 years",
null,
"2 years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
null,
"10+ years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"5 years",
"6 years",
"4 years",
"< 1 year",
"1 year",
"10+ years",
"1 year",
"8 years",
"3 years",
"9 years",
"6 years",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"7 years",
"10+ years",
"6 years",
"3 years",
"8 years",
"1 year",
"10+ years",
"7 years",
"3 years",
"4 years",
"6 years",
"2 years",
"< 1 year",
"10+ years",
"3 years",
"4 years",
"10+ years",
"1 year",
"9 years",
null,
"7 years",
"8 years",
"6 years",
"10+ years",
"10+ years",
"9 years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"6 years",
"5 years",
"6 years",
"< 1 year",
"10+ years",
"5 years",
"8 years",
"3 years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"< 1 year",
"< 1 year",
null,
"4 years",
"10+ years",
"9 years",
"3 years",
"2 years",
"< 1 year",
"10+ years",
"5 years",
"3 years",
"9 years",
"4 years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"2 years",
"10+ years",
"9 years",
"7 years",
"10+ years",
null,
"10+ years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"1 year",
"8 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"4 years",
"6 years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"3 years",
"6 years",
"< 1 year",
"2 years",
"6 years",
"2 years",
"3 years",
"10+ years",
null,
"10+ years",
"10+ years",
"6 years",
"7 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"4 years",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"6 years",
"4 years",
"10+ years",
"7 years",
"9 years",
"5 years",
"10+ years",
"7 years",
"10+ years",
null,
"10+ years",
"1 year",
null,
"< 1 year",
"1 year",
"3 years",
"10+ years",
"6 years",
"9 years",
"10+ years",
"2 years",
"5 years",
"7 years",
"10+ years",
"2 years",
"3 years",
null,
"3 years",
"6 years",
"2 years",
"2 years",
"6 years",
"1 year",
"3 years",
"< 1 year",
null,
"4 years",
"5 years",
"< 1 year",
"6 years",
"5 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"5 years",
"4 years",
null,
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"2 years",
"10+ years",
null,
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"9 years",
"8 years",
null,
"< 1 year",
"6 years",
"1 year",
"2 years",
null,
"2 years",
"8 years",
"10+ years",
"2 years",
"10+ years",
"9 years",
"2 years",
"2 years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"9 years",
"4 years",
"< 1 year",
"2 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"1 year",
"< 1 year",
"10+ years",
"7 years",
"1 year",
"5 years",
"1 year",
"10+ years",
"6 years",
"10+ years",
"3 years",
"< 1 year",
"2 years",
"< 1 year",
"4 years",
"2 years",
"2 years",
"2 years",
"8 years",
"4 years",
"10+ years",
"8 years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
null,
"9 years",
"2 years",
"3 years",
"< 1 year",
"3 years",
"2 years",
"8 years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"5 years",
"6 years",
"1 year",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"< 1 year",
"2 years",
"10+ years",
"2 years",
"5 years",
"4 years",
"10+ years",
"2 years",
"< 1 year",
"< 1 year",
"5 years",
"< 1 year",
"10+ years",
"4 years",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"5 years",
"9 years",
"2 years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"1 year",
"2 years",
null,
"10+ years",
"10+ years",
"7 years",
"10+ years",
"5 years",
"< 1 year",
"8 years",
"2 years",
"10+ years",
"10+ years",
"1 year",
"9 years",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"9 years",
"3 years",
null,
"7 years",
"7 years",
"10+ years",
null,
"7 years",
"2 years",
"4 years",
"2 years",
"4 years",
"8 years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"6 years",
"8 years",
"7 years",
"8 years",
"1 year",
"10+ years",
"2 years",
"1 year",
"1 year",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"6 years",
null,
"6 years",
"10+ years",
"10+ years",
"8 years",
"6 years",
"1 year",
"4 years",
"3 years",
"10+ years",
"< 1 year",
"4 years",
"2 years",
"10+ years",
"5 years",
"2 years",
"9 years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"1 year",
"6 years",
"8 years",
"6 years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"10+ years",
null,
"5 years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"4 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"1 year",
"2 years",
"1 year",
"10+ years",
"4 years",
"< 1 year",
null,
"10+ years",
"7 years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"3 years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"4 years",
"7 years",
"8 years",
"10+ years",
"3 years",
"5 years",
"4 years",
"1 year",
"4 years",
"9 years",
"3 years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"4 years",
"4 years",
"10+ years",
"1 year",
"9 years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"3 years",
"7 years",
"4 years",
"2 years",
"1 year",
"1 year",
"< 1 year",
"< 1 year",
"2 years",
"8 years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"5 years",
"3 years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"9 years",
"4 years",
"10+ years",
"4 years",
"2 years",
"2 years",
"10+ years",
"4 years",
"7 years",
"3 years",
"10+ years",
"9 years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
null,
"10+ years",
"6 years",
"8 years",
"2 years",
"10+ years",
"2 years",
"6 years",
"< 1 year",
"9 years",
"1 year",
"4 years",
null,
"2 years",
null,
"10+ years",
null,
"5 years",
"4 years",
"10+ years",
"7 years",
"6 years",
"1 year",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"9 years",
"10+ years",
null,
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"1 year",
"10+ years",
null,
"9 years",
"3 years",
"3 years",
"4 years",
"4 years",
"8 years",
"4 years",
"9 years",
"5 years",
"9 years",
"1 year",
"2 years",
"4 years",
"4 years",
"10+ years",
null,
"< 1 year",
"5 years",
"5 years",
"2 years",
"< 1 year",
"5 years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"3 years",
"5 years",
"8 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
null,
"< 1 year",
"1 year",
"8 years",
"7 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"2 years",
"4 years",
"8 years",
"2 years",
"7 years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"2 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"7 years",
"3 years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"9 years",
"6 years",
"10+ years",
"4 years",
"1 year",
"9 years",
"7 years",
"8 years",
"1 year",
"8 years",
"10+ years",
"4 years",
"3 years",
"5 years",
"3 years",
"< 1 year",
"4 years",
"10+ years",
null,
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"4 years",
null,
"7 years",
null,
"10+ years",
"6 years",
null,
"5 years",
"8 years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"2 years",
null,
"10+ years",
"10+ years",
"5 years",
"2 years",
"7 years",
"< 1 year",
"3 years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"6 years",
"6 years",
"10+ years",
"1 year",
"7 years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"4 years",
"1 year",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"2 years",
"5 years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"6 years",
"10+ years",
"5 years",
"10+ years",
"1 year",
"3 years",
"8 years",
"3 years",
"10+ years",
"8 years",
"7 years",
"10+ years",
"1 year",
"5 years",
"8 years",
"3 years",
"7 years",
"5 years",
"2 years",
"< 1 year",
"10+ years",
"< 1 year",
"7 years",
"1 year",
"5 years",
"5 years",
"10+ years",
"3 years",
"6 years",
"10+ years",
"6 years",
"8 years",
"8 years",
"< 1 year",
"3 years",
"4 years",
"4 years",
"3 years",
"3 years",
"< 1 year",
"9 years",
"10+ years",
"3 years",
null,
"3 years",
"1 year",
"5 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
null,
"10+ years",
"10+ years",
"2 years",
"2 years",
"2 years",
"8 years",
"2 years",
"6 years",
"10+ years",
"1 year",
"6 years",
"2 years",
"7 years",
"< 1 year",
"10+ years",
"< 1 year",
"2 years",
"9 years",
"10+ years",
"7 years",
"3 years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"2 years",
"4 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"3 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"4 years",
null,
"6 years",
"2 years",
"8 years",
"< 1 year",
"3 years",
"< 1 year",
null,
"< 1 year",
"6 years",
"4 years",
"1 year",
"10+ years",
"1 year",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"< 1 year",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"9 years",
"5 years",
null,
"9 years",
"10+ years",
"2 years",
"8 years",
"3 years",
null,
"2 years",
"10+ years",
"1 year",
"10+ years",
"7 years",
"3 years",
"2 years",
"8 years",
"9 years",
"6 years",
"10+ years",
"10+ years",
"1 year",
"7 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"2 years",
"< 1 year",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
"9 years",
"6 years",
"10+ years",
"10+ years",
"7 years",
"9 years",
"1 year",
"2 years",
"7 years",
"10+ years",
null,
"10+ years",
"1 year",
"10+ years",
"< 1 year",
null,
"2 years",
"10+ years",
"9 years",
"10+ years",
"3 years",
"3 years",
"< 1 year",
"9 years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
null,
"3 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"7 years",
"6 years",
"4 years",
"5 years",
"4 years",
"5 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"< 1 year",
"10+ years",
"5 years",
"5 years",
"< 1 year",
"3 years",
"10+ years",
"7 years",
"10+ years",
"< 1 year",
"8 years",
"5 years",
"10+ years",
"< 1 year",
"9 years",
"9 years",
"4 years",
"5 years",
"10+ years",
"< 1 year",
"2 years",
null,
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"1 year",
"< 1 year",
"4 years",
"< 1 year",
"1 year",
"8 years",
"8 years",
"3 years",
"7 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"3 years",
"< 1 year",
null,
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"1 year",
"1 year",
"1 year",
"8 years",
"7 years",
"10+ years",
"2 years",
"1 year",
"3 years",
"4 years",
"7 years",
"< 1 year",
null,
"9 years",
"5 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"8 years",
"10+ years",
"10+ years",
"3 years",
null,
"10+ years",
"< 1 year",
"1 year",
"1 year",
"2 years",
"10+ years",
"10+ years",
"1 year",
"8 years",
null,
null,
"< 1 year",
"1 year",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"3 years",
"10+ years",
"6 years",
"< 1 year",
null,
"2 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"5 years",
"2 years",
"2 years",
"3 years",
"3 years",
"10+ years",
"3 years",
"1 year",
"6 years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"2 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"1 year",
"3 years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"3 years",
"2 years",
"9 years",
"10+ years",
"< 1 year",
null,
"8 years",
"10+ years",
"5 years",
"9 years",
null,
"5 years",
"2 years",
"10+ years",
"2 years",
"1 year",
"6 years",
"4 years",
"3 years",
"7 years",
"6 years",
"1 year",
"4 years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"8 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"1 year",
null,
"2 years",
"5 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"2 years",
"9 years",
"10+ years",
"10+ years",
"4 years",
"7 years",
"7 years",
null,
"7 years",
"1 year",
"9 years",
"4 years",
"10+ years",
null,
"10+ years",
"5 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
null,
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"3 years",
"4 years",
"1 year",
"10+ years",
"4 years",
"10+ years",
"7 years",
"10+ years",
"9 years",
"5 years",
"< 1 year",
"10+ years",
"1 year",
"8 years",
"9 years",
"1 year",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"2 years",
"1 year",
"10+ years",
"5 years",
"8 years",
"< 1 year",
"1 year",
"< 1 year",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"2 years",
"< 1 year",
"< 1 year",
"3 years",
"7 years",
"10+ years",
"2 years",
"< 1 year",
"9 years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"7 years",
"5 years",
"10+ years",
"2 years",
"< 1 year",
"9 years",
"< 1 year",
"7 years",
"5 years",
null,
"1 year",
"10+ years",
"1 year",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"9 years",
"6 years",
"10+ years",
null,
"1 year",
"8 years",
"7 years",
"10+ years",
"8 years",
"4 years",
"10+ years",
"5 years",
"6 years",
"6 years",
"6 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"10+ years",
null,
"3 years",
"10+ years",
"2 years",
"6 years",
"8 years",
"6 years",
"3 years",
"5 years",
"7 years",
"7 years",
"10+ years",
null,
"10+ years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"3 years",
null,
"5 years",
"10+ years",
"< 1 year",
"6 years",
"1 year",
"4 years",
"10+ years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"2 years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"8 years",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"2 years",
null,
"3 years",
"7 years",
"7 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"10+ years",
"1 year",
"< 1 year",
"5 years",
"< 1 year",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"5 years",
"8 years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
null,
"< 1 year",
"2 years",
"10+ years",
"9 years",
"3 years",
"4 years",
"2 years",
"2 years",
"10+ years",
"1 year",
"< 1 year",
"< 1 year",
"9 years",
"< 1 year",
"8 years",
"10+ years",
null,
"3 years",
"8 years",
"6 years",
"9 years",
"7 years",
"6 years",
"2 years",
"4 years",
"9 years",
"3 years",
null,
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"6 years",
"10+ years",
"8 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"3 years",
"< 1 year",
"2 years",
"2 years",
"10+ years",
"8 years",
"3 years",
"2 years",
"10+ years",
"1 year",
"5 years",
"4 years",
"1 year",
"9 years",
"10+ years",
"7 years",
"7 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"1 year",
"9 years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"1 year",
"6 years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"3 years",
null,
null,
"10+ years",
"4 years",
"7 years",
"8 years",
null,
"10+ years",
"3 years",
"7 years",
"1 year",
"6 years",
"10+ years",
"< 1 year",
"< 1 year",
"7 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"3 years",
"9 years",
"8 years",
"1 year",
"< 1 year",
"7 years",
null,
"1 year",
"10+ years",
"5 years",
"8 years",
"8 years",
"< 1 year",
"6 years",
"< 1 year",
"2 years",
"1 year",
"10+ years",
"5 years",
"4 years",
"3 years",
"4 years",
"10+ years",
"3 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"7 years",
"7 years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"3 years",
"9 years",
"< 1 year",
"2 years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"8 years",
"2 years",
"9 years",
null,
"4 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"6 years",
"5 years",
"2 years",
"7 years",
"2 years",
"10+ years",
"5 years",
"4 years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"9 years",
"5 years",
"6 years",
"3 years",
"10+ years",
"3 years",
"3 years",
"2 years",
"10+ years",
null,
"10+ years",
"3 years",
"2 years",
"2 years",
"1 year",
"7 years",
"2 years",
"2 years",
"4 years",
"8 years",
"8 years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"9 years",
"4 years",
"< 1 year",
"10+ years",
"1 year",
"2 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"1 year",
"< 1 year",
"4 years",
"3 years",
"3 years",
"4 years",
null,
"10+ years",
"1 year",
"8 years",
"2 years",
"2 years",
"9 years",
"3 years",
"1 year",
"< 1 year",
"10+ years",
"8 years",
"6 years",
"< 1 year",
"10+ years",
"7 years",
"2 years",
"2 years",
null,
"9 years",
"2 years",
"6 years",
"10+ years",
"7 years",
"3 years",
"5 years",
"5 years",
"1 year",
"10+ years",
null,
"2 years",
"5 years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"8 years",
"4 years",
"< 1 year",
"8 years",
"2 years",
"10+ years",
"4 years",
"< 1 year",
"5 years",
"1 year",
"5 years",
"3 years",
"4 years",
"10+ years",
"10+ years",
null,
"< 1 year",
"< 1 year",
"8 years",
"4 years",
"10+ years",
null,
"< 1 year",
"9 years",
"< 1 year",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"2 years",
"9 years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"5 years",
"5 years",
"10+ years",
"6 years",
"4 years",
"3 years",
"1 year",
"5 years",
"2 years",
"5 years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"1 year",
"2 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"6 years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"7 years",
"4 years",
"6 years",
"10+ years",
"10+ years",
"5 years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
null,
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"< 1 year",
"6 years",
"4 years",
"10+ years",
"5 years",
"4 years",
"10+ years",
"6 years",
"1 year",
"10+ years",
"10+ years",
"9 years",
"2 years",
"5 years",
"5 years",
"9 years",
"2 years",
"10+ years",
"2 years",
"2 years",
"< 1 year",
"4 years",
"7 years",
"< 1 year",
"< 1 year",
"5 years",
"< 1 year",
"8 years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"2 years",
"5 years",
"5 years",
"4 years",
"4 years",
"7 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"4 years",
"< 1 year",
"4 years",
"3 years",
"5 years",
null,
null,
"3 years",
"5 years",
"4 years",
"1 year",
"10+ years",
"5 years",
"10+ years",
"9 years",
"10+ years",
"7 years",
"7 years",
"10+ years",
"8 years",
"9 years",
"1 year",
"2 years",
"1 year",
"8 years",
"10+ years",
"10+ years",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"4 years",
null,
"< 1 year",
"10+ years",
"< 1 year",
"2 years",
null,
"2 years",
"4 years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"1 year",
"4 years",
"4 years",
"7 years",
"3 years",
"6 years",
"10+ years",
"7 years",
"4 years",
"4 years",
"10+ years",
null,
"6 years",
"< 1 year",
"< 1 year",
"10+ years",
"3 years",
"< 1 year",
"3 years",
null,
"8 years",
"2 years",
"1 year",
"10+ years",
"10+ years",
null,
"5 years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"< 1 year",
"9 years",
"8 years",
"10+ years",
"6 years",
"2 years",
"1 year",
"6 years",
"< 1 year",
"7 years",
"7 years",
"3 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"< 1 year",
"1 year",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"5 years",
"2 years",
null,
"8 years",
"10+ years",
"< 1 year",
null,
"2 years",
"8 years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"6 years",
"< 1 year",
null,
"3 years",
null,
"< 1 year",
"4 years",
"6 years",
"6 years",
"1 year",
"2 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"8 years",
"< 1 year",
"10+ years",
"8 years",
"6 years",
"2 years",
"3 years",
"4 years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"7 years",
"1 year",
"7 years",
null,
"10+ years",
"2 years",
"1 year",
"10+ years",
"8 years",
"6 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"8 years",
"7 years",
"< 1 year",
"2 years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"8 years",
null,
"9 years",
null,
"2 years",
"< 1 year",
"9 years",
"< 1 year",
"10+ years",
"7 years",
"3 years",
"1 year",
"3 years",
"8 years",
"3 years",
"10+ years",
"5 years",
"7 years",
"10+ years",
"9 years",
"4 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"4 years",
null,
"10+ years",
"3 years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"1 year",
"2 years",
"7 years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"8 years",
"8 years",
"3 years",
"5 years",
"10+ years",
"3 years",
"8 years",
"4 years",
"< 1 year",
"8 years",
"4 years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"5 years",
"8 years",
"4 years",
"10+ years",
"5 years",
"8 years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"6 years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"8 years",
"2 years",
"3 years",
"4 years",
"< 1 year",
"< 1 year",
"4 years",
null,
"1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"5 years",
"9 years",
"< 1 year",
"2 years",
"2 years",
"6 years",
"1 year",
"3 years",
"3 years",
"10+ years",
"< 1 year",
null,
"3 years",
"10+ years",
"5 years",
"10+ years",
"1 year",
"< 1 year",
null,
"9 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
null,
"10+ years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
null,
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"4 years",
"10+ years",
"3 years",
"< 1 year",
"3 years",
null,
"5 years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"2 years",
null,
"< 1 year",
"4 years",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"4 years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"7 years",
"6 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"8 years",
"8 years",
"4 years",
"10+ years",
"9 years",
null,
"6 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"7 years",
"9 years",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
null,
"4 years",
"3 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"5 years",
null,
"10+ years",
"7 years",
null,
"10+ years",
"4 years",
"4 years",
"5 years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"7 years",
null,
"8 years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"3 years",
null,
"< 1 year",
null,
"3 years",
"2 years",
null,
"10+ years",
"6 years",
"10+ years",
"< 1 year",
null,
"10+ years",
null,
"4 years",
"2 years",
"5 years",
"10+ years",
"8 years",
"5 years",
"3 years",
"7 years",
"7 years",
"10+ years",
"5 years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"4 years",
"6 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"1 year",
"9 years",
"2 years",
"< 1 year",
"10+ years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"7 years",
"5 years",
"10+ years",
null,
"10+ years",
"10+ years",
"9 years",
"8 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"< 1 year",
"5 years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"10+ years",
null,
"10+ years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"3 years",
"8 years",
"10+ years",
"6 years",
"4 years",
"< 1 year",
"5 years",
"6 years",
"4 years",
"2 years",
"10+ years",
"8 years",
"5 years",
"3 years",
"5 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"3 years",
"5 years",
"9 years",
"2 years",
"2 years",
"5 years",
"2 years",
"7 years",
"10+ years",
"< 1 year",
"5 years",
"7 years",
"8 years",
"2 years",
"10+ years",
"5 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"8 years",
"8 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"5 years",
"2 years",
"< 1 year",
"6 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"6 years",
"4 years",
"6 years",
"10+ years",
"2 years",
"10+ years",
"6 years",
"2 years",
"1 year",
null,
"7 years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"8 years",
"9 years",
"7 years",
"10+ years",
"3 years",
"8 years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"8 years",
"7 years",
"6 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
null,
"3 years",
"6 years",
"< 1 year",
"2 years",
null,
"4 years",
"3 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"5 years",
"< 1 year",
"6 years",
"2 years",
"< 1 year",
"< 1 year",
null,
"10+ years",
"1 year",
"5 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"9 years",
"10+ years",
"9 years",
"2 years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"5 years",
"10+ years",
null,
"2 years",
"5 years",
"8 years",
"10+ years",
"1 year",
"2 years",
"10+ years",
"8 years",
"< 1 year",
"2 years",
"3 years",
null,
"10+ years",
null,
"10+ years",
"10+ years",
"8 years",
"1 year",
"6 years",
"4 years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"5 years",
"1 year",
"< 1 year",
"4 years",
null,
"1 year",
null,
"10+ years",
"9 years",
"9 years",
null,
"10+ years",
"10+ years",
"5 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"< 1 year",
"9 years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"5 years",
"< 1 year",
"3 years",
"4 years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"3 years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"3 years",
"< 1 year",
"10+ years",
"2 years",
"7 years",
"10+ years",
"8 years",
"6 years",
"8 years",
"10+ years",
"2 years",
"5 years",
null,
"10+ years",
"4 years",
"5 years",
null,
"4 years",
"10+ years",
null,
"10+ years",
"3 years",
"9 years",
"5 years",
"8 years",
"3 years",
"2 years",
"3 years",
"6 years",
"< 1 year",
"1 year",
"3 years",
"3 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"6 years",
"7 years",
"10+ years",
"2 years",
null,
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"4 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
null,
"10+ years",
"10+ years",
"6 years",
"8 years",
"5 years",
"2 years",
"4 years",
"2 years",
"1 year",
"6 years",
"9 years",
"3 years",
"1 year",
"9 years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"5 years",
"10+ years",
"9 years",
"10+ years",
"7 years",
"3 years",
null,
"6 years",
"1 year",
"2 years",
"< 1 year",
"1 year",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
null,
"10+ years",
"6 years",
"3 years",
"3 years",
"10+ years",
"1 year",
"3 years",
"1 year",
"10+ years",
"10+ years",
"9 years",
"7 years",
"6 years",
"6 years",
"8 years",
"10+ years",
"8 years",
"3 years",
"9 years",
"10+ years",
"7 years",
null,
null,
"6 years",
"4 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"8 years",
"5 years",
"5 years",
"2 years",
"9 years",
"< 1 year",
"4 years",
"5 years",
"10+ years",
"9 years",
"10+ years",
"2 years",
"2 years",
"9 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"3 years",
"4 years",
"6 years",
"10+ years",
"9 years",
"8 years",
"7 years",
"4 years",
"10+ years",
"< 1 year",
"5 years",
"4 years",
"10+ years",
"7 years",
"7 years",
"3 years",
"< 1 year",
"10+ years",
"3 years",
"3 years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"4 years",
"< 1 year",
"6 years",
"10+ years",
"5 years",
null,
"1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
null,
"5 years",
"5 years",
"2 years",
"8 years",
"1 year",
"5 years",
"10+ years",
"1 year",
"10+ years",
"9 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"6 years",
null,
null,
"2 years",
"7 years",
"5 years",
"10+ years",
"5 years",
"1 year",
"3 years",
"5 years",
"10+ years",
"2 years",
"6 years",
"7 years",
"< 1 year",
"7 years",
"7 years",
"10+ years",
"< 1 year",
"9 years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"3 years",
"1 year",
"7 years",
"5 years",
null,
"10+ years",
"9 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"9 years",
"2 years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"9 years",
"3 years",
null,
"6 years",
"2 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"5 years",
"10+ years",
"1 year",
"6 years",
"1 year",
"5 years",
"1 year",
"6 years",
"< 1 year",
"2 years",
"3 years",
"10+ years",
"1 year",
"2 years",
"4 years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"5 years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"6 years",
"5 years",
"10+ years",
"4 years",
"9 years",
"1 year",
"1 year",
"10+ years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"8 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"3 years",
"10+ years",
"3 years",
"1 year",
"< 1 year",
"4 years",
"10+ years",
null,
"8 years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"4 years",
"4 years",
"3 years",
"5 years",
"2 years",
"< 1 year",
"1 year",
"< 1 year",
"2 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
null,
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"5 years",
null,
"10+ years",
"2 years",
"10+ years",
"5 years",
"2 years",
"8 years",
"7 years",
"8 years",
"10+ years",
"1 year",
"5 years",
"10+ years",
"8 years",
"10+ years",
"1 year",
"2 years",
"9 years",
"7 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"9 years",
"9 years",
"< 1 year",
"8 years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"7 years",
"10+ years",
"5 years",
"8 years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"8 years",
"10+ years",
null,
"4 years",
"2 years",
"10+ years",
"1 year",
null,
"1 year",
"3 years",
"10+ years",
"1 year",
"6 years",
"5 years",
"4 years",
"< 1 year",
"2 years",
"1 year",
"1 year",
"5 years",
"5 years",
"< 1 year",
"< 1 year",
"10+ years",
"6 years",
"1 year",
"4 years",
"10+ years",
"10+ years",
"4 years",
"7 years",
null,
"10+ years",
"2 years",
"6 years",
"1 year",
"10+ years",
"< 1 year",
"1 year",
"1 year",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"1 year",
"2 years",
"7 years",
"1 year",
"10+ years",
"< 1 year",
"2 years",
"3 years",
"5 years",
"10+ years",
"8 years",
"2 years",
"3 years",
"10+ years",
null,
"8 years",
"< 1 year",
"2 years",
"4 years",
null,
"4 years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
null,
"2 years",
"3 years",
"7 years",
"10+ years",
"< 1 year",
"1 year",
"2 years",
"1 year",
"10+ years",
"7 years",
"< 1 year",
"8 years",
"2 years",
"10+ years",
"5 years",
"1 year",
null,
"< 1 year",
"2 years",
"10+ years",
"9 years",
"< 1 year",
"8 years",
"10+ years",
"1 year",
"4 years",
"3 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"3 years",
null,
"10+ years",
"10+ years",
"6 years",
"2 years",
"4 years",
"10+ years",
"10+ years",
"7 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"1 year",
"< 1 year",
"10+ years",
"1 year",
"7 years",
null,
"< 1 year",
"2 years",
"10+ years",
"2 years",
"9 years",
"6 years",
"7 years",
"3 years",
"10+ years",
"4 years",
"10+ years",
"9 years",
"10+ years",
"3 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
null,
null,
"10+ years",
"4 years",
"10+ years",
"< 1 year",
null,
"2 years",
"4 years",
"< 1 year",
"5 years",
"2 years",
"10+ years",
null,
"9 years",
"< 1 year",
"3 years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"5 years",
"10+ years",
null,
"5 years",
"2 years",
"10+ years",
"7 years",
"9 years",
"1 year",
"5 years",
"2 years",
"3 years",
"3 years",
"8 years",
null,
"8 years",
"2 years",
"7 years",
"1 year",
"3 years",
"1 year",
"3 years",
"5 years",
"1 year",
"5 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"8 years",
"8 years",
"10+ years",
"6 years",
"4 years",
"6 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"1 year",
"3 years",
"2 years",
"< 1 year",
"4 years",
"6 years",
"4 years",
"1 year",
"8 years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"6 years",
"1 year",
null,
"8 years",
"10+ years",
"9 years",
"5 years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"9 years",
"7 years",
"10+ years",
"2 years",
"3 years",
"7 years",
"3 years",
"2 years",
"3 years",
"7 years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"2 years",
"8 years",
"2 years",
"3 years",
"8 years",
null,
"10+ years",
"10+ years",
"10+ years",
"7 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"< 1 year",
"6 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"2 years",
null,
"10+ years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
null,
"3 years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"7 years",
"7 years",
null,
"2 years",
"10+ years",
"4 years",
null,
"3 years",
"3 years",
"8 years",
"5 years",
"10+ years",
"10+ years",
"6 years",
"< 1 year",
"1 year",
"1 year",
"4 years",
"7 years",
"4 years",
"10+ years",
"10+ years",
"8 years",
null,
"10+ years",
null,
"3 years",
"< 1 year",
"2 years",
"10+ years",
null,
"10+ years",
"8 years",
"10+ years",
"8 years",
"5 years",
"9 years",
"10+ years",
null,
"10+ years",
"3 years",
"6 years",
"5 years",
null,
"< 1 year",
"10+ years",
null,
"< 1 year",
"3 years",
"< 1 year",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"2 years",
"6 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"4 years",
"7 years",
"3 years",
"10+ years",
"1 year",
"5 years",
"10+ years",
"< 1 year",
null,
"10+ years",
null,
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"9 years",
null,
"3 years",
"< 1 year",
"6 years",
"2 years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
null,
"< 1 year",
"7 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
null,
"5 years",
null,
"10+ years",
"7 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
null,
"10+ years",
"9 years",
"7 years",
"4 years",
null,
"1 year",
"10+ years",
"10+ years",
"1 year",
"8 years",
"2 years",
"10+ years",
"7 years",
"7 years",
"2 years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"5 years",
"8 years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"7 years",
"4 years",
null,
"10+ years",
"7 years",
"2 years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
null,
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"8 years",
"3 years",
"< 1 year",
"2 years",
"1 year",
"10+ years",
"7 years",
"4 years",
"7 years",
"10+ years",
"10+ years",
null,
"5 years",
"10+ years",
"6 years",
"10+ years",
"9 years",
"1 year",
null,
"< 1 year",
"10+ years",
"5 years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"3 years",
"9 years",
"1 year",
"6 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"3 years",
"2 years",
null,
"10+ years",
"10+ years",
"10+ years",
"1 year",
"7 years",
"10+ years",
null,
"2 years",
null,
"10+ years",
null,
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"9 years",
"2 years",
"4 years",
null,
"7 years",
"3 years",
"1 year",
"1 year",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"8 years",
"< 1 year",
"6 years",
"8 years",
"10+ years",
"< 1 year",
"1 year",
"1 year",
"< 1 year",
"5 years",
"4 years",
"9 years",
"5 years",
"< 1 year",
"3 years",
"10+ years",
"6 years",
"5 years",
"2 years",
"8 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"5 years",
"4 years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
null,
"10+ years",
"4 years",
"3 years",
"< 1 year",
"10+ years",
null,
"2 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"1 year",
"2 years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"6 years",
"9 years",
"10+ years",
"< 1 year",
"3 years",
"2 years",
"10+ years",
"2 years",
"1 year",
"4 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"10+ years",
"3 years",
"3 years",
"7 years",
"4 years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"4 years",
"7 years",
"9 years",
"3 years",
"1 year",
"1 year",
"8 years",
"3 years",
"< 1 year",
"10+ years",
"7 years",
"1 year",
"10+ years",
"8 years",
"2 years",
"10+ years",
"1 year",
null,
"7 years",
"10+ years",
"7 years",
"3 years",
"10+ years",
"10+ years",
"6 years",
"< 1 year",
"< 1 year",
"5 years",
"6 years",
"4 years",
"10+ years",
"7 years",
"10+ years",
"1 year",
null,
"6 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"3 years",
"6 years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"4 years",
"7 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
null,
"2 years",
"10+ years",
"8 years",
"1 year",
"1 year",
null,
"5 years",
"10+ years",
"8 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"7 years",
null,
"< 1 year",
"2 years",
"9 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"2 years",
"1 year",
"10+ years",
"4 years",
"2 years",
"3 years",
"5 years",
"4 years",
null,
"10+ years",
"4 years",
"10+ years",
"1 year",
"6 years",
"< 1 year",
"< 1 year",
"10+ years",
"1 year",
"< 1 year",
"1 year",
"4 years",
"5 years",
"4 years",
"< 1 year",
null,
"10+ years",
"2 years",
"3 years",
"1 year",
"1 year",
"7 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"6 years",
"1 year",
"< 1 year",
"10+ years",
"7 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"4 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"8 years",
null,
"< 1 year",
null,
"10+ years",
"2 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"4 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
null,
"< 1 year",
"2 years",
"6 years",
"8 years",
"1 year",
"10+ years",
"3 years",
"2 years",
"10+ years",
"2 years",
null,
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"3 years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"7 years",
null,
"5 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"4 years",
"2 years",
"2 years",
"3 years",
"9 years",
"6 years",
null,
"10+ years",
"10+ years",
"2 years",
"10+ years",
null,
"3 years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"2 years",
"3 years",
"7 years",
"2 years",
"< 1 year",
"10+ years",
"9 years",
"10+ years",
"4 years",
"5 years",
"3 years",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
"9 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
null,
"5 years",
"10+ years",
"< 1 year",
"4 years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"8 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"8 years",
"5 years",
null,
"3 years",
"4 years",
"7 years",
"2 years",
"3 years",
"10+ years",
"10+ years",
null,
"10+ years",
"6 years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"4 years",
"9 years",
"2 years",
"4 years",
"2 years",
"2 years",
"2 years",
"1 year",
"2 years",
"6 years",
"10+ years",
"< 1 year",
"5 years",
"< 1 year",
null,
"2 years",
"7 years",
null,
"1 year",
"3 years",
"2 years",
"5 years",
"1 year",
"10+ years",
"8 years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"7 years",
"< 1 year",
"6 years",
"7 years",
"2 years",
"9 years",
"< 1 year",
"8 years",
"10+ years",
"3 years",
"< 1 year",
"3 years",
"10+ years",
"7 years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"8 years",
"2 years",
"< 1 year",
"5 years",
"7 years",
"10+ years",
"10+ years",
"6 years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"8 years",
"2 years",
"3 years",
"5 years",
null,
"10+ years",
"6 years",
"10+ years",
"2 years",
"2 years",
"4 years",
"10+ years",
"1 year",
"2 years",
"1 year",
"4 years",
"< 1 year",
"7 years",
"7 years",
"10+ years",
null,
"8 years",
"3 years",
"2 years",
"< 1 year",
"1 year",
"2 years",
"3 years",
"10+ years",
"5 years",
null,
"6 years",
"10+ years",
"3 years",
"7 years",
"< 1 year",
"3 years",
"4 years",
"3 years",
"10+ years",
"8 years",
"5 years",
"9 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"8 years",
"8 years",
"9 years",
"3 years",
"< 1 year",
"9 years",
"5 years",
"10+ years",
"2 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
null,
"6 years",
"10+ years",
null,
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"7 years",
"5 years",
"2 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"10+ years",
"1 year",
"5 years",
"7 years",
"1 year",
"8 years",
"10+ years",
"4 years",
"10+ years",
null,
"5 years",
"1 year",
"8 years",
"< 1 year",
"4 years",
"7 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
null,
"3 years",
"1 year",
"4 years",
"2 years",
"7 years",
"1 year",
"8 years",
"8 years",
null,
"1 year",
"10+ years",
"1 year",
"10+ years",
"8 years",
"5 years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"3 years",
"7 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"4 years",
null,
"10+ years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"5 years",
null,
"1 year",
"10+ years",
"7 years",
"4 years",
"6 years",
"10+ years",
"< 1 year",
"1 year",
"9 years",
"10+ years",
"2 years",
"3 years",
"5 years",
"3 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
null,
"1 year",
null,
"9 years",
"3 years",
null,
"1 year",
"1 year",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"2 years",
"6 years",
"5 years",
"5 years",
"10+ years",
"< 1 year",
"4 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"3 years",
"9 years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"5 years",
"7 years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"2 years",
"4 years",
"4 years",
"< 1 year",
"4 years",
"5 years",
null,
"7 years",
"2 years",
"1 year",
"2 years",
"2 years",
"5 years",
null,
"3 years",
"2 years",
"10+ years",
"2 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"6 years",
"3 years",
"4 years",
"9 years",
"10+ years",
"2 years",
"2 years",
"1 year",
"6 years",
"7 years",
null,
"10+ years",
"6 years",
"5 years",
"4 years",
"10+ years",
"3 years",
"3 years",
"8 years",
"10+ years",
"3 years",
"2 years",
"7 years",
"3 years",
"4 years",
null,
"3 years",
"10+ years",
"7 years",
"6 years",
"1 year",
"9 years",
"4 years",
"2 years",
"2 years",
"6 years",
"< 1 year",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"9 years",
"6 years",
"3 years",
"10+ years",
"4 years",
"8 years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"8 years",
"7 years",
null,
"< 1 year",
"< 1 year",
"10+ years",
"5 years",
"9 years",
null,
"10+ years",
"7 years",
"6 years",
"10+ years",
"< 1 year",
null,
"10+ years",
"6 years",
"10+ years",
"8 years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"2 years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"9 years",
"3 years",
"6 years",
"1 year",
null,
"5 years",
"7 years",
"10+ years",
"2 years",
"5 years",
"10+ years",
null,
"10+ years",
null,
"6 years",
"7 years",
"10+ years",
null,
"3 years",
"5 years",
"< 1 year",
"< 1 year",
"3 years",
"10+ years",
"2 years",
"3 years",
"7 years",
"5 years",
"9 years",
"4 years",
"1 year",
"2 years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"4 years",
null,
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"4 years",
"2 years",
"< 1 year",
"8 years",
null,
"10+ years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"7 years",
"2 years",
"10+ years",
"2 years",
"9 years",
"10+ years",
"7 years",
"6 years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"1 year",
"7 years",
"2 years",
"4 years",
null,
"2 years",
"8 years",
"3 years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"4 years",
"2 years",
"3 years",
"< 1 year",
"2 years",
"6 years",
"10+ years",
"5 years",
"7 years",
"3 years",
"8 years",
"3 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"1 year",
"10+ years",
null,
"6 years",
"3 years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"1 year",
"6 years",
null,
"10+ years",
null,
"< 1 year",
"7 years",
"3 years",
"10+ years",
"5 years",
"7 years",
null,
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
null,
"6 years",
"1 year",
"< 1 year",
"< 1 year",
"10+ years",
"2 years",
"1 year",
null,
"10+ years",
"7 years",
"1 year",
"8 years",
"3 years",
"5 years",
"1 year",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"3 years",
null,
"10+ years",
"6 years",
"8 years",
"10+ years",
"10+ years",
"1 year",
"6 years",
"6 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"2 years",
"8 years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"3 years",
"2 years",
null,
"10+ years",
"< 1 year",
"6 years",
"8 years",
"< 1 year",
"< 1 year",
"3 years",
"4 years",
"< 1 year",
"2 years",
"10+ years",
"6 years",
"8 years",
"6 years",
"10+ years",
"2 years",
"6 years",
"5 years",
"8 years",
"3 years",
"10+ years",
"4 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"< 1 year",
"7 years",
"2 years",
"4 years",
"10+ years",
"5 years",
"10+ years",
"3 years",
null,
null,
"1 year",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"1 year",
"4 years",
null,
"10+ years",
"3 years",
"2 years",
"10+ years",
null,
"10+ years",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"7 years",
"2 years",
"8 years",
"8 years",
"4 years",
"3 years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"7 years",
"7 years",
"10+ years",
"10+ years",
"1 year",
"4 years",
"7 years",
"6 years",
null,
"3 years",
"1 year",
"10+ years",
"3 years",
"6 years",
"7 years",
"3 years",
"< 1 year",
"< 1 year",
"10+ years",
"< 1 year",
null,
"10+ years",
"6 years",
"1 year",
"4 years",
"6 years",
"< 1 year",
"4 years",
"3 years",
"10+ years",
"1 year",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"< 1 year",
"8 years",
"5 years",
"7 years",
"2 years",
"3 years",
"1 year",
"5 years",
"5 years",
"2 years",
"2 years",
"5 years",
"10+ years",
null,
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"5 years",
"5 years",
"2 years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"4 years",
"2 years",
"10+ years",
null,
"< 1 year",
null,
"4 years",
"2 years",
"6 years",
"8 years",
"3 years",
null,
"1 year",
null,
"2 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"4 years",
"5 years",
"5 years",
"9 years",
"2 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"9 years",
"10+ years",
"2 years",
"7 years",
"3 years",
"3 years",
"7 years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"3 years",
"6 years",
"8 years",
"10+ years",
"8 years",
null,
"10+ years",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
null,
"8 years",
"< 1 year",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"6 years",
"5 years",
"4 years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"3 years",
"10+ years",
null,
"9 years",
"10+ years",
"9 years",
"10+ years",
"2 years",
null,
"10+ years",
"10+ years",
"9 years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"1 year",
"7 years",
"10+ years",
"8 years",
"2 years",
"< 1 year",
"7 years",
"5 years",
"7 years",
"5 years",
null,
"< 1 year",
"< 1 year",
"4 years",
"8 years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"9 years",
"6 years",
"7 years",
"7 years",
"8 years",
"10+ years",
"10+ years",
"2 years",
null,
"10+ years",
"7 years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"4 years",
"10+ years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"8 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"6 years",
"< 1 year",
"5 years",
"10+ years",
null,
"9 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"8 years",
"8 years",
"4 years",
"2 years",
"8 years",
"10+ years",
"4 years",
"4 years",
"< 1 year",
"7 years",
"10+ years",
"9 years",
"8 years",
"9 years",
"< 1 year",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"7 years",
"8 years",
"8 years",
"< 1 year",
"6 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
null,
"1 year",
"2 years",
"2 years",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"9 years",
"8 years",
"10+ years",
"6 years",
"3 years",
"10+ years",
"10+ years",
"9 years",
"1 year",
"10+ years",
"2 years",
"4 years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"< 1 year",
"10+ years",
"4 years",
"2 years",
"5 years",
"1 year",
"10+ years",
"3 years",
"6 years",
"2 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"2 years",
"4 years",
"10+ years",
"10+ years",
"1 year",
"9 years",
"3 years",
null,
"1 year",
"7 years",
"10+ years",
"3 years",
"2 years",
"< 1 year",
"4 years",
"1 year",
"10+ years",
"1 year",
"2 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"< 1 year",
"1 year",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"5 years",
"4 years",
"2 years",
"< 1 year",
"1 year",
"7 years",
"7 years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"< 1 year",
"8 years",
"3 years",
"3 years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"7 years",
"1 year",
"10+ years",
"4 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"2 years",
"8 years",
"9 years",
"6 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"6 years",
"2 years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"9 years",
"10+ years",
"1 year",
"6 years",
"3 years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
null,
"2 years",
"5 years",
"4 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
null,
"9 years",
"10+ years",
"9 years",
"2 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
null,
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"6 years",
"2 years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"9 years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"7 years",
"4 years",
"9 years",
"7 years",
null,
"10+ years",
"5 years",
"10+ years",
"3 years",
"7 years",
"6 years",
"6 years",
"10+ years",
"10+ years",
"8 years",
"6 years",
"8 years",
"< 1 year",
"3 years",
"9 years",
"9 years",
"7 years",
"2 years",
"5 years",
"10+ years",
"< 1 year",
"4 years",
"5 years",
"7 years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"4 years",
"10+ years",
null,
"1 year",
"2 years",
"9 years",
"3 years",
"8 years",
"10+ years",
"5 years",
"6 years",
"6 years",
"3 years",
"1 year",
null,
"2 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"4 years",
"8 years",
"5 years",
"6 years",
"8 years",
"5 years",
"10+ years",
"10+ years",
"7 years",
"6 years",
"10+ years",
"2 years",
"2 years",
"4 years",
"3 years",
"10+ years",
"8 years",
"5 years",
"10+ years",
null,
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"9 years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"6 years",
"10+ years",
"7 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"7 years",
"5 years",
"6 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"4 years",
"10+ years",
"9 years",
"3 years",
"7 years",
"1 year",
"1 year",
"10+ years",
"5 years",
"9 years",
"2 years",
"10+ years",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"2 years",
"< 1 year",
"3 years",
"5 years",
"1 year",
"6 years",
"5 years",
"3 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"5 years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"4 years",
"7 years",
"8 years",
"1 year",
"10+ years",
"3 years",
"7 years",
"3 years",
"10+ years",
"9 years",
"1 year",
"< 1 year",
"< 1 year",
"8 years",
"2 years",
"9 years",
null,
"10+ years",
"< 1 year",
"7 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"2 years",
"7 years",
"5 years",
"9 years",
"3 years",
"< 1 year",
"3 years",
"9 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"8 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"4 years",
"4 years",
"9 years",
"4 years",
"10+ years",
null,
"10+ years",
"10+ years",
"2 years",
"3 years",
"2 years",
"10+ years",
"2 years",
"8 years",
"6 years",
"5 years",
"10+ years",
"6 years",
"10+ years",
"4 years",
"8 years",
null,
"3 years",
"2 years",
"10+ years",
"10+ years",
"9 years",
"7 years",
"3 years",
"2 years",
"< 1 year",
"< 1 year",
"10+ years",
"2 years",
"8 years",
"1 year",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"8 years",
"10+ years",
null,
"2 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"7 years",
null,
"10+ years",
"9 years",
"5 years",
"1 year",
"2 years",
"10+ years",
"< 1 year",
"4 years",
"5 years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"4 years",
"10+ years",
null,
"9 years",
"5 years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"8 years",
"1 year",
"10+ years",
"6 years",
"3 years",
"10+ years",
"1 year",
"5 years",
"8 years",
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"2 years",
"2 years",
"7 years",
"10+ years",
"8 years",
"< 1 year",
"4 years",
"10+ years",
null,
"2 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"8 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"3 years",
"3 years",
null,
null,
"10+ years",
"5 years",
"3 years",
"4 years",
"8 years",
"2 years",
null,
"3 years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"10+ years",
"9 years",
"1 year",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"1 year",
"6 years",
"6 years",
"10+ years",
"10+ years",
"8 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"5 years",
"6 years",
"1 year",
"8 years",
"2 years",
"8 years",
"3 years",
"2 years",
"1 year",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"2 years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"9 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"1 year",
"4 years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"5 years",
"10+ years",
"1 year",
"8 years",
"7 years",
"10+ years",
"10+ years",
"3 years",
null,
"2 years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"4 years",
"5 years",
"8 years",
"10+ years",
"10+ years",
null,
"3 years",
"< 1 year",
"10+ years",
"7 years",
"6 years",
"3 years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
null,
"8 years",
"< 1 year",
"7 years",
"10+ years",
null,
"2 years",
"5 years",
"1 year",
null,
"9 years",
"4 years",
"6 years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"6 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"5 years",
"6 years",
"10+ years",
"1 year",
"10+ years",
"2 years",
null,
"10+ years",
"5 years",
"9 years",
"6 years",
"10+ years",
"3 years",
"< 1 year",
"1 year",
"2 years",
"< 1 year",
null,
"10+ years",
"4 years",
"3 years",
"5 years",
"10+ years",
"4 years",
"8 years",
"< 1 year",
"10+ years",
"1 year",
"4 years",
"2 years",
null,
"3 years",
"3 years",
"10+ years",
"8 years",
"5 years",
"8 years",
"6 years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"1 year",
"7 years",
"4 years",
"7 years",
"7 years",
"7 years",
"6 years",
"10+ years",
"7 years",
"8 years",
null,
"1 year",
"3 years",
"4 years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"3 years",
"9 years",
"7 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"1 year",
"1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"< 1 year",
"< 1 year",
"10+ years",
"2 years",
"2 years",
"5 years",
"3 years",
"3 years",
"8 years",
"5 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"< 1 year",
"< 1 year",
"10+ years",
"1 year",
"1 year",
"4 years",
"1 year",
"9 years",
"4 years",
"10+ years",
"7 years",
"5 years",
"8 years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"2 years",
null,
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"9 years",
"< 1 year",
"8 years",
"3 years",
"2 years",
"2 years",
"6 years",
"10+ years",
"1 year",
"4 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"4 years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"6 years",
"7 years",
"4 years",
"2 years",
null,
"7 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"5 years",
"10+ years",
"2 years",
"4 years",
"10+ years",
null,
null,
"7 years",
"3 years",
"4 years",
"< 1 year",
"9 years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"5 years",
"3 years",
"3 years",
"2 years",
"10+ years",
"8 years",
"9 years",
null,
null,
"3 years",
"2 years",
"4 years",
"1 year",
"7 years",
"10+ years",
"8 years",
"8 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"7 years",
"7 years",
"2 years",
"2 years",
"10+ years",
"9 years",
"3 years",
"2 years",
"4 years",
"3 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"9 years",
null,
null,
"6 years",
"7 years",
"10+ years",
null,
"7 years",
"5 years",
"10+ years",
"< 1 year",
"1 year",
"9 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"2 years",
"10+ years",
null,
"10+ years",
"7 years",
"3 years",
"10+ years",
null,
"4 years",
"7 years",
"10+ years",
"6 years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"2 years",
"1 year",
"3 years",
null,
"9 years",
"10+ years",
"2 years",
"5 years",
"7 years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"3 years",
"< 1 year",
"8 years",
"4 years",
"8 years",
"10+ years",
"5 years",
"7 years",
"10+ years",
"10+ years",
"3 years",
null,
"2 years",
"10+ years",
null,
"4 years",
"10+ years",
"6 years",
"6 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"10+ years",
null,
"5 years",
"3 years",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"9 years",
"1 year",
null,
"1 year",
"10+ years",
"7 years",
"10+ years",
"9 years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"2 years",
"1 year",
"2 years",
"9 years",
"1 year",
"< 1 year",
"9 years",
"5 years",
"10+ years",
"9 years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
null,
"7 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"8 years",
"9 years",
"9 years",
"10+ years",
"1 year",
"2 years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"1 year",
"10+ years",
"9 years",
"5 years",
"7 years",
"2 years",
"2 years",
"10+ years",
"6 years",
"3 years",
"1 year",
"5 years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"9 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"9 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"7 years",
"9 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"7 years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"3 years",
"< 1 year",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"4 years",
"10+ years",
"8 years",
"1 year",
"4 years",
"10+ years",
"2 years",
"2 years",
"4 years",
"5 years",
"< 1 year",
"10+ years",
"7 years",
"3 years",
"6 years",
"8 years",
"3 years",
"< 1 year",
"1 year",
"1 year",
"1 year",
"8 years",
"10+ years",
"6 years",
"4 years",
"10+ years",
"6 years",
"2 years",
"3 years",
null,
"8 years",
"10+ years",
"8 years",
"< 1 year",
"4 years",
"< 1 year",
"6 years",
"10+ years",
"6 years",
"10+ years",
"7 years",
"5 years",
"5 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"9 years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"8 years",
"3 years",
"4 years",
"10+ years",
"4 years",
"10+ years",
"4 years",
"8 years",
"6 years",
"10+ years",
"< 1 year",
"1 year",
"7 years",
"5 years",
"6 years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"5 years",
"5 years",
"2 years",
"7 years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"3 years",
"2 years",
"7 years",
"10+ years",
"6 years",
"5 years",
null,
"< 1 year",
"10+ years",
"7 years",
"8 years",
null,
"< 1 year",
"3 years",
"4 years",
"4 years",
null,
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"9 years",
null,
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"1 year",
"2 years",
"1 year",
"7 years",
"10+ years",
"10+ years",
"5 years",
"8 years",
"2 years",
null,
"7 years",
"2 years",
"< 1 year",
"10+ years",
"3 years",
"9 years",
null,
"< 1 year",
null,
"< 1 year",
"4 years",
"10+ years",
"2 years",
"8 years",
"< 1 year",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"3 years",
"6 years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"9 years",
"6 years",
"10+ years",
"6 years",
"3 years",
"10+ years",
"9 years",
"8 years",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"< 1 year",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"3 years",
"2 years",
"1 year",
"6 years",
"5 years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
null,
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"2 years",
"8 years",
"6 years",
"2 years",
"1 year",
"2 years",
"< 1 year",
"1 year",
"1 year",
"1 year",
"8 years",
"4 years",
"10+ years",
"1 year",
"6 years",
null,
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"8 years",
"1 year",
"10+ years",
"7 years",
"5 years",
"2 years",
"9 years",
"5 years",
"9 years",
"8 years",
"3 years",
"5 years",
"3 years",
"10+ years",
"8 years",
"< 1 year",
"3 years",
null,
"6 years",
"2 years",
"3 years",
"9 years",
"8 years",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"1 year",
"4 years",
"1 year",
null,
"4 years",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
null,
"2 years",
"5 years",
"2 years",
"10+ years",
"7 years",
"7 years",
"4 years",
"7 years",
"7 years",
"4 years",
"5 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"1 year",
"3 years",
"9 years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"6 years",
"2 years",
"2 years",
"1 year",
"5 years",
null,
"10+ years",
"1 year",
"8 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"3 years",
"7 years",
"3 years",
"6 years",
"9 years",
"3 years",
null,
"2 years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"2 years",
"8 years",
null,
"10+ years",
"8 years",
"4 years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"< 1 year",
"6 years",
"8 years",
"7 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
null,
"4 years",
"8 years",
"10+ years",
"4 years",
"7 years",
"6 years",
"10+ years",
"1 year",
"9 years",
"10+ years",
"6 years",
"7 years",
"9 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"8 years",
null,
"8 years",
"4 years",
"7 years",
"8 years",
"< 1 year",
"8 years",
null,
"10+ years",
"3 years",
"2 years",
"1 year",
"1 year",
"10+ years",
"5 years",
null,
"3 years",
"10+ years",
"1 year",
"6 years",
"2 years",
"7 years",
"4 years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"2 years",
"4 years",
"10+ years",
"9 years",
"6 years",
"10+ years",
"8 years",
null,
"10+ years",
"10+ years",
"2 years",
"10+ years",
"9 years",
"4 years",
"3 years",
"10+ years",
"7 years",
"2 years",
"8 years",
"< 1 year",
"6 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"6 years",
"2 years",
"5 years",
"5 years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"6 years",
"2 years",
"9 years",
"3 years",
"6 years",
"9 years",
"10+ years",
"< 1 year",
"4 years",
"< 1 year",
"4 years",
"10+ years",
null,
"10+ years",
"7 years",
null,
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"< 1 year",
"9 years",
"2 years",
"2 years",
"3 years",
"4 years",
"6 years",
"9 years",
"9 years",
"4 years",
"6 years",
null,
"10+ years",
"2 years",
"< 1 year",
null,
"10+ years",
"3 years",
"3 years",
"10+ years",
"5 years",
"9 years",
"9 years",
"10+ years",
"3 years",
"< 1 year",
"1 year",
"3 years",
"10+ years",
"1 year",
"10+ years",
"2 years",
"4 years",
"9 years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"3 years",
"1 year",
"7 years",
null,
"10+ years",
"10+ years",
"6 years",
"2 years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"1 year",
"4 years",
"< 1 year",
"9 years",
"10+ years",
"2 years",
"6 years",
"2 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
null,
null,
"7 years",
"10+ years",
"2 years",
"5 years",
"6 years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"5 years",
"1 year",
"2 years",
"5 years",
"8 years",
"10+ years",
"2 years",
"2 years",
"5 years",
"1 year",
"10+ years",
"2 years",
"2 years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
null,
"2 years",
"10+ years",
"1 year",
"10+ years",
"9 years",
"10+ years",
"7 years",
"8 years",
"4 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"5 years",
"1 year",
"1 year",
"8 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"7 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"3 years",
"7 years",
"6 years",
null,
"10+ years",
"9 years",
"1 year",
"10+ years",
"9 years",
"9 years",
"10+ years",
"1 year",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"6 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"6 years",
"< 1 year",
"6 years",
"10+ years",
"1 year",
"< 1 year",
"4 years",
"8 years",
"< 1 year",
null,
"10+ years",
"7 years",
"6 years",
"10+ years",
"3 years",
"3 years",
"4 years",
"3 years",
"< 1 year",
"10+ years",
"8 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"6 years",
"7 years",
"7 years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"7 years",
"4 years",
"9 years",
"4 years",
"< 1 year",
"10+ years",
"9 years",
"2 years",
"8 years",
"5 years",
"3 years",
"2 years",
"9 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"3 years",
"< 1 year",
"8 years",
"< 1 year",
"3 years",
"8 years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"5 years",
"< 1 year",
"3 years",
"7 years",
"10+ years",
"6 years",
"6 years",
"4 years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"5 years",
"2 years",
"2 years",
"8 years",
"7 years",
"6 years",
"3 years",
"7 years",
"6 years",
"4 years",
"8 years",
"7 years",
"10+ years",
"1 year",
"4 years",
null,
"7 years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"1 year",
"< 1 year",
"10+ years",
"7 years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
null,
"4 years",
"6 years",
"< 1 year",
"10+ years",
"5 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"6 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"5 years",
"< 1 year",
"3 years",
"10+ years",
"6 years",
"5 years",
"1 year",
"10+ years",
"7 years",
"8 years",
"8 years",
null,
"3 years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"2 years",
"3 years",
"< 1 year",
"5 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"9 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"7 years",
null,
"10+ years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
null,
"10+ years",
"7 years",
null,
"2 years",
"3 years",
"5 years",
"5 years",
"10+ years",
"5 years",
"9 years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"7 years",
"6 years",
"7 years",
"10+ years",
"4 years",
"7 years",
null,
"< 1 year",
"< 1 year",
"1 year",
"7 years",
"3 years",
"1 year",
"< 1 year",
"2 years",
"3 years",
"10+ years",
"5 years",
null,
"10+ years",
"10+ years",
"9 years",
"4 years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"3 years",
"3 years",
null,
"1 year",
null,
"1 year",
"10+ years",
"3 years",
"8 years",
"5 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"7 years",
"2 years",
"4 years",
"10+ years",
"3 years",
"2 years",
"2 years",
"5 years",
"10+ years",
"9 years",
"6 years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"6 years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
null,
"3 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"7 years",
"6 years",
"1 year",
"< 1 year",
"< 1 year",
"10+ years",
"2 years",
"5 years",
"2 years",
"1 year",
"9 years",
"10+ years",
"10+ years",
"5 years",
"1 year",
"1 year",
"< 1 year",
"10+ years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"3 years",
"9 years",
"< 1 year",
"10+ years",
"4 years",
"8 years",
"10+ years",
"1 year",
"5 years",
"10+ years",
"10+ years",
"10+ years",
null,
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
null,
"8 years",
"3 years",
"< 1 year",
"6 years",
"< 1 year",
"< 1 year",
null,
"5 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"8 years",
"2 years",
"10+ years",
"10+ years",
null,
"7 years",
"< 1 year",
"3 years",
"3 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"3 years",
"8 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"1 year",
null,
"10+ years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"7 years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"7 years",
"10+ years",
"7 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"4 years",
"10+ years",
"4 years",
"5 years",
null,
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"3 years",
"1 year",
"10+ years",
"9 years",
"10+ years",
"2 years",
"3 years",
"< 1 year",
"5 years",
"< 1 year",
"7 years",
"5 years",
"7 years",
"3 years",
"10+ years",
"2 years",
"1 year",
null,
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"7 years",
"2 years",
"4 years",
"8 years",
"4 years",
"< 1 year",
"10+ years",
"4 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"4 years",
"2 years",
"10+ years",
"10+ years",
null,
"4 years",
"< 1 year",
"10+ years",
"9 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"10+ years",
"5 years",
"1 year",
"3 years",
"< 1 year",
"9 years",
"5 years",
"2 years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"7 years",
"4 years",
"10+ years",
"< 1 year",
"2 years",
"7 years",
"10+ years",
"2 years",
"8 years",
"< 1 year",
"10+ years",
"9 years",
"6 years",
"10+ years",
"6 years",
null,
"8 years",
"2 years",
"4 years",
"< 1 year",
"< 1 year",
"4 years",
"1 year",
"6 years",
"10+ years",
"3 years",
"6 years",
"8 years",
"10+ years",
"4 years",
"2 years",
"2 years",
"9 years",
"1 year",
"7 years",
"< 1 year",
"4 years",
"4 years",
"9 years",
"10+ years",
"4 years",
"9 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
null,
"3 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"7 years",
"2 years",
null,
"7 years",
"3 years",
"9 years",
"4 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"6 years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
null,
"10+ years",
"4 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"6 years",
"10+ years",
"9 years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"< 1 year",
"8 years",
"1 year",
"2 years",
"2 years",
"6 years",
"10+ years",
null,
"10+ years",
null,
null,
"9 years",
"10+ years",
"9 years",
"4 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"1 year",
"7 years",
null,
"10+ years",
"7 years",
"2 years",
"6 years",
"8 years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"7 years",
"5 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"2 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"2 years",
null,
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"< 1 year",
"1 year",
"4 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"9 years",
"7 years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"1 year",
"1 year",
"4 years",
"3 years",
"7 years",
"1 year",
"3 years",
"3 years",
"4 years",
"10+ years",
"1 year",
"8 years",
"10+ years",
"1 year",
"10+ years",
"8 years",
"2 years",
"10+ years",
"< 1 year",
null,
"6 years",
"3 years",
"10+ years",
"9 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"1 year",
"7 years",
"3 years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"1 year",
"5 years",
"4 years",
"4 years",
"1 year",
"2 years",
"5 years",
"10+ years",
"2 years",
null,
"3 years",
"4 years",
"2 years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"6 years",
"2 years",
"10+ years",
"1 year",
"2 years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"2 years",
"4 years",
"3 years",
"5 years",
"10+ years",
null,
"2 years",
null,
"9 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"10+ years",
null,
"2 years",
"3 years",
"4 years",
"6 years",
"9 years",
"< 1 year",
"3 years",
"10+ years",
"2 years",
"8 years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"7 years",
"6 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"9 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
null,
"10+ years",
"1 year",
"10+ years",
"1 year",
"6 years",
"2 years",
"10+ years",
"2 years",
"9 years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"6 years",
"2 years",
"10+ years",
"5 years",
"< 1 year",
"5 years",
"6 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"7 years",
"10+ years",
"6 years",
"10+ years",
null,
"10+ years",
"5 years",
"5 years",
"6 years",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
null,
"10+ years",
"9 years",
"5 years",
"7 years",
"10+ years",
"10+ years",
"5 years",
"5 years",
"5 years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"9 years",
"6 years",
"< 1 year",
"4 years",
"4 years",
"10+ years",
"10+ years",
"1 year",
"6 years",
"3 years",
"5 years",
"10+ years",
"6 years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"1 year",
"8 years",
"1 year",
"7 years",
null,
"5 years",
"9 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"4 years",
"3 years",
"6 years",
"4 years",
"10+ years",
"10+ years",
"7 years",
"6 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"5 years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"7 years",
"9 years",
"10+ years",
"8 years",
"2 years",
"2 years",
"7 years",
"6 years",
"10+ years",
"2 years",
"1 year",
"7 years",
"10+ years",
"9 years",
"1 year",
"< 1 year",
"6 years",
null,
"10+ years",
"8 years",
"< 1 year",
"2 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"8 years",
"10+ years",
"2 years",
null,
"3 years",
"10+ years",
"8 years",
"5 years",
"< 1 year",
"6 years",
null,
"5 years",
null,
"4 years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"6 years",
"3 years",
"4 years",
"9 years",
"5 years",
"2 years",
"7 years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"6 years",
"10+ years",
"7 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"3 years",
"8 years",
"2 years",
"4 years",
"10+ years",
"1 year",
"2 years",
"10+ years",
"10+ years",
null,
"6 years",
"8 years",
"3 years",
"3 years",
"10+ years",
"9 years",
"2 years",
"7 years",
"10+ years",
"4 years",
"8 years",
"5 years",
null,
"10+ years",
"< 1 year",
"3 years",
"6 years",
"4 years",
"7 years",
"< 1 year",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"4 years",
"2 years",
"7 years",
"10+ years",
"3 years",
"1 year",
"7 years",
"10+ years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"4 years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"9 years",
"4 years",
"8 years",
"10+ years",
"< 1 year",
"< 1 year",
"5 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"< 1 year",
"10+ years",
"5 years",
"3 years",
"8 years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"5 years",
"3 years",
"1 year",
null,
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"3 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"3 years",
"2 years",
"4 years",
"4 years",
"10+ years",
"8 years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"5 years",
"2 years",
"2 years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"10+ years",
"9 years",
"7 years",
"5 years",
"9 years",
"6 years",
"5 years",
"10+ years",
"9 years",
"2 years",
"10+ years",
"< 1 year",
"1 year",
"3 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"9 years",
"10+ years",
"1 year",
"7 years",
"< 1 year",
"7 years",
"8 years",
"6 years",
"3 years",
"9 years",
"10+ years",
"6 years",
"1 year",
"10+ years",
"7 years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"9 years",
"5 years",
"< 1 year",
"3 years",
"1 year",
"< 1 year",
"10+ years",
"4 years",
"3 years",
"10+ years",
"5 years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"3 years",
"9 years",
null,
"< 1 year",
"10+ years",
"2 years",
"5 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"1 year",
"7 years",
"< 1 year",
"10+ years",
"6 years",
null,
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"9 years",
"3 years",
"9 years",
"3 years",
"8 years",
null,
null,
"7 years",
"5 years",
"10+ years",
"1 year",
"1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"9 years",
"10+ years",
"10+ years",
"8 years",
"7 years",
"2 years",
"10+ years",
"8 years",
"8 years",
"1 year",
"5 years",
"3 years",
"< 1 year",
"9 years",
null,
"10+ years",
"< 1 year",
"4 years",
"< 1 year",
"6 years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"7 years",
"2 years",
"1 year",
"2 years",
"1 year",
"10+ years",
"10+ years",
null,
"10+ years",
"6 years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"< 1 year",
"8 years",
"4 years",
null,
"5 years",
"10+ years",
"5 years",
"2 years",
"6 years",
"4 years",
"1 year",
"9 years",
"8 years",
"2 years",
"6 years",
"3 years",
"6 years",
"10+ years",
null,
"7 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"< 1 year",
"6 years",
"4 years",
"6 years",
null,
"3 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"2 years",
"10+ years",
null,
"3 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"3 years",
"10+ years",
null,
"8 years",
"6 years",
"3 years",
"9 years",
"10+ years",
"8 years",
"2 years",
"4 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"6 years",
"< 1 year",
"8 years",
"5 years",
"2 years",
null,
"< 1 year",
"1 year",
"9 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
null,
"10+ years",
"4 years",
null,
"10+ years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"2 years",
"1 year",
null,
"2 years",
"9 years",
"2 years",
"9 years",
"10+ years",
"2 years",
"4 years",
"< 1 year",
"8 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"4 years",
"10+ years",
null,
"3 years",
"< 1 year",
"3 years",
"10+ years",
"7 years",
"3 years",
null,
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"8 years",
"4 years",
"9 years",
"3 years",
"8 years",
"4 years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"1 year",
"3 years",
"10+ years",
"< 1 year",
"3 years",
"4 years",
"< 1 year",
"10+ years",
"3 years",
"< 1 year",
"1 year",
"10+ years",
"2 years",
"9 years",
"3 years",
"3 years",
"3 years",
"4 years",
"9 years",
"< 1 year",
"4 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"2 years",
"1 year",
"8 years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"8 years",
"9 years",
"4 years",
"1 year",
null,
"10+ years",
"10+ years",
"8 years",
"8 years",
"9 years",
"10+ years",
"< 1 year",
"< 1 year",
"4 years",
"4 years",
"6 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"2 years",
"< 1 year",
"2 years",
"5 years",
"5 years",
"10+ years",
"< 1 year",
"1 year",
"7 years",
"4 years",
null,
"10+ years",
"2 years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"4 years",
"4 years",
"2 years",
"2 years",
"10+ years",
"9 years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"7 years",
"2 years",
"10+ years",
"5 years",
"4 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"2 years",
"10+ years",
null,
"7 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
null,
"10+ years",
"< 1 year",
"10+ years",
null,
"10+ years",
"8 years",
"6 years",
"2 years",
"9 years",
"6 years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
null,
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"< 1 year",
"8 years",
"7 years",
"2 years",
"3 years",
"5 years",
"5 years",
"2 years",
"10+ years",
"3 years",
"2 years",
"4 years",
"< 1 year",
"4 years",
"1 year",
"9 years",
"3 years",
"10+ years",
"2 years",
"3 years",
"1 year",
"7 years",
"10+ years",
"1 year",
"10+ years",
"2 years",
"2 years",
"4 years",
"3 years",
"9 years",
"10+ years",
null,
"10+ years",
"1 year",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"1 year",
"4 years",
"7 years",
"6 years",
"< 1 year",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
null,
"4 years",
"2 years",
"10+ years",
"10+ years",
"6 years",
null,
"< 1 year",
"5 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"7 years",
"1 year",
"3 years",
"5 years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"8 years",
"1 year",
"< 1 year",
"2 years",
"3 years",
"4 years",
"8 years",
"1 year",
"4 years",
"3 years",
"10+ years",
null,
"1 year",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"4 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"1 year",
"4 years",
"7 years",
"7 years",
"7 years",
"10+ years",
"9 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"10+ years",
null,
"5 years",
"9 years",
"6 years",
"7 years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"9 years",
"6 years",
"5 years",
"10+ years",
"2 years",
null,
"3 years",
"2 years",
"9 years",
"1 year",
"4 years",
"4 years",
"4 years",
"3 years",
null,
"7 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"9 years",
"9 years",
"5 years",
"10+ years",
"< 1 year",
"3 years",
"9 years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"7 years",
"10+ years",
"7 years",
"< 1 year",
"3 years",
"5 years",
"8 years",
null,
null,
"1 year",
"5 years",
"5 years",
"6 years",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"3 years",
"5 years",
"7 years",
"9 years",
"10+ years",
"1 year",
"4 years",
"10+ years",
"< 1 year",
"9 years",
"6 years",
"3 years",
"2 years",
"3 years",
"3 years",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"9 years",
"< 1 year",
"6 years",
"4 years",
"10+ years",
"9 years",
null,
"10+ years",
"2 years",
"10+ years",
null,
"7 years",
null,
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"6 years",
"3 years",
"5 years",
"1 year",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"9 years",
"4 years",
"1 year",
"1 year",
"9 years",
"7 years",
"8 years",
null,
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"2 years",
"8 years",
null,
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"3 years",
null,
"1 year",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"9 years",
"9 years",
"3 years",
"5 years",
null,
"1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
null,
"2 years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"< 1 year",
"5 years",
"8 years",
"6 years",
"10+ years",
"10+ years",
"7 years",
"< 1 year",
"8 years",
"10+ years",
"3 years",
"2 years",
"5 years",
"10+ years",
"< 1 year",
"5 years",
"3 years",
"< 1 year",
"9 years",
"10+ years",
"6 years",
"8 years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"6 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"3 years",
null,
"4 years",
"10+ years",
"5 years",
"4 years",
"2 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"8 years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"9 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"7 years",
"3 years",
"4 years",
"6 years",
"9 years",
"10+ years",
"10+ years",
"6 years",
"5 years",
"9 years",
"< 1 year",
"7 years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
null,
"< 1 year",
"9 years",
"10+ years",
"2 years",
"2 years",
"1 year",
"6 years",
"2 years",
"< 1 year",
"10+ years",
"6 years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"2 years",
null,
"10+ years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"2 years",
"8 years",
"5 years",
"4 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"2 years",
"2 years",
null,
"6 years",
"3 years",
"7 years",
"7 years",
"8 years",
"10+ years",
"4 years",
"2 years",
"10+ years",
"7 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"4 years",
"9 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"3 years",
"4 years",
"4 years",
"3 years",
"2 years",
"10+ years",
"1 year",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"7 years",
"4 years",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"4 years",
"< 1 year",
"6 years",
"5 years",
"7 years",
"6 years",
"1 year",
null,
"2 years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"1 year",
"9 years",
"< 1 year",
"3 years",
"1 year",
"10+ years",
"1 year",
"6 years",
"5 years",
"4 years",
null,
"10+ years",
"6 years",
"6 years",
"10+ years",
"10+ years",
"5 years",
"6 years",
"10+ years",
"7 years",
"9 years",
"< 1 year",
"9 years",
"8 years",
"9 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"4 years",
"6 years",
"2 years",
"10+ years",
"5 years",
"6 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"7 years",
"10+ years",
null,
"2 years",
"3 years",
"10+ years",
null,
"4 years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
null,
"4 years",
"2 years",
"1 year",
"2 years",
"8 years",
"4 years",
"2 years",
"< 1 year",
"10+ years",
"7 years",
"< 1 year",
"3 years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"2 years",
"3 years",
"5 years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"6 years",
"6 years",
"7 years",
"7 years",
"< 1 year",
null,
"1 year",
"9 years",
"2 years",
"9 years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"8 years",
"3 years",
"10+ years",
"5 years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"2 years",
"10+ years",
"1 year",
"3 years",
"8 years",
"9 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
null,
"2 years",
"7 years",
"10+ years",
"4 years",
"9 years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"1 year",
"2 years",
null,
"10+ years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"3 years",
"5 years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"6 years",
"2 years",
"3 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"9 years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"10+ years",
"5 years",
"6 years",
"10+ years",
"4 years",
"6 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"8 years",
"< 1 year",
"2 years",
null,
"4 years",
"< 1 year",
"5 years",
"< 1 year",
"4 years",
"8 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"4 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"2 years",
"< 1 year",
"2 years",
"5 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"4 years",
"8 years",
"10+ years",
"1 year",
"9 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"3 years",
"7 years",
"5 years",
"3 years",
"10+ years",
"4 years",
"2 years",
"6 years",
"8 years",
"3 years",
"6 years",
"8 years",
"10+ years",
"1 year",
null,
"10+ years",
"< 1 year",
"2 years",
"8 years",
"1 year",
"3 years",
"10+ years",
"3 years",
"6 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"2 years",
"< 1 year",
"5 years",
null,
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"4 years",
null,
null,
"6 years",
"5 years",
"1 year",
"4 years",
"5 years",
"4 years",
"3 years",
"2 years",
"4 years",
"3 years",
"7 years",
null,
"2 years",
"3 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"< 1 year",
"3 years",
"< 1 year",
"7 years",
"3 years",
"10+ years",
"8 years",
"3 years",
"2 years",
"4 years",
"4 years",
"10+ years",
"8 years",
"6 years",
"2 years",
"8 years",
null,
"9 years",
"9 years",
"8 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
null,
"5 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"4 years",
"1 year",
null,
"7 years",
"< 1 year",
"9 years",
"8 years",
"2 years",
null,
"1 year",
"< 1 year",
"1 year",
"5 years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"3 years",
"< 1 year",
"8 years",
"1 year",
"10+ years",
"4 years",
"3 years",
"5 years",
"10+ years",
"< 1 year",
"1 year",
null,
"2 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"7 years",
"10+ years",
"9 years",
"4 years",
"7 years",
"6 years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
null,
"10+ years",
"7 years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
null,
"3 years",
"10+ years",
"5 years",
"8 years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"9 years",
"10+ years",
"1 year",
"10+ years",
"5 years",
"3 years",
"10+ years",
"9 years",
"2 years",
null,
"3 years",
"3 years",
"6 years",
"9 years",
"10+ years",
"1 year",
"10+ years",
"8 years",
"3 years",
"10+ years",
"9 years",
null,
"1 year",
"6 years",
"10+ years",
"1 year",
"1 year",
"1 year",
"10+ years",
"10+ years",
"1 year",
"8 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"3 years",
"8 years",
"10+ years",
"10+ years",
null,
"5 years",
"1 year",
"6 years",
"3 years",
"10+ years",
"1 year",
"1 year",
"2 years",
"4 years",
"10+ years",
"4 years",
"8 years",
"6 years",
"9 years",
"5 years",
"4 years",
"< 1 year",
"6 years",
"2 years",
"5 years",
"9 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"1 year",
null,
"10+ years",
"7 years",
"2 years",
"5 years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
null,
"10+ years",
"5 years",
"3 years",
"3 years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"2 years",
"10+ years",
"2 years",
"2 years",
"1 year",
"10+ years",
"3 years",
"9 years",
"3 years",
"< 1 year",
"10+ years",
"8 years",
"5 years",
"9 years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"9 years",
"2 years",
"7 years",
"10+ years",
"2 years",
"4 years",
"8 years",
"10+ years",
"4 years",
"1 year",
"8 years",
"10+ years",
"8 years",
"7 years",
"10+ years",
"10+ years",
"8 years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"9 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"4 years",
"1 year",
"9 years",
null,
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
null,
"5 years",
"10+ years",
null,
"6 years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"5 years",
"7 years",
"7 years",
"9 years",
"10+ years",
"1 year",
"8 years",
"4 years",
null,
null,
"5 years",
null,
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"9 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
null,
"1 year",
"6 years",
null,
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"2 years",
"6 years",
"8 years",
"10+ years",
"7 years",
"9 years",
"7 years",
"5 years",
"1 year",
"5 years",
"9 years",
"10+ years",
"2 years",
"2 years",
"8 years",
"5 years",
"6 years",
"10+ years",
"8 years",
"10+ years",
null,
"7 years",
"10+ years",
null,
"4 years",
"4 years",
"10+ years",
"4 years",
"3 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"6 years",
"7 years",
"4 years",
"5 years",
"5 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"4 years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"< 1 year",
"3 years",
"4 years",
"5 years",
"9 years",
"2 years",
"10+ years",
"3 years",
"5 years",
"1 year",
"10+ years",
"3 years",
"2 years",
"10+ years",
"2 years",
"5 years",
"1 year",
"8 years",
"< 1 year",
"10+ years",
"5 years",
"7 years",
"2 years",
"10+ years",
"6 years",
"8 years",
"< 1 year",
"2 years",
"1 year",
null,
"10+ years",
"3 years",
"2 years",
"< 1 year",
"3 years",
"1 year",
"4 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"8 years",
"5 years",
"10+ years",
"6 years",
"4 years",
"10+ years",
"7 years",
null,
"8 years",
"3 years",
null,
"10+ years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
null,
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"7 years",
"< 1 year",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"8 years",
null,
"10+ years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"6 years",
"2 years",
"10+ years",
"3 years",
"9 years",
"2 years",
"5 years",
"2 years",
"5 years",
"10+ years",
"3 years",
null,
"3 years",
"5 years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"4 years",
"4 years",
"2 years",
"< 1 year",
"< 1 year",
"< 1 year",
"7 years",
"< 1 year",
"2 years",
null,
"10+ years",
"3 years",
"10+ years",
"6 years",
"2 years",
null,
"10+ years",
"7 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"3 years",
"7 years",
"3 years",
"10+ years",
"7 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"7 years",
"3 years",
"10+ years",
"7 years",
"7 years",
"2 years",
"10+ years",
"7 years",
"3 years",
"5 years",
"3 years",
"10+ years",
"9 years",
"8 years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"5 years",
"5 years",
"10+ years",
null,
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"2 years",
"3 years",
"< 1 year",
"< 1 year",
"2 years",
"2 years",
"10+ years",
"10+ years",
"9 years",
"8 years",
"2 years",
"1 year",
"5 years",
null,
"2 years",
"7 years",
"5 years",
null,
"10+ years",
"4 years",
"10+ years",
"1 year",
"3 years",
"< 1 year",
"8 years",
"< 1 year",
null,
"2 years",
"10+ years",
"1 year",
"8 years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"9 years",
"10+ years",
"5 years",
"5 years",
"10+ years",
"2 years",
"< 1 year",
"9 years",
"5 years",
"3 years",
"1 year",
"3 years",
"10+ years",
"5 years",
"5 years",
"5 years",
"8 years",
"10+ years",
"10+ years",
null,
"1 year",
"10+ years",
"2 years",
"3 years",
"10+ years",
"5 years",
"8 years",
"10+ years",
"5 years",
"7 years",
"7 years",
"8 years",
"10+ years",
null,
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"< 1 year",
"7 years",
"< 1 year",
null,
"3 years",
"4 years",
null,
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"10+ years",
"5 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"8 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"5 years",
"2 years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"2 years",
"9 years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"3 years",
"1 year",
"4 years",
"10+ years",
"10+ years",
"7 years",
"9 years",
"5 years",
"< 1 year",
"< 1 year",
"1 year",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"5 years",
"8 years",
"9 years",
"2 years",
"< 1 year",
"8 years",
"9 years",
"5 years",
"9 years",
"< 1 year",
"8 years",
"7 years",
"10+ years",
null,
"5 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"8 years",
"2 years",
"2 years",
"10+ years",
"9 years",
"5 years",
"10+ years",
"6 years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"6 years",
"8 years",
"6 years",
null,
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"8 years",
"6 years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"7 years",
"1 year",
"< 1 year",
"7 years",
"8 years",
null,
"10+ years",
"7 years",
"1 year",
"8 years",
"2 years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"8 years",
"8 years",
"5 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"4 years",
null,
"10+ years",
null,
"3 years",
"8 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"1 year",
"2 years",
"2 years",
"1 year",
null,
"10+ years",
null,
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"5 years",
"10+ years",
null,
"9 years",
"1 year",
"7 years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"8 years",
"6 years",
"10+ years",
"6 years",
"7 years",
"10+ years",
"7 years",
"5 years",
"4 years",
"8 years",
"7 years",
"3 years",
"10+ years",
"4 years",
"4 years",
null,
"10+ years",
"1 year",
"10+ years",
"3 years",
"3 years",
"6 years",
"10+ years",
"10+ years",
"5 years",
null,
"5 years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"2 years",
"1 year",
"7 years",
"3 years",
"2 years",
"1 year",
"2 years",
"2 years",
"3 years",
"10+ years",
"6 years",
"4 years",
"7 years",
"8 years",
"10+ years",
"10+ years",
"6 years",
"1 year",
"3 years",
"4 years",
"7 years",
"4 years",
"9 years",
"10+ years",
"1 year",
"4 years",
"3 years",
null,
"10+ years",
null,
"10+ years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"4 years",
null,
"4 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"5 years",
null,
"10+ years",
"5 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"9 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"6 years",
"< 1 year",
"8 years",
"6 years",
"10+ years",
null,
"6 years",
"1 year",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"8 years",
null,
"9 years",
"10+ years",
"7 years",
"10+ years",
"< 1 year",
"< 1 year",
"6 years",
"1 year",
"6 years",
"9 years",
"9 years",
"10+ years",
"5 years",
"8 years",
"4 years",
"10+ years",
"8 years",
"3 years",
"10+ years",
null,
"5 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"1 year",
"1 year",
"4 years",
"5 years",
"2 years",
"2 years",
"8 years",
"4 years",
"3 years",
"7 years",
"6 years",
"6 years",
"1 year",
"10+ years",
"7 years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"1 year",
"3 years",
"1 year",
"5 years",
"5 years",
"5 years",
"10+ years",
"5 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"4 years",
"10+ years",
"< 1 year",
"9 years",
"< 1 year",
"10+ years",
null,
"2 years",
"7 years",
"4 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"1 year",
"2 years",
"10+ years",
"< 1 year",
"4 years",
"4 years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"5 years",
"9 years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"1 year",
"10+ years",
"8 years",
"< 1 year",
"6 years",
"4 years",
"2 years",
"4 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"1 year",
null,
"10+ years",
"10+ years",
"4 years",
"7 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"4 years",
null,
"3 years",
"1 year",
"3 years",
"10+ years",
"7 years",
"9 years",
null,
"< 1 year",
"10+ years",
"6 years",
"2 years",
null,
"2 years",
"< 1 year",
"< 1 year",
"3 years",
"3 years",
"< 1 year",
"4 years",
"10+ years",
"6 years",
"4 years",
"5 years",
"5 years",
"6 years",
"5 years",
"< 1 year",
"10+ years",
"3 years",
"2 years",
"< 1 year",
"10+ years",
"9 years",
"< 1 year",
"7 years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"2 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"9 years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"4 years",
"9 years",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"6 years",
"1 year",
"10+ years",
"< 1 year",
"4 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"9 years",
"10+ years",
"9 years",
"8 years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"1 year",
"8 years",
"2 years",
"10+ years",
"1 year",
null,
"< 1 year",
"8 years",
"1 year",
"10+ years",
"3 years",
"7 years",
"< 1 year",
"3 years",
"10+ years",
"9 years",
"2 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"8 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"2 years",
"2 years",
"4 years",
"< 1 year",
"4 years",
null,
"6 years",
null,
"2 years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"9 years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"2 years",
null,
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"8 years",
"7 years",
"2 years",
"1 year",
"6 years",
"2 years",
"3 years",
"2 years",
"3 years",
"10+ years",
"3 years",
"4 years",
"10+ years",
null,
"10+ years",
"2 years",
"3 years",
"7 years",
"< 1 year",
"4 years",
"2 years",
"7 years",
"10+ years",
"9 years",
"3 years",
"4 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"9 years",
null,
"5 years",
"1 year",
"8 years",
"6 years",
"9 years",
"6 years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"5 years",
"5 years",
"3 years",
"5 years",
"2 years",
"5 years",
"< 1 year",
"10+ years",
"3 years",
"< 1 year",
"1 year",
"6 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"7 years",
"6 years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
null,
"8 years",
"10+ years",
"7 years",
"10+ years",
"6 years",
"10+ years",
"4 years",
"5 years",
null,
"6 years",
"2 years",
"3 years",
"3 years",
"10+ years",
null,
"5 years",
"3 years",
"2 years",
"2 years",
"10+ years",
"5 years",
"7 years",
"8 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"2 years",
"3 years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"6 years",
"6 years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"7 years",
"6 years",
"< 1 year",
"3 years",
"5 years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"9 years",
"4 years",
"3 years",
"10+ years",
"3 years",
"6 years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"8 years",
"1 year",
"3 years",
"10+ years",
"1 year",
"5 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"9 years",
"7 years",
"< 1 year",
"8 years",
"1 year",
"10+ years",
"5 years",
"10+ years",
"1 year",
"< 1 year",
"2 years",
null,
"5 years",
"10+ years",
"2 years",
"1 year",
"2 years",
"7 years",
"4 years",
"4 years",
"3 years",
"2 years",
"10+ years",
null,
"8 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"4 years",
"1 year",
"8 years",
"10+ years",
"7 years",
"4 years",
"10+ years",
"6 years",
"10+ years",
"8 years",
"9 years",
"10+ years",
"10+ years",
"8 years",
null,
"6 years",
"4 years",
"3 years",
"10+ years",
"2 years",
"1 year",
"1 year",
"< 1 year",
"10+ years",
"< 1 year",
null,
"4 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"7 years",
"< 1 year",
"3 years",
"4 years",
"< 1 year",
"1 year",
"5 years",
"10+ years",
"1 year",
"6 years",
"10+ years",
"7 years",
"5 years",
"9 years",
"9 years",
"10+ years",
"10+ years",
"6 years",
"< 1 year",
"< 1 year",
"2 years",
"9 years",
"10+ years",
"10+ years",
"5 years",
"5 years",
"10+ years",
"1 year",
"9 years",
"7 years",
"8 years",
"5 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
null,
"9 years",
"5 years",
"3 years",
"4 years",
"8 years",
"3 years",
"9 years",
"< 1 year",
"10+ years",
"8 years",
"9 years",
"2 years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"6 years",
"5 years",
"8 years",
"10+ years",
"1 year",
null,
"4 years",
"4 years",
"5 years",
"10+ years",
"9 years",
"1 year",
"10+ years",
"1 year",
"1 year",
"6 years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"5 years",
"1 year",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"8 years",
"7 years",
"10+ years",
"4 years",
"5 years",
"10+ years",
null,
"10+ years",
"6 years",
null,
"7 years",
"7 years",
"10+ years",
"8 years",
"6 years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"7 years",
"< 1 year",
"10+ years",
"6 years",
"1 year",
"2 years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"8 years",
"4 years",
"2 years",
"2 years",
"3 years",
"8 years",
"5 years",
"10+ years",
"3 years",
"2 years",
"8 years",
"5 years",
"1 year",
"9 years",
"10+ years",
"8 years",
"6 years",
"1 year",
"1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"1 year",
"9 years",
"3 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"9 years",
"10+ years",
null,
"10+ years",
"7 years",
"5 years",
"9 years",
null,
"10+ years",
"10+ years",
"4 years",
"1 year",
"8 years",
"2 years",
"10+ years",
"2 years",
"9 years",
"1 year",
"10+ years",
"1 year",
"5 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"3 years",
"6 years",
"2 years",
"8 years",
"2 years",
"7 years",
"2 years",
"8 years",
null,
"3 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"1 year",
"6 years",
"2 years",
"10+ years",
"8 years",
"4 years",
"10+ years",
"6 years",
"3 years",
"6 years",
"< 1 year",
"7 years",
"4 years",
"8 years",
"10+ years",
null,
"10+ years",
"6 years",
"10+ years",
"4 years",
"4 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"6 years",
"4 years",
"7 years",
"5 years",
null,
"10+ years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"10+ years",
null,
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"3 years",
"10+ years",
"2 years",
"< 1 year",
"3 years",
"5 years",
"10+ years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"< 1 year",
null,
"4 years",
null,
"3 years",
"3 years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"4 years",
"< 1 year",
"10+ years",
"5 years",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
null,
null,
"9 years",
"2 years",
"2 years",
"1 year",
"1 year",
"3 years",
null,
"1 year",
"8 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"8 years",
"7 years",
"7 years",
"4 years",
"1 year",
"1 year",
"8 years",
"7 years",
"10+ years",
"3 years",
"5 years",
"3 years",
"2 years",
"9 years",
"10+ years",
"3 years",
null,
"3 years",
"3 years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"2 years",
null,
"< 1 year",
"7 years",
"10+ years",
"6 years",
"7 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"5 years",
"2 years",
"7 years",
"2 years",
null,
"3 years",
"8 years",
"5 years",
"6 years",
"10+ years",
"1 year",
"6 years",
"3 years",
"5 years",
"10+ years",
null,
"1 year",
"10+ years",
"4 years",
"3 years",
"1 year",
"2 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"5 years",
"4 years",
"9 years",
"3 years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"3 years",
"10+ years",
null,
"1 year",
"3 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"7 years",
"10+ years",
"8 years",
"3 years",
"< 1 year",
"5 years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"2 years",
null,
"8 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"2 years",
"< 1 year",
"5 years",
"5 years",
"2 years",
"7 years",
"< 1 year",
"10+ years",
null,
"10+ years",
"5 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"9 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
null,
"6 years",
"5 years",
"8 years",
"6 years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"6 years",
"4 years",
"1 year",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"8 years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"7 years",
"1 year",
"5 years",
"10+ years",
null,
"10+ years",
"2 years",
"6 years",
"4 years",
"< 1 year",
"3 years",
"8 years",
"10+ years",
"10+ years",
"4 years",
"4 years",
"6 years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"7 years",
"8 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"6 years",
"8 years",
"10+ years",
"9 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"3 years",
null,
"10+ years",
"< 1 year",
null,
"10+ years",
"10+ years",
"7 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"< 1 year",
"3 years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"7 years",
"1 year",
"5 years",
"2 years",
"7 years",
"8 years",
"10+ years",
"2 years",
"5 years",
"3 years",
"1 year",
"< 1 year",
"2 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"7 years",
"1 year",
"10+ years",
"< 1 year",
"2 years",
"8 years",
"10+ years",
"8 years",
"2 years",
"5 years",
"< 1 year",
"2 years",
"1 year",
"2 years",
"1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"2 years",
"9 years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"4 years",
"3 years",
"2 years",
"5 years",
null,
"4 years",
"10+ years",
"< 1 year",
"9 years",
"1 year",
"2 years",
"4 years",
"< 1 year",
"1 year",
"9 years",
"1 year",
"10+ years",
"10+ years",
"7 years",
"1 year",
"3 years",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"6 years",
null,
"5 years",
"1 year",
"7 years",
"2 years",
"5 years",
"1 year",
"< 1 year",
"8 years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"1 year",
"< 1 year",
"8 years",
"2 years",
"5 years",
"10+ years",
"3 years",
"< 1 year",
"3 years",
"10+ years",
"6 years",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"5 years",
"10+ years",
"< 1 year",
null,
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"< 1 year",
"2 years",
"3 years",
"< 1 year",
"6 years",
"3 years",
"10+ years",
"2 years",
null,
"4 years",
"3 years",
"1 year",
"7 years",
"10+ years",
"10+ years",
"8 years",
"1 year",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"5 years",
"1 year",
"4 years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"7 years",
"6 years",
"7 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"< 1 year",
"< 1 year",
"3 years",
"3 years",
"9 years",
"10+ years",
"2 years",
"4 years",
"1 year",
"3 years",
"< 1 year",
"< 1 year",
"7 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"< 1 year",
"< 1 year",
"5 years",
"10+ years",
"< 1 year",
"< 1 year",
"1 year",
"< 1 year",
"8 years",
"10+ years",
"9 years",
"9 years",
"6 years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"6 years",
"1 year",
"2 years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"9 years",
"10+ years",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"8 years",
"8 years",
null,
"10+ years",
"< 1 year",
"10+ years",
null,
"1 year",
"10+ years",
"1 year",
"2 years",
"10+ years",
"8 years",
"2 years",
"2 years",
"1 year",
"3 years",
"< 1 year",
"5 years",
"8 years",
"1 year",
"10+ years",
null,
"9 years",
"3 years",
"8 years",
"2 years",
"< 1 year",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"3 years",
"< 1 year",
"4 years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"4 years",
"5 years",
"10+ years",
null,
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"2 years",
"4 years",
"2 years",
"10+ years",
null,
"5 years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"7 years",
"10+ years",
null,
"< 1 year",
"8 years",
"1 year",
"10+ years",
"1 year",
"3 years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"< 1 year",
"10+ years",
"5 years",
"7 years",
"10+ years",
null,
"5 years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"9 years",
"8 years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"9 years",
"8 years",
"10+ years",
"9 years",
"4 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
null,
null,
"5 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"10+ years",
null,
"10+ years",
"7 years",
"3 years",
"1 year",
"5 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"9 years",
"< 1 year",
"6 years",
"10+ years",
"1 year",
"9 years",
"2 years",
"< 1 year",
"1 year",
"2 years",
"< 1 year",
"10+ years",
"7 years",
"5 years",
"4 years",
"3 years",
"1 year",
"< 1 year",
"5 years",
"1 year",
"8 years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"7 years",
"3 years",
"10+ years",
"1 year",
"2 years",
"4 years",
"5 years",
"10+ years",
"8 years",
"< 1 year",
"< 1 year",
"< 1 year",
"1 year",
"10+ years",
"5 years",
"10+ years",
"7 years",
"10+ years",
"6 years",
"4 years",
"2 years",
"2 years",
null,
"5 years",
"7 years",
"10+ years",
"4 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"7 years",
"3 years",
"< 1 year",
null,
"10+ years",
"7 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"10+ years",
"8 years",
"10+ years",
"6 years",
"1 year",
"10+ years",
"< 1 year",
"7 years",
"8 years",
"10+ years",
"8 years",
"7 years",
"6 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"7 years",
"10+ years",
"1 year",
"7 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
null,
"9 years",
"8 years",
"7 years",
"5 years",
"6 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"9 years",
"7 years",
"7 years",
null,
"1 year",
"10+ years",
"4 years",
null,
"1 year",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"7 years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"3 years",
"10+ years",
null,
"9 years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"9 years",
"5 years",
null,
"10+ years",
"6 years",
"9 years",
"10+ years",
"6 years",
"10+ years",
null,
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"2 years",
"6 years",
"5 years",
"10+ years",
null,
"3 years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"1 year",
"10+ years",
null,
"3 years",
"8 years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"1 year",
"10+ years",
"7 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"5 years",
"2 years",
"1 year",
"< 1 year",
"4 years",
null,
"7 years",
"4 years",
"4 years",
"7 years",
"6 years",
"3 years",
"8 years",
"8 years",
"5 years",
"1 year",
"3 years",
"4 years",
"4 years",
"2 years",
"1 year",
"10+ years",
"2 years",
"5 years",
"8 years",
"< 1 year",
"< 1 year",
"9 years",
"10+ years",
"6 years",
"1 year",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
null,
"9 years",
"< 1 year",
"8 years",
"8 years",
"2 years",
"2 years",
"4 years",
"1 year",
"10+ years",
null,
"5 years",
"< 1 year",
"10+ years",
"5 years",
"3 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"8 years",
"1 year",
"2 years",
"9 years",
"10+ years",
"2 years",
"5 years",
"4 years",
"2 years",
"3 years",
"8 years",
null,
"2 years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"7 years",
"5 years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"1 year",
"4 years",
"10+ years",
"2 years",
"3 years",
"3 years",
"1 year",
"10+ years",
"10+ years",
null,
"10+ years",
"8 years",
"1 year",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"< 1 year",
"4 years",
"5 years",
"3 years",
"4 years",
"7 years",
"5 years",
"3 years",
"8 years",
"1 year",
"10+ years",
"7 years",
"8 years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"7 years",
"3 years",
"5 years",
"8 years",
"7 years",
"4 years",
"6 years",
"7 years",
"3 years",
"4 years",
"10+ years",
"3 years",
"7 years",
"2 years",
"8 years",
"5 years",
"< 1 year",
"4 years",
"< 1 year",
"3 years",
"1 year",
"10+ years",
"3 years",
"9 years",
"8 years",
"3 years",
"10+ years",
"< 1 year",
"1 year",
null,
"10+ years",
"6 years",
"10+ years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"9 years",
"4 years",
"10+ years",
"6 years",
"1 year",
"8 years",
"2 years",
"10+ years",
"1 year",
"6 years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"2 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"5 years",
"3 years",
"6 years",
"9 years",
"2 years",
null,
"10+ years",
"10+ years",
"6 years",
null,
"6 years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
null,
"9 years",
"8 years",
"5 years",
"3 years",
"9 years",
null,
"9 years",
null,
"1 year",
"9 years",
"10+ years",
"< 1 year",
"< 1 year",
"2 years",
"< 1 year",
"10+ years",
"3 years",
"2 years",
"9 years",
"6 years",
"4 years",
"6 years",
"4 years",
"3 years",
"6 years",
"2 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"8 years",
"7 years",
"5 years",
"4 years",
"4 years",
"< 1 year",
"10+ years",
"4 years",
"9 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"7 years",
"4 years",
"3 years",
"< 1 year",
"4 years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"7 years",
"6 years",
"4 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"5 years",
"6 years",
"4 years",
"4 years",
"7 years",
"10+ years",
"7 years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"2 years",
"8 years",
"1 year",
"2 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
null,
"8 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"6 years",
"10+ years",
"2 years",
"2 years",
"5 years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"9 years",
null,
"6 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"6 years",
"10+ years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"10+ years",
"9 years",
"10+ years",
"7 years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
null,
"6 years",
"9 years",
"8 years",
"2 years",
"2 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
null,
"5 years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"4 years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"7 years",
"9 years",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
null,
"6 years",
"10+ years",
"10+ years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"10+ years",
"8 years",
"10+ years",
"6 years",
"4 years",
"10+ years",
"10+ years",
"9 years",
"5 years",
"10+ years",
"7 years",
"8 years",
"6 years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"4 years",
"6 years",
"< 1 year",
"3 years",
null,
"5 years",
"2 years",
"10+ years",
"1 year",
null,
"2 years",
"2 years",
"6 years",
"2 years",
"2 years",
"10+ years",
"6 years",
"8 years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"1 year",
"2 years",
"8 years",
"1 year",
"6 years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"6 years",
"< 1 year",
"2 years",
"8 years",
null,
"4 years",
"6 years",
"5 years",
"7 years",
"2 years",
"7 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"8 years",
null,
"10+ years",
"< 1 year",
"10+ years",
"9 years",
"10+ years",
"5 years",
"4 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"5 years",
"2 years",
"1 year",
"10+ years",
null,
"2 years",
"10+ years",
"7 years",
"6 years",
"7 years",
"10+ years",
"< 1 year",
"6 years",
"7 years",
"3 years",
"7 years",
"1 year",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"6 years",
"5 years",
"4 years",
"8 years",
"2 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"4 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"1 year",
"10+ years",
"2 years",
"7 years",
"10+ years",
null,
"< 1 year",
"3 years",
null,
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"< 1 year",
"8 years",
"7 years",
"6 years",
"< 1 year",
"7 years",
"1 year",
"6 years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
null,
"5 years",
null,
"< 1 year",
"9 years",
"4 years",
"4 years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"8 years",
"10+ years",
"9 years",
"7 years",
"10+ years",
"4 years",
"5 years",
null,
"8 years",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"2 years",
"5 years",
"8 years",
"5 years",
"9 years",
"3 years",
"< 1 year",
"1 year",
"4 years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
null,
"10+ years",
"8 years",
null,
"1 year",
"6 years",
"8 years",
"5 years",
"10+ years",
"1 year",
"7 years",
"< 1 year",
"3 years",
"2 years",
"10+ years",
"10+ years",
null,
"10+ years",
"8 years",
null,
"10+ years",
"4 years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"2 years",
"4 years",
"6 years",
"7 years",
null,
"10+ years",
"3 years",
"10+ years",
"7 years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"1 year",
"10+ years",
"6 years",
"3 years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"< 1 year",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"1 year",
"10+ years",
"5 years",
"6 years",
"8 years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"5 years",
"4 years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"8 years",
"4 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"1 year",
"8 years",
null,
"9 years",
"9 years",
"2 years",
"6 years",
"7 years",
"< 1 year",
"5 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"< 1 year",
"4 years",
"8 years",
"2 years",
"6 years",
"6 years",
null,
"2 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"4 years",
"< 1 year",
"3 years",
"10+ years",
"1 year",
"5 years",
"1 year",
"2 years",
"7 years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"9 years",
"1 year",
"9 years",
"< 1 year",
"5 years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
null,
"10+ years",
"5 years",
null,
"10+ years",
"4 years",
"10+ years",
"7 years",
"10+ years",
"5 years",
"1 year",
"5 years",
"5 years",
"< 1 year",
"5 years",
"6 years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"3 years",
"2 years",
"4 years",
"5 years",
"4 years",
null,
"10+ years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"2 years",
"10+ years",
"2 years",
"1 year",
"9 years",
"2 years",
"8 years",
"< 1 year",
null,
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"2 years",
"7 years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"8 years",
"3 years",
"4 years",
"7 years",
"< 1 year",
"10+ years",
"1 year",
"4 years",
"3 years",
"10+ years",
"5 years",
"3 years",
"< 1 year",
"< 1 year",
"1 year",
"1 year",
"7 years",
"10+ years",
"3 years",
"6 years",
"5 years",
"4 years",
"4 years",
"1 year",
"4 years",
null,
"10+ years",
"7 years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"5 years",
"1 year",
"10+ years",
"10+ years",
"1 year",
"9 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
null,
"8 years",
null,
"8 years",
"1 year",
"2 years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"9 years",
"1 year",
"6 years",
"10+ years",
"1 year",
"7 years",
"2 years",
"10+ years",
"5 years",
"5 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
null,
"10+ years",
"1 year",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"7 years",
"2 years",
"5 years",
null,
"10+ years",
"6 years",
"3 years",
"10+ years",
"< 1 year",
"6 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"4 years",
"8 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"1 year",
"6 years",
"4 years",
"1 year",
"10+ years",
"10+ years",
"7 years",
"6 years",
"7 years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"1 year",
"3 years",
"7 years",
"5 years",
"5 years",
"1 year",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"9 years",
null,
"< 1 year",
"2 years",
"6 years",
"< 1 year",
"3 years",
"10+ years",
"4 years",
"3 years",
"6 years",
"10+ years",
null,
"6 years",
"8 years",
"2 years",
"5 years",
"6 years",
"2 years",
"10+ years",
"3 years",
"8 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"6 years",
"4 years",
"5 years",
"10+ years",
"< 1 year",
"2 years",
"4 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"9 years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"1 year",
"6 years",
"10+ years",
"1 year",
"10+ years",
"8 years",
"1 year",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"5 years",
"4 years",
"10+ years",
"5 years",
"5 years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"6 years",
"10+ years",
"3 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
null,
"7 years",
"3 years",
"2 years",
"6 years",
"10+ years",
null,
"3 years",
"3 years",
"10+ years",
"5 years",
"3 years",
"5 years",
"10+ years",
"8 years",
"10+ years",
"9 years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"4 years",
"3 years",
"2 years",
"1 year",
"3 years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"5 years",
"10+ years",
"4 years",
"10+ years",
"2 years",
null,
"3 years",
"10+ years",
"10+ years",
"7 years",
"< 1 year",
"7 years",
"< 1 year",
null,
"10+ years",
"4 years",
null,
"2 years",
"10+ years",
"2 years",
null,
"5 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"10+ years",
"7 years",
null,
"8 years",
"3 years",
"4 years",
"1 year",
"1 year",
"5 years",
"6 years",
"3 years",
"10+ years",
"5 years",
"5 years",
"9 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"7 years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"7 years",
"2 years",
"< 1 year",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"8 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"< 1 year",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"5 years",
"< 1 year",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"10+ years",
null,
"10+ years",
"3 years",
"2 years",
"9 years",
"< 1 year",
"10+ years",
null,
"10+ years",
"4 years",
"7 years",
"1 year",
"7 years",
"2 years",
"2 years",
"5 years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"9 years",
"3 years",
"< 1 year",
"8 years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"6 years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"3 years",
"4 years",
"2 years",
"2 years",
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"< 1 year",
"3 years",
"1 year",
"4 years",
"8 years",
"4 years",
"4 years",
"8 years",
"3 years",
"8 years",
null,
"1 year",
"10+ years",
"6 years",
"7 years",
"10+ years",
"4 years",
"10+ years",
null,
"10+ years",
"8 years",
"4 years",
null,
"9 years",
"4 years",
"3 years",
"10+ years",
"< 1 year",
"1 year",
"7 years",
"6 years",
"5 years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"3 years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"< 1 year",
"1 year",
"2 years",
"3 years",
"10+ years",
"3 years",
"3 years",
"2 years",
"< 1 year",
"10+ years",
"< 1 year",
"< 1 year",
"5 years",
"6 years",
"6 years",
null,
"10+ years",
"2 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"3 years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"2 years",
"3 years",
"5 years",
"8 years",
"4 years",
"10+ years",
"< 1 year",
"5 years",
null,
"5 years",
"5 years",
"9 years",
"10+ years",
"10+ years",
null,
"7 years",
"10+ years",
null,
"10+ years",
"7 years",
"10+ years",
"6 years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
null,
"7 years",
"5 years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"10+ years",
"1 year",
"4 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"5 years",
"5 years",
"7 years",
null,
"10+ years",
"6 years",
"10+ years",
"7 years",
"3 years",
"1 year",
"5 years",
"10+ years",
"2 years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"8 years",
"2 years",
"10+ years",
"2 years",
"2 years",
"8 years",
"7 years",
"3 years",
null,
"10+ years",
"7 years",
"1 year",
"7 years",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"2 years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"1 year",
"3 years",
"7 years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"6 years",
"4 years",
"2 years",
"6 years",
"9 years",
"3 years",
"10+ years",
null,
"10+ years",
"1 year",
null,
"10+ years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"10+ years",
"2 years",
"4 years",
"10+ years",
null,
"5 years",
"10+ years",
null,
"< 1 year",
"3 years",
"3 years",
null,
"1 year",
"10+ years",
"7 years",
"1 year",
"10+ years",
"4 years",
"4 years",
"5 years",
"< 1 year",
"3 years",
"3 years",
"10+ years",
null,
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
null,
"8 years",
"3 years",
"3 years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"1 year",
"10+ years",
"5 years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"5 years",
"10+ years",
null,
"7 years",
"8 years",
"10+ years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"7 years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"9 years",
"2 years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"3 years",
"2 years",
"8 years",
"1 year",
"10+ years",
null,
"2 years",
"8 years",
"7 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"3 years",
"4 years",
"1 year",
"2 years",
"2 years",
"4 years",
"4 years",
"4 years",
"3 years",
"10+ years",
"6 years",
"3 years",
"9 years",
"4 years",
"9 years",
"10+ years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"2 years",
"1 year",
"< 1 year",
"7 years",
"7 years",
"10+ years",
"9 years",
"10+ years",
"5 years",
"9 years",
"5 years",
"1 year",
"10+ years",
"3 years",
"1 year",
"< 1 year",
"5 years",
"2 years",
"5 years",
"8 years",
"7 years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"< 1 year",
"8 years",
"10+ years",
"2 years",
"< 1 year",
"2 years",
"4 years",
"< 1 year",
"6 years",
"10+ years",
null,
"10+ years",
null,
"1 year",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"7 years",
"5 years",
null,
"3 years",
"10+ years",
"5 years",
"9 years",
"10+ years",
"3 years",
"4 years",
"9 years",
"5 years",
"10+ years",
"10+ years",
"8 years",
"9 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"2 years",
"9 years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"8 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
null,
"< 1 year",
"10+ years",
"9 years",
"6 years",
"3 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"3 years",
"2 years",
"1 year",
"< 1 year",
"< 1 year",
"7 years",
"5 years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"1 year",
"6 years",
"10+ years",
"2 years",
"10+ years",
"8 years",
"7 years",
"1 year",
"10+ years",
"3 years",
"5 years",
"1 year",
"10+ years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"2 years",
"5 years",
"5 years",
"7 years",
"10+ years",
"2 years",
null,
"6 years",
"5 years",
"< 1 year",
"2 years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"< 1 year",
"3 years",
"5 years",
"10+ years",
"< 1 year",
null,
"3 years",
"5 years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"1 year",
"7 years",
"3 years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"4 years",
"4 years",
null,
"10+ years",
"6 years",
"7 years",
"10+ years",
"3 years",
"2 years",
"1 year",
"< 1 year",
"5 years",
"< 1 year",
"8 years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"8 years",
"6 years",
"10+ years",
"1 year",
"7 years",
"< 1 year",
"10+ years",
"3 years",
"4 years",
"5 years",
"2 years",
"10+ years",
"2 years",
"1 year",
"4 years",
"< 1 year",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"6 years",
"9 years",
"10+ years",
"5 years",
"8 years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
null,
"9 years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"4 years",
null,
"8 years",
"10+ years",
"9 years",
"7 years",
"1 year",
null,
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"8 years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"< 1 year",
"7 years",
"2 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"5 years",
"5 years",
"< 1 year",
"10+ years",
"3 years",
"4 years",
"10+ years",
"6 years",
"1 year",
"10+ years",
"4 years",
null,
"10+ years",
"1 year",
"2 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"1 year",
"10+ years",
"2 years",
"4 years",
"8 years",
"4 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"1 year",
"10+ years",
"7 years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"6 years",
"10+ years",
"6 years",
"10+ years",
"4 years",
"9 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"1 year",
"9 years",
"5 years",
"5 years",
"6 years",
"10+ years",
"9 years",
"9 years",
"6 years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"9 years",
"4 years",
null,
"10+ years",
"9 years",
"3 years",
"< 1 year",
"6 years",
"10+ years",
"6 years",
"7 years",
"2 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"3 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"8 years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"3 years",
"5 years",
null,
"5 years",
"10+ years",
"1 year",
"3 years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"4 years",
"9 years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"3 years",
"1 year",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"2 years",
"9 years",
"< 1 year",
"10+ years",
"4 years",
null,
"10+ years",
"6 years",
"7 years",
"2 years",
"10+ years",
"2 years",
"1 year",
"< 1 year",
"8 years",
"2 years",
"7 years",
"10+ years",
"3 years",
"2 years",
null,
"< 1 year",
"1 year",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"5 years",
"3 years",
"5 years",
"7 years",
"7 years",
"3 years",
"5 years",
"8 years",
"7 years",
"1 year",
"5 years",
"< 1 year",
"2 years",
"7 years",
"1 year",
"7 years",
"3 years",
"7 years",
"5 years",
"1 year",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"4 years",
"< 1 year",
"2 years",
"< 1 year",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"4 years",
"6 years",
"9 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"9 years",
"5 years",
"8 years",
null,
"10+ years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"3 years",
"1 year",
"8 years",
"5 years",
"10+ years",
"3 years",
"3 years",
"< 1 year",
"1 year",
"10+ years",
null,
"4 years",
null,
null,
"3 years",
"7 years",
"2 years",
"10+ years",
"2 years",
null,
"6 years",
"2 years",
"9 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
null,
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"2 years",
"10+ years",
"3 years",
"3 years",
"6 years",
"2 years",
"< 1 year",
"3 years",
"2 years",
"3 years",
"10+ years",
"6 years",
"< 1 year",
"< 1 year",
"3 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
null,
"10+ years",
"4 years",
"10+ years",
"7 years",
"10+ years",
null,
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"8 years",
"10+ years",
null,
"10+ years",
"10+ years",
"6 years",
null,
"10+ years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"5 years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"3 years",
"4 years",
null,
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"< 1 year",
"1 year",
"7 years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"4 years",
"8 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"2 years",
"4 years",
"< 1 year",
"10+ years",
"8 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"2 years",
"5 years",
"3 years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"2 years",
"2 years",
null,
null,
"2 years",
"10+ years",
"7 years",
"8 years",
"3 years",
"9 years",
"10+ years",
"7 years",
null,
"2 years",
"5 years",
"1 year",
"9 years",
"5 years",
"7 years",
"10+ years",
"< 1 year",
"9 years",
"8 years",
"9 years",
"10+ years",
"10+ years",
null,
"2 years",
"8 years",
"9 years",
"2 years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"9 years",
null,
"10+ years",
null,
"3 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"8 years",
"5 years",
"10+ years",
"10+ years",
"9 years",
"6 years",
"3 years",
"5 years",
"10+ years",
"5 years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"3 years",
"3 years",
"4 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"3 years",
"5 years",
"2 years",
"7 years",
"3 years",
"2 years",
"9 years",
"6 years",
null,
"2 years",
"4 years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"2 years",
"10+ years",
null,
"10+ years",
"6 years",
"5 years",
"3 years",
"6 years",
"10+ years",
"5 years",
"8 years",
"2 years",
"3 years",
"10+ years",
"3 years",
"9 years",
"4 years",
"10+ years",
"1 year",
"4 years",
"1 year",
"10+ years",
"5 years",
"2 years",
"3 years",
"1 year",
"4 years",
"5 years",
null,
"6 years",
"9 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"7 years",
"1 year",
"7 years",
"10+ years",
"8 years",
"< 1 year",
null,
"5 years",
"5 years",
"10+ years",
"10+ years",
"8 years",
"1 year",
"5 years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
null,
"3 years",
"5 years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"1 year",
null,
"1 year",
"< 1 year",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
null,
"3 years",
null,
"1 year",
"6 years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"2 years",
"< 1 year",
"2 years",
"2 years",
"2 years",
null,
"4 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"5 years",
"10+ years",
"7 years",
"10+ years",
"1 year",
"10+ years",
"8 years",
"2 years",
"9 years",
"5 years",
"5 years",
"10+ years",
"9 years",
"7 years",
"5 years",
"3 years",
"10+ years",
"< 1 year",
null,
"8 years",
"6 years",
"2 years",
"9 years",
"2 years",
"7 years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"8 years",
"1 year",
"2 years",
null,
"2 years",
"1 year",
"4 years",
"6 years",
"2 years",
null,
"6 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"4 years",
"2 years",
"6 years",
"< 1 year",
"< 1 year",
"6 years",
"2 years",
"7 years",
"5 years",
"< 1 year",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"3 years",
"8 years",
"10+ years",
"3 years",
"< 1 year",
"6 years",
"10+ years",
"8 years",
"3 years",
"3 years",
"3 years",
"< 1 year",
"2 years",
"9 years",
"10+ years",
"8 years",
"< 1 year",
"6 years",
"1 year",
"1 year",
"6 years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"5 years",
"6 years",
"5 years",
"10+ years",
"4 years",
"10+ years",
"4 years",
"2 years",
"1 year",
"5 years",
null,
null,
"10+ years",
"10+ years",
null,
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"6 years",
"10+ years",
"5 years",
"7 years",
"3 years",
"10+ years",
"2 years",
"10+ years",
null,
"10+ years",
"4 years",
"10+ years",
"5 years",
"< 1 year",
"6 years",
"7 years",
"1 year",
"< 1 year",
"8 years",
"< 1 year",
"5 years",
"4 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
null,
"10+ years",
"10+ years",
"10+ years",
"7 years",
"5 years",
"4 years",
"9 years",
"4 years",
"8 years",
"9 years",
"10+ years",
"2 years",
"1 year",
"9 years",
"10+ years",
"< 1 year",
"1 year",
"3 years",
"3 years",
"< 1 year",
"2 years",
"6 years",
"10+ years",
"10+ years",
"4 years",
"6 years",
"4 years",
"10+ years",
"10+ years",
null,
"3 years",
"2 years",
"4 years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"< 1 year",
"< 1 year",
"6 years",
"7 years",
"10+ years",
"4 years",
"7 years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"2 years",
"6 years",
"< 1 year",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"6 years",
"10+ years",
"4 years",
"< 1 year",
"9 years",
"5 years",
"10+ years",
null,
"< 1 year",
"3 years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"6 years",
"5 years",
"4 years",
"3 years",
"8 years",
"10+ years",
"2 years",
"1 year",
"1 year",
null,
"8 years",
"10+ years",
"4 years",
null,
null,
"2 years",
"10+ years",
null,
"7 years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"4 years",
"10+ years",
"4 years",
"8 years",
"7 years",
"8 years",
"6 years",
"10+ years",
"7 years",
"4 years",
"3 years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"7 years",
"1 year",
"9 years",
"3 years",
null,
null,
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"1 year",
"10+ years",
"5 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"7 years",
"4 years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"6 years",
"7 years",
"10+ years",
"< 1 year",
"3 years",
"5 years",
"8 years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"10+ years",
"< 1 year",
null,
"4 years",
"10+ years",
"10+ years",
"10+ years",
null,
"6 years",
"9 years",
"7 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"2 years",
"7 years",
"3 years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"3 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"8 years",
"3 years",
"< 1 year",
"4 years",
"< 1 year",
"1 year",
"< 1 year",
null,
"7 years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"4 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"2 years",
"1 year",
"3 years",
"7 years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"8 years",
"3 years",
"6 years",
"10+ years",
"2 years",
"3 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"2 years",
"7 years",
"< 1 year",
"3 years",
null,
"< 1 year",
"3 years",
"4 years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
null,
"10+ years",
"4 years",
"< 1 year",
"3 years",
"4 years",
"2 years",
"10+ years",
null,
"5 years",
"1 year",
"10+ years",
"5 years",
"1 year",
"9 years",
"4 years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"3 years",
"6 years",
"10+ years",
null,
"1 year",
"10+ years",
"2 years",
"3 years",
"< 1 year",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"10+ years",
null,
"3 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"5 years",
"< 1 year",
"2 years",
"10+ years",
"4 years",
"8 years",
"8 years",
"10+ years",
"< 1 year",
"2 years",
"5 years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"10+ years",
null,
"10+ years",
"6 years",
"6 years",
"6 years",
"< 1 year",
null,
"10+ years",
null,
"2 years",
"4 years",
"4 years",
"5 years",
"5 years",
"2 years",
"6 years",
"2 years",
"5 years",
"2 years",
"1 year",
"1 year",
"< 1 year",
"10+ years",
"1 year",
"9 years",
"5 years",
null,
"5 years",
"5 years",
"10+ years",
"7 years",
"1 year",
"7 years",
"4 years",
"< 1 year",
"10+ years",
"2 years",
"3 years",
"< 1 year",
"5 years",
"< 1 year",
"10+ years",
"5 years",
"4 years",
null,
"4 years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"5 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
null,
"10+ years",
"1 year",
"10+ years",
"2 years",
"3 years",
"4 years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"1 year",
"2 years",
"< 1 year",
"2 years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"6 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"8 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"1 year",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"6 years",
"10+ years",
"< 1 year",
"< 1 year",
"< 1 year",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"7 years",
"4 years",
null,
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"9 years",
"3 years",
"10+ years",
"5 years",
"4 years",
"5 years",
null,
"4 years",
"1 year",
"8 years",
"6 years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"6 years",
"3 years",
"10+ years",
"9 years",
"3 years",
"2 years",
"8 years",
"2 years",
"10+ years",
"4 years",
"6 years",
"5 years",
null,
"2 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"3 years",
"2 years",
"4 years",
"10+ years",
"1 year",
"1 year",
"2 years",
"10+ years",
"3 years",
"2 years",
"4 years",
"3 years",
"< 1 year",
"7 years",
null,
"1 year",
"3 years",
"2 years",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"9 years",
"10+ years",
"7 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"6 years",
"< 1 year",
"10+ years",
null,
"1 year",
"7 years",
"6 years",
"9 years",
"3 years",
"5 years",
"4 years",
"8 years",
"8 years",
"9 years",
"2 years",
"< 1 year",
"10+ years",
"6 years",
"1 year",
"10+ years",
"6 years",
"2 years",
"10+ years",
"4 years",
"5 years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"8 years",
"3 years",
"8 years",
"9 years",
"4 years",
"1 year",
null,
"10+ years",
"2 years",
"10+ years",
null,
"2 years",
"3 years",
"< 1 year",
"1 year",
"3 years",
"10+ years",
"4 years",
"1 year",
"1 year",
"8 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"< 1 year",
"2 years",
"5 years",
"10+ years",
"1 year",
"1 year",
"6 years",
"10+ years",
"8 years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
null,
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"3 years",
"6 years",
"1 year",
"10+ years",
"< 1 year",
"8 years",
"8 years",
"2 years",
"9 years",
"9 years",
"8 years",
"10+ years",
"3 years",
"9 years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"7 years",
"7 years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"1 year",
"2 years",
"< 1 year",
"10+ years",
"7 years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"4 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"7 years",
"2 years",
"2 years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"4 years",
"6 years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"9 years",
"5 years",
"6 years",
"5 years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"5 years",
"5 years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"5 years",
"3 years",
"8 years",
"9 years",
"< 1 year",
"7 years",
"10+ years",
"2 years",
"4 years",
"10+ years",
"8 years",
"3 years",
null,
"7 years",
"9 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"3 years",
null,
"4 years",
"9 years",
"10+ years",
"3 years",
"9 years",
"1 year",
"4 years",
"1 year",
"10+ years",
"9 years",
"< 1 year",
"5 years",
"1 year",
"9 years",
"1 year",
"10+ years",
"4 years",
"3 years",
"10+ years",
null,
null,
"7 years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"3 years",
null,
"< 1 year",
"< 1 year",
null,
"1 year",
"7 years",
null,
"5 years",
"10+ years",
"2 years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"2 years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"2 years",
"1 year",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"< 1 year",
"5 years",
"3 years",
"3 years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"1 year",
"6 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
null,
"5 years",
"10+ years",
"10+ years",
"1 year",
"8 years",
"2 years",
"2 years",
"< 1 year",
"6 years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"1 year",
"6 years",
"5 years",
"5 years",
"9 years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"6 years",
"8 years",
"10+ years",
"4 years",
"10+ years",
"1 year",
"2 years",
"2 years",
"< 1 year",
"2 years",
"7 years",
null,
"5 years",
"4 years",
null,
"2 years",
"1 year",
"8 years",
"10+ years",
"10+ years",
"9 years",
"8 years",
"4 years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
"5 years",
"4 years",
null,
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
null,
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"3 years",
"8 years",
"10+ years",
"7 years",
"3 years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"4 years",
"3 years",
"8 years",
null,
"10+ years",
"8 years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"9 years",
null,
"6 years",
"4 years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"3 years",
"8 years",
"9 years",
"< 1 year",
null,
"4 years",
"< 1 year",
"3 years",
"10+ years",
"4 years",
"10+ years",
null,
"2 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"3 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"6 years",
"9 years",
"7 years",
null,
"< 1 year",
"10+ years",
"1 year",
"5 years",
"4 years",
"7 years",
"1 year",
"7 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"< 1 year",
"1 year",
"9 years",
"9 years",
"< 1 year",
"5 years",
"9 years",
"7 years",
"3 years",
"10+ years",
"9 years",
"5 years",
"2 years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"< 1 year",
"8 years",
"1 year",
"2 years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"2 years",
"10+ years",
"5 years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"1 year",
"2 years",
"5 years",
"10+ years",
"5 years",
"10+ years",
null,
"3 years",
"5 years",
"2 years",
"6 years",
"6 years",
"10+ years",
"10+ years",
"8 years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"6 years",
"7 years",
"5 years",
"10+ years",
"7 years",
"1 year",
"9 years",
"5 years",
"10+ years",
"2 years",
"1 year",
"8 years",
"2 years",
"8 years",
"7 years",
"7 years",
"< 1 year",
"1 year",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"1 year",
"9 years",
"4 years",
"10+ years",
null,
"2 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"3 years",
"4 years",
"6 years",
"5 years",
"4 years",
"10+ years",
"9 years",
"3 years",
"5 years",
"10+ years",
"4 years",
"4 years",
"10+ years",
"5 years",
"1 year",
"7 years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"1 year",
"10+ years",
null,
"2 years",
"2 years",
null,
"3 years",
"10+ years",
"9 years",
"4 years",
"1 year",
"10+ years",
"5 years",
"10+ years",
null,
"< 1 year",
"10+ years",
"8 years",
"7 years",
"2 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"6 years",
"2 years",
"6 years",
"6 years",
"8 years",
"10+ years",
"7 years",
"1 year",
"4 years",
"4 years",
null,
"6 years",
"5 years",
"9 years",
"2 years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"1 year",
"2 years",
"9 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"2 years",
"2 years",
"< 1 year",
"10+ years",
"9 years",
"5 years",
"1 year",
"1 year",
"1 year",
null,
"1 year",
null,
"10+ years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"6 years",
"5 years",
"8 years",
"8 years",
"6 years",
"9 years",
"3 years",
null,
"10+ years",
"5 years",
null,
"2 years",
"< 1 year",
"10+ years",
"1 year",
"6 years",
null,
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"4 years",
"9 years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"4 years",
null,
"1 year",
"5 years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"< 1 year",
"6 years",
"4 years",
"7 years",
"3 years",
"2 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
"3 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"7 years",
"3 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"5 years",
"10+ years",
"6 years",
"< 1 year",
"< 1 year",
"9 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"6 years",
"10+ years",
"4 years",
null,
"10+ years",
"5 years",
"< 1 year",
"8 years",
"1 year",
"6 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"4 years",
null,
"7 years",
"1 year",
"8 years",
"4 years",
"10+ years",
"5 years",
"3 years",
"8 years",
"5 years",
"3 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"2 years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"2 years",
"6 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"8 years",
"3 years",
"7 years",
"7 years",
"9 years",
"5 years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"4 years",
"10+ years",
"2 years",
"1 year",
"4 years",
"2 years",
"8 years",
"10+ years",
"7 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"7 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"< 1 year",
"10+ years",
"3 years",
"5 years",
"7 years",
null,
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"9 years",
null,
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"7 years",
"7 years",
"5 years",
"3 years",
"1 year",
"10+ years",
"2 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
null,
"3 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"2 years",
"2 years",
"4 years",
"8 years",
"< 1 year",
"< 1 year",
"1 year",
"2 years",
"5 years",
"5 years",
"10+ years",
"3 years",
null,
"10+ years",
"10+ years",
"4 years",
"8 years",
"6 years",
"4 years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"3 years",
"2 years",
"1 year",
"7 years",
"9 years",
"1 year",
"2 years",
"9 years",
"< 1 year",
"2 years",
"1 year",
"4 years",
null,
"6 years",
"10+ years",
"10+ years",
null,
"5 years",
"4 years",
"6 years",
null,
"1 year",
null,
"10+ years",
"2 years",
"1 year",
"2 years",
"3 years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"2 years",
"7 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
null,
"4 years",
"6 years",
"1 year",
"2 years",
"10+ years",
"4 years",
"5 years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"6 years",
"2 years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"6 years",
"5 years",
"5 years",
"3 years",
"5 years",
"3 years",
null,
null,
null,
"1 year",
"10+ years",
"9 years",
"10+ years",
"8 years",
"3 years",
"9 years",
"< 1 year",
"5 years",
null,
"2 years",
"3 years",
"7 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"8 years",
"8 years",
"< 1 year",
"2 years",
"2 years",
"< 1 year",
"10+ years",
"5 years",
"8 years",
"4 years",
"8 years",
"7 years",
"10+ years",
"8 years",
null,
"4 years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"5 years",
"2 years",
"5 years",
"2 years",
"9 years",
"5 years",
"< 1 year",
"9 years",
"< 1 year",
"1 year",
"2 years",
"1 year",
"8 years",
"8 years",
"10+ years",
"5 years",
"7 years",
"10+ years",
"8 years",
"5 years",
"< 1 year",
"< 1 year",
"1 year",
"9 years",
"10+ years",
"1 year",
"5 years",
"7 years",
"9 years",
"10+ years",
"4 years",
"< 1 year",
"8 years",
"1 year",
"2 years",
"9 years",
"5 years",
"< 1 year",
"5 years",
"10+ years",
"1 year",
"< 1 year",
"2 years",
"8 years",
"4 years",
"2 years",
"4 years",
"1 year",
"10+ years",
"10+ years",
null,
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
null,
"3 years",
"1 year",
"6 years",
"10+ years",
"5 years",
"6 years",
"5 years",
"1 year",
"1 year",
"< 1 year",
"10+ years",
null,
"10+ years",
"4 years",
"2 years",
"10+ years",
"2 years",
"3 years",
"3 years",
"5 years",
"3 years",
"4 years",
"10+ years",
"4 years",
"10+ years",
"2 years",
null,
"1 year",
"7 years",
"2 years",
"2 years",
"10+ years",
"2 years",
null,
"10+ years",
"10+ years",
"6 years",
"5 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"8 years",
null,
"< 1 year",
"< 1 year",
"3 years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"3 years",
"< 1 year",
"1 year",
"2 years",
"6 years",
"5 years",
"1 year",
"10+ years",
"3 years",
"7 years",
"2 years",
"< 1 year",
"< 1 year",
"4 years",
"5 years",
"< 1 year",
"2 years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"4 years",
"8 years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"2 years",
"< 1 year",
"2 years",
"< 1 year",
"1 year",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"8 years",
"10+ years",
"1 year",
"4 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"3 years",
null,
"3 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"1 year",
"10+ years",
"5 years",
"3 years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"6 years",
"6 years",
"2 years",
null,
"4 years",
"5 years",
"4 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"1 year",
"8 years",
"3 years",
"4 years",
"10+ years",
"5 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
null,
"2 years",
"4 years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"6 years",
"3 years",
"5 years",
"2 years",
"8 years",
"3 years",
"10+ years",
"9 years",
"1 year",
"2 years",
"7 years",
"9 years",
"8 years",
null,
"2 years",
"2 years",
null,
"4 years",
"10+ years",
"1 year",
"1 year",
"8 years",
"3 years",
"6 years",
"1 year",
"3 years",
"5 years",
"1 year",
"10+ years",
"2 years",
"9 years",
"3 years",
"9 years",
"9 years",
"10+ years",
"7 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"1 year",
"1 year",
null,
"10+ years",
"10+ years",
"6 years",
"4 years",
"6 years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"4 years",
null,
"1 year",
"1 year",
"3 years",
"10+ years",
"2 years",
"2 years",
"3 years",
"6 years",
"2 years",
"4 years",
"9 years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"5 years",
"1 year",
"4 years",
"5 years",
"3 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"7 years",
"10+ years",
"2 years",
null,
"1 year",
"8 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"6 years",
"8 years",
"< 1 year",
null,
"10+ years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"5 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"9 years",
"1 year",
"6 years",
"10+ years",
null,
"5 years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"4 years",
null,
"7 years",
"4 years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"8 years",
"7 years",
"5 years",
"< 1 year",
"10+ years",
"2 years",
"6 years",
null,
"10+ years",
"8 years",
"10+ years",
"10+ years",
"5 years",
"6 years",
null,
"10+ years",
"7 years",
"8 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"< 1 year",
"6 years",
"3 years",
"6 years",
"10+ years",
"4 years",
"10+ years",
"6 years",
"8 years",
"10+ years",
"5 years",
"1 year",
"9 years",
"10+ years",
"2 years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"< 1 year",
"5 years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"6 years",
"6 years",
"8 years",
"1 year",
"3 years",
"< 1 year",
"6 years",
"< 1 year",
"8 years",
"3 years",
"1 year",
null,
"2 years",
"2 years",
"7 years",
"5 years",
"< 1 year",
"2 years",
"10+ years",
"1 year",
"3 years",
"3 years",
"4 years",
"8 years",
"1 year",
"5 years",
"10+ years",
"9 years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"4 years",
"4 years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"3 years",
"6 years",
"< 1 year",
"8 years",
"3 years",
"9 years",
"3 years",
"10+ years",
"3 years",
"1 year",
"< 1 year",
"3 years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"9 years",
"2 years",
"1 year",
"1 year",
"10+ years",
null,
"5 years",
"10+ years",
"10+ years",
"3 years",
"6 years",
"10+ years",
"1 year",
null,
"10+ years",
"4 years",
"10+ years",
"2 years",
"2 years",
null,
"3 years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"2 years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
null,
"5 years",
null,
"2 years",
"2 years",
null,
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"2 years",
"2 years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"4 years",
"10+ years",
"1 year",
"2 years",
"10+ years",
null,
"< 1 year",
"< 1 year",
"2 years",
"5 years",
"10+ years",
"1 year",
"9 years",
"10+ years",
"7 years",
"2 years",
"9 years",
"10+ years",
"1 year",
"5 years",
"3 years",
"10+ years",
"10+ years",
null,
"< 1 year",
"9 years",
"10+ years",
"6 years",
"9 years",
"10+ years",
"8 years",
"6 years",
"1 year",
"< 1 year",
"3 years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"1 year",
"8 years",
"10+ years",
"4 years",
"1 year",
null,
"2 years",
"8 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
null,
"1 year",
"8 years",
"2 years",
null,
null,
"10+ years",
"10+ years",
null,
"1 year",
"3 years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"7 years",
"9 years",
"7 years",
"< 1 year",
"< 1 year",
"10+ years",
"< 1 year",
null,
"2 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"4 years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"6 years",
"5 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"9 years",
"9 years",
"1 year",
"2 years",
null,
"1 year",
"10+ years",
"10+ years",
"5 years",
"8 years",
"3 years",
"5 years",
"7 years",
"1 year",
"2 years",
null,
"9 years",
"10+ years",
"7 years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"5 years",
"10+ years",
null,
"8 years",
"2 years",
null,
"< 1 year",
null,
"10+ years",
"5 years",
"< 1 year",
"7 years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"9 years",
"1 year",
"5 years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"10+ years",
"6 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
null,
"1 year",
"2 years",
"2 years",
"4 years",
"10+ years",
"2 years",
"6 years",
"10+ years",
null,
null,
"5 years",
null,
"2 years",
null,
"5 years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"6 years",
"4 years",
"10+ years",
"8 years",
"10+ years",
"6 years",
"1 year",
"9 years",
"8 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"5 years",
"4 years",
"5 years",
"6 years",
"1 year",
"6 years",
"3 years",
"2 years",
"8 years",
"2 years",
"< 1 year",
"10+ years",
"9 years",
"1 year",
"7 years",
"10+ years",
"6 years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"1 year",
"8 years",
"2 years",
"7 years",
"3 years",
"6 years",
"3 years",
"2 years",
null,
"7 years",
"10+ years",
"8 years",
"10+ years",
"4 years",
"5 years",
"8 years",
"1 year",
"3 years",
"6 years",
"2 years",
"3 years",
"4 years",
null,
"10+ years",
"4 years",
"10+ years",
"10+ years",
"5 years",
"7 years",
"6 years",
"10+ years",
"3 years",
null,
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"10+ years",
"< 1 year",
"< 1 year",
"3 years",
"9 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"7 years",
"3 years",
"5 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
null,
"2 years",
"10+ years",
"7 years",
"10+ years",
"5 years",
"7 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"3 years",
"2 years",
"2 years",
"10+ years",
"< 1 year",
"5 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"5 years",
"10+ years",
"< 1 year",
"4 years",
"4 years",
"10+ years",
"3 years",
"3 years",
"3 years",
null,
"2 years",
"1 year",
"5 years",
"10+ years",
"1 year",
"2 years",
"3 years",
"10+ years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"2 years",
"4 years",
"7 years",
"8 years",
"3 years",
"8 years",
null,
"8 years",
null,
"10+ years",
"2 years",
"7 years",
"9 years",
"7 years",
"7 years",
"3 years",
"< 1 year",
"8 years",
"1 year",
null,
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"1 year",
"6 years",
"2 years",
"< 1 year",
"9 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"10+ years",
"4 years",
"10+ years",
null,
"10+ years",
"3 years",
"3 years",
"10+ years",
"9 years",
"2 years",
"< 1 year",
"2 years",
"3 years",
"< 1 year",
null,
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"2 years",
"< 1 year",
"1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
null,
"3 years",
"8 years",
"3 years",
"< 1 year",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"5 years",
"8 years",
null,
"10+ years",
"< 1 year",
"9 years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"5 years",
"2 years",
"10+ years",
"7 years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"9 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"7 years",
"6 years",
"5 years",
"3 years",
"9 years",
"9 years",
"3 years",
"10+ years",
"4 years",
"2 years",
"10+ years",
"1 year",
null,
"9 years",
null,
"< 1 year",
"< 1 year",
"10+ years",
"5 years",
"1 year",
null,
"10+ years",
"10+ years",
"7 years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
null,
"5 years",
"2 years",
"9 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"4 years",
null,
"8 years",
"6 years",
"10+ years",
"8 years",
"3 years",
"4 years",
"10+ years",
"4 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"9 years",
"7 years",
"< 1 year",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"1 year",
"7 years",
"6 years",
"10+ years",
"2 years",
"5 years",
"3 years",
null,
"2 years",
"6 years",
"1 year",
"10+ years",
"10+ years",
"6 years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"6 years",
"< 1 year",
"10+ years",
"3 years",
"8 years",
"10+ years",
"< 1 year",
"7 years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"2 years",
"9 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"5 years",
"2 years",
"< 1 year",
"9 years",
"10+ years",
"9 years",
"4 years",
"8 years",
"10+ years",
"8 years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"5 years",
"8 years",
"6 years",
"1 year",
"10+ years",
"9 years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"4 years",
"10+ years",
"5 years",
"1 year",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"9 years",
"10+ years",
"4 years",
"5 years",
"1 year",
"10+ years",
null,
"10+ years",
"< 1 year",
"5 years",
"2 years",
"< 1 year",
"3 years",
"7 years",
"10+ years",
null,
"5 years",
"10+ years",
"9 years",
"10+ years",
"5 years",
"2 years",
"2 years",
"10+ years",
"8 years",
"7 years",
"2 years",
"10+ years",
"9 years",
"9 years",
"4 years",
"2 years",
"9 years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"2 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"3 years",
"9 years",
"6 years",
"2 years",
"5 years",
"8 years",
"6 years",
"2 years",
"7 years",
"2 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"2 years",
"1 year",
"3 years",
"2 years",
"4 years",
"7 years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"6 years",
null,
"< 1 year",
null,
"10+ years",
"2 years",
"6 years",
"5 years",
"< 1 year",
"2 years",
"2 years",
"2 years",
"5 years",
null,
"1 year",
"1 year",
"7 years",
"6 years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
null,
"< 1 year",
"2 years",
"2 years",
"2 years",
"7 years",
null,
"2 years",
"10+ years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"5 years",
"5 years",
"2 years",
"5 years",
null,
"6 years",
"< 1 year",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"2 years",
"3 years",
"5 years",
"2 years",
null,
"2 years",
"5 years",
"9 years",
"3 years",
null,
"< 1 year",
"10+ years",
"7 years",
null,
null,
"1 year",
"5 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"7 years",
"8 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"3 years",
"10+ years",
"10+ years",
null,
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"5 years",
"5 years",
"10+ years",
"8 years",
"10+ years",
"9 years",
"10+ years",
"2 years",
"< 1 year",
"< 1 year",
"2 years",
null,
"10+ years",
"1 year",
"10+ years",
"8 years",
"7 years",
"5 years",
"3 years",
"3 years",
"7 years",
"2 years",
"6 years",
"< 1 year",
"7 years",
"5 years",
"7 years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"6 years",
"2 years",
"7 years",
"10+ years",
"3 years",
"9 years",
"2 years",
"10+ years",
null,
"4 years",
"5 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"3 years",
"8 years",
"3 years",
null,
null,
"1 year",
"< 1 year",
"10+ years",
"7 years",
"4 years",
"2 years",
"10+ years",
"4 years",
"5 years",
"2 years",
null,
"10+ years",
"1 year",
"3 years",
"2 years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"9 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"3 years",
"9 years",
"4 years",
"2 years",
"7 years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"2 years",
null,
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"9 years",
"5 years",
"< 1 year",
"7 years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"6 years",
"2 years",
"1 year",
"1 year",
"4 years",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"10+ years",
"7 years",
"2 years",
"2 years",
"1 year",
"6 years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"6 years",
"6 years",
"1 year",
"10+ years",
"10+ years",
"8 years",
"7 years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"4 years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"8 years",
"4 years",
"7 years",
"2 years",
"3 years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"2 years",
"3 years",
null,
"3 years",
"7 years",
"3 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"7 years",
"7 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"3 years",
"1 year",
"8 years",
"7 years",
"6 years",
"7 years",
"5 years",
"5 years",
"1 year",
"4 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"6 years",
"8 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"6 years",
"10+ years",
"7 years",
null,
"10+ years",
"4 years",
"5 years",
"8 years",
null,
"10+ years",
"3 years",
"3 years",
"5 years",
null,
"10+ years",
"10+ years",
"2 years",
null,
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"9 years",
"10+ years",
"2 years",
"7 years",
"7 years",
"8 years",
"10+ years",
null,
"2 years",
"4 years",
"10+ years",
null,
"2 years",
"1 year",
"1 year",
"3 years",
"4 years",
"10+ years",
"6 years",
"7 years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"7 years",
null,
null,
"5 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"1 year",
"8 years",
"4 years",
"5 years",
"7 years",
"5 years",
"10+ years",
"< 1 year",
"7 years",
null,
"< 1 year",
"1 year",
"10+ years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"6 years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"8 years",
"2 years",
null,
"4 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"2 years",
"7 years",
"2 years",
"8 years",
"6 years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"1 year",
"9 years",
"< 1 year",
"< 1 year",
"10+ years",
null,
"3 years",
"3 years",
"10+ years",
"1 year",
"4 years",
"5 years",
"2 years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"6 years",
"8 years",
"1 year",
"4 years",
"< 1 year",
"7 years",
null,
"< 1 year",
"10+ years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"1 year",
"2 years",
"4 years",
"10+ years",
"8 years",
"< 1 year",
null,
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"6 years",
"10+ years",
null,
"10+ years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"7 years",
"6 years",
"10+ years",
"4 years",
"< 1 year",
"2 years",
"5 years",
"9 years",
"10+ years",
"3 years",
"5 years",
"7 years",
null,
"3 years",
"4 years",
"< 1 year",
"5 years",
"6 years",
"4 years",
null,
"4 years",
"6 years",
"< 1 year",
"9 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"6 years",
"10+ years",
"7 years",
"3 years",
"10+ years",
"6 years",
"3 years",
"< 1 year",
"2 years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"6 years",
"10+ years",
"6 years",
"3 years",
"< 1 year",
"5 years",
"6 years",
"1 year",
"10+ years",
"10+ years",
"9 years",
"4 years",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"1 year",
"7 years",
"5 years",
"5 years",
"6 years",
"< 1 year",
null,
"10+ years",
"9 years",
"10+ years",
null,
"10+ years",
null,
"< 1 year",
"10+ years",
"4 years",
"4 years",
"6 years",
"10+ years",
"7 years",
"6 years",
"10+ years",
"9 years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"1 year",
"2 years",
"1 year",
null,
"9 years",
"5 years",
"5 years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"4 years",
"8 years",
"10+ years",
"7 years",
null,
"6 years",
"2 years",
"2 years",
"3 years",
null,
"6 years",
"2 years",
"5 years",
"8 years",
"10+ years",
"2 years",
"2 years",
"6 years",
"2 years",
null,
"1 year",
"1 year",
null,
"2 years",
"< 1 year",
"8 years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"5 years",
null,
"8 years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"7 years",
"8 years",
null,
"10+ years",
"1 year",
"5 years",
"2 years",
"10+ years",
"2 years",
"3 years",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"5 years",
"3 years",
"6 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"8 years",
"3 years",
"8 years",
null,
"10+ years",
"9 years",
"5 years",
"4 years",
"< 1 year",
"9 years",
"10+ years",
"10+ years",
null,
"7 years",
"10+ years",
"5 years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
null,
"7 years",
"4 years",
"7 years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"< 1 year",
"< 1 year",
"10+ years",
"4 years",
"2 years",
"5 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"2 years",
"2 years",
"3 years",
"1 year",
"10+ years",
null,
"8 years",
"5 years",
"10+ years",
"5 years",
"8 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"7 years",
"< 1 year",
"3 years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"2 years",
"1 year",
"1 year",
null,
"2 years",
"8 years",
"10+ years",
"10+ years",
null,
"6 years",
"7 years",
"10+ years",
"7 years",
"3 years",
"10+ years",
"7 years",
"10+ years",
"4 years",
"6 years",
"10+ years",
"3 years",
"10+ years",
null,
"2 years",
"10+ years",
"3 years",
"1 year",
"3 years",
"2 years",
"6 years",
"8 years",
"10+ years",
"5 years",
"1 year",
"2 years",
"5 years",
"4 years",
"10+ years",
"7 years",
"< 1 year",
"7 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"6 years",
"1 year",
"2 years",
"10+ years",
"9 years",
"10+ years",
"2 years",
"7 years",
null,
"10+ years",
"2 years",
"10+ years",
"4 years",
null,
"5 years",
"6 years",
"10+ years",
"< 1 year",
"< 1 year",
null,
"2 years",
null,
"10+ years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"< 1 year",
"3 years",
"8 years",
"10+ years",
"6 years",
"3 years",
"6 years",
"< 1 year",
"2 years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"6 years",
"9 years",
"7 years",
"2 years",
"3 years",
"2 years",
"7 years",
"10+ years",
"5 years",
"2 years",
null,
"2 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"4 years",
"< 1 year",
"10+ years",
"9 years",
"< 1 year",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"2 years",
"8 years",
"5 years",
"10+ years",
"6 years",
"8 years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"3 years",
null,
"10+ years",
"10+ years",
"8 years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"< 1 year",
"3 years",
"4 years",
"10+ years",
"< 1 year",
"< 1 year",
"4 years",
"10+ years",
"< 1 year",
"< 1 year",
"3 years",
"6 years",
"8 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"6 years",
"< 1 year",
"7 years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"9 years",
null,
"10+ years",
"10+ years",
null,
"9 years",
"< 1 year",
"6 years",
"2 years",
"8 years",
"7 years",
"10+ years",
"10+ years",
null,
"2 years",
"7 years",
null,
"4 years",
"10+ years",
null,
"10+ years",
null,
"2 years",
"8 years",
"10+ years",
"2 years",
"1 year",
null,
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"6 years",
"5 years",
"3 years",
"1 year",
"10+ years",
"7 years",
null,
"3 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"8 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"2 years",
"7 years",
"2 years",
"7 years",
"4 years",
"4 years",
"9 years",
"9 years",
"6 years",
"10+ years",
"7 years",
"8 years",
"10+ years",
"6 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"2 years",
"9 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"1 year",
"8 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"2 years",
"5 years",
"1 year",
"3 years",
"10+ years",
"1 year",
null,
"3 years",
"10+ years",
"4 years",
"5 years",
"2 years",
null,
"10+ years",
"4 years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"1 year",
"< 1 year",
"1 year",
"5 years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"8 years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"2 years",
"< 1 year",
"2 years",
"9 years",
"9 years",
"10+ years",
"3 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"7 years",
"4 years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"7 years",
"6 years",
"7 years",
"< 1 year",
"10+ years",
"4 years",
"3 years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
null,
"8 years",
"1 year",
"1 year",
"6 years",
"3 years",
"2 years",
"10+ years",
"< 1 year",
"1 year",
"4 years",
"9 years",
"10+ years",
"5 years",
"3 years",
"3 years",
"5 years",
"4 years",
"10+ years",
"8 years",
"9 years",
"7 years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"< 1 year",
"6 years",
"10+ years",
null,
"7 years",
"3 years",
"6 years",
"7 years",
"10+ years",
"3 years",
"< 1 year",
"4 years",
"1 year",
"1 year",
"7 years",
"4 years",
"5 years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"3 years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"9 years",
null,
"5 years",
"7 years",
"2 years",
"6 years",
"4 years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"8 years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"3 years",
"1 year",
"< 1 year",
"10+ years",
"2 years",
"1 year",
"3 years",
"10+ years",
"9 years",
"3 years",
"1 year",
"10+ years",
"7 years",
"2 years",
"9 years",
"6 years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"7 years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"4 years",
"4 years",
"5 years",
"9 years",
"4 years",
"10+ years",
"< 1 year",
"2 years",
"3 years",
null,
"10+ years",
null,
"6 years",
null,
"10+ years",
"10+ years",
null,
"10+ years",
"6 years",
"7 years",
"3 years",
"< 1 year",
"9 years",
"2 years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"9 years",
"10+ years",
"7 years",
"3 years",
"< 1 year",
null,
"4 years",
null,
"2 years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"4 years",
"5 years",
null,
"3 years",
"7 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"< 1 year",
"6 years",
"8 years",
"5 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"2 years",
"5 years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"4 years",
"10+ years",
"10+ years",
null,
"3 years",
"2 years",
"< 1 year",
"6 years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"3 years",
"8 years",
"4 years",
"9 years",
"7 years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"3 years",
"8 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
null,
"2 years",
"6 years",
"10+ years",
"7 years",
"8 years",
"< 1 year",
"10+ years",
"2 years",
"2 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"6 years",
"8 years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"1 year",
"10+ years",
null,
null,
"10+ years",
"1 year",
"4 years",
"1 year",
"3 years",
"3 years",
"10+ years",
"2 years",
"5 years",
"3 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
null,
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"6 years",
"8 years",
"7 years",
null,
"5 years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"1 year",
"10+ years",
"4 years",
"3 years",
"< 1 year",
"10+ years",
"< 1 year",
"4 years",
"1 year",
"1 year",
"5 years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"3 years",
"2 years",
"10+ years",
"1 year",
"8 years",
"10+ years",
"8 years",
"10+ years",
null,
"2 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"5 years",
"10+ years",
"6 years",
null,
"3 years",
"8 years",
"2 years",
"6 years",
null,
"3 years",
"5 years",
"4 years",
"5 years",
"2 years",
null,
"< 1 year",
"< 1 year",
"10+ years",
"3 years",
"7 years",
"2 years",
"< 1 year",
"3 years",
"10+ years",
"3 years",
"2 years",
null,
"4 years",
"< 1 year",
"8 years",
"7 years",
"6 years",
"8 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"8 years",
"8 years",
"9 years",
"10+ years",
"8 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"< 1 year",
"10+ years",
"9 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"7 years",
"2 years",
"6 years",
"1 year",
"2 years",
"10+ years",
"4 years",
"3 years",
"5 years",
"2 years",
"2 years",
null,
"10+ years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"6 years",
"10+ years",
"6 years",
"< 1 year",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"3 years",
"< 1 year",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"7 years",
null,
"10+ years",
"7 years",
"10+ years",
"2 years",
"3 years",
"< 1 year",
"9 years",
null,
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"2 years",
"8 years",
"6 years",
"< 1 year",
"2 years",
"1 year",
"2 years",
"2 years",
null,
"10+ years",
"5 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"1 year",
"2 years",
"8 years",
"10+ years",
"10+ years",
"1 year",
"9 years",
"1 year",
"< 1 year",
"5 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"4 years",
null,
"10+ years",
"6 years",
"7 years",
"< 1 year",
"1 year",
"6 years",
"6 years",
"5 years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"7 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"4 years",
"7 years",
"4 years",
"10+ years",
"5 years",
"7 years",
"6 years",
"8 years",
"2 years",
"10+ years",
"6 years",
"8 years",
"4 years",
null,
"4 years",
"4 years",
"3 years",
"1 year",
"4 years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"4 years",
"7 years",
"1 year",
null,
"10+ years",
"2 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"6 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"4 years",
"< 1 year",
"7 years",
"3 years",
"2 years",
"4 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"8 years",
"4 years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"8 years",
"1 year",
"3 years",
"1 year",
"2 years",
"4 years",
"10+ years",
"5 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
null,
"1 year",
"3 years",
"8 years",
"6 years",
"< 1 year",
"2 years",
"7 years",
"4 years",
"5 years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"2 years",
"7 years",
"3 years",
"10+ years",
"3 years",
"7 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"6 years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"4 years",
"9 years",
"10+ years",
"2 years",
"10+ years",
"4 years",
"2 years",
"1 year",
"9 years",
"10+ years",
"< 1 year",
"< 1 year",
"8 years",
"10+ years",
"2 years",
"10+ years",
null,
"3 years",
"1 year",
"< 1 year",
"7 years",
"1 year",
"6 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"3 years",
"4 years",
"8 years",
"< 1 year",
"6 years",
"7 years",
"10+ years",
"8 years",
null,
"7 years",
"10+ years",
"3 years",
"10+ years",
null,
"5 years",
"6 years",
"< 1 year",
"10+ years",
"4 years",
"2 years",
null,
"10+ years",
"2 years",
"8 years",
"9 years",
"2 years",
"4 years",
"5 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"8 years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"4 years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
null,
"2 years",
"3 years",
"10+ years",
"1 year",
"5 years",
"1 year",
"5 years",
"10+ years",
"7 years",
"10+ years",
"1 year",
"3 years",
"9 years",
"5 years",
"6 years",
"10+ years",
"4 years",
"2 years",
"7 years",
"2 years",
"7 years",
"10+ years",
"7 years",
"8 years",
"10+ years",
"6 years",
"5 years",
"10+ years",
"6 years",
"8 years",
"6 years",
"3 years",
"10+ years",
"8 years",
"7 years",
"10+ years",
"< 1 year",
null,
"7 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"3 years",
"1 year",
"9 years",
"10+ years",
"10+ years",
null,
"3 years",
"10+ years",
null,
"2 years",
"10+ years",
"5 years",
"1 year",
"5 years",
"< 1 year",
"8 years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"6 years",
null,
"7 years",
"1 year",
"10+ years",
"6 years",
"8 years",
"6 years",
"8 years",
"5 years",
"8 years",
"< 1 year",
"10+ years",
"1 year",
"8 years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"1 year",
"4 years",
"4 years",
null,
"6 years",
"10+ years",
"10+ years",
"6 years",
"5 years",
"1 year",
"6 years",
"1 year",
"8 years",
"7 years",
"4 years",
"< 1 year",
"5 years",
"5 years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"1 year",
"4 years",
"7 years",
"2 years",
"5 years",
"4 years",
"1 year",
"10+ years",
"5 years",
null,
"4 years",
"1 year",
"10+ years",
"1 year",
"1 year",
null,
"10+ years",
"6 years",
"7 years",
"3 years",
"2 years",
"8 years",
"1 year",
"3 years",
"3 years",
"< 1 year",
"10+ years",
"5 years",
"5 years",
"10+ years",
"< 1 year",
"4 years",
"3 years",
"4 years",
"10+ years",
"4 years",
"10+ years",
null,
"2 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
null,
"5 years",
"7 years",
null,
"3 years",
"2 years",
"1 year",
"7 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"4 years",
"1 year",
"5 years",
"10+ years",
"6 years",
"10+ years",
"3 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"7 years",
"< 1 year",
"9 years",
"4 years",
"2 years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"8 years",
"2 years",
"3 years",
"10+ years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"2 years",
null,
"6 years",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"3 years",
"7 years",
"10+ years",
null,
"6 years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"8 years",
null,
"3 years",
"1 year",
"6 years",
"10+ years",
"1 year",
"2 years",
"2 years",
null,
"10+ years",
"10+ years",
"6 years",
"< 1 year",
"6 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
null,
"7 years",
"10+ years",
"6 years",
"7 years",
"10+ years",
"10+ years",
null,
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"7 years",
"7 years",
"< 1 year",
"3 years",
"1 year",
"8 years",
"3 years",
"6 years",
"4 years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
null,
"10+ years",
"2 years",
"3 years",
"4 years",
"10+ years",
"7 years",
"< 1 year",
"6 years",
"5 years",
"4 years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"5 years",
"< 1 year",
null,
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"1 year",
"2 years",
"1 year",
"1 year",
"< 1 year",
"10+ years",
"8 years",
null,
null,
"6 years",
"4 years",
"5 years",
"10+ years",
"4 years",
"< 1 year",
"< 1 year",
"2 years",
"3 years",
"10+ years",
"9 years",
"4 years",
"2 years",
"6 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"9 years",
"9 years",
"7 years",
"9 years",
"2 years",
"5 years",
"2 years",
"1 year",
null,
"< 1 year",
"8 years",
"2 years",
null,
"7 years",
"7 years",
"3 years",
"8 years",
"10+ years",
"9 years",
"6 years",
"10+ years",
"8 years",
"9 years",
"10+ years",
"10+ years",
"7 years",
null,
"10+ years",
"9 years",
"1 year",
"2 years",
"< 1 year",
"6 years",
"10+ years",
"8 years",
"< 1 year",
"3 years",
"10+ years",
"4 years",
"1 year",
"3 years",
"9 years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"6 years",
"1 year",
"10+ years",
"3 years",
"8 years",
"10+ years",
"3 years",
"7 years",
"3 years",
"3 years",
null,
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"4 years",
"10+ years",
"10+ years",
"8 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"8 years",
"8 years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"10+ years",
"9 years",
"1 year",
null,
"5 years",
"< 1 year",
"10+ years",
"< 1 year",
"4 years",
null,
"< 1 year",
"1 year",
"10+ years",
"3 years",
"7 years",
"8 years",
"9 years",
"3 years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"2 years",
"5 years",
"1 year",
"2 years",
"3 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"8 years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"4 years",
"7 years",
"10+ years",
"10+ years",
null,
null,
null,
"< 1 year",
"10+ years",
"4 years",
"3 years",
"10+ years",
"5 years",
"< 1 year",
"2 years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"9 years",
null,
"10+ years",
"6 years",
"9 years",
"5 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
null,
"5 years",
"5 years",
"2 years",
"10+ years",
null,
"10+ years",
"9 years",
"10+ years",
"2 years",
"10+ years",
"8 years",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"1 year",
"3 years",
"7 years",
"2 years",
"3 years",
"7 years",
"5 years",
"2 years",
"10+ years",
"10+ years",
null,
"5 years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"2 years",
"6 years",
"9 years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"3 years",
"9 years",
"3 years",
"9 years",
"4 years",
"8 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
null,
"4 years",
"9 years",
"5 years",
"9 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
null,
"< 1 year",
"1 year",
"9 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"7 years",
"< 1 year",
"9 years",
"8 years",
"4 years",
null,
"10+ years",
"1 year",
"4 years",
"9 years",
"10+ years",
"10+ years",
"6 years",
null,
"3 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"1 year",
"10+ years",
"1 year",
"6 years",
"10+ years",
"7 years",
"5 years",
"8 years",
"7 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"8 years",
"< 1 year",
"6 years",
"6 years",
"10+ years",
"1 year",
"3 years",
"2 years",
null,
"< 1 year",
"5 years",
"10+ years",
"6 years",
"5 years",
"10+ years",
"3 years",
"10+ years",
null,
"10+ years",
"7 years",
"10+ years",
"5 years",
"7 years",
null,
"3 years",
"< 1 year",
"2 years",
"10+ years",
"2 years",
"10+ years",
"6 years",
"4 years",
"7 years",
"7 years",
"8 years",
"2 years",
"10+ years",
"3 years",
"3 years",
"4 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
null,
"10+ years",
"5 years",
"6 years",
"10+ years",
"1 year",
"1 year",
"7 years",
"8 years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"1 year",
"9 years",
null,
"2 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"3 years",
"6 years",
"10+ years",
"7 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"10+ years",
"9 years",
"5 years",
"1 year",
"10+ years",
"2 years",
null,
"1 year",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"4 years",
"10+ years",
"8 years",
"6 years",
"3 years",
"2 years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"1 year",
"2 years",
"4 years",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"1 year",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"8 years",
"2 years",
"2 years",
"6 years",
"10+ years",
"6 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"1 year",
"10+ years",
"2 years",
"< 1 year",
"3 years",
"2 years",
"10+ years",
"7 years",
"4 years",
null,
"10+ years",
"10+ years",
"8 years",
null,
"10+ years",
"10+ years",
"4 years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"2 years",
null,
"< 1 year",
"5 years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"7 years",
"4 years",
null,
"8 years",
"2 years",
"1 year",
"10+ years",
"2 years",
"1 year",
"7 years",
"3 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"10+ years",
"5 years",
"3 years",
"9 years",
"3 years",
"1 year",
"10+ years",
"9 years",
"5 years",
"3 years",
"4 years",
"3 years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
null,
"9 years",
"10+ years",
"10+ years",
"8 years",
null,
"5 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"7 years",
"10+ years",
"4 years",
null,
null,
"10+ years",
"10+ years",
"6 years",
"2 years",
"2 years",
"4 years",
"8 years",
"4 years",
null,
"6 years",
"1 year",
null,
"2 years",
"4 years",
"10+ years",
"10+ years",
"1 year",
"3 years",
null,
"10+ years",
"4 years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"6 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"< 1 year",
"1 year",
"5 years",
"8 years",
"6 years",
"10+ years",
"3 years",
"2 years",
"4 years",
"1 year",
"2 years",
"3 years",
"7 years",
"5 years",
"1 year",
"10+ years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"6 years",
"5 years",
"6 years",
null,
"3 years",
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"4 years",
"6 years",
"4 years",
"< 1 year",
"1 year",
"10+ years",
"9 years",
"10+ years",
"3 years",
"3 years",
"< 1 year",
"< 1 year",
"1 year",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"6 years",
"5 years",
"< 1 year",
"6 years",
"10+ years",
"7 years",
"4 years",
"2 years",
"5 years",
"1 year",
"7 years",
"8 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"8 years",
"6 years",
null,
"4 years",
"10+ years",
"4 years",
"9 years",
"10+ years",
"2 years",
"7 years",
"8 years",
"10+ years",
"10+ years",
null,
null,
"10+ years",
"2 years",
"1 year",
"10+ years",
"2 years",
null,
"6 years",
null,
"2 years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"5 years",
"4 years",
"10+ years",
"6 years",
"8 years",
"5 years",
"1 year",
"8 years",
"7 years",
"3 years",
"3 years",
"10+ years",
"4 years",
"3 years",
null,
"9 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"4 years",
"1 year",
null,
"10+ years",
"3 years",
"10+ years",
"2 years",
"7 years",
"5 years",
"3 years",
"5 years",
"1 year",
"10+ years",
null,
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"3 years",
"10+ years",
"7 years",
"5 years",
"10+ years",
"10+ years",
"6 years",
"9 years",
"4 years",
"10+ years",
"6 years",
"9 years",
"< 1 year",
"< 1 year",
"10+ years",
"2 years",
"4 years",
"10+ years",
"1 year",
"2 years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"2 years",
"3 years",
"10+ years",
"10+ years",
null,
"10+ years",
"4 years",
"< 1 year",
"3 years",
null,
"2 years",
"2 years",
"2 years",
"10+ years",
"< 1 year",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"6 years",
"7 years",
"7 years",
"10+ years",
"9 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"6 years",
"2 years",
"7 years",
"8 years",
"5 years",
"3 years",
"10+ years",
"7 years",
"2 years",
"8 years",
"2 years",
"4 years",
"4 years",
"2 years",
"10+ years",
"4 years",
"7 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"2 years",
"< 1 year",
"6 years",
"7 years",
"3 years",
"1 year",
null,
"1 year",
"10+ years",
"2 years",
"< 1 year",
"9 years",
"9 years",
"10+ years",
"9 years",
"2 years",
"10+ years",
"10+ years",
"1 year",
null,
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"5 years",
"1 year",
"1 year",
"2 years",
"10+ years",
"9 years",
"4 years",
"8 years",
"< 1 year",
"9 years",
null,
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"8 years",
"1 year",
"4 years",
"3 years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"6 years",
"2 years",
"4 years",
"6 years",
"1 year",
"1 year",
"10+ years",
null,
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"9 years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"4 years",
"10+ years",
null,
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"2 years",
"5 years",
"< 1 year",
"10+ years",
"< 1 year",
"1 year",
"5 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"1 year",
"1 year",
null,
"10+ years",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"8 years",
"8 years",
"4 years",
null,
"10+ years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
null,
"4 years",
"10+ years",
"5 years",
"2 years",
"4 years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"9 years",
"4 years",
"3 years",
"5 years",
"2 years",
"10+ years",
"3 years",
"5 years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"1 year",
"4 years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"7 years",
"< 1 year",
"2 years",
"10+ years",
"8 years",
"8 years",
"6 years",
"3 years",
"7 years",
"7 years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"5 years",
"8 years",
"8 years",
"8 years",
"9 years",
"8 years",
"4 years",
"4 years",
"8 years",
"10+ years",
null,
"6 years",
"10+ years",
"< 1 year",
"5 years",
"2 years",
"8 years",
null,
"4 years",
"4 years",
"5 years",
"3 years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
null,
"< 1 year",
"2 years",
null,
"10+ years",
"6 years",
"4 years",
"2 years",
"4 years",
"10+ years",
"8 years",
"1 year",
"10+ years",
"4 years",
"1 year",
"4 years",
"7 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"4 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"9 years",
"3 years",
"9 years",
"1 year",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"< 1 year",
"5 years",
"7 years",
"< 1 year",
"8 years",
"< 1 year",
"8 years",
"1 year",
"5 years",
"10+ years",
"5 years",
"< 1 year",
"5 years",
"10+ years",
null,
"1 year",
"10+ years",
"6 years",
"7 years",
"6 years",
"< 1 year",
"5 years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"9 years",
"< 1 year",
"4 years",
"9 years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
null,
"9 years",
"10+ years",
"8 years",
"8 years",
"6 years",
"< 1 year",
"7 years",
"8 years",
"8 years",
"7 years",
"6 years",
"2 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"1 year",
"10+ years",
"7 years",
"6 years",
"7 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"9 years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"7 years",
"3 years",
"6 years",
"10+ years",
"2 years",
"2 years",
"2 years",
"7 years",
"9 years",
"1 year",
"10+ years",
"5 years",
"< 1 year",
"2 years",
"2 years",
"< 1 year",
"2 years",
"3 years",
"6 years",
"9 years",
"6 years",
"3 years",
"10+ years",
"1 year",
null,
null,
"9 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"4 years",
"3 years",
"10+ years",
"< 1 year",
"8 years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"8 years",
"2 years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"4 years",
"2 years",
"3 years",
"< 1 year",
null,
"10+ years",
null,
"10+ years",
"10+ years",
"2 years",
"2 years",
"4 years",
"4 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"2 years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"9 years",
"4 years",
"1 year",
"5 years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"10+ years",
"6 years",
"4 years",
"7 years",
"10+ years",
"9 years",
"6 years",
"6 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"7 years",
"7 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"7 years",
"< 1 year",
"4 years",
"10+ years",
"7 years",
"7 years",
"10+ years",
"8 years",
"4 years",
"2 years",
"2 years",
"4 years",
null,
"10+ years",
"1 year",
"1 year",
"< 1 year",
"5 years",
"1 year",
"8 years",
"8 years",
"< 1 year",
"1 year",
"8 years",
"7 years",
"8 years",
"4 years",
"4 years",
null,
"2 years",
"< 1 year",
"< 1 year",
"3 years",
"1 year",
"5 years",
"2 years",
"2 years",
"4 years",
"9 years",
null,
"1 year",
"8 years",
"4 years",
"10+ years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"6 years",
"4 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"< 1 year",
null,
"10+ years",
"5 years",
"10+ years",
null,
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"9 years",
"7 years",
"6 years",
"4 years",
"3 years",
"< 1 year",
"10+ years",
"< 1 year",
"6 years",
"6 years",
"7 years",
"10+ years",
"3 years",
"3 years",
"8 years",
"2 years",
"9 years",
"< 1 year",
"1 year",
"< 1 year",
"1 year",
"< 1 year",
null,
"10+ years",
"6 years",
"5 years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
null,
"2 years",
"10+ years",
"6 years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"10+ years",
null,
"3 years",
"10+ years",
"10+ years",
null,
"5 years",
"2 years",
"10+ years",
"10+ years",
"9 years",
"5 years",
"2 years",
"10+ years",
"2 years",
"4 years",
"< 1 year",
"3 years",
"5 years",
"5 years",
"10+ years",
"5 years",
"1 year",
"< 1 year",
"10+ years",
"< 1 year",
"2 years",
"< 1 year",
"9 years",
"10+ years",
"2 years",
"4 years",
"9 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
null,
"5 years",
null,
"8 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"2 years",
"3 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"8 years",
"3 years",
"< 1 year",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"3 years",
"2 years",
"4 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"3 years",
null,
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"6 years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"6 years",
"10+ years",
"3 years",
"< 1 year",
"5 years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"5 years",
"8 years",
"2 years",
"6 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"6 years",
"7 years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"10+ years",
"3 years",
"< 1 year",
"7 years",
"5 years",
"4 years",
"< 1 year",
"6 years",
"10+ years",
"1 year",
"3 years",
"9 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"4 years",
"< 1 year",
null,
"8 years",
"4 years",
"3 years",
"10+ years",
"6 years",
"4 years",
"10+ years",
"10+ years",
"3 years",
"1 year",
null,
"10+ years",
"10+ years",
"1 year",
"5 years",
null,
"10+ years",
"9 years",
"5 years",
null,
"3 years",
"10+ years",
"10+ years",
null,
"10+ years",
"6 years",
"10+ years",
"7 years",
null,
"1 year",
"10+ years",
"2 years",
"7 years",
"4 years",
"5 years",
"4 years",
"9 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"1 year",
"2 years",
"9 years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"6 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"2 years",
"8 years",
"2 years",
"5 years",
"1 year",
"2 years",
"6 years",
null,
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"1 year",
"< 1 year",
"< 1 year",
"6 years",
"10+ years",
"1 year",
"8 years",
"2 years",
"6 years",
"6 years",
"5 years",
"2 years",
"8 years",
"1 year",
null,
"9 years",
"3 years",
"7 years",
"3 years",
"10+ years",
"1 year",
null,
"10+ years",
"7 years",
"10+ years",
"1 year",
"6 years",
"2 years",
"10+ years",
"7 years",
"< 1 year",
"4 years",
"6 years",
"2 years",
"10+ years",
"6 years",
"3 years",
"2 years",
"3 years",
"10+ years",
"6 years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"5 years",
"2 years",
"10+ years",
"9 years",
null,
"< 1 year",
"1 year",
"5 years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"8 years",
"9 years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"1 year",
null,
"10+ years",
"1 year",
"< 1 year",
"4 years",
"2 years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"4 years",
"7 years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"< 1 year",
"3 years",
"5 years",
"10+ years",
"< 1 year",
"4 years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"9 years",
"4 years",
"2 years",
"3 years",
"10+ years",
"8 years",
"4 years",
"10+ years",
"1 year",
"4 years",
"3 years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"7 years",
"< 1 year",
null,
"3 years",
"2 years",
null,
"10+ years",
"8 years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
null,
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"7 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"3 years",
"1 year",
"< 1 year",
"4 years",
"10+ years",
"< 1 year",
"2 years",
"< 1 year",
"< 1 year",
"8 years",
"10+ years",
"8 years",
"6 years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"1 year",
"3 years",
"1 year",
"1 year",
"5 years",
"10+ years",
"5 years",
"2 years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"1 year",
"2 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
null,
"2 years",
"1 year",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"3 years",
null,
"1 year",
"10+ years",
"9 years",
"7 years",
"8 years",
"4 years",
"7 years",
"10+ years",
"1 year",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"4 years",
"1 year",
"4 years",
"2 years",
"2 years",
null,
"< 1 year",
"10+ years",
"4 years",
"8 years",
"10+ years",
"9 years",
"3 years",
"7 years",
"5 years",
"< 1 year",
"10+ years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"8 years",
"6 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"7 years",
"7 years",
"9 years",
"1 year",
"2 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"< 1 year",
null,
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
null,
"< 1 year",
"2 years",
null,
"8 years",
"1 year",
"6 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"9 years",
"< 1 year",
"10+ years",
"2 years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
null,
"1 year",
"8 years",
"2 years",
"1 year",
"10+ years",
"4 years",
"8 years",
"1 year",
"1 year",
"9 years",
"10+ years",
"10+ years",
"4 years",
"7 years",
null,
"10+ years",
"1 year",
"2 years",
"6 years",
"4 years",
"3 years",
"5 years",
"8 years",
"3 years",
"1 year",
"7 years",
"5 years",
"10+ years",
"3 years",
"1 year",
"10+ years",
"5 years",
"10+ years",
"2 years",
"4 years",
"10+ years",
"7 years",
"10+ years",
"5 years",
"8 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"7 years",
"1 year",
"9 years",
"7 years",
"8 years",
"4 years",
"8 years",
"10+ years",
"10+ years",
"1 year",
"9 years",
"5 years",
"< 1 year",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"6 years",
"4 years",
"2 years",
"2 years",
"8 years",
"6 years",
"1 year",
"3 years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"7 years",
null,
"10+ years",
"< 1 year",
"6 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"3 years",
"2 years",
"2 years",
"10+ years",
"9 years",
"6 years",
"4 years",
"8 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"2 years",
"7 years",
"10+ years",
"9 years",
"3 years",
"< 1 year",
"2 years",
"10+ years",
"1 year",
"3 years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"7 years",
"3 years",
"< 1 year",
"6 years",
null,
"10+ years",
"< 1 year",
null,
"2 years",
null,
"1 year",
"< 1 year",
"7 years",
"1 year",
"3 years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"2 years",
"5 years",
"1 year",
"5 years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"3 years",
"< 1 year",
"3 years",
"4 years",
"2 years",
"10+ years",
"3 years",
"1 year",
"4 years",
null,
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"9 years",
"10+ years",
"5 years",
"6 years",
"10+ years",
"6 years",
null,
"5 years",
null,
"4 years",
"2 years",
"4 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"4 years",
"6 years",
"6 years",
"1 year",
"< 1 year",
"6 years",
"2 years",
"4 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"3 years",
"6 years",
"2 years",
"10+ years",
"6 years",
"6 years",
"10+ years",
"6 years",
"8 years",
"2 years",
"10+ years",
"1 year",
"2 years",
"2 years",
"7 years",
"1 year",
"4 years",
"10+ years",
"6 years",
"9 years",
"1 year",
"7 years",
"< 1 year",
"6 years",
"< 1 year",
"8 years",
"3 years",
"6 years",
"1 year",
"6 years",
"4 years",
"2 years",
"10+ years",
"6 years",
"6 years",
"10+ years",
"9 years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"7 years",
"1 year",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"9 years",
null,
"10+ years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"2 years",
"6 years",
"8 years",
"8 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"6 years",
"8 years",
"2 years",
null,
"8 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"< 1 year",
"1 year",
"< 1 year",
"6 years",
"10+ years",
"2 years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"4 years",
"5 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"8 years",
"10+ years",
null,
"10+ years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"5 years",
"9 years",
"6 years",
"10+ years",
"3 years",
"9 years",
"10+ years",
"10+ years",
"9 years",
null,
"< 1 year",
"5 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"5 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
null,
null,
"5 years",
"7 years",
"3 years",
"5 years",
"< 1 year",
"8 years",
"10+ years",
"3 years",
null,
"10+ years",
"4 years",
"10+ years",
null,
"3 years",
"9 years",
"3 years",
"1 year",
"10+ years",
"1 year",
"5 years",
"3 years",
"10+ years",
"6 years",
"9 years",
null,
"4 years",
null,
"5 years",
"10+ years",
"3 years",
"5 years",
"5 years",
"6 years",
"2 years",
"9 years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"6 years",
"5 years",
"10+ years",
"1 year",
"8 years",
"2 years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"2 years",
"9 years",
"10+ years",
null,
"10+ years",
"< 1 year",
"< 1 year",
"4 years",
"10+ years",
"2 years",
"1 year",
"5 years",
"1 year",
"2 years",
"9 years",
"8 years",
null,
"2 years",
"10+ years",
"< 1 year",
"2 years",
"6 years",
"< 1 year",
"7 years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"9 years",
"1 year",
"7 years",
"7 years",
"8 years",
"5 years",
"4 years",
"10+ years",
"8 years",
"4 years",
"2 years",
"5 years",
"10+ years",
"2 years",
"4 years",
"4 years",
"< 1 year",
"10+ years",
"7 years",
"< 1 year",
"2 years",
"10+ years",
"< 1 year",
"< 1 year",
"2 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
null,
"3 years",
"7 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"4 years",
"1 year",
"8 years",
"2 years",
"3 years",
"5 years",
"9 years",
"5 years",
"1 year",
"5 years",
"10+ years",
"8 years",
"< 1 year",
"< 1 year",
"3 years",
"5 years",
"2 years",
"10+ years",
null,
"6 years",
null,
null,
"2 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"< 1 year",
null,
"2 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"7 years",
"2 years",
"1 year",
"4 years",
"6 years",
"7 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"9 years",
"1 year",
"9 years",
"4 years",
"1 year",
"4 years",
"5 years",
"10+ years",
"8 years",
"6 years",
"3 years",
"10+ years",
"2 years",
null,
"10+ years",
"< 1 year",
"2 years",
"3 years",
"7 years",
"10+ years",
"4 years",
"1 year",
"2 years",
"1 year",
"< 1 year",
"10+ years",
"7 years",
"8 years",
"9 years",
"2 years",
"10+ years",
"9 years",
"2 years",
"4 years",
"4 years",
null,
"10+ years",
"3 years",
"10+ years",
"2 years",
"4 years",
"< 1 year",
"< 1 year",
"10+ years",
"< 1 year",
"2 years",
"< 1 year",
null,
"1 year",
"10+ years",
"10+ years",
null,
"2 years",
"< 1 year",
"7 years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"1 year",
"< 1 year",
"3 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"4 years",
"3 years",
"2 years",
"10+ years",
"1 year",
"9 years",
"1 year",
"1 year",
"10+ years",
"1 year",
"5 years",
"10+ years",
"1 year",
"10+ years",
"4 years",
"7 years",
"2 years",
"2 years",
"10+ years",
"6 years",
"5 years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"8 years",
"5 years",
"4 years",
"2 years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"8 years",
"5 years",
"2 years",
"2 years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"4 years",
"10+ years",
"4 years",
"10+ years",
"4 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"9 years",
"3 years",
"< 1 year",
"10+ years",
"1 year",
"3 years",
"1 year",
"< 1 year",
"2 years",
"8 years",
null,
"4 years",
"2 years",
"6 years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"5 years",
"10+ years",
null,
"8 years",
"7 years",
"5 years",
"10+ years",
null,
"1 year",
"8 years",
null,
"8 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"7 years",
"8 years",
"9 years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"7 years",
"5 years",
"10+ years",
"< 1 year",
"2 years",
"3 years",
"10+ years",
"6 years",
null,
"2 years",
"8 years",
"1 year",
"10+ years",
"3 years",
"6 years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"4 years",
"10+ years",
"7 years",
"4 years",
"< 1 year",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"2 years",
"3 years",
"7 years",
"7 years",
"4 years",
"< 1 year",
null,
"1 year",
"1 year",
"8 years",
"6 years",
"2 years",
"3 years",
"< 1 year",
"4 years",
"1 year",
"4 years",
"4 years",
"5 years",
"10+ years",
"< 1 year",
"1 year",
"4 years",
"4 years",
"3 years",
"4 years",
"6 years",
"4 years",
"4 years",
"10+ years",
"8 years",
"2 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"< 1 year",
"5 years",
"< 1 year",
"3 years",
"3 years",
null,
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"5 years",
"10+ years",
null,
"1 year",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"5 years",
"7 years",
"2 years",
"9 years",
"10+ years",
"4 years",
null,
"10+ years",
null,
"10+ years",
"< 1 year",
null,
"3 years",
"8 years",
"< 1 year",
"8 years",
"9 years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"5 years",
"7 years",
"6 years",
"10+ years",
"3 years",
"4 years",
"1 year",
"10+ years",
"10+ years",
"7 years",
"3 years",
"8 years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"7 years",
"1 year",
"1 year",
null,
"2 years",
"9 years",
"< 1 year",
"5 years",
"10+ years",
null,
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"2 years",
"3 years",
"1 year",
"6 years",
"6 years",
"< 1 year",
"4 years",
"3 years",
"3 years",
"10+ years",
"6 years",
null,
"10+ years",
"3 years",
"10+ years",
"5 years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"6 years",
"2 years",
"2 years",
null,
null,
"10+ years",
"10+ years",
"4 years",
"9 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"8 years",
"2 years",
"9 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"4 years",
"< 1 year",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"8 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"6 years",
"4 years",
"10+ years",
"3 years",
null,
"8 years",
"10+ years",
"6 years",
"< 1 year",
"3 years",
"5 years",
"10+ years",
"2 years",
"2 years",
"2 years",
"4 years",
"2 years",
"9 years",
"3 years",
"7 years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"< 1 year",
"8 years",
"3 years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"9 years",
"6 years",
"10+ years",
"7 years",
"5 years",
"5 years",
"7 years",
"< 1 year",
"10+ years",
null,
"1 year",
"10+ years",
"1 year",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"4 years",
"< 1 year",
"6 years",
null,
"4 years",
"9 years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"9 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"5 years",
"3 years",
"2 years",
"10+ years",
"8 years",
"3 years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"8 years",
"< 1 year",
"1 year",
"10+ years",
"8 years",
"4 years",
"10+ years",
null,
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"< 1 year",
"< 1 year",
null,
null,
"3 years",
"4 years",
"7 years",
"< 1 year",
"8 years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"7 years",
"9 years",
"7 years",
"2 years",
"10+ years",
null,
"10+ years",
"10+ years",
"9 years",
"< 1 year",
null,
"10+ years",
"10+ years",
"9 years",
"3 years",
"9 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"7 years",
"10+ years",
"10+ years",
"6 years",
"4 years",
"5 years",
"5 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
null,
"1 year",
null,
"4 years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"6 years",
"1 year",
"8 years",
"8 years",
"7 years",
null,
"8 years",
"3 years",
"10+ years",
"5 years",
"7 years",
"5 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"9 years",
"8 years",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"< 1 year",
"6 years",
"4 years",
"7 years",
"1 year",
null,
"6 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"6 years",
null,
"10+ years",
"3 years",
"5 years",
"7 years",
"7 years",
"9 years",
"< 1 year",
"8 years",
"2 years",
"5 years",
"2 years",
"5 years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"5 years",
"3 years",
"2 years",
"9 years",
"< 1 year",
"7 years",
"5 years",
"4 years",
"3 years",
"10+ years",
"9 years",
"2 years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
null,
"< 1 year",
"< 1 year",
"8 years",
"10+ years",
"7 years",
"3 years",
"8 years",
"4 years",
"7 years",
"< 1 year",
"4 years",
"7 years",
"1 year",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"4 years",
"3 years",
null,
"4 years",
"4 years",
null,
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"9 years",
"3 years",
"1 year",
"5 years",
"< 1 year",
"2 years",
null,
"3 years",
"6 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"6 years",
"2 years",
"7 years",
"2 years",
"2 years",
"10+ years",
"2 years",
"2 years",
"6 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
null,
"5 years",
"1 year",
"5 years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"4 years",
"1 year",
"8 years",
"10+ years",
"10+ years",
null,
"4 years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"5 years",
"3 years",
"< 1 year",
"7 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
null,
"3 years",
"4 years",
"1 year",
"6 years",
"5 years",
"8 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
null,
"< 1 year",
"5 years",
"4 years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"< 1 year",
"1 year",
"7 years",
"3 years",
"3 years",
"10+ years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"6 years",
"1 year",
"1 year",
"9 years",
"9 years",
null,
"< 1 year",
"4 years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
null,
"10+ years",
"8 years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"6 years",
"4 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"< 1 year",
"1 year",
"2 years",
"< 1 year",
"5 years",
"< 1 year",
"4 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"2 years",
"9 years",
"6 years",
"6 years",
"< 1 year",
"7 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"6 years",
"1 year",
"10+ years",
"5 years",
"8 years",
"1 year",
"10+ years",
"3 years",
"8 years",
"10+ years",
"10+ years",
"7 years",
"< 1 year",
"< 1 year",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"3 years",
"2 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"1 year",
"4 years",
"10+ years",
"4 years",
"7 years",
"2 years",
"10+ years",
"8 years",
"7 years",
"10+ years",
"2 years",
null,
null,
"9 years",
"1 year",
"2 years",
"< 1 year",
null,
"10+ years",
"2 years",
"9 years",
"5 years",
"8 years",
"2 years",
"9 years",
null,
"10+ years",
"1 year",
"10+ years",
"2 years",
"6 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"8 years",
"5 years",
"5 years",
"10+ years",
"8 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
null,
"4 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"3 years",
null,
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"5 years",
"7 years",
"5 years",
"1 year",
null,
"3 years",
"8 years",
"1 year",
"4 years",
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"6 years",
"2 years",
"10+ years",
"3 years",
"3 years",
"9 years",
"9 years",
"3 years",
"5 years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
null,
"2 years",
"2 years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"5 years",
"7 years",
"1 year",
"10+ years",
"< 1 year",
"2 years",
"4 years",
"< 1 year",
"10+ years",
"< 1 year",
"3 years",
"5 years",
"4 years",
"10+ years",
null,
"10+ years",
"2 years",
"10+ years",
"8 years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"2 years",
"< 1 year",
"3 years",
"2 years",
"10+ years",
"10+ years",
null,
"4 years",
"1 year",
"10+ years",
"2 years",
"< 1 year",
"3 years",
"1 year",
"10+ years",
null,
"10+ years",
"5 years",
"10+ years",
"3 years",
"1 year",
"8 years",
"1 year",
"10+ years",
"6 years",
"2 years",
"1 year",
"3 years",
"1 year",
null,
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"6 years",
"10+ years",
"2 years",
"6 years",
"9 years",
"< 1 year",
"9 years",
"7 years",
"7 years",
"10+ years",
null,
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"5 years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"1 year",
"3 years",
"< 1 year",
"10+ years",
null,
null,
"10+ years",
"< 1 year",
"4 years",
"8 years",
"2 years",
"3 years",
"10+ years",
"2 years",
null,
"7 years",
"2 years",
"< 1 year",
"< 1 year",
null,
"4 years",
"7 years",
null,
"9 years",
"8 years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"7 years",
"10+ years",
"2 years",
"1 year",
"3 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"< 1 year",
"1 year",
"< 1 year",
"< 1 year",
"8 years",
"10+ years",
"1 year",
"7 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"6 years",
"< 1 year",
"2 years",
"10+ years",
"2 years",
"2 years",
"< 1 year",
"4 years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"3 years",
"5 years",
"1 year",
"10+ years",
"6 years",
"8 years",
"6 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"6 years",
"10+ years",
"10+ years",
"5 years",
"8 years",
"10+ years",
"< 1 year",
"5 years",
"8 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"9 years",
"10+ years",
"8 years",
"4 years",
"8 years",
"8 years",
"2 years",
null,
"10+ years",
"7 years",
"10+ years",
null,
"4 years",
null,
"10+ years",
"9 years",
"10+ years",
"2 years",
"3 years",
"< 1 year",
"4 years",
"4 years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"7 years",
"1 year",
"4 years",
"10+ years",
"2 years",
"9 years",
"10+ years",
"< 1 year",
"2 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"6 years",
"< 1 year",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"7 years",
"6 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"2 years",
null,
"4 years",
"7 years",
"2 years",
"5 years",
null,
"10+ years",
"7 years",
"5 years",
null,
"5 years",
"6 years",
"< 1 year",
"10+ years",
"2 years",
"1 year",
"5 years",
"3 years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"4 years",
"3 years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"1 year",
null,
"5 years",
"10+ years",
"10+ years",
"5 years",
"9 years",
"4 years",
"4 years",
"8 years",
"6 years",
"< 1 year",
"10+ years",
"9 years",
"5 years",
"10+ years",
null,
"6 years",
null,
"2 years",
"3 years",
"5 years",
null,
"10+ years",
"10+ years",
"10+ years",
null,
"2 years",
"3 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"7 years",
"1 year",
"9 years",
"9 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"6 years",
"< 1 year",
"3 years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"8 years",
"3 years",
"10+ years",
null,
"10+ years",
null,
"7 years",
"2 years",
"10+ years",
null,
"< 1 year",
null,
"8 years",
null,
null,
"2 years",
"2 years",
null,
"1 year",
"2 years",
"1 year",
null,
"10+ years",
"8 years",
"8 years",
null,
"7 years",
"3 years",
"5 years",
"5 years",
"< 1 year",
"8 years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
null,
"6 years",
"6 years",
"10+ years",
"< 1 year",
"7 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"2 years",
"1 year",
"10+ years",
"1 year",
"2 years",
"10+ years",
null,
"10+ years",
"10+ years",
"2 years",
"4 years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"9 years",
"10+ years",
"3 years",
"2 years",
"< 1 year",
null,
"9 years",
"7 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"1 year",
"3 years",
"9 years",
"7 years",
"9 years",
null,
"10+ years",
"7 years",
"2 years",
null,
"5 years",
"2 years",
"1 year",
"10+ years",
"8 years",
"5 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"1 year",
"8 years",
"10+ years",
"9 years",
"6 years",
"< 1 year",
"4 years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"1 year",
"9 years",
"3 years",
"2 years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"5 years",
"5 years",
"6 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
null,
"2 years",
"1 year",
"2 years",
"10+ years",
"1 year",
null,
"10+ years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"1 year",
"3 years",
null,
"8 years",
null,
"10+ years",
"4 years",
"10+ years",
"9 years",
"10+ years",
"7 years",
"5 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"1 year",
"2 years",
"4 years",
"2 years",
"10+ years",
"3 years",
"1 year",
"10+ years",
"2 years",
"3 years",
"10+ years",
"5 years",
null,
"3 years",
"8 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
null,
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
null,
"2 years",
"8 years",
"8 years",
"7 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"1 year",
null,
"7 years",
"10+ years",
"4 years",
null,
"3 years",
"10+ years",
"1 year",
"2 years",
"6 years",
"10+ years",
"2 years",
"3 years",
"< 1 year",
"2 years",
null,
"3 years",
"8 years",
"7 years",
"6 years",
"3 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"2 years",
"< 1 year",
"5 years",
"6 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
null,
"1 year",
"8 years",
"4 years",
"2 years",
null,
"< 1 year",
"10+ years",
"6 years",
"7 years",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"2 years",
"3 years",
null,
"4 years",
"10+ years",
"10+ years",
"7 years",
"5 years",
"10+ years",
"4 years",
"2 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"8 years",
"10+ years",
"2 years",
null,
"6 years",
null,
"8 years",
"10+ years",
"10+ years",
null,
"4 years",
"4 years",
"8 years",
"3 years",
"< 1 year",
"2 years",
"2 years",
"2 years",
"6 years",
"1 year",
"< 1 year",
"1 year",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"3 years",
"2 years",
"6 years",
null,
"< 1 year",
"2 years",
"10+ years",
null,
"< 1 year",
"5 years",
"< 1 year",
"10+ years",
"3 years",
"4 years",
"5 years",
"7 years",
"10+ years",
"3 years",
"8 years",
"2 years",
"9 years",
"8 years",
"< 1 year",
"< 1 year",
"5 years",
"2 years",
"3 years",
"6 years",
"3 years",
"< 1 year",
"7 years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"3 years",
"3 years",
"10+ years",
"9 years",
"10+ years",
"7 years",
"6 years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"2 years",
"9 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"6 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"7 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"6 years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"2 years",
"7 years",
"< 1 year",
"1 year",
"2 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"4 years",
"4 years",
"6 years",
"2 years",
"2 years",
"7 years",
"2 years",
"1 year",
"10+ years",
null,
"10+ years",
"3 years",
"10+ years",
"1 year",
"9 years",
"1 year",
"4 years",
"6 years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"4 years",
"8 years",
"7 years",
"8 years",
"8 years",
"8 years",
"3 years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"8 years",
"< 1 year",
null,
"5 years",
"3 years",
"10+ years",
"3 years",
"1 year",
"4 years",
"10+ years",
"9 years",
"3 years",
"9 years",
"2 years",
"1 year",
"2 years",
null,
"3 years",
"1 year",
"< 1 year",
"3 years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"9 years",
"5 years",
null,
"9 years",
"< 1 year",
"3 years",
"4 years",
"5 years",
"8 years",
"6 years",
null,
"1 year",
"1 year",
"9 years",
"2 years",
"10+ years",
"2 years",
"8 years",
"1 year",
"< 1 year",
"3 years",
"4 years",
"6 years",
"9 years",
"3 years",
"1 year",
"2 years",
"2 years",
null,
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"3 years",
"7 years",
"10+ years",
null,
"10+ years",
null,
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
null,
"4 years",
"10+ years",
null,
"2 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"7 years",
"2 years",
"4 years",
null,
null,
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"1 year",
"10+ years",
"7 years",
null,
"10+ years",
"7 years",
"6 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"2 years",
"1 year",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"10+ years",
"6 years",
"2 years",
"4 years",
"10+ years",
"10+ years",
null,
"10+ years",
"5 years",
"4 years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"1 year",
null,
"6 years",
"6 years",
"8 years",
"5 years",
"< 1 year",
"4 years",
"1 year",
"2 years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"4 years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"6 years",
"8 years",
"9 years",
"5 years",
"5 years",
null,
"2 years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"9 years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"4 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"2 years",
"6 years",
"1 year",
"10+ years",
"2 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"1 year",
"< 1 year",
null,
"2 years",
"3 years",
"9 years",
"< 1 year",
null,
"2 years",
"< 1 year",
"6 years",
"1 year",
null,
"10+ years",
"7 years",
"9 years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"9 years",
"1 year",
"5 years",
"7 years",
"1 year",
"2 years",
"6 years",
"10+ years",
"2 years",
"5 years",
"6 years",
"3 years",
null,
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"2 years",
"3 years",
"< 1 year",
"5 years",
"1 year",
"1 year",
"6 years",
"1 year",
"4 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"5 years",
"2 years",
"9 years",
"2 years",
"5 years",
"10+ years",
"9 years",
"2 years",
"10+ years",
"4 years",
"3 years",
"10+ years",
"1 year",
"7 years",
"9 years",
"10+ years",
"7 years",
"5 years",
null,
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"3 years",
"1 year",
"< 1 year",
"7 years",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"9 years",
"10+ years",
"6 years",
"10+ years",
"8 years",
"< 1 year",
"2 years",
"< 1 year",
"4 years",
"3 years",
"7 years",
"10+ years",
"10+ years",
null,
"5 years",
"< 1 year",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"< 1 year",
"7 years",
"10+ years",
null,
"10+ years",
"3 years",
"10+ years",
"4 years",
"4 years",
null,
"2 years",
"5 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"5 years",
"8 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"3 years",
"3 years",
"7 years",
"< 1 year",
"2 years",
"< 1 year",
"5 years",
"5 years",
"1 year",
"3 years",
"2 years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"9 years",
"10+ years",
"8 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"8 years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"7 years",
"6 years",
"2 years",
"2 years",
"10+ years",
"9 years",
"7 years",
null,
"8 years",
null,
"10+ years",
"5 years",
"5 years",
"2 years",
"10+ years",
"2 years",
"1 year",
"2 years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"9 years",
"5 years",
"6 years",
"2 years",
"7 years",
"7 years",
"1 year",
"7 years",
"10+ years",
"1 year",
"9 years",
"4 years",
"10+ years",
"8 years",
"6 years",
"10+ years",
"9 years",
"6 years",
null,
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"6 years",
null,
"3 years",
"10+ years",
"6 years",
"3 years",
"5 years",
"10+ years",
"< 1 year",
"3 years",
null,
"2 years",
"2 years",
"9 years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"2 years",
null,
"6 years",
"8 years",
"4 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"10+ years",
null,
"10+ years",
"6 years",
"10+ years",
"2 years",
"3 years",
"< 1 year",
"10+ years",
"2 years",
"6 years",
"3 years",
"10+ years",
"5 years",
"6 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"6 years",
"5 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
null,
null,
"10+ years",
"8 years",
"10+ years",
"2 years",
"< 1 year",
"2 years",
"10+ years",
"3 years",
null,
"10+ years",
"1 year",
"< 1 year",
"8 years",
"9 years",
"8 years",
"5 years",
"< 1 year",
"< 1 year",
"10+ years",
"5 years",
"2 years",
null,
"5 years",
"2 years",
"< 1 year",
"4 years",
"9 years",
"8 years",
"2 years",
"6 years",
"7 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"8 years",
"< 1 year",
"1 year",
null,
"10+ years",
"5 years",
"2 years",
"4 years",
"< 1 year",
"2 years",
"10+ years",
"4 years",
"2 years",
"10+ years",
"6 years",
"4 years",
"10+ years",
"3 years",
"10+ years",
null,
"7 years",
"6 years",
"10+ years",
"4 years",
"10+ years",
"1 year",
"7 years",
"9 years",
"10+ years",
"6 years",
"6 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"3 years",
"9 years",
"10+ years",
"< 1 year",
"6 years",
"3 years",
null,
"2 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"6 years",
"< 1 year",
"7 years",
"9 years",
null,
"< 1 year",
"3 years",
"10+ years",
"1 year",
"8 years",
null,
"10+ years",
"8 years",
"9 years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"8 years",
"4 years",
"10+ years",
"3 years",
null,
"10+ years",
"6 years",
"1 year",
"< 1 year",
"3 years",
"2 years",
"10+ years",
"9 years",
"10+ years",
null,
"4 years",
"2 years",
"6 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"8 years",
"10+ years",
"3 years",
"5 years",
"< 1 year",
"10+ years",
null,
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"5 years",
"< 1 year",
"1 year",
"5 years",
"4 years",
"10+ years",
"2 years",
null,
"< 1 year",
null,
"7 years",
"4 years",
null,
"5 years",
"9 years",
"7 years",
"1 year",
"3 years",
"6 years",
"1 year",
"1 year",
"3 years",
null,
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
null,
"9 years",
"10+ years",
"8 years",
"9 years",
"2 years",
"5 years",
"5 years",
null,
"8 years",
"1 year",
"10+ years",
"9 years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"7 years",
"10+ years",
"2 years",
"7 years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"6 years",
"9 years",
"4 years",
"< 1 year",
"8 years",
null,
"2 years",
"6 years",
"6 years",
"8 years",
"2 years",
"2 years",
"5 years",
"3 years",
"9 years",
"2 years",
"1 year",
"< 1 year",
"6 years",
"10+ years",
null,
"10+ years",
"6 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
null,
null,
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"4 years",
"9 years",
"2 years",
"4 years",
"10+ years",
"10+ years",
"5 years",
"8 years",
"3 years",
"1 year",
"1 year",
"5 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"9 years",
"3 years",
"10+ years",
"1 year",
"2 years",
"8 years",
"2 years",
"10+ years",
null,
"10+ years",
"6 years",
"9 years",
"5 years",
"8 years",
"10+ years",
"7 years",
"3 years",
"6 years",
"10+ years",
"5 years",
"8 years",
"9 years",
"1 year",
"< 1 year",
"9 years",
null,
"5 years",
"2 years",
null,
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"2 years",
"3 years",
"10+ years",
"4 years",
null,
"10+ years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"4 years",
"4 years",
null,
"10+ years",
null,
"5 years",
"8 years",
"4 years",
"8 years",
"10+ years",
null,
"10+ years",
"2 years",
"7 years",
"< 1 year",
null,
"9 years",
"3 years",
"2 years",
"5 years",
"10+ years",
"8 years",
"10+ years",
"8 years",
"9 years",
"8 years",
"10+ years",
"4 years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"< 1 year",
"3 years",
"10+ years",
"3 years",
null,
"2 years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"< 1 year",
"6 years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"7 years",
null,
"10+ years",
"5 years",
"7 years",
"10+ years",
"3 years",
"< 1 year",
"9 years",
"8 years",
"7 years",
"10+ years",
"5 years",
"10+ years",
"6 years",
"2 years",
"1 year",
"1 year",
"4 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"2 years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"6 years",
null,
"10+ years",
"5 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
null,
"10+ years",
"9 years",
"10+ years",
"1 year",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"7 years",
"5 years",
"< 1 year",
"9 years",
"10+ years",
"6 years",
"9 years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"< 1 year",
"5 years",
"6 years",
"1 year",
"7 years",
"8 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"5 years",
"4 years",
"< 1 year",
"10+ years",
"2 years",
"6 years",
"8 years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"4 years",
"7 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"5 years",
"9 years",
"8 years",
"8 years",
"10+ years",
null,
"5 years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"1 year",
"4 years",
"10+ years",
"5 years",
"2 years",
"7 years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"5 years",
"1 year",
"10+ years",
"< 1 year",
null,
"< 1 year",
"10+ years",
"6 years",
"3 years",
"1 year",
"2 years",
"9 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"4 years",
"10+ years",
"1 year",
"7 years",
"10+ years",
null,
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"1 year",
"6 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"9 years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"9 years",
"10+ years",
"10+ years",
"4 years",
"5 years",
"5 years",
"10+ years",
"10+ years",
"7 years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
null,
"10+ years",
"< 1 year",
"1 year",
"1 year",
"10+ years",
"< 1 year",
"7 years",
"5 years",
"6 years",
"< 1 year",
"10+ years",
"5 years",
"2 years",
"9 years",
null,
"10+ years",
"10+ years",
null,
null,
"< 1 year",
"3 years",
"< 1 year",
"1 year",
"10+ years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"< 1 year",
"2 years",
"2 years",
"1 year",
"3 years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"9 years",
"7 years",
"2 years",
null,
"2 years",
"9 years",
"5 years",
null,
null,
"6 years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"2 years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"4 years",
"6 years",
"5 years",
"10+ years",
"1 year",
"1 year",
"1 year",
"1 year",
"4 years",
"8 years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"9 years",
null,
"5 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"1 year",
"3 years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"3 years",
"3 years",
null,
"9 years",
null,
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"9 years",
"10+ years",
"3 years",
null,
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"4 years",
"5 years",
"3 years",
"10+ years",
"4 years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"6 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"6 years",
"9 years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"< 1 year",
"< 1 year",
"10+ years",
"6 years",
"5 years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"9 years",
"1 year",
"3 years",
"4 years",
"3 years",
"5 years",
"2 years",
"4 years",
"2 years",
"4 years",
"4 years",
"3 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"9 years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"< 1 year",
"6 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"6 years",
"1 year",
"10+ years",
"9 years",
"2 years",
"6 years",
"10+ years",
"6 years",
"10+ years",
null,
"5 years",
"1 year",
"10+ years",
"8 years",
"2 years",
"4 years",
"6 years",
"10+ years",
"2 years",
null,
"8 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"7 years",
"10+ years",
"5 years",
"5 years",
"5 years",
"10+ years",
null,
"10+ years",
"2 years",
"2 years",
"10+ years",
"5 years",
"1 year",
null,
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
"2 years",
"4 years",
"6 years",
"5 years",
"10+ years",
"< 1 year",
"9 years",
"10+ years",
"5 years",
"5 years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"1 year",
"2 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
null,
"1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"7 years",
null,
"2 years",
"3 years",
"9 years",
"7 years",
"4 years",
"< 1 year",
"2 years",
"2 years",
"2 years",
"10+ years",
"4 years",
"< 1 year",
null,
"10+ years",
"3 years",
"2 years",
"10+ years",
"< 1 year",
"4 years",
null,
"10+ years",
"10+ years",
"10+ years",
"7 years",
"4 years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"9 years",
"10+ years",
"10+ years",
null,
"10+ years",
"7 years",
"9 years",
"< 1 year",
"< 1 year",
"7 years",
"5 years",
"4 years",
"8 years",
"1 year",
"6 years",
"6 years",
"< 1 year",
"5 years",
"2 years",
"9 years",
"1 year",
"9 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"9 years",
"10+ years",
"10+ years",
"8 years",
null,
"4 years",
"2 years",
"8 years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"1 year",
"2 years",
"4 years",
"6 years",
"3 years",
"2 years",
"1 year",
"10+ years",
"1 year",
"< 1 year",
"5 years",
"8 years",
"10+ years",
"5 years",
"4 years",
"10+ years",
"10+ years",
"6 years",
"9 years",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"8 years",
"8 years",
null,
"< 1 year",
"4 years",
null,
"10+ years",
"5 years",
"10+ years",
"7 years",
null,
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"9 years",
null,
null,
"< 1 year",
"< 1 year",
"5 years",
"7 years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"9 years",
"2 years",
"< 1 year",
"2 years",
"2 years",
"10+ years",
"3 years",
"9 years",
"10+ years",
"9 years",
"10+ years",
"7 years",
"6 years",
"10+ years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"6 years",
"< 1 year",
"5 years",
"5 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"4 years",
"7 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"1 year",
"10+ years",
"9 years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"6 years",
"4 years",
"10+ years",
"10+ years",
"4 years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"5 years",
"< 1 year",
"10+ years",
null,
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"1 year",
"< 1 year",
"1 year",
"5 years",
"2 years",
"10+ years",
"5 years",
null,
"5 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"5 years",
"6 years",
"2 years",
"10+ years",
"2 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
null,
"6 years",
"1 year",
"2 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"2 years",
"1 year",
"1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"1 year",
"3 years",
"4 years",
"6 years",
"4 years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"5 years",
"10+ years",
null,
"10+ years",
"7 years",
"2 years",
"2 years",
"2 years",
"10+ years",
"8 years",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"< 1 year",
"6 years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"2 years",
"9 years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"1 year",
"3 years",
"10+ years",
"5 years",
"8 years",
"2 years",
"7 years",
"3 years",
"10+ years",
"10+ years",
"3 years",
null,
"6 years",
"2 years",
"3 years",
"2 years",
"10+ years",
"3 years",
"2 years",
"5 years",
"4 years",
"2 years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"5 years",
"6 years",
"< 1 year",
"6 years",
"7 years",
"10+ years",
"5 years",
"2 years",
"8 years",
"10+ years",
"2 years",
"6 years",
"8 years",
"< 1 year",
"1 year",
"10+ years",
"6 years",
"1 year",
"10+ years",
null,
"< 1 year",
"1 year",
"6 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"6 years",
null,
"10+ years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"6 years",
"< 1 year",
"10+ years",
null,
"7 years",
"10+ years",
"10+ years",
null,
"10+ years",
"4 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"4 years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"4 years",
"6 years",
"3 years",
"3 years",
"10+ years",
"7 years",
"3 years",
"4 years",
"10+ years",
"9 years",
"1 year",
"10+ years",
"5 years",
"2 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"3 years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"9 years",
"4 years",
"2 years",
"6 years",
"7 years",
"9 years",
"< 1 year",
"10+ years",
"< 1 year",
"6 years",
"4 years",
"4 years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"5 years",
"3 years",
"< 1 year",
"10+ years",
"2 years",
"< 1 year",
"7 years",
"1 year",
"7 years",
"10+ years",
null,
null,
"8 years",
"6 years",
"10+ years",
"8 years",
"4 years",
"10+ years",
"10+ years",
"4 years",
"4 years",
"10+ years",
null,
"4 years",
"10+ years",
"7 years",
"< 1 year",
null,
"10+ years",
null,
"7 years",
"8 years",
"3 years",
"2 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"9 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"10+ years",
null,
"6 years",
"3 years",
"2 years",
"5 years",
"5 years",
"6 years",
"2 years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"9 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"4 years",
"9 years",
"2 years",
"10+ years",
"10+ years",
"9 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"9 years",
"3 years",
"9 years",
"4 years",
"5 years",
"3 years",
"4 years",
"1 year",
"2 years",
null,
"3 years",
"7 years",
"2 years",
"< 1 year",
"6 years",
null,
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"1 year",
"6 years",
"7 years",
"6 years",
"< 1 year",
"10+ years",
"9 years",
null,
"10+ years",
"8 years",
"5 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"8 years",
"4 years",
"2 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"5 years",
"< 1 year",
"< 1 year",
"10+ years",
"2 years",
"9 years",
"2 years",
"6 years",
"10+ years",
"9 years",
"< 1 year",
"2 years",
"2 years",
"10+ years",
null,
"1 year",
"10+ years",
"8 years",
"< 1 year",
"5 years",
null,
"3 years",
"2 years",
"3 years",
"10+ years",
"9 years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
null,
null,
"10+ years",
"5 years",
"4 years",
"9 years",
"2 years",
"< 1 year",
"3 years",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"6 years",
"3 years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"3 years",
null,
"10+ years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"4 years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
null,
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"8 years",
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"8 years",
"4 years",
"2 years",
"10+ years",
"6 years",
"1 year",
"2 years",
"< 1 year",
null,
"10+ years",
"6 years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"6 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
null,
"4 years",
"10+ years",
"4 years",
"2 years",
"4 years",
"4 years",
"8 years",
"10+ years",
null,
"5 years",
"9 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"6 years",
"2 years",
"9 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"< 1 year",
"2 years",
"5 years",
"2 years",
"1 year",
"3 years",
"10+ years",
null,
"3 years",
"10+ years",
null,
"10+ years",
"2 years",
"< 1 year",
"9 years",
"7 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
null,
"< 1 year",
null,
"9 years",
"1 year",
"7 years",
"3 years",
"10+ years",
"4 years",
null,
"2 years",
"4 years",
"1 year",
null,
"4 years",
"9 years",
"< 1 year",
"4 years",
"9 years",
"< 1 year",
"7 years",
"3 years",
"10+ years",
"5 years",
"3 years",
"9 years",
"8 years",
"4 years",
"< 1 year",
"1 year",
"4 years",
"7 years",
null,
"2 years",
"2 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"5 years",
"10+ years",
"9 years",
"2 years",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"9 years",
"1 year",
"< 1 year",
"10+ years",
"2 years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"3 years",
"< 1 year",
"6 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"1 year",
"2 years",
"10+ years",
"10+ years",
null,
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"3 years",
null,
"5 years",
"2 years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"5 years",
null,
"10+ years",
"6 years",
"2 years",
"< 1 year",
null,
null,
"1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"5 years",
"1 year",
"6 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
null,
"< 1 year",
"8 years",
"1 year",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"7 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"9 years",
null,
"2 years",
"< 1 year",
"2 years",
"2 years",
"3 years",
"4 years",
"4 years",
"10+ years",
"2 years",
"2 years",
"5 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"6 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"7 years",
"6 years",
"3 years",
"1 year",
"10+ years",
"4 years",
"8 years",
"7 years",
"4 years",
"3 years",
"10+ years",
"5 years",
"5 years",
"2 years",
"10+ years",
"8 years",
"1 year",
"5 years",
"5 years",
"3 years",
"10+ years",
"7 years",
"10+ years",
"1 year",
"2 years",
"6 years",
"2 years",
"2 years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"2 years",
null,
"< 1 year",
"1 year",
null,
"10+ years",
"6 years",
"10+ years",
"5 years",
"2 years",
"6 years",
"4 years",
"10+ years",
"4 years",
null,
"5 years",
"10+ years",
"10+ years",
"5 years",
"1 year",
"7 years",
"5 years",
"1 year",
"< 1 year",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"9 years",
"8 years",
"2 years",
"1 year",
"2 years",
"10+ years",
"5 years",
"3 years",
"6 years",
"1 year",
"4 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"2 years",
"6 years",
"< 1 year",
null,
"3 years",
"5 years",
"10+ years",
"8 years",
"10+ years",
"6 years",
"< 1 year",
null,
"6 years",
"10+ years",
"2 years",
"2 years",
"8 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"7 years",
"6 years",
"5 years",
"6 years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
null,
"2 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"6 years",
"1 year",
"10+ years",
"1 year",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"9 years",
"2 years",
"7 years",
"9 years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"6 years",
"10+ years",
"7 years",
"3 years",
"10+ years",
null,
"< 1 year",
"10+ years",
"9 years",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
null,
"10+ years",
"2 years",
null,
"10+ years",
"4 years",
"5 years",
"3 years",
"8 years",
"< 1 year",
"2 years",
"10+ years",
"7 years",
"7 years",
"4 years",
"5 years",
"1 year",
"4 years",
"< 1 year",
"2 years",
"1 year",
"1 year",
"4 years",
"< 1 year",
"7 years",
"10+ years",
null,
"10+ years",
"4 years",
"8 years",
"10+ years",
"7 years",
"7 years",
"1 year",
"10+ years",
null,
"2 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"5 years",
"5 years",
"4 years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"2 years",
"4 years",
"10+ years",
"8 years",
"2 years",
"7 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"6 years",
"4 years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"10+ years",
null,
"10+ years",
"7 years",
"7 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"4 years",
"1 year",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"5 years",
"3 years",
"6 years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"7 years",
null,
"7 years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"2 years",
"8 years",
null,
"< 1 year",
null,
"3 years",
"7 years",
"2 years",
"9 years",
"2 years",
"3 years",
"10+ years",
"5 years",
"3 years",
"4 years",
"3 years",
"8 years",
"4 years",
"10+ years",
"3 years",
"8 years",
"2 years",
"10+ years",
"3 years",
null,
"10+ years",
"< 1 year",
null,
"1 year",
"1 year",
"2 years",
"10+ years",
"1 year",
"1 year",
"8 years",
"9 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
null,
null,
"10+ years",
"4 years",
"10+ years",
"5 years",
null,
"1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"3 years",
"7 years",
"8 years",
"5 years",
"3 years",
"10+ years",
"1 year",
"3 years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"9 years",
"2 years",
"2 years",
null,
"< 1 year",
null,
"10+ years",
"< 1 year",
"7 years",
"1 year",
"7 years",
"< 1 year",
"3 years",
"10+ years",
"1 year",
null,
"1 year",
"10+ years",
"4 years",
"10+ years",
"7 years",
"6 years",
"3 years",
"1 year",
"10+ years",
null,
"3 years",
"3 years",
"1 year",
"2 years",
"4 years",
"10+ years",
"9 years",
"2 years",
"6 years",
"10+ years",
"10+ years",
"8 years",
"3 years",
null,
"8 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"2 years",
"6 years",
null,
"10+ years",
"1 year",
"< 1 year",
"3 years",
"8 years",
"1 year",
null,
"10+ years",
"9 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"8 years",
"7 years",
"9 years",
null,
"10+ years",
"10+ years",
"2 years",
"3 years",
"7 years",
"9 years",
"7 years",
"4 years",
"10+ years",
"8 years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"4 years",
"8 years",
"1 year",
"3 years",
"10+ years",
"1 year",
"4 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"8 years",
"2 years",
"2 years",
"3 years",
"2 years",
"7 years",
"8 years",
"10+ years",
"4 years",
"5 years",
"6 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"8 years",
"4 years",
"3 years",
"2 years",
"1 year",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"1 year",
"7 years",
"7 years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"5 years",
"10+ years",
"1 year",
"2 years",
"4 years",
"1 year",
"2 years",
null,
"8 years",
"10+ years",
"4 years",
"< 1 year",
"6 years",
"8 years",
"7 years",
"1 year",
"5 years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"1 year",
"4 years",
"3 years",
"4 years",
"< 1 year",
"5 years",
"3 years",
"2 years",
"5 years",
"4 years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"3 years",
null,
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"5 years",
"8 years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"7 years",
"2 years",
"6 years",
"3 years",
"4 years",
"2 years",
"6 years",
"8 years",
"10+ years",
"10+ years",
"7 years",
"5 years",
"1 year",
"10+ years",
"7 years",
null,
"3 years",
"4 years",
"< 1 year",
"10+ years",
"2 years",
"9 years",
"2 years",
"1 year",
"10+ years",
"3 years",
"< 1 year",
"8 years",
"< 1 year",
"2 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
null,
"5 years",
"9 years",
"10+ years",
"5 years",
"4 years",
"10+ years",
"1 year",
"4 years",
"8 years",
"10+ years",
"8 years",
null,
"10+ years",
"10+ years",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
null,
"6 years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"3 years",
"6 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"3 years",
"< 1 year",
"10+ years",
"< 1 year",
"1 year",
"3 years",
"6 years",
"3 years",
"4 years",
"6 years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"6 years",
"10+ years",
"5 years",
"10+ years",
"8 years",
"1 year",
"3 years",
null,
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"< 1 year",
"8 years",
"< 1 year",
"10+ years",
"4 years",
"9 years",
null,
"3 years",
"< 1 year",
"5 years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"7 years",
"3 years",
"6 years",
"10+ years",
"10+ years",
"8 years",
"2 years",
"7 years",
"3 years",
"9 years",
"7 years",
"< 1 year",
"4 years",
"5 years",
"7 years",
"6 years",
"10+ years",
"2 years",
"10+ years",
"8 years",
"6 years",
"< 1 year",
"2 years",
"< 1 year",
"6 years",
null,
"< 1 year",
"< 1 year",
"8 years",
"9 years",
"10+ years",
"1 year",
"< 1 year",
"9 years",
"3 years",
"10+ years",
null,
"8 years",
"10+ years",
"6 years",
"2 years",
null,
"10+ years",
"4 years",
"8 years",
"< 1 year",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
null,
"4 years",
"2 years",
"4 years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"4 years",
"9 years",
null,
"2 years",
"10+ years",
null,
"5 years",
"7 years",
"1 year",
"10+ years",
"< 1 year",
"< 1 year",
"2 years",
"3 years",
"2 years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
null,
"10+ years",
"5 years",
null,
"10+ years",
"7 years",
"< 1 year",
"2 years",
"5 years",
null,
"7 years",
"5 years",
"3 years",
"1 year",
"1 year",
"7 years",
"7 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"5 years",
"< 1 year",
"10+ years",
"2 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"5 years",
"2 years",
"6 years",
"4 years",
"1 year",
"3 years",
"10+ years",
"3 years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"2 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"7 years",
"6 years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
null,
"< 1 year",
null,
"2 years",
"5 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"2 years",
"10+ years",
"2 years",
"5 years",
null,
"8 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
null,
"5 years",
"2 years",
"6 years",
"10+ years",
"1 year",
"2 years",
"9 years",
"7 years",
"3 years",
"5 years",
"4 years",
"5 years",
"3 years",
"5 years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"9 years",
"7 years",
"10+ years",
"10+ years",
"8 years",
"7 years",
"10+ years",
null,
"6 years",
null,
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"1 year",
null,
"10+ years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"2 years",
"< 1 year",
"5 years",
"1 year",
"4 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"7 years",
"< 1 year",
"< 1 year",
"10+ years",
"7 years",
"< 1 year",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
null,
"3 years",
"5 years",
null,
"7 years",
"3 years",
"< 1 year",
"4 years",
"1 year",
"5 years",
"< 1 year",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"6 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
null,
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"2 years",
"10+ years",
"1 year",
"4 years",
"10+ years",
"4 years",
null,
"3 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"9 years",
"1 year",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"2 years",
"3 years",
null,
"10+ years",
"10+ years",
"1 year",
"4 years",
"4 years",
"5 years",
null,
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"7 years",
null,
"2 years",
"< 1 year",
"6 years",
"2 years",
"10+ years",
"< 1 year",
"4 years",
"3 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
null,
null,
"6 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"6 years",
"4 years",
"10+ years",
null,
"< 1 year",
"8 years",
null,
"1 year",
"10+ years",
null,
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"3 years",
"4 years",
"9 years",
"10+ years",
"9 years",
"2 years",
"1 year",
"7 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
null,
"10+ years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
null,
"6 years",
"10+ years",
"10+ years",
"2 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
null,
"9 years",
"1 year",
"8 years",
"< 1 year",
"2 years",
"1 year",
"4 years",
"2 years",
null,
"< 1 year",
"10+ years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
null,
"5 years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"2 years",
"3 years",
"10+ years",
"1 year",
"2 years",
"2 years",
"8 years",
"3 years",
"4 years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"4 years",
"1 year",
"6 years",
"9 years",
"6 years",
"1 year",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"< 1 year",
"2 years",
"5 years",
"8 years",
"7 years",
"10+ years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"9 years",
"3 years",
"9 years",
"1 year",
"3 years",
"< 1 year",
"6 years",
"6 years",
"5 years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"2 years",
"7 years",
"10+ years",
"3 years",
"2 years",
"2 years",
"8 years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"1 year",
"1 year",
null,
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"4 years",
null,
"7 years",
"6 years",
"10+ years",
"2 years",
"7 years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"7 years",
"4 years",
"5 years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"6 years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"8 years",
"6 years",
null,
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"< 1 year",
"4 years",
"2 years",
"5 years",
"4 years",
"7 years",
"1 year",
"10+ years",
"7 years",
null,
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
null,
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"7 years",
"4 years",
"10+ years",
"< 1 year",
"3 years",
"4 years",
"< 1 year",
"4 years",
"10+ years",
"9 years",
"< 1 year",
"1 year",
"1 year",
"3 years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"8 years",
"2 years",
"9 years",
"10+ years",
"10+ years",
"9 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"4 years",
"10+ years",
"9 years",
"10+ years",
"4 years",
"1 year",
"3 years",
"10+ years",
"8 years",
"10+ years",
"4 years",
"6 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"< 1 year",
"3 years",
"2 years",
"7 years",
"5 years",
"8 years",
"1 year",
"10+ years",
"10+ years",
null,
"2 years",
null,
"5 years",
"5 years",
"3 years",
"10+ years",
"4 years",
"1 year",
"9 years",
"4 years",
"2 years",
"10+ years",
"1 year",
"1 year",
"< 1 year",
"10+ years",
"2 years",
"4 years",
"10+ years",
"< 1 year",
"3 years",
"9 years",
null,
"7 years",
"2 years",
"1 year",
"3 years",
"2 years",
"10+ years",
null,
null,
"5 years",
"1 year",
"6 years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"8 years",
null,
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"3 years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"2 years",
"6 years",
"2 years",
"1 year",
"3 years",
"2 years",
"7 years",
"2 years",
"4 years",
"3 years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"1 year",
"4 years",
"1 year",
"10+ years",
"2 years",
"5 years",
"10+ years",
null,
"1 year",
"7 years",
"3 years",
"< 1 year",
"9 years",
"10+ years",
"8 years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"7 years",
"5 years",
"4 years",
"10+ years",
"1 year",
"4 years",
"3 years",
"4 years",
null,
"4 years",
"4 years",
"10+ years",
null,
"7 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"6 years",
"4 years",
"4 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"1 year",
"7 years",
"10+ years",
"6 years",
"1 year",
"< 1 year",
"8 years",
"10+ years",
"1 year",
"10+ years",
"5 years",
"10+ years",
"6 years",
"3 years",
"6 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"7 years",
"7 years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"10+ years",
"7 years",
"10+ years",
"8 years",
null,
"7 years",
"2 years",
"4 years",
"9 years",
"10+ years",
"3 years",
"< 1 year",
"4 years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"3 years",
"2 years",
"2 years",
"3 years",
"9 years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"8 years",
"2 years",
"10+ years",
"8 years",
"9 years",
null,
"5 years",
"2 years",
"< 1 year",
"< 1 year",
"10+ years",
"2 years",
"2 years",
"3 years",
"6 years",
"10+ years",
null,
"10+ years",
"10+ years",
"4 years",
"2 years",
"8 years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"5 years",
"6 years",
"3 years",
"7 years",
"3 years",
"10+ years",
"1 year",
"7 years",
"3 years",
"5 years",
"10+ years",
"1 year",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"9 years",
"10+ years",
"9 years",
"10+ years",
"5 years",
"9 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"6 years",
"8 years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"6 years",
"10+ years",
"1 year",
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"2 years",
"< 1 year",
"2 years",
"9 years",
"< 1 year",
"8 years",
"5 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"< 1 year",
"6 years",
"10+ years",
"7 years",
"7 years",
"2 years",
"5 years",
"8 years",
"10+ years",
"7 years",
"1 year",
"9 years",
"3 years",
"2 years",
"3 years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"4 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
null,
"< 1 year",
"10+ years",
"6 years",
"4 years",
"2 years",
"8 years",
"< 1 year",
"3 years",
"7 years",
"2 years",
"10+ years",
"5 years",
"2 years",
"1 year",
"5 years",
"8 years",
"8 years",
"7 years",
"10+ years",
"< 1 year",
"3 years",
"< 1 year",
"4 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"7 years",
"7 years",
"6 years",
"10+ years",
"< 1 year",
"4 years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"7 years",
"< 1 year",
"10+ years",
"2 years",
"3 years",
"< 1 year",
"9 years",
"< 1 year",
"5 years",
"3 years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"3 years",
"8 years",
"10+ years",
"10+ years",
null,
"5 years",
"9 years",
"10+ years",
"8 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"< 1 year",
"8 years",
"7 years",
"9 years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"5 years",
"1 year",
"10+ years",
"9 years",
"6 years",
"< 1 year",
"7 years",
"7 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
null,
null,
"6 years",
"2 years",
"4 years",
"10+ years",
"4 years",
"2 years",
"8 years",
"8 years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
"3 years",
"< 1 year",
"3 years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"5 years",
"< 1 year",
"10+ years",
"< 1 year",
"8 years",
"2 years",
"7 years",
"< 1 year",
"3 years",
"5 years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"1 year",
"9 years",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"2 years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"8 years",
"< 1 year",
"5 years",
"10+ years",
"9 years",
"4 years",
"4 years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"8 years",
"4 years",
"5 years",
"7 years",
"< 1 year",
"7 years",
"< 1 year",
"3 years",
null,
"2 years",
"7 years",
"6 years",
"10+ years",
"5 years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"5 years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
null,
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"2 years",
"6 years",
"5 years",
"10+ years",
"5 years",
"< 1 year",
"1 year",
"10+ years",
"7 years",
"1 year",
"2 years",
"6 years",
"7 years",
"4 years",
"8 years",
"1 year",
"10+ years",
"8 years",
"4 years",
"7 years",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"8 years",
"5 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"7 years",
"3 years",
"9 years",
"9 years",
"6 years",
"1 year",
"2 years",
"4 years",
"2 years",
"< 1 year",
"9 years",
"10+ years",
"3 years",
"1 year",
null,
"8 years",
"6 years",
"2 years",
"7 years",
"10+ years",
null,
"1 year",
"10+ years",
"5 years",
"5 years",
"7 years",
"6 years",
"5 years",
"7 years",
"< 1 year",
"7 years",
"1 year",
"9 years",
null,
"3 years",
"< 1 year",
"3 years",
"3 years",
null,
"10+ years",
"10+ years",
"4 years",
"10+ years",
"7 years",
"2 years",
"< 1 year",
"5 years",
"8 years",
"2 years",
"10+ years",
null,
"10+ years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"2 years",
"< 1 year",
"5 years",
"5 years",
"4 years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"6 years",
"1 year",
null,
"10+ years",
"6 years",
"3 years",
"10+ years",
"9 years",
"9 years",
"3 years",
"7 years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"6 years",
"2 years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"< 1 year",
"10+ years",
"3 years",
"1 year",
"6 years",
"4 years",
"9 years",
"1 year",
"10+ years",
"4 years",
"5 years",
"8 years",
"3 years",
"9 years",
"5 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"4 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"8 years",
"9 years",
"4 years",
"3 years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"8 years",
"5 years",
"9 years",
"10+ years",
"10+ years",
"1 year",
"7 years",
"10+ years",
"2 years",
"< 1 year",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"2 years",
"3 years",
"9 years",
"2 years",
"2 years",
"3 years",
"1 year",
null,
null,
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"< 1 year",
"10+ years",
"5 years",
"6 years",
"5 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"10+ years",
null,
"5 years",
"< 1 year",
"10+ years",
"2 years",
"3 years",
"5 years",
"< 1 year",
"2 years",
"6 years",
"5 years",
"1 year",
"8 years",
"6 years",
"2 years",
"4 years",
"9 years",
"10+ years",
"10+ years",
null,
"< 1 year",
"3 years",
"< 1 year",
"5 years",
"2 years",
"5 years",
"8 years",
null,
null,
"10+ years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"8 years",
"5 years",
"6 years",
"4 years",
"2 years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"5 years",
"3 years",
"10+ years",
"5 years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
null,
"8 years",
"4 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"6 years",
"2 years",
"2 years",
"< 1 year",
"9 years",
"2 years",
"10+ years",
"8 years",
null,
"5 years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"1 year",
"1 year",
null,
"10+ years",
"3 years",
"1 year",
"7 years",
"8 years",
"< 1 year",
"10+ years",
"2 years",
"2 years",
"4 years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"5 years",
"2 years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"7 years",
"10+ years",
"4 years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"9 years",
null,
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"7 years",
"7 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"6 years",
"< 1 year",
"8 years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"4 years",
"7 years",
"7 years",
"< 1 year",
"10+ years",
"3 years",
"8 years",
"2 years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"10+ years",
"8 years",
"2 years",
"2 years",
"6 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"2 years",
null,
"2 years",
"5 years",
"9 years",
"7 years",
"5 years",
"2 years",
"9 years",
"3 years",
"3 years",
null,
"10+ years",
"< 1 year",
"3 years",
null,
"10+ years",
"10+ years",
"6 years",
"4 years",
"10+ years",
"9 years",
"10+ years",
"7 years",
"6 years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"7 years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"< 1 year",
"< 1 year",
"5 years",
"5 years",
"3 years",
"10+ years",
null,
"5 years",
null,
"5 years",
"6 years",
"< 1 year",
"< 1 year",
"9 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"1 year",
"3 years",
"10+ years",
"5 years",
"5 years",
"7 years",
null,
"9 years",
"7 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"2 years",
"9 years",
"9 years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"5 years",
"10+ years",
null,
null,
"10+ years",
"6 years",
"< 1 year",
"7 years",
"8 years",
"3 years",
"8 years",
"3 years",
null,
"10+ years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"10+ years",
"3 years",
"8 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"1 year",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"7 years",
null,
"9 years",
"1 year",
"10+ years",
"2 years",
"< 1 year",
null,
"6 years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"6 years",
"6 years",
"10+ years",
"3 years",
"2 years",
"1 year",
"10+ years",
"1 year",
"2 years",
"1 year",
"9 years",
"10+ years",
"10+ years",
null,
"4 years",
"10+ years",
"10+ years",
null,
"5 years",
null,
"6 years",
"8 years",
"7 years",
"6 years",
"9 years",
"10+ years",
"6 years",
"10+ years",
"9 years",
"4 years",
"2 years",
"2 years",
"< 1 year",
"2 years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"8 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"9 years",
"4 years",
"8 years",
"< 1 year",
null,
"9 years",
"9 years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"4 years",
"5 years",
"6 years",
"8 years",
"5 years",
"2 years",
"1 year",
"10+ years",
null,
"9 years",
"6 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"2 years",
"2 years",
"1 year",
"4 years",
"6 years",
"10+ years",
"10+ years",
"9 years",
null,
"2 years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"6 years",
"1 year",
"2 years",
"1 year",
"5 years",
"3 years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
null,
"10+ years",
"7 years",
"9 years",
"2 years",
"1 year",
"< 1 year",
null,
"5 years",
"2 years",
null,
"10+ years",
"10+ years",
"8 years",
"1 year",
"3 years",
"1 year",
"< 1 year",
"6 years",
"4 years",
"< 1 year",
"8 years",
"10+ years",
"5 years",
"10+ years",
"1 year",
null,
"10+ years",
"< 1 year",
"3 years",
"< 1 year",
"2 years",
"8 years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"5 years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"7 years",
"5 years",
"7 years",
"10+ years",
null,
"5 years",
"2 years",
"6 years",
"7 years",
"2 years",
"10+ years",
"1 year",
"8 years",
"4 years",
"< 1 year",
null,
"9 years",
"8 years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"7 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"8 years",
"1 year",
"6 years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"5 years",
"10+ years",
"4 years",
"8 years",
"< 1 year",
"4 years",
"2 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
null,
"3 years",
"8 years",
"10+ years",
"9 years",
"5 years",
"8 years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"2 years",
"4 years",
"7 years",
"1 year",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"5 years",
"5 years",
"10+ years",
"6 years",
"1 year",
"10+ years",
null,
"10+ years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"3 years",
"4 years",
"2 years",
"1 year",
"5 years",
"2 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"1 year",
"10+ years",
"8 years",
"2 years",
"10+ years",
"4 years",
"5 years",
"4 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"8 years",
"8 years",
"4 years",
"10+ years",
"10+ years",
"6 years",
"5 years",
"3 years",
"10+ years",
"1 year",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"2 years",
"1 year",
"8 years",
"10+ years",
"1 year",
"3 years",
"7 years",
"10+ years",
"6 years",
"3 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"2 years",
"< 1 year",
"10+ years",
null,
"< 1 year",
"10+ years",
null,
"10+ years",
"10+ years",
null,
"10+ years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"10+ years",
null,
"10+ years",
"10+ years",
"3 years",
"5 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"7 years",
"3 years",
"< 1 year",
"< 1 year",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"5 years",
"3 years",
null,
"6 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
null,
"8 years",
"10+ years",
"4 years",
"4 years",
"7 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"1 year",
"4 years",
"5 years",
"< 1 year",
"7 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"9 years",
"2 years",
"8 years",
"< 1 year",
"< 1 year",
"< 1 year",
"1 year",
"2 years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"4 years",
"4 years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"8 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"1 year",
"7 years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"2 years",
"10+ years",
"1 year",
"2 years",
"3 years",
"6 years",
"9 years",
"10+ years",
"8 years",
"3 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"8 years",
"9 years",
"9 years",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
null,
"8 years",
"7 years",
"2 years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"< 1 year",
"< 1 year",
"4 years",
"< 1 year",
"7 years",
"2 years",
"< 1 year",
"10+ years",
"9 years",
"4 years",
"3 years",
"3 years",
"10+ years",
"2 years",
"5 years",
"7 years",
"3 years",
"2 years",
null,
"5 years",
"4 years",
"4 years",
"9 years",
"5 years",
null,
"2 years",
"10+ years",
null,
"10+ years",
"5 years",
null,
"4 years",
"5 years",
"10+ years",
null,
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"10+ years",
null,
"10+ years",
"< 1 year",
"4 years",
null,
"2 years",
"7 years",
"2 years",
"10+ years",
"6 years",
"8 years",
"10+ years",
"8 years",
"10+ years",
"1 year",
"< 1 year",
null,
"10+ years",
"6 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"2 years",
null,
null,
"7 years",
"1 year",
"< 1 year",
"8 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"4 years",
"< 1 year",
"10+ years",
"3 years",
"8 years",
"2 years",
"6 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"1 year",
"8 years",
"8 years",
"10+ years",
"2 years",
"8 years",
"9 years",
"2 years",
"7 years",
"3 years",
"2 years",
"< 1 year",
"7 years",
"10+ years",
"9 years",
"2 years",
"5 years",
null,
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
null,
"7 years",
"10+ years",
null,
null,
"7 years",
"3 years",
"2 years",
"10+ years",
"< 1 year",
"< 1 year",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"< 1 year",
"10+ years",
"5 years",
"9 years",
"1 year",
"10+ years",
"7 years",
"4 years",
"1 year",
"10+ years",
"5 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"4 years",
"1 year",
"< 1 year",
"3 years",
null,
"1 year",
"7 years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"10+ years",
"4 years",
"3 years",
"10+ years",
"8 years",
"2 years",
"1 year",
"4 years",
"2 years",
"10+ years",
"6 years",
"< 1 year",
"8 years",
"10+ years",
"3 years",
"5 years",
"2 years",
"4 years",
"6 years",
"5 years",
"8 years",
"< 1 year",
"10+ years",
"3 years",
"3 years",
"3 years",
"10+ years",
"4 years",
"4 years",
"10+ years",
"2 years",
"8 years",
"9 years",
"8 years",
"10+ years",
"4 years",
null,
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
null,
"1 year",
"10+ years",
"4 years",
"3 years",
"5 years",
"1 year",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"5 years",
"6 years",
"7 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"1 year",
"5 years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
null,
"3 years",
"10+ years",
"10+ years",
"9 years",
"2 years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
null,
null,
null,
"7 years",
"7 years",
"10+ years",
"6 years",
"3 years",
"4 years",
"< 1 year",
"2 years",
"2 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"3 years",
"2 years",
"4 years",
"8 years",
"4 years",
"< 1 year",
null,
null,
"10+ years",
"3 years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"7 years",
"4 years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"3 years",
"7 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"10+ years",
null,
"9 years",
"10+ years",
"6 years",
"10+ years",
null,
null,
"5 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"7 years",
"6 years",
"1 year",
"3 years",
"2 years",
"2 years",
"10+ years",
"5 years",
"6 years",
"10+ years",
"1 year",
"10+ years",
"6 years",
"< 1 year",
"4 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"5 years",
"1 year",
"< 1 year",
"10+ years",
"1 year",
"1 year",
"10+ years",
"7 years",
"3 years",
"< 1 year",
"10+ years",
"4 years",
null,
"< 1 year",
"6 years",
null,
"2 years",
"4 years",
"1 year",
"7 years",
"10+ years",
null,
"5 years",
"2 years",
"8 years",
"8 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"10+ years",
null,
"4 years",
"5 years",
"5 years",
"9 years",
"10+ years",
"3 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"9 years",
"4 years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
null,
"9 years",
"2 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"< 1 year",
"4 years",
"5 years",
"10+ years",
"7 years",
"5 years",
"6 years",
"6 years",
"2 years",
"< 1 year",
"3 years",
"8 years",
"8 years",
"5 years",
"10+ years",
"3 years",
"< 1 year",
"4 years",
"4 years",
"2 years",
"8 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"9 years",
"10+ years",
"7 years",
"3 years",
"5 years",
"6 years",
"4 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"6 years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"< 1 year",
"4 years",
"7 years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"5 years",
"1 year",
"1 year",
"4 years",
"3 years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"10+ years",
null,
"3 years",
"3 years",
"10+ years",
"1 year",
"4 years",
"1 year",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"2 years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"6 years",
"7 years",
"2 years",
null,
"9 years",
null,
"2 years",
"< 1 year",
"9 years",
"2 years",
"8 years",
"2 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"2 years",
"9 years",
"6 years",
"10+ years",
"1 year",
"4 years",
"9 years",
"5 years",
"9 years",
"< 1 year",
"9 years",
"2 years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"5 years",
null,
"4 years",
"6 years",
"6 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"3 years",
"7 years",
"1 year",
"3 years",
"3 years",
"4 years",
"3 years",
"2 years",
"1 year",
"3 years",
null,
"7 years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"6 years",
"3 years",
"8 years",
"1 year",
null,
"10+ years",
"8 years",
"10+ years",
"6 years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"5 years",
"9 years",
"3 years",
"5 years",
null,
"10+ years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"2 years",
"10+ years",
"2 years",
"< 1 year",
"1 year",
"1 year",
"2 years",
"3 years",
"< 1 year",
"5 years",
"2 years",
"10+ years",
"3 years",
"9 years",
"10+ years",
"8 years",
"6 years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"9 years",
null,
"7 years",
"1 year",
"7 years",
"7 years",
"8 years",
"5 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"< 1 year",
"< 1 year",
"3 years",
"< 1 year",
"5 years",
"8 years",
"5 years",
"1 year",
"5 years",
"< 1 year",
"8 years",
"4 years",
"6 years",
"1 year",
"2 years",
"5 years",
"10+ years",
"6 years",
"3 years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
null,
"5 years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"2 years",
"4 years",
"2 years",
"10+ years",
"2 years",
"7 years",
"2 years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"< 1 year",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"5 years",
"6 years",
"5 years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"8 years",
"6 years",
"7 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"1 year",
"4 years",
"9 years",
"10+ years",
"< 1 year",
null,
"6 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"6 years",
"2 years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"3 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
null,
"1 year",
"7 years",
null,
null,
"2 years",
"10+ years",
"5 years",
"6 years",
"3 years",
"10+ years",
"3 years",
"6 years",
"1 year",
"7 years",
"1 year",
"2 years",
"8 years",
"2 years",
"4 years",
"10+ years",
"10+ years",
null,
null,
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"8 years",
"6 years",
"3 years",
"2 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
null,
null,
"9 years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"6 years",
"2 years",
"10+ years",
"2 years",
"7 years",
"5 years",
"10+ years",
"1 year",
"9 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"8 years",
"9 years",
"2 years",
"6 years",
"< 1 year",
"5 years",
null,
"6 years",
"10+ years",
"8 years",
"8 years",
"2 years",
"10+ years",
"4 years",
"2 years",
"3 years",
"1 year",
"2 years",
"< 1 year",
"9 years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"1 year",
null,
"1 year",
"2 years",
"10+ years",
"10+ years",
"8 years",
"2 years",
"8 years",
"8 years",
"10+ years",
"6 years",
"3 years",
"< 1 year",
"7 years",
"3 years",
"2 years",
"8 years",
"2 years",
"10+ years",
"2 years",
"3 years",
"4 years",
"10+ years",
"2 years",
"4 years",
"9 years",
"7 years",
"2 years",
"< 1 year",
"< 1 year",
"10+ years",
"< 1 year",
"1 year",
"2 years",
"10+ years",
"8 years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"6 years",
"3 years",
null,
"6 years",
"4 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"6 years",
"6 years",
"7 years",
"10+ years",
"3 years",
null,
"5 years",
"10+ years",
"6 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"7 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"5 years",
"6 years",
"2 years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"2 years",
"7 years",
"3 years",
"3 years",
"4 years",
"4 years",
"7 years",
"5 years",
"10+ years",
"9 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"7 years",
"4 years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"9 years",
null,
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"9 years",
"7 years",
"1 year",
"< 1 year",
"5 years",
"6 years",
"5 years",
"9 years",
"5 years",
"5 years",
null,
"5 years",
"10+ years",
"1 year",
"3 years",
"6 years",
"7 years",
"2 years",
"10+ years",
"< 1 year",
"3 years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"< 1 year",
"3 years",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"3 years",
"9 years",
"10+ years",
null,
"3 years",
"8 years",
"10+ years",
"6 years",
null,
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"4 years",
"3 years",
"6 years",
"10+ years",
"2 years",
"9 years",
"5 years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
null,
"8 years",
"1 year",
"3 years",
"1 year",
"3 years",
"6 years",
"10+ years",
"4 years",
null,
"4 years",
"10+ years",
"10+ years",
"6 years",
"4 years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"8 years",
null,
"1 year",
"4 years",
"10+ years",
"3 years",
"< 1 year",
"7 years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"6 years",
"5 years",
"2 years",
"10+ years",
"6 years",
"1 year",
"2 years",
null,
"10+ years",
"3 years",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"8 years",
"10+ years",
"4 years",
null,
"10+ years",
null,
"10+ years",
null,
"4 years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"4 years",
"6 years",
"4 years",
"8 years",
"1 year",
"7 years",
"< 1 year",
"7 years",
"6 years",
"9 years",
"10+ years",
"2 years",
"1 year",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"7 years",
"10+ years",
"6 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"8 years",
null,
"10+ years",
"1 year",
"3 years",
"10+ years",
"1 year",
"7 years",
"10+ years",
"1 year",
"5 years",
"10+ years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"1 year",
"8 years",
"7 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"7 years",
"2 years",
"< 1 year",
"1 year",
"1 year",
"5 years",
"4 years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"8 years",
"2 years",
"1 year",
"10+ years",
"1 year",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"9 years",
"2 years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"5 years",
"7 years",
"9 years",
"6 years",
"5 years",
"< 1 year",
"2 years",
"< 1 year",
"9 years",
"4 years",
"10+ years",
"2 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"2 years",
"7 years",
"7 years",
null,
"< 1 year",
"6 years",
"10+ years",
"7 years",
"3 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"9 years",
"2 years",
"< 1 year",
"1 year",
"5 years",
"< 1 year",
"9 years",
"2 years",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"1 year",
"3 years",
"10+ years",
"5 years",
"4 years",
"5 years",
"8 years",
"10+ years",
null,
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"4 years",
null,
"3 years",
"10+ years",
null,
null,
"6 years",
"< 1 year",
"8 years",
"10+ years",
"1 year",
"< 1 year",
null,
"10+ years",
null,
"10+ years",
"3 years",
"10+ years",
"1 year",
"5 years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"3 years",
"6 years",
"< 1 year",
"1 year",
"7 years",
"10+ years",
"2 years",
"< 1 year",
"3 years",
"< 1 year",
"3 years",
"2 years",
"3 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"5 years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"5 years",
"9 years",
"4 years",
"1 year",
"10+ years",
"8 years",
"10+ years",
"1 year",
null,
"10+ years",
"2 years",
"10+ years",
"4 years",
"2 years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"9 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"4 years",
"10+ years",
"1 year",
"10+ years",
null,
"10+ years",
"4 years",
"10+ years",
"5 years",
"10+ years",
"9 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"2 years",
"3 years",
"< 1 year",
"< 1 year",
"10+ years",
"5 years",
null,
"6 years",
"1 year",
"5 years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"9 years",
"8 years",
"8 years",
"6 years",
null,
"6 years",
"7 years",
"< 1 year",
null,
"10+ years",
"10+ years",
"3 years",
"10+ years",
null,
"8 years",
"9 years",
"8 years",
"5 years",
"5 years",
null,
"2 years",
"2 years",
"5 years",
"10+ years",
"2 years",
"2 years",
"1 year",
"8 years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"3 years",
"3 years",
null,
"10+ years",
"4 years",
null,
"10+ years",
"10+ years",
null,
"10+ years",
"6 years",
"10+ years",
"9 years",
"< 1 year",
"5 years",
"8 years",
"1 year",
"9 years",
"8 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"1 year",
"4 years",
"< 1 year",
"10+ years",
"2 years",
"3 years",
"10+ years",
"3 years",
"3 years",
"1 year",
"8 years",
"< 1 year",
"< 1 year",
"5 years",
null,
"10+ years",
"1 year",
"3 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"< 1 year",
"6 years",
"7 years",
"3 years",
"9 years",
"10+ years",
"9 years",
"2 years",
"6 years",
"10+ years",
"8 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"2 years",
"4 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
null,
"< 1 year",
"4 years",
"1 year",
"1 year",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"7 years",
"10+ years",
null,
"7 years",
"10+ years",
"9 years",
"5 years",
"5 years",
"1 year",
"< 1 year",
"< 1 year",
"5 years",
"2 years",
"6 years",
"2 years",
null,
"6 years",
"4 years",
"7 years",
"3 years",
"2 years",
"4 years",
"10+ years",
"5 years",
"3 years",
"4 years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"6 years",
"< 1 year",
"9 years",
"4 years",
"3 years",
"3 years",
"< 1 year",
"8 years",
"3 years",
"5 years",
"5 years",
"10+ years",
"10+ years",
null,
null,
"10+ years",
"8 years",
"10+ years",
"8 years",
"9 years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"7 years",
"6 years",
"2 years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
null,
"2 years",
"7 years",
"3 years",
"1 year",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"7 years",
"6 years",
"10+ years",
"< 1 year",
null,
"4 years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
null,
"1 year",
"10+ years",
"10+ years",
"2 years",
null,
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
null,
"10+ years",
"7 years",
"2 years",
"2 years",
"7 years",
"2 years",
"1 year",
null,
"10+ years",
"10+ years",
"4 years",
"4 years",
"5 years",
"< 1 year",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"6 years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"7 years",
"2 years",
null,
"10+ years",
"9 years",
"1 year",
"2 years",
"2 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"8 years",
"3 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"5 years",
"2 years",
"6 years",
"4 years",
"1 year",
"10+ years",
"6 years",
"10+ years",
"5 years",
"< 1 year",
"3 years",
null,
"2 years",
"7 years",
"1 year",
"5 years",
"3 years",
"10+ years",
"5 years",
null,
"8 years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"10+ years",
"7 years",
"< 1 year",
"3 years",
"4 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
null,
"7 years",
"1 year",
"9 years",
"8 years",
"9 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"5 years",
"7 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
null,
"10+ years",
"8 years",
"7 years",
null,
"7 years",
"7 years",
"1 year",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"5 years",
"4 years",
"9 years",
"1 year",
"< 1 year",
"8 years",
"8 years",
"5 years",
"10+ years",
"6 years",
"3 years",
"8 years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"6 years",
"8 years",
"6 years",
"10+ years",
"4 years",
"< 1 year",
"< 1 year",
"8 years",
"10+ years",
"4 years",
"1 year",
"3 years",
"1 year",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"3 years",
"9 years",
"< 1 year",
"10+ years",
"1 year",
"5 years",
"7 years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"3 years",
"3 years",
"5 years",
"< 1 year",
"8 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"4 years",
"6 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"6 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"9 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"6 years",
"5 years",
"5 years",
"3 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"9 years",
"10+ years",
"1 year",
"2 years",
null,
"2 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"1 year",
"9 years",
"5 years",
"< 1 year",
"3 years",
"3 years",
"< 1 year",
"9 years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"6 years",
"5 years",
"9 years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"5 years",
"9 years",
"7 years",
"1 year",
"10+ years",
null,
"10+ years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"7 years",
"10+ years",
"5 years",
"6 years",
"< 1 year",
"9 years",
"6 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"1 year",
"3 years",
"1 year",
"10+ years",
null,
"3 years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
null,
"7 years",
"6 years",
"8 years",
"10+ years",
"8 years",
"10+ years",
"7 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"10+ years",
"9 years",
"< 1 year",
null,
null,
"10+ years",
"2 years",
"10+ years",
"1 year",
"10+ years",
null,
null,
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"2 years",
"10+ years",
"5 years",
"9 years",
"4 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"7 years",
"2 years",
"10+ years",
null,
"10+ years",
"10+ years",
"1 year",
"6 years",
"7 years",
"4 years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"1 year",
"2 years",
"3 years",
"10+ years",
"2 years",
"2 years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"3 years",
"< 1 year",
"1 year",
"4 years",
"6 years",
"7 years",
"10+ years",
"10+ years",
"3 years",
"9 years",
"10+ years",
"6 years",
"6 years",
"< 1 year",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
null,
"10+ years",
"3 years",
"1 year",
"10+ years",
"5 years",
"10+ years",
"6 years",
"< 1 year",
"10+ years",
null,
null,
"5 years",
"3 years",
"10+ years",
"7 years",
"2 years",
"3 years",
"1 year",
"3 years",
"10+ years",
null,
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"5 years",
"5 years",
"5 years",
"7 years",
"8 years",
"9 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"1 year",
"3 years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"4 years",
"2 years",
null,
"10+ years",
"6 years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"1 year",
"9 years",
"10+ years",
null,
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"6 years",
"3 years",
"10+ years",
"6 years",
null,
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"9 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"7 years",
null,
"10+ years",
"6 years",
"2 years",
"10+ years",
"9 years",
"9 years",
"< 1 year",
null,
"9 years",
"10+ years",
null,
"1 year",
"10+ years",
"4 years",
"1 year",
"5 years",
"4 years",
"6 years",
null,
"2 years",
"5 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
null,
"7 years",
"1 year",
"4 years",
"< 1 year",
"10+ years",
"1 year",
"2 years",
"4 years",
"7 years",
"7 years",
"1 year",
"8 years",
"7 years",
"2 years",
"9 years",
"8 years",
"2 years",
"3 years",
"9 years",
"1 year",
null,
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"1 year",
"3 years",
"7 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"2 years",
"2 years",
"10+ years",
"8 years",
"7 years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"7 years",
"3 years",
"5 years",
"10+ years",
null,
"10+ years",
"6 years",
"7 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"1 year",
"10+ years",
"2 years",
"4 years",
"8 years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"8 years",
"1 year",
"10+ years",
"10+ years",
"7 years",
"2 years",
"6 years",
"7 years",
"3 years",
"2 years",
"< 1 year",
"5 years",
"7 years",
"7 years",
"10+ years",
"5 years",
"9 years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
null,
"1 year",
"< 1 year",
"10+ years",
null,
"4 years",
"9 years",
"7 years",
"5 years",
"10+ years",
"10+ years",
null,
"7 years",
"10+ years",
"< 1 year",
"2 years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"6 years",
"2 years",
"< 1 year",
"10+ years",
null,
"2 years",
"1 year",
"7 years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"10+ years",
"4 years",
"7 years",
null,
"10+ years",
"6 years",
"6 years",
"3 years",
"8 years",
"< 1 year",
null,
"3 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
null,
null,
"4 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"6 years",
"10+ years",
"7 years",
"10+ years",
"4 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"1 year",
"4 years",
"10+ years",
"10+ years",
"6 years",
"< 1 year",
"3 years",
"7 years",
"9 years",
"8 years",
null,
"6 years",
"10+ years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"1 year",
"5 years",
null,
"< 1 year",
"7 years",
null,
"10+ years",
"3 years",
null,
"10+ years",
"4 years",
"2 years",
null,
"< 1 year",
"2 years",
"< 1 year",
"9 years",
"3 years",
"1 year",
null,
"5 years",
"8 years",
"1 year",
"2 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"6 years",
"3 years",
"6 years",
"< 1 year",
"5 years",
"5 years",
"5 years",
"6 years",
"2 years",
"4 years",
"10+ years",
"1 year",
"8 years",
"< 1 year",
null,
"4 years",
"9 years",
"< 1 year",
"3 years",
"1 year",
"2 years",
"1 year",
"10+ years",
"10+ years",
"5 years",
null,
"6 years",
"3 years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"2 years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"8 years",
"5 years",
"5 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"5 years",
"5 years",
"9 years",
"5 years",
"< 1 year",
"1 year",
"10+ years",
"2 years",
"8 years",
"1 year",
"< 1 year",
"1 year",
"4 years",
"< 1 year",
"5 years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
null,
"6 years",
"< 1 year",
null,
"< 1 year",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"6 years",
"4 years",
"2 years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"8 years",
"10+ years",
"10+ years",
"5 years",
null,
"5 years",
"5 years",
"6 years",
"10+ years",
"10+ years",
"9 years",
"3 years",
"5 years",
"< 1 year",
"10+ years",
"6 years",
"1 year",
"2 years",
"8 years",
"< 1 year",
"3 years",
"< 1 year",
"7 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"3 years",
"10+ years",
"8 years",
"2 years",
"6 years",
"9 years",
"1 year",
"9 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"7 years",
"4 years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"5 years",
"6 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"6 years",
"4 years",
"3 years",
"8 years",
"4 years",
"10+ years",
"6 years",
"< 1 year",
"10+ years",
"9 years",
"9 years",
"< 1 year",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"< 1 year",
null,
null,
null,
"2 years",
"6 years",
"3 years",
"4 years",
"1 year",
"3 years",
"10+ years",
"7 years",
"5 years",
"2 years",
"3 years",
"8 years",
null,
"10+ years",
"< 1 year",
"1 year",
"9 years",
"10+ years",
"8 years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"7 years",
"7 years",
"10+ years",
"< 1 year",
"9 years",
"5 years",
"6 years",
"6 years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"7 years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"4 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"10+ years",
"3 years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"2 years",
"5 years",
"9 years",
"3 years",
"10+ years",
"3 years",
"1 year",
"3 years",
"2 years",
"9 years",
"10+ years",
null,
"10+ years",
"7 years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"4 years",
"1 year",
"9 years",
"< 1 year",
"3 years",
null,
"< 1 year",
"10+ years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"5 years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"8 years",
"10+ years",
"8 years",
"10+ years",
"4 years",
"6 years",
null,
"4 years",
"2 years",
"< 1 year",
"3 years",
"10+ years",
"2 years",
"4 years",
"6 years",
null,
"3 years",
"9 years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"1 year",
"2 years",
"4 years",
"4 years",
"10+ years",
"8 years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"1 year",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"6 years",
"3 years",
"10+ years",
"3 years",
"5 years",
"5 years",
"1 year",
"10+ years",
"6 years",
"2 years",
"2 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"6 years",
null,
"10+ years",
"5 years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"1 year",
null,
"4 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"9 years",
"7 years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"5 years",
"10+ years",
"3 years",
"1 year",
"6 years",
"10+ years",
"9 years",
"4 years",
null,
"2 years",
"10+ years",
"7 years",
"4 years",
"3 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"4 years",
"6 years",
"9 years",
"10+ years",
"1 year",
"2 years",
"2 years",
"10+ years",
"2 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"3 years",
"3 years",
"9 years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"8 years",
"3 years",
"3 years",
"< 1 year",
"3 years",
"7 years",
"< 1 year",
"6 years",
"3 years",
"< 1 year",
"10+ years",
"2 years",
null,
"1 year",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"2 years",
"7 years",
"8 years",
"10+ years",
"7 years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"6 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"7 years",
null,
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"1 year",
"7 years",
"9 years",
"6 years",
"5 years",
"9 years",
"6 years",
"10+ years",
"2 years",
"< 1 year",
"3 years",
"6 years",
"4 years",
"4 years",
"6 years",
"2 years",
"4 years",
"8 years",
"2 years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"< 1 year",
"< 1 year",
"7 years",
"10+ years",
"1 year",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"2 years",
"3 years",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"9 years",
"2 years",
"9 years",
"4 years",
"4 years",
"10+ years",
"8 years",
"8 years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"2 years",
"2 years",
"1 year",
"2 years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"3 years",
null,
"10+ years",
"10+ years",
"8 years",
"5 years",
"< 1 year",
"3 years",
"3 years",
null,
"10+ years",
"6 years",
"10+ years",
null,
"3 years",
null,
"10+ years",
"6 years",
"9 years",
"< 1 year",
"9 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"2 years",
"9 years",
"2 years",
"3 years",
"1 year",
"3 years",
"8 years",
"2 years",
"5 years",
"10+ years",
null,
"2 years",
"10+ years",
"8 years",
"9 years",
"9 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"4 years",
"2 years",
"1 year",
"5 years",
null,
"10+ years",
"10+ years",
"9 years",
"1 year",
"2 years",
"10+ years",
"6 years",
"1 year",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"2 years",
null,
"< 1 year",
null,
"10+ years",
"5 years",
"10+ years",
"4 years",
null,
"< 1 year",
"3 years",
"2 years",
"10+ years",
"5 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"6 years",
"10+ years",
"10+ years",
"2 years",
"7 years",
"1 year",
"4 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"9 years",
"6 years",
null,
"10+ years",
"6 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"4 years",
"8 years",
"8 years",
"10+ years",
"7 years",
"9 years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"10+ years",
"9 years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"9 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"3 years",
"4 years",
"5 years",
"6 years",
"9 years",
"8 years",
"10+ years",
"10+ years",
null,
"8 years",
"< 1 year",
"2 years",
"10+ years",
"2 years",
"9 years",
null,
"10+ years",
"< 1 year",
null,
"3 years",
"9 years",
"10+ years",
"7 years",
"8 years",
null,
"7 years",
"10+ years",
"10+ years",
"1 year",
"4 years",
"9 years",
"10+ years",
"4 years",
"3 years",
"< 1 year",
"10+ years",
null,
"10+ years",
"7 years",
"10+ years",
"1 year",
"10+ years",
"4 years",
"4 years",
"< 1 year",
"2 years",
"10+ years",
"2 years",
"3 years",
"< 1 year",
"10+ years",
"2 years",
"8 years",
"10+ years",
"9 years",
"< 1 year",
"8 years",
"7 years",
"3 years",
"4 years",
"10+ years",
"9 years",
null,
"4 years",
"5 years",
"< 1 year",
"10+ years",
"6 years",
"5 years",
"6 years",
"3 years",
"2 years",
"2 years",
"10+ years",
"3 years",
"6 years",
"6 years",
"10+ years",
"1 year",
"9 years",
"3 years",
"< 1 year",
"6 years",
"10+ years",
null,
"10+ years",
"5 years",
null,
"10+ years",
"6 years",
"10+ years",
null,
"1 year",
"7 years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"9 years",
"9 years",
"10+ years",
"10+ years",
"5 years",
"6 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"7 years",
"3 years",
"4 years",
"7 years",
null,
"< 1 year",
"< 1 year",
"10+ years",
"4 years",
"2 years",
"2 years",
"8 years",
"10+ years",
"4 years",
"2 years",
"4 years",
"10+ years",
"1 year",
"10+ years",
"8 years",
"1 year",
"5 years",
"8 years",
"10+ years",
"3 years",
"4 years",
"7 years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
null,
null,
"9 years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"9 years",
null,
"6 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"2 years",
null,
"10+ years",
"5 years",
"10+ years",
"4 years",
"7 years",
"6 years",
null,
"10+ years",
"4 years",
"3 years",
"1 year",
"7 years",
"< 1 year",
"3 years",
"10+ years",
"7 years",
"< 1 year",
"8 years",
"2 years",
"10+ years",
null,
"6 years",
"3 years",
"1 year",
"3 years",
"8 years",
"< 1 year",
"1 year",
"8 years",
"10+ years",
"8 years",
"9 years",
"3 years",
"8 years",
"2 years",
"2 years",
"2 years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"1 year",
null,
"10+ years",
"1 year",
"3 years",
"1 year",
"< 1 year",
"10+ years",
"1 year",
null,
"7 years",
"10+ years",
"< 1 year",
null,
"2 years",
"10+ years",
"9 years",
"< 1 year",
"1 year",
"8 years",
"5 years",
"10+ years",
"7 years",
null,
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"6 years",
"1 year",
"9 years",
"7 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"2 years",
"3 years",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"7 years",
"10+ years",
"7 years",
"4 years",
"3 years",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"9 years",
"1 year",
"8 years",
"10+ years",
"1 year",
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
null,
"< 1 year",
"10+ years",
"6 years",
"< 1 year",
"10+ years",
"< 1 year",
"2 years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
null,
"5 years",
"3 years",
"2 years",
"10+ years",
"5 years",
"5 years",
"10+ years",
"3 years",
"5 years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
null,
"< 1 year",
"3 years",
"6 years",
"6 years",
"8 years",
"8 years",
"6 years",
"7 years",
null,
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"< 1 year",
"2 years",
"4 years",
"3 years",
"5 years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"6 years",
"< 1 year",
"8 years",
"< 1 year",
"1 year",
null,
"2 years",
"< 1 year",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"4 years",
"7 years",
"10+ years",
"10+ years",
"2 years",
"6 years",
"2 years",
"< 1 year",
"4 years",
"6 years",
"8 years",
"10+ years",
"1 year",
"3 years",
"2 years",
"10+ years",
"8 years",
"5 years",
"4 years",
"< 1 year",
"5 years",
"4 years",
"1 year",
"1 year",
"10+ years",
"8 years",
"4 years",
"3 years",
"1 year",
null,
"1 year",
"3 years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"10+ years",
"1 year",
"5 years",
"10+ years",
"6 years",
"8 years",
"10+ years",
"10+ years",
"8 years",
"9 years",
"7 years",
"4 years",
"10+ years",
"7 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"4 years",
"9 years",
"10+ years",
"10+ years",
"6 years",
"8 years",
"2 years",
null,
"9 years",
"10+ years",
"5 years",
"8 years",
"10+ years",
"2 years",
"2 years",
"4 years",
"3 years",
"2 years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"6 years",
"10+ years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"4 years",
"1 year",
"6 years",
"8 years",
"4 years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
null,
"4 years",
"3 years",
"10+ years",
"7 years",
"4 years",
"5 years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"< 1 year",
"8 years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"1 year",
null,
"5 years",
"10+ years",
"< 1 year",
"< 1 year",
"6 years",
"< 1 year",
"7 years",
"3 years",
"7 years",
"3 years",
"10+ years",
"7 years",
"5 years",
"1 year",
"7 years",
null,
"3 years",
"10+ years",
null,
"8 years",
"10+ years",
"10+ years",
null,
"2 years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"2 years",
"1 year",
"8 years",
"9 years",
"10+ years",
"7 years",
"3 years",
"2 years",
"8 years",
"1 year",
"10+ years",
"1 year",
"4 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"2 years",
"3 years",
"5 years",
"3 years",
"9 years",
"10+ years",
"3 years",
"7 years",
"9 years",
"< 1 year",
"3 years",
"10+ years",
"2 years",
"2 years",
"< 1 year",
"10+ years",
null,
"10+ years",
"5 years",
"5 years",
"10+ years",
"1 year",
"3 years",
"6 years",
"10+ years",
"10+ years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"7 years",
"5 years",
"8 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"9 years",
"5 years",
"10+ years",
"3 years",
"3 years",
"< 1 year",
"10+ years",
"1 year",
"8 years",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"4 years",
"1 year",
"1 year",
"3 years",
"8 years",
"6 years",
"2 years",
"4 years",
"10+ years",
"3 years",
"5 years",
"4 years",
null,
"2 years",
"7 years",
"3 years",
"6 years",
"4 years",
"10+ years",
"10+ years",
null,
"1 year",
"10+ years",
"7 years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"7 years",
"6 years",
"7 years",
"4 years",
"4 years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
null,
"5 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"9 years",
"2 years",
"1 year",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"1 year",
"5 years",
"7 years",
"10+ years",
"8 years",
"7 years",
"8 years",
"9 years",
"8 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"7 years",
"8 years",
"5 years",
"10+ years",
"2 years",
"2 years",
null,
"5 years",
"2 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"3 years",
null,
"10+ years",
"10+ years",
"3 years",
"2 years",
"8 years",
"8 years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"5 years",
"8 years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"9 years",
"3 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"3 years",
"4 years",
"2 years",
"10+ years",
"6 years",
"6 years",
"4 years",
"10+ years",
"6 years",
"1 year",
"10+ years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"7 years",
null,
"7 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"7 years",
"4 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"4 years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"3 years",
null,
"3 years",
"1 year",
"1 year",
"10+ years",
null,
"1 year",
"4 years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
null,
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"3 years",
"7 years",
"4 years",
"10+ years",
"2 years",
"2 years",
"6 years",
null,
"1 year",
"8 years",
"3 years",
"9 years",
"10+ years",
"10+ years",
"6 years",
"< 1 year",
null,
"10+ years",
null,
"8 years",
null,
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"10+ years",
"1 year",
"3 years",
null,
"10+ years",
"6 years",
"2 years",
null,
"2 years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"5 years",
"2 years",
"2 years",
"8 years",
"6 years",
"10+ years",
"1 year",
"5 years",
"2 years",
"8 years",
"6 years",
"5 years",
"10+ years",
"< 1 year",
"3 years",
null,
"< 1 year",
null,
"10+ years",
"< 1 year",
"8 years",
"7 years",
"< 1 year",
"9 years",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"< 1 year",
"1 year",
"3 years",
"< 1 year",
"2 years",
"4 years",
"7 years",
"9 years",
"6 years",
"10+ years",
"9 years",
null,
"9 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"6 years",
"4 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"2 years",
"2 years",
"3 years",
"< 1 year",
"10+ years",
"9 years",
null,
"10+ years",
"9 years",
"10+ years",
"3 years",
null,
"2 years",
"7 years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
null,
"5 years",
"6 years",
"3 years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"< 1 year",
"1 year",
"5 years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"7 years",
"3 years",
"9 years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"1 year",
"4 years",
"5 years",
"1 year",
"3 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
null,
"6 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"6 years",
"2 years",
"5 years",
"8 years",
null,
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"6 years",
"1 year",
"3 years",
null,
"3 years",
null,
null,
"1 year",
"10+ years",
"10+ years",
"3 years",
"5 years",
"5 years",
"5 years",
"1 year",
"7 years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"1 year",
"5 years",
"3 years",
"10+ years",
"1 year",
"9 years",
"10+ years",
"10+ years",
"8 years",
"1 year",
"10+ years",
"4 years",
"10+ years",
"5 years",
"2 years",
"4 years",
"8 years",
"3 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"5 years",
"1 year",
"1 year",
"1 year",
"3 years",
"9 years",
"7 years",
"< 1 year",
"7 years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"10+ years",
null,
"5 years",
null,
"10+ years",
"3 years",
"5 years",
"6 years",
"< 1 year",
"3 years",
"10+ years",
"6 years",
"5 years",
"1 year",
"< 1 year",
"10+ years",
"8 years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
null,
"3 years",
"5 years",
"1 year",
"6 years",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"< 1 year",
null,
"10+ years",
null,
"7 years",
"10+ years",
null,
"7 years",
"4 years",
"3 years",
"5 years",
"10+ years",
"1 year",
"2 years",
"< 1 year",
"< 1 year",
"3 years",
"7 years",
"10+ years",
"7 years",
"4 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"2 years",
"3 years",
null,
"10+ years",
"2 years",
"10+ years",
"9 years",
"2 years",
"4 years",
"< 1 year",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"8 years",
"5 years",
"3 years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"1 year",
"< 1 year",
null,
"3 years",
"10+ years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"10+ years",
"6 years",
"1 year",
null,
"10+ years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"2 years",
"10+ years",
"9 years",
"10+ years",
"1 year",
"6 years",
"< 1 year",
"5 years",
"< 1 year",
"10+ years",
"6 years",
"7 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"3 years",
null,
"10+ years",
"8 years",
"1 year",
"6 years",
"10+ years",
"9 years",
"10+ years",
"2 years",
null,
"3 years",
"1 year",
"2 years",
"7 years",
"10+ years",
"8 years",
"3 years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"2 years",
"< 1 year",
"10+ years",
"9 years",
null,
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
null,
"2 years",
"5 years",
"10+ years",
"6 years",
null,
"6 years",
"3 years",
"6 years",
"10+ years",
"10+ years",
"4 years",
null,
"10+ years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"6 years",
"3 years",
"< 1 year",
"2 years",
"6 years",
"7 years",
"1 year",
"3 years",
"2 years",
"10+ years",
"2 years",
"4 years",
"10+ years",
"< 1 year",
"3 years",
"4 years",
"10+ years",
null,
"5 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"4 years",
"10+ years",
null,
"10+ years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"2 years",
"4 years",
"7 years",
"3 years",
"< 1 year",
null,
"7 years",
"< 1 year",
"5 years",
"10+ years",
"9 years",
"4 years",
"4 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
null,
"10+ years",
"7 years",
"5 years",
"7 years",
"2 years",
"4 years",
"< 1 year",
"2 years",
"10+ years",
"1 year",
"10+ years",
"4 years",
"3 years",
"3 years",
"2 years",
"10+ years",
"5 years",
null,
"1 year",
"10+ years",
"10+ years",
"4 years",
"3 years",
null,
"9 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"6 years",
"1 year",
"2 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"2 years",
"2 years",
"4 years",
"3 years",
"10+ years",
"9 years",
"7 years",
"< 1 year",
"2 years",
"< 1 year",
"5 years",
"5 years",
"10+ years",
"9 years",
"3 years",
"5 years",
"4 years",
"6 years",
"4 years",
"2 years",
"3 years",
"< 1 year",
"9 years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"4 years",
null,
"4 years",
"5 years",
"8 years",
"9 years",
"10+ years",
"9 years",
"3 years",
"10+ years",
"1 year",
"2 years",
"4 years",
"2 years",
"7 years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"5 years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"9 years",
"10+ years",
"7 years",
"5 years",
"1 year",
"10+ years",
"9 years",
"10+ years",
null,
"9 years",
"5 years",
"10+ years",
"< 1 year",
"9 years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"9 years",
"10+ years",
"3 years",
"< 1 year",
"9 years",
"< 1 year",
"10+ years",
"5 years",
"< 1 year",
"6 years",
"1 year",
"2 years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"9 years",
"< 1 year",
"2 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"9 years",
"7 years",
"7 years",
"10+ years",
"3 years",
"8 years",
"1 year",
"2 years",
"< 1 year",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"3 years",
"3 years",
"5 years",
null,
"10+ years",
null,
"10+ years",
"10+ years",
"7 years",
"6 years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"10+ years",
null,
"3 years",
"7 years",
null,
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
"5 years",
"10+ years",
"8 years",
"9 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"9 years",
"10+ years",
"6 years",
"8 years",
"5 years",
"6 years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"2 years",
"3 years",
"10+ years",
"5 years",
null,
"5 years",
"2 years",
"3 years",
"10+ years",
"2 years",
"< 1 year",
"6 years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"5 years",
"9 years",
"9 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"5 years",
"3 years",
"10+ years",
"9 years",
null,
"10+ years",
"8 years",
"10+ years",
"4 years",
"3 years",
"8 years",
"6 years",
null,
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"9 years",
"7 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"7 years",
"6 years",
"9 years",
"10+ years",
"8 years",
"6 years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"8 years",
"9 years",
"3 years",
"10+ years",
"8 years",
"3 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"7 years",
"10+ years",
"< 1 year",
"9 years",
"10+ years",
"4 years",
"8 years",
"10+ years",
"5 years",
"< 1 year",
"6 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"8 years",
"2 years",
"8 years",
"10+ years",
"6 years",
"9 years",
"3 years",
"10+ years",
"< 1 year",
"6 years",
"2 years",
"6 years",
"5 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"3 years",
"2 years",
"4 years",
"6 years",
"3 years",
"< 1 year",
"3 years",
"1 year",
"2 years",
null,
"3 years",
null,
"10+ years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"< 1 year",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"5 years",
null,
"10+ years",
null,
"10+ years",
"4 years",
"10+ years",
"4 years",
"< 1 year",
"9 years",
"7 years",
"10+ years",
"10+ years",
"8 years",
"7 years",
"10+ years",
"3 years",
"< 1 year",
"3 years",
"6 years",
null,
"5 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"< 1 year",
"5 years",
null,
"10+ years",
"2 years",
"2 years",
"1 year",
null,
"10+ years",
"7 years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"9 years",
"5 years",
"4 years",
"8 years",
"1 year",
"6 years",
"10+ years",
"< 1 year",
null,
null,
"9 years",
null,
"1 year",
"10+ years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"4 years",
"8 years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"5 years",
"7 years",
"10+ years",
"6 years",
"5 years",
"5 years",
"10+ years",
"10+ years",
null,
"3 years",
"1 year",
"1 year",
"2 years",
"10+ years",
"< 1 year",
"5 years",
"3 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"5 years",
null,
"10+ years",
"7 years",
"10+ years",
"9 years",
"7 years",
"7 years",
"10+ years",
"1 year",
"10+ years",
"2 years",
"5 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"2 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"8 years",
"10+ years",
"2 years",
"6 years",
"2 years",
"1 year",
"4 years",
null,
"2 years",
"< 1 year",
"10+ years",
"2 years",
"1 year",
"7 years",
"7 years",
"5 years",
"2 years",
"2 years",
"8 years",
null,
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"9 years",
"6 years",
"5 years",
"10+ years",
"4 years",
null,
"3 years",
"5 years",
"2 years",
"10+ years",
null,
"5 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"4 years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"9 years",
"< 1 year",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"7 years",
"< 1 year",
"4 years",
"2 years",
"8 years",
"< 1 year",
"9 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"5 years",
"10+ years",
"8 years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"6 years",
"4 years",
"1 year",
"5 years",
"2 years",
"2 years",
"5 years",
"1 year",
"5 years",
"2 years",
"10+ years",
"2 years",
"3 years",
"5 years",
"4 years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"8 years",
"1 year",
"1 year",
"< 1 year",
"10+ years",
"8 years",
"9 years",
"5 years",
"3 years",
"10+ years",
"8 years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"2 years",
"< 1 year",
"7 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"3 years",
"6 years",
"4 years",
"6 years",
"4 years",
null,
null,
"9 years",
"3 years",
"4 years",
"2 years",
"10+ years",
"6 years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"9 years",
"4 years",
null,
"2 years",
"1 year",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"5 years",
null,
"1 year",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"8 years",
"7 years",
"5 years",
null,
"3 years",
"6 years",
"7 years",
"4 years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"4 years",
"5 years",
"7 years",
"6 years",
"5 years",
"5 years",
"7 years",
"< 1 year",
"3 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"8 years",
"7 years",
"7 years",
"3 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"6 years",
"1 year",
"7 years",
"4 years",
"2 years",
"< 1 year",
"4 years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"6 years",
"2 years",
"4 years",
"4 years",
"< 1 year",
"3 years",
"10+ years",
"8 years",
"5 years",
"5 years",
"8 years",
"7 years",
"6 years",
"2 years",
"10+ years",
"8 years",
"4 years",
"10+ years",
"4 years",
null,
"7 years",
"10+ years",
"3 years",
"5 years",
"5 years",
"6 years",
"5 years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"9 years",
"2 years",
"10+ years",
"10+ years",
"7 years",
"9 years",
null,
"2 years",
"< 1 year",
"10+ years",
"< 1 year",
"4 years",
"8 years",
"7 years",
"4 years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"3 years",
"9 years",
"7 years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"8 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"5 years",
"10+ years",
"< 1 year",
"2 years",
"5 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"9 years",
"10+ years",
"8 years",
"5 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"4 years",
"< 1 year",
"4 years",
null,
"4 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"5 years",
"< 1 year",
"2 years",
"7 years",
"5 years",
"4 years",
"< 1 year",
"6 years",
"2 years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"8 years",
null,
"3 years",
"5 years",
"9 years",
"8 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"10+ years",
"5 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"5 years",
"2 years",
"2 years",
"< 1 year",
null,
"2 years",
"< 1 year",
null,
"1 year",
"10+ years",
"2 years",
"8 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"2 years",
"10+ years",
"10+ years",
"10+ years",
null,
"7 years",
null,
"10+ years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"7 years",
"8 years",
"10+ years",
"3 years",
"4 years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"2 years",
null,
"10+ years",
"4 years",
"4 years",
"9 years",
"4 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"10+ years",
null,
"1 year",
"10+ years",
"2 years",
"4 years",
"10+ years",
"1 year",
"2 years",
"1 year",
"10+ years",
"7 years",
"10+ years",
"< 1 year",
"5 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"6 years",
"3 years",
"5 years",
"5 years",
"7 years",
"10+ years",
null,
"3 years",
"4 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"8 years",
"10+ years",
"6 years",
"< 1 year",
"4 years",
"6 years",
"< 1 year",
"8 years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"8 years",
"< 1 year",
"8 years",
"7 years",
"8 years",
"10+ years",
"1 year",
"2 years",
"4 years",
"< 1 year",
"7 years",
"10+ years",
"< 1 year",
"4 years",
"3 years",
"10+ years",
"2 years",
"7 years",
"4 years",
"10+ years",
"5 years",
"7 years",
"7 years",
"6 years",
"10+ years",
"8 years",
null,
"10+ years",
"3 years",
"< 1 year",
"2 years",
"5 years",
"9 years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"9 years",
"2 years",
"10+ years",
"6 years",
"8 years",
"5 years",
"< 1 year",
"5 years",
"10+ years",
"6 years",
"10+ years",
"1 year",
"4 years",
"< 1 year",
null,
"4 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"4 years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"5 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"4 years",
"5 years",
"5 years",
"5 years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"1 year",
"2 years",
"2 years",
null,
"10+ years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"4 years",
"4 years",
"6 years",
"10+ years",
"10+ years",
"7 years",
null,
"10+ years",
"5 years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"2 years",
"9 years",
"3 years",
"10+ years",
null,
"4 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"6 years",
"7 years",
"3 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"8 years",
"< 1 year",
"1 year",
"3 years",
"10+ years",
"< 1 year",
"10+ years",
"4 years",
"< 1 year",
"< 1 year",
"1 year",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"6 years",
"10+ years",
null,
"10+ years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"4 years",
"10+ years",
"4 years",
"9 years",
null,
"9 years",
"3 years",
"10+ years",
"3 years",
"5 years",
"4 years",
"8 years",
"10+ years",
"6 years",
"2 years",
"10+ years",
"2 years",
"< 1 year",
"9 years",
"3 years",
"4 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"9 years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"5 years",
"10+ years",
"10+ years",
"8 years",
"2 years",
"< 1 year",
"< 1 year",
"3 years",
null,
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"7 years",
"10+ years",
"7 years",
"1 year",
null,
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"3 years",
"< 1 year",
"< 1 year",
"10+ years",
"8 years",
"8 years",
"1 year",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"8 years",
"7 years",
"10+ years",
"< 1 year",
"7 years",
null,
"10+ years",
"2 years",
"10+ years",
"7 years",
"< 1 year",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"8 years",
"2 years",
"10+ years",
"4 years",
"8 years",
"10+ years",
"9 years",
"< 1 year",
"2 years",
"8 years",
"6 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"1 year",
"10+ years",
"10+ years",
"9 years",
"4 years",
"4 years",
"3 years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"1 year",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"1 year",
null,
"3 years",
"7 years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
null,
"5 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
null,
null,
"10+ years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"4 years",
"9 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"3 years",
"< 1 year",
"6 years",
"1 year",
"4 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"3 years",
"3 years",
"10+ years",
"4 years",
"10+ years",
"7 years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"< 1 year",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"9 years",
"< 1 year",
null,
"3 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"2 years",
"10+ years",
"4 years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"5 years",
"1 year",
"5 years",
"10+ years",
"3 years",
"5 years",
"7 years",
"1 year",
"3 years",
"10+ years",
"6 years",
"3 years",
"8 years",
"10+ years",
"4 years",
"8 years",
"< 1 year",
"6 years",
"10+ years",
"6 years",
"6 years",
"5 years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
null,
null,
"10+ years",
null,
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"9 years",
"6 years",
"10+ years",
"6 years",
"8 years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"10+ years",
null,
null,
"9 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"1 year",
"2 years",
"< 1 year",
"1 year",
"10+ years",
"9 years",
"5 years",
"< 1 year",
"7 years",
"1 year",
"< 1 year",
"1 year",
null,
"10+ years",
"10+ years",
"1 year",
"10+ years",
"4 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"1 year",
"3 years",
"4 years",
"6 years",
"1 year",
"2 years",
"7 years",
"10+ years",
"6 years",
"6 years",
"< 1 year",
"10+ years",
"4 years",
null,
"5 years",
"2 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"3 years",
"1 year",
null,
"10+ years",
null,
"< 1 year",
"4 years",
"< 1 year",
null,
"5 years",
"10+ years",
"9 years",
"8 years",
"9 years",
null,
null,
"4 years",
"< 1 year",
"< 1 year",
"< 1 year",
"8 years",
null,
"10+ years",
"8 years",
"1 year",
"8 years",
"9 years",
"8 years",
"5 years",
"10+ years",
"5 years",
"4 years",
"10+ years",
"10+ years",
"5 years",
"1 year",
"10+ years",
"5 years",
"3 years",
"1 year",
null,
"4 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"3 years",
"10+ years",
"6 years",
"3 years",
"6 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"1 year",
"10+ years",
"7 years",
"10+ years",
"8 years",
"1 year",
"3 years",
"4 years",
"10+ years",
"7 years",
"5 years",
"< 1 year",
"9 years",
"4 years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"2 years",
"2 years",
"9 years",
"3 years",
"3 years",
"2 years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"4 years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"8 years",
"10+ years",
"1 year",
null,
"8 years",
"7 years",
"7 years",
"10+ years",
"10+ years",
null,
"< 1 year",
"8 years",
"9 years",
"5 years",
"4 years",
"10+ years",
"10+ years",
"5 years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"3 years",
"2 years",
"1 year",
null,
"10+ years",
"8 years",
"10+ years",
null,
"10+ years",
"2 years",
"10+ years",
"6 years",
null,
"6 years",
"2 years",
"5 years",
"7 years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"1 year",
"7 years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"8 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
null,
"< 1 year",
"3 years",
null,
"6 years",
"6 years",
null,
"8 years",
"9 years",
"8 years",
null,
"9 years",
"3 years",
"1 year",
"8 years",
"8 years",
"7 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"6 years",
"5 years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"6 years",
"5 years",
"7 years",
"8 years",
"7 years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"6 years",
"3 years",
"7 years",
null,
"10+ years",
"2 years",
"9 years",
"< 1 year",
"7 years",
"5 years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"1 year",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"9 years",
"10+ years",
"6 years",
"1 year",
null,
"7 years",
"10+ years",
null,
"10+ years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"3 years",
"< 1 year",
"7 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"< 1 year",
"2 years",
"10+ years",
"6 years",
"6 years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"4 years",
"4 years",
"3 years",
"2 years",
"6 years",
"4 years",
"3 years",
null,
null,
"5 years",
"4 years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"8 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"4 years",
"10+ years",
"10+ years",
"7 years",
"5 years",
"6 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"3 years",
"9 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"2 years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"7 years",
"< 1 year",
"5 years",
"7 years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"9 years",
"5 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"3 years",
"6 years",
"< 1 year",
"8 years",
"10+ years",
"6 years",
"1 year",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"9 years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"3 years",
"< 1 year",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"7 years",
"10+ years",
"4 years",
"3 years",
"7 years",
"5 years",
"2 years",
"5 years",
"10+ years",
"2 years",
null,
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"1 year",
"2 years",
"3 years",
"9 years",
"< 1 year",
"4 years",
"6 years",
"< 1 year",
"1 year",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
null,
"5 years",
"6 years",
"< 1 year",
"5 years",
"10+ years",
"2 years",
"8 years",
"7 years",
"4 years",
"10+ years",
"< 1 year",
"6 years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"1 year",
"< 1 year",
"7 years",
"7 years",
"10+ years",
"1 year",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"8 years",
"10+ years",
"9 years",
"4 years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"1 year",
"4 years",
"9 years",
"2 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"9 years",
"10+ years",
"5 years",
"7 years",
null,
"2 years",
"10+ years",
"7 years",
"5 years",
"10+ years",
"< 1 year",
null,
"5 years",
"7 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"10+ years",
null,
"1 year",
"10+ years",
"3 years",
"3 years",
"7 years",
"3 years",
"2 years",
"6 years",
"10+ years",
"8 years",
"10+ years",
"1 year",
"7 years",
"1 year",
null,
"5 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"9 years",
"1 year",
"9 years",
"1 year",
"1 year",
"7 years",
"1 year",
null,
"10+ years",
"3 years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"< 1 year",
"< 1 year",
"1 year",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"1 year",
"2 years",
"7 years",
"8 years",
"8 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"2 years",
"< 1 year",
"10+ years",
"4 years",
"8 years",
"10+ years",
"10+ years",
"6 years",
"4 years",
"1 year",
"1 year",
"3 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"3 years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"3 years",
"5 years",
"9 years",
"4 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"4 years",
"< 1 year",
"10+ years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"4 years",
"4 years",
"< 1 year",
"6 years",
"5 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
null,
"10+ years",
"< 1 year",
"5 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"8 years",
"< 1 year",
"5 years",
"10+ years",
"8 years",
"10+ years",
"8 years",
"1 year",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"8 years",
"3 years",
"5 years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
"1 year",
"4 years",
"2 years",
"1 year",
"7 years",
"8 years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"5 years",
"3 years",
"8 years",
"10+ years",
"6 years",
null,
"5 years",
"10+ years",
"5 years",
"5 years",
"1 year",
"4 years",
"2 years",
"9 years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"6 years",
"9 years",
"1 year",
"7 years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"9 years",
"9 years",
"9 years",
"2 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"7 years",
"9 years",
"5 years",
"9 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"9 years",
"3 years",
"2 years",
"< 1 year",
"10+ years",
"2 years",
"4 years",
"4 years",
"10+ years",
"2 years",
"7 years",
"5 years",
"10+ years",
"10+ years",
"7 years",
"3 years",
null,
"4 years",
"6 years",
"7 years",
"1 year",
"3 years",
"3 years",
"3 years",
null,
"4 years",
"5 years",
"2 years",
"3 years",
"10+ years",
"7 years",
"3 years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"1 year",
"7 years",
"3 years",
null,
null,
"8 years",
"< 1 year",
"< 1 year",
"5 years",
"1 year",
"1 year",
"10+ years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"1 year",
"2 years",
"10+ years",
"2 years",
"6 years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"5 years",
"4 years",
"10+ years",
"10+ years",
"4 years",
null,
"1 year",
"10+ years",
"3 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"7 years",
null,
"10+ years",
null,
"2 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"6 years",
"10+ years",
"3 years",
"7 years",
"4 years",
"3 years",
"10+ years",
"7 years",
"1 year",
"1 year",
"8 years",
"10+ years",
"3 years",
"6 years",
"9 years",
"2 years",
"5 years",
"7 years",
"10+ years",
"3 years",
"3 years",
"5 years",
"3 years",
"2 years",
"10+ years",
"2 years",
"2 years",
"7 years",
"2 years",
"2 years",
"1 year",
"1 year",
"8 years",
"6 years",
"1 year",
"3 years",
"3 years",
"3 years",
"4 years",
"2 years",
"4 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"9 years",
"10+ years",
null,
"10+ years",
"10+ years",
"7 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"6 years",
"4 years",
null,
"4 years",
null,
"8 years",
"10+ years",
"10+ years",
"7 years",
"3 years",
"< 1 year",
null,
"2 years",
"< 1 year",
null,
null,
"10+ years",
"10+ years",
"3 years",
"5 years",
"5 years",
"5 years",
"< 1 year",
"1 year",
"10+ years",
null,
"2 years",
"4 years",
"7 years",
"10+ years",
"5 years",
"9 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"1 year",
"4 years",
"10+ years",
"1 year",
"< 1 year",
"2 years",
"4 years",
"10+ years",
"1 year",
"5 years",
"10+ years",
"7 years",
"7 years",
"10+ years",
"7 years",
"10+ years",
"2 years",
null,
null,
null,
"10+ years",
"5 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"1 year",
"4 years",
null,
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"3 years",
"8 years",
"9 years",
"7 years",
null,
"5 years",
"4 years",
"< 1 year",
null,
"10+ years",
"6 years",
"10+ years",
"4 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"2 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"1 year",
"8 years",
"5 years",
"5 years",
"5 years",
"7 years",
"< 1 year",
"6 years",
"8 years",
"10+ years",
"3 years",
null,
"9 years",
"< 1 year",
"1 year",
"2 years",
"2 years",
"2 years",
"5 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"4 years",
"9 years",
"8 years",
"2 years",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"5 years",
"8 years",
"9 years",
"10+ years",
null,
"2 years",
"10+ years",
"9 years",
"2 years",
"3 years",
"3 years",
"4 years",
null,
"2 years",
"10+ years",
"10+ years",
"5 years",
"9 years",
"8 years",
"8 years",
"6 years",
"10+ years",
"8 years",
"9 years",
"< 1 year",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"3 years",
"4 years",
"3 years",
"< 1 year",
"4 years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"< 1 year",
"10+ years",
"7 years",
"5 years",
"7 years",
"3 years",
"2 years",
"5 years",
"8 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"7 years",
"< 1 year",
"3 years",
null,
"< 1 year",
"3 years",
"10+ years",
"5 years",
"10+ years",
null,
"10+ years",
"2 years",
"5 years",
"7 years",
"6 years",
"8 years",
"8 years",
null,
"10+ years",
null,
"8 years",
"10+ years",
"8 years",
"5 years",
"4 years",
"1 year",
"3 years",
"6 years",
"10+ years",
"5 years",
"7 years",
"4 years",
"10+ years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"3 years",
"< 1 year",
"3 years",
null,
"10+ years",
"10+ years",
"10+ years",
"8 years",
"6 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"1 year",
"2 years",
"< 1 year",
"4 years",
"9 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"7 years",
"3 years",
"1 year",
"10+ years",
"2 years",
"1 year",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"6 years",
null,
"2 years",
"2 years",
"10+ years",
"2 years",
"2 years",
"1 year",
"10+ years",
"5 years",
"3 years",
"< 1 year",
null,
"5 years",
"8 years",
"4 years",
"10+ years",
"7 years",
"1 year",
"2 years",
"10+ years",
"5 years",
"10+ years",
null,
"10+ years",
"10+ years",
"2 years",
"8 years",
"8 years",
"2 years",
"< 1 year",
"3 years",
"2 years",
"4 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"9 years",
"9 years",
"7 years",
"10+ years",
null,
"7 years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"9 years",
"9 years",
"4 years",
"< 1 year",
"< 1 year",
"5 years",
"10+ years",
"5 years",
"7 years",
null,
"3 years",
"2 years",
"7 years",
"7 years",
"< 1 year",
"10+ years",
"< 1 year",
"1 year",
"1 year",
"7 years",
"9 years",
"1 year",
"7 years",
"6 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
null,
"3 years",
"8 years",
"5 years",
"5 years",
"5 years",
"10+ years",
"1 year",
"8 years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
null,
"10+ years",
null,
"6 years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"1 year",
null,
"< 1 year",
"8 years",
"2 years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"8 years",
null,
"10+ years",
"10+ years",
"10+ years",
"4 years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"6 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"9 years",
null,
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"7 years",
"6 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"4 years",
"9 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
null,
"7 years",
"2 years",
"5 years",
"2 years",
"4 years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"1 year",
"1 year",
"7 years",
"10+ years",
"1 year",
"9 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"4 years",
"3 years",
"< 1 year",
"3 years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"4 years",
"2 years",
"10+ years",
"9 years",
"8 years",
"< 1 year",
"10+ years",
null,
"9 years",
"10+ years",
null,
"3 years",
"7 years",
"4 years",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"5 years",
"3 years",
"< 1 year",
"2 years",
"10+ years",
"8 years",
"5 years",
"1 year",
"10+ years",
"10+ years",
null,
"< 1 year",
"< 1 year",
"< 1 year",
"10+ years",
"7 years",
"< 1 year",
"< 1 year",
"4 years",
"5 years",
"10+ years",
null,
"8 years",
"3 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"3 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"7 years",
"6 years",
"1 year",
"10+ years",
"6 years",
"10+ years",
"6 years",
"10+ years",
"8 years",
"8 years",
null,
"7 years",
"< 1 year",
"4 years",
"8 years",
"10+ years",
null,
"5 years",
"3 years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"8 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"7 years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
null,
"2 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"8 years",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"5 years",
"10+ years",
null,
"< 1 year",
"2 years",
"< 1 year",
"< 1 year",
null,
"7 years",
"3 years",
"10+ years",
"1 year",
"9 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"5 years",
"7 years",
"3 years",
"2 years",
"9 years",
"10+ years",
"10+ years",
"7 years",
null,
"5 years",
"10+ years",
"1 year",
"< 1 year",
"1 year",
"9 years",
"< 1 year",
"10+ years",
"3 years",
"3 years",
"2 years",
"9 years",
"4 years",
"4 years",
"7 years",
"2 years",
"5 years",
null,
"5 years",
"< 1 year",
"3 years",
"10+ years",
"4 years",
"2 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
null,
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"2 years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"9 years",
"6 years",
"5 years",
"4 years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"9 years",
null,
"3 years",
"4 years",
"5 years",
"6 years",
"10+ years",
"2 years",
"6 years",
"10+ years",
"2 years",
"5 years",
"4 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"5 years",
"4 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"6 years",
"< 1 year",
"5 years",
"2 years",
"< 1 year",
"5 years",
"9 years",
null,
"< 1 year",
null,
"10+ years",
"10+ years",
"2 years",
"5 years",
"3 years",
"4 years",
"6 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"4 years",
"4 years",
"10+ years",
null,
"3 years",
"6 years",
"10+ years",
"4 years",
"5 years",
"3 years",
"5 years",
"10+ years",
"6 years",
"6 years",
"10+ years",
"2 years",
"10+ years",
"7 years",
"8 years",
"8 years",
"3 years",
"6 years",
"< 1 year",
"7 years",
"1 year",
"1 year",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"10+ years",
"1 year",
"10+ years",
null,
"10+ years",
"8 years",
"10+ years",
"6 years",
"10+ years",
"6 years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"2 years",
"7 years",
"5 years",
"4 years",
"5 years",
"8 years",
"8 years",
"10+ years",
"7 years",
"2 years",
"1 year",
"5 years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"10+ years",
"6 years",
"4 years",
"< 1 year",
"3 years",
"2 years",
"2 years",
"10+ years",
"1 year",
"6 years",
"5 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"7 years",
"9 years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"5 years",
"10+ years",
"5 years",
"10+ years",
"4 years",
"3 years",
"9 years",
"4 years",
"10+ years",
"2 years",
null,
"4 years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
null,
"3 years",
"10+ years",
"10+ years",
null,
"2 years",
"8 years",
"8 years",
"10+ years",
"5 years",
"5 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"9 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"< 1 year",
"1 year",
"7 years",
"5 years",
"5 years",
"6 years",
"5 years",
"10+ years",
"5 years",
"2 years",
"10+ years",
null,
"< 1 year",
"1 year",
"10+ years",
"7 years",
"10+ years",
"8 years",
"2 years",
"10+ years",
"10+ years",
null,
"1 year",
"5 years",
"10+ years",
"4 years",
"2 years",
"7 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"< 1 year",
"3 years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"6 years",
"9 years",
"< 1 year",
null,
"8 years",
"3 years",
"6 years",
"6 years",
"8 years",
"6 years",
"7 years",
"2 years",
"9 years",
"< 1 year",
"7 years",
"1 year",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"3 years",
"5 years",
"9 years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"3 years",
"1 year",
"2 years",
"< 1 year",
"4 years",
"7 years",
"5 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"3 years",
"< 1 year",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"9 years",
"10+ years",
null,
"5 years",
"8 years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"1 year",
null,
"3 years",
"10+ years",
"4 years",
"2 years",
"10+ years",
"6 years",
"2 years",
"2 years",
"4 years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"9 years",
null,
"2 years",
"2 years",
"9 years",
"3 years",
"10+ years",
"1 year",
"6 years",
"4 years",
"< 1 year",
"2 years",
"8 years",
"10+ years",
"10+ years",
"6 years",
"8 years",
null,
"10+ years",
"10+ years",
"3 years",
"5 years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"7 years",
"7 years",
"7 years",
"6 years",
"6 years",
"2 years",
"10+ years",
"1 year",
null,
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"9 years",
"1 year",
"9 years",
"8 years",
"3 years",
"2 years",
"10+ years",
"4 years",
"2 years",
"7 years",
"2 years",
"9 years",
"2 years",
"10+ years",
"6 years",
"5 years",
"1 year",
"2 years",
"< 1 year",
"10+ years",
"9 years",
"6 years",
"2 years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"9 years",
null,
"9 years",
"9 years",
"2 years",
"1 year",
"< 1 year",
"8 years",
"7 years",
"8 years",
"5 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"4 years",
"4 years",
"10+ years",
"7 years",
"7 years",
"< 1 year",
"8 years",
"2 years",
"3 years",
"5 years",
"3 years",
"4 years",
"10+ years",
"1 year",
"10+ years",
"8 years",
"8 years",
"3 years",
"9 years",
"2 years",
"7 years",
"< 1 year",
"10+ years",
"5 years",
"5 years",
"1 year",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
null,
null,
"6 years",
"5 years",
"10+ years",
null,
"10+ years",
"2 years",
"7 years",
null,
"10+ years",
"7 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"2 years",
"2 years",
"4 years",
"10+ years",
"2 years",
"9 years",
null,
"2 years",
"8 years",
"10+ years",
"6 years",
"3 years",
"5 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"< 1 year",
null,
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"2 years",
"6 years",
"5 years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"< 1 year",
"4 years",
"8 years",
"8 years",
"10+ years",
"5 years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"9 years",
"2 years",
"10+ years",
null,
"1 year",
"1 year",
"4 years",
"8 years",
"3 years",
"4 years",
"< 1 year",
"4 years",
"3 years",
"10+ years",
"2 years",
"7 years",
"< 1 year",
"7 years",
"10+ years",
"4 years",
"3 years",
"10+ years",
"10+ years",
null,
"5 years",
"9 years",
"8 years",
"5 years",
"5 years",
null,
"5 years",
"3 years",
"10+ years",
"10+ years",
"5 years",
"8 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"1 year",
"3 years",
"3 years",
"< 1 year",
"8 years",
"2 years",
"9 years",
"8 years",
"10+ years",
"10+ years",
"1 year",
"4 years",
"2 years",
"10+ years",
"2 years",
"1 year",
"1 year",
"10+ years",
"3 years",
"1 year",
"2 years",
"10+ years",
"2 years",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"3 years",
"3 years",
"10+ years",
"3 years",
"6 years",
"10+ years",
null,
"10+ years",
"7 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"4 years",
"5 years",
"2 years",
"5 years",
"4 years",
"10+ years",
"6 years",
"7 years",
"7 years",
"10+ years",
"10+ years",
"8 years",
"6 years",
"10+ years",
"7 years",
"5 years",
"7 years",
null,
"5 years",
"2 years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"4 years",
"9 years",
"10+ years",
null,
null,
"< 1 year",
"4 years",
"6 years",
"10+ years",
"5 years",
"6 years",
"< 1 year",
"8 years",
"10+ years",
null,
"5 years",
"10+ years",
"3 years",
"9 years",
"10+ years",
"5 years",
"8 years",
"4 years",
"3 years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"5 years",
"3 years",
"10+ years",
"3 years",
"2 years",
"4 years",
"8 years",
"6 years",
"4 years",
"4 years",
"3 years",
"1 year",
"1 year",
"10+ years",
"2 years",
"9 years",
"1 year",
"10+ years",
"1 year",
null,
null,
"6 years",
"6 years",
"10+ years",
"10+ years",
null,
"6 years",
"2 years",
"5 years",
"< 1 year",
null,
null,
"10+ years",
"< 1 year",
"3 years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
null,
"6 years",
"5 years",
null,
"2 years",
"4 years",
"10+ years",
"1 year",
"7 years",
null,
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"5 years",
"2 years",
"10+ years",
null,
"3 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"5 years",
"5 years",
"6 years",
"10+ years",
"7 years",
"1 year",
"10+ years",
"3 years",
"9 years",
"4 years",
"5 years",
"1 year",
"3 years",
"< 1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"3 years",
"2 years",
"2 years",
"5 years",
"5 years",
"2 years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"5 years",
"10+ years",
"2 years",
"4 years",
"4 years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"< 1 year",
"6 years",
"7 years",
"10+ years",
"4 years",
"5 years",
"2 years",
"10+ years",
null,
"2 years",
"4 years",
null,
"4 years",
"1 year",
"9 years",
"2 years",
"10+ years",
"2 years",
null,
"< 1 year",
"9 years",
"2 years",
"3 years",
"5 years",
null,
"5 years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"8 years",
null,
"2 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
null,
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"7 years",
"< 1 year",
"4 years",
"2 years",
"10+ years",
"4 years",
"3 years",
"2 years",
"8 years",
"1 year",
"6 years",
"< 1 year",
null,
"10+ years",
"1 year",
"9 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"2 years",
"2 years",
"10+ years",
"1 year",
"5 years",
"9 years",
"3 years",
"10+ years",
null,
"2 years",
null,
"5 years",
"10+ years",
"< 1 year",
"2 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"< 1 year",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"2 years",
"7 years",
"3 years",
"< 1 year",
"10+ years",
null,
"4 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
null,
"5 years",
"9 years",
"10+ years",
"< 1 year",
"6 years",
null,
"6 years",
"10+ years",
"8 years",
"3 years",
"10+ years",
"4 years",
"7 years",
"4 years",
"10+ years",
"1 year",
"10+ years",
"6 years",
"10+ years",
"9 years",
"3 years",
"5 years",
"2 years",
"< 1 year",
"1 year",
"9 years",
"9 years",
"2 years",
"10+ years",
"6 years",
"5 years",
"7 years",
null,
"4 years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"5 years",
"3 years",
"2 years",
"10+ years",
"2 years",
"2 years",
"1 year",
"8 years",
"10+ years",
null,
"5 years",
"6 years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
null,
"4 years",
"8 years",
"10+ years",
"8 years",
"6 years",
"10+ years",
"3 years",
"10+ years",
"2 years",
"< 1 year",
"7 years",
"1 year",
"6 years",
"7 years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"10+ years",
"7 years",
"< 1 year",
"10+ years",
"2 years",
"8 years",
"< 1 year",
"1 year",
"10+ years",
"7 years",
"< 1 year",
"< 1 year",
"3 years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"2 years",
"2 years",
"10+ years",
"10+ years",
null,
"10+ years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"9 years",
"3 years",
"2 years",
"10+ years",
null,
"4 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"5 years",
"6 years",
"5 years",
"5 years",
"10+ years",
null,
"9 years",
"2 years",
"4 years",
"10+ years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"7 years",
"9 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"6 years",
null,
"2 years",
"< 1 year",
"10+ years",
"6 years",
"4 years",
"3 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"1 year",
"4 years",
"4 years",
"10+ years",
"2 years",
"7 years",
"2 years",
"3 years",
"2 years",
"9 years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"4 years",
"2 years",
"2 years",
"3 years",
"10+ years",
"9 years",
"4 years",
"5 years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"5 years",
"5 years",
"10+ years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"5 years",
"6 years",
"10+ years",
"4 years",
"4 years",
"10+ years",
"8 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"7 years",
"3 years",
"9 years",
"6 years",
"5 years",
"10+ years",
"10+ years",
"7 years",
"6 years",
"10+ years",
null,
"10+ years",
"5 years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"1 year",
"8 years",
"10+ years",
"10+ years",
"1 year",
"1 year",
"6 years",
"8 years",
"7 years",
"6 years",
"10+ years",
"8 years",
"7 years",
"10+ years",
"3 years",
null,
"10+ years",
"7 years",
"< 1 year",
"3 years",
"6 years",
"4 years",
"2 years",
"10+ years",
"4 years",
"< 1 year",
"2 years",
"10+ years",
"8 years",
"6 years",
"< 1 year",
"9 years",
"7 years",
"1 year",
"5 years",
null,
"6 years",
"5 years",
"3 years",
null,
"10+ years",
"3 years",
"3 years",
"10+ years",
"7 years",
"< 1 year",
"9 years",
"5 years",
"5 years",
"3 years",
"< 1 year",
"8 years",
"8 years",
"6 years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"9 years",
null,
"3 years",
"8 years",
"2 years",
"2 years",
null,
"3 years",
"6 years",
"10+ years",
"6 years",
"9 years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"< 1 year",
"6 years",
"3 years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"9 years",
"10+ years",
"5 years",
"8 years",
"7 years",
"10+ years",
"10+ years",
"9 years",
"7 years",
null,
"8 years",
"10+ years",
"5 years",
"< 1 year",
"6 years",
"4 years",
"10+ years",
"8 years",
"7 years",
"7 years",
"10+ years",
"4 years",
null,
"10+ years",
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"5 years",
"4 years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"7 years",
"10+ years",
"10+ years",
"1 year",
null,
"2 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"3 years",
"3 years",
"10+ years",
"7 years",
"4 years",
"7 years",
"10+ years",
"6 years",
null,
"< 1 year",
"10+ years",
"4 years",
"8 years",
"2 years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"4 years",
"5 years",
"6 years",
null,
"10+ years",
"1 year",
"1 year",
"10+ years",
"1 year",
"9 years",
"10+ years",
"10+ years",
"6 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"1 year",
"6 years",
"8 years",
"10+ years",
"10+ years",
"7 years",
"8 years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"1 year",
"4 years",
"< 1 year",
"6 years",
"2 years",
"10+ years",
"5 years",
"7 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"6 years",
"10+ years",
"3 years",
"1 year",
"6 years",
"8 years",
"6 years",
"7 years",
"2 years",
"9 years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"2 years",
"10+ years",
null,
null,
"10+ years",
"5 years",
"3 years",
"10+ years",
"2 years",
"10+ years",
"3 years",
"2 years",
"2 years",
"5 years",
"1 year",
"2 years",
"4 years",
"< 1 year",
"8 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
null,
"8 years",
null,
"10+ years",
"10+ years",
"4 years",
"10+ years",
null,
"7 years",
"2 years",
"10+ years",
"1 year",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
null,
null,
"6 years",
"< 1 year",
"< 1 year",
"< 1 year",
"7 years",
"6 years",
"10+ years",
"10+ years",
"9 years",
"< 1 year",
"10+ years",
"4 years",
null,
"10+ years",
"5 years",
"< 1 year",
"5 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"6 years",
"6 years",
"8 years",
"5 years",
null,
"4 years",
"7 years",
"3 years",
"9 years",
"5 years",
"< 1 year",
"10+ years",
"7 years",
"5 years",
"4 years",
"8 years",
"10+ years",
"7 years",
"10+ years",
"5 years",
"4 years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"< 1 year",
"9 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"7 years",
"1 year",
"6 years",
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"7 years",
"3 years",
null,
"5 years",
"4 years",
"1 year",
"2 years",
"2 years",
"6 years",
"< 1 year",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"4 years",
"8 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"3 years",
"2 years",
"5 years",
"< 1 year",
"8 years",
"< 1 year",
"2 years",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"< 1 year",
"10+ years",
"9 years",
"10+ years",
"7 years",
"8 years",
"10+ years",
"10+ years",
"8 years",
"8 years",
"4 years",
null,
"3 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
null,
"2 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"9 years",
"1 year",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"4 years",
"8 years",
"10+ years",
"1 year",
"10+ years",
"5 years",
"10+ years",
"2 years",
"4 years",
"5 years",
"10+ years",
"10+ years",
"6 years",
"< 1 year",
"2 years",
"2 years",
"< 1 year",
"2 years",
"6 years",
"2 years",
"9 years",
"2 years",
"10+ years",
"10+ years",
"8 years",
"3 years",
"2 years",
"3 years",
"3 years",
"8 years",
"9 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
null,
"4 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
null,
"4 years",
null,
"10+ years",
"< 1 year",
"1 year",
"2 years",
"6 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"2 years",
"10+ years",
"< 1 year",
"7 years",
"10+ years",
"10+ years",
"8 years",
"7 years",
"10+ years",
null,
"6 years",
null,
"8 years",
"10+ years",
"10+ years",
"8 years",
"8 years",
"< 1 year",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"< 1 year",
"6 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"9 years",
null,
"10+ years",
"7 years",
"10+ years",
"10+ years",
"4 years",
"4 years",
"10+ years",
null,
"< 1 year",
"10+ years",
"5 years",
"4 years",
"10+ years",
"4 years",
"1 year",
"6 years",
"3 years",
"< 1 year",
"4 years",
"10+ years",
null,
null,
"2 years",
"3 years",
"4 years",
"1 year",
"6 years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"9 years",
"9 years",
"4 years",
"3 years",
"10+ years",
"10+ years",
null,
"2 years",
"10+ years",
null,
"7 years",
"1 year",
"4 years",
"4 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"4 years",
"6 years",
"2 years",
"4 years",
"3 years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"1 year",
"2 years",
"4 years",
"9 years",
"10+ years",
"5 years",
"< 1 year",
"6 years",
"4 years",
"10+ years",
"5 years",
"3 years",
"8 years",
"1 year",
null,
"10+ years",
null,
"2 years",
"2 years",
"7 years",
"10+ years",
"< 1 year",
"2 years",
"10+ years",
"2 years",
"4 years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"< 1 year",
"8 years",
"3 years",
"10+ years",
"3 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"2 years",
"2 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"4 years",
null,
"10+ years",
"10+ years",
"1 year",
"1 year",
"10+ years",
"7 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"9 years",
"2 years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"5 years",
"5 years",
"8 years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"7 years",
"2 years",
"3 years",
"10+ years",
"2 years",
"2 years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"8 years",
"6 years",
"6 years",
"< 1 year",
"7 years",
"10+ years",
"< 1 year",
"10+ years",
"8 years",
"5 years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"8 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"2 years",
"4 years",
"4 years",
"2 years",
"10+ years",
"10+ years",
null,
"1 year",
"3 years",
null,
"2 years",
"10+ years",
"10+ years",
"5 years",
"10+ years",
"8 years",
"10+ years",
"3 years",
"2 years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"5 years",
"4 years",
null,
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"3 years",
"10+ years",
"4 years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"2 years",
"6 years",
"9 years",
"10+ years",
"4 years",
"10+ years",
"9 years",
"10+ years",
"10+ years",
"5 years",
"7 years",
"4 years",
"< 1 year",
"8 years",
"10+ years",
"3 years",
"< 1 year",
"10+ years",
"5 years",
"2 years",
"5 years",
"4 years",
"9 years",
"5 years",
"< 1 year",
"3 years",
"2 years",
"6 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"8 years",
"7 years",
"8 years",
"< 1 year",
"8 years",
"10+ years",
"5 years",
"5 years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"3 years",
"10+ years",
null,
"5 years",
"10+ years",
"10+ years",
"5 years",
"5 years",
"1 year",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"2 years",
"4 years",
"10+ years",
"2 years",
"3 years",
"< 1 year",
"7 years",
"9 years",
"1 year",
"1 year",
"9 years",
"< 1 year",
"2 years",
"2 years",
"8 years",
"10+ years",
"4 years",
"2 years",
"8 years",
null,
"8 years",
"8 years",
"6 years",
"1 year",
"2 years",
"7 years",
"10+ years",
"< 1 year",
"< 1 year",
"< 1 year",
"< 1 year",
"3 years",
"7 years",
"2 years",
"10+ years",
"3 years",
"9 years",
"8 years",
"3 years",
"3 years",
"3 years",
"3 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
null,
"8 years",
"5 years",
null,
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"2 years",
"3 years",
"4 years",
"5 years",
"2 years",
"4 years",
"5 years",
"3 years",
"7 years",
"3 years",
"10+ years",
null,
"< 1 year",
"10+ years",
"4 years",
"3 years",
"< 1 year",
"10+ years",
"9 years",
"3 years",
"10+ years",
"5 years",
"4 years",
"10+ years",
"10+ years",
"1 year",
"6 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"3 years",
"2 years",
"10+ years",
"3 years",
"1 year",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"6 years",
"2 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"3 years",
"3 years",
"10+ years",
"1 year",
"3 years",
"5 years",
"8 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"5 years",
"10+ years",
"2 years",
"9 years",
"8 years",
"< 1 year",
"10+ years",
"5 years",
"5 years",
"10+ years",
"< 1 year",
"10+ years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"1 year",
null,
"10+ years",
"2 years",
"< 1 year",
"3 years",
"6 years",
null,
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"9 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"3 years",
"7 years",
"5 years",
"3 years",
"8 years",
"6 years",
"9 years",
"7 years",
"< 1 year",
"1 year",
"1 year",
"9 years",
"8 years",
"10+ years",
"4 years",
"2 years",
"2 years",
"5 years",
"6 years",
"3 years",
"7 years",
null,
"1 year",
"10+ years",
"5 years",
"9 years",
"8 years",
"2 years",
"6 years",
"1 year",
"3 years",
"7 years",
"10+ years",
"3 years",
"10+ years",
"5 years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"< 1 year",
"2 years",
null,
"2 years",
"4 years",
"6 years",
"9 years",
"10+ years",
"< 1 year",
"8 years",
"10+ years",
"1 year",
"6 years",
"< 1 year",
"8 years",
"1 year",
"3 years",
"7 years",
"10+ years",
"2 years",
"< 1 year",
"2 years",
"6 years",
"7 years",
"3 years",
"1 year",
"7 years",
"2 years",
"< 1 year",
"9 years",
"1 year",
"2 years",
"1 year",
"1 year",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"4 years",
"6 years",
"10+ years",
"8 years",
"7 years",
"10+ years",
"10+ years",
"6 years",
"5 years",
"10+ years",
"7 years",
null,
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"9 years",
"7 years",
"9 years",
"1 year",
"8 years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"3 years",
"8 years",
"8 years",
"2 years",
"3 years",
"6 years",
"8 years",
"10+ years",
"5 years",
"10+ years",
"10+ years",
"< 1 year",
"6 years",
"6 years",
null,
"10+ years",
"< 1 year",
"4 years",
"8 years",
"7 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"9 years",
"10+ years",
"3 years",
"2 years",
null,
"< 1 year",
"9 years",
"10+ years",
"3 years",
"4 years",
"5 years",
"10+ years",
"10+ years",
null,
"1 year",
"9 years",
"10+ years",
"6 years",
"2 years",
"10+ years",
null,
"< 1 year",
"7 years",
"10+ years",
"10+ years",
null,
"7 years",
"1 year",
"7 years",
"3 years",
"1 year",
"10+ years",
"1 year",
"10+ years",
"9 years",
"3 years",
"10+ years",
null,
"10+ years",
"10+ years",
"< 1 year",
"5 years",
"< 1 year",
"10+ years",
"2 years",
"7 years",
"4 years",
"8 years",
"7 years",
"2 years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"9 years",
"6 years",
"10+ years",
"6 years",
"3 years",
"4 years",
"3 years",
"10+ years",
"7 years",
"5 years",
"< 1 year",
"10+ years",
"2 years",
"10+ years",
"2 years",
"< 1 year",
"6 years",
"2 years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"3 years",
"10+ years",
"2 years",
"3 years",
"5 years",
"3 years",
"10+ years",
"2 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"6 years",
"9 years",
"< 1 year",
"1 year",
"< 1 year",
"5 years",
"10+ years",
"5 years",
"5 years",
"10+ years",
"9 years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"4 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"2 years",
"1 year",
"8 years",
"4 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"5 years",
"< 1 year",
"10+ years",
"7 years",
"10+ years",
"3 years",
"< 1 year",
"6 years",
null,
"8 years",
"2 years",
"9 years",
"5 years",
"1 year",
"8 years",
"10+ years",
"5 years",
"4 years",
"1 year",
"< 1 year",
"< 1 year",
null,
"10+ years",
"10+ years",
"< 1 year",
null,
"10+ years",
"10+ years",
"8 years",
"10+ years",
"10+ years",
"3 years",
"9 years",
"10+ years",
"< 1 year",
null,
"5 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"1 year",
"< 1 year",
"3 years",
"4 years",
"10+ years",
"3 years",
"1 year",
"1 year",
"2 years",
"10+ years",
"7 years",
"3 years",
"5 years",
"1 year",
"10+ years",
"2 years",
"8 years",
"10+ years",
"3 years",
"2 years",
"4 years",
"10+ years",
"3 years",
"5 years",
"7 years",
"5 years",
"10+ years",
"4 years",
"< 1 year",
"6 years",
"3 years",
null,
"5 years",
"2 years",
"4 years",
"9 years",
"10+ years",
"10+ years",
"10+ years",
"1 year",
"7 years",
"10+ years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"1 year",
"1 year",
"4 years",
"7 years",
"10+ years",
"4 years",
"< 1 year",
"1 year",
"10+ years",
"7 years",
"4 years",
"< 1 year",
"7 years",
"10+ years",
"5 years",
"3 years",
"10+ years",
"4 years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"2 years",
"10+ years",
null,
"10+ years",
null,
"< 1 year",
"10+ years",
null,
"2 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"7 years",
"8 years",
"< 1 year",
"8 years",
"< 1 year",
"5 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"5 years",
"9 years",
null,
"< 1 year",
"6 years",
"10+ years",
"< 1 year",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"1 year",
"8 years",
"8 years",
"7 years",
null,
"< 1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"1 year",
"5 years",
"8 years",
"10+ years",
"5 years",
"8 years",
null,
"10+ years",
"1 year",
"10+ years",
null,
"2 years",
"7 years",
"4 years",
"2 years",
"2 years",
"< 1 year",
"1 year",
"10+ years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"7 years",
"8 years",
"< 1 year",
"7 years",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
null,
"1 year",
"6 years",
null,
"4 years",
"10+ years",
null,
"10+ years",
"6 years",
"7 years",
"3 years",
"6 years",
null,
"9 years",
"7 years",
"10+ years",
"10+ years",
"5 years",
"4 years",
"4 years",
"10+ years",
"6 years",
"< 1 year",
"10+ years",
"7 years",
"1 year",
null,
"10+ years",
"5 years",
"8 years",
"10+ years",
"1 year",
"< 1 year",
"4 years",
"7 years",
"5 years",
"3 years",
"10+ years",
"6 years",
"9 years",
"8 years",
"10+ years",
"3 years",
"< 1 year",
"4 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
null,
"10+ years",
"3 years",
"3 years",
"10+ years",
"< 1 year",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"10+ years",
null,
"10+ years",
"7 years",
"7 years",
"3 years",
"10+ years",
"10+ years",
"4 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"1 year",
"7 years",
"5 years",
"4 years",
"10+ years",
"4 years",
"6 years",
"2 years",
"4 years",
"10+ years",
"8 years",
"6 years",
"10+ years",
"2 years",
"3 years",
"5 years",
"10+ years",
"2 years",
null,
"10+ years",
"8 years",
"10+ years",
"8 years",
"5 years",
"< 1 year",
"8 years",
"8 years",
"< 1 year",
"2 years",
"4 years",
"3 years",
"5 years",
"10+ years",
null,
"10+ years",
"< 1 year",
null,
"10+ years",
"10+ years",
"1 year",
"2 years",
"2 years",
"2 years",
"7 years",
"10+ years",
"1 year",
"1 year",
"10+ years",
null,
"2 years",
"1 year",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
null,
"8 years",
"2 years",
"10+ years",
"10+ years",
"6 years",
"9 years",
"2 years",
"1 year",
"5 years",
"10+ years",
"< 1 year",
"5 years",
"10+ years",
"10+ years",
null,
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"< 1 year",
"3 years",
"< 1 year",
"3 years",
"3 years",
"10+ years",
"7 years",
"2 years",
"1 year",
"10+ years",
"10+ years",
"< 1 year",
"4 years",
"4 years",
"2 years",
"5 years",
"10+ years",
"7 years",
"1 year",
"4 years",
"10+ years",
"7 years",
"10+ years",
"10+ years",
"3 years",
"8 years",
"1 year",
"6 years",
"< 1 year",
"10+ years",
"10+ years",
"9 years",
"10+ years",
"< 1 year",
"10+ years",
"3 years",
"10+ years",
"8 years",
"5 years",
null,
"9 years",
"10+ years",
"5 years",
"< 1 year",
"10+ years",
"10+ years",
null,
"10+ years",
"7 years",
"4 years",
"9 years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"9 years",
"6 years",
"6 years",
"4 years",
"1 year",
"10+ years",
null,
"9 years",
"3 years",
"10+ years",
"< 1 year",
null,
"10+ years",
"10+ years",
"10+ years",
"7 years",
"10+ years",
"2 years",
"5 years",
"10+ years",
"10+ years",
"10+ years",
null,
"< 1 year",
"3 years",
"2 years",
"10+ years",
"< 1 year",
"3 years",
"2 years",
"9 years",
"10+ years",
"< 1 year",
"2 years",
"3 years",
null,
null,
"7 years",
"3 years",
"10+ years",
"10+ years",
"2 years",
"< 1 year",
"10+ years",
"10+ years",
"2 years",
"5 years",
"5 years",
"2 years",
"9 years",
"< 1 year",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"< 1 year",
"3 years",
"7 years",
null,
"3 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"2 years",
"9 years",
"8 years",
"10+ years",
"3 years",
"10+ years",
"9 years",
"10+ years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"6 years",
"< 1 year",
"10+ years",
null,
"2 years",
"2 years",
"1 year",
"10+ years",
"1 year",
"1 year",
"8 years",
"10+ years",
"3 years",
"4 years",
"10+ years",
"6 years",
"10+ years",
"2 years",
"< 1 year",
"1 year",
"3 years",
"1 year",
"10+ years",
null,
"2 years",
"9 years",
"10+ years",
null,
"< 1 year",
"10+ years",
null,
"10+ years",
"3 years",
"10+ years",
"10+ years",
"6 years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"2 years",
"2 years",
"2 years",
"4 years",
"< 1 year",
"8 years",
"10+ years",
"5 years",
"< 1 year",
"4 years",
"1 year",
"5 years",
"1 year",
"9 years",
"4 years",
"6 years",
"5 years",
"8 years",
"9 years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"4 years",
"3 years",
"2 years",
"< 1 year",
"10+ years",
"9 years",
"1 year",
"4 years",
"10+ years",
"< 1 year",
"2 years",
"2 years",
"7 years",
null,
"5 years",
"10+ years",
"3 years",
"1 year",
"3 years",
"3 years",
null,
"10+ years",
"8 years",
"10+ years",
"10+ years",
"6 years",
null,
"3 years",
"3 years",
"2 years",
"10+ years",
"2 years",
"4 years",
"3 years",
"< 1 year",
"10+ years",
"3 years",
"7 years",
"2 years",
"2 years",
"10+ years",
"2 years",
"3 years",
"1 year",
"3 years",
"< 1 year",
"1 year",
"< 1 year",
"10+ years",
"3 years",
"4 years",
"2 years",
null,
"< 1 year",
"10+ years",
"5 years",
"2 years",
"10+ years",
null,
"3 years",
"9 years",
"4 years",
"1 year",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"2 years",
"9 years",
"3 years",
null,
"2 years",
"10+ years",
"10+ years",
"< 1 year",
"10+ years",
"1 year",
"4 years",
"8 years",
"10+ years",
"5 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"3 years",
"10+ years",
"3 years",
"5 years",
"10+ years",
"1 year",
"4 years",
"10+ years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
null,
"< 1 year",
"3 years",
"3 years",
"3 years",
"< 1 year",
"4 years",
"10+ years",
"< 1 year",
"5 years",
"< 1 year",
"5 years",
"4 years",
null,
"4 years",
"10+ years",
"< 1 year",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"6 years",
"9 years",
"3 years",
"10+ years",
"7 years",
"10+ years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"6 years",
"< 1 year",
"5 years",
"7 years",
"5 years",
"6 years",
"1 year",
"2 years",
"< 1 year",
"< 1 year",
"10+ years",
null,
"10+ years",
"2 years",
"10+ years",
"1 year",
"7 years",
"7 years",
"4 years",
"10+ years",
"3 years",
"7 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"8 years",
"9 years",
"5 years",
"< 1 year",
"10+ years",
"1 year",
"10+ years",
"4 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"7 years",
"10+ years",
"1 year",
"10+ years",
"1 year",
"4 years",
"1 year",
"< 1 year",
"9 years",
"10+ years",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"8 years",
"10+ years",
"9 years",
"8 years",
"10+ years",
"2 years",
"4 years",
"7 years",
"10+ years",
"5 years",
"1 year",
"< 1 year",
"5 years",
"3 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"4 years",
"5 years",
"10+ years",
"6 years",
"< 1 year",
"7 years",
"10+ years",
"5 years",
"10+ years",
"5 years",
"3 years",
"7 years",
"5 years",
"< 1 year",
"8 years",
"2 years",
"10+ years",
"3 years",
"10+ years",
"4 years",
"2 years",
"< 1 year",
"2 years",
"3 years",
"< 1 year",
"1 year",
"1 year",
"8 years",
null,
null,
"10+ years",
"7 years",
null,
"9 years",
"2 years",
"7 years",
"10+ years",
"5 years",
null,
"2 years",
"10+ years",
"10+ years",
"4 years",
null,
"10+ years",
"10+ years",
null,
"7 years",
"4 years",
"7 years",
"2 years",
null,
"2 years",
"7 years",
null,
"5 years",
"10+ years",
"1 year",
"10+ years",
"5 years",
null,
"10+ years",
"1 year",
"10+ years",
"3 years",
"8 years",
null,
"10+ years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"5 years",
"2 years",
"< 1 year",
"7 years",
"5 years",
"10+ years",
"1 year",
"10+ years",
"5 years",
null,
"1 year",
"10+ years",
null,
"9 years",
"< 1 year",
"< 1 year",
"3 years",
"1 year",
"10+ years",
"10+ years",
"2 years",
null,
"8 years",
"5 years",
"9 years",
"< 1 year",
"6 years",
"10+ years",
"10+ years",
"10+ years",
"< 1 year",
"< 1 year",
"1 year",
"10+ years",
"3 years",
"10+ years",
"8 years",
"10+ years",
"3 years",
null,
"5 years",
"7 years",
"2 years",
"10+ years",
"10+ years",
"3 years",
"2 years",
"2 years",
"3 years",
"< 1 year",
"4 years",
null,
"< 1 year",
"< 1 year",
"8 years",
"8 years",
"4 years",
"5 years",
null,
"3 years",
"5 years",
"10+ years",
"< 1 year",
"< 1 year",
"10+ years",
"10+ years",
"< 1 year",
"1 year",
"10+ years",
"10+ years",
"3 years",
"3 years",
"7 years",
"4 years",
"< 1 year",
"2 years",
"6 years",
"10+ years",
"10+ years",
"5 years",
"3 years",
"6 years",
"2 years",
"1 year",
"3 years",
"1 year",
"2 years",
"1 year",
"10+ years",
"10+ years",
"5 years",
"9 years",
"2 years",
null,
"10+ years",
"2 years",
"10+ years",
"7 years",
"2 years",
"10+ years",
"< 1 year",
"9 years",
"2 years",
"10+ years",
"6 years",
"3 years",
null,
"10+ years",
"9 years",
"9 years",
"10+ years",
"5 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"4 years",
"4 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
null,
"8 years",
"10+ years",
"6 years",
"< 1 year",
"8 years",
"1 year",
"2 years",
"10+ years",
"10+ years",
"10+ years",
"3 years",
"10+ years",
"< 1 year",
"6 years",
"5 years",
"10+ years",
"1 year",
"2 years",
"10+ years",
"7 years",
"7 years",
"10+ years",
"5 years",
"3 years",
"1 year",
"5 years",
"10+ years",
"6 years",
"3 years",
"1 year",
"7 years",
"4 years",
"10+ years",
"7 years",
"1 year",
"5 years",
"2 years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"2 years",
"< 1 year",
"10+ years",
"4 years",
"1 year",
"4 years",
"10+ years",
null,
"5 years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"3 years",
"10+ years",
"< 1 year",
"6 years",
"4 years",
"1 year",
"10+ years",
"10+ years",
"6 years",
"2 years",
"9 years",
"10+ years",
"10+ years",
"8 years",
"< 1 year",
"2 years",
"4 years",
"7 years",
"8 years",
"10+ years",
"10+ years",
"2 years",
"10+ years",
"5 years",
"7 years",
"7 years",
"1 year",
"10+ years",
"1 year",
"1 year",
"1 year",
"7 years",
null,
"3 years",
"7 years",
"10+ years",
"10+ years",
"6 years",
"6 years",
"2 years",
"3 years",
"10+ years",
"10+ years",
"10+ years",
"2 years",
null,
"< 1 year",
"10+ years",
"5 years",
"2 years",
"10+ years",
"4 years",
"10+ years",
"2 years",
"8 years",
"10+ years",
"10+ years",
"4 years",
null,
"10+ years",
"4 years",
"10+ years",
null,
"10+ years",
"8 years",
"10+ years",
"10+ years",
"2 years",
"5 years",
"1 year",
"1 year",
"2 years",
"10+ years",
"4 years",
"10+ years",
"1 year",
"10+ years",
"10+ years",
"3 years",
"6 years",
"10+ years",
"10+ years",
"< 1 year",
"7 years",
"< 1 year",
"10+ years",
"10+ years",
"3 years",
"1 year",
"2 years",
"8 years",
"10+ years",
"5 years",
"2 years",
"2 years",
"6 years",
"5 years",
"3 years",
"< 1 year",
"10+ years",
"8 years",
"3 years",
"10+ years",
"7 years",
"2 years",
"8 years",
"10+ years",
"8 years",
"4 years",
"4 years",
null,
"< 1 year",
"1 year",
"6 years",
"9 years",
"1 year",
"10+ years",
"10+ years",
"10+ years",
"2 years",
"2 years",
"< 1 year",
"2 years",
"2 years",
"3 years",
"5 years"
]
}
],
"layout": {
"legend": {
"bgcolor": "#F5F6F9",
"font": {
"color": "#4D5663"
}
},
"paper_bgcolor": "#F5F6F9",
"plot_bgcolor": "#F5F6F9",
"template": {
"data": {
"bar": [
{
"error_x": {
"color": "#2a3f5f"
},
"error_y": {
"color": "#2a3f5f"
},
"marker": {
"line": {
"color": "#E5ECF6",
"width": 0.5
}
},
"type": "bar"
}
],
"barpolar": [
{
"marker": {
"line": {
"color": "#E5ECF6",
"width": 0.5
}
},
"type": "barpolar"
}
],
"carpet": [
{
"aaxis": {
"endlinecolor": "#2a3f5f",
"gridcolor": "white",
"linecolor": "white",
"minorgridcolor": "white",
"startlinecolor": "#2a3f5f"
},
"baxis": {
"endlinecolor": "#2a3f5f",
"gridcolor": "white",
"linecolor": "white",
"minorgridcolor": "white",
"startlinecolor": "#2a3f5f"
},
"type": "carpet"
}
],
"choropleth": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "choropleth"
}
],
"contour": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "contour"
}
],
"contourcarpet": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "contourcarpet"
}
],
"heatmap": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "heatmap"
}
],
"heatmapgl": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "heatmapgl"
}
],
"histogram": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "histogram"
}
],
"histogram2d": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "histogram2d"
}
],
"histogram2dcontour": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "histogram2dcontour"
}
],
"mesh3d": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "mesh3d"
}
],
"parcoords": [
{
"line": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "parcoords"
}
],
"pie": [
{
"automargin": true,
"type": "pie"
}
],
"scatter": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatter"
}
],
"scatter3d": [
{
"line": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatter3d"
}
],
"scattercarpet": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattercarpet"
}
],
"scattergeo": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattergeo"
}
],
"scattergl": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattergl"
}
],
"scattermapbox": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattermapbox"
}
],
"scatterpolar": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterpolar"
}
],
"scatterpolargl": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterpolargl"
}
],
"scatterternary": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterternary"
}
],
"surface": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "surface"
}
],
"table": [
{
"cells": {
"fill": {
"color": "#EBF0F8"
},
"line": {
"color": "white"
}
},
"header": {
"fill": {
"color": "#C8D4E3"
},
"line": {
"color": "white"
}
},
"type": "table"
}
]
},
"layout": {
"annotationdefaults": {
"arrowcolor": "#2a3f5f",
"arrowhead": 0,
"arrowwidth": 1
},
"coloraxis": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"colorscale": {
"diverging": [
[
0,
"#8e0152"
],
[
0.1,
"#c51b7d"
],
[
0.2,
"#de77ae"
],
[
0.3,
"#f1b6da"
],
[
0.4,
"#fde0ef"
],
[
0.5,
"#f7f7f7"
],
[
0.6,
"#e6f5d0"
],
[
0.7,
"#b8e186"
],
[
0.8,
"#7fbc41"
],
[
0.9,
"#4d9221"
],
[
1,
"#276419"
]
],
"sequential": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"sequentialminus": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
]
},
"colorway": [
"#636efa",
"#EF553B",
"#00cc96",
"#ab63fa",
"#FFA15A",
"#19d3f3",
"#FF6692",
"#B6E880",
"#FF97FF",
"#FECB52"
],
"font": {
"color": "#2a3f5f"
},
"geo": {
"bgcolor": "white",
"lakecolor": "white",
"landcolor": "#E5ECF6",
"showlakes": true,
"showland": true,
"subunitcolor": "white"
},
"hoverlabel": {
"align": "left"
},
"hovermode": "closest",
"mapbox": {
"style": "light"
},
"paper_bgcolor": "white",
"plot_bgcolor": "#E5ECF6",
"polar": {
"angularaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"bgcolor": "#E5ECF6",
"radialaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
}
},
"scene": {
"xaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
},
"yaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
},
"zaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
}
},
"shapedefaults": {
"line": {
"color": "#2a3f5f"
}
},
"ternary": {
"aaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"baxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"bgcolor": "#E5ECF6",
"caxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
}
},
"title": {
"x": 0.05
},
"xaxis": {
"automargin": true,
"gridcolor": "white",
"linecolor": "white",
"ticks": "",
"title": {
"standoff": 15
},
"zerolinecolor": "white",
"zerolinewidth": 2
},
"yaxis": {
"automargin": true,
"gridcolor": "white",
"linecolor": "white",
"ticks": "",
"title": {
"standoff": 15
},
"zerolinecolor": "white",
"zerolinewidth": 2
}
}
},
"title": {
"font": {
"color": "#4D5663"
},
"text": "emp_length Box plot"
},
"xaxis": {
"gridcolor": "#E1E5ED",
"showgrid": true,
"tickfont": {
"color": "#4D5663"
},
"title": {
"font": {
"color": "#4D5663"
},
"text": ""
},
"zerolinecolor": "#E1E5ED"
},
"yaxis": {
"gridcolor": "#E1E5ED",
"showgrid": true,
"tickfont": {
"color": "#4D5663"
},
"title": {
"font": {
"color": "#4D5663"
},
"text": ""
},
"zerolinecolor": "#E1E5ED"
}
}
},
"text/html": [
"\n",
" \n",
" \n",
" \n",
" \n",
"
"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"Null value summary: \n",
" Total Percent\n",
"verification_status_joint 63971 99.956249\n",
"desc 54849 85.702902\n",
"mths_since_last_record 54349 84.921639\n",
"mths_since_last_major_derog 48155 75.243363\n",
"mths_since_last_delinq 32831 51.299239\n",
"batch_enrolled 10264 16.037751\n",
"tot_cur_bal 5124 8.006375\n",
"tot_coll_amt 5124 8.006375\n",
"total_rev_hi_lim 5124 8.006375\n",
"emp_title 3826 5.978218\n",
"emp_length 3324 5.193831\n",
"revol_util 29 0.045313\n",
"title 13 0.020313\n",
"collections_12_mths_ex_med 8 0.012500\n",
"columns dropped Index(['verification_status_joint', 'desc', 'mths_since_last_record',\n",
" 'mths_since_last_major_derog', 'mths_since_last_delinq'],\n",
" dtype='object')\n",
"\n",
"\n",
"columns dropped \n",
"\n",
" ['verification_status_joint', 'desc', 'mths_since_last_record', 'mths_since_last_major_derog', 'mths_since_last_delinq'] \n",
" ['member_id', 'pymnt_plan', 'batch_enrolled']\n"
]
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAe0AAAIRCAYAAABnDOUEAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADt0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjByYzEsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy/xvVyzAAAgAElEQVR4nOzdeZgsZXn38e+PTTZRkYM7i0ZRREVzxPVFEDXivqNxQ2NQY1DcNYniGiOKS4wacUMTVxDUqKiIoBHcQNkUNAoIuIGigCib3O8fVSN9+vTM6XNOT9dUz/dzXX1N19JVd/X0zN3PU8+SqkKSJC19G3QdgCRJGo9JW5KknjBpS5LUEyZtSZJ6wqQtSVJPmLQlSeoJk7bWWZJXJamBxy+SfCrJrbqObW0leUmSPRb5HIcmOXGpHm894vhNklet5WsekOSACcawqO9FkocnOSPJlUnOmfCxJ/peaLaZtLW+Lgbu0T5eBOwKHJNki06jWnsvAfZY5HO8Fth3CR9vmh4A9CJRJdkQ+DBwCnBf4JETPkVv3gt1b6OuA1DvXV1V32qffyvJucD/Ag8CDluXAybZrKr+NKkAl4qq+ulSPp7mdRNgK+CjVfWNroNZk1n9+1HDkrYm7aT25w4ASTZNclCS85JckeSUJA8afEGSc5IcnOQVSc4HLmnXb5jk5Ul+3L72/CSHDr324UlOTHJ5kl+159p4YPur2urbOyf5VpI/Jvl+kv83eH7ghsCBA1X9e4y6uCR7tNv3SvKZJJcl+b+2inPDJG9qz/fzJC8Yeu0qVbhJrp/kfe1thcuTnJvkvQPbb57kk0kuSPKnJD9N8toFjrdvG9sdkhzdxnZmkkcNxZEkr22Pe0mSDyR5fPvaHUZd98Brd29/h5cnOSnJPUfs8+D2/HPH/1aSBwz+ToAXAtsPvN+HttvukeSz7XtyWZKTkzxxoZiGzv2I9povT/KNJDsPbDssybEjXvPqJL8e/NwMbNsXOK9d/Ewb66vabRskeVmSn7Sfzx8neeoE34vjkhw+dLy5z98u7fIO7fITk3w4ye+B/2m3bZ3kPe21XZ7khCR3G/e91NJkSVuTtkP781ftz8OB3YADgZ8CjwM+m2RlVZ088Lq/BX4A/APXfi7fAzwFOAj4GrA18Ji5FyR5HPCxdr9/Am4FvIHmy+iLBo69OfAh4K1tXAcCRybZrqr+SFPdeWwb6/va1/xwDdf5nvbxTpqq9cOBjwBpr+XBwMFJThioiRj2FuCewPPbuG4B7D6w/cPAZsB+wO+BWwK3XUNcAB8FDgHeBOwPfDzJLavq/Hb7ATTv1+uBbwAPp3mPF5TkpsBRwHdofg83ba9586Fdd6RJHG8GrgH2Bo5KsntVHU/zHt+aVauaL2x/bg8cD/wncDlwL+CDSa6pqo+tIcTtad7TVwB/Al4NfCnJravq8va8RyXZsarObq8pNJ+x/66qq0Yc8/PAo4AjaD5TxwNz7+M7gKcCrwG+B9wf+ECS31bV5ybwXqyNN7cxPhb4c5LrAF8Brg+8GLgAeDbwlfb9+NW8R9LSVlU+fKzTA3gV8BuaJLsRcBua5HcJTZXiXkAB9xl63deBwwaWzwF+CWw6sO627WufO8+5A/wM+ODQ+qfT/MO+4UCMBdx3YJ9d23UPHFj3G+BVY1zzHu1rDxxYt3O77qsD6zagScRvHFh3KHDiwPLpwP4LnOsPwEMX2D58vH3bOJ4+sO6GwNXAs9rlDdv3+p1Dx/pC+9odFjjfQcBvgc0H1j2xfd3I9659HzYCvgR8YGD9m4Fz1vBep33tewbf2wXeiwLuObBu+6Fr36D9zLx6YJ/7tq/bZYFj79Du85CBdX9Fk4SfOrTvh4HvTuK9AI4DDp/n87fLUGxHDu33d8CVwK0H1m1E88X5TWv6nPtYug+rx7W+bghc1T5+RFMa3KeqfgncjyZxHZ9ko7kHcAywcug4x1RTGpqzZ/vz0HnOextgO+CTQ8f+KrApsMvAvlfR/AOcM1eKvvnYV7m6Ywae/6T9+dW5FVV1DXAWcLMFjnEy8OIk/5DkNvNsf0Nb7b3dWsT25YE4fktTypq71lsANwY+O/Sa4eVRdgOOrqZ2Ys4Rwzu11fofSvJzmqR5FU1jq1HXOPzaGyT59yQ/49rP1X7jvBa4oKpOmFuoqp/R3K7ZrV2+hubz9JS2hA3NF50Tq+r0MY4/aC+apH3kiM/2rmkar63Xe7GWPj+0fD+aaz97IDZoaqyG//bUI1aPa31dTPMPomgS9C+q/VoPbEOTIEZVO/55aPnXQ8s3BC6rqkvmOe827c8vzLP9FgPPL2n/YQNQVVe2/7M3nee14/j9iOP9fmifK9dwjn+kqVp9JfDOJD8BXlFVH2+370NThf1W4PpJTgFeWFXHjDzaiNhGxHHj9udwFew4VbI3Bk4dXFFVf0ryh7nlJBvQfAG4Ls11/QS4jOY6tx3jHIcCd6dpGf9DmlqbZ9NU4a/JBfOsu8nA8gdpqs/3TPJd4NGseitlXNvQ1FpcPM/2myT5Bev3XqyN4b+fbWjex1F/ezZg7DGTttbX1VU1X//Yi4CfA48Y4zjDc8T+FtgiyVbzJO6L2p/7Ad8fsf3sMc7Zqar6PfBc4LlJ7khzb/wjSU6tqh9W1c+BfdtEuBtNVf9n23vxv13H087dy1wxtH54eb7XrpJskmwGbDmw6q+AOwN7V9UXh/ZbUJJNadoC/GNV/efA+nFrBEclwm1p2koAUFXnJPkKTQl7R5oq6zXdKx/lIpqS871oStzDLmA93ovW5cAmQ+u2nmff4b+fi4ATab7wDLtizPNrCTJpazEdQ9My9g9VdeZavnauqvkpwH+M2P4jmi8EO1TVe0dsX1trKhUvqqo6NcmLae4R35aBhnBtLcG3krwaOIHmXu26Ju3zaJLvw2nurc552Biv/S7w9CSbD1SRP2pon7mE9JfEkGR7muQ2WEof9X5fh6b0Ovja67axDSelUbZNcs+5KvL2lsJdaErXg94PfAC4PfDp9svT2vpqG+v1quroUTsMJOd1eS+gafC2+9C6+48Z3zE01fDnVtWoGgj1lElbi+lomsRwdJI30pR4tqJpCLZpVb18vhdW1Y+SHELTAntbmsZr1wceU1WPr6prkrwQ+K8kW9G0ar6S5p76I9r9/jjf8Uc4E3hwki/SNAD7UVVdurYXvDaSfAM4kqZBWgF/T1N9+p0k16N57z4M/Jgmob2QJuGesa7nrKo/J3kT8KYkF9K0hn4YcId2l1GlxjlvA54DfC7JW2haj7+cpuHfnDNpks3BSV5BUzX8apovWAztd6O2S9XpwG/aUvB3gVcmuaSN5WU0VdBbjXF5v6H5PMy1Hn8NTYn30KH9Pg28iyahz/sZXEj7+fxPmpb5B9GUajel+SJwm6p6Buv5XtB8Nv4uyVtp7lnvCfzNmCF+GHgWcFySN9O0r7ghTY3Nr6rqrety3VoCum4J56O/D9rW42vY5zo0/6h+QpNUfwV8EXjwwD7nAG8e8doNabomndW+9nxWby2+N81gLpfR3P88GXgdsNFCMdIkyX8cWP5r4FvtcQrYY57r2YMRrY2Hj9euO46B1r+s3tr7TcBpwKU096GPBf7fwPv2XpoahT/SJKTPAXdY4Hj7tnFsORTHKu8vTavs19Lcx76UptvWs9vXXn8Nv889aEqJV7Tv9b0YankP3JWmW9ifgP9r4xqOdVOaEvAF7XkPbdf/FU0p9jLgXJpbBuN8zg6lSZyPovmScwXNF5KRrcKB/26Pv8EYn/MdGGo9PvA+HkDzZfSK9v38GvCUSbwX7baX09SOXNrGPFfrMNx6/CEj4r4e8Pb29XN/P0cA9+r6f4ePdX+k/eVKWsaSvA+4f1Vt33Usi61tSf0zmm5Xr+g6HmltWD0uLTPtaFr70Nwfnxvw42nAS7uMa7El2QS4E83gNzek6f8t9YpJW1p+LgPuTdPlbAuaUudLgYO7DGoKbkpTVX0B8My6doQ4qTesHpckqSccEU2SpJ4waUuS1BNL/p72NttsUzvssEPXYUiSNBUnnXTSb6pq5CiFSz5p77DDDpx44nyjZEqSNFvaCXNGsnpckqSeMGlLktQTJm1JknrCpC1JUk+YtCVJ6gmTtiRJPWHSliSpJ0zakiT1hElbkqSeMGlLktQTU0/aSZ6f5AdJTk/ysSSbTjsGSZL6aKpJO8nNgOcCK6tqF2BD4PHTjEGSpL7qonp8I2CzJBsBmwO/6CAGSZJ6Z6qzfFXVz5O8GTgX+BPw5ar68vB+SfYD9gPYbrvtVjvOngfvuciRTt6xLzx27H29vqVlba5NkhbTtKvHbwA8HNgRuCmwRZInDe9XVYdU1cqqWrlixcgpRSVJWnamXT1+P+Dsqrqwqq4CjgDuOeUYJEnqpWkn7XOBuyfZPEmAvYAzphyDJEm9NNWkXVXfBg4Hvgec1p7/kGnGIElSX021IRpAVR0IHDjt80qS1HeOiCZJUk+YtCVJ6gmTtiRJPWHSliSpJ0zakiT1hElbkqSeMGlLktQTJm1JknrCpC1JUk+YtCVJ6gmTtiRJPWHSliSpJ0zakiT1hElbkqSeMGlLktQTJm1JknrCpC1JUk+YtCVJ6gmTtiRJPWHSliSpJ0zakiT1hElbkqSeMGlLktQTJm1JknrCpC1JUk+YtCVJ6gmTtiRJPWHSliSpJ0zakiT1hElbkqSemGrSTrJTkpMHHpckOWCaMUiS1FcbTfNkVfUjYFeAJBsCPweOnGYMkiT1VZfV43sBP62qn3UYgyRJvdFl0n488LFRG5Lsl+TEJCdeeOGFUw5LkqSlqZOknWQT4GHAYaO2V9UhVbWyqlauWLFiusFJkrREdVXS3hv4XlX9uqPzS5LUO10l7ScwT9W4JEkabepJO8nmwP2BI6Z9bkmS+myqXb4AquqPwA2nfV5JkvrOEdEkSeoJk7YkST1h0pYkqSdM2pIk9YRJW5KknjBpS5LUEyZtSZJ6wqQtSVJPmLQlSeqJsZJ2kv+X5OEDy9sk+WiSk5McnGTjxQtRkiTB+CXtg4BdBpbfDuwFfAvYF3j1ZMOSJEnDxk3aOwEnwV8m/Hgk8LyqehbwEmCfxQlPkiTNGTdpbwJc3j6/F81EI59vl38M3GTCcUmSpCHjJu0zgQe2z58IfLOqLm2XbwpcNOnAJEnSqsadmvM1wGFJ/g64HvDwgW0PBL4/6cAkSdKqxkraVfXZJLcD7gycVlU/Htj8TeDUxQhOkiRda9ySNlV1FnDWiPWHTDQiSZI00tiDqyS5Y5JPJPlpkiuS3KVd//okey9eiJIkCcYfXGVvmi5fNwY+DAwOpnIFsP/kQ5MkSYPGLWm/ATi0qu4DvH5o28nArhONSpIkrWbcpH1b4BPt8xradgmw9cQikiRJI42btC8AbjnPttsD504mHEmSNJ9xk/bHgdckuffAukpyG+ClwEcmHpkkSVrFuF2+XgHsDHwN+FW77jM0DdO+DPzr5EOTJEmDxh1c5QrgIUn2opndaxuaoUuPqaqjFzE+SZLUGntwFYCqOgY4ZpFikSRJCxgraSfZeU37VNUP1z8cSZI0n3FL2qezelevYRuuZyySJGkB4ybtPUes2xp4QPt43sQikiRJI43bEO1r82w6MsnrgMcBn5tYVJIkaTVjTxiygGNZdX7tBSW5fpLDk5yZ5Iwk95hADJIkzby1aj0+jwcDv1+L/d8OfLGqHpNkE2DzCcQgSdLMG7f1+CdHrN6EZkzyWwP/NOZxtgJ2B/YFqKorgSvHea0kScvduCXtFSPWXQ78L/CCqvrCmMe5JXAh8MEkd6KZ7vN5VXXZ4E5J9gP2A9huu+3GPLQkSbNt3IZoo1qPr+v57gLsX1XfTvJ24GU0w6QOnu8Q4BCAlStXrqmrmbSk7HnwpP5cpuPYFx7bdQiSxjSJhmhr43zg/Kr6drt8OE0SlyRJazBvSTvJQWtxnKqql46x06+SnJdkp6r6Ec045o6kJknSGBaqHn/sWhynaKboHMf+wEfaluNnAU9bi/NIkrRszZu0q2rHxThhVZ0MrFyMY0uSNMumfU9bkiSto7EHV0kS4F7AbYBNh7dX1bsmGJckSRoy7uAqN6KZR3tnmvvXaTcNdscyaUuStIjGrR4/GLgYuAVNwr4bsANN/+r/oyl9S5KkRTRu9fh9aKbf/GW7nKo6F/jXJBvQlLL/ZhHikyRJrXFL2tcHLqyqa4BLgG0Htp0A3HPSgUmSpFWNm7TPBm7SPv8B8MSBbQ8FLppkUJIkaXXjVo9/HngA8EngdcBnkpwPXAVsx/gDq0iSpHU07oQhLx94flSSewKPBDYDjq6qoxYpPkmS1Bq7n/agqjoROHHCsUiSpAWMdU87yTlJ3pjkzosdkCRJGm3chmiHA/sAJyb5cZLXJNllEeOSJElDxkraVfWiqtoBuDfwBeDpwClJTk/yiiS3XsQYJUkSazlhSFV9s6oOoBkZbQ/gOJqpNs+YeGSSJGkV6zrL1xY0Xb22B64HXDGxiCRJ0khjJ+0kmyV5XJJPARcA76eZMOTpwI0WKT5JktQad5avTwAPBq4DfBV4DnBkVf1+EWOTJEkDxu2nfSPgRcDhVfWbRYxHkiTNY9wR0fZY5DgkSdIarGtDNEmSNGUmbUmSesKkLUlST5i0JUnqCZO2JEk9MW4/7VcusPka4BLglKr62kSikiRJqxm3n/b+wKY0w5cC/AHYsn1+WXuc6yQ5Gdi7qn490SglLQl7Hrxn1yGstWNfeGzXIUgTM271+IOAX9JMz7lZVW0FbAY8vl1/P2B3YAVw8CLEKUnSsjduSfs/gH+rqsPmVlTVFcAnk1wXeEdV3SXJ64DXLUKckiQte+OWtO8I/Gqebb8Ebtc+PxO47voGJUmSVjduSfvHwPOSfKWqrpxbmeQ6wPOBH7WrbgwseD87yTnApcCfgaurauXaBi1J0nI0btJ+HvB54PwkRwMX0ty/vj9N47QHtfvdGThijOPt6cQjkiStnXEnDDkuya1pStUrgbvQVJcfCrytqn7R7veyRYpTkqRlb9ySNm1ifvEEzlnAl5MU8J6qOmQCx5QkaeaNnbQn6F5V9Ysk2wJHJzmzqr4+uEOS/YD9ALbbbrsOQpQkaekZq/V4ko2TvCjJCUnOTXLB8GPcEw5UpV8AHAnsNmKfQ6pqZVWtXLFixbiHliRppo1b0n4r8Ezgc8CxwJUL7z5aki2ADarq0vb5A4DXrMuxJElabsZN2o8FXlZV6zva2Y2AI5PMnfujVfXF9TymJEnLwrhJO8Cp63uyqjoLuNP6HkeSpOVo3BHR3gs8YTEDkSRJCxu3pP1r4IlJjgWOBn4/tL2q6t0TjUySJK1i3KT9tvbndsB9RmwvwKQtSdIiGndEtHGr0SVJ0iIxGUuS1BPzlrST7Az8tKquaJ8vqKp+ONHIJEnSKhaqHj8duDvwnfZ5zbNf2m0bTjY0SZI0aKGkvSfww4HnkiSpQ/Mm7ar62qjnkiSpG+NOGLJtkh0HlpNkvyRvS/LQxQtPkiTNGbf1+KHA8weWXw28C3ggzVji+042LEmSNGzcpH0X4KsASTYAng38U1XdFng9cMDihCdJkuaMm7SvB/y2ff7XwNbAR9rlrwJ/NeG4JEnSkHGT9vnAXF/tBwNnVtXP2+XrAZdPOjBJkrSqccce/wBwUJL70STtlw9suztwxqQDkyRJqxp37PE3JPk5cFdgf5okPmdr4H2LEJskSRowbkmbqvow8OER65810YgkSdJI4/bTvl2Suw8sb57kX5N8Osn+ixeeJEmaM25DtHcBg4OovAl4HrAp8MYkL550YJIkaVXjJu1dgG8CJNkYeBJwQFU9EPgn4OmLE54kSZozbtLeArikfX73dvmIdvl7wPYTjkuSJA0ZN2mfRZOsAR4JfL+q5gZb2Qa4dNKBSZKkVY3bevytwLuTPBa4M/C0gW17AKdOOC5JkjRk3H7a70/yfzT9tF9WVccMbL4IeNtiBCdJkq61Nv20vw58fcT6V00yIEmSNNq8STvJzsBPq+qK9vmCquqHE41MkiStYqGS9uk0jc++0z6vefZLu23DyYYmSZIGLZS09wR+OPBckiR1aN6kXVVfG/VckiR1Y+yGaHOSbARsMry+qv44kYgkSdJI404Ycr0k70ryS+BymsFUhh9jS7Jhku8n+dzaBixJ0nI1bkn7UOA+wHuBnwBXrud5nwecAWy1nseRJGnZGDdp7wU8s6o+tr4nTHJz4MHA64EXrO/xJElaLsYde/xcYFL3rN8GvAS4Zr4dkuyX5MQkJ1544YUTOq0kSf02btJ+CfAvSbZbn5MleQhwQVWdtNB+VXVIVa2sqpUrVqxYn1NKkjQzxh17/AtJ7gf8JMk5wO9H7LPbGIe6F/CwJA8CNgW2SvLfVfWktYhZkqRlaaykneTNwAHAd1mPhmhV9XLg5e0x9wBeZMKWJGk84zZEewbwz1X1hsUMRpIkzW/cpP1HYMH70Gurqo4DjpvkMSVJmmXjNkR7O7BfkixmMJIkaX7jlrS3Ae4G/CjJcazeEK2q6qWTDEySJK1q3KT9GOBqYGPg/iO2F2DSliRpEY3b5WvHxQ5EkiQtbNx72pIkqWMmbUmSesKkLUlST5i0JUnqiXmTdpLdk2w5zWAkSdL8FippHwvsDJDkrCR3mk5IkiRplIWS9qXADdrnOwCbLHo0kiRpXgv10z4BeF+Sb7fLb0hy0Tz7VlXtM9nQJEnSoIWS9tOBfwZuSzPi2Q2ADacRlCRJWt28SbuqfgXsD5DkGuDZVfWdaQUmSZJWNe4wpnYNkySpY+NOGEKS6wPPBO4NbA1cBPwvcEhVDc/6JUmSJmysEnSSWwGnAa8BtgDObX++Bji13S5JkhbRuCXtt9LMoX33qvr53MokNwOOAt4CPHzy4UmSpDnj3qveA3jlYMIGaJdfDew54bgkSdKQcZN2MX93rw3a7ZIkaRGNm7SPBV6bZPvBle3ya4BjJh2YJEla1bj3tA8Avgr8X5LvAb8GtgX+GjgPeMHihCdJkuaMVdKuqnNoRkZ7LvADYGPgh8A/Ardrt0uSpEU0dj/tqroS+M/2IUmSpsyRziRJ6gmTtiRJPWHSliSpJ0zakiT1xLhjj++eZMt5tm2ZZPfJhiVJkoatzeAqO8+zbad2uyRJWkTjJu0ssG1L4I9jHSTZNMl3kpyS5AdJXj3m+SVJWvbm7afdVnnvMbDqGUkeOLTbpsCDaabtHMcVwH2r6g9JNga+keSoqvrWWsQsSdKytNDgKncD9m+fF/BY4Oqhfa4EzgRePM7JqqqAP7SLG7cPJxuRJGkM8ybtqnoT8CaAJGcDj6iqU9b3hEk2BE4C/gp4Z1V9e8Q++wH7AWy33Xbre0pJkmbCuGOP7ziJhN0e689VtStwc2C3JLuM2OeQqlpZVStXrFgxidNKktR7Y489nmRTYHeaZLvp0OaqqnevzYmr6vdJjgMeCJy+Nq+VJGk5GitpJ7k3cASwzTy7FLDGpJ1kBXBVm7A3A+4HvHHMWCVJWtbGLWn/O/BT4P7AD6vqqnU8302AD7X3tTcAPllVn1vHY0mStKyMm7R3Ah61vve1q+pU4M7rcwxJkparcQdXORW48WIGIkmSFjZu0n428Pwk91nMYCRJ0vzGrR4/Gtgc+GqSq4BLhneoqm0nGZgkSVrVuEn7nThymSRJnRoraVfVqxY5DkmStAZjD64CkOQGwC7ALYCjqup37aArV1bVNYsRoCRJaozVEC3JRkkOAs4Hvgb8F7Bju/lTwIGLE54kSZozbuvx1wN/D/wjcEtWnV/7M8BDJxyXJEkaMm71+FOAl1XVB9vRzAb9lCaRS5KkRTRuSfv6NMl5lE2A4UQuSZImbNykfTrw8Hm27Q18bzLhSJKk+YxbPf464FPtzFyH0fTZ3jXJI4FnAg9bpPgkSVJrrJJ2VX0G+FuaqTSPommI9j5gX+DJVfWlxQpQkiQ1xu6nXVWfBD6Z5DY082pfBPyoqhwpTZKkKVirwVUAqurHwI8XIRZJkrSAcQdX+UCST8yz7WNJ3jfZsCRJ0rBxW4/fHzh8nm2fAh4wmXAkSdJ8xk3aK2juYY/yO8BpOSVJWmTjJu2fAbvPs213mjHJJUnSIho3aR8KvDTJc5JsCZBkyyT/ALyEpvuXJElaROO2Hn8jcCvgHcC/J7kM2IKmv/Yh7XZJkrSIxkra7VzZz0jyJmBP4IbAb4Gvtl3AJEnSIltj0k6yKXAxsE9VfRr40aJHJUmSVrPGe9pVdTlwAXD14ocjSZLmM25DtPcAz02y8WIGI0mS5jduQ7TrA7sA5yQ5Bvg1zUxfc6qqXjrp4CRJ0rXGTdqPBq5on/+/EdsLMGlLkrSIxm09vuNiByJJkhY27j1tSZLUsbGTdpI7JvlEkp8muSLJXdr1r0+y9+KFKEmSYPypOfcGTgJuDHwYGGxFfgWw/5jHuUWSY5OckeQHSZ63tgFLkrRcjVvSfgNwaFXdB3j90LaTgV3HPM7VwAur6nbA3YHnJNl5zNdKkrSsjZu0bwt8on1eQ9suAbYe5yBV9cuq+l77/FLgDOBmY8YgSdKyNm7SvgC45Tzbbg+cu7YnTrIDcGfg2yO27ZfkxCQnXnjhhWt7aEmSZtK4SfvjwGuS3HtgXSW5DU3/7I+szUnb6T0/BRxQVZcMb6+qQ6pqZVWtXLFixdocWpKkmTXu4CqvAHYGvg78sl33GZqGaV8G/nXcE7ZDoX4K+EhVHTF+qJIkLW/jDq5yBfCQJHsBewHbABcBx1TV0eOeLEmA9wNnVNVb1iFeSZKWrQWTdpLNgAcBO9CUsI+pqmPW43z3Ap4MnJbk5HbdP1XVF9bjmJIkLQvzJu0ktwS+QpOw51yS5HFV9eV1OVlVfQPIurxWkqTlbqGGaAcB19BMELI5TSvx79NM0ylJkqZsoaR9D+Bfqur4qrq8qs4Anglsl+Qm0wlPkiTNWShp3wQ4a2jdT2mqt2+8aBFJkqSR1tRPe3j0M0mS1JE1dfn6UpKrR6w/Znh9VW07ubAkSdKwhZL2q6cWhSRJWqN5k3ZVmbQlSVpCxh17XJIkdcykLUlST5i0JUnqCZO2JKYzuVwAAB7NSURBVEk9YdKWJKknTNqSJPWESVuSpJ4waUuS1BMmbUmSesKkLUlST5i0JUnqCZO2JEk9YdKWJKknTNqSJPWESVuSpJ4waUuS1BMmbUmSesKkLUlST5i0JUnqCZO2JEk9YdKWJKknTNqSJPWESVuSpJ6YatJO8oEkFyQ5fZrnlSRpFky7pH0o8MApn1OSpJkw1aRdVV8HLprmOSVJmhVL8p52kv2SnJjkxAsvvLDrcCRJWhKWZNKuqkOqamVVrVyxYkXX4UiStCQsyaQtSZJWZ9KWJKknpt3l62PAN4Gdkpyf5O+meX5Jkvpso2merKqeMM3zSZI0S6welySpJ0zakiT1hElbkqSeMGlLktQTJm1JknrCpC1JUk+YtCVJ6gmTtiRJPWHSliSpJ0zakiT1hElbkqSeMGlLktQTJm1JknrCpC1JUk+YtCVJ6gmTtiRJPWHSliSpJ0zakiT1hElbkqSeMGlLktQTJm1JknrCpC1JUk+YtCVJ6gmTtiRJPWHSliSpJ0zakiT1hElbkqSeMGlLktQTJm1Jknpi6kk7yQOT/CjJT5K8bNrnlySpr6aatJNsCLwT2BvYGXhCkp2nGYMkSX210ZTPtxvwk6o6CyDJx4GHAz+cchyStJo9D96z6xDW2rEvPLbrEDRF007aNwPOG1g+H7jblGOQpGVp1r+U9O361uULV6pqEUKZ52TJY4G/qapntMtPBnarqv2H9tsP2K9d3An40ZRC3Ab4zZTO1QWvr9+8vv6a5WsDr2/Stq+qFaM2TLukfT5wi4HlmwO/GN6pqg4BDplWUHOSnFhVK6d93mnx+vrN6+uvWb428Pqmadqtx78L3DrJjkk2AR4PfHbKMUiS1EtTLWlX1dVJ/hH4ErAh8IGq+sE0Y5Akqa+mXT1OVX0B+MK0zzumqVfJT5nX129eX3/N8rWB1zc1U22IJkmS1p3DmEqS1BMmbUmSesKkLUlST0y9IdpSkWTrhbZX1UXTimUxJXlsVR22pnVa2pJsUVWXdR3HYmjnJLgRA/+Pqurc7iLSuGbxc5nkLgttr6rvTSuWUZZtQ7QkZwMFZMTmqqpbTjmkRZHke1V1lzWt66v2H/6DgR1Y9Z/+W7qKaZKS3BN4H7BlVW2X5E7AM6vqHzoObSKS7A8cCPwauKZdXVV1x+6iWn9JTqP5/7LaJmbj+mb2c5lkbmzRTYGVwCk0v7c7At+uqnt3FRss45J2Ve3YdQyLKcnewIOAmyX594FNWwFXdxPVovgf4HLgNK79pz9L3gr8De0gRFV1SpLduw1pop4H7FRVv+06kAl7SNcBLLKZ/VxW1Z7wlwmt9quq09rlXYAXdRkbLOOkPSjJDYBb03yzAqCqvt5dRBPxC+BE4GHASQPrLwWe30lEi+PmfS+1rElVnZesUiH0565iWQTnARd3HcSkVdXPuo5hsc345xLgtnMJG6CqTk+ya5cBgUmbJM+g+bZ/c+Bk4O7AN4H7dhnX+qqqU4BTkny0qq7qOp5FdFSSB1TVl7sOZJGc11ZFVjv073OBMzqOab0leUH79CzguCSfB66Y29732xtJvlFV905yKatWk89Vj2/VUWiTMpOfyyFnJHkf8N80v8MnsQSucdne057T3nu6K/Ctqto1yW2BV1fVPh2HNhFJHgK8Ftie5kvarPzTACDJI2n+qDYArmL2rm8b4O3A/Wiu7cvA8/penZzkwAU2V1W9ZmrBaK3N6udyUJJNgWcDc9X+XwfeXVWXdxeVSZsk362quyY5GbhbVV2R5OSq6rwaZBKS/AR4FHBazeAvO8lZwCOY0eubdbPeuyHJf1XVk9e0TktTks2A7apqWtNDr9Gyrx4Hzk9yfeDTwNFJfseI6UJ77Dzg9BlOaP/HDF5fkncwuvUxAFX13CmGs5heDgwn6FHr+ur2gwtJNgL+uqNY1tsy+lyS5GHAm4BNgB3b+9mvqaqHdRnXsk/aVfXI9umr2qb+1wO+2GFIk/YS4AtJvsYM3TMc8Euae6JHMVvXd2LXASymWe/dkOTlwD8BmyW5ZG41cCVLaPKJdTDTn8shBwK7AccBVNXJSXboMB7ApA38pTP9vWm+QR5fVVd2HNIkvR74A03L+E06jmUxnN0+NmGGrq+qPgTzVx93E9VEzXTvhqp6A/CGJG+oqpd3Hc+kLIPP5aCrq+rioRbynfOedvJK4LHAEe2qRwCHVdXruotqcpKcWFUru45D62YZDI6z8Sz3bpiv73Lfu5TO+ucSIMn7gWOAlwGPpmkhv3FVPavTuEzaOQO481yLwLbhwfeq6nbdRjYZSf4N+OqsdYlK8raqOiDJ/zDiHlvX953W10D18eOATwxs2grYuap26ySwCZtn5LCLaUrhr+t7a+T28zlnU5rq1pOqqpddSpfL5xIgyebAPwMPoLm18SXgtV23Hrd6HM6h+WOa+0VcB/hpZ9FM3nOAlyS5gtnqEvVf7c83dxrF4pnp6uMBR9EMyvHRdvnxNJ/Ri4FDgYd2E9ZkVNUq8Se5BXBQR+FMwnL5XFJVf6RJ2v/cdSyDlm1Je6AV5HY0/bSPbpfvD3yjqh7fYXgS0LQ2rqreN8yaT5Ljq+peo9YlOa2q7tBVbIshzQ3SU/t+XbN+WwMgyUqaxoQ7sOq8Bp2OwLicS9pzrSBPAo4cWH/c9ENZXLM4TOsCEzIA3f9hra8kn6yqxwHfTzKq+r/X1zdgyyR3q6pvAyTZDdiy3db7LytDXaQ2AHalmYCilwY+l9+b8c8lwEeAF7PE5jVYtiXtcSX5VFU9uus41tV8w7T29Z7anCTbL7S972M/J7lJVf1yvuvs+/XNSXJX4AM0iTrAJcAzgB8AD66qT3YY3npL8tSBxauBc6rq+K7iWV8Dn8tP0iS0v2wCDmoT+kyYG4q26ziGmbTXIMn3q+rOXcexrmZ9mNY1SfLNqrpH13GsqyRvrKqXrmld3yW5Hs3/o993Hcs09bVQME/r8VNnqaSdZC/gCTQtyAfHgDhi3hdNwXKuHh9X37/VXF5VlychyXWq6swkO3Ud1BRtuuZdlrT7A8MJeu8R63opyXVoutPsAGw01yd2GY09fsuuA1gbSZ4N/ANwyySnDmy6LtDbGoR5PA24LbAxA3O9c2334E6YtGffrA/Tuia9/NK1jP45foampfhJDJRmlpG+fT4/StPi/w00/ZfnXFpVF3UT0qK501JsMGj1+Br0vXp8UJL70A7TOjfqW5IbVNXvuo1s8fR1wIe2uvgGrOGfY99/f0lOr6pduo6jK339fC4HSd4LvLWqfth1LIOWdUk7yYbAh6rqSQvsNhPVkABV9bURq48BZvmfxtIag3BMVXUxTQn0CWvYte+/vxOS3KGqTus6kI708vO5TNwbeGqSs2lqgebGuLDLV1eq6s9JViTZZL7xxmdtJLERZv2fxqxPgdj339+9gX2X2j/GKZqZQsEMeuBCG7uq5VrWSbt1DnB8ks8Cl82tnIFZosbVy/sjc90xklzKqtewyohvVXV6JwFOTy9/fwP27jqAxbDAOAKrfClZBoWC3hqjW2UntVwm7aZR1i9oBj64bsexaExz/Seryt9Zj1XVz5LcG7h1VX0wyQquHVylzx7SdQBadJ3Uci37pF1Vr+46ho71vXp1rm3CjVh1qMFzu4toqnr9+0tyILAS2An4IE33mv8G7rXQ65a6wVJakhvRjJUA8J2quqCbqDRhndRyLfukneRYRs8S1fcRw7ZeaPtAC+S9phDOokmyP81k9b9m1b6UM3NPdMR8798b2Nzr3x/wSODOwPcAquoXSWam9iTJ44A30QyPHOAdSV5cVYd3Gph6a9knbeBFA883pRnoofdjHtP0ey1Gl8SKdlCHGehb+Txgp75P4TifEfO9fzDJX+Z7n4Hf35VVVXPjWCfZouuAJuyfgbvOla7b6v+vACbt/rN6vAtVddLQquOTjOoa1StVtWPXMUzJeTRdo2bVE1h1vvd/oymVvq7TqCbnk0neA1w/yd8DTwfe23FMk7TBUHX4b2naz2iJS3K/qvrK0LqnVtWH2sVOarmWfdIeqkbeAPhr4MYdhTMxbZXqvIaqWHsnyQvap2cBxyX5PKuODzwrrf/PYYbne6+qNye5P81EITsBr6yqozsOa5K+mORLwMfa5X2AL3QYj8b3yiSPpqmN3RJ4H83/mA9Bd7Vcy35EtLZ/6Fw18tXA2cBrquobnQa2ntp79fOpGbhnf+BC22elgWGSTzNivnfgAoCqem530WkcSR5F0yYhwNer6sg1vERLQDv3+QuBZ7arXllVH1vgJVOx7JO2ZluSd1TV/l3Hsa6GpnZczUBVXa+M6F//l00M9LPvuyTPBw6rqvO7jkVrp62FfQ9NV+Cb0/RqeGN1nDStHk+eA3xkbkrAJDcAnlBV7+o2sslIsjHwbGD3dtVxwHuq6qrOgpquvncd6mVSXpNx+9f3fWx1YCvgS0kuAj4OHF5Vv+44Jo3nW8C/VdUHkmwGvJFmsp57dhnUsi9pJzm5qnYdWjdLk4S8j6bv69w//ycDf66qZ3QX1fT0fUKGJA8BXgtsT/Mle6ZKomvS99/fnCR3pLmf/Wjg/Kq6X8chaQ2SbDc83kOS3avq613FBJa0ATZIkrkqj3agjk06jmmS7lpVdxpY/mqSUzqLRmvrbcCjgNO6rpbrSK8HjxlwAfArmtbj23Yci8bzmySvALarqr9PcmuampNO2fUAvkTT7WSvJPelaeX5xY5jmqQ/J7nV3EKSWwJ/7jCeaev7P/3zgNOXacKGno+tnuTZSY6jGad6G+Dvl9FkKH33QZrW4vdol89nCXS1tKTdzLKzH8193wBfpmnaPyteDByb5Cya69seeFq3IU1OkjtX1fcX2OXtUwtmcbwE+EI7dsAsdmmbddsDB1TVyV0HorV2q6raJ8kTAKrqT22L8k4t+3vaa5LkU1X16K7jWB9JrkPTBzbAmVV1xRpe0htt17abAIcBH6+qH3Qc0kQl+TLwB+A0rh2mdWa6tK3JLLQvGTUhSlWd3XVcWliSE2gGUDm+qu7S1lh+rKp26zQuk/bC+v5PY9ZbxwMkuTHwOJqGPlsBn5gb5rPvkpxYVSu7jmMxLTS2epKt+zxU6+CEKFV1myQ3pekC1uteDctBO+jPvwA709TA3gvYt6qO6zQuk/bC+t56ddZbxw9Kcgea6uR9qmomGhO2w5Z+dVbnXR4xtvojaJLarHzpOpl2QpS5v7kkp3pfux+S3BC4O00t5beq6jcD227fRc2e97Rn30y3jk9yO5oS9mOB39D0hX1hp0FN1nOAFye5EriK2evyNetjq8/6hCgzrZ2I6PPzbP4vYOoFOpP2mnXe8GA9zbWO/0+a6sdnMVut4z9I0+L//lX1i66DWQTXA54I7FhVr0myHc09/FlxDjM6tnrbaOlzMz4hynLWSW5Y9tXjSZ5XVW+fb12SB/S5ajLJBjSt4+/HQOv4qpqZbl/taEXbVdWPuo5l0pK8m6YB2n2r6nZtm4QvV9VdOw5tImZ9bPUk36PpofIAmr+/L83YhCjLVle3Tk3aI974Wb3nO0rfW8cneSjwZmCTqtoxya40E748rOPQJmLu8zn4mUxyytCAOb01q2Orz0nyTuDQqvpu17FosrpK2su2erzte/e3wI5JPjuw6bo0oxYtF7fsOoD19CpgN5ox1amqk5Ps0F04E3dV2w5h7p7oCga6fvVd35PyGPYEnpnkZ8BlcyttiDYTruzipMs2aQMnAL+kGaXo4IH1lwKndhJRN/pe1XJ1VV28BMY8WCz/DhwJbJvk9cBjaLqhzIRlMLb63l0HoHWT5F7AyVV1WZIn0TQ6e3tV/Qygqu7eSVzLvXocIMmNaO6rAXynqi7oMp5pmoEube+nGSLyZTSTMTwX2LiqntVpYBOU5LY0gzwEOKaqzug4pIlJ8hOW99jqWqKSnArcCbgjTUvx9wOPqqr7dBnXsh97PMljge/QdBl6HPDtJI/pNqqp6nsRdX/g9jRDfH4UuBg4oNOIJqyqzqyqd1bVf8xSwm4t97HVtXRd3X4uH05Twn47ze3TTi37knY749X950rX7T3Dr8xQQ5+ZbR3f3uv9ktMc9leSu9JUjzu2upaUdrz/L9LM1bA7cCFNdfkduoxr2Ze0gQ2GqsN/y2y9L6Na5+4796SvCRug7bb2xyTX6zoWrbPXA3+k6at93YGH1LV9aL5I/l1V/Qq4GfCmbkNa3g3R5hyV5Es0A3RA84v6QofxTMQyah1/OXBakqNZtXVur/v3LiNbV9UDug5CGtYm6rcMLJ8LfLi7iBom7ab19HtoJiwIcAjNWLN9t1xax3+e+YcZ1NL3lT7fotHsSvIo4I3AtjS5YUn0bPCe9ujBVWZqQP9l3jq+14PHzLoklwKb0/R5ncWx1dVTbc+Ghy61xp+zdO92rSR5dpLTgJ2SnDrwOJsZKonaOr73g8fMuuvRtLF4Q5uob08zlKnUtV8vtYQNy7ik3TZeugHwBpo+vnMu7fP8vcNmvXX8mvS9H/qsm/Wx1dU/bbU4wH2AGwOfZtWeDUeMet20LNt72lV1MU2f3id0Hcsim/XW8eq3u82NrQ5QVb9LMjNTx6qXHjrw/I80k73MKa6d+70TyzZpLyMz2Tp+LfR98JhZN9Njq6t/qupp0AxjWlXHD25rhzbtlCWu2TfXOv6ONEPyHdJtOFP30q4D0IKGx1b/BvCv3YYkAfCOMddN1bK9p71czGrr+LYR4agP71zr415f33Iyy2Orq3+S3AO4J81wyG8d2LQV8Miu2wNZPT6jkjwb+Afglu3A93OuCxw/+lW98pCuA9BkVNWZwJldxyG1NgG2pMmPg6PzXUIzy16nLGnPqOXSOl6SFkOS7eem4VxKTNrqtSR3p7nPdDuab8gbApc5OIek9ZFkJfDPXDvXOwBd33qzelx99x/A44HDgJXAU4C/6jQiSbPgI8CLgdNYQj0aTNrqvar6SZIN21m/PpjkhK5jktR7F1bVZ9e823SZtNV3f2wH4zg5yUE0k6Rs0XFMkvrvwCTvA45hCY2I5j1t9VqS7YFf09zPfj7NWNbvrKqfdhqYpF5L8t/AbYEfcG31eFXV07uLyqStnkvyvKp6+5rWSdLaSHJaVd2h6ziGOSKa+u6pI9btO+0gJM2cbyXZuesghlnSVi8leQLwt8C9gf8d2LQVcHVV3a+TwCTNhCRnALcCzqa5p70kRlu0IZr66gSaRmfbAAcPrL+UGZoPXVJnHrjQxiQ3qKrfTSuYv5zXkrb6LsmNgLn5l78zNBWpJE3cqHkdpsF72uq1JI8FvgM8Fngc8O0knY8PLGnmdTLtr9Xj6rt/Ae46V7pu52P+CnB4p1FJmnWdVFNb0lbfbTBUHf5b/FxLmlGWtNV3RyX5EvCxdnkf4AsdxiNpeeiketwSifqugPcAdwTuBBzSbTiSlom9ujiprcfVa6NacCY5teu+lJL6KckdgPcCNwOOAl4617UryXeqarcu47OkrV5K8uwkpwE7JTl14HE29tOWtO7eDbwKuAPwY+AbSW7Vbtu4q6DmWNJWLyW5HnAD4A3AywY2XVpVF3UTlaS+S3JyVe06sLwnzW23JwPv6qJv9iCTtiRJrSSnALtX1cUD6+4IfArYuqpu2FlwWD0uSdKgNwK3G1xRVafSNDzrdC5tsKQtSVJvWNKWJGkMSTrvUurgKpIktZJsPd8m4EHTjGUUk7YkSde6EPgZq454Vu3ytp1ENMCkLUnStc4C9qqqc4c3JDmvg3hW4T1tSZKu9TaaMSBGOWiagYxi63FJktZSkvtX1dFTP69JW5KktTNq3oNpsHpckqS159SckiT1RCfV1CZtSZJ6wqQtSdLaO6eLk5q0JUkakuSxSa7bPv+XJEck+UvDs6p6VBdxmbQlSVrdK6rq0iT3Bv4G+BDw7o5jMmlLkjTCn9ufDwbeXVWfATbpMB7ApC1J0ig/T/Ie4HHAF5JchyWQMx1cRZKkIUk2Bx4InFZV/5fkJsAdqurLncZl0pYkaXVJNgRuxMDkWqMmEpkmZ/mSJGlIkv2BA4FfA9e0qwu4Y2dBYUlbkqTVJPkJcLeq+m3XsQzq/Ka6JElL0HnAxV0HMczqcUmSVncWcFySzwNXzK2sqrd0F5JJW5KkUc5tH5uwBPpnz/GetiRJ82iHMq2q+kPXsYD3tCVJWk2SXZJ8Hzgd+EGSk5Lcvuu4TNqSJK3uEOAFVbV9VW0PvBB4b8cxmbQlSRphi6o6dm6hqo4DtugunIYN0SRJWt1ZSV4B/Fe7/CTg7A7jASxpS5I0ytOBFcARwJHt86d1GhG2HpckqTesHpckqZXkbVV1QJL/oRlrfBVV9bAOwvoLk7YkSdeau4f95k6jmIdJW5KkVlWd1D7dtarePrgtyfOAr00/qmvZEE2SpNU9dcS6facdxDBL2pIktZI8AfhbYMcknx3YdF2g82k6TdqSJF3rBOCXwDbAwQPrLwVO7SSiAXb5kiRpSJJbAr+oqsvb5c2AG1XVOV3G5T1tSZJW90ngmoHlPwOHdRTLX5i0JUla3UZVdeXcQvu883m1TdqSJK3uwiR/GUglycOB33QYTxOH97QlSVpVklsBHwFuRjMy2vnAU6rqJ53GZdKWJGm0JFvS5MpLu44FrB6XJGk1SW6U5P3AYVV1aZKdk/xd13GZtCVJWt2hwJeAm7bLPwYO6CyalklbkqTVbVNVf+n2VVVX03T76pRJW5Kk1V2W5Ia003MmuTtwcbchOYypJEmjvAD4LHCrJMcDK4DHdBuSrcclSRopyUbATkCAH1XVVR2HZNKWJGlOkkcttL2qjphWLKNYPS5J0rUeusC2AjpN2pa0JUnqCUvakiS1krxgoe1V9ZZpxTKKSVuSpGtdt+sAFmL1uCRJPeHgKpIkDUly8yRHJrkgya+TfCrJzbuOy6QtSdLqPkgzuMpNaabn/J92XaesHpckaUiSk6tq1zWtmzZL2pIkre43SZ6UZMP28STgt10HZUlbkqQhSbYD/gO4B82gKicAz62qczuNy6QtSdKqknwIOKCqftcubw28uaqe3mVcVo9LkrS6O84lbICqugi4c4fxACZtSZJG2SDJDeYW2pJ25wOSdR6AJElL0MHACUkOp7mn/Tjg9d2G5D1tSZJGSrIzcF+a+bSPqaofdhySSVuSpL7wnrYkST1h0pYkqSdM2tISluRVSWrE4ysTPMduSV41qeNJWjy2HpeWvouBB45YNym7AQcCr5rgMSUtApO2tPRdXVXf6jqIcSXZrKr+1HUc0iyyelzqsSTPSPKDJFck+VmSlwxtv0eSzyb5RZLLkpyc5IkD2/cF3tE+n6t6P65dPjTJiUPH26Hd5yED6yrJC5K8LcmFwGnt+k2THJTkvDa+U5I8aOh4D0tyUhvb75J8O8l9JvsuSbPDkrbUA0mG/1b/DLwI+FfgIOA44K+B1yb5Y1X9R7vf9sDxwH8ClwP3Aj6Y5Jqq+hjweZpBJF5IMzECwCXrEOKLga8DT+bawsDhXFv1/lOawSk+m2RlVZ2c5FbtPm9vX79pew1br8P5pWXBpC0tfTcErhpa93CaZPi6qnp1u+7oJJsD/5Lk3VX156r6+NwLkoQmsd4c+HvgY1V1YZJzANazCv5XVbXPwLn2Ah4M7FFV/7+9+wmxKYzDOP59kKYmMykiJTbG1oJiJYVS8q+UWLEgpcZGiCxYMSVjZSINCxaSPzViNFMakuz8y6w0hUhN7lCGkZ/Fe6aucxtz5S7mzH0+dbr3vPe95/y6m6fznl/nPsiGuyW1AEeAraTnOH+JiANlx7nzHzWYTXpeHjeb+ErAstwmoBG4Jmna6Ab0AnNIwYykmZLOShogBf8IsBtoqXGNXbn91cAH4FGuvh5gaTbnOdAs6ZKktZIaa1yT2aTjK22zie9nROTvLS/O3r4c4zvzgQGgE1gOnABekZa+95Ku1GvpY25/FjCXyhUCSEv7RES/pI3AIdIV9oikG0BrRHyqcX1mk4JD26yYBrPX9VQGJkC/pAbSEvW+iDg3+oGkalfYhoHpubGx7jfnn4c8CLwDNv3tBBHRBXRJas5qPUNqjNtWZY1mdcWhbVZMj4FvwLws+CpkQTgV+F42NgPYwJ8h+yP7rCEihsvG3wILc+Nrqqyvh9Tc9jUiXo83OSJKwJWsc3zFePPN6pVD26yAIuJz9hSzdkkLSA1mU0j3qldFxOaIKEl6ChyTNAT8Ii1Fl4CmssONhmqrpF5gKCL6gZvAceCCpE5S49jOKku8D9wjNcedJC3jNwFLgIaIOCxpDymg7wLvgUWkBrXL//yDmNUJN6KZFVREnCI1la0DbgFXgR1AX9m07cAbUhC2A9epDMU+oA1oBZ4AHdnxXwC7SMF6G1iZ7VdTWwBbgIvAflKAd2THephNewbMBk4D3cBR4DxwsJpzmNUj/zWnmZlZQfhK28zMrCAc2mZmZgXh0DYzMysIh7aZmVlBOLTNzMwKwqFtZmZWEA5tMzOzgnBom5mZFYRD28zMrCB+A5ww+nHYccp/AAAAAElFTkSuQmCC\n",
"text/plain": [
""
]
},
"metadata": {
"needs_background": "light"
},
"output_type": "display_data"
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"\n",
"columns inputed with : unknown are ['emp_title', 'title']\n",
"\n",
" unknown Filled inplace of NaNs\n",
"\n",
"\n",
" unknown Filled inplace of NaNs\n",
"\n"
]
},
{
"data": {
"application/vnd.plotly.v1+json": {
"config": {
"linkText": "Export to plot.ly",
"plotlyServerURL": "https://plot.ly",
"showLink": true
},
"data": [
{
"histfunc": "count",
"histnorm": "",
"marker": {
"color": "rgba(255, 153, 51, 1.0)",
"line": {
"color": "#4D5663",
"width": 1.3
}
},
"name": "revol_util",
"opacity": 0.8,
"orientation": "v",
"type": "histogram",
"x": [
73.1,
23.2,
31.2,
55.5,
76.2,
64.5,
23.9,
29.5,
76.6,
90.5,
50.8,
71.9,
34.2,
27.2,
41.4,
35.4,
96.2,
99.4,
54.7,
76.7,
68.7,
12.2,
82.4,
60.6,
54.2,
46.7,
32,
87.3,
48.4,
58.1,
69.6,
70.7,
97.5,
52.7,
12.3,
54.9,
82.2,
48.3,
64.1,
65.2,
78.2,
36.7,
26.2,
30.5,
70.5,
95.8,
33.2,
80,
51.7,
76.9,
45.7,
51.2,
1.7,
71.4,
19.5,
70,
38.4,
36.6,
45.7,
15.9,
40.2,
78.4,
15.3,
68,
5.5,
53.7,
2.9,
80.1,
63.6,
35.7,
67.8,
76.2,
78.4,
58.2,
93.4,
70.7,
53.3,
79.2,
44.4,
85.1,
45,
18.1,
97,
67.4,
44.7,
76,
44.3,
57.9,
19.1,
81.1,
96.3,
77,
null,
57.5,
66.8,
37,
49.1,
86.4,
48.8,
65.1,
37.5,
61.5,
46.6,
18.2,
68.5,
38.4,
49.3,
61,
33,
26.9,
13.7,
47.7,
49.3,
38.9,
25.8,
38.2,
58,
20.3,
43.1,
84.3,
54.2,
80.7,
12.2,
69,
55.2,
75.9,
21.3,
20.5,
85.1,
77.7,
58.7,
65,
65.6,
42.5,
46.2,
76.9,
39,
45.2,
22.2,
45.1,
41.1,
36,
77.9,
55,
96.3,
53,
68.5,
47.4,
52.9,
68.3,
93.2,
67.6,
88.7,
52.9,
88.4,
50.3,
26.4,
10,
34.7,
66.8,
33.2,
57.6,
40.8,
96.3,
3.4,
85.2,
103.5,
11.5,
8.2,
74.2,
54,
26.1,
27.4,
41.1,
15.9,
76.3,
25.3,
51.3,
62.9,
66.3,
20.2,
62.2,
53.6,
53.3,
58.9,
49.7,
97.6,
22.9,
82.4,
62.1,
71.7,
52.1,
42.4,
57.4,
28.1,
64.8,
35.1,
13.2,
51.4,
68.8,
42,
32.4,
49,
47.2,
67.4,
77.7,
89.4,
88.1,
93.1,
73.7,
62,
18.1,
69.1,
52.5,
40.3,
36.2,
74.8,
85.5,
26.3,
41.3,
47.9,
67.3,
57.6,
67.4,
48.6,
18.2,
46.5,
95.1,
57.3,
14.4,
47.3,
40.6,
27.1,
23.9,
39.2,
21.1,
33.2,
66.8,
25,
53.8,
74.1,
54.4,
69.6,
43.9,
86.3,
81,
62.7,
69.1,
49.4,
84.9,
28.7,
93.9,
77.3,
31.1,
69.3,
73.2,
16.4,
78.8,
46,
33.7,
51.1,
77.4,
95.6,
81.3,
80,
49.6,
59.7,
27,
46.1,
69.4,
52.5,
99.1,
23.9,
52,
72.7,
54.1,
57,
78.8,
48.6,
64.7,
34.2,
55,
49.2,
66.4,
30,
93.5,
95.6,
62.3,
37.3,
39.2,
82.8,
26.6,
67.5,
14,
45,
97,
21.5,
57.8,
13.8,
74,
50.1,
81.4,
5.8,
66,
64.7,
49.3,
50.6,
90,
71,
50,
29.7,
23.4,
86.3,
25.5,
37.1,
61.5,
83.2,
31.5,
50.5,
51.4,
55.8,
69.5,
55.4,
76.7,
55.8,
44.5,
66.5,
77.1,
47.7,
69.3,
46.2,
28.2,
29.4,
88.6,
44.5,
95.8,
41.2,
56.7,
12.1,
88.3,
47,
73.2,
58.3,
25.5,
96,
33.6,
24.9,
15.9,
102.7,
64.1,
81.1,
76.8,
53.3,
64.8,
5.2,
40.8,
64.7,
56.5,
26.8,
68.1,
19.7,
80.6,
28.5,
76.2,
52,
1.9,
78.6,
69.2,
39.8,
53.9,
39.1,
76.7,
56,
34.1,
28.8,
10,
58.7,
58.3,
27.1,
77.8,
65.6,
89,
76.9,
9.7,
76.5,
56.9,
41.8,
79.1,
85.9,
43.3,
53.3,
30.6,
58.4,
78.8,
69.8,
19.7,
93.6,
71.7,
91.3,
42.1,
32.8,
63.3,
27.5,
50.1,
54.2,
49.9,
63.5,
90.2,
67.3,
42.7,
26.3,
25.6,
38.7,
93.2,
34.7,
59.7,
55.3,
88.2,
86.3,
31.6,
61.6,
80.2,
27.5,
48.2,
68.7,
58.5,
35.1,
45.1,
44.8,
57.2,
61.9,
74.5,
56.1,
56.4,
34,
98.9,
14.2,
48.6,
48.6,
28.7,
60,
18.4,
69.3,
56.8,
43.4,
71.5,
47.6,
94.3,
45.5,
70.6,
43.9,
21.3,
26.3,
28.5,
26.3,
98.7,
80.6,
51.3,
28,
25.1,
98.4,
71.5,
54.6,
26.9,
19.8,
53.3,
36.7,
94.2,
47.7,
89.9,
95.8,
55.8,
19.9,
85.4,
38.2,
35.1,
86.1,
58.8,
91.5,
88.8,
96.1,
68.5,
57.9,
27.6,
60.5,
39.4,
62.7,
60.1,
27.6,
91.6,
38.2,
27.6,
69.8,
79.1,
73.5,
82.6,
32.3,
35.8,
93.1,
44.3,
84.4,
71.9,
47,
89.8,
66.3,
66.3,
68.9,
78,
85.9,
50,
85,
34.1,
66.8,
85.3,
65.9,
52.5,
37.7,
61.1,
52.5,
71,
86.3,
39.6,
82.5,
43.5,
53.3,
51.6,
76,
55.1,
37.6,
37.7,
32.3,
54.8,
40.3,
32.9,
57.3,
66.9,
43.1,
76.1,
51.3,
49.9,
83.7,
57.9,
31.9,
14.9,
8,
92.5,
45.8,
46.6,
63.8,
90.7,
55.8,
83.5,
59.5,
15.4,
66.6,
67.1,
43.5,
89.7,
58.2,
97.6,
58.4,
77.7,
57.3,
52.4,
49.4,
41.2,
42.7,
17.6,
24.3,
61.4,
67.6,
87.9,
38.4,
76.5,
95.4,
59.2,
65.2,
51.1,
63,
29.1,
39,
24.1,
54,
44.8,
71.1,
58.4,
33.1,
52.1,
86.8,
86.7,
64.2,
86.4,
37.8,
92.8,
43.5,
50.2,
48.6,
43.8,
44.9,
36.4,
43.8,
43.2,
66.5,
10.9,
67.4,
64.1,
35.3,
74.5,
59.7,
53.4,
71.6,
73.7,
51.4,
75.4,
57.5,
40.1,
95.4,
32.2,
79.5,
29.3,
78.2,
46.5,
63.3,
61.4,
50,
92.9,
30.8,
32.1,
19.2,
60.5,
74.9,
50.2,
26.9,
76.5,
87.3,
79.1,
57.5,
55.6,
47.4,
35,
68.8,
2.8,
86.8,
51.3,
20,
45.8,
48.8,
80.9,
92.5,
31.5,
90.5,
25.8,
10.8,
63.3,
65.2,
9.3,
33.3,
30.1,
18.5,
81.2,
33.5,
71.8,
95.1,
89.1,
71.7,
66.3,
22.9,
37.3,
85.2,
60.1,
29.5,
85.9,
3.3,
4,
75.9,
37.1,
94.5,
36.4,
57.7,
47.9,
10.3,
98,
30.8,
84.3,
100.7,
39.9,
52.4,
32.3,
27.4,
55.2,
48.8,
69,
92.3,
18.8,
65.8,
35.1,
43,
89.9,
26.4,
42.3,
57.1,
53,
64.3,
11.8,
76.5,
26.2,
50.9,
40.5,
57.6,
56.2,
44.2,
26.2,
29.9,
36.3,
54.9,
76.2,
27.8,
95.9,
43,
24,
87.6,
61.8,
54,
14.7,
27,
51.5,
61.7,
47.6,
16.2,
81.8,
16,
63.1,
35.3,
28.1,
70.5,
59.6,
55.8,
46.3,
59.4,
91.1,
45.9,
50.4,
67.6,
93.4,
93,
71.2,
28,
60.2,
17.8,
77.8,
66.9,
24.9,
49.6,
61.4,
78.8,
46.3,
53.3,
27.6,
86.9,
27.3,
77.6,
88,
41.7,
61.4,
46.1,
53.7,
67.1,
87.7,
46.3,
50.1,
91,
36.7,
61.4,
40.2,
55.7,
1.7,
41.9,
98.3,
65.1,
39,
41.5,
38.1,
53.1,
93.6,
64.3,
34.8,
45.2,
66.1,
96,
49.6,
52,
29,
62.2,
66.7,
51.1,
48,
86.2,
83.5,
73,
67.2,
68.4,
77.1,
49.3,
47.8,
80.3,
36.5,
89,
89.2,
96.8,
74,
31,
94.4,
70.6,
57.2,
61.6,
43.7,
75.4,
60.1,
83.5,
66.3,
12.6,
55.9,
59,
43.9,
57.8,
53.3,
78.1,
91.2,
13.3,
32.5,
70.4,
69,
66.2,
80.8,
26.2,
80.4,
65,
87.7,
53.2,
57.7,
74.2,
28.3,
59.1,
69.5,
79.3,
49.4,
44.9,
73.9,
66.7,
73.3,
86.9,
9.9,
98.4,
67.1,
38.5,
54.3,
57,
90.6,
61.5,
83.9,
37.7,
77.9,
73.7,
41.8,
65,
77.9,
16,
91.9,
null,
39.1,
72.5,
25.3,
82.6,
38.4,
65.9,
85.4,
29,
67,
24.8,
84.9,
17.7,
88.1,
48.3,
66.7,
42.3,
46.5,
75,
62,
54.3,
46.7,
54.3,
42.5,
46.6,
53.2,
26.4,
56.9,
86,
67.6,
54.5,
46.5,
32.3,
74,
47.1,
37.6,
26.6,
16,
50.6,
65,
52.7,
16,
95,
39.3,
90.3,
89.4,
38.5,
27.8,
74.2,
38.5,
42.1,
76,
12,
66.8,
69.5,
74,
24.9,
48.4,
83.4,
52,
99.5,
1.8,
69.5,
59.6,
63,
28.8,
49.3,
73.4,
87.3,
4.3,
70.7,
92.3,
47.7,
47.3,
73.9,
79,
77.8,
6.8,
84.6,
20.9,
15,
53.7,
89.5,
67.2,
61.1,
45.7,
89.4,
95.7,
49,
51.6,
23.9,
55.5,
52.6,
22.2,
93.1,
84.8,
61.8,
69.7,
51.7,
9.9,
25.2,
97,
24.2,
76.3,
29.1,
61.5,
91.9,
23.1,
64.1,
27.3,
52.2,
22.4,
54.3,
50.7,
81.6,
66.8,
73,
69.6,
10.8,
16.2,
74.8,
86,
49.2,
67.6,
52,
71.5,
99,
73.5,
64.5,
61.4,
44,
32.9,
44.5,
87.6,
38.5,
49.2,
20.4,
78,
79.2,
55.4,
80.1,
91.1,
44.3,
74.1,
24.1,
41.8,
87.6,
71,
62.1,
81.1,
72.7,
61.7,
88.2,
24.4,
54.9,
52.7,
44.4,
58.2,
73.4,
57.7,
70.1,
49,
86.7,
44.3,
84.2,
81,
92.7,
73.9,
33.6,
61.6,
76.7,
40,
48,
56.9,
40.6,
47.6,
47.6,
10.1,
58.5,
15.6,
3.1,
40.9,
72.7,
18,
24.1,
42.9,
57.1,
38.6,
67.7,
65.2,
61.5,
68.1,
46.5,
60.7,
79.1,
65.8,
32.6,
66,
6.2,
29.3,
36.6,
94.1,
67,
73.7,
69.1,
13.2,
59.5,
63.2,
66,
31.6,
31.8,
69.3,
78.8,
78.5,
73.5,
81.9,
33.6,
49.8,
98.7,
62.9,
70,
99.7,
66,
61.2,
52.4,
56.8,
56.8,
66,
76.7,
22.1,
80.1,
26.6,
49.1,
52.6,
67.8,
57.2,
41.5,
85.9,
33.4,
58.4,
55.2,
22.3,
21.8,
74.4,
42.3,
52.5,
90,
46.7,
61.7,
72.1,
97.6,
57.5,
54.8,
42.6,
23,
57.5,
37.7,
6.7,
91.8,
59.8,
48.2,
69.8,
42.8,
31.4,
11,
76.6,
69,
18.6,
68.5,
65,
5,
52.5,
87.2,
76.3,
77.9,
58.2,
83.2,
37.3,
28.5,
77.8,
82.9,
77.2,
1.3,
59,
84.7,
41.8,
74.9,
57.3,
55.3,
65.9,
51.4,
25.1,
70.7,
57.2,
59.2,
79.3,
86.8,
96.9,
67.9,
74.8,
80.8,
61.9,
29.2,
86.8,
29.1,
42,
24.3,
86.7,
88.2,
44.2,
83.5,
43.1,
36.2,
89.4,
62.8,
30.4,
61.7,
62.6,
71.6,
87.4,
23.8,
34.5,
35.9,
85,
32.4,
97.9,
96.4,
95.2,
42.1,
53.6,
3.3,
64,
20.3,
51,
59.3,
34,
8.9,
39.7,
25.6,
100.1,
26.8,
95.8,
0.3,
77.9,
33.4,
51.2,
45,
39,
69.6,
61.1,
38.6,
38.8,
55.1,
78.2,
24.8,
1.1,
82,
59,
65.5,
33.5,
65.3,
35.6,
48.8,
64,
19.9,
68.6,
55.4,
57.8,
49.1,
64.8,
6.3,
49.1,
62,
69.5,
22.6,
83.7,
81.6,
66.1,
34,
38,
0,
95.6,
58.5,
58.6,
47,
51.6,
52.8,
15.6,
73.7,
63.9,
67.7,
20.6,
50.8,
85.3,
50.2,
50.1,
91.9,
32.5,
14.6,
61.6,
63.4,
18.7,
78.5,
45.2,
58.1,
29.6,
47.9,
38.2,
54.6,
74.5,
74.2,
69.9,
72.9,
44.4,
47.7,
99.9,
39.1,
64.1,
86.9,
40.4,
67.2,
33,
46.4,
11.1,
83.8,
83.9,
27.5,
59.2,
0,
92.1,
39,
70,
38.6,
66,
56.5,
3,
19.5,
26,
80.3,
41,
30.7,
74.4,
56,
63.4,
77.9,
74.6,
80.3,
67.6,
32.2,
43,
52.9,
50.7,
10.5,
20.5,
63.5,
36.2,
30,
60.7,
67.9,
84.4,
75,
8.7,
45.7,
33.3,
73,
20.9,
24.2,
32.1,
94.9,
58,
51.3,
59.5,
40.8,
2.6,
63.9,
47.4,
66.5,
47.4,
51.3,
63.4,
43.1,
33.5,
24.2,
29.2,
68.7,
56.5,
48.7,
31.5,
28.2,
57,
61.3,
25.7,
60.6,
24.1,
36.7,
11.1,
85.4,
83.3,
51.2,
43.1,
17.7,
9.2,
86.4,
12.3,
32.9,
44.4,
42.2,
81,
93.9,
59.5,
45.8,
12.2,
55.1,
69.8,
69.3,
66.2,
48.6,
28.4,
85,
83.1,
87.8,
45.7,
40.4,
31,
52,
33.5,
58.4,
68.8,
73.5,
77.7,
85,
46,
71.4,
88.7,
13.1,
2.8,
17.5,
39.7,
22.4,
83.1,
93.6,
24.4,
43.8,
57.4,
87.9,
76.4,
60,
37,
43.4,
74.4,
47,
61.1,
59.9,
77.4,
51,
10.9,
92.8,
23.4,
61.1,
49.5,
42.5,
52.5,
22,
23.3,
87.1,
41,
30.6,
84.2,
49.1,
97.5,
19.2,
62.5,
29,
72.3,
73,
68.3,
12.6,
90.8,
65.8,
72.4,
11.9,
74.4,
58.8,
43.4,
31.2,
27.8,
45.6,
46.9,
79.9,
47.3,
90.4,
12.1,
43.6,
67,
47.9,
90.2,
26.2,
66.2,
59.4,
54.5,
38.8,
26.6,
49.1,
76.1,
70,
43.2,
54.8,
54,
89.7,
61.1,
50.3,
43,
70.3,
58.1,
21.1,
62.1,
6.6,
64.4,
37.4,
52.7,
97.3,
62.7,
33.4,
38.1,
96,
69.2,
82.8,
45.7,
28.1,
84.7,
65.3,
20.7,
74.1,
14.5,
54.2,
46,
52.9,
11.5,
19.4,
89,
64,
52.8,
48.2,
15.8,
62,
74.7,
70.3,
17,
16.1,
30.6,
34.3,
73.8,
93.2,
46.9,
78.5,
56.9,
42.6,
98.3,
54.9,
63.5,
76.6,
6.3,
23.1,
71.6,
46,
39.6,
32,
57,
35.2,
58.5,
83,
53.7,
59.1,
72.2,
44.8,
62.6,
64,
44,
36.4,
54.1,
33.9,
51.5,
59.8,
92,
82,
51.4,
62.1,
84.3,
96.1,
49.4,
62.1,
50.2,
67.4,
26.8,
49.7,
37.6,
46.1,
82.4,
43.7,
49.8,
0,
98.8,
41.9,
57.3,
37.8,
75,
68.6,
37.7,
63.7,
40.7,
98.8,
50.5,
86.2,
78.9,
48.8,
67.8,
35.2,
49.6,
68,
67.8,
94.5,
70.4,
8.3,
65.4,
56.7,
44.8,
17.1,
91.4,
94.7,
90.4,
54.1,
59.7,
82.1,
38.4,
52.2,
58.3,
63.9,
30.6,
45,
26,
55.2,
73.5,
89,
50.1,
51.4,
48.7,
81.2,
35.6,
43,
76.3,
90.7,
60.2,
99.3,
23.8,
32.7,
55,
81.7,
70.9,
48.8,
63.3,
55.8,
48.4,
0,
76.2,
38.2,
54.7,
69.7,
98.7,
62.8,
84.9,
95.7,
70.5,
69.9,
79.8,
34.9,
9.3,
98.1,
31.3,
15.8,
55.1,
81.1,
80.9,
84.4,
69,
89.5,
91.7,
52.5,
64.4,
18.9,
64.6,
36.3,
90.6,
53.1,
66.5,
54.2,
81.9,
84.5,
18.2,
58.1,
49.7,
32.4,
40.1,
72.1,
37.5,
37.4,
41.4,
50,
53.9,
56,
24,
49.7,
28.7,
6.9,
10,
58.7,
65.2,
17,
69.1,
10,
27,
50.7,
65.8,
31.5,
57.5,
77.4,
90.9,
84,
62.6,
26.8,
17.4,
58.3,
24.2,
36.9,
64.2,
100.4,
46.5,
31.2,
36.1,
48.9,
26.3,
38.1,
20.5,
92.5,
70.1,
59,
19.6,
79.9,
65.6,
57.5,
69,
11.4,
83.2,
85.1,
73.3,
78.7,
86.6,
64.3,
57.9,
86.6,
41.2,
82.4,
53,
96.3,
79.3,
28.8,
58.8,
62.6,
92.8,
65.9,
25.2,
13,
26.3,
47.9,
39.7,
27.3,
31.6,
36.8,
34.9,
56.3,
38,
34.5,
40.6,
67.8,
100.6,
59.3,
null,
60.6,
56.1,
43.8,
70.7,
99.3,
59,
41.5,
32.6,
40.1,
33.8,
48.7,
93.2,
67.4,
51.1,
62.2,
19.7,
69.6,
36.3,
92.9,
55.8,
51.8,
7.2,
41.1,
29.1,
93.1,
55.9,
92.2,
45,
35.2,
20.8,
49.5,
29.7,
89.5,
52,
45.4,
63.7,
46.8,
46.1,
65.1,
54,
33.7,
42.8,
84.6,
65,
33.8,
80.6,
36,
41.2,
45.1,
75,
41.3,
32.2,
68.8,
40.4,
59.9,
66.7,
22.8,
83.8,
51.6,
42.6,
46.5,
65,
27.7,
66.9,
28.2,
57.7,
21,
55.4,
77.3,
72,
16.4,
62.2,
68,
80.7,
87.4,
53.1,
39.1,
58.9,
61.5,
67.4,
50,
64.8,
27.4,
65.2,
37.4,
66,
65.6,
51.9,
26,
14,
56.9,
78.5,
70,
72.7,
75.5,
38.1,
50.9,
23.8,
80.9,
28.5,
47.3,
71.8,
64.4,
24.4,
44,
52.2,
88.8,
51.8,
45.6,
94.3,
57,
12.4,
78.5,
80,
36,
69.2,
64.2,
35.1,
54.1,
61.6,
40.1,
41.5,
57.8,
31.4,
59.9,
39,
77.2,
73.3,
24.1,
66.3,
53.2,
40.4,
33.9,
76,
33.6,
85.5,
53,
94,
85,
66.3,
40.8,
59,
18.7,
46.8,
28.3,
76,
23.3,
18.3,
60.9,
89.6,
51.9,
53.1,
88.7,
63.2,
28.4,
29.9,
46.1,
62,
48.4,
19.7,
78.5,
59.1,
47.9,
61.7,
56,
64.5,
51.9,
56.8,
56,
61.5,
47,
97.2,
73.5,
34.7,
76.3,
83.2,
76.5,
30.2,
16.5,
77.9,
29.6,
32.4,
50.7,
88.2,
55.6,
47.1,
72.1,
65.8,
75.8,
83.6,
11.8,
0,
14.8,
85,
27.4,
7.5,
31.3,
28.5,
90.8,
28.5,
83.6,
20.7,
73,
34,
49.1,
53.2,
54,
84.5,
77,
65.8,
28.5,
82.2,
5.3,
22.2,
35.2,
60.8,
82.1,
61.6,
49.6,
30.8,
99.7,
87.2,
61.4,
49.8,
66.6,
93.5,
35.2,
70.3,
62.8,
46.1,
56.4,
56.9,
51,
53.2,
42.4,
63.9,
80.8,
87.9,
61,
64.2,
24.5,
33.1,
38.7,
41.4,
35.6,
64.1,
60,
57.5,
29,
74.6,
76.1,
70.2,
37.1,
39,
73,
27,
86.7,
90.3,
19.4,
99.4,
91.2,
16.6,
35.4,
82.7,
0,
80.1,
65.7,
87.1,
49.6,
42.5,
29.2,
26.7,
88.5,
58.8,
75.7,
85.4,
25.8,
53.1,
59.8,
83.2,
88.8,
48.4,
44,
38.9,
82.4,
93.3,
37.1,
26.5,
18.2,
99.1,
48.8,
35.6,
91.7,
67.9,
16.3,
17.6,
61.6,
49.5,
54.8,
28.2,
36.4,
24,
44,
105.4,
41.1,
19.7,
57.8,
38.9,
46.4,
42.7,
101.2,
52.8,
25.6,
56,
59.3,
77.1,
18.5,
74.5,
27.4,
54.6,
16.8,
7.2,
62.7,
64.7,
60.5,
46.5,
30,
88,
48.9,
5,
55.7,
32.5,
53.9,
54.7,
45.3,
37.4,
41.7,
18.3,
69.7,
68.5,
76.9,
86.2,
50.8,
34.1,
55.6,
14.7,
27.7,
49,
33.4,
11.2,
81.4,
63.8,
42.1,
61.6,
25.3,
42.4,
54.1,
21.7,
52.4,
70.9,
60.2,
35.9,
43.9,
52,
76.6,
59.3,
63.1,
30.2,
40,
83,
39,
9.3,
69,
58.3,
43.7,
40.4,
66.2,
37.7,
90.6,
52.3,
90.2,
64.9,
0,
13,
42.1,
6.3,
19,
21.1,
76.8,
43,
44.5,
93.1,
65.5,
61.4,
91.3,
41,
79.1,
51.5,
31.4,
48.7,
58,
86.1,
43,
67.3,
28.4,
89.2,
63.5,
33.6,
22.3,
27.9,
67.2,
100,
20.2,
46,
92.2,
79.9,
60.9,
73,
82.9,
49.7,
31,
46.1,
89.2,
50.7,
65.5,
59.6,
51.3,
52.7,
74.6,
85,
97.4,
36.2,
35.7,
86.7,
47.6,
0,
43.2,
44.7,
59,
43.6,
14.9,
46.8,
86.8,
40.5,
30.4,
34.1,
98.5,
56.2,
26.5,
25.7,
72.5,
50,
10.4,
81,
80,
10,
58.9,
28.1,
37,
56.1,
73.6,
8.4,
75.5,
31.2,
73.2,
80.4,
75.1,
35.8,
14.9,
98.1,
2.3,
91.7,
8.9,
97,
63.3,
47,
81.9,
86,
52.2,
54.6,
97.2,
73.5,
38.1,
56.7,
91.9,
28.4,
95.2,
96.4,
93.5,
66.6,
85.8,
35.9,
69.4,
75,
21.6,
46.1,
38.8,
90.2,
26,
74.5,
54.1,
48.8,
18.2,
87.6,
39.7,
77.6,
27.9,
33.9,
29.9,
74.4,
28.9,
60.5,
75.9,
29.6,
27.4,
82.7,
96.2,
58.1,
41.2,
28.2,
46.9,
31.8,
38.7,
93.4,
63.2,
95.7,
35.3,
42.6,
48.5,
86.8,
45,
70.4,
93.1,
75.8,
40.7,
59.2,
46.8,
72.9,
43.6,
7.3,
46.7,
72,
76.4,
66.7,
29.8,
19.5,
45.2,
32.4,
51.9,
15.5,
90.7,
45.1,
86.6,
42.5,
59.7,
56.7,
90.5,
39.6,
56.2,
93.2,
75,
90.6,
30.9,
82.4,
62,
61.3,
81.2,
64.3,
32,
63,
85.9,
55,
60.9,
55.8,
22.4,
42.7,
75.5,
45.4,
95,
61.2,
97.4,
59.1,
40.9,
40.7,
76.6,
30.4,
44.1,
38.2,
54.7,
44.6,
34.7,
76.6,
69.7,
102.7,
83.1,
35.1,
32.7,
34.7,
44.3,
23.3,
64.3,
72.7,
51.1,
20.6,
11.5,
74.7,
50.2,
42.9,
13.6,
43.8,
82.8,
94.7,
33.1,
34.2,
53.6,
16,
63,
78.5,
75.8,
59.3,
41.1,
18.8,
51.4,
64.1,
34.3,
11,
69.7,
54.4,
41,
24.3,
37.3,
29.4,
37.6,
87,
38.4,
69.3,
79,
33.9,
76.6,
17.9,
71.1,
66.3,
62.2,
51.5,
31,
87.5,
53,
31.2,
61.6,
59,
73.6,
30.3,
82.6,
83.2,
66.1,
28.5,
21.9,
61.7,
46.5,
52.9,
88,
63.6,
51.7,
65.3,
97.2,
25.4,
68.2,
48,
86.7,
71.4,
97.1,
38.1,
80.7,
39.1,
35.4,
34.5,
66.6,
0.7,
66.3,
39.4,
16.4,
48,
38.5,
53,
18.9,
27.8,
83.3,
75.1,
82.7,
28.2,
42.4,
26,
2.2,
45,
67.5,
60.2,
66.8,
41.5,
84.6,
45.2,
24.1,
31.7,
63,
52.4,
14,
52.9,
0,
38.2,
12.2,
86,
81.7,
29.1,
33.2,
79.4,
71.5,
15.9,
90.7,
63.9,
95.5,
34.5,
43,
96.2,
76.3,
48.2,
60.1,
58,
80.2,
31.5,
63.1,
98,
51,
68,
37.1,
82.5,
24.6,
32.5,
32.1,
68.1,
88.7,
30.1,
50.9,
49.9,
97,
88.8,
71.4,
22,
50.7,
60.1,
90.5,
45,
11.3,
78.6,
68.4,
61,
29.3,
62.9,
84.3,
90.7,
83,
60,
92.3,
64.4,
65.7,
54.9,
65.6,
30.6,
24.2,
45,
59.8,
74.1,
58.7,
68.6,
58.2,
80.8,
53.3,
50.6,
58.7,
44.7,
67.4,
28.2,
40.7,
32.3,
46,
57.4,
65.5,
52.8,
18.5,
55.5,
55.9,
76.1,
63.8,
18.5,
17.2,
34,
67.5,
24.3,
71.6,
92.7,
60.5,
43.7,
70.9,
62.9,
57.1,
22.3,
79.6,
19.4,
54.2,
58.4,
96.1,
84.9,
55.3,
49.8,
39.6,
85.9,
74.5,
4.8,
10.8,
68,
80.4,
79.9,
47.7,
38.5,
55.9,
62.6,
33.9,
39.4,
22.2,
57.8,
82.6,
55.7,
70.8,
92.8,
92.3,
76.7,
63,
40.8,
46.1,
43.7,
9.9,
76.6,
44.3,
58.3,
46.7,
65.7,
36.9,
88.4,
33,
57.1,
30.2,
7.5,
24.4,
16.4,
92.9,
23.2,
54.3,
50.9,
12.8,
48.4,
23.2,
36.2,
94.6,
64.8,
16.4,
62.3,
33.5,
47.8,
53.6,
47.5,
50.2,
79.5,
53.5,
28.8,
34,
34.4,
43.8,
74.2,
38.7,
33.2,
50.3,
43,
43.5,
67.9,
66.3,
54.4,
51.3,
74.1,
43.3,
44,
85.4,
31.2,
37,
68.5,
43.3,
37.8,
69,
55.7,
32,
93.7,
59,
92,
78.4,
87.8,
69.7,
76.8,
35,
47.1,
48.7,
6.2,
22,
32.8,
39.9,
62,
47.2,
54.1,
92,
54,
35.1,
16.2,
91.9,
93.9,
76.4,
58.1,
81.5,
70.2,
35.4,
57.6,
35.7,
76.9,
35.1,
38.6,
59.7,
47.4,
90.3,
90.2,
79.7,
45.9,
69.9,
48.7,
64.9,
68.5,
69.4,
98.3,
31.4,
44.5,
51.5,
88.9,
34.1,
31.7,
39.3,
46.5,
66.8,
21.4,
91.4,
89,
89.7,
61.1,
22.9,
36.5,
32.8,
85.7,
31.3,
24.9,
75.2,
21.3,
61.8,
53.1,
48.1,
59.6,
65.9,
19.3,
51.6,
45.4,
71.7,
51.5,
26.7,
77.7,
86.1,
95,
83.4,
56.1,
68.8,
79.8,
31.2,
51.9,
44,
25.4,
57.5,
66.8,
78.6,
15.9,
42.2,
63.7,
67.5,
57.3,
45.7,
16,
80.8,
99,
89,
94.7,
75,
63.4,
56.8,
20.3,
99.4,
46.7,
43.3,
36.3,
61.8,
92.4,
16.4,
68.3,
52.4,
80,
4.8,
63.8,
22.9,
82.9,
64.3,
69.8,
32.5,
24.1,
66.1,
61.9,
51.7,
39.7,
44.8,
67.4,
26.8,
71.2,
24.1,
19.7,
75.4,
78,
50,
78.8,
39.6,
70.1,
61.9,
25.6,
42.6,
37.7,
40.6,
60.8,
85.8,
29.5,
45.9,
44,
60.9,
49,
76.6,
73.1,
62.9,
49.9,
45.9,
57.6,
72.8,
12,
43.1,
80.8,
55.1,
52.9,
61.2,
43.8,
39.7,
76.7,
67.8,
71,
37.3,
78.4,
87.9,
7.4,
72,
22.3,
82.7,
98.9,
35.6,
100,
80.9,
56.7,
92.4,
23.8,
63.6,
11.9,
62.7,
97.8,
70.4,
95.2,
43.6,
96.8,
52.1,
51.8,
77.2,
51.6,
83.1,
42.9,
38.5,
84.6,
25.9,
67.1,
35.4,
46.6,
72.1,
72.4,
47,
37.8,
4.9,
66.7,
50.6,
50.5,
94.6,
35.6,
55.4,
60.7,
58.8,
68.8,
74.5,
35,
69.9,
32.7,
80.3,
36.7,
44.4,
28.3,
68.3,
44.6,
81.6,
52.1,
42.7,
33.4,
8.4,
34.5,
78.4,
52.1,
43.9,
14.8,
22.8,
87.7,
34.6,
47.4,
41,
52.8,
84.1,
70.4,
79.4,
54.3,
76.5,
80.7,
74.2,
60.3,
38.9,
32.4,
59.7,
84.2,
15.4,
59.5,
90.8,
70.6,
90.4,
20.3,
70.6,
62.7,
91,
68.6,
91,
53.2,
42.6,
73.5,
0,
42.1,
91,
73.2,
16.8,
73.5,
10.6,
92.8,
34.6,
56.2,
67.5,
74.1,
79.2,
37.7,
26.7,
82,
58.6,
33.5,
67.9,
47.7,
42.9,
95.3,
61.2,
37.4,
66,
93.9,
30.7,
42.2,
16.2,
40.1,
1.4,
64.9,
49.4,
8.7,
8,
75.3,
21.1,
43.4,
72.4,
40,
57.1,
0,
63.9,
27.1,
8.8,
82.4,
7,
74.2,
60.8,
72.1,
77.7,
87.6,
74.6,
13.9,
72.9,
32.4,
56.5,
72.8,
76,
85,
68,
70.9,
55.2,
10.4,
62,
63.5,
36.8,
78.9,
41.6,
48.9,
40.4,
97.7,
89,
53.5,
0.3,
15.6,
62.9,
59.4,
58.8,
51.2,
44.5,
28.3,
90.9,
76.3,
52.7,
32.9,
51.5,
80.8,
74.6,
47.6,
73.4,
74.3,
39.9,
44.8,
68,
86.1,
46.7,
70.2,
30.5,
83.4,
44.9,
16.9,
37.3,
106.6,
58.6,
48.1,
58.9,
60.1,
79.6,
61.1,
29.6,
25.3,
20.7,
36.4,
37.1,
23.8,
51.4,
53.7,
89.7,
55.5,
32.4,
26.6,
29.8,
91.1,
89.9,
73.6,
53.7,
55.2,
33.1,
81.4,
75.8,
74.5,
66.9,
65.8,
65.8,
94.1,
65.7,
74,
18.6,
64.3,
0,
60.9,
50.9,
50.2,
73.7,
89.4,
99.6,
51.2,
61.5,
55.9,
57.5,
47,
51.3,
26.5,
93.2,
83.1,
27,
61,
55.1,
43.2,
69.3,
74.9,
54.2,
59.1,
42.9,
90.5,
25.2,
57.6,
28.3,
75,
82.6,
34.5,
84.5,
55.2,
44.6,
72,
49,
91.6,
53,
68.3,
38.2,
32,
42.3,
93,
95.2,
82.7,
89.9,
56.7,
55.5,
68.9,
80.3,
26.6,
59.3,
35.8,
29.1,
99.8,
59.5,
68.9,
65.2,
48.6,
73.9,
51.2,
39.3,
33.9,
61.4,
75.4,
33.1,
60.9,
37.8,
69.9,
22.2,
75.7,
82.1,
49,
94.1,
53.2,
46.7,
92.8,
19.2,
88,
74.9,
91.4,
49.1,
76.1,
71.3,
43.8,
94.1,
54.2,
42.2,
84,
65.4,
37.7,
53.4,
97.7,
52.9,
64.2,
84.1,
12.8,
58,
77.2,
19.9,
76.4,
87.1,
93.9,
45.9,
50.1,
93.3,
41.5,
78.7,
34.8,
74.5,
88,
58.9,
32.2,
0,
39.9,
83.2,
51.7,
82,
84.4,
58,
12,
28.6,
68.8,
103,
95.6,
45.3,
70.8,
81.7,
47,
95,
68.3,
76.1,
72.7,
98.6,
60.8,
87.6,
37.2,
40.5,
55.9,
60.8,
32.5,
68.2,
62.5,
84.6,
42.5,
78.8,
29.5,
38.3,
77.5,
40.3,
24.5,
11.6,
55,
80.3,
59.6,
53,
46.5,
44.1,
90.7,
28,
39.8,
80.6,
58.5,
61.1,
19.1,
46.3,
49.5,
83.1,
25.9,
20.4,
82.6,
48.4,
82.7,
39.6,
91.6,
70.3,
66.4,
92.8,
52.8,
33.9,
84.9,
82.3,
38.4,
47.4,
28.1,
44.3,
30.9,
32.6,
96.5,
70.3,
21.7,
3.5,
55.1,
64.3,
29.1,
7.2,
63.6,
32,
44,
56,
29.7,
13.2,
100.7,
73.3,
52.8,
4.5,
19.9,
56.6,
48,
96,
46,
56.4,
83,
17.4,
7.8,
12.8,
42.8,
67.3,
21.3,
51,
72.4,
46.5,
45,
53.8,
74.6,
80.3,
69.8,
68,
83.9,
63.7,
0.3,
59.2,
29.1,
63.4,
82.6,
58.5,
53.2,
30.1,
53.2,
73.9,
23.1,
79.6,
82.7,
35.5,
72.1,
26.8,
68.4,
77.1,
60,
40.5,
57.6,
8.8,
18.1,
48,
29.3,
32.7,
39.8,
47.7,
64.9,
24.4,
88.5,
40.3,
30.9,
48.9,
50.2,
81.3,
22,
6.1,
58.9,
26.8,
33.9,
21.7,
53.2,
90.6,
80.1,
31.7,
70.9,
26.6,
93.1,
83.8,
36,
66.9,
62.4,
29.6,
12.8,
86.2,
98.9,
44.4,
93.6,
29.6,
16.6,
93.6,
84,
65.1,
51.3,
21.2,
96,
78.2,
52.1,
81.1,
76.3,
61.8,
22.7,
27.9,
24.8,
64.7,
43.6,
23.4,
16.9,
57.7,
82.1,
34.7,
68.3,
35.9,
67.5,
54,
74,
15.9,
69.1,
11.1,
44.3,
41.3,
5.3,
91.3,
82.8,
29,
49.1,
78.9,
46.9,
40,
80.4,
96.9,
25.4,
31.3,
77.6,
9,
99.8,
81.9,
62.9,
52,
83.3,
17.2,
51.8,
76.1,
51,
0,
4.2,
81.9,
54.1,
76.8,
59.1,
72.8,
45,
55.8,
49.8,
54,
48.7,
88.9,
56.5,
88.5,
52.9,
12.8,
44.9,
86.6,
97.3,
16,
71.9,
89.7,
53.1,
95.4,
75.6,
81.4,
28.2,
31.4,
67.1,
53.6,
3,
58.3,
71.7,
33.4,
70.7,
39.6,
40.6,
62.7,
59.4,
10,
84.3,
60.3,
17.9,
57.1,
27.2,
75.3,
91,
74.2,
58.6,
56,
34.6,
81.4,
43.1,
72.1,
73.7,
33,
41.3,
38.3,
86.1,
43.8,
48.1,
32.2,
91.7,
81.8,
88.5,
89.9,
34.1,
31.9,
58,
2.6,
51,
27.3,
61.9,
64.5,
84.5,
10,
47.6,
87.9,
50,
67.5,
32.5,
79.6,
63.2,
35.7,
80.1,
36.6,
31.7,
55,
77.4,
50,
74.7,
34.2,
49.3,
64.6,
64.2,
64.1,
12.4,
52.3,
57.6,
85.6,
34.3,
92.3,
76.4,
77.7,
91.8,
71.6,
9.7,
65.9,
0,
70.1,
72.9,
70.1,
25.7,
66.6,
92.1,
64.3,
7.1,
56.3,
56,
63.1,
64,
56.5,
56.4,
75.1,
71.2,
42.9,
46.3,
40.2,
64.1,
74.4,
70.8,
52.4,
84.1,
40.5,
29.4,
53.9,
89,
54.8,
42.4,
17.8,
74,
64,
85.7,
83.9,
26.2,
55.6,
41.2,
77.9,
72.9,
21.4,
74.8,
77.1,
34.9,
58.4,
51.1,
82.6,
25.7,
43.7,
35,
59.2,
78,
73.4,
83.4,
49.2,
40.7,
68.7,
59.2,
41.7,
21.1,
39.8,
95.8,
59,
70.9,
28.7,
69.5,
96.3,
48.8,
97.9,
96.5,
86,
43.4,
9.5,
48.2,
88.6,
36.9,
65.1,
27.9,
99.6,
33.5,
35.7,
40,
0,
37.6,
11.1,
42.8,
80.8,
54.4,
95.8,
33.2,
6.3,
48,
75.9,
40.6,
39.3,
73.4,
40.3,
19.8,
81.4,
49.3,
10.7,
40,
65.7,
31.4,
0,
62.9,
63,
59.9,
63.5,
38.9,
71.5,
28,
50.2,
92.9,
71.4,
83.1,
12.6,
44,
54.9,
61.6,
37.5,
87.8,
77.3,
92.6,
31.9,
85.7,
88.3,
30.3,
54.7,
40.4,
18.5,
73.7,
43.1,
80.6,
72.3,
31.2,
22.8,
4.4,
60.9,
72,
25.7,
20.6,
57.8,
39.8,
30.8,
63.2,
95.7,
61.4,
66.7,
62.7,
50.2,
40.9,
53.9,
41.6,
85.6,
31.3,
36,
20.3,
68.3,
38.4,
53,
8.9,
58.4,
47.4,
48.8,
6.5,
59.5,
58.9,
59.3,
81.7,
74.8,
54.1,
73.6,
26,
81.2,
54.8,
77.3,
76.6,
78.6,
78,
71,
75.5,
56,
46.7,
60.4,
50,
46.6,
49.6,
83.2,
20.7,
75,
94.9,
40.2,
24.7,
6.3,
94.9,
83,
70,
42.9,
86.3,
74,
85.6,
77.1,
69.4,
39.9,
72.5,
72.5,
16.1,
33.3,
70.5,
23.1,
58.4,
42.2,
27,
13.2,
22.1,
70.5,
53.4,
38.6,
88.4,
95.1,
45,
28.2,
53.1,
76.7,
83.6,
43.7,
68.2,
53.7,
31.6,
0,
61.3,
76.1,
74.8,
35.8,
25.3,
98.1,
84.7,
83.8,
14.9,
67,
85.3,
61,
38.2,
72.1,
71,
83.5,
84.6,
72.3,
85.5,
51.1,
36.9,
48.3,
72.6,
93.1,
49.7,
70.1,
72.7,
3.5,
63.2,
37.6,
21.5,
6,
57.6,
69.2,
73.6,
47.6,
27.4,
61.6,
49.8,
74.1,
42.4,
44.7,
89.6,
67.5,
41.5,
71.5,
43.8,
70,
29.1,
79.1,
23.7,
74.3,
93.3,
34,
61.1,
57.5,
51.1,
29.3,
60.6,
40,
86.3,
60,
50.5,
50.9,
76.4,
43.1,
68,
21.2,
47.8,
44.8,
15,
29,
88,
44.4,
81.8,
78.2,
64.3,
39.7,
71.4,
49.4,
82.5,
7.5,
46.7,
45.6,
63.1,
58.3,
91.3,
78,
23.8,
70.7,
6.1,
12.6,
56,
41.2,
28.3,
36.1,
74.9,
71.5,
36,
77.3,
30.8,
80.6,
67.1,
91.5,
58.2,
51.5,
41.6,
13,
53.6,
58,
76,
13.6,
93.4,
100.5,
70.5,
31.4,
35.4,
75.5,
16.8,
64.6,
77.1,
51.3,
68.7,
93.8,
28.8,
41.6,
29.4,
58.8,
18.8,
91.1,
74.7,
36.4,
45.3,
59.9,
14.1,
81.5,
49,
83.4,
62.2,
90.9,
33.5,
31,
45.2,
61.6,
81.4,
92.7,
26.6,
43.9,
84.6,
17.8,
61.8,
49.3,
4,
65.8,
32.2,
78,
40.3,
64.4,
50.4,
70,
89.5,
54.3,
0,
27.6,
73,
40,
45.6,
50.5,
62.7,
84.9,
21.6,
29.5,
92.1,
93.6,
61.8,
3.8,
72.7,
28,
76.4,
84.3,
70.2,
72.4,
29.3,
54.1,
84.4,
50.4,
60.1,
0,
52.8,
0,
63,
39.3,
41.4,
40.9,
79.1,
29.4,
72.4,
91.9,
44.9,
70.6,
26.9,
40.5,
73.9,
71.6,
2.5,
79.9,
22,
47.2,
35.2,
66.2,
56.7,
28.9,
31,
49.4,
70.7,
71.1,
58.3,
19.1,
58,
50.1,
66.8,
80,
23.5,
32,
23.5,
33.5,
10.8,
33,
63.5,
33.5,
20.4,
81,
66.4,
45.6,
63,
59.1,
44,
72.6,
70,
65,
45.1,
69.2,
100.7,
41.7,
49.3,
49.9,
61,
79.9,
36.9,
98.3,
88,
14.8,
48.1,
1.8,
61,
32.2,
63.5,
17.1,
8.1,
68.9,
50.3,
58,
2.3,
79.8,
85.1,
45.6,
74,
20,
45.5,
79.7,
60.4,
62.7,
78.1,
26.1,
43.7,
71.1,
30.3,
52.6,
66,
56.2,
54.2,
54.2,
0.9,
50.4,
51.1,
77.2,
71.6,
79.3,
32.1,
52.6,
90.3,
44.8,
63.1,
80.3,
35.6,
66.7,
57.8,
69.6,
67.6,
40,
55.9,
35,
65.7,
53.6,
43,
9.2,
76.2,
64.6,
62.5,
77.7,
5.3,
49.4,
66.8,
58.1,
67.1,
72,
18.7,
26.8,
50.9,
88.1,
64.1,
77.8,
30.8,
83.2,
29.3,
55.8,
66.9,
77.2,
48.1,
44.9,
26.7,
47.1,
18.4,
32,
50.6,
63,
49.9,
78.5,
67.3,
88.8,
60.1,
94.9,
74.3,
50.3,
53.8,
21,
54.8,
21.7,
68.4,
33.7,
60.6,
79,
65.6,
56.8,
50.8,
88.2,
32.7,
54.1,
26.9,
26,
43.6,
66.5,
35.3,
43.2,
61.4,
39.9,
55,
35.3,
39.5,
51,
40.5,
78.2,
0,
51.5,
51.7,
89.3,
28.4,
23.9,
46.9,
29.2,
29.7,
17.9,
0,
55,
40,
77.1,
42.3,
47,
32.7,
76.9,
71.1,
59.1,
59.6,
27.4,
68.3,
17.6,
61.7,
75,
57.6,
55.5,
59.2,
50.3,
45.5,
55.4,
69.9,
52.5,
54.7,
48.2,
76.8,
83.2,
40.9,
87.7,
39.5,
68.7,
52.3,
72,
17.1,
39.5,
55.2,
48.8,
64.3,
95.7,
41.1,
52.1,
39.5,
79.3,
89.2,
68.8,
20.8,
90.6,
43.5,
31.3,
37.5,
70.6,
68.4,
47.1,
77,
60.6,
43.6,
50,
0,
84,
22,
50.5,
49.3,
72.8,
33.3,
23.2,
6.5,
60.4,
50.8,
31.8,
36.3,
77.4,
49,
40.2,
29,
37.1,
0,
76.7,
49.8,
79.2,
85,
41,
54.8,
100.2,
51.2,
63.1,
66.5,
35.3,
39.1,
35.9,
15.2,
58.8,
32.1,
95.2,
54.7,
69.3,
13.1,
3.5,
84.6,
38.8,
50.7,
1.5,
46,
11.2,
65.6,
84.4,
97.1,
47.7,
35.3,
81,
21.7,
40.9,
44.9,
63.4,
82.8,
33.9,
53.9,
40.1,
null,
96.2,
75.4,
7.5,
38.5,
7.7,
16.1,
37.1,
31.1,
46.7,
46.9,
95.6,
44,
24.8,
79.7,
61.9,
29.3,
65,
46.7,
70.8,
56.2,
18,
37.7,
55,
64.5,
39.6,
22.2,
72.2,
29.7,
49.2,
19.4,
65,
13,
11.6,
1.9,
30,
13.5,
80.5,
48.6,
104.6,
48.4,
55.7,
49.2,
59.8,
58.6,
46,
76.9,
26.8,
0,
43.5,
68.3,
46.9,
22.5,
90,
90.3,
50.1,
36.1,
99.8,
82.4,
97.8,
80.6,
78.8,
64.9,
66.7,
28.7,
22.3,
53.8,
72.3,
6.4,
34.7,
26.4,
48.4,
85.1,
48.5,
79.4,
80.8,
57.5,
67.8,
87.7,
55.9,
95.4,
31.7,
47,
60,
77,
99.5,
57.7,
76.6,
49.5,
58,
59.3,
69.4,
57.2,
67.8,
64.2,
38.8,
11.4,
65,
16.2,
13.1,
79.2,
37.8,
62.2,
89.4,
86.7,
81.8,
8.9,
15.7,
29,
25.8,
36.5,
82.8,
32.3,
70,
33.8,
18.8,
90.1,
73,
56.4,
23.6,
70.6,
53.4,
60.3,
84,
23.4,
47.6,
38.3,
20,
54.3,
61.2,
77.2,
65.4,
48.8,
56.2,
51.3,
70.3,
74,
39.5,
58.4,
77.6,
66.7,
34.5,
21.7,
61.4,
55.1,
89.3,
58.1,
59.9,
22.7,
64.9,
26.4,
12.3,
61.1,
44.5,
63.6,
18.6,
77,
98.8,
60.3,
53.3,
26.4,
46.6,
65.9,
89.7,
80.3,
61.9,
90.7,
36.6,
49.8,
15.7,
78.2,
45.2,
54.7,
74,
22.9,
68.8,
38.4,
88.8,
74.7,
33.8,
72.4,
72,
56.1,
42.7,
43.8,
54.4,
89.4,
32.9,
53.4,
40,
65.6,
52.7,
60.1,
87.5,
70.4,
28.5,
49,
79.3,
49.9,
83.8,
61.3,
57.1,
62.1,
39.9,
82,
50.9,
93,
74.3,
35.4,
52.9,
14.5,
87,
88,
49.9,
48.6,
31.3,
87.2,
63.3,
74.8,
85.4,
27.7,
79.9,
58,
24.6,
85.5,
33.6,
72.8,
70.5,
60.6,
63,
29.4,
100.9,
31.2,
37.8,
37.1,
42.8,
56.5,
72.6,
52.3,
35.8,
74.5,
53.1,
40.3,
5.2,
83.9,
53.1,
74,
67.5,
48,
7.9,
55.8,
32.8,
23.9,
78.4,
35.6,
84.6,
81.1,
39.7,
72.9,
63.2,
49.8,
47.4,
49.7,
46.7,
84.1,
20.4,
61.2,
60.4,
59,
83.5,
24.8,
85.9,
8.9,
48.6,
50.2,
66.7,
45,
24.7,
39,
50,
23.3,
25,
13,
61,
92.8,
32.8,
70.5,
97.2,
0.4,
91.7,
79.5,
52.2,
46.3,
73.1,
64.8,
47.8,
52.4,
39,
71,
54.2,
50.1,
46.5,
75.1,
69.3,
64.3,
38.9,
48.7,
70.5,
33.3,
66.2,
24.5,
41.7,
81.4,
53.4,
54.4,
74,
4,
58.6,
37,
68.2,
48.7,
46.2,
85.2,
37.6,
46.9,
96.9,
70.3,
62.8,
90.3,
49.1,
34.3,
89.6,
72.6,
56.7,
82,
50.1,
19.3,
58.7,
12.1,
33.6,
93.3,
58.7,
94.9,
94.8,
90,
92,
49.8,
96.6,
90.7,
54.6,
47.6,
65.4,
69.8,
39,
1.3,
71.9,
40.8,
15.2,
46.5,
79.6,
72.9,
0,
49.4,
55.1,
10,
34.7,
41.3,
49.1,
87.6,
45.2,
80.1,
63.2,
91,
33.3,
36.1,
49.5,
69.7,
95,
66.5,
34.8,
77.4,
33.1,
4,
72.1,
16.5,
19.2,
34.6,
61.5,
16.1,
68.5,
16.9,
30.5,
35.4,
42,
53.9,
12.8,
84.3,
91,
67.4,
50,
88.6,
50.3,
8,
82,
75.2,
95.5,
45.8,
12.3,
71,
68,
63.9,
64.8,
68.4,
14,
31.4,
7.8,
74.1,
77.4,
53.6,
49.6,
38.5,
64.5,
54.2,
48.9,
93.4,
66.8,
87.4,
82.1,
27.3,
97.6,
54.8,
9.6,
4.9,
88,
81.8,
34.4,
50.2,
57.7,
70.1,
49.2,
46.5,
62.1,
41,
25.9,
103.3,
73.3,
12.8,
0.3,
49.7,
52,
59.7,
35.7,
5.5,
21.5,
51,
93.7,
27.9,
82.6,
46.7,
10.7,
35.6,
48.2,
53.8,
77.8,
56.3,
45.1,
80.3,
74,
85.9,
78.7,
26,
81.5,
19.1,
53.7,
88.4,
70.6,
41.3,
72.8,
61.8,
92.3,
20.5,
67.3,
48.3,
56.2,
35.2,
61.5,
29.2,
70.9,
89.5,
36.1,
86.2,
48.7,
80.1,
28.3,
33.3,
51.6,
55.2,
24.7,
67.6,
54.4,
69.5,
0.8,
67.4,
78.6,
74.1,
73.9,
60.2,
21.8,
51.9,
45.3,
94.9,
81.4,
18.1,
63.9,
92.3,
34.5,
61.4,
71.1,
37.4,
25.4,
95.5,
89.4,
22.6,
61.5,
70.9,
94.2,
95.1,
58.9,
72.8,
32,
89.4,
75.7,
42.1,
21.7,
77.8,
43.2,
86.9,
85.3,
62.7,
40.3,
6.2,
22.5,
38.9,
62,
68.4,
93,
42.7,
23.6,
91,
21.5,
51.2,
41.6,
22,
76.9,
83.4,
80.1,
49.3,
72,
71.6,
70.1,
59.8,
55.8,
53.9,
68.3,
27.3,
10.1,
97.1,
51.6,
62.1,
67,
65,
73.2,
82.2,
53.2,
113.5,
80.9,
2.9,
36.4,
43.7,
66.7,
85.4,
47.9,
59.4,
46.5,
84,
78.8,
56.3,
52.6,
77.4,
64.6,
46.2,
96.1,
9.5,
51.5,
42.8,
50.6,
76.1,
80.2,
58.2,
61.1,
39.7,
59.1,
85.8,
81.1,
51.4,
88.4,
68,
58.7,
36.6,
33.9,
42.3,
12.9,
53.8,
62.5,
72.5,
48.5,
96.7,
10.1,
85.7,
57.7,
28.9,
17,
87,
36.8,
81.8,
67.5,
13.7,
28.3,
45.7,
59.2,
31.7,
55.2,
43,
59.9,
35.7,
72,
48.1,
26,
44.2,
88.5,
95,
85.9,
76.1,
48.4,
52.7,
38.7,
79.5,
88.8,
29.1,
40.8,
82.3,
80.7,
46.8,
73.7,
72.2,
49.8,
48,
30.8,
61.5,
48.6,
26.4,
28.9,
62.8,
64.6,
13.4,
89.1,
11.9,
51.3,
40,
95.8,
42.2,
20.1,
51.9,
83.2,
50.5,
60.9,
35.3,
34.3,
66.3,
54.1,
58.8,
61.4,
68.6,
32.6,
34,
27,
94.1,
36.7,
57.6,
19.9,
32.4,
41.5,
45.2,
48.5,
64.6,
55.3,
58.9,
53.2,
17.1,
61.2,
38.2,
13.9,
33.1,
75.1,
54.9,
65.6,
55.8,
76.8,
55.9,
55.7,
32.8,
30.6,
29.1,
45.9,
73.5,
57.8,
61.2,
44.8,
64,
60.2,
75.1,
65.9,
19.6,
55.2,
89.9,
39.6,
23.5,
11.4,
69.2,
87.2,
56.6,
84.6,
23.2,
60.3,
52.3,
58.7,
6.7,
74.9,
88.8,
85.3,
77.6,
70,
65.5,
52.6,
75,
41.8,
88.5,
34.3,
86.5,
78.3,
4.1,
93.1,
59.2,
21.1,
90,
24.3,
15.4,
66.5,
66.6,
74.5,
88.1,
71.9,
85,
55.1,
84.3,
42.1,
27.2,
48.3,
1.1,
84.5,
68.8,
71.7,
30.6,
55.3,
52.8,
31.7,
82.6,
46.6,
41.6,
4.1,
83.2,
43.9,
34.5,
60.4,
40.3,
71.1,
69.2,
57.5,
48.7,
46,
48.8,
78.1,
31.9,
73.4,
75.3,
48.3,
72.7,
98.8,
16.9,
86.3,
55,
82.4,
24.1,
55,
20.8,
93.2,
75.6,
69,
65.2,
7.4,
62.8,
22,
52.8,
66.2,
52.2,
83.7,
32.1,
71.2,
79.7,
83,
76.2,
37,
54.2,
17.7,
79.2,
44.7,
53.1,
53.3,
47.8,
39,
73.3,
31.2,
3.6,
21.5,
45.8,
83.1,
92.8,
84.1,
94.3,
79.5,
47.2,
29.6,
13.3,
75.1,
10.1,
8.8,
67,
66.8,
65.7,
55.2,
83.6,
38.3,
81.4,
91.7,
50.4,
30,
53.3,
97.9,
75.7,
83,
62.3,
40.5,
63.7,
80.1,
64.6,
3.7,
46.6,
25,
89.6,
56.5,
64.2,
62.3,
51.5,
65.3,
68.8,
68.2,
5.2,
63.2,
31.9,
61.5,
50.3,
19.2,
73.7,
21.2,
36.1,
19.4,
80.5,
24.2,
63.6,
78.1,
71.1,
44.2,
82.7,
53.8,
27.2,
89,
65.7,
47.8,
71.9,
38.2,
91.8,
83.3,
38.4,
0.5,
20.3,
56.9,
95.6,
86.4,
71.2,
61.8,
81.9,
75.8,
48,
47.7,
88,
34.1,
55.8,
47.7,
28,
62.6,
87.3,
71.6,
79.1,
49.9,
68.6,
20.8,
22.1,
64,
40,
53.6,
81.6,
18.3,
49.3,
28.4,
30.5,
69.3,
19.1,
58.8,
36,
82,
19.9,
74.4,
46.9,
52.1,
56.6,
32.5,
82.4,
22.8,
56.3,
15.8,
74.5,
70.1,
57.4,
37,
54.2,
17.4,
51.3,
71.9,
80.6,
50.7,
47.4,
76.8,
37.6,
66,
19.5,
90.2,
58.2,
83.4,
29.9,
17,
72,
82.3,
49.7,
94.8,
81.5,
37.8,
60.1,
66.4,
3,
41.5,
80.9,
63.7,
37.8,
53.7,
79.4,
65.2,
73.7,
27,
50.5,
22.4,
70.1,
52.7,
32.6,
57.5,
50.3,
77.8,
92.6,
47,
62.7,
71.3,
57.2,
70.2,
93.8,
54.8,
41.8,
39.5,
82.5,
38.7,
69.9,
48.5,
29.1,
34.1,
77.6,
30.2,
62.9,
15.6,
63.1,
56.4,
76.6,
87.5,
90.9,
36.4,
46.7,
5,
65.1,
23,
75.5,
89.6,
62.5,
83.3,
1,
32.4,
79.1,
63.8,
64.5,
33.8,
45.8,
3.3,
93,
70.9,
29.2,
39.8,
81.4,
89.5,
87.7,
68.6,
32.8,
53.9,
33,
53.9,
70.1,
37.7,
40.8,
10.1,
90.6,
47.7,
76.8,
9.6,
54.1,
51.9,
48.2,
64,
86.4,
64.5,
65.1,
92.1,
62.4,
75.1,
46,
78.2,
55.7,
23,
81.7,
51.1,
78.4,
28.3,
31,
26.7,
32.1,
42.2,
95.9,
72,
97,
93,
49.4,
28.3,
69.5,
61.2,
12.5,
86.8,
28.1,
85.7,
97.3,
75.4,
96.9,
76.2,
92.1,
78,
57.1,
12.3,
33.7,
51,
70.8,
72,
12.6,
12.2,
55.4,
0.3,
51.7,
34.2,
66.6,
81.3,
46.8,
51.2,
95.6,
32.4,
49.9,
83.7,
17.1,
89.6,
100.2,
42.2,
74.6,
61,
62.2,
68.2,
54.1,
86.2,
66.1,
37.4,
41.4,
38.2,
83.4,
100.1,
44,
21.1,
18.4,
38,
48.5,
56.3,
85.5,
22.6,
14.8,
90.7,
52.2,
74.4,
87.2,
78.1,
95.6,
73.1,
6.6,
75.2,
93.8,
68,
75.9,
67,
55,
45.5,
83.3,
62.2,
84.7,
66.4,
42.4,
85.2,
38,
42.4,
40.3,
63.6,
82.7,
80.7,
37,
67.8,
67.4,
57,
70.1,
52.4,
75.8,
75.5,
93.2,
66.7,
26.7,
53,
17.1,
2.9,
62.7,
74.6,
35.7,
58.3,
49.7,
79.5,
71.5,
86.7,
58.7,
91.9,
6.3,
83.9,
48.5,
76.6,
84.4,
78.1,
76.3,
57.6,
16,
82,
58.4,
73.6,
73.9,
82.3,
57.6,
15.1,
31.6,
22.2,
50.5,
28.1,
35.1,
52.5,
58,
0,
52.9,
73.1,
87.8,
60.4,
10,
4,
45.4,
42.9,
21.9,
8.3,
10.5,
59.3,
23.9,
36,
54.7,
27.6,
38.6,
19.3,
41.6,
38.5,
55.1,
88.7,
25.4,
49.1,
67.1,
80.4,
95,
48.6,
50.8,
61.4,
42.3,
38.4,
11.1,
27.9,
49.5,
61.1,
70.1,
52.6,
42,
89.7,
60.6,
79,
44.4,
82.1,
36.6,
92.1,
69.1,
41.7,
55,
49.8,
70,
83.4,
81.7,
62,
38.8,
68.3,
82.6,
45.1,
94.6,
89.8,
81.8,
72.6,
49.9,
83.2,
84,
83.3,
48.4,
68.4,
54.3,
24.8,
53,
60.8,
44.3,
92.8,
29.4,
22.8,
34.6,
33.1,
93.7,
23,
92.3,
54.9,
95.8,
69.5,
92.9,
5.3,
46.5,
38.1,
39.8,
81.9,
55.6,
88.7,
19.8,
72,
64,
66.2,
20.9,
76,
48.8,
57.5,
93.2,
70.7,
89.9,
52,
7.7,
52.7,
69.2,
35.6,
59.4,
78.3,
64.2,
43.2,
1.3,
43,
52.3,
49.9,
23.2,
39.2,
86.2,
62.6,
72.9,
57.6,
94.3,
61.8,
29.2,
58,
68,
53.7,
62.9,
80.1,
6.3,
30.8,
42.2,
72,
86.2,
81.9,
45.8,
41,
79.7,
38.5,
29.4,
54.4,
37.1,
38.8,
73.7,
29.6,
12,
82.6,
15.8,
46.3,
77.3,
17.6,
16.2,
92,
56,
72.6,
63.6,
27.2,
84.9,
48.3,
22.5,
61,
87.6,
96.5,
92.4,
27,
50.8,
67.1,
57.3,
68.7,
79.9,
73,
28.3,
37.5,
54.9,
75.7,
17.8,
62.7,
73.6,
77.4,
86.9,
29.6,
62.5,
0.2,
68,
36.3,
52.1,
55.6,
70.8,
29.6,
25.6,
44.8,
63.2,
40.3,
51.9,
45.5,
83.4,
2.1,
91.1,
39.1,
61.6,
60.3,
70.9,
74.4,
4.3,
26.4,
46.5,
30.2,
71.4,
47.7,
25.1,
47.1,
66.5,
83.5,
22.4,
48.6,
57,
7.4,
77.5,
36.5,
82,
90.2,
90.9,
22.9,
64.9,
40.2,
8.2,
47.7,
69.2,
91.3,
76.7,
62.8,
81.1,
85.6,
33,
60.4,
28,
36.4,
33.8,
66.8,
46.6,
14.8,
46,
59.5,
42.8,
35.8,
16.7,
26,
3.4,
52.2,
37.1,
22.2,
23.7,
66.4,
8.6,
10.5,
32.9,
87.2,
40,
83.8,
79.7,
44.8,
28.7,
58.3,
52.2,
59,
7,
15.3,
19.8,
49,
92.2,
73.3,
97.7,
17,
60.3,
38.4,
68,
57.7,
11.1,
48.6,
34.8,
67.1,
75,
27.9,
49.3,
48.9,
76,
79.6,
62.4,
77.4,
26,
59.2,
53.3,
35.4,
18.2,
73.9,
42.8,
66.6,
89.8,
59.1,
48.4,
51.5,
38.5,
39.8,
94.3,
86.1,
84.5,
63.3,
52.8,
31.2,
36.6,
70.3,
54.1,
0.2,
20.6,
89,
54.6,
68.9,
18.2,
84.9,
55.3,
94.7,
61.1,
74.3,
56.6,
66,
30,
67.6,
87.6,
60.6,
25.7,
77.6,
72.4,
78.1,
60,
65.4,
78,
34.4,
66.7,
33.3,
29.5,
7.7,
52.2,
80.9,
83.8,
88.1,
45.9,
94,
91.2,
38.5,
33.8,
40.9,
77.9,
83.9,
80.4,
68,
74.2,
63.7,
52.1,
91.8,
53.9,
41.5,
26.3,
31.7,
53.7,
96.5,
63.4,
25.9,
74.7,
98.7,
98.7,
31.9,
77.8,
37.2,
30.7,
9.5,
30.2,
40.3,
84.2,
54.4,
83.6,
62.1,
90.6,
76.7,
25.2,
76.5,
66,
35.9,
27.7,
90.7,
74.3,
44.8,
87.7,
71.9,
60.9,
3.7,
99.7,
68.7,
78.5,
95.4,
28.6,
65.3,
78.1,
81.4,
81.7,
70.5,
64.7,
76.2,
34.2,
59.7,
66,
43.6,
45.3,
45.2,
55.9,
5.9,
32.6,
73.1,
48.2,
81.4,
51.8,
63.6,
64,
48.3,
43.1,
72.5,
38.9,
64.1,
43.7,
18.3,
34.4,
90.2,
91,
48.5,
92.4,
33.4,
58.7,
66.7,
78.3,
52.2,
82.8,
30.8,
71.1,
26.2,
52.2,
56,
79.1,
18.7,
47.3,
36.8,
26.5,
66.8,
80.4,
31.9,
71.7,
80.3,
66.6,
83.4,
49.2,
33.3,
53.5,
23.7,
84.5,
49.9,
11,
68.9,
41.1,
88,
40,
49.4,
7.6,
75,
65.2,
52,
39,
48.2,
44.2,
58.3,
46.6,
76,
75.6,
87.8,
25.9,
48,
40.4,
43.2,
8.6,
70.2,
64.7,
39.4,
46.9,
70.3,
79.9,
85.6,
72.9,
45.3,
58.2,
58.9,
32.9,
67.9,
58.6,
41.4,
34.2,
43.7,
10.6,
59.9,
52.4,
32,
45.8,
19.6,
27,
90.6,
96.8,
52.9,
36.2,
45.4,
27,
0,
41.8,
64.2,
43.1,
46.4,
70.6,
51.1,
36.7,
31.3,
63.3,
38.1,
82.5,
56.8,
38.1,
78.2,
78,
78,
68.3,
71.3,
61.2,
71.1,
20.7,
80.6,
87.5,
38,
54.5,
44.4,
99.6,
32.8,
63.4,
10.6,
70.7,
66,
27.8,
69.5,
65.4,
64.3,
76.5,
41.7,
65.1,
65.3,
39.1,
61.4,
98.5,
57.2,
43.1,
72.5,
45.4,
75.9,
21.3,
75,
24.3,
72.5,
27.2,
50.9,
31.3,
52.8,
34.8,
30.2,
67.2,
59.7,
85.7,
51.2,
72.5,
40.6,
41.8,
50.3,
67.8,
18,
83.9,
54.8,
60.9,
49.5,
83,
3.9,
63.1,
87.2,
86.1,
54.6,
72.4,
40.9,
16.3,
79.5,
11.5,
54.8,
70,
0,
98.7,
49.8,
40.3,
23.9,
50.9,
84.3,
67.8,
35.7,
67.5,
43.5,
37,
74.1,
86.4,
71.6,
3.6,
79.4,
11.5,
42.2,
43.8,
47.6,
50.2,
79.5,
56.2,
85.8,
46.1,
14.8,
48.9,
51.7,
73.6,
35.7,
24.5,
51.2,
66.2,
42.8,
73.9,
81.9,
31.3,
51.4,
51.8,
36.2,
30.4,
67.7,
69.3,
63,
45.3,
45,
20.6,
46.1,
33.7,
23.6,
48.5,
97.4,
65.4,
72.2,
90,
63.1,
50.4,
57.7,
8.7,
79.4,
44.8,
61.5,
26.9,
51.5,
69.7,
51.4,
62,
42,
0,
83.9,
85.2,
53.9,
19.7,
31.1,
17.5,
10.9,
58.7,
36.9,
91.8,
67.4,
66.7,
3,
97,
71,
47.6,
43,
71.2,
2.7,
62.5,
95.1,
59.1,
45.7,
83.1,
41.5,
54.8,
45.3,
6.2,
19.1,
47.4,
38.2,
50.9,
43.1,
65.8,
32,
49.2,
4.8,
62.6,
30.9,
50.7,
32,
97.1,
31.3,
84,
74.5,
71.4,
74.5,
69.7,
59.2,
69.9,
73,
71.2,
100.3,
49,
100.8,
77.3,
0.7,
47,
1.8,
76.6,
17.9,
32.9,
51.3,
56,
88.8,
32.3,
29,
45.3,
62,
48.4,
66.3,
23.2,
56.3,
59.9,
64.4,
5.4,
56.2,
19.7,
54.4,
51.8,
28.5,
36.6,
89.1,
86.1,
21.8,
81.8,
46.4,
99.5,
85.1,
74.2,
69.1,
58,
38.8,
86.7,
97.4,
51.5,
67.6,
53.5,
88,
50.2,
27.8,
58.2,
65.9,
57.6,
2,
77.6,
55.7,
47.6,
63.3,
69.8,
40.1,
24.2,
59.7,
38.9,
77,
60.5,
7.1,
77,
14.7,
44.3,
83.6,
63.5,
90.8,
59.8,
24.2,
51.8,
48.7,
76,
54.8,
53.6,
25.1,
61.9,
87.5,
62,
79.8,
108.1,
15.9,
64.3,
51.6,
80,
31.6,
37.7,
66.4,
62.5,
94.6,
90.2,
16.7,
45.7,
61.3,
96.4,
98.3,
87.4,
52,
64.1,
70.6,
60.9,
31.1,
37,
80,
30.9,
70.4,
5,
51.8,
88,
24.8,
59.5,
75.1,
49,
84.1,
44.4,
78.3,
26.6,
83.5,
63.5,
14.4,
39.7,
18.6,
67.9,
87.4,
40.9,
46.7,
69.8,
52.1,
82.4,
37.7,
43.3,
51.7,
69.5,
61.1,
58.9,
21.4,
16,
68.4,
41.8,
12.7,
35.8,
62,
60.7,
71.1,
34,
79.5,
55.8,
86.3,
75.2,
78.5,
33.2,
97.1,
15.6,
15.2,
90.1,
56.1,
55.3,
85.9,
72.7,
37.8,
86.2,
84.8,
55.5,
52.3,
62.5,
38.8,
42.5,
66.3,
58.9,
0,
36.9,
45.8,
63.9,
33.7,
66.2,
53.2,
59,
24.2,
70.6,
25.8,
46.3,
6.2,
67.2,
76.7,
36.9,
55,
6.6,
63.9,
83.3,
67.2,
21.5,
69.4,
67.7,
88.6,
34.6,
76.7,
11.2,
46.7,
72.2,
20.2,
38.3,
57,
64.3,
7.5,
55.2,
98.2,
45.8,
58.9,
29.8,
89.4,
30.5,
39,
55.9,
56.3,
59.8,
56.1,
76.9,
57,
11.4,
85.2,
26.7,
79.8,
71,
76.4,
22.1,
64.6,
70,
41.4,
54,
49.4,
66.8,
28.1,
37.8,
60.1,
66.7,
89.7,
86.2,
71.6,
47.4,
69.1,
80.3,
89.4,
69.6,
71.9,
90.2,
91.4,
75,
64.4,
45.1,
75,
49.3,
56.4,
61.4,
32.3,
32.1,
74.6,
86.3,
11.9,
48.1,
95.9,
72.9,
49.9,
59.8,
59.2,
76.5,
69.8,
22.1,
89.3,
58.6,
53.1,
53.2,
85.3,
56,
56.7,
40.6,
28.4,
95.7,
88.4,
84.6,
100.4,
11.3,
19.6,
14.2,
45.2,
65,
14.9,
53.2,
92,
72.8,
39.4,
30.8,
25.1,
75.7,
30,
41.1,
36.3,
54.6,
48.7,
97.2,
79.1,
34.2,
82.9,
50.6,
60,
97.6,
80.7,
25.2,
55.4,
19.6,
53.2,
36.5,
33.3,
7.8,
52.9,
10.3,
70.6,
78.1,
75.2,
60.7,
57.5,
80.1,
60.5,
51.2,
45.2,
25.3,
85.6,
78.4,
60.6,
88.5,
61.7,
64.7,
9.6,
25.1,
38.1,
99.5,
56.3,
10.1,
16.2,
44.9,
95.9,
46.2,
78.6,
70.2,
28.4,
62.8,
73.8,
37.6,
68,
85.9,
88,
90.2,
37,
39.5,
77.5,
89.6,
78.6,
53.8,
65.6,
75.6,
92.2,
26.5,
55.1,
25,
94.4,
64.6,
63.1,
40.6,
53.9,
70.2,
66.7,
88.2,
68,
57.8,
9.5,
86.5,
24.7,
98.5,
78.5,
89.6,
62.1,
13.6,
28.1,
78.1,
57.7,
39.9,
62.5,
40.5,
77.4,
87.5,
25.3,
39,
56,
76.6,
90.9,
11.5,
76,
38.3,
73.8,
48.5,
92,
49.9,
7.8,
99.9,
40.2,
61.3,
52.3,
42.1,
97.1,
39.1,
80.5,
35.2,
30.3,
51.4,
27.5,
64.9,
97.3,
56.9,
31.9,
87.9,
51,
48.6,
52.8,
53.5,
23.8,
44,
28.5,
52.4,
52.5,
20,
64,
74.5,
92,
29.7,
82.5,
44.1,
66.6,
5.1,
61.9,
70.3,
58.3,
81.4,
61.1,
78.4,
67.5,
25.3,
57.7,
54.4,
70.8,
82.8,
69.6,
86.9,
32.6,
67.4,
82.8,
31.4,
39.2,
66.8,
33.8,
96.8,
42.5,
32.4,
44.8,
58.8,
71.3,
74.1,
55.7,
43.5,
69.9,
63.7,
54.7,
38.9,
95.7,
44.3,
56.2,
49.4,
43.2,
68.9,
4.8,
48.3,
16.7,
93.9,
52.9,
82.4,
38.2,
46.1,
46.6,
8.5,
48.3,
53.2,
51.1,
15.5,
25.5,
81.9,
95.4,
47.6,
54.9,
64.8,
80.9,
61.2,
62.8,
63.5,
34,
21.1,
87.4,
75.1,
77.4,
56.7,
67.8,
51.5,
13.2,
35.9,
87.3,
53,
47.2,
37,
77.5,
85.6,
58.5,
23.7,
47.4,
31.6,
79.4,
44,
34.9,
38.2,
2.3,
73,
88,
58.6,
43.2,
38.8,
50,
26.6,
74.4,
74.4,
36.3,
61.4,
76.9,
54.4,
83.3,
53,
79.8,
21.4,
96.4,
58,
99.1,
61.7,
62,
23,
92.1,
30.9,
79.5,
39.8,
41.7,
48,
67.9,
92.2,
43.8,
68.7,
32.4,
91,
16.3,
74.8,
80,
22,
75,
34.4,
82,
41.4,
66.2,
54.6,
63.3,
31.2,
16.5,
68.3,
73,
46.4,
34,
82.8,
39,
95.3,
50.2,
96,
60,
77.1,
48.9,
99.3,
4,
61.3,
35.9,
47.6,
21.5,
10.6,
58.9,
34,
43.6,
59.8,
58.5,
12.9,
72.8,
73.9,
87,
76.5,
41.8,
45.2,
46.3,
96.2,
88.7,
64.4,
8.2,
53.5,
46.3,
69.4,
58,
66.5,
71.1,
44.8,
17.2,
83.2,
116.1,
61,
5.4,
65.7,
55,
63.6,
18.4,
21.7,
20.5,
70.8,
1.4,
89.6,
63.3,
83.5,
45.2,
20.9,
18.4,
73.1,
24.9,
97.5,
51.1,
3.6,
19.8,
6.8,
36.7,
89.1,
49.7,
48,
31.2,
65.7,
24.5,
52,
57.8,
73.4,
71.7,
62.2,
77.7,
62.6,
54.2,
31.3,
65,
29,
53.8,
71.1,
49.2,
32.9,
4.6,
56.3,
22.8,
61.7,
50.5,
64.5,
49.4,
91.3,
65.3,
71.8,
47,
37.7,
70.7,
58,
27.4,
31,
43.5,
20.9,
30.6,
52.5,
60.2,
55.7,
53.9,
76.7,
47.8,
32,
75.9,
96.9,
68.9,
91.1,
67.1,
74.5,
17.7,
61.5,
73.5,
57.5,
27,
48.9,
47.3,
82.9,
63.2,
76.6,
56.3,
69.1,
35.3,
87.5,
47.9,
44.1,
77.8,
47.9,
70.4,
32.5,
12.6,
72.9,
72.2,
93.4,
24.3,
28,
43.7,
75.6,
38.7,
84.6,
72.3,
50.8,
84.3,
86.1,
50.4,
94,
29.1,
23,
48,
37.3,
65.1,
6.2,
35.9,
39.6,
44.3,
89.2,
9,
29.9,
78,
96.7,
84,
99.4,
51.3,
85.6,
49.7,
44.1,
68.4,
56.3,
82.7,
98.9,
94.9,
56.7,
8.1,
59,
72.7,
53.7,
88.3,
40.6,
63.9,
0.4,
74.2,
90,
41.2,
96.5,
29.3,
42.2,
65.9,
99.6,
77.8,
28.8,
89.2,
72.3,
67.6,
52.3,
49.9,
74.3,
66.2,
37.8,
33.6,
35.6,
21.3,
86.1,
18.7,
65.4,
49.8,
43.7,
40.4,
0.3,
41.9,
31.5,
90.6,
50.5,
85,
23.7,
73.4,
7.9,
48.9,
28.3,
33.4,
87.5,
52.6,
43,
85.6,
37.6,
88.7,
82,
14.3,
74.8,
68.8,
53.6,
19.4,
83.9,
54.8,
88.4,
46.4,
72.1,
57.3,
60.7,
64.6,
57,
76.1,
40.4,
27,
55.1,
50.7,
53.4,
73.7,
45.9,
23,
22.4,
22,
28.8,
48.9,
42.8,
54.1,
43.8,
35.5,
65.2,
42,
98.7,
56.9,
33.2,
67.3,
76.1,
49.3,
28.7,
80.5,
68.8,
57.2,
58.8,
0,
73.3,
84.8,
47.6,
72.2,
50.1,
22.8,
25.6,
85.5,
42.9,
61.6,
25.7,
77.4,
57,
50.8,
47.2,
77.1,
89.4,
59.2,
49.8,
96.2,
82.7,
27.5,
68.2,
23.1,
86.3,
51.4,
55.6,
53.4,
46.2,
72.6,
81.9,
52.9,
62.4,
87.8,
92.7,
44.6,
67.6,
37.2,
74.1,
66.2,
88.8,
23.3,
35.1,
96.8,
48.1,
35.7,
69.3,
31,
15.3,
89.5,
52.8,
80.2,
38.2,
23.7,
52.7,
77.2,
6.2,
45.8,
52.9,
61.1,
60.6,
95.7,
78.2,
79,
2.1,
56,
93.3,
11.5,
94.6,
22.8,
50,
88,
12.1,
38,
10.4,
93.1,
64.7,
59.6,
52.4,
52,
58.3,
25.7,
1.1,
72.1,
67.6,
50.7,
65.4,
13.5,
61.4,
46.2,
45.4,
74.7,
43.4,
67.8,
68.8,
4.1,
83.9,
42.2,
33.2,
55.3,
62.9,
77.8,
12.8,
24.2,
39.9,
71.4,
13.5,
59.5,
6.8,
45.4,
61,
41.4,
80.1,
54.1,
60.1,
47.8,
28.1,
23.5,
22,
68.8,
29.1,
50.8,
40.5,
86.8,
24.6,
44.5,
76.6,
53.4,
28.6,
69.6,
92.5,
39,
51.8,
25.2,
58.8,
57.2,
70.8,
100,
44.9,
54.4,
44.2,
90.8,
82.3,
72.1,
50.4,
62.3,
34.7,
41.5,
99.6,
79.3,
24.9,
81.6,
83.3,
39.2,
0,
72.3,
56.8,
93.9,
92.7,
84.1,
21.5,
80,
57.2,
30.2,
35.7,
57,
45.6,
59.8,
38.4,
56.3,
84,
76.2,
73.9,
34.9,
44.8,
86.8,
21.4,
80.6,
75.4,
61.6,
71.9,
26.1,
46.4,
56.7,
72.7,
41.1,
41.7,
14.2,
35.3,
24.2,
73.7,
35.5,
39.2,
50.2,
67.4,
43.1,
40.3,
88.4,
5.1,
46.5,
80.6,
59.6,
63.5,
47,
30.6,
45.2,
60.3,
78.7,
58.5,
39.1,
56.2,
24.3,
82.8,
38.4,
62.5,
61.2,
48.6,
78.7,
39.9,
61.1,
69.1,
40.5,
28.5,
102.1,
55.2,
50,
74.8,
46.5,
54,
33.8,
86.9,
64.4,
93.6,
35.8,
93.2,
28.5,
56.7,
73.4,
44.2,
33.5,
43.4,
76.3,
17.1,
21.5,
42.2,
50.3,
77.4,
54.1,
10.3,
71.5,
62.3,
13,
26.7,
101.6,
57,
58.6,
2.5,
87.3,
44.5,
83.5,
37.9,
41.9,
74.3,
33.2,
73,
60.3,
61.4,
15.9,
72.9,
49.4,
13.4,
44.6,
40.3,
69,
6.6,
17.6,
45.6,
81.6,
25.1,
85.3,
89.3,
57.9,
27.6,
45.5,
98.7,
62.6,
26.3,
70,
21.9,
47.3,
97,
94.4,
50.8,
61.9,
80.8,
45.5,
92,
31.8,
84,
41.7,
62,
65.9,
45,
20.4,
28.2,
80.7,
61.7,
15.1,
47.7,
68.2,
34.4,
64.5,
31.4,
47.9,
52.9,
12.8,
54.8,
89.5,
23.9,
1.9,
100,
39.2,
55.9,
84.1,
80.7,
55.7,
26.8,
4.3,
47.4,
52.4,
79.4,
79.8,
44,
70,
52.2,
40.7,
42,
26,
56.1,
55.9,
65.3,
18.7,
35.8,
49.2,
89.6,
86.4,
27.7,
61,
54,
74.7,
95.4,
68.1,
79.5,
87.9,
50.3,
96.2,
55,
20.3,
21.1,
82,
32.1,
4.7,
85.8,
45.2,
76.6,
67,
74.3,
26.9,
75.7,
71.4,
81.3,
70.5,
57.2,
93.7,
48.9,
29.7,
1.1,
38.9,
88.2,
83.1,
23.1,
61.1,
27.6,
69.7,
39,
29.7,
57.9,
74.4,
79,
56,
71.8,
47.9,
71.5,
72.8,
32.1,
55.8,
87.8,
71.8,
30.5,
57.9,
15.5,
47.1,
21.6,
51.2,
75.2,
66.5,
57.4,
69.6,
24.6,
27.3,
63.1,
72,
48.6,
79.9,
45.8,
38.6,
55.6,
80.6,
35.2,
85,
92.5,
10.7,
14.5,
76.3,
87.6,
86.9,
47.8,
28.4,
54.9,
47.2,
52.9,
28.9,
73.1,
97.2,
55,
68.3,
87.4,
32.5,
52,
47.5,
26,
44.9,
29.2,
39.2,
48,
54.2,
51.6,
77.5,
44.3,
2.7,
12.8,
41.9,
61.7,
40.2,
26.8,
65.5,
49.5,
58.5,
83,
75.9,
26.5,
62.4,
39,
74.8,
37.1,
91.8,
35.3,
15.1,
13.3,
25.6,
47.9,
16.4,
40.9,
19.8,
19.7,
59.5,
38.4,
79.1,
37,
68.2,
0,
60.7,
59.8,
74,
33.7,
49.5,
78.9,
67.2,
57.5,
48.2,
57.6,
40.6,
0,
63,
54.4,
39.2,
13,
70.2,
29.7,
27.3,
30.8,
46,
79,
73.4,
23.8,
73,
61.6,
44.7,
55.1,
46.1,
70.1,
49.9,
32.3,
45.6,
41.5,
26.5,
67.2,
44.2,
47.8,
98,
45.9,
52,
72.4,
82.8,
52.3,
52.8,
43.5,
49,
30.3,
69.9,
11.5,
44.1,
64.1,
56.8,
36.6,
87.9,
67.8,
64,
77.5,
32.3,
85.5,
82,
82.3,
64.1,
40.7,
49.8,
86.2,
81.8,
39.6,
78.4,
77.6,
47.4,
51,
95,
58.8,
49.9,
95.8,
21.8,
49,
85.5,
39,
47.8,
30.1,
82.8,
91.8,
69.7,
91.1,
69.6,
63.5,
40.7,
55.5,
32.5,
48.6,
16.7,
59.7,
67,
51,
94.8,
22.7,
94.5,
67,
93.3,
55,
43.8,
77.2,
11.6,
41.6,
57.5,
36.3,
46.6,
56.8,
49.2,
48.5,
20,
69.6,
38.9,
50.8,
75.5,
74.3,
79.4,
22.2,
56.5,
37.2,
53.6,
51.5,
39.1,
37.9,
88,
83.4,
84.1,
53.5,
10,
55.2,
66.6,
81.4,
33.6,
80,
61.4,
72.1,
46.4,
78.4,
42.8,
81.2,
43.6,
71.5,
64.3,
40.9,
32.9,
66,
93.6,
70.4,
83.5,
51.2,
2.9,
33.2,
99.2,
66.4,
73.5,
76,
17,
40,
3.3,
45.8,
28,
40.6,
28,
45.2,
68.3,
30.2,
88.6,
15.9,
56.7,
28.8,
28.9,
89.7,
19.7,
0,
35.6,
41.6,
52.1,
57.9,
28.8,
54.7,
75.9,
75.2,
83.1,
75,
98.5,
96.8,
38.2,
18.1,
47.7,
67.3,
45,
70.9,
79.5,
48.2,
74.5,
81.2,
48.7,
58.7,
72.4,
43.6,
64.1,
11.6,
81.9,
83.2,
68.8,
80.2,
50.8,
26.9,
76.8,
56.7,
16.6,
74.4,
54.8,
82,
72,
47.1,
21.2,
71.9,
29.3,
68.5,
43.4,
86.5,
81.3,
2.7,
19.5,
4.5,
67,
62.5,
15.7,
56.1,
64,
97.3,
59.6,
0,
77.5,
71.5,
100.2,
98.7,
96.1,
90.8,
84.9,
48.6,
89.4,
56.7,
94.9,
95.3,
85.3,
4,
74.4,
2,
18.8,
53.2,
79,
35.8,
60.9,
61.6,
26.4,
36.3,
35.8,
29.6,
67.1,
61.9,
39.6,
80.3,
0,
53,
67.6,
70.8,
65,
59.8,
71.4,
99.9,
89.8,
73.3,
65.3,
71,
75.2,
64.6,
30.3,
38.3,
60.3,
4.1,
29.8,
50.1,
89.8,
46.8,
75,
97.4,
7,
89.7,
65,
54.1,
46.6,
37,
81.3,
47.8,
40.7,
88.3,
31,
47.6,
83.4,
93.4,
65.5,
26.3,
58.9,
35.8,
76.1,
40.1,
61.7,
27.4,
84.8,
70.8,
37.5,
63.9,
65.8,
36,
66.7,
85.1,
78.2,
47.3,
38.3,
72.4,
88.4,
64.8,
82.8,
98.3,
70.2,
54.8,
95.8,
56.1,
48,
63.1,
53.7,
0.3,
61.3,
21,
57.2,
89.4,
46.1,
39.9,
34.5,
54.4,
91.8,
85.5,
48,
64.5,
37,
89.3,
67.2,
39.6,
39.6,
63.2,
97.1,
49.2,
64.2,
61.2,
67.9,
56.6,
78.2,
92.8,
49.5,
87.5,
93.4,
85.5,
67.2,
13.9,
48.4,
71.5,
63.5,
57.6,
34.3,
92.6,
96,
39.4,
92.6,
47.5,
45.8,
69.2,
41.2,
62.5,
71.3,
30,
65.5,
8.1,
52.7,
73.8,
49,
52.3,
36.5,
81.6,
47.7,
86.1,
93.1,
60,
32,
27.9,
31.5,
54.8,
42.5,
101,
67.9,
20.3,
37.2,
69.3,
54.3,
67.1,
92.5,
84.5,
83.6,
82.3,
32.9,
64.7,
24.5,
37.4,
75.7,
61.3,
17.7,
78,
58.9,
48,
39.1,
29.7,
48,
53.3,
52.2,
62.4,
42.9,
6.7,
85.9,
14,
36.5,
39,
54.1,
28,
70.7,
82.4,
84.9,
25,
73.9,
67.7,
46.2,
58.3,
54.5,
24.7,
12.7,
51.1,
42.3,
67.9,
27.8,
63.4,
41.3,
48.3,
84.2,
65,
48.6,
53.3,
66.7,
60.4,
68.8,
67.8,
87.3,
81.3,
64.4,
44,
21.4,
38.9,
37,
42.7,
79.2,
42.8,
18.5,
91.4,
17.2,
56.7,
69.7,
41.1,
31,
34.6,
55.5,
43.1,
74.1,
55.7,
21.5,
66.3,
30.8,
94.7,
79.1,
3.2,
80.3,
85.5,
81.3,
63.6,
38.9,
71.8,
10.2,
25.6,
37.9,
13.4,
16.8,
88.3,
57.6,
83,
43.6,
19.5,
64.6,
51.5,
40.4,
36.3,
77.9,
54.5,
71.4,
68.1,
72.9,
35.4,
52.2,
63,
33.1,
78.8,
73.7,
19.3,
45.5,
52,
62.4,
23.8,
65,
48.5,
46.4,
58.9,
70.7,
82.5,
2,
86.1,
50,
90.7,
45.3,
83.5,
95.2,
60.6,
21.2,
99,
68.5,
66,
66.7,
47.4,
71.3,
89,
58.8,
17.7,
41.3,
57,
46.3,
4.5,
63.1,
54.7,
49.5,
67.2,
47.8,
34.6,
60,
38.7,
13,
46.5,
46.4,
74.1,
44.4,
27.1,
51.5,
47.9,
8.5,
79.9,
46.8,
93.7,
70.8,
93.1,
69.6,
62.7,
87.3,
96.5,
97.9,
81.6,
57.8,
33.6,
26.5,
85.1,
19.4,
84.9,
86.3,
75.4,
22.6,
53.7,
47.5,
71.2,
30.8,
15,
45.5,
62.2,
54.8,
39.9,
51.9,
23,
52,
54.5,
44.3,
77.6,
53.6,
40.5,
47.4,
46.4,
30.2,
61.8,
35.5,
10.6,
58.3,
65,
40.2,
59.5,
40,
63.1,
47.1,
60.7,
61.5,
5.3,
97.5,
59.9,
96.8,
46.4,
96.5,
64.3,
20,
26.3,
73.1,
29.2,
81.4,
80.8,
54.2,
49.2,
55.3,
64.5,
30.5,
61.3,
40.3,
56.1,
79.5,
20.2,
9.6,
50.3,
83,
4.4,
85.2,
36,
74.6,
22.4,
100,
89.1,
57.2,
54.9,
76.8,
39.9,
82.4,
0.1,
51,
81.4,
10.5,
68.9,
12.7,
48.6,
81.4,
40.5,
63.2,
76.6,
77.2,
0.3,
48.6,
38.9,
22.3,
25.5,
68.3,
82.8,
17.4,
36.6,
52.6,
72.3,
33.7,
86.6,
68.3,
59.8,
16.7,
86.1,
54.9,
83.4,
39.6,
72.2,
15.4,
44.1,
51.7,
89,
54.9,
49.6,
89.7,
77,
59,
78.1,
39.4,
35.2,
54.1,
46.8,
53.9,
74,
79.2,
63.8,
59.3,
48.6,
91.2,
34.2,
91.6,
96.2,
66.4,
41.6,
59.4,
11.8,
40.2,
50.1,
68.5,
22.1,
71,
78,
18.7,
93.8,
54,
42.2,
96.1,
85.5,
49.4,
31.9,
85.6,
66.3,
65.3,
39,
79.8,
61.9,
98.7,
29.7,
36.7,
52.3,
43.7,
46.6,
13.1,
63.5,
72.1,
56.2,
75.5,
30.3,
81.5,
95.6,
53.6,
26.1,
86,
18.7,
74.8,
83.9,
40.5,
6,
0.5,
21.8,
85.1,
65.4,
39.7,
89.8,
56.5,
26.6,
36.4,
48.4,
94.9,
59.4,
48.4,
65.4,
28.6,
59,
40.6,
56.2,
57.9,
98.3,
77.8,
48.4,
23.5,
80.2,
7.7,
80,
29.5,
35.9,
35.8,
19.9,
67,
79.9,
12.4,
51.2,
61.2,
48.2,
88.5,
76.8,
57,
86.2,
9.6,
56.6,
84.5,
64.1,
49.6,
42.9,
37.4,
93,
21.1,
63.6,
69.9,
41.3,
53.1,
41.6,
60.6,
77.3,
60.2,
67.6,
43.8,
27.7,
59.5,
74.9,
79.9,
55.9,
29.2,
34.2,
98.1,
66.7,
66.7,
70.6,
26.6,
46.1,
90.1,
30,
36.3,
59,
70.2,
36.4,
93.8,
73.5,
65.6,
52.3,
42.2,
52.2,
36.7,
67.2,
63.8,
67.7,
29.9,
53.1,
81.5,
22.4,
26.8,
83.7,
39.1,
44.9,
56.8,
28.2,
47.9,
94.9,
42,
61.8,
33.4,
34.2,
87.7,
34.6,
68,
5.6,
37.1,
47.9,
11.4,
40.7,
50.2,
21.4,
62.8,
69,
48.8,
30,
80.8,
0,
67.5,
79.3,
80.6,
57.4,
31.6,
93.2,
94.1,
37.4,
75.5,
25.9,
39.6,
57.6,
43.3,
57.6,
46.3,
49.2,
43.8,
24,
62,
27.4,
17.7,
50,
22,
59.8,
35.6,
63.3,
40.6,
59.9,
52.6,
45.1,
46,
50.2,
98.4,
58.2,
34.2,
69.4,
44.3,
54.7,
62.3,
53,
99.3,
78.5,
8.7,
53.6,
81.5,
6.4,
80.4,
21.4,
87.2,
1.7,
10,
70.5,
53.3,
66.9,
80,
83.2,
24.1,
87.1,
32.6,
59.4,
72.8,
70,
18.3,
75.1,
66.8,
85.7,
87.1,
44.7,
63.8,
0.5,
51.9,
43.2,
29.6,
15.6,
68.8,
92.2,
86.2,
69.9,
37.8,
94.5,
69.5,
88.1,
71.4,
30.2,
62.5,
57.7,
62.1,
67.4,
37.1,
67.7,
54,
75.8,
100,
73.9,
11.3,
34.3,
79.3,
88.5,
24.6,
70.3,
32.3,
65.3,
81.5,
25.4,
26.6,
69,
22.1,
82.5,
77.9,
6.8,
27.7,
23.2,
58.7,
null,
18.8,
49.3,
47.7,
33.3,
19.7,
48.3,
49.9,
58.7,
32.7,
74.9,
88.2,
32.9,
73,
74.5,
56.8,
76.1,
68.8,
64.1,
24.6,
45.3,
30.2,
38.8,
32.2,
50.9,
50,
38,
80.7,
36.6,
60.4,
97,
27.7,
41.7,
58.3,
68.7,
92,
56.8,
15.5,
41.4,
29.6,
35.2,
79.1,
59.5,
13.8,
41.3,
42.5,
16.7,
88.1,
56.9,
10.9,
55,
54.1,
29.7,
80.7,
59.1,
73.1,
72.4,
88.5,
24.4,
80.8,
35.9,
94.4,
40.4,
71.2,
37.9,
68.3,
53.4,
84.5,
69.4,
42.7,
31.4,
67.6,
38.7,
26.1,
51.7,
40.1,
11.9,
81.8,
77.4,
21,
23.9,
35.5,
58.7,
82.4,
38.5,
39.7,
65.7,
62.9,
41.3,
50.7,
61.7,
62,
11.7,
47.1,
70.4,
87.3,
87.1,
76.3,
80.2,
47.4,
17.9,
43.3,
10.7,
70.3,
28.2,
82,
22.9,
22.4,
48.2,
59.3,
20.2,
92.7,
76.4,
59.6,
24.9,
39.6,
42.9,
80.8,
41.5,
0.2,
51.5,
3.4,
67,
98.7,
15.4,
35.3,
70.7,
69.3,
58.6,
88.2,
44.1,
57.5,
38.4,
26.5,
46.6,
50.4,
61.5,
83.5,
42.9,
55.7,
8.3,
43.7,
18.8,
68.6,
48.1,
63.2,
44,
98.7,
38.8,
50.7,
72.7,
96.8,
69.1,
61.9,
70.1,
72.9,
59.5,
63,
78.3,
60.8,
84.2,
60.1,
7.4,
62.2,
55.7,
66,
82.1,
66.5,
39.3,
69.6,
70.6,
50.4,
50.8,
25.3,
83.1,
56.4,
1.3,
98.3,
21.4,
87,
92,
97.1,
53.2,
87.2,
14.4,
36.7,
34,
62.2,
35,
44.9,
57,
25,
69.2,
57,
63.6,
70.3,
43,
45.1,
8.7,
97.1,
16.5,
30.9,
28.7,
23.2,
17.4,
27.2,
40,
39.1,
43.2,
58.1,
55.4,
75,
75.2,
59,
62.4,
52.9,
60.9,
40.5,
93,
53,
72,
67.8,
53.9,
85.2,
33.1,
77.1,
11,
88.7,
58.8,
56.5,
71.4,
53.9,
42.7,
51,
73.8,
31.1,
41.6,
37.5,
57.2,
65.6,
25.5,
91,
77.8,
73.7,
91.2,
19.7,
96.9,
44,
50.4,
97.6,
81.2,
52,
90.3,
6.7,
54.7,
25.7,
58.6,
41,
66.3,
99.3,
24.2,
61.1,
17.3,
49.6,
30.7,
38.7,
49.1,
45.6,
45.1,
83.6,
50.2,
32.5,
90,
48.6,
52.8,
48.6,
46.6,
67.5,
66.6,
20.8,
35.3,
42.2,
49.4,
56.9,
30.2,
83,
41.9,
73.9,
44.1,
42.3,
26.3,
73.4,
7.7,
104.1,
22.5,
88.6,
60.2,
99.6,
37,
12.7,
24.6,
27.1,
35.5,
54.5,
83.1,
18.6,
60.5,
73.8,
55.8,
71.9,
43.4,
33.1,
94.4,
56.9,
62,
76.5,
53.4,
75.1,
104.5,
83.5,
54.1,
74.5,
48.6,
8.5,
62.2,
63.5,
51.3,
35.9,
83.8,
77.5,
18.6,
19.1,
52.2,
69.1,
56.7,
78.7,
59.1,
57.2,
70.4,
42.5,
63.9,
73.3,
26.9,
83.4,
29.1,
23.2,
77.6,
32.5,
61.5,
97.2,
66.5,
81.2,
23.8,
48.7,
51,
65,
73.2,
31.4,
65.1,
49.9,
15.8,
82,
86.2,
39.4,
39.8,
64.6,
11,
44.9,
69.3,
87.8,
41.6,
70.9,
77.1,
30.7,
50.2,
37.7,
87,
44.7,
83.2,
82,
37.7,
57,
74.2,
36.8,
77,
43.6,
26.4,
40.7,
19.7,
22.3,
67.1,
67.8,
60,
22.1,
10.5,
69.1,
38.6,
31,
20.9,
42.1,
69.2,
77.5,
31.9,
69.8,
80.4,
50,
41.8,
61,
78.3,
22,
35.6,
15.6,
2.9,
69.1,
43.9,
69.7,
51,
72.2,
56,
85.4,
39,
13.4,
58.7,
46.7,
24.1,
31.9,
66.1,
82.5,
94.1,
67.1,
20.6,
34.5,
73,
26,
82.2,
37.9,
89.6,
28.1,
50.6,
55.5,
16.4,
6.3,
67.2,
19.4,
98.5,
60.5,
43,
40.5,
51.3,
79.4,
54.3,
27,
26.3,
77.1,
60.4,
49.5,
76,
72.8,
53.4,
11.5,
61.3,
72.9,
29.6,
54.3,
76,
29.2,
57.7,
65.8,
65.2,
36.6,
43.3,
41.1,
43.8,
74.5,
49,
71.3,
18.6,
63.2,
78.8,
53.5,
52.9,
34.9,
33.6,
59.9,
38.5,
43.9,
44,
56,
32.3,
88.9,
59.1,
8,
99.6,
23.9,
99.2,
54.7,
8.4,
89.1,
84.1,
71.7,
68.1,
101.8,
62.4,
79.8,
55,
79.2,
63.7,
48.1,
69,
70,
2.9,
47.3,
44.1,
9,
27.1,
62.4,
77.6,
59.3,
66.9,
62.2,
92.8,
44.4,
40.1,
42.7,
12.5,
50.9,
47.2,
27.2,
53,
43.8,
42.6,
80.8,
80.8,
63.6,
28.5,
9.1,
46.1,
40.9,
82.5,
3.6,
36.5,
67.3,
69.3,
51.4,
40.6,
87.7,
8.2,
51.5,
80.8,
71.7,
37.6,
26.6,
45.6,
38.9,
53.8,
41.6,
51.2,
68.4,
51,
16.3,
57.2,
43,
51.7,
60.5,
81.3,
52.4,
43,
61,
84.7,
65.4,
51.1,
69.6,
46,
16.8,
68.8,
95.7,
21.8,
91.4,
51.6,
62.1,
71.5,
17.4,
24.8,
87.5,
88.6,
75,
59.1,
48.5,
99.1,
38.4,
41.3,
69.8,
25.7,
48.7,
51.4,
68.1,
41.5,
49.5,
44,
24.4,
35.6,
67.1,
36.6,
68.4,
72.2,
73.9,
80,
70.1,
61.3,
77,
62.2,
51.1,
79.4,
46.8,
17,
69.5,
58.9,
8.8,
13,
8.6,
58.4,
62.1,
82.5,
48.9,
89.2,
59.2,
26.5,
66,
58.3,
19.2,
88.5,
8.7,
21.5,
67.2,
91.8,
42.1,
32.3,
80.3,
81.5,
67.5,
65.5,
65.9,
39.7,
67.6,
59.5,
70.1,
41.7,
81,
26.6,
55,
90.7,
51.1,
53.1,
70.5,
22.4,
77.3,
17.8,
54.3,
32.7,
41.4,
10.2,
42,
24.6,
79.8,
59.5,
73,
42.9,
53.2,
59.9,
31,
51.7,
66.6,
71.5,
99.1,
47,
96.8,
40.5,
88,
53.8,
55.7,
40.7,
7.1,
53,
45.1,
85.5,
80.7,
50.1,
20.6,
33.9,
58.6,
54.2,
58.5,
82.9,
28.4,
39.8,
39.2,
2.9,
83.3,
57.5,
80.3,
42.1,
51.7,
68.7,
52,
65.4,
51.8,
52.7,
92.6,
44.7,
61.5,
28.2,
91.5,
32.9,
69,
34.1,
27.2,
47,
0,
37.9,
19,
93.2,
76.4,
94.5,
91.4,
43.3,
30.5,
21.6,
77.3,
55.5,
48.5,
46.9,
74.2,
25.4,
75.9,
61.4,
9.5,
32.6,
92.1,
85.5,
19.3,
66.2,
63.8,
10,
95.2,
51,
77.4,
70,
54.2,
45.9,
35.9,
60.4,
36.6,
27,
78.7,
55,
60.3,
79,
28.3,
10.9,
11.4,
47.7,
71.9,
73.6,
49.2,
74.8,
78.8,
15.1,
80.8,
42.7,
26.7,
77.7,
null,
52.6,
87.8,
84.5,
83.6,
25.3,
40.7,
42.2,
58.9,
12.7,
2.4,
76.2,
77.7,
69.3,
70.5,
32.6,
35.5,
4.5,
54.6,
10.5,
41.6,
58.2,
35.7,
78.7,
27.9,
89.6,
0,
55.6,
8.6,
49.1,
91.3,
70.7,
82.5,
43.9,
65.7,
35.7,
42.2,
34.3,
14.4,
47.9,
50.6,
53.3,
86.3,
59.7,
34.7,
54.2,
38,
16.7,
32,
75.9,
24.9,
49.3,
61.7,
39.2,
59.9,
90,
81.4,
11.2,
21.2,
96,
61.9,
28.1,
74.2,
85,
32,
19.6,
51.4,
43.6,
58.7,
1.4,
33,
18.7,
69.7,
45.3,
68.8,
89.3,
47.8,
48.5,
51.1,
44.9,
62,
87.2,
66.4,
60.1,
21.5,
44,
45.4,
71.1,
35.8,
36.8,
55.8,
50.7,
61.3,
46,
45.6,
80,
44.3,
57.3,
50.1,
52.5,
74.9,
60.9,
16,
96.1,
67.9,
55.9,
57.6,
37.1,
81.1,
70.4,
66.4,
89.1,
39.5,
0,
77,
44.4,
4,
45.8,
23.7,
22.7,
95.6,
72,
51.4,
22.2,
36.6,
60.3,
5.4,
32.7,
40,
58.4,
80.4,
61.3,
95.5,
40,
77.2,
17.5,
77.4,
61.5,
59.5,
73.3,
40.4,
49.4,
75.4,
33,
15.1,
14,
73.9,
34.6,
92.4,
43.7,
45.2,
39.6,
34.3,
30.4,
54.9,
83.7,
40.8,
94.3,
66.5,
78.1,
39.1,
74.8,
24.7,
17.9,
13,
26.3,
73.7,
67.4,
68.7,
30.5,
66.6,
64.6,
56.9,
36.6,
56.1,
7.4,
62.9,
93.4,
96.5,
54,
55.8,
10.3,
66.7,
76,
91.9,
43.9,
66.2,
76.8,
44.4,
86.2,
23.4,
92.3,
47,
19.7,
73.6,
30.5,
12.3,
74.2,
7.7,
64.3,
43,
78.1,
11.5,
95.5,
50.7,
55.9,
24.4,
49.9,
62,
34.5,
91,
57.1,
22.9,
67.7,
86.4,
89.5,
45.5,
97.9,
52,
40.2,
53,
23.9,
77,
38,
10.8,
87.3,
41.3,
85.2,
53.7,
81.9,
77.8,
58.2,
27,
14.9,
77.3,
26.8,
57.7,
0.2,
58.4,
67,
40.1,
51,
33.6,
97.3,
60.5,
81.4,
84.9,
38.3,
47,
22.5,
52.3,
47.2,
50,
53,
39,
68.5,
10.3,
39.5,
45.2,
25.8,
30,
67.9,
33.7,
11.3,
71.5,
79.7,
91.3,
64.1,
13.4,
67.4,
23.1,
83.8,
36.7,
49.2,
23,
20.1,
47.7,
36,
15,
34.9,
88.2,
53.5,
70.2,
61.4,
58.5,
16.8,
18.5,
10.4,
31.8,
17,
64.6,
26.7,
49.5,
90.5,
61,
84.7,
89.2,
56.7,
93.7,
53.1,
65,
85.3,
79.9,
87.6,
54.2,
90.9,
60.8,
45.6,
81,
12.7,
47.9,
48.2,
42.6,
30.8,
27.4,
94.5,
36.4,
56.2,
65.1,
67.4,
83.8,
28,
27.9,
49.2,
99.9,
61,
99.4,
60.4,
63.1,
68.2,
43.4,
0,
84.8,
29.6,
91,
78.3,
31.5,
76.6,
31,
100.3,
40.4,
34.1,
60.7,
62.6,
70.8,
70.7,
21.2,
6,
77.2,
35.4,
23.8,
60.9,
21.6,
13.5,
64.5,
46,
46.8,
41.9,
85.2,
17.3,
71.4,
63.3,
80.1,
69.2,
56,
40.7,
87.9,
43.8,
91.3,
11.8,
86.4,
29.4,
36.6,
58.1,
79.7,
49.1,
38.2,
74.7,
42.7,
47.4,
68.1,
63.5,
73.7,
97.9,
49.9,
99.3,
81.6,
36.4,
78.4,
96.6,
75.1,
41.6,
43.1,
49.5,
80.3,
75.5,
74,
34.1,
51.3,
56.2,
38.8,
67.9,
27,
49.3,
85.9,
58.7,
40.2,
49.3,
34.2,
82.7,
81.6,
76.6,
53.6,
65.5,
71.6,
24.3,
28.5,
82.9,
48.5,
37.6,
52.4,
90.9,
37.7,
49.1,
54,
16.4,
59.7,
14.7,
30.2,
68,
53.3,
68.8,
50.4,
86.8,
23.5,
35.8,
59.8,
44.2,
43,
98.4,
81.6,
41.4,
92.4,
66.9,
62.3,
54.6,
42,
22.9,
21.3,
42.9,
44.9,
94.6,
74.5,
21.4,
73.8,
10.9,
66,
54.1,
47.5,
94.3,
50.7,
74.3,
49.2,
48.6,
43.9,
94.1,
51.1,
48.2,
77.5,
60.69,
99.3,
42,
64.1,
25.1,
47.1,
56,
42.7,
27.3,
29.1,
65.8,
51.8,
76.2,
75.3,
49.4,
15.4,
68.5,
85.8,
39.1,
40.6,
27.3,
70.8,
29.2,
45.6,
90.6,
71.6,
86.2,
20.1,
54.2,
90.2,
20.3,
26.8,
44.4,
60.1,
93.4,
23.8,
54.4,
72.8,
91.8,
65.7,
38.5,
65.1,
15.6,
77,
39.4,
101.8,
66.6,
40.7,
43.1,
92.5,
59.7,
62.1,
8.1,
21.4,
64.4,
62.5,
75.5,
22.3,
62,
70.4,
83.8,
19.6,
20.6,
56.2,
62.1,
11.5,
29.4,
55,
21.9,
53.8,
65.2,
85.6,
35.1,
83,
69.3,
30.2,
67.2,
95.5,
15.7,
37.4,
75.6,
83.2,
32.9,
81,
15.9,
12,
32.8,
42.4,
67.3,
43.2,
53.9,
97.5,
63.9,
67.7,
83.3,
67.6,
43.3,
54.4,
72.7,
31,
69.8,
53.6,
84,
58.7,
89.3,
19.5,
50,
84.1,
58.4,
65.6,
83.9,
48.3,
45,
47,
33,
56.5,
27.5,
52.5,
51.8,
98.9,
48.9,
28.6,
77.4,
65.7,
38.8,
39.5,
30.2,
46.4,
86.2,
63,
56.4,
60.5,
79.6,
55.1,
37.3,
82,
78.1,
52.5,
62,
80,
59,
73.6,
59.5,
36.2,
47.7,
37.7,
17.8,
40.6,
52.9,
12,
16.2,
50,
45.4,
41.6,
56.4,
92.7,
58.2,
51.2,
45.5,
68.1,
71,
13.7,
85.8,
64.4,
34.1,
85.7,
72.5,
6.9,
34.9,
63.7,
42.6,
16.3,
82.2,
83.5,
8.4,
55.1,
89.8,
78,
20.5,
0,
67.2,
67.5,
77.1,
23.2,
30,
64.7,
62.9,
0,
23,
48.5,
89.7,
79.3,
35.4,
39.2,
59.7,
11.3,
37.1,
51,
90.6,
69.1,
32.6,
97.3,
4.7,
46.7,
65.4,
38,
73.9,
91.4,
42.4,
32.3,
101.8,
59.4,
62.1,
3.3,
75.5,
20.4,
50.8,
16.8,
26.2,
46.8,
72.2,
90.8,
15.8,
47.1,
79.3,
49,
72.4,
74.2,
52,
33,
40.7,
71.5,
19.8,
44.9,
24.7,
82.2,
73.4,
43.2,
22.9,
80.9,
13.7,
71.9,
7.8,
44.2,
52.9,
67.5,
50,
58.3,
45,
42.5,
87.1,
64.3,
23.5,
26.9,
91.5,
63.9,
67.4,
50,
79.1,
4.5,
66.2,
68,
39.5,
31.4,
96.2,
27.9,
91.5,
96.9,
31.1,
89.9,
55.8,
27,
63.4,
72.4,
17.7,
59.1,
20.5,
60.3,
54.1,
46.5,
45.5,
44.6,
71.1,
73,
80.3,
64.6,
41.3,
70.8,
48.1,
72,
53.4,
44.6,
92.9,
34.5,
53,
40.4,
18.6,
24.8,
52.5,
62,
58.4,
88.5,
55.5,
54.5,
54.8,
52.1,
47,
18,
69,
63.5,
54.7,
23.6,
61.6,
81.7,
44.1,
46.6,
62.9,
66.1,
47.1,
43.6,
31.2,
22,
88,
0.4,
23.9,
36.3,
48.9,
80.3,
32.9,
43.9,
92.6,
86.3,
59.8,
87.5,
44.4,
90,
82.4,
89.6,
32.5,
92.4,
72.3,
33.8,
39.2,
29.6,
50.4,
101.3,
57.9,
56,
47.5,
61.2,
70.1,
91.5,
41.9,
97.1,
78.5,
11.3,
52.7,
43.4,
83.7,
73.9,
80.4,
49.6,
89.3,
88.7,
42.2,
58.2,
8.3,
80.2,
20.2,
49,
66.9,
77.9,
24.5,
22.7,
65.2,
63.5,
93.2,
65.8,
41.2,
51.4,
40.2,
75.1,
47.7,
70.5,
54.1,
83.3,
57.7,
75.7,
67,
33.9,
38.7,
84.1,
23.6,
30.4,
15.7,
47,
68.7,
54.5,
59.3,
13.5,
4.9,
68.3,
42.1,
38.2,
87.9,
70.5,
51.4,
36.4,
86.6,
89.6,
100.5,
65.6,
68.6,
53.1,
89.3,
46,
68.4,
44.4,
84,
82.8,
49.4,
37.9,
41.3,
81,
64.5,
39.3,
88.7,
49.6,
6.3,
51.8,
68,
52.6,
63.6,
87.9,
48,
58.5,
85.4,
70.8,
63.9,
77.8,
89.4,
42.3,
80.9,
90.1,
12.5,
45.7,
16,
43.9,
35.3,
15.2,
38.9,
46,
75.8,
73.5,
48,
65.8,
48,
61.4,
58.7,
56.8,
54.8,
77.8,
57.6,
25,
70.7,
89.6,
66.4,
82.1,
77.7,
85.9,
58,
13.1,
51.3,
65.4,
44.3,
53.2,
61,
77.1,
58.5,
69.5,
82,
53.6,
67.4,
63,
25.4,
32.3,
62.5,
81.3,
90.7,
84.8,
96.9,
78.2,
51.1,
67.3,
52.1,
61.1,
50,
40.9,
94,
75.6,
24.6,
33,
38.4,
43.8,
71,
12.6,
61,
39,
10.1,
47.8,
41,
91.8,
15.9,
67.2,
37.3,
86.9,
98.9,
80.9,
24.2,
76.6,
50.4,
47.4,
28.9,
26,
88.3,
88.3,
49.5,
27.6,
66.5,
81.1,
13.7,
59.9,
56.1,
39,
75.4,
95.7,
40.5,
87.4,
78.9,
58.5,
87.2,
49.6,
3.5,
63.7,
81,
83.9,
87.1,
51.7,
88.3,
21.8,
85.1,
35.4,
58.9,
80.3,
12.9,
9.9,
67.3,
94,
37.2,
25.2,
75,
24.2,
25.2,
63.6,
31.6,
77.8,
26.6,
55.8,
66.4,
59.5,
37.7,
62.1,
70.4,
13,
48.4,
46.8,
19.3,
35.8,
43.7,
37.7,
75.3,
42.8,
69,
76.8,
70.8,
55.9,
68.1,
58.9,
34.4,
81.7,
20.5,
61.5,
64.2,
65.2,
47.8,
78.4,
35.3,
96,
73.2,
53.5,
27,
45,
50.9,
43.6,
99.7,
32.8,
68.5,
41.4,
43.2,
40.4,
27.2,
43.3,
67,
92,
91.3,
31.8,
30.5,
44.3,
66.7,
52.6,
42.9,
30.5,
6.5,
41,
68.5,
77.4,
49.9,
53.5,
45.9,
28.2,
76.4,
87,
31,
83.2,
99.2,
56.2,
88.6,
54.5,
84.3,
32.7,
75.3,
83,
81.1,
70,
94.8,
75.2,
42.4,
47.3,
34.7,
60.1,
35.2,
13.5,
96.8,
65.1,
55.9,
24.7,
67.9,
66.7,
33.2,
29.8,
38.9,
64.9,
82,
41.2,
89.5,
48.9,
52.8,
22.2,
36.3,
75.3,
67.9,
33.6,
35.6,
46.7,
74.3,
12,
54.3,
73.2,
90.3,
31,
59.8,
84.6,
53.9,
47.1,
3.7,
74.7,
41.2,
59.9,
61.1,
71.1,
42.6,
0,
16.1,
32.9,
7.8,
69.3,
68.6,
10,
18,
69.9,
22.3,
8.9,
94.7,
45.1,
33,
78.5,
10.2,
33.9,
48.6,
54.9,
73.5,
49.3,
60.2,
61,
43.2,
63.7,
90.7,
36.4,
1.7,
9.8,
22.5,
26,
92.8,
73.5,
51.6,
37,
74.7,
57.4,
52,
44,
65,
71.9,
15.2,
0,
9.3,
41.2,
34.8,
72.5,
53.5,
39.6,
48.5,
29.2,
9,
29.2,
19.8,
21.4,
76.3,
40,
58,
52.5,
64.4,
24.3,
0,
92.7,
69.5,
84.3,
76.3,
45.3,
28.9,
67.3,
15.1,
45.7,
40.5,
10.2,
73.2,
44,
93.1,
85.1,
75.1,
35.4,
43.6,
78.8,
70.2,
29.8,
87.2,
17,
46.1,
45.1,
30.3,
56.7,
71.3,
47.7,
82.5,
77.5,
29.9,
49.4,
41.5,
85.3,
37.4,
12,
53.6,
72.2,
96.1,
87.5,
63.1,
89,
63,
35.6,
31.5,
62.2,
61.1,
29.9,
51.8,
34,
41.2,
23,
75,
54.7,
35.8,
61.9,
1.8,
88.3,
83.5,
98.4,
68.9,
52.9,
79.8,
75.6,
43,
82.9,
60.7,
43.6,
23.6,
87.3,
61.2,
52.6,
9,
87,
40.9,
35.9,
57.8,
31.2,
72.2,
60,
50.6,
54.8,
72,
70.3,
85.9,
54.4,
5.8,
3.6,
77.3,
19.3,
26.7,
5.4,
84.8,
34.3,
27.6,
45.9,
53.3,
45.4,
54.3,
97.7,
62.6,
41.7,
89.1,
10.1,
42.5,
80.5,
54.2,
44.9,
48.3,
60,
75.7,
13.2,
74,
36,
72.3,
77.5,
83.5,
61,
78.8,
60.5,
56.9,
94.5,
77.8,
97.7,
86.5,
71.9,
62.7,
46,
93.3,
61.8,
64.9,
71,
96.8,
29.2,
67.3,
68.5,
74.7,
36.7,
77.7,
72.6,
19.3,
25.9,
43,
15,
83.4,
16.8,
34.8,
29.6,
76.7,
29.9,
81.4,
95.3,
29,
31.9,
57.3,
76.8,
61.4,
37.6,
55.2,
78,
76.5,
55.6,
57.7,
39.3,
44.2,
60.4,
33.2,
12.4,
72.1,
17.4,
16.8,
50.8,
24.7,
63.8,
3.3,
44.9,
78.5,
53.1,
59.4,
44,
55.4,
41.6,
69.9,
80.3,
41.7,
29.8,
0.6,
51.1,
90.3,
39,
90.5,
23.8,
69.3,
52.3,
85.6,
53.9,
68.5,
69.9,
77.7,
69.6,
53.4,
46.4,
40.3,
89.4,
49.8,
82.6,
18.4,
29.3,
56.2,
98.7,
16.6,
36.8,
58.8,
72.2,
64.3,
40,
70.6,
50.3,
96.8,
51.7,
17.3,
11.6,
40.4,
57.8,
61.4,
86.3,
70.5,
25.4,
55.9,
92,
14.2,
39.9,
49.9,
96.5,
12.9,
27,
63.8,
87.5,
78.6,
72.2,
25.2,
40.8,
37.2,
68.2,
31.9,
93.6,
53.4,
86.1,
57.5,
37.4,
51.5,
66,
69.8,
65.9,
83.2,
94.3,
51.8,
43.2,
93,
44.9,
43.8,
57.5,
59.4,
27.8,
59.6,
65,
62.7,
56.5,
42.8,
24.3,
77.4,
74.6,
67.5,
22.4,
58.1,
66.8,
43,
84.2,
39.8,
85.4,
56.5,
26.6,
71.5,
28.7,
62.9,
53.4,
63.4,
10,
50.2,
48.2,
80.5,
62.7,
35.1,
58.9,
19.3,
19.4,
40.4,
43.3,
31,
24,
13.5,
48.4,
27.3,
89.8,
59.8,
44.7,
81.1,
67.2,
64,
23.2,
28.2,
3.1,
48.4,
62.5,
90.3,
84.6,
45.2,
50.2,
31.1,
35.6,
42,
12.2,
72.2,
88.6,
63.4,
47.9,
55.8,
66.1,
49.3,
35.3,
58.8,
19.2,
74.6,
14.9,
95.6,
6,
5.2,
82.9,
75.8,
63.4,
38.4,
87.2,
28.8,
53.8,
82.8,
98.1,
80.9,
34.7,
53,
52.9,
25.9,
17.2,
39.7,
6.5,
86.4,
52.6,
55.7,
99,
59.9,
22.3,
57,
37.3,
58,
76.2,
61.3,
100.2,
71.2,
81.9,
80.8,
39.2,
21,
32.9,
71.2,
7,
45.9,
47.8,
54.7,
26.3,
41.5,
31.3,
49.3,
26.9,
38.3,
45.5,
52.6,
95.5,
15.1,
72.4,
60.8,
75.8,
52.8,
59.5,
97.7,
33.7,
74.9,
40.7,
14.1,
32,
91.5,
66.4,
5.2,
44.2,
71.8,
46.2,
5.3,
69.3,
62.1,
58.6,
53.9,
80,
87,
12.1,
72.2,
72.7,
50.9,
68.4,
57.7,
64.9,
76.2,
10.5,
71.7,
71.2,
65.1,
40,
73.1,
20.6,
99.2,
64.4,
94.9,
25.5,
38.1,
50.1,
56.6,
64.5,
47.4,
67.6,
11.4,
63.4,
97.3,
44.1,
55.3,
56,
52.5,
30.4,
13.9,
66,
74.8,
63.7,
68.2,
76,
29.6,
25.6,
85.3,
0,
94.2,
33.9,
59.5,
15.5,
70.5,
62.8,
22.6,
56.3,
88.7,
64.8,
78.5,
75.7,
24.1,
41.6,
69.7,
19.7,
29.1,
63.2,
10.5,
47.8,
51,
6.8,
32.6,
33.8,
41.1,
49.4,
60.7,
75.9,
28,
2.6,
14.3,
58.1,
52.1,
38.3,
36.8,
30.8,
33.6,
69.1,
62.8,
98.7,
72.8,
0,
92.9,
49.4,
38.1,
50.9,
62.7,
45,
83.6,
16.7,
38.2,
75.4,
42.7,
75.1,
35.6,
75.2,
31,
28.5,
75,
29,
41.7,
77.5,
54.1,
47.7,
26.4,
44.1,
76,
50.2,
42.7,
72.3,
95.2,
9.7,
10,
27.6,
7.5,
51,
64.9,
83.4,
62.9,
17.2,
76.7,
72.7,
80.3,
56.8,
83.9,
44.6,
10.4,
82.2,
27.3,
98.5,
27.1,
65.9,
87.6,
84,
31.5,
35.9,
54.8,
55.3,
83.9,
55.3,
60,
86.3,
47.9,
36.1,
64.4,
31.5,
61.6,
69.5,
65.3,
39.3,
35.8,
53.8,
43.8,
45.3,
43.7,
57.5,
29.3,
29.5,
93.8,
51.5,
71.5,
45.5,
93.3,
52.4,
34.1,
51.6,
68.4,
87,
39.2,
86.5,
71.7,
26.8,
72.8,
55.3,
83.7,
83.7,
50.7,
20.5,
92.8,
36.7,
45.1,
43.7,
34.6,
57.5,
81.5,
81.2,
81.5,
48.6,
21.4,
55.3,
18.1,
83.5,
45.6,
47.2,
96.5,
14.9,
0,
45,
52,
81.2,
21.4,
75.1,
65.6,
43.8,
68.2,
6.7,
73.2,
43.2,
80.3,
57.9,
72,
42.4,
91.4,
45.3,
33.8,
87.7,
87.1,
78,
41.6,
36.4,
60,
87.9,
80.2,
33.1,
42.5,
45.4,
60.8,
44,
97.3,
60.7,
44.6,
76.9,
55.2,
73.9,
48.7,
32.1,
69,
47.6,
36.4,
56.1,
17,
68.6,
58.1,
69.9,
64.3,
29.1,
64.3,
48.1,
74.2,
8.3,
9.4,
59.5,
30.8,
32.3,
40.8,
51.7,
83.6,
19.9,
48.6,
40.8,
12.8,
40.2,
53.5,
63.3,
51.7,
32.2,
43.7,
56.1,
63.4,
84.1,
29.8,
77.5,
30.3,
52.8,
75.1,
32.1,
90,
52,
83.4,
69.5,
60,
7.2,
96.6,
51.2,
58.9,
52.6,
17.6,
81,
1.9,
10.4,
6.8,
60.8,
53.8,
55,
58.5,
37.4,
73.5,
39.5,
28,
83.3,
1.3,
66.7,
63.5,
65.6,
89.3,
84.2,
37.7,
83.9,
20.8,
61.4,
47,
65.1,
76.5,
34,
63.2,
27.1,
32.3,
55.9,
37.8,
73.2,
91.2,
80.9,
43.5,
16.2,
47,
71.8,
69.1,
33.5,
82,
48.7,
61.1,
86.7,
61.4,
16.5,
61.5,
57.8,
31.5,
49.8,
67,
78.3,
80.4,
17.5,
50.8,
57.1,
50.6,
35.9,
51.1,
53.1,
63.9,
50.5,
53.6,
71.4,
54.5,
97.4,
41,
55.9,
91.5,
67.9,
44.9,
16.1,
76.9,
94,
61,
41.7,
85.4,
48,
53.4,
61.4,
19.7,
14.2,
91.1,
95,
58,
68.3,
18.7,
38.7,
61.4,
40,
54,
90,
47.4,
70.2,
56.7,
74.9,
38.4,
51.8,
null,
42.5,
76.5,
79.6,
69.3,
83,
58.4,
31.7,
44.8,
64,
46.5,
62.2,
52.1,
77.2,
48,
56.8,
47.3,
34.9,
57,
35.1,
74.5,
57.1,
25.8,
79.6,
52.4,
70.4,
59.9,
61.2,
79.2,
89.5,
69,
65.2,
73.8,
33.2,
63.2,
93,
45.8,
63.2,
83.6,
67.7,
68.8,
38,
3.2,
36,
91.1,
94.4,
58.5,
72.4,
70.5,
55,
54,
82.6,
17.5,
21.5,
46,
38.8,
57.1,
2.8,
43.8,
41.3,
38.1,
62.9,
74.3,
65.8,
57.8,
16.1,
70.9,
42,
61.1,
85.4,
83.7,
90.1,
70.6,
30.2,
70.4,
96.2,
43.1,
48.9,
58.9,
21.4,
91.3,
58.4,
7.3,
88.7,
79.7,
78,
56.9,
54.6,
57.8,
83.5,
96.2,
81.7,
44.9,
55.9,
47.5,
29.3,
55.5,
63.5,
29.3,
18.6,
38.5,
13.2,
32.1,
39.5,
57,
79.3,
33.7,
81.8,
29.5,
55.2,
66.8,
1,
26.6,
39.4,
77.5,
22.4,
27,
35.7,
29.1,
74.4,
27.4,
54.9,
83,
63,
52.4,
58,
55.7,
36,
0.4,
75.8,
57.4,
83.2,
50.1,
73.6,
51,
73.1,
47.1,
51.6,
74,
57,
66.8,
91.3,
71.8,
94.4,
26.8,
64.6,
97.2,
64.5,
98.2,
68.6,
71,
53.3,
53.3,
56.2,
77.4,
91.6,
62,
46.1,
75.6,
84.9,
48.7,
36.4,
71.1,
90.8,
74.1,
50.6,
26,
40.1,
17.8,
50.5,
64.7,
81.8,
6.5,
28.1,
69.4,
65.5,
12,
54.6,
55.3,
86.5,
96,
38.4,
46.8,
24.9,
31.6,
67.4,
63.4,
62.8,
44,
66,
24,
51.9,
96.2,
47.3,
77.3,
83.1,
70.4,
36.8,
98,
26.4,
74,
94.6,
64.6,
31.5,
30.8,
73.3,
71.1,
96.8,
94.5,
62.7,
78,
42.5,
43.3,
85.5,
14.1,
42.8,
32.5,
56.2,
66.6,
47.1,
33.9,
85.8,
36.1,
53.7,
39.1,
23.1,
55.6,
73.8,
78.4,
42.8,
44.7,
22,
46.3,
81,
72.1,
32.3,
75.4,
84.3,
68.1,
31.1,
69.2,
65.4,
40,
23.5,
38.5,
40.7,
57.9,
78.5,
60,
69.1,
11.2,
48,
52,
80.1,
38.8,
32.4,
26.7,
33.9,
93.1,
21.9,
66.8,
30.9,
81.9,
25.9,
39.5,
14,
65,
24.9,
58,
83.2,
85.3,
60,
18,
19.7,
68.1,
16.7,
56.8,
78.2,
44.5,
30,
80.1,
89.7,
47.8,
0,
62.3,
51.6,
84.5,
52.4,
63.1,
19.5,
66.2,
22.5,
77.1,
12.8,
81.3,
47.7,
69.4,
51.4,
13.4,
72.2,
35.8,
91.6,
73.1,
49.3,
70.4,
1.5,
37.6,
72.8,
94.7,
60.2,
68,
44.2,
52.4,
75.3,
52.1,
76.2,
6.4,
31.1,
11.1,
93.3,
71.7,
51.4,
27,
27.6,
96.6,
53.5,
39.4,
55.6,
94.1,
87.6,
21.9,
39.9,
94.5,
97,
65.9,
70.2,
72.5,
76.7,
22.3,
55.4,
23.6,
29.6,
96.1,
64.5,
0,
39,
63.3,
78.2,
83.2,
100.3,
17.6,
50.8,
80.4,
61.7,
42.5,
47.1,
58,
41.5,
65.5,
71.7,
51.9,
56.9,
69.6,
45.4,
44.7,
91.5,
29.3,
40.6,
56,
40,
19.2,
94.2,
60.1,
65.2,
61.6,
81.6,
57,
24.2,
62.2,
48.1,
48.9,
70.1,
34.6,
45,
0.1,
40.9,
45,
26.4,
57.4,
66.6,
61.1,
93.1,
40.4,
13.4,
62.2,
28.3,
68.1,
41.4,
73.6,
75.2,
90.2,
89.1,
19.5,
75.2,
55.8,
51.3,
61.3,
81.8,
51.3,
83.6,
31.5,
54.8,
33.1,
38.1,
94.5,
64.3,
79.4,
74.7,
62.5,
76.9,
58.1,
76.4,
69.5,
60.1,
74.9,
67.9,
22.7,
0,
53.9,
94.9,
86,
96,
80.5,
65.5,
81.8,
43.2,
32.2,
88.5,
44.7,
77.9,
25,
66.8,
29,
75.8,
70.4,
4.5,
64.6,
93.9,
67,
84.2,
45.8,
54.4,
33.2,
18.7,
35.3,
25.2,
43.3,
87,
75,
60.8,
40.2,
63.1,
34.8,
47.7,
3.6,
45.9,
52,
13.5,
75.3,
33.2,
43.4,
58.7,
51.1,
71.4,
63.7,
63.6,
59.6,
58.5,
43.1,
70.6,
79.6,
2,
43.9,
9.1,
80.6,
45.9,
84.9,
87.6,
61.9,
59.2,
61.2,
54.2,
48.6,
91.7,
71.9,
46.7,
94.2,
82.8,
64,
93.2,
95.8,
36.9,
53.6,
59.7,
75,
76.3,
65.7,
96,
95.6,
55.2,
27.8,
24.6,
39.4,
34.5,
52.8,
14.3,
76.9,
73.9,
60.2,
47.8,
55.3,
61.9,
43.8,
56.7,
64.9,
63.6,
61.4,
54.3,
101,
44.6,
39.3,
56.4,
2.3,
62.5,
11.5,
44.4,
79.7,
77.3,
92.4,
57.9,
70.8,
44.8,
39,
11.6,
63.4,
61,
70.6,
59.1,
65.6,
92.3,
54.7,
9.9,
40,
43,
51.1,
83.4,
60,
36.4,
89.6,
59.1,
66.8,
33.2,
17.5,
27.5,
34.8,
35.6,
80.6,
78.4,
36.2,
63.9,
16.4,
31.3,
40.1,
53.3,
48.4,
76.3,
62.8,
88.8,
33.7,
81.5,
67.5,
89.3,
60.4,
50.1,
22.2,
80.1,
55.6,
69.5,
88.7,
67.7,
69,
56.1,
66.8,
65,
7.8,
51.9,
20,
96.6,
39.9,
69.8,
52.7,
96.8,
2.2,
68,
93.1,
35.5,
80.7,
8.3,
51.9,
89.3,
60.6,
48.5,
52.8,
33.1,
28.3,
64,
75.2,
48.5,
71.3,
36,
99,
44.6,
27.6,
86.7,
78.2,
5.5,
76.3,
2.2,
98.2,
31,
65,
65.4,
96.4,
66.3,
43.4,
9.2,
78.3,
67.1,
43.8,
62.6,
87.3,
52.1,
84.6,
58,
80.1,
83.6,
39,
62.1,
42.8,
69.1,
72,
66.5,
55.5,
43.7,
42.9,
72.5,
23.9,
36,
50.7,
0.4,
82.2,
73.9,
14.2,
95.3,
50.8,
59,
66.5,
54.1,
72.4,
66.8,
72.4,
55.3,
45.4,
36.5,
45.7,
86.5,
90.8,
36.5,
36.3,
75,
62.9,
68.5,
90.1,
57.6,
69.6,
72.3,
37.4,
66.1,
57.3,
82.2,
9.3,
70.8,
31.6,
53.4,
59.8,
13.2,
61.7,
71.2,
77.9,
57.3,
55.7,
91.2,
22.4,
52.1,
57.3,
70.2,
60.4,
66.1,
60.2,
63.7,
69.1,
48,
42.3,
15.5,
66.9,
60.1,
81,
43.9,
33.4,
15.5,
80.2,
53.6,
87.3,
54,
90.6,
31,
8.4,
36.2,
36.2,
32.8,
15.3,
28.4,
31.4,
52.6,
78.3,
71.5,
94.1,
45.9,
11.8,
58.1,
59.5,
90.9,
67,
37,
85.2,
68.8,
81.4,
27.4,
17.4,
85.7,
61.2,
89.5,
22.2,
22.9,
89.7,
69.3,
54.7,
96.5,
13.9,
46.9,
66.6,
63.3,
46.5,
11.4,
90.1,
44.5,
32.4,
76.6,
58.4,
47.1,
60.3,
69.9,
83.5,
70.7,
41.4,
78,
59.9,
87.4,
84.2,
11,
64.7,
102.1,
20.2,
73.3,
70.7,
29.6,
37.2,
47.8,
19.5,
64.1,
57.8,
72.8,
88,
28.5,
78.2,
28.6,
74.3,
22.7,
0,
59.1,
12,
54.7,
89.5,
67.7,
20.2,
53,
43.5,
27.2,
54.1,
64,
60.9,
65.6,
43.3,
45.6,
43.8,
77,
21.8,
35.2,
49.9,
29.1,
51,
1.2,
51.5,
22.1,
56.6,
49.6,
41,
60.5,
15,
76.6,
24.7,
38.5,
31.6,
85.7,
81.1,
82.4,
15.5,
89.5,
26.5,
81.2,
25.6,
18.4,
85.7,
80,
75.4,
64.9,
95.5,
34.3,
46.2,
19.4,
80.7,
47.4,
38.9,
53.4,
73.7,
69.8,
24.9,
76.8,
93.5,
70.7,
4.1,
54,
28.7,
12.3,
48.2,
80.3,
80.2,
12.8,
45.5,
14.3,
17.1,
72.4,
40.5,
20.8,
60,
71.2,
50.7,
63.8,
61.9,
47.3,
57.5,
19.9,
80.6,
78,
16.7,
43.8,
96.2,
91.5,
83.8,
89.8,
65.5,
26.8,
76.2,
68.6,
7.4,
50,
88.1,
80.2,
77.4,
28.6,
81.9,
55,
48.9,
44.3,
27.9,
50.9,
33.2,
51.1,
60.1,
22.1,
17.5,
36.6,
4.2,
79.6,
15.5,
15.1,
54,
54.5,
59.9,
5.5,
53.2,
49.2,
57.3,
37.1,
50.7,
83.5,
28,
19.2,
31,
44,
78.4,
67,
0,
72.4,
62,
74.5,
68,
36.2,
60.5,
25.5,
1.5,
75.2,
54.1,
52,
59.4,
79.5,
35.2,
50.8,
26,
90.3,
80.1,
71.7,
47.6,
34,
48.1,
61.6,
22.7,
49.6,
55.8,
32.2,
24.8,
23,
61.1,
63.4,
84.6,
67.2,
41.6,
63.7,
83.7,
69.5,
56.1,
17.8,
66.9,
46.9,
66.3,
76.6,
40.5,
82,
90,
42.5,
63.8,
59,
85.3,
81.7,
99.1,
9.1,
60.9,
61.7,
55.2,
61.1,
72.6,
9.2,
32.5,
39.8,
72.4,
28.8,
54.7,
66.4,
51.8,
30.9,
75.1,
70,
78.9,
80.1,
71.4,
87.2,
44.5,
48.7,
46.9,
85.5,
90.4,
90.7,
82.2,
65.1,
55.5,
38.1,
47.9,
56.4,
47.7,
47.3,
49.7,
83.2,
77,
61,
59.5,
50.6,
3.4,
22.8,
41.2,
27.5,
93.2,
78.5,
46.9,
41.8,
38.9,
16.5,
43.9,
34.6,
76.7,
0,
68.1,
71.1,
61.6,
78.6,
77.5,
47,
64.7,
56.1,
73.5,
71.3,
68.3,
53,
6.6,
42.5,
47.5,
75.9,
10.3,
74.3,
36,
19.3,
70,
59.4,
94,
36.5,
94.6,
32.4,
55.1,
7.8,
96.1,
12.8,
61,
41.6,
62.4,
69,
47.2,
57.2,
45.4,
73.5,
79.1,
66.8,
81.2,
25.9,
52.7,
55.7,
49.9,
55,
81.9,
84.5,
80,
99.2,
11.8,
34.3,
58.2,
42,
56.5,
26,
68.8,
59.4,
77.3,
54.7,
47,
81.9,
29.6,
61.5,
27,
23.6,
28.2,
69.3,
29.9,
41.2,
50.4,
38.8,
86.8,
21.1,
27.2,
83.8,
76,
96,
31.7,
59.3,
43,
57.6,
83.4,
72.7,
49.5,
100.3,
89.6,
53.3,
18.8,
9.5,
54.9,
22.8,
50.8,
43.4,
88.1,
88,
70.9,
99.5,
80,
76.3,
66.6,
66.7,
41.8,
46.6,
94,
40.2,
49.3,
25.1,
31.5,
36,
22.1,
94.8,
64.9,
35.7,
56.5,
95.4,
58.3,
89.2,
51.4,
37.5,
94.1,
40.5,
21.4,
7.9,
39.1,
8.4,
3.4,
20.7,
76.9,
42.4,
64.6,
63.6,
82.4,
59,
33,
16.7,
31.6,
78,
40.2,
48.3,
76.3,
28.8,
49,
78.6,
47.8,
70,
89.2,
68,
95.6,
62,
80.4,
39.2,
50.3,
38,
67.2,
46,
88.5,
28.9,
37,
26.5,
63.6,
46,
8.3,
87.8,
21.4,
41.2,
35.6,
42.7,
76.8,
59.6,
26.9,
32.1,
32.9,
58.8,
47.5,
30.9,
45.3,
33,
49,
33.5,
67.5,
56.1,
92.6,
12,
9.5,
71.6,
28.2,
24.1,
50.9,
89.3,
58.4,
22.3,
85.4,
5.1,
40.3,
49.3,
39.5,
68.9,
42.8,
71.1,
52.7,
78.5,
60.9,
49.6,
19.4,
82.6,
78.7,
78.6,
8.6,
47.5,
34.6,
41.6,
20,
85.4,
84.3,
63,
67.9,
25.6,
84.3,
26.3,
49,
56.7,
30.8,
76,
57,
64.6,
86.2,
42.3,
17.6,
57.3,
39.9,
46.4,
83.5,
55.6,
11.4,
73.6,
52.8,
29,
34.3,
20.1,
11,
29.3,
48.4,
72,
13.1,
74.4,
65,
20.5,
50.2,
82.5,
3,
51.3,
69,
78.9,
74.5,
39.5,
51.9,
68.1,
91.6,
33.8,
67.6,
31.6,
60.9,
30.2,
78.4,
96.3,
19.2,
6.1,
75.6,
38.5,
83.4,
39.7,
72.9,
90.1,
75.5,
56.5,
48.1,
70.4,
53.7,
59,
70,
33.4,
71.4,
76.8,
61.9,
16.2,
82,
99,
85.2,
28,
17.5,
45.9,
67.7,
13.5,
63.1,
65.3,
67.5,
62.3,
70.7,
58.6,
18.8,
77,
76.8,
35,
48.2,
25.8,
24,
64.1,
38.6,
19.6,
24.3,
58.4,
64.7,
22,
40.6,
0,
95.5,
51.8,
52.6,
55.6,
7.7,
30,
65.3,
92,
92.9,
77,
66.5,
54.8,
15.3,
56.2,
72.1,
60.8,
71.2,
0.7,
20.6,
89.9,
67.9,
94.1,
52.4,
53.4,
82.8,
72.7,
98.1,
36.5,
21,
27.1,
54.9,
58.5,
62.9,
69,
75.5,
70.3,
6.9,
68.1,
83.6,
58.5,
73.1,
36,
70.7,
48.5,
27.6,
42.8,
37.7,
37.9,
81.4,
19.9,
6.5,
50.3,
56.9,
84.8,
19.6,
46,
72.9,
80.3,
35.5,
64.2,
87.4,
83.3,
76.2,
72.6,
89.9,
57,
72.1,
84.6,
68,
80.2,
48.3,
67.3,
26.8,
44.8,
71.5,
65.3,
18.9,
67.2,
54.6,
4.3,
46.6,
75.9,
91.7,
58.5,
61.5,
58.3,
21.2,
38.7,
22.6,
61.3,
71.9,
48,
28.4,
58.9,
65.3,
79.1,
36.2,
34.8,
49.6,
39,
17.7,
42.2,
70.9,
22.2,
69.3,
70.5,
69.2,
35.7,
48.9,
53.4,
55.8,
36.8,
40.5,
74.8,
62,
18.2,
72.7,
70.1,
80.9,
17.5,
63.6,
19.5,
102,
47.2,
53.9,
79.8,
50.2,
21.7,
24.1,
46.7,
24.8,
92.5,
0.7,
62.9,
8.3,
11.4,
22,
55.7,
75.7,
26.2,
86.3,
60,
53.2,
63.2,
91,
25.3,
36.7,
71.9,
47,
21.8,
54.9,
84.8,
94.2,
90.7,
56.1,
52.4,
31.2,
56.1,
9.2,
45,
7.5,
50.6,
47.2,
61.3,
74.7,
9.2,
97.5,
65.4,
31.1,
84.9,
69.6,
97.1,
21,
87.8,
48,
75,
69.5,
0,
95.6,
92.6,
14.5,
57,
89.9,
63.8,
31.3,
93.7,
67.6,
16.7,
43.2,
46.7,
79.7,
63.4,
29.4,
89.7,
55,
29.3,
44.7,
28.5,
47,
25,
66.3,
89.1,
98.5,
87.1,
69,
10.7,
58.9,
58.5,
25.9,
13.2,
29.6,
29.7,
76.1,
7.7,
90.9,
39,
69.5,
39.9,
28.9,
27.4,
93.5,
63.9,
31.5,
68.6,
80.7,
45,
50.1,
76.4,
28.5,
83.6,
61,
28.8,
67.8,
21.9,
0,
74.4,
46.2,
57.8,
22.9,
18.9,
54.3,
64.9,
62.9,
63.2,
19.9,
89,
48.4,
53,
70.2,
88.4,
21.4,
20,
70.8,
71,
91.3,
17.4,
68.3,
16.7,
48.2,
72.5,
90.5,
55.8,
83.8,
53,
36.2,
56.9,
86,
67.9,
70.5,
27.3,
48.3,
80.2,
57.7,
40.3,
46.4,
63.9,
9.4,
93.3,
82.7,
80.2,
46,
70,
49.8,
57.2,
19.3,
82.3,
83,
78.7,
30.1,
63.2,
58.9,
45.6,
30,
69.9,
31.5,
54,
33.2,
91.3,
78.1,
44.1,
74.6,
6.5,
33.2,
54.3,
75.7,
28,
73,
70.7,
97.9,
83.1,
11.1,
31.7,
61.9,
53.9,
59.5,
95.4,
38,
51.6,
86.5,
83.3,
8.4,
37.4,
50.9,
35.1,
54.8,
67.2,
60.8,
91,
82.4,
27.7,
54.1,
69.7,
41.4,
58.8,
39.2,
41.4,
42.4,
90.7,
82.7,
74.4,
52.3,
45.2,
55.7,
0.4,
67.9,
48,
51.4,
37.7,
46.3,
12,
31.9,
32.1,
33.9,
54.3,
76,
39.5,
49.8,
76.8,
67.9,
76.2,
65.3,
20.3,
72.7,
77.6,
36.9,
88.3,
84.8,
33.8,
47.3,
47.6,
35.2,
40.1,
61.6,
34.7,
24.5,
40.4,
76.6,
22.1,
61.7,
62.1,
95.5,
43.4,
60.3,
90.7,
75,
27.8,
34.4,
27.7,
98.1,
96.2,
66.8,
86,
50.9,
61.9,
63.7,
79.8,
39,
23.4,
82.1,
41.6,
48.8,
53.8,
25.3,
31.5,
33.2,
52.9,
44.6,
78,
48.2,
59.8,
50.1,
67.6,
36.5,
54.3,
12.4,
47.8,
76.6,
56,
34.3,
44.9,
32.9,
70.5,
54.6,
79.9,
20.1,
21.5,
72.5,
86.1,
90.3,
73.8,
26.6,
25.9,
41.5,
62.3,
73.4,
19.9,
27,
51.6,
60,
47.1,
61.7,
57.1,
62.8,
28.9,
52.4,
60.6,
48.9,
47,
13.7,
93.1,
77.6,
18,
78.6,
54.9,
61.9,
43.1,
65.1,
51.3,
73.1,
55,
50,
65.5,
27,
88.6,
36.2,
99.1,
47.6,
89.3,
34.8,
72.1,
32,
66.6,
64.2,
87.5,
75.3,
70.5,
42.2,
75.9,
33.6,
58.5,
30.6,
86,
48.2,
40.5,
51.6,
29.2,
94.5,
35.8,
98.5,
43.5,
81.4,
71.4,
64.6,
63.6,
51.7,
28.6,
97,
80.8,
46.6,
39,
26.7,
52.2,
76.9,
42.3,
71.4,
30.2,
15.8,
27.9,
41.1,
25,
54.3,
48.9,
30.5,
71.8,
79,
83.3,
66.2,
24.5,
38.6,
35.2,
67.8,
30.2,
45.6,
58,
79.3,
15.8,
45.6,
85.8,
31,
1.9,
55.8,
79.8,
42.6,
57.9,
58.4,
32.6,
56,
71.4,
75.5,
75.6,
63.1,
36.9,
91,
46.2,
61.5,
32.3,
88.8,
71.8,
37.4,
83.4,
90.5,
34.6,
32.9,
69.2,
81.6,
16.9,
13.9,
50.3,
24.1,
96.4,
57.8,
25,
83.3,
74.3,
1.7,
48.1,
58.8,
71.3,
61,
83.6,
55.6,
25.2,
83.9,
33.2,
27.5,
28.8,
31.1,
46.5,
43,
89.6,
36.3,
25.8,
96.4,
77.6,
51.1,
48,
46.3,
4,
88.9,
50.1,
39,
22.2,
81.5,
39,
53.4,
62.6,
90.7,
39.8,
33.9,
20.9,
84.8,
40.4,
60.1,
59,
98.8,
75,
59,
52.5,
45.5,
63.1,
35.1,
85.4,
54.4,
13.6,
72.5,
87.5,
64.9,
84.5,
41.9,
27.8,
23,
77.3,
91.1,
70.9,
68.1,
12.6,
37.4,
98.8,
55.3,
90,
23.5,
69.9,
28.9,
21.1,
64.2,
16.8,
97.8,
28.9,
77.9,
43.7,
24.9,
46.4,
74.6,
77,
69.7,
99.5,
68.6,
61.1,
67.2,
71.1,
58.2,
38.9,
101.2,
68.4,
33.8,
6.7,
52.6,
40.5,
50.7,
77.9,
80.9,
67.8,
48.8,
56.6,
95,
56.6,
76,
45.6,
45.3,
94.4,
60,
40.9,
15,
84.5,
38,
83.3,
81.2,
83.3,
27,
26,
17.9,
48.8,
90.8,
72.9,
50.8,
22,
71.2,
49,
71.8,
19.8,
65.1,
53.1,
19.9,
74.2,
38.3,
61,
53.2,
93.6,
53.7,
87.7,
54.5,
47.7,
64.7,
27.9,
83.7,
51.6,
64.4,
58.6,
44.1,
47,
8.9,
69.8,
49.3,
56.9,
52.4,
57.7,
60.2,
28.8,
25.1,
63.8,
59.7,
69.8,
45.8,
86.9,
10.5,
36,
48.1,
63.3,
93.9,
104.7,
62.8,
32.9,
21,
59,
93.8,
65.5,
70.6,
60.5,
27.4,
75.9,
65.3,
55.7,
84.1,
72.1,
78.8,
70.8,
48.3,
16.5,
50.9,
48,
63,
80,
93.8,
98.7,
28.8,
40.9,
49.6,
34.9,
27.4,
38.2,
52,
33.5,
38.4,
55.2,
16.8,
70.5,
33.4,
48.7,
41.2,
60.4,
35.7,
31.3,
65.7,
28.8,
7.7,
42.2,
28.2,
34,
34.7,
10.7,
52.7,
87.7,
19.9,
55.3,
74.6,
18.3,
2.3,
23.4,
44.8,
92.4,
70.6,
46.5,
87.9,
0,
33.8,
70,
91.5,
46.1,
0.1,
59.8,
36.8,
75,
80.7,
39.6,
58.8,
16.8,
26,
0,
57.5,
73.8,
60.6,
72.2,
3.8,
59.9,
85,
98.7,
39.1,
44.9,
68.8,
33.7,
83.9,
59.7,
64.7,
49.9,
83.5,
38.5,
46.5,
25.7,
26.5,
50.3,
32.5,
29.9,
66,
83,
45.9,
73.6,
44.8,
48.8,
85,
99.2,
40.6,
33.2,
57.7,
36.5,
77,
57.3,
50.2,
48.4,
99,
86.8,
103.7,
61.5,
45.7,
81.4,
65.1,
36.5,
38.2,
84.9,
35,
84.3,
30.4,
38.7,
49.5,
43.1,
84.5,
89.7,
47,
76.6,
33.4,
29.7,
65.3,
94.6,
94.8,
91.7,
44.9,
57.6,
53.3,
64.9,
61.6,
66.1,
56.9,
27.3,
35,
91.5,
29.4,
50.2,
22.3,
90.1,
48.1,
86.7,
44.4,
74.5,
88,
26.2,
42.4,
42.7,
60.4,
67.7,
63.6,
49.1,
72.7,
94.3,
59.3,
20.6,
67.7,
74.3,
73.9,
37.5,
33.4,
62,
73.3,
77.8,
74.5,
66.7,
18.1,
38,
57.3,
56.1,
27.4,
74.2,
58,
44.4,
9.4,
98.5,
97.5,
88.1,
16.8,
26.3,
90.6,
42.2,
81.1,
80,
61.6,
81.9,
76,
62.1,
57.9,
59.2,
24.3,
49.4,
48.1,
78.4,
67.8,
84,
86.5,
6.1,
53.7,
50.3,
51.4,
46.8,
43.5,
59.4,
86.3,
46.6,
7.5,
47.2,
39.7,
51.9,
61.5,
1.6,
46.9,
60.4,
88.4,
66,
5.7,
53.8,
28.5,
12.8,
88.8,
57.2,
55.3,
37,
31,
5.4,
31.5,
52.4,
100.5,
79.8,
47.1,
84.1,
62.2,
64.1,
88.2,
94.3,
61.6,
37.3,
53.1,
60,
36.5,
96.3,
45.8,
93.8,
8.7,
33.6,
54.3,
10.1,
46,
29.6,
84.3,
49.5,
69.9,
66.3,
77.2,
8.3,
56.7,
70.8,
0,
31.1,
80.8,
20.2,
15,
72.4,
25.3,
77.8,
70.1,
59.5,
84.8,
65.8,
34.5,
97.3,
87.6,
53.1,
39.7,
71.1,
14.9,
91.1,
56.6,
75.8,
49.9,
67.1,
40.2,
79.8,
25.8,
41.9,
45.8,
55.9,
67.6,
62.7,
84.5,
28.6,
77.2,
35.7,
68.1,
64.6,
46.9,
72.8,
73.7,
35.4,
63.9,
89.7,
62.7,
55.6,
93.1,
75.5,
99,
57.8,
87.1,
86.4,
32.9,
30.2,
30.2,
59.1,
25,
85,
61.1,
47,
60.6,
48.9,
73.4,
96.9,
49.1,
90,
69,
41.3,
85.9,
80.9,
44.9,
72.3,
73.4,
37.6,
49.2,
53.9,
70.4,
38.8,
46.4,
69.4,
62,
38.8,
5.8,
85,
91,
69.8,
86.7,
86.5,
65.8,
52.3,
82.7,
33.1,
82.4,
32.5,
80.2,
92.7,
44.5,
52,
20.3,
33.4,
21.2,
54.3,
41,
45.4,
70.8,
70,
91.5,
57.9,
31.6,
41.6,
41,
30.4,
93.8,
53,
21.1,
0,
28.4,
61.4,
56,
50.1,
65.6,
45.4,
9.8,
24.6,
53.7,
93.5,
65.6,
0.5,
69,
80.3,
74.9,
76,
85.4,
32.9,
70.6,
38.9,
41.6,
30,
30.2,
67.8,
48,
78,
41.9,
53.7,
27.2,
58.3,
37,
24,
17.7,
47.4,
91.3,
74.7,
56.7,
58.7,
75.9,
31.2,
68.5,
68,
55.5,
63.5,
45.2,
43.7,
30.3,
72.4,
62.5,
46.2,
66.6,
24.2,
40.5,
86.2,
38.8,
42.4,
44.4,
64,
36.7,
84,
26.7,
23.8,
78,
27.9,
53.3,
51.3,
83.9,
84.5,
79.9,
70.9,
73.2,
82.6,
34,
34.2,
66.9,
47.3,
81.4,
72.6,
70.4,
49,
49.7,
18.1,
99.5,
50.7,
57.4,
84.6,
64.8,
8.4,
32.1,
70.3,
90.5,
42.6,
90.7,
77,
91.4,
64.4,
60.7,
57.9,
42.6,
90.2,
47.9,
53.5,
51.9,
76.3,
35,
77.7,
55.9,
62.6,
85.1,
71.9,
76.6,
81.9,
75.8,
2,
29.6,
23.4,
78.8,
36,
88,
51.6,
84,
87.2,
95.8,
23.3,
47.8,
43.5,
43.8,
33.3,
88.4,
43.6,
84.1,
47.9,
32.3,
74.2,
85.2,
80.6,
49.5,
17.8,
52.5,
18.9,
90.7,
23.6,
75.5,
25.4,
31.2,
56.7,
38.6,
93.9,
55,
44.6,
100.1,
53.9,
39.6,
10.8,
35.3,
84.5,
64.5,
93.7,
39.3,
9.4,
96.3,
56.5,
49.3,
39,
93.3,
56.6,
90.2,
50.2,
35.7,
57.5,
31.8,
2.3,
82.1,
81,
48,
79.4,
23.2,
66.6,
89.5,
48.9,
6.7,
55.6,
67.7,
51.4,
68.8,
47.8,
74.8,
45.3,
79.4,
62.2,
60,
64.6,
55.4,
53.7,
12.8,
34.3,
58.9,
7.9,
14,
38.5,
22.1,
0.2,
76.6,
58.9,
27.3,
73.4,
64.6,
95.3,
68.3,
26.7,
93.9,
72.7,
5.5,
64.4,
60.2,
12.3,
32.4,
4.6,
57.6,
55.2,
51.2,
45.7,
76.9,
63,
90.8,
37.4,
41.4,
61,
69,
29.4,
69.2,
41,
26.7,
57.9,
100.1,
78.8,
75.7,
26.9,
94.8,
27.2,
55.1,
62.6,
13.5,
53.7,
53.6,
47.6,
55.6,
79.6,
18.4,
32.8,
34.7,
21,
23,
65.9,
2.4,
44.2,
89.2,
58.6,
47.3,
4.2,
13.4,
16,
74.2,
94.7,
28.4,
31.6,
38.2,
96.4,
82,
71.4,
87.4,
71.8,
2.9,
58.2,
80.2,
38.6,
68.3,
29.2,
21.5,
8.3,
32.2,
52.6,
91.3,
52.8,
39.1,
91.4,
17.9,
2.3,
79.6,
58.6,
28.3,
28.9,
68.8,
44.1,
19.8,
14.1,
40.4,
40.4,
53.4,
42.4,
67.2,
68.5,
12.4,
51.6,
33.5,
93.1,
3.3,
64.5,
78.5,
27.9,
38.6,
51.3,
78.1,
60.7,
41.5,
43.1,
65.2,
31.7,
27.2,
44.2,
18.7,
69.2,
96.3,
53.1,
72,
85,
83.9,
36.8,
67.7,
40.6,
27.3,
30.3,
90.5,
20.3,
29.1,
34.7,
32.4,
64.2,
21.1,
66.2,
51,
30.7,
71.6,
81,
64,
57,
27,
95.7,
51.5,
42.2,
76.9,
28,
58.9,
58.7,
50,
26.6,
60.8,
62,
35.6,
63,
76.2,
86.5,
70.3,
48.8,
75.3,
63.8,
54.5,
84.3,
41.3,
36.1,
19.1,
65.9,
65.3,
84.1,
0.7,
42.5,
32.5,
46.4,
75.6,
89,
94.5,
65.8,
93.1,
50,
68.8,
33.8,
54.7,
41.9,
25.4,
44.9,
26.5,
50,
5.4,
39.9,
38.9,
97.1,
75,
79.6,
47.8,
72.7,
34.8,
98.6,
58.1,
102.2,
44.3,
59.9,
7.2,
49,
38.1,
34.2,
29.5,
58.4,
61.2,
37.5,
55,
18.6,
86.9,
39.4,
23.7,
99.7,
56.1,
76.8,
91.5,
45.8,
24,
65.2,
35.9,
76,
69,
64.2,
44.6,
59.6,
38.7,
91.7,
65.3,
56.1,
75.1,
40,
31.4,
78.2,
47.2,
64.8,
30.4,
61.1,
56.3,
58.8,
100.6,
85,
45.4,
76.6,
58.5,
21.4,
65.9,
62.1,
53.6,
50.9,
46.2,
75.9,
70.7,
98.5,
82,
50.6,
27.3,
45.8,
20.9,
43.7,
69.7,
41.2,
76.1,
48.2,
26.9,
56.8,
74,
94.6,
45.9,
82.3,
59,
44.7,
65.4,
31.2,
87.1,
48.1,
80.6,
95.3,
50.6,
27.6,
88.8,
37.8,
54.4,
18.4,
3.9,
56,
72,
70.2,
75.4,
84.8,
76.4,
61.3,
68.9,
54.6,
81.3,
99.2,
65.1,
78.6,
18,
61.5,
59.8,
10.4,
92.6,
81.2,
34.9,
90.5,
59.4,
30.8,
70.7,
68.6,
70.4,
97.3,
90.5,
25.9,
13.8,
36,
30.5,
64,
30.9,
38.5,
68.1,
40.7,
49.2,
0.8,
62.3,
47.9,
58.4,
54.3,
47.9,
44.7,
73.8,
74.9,
98,
50.5,
58.5,
72.5,
72.9,
96.4,
48,
48,
35.8,
34.1,
22,
52.7,
87.5,
37.1,
57.4,
80.2,
67.1,
6,
54.4,
76.1,
60.6,
58.1,
20.6,
82.4,
76.9,
62.2,
96.2,
83.5,
26.6,
66,
31.8,
29.7,
3.9,
85.9,
25.9,
69.5,
15.9,
55.7,
95,
30.2,
33.3,
72.2,
30.1,
57,
78.8,
78.9,
29.8,
61.8,
40,
78.4,
62.3,
37.8,
71.9,
93.6,
48.4,
63.9,
53.7,
17.8,
89.6,
40,
48.6,
42.9,
83.1,
70.4,
84.6,
18.3,
23.3,
30,
75.9,
84,
27.3,
77.3,
84.9,
7.8,
84,
51.9,
91.9,
45.3,
33.6,
53.9,
40.4,
41.3,
52.4,
2,
53.1,
77.2,
9.7,
87.2,
63.2,
91.6,
79.7,
62,
18.3,
49.9,
63.5,
42.4,
88.1,
50.2,
43.3,
43.3,
63.5,
42.3,
56.1,
55,
79.3,
47,
68.3,
73.5,
58.7,
86.4,
50.6,
32.7,
88.2,
86.8,
34.8,
50,
33.1,
76.2,
65.4,
44,
80.6,
70.6,
74.4,
61,
44.6,
52.8,
61.6,
38,
28,
72,
76.5,
80.1,
74.2,
81.7,
82.2,
6.8,
56.5,
35.7,
83.3,
41.8,
72.6,
37,
70.7,
46.4,
84.3,
66.5,
25.4,
12.4,
92.2,
65,
90.7,
17.2,
68,
74.4,
36.7,
97.1,
35.3,
6.3,
19.7,
38.6,
0,
69,
78,
67.9,
99.9,
36.6,
34.6,
45.5,
58,
48.1,
42.9,
48.7,
65.1,
80.9,
87.7,
75.1,
59.2,
44,
65.1,
15,
100.7,
81.4,
54.3,
17,
75.7,
46.4,
44.7,
31,
73.2,
62.9,
99.3,
80.2,
70.1,
56.4,
77.3,
58.1,
39.3,
52.7,
70.6,
38.3,
1,
93.6,
70.1,
30.6,
20,
66.4,
33.9,
36.9,
42.3,
69,
95.2,
62.7,
50.9,
66.1,
4,
35.4,
99.8,
62,
35.7,
57.2,
73.5,
95.4,
53.5,
24.3,
29.9,
25,
35.4,
86.8,
9.6,
64.8,
62.3,
59,
41.8,
62.5,
69.2,
51.5,
50,
96.8,
75.2,
86.6,
73.4,
24.9,
83,
13.9,
83.4,
57,
58.4,
42.4,
76.3,
68.2,
56.4,
70.8,
28.8,
51.7,
92.6,
63.2,
11.1,
44.2,
40.1,
49.6,
8.9,
10.4,
91.7,
4.3,
44.7,
72.5,
61.6,
59.6,
58.8,
50.7,
82.9,
72.6,
6,
29.3,
43.3,
49.5,
67.4,
26.1,
74.2,
100,
72.5,
93.9,
24.2,
81.5,
91,
64.7,
74.3,
61.9,
34,
60.4,
65,
57.1,
73,
48.5,
63.9,
67.6,
72.1,
54.4,
87.1,
33.1,
46,
70.6,
53.8,
63.1,
95.4,
85,
61.1,
49.8,
72.1,
53.1,
83.7,
96.3,
91,
65.4,
30,
51.8,
89.6,
39.9,
72.1,
97,
38.9,
41.9,
48.3,
58.1,
71.6,
35,
45.4,
27.6,
71.1,
37,
22.6,
65.5,
51,
53.4,
52.8,
75,
4.9,
25.2,
18.3,
87.3,
56.8,
73.8,
84.3,
76,
36.5,
25.3,
46.8,
28,
34.2,
73.2,
39.5,
81.9,
82.6,
69.8,
35.8,
71.3,
99.7,
21.3,
17.5,
67.9,
47.3,
34.6,
29.9,
84.3,
41.5,
64.4,
34.7,
37.5,
45.7,
64.1,
37.1,
7.1,
87.7,
56.5,
100,
69.7,
58.8,
73.1,
94.6,
86,
21.7,
56,
33.3,
49,
30.9,
47.3,
18.4,
19.9,
22.1,
66.7,
15.2,
53.6,
43.2,
50.6,
41.4,
63.5,
37.7,
56.8,
69,
22,
83.8,
24.4,
86.8,
83.3,
45.8,
19,
82.3,
58,
46.9,
80.9,
75.4,
50.3,
76.5,
66.5,
51.2,
47.6,
77.4,
95.1,
50.1,
57.8,
35.8,
71.4,
63,
48.5,
86,
52.7,
5.7,
65.1,
86.4,
55.2,
72.4,
89.7,
53.6,
41,
37.9,
63.7,
84.1,
87.4,
63.6,
64.1,
38.6,
77.6,
20.4,
35.6,
71,
71.9,
79.4,
69.9,
51.3,
67.5,
88.4,
13.7,
97.4,
67.1,
62.5,
76.6,
88.2,
74.5,
43.7,
29,
23.7,
44.4,
15.8,
90.6,
45.6,
46.7,
70.3,
69.9,
72.6,
82,
63.3,
20,
70.1,
33.1,
42.6,
69.9,
69.4,
49.1,
74.8,
47.6,
25.4,
69.8,
77.5,
60.3,
62.1,
68.3,
78.8,
89.8,
58.4,
11.2,
84.2,
96.1,
58.4,
60.4,
65.1,
66.3,
84,
20.4,
58.9,
61.5,
50.8,
76.1,
88.4,
65.3,
61.7,
41.4,
67.9,
55.1,
35,
29.8,
62.6,
15.1,
95.6,
77,
80.3,
42.5,
57.3,
69.4,
75.3,
74.1,
72.5,
22.2,
57.9,
21.5,
27.5,
9.1,
44.7,
93.6,
50.5,
52.8,
21.3,
67.7,
33.6,
65.5,
83.2,
65.6,
61.7,
47,
55,
61.8,
48,
25,
42.7,
9,
13.4,
24.2,
88.8,
62.5,
97,
61,
80.8,
34.8,
75.3,
56.6,
61.6,
59.9,
98.6,
75,
91.8,
68.7,
92.1,
59,
51.4,
72.3,
57.2,
36.2,
84.5,
67.8,
77.3,
62,
74.4,
91.9,
59.6,
77.2,
84,
65.2,
61.1,
80.5,
29.6,
48.8,
18.4,
47.2,
55.8,
64,
31.5,
93.6,
100.4,
46.3,
78.1,
41.6,
8.9,
40.1,
51.2,
92.4,
92.9,
51.1,
72.5,
22.7,
54.6,
61.4,
59.4,
21.1,
84.9,
81.8,
53.8,
73.5,
39,
35,
60.7,
44.4,
29.8,
48.2,
64.2,
34.5,
18,
23,
18.9,
50.4,
50,
49.8,
92.5,
55.9,
18.3,
62.8,
50.8,
36.9,
93.5,
78.9,
63.3,
51,
29.2,
69.6,
41.4,
35.1,
3.9,
36.3,
61,
38.5,
26.3,
52.7,
81.1,
68,
79.2,
80.5,
59.8,
76.8,
56.1,
8.7,
96.5,
94.3,
67,
63.9,
92.7,
78.1,
58.2,
43,
47,
82.2,
71.9,
40.1,
41,
19.8,
25.7,
74.2,
21.5,
60,
3.8,
61.8,
79.5,
62.8,
70.3,
26.1,
82.7,
59,
53.2,
72.2,
49.8,
57.5,
54.8,
21.4,
47.9,
66.3,
81.2,
95,
67.8,
58.7,
44.9,
53.4,
6.6,
42.3,
50.2,
26.6,
46.3,
36.9,
60.9,
80.2,
90.8,
75,
88.6,
43.6,
43.1,
61.2,
64.4,
87.7,
74.3,
45.8,
32.7,
49.1,
82.4,
87.2,
44.2,
19.1,
39.8,
92.3,
40.3,
20.5,
72.9,
97.6,
82.7,
35.9,
90.2,
33,
37.5,
59.8,
47.9,
34.7,
85.9,
40.3,
58.2,
26.4,
80.5,
81.1,
5.7,
58.9,
49.5,
47.4,
61.2,
22.4,
38.4,
99.9,
61.2,
90.6,
22.5,
79,
35.5,
45.7,
55.8,
80.5,
74.6,
20.6,
53.5,
17.9,
38,
5.2,
33.8,
23.9,
26.6,
90.6,
89.1,
91.9,
24.1,
64.4,
56.2,
92.5,
88.2,
55.4,
53.2,
77.3,
75.4,
24.2,
43.3,
46.5,
67.5,
67.9,
41.8,
90.4,
62.8,
21.6,
97.8,
28.8,
76.2,
82,
92.6,
87.2,
26.7,
64.3,
67,
33,
11.4,
88.8,
57.7,
74.4,
53.8,
25.6,
24.6,
79.1,
70.8,
95.7,
77.5,
22.2,
78.9,
55.7,
59.1,
75.3,
27.4,
36.3,
47.5,
45.6,
60.4,
85.6,
37.7,
67.4,
44.2,
32.1,
43.4,
65.5,
75.2,
49.6,
59.2,
48.8,
18.4,
41.8,
78.5,
9.3,
88.3,
56.1,
38.9,
94.2,
97,
66.7,
39.7,
92,
12.7,
73.6,
63.8,
72.2,
42.8,
59.2,
54.8,
45.8,
79.1,
37,
62.8,
51.8,
88.4,
51.1,
34.2,
59.8,
96,
59.9,
65.5,
44.9,
63.3,
69.6,
27.1,
69.1,
47,
61.6,
62.2,
1.5,
45.7,
50.8,
63.5,
36.8,
81.8,
35,
57.5,
70.6,
85.8,
25.7,
97,
42,
77.3,
17.8,
41.4,
64.5,
81.1,
84.9,
40.3,
88.1,
13.8,
89.3,
73.9,
47.4,
39.8,
66.5,
78.6,
63.6,
79.5,
91,
79,
22.5,
31,
85.6,
15.1,
32.4,
10.7,
17.3,
38.5,
25.8,
76,
90,
85.4,
25.5,
4.6,
46.2,
83.5,
71,
33.2,
59.9,
82.2,
83.7,
88.2,
36.7,
18.7,
35.9,
14.2,
64.4,
70.1,
51.1,
89,
59.8,
74,
91.5,
76.8,
86.3,
56.1,
74.8,
69.1,
80.3,
54.2,
68.5,
88.7,
57.3,
65.2,
70.1,
35.2,
71.5,
23.4,
90.6,
54.8,
26.1,
59.7,
20.9,
44,
67.2,
20.2,
51.2,
36.8,
60.9,
97.5,
61.4,
92.5,
19.9,
72.4,
51.9,
78,
34.6,
72.3,
78.9,
74.2,
51,
70.3,
78.9,
36.6,
61.6,
76.2,
84.5,
88,
24.4,
57.2,
47.5,
36.3,
31.8,
55,
49.6,
75.9,
10.4,
68.6,
35.4,
91.2,
88.6,
34.1,
90.3,
53.3,
61,
55,
58.5,
89.1,
13.8,
66.1,
2.8,
37,
17.9,
42.9,
71.7,
15.9,
0.1,
22.5,
42.6,
73.6,
54.1,
50,
90.1,
86.8,
45.2,
66.2,
84.4,
80.5,
84.9,
80.5,
42.6,
30,
54.1,
13.1,
66.3,
90.4,
72.3,
82.7,
72.7,
81.5,
77.6,
27.6,
77.7,
62.4,
52.6,
18.2,
80.3,
11.4,
98.1,
14.9,
69.7,
58.1,
27.8,
88.8,
4.6,
82.8,
35.4,
7.9,
59.1,
93.5,
62.9,
49.9,
71.7,
38.9,
55.9,
40.7,
72,
96.6,
95.9,
55.6,
53.2,
88.5,
42.3,
18.1,
74,
29.9,
96.3,
42.2,
39.6,
22.2,
62.3,
64.3,
49.9,
56,
66.8,
41.8,
40,
64.3,
53.5,
76.9,
69.4,
27.8,
34.3,
40.3,
90.1,
95.9,
35.8,
94.7,
99.4,
94.4,
66.2,
46.2,
55.9,
38.6,
48,
19.9,
97.9,
47.5,
86,
41.7,
58,
76.3,
81.4,
55.2,
56.4,
64.2,
46.3,
57.7,
59.2,
76.3,
64.7,
53,
56.8,
52,
51,
62.2,
83.3,
52,
63.1,
73.8,
69.6,
97.9,
74.1,
28.9,
39.5,
42.4,
72.7,
21.8,
83.1,
55,
59,
76.1,
47.6,
85.5,
65.9,
32.3,
6.8,
60.6,
67.3,
48.9,
84.6,
42.5,
58,
23.9,
93,
17.2,
70.2,
69.8,
70.6,
71.4,
17.9,
59,
33.8,
89.7,
70.9,
60.9,
62.2,
94.3,
79.6,
38.6,
68.3,
67.4,
53.2,
96.5,
87.9,
73.7,
27.5,
28,
75.6,
78.3,
74.7,
46.6,
70.5,
97.1,
23.9,
26.7,
66.7,
85.3,
51.9,
18.6,
63.7,
47.4,
14.1,
40.1,
61.2,
15.9,
21.2,
21.3,
70.6,
59.1,
29.6,
78,
70.5,
89.3,
85.7,
89.3,
95.9,
71.7,
34.3,
61.8,
24.4,
43.8,
51.2,
63.3,
40.3,
44.7,
64,
0,
85.5,
36,
77.1,
48.6,
62.3,
39.4,
66.1,
94.8,
84.9,
80.6,
53.9,
28.3,
50.9,
82.6,
91.7,
33,
8.5,
57.2,
91.1,
57.7,
33.8,
48.9,
33.9,
30.2,
66.3,
11.5,
90,
76.9,
50.8,
62.7,
24.3,
70.3,
55.1,
39.3,
30.6,
27.1,
34.1,
71,
72.1,
72.5,
51.2,
81.3,
97.7,
52.9,
36.9,
77.9,
58.8,
51.5,
81.7,
61.1,
76.1,
61.9,
89.2,
75.5,
67.1,
92.6,
68.1,
41.6,
19.4,
33.6,
84.3,
34.4,
27.8,
46.6,
71.4,
25.7,
63.4,
83.9,
74,
68.4,
75.8,
45,
46.9,
63.8,
43.5,
47.1,
32.6,
45.2,
68.5,
44.6,
72.2,
49.7,
44.1,
95.7,
24,
74.6,
38.7,
94.5,
62,
68.6,
59.3,
72.7,
86.9,
24.3,
67.3,
73.9,
32.4,
30.6,
62.1,
28.7,
73.6,
74.6,
88.5,
55.2,
61.5,
55.1,
47.7,
43.4,
30.6,
86.7,
46.6,
32.3,
90.7,
18.9,
23,
58.6,
58.2,
82.8,
94.6,
44.5,
66.7,
51.4,
8.5,
75.1,
61.3,
76.1,
38.2,
71,
30.6,
94.6,
59,
45.7,
65.2,
79.4,
68.4,
75.4,
45.1,
64,
41.4,
46.7,
96.2,
39.2,
16.6,
25.1,
5.6,
62,
24.5,
98.6,
78,
74.6,
100.7,
53.6,
51.8,
96.4,
7.8,
43.7,
48.9,
29.5,
77.1,
67.6,
68.9,
75.9,
89.3,
62.9,
44.1,
43.5,
58.3,
69.7,
65.7,
24.5,
23.9,
50.5,
66.2,
13.9,
28.3,
65.6,
26,
86.5,
33.7,
63.3,
61.1,
57.9,
79,
49.4,
49.8,
32.8,
70,
70.4,
58.3,
69.4,
33,
24.6,
81.9,
71.8,
38.3,
89.8,
81.9,
57.4,
57.4,
50,
69.9,
52.9,
52.5,
27.3,
82.6,
16.4,
35.7,
73.9,
90.7,
74.3,
53.5,
93,
79.5,
48.9,
36.4,
49.3,
55.3,
39.5,
26.1,
39.1,
78.8,
54.1,
72,
77,
66,
51.8,
75.4,
72.8,
93.8,
76.4,
78.5,
35.8,
79.2,
95.4,
38.7,
27.3,
45.1,
61.7,
29.9,
9.6,
31,
61.7,
98,
60.8,
43.1,
63.9,
32.5,
42.5,
11.1,
48.8,
70.8,
69.9,
69.8,
72.1,
91,
56.9,
76.8,
19.1,
89.6,
23.7,
45.7,
55.3,
76.5,
68,
38.3,
38.8,
47.3,
78.3,
41.7,
44.1,
89.8,
88.4,
21.8,
3.9,
44.5,
41.7,
64.9,
63.5,
21.5,
96.9,
59.7,
43.4,
61.7,
34.7,
53.2,
66.7,
57.6,
97,
79,
68.8,
51.7,
58.8,
30.8,
98.2,
30.3,
43.6,
52.6,
58.1,
89.6,
35.5,
10.8,
67.4,
51.4,
94.8,
71,
45.5,
19.7,
85.3,
47.7,
65,
82.4,
94.8,
94.3,
62.2,
56.8,
27.2,
50.3,
54.2,
34.8,
54,
64.7,
33,
64.6,
62.1,
97.4,
36.1,
85.3,
42.7,
55.6,
21.4,
18.9,
38.8,
50.4,
50.3,
15.6,
43.1,
48.4,
69.2,
86.2,
28.9,
86,
82.7,
52.3,
35,
71.1,
52.3,
57,
74.3,
25.1,
56.5,
40.4,
16.4,
40.6,
66.1,
20.1,
50.4,
90,
25.6,
51.9,
87.9,
42,
26.5,
50,
61.7,
26.3,
53.7,
69.7,
11.4,
0,
55.1,
47.2,
38.5,
74.2,
93.3,
90.5,
68,
59.4,
74.6,
67.9,
57.8,
23.2,
38.8,
69.4,
27.9,
68.3,
31.1,
88.4,
62,
62.1,
45.1,
77.1,
43.9,
54,
42.7,
66,
56.8,
31.6,
83.8,
56,
94.5,
92.9,
46.8,
27,
42.4,
82.9,
97.9,
4.9,
48.1,
48.3,
78,
41.3,
76.7,
59.5,
89.9,
29.1,
27.8,
49.1,
27.6,
51.5,
80.2,
83.2,
19.1,
63.9,
55.1,
85.5,
63.3,
67.7,
70.6,
78.7,
19.4,
26.1,
71.5,
64.4,
4.3,
55,
91.4,
43.8,
50,
51.6,
66.6,
77.2,
27.8,
61.7,
73.7,
90,
51.1,
46.5,
42.7,
93.7,
42.9,
8,
105.1,
94,
73.1,
37.5,
48.8,
69.6,
94.1,
84.7,
27.4,
59.5,
25.8,
75.1,
70.3,
44.2,
18.9,
61.1,
42.8,
19.5,
74,
53.2,
72.3,
54.2,
15.5,
57.9,
42,
82.9,
90.9,
24,
54.3,
10.9,
32.7,
78.8,
14.9,
87.7,
40,
73.3,
40.6,
66.5,
85,
76.9,
49.7,
51.2,
52.6,
85.5,
78.5,
65.4,
46,
28.9,
63.6,
79.7,
79.2,
82.1,
95,
75.6,
65.3,
82.3,
84.7,
64,
79.9,
56.1,
50,
71.1,
29.5,
27.4,
62.5,
55.6,
60.4,
88.5,
59.2,
55.5,
22.9,
19.2,
47.7,
53,
71.3,
96.8,
54.5,
16.5,
42.2,
79,
96.1,
31.6,
83,
74.8,
65.7,
59.7,
26.6,
39.2,
24.6,
38.4,
69.1,
89,
61.1,
50.5,
60.9,
45.6,
26.7,
74.7,
56.7,
66.7,
66.3,
37.5,
90.7,
85.1,
35,
27.5,
62.3,
23.8,
55.9,
79.9,
25.9,
44,
5.1,
25,
85,
50.7,
30.7,
61.5,
63.2,
95.6,
71.5,
84,
23.8,
91.9,
67.3,
39.5,
85.5,
26.4,
67.6,
36.9,
49.8,
79.3,
68.7,
56.2,
34.9,
26.2,
56.3,
69.2,
20.8,
61.4,
81.7,
35.6,
73.5,
24,
91.3,
77.8,
78.6,
9.7,
89.9,
92.9,
0,
77.3,
17.6,
75.8,
76.1,
9.8,
68.1,
40.2,
81.2,
28.7,
4.9,
77.7,
0,
10.2,
54,
75.2,
53.5,
8.1,
13.9,
39.5,
59.4,
78.3,
58.3,
23.1,
55.8,
12.5,
63.9,
81.1,
95.5,
53.5,
74,
19.9,
85.1,
52,
35.4,
96.2,
68.1,
93.6,
44.6,
null,
81.3,
52.7,
72.5,
19.4,
24.5,
59.9,
71.3,
42,
61.5,
44.1,
66,
14.9,
64.6,
81,
80,
78.6,
58.1,
89.6,
84.3,
15.4,
28.4,
71.4,
28.1,
61.3,
74.2,
20.2,
49.5,
70.5,
31.7,
33.7,
34.3,
64.3,
35.6,
66.8,
59,
11.6,
84.6,
63.3,
70.1,
56.1,
43.6,
43.2,
81.1,
45.6,
44.7,
51.3,
24,
83.7,
54.6,
54.1,
19.8,
60.7,
35.3,
96.6,
77.9,
23.2,
2.9,
42.1,
63.9,
72.1,
44.8,
78.4,
13,
73.9,
69.5,
70.6,
41,
94,
28.7,
75.2,
69.7,
38.5,
44,
40.8,
48.3,
35.8,
52.4,
55.4,
56.6,
50.4,
60.7,
96.9,
93.7,
75,
81.2,
35.6,
25.4,
97.1,
54.1,
47.7,
59.2,
42.5,
89.4,
55.4,
98.9,
63.7,
93.9,
54.2,
92.8,
43.6,
64.1,
73.1,
36.5,
77.6,
91.6,
54,
64.7,
43.3,
67.5,
25.7,
64.4,
53.9,
11,
77.9,
92.5,
74,
35.4,
90.1,
87.5,
18.9,
67.8,
95.3,
12.2,
75.5,
26.5,
86.4,
87.3,
64.4,
70,
0,
52.1,
77.9,
99.2,
56.2,
82.2,
11.7,
46.7,
85.9,
42.8,
35.6,
58.6,
71.9,
2.9,
15.5,
73.1,
23,
72.6,
88.6,
81.7,
87.9,
27.8,
38.5,
35.4,
81.2,
8.5,
83.5,
68.5,
41,
52.5,
67.5,
35.5,
43.3,
52.5,
82.2,
43,
16.7,
8.1,
47.3,
22.5,
40.1,
69.9,
20.2,
4.7,
36.5,
94.2,
71.4,
58.8,
43.3,
79.5,
65.5,
76.3,
69.2,
45.7,
72.3,
59.8,
95.6,
69.9,
47.6,
100.2,
36.8,
63.6,
86.3,
44.6,
56.7,
79.9,
48.5,
83.6,
28.2,
89.9,
72.8,
31.2,
68,
75.1,
62.8,
62.7,
77.5,
56.3,
36.5,
69,
93.9,
33,
33.5,
82.6,
85.4,
64,
71.8,
12.8,
63.7,
78.1,
39.3,
30,
71.1,
69.4,
73,
81.4,
41.9,
49.6,
21.4,
58.5,
17.1,
57.4,
46.6,
35.2,
50.9,
39,
85.4,
4.6,
70.2,
45.9,
58.8,
47.8,
37.4,
81.9,
55.7,
55.1,
22,
49.6,
12.6,
44.1,
94.5,
38.3,
87,
62.5,
71.4,
72,
79,
60.6,
50.9,
11.3,
20.9,
47,
99.2,
41,
60,
47.6,
36.3,
32.9,
46.1,
44.1,
21.6,
75.7,
62.4,
67.2,
65,
53.5,
33.5,
88.7,
90.1,
13.8,
47.4,
62.6,
89.1,
66.9,
69.8,
33.8,
52.1,
45.4,
39,
46.8,
58.2,
34.4,
25,
21.8,
78.5,
67.5,
69,
0.5,
43.6,
26.7,
6,
77.6,
56.2,
49.9,
64.6,
77.8,
28.6,
59,
26.5,
66.5,
82,
42.2,
28.4,
82.4,
85.9,
130.8,
53.1,
55.2,
77.5,
80.4,
36.8,
76.8,
89.1,
9.9,
92.9,
99.3,
55.5,
88.7,
17.7,
89.1,
34.2,
96.3,
94.5,
65.3,
25,
24.5,
62.4,
45.2,
83.8,
28,
36.9,
59.4,
61.2,
25.4,
70,
54,
77,
0.2,
66,
62.7,
83.2,
52.2,
50.7,
29.7,
42.1,
13.8,
66.7,
67.6,
75.4,
16.6,
1.9,
88.8,
47.4,
39.6,
86.5,
51.5,
82.1,
82.6,
91.4,
79.1,
53.4,
8.1,
53.3,
18,
82.6,
54.3,
75,
50.6,
91.5,
46.9,
45.8,
41,
32.2,
6.8,
28.2,
69.2,
53.7,
97.2,
49.5,
86.4,
75.4,
22.1,
28.6,
10,
78.9,
66.5,
48.1,
66.1,
15.7,
87.9,
72.4,
68.6,
35.5,
68.5,
32.5,
12.2,
66,
90.2,
32.4,
81,
18,
0.8,
51.4,
28.4,
90,
29.4,
54,
39.7,
34.1,
63.1,
35.7,
42.3,
72,
95.3,
30,
39,
53.4,
20,
60.1,
12.1,
60.1,
91.8,
93.6,
34.2,
96.3,
64,
44.9,
30.2,
87.3,
47.4,
24.9,
67.1,
94.8,
63,
90,
82.4,
97.2,
36.7,
56.9,
68.6,
59.3,
47.6,
64.3,
50.6,
89.9,
46.8,
45.1,
95.9,
68,
85.4,
17.6,
76.1,
8.6,
0.9,
26.8,
47.1,
81.1,
47.7,
82.3,
28.7,
43.5,
49,
53,
73.8,
71.9,
64,
50.5,
39.8,
23.4,
28,
8.2,
34.2,
28.3,
65.4,
32.4,
64.6,
58.1,
66.9,
32.5,
46.2,
89.7,
59,
72.4,
27.4,
66.5,
45,
20.7,
62.5,
95.8,
35.9,
43.1,
80.6,
87.6,
63.5,
59.5,
62.5,
20.8,
24.3,
28.2,
23.7,
31.3,
22.4,
84.8,
55.8,
96.6,
45,
66.1,
66.9,
32,
30.9,
67.5,
59.5,
93.7,
32,
83.4,
60.3,
13.9,
13.7,
94.7,
50.9,
82.3,
0.8,
92.5,
38.8,
64.8,
84.6,
66.7,
95.4,
26,
51.8,
34.7,
37.3,
53.2,
22.4,
84.2,
45.9,
72.7,
81.9,
59.9,
23.2,
72.6,
92.6,
64.5,
67.4,
14.6,
56.6,
31.3,
46,
85.6,
69.8,
21,
61.4,
4.9,
47.3,
77.3,
44.8,
45.3,
64.4,
52.2,
14.5,
76.7,
46.7,
32.5,
71.8,
56.5,
75.7,
92.4,
52.6,
35.3,
94.7,
88.8,
42.7,
55.2,
38.7,
73.5,
88,
8.5,
49,
74.2,
43.2,
56.6,
92,
93.2,
76.3,
29.5,
48.9,
29,
23.4,
64,
66.8,
96.4,
62.6,
42.8,
50.2,
87.9,
62.3,
32.7,
43.4,
12.6,
50.6,
36.8,
41.9,
82.3,
37,
79.4,
71.6,
46,
46.8,
91.8,
50.8,
92.5,
64.6,
37.5,
80.1,
19,
94,
71.7,
72.3,
33.4,
87.6,
54.2,
12.2,
52.1,
61.2,
98.2,
84.9,
94.2,
6.5,
33.9,
67.3,
74,
30.8,
25.1,
79.8,
63.8,
69,
83.5,
47.6,
60.5,
61.4,
74,
35.2,
53.3,
85,
45.6,
96,
45.5,
39.3,
89.1,
19.3,
68,
44.5,
29.3,
60.7,
85.5,
87.2,
80.5,
55.7,
88.2,
55.4,
30.1,
25.2,
95,
71.1,
62.9,
79.9,
53.1,
22.9,
24.8,
74.9,
62.5,
81.4,
66.6,
2.5,
18.9,
44.6,
19.4,
82.7,
66.5,
23.4,
88.3,
15.8,
31.8,
87.9,
36.9,
54.6,
51.8,
87.5,
42.4,
37.4,
31.2,
60,
51.3,
84.3,
26.3,
74.4,
27.4,
44.4,
28.3,
54.7,
37.4,
57.8,
47,
67.9,
40.2,
43.2,
29.1,
45.6,
81.4,
79.8,
76.8,
49.9,
89,
51.2,
28.3,
14.7,
72.4,
95.1,
61.8,
81.6,
69.9,
91.7,
42,
55,
82.7,
18.6,
72,
32.9,
28.5,
35,
68.5,
58.6,
61.8,
69.9,
85.3,
57.5,
55,
49.3,
82,
49.5,
65.8,
79.4,
89.5,
74.8,
90,
80.2,
75,
39,
38.2,
24.6,
77.5,
15.3,
36.7,
45.1,
41.8,
56.3,
82,
43.3,
28.8,
50.4,
72.1,
52.3,
48.5,
91.8,
13.9,
46,
87,
68.4,
65.3,
47.4,
90.1,
57,
68.9,
53.8,
65.6,
36.1,
37.9,
11.1,
60.4,
90.7,
64.4,
41.4,
40.3,
73.4,
31.9,
38,
88.3,
80.4,
91,
30.3,
60.5,
65.2,
22.1,
86.8,
58.5,
49.3,
100.5,
34.7,
76.8,
63.7,
39.2,
32.7,
31.8,
43.4,
7.2,
59,
40.2,
73,
71.4,
48.3,
53,
95.7,
37.8,
33.1,
42.3,
25.1,
60.2,
28.5,
61,
12.9,
87.4,
37.5,
70.7,
38.8,
24.9,
72,
36,
7.2,
66.9,
89.7,
69.9,
11,
51.2,
63.9,
35,
39,
75.7,
30.6,
11.2,
57,
42.3,
83.4,
67.3,
11.7,
92.6,
89.1,
97.4,
66.3,
56.7,
57.3,
55.7,
95.5,
46,
75.2,
64.5,
81.1,
42.1,
58.8,
26.9,
46.3,
48.7,
33.5,
17.5,
24.4,
35.5,
60,
41.9,
70.7,
38.3,
68.2,
24.4,
0,
54.3,
51.2,
86.9,
52.2,
23.2,
6.5,
87.7,
34.5,
36.7,
72.6,
100,
68.6,
89.9,
90,
78.6,
59.5,
89.8,
45.3,
73,
31.1,
83.1,
73.7,
1.7,
83.7,
0.3,
34.5,
47.7,
83,
81.9,
98.7,
55.2,
80.5,
43.8,
23.6,
65.4,
49.9,
72.8,
42.6,
38.2,
13.7,
78.8,
75.3,
45.8,
45,
45.3,
66.5,
81.4,
69.8,
85.2,
39,
74,
42.2,
7.4,
50.9,
85.9,
50.1,
53.2,
13.9,
88,
58.9,
57.1,
32.9,
59.9,
9.8,
46.1,
48,
82.6,
75.7,
49.3,
100.5,
90.5,
65,
7.4,
56.3,
59.4,
63.4,
62.5,
51.8,
33.3,
50.9,
67.3,
75.8,
76,
59.7,
36,
83,
40,
67.3,
60.2,
66.4,
81.8,
43.5,
65.4,
49.7,
63.4,
48.6,
44.3,
91.8,
24.2,
101,
20.2,
29.6,
75.7,
37.8,
77.4,
25.2,
76,
69.7,
43.7,
44.4,
66.7,
63.9,
54.7,
82.5,
75.6,
32.7,
62.2,
34.2,
99.1,
44.6,
46.7,
83.7,
50.2,
47.9,
88.1,
102,
8.6,
60.7,
44,
56,
58,
24.5,
73.3,
69.2,
53.6,
45,
71.3,
30.7,
45.1,
37.4,
38.1,
93.7,
56.4,
75.9,
72,
46.6,
29.4,
36.6,
55.4,
95.7,
19.6,
64.4,
51.7,
80.9,
86,
82.9,
84.3,
40,
19.8,
68.1,
57,
71.8,
70.7,
53.8,
30.5,
69.3,
71.6,
70.2,
38.8,
15.4,
60.7,
88.2,
53.4,
19.6,
74,
71.2,
58.1,
81.3,
33.4,
44.3,
77.1,
8.6,
59.4,
60.3,
38.6,
8.8,
75.1,
94.7,
20.6,
88,
45.1,
28.2,
78.6,
66.8,
80.7,
77.5,
12.9,
69.8,
84.1,
66.6,
68.3,
69.1,
21.9,
69.8,
37.8,
76,
44.8,
88,
57.1,
63,
67.8,
53.8,
52.2,
69.5,
91.3,
44.8,
81.7,
73.4,
16,
42.4,
80.8,
88.8,
38.7,
83,
101.4,
49.4,
36.4,
53.8,
45.1,
43.3,
63,
41.1,
75.3,
44,
91.4,
35.1,
17.1,
70.1,
17.8,
70.7,
22.1,
76.5,
74,
18.7,
62.9,
92.3,
82,
65.7,
82,
14.3,
97.6,
61.8,
3,
64.4,
27.2,
49.3,
64.5,
46.1,
48.6,
34.4,
80.1,
26.5,
24.3,
32.6,
40.3,
64.3,
33.1,
80.2,
67.7,
81,
62.2,
97.2,
68.1,
79,
19,
67,
78.4,
71.2,
93.1,
81.8,
67.4,
50.3,
80.3,
65.7,
0.8,
73.6,
44.7,
11.1,
19.8,
26,
83.1,
51.3,
54,
54.6,
5.9,
37.3,
26.1,
60.4,
17.4,
66.9,
20.9,
20.7,
94.1,
64.1,
84.4,
92.2,
32.8,
69.5,
33.9,
56.6,
26.3,
61.6,
40.7,
64.1,
43.4,
56.9,
81.7,
41.1,
85.5,
71,
54.1,
84.9,
30.1,
31,
82.6,
48.1,
28.3,
29.2,
39.5,
58.1,
51.3,
82.1,
72.3,
57.9,
19.6,
41.2,
68.4,
36.8,
55.8,
70.9,
46.2,
34.5,
51.7,
59,
74.1,
52,
93.9,
36.5,
75.9,
87.1,
47.3,
35.9,
71.5,
71.4,
72.8,
44.5,
60.8,
66.5,
33,
30.4,
38,
49.4,
55.4,
57.7,
60.4,
44,
48.2,
40.6,
55.1,
48.2,
77,
77.6,
56.9,
75.5,
34.1,
35.9,
51.8,
37.8,
97.5,
15.8,
32,
77.5,
48.7,
19.9,
45,
63.8,
92.8,
57.3,
63.6,
42.6,
80.6,
63.9,
45.1,
62.4,
92.8,
66.7,
84.9,
58.2,
81.3,
50.9,
43.7,
38.9,
53.1,
35,
74.8,
32.2,
54.6,
41.4,
33.3,
3.2,
71.4,
72,
55.4,
4.8,
60.3,
56.1,
20.3,
49.6,
76.4,
92,
20.6,
51.2,
64.1,
71.2,
77.4,
1.7,
45.8,
35.1,
39.5,
57.2,
97.2,
83.9,
94.3,
16.8,
38.4,
68.3,
72.8,
90.8,
57.4,
42.4,
47.4,
12.3,
33.5,
66.7,
68.9,
20.3,
19.1,
36.8,
53,
39.3,
40.7,
55.5,
61.9,
52.8,
73.8,
58.4,
61.3,
77.6,
10,
88,
33.6,
27.6,
57.7,
57.8,
43.1,
98.6,
43,
65.8,
89,
74.5,
95.3,
22.8,
62.8,
43.2,
37.1,
50.4,
83.4,
63.4,
79.8,
52.6,
7.6,
9.5,
75.8,
34.6,
44.7,
87.2,
63.7,
70.7,
98.3,
46.1,
78,
64,
28,
60.8,
64.5,
57.3,
66.6,
57.3,
79.6,
65.8,
60.3,
46.2,
25.6,
64.9,
82.3,
66,
66.4,
63.7,
65.2,
43.8,
45.4,
64,
39,
82.6,
29.3,
27.7,
84.5,
56.5,
18.2,
50.7,
81.3,
67.2,
67.7,
73.6,
53.8,
52,
16,
26.9,
18,
68.4,
73.1,
40.7,
44.8,
53.1,
53,
11.4,
38.9,
14.7,
49.9,
52.1,
66.5,
35.4,
55,
95.4,
47.5,
55.8,
74.8,
62.6,
46.6,
60.7,
72.1,
20.4,
77.1,
48.4,
62.6,
79.1,
84.9,
87.3,
53.7,
54.6,
25.8,
33.8,
26,
85.3,
58.8,
27.2,
42,
33.7,
91.8,
48.8,
25.8,
57.8,
57.7,
90,
13.7,
32.9,
26.9,
87.2,
40.8,
77.8,
61.4,
48.8,
46.3,
45.4,
37.4,
81,
32.5,
63.1,
79.4,
51.4,
37.1,
48.3,
49.1,
45.1,
37.4,
65.6,
66.5,
66.9,
36.8,
44.7,
54.4,
88.2,
65.3,
84.4,
40,
46.7,
87.2,
97.5,
38.1,
73.5,
42,
58.5,
83.9,
54.3,
36.7,
91.2,
59.3,
94.6,
30.2,
48.7,
52.1,
86.7,
3.8,
68.1,
63,
26.4,
48,
73,
25.8,
87.4,
27,
70.5,
44.2,
74.5,
61.6,
87.9,
42,
58.4,
54.3,
66.9,
76,
83.7,
73.7,
77.8,
68,
91.1,
72.5,
45.3,
90.2,
71.3,
66.4,
63.4,
48.9,
20,
26.2,
67.8,
56,
88,
59.3,
35,
78.1,
104.6,
70.4,
75,
56.5,
84.2,
55.9,
69.8,
87.6,
45.4,
91.8,
65,
92.3,
54.4,
79.3,
39,
32.7,
56,
64.6,
8.9,
67.7,
16.4,
62,
56.5,
38.8,
82.2,
72.8,
59.2,
30.1,
40.2,
64.3,
51.7,
69.5,
39.9,
5.5,
64,
65.5,
63.1,
48.3,
45.2,
36.6,
75.4,
51.2,
76.3,
82.2,
33.1,
72.2,
38.5,
46,
44.5,
65,
85.6,
53.1,
4,
38.2,
41.1,
62.6,
20.3,
81.8,
5.9,
93.9,
93.2,
35.3,
85.7,
66,
98.6,
8.3,
2.3,
9.5,
53.5,
83.1,
18.9,
77,
55.2,
26.7,
39.1,
66,
89.5,
22.3,
88.3,
51.1,
90,
16.1,
64,
72.9,
87.4,
77.7,
21.7,
17,
43,
56.5,
54.1,
68.2,
84.9,
76,
43.7,
71,
92.4,
76,
71.7,
14.9,
66.6,
39.1,
81,
75,
63.4,
27.2,
59.3,
35.8,
17.7,
40,
65.6,
34.4,
77.4,
90.2,
61.4,
61.5,
84.9,
26.4,
89.9,
29.1,
72.9,
37.1,
96.5,
48.5,
15.2,
43.5,
8.4,
70.9,
49.7,
60.8,
88.2,
44.6,
70.7,
31.6,
53.6,
54.6,
72.3,
93.9,
38.4,
12.4,
29,
49.4,
43.8,
12.9,
33.2,
92.1,
20.6,
75.6,
59,
91.1,
50.2,
53.5,
69.1,
60.2,
49.9,
17.6,
68.1,
82.4,
62.9,
73.1,
24,
58.7,
41.9,
48.3,
30.4,
41.2,
90.1,
31,
63.2,
49.8,
40.7,
47.1,
80.6,
95.8,
56.4,
78,
84.9,
26.4,
75.3,
55.1,
82.7,
40.9,
18.3,
0,
41.6,
95.5,
19.6,
28.1,
96.6,
33.1,
57.4,
71.7,
81.3,
36.4,
56.9,
67.1,
48,
49.5,
88.6,
63.6,
85.6,
77.6,
54.7,
16,
87.8,
54,
90.8,
17.7,
66.4,
64.9,
60.7,
19,
80.7,
20.7,
47.9,
35.4,
84.5,
73,
50.9,
24.2,
13.6,
21.5,
58.5,
80.9,
96,
55.8,
24,
49.4,
92.3,
63.3,
59.8,
90,
60.1,
94.5,
26.9,
51.6,
48.8,
64.4,
0,
58.1,
64.1,
16.8,
73.5,
28.4,
94.6,
34.5,
95.7,
84.1,
56.6,
81.3,
65.6,
22.9,
40.3,
70.2,
79.3,
45.8,
83.7,
26.8,
33.3,
41,
46.4,
22.1,
19.2,
56,
77.3,
44.5,
16,
96.4,
46.3,
73.1,
43.6,
55.2,
16.8,
45.6,
77.8,
86.3,
82.2,
62.4,
55.4,
32.3,
67.8,
35.1,
77.7,
65.6,
59.6,
71.9,
54.2,
33,
62,
52.8,
5.8,
82.5,
71.8,
34.5,
66.4,
77.7,
76.4,
52,
45.5,
34.1,
85,
45.6,
57.1,
31.6,
59.9,
93.2,
68.8,
60.5,
58.2,
39.5,
53.7,
30.1,
17,
57.5,
36.6,
76,
83.1,
79.3,
35.8,
41.8,
54.3,
60,
38.5,
30.2,
60,
26.3,
39.6,
82.3,
52.6,
61.3,
83.2,
90.1,
70.6,
61.1,
47.7,
54,
84.6,
90.8,
94.1,
10.2,
74,
86.3,
63.7,
59.9,
22.8,
31.3,
19.6,
24.9,
79.6,
27.1,
67.2,
21.3,
71.2,
56,
50.2,
53.1,
68.8,
57.2,
4.9,
36,
55.8,
50.4,
9.7,
17.3,
54.3,
39.7,
86.8,
82.1,
42,
26.2,
31.2,
75.2,
33.3,
32.5,
66.1,
48.7,
50.7,
67.1,
67.7,
52.5,
66.5,
65.2,
45.2,
49.8,
70.1,
76.9,
80.2,
30.2,
91.5,
29,
39.3,
52,
49.1,
30.3,
63.4,
34.5,
82.4,
94.9,
76.6,
61.5,
73.6,
85.1,
12.2,
89.1,
24.9,
63.6,
16.1,
69.9,
9.2,
8.5,
78.9,
22.3,
58.1,
19.6,
91.8,
44.3,
40.8,
75.9,
30,
54.5,
64.7,
91,
30.2,
66.6,
71.4,
65.2,
59.9,
99.1,
68.4,
69.4,
63.2,
49.5,
79.4,
42.9,
95.4,
59.7,
67.8,
48.7,
42.5,
20.8,
96.9,
56,
94.8,
84,
82,
58.9,
27.5,
53.2,
79.3,
82.1,
85.1,
36.7,
24.1,
41.6,
79,
78,
33.8,
92.9,
51.5,
39.6,
59.7,
31.1,
51.4,
97,
35.5,
60.4,
19.9,
87.2,
29.2,
64.4,
39,
39.8,
78,
66.6,
81.3,
58,
96.8,
86.2,
79.3,
97.8,
59.9,
22.2,
68.8,
30.6,
61.5,
36,
92.5,
36.9,
48.7,
45.1,
48,
36.4,
78.8,
82.8,
45.5,
74.3,
21.3,
77.1,
23.4,
76.8,
104.2,
39.1,
24.6,
34.7,
81,
61.8,
23,
54,
80.2,
85.6,
9.1,
19.1,
33,
48.6,
93.7,
81.1,
48.7,
17.2,
67,
27.4,
65.7,
76,
34.7,
49.7,
39.1,
51.2,
48.9,
40.3,
56.4,
43.3,
99.2,
75.8,
69.2,
77.4,
71.8,
51.1,
46.6,
45.9,
0.6,
39.2,
42.1,
53.6,
44.1,
68.6,
85.6,
54.9,
54.6,
95.2,
20.5,
1.4,
68.6,
95.5,
9.7,
49.3,
39.3,
86.9,
22.3,
79.7,
94.5,
68.6,
48.3,
73.5,
101.6,
73.6,
47.2,
58.5,
59.9,
8.4,
81.4,
24.2,
59.3,
30,
35.9,
74.8,
62.4,
33.8,
58.1,
21,
65.2,
57.3,
40.2,
70.2,
83.8,
66.3,
27.4,
32.7,
71.6,
50.4,
3.1,
88.2,
40,
68.5,
42.6,
85.9,
48.4,
85,
1.5,
40.5,
57.1,
81.8,
56.6,
32.5,
61.3,
94.4,
84.7,
90.5,
31.7,
50.5,
31,
32.3,
15.7,
44.1,
66.3,
63.6,
85.9,
65.3,
4.2,
23.2,
69,
95,
57.2,
64.3,
77.9,
54.9,
75.6,
54.6,
87.1,
32.5,
60,
15.3,
55,
78.7,
30.7,
42.9,
99,
73.6,
57.7,
89.8,
41.3,
81.5,
56.2,
87,
10.9,
61.3,
63.7,
51,
27.5,
93.7,
100,
60.2,
87.8,
54.2,
50.1,
55.9,
81.9,
20.4,
65.2,
72.4,
8.3,
55.1,
74.5,
71.4,
21.2,
27.7,
47.7,
37.7,
78,
80.8,
83.9,
31,
75.1,
77.5,
28.6,
31.7,
11.8,
25.2,
32.7,
41.9,
38.9,
38.2,
53,
46.8,
25.1,
89.1,
14.5,
62.5,
71.6,
52.6,
40.9,
47.2,
97,
33.3,
28.6,
36.6,
93.6,
64.3,
46.4,
71.2,
45.5,
36.2,
48.2,
51.9,
76.2,
30.4,
53.4,
93.7,
38.8,
46.4,
92.3,
26.6,
32.9,
78.7,
89.8,
74.3,
65,
78.4,
58.6,
38.9,
36,
41.9,
66.8,
56.9,
73.6,
63.9,
63.8,
40.1,
20.9,
58.7,
74,
80.2,
37,
49.5,
40.8,
66.3,
50.8,
11.9,
24.3,
35.9,
11.3,
58.4,
27.2,
36.6,
77.8,
23.2,
37.7,
47.1,
33.2,
37.1,
93.9,
17.4,
46.4,
88.2,
74.1,
46.7,
97.7,
33.7,
40.9,
65.3,
70,
65.1,
84.4,
18.7,
66.2,
24.7,
92.1,
37.4,
81.3,
14.6,
90.9,
53,
73.6,
85.3,
41.1,
48.9,
53.6,
48.2,
45,
93.1,
33.2,
75.7,
56.5,
43,
49.4,
54.5,
43.8,
59.2,
67,
68.2,
30.6,
65.6,
58.8,
76.2,
92.6,
80,
99.6,
56.5,
82,
43.7,
44.9,
67.6,
37.7,
29.9,
46.6,
90,
52.1,
72,
61.4,
30.5,
36.9,
40.1,
90.9,
82.9,
32.6,
92.1,
35.5,
66.3,
53.3,
63.1,
93.1,
56.4,
85,
69.3,
71,
36.3,
28.7,
58,
84,
32.6,
15.8,
74.7,
82.8,
81.4,
30.9,
56.3,
53,
65.6,
41.6,
83.5,
48.4,
24.9,
74.4,
86,
65.2,
74.8,
18.5,
59.1,
47.5,
46.4,
63.7,
16.6,
18.7,
30.5,
41.1,
81,
19.8,
80.5,
24.1,
92.3,
71.8,
78.3,
35.9,
89.5,
87,
46.7,
4.6,
40.4,
17.6,
71.1,
35.9,
20.2,
70.7,
79.2,
28,
36.7,
46.3,
57.2,
16.2,
45.4,
44.7,
74.9,
93.5,
41.9,
91.3,
59.4,
42,
66.1,
78,
0.1,
78,
70,
39.2,
47.8,
50.9,
48.1,
86.1,
76.6,
40.1,
9.9,
90,
25.2,
79.6,
45.3,
70.9,
62,
52,
51.5,
74.8,
28.8,
60.5,
55.1,
83.4,
1.5,
44.9,
67.4,
45.9,
54.9,
85.4,
30,
34.4,
97.5,
92.7,
27.6,
65.1,
53.7,
21.2,
0.8,
39.3,
63,
75.2,
78.5,
59.8,
61.4,
34.5,
20,
17.6,
72,
41.6,
99.6,
43.2,
14.1,
70.9,
15,
50.3,
75.8,
33.9,
38.9,
34.5,
43.6,
86.7,
88.6,
89.6,
88.9,
51,
84.2,
43,
66.3,
13.2,
36.3,
61.9,
78.2,
76.9,
60.3,
85.5,
38.9,
64,
53.4,
14.3,
99.9,
38.8,
20.5,
76,
46.7,
62.6,
64.9,
94.5,
29.9,
65.3,
50.4,
68.7,
48.8,
62.6,
44.7,
64.2,
72.2,
25.7,
69.6,
54.3,
43.2,
44.4,
28.5,
90.4,
71.7,
62.6,
89.5,
42,
89.1,
85,
57.4,
66.3,
49.6,
52.5,
42.7,
46,
24.1,
25.5,
42.2,
88.3,
39.7,
89.7,
72.4,
90.3,
37,
86.3,
94,
50.5,
88.5,
24.9,
66.2,
57.8,
101,
25.6,
51,
23.7,
71.1,
93.8,
43,
77.2,
50.2,
42.8,
11.1,
71.3,
43.4,
37.4,
50.6,
38.9,
29,
74.9,
47.4,
50.4,
58.1,
88.1,
47.6,
69.2,
51.4,
59,
27.4,
38.8,
10.5,
12.5,
80,
73,
1.3,
88.1,
38.9,
82.3,
75.5,
29.4,
77.4,
51.9,
33.2,
75.1,
71.4,
37.1,
31.7,
100.3,
55.9,
65.7,
36,
26.3,
38.8,
84.1,
56.5,
90.5,
87.1,
26,
56.4,
84.4,
11.8,
74.4,
50.7,
90.4,
66.7,
22.8,
54.9,
95.8,
51.8,
76.9,
84.3,
48.9,
71.2,
65,
42.7,
91.7,
83.7,
83.5,
39.8,
78,
66.7,
66.9,
66.1,
61.3,
26.6,
30.9,
62,
49.8,
33,
44.8,
37.3,
31.8,
9.9,
7.3,
87.6,
70.5,
48.7,
53.7,
97.4,
86,
19.1,
79.7,
84.5,
52.5,
42.8,
29.1,
84.9,
73.6,
44.7,
58.3,
76.1,
74.5,
73.8,
77,
59.3,
23.9,
81.4,
53.7,
40.7,
77.7,
75.6,
32.9,
37.5,
53.5,
101.9,
62.3,
27.4,
30.7,
32.5,
81.6,
78.5,
59.8,
33,
60.7,
75.6,
95,
34.5,
96.5,
49.3,
18.7,
57.7,
69.9,
42.8,
27.4,
51.7,
38.8,
29.5,
36,
48.5,
61.4,
17.1,
49.3,
95.4,
67.9,
32.1,
17.3,
81.8,
94.9,
34.2,
56.1,
66.8,
67.7,
35.2,
56.5,
32.6,
38.5,
38.8,
50.7,
37.7,
33.2,
66.1,
32.3,
39.5,
41,
31.7,
72.2,
52.5,
59.3,
94.8,
29,
61.5,
46,
72.6,
74.2,
2.5,
80.8,
43,
60,
37.1,
65.8,
91,
71.1,
48.1,
82.9,
43.2,
49.6,
79.1,
56.2,
74.8,
74.5,
37,
65.7,
31.2,
79,
91.5,
57.2,
46.1,
77,
65.6,
38.2,
63.9,
59.7,
30.1,
35.5,
74.5,
70.7,
25.5,
85.1,
65.4,
64.6,
49.6,
96.3,
53.7,
26.7,
56.4,
75.7,
42,
97.7,
96.3,
48.2,
67.2,
57,
67.6,
86,
82.4,
48.9,
50.5,
64.3,
51.3,
89.7,
36.8,
60.7,
91.2,
81,
72.2,
40.6,
88.7,
67.8,
33.5,
84.4,
28,
53.3,
53.9,
38,
40.5,
25.2,
59.7,
50.9,
54.2,
64.7,
71.1,
56.1,
80.1,
81.2,
47.8,
51.5,
28,
37.3,
75.3,
45.6,
94.6,
77.3,
31.5,
26,
59.2,
65.7,
34.8,
30.9,
49.4,
51,
64.4,
5.6,
59.7,
42.8,
40.6,
90.7,
80.9,
44.8,
75.2,
21.9,
72.8,
66.1,
67.1,
32.2,
50,
49,
42,
54.8,
35.5,
69.7,
36,
47.4,
41.9,
66.9,
80.6,
79.5,
79.2,
23,
43.8,
27.5,
65.3,
79.2,
21.9,
51.1,
15.5,
74.3,
85.7,
58.8,
43.6,
42.5,
100,
10.4,
74.9,
79.7,
72.6,
27.8,
31.2,
57.6,
89.4,
35.5,
72.6,
61,
31,
43.3,
69,
45.5,
46,
68.6,
96.3,
51.6,
74.1,
24,
51.1,
5.4,
62.6,
82.2,
37.6,
16.5,
81.1,
39,
68.6,
39.2,
69.8,
74.1,
38.2,
55.5,
23.6,
34,
0,
31.3,
67.6,
89.7,
66.4,
87.5,
39.1,
86.1,
36.5,
11.7,
53.5,
22,
19.2,
38.8,
55.6,
64.4,
61.9,
97.1,
50.8,
92.5,
20.7,
28,
75.1,
33.6,
51.5,
50.5,
32.5,
31.5,
63.9,
74.3,
48.8,
42.5,
17,
46.7,
40.7,
0,
55,
74.5,
19,
67.5,
66.3,
89.2,
83.1,
49.9,
77.5,
51.3,
18.9,
24.5,
32.9,
77,
47.6,
21.4,
73.5,
41.5,
49.1,
35.1,
77.4,
36.9,
18.5,
60.9,
79.4,
100.5,
48,
55.4,
10,
68.8,
36.9,
73,
65,
47,
59.5,
78.8,
37.4,
75.7,
29.5,
64,
99.6,
67,
58.8,
74.6,
64.6,
47.1,
93.5,
21.9,
54.3,
81.4,
54.2,
65.2,
77.6,
35,
79.4,
66.1,
80.7,
36,
51.5,
39.6,
1.7,
55.9,
44.8,
10,
29.9,
72.9,
91,
64.1,
61.7,
33.5,
21.9,
6,
33.9,
50.4,
47.4,
70.5,
83.5,
75.9,
85.5,
37.3,
77.8,
47.6,
78.7,
6.8,
23.8,
60.7,
47.7,
48.9,
44.1,
45.4,
25.3,
11.4,
68.4,
84.4,
19.6,
45.3,
63.8,
89.6,
45.9,
90,
48.2,
88.8,
85.7,
78.4,
77.1,
39.2,
32.3,
66.7,
16.5,
69.8,
64.7,
35.5,
58.3,
75.5,
61.9,
22.6,
15.6,
72.1,
47.7,
26.8,
87.2,
37.3,
34.2,
75,
45.2,
67.8,
44.7,
42,
71.9,
72.7,
96.2,
71.7,
23.9,
30,
54.5,
85,
53.6,
70.7,
3.2,
40,
50.9,
91.1,
43.3,
85.3,
98.3,
87.8,
29.2,
79.8,
81.5,
37.5,
11.7,
47.8,
86.9,
25.7,
43,
64.3,
80.6,
44.9,
83.8,
43.8,
74.8,
67.6,
95.4,
73.1,
65.3,
68.4,
22.3,
66.4,
46.3,
44,
58,
61.8,
38.8,
53.6,
86.5,
32.6,
47.7,
77.9,
37,
42.3,
76.9,
67.3,
57.9,
43.3,
58,
83,
42.3,
55.3,
28.2,
48.5,
45.9,
70.4,
26.7,
42.8,
30,
53.7,
22.4,
26.7,
54.4,
71.5,
33.4,
84.7,
9.4,
67.3,
12.2,
54.7,
82.5,
6.6,
58.2,
72.4,
10.1,
61.3,
89.2,
55.7,
62.1,
2.5,
36.1,
43.1,
91.2,
49.2,
47.6,
81.4,
41,
77.2,
13.1,
39.4,
78,
113.4,
72,
49,
24.8,
67.6,
1.6,
5.9,
30.7,
78.9,
34.7,
75.9,
47.4,
62.9,
31.4,
46.5,
61.7,
49.7,
8.7,
68.6,
35.5,
16.4,
22.6,
20.4,
31.7,
22.2,
58,
97.4,
95.1,
67.2,
82.5,
61.5,
45.3,
69,
32.4,
65.2,
34.5,
86.4,
75,
31.2,
69.3,
17.6,
56.4,
92,
38.5,
33.3,
89.8,
84,
44.1,
16.7,
12.1,
63.7,
45.4,
55.4,
75.3,
61.7,
83.7,
35.1,
76.2,
83.1,
35.1,
59.8,
71.8,
67.2,
98,
72.8,
53.5,
87.2,
75.5,
53.4,
52.8,
90.2,
36.7,
72.4,
70.2,
92,
62.6,
42.6,
38.9,
25.5,
53.3,
73.9,
80.7,
87.1,
54,
59.5,
95.9,
6,
25,
26.4,
27.1,
49.5,
41.2,
91.7,
27.8,
90,
28.9,
76.3,
42.3,
19.6,
73,
56.9,
40.3,
70,
40.9,
63.3,
33.1,
18.4,
24.7,
48.6,
35.1,
64.7,
21.9,
61.3,
64.6,
24.3,
65.4,
47.9,
58.5,
56.3,
58.7,
44.9,
87.4,
86.5,
47.7,
29.4,
12.8,
33.1,
60.5,
54.3,
83.7,
72.8,
71.8,
31.2,
33.9,
90.7,
70.2,
65.9,
46,
64.7,
54.4,
73.6,
79.9,
22.7,
15,
27.4,
92.6,
44.8,
71.8,
50.4,
79.5,
26.6,
93,
26.7,
55.6,
51.5,
36.8,
18.1,
57.1,
90.7,
46,
55.2,
70.5,
76.3,
66.8,
57.5,
42.8,
68.7,
76.8,
53,
64.6,
7.1,
54.3,
32.2,
47.3,
35.4,
69.1,
37.8,
64.4,
46.9,
68.1,
31.9,
24.7,
73.2,
32.2,
52.2,
76,
43.2,
14.8,
49,
55.5,
33.3,
76.2,
66.3,
44,
91.3,
66,
43.4,
72.4,
66.8,
83.8,
33.7,
44.1,
70.5,
87.3,
13.5,
43.9,
73.1,
69.3,
32.5,
92.4,
65.9,
61.5,
95.7,
27,
69.6,
43.3,
29.6,
46,
93.7,
47.9,
9.5,
58.7,
26.7,
57.2,
88.5,
23.7,
35.6,
6.2,
22.8,
40,
26.9,
50.6,
17.9,
82.9,
24.1,
63.7,
57.8,
82.4,
53.8,
78.7,
64.3,
54,
89.7,
45.1,
74.2,
65.1,
77.8,
85.3,
60.5,
27.6,
44.4,
95.2,
8.3,
66.1,
54.5,
76.2,
93.6,
38.3,
null,
33.5,
57.5,
57.8,
33.4,
36,
85.9,
80.8,
63.1,
24.9,
58.4,
98.4,
69.8,
61.2,
45.5,
60,
75.5,
86.3,
69.2,
69,
81.6,
38,
32.8,
35.2,
61.3,
72.6,
69.4,
79.6,
47.1,
63.3,
74.1,
69.1,
61.5,
26.9,
77.4,
63.7,
62,
19.4,
37.2,
64.1,
51,
51,
74.2,
41.4,
29.7,
77.9,
48,
77.1,
55,
45.2,
63.2,
18.7,
36.1,
40.9,
78.1,
80.4,
48,
37.3,
35.6,
28.9,
69.3,
21,
69.9,
47.2,
95.1,
61.1,
89,
38,
31.7,
44.4,
72,
68.4,
22.4,
84.7,
4.5,
1.6,
44.5,
63.9,
22.4,
69.1,
46,
19.2,
68.1,
46.8,
78.5,
83.1,
91,
38.2,
88.3,
17.8,
94.2,
2.8,
17.9,
53.8,
74.6,
60.5,
60.3,
47.3,
44.5,
2.6,
72.5,
80.1,
83.4,
35.6,
41.6,
34.2,
61.9,
82.9,
95.4,
4.1,
98.5,
75.4,
28.8,
51.9,
87.6,
57.3,
96.8,
73.7,
70.8,
25.2,
19,
100.5,
46.5,
26.1,
46.3,
53.1,
93.1,
60.7,
54.9,
79.9,
66.6,
75.6,
70.4,
39.8,
33.2,
74,
71.4,
82.4,
52.7,
77.7,
28.3,
71.1,
64.7,
82.6,
64.6,
86.1,
50.6,
42.3,
50.4,
68.8,
44.8,
44.1,
66.7,
65.8,
39,
66.7,
75.8,
45.8,
30.4,
10.8,
94.5,
63,
79.1,
46.5,
0.4,
79,
72.9,
30.5,
79.2,
53.6,
73.7,
32.3,
45.9,
58.5,
88.7,
85.8,
67.3,
88.7,
81,
37.5,
83.1,
90.7,
76.3,
44.6,
32.1,
77.8,
37.6,
48.2,
3.1,
40,
56.2,
20.9,
41.6,
85.6,
52.6,
36.2,
37,
90,
37.2,
8.9,
53.1,
41.4,
57.1,
47.3,
46,
64.2,
82.5,
60.8,
65.1,
43.7,
64.4,
71.8,
82.6,
10.2,
58,
41.8,
26.5,
16.2,
53,
64.4,
36.3,
58.8,
47.2,
96.4,
23.8,
43.9,
79.5,
35.8,
55,
59.4,
32.3,
34.2,
65,
76.8,
77.7,
96.4,
77.6,
3.9,
51.3,
67.1,
65.3,
76.4,
27.8,
39,
75.1,
56.3,
97.9,
74.7,
54.9,
59.8,
21.7,
33.6,
62,
62.6,
29.6,
32.2,
34.5,
49.5,
9.7,
57.1,
55,
82.4,
82.8,
81.4,
39.9,
48,
6.5,
89.4,
46.8,
94.3,
65.4,
53.2,
77,
63.3,
26.9,
98,
82.4,
14.1,
53.1,
77.2,
45.8,
46.2,
72.6,
71.4,
47.8,
51.7,
95,
44,
82.3,
48.6,
50,
56.8,
73.5,
76.7,
55.3,
36.2,
77,
49.7,
26.7,
81.8,
34.8,
17.9,
55.5,
32.6,
9,
88.5,
31.1,
74.1,
47,
64.5,
27.7,
43.2,
51.1,
23.7,
96.7,
28.7,
29.9,
11.4,
52.8,
31.1,
51.5,
37,
79.7,
37.6,
77.3,
28.6,
64.1,
68.3,
80.5,
48,
47.8,
52.1,
81.7,
54.9,
71.6,
39.5,
61.1,
58.6,
62.5,
16.5,
69,
33.6,
48.7,
80.1,
44.3,
79.2,
73.2,
90.4,
69.4,
14.8,
37.6,
67.4,
23.3,
94.9,
74,
56.3,
86,
46.5,
22,
44.1,
35.8,
1.7,
21.3,
30.1,
7.6,
66.8,
62.5,
77.5,
46.6,
0,
45.7,
53,
27.9,
42.9,
69,
47.7,
50.1,
67.8,
45.6,
66.9,
14.8,
83.5,
92.3,
100.7,
17.7,
38,
45.1,
39,
49.2,
83.7,
17.8,
46.3,
66.3,
37.2,
67.9,
50.8,
63.6,
43.3,
34,
42.1,
23.4,
39.7,
0,
85.6,
61.8,
64.9,
60,
69.6,
41.5,
97.9,
42.7,
16.1,
40.7,
63.1,
44.8,
94.5,
30.2,
50.3,
4.4,
16.6,
41.1,
65.8,
34,
75.5,
50.3,
50.9,
76.5,
0.2,
75.6,
77.5,
91.1,
96.1,
47.5,
27.3,
57.1,
38.4,
64.8,
46.3,
42.3,
73.7,
34,
87.4,
84.4,
33.7,
49.7,
66.1,
87,
55.8,
1.2,
24.4,
87.1,
77.7,
80.2,
96.6,
94,
5.7,
12.3,
78.2,
4.2,
23.8,
43.6,
61.4,
74.7,
48.2,
64.6,
23,
16.5,
52.7,
7.4,
66.4,
51.6,
52.5,
70,
93,
51.3,
81.6,
70,
71.3,
61.3,
73.7,
14.2,
73,
39.6,
57.7,
24.8,
62.6,
40,
23.1,
90.5,
70.1,
37,
71.3,
24.5,
36.5,
31.9,
0,
41.4,
54.6,
69.7,
28.4,
73,
34.6,
11,
68.7,
74.9,
10.1,
67.6,
64,
38.6,
52.5,
36,
39.7,
52,
49,
56.9,
65,
40.2,
72.4,
57.3,
82.6,
0.3,
65.4,
94.1,
30.6,
5.6,
0,
70.3,
53.9,
56.6,
61.7,
95.5,
41.5,
12.5,
34.6,
70.9,
19.4,
78.1,
76,
48.8,
24.7,
85,
80,
71.1,
61.8,
78.6,
5.9,
59.2,
1.3,
68.6,
78.9,
63.5,
24.8,
61.9,
97.1,
56.5,
55.6,
21.9,
69.8,
28.4,
73.9,
69.5,
61.2,
21.1,
38.7,
42,
35.3,
46,
85.5,
55.6,
49.9,
61.8,
1.9,
49.8,
51.5,
17.5,
99.1,
37.9,
59.9,
86.2,
49,
93.1,
49.9,
29.2,
24.7,
44.2,
53,
51.5,
53.8,
26.8,
47.6,
11.9,
17.6,
38.2,
74.8,
95.2,
67.7,
84.1,
66.9,
17.6,
66.6,
92.1,
73.7,
40.3,
0,
59.5,
67.1,
43.6,
28.6,
91.8,
85.9,
74.8,
43.5,
55.9,
35.2,
37.4,
64.5,
61.4,
44.8,
40.5,
62.2,
55.9,
19.3,
46.2,
22.1,
22.6,
63,
73.5,
34.2,
72.5,
84.4,
29.8,
14,
66.3,
69.8,
61.4,
75.5,
45.5,
49.2,
80.6,
48.8,
86.4,
21.9,
19.3,
26.3,
24.3,
88.4,
69.9,
4.6,
78.8,
51.8,
23.4,
69.6,
77.5,
87.5,
67.1,
15.3,
5.3,
69,
27.4,
59.9,
24.7,
67.4,
41.6,
51.3,
15,
40.9,
89.5,
28.3,
91.3,
44.2,
91.8,
62.2,
33.4,
52.3,
7.8,
97,
32.7,
29.7,
40.6,
42.4,
83.2,
43.2,
81.7,
32.3,
61.1,
67.2,
53.2,
79.7,
79.1,
55.1,
63.7,
67.6,
72.7,
22.7,
72.6,
33.9,
54.2,
16.8,
45.6,
15,
24.9,
22.8,
85,
19.5,
48.9,
87.7,
77.5,
74,
46.3,
33.1,
31.3,
43.3,
10.1,
64.4,
18,
23.5,
67.8,
21.7,
70.6,
98.5,
64.2,
55.7,
89.1,
28.4,
28.7,
72.1,
74.3,
55,
39.2,
46.3,
40.7,
9.5,
56.5,
68.7,
64.7,
52.8,
96,
82.4,
55.8,
71.1,
68.2,
28.8,
44.9,
38.6,
31.8,
48,
70.4,
28.8,
19.4,
59.1,
65.5,
16,
36.7,
43,
49.6,
93.5,
55.7,
27.8,
96.4,
39.6,
95.5,
70.4,
75.4,
4.8,
58,
52,
38.7,
54.4,
38.1,
60.6,
71.5,
76.9,
63.2,
70.5,
21.5,
47.6,
21.6,
34.9,
92.9,
75.5,
78,
6,
32.2,
66.8,
56.9,
20.9,
85.7,
74.6,
80.3,
40,
49.4,
47.9,
31.1,
73.9,
3.9,
47.5,
29.1,
34.2,
59.5,
44.8,
91.2,
33.3,
29.1,
86.4,
59.8,
50,
35.5,
61.2,
31.8,
28.2,
96.1,
57.3,
22.7,
0.7,
5.1,
46.1,
55.9,
58.8,
63.5,
55.4,
63.8,
23.3,
66,
5.4,
52,
14.9,
52.6,
46.1,
71,
57.1,
67.7,
85.4,
98.1,
55.8,
84.1,
65.5,
43.7,
15.1,
55,
49.9,
11.8,
85.2,
51.5,
75.5,
53.7,
46.6,
72.4,
42.9,
22.2,
66.7,
24.4,
89.7,
69,
47.9,
66.2,
13,
53.1,
57.9,
35.1,
48.7,
95.2,
88.5,
40,
44.9,
90.3,
42.5,
86.9,
22.9,
6.4,
96.2,
54.3,
98.9,
52.7,
85.1,
73.4,
69.5,
62.9,
68,
48.4,
55.8,
103.6,
73,
37.8,
88.1,
28.3,
59.1,
93.4,
32,
27,
36.6,
36.7,
30.6,
40.4,
63.3,
55.7,
53.4,
46.6,
79.4,
60.3,
35,
71.4,
43.8,
99.3,
51.3,
24.7,
60.8,
29.4,
29.2,
83,
37.8,
92.4,
50.1,
30.1,
78.6,
7.7,
68.6,
80.2,
27.4,
48.2,
40.9,
71.1,
28.4,
40,
71.5,
78.1,
70,
83.1,
40.2,
54.2,
35,
78.7,
55.6,
94.6,
57.6,
10.8,
92.3,
48,
15.5,
90.2,
39.2,
75,
40.8,
95.5,
16.6,
83.1,
71.1,
49.7,
72,
75.7,
18.6,
96.3,
32.9,
21.7,
0,
75.1,
60.4,
67.9,
30.1,
22.7,
56.8,
78,
52.2,
64.1,
67.4,
58.7,
83.4,
70,
44.8,
68.9,
26.3,
0,
21.2,
31.1,
33.5,
45.3,
42.2,
60.4,
45.8,
98.2,
73.9,
85.7,
46.6,
17.7,
30.3,
49.2,
67.6,
32.2,
30.2,
39.1,
48.6,
77,
71.4,
81.9,
13.5,
70.4,
73.7,
50.9,
62.6,
78.4,
88,
48.6,
56.8,
102.6,
73.6,
38.4,
64,
23,
91.9,
55,
70.5,
39.6,
55.7,
32.8,
53.7,
56.5,
48.8,
94,
69.3,
62.1,
48.9,
27.9,
37.6,
47.2,
92.3,
38.4,
40.2,
48.5,
66.9,
23.8,
73,
2.2,
39.2,
77.7,
69.1,
99,
98.2,
65.8,
34.5,
45.5,
71.8,
39.3,
58.2,
63.3,
50.5,
97.4,
70.5,
89.1,
42.6,
65.1,
76.1,
89.3,
97.5,
22.1,
81.1,
31.4,
24.7,
25.1,
80.2,
78.9,
54.5,
31.7,
53,
95,
50.5,
58,
61.5,
84.9,
73,
87.1,
37.5,
3.4,
35,
90,
39.7,
49,
11.4,
78.4,
81.2,
59,
0.9,
97.3,
15.3,
44.2,
92,
72.3,
19.5,
62,
56.1,
39.9,
97.2,
73.7,
32.3,
24.2,
77.5,
34.4,
84.7,
76.3,
92.8,
48.7,
72,
74.6,
34.4,
67.3,
65.4,
94.1,
68,
53.3,
68,
38.3,
57.2,
71.9,
83.6,
43.4,
62.5,
96.5,
10.9,
31.4,
71.6,
94,
43.2,
79.6,
81.4,
18.4,
56.6,
30.3,
50.4,
46.2,
36.3,
39.4,
48,
34.2,
61.3,
35.3,
83.5,
48.9,
43.9,
75.3,
19.4,
33.5,
45.7,
69.1,
66.9,
77.5,
90.6,
43.5,
0.1,
51.9,
84.9,
46,
28.4,
6.4,
1.5,
58.8,
40.8,
4.2,
95.2,
54.8,
28,
52.4,
52.7,
68.5,
64.3,
95.7,
31.9,
86,
84.6,
13.5,
48.5,
98.2,
32.4,
64.6,
66.6,
49.3,
52.8,
78,
36.3,
60.6,
86,
68.5,
80.6,
39.8,
66.1,
85.2,
64.6,
32.5,
76.8,
69.6,
92.8,
38.9,
40.5,
65.5,
95.6,
43.7,
58.4,
30.2,
29.1,
84.5,
73.2,
79.9,
32.8,
47.3,
96.5,
58.8,
47.9,
11,
92.2,
39.6,
79.9,
41.5,
82.6,
83,
41.7,
80.3,
30.4,
27,
79.4,
46.7,
55.4,
80.5,
38.4,
68,
2.3,
78.8,
70.1,
86.4,
81,
62.3,
37.8,
53.8,
44.6,
68.4,
12.2,
97.5,
35.8,
49.4,
72.1,
74.9,
24.4,
53.2,
48.2,
60.4,
69.9,
37.6,
81,
50.8,
25.3,
78.1,
10.1,
34.6,
52.7,
9.6,
64.3,
63.3,
86.6,
30.7,
37.6,
61.4,
0.1,
5.4,
68.5,
73.9,
62,
23.1,
59.8,
55.7,
35.9,
22.4,
67.8,
30.7,
54.7,
89.9,
41.5,
56,
92.1,
34.9,
86,
87.9,
90,
44.1,
63.9,
93.8,
90.3,
97.5,
36.4,
51,
85.2,
35.2,
86.9,
76.2,
95.1,
79,
68.1,
78.4,
81.9,
74.5,
72.6,
54.5,
47.8,
91.6,
33,
12.7,
43.8,
48.4,
33.1,
49.4,
80.8,
68.5,
47.5,
68.2,
69.1,
78.4,
24.3,
35,
63.1,
38.9,
52.5,
45.9,
3.8,
97.2,
51.7,
61.2,
91.7,
4.1,
53,
4.2,
35.1,
27.4,
61,
14.8,
65.1,
38.7,
31.4,
26.7,
96.3,
92.6,
51.5,
62.1,
78,
83,
79.7,
36.5,
58.5,
67.9,
43.4,
74.8,
53.6,
83.7,
98.8,
58.8,
64.5,
67,
52.5,
24.6,
15,
75.3,
84.5,
22.6,
10.6,
90.8,
16.9,
61.3,
58.9,
83,
34.1,
98.5,
71.4,
70,
47.2,
6,
28.6,
58.6,
94.6,
86.6,
70.3,
92.7,
30.3,
28.8,
39,
39,
20.7,
51.6,
46.9,
58.6,
51.1,
55.2,
30.5,
23.6,
58.7,
90.1,
67.7,
36.7,
81.3,
30.6,
51,
78.4,
46.1,
94.4,
57,
49.7,
68.7,
86.5,
63.3,
93.1,
66.6,
61,
48,
15,
71.8,
53.9,
84.1,
25.7,
19.2,
63.2,
38.2,
39.9,
53.4,
43,
88.2,
53.3,
71.6,
32.8,
36.2,
23.8,
73.3,
29.3,
23,
87.4,
80.9,
50.6,
85.4,
37.6,
62.6,
16.3,
75.1,
14,
98,
11.3,
92.6,
12.6,
33.1,
66.9,
32.1,
70.7,
14.3,
89.8,
72,
46.7,
70.7,
19.7,
100.1,
72.1,
31.7,
96.3,
48,
45.9,
98.8,
75,
53.3,
85.5,
72.2,
83.8,
0,
43,
25,
31.6,
63.1,
49.7,
31.1,
63.9,
18.1,
82.9,
62.7,
58.3,
33,
61.2,
76.3,
60,
76,
42.3,
49.1,
29.6,
66.6,
69.9,
30.1,
23,
46.5,
48.9,
68.9,
28,
46.4,
19.7,
66.4,
60.6,
44.3,
17.4,
78.6,
47.4,
80.6,
77.5,
53.1,
81.5,
44.2,
61,
49.2,
82.5,
50.6,
62.7,
57.1,
49.6,
40.8,
62.7,
71.8,
8.3,
74.5,
27.5,
96.4,
74.5,
52.1,
32.5,
55.9,
60.9,
77.8,
55.8,
44.4,
44.5,
18.9,
64.3,
25.9,
83.5,
84.9,
65.8,
7.5,
90.5,
94.4,
79.6,
16.7,
96.3,
8.2,
32.9,
8,
27.2,
87.6,
76.1,
42.2,
30.4,
72.5,
80.8,
77.4,
19.3,
76.7,
92.1,
43,
33.2,
64.2,
69.9,
94.8,
9.6,
36.6,
82.6,
62.5,
87.7,
48,
78,
93.1,
57,
69.2,
27.9,
22.6,
88,
88.7,
87.3,
51.6,
75.4,
66.5,
98.3,
30.1,
9,
34.3,
77,
77.8,
93.1,
53,
39.5,
46.1,
91.3,
67.2,
75.3,
75.3,
37,
62.1,
37.2,
35.5,
13.9,
92.9,
54.4,
8.3,
85,
10.8,
93.2,
66,
50.7,
13.3,
36.7,
43.9,
67.8,
64.6,
56.7,
82.3,
49.7,
71,
80.8,
99,
77.5,
80.3,
77.3,
74.9,
40.2,
69.8,
81.3,
17.2,
39.9,
85,
90.4,
58.3,
87,
92.6,
47.8,
39.8,
78.4,
44.4,
14.3,
36.9,
38.4,
26.8,
77.6,
66,
85,
69.7,
26.5,
55.7,
96.5,
9.5,
20.8,
38.4,
40.1,
81.7,
75.9,
60.2,
71.9,
42.7,
23.3,
53.6,
97.5,
62.2,
39.5,
46.6,
92.5,
90.9,
37,
81.6,
3.6,
62.3,
77,
68.3,
59.4,
9.5,
5.6,
81,
39.8,
30.6,
69.1,
63,
85.5,
90.4,
35.6,
58.1,
79.6,
29.7,
51.6,
29.6,
84,
40.2,
75.7,
50.8,
52.4,
96.4,
85.5,
44.3,
54.6,
64.1,
33.3,
66.1,
28,
33,
44.3,
76.3,
34.6,
62.8,
52.5,
70.9,
40.3,
76.4,
41.6,
90.5,
45.7,
42.7,
85.2,
35.4,
39.9,
12.7,
37.3,
59.7,
79.2,
55,
13.6,
47.1,
78,
47.8,
39.5,
13.4,
17.2,
88.9,
47.6,
68,
18.2,
39.9,
86.3,
58.6,
61.3,
72,
0.3,
96,
92.5,
48.9,
36.4,
66.5,
22.7,
70.9,
50.5,
36.1,
72,
68,
32.4,
52.9,
25.7,
88.9,
33.8,
70.1,
88.7,
79.6,
60.2,
65,
73.9,
81.8,
31.7,
80.3,
44.2,
73.6,
15.7,
75.9,
86.6,
50.7,
19.3,
59.3,
41.1,
65.9,
67.5,
59.2,
40.8,
29.7,
64.8,
22.2,
79.9,
25.5,
33.6,
47.8,
70.9,
80.3,
97.5,
73.2,
48.8,
68.6,
89.1,
71.7,
77.8,
56.4,
10.9,
53.6,
92.6,
61.2,
82.7,
6.1,
16.9,
59.2,
82.4,
54,
76.5,
69.4,
63.8,
13.1,
46.3,
83.3,
59.7,
6.1,
88.8,
18.5,
86.6,
55.4,
89.1,
65.1,
78.8,
49.1,
98.5,
53.2,
39.8,
36.7,
37.8,
86.2,
48.1,
55.7,
55.3,
57.8,
61.2,
52.3,
72.5,
66.6,
77.9,
78.3,
13.2,
97.2,
101,
51.1,
42.5,
39.1,
81.2,
46.3,
70.5,
78.6,
9.6,
68.1,
89.6,
34.8,
68.8,
62.3,
26,
68.4,
83.2,
13.4,
78.7,
40.4,
75.5,
42.8,
16.9,
60.7,
45,
29.7,
63.1,
95.7,
36.6,
92.1,
68.5,
38.8,
47.5,
8.7,
49.6,
30,
62.3,
57.6,
10,
35.5,
47.8,
81.3,
15.1,
97.6,
92.5,
27,
57.2,
36.5,
66,
25.3,
81,
82.5,
87.8,
32.2,
29.8,
75.8,
15.1,
74.5,
39.8,
89.4,
75.2,
44.8,
31.5,
42.9,
18.7,
52.8,
77.1,
40.1,
66,
64.9,
62.8,
84.9,
59,
6.8,
30.8,
20.7,
25.3,
34.9,
69.9,
61,
12.7,
62.4,
26.3,
38.9,
87.7,
81.3,
12.6,
67.3,
46.1,
61.3,
65.7,
27.3,
48.7,
4.9,
86,
75.2,
78.9,
41.6,
61.6,
41,
65.2,
36.8,
98.7,
73,
12.6,
46.4,
45.9,
75.6,
78.3,
37,
19.8,
82,
52.1,
47.9,
14.2,
25.4,
67.5,
100.9,
73.1,
76.1,
64.8,
68.1,
53,
81.8,
5.8,
72,
56.1,
42.4,
85.6,
57.9,
95.6,
23,
50.2,
45.4,
77.2,
0.5,
78.4,
48.9,
59.8,
69.4,
52.8,
16.1,
53,
60,
70.7,
56.4,
77.5,
83.3,
42.3,
60.5,
88.3,
32,
41.8,
46.5,
30.1,
22.9,
44.2,
29.4,
72.8,
12,
46.5,
34.3,
88.1,
24.9,
45.7,
45.1,
37.2,
28.8,
55.1,
89.8,
42.4,
88.5,
43.5,
32.7,
100.4,
75.6,
63.7,
46,
46,
66.8,
81.8,
41.6,
24.2,
76.2,
45.6,
21.4,
66.3,
56.6,
49.9,
33.3,
37.2,
21.9,
78.2,
79.7,
30.7,
79.9,
29,
74.8,
51.5,
74.8,
67.2,
32.5,
77.3,
74.2,
92.7,
62.7,
68,
96.8,
39.8,
67.1,
42.9,
49.9,
85.5,
55.1,
22.1,
68.2,
26.7,
50.7,
60.9,
24.3,
48.1,
54.1,
99.7,
22.5,
60.7,
57.1,
49.1,
59.8,
64.8,
40.1,
12.3,
57.1,
74,
22.3,
0,
44.3,
61.1,
55.5,
65.9,
61.5,
75.5,
31,
76.8,
72.2,
54.7,
51.4,
83.2,
36.4,
64,
19.5,
85.5,
43.6,
89.3,
81.3,
38.2,
85.2,
54,
41,
74,
44.9,
7.5,
62.6,
85.3,
2.5,
30,
31,
34.7,
99.4,
48.8,
67.7,
70.4,
14.6,
25.7,
65.1,
43.6,
92.2,
82.4,
78.2,
78.2,
22.7,
25.8,
50.8,
91,
42.4,
88.5,
36.8,
7.9,
58.6,
74.4,
28.9,
40.2,
84.8,
86.2,
32.3,
71.2,
92.6,
77.5,
30,
22,
46.3,
40.9,
59,
45.7,
33.6,
69.9,
70.2,
54.1,
48.6,
41.1,
63,
42.9,
38,
29.4,
30.9,
50.9,
59.4,
47.1,
48.6,
83,
23.1,
57.8,
41.8,
83.5,
68.7,
48.5,
67.8,
32.2,
50.9,
36.2,
89,
82.8,
46.7,
32.4,
41.3,
29.7,
68.5,
65.3,
67.6,
98.9,
90.1,
68.7,
98.7,
79.8,
57,
53,
22.1,
60.6,
59.8,
49.7,
48.8,
54.2,
20.6,
82.7,
43.4,
16.5,
40.1,
65.6,
36.2,
36.1,
93,
71.4,
80.5,
61.9,
33.6,
81.2,
98.1,
23.3,
94,
85.2,
77.3,
71.2,
70,
73.4,
15.6,
88.8,
43.3,
28.4,
66.3,
30.8,
53.1,
0,
30,
61.7,
74.4,
21.7,
56.8,
0,
68.5,
88,
84.2,
65.7,
1.1,
26.6,
94.3,
56.7,
38.6,
63.4,
29.7,
69.8,
44.5,
44.2,
85.2,
68.5,
45.1,
33,
48.5,
69.3,
82.1,
40.5,
68,
63.3,
54.7,
0,
47.5,
63.9,
44.7,
72.2,
44.2,
53.9,
88.3,
44.6,
59.4,
38.2,
58.8,
80.3,
14.3,
42.8,
75.4,
46.5,
68.6,
42.5,
98.6,
74.7,
39.5,
75,
26.5,
54,
52.5,
26.7,
70.4,
5.9,
62.1,
66.4,
76.8,
34.9,
66.3,
53.9,
92.6,
43.8,
60.9,
14.4,
66.7,
43.4,
53.4,
69.1,
38,
78.8,
52.3,
70.4,
79.2,
56.6,
74.5,
47.8,
68.5,
45,
70.4,
47.9,
58.8,
61.1,
20.3,
45.4,
91,
53,
86.3,
69.5,
81.3,
27.7,
25.7,
41.3,
80.8,
24.8,
76.2,
38,
92.2,
57.2,
71.2,
51.7,
52.9,
95.9,
46.1,
7.3,
73.4,
23.7,
85,
23.9,
58.9,
37.6,
41.4,
61.3,
48.3,
22.4,
49,
36.1,
52.8,
49.4,
78,
45.6,
35.3,
35.3,
33.4,
58.5,
6.4,
68.6,
24.5,
36.2,
22.2,
54.4,
36.7,
64.8,
87.2,
55.3,
61.9,
54.4,
47.3,
50.2,
38.2,
32.1,
76.1,
34.4,
12.8,
38.5,
48.6,
43.6,
72.8,
14.1,
55.5,
58,
84.5,
74.1,
68.4,
52.2,
68.3,
42.2,
97.4,
88.6,
74.2,
45.4,
65.1,
13.6,
35.2,
81.8,
33.7,
83.9,
65,
48.9,
38.7,
4.1,
49.4,
33.6,
79.4,
35.9,
71.1,
79,
44.2,
34.8,
48.5,
33.9,
62.1,
22.3,
24.7,
59.4,
70.6,
54.6,
86.7,
52.4,
61.5,
22.6,
50.1,
29.9,
51.6,
46.6,
34,
62.8,
48.6,
63.9,
72.5,
38,
45.9,
87.6,
55.7,
80.5,
92.8,
92,
58.9,
78.4,
58.8,
59.3,
31.9,
null,
41.3,
33.9,
43.9,
65.7,
35,
30.3,
83.7,
62.8,
56.7,
44.3,
37.3,
54.8,
64.4,
81.9,
22.6,
47.2,
27,
18,
72.5,
46,
79,
36.7,
21.5,
42.3,
37.6,
47.3,
50.6,
33.2,
57,
74.3,
53.4,
44.3,
51.6,
72.1,
44.1,
90.1,
43.8,
40.4,
78.3,
72.3,
60.8,
88.5,
87,
29.6,
57.7,
22.8,
87.2,
52.9,
18.6,
56.5,
48,
25.7,
22.9,
88.7,
40.3,
99.3,
86,
35,
34.7,
34.6,
42.4,
71.3,
64.6,
82.1,
43.9,
75.4,
38.4,
9.6,
45.9,
49.9,
75.6,
2,
30.2,
35.7,
52.9,
29.3,
45.6,
44.9,
79.4,
45,
25.9,
66.1,
14.9,
79.3,
12.3,
33.2,
86.5,
67.4,
19.8,
25.8,
99.1,
90.5,
64.7,
63.8,
88.5,
35.5,
49.1,
50.6,
50.9,
35.6,
32.7,
93.7,
2.1,
55.7,
92.3,
49.4,
46,
81.2,
94.9,
39.1,
50.1,
44.4,
82.4,
68.6,
39.3,
68.3,
52.6,
48.4,
73.9,
47.9,
66.1,
28.1,
61.8,
41.2,
43.9,
45,
77.8,
28.5,
57.4,
93.5,
81,
60.5,
66.7,
49.6,
64.2,
80.6,
70.5,
42.7,
34.5,
78,
27.3,
46.9,
78.3,
63.8,
78.7,
40,
26.2,
73.9,
23.7,
43,
51.4,
73.1,
42.2,
83.6,
76.7,
16.8,
51.8,
56.6,
59.2,
36.9,
26.2,
17.6,
22.2,
68.3,
83,
43.5,
52,
33.4,
34.9,
34.1,
34,
98.2,
78.5,
62.6,
48.3,
40.9,
92.5,
91.2,
65,
79.9,
81.5,
15.8,
52.8,
73.9,
51.4,
97.9,
58.5,
59,
7.8,
26.5,
79.9,
22.1,
45.2,
50.6,
97.3,
12.7,
13.9,
5.6,
43.4,
54.2,
95.7,
25.2,
37.9,
57.1,
83.3,
71.5,
53.9,
77.9,
32.4,
38.1,
54,
54.2,
96.6,
24.5,
12.6,
68.6,
17.8,
74,
48.7,
89.1,
36.8,
66.4,
38.8,
70,
100.2,
2.3,
54,
45.4,
69.6,
47.6,
71.2,
78.7,
75.4,
47.8,
53.6,
34.5,
73.7,
40.8,
48.5,
70.1,
85.6,
18.4,
64.8,
88.5,
29,
60,
89.2,
36.6,
85.3,
34.1,
29.2,
58.2,
81.3,
52.7,
46.3,
21.1,
72.3,
97.3,
82.1,
14.5,
29.1,
24.6,
41,
56.9,
32.6,
31.1,
37.2,
92.2,
54.7,
76,
60,
59.6,
24.5,
58.6,
0.3,
49.6,
16.7,
51.4,
65,
31.2,
13.9,
73.9,
57.3,
31.4,
75.6,
29.7,
87.4,
74.4,
63.4,
75.3,
44.5,
17.8,
15.6,
51.7,
89.9,
56.4,
51.6,
57.3,
79.1,
68.5,
62.6,
29,
72.2,
38.4,
5.3,
37.3,
71,
63.5,
79,
70.1,
69,
67,
44.2,
73.6,
83.6,
43.4,
64.3,
19.1,
50.8,
33.8,
22.4,
58.6,
6.1,
19.8,
49.4,
55.6,
43,
95.4,
67,
40.5,
64.7,
52.4,
71.7,
44.3,
53.9,
50.5,
49.8,
52.6,
71.8,
60,
42.4,
67,
34.3,
40.9,
6.2,
44.4,
78.9,
74.3,
40.4,
32,
48.4,
98.3,
65.4,
53.5,
77,
34.8,
92.2,
94.3,
65.4,
83.7,
36.2,
83.5,
45.3,
55.6,
66.7,
75.6,
43.8,
28.5,
35.4,
57.7,
85.3,
34,
2.2,
65.3,
98.1,
72.2,
38.9,
85.1,
96.2,
17.2,
86.2,
59.3,
79.3,
66.5,
61.7,
76.3,
69.7,
53.5,
33.1,
41.8,
81.1,
31.2,
29.7,
72.6,
77.1,
17.1,
65.3,
79.4,
38,
1.9,
70.2,
80.6,
64.2,
83,
10.2,
61.6,
62,
25.2,
38.5,
7.4,
24.5,
57.1,
77.4,
56.9,
50.1,
59.3,
58.3,
94.9,
34.6,
3.5,
63.3,
64.4,
75.3,
79.9,
11.5,
9.4,
70.4,
77.9,
64,
95.8,
30.1,
66.2,
70.4,
60.8,
11.5,
42.9,
37.5,
44.7,
36.4,
49,
62.8,
71.6,
83.1,
14.5,
80.2,
27.5,
98.5,
81.8,
46.7,
84.5,
5.6,
62.7,
63.5,
48.1,
61.9,
18.2,
48.6,
75,
60.2,
59.3,
56.3,
31.1,
44.8,
33.6,
92.2,
74,
33.8,
63.7,
47.4,
77,
69.8,
93.8,
36.5,
42.5,
33.2,
13.4,
34,
95.6,
53,
83.5,
52.6,
80.5,
46.1,
36.7,
79.4,
61.9,
63.5,
71.2,
80.3,
89.7,
46,
54.7,
38,
96.2,
37.2,
56.9,
72.3,
58.4,
92.6,
62.2,
33,
31.9,
84.1,
84.7,
36.5,
60.1,
81.5,
41.1,
53.9,
87.8,
49.5,
57.2,
49.7,
98.3,
62.3,
94.3,
40.7,
86.9,
8.7,
61.4,
57.5,
68,
87,
52.7,
21.8,
66.8,
63.3,
44,
61.7,
58.7,
76,
60.6,
88,
79.2,
94,
54.6,
99.1,
null,
85.2,
40.7,
70.5,
58,
51.8,
81.1,
53.8,
58.2,
83.7,
57.1,
66.8,
45.9,
77,
77.6,
69.4,
25.7,
63.5,
58.9,
72.2,
46.4,
96.5,
79.1,
50,
74.5,
71.7,
88.1,
77.9,
47.4,
49.6,
55,
66.2,
52.5,
73.3,
85,
70.4,
29.9,
47.7,
56.8,
76.3,
63.8,
46,
44.9,
9,
82.6,
53.7,
23.7,
78.8,
42.6,
17.3,
34.8,
16.1,
9.7,
51.4,
39.5,
69.8,
9,
24.2,
9.9,
92.8,
89.7,
44.6,
95,
18.7,
25.4,
53.8,
62.7,
62.3,
44.7,
84.9,
1.2,
84.4,
36.3,
14.5,
87,
87.3,
58.7,
91.1,
55.2,
88.9,
38.2,
67.8,
29.6,
87.8,
50.7,
50.9,
75.1,
75.6,
37.1,
8.9,
45.1,
59.1,
38.9,
58,
60,
90.1,
37.6,
67.9,
40.6,
33.8,
65,
61,
60.8,
74,
65.3,
63.1,
57.4,
84.1,
48.3,
59.1,
62,
71.4,
67.7,
58.1,
22.8,
20.2,
39.2,
64.3,
79.7,
64.7,
93,
64.5,
42.2,
82.8,
28.9,
34.5,
90.6,
32.9,
59.7,
20.7,
25.1,
19.1,
39,
91.6,
69.3,
88.7,
26.7,
57.3,
30.8,
89.1,
47.1,
72.6,
37.2,
72.9,
81,
91.6,
9.3,
48.9,
38,
91,
91.8,
92.6,
70.3,
25.2,
92.8,
9.9,
5.8,
48.8,
70,
47.5,
80.8,
54.2,
56.6,
46.9,
56,
74.1,
62.7,
85.3,
35.9,
55.6,
99.7,
65.8,
78.5,
81.7,
90.9,
88.3,
48,
41.5,
30.2,
51.2,
21,
56.1,
63.3,
94.4,
40,
74.2,
42.9,
91,
53,
74.1,
25.5,
45.7,
46.3,
80.9,
47.1,
54.1,
76,
91.8,
83.8,
62.6,
41.4,
47.6,
50.1,
47.9,
63.1,
62.3,
49.1,
67.3,
33.8,
28.6,
80.2,
79.5,
51.5,
33.6,
39,
56.8,
78.3,
83.9,
8.9,
41.9,
16.4,
42.6,
43.2,
60.6,
62.7,
62.5,
91.4,
70.5,
82.1,
82.3,
81,
34.7,
23.8,
98.8,
76.7,
87.1,
65,
13.6,
96.8,
57.9,
84.9,
53.3,
0.3,
51.8,
56.8,
51.1,
76.9,
38.3,
72.5,
44,
73.8,
70.2,
63.9,
41,
61.4,
82.3,
65.2,
82.5,
62.9,
90.8,
33.3,
8,
45.2,
88.3,
50,
23.2,
41,
59.1,
46,
83.7,
90.9,
59.9,
46.1,
28.3,
20.2,
44,
55.3,
78.6,
74.2,
43.7,
45,
24.7,
35.2,
8.2,
24.3,
12.5,
50,
27.8,
63.8,
65.5,
45.5,
54.6,
0.7,
52.8,
26.3,
46.5,
70.1,
87.3,
1.7,
67.3,
32.2,
28,
44.3,
76.7,
82,
64.7,
93.5,
87.8,
92.3,
23.4,
55.9,
66.1,
46,
60.8,
87.7,
27,
48.7,
77.8,
56.7,
24,
78.9,
39.2,
86.4,
53.4,
45.6,
60.9,
34.7,
61.2,
61,
30.3,
96.2,
57.9,
32.3,
15.8,
62.4,
60.6,
21.2,
0,
56.5,
39.7,
91,
36.2,
24.1,
42.1,
42.3,
10.4,
84.4,
87,
81.7,
41.1,
71.4,
70.1,
39.2,
76.1,
62.7,
57.3,
69.6,
56.4,
13.3,
72.9,
58.8,
43.7,
31,
79.5,
25.5,
24,
53.2,
97.6,
51.3,
87.3,
44,
59.7,
47.4,
65,
49.6,
80.3,
54.7,
62.5,
78.2,
58.5,
70.5,
71.7,
17.6,
42.3,
42.5,
47.8,
15.7,
13.2,
51.3,
97.7,
29.8,
34.7,
73,
38,
17.9,
41.5,
43.9,
70.5,
83.3,
61,
85.5,
89.1,
50.3,
30.9,
28.3,
12,
91.4,
18.2,
51.6,
82.6,
84.5,
79.2,
38.5,
32,
45.7,
24.9,
21.1,
29.9,
50.1,
77.8,
18.8,
64.4,
51,
79.6,
78.4,
14.1,
101.4,
31.4,
53.6,
57.2,
78.8,
19.7,
98,
59.2,
63.3,
84.3,
50.4,
96.5,
49.5,
51.9,
68.6,
30,
5.8,
67.3,
10.8,
33.9,
53.2,
72.1,
86.7,
100.3,
94.5,
59.5,
62.9,
83.4,
63.9,
4.9,
43.6,
32.1,
35,
51.4,
9.5,
74,
37.2,
15.1,
54.5,
51.2,
30.2,
64.2,
85.1,
73.9,
26.5,
83.2,
32.5,
20.6,
63.3,
23.3,
45.8,
51.3,
72.4,
70.6,
84.9,
6.2,
37.5,
17.5,
94.1,
68.8,
23.9,
57.3,
41,
45.4,
33.3,
46.4,
76.5,
69.9,
96.3,
44.7,
24.4,
94.6,
83.1,
2.6,
76.7,
65.9,
34.3,
34,
74.5,
60.5,
23.3,
37.5,
94.4,
66.6,
47.9,
99.4,
46.5,
57,
78,
71.2,
68.6,
22.3,
34.9,
34.9,
39.4,
93.1,
23.5,
68.8,
51.7,
23.1,
31,
38.5,
57.4,
98.3,
19.4,
27.1,
43.6,
68.1,
45.6,
35.9,
79.8,
93.7,
44.8,
41.4,
35,
41.2,
77,
97.8,
35.6,
12.8,
43.6,
64.3,
92.8,
73,
46.4,
16,
5.3,
62.8,
65,
90.8,
70.8,
49.1,
62.4,
68,
2.6,
63.5,
9.8,
54.4,
38.4,
4.2,
56.7,
26.7,
0.3,
67,
62.9,
46.4,
69.8,
53.8,
28.5,
5.9,
47.3,
43.4,
67.5,
24.1,
67.2,
99,
91.6,
96.1,
36.3,
43.2,
60.1,
71.8,
45.5,
22.1,
57.5,
48.7,
76.3,
47.6,
81.4,
59.1,
48.9,
57.9,
77.7,
50.6,
35,
56.1,
54.8,
14.2,
34.7,
24.3,
40.6,
56,
69.6,
60,
14.5,
27.7,
29.9,
66.3,
74.1,
90.4,
84.7,
47.5,
67.6,
64.3,
99,
86.8,
74.3,
64.6,
73.3,
31.6,
92.5,
40.2,
14.7,
76.4,
71,
46.1,
75.8,
98.5,
57,
92.7,
56.2,
67.8,
57.6,
95.5,
51.5,
62.3,
37.3,
37.4,
30.8,
93,
64,
49.4,
36.8,
70.5,
86.3,
92,
65.1,
71.2,
77.8,
55.9,
62.2,
93,
21,
29.3,
81.3,
54.8,
101.5,
59.1,
95.3,
80.4,
50.6,
91.9,
59.9,
77,
31.3,
26.9,
34.5,
51.1,
9.6,
32.6,
12.8,
46,
88.1,
86.3,
89,
72,
24.7,
36.2,
86.9,
53.8,
40.9,
85.5,
29.6,
82.9,
95,
88.6,
83.7,
7.2,
48.4,
29.9,
90.9,
51.8,
99.1,
49.5,
95.4,
93.3,
102.3,
72.2,
93,
47.2,
93.5,
43.3,
9.2,
43.6,
19.5,
81.4,
67.3,
38.5,
43.8,
69.2,
78.6,
94.2,
67.5,
56.6,
65,
64.8,
60,
42.1,
94.2,
53.3,
51.2,
28.6,
58.5,
54.9,
18.7,
31.6,
60,
85.4,
51.6,
72.6,
62.7,
91.4,
86.6,
46.5,
66,
1.7,
74.6,
105.4,
66.1,
97.9,
69.8,
72.5,
77.7,
9.2,
54.2,
27.3,
54.7,
45.8,
58.5,
92.4,
75.5,
65.3,
75,
2,
81.4,
63.9,
1.1,
77.2,
43.8,
56,
43.2,
51.1,
87.2,
38.1,
37.5,
8.2,
38.2,
78.3,
38,
47.6,
92.4,
49.9,
36.1,
42.9,
74.2,
42.6,
76,
88.4,
33.3,
23.3,
95,
51.8,
98.9,
54.5,
49.3,
84.6,
50.2,
33,
12.5,
20.7,
55.8,
30.2,
91,
68.2,
37.9,
60.1,
74.1,
36.5,
82.3,
87,
54.8,
42.1,
64.7,
36.5,
98.7,
47.5,
56.1,
53.6,
27.1,
55.1,
40.6,
20.8,
55.2,
49.3,
80,
62.9,
99.1,
91.7,
44.1,
37.1,
23.7,
80.8,
10.2,
27.3,
66.6,
41.2,
45.8,
0.4,
86.4,
51.1,
78.2,
68.2,
58.8,
48.4,
42.4,
81.8,
51.6,
57.2,
69,
74.7,
91.9,
92.6,
77.2,
60.4,
58.3,
53.1,
78,
41.7,
55.3,
72.4,
26.9,
40.2,
24.9,
35.7,
79.7,
64.7,
71.9,
56.1,
44.1,
86.9,
66,
14.5,
51,
30.2,
21,
2.4,
21.7,
20.7,
66.5,
55.5,
79.9,
92.1,
85,
49.2,
51.4,
32.7,
55,
69.4,
55.8,
58.1,
7,
81.8,
94.1,
72.1,
33.5,
31.5,
90.1,
31.2,
53.9,
69.7,
79.5,
25.3,
36.3,
92.6,
60.4,
88.2,
75,
50.9,
52.3,
1.8,
71.7,
80.8,
18.6,
60.8,
75.3,
10.5,
78.2,
51.6,
99.5,
8.8,
95.1,
76,
3.7,
40.1,
91.8,
7.9,
77.2,
47.6,
15.1,
75.4,
43.5,
71.8,
80.6,
66.6,
82.4,
25.4,
15.4,
89.8,
57.1,
38.3,
85.8,
71.4,
45,
43.3,
30.5,
72.1,
53.8,
85.7,
56.8,
30.3,
67.1,
68,
60.1,
5.2,
76.8,
35.2,
92.6,
81.6,
39.8,
48.6,
89.1,
46.3,
31.9,
28.8,
77.1,
76.5,
83,
32.1,
49,
33.8,
4.4,
83.4,
73,
19.4,
54.9,
60.7,
70.4,
70.7,
28.7,
38,
56.8,
36.7,
65.9,
46.6,
35.6,
72.6,
18.2,
58,
45.2,
74.2,
61.6,
4.2,
20.5,
81.1,
58.3,
44.9,
28.8,
31.2,
75.9,
49.5,
89.7,
91,
51.8,
70,
81.2,
61.6,
43.6,
65.2,
58.2,
38.4,
64.8,
79.8,
80.3,
57,
14.1,
45.7,
94.7,
23.8,
83.6,
54.6,
85.8,
77.7,
81.5,
54.9,
45.6,
38.5,
44.7,
15,
74.2,
35.8,
43,
76.3,
36.4,
87.9,
46.5,
71.6,
34.8,
51.2,
52.9,
47.6,
40.3,
31.9,
0,
39,
50.4,
71.4,
48.4,
60.1,
51.2,
43.8,
50.7,
54.3,
63.2,
32.5,
35.8,
20.8,
88,
67,
95,
80.9,
87.6,
78.5,
48,
31.5,
50.2,
12.8,
46.8,
35.2,
58.5,
41.4,
94.2,
39.2,
43.7,
44.6,
87.2,
30,
82.2,
49.2,
5.2,
96.9,
64.2,
80.6,
84.7,
32.4,
36.2,
13.8,
39,
56.8,
98.3,
52.7,
59.5,
82.1,
65,
26.4,
10,
55.4,
61.8,
16.5,
82.2,
31,
10.5,
93.9,
12,
74.3,
39.2,
30.6,
61.3,
53.9,
58,
33,
0.7,
38.2,
43.4,
67.8,
40.9,
83.8,
61.6,
34.2,
33.6,
49.9,
74.7,
27.6,
47,
88.9,
57.7,
19.5,
73.1,
27.6,
96.1,
77,
43.9,
16.2,
54.8,
70.9,
76.3,
98.2,
64.3,
49.4,
18.3,
76.1,
48.4,
43.3,
46.5,
46.8,
12,
89.4,
44.9,
35.6,
96.1,
14.8,
72.4,
54,
59.8,
23.9,
53.3,
46.9,
75.7,
67,
55.2,
92.2,
6.7,
36,
41.7,
68.1,
68,
49.9,
81.7,
57.7,
63.7,
70.3,
32.1,
25.5,
90.3,
73.8,
67.6,
55.9,
48.1,
54,
95.7,
60,
47.6,
55.1,
39.9,
63.4,
46.2,
52.4,
68.6,
79.2,
55.7,
14.9,
88,
67.5,
78.8,
64.8,
33,
47.5,
9.3,
22.1,
34.5,
32,
76.8,
47,
52.9,
78.3,
39.6,
60.4,
64.4,
54.1,
82.5,
42.7,
36.9,
10,
76.2,
20.2,
10.8,
66.7,
20.4,
43.2,
97.5,
82.6,
52.4,
49.8,
48.7,
72.8,
93.6,
36.7,
68.3,
32.6,
68,
81,
30.5,
7.3,
83.9,
99.8,
48.1,
48.8,
62.7,
76.9,
74.9,
24,
23.2,
93.5,
75.7,
74.1,
48.5,
90.4,
56.3,
47.7,
82.6,
78.5,
3.2,
42.6,
42.5,
43.8,
22.2,
22.6,
55,
78.1,
79.4,
20.5,
43.3,
34.4,
59.6,
33.3,
81.4,
39,
69.4,
82.5,
70.6,
51.7,
29.3,
32,
64.6,
41.8,
82.5,
67.6,
71.4,
41.3,
62,
38.5,
42.8,
70.2,
64.9,
77.5,
68.2,
74.5,
79,
64.4,
60.8,
73.4,
43.8,
58.4,
7.6,
56.8,
26.4,
83.5,
13,
27.2,
74.7,
74.5,
83.3,
34,
83.8,
71.3,
39.8,
97.3,
58.8,
73.8,
57,
59,
16.3,
71.9,
66.9,
33.9,
85.6,
21.5,
38.4,
49.6,
40.7,
null,
48.1,
71.3,
78.4,
81.5,
88.4,
23.3,
57.7,
73.3,
20.8,
67.6,
60.2,
60.2,
53.2,
35,
80.6,
45,
46.8,
48.6,
55.8,
28.1,
64.1,
87.4,
51.2,
99.4,
57.8,
56,
33.4,
34.8,
43.5,
44.9,
60.1,
49,
38.2,
36.9,
52.9,
1.2,
58.7,
94,
57.3,
49.3,
15.3,
88.8,
87.8,
95.4,
62.7,
15.9,
68.6,
51.4,
94.9,
75.2,
60.6,
22.6,
43.1,
51.1,
18.2,
76.1,
20.9,
74.8,
51,
91,
31.4,
98.9,
37.9,
70.1,
40.4,
92,
75.4,
89,
94.6,
64.3,
89.7,
49.9,
46.9,
77.4,
56.9,
73.6,
43,
79.7,
18.5,
82.9,
44.6,
10.2,
69.3,
55.8,
89.3,
99.6,
57.2,
43.1,
42.3,
78.7,
94.3,
83.1,
82.3,
56.1,
58.2,
59.9,
33.9,
30.9,
35.7,
71.8,
88.2,
42.1,
40.4,
44,
77.2,
13.3,
24.5,
43,
33,
23.4,
20.6,
30.2,
84.3,
48.6,
41.2,
33,
30,
15,
30.9,
49,
76.9,
50.7,
98.8,
36.9,
36.4,
83.4,
61.1,
47.9,
8.3,
89.2,
53.7,
27.1,
70.1,
58.9,
101.9,
39.4,
61.3,
27.6,
27,
60.6,
20.6,
70.1,
64.2,
60,
47.7,
52.9,
51,
39.5,
54.7,
16.4,
94.9,
73.6,
96.9,
64.4,
68.8,
84.8,
68.1,
41.7,
24.5,
22.7,
32,
42,
29.6,
62.4,
38.6,
95.4,
66,
50,
9.2,
75.8,
56.3,
20.2,
56.8,
55.1,
8.2,
22.1,
4.7,
31.7,
46.1,
50.3,
31.3,
92.7,
10.6,
7.5,
64,
4.9,
30.5,
56.2,
87.1,
59.7,
39.8,
72.3,
70,
69.9,
12.8,
38.1,
55.9,
16.7,
85.8,
54.6,
47.2,
50.5,
19.6,
65.4,
87.4,
70.9,
83.3,
22.4,
57.5,
45.9,
70.7,
21.1,
95.2,
23.8,
77.7,
47.4,
80,
88.3,
35.7,
42.5,
38.2,
73.8,
35.7,
11.5,
72.3,
77.2,
46.2,
65.3,
83.7,
71,
71.8,
21.8,
54.2,
38.1,
71.4,
81,
73.8,
50.3,
58.9,
41.3,
94.9,
12.9,
11.1,
28,
17.1,
59.4,
33.8,
93.3,
31,
29.5,
0,
20.7,
20.9,
68.9,
66.6,
36.3,
72.7,
87.1,
38.9,
61.8,
29.5,
61.7,
31.5,
90.6,
75.1,
69.7,
25.3,
45.7,
70.7,
39.1,
56.2,
16.7,
34.1,
67.6,
4.1,
53.9,
44.4,
45.3,
36.9,
44.3,
90.6,
30.7,
27.2,
77.7,
90.9,
74.3,
36.7,
72.1,
75.4,
38,
6.7,
18.2,
45.2,
85.5,
79.5,
77.1,
73,
19,
97.1,
44.7,
81,
56.8,
75.1,
65.2,
58.5,
82.1,
45.4,
74.1,
64.1,
70.2,
31,
75.9,
55.4,
99,
65.9,
56.4,
32.4,
55,
38.2,
46.7,
30.5,
37.8,
88.6,
46.8,
70.2,
37.9,
75.9,
47.6,
56.7,
62,
60,
37.8,
69.1,
68.2,
37.7,
32.2,
79.1,
35.1,
38.4,
85.3,
84.8,
101.3,
27,
20.7,
97,
81.7,
64.4,
54.9,
24.4,
72.6,
63.7,
63.5,
63.8,
38.8,
73.6,
53.1,
21.2,
31.4,
50.5,
89.9,
68.4,
43.1,
68.1,
1.5,
58.1,
58.9,
92.7,
55.1,
41.3,
61.1,
17.7,
94.8,
62.8,
48.8,
66.2,
94.8,
34,
52,
85.6,
21.3,
36.3,
58.7,
12.5,
56.1,
59.2,
56.4,
21.4,
12,
71.5,
21,
68.6,
44.5,
42.7,
0,
40.8,
35.5,
77.3,
34.2,
19,
5.4,
78.2,
55.9,
87.2,
52.9,
42.9,
36.2,
91.8,
61,
30.3,
59.1,
29.3,
54.6,
98.5,
55,
76,
72.4,
52.4,
52.2,
81.8,
81,
58.5,
72.9,
43.2,
89.4,
29.4,
36.4,
27.3,
33.9,
50,
66.1,
26.5,
32.6,
32.9,
83.1,
61.8,
16.3,
24.9,
38,
93.2,
61,
69.4,
26.3,
51,
42.8,
80.9,
68.9,
59.7,
38.2,
96.5,
38,
51.2,
81.2,
44.6,
80.2,
50.2,
48.3,
72.3,
35.5,
35.5,
68.6,
82.5,
59,
75.6,
72.1,
84,
52.3,
70.3,
71.7,
0.1,
46,
7.8,
46.3,
54.6,
49.6,
82.2,
3.5,
44.7,
31.3,
58.6,
63.4,
58.6,
66.3,
36.8,
66,
93.5,
48.9,
57,
24.5,
39.7,
61.4,
78.1,
64,
87.5,
51.4,
37,
12.4,
44.4,
34.9,
66.6,
42,
69.3,
65.1,
49.4,
85.6,
93.8,
79.6,
54.6,
88.9,
93.2,
59.7,
78,
50.2,
87.1,
52.9,
53.1,
67.6,
27.8,
29,
38.1,
49.3,
66.6,
42.4,
66.9,
60.7,
47.7,
6.4,
87.6,
79.2,
98.1,
57.4,
80,
34,
49.2,
19.5,
8.8,
32.8,
91.9,
47.2,
33.7,
53.4,
28.5,
61,
13.9,
73.6,
93.4,
84.9,
30.4,
59.1,
23.9,
9.2,
66.7,
51.9,
87.9,
49.1,
88.8,
66.3,
69.7,
28.9,
84.8,
38.7,
12,
31.7,
24.6,
54.2,
31,
59.5,
87.9,
10.5,
61.3,
22.9,
17.7,
84.3,
47.7,
45,
70.9,
30.4,
64.3,
77.4,
51.4,
73.6,
77,
38.8,
65.3,
39.6,
42.9,
56.5,
23.6,
73.8,
57.6,
31.8,
46.4,
35.3,
43.3,
48.5,
33.7,
20.7,
32.8,
32.4,
64,
28,
37.9,
64.9,
51.5,
57,
28.1,
50.6,
78.6,
96.2,
63.9,
36.5,
62,
25.7,
63.7,
74.1,
81.5,
65.3,
65.8,
38.9,
46.9,
72.7,
91.9,
68,
88.5,
81.9,
24,
35.5,
10.9,
41.7,
73.3,
81,
91.5,
35.5,
64.5,
86.8,
53.3,
83.1,
97.5,
16.3,
53.6,
29.5,
87.3,
39,
46.8,
69.8,
25,
92.2,
32.8,
82.2,
68.8,
44.5,
51.1,
14.5,
19.8,
55.2,
38.1,
78,
75.7,
91.1,
29.9,
14.1,
58,
39.5,
93.2,
80,
86.4,
36.1,
18,
22,
57.3,
86.1,
47.7,
32.8,
30.7,
58,
71.3,
68.3,
69.3,
31.3,
55.2,
11.9,
56.9,
32,
59.4,
17.8,
61,
5.4,
36.9,
57,
65,
50.7,
91.7,
56.1,
88.7,
18.8,
44.3,
32,
60.4,
71.1,
27.4,
34.1,
48.7,
39.2,
29.5,
24.9,
39.9,
90.8,
45.9,
24.2,
75.7,
97.3,
37.7,
59.9,
32.5,
73.3,
52.4,
38.6,
71.8,
89.4,
53.3,
59.3,
67.1,
97.6,
8.8,
29.9,
11,
39.6,
43.1,
71,
38.2,
72.2,
24.3,
59.1,
67.9,
41.3,
73.4,
33.4,
60,
66.6,
1.4,
29.7,
63.6,
74.6,
33.5,
78.6,
36.7,
16,
68,
66.5,
65.4,
78.9,
30.2,
16.7,
94.6,
68.1,
12.9,
48.4,
29.6,
20.6,
59.5,
46.5,
54.4,
47.8,
77.7,
19.8,
71,
38.3,
76,
27.5,
64.1,
90.5,
61.6,
54.9,
83.6,
36.4,
18.4,
38.7,
49.1,
36.1,
79.4,
42.8,
56.9,
59.1,
55.8,
41,
68.4,
27.2,
25.4,
43.5,
40.2,
31,
3.8,
83.7,
83.5,
16.5,
71.7,
79.3,
30.1,
79.5,
15.6,
17.6,
53,
67.3,
63.7,
27.9,
95.5,
56.7,
66,
102.1,
45.5,
79.7,
38,
80,
87.1,
33.1,
79.8,
37.8,
41.4,
34.5,
37,
32,
37.3,
84.6,
47.6,
97.2,
75,
88.5,
48.3,
17.4,
35.7,
50.2,
45,
47.1,
72,
11.9,
37.2,
79.4,
60.3,
31.7,
91.8,
76.4,
46,
54.7,
38,
98.3,
34.3,
71.7,
51.4,
18.5,
68.8,
84.6,
72.5,
10.9,
20,
53,
37.5,
28,
3,
61.8,
67.5,
68.6,
94.1,
53,
46.2,
55.5,
42.9,
48.9,
66.9,
67.7,
61,
30.1,
80,
87.7,
71.6,
57.2,
69,
35.7,
59.7,
41.8,
43.6,
88.7,
74.9,
53.4,
24.2,
31.3,
42.7,
59.8,
55.2,
60.2,
88.2,
54.5,
77.3,
25.1,
65.3,
90.6,
51.7,
49.2,
80.4,
54.6,
48.8,
78.5,
61,
14.1,
68.6,
59.4,
55.3,
19,
57.5,
36.1,
30.6,
22.9,
57.7,
67,
47,
24.4,
45.9,
42.3,
89.2,
88.5,
50.9,
71.4,
48.6,
18,
53.1,
62.5,
65.5,
60.8,
26.9,
29.4,
26,
53.4,
45.4,
31.7,
70.9,
59.3,
76.1,
42.1,
25.9,
55.3,
58.6,
98.6,
37,
61.1,
60.5,
34.2,
49.3,
66,
6.3,
52.3,
39.5,
53.4,
44.6,
58.6,
15.3,
99.3,
41.5,
22.3,
36.6,
32.5,
52.7,
71.9,
84.1,
75.3,
67.4,
90,
80.8,
5.6,
75,
72.1,
70.3,
94.9,
74.4,
92.5,
25.8,
64.1,
36,
25.3,
91.6,
8.3,
48.9,
47.3,
53.9,
30.7,
64.9,
36.2,
39.8,
54.2,
99,
78,
31.3,
63,
83.1,
44.5,
51.7,
59.5,
65.5,
93.1,
53.1,
85,
2.2,
69.3,
91.7,
80.4,
44.3,
64.9,
44.3,
77.1,
52.3,
54.9,
25.7,
62.5,
82.1,
57.6,
28.8,
72.5,
13,
49.9,
66,
61.2,
71.2,
43.2,
65.5,
30,
26.1,
52,
42.5,
75.2,
48.8,
46.4,
95.2,
56.6,
57.4,
56.9,
50.6,
63.6,
77.4,
94.7,
32.3,
59.7,
67.2,
42.9,
65.8,
85.7,
53.6,
56.9,
36.6,
21,
32.7,
25.5,
56.3,
72.5,
64.7,
69.1,
82,
83.1,
32.8,
66,
16.8,
40.8,
34.2,
50.7,
30.2,
95.4,
92.6,
68.1,
67.1,
77.8,
38.7,
18.7,
5.4,
49.8,
74.1,
62.7,
31.6,
79.1,
36.6,
47.5,
89.1,
56.4,
79.2,
71.8,
5.1,
52.5,
44.4,
17.9,
87.8,
48.9,
96.8,
95.8,
64,
5,
72.1,
31.9,
97.4,
98.9,
4.2,
72.6,
60,
59.7,
64.4,
52.3,
62.8,
90.9,
31,
83.2,
87.9,
49.5,
58.1,
93,
14.7,
72.8,
71.4,
21.7,
26.3,
95.9,
33,
49.3,
61,
64.9,
42.6,
54,
36.5,
29.6,
85.9,
54.8,
91.5,
27.2,
54.1,
98,
50.7,
42.5,
43,
21.2,
57.2,
72.7,
77.1,
55.5,
60.5,
21.8,
33.1,
36,
40.3,
78.4,
60.5,
47.6,
74,
82.3,
77.1,
71.8,
72.6,
84.5,
61.1,
46.1,
60.8,
71.3,
66.3,
52.4,
84.8,
59.7,
56.5,
58.3,
78.5,
81.5,
53.7,
44,
23.4,
87.2,
32.4,
88.2,
52.5,
72,
22.9,
79,
45.7,
56.7,
27.7,
43.5,
54.8,
94.3,
59.1,
0.4,
63.5,
46.3,
61.8,
69.4,
53.3,
52.2,
82.1,
69.1,
70.9,
25.8,
70.2,
44.4,
28.3,
54.5,
100.5,
74.5,
51.4,
65.2,
60,
82.2,
14.9,
35.2,
67.2,
36.7,
65.9,
60.7,
69.5,
31.6,
36,
52.6,
49.7,
100.9,
15.4,
43.8,
18.2,
75.5,
93.6,
45.1,
48.3,
39,
66.7,
27.1,
86.5,
92.8,
59.3,
82.2,
53.6,
2.6,
68.6,
59.4,
75.7,
18.2,
7.9,
84.9,
66.8,
70,
52.7,
77,
76.4,
77.7,
57.4,
23.1,
74.9,
20.3,
63.6,
71.5,
9.5,
33.8,
48.3,
61,
64.9,
43,
47.3,
44.5,
73.3,
24.3,
59.4,
55.9,
74.2,
66.2,
58.7,
51.5,
63.6,
68.3,
22.4,
38.8,
88.3,
22.9,
62.9,
62.6,
69,
71,
43.4,
92.9,
36.9,
68,
53,
44.2,
88.7,
64.4,
37.1,
37.7,
15.3,
97.4,
53.7,
78,
79.2,
49.9,
91.8,
62.7,
52.1,
13.7,
36,
28.2,
46.6,
17.4,
37.2,
94.6,
73.1,
60.2,
70.7,
72.7,
13.5,
75.6,
32.6,
44.9,
64.5,
47.3,
44,
69,
40.7,
40.6,
64.2,
91.7,
87.9,
94.5,
14.3,
55,
89.7,
77.8,
78.7,
39.7,
75.6,
41.2,
16.6,
89.9,
49.6,
92.2,
16.7,
30.2,
54.8,
50.5,
49.5,
62.4,
64.6,
16.2,
43.9,
82.5,
76.7,
66.6,
78.1,
98.7,
69.3,
88.9,
54.3,
79,
57.9,
44.4,
42.7,
85,
48,
89.7,
84.2,
75,
70.8,
29.9,
77.3,
45.3,
28.4,
49.6,
17.6,
26,
56.4,
12.1,
22.7,
72.8,
41.8,
71.1,
22.2,
97.7,
50.7,
41.6,
59,
34.8,
45.3,
48.2,
36.4,
65.9,
23.4,
69.9,
71.5,
68.9,
8.7,
45.3,
21.7,
39.3,
40.7,
51.6,
63.6,
41,
52,
93,
48,
23.2,
52.3,
51.1,
50.8,
98.2,
81.5,
52.9,
96,
29.1,
77.9,
99,
59.3,
40.9,
25.6,
46.3,
50.5,
53.3,
26.2,
57.1,
31.8,
37.7,
17.2,
58.2,
55.9,
69.5,
51.7,
48.8,
41.4,
61.1,
88.1,
27,
18.3,
78,
45,
79,
63.5,
29.4,
64.7,
15.9,
18.4,
67.3,
46.5,
52.3,
87.4,
56.8,
25.1,
46.2,
78.6,
45.8,
52.3,
64,
61.5,
53.4,
77.5,
17,
59.2,
64.4,
43.5,
87.9,
44,
69.9,
29.5,
74.4,
45.8,
70.3,
22.1,
30,
30.8,
53,
59.5,
37.8,
67.8,
44.1,
97,
69,
72.7,
89.5,
73.9,
58.8,
95,
91,
67.8,
24.3,
21.8,
52.5,
37,
51.9,
15.1,
52.3,
58.5,
28.6,
86.5,
98,
42.8,
48,
71.1,
46.3,
55.1,
26.3,
75.1,
56.1,
80.9,
56.2,
63,
55.3,
79.3,
73.2,
53.8,
29.4,
77.8,
63,
62.7,
57.4,
60.3,
70.4,
37.5,
95.4,
67.1,
67.5,
88.2,
34.4,
17.2,
79.5,
62.4,
64.5,
85.5,
72.1,
60.2,
6.5,
76.1,
75.2,
95,
57.1,
68.3,
68.7,
61.7,
34.4,
18.9,
35.5,
73.1,
61.9,
8.2,
58.6,
85.7,
89.1,
54.7,
53.1,
92.6,
100.9,
49.1,
94.7,
41,
78.7,
93.7,
64.6,
78,
72.7,
43.7,
70.4,
75,
55.2,
96.3,
58.3,
42.3,
90.1,
100.2,
59.3,
54.7,
41,
23.5,
52.1,
33,
49.5,
42.5,
43.4,
57.7,
73.9,
67.9,
42.1,
35.8,
37.5,
41.5,
26.2,
45.9,
42.6,
62,
61.9,
71.2,
21.5,
82.8,
59.5,
12.4,
15,
60.7,
53.1,
38.5,
86.9,
66,
44.3,
62.4,
75.4,
71.5,
41.2,
31.5,
48.2,
53.5,
37,
66.5,
46.6,
26.7,
88.9,
96.5,
24.3,
20.6,
87,
76.3,
58.8,
69,
39.5,
20.5,
64,
81,
47.1,
49.4,
51.2,
71.2,
79.6,
50.7,
38,
81.7,
99.2,
53.1,
70.6,
78.7,
19.9,
52.2,
61.3,
22.1,
56.9,
63.7,
71.9,
65.5,
26.6,
83.4,
22.6,
16.1,
41.5,
98.1,
94.3,
39.5,
68,
95.9,
67.8,
82.9,
97.3,
52.2,
58.1,
62.6,
41.4,
56.7,
16.5,
57.5,
27.6,
57.8,
9.1,
38.1,
42.8,
46.8,
68.6,
20.1,
51.7,
7.1,
24,
93.2,
54.6,
15.7,
25.1,
25.5,
70.8,
72.7,
28.1,
8.3,
79.4,
76.1,
90.7,
55.3,
36.8,
60.3,
97.1,
46.8,
37.6,
61.2,
61.2,
54.4,
18.8,
60.9,
84.8,
64.8,
38.8,
88.6,
46.3,
52.3,
90.6,
64.2,
55.9,
48.5,
56.3,
30.5,
66.3,
41.5,
42.8,
62.8,
25.1,
33.7,
55.9,
0,
88.9,
102.1,
31,
79.5,
31.6,
19.6,
51.3,
69.5,
18.6,
6.2,
57.3,
99.3,
5.2,
45.1,
84,
54.7,
61.7,
61.2,
84.8,
45.5,
9.5,
65.4,
48.4,
76.1,
76.8,
64.9,
64,
43.2,
22.2,
66.1,
85.1,
91.7,
71,
46,
43.1,
99.3,
47.8,
88,
58.2,
29,
57.6,
70.8,
53.5,
54.1,
60.6,
17.1,
61.2,
24.5,
47.6,
40.5,
47.2,
21.1,
79.9,
60.6,
56.2,
30.9,
77.2,
98.1,
25.3,
32.2,
42.8,
0,
44,
56.4,
72,
77,
87.2,
59.9,
97.3,
85,
32.7,
51,
50,
58.7,
59.8,
21.5,
90.3,
43.4,
59.4,
41.3,
76.3,
40.8,
33.2,
24.4,
70.2,
60,
87.4,
20.7,
54.4,
93.2,
38,
78.3,
94,
4.9,
59.9,
57.9,
83.2,
37.1,
54.2,
52.8,
22.4,
51,
62.4,
64.8,
43.5,
59.6,
54,
96.7,
26.4,
74.2,
57,
94.7,
75.6,
55.6,
72.7,
51.7,
51.5,
63.8,
48.3,
38.2,
16.9,
92,
47.1,
56.8,
62.1,
74.2,
5.2,
66.5,
70.2,
40.2,
56.5,
42.9,
81.9,
8.3,
14,
92.4,
76.9,
66.7,
61.8,
21.2,
68.7,
32.8,
43.8,
78.5,
38.4,
61.2,
60.1,
8.4,
83.2,
82.9,
43.4,
39.9,
27.1,
21.8,
77.1,
45.4,
53.9,
48.5,
72.6,
47.7,
65.7,
60.6,
50.7,
92.8,
82.1,
90,
59.6,
32.6,
54.7,
16.5,
56.4,
74.8,
60.9,
80.9,
30.3,
17.6,
29.9,
55,
19.1,
69.3,
35.2,
66.8,
34.9,
41.6,
69.1,
49.4,
35.9,
0,
44.3,
85.5,
70.4,
85.7,
89.3,
89.6,
75,
39.6,
56.8,
75.2,
39.9,
64.5,
46.7,
55.2,
14.6,
46.4,
54.1,
79.2,
59.3,
53.9,
67.6,
65.8,
57,
25.3,
46.1,
76.8,
99.2,
44.8,
28.2,
3.5,
73.9,
36.5,
27.9,
54.7,
40,
25.4,
44.8,
26.4,
57.4,
53.2,
91.8,
3.2,
81.5,
38.7,
93.1,
62.8,
17.6,
38.6,
79.9,
91.1,
52,
52.2,
61,
44.1,
54.7,
59.1,
11.8,
78.7,
42,
97.8,
55.9,
51.6,
72.9,
63.2,
34,
42.8,
28.3,
84.4,
26.1,
52.1,
37.3,
78.6,
53.4,
84.7,
64.1,
57.7,
57.1,
56.3,
56.3,
66.6,
42.4,
52.9,
48.2,
30.7,
65.8,
59.9,
10.3,
77.1,
79.5,
62.1,
39.1,
60.7,
48.9,
12.4,
67.9,
29.1,
47.3,
11.5,
74.3,
56,
58.3,
61.8,
70.3,
62.1,
60.5,
62.9,
23.5,
47.7,
71,
48.7,
64.1,
68.6,
42.7,
65.9,
68.5,
17.7,
29.9,
26.6,
62.8,
31.7,
52.8,
65.4,
21.3,
67.1,
98.4,
46.5,
43.4,
45,
66.7,
36.9,
89.6,
33,
86.1,
95.9,
85.8,
67.2,
8.9,
37.5,
63.9,
44.6,
21.4,
40.2,
53.9,
72.5,
12.6,
45.2,
87.3,
48.9,
24.7,
68.3,
47.1,
72.9,
10.3,
68.7,
65,
25.2,
83.7,
48.6,
45.6,
66.5,
34.6,
6,
77.2,
59,
90,
28.3,
48,
58.7,
58,
67.6,
55.2,
68.2,
65.3,
74.4,
49.3,
38.4,
81.2,
64.5,
85.2,
13.1,
38,
15.4,
50,
32.5,
58.2,
98,
42.2,
95.9,
39.5,
11.7,
75,
52.9,
87.8,
92,
79.6,
45.4,
62.5,
26.5,
20.3,
89.2,
67.1,
84.6,
48.1,
70,
68.9,
50.6,
81.9,
94.6,
7.3,
37.8,
94.4,
20.8,
74.2,
35.8,
49.1,
31.9,
19.4,
66.7,
91,
64.4,
53.8,
36.6,
84.9,
0,
57.3,
15.8,
46.7,
59.6,
72.7,
86.7,
79.9,
40.1,
81,
41.2,
57.1,
9.6,
80.7,
71.6,
42.5,
41.5,
48.4,
41.2,
59.3,
83.9,
92,
37,
77.9,
62.8,
71.2,
72.3,
50.3,
38.5,
45.4,
89.2,
72,
57.3,
52.4,
68,
36.2,
60.9,
98.6,
59.5,
32.9,
34.4,
95.1,
57.5,
66.8,
60.2,
34.5,
56.4,
72.4,
8.9,
56.5,
20.1,
45.2,
60.1,
78.8,
64,
35.1,
51.7,
58.3,
83.2,
58.2,
18,
54.9,
45.1,
61.3,
79.2,
51.5,
98.8,
57.8,
44,
76.4,
24,
45,
41.3,
23.7,
54.2,
77.6,
42.6,
75.1,
54.7,
77.7,
71.7,
11.8,
40.1,
63.1,
60.4,
43,
46.9,
98.1,
56.8,
6.9,
42.2,
87.3,
43.7,
82.2,
100.5,
33,
45.9,
59.7,
66.6,
81.2,
75,
63.5,
44.8,
52.9,
89,
44.1,
33.2,
84.8,
3.3,
10,
56.7,
63,
43.2,
34.8,
56.3,
33.9,
35.9,
59.2,
74.6,
75.4,
82.9,
14.4,
78,
93,
37.1,
61,
29.3,
3.8,
44.9,
75.9,
73.7,
91.2,
53.7,
96.7,
65.1,
32.4,
37.2,
76.4,
87.4,
66.9,
48.8,
48.9,
11.2,
60.7,
81,
15.3,
74.1,
65.2,
70.9,
8.7,
61.6,
54.7,
89.6,
78,
11.7,
34.1,
66.1,
56,
36.4,
49.4,
72.7,
92.5,
40.7,
11.8,
24.2,
33,
75.5,
80.6,
84.7,
37,
20.6,
55.3,
97.5,
76.8,
68.5,
55,
89.4,
71.3,
68.3,
24.2,
98.1,
53.8,
69.2,
76.8,
1,
72,
41.3,
12,
34.7,
94.9,
44.8,
55.6,
32.9,
29.1,
86.3,
70,
30.1,
0,
53.5,
64.7,
19.8,
25.9,
40.4,
33.1,
64.3,
88.4,
54.2,
22.5,
73.2,
37.1,
75.2,
97.4,
90.8,
70.6,
23.6,
77.1,
33.1,
70.8,
49.2,
84,
58.6,
66.5,
71.3,
99.8,
15.7,
29.7,
69.2,
68.9,
45.7,
64.8,
70.7,
95.9,
62.7,
26.9,
56.5,
40.4,
19,
43.8,
88.1,
61.6,
56.2,
42.7,
47.9,
53.9,
29.5,
27.3,
61.3,
54,
85.7,
88.6,
49.7,
56.2,
29.2,
27.7,
57.2,
17.3,
24.1,
75.7,
38,
39.7,
21.2,
80,
43,
35.7,
46.6,
7.3,
39.9,
68,
105.9,
75.2,
53.3,
86.4,
8.8,
4,
7.3,
33.8,
25.4,
32.1,
12,
50.5,
64.7,
64,
72.5,
14.7,
75.4,
22.6,
88.5,
47.8,
71.6,
20.6,
64.8,
47.8,
7.7,
11.8,
32.4,
77.6,
56.4,
49.2,
87.7,
63.5,
28.2,
49,
61.6,
100,
67.7,
71.4,
13.2,
78.9,
91.7,
15.8,
54.1,
50.5,
27.9,
55.8,
38,
66,
85.2,
78.2,
77,
16.9,
51.9,
7.7,
63.2,
70,
71.4,
31.8,
18.1,
33,
38.7,
86,
49,
62,
59.3,
62.7,
30,
69.9,
49,
55.7,
32.8,
54.2,
46.8,
85.9,
29.5,
37.3,
85.1,
58.9,
4.6,
6.8,
67.6,
47.2,
60.8,
29.6,
74.9,
4.6,
72.2,
95.8,
38.4,
56.6,
65,
88.2,
49.7,
73.7,
24.1,
59.3,
62.1,
39.3,
41.5,
5,
30,
72.1,
93.5,
30.1,
60.8,
89,
92.1,
63.8,
41.8,
54.6,
91.1,
66.1,
36.1,
25.1,
87.1,
14.9,
122.8,
23.3,
68.8,
82.5,
70.3,
95.4,
29,
7.6,
60.2,
92.3,
55.2,
25.6,
54.5,
55.7,
94.5,
62,
28.8,
21,
65.9,
42.8,
55.6,
0,
36.8,
4.6,
76.6,
92.9,
7.5,
79.6,
34,
76.7,
35.7,
96.1,
2.2,
73,
85.7,
43,
81.4,
47.8,
55.9,
52,
28.9,
49.9,
59.5,
48,
70.8,
41.5,
57.8,
71.7,
39.7,
80.6,
58.5,
24.2,
50.1,
81,
58.8,
55.4,
96,
94.6,
83,
83.4,
100.9,
34.2,
44.9,
96.8,
68.6,
48.1,
24.1,
69.9,
46.7,
34.2,
58.2,
2.8,
91.7,
31.9,
33.6,
66.5,
26.7,
45.3,
49.4,
51.3,
58.8,
34.3,
77.8,
81.2,
38,
35.3,
65.3,
22.9,
75,
75.2,
60,
56.4,
38.8,
34,
82.2,
88,
15.9,
69.1,
40.7,
60.7,
59.4,
65.9,
21,
50.4,
95.9,
66.2,
9.9,
19,
54,
42.2,
56.2,
75.8,
76.2,
82.4,
80.2,
63,
49,
67.3,
79.1,
61.6,
45.5,
59.8,
27.7,
54.7,
75,
48.2,
36.1,
34,
63.8,
80.2,
59.6,
83.1,
88.8,
19.4,
71,
62.9,
3.4,
88.8,
12.1,
94.3,
86.2,
57.4,
92.4,
86,
66.9,
97.1,
63.9,
63.3,
51.6,
48.5,
63.4,
58.6,
36.4,
83.7,
87.5,
73,
60.8,
55,
78.8,
33.5,
27.5,
64,
63.2,
87.5,
24.6,
26.6,
37.6,
97.4,
54.5,
57.7,
29.8,
33.4,
43.4,
35.1,
78.6,
56.1,
61,
28.9,
96.8,
23.8,
49.4,
46.9,
75.4,
83.5,
53.4,
36.3,
82.7,
95.7,
19.8,
67.5,
17.3,
85,
61,
49,
33.2,
72.5,
23.5,
22.2,
17,
46.3,
16.3,
25.5,
71.9,
68.4,
43.5,
26.6,
40,
94.7,
67.5,
35.8,
77.4,
36.3,
15.2,
74.2,
63.8,
75.5,
22.4,
83.5,
37.9,
30.5,
83,
95.3,
47.3,
49.9,
49.5,
31.3,
36.2,
24.9,
22,
88.5,
11.9,
43.5,
66.3,
53,
21,
57,
38.6,
97.4,
66.3,
73,
92.4,
45.7,
50.3,
34.6,
59.2,
68.6,
24.3,
61.3,
43.8,
60,
61.7,
60.8,
71.7,
81.3,
10.5,
31.7,
50.9,
57,
83.7,
99.8,
31.6,
79.7,
73.5,
61.8,
47.1,
57,
56,
50.1,
62.8,
49,
94.2,
94.2,
85.9,
83.1,
81.3,
73.4,
94.5,
58,
76.7,
79.7,
15.7,
81,
92.3,
43.4,
66.9,
23.8,
31.2,
10.9,
59.4,
90.3,
74.2,
48.1,
38.1,
66.3,
58.2,
51.4,
79.6,
31.7,
69.7,
23.8,
17,
83.5,
37.5,
32.8,
66.7,
3.3,
82.4,
25.1,
73.9,
60.2,
7.7,
91.8,
33.2,
49.8,
90.9,
81.6,
67.2,
80.1,
16.5,
44.4,
26.4,
0,
37.1,
83.4,
16.3,
88.4,
42.2,
53.3,
52,
36.4,
79.3,
49.3,
19,
33.3,
3.6,
38.8,
75.5,
41.8,
89.4,
54.5,
84.8,
72,
51.7,
52.7,
85.8,
96.4,
65,
91.6,
86,
41.5,
83.2,
25.9,
49.5,
95.9,
58,
75.8,
48.6,
18.8,
52,
86,
39.2,
51.6,
19.3,
41.2,
53.8,
70.1,
33.6,
82.1,
43.5,
43.2,
52.3,
71.2,
60.3,
48.9,
64.3,
57.4,
55.9,
67.6,
79.1,
42.1,
62.8,
90,
16.3,
68.8,
36.7,
34.9,
47.8,
35.7,
26.8,
2.8,
78.8,
36.5,
81.1,
21.9,
89,
43.7,
0,
56.5,
81.3,
27,
64,
55.2,
20.1,
61.3,
39.2,
42.2,
45.9,
42.2,
20,
22.4,
56.2,
58.1,
49.3,
34,
72.1,
97,
68.6,
64.2,
24.6,
53.6,
66,
29,
78.9,
50.1,
69,
56.1,
58.7,
61.5,
1.2,
48.8,
45,
85.6,
57.8,
29.1,
77.5,
67.7,
32,
38.3,
73.8,
69.2,
66.9,
75.1,
12.6,
41.6,
46.8,
20.6,
4.1,
38,
74.3,
57.5,
79.1,
31.1,
43,
65.9,
31.2,
63.6,
55.2,
18.1,
36.8,
87.1,
66.6,
20.8,
7,
88,
9.4,
69.5,
40.9,
80.9,
44,
60.8,
94.5,
17.9,
66.6,
59.8,
40.2,
47.2,
97.1,
76,
65.1,
36.4,
75.3,
74,
81,
59,
68.1,
58.4,
29.6,
49.3,
84.7,
23.4,
64.3,
60.3,
55.7,
33.6,
58.9,
45.5,
66.7,
69.7,
92.3,
87.6,
28.3,
68.6,
39,
45.6,
60.5,
61.9,
64.7,
76.5,
83.2,
44.6,
68.4,
54,
105.2,
67.9,
69.4,
57.6,
83.4,
70.8,
59.1,
56.2,
88.6,
26.4,
85.5,
46.6,
65.7,
49.4,
62.9,
53.6,
50.2,
25,
80.8,
95.8,
86.8,
26.8,
19.9,
84.8,
31.8,
47.2,
37.5,
83,
76.2,
63.8,
61.2,
36.9,
68.6,
60.1,
59.7,
36.8,
74.9,
29.3,
80.5,
86.6,
59.9,
63.9,
57.1,
85.3,
29,
44,
72.2,
38.4,
58.8,
62.8,
44.2,
65.8,
59.5,
75.3,
38.1,
32.9,
41,
75.1,
34.9,
73.7,
88,
59,
74.5,
42.3,
30.4,
31.1,
98.6,
35.5,
44.4,
83.4,
34,
4.2,
81.8,
77.2,
68,
38.1,
34,
38.1,
19.1,
16.7,
38.2,
53.6,
82.5,
62.8,
66.2,
95.1,
62.1,
63,
95.5,
64.1,
18.4,
61.7,
44.2,
54.5,
31.2,
28.5,
45.7,
42.9,
74,
38.7,
62.1,
74.6,
22.7,
31.7,
40.8,
98.5,
64,
89.2,
15.9,
76.2,
52.8,
87,
21.3,
61.1,
55.2,
68.5,
43.8,
60.9,
81,
52.6,
72.8,
30.4,
63.6,
41.3,
19.6,
58.2,
48.1,
99.9,
46,
80.8,
89.3,
71,
40.1,
20.8,
70.3,
97.8,
91.7,
51.5,
84.1,
68.2,
93.4,
56.3,
67.8,
88.6,
61.6,
81.3,
15.5,
67.1,
51.4,
33.6,
67,
65.8,
59.2,
7.4,
1,
59.5,
72.5,
66.7,
40.7,
95.7,
95.1,
23.9,
43.5,
84.5,
48.6,
69.9,
32.7,
39.4,
68.5,
36.5,
45.4,
16.7,
85,
42.7,
39.3,
4.7,
92.8,
18.9,
98.9,
19.8,
62.8,
68,
36.5,
30.6,
57.7,
25.5,
18,
72.8,
24.2,
9.2,
36.3,
41.7,
82.5,
68,
34.4,
41.9,
89.1,
28.6,
70.9,
56.4,
8,
86.7,
4.8,
86.4,
90.9,
46.9,
69.6,
46.7,
36.8,
27.8,
50.3,
45.4,
74.9,
36.7,
25.3,
23,
28.7,
67,
71.1,
72.2,
79.9,
31.3,
90.6,
57.9,
38.2,
29,
52.5,
69.9,
59.6,
88.3,
16.3,
46.3,
42.4,
58.5,
47.6,
76.9,
47.3,
71.9,
68.2,
53,
64.9,
49.5,
21.1,
57.6,
59,
70.4,
30,
50.7,
54.3,
33,
25.2,
27.2,
11.5,
59.6,
97.7,
82.6,
85.6,
39.6,
86.8,
23.2,
44.2,
42.1,
66.2,
37.6,
70.1,
63.8,
21.5,
38.6,
58.6,
56,
80,
37.8,
12.1,
68.6,
81.9,
53.2,
36.2,
46.2,
75.6,
22.5,
63.8,
89.4,
85.3,
40.1,
80.1,
79.7,
78.6,
31.8,
96.6,
77.4,
79.5,
54.2,
66.3,
74.8,
27.8,
35,
19.3,
65.6,
52.5,
20.6,
38.5,
86.6,
75.2,
13.5,
53.2,
71.5,
23.6,
84.6,
48,
82.1,
52.9,
30,
96,
82.2,
77.9,
39.4,
70.5,
81.1,
98.5,
89.7,
55.7,
79.7,
62.7,
48.3,
20.8,
64.4,
81.9,
67.1,
80.7,
65.1,
34.4,
44,
47.8,
20.7,
73.1,
17.5,
43.8,
51.4,
50.6,
51.7,
72.8,
96.1,
65.5,
64.3,
2.5,
31.1,
11.3,
43.6,
13.8,
87.2,
46.2,
83.6,
49.2,
63.6,
31.6,
70.3,
88.8,
20,
32.4,
37.1,
43.4,
69,
65.2,
47.5,
57.2,
51.8,
50.2,
82.8,
3.6,
62.6,
83.7,
79,
61.3,
43.5,
81.4,
97.4,
95.6,
56.7,
65.6,
64,
43.8,
77.1,
97.1,
51.5,
96.9,
68.3,
50,
56.4,
24,
65.6,
67.1,
49.2,
39.8,
76.7,
44.3,
72.6,
31,
69,
58.9,
71.6,
95.9,
40.1,
64.6,
59,
38.2,
73.6,
4.8,
62.8,
27.5,
46.6,
36.5,
28.5,
88.1,
75.4,
50.6,
5.8,
57.4,
72.1,
76.9,
72.8,
57.7,
15,
59.4,
71.8,
46.3,
94.7,
27.3,
35.6,
71.7,
56.7,
36.5,
62.9,
50.9,
59.1,
83.7,
12.3,
36.5,
57.7,
84.2,
34.1,
60.9,
58.5,
31.9,
68.9,
46.6,
72.3,
66.1,
55.2,
57.4,
46.6,
26.3,
33.3,
72,
45,
68.7,
62.9,
92.8,
80.6,
55,
20.9,
48.1,
47.3,
48.7,
66.6,
84.4,
42.4,
45.4,
61.4,
37.2,
54.7,
93.7,
16,
51.3,
37,
57.5,
90,
38.9,
79.6,
55.4,
54.6,
32,
61.7,
61.9,
83.1,
0,
2.9,
90.6,
91.8,
61.8,
60.5,
38.4,
89.1,
87.2,
41.4,
52.5,
73.8,
95.8,
20.1,
26.6,
53.3,
68.4,
67.7,
17.8,
48.4,
37.3,
36.4,
87.5,
28.7,
58.5,
17,
30.5,
30,
34.9,
33.9,
68.8,
43,
55.6,
66.1,
27.6,
71.5,
61.9,
72.5,
76,
65.5,
78,
46.7,
30.4,
93,
83.3,
46,
84.2,
84.8,
17.8,
30,
97.7,
73.5,
41.2,
47.7,
54,
21.2,
85.1,
21.3,
51.7,
33.1,
14.8,
2.6,
77,
11.6,
81.1,
71,
47.1,
33,
68.2,
63.1,
70.1,
46.1,
21.7,
80.3,
98.3,
90,
79.9,
77.2,
82.5,
49.6,
82.2,
32,
13.1,
69.5,
82.6,
69.6,
90.2,
74.9,
67.3,
37.7,
40.3,
37.1,
90.3,
71.8,
24.9,
35.2,
65.2,
81.2,
92.8,
22.1,
78.8,
46.3,
2.9,
82,
65.5,
80.8,
29.3,
26.5,
56.1,
85.4,
80.4,
48.2,
59.5,
58.1,
90.7,
60,
92.5,
65.1,
87.9,
47.3,
93.2,
19.2,
89.1,
87.8,
73,
29.5,
7,
54.3,
84.9,
94.2,
41.5,
47,
45.2,
64.8,
22.1,
43.7,
47,
63.2,
54.2,
69.3,
48.9,
42.2,
63.2,
41.2,
68.8,
33.8,
55.6,
63.8,
36.8,
59.5,
67.3,
88.9,
55.9,
13.1,
61.9,
48.1,
69.1,
38.4,
20.2,
87.1,
17.3,
66.2,
76.9,
50.7,
90.5,
96.5,
54.7,
19.5,
51.8,
90.1,
37.7,
57.5,
35.5,
38.6,
51.8,
45.7,
39.6,
87.5,
50.5,
90.4,
79,
79.1,
80.1,
41.7,
39.7,
81,
52.2,
85.7,
27.7,
50.6,
63.3,
82,
78.9,
94.9,
56.2,
87.8,
53.3,
70.6,
73.8,
94.3,
41.3,
37.4,
32,
69.3,
27.4,
87.3,
57,
49.6,
58.3,
47.7,
57.5,
70,
84,
50.7,
60.4,
36.7,
72.1,
29.3,
25.7,
66.4,
35.3,
42.5,
38.5,
43.4,
64.6,
72.9,
84.3,
38.9,
50.8,
3.9,
58.5,
87,
4.5,
94.4,
18.6,
32.6,
61.5,
50.9,
69.4,
79,
71.3,
14.7,
92.7,
54.7,
84.5,
55.8,
53.3,
7.3,
96.3,
46,
66.7,
29.7,
94.2,
35.3,
82.6,
85.9,
89.8,
84.2,
49.3,
49.4,
20.1,
67.1,
70,
57.8,
69.1,
46.9,
58.5,
37.9,
58.5,
82.4,
47.8,
28.1,
57.1,
48.6,
51.6,
39.7,
6.8,
36.7,
56.8,
57.9,
18.8,
28.6,
32.6,
57.1,
84.2,
23.9,
22.5,
34.6,
70.9,
30.2,
62.8,
48.1,
35,
46.5,
73.5,
30.9,
37.3,
65.7,
80,
43.9,
63.1,
63,
51.7,
71.5,
79.6,
0,
92.7,
100.4,
46,
49.5,
89.7,
63.1,
52.5,
23.4,
44.6,
38.2,
99.7,
37.6,
80.7,
74.2,
100.8,
74,
70.1,
53.4,
13.8,
57.1,
0,
48.1,
74,
40.6,
32.3,
11.9,
5.6,
13.3,
71.8,
43,
46.4,
6.3,
14.2,
1.2,
64,
17,
66.9,
31.8,
37,
39.6,
54.2,
71.7,
61.6,
74.9,
72.8,
43.3,
25,
45.4,
23.2,
56.8,
69.6,
49,
68.3,
20.9,
89.1,
23,
59.1,
88.4,
46.8,
37.9,
66,
39.8,
88.6,
44.5,
40,
46.7,
61.2,
8.7,
74.6,
60.4,
70.9,
76.4,
88.6,
64.7,
36.5,
41.7,
25,
53.9,
64,
5.3,
48.4,
81.5,
17.8,
35.4,
57.5,
26.7,
96.3,
86.9,
63.5,
57.4,
86.5,
5.6,
56.3,
70.4,
47.2,
60.7,
51.4,
56.8,
18.1,
56.7,
30.4,
50,
48,
66.9,
97.2,
29,
87.6,
34,
61,
49.4,
69,
49.9,
66,
58.8,
59.4,
4.1,
55.3,
92.8,
60.1,
58.9,
79,
94.6,
12.5,
39,
12.2,
62,
47.3,
41.7,
86.5,
53.7,
61.8,
43.7,
38.9,
34.1,
24.8,
11,
44.6,
80.3,
21.4,
61.8,
41.9,
70.2,
57.7,
97.9,
91.1,
42.9,
49.5,
50.8,
37.6,
78.2,
14.9,
56.2,
69.1,
79.1,
83.7,
18.1,
80.9,
39.7,
60.5,
85.1,
83.9,
46.2,
82.7,
0.1,
19,
44.2,
55.6,
22,
23.8,
67.8,
65.2,
40.9,
66,
68.6,
90.3,
2.8,
94.6,
26.1,
31.2,
68.1,
70.3,
51.7,
44.7,
71.3,
86.8,
49.5,
50.8,
57,
34,
78.8,
5.7,
85.7,
82.6,
64.6,
27.5,
31.8,
54.3,
79.6,
96.9,
82.6,
65.8,
57.8,
22.9,
69.5,
89.1,
69.8,
36.3,
80.7,
24,
72.1,
59.3,
46,
77.6,
84.6,
89.5,
90.8,
38.4,
56.2,
30.4,
97.9,
36.3,
73.1,
49.7,
55.7,
65.9,
42.4,
64,
60.7,
32.6,
48.5,
31.9,
28.6,
3.7,
23,
39.4,
37.7,
65.9,
28.7,
29,
39,
84.4,
34.8,
38.6,
43.1,
55.3,
59.1,
48.3,
7.6,
51.7,
78,
71.9,
59.3,
52.2,
57.9,
63,
49.7,
15.3,
96.3,
78.5,
6.5,
63.1,
55.1,
56.2,
76.2,
70.5,
70.1,
37,
34.5,
83.5,
64.3,
72.8,
71.9,
35.5,
30.2,
47.6,
9.7,
49.7,
38.4,
17,
85.9,
66.3,
78.8,
96.2,
49.9,
33.4,
35.5,
57.9,
57.2,
54.3,
59.1,
27.5,
57.2,
65.4,
30.9,
98.9,
93.6,
27.8,
92.7,
6,
81.6,
73.5,
59.2,
38.6,
0,
66.3,
97,
37.7,
54.9,
79,
36.7,
19,
23.1,
60.6,
62.1,
28,
48.9,
90.6,
73.5,
57.5,
69.8,
85.9,
32.9,
87,
90,
46.4,
90.9,
60.5,
41.7,
37.5,
14.5,
36.5,
41.8,
28.2,
66.2,
76.6,
68,
1.6,
11.7,
64.6,
47,
44.1,
65.6,
58.6,
65.9,
51.3,
66.6,
1.9,
32.2,
69.5,
42,
50,
4.4,
54.4,
10.1,
57,
69.1,
80,
79.4,
72.7,
47.9,
56.6,
56.4,
41.8,
77.9,
18.7,
27.8,
47.1,
52,
35,
50,
35.5,
29.5,
1.9,
47,
95.3,
13.3,
50.9,
43.2,
56.4,
23.2,
25.9,
64.8,
33.9,
27.9,
13.2,
74,
70.8,
80,
40.2,
39.5,
96.1,
80.3,
72.1,
36.3,
76,
60.3,
36.7,
51.7,
61.2,
77.9,
59.2,
65.8,
76.7,
13.5,
86.3,
98.5,
62.3,
40.9,
56.4,
82.1,
80.1,
92.6,
27.3,
34.1,
61.9,
42.1,
61.2,
72.1,
36.3,
65,
64.4,
58.2,
38.6,
29.3,
70.2,
53.3,
82.3,
44.1,
68.7,
58.2,
83.8,
43.7,
29.1,
34,
81.8,
60.2,
60,
60.5,
76.6,
49,
85,
50.4,
52.8,
88.4,
62.1,
92,
52.7,
50.2,
67.9,
55,
53.9,
43.4,
55.2,
73.3,
63,
81.6,
75.4,
15,
88.6,
43.1,
53.2,
22.9,
25.6,
49.3,
36.4,
15.1,
63.9,
12.1,
87.7,
44.6,
81.8,
31.8,
18.9,
44.4,
94.2,
59.9,
83.2,
59,
80.6,
95.3,
36.8,
35.8,
57.8,
61.4,
94.4,
91.1,
56.9,
40.3,
37.1,
34.4,
70.4,
55,
65.7,
70.8,
67.8,
84.8,
53.5,
49.9,
63.1,
37.1,
68.8,
54.5,
92.5,
68.8,
65.1,
50.2,
21.9,
92.4,
25.5,
35.1,
49.3,
47.1,
17,
98.9,
42.4,
54,
24,
74.8,
80,
94.1,
30.8,
25.1,
66.6,
54.6,
15.5,
68.9,
60.8,
37,
69.7,
45.5,
87.9,
24.3,
54.2,
63.4,
15.2,
22.8,
60.9,
72.9,
68.9,
93.9,
36.4,
29.9,
36.7,
48.6,
0.9,
72.3,
35.6,
47.1,
91.2,
19,
22.4,
48.5,
72.3,
19.6,
28.6,
69.7,
46.2,
36.8,
55.2,
66.5,
25.9,
62.3,
18.8,
36.1,
73.6,
90.2,
55.8,
75.2,
67.7,
36.8,
26.1,
56.7,
91.6,
60.8,
31.1,
94.9,
47.9,
55,
84.6,
71.4,
72.2,
71,
97.1,
2,
87.5,
38,
95,
61,
46.3,
35.1,
7.9,
66.6,
89.2,
47.2,
94.4,
50.5,
84.2,
46.4,
17.4,
85.1,
65.8,
67,
64.4,
61.4,
86.8,
60.5,
48.8,
36.9,
50.4,
44.8,
95.2,
74.4,
7.8,
79.3,
52.3,
34.8,
75.5,
52.1,
65.8,
81.1,
21.5,
45.6,
52.9,
14.1,
42.6,
59.9,
71.1,
55,
40.4,
95.8,
59.8,
60.4,
80.3,
48,
52.6,
57.6,
90.9,
83.7,
16.8,
80.7,
85,
73.4,
66.7,
65.3,
76.2,
15.5,
89.8,
88.8,
51.8,
74.2,
70.6,
81.7,
44.9,
95.4,
52.2,
32.2,
96.6,
65.6,
76.2,
87,
64.6,
25.4,
93.9,
59.4,
20.3,
61.6,
4.7,
71.7,
96.9,
77.1,
67.3,
69.1,
64.9,
66.6,
32.8,
61.5,
55.9,
94.2,
25.9,
46.9,
11.5,
28,
40,
37.4,
60.4,
78.1,
47.9,
44.1,
26.5,
16.4,
8.7,
85.9,
79.3,
87,
65.9,
33.4,
60.7,
60.5,
25.5,
75.3,
59.1,
18.8,
54.3,
61,
27.4,
63.2,
54.6,
82,
52.5,
56.5,
59.1,
73.4,
30.2,
58.2,
87.4,
78.9,
101,
83.5,
38.2,
48.2,
81.5,
43,
81.1,
89.6,
73.1,
83.4,
10.7,
5.8,
86,
62,
35.7,
48.4,
97.7,
16.1,
24.8,
33,
56.1,
37.3,
23.3,
76.2,
97.4,
46.5,
48.7,
89.6,
45.5,
49.1,
43.5,
35.1,
62.4,
87.9,
17.6,
64.5,
94.3,
38.1,
59,
74.5,
68.4,
47.7,
49.8,
44,
55.9,
39.7,
41.4,
45.2,
14,
10.2,
69.5,
83.1,
23.3,
63.3,
86.6,
8.6,
17.2,
50.6,
54.1,
74.2,
31.5,
74.3,
89.4,
97.6,
15,
67.2,
53.5,
49.9,
89.1,
64.1,
78.2,
64.3,
79.5,
75.6,
32.3,
63.4,
38.8,
19,
88,
37.8,
49.3,
47.1,
27.4,
74.4,
86.1,
87,
43.6,
92.4,
28.3,
79.5,
89,
80.5,
86.2,
15.7,
90.2,
36,
66.3,
65,
75.8,
64.6,
66.8,
53.2,
78.5,
17,
49.6,
34.5,
94.8,
69.3,
32,
6.1,
44.6,
84.8,
49.7,
25.2,
46,
49.8,
49.6,
65.9,
58.4,
78.9,
38.8,
43.2,
84.3,
63.8,
35.1,
42.6,
67.1,
68.4,
20.7,
52.4,
76.7,
56.3,
68.6,
58,
53.9,
96,
65.3,
75.8,
68.1,
38.3,
41.1,
65.5,
79,
60,
2.7,
67.2,
40.9,
18.1,
41.2,
63.2,
19,
50.1,
75.2,
63.8,
41,
70.2,
32.4,
70.4,
23.4,
46.5,
31.1,
1.9,
11.2,
83.3,
41.3,
23.7,
89.2,
82.2,
81.5,
21.6,
66.2,
91.5,
29.1,
9.9,
66.4,
61.6,
33.3,
35.7,
49.7,
66.7,
91.8,
67.8,
15.4,
38.4,
48.3,
7.2,
85.7,
71.2,
40.6,
75,
37.6,
70.3,
26.2,
85,
71.7,
60.8,
44.2,
63.5,
72.8,
106.4,
8.6,
10.1,
50.6,
43.8,
74.7,
87.8,
38.5,
50.7,
63.7,
43.6,
74.5,
77.9,
60,
2.6,
93.2,
81.5,
78.5,
45.8,
53.4,
55.5,
61.5,
56.6,
65.9,
60,
88.9,
84.1,
9.7,
76,
72.8,
94.2,
57.2,
12.9,
27.7,
19.5,
86.4,
31.2,
81.2,
57.1,
56,
63,
62.5,
54.7,
73.6,
10.6,
50.1,
82.6,
17.2,
47,
55.9,
41.2,
83.4,
61,
79.3,
67.1,
11.6,
59.2,
51.6,
61,
41.8,
53.7,
62.6,
45,
65.1,
32.4,
34.8,
90.1,
98.3,
48.7,
50.3,
71.7,
54.5,
51.7,
40.6,
75.9,
92.3,
80.2,
52.9,
45.5,
90.7,
55.3,
24.7,
0.7,
49,
72,
43,
85.3,
14.5,
38.3,
34.9,
78.1,
4.8,
93.7,
1.7,
14.4,
47.6,
8.9,
43.9,
47.4,
38.9,
56.7,
63,
90.3,
66.1,
68.6,
56.5,
44.6,
37.3,
75.3,
55.1,
48.6,
70.7,
51,
52.9,
70.9,
26.8,
70,
42.6,
74.9,
37.6,
75.2,
54.7,
65.6,
66.8,
23.4,
77.1,
92.9,
89,
34,
46.9,
69.4,
72.8,
9.4,
61.1,
53.6,
14,
30.7,
50.6,
65.8,
57.5,
26.1,
36,
1.6,
79.9,
61,
64.9,
71.8,
35.4,
75.7,
22.4,
13.2,
80.3,
47.2,
78.3,
32.1,
79.3,
65.4,
48.2,
79.2,
40.2,
59.5,
45,
42.1,
72.4,
79.6,
59.9,
45.6,
69,
49.1,
70.8,
65.2,
65.9,
49.4,
51.6,
7.1,
29.9,
64.6,
41.1,
16,
77,
79.3,
46.6,
57.6,
81.3,
91.3,
56.9,
58.9,
52.4,
77.3,
48.9,
98.9,
68.3,
62.7,
34.8,
94.4,
50.5,
46.7,
70.1,
83,
44.4,
69.6,
45.5,
82.5,
74.2,
60.8,
81.8,
15.3,
22.7,
36.6,
89.5,
49.5,
89.5,
84.6,
60.8,
58,
44.8,
65.3,
87.8,
65,
89,
48.1,
62.7,
73.4,
77.8,
64.5,
49,
53.3,
25,
60,
77.4,
7.6,
81.9,
40.5,
58.2,
19.8,
1.4,
89.7,
17.3,
45.5,
50.3,
62.9,
39.5,
22.4,
49.3,
63.8,
68.9,
58.7,
61.5,
97.4,
32,
59,
73.1,
48.6,
64.6,
63.8,
20.6,
70.9,
29.5,
50.4,
47.9,
48.3,
72.3,
92,
38.9,
32.5,
26.6,
56.1,
79.9,
68.7,
86.5,
54.2,
53.5,
78,
34.3,
28.2,
68.9,
21.1,
85.7,
45.2,
72.8,
38.9,
34.3,
44.9,
35.7,
32.1,
29.7,
12.2,
76.6,
53.9,
64.4,
75.4,
54,
32.1,
84.3,
57.6,
0,
77.3,
33.7,
39.7,
76.7,
99.6,
13.2,
65.8,
36.9,
70,
101.5,
81.9,
98.4,
80.3,
93.4,
50.8,
77.5,
69.5,
67.2,
22.2,
61.5,
56.3,
13.1,
95.9,
43.1,
65,
32.5,
49.5,
61.7,
87.7,
42.3,
87.9,
12.7,
75.6,
59.4,
43.8,
96.1,
22.1,
66.1,
36.8,
50,
79,
69.4,
73.6,
43.3,
88,
88.8,
37.9,
45.5,
63.7,
69.9,
33.8,
15.1,
88.2,
2.3,
54,
85.1,
73.1,
53.5,
81.8,
52.9,
69.2,
91.9,
100.1,
21.7,
35.4,
96.9,
54.7,
82.6,
52.3,
97.3,
70.2,
64.5,
29.8,
61.1,
20.9,
65,
88.7,
82.1,
23.1,
48.5,
41.9,
62.2,
49.4,
45.6,
83.3,
84.1,
96.1,
38.8,
66.3,
49.5,
65.8,
86.3,
35.5,
26.3,
57.9,
43.5,
17,
96.9,
7.9,
85.9,
70,
86.7,
77.8,
66.8,
65.8,
71.4,
39.9,
25,
71.3,
25.7,
60.9,
90.1,
16.4,
77.8,
49,
19.6,
83.1,
39.2,
55.8,
74.1,
72.5,
23.2,
39.8,
64,
97.9,
36.6,
79.3,
41.4,
77.4,
71.7,
63.8,
26.5,
38,
55.3,
76.1,
55,
43.2,
19,
75.2,
68.3,
39,
72.8,
44.9,
49.9,
102.5,
54.1,
11.5,
59,
43.1,
95.1,
47,
42.2,
56.5,
41.1,
83.2,
0,
38,
1.2,
152.7,
65.2,
88.4,
49,
79.2,
31.9,
40.8,
43.8,
91.4,
79.4,
15.1,
72.2,
39.2,
79.6,
52.1,
92,
56.9,
53.9,
93,
47.9,
39.2,
62.8,
47,
100,
52.3,
50.7,
16.7,
84.3,
63.4,
49.2,
86.3,
73,
54.6,
92.4,
75.8,
73.3,
59.9,
31,
42.6,
55.7,
42,
46.3,
47.2,
91.1,
75.6,
62.9,
54,
48.1,
62,
81.1,
70,
53.1,
39.9,
75.9,
50.7,
30.2,
72.2,
7.3,
49.1,
72.3,
89.4,
81.3,
28.7,
22.3,
69,
90.2,
59.1,
74.7,
75.5,
93.2,
41.8,
79.4,
71.7,
42.9,
43.6,
0.5,
26.1,
49.4,
58.6,
31.1,
45.2,
63.6,
48.5,
8.7,
75.7,
62.1,
56.5,
19.2,
67,
43.1,
65.4,
83.3,
17,
92.3,
80.2,
59.4,
39,
48,
22.6,
29.2,
21.9,
49.1,
28.2,
93,
40.8,
53.1,
36.7,
65,
79,
81.9,
64.3,
79.5,
53.3,
76.8,
4.5,
19.7,
32.5,
45.5,
4.3,
35.7,
63.1,
58.6,
41.8,
27.8,
55.1,
23,
72,
86.5,
37.1,
30.5,
38.5,
42.1,
54.3,
30.5,
26.1,
45.5,
44.9,
52.9,
67.2,
55,
24.3,
48.1,
57,
38.3,
81,
68.8,
69.8,
30.2,
75.3,
64.2,
34.6,
19.8,
85.4,
69.6,
55.1,
61.4,
60.7,
66.7,
63.4,
33.7,
63.9,
41.4,
25.8,
82.6,
26.1,
91,
59,
71.7,
71.9,
44.4,
33.6,
14.9,
41.9,
38,
36.5,
57.3,
59.8,
44.4,
65.6,
42.3,
78.1,
17.6,
43.2,
52.6,
10.2,
80.3,
98.9,
79.3,
58,
22.3,
34.5,
49.6,
67.5,
93.7,
85.3,
77.1,
72.6,
10.7,
61,
29.1,
17.5,
13.2,
65,
13.6,
70.2,
76.8,
23.8,
50,
35.1,
52,
28.7,
72.3,
70.4,
44,
52.3,
79.3,
80.1,
42.3,
89.1,
27.9,
73.1,
96,
47.8,
56.3,
76.4,
61.3,
82.9,
97.3,
16.3,
95.4,
72.2,
90.8,
81.6,
61.7,
39.7,
17.2,
54.9,
20.3,
23,
55.1,
68.3,
82.5,
38.1,
14.1,
31.6,
56,
19.2,
63.7,
59.2,
76.3,
22.8,
90.4,
31.5,
70.3,
52.4,
54.3,
50,
55.5,
91.2,
84,
22.9,
57.1,
50.4,
78.2,
47.5,
74.6,
60.3,
22.2,
66,
21.6,
20.7,
73.1,
32.6,
37.6,
42.4,
84.9,
54.6,
46.9,
20.6,
22.7,
3,
45,
77.7,
86.5,
48.7,
33.6,
35.4,
79.5,
65.7,
68.5,
19.7,
38.1,
80.9,
79.3,
3.9,
45.4,
86.1,
47,
26.3,
47.2,
42.2,
42.2,
46.5,
55.2,
24.4,
85.9,
22.2,
45.7,
64.9,
93.9,
77.5,
59.9,
29.2,
87.2,
46.6,
53.3,
82.5,
72.9,
85,
18.5,
58.9,
61.3,
63.2,
50.3,
21.8,
86.6,
71.6,
91.1,
16.6,
54.6,
39.5,
77.6,
22.4,
93.3,
68.9,
87.6,
75,
10.2,
40.9,
90.6,
65,
90.9,
75.6,
54.2,
31.2,
72,
71.7,
12.6,
83.4,
70,
22.4,
47.6,
28.6,
68,
51.1,
88,
10.6,
40,
46.3,
40.1,
89.2,
57.8,
77.8,
46,
25.7,
53.6,
53,
78.9,
66.1,
24.1,
91.2,
90.6,
42.9,
65.6,
60,
92.3,
61.2,
15,
38.9,
61.6,
39,
86.8,
23.1,
24.6,
47.9,
67,
63.2,
93.2,
62.7,
4.5,
67.3,
68.9,
52,
73.2,
57.5,
77.5,
6.6,
34,
86.4,
66.8,
97.7,
42.8,
54.3,
83.1,
61.7,
75.1,
33.4,
67.3,
71.8,
70,
39,
58.5,
40.9,
58.8,
84,
85.8,
57.3,
53.8,
66.4,
53.4,
77.3,
34.5,
63.7,
38.2,
9.3,
59,
68.2,
53.2,
63,
55.7,
81.6,
24.6,
50,
92.2,
35.8,
48.4,
98.8,
83.1,
3.4,
53.6,
54.5,
77,
57.6,
69.1,
43.4,
66.1,
61.2,
81,
2.3,
75,
94.3,
88.6,
16.3,
54,
75,
71.6,
35.5,
21.6,
82.6,
49.8,
67,
38.9,
80.4,
36.9,
57.2,
38.7,
30.2,
62.9,
94.6,
41.8,
47.1,
85.2,
99.3,
35.2,
78,
21.5,
21.5,
85.4,
57.4,
35,
79.4,
21.8,
82.5,
68.6,
87.5,
83.3,
23.6,
36.6,
69.3,
52,
99.3,
44.4,
35.6,
73,
50.2,
46.7,
4.5,
65.2,
10.8,
46.4,
79,
92.9,
71.8,
94.3,
22.4,
53.4,
95,
85.8,
37.5,
30.2,
30,
38.9,
74.7,
33.2,
74.9,
49.9,
54.2,
87.1,
77.9,
52.5,
26.3,
60.4,
46.9,
31.7,
28.2,
22.9,
59.1,
30.7,
27,
86,
34.7,
39.1,
34.5,
36.1,
27.8,
39.8,
63.1,
1.3,
76.8,
36.5,
92.6,
47.2,
59.5,
74.2,
32,
13.5,
78.3,
16.3,
45.3,
39.7,
48.4,
23.9,
28.6,
23.3,
78.6,
34.2,
11.3,
20.3,
58.6,
71.5,
24.9,
41,
46.6,
53.5,
60.1,
17.3,
22.4,
20.1,
53.3,
12.4,
78.4,
41.5,
76.3,
38.4,
83.5,
26.9,
21.2,
23.5,
17.5,
75,
93.2,
49.5,
72.8,
67.7,
55.1,
22.2,
57,
39.2,
40.4,
77.2,
75.1,
85.3,
47.3,
44,
70.8,
34,
65.5,
19.5,
52.9,
33.7,
15.3,
32.5,
55.5,
67.8,
36.6,
96.2,
42,
87.3,
92.4,
85.9,
90.6,
52.1,
33.4,
32.2,
94.5,
43.1,
80.6,
29.4,
10.3,
66.7,
0,
53.9,
58.5,
62.7,
55.4,
66.9,
25.2,
56.9,
52.2,
63.2,
74,
1.6,
30.6,
48.5,
56.7,
3.2,
57.6,
28,
58.3,
54.6,
63.5,
52.7,
50.3,
81.1,
70.4,
66.7,
7.1,
4.5,
78.9,
35.7,
46.7,
96.7,
82,
13.8,
48.7,
57.8,
29.7,
57.4,
92.8,
38.8,
79.4,
62.6,
83.1,
45.1,
83.6,
43.3,
62.3,
35.9,
94.2,
58.2,
56.2,
56,
47,
73.2,
65.2,
52.9,
29.9,
72.7,
70.7,
70.1,
78,
50,
55.4,
61.6,
10.6,
58.3,
70.7,
33.3,
98.5,
42,
91.6,
41.3,
69.4,
43.5,
60.4,
73.7,
84.2,
51.5,
97,
47.6,
83.7,
38.4,
62.4,
39.6,
66.4,
16.3,
67.4,
65.3,
29.6,
82.8,
83,
82.2,
50.7,
0,
66.4,
47,
49.1,
56.2,
67.9,
55.2,
37.9,
19.9,
43.1,
6.2,
33.5,
44.3,
86.9,
40,
55,
43.7,
66.6,
92.9,
60.8,
46.6,
47,
70.9,
41.3,
65.7,
31.2,
0.5,
15.1,
50.1,
44.4,
55.6,
89.7,
34.4,
95.3,
84,
69.8,
80.5,
25.6,
34.9,
74,
60.7,
57.8,
89.3,
80.9,
101,
61.7,
56.5,
59.6,
55.2,
11.5,
41.9,
85.5,
16.2,
53.9,
81.8,
82.5,
0.1,
89.6,
29.4,
59.7,
88.2,
26.1,
52.6,
96.3,
11.2,
57.8,
31.7,
73.4,
20.7,
76.5,
21.9,
62.2,
75,
40,
72.1,
68.3,
66.1,
27.7,
54.8,
39.4,
86.9,
66.4,
32.4,
27.3,
52.2,
33.3,
30.8,
94,
34.3,
67.3,
38.3,
59,
87.3,
66.3,
34.6,
75.4,
59.8,
77,
64.3,
70.5,
26.7,
60.5,
76.1,
1.1,
70,
34.6,
83.8,
24,
98.7,
53.6,
28.9,
85,
25.6,
51.4,
80.6,
88,
85.3,
74.7,
57.1,
67.2,
53.5,
64.2,
35,
48.5,
81.4,
88.3,
22,
34.9,
40,
65.7,
16.6,
55,
30.2,
36.8,
21.4,
19.4,
66.7,
6.5,
76.6,
50.6,
20.4,
60.7,
44.5,
59.3,
0,
38.7,
88.9,
41.4,
70.3,
70.6,
78.3,
30.6,
69.7,
85.9,
84.2,
71.4,
42,
27.1,
82.1,
51.2,
55,
67.5,
67.1,
77.3,
58.3,
61.9,
46,
31.6,
41,
77.4,
91.1,
76.8,
61.1,
15.1,
74.3,
24.1,
92.9,
57.7,
96.4,
93.5,
74.1,
60.3,
98.3,
29.8,
57.4,
56.7,
4.5,
68.4,
47,
37.8,
83.5,
8.9,
81.1,
74.9,
64.1,
77.5,
8.8,
89,
37.8,
75.4,
58.4,
70,
50,
13,
58.9,
60.2,
101.5,
93.8,
61.3,
48,
9.5,
42.2,
95.5,
58.4,
59.3,
52.1,
28.9,
53,
62.6,
17.1,
42.5,
57.2,
89,
78.4,
60.4,
48.5,
22.2,
49.6,
21.5,
33.7,
55.7,
46,
54.7,
51.9,
69.4,
97.9,
31.5,
53.2,
57.5,
83,
60.4,
86.6,
71.5,
51.2,
80.7,
96,
1.4,
17.1,
51.4,
97.1,
81.8,
51.6,
40.5,
93,
44.5,
59.1,
44.1,
91.1,
89.8,
69.7,
63.5,
41.5,
68.7,
94.6,
39.9,
86.4,
54.4,
71.1,
64.8,
23.4,
29.7,
77.9,
37.6,
88.6,
73.7,
45.8,
84.6,
53.2,
59.9,
68.8,
86.5,
12,
82.3,
65.6,
84.8,
44.8,
51.9,
4.4,
42,
45.3,
54.2,
47.5,
15.5,
29.2,
23.7,
95,
20.5,
51.4,
59.5,
29.9,
86.7,
58,
68.7,
21.7,
89.9,
64.5,
51.4,
88.1,
16.2,
61.2,
38.6,
58.2,
65.7,
95.4,
80.4,
43.4,
45.5,
85.4,
36.3,
50,
45.4,
93.5,
70.4,
47.4,
52.2,
65.7,
26.5,
75.2,
66.9,
47.7,
66.4,
77,
51.2,
64,
93.7,
40.1,
83.6,
47,
42.6,
82.7,
84,
7.5,
88,
75,
43.5,
99.6,
40.1,
75.2,
25.4,
67.2,
0.5,
8.9,
76.8,
57.9,
28.6,
40.3,
47.8,
47.3,
47.2,
84.5,
31.5,
0,
58.2,
24,
39.7,
17,
83.4,
45.7,
68.8,
91.5,
52.1,
25.2,
38.2,
27.1,
46.3,
36.3,
31,
6,
50.4,
44.4,
45.4,
55.8,
31.7,
62.1,
92.4,
22.1,
45.6,
79.4,
80.7,
57.7,
64.8,
81.8,
0.2,
26.5,
59.5,
91.2,
39.2,
60.6,
62.9,
54,
92.1,
83,
59.8,
98,
52.6,
53.4,
35.9,
29.1,
61.9,
43.3,
64.8,
61.6,
9.2,
47,
60.8,
32.7,
62,
58.1,
90.6,
21.9,
50.3,
85,
56.3,
52,
63.2,
97.5,
78.5,
62.7,
26.6,
45.6,
55.1,
62.8,
76.7,
78.3,
56.9,
74,
25.6,
75.1,
58.6,
32.7,
37,
24.9,
31.3,
35.2,
67.4,
91.1,
39.7,
32.4,
96.2,
70.1,
59.7,
68.4,
14.9,
43.5,
98.6,
34.8,
24.5,
36.9,
35.8,
76.5,
53.2,
51.4,
16,
49.2,
23.1,
27.8,
37.6,
62.3,
34.6,
47.2,
25.9,
51,
82.6,
39.1,
78.5,
51.5,
84,
65.3,
69.1,
12.8,
97.8,
98.9,
0,
69.7,
69.9,
37.9,
48.4,
83,
63.6,
66.1,
57.3,
71.6,
52.5,
38.7,
85.6,
23.2,
62,
7,
42.1,
15.4,
8.8,
60.2,
40.8,
14.6,
33.9,
69.6,
75,
92.7,
95.6,
72.8,
28.3,
63.2,
98,
9,
37.1,
79,
85.9,
15.9,
86.5,
73,
67.4,
41,
49.9,
75.3,
15.5,
66.1,
63,
30.1,
73.1,
24.3,
70.7,
7.8,
27.4,
91.5,
33.9,
91.3,
75.1,
59.2,
75.1,
78.1,
65.3,
72.2,
84.4,
29.8,
51.8,
79.6,
26.8,
16.4,
46.2,
72.3,
47.7,
4.9,
26.9,
81.2,
48.1,
84.5,
32.7,
63.9,
74.6,
40.7,
86.7,
67.5,
68.2,
41.7,
45,
73,
88.8,
87.4,
23.4,
81.2,
58.5,
95.1,
55.1,
49.7,
54,
72,
82.4,
68.1,
54.4,
48.5,
77.5,
21.3,
92.1,
24.9,
75.1,
90.3,
72,
33.6,
86.8,
62.7,
68,
81,
96,
72.8,
60.1,
100,
46.7,
39.4,
81.3,
102,
59.3,
70.9,
65.9,
87.3,
73.6,
7.28,
46.9,
48.9,
88.4,
82,
62.3,
8.5,
34,
25.3,
62,
40.9,
36.7,
87.1,
33.1,
60.2,
58.6,
68.7,
59.5,
54.8,
63.1,
48.9,
23.5,
67.9,
54.1,
47.1,
9.2,
94.6,
74.6,
13.9,
40.3,
64.2,
82.4,
53,
73.6,
71.4,
78.9,
69.8,
60.3,
94.1,
76.7,
35.4,
37.1,
50.5,
0,
84.2,
5.3,
70.1,
69.6,
65.4,
55.3,
32.6,
52.8,
58,
31,
94.5,
32.8,
62.8,
41.8,
18.1,
10,
67.1,
74.2,
62.1,
84.7,
58.3,
10.4,
90.1,
81.1,
51,
50,
58,
58,
38.8,
93.4,
60,
48.9,
39.6,
29.3,
59.1,
13.7,
48.6,
96.6,
39.9,
78.3,
67.7,
12.4,
62,
73.1,
66,
85,
73.9,
31,
29.4,
46.4,
70.1,
82.4,
66,
52,
90.8,
84.4,
68.4,
59.5,
65.6,
87,
20.8,
71.2,
56.4,
26.2,
41.3,
54.4,
102.5,
10.8,
17.7,
78.7,
66.6,
48.8,
64.9,
62.3,
24.9,
71.9,
53,
79.9,
46.9,
0,
65.8,
51.2,
67.7,
62.4,
54.2,
37,
70.9,
75.2,
38.3,
81.7,
100.7,
72.8,
52.2,
56.3,
58.1,
74.1,
54.9,
0,
92.3,
50.1,
58.4,
82.9,
37.6,
14,
84.4,
80.7,
39.4,
55.4,
24.8,
94.4,
9.9,
52.3,
99.4,
87.4,
50.4,
51,
7.5,
52.4,
61.6,
79.2,
34.8,
13.1,
62,
77.3,
34.7,
75.3,
49.6,
53.8,
45.8,
63.1,
99.4,
67.9,
40.9,
20.7,
90.9,
56.6,
65.3,
43.5,
38.6,
29.5,
32.2,
29.6,
58.4,
70.7,
97.4,
74.6,
43.7,
59,
31.1,
67.3,
53,
64.3,
70.1,
30.2,
50.8,
59.2,
33.2,
46.5,
61.5,
57.9,
31.5,
39.3,
93.9,
27.2,
58.8,
58.3,
75.1,
44,
96,
35.1,
27.6,
31.8,
44.3,
10.4,
62,
42,
37.9,
39.3,
54.1,
34.3,
89.5,
31.9,
36.7,
92.5,
35.9,
82.7,
82,
58.9,
76.3,
47.1,
0,
31.6,
41.7,
29.8,
69.5,
10.5,
62.7,
83.1,
79.7,
42.6,
50.6,
49.5,
83.5,
44.4,
54.6,
11.6,
94,
51.8,
40,
71.8,
66.7,
93.7,
44,
44.9,
55.1,
52.8,
32.8,
64.6,
85.8,
43.7,
88.4,
10.2,
74.4,
59.3,
42.4,
3.4,
38.5,
46.9,
11.7,
54.6,
86.6,
32.3,
76.1,
90.5,
15.6,
87.4,
17,
37.1,
30.5,
66.5,
69.1,
71.3,
63.3,
82.3,
33.3,
90.3,
48.7,
79.8,
68.8,
30.7,
52.9,
69.8,
71.2,
50.1,
46.7,
4,
88.3,
34.5,
84.4,
44.8,
49.7,
7.6,
18.2,
88.2,
53.6,
20,
55.2,
45.2,
44.8,
74.5,
25.7,
41.3,
40.5,
87.1,
48.7,
83.8,
63.6,
87.7,
100.4,
96.7,
85.1,
97.7,
89.9,
35.4,
43.3,
28.9,
95,
25.8,
5.3,
66.8,
71.6,
79,
45.3,
5.7,
70.2,
56.9,
76.4,
28.4,
75.4,
79.6,
71.5,
97,
63,
53.6,
66.6,
92,
71.8,
73.3,
46.7,
39.2,
68.6,
18.8,
48.3,
51.8,
54,
24.8,
31.3,
17.8,
97,
87.2,
71.5,
63.6,
72.9,
85.8,
69,
56,
26.8,
96.9,
47.3,
96.4,
95.7,
58,
23,
83.6,
87.4,
39.6,
0.8,
47.7,
0,
31.7,
58,
70.1,
72.1,
43.6,
76.4,
82.2,
44.8,
10.9,
72.9,
15,
66.9,
50.9,
83.8,
77.2,
67.8,
74.4,
93.6,
49.4,
56.6,
52.4,
47.2,
44.6,
36.7,
77,
89.2,
48,
37,
56.5,
null,
63.7,
82.9,
52.2,
8.7,
107.4,
58.6,
52.4,
51.5,
71.7,
36.2,
63.5,
77.6,
50.7,
49.3,
27,
40.8,
83.1,
84.8,
37.9,
57.8,
76.5,
51.7,
50.7,
35,
40.8,
24,
88,
48.4,
71.7,
48,
58.1,
49.1,
11.8,
80.8,
12.8,
20.3,
90.8,
72.5,
59.9,
75.1,
33.9,
93.8,
66.1,
84.6,
61.6,
88.2,
39.7,
17.1,
67.8,
74.2,
1.6,
75,
51.3,
79.3,
40.9,
70.1,
13.3,
48.7,
71.3,
85,
60,
56.2,
74.8,
80.3,
81.8,
40.7,
80.3,
46.2,
46.8,
63.1,
39.9,
45.8,
74.9,
87.1,
24,
63.8,
32.1,
55.9,
32,
32.5,
66.4,
68.7,
72,
19.6,
57.9,
21.1,
36,
56.7,
64.8,
77.4,
37.2,
56.4,
71,
60.5,
22.8,
21.2,
77,
36.9,
62,
21.2,
42.8,
67.6,
39,
61,
49.6,
37.2,
8.8,
52.8,
91,
92.3,
33.9,
29.3,
72.6,
49.6,
40.4,
94.9,
79.9,
58.3,
57.9,
72.4,
94.9,
45.3,
66.7,
36.4,
55.8,
18.1,
59.9,
73.5,
49.6,
72.8,
62.3,
62,
15.2,
59.9,
86.6,
34.1,
58.8,
94.9,
47,
61.1,
56.9,
90.2,
69.4,
87.5,
41.5,
48.2,
57.3,
108,
9.6,
13.7,
88.7,
73.7,
99.2,
75.6,
59.6,
89.9,
60.5,
86,
48.6,
57.3,
72.9,
73.2,
34,
42.7,
39,
29,
5.3,
74,
126.4,
95.9,
82,
65,
71.1,
58,
1.1,
90.9,
26.7,
93.3,
63,
89,
91.2,
65,
54.4,
37.9,
48.4,
77.4,
54.9,
47.8,
71,
81,
12.5,
67.5,
17.8,
85.4,
82,
40.1,
95.2,
90,
65.9,
35.3,
65.3,
95.6,
0,
15.3,
49.5,
20.5,
36.8,
60.3,
72.5,
41.8,
26.7,
30.8,
59.3,
84.6,
78.5,
74.3,
69.7,
37.4,
67.9,
63,
78,
95.5,
46,
86.8,
72.5,
85.1,
66,
62.7,
32.8,
92,
68.8,
53.2,
88.1,
92.9,
21,
45.6,
63.1,
45.4,
49.8,
58.2,
68.9,
66.7,
16.4,
74.8,
71.3,
68.4,
72.2,
43.7,
57.2,
52,
43.8,
46.2,
67.3,
65.9,
19.7,
56,
53.8,
35.6,
65.7,
42.1,
82.2,
89.7,
37.2,
81,
28.3,
22.4,
20.5,
55,
32.6,
67.1,
59.2,
31.5,
64.7,
60,
29,
70,
93,
52.9,
96.3,
60.5,
91.9,
52.3,
53.6,
14.1,
88,
77.9,
89.1,
11.4,
76.1,
42.1,
58.8,
7.3,
52.2,
63.7,
27,
10.1,
21.5,
68.6,
57.1,
24.3,
33.9,
70.4,
9.2,
73.5,
64.4,
65.7,
4.3,
19.5,
31.2,
95.1,
27,
77.9,
67.8,
56.8,
94.5,
78.7,
50.6,
42.1,
65.3,
55.8,
74.2,
38.5,
70.6,
55.8,
73.8,
60.8,
51.1,
27.6,
31.9,
40.8,
37.4,
46.8,
72,
36,
93.5,
3.2,
17.3,
18.5,
50.1,
37,
27.8,
85.9,
89.7,
59.4,
38.2,
69,
50.8,
39,
51,
64.1,
61.9,
79.2,
30.9,
87,
23,
65.9,
67.9,
28,
36,
75,
34.4,
57.7,
9.6,
85.4,
35.3,
59,
41.1,
64.1,
34.7,
82.3,
82.8,
48.4,
85.1,
21.4,
48.3,
58.1,
86,
81.2,
52.1,
47.1,
81.6,
93,
77.5,
79.6,
33.4,
36.1,
69.3,
60.3,
29.1,
78,
30.6,
76.9,
74.2,
25,
82.3,
82.2,
94.1,
46.5,
27.3,
76,
37.8,
58.1,
72.7,
40.4,
37.3,
84.2,
54.8,
41.6,
61.4,
33.4,
48.5,
51.7,
8.5,
36.8,
78.7,
51.1,
84.6,
74.4,
32.8,
49.8,
82.2,
36.8,
56.5,
48.2,
49.1,
63.7,
74.4,
83.1,
72.1,
10.6,
45.3,
39,
95.7,
83.2,
72.7,
63.3,
82.9,
39.8,
48.1,
74,
56.8,
83.5,
56.2,
38.1,
50.8,
15.4,
88.8,
78.9,
64.9,
52,
30.7,
62.4,
67.6,
46.7,
67.4,
40.5,
50.2,
84.9,
72.4,
43.2,
14.6,
19,
78.1,
87.2,
36.1,
19.9,
73,
89,
41.6,
25.5,
90,
5.8,
28.4,
33,
58.5,
24,
23.9,
34,
78.7,
65.8,
52.3,
43.4,
28.5,
30.7,
79.7,
0,
21.9,
48.5,
89,
45.9,
25.1,
73.5,
9.5,
42.8,
40.2,
73.5,
69.5,
40.7,
8.8,
76.6,
31.6,
57.8,
36.1,
64.5,
69.9,
69.9,
92,
28.6,
19.1,
30.1,
26.8,
53.8,
27.9,
94.9,
80.7,
51.6,
22.1,
80.4,
55.3,
88.7,
52.3,
58.6,
24.2,
77.8,
65,
96.6,
18,
87.2,
75.8,
21.6,
21.2,
52,
33,
59,
79.1,
86.7,
69.1,
56.9,
78.8,
81,
47.7,
63.7,
55.2,
86.1,
27.8,
23.11,
53.1,
64.5,
26.5,
73.7,
91.9,
62.3,
18.3,
64,
65.7,
17.1,
48.9,
29.8,
56.3,
88.8,
52.6,
83.9,
76.8,
47.6,
69.2,
73.5,
57.6,
88.7,
87.7,
70.2,
36.7,
27.2,
79.9,
0.3,
88.5,
59.2,
88.2,
52.7,
89,
64.4,
100,
51.4,
10.6,
76.3,
38.6,
31.1,
85.6,
38.9,
69.7,
46.3,
48,
91.1,
91.4,
82,
53.1,
60.7,
16.9,
51.2,
49.9,
57.5,
12.7,
28.2,
67.3,
39.2,
35.8,
70.3,
33.8,
11,
58.2,
69.8,
26.2,
79.2,
58.9,
35.9,
24.7,
62.5,
45.3,
77,
56.6,
94.1,
43,
48,
53.5,
70.7,
61,
6.4,
99,
71.4,
61.6,
66,
56.2,
37.5,
49.6,
63.1,
62.3,
73.6,
69.6,
40.3,
12,
85.5,
43.8,
62.5,
41.7,
94.5,
68.3,
13.5,
21.1,
69,
67.8,
68.3,
44.3,
20.3,
51.6,
15.5,
36.2,
59.9,
47,
87,
13.6,
72.6,
41.7,
83.3,
36.7,
35.8,
61.8,
47.6,
31.5,
56.4,
37.6,
63.8,
87.6,
34.8,
79.4,
86.1,
40.8,
60.6,
57.3,
54.3,
53,
20.4,
55.5,
69.1,
70.6,
22.9,
63.2,
33.7,
29.5,
74.4,
26.6,
77.4,
70,
14.5,
81.4,
65.3,
53.3,
66.1,
81.8,
75,
69.9,
72,
51.5,
64.8,
57.4,
12.7,
92.3,
18.7,
94.7,
81.2,
44.2,
89.3,
77.2,
54,
40.1,
34.6,
80.6,
59,
21.3,
36.3,
80.8,
69.6,
49.9,
92.2,
15,
46.8,
56.2,
73,
61,
63.9,
56.5,
55.7,
91.8,
50,
86.9,
67.8,
7.5,
60.4,
39.7,
39.3,
87.8,
31,
91.5,
44.7,
56.7,
85,
34.1,
56.3,
84.9,
69.5,
67.8,
75.7,
50.1,
37.7,
75.2,
55,
49.3,
56.5,
73.7,
15.9,
48.2,
4.4,
31.5,
69.9,
86.8,
67,
9.3,
62.1,
73.5,
1.8,
10.3,
26.9,
33.9,
84.3,
57.6,
24.9,
63.2,
20.7,
34,
12.9,
14,
92.9,
71.5,
40.1,
97.8,
44.4,
93.9,
40.8,
87.1,
77.1,
31.4,
46.3,
46.3,
50.3,
56,
51.9,
48.9,
20.1,
77.2,
98.6,
8,
59.6,
66.1,
87.6,
78.4,
3.7,
83.2,
55.6,
65.1,
33.1,
52.8,
86.7,
35.7,
0,
58.9,
3.6,
33.6,
50.6,
35.7,
47.5,
24.8,
60.5,
30.9,
55.3,
73.8,
77.9,
63.4,
26.5,
79.1,
93.5,
49.7,
31,
49.1,
24.4,
89.9,
43.5,
49.3,
25.7,
34.7,
94.4,
42.2,
66,
73.5,
16.3,
61.1,
45.2,
60.3,
43,
70.6,
36.1,
41,
82.8,
19.7,
78.4,
48.9,
29.7,
55.4,
6.6,
83.6,
51.2,
50.6,
83.7,
85.2,
49.2,
56.3,
48.6,
96.3,
32.9,
92.7,
46.8,
47,
92.9,
57.8,
48.7,
27.7,
63,
74.5,
76.6,
48.8,
52,
44,
89.2,
67.9,
39.9,
27.9,
48.4,
96.5,
30.5,
68.5,
24.3,
66.3,
8.4,
56.8,
48.7,
37,
9.2,
75.3,
63.6,
14.5,
54.7,
23.1,
34.3,
63,
39.8,
34.8,
49.6,
58.6,
13.4,
50,
76.8,
83.8,
90.7,
69.7,
40,
88.9,
15.9,
55.6,
84.3,
81.9,
59.5,
81,
81.1,
56.4,
44,
80.1,
19.8,
27.5,
50.9,
83.6,
17.7,
40,
45,
88.3,
0.2,
45.6,
98,
80.5,
69.6,
39.2,
36.2,
82,
57.8,
79.1,
39.4,
59,
34.2,
56.5,
72.4,
85.6,
85,
24,
45.5,
53.6,
89.4,
29.5,
62.2,
37,
84,
9.6,
76.3,
33.9,
63.3,
45.8,
71.5,
51.2,
26.6,
69.5,
54.5,
21.3,
38,
23.1,
21.8,
53.7,
61.7,
65.9,
66.7,
38.3,
39,
18.3,
62.6,
37,
45.8,
76.9,
58.6,
84.8,
33.9,
50,
87.5,
99.1,
84.9,
36.2,
9.5,
89.9,
65.6,
65,
46.9,
55.4,
78.1,
23.1,
56.6,
88.4,
53.5,
73,
85.8,
84,
55.6,
46.8,
78.1,
94.1,
49.4,
55.2,
18.6,
87,
31.1,
83.9,
47,
49,
34.7,
32.4,
65.7,
88.2,
35.2,
97,
56.2,
68.4,
79.5,
40.6,
86,
3.1,
10.1,
48.8,
42.9,
40.6,
77.2,
40.9,
39.5,
39.9,
46.5,
47.1,
17.9,
74,
55.4,
64.9,
97,
80.3,
64.9,
46.1,
39.4,
69.8,
50.7,
69.1,
96.1,
64.7,
93.3,
28.8,
1.3,
74.7,
84.9,
49.3,
93.5,
58.4,
92.7,
71.2,
62.7,
45.3,
88,
67.3,
38.1,
59.1,
65.4,
64.9,
78,
48.1,
51.9,
72.7,
83,
74.6,
60.4,
79.6,
11.8,
83,
82.4,
14.7,
28.3,
58.6,
78.3,
49.1,
59.2,
71.1,
55.1,
70.1,
78.1,
73.4,
45.9,
70.3,
61.1,
37.3,
47.7,
82.3,
62.6,
50.3,
24.1,
61.2,
49.2,
66.2,
72.3,
40.7,
57,
80.2,
52.9,
60.4,
55.6,
57.4,
67.7,
91.7,
3.9,
35.3,
65.4,
87.4,
55.1,
66.6,
88.4,
0,
79,
25,
90.3,
18.9,
60.1,
73.1,
57.7,
65,
13.2,
39.1,
78.2,
69.9,
15.5,
93.6,
74.3,
27.8,
59.9,
28.6,
12.3,
59.5,
60.7,
44.4,
76,
8.6,
14.3,
36.2,
29.3,
57.5,
75.3,
40.6,
11.4,
65.9,
28.5,
52.7,
42.4,
78.4,
82,
39.6,
46.2,
67,
64.5,
50.3,
24.8,
80.9,
74.3,
37.6,
67.3,
55.4,
69.7,
61.3,
55.5,
57.7,
23.6,
25.4,
65.7,
93.9,
35,
62,
73,
32,
43,
22,
48.1,
61.3,
78,
60.5,
75,
36.7,
39,
77.4,
64.2,
56.7,
70.9,
74.1,
85.3,
76,
46,
32.3,
54.7,
77.8,
68,
46.6,
73,
40.3,
65.2,
73.4,
91.6,
55,
35.2,
65.1,
38.8,
24.9,
54.8,
32.2,
19,
33.6,
54.7,
62.2,
34.1,
86.4,
63.2,
83,
83.7,
12.9,
89.1,
29.9,
89.5,
82.3,
31.3,
66.8,
69,
36.5,
46.7,
75.9,
82.5,
70.7,
83.5,
97.2,
84.3,
11.4,
91.5,
39.9,
56,
54.8,
60,
53.2,
72,
117.5,
86,
71.7,
80.6,
19.1,
73.4,
82.2,
43.3,
64.1,
71.8,
54.2,
72.3,
23,
74.2,
56.1,
62.5,
48.1,
64.1,
34.4,
20.4,
80.6,
91.4,
36.5,
26.7,
23.8,
17.3,
55.5,
61.9,
12.8,
48.4,
79.2,
72.3,
44.7,
53,
70.8,
49.1,
65.9,
69.7,
59.2,
73.6,
31.4,
54.3,
61.3,
39,
67.6,
89.1,
85.3,
50,
48.3,
13.4,
82.5,
32.6,
21.6,
21,
36.2,
82.4,
29.1,
82.2,
32.4,
56.8,
63,
41.5,
88.3,
33.2,
19.6,
67.7,
64.9,
38.3,
55.9,
24.7,
78.9,
83.5,
91.4,
49.7,
65.6,
10.2,
79,
27.7,
25.3,
75,
64.6,
45.7,
36.4,
9.7,
76.5,
58.3,
40.2,
30.1,
59.6,
12,
84,
72.9,
52,
96.1,
72.5,
23.2,
43.1,
51.6,
38.5,
51.2,
47.7,
60.2,
89.9,
59.7,
46,
42.6,
63.6,
88.1,
73.2,
36.6,
96.9,
55.5,
37.5,
89.8,
82.7,
52.1,
91.4,
18.4,
31.2,
48.8,
56.5,
84.8,
35,
69.6,
38.8,
1.2,
50.4,
9.7,
50,
59.1,
26,
1.3,
90.2,
38.4,
59,
40.1,
35.9,
79.4,
86.9,
66.9,
44.4,
57.7,
54.5,
86,
87.1,
56.7,
66.5,
68.3,
87.2,
87.7,
25.9,
89.8,
37.6,
100.3,
65,
80.6,
34.4,
86.8,
77.8,
57,
63.7,
72.9,
91.4,
51.8,
37,
44.4,
96.4,
98.4,
91,
46.1,
28.6,
49.3,
91.8,
81.8,
27,
71.5,
92.3,
16.3,
33,
62.9,
64,
68.3,
50.6,
41.5,
99,
45.2,
67.6,
83.4,
85.6,
72.3,
70,
62.3,
72.3,
28,
45.5,
81,
90.2,
64.7,
26.1,
57.3,
66.8,
10.3,
17,
46.3,
41.1,
92,
65,
97,
59.7,
55.9,
34.8,
70.8,
76.9,
76.5,
73,
87.4,
69.4,
60,
63.7,
28.6,
41.8,
86.7,
73.5,
79.4,
80.2,
63.1,
64.8,
41.4,
39.7,
59.6,
52.5,
57.2,
79.5,
63.8,
68.5,
91,
69.9,
94,
71.3,
41.7,
49.3,
84.9,
50.8,
77,
78.9,
85.6,
85.8,
62.7,
52.3,
25.1,
94.1,
57.1,
29,
23.6,
4.7,
44.9,
57.1,
10.4,
86.8,
60.7,
30.9,
46,
64.9,
85.3,
71.1,
63.5,
61.3,
26,
96.5,
39.3,
20.7,
58,
18.6,
80.5,
40.4,
54.9,
27.5,
73.9,
2.2,
40.8,
42.5,
35.4,
70.9,
78.3,
52.5,
80.5,
88,
89.5,
58,
55.5,
2.1,
26.8,
39.1,
35.1,
16.1,
0,
64.6,
29,
40.6,
61.7,
68,
87.9,
22.2,
89.3,
21,
40.8,
28.5,
28.9,
65.3,
19.1,
58.4,
59.1,
116.1,
84.6,
70.5,
36.1,
88.9,
52.6,
75.9,
83.4,
30.2,
10,
57.4,
25.4,
15.2,
73.5,
40.9,
86.1,
97.3,
91.5,
75.7,
66.3,
68.2,
87.8,
21.5,
37.2,
90.8,
37,
54.1,
78.9,
93,
47.8,
96.3,
60.4,
74.3,
91.9,
20.3,
38.2,
61.3,
51.9,
32.3,
65.5,
96.7,
93.6,
39,
79.7,
96.9,
4.3,
72.3,
91.7,
95,
44.2,
87.3,
44.9,
20.4,
85.3,
55.7,
78.3,
48,
5.9,
55.2,
31.1,
95.9,
43.1,
26.9,
94.9,
79.3,
50.7,
17.6,
51.7,
53.7,
32.8,
90.3,
86.6,
27.1,
36.1,
28.5,
68.3,
40,
29.6,
70.1,
90.6,
28.3,
63.4,
83.8,
63,
89.5,
98.2,
44.9,
75.1,
78.3,
54.3,
35.7,
1.5,
81.9,
65.6,
47.7,
17.9,
65.2,
78.8,
51.2,
67.2,
61.8,
48.9,
11.1,
46,
45.3,
94.2,
66.4,
2.3,
59.3,
20.9,
46.7,
98,
50.2,
65.5,
95.1,
74,
89.9,
60.9,
38.5,
47.4,
99.5,
88.4,
34,
36.3,
92.7,
26.8,
52.6,
47.3,
31,
48.5,
89.7,
21.3,
38.1,
77.5,
55.7,
33.4,
36.6,
99.1,
74.7,
32.3,
78.7,
58.3,
78.6,
30,
43.1,
39.2,
56.4,
84,
52.6,
51.3,
77.4,
79.3,
0,
66.4,
56.8,
53.7,
91.6,
54.7,
29.5,
70.8,
12.1,
37,
25.5,
86.3,
61.9,
58,
14,
39.4,
77.3,
76.7,
57.8,
16,
63,
34.2,
96.2,
49.8,
28.6,
88.3,
80.5,
27.3,
51.4,
96.9,
46.8,
31.6,
37.6,
8.5,
52.2,
4.5,
69.2,
52.5,
4.6,
56.3,
82.2,
63.9,
53.9,
25.1,
33.9,
37.2,
42.8,
43.4,
78.4,
41,
86,
58.6,
59.9,
20.7,
13.4,
17.6,
41.2,
12.4,
42.7,
56.2,
67.9,
83.1,
49,
33,
61.5,
68.5,
26.1,
72.8,
12.1,
69,
52.6,
71.1,
67.6,
51.9,
37.3,
62,
52.8,
19.7,
88.7,
28.5,
51.6,
52.6,
69.8,
53.2,
46.3,
54.1,
17.5,
62.2,
5.7,
71.3,
63,
38.9,
91,
36.3,
12.6,
87.7,
32.6,
71,
52.9,
23.9,
62.7,
59.2,
78.4,
60,
7.8,
76.4,
81.7,
83.5,
72.7,
59,
69.9,
43.7,
43.7,
47.5,
88.3,
90.2,
39.9,
60.2,
55.3,
80.2,
33.2,
35.6,
68.8,
69.8,
92.8,
41.2,
73.5,
49.7,
17.5,
16.1,
55.9,
56.2,
90.1,
89.2,
62.2,
59.2,
47.7,
76.1,
81.5,
14.5,
40.4,
32.6,
50.3,
53,
41.1,
77.7,
93.6,
84.3,
91.7,
7.1,
77.8,
87.7,
84.8,
38.8,
43.7,
60.8,
70.6,
23.7,
61.8,
28.6,
18.5,
84.5,
55.8,
54.5,
28,
37.5,
91.4,
80.6,
47.4,
71.9,
14.3,
88.6,
29.5,
51.8,
55,
25.9,
100.2,
12.7,
82,
69.2,
84.3,
45.2,
74.2,
97.7,
80.9,
68.5,
61.1,
42.1,
97.5,
32.7,
64.8,
47.6,
14.7,
86.5,
79.9,
24.2,
83.8,
49.8,
61.3,
81.6,
73,
53.3,
37.1,
57.4,
72.1,
8.7,
50.3,
54,
22.9,
17,
41.5,
80.3,
16.6,
23,
79.9,
84.7,
40.4,
76.4,
74.3,
40.1,
7.6,
49,
44.8,
91.5,
8.6,
55.7,
21.6,
91.2,
56.4,
31.6,
71.6,
65,
79.8,
65.1,
71.6,
38.3,
75.8,
42.9,
56.3,
66.7,
34,
33.3,
71.8,
49.2,
80.5,
69,
10.5,
52.7,
50.1,
46.8,
84,
88.8,
64.9,
30.5,
88.4,
70.6,
75.6,
61.2,
34.6,
39.7,
41.4,
42.4,
90.1,
28,
59.5,
77.4,
70,
71.4,
45.4,
25.8,
33.4,
75,
48.8,
91.6,
75.5,
93,
32.8,
43.7,
43.1,
31.4,
79.5,
15.7,
41.4,
89.3,
47.1,
58.3,
90.5,
37.6,
84.3,
20.8,
52.2,
79.9,
18.6,
46.5,
53.3,
75.4,
27.9,
73.8,
97.6,
86.5,
77.6,
69.6,
52.4,
85,
81.6,
76.3,
97.7,
35.1,
20,
86.2,
49.1,
55,
75.1,
18.6,
63.2,
41.2,
48.8,
86.9,
62.1,
79.1,
65.4,
69.2,
43.1,
39.9,
48.8,
37.1,
18.5,
43.4,
21.9,
4.7,
76.4,
38,
45.3,
17.7,
20.1,
64,
93.3,
51.1,
58.7,
50,
82.8,
28.8,
53.4,
42.5,
50.9,
47.4,
26,
65.1,
35.6,
76,
62.4,
34.9,
35.5,
47.1,
71.1,
60.6,
13,
29.4,
26.4,
35.7,
63.4,
17,
59.2,
53,
59.9,
22.1,
93.6,
72.7,
69.1,
72.7,
47.3,
79.4,
78.7,
43.1,
39,
65.7,
89.9,
69.2,
5.4,
65.9,
74.1,
68,
17.2,
83.6,
89.9,
63.1,
70.1,
63.9,
12.2,
64.5,
62,
57.3,
37.3,
91,
74.8,
35.6,
67.9,
4.6,
41.4,
40.5,
73.9,
32,
78.3,
75.3,
25,
41.2,
68.1,
60.5,
42.6,
39.7,
2.7,
88.5,
55.1,
34.8,
57.6,
14.6,
20.3,
45.6,
36,
69,
32.5,
76.6,
81.1,
63.4,
67.9,
15.8,
79.1,
82.4,
60.2,
40.2,
66.1,
43.3,
68.6,
41.6,
41.2,
70.2,
85.1,
12.2,
20.2,
53.7,
46.3,
32.5,
68.6,
25.8,
73,
73.1,
43.5,
31.3,
76.6,
57.7,
72.9,
86,
15.5,
8.9,
66.5,
63.9,
59.1,
86.7,
71.1,
30.9,
15.6,
57.2,
0,
32.5,
57.3,
74,
76.3,
57.9,
13.4,
93.8,
36.6,
34,
83.2,
4.1,
89.4,
44.7,
35,
23.3,
82.7,
2.2,
58.6,
42.2,
23.6,
38.2,
82.5,
71.7,
46.5,
89.5,
76,
103.1,
67.2,
15.6,
60.4,
97.8,
53.4,
95.5,
58.8,
88,
53,
93.9,
45.6,
56.7,
51.8,
0,
75.4,
23.5,
53.5,
61.8,
13.1,
40,
94.3,
24.8,
49.4,
68.4,
75.4,
38.8,
67.6,
70.6,
33.9,
62,
84.6,
25.9,
36.8,
69.7,
58.8,
8.4,
38.5,
14.2,
67.6,
66.9,
55.4,
49.9,
50.6,
45.4,
48.4,
23.5,
56.3,
79.8,
52.8,
32,
68,
60.5,
42.5,
29.4,
95.3,
32.4,
51.2,
53,
35.1,
51.8,
75.5,
15.1,
55.7,
47,
15,
42,
38.8,
46.5,
22.9,
39.3,
88,
30.8,
62.8,
72.4,
76,
42.7,
78.7,
0,
47.1,
23.7,
20,
83.9,
58.4,
70.7,
53,
60.8,
94.8,
60,
43.8,
92.9,
97.9,
80.4,
35.7,
25.3,
74.4,
22.2,
61.8,
61.8,
33.8,
52.2,
21.7,
89.5,
72.6,
41.6,
58.9,
30.1,
84.8,
25.5,
54.6,
63.4,
56.6,
4,
9.7,
100.8,
59,
10.8,
66.5,
43.6,
61.2,
51.2,
44.3,
78.4,
51.8,
68.4,
36.5,
82.2,
85.1,
53.3,
42.3,
12,
69.9,
54.3,
53.9,
13.2,
54.9,
64.4,
50,
17.7,
40.8,
54.8,
97.7,
60,
57.3,
53.1,
39.9,
1,
35.9,
58.4,
37.5,
68.2,
36.9,
49.6,
1.3,
40.6,
0,
61.1,
61.3,
9.9,
49.4,
50.8,
58.2,
31,
44.8,
94,
74.9,
51.7,
67,
95.4,
34.9,
55.2,
30.4,
48,
42.1,
33.5,
52.8,
44.8,
57.7,
0.2,
41.8,
51.1,
41.2,
65.8,
99.7,
50,
44.6,
16.9,
23.7,
44.5,
34.5,
52.8,
52.8,
85.8,
5.5,
0,
59.2,
27.4,
19.1,
36.5,
79.5,
31.3,
55.8,
56.8,
58.7,
53.9,
38.3,
67.8,
34.5,
64.8,
64,
59.3,
41.7,
88.5,
25.5,
59.7,
65.1,
71,
27.2,
103.5,
24.8,
36.4,
87.6,
76,
38.4,
56.6,
4,
9.3,
28.6,
58.2,
33.3,
67.9,
66.9,
16.9,
46.3,
60,
33.5,
4.2,
27.7,
33.3,
58.7,
88.7,
33.7,
89.7,
56.3,
12.5,
57,
106.6,
49,
94.4,
47.8,
41.4,
38.3,
9.6,
60.8,
68.9,
63.8,
12.1,
71.6,
71.8,
10.5,
83.6,
50.2,
56,
55.4,
46,
80.1,
98.9,
61.5,
73.9,
67.4,
69.3,
67.3,
62.8,
40.7,
63,
16.2,
50.4,
67.9,
88,
62.8,
45,
49.1,
44,
68,
14.3,
60.7,
31.6,
48,
83.3,
0.3,
50.6,
58.5,
93.3,
55.6,
55.4,
34.6,
77.3,
46.9,
59.9,
80.5,
12.7,
89.4,
59.6,
64.5,
0,
57.6,
96.5,
2.7,
72.1,
65.4,
42.6,
46.7,
92.5,
99.1,
49.3,
28.8,
56.9,
77.1,
60.5,
88.5,
56.3,
60,
57.2,
22,
67.3,
79.3,
96,
50.8,
42.3,
37.7,
57.7,
42.4,
85.3,
73.1,
97.6,
39,
1.8,
44,
29,
63,
77.7,
19.8,
8.9,
65,
36,
50.8,
64.5,
65.8,
46.9,
21.6,
78.4,
67.8,
46,
30.8,
46.2,
79.2,
88.4,
101.2,
73.7,
9.5,
64.1,
25.1,
13.1,
54.4,
22.7,
69.1,
59.8,
73.4,
90.5,
66.9,
46.3,
97.6,
89.1,
74,
7.5,
49.8,
18.2,
62.6,
2.9,
35.1,
67.6,
46.1,
47,
23.4,
85.6,
31.9,
22.6,
8.3,
89,
25,
46.1,
37.6,
58.4,
48.8,
48,
95.4,
57.1,
37.3,
60,
50.1,
19.1,
37,
62.1,
30.7,
33.9,
94.3,
72.4,
28,
75.6,
53.4,
46.6,
42.5,
44.1,
61.9,
65.1,
48.7,
88.2,
46.7,
45.2,
56.6,
43.1,
21.2,
41.1,
50.3,
70.6,
96.7,
62.7,
42.7,
55.3,
70.6,
11,
84.4,
42.8,
60.9,
32.9,
84.4,
52.5,
47.2,
72.1,
71.3,
54.2,
52,
53.4,
88.8,
76.4,
28.5,
61.1,
61.8,
35.7,
73.6,
46.4,
31.2,
75,
64.8,
18.1,
57,
42.7,
97.2,
43.9,
40.7,
42.3,
81.7,
61.7,
41.2,
45.5,
59.5,
30,
20.4,
39.3,
22.4,
10.6,
77.5,
73.7,
42.2,
74,
63.5,
31.7,
17,
85.6,
62.5,
10.9,
71.9,
20.7,
75,
7.2,
60.7,
67.6,
46.2,
48.1,
93.3,
65.3,
12.6,
2.6,
79.4,
66.5,
56.7,
76,
67.8,
86.7,
64.9,
5.5,
95.6,
63.3,
30.6,
99.1,
90.2,
44.5,
33.3,
47.9,
31,
69.5,
24.4,
34.8,
54.1,
42.5,
53.6,
25.1,
65.2,
35.9,
68,
85.7,
53,
83.2,
77.3,
86.4,
82.6,
61.8,
53.9,
59.8,
79.5,
90.4,
65.2,
24.2,
93.6,
68,
61.1,
43.6,
100.3,
58.4,
49,
18.7,
46.7,
52.6,
90.3,
40.1,
70.3,
92.2,
74.7,
58.7,
84.3,
48.9,
82.8,
89.3,
71.2,
23.6,
72.6,
16.8,
69.9,
84.3,
29.9,
54.7,
27.1,
58.4,
35.4,
51,
7.2,
64,
81.8,
82.5,
67.4,
54.3,
57.1,
89,
50,
67,
23.5,
10,
28.4,
47.4,
87.7,
33.9,
72.4,
71.7,
59.5,
49.4,
87,
48.8,
11.7,
68.2,
47.1,
63.7,
52,
42.1,
48.1,
69.1,
82.9,
40.9,
51.9,
45.7,
74.5,
70.2,
76.2,
76.4,
46.1,
96.3,
68.4,
84.9,
32,
63.1,
52.1,
61.1,
17.7,
65.5,
70.5,
81.1,
55.7,
56.1,
35.4,
93.2,
96.3,
56.9,
56.3,
32.8,
93.4,
44.7,
41.3,
67.1,
40.6,
18.6,
29.2,
45,
60.7,
84.3,
26.7,
56.5,
38.7,
60.7,
57.8,
37.8,
89.6,
48.1,
1.3,
65.4,
51.2,
45.8,
17.6,
98.4,
98.4,
5.4,
28.6,
36.9,
96.1,
76.5,
85.1,
52.5,
37,
83,
14.4,
90.6,
14.5,
88.5,
82.3,
97.4,
80.4,
28.6,
43.3,
81.5,
5.6,
98.5,
47.5,
18.6,
74.5,
61.1,
47.2,
42.2,
0.4,
83.6,
64,
72.2,
82.8,
53.6,
60.1,
70.4,
79.5,
31.1,
16,
75.5,
75.4,
17.6,
50.1,
62.9,
63.6,
81.6,
46.6,
20.1,
56.5,
75.3,
83.5,
29,
75.5,
77.7,
68.3,
83.5,
72.1,
5.9,
87.1,
39.5,
61.8,
79.3,
67.2,
66.5,
68.9,
34.5,
102.7,
71.2,
49,
36.5,
43.3,
42.7,
93.5,
58.1,
85.9,
37.7,
96.7,
96.7,
44.7,
67.1,
47.7,
36.1,
85,
44.7,
43.1,
99.5,
53.7,
89.4,
49.9,
27.8,
24.1,
60,
58.8,
20.8,
77.1,
26.8,
58,
43,
53.9,
65,
95.9,
71.4,
55.5,
23.8,
80.4,
48.4,
30.4,
84.8,
39.2,
74.2,
55.6,
69.8,
55.5,
64.8,
46,
77.3,
63.1,
33.9,
5.4,
31.3,
44.3,
32.6,
40,
80.6,
56.4,
66.2,
81.3,
81.6,
37.4,
76.9,
36.6,
73.4,
14.3,
10.9,
74.7,
48.5,
53.3,
96.4,
59.4,
43.1,
92.3,
49,
87.9,
45.5,
37.5,
52.7,
60.4,
64.2,
68.9,
66.4,
59.4,
33.1,
39.3,
1.8,
81.1,
52.7,
50.2,
58.1,
85.1,
39.2,
94,
18.4,
40,
50.3,
31.2,
70.2,
71.2,
85.1,
25.5,
63.5,
86.5,
32.4,
45.4,
61.9,
91.6,
25.8,
38.9,
47,
57.5,
64.2,
70.4,
85,
38,
38.7,
13.6,
29.3,
93,
65.4,
64.9,
68.3,
47.6,
63.1,
94.1,
66.1,
75.8,
46.7,
74.9,
8.5,
23.9,
6.6,
64.8,
59.9,
46.3,
68.4,
43.8,
41.7,
67.2,
19.5,
49.9,
56,
49.4,
61.7,
32.9,
83,
53,
85.2,
86.8,
84.8,
74.1,
77.5,
67.4,
18,
54.1,
40.9,
41,
34.1,
78.3,
27.2,
42.9,
82.3,
63.3,
34.6,
67,
47.6,
4.7,
26.3,
66.1,
44.2,
73.2,
88.1,
76.2,
54,
53.9,
63.7,
95.2,
46.9,
85,
59.6,
29.2,
44.8,
45,
97.3,
51.6,
97.9,
61.1,
61.2,
45.4,
48.2,
38,
47.7,
47.5,
18.1,
51.1,
68.1,
74.9,
57.5,
69.5,
57.2,
11.6,
46.5,
54.6,
6.7,
68.1,
41.7,
86.1,
10,
13.5,
0.5,
39.8,
65.2,
84.4,
55.3,
3.8,
43.1,
14.6,
83.4,
72.2,
25,
17.4,
41.4,
38.6,
74.2,
93.6,
72.2,
61.7,
32.6,
82.1,
95.3,
24.7,
22.1,
83.1,
22.4,
43.6,
28.6,
65.2,
54.2,
39.6,
48.3,
85.6,
49.7,
31.3,
54.1,
37,
42.5,
87.3,
80.7,
56.3,
60.3,
61.6,
38.3,
27.6,
65.4,
61.8,
16,
63.7,
7.3,
75.1,
60.4,
67.5,
16.1,
57.6,
80.8,
69.9,
43.3,
54.8,
40.3,
52.1,
64.9,
73.3,
95.7,
83.8,
24.1,
32.1,
25,
61.6,
87,
78.1,
59.8,
56.9,
52.4,
5.79,
37.2,
74.2,
73.5,
50.5,
47.9,
42.3,
47.5,
80.1,
24.6,
46.3,
63,
77.2,
2,
0.5,
84.2,
32.5,
99.7,
75.8,
76.8,
38,
10.9,
29.4,
76.4,
88.4,
63.7,
90.8,
50.9,
18.6,
35,
51.7,
38.8,
90,
51.2,
42.9,
65.3,
75.9,
69.7,
72.5,
51.6,
74.4,
72.2,
101.3,
86.7,
70.6,
100.9,
33.4,
63.2,
57.7,
31.7,
72.9,
57.9,
63.2,
54.6,
58,
93.6,
91,
45.8,
68.3,
43.7,
18.5,
59.5,
85.4,
80,
32.1,
54.4,
86.9,
47.8,
86.3,
44.5,
37.7,
99,
52.9,
73,
30.6,
58.6,
19.7,
95.4,
84.2,
88.3,
80.3,
66.6,
78,
59.2,
32.9,
71.1,
99.2,
21.3,
25.7,
70.4,
56.6,
49.2,
57.9,
19.3,
57,
51,
48.6,
53.8,
54.4,
54.2,
24.3,
48.6,
16.4,
18.5,
53.4,
48.9,
21.8,
47.3,
50.6,
84.7,
51.1,
11,
87.7,
52.2,
57.3,
34.5,
48.4,
60.9,
15.6,
63.5,
21,
23.2,
52.6,
8.8,
74.1,
61.6,
43,
75.9,
43.8,
49.8,
28.2,
57.2,
50,
47,
27.3,
84.3,
22.6,
85,
53.8,
72.9,
53.4,
52.3,
47.9,
77.6,
79.5,
56.6,
67.6,
40.1,
58.6,
76.3,
38.9,
25,
69.1,
36.6,
47.8,
56.5,
45.2,
81.5,
53.8,
77.4,
57.3,
41.1,
28.1,
44.9,
74.1,
51.6,
58,
70.9,
63.2,
37.1,
47.8,
62.8,
67,
100.2,
47.4,
80.8,
92.2,
73.2,
67,
0.2,
60,
34.2,
56,
44.1,
31.2,
45.4,
34.8,
48.2,
41.7,
66.1,
70.1,
75.8,
0,
66.8,
46,
62,
28,
0,
52,
55.2,
84.2,
84.9,
83.1,
32.6,
82.8,
40.9,
25.8,
30.4,
58.2,
68.3,
94.6,
49.8,
17.9,
38.6,
49.9,
50.7,
77,
65.9,
97.4,
48.4,
91,
58.3,
57.5,
30.2,
7.5,
92.4,
58.1,
64.5,
15.1,
52.9,
79.7,
45.9,
48.2,
56.9,
34,
11.1,
23.9,
37.6,
37.2,
39.1,
43.5,
86.6,
54,
8.5,
34.7,
39.4,
69.4,
8.3,
86.8,
40.2,
59.3,
69.1,
86.8,
63,
42.6,
38.2,
56.1,
32.1,
34.9,
22.2,
82.1,
77.1,
47.1,
95.7,
47.6,
62.1,
62.1,
33.2,
85.4,
61.6,
41.7,
88.4,
52.3,
78.5,
95.9,
14.9,
51.7,
45.5,
23.7,
23.4,
70.2,
35.7,
67.3,
52.5,
31.8,
42.3,
43.5,
12.2,
10.6,
73.8,
31.1,
47.8,
29.4,
82.2,
37,
82.2,
25.1,
93.1,
85.9,
60.8,
89.2,
69.4,
79.9,
45.2,
54.2,
35,
53.8,
1.1,
30.8,
16,
55.4,
89.8,
76,
35.3,
30.9,
79.3,
35.5,
50.1,
92.2,
49.8,
88.3,
68.4,
79.7,
53,
84.9,
31.3,
75.9,
61.6,
67.7,
54.1,
61.6,
49.1,
62.9,
24.5,
62.8,
64.1,
45.2,
65.6,
7.1,
23.6,
93,
81.4,
15.6,
51.8,
95.9,
33.8,
68.4,
63.9,
44.9,
22.9,
48.7,
66.9,
67.2,
24.6,
53,
52.9,
61.4,
92.6,
19.6,
72.2,
69.6,
87.6,
64.3,
99.1,
89.1,
88.7,
70.5,
43,
74.8,
13.8,
50.2,
47.5,
81,
31.9,
48.4,
64.5,
40.9,
47.1,
83.4,
63.4,
44.7,
55.1,
65.6,
27.8,
75.6,
30.9,
47.7,
84.1,
49.2,
5.6,
53.8,
33.4,
49.2,
60.4,
33.3,
26,
39,
33.8,
6.3,
30.3,
96.8,
42.1,
74.7,
74.6,
74,
81,
33.5,
61.6,
10.8,
52.5,
82.5,
52,
47,
78,
43.4,
42.8,
25.5,
39.7,
42.8,
37,
5,
25.8,
42.3,
24,
59.9,
49.4,
35.8,
44.2,
77.1,
17.5,
71.7,
92.1,
92.2,
92.6,
98.4,
29.3,
69,
80,
82.9,
25.3,
86,
38.1,
100.4,
23.4,
52.1,
65.3,
16.9,
57,
54.1,
38.6,
69.4,
98.8,
37.9,
46.9,
55.7,
39.4,
50,
84.3,
69.9,
69.3,
56,
8.5,
52.7,
2,
26,
66.5,
83.7,
28.1,
23.1,
53.2,
91.7,
42.6,
16,
31.6,
69.2,
45,
6.1,
44.2,
76.1,
34.6,
60.5,
83.9,
42.4,
63.3,
51.2,
61.2,
84,
44.7,
54.2,
76.5,
80.4,
64.2,
83.6,
82.8,
82.9,
41.7,
61.6,
61.6,
83.2,
96.9,
41.2,
25.1,
45.3,
18.6,
77.6,
54.8,
31.9,
52.8,
54.6,
31.3,
45.3,
38.7,
69.2,
66.8,
13.9,
14,
68.7,
17,
46.3,
27.1,
55.3,
37.6,
30,
68.2,
22.5,
59.4,
81.1,
30.5,
51.8,
35.5,
34,
89.9,
70.2,
53.9,
61.2,
44.1,
42.9,
58.3,
78.4,
88,
18.2,
40,
63.6,
82.1,
46.5,
73.4,
31.7,
60.5,
70.3,
60,
33.8,
1,
98.5,
45.4,
17.9,
72.6,
59.5,
33.4,
17.6,
68.7,
9.8,
59.4,
49.6,
60,
48.4,
47.4,
52.8,
31.4,
55.7,
58.4,
100,
23.5,
38.3,
30.9,
39.4,
84.6,
67.1,
28.6,
52.2,
43.3,
74.8,
48.4,
81.5,
39.2,
47.6,
50.2,
89.4,
83,
44.4,
59.1,
85.4,
15.7,
91.7,
42,
73.5,
15.6,
36.4,
45.1,
34.1,
54.1,
37.4,
66.4,
37.8,
3.3,
51,
42,
68.8,
82.8,
48.3,
98.1,
56.2,
71.5,
66.1,
37.3,
47,
67.8,
46.8,
30,
60.7,
93.4,
74,
35.7,
37,
84.2,
73.7,
92.6,
84.1,
40,
40.9,
83.7,
73,
49.4,
35.2,
52.4,
47.3,
59.3,
64.4,
11.5,
50,
49.6,
50,
88.3,
72.8,
50.7,
65.1,
64.9,
22,
75.1,
59.2,
32,
58.3,
39,
31.5,
26.3,
64.1,
74.9,
55.7,
50,
60.3,
57.9,
70.2,
87.6,
43,
60.2,
51.8,
77,
33.4,
93.8,
63.2,
70.3,
25.8,
42.4,
53.4,
75.9,
54,
7.9,
71.2,
21.2,
86.3,
58.3,
76.2,
95.6,
48.6,
75,
77.7,
52,
41.7,
49,
35,
72.6,
60,
62.3,
60.3,
44.1,
19.1,
83.7,
88.5,
63.3,
81.2,
30.6,
51.7,
30.9,
50.5,
79.2,
56.3,
44.5,
41.8,
30,
58.8,
82.8,
67.9,
50.6,
47.5,
2.5,
40.1,
92.6,
21.3,
30,
40,
8.5,
83.4,
55.4,
92.8,
32.2,
84.6,
64.9,
59.6,
37.4,
47.4,
68.8,
53.3,
96.5,
34.4,
84.8,
82.3,
75.5,
68.1,
91.7,
83.7,
37.4,
29.1,
63.3,
47,
27.2,
48.3,
54.6,
52.1,
86.3,
65.9,
77.8,
54.9,
7,
94.7,
68.1,
6.8,
79.2,
34.7,
23.3,
49.2,
83.3,
1.1,
67.2,
11.5,
78.6,
72.3,
23.4,
19,
41.5,
60.6,
55.8,
51.1,
73.1,
61.6,
52,
39.5,
33.1,
65.5,
2,
44,
1.7,
40.4,
77.8,
56.2,
57.5,
27.9,
94.4,
74.5,
71.7,
53.5,
69.9,
62,
91,
40.2,
74.9,
40.1,
42.2,
98,
44.7,
50.6,
39.8,
3.9,
41.5,
25.8,
19.2,
78.2,
54.3,
44,
21.7,
94.9,
40.6,
60.8,
25.8,
34.9,
47.9,
11.9,
77.6,
26.8,
73.1,
66.8,
18.6,
66.9,
53.8,
50.8,
25.9,
7.9,
93.7,
67,
63.2,
27.8,
41,
69.9,
35,
60.1,
6.6,
59.3,
52.8,
70,
63.4,
34.5,
23.1,
39,
43.6,
87.7,
14.5,
80.5,
33.4,
19,
79.4,
0.7,
32.7,
84.5,
55.8,
51.9,
28.4,
56.4,
96.4,
64.6,
91.2,
45.2,
50.4,
68.5,
62.7,
72.2,
99.4,
69.5,
38,
44.4,
73.1,
57,
79,
79.2,
67,
58.5,
28.7,
0.7,
75,
86,
35,
31.9,
60.4,
56.2,
38,
61.5,
77.5,
54.9,
65.2,
26.3,
67.9,
16.2,
70.9,
33.2,
79.8,
76.7,
98.3,
24.4,
89.7,
62.7,
18.2,
92.4,
29.2,
50.1,
54.4,
57.1,
43.9,
40.7,
79,
74.8,
89.1,
95.7,
83.6,
15.5,
76.5,
95.6,
64.7,
72.6,
23.9,
62.6,
75,
62.8,
63.5,
60.4,
13.2,
37.9,
46.8,
83.8,
26,
55.1,
47.1,
53,
80.1,
62.7,
90.2,
41.6,
58.9,
41,
7.1,
42.6,
34.9,
16.7,
75.1,
90.2,
69.6,
50.5,
80.2,
15.6,
31.1,
9.1,
26.6,
67,
12.2,
96.2,
24.3,
66.9,
46,
21.2,
33.9,
37.7,
69.4,
84.7,
0.3,
67.6,
69.6,
60.9,
75.5,
49.9,
84.1,
93.6,
30.7,
67,
47.2,
0.6,
52,
50.2,
65.6,
71.5,
40,
98.5,
88.4,
91.4,
97.7,
46.3,
31.2,
17.4,
59.2,
97.9,
48.5,
0.5,
43.2,
44.9,
85,
57.2,
49.6,
60.4,
81.9,
37.2,
7,
50.5,
61.5,
89.3,
37.8,
70.2,
70.5,
22.8,
47.2,
38.1,
36.1,
92.1,
26,
28.8,
22.3,
71.8,
12.6,
13.9,
69.5,
43.1,
71.6,
49.7,
18,
49.8,
63.5,
63.6,
48.1,
47.5,
58.9,
68.2,
60,
97.2,
68.9,
67.7,
80.7,
81.6,
54.2,
73.3,
77.7,
29,
13.9,
67.7,
20.8,
17.5,
24.9,
85.8,
70.1,
90.6,
91.5,
84.8,
6.5,
92.5,
32.4,
35,
53.4,
25.9,
48.2,
56.3,
73.7,
49.7,
78.4,
69.2,
79.5,
44,
31,
49.8,
85.8,
65.8,
96.1,
36.6,
48.2,
13.2,
83.9,
85.2,
55,
74.6,
90.3,
43.9,
43,
60.2,
32,
null,
86.8,
47.3,
57.8,
46,
65.7,
65.9,
40.1,
68.8,
20,
63.7,
47.2,
8.8,
47.7,
66,
83.2,
79.8,
53.6,
67.1,
24.4,
59.4,
15.8,
96.9,
74.6,
33.8,
36,
70.2,
78.3,
90,
62,
44,
81.5,
41,
94.2,
79.3,
39.2,
15.2,
87.5,
14.3,
61.2,
79.5,
25.6,
22,
54.4,
35.8,
54,
25.8,
47.2,
76.3,
22.5,
80.2,
89.4,
43.9,
27.2,
60.4,
8.9,
5.6,
63.7,
29,
49,
33.6,
7.2,
56.9,
90.1,
79.1,
32.3,
84.8,
71.1,
62.6,
73.4,
15.6,
95.8,
57.1,
27.1,
55.7,
31.5,
67.2,
16.6,
29.9,
54.2,
60.4,
28.9,
61.7,
54.2,
25,
90.6,
72,
4.6,
73.1,
95,
66,
50.7,
35,
52,
43.9,
59.4,
59,
32.1,
54.2,
50.3,
34.2,
72.4,
2.2,
79.2,
24.4,
40.8,
44.6,
56.5,
59.8,
63.9,
43.3,
48.2,
34.5,
30.1,
52.9,
30.3,
93.4,
13.3,
81.6,
70.7,
90.8,
74,
9.4,
56,
68.9,
61.1,
49.8,
36.7,
64.6,
38.6,
73,
18.6,
39.7,
21.8,
49.8,
96.6,
80,
79.5,
87.6,
51.4,
95.8,
55.9,
82.2,
16.1,
65.6,
73,
37,
86.7,
88.9,
15.7,
69.6,
55.1,
38.9,
0,
16.9,
66.3,
81.9,
55.6,
49.7,
66.4,
37,
61.8,
34.5,
75.6,
26.3,
56.9,
58.7,
34.7,
45.6,
93.6,
50.8,
83.3,
38.2,
69.7,
49.8,
60.8,
54,
41.3,
28.9,
47.8,
100,
64.2,
66,
80.1,
96.1,
29.9,
23.4,
46.4,
75.4,
40.4,
22.9,
46,
42.4,
82.1,
61.1,
69.3,
94,
25.5,
20,
46,
35.3,
37.5,
26.8,
93.3,
44.5,
59.6,
29.5,
10,
63.6,
75.6,
29.8,
73.2,
3.7,
78.2,
41.6,
97,
72.1,
82.7,
82.3,
53.4,
26.2,
53.7,
55.7,
94.6,
69.6,
73.7,
72,
22.6,
43.3,
60.4,
86.3,
70.6,
29.6,
69.7,
71.9,
70.6,
60,
54.3,
57,
48.6,
26.9,
49.8,
71.4,
32.2,
15.6,
58.2,
99.8,
36.9,
68.4,
73.3,
59.4,
74,
82.3,
41,
41.2,
22,
57,
43.7,
63.5,
14.1,
70.2,
41.7,
50.4,
77.7,
53.2,
55.5,
48.7,
61.3,
78,
53.4,
45.6,
47.3,
5.1,
50.8,
61,
46.9,
43.7,
43.9,
35.8,
61.8,
71.2,
68.1,
40.1,
19.3,
48.6,
82.5,
91.2,
75.2,
51,
42.8,
23.4,
79.1,
45.8,
81.2,
38.3,
93,
78.2,
41.8,
64.4,
65.3,
21.7,
11.2,
26.2,
60.7,
8.8,
89.2,
38.6,
95.2,
47.9,
73.4,
30.6,
23,
68.6,
9.5,
83.6,
90.8,
76.3,
83.3,
66.5,
73.8,
92.7,
90.1,
69.1,
91.7,
83.3,
81.8,
58.8,
88.4,
47,
40,
4.5,
73.3,
58.8,
47.6,
52.9,
54.1,
59.3,
42.9,
50.7,
91.3,
97,
42.1,
29.5,
69.3,
53.5,
85,
38,
45.7,
47,
15.8,
59,
36,
20,
100.1,
54.3,
36.7,
10.3,
40.5,
37.1,
47.3,
86.4,
51.6,
74.5,
75.5,
55.7,
79.7,
57.7,
40.3,
44.6,
24.9,
39.4,
29.5,
71.7,
76.8,
76.7,
1,
82.5,
30.3,
9.4,
61.4,
73.6,
35,
73.5,
1.6,
29,
54.8,
8,
47,
63.1,
54.6,
26.6,
33.7,
53.9,
27.1,
86.2,
39,
76.1,
57.1,
66.6,
53.7,
34.1,
0,
46.2,
51.2,
49,
31.6,
84.3,
42.3,
21.2,
27.6,
83.8,
34.1,
22.4,
35.3,
34.4,
63,
76.6,
87.3,
16.1,
57.4,
49.4,
41,
61.3,
75.6,
40.4,
72.6,
70.5,
26.4,
83,
85.6,
76.7,
77.6,
78.5,
86.5,
64,
68,
87.6,
29.9,
38.9,
40.5,
75.3,
27.1,
88.5,
40.6,
80.7,
58.3,
48.7,
31.4,
92.4,
54.7,
45,
72.5,
62.6,
86.2,
95.5,
48.3,
29.7,
61.9,
61.9,
72.7,
28.9,
24.1,
64.3,
98.2,
13.8,
60.2,
47.7,
3.7,
32.6,
3.4,
68.4,
73.1,
61.5,
48.7,
52.4,
60.1,
29.8,
70.2,
64.3,
84.7,
41.8,
72,
63.6,
78,
23.2,
75.1,
24.7,
52.3,
87,
45.6,
30.5,
78,
22,
21,
58.9,
56.8,
95.7,
50.8,
53.6,
53,
98.6,
5.7,
37.8,
77.9,
56.7,
72,
23.4,
70,
72.3,
86.5,
45.9,
56.1,
84.9,
47.6,
20.7,
34.5,
52.8,
76,
5.4,
77.1,
5.6,
76.7,
41.5,
62.4,
86.6,
101,
81.9,
91.4,
74.4,
73.9,
66.7,
88.1,
68.8,
95.3,
23,
68.3,
51.4,
52.6,
49,
40.6,
43.4,
6.2,
41.7,
80.9,
58.4,
49.6,
5.3,
90.1,
0,
67.2,
99.3,
38.4,
2.2,
35.4,
94.1,
33.7,
64.7,
48.4,
62.7,
64.2,
87.4,
44.9,
99,
96.3,
67,
75.3,
51,
41.3,
94.5,
31.7,
67.3,
69.4,
83.1,
82.9,
60.7,
13.7,
54.4,
39.1,
46.4,
53.6,
84.5,
44.3,
25.4,
77.6,
67.2,
102.9,
27.1,
63.9,
39.7,
74.2,
86.2,
54,
51.6,
69.3,
70.5,
58.7,
77.8,
82.9,
39.1,
44.4,
57,
60,
66,
72.4,
36.2,
27.6,
15.6,
44.8,
69.4,
35.8,
46.8,
100.3,
7.5,
84.3,
64.4,
57.1,
76.9,
65,
73.2,
80.6,
83.3,
100,
34.9,
57.7,
61.7,
36.7,
58.9,
74.1,
61.3,
58.6,
76.5,
63.8,
49.3,
77.5,
59.8,
94,
47.5,
15.5,
37,
20.2,
22.8,
58,
45.9,
62,
39.5,
60.2,
53.5,
14.7,
38,
59.7,
58.7,
68.1,
49.6,
42.5,
53.6,
31.3,
92,
28.3,
72.4,
39.3,
71.7,
7.1,
76.1,
93.7,
38,
42.7,
96,
32.7,
58.3,
91.8,
53,
72.1,
86.4,
16.8,
20.7,
72.8,
44.1,
46.2,
65.8,
12.6,
51.6,
18,
68.2,
67.3,
45.9,
82.4,
84.4,
65.5,
81.4,
46.1,
53.4,
28.2,
87.3,
33.5,
76.8,
81.2,
65,
58.5,
81.6,
41.7,
14.3,
65.4,
17,
89.7,
65.1,
66.4,
79.5,
42.8,
32.8,
56.9,
63.3,
82.3,
50.9,
8.3,
37.2,
72,
16.3,
85.9,
47.2,
90.3,
26.4,
7.7,
49,
13.2,
78,
88.1,
18.9,
76.1,
13.7,
0.6,
84.2,
29.9,
23.9,
30.3,
43.4,
42.3,
66.8,
84.4,
93.8,
67.5,
72.5,
67.3,
64.6,
83.5,
67.1,
71,
63.1,
48.1,
71,
34.1,
51.8,
54.4,
38.2,
77.6,
95,
47.1,
59.5,
9.7,
53.5,
29.7,
56.8,
76.2,
37.7,
49.8,
33.7,
31.3,
57.9,
72,
61.6,
51.6,
94.7,
3.5,
67.2,
84.6,
42.3,
59.3,
3.5,
35.9,
94.6,
42.8,
58,
74,
21.4,
83.7,
34.6,
81.5,
80.5,
97.8,
38.2,
61.5,
62.6,
61.9,
12.1,
33.6,
49.1,
51.4,
52.8,
57.3,
81,
83.6,
41.2,
57.4,
3.2,
49.9,
65.5,
69.3,
57.4,
50.1,
31.3,
73,
63.8,
19.5,
64.1,
83.6,
66,
92.4,
43.4,
70.3,
65.8,
20.2,
51.5,
54.2,
37.3,
73.7,
39.2,
38.8,
39.1,
10.3,
45.7,
0,
71,
76.2,
60,
70.6,
96.4,
8.7,
54,
62.1,
94.8,
67.9,
48.2,
64,
71.8,
77.6,
49,
57.1,
41.7,
61.2,
94.8,
53.8,
49.1,
27.1,
43.5,
29.7,
66.5,
54.5,
38.3,
45,
59.8,
5.5,
12,
50.2,
57.1,
39.3,
59.7,
56.6,
30,
27.9,
57.1,
39.3,
82.2,
40.3,
68,
69.3,
47.3,
90.6,
56.7,
31.3,
36.5,
28.8,
27.6,
58.6,
91.6,
50,
51.7,
76.3,
74.9,
39.8,
83.5,
13,
53.4,
18.9,
59.8,
50.7,
33.1,
76.5,
55,
70.2,
67.9,
97.6,
40.2,
51.7,
42.2,
31.1,
94.1,
40.5,
55.7,
65,
25.1,
85.6,
63,
7.7,
50.7,
86.3,
70,
25.5,
10,
92.7,
73.4,
34.9,
55.5,
39.7,
56.5,
59.6,
89.7,
68.5,
37.2,
73,
82.1,
71.6,
57.3,
92.2,
23.3,
53.4,
87.2,
38,
64.7,
64.2,
86.5,
8.8,
75.7,
35.8,
38.7,
60.2,
37.6,
41.2,
55.3,
65.7,
59,
82.9,
79.4,
59.5,
98.6,
20.7,
56.4,
59.9,
90.9,
71.2,
80.2,
83.6,
20,
65.7,
9.8,
48.2,
44.7,
81.4,
29.9,
42.8,
21.8,
91.2,
32.6,
29.5,
76.6,
40.3,
95.1,
49.2,
35.3,
29.4,
34.7,
11.4,
54.1,
30.7,
91.4,
16.9,
33,
95.6,
47.5,
78.5,
47.3,
16.9,
38.3,
73.8,
87.2,
39.9,
34.2,
52.3,
36.8,
45.2,
47.7,
83.5,
29.8,
66.9,
50,
82.5,
95.1,
56.4,
48,
63.9,
49.7,
64.6,
47.2,
42.7,
94.1,
79,
29.9,
69.4,
61.9,
53.9,
54.1,
37,
32.5,
73.1,
11.7,
63.6,
88.8,
28.4,
73,
54.2,
40,
93.8,
95,
40.5,
28.1,
61,
44.8,
21.4,
24.5,
24.8,
62,
58.2,
64,
54.3,
73,
75.6,
23.8,
58.2,
87.9,
78.9,
41,
91.3,
83.8,
40.8,
33.4,
49.9,
12.3,
57.2,
69.3,
39.4,
43.5,
46.1,
53.3,
29.1,
82,
42.1,
4.1,
47.6,
38.8,
41.2,
33.1,
69,
87.9,
30.8,
31.9,
70.6,
60.2,
48.6,
88.2,
55.7,
55,
46.8,
66.9,
64,
36.9,
5.2,
38.7,
60.5,
61.4,
51.4,
40,
46.2,
84.1,
31,
81.2,
99.7,
70.7,
41.2,
59.9,
59,
74.9,
37.5,
47.2,
13.2,
30.8,
8.6,
46.4,
56.7,
74.7,
50.2,
77.8,
64.6,
35.2,
31.5,
49,
22.1,
82.2,
58.1,
44,
46.8,
40.6,
44.1,
83.7,
59.7,
59.9,
28.3,
48.2,
73.5,
24.3,
53.2,
40,
27.8,
71.6,
66.3,
60.6,
63.9,
67.7,
26,
13.3,
64,
35.2,
30.4,
95.4,
0,
10.8,
80.8,
49.3,
53.5,
40.8,
102.9,
65.5,
87.5,
33.7,
88.5,
54.7,
20.3,
68.6,
76.8,
0.4,
86.7,
69.9,
40.2,
97.5,
105.3,
92.7,
91.1,
33.3,
40.6,
69.8,
37,
97.4,
49,
47.1,
90.9,
43,
24.3,
11.7,
96.2,
54.4,
89,
85.2,
65.2,
57.8,
43.8,
56.7,
43.6,
51.2,
4.2,
58.8,
61.4,
88,
77.5,
56.9,
84.2,
44.2,
69.1,
55.2,
80.4,
14.4,
68.7,
53.3,
24.3,
36.6,
61.5,
76.5,
61.4,
28.3,
80.9,
47,
43.8,
45,
46,
37,
82.1,
36.7,
27.3,
15.1,
52,
34.2,
56.5,
79.7,
38.6,
57.3,
61.1,
38.2,
48.9,
62.1,
77.1,
55.4,
55.7,
56.6,
87.3,
96.8,
32.7,
81.5,
40.6,
85.9,
77.6,
48.5,
48.1,
71,
64.4,
53.8,
17,
51,
76.9,
69.1,
49.4,
47.3,
79.2,
22.8,
56.9,
50.4,
77.5,
30.2,
9.2,
71.4,
92.5,
14.3,
71.6,
87.3,
48.5,
31,
75.7,
36.5,
75.2,
96.1,
0.6,
100,
52.4,
65.1,
71,
59.7,
61.9,
64.7,
51.5,
64.3,
57.9,
70.4,
92.1,
58.8,
16.4,
65.3,
35.7,
92.8,
54.3,
20.1,
69,
54.1,
51.3,
72.8,
12.7,
80.8,
70,
71.6,
40,
74.7,
43.3,
84,
81,
60.6,
2.4,
45.7,
101.9,
15.1,
26.5,
31.2,
95.3,
38.8,
45.2,
66.3,
27.3,
93.9,
33.9,
50.5,
5.4,
63,
6.7,
68,
88.2,
64.3,
95.6,
42.9,
85.3,
75.5,
74,
51.6,
88.5,
57.7,
77.6,
41.9,
22.6,
12,
22.1,
27.7,
64,
57.2,
63.3,
68.2,
18.7,
58.1,
65.1,
66,
34.7,
62.1,
24.7,
86.5,
62.6,
49,
28.8,
50.4,
41.4,
58.5,
29,
64.8,
9.1,
38.7,
48.6,
64.5,
37.8,
30.5,
80,
88.4,
76.4,
20.3,
60.5,
64.1,
70.7,
41.4,
92.5,
41.2,
18.2,
25.5,
101.8,
43.5,
57.9,
17.6,
82.8,
91,
69.9,
69.9,
57.9,
46,
70.6,
93.9,
32,
0,
74.8,
28.1,
37.4,
56.1,
29.8,
80.6,
58.7,
22.3,
46.8,
58.1,
42.8,
45.4,
93.9,
25.3,
99.7,
48.5,
31.7,
47.2,
79.8,
36.1,
29.4,
58,
58.6,
79.7,
51.1,
44.5,
92.5,
68.2,
56.6,
25.9,
93.3,
63.5,
0.3,
79.9,
78.3,
89.4,
97.5,
0,
73.4,
37.9,
92.2,
59.4,
61.5,
42.2,
85.4,
20,
52.8,
43.5,
49.9,
92.9,
91.9,
69.4,
1.2,
80.3,
76.2,
47.4,
84.5,
39.5,
64.6,
51.2,
86.6,
46.1,
55.9,
41.5,
27,
33.9,
22.2,
37.6,
58.1,
59.3,
63.5,
37.8,
95.7,
74.7,
50.7,
72.3,
79,
39.2,
83.8,
51.5,
61.6,
40,
80.6,
75.6,
77.1,
70.5,
78,
98.2,
0.3,
69.6,
15.6,
78.3,
30.6,
92.4,
28.4,
12.3,
29.5,
98.5,
59,
64.5,
15.1,
53,
31.7,
65.7,
72.8,
28.4,
96.7,
75.3,
27.6,
63.1,
40.9,
43.6,
9.1,
16,
96.5,
43.8,
52.3,
70.3,
61.5,
38.1,
23.1,
30.7,
58,
65.6,
40,
50.7,
62.8,
31.9,
70.4,
47.5,
85.4,
44.8,
59.1,
53.5,
63.6,
61.3,
28.6,
29.8,
73.6,
84.4,
22.3,
71.9,
58,
47.4,
6.5,
20.8,
35,
46,
72.8,
43.3,
30.5,
61.6,
4.1,
44.6,
76.3,
86.5,
71.3,
76.2,
27.6,
47.7,
97.8,
67.3,
35.5,
20.6,
76.2,
46.1,
81.4,
46,
64.3,
70.4,
60.5,
28.5,
52.3,
43.8,
67.6,
26.4,
57.4,
67.8,
61.9,
52.7,
73.4,
72.3,
90.2,
74.2,
66.8,
48.8,
41.1,
7,
32.9,
41.1,
67.3,
47.6,
15.7,
42.7,
73.6,
16.8,
37.8,
39,
86,
63.6,
66.4,
82,
29.3,
44.2,
67.1,
52.8,
32.1,
60.4,
48.9,
4.7,
64.7,
55.6,
51.3,
16.7,
95.5,
68,
48.8,
26.2,
75.4,
91.2,
64.1,
89.2,
45.9,
12.6,
77.2,
42.7,
66,
60.4,
89,
86.1,
54.8,
78.7,
42.5,
65.4,
83.3,
55.7,
70.9,
49.3,
27.4,
38.7,
68.5,
55.1,
79.5,
30.3,
39.7,
50,
38,
54.8,
39.3,
76.1,
68.7,
31.4,
60.5,
40,
60.2,
40.9,
38.8,
70.7,
49,
71.7,
73.8,
96.9,
52.2,
37.4,
71.4,
66.9,
52.1,
85.8,
87,
66.7,
88.7,
56.1,
80.3,
97.7,
23.8,
72.3,
63,
10.4,
80.5,
63.8,
70.7,
12.9,
59.6,
61.4,
87,
47.8,
23.6,
63.9,
43,
68,
70.4,
76,
80.6,
61,
76.7,
70.7,
39.8,
42.3,
32.9,
24.4,
79.9,
88.6,
0.6,
13.4,
8.2,
93.7,
25.7,
71.5,
87.2,
40.3,
30.6,
81.5,
43,
78,
55.1,
65,
29.4,
38.9,
53.9,
42.4,
57.5,
38.1,
32.2,
74.7,
81.9,
58.7,
13.3,
61.5,
60.3,
91.3,
1.4,
54.3,
42,
47.8,
18.9,
83.1,
78.7,
13.5,
97.8,
23.8,
22.1,
61.6,
73,
77,
39.8,
31.5,
98.1,
84.5,
53,
59.1,
45.4,
29.5,
86.4,
18.2,
29.7,
55,
67.6,
84.2,
53.8,
43.6,
66.1,
52.4,
61.1,
83.1,
43.4,
37,
49.9,
20.1,
37.2,
37.1,
81.5,
29.9,
84,
72.6,
43,
73.1,
59.2,
26,
58,
53.6,
79.3,
68.9,
34.6,
84.8,
49.8,
30,
92.7,
81.9,
65.6,
44.9,
80.1,
87.7,
61.2,
72.2,
83.7,
15.1,
37,
52.9,
93.4,
31.1,
58.4,
98,
62.7,
49.3,
95.4,
19.9,
69.4,
76.6,
91.8,
70.8,
29.5,
81.9,
49.8,
53.5,
48.9,
13.3,
64.3,
40.8,
87.3,
56.3,
45.8,
53.7,
91,
68.1,
66.6,
58.7,
54.7,
15.3,
11.2,
22.3,
57.4,
52,
83.6,
98.8,
25.1,
43.7,
90.3,
92.5,
69.7,
91.6,
36.7,
60.5,
34.5,
77.8,
48.7,
61.2,
79,
70.1,
14.2,
48.2,
45.7,
68.8,
77.6,
51.4,
83.1,
20.2,
72.3,
78.5,
25.1,
91.2,
73.3,
41.1,
60.7,
92.6,
2.6,
64.7,
55.4,
94.9,
4.6,
22.8,
8.9,
47,
79.3,
16.3,
55,
57.9,
33.9,
95.5,
79,
91.3,
48.9,
54.2,
74.6,
78.3,
31.8,
85.5,
66.9,
83.9,
38.7,
28,
41.7,
76,
66.5,
86.1,
38.4,
58.8,
44.2,
80.8,
68.8,
58.8,
61.4,
50.1,
83.1,
0,
73.1,
71.5,
51.3,
76.4,
46.1,
64.6,
55.8,
48.9,
70,
18.9,
36.3,
21.2,
57.3,
63.2,
77.1,
73.6,
85.4,
82.5,
60.7,
98.3,
36.8,
93.6,
57.7,
14.3,
31.4,
47.3,
79.8,
28.8,
77.8,
79.5,
72.9,
20.7,
30,
59.4,
63.7,
58.4,
80.5,
49.7,
34.9,
57.5,
39.7,
55.1,
63.6,
25.8,
59.3,
66.7,
15.3,
38.8,
0,
63.7,
76.5,
13.5,
71.9,
36.4,
32.9,
76,
33.2,
48.4,
73.6,
50,
93.5,
79.9,
86.2,
40.4,
49.9,
81.2,
71.9,
62.8,
51.1,
95.7,
58.4,
41.7,
81.1,
79.5,
60.3,
43,
41.1,
45.4,
65.8,
77.3,
64.2,
54.8,
57,
42.2,
25.9,
10.7,
51.1,
42,
65.6,
89.3,
87.1,
null,
34.1,
67.1,
73.2,
41.1,
31.1,
1,
51.4,
75.4,
43.8,
64.1,
90.3,
54.7,
28,
26.2,
34.8,
30.3,
54,
26.5,
90.5,
50.3,
46.7,
5,
70.9,
93.6,
95.4,
43.1,
71.9,
32.2,
26.1,
80.4,
43.3,
61.5,
16.7,
66.2,
75.6,
96.7,
36.7,
61.2,
54.1,
32,
9.2,
70.3,
60.6,
43.7,
67.8,
60.3,
76.5,
75.6,
57.8,
84.2,
53.3,
92.2,
19.3,
71.5,
75.7,
37.6,
78.4,
11.3,
39.1,
43.3,
82.3,
60,
55.4,
71.3,
56.9,
19.9,
7,
62.5,
20.2,
64.4,
63.8,
16.2,
0,
36,
57.9,
21.6,
51,
83,
62,
70.9,
50.6,
34.9,
60,
96.9,
43.5,
36.2,
13.3,
21,
84,
39.6,
15.2,
11.4,
6.1,
78,
42.9,
56.8,
31.1,
80,
17.9,
41.7,
35.6,
53.1,
63.8,
16.2,
53.5,
76.2,
14.2,
91.4,
64.3,
31.8,
43.7,
43.4,
21.8,
40.9,
53.4,
79.2,
46.1,
29.2,
79.4,
80.7,
62.3,
59.9,
80.8,
6.3,
34.2,
0,
0,
53.5,
47.3,
68.6,
73,
52.1,
42.7,
39,
38.5,
52.4,
17.2,
87.5,
15.7,
74.5,
66.6,
62.6,
58.2,
21.4,
57.4,
60.4,
42.7,
26.2,
66.9,
94.1,
74.6,
81.6,
65.1,
85.6,
61.7,
72.2,
66.5,
76.1,
19.1,
64.2,
70.2,
26,
27.5,
73.4,
20.2,
25.7,
5.7,
96.8,
80.1,
5.1,
49.6,
54.1,
32,
58,
23.1,
59.1,
84.6,
58,
21.7,
56.1,
94.8,
54.9,
75,
37.8,
37,
36.7,
21,
62.8,
42.2,
95.1,
39,
62.4,
47.4,
36,
61.9,
87.9,
18.6,
66,
27.8,
21.5,
72.3,
31.8,
87.7,
55.8,
39.1,
50.1,
83.2,
44.1,
85.3,
11.3,
68,
68.8,
69.5,
65.9,
79.9,
42.9,
87.4,
94.8,
45.2,
45.1,
64.4,
62.5,
58.6,
42.6,
12.9,
89.4,
75.9,
80.5,
89,
1.5,
31.2,
42.2,
55,
7.1,
56.1,
36.1,
64,
62,
80.6,
33.3,
46.5,
47.8,
70.5,
59.6,
15.7,
79.5,
46,
20.8,
27.8,
50.9,
49.6,
62.4,
56,
86.1,
44.2,
13.3,
42.8,
61.6,
43.1,
79.7,
4.3,
6.1,
68.1,
70.2,
7.6,
22.1,
46.5,
89.2,
46,
64.3,
65.6,
61,
54.9,
83.6,
49.7,
51.3,
37,
68.1,
27.7,
44.7,
16.1,
43.1,
90.4,
77.4,
81.8,
9.4,
83.6,
37.5,
29.2,
50.4,
17.4,
80.8,
55.4,
70,
0,
56.1,
75.5,
34.6,
5.6,
84.4,
36,
46.5,
64.8,
52.6,
67.5,
26,
49.3,
42.8,
21.3,
51.1,
84.1,
35.6,
50.6,
55.6,
88.2,
57.7,
57.5,
56.4,
32.7,
23.6,
73.5,
89.1,
95,
47.4,
36.4,
50.5,
84.7,
79,
57.2,
46.5,
77.4,
12.8,
75.4,
64.2,
32.9,
85.6,
21.2,
58.4,
55.1,
43.3,
32.3,
59.5,
81.3,
32,
70,
91.6,
61,
49.5,
51.2,
36,
58.6,
94.1,
52.9,
43.4,
0,
27.3,
40.3,
87.9,
35.3,
64.5,
50.9,
21.6,
85.9,
9.8,
77.8,
90.5,
39.5,
97,
47.5,
39.7,
46.5,
28.7,
19.8,
62,
94.6,
74.1,
51.1,
57.4,
85.3,
73.3,
25.1,
64.8,
54.3,
48,
86.1,
73.5,
87.9,
62.8,
98.7,
94.8,
60.8,
56,
76,
80.1,
58.5,
33.2,
51.4,
10.7,
21.1,
78.2,
66.3,
23,
64.4,
57,
53.3,
53.7,
48.7,
30,
42.8,
8.8,
89.2,
53.3,
48.9,
78.1,
54.3,
36.9,
47.9,
51.3,
100.4,
72.8,
56.9,
25.7,
63.5,
76,
59,
51.6,
78.9,
58.2,
57.3,
28.6,
76,
62.3,
89.5,
85.1,
57.6,
33.9,
77.1,
97,
41.8,
56.6,
65.7,
33.4,
78.6,
48,
59,
34.8,
39.3,
62.5,
86.2,
41.9,
16,
26.4,
26.1,
24.1,
50.5,
42.4,
18.2,
73.1,
62.6,
80.8,
86.9,
42.9,
16.2,
67.9,
8.1,
50.4,
54.3,
49.8,
43.1,
68.6,
53.6,
73,
88.3,
0,
7.3,
73.4,
2.1,
41.5,
48,
8.7,
42.5,
64.2,
94.8,
85.4,
83.9,
38.5,
50,
33.9,
81.1,
84.3,
62.9,
39.1,
49.8,
98.1,
86.7,
47.4,
63.5,
34.8,
95.4,
37.1,
90,
78.9,
64.6,
63.5,
71.5,
69.8,
53.5,
88.5,
71.8,
43.3,
68.4,
49.9,
95.6,
43.2,
67.9,
19.3,
8.4,
24.8,
77.3,
81.3,
98.5,
54.9,
47.8,
54.9,
44.3,
96.6,
26.4,
48.1,
36.4,
41.5,
39,
67.2,
63.8,
64,
59.4,
23.3,
83.2,
64.5,
49.5,
51.6,
80.1,
35.7,
93,
92.8,
60.7,
42.8,
57.6,
14.7,
62.9,
67.9,
52.2,
53.2,
35.5,
62.7,
10.4,
22.5,
19.5,
44.6,
29.6,
23.4,
84.2,
45.4,
46.6,
29.8,
62.7,
99.2,
46.7,
54.4,
17.8,
73.1,
56.6,
50.4,
89.6,
32.9,
49.8,
24.3,
49.1,
69.7,
69.5,
33.4,
49.3,
90.5,
40.9,
71.3,
72.3,
30,
55.2,
50.7,
55,
54.5,
48.1,
45.8,
43.3,
53,
47.2,
80,
70.3,
37,
38.2,
41.2,
75.6,
76.7,
79.3,
94.3,
56.9,
28.8,
85.7,
66.7,
29.6,
23.1,
74.4,
43.2,
5.3,
30.8,
19.5,
58.6,
67.1,
91.2,
56.2,
74.5,
75.6,
23.2,
45.2,
60.7,
91.6,
65.9,
88.6,
56.1,
46,
100.1,
53.5,
49.1,
75.1,
6,
20.2,
0,
101.5,
50.3,
84.1,
45.9,
39.4,
55.1,
44.8,
81.6,
91.1,
61.8,
64.1,
69.2,
62.9,
6.3,
87,
82.4,
79.1,
94.7,
83.1,
11.8,
49.6,
44.9,
87.1,
67.9,
84.6,
59.2,
42,
28.2,
69.6,
38.4,
76.1,
28.7,
94.1,
23.7,
95,
55.1,
37.5,
86.6,
43.5,
71.5,
32.1,
93.7,
26.9,
41.2,
66.1,
18.2,
54.5,
12.2,
91.2,
54.7,
15.6,
21,
27.1,
45.6,
24.1,
54.9,
33.8,
0,
48.6,
38.3,
75.4,
40.6,
46.9,
36.3,
35.2,
73.5,
49.1,
26.3,
62,
64.6,
94.2,
49,
87,
32.1,
56.1,
77.3,
42.3,
20.4,
17,
87.9,
62.6,
57.7,
26.4,
37,
27.6,
54.9,
1.1,
55.4,
95.3,
21.8,
39.1,
69.7,
52.1,
94.2,
76.3,
15.2,
49.7,
87.7,
24,
38.2,
50.9,
47.5,
68.9,
87.2,
44.4,
78.3,
87.2,
91.6,
27.7,
97.1,
40.9,
71.1,
51.7,
87.3,
82.6,
67.6,
67.6,
51.7,
72.7,
42.1,
54,
12.3,
76.3,
72.3,
88.3,
32.4,
48.6,
0.8,
56.1,
81.2,
60.4,
64.4,
67.5,
32.7,
38.2,
79.2,
42.1,
79.4,
69.3,
66.6,
76.9,
1.5,
97.4,
78,
78.3,
81.3,
54.3,
60.9,
42.2,
48.7,
54.9,
19.9,
63.9,
76.5,
84,
92,
53.9,
68.9,
20.2,
81.8,
93.6,
11.2,
91,
86.2,
41.4,
63.9,
35.6,
87.7,
46.1,
64.5,
84.2,
2.1,
66.8,
33.7,
58.3,
76.7,
67.7,
84.4,
15.4,
74.3,
81.7,
24.3,
59.3,
82.3,
13.4,
81,
82.8,
18.2,
0,
41.5,
39.1,
27.5,
60,
56.9,
63.8,
78.2,
55.3,
84.6,
42.7,
98.9,
61.2,
38.8,
73.3,
23.9,
46.1,
58.3,
38.7,
73.6,
18.4,
86.8,
65.3,
92.8,
1.4,
89.6,
79.7,
31.6,
55.1,
59.1,
86.8,
33,
70.3,
88.2,
34.5,
6,
33,
39.7,
69.6,
56.3,
17,
82.1,
93.2,
56.5,
33.4,
31.1,
45.2,
69.6,
47.8,
66.4,
35.2,
64.4,
88.7,
76.9,
5.5,
64.4,
73.8,
76.4,
69.7,
49.2,
72.1,
38.1,
63,
83.1,
31.2,
20.1,
80.8,
44,
52,
15.7,
78.9,
37.7,
95.1,
23.9,
54.4,
33.4,
54.5,
52.2,
69.1,
83,
61.1,
11,
38.3,
67.8,
43.3,
38.2,
78.4,
27.3,
58.7,
5.9,
70.8,
38.7,
78.7,
94.5,
47.2,
44.8,
72.4,
68,
45.4,
40.7,
26.1,
85.2,
26.4,
70.9,
20.6,
86.7,
99.3,
72.3,
76.9,
3.6,
42,
30.4,
96,
62.6,
80.4,
74.7,
79.9,
57.2,
38.3,
64.1,
42,
46.1,
57.9,
46.7,
77.3,
82.1,
70.8,
79.6,
52.7,
15.4,
37.2,
71,
88.2,
34,
13.5,
44,
24.4,
73.8,
19.4,
10.1,
48.9,
59.9,
91.8,
55,
40.6,
61.1,
46.6,
56.1,
46.2,
31.1,
54,
44.2,
52.7,
45,
50.8,
45.2,
31.3,
82.9,
98,
91.3,
87.9,
69.5,
83.3,
30.8,
74,
60.8,
72.8,
13.6,
43.6,
95.7,
89.2,
48.1,
84.3,
13.9,
57.4,
81.2,
83.7,
81,
75.4,
56.2,
80.3,
88,
22.1,
53.3,
33.4,
88.5,
87.7,
28,
76.4,
68.5,
32.5,
31.5,
74.3,
21,
41.1,
58.7,
34.3,
84.4,
67.1,
75.5,
65.1,
45.5,
72.1,
49.8,
11.7,
69.3,
80.5,
79.7,
34.1,
71.4,
82.4,
46.6,
65.6,
83.4,
49.4,
42,
43.2,
24.8,
67.3,
59.9,
47.7,
88.8,
8.4,
39.5,
78.8,
74,
50.9,
91.8,
37.6,
82.6,
73.9,
71.2,
34.2,
51.1,
95.1,
68,
54.7,
72.1,
24.3,
39.1,
41.3,
93.6,
91.8,
48.1,
92,
87,
14.4,
66.2,
56.4,
57.6,
63.4,
44.9,
77.9,
60.9,
42.8,
21.4,
45.2,
73.1,
21,
80.8,
72.3,
56.6,
78.4,
18.2,
37.4,
14.2,
53.4,
63.2,
94.3,
36,
61.3,
55,
53.4,
47,
38.2,
50,
48.7,
42.4,
36.4,
87.4,
70.7,
79.8,
22.2,
36.9,
58.1,
30.2,
58.6,
63.4,
78.7,
70,
54.7,
45.3,
86.2,
35.8,
64.6,
22.9,
36.3,
37.1,
89.7,
71.2,
95.7,
28.7,
76.8,
71.3,
25,
76.5,
84.1,
55.3,
41.2,
19.9,
41.2,
81.6,
12.9,
15.9,
14.6,
81.5,
62.4,
23.9,
62.8,
65.7,
65,
40.5,
81.8,
91.2,
66.6,
35,
90.2,
27.2,
49.4,
27,
98.6,
58.4,
21.9,
90.8,
37.1,
48.3,
51.1,
65,
31.1,
57.9,
28,
37.1,
65.2,
87.2,
55.4,
52,
65.8,
35.8,
57.5,
59.5,
55.4,
72,
60.4,
75.5,
39.7,
65.9,
64.3,
74,
67,
72.3,
81.8,
64.8,
26.7,
75.1,
75.6,
62.7,
50.9,
87.6,
56.9,
38.2,
53.6,
21.1,
98.6,
88,
31.8,
66,
5,
41,
53,
12.2,
93,
27.8,
41.5,
21.9,
37.6,
59,
72,
41.4,
70.1,
69.7,
76.7,
45.3,
24.4,
4.5,
8.8,
48.9,
32.3,
67.9,
85.3,
76.6,
89.9,
76,
38,
38.2,
89.1,
50.1,
57.5,
42,
29.1,
79,
71.9,
86.2,
86.7,
38.5,
77.8,
68,
38.1,
20.8,
0,
59.5,
81.6,
97.4,
28,
37.8,
96.7,
36.3,
48.2,
94,
76.3,
83.1,
68.4,
52.9,
87.8,
46.7,
15.9,
77.8,
34.6,
41.6,
79.1,
58.2,
68.9,
46,
46,
52.1,
84.2,
22.2,
54,
35.3,
93.3,
97.1,
0,
26.9,
63.8,
64.7,
63.3,
54.7,
39.1,
50.3,
45.6,
57.3,
69.4,
36.6,
24.4,
16.6,
78.7,
10.8,
76.8,
80.9,
16.7,
50.6,
56.8,
38.2,
64.3,
72,
61.5,
72,
52.4,
48,
59,
82.5,
52.6,
50.4,
56.1,
82.9,
35.9,
20.7,
36.4,
58.7,
81.6,
47.8,
52.2,
53.9,
0.5,
25,
101.3,
31.5,
37.4,
49.8,
50.6,
22.6,
45.1,
17,
69.2,
87.7,
39.3,
41.8,
52.8,
58.7,
88.8,
65.8,
66.2,
43.9,
71.3,
10.5,
77.7,
71.1,
17.9,
92.6,
77.9,
33,
29.8,
82.2,
66.5,
47,
21.6,
51,
49.4,
5.2,
73.4,
35.6,
85.6,
48,
16.1,
35.9,
32.9,
54,
82.1,
25.7,
2.9,
69.2,
81.6,
75.8,
33.8,
65.4,
54.5,
77.8,
49.9,
47.3,
54.5,
94.6,
49.8,
95.4,
62.2,
60.1,
61.8,
40.6,
19.8,
31.9,
86.3,
33.7,
80.9,
24.4,
70.9,
83.2,
40.3,
27.7,
92.9,
75.1,
77.6,
30.1,
65.1,
32.4,
86.1,
75.7,
32,
63.5,
13.3,
17.1,
68.6,
60.2,
60.2,
79,
89.6,
79.3,
62.3,
35.7,
58.6,
57.3,
14,
72.7,
44.4,
33.3,
68.3,
9.7,
79.7,
51.1,
20.7,
90.3,
60.2,
16.2,
64.7,
68.1,
35.1,
74.5,
65.7,
75.5,
17.9,
61.4,
68.5,
21.4,
53.7,
7.7,
76.8,
70.2,
63.6,
67.9,
68.3,
79.1,
47.3,
60.4,
68.8,
50.1,
42.8,
48.3,
70.7,
65.2,
87.8,
74.7,
92.9,
86.6,
92.9,
65,
45,
35.5,
70.5,
49,
46.7,
17.4,
50.8,
79.6,
72.3,
33.1,
46.2,
35.4,
53.5,
40.5,
46.4,
78.5,
63.1,
51.8,
94.1,
32.6,
85.6,
81.3,
73.5,
58.3,
64.4,
55.1,
62.6,
45.2,
67.5,
46.2,
84.1,
60.1,
65.4,
52.7,
76.4,
93,
67.5,
35.2,
69.1,
74.3,
18.1,
72.4,
88.9,
55.7,
71.7,
53.2,
40,
57.4,
44,
65.9,
82.9,
83.5,
79.4,
42.8,
38,
31.8,
47.7,
53.7,
72.5,
73.4,
81.7,
36.3,
9,
76.4,
51.4,
79.5,
66.6,
73.6,
102,
36.6,
28.2,
61.4,
34.3,
29.9,
52.1,
65.9,
91.3,
31,
61.1,
59.5,
25.4,
64.1,
82.4,
67.8,
63.4,
29.8,
66.1,
24.2,
10.9,
46.9,
65.5,
19.6,
39,
58.9,
32.6,
37.3,
6,
21,
89.1,
30.1,
2.2,
49.7,
63.2,
83.7,
95.7,
27.9,
61.7,
82.9,
71.6,
66.2,
24.7,
27.5,
20.4,
16,
71.9,
47.6,
20.9,
87.4,
2.5,
49.9,
97.4,
54.9,
55.1,
61.1,
47.3,
69.4,
47.7,
83.5,
33.1,
58.2,
57.1,
54,
68.4,
49,
46.7,
71.4,
29.9,
36.3,
83.2,
56.2,
90,
39.1,
41.8,
58.8,
43,
58,
27.4,
60.1,
31.3,
72.3,
50.1,
50.3,
41.7,
52.7,
48.5,
75.7,
75.9,
72,
33.2,
64.4,
85.7,
68.5,
48,
42,
77.6,
55.1,
33.8,
90.5,
33.5,
18,
50.4,
49.6,
25.5,
60.7,
71.7,
71.4,
35.8,
33,
55.8,
92.5,
36.6,
43.1,
24.3,
79.7,
64.1,
53.7,
50.8,
79.2,
70.6,
50,
37.2,
33.1,
69.9,
87.4,
31.1,
85.8,
44.1,
86,
22.3,
84.7,
59.3,
79.9,
36.2,
8.5,
64.6,
7.1,
48,
51.9,
59.1,
56,
50.3,
86.5,
67,
62.8,
95.9,
77.5,
97.3,
83,
57.4,
83.8,
93.6,
43,
83,
45.6,
73.6,
60.6,
99.7,
39.8,
65,
79.1,
78.2,
85.7,
79.4,
74,
19.4,
82.6,
88.6,
53.8,
37.7,
34.8,
85.2,
12.4,
96.9,
79.9,
63.1,
64.6,
10.7,
62.7,
49,
86.1,
70.4,
9.1,
34.4,
72.5,
48.5,
22.3,
72.6,
54.4,
73.8,
62.9,
21.9,
67.3,
81.9,
48.6,
77,
75.7,
17.7,
30.1,
36.5,
76.9,
37.8,
66.1,
81,
69.6,
63.6,
65.7,
28.8,
84.5,
96.4,
48.6,
53.2,
38.8,
2.2,
65.2,
65.2,
52.3,
51.2,
40.7,
30.8,
96,
57.2,
61.9,
27.7,
82.9,
37.2,
69.5,
91,
67.6,
31.9,
58.5,
54.2,
71.5,
34,
62,
16.2,
84.1,
78.4,
89.1,
50.1,
37.1,
56.1,
27.1,
42.8,
69.5,
61.8,
44.8,
51.7,
40.8,
76.3,
34.2,
43.1,
64.7,
62,
95,
75.7,
28.2,
50.8,
38.5,
32,
34.3,
73.4,
35.7,
46.4,
85.5,
59.3,
20.6,
65.3,
72.6,
78.5,
75.4,
4,
32,
47,
86.7,
70.1,
57.5,
30.7,
62.2,
53.3,
56.4,
53.7,
40.8,
74.5,
41,
80,
74.5,
54.2,
76.5,
40.2,
60,
55.4,
68.2,
38.7,
10.1,
70.7,
94.9,
34,
37.9,
84.3,
37.4,
42.1,
57.6,
80.1,
56.4,
56,
31.9,
45.6,
40,
31.8,
83.1,
62.9,
36.4,
33.8,
80.4,
84.4,
32.2,
86.5,
56.6,
42.5,
39,
39.5,
80,
53.8,
54.2,
47.1,
61.9,
8.2,
80.6,
58.2,
47.5,
76.7,
42.1,
63.9,
85.8,
75,
1.2,
77.6,
62.7,
62.1,
80.3,
47.1,
14.7,
70.8,
95.1,
2.6,
66.8,
77.4,
34.5,
80.2,
42.3,
61.9,
85.2,
89.1,
76.8,
44.4,
71,
59.6,
64.7,
33,
22.3,
59.6,
17.5,
85.1,
85.9,
58.3,
47,
56.5,
43.9,
77.7,
51.6,
81.1,
82.9,
54.1,
21.8,
55.4,
7.4,
56.9,
66.1,
59.8,
40.1,
15.9,
93.3,
27.5,
31.9,
39.7,
57.6,
69,
60.9,
88,
89,
59.1,
60.8,
96,
17,
33.3,
45.7,
65.5,
86.1,
76.5,
17.3,
76.7,
33.8,
66.5,
73.9,
30.9,
26.9,
84.9,
60.8,
89.1,
19.2,
28.4,
91.3,
20.4,
32.3,
59,
85.1,
25.5,
98.1,
83.7,
89.4,
9.9,
31.6,
82.1,
62.5,
25.8,
24.8,
74.3,
28.7,
93.2,
56.5,
24.1,
49.1,
54.5,
38.2,
22,
37,
53.2,
25,
54,
80.5,
49.4,
20.4,
39.3,
15.2,
49.8,
41.7,
42.3,
80.9,
35.9,
36,
5.9,
80.2,
44.9,
32.6,
93,
86,
40.2,
78.7,
49.3,
65.4,
82.5,
89.1,
48.4,
65,
64.2,
88.3,
58.3,
25.2,
48.9,
87.7,
39.2,
59.5,
40.8,
24.8,
60.6,
87.5,
61.4,
85.7,
79.6,
10,
32.3,
65.2,
1.3,
78.9,
51,
47.6,
47.8,
76,
74.8,
55.9,
57.1,
43.8,
48.9,
20.9,
39.9,
44.5,
63.4,
6.1,
38.5,
83.5,
64.6,
80.1,
68.2,
61,
89.8,
7.4,
5.4,
60.3,
62.8,
53.5,
92.4,
67.5,
53.9,
70.7,
79.8,
57.8,
56.3,
75.9,
87.5,
74.8,
58.1,
21.9,
68.9,
26.6,
69.6,
51.7,
62.6,
75.5,
58.1,
42.7,
0,
40.6,
51.4,
99.2,
16.8,
74.9,
49.1,
98.3,
45.1,
83.3,
72.5,
41.2,
89.4,
73.7,
29.3,
66.7,
20.8,
12.3,
42,
61.6,
2.5,
63.5,
25.4,
88.3,
41,
37.7,
87.9,
83.2,
77.3,
6.4,
78.7,
95.3,
69.8,
30.1,
22.1,
61.2,
28.5,
31.8,
78.9,
54.2,
43.3,
89.9,
45.7,
98.4,
64,
51.1,
62,
47.6,
59.3,
98.1,
59.5,
84.6,
71,
55.9,
52.6,
93.4,
63.6,
96.1,
49.5,
28.8,
14,
33.2,
45.2,
57.6,
29,
33,
66.2,
74.4,
14.8,
16.9,
65.7,
55.3,
93.3,
50.6,
34.7,
10.2,
38,
59.6,
76.8,
46.2,
51.1,
59.8,
64.2,
73.1,
52,
95.3,
36.4,
71.1,
65.4,
82.7,
99.4,
72.5,
62.7,
40.8,
94,
51.2,
61.4,
18.7,
64,
24.2,
57.2,
85,
85.3,
8.2,
9.5,
62.8,
75.4,
73.9,
48.1,
84.3,
52.3,
40.3,
22.5,
55.2,
88.1,
53.7,
51.7,
74,
76.3,
65.4,
3.5,
66.4,
76.3,
59.8,
73.3,
86.2,
98.7,
57.1,
41.4,
91.2,
41.5,
76.7,
44.7,
39.5,
23.3,
38.2,
46,
64.1,
42.5,
70.8,
86.3,
94.2,
68.1,
36.4,
84.1,
35.8,
62.1,
79.8,
51.6,
90.9,
75.1,
41.9,
58.5,
25.2,
39,
65.7,
40.7,
85.1,
70.2,
30.8,
35.1,
43.8,
83.9,
69.4,
60.9,
79.9,
48.4,
44.7,
50.2,
24.3,
29.5,
60.4,
57.5,
49.1,
43.5,
26.5,
49.6,
91.1,
22.1,
46.8,
57.2,
2.2,
91.5,
30.5,
40.6,
63,
23.6,
63.1,
59.6,
31.1,
83.1,
33.8,
35.2,
84.2,
53.6,
74.2,
22.6,
66.3,
79.5,
85.6,
80.9,
89.5,
48.5,
84.7,
84,
31.7,
62.3,
36,
63.9,
55.4,
57.2,
68.4,
44.1,
38,
28.8,
60.3,
16.7,
49.6,
21.5,
36,
51.7,
59.6,
6.5,
13.8,
66.8,
41.8,
37.8,
83.3,
43.3,
44.3,
47.3,
26.8,
43.3,
66,
93.7,
39.6,
35.5,
28.9,
12.4,
39.1,
26.7,
53.2,
46.1,
68.9,
31.4,
93.2,
38.9,
87.8,
53.3,
48.1,
37,
64.7,
77,
74.1,
47.2,
25.3,
18,
30.9,
61.3,
55,
61.4,
67.5,
78,
48.5,
44.3,
54.6,
47.4,
5.4,
59.1,
4.9,
77.7,
27.9,
52.6,
58.9,
7.1,
40.6,
79.4,
28,
76.6,
89.6,
52.9,
8.4,
35.5,
94.3,
82.6,
67.5,
56.2,
61.9,
70.3,
44.1,
81,
55.2,
67.4,
73.9,
37.8,
95,
26,
62,
1.3,
62,
32.5,
54.5,
63,
50.9,
80.5,
4.9,
45.9,
50.7,
69.2,
0,
55.8,
74.4,
32.9,
0,
32.4,
40.8,
64,
84,
38.2,
80.7,
79.4,
29.8,
15.3,
42.8,
73.6,
79.9,
35.2,
26.1,
39.9,
79.4,
61.9,
61.1,
66.9,
19.5,
42.7,
100,
20.8,
69.3,
32.2,
68.2,
56,
81.3,
38.6,
18.7,
28.6,
67,
42.7,
50.8,
82.2,
34.6,
60.1,
46,
24.9,
85.7,
85.4,
95.3,
62.6,
86,
81.4,
46.4,
15.2,
37.8,
89.1,
97,
76.8,
46.1,
99.6,
59.7,
16.7,
74.1,
79.4,
34.5,
78.4,
52.4,
72.9,
35.4,
28.2,
48.4,
69,
46.8,
78.2,
69.5,
85.8,
38.4,
2.7,
73,
73.7,
7.1,
54,
50.9,
34.7,
93.3,
36.6,
29.1,
29.9,
58.6,
38.2,
45.5,
55.1,
41.5,
29.7,
16.6,
64.3,
75.4,
78.8,
56.9,
59.8,
56.6,
30.2,
42.4,
42.9,
69.6,
70.9,
89.5,
88,
67.1,
82.2,
17.9,
49.9,
26.2,
66.8,
11.6,
77.1,
54,
40.8,
78.7,
62.5,
85,
52.7,
80.6,
20.3,
29.7,
81.9,
68.6,
24.7,
68.1,
8,
82.8,
76.7,
43.8,
55.1,
19.1,
61.2,
46,
70.2,
64.6,
58,
48.7,
22,
37.7,
56.4,
76.5,
77.5,
55.9,
82.7,
23.2,
104.9,
23,
61,
91,
36.3,
5.4,
68.1,
91.9,
95.9,
90.5,
39.5,
35.1,
85,
24,
57.8,
100.7,
81.8,
94,
66.3,
45.6,
92,
29.8,
96,
17.9,
89.2,
81,
17,
75.3,
54,
25.4,
38,
38.9,
113.8,
97.9,
42.5,
13.8,
54,
8.4,
97.2,
32.4,
65.3,
73.5,
77.7,
42.9,
35.7,
36.1,
45,
42.4,
48.9,
61.6,
25.6,
73.7,
47.4,
61.6,
46.8,
46.1,
23.1,
55.2,
67.5,
65.5,
40.9,
33.1,
18.9,
64.3,
79,
60.4,
70.7,
77.9,
44,
48.1,
70.8,
5.8,
68.4,
36.2,
77.4,
41.8,
41.9,
6.7,
100,
27.9,
82.7,
68.6,
84,
72.9,
47.1,
35.4,
5.1,
69.9,
12,
100.2,
96.5,
38.2,
5.3,
58,
28.5,
46.4,
89,
20.6,
67.2,
94.9,
56.8,
66.9,
69.1,
1.8,
50.4,
93.5,
71.7,
65.5,
59.9,
76.2,
73.3,
67.1,
86.9,
39.2,
49,
77.8,
20.7,
18.7,
30.2,
48.7,
62.4,
95.9,
102.6,
21.2,
62.4,
7.2,
92,
37.2,
53.6,
50.2,
82.4,
71,
47,
60.5,
44.3,
38.6,
71.7,
100.9,
3.8,
62.3,
33.1,
9.7,
71.9,
75.2,
69.9,
28.7,
74.3,
59.8,
71,
41.3,
43.6,
70.2,
22.5,
63.5,
52.3,
52.1,
60.7,
55.5,
47.7,
13.3,
85.8,
80.8,
71.1,
67.2,
70.4,
40.1,
87.8,
45.7,
39.6,
91.4,
51.3,
54.3,
82.8,
50.5,
67.5,
40,
54.8,
93,
51.5,
58.7,
51.6,
39.5,
30.5,
15.9,
87.1,
70.4,
29.7,
15.3,
66.2,
23.7,
52.2,
59.7,
63.3,
58.1,
59.8,
74.1,
57.3,
62.9,
48.4,
53.9,
70.1,
72.7,
72.9,
31.4,
27.8,
46,
7.9,
45.2,
77.4,
81.8,
89.7,
69,
61.2,
47.6,
98.7,
43.9,
31.1,
11.9,
74.1,
28.8,
46.3,
68,
46.8,
78.1,
61.5,
62.2,
45.3,
12,
27.7,
17.5,
77.7,
28.3,
28.8,
48.7,
62.8,
48.9,
44,
39,
39.3,
45.3,
83.1,
61.8,
21.5,
54.8,
29.3,
67.4,
66.7,
53.2,
28.4,
89.7,
46.9,
27,
0.2,
59.4,
95,
40.1,
54,
77,
50,
58.7,
27.6,
7.7,
64.3,
57.1,
27,
62.2,
29.4,
39.1,
36.1,
48.5,
83.2,
38.3,
null,
73.8,
46.6,
71.9,
63.9,
80,
71.5,
78.3,
0,
85.7,
100.4,
48.8,
91.9,
37.9,
18.5,
65.3,
11.6,
46.4,
30.6,
34.6,
69.8,
58.8,
66.8,
64.2,
43.3,
68.1,
66.7,
46.7,
54.6,
61.7,
85.8,
83.4,
39,
92.5,
78,
39.8,
89,
42,
87.7,
54.1,
55.1,
62,
44.5,
92.5,
68.1,
85.2,
77.1,
63.4,
93.7,
63.9,
56,
8.8,
8.6,
41,
61.1,
31.7,
71.1,
68,
50.6,
30.3,
38,
62.4,
78,
76.6,
51.4,
13.6,
87,
53.2,
76,
81.2,
43.9,
71.1,
51.3,
54.5,
61,
53.9,
65.5,
37.3,
42.7,
58.3,
61.7,
37.3,
45.9,
32,
78.8,
37.6,
77.8,
70.4,
44.6,
74.4,
75.2,
86.3,
50.2,
19.8,
65.2,
49.8,
32.3,
75,
59.2,
43.7,
95.5,
68.5,
63.8,
19.8,
91.8,
89.3,
83.9,
71,
92.5,
27.9,
32.1,
40.1,
86.6,
84.2,
57.6,
85.2,
61.3,
88.9,
53.3,
57,
65.9,
58.3,
82.4,
66.9,
32.7,
41.5,
79.3,
30.2,
87.3,
99.3,
37,
90.8,
51.5,
62.7,
52.5,
66.2,
88,
71.7,
9.9,
10.4,
40.9,
43,
53.1,
71.1,
61.5,
10,
32.8,
75,
87.2,
81.8,
50,
41.7,
97.6,
71.8,
52.8,
89.1,
53,
56.2,
56.8,
22.8,
71.6,
76.7,
54.2,
10.3,
88.2,
43.4,
88,
36.5,
80.2,
78.5,
40.6,
82.7,
34,
63.5,
55.5,
44.6,
81.9,
22.4,
47.1,
83.8,
27,
54,
64.3,
63.2,
58,
80.2,
61,
87.9,
80.9,
25.3,
55.3,
43.2,
55.2,
29.6,
56.3,
10.6,
64.3,
96.2,
90.7,
71,
72.6,
26.6,
97.2,
98.5,
69.1,
61.2,
36.1,
46.4,
67.1,
98.9,
20.6,
72.1,
100.1,
85.4,
23,
0,
38,
66.4,
47.3,
53,
29.6,
50.2,
91,
56.3,
65.2,
34.2,
17.5,
16,
85.9,
61.3,
51.2,
70.8,
96.5,
8.2,
54.9,
82.3,
83,
76.4,
78.5,
75.9,
18.9,
29.2,
87.9,
53.2,
94,
38.8,
35.1,
37,
37.7,
55.5,
62.1,
45.8,
15.5,
8.8,
79.8,
74.8,
13,
75.3,
87,
21.2,
48.8,
86.8,
85.2,
5.2,
72.8,
58.7,
43.7,
98,
36,
37.9,
86.4,
26.4,
75.4,
56.1,
65.2,
59.2,
43.3,
45.4,
71,
48.4,
36.8,
92.3,
87.9,
35.9,
0.9,
34.1,
65.6,
90,
50.9,
55.6,
50.5,
53.1,
39.9,
61.9,
79.3,
69.6,
33.6,
26.5,
64.3,
53.1,
60.5,
44.9,
79.3,
80.7,
85.3,
45.8,
1.9,
47.6,
61.8,
49,
43,
68.7,
31.9,
28.9,
51.1,
55.1,
35.2,
85.5,
90.6,
69,
51.7,
31,
71.9,
40.4,
37.3,
39.1,
69,
24.8,
90,
100.9,
25.7,
39.4,
61.6,
63.7,
46.3,
41.2,
77,
68.7,
43.2,
86.2,
17,
95.7,
29.9,
93,
42.6,
76.6,
30.3,
72.9,
48.5,
43.3,
74.7,
67.7,
68.5,
30.4,
59.6,
30.4,
68.3,
44,
63.7,
72,
47,
53.2,
73.6,
68.4,
71.8,
43.9,
25.3,
39,
30.8,
54.3,
46,
27,
55.7,
92.6,
36.9,
43.5,
28.8,
98,
93,
73.4,
50.9,
28.2,
15,
98.9,
46.7,
80.8,
101,
77,
83.7,
34.8,
87.5,
42.4,
55.7,
48.2,
38.7,
80.9,
59.1,
30.6,
73.3,
62.3,
14.1,
86.6,
88.9,
36.3,
69.6,
56.8,
27.1,
95.7,
45.1,
32.8,
53.3,
38.7,
44.9,
47.1,
55.7,
54.2,
64.7,
4.2,
56.5,
94.2,
62.2,
87,
15.4,
31.9,
50.7,
64.8,
72,
16.1,
93.7,
89.3,
26.4,
81.2,
56.4,
16.4,
45,
74.6,
46,
84.4,
75.6,
63.7,
45,
17.3,
68.8,
82.6,
57.2,
72.5,
47,
52.1,
24.8,
77.1,
26.2,
48.2,
66.9,
97.8,
23.2,
32.9,
38.3,
60.6,
6.6,
25,
43.8,
86.3,
63.7,
63.9,
24.5,
22.2,
86,
92.8,
26,
39.4,
72.8,
30.1,
39.1,
69.2,
87.8,
60.1,
57.8,
36.8,
47.8,
11.5,
38.9,
50.5,
69.4,
12.3,
26.2,
85.9,
92.3,
61.8,
26.3,
23.1,
74.9,
62.8,
56.7,
67.5,
67.1,
42.3,
51.6,
87,
82.3,
74.4,
61,
34.3,
89.3,
1.1,
112,
80.1,
5,
39,
68.6,
75.9,
87.2,
39.1,
76,
83.9,
39.1,
92,
71.4,
98.3,
62.7,
63.1,
55,
60.2,
59.9,
41,
43.1,
34.8,
35,
58.3,
64.7,
54.9,
79.8,
52.1,
36.8,
87.9,
12.3,
36,
36.1,
62.9,
101.8,
40.9,
59.3,
71.7,
75.8,
83.8,
94.5,
72,
32.3,
45.9,
35.1,
45.6,
49.4,
68.3,
79,
12.9,
57.3,
44.4,
85.1,
1.4,
54.6,
50.1,
18.7,
78,
39.8,
58.4,
56.4,
54.9,
33.3,
67.3,
26.5,
28,
91.9,
75.3,
46.6,
68.4,
55.6,
85.4,
97,
41.6,
51.2,
31.1,
36.8,
50.4,
74,
33.4,
68.2,
76.8,
55,
88.5,
25.8,
63,
22.8,
62.7,
29.8,
32.2,
43.2,
64.8,
16.3,
94.8,
32.8,
72.3,
90.3,
47.1,
35.3,
90.5,
8.7,
65.6,
90.2,
65,
76.5,
97.4,
14.8,
49.4,
56.3,
27.1,
49.7,
41.9,
8.4,
79,
83.3,
67.6,
54,
79.3,
44.4,
50.6,
70,
57.4,
41.5,
50,
69.5,
28.5,
28.1,
20.5,
83.4,
59.5,
38.4,
52.4,
65.8,
81.7,
77.7,
56.5,
80.9,
52.6,
13.6,
76.7,
57.1,
65.7,
56.6,
51.9,
94,
95.8,
82.3,
91.6,
47.1,
98.8,
72,
69.8,
64.7,
49.1,
43.2,
52.2,
63.6,
56,
9.5,
28.7,
2.8,
59.5,
97.5,
89.4,
32,
38,
49.6,
26,
20.6,
29.4,
56.9,
68.9,
43,
75.6,
38.8,
63.4,
82.2,
29.6,
18.2,
28.3,
26.2,
26.2,
26.8,
9,
56.3,
51.6,
31.4,
62.3,
68.3,
56.6,
70.9,
78.8,
36.5,
68,
82.7,
18.6,
36,
48.3,
92.1,
86.3,
13.4,
22.2,
37.5,
31,
45.4,
40,
44.9,
73.2,
5.2,
18.1,
3.7,
60.5,
70.8,
61.2,
48.2,
39.6,
56.8,
39.8,
11.6,
82.4,
19.2,
41.7,
96.1,
29.6,
82.4,
61,
31.4,
31.3,
47.8,
24,
87.1,
95.9,
35.6,
20,
55,
24.1,
60.2,
59.9,
65.6,
40.1,
90.5,
68.6,
81,
51.5,
44.6,
2.4,
38.5,
79.2,
72.4,
50.8,
9,
99,
32.3,
51,
69.2,
61,
79,
65.9,
76.1,
58,
69.1,
62.8,
39.1,
87.8,
75.2,
27.9,
51.9,
32.8,
96.6,
23,
78.7,
88.3,
22.7,
67.7,
83.5,
52.2,
68.8,
43.7,
44.6,
52,
39.9,
98,
72.2,
19.6,
59.4,
59.9,
68.1,
63.1,
48.8,
47.4,
70.4,
49.5,
66.2,
62.7,
5.2,
97,
72.5,
65.8,
88.9,
77.2,
40.4,
46.3,
40.8,
36.1,
67.7,
48.5,
86.7,
58.1,
48.1,
30.8,
64.3,
18,
45.4,
40.1,
69.3,
58.6,
41.7,
62.5,
86.1,
80.2,
59.8,
52.4,
59.2,
54.9,
48.1,
49.1,
37.6,
80.6,
52.1,
52.7,
98.8,
87.9,
70.1,
99.8,
47,
1.8,
28.8,
55.2,
37.7,
66.7,
64,
79.6,
18.9,
82.7,
40.6,
38.3,
91.3,
62.9,
94.9,
98,
48.9,
38.6,
61,
51.3,
34.2,
35.4,
49.1,
32.7,
34.9,
44.5,
39.8,
41.2,
78.6,
95.1,
60.1,
28.1,
54.8,
2.5,
35.2,
70.7,
61.4,
22.2,
56.5,
36.8,
41.6,
24.3,
69.9,
45.1,
70.2,
30.6,
91.8,
82.7,
41.2,
49.3,
96.1,
45.5,
43.4,
55.2,
91.7,
16.1,
70.9,
66.6,
9.5,
28.4,
63.6,
67.2,
50,
67,
45.4,
39.2,
58,
87.5,
54.1,
30.7,
52,
73.3,
44.7,
7.9,
91,
98.5,
34.6,
54.8,
56.3,
31.8,
0.3,
85.9,
46,
21.8,
4.4,
44.6,
94.6,
42.5,
40.9,
32.6,
22.8,
27.5,
25.8,
41.5,
89.6,
41,
16.7,
57.9,
48.2,
82.1,
43.8,
54.9,
32.8,
31.9,
7.6,
41,
19.7,
53.4,
56.5,
40.7,
63.2,
6.3,
52.7,
37.9,
90.5,
33.8,
63.8,
75.9,
58.3,
50.5,
44,
70.9,
88.2,
84.2,
81,
55.2,
92.9,
88.1,
86.3,
10,
91.6,
56.3,
81.8,
35.5,
78,
53.3,
53.6,
78.2,
61.4,
59,
54.9,
66.1,
69.9,
42.8,
65.6,
59.9,
81.4,
20.4,
72.2,
22.4,
55.9,
52,
56.8,
37,
11.8,
59.8,
76.1,
21.9,
59.8,
89.5,
88,
88.1,
46.7,
73.8,
45.6,
82.2,
82.9,
52.3,
65.3,
43.1,
59.3,
33.4,
73.4,
81.9,
30.1,
98.5,
50.8,
29.1,
18.6,
43.3,
66.7,
13.7,
25.8,
61.7,
52.2,
76.7,
47.1,
74.3,
8.8,
86.5,
66.6,
74.2,
28,
48.3,
60.4,
43.2,
44.2,
52.7,
43.3,
74.2,
34,
16.8,
99.2,
13,
73.7,
77.7,
16.8,
86.1,
68.7,
53.2,
7.2,
60.7,
53.8,
48.2,
45.3,
97.4,
64.3,
44,
85.8,
93.5,
61.3,
71.4,
56.8,
82.6,
86.1,
51.1,
76.2,
70.5,
41.9,
45.8,
68.9,
46,
44.8,
56.6,
30.5,
56.3,
59.8,
44.6,
31.2,
92.1,
79.2,
73.4,
44.2,
88.9,
82.5,
52.3,
78.5,
41.3,
77.7,
82.5,
74.6,
25.7,
47.1,
24.6,
38.8,
35.5,
40.5,
44.8,
33.14,
68.9,
37.2,
49.3,
2.5,
83,
30.6,
89.8,
34.5,
84.7,
36.9,
56.8,
83.1,
24.4,
69,
95.6,
19.2,
75.5,
3.5,
95,
84.1,
52.3,
23.3,
46.2,
85.8,
87,
48.9,
60.2,
48.9,
43.1,
63.1,
77.2,
3.6,
64.8,
69.1,
47.4,
43.7,
55.4,
78.6,
66.9,
73.2,
32.4,
56.4,
57.4,
54.5,
87.1,
79.7,
61.6,
91.7,
71.8,
31.4,
45.4,
40.7,
35.8,
85,
59.9,
75,
24.6,
77.8,
11,
40.6,
85.7,
44.8,
39.1,
68.9,
76.8,
23.2,
67,
55.6,
32.1,
11.7,
39.5,
39.2,
42.5,
50.4,
54.8,
59.7,
42.2,
90.7,
73.8,
80.7,
27.5,
41.4,
91.9,
83.4,
94.9,
62.7,
24.1,
85.2,
72.3,
0,
18.9,
59.5,
44.9,
18.5,
57.5,
87.8,
60.3,
20.1,
77,
55,
64,
60.9,
82.3,
39.5,
74.4,
81.9,
75.2,
56.8,
39.5,
45.3,
37.5,
48.9,
79.7,
83.1,
47.7,
62.9,
50.5,
88.6,
67.4,
82.2,
68.8,
48,
54.1,
69.9,
50.2,
50.7,
57.4,
81.7,
81.6,
37.9,
35.8,
93.9,
80.3,
41.7,
50.3,
59.4,
88.8,
90.7,
95.2,
23.9,
33.3,
61.2,
77.3,
80.2,
69.5,
50.5,
49.6,
33.8,
18.8,
42.8,
29.9,
96.4,
25.7,
55.7,
54.2,
36.5,
37.5,
53.1,
56.3,
70.6,
65.1,
54.1,
52.4,
39.8,
93.9,
66.7,
47.8,
78,
60,
96.9,
90.6,
19.8,
34.9,
58.3,
18.4,
42,
72.8,
37,
48.6,
73.6,
42.4,
92.6,
38.9,
65.4,
75.4,
49.6,
43.5,
38.9,
78.6,
83.7,
62.2,
48.4,
98.6,
91.6,
61.9,
86.4,
72.2,
52.4,
88.1,
66.8,
88,
31.9,
40.8,
32.5,
17.7,
62.1,
75.1,
76,
66.2,
43.6,
41.4,
40.2,
77.2,
71.4,
41.9,
79.2,
91.8,
92.7,
39,
34.4,
82.3,
46.8,
44,
37.1,
71.1,
23.9,
68,
52,
48.1,
59.4,
49.3,
83.3,
39.7,
30.4,
31.5,
48.8,
30,
58.1,
64.7,
52,
58.8,
76.1,
73.5,
73.3,
87.3,
95.3,
55,
23.6,
39.3,
105.1,
80.2,
68.5,
44.2,
60.8,
18.7,
73.9,
78.2,
48,
62.5,
56.4,
14.2,
33.3,
85.3,
9.2,
95.2,
47.4,
66.4,
56.4,
28.3,
6,
20.1,
78.4,
25.5,
69.7,
48.9,
27.3,
5.3,
73.5,
50.9,
29.9,
31.3,
38.8,
96.7,
17.4,
38.3,
45.4,
52,
52.3,
79.8,
71,
25.1,
99,
48.2,
79.3,
17.5,
43.8,
53.9,
14.9,
62.4,
22,
71.9,
18.4,
4.2,
43.4,
87.2,
45.4,
100.8,
62.3,
92.4,
39.1,
41.2,
87.7,
31.6,
70.3,
65.9,
69.6,
30,
20,
5.1,
76.4,
60.6,
38.2,
90.3,
71.4,
92.2,
59,
22.8,
21.4,
17.2,
66.1,
35.9,
8.2,
38.7,
17.5,
57.4,
66.9,
58.8,
82.7,
73,
59.2,
13.7,
62.6,
49.3,
61.2,
25.3,
69.7,
49.6,
71.2,
94,
82.6,
83.9,
66.4,
23.4,
49.9,
82.4,
40.5,
62,
36.7,
52.4,
62,
71.9,
34.6,
22.9,
38.2,
59.5,
5.2,
88,
26.3,
29.9,
90.4,
46.6,
30.4,
41.5,
0.8,
57.7,
36.4,
26.7,
56.5,
69.2,
52.6,
77.9,
23.5,
41.5,
37.5,
23.8,
24.1,
35.7,
76.9,
36.5,
72.2,
88.2,
44.2,
20.8,
88.4,
63.9,
94.2,
70.9,
46.3,
21.2,
56.9,
57.4,
44.3,
74,
74.9,
56.7,
80.1,
54.1,
52.6,
46.4,
60.2,
87.8,
81.5,
65.3,
80.4,
28.9,
47.9,
63.1,
95,
57.4,
17,
71.2,
73,
26.9,
52.1,
61.7,
84.3,
83.4,
78.1,
28.8,
57.3,
39.1,
37.7,
90.9,
41.1,
62.1,
87.3,
36.9,
39.5,
68,
62.6,
46.5,
34.9,
77.7,
63.5,
53.6,
61.7,
59.3,
73.7,
31.6,
31.6,
55.7,
96.3,
85.9,
45.9,
9.2,
86.7,
54.2,
71.1,
60.4,
8.6,
51.5,
56.3,
44.8,
66.7,
75.1,
17.6,
53.9,
61.4,
76.5,
69.6,
14.1,
84.8,
34,
41.1,
49.3,
62,
85.6,
35.1,
74.3,
71,
10.6,
45.7,
62.8,
4.3,
34.5,
22.6,
84.4,
67.4,
3,
23.5,
63.5,
84.6,
49.1,
38.1,
50.2,
52.4,
34.1,
72.4,
51.1,
38.7,
84.7,
41.1,
44.1,
56,
30.5,
43.3,
92.7,
72,
67.8,
39.6,
48.1,
14.3,
61.4,
34.5,
69.4,
69.2,
63.8,
94.4,
97.1,
85.5,
33.3,
32.5,
87,
43.6,
45.2,
34.6,
86.7,
34.4,
55.4,
98,
21.1,
54.4,
24.3,
33.2,
46.1,
85.3,
57,
33.4,
65.8,
70.1,
81,
59.6,
82.7,
67.3,
70.2,
51.7,
95,
83.8,
93,
41.2,
8.4,
51.8,
37.5,
42.9,
67.8,
66,
37.2,
75.8,
64.2,
14.8,
63.7,
38.5,
49,
23.1,
66.9,
92.1,
29.1,
89.3,
68.6,
64.9,
90.1,
47.1,
59.4,
93.8,
27.6,
69.4,
19.7,
62.9,
33.8,
10,
85.3,
72.6,
25.3,
74.6,
77.8,
45.1,
32,
65.5,
40.3,
89.4,
66.1,
16.3,
79.1,
50.6,
62.7,
97.2,
59.9,
51,
39.8,
76.9,
51.9,
54.8,
35.7,
44,
52,
52.4,
71,
62.7,
52.3,
99.3,
79.1,
27.8,
31.2,
88.3,
37.1,
36,
73.2,
61.1,
84.2,
83.9,
21.5,
68.4,
66,
40.6,
45.4,
75.5,
39.9,
64,
85,
42,
24.6,
91.5,
31.2,
85.4,
103.8,
29,
44.6,
34.6,
51.3,
72.8,
82.7,
63.6,
89.3,
113.1,
70,
66.5,
25.2,
16.2,
29.3,
57,
67.5,
53.6,
23.7,
93.9,
63.1,
69.6,
6.6,
67.1,
23.4,
12.1,
54.4,
40.9,
78,
79.1,
83.1,
81.6,
94.9,
18.1,
76,
43.7,
38.7,
90.2,
66.1,
71.2,
28.1,
53.9,
33.7,
17.3,
31.4,
86.1,
54,
48.3,
51.4,
30,
null,
85.1,
54.5,
73.7,
72.8,
62.3,
18.2,
39.1,
84.6,
62.2,
76.7,
65.3,
33.1,
64.7,
27.1,
57.5,
43.8,
68.1,
5.6,
74.4,
0.4,
29.9,
39.7,
97.4,
68.2,
67.7,
32.5,
54.8,
79.6,
32.6,
72.7,
69.3,
57,
35.2,
93.5,
47.4,
14.8,
88,
85.1,
95.9,
88.7,
71.9,
80.9,
57.8,
61.8,
24.8,
78.9,
65.3,
94.7,
22.5,
72.3,
77.7,
81.2,
62.5,
62.7,
96.1,
57.9,
21.7,
88.5,
62.6,
53.5,
67.5,
75.7,
0.7,
47.4,
48,
67.2,
22.4,
67.3,
44.4,
77.9,
47.7,
67.2,
83.2,
70.4,
42.4,
54.3,
77.8,
39.9,
94.8,
54.9,
26.6,
45.2,
32.4,
28.4,
78.9,
7.7,
1.9,
47.3,
84.1,
88.1,
58.6,
6.3,
26.2,
37.7,
55.9,
42,
85.9,
15,
62.5,
42.5,
58.6,
65.5,
66.3,
79.7,
70.9,
14.4,
50,
29.7,
49.8,
50.1,
86.9,
76.3,
62.8,
52,
28.2,
59.5,
72,
82.8,
15,
76,
38.5,
73.1,
32.3,
36.2,
56.2,
73.2,
99.8,
58.7,
52,
71.9,
56,
41.5,
35,
79.3,
32.6,
53.7,
29.5,
37.9,
87.5,
56.9,
60.3,
79.1,
34,
75.1,
43.5,
81.2,
97,
38,
20.7,
33.7,
17.6,
67.6,
25,
0.6,
82.9,
32.9,
29.6,
4.3,
24,
15.1,
14.5,
82.4,
94.3,
98,
43.4,
70.8,
57.1,
51.3,
70.9,
54.2,
4.9,
77.1,
88.7,
58.7,
22,
19.2,
28.2,
73.7,
67.2,
0,
61.5,
43,
19.3,
33.4,
3,
68.2,
76.9,
66.8,
43.6,
71.8,
39.3,
66,
80.7,
52.8,
69,
90.2,
73,
32.1,
53.6,
49,
87.4,
17.8,
51,
82.8,
32.7,
34.1,
67.2,
55.1,
25.2,
50.1,
90.4,
52.6,
70.5,
23.3,
70.8,
35.2,
58.2,
32.3,
92.1,
80.4,
53.8,
39.7,
56.2,
78.7,
101.9,
56.6,
91.4,
33.4,
103.7,
40,
75.9,
56.9,
61.9,
67.9,
63,
0.5,
77.7,
37.8,
43.8,
3.1,
63,
70.1,
63,
56.6,
77,
82.1,
42,
47,
63.8,
18.8,
66.5,
86.4,
45.3,
69,
59.1,
36.4,
56.8,
70.9,
81.3,
72,
49.7,
46.1,
60.4,
47.8,
15.3,
11.1,
41.2,
31.5,
81.9,
66.6,
71.6,
46,
57.9,
61.1,
48,
50.7,
72.4,
44.9,
44,
7.4,
20.2,
20,
71.3,
11.9,
47.9,
72,
0.3,
80.4,
73.1,
31.3,
54.6,
83.8,
63.9,
51,
64.4,
12.1,
89.1,
39.7,
9.9,
40.6,
92.4,
38.6,
55.6,
78.5,
44.4,
80.7,
97.3,
65.5,
22.5,
23.2,
15.4,
74,
80.3,
28.8,
81,
48.4,
59.3,
72.1,
24.3,
68.5,
82.5,
77.4,
13.2,
69.6,
45.8,
22.4,
47.4,
73.4,
33.4,
68.6,
80,
43,
21.3,
74.2,
80.4,
28.3,
39.2,
35.4,
61.9,
55,
81.4,
65.4,
38.5,
12.5,
63,
60.2,
61,
73.5,
44,
56.3,
92.8,
93.6,
55.5,
6.6,
37.6,
63.5,
54,
42,
34,
83.5,
13.8,
45.8,
42.7,
91.3,
76.3,
67.6,
82.4,
93.3,
94.8,
86.5,
68,
96.2,
62,
51.7,
47.9,
82.8,
34.5,
31,
37.9,
40.9,
53.8,
92.2,
46.4,
20,
42.7,
81.3,
52.8,
81.1,
57.5,
79.5,
45.1,
52.2,
75.9,
43.1,
2.5,
60.1,
42.5,
41.5,
21.7,
94.1,
19.2,
70,
71.7,
37.5,
92.7,
91.4,
39.9,
23.1,
94.4,
64.5,
78.7,
50.5,
18.7,
29.7,
63,
39.9,
37.5,
97.5,
42,
64.7,
17.3,
8.4,
49.4,
91.9,
81.9,
46.3,
70.1,
52.7,
80.6,
34.6,
81,
70,
50.4,
49.8,
84.9,
75.8,
77,
50.6,
63.9,
36.4,
43.3,
47.1,
66.8,
75.2,
65.8,
58.3,
94.6,
65,
44.9,
45.3,
75,
39.1,
73.6,
58.2,
47.7,
39.1,
64,
71.8,
67.7,
72.4,
69.8,
75.6,
10,
40.9,
41.1,
51.1,
31.8,
83.1,
72.3,
79.8,
58.3,
69,
54.3,
71.9,
42.2,
83.4,
41,
88.4,
70,
21.7,
56.5,
9.8,
93.2,
35.6,
19.6,
56,
40.6,
61,
56,
65.4,
41,
62.8,
47.9,
59,
61,
90.1,
91.8,
60.9,
28.7,
36.2,
3.2,
87,
51.4,
33.7,
57.5,
21.8,
86.2,
67.5,
67.5,
24.2,
77.3,
77.3,
24.1,
51.6,
68.4,
91.6,
9.4,
61.4,
50.3,
53.4,
92.4,
27.7,
68.5,
20.9,
78.8,
84.1,
94.8,
43.6,
95,
50.5,
25.2,
19.2,
57.9,
82.9,
52.4,
52.3,
49,
65.5,
78,
74.8,
47.3,
62.3,
42.2,
60.2,
74,
58.8,
47.8,
89.3,
44.4,
42.9,
59,
96.7,
74.1,
37.2,
10.3,
18.3,
65.4,
57.2,
68.3,
68.9,
14.7,
66.2,
75.8,
23.7,
53.6,
22.1,
68.3,
32,
54.2,
70.9,
27.1,
50.2,
33.8,
39.2,
28.6,
60.4,
54.6,
82.2,
29.7,
43.7,
48.9,
74,
74.1,
42.1,
37.2,
70.7,
74.8,
81.2,
21.1,
74.6,
45.3,
68.8,
43.6,
66.8,
97.7,
72.1,
28.7,
68,
64.5,
24.4,
88.3,
85,
59.8,
54.3,
95.7,
67.9,
89.5,
71.7,
40.4,
32.1,
76,
70.1,
1.4,
92.8,
50.6,
37.7,
10.5,
63.8,
69,
50.5,
87.7,
53.4,
46.1,
80.7,
76.3,
14.3,
72.9,
35.8,
99.5,
66,
5.1,
70.2,
96.5,
50.4,
43,
82.8,
32.2,
13.7,
89.9,
2.5,
71.6,
23.2,
41.3,
78.8,
46,
10.5,
59.2,
45.7,
53,
57.5,
20.9,
7.2,
38.5,
30.8,
62.1,
98.9,
95.3,
15,
50,
53.1,
36,
34.4,
88.7,
29.7,
71.7,
61,
57.6,
75.7,
29.1,
49.2,
22,
58.4,
69.5,
51.1,
63.2,
26.1,
65.1,
25.9,
52.4,
11.6,
79.8,
49.5,
26.7,
58.2,
9.2,
22.4,
92.4,
47,
74.6,
48.9,
99,
82.6,
41.6,
9.8,
61.7,
80.3,
39.7,
88.9,
11.2,
95.5,
77.6,
78.7,
33.1,
38.1,
71.8,
100.7,
77.3,
50.9,
23.7,
31.1,
36.5,
51.4,
42.8,
52,
88.2,
59.9,
55,
79.6,
53.4,
4.8,
81.5,
80.8,
17.7,
68.7,
55,
77.4,
84.8,
16.3,
0.4,
60.9,
37.7,
55.8,
80.4,
83.8,
85.5,
27.3,
53.8,
57.9,
94.4,
82,
64.8,
0,
99,
84.4,
80.3,
24.4,
39.7,
0,
24,
51.3,
60.2,
77.1,
50.7,
62.4,
21.7,
22.5,
49.4,
0,
78.8,
13.6,
17.2,
62.8,
47.7,
62.9,
85.7,
92.1,
43.9,
68.4,
72.2,
60.8,
20.2,
85.5,
84.5,
36.8,
37.5,
77.2,
24.4,
21.1,
76,
51.9,
40.9,
45.4,
71.8,
49.9,
45.5,
36.4,
33.7,
95.5,
79.1,
60.6,
78.4,
86.1,
54.8,
91,
90.8,
84.7,
45,
56.6,
63.3,
73.5,
34.6,
18.2,
76.6,
66.8,
29.2,
75.6,
34.7,
62.9,
71.3,
47.5,
37.7,
78.9,
36.2,
62.4,
44.4,
79.1,
72.1,
16.3,
55.3,
73,
61.5,
41.8,
66.5,
27.9,
19.6,
80.3,
63.9,
58.3,
52.9,
71.1,
83.5,
51.7,
61.5,
80,
0,
67.6,
80.8,
56,
55.1,
15.5,
44,
2.4,
77.9,
100.5,
49.2,
67.3,
14.7,
52.7,
71.5,
35.4,
4.1,
87,
83.1,
81.1,
49.4,
79.7,
35.2,
41.9,
50.7,
23.8,
57.3,
46.9,
22.8,
33.6,
93.6,
33.5,
85.7,
72.5,
96.4,
64,
87.2,
63.8,
8.7,
65.9,
94.6,
35.3,
10.9,
42.7,
96,
88.7,
76.6,
57.1,
35.3,
46.4,
79,
115.3,
63.5,
82.4,
79.8,
53.2,
15.1,
19.6,
60,
29.7,
87.5,
53.3,
96.7,
77.5,
29.7,
32.2,
46.6,
47.5,
30.6,
25.1,
46.4,
26.8,
90.2,
69.7,
72,
63.9,
93.3,
16.8,
29.8,
45.9,
39.7,
78.7,
81.9,
44.7,
85.8,
34,
48.1,
58,
56.8,
44.2,
52.6,
59.9,
28.1,
57.2,
55.3,
37.7,
59.1,
79.7,
0,
85.7,
79.9,
59.9,
60,
60.1,
15.5,
60,
48.7,
70.5,
69.5,
56.9,
40.7,
55,
87.8,
20.2,
12.6,
59.2,
19.3,
87.6,
83.5,
62.9,
89.1,
68,
48.7,
78.5,
30.4,
86.1,
61,
31.8,
59,
46.1,
43.1,
45,
50.8,
78.2,
81.1,
48.8,
64.5,
52.1,
73,
73.4,
64.6,
74.7,
48.6,
78.3,
35.3,
53.4,
84.7,
71.6,
86.1,
25.8,
66.2,
45.7,
89.9,
59.5,
78.5,
49.3,
82.2,
73.8,
55.2,
25.5,
69.9,
67,
73.5,
101.3,
92.8,
78.6,
77.9,
8,
74.6,
65.6,
40.2,
93.1,
39.9,
99,
60.3,
70.4,
26.4,
46.8,
21.8,
75.5,
91.4,
39,
11.6,
91.5,
87.3,
9.9,
78.9,
54.6,
18.1,
21.5,
62,
57.3,
79.4,
50.8,
58,
62.6,
34.9,
43,
0.8,
77.9,
64.6,
99.5,
49.9,
75,
68.8,
15.5,
52.5,
90.4,
24.7,
63,
69.5,
66.6,
39.1,
88.2,
65,
67.1,
27,
76.6,
86,
73.3,
31.1,
77.2,
87,
72.4,
24.5,
84.5,
48.1,
72.5,
52.3,
18.9,
78.4,
78.9,
47.5,
77.2,
0,
87.9,
77.6,
61.3,
18.1,
25,
67.2,
52.6,
66.5,
21.5,
47.4,
87.5,
25,
89.4,
72.4,
69.5,
84.9,
39.6,
65,
43.3,
69.2,
52.6,
40.2,
66.6,
60.2,
87.1,
80.1,
68.2,
2.2,
23.1,
86.7,
82.4,
22.3,
81.2,
72.3,
57.7,
46.9,
90.4,
96.7,
94.3,
0,
96.7,
78.2,
17.6,
79,
55.2,
90.2,
74.8,
57.7,
55,
70.6,
76,
25,
33.5,
78.1,
45.3,
86.2,
36.1,
56.2,
70,
56.5,
55.4,
40.5,
91.8,
66,
63,
99.3,
44.2,
18.4,
38.6,
47.4,
56.3,
57.6,
91.7,
40.4,
45.6,
58,
57.4,
76,
85.8,
74.8,
87.3,
52.7,
74.2,
71,
68.2,
54.5,
74.5,
81.7,
74.9,
50.5,
80.5,
35.5,
57.7,
52,
62,
58,
42.7,
93.5,
87.1,
37.2,
52.3,
38.9,
25.2,
69.9,
42.8,
38.1,
26.6,
68.8,
50.7,
72.1,
34.8,
82.6,
42.8,
53.4,
82.3,
60.2,
39.9,
52.7,
64.8,
77.4,
61.9,
80.9,
34,
48,
29,
28.3,
54.7,
82.7,
28,
25.5,
67.9,
63.4,
48.2,
82.1,
83.5,
48.7,
56,
59.3,
65.7,
56.1,
32.8,
59.7,
45.9,
48.4,
75.4,
92.3,
33,
75.4,
33.2,
60.3,
8.7,
40.9,
50.4,
72.2,
20.3,
42.3,
88,
49.5,
92.9,
88.7,
56.6,
83.1,
98,
50.1,
1.3,
36,
85.5,
12,
39,
62,
4,
58.9,
52.4,
67.5,
41.7,
55.3,
97.6,
50.4,
75.8,
74,
16,
89.7,
58,
32.3,
58.5,
34.1,
47.5,
69.7,
60.3,
39.4,
68.3,
67.9,
52.7,
53,
23.7,
57,
61.7,
53.8,
16.6,
52,
39,
27.4,
91.8,
95.3,
20.3,
80,
53.9,
41.2,
38.4,
62.5,
72.3,
53.1,
50.7,
48.8,
59.9,
83.3,
33.8,
53.2,
77.8,
49.9,
49.3,
68.6,
13.2,
72.2,
60.9,
49.2,
16.1,
82.8,
58.5,
79.6,
32.3,
51.2,
88.6,
69.6,
59.7,
81.6,
47.1,
66.3,
67.2,
22,
80.7,
66.7,
55.6,
94.6,
18.5,
47.6,
58.7,
46.5,
84.2,
69.2,
13.9,
11.6,
14.5,
80.3,
53.9,
39.4,
52,
58,
71.1,
13,
40.7,
51.3,
43.1,
81,
27.1,
50,
86.3,
37,
36.2,
79.4,
35.4,
71.4,
98,
31.9,
33.9,
68.3,
36.8,
80.1,
32.7,
71.8,
18.7,
94.9,
18.3,
36.4,
59,
96.3,
11.2,
52.1,
63.2,
63.7,
97.4,
23.2,
45.5,
30.5,
2.3,
12,
83.9,
43.4,
72.6,
72.3,
59.4,
66.3,
80.2,
62.6,
49.7,
62.1,
28.3,
56.6,
80,
55,
56,
45.7,
86.4,
54,
50.8,
73.4,
14.3,
45.8,
97.5,
36.2,
0,
68.8,
8.8,
49.3,
49.8,
86.8,
41.5,
48,
75.8,
49.8,
93.9,
63.5,
92.8,
55.4,
57.2,
35,
42.6,
50.2,
62.5,
32.5,
62.2,
50.4,
52.2,
84.5,
71.7,
74.8,
26.1,
40,
61.5,
76.2,
39.3,
46.4,
86.9,
57.7,
45.1,
80.1,
64.1,
76.5,
54.8,
48.3,
52.6,
79.4,
12.2,
96.7,
87,
73.3,
10.1,
66.3,
71,
70,
77.5,
53.1,
78.7,
36.1,
42.2,
55,
56.3,
80.5,
64.8,
81.3,
61.9,
47.2,
73.6,
69.5,
23.8,
61,
53.6,
95.8,
75.2,
36.2,
79.1,
68,
96.3,
100.1,
9.7,
46.8,
76.2,
72.8,
30,
87,
77.7,
52,
72.2,
51.7,
38.4,
63.4,
55.3,
50.9,
82.9,
82,
72.4,
11.9,
41.2,
19.6,
83.9,
37.4,
76.8,
40.4,
6.5,
80.3,
49.8,
46.4,
78.7,
50,
20.4,
46,
33.7,
15.7,
71.4,
26.8,
27.1,
86.2,
64.4,
47.9,
71.2,
40.2,
83.9,
65.8,
84.6,
38.6,
60.3,
34.3,
36.3,
77.6,
69.6,
1.1,
7.7,
41.3,
66.2,
6.5,
28.8,
54.8,
84.4,
59.7,
79.3,
73,
78,
45.7,
52.3,
59.6,
70.9,
38.5,
64.2,
61.8,
40.9,
55.3,
25.4,
44.7,
41.8,
0.1,
72.2,
42.8,
64.4,
59.6,
60.1,
27.7,
83.6,
53.5,
86,
58.2,
24.8,
41.9,
26.1,
64.6,
35.2,
56.2,
35.7,
78.9,
67.9,
82.8,
45.6,
46,
29.8,
23.8,
26.9,
19.5,
56,
30.5,
76.1,
47.8,
69.6,
83.7,
45.6,
6.2,
67.3,
36.1,
56.7,
53.8,
89.6,
88.4,
35,
7.1,
72.2,
72.6,
44.9,
23.2,
96.9,
50.9,
66.5,
46.7,
62.2,
84.2,
57.5,
93.5,
69.1,
36.3,
35.7,
72.1,
80.2,
67,
49.7,
30.2,
40.3,
94.9,
29.6,
33.1,
82.2,
95.4,
36.4,
55.5,
65.2,
37.8,
47.3,
67.6,
10.4,
64.6,
66.6,
35.4,
51.3,
67.4,
42.2,
77.1,
54.3,
73,
54.6,
49.2,
62.2,
101.5,
89.9,
22.1,
21.4,
36.7,
90.1,
26.3,
22.4,
54,
36.2,
57.7,
55,
28.4,
62.9,
4.5,
50.8,
60.5,
65,
66.8,
94.6,
71.8,
9.7,
85,
86,
63.8,
31.3,
18.9,
85.8,
63.5,
28.2,
20.7,
24.3,
98.4,
23.7,
59.9,
62.7,
51.6,
66.5,
67.8,
62.5,
79.1,
38.6,
14.5,
81.7,
51.4,
60.1,
15.5,
74,
78.4,
64.5,
29,
37.9,
70.4,
24.3,
34.1,
67.5,
87.6,
15.8,
74,
67.7,
48.2,
78.2,
59.6,
50.2,
44.9,
49,
42,
44.3,
48,
68.7,
79.2,
68.3,
46.5,
66.6,
92.9,
65,
66.6,
26.5,
59.9,
93.8,
67.8,
63.2,
36,
63.8,
31.1,
43.7,
36.5,
56,
29.9,
16.3,
87.1,
53.8,
52.8,
61.9,
92.4,
67,
48.1,
61.2,
93,
90.5,
79.9,
11.1,
67.4,
100.1,
20.4,
15.7,
56.2,
8,
68.8,
85.3,
96.4,
73.3,
47.6,
10.7,
57.6,
18.7,
68.1,
79.4,
34.5,
78.4,
53.3,
25.3,
98.5,
25.3,
46.7,
45.3,
83.9,
60.3,
10.8,
70.4,
69.6,
49.4,
66.9,
58.2,
57.6,
92.8,
47.8,
58.8,
29.5,
53.5,
53.7,
81,
53.4,
76.4,
4.3,
80.1,
25.4,
67.5,
95,
98.6,
71.2,
78.3,
69.9,
67.3,
39.6,
53.2,
21.8,
55.3,
44.1,
42.4,
71.6,
52,
15.5,
78.6,
94.3,
49.6,
86,
70,
58.1,
24.6,
33,
33.5,
59.3,
52,
81.6,
62.5,
97.6,
80.4,
8,
81.7,
33.3,
64.1,
79.3,
83.4,
92.1,
5.7,
74.2,
98,
5,
3.8,
35,
92,
81.8,
74.9,
35,
59,
64.4,
68.4,
59.1,
44.3,
61.9,
72.9,
12.4,
69.9,
68.6,
61.4,
77.3,
77.7,
41.2,
56.2,
35.7,
20.9,
47.9,
63.8,
37.3,
39.4,
97.9,
43.3,
16.5,
7.6,
50.7,
59.1,
62,
69.3,
27.5,
81.7,
81.5,
44.8,
63.4,
100.7,
55.9,
92.8,
85.7,
38.5,
63.6,
56.5,
51.4,
34.7,
73.8,
7.5,
85.9,
41.1,
93.4,
67.1,
58.2,
65.9,
89.8,
73.5,
20.5,
98.1,
38.6,
24.6,
21.8,
57.2,
45.8,
92.6,
81.4,
79,
56,
91.8,
69.2,
83.9,
0.6,
90.7,
28.4,
18.1,
49.7,
51.4,
75.8,
35.5,
92.8,
47.7,
88,
70.2,
56.9,
31,
52.7,
0,
92.5,
71,
63.4,
82.3,
92.9,
59.7,
52.4,
42.1,
24.6,
22,
38.5,
82,
75,
60.3,
78,
59.8,
42.6,
41.9,
29.3,
70.7,
57.8,
46.8,
66.1,
67.9,
82,
92,
49.8,
36.9,
48.4,
93.4,
32.4,
87.2,
70.2,
89.2,
69.3,
16.3,
45.8,
77.7,
96,
56,
54.2,
65.2,
87,
42.4,
22.5,
21.4,
7.3,
55.2,
82.8,
78.2,
68.4,
94.3,
66.2,
59.5,
59.8,
93.9,
30.9,
44.3,
68.9,
44.5,
44.7,
98.9,
92.4,
32.6,
53.1,
21.4,
50.5,
29.7,
55.7,
26.4,
14.6,
70.6,
75.1,
67.4,
12.8,
52.4,
29.1,
56.4,
30,
23,
60.2,
79.1,
42.1,
34,
73,
20.5,
95.7,
33.2,
13,
93.9,
47.9,
2.3,
84.9,
86.5,
41.2,
41.3,
63,
53.9,
46.4,
23.2,
44.3,
77,
87.1,
49.3,
76.5,
10.3,
78.5,
55.2,
60.4,
81.6,
58.7,
36.7,
29.5,
56.4,
77.3,
43.4,
32.2,
39.6,
78.6,
79.9,
63.9,
64,
67.7,
47,
71.9,
76.2,
41.8,
4.4,
0.8,
37.4,
73.3,
79.8,
38.3,
58.6,
26,
76,
22.7,
64.3,
43.2,
37.7,
62.6,
73.1,
82.6,
52.4,
45,
43.1,
23.9,
38.6,
27.5,
54.4,
80,
88.2,
31.3,
90,
68.8,
65,
12.7,
77.6,
62.3,
83.1,
39.3,
40,
40.7,
38.1,
25.5,
39.4,
51.7,
46.8,
65.6,
80,
88.2,
38.8,
45.7,
69.4,
40,
93,
62.8,
39.4,
79.9,
71,
71,
56.8,
28.9,
68.2,
45.5,
8.4,
62,
95.9,
44,
53.6,
87,
69.9,
61.5,
57,
41.2,
53.4,
100.3,
96.7,
25.7,
68.9,
73.3,
91.5,
25.7,
64.2,
53.2,
62.8,
27.1,
39.8,
63.3,
42.6,
25.6,
20.3,
66.1,
55.1,
67.8,
63,
17.3,
64.8,
78.4,
94.3,
11.2,
91,
9,
74.6,
48.5,
50.8,
33.5,
2.2,
62,
66.8,
54.2,
54.7,
70.9,
62.4,
71,
83.2,
43.7,
47.5,
50.1,
55.8,
77.6,
52.8,
28.8,
83,
67.1,
87.6,
69.6,
46,
47.9,
91.9,
57.4,
35.7,
69.5,
33.3,
61.9,
5.7,
57.9,
39.4,
83.5,
80.8,
50.2,
71.3,
86.4,
73.7,
82,
97.3,
76.5,
41.4,
76.9,
93.8,
52.1,
47.2,
81.5,
71.9,
65.8,
26.3,
47.2,
60.6,
13.9,
51.3,
47.8,
72.3,
91.3,
59.4,
23.2,
77.6,
59.3,
31.7,
75.6,
95.3,
74.8,
35.3,
72.6,
39.8,
74.3,
69.6,
64.9,
48.7,
10.7,
59.7,
37.5,
84.5,
72.4,
90.8,
64.7,
78.4,
71,
6.5,
61.5,
25.9,
32.1,
77,
56.2,
23.7,
53.3,
27.3,
74.8,
43.1,
24.7,
29.2,
53.8,
42.4,
67.2,
77.9,
87.6,
86.7,
94.7,
25.6,
50.9,
43.9,
59.1,
94.3,
47.8,
76.7,
39,
42.5,
51.6,
58.9,
65.6,
93.5,
81.8,
69.7,
60.6,
62.9,
59,
28.8,
85.8,
86.4,
57.2,
44.4,
45.9,
32.5,
67.9,
87.8,
48.6,
82.5,
77.7,
59.2,
27.9,
7.9,
36.7,
76,
94.8,
22.5,
46.6,
60.3,
36.6,
31.9,
51,
99.3,
59.5,
71.1,
33.2,
27.9,
38.4,
38.5,
80.7,
70.1,
72.5,
69,
46.9,
48.6,
52.7,
78.6,
55.8,
77.4,
51.9,
15,
49.8,
37,
33.8,
37.3,
46.4,
63.6,
8.7,
62.2,
30.4,
35.5,
96.9,
53,
53.6,
74.4,
11.5,
97.8,
24.3,
57.3,
72.2,
46.6,
43.6,
85.2,
30.4,
62.4,
63,
55,
79.7,
14.4,
100.3,
61.5,
42.4,
59.2,
42.5,
29.8,
69.9,
37.1,
54,
54.3,
47.2,
80.4,
15.1,
39.1,
39.3,
6.2,
31.3,
91.1,
28.4,
56.5,
46.5,
66.5,
36.6,
67.6,
7.9,
52.2,
34.1,
15.9,
35.8,
58.4,
41,
33.7,
59.6,
68.5,
72.9,
53.5,
56.4,
73.6,
21.7,
55.5,
15.1,
42.8,
83.2,
62.7,
97.4,
39.1,
31.1,
44,
78.8,
55.3,
83.7,
13.3,
44.9,
67.7,
57.8,
63.6,
86.3,
91.6,
55.9,
42.9,
45.9,
49.1,
57.9,
68,
9.8,
18.9,
54.2,
9.1,
33.4,
96,
74.7,
51,
26.7,
61.6,
62.8,
27.6,
80.6,
26.3,
23.9,
68.6,
52,
32.6,
32.7,
96.7,
90.7,
20.7,
62.6,
59.4,
43.9,
66.5,
44.7,
10.3,
94.3,
41.6,
49.7,
97.8,
29.3,
42.1,
31,
14.2,
20.5,
44.8,
32.8,
89.1,
64.2,
34.3,
90,
54,
53.4,
39,
51.7,
26.5,
27.7,
86.1,
75.6,
54.7,
70.5,
77.4,
20.5,
80.8,
53,
88.5,
29.9,
53.5,
46.5,
33.2,
50.7,
75.4,
81.4,
52.3,
29.3,
22.6,
12.3,
45.3,
55.8,
67.9,
50.5,
68,
29.2,
84.1,
39.6,
82.4,
35.5,
12.2,
40.9,
69.9,
41.4,
47.2,
73.1,
50.6,
66.7,
29.8,
78.4,
93.8,
88.6,
11.7,
19,
42,
67,
29.7,
72.7,
59.6,
28.4,
61.1,
66.9,
44.7,
48.6,
53.1,
49.1,
35.6,
48.6,
97.7,
51.9,
39.7,
39.9,
31.3,
40.5,
50.9,
70.1,
50.8,
33.4,
75.7,
85.3,
63.2,
59.5,
44,
70.8,
13.1,
67.3,
39.6,
80,
60.4,
90,
22.7,
85.8,
71.7,
15.4,
25.8,
22,
39.6,
40.8,
39.3,
76.6,
76.3,
88.7,
84.7,
89.6,
35.6,
62.5,
22.9,
60,
48,
38,
80,
53.3,
61.2,
75.8,
65.3,
45.8,
52.5,
44.4,
66,
8,
36.3,
25.5,
64.1,
59.3,
61.6,
75.5,
62.2,
5.7,
92.5,
30,
17.5,
33.1,
45.3,
58.3,
74.8,
79,
80.5,
5.6,
60.5,
75,
74.3,
36.2,
66.7,
25.3,
58,
37.2,
56,
43.9,
17.6,
48.8,
39,
29,
45.7,
41.7,
69.7,
68.7,
31.3,
28.2,
66,
78.7,
57.1,
48.2,
30,
48.9,
39.9,
72.3,
60.1,
72.1,
21.3,
71.7,
23.8,
41.4,
62.5,
57,
58.3,
80.4,
67,
92,
7.4,
69.2,
65.3,
74,
51,
80.7,
96.3,
96.3,
61,
27.2,
73.9,
44.9,
83.9,
32.4,
61.5,
48.1,
62.6,
96.1,
66.3,
23.1,
56.9,
34.2,
92.9,
21.2,
79.8,
16.7,
19.8,
19.2,
26.7,
78,
52,
40.1,
65.9,
35.6,
62.5,
48.3,
60.7,
34.4,
55.1,
35.9,
10.1,
26.9,
19.6,
26.1,
70.1,
65.3,
67.7,
54.3,
65.7,
39.7,
38,
92.5,
98.8,
54.7,
34.4,
46.3,
25.6,
81.8,
75.3,
15.8,
67.3,
54.4,
34.9,
81.8,
97.1,
34.5,
94,
68.8,
70.6,
23.4,
16.7,
59.5,
32.8,
62.2,
81.4,
49.7,
70.2,
15.7,
28.9,
46.5,
51.3,
48.1,
81.4,
41.4,
28.2,
81.6,
51.1,
23.1,
91.3,
38.5,
71.1,
86.6,
71.1,
55.3,
56.6,
73.9,
30.1,
2.4,
33.8,
46.4,
81.1,
35.4,
70.7,
60.7,
22.1,
61.2,
92.2,
94.9,
63,
18.6,
29.8,
7.7,
76.5,
97,
68,
68,
29.7,
9.9,
33.8,
36.1,
95.4,
56,
75.5,
57.5,
48.8,
71.7,
96.7,
71.6,
82.9,
37.7,
47.9,
68.1,
19.5,
80.1,
35.6,
62.2,
17,
86.8,
74.7,
25.2,
62.6,
84.9,
64.7,
41.7,
82.8,
25.2,
68,
27,
69.1,
53.2,
24.9,
53.6,
46.6,
89.3,
81.4,
77.7,
76.7,
96.9,
51.9,
68.9,
55.8,
74.1,
73.1,
81.8,
55.3,
70.4,
18.8,
67.7,
81.9,
70,
34.5,
72.6,
58.8,
54.2,
53.6,
89.9,
38.2,
60.3,
88.5,
62.9,
29.4,
34.6,
40.9,
17.8,
46.3,
81.1,
70.1,
33.8,
85.4,
40.8,
63.1,
92.5,
37.7,
61.2,
63.2,
64.1,
47.4,
26.5,
90.4,
47,
47.2,
63.6,
36,
99.3,
87.9,
71.1,
90.2,
36.8,
12.1,
58.5,
30.5,
56.1,
24.9,
57.2,
45.7,
64.7,
65.6,
77.8,
24,
53.2,
4.7,
76.7,
63.4,
53.3,
63,
53.3,
81.3,
70.9,
95.2,
47.8,
14.8,
59.9,
90.8,
94.6,
10.8,
75.5,
42.1,
19.2,
48.4,
48.5,
51.9,
48.6,
66.1,
49.3,
6.1,
27.5,
77.7,
37.9,
90.6,
71,
56.7,
38.7,
51.6,
45,
49.3,
56.4,
60.8,
64,
86.2,
83.6,
36,
56.8,
79.7,
88,
32.2,
29.5,
58.3,
71.8,
63.2,
64.7,
13.1,
38.8,
101.9,
70.2,
16.8,
37.6,
78.1,
37.9,
20.1,
26.4,
91.2,
16.8,
53.8,
32.2,
40,
42.9,
71.7,
23.4,
0,
0.3,
75.2,
72.7,
53.7,
75.4,
66.6,
64,
50.3,
61.6,
43,
52.4,
40.8,
34.4,
62.2,
54.8,
46.2,
48.4,
64.3,
13.4,
41.8,
86.6,
44.6,
50.3,
84.1,
68.5,
60.2,
44,
46.5,
99.7,
12.4,
68.9,
41.8,
97.5,
78,
75.3,
60.4,
81,
36.2,
64,
59.1,
42.6,
33,
69.2,
97.8,
55.7,
45.2,
72.2,
71.9,
99,
7.8,
76.4,
87,
77,
44,
65.1,
35.9,
69.7,
20.9,
42.9,
28.1,
70.7,
69.1,
46.6,
42.4,
65.8,
23.9,
42.9,
75.2,
81.4,
66.7,
73.2,
83.5,
44,
83.4,
89,
60.4,
64.9,
58.2,
10.3,
60,
52.7,
35.3,
52.1,
94.6,
86.4,
61.1,
76.1,
65.6,
35.1,
30.3,
46.3,
29,
27.4,
40.9,
70.8,
50.8,
74.6,
31.8,
44,
73.9,
77.7,
34.3,
65.7,
62.3,
31,
30.7,
54.4,
83.8,
70.2,
73.3,
77.5,
55.9,
69.3,
61.3,
70,
82,
20.8,
72.5,
93.9,
37.8,
46.3,
75.5,
44.5,
73.6,
39.4,
36.8,
40.5,
47.5,
54.5,
22,
61.9,
49,
54.3,
28.2,
42.6,
36,
64.4,
53.8,
51.4,
64.2,
61.4,
61.1,
35.3,
79.6,
45.6,
0,
53.3,
58.3,
88.3,
52.9,
57.2,
48.2,
96.2,
12.6,
44,
81.6,
46,
50.3,
39.2,
15.7,
26.6,
72.7,
75,
35,
99.6,
84.4,
33.4,
99.7,
53.9,
36.8,
66.2,
82.2,
75.4,
51.6,
75.2,
60.4,
60.3,
95.3,
7,
94.3,
38.4,
42,
46.8,
63.2,
37,
80.1,
85.8,
49.2,
62.4,
0.2,
52,
29,
35.9,
81.2,
99,
28.4,
55.5,
31.9,
49,
21.7,
72.3,
31.2,
86.5,
64.4,
83.6,
29,
39.7,
30,
94.5,
54.6,
73.6,
53.5,
null,
79.3,
79.7,
73.2,
90.7,
24,
76,
87.8,
51.2,
24.5,
32.3,
80.4,
41.7,
76.5,
20,
37,
37.8,
58,
87.5,
11.8,
24.1,
88,
30.1,
30.7,
78.6,
80.4,
40.1,
68.5,
60.3,
75.1,
54.3,
85.3,
79.1,
33.3,
63.8,
76,
38.4,
79,
31.8,
31.5,
0.1,
73.2,
65.5,
68.6,
95.6,
44.1,
53.7,
60.5,
50.2,
56.7,
81.7,
59.3,
32.2,
40,
71.6,
37.1,
68.6,
44.3,
41.3,
24.6,
11,
20.9,
45.7,
54.3,
60.6,
40.6,
49.3,
17.1,
59.3,
37.8,
75.1,
80.7,
41.4,
32.1,
55.3,
10.6,
64.8,
63,
68.2,
46.2,
94.3,
49.7,
84.9,
20,
32.7,
85.8,
48.9,
52.9,
45.5,
73.7,
85.7,
63,
28,
97.3,
95.2,
52.4,
56.9,
77.3,
80.2,
40.6,
71.9,
15.4,
60,
32.3,
33.9,
77.5,
43.9,
56.5,
36,
19.3,
6.9,
70,
37.1,
20.7,
49.5,
43,
50.5,
78.6,
6.7,
47.8,
31.3,
60.3,
29.4,
83.5,
54.7,
57.5,
89.4,
16.1,
37.5,
80.9,
84.3,
64.9,
24.5,
91,
29.7,
17.3,
50.9,
43.8,
86.7,
59.5,
75.4,
33.3,
26.3,
49.1,
74.8,
63.1,
10.8,
65.4,
73,
21.1,
4.9,
70.3,
24,
0.1,
57.2,
38.2,
16.7,
30.1,
83,
14.5,
34,
65.2,
19.5,
30.7,
35,
51,
49.8,
77.4,
44.4,
43.4,
43,
7.9,
40,
65.7,
47.8,
52.5,
64.9,
26.8,
47.7,
89.7,
68,
4.9,
43.4,
64.9,
63.2,
70,
59.9,
13.2,
64,
10.2,
83.3,
43.6,
14.3,
64.3,
62.3,
45.9,
63.2,
54,
95.5,
88.5,
75.8,
50,
10.9,
44.4,
44.4,
35.8,
11.5,
73,
14.7,
86.6,
35.7,
28.6,
99.4,
38.5,
41.2,
42.3,
75.3,
28.5,
58,
54.8,
60.6,
54.8,
7,
72,
44.6,
49.1,
50.6,
50.3,
54.2,
29.6,
9.4,
56.3,
35.5,
10,
93.8,
18,
15.1,
85.3,
74.6,
51.1,
87.5,
70.1,
80.9,
74.3,
43.7,
78.9,
15.6,
53.6,
48.5,
68.6,
47.3,
26.9,
98.2,
51.2,
54.6,
79.7,
69.3,
48.8,
50.3,
24.9,
24.8,
96,
35.4,
66.3,
49.3,
35,
46.8,
40,
16.8,
33.8,
69.4,
55.2,
81.8,
38.4,
55.2,
61.6,
48.7,
38.6,
80.9,
21,
56.5,
53.8,
44.4,
54.6,
40.3,
76.8,
48.9,
53.1,
81.8,
44.2,
91.7,
39.8,
19.4,
91.4,
65,
51,
63.4,
47.8,
35.8,
60.6,
70.8,
64.9,
58.3,
60.7,
6.8,
51.1,
61.8,
77.8,
60.8,
65.5,
68.7,
72.5,
41.8,
74.2,
50.7,
88.7,
74.1,
51.5,
95.6,
55.7,
40.1,
55.4,
35.5,
24.2,
39.2,
45.6,
59.1,
60.5,
45,
94.6,
11.1,
37.3,
26,
90.5,
97.3,
39.7,
86.5,
25.4,
53.9,
63,
74.9,
61,
84,
58.1,
54.8,
81.4,
43.6,
76.2,
69.5,
23,
65,
67.8,
27.5,
51,
42.1,
56.2,
49,
92.4,
3,
42,
71,
18.9,
58.9,
89,
66,
41.3,
93.1,
13.2,
64.1,
61.6,
89.2,
102,
79.8,
38.5,
79.5,
70.3,
76.4,
8.8,
35.5,
80.6,
13.2,
36.9,
57.9,
61.3,
15.4,
23.3,
73.4,
15.3,
70.9,
37.9,
16.1,
47.1,
30,
88.6,
76.5,
31,
72.9,
37.4,
64,
94.8,
32.8,
39.4,
56.2,
40.4,
1.2,
87.8,
69.9,
56.4,
44.2,
59.4,
69.6,
32.1,
70.7,
18.5,
98.6,
50.7,
42.5,
33,
59.5,
76.7,
60.5,
62.3,
67,
98.1,
87.1,
51.3,
68.5,
85.6,
70.1,
74.4,
90.9,
27.3,
43.5,
57.2,
26.5,
37.5,
55.3,
99.4,
58,
50.5,
21.2,
1.1,
42.3,
91.4,
67.7,
62.6,
80.2,
48.4,
57.9,
60.1,
98.4,
67.4,
35.7,
72.6,
57.4,
83.9,
24.9,
94.8,
27.8,
60.9,
66.8,
86.5,
0.2,
51,
62.8,
40.8,
58.1,
11.4,
41.3,
46.9,
69.8,
19.1,
77.3,
78.3,
18.1,
50.9,
79.7,
23.7,
38.3,
37.3,
67.5,
20.9,
98.1,
81.2,
18.2,
95.5,
48.7,
62,
89.7,
77.1,
73.4,
43.9,
60.3,
41.2,
78.2,
30.8,
88.9,
57.1,
92.6,
49.5,
99.7,
42.8,
32.4,
36.8,
34.5,
16.2,
68.9,
18.9,
51.3,
62.9,
80.6,
87.3,
83.9,
63.3,
86.2,
62.3,
94.6,
62,
40.7,
56.6,
68.1,
34.4,
62.2,
60.7,
82.9,
72.4,
50,
74.7,
16,
4.2,
24.6,
43.5,
18.5,
44.2,
54,
41.1,
48.4,
19,
31.5,
77.1,
44.9,
61,
42.7,
27.9,
66.2,
63.3,
26.9,
78.1,
84,
21.6,
48.6,
33.6,
21.7,
64.4,
18.4,
43.9,
41.5,
54.3,
81.5,
50.4,
40.8,
79.2,
77,
56.1,
33.2,
62.6,
28.4,
26.7,
92.4,
53.8,
93.1,
31.4,
86.9,
34.4,
56.8,
61.6,
84.6,
67.4,
74.7,
34.3,
43.8,
33.5,
74.8,
68.4,
59.2,
68.8,
80.1,
80.8,
28.6,
63.9,
26.8,
49.7,
23.2,
43,
65.5,
66.4,
75.6,
17.9,
42.2,
55.5,
85.5,
85.9,
78,
94.1,
93.3,
23.8,
36,
38.8,
52.4,
68.6,
86.8,
36.4,
38.9,
36.7,
23.9,
93.8,
76.2,
55.5,
69.6,
55.1,
24.6,
38.6,
73.7,
29.8,
50.8,
78.8,
75.9,
67.3,
24,
62.8,
21.1,
54.3,
53.3,
52.4,
27.3,
85.7,
42.9,
43.9,
0.9,
46.2,
89.6,
74.3,
53,
78.2,
9.4,
46.4,
24.7,
24.7,
39.9,
1.2,
97.5,
76,
25.3,
85.8,
79.2,
71.1,
19.3,
80.6,
85.1,
71.8,
49.1,
92.6,
0,
34.2,
72.1,
48.7,
16.3,
86.9,
71.3,
41.6,
95.3,
62.1,
78.3,
75.9,
71.6,
66.4,
49.3,
71.1,
52.4,
33.7,
0.4,
69.5,
47.2,
54.2,
63.4,
12,
33.3,
46.8,
84.5,
37.4,
82.8,
32.4,
81.7,
46.3,
63.9,
47.8,
40.5,
60.9,
62.9,
74.4,
26.2,
27,
33.1,
85.8,
94.2,
8,
71.4,
47,
45.8,
22.5,
52.2,
63.2,
77.5,
79,
67.5,
15,
80.2,
38.2,
34,
53,
50.9,
39.1,
11.6,
74.4,
92.2,
88.3,
64.8,
54.7,
90.6,
41,
42.2,
39.5,
54.6,
30.2,
38.4,
86.3,
29.6,
34.3,
47.5,
55.8,
71.8,
56.9,
79.3,
53.5,
62.4,
54.5,
46.4,
23.1,
59.6,
51.6,
58.8,
19.1,
30.7,
4.6,
15.5,
73,
21.3,
71.2,
62.5,
49.8,
32,
57.4,
61.2,
74.6,
66.1,
34.9,
25.8,
61.8,
48.6,
33.9,
66.2,
72,
47.9,
100.5,
71.5,
70.6,
77.8,
81.3,
103.9,
57.3,
16.4,
82.9,
38,
81.3,
40.4,
16.3,
55.5,
22.1,
80,
55.1,
52.2,
49.1,
69.9,
64.8,
53.8,
65.5,
48.5,
9.9,
47,
35.4,
50.6,
22.3,
41,
29.6,
73.5,
85.2,
46.8,
88.7,
27.8,
64.3,
54.7,
50.7,
97.2,
29.5,
40.5,
47.3,
60.6,
41.1,
0.1,
63,
0,
35.3,
65.2,
98.1,
49.8,
86.1,
67.3,
73.1,
41.5,
45.1,
27.6,
16.8,
30.7,
57.7,
28.3,
40.8,
15.3,
98.5,
27.3,
45.2,
70.4,
73.8,
35,
27.5,
35.9,
62.8,
69.3,
27.1,
55.6,
97.6,
17.1,
74.8,
47.5,
42.9,
62.9,
94.3,
74.6,
81.5,
28.4,
81.4,
40.5,
78.3,
43.3,
60.9,
73.8,
39.9,
56.2,
57.6,
32.4,
14.6,
49.4,
70.1,
73.8,
18.6,
49.8,
12.3,
30.8,
96.6,
87.9,
50.2,
77,
40.4,
56.7,
72.5,
10.1,
56.6,
35.6,
40.8,
34.1,
81.3,
16.7,
78.8,
33.7,
9.3,
21,
16.5,
56,
43.8,
94.5,
57,
84.6,
81.4,
50.6,
32,
32.1,
33.2,
95.2,
14.9,
75.8,
93.3,
58.3,
52.4,
49.2,
44,
71.3,
49.3,
27.1,
58.1,
52.3,
57.6,
76.5,
77.7,
76.4,
33.7,
94.3,
72.5,
9,
87.5,
65.5,
61.8,
64.6,
40.9,
50.8,
30.3,
40,
31,
65.3,
49.4,
93.5,
61.2,
92.1,
28.5,
86.5,
61.2,
83.8,
37.7,
48.6,
25.9,
82,
56.3,
45.2,
49.8,
71.6,
73,
78.9,
69.7,
43.3,
53.8,
66.9,
80.6,
55.4,
2.4,
80.5,
4.1,
73.9,
83.2,
56.8,
23.8,
52,
59.2,
51.1,
54.6,
37.9,
60.7,
32.9,
26.6,
67.6,
71.7,
56,
59.9,
46.2,
41.3,
71.6,
31.2,
43.8,
86.5,
55,
42,
38.5,
69.2,
72.6,
79.4,
66.7,
71,
41.4,
75,
29.6,
84.8,
78.1,
54.9,
28.6,
41.1,
75.7,
12.7,
37.6,
97.1,
71.8,
38.4,
85.9,
58,
55.5,
35.9,
97.2,
59.7,
30.1,
80.7,
62,
98.3,
10.3,
51,
47.6,
81.5,
52,
67.5,
68.9,
78.8,
60.6,
76.6,
45.1,
20.2,
81.9,
49.1,
22.1,
58.7,
66.3,
34.9,
55.2,
90.1,
43.6,
40.4,
80.7,
35.2,
69,
73.2,
84.2,
13.9,
82.8,
54.1,
57.7,
59.7,
60.4,
17.2,
40.2,
47.5,
70.5,
46.4,
22,
64,
34.3,
30.1,
67.7,
43.6,
53.1,
87.7,
22.4,
68.7,
44.2,
70.7,
73.9,
85.5,
21,
61.7,
97.2,
69.2,
42.8,
79,
56.6,
64.4,
60.8,
87.6,
44.1,
95.8,
70.9,
60.7,
15.6,
39.9,
79.4,
65.6,
68.9,
78.6,
63.5,
30.4,
23.9,
63.1,
35.1,
22.1,
41,
88.9,
38.8,
62.8,
67.8,
72,
20.6,
46.6,
65.9,
33.2,
73.7,
45.5,
15.6,
69.7,
0,
15.7,
33.6,
66.6,
49.9,
31.7,
60,
49.8,
40.5,
8.4,
55.6,
79.3,
62.2,
16.3,
38.5,
57,
51.8,
18.5,
6,
90.5,
88.7,
32.7,
98.7,
43.6,
73.1,
83.3,
30,
81.2,
51.9,
30.2,
42.1,
51,
70.7,
36.9,
62.9,
68.7,
75.8,
81.4,
48.5,
105.1,
58.4,
54.4,
76.6,
75.1,
26.1,
26.7,
47.5,
89.8,
54.3,
75.6,
52.1,
92.3,
63.7,
57.5,
84.5,
16.5,
40.3,
47.1,
21.1,
29.7,
56.1,
21.4,
53,
5.9,
53.9,
45.3,
43.5,
43.3,
31.9,
53.8,
82,
97.1,
41.9,
29.8,
76.2,
84.8,
70.5,
35.4,
47,
34.3,
53.1,
71.3,
19.2,
49.2,
81,
70.8,
37.7,
35.9,
35.3,
50.4,
44,
72.1,
44.8,
56.2,
48.5,
47.2,
65.1,
50.1,
82.7,
38.8,
51.5,
76.4,
77.9,
55.8,
52.4,
24.9,
13,
98.3,
36.2,
75.5,
29.5,
84.2,
8.2,
44.6,
0,
78.2,
86.6,
67.9,
47.1,
53,
37,
60.8,
59.8,
32.7,
70.2,
21.8,
93,
76.9,
37.1,
87.1,
41.6,
46.7,
70.4,
36,
17.5,
97.5,
15.6,
81.3,
61.8,
56.5,
37,
60.7,
80,
42.7,
60.5,
64.3,
14.7,
46,
47.1,
70.2,
62.7,
42.4,
22.6,
61.2,
62.2,
78,
92.3,
11,
35.5,
44.7,
39.3,
54.4,
37.3,
74.6,
22.6,
98.2,
78.7,
82.1,
77.8,
28,
65.8,
97.2,
50.3,
68.5,
76,
85,
76.5,
23.5,
87.5,
51.4,
44.8,
57.6,
63.3,
15.2,
54,
39.3,
89.8,
35,
29.4,
106.2,
28.5,
54.4,
75,
20.3,
90.5,
65.2,
15.3,
55.7,
82.1,
21.7,
82.2,
3.4,
77.6,
64,
47,
50.5,
48.5,
47,
27.3,
57.1,
62,
51.2,
11.1,
86.6,
52.9,
51,
99,
63,
24.8,
26.2,
79.8,
42.6,
45.7,
72.6,
27.6,
61.7,
32.4,
48,
35,
87.6,
83.4,
45.2,
31,
41.3,
67.6,
60,
32.4,
82.2,
16.9,
94,
62.4,
78.1,
59.3,
70.7,
72.9,
71.6,
98.4,
65.3,
34.3,
69.5,
50,
58.2,
14.1,
51.1,
87.5,
52.8,
95.7,
37.1,
13.5,
10.8,
25.5,
99.3,
41.6,
11.8,
55.7,
32.6,
2.3,
48,
59.3,
73.6,
50.7,
21.1,
35.7,
48.5,
81.9,
85.9,
82.1,
73,
56.2,
88.8,
56.6,
81.1,
92.8,
41.2,
66.3,
71.7,
59.3,
88.6,
53.9,
33.8,
68.1,
27.5,
37.8,
65.4,
83,
14.7,
59.2,
71.5,
48.8,
9,
79.2,
81.5,
60.4,
93.3,
9.7,
62.9,
62.9,
88.2,
36.8,
61.8,
55.7,
52.3,
88.3,
74.1,
53.1,
18.8,
61.3,
48.4,
32.5,
55.5,
46,
69.8,
72.5,
57.2,
34,
38.7,
74.4,
20.3,
81.5,
33.4,
54.7,
57.2,
80.3,
29.1,
91.5,
62.2,
63.4,
34.4,
10.2,
65,
88.9,
51.3,
67.3,
52.5,
40.4,
26.9,
70,
56.5,
45.9,
19.6,
85.6,
46.7,
91.7,
54.8,
74.1,
49,
61.9,
45.7,
54.6,
45.8,
52.3,
49.7,
63,
67.1,
75.9,
41.3,
36.9,
4.7,
56.1,
10.3,
43.7,
97.2,
74,
41.5,
36.1,
93.5,
50.6,
69,
50,
77.3,
46.2,
70.5,
5,
66.7,
53,
20.4,
72.8,
58.9,
86.3,
92.2,
48,
38.5,
74.8,
87.8,
77.5,
86.3,
53.7,
72.9,
69.3,
36.8,
74,
47.5,
33.5,
45.9,
51.4,
91.4,
70,
69.2,
61.3,
65.1,
44.7,
66.4,
86.3,
6.1,
69,
16.7,
62.8,
70.7,
33.6,
60.7,
54.8,
73.2,
32.1,
58,
65.6,
65,
35.2,
92.4,
66.8,
50.4,
24.7,
27.6,
31.8,
55.2,
86.2,
79.3,
69.9,
83.9,
82.2,
35.5,
64,
82.7,
67.6,
80.5,
null,
36.3,
48,
37.9,
89.3,
66.6,
34,
41.1,
51.1,
45.4,
29.7,
50.1,
93.5,
35.7,
36.8,
42.2,
2.8,
74.2,
92.5,
95.1,
41,
16.3,
47.3,
66.5,
18.5,
68.2,
78.1,
40,
65.1,
27,
52.6,
97.4,
38.6,
66.5,
84.7,
51.9,
56.4,
32,
14.4,
60.9,
73.3,
76.9,
19.9,
60.2,
50.3,
34.5,
52.4,
81.8,
37.1,
47.7,
27.5,
90.7,
11.6,
42.7,
7.4,
64.8,
49.9,
48.1,
47.9,
82.8,
34.9,
65.3,
33.5,
49.1,
53,
49.9,
25.6,
52,
82.4,
47.7,
51.6,
98.6,
75.7,
78.8,
56.3,
16.9,
14.2,
15.4,
64.7,
78.7,
51.9,
21.6,
61.2,
17.7,
55.3,
26,
59.3,
66.7,
52.2,
1.5,
58.5,
87,
64.4,
54.7,
83.3,
73.9,
41.6,
62.9,
64.7,
11.5,
40.2,
59.8,
41.6,
91.7,
43,
50.3,
58.1,
46.3,
75.5,
69.2,
74.6,
44.2,
40.1,
63.1,
50.4,
55.8,
37.4,
72.4,
30.6,
49,
38.6,
25.3,
44.2,
7.6,
58.8,
60.6,
77,
55.8,
26,
58.8,
83.2,
83.7,
74.8,
50,
41.3,
51.8,
39.3,
83.9,
58.8,
66.1,
56.9,
49.2,
78.9,
40.8,
25,
57.6,
74.5,
49.9,
84.4,
72.3,
42.2,
79.6,
67,
49,
64.8,
42.9,
49.6,
47.6,
15.6,
82.7,
54.1,
67.9,
45.2,
29.7,
61.4,
13.3,
94.3,
48.4,
46.9,
9.9,
62.7,
49.2,
61.1,
58.7,
20.5,
47.2,
15.9,
73.8,
19,
61.8,
70,
86.1,
47.5,
0.7,
39.5,
41.2,
66.7,
68.3,
53.6,
10.2,
89.5,
49,
50.7,
22.6,
55,
64.2,
53.5,
67,
74.2,
64.7,
85,
42.4,
97.3,
61.2,
21.2,
46.2,
66.1,
78.2,
16.1,
45.8,
17.3,
49,
51,
94,
53.6,
9.6,
68.7,
64.1,
75.2,
0,
84.1,
60.6,
88.3,
53.2,
66.6,
33,
30.1,
40.9,
59.7,
32.5,
79.1,
53.2,
73.5,
70.8,
29.3,
46.1,
60.1,
96,
68,
24.2,
70.7,
47.9,
76.1,
18,
71.4,
17,
82.7,
27.4,
68,
15.1,
81.3,
84.3,
63.7,
50.6,
87.9,
26,
45.5,
9.6,
14.3,
62.7,
17.8,
7.4,
44.5,
76.9,
42.5,
57.2,
67.6,
67.5,
67.1,
4.1,
81.2,
28,
65.2,
47.5,
55.8,
19.6,
54.7,
9.9,
51.1,
50.7,
37.2,
50.1,
59.7,
70.7,
89.3,
60.1,
49.2,
91.8,
70.5,
53.5,
47.1,
11.5,
60,
76.5,
69.4,
84.2,
89,
64.5,
97,
10.1,
37.7,
53.1,
34,
41.7,
79.4,
40.9,
40,
44.1,
62.1,
35.4,
63.2,
98.5,
38.6,
25.4,
99.1,
32.5,
40.6,
13.3,
73.3,
20,
63.7,
58,
88.3,
67.1,
71.7,
74,
17.7,
56.3,
74.8,
77.8,
84.5,
40.5,
30,
0,
83.9,
45.4,
28.1,
65.1,
85.7,
20.5,
44.5,
66.4,
69.4,
88.5,
59.1,
12.3,
78.8,
50.5,
57.6,
84.7,
48.6,
56,
54.5,
29.9,
31.7,
46.8,
64.3,
42.7,
53.6,
56.5,
78.4,
34.4,
75.5,
39.8,
70.4,
99.7,
39.6,
44.9,
30.8,
8.3,
37.8,
63,
68.5,
33.2,
85.4,
66,
18.2,
61.5,
56.7,
25,
41.1,
42.4,
75,
62.9,
78,
52.2,
71.8,
49.3,
74.8,
87.6,
31.9,
70.5,
93.3,
65.8,
12.2,
64.4,
65.3,
19.8,
48.5,
50.5,
42.9,
93.3,
74.2,
15.4,
42.4,
44.8,
52.9,
40.9,
71.1,
43.1,
71.3,
31.5,
57,
95.1,
76.6,
27.4,
95.4,
16.1,
47.1,
56.6,
32.8,
59.2,
96.3,
37.7,
90.1,
5.3,
80.7,
76.5,
52.1,
14.4,
57.8,
79.6,
69.6,
25.6,
37.7,
14.7,
72.1,
78.5,
34.7,
38.1,
31,
38.3,
57.7,
20.2,
46.5,
24.8,
72.8,
98.1,
60.4,
92.2,
89.9,
64.6,
99,
55.8,
29.3,
47.9,
91.7,
69.7,
88.2,
33.9,
15.1,
75.5,
72.4,
30.5,
40.3,
88,
39.4,
20.9,
51.9,
46.1,
48.2,
62.9,
60.1,
22,
89.4,
78.8,
53.6,
71.4,
25.2,
82.2,
22.1,
30.1,
82.1,
49.5,
71.5,
69.2,
30.1,
47.4,
94.8,
72.1,
37.8,
81.5,
49.7,
73.4,
35.4,
104,
35.5,
35.6,
59.9,
69.2,
65.4,
61.2,
37.6,
49.1,
40.4,
62.7,
86.6,
67.6,
78.5,
72.8,
64.5,
36.7,
39.2,
50.9,
82.9,
88.9,
32,
80,
52.6,
9.4,
92.8,
65.1,
46.9,
54.4,
57.8,
60.4,
25.7,
30.5,
51.9,
34.1,
66.8,
18.9,
46,
36.4,
82.2,
89.3,
10.1,
44.2,
67.5,
42.3,
9.9,
86,
94.2,
62.7,
55,
52.5,
37.9,
54.9,
76.8,
59.4,
63.7,
21.5,
56.6,
32.4,
71.8,
58,
81.8,
66,
56.1,
49.7,
38.9,
73.4,
66.4,
48.7,
11.4,
7.1,
77.2,
52.7,
45.7,
60.1,
71.2,
15.2,
25.9,
44,
89,
65,
60,
12.4,
38.4,
95.3,
80.8,
81.5,
34.2,
29.5,
94,
71.3,
22.1,
17.6,
53.6,
30.1,
41.5,
82.8,
91.1,
13.1,
89.7,
35.1,
35.3,
43.2,
20.5,
70.4,
39.7,
10.3,
54.9,
49.3,
88.7,
43.7,
47.7,
74.9,
61.4,
44.8,
29,
47.1,
31.7,
1.9,
34,
86.4,
82.6,
39.8,
76.3,
20.1,
42.3,
77.6,
14.7,
58.9,
52,
52,
96.9,
62.6,
27,
40.3,
69.6,
63.3,
22.4,
84.2,
41.2,
58.9,
73.3,
75.1,
68.4,
43.5,
57.6,
27.6,
24.2,
31.2,
69.1,
47.9,
40.6,
66.8,
81.8,
60.5,
76.2,
39.4,
17.3,
25.3,
43.8,
65.4,
25.9,
34.9,
81.2,
42.2,
76.9,
77.8,
25.3,
89.9,
62.4,
48.9,
52.7,
48.5,
94.2,
79,
97.9,
61.2,
64.9,
8.4,
34.8,
50,
44.4,
75.4,
81.3,
54,
52.9,
52.6,
73.4,
47.9,
85.8,
72.7,
76.2,
72.9,
38.2,
53.2,
42.9,
47.9,
69.1,
53.9,
20.2,
72.4,
40.6,
27.7,
29.1,
37.2,
48.4,
74.7,
64.5,
30.8,
8.5,
92.2,
74.4,
88,
72.7,
88.5,
87.5,
74.1,
59.6,
39.7,
46.5,
59.3,
95.7,
40.4,
47.5,
64.3,
85.1,
24.1,
61.4,
20.7,
56,
53.6,
35.9,
101,
67.2,
80.5,
73.2,
49.6,
24.8,
71.2,
66.9,
62.6,
89.9,
48.7,
83.5,
92.6,
85.3,
37.2,
73.9,
90.4,
47.4,
81.9,
69.6,
52.1,
45.2,
73.6,
85,
25.2,
80.1,
86.1,
10.5,
60,
53.1,
20.9,
51.6,
70.1,
28.9,
33.7,
42.4,
22.4,
62.9,
50.8,
34.6,
22,
66.9,
97.5,
20,
47.9,
54.5,
57.5,
44.7,
87.6,
77.6,
0,
34.8,
45.2,
66,
70.6,
45.7,
85.2,
58.8,
1.9,
72.1,
37.1,
95.2,
46.7,
36.5,
75,
38.9,
48.9,
60.3,
84,
74,
80.2,
35.8,
63.8,
60.9,
94.5,
73.2,
72.7,
76.5,
79.5,
59.5,
6.2,
35.6,
72.5,
33.8,
54.2,
76.7,
52.7,
45.8,
50.8,
56,
60.4,
35.4,
48.3,
81,
33.3,
90.8,
61.6,
23.6,
40.7,
57.1,
41.4,
43.6,
62.9,
95,
25.8,
45.3,
94.5,
78.2,
92.9,
71.7,
47,
56.6,
79.3,
68.9,
82.5,
21.8,
40.6,
38.3,
27,
16.5,
77.1,
68.6,
9.1,
58.8,
24.9,
38.7,
62,
83.8,
65.2,
59.5,
80,
23.7,
80.9,
49.3,
23.1,
18.4,
44.5,
46.7,
48.6,
82,
88.5,
84.8,
34.1,
62.4,
73.9,
67.9,
75.6,
95.9,
45.9,
57.5,
75.1,
5.3,
50.5,
78.4,
73.6,
65.6,
70.2,
57.6,
57.4,
51.5,
60.7,
66.9,
81.5,
26.5,
57.2,
79.8,
4,
69.6,
18.5,
40.8,
63.3,
66,
56.4,
56.2,
32.4,
100,
16.1,
22.5,
31.3,
39.9,
69.4,
70.2,
62.3,
70.6,
90.7,
77.1,
95.2,
25,
73.1,
53,
60.9,
58,
99.7,
49.5,
83.4,
52.1,
24.4,
64.9,
48.6,
46.4,
71.1,
34.9,
33.3,
13.5,
61,
30.1,
42.3,
97.8,
46.9,
74.3,
29,
60.2,
30.5,
49.8,
40,
22.2,
57.5,
67.1,
11,
64.4,
52.6,
25.7,
82.6,
54,
51,
89.1,
83.8,
76.7,
61.4,
39.5,
84.4,
35.9,
34,
51.9,
50.3,
34.9,
56.1,
51.5,
56.6,
23.8,
96.8,
32.9,
46.9,
40.5,
66.5,
16.4,
66.4,
47.5,
50.4,
47.8,
97.1,
57.3,
39.9,
95.5,
11.8,
98.3,
82.3,
43.5,
7.9,
86.5,
83.7,
47.2,
96.4,
39.6,
74.9,
57.8,
22.6,
24.9,
70.6,
85.9,
72.1,
98.1,
59.4,
52.8,
52.4,
41.3,
76.3,
93.9,
84.7,
60,
59.3,
35.3,
1.8,
68,
91.9,
72.8,
20.3,
71.9,
38.3,
96.3,
29.8,
51.3,
99.1,
59.9,
43,
76.1,
62.7,
69.9,
55.1,
58.3,
78,
40.6,
14.6,
48.4,
11.4,
56.1,
54.6,
46.8,
80.4,
46.6,
55.3,
80.1,
28.4,
61.9,
70.4,
56.4,
81.2,
63.5,
72.6,
76,
79.3,
38.1,
71.7,
44.9,
45.9,
43.9,
82.6,
81.2,
74.3,
36,
88.1,
81.3,
54.9,
2.7,
26,
52.4,
31.2,
51.6,
59.2,
43.2,
17.2,
51.6,
32.6,
31.2,
18.7,
98.2,
51.2,
82.9,
15.4,
57.2,
85.1,
20.7,
79.4,
38.6,
100,
53.6,
64.9,
21,
76.7,
67.6,
53.5,
80.9,
63.5,
95.4,
34.2,
11.5,
56.9,
66.2,
52.5,
48.7,
35,
23.8,
57.6,
19.9,
78.9,
20.3,
85.9,
44.3,
57.6,
87.6,
62.9,
56.7,
62.6,
29.1,
39.4,
27.6,
62,
28.9,
99.7,
52.1,
42.6,
56.1,
34.6,
72.1,
22.4,
17.7,
43.3,
58.7,
76.7,
20.3,
57.1,
67,
36.4,
19,
72.3,
70.6,
38.7,
37.7,
73.1,
52,
74.4,
40,
86.5,
59.1,
48,
76.5,
44.7,
66.7,
54.6,
49.6,
25.3,
83.8,
64.7,
34.3,
29.9,
78.7,
84.7,
72.9,
61.1,
22,
64.9,
49.5,
93.7,
91.7,
41,
42.5,
81.7,
43.8,
0,
23.3,
70.5,
3.8,
14.7,
11.1,
96.9,
9.9,
60.5,
75.2,
55.4,
77.6,
73.6,
18.6,
36.5,
41,
62.6,
73.9,
25.7,
25.5,
41.2,
68.1,
61.2,
91.1,
17.7,
40.9,
88.7,
41.1,
46.5,
56.4,
43.3,
35.8,
58.5,
26.4,
32.8,
47.2,
53,
81.8,
71.4,
49.7,
34.7,
28.7,
17.4,
43.3,
49.4,
35.1,
97.4,
73.2,
69.3,
23.8,
66.2,
6.6,
102.4,
49.6,
47.2,
95.5,
2.1,
76.9,
29.8,
89.8,
55.8,
84.4,
74.1,
43.2,
92.5,
59.5,
25,
63,
80,
60.6,
54.3,
55.9,
91.9,
52.6,
38,
54.1,
41.5,
29,
66.2,
83.7,
43.8,
89.7,
57.3,
10.1,
7.5,
18.2,
99.7,
23.9,
92.8,
61.6,
76.6,
87.1,
78.7,
59.1,
93.3,
94,
39.1,
86.2,
34.7,
83.7,
77.2,
60.8,
54.6,
60.8,
42.7,
37,
38.5,
82.5,
59.2,
23.8,
68.8,
63.4,
72.2,
10.2,
96.1,
14.4,
76.6,
11.5,
51.7,
44.1,
88,
62.8,
39.4,
62.2,
53.4,
77,
48.1,
64.8,
47,
44,
1.5,
45.6,
57.4,
66.4,
39.5,
77.2,
35.7,
77.6,
89.5,
36.5,
67.2,
84.3,
72.5,
15.9,
54.2,
27.6,
72.1,
3.5,
90.3,
87.6,
57.8,
82.3,
57.9,
66.7,
88.7,
48.9,
69.7,
66.7,
39.4,
27.6,
36.7,
65.1,
66.1,
82.6,
90.7,
43.2,
6.7,
22.8,
40.4,
78.1,
36.8,
62.2,
79.5,
55.2,
42.5,
62.3,
16.3,
94.5,
77.6,
65.2,
53.3,
54.3,
71.3,
57.1,
31.3,
61.3,
0.3,
41.2,
64.4,
1.2,
69.8,
66.5,
44.7,
68.2,
50.6,
64.4,
67.3,
41.6,
47.8,
24,
26.9,
59.1,
55.4,
55.8,
16.2,
84.8,
33.6,
20.2,
53.8,
70,
90.8,
78.5,
88.2,
26.8,
45,
82.5,
30,
12.4,
71.3,
20.9,
68.6,
15.7,
42.5,
51.8,
90.7,
31.1,
91.1,
74.1,
44,
78.3,
73.4,
94.3,
90,
80,
59.1,
83.9,
54.7,
50,
33.7,
56.7,
63.1,
8.9,
94.5,
58.1,
16.7,
75,
47.3,
32.7,
26,
70.8,
76.4,
70.4,
73.4,
27,
83.3,
49.2,
36.2,
15.2,
81.4,
64.1,
49.3,
87,
43.7,
49.7,
9.6,
71,
54.8,
66.9,
90.2,
75.3,
68.3,
49.5,
79.4,
40.6,
8.3,
62.1,
8.5,
46.9,
39.2,
46.4,
66.5,
50.3,
63.7,
32.3,
78.2,
50,
51.6,
88.8,
31.9,
92.2,
78.1,
85.5,
87.2,
36.9,
95.8,
55.9,
100.6,
2.1,
53.9,
98.9,
58.4,
70.6,
73.8,
52.9,
90.6,
21.6,
0.8,
70.2,
56,
41.7,
80,
54.9,
40.3,
9.2,
28.5,
92,
19.8,
29.2,
27,
50.8,
56,
32.9,
71.3,
55.2,
73,
83.7,
41.2,
69.1,
84.6,
3.6,
58.8,
86.8,
77,
58.5,
4.6,
55.3,
67,
57.9,
96.7,
28,
0.3,
38,
45.2,
37.7,
59,
42.7,
99.1,
48.8,
34.1,
49.4,
76,
55.1,
91.1,
36.5,
88.2,
28.9,
48.5,
56.2,
62.7,
85.2,
70.2,
16.7,
56.4,
17,
68.8,
16.9,
51.1,
33.2,
27.5,
38.4,
80,
72.3,
99.7,
81.2,
53.2,
25.5,
20.3,
78.5,
60.6,
27.5,
42.7,
46,
68.9,
20,
90.1,
68.7,
62.4,
68.1,
34.1,
49.7,
67.5,
92.5,
94.1,
68.8,
85.7,
58.7,
95.8,
52.5,
47.9,
60.1,
66.3,
53.9,
83.3,
57.4,
5.5,
48.5,
69.4,
16.2,
96.1,
33.7,
9.5,
63.2,
57.8,
45.8,
94.7,
35.3,
68.3,
84.5,
64.3,
60.7,
17.7,
28.6,
54.6,
99.9,
44.2,
49.1,
87.4,
28.7,
39.2,
28.6,
85.6,
64.5,
74.1,
95.3,
52,
61.9,
49,
14,
59.9,
49.8,
12.4,
63.7,
36.6,
53.2,
7.5,
41.9,
70.9,
85.3,
52.5,
56,
28.3,
48,
94.4,
51.8,
23.4,
47.1,
51.3,
83.6,
58.2,
41.4,
91.7,
44,
30.3,
80.2,
35.6,
12.8,
82.5,
20.7,
49,
39.2,
58.5,
40.5,
90.8,
33.1,
48.3,
39.5,
34.9,
44.9,
22.8,
67.6,
0,
34.6,
4,
88.2,
77.6,
85,
74.5,
22.2,
62.1,
67.3,
72.1,
1.3,
55.7,
25,
29.7,
54.1,
82.3,
35.4,
85.8,
15,
56.3,
102.4,
12.9,
89.9,
75.6,
43.7,
43.3,
90.2,
64.1,
24.5,
75.1,
13.7,
55,
22.3,
67,
23.6,
80.8,
21.6,
48.7,
49.1,
39.2,
50.4,
68.3,
69.9,
87.4,
41.5,
88.7,
28.5,
27,
59.5,
82.9,
46.5,
0.2,
97.3,
87.9,
86.6,
12.2,
34.4,
48.7,
56.8,
79,
66.2,
27.9,
75.2,
66.7,
71.4,
35.2,
78.9,
87.3,
60.8,
68.6,
68.2,
7.8,
80,
5.5,
34.1,
43.4,
91.3,
20.5,
60,
29.7,
96,
82,
71.3,
55,
23.3,
88.4,
46.5,
70.5,
38.5,
78.1,
18.9,
79,
53.7,
50.3,
69.7,
103.3,
20.2,
64.9,
72,
49.5,
68.3,
40.4,
38.8,
52.6,
59.7,
51.9,
28.8,
57.5,
56.5,
77.7,
89.3,
86.1,
82.9,
44.8,
60.6,
39,
34.6,
59,
45,
85,
74.5,
74.2,
45.1,
72.2,
55.1,
84,
19.5,
76.3,
79.1,
28.2,
50,
68.8,
38.4,
81.8,
51.5,
53,
73.6,
32,
24.6,
50.8,
33.5,
39.3,
57.6,
67.4,
47,
54.2,
26.3,
25,
89.8,
20.2,
31.1,
51.1,
61.3,
57.3,
78.6,
64.7,
10.7,
65.2,
72.9,
59.9,
62,
67.5,
33.2,
74.7,
18.9,
43,
77.2,
56.3,
81.7,
48.8,
38.8,
37.8,
77,
69.1,
90.3,
111.4,
85.2,
37,
8.4,
54.2,
51.6,
34.1,
61.4,
67.3,
0,
57.7,
80.4,
78,
71,
52.2,
69,
94.3,
63.3,
63,
90.1,
45.8,
74.3,
68.8,
60.5,
102.7,
53.5,
23.5,
94.4,
21.9,
69.1,
76.7,
77.3,
90.5,
75.3,
35.3,
84.9,
62.9,
56.2,
59.1,
56.8,
22.4,
80.9,
53.3,
94.3,
30.9,
43,
40.2,
60.6,
68.2,
94.1,
73.7,
31,
51.9,
45.2,
16.9,
97.8,
62.8,
40.2,
75,
99.8,
29.6,
61.3,
81.9,
42.2,
76.9,
75.9,
84.5,
78.6,
21.8,
44.8,
50,
27.8,
71.5,
81.7,
26.4,
75,
63.9,
62.3,
28.8,
43.8,
46,
77.3,
67.9,
46.9,
69.9,
45.7,
68.7,
100,
84.3,
29.8,
45.7,
92.1,
46.6,
93.1,
59.8,
57.1,
68.9,
55.7,
47.7,
60.6,
86.1,
10,
57.5,
57.8,
50.6,
51.4,
92.1,
63.6,
78.1,
37,
56,
27.7,
71.2,
89.6,
51.5,
68.9,
66.8,
14.6,
78.4,
14.3,
65.5,
48.7,
35.5,
47.3,
84,
83.5,
53.1,
27,
44,
22.3,
86.5,
46.4,
14.5,
40.5,
53.2,
81,
69.3,
81.5,
81.4,
19.5,
54.9,
66.3,
29.4,
59,
46.3,
63,
77.3,
13.6,
55.3,
54,
55.2,
92.9,
37.6,
91.1,
4.6,
81.9,
51,
30.2,
49.5,
35.5,
50.4,
67.3,
62.9,
92.5,
36.3,
78.3,
34.2,
0,
44,
87.7,
22.5,
57.3,
77.5,
71.4,
32.5,
77.1,
43,
30.1,
98.6,
42.8,
30.6,
68.8,
83.7,
70.4,
83.1,
48.7,
16.2,
64.2,
58.6,
82.9,
72.8,
51.5,
30.4,
43.7,
52.1,
16.7,
78.4,
30.3,
89.5,
87.8,
26.4,
6.7,
47.4,
80.2,
93.6,
79.6,
76.1,
62.3,
35.1,
41,
71.9,
85.7,
54.3,
84,
90.9,
41.7,
86.6,
79.7,
82.5,
66.9,
37.4,
83.5,
49.6,
2,
63.2,
83.7,
72,
94.4,
61.9,
64.1,
49.5,
99,
33.5,
30.4,
42.5,
47.7,
64.6,
47.3,
33.2,
59.1,
85.8,
86.3,
97.4,
52,
22.5,
80.6,
34.5,
91.9,
61.3,
48.2,
79,
80.7,
48.5,
31.3,
93.3,
30.6,
75.3,
59.6,
44.9,
18.6,
14.6,
51.1,
74.1,
74.8,
58.5,
56.6,
73.7,
79.3,
40.9,
90.8,
86,
91.5,
46.1,
70.5,
49,
29.5,
68.9,
98.4,
61.5,
56.1,
40.5,
63.3,
89.3,
39.9,
54.6,
94.6,
57.1,
29.3,
19,
65.7,
84,
62.2,
86.1,
41.3,
68.9,
6.1,
68.5,
66.5,
48.5,
58.7,
82.6,
97.6,
89.9,
27.6,
38.4,
61.1,
91,
57.3,
10.8,
43.8,
43.6,
34.3,
54.6,
61.4,
61.5,
94.8,
57.7,
62.9,
59.3,
56.5,
88,
83.8,
82.1,
28.7,
4.6,
77.1,
97.7,
67.6,
41.1,
46.9,
74.7,
70.6,
56.3,
17.7,
81.4,
93.1,
50.3,
98.8,
54.9,
46.3,
31.8,
58.7,
63.5,
50.3,
55.5,
21.9,
38.3,
13.1,
61.9,
79.5,
20.2,
52.6,
49.4,
66.1,
56,
19.4,
56.9,
32,
9.7,
20.2,
77.7,
19.5,
44.6,
44.7,
83.8,
24.2,
77.9,
100.5,
71.8,
42,
32.4,
31.7,
84.8,
69.4,
0,
74.3,
50.5,
64.6,
46.5,
91.4,
60.9,
84.1,
79.8,
99.7,
70.6,
51.4,
54.6,
57.2,
60.5,
52.4,
75.3,
64.5,
87.1,
72.5,
36.4,
53.5,
80,
78.8,
39.7,
21.1,
63.6,
57,
62.7,
74.9,
50,
76.3,
58.8,
50.9,
39.7,
52.4,
75.3,
86.1,
93.8,
48.9,
40.5,
15.2,
41.7,
99.5,
49.3,
10,
60.9,
43.4,
25.5,
22.8,
88.1,
96.5,
0,
80,
21.8,
62.2,
54.6,
60.2,
37.8,
52.3,
94.4,
55.3,
56.4,
32.1,
65.7,
12.8,
99.9,
43,
46.9,
88.4,
22.9,
34.9,
88.4,
94.2,
84.2,
72.2,
34.7,
100.4,
55.6,
0,
70.9,
78.8,
89,
4.7,
69.2,
34.9,
90.1,
46.8,
70.1,
78.1,
22.1,
20.7,
36.9,
93.4,
70,
52.2,
68,
23.2,
82.6,
77.1,
90.3,
68.8,
90.8,
92.7,
72.4,
31.9,
69.3,
40.1,
93.8,
96.5,
34.5,
59.3,
23.8,
13.5,
77.8,
24.9,
66.3,
64.2,
41.2,
53.8,
42.4,
24.3,
58,
66,
11.5,
43.5,
40.1,
57.5,
35.5,
88.4,
49.4,
57.7,
34.4,
65.2,
21,
25.2,
84.3,
38.6,
64.9,
55,
58.1,
67.9,
78.9,
35,
46.5,
91.4,
93.7,
78.9,
37.6,
3.8,
70.5,
55.4,
61.2,
23.3,
86,
8.7,
53.4,
63.6,
35.9,
57,
69,
79,
101.1,
63.3,
55.6,
72.7,
86.6,
89.2,
54.7,
69.5,
25.2,
33.1,
38.8,
57.3,
81,
97.1,
16.2,
37.4,
38.2,
40.7,
27.2,
83.7,
84.9,
66.1,
35.8,
32.6,
61.3,
85.5,
38.9,
52.1,
65.2,
81.9,
51,
80,
26.9,
60.2,
47.1,
91.9,
23.2,
25.7,
71.6,
45,
50.3,
38,
46.9,
67.3,
35.9,
69.4,
36.7,
56.1,
60.1,
55.2,
70.5,
78.8,
62.3,
89.1,
58.9,
54.3,
11.6,
60.6,
66.6,
78.6,
87.3,
88.5,
18.3,
80.4,
68.3,
36.4,
39.1,
79.1,
100,
58.3,
82.5,
47.2,
42.9,
12.5,
25.5,
64.2,
67,
67.9,
60,
97.6,
45,
52.2,
68.2,
19.6,
43.9,
22.6,
48.1,
46.4,
61,
47.9,
59.7,
91,
76.3,
99,
17.3,
75.5,
66,
32.1,
76.1,
36.4,
29.8,
51.4,
25.8,
46.5,
25,
83.5,
60.1,
46.3,
28.7,
80.1,
71.4,
69.4,
36.7,
8.8,
57.3,
59.8,
44.5,
51.4,
41.1,
9.4,
38.2,
61.6,
77.3,
76.9,
104.2,
50.7,
49.5,
44,
80.9,
62.5,
34.2,
51.8,
58.5,
44.5,
86.4,
42.3,
58.6,
63.7,
13.7,
89.6,
20.2,
28.6,
68,
52.1,
26.8,
65.3,
52,
51.7,
58,
69.8,
2.1,
51.4,
64.4,
86.3,
43.1,
35,
85.7,
64.1,
84,
21.3,
49.8,
86.7,
47.5,
32.4,
67.4,
33.8,
42.2,
29.8,
95.4,
58.5,
22.2,
81.4,
58.3,
83.4,
3.7,
58.8,
70.1,
83.3,
49.4,
46.8,
25.2,
55.8,
55.6,
62.2,
52.9,
3.5,
96.6,
80.9,
13.9,
68.7,
40.4,
27.3,
52,
27.5,
41,
27.9,
61.9,
67.5,
64,
76.8,
94.5,
53.4,
79.4,
83.2,
83.7,
61.3,
39.8,
41.1,
81.8,
87.6,
70.6,
22.8,
56,
46,
76,
89.1,
60,
36.4,
25.6,
60,
71.8,
52.4,
46.7,
44.2,
28.4,
72.2,
72.3,
88.2,
31.7,
1.8,
94.9,
56.3,
22.7,
66.6,
83.1,
48,
53.9,
83.8,
30.9,
75.9,
71.9,
45,
67.1,
72.9,
65.3,
73.9,
43.4,
49.4,
44.8,
35.5,
78.2,
43.5,
82,
64.1,
36.2,
79.8,
81.9,
71.6,
41.5,
0,
4.5,
58.5,
79.4,
35.5,
93.5,
59,
33.1,
27.9,
51,
92,
21.9,
42.9,
79.8,
60,
63.6,
79.5,
72.5,
76,
45.8,
77.6,
29.4,
60,
65.3,
35.1,
85.3,
67.9,
50.9,
68.9,
99.2,
67.1,
88.8,
65.9,
32.4,
39.2,
85.2,
22.2,
7.8,
30.7,
60.5,
63.5,
50,
85.9,
51.1,
56.4,
62.7,
96.3,
55.9,
60.8,
62.6,
39.4,
21.5,
70.4,
17.7,
43.5,
60.6,
37.7,
16,
67.4,
24,
64.7,
46.3,
85.7,
77.3,
92.5,
49.3,
48.7,
40.9,
49,
90.4,
60,
42.7,
49.2,
34.4,
51.6,
39.6,
47.9,
33,
18.4,
69.2,
42.3,
39.9,
3,
93.6,
67.2,
84.2,
35.5,
33.7,
37.6,
92.9,
0,
69.2,
39.5,
29.4,
93.8,
73.3,
18.5,
86.2,
45.6,
23.8,
47.3,
49.3,
54.3,
50,
65.9,
15.3,
93.7,
73.3,
38.3,
94.6,
25.9,
88.3,
87.1,
95.4,
39.5,
78.3,
94.3,
53.3,
37.3,
62,
53.8,
94.2,
63,
57.2,
49.9,
72.6,
54,
36.1,
78.2,
68.2,
44.3,
32,
22.3,
8.5,
87,
84.3,
90.6,
61.8,
36.8,
17.8,
87.7,
43.7,
59.8,
46.8,
65,
7.7,
86,
39.4,
76.8,
4.8,
44.9,
38.6,
1.2,
66.4,
71.9,
85.2,
65,
28.5,
34.2,
46,
50.7,
61.5,
95.1,
75.7,
68.1,
91.3,
55.4,
85.9,
56,
42.8,
73.9,
77,
42.9,
13.7,
57.3,
48.9,
42.7,
46.3,
83.9,
44.8,
93.4,
60.7,
52.1,
19.8,
45.8,
43.7,
43.2,
45.9,
24.5,
57.7,
48.9,
97.1,
31.1,
34.9,
41.9,
92,
3.3,
17.7,
75.5,
64.4,
99.2,
66.1,
34.8,
71.2,
71,
25.6,
42,
78.6,
45.9,
83.3,
25.5,
51.8,
44.6,
43.4,
47.6,
65.4,
65.7,
69.2,
67.3,
52.5,
72.2,
54.7,
76,
33.7,
91.8,
41.7,
72.6,
69,
38.1,
46.2,
95.4,
51.2,
87,
59.2,
70.7,
35.3,
36.4,
61.2,
9.5,
32.8,
38.1,
13.7,
58.6,
77.8,
94.5,
74.1,
18.4,
75.5,
24.1,
51.2,
34,
32.9,
36.3,
44.4,
15.8,
12.4,
51,
56.5,
24.9,
93.2,
52.5,
82.2,
40.6,
58.4,
16.3,
88.2,
64,
78.8,
34.2,
53.1,
57.1,
58.5,
100.1,
69.3,
70.3,
5.2,
47.5,
72.7,
26.7,
43.6,
20.9,
34,
88.7,
28.9,
62,
68.2,
53.4,
60.4,
58,
60.6,
92.6,
81.3,
17.8,
17.2,
40.8,
76,
81.2,
68.5,
70.8,
36.8,
15.6,
63,
79.9,
36.5,
57.3,
37.6,
53.8,
36,
84,
0.6,
19.6,
46,
49.7,
57.6,
41.6,
86.9,
66,
44.7,
78,
90.9,
52.7,
61,
58.6,
74,
62.9,
71.3,
81.8,
51.5,
88.2,
42.5,
87,
49.1,
59.8,
9.2,
36.9,
69.8,
14,
31,
87,
64.7,
32.6,
49.5,
57.7,
78.5,
73.6,
49.7,
100.6,
25.9,
51.5,
37.2,
78.8,
60.6,
78.1,
45.5,
51.3,
92.5,
47.3,
81.8,
52.5,
110.4,
73.5,
97.3,
47.8,
61.6,
93.9,
21.6,
25.8,
60.3,
70.6,
61,
88.5,
36,
66,
9.2,
67.7,
58,
62.7,
56.4,
27.3,
60.6,
40.1,
40.3,
65.7,
54.5,
0,
101.1,
11.1,
47.9,
83.2,
65.9,
74.5,
76.5,
43.4,
35.7,
91.5,
74.4,
88,
6.7,
87.4,
95.1,
52,
47.3,
62.4,
64.4,
50.2,
71,
78,
98.4,
89.5,
44.2,
81.4,
69.2,
49.4,
37.1,
94.7,
44.9,
64.6,
50.4,
72.1,
94.7,
87.2,
79.3,
6.2,
70.6,
33.8,
12.1,
62.4,
81.9,
72.1,
68.2,
34.2,
56,
26.8,
88.3,
50.5,
79,
48.6,
79.3,
29.3,
68.7,
38,
24.1,
50,
62.7,
58.7,
42.7,
48.4,
57.9,
48.1,
79.2,
90.8,
49.3,
56.1,
24.8,
63.2,
54.1,
71.2,
62.7,
57.8,
95.4,
61.5,
62.6,
87.9,
68,
27.4,
67.4,
71.5,
99.6,
59.5,
68,
15.6,
44.7,
65.4,
31.8,
51.4,
77.5,
66.2,
31,
74.6,
83.4,
33,
73.8,
73.4,
43.2,
17,
72.1,
34.1,
33.5,
60.2,
45.9,
41.8,
38.7,
7.5,
44.8,
33.3,
89.1,
27,
53.8,
54.9,
46.6,
78.4,
28.9,
49,
61.7,
58.5,
83.6,
60.4,
43.1,
17.9,
88.3,
41.5,
42.6,
49.5,
89.4,
83.4,
41.9,
48.8,
66.5,
36.2,
96.2,
34,
33.1,
86.7,
57.8,
28.4,
49.9,
44.8,
51.5,
51.2,
63,
86.7,
92.9,
71.2,
17,
61.6,
56.1,
13.2,
27.8,
80.3,
64.9,
52.1,
69.7,
93.2,
10.5,
51,
77.9,
75.5,
3.6,
76.6,
81.2,
43.1,
45.4,
51.8,
67.9,
74.4,
44.5,
40.7,
60.9,
83.4,
57.1,
61.9,
68.2,
47.6,
89.7,
78.2,
50.5,
63.5,
48.2,
0,
62.3,
57.8,
78.6,
62.2,
27.1,
104.6,
86.5,
38.6,
38,
71.7,
93.3,
47.7,
88.8,
79.6,
57,
35.3,
75.3,
0,
63.8,
89.1,
56,
30.9,
55.2,
88.5,
94.8,
83.3,
41.1,
79.7,
48.5,
33.5,
41.9,
61.5,
29.6,
82.6,
48.8,
36.6,
90,
72.8,
46,
76.3,
67.6,
49.7,
31.3,
71,
33,
73,
58.5,
81.7,
39.1,
57.3,
17.3,
25.1,
44.9,
50.3,
77.2,
10.9,
52.8,
48.8,
36.7,
10.6,
61,
78,
41.2,
42,
91.5,
81.6,
31.8,
73.6,
26.5,
80.1,
62.6,
101.7,
4.3,
72.4,
1.5,
43.4,
45,
74.4,
64.3,
55.4,
64.3,
82.4,
51.2,
59.2,
71.2,
17.9,
77.2,
6.1,
75.6,
67.8,
49.8,
37.4,
79,
72.3,
58.3,
58.4,
13.8,
40.3,
59,
29.7,
70,
45.9,
38,
55.7,
62.3,
69.2,
74.1,
42.2,
71.8,
31.3,
98,
95.6,
29.1,
49.3,
77.4,
92.6,
75.7,
74.9,
27,
70.4,
30.5,
73.7,
38.3,
44.6,
32.3,
50.9,
64.3,
14.4,
55.5,
28,
7.6,
48.9,
64,
88.1,
30.4,
79.8,
87.8,
23.1,
8.6,
76.4,
56.3,
30,
79.6,
100.2,
73.2,
84.8,
15,
85.8,
65.4,
58.5,
81.4,
18.6,
73.2,
77.1,
57.7,
73.4,
60.7,
49,
37.6,
86.3,
62.1,
44.8,
38.7,
74.9,
71,
34.3,
70.3,
58.1,
51.7,
99.1,
55,
46.8,
50.2,
67.4,
18.1,
79.4,
70.8,
28.6,
47,
83.7,
47.4,
64,
75,
87.5,
43.4,
55.2,
67.4,
47.2,
15.6,
77,
38.4,
42.5,
56.4,
68.9,
66.4,
47.4,
88.3,
64.2,
91.9,
56.6,
52,
43.3,
60.8,
57.7,
60.3,
19.3,
48.5,
0,
35.4,
2,
36.2,
30.7,
86.4,
65.1,
60.1,
40.2,
49.1,
10.5,
39.7,
38,
43.7,
76.5,
32.7,
69.4,
88.1,
20.4,
62.9,
86.3,
51.7,
48.2,
57.5,
15.8,
54,
8.1,
94.2,
74.7,
6.9,
39.4,
53.6,
81.5,
59.3,
38.4,
77.1,
89.3,
59.8,
63.8,
32.1,
42.6,
37.4,
41.2,
21,
94.9,
82.1,
38.5,
61.6,
75.3,
34.4,
4.5,
33.3,
79.1,
66.1,
39.7,
69.1,
40,
75.5,
84.2,
41.4,
72.3,
55.5,
23.9,
79.6,
28.8,
38.1,
59.8,
58.5,
86.4,
66.3,
55,
70.5,
24,
25.7,
69.6,
55.3,
45.7,
78.3,
82.4,
91.7,
45.8,
0,
66.4,
95,
30.7,
10.5,
41.6,
59.3,
34.3,
96.2,
90.2,
73.3,
72.5,
75,
53.7,
59.5,
88.1,
27.9,
21.7,
84.9,
18.2,
58.2,
76.5,
0,
77.3,
54.4,
56.5,
54.6,
66,
7.4,
51.5,
76.2,
65.1,
70.1,
49.4,
70.4,
57.2,
30.9,
43.9,
44.3,
37.7,
70.3,
14.6,
64.4,
71.8,
23,
41.7,
19.5,
57.2,
55.5,
85.3,
22.8,
79.9,
87.2,
73.1,
75.2,
22.9,
35.7,
46.8,
17.2,
80,
44.9,
43.7,
24,
79.4,
37.8,
68.5,
17.5,
41.8,
88.2,
44.8,
87.1,
60.1,
40.7,
27.9,
61.2,
90.4,
27.8,
68.6,
69.8,
64.8,
95.6,
96.7,
8.3,
60.3,
78.2,
34,
96.5,
20,
39.6,
63.2,
91.4,
65.3,
70.6,
28.8,
40,
37.3,
37.6,
101.1,
28.9,
54,
48.2,
81.7,
51.7,
56.4,
24.9,
47,
33.2,
53.9,
46.1,
69.4,
86.1,
62.1,
18.3,
5.7,
60.9,
29.1,
56,
21.9,
69.5,
75.4,
88,
28.8,
26,
19.4,
69.1,
79.1,
67.5,
97.9,
93.6,
62.7,
80.6,
10.5,
56.8,
69.8,
69.3,
54,
25.5,
77.1,
82.4,
64.3,
77.3,
24.4,
33.4,
58.7,
95.8,
67,
34.9,
74.3,
94,
64,
83.2,
36.5,
101.1,
99.3,
70.1,
69.6,
11.3,
25.8,
81,
73.1,
89.5,
102.6,
19.5,
89.5,
51.8,
46.6,
56.8,
73.4,
80.1,
89.1,
21.8,
52.7,
17.8,
25.7,
52.3,
44,
72.9,
74.6,
73.5,
26.1,
91,
52.2,
84.7,
23,
61.7,
94.5,
51.6,
34.9,
88.3,
60,
26.4,
49,
59.2,
27.5,
46,
75.5,
60.7,
41,
75.6,
17.8,
48.8,
43.3,
79.1,
74.2,
29.2,
25.1,
26,
66.9,
91.6,
79.6,
15.9,
77.6,
57.2,
18.9,
63.4,
28.3,
51.5,
76,
52.6,
59,
52.5,
45.4,
84.9,
59.6,
82,
53.3,
44.7,
45.2,
83.5,
57.9,
63.3,
62.2,
50.3,
81.9,
5.3,
73.2,
0,
48.4,
60.2,
39.1,
95.2,
67,
53.5,
83.9,
81.3,
54.8,
44.4,
62.3,
22.9,
18.8,
36.1,
24.5,
92.3,
80.6,
92,
50.5,
79.9,
37.9,
25.2,
41.7,
60.7,
68,
44.9,
43.7,
61,
25.5,
15,
26,
78.4,
58.2,
27.3,
65.2,
57.3,
76.6,
94.6,
56.1,
61.8,
86.3,
47.7,
85.5,
62.9,
55.9,
84.8,
61.8,
89,
21,
38.5,
97.8,
42.9,
26.8,
69.1,
42.2,
78.1,
86.1,
65.8,
75.2,
70.6,
42.4,
15.1,
81.6,
15.4,
39.8,
7,
55.8,
76.1,
10,
57.3,
0.5,
60.3,
50.6,
83.8,
87.7,
49.1,
72.9,
66.9,
26.7,
77.1,
45.7,
34.3,
68.6,
86.2,
20.2,
45.7,
3.4,
29.9,
22.2,
42.6,
33.5,
80,
82.9,
32.4,
89.4,
77.6,
19.4,
68.1,
84.7,
49.9,
53.7,
30.3,
61.7,
68.3,
68.3,
26.1,
16.5,
80.3,
50.3,
70.4,
65,
33,
68.3,
34.9,
89.8,
28.2,
71.7,
75.5,
35,
40.5,
43.1,
50.5,
41.9,
58.7,
84.3,
42.8,
70.2,
null,
79.6,
64.2,
51.1,
68.9,
95.3,
42.1,
7.5,
67.9,
52.4,
11.2,
86.2,
53,
77.9,
12.4,
88.2,
49.1,
27,
69.4,
99.3,
84.4,
89.3,
2.7,
21.1,
47.9,
47.8,
97.4,
88.2,
43.8,
37.7,
22.4,
15.8,
87.3,
66.2,
47.2,
13.4,
74,
98.5,
40.9,
89.2,
74.5,
23.3,
61,
39.3,
12,
27.9,
25,
74.3,
42.6,
70.9,
62.5,
48.6,
55.8,
97.6,
34,
79.3,
5.5,
52.1,
49.3,
48.3,
60.6,
80.3,
38.4,
27.4,
90.9,
33.7,
9.2,
57.7,
61.3,
73,
33.2,
44.3,
92.7,
47.2,
28.2,
31.6,
71.1,
27.7,
14.9,
42.5,
44.7,
40.6,
97.6,
56.5,
54.2,
84.5,
61.7,
62.8,
27.9,
87.5,
91.7,
65.7,
57.8,
59.9,
33.6,
56.2,
14.6,
80,
53,
18,
50.4,
18.6,
49.3,
102.2,
33.6,
98.3,
2.9,
30.2,
32.4,
0,
0.8,
76.5,
50.8,
40.3,
10.7,
45.4,
34.5,
31.6,
51.6,
45,
13.1,
66.2,
78.9,
88.6,
62.3,
60.2,
49.5,
64.4,
70.7,
79,
70,
25.7,
20.8,
89.6,
35.5,
96.6,
38.3,
96,
49.9,
16.9,
31,
52.7,
24.3,
32.7,
10.3,
75,
68.6,
95.9,
53.7,
48,
41.2,
46.4,
26.7,
25.7,
65.1,
48.1,
38.3,
28.5,
33.2,
64,
70.3,
81.1,
15.8,
43.4,
63,
27.1,
70.4,
45.4,
88.7,
50.7,
74.8,
44.3,
30.1,
73.4,
85.7,
44,
42.1,
76.8,
31.2,
85,
50.6,
37.3,
47.4,
39.8,
36.2,
26,
20.5,
26.2,
65.6,
26,
31.2,
55.3,
99.8,
69.1,
59.8,
60.6,
41.7,
32.6,
84.8,
49.3,
61.5,
83.3,
31.4,
0,
85.1,
28.5,
66.9,
39.8,
61.4,
65.3,
38.1,
39.5,
33.2,
79.9,
86.1,
31.6,
37,
57.9,
68.8,
62.1,
86.1,
70.2,
71.1,
73.9,
21.8,
52.5,
66.4,
85.2,
53.4,
27.4,
29.4,
29.5,
69.6,
57.4,
48,
22.4,
83.5,
84.8,
34.2,
28.5,
70.6,
76.7,
88.3,
60.8,
63,
66.9,
90.5,
61.1,
60.7,
86.4,
67.1,
81.5,
42.2,
13.3,
66.4,
60.2,
75,
73.3,
40.7,
25.3,
82.7,
74.9,
52.8,
27.6,
37.3,
42.7,
50.4,
49.6,
35.9,
26.4,
79.1,
53.1,
75.4,
39,
33.8,
62.9,
69.6,
58.8,
53.3,
54.1,
72.8,
79.7,
61.2,
85.4,
100,
48.4,
81.1,
11.1,
97.4,
34,
37.8,
39.9,
70.1,
25,
81.6,
26.3,
22.8,
28.7,
49.9,
73,
76.1,
57.1,
54.9,
81.3,
47.9,
87.3,
78.4,
21.3,
65.7,
34.1,
79.4,
80.5,
52.3,
49,
81.8,
73.8,
46.5,
79.3,
76.6,
55.6,
18.9,
79,
63.7,
84.8,
62.8,
54.5,
33.6,
84.7,
80,
17.7,
36.5,
17.4,
53.5,
53.6,
52.3,
47,
18.3,
53.2,
93.1,
81,
84.8,
94.4,
51.4,
25.6,
30.2,
18.2,
27.6,
24.7,
53.5,
34.9,
96.2,
47.5,
84.7,
63.2,
22,
60.2,
54.3,
93.3,
69.2,
51.7,
4.6,
75.4,
14.7,
35.7,
31.1,
36.3,
59.5,
58.6,
40.4,
43.6,
20.6,
70.7,
52.3,
53.9,
61.6,
79.6,
82,
47.9,
91.5,
36.2,
0.2,
32.2,
26,
78.4,
11.1,
67.8,
47.7,
6.3,
19.8,
72.2,
45.5,
84.9,
73.7,
10.5,
61.8,
80.2,
42.3,
69,
11.4,
53.6,
80.9,
16.9,
42.3,
60,
97.8,
99,
25.5,
47.2,
58.9,
3.7,
57.1,
75,
27.6,
94.7,
54.8,
85.1,
84.2,
32.1,
18.3,
55.6,
79.7,
82.4,
45.7,
33.2,
51.6,
51.7,
68.1,
48.2,
76.3,
81.6,
69,
30.6,
27.9,
74,
49.3,
44,
81,
29.2,
63.7,
77.2,
38.4,
60,
66.1,
95.4,
31.6,
36.1,
52.9,
34.1,
84.2,
42,
73.8,
82.3,
40.2,
15.4,
87.3,
87.7,
82.1,
41.1,
75.2,
28,
23.1,
71.6,
53.7,
67.8,
90.3,
30.2,
50.7,
43.4,
27.8,
38.9,
67.3,
53.6,
27.3,
29.6,
16.6,
52.8,
13.4,
51.4,
75.2,
25.9,
38.8,
89.8,
62.7,
59.3,
31.1,
81.6,
13.2,
18.8,
44.3,
60.6,
66,
49.9,
63,
17,
81.7,
60.6,
69,
26.1,
53.8,
36.2,
60.8,
72.3,
56.3,
84,
73.7,
79.5,
17.6,
36,
35.5,
59,
83.4,
67,
19.9,
47.5,
52.4,
81.8,
78.6,
50.9,
21.8,
70.8,
55.7,
65.1,
39.6,
33.4,
99.9,
50,
33.3,
92.6,
22.6,
83.1,
73.8,
66.5,
58.2,
55.6,
67.5,
83.2,
42.1,
85.4,
79.7,
47.1,
71.1,
55.1,
100,
28.9,
92.9,
16.9,
47.7,
101.8,
82.2,
60,
64.7,
93.2,
19.9,
33.3,
34.9,
44.5,
86.9,
72.5,
37.8,
74.5,
43.6,
40,
91,
17,
67.8,
12.2,
30.5,
32.7,
66,
70.7,
29.2,
62.3,
28.2,
80.4,
60.1,
57.2,
57.4,
43.3,
93.4,
30.9,
84.4,
54.4,
91.6,
85.8,
67.5,
81.9,
78,
48,
83.6,
85.1,
42.2,
45.3,
76.6,
43.4,
50.9,
61.1,
56,
96.6,
70.1,
23,
79.5,
67.1,
58,
58.2,
39.2,
80.3,
54,
22.2,
30.8,
50.9,
79.9,
80.1,
57,
85.6,
34.5,
71.6,
53.6,
91.7,
50.4,
88.8,
40,
87.7,
60.5,
12.1,
60.5,
74.2,
62.9,
93.8,
30.9,
38.4,
56.9,
58.1,
58.8,
67.9,
14.4,
56.7,
43.2,
9.9,
90.9,
76.9,
48.3,
51.8,
48.9,
40.4,
65.4,
20.4,
45.5,
90,
44.2,
37.6,
66,
48,
63.4,
73.9,
27.8,
61.6,
10.7,
81.3,
45.4,
84.9,
41,
57.1,
20.9,
68,
12.3,
60.9,
94.9,
95.2,
50.5,
88.7,
95.1,
81.1,
91.6,
74.4,
63,
15.7,
51,
62.7,
14.4,
18,
40.7,
35.7,
66.6,
51.5,
52.9,
88.5,
93.1,
43.3,
81.4,
57.1,
73.2,
50.7,
2.2,
63.2,
63.4,
94.9,
28.7,
2,
7.6,
69.8,
32.6,
66.6,
88.6,
69.6,
89.4,
70.3,
50.2,
53.2,
33,
27,
80.2,
32,
1.3,
44.3,
36.3,
15.6,
31.8,
91,
25.7,
74.6,
28.2,
90.8,
72,
25.2,
68.1,
50.5,
51.3,
42.9,
59.9,
61.2,
25,
56.8,
71,
66.1,
14.9,
58.7,
86.3,
59.9,
75.6,
98.6,
40.3,
50.6,
5.7,
86.4,
41.1,
51.1,
26.2,
81.4,
12.4,
65.2,
63.5,
57.2,
61.9,
23.8,
30,
28,
54.7,
39.7,
92.3,
48,
58.9,
15.9,
33.6,
61.5,
68.5,
78.7,
46.2,
75.1,
77.1,
95.4,
57.2,
89.3,
30.1,
34.1,
31.4,
65.2,
41.3,
19.3,
40.1,
57,
89.6,
35.5,
33.8,
51.5,
87.8,
39,
68.7,
67.4,
65.9,
74.1,
25.6,
50.9,
77.8,
73.5,
37.3,
71.7,
30.9,
86.3,
84.4,
65.3,
55.8,
67.2,
4.9,
41.8,
73,
46.2,
97.3,
24.6,
73,
46.1,
85.3,
12.7,
49.3,
93.1,
29.5,
60.4,
70,
73.8,
87.1,
32.4,
70.8,
24.1,
72.3,
45.8,
24.7,
24.5,
70.8,
76.5,
52.1,
92.1,
60.6,
28.4,
33.2,
99.8,
35,
32.6,
58.3,
67.5,
72.7,
66.2,
64.4,
84.2,
54.9,
2.4,
80.4,
25.7,
51.4,
48.9,
82.4,
87,
27.6,
66.9,
52.9,
46.5,
77.5,
59.2,
31.7,
46.9,
20.6,
99.2,
54,
18.9,
69.5,
52.2,
24.3,
79.3,
36.6,
98.7,
90,
72.4,
56.5,
51.6,
62.8,
49,
59.6,
37.3,
55.4,
1.4,
30.9,
22.1,
77.3,
39.7,
68.8,
83.5,
50,
74.1,
34.6,
62.4,
77.2,
82.1,
35.4,
21.9,
8.5,
62,
73.7,
85.5,
58.3,
51.7,
43.1,
48.4,
86.2,
35.5,
57.6,
61.2,
72.3,
18.4,
63.6,
36,
51.7,
70.2,
77.5,
60.2,
78.6,
85.5,
15.2,
92.7,
71.6,
91.4,
85.1,
55.5,
80.7,
72.7,
44.1,
75.3,
67.5,
37.5,
75.7,
31.7,
38.6,
59.5,
26.2,
20.6,
88.8,
72.5,
11.8,
81.8,
43.1,
51.4,
38.5,
84.3,
61.2,
21.2,
48.4,
71.5,
38.2,
52.6,
43,
73.5,
83.2,
19.1,
58.4,
81.1,
22.1,
55.3,
48.4,
5.8,
73.3,
72.9,
28.2,
83.3,
79.1,
57.9,
73,
41.4,
72.9,
57.7,
78.8,
48.5,
76.1,
98,
47.7,
55.5,
5,
44.8,
38.4,
63.8,
18.5,
37.7,
76.2,
58.8,
42.5,
47,
87.7,
37.6,
55.8,
57.1,
43.3,
69.6,
92.4,
42.2,
65.1,
29.5,
77.1,
90.4,
67.7,
56.5,
90.2,
74.8,
79.9,
98.1,
24.4,
91.3,
59.7,
65,
30.2,
79.4,
100.7,
50.4,
87.6,
85.6,
36.5,
9,
5.9,
92.9,
75,
6.5,
84,
21.1,
62.2,
45.4,
37.9,
11.8,
77.5,
84.2,
65.3,
73.1,
30.5,
74.7,
77.2,
12.1,
69.4,
63.7,
79.5,
85.5,
61.4,
63.7,
95.8,
46,
101,
79.9,
59,
86.1,
94.6,
58.2,
34.4,
62.5,
44.1,
21.3,
91.8,
27.9,
76,
70.5,
17.5,
90.5,
65.7,
68.5,
90,
64.3,
65.7,
88.3,
94,
38.1,
36,
12.2,
52.8,
20.6,
14.3,
27.6,
43.9,
73.7,
49.2,
63.6,
20.8,
34.6,
22.6,
81.7,
74.1,
61.1,
87.5,
82.8,
53.6,
61.1,
40.8,
50,
87,
69.4,
29.7,
72.8,
36.2,
77.9,
66.9,
63,
44.3,
0.7,
56.5,
57.3,
33.8,
86.4,
65.2,
44,
66.6,
74.9,
46.1,
31.8,
50,
61.2,
77.9,
93.3,
68.8,
62.6,
10.8,
49.9,
79.6,
0,
24.2,
45,
77.9,
58.6,
67.9,
84.1,
41.1,
77,
31.1,
8.2,
42.2,
73,
86.9,
22.7,
50.3,
41,
3.7,
92.9,
78.2,
56.9,
66,
75.4,
87.7,
42.9,
38.4,
69.1,
37.8,
76.6,
58.1,
73.2,
48.3,
63,
72.9,
56.3,
38.7,
51.5,
80.7,
64.3,
55.6,
24.6,
44.8,
27.4,
82.8,
30.9,
57.2,
48.6,
49.9,
50.7,
64.2,
13.4,
33.3,
86.2,
30.6,
19.8,
77.4,
59.2,
87.6,
83.9,
46,
66.6,
61.5,
39.7,
82.6,
57.5,
85.7,
39.2,
59.4,
50.1,
77.5,
58.4,
77.1,
81.6,
46.7,
73.9,
40.3,
82.1,
82.3,
6,
44.4,
46.7,
63.6,
0.2,
16.4,
13.8,
92.3,
28.9,
75.8,
70.1,
33.5,
74.4,
83,
46.7,
44.4,
29.4,
49.7,
23,
58.9,
26.5,
3.5,
45.4,
30.8,
21.5,
70.2,
48,
44,
90.4,
17.3,
58.7,
56.3,
89.8,
41.8,
69.9,
54.9,
85.2,
84.7,
39.3,
72.1,
70.8,
36.3,
72.1,
9.5,
66.6,
68,
76.8,
60.4,
50.5,
73.4,
23.1,
37.4,
44.5,
85.1,
31.5,
78.2,
19.8,
45.5,
70.5,
77.9,
91.5,
54.6,
76.2,
45.7,
72.5,
36.1,
90.1,
41.5,
49.2,
52.1,
24.9,
58.8,
39.1,
89.3,
0.5,
7.2,
68.6,
31.7,
79.7,
39.6,
76.3,
72.7,
31.1,
35,
54.1,
70.7,
53,
70.1,
79.4,
69.8,
67.1,
41.6,
82.5,
71.1,
32.6,
20.5,
71.6,
79.1,
16.3,
91.5,
45.9,
92.2,
0,
55.1,
49,
25.6,
51.7,
45,
45,
32.8,
80.2,
74.4,
31.8,
46.8,
49,
32.1,
64,
47.8,
49.1,
65.1,
65,
56.8,
44,
65.1,
70.6,
34.4,
77,
72.9,
81.5,
57.6,
48.1,
51.6,
54,
61.2,
91.4,
47.1,
33.7,
28.5,
61.2,
32.9,
46,
67.7,
88,
4.9,
88.5,
73.3,
71.4,
60,
53.1,
70.7,
95.2,
39.1,
66.4,
87.4,
53.6,
84.5,
78.9,
77.1,
54.6,
57.3,
42.9,
98.4,
55,
25.7,
46.5,
74.8,
62.2,
46.6,
31.1,
40.1,
82.6,
59.9,
38.8,
71.6,
63,
26.1,
76.6,
41.1,
17,
22.9,
57.2,
36.4,
45.9,
49.3,
69.8,
83.8,
83.3,
54.3,
73.4,
56,
35.4,
87.9,
71,
94.3,
78.6,
0,
37.7,
23.6,
85.4,
38.9,
41.2,
5.1,
50.2,
79.8,
62.7,
32.1,
73.8,
73.2,
54.2,
73.1,
87.3,
50.2,
23.8,
30.2,
74.6,
40,
70,
23.8,
76,
86.1,
50,
58.6,
71.8,
26.4,
8.9,
55.5,
69.9,
45,
74.3,
35.4,
97.7,
26.4,
27.9,
79.7,
92.8,
63.6,
0,
43,
61.1,
14.1,
62,
39.2,
74.2,
55.3,
45.1,
74,
83.9,
77.9,
69.1,
27.3,
42.8,
0,
22.8,
33,
56,
14.1,
0,
56.4,
50.7,
79.4,
67.3,
87.2,
81.7,
46.3,
64.7,
84.9,
55.2,
68.7,
38.8,
48.7,
90.8,
51.4,
63.8,
29,
47.5,
0,
96,
26.8,
54.2,
17.7,
50.5,
24.8,
73.4,
7.6,
81.6,
41.4,
30.7,
53,
28.7,
21,
20.7,
64,
38.9,
65.3,
72.3,
27.7,
73.4,
83.3,
65,
80.7,
99.8,
98.5,
86.6,
72.1,
50,
44.4,
65.7,
48.9,
51.2,
72.5,
51,
85.3,
63.5,
39.5,
54.7,
45.3,
55.7,
97,
68.3,
55.5,
73.8,
84.1,
85.1,
46.3,
26.8,
28.8,
30.8,
49.4,
47.2,
54.9,
49.2,
43.7,
71.8,
99.2,
39.3,
82.5,
66,
21.7,
35,
90.5,
75.2,
69.3,
28,
88.9,
93.3,
87.6,
99.2,
55.5,
34,
43.3,
74.2,
60.9,
50.2,
49,
60.8,
17.4,
33.6,
25.3,
57.1,
56.3,
20,
45.7,
59.1,
34.9,
3.8,
73,
54.4,
39.9,
51.4,
39.1,
82.7,
6.2,
59.3,
63,
66.5,
76.9,
28.2,
57.7,
73.7,
49.7,
21.2,
63.9,
4.1,
11.5,
22,
38.2,
63.1,
45.5,
49.9,
34.2,
18.5,
70.8,
79.9,
76.1,
39.4,
9.8,
96.3,
32.2,
67.6,
58.2,
94.2,
86.3,
31.7,
40.6,
7.8,
76.7,
63.7,
24.7,
54.9,
63.7,
66.1,
79.8,
91.2,
102.4,
56.9,
86.9,
89.3,
51.3,
76.4,
21.5,
59.5,
40.8,
58.8,
41.3,
71.1,
55.5,
79,
62.8,
34.4,
78.7,
89.6,
10.6,
41.6,
26.9,
19,
62.5,
39.4,
86.9,
82.4,
39,
69.1,
74.3,
82.4,
91.6,
81,
40.5,
78.5,
84.3,
33.4,
95.5,
23.6,
36.2,
58.3,
64.7,
49.2,
44.2,
48.2,
80.5,
64.7,
28.3,
97.2,
78.6,
96,
97.3,
56,
84.5,
34.4,
25.7,
69.9,
64.6,
52.3,
128.4,
41.2,
64.7,
69.1,
54.7,
87.7,
64.2,
94.9,
43.6,
43.3,
58.6,
57.4,
88,
45.4,
57.8,
81.2,
50.5,
77,
60.3,
9.1,
47.8,
23.5,
10.5,
68.9,
38.6,
52,
53.9,
35.1,
48.6,
88.9,
57.7,
89,
71.9,
12.1,
10.5,
63,
76.7,
13.9,
27.1,
47.1,
77,
77.6,
56.8,
54.1,
59.1,
15.1,
55.6,
64.8,
21,
48.1,
73.4,
81.7,
41.6,
12.7,
50.9,
36.3,
21.7,
57.9,
30.8,
51.8,
30.3,
46.2,
16.4,
48.1,
17,
25.2,
54.3,
20.3,
90,
48.1,
4,
89.5,
22.5,
87.4,
65.1,
17.7,
97,
60.4,
61.8,
34,
27.6,
52,
64.9,
57.2,
71.2,
33.1,
73.7,
74.8,
84.1,
72.6,
45.5,
67.1,
48.3,
55.4,
14.6,
76.7,
80.8,
47.1,
70.3,
58.8,
33.5,
29.7,
79.2,
35.7,
21,
78.4,
76.4,
69.2,
82.7,
46.3,
22.1,
51.8,
36.8,
92.9,
78.9,
88.4,
44.6,
60.7,
71.8,
28.9,
58.3,
53,
33.4,
46.6,
41,
57.4,
54.3,
70.2,
40.3,
62.8,
97,
62.5,
34.7,
54.6,
38.2,
76.2,
64,
65.2,
56.4,
90.4,
63.6,
95.3,
69.1,
76.9,
51.2,
76,
24.5,
42.3,
37.7,
61.4,
92.5,
90.8,
56,
51.3,
82.7,
62.9,
53.5,
67,
61.8,
25.8,
98.5,
40,
71.7,
82.5,
66.1,
69.7,
26.8,
49.3,
86.1,
57.3,
27.6,
16.2,
95.9,
42.8,
66,
43.3,
44.8,
64.7,
78.3,
69,
36.4,
75,
95.7,
45.1,
24.9,
50.3,
73.2,
35.9,
101.9,
98.3,
65,
71.6,
78.2,
59.2,
42.2,
56.6,
83.8,
54,
63,
44.4,
94.6,
7.2,
32.9,
44.3,
60.3,
41.2,
79.1,
97,
10.2,
71.5,
13.7,
11.3,
45.1,
41.3,
33.8,
51.2,
92.1,
49.6,
58,
55.3,
2.7,
21.5,
35.2,
58.5,
45.6,
61.4,
89.8,
64.6,
54.5,
43.2,
33.7,
51.6,
86.7,
88.4,
54.2,
16.4,
0.8,
60.5,
69.7,
21.9,
70.2,
22.3,
39.9,
74.4,
53.3,
42.1,
46.7,
22.1,
63.6,
49.9,
19.9,
22.7,
76.9,
58.4,
38.9,
43.4,
73.8,
89.8,
53.3,
92.1,
65.6,
54.4,
64.8,
56.2,
56.9,
90,
19.7,
46.6,
26.7,
26.3,
48.6,
0,
17.9,
80.6,
71.1,
63.7,
0.4,
74.1,
73.9,
50.2,
38.6,
24.2,
31.7,
35.4,
64.2,
79.6,
65,
43.9,
20.1,
50,
29.9,
16.8,
28.1,
44.5,
28.7,
33.2,
17.2,
61.5,
23.6,
30.8,
38.4,
77.1,
63.1,
87.3,
14.7,
73.7,
70,
61.8,
51.1,
56.7,
26.8,
70.7,
38.1,
55.9,
55.1,
66.5,
84,
78.4,
77.3,
80.2,
59.8,
95.8,
42.4,
58.3,
52.3,
94.5,
97.3,
73.6,
60.2,
24.3,
46.1,
79.2,
39.3,
62.4,
40.7,
null,
60.8,
27.6,
85.4,
27.8,
71,
90.6,
42.8,
89.3,
64.8,
67.8,
33.2,
83.1,
59,
39.6,
81.8,
77.2,
32.2,
62.2,
27,
38.3,
78.8,
50.8,
87.4,
73.8,
91,
41.6,
91.1,
51.4,
46.9,
55.2,
79.3,
49.8,
49.7,
82.3,
69.9,
19,
47.3,
52.5,
75.9,
62.9,
67.5,
40.2,
85.2,
90.8,
86.3,
84.7,
21.5,
51.1,
72.2,
31.9,
64,
43.5,
59.3,
100.9,
2.3,
2.5,
58.1,
45,
33.9,
31.2,
31.3,
46.5,
94.2,
58.1,
51,
52.4,
65.6,
82.5,
21.9,
62.2,
38.2,
63.9,
57,
90.2,
93.1,
54.9,
56.4,
48.2,
60.8,
50.7,
55.4,
87.3,
96.4,
66.2,
13.4,
80.6,
73,
13.7,
21.2,
55.4,
66.9,
19.6,
70.6,
42.2,
64,
67.6,
11.8,
88.6,
79.4,
57.3,
76.6,
82.1,
45.2,
85.3,
90.8,
65.7,
86.8,
24.8,
99.3,
96.2,
40.3,
55.1,
52,
44.8,
13.9,
60.6,
99,
67.2,
90,
33.8,
59.8,
68.3,
90.1,
44,
57.2,
84.7,
58.6,
61.7,
52,
47.8,
72.5,
63.9,
16.4,
35.4,
42.1,
3.1,
62.6,
59.1,
17.6,
57.2,
67.1,
35.1,
77.7,
32.2,
36.9,
78.7,
79.4,
77.5,
48.3,
80.2,
47.5,
94.7,
50.8,
37,
55.7,
45.6,
93.6,
82.8,
63,
56.3,
46.1,
35.6,
47.4,
49.7,
96.2,
2.7,
65.4,
47.5,
74,
10.9,
51.9,
88.4,
50.7,
83.7,
44.7,
31.1,
76,
58.8,
83.9,
82,
45,
24.3,
48,
35.8,
56.2,
13.9,
20.2,
52,
55.1,
30.2,
35.9,
15.9,
65.6,
96.5,
13.5,
77,
42.4,
46,
77.6,
41.4,
44.4,
50,
55.8,
87.5,
96.2,
67,
40.8,
47.1,
16.2,
45.5,
68,
19.2,
94.8,
71.1,
24.4,
48.7,
84.4,
67.4,
62.9,
69.7,
88.6,
62.4,
70.9,
44.2,
79.8,
36.6,
57.5,
56.2,
22.4,
88.7,
54.7,
66.4,
59.3,
64.3,
69.7,
86.5,
61.1,
62.2,
55,
51.9,
19.3,
92.3,
43.5,
69.9,
58.1,
89.7,
94.1,
47.5,
46.8,
83.6,
54.2,
75.2,
67.5,
51.9,
77.7,
92.9,
80.5,
19.7,
97.4,
74,
45.6,
101,
4.7,
90.7,
64.6,
40.2,
49.7,
63.1,
92.6,
3.3,
34,
79.1,
59.5,
14,
0.8,
44.3,
57.2,
68.2,
5.8,
63.3,
60.3,
49.1,
67.9,
52.5,
87.2,
0,
17.7,
46.6,
65.5,
57.4,
83.6,
3.7,
53.4,
19.3,
83.8,
38.1,
78.1,
20.5,
52.4,
29.5,
82,
74.9,
74.6,
69.6,
65.3,
45.3,
72.6,
40.3,
20,
91.7,
45.6,
7.1,
35,
53.2,
44.1,
21.9,
39.1,
68.9,
48.1,
52.9,
34.2,
19,
47.1,
37.8,
38.7,
93.5,
77,
36.1,
53.4,
37,
55.3,
42.8,
29.5,
56.8,
67.3,
0,
80.7,
46.8,
54,
72.2,
98.7,
73,
59,
73.4,
35.3,
14,
9.7,
42.9,
61.8,
38,
66.2,
97.3,
41.1,
11.6,
56,
18.3,
28.9,
6.2,
71.7,
56.3,
81.1,
45.4,
48.8,
41.3,
66.4,
53.3,
86,
26.7,
59.8,
10.9,
77.2,
41,
72.1,
71.4,
null,
88.9,
50.7,
33.6,
4.9,
47,
26.5,
92.5,
50.4,
23.7,
45.5,
71,
24.8,
94.1,
13,
90.1,
33.7,
69.6,
43.5,
71.6,
76,
63.7,
49.7,
37.4,
64.2,
21.7,
8.5,
74.7,
48.1,
17.4,
52,
43.4,
29.8,
88.1,
65.4,
28.2,
78.3,
47.8,
65.1,
95.2,
27.4,
42.9,
80.2,
38.7,
68,
6.3,
55.9,
49,
47.7,
73.9,
38.6,
6.4,
52.7,
93.3,
64.4,
44.4,
73.2,
46.4,
99.1,
84.3,
33.1,
75.3,
84.9,
44.5,
66.8,
71.6,
66.2,
84.1,
93.5,
56.3,
42.2,
23,
66.1,
48.6,
63,
44.8,
77.7,
68.1,
59.8,
93,
32.7,
91.9,
83.6,
26.5,
66.2,
31.5,
36,
62.4,
57.2,
69.4,
36.8,
39.2,
59.4,
58.8,
46.2,
29.3,
101.4,
44.5,
59,
53,
6.8,
42.1,
82.6,
76.5,
27.4,
10.4,
27.4,
93.9,
37.4,
43.4,
50.7,
67.1,
60.1,
31,
39.4,
29.1,
67,
78.1,
56.1,
67.9,
90.1,
86.9,
39.5,
88.8,
65.2,
42.2,
70,
51.7,
34.7,
81.7,
25.1,
60.2,
32.8,
27.3,
34.8,
98.5,
54.9,
30.9,
82.1,
25,
78.8,
37.2,
89,
91.2,
40.5,
54.9,
67.7,
42.4,
53.4,
46.3,
34.8,
59.1,
80.6,
67.2,
83,
87.5,
13.2,
62.4,
67.5,
45.9,
76.1,
35.9,
54.4,
73.5,
15.3,
66.5,
73.2,
68.1,
48.7,
75.7,
70,
65.6,
73.2,
62.5,
48.5,
73.8,
79.4,
65.8,
44.2,
49.3,
67.4,
80.4,
64.8,
74.3,
54,
56.5,
97.2,
25.8,
52.3,
38.3,
88.6,
46.4,
82.7,
31.4,
36.1,
84.7,
44.7,
44.6,
56.3,
14.4,
83.7,
60.8,
48.9,
34.3,
29.3,
51.9,
87.6,
16.4,
42.2,
94.9,
69.1,
57.8,
44.5,
23.5,
75.6,
77.3,
39.6,
81.4,
97.5,
36.1,
37.4,
90.6,
60.1,
81.9,
85.4,
78.7,
66.9,
1.6,
46.9,
29.3,
85.2,
70.8,
8.7,
41.2,
44.2,
71.6,
75.4,
65.8,
37.1,
0,
32.9,
29.1,
32.1,
66.1,
37.4,
36.6,
44.8,
88.1,
21.6,
95.9,
55.6,
27.7,
37.4,
68.5,
52.7,
29.7,
10.2,
97.8,
49,
36.2,
18.7,
43,
55.8,
77.8,
53.4,
64,
36,
58.2,
38,
60.5,
75.1,
36.4,
82,
80.9,
55.8,
29.3,
83.6,
87.6,
50.4,
58.4,
1.5,
69.8,
118.4,
39.9,
20.7,
12.4,
59.8,
90.6,
23,
16.2,
26.9,
52.8,
33.4,
28.6,
57.1,
66.8,
53.5,
65.1,
59.4,
49,
90.6,
29.5,
46.6,
61.5,
74.1,
15.2,
7.3,
79.5,
59.6,
42.6,
24.7,
39.5,
71.1,
90.2,
41.1,
61.7,
32.7,
56.6,
8.1,
78.6,
77,
98.2,
47.9,
37,
84.1,
62.9,
78.2,
66.5,
53.8,
62.8,
51.2,
72.2,
64.8,
14.6,
34.8,
37.5,
75.6,
46.1,
37.5,
52.3,
6.4,
16,
41.4,
35.7,
10.9,
22.3,
53.4,
78.1,
40.4,
80.6,
70.9,
46.2,
97,
26.7,
86,
48.7,
86.3,
16.9,
64,
72,
62.6,
87.6,
57.6,
14.1,
84.8,
71.4,
22.3,
83,
77.1,
61.5,
54.9,
76.4,
51,
34,
62.3,
20.9,
72.3,
33.8,
57.6,
30.8,
67.5,
93.6,
26.8,
26.2,
52,
39.2,
27.1,
64.7,
93.6,
62.6,
91.8,
86.4,
41.5,
null,
58.2,
81,
68.1,
54.8,
23.1,
32,
29.8,
86.8,
67.5,
49.5,
86.9,
86.6,
38.5,
57.5,
51.8,
51.6,
24.2,
32.2,
40,
46.1,
73.5,
61.8,
62.2,
33.9,
72.9,
69.4,
57.3,
45.2,
26.6,
43.9,
66.5,
76,
97.2,
50.4,
31.7,
21.5,
78.4,
77,
13.6,
38.8,
86.9,
57.9,
83.7,
52.4,
31.9,
22.3,
67.7,
44.8,
41.9,
46.8,
40,
54.3,
72.6,
86.9,
74.7,
62.6,
50.5,
13.3,
39.7,
26.8,
19.4,
0.7,
62,
35.9,
30.5,
75.2,
78,
80.2,
52.3,
69.7,
69.8,
69.7,
8.2,
53.3,
38.7,
56.2,
73,
94.7,
66.6,
26.1,
58.1,
51.5,
80.8,
63.4,
85.3,
60.2,
13.4,
65.1,
24.3,
46.8,
34.3,
98,
81.2,
97.8,
70.9,
87.4,
57.9,
23.8,
31.3,
61.1,
49.9,
70.6,
93.3,
73.1,
15,
36.4,
44.1,
78.8,
65.8,
30.4,
82.4,
68.5,
71,
73.6,
19.9,
52.2,
52.8,
91,
89.2,
0.8,
65.2,
82.1,
72.6,
48.3,
75.3,
82,
67.2,
33.2,
37.2,
33.9,
52.4,
46.2,
36,
53.3,
71.8,
9.3,
73.6,
50.4,
95.3,
89.2,
64,
70.3,
18.5,
81.8,
31.5,
17.4,
null,
62,
50.9,
75.9,
29,
2.8,
48.7,
83.7,
23.9,
91.4,
47.7,
28.1,
83.7,
103.9,
47.6,
10,
57.6,
69.2,
55.1,
2.6,
37,
97.3,
35.5,
97.8,
31.3,
63.2,
16.3,
84.6,
77.2,
54.4,
69.4,
80,
73,
58.9,
7.4,
70.2,
95.3,
58.6,
68.1,
76.6,
72.8,
87.7,
67.6,
46.4,
65.8,
74.4,
66,
38.5,
31.1,
50.7,
32.9,
90.8,
66.6,
69.3,
95.1,
39,
19.3,
50.3,
69.7,
83.9,
87.1,
40.5,
64.8,
59.5,
55.9,
49.1,
81,
92.8,
78.9,
82,
1.3,
49.8,
33.5,
12.1,
0.6,
78.1,
87.5,
88.9,
36.3,
85.6,
78.5,
97.7,
61,
79.4,
37.3,
77.3,
3,
24.5,
79.9,
55.2,
45.1,
42,
45.9,
46.9,
74.3,
77.6,
57.7,
11.3,
40.8,
45,
43,
5.3,
85.4,
89.9,
69.3,
69.3,
88.9,
41,
97.9,
13.7,
39.6,
47.9,
5.7,
57.6,
48.2,
71.3,
20.2,
36.2,
28.7,
42.2,
63.4,
42.5,
51.8,
66.9,
30.4,
80.1,
12.2,
65.6,
51.5,
26.5,
101.6,
72.8,
28,
59.5,
83.2,
54.1,
82.7,
85.9,
79,
51.8,
80.4,
74.7,
32.6,
88.5,
53,
91.3,
37,
64.8,
34,
49.2,
46.7,
80.2,
58.1,
60.1,
47.9,
49.9,
29.7,
100.6,
16.7,
83.2,
83.9,
51.1,
30.9,
66,
94.3,
74.6,
56.6,
21,
39.1,
91.8,
39.2,
36,
34,
83.6,
83.1,
57.4,
100.4,
45.3,
77.5,
38.8,
12,
87.2,
39.2,
85,
56,
39.8,
37.3,
84.6,
46.2,
46.2,
45.1,
35.4,
69.7,
96,
73.3,
57.6,
79,
37.7,
32.7,
59.3,
46.9,
17.4,
58.7,
71.7,
67.7,
69.9,
45.4,
79.2,
17.7,
62.7,
80.3,
19.9,
69.6,
61.6,
79.1,
60.5,
41.9,
82.1,
85.9,
78.2,
81.1,
74.6,
76.6,
17.4,
56.9,
46.5,
33.4,
33.7,
58.9,
62.5,
62.8,
84,
85.1,
47.1,
77.9,
59.3,
94.7,
19.8,
48.9,
2.4,
37.3,
65.9,
59.1,
36,
65.1,
44.8,
30.5,
65.2,
28.4,
72.6,
74.9,
30.6,
38.2,
62.9,
41.9,
67.8,
66.1,
55.4,
5.7,
41.9,
75.3,
83.1,
45.5,
66.1,
44.3,
73.6,
70.1,
81.7,
8.1,
61.2,
89.5,
79.7,
74.7,
76.8,
45.8,
71.1,
98.7,
45.3,
75.8,
41.9,
65.7,
89,
11.4,
74.2,
48.3,
68,
69.1,
42.5,
70.7,
94.1,
21.8,
68.3,
22.9,
36.2,
87.1,
69,
52.9,
51.3,
93.8,
42.6,
31.8,
62.2,
47.2,
23.9,
null,
29.6,
37.3,
60.4,
29.3,
79.7,
51.4,
35,
59.2,
82.6,
69.9,
51.3,
53.8,
39.1,
53.7,
15.7,
68.8,
62,
78.5,
71.6,
87.1,
61.4,
93.7,
31.8,
75,
84.3,
62.7,
59.1,
29.5,
38.4,
49.7,
91,
70.6,
22,
59.6,
11.7,
74,
92.4,
43.8,
39.6,
33.6,
60.1,
61.7,
28,
80.8,
72.9,
60,
66.3,
41.7,
82.8,
41.8,
57.3,
22.7,
72.6,
10,
41.6,
40.4,
91.2,
48,
37.1,
55.7,
10.4,
6.5,
41.3,
78.4,
6.4,
98.3,
98.3,
97.5,
42.2,
52,
46.7,
88.4,
99.8,
53.7,
48.8,
63.9,
62.4,
46.5,
39.8,
94.7,
25.3,
15.7,
13.8,
9.4,
65.9,
47.9,
53,
85.7,
22.2,
72.8,
32.4,
51.2,
87.4,
42,
82.8,
78.8,
58.7,
59.9,
33.5,
26.5,
12,
27.8,
37.7,
31.1,
37.6,
86.7,
70.3,
51.8,
53.6,
37.1,
77.4,
25.8,
43.9,
96.4,
73,
21,
25.7,
44.3,
60.4,
56.4,
61.4,
38.5,
56.5,
43.9,
37.6,
15.4,
11,
10.7,
17.8,
52.8,
50,
66.4,
92.8,
71.9,
85.5,
49.8,
68.3,
85.6,
68.5,
56.9,
36,
85.8,
84,
87.7,
65,
53.6,
42.2,
38.2,
37,
88.4,
39,
58.7,
54.3,
81.2,
51.9,
75.3,
39.9,
95.2,
61.9,
51.5,
58.2,
53.2,
71,
18.4,
92.6,
40.6,
40.1,
59.2,
41.8,
50.9,
87.8,
58.7,
15.7,
52.6,
68.6,
24.4,
12.8,
40.8,
82,
70.5,
48.6,
78.2,
74.4,
43.1,
65.4,
63.6,
57.4,
27.8,
66.5,
47.8,
26.1,
41.8,
90.8,
28.8,
68,
60.4,
59,
33.4,
58.3,
44.9,
97.7,
61.7,
59.6,
44.4,
68.6,
22.4,
18.3,
86.1,
69.9,
80.3,
75.7,
90.9,
39.6,
86.9,
50.7,
80.2,
46.1,
21,
71.3,
94.6,
56.4,
39.9,
68.7,
85.3,
55.3,
57.4,
66.6,
47.7,
48.5,
67.2,
92.1,
61.8,
50.8,
68.5,
72.3,
6,
52.9,
70.4,
35.4,
68.2,
80.6,
69.5,
19.4,
38.4,
81.8,
63.7,
95.3,
52.5,
70.8,
69.6,
30.5,
82.5,
67.9,
25.4,
56.7,
47.3,
55.6,
36.4,
79.6,
24.2,
98.3,
94,
34.3,
91.7,
62.9,
43.4,
46,
64,
80.2,
55.4,
77.3,
71.2,
50.7,
68.7,
84.4,
60,
50.2,
36.5,
15.4,
79,
79.2,
92.6,
69.5,
71.2,
52.6,
34.7,
63.3,
97.2,
65.9,
97.2,
81.7,
91.3,
75.8,
66.8,
32.5,
41.4,
19,
68.9,
62.9,
44.7,
36.3,
43.7,
56.8,
79,
62.3,
37.9,
71.8,
28.2,
95.9,
87.4,
58.9,
16.3,
84.1,
51.3,
25.7,
40.7,
27.2,
57.4,
61,
87.2,
81.6,
22.5,
13.8,
93.9,
9.1,
7.7,
35.5,
71.9,
9.1,
70.9,
35.4,
40.6,
48.8,
57.7,
60.7,
34,
21.9,
7.1,
55.9,
92.6,
24.9,
35.6,
81.2,
88.6,
11.7,
65.9,
68.7,
81.4,
77.9,
64.3,
68.4,
0.1,
51.8,
69.2,
96.6,
65.3,
38.5,
27.7,
68.1,
44.6,
29.4,
38.2,
71.2,
51.4,
59.3,
72.4,
64.9,
81,
23.1,
68,
16.4,
95.1,
60.9,
23.5,
64.3,
66.8,
78.4,
85.7,
44.8,
21.7,
18.8,
56,
48.4,
18.5,
77.5,
58.2,
33.6,
72.4,
61.3,
77.8,
83.2,
32.7,
40.4,
51,
69,
54.8,
73.8,
43.6,
38.5,
54.4,
85.9,
10.2,
77.2,
77.4,
33.9,
55.2,
56.3,
53.8,
24.2,
40.2,
95.6,
97.8,
69.1,
81.5,
32.3,
34.7,
79,
25.4,
44.2,
31.5,
51.4,
100,
64.4,
65.6,
54.8,
42.7,
53.5,
66.9,
41.4,
37.9,
37.3,
80.2,
28.5,
5.4,
2.1,
95.4,
55.8,
87.6,
35.8,
47.9,
20.6,
82.2,
94.3,
32,
68,
34.4,
41,
57.1,
66.4,
30.9,
47.5,
51,
48.4,
62.6,
64.2,
88.9,
47,
21.4,
21.8,
68.9,
42.5,
5.6,
19.5,
55,
63.3,
24.8,
21.4,
31.9,
79.3,
34.9,
77.8,
40.7,
57.9,
10.8,
50,
67.7,
48.6,
63.4,
42.1,
68.2,
99.9,
20.5,
23.3,
64.8,
72.7,
68.1,
99,
51.3,
38.9,
44.7,
0.2,
27.6,
25,
62.1,
34.2,
78,
42.1,
81.2,
98.3,
14.7,
87.6,
91,
70.2,
90.2,
49.4,
77,
51.9,
42.8,
42,
66.9,
37.3,
55.8,
41.3,
42.9,
30.3,
40,
69.4,
81.6,
23.8,
9.8,
77.6,
25.4,
36.2,
87.7,
67.1,
24.5,
56.8,
26.1,
48.5,
23.7,
46.4,
81,
45.4,
80.9,
75.4,
55.1,
69.2,
49.3,
89.7,
20.4,
12.2,
25.4,
30,
40.8,
47.3,
78.8,
89.9,
48.1,
65.4,
67.5,
62.6,
96.7,
61.6,
0.5,
15.7,
47,
45,
65.8,
47.9,
78.8,
52.9,
85.8,
34.8,
36.2,
86.4,
31.3,
42.5,
89,
65.7,
43.3,
56.2,
58.2,
70,
73.8,
20.5,
76.3,
72,
27.5,
59.6,
54.8,
75.1,
57.7,
82.8,
66,
50.3,
75.4,
52.1,
7.7,
100.2,
32.3,
29,
50.2,
37.4,
39.5,
48,
0.2,
56.4,
58.6,
69.7,
78.2,
0,
47.2,
64.5,
64.7,
71.7,
61.8,
35.6,
26.7,
65.8,
33.9,
81.5,
0.1,
36,
81.1,
66.3,
49.2,
23.7,
36.7,
62.7,
44.1,
28.6,
43.5,
21,
49.5,
34.5,
72,
67,
86.2,
95.5,
2.2,
19.5,
39.3,
24.2,
67,
13.2,
27,
85,
22,
47.5,
87.8,
52.5,
40,
39.4,
31.4,
61.1,
90.1,
17.7,
24,
48.1,
30.7,
73.6,
75,
64.6,
54.5,
45.3,
59,
3.1,
28.9,
79.8,
63.9,
16.6,
30.8,
42.1,
47,
72.1,
68.8,
91.1,
69.2,
29.5,
57.6,
29.8,
33.9,
61.1,
21.7,
61.4,
67.8,
6.3,
84,
78.1,
23.2,
59.7,
49.5,
85.2,
27.8,
75.9,
73,
58.3,
71.4,
72.6,
30.1,
42.9,
46,
30,
35.4,
61,
63,
65.4,
42.8,
94.3,
74.5,
91.7,
51,
50.8,
28.2,
40.7,
59.8,
63.2,
56.9,
42.2,
57.3,
54.3,
74.3,
73.4,
36.9,
81.4,
56.8,
91.7,
53,
50.8,
24.3,
84.7,
91.2,
52.3,
65.6,
57.4,
49.6,
61.4,
64.7,
79.7,
69.7,
43.5,
92.9,
44.8,
42.5,
37.4,
49,
44.2,
84.2,
11.8,
59.5,
69.8,
33.9,
60,
62.2,
47.6,
27.4,
101.6,
68.9,
85.1,
54.6,
60.3,
62,
47.2,
8.7,
36,
67.3,
77.3,
23.6,
48.5,
92.3,
41.3,
94.8,
27.6,
46.7,
94.3,
3.7,
54.1,
41.4,
74.5,
53,
62.7,
96.9,
89.4,
91.3,
64.9,
54.9,
36.9,
74.5,
74,
49.8,
48.5,
96.2,
67.3,
34.4,
64.2,
89.8,
86.6,
35.8,
28,
82.6,
73.7,
27.1,
69.6,
52.1,
50.9,
36,
60.7,
42.5,
44.6,
36,
30.3,
43.6,
37.4,
55.3,
32.5,
53.8,
97.5,
23.3,
80,
56,
80.4,
98.6,
99.1,
62.6,
20.6,
65.3,
70.4,
80.8,
10.3,
69.1,
0,
47.6,
65.8,
86.7,
78.9,
60.6,
13.1,
15.2,
84.6,
28.3,
52.7,
35.6,
65.2,
72,
18.6,
26.1,
50.6,
50.7,
62.7,
55.6,
83.1,
51.1,
67.7,
10.3,
47.4,
43.9,
36.3,
20,
88.1,
41.6,
69.3,
83.1,
45.8,
69,
51.3,
63.8,
8.7,
40,
52.9,
51.4,
16.6,
53.4,
15.8,
70.9,
73,
28.2,
141.1,
89.6,
61.1,
46.4,
98.7,
88.2,
62.1,
94,
53.9,
49,
79.4,
38,
23.3,
88.4,
67.3,
31.1,
58.1,
61.7,
63.7,
67.5,
67.9,
11.6,
10.2,
86.7,
40.9,
59,
47.9,
54.4,
57,
56.7,
7.5,
35.8,
57.8,
79.5,
43.8,
41.7,
40,
45.6,
73.5,
90.9,
53.8,
72.3,
52.6,
34.1,
73.7,
1.7,
20.3,
48.8,
59.3,
41,
77.9,
48,
38.2,
74,
96.3,
42.3,
82.1,
40,
61.9,
68.8,
34.8,
34,
57.1,
64.6,
76.5,
45.9,
78.4,
66.3,
65,
81.2,
50.3,
69.7,
47.2,
62.6,
67.5,
56.1,
62.2,
11.7,
84.7,
65.5,
90.8,
99.1,
43,
78.7,
50.5,
46.3,
89.5,
1.4,
35.7,
65.4,
34.9,
23.2,
44.5,
31.4,
46.1,
60.5,
22.4,
94.4,
16.7,
1.1,
7.1,
45.7,
41.4,
18.1,
8.3,
36,
36.7,
61.2,
56.3,
75.5,
66.1,
54.9,
56,
46.3,
70.8,
64.3,
65.1,
30.8,
32.2,
94.7,
57.1,
72.7,
61,
82.8,
70.6,
3.1,
77.5,
82.5,
37.4,
72,
51.7,
45.8,
96.6,
24.3,
47.4,
78.7,
62.6,
31,
63.7,
56.8,
70.7,
87.2,
47.4,
23.5,
97.1,
34.4,
45.9,
36.9,
35.6,
21.9,
40.8,
58.3,
38.6,
28.8,
99.2,
83.8,
14.9,
35.5,
24.8,
42.8,
65,
15.3,
78,
95.4,
98.8,
76.7,
60.4,
85.7,
20,
71.7,
83.8,
79.5,
47.1,
63.7,
35.3,
49.4,
52.9,
83.9,
99.3,
34.3,
56.2,
47.8,
26,
94.3,
51.8,
45,
66.6,
53,
54.2,
95,
17.4,
54.1,
96.9,
64.6,
64.6,
64.7,
36,
74.2,
83.7,
93.8,
54.2,
57.2,
67,
95.9,
64.1,
83.1,
67.6,
61.3,
2,
97.5,
91.8,
13,
64.7,
40.2,
38.4,
43.2,
77.4,
59.1,
26.6,
36.4,
55.5,
41.4,
83.7,
36.7,
73.8,
29.2,
54.8,
58.5,
76,
69.2,
80.5,
67.9,
64.4,
73.5,
30.6,
46.6,
29.7,
51.3,
71,
88.5,
53.8,
60.7,
27.6,
71,
32.9,
5.5,
12,
28.5,
57,
21,
35.7,
86.5,
39.9,
55.8,
54.5,
32.4,
59.8,
77.1,
30.5,
58.5,
44.4,
63.5,
95,
51.6,
39.6,
74.9,
10.8,
22.8,
49.5,
53.3,
33.9,
59,
64.7,
57.8,
66.8,
13.9,
38.8,
47.2,
19.2,
31,
80.3,
78.1,
56.9,
34.3,
13.8,
88.8,
80.6,
17.9,
75.2,
10.6,
37.8,
60.8,
55.1,
16.8,
15.9,
51.2,
66.4,
74.8,
51.2,
91.9,
63.8,
51.6,
81.8,
52.1,
77.5,
41.7,
58.9,
65.6,
47.1,
29.2,
32.1,
92.8,
82.3,
87.8,
47.7,
69,
15.2,
39.7,
73.5,
48.1,
91.1,
40.5,
86.9,
57.3,
36,
67.3,
86.5,
60.3,
60.4,
52.3,
72.8,
82.4,
27.8,
54,
50.6,
57.9,
76.9,
74.5,
96.6,
45.9,
23.5,
49.3,
52.9,
60.1,
71.2,
57.2,
36.8,
53.5,
49.4,
62.7,
69.7,
32.7,
25.7,
58.2,
25.9,
59,
57,
83.6,
44,
72.7,
46.9,
83.2,
60.7,
53.9,
81,
86.9,
89.3,
18.9,
35,
47.3,
49.4,
28.4,
73.3,
99,
75.9,
69.7,
50.4,
57.8,
48.9,
69,
69.8,
50,
57.4,
70.4,
56.6,
55.1,
58.7,
13.9,
42.9,
92.1,
72.8,
75,
40,
73.2,
58.1,
17.9,
46.9,
50.9,
94,
41.5,
38.1,
57.3,
81.8,
62.9,
76.5,
45.5,
70,
28.4,
60.5,
74,
92.2,
93.8,
28.5,
17.1,
38.2,
89.8,
54.5,
50.8,
80.5,
60,
62.5,
37.8,
42,
2.2,
57.7,
39.8,
84.3,
25.5,
36,
30.1,
19.5,
36.5,
97.9,
29.9,
91.4,
9,
11.2,
41.1,
33,
84,
38.7,
90.7,
56.5,
66.9,
21.8,
43.5,
67.4,
49.9,
84.3,
58,
88.7,
51.3,
57.1,
11.9,
93.9,
44.9,
79.7,
3.2,
37,
37.7,
97.2,
87.4,
65.1,
60.3,
74.3,
34.5,
39,
13.2,
25.5,
37.4,
71.2,
81.2,
27.5,
78.7,
63.4,
63.1,
32,
69.3,
12.1,
65.7,
60.4,
71.2,
87.6,
66.3,
95,
24.8,
31.5,
89.8,
99.3,
39,
52.6,
80,
43.7,
59.1,
54.7,
47.8,
65.5,
39.4,
72.5,
85.5,
89.8,
72.1,
91,
46.7,
74,
61.8,
45.9,
36.3,
33.1,
1.2,
3.3,
14.1,
51.1,
63.2,
22.3,
35.8,
58.1,
92.7,
74.2,
56,
34.4,
79,
5.5,
68.1,
72.5,
83.6,
75,
70.2,
60.7,
61.1,
0.2,
41.2,
95.8,
53.9,
44.6,
72.7,
29.8,
57.8,
12.6,
76.2,
28.9,
59.1,
10.5,
54.5,
58.1,
43,
75,
53.4,
95.3,
57.3,
45.1,
78.6,
87.3,
54.8,
97.2,
51.8,
74.8,
92.7,
43.8,
31.3,
50.1,
48.7,
35.7,
7.4,
36.3,
66.8,
67.6,
46.7,
92.7,
27.6,
48.1,
9,
71.4,
90.7,
92.9,
75.9,
68.2,
68.7,
74.5,
47.5,
35.1,
17.7,
8.6,
0,
65.3,
45.1,
44.8,
69.2,
70.6,
48.5,
57.8,
52,
17.8,
92.3,
46.5,
44.4,
53.6,
49.9,
49.2,
66.7,
31.5,
29.4,
40,
52.4,
81.1,
23.9,
11.9,
25.5,
10.7,
59.3,
64.3,
26.8,
90.9,
51.9,
35.3,
58.7,
78.2,
66.2,
10.4,
77.5,
102.8,
56.2,
58.1,
9,
43.9,
26,
85,
34.1,
66.2,
61.6,
68,
44.8,
37.1,
73.7,
64.1,
75.3,
23.1,
14.9,
34.7,
51.5,
34.1,
38.2,
66.8,
56.1,
75,
63,
6.3,
39.5,
52.9,
32.7,
27.9,
84.4,
87.6,
39.5,
67.7,
64.4,
60.6,
79.8,
54.2,
62.9,
97.7,
71.3,
64.4,
18.4,
61.4,
38.2,
39.5,
58.3,
62.6,
51.7,
51.2,
97.8,
63.2,
57.8,
46.4,
38.4,
90.3,
68.9,
92.9,
88.9,
73,
21.6,
56.5,
63.4,
26.2,
70.3,
97.5,
81.3,
4.4,
25.8,
70.4,
23.8,
44.8,
19.9,
32.5,
65.5,
23.6,
4.4,
37.2,
83.2,
46.7,
54.4,
73.3,
65.6,
48.6,
57.4,
46.5,
60.4,
76.6,
64,
52.4,
61.2,
24.9,
86.5,
25,
97.1,
49.3,
81.3,
27.7,
23.2,
53.9,
41,
30.1,
5.6,
33.9,
70.3,
56,
64,
56.6,
71.2,
27,
39.9,
71.5,
30.4,
67.5,
53.9,
44.1,
48.8,
73.2,
47.5,
86.7,
56.4,
83.2,
28,
47.7,
14.4,
40.1,
55.3,
97.9,
36.1,
49.1,
40.5,
43.5,
44.3,
62.1,
83.1,
18.6,
22.1,
64.1,
60.7,
88,
59,
43.1,
35.4,
86.6,
73.1,
47.4,
94.2,
7.2,
71,
57.4,
33,
82.1,
38.8,
31.3,
77.8,
62.9,
34,
74.7,
84.6,
34.9,
79.4,
52.4,
32.3,
75,
10.7,
80.9,
20.5,
81.7,
56.1,
92.8,
63,
98.9,
62.6,
86,
46.4,
69.9,
48.8,
87.2,
51.8,
67.2,
32.9,
38.3,
81.5,
56.2,
77.9,
32.4,
66.7,
86.9,
41.5,
12,
59.6,
28.2,
57,
48.3,
56,
96.4,
31.8,
72,
93,
90.8,
35.6,
33.1,
75.2,
58.5,
47.3,
57.8,
60.1,
62.2,
57.2,
31.9,
88.6,
60.8,
82.6,
53.6,
99.1,
41.1,
90,
44.5,
68.1,
19.1,
90.4,
80.7,
58.9,
13.6,
16.3,
68.5,
92.8,
35.6,
68,
69.1,
19.7,
0,
91,
79.6,
19.3,
20,
81.8,
67.7,
62.7,
33,
55,
14.7,
55.8,
81.5,
11.9,
49,
47.8,
59,
87.1,
49.6,
35.7,
40.3,
49,
58.7,
78.9,
9.2,
54.8,
47.4,
50.1,
43.5,
72.2,
14.4,
69.3,
31.7,
44.1,
52.7,
55.3,
57.6,
19.1,
31.8,
46.6,
21,
22,
68.4,
16.1,
72,
31.7,
86.2,
81.3,
80.7,
45.1,
46,
70.1,
51.4,
48.4,
30.6,
77.8,
69.7,
88.5,
47.7,
81.9,
15.2,
35.6,
92.9,
48.1,
81.3,
67.2,
25.1,
41.1,
55.1,
24.5,
42.1,
69.6,
55.4,
40.2,
60.1,
35.6,
91,
97.7,
29.7,
84.8,
23.9,
68.6,
27.3,
19.3,
44.8,
98.5,
70.4,
84.5,
70,
94.1,
36.6,
43,
43.3,
49.7,
55,
43.6,
30.7,
84.1,
20,
53.1,
83.9,
94.8,
86.8,
69.3,
81.3,
47.8,
64,
43.1,
68.2,
44.4,
60.1,
10.9,
58,
52.1,
11.6,
52,
58.6,
29.4,
18.1,
96.2,
36.1,
27.9,
73.7,
75,
68.3,
24.7,
32.3,
101,
54.2,
47.5,
81.6,
77.4,
67.2,
79.1,
28.6,
92.6,
69.7,
60.7,
22.4,
87.7,
7.7,
86.9,
61.2,
93.6,
56.6,
48.7,
64.1,
80,
72.2,
44.9,
49.9,
58.9,
89,
57.1,
82.5,
32,
46.2,
64.9,
17.2,
36,
62.4,
36.2,
42.5,
33.2,
68.4,
38.8,
49,
37.8,
20.3,
46.1,
68.4,
72.6,
70.3,
17.7,
21.8,
75,
64.3,
48,
89.4,
42.7,
37.4,
43.9,
51.2,
62.1,
38.1,
97.2,
20.9,
48.4,
47.5,
76,
66.9,
53,
91.2,
34.1,
30.8,
68,
51.1,
84.8,
47.4,
38.3,
77.8,
76.4,
83.7,
83.8,
33.7,
2.3,
73,
51.6,
88.1,
55.3,
50.9,
55.7,
58.7,
89.1,
39.2,
63.3,
57,
59.9,
64.2,
47.7,
92.3,
24.6,
76.8,
18.8,
61.5,
23.7,
80.5,
78,
47,
50.5,
80.3,
79,
59.4,
94.9,
54.2,
99.6,
53.1,
0,
37.3,
51.5,
43.9,
36.7,
14.3,
31.8,
21.9,
30.2,
57.3,
55.3,
3.4,
31.1,
44,
32.5,
81.8,
54.8,
91.1,
82.3,
24.3,
51.3,
63.1,
82.9,
41,
75.2,
49.7,
60.2,
45.6,
30.1,
37.6,
91.5,
71.7,
70.9,
52.2,
85.6,
93.9,
80.3,
40.5,
81.7,
25.8,
0.3,
16.8,
17.2,
62.1,
30.6,
66,
85,
68.1,
51.2,
58.8,
101.6,
95.1,
55.5,
64.3,
93,
48.9,
59.6,
83.2,
86.9,
25,
67,
21.9,
33.6,
68.5,
63.1,
93.6,
67.4,
76.6,
29.6,
92.9,
27.2,
84.7,
67,
13.5,
58,
92.2,
71.5,
38.9,
54.4,
3.3,
58.2,
46.5,
87.9,
55.6,
82.4,
42.1,
43.7,
44.2,
83,
95,
63.5,
60.2,
51.9,
50.8,
59.7,
98.1,
41.1,
55.8,
78.7,
19.1,
7,
36.2,
93.4,
72.5,
51.6,
49,
8.2,
66.1,
36.78,
74.1,
49.8,
81.2,
41.5,
19.6,
39.2,
70.6,
42.4,
19.5,
56.9,
62.4,
56.8,
86.3,
23.3,
2.5,
30.4,
76.3,
29.8,
55,
23.6,
23.6,
62.6,
17.6,
76.7,
64.6,
9.5,
67.5,
59.7,
20.7,
48.5,
58,
11.1,
30.6,
15.1,
71,
99.7,
49.4,
38.5,
94.5,
9.5,
81.6,
40.1,
70,
70.5,
63.6,
53.9,
58.8,
15.2,
62.3,
62.6,
64.1,
60.7,
34.8,
69,
55.9,
26,
47.3,
71.9,
55,
54.7,
70,
45.5,
70.6,
25.3,
55.8,
64.6,
88,
44.3,
15.9,
20.2,
50.2,
26,
88.1,
56.6,
21.9,
9.6,
55.3,
73,
81.4,
91.4,
30.5,
43.1,
13.4,
91.5,
46.9,
3.2,
60.8,
14.6,
47.1,
33,
96.4,
88.8,
15,
61.4,
21.3,
33,
62.9,
27.6,
68.9,
40.6,
68.3,
77.8,
73.7,
55.8,
40.6,
52.6,
55.1,
33.2,
52.1,
71.1,
65.7,
63.1,
83,
44.1,
78.5,
93.5,
66.3,
101.2,
62.4,
78.8,
22.6,
36.9,
69,
67.3,
25.6,
70,
21.7,
18.4,
23.8,
26.7,
57.7,
30.9,
12.2,
86,
11.3,
41.2,
29.9,
69.9,
79.2,
86.2,
28.7,
20.7,
61.3,
41,
70.6,
63.3,
37.3,
67.9,
76.9,
20.6,
35.4,
82.4,
67.8,
89,
68.9,
70.6,
80.8,
90.6,
58.9,
87.4,
72,
26.2,
74.7,
62.8,
87.3,
47.2,
69.6,
49.7,
41.4,
65.9,
83.8,
59.5,
10,
51.9,
18.9,
34.1,
3.6,
38,
54.2,
79.3,
56.5,
34.7,
28.9,
50.7,
37.4,
26.7,
57.5,
48.6,
66.1,
10,
47.3,
75.4,
62.4,
56.1,
50.5,
50.7,
38.3,
52.4,
56.1,
58.1,
86.8,
46.4,
53.3,
40.1,
51.1,
60.9,
81.7,
0,
37.5,
45.3,
42.5,
70.8,
47,
61,
38,
35.9,
12.9,
29.3,
22.4,
76.7,
20.4,
68,
37.3,
65.8,
36.5,
76.1,
24.1,
48.6,
34.6,
34.7,
9.5,
74.2,
94.5,
10.4,
28.9,
81.2,
32,
69.7,
54.9,
32.9,
87.3,
92.4,
84.9,
66.7,
28.3,
51.7,
70.5,
77.4,
10,
41.3,
42.3,
57,
35.1,
72.8,
73.3,
62.2,
77.3,
68.9,
84.5,
65.1,
60.9,
45.9,
68.4,
59.3,
47.2,
25.5,
87.6,
77.4,
21.5,
57.6,
79.1,
32.4,
35.3,
77.9,
77.8,
59.8,
24.5,
25.3,
25,
88.1,
31.3,
44.9,
56.5,
73.4,
27.5,
80.4,
83.9,
44.4,
72.6,
46.5,
62.5,
46.5,
78.4,
36.9,
16.3,
49.1,
30.5,
91.8,
67.3,
43.9,
10.3,
25.7,
36.7,
86.7,
26.5,
93.3,
18.7,
60,
38.7,
48.8,
71.6,
22.9,
76.4,
23.1,
90.8,
37.4,
13,
1.8,
89.8,
89,
70.1,
83,
42.9,
76.7,
45.1,
83.9,
80.6,
59.2,
87,
93.2,
62.2,
48.2,
36.3,
48.1,
83.6,
81.3,
91.1,
8.8,
26.8,
110.4,
44.9,
67.7,
58.1,
92,
29.7,
73.7,
53.5,
15.4,
62.9,
91,
79.5,
42.2,
3.6,
5.3,
20.9,
33.8,
13.8,
43.1,
64.7,
57.7,
26.8,
18,
68.6,
45.7,
19.4,
59.4,
72.8,
22.8,
46.7,
92.1,
80.6,
54.2,
54.9,
76.4,
49.9,
0.5,
64,
64.2,
75.6,
80.2,
79.8,
69.5,
2,
95,
44,
55.7,
47.5,
50.2,
82.8,
49.6,
43.8,
41.9,
66.2,
54.2,
45,
67.9,
59.7,
66.3,
69.4,
33.9,
34.3,
20.8,
32.5,
19.2,
0,
54.2,
99.2,
92.7,
74,
54.4,
43.9,
81.2,
94,
61.7,
56.6,
40.4,
22.7,
40.2,
61.2,
69.7,
63.6,
19.8,
40.2,
14.6,
72.4,
76.2,
54.8,
35,
55.7,
74.7,
2.2,
19.3,
88.8,
63.3,
50.9,
71.5,
1.7,
17.1,
99.4,
79.4,
50.4,
71,
61.8,
65.9,
35.8,
21.5,
47.7,
76.5,
94.1,
29.3,
80.6,
62,
52.6,
91.1,
78.5,
81.4,
21.3,
46.3,
44.3,
66.2,
16,
77.4,
54.5,
63.2,
10.4,
12.3,
67.2,
84.6,
50.7,
33.7,
32.8,
63.8,
41.9,
67.7,
39.4,
58.9,
29.1,
26.1,
84.3,
65,
1.2,
77.3,
67.7,
60.2,
85.7,
78.8,
63.2,
49.1,
63.8,
35.9,
47.4,
59.3,
61.9,
85.1,
77.6,
75.3,
16.9,
24.7,
46.5,
47.6,
27.6,
62,
54.4,
42.6,
38.7,
39.1,
65.9,
87.8,
65.9,
59.6,
70.5,
22.8,
61.9,
76.4,
5.9,
31.8,
26.5,
13.1,
48.5,
82.5,
52.1,
60.3,
88.2,
65.6,
62.9,
82.8,
66,
24.2,
54,
62.8,
81.3,
17.7,
32.9,
4.6,
39,
28.9,
18,
72.1,
66.1,
69.6,
83.3,
47.7,
27.3,
57.7,
72.7,
84.7,
55.8,
70.6,
74.9,
33.9,
43.8,
67.3,
42.7,
67.2,
59.7,
22,
22.9,
82,
79.6,
42.8,
15.3,
25.9,
55.8,
91.6,
22,
84.9,
48.4,
85.6,
29.5,
73.4,
80.1,
72.1,
75.9,
90.5,
22.4,
45.6,
51.8,
90.7,
53,
31.6,
54,
14.6,
87,
102.2,
60.6,
73.7,
99.5,
44.3,
91.5,
45.2,
47.2,
84.2,
93.3,
31.6,
72.9,
21.7,
68.5,
69,
44.2,
30.3,
61.2,
98.6,
46.1,
33.7,
84.4,
96.7,
24.2,
73.2,
76.1,
54.2,
56.1,
27.8,
51.2,
24.3,
74.5,
55.4,
42.1,
50.9,
113,
47,
21.8,
89.4,
63.7,
8.3,
40,
68.1,
58,
42.9,
73.4,
37.7,
86.3,
79.7,
69,
81.9,
43.1,
82.1,
96.8,
50.4,
38.2,
29.9,
48.2,
43.7,
22,
37.9,
65,
77.6,
93.6,
57.9,
44.8,
67.3,
58,
61.6,
74.5,
63.1,
97.2,
33.6,
99.7,
30.4,
19.7,
49.3,
54.5,
25,
0.9,
48.3,
3.1,
21.4,
56.6,
79.2,
30.4,
82.6,
94,
84.5,
69.2,
21.5,
48.8,
47.2,
29.3,
19.5,
91.6,
68,
77.5,
65.6,
87,
31.8,
75.8,
60.6,
42.1,
63.9,
54.5,
41.9,
52.8,
2.8,
31.9,
90.4,
97.9,
85.7,
18.1,
72.7,
70,
44.2,
94.3,
86.1,
25.9,
78.7,
56.5,
40.8,
76.9,
84.1,
69.2,
90.6,
102.7,
89.6,
37.8,
56.4,
52,
55.5,
22.6,
51,
62.9,
62.7,
75.8,
54.2,
41.6,
40.1,
26,
33.3,
13.5,
23.5,
74.3,
35.7,
97.9,
45.8,
54.3,
49,
68.4,
64.7,
15.1,
34.9,
24.3,
37.6,
69.6,
40.7,
28.7,
65.7,
0,
67.8,
58,
55,
68.2,
59,
76.9,
60.1,
35.9,
31.4,
46.9,
48.1,
54.4,
11.4,
70.3,
93.2,
85.5,
57.4,
56.5,
42,
92.8,
58.6,
70.1,
25.4,
38,
62.9,
88,
25.2,
14,
91.4,
56.1,
38.3,
76.9,
16.1,
38.8,
63.2,
52.8,
28.9,
12.4,
24.1,
66.2,
57.8,
73.3,
65.4,
41.5,
69.1,
37.8,
63.5,
54.3,
10.6,
60.2,
49.7,
7.6,
38,
57.2,
45.4,
38.6,
31.7,
94.3,
80.6,
56.6,
42.7,
69.3,
94,
70.7,
83.8,
16.4,
35.5,
15.5,
38.6,
67.1,
60.2,
94.3,
62.3,
50.5,
15.5,
33.4,
67.7,
19.2,
7,
36.5,
68.1,
59,
71.8,
72.8,
5.4,
64.6,
54.9,
46.5,
80.2,
91.9,
64.6,
5.1,
44,
20.6,
91.3,
69.9,
56.3,
55.5,
95.2,
42.8,
48.7,
80.9,
40.2,
11.6,
19.1,
20,
54.7,
26.6,
95,
80,
86.8,
58.4,
48.7,
70.7,
48.7,
46.5,
92.5,
86.6,
62.9,
79.9,
74.7,
17.8,
49,
62.9,
27.4,
84.9,
97.6,
72.6,
42.7,
73.7,
70.7,
63.8,
79.7,
66.6,
85.4,
33.9,
45.3,
68.2,
67.1,
32.1,
83.4,
66.6,
69.9,
31.7,
10.7,
68.3,
45.4,
53.6,
92.9,
74.6,
55.4,
77.8,
73.3,
51.3,
45.6,
38.9,
87.7,
66.2,
34.2,
64,
78.1,
81.9,
68.9,
71,
68.6,
43.4,
63.4,
38.7,
72.1,
27.1,
37.2,
40.5,
19.2,
119.1,
53.4,
54.3,
33.3,
93.1,
79.9,
41.7,
33.2,
17.3,
36.7,
86.3,
77.6,
60.9,
39.6,
81.2,
54.7,
51.7,
60.2,
31.2,
80.3,
82.2,
80.3,
79.1,
26.5,
67.3,
92.3,
42.4,
76.5,
67,
66.8,
39.5,
58.8,
60.4,
58.6,
29.7,
17.5,
95,
18.2,
4.8,
86.7,
41.3,
23,
66.8,
53.4,
35.9,
10.4,
16.3,
50.5,
33.5,
66,
68.4,
33.8,
75.7,
38.5,
34.7,
79.1,
86.2,
83.9,
59.2,
80,
76.2,
89.1,
52.6,
77.8,
44.7,
51.9,
81.5,
33.9,
34.4,
85.2,
35.8,
34.8,
62.3,
70.4,
79.3,
18.6,
0,
61.5,
52.9,
53.3,
35.6,
27.9,
61.5,
88.8,
37.4,
73.2,
31.4,
45.1,
56.3,
48.1,
66.8,
82.2,
29.9,
14.5,
79.4,
45.9,
45.1,
35.9,
39.3,
99.4,
47,
34.7,
30.2,
71.1,
95.3,
74.3,
31.1,
80.6,
99.3,
78.2,
52.4,
94,
32.6,
38.3,
23.1,
19,
46.6,
127.6,
20,
62.7,
75,
28.3,
49,
70.7,
17.5,
13.4,
85.9,
54,
43.6,
8.4,
39.3,
50.3,
50.1,
89.3,
63.6,
55.1,
37.6,
29.8,
99.2,
67.6,
85.7,
51.4,
20.2,
75.4,
29.9,
50.1,
88.5,
53.7,
89.7,
23.6,
70,
78,
38,
40.6,
39.8,
70.1,
37.4,
74,
37.7,
62.2,
54.6,
24.8,
37,
12.3,
72.7,
29.3,
23.5,
52.8,
20.4,
17.1,
16.1,
53.6,
42,
27.3,
31.2,
78,
72.3,
57.3,
47.9,
89.3,
77.9,
57.5,
24.7,
46,
36,
57,
76.9,
38.6,
62,
84.2,
24.5,
73.3,
86.4,
82.5,
92.7,
59.6,
34.4,
20.9,
45.2,
96.6,
77.6,
51.1,
53.3,
66,
76.2,
88.9,
80.8,
52.6,
0,
83.2,
55.2,
20.5,
41,
81.9,
64.7,
85.9,
73,
21,
65.2,
37.5,
15.6,
38.3,
86.9,
66.5,
86.9,
35.2,
75.9,
39.1,
18.7,
11.2,
47.5,
36.8,
91.7,
45.7,
33.5,
61.5,
24.6,
61.9,
43.3,
75.5,
41.2,
87.7,
16.3,
62.9,
77.3,
90.2,
63.9,
63.6,
55.8,
35.1,
66.1,
58.8,
80.2,
40.1,
13.8,
45.5,
81.9,
71.3,
61.1,
59.6,
75.8,
48.2,
27.3,
80.8,
54.3,
29.1,
34.5,
58.7,
35.4,
24.6,
58.8,
30.6,
41.7,
53,
37,
12.4,
16.2,
57.7,
39.5,
42.5,
38.5,
92.6,
3.1,
54.1,
73.1,
86.5,
8.4,
74.4,
37.8,
54,
85.6,
39,
73.1,
70.3,
69,
0.5,
47.8,
30.9,
43.4,
65.8,
81.6,
17.2,
31,
76.5,
70.1,
91.8,
56.7,
31.9,
58.6,
32.8,
33.5,
38.4,
7.9,
97.7,
24.7,
27.3,
56,
61.9,
46.8,
97.8,
45.5,
88.4,
72.4,
16.8,
63.4,
20.3,
23.5,
28,
79,
64.1,
36.7,
18,
51.4,
50.9,
83.8,
80.3,
47,
94.1,
43.3,
91.8,
90,
68.5,
74.1,
99.1,
39.9,
52.2,
62.3,
26,
75.2,
31.8,
22.4,
69,
79.9,
77.4,
57.3,
59.6,
0.9,
20.8,
65.5,
70.7,
31,
45.9,
59.6,
66.3,
43.1,
48.1,
86.1,
51.7,
90.4,
87,
30.6,
95.4,
95.5,
38,
83,
5,
71.9,
45.9,
65.2,
21.4,
71.4,
45.3,
23.8,
74.5,
48.9,
35,
73,
19.1,
98.7,
25.1,
80.8,
55.3,
34.1,
94.9,
12.8,
7.2,
60.4,
46.1,
52.3,
52.6,
46.6,
76.5,
58.9,
63.7,
36,
70.7,
43.6,
41.5,
39.2,
21,
61.8,
29.4,
39.5,
64.1,
64.4,
75.5,
72.6,
15.6,
10.2,
29.2,
78.1,
85.5,
39.3,
24.4,
90,
50.1,
85.7,
14.7,
23.9,
12.5,
29,
15.6,
9,
14.8,
80,
18.6,
76.8,
73.5,
67.3,
29.9,
91.4,
16.8,
34.8,
37.4,
25.9,
77.9,
73.7,
39.3,
45.2,
56,
22.5,
100.4,
97.4,
60.2,
91.9,
37.1,
26.1,
76.4,
19.5,
64.6,
62.6,
43.1,
55.6,
50.9,
22.3,
74.3,
56.8,
61.1,
16.7,
40.3,
42.9,
76,
30.1,
36.6,
48.9,
58.5,
47.7,
75.8,
14.9,
41.2,
18.3,
25,
84.7,
54.5,
63.8,
87.6,
67.7,
79.1,
51.7,
85.9,
9.2,
87.8,
70,
89.5,
51.8,
42.7,
54.7,
84.7,
55.5,
18.4,
41.7,
30.9,
76.3,
35.7,
49,
16.1,
72.3,
70.5,
19.2,
33,
3.1,
41.8,
38.8,
51.6,
51.9,
49.3,
75.3,
77.8,
49.4,
85.5,
5.8,
90.5,
84.3,
81.7,
70.4,
46.9,
31,
30.1,
66.9,
54.7,
72.7,
38.9,
17.5,
66.5,
47.1,
45.7,
73.1,
71,
47.6,
64.6,
53.4,
71.9,
27,
56.2,
81.4,
72.4,
31.9,
100,
35.7,
38.1,
37.3,
34.7,
67.9,
90.3,
80.4,
28.8,
12.1,
27,
5.1,
61.9,
54.7,
32.5,
61.4,
45.3,
97.8,
88.2,
96.2,
94.9,
4,
22.4,
71.1,
64.6,
93.7,
90.1,
79.1,
91.7,
46.4,
44.4,
71.9,
18.1,
59.6,
75.6,
74.3,
57.6,
98.9,
33,
71,
87.6,
72.9,
33.6,
66,
83.8,
74.5,
91.2,
39.5,
44.4,
28.5,
40.6,
27.5,
48.6,
68.6,
88.5,
43.2,
61.9,
32.7,
26.8,
48.4,
49.6,
46,
63.7,
54.3,
80.6,
69.2,
39.5,
36.2,
64.8,
52.8,
49.4,
27.6,
73.9,
19.9,
48,
31,
69.7,
39.3,
97.7,
46,
78.3,
59.5,
57.6,
56.1,
40.5,
71.4,
13.4,
40.2,
33,
42,
30,
86.9,
53.6,
68.7,
88.9,
79.7,
22.1,
40.3,
64.4,
91.8,
37.8,
39,
51.9,
32.9,
84.8,
30.7,
67.5,
45.5,
28.5,
67.9,
56.6,
0,
55.1,
72.7,
95.1,
62.9,
43.6,
10.1,
80.6,
72.8,
26.7,
73.6,
36.9,
15.1,
84.8,
39.1,
75.2,
42.1,
34.4,
30.3,
64,
74.7,
98.3,
35.3,
83.4,
81.4,
96,
97.2,
78.6,
40.6,
47.3,
68.9,
90.6,
22.3,
21.5,
31.3,
36.5,
44.6,
54.1,
81.4,
35.5,
45.6,
8.6,
28.5,
61.7,
94.9,
66.5,
90.7,
77,
71.1,
69.1,
66.8,
37.4,
70.6,
44.1,
42.3,
62,
75.4,
76.9,
39.7,
25.1,
0,
75.8,
65.1,
46,
37.3,
54.1,
58.6,
15.1,
81.2,
47.6,
28.2,
77.6,
92.9,
63.9,
79.3,
98.1,
55,
86.5,
70.7,
42.8,
54,
85.5,
83.9,
44.4,
57.6,
19.7,
14.5,
95,
37.8,
60.7,
10.9,
74.6,
92.4,
84.5,
68.8,
66.4,
62.4,
35.5,
61.4,
80.7,
49.4,
69.4,
82.2,
31.3,
43.2,
64.1,
56.1,
50.9,
49.7,
51,
96,
92.3,
70.3,
46.9,
73,
46.9,
34.5,
73.6,
54.9,
74,
23,
46.3,
70.8,
88,
70.4,
21.4,
49,
93.8,
44.2,
94.6,
4,
77.5,
87.1,
93,
68.6,
3.9,
91.9,
63.3,
20.3,
45.7,
46.2,
58.4,
68,
90.4,
34.6,
73.1,
53.9,
83.9,
36.4,
85.1,
83.5,
3.8,
52.9,
59,
32.8,
85,
54.2,
76.6,
67.1,
35.9,
42.5,
20.3,
22.2,
84.9,
56,
48.3,
77.6,
77.7,
0,
76,
74.6,
55.2,
85.9,
68.5,
39.5,
20.4,
6.6,
62.2,
81.2,
35,
22.6,
40.4,
84,
65.8,
55.1,
97.5,
76.1,
77.7,
55.2,
62.3,
44.2,
50.2,
69.3,
7.1,
13.3,
79.8,
18.3,
26.5,
60.5,
67.5,
101.6,
70.5,
13.1,
34.4,
89.6,
4.1,
65.4,
66.5,
77.6,
28.4,
86.8,
58.6,
21.3,
55.8,
81.9,
73.3,
63.3,
50.6,
54.5,
51.6,
65.8,
20.5,
98.6,
98.1,
22.1,
76.2,
64.4,
37.8,
48.5,
34.3,
46.9,
75.5,
91.9,
34.4,
41.2,
45.8,
30.4,
60.1,
18,
59.4,
44.6,
38.3,
70,
63.2,
75.1,
60.4,
35.3,
64.3,
36.8,
68.2,
57.1,
89,
71.9,
12.3,
6.2,
49.6,
84.1,
85.5,
62.9,
13.6,
49.8,
49.7,
51.9,
64.1,
71.6,
18,
6.9,
53.9,
42,
55,
77.6,
25.9,
70.4,
78.1,
90.7,
86.8,
96.8,
1.8,
94.1,
72,
96.6,
54.7,
44.8,
37.8,
78,
7.6,
75,
93.7,
33,
50.6,
35.6,
28,
28.4,
75.3,
47.8,
54,
46.4,
45.5,
10.5,
17.3,
48.7,
30.3,
38.5,
70.7,
51.2,
82.2,
89.4,
59.9,
80.3,
3.1,
75.6,
75.5,
62.9,
34,
84.4,
77.8,
29.6,
15.2,
73.6,
73.3,
47,
85,
70.7,
84.5,
79.1,
68.8,
71.9,
35.9,
22,
46.1,
72.1,
97.7,
52.5,
70.2,
22.2,
36.2,
46.9,
59.4,
40.8,
86.2,
99,
66.5,
53.1,
65.3,
56.4,
40.6,
61.2,
28.3,
79.2,
63,
42.5,
67.9,
50,
58.7,
23.8,
64.1,
69,
35.6,
77.4,
33.4,
20.5,
64.7,
47.9,
94.7,
34.7,
27.2,
25.6,
73.6,
49,
8.2,
17.5,
72,
53.6,
69.1,
41.6,
29.3,
55,
80.2,
55.9,
1.3,
69.5,
51.3,
84.2,
90.8,
69.9,
54.8,
85.8,
83.7,
78.1,
53.3,
45.2,
48.3,
65.6,
28.5,
97,
14.5,
18.9,
79,
40.2,
74.4,
83.5,
37,
43,
71.1,
62.1,
61.2,
72.5,
45.9,
79.7,
69.6,
67.2,
56.5,
59.9,
52.7,
17.5,
32.6,
79.9,
27,
38.3,
98.4,
61.8,
23.6,
67.7,
92.4,
75.8,
19.9,
50.6,
24.8,
26.8,
67.6,
44.2,
59.6,
69.6,
46,
68.5,
26.6,
50.9,
69.1,
55.6,
26.3,
90.5,
47.9,
24,
60,
45.5,
37.8,
86,
85.4,
64.8,
60.5,
58.6,
37.7,
35.8,
81.2,
74.1,
80,
41.3,
84.8,
60.8,
91.1,
30.8,
78,
49.9,
65.8,
42,
75.9,
46.6,
21.1,
29.3,
56.6,
26.7,
24.7,
74.3,
79.5,
41.7,
94.5,
85.6,
28.5,
98.1,
13.2,
39.9,
56.9,
92.5,
31.9,
75,
3.4,
62.3,
46.4,
77.6,
40.3,
49.1,
44.7,
46,
28.8,
84.8,
40.4,
55,
3.3,
73.7,
94.4,
73.6,
71.3,
41.4,
49.2,
79.3,
61.8,
43.4,
64.2,
97,
48.5,
57.2,
76.5,
50.4,
56.3,
53.9,
43.1,
16.7,
73.9,
54.4,
88.7,
92.9,
98.7,
37.4,
51.1,
33.3,
81,
18.5,
69.5,
74.4,
51,
74.9,
30,
27.7,
52.7,
90.8,
54.4,
0,
77.4,
62.7,
80.3,
71.3,
43.4,
76.9,
42.2,
72.9,
22.4,
39.1,
82.3,
9.2,
94.6,
79.4,
27.5,
59.6,
36.5,
44.6,
49.6,
68,
65.7,
null,
18.6,
32.6,
76.6,
31.4,
19.9,
78.7,
80.5,
10.2,
58.3,
24.7,
111.2,
32.9,
28.2,
42.2,
71.3,
18,
35.6,
17.2,
40.8,
81.9,
15.6,
51.7,
78.1,
11.8,
30.5,
63.9,
23.8,
49.6,
52.7,
89.2,
55.5,
53.7,
24.5,
66.6,
79.8,
40.4,
48.9,
28.6,
15.1,
48.5,
28.6,
59.9,
50.6,
80.9,
19.6,
31,
61.6,
77.2,
70.8,
19.2,
38,
97.4,
46.5,
67.2,
93.6,
25,
32.1,
42.8,
42.9,
12.2,
73,
14,
51.8,
69.1,
63.8,
32.5,
21.2,
18.3,
22.8,
14.7,
55,
50.9,
82.3,
83,
52.1,
26.6,
71.4,
64.6,
49.8,
78.2,
88.3,
86.3,
80.2,
80.2,
38.1,
47.7,
24.3,
62,
4.1,
83.5,
70.2,
54,
23.8,
72.5,
20.6,
92.3,
78.1,
51.6,
89.4,
77.3,
75.4,
52.4,
28,
24.6,
56.5,
81.8,
17.3,
48.4,
55.2,
89.3,
29.3,
23,
96.4,
50.2,
58.3,
23.5,
64.6,
97.4,
95.2,
59.5,
19.2,
7,
69.4,
40.3,
86.9,
96,
46.1,
30.6,
73.7,
35.7,
41.8,
92,
15.7,
67.9,
82.9,
37.7,
84.5,
60.8,
91.5,
56,
42.9,
46.7,
99.3,
79.8,
38.3,
93.4,
57.2,
57,
72.1,
8,
58.6,
34.5,
102.3,
74.4,
46,
93.8,
95,
73,
86.9,
74,
63.9,
47.8,
16.3,
45.6,
28.4,
67.5,
65.1,
1.4,
57.1,
48.6,
25.1,
65.6,
43.7,
67,
96.5,
74.8,
58.2,
35,
94.1,
72.6,
17.3,
24.8,
47,
51.2,
43.2,
40.3,
83.6,
41.6,
86.5,
32.4,
34.2,
49.8,
58.3,
35.8,
76.2,
32.9,
71.7,
56.2,
33,
88.4,
64.6,
18.6,
91.2,
63.5,
40.8,
57.9,
65.5,
27.9,
61.3,
10.4,
12.9,
78.8,
69,
25.9,
26.8,
59.9,
0.1,
82.1,
60.2,
51.5,
6.9,
69.1,
31.7,
96.1,
75.4,
18.8,
70.1,
90.2,
37,
39.1,
59.1,
70,
25.9,
37.8,
84.2,
46.7,
73.6,
67.1,
47.3,
57.4,
54.7,
66.2,
53.1,
91.6,
59.6,
33.6,
62.5,
13.9,
22.7,
93,
44.8,
44.7,
73.4,
43.8,
50,
87.8,
13.5,
42.4,
53,
63,
85.2,
46.3,
1.4,
54,
16.9,
41.4,
36.8,
11.6,
79.6,
57.9,
61.7,
74.2,
76.8,
56,
33.1,
79.5,
72.4,
65.2,
44.2,
54.2,
70.2,
55.3,
93.5,
50.8,
87.2,
24.7,
52.4,
46.7,
93.6,
87.9,
43,
12.9,
57.3,
54.8,
27.4,
72.5,
42.7,
66.7,
81.3,
48.2,
66.1,
30.5,
14,
54.8,
80.4,
44.3,
87.4,
22.3,
65.7,
41.5,
37.9,
81.5,
52.9,
70.7,
25.6,
65.8,
74.8,
82.1,
53,
80.8,
28.4,
56.7,
16.3,
40,
47.2,
72.1,
96.2,
56.2,
21.8,
44,
16.1,
43.7,
64.2,
80,
66.9,
15.4,
28.9,
66.6,
66,
41.8,
27.3,
64.3,
26.4,
73,
61.8,
58.7,
29,
3.6,
20.6,
45.1,
90.4,
11.7,
20.1,
39.6,
37.1,
62.6,
11.9,
54.3,
6.2,
93,
57.6,
14.6,
8.2,
78.6,
41.2,
86.5,
90.2,
69.6,
7.4,
31.5,
71,
93.6,
50.5,
45.2,
0.4,
67.1,
66.1,
78.6,
53.9,
46.6,
73.9,
62.2,
75.7,
51.4,
56,
36.9,
83,
53.6,
54,
41.5,
93.7,
48,
15.1,
22,
87.4,
98.1,
60.7,
93,
94.2,
76.6,
19.1,
50.8,
32.3,
79.9,
62.3,
74.2,
9.2,
42.7,
82.9,
61,
88.8,
73.7,
60.4,
19.5,
68.1,
36.8,
57.1,
7.1,
7.6,
84,
66.4,
45.3,
81.5,
66.5,
60.6,
32.9,
85.8,
49.9,
78.4,
39.5,
44,
15,
76.6,
80.6,
68.4,
19.4,
75,
48.3,
46.6,
19,
35.4,
58.4,
75.3,
56.4,
79.6,
93.1,
48.5,
68.4,
86,
64.9,
55.1,
78.6,
76.8,
92.3,
74.5,
77.4,
13.4,
62.4,
77.2,
51.7,
67,
69.3,
51.7,
57.6,
98.6,
6.9,
78.1,
38.4,
86,
26.3,
51.2,
62,
92.4,
90.6,
77,
47.7,
34.6,
40.7,
93.8,
49.9,
85.5,
66.3,
76,
55.4,
68.6,
57.5,
21,
37.9,
78.4,
70,
44.5,
41.3,
49.4,
77.4,
63.9,
40,
38.8,
52.2,
62.2,
56.2,
62,
3,
67.4,
88,
71.8,
9.9,
62.3,
76,
25.5,
86.2,
76.1,
20.7,
0,
52.8,
50.3,
32.8,
84.9,
63.6,
43.4,
57.3,
72.1,
71.6,
26.1,
50.6,
82.5,
46.8,
72.9,
48.8,
75.8,
94.9,
92.3,
34,
76.6,
50.9,
67.8,
52.6,
71.1,
49.9,
74.9,
46.4,
95,
23.4,
76.5,
43.7,
44.3,
43.7,
70,
51.1,
75.6,
62.2,
86.7,
7.6,
32.5,
50.5,
41.5,
45.9,
80.9,
88.1,
59.8,
78.9,
88.5,
80,
56.8,
75.8,
89.9,
34.7,
53.4,
44.9,
85.8,
80.4,
58.7,
29.7,
18.6,
23.8,
72,
79.3,
43.7,
38.3,
67.6,
46.5,
95.2,
89,
13.5,
66.9,
0,
27.8,
83,
24.3,
5,
76.1,
77.3,
43.9,
83.1,
67.7,
69.7,
38.7,
95.4,
63.6,
13.4,
66.5,
25.2,
35.3,
38,
30.9,
63.2,
47.6,
40.7,
27.4,
96,
30,
39.4,
72.2,
32.4,
10.7,
61,
54.5,
40.5,
86.3,
58.9,
34.8,
84.1,
87.6,
90,
64.6,
82.3,
72.3,
49.2,
60.4,
5,
56.7,
11.7,
42.6,
78.1,
26.3,
73.6,
74.3,
62.3,
19.4,
37.6,
25.2,
63.6,
78.8,
55.8,
72.7,
52.2,
80.7,
35,
68.5,
94.4,
75.6,
34,
54.1,
57.1,
14.9,
50,
80.3,
71.8,
88.8,
39.3,
76.2,
52.7,
73.1,
44.8,
37.6,
63.9,
34.6,
93.7,
74.6,
80.8,
94.6,
71.6,
1.9,
29.5,
54.1,
65.8,
48.4,
56.2,
37,
72,
98.6,
79.4,
18.2,
92.9,
54.7,
33.1,
37.4,
87.9,
78.7,
33.8,
14.7,
50.6,
90.9,
76.3,
66.2,
22.9,
94.1,
33.9,
63.2,
46.4,
47.9,
71.2,
80.2,
47.9,
70.2,
63.3,
58.5,
92,
69.5,
80.5,
45.5,
73.6,
94.1,
86.6,
60.4,
61.9,
37,
3.4,
77.2,
65,
51.7,
55.4,
66.7,
83.4,
83.5,
47,
22.9,
81.1,
62.1,
32.9,
43.6,
72.9,
42.1,
6.6,
90.7,
53,
58.3,
40.2,
58.9,
28.7,
56.2,
70.3,
82,
89.5,
19.8,
23.7,
89.1,
77.8,
38.8,
59.8,
9,
84,
82.9,
61,
0,
27.6,
94.7,
64,
53.7,
63.5,
100.8,
64.3,
59,
62.5,
46.6,
37.9,
91.7,
61.6,
93.8,
40.4,
64.1,
7.4,
26.4,
71.8,
90.6,
59,
41.4,
67.5,
39.2,
63.3,
28.2,
95.5,
41.2,
80.7,
17.9,
79,
20.8,
62.7,
22.2,
73.3,
29.3,
44.2,
70.7,
23.5,
91.4,
42.1,
94.9,
18.4,
76,
76.4,
85.1,
76.1,
9.6,
60.5,
39.3,
21.7,
18.1,
42.7,
69,
67.1,
70.8,
10.6,
76.6,
85.6,
68.6,
5.6,
75,
9,
49.9,
78.9,
59.2,
25.9,
49.7,
82,
57.4,
59.1,
59.9,
22.3,
25.4,
22.1,
68.6,
38.1,
58.3,
16,
47.8,
63.7,
25.1,
76.5,
47.9,
39,
61.2,
66.2,
78.9,
87.8,
68.8,
70.3,
73.1,
64.2,
40.4,
10,
65.5,
67.5,
55.1,
48,
84,
86.2,
96.9,
80.5,
14.7,
51.8,
31.3,
46.6,
49.8,
72.4,
27.1,
57.2,
90.5,
0,
3.7,
35.2,
90.9,
10.9,
63,
45.7,
25.1,
20.5,
75,
70.5,
74.9,
19,
52.2,
47.1,
64.6,
58.4,
29.6,
67.1,
42.2,
39.1,
47.3,
28.4,
53.2,
64.3,
85.1,
81.3,
51.1,
78.8,
55,
31,
93.2,
56,
40.4,
0.8,
56,
80.1,
33.9,
52.8,
47.4,
53.3,
68.1,
56.7,
38.6,
73.2,
35.6,
71.2,
79.2,
51.5,
74.7,
58.9,
14.5,
28.3,
73.2,
91.1,
70,
35.3,
79.4,
35.4,
71.1,
55,
70.7,
56.7,
85.1,
38.4,
58.3,
80,
92.6,
23.2,
13.9,
80.3,
56.3,
40.5,
29.4,
55.1,
82.6,
28.7,
70.9,
38.6,
9.1,
16.2,
53.1,
21,
1.5,
35.4,
71,
49.3,
84.6,
83.7,
58.8,
58.9,
48.3,
62.9,
18.2,
8.2,
59.5,
67.3,
38.9,
22.8,
57.2,
33.4,
48.5,
50,
24.6,
58.4,
68.2,
54.7,
69.1,
52.1,
32.5,
60.9,
44.1,
59.8,
42.5,
35.6,
29.1,
83.3,
84.6,
70.2,
82.3,
77.1,
73.9,
42.4,
43.1,
67.2,
54.1,
44.2,
75,
66.3,
65.1,
21.2,
56.4,
97.3,
75,
59.4,
69.1,
61.6,
38.8,
77.4,
69.2,
71.1,
84.7,
58.2,
38.8,
69,
24.6,
57,
34,
43.1,
90.5,
55.6,
65.6,
56.2,
37.2,
25.3,
6.9,
56.1,
70.2,
41.5,
102,
43.9,
72,
48.3,
63.6,
49.2,
80.6,
60,
84,
83.7,
28.4,
81.2,
30.4,
83.7,
91.8,
65.8,
33,
52.3,
64,
44.5,
91,
48.7,
57.9,
61.6,
59.8,
58.1,
93.3,
60.8,
95.3,
39.2,
74.3,
28.4,
37.2,
25.5,
27,
13.8,
47.6,
65,
48.4,
43.4,
79,
29.2,
85.3,
63.4,
46.1,
80.7,
49.9,
92,
88.5,
64.5,
64.3,
7.4,
63.9,
44.8,
56.1,
49.3,
44,
57.7,
72.4,
59,
63.2,
52.8,
23.9,
60.6,
70,
47.1,
23.3,
62.9,
37.5,
69.4,
57.9,
63.7,
50.2,
79.6,
55.4,
54.6,
51.8,
44.4,
82.4,
57.4,
67.6,
53.8,
58.8,
36.7,
59.6,
39.5,
86,
4,
47.2,
61.1,
66.8,
58,
74.1,
91.7,
78.2,
61.7,
59.9,
18.4,
67.7,
17.4,
55.1,
28,
12.3,
86.7,
31.6,
60.1,
58,
68.8,
74.4,
66.3,
87.5,
45.1,
54.2,
35.9,
62.2,
78.5,
94.5,
68.7,
82.4,
69.6,
63.9,
96.8,
41.2,
0.2,
8.3,
83.1,
66.5,
43.3,
29.1,
29.7,
42.7,
84.7,
49.3,
71.8,
59.1,
56.1,
76.6,
66,
83,
49.5,
61.4,
72.3,
47.5,
80.3,
15.2,
73.9,
79.1,
88.1,
9.9,
67.5,
5.8,
94.7,
38.9,
null,
89.9,
36.7,
71.5,
25.8,
78.4,
96.7,
69.9,
83,
34.1,
65,
70.8,
27.6,
57.8,
98.6,
39.7,
62.3,
65.1,
52.6,
40.4,
58.1,
97.8,
59.4,
68,
88.4,
66.7,
20.9,
71.4,
43.2,
79.4,
63.9,
83,
77.8,
53.1,
97,
70.4,
61,
20,
73.7,
7,
91.2,
59,
39.5,
96,
68.9,
36.6,
24.2,
22.8,
77.9,
36.8,
49.4,
36.5,
56.8,
26.8,
76.4,
30.8,
0.9,
49.4,
83.7,
94.5,
54.9,
68.1,
59.5,
57.1,
52,
63.6,
89.7,
53,
86.3,
56.4,
45.5,
62.1,
67.5,
11.7,
48.1,
68,
57,
82.3,
57.5,
63.6,
52.9,
84.1,
82.8,
79.4,
28.1,
21.2,
40.6,
37,
94.4,
19.7,
74.7,
60.8,
24.8,
57.4,
52.3,
93.8,
68.6,
66.4,
41.7,
75.4,
44.4,
30.3,
60.7,
65.7,
85.5,
39.1,
93.3,
55.5,
80,
33.8,
84.6,
73.1,
95.7,
5.5,
53.4,
68.3,
49,
29.3,
66.8,
2.9,
68.9,
31.3,
56.5,
27.7,
91.9,
54,
63.7,
49,
35.3,
64.9,
67,
77,
83.6,
35.9,
37.8,
37.3,
9.7,
15.2,
24.2,
44.3,
85.1,
84.3,
72.9,
75.2,
44.9,
61.6,
1.7,
56.8,
65.6,
40.8,
44.3,
63.2,
75,
87.5,
12,
47.3,
83.5,
20.9,
33.7,
56.2,
68,
37.4,
78.5,
82.1,
87.4,
64.1,
52.6,
88.3,
32.5,
72.6,
0,
100,
86.3,
93.7,
23,
72.7,
47,
75.3,
18.1,
79.6,
61.2,
79.5,
45.7,
58.9,
75.2,
98.8,
38,
56.8,
45.2,
69.8,
44.6,
61.3,
61.2,
27.2,
56.1,
40.4,
53.7,
35.7,
87.9,
32.3,
48.3,
33.9,
98.7,
85.2,
61.4,
46.6,
29,
85.3,
76.7,
56.6,
49,
67.2,
60.4,
69,
82.3,
33.2,
8.7,
40.7,
89.1,
7.1,
74.9,
69.4,
19.9,
43.3,
78.7,
49.9,
58.5,
79.8,
72.2,
42.3,
32.9,
71.4,
56.4,
26.9,
88.1,
30.3,
68.2,
96.4,
44.7,
94.5,
70.9,
80.8,
46.4,
7.6,
70.7,
59.9,
14.1,
80.4,
28.4,
31.6,
36.7,
47.7,
31,
62.2,
59.3,
57.1,
96.3,
73.1,
22.3,
10.8,
75.5,
33.9,
41.3,
75.3,
17,
21.7,
77.8,
48.2,
86.1,
15.2,
26.5,
43,
47.9,
6.8,
19,
59.5,
55.5,
86.2,
77.7,
25.7,
47.6,
54,
50.1,
69.3,
80,
57.7,
42.3,
15.9,
61.2,
43.3,
49.1,
58.4,
39.4,
80.4,
37.9,
77.4,
8.6,
24,
76.4,
32.2,
45,
23.3,
10.5,
75.2,
53.2,
59.8,
78.9,
23.7,
45.5,
28.3,
25,
4.5,
51.9,
42.9,
96.6,
82,
12,
60.9,
38.9,
1.7,
20.6,
82,
42.7,
71.8,
66.4,
26.4,
76.2,
53.3,
6,
89.3,
54.5,
2.9,
98.5,
50,
46,
26.8,
69.9,
26.3,
36.4,
27.7,
19.9,
90.3,
38,
11.3,
62.1,
64.7,
73.6,
37.1,
75,
59,
27.3,
25,
60.6,
63.8,
25.5,
80,
74.7,
63.2,
89.4,
75.3,
29.9,
60.4,
78.3,
98.2,
43.1,
59.4,
24.4,
74.5,
25,
57.1,
63.6,
12.8,
32,
85.3,
39.8,
25.7,
56.8,
68.8,
71.5,
97.6,
37.6,
53.5,
28.4,
89.2,
90.1,
9.3,
43,
40.7,
57.8,
27.8,
32.1,
14.3,
39.2,
91.2,
26.6,
78.7,
96.1,
33.5,
41.1,
100.9,
81.7,
43.1,
77.2,
38.8,
21.2,
6.1,
17.4,
3.6,
31,
32.5,
73.4,
19.4,
82.2,
92.4,
83.3,
35.3,
63.3,
90.1,
22.1,
81.2,
13.6,
43.5,
26.1,
10.3,
72.6,
13.6,
23.4,
66.7,
45.3,
99,
97.6,
23.5,
62.9,
41.6,
97.5,
11.1,
82.5,
93.1,
12.3,
65.7,
41.5,
61.9,
77.6,
17.2,
27,
78.2,
61.3,
41.8,
89.3,
39,
97.9,
5.7,
92,
34.6,
14.3,
52.8,
93.7,
70.5,
82.4,
13.8,
42.3,
59.4,
75.7,
16.3,
67.2,
19.7,
34.9,
43.2,
77,
65,
37,
77.1,
66.9,
84,
74,
90.3,
27.1,
46.7,
46,
63.4,
18,
89.3,
45.4,
75.3,
74.1,
61.2,
96.7,
70.6,
62.4,
84.3,
49.4,
90.1,
68.7,
89.7,
58.6,
86.4,
77,
69.4,
57.1,
62,
57.4,
52.6,
96.6,
88.7,
31.7,
31.1,
96.6,
50,
72.1,
34.1,
58,
28.5,
82.7,
97.5,
78.5,
42,
44,
42.3,
7,
47.6,
49.6,
31.3,
30,
85.4,
82,
73.5,
90.7,
66.7,
91.2,
75.1,
46.2,
55.9,
57.4,
43.1,
33.3,
24.9,
48.8,
62,
49.4,
36.4,
42.6,
56,
29.7,
53.5,
0,
74.8,
63.5,
39.1,
70.5,
28.7,
50,
9.8,
87.2,
59.7,
62,
63.1,
68.7,
64.9,
30.3,
95.5,
28.7,
95.6,
48.4,
72.8,
88,
50,
25.8,
15.9,
46.1,
66.7,
81.6,
39.6,
82.6,
48.2,
62.8,
89,
0,
84.7,
64.9,
65.2,
18,
86.5,
33.7,
81.8,
67.1,
65.9,
4.1,
88.2,
52.3,
1.1,
45.1,
44.1,
78.7,
27.4,
86.1,
84.2,
70,
41.1,
53.7,
26.6,
19.8,
56.4,
57.6,
6.5,
76.4,
91.1,
84,
87.6,
82.1,
62,
84.4,
55.7,
42.4,
44.1,
78.9,
39,
65.5,
34.3,
59.5,
38.2,
70,
88.9,
83.7,
62.6,
71.4,
49,
24.6,
42.4,
41.6,
74.9,
62,
49.8,
80.2,
69.8,
86.4,
16.1,
30,
64.5,
78.7,
34.6,
68.9,
56.3,
38.6,
74.2,
90.1,
93.6,
56.4,
24.9,
41,
31.5,
34.6,
54.1,
70.5,
56.7,
63.5,
78.1,
25.5,
16.7,
51.3,
43.5,
49.7,
97.8,
42.6,
29.6,
49.6,
41.4,
95.1,
92.2,
59.4,
83.7,
31.7,
26.9,
89.2,
64.5,
33.2,
57.1,
2.3,
69.6,
94.6,
95.4,
51.6,
15.8,
57,
74.7,
92.7,
47.9,
31.1,
96.3,
29.3,
76.8,
41.7,
16.2,
55.3,
78.4,
36.1,
69.5,
82.2,
59.4,
63.4,
41.9,
79.7,
53,
12.8,
46.4,
100.4,
59.4,
98.7,
78.2,
89.5,
50,
47.8,
81.3,
77.3,
81.9,
71.2,
86.3,
83,
41,
70.3,
50.1,
77.5,
49.8,
69.9,
23.2,
70.8,
63.8,
65.9,
75.5,
59.4,
54,
53.5,
83.9,
1.3,
71.7,
12,
33.4,
19.6,
37.9,
59.5,
40.2,
78.7,
89.9,
60.2,
77.7,
48.4,
75.4,
72,
49.1,
63,
48.8,
31.8,
55.8,
1.8,
85.1,
33,
67.7,
97.5,
66.5,
21.5,
49.7,
59.7,
42.1,
35.9,
29.1,
51.5,
73.8,
33.2,
37.6,
60.2,
48.1,
30.4,
84.1,
63.7,
46.5,
34.2,
80.7,
4.6,
45.2,
93.3,
48,
53.6,
42.6,
53.4,
83.3,
49.3,
74.9,
60.6,
21.2,
28.4,
28.8,
76.5,
90.9,
81,
39.9,
37.4,
60.7,
86.7,
27.1,
59,
43.2,
95.1,
45.3,
31.7,
80.6,
27.8,
85.2,
102.8,
36.5,
31.7,
43,
52.6,
26.5,
6.3,
60.7,
75,
51.4,
52.9,
31.2,
74.2,
88.7,
14.5,
80.8,
79.2,
45,
57.1,
41.1,
45.5,
25.2,
73.9,
76,
93.9,
4.3,
0,
80.7,
55.3,
98,
53,
75.9,
44.3,
53.3,
61.4,
24.8,
67.8,
52.7,
63.4,
69.1,
13.9,
4,
23.7,
0,
29.8,
24.9,
42,
61,
6.3,
66.5,
21,
40,
10.5,
76.6,
38.9,
41.6,
36.8,
42.6,
61.6,
37.5,
66.7,
45.2,
67.9,
37.2,
62,
54.9,
30.1,
51,
0,
3.7,
52.4,
66.1,
54.3,
71,
58.4,
53.8,
62,
32.3,
37.3,
0.5,
71.5,
77.4,
78.3,
47.5,
50.1,
48.9,
57.9,
48.6,
8.8,
48.4,
72.2,
35.2,
97,
54.7,
42.6,
55,
98.4,
84.4,
68.7,
48,
97.3,
27,
54.4,
100.2,
28.8,
42.5,
5.8,
10.7,
58.5,
31.1,
39.1,
32.7,
26.3,
73,
88.1,
73.3,
86.4,
36,
55.2,
26.5,
75.2,
78.6,
65.9,
88.7,
60.7,
80,
38.4,
46.6,
28.8,
28.4,
80.2,
84.3,
61,
65,
98.4,
94.8,
76.4,
48.7,
80,
47.4,
29.9,
54.4,
55.6,
53.7,
45.3,
88.8,
64.8,
32.9,
100,
29,
48.5,
77.8,
58.2,
85.5,
18.9,
57.2,
54,
26,
39.6,
65.6,
14.1,
71.7,
67.4,
59.4,
71.5,
40.7,
68.3,
85.4,
36.5,
32.1,
51,
50.4,
92.7,
43.6,
30.7,
70.6,
64.7,
28.9,
36.4,
20.4,
17.3,
98.2,
69.1,
99.9,
50.3,
79.4,
22.4,
11.6,
69,
90,
57.4,
77.8,
55.9,
43.6,
45.2,
77.1,
50.9,
50.8,
0,
14.2,
90,
71.9,
52.7,
50.4,
25.2,
35.7,
76.1,
37.8,
28.3,
58,
72.9,
56.6,
50.4,
94.3,
80.6,
97.7,
68.1,
53.8,
72,
1.5,
64.3,
37.1,
13,
92.9,
41.7,
95.8,
94.4,
97.7,
84.5,
50.8,
49.3,
31.9,
69.7,
75.8,
72.3,
23.6,
0.12,
92.2,
82.3,
68.3,
78.5,
41.6,
67,
51.1,
11.4,
61.7,
68,
26.6,
95.3,
78,
59.2,
45.5,
23.5,
90.8,
38.9,
42.4,
35.6,
40.3,
67.6,
26.2,
41.4,
74,
28.8,
49.2,
23.1,
87.8,
68.4,
35.2,
83.6,
75.4,
54.3,
56.4,
59.9,
30.5,
36.7,
33.2,
12.9,
89.3,
19.2,
33.3,
62,
44.8,
71.4,
83.5,
42.5,
91.9,
23.1,
8,
62.5,
48.8,
52.5,
72.1,
90.2,
45.8,
53,
76.5,
64.1,
39.5,
35.9,
28.5,
58.3,
null,
53,
79.7,
119.8,
67.4,
54.9,
67.3,
63,
66.7,
67.2,
33.3,
43.5,
66,
93.7,
68,
85.5,
59.3,
54.2,
53.7,
94.5,
61.6,
25.8,
92.7,
49,
59.2,
96.9,
54.1,
95.9,
88.6,
65.8,
32.2,
3.2,
66.5,
65.1,
86.4,
100.5,
60.3,
70.4,
61.5,
34.1,
78,
80.3,
69.8,
94.1,
11.3,
23,
100.8,
45.4,
72,
80.4,
5,
66.1,
53.5,
25.9,
58,
40.6,
89.6,
66.1,
54.3,
39,
94.8,
78.3,
59.8,
98.7,
47.4,
59,
43.7,
63.9,
48.6,
26.2,
57.7,
53,
77.7,
63.3,
44.7,
3.9,
59.1,
85.9,
50.7,
23.4,
62.5,
46.2,
78.9,
61.4,
40.4,
73.1,
25.5,
38.8,
93.3,
43.6,
99.8,
41.2,
84.7,
53.7,
64.1,
100.9,
51.9,
1.8,
43.4,
45.5,
33.6,
19.9,
63.6,
97.3,
53.5,
59.5,
23.9,
45.9,
67.5,
40.3,
49.3,
0.8,
62.5,
34.7,
25.7,
51.4,
54.8,
48.5,
36.5,
67.9,
83.1,
98.9,
74.5,
57.9,
22.7,
98.4,
61.6,
43,
36.8,
66.7,
25.9,
48,
29.1,
10.4,
86,
50.8,
27.6,
68.1,
55,
52.2,
26.4,
73.3,
92.5,
23,
11.4,
49.4,
36.3,
63.3,
64.9,
38.8,
67.3,
26.1,
33.7,
30.6,
66.2,
97.3,
33,
69.1,
23.1,
41.1,
76.5,
81,
82.2,
57,
33.1,
48.8,
72.6,
26.6,
54.3,
53.1,
31.2,
9,
48.5,
24.6,
28.6,
68.3,
52.6,
29.5,
51.6,
45.2,
64.9,
35.1,
66.6,
42,
49,
42,
85.1,
100,
63,
91,
67.3,
0,
60.2,
46,
20.9,
31,
48.5,
96.6,
52.6,
86.3,
58.4,
14.5,
54.1,
84.2,
49.9,
60.9,
58.4,
8.1,
68.9,
37.4,
7.7,
41.1,
81.5,
10.4,
52.4,
90.8,
58.6,
50.4,
44.3,
87.1,
81,
87.1,
58.7,
47.1,
65.6,
36.2,
79.4,
50.4,
43,
68.5,
40.3,
40.6,
91.8,
70.9,
45.3,
22.2,
7.8,
24.7,
95.6,
25.9,
44.4,
71.4,
50.1,
70.8,
65.8,
48.7,
69.1,
25.9,
69,
36.8,
69.3,
27.4,
44.5,
75.5,
54,
31.3,
43.4,
70.5,
56.1,
55.5,
29.2,
75.2,
7.4,
20.6,
48.2,
15.1,
0.3,
32.4,
17.7,
40.9,
12.2,
54.1,
89.8,
48.7,
81,
46.3,
77.5,
61.6,
60.9,
82.3,
46.3,
35.9,
92.8,
56.8,
33,
45.4,
64.9,
24.6,
72.7,
77.2,
42.6,
7,
49.9,
74.5,
54.2,
49,
58.7,
34.8,
65.5,
72.9,
22.2,
77.2,
91.3,
10.1,
19,
44.2,
88.1,
79.9,
37.4,
79.9,
62.1,
87.7,
10.3,
60.7,
30.4,
40.2,
77.4,
17.8,
68.6,
53.1,
40.5,
42.9,
54,
9.2,
43.3,
5.2,
42.1,
81.1,
97.2,
69.1,
89,
62.6,
80.1,
63,
61.7,
69.2,
59.7,
70.2,
27.9,
80.9,
49,
54.1,
26.4,
16.2,
34.4,
63.7,
41.6,
68.1,
83.2,
61.2,
47.4,
72.6,
86.7,
24,
5.2,
21.1,
88.8,
7.9,
59,
70.2,
59.1,
86.8,
64,
50.7,
57.9,
70.4,
67,
56.9,
79.3,
30.3,
83.3,
26.4,
37.3,
79.3,
37.2,
41.5,
60.4,
88.3,
66.2,
89.3,
23.4,
48.5,
82.6,
94.1,
20.6,
83.3,
41.8,
41.5,
25.8,
53.9,
50,
60.3,
38.1,
19.3,
16,
36,
45.3,
98,
66.4,
83.5,
18,
81.3,
62,
51.3,
54.9,
41.9,
76.2,
33.8,
47.9,
26.6,
34.8,
28.1,
87.4,
27.6,
25.1,
46.7,
62.6,
37.8,
90.3,
68.4,
88.2,
61.6,
22.5,
61.1,
83.4,
71.1,
73.7,
52,
55.1,
49,
31,
87.4,
72,
47.5,
54.3,
19.6,
82.6,
50.9,
44,
51.9,
34.3,
69.5,
65.9,
71.4,
50.7,
56,
15.4,
95,
69.8,
62.7,
61.1,
78.8,
90.9,
84.3,
71,
47.9,
59.2,
40.4,
54.4,
71.7,
14.4,
76.3,
90.5,
70.5,
77,
101.5,
46.4,
16.6,
78.1,
61.1,
80.2,
57.1,
12.7,
59.6,
69.7,
54.1,
27.1,
32.1,
62.5,
71.4,
91.2,
45.3,
34.7,
45,
76.6,
30.9,
29.9,
66.2,
51.1,
68.3,
53.9,
38.4,
66.5,
51.7,
55.7,
56,
63.1,
26.1,
95.3,
96.3,
80.3,
35.1,
71.3,
61.4,
88.7,
38.9,
71.9,
66.4,
52.1,
53,
89,
86.9,
27.7,
83.3,
44.6,
71.1,
94.6,
22.6,
53.8,
43.5,
8.4,
32.9,
57.3,
40.8,
11.9,
93.7,
71,
20.7,
29.5,
58.8,
64,
76,
58.1,
91,
41.7,
42.6,
69.7,
85.8,
43.9,
62.6,
65.5,
38.5,
37.1,
65.9,
68.7,
35.3,
90.6,
49.4,
23.4,
31.1,
77.4,
30.4,
58.6,
68.5,
71.3,
85.8,
41.4,
67,
76.6,
53,
6,
71.8,
58,
78.5,
49.6,
58.5,
55.8,
17.1,
59.7,
45.9,
77.2,
32.9,
76.5,
21.8,
45.2,
54.7,
88.3,
84.7,
52.4,
38.3,
8.2,
82.3,
32.7,
46.9,
7.1,
51.6,
52,
61.2,
43.4,
42.4,
78.6,
81.8,
52.7,
67.3,
84.9,
73.1,
59.1,
35.1,
55,
14.5,
8.7,
56.3,
85,
71.6,
57.7,
49.7,
68,
65.8,
66.7,
93,
66.1,
84.7,
71.9,
85.5,
37.1,
49.2,
89.4,
65.7,
85.7,
40,
73.6,
42.5,
93.8,
50.4,
72.2,
25.4,
77.1,
57.1,
61.2,
28.3,
53,
46.9,
56.6,
50.9,
86.8,
72.6,
49.6,
79,
4.3,
56.4,
97,
62.5,
2.8,
35.7,
8.6,
52.1,
55,
77,
39.8,
30.8,
86,
37.8,
44.1,
36.1,
71.4,
44.5,
27.6,
22,
85.4,
85.8,
66,
89.1,
97.7,
50.8,
23.8,
72.5,
45.7,
76.3,
56.7,
76.8,
68,
75.9,
35.1,
33.6,
76.2,
66.8,
46.3,
65.1,
92.1,
38.8,
8.1,
73.5,
91.5,
40.3,
70.4,
68.3,
79.4,
25.6,
59.4,
32.4,
53.4,
61,
63.1,
25.5,
18.4,
78.7,
72.1,
27.3,
34.4,
56.6,
62.5,
74.8,
54.6,
71.8,
53.9,
62.1,
32.6,
52.7,
84.9,
22.4,
31.6,
26.8,
38.7,
72.4,
96.5,
37.5,
43.9,
0,
95.5,
48,
26,
32.2,
49.5,
37.9,
28.5,
89,
85.1,
37.1,
89.8,
64.5,
51.3,
55.7,
27.6,
29.9,
2.5,
62.1,
62.2,
83.9,
96.4,
15.7,
94,
56.4,
55.4,
56.6,
55.5,
48,
56.2,
43,
58,
50.8,
42.2,
50.5,
71.4,
56.6,
21.4,
66,
38.6,
44,
79,
56.6,
21.8,
60.6,
56.1,
24.3,
65.7,
54.3,
60.8,
58.7,
64,
7.5,
35,
20.1,
64.9,
56.8,
81.1,
3.4,
32.2,
8.6,
47.7,
70,
21,
7.6,
90.5,
78.1,
69,
39.2,
5.3,
47.5,
50.2,
18.6,
21.3,
21.3,
77.8,
66.2,
9.3,
48.8,
66,
31,
46.3,
98.1,
60.5,
53,
57.5,
14.9,
31,
71.5,
77.5,
22.4,
82.3,
28.8,
56.1,
65.6,
35.5,
74.7,
18.7,
29,
15,
50.5,
81,
42.9,
55.5,
48.2,
90.9,
77.4,
44.4,
19.5,
72.9,
42.2,
47.6,
45,
69.4,
84,
43.5,
92.4,
60.4,
44.6,
27.3,
35.9,
60.8,
87.8,
82.4,
77,
85,
46,
87.4,
66.4,
89.9,
47.6,
51.2,
78.4,
41.1,
59.4,
63,
35.7,
66.4,
96.5,
36,
74.4,
78.2,
67.1,
77,
27.7,
46.5,
45,
69.7,
67,
75.1,
49.7,
58.3,
45.4,
54.7,
28.8,
59.2,
66,
70.6,
51.1,
65.2,
86.7,
35.2,
75.8,
89.1,
52.3,
84.4,
9.3,
44.3,
31.4,
60.8,
65.1,
47.8,
64.5,
27.6,
74.1,
90.5,
35.7,
58.4,
31.1,
67.5,
30.2,
77.9,
49.9,
27.5,
36.1,
78,
10.6,
42.9,
30.8,
8.4,
34.3,
50.3,
59.3,
76.4,
46.9,
38.9,
84.8,
11.5,
60,
0.3,
53,
54.8,
57.8,
69.5,
69.1,
94.2,
32.7,
11.8,
77.9,
1,
61.7,
52.6,
59.2,
22.2,
95.7,
66.6,
73,
71.6,
71.3,
38.2,
11,
67.1,
66.7,
50,
90.4,
57.6,
58.7,
70,
42.6,
26.4,
61.2,
56.3,
95.8,
53.9,
12.8,
55.9,
16.3,
93.7,
74.9,
65,
12.2,
96.4,
59.4,
63.3,
59.7,
87.5,
88,
81.8,
72.6,
58.7,
61,
71.6,
16.5,
45.8,
67.8,
36,
81.7,
38.6,
75.9,
61.5,
5.3,
21.1,
8.3,
47.8,
90.9,
55.2,
66.2,
78.9,
56.4,
51.3,
52.2,
44.1,
86.8,
76.8,
41.3,
63.9,
53.8,
59.7,
13.4,
40,
69.5,
71.4,
92.5,
68.9,
64,
97.4,
76,
78.4,
62.3,
68.4,
10.6,
58.8,
66.6,
14.1,
46.2,
62.2,
51.3,
63,
88.7,
98.4,
58,
65.2,
40.1,
69,
43.5,
54.4,
26.4,
100,
5.8,
56.3,
36.5,
90.1,
30.5,
87.6,
67.4,
71.7,
66.2,
56.5,
72.5,
53.1,
32.7,
19.2,
90.7,
68.4,
68.2,
94.1,
30.3,
32.5,
90,
40.3,
86.4,
43.5,
41.4,
64,
46,
48.9,
32,
33.6,
67.6,
13.8,
81.3,
62.6,
60.3,
60.8,
25.1,
92.4,
83.1,
26.5,
37.4,
50.2,
73.6,
71.2,
50.3,
44,
49.5,
89.1,
67.2,
99.7,
59.8,
56.9,
50.6,
79.6,
96.3,
32.5,
85,
38.5,
54.5,
67.4,
22.7,
92.6,
80.8,
45.1,
86.2,
20.2,
49.7,
78.1,
72.3,
6.1,
37.6,
53.5,
34.7,
87.2,
77.9,
64.8,
80.5,
48.5,
31,
71.9,
73.3,
66.5,
58.9,
28.1,
74,
17.5,
16.4,
44.6,
81.3,
47.9,
68.9,
89.8,
57.9,
55.2,
48.4,
47.1,
71.4,
66.9,
44.2,
8.2,
12,
52.8,
43.3,
55.8,
59,
43.2,
58.5,
56.4,
65.7,
24.6,
65,
67.8,
19.7,
50.4,
0.7,
71.5,
76.2,
46.3,
50,
86.3,
55.4,
80.7,
56.6,
25,
16.6,
18.9,
53.4,
2.5,
90.1,
51.3,
90.4,
80.4,
12.2,
39.6,
14.6,
8,
99.4,
95.2,
73.7,
25.5,
57.9,
36.6,
25.7,
80.9,
58,
67.1,
49.3,
86.3,
79.6,
48.1,
37.7,
59.4,
71,
30.5,
2.5,
54.6,
34.7,
81.8,
95.2,
78.3,
62.5,
64.2,
62.4,
86.4,
81.7,
34.5,
5.1,
56.7,
55.2,
67.5,
14.5,
96.8,
18.4,
68.2,
57.7,
83.2,
87,
67.5,
93.6,
18,
37.7,
45.8,
97.6,
99.5,
80.6,
34,
63.5,
60,
45.1,
57,
29,
91.6,
87,
82.5,
42.3,
12,
93.5,
58.6,
66.6,
17,
48,
77.4,
56.2,
24.3,
66.3,
83.2,
53.7,
42.4,
92.4,
97.7,
7.9,
91.9,
9.2,
42.5,
0,
78.3,
2,
40.4,
29.4,
28.8,
75.1,
7.3,
64.6,
53.4,
70.5,
38.6,
43.8,
84.2,
71.4,
80,
47.3,
53.8,
72.8,
51.8,
86.6,
57.2,
50.3,
39.4,
55.6,
27.4,
55.8,
15.4,
62.6,
74.5,
43.1,
50,
55.5,
56.8,
65.1,
68.9,
8,
17.4,
60.9,
84.8,
63.3,
91.4,
52,
71.6,
71,
42.8,
57.4,
38.2,
49,
63,
100.6,
26.7,
33.2,
83.8,
27.9,
73,
72.9,
90.1,
29.9,
60.1,
37.9,
92.1,
30.8,
5.8,
73,
49.4,
81.3,
33.2,
75.6,
75,
73.4,
40,
36.5,
74.3,
68.6,
45.5,
63,
48.5,
75.6,
71.9,
47.8,
0,
12,
38.7,
31.7,
82.4,
58.1,
59,
56.6,
82.9,
16,
0.5,
60.6,
73.1,
4.6,
48.2,
28.8,
85.1,
70,
47.2,
82.9,
87.7,
71.4,
7.4,
38,
57.9,
39.6,
78,
44.4,
60.5,
51.9,
43.2,
72.3,
30.8,
35,
75.6,
66.9,
49,
65,
48.8,
44.6,
81.9,
78.3,
66.1,
86.6,
68.1,
74.6,
30.4,
12,
78.3,
67.9,
48.8,
40.5,
69.3,
69.9,
57.6,
5.7,
92.9,
66.4,
31.9,
65,
78.6,
57,
86.3,
81.3,
69,
33,
89.5,
29,
41.5,
72.6,
49.9,
41.3,
80.7,
48.8,
29.9,
94,
58,
55.9,
82,
2,
83.1,
56.5,
40.2,
55,
40.2,
61.4,
68.1,
74.4,
20.8,
12.4,
74.5,
71.7,
37.9,
86.2,
7.7,
3,
24.4,
42,
21.3,
73.6,
29,
71.6,
58.7,
38.7,
50.5,
69.5,
51.1,
43.5,
77.7,
67,
14.8,
90.9,
30.7,
37.9,
41.8,
75.2,
27,
38,
64.2,
39.6,
82.4,
39.5,
92.9,
20.3,
20.2,
28.3,
49.2,
60.9,
43.3,
60.9,
76.6,
32.1,
55,
53.3,
83.9,
23.9,
88.7,
58.7,
88.4,
47.4,
63.6,
65.2,
71.1,
61.9,
72.2,
60.6,
94.9,
19.9,
18,
41,
85.5,
30.8,
36.3,
42.7,
67.4,
78.6,
59.9,
56.8,
76.5,
74.6,
33,
37.7,
68.2,
23.1,
76.4,
6.6,
86.2,
28.3,
53.1,
37.3,
88.5,
83.2,
39,
78.3,
57.8,
89.7,
53,
84.7,
9.7,
31.1,
30.8,
71.5,
36.9,
91.1,
54.5,
78.9,
20.2,
69,
50.2,
48.3,
21.5,
60.5,
78.8,
14.1,
67.6,
48.8,
57,
61.3,
38.5,
65.4,
68.3,
0.1,
29.4,
57,
40.6,
67.9,
70,
57.8,
76,
63.2,
60.4,
51.8,
90.1,
54,
40.1,
78.7,
38.6,
34.3,
76.3,
84.5,
57.1,
55.8,
15.1,
55.3,
59.5,
44.9,
33.1,
61.8,
12.7,
74.1,
54.8,
61.2,
98,
45.3,
44.7,
39.3,
18.3,
79.4,
30.2,
42.7,
71.1,
47.6,
86.9,
68.3,
68.2,
52,
72,
64,
66.6,
14.2,
11.6,
37.4,
69.6,
67.3,
64,
96.9,
77.3,
60.1,
31.8,
57.2,
67.6,
27.4,
88.2,
62,
40.9,
98.3,
87,
72.6,
45.6,
60.8,
74.8,
44.5,
40.5,
51.2,
64.8,
83.6,
62.5,
43.2,
60.8,
2.8,
51.5,
61.9,
45,
65.1,
2,
52.7,
78.6,
13.3,
82.7,
65.3,
70.5,
82.4,
51.9,
90.8,
50.7,
74.3,
91.8,
61.1,
51.6,
90.9,
42.4,
81.7,
52.4,
88.1,
55.1,
70,
50.6,
71.1,
37.1,
63.1,
90.5,
40,
45.2,
29.5,
25,
41.5,
35.8,
25.5,
8.8,
0.6,
53.4,
46.2,
58.3,
59.6,
44,
80.7,
53.2,
82.7,
35,
63.3,
59.6,
52.1,
69.7,
70.6,
80.5,
41.5,
49.5,
43.2,
86.3,
69.7,
71.4,
50.2,
28.7,
66.5,
62.7,
38.2,
28.7,
49.5,
55.7,
12.3,
30.5,
89.7,
23.7,
95.2,
93.1,
26.1,
9.5,
36.1,
51.2,
84.2,
63.1,
92.2,
34.9,
56.7,
30.7,
93,
71,
89.4,
30.2,
85.8,
32.2,
56.1,
91.9,
32.7,
19.5,
64,
11.7,
90.2,
75.5,
20.2,
44,
58.2,
78.5,
43.4,
64.9,
71.3,
56.4,
41.7,
36.8,
91.1,
43.6,
61,
37,
39.7,
93.2,
26.4,
25,
25.2,
3.6,
32.7,
30.1,
31.2,
59,
43.2,
41.3,
52.5,
93.1,
59.8,
48.7,
46.1,
71.8,
53.7,
71.2,
106.5,
71.9,
87.9,
42.3,
62.1,
62.5,
73,
76,
96,
10.8,
97.4,
31.3,
50.7,
69.4,
59.8,
72.1,
61,
95.1,
22.2,
53.8,
80.1,
22.5,
93.3,
54,
66.4,
32.3,
90.9,
19.1,
50.7,
50.8,
10.4,
73.4,
12.8,
77.5,
20.4,
79,
53.4,
1.5,
17.5,
72.9,
35.8,
60.9,
64,
67.9,
74.4,
98.6,
40.7,
43,
78.4,
31.1,
44.5,
51.1,
64.8,
49.8,
49.5,
86.1,
11.3,
72.6,
21.9,
44.7,
49,
4.85,
52.1,
84.8,
35,
63.1,
43.8,
80.8,
41.4,
58.4,
41.7,
92.5,
49.7,
38.9,
36.9,
66.2,
19.6,
64.3,
39.6,
85.4,
41.5,
70.5,
92.2,
83.8,
65.4,
95.9,
66.2,
76.6,
84.5,
46.2,
80.9,
30.3,
74.4,
12,
52.5,
7.1,
67.9,
78.5,
59.5,
81.7,
36.2,
41.8,
79.8,
85.7,
88.7,
47,
21.4,
88.1,
40,
81.4,
89.3,
47.7,
76.4,
60.5,
78.9,
65.9,
56.6,
48.2,
91.3,
58.1,
83.8,
0.4,
70.6,
58.5,
51.7,
77.8,
92.5,
73.3,
77.5,
38.3,
63.5,
60.3,
9.4,
69.9,
41,
76.5,
13.4,
73.4,
70.3,
98.6,
21.1,
35.7,
65.7,
72.8,
55.3,
28.5,
70.6,
57.3,
77,
61.2,
19.3,
13.4,
21.6,
88.9,
63.6,
66.7,
25.9,
28.8,
30,
69.8,
83.9,
44.9,
70.7,
48.6,
66,
22,
46.6,
40.8,
35.1,
31.6,
84.9,
25.7,
52.2,
12,
32.8,
25.8,
66.9,
84.9,
57.8,
86.2,
85.3,
72.8,
72.8,
88.8,
55.4,
71.5,
68.3,
42,
53.9,
41,
59.9,
68.1,
81,
43.8,
7.6,
31.4,
36.4,
58.3,
24,
76.8,
54.6,
69.8,
80.8,
89.7,
13,
53.5,
7.1,
72.3,
56,
63,
4,
40.7,
43.4,
73.7,
76.3,
65.8,
93,
24.5,
70.3,
1,
58.9,
58.7,
67.4,
98.1,
93.2,
69.4,
97.7,
20.6,
59.7,
40.3,
20.7,
84,
44.6,
29.5,
43.9,
33,
79.3,
50.9,
72,
24.8,
50.7,
50.6,
83.6,
54.9,
60.2,
83.3,
68.2,
47.3,
19.9,
27.4,
70.3,
69.1,
99,
26.7,
49.1,
72.7,
63.4,
52.8,
54.3,
62.2,
54.5,
81.3,
55.3,
97.8,
21.8,
72.9,
40.5,
63.6,
68.4,
40.4,
100,
56.5,
75.5,
84.7,
81.5,
61.6,
47.8,
53.5,
28,
50.7,
70.6,
65.1,
52.8,
25.2,
26.7,
39.5,
59.1,
49.4,
60.2,
89.1,
48.1,
43,
88.7,
55.7,
53.7,
43.3,
91.6,
20.1,
96,
69.7,
53.7,
88.5,
74.6,
30,
58.7,
26.7,
85.2,
43.4,
24.9,
43.1,
98,
67.4,
79,
67.4,
null,
31,
72.8,
56,
28.4,
98.8,
74.3,
24.4,
68.7,
9.5,
25.8,
54.4,
79.7,
80.6,
26.6,
20.2,
0,
87.4,
60.7,
57.5,
53.3,
10.2,
48.2,
66.1,
31.3,
52.7,
56.5,
100.6,
84.8,
71.2,
94.6,
69.1,
64.6,
48,
0.9,
43.7,
75.4,
98.4,
27,
59.3,
32.7,
64.9,
77.5,
27.4,
47.1,
73,
1.5,
46.2,
63.8,
35.8,
16.6,
85.1,
84.1,
74.4,
80.9,
64,
63.5,
50.6,
60.1,
69,
61,
43,
92,
41.3,
30.4,
67.2,
9.1,
35.8,
37.4,
74.5,
74.1,
16.6,
48.6,
45.2,
64.4,
59.6,
68.6,
39.4,
12.2,
21.6,
38.3,
49.8,
77.7,
50.1,
37.5,
54,
98.1,
24.5,
4.7,
64.8,
34.2,
44.4,
87,
77.6,
58.4,
77.5,
63.8,
77.5,
48.9,
86.2,
45.7,
40.4,
57,
67.2,
29.8,
78.1,
74.2,
70.6,
50.3,
72.6,
29.6,
56.6,
70.2,
91,
21.7,
98.4,
25.4,
94.4,
64.3,
72.9,
36.6,
59.5,
40,
56.8,
96.3,
60.2,
47.6,
59.4,
88.4,
16.2,
68.8,
9.3,
43.8,
64.5,
51.8,
47.4,
81.1,
91.8,
93.6,
53.7,
89.8,
21.1,
43.1,
66.8,
84.4,
98,
62.6,
52.9,
97.9,
35.9,
74,
38.1,
19.2,
42.5,
59.2,
21.7,
47.9,
33.8,
62.4,
46.9,
50.6,
57.5,
40,
76.1,
57.5,
68.3,
44.1,
50.6,
83.3,
76.9,
75.9,
29.8,
92.9,
34,
76,
45.1,
88,
38.7,
78.3,
50.2,
33.5,
85.9,
87.5,
7,
31.5,
44.1,
38.2,
52.3,
32.8,
89.5,
26,
31.4,
41.6,
19.2,
55.5,
51.7,
49.3,
61.5,
19.6,
34.1,
18.7,
56.1,
37.8,
57.6,
47.5,
82,
63.6,
73,
38.5,
45.1,
78.8,
98.2,
18.4,
51.4,
9.7,
28.2,
33.6,
42.7,
85.2,
20.7,
80.4,
21.9,
38.6,
37.1,
20.4,
65.4,
56.2,
38.3,
57.5,
26.3,
17.5,
33.7,
78.4,
59.7,
51.7,
84.8,
32.5,
12.5,
92.2,
41.8,
75.8,
18.4,
67.8,
85.4,
48.4,
91,
79.8,
90.9,
55.5,
75.2,
51.2,
57.3,
76.3,
99.8,
48.4,
22.1,
44.1,
78,
28.2,
60.5,
57.6,
54.1,
6.5,
53.6,
48.2,
67.8,
71,
71.8,
22.2,
69.9,
91.8,
80,
33.1,
58.7,
78,
79,
39.5,
26,
70.1,
19.8,
63.3,
91.3,
55.1,
76.4,
53.2,
88.8,
56,
44.9,
67,
63.6,
52.7,
44.2,
36.3,
85,
49.4,
14,
72.6,
73.9,
3.9,
65.5,
63.6,
45.2,
40.3,
63.9,
31.3,
62.8,
8.9,
66.9,
86.7,
0,
63.4,
79.7,
17.7,
27.6,
98.6,
65.4,
29.4,
46.7,
56.3,
85.1,
69.7,
42.9,
89.7,
43.2,
85.5,
60.7,
72.4,
24,
63.3,
66.2,
71.8,
68.3,
9.4,
40.1,
60.7,
40,
76,
6,
89.4,
81.5,
56.2,
31.6,
68,
63.9,
73.9,
82.5,
69.7,
42.1,
78.6,
64.3,
32.6,
70.7,
63.5,
66.2,
47.1,
44,
34,
85.1,
78.8,
47.3,
41.9,
48.4,
24.5,
41,
74.4,
77.4,
74.5,
40.4,
72.5,
34,
64.7,
18.6,
50.5,
60,
43.5,
57.9,
30.3,
74,
32.2,
73.4,
51.8,
21,
29.8,
85.5,
46,
72.5,
70.2,
79.4,
43.4,
73.1,
45.8,
39.7,
34.1,
45.1,
61.5,
72.1,
85.6,
70.2,
24.2,
68.3,
50.1,
67,
60.8,
30.3,
20.9,
83.8,
16.3,
59.4,
48.4,
43.6,
48.5,
86.2,
83.6,
37.3,
101.9,
75.7,
100.3,
71.7,
72.7,
18.1,
36.8,
83.3,
43.2,
22.9,
91.3,
63,
69.6,
7,
61.9,
52.5,
95.3,
42.1,
65.5,
58.4,
59.4,
90.2,
30.1,
44.1,
12.1,
54.2,
62.4,
23.9,
84.6,
33.8,
47.2,
57.7,
9,
19.4,
84.7,
55.1,
53.2,
70.5,
62.2,
59.9,
65.6,
51.2,
40,
91.8,
49.5,
91.1,
101,
88.6,
33.4,
71.9,
14.8,
26.2,
75.3,
78.5,
57.4,
24.7,
64.5,
16.6,
89,
68.9,
48.6,
71.8,
54.5,
28.5,
41.2,
40.6,
52.7,
64,
19.4,
86.6,
54.2,
75,
87.5,
42.7,
78.8,
65.1,
76.2,
68.8,
24.4,
85.6,
28.1,
41.2,
41.3,
89.9,
72.8,
53.5,
35.2,
56.7,
66.2,
83.5,
68.7,
26.3,
67,
44.3,
75.1,
54.8,
30.9,
71.7,
85,
46.8,
47.7,
47.6,
75.1,
26.6,
75.1,
43,
43.9,
81.3,
44.9,
59.2,
75.6,
55.3,
32.2,
37,
48.1,
91.3,
69.5,
15,
2.9,
46.6,
53.1,
16.1,
91.2,
77.9,
51.8,
4.1,
27.4,
41.7,
50.1,
73.3,
43.1,
26.9,
29.4,
38,
53.3,
80,
57.3,
72.1,
77,
14.8,
36,
17.5,
40.8,
22.5,
75.7,
66.5,
6.2,
13.1,
43.7,
77,
16.7,
63.5,
26.6,
24.3,
84.7,
79.5,
61.8,
54.2,
85.2,
54.4,
58.5,
56,
95.9,
37.4,
44.9,
71.5,
49.9,
62.5,
80,
46,
39.9,
51.8,
44.1,
38.9,
98.1,
56.7,
41.9,
50.6,
45.8,
46.8,
69.4,
4.5,
16.3,
32.8,
59.1,
35.6,
35.8,
83.6,
15.1,
13.7,
12.4,
79.9,
33.1,
55.4,
24.6,
80.9,
76.5,
36.4,
92.1,
61,
81.8,
48,
78.1,
1.7,
25.5,
62.6,
63.8,
46.8,
41.8,
56.7,
21.6,
51.7,
94,
48.3,
66.3,
24.8,
65.7,
31.4,
95.4,
61.5,
14.9,
65.5,
17.7,
52.5,
36.9,
32,
41,
3,
89.4,
60.6,
82.7,
73.4,
21.2,
65.6,
56.8,
35.8,
50.5,
62.3,
65.9,
48.6,
39.5,
18.9,
45.3,
79.2,
46.4,
78.6,
3.5,
43.5,
79,
43.5,
44.2,
78.8,
83.3,
63.6,
57.4,
78.3,
45.6,
42.9,
37.7,
96.1,
61.4,
59.1,
16.3,
91.2,
64,
75,
25.6,
41.4,
68.5,
49.5,
68.4,
66.8,
67.2,
35.3,
60.9,
10.1,
35.2,
23.7,
47.8,
63.1,
84.7,
83.3,
61.2,
65.3,
46.1,
65.1,
89.9,
59.7,
33.8,
27.6,
5.7,
61.6,
74.3,
93.8,
72.2,
69.8,
74.8,
51.7,
66.6,
74.9,
64.3,
97.5,
45.8,
64.9,
80.7,
50,
33.5,
61.6,
45.5,
35.2,
47,
39.6,
33.8,
36.5,
55.8,
86.4,
69,
54.5,
66.8,
10.6,
21.9,
43.2,
64.8,
98,
90.6,
4.5,
29,
58,
40.3,
26.4,
66.6,
82.7,
92.2,
44.7,
21.5,
49.9,
47.5,
82.2,
36.8,
53.5,
42.1,
102,
89,
78.4,
94.9,
71,
72.3,
53.3,
87.1,
84.3,
80.6,
27.4,
52,
98,
0,
94.4,
30.1,
89.9,
39.9,
45.4,
52.5,
46.9,
14.2,
60,
62.6,
52.9,
24.6,
74,
20.7,
48.6,
76.6,
38,
90.4,
24.5,
46.5,
22.7,
47.8,
78.3,
57.6,
89.3,
22.1,
75,
40.9,
45.2,
58.5,
28.7,
40.7,
70.1,
72.9,
36,
58.9,
83.8,
83.9,
63.2,
67.8,
35.2,
74.3,
92.8,
88.8,
46.9,
58.3,
63,
60.5,
93.1,
54.6,
100.4,
63.8,
38,
26.7,
63.2,
89,
63.5,
86,
7.3,
77.8,
19.6,
25.3,
62.8,
58.5,
38.6,
8.2,
61.9,
78.1,
33.4,
30,
70.5,
0.3,
39.4,
79.8,
59.7,
34.7,
2.3,
48,
6,
85,
92,
58.5,
27.9,
96.3,
57.1,
27.6,
67.8,
98.3,
18.7,
84,
71.5,
76.2,
69.7,
62.6,
1,
72.8,
27.1,
51.2,
44,
40.9,
5.7,
91.5,
20.1,
88.3,
64.1,
60.4,
16.3,
100.4,
47.6,
54.7,
61.9,
84,
57.9,
76.1,
61.2,
67.3,
50.5,
98,
31.1,
51.1,
67.6,
75.8,
61,
40.9,
51.6,
54.2,
73.7,
92.8,
49.9,
75.3,
61.5,
21.6,
37.5,
89.9,
52.9,
68.9,
63.5,
60,
52.9,
65.5,
76.6,
86.8,
73.6,
53.7,
59.9,
67.6,
63,
41,
62.8,
71.7,
34.2,
2.5,
84.3,
31.7,
16,
57.8,
45.3,
59.7,
18.9,
46.7,
27.5,
64,
90,
23.3,
72.3,
2.4,
76.6,
91.7,
91,
21.5,
82.7,
49.1,
73.7,
76.2,
7.8,
33.5,
11.6,
70.9,
43.9,
47,
100.1,
37.5,
87.6,
78.6,
55.7,
28.2,
87.4,
87.8,
32.7,
89,
42.6,
30,
66.4,
84.1,
8.1,
56.1,
56.9,
7,
33.4,
0.3,
21.2,
36.3,
62.9,
16,
92.6,
71.6,
19.1,
71.7,
74.2,
42,
65.9,
39.3,
61.5,
43.9,
93.6,
47.7,
76.9,
45.6,
48,
48.8,
51.6,
77.5,
91.4,
77,
35.1,
38.5,
61.7,
64.3,
28.4,
53.1,
32.9,
43.7,
37.8,
28.7,
85.9,
81,
85.8,
59.4,
54.5,
35,
75.7,
91.3,
18.5,
65.7,
62.7,
33.2,
83.9,
88.5,
22,
90.2,
52.8,
51.7,
74.3,
7.4,
68.6,
91.9,
81,
71.8,
64.7,
35.1,
56.8,
0.5,
40.8,
67,
38.7,
61.4,
73.8,
85.5,
86.1,
78.1,
3.9,
84,
48.5,
63.8,
58,
94,
31.9,
79.4,
72.6,
0,
27.6,
49.2,
84.7,
69,
14.9,
43.5,
37.5,
59.7,
39.5,
72.1,
35.2,
95.4,
49.2,
75,
68.1,
57.2,
74.5,
52.9,
45.4,
25.3,
76.2,
91.7,
62.8,
92,
47.3,
34.7,
43.6,
31.6,
94.2,
56.8,
54,
25.2,
8.1,
23,
16.8,
62.6,
0.8,
54,
51.6,
30.3,
77.6,
72.7,
15.8,
81.6,
62.4,
39.2,
79.3,
28.2,
80,
42.3,
73.8,
33.6,
12.7,
61.2,
11.4,
75.5,
85,
95.8,
86,
100.8,
82.3,
54.9,
75.6,
38,
76.1,
49.4,
33.9,
53.4,
38.2,
24.4,
31.2,
39.8,
68.8,
85.6,
66.2,
86,
57.9,
90.7,
64.2,
22.4,
79.6,
22.4,
76.3,
47.9,
11.3,
62.7,
57.2,
31.7,
84.2,
35.4,
64.7,
78.9,
25.9,
70.8,
23.8,
62.9,
24.8,
37.6,
81.5,
28,
73.9,
71.5,
62.7,
92.1,
59.9,
68.2,
20.6,
69,
94.6,
9.2,
62,
52.2,
49.3,
33.9,
45.2,
65.8,
78.6,
11,
55.9,
94.8,
48.6,
61.9,
79,
67,
26.4,
54.4,
95.3,
29.5,
26.6,
85,
60,
33.2,
48.8,
62.6,
79.5,
53.5,
81.7,
10.5,
79.3,
98.6,
31.3,
37.2,
64.7,
54.8,
89.3,
31.1,
96.5,
63.1,
20.2,
60.3,
54.6,
53.8,
43.4,
11.6,
83.2,
77.4,
81,
112.9,
64.9,
70.9,
46.6,
27.6,
48.9,
63,
49.8,
56,
25.7,
48,
53.5,
67.8,
50.8,
58.9,
46.5,
51.5,
4,
45.7,
20.4,
92.9,
42.7,
42.5,
33,
86.4,
29.7,
27.4,
25.8,
60,
57.1,
65.1,
30.2,
32.4,
11.2,
44.5,
73.5,
48.8,
28.6,
78.2,
30,
83.3,
17.1,
28,
93.3,
36.7,
59.9,
69.8,
74,
70.4,
88.7,
81.9,
39,
12.7,
64.3,
78.4,
59.4,
27,
67.6,
77.4,
75.2,
32.8,
33,
55.2,
62.8,
45,
54.4,
50.7,
83.7,
70.7,
56.8,
66.7,
33.3,
50.2,
25.3,
70.9,
32.2,
45.5,
7,
31.5,
14.5,
62,
50.8,
43.9,
36.1,
26.7,
43,
73.8,
97,
69,
51.1,
21.9,
89.7,
61.2,
53.8,
60.4,
75,
45.6,
49.9,
31.4,
68.8,
63.7,
72.3,
55.1,
44.7,
0,
18.7,
49.5,
31.8,
30.2,
73.2,
37.7,
58.2,
54.8,
49.4,
26.2,
46.5,
79.9,
25,
51.3,
43.8,
66.9,
40.6,
28.6,
98.7,
61.8,
58,
80.9,
93.4,
43.4,
64.4,
64,
36,
5,
84.7,
11,
41.6,
25.4,
85,
96.7,
39,
24.9,
33.2,
25.8,
63.9,
60.9,
56.7,
63.3,
49.9,
79.2,
94.7,
84.2,
39.9,
8.6,
97.2,
30.8,
73.2,
53.3,
38.7,
26.6,
23.7,
35.9,
49.2,
72.5,
55.9,
36,
72,
97.4,
84.4,
35.1,
62.4,
83.2,
91.3,
24.2,
64.6,
9.7,
50.9,
86.9,
16.3,
32.4,
75.4,
65.8,
89.1,
84.6,
16,
77.1,
26.8,
42.2,
48.7,
38.2,
10.2,
78.1,
56.6,
77.9,
15,
63.2,
42.3,
86,
69.3,
40.6,
68.2,
49.7,
35.6,
87.7,
62.8,
0,
39.1,
57.6,
52.4,
60.6,
57.9,
42.7,
73.5,
64.4,
25,
63.9,
27.7,
95.4,
28.7,
2.3,
86.6,
53.6,
66.3,
61.2,
58.2,
37.9,
58.4,
71.8,
11.4,
9.5,
74,
37.8,
40.9,
86.9,
84.4,
44.1,
64.9,
58.7,
74.6,
80.1,
75,
68.9,
74.7,
40.7,
1.5,
36.2,
48.8,
45.7,
42.7,
29.7,
29.9,
4.2,
76,
83.9,
50,
62.4,
60.1,
17,
44.1,
56.8,
26.2,
86.6,
25.8,
47,
97.7,
35.9,
2.7,
20.4,
40.8,
66.9,
39.8,
59.1,
88.9,
16.4,
95.9,
44.4,
57.1,
50.2,
62.3,
19.4,
24,
27.2,
70.6,
10.7,
45.2,
84.4,
91.6,
36.9,
94.8,
3.8,
41.9,
64.6,
14.4,
29,
91,
86.6,
95.2,
40.6,
69.2,
5.7,
33.7,
59.7,
46.2,
101.8,
78.5,
88.9,
14,
35.6,
74.9,
50.3,
64.3,
8.5,
70.1,
65.2,
71.7,
61.1,
56.8,
37.1,
35.9,
95.4,
62.2,
57,
63,
53.9,
64.1,
85.7,
74.7,
97.6,
53.1,
62.4,
98.6,
25.8,
34.1,
84.1,
42,
59.3,
43.2,
54,
51,
48.3,
25.9,
90,
89.5,
67.8,
72,
44,
56,
50.2,
36,
70.8,
12.1,
36,
41.3,
97.8,
87.5,
36.7,
41.1,
46.5,
20.6,
60.7,
45.2,
37,
90.2,
72,
9.8,
81.1,
34.6,
52.3,
79.6,
36.7,
35.7,
48.9,
26.4,
13.6,
74.7,
67.1,
86,
66,
56,
75.1,
81.7,
10.6,
13.2,
26.5,
57.4,
12.7,
71.8,
49.7,
86.8,
63.9,
61.3,
85.4,
31.9,
54.7,
8.7,
23.1,
93.4,
51.5,
39.2,
95.3,
33.2,
73.3,
54.8,
55.4,
25.2,
63.8,
71.3,
72.9,
25,
37.3,
49.9,
43.1,
54.4,
52.9,
77.6,
16.9,
7.3,
36.1,
43.5,
50,
37.9,
55.3,
28.3,
69.9,
108.6,
74.6,
58,
14.1,
86.7,
27.6,
49,
7.5,
56.5,
95.5,
38.7,
60.4,
40.8,
37,
45.4,
72.2,
98.2,
96.4,
63,
70.4,
48.9,
72.3,
29.8,
58.7,
61,
97.2,
78.4,
41.4,
80.7,
52.5,
71.8,
63.4,
73.4,
11.2,
30.4,
45.5,
80.4,
46.1,
72.8,
8,
42,
43.4,
71.7,
48.1,
82.3,
44,
25,
35.8,
59,
14.1,
38.6,
64.9,
83.3,
67.4,
20.2,
16.7,
40,
77.2,
65.1,
69.4,
84.9,
51.7,
41.1,
7.4,
15.4,
26.3,
70.5,
93.5,
60,
54.7,
11.3,
48.8,
72.6,
9.3,
50.7,
78.5,
60.4,
55,
2.4,
65.5,
86.8,
50.8,
64.7,
44,
83.8,
46.6,
59,
50.5,
36.4,
54.2,
81.4,
58.9,
63.8,
79.8,
28.6,
10.6,
16.1,
74.8,
87,
58.2,
30,
64.7,
13.4,
39.5,
52.4,
81.4,
69.9,
89.9,
95.4,
58.3,
17.5,
67.8,
87.6,
60.5,
25.3,
71.2,
57.7,
94.3,
38.3,
62.4,
97.4,
36.2,
43.8,
41,
55.2,
47.3,
59.9,
100.7,
62,
93.3,
22.5,
43.3,
31.5,
83.5,
68,
20.9,
61.8,
79.1,
20.5,
48.9,
53,
69.1,
49.6,
62.6,
22.8,
46.5,
52.7,
36.3,
83,
75,
86.7,
26.6,
28.9,
44,
80.1,
46.5,
49.9,
36.1,
96.7,
70.9,
62.1,
35.6,
9.3,
62.2,
58.4,
33.2,
50.8,
74.5,
79.8,
17.7,
74.5,
15.4,
23.9,
74,
42.6,
64.6,
69.6,
50.5,
11,
49.1,
54.1,
68,
63.3,
30.9,
19.6,
85.1,
77.9,
81.9,
41.6,
56.7,
96.4,
64.6,
70.9,
28.4,
39.4,
66.7,
17.8,
79.3,
72.5,
58.1,
52.2,
41.9,
66.2,
40.7,
120.5,
92.4,
62,
26.9,
23.1,
84,
54.2,
54.2,
45.5,
67.4,
75,
94.2,
67.5,
22.7,
85.2,
29.3,
94.6,
79.2,
57,
59.9,
56.4,
90.9,
16.2,
28,
29.2,
85.3,
28.9,
72.4,
89.7,
56.2,
80,
47.3,
55.4,
55.3,
42.5,
44.8,
76.6,
17.2,
12.8,
29.2,
65.5,
3.4,
32.6,
8.4,
42.4,
45.3,
94.4,
91.7,
52.7,
77.9,
67.6,
80.2,
23.2,
31.3,
66.8,
93.9,
44.6,
56.6,
85.1,
16.7,
92.8,
45.4,
41.8,
51.5,
58.3,
18,
18.1,
63.9,
45.4,
0.2,
18,
21.9,
54.9,
87.3,
93.6,
10.5,
80.8,
22.6,
66.5,
47.1,
29.8,
35.4,
85,
23.6,
38.7,
90.5,
77.4,
59.9,
61.1,
59.5,
39.3,
92.5,
43,
92.7,
74.6,
34,
59.5,
70.6,
13.9,
74.7,
69.9,
68.1,
35.9,
67,
23,
71.1,
51.3,
11.9,
31.7,
22.4,
43.7,
96.9,
52.1,
57.7,
81.6,
74.2,
33.3,
95.3,
73.8,
73.8,
44.1,
42,
83.4,
37.7,
49.7,
27.2,
95.9,
92.7,
57,
64.6,
53.3,
44.9,
43.3,
25,
79.2,
57.7,
84.9,
75.1,
76,
46.9,
73.2,
31,
91.3,
42.8,
20.6,
49.5,
25.9,
78.8,
52.7,
37.8,
73.8,
59.6,
77.9,
38.1,
75.5,
37,
56.4,
18.9,
89.6,
74.8,
23.8,
58.8,
96.3,
56.2,
22.6,
21.1,
94.8,
57.4,
51,
33.9,
69.5,
81.1,
45.3,
98.9,
52.6,
59.4,
32,
4.1,
88.9,
68.2,
52.8,
70.3,
6.7,
7.2,
84,
58.9,
38.3,
92.5,
56,
85.7,
33.5,
50,
65.2,
25.2,
47.4,
57.3,
25.8,
60.9,
60.7,
3.6,
98.8,
87.3,
21.8,
48.1,
57.8,
83.5,
85.3,
36.6,
72.6,
65,
7.2,
57.3,
49.6,
64.5,
31.2,
69.9,
57,
62.1,
66.6,
49.5,
78.7,
74.1,
64.8,
95.9,
84.3,
42.7,
33.8,
87.3,
69.3,
57.2,
78,
42.4,
47.1,
14,
46,
20.7,
91.8,
27,
18.5,
81,
88.4,
83.1,
7.7,
90.7,
33.7,
24.1,
64.1,
92.5,
79.1,
24,
46.2,
66.1,
25.2,
90.7,
22.6,
27.7,
83.5,
80.6,
91.3,
8,
79.6,
72.2,
65.1,
48.6,
73.3,
85.3,
71.3,
40.7,
29,
14.4,
75.7,
93.9,
76.4,
73.8,
81.3,
68.2,
35.8,
85.3,
65,
63.6,
94.2,
54.3,
42.8,
56,
53.3,
60.7,
24.1,
83.3,
62.6,
83.9,
84.3,
13.9,
71.9,
34.9,
13.7,
45,
7.7
]
}
],
"layout": {
"barmode": "overlay",
"legend": {
"bgcolor": "#F5F6F9",
"font": {
"color": "#4D5663"
}
},
"paper_bgcolor": "#F5F6F9",
"plot_bgcolor": "#F5F6F9",
"template": {
"data": {
"bar": [
{
"error_x": {
"color": "#2a3f5f"
},
"error_y": {
"color": "#2a3f5f"
},
"marker": {
"line": {
"color": "#E5ECF6",
"width": 0.5
}
},
"type": "bar"
}
],
"barpolar": [
{
"marker": {
"line": {
"color": "#E5ECF6",
"width": 0.5
}
},
"type": "barpolar"
}
],
"carpet": [
{
"aaxis": {
"endlinecolor": "#2a3f5f",
"gridcolor": "white",
"linecolor": "white",
"minorgridcolor": "white",
"startlinecolor": "#2a3f5f"
},
"baxis": {
"endlinecolor": "#2a3f5f",
"gridcolor": "white",
"linecolor": "white",
"minorgridcolor": "white",
"startlinecolor": "#2a3f5f"
},
"type": "carpet"
}
],
"choropleth": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "choropleth"
}
],
"contour": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "contour"
}
],
"contourcarpet": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "contourcarpet"
}
],
"heatmap": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "heatmap"
}
],
"heatmapgl": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "heatmapgl"
}
],
"histogram": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "histogram"
}
],
"histogram2d": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "histogram2d"
}
],
"histogram2dcontour": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "histogram2dcontour"
}
],
"mesh3d": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "mesh3d"
}
],
"parcoords": [
{
"line": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "parcoords"
}
],
"pie": [
{
"automargin": true,
"type": "pie"
}
],
"scatter": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatter"
}
],
"scatter3d": [
{
"line": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatter3d"
}
],
"scattercarpet": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattercarpet"
}
],
"scattergeo": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattergeo"
}
],
"scattergl": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattergl"
}
],
"scattermapbox": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattermapbox"
}
],
"scatterpolar": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterpolar"
}
],
"scatterpolargl": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterpolargl"
}
],
"scatterternary": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterternary"
}
],
"surface": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "surface"
}
],
"table": [
{
"cells": {
"fill": {
"color": "#EBF0F8"
},
"line": {
"color": "white"
}
},
"header": {
"fill": {
"color": "#C8D4E3"
},
"line": {
"color": "white"
}
},
"type": "table"
}
]
},
"layout": {
"annotationdefaults": {
"arrowcolor": "#2a3f5f",
"arrowhead": 0,
"arrowwidth": 1
},
"coloraxis": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"colorscale": {
"diverging": [
[
0,
"#8e0152"
],
[
0.1,
"#c51b7d"
],
[
0.2,
"#de77ae"
],
[
0.3,
"#f1b6da"
],
[
0.4,
"#fde0ef"
],
[
0.5,
"#f7f7f7"
],
[
0.6,
"#e6f5d0"
],
[
0.7,
"#b8e186"
],
[
0.8,
"#7fbc41"
],
[
0.9,
"#4d9221"
],
[
1,
"#276419"
]
],
"sequential": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"sequentialminus": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
]
},
"colorway": [
"#636efa",
"#EF553B",
"#00cc96",
"#ab63fa",
"#FFA15A",
"#19d3f3",
"#FF6692",
"#B6E880",
"#FF97FF",
"#FECB52"
],
"font": {
"color": "#2a3f5f"
},
"geo": {
"bgcolor": "white",
"lakecolor": "white",
"landcolor": "#E5ECF6",
"showlakes": true,
"showland": true,
"subunitcolor": "white"
},
"hoverlabel": {
"align": "left"
},
"hovermode": "closest",
"mapbox": {
"style": "light"
},
"paper_bgcolor": "white",
"plot_bgcolor": "#E5ECF6",
"polar": {
"angularaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"bgcolor": "#E5ECF6",
"radialaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
}
},
"scene": {
"xaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
},
"yaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
},
"zaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
}
},
"shapedefaults": {
"line": {
"color": "#2a3f5f"
}
},
"ternary": {
"aaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"baxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"bgcolor": "#E5ECF6",
"caxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
}
},
"title": {
"x": 0.05
},
"xaxis": {
"automargin": true,
"gridcolor": "white",
"linecolor": "white",
"ticks": "",
"title": {
"standoff": 15
},
"zerolinecolor": "white",
"zerolinewidth": 2
},
"yaxis": {
"automargin": true,
"gridcolor": "white",
"linecolor": "white",
"ticks": "",
"title": {
"standoff": 15
},
"zerolinecolor": "white",
"zerolinewidth": 2
}
}
},
"title": {
"font": {
"color": "#4D5663"
},
"text": "revol_util Distribution"
},
"xaxis": {
"gridcolor": "#E1E5ED",
"showgrid": true,
"tickfont": {
"color": "#4D5663"
},
"title": {
"font": {
"color": "#4D5663"
},
"text": ""
},
"zerolinecolor": "#E1E5ED"
},
"yaxis": {
"gridcolor": "#E1E5ED",
"showgrid": true,
"tickfont": {
"color": "#4D5663"
},
"title": {
"font": {
"color": "#4D5663"
},
"text": ""
},
"zerolinecolor": "#E1E5ED"
}
}
},
"text/html": [
"
value=%{value}", "labels": [ 0, 1 ], "legendgroup": "", "name": "", "showlegend": true, "type": "pie", "values": [ 48802, 15197 ] } ], "layout": { "legend": { "tracegroupgap": 0 }, "template": { "data": { "bar": [ { "error_x": { "color": "#2a3f5f" }, "error_y": { "color": "#2a3f5f" }, "marker": { "line": { "color": "#E5ECF6", "width": 0.5 } }, "type": "bar" } ], "barpolar": [ { "marker": { "line": { "color": "#E5ECF6", "width": 0.5 } }, "type": "barpolar" } ], "carpet": [ { "aaxis": { "endlinecolor": "#2a3f5f", "gridcolor": "white", "linecolor": "white", "minorgridcolor": "white", "startlinecolor": "#2a3f5f" }, "baxis": { "endlinecolor": "#2a3f5f", "gridcolor": "white", "linecolor": "white", "minorgridcolor": "white", "startlinecolor": "#2a3f5f" }, "type": "carpet" } ], "choropleth": [ { "colorbar": { "outlinewidth": 0, "ticks": "" }, "type": "choropleth" } ], "contour": [ { "colorbar": { "outlinewidth": 0, "ticks": "" }, "colorscale": [ [ 0, "#0d0887" ], [ 0.1111111111111111, "#46039f" ], [ 0.2222222222222222, "#7201a8" ], [ 0.3333333333333333, "#9c179e" ], [ 0.4444444444444444, "#bd3786" ], [ 0.5555555555555556, "#d8576b" ], [ 0.6666666666666666, "#ed7953" ], [ 0.7777777777777778, "#fb9f3a" ], [ 0.8888888888888888, "#fdca26" ], [ 1, "#f0f921" ] ], "type": "contour" } ], "contourcarpet": [ { "colorbar": { "outlinewidth": 0, "ticks": "" }, "type": "contourcarpet" } ], "heatmap": [ { "colorbar": { "outlinewidth": 0, "ticks": "" }, "colorscale": [ [ 0, "#0d0887" ], [ 0.1111111111111111, "#46039f" ], [ 0.2222222222222222, "#7201a8" ], [ 0.3333333333333333, "#9c179e" ], [ 0.4444444444444444, "#bd3786" ], [ 0.5555555555555556, "#d8576b" ], [ 0.6666666666666666, "#ed7953" ], [ 0.7777777777777778, "#fb9f3a" ], [ 0.8888888888888888, "#fdca26" ], [ 1, "#f0f921" ] ], "type": "heatmap" } ], "heatmapgl": [ { "colorbar": { "outlinewidth": 0, "ticks": "" }, "colorscale": [ [ 0, "#0d0887" ], [ 0.1111111111111111, "#46039f" ], [ 0.2222222222222222, "#7201a8" ], [ 0.3333333333333333, "#9c179e" ], [ 0.4444444444444444, "#bd3786" ], [ 0.5555555555555556, "#d8576b" ], [ 0.6666666666666666, "#ed7953" ], [ 0.7777777777777778, "#fb9f3a" ], [ 0.8888888888888888, "#fdca26" ], [ 1, "#f0f921" ] ], "type": "heatmapgl" } ], "histogram": [ { "marker": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "histogram" } ], "histogram2d": [ { "colorbar": { "outlinewidth": 0, "ticks": "" }, "colorscale": [ [ 0, "#0d0887" ], [ 0.1111111111111111, "#46039f" ], [ 0.2222222222222222, "#7201a8" ], [ 0.3333333333333333, "#9c179e" ], [ 0.4444444444444444, "#bd3786" ], [ 0.5555555555555556, "#d8576b" ], [ 0.6666666666666666, "#ed7953" ], [ 0.7777777777777778, "#fb9f3a" ], [ 0.8888888888888888, "#fdca26" ], [ 1, "#f0f921" ] ], "type": "histogram2d" } ], "histogram2dcontour": [ { "colorbar": { "outlinewidth": 0, "ticks": "" }, "colorscale": [ [ 0, "#0d0887" ], [ 0.1111111111111111, "#46039f" ], [ 0.2222222222222222, "#7201a8" ], [ 0.3333333333333333, "#9c179e" ], [ 0.4444444444444444, "#bd3786" ], [ 0.5555555555555556, "#d8576b" ], [ 0.6666666666666666, "#ed7953" ], [ 0.7777777777777778, "#fb9f3a" ], [ 0.8888888888888888, "#fdca26" ], [ 1, "#f0f921" ] ], "type": "histogram2dcontour" } ], "mesh3d": [ { "colorbar": { "outlinewidth": 0, "ticks": "" }, "type": "mesh3d" } ], "parcoords": [ { "line": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "parcoords" } ], "pie": [ { "automargin": true, "type": "pie" } ], "scatter": [ { "marker": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "scatter" } ], "scatter3d": [ { "line": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "marker": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "scatter3d" } ], "scattercarpet": [ { "marker": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "scattercarpet" } ], "scattergeo": [ { "marker": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "scattergeo" } ], "scattergl": [ { "marker": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "scattergl" } ], "scattermapbox": [ { "marker": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "scattermapbox" } ], "scatterpolar": [ { "marker": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "scatterpolar" } ], "scatterpolargl": [ { "marker": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "scatterpolargl" } ], "scatterternary": [ { "marker": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "scatterternary" } ], "surface": [ { "colorbar": { "outlinewidth": 0, "ticks": "" }, "colorscale": [ [ 0, "#0d0887" ], [ 0.1111111111111111, "#46039f" ], [ 0.2222222222222222, "#7201a8" ], [ 0.3333333333333333, "#9c179e" ], [ 0.4444444444444444, "#bd3786" ], [ 0.5555555555555556, "#d8576b" ], [ 0.6666666666666666, "#ed7953" ], [ 0.7777777777777778, "#fb9f3a" ], [ 0.8888888888888888, "#fdca26" ], [ 1, "#f0f921" ] ], "type": "surface" } ], "table": [ { "cells": { "fill": { "color": "#EBF0F8" }, "line": { "color": "white" } }, "header": { "fill": { "color": "#C8D4E3" }, "line": { "color": "white" } }, "type": "table" } ] }, "layout": { "annotationdefaults": { "arrowcolor": "#2a3f5f", "arrowhead": 0, "arrowwidth": 1 }, "coloraxis": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "colorscale": { "diverging": [ [ 0, "#8e0152" ], [ 0.1, "#c51b7d" ], [ 0.2, "#de77ae" ], [ 0.3, "#f1b6da" ], [ 0.4, "#fde0ef" ], [ 0.5, "#f7f7f7" ], [ 0.6, "#e6f5d0" ], [ 0.7, "#b8e186" ], [ 0.8, "#7fbc41" ], [ 0.9, "#4d9221" ], [ 1, "#276419" ] ], "sequential": [ [ 0, "#0d0887" ], [ 0.1111111111111111, "#46039f" ], [ 0.2222222222222222, "#7201a8" ], [ 0.3333333333333333, "#9c179e" ], [ 0.4444444444444444, "#bd3786" ], [ 0.5555555555555556, "#d8576b" ], [ 0.6666666666666666, "#ed7953" ], [ 0.7777777777777778, "#fb9f3a" ], [ 0.8888888888888888, "#fdca26" ], [ 1, "#f0f921" ] ], "sequentialminus": [ [ 0, "#0d0887" ], [ 0.1111111111111111, "#46039f" ], [ 0.2222222222222222, "#7201a8" ], [ 0.3333333333333333, "#9c179e" ], [ 0.4444444444444444, "#bd3786" ], [ 0.5555555555555556, "#d8576b" ], [ 0.6666666666666666, "#ed7953" ], [ 0.7777777777777778, "#fb9f3a" ], [ 0.8888888888888888, "#fdca26" ], [ 1, "#f0f921" ] ] }, "colorway": [ "#636efa", "#EF553B", "#00cc96", "#ab63fa", "#FFA15A", "#19d3f3", "#FF6692", "#B6E880", "#FF97FF", "#FECB52" ], "font": { "color": "#2a3f5f" }, "geo": { "bgcolor": "white", "lakecolor": "white", "landcolor": "#E5ECF6", "showlakes": true, "showland": true, "subunitcolor": "white" }, "hoverlabel": { "align": "left" }, "hovermode": "closest", "mapbox": { "style": "light" }, "paper_bgcolor": "white", "plot_bgcolor": "#E5ECF6", "polar": { "angularaxis": { "gridcolor": "white", "linecolor": "white", "ticks": "" }, "bgcolor": "#E5ECF6", "radialaxis": { "gridcolor": "white", "linecolor": "white", "ticks": "" } }, "scene": { "xaxis": { "backgroundcolor": "#E5ECF6", "gridcolor": "white", "gridwidth": 2, "linecolor": "white", "showbackground": true, "ticks": "", "zerolinecolor": "white" }, "yaxis": { "backgroundcolor": "#E5ECF6", "gridcolor": "white", "gridwidth": 2, "linecolor": "white", "showbackground": true, "ticks": "", "zerolinecolor": "white" }, "zaxis": { "backgroundcolor": "#E5ECF6", "gridcolor": "white", "gridwidth": 2, "linecolor": "white", "showbackground": true, "ticks": "", "zerolinecolor": "white" } }, "shapedefaults": { "line": { "color": "#2a3f5f" } }, "ternary": { "aaxis": { "gridcolor": "white", "linecolor": "white", "ticks": "" }, "baxis": { "gridcolor": "white", "linecolor": "white", "ticks": "" }, "bgcolor": "#E5ECF6", "caxis": { "gridcolor": "white", "linecolor": "white", "ticks": "" } }, "title": { "x": 0.05 }, "xaxis": { "automargin": true, "gridcolor": "white", "linecolor": "white", "ticks": "", "title": { "standoff": 15 }, "zerolinecolor": "white", "zerolinewidth": 2 }, "yaxis": { "automargin": true, "gridcolor": "white", "linecolor": "white", "ticks": "", "title": { "standoff": 15 }, "zerolinecolor": "white", "zerolinewidth": 2 } } }, "title": { "text": "Percentage data of loan_status" } } }, "text/html": [ ""
]
},
"metadata": {},
"output_type": "display_data"
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"\n",
" *************** Random Forest ***************\n",
"\n"
]
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAqQAAAGwCAYAAAB/6Xe5AAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADt0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjByYzEsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy/xvVyzAAAgAElEQVR4nO3de7yv9Zz//8dTpVJbWwoV2Qkl0Wk7hFSEGYMwyGGwGRNjlMwvpi/fIWOMjDP9jNkTGuRUGcJ0cOgkUnvXrl1oHIoomorOpb17ff+4rqVPnz5rrc86Xmut/bjfbp/b+qz39b6u6/V5f671Wc91nVaqCkmSJKkr9+i6AEmSJK3bDKSSJEnqlIFUkiRJnTKQSpIkqVMGUkmSJHXKQCpJkqROGUgl/UmSZUkqybKua5EkrTsMpNIMaYNd72NtkmuTnNYGv3Rd43yX5PAB49z7uKzrGiejrf20Scx39DjjMeFlTlZPLUtma53TJck+sz1eXfGPUM0V63ddgLQOeGf7dQPgocDzgL2BpcAbuipqgTkdOG1A+x9muY654mvAqgHtl81yHZI0FAOpNMOq6vDe75M8ETgDeH2SD1TVpZ0UtrCc1j/O67ivVtXRXRchScPykL00y6rqLOAnQIA9eqcl2SPJR5Jc0B7evzXJT5N8IMl9+pfVe7gtyb7t6QA3JLk+yTeTPGJQDUkemuTYJL9PclOS7yf5i7Hqbms7PslVSW5L8sskH0+y1YC+I4drt0vyhiQ/al/LZUneOnK6QpIXJjmnreGqJEcm2WgCwzkhk3wND0lyUJILk9zSexg3yeZJ3pPkx+2065J8J8nTByzvnkkOTnJeO+43t+PxtST7tX2WJRn5f8579x1uP3wGxuMlSU5t67m1fR3/N8mGA/o+N8nnkvxP+37dmGRl+5ru0de3gFe231466BSK9rVfxgC581SMffqX227jD0hyVJLfpDkVZllPn8clOS7Jb5P8McnlSf49ydaTHaeeZff+vD0tyZntOPxvkk8nWdz22y3JN9pxvTHJCRlw6kL7WirJhkn+Ocml7Xb58yTvSHLPUep4apKTcudnxP8kOSLJZmOs455J3p7kknYdR7fb8qfbrp/u296WtPNv3c53Vs+YXpHk8xnw+ZJkSTv/0e3zLya5uq1zRZJnjTG+B7Q/PyOv67IkX0iydEDfobddzQ/uIZW6MXL+6O197X9Dc0j/dODbwHrA7sDfA3+e5HFVdcOA5T0L2B84EfgEsBPwTOAxSXaqqqv/tOLkYcAPgPu2/VfRnErw1fb7uxfb/BI5vq37OOCXNGH6b4H9kzyxqi4bMOv7gX2ArwOnAM8B3g3cM8m1wBHtes8Engb8Xfua/3ZQHVMxhdfwEWAv4JvAfwNr2+U9mOY0gSVt/ScBm9C8FycleW1V/UfPco4GXgJcBHwGuAXYGngS8Gc07/cqmlM83tHWd3TP/KdN9rUPkuSTwKuBXwNfoTm94fHAu4CnJnlaVa3pmeUI4A7gh8BvgM2Ap9CMz2OAl/f0fSfwXGCXdvrIqRPTcQrF5sDZwI1t3XcAv2tf06uA/wBuA04ALgceBrwGeHaSx1fVr6ahhufQvM/foPl5ewKwDNguyWHAd2i2iU8CjwKeDWyf5FFVdceA5X2ZZgyPo/lM2B84HFia5DlVNfJHCkleC/wbcBNwLHAVzc/YP7Sv8YlVNWicj2/XcSLNz9xVNNvUH9r19Z/mMbKMJwOHAae2y7iRZkxfADynXd8FA9b3YOAc4BfAZ2netwOAryXZr6pO7XlNoQnGrwSupnlf/xd4ILAvcAmwoqf/RLddzQdV5cOHjxl4ANX8iN2t/ck0oeY2YKu+aQ8G1hswz1+3y/uHvvZlbfsa4Kl9097TTntLX/spbfsb+9r3H6kZWNbTvinNL4m1wF598/xD2/+Uvvaj2/bLgG162he3y7qJ5hfOI3qmbQj8qB2X+w05xoe36zmtfd7/WDINr+E3wHYD1n0aTRh6cV/7Yppf7LcA92/bNmv7rhjl/b3vgG3ntElscyM1f3WU8Vjct918Bdh4lDHt3z62H7C+ewD/2fZ/3Ci1LBml1suAy8Z5X/cZ9DNFE+jX75v2cOCPwM96t7l22lPa9/6/hhzHfQa9B9z1523vvnH4VjvtWuBlffN9sp22/4BtqID/Ae7T074RzR+NBby8p/3BND8f1wM79i3r423/5aOs40JgiwGvdeQ1LRtlLO4HLBrQvgtNOD2xr31Jz/v0jr5pz2jb/7uv/cC2/Rxgs75p69HzOTmZbdfH/Hh0XoAPHwv10fOhfHj7eDfwpfaX5h3AQRNYVoDrgO/2tY98OH9uwDzbtdOO62l7YNv2CwYHo5FfXst62l7Wtn1+QP/1gUvb6dv2tB/dtv31gHk+1U77pwHT3tFO23vIcRn5BTTaY59peA13++XW/jIu4NhR6hoJ969vv793+/1ZQIbcdk6bxDY3UvNojyVtv/Np9sQtHrCM9WjC+zlDrnP3dtlvH6WWJaPMdxmTC6QD/2ABPtRO/4tRlvlfNEHybuFqQN99Br0H3Pnz9tkB87yinXbGgGl7MzignUZf6BxQw6k9bW9r2/5lQP/70ATVW4ANB6xj//55+l7TskHTxxmnE4BbgQ162pZw5x+jgz5jfglc3de2up1ntyHWOW3bro+59fCQvTTz3tH3/UhQ+3R/xyQbAK8FXkxz2H0z7nqu9zajrGPFgLbL26+9557u1n79XlWtHTDPaTS/PHvt3n79bn/nqlqT5AyaX0K7Af2HQwfVdUX7deWAab9pvz5wwLSxvLPGvqhpKq/hnAHL27P9ulkGn9u5Zfv1Ee06rk/ydZpDt6uSHE9zSPeHVXXzGHVP1qtqlIuaktyLJlBfDRySwXcfu22k9p757gu8meZUkIfQnJ7Qa7Rtc7pdVlVXDWgfeU/2TvKYAdPvRxNYHs7gbW8ipnu7Pn1A25k0AXq3nraxtuPfJzmf5gjMjkD/YfRB2/FQ0pxf/jqaO4Nswd1P99sCuLKvbdUonzGXc+d7RZJNgJ2B31XV+ePUMaltV/ODgVSaYVU1cgHPJjQfxJ8EPpHkl1XV/4vlSzTnkP6C5pyu39J8wAIcQnNYe5C7nTPWBi1ofgmPGLno4XejLOe3A9pG5un/hUNf++IB064b0LZmiGkbjLKuyZrKaxg0Jvdtvz6tfYxm057nB9CcHvBS7rwV2K1JjgMOrarR3pPpdh+aPe5bcvc/lgZqL9Y5l2av+zk0h8yvpXm/FgNvZPRtc7oNej/gzvfkzePMv+k404cx3dv13d77qlqb5BqaID1iurfjcSU5mOY84N/TnJbwK+Bmmj+sR84THvTej3a+8Bru+kf2SK2/GdC334S3Xc0fBlJpllTVTcC3kzwbOA/4zyQ7jOwha68kfR7NxS3PrKo/XfCU5irmt0xDGSO/LO8/yvQHjDHPoGkAW/X1m4um8hpqjOW9sao+OkwBVXUL7ekbSR5EsydrGfBXNHtn9xpmOdNgpPbzq2r3MXve6TU0YfRue6KT7EkTSCfqDmDgVeQMDlQjBr0fcOfr2qyqrp9EPV26P3175pOsRxOye19L73Z88YDljLodV9Vo4zaqJOvT/PH0W2D3qrqyb/qeA2ecmJHgOswe9slsu5onvO2TNMuq6kKaK4EfCLypZ9JD268n9IbR1mOBjadh9SOHxJ7U/sLrt88Y89xtWvsL60ntt+dNtbgZNN2v4ez266RCZFVdXlXH0Fzk8VOa9+O+PV3u4K57tqdNVd1IE2YemWTzIWcb2TaPHzCt/xSPESOHa0d7Hb8H7t+eptLvbrf5GcKU3pOODRrDvWh2GvUexh5rO14M7EpzTuePJ7Dusd6nLWj+OPj+gDC6KXeeQjBp7R/qF9FsC7uN03cy267mCQOp1I1/pvnFcWjuvL/oZe3XfXo7Jrkf8P9Px0qr6tc0h922o++/RCXZn8G/GL9Kc3j2JUke3zftEJrzCb9d03M7nZkyra+hqlbQnOP3/CSvHtQnyaPa944kWyZ53IBumwCLaA5j/rGn/RrgQcPUMkkfpNk7+ak2yNxFkvsk6Q0bl7Vf9+nrtxvwf0ZZxzXt121HmX4OTeB6Vd8ylwFPHL30UR1Jc7HLh5I8vH9iex/OuRpW/7Hnc4A09+J9T/tt77nmn6N5jQcleSh39S6ai+c+V1W3Mbyx3qeraA7P79EG0JH6NqA5jL/FBNYzlpGjDP+evnupJrlH7nqf4Iluu5onPGQvdaCqfpPk32kOdb6F5pf6uTRXYT8/yfeB79EcyvtzmvvwXTHK4ibq72huKfPhNDdwv4A7/6XpyIU3vbXe2IauY4HTkxxLc3hxD+DpNIfzXjtNtc2IGXoNL6W5uOST7Xl2P6Q5/PhA4NE0F2rsSfNLfRvg7CQ/ptkLezlNeHgWzeHXj9Zd7y/7HeDF7YVQK2kC6xlVdcZEX/sgVfWpJHsArwd+nuRkmvHYnOaPlSfTBKHXtbN8hubczA8n2Zdmr+7D2vq/QnN+bL/vtPP8R3ue7I3AH6rqyHb6x2jC6L8leSrNmOxCc0/Pb7TLnshr+kn7Hn8KuDjJSTS3U9qAJmztRXOrsR0nstxZ8mOamnvvQ7o9zb1vPzvSqaouS3IIzR+o5yX5Ms1r2ptmW/sJzXnKE/EDmtB5SLvXceR81o9V1XVJPkpzH9LVSb5GEwb3pdlWTm2fT9VRNEcpXgH8tF3P/9Lcp/cpNO/p4TCpbVfzRdeX+fvwsVAfjHIf0p7p96e5H+dN3Hm/ys1p7id4Gc0e1J8D/wLciwG3yWH8ewgOvH0QTQA9jiZA3UTzS+kvxloezU21/4vmF8UfaX4J/Buw9YC+RzPKLX8Y5ZY+w7yeMZZ1+JD9p+U19PRZBLyVJjTeSHPLnUtpgsSBwCZtv8XA22kC7G9oLlS7kuauBi+h71ZQNBeyfJ4mHKwd9jX21Dzs+I3c3P2qdjx+S7Pn8p+5+30ud6K5zc9V7Tazkubc0iXtOo8esPy/pwlbt7V9+rffJ9H8G92bac6V/CZNmB+4jYy2Pff1eVQ7Dr9s13stzSHhfweeMuS47DNoXWNtnz3z3O19Gm2MuPOWTBu2Y35pW/MvaC7a2XCU+p5Ocz/h37f9fwb8K4NvhXQaY3wOtX3+jOYz4Ebufouw9dv38Uc02/dvaULygxnwMzLW9jBePTS3Zzud5lzRW9vxOIbm/NVJb7s+5scj7RsrSZJmUZp/3bl3tXfikNZlnkMqSZKkThlIJUmS1CkDqSRJkjrlOaSSJEnqlLd9mue22GKLWrJkSddlSJIkjWvlypVXV9WW/e0G0nluyZIlrFixousyJEmSxpXkl4PaPYdUkiRJnTKQSpIkqVMesp/nfvzra9jjzZ/pugxJkjRPrXzfK7ouwT2kkiRJ6paBVJIkSZ0ykEqSJKlTBlJJkiR1ykAqSZKkThlIJUmS1CkDqSRJkjplIJUkSVKnDKSSJEnqlIFUkiRJnTKQSpIkqVMGUkmSJHVqxgJpku8P0eeoJDu1z986iflvHGPakiQXtc+XJvnoOH1fOt76Bsy3OMnrp6ufJEnSumjGAmlVPWGIPq+pqh+13761b9q480+glhVVdfAYXZYAEw6kwGJgmKA5bD9JkqR1zkzuIb2x/bpPktOSHJfkJ0mOSZJ22mnt3ssjgI2TrEpyTN/8myb5TpLzkqxOsv8katknyTfa53u361mV5Pwki4AjgL3atjeNsoxHJjmn7XNhkoe1823ftr1vjFr7+/2pnnbZRyZZ1j4/IsmP2nW8f5RaDkyyIsmKNTffMNHhkCRJmlPWn6X17AY8ErgCOAt4IvC9kYlVdViSN1TVrgPmvRV4XlVdn2QL4OwkJ1RVTbKWQ4G/q6qzkmzaLv8w4NCqetYY870O+EhVHZPknsB67Xw7j9SdZP1BtQ7ot8+gFSTZHHgesGNVVZLFg/pV1XJgOcAmD9husuMgSZI0J8zWRU3nVNWvq+oOYBXNIfJhBfiXJBcC3wa2Ae4/hVrOAj6Y5GBgcVWtGXK+HwBvTfIPwIOr6pYZqPV6moB8VJLnAzdPYF5JkqR5abYC6W09z9cysT2zLwO2BPZo9zD+DthosoVU1RHAa4CNafZg7jjkfJ8HngPcApyc5ClTqHUNdx37jdp1rAEeCxwPPBc4aZjaJEmS5rPZOmQ/jNuTbFBVt/e1bwZcVVW3J9kXePBUVpJk+6paDaxOsiewI3A5sGic+R4C/KKqPto+fzRwQd98o9V6Q1+/XwI7JdmQJow+FfheewrBvarqv5OcDfxsKq9VkiRpPphLgXQ5cGGS86rqZT3txwBfT7KC5nD/T6a4nkPasLgW+BFwInAHsCbJBcDRVfWhAfMdAPxVktuB3wL/VFXXJjmrvb3UicB7B9VaVdf09quqNyf5MnAh8FPg/HYdi4CvJdmI5vD/wAusJEmSFpJM/togzQWbPGC72vHl7+y6DEmSNE+tfN8rZm1dSVZW1dL+dv9TkyRJkjo1lw7ZT0qSRwGf7Wu+raoeN8nlPYPm0HuvS6vqeZNZniRJksY27wNpe4HSoPuXTnZ5JwMnT9fyJEmSNDYP2UuSJKlTBlJJkiR1ykAqSZKkThlIJUmS1CkDqSRJkjplIJUkSVKn5v1tn9Z1j3jgfVkxi/9hQZIkabq5h1SSJEmdMpBKkiSpUwZSSZIkdcpAKkmSpE4ZSCVJktQpA6kkSZI65W2f5rk/Xnkxv/qnR3VdhiRJArZ9++quS5iX3EMqSZKkThlIJUmS1CkDqSRJkjplIJUkSVKnDKSSJEnqlIFUkiRJnTKQSpIkqVMGUkmSJHXKQCpJkqROGUglSZLUKQOpJEmSOmUgnQFJFid5fft86yTHtc93TfLMnn7LkhzZVZ2SJElzgYF0ZiwGXg9QVVdU1Qva9l2BZ446lyRJ0jpo/a4LWKCOALZPsgr4KfAIYHfgn4CNkzwJeE/vDEm2BD4BbNs2HVJVZ81eyZIkSd1wD+nMOAz4eVXtCrwZoKr+CLwd+FJV7VpVX+qb5yPAh6rqMcBfAkeNtvAkByZZkWTFtTetnZlXIEmSNEvcQzp37AfslGTk+3snWVRVN/R3rKrlwHKAR2+zcc1eiZIkSdPPQDp33APYs6pu6boQSZKk2eQh+5lxA7BoAu0ApwBvGPkmya4zUJckSdKcYyCdAVV1DXBWkouA9/VMOpXmsPyqJAf0zXYwsDTJhUl+BLxulsqVJEnqlIfsZ0hVvXRA27XAY/qaj26nXQ30h1RJkqQFzz2kkiRJ6pSBVJIkSZ0ykEqSJKlTBlJJkiR1ykAqSZKkThlIJUmS1CkDqSRJkjplIJUkSVKnDKSSJEnqlIFUkiRJnfJfh85z99zqkWz79hVdlyFJkjRp7iGVJElSpwykkiRJ6pSBVJIkSZ0ykEqSJKlTBlJJkiR1ykAqSZKkTnnbp3nuJ1f9hCd+7IldlyFJ0qw666Czui5B08g9pJIkSeqUgVSSJEmdMpBKkiSpUwZSSZIkdcpAKkmSpE4ZSCVJktQpA6kkSZI6ZSCVJElSpwykkiRJ6pSBVJIkSZ0ykEqSJKlTBlJJkiR1asEE0iSLk7x+nD5Lkrx0tmrqWe+yJEdOcJ7LkmwxUzVJkiTNFQsmkAKLgTEDKbAEmLFAmmT9mVq2JEnSQrWQAukRwPZJViV5X/u4KMnqJAf09Nmr7fOmQQtJsl6S97fzXZjkoLb9T3sskyxNclr7/PAky5OcAnxmjPoelOSkJJckeUfP+r6aZGWSi5McOMwLTXJgkhVJVtx+4+3DzCJJkjRnLaQ9eocBO1fVrkn+EngdsAuwBXBukjPaPodW1bPGWM6BwHbAblW1JsnmQ6x7D+BJVXXLGH0eC+wM3NzW882qWgG8uqquTbJx2358VV0z1sqqajmwHGDTbTetIeqTJEmasxbSHtJeTwK+UFVrq+p3wOnAY4acdz/gE1W1BqCqrh1inhPGCaMA36qqa9p+X2lrBDg4yQXA2cCDgIcNWackSdKCsJD2kPbKFOcdtNdxDXcG+I36pt00xHL7l1lJ9qEJwHtW1c3taQD9y5YkSVrQFtIe0huARe3zM4AD2vNBtwSeDJzT12c0pwCvG7lAqeeQ/WU0h+YB/nIS9T0tyebtofnnAmcBmwG/b8PojsDjJ7FcSZKkeW3BBNL2vMuzklwE7AlcCFwAfBd4S1X9tm1bk+SC0S5qAo4CfgVc2B5KH7kq/53AR5KcCaydRInfAz4LrAKOb88fPQlYP8mFwLtoDttLkiStU1LlNTHz2abbblq7vHmXrsuQJGlWnXXQWV2XoElIsrKqlva3L5g9pJIkSZqfFupFTeNK8gzgvX3Nl1bV8+bSMiVJkha6dTaQVtXJwMlzfZmSJEkLnYfsJUmS1CkDqSRJkjplIJUkSVKnDKSSJEnqlIFUkiRJnTKQSpIkqVPr7G2fFood77ej/61CkiTNa+4hlSRJUqcMpJIkSeqUgVSSJEmdMpBKkiSpUwZSSZIkdcpAKkmSpE5526d57oZLLuH0J+/ddRmSpBmw9xmnd12CNCvcQypJkqROGUglSZLUKQOpJEmSOmUglSRJUqcMpJIkSeqUgVSSJEmdMpBKkiSpUwZSSZIkdcpAKkmSpE4ZSCVJktQpA6kkSZI6ZSCVJElSp+ZEIE1y4yTnOyTJvaa7nnHWeXSSF8zmOiVJkhayORFIp+AQYFYDqSRJkqbXnAqkSTZN8p0k5yVZnWT/tn2TJN9MckGSi5IckORgYGvg1CSnjrK8FyX5YPv8jUl+0T7fPsn32ud7JDk9ycokJyfZqqfPSW37mUl2HLD8d7V7TAeOY5LLkrw3yTnt46Ft+7OT/DDJ+Um+neT+Se6R5KdJtmz73CPJz5JsMWC5ByZZkWTFdbffPvGBliRJmkPmVCAFbgWeV1W7A/sCH0gS4M+AK6pql6raGTipqj4KXAHsW1X7jrK8M4C92ud7Adck2QZ4EnBmkg2AjwEvqKo9gE8B7277LwcOatsPBT7eu+Ak/wrcD3hVVd0xxmu6vqoeCxwJfLht+x7w+KraDfgi8JZ2GZ8DXtb22Q+4oKqu7l9gVS2vqqVVtXSzDTYYY9WSJElz3/pdF9AnwL8keTJwB7ANcH9gNfD+JO8FvlFVZw6zsKr6bbvXdRHwIODzwJNpwulXgB2AnYFvNbmX9YArk2wKPAE4tm0H2LBn0f8I/LCqDhyijC/0fP1Q+/yBwJfavbH3BC5t2z8FfI0muL4a+PQwr1OSJGk+m2t7SF8GbAnsUVW7Ar8DNqqq/wH2oAmm70ny9gks8wfAq4BLgDNpwuiewFk0Afjiqtq1fTyqqp5OMy5/6Gnftaoe0bPMc4E9kmw+xPprwPOPAUdW1aOA1wIbAVTV5cDvkjwFeBxw4gRepyRJ0rw01wLpZsBVVXV7kn2BBwMk2Rq4uao+B7wf2L3tfwOwaJxlnkFzyP0M4HyaUwFuq6rraELqlkn2bNezQZJHVtX1wKVJXti2J8kuPcs8CTgC+Ga793UsB/R8/UHP6/xN+/yVff2Pojl0/+WqWjvOsiVJkua9uXbI/hjg60lWAKuAn7TtjwLel+QO4Hbgb9v25cCJSa4c4zzSM2kO159RVWuTXD6y3Kr6Y3sLp48m2YxmPD4MXEyzt/bfkvxfYAOacz0vGFloVR3bhtETkjyzqm4ZZf0bJvkhTfh/Sdt2OM3pAL8Bzga26+l/As2heg/XS5KkdUKqavxempQklwFLB12YNMY8S4EPVdVe43YGdli0qJbvtvv4HSVJ887eZ5zedQnStEqysqqW9rfPtT2k67Qkh9Hs/X3ZeH0lSZIWigUTSNvD4hv2Nb+8qlbPwrr/i7sedgf4h6paMpHlVNURNOemSpIkrTMWTCCtqsd1uO7ndbVuSZKk+W6uXWUvSZKkdYyBVJIkSZ0ykEqSJKlTBlJJkiR1ykAqSZKkThlIJUmS1KkFc9unddWiHXbwP3lIkqR5zT2kkiRJ6pSBVJIkSZ0ykEqSJKlTBlJJkiR1ykAqSZKkThlIJUmS1Clv+zTPXfXr6zjy//t612VI0qx4wwee3XUJkmaAe0glSZLUKQOpJEmSOmUglSRJUqcMpJIkSeqUgVSSJEmdMpBKkiSpUwZSSZIkdcpAKkmSpE4ZSCVJktQpA6kkSZI6ZSCVJElSpwykkiRJ6tSsBtIki5O8fpw+S5K8dIhlLUly0fRVN74khyc5dJRp3x9jvj/VmmRpko/OVI2SJEnzzWzvIV0MjBlIgSXAuIF0IpKsP53LG6SqnjBkvxVVdfBM1yNJkjRfzHYgPQLYPsmqJO9rHxclWZ3kgJ4+e7V93tTuXTwzyXntY6jgl2RZkmOTfB04JckmST6V5Nwk5yfZv+33wySP7JnvtCR7jLHondo+v0hycM98Nw5Z1z5JvtE+PzzJfyY5JcllSZ6f5F/b8TgpyQbDLFOSJGk+GyqQJtk+yYbt832SHJxk8STWdxjw86raFTgb2BXYBdgPeF+Srdo+Z1bVrlX1IeAq4GlVtTtwADCRw917Aq+sqqcAbwO+W1WPAfZt17cJ8EXgRe1r2wrYuqpWjrHMHYFnAI8F3jENoXF74C+A/YHPAadW1aOAW9r2u0lyYJIVSVbcePN1U1y9JElSt4bdQ3o8sDbJQ4FPAtsBn5/iup8EfKGq1lbV74DTgccM6LcB8B9JVgPHAjtNYB3fqqpr2+dPBw5Lsgo4DdgI2Bb4MvDCts+L2nWM5ZtVdVtVXU0Tlu8/gXoGObGqbgdWA+sBJ7Xtq2lOX7ibqlpeVUuraumm99psiquXJEnq1rDnVt5RVWuSPA/4cFV9LMn5U1x3huz3JuB3NHtS7wHcOoF13NS3vr+sqkvuVkhyTZJH0+yBfe04y7yt5/lahh/DMZdXVXckub2qqm2/YxqWLUmSNOcNu4f09iQvAV4JfKNtm8yh6huARe3zM4ADkqyXZEvgycA5fX0ANgOurKo7gJfT7EWcjJOBg5IEIMluPdO+CLwF2KyqVk9y+ZIkSZqEYQPpq2jOx3x3VV2aZDua8x0npKquAc5qb4G0J3AhcAHwXeAtVfXbtm1NkguSvAn4OPDKJIk4Rr0AABVpSURBVGcDD+euez0n4l00IfrCdv3v6pl2HPBimsP3kiRJmkW58wjxOB2TjYFtBx3yVne2fcDD6i0v+2DXZUjSrHjDB57ddQmSpiDJyqpa2t8+7FX2zwZW0V5wk2TXJCdMb4mSJElaFw170czhNLc5Og2gqla1h+07l+QZwHv7mi+tqudNYZmvAt7Y13xWVf3dOPM9CvhsX/NtVfW4ydYiSZK00A0bSNdU1XXt9UAjhjvWP8Oq6mSaC5amc5mfBj49iflW09xbVZIkSUMaNpBe1P5/+fWSPAw4GBj1f7dLkiRJwxr2KvuDgEfS3DPz88B1wCEzVZQkSZLWHePuIU2yHnBCVe1H8+83JUmSpGkz7h7SqloL3JzE/1EpSZKkaTfsOaS3AquTfIueG9NX1cEzUpUkSZLWGcMG0m+2D0mSJGlaDf2fmjQ3LV26tFasWNF1GZIkSeMa7T81DbWHNMmlDLjvaFU9ZBpqkyRJ0jps2EP2vUl2I+CFwObTX44kSZLWNUPdh7Sqrul5/KaqPgw8ZYZrkyRJ0jpg2EP2u/d8ew+aPaaLZqQiSZIkrVOGPWT/gZ7na4BLgRdNfzmSJEla1wwbSP+6qn7R25BkuxmoR5IkSeuYoW77lOS8qtq9r21lVe0xY5VpKNvc9z71+j9/atdlSNPubZ87rusSJEnTbFK3fUqyI/BIYLMkz++ZdG+aq+0lSZKkKRnvkP0OwLOAxcCze9pvAP5mpoqSJEnSumPMQFpVXwO+lmTPqvrBLNUkSZKkdciwFzWdn+TvaA7f/+lQfVW9ekaqkiRJ0jpjqBvjA58FHgA8AzgdeCDNYXtJkiRpSoYNpA+tqn8Ebqqq/wT+AnjUzJUlSZKkdcWwgfT29usfkuwMbAYsmZGKJEmStE4Z9hzS5UnuA/wjcAKwKfD2GatKkiRJ64yhAmlVHdU+PR14yMyVI0mSpHXNUIfsk9w/ySeTnNh+v1OSv57Z0iRJkrQuGPYc0qOBk4Gt2+//BzhkJgqSJEnSumXYQLpFVX0ZuAOgqtYAa2esqnVIksOTHJpkWZKte9qPSrJTl7VJkiTNhmEvaropyX2BAkjyeOC6Gatq3bQMuAi4AqCqXtNpNZIkSbNk2D2kf09zdf32Sc4CPgMcNGNVLXBJ3pbkkiTfBnZom5cCxyRZlWTjJKclWdphmZIkSbNizD2kSbatql9V1XlJ9qYJTwEuqarbx5pXgyXZA3gxsBvN+J8HrARWAIdW1Yq2X2c1SpIkzabx9pB+tef5l6rq4qq6yDA6JXsB/1VVN1fV9TR7nickyYFJViRZcdOtt01/hZIkSbNovEDau5vO+49On5rSzFXLq2ppVS3dZKMNp6smSZKkTowXSGuU55q8M4DnteeJLgKe3bbfACzqrixJkqRujHeV/S5JrqfZU7px+5z2+6qqe89odQtQez7ul4BVwC+BM9tJRwOfSHILsGdH5UmSJM26MQNpVa03W4WsS6rq3cC7B0w6vuf5PrNTjSRJUreGve2TJEmSNCMMpJIkSeqUgVSSJEmdMpBKkiSpUwZSSZIkdcpAKkmSpE4ZSCVJktQpA6kkSZI6ZSCVJElSpwykkiRJ6tR4/8tec9xW223P2z53XNdlSJIkTZp7SCVJktQpA6kkSZI6ZSCVJElSpwykkiRJ6pSBVJIkSZ0ykEqSJKlT3vZpnrv1yhv48bu/23UZ0lAe8bandF2CJGkOcg+pJEmSOmUglSRJUqcMpJIkSeqUgVSSJEmdMpBKkiSpUwZSSZIkdcpAKkmSpE4ZSCVJktQpA6kkSZI6ZSCVJElSpwykkiRJ6pSBVJIkSZ2ad4E0yeIkrx+nz5IkLx1iWUuSXDR91Y0vyVFJdhqnz3PH6yNJkrRQzLtACiwGxgykwBJg3EA6EUnWn47lVNVrqupH43R7LmAglSRJ64T5GEiPALZPsirJ+9rHRUlWJzmgp89ebZ83tXtCz0xyXvt4wjArSrIsybFJvg6ckmSTJJ9Kcm6S85Ps3/ZbL8n72xouTHLQGMs8LcnS9vmNSd6d5IIkZye5f1vbc4D3tfVvP5XBkiRJmuumZa/fLDsM2Lmqdk3yl8DrgF2ALYBzk5zR9jm0qp4FkORewNOq6tYkDwO+ACwdcn17Ao+uqmuT/Avw3ap6dZLFwDlJvg28AtgO2K2q1iTZfMhlbwKcXVVvS/KvwN9U1T8nOQH4RlUdN2imJAcCBwJstdn9hlyVJEnS3DQfA2mvJwFfqKq1wO+SnA48Bri+r98GwJFJdgXWAg+fwDq+VVXXts+fDjwnyaHt9xsB2wL7AZ+oqjUAPf3H80fgG+3zlcDThpmpqpYDywF23maHGnJdkiRJc9J8D6QZst+bgN/R7Em9B3DrBNZxU9/6/rKqLrlLEUmAyQTD26tqZL61zP/3Q5IkacLm4zmkNwCL2udnAAe053BuCTwZOKevD8BmwJVVdQfwcmC9Sa77ZOCgNoCSZLe2/RTgdSMXPk3gkP1o+uuXJElasOZdIK2qa4Cz2ts17QlcCFwAfBd4S1X9tm1b014s9Cbg48Ark5xNc7j+psFLH9e7aA7/X9iu/11t+1HAr9r2C5j6Ff5fBN7cXjjlRU2SJGlBy51HjDUf7bzNDnXs6/+t6zKkoTzibU/pugRJUoeSrKyqu11YPu/2kEqSJGlh8SIaIMkzgPf2NV9aVc+bwjL/i+ZWUL3+oapOnuwyJUmSFiIDKdCGxGkNilMJs5IkSesSD9lLkiSpUwZSSZIkdcpAKkmSpE4ZSCVJktQpA6kkSZI6ZSCVJElSp7zt0zy30VaL/O83kiRpXnMPqSRJkjplIJUkSVKnDKSSJEnqlIFUkiRJnTKQSpIkqVMGUkmSJHXK2z7Nc1dccQWHH35412VIAG6LkqRJcQ+pJEmSOmUglSRJUqcMpJIkSeqUgVSSJEmdMpBKkiSpUwZSSZIkdcpAKkmSpE4ZSCVJktQpA6kkSZI6ZSCVJElSpwykkiRJ6pSBVJIkSZ0ykE6DJIuTvL7rOiRJkuYjA+n0WAwMHUjTcOwlSZIwkE6XI4Dtk6xK8r4kb05ybpILk7wTIMmSJD9O8nHgPGCvJD9JclSSi5Ick2S/JGcl+WmSx3b6iiRJkmaJgXR6HAb8vKp2Bb4FPAx4LLArsEeSJ7f9dgA+U1W7Ab8EHgp8BHg0sCPwUuBJwKHAW0dbWZIDk6xIsuLmm2+eoZckSZI0O9bvuoAF6Ont4/z2+01pAuqvgF9W1dk9fS+tqtUASS4GvlNVlWQ1sGS0FVTVcmA5wNZbb13T/gokSZJmkYF0+gV4T1X9+10akyXATX19b+t5fkfP93fgeyNJktYRHrKfHjcAi9rnJwOvTrIpQJJtktyvs8okSZLmOPfCTYOquqa9GOki4ETg88APkgDcCPwVsLbDEiVJkuYsA+k0qaqX9jV9ZEC3nXv6X9b3/bLRpkmSJC1kHrKXJElSpwykkiRJ6pSBVJIkSZ0ykEqSJKlTBlJJkiR1ykAqSZKkThlIJUmS1CkDqSRJkjplIJUkSVKnUlVd16ApWLp0aa1YsaLrMiRJksaVZGVVLe1vdw+pJEmSOmUglSRJUqcMpJIkSeqUgVSSJEmdMpBKkiSpUwZSSZIkdcpAKkmSpE6t33UBmprf//7HfPnYx3ZdhuapF73wnK5LkCTJPaSSJEnqloFUkiRJnTKQSpIkqVMGUkmSJHXKQCpJkqROGUglSZLUKQOpJEmSOmUglSRJUqcMpJIkSeqUgVSSJEmdMpBKkiSpUwbSWZTkOUkO67oOSZKkuWT9rguYDUkCpKru6LCG9avqBOCErmqQJEmaixbsHtIkS5L8OMnHgfOAf0xybpILk7yzp98r2rYLkny2bXtwku+07d9Jsm2SzZJcluQebZ97Jbk8yQZJtk9yUpKVSc5MsmPb5+gkH0xyKvDeJMuSHNlO2zLJ8W1N5yZ5Ytu+d5JV7eP8JItmeegkSZJm1ULfQ7oD8Crgq8ALgMcCAU5I8mTgGuBtwBOr6uokm7fzHQl8pqr+M8mrgY9W1XOTXADsDZwKPBs4uapuT7IceF1V/TTJ44CPA09pl/VwYL+qWptkWU9tHwE+VFXfS7ItcDLwCOBQ4O+q6qwkmwK39r+oJAcCBwJsscU9p2OcJEmSOrPQA+kvq+rsJO8Hng6c37ZvCjwM2AU4rqquBqiqa9vpewLPb59/FvjX9vmXgANoAumLgY+3ofEJwLHNmQEAbNhTw7FVtXZAbfsBO/XMc+92b+hZwAeTHAN8pap+3T9jVS0HlgNsv/0mNcxASJIkzVULPZDe1H4N8J6q+vfeiUkOBoYJdCN9TgDe0+5J3QP4LrAJ8Ieq2nWcGvrdA9izqm7paz8iyTeBZwJnJ9mvqn4yRI2SJEnz0oI9h7TPycCr272ZJNkmyf2A7wAvSnLftn3kkP33afaAArwM+B5AVd0InENzuP0bVbW2qq4HLk3ywnYZSbLLEDWdArxh5Jsku7Zft6+q1VX1XmAFsOMUXrckSdKct04E0qo6Bfg88IMkq4HjgEVVdTHwbuD09vzQD7azHAy8KsmFwMuBN/Ys7kvAX7VfR7wM+Ot2GRcD+w9R1sHA0vbCqR8Br2vbD0lyUbusW4ATJ/6KJUmS5o9UeQrifLb99pvUe454ZNdlaJ560QvP6boESdI6JMnKqlra375O7CGVJEnS3GUglSRJUqcMpJIkSeqUgVSSJEmdMpBKkiSpUwZSSZIkdcpAKkmSpE4ZSCVJktQpA6kkSZI6tX7XBWhq7nOfR/jfdiRJ0rzmHlJJkiR1ykAqSZKkThlIJUmS1CkDqSRJkjplIJUkSVKnDKSSJEnqlIFUkiRJnfI+pPPcj35/Pbscd3LXZWiOueAFz+i6BEmShuYeUkmSJHXKQCpJkqROGUglSZLUKQOpJEmSOmUglSRJUqcMpJIkSeqUgVSSJEmdMpBKkiSpUwZSSZIkdcpAKkmSpE4ZSCVJktQpA6kkSZI6ZSDtkeT7Q/Q5JMm9pml9y5JsPR3LkiRJmq8MpD2q6glDdDsEGDqQJllvjMnLAAOpJElapxlIeyS5sf26T5LTkhyX5CdJjknjYJoAeWqSU8daTpJ/SvJDYM8kb09ybpKLkixvl/UCYClwTJJVSTZOskeS05OsTHJykq1GWf6BSVYkWbHm+utmYCQkSZJmj4F0dLvR7A3dCXgI8MSq+ihwBbBvVe07xrybABdV1eOq6nvAkVX1mKraGdgYeFZVHQesAF5WVbsCa4CPAS+oqj2ATwHvHrTwqlpeVUuraun6995sel6tJElSR9bvuoA57Jyq+jVAklXAEuB7Q867Fji+5/t9k7yF5lD/5sDFwNf75tkB2Bn4VhKA9YArJ1u8JEnSfGEgHd1tPc/XMrGxurWq1gIk2Qj4OLC0qi5Pcjiw0YB5AlxcVXtOsl5JkqR5yUP2E3cDsGgC/UfC59VJNgVeMMqyLgG2TLInQJINkjxyqsVKkiTNdQbSiVsOnDjWRU29quoPwH8Aq4GvAuf2TD4a+ER7SsB6NGH1vUkuAFYBw1z1L0mSNK+lqrquQVNwr+0fXg9778e6LkNzzAUveEbXJUiSdDdJVlbV0v5295BKkiSpU17UNAXtfUY37Gt+eVWt7qIeSZKk+chAOgVV9biua5AkSZrvPGQvSZKkThlIJUmS1CkDqSRJkjplIJUkSVKnDKSSJEnqlFfZz3M73eferPAm6JIkaR5zD6kkSZI6ZSCVJElSpwykkiRJ6lSqqusaNAVJbgAu6bqOOWwL4Oqui5jjHKPxOUbjc4zG5xiNzfEZ30IYowdX1Zb9jV7UNP9dUlVLuy5irkqywvEZm2M0PsdofI7R+ByjsTk+41vIY+Qhe0mSJHXKQCpJkqROGUjnv+VdFzDHOT7jc4zG5xiNzzEan2M0NsdnfAt2jLyoSZIkSZ1yD6kkSZI6ZSCVJElSpwykc1SSP0tySZKfJTlswPQk+Wg7/cIkuw8770Ix2TFK8qAkpyb5cZKLk7xx9qufHVPZjtrp6yU5P8k3Zq/q2TPFn7PFSY5L8pN2W9pzdqufHVMcoze1P2MXJflCko1mt/rZMcQY7ZjkB0luS3LoROZdKCY7Rn5e32X6qNtRO31+f15XlY859gDWA34OPAS4J3ABsFNfn2cCJwIBHg/8cNh5F8JjimO0FbB7+3wR8D+O0V3HqGf63wOfB77R9euZa+MD/Cfwmvb5PYHFXb+muTRGwDbApcDG7fdfBpZ1/Zo6GqP7AY8B3g0cOpF5F8JjimPk5/U4Y9QzfV5/XruHdG56LPCzqvpFVf0R+CKwf1+f/YHPVONsYHGSrYacdyGY9BhV1ZVVdR5AVd0A/Jjml+dCM5XtiCQPBP4COGo2i55Fkx6fJPcGngx8EqCq/lhVf5jN4mfJlLYhmn++snGS9YF7AVfMVuGzaNwxqqqrqupc4PaJzrtATHqM/Ly+0xjb0YL4vDaQzk3bAJf3fP9r7v4DOFqfYeZdCKYyRn+SZAmwG/DDaa+we1Mdow8DbwHumKkCOzaV8XkI8L/Ap9tDZEcl2WQmi+3IpMeoqn4DvB/4FXAlcF1VnTKDtXZlKp+5fl5PgJ/XY5r3n9cG0rkpA9r67881Wp9h5l0IpjJGzcRkU+B44JCqun4aa5srJj1GSZ4FXFVVK6e/rDljKtvQ+sDuwL9V1W7ATcBCPP9vKtvQfWj28GwHbA1skuSvprm+uWAqn7l+Xg+7AD+vR59xgXxeG0jnpl8DD+r5/oHc/VDXaH2GmXchmMoYkWQDmg+3Y6rqKzNYZ5emMkZPBJ6T5DKaQ0dPSfK5mSu1E1P9Oft1VY3sqTmOJqAuNFMZo/2AS6vqf6vqduArwBNmsNauTOUz18/rIfh5Pa4F8XltIJ2bzgUelmS7JPcEXgyc0NfnBOAV7RWuj6c5HHblkPMuBJMeoyShOffvx1X1wdkte1ZNeoyq6v9U1QOrakk733eraqHt3ZrK+PwWuDzJDm2/pwI/mrXKZ89UPot+BTw+yb3an7mn0pz/t9BM5TPXz+tx+Hk9voXyeb1+1wXo7qpqTZI3ACfTXHn3qaq6OMnr2umfAP6b5urWnwE3A68aa94OXsaMmsoY0fw1+XJgdZJVbdtbq+q/Z/M1zLQpjtGCNw3jcxBwTPvL4xcswLGb4mfRD5McB5wHrAHOZwH+28NhxijJA4AVwL2BO5IcQnMF9fV+Xo89RsCj8fN63O2os8Knkf86VJIkSZ3ykL0kSZI6ZSCVJElSpwykkiRJ6pSBVJIkSZ0ykEqSJKlTBlJJkiR1ykAqSZKkTv0/Idn/yEbr2E8AAAAASUVORK5CYII=\n",
"text/plain": [
"
\n",
" \n",
" \n",
" \n",
" \n",
"
"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"application/vnd.plotly.v1+json": {
"config": {
"linkText": "Export to plot.ly",
"plotlyServerURL": "https://plot.ly",
"showLink": true
},
"data": [
{
"boxpoints": false,
"line": {
"width": 1.3
},
"marker": {
"color": "rgba(255, 153, 51, 1.0)"
},
"name": "revol_util",
"orientation": "v",
"type": "box",
"y": [
73.1,
23.2,
31.2,
55.5,
76.2,
64.5,
23.9,
29.5,
76.6,
90.5,
50.8,
71.9,
34.2,
27.2,
41.4,
35.4,
96.2,
99.4,
54.7,
76.7,
68.7,
12.2,
82.4,
60.6,
54.2,
46.7,
32,
87.3,
48.4,
58.1,
69.6,
70.7,
97.5,
52.7,
12.3,
54.9,
82.2,
48.3,
64.1,
65.2,
78.2,
36.7,
26.2,
30.5,
70.5,
95.8,
33.2,
80,
51.7,
76.9,
45.7,
51.2,
1.7,
71.4,
19.5,
70,
38.4,
36.6,
45.7,
15.9,
40.2,
78.4,
15.3,
68,
5.5,
53.7,
2.9,
80.1,
63.6,
35.7,
67.8,
76.2,
78.4,
58.2,
93.4,
70.7,
53.3,
79.2,
44.4,
85.1,
45,
18.1,
97,
67.4,
44.7,
76,
44.3,
57.9,
19.1,
81.1,
96.3,
77,
null,
57.5,
66.8,
37,
49.1,
86.4,
48.8,
65.1,
37.5,
61.5,
46.6,
18.2,
68.5,
38.4,
49.3,
61,
33,
26.9,
13.7,
47.7,
49.3,
38.9,
25.8,
38.2,
58,
20.3,
43.1,
84.3,
54.2,
80.7,
12.2,
69,
55.2,
75.9,
21.3,
20.5,
85.1,
77.7,
58.7,
65,
65.6,
42.5,
46.2,
76.9,
39,
45.2,
22.2,
45.1,
41.1,
36,
77.9,
55,
96.3,
53,
68.5,
47.4,
52.9,
68.3,
93.2,
67.6,
88.7,
52.9,
88.4,
50.3,
26.4,
10,
34.7,
66.8,
33.2,
57.6,
40.8,
96.3,
3.4,
85.2,
103.5,
11.5,
8.2,
74.2,
54,
26.1,
27.4,
41.1,
15.9,
76.3,
25.3,
51.3,
62.9,
66.3,
20.2,
62.2,
53.6,
53.3,
58.9,
49.7,
97.6,
22.9,
82.4,
62.1,
71.7,
52.1,
42.4,
57.4,
28.1,
64.8,
35.1,
13.2,
51.4,
68.8,
42,
32.4,
49,
47.2,
67.4,
77.7,
89.4,
88.1,
93.1,
73.7,
62,
18.1,
69.1,
52.5,
40.3,
36.2,
74.8,
85.5,
26.3,
41.3,
47.9,
67.3,
57.6,
67.4,
48.6,
18.2,
46.5,
95.1,
57.3,
14.4,
47.3,
40.6,
27.1,
23.9,
39.2,
21.1,
33.2,
66.8,
25,
53.8,
74.1,
54.4,
69.6,
43.9,
86.3,
81,
62.7,
69.1,
49.4,
84.9,
28.7,
93.9,
77.3,
31.1,
69.3,
73.2,
16.4,
78.8,
46,
33.7,
51.1,
77.4,
95.6,
81.3,
80,
49.6,
59.7,
27,
46.1,
69.4,
52.5,
99.1,
23.9,
52,
72.7,
54.1,
57,
78.8,
48.6,
64.7,
34.2,
55,
49.2,
66.4,
30,
93.5,
95.6,
62.3,
37.3,
39.2,
82.8,
26.6,
67.5,
14,
45,
97,
21.5,
57.8,
13.8,
74,
50.1,
81.4,
5.8,
66,
64.7,
49.3,
50.6,
90,
71,
50,
29.7,
23.4,
86.3,
25.5,
37.1,
61.5,
83.2,
31.5,
50.5,
51.4,
55.8,
69.5,
55.4,
76.7,
55.8,
44.5,
66.5,
77.1,
47.7,
69.3,
46.2,
28.2,
29.4,
88.6,
44.5,
95.8,
41.2,
56.7,
12.1,
88.3,
47,
73.2,
58.3,
25.5,
96,
33.6,
24.9,
15.9,
102.7,
64.1,
81.1,
76.8,
53.3,
64.8,
5.2,
40.8,
64.7,
56.5,
26.8,
68.1,
19.7,
80.6,
28.5,
76.2,
52,
1.9,
78.6,
69.2,
39.8,
53.9,
39.1,
76.7,
56,
34.1,
28.8,
10,
58.7,
58.3,
27.1,
77.8,
65.6,
89,
76.9,
9.7,
76.5,
56.9,
41.8,
79.1,
85.9,
43.3,
53.3,
30.6,
58.4,
78.8,
69.8,
19.7,
93.6,
71.7,
91.3,
42.1,
32.8,
63.3,
27.5,
50.1,
54.2,
49.9,
63.5,
90.2,
67.3,
42.7,
26.3,
25.6,
38.7,
93.2,
34.7,
59.7,
55.3,
88.2,
86.3,
31.6,
61.6,
80.2,
27.5,
48.2,
68.7,
58.5,
35.1,
45.1,
44.8,
57.2,
61.9,
74.5,
56.1,
56.4,
34,
98.9,
14.2,
48.6,
48.6,
28.7,
60,
18.4,
69.3,
56.8,
43.4,
71.5,
47.6,
94.3,
45.5,
70.6,
43.9,
21.3,
26.3,
28.5,
26.3,
98.7,
80.6,
51.3,
28,
25.1,
98.4,
71.5,
54.6,
26.9,
19.8,
53.3,
36.7,
94.2,
47.7,
89.9,
95.8,
55.8,
19.9,
85.4,
38.2,
35.1,
86.1,
58.8,
91.5,
88.8,
96.1,
68.5,
57.9,
27.6,
60.5,
39.4,
62.7,
60.1,
27.6,
91.6,
38.2,
27.6,
69.8,
79.1,
73.5,
82.6,
32.3,
35.8,
93.1,
44.3,
84.4,
71.9,
47,
89.8,
66.3,
66.3,
68.9,
78,
85.9,
50,
85,
34.1,
66.8,
85.3,
65.9,
52.5,
37.7,
61.1,
52.5,
71,
86.3,
39.6,
82.5,
43.5,
53.3,
51.6,
76,
55.1,
37.6,
37.7,
32.3,
54.8,
40.3,
32.9,
57.3,
66.9,
43.1,
76.1,
51.3,
49.9,
83.7,
57.9,
31.9,
14.9,
8,
92.5,
45.8,
46.6,
63.8,
90.7,
55.8,
83.5,
59.5,
15.4,
66.6,
67.1,
43.5,
89.7,
58.2,
97.6,
58.4,
77.7,
57.3,
52.4,
49.4,
41.2,
42.7,
17.6,
24.3,
61.4,
67.6,
87.9,
38.4,
76.5,
95.4,
59.2,
65.2,
51.1,
63,
29.1,
39,
24.1,
54,
44.8,
71.1,
58.4,
33.1,
52.1,
86.8,
86.7,
64.2,
86.4,
37.8,
92.8,
43.5,
50.2,
48.6,
43.8,
44.9,
36.4,
43.8,
43.2,
66.5,
10.9,
67.4,
64.1,
35.3,
74.5,
59.7,
53.4,
71.6,
73.7,
51.4,
75.4,
57.5,
40.1,
95.4,
32.2,
79.5,
29.3,
78.2,
46.5,
63.3,
61.4,
50,
92.9,
30.8,
32.1,
19.2,
60.5,
74.9,
50.2,
26.9,
76.5,
87.3,
79.1,
57.5,
55.6,
47.4,
35,
68.8,
2.8,
86.8,
51.3,
20,
45.8,
48.8,
80.9,
92.5,
31.5,
90.5,
25.8,
10.8,
63.3,
65.2,
9.3,
33.3,
30.1,
18.5,
81.2,
33.5,
71.8,
95.1,
89.1,
71.7,
66.3,
22.9,
37.3,
85.2,
60.1,
29.5,
85.9,
3.3,
4,
75.9,
37.1,
94.5,
36.4,
57.7,
47.9,
10.3,
98,
30.8,
84.3,
100.7,
39.9,
52.4,
32.3,
27.4,
55.2,
48.8,
69,
92.3,
18.8,
65.8,
35.1,
43,
89.9,
26.4,
42.3,
57.1,
53,
64.3,
11.8,
76.5,
26.2,
50.9,
40.5,
57.6,
56.2,
44.2,
26.2,
29.9,
36.3,
54.9,
76.2,
27.8,
95.9,
43,
24,
87.6,
61.8,
54,
14.7,
27,
51.5,
61.7,
47.6,
16.2,
81.8,
16,
63.1,
35.3,
28.1,
70.5,
59.6,
55.8,
46.3,
59.4,
91.1,
45.9,
50.4,
67.6,
93.4,
93,
71.2,
28,
60.2,
17.8,
77.8,
66.9,
24.9,
49.6,
61.4,
78.8,
46.3,
53.3,
27.6,
86.9,
27.3,
77.6,
88,
41.7,
61.4,
46.1,
53.7,
67.1,
87.7,
46.3,
50.1,
91,
36.7,
61.4,
40.2,
55.7,
1.7,
41.9,
98.3,
65.1,
39,
41.5,
38.1,
53.1,
93.6,
64.3,
34.8,
45.2,
66.1,
96,
49.6,
52,
29,
62.2,
66.7,
51.1,
48,
86.2,
83.5,
73,
67.2,
68.4,
77.1,
49.3,
47.8,
80.3,
36.5,
89,
89.2,
96.8,
74,
31,
94.4,
70.6,
57.2,
61.6,
43.7,
75.4,
60.1,
83.5,
66.3,
12.6,
55.9,
59,
43.9,
57.8,
53.3,
78.1,
91.2,
13.3,
32.5,
70.4,
69,
66.2,
80.8,
26.2,
80.4,
65,
87.7,
53.2,
57.7,
74.2,
28.3,
59.1,
69.5,
79.3,
49.4,
44.9,
73.9,
66.7,
73.3,
86.9,
9.9,
98.4,
67.1,
38.5,
54.3,
57,
90.6,
61.5,
83.9,
37.7,
77.9,
73.7,
41.8,
65,
77.9,
16,
91.9,
null,
39.1,
72.5,
25.3,
82.6,
38.4,
65.9,
85.4,
29,
67,
24.8,
84.9,
17.7,
88.1,
48.3,
66.7,
42.3,
46.5,
75,
62,
54.3,
46.7,
54.3,
42.5,
46.6,
53.2,
26.4,
56.9,
86,
67.6,
54.5,
46.5,
32.3,
74,
47.1,
37.6,
26.6,
16,
50.6,
65,
52.7,
16,
95,
39.3,
90.3,
89.4,
38.5,
27.8,
74.2,
38.5,
42.1,
76,
12,
66.8,
69.5,
74,
24.9,
48.4,
83.4,
52,
99.5,
1.8,
69.5,
59.6,
63,
28.8,
49.3,
73.4,
87.3,
4.3,
70.7,
92.3,
47.7,
47.3,
73.9,
79,
77.8,
6.8,
84.6,
20.9,
15,
53.7,
89.5,
67.2,
61.1,
45.7,
89.4,
95.7,
49,
51.6,
23.9,
55.5,
52.6,
22.2,
93.1,
84.8,
61.8,
69.7,
51.7,
9.9,
25.2,
97,
24.2,
76.3,
29.1,
61.5,
91.9,
23.1,
64.1,
27.3,
52.2,
22.4,
54.3,
50.7,
81.6,
66.8,
73,
69.6,
10.8,
16.2,
74.8,
86,
49.2,
67.6,
52,
71.5,
99,
73.5,
64.5,
61.4,
44,
32.9,
44.5,
87.6,
38.5,
49.2,
20.4,
78,
79.2,
55.4,
80.1,
91.1,
44.3,
74.1,
24.1,
41.8,
87.6,
71,
62.1,
81.1,
72.7,
61.7,
88.2,
24.4,
54.9,
52.7,
44.4,
58.2,
73.4,
57.7,
70.1,
49,
86.7,
44.3,
84.2,
81,
92.7,
73.9,
33.6,
61.6,
76.7,
40,
48,
56.9,
40.6,
47.6,
47.6,
10.1,
58.5,
15.6,
3.1,
40.9,
72.7,
18,
24.1,
42.9,
57.1,
38.6,
67.7,
65.2,
61.5,
68.1,
46.5,
60.7,
79.1,
65.8,
32.6,
66,
6.2,
29.3,
36.6,
94.1,
67,
73.7,
69.1,
13.2,
59.5,
63.2,
66,
31.6,
31.8,
69.3,
78.8,
78.5,
73.5,
81.9,
33.6,
49.8,
98.7,
62.9,
70,
99.7,
66,
61.2,
52.4,
56.8,
56.8,
66,
76.7,
22.1,
80.1,
26.6,
49.1,
52.6,
67.8,
57.2,
41.5,
85.9,
33.4,
58.4,
55.2,
22.3,
21.8,
74.4,
42.3,
52.5,
90,
46.7,
61.7,
72.1,
97.6,
57.5,
54.8,
42.6,
23,
57.5,
37.7,
6.7,
91.8,
59.8,
48.2,
69.8,
42.8,
31.4,
11,
76.6,
69,
18.6,
68.5,
65,
5,
52.5,
87.2,
76.3,
77.9,
58.2,
83.2,
37.3,
28.5,
77.8,
82.9,
77.2,
1.3,
59,
84.7,
41.8,
74.9,
57.3,
55.3,
65.9,
51.4,
25.1,
70.7,
57.2,
59.2,
79.3,
86.8,
96.9,
67.9,
74.8,
80.8,
61.9,
29.2,
86.8,
29.1,
42,
24.3,
86.7,
88.2,
44.2,
83.5,
43.1,
36.2,
89.4,
62.8,
30.4,
61.7,
62.6,
71.6,
87.4,
23.8,
34.5,
35.9,
85,
32.4,
97.9,
96.4,
95.2,
42.1,
53.6,
3.3,
64,
20.3,
51,
59.3,
34,
8.9,
39.7,
25.6,
100.1,
26.8,
95.8,
0.3,
77.9,
33.4,
51.2,
45,
39,
69.6,
61.1,
38.6,
38.8,
55.1,
78.2,
24.8,
1.1,
82,
59,
65.5,
33.5,
65.3,
35.6,
48.8,
64,
19.9,
68.6,
55.4,
57.8,
49.1,
64.8,
6.3,
49.1,
62,
69.5,
22.6,
83.7,
81.6,
66.1,
34,
38,
0,
95.6,
58.5,
58.6,
47,
51.6,
52.8,
15.6,
73.7,
63.9,
67.7,
20.6,
50.8,
85.3,
50.2,
50.1,
91.9,
32.5,
14.6,
61.6,
63.4,
18.7,
78.5,
45.2,
58.1,
29.6,
47.9,
38.2,
54.6,
74.5,
74.2,
69.9,
72.9,
44.4,
47.7,
99.9,
39.1,
64.1,
86.9,
40.4,
67.2,
33,
46.4,
11.1,
83.8,
83.9,
27.5,
59.2,
0,
92.1,
39,
70,
38.6,
66,
56.5,
3,
19.5,
26,
80.3,
41,
30.7,
74.4,
56,
63.4,
77.9,
74.6,
80.3,
67.6,
32.2,
43,
52.9,
50.7,
10.5,
20.5,
63.5,
36.2,
30,
60.7,
67.9,
84.4,
75,
8.7,
45.7,
33.3,
73,
20.9,
24.2,
32.1,
94.9,
58,
51.3,
59.5,
40.8,
2.6,
63.9,
47.4,
66.5,
47.4,
51.3,
63.4,
43.1,
33.5,
24.2,
29.2,
68.7,
56.5,
48.7,
31.5,
28.2,
57,
61.3,
25.7,
60.6,
24.1,
36.7,
11.1,
85.4,
83.3,
51.2,
43.1,
17.7,
9.2,
86.4,
12.3,
32.9,
44.4,
42.2,
81,
93.9,
59.5,
45.8,
12.2,
55.1,
69.8,
69.3,
66.2,
48.6,
28.4,
85,
83.1,
87.8,
45.7,
40.4,
31,
52,
33.5,
58.4,
68.8,
73.5,
77.7,
85,
46,
71.4,
88.7,
13.1,
2.8,
17.5,
39.7,
22.4,
83.1,
93.6,
24.4,
43.8,
57.4,
87.9,
76.4,
60,
37,
43.4,
74.4,
47,
61.1,
59.9,
77.4,
51,
10.9,
92.8,
23.4,
61.1,
49.5,
42.5,
52.5,
22,
23.3,
87.1,
41,
30.6,
84.2,
49.1,
97.5,
19.2,
62.5,
29,
72.3,
73,
68.3,
12.6,
90.8,
65.8,
72.4,
11.9,
74.4,
58.8,
43.4,
31.2,
27.8,
45.6,
46.9,
79.9,
47.3,
90.4,
12.1,
43.6,
67,
47.9,
90.2,
26.2,
66.2,
59.4,
54.5,
38.8,
26.6,
49.1,
76.1,
70,
43.2,
54.8,
54,
89.7,
61.1,
50.3,
43,
70.3,
58.1,
21.1,
62.1,
6.6,
64.4,
37.4,
52.7,
97.3,
62.7,
33.4,
38.1,
96,
69.2,
82.8,
45.7,
28.1,
84.7,
65.3,
20.7,
74.1,
14.5,
54.2,
46,
52.9,
11.5,
19.4,
89,
64,
52.8,
48.2,
15.8,
62,
74.7,
70.3,
17,
16.1,
30.6,
34.3,
73.8,
93.2,
46.9,
78.5,
56.9,
42.6,
98.3,
54.9,
63.5,
76.6,
6.3,
23.1,
71.6,
46,
39.6,
32,
57,
35.2,
58.5,
83,
53.7,
59.1,
72.2,
44.8,
62.6,
64,
44,
36.4,
54.1,
33.9,
51.5,
59.8,
92,
82,
51.4,
62.1,
84.3,
96.1,
49.4,
62.1,
50.2,
67.4,
26.8,
49.7,
37.6,
46.1,
82.4,
43.7,
49.8,
0,
98.8,
41.9,
57.3,
37.8,
75,
68.6,
37.7,
63.7,
40.7,
98.8,
50.5,
86.2,
78.9,
48.8,
67.8,
35.2,
49.6,
68,
67.8,
94.5,
70.4,
8.3,
65.4,
56.7,
44.8,
17.1,
91.4,
94.7,
90.4,
54.1,
59.7,
82.1,
38.4,
52.2,
58.3,
63.9,
30.6,
45,
26,
55.2,
73.5,
89,
50.1,
51.4,
48.7,
81.2,
35.6,
43,
76.3,
90.7,
60.2,
99.3,
23.8,
32.7,
55,
81.7,
70.9,
48.8,
63.3,
55.8,
48.4,
0,
76.2,
38.2,
54.7,
69.7,
98.7,
62.8,
84.9,
95.7,
70.5,
69.9,
79.8,
34.9,
9.3,
98.1,
31.3,
15.8,
55.1,
81.1,
80.9,
84.4,
69,
89.5,
91.7,
52.5,
64.4,
18.9,
64.6,
36.3,
90.6,
53.1,
66.5,
54.2,
81.9,
84.5,
18.2,
58.1,
49.7,
32.4,
40.1,
72.1,
37.5,
37.4,
41.4,
50,
53.9,
56,
24,
49.7,
28.7,
6.9,
10,
58.7,
65.2,
17,
69.1,
10,
27,
50.7,
65.8,
31.5,
57.5,
77.4,
90.9,
84,
62.6,
26.8,
17.4,
58.3,
24.2,
36.9,
64.2,
100.4,
46.5,
31.2,
36.1,
48.9,
26.3,
38.1,
20.5,
92.5,
70.1,
59,
19.6,
79.9,
65.6,
57.5,
69,
11.4,
83.2,
85.1,
73.3,
78.7,
86.6,
64.3,
57.9,
86.6,
41.2,
82.4,
53,
96.3,
79.3,
28.8,
58.8,
62.6,
92.8,
65.9,
25.2,
13,
26.3,
47.9,
39.7,
27.3,
31.6,
36.8,
34.9,
56.3,
38,
34.5,
40.6,
67.8,
100.6,
59.3,
null,
60.6,
56.1,
43.8,
70.7,
99.3,
59,
41.5,
32.6,
40.1,
33.8,
48.7,
93.2,
67.4,
51.1,
62.2,
19.7,
69.6,
36.3,
92.9,
55.8,
51.8,
7.2,
41.1,
29.1,
93.1,
55.9,
92.2,
45,
35.2,
20.8,
49.5,
29.7,
89.5,
52,
45.4,
63.7,
46.8,
46.1,
65.1,
54,
33.7,
42.8,
84.6,
65,
33.8,
80.6,
36,
41.2,
45.1,
75,
41.3,
32.2,
68.8,
40.4,
59.9,
66.7,
22.8,
83.8,
51.6,
42.6,
46.5,
65,
27.7,
66.9,
28.2,
57.7,
21,
55.4,
77.3,
72,
16.4,
62.2,
68,
80.7,
87.4,
53.1,
39.1,
58.9,
61.5,
67.4,
50,
64.8,
27.4,
65.2,
37.4,
66,
65.6,
51.9,
26,
14,
56.9,
78.5,
70,
72.7,
75.5,
38.1,
50.9,
23.8,
80.9,
28.5,
47.3,
71.8,
64.4,
24.4,
44,
52.2,
88.8,
51.8,
45.6,
94.3,
57,
12.4,
78.5,
80,
36,
69.2,
64.2,
35.1,
54.1,
61.6,
40.1,
41.5,
57.8,
31.4,
59.9,
39,
77.2,
73.3,
24.1,
66.3,
53.2,
40.4,
33.9,
76,
33.6,
85.5,
53,
94,
85,
66.3,
40.8,
59,
18.7,
46.8,
28.3,
76,
23.3,
18.3,
60.9,
89.6,
51.9,
53.1,
88.7,
63.2,
28.4,
29.9,
46.1,
62,
48.4,
19.7,
78.5,
59.1,
47.9,
61.7,
56,
64.5,
51.9,
56.8,
56,
61.5,
47,
97.2,
73.5,
34.7,
76.3,
83.2,
76.5,
30.2,
16.5,
77.9,
29.6,
32.4,
50.7,
88.2,
55.6,
47.1,
72.1,
65.8,
75.8,
83.6,
11.8,
0,
14.8,
85,
27.4,
7.5,
31.3,
28.5,
90.8,
28.5,
83.6,
20.7,
73,
34,
49.1,
53.2,
54,
84.5,
77,
65.8,
28.5,
82.2,
5.3,
22.2,
35.2,
60.8,
82.1,
61.6,
49.6,
30.8,
99.7,
87.2,
61.4,
49.8,
66.6,
93.5,
35.2,
70.3,
62.8,
46.1,
56.4,
56.9,
51,
53.2,
42.4,
63.9,
80.8,
87.9,
61,
64.2,
24.5,
33.1,
38.7,
41.4,
35.6,
64.1,
60,
57.5,
29,
74.6,
76.1,
70.2,
37.1,
39,
73,
27,
86.7,
90.3,
19.4,
99.4,
91.2,
16.6,
35.4,
82.7,
0,
80.1,
65.7,
87.1,
49.6,
42.5,
29.2,
26.7,
88.5,
58.8,
75.7,
85.4,
25.8,
53.1,
59.8,
83.2,
88.8,
48.4,
44,
38.9,
82.4,
93.3,
37.1,
26.5,
18.2,
99.1,
48.8,
35.6,
91.7,
67.9,
16.3,
17.6,
61.6,
49.5,
54.8,
28.2,
36.4,
24,
44,
105.4,
41.1,
19.7,
57.8,
38.9,
46.4,
42.7,
101.2,
52.8,
25.6,
56,
59.3,
77.1,
18.5,
74.5,
27.4,
54.6,
16.8,
7.2,
62.7,
64.7,
60.5,
46.5,
30,
88,
48.9,
5,
55.7,
32.5,
53.9,
54.7,
45.3,
37.4,
41.7,
18.3,
69.7,
68.5,
76.9,
86.2,
50.8,
34.1,
55.6,
14.7,
27.7,
49,
33.4,
11.2,
81.4,
63.8,
42.1,
61.6,
25.3,
42.4,
54.1,
21.7,
52.4,
70.9,
60.2,
35.9,
43.9,
52,
76.6,
59.3,
63.1,
30.2,
40,
83,
39,
9.3,
69,
58.3,
43.7,
40.4,
66.2,
37.7,
90.6,
52.3,
90.2,
64.9,
0,
13,
42.1,
6.3,
19,
21.1,
76.8,
43,
44.5,
93.1,
65.5,
61.4,
91.3,
41,
79.1,
51.5,
31.4,
48.7,
58,
86.1,
43,
67.3,
28.4,
89.2,
63.5,
33.6,
22.3,
27.9,
67.2,
100,
20.2,
46,
92.2,
79.9,
60.9,
73,
82.9,
49.7,
31,
46.1,
89.2,
50.7,
65.5,
59.6,
51.3,
52.7,
74.6,
85,
97.4,
36.2,
35.7,
86.7,
47.6,
0,
43.2,
44.7,
59,
43.6,
14.9,
46.8,
86.8,
40.5,
30.4,
34.1,
98.5,
56.2,
26.5,
25.7,
72.5,
50,
10.4,
81,
80,
10,
58.9,
28.1,
37,
56.1,
73.6,
8.4,
75.5,
31.2,
73.2,
80.4,
75.1,
35.8,
14.9,
98.1,
2.3,
91.7,
8.9,
97,
63.3,
47,
81.9,
86,
52.2,
54.6,
97.2,
73.5,
38.1,
56.7,
91.9,
28.4,
95.2,
96.4,
93.5,
66.6,
85.8,
35.9,
69.4,
75,
21.6,
46.1,
38.8,
90.2,
26,
74.5,
54.1,
48.8,
18.2,
87.6,
39.7,
77.6,
27.9,
33.9,
29.9,
74.4,
28.9,
60.5,
75.9,
29.6,
27.4,
82.7,
96.2,
58.1,
41.2,
28.2,
46.9,
31.8,
38.7,
93.4,
63.2,
95.7,
35.3,
42.6,
48.5,
86.8,
45,
70.4,
93.1,
75.8,
40.7,
59.2,
46.8,
72.9,
43.6,
7.3,
46.7,
72,
76.4,
66.7,
29.8,
19.5,
45.2,
32.4,
51.9,
15.5,
90.7,
45.1,
86.6,
42.5,
59.7,
56.7,
90.5,
39.6,
56.2,
93.2,
75,
90.6,
30.9,
82.4,
62,
61.3,
81.2,
64.3,
32,
63,
85.9,
55,
60.9,
55.8,
22.4,
42.7,
75.5,
45.4,
95,
61.2,
97.4,
59.1,
40.9,
40.7,
76.6,
30.4,
44.1,
38.2,
54.7,
44.6,
34.7,
76.6,
69.7,
102.7,
83.1,
35.1,
32.7,
34.7,
44.3,
23.3,
64.3,
72.7,
51.1,
20.6,
11.5,
74.7,
50.2,
42.9,
13.6,
43.8,
82.8,
94.7,
33.1,
34.2,
53.6,
16,
63,
78.5,
75.8,
59.3,
41.1,
18.8,
51.4,
64.1,
34.3,
11,
69.7,
54.4,
41,
24.3,
37.3,
29.4,
37.6,
87,
38.4,
69.3,
79,
33.9,
76.6,
17.9,
71.1,
66.3,
62.2,
51.5,
31,
87.5,
53,
31.2,
61.6,
59,
73.6,
30.3,
82.6,
83.2,
66.1,
28.5,
21.9,
61.7,
46.5,
52.9,
88,
63.6,
51.7,
65.3,
97.2,
25.4,
68.2,
48,
86.7,
71.4,
97.1,
38.1,
80.7,
39.1,
35.4,
34.5,
66.6,
0.7,
66.3,
39.4,
16.4,
48,
38.5,
53,
18.9,
27.8,
83.3,
75.1,
82.7,
28.2,
42.4,
26,
2.2,
45,
67.5,
60.2,
66.8,
41.5,
84.6,
45.2,
24.1,
31.7,
63,
52.4,
14,
52.9,
0,
38.2,
12.2,
86,
81.7,
29.1,
33.2,
79.4,
71.5,
15.9,
90.7,
63.9,
95.5,
34.5,
43,
96.2,
76.3,
48.2,
60.1,
58,
80.2,
31.5,
63.1,
98,
51,
68,
37.1,
82.5,
24.6,
32.5,
32.1,
68.1,
88.7,
30.1,
50.9,
49.9,
97,
88.8,
71.4,
22,
50.7,
60.1,
90.5,
45,
11.3,
78.6,
68.4,
61,
29.3,
62.9,
84.3,
90.7,
83,
60,
92.3,
64.4,
65.7,
54.9,
65.6,
30.6,
24.2,
45,
59.8,
74.1,
58.7,
68.6,
58.2,
80.8,
53.3,
50.6,
58.7,
44.7,
67.4,
28.2,
40.7,
32.3,
46,
57.4,
65.5,
52.8,
18.5,
55.5,
55.9,
76.1,
63.8,
18.5,
17.2,
34,
67.5,
24.3,
71.6,
92.7,
60.5,
43.7,
70.9,
62.9,
57.1,
22.3,
79.6,
19.4,
54.2,
58.4,
96.1,
84.9,
55.3,
49.8,
39.6,
85.9,
74.5,
4.8,
10.8,
68,
80.4,
79.9,
47.7,
38.5,
55.9,
62.6,
33.9,
39.4,
22.2,
57.8,
82.6,
55.7,
70.8,
92.8,
92.3,
76.7,
63,
40.8,
46.1,
43.7,
9.9,
76.6,
44.3,
58.3,
46.7,
65.7,
36.9,
88.4,
33,
57.1,
30.2,
7.5,
24.4,
16.4,
92.9,
23.2,
54.3,
50.9,
12.8,
48.4,
23.2,
36.2,
94.6,
64.8,
16.4,
62.3,
33.5,
47.8,
53.6,
47.5,
50.2,
79.5,
53.5,
28.8,
34,
34.4,
43.8,
74.2,
38.7,
33.2,
50.3,
43,
43.5,
67.9,
66.3,
54.4,
51.3,
74.1,
43.3,
44,
85.4,
31.2,
37,
68.5,
43.3,
37.8,
69,
55.7,
32,
93.7,
59,
92,
78.4,
87.8,
69.7,
76.8,
35,
47.1,
48.7,
6.2,
22,
32.8,
39.9,
62,
47.2,
54.1,
92,
54,
35.1,
16.2,
91.9,
93.9,
76.4,
58.1,
81.5,
70.2,
35.4,
57.6,
35.7,
76.9,
35.1,
38.6,
59.7,
47.4,
90.3,
90.2,
79.7,
45.9,
69.9,
48.7,
64.9,
68.5,
69.4,
98.3,
31.4,
44.5,
51.5,
88.9,
34.1,
31.7,
39.3,
46.5,
66.8,
21.4,
91.4,
89,
89.7,
61.1,
22.9,
36.5,
32.8,
85.7,
31.3,
24.9,
75.2,
21.3,
61.8,
53.1,
48.1,
59.6,
65.9,
19.3,
51.6,
45.4,
71.7,
51.5,
26.7,
77.7,
86.1,
95,
83.4,
56.1,
68.8,
79.8,
31.2,
51.9,
44,
25.4,
57.5,
66.8,
78.6,
15.9,
42.2,
63.7,
67.5,
57.3,
45.7,
16,
80.8,
99,
89,
94.7,
75,
63.4,
56.8,
20.3,
99.4,
46.7,
43.3,
36.3,
61.8,
92.4,
16.4,
68.3,
52.4,
80,
4.8,
63.8,
22.9,
82.9,
64.3,
69.8,
32.5,
24.1,
66.1,
61.9,
51.7,
39.7,
44.8,
67.4,
26.8,
71.2,
24.1,
19.7,
75.4,
78,
50,
78.8,
39.6,
70.1,
61.9,
25.6,
42.6,
37.7,
40.6,
60.8,
85.8,
29.5,
45.9,
44,
60.9,
49,
76.6,
73.1,
62.9,
49.9,
45.9,
57.6,
72.8,
12,
43.1,
80.8,
55.1,
52.9,
61.2,
43.8,
39.7,
76.7,
67.8,
71,
37.3,
78.4,
87.9,
7.4,
72,
22.3,
82.7,
98.9,
35.6,
100,
80.9,
56.7,
92.4,
23.8,
63.6,
11.9,
62.7,
97.8,
70.4,
95.2,
43.6,
96.8,
52.1,
51.8,
77.2,
51.6,
83.1,
42.9,
38.5,
84.6,
25.9,
67.1,
35.4,
46.6,
72.1,
72.4,
47,
37.8,
4.9,
66.7,
50.6,
50.5,
94.6,
35.6,
55.4,
60.7,
58.8,
68.8,
74.5,
35,
69.9,
32.7,
80.3,
36.7,
44.4,
28.3,
68.3,
44.6,
81.6,
52.1,
42.7,
33.4,
8.4,
34.5,
78.4,
52.1,
43.9,
14.8,
22.8,
87.7,
34.6,
47.4,
41,
52.8,
84.1,
70.4,
79.4,
54.3,
76.5,
80.7,
74.2,
60.3,
38.9,
32.4,
59.7,
84.2,
15.4,
59.5,
90.8,
70.6,
90.4,
20.3,
70.6,
62.7,
91,
68.6,
91,
53.2,
42.6,
73.5,
0,
42.1,
91,
73.2,
16.8,
73.5,
10.6,
92.8,
34.6,
56.2,
67.5,
74.1,
79.2,
37.7,
26.7,
82,
58.6,
33.5,
67.9,
47.7,
42.9,
95.3,
61.2,
37.4,
66,
93.9,
30.7,
42.2,
16.2,
40.1,
1.4,
64.9,
49.4,
8.7,
8,
75.3,
21.1,
43.4,
72.4,
40,
57.1,
0,
63.9,
27.1,
8.8,
82.4,
7,
74.2,
60.8,
72.1,
77.7,
87.6,
74.6,
13.9,
72.9,
32.4,
56.5,
72.8,
76,
85,
68,
70.9,
55.2,
10.4,
62,
63.5,
36.8,
78.9,
41.6,
48.9,
40.4,
97.7,
89,
53.5,
0.3,
15.6,
62.9,
59.4,
58.8,
51.2,
44.5,
28.3,
90.9,
76.3,
52.7,
32.9,
51.5,
80.8,
74.6,
47.6,
73.4,
74.3,
39.9,
44.8,
68,
86.1,
46.7,
70.2,
30.5,
83.4,
44.9,
16.9,
37.3,
106.6,
58.6,
48.1,
58.9,
60.1,
79.6,
61.1,
29.6,
25.3,
20.7,
36.4,
37.1,
23.8,
51.4,
53.7,
89.7,
55.5,
32.4,
26.6,
29.8,
91.1,
89.9,
73.6,
53.7,
55.2,
33.1,
81.4,
75.8,
74.5,
66.9,
65.8,
65.8,
94.1,
65.7,
74,
18.6,
64.3,
0,
60.9,
50.9,
50.2,
73.7,
89.4,
99.6,
51.2,
61.5,
55.9,
57.5,
47,
51.3,
26.5,
93.2,
83.1,
27,
61,
55.1,
43.2,
69.3,
74.9,
54.2,
59.1,
42.9,
90.5,
25.2,
57.6,
28.3,
75,
82.6,
34.5,
84.5,
55.2,
44.6,
72,
49,
91.6,
53,
68.3,
38.2,
32,
42.3,
93,
95.2,
82.7,
89.9,
56.7,
55.5,
68.9,
80.3,
26.6,
59.3,
35.8,
29.1,
99.8,
59.5,
68.9,
65.2,
48.6,
73.9,
51.2,
39.3,
33.9,
61.4,
75.4,
33.1,
60.9,
37.8,
69.9,
22.2,
75.7,
82.1,
49,
94.1,
53.2,
46.7,
92.8,
19.2,
88,
74.9,
91.4,
49.1,
76.1,
71.3,
43.8,
94.1,
54.2,
42.2,
84,
65.4,
37.7,
53.4,
97.7,
52.9,
64.2,
84.1,
12.8,
58,
77.2,
19.9,
76.4,
87.1,
93.9,
45.9,
50.1,
93.3,
41.5,
78.7,
34.8,
74.5,
88,
58.9,
32.2,
0,
39.9,
83.2,
51.7,
82,
84.4,
58,
12,
28.6,
68.8,
103,
95.6,
45.3,
70.8,
81.7,
47,
95,
68.3,
76.1,
72.7,
98.6,
60.8,
87.6,
37.2,
40.5,
55.9,
60.8,
32.5,
68.2,
62.5,
84.6,
42.5,
78.8,
29.5,
38.3,
77.5,
40.3,
24.5,
11.6,
55,
80.3,
59.6,
53,
46.5,
44.1,
90.7,
28,
39.8,
80.6,
58.5,
61.1,
19.1,
46.3,
49.5,
83.1,
25.9,
20.4,
82.6,
48.4,
82.7,
39.6,
91.6,
70.3,
66.4,
92.8,
52.8,
33.9,
84.9,
82.3,
38.4,
47.4,
28.1,
44.3,
30.9,
32.6,
96.5,
70.3,
21.7,
3.5,
55.1,
64.3,
29.1,
7.2,
63.6,
32,
44,
56,
29.7,
13.2,
100.7,
73.3,
52.8,
4.5,
19.9,
56.6,
48,
96,
46,
56.4,
83,
17.4,
7.8,
12.8,
42.8,
67.3,
21.3,
51,
72.4,
46.5,
45,
53.8,
74.6,
80.3,
69.8,
68,
83.9,
63.7,
0.3,
59.2,
29.1,
63.4,
82.6,
58.5,
53.2,
30.1,
53.2,
73.9,
23.1,
79.6,
82.7,
35.5,
72.1,
26.8,
68.4,
77.1,
60,
40.5,
57.6,
8.8,
18.1,
48,
29.3,
32.7,
39.8,
47.7,
64.9,
24.4,
88.5,
40.3,
30.9,
48.9,
50.2,
81.3,
22,
6.1,
58.9,
26.8,
33.9,
21.7,
53.2,
90.6,
80.1,
31.7,
70.9,
26.6,
93.1,
83.8,
36,
66.9,
62.4,
29.6,
12.8,
86.2,
98.9,
44.4,
93.6,
29.6,
16.6,
93.6,
84,
65.1,
51.3,
21.2,
96,
78.2,
52.1,
81.1,
76.3,
61.8,
22.7,
27.9,
24.8,
64.7,
43.6,
23.4,
16.9,
57.7,
82.1,
34.7,
68.3,
35.9,
67.5,
54,
74,
15.9,
69.1,
11.1,
44.3,
41.3,
5.3,
91.3,
82.8,
29,
49.1,
78.9,
46.9,
40,
80.4,
96.9,
25.4,
31.3,
77.6,
9,
99.8,
81.9,
62.9,
52,
83.3,
17.2,
51.8,
76.1,
51,
0,
4.2,
81.9,
54.1,
76.8,
59.1,
72.8,
45,
55.8,
49.8,
54,
48.7,
88.9,
56.5,
88.5,
52.9,
12.8,
44.9,
86.6,
97.3,
16,
71.9,
89.7,
53.1,
95.4,
75.6,
81.4,
28.2,
31.4,
67.1,
53.6,
3,
58.3,
71.7,
33.4,
70.7,
39.6,
40.6,
62.7,
59.4,
10,
84.3,
60.3,
17.9,
57.1,
27.2,
75.3,
91,
74.2,
58.6,
56,
34.6,
81.4,
43.1,
72.1,
73.7,
33,
41.3,
38.3,
86.1,
43.8,
48.1,
32.2,
91.7,
81.8,
88.5,
89.9,
34.1,
31.9,
58,
2.6,
51,
27.3,
61.9,
64.5,
84.5,
10,
47.6,
87.9,
50,
67.5,
32.5,
79.6,
63.2,
35.7,
80.1,
36.6,
31.7,
55,
77.4,
50,
74.7,
34.2,
49.3,
64.6,
64.2,
64.1,
12.4,
52.3,
57.6,
85.6,
34.3,
92.3,
76.4,
77.7,
91.8,
71.6,
9.7,
65.9,
0,
70.1,
72.9,
70.1,
25.7,
66.6,
92.1,
64.3,
7.1,
56.3,
56,
63.1,
64,
56.5,
56.4,
75.1,
71.2,
42.9,
46.3,
40.2,
64.1,
74.4,
70.8,
52.4,
84.1,
40.5,
29.4,
53.9,
89,
54.8,
42.4,
17.8,
74,
64,
85.7,
83.9,
26.2,
55.6,
41.2,
77.9,
72.9,
21.4,
74.8,
77.1,
34.9,
58.4,
51.1,
82.6,
25.7,
43.7,
35,
59.2,
78,
73.4,
83.4,
49.2,
40.7,
68.7,
59.2,
41.7,
21.1,
39.8,
95.8,
59,
70.9,
28.7,
69.5,
96.3,
48.8,
97.9,
96.5,
86,
43.4,
9.5,
48.2,
88.6,
36.9,
65.1,
27.9,
99.6,
33.5,
35.7,
40,
0,
37.6,
11.1,
42.8,
80.8,
54.4,
95.8,
33.2,
6.3,
48,
75.9,
40.6,
39.3,
73.4,
40.3,
19.8,
81.4,
49.3,
10.7,
40,
65.7,
31.4,
0,
62.9,
63,
59.9,
63.5,
38.9,
71.5,
28,
50.2,
92.9,
71.4,
83.1,
12.6,
44,
54.9,
61.6,
37.5,
87.8,
77.3,
92.6,
31.9,
85.7,
88.3,
30.3,
54.7,
40.4,
18.5,
73.7,
43.1,
80.6,
72.3,
31.2,
22.8,
4.4,
60.9,
72,
25.7,
20.6,
57.8,
39.8,
30.8,
63.2,
95.7,
61.4,
66.7,
62.7,
50.2,
40.9,
53.9,
41.6,
85.6,
31.3,
36,
20.3,
68.3,
38.4,
53,
8.9,
58.4,
47.4,
48.8,
6.5,
59.5,
58.9,
59.3,
81.7,
74.8,
54.1,
73.6,
26,
81.2,
54.8,
77.3,
76.6,
78.6,
78,
71,
75.5,
56,
46.7,
60.4,
50,
46.6,
49.6,
83.2,
20.7,
75,
94.9,
40.2,
24.7,
6.3,
94.9,
83,
70,
42.9,
86.3,
74,
85.6,
77.1,
69.4,
39.9,
72.5,
72.5,
16.1,
33.3,
70.5,
23.1,
58.4,
42.2,
27,
13.2,
22.1,
70.5,
53.4,
38.6,
88.4,
95.1,
45,
28.2,
53.1,
76.7,
83.6,
43.7,
68.2,
53.7,
31.6,
0,
61.3,
76.1,
74.8,
35.8,
25.3,
98.1,
84.7,
83.8,
14.9,
67,
85.3,
61,
38.2,
72.1,
71,
83.5,
84.6,
72.3,
85.5,
51.1,
36.9,
48.3,
72.6,
93.1,
49.7,
70.1,
72.7,
3.5,
63.2,
37.6,
21.5,
6,
57.6,
69.2,
73.6,
47.6,
27.4,
61.6,
49.8,
74.1,
42.4,
44.7,
89.6,
67.5,
41.5,
71.5,
43.8,
70,
29.1,
79.1,
23.7,
74.3,
93.3,
34,
61.1,
57.5,
51.1,
29.3,
60.6,
40,
86.3,
60,
50.5,
50.9,
76.4,
43.1,
68,
21.2,
47.8,
44.8,
15,
29,
88,
44.4,
81.8,
78.2,
64.3,
39.7,
71.4,
49.4,
82.5,
7.5,
46.7,
45.6,
63.1,
58.3,
91.3,
78,
23.8,
70.7,
6.1,
12.6,
56,
41.2,
28.3,
36.1,
74.9,
71.5,
36,
77.3,
30.8,
80.6,
67.1,
91.5,
58.2,
51.5,
41.6,
13,
53.6,
58,
76,
13.6,
93.4,
100.5,
70.5,
31.4,
35.4,
75.5,
16.8,
64.6,
77.1,
51.3,
68.7,
93.8,
28.8,
41.6,
29.4,
58.8,
18.8,
91.1,
74.7,
36.4,
45.3,
59.9,
14.1,
81.5,
49,
83.4,
62.2,
90.9,
33.5,
31,
45.2,
61.6,
81.4,
92.7,
26.6,
43.9,
84.6,
17.8,
61.8,
49.3,
4,
65.8,
32.2,
78,
40.3,
64.4,
50.4,
70,
89.5,
54.3,
0,
27.6,
73,
40,
45.6,
50.5,
62.7,
84.9,
21.6,
29.5,
92.1,
93.6,
61.8,
3.8,
72.7,
28,
76.4,
84.3,
70.2,
72.4,
29.3,
54.1,
84.4,
50.4,
60.1,
0,
52.8,
0,
63,
39.3,
41.4,
40.9,
79.1,
29.4,
72.4,
91.9,
44.9,
70.6,
26.9,
40.5,
73.9,
71.6,
2.5,
79.9,
22,
47.2,
35.2,
66.2,
56.7,
28.9,
31,
49.4,
70.7,
71.1,
58.3,
19.1,
58,
50.1,
66.8,
80,
23.5,
32,
23.5,
33.5,
10.8,
33,
63.5,
33.5,
20.4,
81,
66.4,
45.6,
63,
59.1,
44,
72.6,
70,
65,
45.1,
69.2,
100.7,
41.7,
49.3,
49.9,
61,
79.9,
36.9,
98.3,
88,
14.8,
48.1,
1.8,
61,
32.2,
63.5,
17.1,
8.1,
68.9,
50.3,
58,
2.3,
79.8,
85.1,
45.6,
74,
20,
45.5,
79.7,
60.4,
62.7,
78.1,
26.1,
43.7,
71.1,
30.3,
52.6,
66,
56.2,
54.2,
54.2,
0.9,
50.4,
51.1,
77.2,
71.6,
79.3,
32.1,
52.6,
90.3,
44.8,
63.1,
80.3,
35.6,
66.7,
57.8,
69.6,
67.6,
40,
55.9,
35,
65.7,
53.6,
43,
9.2,
76.2,
64.6,
62.5,
77.7,
5.3,
49.4,
66.8,
58.1,
67.1,
72,
18.7,
26.8,
50.9,
88.1,
64.1,
77.8,
30.8,
83.2,
29.3,
55.8,
66.9,
77.2,
48.1,
44.9,
26.7,
47.1,
18.4,
32,
50.6,
63,
49.9,
78.5,
67.3,
88.8,
60.1,
94.9,
74.3,
50.3,
53.8,
21,
54.8,
21.7,
68.4,
33.7,
60.6,
79,
65.6,
56.8,
50.8,
88.2,
32.7,
54.1,
26.9,
26,
43.6,
66.5,
35.3,
43.2,
61.4,
39.9,
55,
35.3,
39.5,
51,
40.5,
78.2,
0,
51.5,
51.7,
89.3,
28.4,
23.9,
46.9,
29.2,
29.7,
17.9,
0,
55,
40,
77.1,
42.3,
47,
32.7,
76.9,
71.1,
59.1,
59.6,
27.4,
68.3,
17.6,
61.7,
75,
57.6,
55.5,
59.2,
50.3,
45.5,
55.4,
69.9,
52.5,
54.7,
48.2,
76.8,
83.2,
40.9,
87.7,
39.5,
68.7,
52.3,
72,
17.1,
39.5,
55.2,
48.8,
64.3,
95.7,
41.1,
52.1,
39.5,
79.3,
89.2,
68.8,
20.8,
90.6,
43.5,
31.3,
37.5,
70.6,
68.4,
47.1,
77,
60.6,
43.6,
50,
0,
84,
22,
50.5,
49.3,
72.8,
33.3,
23.2,
6.5,
60.4,
50.8,
31.8,
36.3,
77.4,
49,
40.2,
29,
37.1,
0,
76.7,
49.8,
79.2,
85,
41,
54.8,
100.2,
51.2,
63.1,
66.5,
35.3,
39.1,
35.9,
15.2,
58.8,
32.1,
95.2,
54.7,
69.3,
13.1,
3.5,
84.6,
38.8,
50.7,
1.5,
46,
11.2,
65.6,
84.4,
97.1,
47.7,
35.3,
81,
21.7,
40.9,
44.9,
63.4,
82.8,
33.9,
53.9,
40.1,
null,
96.2,
75.4,
7.5,
38.5,
7.7,
16.1,
37.1,
31.1,
46.7,
46.9,
95.6,
44,
24.8,
79.7,
61.9,
29.3,
65,
46.7,
70.8,
56.2,
18,
37.7,
55,
64.5,
39.6,
22.2,
72.2,
29.7,
49.2,
19.4,
65,
13,
11.6,
1.9,
30,
13.5,
80.5,
48.6,
104.6,
48.4,
55.7,
49.2,
59.8,
58.6,
46,
76.9,
26.8,
0,
43.5,
68.3,
46.9,
22.5,
90,
90.3,
50.1,
36.1,
99.8,
82.4,
97.8,
80.6,
78.8,
64.9,
66.7,
28.7,
22.3,
53.8,
72.3,
6.4,
34.7,
26.4,
48.4,
85.1,
48.5,
79.4,
80.8,
57.5,
67.8,
87.7,
55.9,
95.4,
31.7,
47,
60,
77,
99.5,
57.7,
76.6,
49.5,
58,
59.3,
69.4,
57.2,
67.8,
64.2,
38.8,
11.4,
65,
16.2,
13.1,
79.2,
37.8,
62.2,
89.4,
86.7,
81.8,
8.9,
15.7,
29,
25.8,
36.5,
82.8,
32.3,
70,
33.8,
18.8,
90.1,
73,
56.4,
23.6,
70.6,
53.4,
60.3,
84,
23.4,
47.6,
38.3,
20,
54.3,
61.2,
77.2,
65.4,
48.8,
56.2,
51.3,
70.3,
74,
39.5,
58.4,
77.6,
66.7,
34.5,
21.7,
61.4,
55.1,
89.3,
58.1,
59.9,
22.7,
64.9,
26.4,
12.3,
61.1,
44.5,
63.6,
18.6,
77,
98.8,
60.3,
53.3,
26.4,
46.6,
65.9,
89.7,
80.3,
61.9,
90.7,
36.6,
49.8,
15.7,
78.2,
45.2,
54.7,
74,
22.9,
68.8,
38.4,
88.8,
74.7,
33.8,
72.4,
72,
56.1,
42.7,
43.8,
54.4,
89.4,
32.9,
53.4,
40,
65.6,
52.7,
60.1,
87.5,
70.4,
28.5,
49,
79.3,
49.9,
83.8,
61.3,
57.1,
62.1,
39.9,
82,
50.9,
93,
74.3,
35.4,
52.9,
14.5,
87,
88,
49.9,
48.6,
31.3,
87.2,
63.3,
74.8,
85.4,
27.7,
79.9,
58,
24.6,
85.5,
33.6,
72.8,
70.5,
60.6,
63,
29.4,
100.9,
31.2,
37.8,
37.1,
42.8,
56.5,
72.6,
52.3,
35.8,
74.5,
53.1,
40.3,
5.2,
83.9,
53.1,
74,
67.5,
48,
7.9,
55.8,
32.8,
23.9,
78.4,
35.6,
84.6,
81.1,
39.7,
72.9,
63.2,
49.8,
47.4,
49.7,
46.7,
84.1,
20.4,
61.2,
60.4,
59,
83.5,
24.8,
85.9,
8.9,
48.6,
50.2,
66.7,
45,
24.7,
39,
50,
23.3,
25,
13,
61,
92.8,
32.8,
70.5,
97.2,
0.4,
91.7,
79.5,
52.2,
46.3,
73.1,
64.8,
47.8,
52.4,
39,
71,
54.2,
50.1,
46.5,
75.1,
69.3,
64.3,
38.9,
48.7,
70.5,
33.3,
66.2,
24.5,
41.7,
81.4,
53.4,
54.4,
74,
4,
58.6,
37,
68.2,
48.7,
46.2,
85.2,
37.6,
46.9,
96.9,
70.3,
62.8,
90.3,
49.1,
34.3,
89.6,
72.6,
56.7,
82,
50.1,
19.3,
58.7,
12.1,
33.6,
93.3,
58.7,
94.9,
94.8,
90,
92,
49.8,
96.6,
90.7,
54.6,
47.6,
65.4,
69.8,
39,
1.3,
71.9,
40.8,
15.2,
46.5,
79.6,
72.9,
0,
49.4,
55.1,
10,
34.7,
41.3,
49.1,
87.6,
45.2,
80.1,
63.2,
91,
33.3,
36.1,
49.5,
69.7,
95,
66.5,
34.8,
77.4,
33.1,
4,
72.1,
16.5,
19.2,
34.6,
61.5,
16.1,
68.5,
16.9,
30.5,
35.4,
42,
53.9,
12.8,
84.3,
91,
67.4,
50,
88.6,
50.3,
8,
82,
75.2,
95.5,
45.8,
12.3,
71,
68,
63.9,
64.8,
68.4,
14,
31.4,
7.8,
74.1,
77.4,
53.6,
49.6,
38.5,
64.5,
54.2,
48.9,
93.4,
66.8,
87.4,
82.1,
27.3,
97.6,
54.8,
9.6,
4.9,
88,
81.8,
34.4,
50.2,
57.7,
70.1,
49.2,
46.5,
62.1,
41,
25.9,
103.3,
73.3,
12.8,
0.3,
49.7,
52,
59.7,
35.7,
5.5,
21.5,
51,
93.7,
27.9,
82.6,
46.7,
10.7,
35.6,
48.2,
53.8,
77.8,
56.3,
45.1,
80.3,
74,
85.9,
78.7,
26,
81.5,
19.1,
53.7,
88.4,
70.6,
41.3,
72.8,
61.8,
92.3,
20.5,
67.3,
48.3,
56.2,
35.2,
61.5,
29.2,
70.9,
89.5,
36.1,
86.2,
48.7,
80.1,
28.3,
33.3,
51.6,
55.2,
24.7,
67.6,
54.4,
69.5,
0.8,
67.4,
78.6,
74.1,
73.9,
60.2,
21.8,
51.9,
45.3,
94.9,
81.4,
18.1,
63.9,
92.3,
34.5,
61.4,
71.1,
37.4,
25.4,
95.5,
89.4,
22.6,
61.5,
70.9,
94.2,
95.1,
58.9,
72.8,
32,
89.4,
75.7,
42.1,
21.7,
77.8,
43.2,
86.9,
85.3,
62.7,
40.3,
6.2,
22.5,
38.9,
62,
68.4,
93,
42.7,
23.6,
91,
21.5,
51.2,
41.6,
22,
76.9,
83.4,
80.1,
49.3,
72,
71.6,
70.1,
59.8,
55.8,
53.9,
68.3,
27.3,
10.1,
97.1,
51.6,
62.1,
67,
65,
73.2,
82.2,
53.2,
113.5,
80.9,
2.9,
36.4,
43.7,
66.7,
85.4,
47.9,
59.4,
46.5,
84,
78.8,
56.3,
52.6,
77.4,
64.6,
46.2,
96.1,
9.5,
51.5,
42.8,
50.6,
76.1,
80.2,
58.2,
61.1,
39.7,
59.1,
85.8,
81.1,
51.4,
88.4,
68,
58.7,
36.6,
33.9,
42.3,
12.9,
53.8,
62.5,
72.5,
48.5,
96.7,
10.1,
85.7,
57.7,
28.9,
17,
87,
36.8,
81.8,
67.5,
13.7,
28.3,
45.7,
59.2,
31.7,
55.2,
43,
59.9,
35.7,
72,
48.1,
26,
44.2,
88.5,
95,
85.9,
76.1,
48.4,
52.7,
38.7,
79.5,
88.8,
29.1,
40.8,
82.3,
80.7,
46.8,
73.7,
72.2,
49.8,
48,
30.8,
61.5,
48.6,
26.4,
28.9,
62.8,
64.6,
13.4,
89.1,
11.9,
51.3,
40,
95.8,
42.2,
20.1,
51.9,
83.2,
50.5,
60.9,
35.3,
34.3,
66.3,
54.1,
58.8,
61.4,
68.6,
32.6,
34,
27,
94.1,
36.7,
57.6,
19.9,
32.4,
41.5,
45.2,
48.5,
64.6,
55.3,
58.9,
53.2,
17.1,
61.2,
38.2,
13.9,
33.1,
75.1,
54.9,
65.6,
55.8,
76.8,
55.9,
55.7,
32.8,
30.6,
29.1,
45.9,
73.5,
57.8,
61.2,
44.8,
64,
60.2,
75.1,
65.9,
19.6,
55.2,
89.9,
39.6,
23.5,
11.4,
69.2,
87.2,
56.6,
84.6,
23.2,
60.3,
52.3,
58.7,
6.7,
74.9,
88.8,
85.3,
77.6,
70,
65.5,
52.6,
75,
41.8,
88.5,
34.3,
86.5,
78.3,
4.1,
93.1,
59.2,
21.1,
90,
24.3,
15.4,
66.5,
66.6,
74.5,
88.1,
71.9,
85,
55.1,
84.3,
42.1,
27.2,
48.3,
1.1,
84.5,
68.8,
71.7,
30.6,
55.3,
52.8,
31.7,
82.6,
46.6,
41.6,
4.1,
83.2,
43.9,
34.5,
60.4,
40.3,
71.1,
69.2,
57.5,
48.7,
46,
48.8,
78.1,
31.9,
73.4,
75.3,
48.3,
72.7,
98.8,
16.9,
86.3,
55,
82.4,
24.1,
55,
20.8,
93.2,
75.6,
69,
65.2,
7.4,
62.8,
22,
52.8,
66.2,
52.2,
83.7,
32.1,
71.2,
79.7,
83,
76.2,
37,
54.2,
17.7,
79.2,
44.7,
53.1,
53.3,
47.8,
39,
73.3,
31.2,
3.6,
21.5,
45.8,
83.1,
92.8,
84.1,
94.3,
79.5,
47.2,
29.6,
13.3,
75.1,
10.1,
8.8,
67,
66.8,
65.7,
55.2,
83.6,
38.3,
81.4,
91.7,
50.4,
30,
53.3,
97.9,
75.7,
83,
62.3,
40.5,
63.7,
80.1,
64.6,
3.7,
46.6,
25,
89.6,
56.5,
64.2,
62.3,
51.5,
65.3,
68.8,
68.2,
5.2,
63.2,
31.9,
61.5,
50.3,
19.2,
73.7,
21.2,
36.1,
19.4,
80.5,
24.2,
63.6,
78.1,
71.1,
44.2,
82.7,
53.8,
27.2,
89,
65.7,
47.8,
71.9,
38.2,
91.8,
83.3,
38.4,
0.5,
20.3,
56.9,
95.6,
86.4,
71.2,
61.8,
81.9,
75.8,
48,
47.7,
88,
34.1,
55.8,
47.7,
28,
62.6,
87.3,
71.6,
79.1,
49.9,
68.6,
20.8,
22.1,
64,
40,
53.6,
81.6,
18.3,
49.3,
28.4,
30.5,
69.3,
19.1,
58.8,
36,
82,
19.9,
74.4,
46.9,
52.1,
56.6,
32.5,
82.4,
22.8,
56.3,
15.8,
74.5,
70.1,
57.4,
37,
54.2,
17.4,
51.3,
71.9,
80.6,
50.7,
47.4,
76.8,
37.6,
66,
19.5,
90.2,
58.2,
83.4,
29.9,
17,
72,
82.3,
49.7,
94.8,
81.5,
37.8,
60.1,
66.4,
3,
41.5,
80.9,
63.7,
37.8,
53.7,
79.4,
65.2,
73.7,
27,
50.5,
22.4,
70.1,
52.7,
32.6,
57.5,
50.3,
77.8,
92.6,
47,
62.7,
71.3,
57.2,
70.2,
93.8,
54.8,
41.8,
39.5,
82.5,
38.7,
69.9,
48.5,
29.1,
34.1,
77.6,
30.2,
62.9,
15.6,
63.1,
56.4,
76.6,
87.5,
90.9,
36.4,
46.7,
5,
65.1,
23,
75.5,
89.6,
62.5,
83.3,
1,
32.4,
79.1,
63.8,
64.5,
33.8,
45.8,
3.3,
93,
70.9,
29.2,
39.8,
81.4,
89.5,
87.7,
68.6,
32.8,
53.9,
33,
53.9,
70.1,
37.7,
40.8,
10.1,
90.6,
47.7,
76.8,
9.6,
54.1,
51.9,
48.2,
64,
86.4,
64.5,
65.1,
92.1,
62.4,
75.1,
46,
78.2,
55.7,
23,
81.7,
51.1,
78.4,
28.3,
31,
26.7,
32.1,
42.2,
95.9,
72,
97,
93,
49.4,
28.3,
69.5,
61.2,
12.5,
86.8,
28.1,
85.7,
97.3,
75.4,
96.9,
76.2,
92.1,
78,
57.1,
12.3,
33.7,
51,
70.8,
72,
12.6,
12.2,
55.4,
0.3,
51.7,
34.2,
66.6,
81.3,
46.8,
51.2,
95.6,
32.4,
49.9,
83.7,
17.1,
89.6,
100.2,
42.2,
74.6,
61,
62.2,
68.2,
54.1,
86.2,
66.1,
37.4,
41.4,
38.2,
83.4,
100.1,
44,
21.1,
18.4,
38,
48.5,
56.3,
85.5,
22.6,
14.8,
90.7,
52.2,
74.4,
87.2,
78.1,
95.6,
73.1,
6.6,
75.2,
93.8,
68,
75.9,
67,
55,
45.5,
83.3,
62.2,
84.7,
66.4,
42.4,
85.2,
38,
42.4,
40.3,
63.6,
82.7,
80.7,
37,
67.8,
67.4,
57,
70.1,
52.4,
75.8,
75.5,
93.2,
66.7,
26.7,
53,
17.1,
2.9,
62.7,
74.6,
35.7,
58.3,
49.7,
79.5,
71.5,
86.7,
58.7,
91.9,
6.3,
83.9,
48.5,
76.6,
84.4,
78.1,
76.3,
57.6,
16,
82,
58.4,
73.6,
73.9,
82.3,
57.6,
15.1,
31.6,
22.2,
50.5,
28.1,
35.1,
52.5,
58,
0,
52.9,
73.1,
87.8,
60.4,
10,
4,
45.4,
42.9,
21.9,
8.3,
10.5,
59.3,
23.9,
36,
54.7,
27.6,
38.6,
19.3,
41.6,
38.5,
55.1,
88.7,
25.4,
49.1,
67.1,
80.4,
95,
48.6,
50.8,
61.4,
42.3,
38.4,
11.1,
27.9,
49.5,
61.1,
70.1,
52.6,
42,
89.7,
60.6,
79,
44.4,
82.1,
36.6,
92.1,
69.1,
41.7,
55,
49.8,
70,
83.4,
81.7,
62,
38.8,
68.3,
82.6,
45.1,
94.6,
89.8,
81.8,
72.6,
49.9,
83.2,
84,
83.3,
48.4,
68.4,
54.3,
24.8,
53,
60.8,
44.3,
92.8,
29.4,
22.8,
34.6,
33.1,
93.7,
23,
92.3,
54.9,
95.8,
69.5,
92.9,
5.3,
46.5,
38.1,
39.8,
81.9,
55.6,
88.7,
19.8,
72,
64,
66.2,
20.9,
76,
48.8,
57.5,
93.2,
70.7,
89.9,
52,
7.7,
52.7,
69.2,
35.6,
59.4,
78.3,
64.2,
43.2,
1.3,
43,
52.3,
49.9,
23.2,
39.2,
86.2,
62.6,
72.9,
57.6,
94.3,
61.8,
29.2,
58,
68,
53.7,
62.9,
80.1,
6.3,
30.8,
42.2,
72,
86.2,
81.9,
45.8,
41,
79.7,
38.5,
29.4,
54.4,
37.1,
38.8,
73.7,
29.6,
12,
82.6,
15.8,
46.3,
77.3,
17.6,
16.2,
92,
56,
72.6,
63.6,
27.2,
84.9,
48.3,
22.5,
61,
87.6,
96.5,
92.4,
27,
50.8,
67.1,
57.3,
68.7,
79.9,
73,
28.3,
37.5,
54.9,
75.7,
17.8,
62.7,
73.6,
77.4,
86.9,
29.6,
62.5,
0.2,
68,
36.3,
52.1,
55.6,
70.8,
29.6,
25.6,
44.8,
63.2,
40.3,
51.9,
45.5,
83.4,
2.1,
91.1,
39.1,
61.6,
60.3,
70.9,
74.4,
4.3,
26.4,
46.5,
30.2,
71.4,
47.7,
25.1,
47.1,
66.5,
83.5,
22.4,
48.6,
57,
7.4,
77.5,
36.5,
82,
90.2,
90.9,
22.9,
64.9,
40.2,
8.2,
47.7,
69.2,
91.3,
76.7,
62.8,
81.1,
85.6,
33,
60.4,
28,
36.4,
33.8,
66.8,
46.6,
14.8,
46,
59.5,
42.8,
35.8,
16.7,
26,
3.4,
52.2,
37.1,
22.2,
23.7,
66.4,
8.6,
10.5,
32.9,
87.2,
40,
83.8,
79.7,
44.8,
28.7,
58.3,
52.2,
59,
7,
15.3,
19.8,
49,
92.2,
73.3,
97.7,
17,
60.3,
38.4,
68,
57.7,
11.1,
48.6,
34.8,
67.1,
75,
27.9,
49.3,
48.9,
76,
79.6,
62.4,
77.4,
26,
59.2,
53.3,
35.4,
18.2,
73.9,
42.8,
66.6,
89.8,
59.1,
48.4,
51.5,
38.5,
39.8,
94.3,
86.1,
84.5,
63.3,
52.8,
31.2,
36.6,
70.3,
54.1,
0.2,
20.6,
89,
54.6,
68.9,
18.2,
84.9,
55.3,
94.7,
61.1,
74.3,
56.6,
66,
30,
67.6,
87.6,
60.6,
25.7,
77.6,
72.4,
78.1,
60,
65.4,
78,
34.4,
66.7,
33.3,
29.5,
7.7,
52.2,
80.9,
83.8,
88.1,
45.9,
94,
91.2,
38.5,
33.8,
40.9,
77.9,
83.9,
80.4,
68,
74.2,
63.7,
52.1,
91.8,
53.9,
41.5,
26.3,
31.7,
53.7,
96.5,
63.4,
25.9,
74.7,
98.7,
98.7,
31.9,
77.8,
37.2,
30.7,
9.5,
30.2,
40.3,
84.2,
54.4,
83.6,
62.1,
90.6,
76.7,
25.2,
76.5,
66,
35.9,
27.7,
90.7,
74.3,
44.8,
87.7,
71.9,
60.9,
3.7,
99.7,
68.7,
78.5,
95.4,
28.6,
65.3,
78.1,
81.4,
81.7,
70.5,
64.7,
76.2,
34.2,
59.7,
66,
43.6,
45.3,
45.2,
55.9,
5.9,
32.6,
73.1,
48.2,
81.4,
51.8,
63.6,
64,
48.3,
43.1,
72.5,
38.9,
64.1,
43.7,
18.3,
34.4,
90.2,
91,
48.5,
92.4,
33.4,
58.7,
66.7,
78.3,
52.2,
82.8,
30.8,
71.1,
26.2,
52.2,
56,
79.1,
18.7,
47.3,
36.8,
26.5,
66.8,
80.4,
31.9,
71.7,
80.3,
66.6,
83.4,
49.2,
33.3,
53.5,
23.7,
84.5,
49.9,
11,
68.9,
41.1,
88,
40,
49.4,
7.6,
75,
65.2,
52,
39,
48.2,
44.2,
58.3,
46.6,
76,
75.6,
87.8,
25.9,
48,
40.4,
43.2,
8.6,
70.2,
64.7,
39.4,
46.9,
70.3,
79.9,
85.6,
72.9,
45.3,
58.2,
58.9,
32.9,
67.9,
58.6,
41.4,
34.2,
43.7,
10.6,
59.9,
52.4,
32,
45.8,
19.6,
27,
90.6,
96.8,
52.9,
36.2,
45.4,
27,
0,
41.8,
64.2,
43.1,
46.4,
70.6,
51.1,
36.7,
31.3,
63.3,
38.1,
82.5,
56.8,
38.1,
78.2,
78,
78,
68.3,
71.3,
61.2,
71.1,
20.7,
80.6,
87.5,
38,
54.5,
44.4,
99.6,
32.8,
63.4,
10.6,
70.7,
66,
27.8,
69.5,
65.4,
64.3,
76.5,
41.7,
65.1,
65.3,
39.1,
61.4,
98.5,
57.2,
43.1,
72.5,
45.4,
75.9,
21.3,
75,
24.3,
72.5,
27.2,
50.9,
31.3,
52.8,
34.8,
30.2,
67.2,
59.7,
85.7,
51.2,
72.5,
40.6,
41.8,
50.3,
67.8,
18,
83.9,
54.8,
60.9,
49.5,
83,
3.9,
63.1,
87.2,
86.1,
54.6,
72.4,
40.9,
16.3,
79.5,
11.5,
54.8,
70,
0,
98.7,
49.8,
40.3,
23.9,
50.9,
84.3,
67.8,
35.7,
67.5,
43.5,
37,
74.1,
86.4,
71.6,
3.6,
79.4,
11.5,
42.2,
43.8,
47.6,
50.2,
79.5,
56.2,
85.8,
46.1,
14.8,
48.9,
51.7,
73.6,
35.7,
24.5,
51.2,
66.2,
42.8,
73.9,
81.9,
31.3,
51.4,
51.8,
36.2,
30.4,
67.7,
69.3,
63,
45.3,
45,
20.6,
46.1,
33.7,
23.6,
48.5,
97.4,
65.4,
72.2,
90,
63.1,
50.4,
57.7,
8.7,
79.4,
44.8,
61.5,
26.9,
51.5,
69.7,
51.4,
62,
42,
0,
83.9,
85.2,
53.9,
19.7,
31.1,
17.5,
10.9,
58.7,
36.9,
91.8,
67.4,
66.7,
3,
97,
71,
47.6,
43,
71.2,
2.7,
62.5,
95.1,
59.1,
45.7,
83.1,
41.5,
54.8,
45.3,
6.2,
19.1,
47.4,
38.2,
50.9,
43.1,
65.8,
32,
49.2,
4.8,
62.6,
30.9,
50.7,
32,
97.1,
31.3,
84,
74.5,
71.4,
74.5,
69.7,
59.2,
69.9,
73,
71.2,
100.3,
49,
100.8,
77.3,
0.7,
47,
1.8,
76.6,
17.9,
32.9,
51.3,
56,
88.8,
32.3,
29,
45.3,
62,
48.4,
66.3,
23.2,
56.3,
59.9,
64.4,
5.4,
56.2,
19.7,
54.4,
51.8,
28.5,
36.6,
89.1,
86.1,
21.8,
81.8,
46.4,
99.5,
85.1,
74.2,
69.1,
58,
38.8,
86.7,
97.4,
51.5,
67.6,
53.5,
88,
50.2,
27.8,
58.2,
65.9,
57.6,
2,
77.6,
55.7,
47.6,
63.3,
69.8,
40.1,
24.2,
59.7,
38.9,
77,
60.5,
7.1,
77,
14.7,
44.3,
83.6,
63.5,
90.8,
59.8,
24.2,
51.8,
48.7,
76,
54.8,
53.6,
25.1,
61.9,
87.5,
62,
79.8,
108.1,
15.9,
64.3,
51.6,
80,
31.6,
37.7,
66.4,
62.5,
94.6,
90.2,
16.7,
45.7,
61.3,
96.4,
98.3,
87.4,
52,
64.1,
70.6,
60.9,
31.1,
37,
80,
30.9,
70.4,
5,
51.8,
88,
24.8,
59.5,
75.1,
49,
84.1,
44.4,
78.3,
26.6,
83.5,
63.5,
14.4,
39.7,
18.6,
67.9,
87.4,
40.9,
46.7,
69.8,
52.1,
82.4,
37.7,
43.3,
51.7,
69.5,
61.1,
58.9,
21.4,
16,
68.4,
41.8,
12.7,
35.8,
62,
60.7,
71.1,
34,
79.5,
55.8,
86.3,
75.2,
78.5,
33.2,
97.1,
15.6,
15.2,
90.1,
56.1,
55.3,
85.9,
72.7,
37.8,
86.2,
84.8,
55.5,
52.3,
62.5,
38.8,
42.5,
66.3,
58.9,
0,
36.9,
45.8,
63.9,
33.7,
66.2,
53.2,
59,
24.2,
70.6,
25.8,
46.3,
6.2,
67.2,
76.7,
36.9,
55,
6.6,
63.9,
83.3,
67.2,
21.5,
69.4,
67.7,
88.6,
34.6,
76.7,
11.2,
46.7,
72.2,
20.2,
38.3,
57,
64.3,
7.5,
55.2,
98.2,
45.8,
58.9,
29.8,
89.4,
30.5,
39,
55.9,
56.3,
59.8,
56.1,
76.9,
57,
11.4,
85.2,
26.7,
79.8,
71,
76.4,
22.1,
64.6,
70,
41.4,
54,
49.4,
66.8,
28.1,
37.8,
60.1,
66.7,
89.7,
86.2,
71.6,
47.4,
69.1,
80.3,
89.4,
69.6,
71.9,
90.2,
91.4,
75,
64.4,
45.1,
75,
49.3,
56.4,
61.4,
32.3,
32.1,
74.6,
86.3,
11.9,
48.1,
95.9,
72.9,
49.9,
59.8,
59.2,
76.5,
69.8,
22.1,
89.3,
58.6,
53.1,
53.2,
85.3,
56,
56.7,
40.6,
28.4,
95.7,
88.4,
84.6,
100.4,
11.3,
19.6,
14.2,
45.2,
65,
14.9,
53.2,
92,
72.8,
39.4,
30.8,
25.1,
75.7,
30,
41.1,
36.3,
54.6,
48.7,
97.2,
79.1,
34.2,
82.9,
50.6,
60,
97.6,
80.7,
25.2,
55.4,
19.6,
53.2,
36.5,
33.3,
7.8,
52.9,
10.3,
70.6,
78.1,
75.2,
60.7,
57.5,
80.1,
60.5,
51.2,
45.2,
25.3,
85.6,
78.4,
60.6,
88.5,
61.7,
64.7,
9.6,
25.1,
38.1,
99.5,
56.3,
10.1,
16.2,
44.9,
95.9,
46.2,
78.6,
70.2,
28.4,
62.8,
73.8,
37.6,
68,
85.9,
88,
90.2,
37,
39.5,
77.5,
89.6,
78.6,
53.8,
65.6,
75.6,
92.2,
26.5,
55.1,
25,
94.4,
64.6,
63.1,
40.6,
53.9,
70.2,
66.7,
88.2,
68,
57.8,
9.5,
86.5,
24.7,
98.5,
78.5,
89.6,
62.1,
13.6,
28.1,
78.1,
57.7,
39.9,
62.5,
40.5,
77.4,
87.5,
25.3,
39,
56,
76.6,
90.9,
11.5,
76,
38.3,
73.8,
48.5,
92,
49.9,
7.8,
99.9,
40.2,
61.3,
52.3,
42.1,
97.1,
39.1,
80.5,
35.2,
30.3,
51.4,
27.5,
64.9,
97.3,
56.9,
31.9,
87.9,
51,
48.6,
52.8,
53.5,
23.8,
44,
28.5,
52.4,
52.5,
20,
64,
74.5,
92,
29.7,
82.5,
44.1,
66.6,
5.1,
61.9,
70.3,
58.3,
81.4,
61.1,
78.4,
67.5,
25.3,
57.7,
54.4,
70.8,
82.8,
69.6,
86.9,
32.6,
67.4,
82.8,
31.4,
39.2,
66.8,
33.8,
96.8,
42.5,
32.4,
44.8,
58.8,
71.3,
74.1,
55.7,
43.5,
69.9,
63.7,
54.7,
38.9,
95.7,
44.3,
56.2,
49.4,
43.2,
68.9,
4.8,
48.3,
16.7,
93.9,
52.9,
82.4,
38.2,
46.1,
46.6,
8.5,
48.3,
53.2,
51.1,
15.5,
25.5,
81.9,
95.4,
47.6,
54.9,
64.8,
80.9,
61.2,
62.8,
63.5,
34,
21.1,
87.4,
75.1,
77.4,
56.7,
67.8,
51.5,
13.2,
35.9,
87.3,
53,
47.2,
37,
77.5,
85.6,
58.5,
23.7,
47.4,
31.6,
79.4,
44,
34.9,
38.2,
2.3,
73,
88,
58.6,
43.2,
38.8,
50,
26.6,
74.4,
74.4,
36.3,
61.4,
76.9,
54.4,
83.3,
53,
79.8,
21.4,
96.4,
58,
99.1,
61.7,
62,
23,
92.1,
30.9,
79.5,
39.8,
41.7,
48,
67.9,
92.2,
43.8,
68.7,
32.4,
91,
16.3,
74.8,
80,
22,
75,
34.4,
82,
41.4,
66.2,
54.6,
63.3,
31.2,
16.5,
68.3,
73,
46.4,
34,
82.8,
39,
95.3,
50.2,
96,
60,
77.1,
48.9,
99.3,
4,
61.3,
35.9,
47.6,
21.5,
10.6,
58.9,
34,
43.6,
59.8,
58.5,
12.9,
72.8,
73.9,
87,
76.5,
41.8,
45.2,
46.3,
96.2,
88.7,
64.4,
8.2,
53.5,
46.3,
69.4,
58,
66.5,
71.1,
44.8,
17.2,
83.2,
116.1,
61,
5.4,
65.7,
55,
63.6,
18.4,
21.7,
20.5,
70.8,
1.4,
89.6,
63.3,
83.5,
45.2,
20.9,
18.4,
73.1,
24.9,
97.5,
51.1,
3.6,
19.8,
6.8,
36.7,
89.1,
49.7,
48,
31.2,
65.7,
24.5,
52,
57.8,
73.4,
71.7,
62.2,
77.7,
62.6,
54.2,
31.3,
65,
29,
53.8,
71.1,
49.2,
32.9,
4.6,
56.3,
22.8,
61.7,
50.5,
64.5,
49.4,
91.3,
65.3,
71.8,
47,
37.7,
70.7,
58,
27.4,
31,
43.5,
20.9,
30.6,
52.5,
60.2,
55.7,
53.9,
76.7,
47.8,
32,
75.9,
96.9,
68.9,
91.1,
67.1,
74.5,
17.7,
61.5,
73.5,
57.5,
27,
48.9,
47.3,
82.9,
63.2,
76.6,
56.3,
69.1,
35.3,
87.5,
47.9,
44.1,
77.8,
47.9,
70.4,
32.5,
12.6,
72.9,
72.2,
93.4,
24.3,
28,
43.7,
75.6,
38.7,
84.6,
72.3,
50.8,
84.3,
86.1,
50.4,
94,
29.1,
23,
48,
37.3,
65.1,
6.2,
35.9,
39.6,
44.3,
89.2,
9,
29.9,
78,
96.7,
84,
99.4,
51.3,
85.6,
49.7,
44.1,
68.4,
56.3,
82.7,
98.9,
94.9,
56.7,
8.1,
59,
72.7,
53.7,
88.3,
40.6,
63.9,
0.4,
74.2,
90,
41.2,
96.5,
29.3,
42.2,
65.9,
99.6,
77.8,
28.8,
89.2,
72.3,
67.6,
52.3,
49.9,
74.3,
66.2,
37.8,
33.6,
35.6,
21.3,
86.1,
18.7,
65.4,
49.8,
43.7,
40.4,
0.3,
41.9,
31.5,
90.6,
50.5,
85,
23.7,
73.4,
7.9,
48.9,
28.3,
33.4,
87.5,
52.6,
43,
85.6,
37.6,
88.7,
82,
14.3,
74.8,
68.8,
53.6,
19.4,
83.9,
54.8,
88.4,
46.4,
72.1,
57.3,
60.7,
64.6,
57,
76.1,
40.4,
27,
55.1,
50.7,
53.4,
73.7,
45.9,
23,
22.4,
22,
28.8,
48.9,
42.8,
54.1,
43.8,
35.5,
65.2,
42,
98.7,
56.9,
33.2,
67.3,
76.1,
49.3,
28.7,
80.5,
68.8,
57.2,
58.8,
0,
73.3,
84.8,
47.6,
72.2,
50.1,
22.8,
25.6,
85.5,
42.9,
61.6,
25.7,
77.4,
57,
50.8,
47.2,
77.1,
89.4,
59.2,
49.8,
96.2,
82.7,
27.5,
68.2,
23.1,
86.3,
51.4,
55.6,
53.4,
46.2,
72.6,
81.9,
52.9,
62.4,
87.8,
92.7,
44.6,
67.6,
37.2,
74.1,
66.2,
88.8,
23.3,
35.1,
96.8,
48.1,
35.7,
69.3,
31,
15.3,
89.5,
52.8,
80.2,
38.2,
23.7,
52.7,
77.2,
6.2,
45.8,
52.9,
61.1,
60.6,
95.7,
78.2,
79,
2.1,
56,
93.3,
11.5,
94.6,
22.8,
50,
88,
12.1,
38,
10.4,
93.1,
64.7,
59.6,
52.4,
52,
58.3,
25.7,
1.1,
72.1,
67.6,
50.7,
65.4,
13.5,
61.4,
46.2,
45.4,
74.7,
43.4,
67.8,
68.8,
4.1,
83.9,
42.2,
33.2,
55.3,
62.9,
77.8,
12.8,
24.2,
39.9,
71.4,
13.5,
59.5,
6.8,
45.4,
61,
41.4,
80.1,
54.1,
60.1,
47.8,
28.1,
23.5,
22,
68.8,
29.1,
50.8,
40.5,
86.8,
24.6,
44.5,
76.6,
53.4,
28.6,
69.6,
92.5,
39,
51.8,
25.2,
58.8,
57.2,
70.8,
100,
44.9,
54.4,
44.2,
90.8,
82.3,
72.1,
50.4,
62.3,
34.7,
41.5,
99.6,
79.3,
24.9,
81.6,
83.3,
39.2,
0,
72.3,
56.8,
93.9,
92.7,
84.1,
21.5,
80,
57.2,
30.2,
35.7,
57,
45.6,
59.8,
38.4,
56.3,
84,
76.2,
73.9,
34.9,
44.8,
86.8,
21.4,
80.6,
75.4,
61.6,
71.9,
26.1,
46.4,
56.7,
72.7,
41.1,
41.7,
14.2,
35.3,
24.2,
73.7,
35.5,
39.2,
50.2,
67.4,
43.1,
40.3,
88.4,
5.1,
46.5,
80.6,
59.6,
63.5,
47,
30.6,
45.2,
60.3,
78.7,
58.5,
39.1,
56.2,
24.3,
82.8,
38.4,
62.5,
61.2,
48.6,
78.7,
39.9,
61.1,
69.1,
40.5,
28.5,
102.1,
55.2,
50,
74.8,
46.5,
54,
33.8,
86.9,
64.4,
93.6,
35.8,
93.2,
28.5,
56.7,
73.4,
44.2,
33.5,
43.4,
76.3,
17.1,
21.5,
42.2,
50.3,
77.4,
54.1,
10.3,
71.5,
62.3,
13,
26.7,
101.6,
57,
58.6,
2.5,
87.3,
44.5,
83.5,
37.9,
41.9,
74.3,
33.2,
73,
60.3,
61.4,
15.9,
72.9,
49.4,
13.4,
44.6,
40.3,
69,
6.6,
17.6,
45.6,
81.6,
25.1,
85.3,
89.3,
57.9,
27.6,
45.5,
98.7,
62.6,
26.3,
70,
21.9,
47.3,
97,
94.4,
50.8,
61.9,
80.8,
45.5,
92,
31.8,
84,
41.7,
62,
65.9,
45,
20.4,
28.2,
80.7,
61.7,
15.1,
47.7,
68.2,
34.4,
64.5,
31.4,
47.9,
52.9,
12.8,
54.8,
89.5,
23.9,
1.9,
100,
39.2,
55.9,
84.1,
80.7,
55.7,
26.8,
4.3,
47.4,
52.4,
79.4,
79.8,
44,
70,
52.2,
40.7,
42,
26,
56.1,
55.9,
65.3,
18.7,
35.8,
49.2,
89.6,
86.4,
27.7,
61,
54,
74.7,
95.4,
68.1,
79.5,
87.9,
50.3,
96.2,
55,
20.3,
21.1,
82,
32.1,
4.7,
85.8,
45.2,
76.6,
67,
74.3,
26.9,
75.7,
71.4,
81.3,
70.5,
57.2,
93.7,
48.9,
29.7,
1.1,
38.9,
88.2,
83.1,
23.1,
61.1,
27.6,
69.7,
39,
29.7,
57.9,
74.4,
79,
56,
71.8,
47.9,
71.5,
72.8,
32.1,
55.8,
87.8,
71.8,
30.5,
57.9,
15.5,
47.1,
21.6,
51.2,
75.2,
66.5,
57.4,
69.6,
24.6,
27.3,
63.1,
72,
48.6,
79.9,
45.8,
38.6,
55.6,
80.6,
35.2,
85,
92.5,
10.7,
14.5,
76.3,
87.6,
86.9,
47.8,
28.4,
54.9,
47.2,
52.9,
28.9,
73.1,
97.2,
55,
68.3,
87.4,
32.5,
52,
47.5,
26,
44.9,
29.2,
39.2,
48,
54.2,
51.6,
77.5,
44.3,
2.7,
12.8,
41.9,
61.7,
40.2,
26.8,
65.5,
49.5,
58.5,
83,
75.9,
26.5,
62.4,
39,
74.8,
37.1,
91.8,
35.3,
15.1,
13.3,
25.6,
47.9,
16.4,
40.9,
19.8,
19.7,
59.5,
38.4,
79.1,
37,
68.2,
0,
60.7,
59.8,
74,
33.7,
49.5,
78.9,
67.2,
57.5,
48.2,
57.6,
40.6,
0,
63,
54.4,
39.2,
13,
70.2,
29.7,
27.3,
30.8,
46,
79,
73.4,
23.8,
73,
61.6,
44.7,
55.1,
46.1,
70.1,
49.9,
32.3,
45.6,
41.5,
26.5,
67.2,
44.2,
47.8,
98,
45.9,
52,
72.4,
82.8,
52.3,
52.8,
43.5,
49,
30.3,
69.9,
11.5,
44.1,
64.1,
56.8,
36.6,
87.9,
67.8,
64,
77.5,
32.3,
85.5,
82,
82.3,
64.1,
40.7,
49.8,
86.2,
81.8,
39.6,
78.4,
77.6,
47.4,
51,
95,
58.8,
49.9,
95.8,
21.8,
49,
85.5,
39,
47.8,
30.1,
82.8,
91.8,
69.7,
91.1,
69.6,
63.5,
40.7,
55.5,
32.5,
48.6,
16.7,
59.7,
67,
51,
94.8,
22.7,
94.5,
67,
93.3,
55,
43.8,
77.2,
11.6,
41.6,
57.5,
36.3,
46.6,
56.8,
49.2,
48.5,
20,
69.6,
38.9,
50.8,
75.5,
74.3,
79.4,
22.2,
56.5,
37.2,
53.6,
51.5,
39.1,
37.9,
88,
83.4,
84.1,
53.5,
10,
55.2,
66.6,
81.4,
33.6,
80,
61.4,
72.1,
46.4,
78.4,
42.8,
81.2,
43.6,
71.5,
64.3,
40.9,
32.9,
66,
93.6,
70.4,
83.5,
51.2,
2.9,
33.2,
99.2,
66.4,
73.5,
76,
17,
40,
3.3,
45.8,
28,
40.6,
28,
45.2,
68.3,
30.2,
88.6,
15.9,
56.7,
28.8,
28.9,
89.7,
19.7,
0,
35.6,
41.6,
52.1,
57.9,
28.8,
54.7,
75.9,
75.2,
83.1,
75,
98.5,
96.8,
38.2,
18.1,
47.7,
67.3,
45,
70.9,
79.5,
48.2,
74.5,
81.2,
48.7,
58.7,
72.4,
43.6,
64.1,
11.6,
81.9,
83.2,
68.8,
80.2,
50.8,
26.9,
76.8,
56.7,
16.6,
74.4,
54.8,
82,
72,
47.1,
21.2,
71.9,
29.3,
68.5,
43.4,
86.5,
81.3,
2.7,
19.5,
4.5,
67,
62.5,
15.7,
56.1,
64,
97.3,
59.6,
0,
77.5,
71.5,
100.2,
98.7,
96.1,
90.8,
84.9,
48.6,
89.4,
56.7,
94.9,
95.3,
85.3,
4,
74.4,
2,
18.8,
53.2,
79,
35.8,
60.9,
61.6,
26.4,
36.3,
35.8,
29.6,
67.1,
61.9,
39.6,
80.3,
0,
53,
67.6,
70.8,
65,
59.8,
71.4,
99.9,
89.8,
73.3,
65.3,
71,
75.2,
64.6,
30.3,
38.3,
60.3,
4.1,
29.8,
50.1,
89.8,
46.8,
75,
97.4,
7,
89.7,
65,
54.1,
46.6,
37,
81.3,
47.8,
40.7,
88.3,
31,
47.6,
83.4,
93.4,
65.5,
26.3,
58.9,
35.8,
76.1,
40.1,
61.7,
27.4,
84.8,
70.8,
37.5,
63.9,
65.8,
36,
66.7,
85.1,
78.2,
47.3,
38.3,
72.4,
88.4,
64.8,
82.8,
98.3,
70.2,
54.8,
95.8,
56.1,
48,
63.1,
53.7,
0.3,
61.3,
21,
57.2,
89.4,
46.1,
39.9,
34.5,
54.4,
91.8,
85.5,
48,
64.5,
37,
89.3,
67.2,
39.6,
39.6,
63.2,
97.1,
49.2,
64.2,
61.2,
67.9,
56.6,
78.2,
92.8,
49.5,
87.5,
93.4,
85.5,
67.2,
13.9,
48.4,
71.5,
63.5,
57.6,
34.3,
92.6,
96,
39.4,
92.6,
47.5,
45.8,
69.2,
41.2,
62.5,
71.3,
30,
65.5,
8.1,
52.7,
73.8,
49,
52.3,
36.5,
81.6,
47.7,
86.1,
93.1,
60,
32,
27.9,
31.5,
54.8,
42.5,
101,
67.9,
20.3,
37.2,
69.3,
54.3,
67.1,
92.5,
84.5,
83.6,
82.3,
32.9,
64.7,
24.5,
37.4,
75.7,
61.3,
17.7,
78,
58.9,
48,
39.1,
29.7,
48,
53.3,
52.2,
62.4,
42.9,
6.7,
85.9,
14,
36.5,
39,
54.1,
28,
70.7,
82.4,
84.9,
25,
73.9,
67.7,
46.2,
58.3,
54.5,
24.7,
12.7,
51.1,
42.3,
67.9,
27.8,
63.4,
41.3,
48.3,
84.2,
65,
48.6,
53.3,
66.7,
60.4,
68.8,
67.8,
87.3,
81.3,
64.4,
44,
21.4,
38.9,
37,
42.7,
79.2,
42.8,
18.5,
91.4,
17.2,
56.7,
69.7,
41.1,
31,
34.6,
55.5,
43.1,
74.1,
55.7,
21.5,
66.3,
30.8,
94.7,
79.1,
3.2,
80.3,
85.5,
81.3,
63.6,
38.9,
71.8,
10.2,
25.6,
37.9,
13.4,
16.8,
88.3,
57.6,
83,
43.6,
19.5,
64.6,
51.5,
40.4,
36.3,
77.9,
54.5,
71.4,
68.1,
72.9,
35.4,
52.2,
63,
33.1,
78.8,
73.7,
19.3,
45.5,
52,
62.4,
23.8,
65,
48.5,
46.4,
58.9,
70.7,
82.5,
2,
86.1,
50,
90.7,
45.3,
83.5,
95.2,
60.6,
21.2,
99,
68.5,
66,
66.7,
47.4,
71.3,
89,
58.8,
17.7,
41.3,
57,
46.3,
4.5,
63.1,
54.7,
49.5,
67.2,
47.8,
34.6,
60,
38.7,
13,
46.5,
46.4,
74.1,
44.4,
27.1,
51.5,
47.9,
8.5,
79.9,
46.8,
93.7,
70.8,
93.1,
69.6,
62.7,
87.3,
96.5,
97.9,
81.6,
57.8,
33.6,
26.5,
85.1,
19.4,
84.9,
86.3,
75.4,
22.6,
53.7,
47.5,
71.2,
30.8,
15,
45.5,
62.2,
54.8,
39.9,
51.9,
23,
52,
54.5,
44.3,
77.6,
53.6,
40.5,
47.4,
46.4,
30.2,
61.8,
35.5,
10.6,
58.3,
65,
40.2,
59.5,
40,
63.1,
47.1,
60.7,
61.5,
5.3,
97.5,
59.9,
96.8,
46.4,
96.5,
64.3,
20,
26.3,
73.1,
29.2,
81.4,
80.8,
54.2,
49.2,
55.3,
64.5,
30.5,
61.3,
40.3,
56.1,
79.5,
20.2,
9.6,
50.3,
83,
4.4,
85.2,
36,
74.6,
22.4,
100,
89.1,
57.2,
54.9,
76.8,
39.9,
82.4,
0.1,
51,
81.4,
10.5,
68.9,
12.7,
48.6,
81.4,
40.5,
63.2,
76.6,
77.2,
0.3,
48.6,
38.9,
22.3,
25.5,
68.3,
82.8,
17.4,
36.6,
52.6,
72.3,
33.7,
86.6,
68.3,
59.8,
16.7,
86.1,
54.9,
83.4,
39.6,
72.2,
15.4,
44.1,
51.7,
89,
54.9,
49.6,
89.7,
77,
59,
78.1,
39.4,
35.2,
54.1,
46.8,
53.9,
74,
79.2,
63.8,
59.3,
48.6,
91.2,
34.2,
91.6,
96.2,
66.4,
41.6,
59.4,
11.8,
40.2,
50.1,
68.5,
22.1,
71,
78,
18.7,
93.8,
54,
42.2,
96.1,
85.5,
49.4,
31.9,
85.6,
66.3,
65.3,
39,
79.8,
61.9,
98.7,
29.7,
36.7,
52.3,
43.7,
46.6,
13.1,
63.5,
72.1,
56.2,
75.5,
30.3,
81.5,
95.6,
53.6,
26.1,
86,
18.7,
74.8,
83.9,
40.5,
6,
0.5,
21.8,
85.1,
65.4,
39.7,
89.8,
56.5,
26.6,
36.4,
48.4,
94.9,
59.4,
48.4,
65.4,
28.6,
59,
40.6,
56.2,
57.9,
98.3,
77.8,
48.4,
23.5,
80.2,
7.7,
80,
29.5,
35.9,
35.8,
19.9,
67,
79.9,
12.4,
51.2,
61.2,
48.2,
88.5,
76.8,
57,
86.2,
9.6,
56.6,
84.5,
64.1,
49.6,
42.9,
37.4,
93,
21.1,
63.6,
69.9,
41.3,
53.1,
41.6,
60.6,
77.3,
60.2,
67.6,
43.8,
27.7,
59.5,
74.9,
79.9,
55.9,
29.2,
34.2,
98.1,
66.7,
66.7,
70.6,
26.6,
46.1,
90.1,
30,
36.3,
59,
70.2,
36.4,
93.8,
73.5,
65.6,
52.3,
42.2,
52.2,
36.7,
67.2,
63.8,
67.7,
29.9,
53.1,
81.5,
22.4,
26.8,
83.7,
39.1,
44.9,
56.8,
28.2,
47.9,
94.9,
42,
61.8,
33.4,
34.2,
87.7,
34.6,
68,
5.6,
37.1,
47.9,
11.4,
40.7,
50.2,
21.4,
62.8,
69,
48.8,
30,
80.8,
0,
67.5,
79.3,
80.6,
57.4,
31.6,
93.2,
94.1,
37.4,
75.5,
25.9,
39.6,
57.6,
43.3,
57.6,
46.3,
49.2,
43.8,
24,
62,
27.4,
17.7,
50,
22,
59.8,
35.6,
63.3,
40.6,
59.9,
52.6,
45.1,
46,
50.2,
98.4,
58.2,
34.2,
69.4,
44.3,
54.7,
62.3,
53,
99.3,
78.5,
8.7,
53.6,
81.5,
6.4,
80.4,
21.4,
87.2,
1.7,
10,
70.5,
53.3,
66.9,
80,
83.2,
24.1,
87.1,
32.6,
59.4,
72.8,
70,
18.3,
75.1,
66.8,
85.7,
87.1,
44.7,
63.8,
0.5,
51.9,
43.2,
29.6,
15.6,
68.8,
92.2,
86.2,
69.9,
37.8,
94.5,
69.5,
88.1,
71.4,
30.2,
62.5,
57.7,
62.1,
67.4,
37.1,
67.7,
54,
75.8,
100,
73.9,
11.3,
34.3,
79.3,
88.5,
24.6,
70.3,
32.3,
65.3,
81.5,
25.4,
26.6,
69,
22.1,
82.5,
77.9,
6.8,
27.7,
23.2,
58.7,
null,
18.8,
49.3,
47.7,
33.3,
19.7,
48.3,
49.9,
58.7,
32.7,
74.9,
88.2,
32.9,
73,
74.5,
56.8,
76.1,
68.8,
64.1,
24.6,
45.3,
30.2,
38.8,
32.2,
50.9,
50,
38,
80.7,
36.6,
60.4,
97,
27.7,
41.7,
58.3,
68.7,
92,
56.8,
15.5,
41.4,
29.6,
35.2,
79.1,
59.5,
13.8,
41.3,
42.5,
16.7,
88.1,
56.9,
10.9,
55,
54.1,
29.7,
80.7,
59.1,
73.1,
72.4,
88.5,
24.4,
80.8,
35.9,
94.4,
40.4,
71.2,
37.9,
68.3,
53.4,
84.5,
69.4,
42.7,
31.4,
67.6,
38.7,
26.1,
51.7,
40.1,
11.9,
81.8,
77.4,
21,
23.9,
35.5,
58.7,
82.4,
38.5,
39.7,
65.7,
62.9,
41.3,
50.7,
61.7,
62,
11.7,
47.1,
70.4,
87.3,
87.1,
76.3,
80.2,
47.4,
17.9,
43.3,
10.7,
70.3,
28.2,
82,
22.9,
22.4,
48.2,
59.3,
20.2,
92.7,
76.4,
59.6,
24.9,
39.6,
42.9,
80.8,
41.5,
0.2,
51.5,
3.4,
67,
98.7,
15.4,
35.3,
70.7,
69.3,
58.6,
88.2,
44.1,
57.5,
38.4,
26.5,
46.6,
50.4,
61.5,
83.5,
42.9,
55.7,
8.3,
43.7,
18.8,
68.6,
48.1,
63.2,
44,
98.7,
38.8,
50.7,
72.7,
96.8,
69.1,
61.9,
70.1,
72.9,
59.5,
63,
78.3,
60.8,
84.2,
60.1,
7.4,
62.2,
55.7,
66,
82.1,
66.5,
39.3,
69.6,
70.6,
50.4,
50.8,
25.3,
83.1,
56.4,
1.3,
98.3,
21.4,
87,
92,
97.1,
53.2,
87.2,
14.4,
36.7,
34,
62.2,
35,
44.9,
57,
25,
69.2,
57,
63.6,
70.3,
43,
45.1,
8.7,
97.1,
16.5,
30.9,
28.7,
23.2,
17.4,
27.2,
40,
39.1,
43.2,
58.1,
55.4,
75,
75.2,
59,
62.4,
52.9,
60.9,
40.5,
93,
53,
72,
67.8,
53.9,
85.2,
33.1,
77.1,
11,
88.7,
58.8,
56.5,
71.4,
53.9,
42.7,
51,
73.8,
31.1,
41.6,
37.5,
57.2,
65.6,
25.5,
91,
77.8,
73.7,
91.2,
19.7,
96.9,
44,
50.4,
97.6,
81.2,
52,
90.3,
6.7,
54.7,
25.7,
58.6,
41,
66.3,
99.3,
24.2,
61.1,
17.3,
49.6,
30.7,
38.7,
49.1,
45.6,
45.1,
83.6,
50.2,
32.5,
90,
48.6,
52.8,
48.6,
46.6,
67.5,
66.6,
20.8,
35.3,
42.2,
49.4,
56.9,
30.2,
83,
41.9,
73.9,
44.1,
42.3,
26.3,
73.4,
7.7,
104.1,
22.5,
88.6,
60.2,
99.6,
37,
12.7,
24.6,
27.1,
35.5,
54.5,
83.1,
18.6,
60.5,
73.8,
55.8,
71.9,
43.4,
33.1,
94.4,
56.9,
62,
76.5,
53.4,
75.1,
104.5,
83.5,
54.1,
74.5,
48.6,
8.5,
62.2,
63.5,
51.3,
35.9,
83.8,
77.5,
18.6,
19.1,
52.2,
69.1,
56.7,
78.7,
59.1,
57.2,
70.4,
42.5,
63.9,
73.3,
26.9,
83.4,
29.1,
23.2,
77.6,
32.5,
61.5,
97.2,
66.5,
81.2,
23.8,
48.7,
51,
65,
73.2,
31.4,
65.1,
49.9,
15.8,
82,
86.2,
39.4,
39.8,
64.6,
11,
44.9,
69.3,
87.8,
41.6,
70.9,
77.1,
30.7,
50.2,
37.7,
87,
44.7,
83.2,
82,
37.7,
57,
74.2,
36.8,
77,
43.6,
26.4,
40.7,
19.7,
22.3,
67.1,
67.8,
60,
22.1,
10.5,
69.1,
38.6,
31,
20.9,
42.1,
69.2,
77.5,
31.9,
69.8,
80.4,
50,
41.8,
61,
78.3,
22,
35.6,
15.6,
2.9,
69.1,
43.9,
69.7,
51,
72.2,
56,
85.4,
39,
13.4,
58.7,
46.7,
24.1,
31.9,
66.1,
82.5,
94.1,
67.1,
20.6,
34.5,
73,
26,
82.2,
37.9,
89.6,
28.1,
50.6,
55.5,
16.4,
6.3,
67.2,
19.4,
98.5,
60.5,
43,
40.5,
51.3,
79.4,
54.3,
27,
26.3,
77.1,
60.4,
49.5,
76,
72.8,
53.4,
11.5,
61.3,
72.9,
29.6,
54.3,
76,
29.2,
57.7,
65.8,
65.2,
36.6,
43.3,
41.1,
43.8,
74.5,
49,
71.3,
18.6,
63.2,
78.8,
53.5,
52.9,
34.9,
33.6,
59.9,
38.5,
43.9,
44,
56,
32.3,
88.9,
59.1,
8,
99.6,
23.9,
99.2,
54.7,
8.4,
89.1,
84.1,
71.7,
68.1,
101.8,
62.4,
79.8,
55,
79.2,
63.7,
48.1,
69,
70,
2.9,
47.3,
44.1,
9,
27.1,
62.4,
77.6,
59.3,
66.9,
62.2,
92.8,
44.4,
40.1,
42.7,
12.5,
50.9,
47.2,
27.2,
53,
43.8,
42.6,
80.8,
80.8,
63.6,
28.5,
9.1,
46.1,
40.9,
82.5,
3.6,
36.5,
67.3,
69.3,
51.4,
40.6,
87.7,
8.2,
51.5,
80.8,
71.7,
37.6,
26.6,
45.6,
38.9,
53.8,
41.6,
51.2,
68.4,
51,
16.3,
57.2,
43,
51.7,
60.5,
81.3,
52.4,
43,
61,
84.7,
65.4,
51.1,
69.6,
46,
16.8,
68.8,
95.7,
21.8,
91.4,
51.6,
62.1,
71.5,
17.4,
24.8,
87.5,
88.6,
75,
59.1,
48.5,
99.1,
38.4,
41.3,
69.8,
25.7,
48.7,
51.4,
68.1,
41.5,
49.5,
44,
24.4,
35.6,
67.1,
36.6,
68.4,
72.2,
73.9,
80,
70.1,
61.3,
77,
62.2,
51.1,
79.4,
46.8,
17,
69.5,
58.9,
8.8,
13,
8.6,
58.4,
62.1,
82.5,
48.9,
89.2,
59.2,
26.5,
66,
58.3,
19.2,
88.5,
8.7,
21.5,
67.2,
91.8,
42.1,
32.3,
80.3,
81.5,
67.5,
65.5,
65.9,
39.7,
67.6,
59.5,
70.1,
41.7,
81,
26.6,
55,
90.7,
51.1,
53.1,
70.5,
22.4,
77.3,
17.8,
54.3,
32.7,
41.4,
10.2,
42,
24.6,
79.8,
59.5,
73,
42.9,
53.2,
59.9,
31,
51.7,
66.6,
71.5,
99.1,
47,
96.8,
40.5,
88,
53.8,
55.7,
40.7,
7.1,
53,
45.1,
85.5,
80.7,
50.1,
20.6,
33.9,
58.6,
54.2,
58.5,
82.9,
28.4,
39.8,
39.2,
2.9,
83.3,
57.5,
80.3,
42.1,
51.7,
68.7,
52,
65.4,
51.8,
52.7,
92.6,
44.7,
61.5,
28.2,
91.5,
32.9,
69,
34.1,
27.2,
47,
0,
37.9,
19,
93.2,
76.4,
94.5,
91.4,
43.3,
30.5,
21.6,
77.3,
55.5,
48.5,
46.9,
74.2,
25.4,
75.9,
61.4,
9.5,
32.6,
92.1,
85.5,
19.3,
66.2,
63.8,
10,
95.2,
51,
77.4,
70,
54.2,
45.9,
35.9,
60.4,
36.6,
27,
78.7,
55,
60.3,
79,
28.3,
10.9,
11.4,
47.7,
71.9,
73.6,
49.2,
74.8,
78.8,
15.1,
80.8,
42.7,
26.7,
77.7,
null,
52.6,
87.8,
84.5,
83.6,
25.3,
40.7,
42.2,
58.9,
12.7,
2.4,
76.2,
77.7,
69.3,
70.5,
32.6,
35.5,
4.5,
54.6,
10.5,
41.6,
58.2,
35.7,
78.7,
27.9,
89.6,
0,
55.6,
8.6,
49.1,
91.3,
70.7,
82.5,
43.9,
65.7,
35.7,
42.2,
34.3,
14.4,
47.9,
50.6,
53.3,
86.3,
59.7,
34.7,
54.2,
38,
16.7,
32,
75.9,
24.9,
49.3,
61.7,
39.2,
59.9,
90,
81.4,
11.2,
21.2,
96,
61.9,
28.1,
74.2,
85,
32,
19.6,
51.4,
43.6,
58.7,
1.4,
33,
18.7,
69.7,
45.3,
68.8,
89.3,
47.8,
48.5,
51.1,
44.9,
62,
87.2,
66.4,
60.1,
21.5,
44,
45.4,
71.1,
35.8,
36.8,
55.8,
50.7,
61.3,
46,
45.6,
80,
44.3,
57.3,
50.1,
52.5,
74.9,
60.9,
16,
96.1,
67.9,
55.9,
57.6,
37.1,
81.1,
70.4,
66.4,
89.1,
39.5,
0,
77,
44.4,
4,
45.8,
23.7,
22.7,
95.6,
72,
51.4,
22.2,
36.6,
60.3,
5.4,
32.7,
40,
58.4,
80.4,
61.3,
95.5,
40,
77.2,
17.5,
77.4,
61.5,
59.5,
73.3,
40.4,
49.4,
75.4,
33,
15.1,
14,
73.9,
34.6,
92.4,
43.7,
45.2,
39.6,
34.3,
30.4,
54.9,
83.7,
40.8,
94.3,
66.5,
78.1,
39.1,
74.8,
24.7,
17.9,
13,
26.3,
73.7,
67.4,
68.7,
30.5,
66.6,
64.6,
56.9,
36.6,
56.1,
7.4,
62.9,
93.4,
96.5,
54,
55.8,
10.3,
66.7,
76,
91.9,
43.9,
66.2,
76.8,
44.4,
86.2,
23.4,
92.3,
47,
19.7,
73.6,
30.5,
12.3,
74.2,
7.7,
64.3,
43,
78.1,
11.5,
95.5,
50.7,
55.9,
24.4,
49.9,
62,
34.5,
91,
57.1,
22.9,
67.7,
86.4,
89.5,
45.5,
97.9,
52,
40.2,
53,
23.9,
77,
38,
10.8,
87.3,
41.3,
85.2,
53.7,
81.9,
77.8,
58.2,
27,
14.9,
77.3,
26.8,
57.7,
0.2,
58.4,
67,
40.1,
51,
33.6,
97.3,
60.5,
81.4,
84.9,
38.3,
47,
22.5,
52.3,
47.2,
50,
53,
39,
68.5,
10.3,
39.5,
45.2,
25.8,
30,
67.9,
33.7,
11.3,
71.5,
79.7,
91.3,
64.1,
13.4,
67.4,
23.1,
83.8,
36.7,
49.2,
23,
20.1,
47.7,
36,
15,
34.9,
88.2,
53.5,
70.2,
61.4,
58.5,
16.8,
18.5,
10.4,
31.8,
17,
64.6,
26.7,
49.5,
90.5,
61,
84.7,
89.2,
56.7,
93.7,
53.1,
65,
85.3,
79.9,
87.6,
54.2,
90.9,
60.8,
45.6,
81,
12.7,
47.9,
48.2,
42.6,
30.8,
27.4,
94.5,
36.4,
56.2,
65.1,
67.4,
83.8,
28,
27.9,
49.2,
99.9,
61,
99.4,
60.4,
63.1,
68.2,
43.4,
0,
84.8,
29.6,
91,
78.3,
31.5,
76.6,
31,
100.3,
40.4,
34.1,
60.7,
62.6,
70.8,
70.7,
21.2,
6,
77.2,
35.4,
23.8,
60.9,
21.6,
13.5,
64.5,
46,
46.8,
41.9,
85.2,
17.3,
71.4,
63.3,
80.1,
69.2,
56,
40.7,
87.9,
43.8,
91.3,
11.8,
86.4,
29.4,
36.6,
58.1,
79.7,
49.1,
38.2,
74.7,
42.7,
47.4,
68.1,
63.5,
73.7,
97.9,
49.9,
99.3,
81.6,
36.4,
78.4,
96.6,
75.1,
41.6,
43.1,
49.5,
80.3,
75.5,
74,
34.1,
51.3,
56.2,
38.8,
67.9,
27,
49.3,
85.9,
58.7,
40.2,
49.3,
34.2,
82.7,
81.6,
76.6,
53.6,
65.5,
71.6,
24.3,
28.5,
82.9,
48.5,
37.6,
52.4,
90.9,
37.7,
49.1,
54,
16.4,
59.7,
14.7,
30.2,
68,
53.3,
68.8,
50.4,
86.8,
23.5,
35.8,
59.8,
44.2,
43,
98.4,
81.6,
41.4,
92.4,
66.9,
62.3,
54.6,
42,
22.9,
21.3,
42.9,
44.9,
94.6,
74.5,
21.4,
73.8,
10.9,
66,
54.1,
47.5,
94.3,
50.7,
74.3,
49.2,
48.6,
43.9,
94.1,
51.1,
48.2,
77.5,
60.69,
99.3,
42,
64.1,
25.1,
47.1,
56,
42.7,
27.3,
29.1,
65.8,
51.8,
76.2,
75.3,
49.4,
15.4,
68.5,
85.8,
39.1,
40.6,
27.3,
70.8,
29.2,
45.6,
90.6,
71.6,
86.2,
20.1,
54.2,
90.2,
20.3,
26.8,
44.4,
60.1,
93.4,
23.8,
54.4,
72.8,
91.8,
65.7,
38.5,
65.1,
15.6,
77,
39.4,
101.8,
66.6,
40.7,
43.1,
92.5,
59.7,
62.1,
8.1,
21.4,
64.4,
62.5,
75.5,
22.3,
62,
70.4,
83.8,
19.6,
20.6,
56.2,
62.1,
11.5,
29.4,
55,
21.9,
53.8,
65.2,
85.6,
35.1,
83,
69.3,
30.2,
67.2,
95.5,
15.7,
37.4,
75.6,
83.2,
32.9,
81,
15.9,
12,
32.8,
42.4,
67.3,
43.2,
53.9,
97.5,
63.9,
67.7,
83.3,
67.6,
43.3,
54.4,
72.7,
31,
69.8,
53.6,
84,
58.7,
89.3,
19.5,
50,
84.1,
58.4,
65.6,
83.9,
48.3,
45,
47,
33,
56.5,
27.5,
52.5,
51.8,
98.9,
48.9,
28.6,
77.4,
65.7,
38.8,
39.5,
30.2,
46.4,
86.2,
63,
56.4,
60.5,
79.6,
55.1,
37.3,
82,
78.1,
52.5,
62,
80,
59,
73.6,
59.5,
36.2,
47.7,
37.7,
17.8,
40.6,
52.9,
12,
16.2,
50,
45.4,
41.6,
56.4,
92.7,
58.2,
51.2,
45.5,
68.1,
71,
13.7,
85.8,
64.4,
34.1,
85.7,
72.5,
6.9,
34.9,
63.7,
42.6,
16.3,
82.2,
83.5,
8.4,
55.1,
89.8,
78,
20.5,
0,
67.2,
67.5,
77.1,
23.2,
30,
64.7,
62.9,
0,
23,
48.5,
89.7,
79.3,
35.4,
39.2,
59.7,
11.3,
37.1,
51,
90.6,
69.1,
32.6,
97.3,
4.7,
46.7,
65.4,
38,
73.9,
91.4,
42.4,
32.3,
101.8,
59.4,
62.1,
3.3,
75.5,
20.4,
50.8,
16.8,
26.2,
46.8,
72.2,
90.8,
15.8,
47.1,
79.3,
49,
72.4,
74.2,
52,
33,
40.7,
71.5,
19.8,
44.9,
24.7,
82.2,
73.4,
43.2,
22.9,
80.9,
13.7,
71.9,
7.8,
44.2,
52.9,
67.5,
50,
58.3,
45,
42.5,
87.1,
64.3,
23.5,
26.9,
91.5,
63.9,
67.4,
50,
79.1,
4.5,
66.2,
68,
39.5,
31.4,
96.2,
27.9,
91.5,
96.9,
31.1,
89.9,
55.8,
27,
63.4,
72.4,
17.7,
59.1,
20.5,
60.3,
54.1,
46.5,
45.5,
44.6,
71.1,
73,
80.3,
64.6,
41.3,
70.8,
48.1,
72,
53.4,
44.6,
92.9,
34.5,
53,
40.4,
18.6,
24.8,
52.5,
62,
58.4,
88.5,
55.5,
54.5,
54.8,
52.1,
47,
18,
69,
63.5,
54.7,
23.6,
61.6,
81.7,
44.1,
46.6,
62.9,
66.1,
47.1,
43.6,
31.2,
22,
88,
0.4,
23.9,
36.3,
48.9,
80.3,
32.9,
43.9,
92.6,
86.3,
59.8,
87.5,
44.4,
90,
82.4,
89.6,
32.5,
92.4,
72.3,
33.8,
39.2,
29.6,
50.4,
101.3,
57.9,
56,
47.5,
61.2,
70.1,
91.5,
41.9,
97.1,
78.5,
11.3,
52.7,
43.4,
83.7,
73.9,
80.4,
49.6,
89.3,
88.7,
42.2,
58.2,
8.3,
80.2,
20.2,
49,
66.9,
77.9,
24.5,
22.7,
65.2,
63.5,
93.2,
65.8,
41.2,
51.4,
40.2,
75.1,
47.7,
70.5,
54.1,
83.3,
57.7,
75.7,
67,
33.9,
38.7,
84.1,
23.6,
30.4,
15.7,
47,
68.7,
54.5,
59.3,
13.5,
4.9,
68.3,
42.1,
38.2,
87.9,
70.5,
51.4,
36.4,
86.6,
89.6,
100.5,
65.6,
68.6,
53.1,
89.3,
46,
68.4,
44.4,
84,
82.8,
49.4,
37.9,
41.3,
81,
64.5,
39.3,
88.7,
49.6,
6.3,
51.8,
68,
52.6,
63.6,
87.9,
48,
58.5,
85.4,
70.8,
63.9,
77.8,
89.4,
42.3,
80.9,
90.1,
12.5,
45.7,
16,
43.9,
35.3,
15.2,
38.9,
46,
75.8,
73.5,
48,
65.8,
48,
61.4,
58.7,
56.8,
54.8,
77.8,
57.6,
25,
70.7,
89.6,
66.4,
82.1,
77.7,
85.9,
58,
13.1,
51.3,
65.4,
44.3,
53.2,
61,
77.1,
58.5,
69.5,
82,
53.6,
67.4,
63,
25.4,
32.3,
62.5,
81.3,
90.7,
84.8,
96.9,
78.2,
51.1,
67.3,
52.1,
61.1,
50,
40.9,
94,
75.6,
24.6,
33,
38.4,
43.8,
71,
12.6,
61,
39,
10.1,
47.8,
41,
91.8,
15.9,
67.2,
37.3,
86.9,
98.9,
80.9,
24.2,
76.6,
50.4,
47.4,
28.9,
26,
88.3,
88.3,
49.5,
27.6,
66.5,
81.1,
13.7,
59.9,
56.1,
39,
75.4,
95.7,
40.5,
87.4,
78.9,
58.5,
87.2,
49.6,
3.5,
63.7,
81,
83.9,
87.1,
51.7,
88.3,
21.8,
85.1,
35.4,
58.9,
80.3,
12.9,
9.9,
67.3,
94,
37.2,
25.2,
75,
24.2,
25.2,
63.6,
31.6,
77.8,
26.6,
55.8,
66.4,
59.5,
37.7,
62.1,
70.4,
13,
48.4,
46.8,
19.3,
35.8,
43.7,
37.7,
75.3,
42.8,
69,
76.8,
70.8,
55.9,
68.1,
58.9,
34.4,
81.7,
20.5,
61.5,
64.2,
65.2,
47.8,
78.4,
35.3,
96,
73.2,
53.5,
27,
45,
50.9,
43.6,
99.7,
32.8,
68.5,
41.4,
43.2,
40.4,
27.2,
43.3,
67,
92,
91.3,
31.8,
30.5,
44.3,
66.7,
52.6,
42.9,
30.5,
6.5,
41,
68.5,
77.4,
49.9,
53.5,
45.9,
28.2,
76.4,
87,
31,
83.2,
99.2,
56.2,
88.6,
54.5,
84.3,
32.7,
75.3,
83,
81.1,
70,
94.8,
75.2,
42.4,
47.3,
34.7,
60.1,
35.2,
13.5,
96.8,
65.1,
55.9,
24.7,
67.9,
66.7,
33.2,
29.8,
38.9,
64.9,
82,
41.2,
89.5,
48.9,
52.8,
22.2,
36.3,
75.3,
67.9,
33.6,
35.6,
46.7,
74.3,
12,
54.3,
73.2,
90.3,
31,
59.8,
84.6,
53.9,
47.1,
3.7,
74.7,
41.2,
59.9,
61.1,
71.1,
42.6,
0,
16.1,
32.9,
7.8,
69.3,
68.6,
10,
18,
69.9,
22.3,
8.9,
94.7,
45.1,
33,
78.5,
10.2,
33.9,
48.6,
54.9,
73.5,
49.3,
60.2,
61,
43.2,
63.7,
90.7,
36.4,
1.7,
9.8,
22.5,
26,
92.8,
73.5,
51.6,
37,
74.7,
57.4,
52,
44,
65,
71.9,
15.2,
0,
9.3,
41.2,
34.8,
72.5,
53.5,
39.6,
48.5,
29.2,
9,
29.2,
19.8,
21.4,
76.3,
40,
58,
52.5,
64.4,
24.3,
0,
92.7,
69.5,
84.3,
76.3,
45.3,
28.9,
67.3,
15.1,
45.7,
40.5,
10.2,
73.2,
44,
93.1,
85.1,
75.1,
35.4,
43.6,
78.8,
70.2,
29.8,
87.2,
17,
46.1,
45.1,
30.3,
56.7,
71.3,
47.7,
82.5,
77.5,
29.9,
49.4,
41.5,
85.3,
37.4,
12,
53.6,
72.2,
96.1,
87.5,
63.1,
89,
63,
35.6,
31.5,
62.2,
61.1,
29.9,
51.8,
34,
41.2,
23,
75,
54.7,
35.8,
61.9,
1.8,
88.3,
83.5,
98.4,
68.9,
52.9,
79.8,
75.6,
43,
82.9,
60.7,
43.6,
23.6,
87.3,
61.2,
52.6,
9,
87,
40.9,
35.9,
57.8,
31.2,
72.2,
60,
50.6,
54.8,
72,
70.3,
85.9,
54.4,
5.8,
3.6,
77.3,
19.3,
26.7,
5.4,
84.8,
34.3,
27.6,
45.9,
53.3,
45.4,
54.3,
97.7,
62.6,
41.7,
89.1,
10.1,
42.5,
80.5,
54.2,
44.9,
48.3,
60,
75.7,
13.2,
74,
36,
72.3,
77.5,
83.5,
61,
78.8,
60.5,
56.9,
94.5,
77.8,
97.7,
86.5,
71.9,
62.7,
46,
93.3,
61.8,
64.9,
71,
96.8,
29.2,
67.3,
68.5,
74.7,
36.7,
77.7,
72.6,
19.3,
25.9,
43,
15,
83.4,
16.8,
34.8,
29.6,
76.7,
29.9,
81.4,
95.3,
29,
31.9,
57.3,
76.8,
61.4,
37.6,
55.2,
78,
76.5,
55.6,
57.7,
39.3,
44.2,
60.4,
33.2,
12.4,
72.1,
17.4,
16.8,
50.8,
24.7,
63.8,
3.3,
44.9,
78.5,
53.1,
59.4,
44,
55.4,
41.6,
69.9,
80.3,
41.7,
29.8,
0.6,
51.1,
90.3,
39,
90.5,
23.8,
69.3,
52.3,
85.6,
53.9,
68.5,
69.9,
77.7,
69.6,
53.4,
46.4,
40.3,
89.4,
49.8,
82.6,
18.4,
29.3,
56.2,
98.7,
16.6,
36.8,
58.8,
72.2,
64.3,
40,
70.6,
50.3,
96.8,
51.7,
17.3,
11.6,
40.4,
57.8,
61.4,
86.3,
70.5,
25.4,
55.9,
92,
14.2,
39.9,
49.9,
96.5,
12.9,
27,
63.8,
87.5,
78.6,
72.2,
25.2,
40.8,
37.2,
68.2,
31.9,
93.6,
53.4,
86.1,
57.5,
37.4,
51.5,
66,
69.8,
65.9,
83.2,
94.3,
51.8,
43.2,
93,
44.9,
43.8,
57.5,
59.4,
27.8,
59.6,
65,
62.7,
56.5,
42.8,
24.3,
77.4,
74.6,
67.5,
22.4,
58.1,
66.8,
43,
84.2,
39.8,
85.4,
56.5,
26.6,
71.5,
28.7,
62.9,
53.4,
63.4,
10,
50.2,
48.2,
80.5,
62.7,
35.1,
58.9,
19.3,
19.4,
40.4,
43.3,
31,
24,
13.5,
48.4,
27.3,
89.8,
59.8,
44.7,
81.1,
67.2,
64,
23.2,
28.2,
3.1,
48.4,
62.5,
90.3,
84.6,
45.2,
50.2,
31.1,
35.6,
42,
12.2,
72.2,
88.6,
63.4,
47.9,
55.8,
66.1,
49.3,
35.3,
58.8,
19.2,
74.6,
14.9,
95.6,
6,
5.2,
82.9,
75.8,
63.4,
38.4,
87.2,
28.8,
53.8,
82.8,
98.1,
80.9,
34.7,
53,
52.9,
25.9,
17.2,
39.7,
6.5,
86.4,
52.6,
55.7,
99,
59.9,
22.3,
57,
37.3,
58,
76.2,
61.3,
100.2,
71.2,
81.9,
80.8,
39.2,
21,
32.9,
71.2,
7,
45.9,
47.8,
54.7,
26.3,
41.5,
31.3,
49.3,
26.9,
38.3,
45.5,
52.6,
95.5,
15.1,
72.4,
60.8,
75.8,
52.8,
59.5,
97.7,
33.7,
74.9,
40.7,
14.1,
32,
91.5,
66.4,
5.2,
44.2,
71.8,
46.2,
5.3,
69.3,
62.1,
58.6,
53.9,
80,
87,
12.1,
72.2,
72.7,
50.9,
68.4,
57.7,
64.9,
76.2,
10.5,
71.7,
71.2,
65.1,
40,
73.1,
20.6,
99.2,
64.4,
94.9,
25.5,
38.1,
50.1,
56.6,
64.5,
47.4,
67.6,
11.4,
63.4,
97.3,
44.1,
55.3,
56,
52.5,
30.4,
13.9,
66,
74.8,
63.7,
68.2,
76,
29.6,
25.6,
85.3,
0,
94.2,
33.9,
59.5,
15.5,
70.5,
62.8,
22.6,
56.3,
88.7,
64.8,
78.5,
75.7,
24.1,
41.6,
69.7,
19.7,
29.1,
63.2,
10.5,
47.8,
51,
6.8,
32.6,
33.8,
41.1,
49.4,
60.7,
75.9,
28,
2.6,
14.3,
58.1,
52.1,
38.3,
36.8,
30.8,
33.6,
69.1,
62.8,
98.7,
72.8,
0,
92.9,
49.4,
38.1,
50.9,
62.7,
45,
83.6,
16.7,
38.2,
75.4,
42.7,
75.1,
35.6,
75.2,
31,
28.5,
75,
29,
41.7,
77.5,
54.1,
47.7,
26.4,
44.1,
76,
50.2,
42.7,
72.3,
95.2,
9.7,
10,
27.6,
7.5,
51,
64.9,
83.4,
62.9,
17.2,
76.7,
72.7,
80.3,
56.8,
83.9,
44.6,
10.4,
82.2,
27.3,
98.5,
27.1,
65.9,
87.6,
84,
31.5,
35.9,
54.8,
55.3,
83.9,
55.3,
60,
86.3,
47.9,
36.1,
64.4,
31.5,
61.6,
69.5,
65.3,
39.3,
35.8,
53.8,
43.8,
45.3,
43.7,
57.5,
29.3,
29.5,
93.8,
51.5,
71.5,
45.5,
93.3,
52.4,
34.1,
51.6,
68.4,
87,
39.2,
86.5,
71.7,
26.8,
72.8,
55.3,
83.7,
83.7,
50.7,
20.5,
92.8,
36.7,
45.1,
43.7,
34.6,
57.5,
81.5,
81.2,
81.5,
48.6,
21.4,
55.3,
18.1,
83.5,
45.6,
47.2,
96.5,
14.9,
0,
45,
52,
81.2,
21.4,
75.1,
65.6,
43.8,
68.2,
6.7,
73.2,
43.2,
80.3,
57.9,
72,
42.4,
91.4,
45.3,
33.8,
87.7,
87.1,
78,
41.6,
36.4,
60,
87.9,
80.2,
33.1,
42.5,
45.4,
60.8,
44,
97.3,
60.7,
44.6,
76.9,
55.2,
73.9,
48.7,
32.1,
69,
47.6,
36.4,
56.1,
17,
68.6,
58.1,
69.9,
64.3,
29.1,
64.3,
48.1,
74.2,
8.3,
9.4,
59.5,
30.8,
32.3,
40.8,
51.7,
83.6,
19.9,
48.6,
40.8,
12.8,
40.2,
53.5,
63.3,
51.7,
32.2,
43.7,
56.1,
63.4,
84.1,
29.8,
77.5,
30.3,
52.8,
75.1,
32.1,
90,
52,
83.4,
69.5,
60,
7.2,
96.6,
51.2,
58.9,
52.6,
17.6,
81,
1.9,
10.4,
6.8,
60.8,
53.8,
55,
58.5,
37.4,
73.5,
39.5,
28,
83.3,
1.3,
66.7,
63.5,
65.6,
89.3,
84.2,
37.7,
83.9,
20.8,
61.4,
47,
65.1,
76.5,
34,
63.2,
27.1,
32.3,
55.9,
37.8,
73.2,
91.2,
80.9,
43.5,
16.2,
47,
71.8,
69.1,
33.5,
82,
48.7,
61.1,
86.7,
61.4,
16.5,
61.5,
57.8,
31.5,
49.8,
67,
78.3,
80.4,
17.5,
50.8,
57.1,
50.6,
35.9,
51.1,
53.1,
63.9,
50.5,
53.6,
71.4,
54.5,
97.4,
41,
55.9,
91.5,
67.9,
44.9,
16.1,
76.9,
94,
61,
41.7,
85.4,
48,
53.4,
61.4,
19.7,
14.2,
91.1,
95,
58,
68.3,
18.7,
38.7,
61.4,
40,
54,
90,
47.4,
70.2,
56.7,
74.9,
38.4,
51.8,
null,
42.5,
76.5,
79.6,
69.3,
83,
58.4,
31.7,
44.8,
64,
46.5,
62.2,
52.1,
77.2,
48,
56.8,
47.3,
34.9,
57,
35.1,
74.5,
57.1,
25.8,
79.6,
52.4,
70.4,
59.9,
61.2,
79.2,
89.5,
69,
65.2,
73.8,
33.2,
63.2,
93,
45.8,
63.2,
83.6,
67.7,
68.8,
38,
3.2,
36,
91.1,
94.4,
58.5,
72.4,
70.5,
55,
54,
82.6,
17.5,
21.5,
46,
38.8,
57.1,
2.8,
43.8,
41.3,
38.1,
62.9,
74.3,
65.8,
57.8,
16.1,
70.9,
42,
61.1,
85.4,
83.7,
90.1,
70.6,
30.2,
70.4,
96.2,
43.1,
48.9,
58.9,
21.4,
91.3,
58.4,
7.3,
88.7,
79.7,
78,
56.9,
54.6,
57.8,
83.5,
96.2,
81.7,
44.9,
55.9,
47.5,
29.3,
55.5,
63.5,
29.3,
18.6,
38.5,
13.2,
32.1,
39.5,
57,
79.3,
33.7,
81.8,
29.5,
55.2,
66.8,
1,
26.6,
39.4,
77.5,
22.4,
27,
35.7,
29.1,
74.4,
27.4,
54.9,
83,
63,
52.4,
58,
55.7,
36,
0.4,
75.8,
57.4,
83.2,
50.1,
73.6,
51,
73.1,
47.1,
51.6,
74,
57,
66.8,
91.3,
71.8,
94.4,
26.8,
64.6,
97.2,
64.5,
98.2,
68.6,
71,
53.3,
53.3,
56.2,
77.4,
91.6,
62,
46.1,
75.6,
84.9,
48.7,
36.4,
71.1,
90.8,
74.1,
50.6,
26,
40.1,
17.8,
50.5,
64.7,
81.8,
6.5,
28.1,
69.4,
65.5,
12,
54.6,
55.3,
86.5,
96,
38.4,
46.8,
24.9,
31.6,
67.4,
63.4,
62.8,
44,
66,
24,
51.9,
96.2,
47.3,
77.3,
83.1,
70.4,
36.8,
98,
26.4,
74,
94.6,
64.6,
31.5,
30.8,
73.3,
71.1,
96.8,
94.5,
62.7,
78,
42.5,
43.3,
85.5,
14.1,
42.8,
32.5,
56.2,
66.6,
47.1,
33.9,
85.8,
36.1,
53.7,
39.1,
23.1,
55.6,
73.8,
78.4,
42.8,
44.7,
22,
46.3,
81,
72.1,
32.3,
75.4,
84.3,
68.1,
31.1,
69.2,
65.4,
40,
23.5,
38.5,
40.7,
57.9,
78.5,
60,
69.1,
11.2,
48,
52,
80.1,
38.8,
32.4,
26.7,
33.9,
93.1,
21.9,
66.8,
30.9,
81.9,
25.9,
39.5,
14,
65,
24.9,
58,
83.2,
85.3,
60,
18,
19.7,
68.1,
16.7,
56.8,
78.2,
44.5,
30,
80.1,
89.7,
47.8,
0,
62.3,
51.6,
84.5,
52.4,
63.1,
19.5,
66.2,
22.5,
77.1,
12.8,
81.3,
47.7,
69.4,
51.4,
13.4,
72.2,
35.8,
91.6,
73.1,
49.3,
70.4,
1.5,
37.6,
72.8,
94.7,
60.2,
68,
44.2,
52.4,
75.3,
52.1,
76.2,
6.4,
31.1,
11.1,
93.3,
71.7,
51.4,
27,
27.6,
96.6,
53.5,
39.4,
55.6,
94.1,
87.6,
21.9,
39.9,
94.5,
97,
65.9,
70.2,
72.5,
76.7,
22.3,
55.4,
23.6,
29.6,
96.1,
64.5,
0,
39,
63.3,
78.2,
83.2,
100.3,
17.6,
50.8,
80.4,
61.7,
42.5,
47.1,
58,
41.5,
65.5,
71.7,
51.9,
56.9,
69.6,
45.4,
44.7,
91.5,
29.3,
40.6,
56,
40,
19.2,
94.2,
60.1,
65.2,
61.6,
81.6,
57,
24.2,
62.2,
48.1,
48.9,
70.1,
34.6,
45,
0.1,
40.9,
45,
26.4,
57.4,
66.6,
61.1,
93.1,
40.4,
13.4,
62.2,
28.3,
68.1,
41.4,
73.6,
75.2,
90.2,
89.1,
19.5,
75.2,
55.8,
51.3,
61.3,
81.8,
51.3,
83.6,
31.5,
54.8,
33.1,
38.1,
94.5,
64.3,
79.4,
74.7,
62.5,
76.9,
58.1,
76.4,
69.5,
60.1,
74.9,
67.9,
22.7,
0,
53.9,
94.9,
86,
96,
80.5,
65.5,
81.8,
43.2,
32.2,
88.5,
44.7,
77.9,
25,
66.8,
29,
75.8,
70.4,
4.5,
64.6,
93.9,
67,
84.2,
45.8,
54.4,
33.2,
18.7,
35.3,
25.2,
43.3,
87,
75,
60.8,
40.2,
63.1,
34.8,
47.7,
3.6,
45.9,
52,
13.5,
75.3,
33.2,
43.4,
58.7,
51.1,
71.4,
63.7,
63.6,
59.6,
58.5,
43.1,
70.6,
79.6,
2,
43.9,
9.1,
80.6,
45.9,
84.9,
87.6,
61.9,
59.2,
61.2,
54.2,
48.6,
91.7,
71.9,
46.7,
94.2,
82.8,
64,
93.2,
95.8,
36.9,
53.6,
59.7,
75,
76.3,
65.7,
96,
95.6,
55.2,
27.8,
24.6,
39.4,
34.5,
52.8,
14.3,
76.9,
73.9,
60.2,
47.8,
55.3,
61.9,
43.8,
56.7,
64.9,
63.6,
61.4,
54.3,
101,
44.6,
39.3,
56.4,
2.3,
62.5,
11.5,
44.4,
79.7,
77.3,
92.4,
57.9,
70.8,
44.8,
39,
11.6,
63.4,
61,
70.6,
59.1,
65.6,
92.3,
54.7,
9.9,
40,
43,
51.1,
83.4,
60,
36.4,
89.6,
59.1,
66.8,
33.2,
17.5,
27.5,
34.8,
35.6,
80.6,
78.4,
36.2,
63.9,
16.4,
31.3,
40.1,
53.3,
48.4,
76.3,
62.8,
88.8,
33.7,
81.5,
67.5,
89.3,
60.4,
50.1,
22.2,
80.1,
55.6,
69.5,
88.7,
67.7,
69,
56.1,
66.8,
65,
7.8,
51.9,
20,
96.6,
39.9,
69.8,
52.7,
96.8,
2.2,
68,
93.1,
35.5,
80.7,
8.3,
51.9,
89.3,
60.6,
48.5,
52.8,
33.1,
28.3,
64,
75.2,
48.5,
71.3,
36,
99,
44.6,
27.6,
86.7,
78.2,
5.5,
76.3,
2.2,
98.2,
31,
65,
65.4,
96.4,
66.3,
43.4,
9.2,
78.3,
67.1,
43.8,
62.6,
87.3,
52.1,
84.6,
58,
80.1,
83.6,
39,
62.1,
42.8,
69.1,
72,
66.5,
55.5,
43.7,
42.9,
72.5,
23.9,
36,
50.7,
0.4,
82.2,
73.9,
14.2,
95.3,
50.8,
59,
66.5,
54.1,
72.4,
66.8,
72.4,
55.3,
45.4,
36.5,
45.7,
86.5,
90.8,
36.5,
36.3,
75,
62.9,
68.5,
90.1,
57.6,
69.6,
72.3,
37.4,
66.1,
57.3,
82.2,
9.3,
70.8,
31.6,
53.4,
59.8,
13.2,
61.7,
71.2,
77.9,
57.3,
55.7,
91.2,
22.4,
52.1,
57.3,
70.2,
60.4,
66.1,
60.2,
63.7,
69.1,
48,
42.3,
15.5,
66.9,
60.1,
81,
43.9,
33.4,
15.5,
80.2,
53.6,
87.3,
54,
90.6,
31,
8.4,
36.2,
36.2,
32.8,
15.3,
28.4,
31.4,
52.6,
78.3,
71.5,
94.1,
45.9,
11.8,
58.1,
59.5,
90.9,
67,
37,
85.2,
68.8,
81.4,
27.4,
17.4,
85.7,
61.2,
89.5,
22.2,
22.9,
89.7,
69.3,
54.7,
96.5,
13.9,
46.9,
66.6,
63.3,
46.5,
11.4,
90.1,
44.5,
32.4,
76.6,
58.4,
47.1,
60.3,
69.9,
83.5,
70.7,
41.4,
78,
59.9,
87.4,
84.2,
11,
64.7,
102.1,
20.2,
73.3,
70.7,
29.6,
37.2,
47.8,
19.5,
64.1,
57.8,
72.8,
88,
28.5,
78.2,
28.6,
74.3,
22.7,
0,
59.1,
12,
54.7,
89.5,
67.7,
20.2,
53,
43.5,
27.2,
54.1,
64,
60.9,
65.6,
43.3,
45.6,
43.8,
77,
21.8,
35.2,
49.9,
29.1,
51,
1.2,
51.5,
22.1,
56.6,
49.6,
41,
60.5,
15,
76.6,
24.7,
38.5,
31.6,
85.7,
81.1,
82.4,
15.5,
89.5,
26.5,
81.2,
25.6,
18.4,
85.7,
80,
75.4,
64.9,
95.5,
34.3,
46.2,
19.4,
80.7,
47.4,
38.9,
53.4,
73.7,
69.8,
24.9,
76.8,
93.5,
70.7,
4.1,
54,
28.7,
12.3,
48.2,
80.3,
80.2,
12.8,
45.5,
14.3,
17.1,
72.4,
40.5,
20.8,
60,
71.2,
50.7,
63.8,
61.9,
47.3,
57.5,
19.9,
80.6,
78,
16.7,
43.8,
96.2,
91.5,
83.8,
89.8,
65.5,
26.8,
76.2,
68.6,
7.4,
50,
88.1,
80.2,
77.4,
28.6,
81.9,
55,
48.9,
44.3,
27.9,
50.9,
33.2,
51.1,
60.1,
22.1,
17.5,
36.6,
4.2,
79.6,
15.5,
15.1,
54,
54.5,
59.9,
5.5,
53.2,
49.2,
57.3,
37.1,
50.7,
83.5,
28,
19.2,
31,
44,
78.4,
67,
0,
72.4,
62,
74.5,
68,
36.2,
60.5,
25.5,
1.5,
75.2,
54.1,
52,
59.4,
79.5,
35.2,
50.8,
26,
90.3,
80.1,
71.7,
47.6,
34,
48.1,
61.6,
22.7,
49.6,
55.8,
32.2,
24.8,
23,
61.1,
63.4,
84.6,
67.2,
41.6,
63.7,
83.7,
69.5,
56.1,
17.8,
66.9,
46.9,
66.3,
76.6,
40.5,
82,
90,
42.5,
63.8,
59,
85.3,
81.7,
99.1,
9.1,
60.9,
61.7,
55.2,
61.1,
72.6,
9.2,
32.5,
39.8,
72.4,
28.8,
54.7,
66.4,
51.8,
30.9,
75.1,
70,
78.9,
80.1,
71.4,
87.2,
44.5,
48.7,
46.9,
85.5,
90.4,
90.7,
82.2,
65.1,
55.5,
38.1,
47.9,
56.4,
47.7,
47.3,
49.7,
83.2,
77,
61,
59.5,
50.6,
3.4,
22.8,
41.2,
27.5,
93.2,
78.5,
46.9,
41.8,
38.9,
16.5,
43.9,
34.6,
76.7,
0,
68.1,
71.1,
61.6,
78.6,
77.5,
47,
64.7,
56.1,
73.5,
71.3,
68.3,
53,
6.6,
42.5,
47.5,
75.9,
10.3,
74.3,
36,
19.3,
70,
59.4,
94,
36.5,
94.6,
32.4,
55.1,
7.8,
96.1,
12.8,
61,
41.6,
62.4,
69,
47.2,
57.2,
45.4,
73.5,
79.1,
66.8,
81.2,
25.9,
52.7,
55.7,
49.9,
55,
81.9,
84.5,
80,
99.2,
11.8,
34.3,
58.2,
42,
56.5,
26,
68.8,
59.4,
77.3,
54.7,
47,
81.9,
29.6,
61.5,
27,
23.6,
28.2,
69.3,
29.9,
41.2,
50.4,
38.8,
86.8,
21.1,
27.2,
83.8,
76,
96,
31.7,
59.3,
43,
57.6,
83.4,
72.7,
49.5,
100.3,
89.6,
53.3,
18.8,
9.5,
54.9,
22.8,
50.8,
43.4,
88.1,
88,
70.9,
99.5,
80,
76.3,
66.6,
66.7,
41.8,
46.6,
94,
40.2,
49.3,
25.1,
31.5,
36,
22.1,
94.8,
64.9,
35.7,
56.5,
95.4,
58.3,
89.2,
51.4,
37.5,
94.1,
40.5,
21.4,
7.9,
39.1,
8.4,
3.4,
20.7,
76.9,
42.4,
64.6,
63.6,
82.4,
59,
33,
16.7,
31.6,
78,
40.2,
48.3,
76.3,
28.8,
49,
78.6,
47.8,
70,
89.2,
68,
95.6,
62,
80.4,
39.2,
50.3,
38,
67.2,
46,
88.5,
28.9,
37,
26.5,
63.6,
46,
8.3,
87.8,
21.4,
41.2,
35.6,
42.7,
76.8,
59.6,
26.9,
32.1,
32.9,
58.8,
47.5,
30.9,
45.3,
33,
49,
33.5,
67.5,
56.1,
92.6,
12,
9.5,
71.6,
28.2,
24.1,
50.9,
89.3,
58.4,
22.3,
85.4,
5.1,
40.3,
49.3,
39.5,
68.9,
42.8,
71.1,
52.7,
78.5,
60.9,
49.6,
19.4,
82.6,
78.7,
78.6,
8.6,
47.5,
34.6,
41.6,
20,
85.4,
84.3,
63,
67.9,
25.6,
84.3,
26.3,
49,
56.7,
30.8,
76,
57,
64.6,
86.2,
42.3,
17.6,
57.3,
39.9,
46.4,
83.5,
55.6,
11.4,
73.6,
52.8,
29,
34.3,
20.1,
11,
29.3,
48.4,
72,
13.1,
74.4,
65,
20.5,
50.2,
82.5,
3,
51.3,
69,
78.9,
74.5,
39.5,
51.9,
68.1,
91.6,
33.8,
67.6,
31.6,
60.9,
30.2,
78.4,
96.3,
19.2,
6.1,
75.6,
38.5,
83.4,
39.7,
72.9,
90.1,
75.5,
56.5,
48.1,
70.4,
53.7,
59,
70,
33.4,
71.4,
76.8,
61.9,
16.2,
82,
99,
85.2,
28,
17.5,
45.9,
67.7,
13.5,
63.1,
65.3,
67.5,
62.3,
70.7,
58.6,
18.8,
77,
76.8,
35,
48.2,
25.8,
24,
64.1,
38.6,
19.6,
24.3,
58.4,
64.7,
22,
40.6,
0,
95.5,
51.8,
52.6,
55.6,
7.7,
30,
65.3,
92,
92.9,
77,
66.5,
54.8,
15.3,
56.2,
72.1,
60.8,
71.2,
0.7,
20.6,
89.9,
67.9,
94.1,
52.4,
53.4,
82.8,
72.7,
98.1,
36.5,
21,
27.1,
54.9,
58.5,
62.9,
69,
75.5,
70.3,
6.9,
68.1,
83.6,
58.5,
73.1,
36,
70.7,
48.5,
27.6,
42.8,
37.7,
37.9,
81.4,
19.9,
6.5,
50.3,
56.9,
84.8,
19.6,
46,
72.9,
80.3,
35.5,
64.2,
87.4,
83.3,
76.2,
72.6,
89.9,
57,
72.1,
84.6,
68,
80.2,
48.3,
67.3,
26.8,
44.8,
71.5,
65.3,
18.9,
67.2,
54.6,
4.3,
46.6,
75.9,
91.7,
58.5,
61.5,
58.3,
21.2,
38.7,
22.6,
61.3,
71.9,
48,
28.4,
58.9,
65.3,
79.1,
36.2,
34.8,
49.6,
39,
17.7,
42.2,
70.9,
22.2,
69.3,
70.5,
69.2,
35.7,
48.9,
53.4,
55.8,
36.8,
40.5,
74.8,
62,
18.2,
72.7,
70.1,
80.9,
17.5,
63.6,
19.5,
102,
47.2,
53.9,
79.8,
50.2,
21.7,
24.1,
46.7,
24.8,
92.5,
0.7,
62.9,
8.3,
11.4,
22,
55.7,
75.7,
26.2,
86.3,
60,
53.2,
63.2,
91,
25.3,
36.7,
71.9,
47,
21.8,
54.9,
84.8,
94.2,
90.7,
56.1,
52.4,
31.2,
56.1,
9.2,
45,
7.5,
50.6,
47.2,
61.3,
74.7,
9.2,
97.5,
65.4,
31.1,
84.9,
69.6,
97.1,
21,
87.8,
48,
75,
69.5,
0,
95.6,
92.6,
14.5,
57,
89.9,
63.8,
31.3,
93.7,
67.6,
16.7,
43.2,
46.7,
79.7,
63.4,
29.4,
89.7,
55,
29.3,
44.7,
28.5,
47,
25,
66.3,
89.1,
98.5,
87.1,
69,
10.7,
58.9,
58.5,
25.9,
13.2,
29.6,
29.7,
76.1,
7.7,
90.9,
39,
69.5,
39.9,
28.9,
27.4,
93.5,
63.9,
31.5,
68.6,
80.7,
45,
50.1,
76.4,
28.5,
83.6,
61,
28.8,
67.8,
21.9,
0,
74.4,
46.2,
57.8,
22.9,
18.9,
54.3,
64.9,
62.9,
63.2,
19.9,
89,
48.4,
53,
70.2,
88.4,
21.4,
20,
70.8,
71,
91.3,
17.4,
68.3,
16.7,
48.2,
72.5,
90.5,
55.8,
83.8,
53,
36.2,
56.9,
86,
67.9,
70.5,
27.3,
48.3,
80.2,
57.7,
40.3,
46.4,
63.9,
9.4,
93.3,
82.7,
80.2,
46,
70,
49.8,
57.2,
19.3,
82.3,
83,
78.7,
30.1,
63.2,
58.9,
45.6,
30,
69.9,
31.5,
54,
33.2,
91.3,
78.1,
44.1,
74.6,
6.5,
33.2,
54.3,
75.7,
28,
73,
70.7,
97.9,
83.1,
11.1,
31.7,
61.9,
53.9,
59.5,
95.4,
38,
51.6,
86.5,
83.3,
8.4,
37.4,
50.9,
35.1,
54.8,
67.2,
60.8,
91,
82.4,
27.7,
54.1,
69.7,
41.4,
58.8,
39.2,
41.4,
42.4,
90.7,
82.7,
74.4,
52.3,
45.2,
55.7,
0.4,
67.9,
48,
51.4,
37.7,
46.3,
12,
31.9,
32.1,
33.9,
54.3,
76,
39.5,
49.8,
76.8,
67.9,
76.2,
65.3,
20.3,
72.7,
77.6,
36.9,
88.3,
84.8,
33.8,
47.3,
47.6,
35.2,
40.1,
61.6,
34.7,
24.5,
40.4,
76.6,
22.1,
61.7,
62.1,
95.5,
43.4,
60.3,
90.7,
75,
27.8,
34.4,
27.7,
98.1,
96.2,
66.8,
86,
50.9,
61.9,
63.7,
79.8,
39,
23.4,
82.1,
41.6,
48.8,
53.8,
25.3,
31.5,
33.2,
52.9,
44.6,
78,
48.2,
59.8,
50.1,
67.6,
36.5,
54.3,
12.4,
47.8,
76.6,
56,
34.3,
44.9,
32.9,
70.5,
54.6,
79.9,
20.1,
21.5,
72.5,
86.1,
90.3,
73.8,
26.6,
25.9,
41.5,
62.3,
73.4,
19.9,
27,
51.6,
60,
47.1,
61.7,
57.1,
62.8,
28.9,
52.4,
60.6,
48.9,
47,
13.7,
93.1,
77.6,
18,
78.6,
54.9,
61.9,
43.1,
65.1,
51.3,
73.1,
55,
50,
65.5,
27,
88.6,
36.2,
99.1,
47.6,
89.3,
34.8,
72.1,
32,
66.6,
64.2,
87.5,
75.3,
70.5,
42.2,
75.9,
33.6,
58.5,
30.6,
86,
48.2,
40.5,
51.6,
29.2,
94.5,
35.8,
98.5,
43.5,
81.4,
71.4,
64.6,
63.6,
51.7,
28.6,
97,
80.8,
46.6,
39,
26.7,
52.2,
76.9,
42.3,
71.4,
30.2,
15.8,
27.9,
41.1,
25,
54.3,
48.9,
30.5,
71.8,
79,
83.3,
66.2,
24.5,
38.6,
35.2,
67.8,
30.2,
45.6,
58,
79.3,
15.8,
45.6,
85.8,
31,
1.9,
55.8,
79.8,
42.6,
57.9,
58.4,
32.6,
56,
71.4,
75.5,
75.6,
63.1,
36.9,
91,
46.2,
61.5,
32.3,
88.8,
71.8,
37.4,
83.4,
90.5,
34.6,
32.9,
69.2,
81.6,
16.9,
13.9,
50.3,
24.1,
96.4,
57.8,
25,
83.3,
74.3,
1.7,
48.1,
58.8,
71.3,
61,
83.6,
55.6,
25.2,
83.9,
33.2,
27.5,
28.8,
31.1,
46.5,
43,
89.6,
36.3,
25.8,
96.4,
77.6,
51.1,
48,
46.3,
4,
88.9,
50.1,
39,
22.2,
81.5,
39,
53.4,
62.6,
90.7,
39.8,
33.9,
20.9,
84.8,
40.4,
60.1,
59,
98.8,
75,
59,
52.5,
45.5,
63.1,
35.1,
85.4,
54.4,
13.6,
72.5,
87.5,
64.9,
84.5,
41.9,
27.8,
23,
77.3,
91.1,
70.9,
68.1,
12.6,
37.4,
98.8,
55.3,
90,
23.5,
69.9,
28.9,
21.1,
64.2,
16.8,
97.8,
28.9,
77.9,
43.7,
24.9,
46.4,
74.6,
77,
69.7,
99.5,
68.6,
61.1,
67.2,
71.1,
58.2,
38.9,
101.2,
68.4,
33.8,
6.7,
52.6,
40.5,
50.7,
77.9,
80.9,
67.8,
48.8,
56.6,
95,
56.6,
76,
45.6,
45.3,
94.4,
60,
40.9,
15,
84.5,
38,
83.3,
81.2,
83.3,
27,
26,
17.9,
48.8,
90.8,
72.9,
50.8,
22,
71.2,
49,
71.8,
19.8,
65.1,
53.1,
19.9,
74.2,
38.3,
61,
53.2,
93.6,
53.7,
87.7,
54.5,
47.7,
64.7,
27.9,
83.7,
51.6,
64.4,
58.6,
44.1,
47,
8.9,
69.8,
49.3,
56.9,
52.4,
57.7,
60.2,
28.8,
25.1,
63.8,
59.7,
69.8,
45.8,
86.9,
10.5,
36,
48.1,
63.3,
93.9,
104.7,
62.8,
32.9,
21,
59,
93.8,
65.5,
70.6,
60.5,
27.4,
75.9,
65.3,
55.7,
84.1,
72.1,
78.8,
70.8,
48.3,
16.5,
50.9,
48,
63,
80,
93.8,
98.7,
28.8,
40.9,
49.6,
34.9,
27.4,
38.2,
52,
33.5,
38.4,
55.2,
16.8,
70.5,
33.4,
48.7,
41.2,
60.4,
35.7,
31.3,
65.7,
28.8,
7.7,
42.2,
28.2,
34,
34.7,
10.7,
52.7,
87.7,
19.9,
55.3,
74.6,
18.3,
2.3,
23.4,
44.8,
92.4,
70.6,
46.5,
87.9,
0,
33.8,
70,
91.5,
46.1,
0.1,
59.8,
36.8,
75,
80.7,
39.6,
58.8,
16.8,
26,
0,
57.5,
73.8,
60.6,
72.2,
3.8,
59.9,
85,
98.7,
39.1,
44.9,
68.8,
33.7,
83.9,
59.7,
64.7,
49.9,
83.5,
38.5,
46.5,
25.7,
26.5,
50.3,
32.5,
29.9,
66,
83,
45.9,
73.6,
44.8,
48.8,
85,
99.2,
40.6,
33.2,
57.7,
36.5,
77,
57.3,
50.2,
48.4,
99,
86.8,
103.7,
61.5,
45.7,
81.4,
65.1,
36.5,
38.2,
84.9,
35,
84.3,
30.4,
38.7,
49.5,
43.1,
84.5,
89.7,
47,
76.6,
33.4,
29.7,
65.3,
94.6,
94.8,
91.7,
44.9,
57.6,
53.3,
64.9,
61.6,
66.1,
56.9,
27.3,
35,
91.5,
29.4,
50.2,
22.3,
90.1,
48.1,
86.7,
44.4,
74.5,
88,
26.2,
42.4,
42.7,
60.4,
67.7,
63.6,
49.1,
72.7,
94.3,
59.3,
20.6,
67.7,
74.3,
73.9,
37.5,
33.4,
62,
73.3,
77.8,
74.5,
66.7,
18.1,
38,
57.3,
56.1,
27.4,
74.2,
58,
44.4,
9.4,
98.5,
97.5,
88.1,
16.8,
26.3,
90.6,
42.2,
81.1,
80,
61.6,
81.9,
76,
62.1,
57.9,
59.2,
24.3,
49.4,
48.1,
78.4,
67.8,
84,
86.5,
6.1,
53.7,
50.3,
51.4,
46.8,
43.5,
59.4,
86.3,
46.6,
7.5,
47.2,
39.7,
51.9,
61.5,
1.6,
46.9,
60.4,
88.4,
66,
5.7,
53.8,
28.5,
12.8,
88.8,
57.2,
55.3,
37,
31,
5.4,
31.5,
52.4,
100.5,
79.8,
47.1,
84.1,
62.2,
64.1,
88.2,
94.3,
61.6,
37.3,
53.1,
60,
36.5,
96.3,
45.8,
93.8,
8.7,
33.6,
54.3,
10.1,
46,
29.6,
84.3,
49.5,
69.9,
66.3,
77.2,
8.3,
56.7,
70.8,
0,
31.1,
80.8,
20.2,
15,
72.4,
25.3,
77.8,
70.1,
59.5,
84.8,
65.8,
34.5,
97.3,
87.6,
53.1,
39.7,
71.1,
14.9,
91.1,
56.6,
75.8,
49.9,
67.1,
40.2,
79.8,
25.8,
41.9,
45.8,
55.9,
67.6,
62.7,
84.5,
28.6,
77.2,
35.7,
68.1,
64.6,
46.9,
72.8,
73.7,
35.4,
63.9,
89.7,
62.7,
55.6,
93.1,
75.5,
99,
57.8,
87.1,
86.4,
32.9,
30.2,
30.2,
59.1,
25,
85,
61.1,
47,
60.6,
48.9,
73.4,
96.9,
49.1,
90,
69,
41.3,
85.9,
80.9,
44.9,
72.3,
73.4,
37.6,
49.2,
53.9,
70.4,
38.8,
46.4,
69.4,
62,
38.8,
5.8,
85,
91,
69.8,
86.7,
86.5,
65.8,
52.3,
82.7,
33.1,
82.4,
32.5,
80.2,
92.7,
44.5,
52,
20.3,
33.4,
21.2,
54.3,
41,
45.4,
70.8,
70,
91.5,
57.9,
31.6,
41.6,
41,
30.4,
93.8,
53,
21.1,
0,
28.4,
61.4,
56,
50.1,
65.6,
45.4,
9.8,
24.6,
53.7,
93.5,
65.6,
0.5,
69,
80.3,
74.9,
76,
85.4,
32.9,
70.6,
38.9,
41.6,
30,
30.2,
67.8,
48,
78,
41.9,
53.7,
27.2,
58.3,
37,
24,
17.7,
47.4,
91.3,
74.7,
56.7,
58.7,
75.9,
31.2,
68.5,
68,
55.5,
63.5,
45.2,
43.7,
30.3,
72.4,
62.5,
46.2,
66.6,
24.2,
40.5,
86.2,
38.8,
42.4,
44.4,
64,
36.7,
84,
26.7,
23.8,
78,
27.9,
53.3,
51.3,
83.9,
84.5,
79.9,
70.9,
73.2,
82.6,
34,
34.2,
66.9,
47.3,
81.4,
72.6,
70.4,
49,
49.7,
18.1,
99.5,
50.7,
57.4,
84.6,
64.8,
8.4,
32.1,
70.3,
90.5,
42.6,
90.7,
77,
91.4,
64.4,
60.7,
57.9,
42.6,
90.2,
47.9,
53.5,
51.9,
76.3,
35,
77.7,
55.9,
62.6,
85.1,
71.9,
76.6,
81.9,
75.8,
2,
29.6,
23.4,
78.8,
36,
88,
51.6,
84,
87.2,
95.8,
23.3,
47.8,
43.5,
43.8,
33.3,
88.4,
43.6,
84.1,
47.9,
32.3,
74.2,
85.2,
80.6,
49.5,
17.8,
52.5,
18.9,
90.7,
23.6,
75.5,
25.4,
31.2,
56.7,
38.6,
93.9,
55,
44.6,
100.1,
53.9,
39.6,
10.8,
35.3,
84.5,
64.5,
93.7,
39.3,
9.4,
96.3,
56.5,
49.3,
39,
93.3,
56.6,
90.2,
50.2,
35.7,
57.5,
31.8,
2.3,
82.1,
81,
48,
79.4,
23.2,
66.6,
89.5,
48.9,
6.7,
55.6,
67.7,
51.4,
68.8,
47.8,
74.8,
45.3,
79.4,
62.2,
60,
64.6,
55.4,
53.7,
12.8,
34.3,
58.9,
7.9,
14,
38.5,
22.1,
0.2,
76.6,
58.9,
27.3,
73.4,
64.6,
95.3,
68.3,
26.7,
93.9,
72.7,
5.5,
64.4,
60.2,
12.3,
32.4,
4.6,
57.6,
55.2,
51.2,
45.7,
76.9,
63,
90.8,
37.4,
41.4,
61,
69,
29.4,
69.2,
41,
26.7,
57.9,
100.1,
78.8,
75.7,
26.9,
94.8,
27.2,
55.1,
62.6,
13.5,
53.7,
53.6,
47.6,
55.6,
79.6,
18.4,
32.8,
34.7,
21,
23,
65.9,
2.4,
44.2,
89.2,
58.6,
47.3,
4.2,
13.4,
16,
74.2,
94.7,
28.4,
31.6,
38.2,
96.4,
82,
71.4,
87.4,
71.8,
2.9,
58.2,
80.2,
38.6,
68.3,
29.2,
21.5,
8.3,
32.2,
52.6,
91.3,
52.8,
39.1,
91.4,
17.9,
2.3,
79.6,
58.6,
28.3,
28.9,
68.8,
44.1,
19.8,
14.1,
40.4,
40.4,
53.4,
42.4,
67.2,
68.5,
12.4,
51.6,
33.5,
93.1,
3.3,
64.5,
78.5,
27.9,
38.6,
51.3,
78.1,
60.7,
41.5,
43.1,
65.2,
31.7,
27.2,
44.2,
18.7,
69.2,
96.3,
53.1,
72,
85,
83.9,
36.8,
67.7,
40.6,
27.3,
30.3,
90.5,
20.3,
29.1,
34.7,
32.4,
64.2,
21.1,
66.2,
51,
30.7,
71.6,
81,
64,
57,
27,
95.7,
51.5,
42.2,
76.9,
28,
58.9,
58.7,
50,
26.6,
60.8,
62,
35.6,
63,
76.2,
86.5,
70.3,
48.8,
75.3,
63.8,
54.5,
84.3,
41.3,
36.1,
19.1,
65.9,
65.3,
84.1,
0.7,
42.5,
32.5,
46.4,
75.6,
89,
94.5,
65.8,
93.1,
50,
68.8,
33.8,
54.7,
41.9,
25.4,
44.9,
26.5,
50,
5.4,
39.9,
38.9,
97.1,
75,
79.6,
47.8,
72.7,
34.8,
98.6,
58.1,
102.2,
44.3,
59.9,
7.2,
49,
38.1,
34.2,
29.5,
58.4,
61.2,
37.5,
55,
18.6,
86.9,
39.4,
23.7,
99.7,
56.1,
76.8,
91.5,
45.8,
24,
65.2,
35.9,
76,
69,
64.2,
44.6,
59.6,
38.7,
91.7,
65.3,
56.1,
75.1,
40,
31.4,
78.2,
47.2,
64.8,
30.4,
61.1,
56.3,
58.8,
100.6,
85,
45.4,
76.6,
58.5,
21.4,
65.9,
62.1,
53.6,
50.9,
46.2,
75.9,
70.7,
98.5,
82,
50.6,
27.3,
45.8,
20.9,
43.7,
69.7,
41.2,
76.1,
48.2,
26.9,
56.8,
74,
94.6,
45.9,
82.3,
59,
44.7,
65.4,
31.2,
87.1,
48.1,
80.6,
95.3,
50.6,
27.6,
88.8,
37.8,
54.4,
18.4,
3.9,
56,
72,
70.2,
75.4,
84.8,
76.4,
61.3,
68.9,
54.6,
81.3,
99.2,
65.1,
78.6,
18,
61.5,
59.8,
10.4,
92.6,
81.2,
34.9,
90.5,
59.4,
30.8,
70.7,
68.6,
70.4,
97.3,
90.5,
25.9,
13.8,
36,
30.5,
64,
30.9,
38.5,
68.1,
40.7,
49.2,
0.8,
62.3,
47.9,
58.4,
54.3,
47.9,
44.7,
73.8,
74.9,
98,
50.5,
58.5,
72.5,
72.9,
96.4,
48,
48,
35.8,
34.1,
22,
52.7,
87.5,
37.1,
57.4,
80.2,
67.1,
6,
54.4,
76.1,
60.6,
58.1,
20.6,
82.4,
76.9,
62.2,
96.2,
83.5,
26.6,
66,
31.8,
29.7,
3.9,
85.9,
25.9,
69.5,
15.9,
55.7,
95,
30.2,
33.3,
72.2,
30.1,
57,
78.8,
78.9,
29.8,
61.8,
40,
78.4,
62.3,
37.8,
71.9,
93.6,
48.4,
63.9,
53.7,
17.8,
89.6,
40,
48.6,
42.9,
83.1,
70.4,
84.6,
18.3,
23.3,
30,
75.9,
84,
27.3,
77.3,
84.9,
7.8,
84,
51.9,
91.9,
45.3,
33.6,
53.9,
40.4,
41.3,
52.4,
2,
53.1,
77.2,
9.7,
87.2,
63.2,
91.6,
79.7,
62,
18.3,
49.9,
63.5,
42.4,
88.1,
50.2,
43.3,
43.3,
63.5,
42.3,
56.1,
55,
79.3,
47,
68.3,
73.5,
58.7,
86.4,
50.6,
32.7,
88.2,
86.8,
34.8,
50,
33.1,
76.2,
65.4,
44,
80.6,
70.6,
74.4,
61,
44.6,
52.8,
61.6,
38,
28,
72,
76.5,
80.1,
74.2,
81.7,
82.2,
6.8,
56.5,
35.7,
83.3,
41.8,
72.6,
37,
70.7,
46.4,
84.3,
66.5,
25.4,
12.4,
92.2,
65,
90.7,
17.2,
68,
74.4,
36.7,
97.1,
35.3,
6.3,
19.7,
38.6,
0,
69,
78,
67.9,
99.9,
36.6,
34.6,
45.5,
58,
48.1,
42.9,
48.7,
65.1,
80.9,
87.7,
75.1,
59.2,
44,
65.1,
15,
100.7,
81.4,
54.3,
17,
75.7,
46.4,
44.7,
31,
73.2,
62.9,
99.3,
80.2,
70.1,
56.4,
77.3,
58.1,
39.3,
52.7,
70.6,
38.3,
1,
93.6,
70.1,
30.6,
20,
66.4,
33.9,
36.9,
42.3,
69,
95.2,
62.7,
50.9,
66.1,
4,
35.4,
99.8,
62,
35.7,
57.2,
73.5,
95.4,
53.5,
24.3,
29.9,
25,
35.4,
86.8,
9.6,
64.8,
62.3,
59,
41.8,
62.5,
69.2,
51.5,
50,
96.8,
75.2,
86.6,
73.4,
24.9,
83,
13.9,
83.4,
57,
58.4,
42.4,
76.3,
68.2,
56.4,
70.8,
28.8,
51.7,
92.6,
63.2,
11.1,
44.2,
40.1,
49.6,
8.9,
10.4,
91.7,
4.3,
44.7,
72.5,
61.6,
59.6,
58.8,
50.7,
82.9,
72.6,
6,
29.3,
43.3,
49.5,
67.4,
26.1,
74.2,
100,
72.5,
93.9,
24.2,
81.5,
91,
64.7,
74.3,
61.9,
34,
60.4,
65,
57.1,
73,
48.5,
63.9,
67.6,
72.1,
54.4,
87.1,
33.1,
46,
70.6,
53.8,
63.1,
95.4,
85,
61.1,
49.8,
72.1,
53.1,
83.7,
96.3,
91,
65.4,
30,
51.8,
89.6,
39.9,
72.1,
97,
38.9,
41.9,
48.3,
58.1,
71.6,
35,
45.4,
27.6,
71.1,
37,
22.6,
65.5,
51,
53.4,
52.8,
75,
4.9,
25.2,
18.3,
87.3,
56.8,
73.8,
84.3,
76,
36.5,
25.3,
46.8,
28,
34.2,
73.2,
39.5,
81.9,
82.6,
69.8,
35.8,
71.3,
99.7,
21.3,
17.5,
67.9,
47.3,
34.6,
29.9,
84.3,
41.5,
64.4,
34.7,
37.5,
45.7,
64.1,
37.1,
7.1,
87.7,
56.5,
100,
69.7,
58.8,
73.1,
94.6,
86,
21.7,
56,
33.3,
49,
30.9,
47.3,
18.4,
19.9,
22.1,
66.7,
15.2,
53.6,
43.2,
50.6,
41.4,
63.5,
37.7,
56.8,
69,
22,
83.8,
24.4,
86.8,
83.3,
45.8,
19,
82.3,
58,
46.9,
80.9,
75.4,
50.3,
76.5,
66.5,
51.2,
47.6,
77.4,
95.1,
50.1,
57.8,
35.8,
71.4,
63,
48.5,
86,
52.7,
5.7,
65.1,
86.4,
55.2,
72.4,
89.7,
53.6,
41,
37.9,
63.7,
84.1,
87.4,
63.6,
64.1,
38.6,
77.6,
20.4,
35.6,
71,
71.9,
79.4,
69.9,
51.3,
67.5,
88.4,
13.7,
97.4,
67.1,
62.5,
76.6,
88.2,
74.5,
43.7,
29,
23.7,
44.4,
15.8,
90.6,
45.6,
46.7,
70.3,
69.9,
72.6,
82,
63.3,
20,
70.1,
33.1,
42.6,
69.9,
69.4,
49.1,
74.8,
47.6,
25.4,
69.8,
77.5,
60.3,
62.1,
68.3,
78.8,
89.8,
58.4,
11.2,
84.2,
96.1,
58.4,
60.4,
65.1,
66.3,
84,
20.4,
58.9,
61.5,
50.8,
76.1,
88.4,
65.3,
61.7,
41.4,
67.9,
55.1,
35,
29.8,
62.6,
15.1,
95.6,
77,
80.3,
42.5,
57.3,
69.4,
75.3,
74.1,
72.5,
22.2,
57.9,
21.5,
27.5,
9.1,
44.7,
93.6,
50.5,
52.8,
21.3,
67.7,
33.6,
65.5,
83.2,
65.6,
61.7,
47,
55,
61.8,
48,
25,
42.7,
9,
13.4,
24.2,
88.8,
62.5,
97,
61,
80.8,
34.8,
75.3,
56.6,
61.6,
59.9,
98.6,
75,
91.8,
68.7,
92.1,
59,
51.4,
72.3,
57.2,
36.2,
84.5,
67.8,
77.3,
62,
74.4,
91.9,
59.6,
77.2,
84,
65.2,
61.1,
80.5,
29.6,
48.8,
18.4,
47.2,
55.8,
64,
31.5,
93.6,
100.4,
46.3,
78.1,
41.6,
8.9,
40.1,
51.2,
92.4,
92.9,
51.1,
72.5,
22.7,
54.6,
61.4,
59.4,
21.1,
84.9,
81.8,
53.8,
73.5,
39,
35,
60.7,
44.4,
29.8,
48.2,
64.2,
34.5,
18,
23,
18.9,
50.4,
50,
49.8,
92.5,
55.9,
18.3,
62.8,
50.8,
36.9,
93.5,
78.9,
63.3,
51,
29.2,
69.6,
41.4,
35.1,
3.9,
36.3,
61,
38.5,
26.3,
52.7,
81.1,
68,
79.2,
80.5,
59.8,
76.8,
56.1,
8.7,
96.5,
94.3,
67,
63.9,
92.7,
78.1,
58.2,
43,
47,
82.2,
71.9,
40.1,
41,
19.8,
25.7,
74.2,
21.5,
60,
3.8,
61.8,
79.5,
62.8,
70.3,
26.1,
82.7,
59,
53.2,
72.2,
49.8,
57.5,
54.8,
21.4,
47.9,
66.3,
81.2,
95,
67.8,
58.7,
44.9,
53.4,
6.6,
42.3,
50.2,
26.6,
46.3,
36.9,
60.9,
80.2,
90.8,
75,
88.6,
43.6,
43.1,
61.2,
64.4,
87.7,
74.3,
45.8,
32.7,
49.1,
82.4,
87.2,
44.2,
19.1,
39.8,
92.3,
40.3,
20.5,
72.9,
97.6,
82.7,
35.9,
90.2,
33,
37.5,
59.8,
47.9,
34.7,
85.9,
40.3,
58.2,
26.4,
80.5,
81.1,
5.7,
58.9,
49.5,
47.4,
61.2,
22.4,
38.4,
99.9,
61.2,
90.6,
22.5,
79,
35.5,
45.7,
55.8,
80.5,
74.6,
20.6,
53.5,
17.9,
38,
5.2,
33.8,
23.9,
26.6,
90.6,
89.1,
91.9,
24.1,
64.4,
56.2,
92.5,
88.2,
55.4,
53.2,
77.3,
75.4,
24.2,
43.3,
46.5,
67.5,
67.9,
41.8,
90.4,
62.8,
21.6,
97.8,
28.8,
76.2,
82,
92.6,
87.2,
26.7,
64.3,
67,
33,
11.4,
88.8,
57.7,
74.4,
53.8,
25.6,
24.6,
79.1,
70.8,
95.7,
77.5,
22.2,
78.9,
55.7,
59.1,
75.3,
27.4,
36.3,
47.5,
45.6,
60.4,
85.6,
37.7,
67.4,
44.2,
32.1,
43.4,
65.5,
75.2,
49.6,
59.2,
48.8,
18.4,
41.8,
78.5,
9.3,
88.3,
56.1,
38.9,
94.2,
97,
66.7,
39.7,
92,
12.7,
73.6,
63.8,
72.2,
42.8,
59.2,
54.8,
45.8,
79.1,
37,
62.8,
51.8,
88.4,
51.1,
34.2,
59.8,
96,
59.9,
65.5,
44.9,
63.3,
69.6,
27.1,
69.1,
47,
61.6,
62.2,
1.5,
45.7,
50.8,
63.5,
36.8,
81.8,
35,
57.5,
70.6,
85.8,
25.7,
97,
42,
77.3,
17.8,
41.4,
64.5,
81.1,
84.9,
40.3,
88.1,
13.8,
89.3,
73.9,
47.4,
39.8,
66.5,
78.6,
63.6,
79.5,
91,
79,
22.5,
31,
85.6,
15.1,
32.4,
10.7,
17.3,
38.5,
25.8,
76,
90,
85.4,
25.5,
4.6,
46.2,
83.5,
71,
33.2,
59.9,
82.2,
83.7,
88.2,
36.7,
18.7,
35.9,
14.2,
64.4,
70.1,
51.1,
89,
59.8,
74,
91.5,
76.8,
86.3,
56.1,
74.8,
69.1,
80.3,
54.2,
68.5,
88.7,
57.3,
65.2,
70.1,
35.2,
71.5,
23.4,
90.6,
54.8,
26.1,
59.7,
20.9,
44,
67.2,
20.2,
51.2,
36.8,
60.9,
97.5,
61.4,
92.5,
19.9,
72.4,
51.9,
78,
34.6,
72.3,
78.9,
74.2,
51,
70.3,
78.9,
36.6,
61.6,
76.2,
84.5,
88,
24.4,
57.2,
47.5,
36.3,
31.8,
55,
49.6,
75.9,
10.4,
68.6,
35.4,
91.2,
88.6,
34.1,
90.3,
53.3,
61,
55,
58.5,
89.1,
13.8,
66.1,
2.8,
37,
17.9,
42.9,
71.7,
15.9,
0.1,
22.5,
42.6,
73.6,
54.1,
50,
90.1,
86.8,
45.2,
66.2,
84.4,
80.5,
84.9,
80.5,
42.6,
30,
54.1,
13.1,
66.3,
90.4,
72.3,
82.7,
72.7,
81.5,
77.6,
27.6,
77.7,
62.4,
52.6,
18.2,
80.3,
11.4,
98.1,
14.9,
69.7,
58.1,
27.8,
88.8,
4.6,
82.8,
35.4,
7.9,
59.1,
93.5,
62.9,
49.9,
71.7,
38.9,
55.9,
40.7,
72,
96.6,
95.9,
55.6,
53.2,
88.5,
42.3,
18.1,
74,
29.9,
96.3,
42.2,
39.6,
22.2,
62.3,
64.3,
49.9,
56,
66.8,
41.8,
40,
64.3,
53.5,
76.9,
69.4,
27.8,
34.3,
40.3,
90.1,
95.9,
35.8,
94.7,
99.4,
94.4,
66.2,
46.2,
55.9,
38.6,
48,
19.9,
97.9,
47.5,
86,
41.7,
58,
76.3,
81.4,
55.2,
56.4,
64.2,
46.3,
57.7,
59.2,
76.3,
64.7,
53,
56.8,
52,
51,
62.2,
83.3,
52,
63.1,
73.8,
69.6,
97.9,
74.1,
28.9,
39.5,
42.4,
72.7,
21.8,
83.1,
55,
59,
76.1,
47.6,
85.5,
65.9,
32.3,
6.8,
60.6,
67.3,
48.9,
84.6,
42.5,
58,
23.9,
93,
17.2,
70.2,
69.8,
70.6,
71.4,
17.9,
59,
33.8,
89.7,
70.9,
60.9,
62.2,
94.3,
79.6,
38.6,
68.3,
67.4,
53.2,
96.5,
87.9,
73.7,
27.5,
28,
75.6,
78.3,
74.7,
46.6,
70.5,
97.1,
23.9,
26.7,
66.7,
85.3,
51.9,
18.6,
63.7,
47.4,
14.1,
40.1,
61.2,
15.9,
21.2,
21.3,
70.6,
59.1,
29.6,
78,
70.5,
89.3,
85.7,
89.3,
95.9,
71.7,
34.3,
61.8,
24.4,
43.8,
51.2,
63.3,
40.3,
44.7,
64,
0,
85.5,
36,
77.1,
48.6,
62.3,
39.4,
66.1,
94.8,
84.9,
80.6,
53.9,
28.3,
50.9,
82.6,
91.7,
33,
8.5,
57.2,
91.1,
57.7,
33.8,
48.9,
33.9,
30.2,
66.3,
11.5,
90,
76.9,
50.8,
62.7,
24.3,
70.3,
55.1,
39.3,
30.6,
27.1,
34.1,
71,
72.1,
72.5,
51.2,
81.3,
97.7,
52.9,
36.9,
77.9,
58.8,
51.5,
81.7,
61.1,
76.1,
61.9,
89.2,
75.5,
67.1,
92.6,
68.1,
41.6,
19.4,
33.6,
84.3,
34.4,
27.8,
46.6,
71.4,
25.7,
63.4,
83.9,
74,
68.4,
75.8,
45,
46.9,
63.8,
43.5,
47.1,
32.6,
45.2,
68.5,
44.6,
72.2,
49.7,
44.1,
95.7,
24,
74.6,
38.7,
94.5,
62,
68.6,
59.3,
72.7,
86.9,
24.3,
67.3,
73.9,
32.4,
30.6,
62.1,
28.7,
73.6,
74.6,
88.5,
55.2,
61.5,
55.1,
47.7,
43.4,
30.6,
86.7,
46.6,
32.3,
90.7,
18.9,
23,
58.6,
58.2,
82.8,
94.6,
44.5,
66.7,
51.4,
8.5,
75.1,
61.3,
76.1,
38.2,
71,
30.6,
94.6,
59,
45.7,
65.2,
79.4,
68.4,
75.4,
45.1,
64,
41.4,
46.7,
96.2,
39.2,
16.6,
25.1,
5.6,
62,
24.5,
98.6,
78,
74.6,
100.7,
53.6,
51.8,
96.4,
7.8,
43.7,
48.9,
29.5,
77.1,
67.6,
68.9,
75.9,
89.3,
62.9,
44.1,
43.5,
58.3,
69.7,
65.7,
24.5,
23.9,
50.5,
66.2,
13.9,
28.3,
65.6,
26,
86.5,
33.7,
63.3,
61.1,
57.9,
79,
49.4,
49.8,
32.8,
70,
70.4,
58.3,
69.4,
33,
24.6,
81.9,
71.8,
38.3,
89.8,
81.9,
57.4,
57.4,
50,
69.9,
52.9,
52.5,
27.3,
82.6,
16.4,
35.7,
73.9,
90.7,
74.3,
53.5,
93,
79.5,
48.9,
36.4,
49.3,
55.3,
39.5,
26.1,
39.1,
78.8,
54.1,
72,
77,
66,
51.8,
75.4,
72.8,
93.8,
76.4,
78.5,
35.8,
79.2,
95.4,
38.7,
27.3,
45.1,
61.7,
29.9,
9.6,
31,
61.7,
98,
60.8,
43.1,
63.9,
32.5,
42.5,
11.1,
48.8,
70.8,
69.9,
69.8,
72.1,
91,
56.9,
76.8,
19.1,
89.6,
23.7,
45.7,
55.3,
76.5,
68,
38.3,
38.8,
47.3,
78.3,
41.7,
44.1,
89.8,
88.4,
21.8,
3.9,
44.5,
41.7,
64.9,
63.5,
21.5,
96.9,
59.7,
43.4,
61.7,
34.7,
53.2,
66.7,
57.6,
97,
79,
68.8,
51.7,
58.8,
30.8,
98.2,
30.3,
43.6,
52.6,
58.1,
89.6,
35.5,
10.8,
67.4,
51.4,
94.8,
71,
45.5,
19.7,
85.3,
47.7,
65,
82.4,
94.8,
94.3,
62.2,
56.8,
27.2,
50.3,
54.2,
34.8,
54,
64.7,
33,
64.6,
62.1,
97.4,
36.1,
85.3,
42.7,
55.6,
21.4,
18.9,
38.8,
50.4,
50.3,
15.6,
43.1,
48.4,
69.2,
86.2,
28.9,
86,
82.7,
52.3,
35,
71.1,
52.3,
57,
74.3,
25.1,
56.5,
40.4,
16.4,
40.6,
66.1,
20.1,
50.4,
90,
25.6,
51.9,
87.9,
42,
26.5,
50,
61.7,
26.3,
53.7,
69.7,
11.4,
0,
55.1,
47.2,
38.5,
74.2,
93.3,
90.5,
68,
59.4,
74.6,
67.9,
57.8,
23.2,
38.8,
69.4,
27.9,
68.3,
31.1,
88.4,
62,
62.1,
45.1,
77.1,
43.9,
54,
42.7,
66,
56.8,
31.6,
83.8,
56,
94.5,
92.9,
46.8,
27,
42.4,
82.9,
97.9,
4.9,
48.1,
48.3,
78,
41.3,
76.7,
59.5,
89.9,
29.1,
27.8,
49.1,
27.6,
51.5,
80.2,
83.2,
19.1,
63.9,
55.1,
85.5,
63.3,
67.7,
70.6,
78.7,
19.4,
26.1,
71.5,
64.4,
4.3,
55,
91.4,
43.8,
50,
51.6,
66.6,
77.2,
27.8,
61.7,
73.7,
90,
51.1,
46.5,
42.7,
93.7,
42.9,
8,
105.1,
94,
73.1,
37.5,
48.8,
69.6,
94.1,
84.7,
27.4,
59.5,
25.8,
75.1,
70.3,
44.2,
18.9,
61.1,
42.8,
19.5,
74,
53.2,
72.3,
54.2,
15.5,
57.9,
42,
82.9,
90.9,
24,
54.3,
10.9,
32.7,
78.8,
14.9,
87.7,
40,
73.3,
40.6,
66.5,
85,
76.9,
49.7,
51.2,
52.6,
85.5,
78.5,
65.4,
46,
28.9,
63.6,
79.7,
79.2,
82.1,
95,
75.6,
65.3,
82.3,
84.7,
64,
79.9,
56.1,
50,
71.1,
29.5,
27.4,
62.5,
55.6,
60.4,
88.5,
59.2,
55.5,
22.9,
19.2,
47.7,
53,
71.3,
96.8,
54.5,
16.5,
42.2,
79,
96.1,
31.6,
83,
74.8,
65.7,
59.7,
26.6,
39.2,
24.6,
38.4,
69.1,
89,
61.1,
50.5,
60.9,
45.6,
26.7,
74.7,
56.7,
66.7,
66.3,
37.5,
90.7,
85.1,
35,
27.5,
62.3,
23.8,
55.9,
79.9,
25.9,
44,
5.1,
25,
85,
50.7,
30.7,
61.5,
63.2,
95.6,
71.5,
84,
23.8,
91.9,
67.3,
39.5,
85.5,
26.4,
67.6,
36.9,
49.8,
79.3,
68.7,
56.2,
34.9,
26.2,
56.3,
69.2,
20.8,
61.4,
81.7,
35.6,
73.5,
24,
91.3,
77.8,
78.6,
9.7,
89.9,
92.9,
0,
77.3,
17.6,
75.8,
76.1,
9.8,
68.1,
40.2,
81.2,
28.7,
4.9,
77.7,
0,
10.2,
54,
75.2,
53.5,
8.1,
13.9,
39.5,
59.4,
78.3,
58.3,
23.1,
55.8,
12.5,
63.9,
81.1,
95.5,
53.5,
74,
19.9,
85.1,
52,
35.4,
96.2,
68.1,
93.6,
44.6,
null,
81.3,
52.7,
72.5,
19.4,
24.5,
59.9,
71.3,
42,
61.5,
44.1,
66,
14.9,
64.6,
81,
80,
78.6,
58.1,
89.6,
84.3,
15.4,
28.4,
71.4,
28.1,
61.3,
74.2,
20.2,
49.5,
70.5,
31.7,
33.7,
34.3,
64.3,
35.6,
66.8,
59,
11.6,
84.6,
63.3,
70.1,
56.1,
43.6,
43.2,
81.1,
45.6,
44.7,
51.3,
24,
83.7,
54.6,
54.1,
19.8,
60.7,
35.3,
96.6,
77.9,
23.2,
2.9,
42.1,
63.9,
72.1,
44.8,
78.4,
13,
73.9,
69.5,
70.6,
41,
94,
28.7,
75.2,
69.7,
38.5,
44,
40.8,
48.3,
35.8,
52.4,
55.4,
56.6,
50.4,
60.7,
96.9,
93.7,
75,
81.2,
35.6,
25.4,
97.1,
54.1,
47.7,
59.2,
42.5,
89.4,
55.4,
98.9,
63.7,
93.9,
54.2,
92.8,
43.6,
64.1,
73.1,
36.5,
77.6,
91.6,
54,
64.7,
43.3,
67.5,
25.7,
64.4,
53.9,
11,
77.9,
92.5,
74,
35.4,
90.1,
87.5,
18.9,
67.8,
95.3,
12.2,
75.5,
26.5,
86.4,
87.3,
64.4,
70,
0,
52.1,
77.9,
99.2,
56.2,
82.2,
11.7,
46.7,
85.9,
42.8,
35.6,
58.6,
71.9,
2.9,
15.5,
73.1,
23,
72.6,
88.6,
81.7,
87.9,
27.8,
38.5,
35.4,
81.2,
8.5,
83.5,
68.5,
41,
52.5,
67.5,
35.5,
43.3,
52.5,
82.2,
43,
16.7,
8.1,
47.3,
22.5,
40.1,
69.9,
20.2,
4.7,
36.5,
94.2,
71.4,
58.8,
43.3,
79.5,
65.5,
76.3,
69.2,
45.7,
72.3,
59.8,
95.6,
69.9,
47.6,
100.2,
36.8,
63.6,
86.3,
44.6,
56.7,
79.9,
48.5,
83.6,
28.2,
89.9,
72.8,
31.2,
68,
75.1,
62.8,
62.7,
77.5,
56.3,
36.5,
69,
93.9,
33,
33.5,
82.6,
85.4,
64,
71.8,
12.8,
63.7,
78.1,
39.3,
30,
71.1,
69.4,
73,
81.4,
41.9,
49.6,
21.4,
58.5,
17.1,
57.4,
46.6,
35.2,
50.9,
39,
85.4,
4.6,
70.2,
45.9,
58.8,
47.8,
37.4,
81.9,
55.7,
55.1,
22,
49.6,
12.6,
44.1,
94.5,
38.3,
87,
62.5,
71.4,
72,
79,
60.6,
50.9,
11.3,
20.9,
47,
99.2,
41,
60,
47.6,
36.3,
32.9,
46.1,
44.1,
21.6,
75.7,
62.4,
67.2,
65,
53.5,
33.5,
88.7,
90.1,
13.8,
47.4,
62.6,
89.1,
66.9,
69.8,
33.8,
52.1,
45.4,
39,
46.8,
58.2,
34.4,
25,
21.8,
78.5,
67.5,
69,
0.5,
43.6,
26.7,
6,
77.6,
56.2,
49.9,
64.6,
77.8,
28.6,
59,
26.5,
66.5,
82,
42.2,
28.4,
82.4,
85.9,
130.8,
53.1,
55.2,
77.5,
80.4,
36.8,
76.8,
89.1,
9.9,
92.9,
99.3,
55.5,
88.7,
17.7,
89.1,
34.2,
96.3,
94.5,
65.3,
25,
24.5,
62.4,
45.2,
83.8,
28,
36.9,
59.4,
61.2,
25.4,
70,
54,
77,
0.2,
66,
62.7,
83.2,
52.2,
50.7,
29.7,
42.1,
13.8,
66.7,
67.6,
75.4,
16.6,
1.9,
88.8,
47.4,
39.6,
86.5,
51.5,
82.1,
82.6,
91.4,
79.1,
53.4,
8.1,
53.3,
18,
82.6,
54.3,
75,
50.6,
91.5,
46.9,
45.8,
41,
32.2,
6.8,
28.2,
69.2,
53.7,
97.2,
49.5,
86.4,
75.4,
22.1,
28.6,
10,
78.9,
66.5,
48.1,
66.1,
15.7,
87.9,
72.4,
68.6,
35.5,
68.5,
32.5,
12.2,
66,
90.2,
32.4,
81,
18,
0.8,
51.4,
28.4,
90,
29.4,
54,
39.7,
34.1,
63.1,
35.7,
42.3,
72,
95.3,
30,
39,
53.4,
20,
60.1,
12.1,
60.1,
91.8,
93.6,
34.2,
96.3,
64,
44.9,
30.2,
87.3,
47.4,
24.9,
67.1,
94.8,
63,
90,
82.4,
97.2,
36.7,
56.9,
68.6,
59.3,
47.6,
64.3,
50.6,
89.9,
46.8,
45.1,
95.9,
68,
85.4,
17.6,
76.1,
8.6,
0.9,
26.8,
47.1,
81.1,
47.7,
82.3,
28.7,
43.5,
49,
53,
73.8,
71.9,
64,
50.5,
39.8,
23.4,
28,
8.2,
34.2,
28.3,
65.4,
32.4,
64.6,
58.1,
66.9,
32.5,
46.2,
89.7,
59,
72.4,
27.4,
66.5,
45,
20.7,
62.5,
95.8,
35.9,
43.1,
80.6,
87.6,
63.5,
59.5,
62.5,
20.8,
24.3,
28.2,
23.7,
31.3,
22.4,
84.8,
55.8,
96.6,
45,
66.1,
66.9,
32,
30.9,
67.5,
59.5,
93.7,
32,
83.4,
60.3,
13.9,
13.7,
94.7,
50.9,
82.3,
0.8,
92.5,
38.8,
64.8,
84.6,
66.7,
95.4,
26,
51.8,
34.7,
37.3,
53.2,
22.4,
84.2,
45.9,
72.7,
81.9,
59.9,
23.2,
72.6,
92.6,
64.5,
67.4,
14.6,
56.6,
31.3,
46,
85.6,
69.8,
21,
61.4,
4.9,
47.3,
77.3,
44.8,
45.3,
64.4,
52.2,
14.5,
76.7,
46.7,
32.5,
71.8,
56.5,
75.7,
92.4,
52.6,
35.3,
94.7,
88.8,
42.7,
55.2,
38.7,
73.5,
88,
8.5,
49,
74.2,
43.2,
56.6,
92,
93.2,
76.3,
29.5,
48.9,
29,
23.4,
64,
66.8,
96.4,
62.6,
42.8,
50.2,
87.9,
62.3,
32.7,
43.4,
12.6,
50.6,
36.8,
41.9,
82.3,
37,
79.4,
71.6,
46,
46.8,
91.8,
50.8,
92.5,
64.6,
37.5,
80.1,
19,
94,
71.7,
72.3,
33.4,
87.6,
54.2,
12.2,
52.1,
61.2,
98.2,
84.9,
94.2,
6.5,
33.9,
67.3,
74,
30.8,
25.1,
79.8,
63.8,
69,
83.5,
47.6,
60.5,
61.4,
74,
35.2,
53.3,
85,
45.6,
96,
45.5,
39.3,
89.1,
19.3,
68,
44.5,
29.3,
60.7,
85.5,
87.2,
80.5,
55.7,
88.2,
55.4,
30.1,
25.2,
95,
71.1,
62.9,
79.9,
53.1,
22.9,
24.8,
74.9,
62.5,
81.4,
66.6,
2.5,
18.9,
44.6,
19.4,
82.7,
66.5,
23.4,
88.3,
15.8,
31.8,
87.9,
36.9,
54.6,
51.8,
87.5,
42.4,
37.4,
31.2,
60,
51.3,
84.3,
26.3,
74.4,
27.4,
44.4,
28.3,
54.7,
37.4,
57.8,
47,
67.9,
40.2,
43.2,
29.1,
45.6,
81.4,
79.8,
76.8,
49.9,
89,
51.2,
28.3,
14.7,
72.4,
95.1,
61.8,
81.6,
69.9,
91.7,
42,
55,
82.7,
18.6,
72,
32.9,
28.5,
35,
68.5,
58.6,
61.8,
69.9,
85.3,
57.5,
55,
49.3,
82,
49.5,
65.8,
79.4,
89.5,
74.8,
90,
80.2,
75,
39,
38.2,
24.6,
77.5,
15.3,
36.7,
45.1,
41.8,
56.3,
82,
43.3,
28.8,
50.4,
72.1,
52.3,
48.5,
91.8,
13.9,
46,
87,
68.4,
65.3,
47.4,
90.1,
57,
68.9,
53.8,
65.6,
36.1,
37.9,
11.1,
60.4,
90.7,
64.4,
41.4,
40.3,
73.4,
31.9,
38,
88.3,
80.4,
91,
30.3,
60.5,
65.2,
22.1,
86.8,
58.5,
49.3,
100.5,
34.7,
76.8,
63.7,
39.2,
32.7,
31.8,
43.4,
7.2,
59,
40.2,
73,
71.4,
48.3,
53,
95.7,
37.8,
33.1,
42.3,
25.1,
60.2,
28.5,
61,
12.9,
87.4,
37.5,
70.7,
38.8,
24.9,
72,
36,
7.2,
66.9,
89.7,
69.9,
11,
51.2,
63.9,
35,
39,
75.7,
30.6,
11.2,
57,
42.3,
83.4,
67.3,
11.7,
92.6,
89.1,
97.4,
66.3,
56.7,
57.3,
55.7,
95.5,
46,
75.2,
64.5,
81.1,
42.1,
58.8,
26.9,
46.3,
48.7,
33.5,
17.5,
24.4,
35.5,
60,
41.9,
70.7,
38.3,
68.2,
24.4,
0,
54.3,
51.2,
86.9,
52.2,
23.2,
6.5,
87.7,
34.5,
36.7,
72.6,
100,
68.6,
89.9,
90,
78.6,
59.5,
89.8,
45.3,
73,
31.1,
83.1,
73.7,
1.7,
83.7,
0.3,
34.5,
47.7,
83,
81.9,
98.7,
55.2,
80.5,
43.8,
23.6,
65.4,
49.9,
72.8,
42.6,
38.2,
13.7,
78.8,
75.3,
45.8,
45,
45.3,
66.5,
81.4,
69.8,
85.2,
39,
74,
42.2,
7.4,
50.9,
85.9,
50.1,
53.2,
13.9,
88,
58.9,
57.1,
32.9,
59.9,
9.8,
46.1,
48,
82.6,
75.7,
49.3,
100.5,
90.5,
65,
7.4,
56.3,
59.4,
63.4,
62.5,
51.8,
33.3,
50.9,
67.3,
75.8,
76,
59.7,
36,
83,
40,
67.3,
60.2,
66.4,
81.8,
43.5,
65.4,
49.7,
63.4,
48.6,
44.3,
91.8,
24.2,
101,
20.2,
29.6,
75.7,
37.8,
77.4,
25.2,
76,
69.7,
43.7,
44.4,
66.7,
63.9,
54.7,
82.5,
75.6,
32.7,
62.2,
34.2,
99.1,
44.6,
46.7,
83.7,
50.2,
47.9,
88.1,
102,
8.6,
60.7,
44,
56,
58,
24.5,
73.3,
69.2,
53.6,
45,
71.3,
30.7,
45.1,
37.4,
38.1,
93.7,
56.4,
75.9,
72,
46.6,
29.4,
36.6,
55.4,
95.7,
19.6,
64.4,
51.7,
80.9,
86,
82.9,
84.3,
40,
19.8,
68.1,
57,
71.8,
70.7,
53.8,
30.5,
69.3,
71.6,
70.2,
38.8,
15.4,
60.7,
88.2,
53.4,
19.6,
74,
71.2,
58.1,
81.3,
33.4,
44.3,
77.1,
8.6,
59.4,
60.3,
38.6,
8.8,
75.1,
94.7,
20.6,
88,
45.1,
28.2,
78.6,
66.8,
80.7,
77.5,
12.9,
69.8,
84.1,
66.6,
68.3,
69.1,
21.9,
69.8,
37.8,
76,
44.8,
88,
57.1,
63,
67.8,
53.8,
52.2,
69.5,
91.3,
44.8,
81.7,
73.4,
16,
42.4,
80.8,
88.8,
38.7,
83,
101.4,
49.4,
36.4,
53.8,
45.1,
43.3,
63,
41.1,
75.3,
44,
91.4,
35.1,
17.1,
70.1,
17.8,
70.7,
22.1,
76.5,
74,
18.7,
62.9,
92.3,
82,
65.7,
82,
14.3,
97.6,
61.8,
3,
64.4,
27.2,
49.3,
64.5,
46.1,
48.6,
34.4,
80.1,
26.5,
24.3,
32.6,
40.3,
64.3,
33.1,
80.2,
67.7,
81,
62.2,
97.2,
68.1,
79,
19,
67,
78.4,
71.2,
93.1,
81.8,
67.4,
50.3,
80.3,
65.7,
0.8,
73.6,
44.7,
11.1,
19.8,
26,
83.1,
51.3,
54,
54.6,
5.9,
37.3,
26.1,
60.4,
17.4,
66.9,
20.9,
20.7,
94.1,
64.1,
84.4,
92.2,
32.8,
69.5,
33.9,
56.6,
26.3,
61.6,
40.7,
64.1,
43.4,
56.9,
81.7,
41.1,
85.5,
71,
54.1,
84.9,
30.1,
31,
82.6,
48.1,
28.3,
29.2,
39.5,
58.1,
51.3,
82.1,
72.3,
57.9,
19.6,
41.2,
68.4,
36.8,
55.8,
70.9,
46.2,
34.5,
51.7,
59,
74.1,
52,
93.9,
36.5,
75.9,
87.1,
47.3,
35.9,
71.5,
71.4,
72.8,
44.5,
60.8,
66.5,
33,
30.4,
38,
49.4,
55.4,
57.7,
60.4,
44,
48.2,
40.6,
55.1,
48.2,
77,
77.6,
56.9,
75.5,
34.1,
35.9,
51.8,
37.8,
97.5,
15.8,
32,
77.5,
48.7,
19.9,
45,
63.8,
92.8,
57.3,
63.6,
42.6,
80.6,
63.9,
45.1,
62.4,
92.8,
66.7,
84.9,
58.2,
81.3,
50.9,
43.7,
38.9,
53.1,
35,
74.8,
32.2,
54.6,
41.4,
33.3,
3.2,
71.4,
72,
55.4,
4.8,
60.3,
56.1,
20.3,
49.6,
76.4,
92,
20.6,
51.2,
64.1,
71.2,
77.4,
1.7,
45.8,
35.1,
39.5,
57.2,
97.2,
83.9,
94.3,
16.8,
38.4,
68.3,
72.8,
90.8,
57.4,
42.4,
47.4,
12.3,
33.5,
66.7,
68.9,
20.3,
19.1,
36.8,
53,
39.3,
40.7,
55.5,
61.9,
52.8,
73.8,
58.4,
61.3,
77.6,
10,
88,
33.6,
27.6,
57.7,
57.8,
43.1,
98.6,
43,
65.8,
89,
74.5,
95.3,
22.8,
62.8,
43.2,
37.1,
50.4,
83.4,
63.4,
79.8,
52.6,
7.6,
9.5,
75.8,
34.6,
44.7,
87.2,
63.7,
70.7,
98.3,
46.1,
78,
64,
28,
60.8,
64.5,
57.3,
66.6,
57.3,
79.6,
65.8,
60.3,
46.2,
25.6,
64.9,
82.3,
66,
66.4,
63.7,
65.2,
43.8,
45.4,
64,
39,
82.6,
29.3,
27.7,
84.5,
56.5,
18.2,
50.7,
81.3,
67.2,
67.7,
73.6,
53.8,
52,
16,
26.9,
18,
68.4,
73.1,
40.7,
44.8,
53.1,
53,
11.4,
38.9,
14.7,
49.9,
52.1,
66.5,
35.4,
55,
95.4,
47.5,
55.8,
74.8,
62.6,
46.6,
60.7,
72.1,
20.4,
77.1,
48.4,
62.6,
79.1,
84.9,
87.3,
53.7,
54.6,
25.8,
33.8,
26,
85.3,
58.8,
27.2,
42,
33.7,
91.8,
48.8,
25.8,
57.8,
57.7,
90,
13.7,
32.9,
26.9,
87.2,
40.8,
77.8,
61.4,
48.8,
46.3,
45.4,
37.4,
81,
32.5,
63.1,
79.4,
51.4,
37.1,
48.3,
49.1,
45.1,
37.4,
65.6,
66.5,
66.9,
36.8,
44.7,
54.4,
88.2,
65.3,
84.4,
40,
46.7,
87.2,
97.5,
38.1,
73.5,
42,
58.5,
83.9,
54.3,
36.7,
91.2,
59.3,
94.6,
30.2,
48.7,
52.1,
86.7,
3.8,
68.1,
63,
26.4,
48,
73,
25.8,
87.4,
27,
70.5,
44.2,
74.5,
61.6,
87.9,
42,
58.4,
54.3,
66.9,
76,
83.7,
73.7,
77.8,
68,
91.1,
72.5,
45.3,
90.2,
71.3,
66.4,
63.4,
48.9,
20,
26.2,
67.8,
56,
88,
59.3,
35,
78.1,
104.6,
70.4,
75,
56.5,
84.2,
55.9,
69.8,
87.6,
45.4,
91.8,
65,
92.3,
54.4,
79.3,
39,
32.7,
56,
64.6,
8.9,
67.7,
16.4,
62,
56.5,
38.8,
82.2,
72.8,
59.2,
30.1,
40.2,
64.3,
51.7,
69.5,
39.9,
5.5,
64,
65.5,
63.1,
48.3,
45.2,
36.6,
75.4,
51.2,
76.3,
82.2,
33.1,
72.2,
38.5,
46,
44.5,
65,
85.6,
53.1,
4,
38.2,
41.1,
62.6,
20.3,
81.8,
5.9,
93.9,
93.2,
35.3,
85.7,
66,
98.6,
8.3,
2.3,
9.5,
53.5,
83.1,
18.9,
77,
55.2,
26.7,
39.1,
66,
89.5,
22.3,
88.3,
51.1,
90,
16.1,
64,
72.9,
87.4,
77.7,
21.7,
17,
43,
56.5,
54.1,
68.2,
84.9,
76,
43.7,
71,
92.4,
76,
71.7,
14.9,
66.6,
39.1,
81,
75,
63.4,
27.2,
59.3,
35.8,
17.7,
40,
65.6,
34.4,
77.4,
90.2,
61.4,
61.5,
84.9,
26.4,
89.9,
29.1,
72.9,
37.1,
96.5,
48.5,
15.2,
43.5,
8.4,
70.9,
49.7,
60.8,
88.2,
44.6,
70.7,
31.6,
53.6,
54.6,
72.3,
93.9,
38.4,
12.4,
29,
49.4,
43.8,
12.9,
33.2,
92.1,
20.6,
75.6,
59,
91.1,
50.2,
53.5,
69.1,
60.2,
49.9,
17.6,
68.1,
82.4,
62.9,
73.1,
24,
58.7,
41.9,
48.3,
30.4,
41.2,
90.1,
31,
63.2,
49.8,
40.7,
47.1,
80.6,
95.8,
56.4,
78,
84.9,
26.4,
75.3,
55.1,
82.7,
40.9,
18.3,
0,
41.6,
95.5,
19.6,
28.1,
96.6,
33.1,
57.4,
71.7,
81.3,
36.4,
56.9,
67.1,
48,
49.5,
88.6,
63.6,
85.6,
77.6,
54.7,
16,
87.8,
54,
90.8,
17.7,
66.4,
64.9,
60.7,
19,
80.7,
20.7,
47.9,
35.4,
84.5,
73,
50.9,
24.2,
13.6,
21.5,
58.5,
80.9,
96,
55.8,
24,
49.4,
92.3,
63.3,
59.8,
90,
60.1,
94.5,
26.9,
51.6,
48.8,
64.4,
0,
58.1,
64.1,
16.8,
73.5,
28.4,
94.6,
34.5,
95.7,
84.1,
56.6,
81.3,
65.6,
22.9,
40.3,
70.2,
79.3,
45.8,
83.7,
26.8,
33.3,
41,
46.4,
22.1,
19.2,
56,
77.3,
44.5,
16,
96.4,
46.3,
73.1,
43.6,
55.2,
16.8,
45.6,
77.8,
86.3,
82.2,
62.4,
55.4,
32.3,
67.8,
35.1,
77.7,
65.6,
59.6,
71.9,
54.2,
33,
62,
52.8,
5.8,
82.5,
71.8,
34.5,
66.4,
77.7,
76.4,
52,
45.5,
34.1,
85,
45.6,
57.1,
31.6,
59.9,
93.2,
68.8,
60.5,
58.2,
39.5,
53.7,
30.1,
17,
57.5,
36.6,
76,
83.1,
79.3,
35.8,
41.8,
54.3,
60,
38.5,
30.2,
60,
26.3,
39.6,
82.3,
52.6,
61.3,
83.2,
90.1,
70.6,
61.1,
47.7,
54,
84.6,
90.8,
94.1,
10.2,
74,
86.3,
63.7,
59.9,
22.8,
31.3,
19.6,
24.9,
79.6,
27.1,
67.2,
21.3,
71.2,
56,
50.2,
53.1,
68.8,
57.2,
4.9,
36,
55.8,
50.4,
9.7,
17.3,
54.3,
39.7,
86.8,
82.1,
42,
26.2,
31.2,
75.2,
33.3,
32.5,
66.1,
48.7,
50.7,
67.1,
67.7,
52.5,
66.5,
65.2,
45.2,
49.8,
70.1,
76.9,
80.2,
30.2,
91.5,
29,
39.3,
52,
49.1,
30.3,
63.4,
34.5,
82.4,
94.9,
76.6,
61.5,
73.6,
85.1,
12.2,
89.1,
24.9,
63.6,
16.1,
69.9,
9.2,
8.5,
78.9,
22.3,
58.1,
19.6,
91.8,
44.3,
40.8,
75.9,
30,
54.5,
64.7,
91,
30.2,
66.6,
71.4,
65.2,
59.9,
99.1,
68.4,
69.4,
63.2,
49.5,
79.4,
42.9,
95.4,
59.7,
67.8,
48.7,
42.5,
20.8,
96.9,
56,
94.8,
84,
82,
58.9,
27.5,
53.2,
79.3,
82.1,
85.1,
36.7,
24.1,
41.6,
79,
78,
33.8,
92.9,
51.5,
39.6,
59.7,
31.1,
51.4,
97,
35.5,
60.4,
19.9,
87.2,
29.2,
64.4,
39,
39.8,
78,
66.6,
81.3,
58,
96.8,
86.2,
79.3,
97.8,
59.9,
22.2,
68.8,
30.6,
61.5,
36,
92.5,
36.9,
48.7,
45.1,
48,
36.4,
78.8,
82.8,
45.5,
74.3,
21.3,
77.1,
23.4,
76.8,
104.2,
39.1,
24.6,
34.7,
81,
61.8,
23,
54,
80.2,
85.6,
9.1,
19.1,
33,
48.6,
93.7,
81.1,
48.7,
17.2,
67,
27.4,
65.7,
76,
34.7,
49.7,
39.1,
51.2,
48.9,
40.3,
56.4,
43.3,
99.2,
75.8,
69.2,
77.4,
71.8,
51.1,
46.6,
45.9,
0.6,
39.2,
42.1,
53.6,
44.1,
68.6,
85.6,
54.9,
54.6,
95.2,
20.5,
1.4,
68.6,
95.5,
9.7,
49.3,
39.3,
86.9,
22.3,
79.7,
94.5,
68.6,
48.3,
73.5,
101.6,
73.6,
47.2,
58.5,
59.9,
8.4,
81.4,
24.2,
59.3,
30,
35.9,
74.8,
62.4,
33.8,
58.1,
21,
65.2,
57.3,
40.2,
70.2,
83.8,
66.3,
27.4,
32.7,
71.6,
50.4,
3.1,
88.2,
40,
68.5,
42.6,
85.9,
48.4,
85,
1.5,
40.5,
57.1,
81.8,
56.6,
32.5,
61.3,
94.4,
84.7,
90.5,
31.7,
50.5,
31,
32.3,
15.7,
44.1,
66.3,
63.6,
85.9,
65.3,
4.2,
23.2,
69,
95,
57.2,
64.3,
77.9,
54.9,
75.6,
54.6,
87.1,
32.5,
60,
15.3,
55,
78.7,
30.7,
42.9,
99,
73.6,
57.7,
89.8,
41.3,
81.5,
56.2,
87,
10.9,
61.3,
63.7,
51,
27.5,
93.7,
100,
60.2,
87.8,
54.2,
50.1,
55.9,
81.9,
20.4,
65.2,
72.4,
8.3,
55.1,
74.5,
71.4,
21.2,
27.7,
47.7,
37.7,
78,
80.8,
83.9,
31,
75.1,
77.5,
28.6,
31.7,
11.8,
25.2,
32.7,
41.9,
38.9,
38.2,
53,
46.8,
25.1,
89.1,
14.5,
62.5,
71.6,
52.6,
40.9,
47.2,
97,
33.3,
28.6,
36.6,
93.6,
64.3,
46.4,
71.2,
45.5,
36.2,
48.2,
51.9,
76.2,
30.4,
53.4,
93.7,
38.8,
46.4,
92.3,
26.6,
32.9,
78.7,
89.8,
74.3,
65,
78.4,
58.6,
38.9,
36,
41.9,
66.8,
56.9,
73.6,
63.9,
63.8,
40.1,
20.9,
58.7,
74,
80.2,
37,
49.5,
40.8,
66.3,
50.8,
11.9,
24.3,
35.9,
11.3,
58.4,
27.2,
36.6,
77.8,
23.2,
37.7,
47.1,
33.2,
37.1,
93.9,
17.4,
46.4,
88.2,
74.1,
46.7,
97.7,
33.7,
40.9,
65.3,
70,
65.1,
84.4,
18.7,
66.2,
24.7,
92.1,
37.4,
81.3,
14.6,
90.9,
53,
73.6,
85.3,
41.1,
48.9,
53.6,
48.2,
45,
93.1,
33.2,
75.7,
56.5,
43,
49.4,
54.5,
43.8,
59.2,
67,
68.2,
30.6,
65.6,
58.8,
76.2,
92.6,
80,
99.6,
56.5,
82,
43.7,
44.9,
67.6,
37.7,
29.9,
46.6,
90,
52.1,
72,
61.4,
30.5,
36.9,
40.1,
90.9,
82.9,
32.6,
92.1,
35.5,
66.3,
53.3,
63.1,
93.1,
56.4,
85,
69.3,
71,
36.3,
28.7,
58,
84,
32.6,
15.8,
74.7,
82.8,
81.4,
30.9,
56.3,
53,
65.6,
41.6,
83.5,
48.4,
24.9,
74.4,
86,
65.2,
74.8,
18.5,
59.1,
47.5,
46.4,
63.7,
16.6,
18.7,
30.5,
41.1,
81,
19.8,
80.5,
24.1,
92.3,
71.8,
78.3,
35.9,
89.5,
87,
46.7,
4.6,
40.4,
17.6,
71.1,
35.9,
20.2,
70.7,
79.2,
28,
36.7,
46.3,
57.2,
16.2,
45.4,
44.7,
74.9,
93.5,
41.9,
91.3,
59.4,
42,
66.1,
78,
0.1,
78,
70,
39.2,
47.8,
50.9,
48.1,
86.1,
76.6,
40.1,
9.9,
90,
25.2,
79.6,
45.3,
70.9,
62,
52,
51.5,
74.8,
28.8,
60.5,
55.1,
83.4,
1.5,
44.9,
67.4,
45.9,
54.9,
85.4,
30,
34.4,
97.5,
92.7,
27.6,
65.1,
53.7,
21.2,
0.8,
39.3,
63,
75.2,
78.5,
59.8,
61.4,
34.5,
20,
17.6,
72,
41.6,
99.6,
43.2,
14.1,
70.9,
15,
50.3,
75.8,
33.9,
38.9,
34.5,
43.6,
86.7,
88.6,
89.6,
88.9,
51,
84.2,
43,
66.3,
13.2,
36.3,
61.9,
78.2,
76.9,
60.3,
85.5,
38.9,
64,
53.4,
14.3,
99.9,
38.8,
20.5,
76,
46.7,
62.6,
64.9,
94.5,
29.9,
65.3,
50.4,
68.7,
48.8,
62.6,
44.7,
64.2,
72.2,
25.7,
69.6,
54.3,
43.2,
44.4,
28.5,
90.4,
71.7,
62.6,
89.5,
42,
89.1,
85,
57.4,
66.3,
49.6,
52.5,
42.7,
46,
24.1,
25.5,
42.2,
88.3,
39.7,
89.7,
72.4,
90.3,
37,
86.3,
94,
50.5,
88.5,
24.9,
66.2,
57.8,
101,
25.6,
51,
23.7,
71.1,
93.8,
43,
77.2,
50.2,
42.8,
11.1,
71.3,
43.4,
37.4,
50.6,
38.9,
29,
74.9,
47.4,
50.4,
58.1,
88.1,
47.6,
69.2,
51.4,
59,
27.4,
38.8,
10.5,
12.5,
80,
73,
1.3,
88.1,
38.9,
82.3,
75.5,
29.4,
77.4,
51.9,
33.2,
75.1,
71.4,
37.1,
31.7,
100.3,
55.9,
65.7,
36,
26.3,
38.8,
84.1,
56.5,
90.5,
87.1,
26,
56.4,
84.4,
11.8,
74.4,
50.7,
90.4,
66.7,
22.8,
54.9,
95.8,
51.8,
76.9,
84.3,
48.9,
71.2,
65,
42.7,
91.7,
83.7,
83.5,
39.8,
78,
66.7,
66.9,
66.1,
61.3,
26.6,
30.9,
62,
49.8,
33,
44.8,
37.3,
31.8,
9.9,
7.3,
87.6,
70.5,
48.7,
53.7,
97.4,
86,
19.1,
79.7,
84.5,
52.5,
42.8,
29.1,
84.9,
73.6,
44.7,
58.3,
76.1,
74.5,
73.8,
77,
59.3,
23.9,
81.4,
53.7,
40.7,
77.7,
75.6,
32.9,
37.5,
53.5,
101.9,
62.3,
27.4,
30.7,
32.5,
81.6,
78.5,
59.8,
33,
60.7,
75.6,
95,
34.5,
96.5,
49.3,
18.7,
57.7,
69.9,
42.8,
27.4,
51.7,
38.8,
29.5,
36,
48.5,
61.4,
17.1,
49.3,
95.4,
67.9,
32.1,
17.3,
81.8,
94.9,
34.2,
56.1,
66.8,
67.7,
35.2,
56.5,
32.6,
38.5,
38.8,
50.7,
37.7,
33.2,
66.1,
32.3,
39.5,
41,
31.7,
72.2,
52.5,
59.3,
94.8,
29,
61.5,
46,
72.6,
74.2,
2.5,
80.8,
43,
60,
37.1,
65.8,
91,
71.1,
48.1,
82.9,
43.2,
49.6,
79.1,
56.2,
74.8,
74.5,
37,
65.7,
31.2,
79,
91.5,
57.2,
46.1,
77,
65.6,
38.2,
63.9,
59.7,
30.1,
35.5,
74.5,
70.7,
25.5,
85.1,
65.4,
64.6,
49.6,
96.3,
53.7,
26.7,
56.4,
75.7,
42,
97.7,
96.3,
48.2,
67.2,
57,
67.6,
86,
82.4,
48.9,
50.5,
64.3,
51.3,
89.7,
36.8,
60.7,
91.2,
81,
72.2,
40.6,
88.7,
67.8,
33.5,
84.4,
28,
53.3,
53.9,
38,
40.5,
25.2,
59.7,
50.9,
54.2,
64.7,
71.1,
56.1,
80.1,
81.2,
47.8,
51.5,
28,
37.3,
75.3,
45.6,
94.6,
77.3,
31.5,
26,
59.2,
65.7,
34.8,
30.9,
49.4,
51,
64.4,
5.6,
59.7,
42.8,
40.6,
90.7,
80.9,
44.8,
75.2,
21.9,
72.8,
66.1,
67.1,
32.2,
50,
49,
42,
54.8,
35.5,
69.7,
36,
47.4,
41.9,
66.9,
80.6,
79.5,
79.2,
23,
43.8,
27.5,
65.3,
79.2,
21.9,
51.1,
15.5,
74.3,
85.7,
58.8,
43.6,
42.5,
100,
10.4,
74.9,
79.7,
72.6,
27.8,
31.2,
57.6,
89.4,
35.5,
72.6,
61,
31,
43.3,
69,
45.5,
46,
68.6,
96.3,
51.6,
74.1,
24,
51.1,
5.4,
62.6,
82.2,
37.6,
16.5,
81.1,
39,
68.6,
39.2,
69.8,
74.1,
38.2,
55.5,
23.6,
34,
0,
31.3,
67.6,
89.7,
66.4,
87.5,
39.1,
86.1,
36.5,
11.7,
53.5,
22,
19.2,
38.8,
55.6,
64.4,
61.9,
97.1,
50.8,
92.5,
20.7,
28,
75.1,
33.6,
51.5,
50.5,
32.5,
31.5,
63.9,
74.3,
48.8,
42.5,
17,
46.7,
40.7,
0,
55,
74.5,
19,
67.5,
66.3,
89.2,
83.1,
49.9,
77.5,
51.3,
18.9,
24.5,
32.9,
77,
47.6,
21.4,
73.5,
41.5,
49.1,
35.1,
77.4,
36.9,
18.5,
60.9,
79.4,
100.5,
48,
55.4,
10,
68.8,
36.9,
73,
65,
47,
59.5,
78.8,
37.4,
75.7,
29.5,
64,
99.6,
67,
58.8,
74.6,
64.6,
47.1,
93.5,
21.9,
54.3,
81.4,
54.2,
65.2,
77.6,
35,
79.4,
66.1,
80.7,
36,
51.5,
39.6,
1.7,
55.9,
44.8,
10,
29.9,
72.9,
91,
64.1,
61.7,
33.5,
21.9,
6,
33.9,
50.4,
47.4,
70.5,
83.5,
75.9,
85.5,
37.3,
77.8,
47.6,
78.7,
6.8,
23.8,
60.7,
47.7,
48.9,
44.1,
45.4,
25.3,
11.4,
68.4,
84.4,
19.6,
45.3,
63.8,
89.6,
45.9,
90,
48.2,
88.8,
85.7,
78.4,
77.1,
39.2,
32.3,
66.7,
16.5,
69.8,
64.7,
35.5,
58.3,
75.5,
61.9,
22.6,
15.6,
72.1,
47.7,
26.8,
87.2,
37.3,
34.2,
75,
45.2,
67.8,
44.7,
42,
71.9,
72.7,
96.2,
71.7,
23.9,
30,
54.5,
85,
53.6,
70.7,
3.2,
40,
50.9,
91.1,
43.3,
85.3,
98.3,
87.8,
29.2,
79.8,
81.5,
37.5,
11.7,
47.8,
86.9,
25.7,
43,
64.3,
80.6,
44.9,
83.8,
43.8,
74.8,
67.6,
95.4,
73.1,
65.3,
68.4,
22.3,
66.4,
46.3,
44,
58,
61.8,
38.8,
53.6,
86.5,
32.6,
47.7,
77.9,
37,
42.3,
76.9,
67.3,
57.9,
43.3,
58,
83,
42.3,
55.3,
28.2,
48.5,
45.9,
70.4,
26.7,
42.8,
30,
53.7,
22.4,
26.7,
54.4,
71.5,
33.4,
84.7,
9.4,
67.3,
12.2,
54.7,
82.5,
6.6,
58.2,
72.4,
10.1,
61.3,
89.2,
55.7,
62.1,
2.5,
36.1,
43.1,
91.2,
49.2,
47.6,
81.4,
41,
77.2,
13.1,
39.4,
78,
113.4,
72,
49,
24.8,
67.6,
1.6,
5.9,
30.7,
78.9,
34.7,
75.9,
47.4,
62.9,
31.4,
46.5,
61.7,
49.7,
8.7,
68.6,
35.5,
16.4,
22.6,
20.4,
31.7,
22.2,
58,
97.4,
95.1,
67.2,
82.5,
61.5,
45.3,
69,
32.4,
65.2,
34.5,
86.4,
75,
31.2,
69.3,
17.6,
56.4,
92,
38.5,
33.3,
89.8,
84,
44.1,
16.7,
12.1,
63.7,
45.4,
55.4,
75.3,
61.7,
83.7,
35.1,
76.2,
83.1,
35.1,
59.8,
71.8,
67.2,
98,
72.8,
53.5,
87.2,
75.5,
53.4,
52.8,
90.2,
36.7,
72.4,
70.2,
92,
62.6,
42.6,
38.9,
25.5,
53.3,
73.9,
80.7,
87.1,
54,
59.5,
95.9,
6,
25,
26.4,
27.1,
49.5,
41.2,
91.7,
27.8,
90,
28.9,
76.3,
42.3,
19.6,
73,
56.9,
40.3,
70,
40.9,
63.3,
33.1,
18.4,
24.7,
48.6,
35.1,
64.7,
21.9,
61.3,
64.6,
24.3,
65.4,
47.9,
58.5,
56.3,
58.7,
44.9,
87.4,
86.5,
47.7,
29.4,
12.8,
33.1,
60.5,
54.3,
83.7,
72.8,
71.8,
31.2,
33.9,
90.7,
70.2,
65.9,
46,
64.7,
54.4,
73.6,
79.9,
22.7,
15,
27.4,
92.6,
44.8,
71.8,
50.4,
79.5,
26.6,
93,
26.7,
55.6,
51.5,
36.8,
18.1,
57.1,
90.7,
46,
55.2,
70.5,
76.3,
66.8,
57.5,
42.8,
68.7,
76.8,
53,
64.6,
7.1,
54.3,
32.2,
47.3,
35.4,
69.1,
37.8,
64.4,
46.9,
68.1,
31.9,
24.7,
73.2,
32.2,
52.2,
76,
43.2,
14.8,
49,
55.5,
33.3,
76.2,
66.3,
44,
91.3,
66,
43.4,
72.4,
66.8,
83.8,
33.7,
44.1,
70.5,
87.3,
13.5,
43.9,
73.1,
69.3,
32.5,
92.4,
65.9,
61.5,
95.7,
27,
69.6,
43.3,
29.6,
46,
93.7,
47.9,
9.5,
58.7,
26.7,
57.2,
88.5,
23.7,
35.6,
6.2,
22.8,
40,
26.9,
50.6,
17.9,
82.9,
24.1,
63.7,
57.8,
82.4,
53.8,
78.7,
64.3,
54,
89.7,
45.1,
74.2,
65.1,
77.8,
85.3,
60.5,
27.6,
44.4,
95.2,
8.3,
66.1,
54.5,
76.2,
93.6,
38.3,
null,
33.5,
57.5,
57.8,
33.4,
36,
85.9,
80.8,
63.1,
24.9,
58.4,
98.4,
69.8,
61.2,
45.5,
60,
75.5,
86.3,
69.2,
69,
81.6,
38,
32.8,
35.2,
61.3,
72.6,
69.4,
79.6,
47.1,
63.3,
74.1,
69.1,
61.5,
26.9,
77.4,
63.7,
62,
19.4,
37.2,
64.1,
51,
51,
74.2,
41.4,
29.7,
77.9,
48,
77.1,
55,
45.2,
63.2,
18.7,
36.1,
40.9,
78.1,
80.4,
48,
37.3,
35.6,
28.9,
69.3,
21,
69.9,
47.2,
95.1,
61.1,
89,
38,
31.7,
44.4,
72,
68.4,
22.4,
84.7,
4.5,
1.6,
44.5,
63.9,
22.4,
69.1,
46,
19.2,
68.1,
46.8,
78.5,
83.1,
91,
38.2,
88.3,
17.8,
94.2,
2.8,
17.9,
53.8,
74.6,
60.5,
60.3,
47.3,
44.5,
2.6,
72.5,
80.1,
83.4,
35.6,
41.6,
34.2,
61.9,
82.9,
95.4,
4.1,
98.5,
75.4,
28.8,
51.9,
87.6,
57.3,
96.8,
73.7,
70.8,
25.2,
19,
100.5,
46.5,
26.1,
46.3,
53.1,
93.1,
60.7,
54.9,
79.9,
66.6,
75.6,
70.4,
39.8,
33.2,
74,
71.4,
82.4,
52.7,
77.7,
28.3,
71.1,
64.7,
82.6,
64.6,
86.1,
50.6,
42.3,
50.4,
68.8,
44.8,
44.1,
66.7,
65.8,
39,
66.7,
75.8,
45.8,
30.4,
10.8,
94.5,
63,
79.1,
46.5,
0.4,
79,
72.9,
30.5,
79.2,
53.6,
73.7,
32.3,
45.9,
58.5,
88.7,
85.8,
67.3,
88.7,
81,
37.5,
83.1,
90.7,
76.3,
44.6,
32.1,
77.8,
37.6,
48.2,
3.1,
40,
56.2,
20.9,
41.6,
85.6,
52.6,
36.2,
37,
90,
37.2,
8.9,
53.1,
41.4,
57.1,
47.3,
46,
64.2,
82.5,
60.8,
65.1,
43.7,
64.4,
71.8,
82.6,
10.2,
58,
41.8,
26.5,
16.2,
53,
64.4,
36.3,
58.8,
47.2,
96.4,
23.8,
43.9,
79.5,
35.8,
55,
59.4,
32.3,
34.2,
65,
76.8,
77.7,
96.4,
77.6,
3.9,
51.3,
67.1,
65.3,
76.4,
27.8,
39,
75.1,
56.3,
97.9,
74.7,
54.9,
59.8,
21.7,
33.6,
62,
62.6,
29.6,
32.2,
34.5,
49.5,
9.7,
57.1,
55,
82.4,
82.8,
81.4,
39.9,
48,
6.5,
89.4,
46.8,
94.3,
65.4,
53.2,
77,
63.3,
26.9,
98,
82.4,
14.1,
53.1,
77.2,
45.8,
46.2,
72.6,
71.4,
47.8,
51.7,
95,
44,
82.3,
48.6,
50,
56.8,
73.5,
76.7,
55.3,
36.2,
77,
49.7,
26.7,
81.8,
34.8,
17.9,
55.5,
32.6,
9,
88.5,
31.1,
74.1,
47,
64.5,
27.7,
43.2,
51.1,
23.7,
96.7,
28.7,
29.9,
11.4,
52.8,
31.1,
51.5,
37,
79.7,
37.6,
77.3,
28.6,
64.1,
68.3,
80.5,
48,
47.8,
52.1,
81.7,
54.9,
71.6,
39.5,
61.1,
58.6,
62.5,
16.5,
69,
33.6,
48.7,
80.1,
44.3,
79.2,
73.2,
90.4,
69.4,
14.8,
37.6,
67.4,
23.3,
94.9,
74,
56.3,
86,
46.5,
22,
44.1,
35.8,
1.7,
21.3,
30.1,
7.6,
66.8,
62.5,
77.5,
46.6,
0,
45.7,
53,
27.9,
42.9,
69,
47.7,
50.1,
67.8,
45.6,
66.9,
14.8,
83.5,
92.3,
100.7,
17.7,
38,
45.1,
39,
49.2,
83.7,
17.8,
46.3,
66.3,
37.2,
67.9,
50.8,
63.6,
43.3,
34,
42.1,
23.4,
39.7,
0,
85.6,
61.8,
64.9,
60,
69.6,
41.5,
97.9,
42.7,
16.1,
40.7,
63.1,
44.8,
94.5,
30.2,
50.3,
4.4,
16.6,
41.1,
65.8,
34,
75.5,
50.3,
50.9,
76.5,
0.2,
75.6,
77.5,
91.1,
96.1,
47.5,
27.3,
57.1,
38.4,
64.8,
46.3,
42.3,
73.7,
34,
87.4,
84.4,
33.7,
49.7,
66.1,
87,
55.8,
1.2,
24.4,
87.1,
77.7,
80.2,
96.6,
94,
5.7,
12.3,
78.2,
4.2,
23.8,
43.6,
61.4,
74.7,
48.2,
64.6,
23,
16.5,
52.7,
7.4,
66.4,
51.6,
52.5,
70,
93,
51.3,
81.6,
70,
71.3,
61.3,
73.7,
14.2,
73,
39.6,
57.7,
24.8,
62.6,
40,
23.1,
90.5,
70.1,
37,
71.3,
24.5,
36.5,
31.9,
0,
41.4,
54.6,
69.7,
28.4,
73,
34.6,
11,
68.7,
74.9,
10.1,
67.6,
64,
38.6,
52.5,
36,
39.7,
52,
49,
56.9,
65,
40.2,
72.4,
57.3,
82.6,
0.3,
65.4,
94.1,
30.6,
5.6,
0,
70.3,
53.9,
56.6,
61.7,
95.5,
41.5,
12.5,
34.6,
70.9,
19.4,
78.1,
76,
48.8,
24.7,
85,
80,
71.1,
61.8,
78.6,
5.9,
59.2,
1.3,
68.6,
78.9,
63.5,
24.8,
61.9,
97.1,
56.5,
55.6,
21.9,
69.8,
28.4,
73.9,
69.5,
61.2,
21.1,
38.7,
42,
35.3,
46,
85.5,
55.6,
49.9,
61.8,
1.9,
49.8,
51.5,
17.5,
99.1,
37.9,
59.9,
86.2,
49,
93.1,
49.9,
29.2,
24.7,
44.2,
53,
51.5,
53.8,
26.8,
47.6,
11.9,
17.6,
38.2,
74.8,
95.2,
67.7,
84.1,
66.9,
17.6,
66.6,
92.1,
73.7,
40.3,
0,
59.5,
67.1,
43.6,
28.6,
91.8,
85.9,
74.8,
43.5,
55.9,
35.2,
37.4,
64.5,
61.4,
44.8,
40.5,
62.2,
55.9,
19.3,
46.2,
22.1,
22.6,
63,
73.5,
34.2,
72.5,
84.4,
29.8,
14,
66.3,
69.8,
61.4,
75.5,
45.5,
49.2,
80.6,
48.8,
86.4,
21.9,
19.3,
26.3,
24.3,
88.4,
69.9,
4.6,
78.8,
51.8,
23.4,
69.6,
77.5,
87.5,
67.1,
15.3,
5.3,
69,
27.4,
59.9,
24.7,
67.4,
41.6,
51.3,
15,
40.9,
89.5,
28.3,
91.3,
44.2,
91.8,
62.2,
33.4,
52.3,
7.8,
97,
32.7,
29.7,
40.6,
42.4,
83.2,
43.2,
81.7,
32.3,
61.1,
67.2,
53.2,
79.7,
79.1,
55.1,
63.7,
67.6,
72.7,
22.7,
72.6,
33.9,
54.2,
16.8,
45.6,
15,
24.9,
22.8,
85,
19.5,
48.9,
87.7,
77.5,
74,
46.3,
33.1,
31.3,
43.3,
10.1,
64.4,
18,
23.5,
67.8,
21.7,
70.6,
98.5,
64.2,
55.7,
89.1,
28.4,
28.7,
72.1,
74.3,
55,
39.2,
46.3,
40.7,
9.5,
56.5,
68.7,
64.7,
52.8,
96,
82.4,
55.8,
71.1,
68.2,
28.8,
44.9,
38.6,
31.8,
48,
70.4,
28.8,
19.4,
59.1,
65.5,
16,
36.7,
43,
49.6,
93.5,
55.7,
27.8,
96.4,
39.6,
95.5,
70.4,
75.4,
4.8,
58,
52,
38.7,
54.4,
38.1,
60.6,
71.5,
76.9,
63.2,
70.5,
21.5,
47.6,
21.6,
34.9,
92.9,
75.5,
78,
6,
32.2,
66.8,
56.9,
20.9,
85.7,
74.6,
80.3,
40,
49.4,
47.9,
31.1,
73.9,
3.9,
47.5,
29.1,
34.2,
59.5,
44.8,
91.2,
33.3,
29.1,
86.4,
59.8,
50,
35.5,
61.2,
31.8,
28.2,
96.1,
57.3,
22.7,
0.7,
5.1,
46.1,
55.9,
58.8,
63.5,
55.4,
63.8,
23.3,
66,
5.4,
52,
14.9,
52.6,
46.1,
71,
57.1,
67.7,
85.4,
98.1,
55.8,
84.1,
65.5,
43.7,
15.1,
55,
49.9,
11.8,
85.2,
51.5,
75.5,
53.7,
46.6,
72.4,
42.9,
22.2,
66.7,
24.4,
89.7,
69,
47.9,
66.2,
13,
53.1,
57.9,
35.1,
48.7,
95.2,
88.5,
40,
44.9,
90.3,
42.5,
86.9,
22.9,
6.4,
96.2,
54.3,
98.9,
52.7,
85.1,
73.4,
69.5,
62.9,
68,
48.4,
55.8,
103.6,
73,
37.8,
88.1,
28.3,
59.1,
93.4,
32,
27,
36.6,
36.7,
30.6,
40.4,
63.3,
55.7,
53.4,
46.6,
79.4,
60.3,
35,
71.4,
43.8,
99.3,
51.3,
24.7,
60.8,
29.4,
29.2,
83,
37.8,
92.4,
50.1,
30.1,
78.6,
7.7,
68.6,
80.2,
27.4,
48.2,
40.9,
71.1,
28.4,
40,
71.5,
78.1,
70,
83.1,
40.2,
54.2,
35,
78.7,
55.6,
94.6,
57.6,
10.8,
92.3,
48,
15.5,
90.2,
39.2,
75,
40.8,
95.5,
16.6,
83.1,
71.1,
49.7,
72,
75.7,
18.6,
96.3,
32.9,
21.7,
0,
75.1,
60.4,
67.9,
30.1,
22.7,
56.8,
78,
52.2,
64.1,
67.4,
58.7,
83.4,
70,
44.8,
68.9,
26.3,
0,
21.2,
31.1,
33.5,
45.3,
42.2,
60.4,
45.8,
98.2,
73.9,
85.7,
46.6,
17.7,
30.3,
49.2,
67.6,
32.2,
30.2,
39.1,
48.6,
77,
71.4,
81.9,
13.5,
70.4,
73.7,
50.9,
62.6,
78.4,
88,
48.6,
56.8,
102.6,
73.6,
38.4,
64,
23,
91.9,
55,
70.5,
39.6,
55.7,
32.8,
53.7,
56.5,
48.8,
94,
69.3,
62.1,
48.9,
27.9,
37.6,
47.2,
92.3,
38.4,
40.2,
48.5,
66.9,
23.8,
73,
2.2,
39.2,
77.7,
69.1,
99,
98.2,
65.8,
34.5,
45.5,
71.8,
39.3,
58.2,
63.3,
50.5,
97.4,
70.5,
89.1,
42.6,
65.1,
76.1,
89.3,
97.5,
22.1,
81.1,
31.4,
24.7,
25.1,
80.2,
78.9,
54.5,
31.7,
53,
95,
50.5,
58,
61.5,
84.9,
73,
87.1,
37.5,
3.4,
35,
90,
39.7,
49,
11.4,
78.4,
81.2,
59,
0.9,
97.3,
15.3,
44.2,
92,
72.3,
19.5,
62,
56.1,
39.9,
97.2,
73.7,
32.3,
24.2,
77.5,
34.4,
84.7,
76.3,
92.8,
48.7,
72,
74.6,
34.4,
67.3,
65.4,
94.1,
68,
53.3,
68,
38.3,
57.2,
71.9,
83.6,
43.4,
62.5,
96.5,
10.9,
31.4,
71.6,
94,
43.2,
79.6,
81.4,
18.4,
56.6,
30.3,
50.4,
46.2,
36.3,
39.4,
48,
34.2,
61.3,
35.3,
83.5,
48.9,
43.9,
75.3,
19.4,
33.5,
45.7,
69.1,
66.9,
77.5,
90.6,
43.5,
0.1,
51.9,
84.9,
46,
28.4,
6.4,
1.5,
58.8,
40.8,
4.2,
95.2,
54.8,
28,
52.4,
52.7,
68.5,
64.3,
95.7,
31.9,
86,
84.6,
13.5,
48.5,
98.2,
32.4,
64.6,
66.6,
49.3,
52.8,
78,
36.3,
60.6,
86,
68.5,
80.6,
39.8,
66.1,
85.2,
64.6,
32.5,
76.8,
69.6,
92.8,
38.9,
40.5,
65.5,
95.6,
43.7,
58.4,
30.2,
29.1,
84.5,
73.2,
79.9,
32.8,
47.3,
96.5,
58.8,
47.9,
11,
92.2,
39.6,
79.9,
41.5,
82.6,
83,
41.7,
80.3,
30.4,
27,
79.4,
46.7,
55.4,
80.5,
38.4,
68,
2.3,
78.8,
70.1,
86.4,
81,
62.3,
37.8,
53.8,
44.6,
68.4,
12.2,
97.5,
35.8,
49.4,
72.1,
74.9,
24.4,
53.2,
48.2,
60.4,
69.9,
37.6,
81,
50.8,
25.3,
78.1,
10.1,
34.6,
52.7,
9.6,
64.3,
63.3,
86.6,
30.7,
37.6,
61.4,
0.1,
5.4,
68.5,
73.9,
62,
23.1,
59.8,
55.7,
35.9,
22.4,
67.8,
30.7,
54.7,
89.9,
41.5,
56,
92.1,
34.9,
86,
87.9,
90,
44.1,
63.9,
93.8,
90.3,
97.5,
36.4,
51,
85.2,
35.2,
86.9,
76.2,
95.1,
79,
68.1,
78.4,
81.9,
74.5,
72.6,
54.5,
47.8,
91.6,
33,
12.7,
43.8,
48.4,
33.1,
49.4,
80.8,
68.5,
47.5,
68.2,
69.1,
78.4,
24.3,
35,
63.1,
38.9,
52.5,
45.9,
3.8,
97.2,
51.7,
61.2,
91.7,
4.1,
53,
4.2,
35.1,
27.4,
61,
14.8,
65.1,
38.7,
31.4,
26.7,
96.3,
92.6,
51.5,
62.1,
78,
83,
79.7,
36.5,
58.5,
67.9,
43.4,
74.8,
53.6,
83.7,
98.8,
58.8,
64.5,
67,
52.5,
24.6,
15,
75.3,
84.5,
22.6,
10.6,
90.8,
16.9,
61.3,
58.9,
83,
34.1,
98.5,
71.4,
70,
47.2,
6,
28.6,
58.6,
94.6,
86.6,
70.3,
92.7,
30.3,
28.8,
39,
39,
20.7,
51.6,
46.9,
58.6,
51.1,
55.2,
30.5,
23.6,
58.7,
90.1,
67.7,
36.7,
81.3,
30.6,
51,
78.4,
46.1,
94.4,
57,
49.7,
68.7,
86.5,
63.3,
93.1,
66.6,
61,
48,
15,
71.8,
53.9,
84.1,
25.7,
19.2,
63.2,
38.2,
39.9,
53.4,
43,
88.2,
53.3,
71.6,
32.8,
36.2,
23.8,
73.3,
29.3,
23,
87.4,
80.9,
50.6,
85.4,
37.6,
62.6,
16.3,
75.1,
14,
98,
11.3,
92.6,
12.6,
33.1,
66.9,
32.1,
70.7,
14.3,
89.8,
72,
46.7,
70.7,
19.7,
100.1,
72.1,
31.7,
96.3,
48,
45.9,
98.8,
75,
53.3,
85.5,
72.2,
83.8,
0,
43,
25,
31.6,
63.1,
49.7,
31.1,
63.9,
18.1,
82.9,
62.7,
58.3,
33,
61.2,
76.3,
60,
76,
42.3,
49.1,
29.6,
66.6,
69.9,
30.1,
23,
46.5,
48.9,
68.9,
28,
46.4,
19.7,
66.4,
60.6,
44.3,
17.4,
78.6,
47.4,
80.6,
77.5,
53.1,
81.5,
44.2,
61,
49.2,
82.5,
50.6,
62.7,
57.1,
49.6,
40.8,
62.7,
71.8,
8.3,
74.5,
27.5,
96.4,
74.5,
52.1,
32.5,
55.9,
60.9,
77.8,
55.8,
44.4,
44.5,
18.9,
64.3,
25.9,
83.5,
84.9,
65.8,
7.5,
90.5,
94.4,
79.6,
16.7,
96.3,
8.2,
32.9,
8,
27.2,
87.6,
76.1,
42.2,
30.4,
72.5,
80.8,
77.4,
19.3,
76.7,
92.1,
43,
33.2,
64.2,
69.9,
94.8,
9.6,
36.6,
82.6,
62.5,
87.7,
48,
78,
93.1,
57,
69.2,
27.9,
22.6,
88,
88.7,
87.3,
51.6,
75.4,
66.5,
98.3,
30.1,
9,
34.3,
77,
77.8,
93.1,
53,
39.5,
46.1,
91.3,
67.2,
75.3,
75.3,
37,
62.1,
37.2,
35.5,
13.9,
92.9,
54.4,
8.3,
85,
10.8,
93.2,
66,
50.7,
13.3,
36.7,
43.9,
67.8,
64.6,
56.7,
82.3,
49.7,
71,
80.8,
99,
77.5,
80.3,
77.3,
74.9,
40.2,
69.8,
81.3,
17.2,
39.9,
85,
90.4,
58.3,
87,
92.6,
47.8,
39.8,
78.4,
44.4,
14.3,
36.9,
38.4,
26.8,
77.6,
66,
85,
69.7,
26.5,
55.7,
96.5,
9.5,
20.8,
38.4,
40.1,
81.7,
75.9,
60.2,
71.9,
42.7,
23.3,
53.6,
97.5,
62.2,
39.5,
46.6,
92.5,
90.9,
37,
81.6,
3.6,
62.3,
77,
68.3,
59.4,
9.5,
5.6,
81,
39.8,
30.6,
69.1,
63,
85.5,
90.4,
35.6,
58.1,
79.6,
29.7,
51.6,
29.6,
84,
40.2,
75.7,
50.8,
52.4,
96.4,
85.5,
44.3,
54.6,
64.1,
33.3,
66.1,
28,
33,
44.3,
76.3,
34.6,
62.8,
52.5,
70.9,
40.3,
76.4,
41.6,
90.5,
45.7,
42.7,
85.2,
35.4,
39.9,
12.7,
37.3,
59.7,
79.2,
55,
13.6,
47.1,
78,
47.8,
39.5,
13.4,
17.2,
88.9,
47.6,
68,
18.2,
39.9,
86.3,
58.6,
61.3,
72,
0.3,
96,
92.5,
48.9,
36.4,
66.5,
22.7,
70.9,
50.5,
36.1,
72,
68,
32.4,
52.9,
25.7,
88.9,
33.8,
70.1,
88.7,
79.6,
60.2,
65,
73.9,
81.8,
31.7,
80.3,
44.2,
73.6,
15.7,
75.9,
86.6,
50.7,
19.3,
59.3,
41.1,
65.9,
67.5,
59.2,
40.8,
29.7,
64.8,
22.2,
79.9,
25.5,
33.6,
47.8,
70.9,
80.3,
97.5,
73.2,
48.8,
68.6,
89.1,
71.7,
77.8,
56.4,
10.9,
53.6,
92.6,
61.2,
82.7,
6.1,
16.9,
59.2,
82.4,
54,
76.5,
69.4,
63.8,
13.1,
46.3,
83.3,
59.7,
6.1,
88.8,
18.5,
86.6,
55.4,
89.1,
65.1,
78.8,
49.1,
98.5,
53.2,
39.8,
36.7,
37.8,
86.2,
48.1,
55.7,
55.3,
57.8,
61.2,
52.3,
72.5,
66.6,
77.9,
78.3,
13.2,
97.2,
101,
51.1,
42.5,
39.1,
81.2,
46.3,
70.5,
78.6,
9.6,
68.1,
89.6,
34.8,
68.8,
62.3,
26,
68.4,
83.2,
13.4,
78.7,
40.4,
75.5,
42.8,
16.9,
60.7,
45,
29.7,
63.1,
95.7,
36.6,
92.1,
68.5,
38.8,
47.5,
8.7,
49.6,
30,
62.3,
57.6,
10,
35.5,
47.8,
81.3,
15.1,
97.6,
92.5,
27,
57.2,
36.5,
66,
25.3,
81,
82.5,
87.8,
32.2,
29.8,
75.8,
15.1,
74.5,
39.8,
89.4,
75.2,
44.8,
31.5,
42.9,
18.7,
52.8,
77.1,
40.1,
66,
64.9,
62.8,
84.9,
59,
6.8,
30.8,
20.7,
25.3,
34.9,
69.9,
61,
12.7,
62.4,
26.3,
38.9,
87.7,
81.3,
12.6,
67.3,
46.1,
61.3,
65.7,
27.3,
48.7,
4.9,
86,
75.2,
78.9,
41.6,
61.6,
41,
65.2,
36.8,
98.7,
73,
12.6,
46.4,
45.9,
75.6,
78.3,
37,
19.8,
82,
52.1,
47.9,
14.2,
25.4,
67.5,
100.9,
73.1,
76.1,
64.8,
68.1,
53,
81.8,
5.8,
72,
56.1,
42.4,
85.6,
57.9,
95.6,
23,
50.2,
45.4,
77.2,
0.5,
78.4,
48.9,
59.8,
69.4,
52.8,
16.1,
53,
60,
70.7,
56.4,
77.5,
83.3,
42.3,
60.5,
88.3,
32,
41.8,
46.5,
30.1,
22.9,
44.2,
29.4,
72.8,
12,
46.5,
34.3,
88.1,
24.9,
45.7,
45.1,
37.2,
28.8,
55.1,
89.8,
42.4,
88.5,
43.5,
32.7,
100.4,
75.6,
63.7,
46,
46,
66.8,
81.8,
41.6,
24.2,
76.2,
45.6,
21.4,
66.3,
56.6,
49.9,
33.3,
37.2,
21.9,
78.2,
79.7,
30.7,
79.9,
29,
74.8,
51.5,
74.8,
67.2,
32.5,
77.3,
74.2,
92.7,
62.7,
68,
96.8,
39.8,
67.1,
42.9,
49.9,
85.5,
55.1,
22.1,
68.2,
26.7,
50.7,
60.9,
24.3,
48.1,
54.1,
99.7,
22.5,
60.7,
57.1,
49.1,
59.8,
64.8,
40.1,
12.3,
57.1,
74,
22.3,
0,
44.3,
61.1,
55.5,
65.9,
61.5,
75.5,
31,
76.8,
72.2,
54.7,
51.4,
83.2,
36.4,
64,
19.5,
85.5,
43.6,
89.3,
81.3,
38.2,
85.2,
54,
41,
74,
44.9,
7.5,
62.6,
85.3,
2.5,
30,
31,
34.7,
99.4,
48.8,
67.7,
70.4,
14.6,
25.7,
65.1,
43.6,
92.2,
82.4,
78.2,
78.2,
22.7,
25.8,
50.8,
91,
42.4,
88.5,
36.8,
7.9,
58.6,
74.4,
28.9,
40.2,
84.8,
86.2,
32.3,
71.2,
92.6,
77.5,
30,
22,
46.3,
40.9,
59,
45.7,
33.6,
69.9,
70.2,
54.1,
48.6,
41.1,
63,
42.9,
38,
29.4,
30.9,
50.9,
59.4,
47.1,
48.6,
83,
23.1,
57.8,
41.8,
83.5,
68.7,
48.5,
67.8,
32.2,
50.9,
36.2,
89,
82.8,
46.7,
32.4,
41.3,
29.7,
68.5,
65.3,
67.6,
98.9,
90.1,
68.7,
98.7,
79.8,
57,
53,
22.1,
60.6,
59.8,
49.7,
48.8,
54.2,
20.6,
82.7,
43.4,
16.5,
40.1,
65.6,
36.2,
36.1,
93,
71.4,
80.5,
61.9,
33.6,
81.2,
98.1,
23.3,
94,
85.2,
77.3,
71.2,
70,
73.4,
15.6,
88.8,
43.3,
28.4,
66.3,
30.8,
53.1,
0,
30,
61.7,
74.4,
21.7,
56.8,
0,
68.5,
88,
84.2,
65.7,
1.1,
26.6,
94.3,
56.7,
38.6,
63.4,
29.7,
69.8,
44.5,
44.2,
85.2,
68.5,
45.1,
33,
48.5,
69.3,
82.1,
40.5,
68,
63.3,
54.7,
0,
47.5,
63.9,
44.7,
72.2,
44.2,
53.9,
88.3,
44.6,
59.4,
38.2,
58.8,
80.3,
14.3,
42.8,
75.4,
46.5,
68.6,
42.5,
98.6,
74.7,
39.5,
75,
26.5,
54,
52.5,
26.7,
70.4,
5.9,
62.1,
66.4,
76.8,
34.9,
66.3,
53.9,
92.6,
43.8,
60.9,
14.4,
66.7,
43.4,
53.4,
69.1,
38,
78.8,
52.3,
70.4,
79.2,
56.6,
74.5,
47.8,
68.5,
45,
70.4,
47.9,
58.8,
61.1,
20.3,
45.4,
91,
53,
86.3,
69.5,
81.3,
27.7,
25.7,
41.3,
80.8,
24.8,
76.2,
38,
92.2,
57.2,
71.2,
51.7,
52.9,
95.9,
46.1,
7.3,
73.4,
23.7,
85,
23.9,
58.9,
37.6,
41.4,
61.3,
48.3,
22.4,
49,
36.1,
52.8,
49.4,
78,
45.6,
35.3,
35.3,
33.4,
58.5,
6.4,
68.6,
24.5,
36.2,
22.2,
54.4,
36.7,
64.8,
87.2,
55.3,
61.9,
54.4,
47.3,
50.2,
38.2,
32.1,
76.1,
34.4,
12.8,
38.5,
48.6,
43.6,
72.8,
14.1,
55.5,
58,
84.5,
74.1,
68.4,
52.2,
68.3,
42.2,
97.4,
88.6,
74.2,
45.4,
65.1,
13.6,
35.2,
81.8,
33.7,
83.9,
65,
48.9,
38.7,
4.1,
49.4,
33.6,
79.4,
35.9,
71.1,
79,
44.2,
34.8,
48.5,
33.9,
62.1,
22.3,
24.7,
59.4,
70.6,
54.6,
86.7,
52.4,
61.5,
22.6,
50.1,
29.9,
51.6,
46.6,
34,
62.8,
48.6,
63.9,
72.5,
38,
45.9,
87.6,
55.7,
80.5,
92.8,
92,
58.9,
78.4,
58.8,
59.3,
31.9,
null,
41.3,
33.9,
43.9,
65.7,
35,
30.3,
83.7,
62.8,
56.7,
44.3,
37.3,
54.8,
64.4,
81.9,
22.6,
47.2,
27,
18,
72.5,
46,
79,
36.7,
21.5,
42.3,
37.6,
47.3,
50.6,
33.2,
57,
74.3,
53.4,
44.3,
51.6,
72.1,
44.1,
90.1,
43.8,
40.4,
78.3,
72.3,
60.8,
88.5,
87,
29.6,
57.7,
22.8,
87.2,
52.9,
18.6,
56.5,
48,
25.7,
22.9,
88.7,
40.3,
99.3,
86,
35,
34.7,
34.6,
42.4,
71.3,
64.6,
82.1,
43.9,
75.4,
38.4,
9.6,
45.9,
49.9,
75.6,
2,
30.2,
35.7,
52.9,
29.3,
45.6,
44.9,
79.4,
45,
25.9,
66.1,
14.9,
79.3,
12.3,
33.2,
86.5,
67.4,
19.8,
25.8,
99.1,
90.5,
64.7,
63.8,
88.5,
35.5,
49.1,
50.6,
50.9,
35.6,
32.7,
93.7,
2.1,
55.7,
92.3,
49.4,
46,
81.2,
94.9,
39.1,
50.1,
44.4,
82.4,
68.6,
39.3,
68.3,
52.6,
48.4,
73.9,
47.9,
66.1,
28.1,
61.8,
41.2,
43.9,
45,
77.8,
28.5,
57.4,
93.5,
81,
60.5,
66.7,
49.6,
64.2,
80.6,
70.5,
42.7,
34.5,
78,
27.3,
46.9,
78.3,
63.8,
78.7,
40,
26.2,
73.9,
23.7,
43,
51.4,
73.1,
42.2,
83.6,
76.7,
16.8,
51.8,
56.6,
59.2,
36.9,
26.2,
17.6,
22.2,
68.3,
83,
43.5,
52,
33.4,
34.9,
34.1,
34,
98.2,
78.5,
62.6,
48.3,
40.9,
92.5,
91.2,
65,
79.9,
81.5,
15.8,
52.8,
73.9,
51.4,
97.9,
58.5,
59,
7.8,
26.5,
79.9,
22.1,
45.2,
50.6,
97.3,
12.7,
13.9,
5.6,
43.4,
54.2,
95.7,
25.2,
37.9,
57.1,
83.3,
71.5,
53.9,
77.9,
32.4,
38.1,
54,
54.2,
96.6,
24.5,
12.6,
68.6,
17.8,
74,
48.7,
89.1,
36.8,
66.4,
38.8,
70,
100.2,
2.3,
54,
45.4,
69.6,
47.6,
71.2,
78.7,
75.4,
47.8,
53.6,
34.5,
73.7,
40.8,
48.5,
70.1,
85.6,
18.4,
64.8,
88.5,
29,
60,
89.2,
36.6,
85.3,
34.1,
29.2,
58.2,
81.3,
52.7,
46.3,
21.1,
72.3,
97.3,
82.1,
14.5,
29.1,
24.6,
41,
56.9,
32.6,
31.1,
37.2,
92.2,
54.7,
76,
60,
59.6,
24.5,
58.6,
0.3,
49.6,
16.7,
51.4,
65,
31.2,
13.9,
73.9,
57.3,
31.4,
75.6,
29.7,
87.4,
74.4,
63.4,
75.3,
44.5,
17.8,
15.6,
51.7,
89.9,
56.4,
51.6,
57.3,
79.1,
68.5,
62.6,
29,
72.2,
38.4,
5.3,
37.3,
71,
63.5,
79,
70.1,
69,
67,
44.2,
73.6,
83.6,
43.4,
64.3,
19.1,
50.8,
33.8,
22.4,
58.6,
6.1,
19.8,
49.4,
55.6,
43,
95.4,
67,
40.5,
64.7,
52.4,
71.7,
44.3,
53.9,
50.5,
49.8,
52.6,
71.8,
60,
42.4,
67,
34.3,
40.9,
6.2,
44.4,
78.9,
74.3,
40.4,
32,
48.4,
98.3,
65.4,
53.5,
77,
34.8,
92.2,
94.3,
65.4,
83.7,
36.2,
83.5,
45.3,
55.6,
66.7,
75.6,
43.8,
28.5,
35.4,
57.7,
85.3,
34,
2.2,
65.3,
98.1,
72.2,
38.9,
85.1,
96.2,
17.2,
86.2,
59.3,
79.3,
66.5,
61.7,
76.3,
69.7,
53.5,
33.1,
41.8,
81.1,
31.2,
29.7,
72.6,
77.1,
17.1,
65.3,
79.4,
38,
1.9,
70.2,
80.6,
64.2,
83,
10.2,
61.6,
62,
25.2,
38.5,
7.4,
24.5,
57.1,
77.4,
56.9,
50.1,
59.3,
58.3,
94.9,
34.6,
3.5,
63.3,
64.4,
75.3,
79.9,
11.5,
9.4,
70.4,
77.9,
64,
95.8,
30.1,
66.2,
70.4,
60.8,
11.5,
42.9,
37.5,
44.7,
36.4,
49,
62.8,
71.6,
83.1,
14.5,
80.2,
27.5,
98.5,
81.8,
46.7,
84.5,
5.6,
62.7,
63.5,
48.1,
61.9,
18.2,
48.6,
75,
60.2,
59.3,
56.3,
31.1,
44.8,
33.6,
92.2,
74,
33.8,
63.7,
47.4,
77,
69.8,
93.8,
36.5,
42.5,
33.2,
13.4,
34,
95.6,
53,
83.5,
52.6,
80.5,
46.1,
36.7,
79.4,
61.9,
63.5,
71.2,
80.3,
89.7,
46,
54.7,
38,
96.2,
37.2,
56.9,
72.3,
58.4,
92.6,
62.2,
33,
31.9,
84.1,
84.7,
36.5,
60.1,
81.5,
41.1,
53.9,
87.8,
49.5,
57.2,
49.7,
98.3,
62.3,
94.3,
40.7,
86.9,
8.7,
61.4,
57.5,
68,
87,
52.7,
21.8,
66.8,
63.3,
44,
61.7,
58.7,
76,
60.6,
88,
79.2,
94,
54.6,
99.1,
null,
85.2,
40.7,
70.5,
58,
51.8,
81.1,
53.8,
58.2,
83.7,
57.1,
66.8,
45.9,
77,
77.6,
69.4,
25.7,
63.5,
58.9,
72.2,
46.4,
96.5,
79.1,
50,
74.5,
71.7,
88.1,
77.9,
47.4,
49.6,
55,
66.2,
52.5,
73.3,
85,
70.4,
29.9,
47.7,
56.8,
76.3,
63.8,
46,
44.9,
9,
82.6,
53.7,
23.7,
78.8,
42.6,
17.3,
34.8,
16.1,
9.7,
51.4,
39.5,
69.8,
9,
24.2,
9.9,
92.8,
89.7,
44.6,
95,
18.7,
25.4,
53.8,
62.7,
62.3,
44.7,
84.9,
1.2,
84.4,
36.3,
14.5,
87,
87.3,
58.7,
91.1,
55.2,
88.9,
38.2,
67.8,
29.6,
87.8,
50.7,
50.9,
75.1,
75.6,
37.1,
8.9,
45.1,
59.1,
38.9,
58,
60,
90.1,
37.6,
67.9,
40.6,
33.8,
65,
61,
60.8,
74,
65.3,
63.1,
57.4,
84.1,
48.3,
59.1,
62,
71.4,
67.7,
58.1,
22.8,
20.2,
39.2,
64.3,
79.7,
64.7,
93,
64.5,
42.2,
82.8,
28.9,
34.5,
90.6,
32.9,
59.7,
20.7,
25.1,
19.1,
39,
91.6,
69.3,
88.7,
26.7,
57.3,
30.8,
89.1,
47.1,
72.6,
37.2,
72.9,
81,
91.6,
9.3,
48.9,
38,
91,
91.8,
92.6,
70.3,
25.2,
92.8,
9.9,
5.8,
48.8,
70,
47.5,
80.8,
54.2,
56.6,
46.9,
56,
74.1,
62.7,
85.3,
35.9,
55.6,
99.7,
65.8,
78.5,
81.7,
90.9,
88.3,
48,
41.5,
30.2,
51.2,
21,
56.1,
63.3,
94.4,
40,
74.2,
42.9,
91,
53,
74.1,
25.5,
45.7,
46.3,
80.9,
47.1,
54.1,
76,
91.8,
83.8,
62.6,
41.4,
47.6,
50.1,
47.9,
63.1,
62.3,
49.1,
67.3,
33.8,
28.6,
80.2,
79.5,
51.5,
33.6,
39,
56.8,
78.3,
83.9,
8.9,
41.9,
16.4,
42.6,
43.2,
60.6,
62.7,
62.5,
91.4,
70.5,
82.1,
82.3,
81,
34.7,
23.8,
98.8,
76.7,
87.1,
65,
13.6,
96.8,
57.9,
84.9,
53.3,
0.3,
51.8,
56.8,
51.1,
76.9,
38.3,
72.5,
44,
73.8,
70.2,
63.9,
41,
61.4,
82.3,
65.2,
82.5,
62.9,
90.8,
33.3,
8,
45.2,
88.3,
50,
23.2,
41,
59.1,
46,
83.7,
90.9,
59.9,
46.1,
28.3,
20.2,
44,
55.3,
78.6,
74.2,
43.7,
45,
24.7,
35.2,
8.2,
24.3,
12.5,
50,
27.8,
63.8,
65.5,
45.5,
54.6,
0.7,
52.8,
26.3,
46.5,
70.1,
87.3,
1.7,
67.3,
32.2,
28,
44.3,
76.7,
82,
64.7,
93.5,
87.8,
92.3,
23.4,
55.9,
66.1,
46,
60.8,
87.7,
27,
48.7,
77.8,
56.7,
24,
78.9,
39.2,
86.4,
53.4,
45.6,
60.9,
34.7,
61.2,
61,
30.3,
96.2,
57.9,
32.3,
15.8,
62.4,
60.6,
21.2,
0,
56.5,
39.7,
91,
36.2,
24.1,
42.1,
42.3,
10.4,
84.4,
87,
81.7,
41.1,
71.4,
70.1,
39.2,
76.1,
62.7,
57.3,
69.6,
56.4,
13.3,
72.9,
58.8,
43.7,
31,
79.5,
25.5,
24,
53.2,
97.6,
51.3,
87.3,
44,
59.7,
47.4,
65,
49.6,
80.3,
54.7,
62.5,
78.2,
58.5,
70.5,
71.7,
17.6,
42.3,
42.5,
47.8,
15.7,
13.2,
51.3,
97.7,
29.8,
34.7,
73,
38,
17.9,
41.5,
43.9,
70.5,
83.3,
61,
85.5,
89.1,
50.3,
30.9,
28.3,
12,
91.4,
18.2,
51.6,
82.6,
84.5,
79.2,
38.5,
32,
45.7,
24.9,
21.1,
29.9,
50.1,
77.8,
18.8,
64.4,
51,
79.6,
78.4,
14.1,
101.4,
31.4,
53.6,
57.2,
78.8,
19.7,
98,
59.2,
63.3,
84.3,
50.4,
96.5,
49.5,
51.9,
68.6,
30,
5.8,
67.3,
10.8,
33.9,
53.2,
72.1,
86.7,
100.3,
94.5,
59.5,
62.9,
83.4,
63.9,
4.9,
43.6,
32.1,
35,
51.4,
9.5,
74,
37.2,
15.1,
54.5,
51.2,
30.2,
64.2,
85.1,
73.9,
26.5,
83.2,
32.5,
20.6,
63.3,
23.3,
45.8,
51.3,
72.4,
70.6,
84.9,
6.2,
37.5,
17.5,
94.1,
68.8,
23.9,
57.3,
41,
45.4,
33.3,
46.4,
76.5,
69.9,
96.3,
44.7,
24.4,
94.6,
83.1,
2.6,
76.7,
65.9,
34.3,
34,
74.5,
60.5,
23.3,
37.5,
94.4,
66.6,
47.9,
99.4,
46.5,
57,
78,
71.2,
68.6,
22.3,
34.9,
34.9,
39.4,
93.1,
23.5,
68.8,
51.7,
23.1,
31,
38.5,
57.4,
98.3,
19.4,
27.1,
43.6,
68.1,
45.6,
35.9,
79.8,
93.7,
44.8,
41.4,
35,
41.2,
77,
97.8,
35.6,
12.8,
43.6,
64.3,
92.8,
73,
46.4,
16,
5.3,
62.8,
65,
90.8,
70.8,
49.1,
62.4,
68,
2.6,
63.5,
9.8,
54.4,
38.4,
4.2,
56.7,
26.7,
0.3,
67,
62.9,
46.4,
69.8,
53.8,
28.5,
5.9,
47.3,
43.4,
67.5,
24.1,
67.2,
99,
91.6,
96.1,
36.3,
43.2,
60.1,
71.8,
45.5,
22.1,
57.5,
48.7,
76.3,
47.6,
81.4,
59.1,
48.9,
57.9,
77.7,
50.6,
35,
56.1,
54.8,
14.2,
34.7,
24.3,
40.6,
56,
69.6,
60,
14.5,
27.7,
29.9,
66.3,
74.1,
90.4,
84.7,
47.5,
67.6,
64.3,
99,
86.8,
74.3,
64.6,
73.3,
31.6,
92.5,
40.2,
14.7,
76.4,
71,
46.1,
75.8,
98.5,
57,
92.7,
56.2,
67.8,
57.6,
95.5,
51.5,
62.3,
37.3,
37.4,
30.8,
93,
64,
49.4,
36.8,
70.5,
86.3,
92,
65.1,
71.2,
77.8,
55.9,
62.2,
93,
21,
29.3,
81.3,
54.8,
101.5,
59.1,
95.3,
80.4,
50.6,
91.9,
59.9,
77,
31.3,
26.9,
34.5,
51.1,
9.6,
32.6,
12.8,
46,
88.1,
86.3,
89,
72,
24.7,
36.2,
86.9,
53.8,
40.9,
85.5,
29.6,
82.9,
95,
88.6,
83.7,
7.2,
48.4,
29.9,
90.9,
51.8,
99.1,
49.5,
95.4,
93.3,
102.3,
72.2,
93,
47.2,
93.5,
43.3,
9.2,
43.6,
19.5,
81.4,
67.3,
38.5,
43.8,
69.2,
78.6,
94.2,
67.5,
56.6,
65,
64.8,
60,
42.1,
94.2,
53.3,
51.2,
28.6,
58.5,
54.9,
18.7,
31.6,
60,
85.4,
51.6,
72.6,
62.7,
91.4,
86.6,
46.5,
66,
1.7,
74.6,
105.4,
66.1,
97.9,
69.8,
72.5,
77.7,
9.2,
54.2,
27.3,
54.7,
45.8,
58.5,
92.4,
75.5,
65.3,
75,
2,
81.4,
63.9,
1.1,
77.2,
43.8,
56,
43.2,
51.1,
87.2,
38.1,
37.5,
8.2,
38.2,
78.3,
38,
47.6,
92.4,
49.9,
36.1,
42.9,
74.2,
42.6,
76,
88.4,
33.3,
23.3,
95,
51.8,
98.9,
54.5,
49.3,
84.6,
50.2,
33,
12.5,
20.7,
55.8,
30.2,
91,
68.2,
37.9,
60.1,
74.1,
36.5,
82.3,
87,
54.8,
42.1,
64.7,
36.5,
98.7,
47.5,
56.1,
53.6,
27.1,
55.1,
40.6,
20.8,
55.2,
49.3,
80,
62.9,
99.1,
91.7,
44.1,
37.1,
23.7,
80.8,
10.2,
27.3,
66.6,
41.2,
45.8,
0.4,
86.4,
51.1,
78.2,
68.2,
58.8,
48.4,
42.4,
81.8,
51.6,
57.2,
69,
74.7,
91.9,
92.6,
77.2,
60.4,
58.3,
53.1,
78,
41.7,
55.3,
72.4,
26.9,
40.2,
24.9,
35.7,
79.7,
64.7,
71.9,
56.1,
44.1,
86.9,
66,
14.5,
51,
30.2,
21,
2.4,
21.7,
20.7,
66.5,
55.5,
79.9,
92.1,
85,
49.2,
51.4,
32.7,
55,
69.4,
55.8,
58.1,
7,
81.8,
94.1,
72.1,
33.5,
31.5,
90.1,
31.2,
53.9,
69.7,
79.5,
25.3,
36.3,
92.6,
60.4,
88.2,
75,
50.9,
52.3,
1.8,
71.7,
80.8,
18.6,
60.8,
75.3,
10.5,
78.2,
51.6,
99.5,
8.8,
95.1,
76,
3.7,
40.1,
91.8,
7.9,
77.2,
47.6,
15.1,
75.4,
43.5,
71.8,
80.6,
66.6,
82.4,
25.4,
15.4,
89.8,
57.1,
38.3,
85.8,
71.4,
45,
43.3,
30.5,
72.1,
53.8,
85.7,
56.8,
30.3,
67.1,
68,
60.1,
5.2,
76.8,
35.2,
92.6,
81.6,
39.8,
48.6,
89.1,
46.3,
31.9,
28.8,
77.1,
76.5,
83,
32.1,
49,
33.8,
4.4,
83.4,
73,
19.4,
54.9,
60.7,
70.4,
70.7,
28.7,
38,
56.8,
36.7,
65.9,
46.6,
35.6,
72.6,
18.2,
58,
45.2,
74.2,
61.6,
4.2,
20.5,
81.1,
58.3,
44.9,
28.8,
31.2,
75.9,
49.5,
89.7,
91,
51.8,
70,
81.2,
61.6,
43.6,
65.2,
58.2,
38.4,
64.8,
79.8,
80.3,
57,
14.1,
45.7,
94.7,
23.8,
83.6,
54.6,
85.8,
77.7,
81.5,
54.9,
45.6,
38.5,
44.7,
15,
74.2,
35.8,
43,
76.3,
36.4,
87.9,
46.5,
71.6,
34.8,
51.2,
52.9,
47.6,
40.3,
31.9,
0,
39,
50.4,
71.4,
48.4,
60.1,
51.2,
43.8,
50.7,
54.3,
63.2,
32.5,
35.8,
20.8,
88,
67,
95,
80.9,
87.6,
78.5,
48,
31.5,
50.2,
12.8,
46.8,
35.2,
58.5,
41.4,
94.2,
39.2,
43.7,
44.6,
87.2,
30,
82.2,
49.2,
5.2,
96.9,
64.2,
80.6,
84.7,
32.4,
36.2,
13.8,
39,
56.8,
98.3,
52.7,
59.5,
82.1,
65,
26.4,
10,
55.4,
61.8,
16.5,
82.2,
31,
10.5,
93.9,
12,
74.3,
39.2,
30.6,
61.3,
53.9,
58,
33,
0.7,
38.2,
43.4,
67.8,
40.9,
83.8,
61.6,
34.2,
33.6,
49.9,
74.7,
27.6,
47,
88.9,
57.7,
19.5,
73.1,
27.6,
96.1,
77,
43.9,
16.2,
54.8,
70.9,
76.3,
98.2,
64.3,
49.4,
18.3,
76.1,
48.4,
43.3,
46.5,
46.8,
12,
89.4,
44.9,
35.6,
96.1,
14.8,
72.4,
54,
59.8,
23.9,
53.3,
46.9,
75.7,
67,
55.2,
92.2,
6.7,
36,
41.7,
68.1,
68,
49.9,
81.7,
57.7,
63.7,
70.3,
32.1,
25.5,
90.3,
73.8,
67.6,
55.9,
48.1,
54,
95.7,
60,
47.6,
55.1,
39.9,
63.4,
46.2,
52.4,
68.6,
79.2,
55.7,
14.9,
88,
67.5,
78.8,
64.8,
33,
47.5,
9.3,
22.1,
34.5,
32,
76.8,
47,
52.9,
78.3,
39.6,
60.4,
64.4,
54.1,
82.5,
42.7,
36.9,
10,
76.2,
20.2,
10.8,
66.7,
20.4,
43.2,
97.5,
82.6,
52.4,
49.8,
48.7,
72.8,
93.6,
36.7,
68.3,
32.6,
68,
81,
30.5,
7.3,
83.9,
99.8,
48.1,
48.8,
62.7,
76.9,
74.9,
24,
23.2,
93.5,
75.7,
74.1,
48.5,
90.4,
56.3,
47.7,
82.6,
78.5,
3.2,
42.6,
42.5,
43.8,
22.2,
22.6,
55,
78.1,
79.4,
20.5,
43.3,
34.4,
59.6,
33.3,
81.4,
39,
69.4,
82.5,
70.6,
51.7,
29.3,
32,
64.6,
41.8,
82.5,
67.6,
71.4,
41.3,
62,
38.5,
42.8,
70.2,
64.9,
77.5,
68.2,
74.5,
79,
64.4,
60.8,
73.4,
43.8,
58.4,
7.6,
56.8,
26.4,
83.5,
13,
27.2,
74.7,
74.5,
83.3,
34,
83.8,
71.3,
39.8,
97.3,
58.8,
73.8,
57,
59,
16.3,
71.9,
66.9,
33.9,
85.6,
21.5,
38.4,
49.6,
40.7,
null,
48.1,
71.3,
78.4,
81.5,
88.4,
23.3,
57.7,
73.3,
20.8,
67.6,
60.2,
60.2,
53.2,
35,
80.6,
45,
46.8,
48.6,
55.8,
28.1,
64.1,
87.4,
51.2,
99.4,
57.8,
56,
33.4,
34.8,
43.5,
44.9,
60.1,
49,
38.2,
36.9,
52.9,
1.2,
58.7,
94,
57.3,
49.3,
15.3,
88.8,
87.8,
95.4,
62.7,
15.9,
68.6,
51.4,
94.9,
75.2,
60.6,
22.6,
43.1,
51.1,
18.2,
76.1,
20.9,
74.8,
51,
91,
31.4,
98.9,
37.9,
70.1,
40.4,
92,
75.4,
89,
94.6,
64.3,
89.7,
49.9,
46.9,
77.4,
56.9,
73.6,
43,
79.7,
18.5,
82.9,
44.6,
10.2,
69.3,
55.8,
89.3,
99.6,
57.2,
43.1,
42.3,
78.7,
94.3,
83.1,
82.3,
56.1,
58.2,
59.9,
33.9,
30.9,
35.7,
71.8,
88.2,
42.1,
40.4,
44,
77.2,
13.3,
24.5,
43,
33,
23.4,
20.6,
30.2,
84.3,
48.6,
41.2,
33,
30,
15,
30.9,
49,
76.9,
50.7,
98.8,
36.9,
36.4,
83.4,
61.1,
47.9,
8.3,
89.2,
53.7,
27.1,
70.1,
58.9,
101.9,
39.4,
61.3,
27.6,
27,
60.6,
20.6,
70.1,
64.2,
60,
47.7,
52.9,
51,
39.5,
54.7,
16.4,
94.9,
73.6,
96.9,
64.4,
68.8,
84.8,
68.1,
41.7,
24.5,
22.7,
32,
42,
29.6,
62.4,
38.6,
95.4,
66,
50,
9.2,
75.8,
56.3,
20.2,
56.8,
55.1,
8.2,
22.1,
4.7,
31.7,
46.1,
50.3,
31.3,
92.7,
10.6,
7.5,
64,
4.9,
30.5,
56.2,
87.1,
59.7,
39.8,
72.3,
70,
69.9,
12.8,
38.1,
55.9,
16.7,
85.8,
54.6,
47.2,
50.5,
19.6,
65.4,
87.4,
70.9,
83.3,
22.4,
57.5,
45.9,
70.7,
21.1,
95.2,
23.8,
77.7,
47.4,
80,
88.3,
35.7,
42.5,
38.2,
73.8,
35.7,
11.5,
72.3,
77.2,
46.2,
65.3,
83.7,
71,
71.8,
21.8,
54.2,
38.1,
71.4,
81,
73.8,
50.3,
58.9,
41.3,
94.9,
12.9,
11.1,
28,
17.1,
59.4,
33.8,
93.3,
31,
29.5,
0,
20.7,
20.9,
68.9,
66.6,
36.3,
72.7,
87.1,
38.9,
61.8,
29.5,
61.7,
31.5,
90.6,
75.1,
69.7,
25.3,
45.7,
70.7,
39.1,
56.2,
16.7,
34.1,
67.6,
4.1,
53.9,
44.4,
45.3,
36.9,
44.3,
90.6,
30.7,
27.2,
77.7,
90.9,
74.3,
36.7,
72.1,
75.4,
38,
6.7,
18.2,
45.2,
85.5,
79.5,
77.1,
73,
19,
97.1,
44.7,
81,
56.8,
75.1,
65.2,
58.5,
82.1,
45.4,
74.1,
64.1,
70.2,
31,
75.9,
55.4,
99,
65.9,
56.4,
32.4,
55,
38.2,
46.7,
30.5,
37.8,
88.6,
46.8,
70.2,
37.9,
75.9,
47.6,
56.7,
62,
60,
37.8,
69.1,
68.2,
37.7,
32.2,
79.1,
35.1,
38.4,
85.3,
84.8,
101.3,
27,
20.7,
97,
81.7,
64.4,
54.9,
24.4,
72.6,
63.7,
63.5,
63.8,
38.8,
73.6,
53.1,
21.2,
31.4,
50.5,
89.9,
68.4,
43.1,
68.1,
1.5,
58.1,
58.9,
92.7,
55.1,
41.3,
61.1,
17.7,
94.8,
62.8,
48.8,
66.2,
94.8,
34,
52,
85.6,
21.3,
36.3,
58.7,
12.5,
56.1,
59.2,
56.4,
21.4,
12,
71.5,
21,
68.6,
44.5,
42.7,
0,
40.8,
35.5,
77.3,
34.2,
19,
5.4,
78.2,
55.9,
87.2,
52.9,
42.9,
36.2,
91.8,
61,
30.3,
59.1,
29.3,
54.6,
98.5,
55,
76,
72.4,
52.4,
52.2,
81.8,
81,
58.5,
72.9,
43.2,
89.4,
29.4,
36.4,
27.3,
33.9,
50,
66.1,
26.5,
32.6,
32.9,
83.1,
61.8,
16.3,
24.9,
38,
93.2,
61,
69.4,
26.3,
51,
42.8,
80.9,
68.9,
59.7,
38.2,
96.5,
38,
51.2,
81.2,
44.6,
80.2,
50.2,
48.3,
72.3,
35.5,
35.5,
68.6,
82.5,
59,
75.6,
72.1,
84,
52.3,
70.3,
71.7,
0.1,
46,
7.8,
46.3,
54.6,
49.6,
82.2,
3.5,
44.7,
31.3,
58.6,
63.4,
58.6,
66.3,
36.8,
66,
93.5,
48.9,
57,
24.5,
39.7,
61.4,
78.1,
64,
87.5,
51.4,
37,
12.4,
44.4,
34.9,
66.6,
42,
69.3,
65.1,
49.4,
85.6,
93.8,
79.6,
54.6,
88.9,
93.2,
59.7,
78,
50.2,
87.1,
52.9,
53.1,
67.6,
27.8,
29,
38.1,
49.3,
66.6,
42.4,
66.9,
60.7,
47.7,
6.4,
87.6,
79.2,
98.1,
57.4,
80,
34,
49.2,
19.5,
8.8,
32.8,
91.9,
47.2,
33.7,
53.4,
28.5,
61,
13.9,
73.6,
93.4,
84.9,
30.4,
59.1,
23.9,
9.2,
66.7,
51.9,
87.9,
49.1,
88.8,
66.3,
69.7,
28.9,
84.8,
38.7,
12,
31.7,
24.6,
54.2,
31,
59.5,
87.9,
10.5,
61.3,
22.9,
17.7,
84.3,
47.7,
45,
70.9,
30.4,
64.3,
77.4,
51.4,
73.6,
77,
38.8,
65.3,
39.6,
42.9,
56.5,
23.6,
73.8,
57.6,
31.8,
46.4,
35.3,
43.3,
48.5,
33.7,
20.7,
32.8,
32.4,
64,
28,
37.9,
64.9,
51.5,
57,
28.1,
50.6,
78.6,
96.2,
63.9,
36.5,
62,
25.7,
63.7,
74.1,
81.5,
65.3,
65.8,
38.9,
46.9,
72.7,
91.9,
68,
88.5,
81.9,
24,
35.5,
10.9,
41.7,
73.3,
81,
91.5,
35.5,
64.5,
86.8,
53.3,
83.1,
97.5,
16.3,
53.6,
29.5,
87.3,
39,
46.8,
69.8,
25,
92.2,
32.8,
82.2,
68.8,
44.5,
51.1,
14.5,
19.8,
55.2,
38.1,
78,
75.7,
91.1,
29.9,
14.1,
58,
39.5,
93.2,
80,
86.4,
36.1,
18,
22,
57.3,
86.1,
47.7,
32.8,
30.7,
58,
71.3,
68.3,
69.3,
31.3,
55.2,
11.9,
56.9,
32,
59.4,
17.8,
61,
5.4,
36.9,
57,
65,
50.7,
91.7,
56.1,
88.7,
18.8,
44.3,
32,
60.4,
71.1,
27.4,
34.1,
48.7,
39.2,
29.5,
24.9,
39.9,
90.8,
45.9,
24.2,
75.7,
97.3,
37.7,
59.9,
32.5,
73.3,
52.4,
38.6,
71.8,
89.4,
53.3,
59.3,
67.1,
97.6,
8.8,
29.9,
11,
39.6,
43.1,
71,
38.2,
72.2,
24.3,
59.1,
67.9,
41.3,
73.4,
33.4,
60,
66.6,
1.4,
29.7,
63.6,
74.6,
33.5,
78.6,
36.7,
16,
68,
66.5,
65.4,
78.9,
30.2,
16.7,
94.6,
68.1,
12.9,
48.4,
29.6,
20.6,
59.5,
46.5,
54.4,
47.8,
77.7,
19.8,
71,
38.3,
76,
27.5,
64.1,
90.5,
61.6,
54.9,
83.6,
36.4,
18.4,
38.7,
49.1,
36.1,
79.4,
42.8,
56.9,
59.1,
55.8,
41,
68.4,
27.2,
25.4,
43.5,
40.2,
31,
3.8,
83.7,
83.5,
16.5,
71.7,
79.3,
30.1,
79.5,
15.6,
17.6,
53,
67.3,
63.7,
27.9,
95.5,
56.7,
66,
102.1,
45.5,
79.7,
38,
80,
87.1,
33.1,
79.8,
37.8,
41.4,
34.5,
37,
32,
37.3,
84.6,
47.6,
97.2,
75,
88.5,
48.3,
17.4,
35.7,
50.2,
45,
47.1,
72,
11.9,
37.2,
79.4,
60.3,
31.7,
91.8,
76.4,
46,
54.7,
38,
98.3,
34.3,
71.7,
51.4,
18.5,
68.8,
84.6,
72.5,
10.9,
20,
53,
37.5,
28,
3,
61.8,
67.5,
68.6,
94.1,
53,
46.2,
55.5,
42.9,
48.9,
66.9,
67.7,
61,
30.1,
80,
87.7,
71.6,
57.2,
69,
35.7,
59.7,
41.8,
43.6,
88.7,
74.9,
53.4,
24.2,
31.3,
42.7,
59.8,
55.2,
60.2,
88.2,
54.5,
77.3,
25.1,
65.3,
90.6,
51.7,
49.2,
80.4,
54.6,
48.8,
78.5,
61,
14.1,
68.6,
59.4,
55.3,
19,
57.5,
36.1,
30.6,
22.9,
57.7,
67,
47,
24.4,
45.9,
42.3,
89.2,
88.5,
50.9,
71.4,
48.6,
18,
53.1,
62.5,
65.5,
60.8,
26.9,
29.4,
26,
53.4,
45.4,
31.7,
70.9,
59.3,
76.1,
42.1,
25.9,
55.3,
58.6,
98.6,
37,
61.1,
60.5,
34.2,
49.3,
66,
6.3,
52.3,
39.5,
53.4,
44.6,
58.6,
15.3,
99.3,
41.5,
22.3,
36.6,
32.5,
52.7,
71.9,
84.1,
75.3,
67.4,
90,
80.8,
5.6,
75,
72.1,
70.3,
94.9,
74.4,
92.5,
25.8,
64.1,
36,
25.3,
91.6,
8.3,
48.9,
47.3,
53.9,
30.7,
64.9,
36.2,
39.8,
54.2,
99,
78,
31.3,
63,
83.1,
44.5,
51.7,
59.5,
65.5,
93.1,
53.1,
85,
2.2,
69.3,
91.7,
80.4,
44.3,
64.9,
44.3,
77.1,
52.3,
54.9,
25.7,
62.5,
82.1,
57.6,
28.8,
72.5,
13,
49.9,
66,
61.2,
71.2,
43.2,
65.5,
30,
26.1,
52,
42.5,
75.2,
48.8,
46.4,
95.2,
56.6,
57.4,
56.9,
50.6,
63.6,
77.4,
94.7,
32.3,
59.7,
67.2,
42.9,
65.8,
85.7,
53.6,
56.9,
36.6,
21,
32.7,
25.5,
56.3,
72.5,
64.7,
69.1,
82,
83.1,
32.8,
66,
16.8,
40.8,
34.2,
50.7,
30.2,
95.4,
92.6,
68.1,
67.1,
77.8,
38.7,
18.7,
5.4,
49.8,
74.1,
62.7,
31.6,
79.1,
36.6,
47.5,
89.1,
56.4,
79.2,
71.8,
5.1,
52.5,
44.4,
17.9,
87.8,
48.9,
96.8,
95.8,
64,
5,
72.1,
31.9,
97.4,
98.9,
4.2,
72.6,
60,
59.7,
64.4,
52.3,
62.8,
90.9,
31,
83.2,
87.9,
49.5,
58.1,
93,
14.7,
72.8,
71.4,
21.7,
26.3,
95.9,
33,
49.3,
61,
64.9,
42.6,
54,
36.5,
29.6,
85.9,
54.8,
91.5,
27.2,
54.1,
98,
50.7,
42.5,
43,
21.2,
57.2,
72.7,
77.1,
55.5,
60.5,
21.8,
33.1,
36,
40.3,
78.4,
60.5,
47.6,
74,
82.3,
77.1,
71.8,
72.6,
84.5,
61.1,
46.1,
60.8,
71.3,
66.3,
52.4,
84.8,
59.7,
56.5,
58.3,
78.5,
81.5,
53.7,
44,
23.4,
87.2,
32.4,
88.2,
52.5,
72,
22.9,
79,
45.7,
56.7,
27.7,
43.5,
54.8,
94.3,
59.1,
0.4,
63.5,
46.3,
61.8,
69.4,
53.3,
52.2,
82.1,
69.1,
70.9,
25.8,
70.2,
44.4,
28.3,
54.5,
100.5,
74.5,
51.4,
65.2,
60,
82.2,
14.9,
35.2,
67.2,
36.7,
65.9,
60.7,
69.5,
31.6,
36,
52.6,
49.7,
100.9,
15.4,
43.8,
18.2,
75.5,
93.6,
45.1,
48.3,
39,
66.7,
27.1,
86.5,
92.8,
59.3,
82.2,
53.6,
2.6,
68.6,
59.4,
75.7,
18.2,
7.9,
84.9,
66.8,
70,
52.7,
77,
76.4,
77.7,
57.4,
23.1,
74.9,
20.3,
63.6,
71.5,
9.5,
33.8,
48.3,
61,
64.9,
43,
47.3,
44.5,
73.3,
24.3,
59.4,
55.9,
74.2,
66.2,
58.7,
51.5,
63.6,
68.3,
22.4,
38.8,
88.3,
22.9,
62.9,
62.6,
69,
71,
43.4,
92.9,
36.9,
68,
53,
44.2,
88.7,
64.4,
37.1,
37.7,
15.3,
97.4,
53.7,
78,
79.2,
49.9,
91.8,
62.7,
52.1,
13.7,
36,
28.2,
46.6,
17.4,
37.2,
94.6,
73.1,
60.2,
70.7,
72.7,
13.5,
75.6,
32.6,
44.9,
64.5,
47.3,
44,
69,
40.7,
40.6,
64.2,
91.7,
87.9,
94.5,
14.3,
55,
89.7,
77.8,
78.7,
39.7,
75.6,
41.2,
16.6,
89.9,
49.6,
92.2,
16.7,
30.2,
54.8,
50.5,
49.5,
62.4,
64.6,
16.2,
43.9,
82.5,
76.7,
66.6,
78.1,
98.7,
69.3,
88.9,
54.3,
79,
57.9,
44.4,
42.7,
85,
48,
89.7,
84.2,
75,
70.8,
29.9,
77.3,
45.3,
28.4,
49.6,
17.6,
26,
56.4,
12.1,
22.7,
72.8,
41.8,
71.1,
22.2,
97.7,
50.7,
41.6,
59,
34.8,
45.3,
48.2,
36.4,
65.9,
23.4,
69.9,
71.5,
68.9,
8.7,
45.3,
21.7,
39.3,
40.7,
51.6,
63.6,
41,
52,
93,
48,
23.2,
52.3,
51.1,
50.8,
98.2,
81.5,
52.9,
96,
29.1,
77.9,
99,
59.3,
40.9,
25.6,
46.3,
50.5,
53.3,
26.2,
57.1,
31.8,
37.7,
17.2,
58.2,
55.9,
69.5,
51.7,
48.8,
41.4,
61.1,
88.1,
27,
18.3,
78,
45,
79,
63.5,
29.4,
64.7,
15.9,
18.4,
67.3,
46.5,
52.3,
87.4,
56.8,
25.1,
46.2,
78.6,
45.8,
52.3,
64,
61.5,
53.4,
77.5,
17,
59.2,
64.4,
43.5,
87.9,
44,
69.9,
29.5,
74.4,
45.8,
70.3,
22.1,
30,
30.8,
53,
59.5,
37.8,
67.8,
44.1,
97,
69,
72.7,
89.5,
73.9,
58.8,
95,
91,
67.8,
24.3,
21.8,
52.5,
37,
51.9,
15.1,
52.3,
58.5,
28.6,
86.5,
98,
42.8,
48,
71.1,
46.3,
55.1,
26.3,
75.1,
56.1,
80.9,
56.2,
63,
55.3,
79.3,
73.2,
53.8,
29.4,
77.8,
63,
62.7,
57.4,
60.3,
70.4,
37.5,
95.4,
67.1,
67.5,
88.2,
34.4,
17.2,
79.5,
62.4,
64.5,
85.5,
72.1,
60.2,
6.5,
76.1,
75.2,
95,
57.1,
68.3,
68.7,
61.7,
34.4,
18.9,
35.5,
73.1,
61.9,
8.2,
58.6,
85.7,
89.1,
54.7,
53.1,
92.6,
100.9,
49.1,
94.7,
41,
78.7,
93.7,
64.6,
78,
72.7,
43.7,
70.4,
75,
55.2,
96.3,
58.3,
42.3,
90.1,
100.2,
59.3,
54.7,
41,
23.5,
52.1,
33,
49.5,
42.5,
43.4,
57.7,
73.9,
67.9,
42.1,
35.8,
37.5,
41.5,
26.2,
45.9,
42.6,
62,
61.9,
71.2,
21.5,
82.8,
59.5,
12.4,
15,
60.7,
53.1,
38.5,
86.9,
66,
44.3,
62.4,
75.4,
71.5,
41.2,
31.5,
48.2,
53.5,
37,
66.5,
46.6,
26.7,
88.9,
96.5,
24.3,
20.6,
87,
76.3,
58.8,
69,
39.5,
20.5,
64,
81,
47.1,
49.4,
51.2,
71.2,
79.6,
50.7,
38,
81.7,
99.2,
53.1,
70.6,
78.7,
19.9,
52.2,
61.3,
22.1,
56.9,
63.7,
71.9,
65.5,
26.6,
83.4,
22.6,
16.1,
41.5,
98.1,
94.3,
39.5,
68,
95.9,
67.8,
82.9,
97.3,
52.2,
58.1,
62.6,
41.4,
56.7,
16.5,
57.5,
27.6,
57.8,
9.1,
38.1,
42.8,
46.8,
68.6,
20.1,
51.7,
7.1,
24,
93.2,
54.6,
15.7,
25.1,
25.5,
70.8,
72.7,
28.1,
8.3,
79.4,
76.1,
90.7,
55.3,
36.8,
60.3,
97.1,
46.8,
37.6,
61.2,
61.2,
54.4,
18.8,
60.9,
84.8,
64.8,
38.8,
88.6,
46.3,
52.3,
90.6,
64.2,
55.9,
48.5,
56.3,
30.5,
66.3,
41.5,
42.8,
62.8,
25.1,
33.7,
55.9,
0,
88.9,
102.1,
31,
79.5,
31.6,
19.6,
51.3,
69.5,
18.6,
6.2,
57.3,
99.3,
5.2,
45.1,
84,
54.7,
61.7,
61.2,
84.8,
45.5,
9.5,
65.4,
48.4,
76.1,
76.8,
64.9,
64,
43.2,
22.2,
66.1,
85.1,
91.7,
71,
46,
43.1,
99.3,
47.8,
88,
58.2,
29,
57.6,
70.8,
53.5,
54.1,
60.6,
17.1,
61.2,
24.5,
47.6,
40.5,
47.2,
21.1,
79.9,
60.6,
56.2,
30.9,
77.2,
98.1,
25.3,
32.2,
42.8,
0,
44,
56.4,
72,
77,
87.2,
59.9,
97.3,
85,
32.7,
51,
50,
58.7,
59.8,
21.5,
90.3,
43.4,
59.4,
41.3,
76.3,
40.8,
33.2,
24.4,
70.2,
60,
87.4,
20.7,
54.4,
93.2,
38,
78.3,
94,
4.9,
59.9,
57.9,
83.2,
37.1,
54.2,
52.8,
22.4,
51,
62.4,
64.8,
43.5,
59.6,
54,
96.7,
26.4,
74.2,
57,
94.7,
75.6,
55.6,
72.7,
51.7,
51.5,
63.8,
48.3,
38.2,
16.9,
92,
47.1,
56.8,
62.1,
74.2,
5.2,
66.5,
70.2,
40.2,
56.5,
42.9,
81.9,
8.3,
14,
92.4,
76.9,
66.7,
61.8,
21.2,
68.7,
32.8,
43.8,
78.5,
38.4,
61.2,
60.1,
8.4,
83.2,
82.9,
43.4,
39.9,
27.1,
21.8,
77.1,
45.4,
53.9,
48.5,
72.6,
47.7,
65.7,
60.6,
50.7,
92.8,
82.1,
90,
59.6,
32.6,
54.7,
16.5,
56.4,
74.8,
60.9,
80.9,
30.3,
17.6,
29.9,
55,
19.1,
69.3,
35.2,
66.8,
34.9,
41.6,
69.1,
49.4,
35.9,
0,
44.3,
85.5,
70.4,
85.7,
89.3,
89.6,
75,
39.6,
56.8,
75.2,
39.9,
64.5,
46.7,
55.2,
14.6,
46.4,
54.1,
79.2,
59.3,
53.9,
67.6,
65.8,
57,
25.3,
46.1,
76.8,
99.2,
44.8,
28.2,
3.5,
73.9,
36.5,
27.9,
54.7,
40,
25.4,
44.8,
26.4,
57.4,
53.2,
91.8,
3.2,
81.5,
38.7,
93.1,
62.8,
17.6,
38.6,
79.9,
91.1,
52,
52.2,
61,
44.1,
54.7,
59.1,
11.8,
78.7,
42,
97.8,
55.9,
51.6,
72.9,
63.2,
34,
42.8,
28.3,
84.4,
26.1,
52.1,
37.3,
78.6,
53.4,
84.7,
64.1,
57.7,
57.1,
56.3,
56.3,
66.6,
42.4,
52.9,
48.2,
30.7,
65.8,
59.9,
10.3,
77.1,
79.5,
62.1,
39.1,
60.7,
48.9,
12.4,
67.9,
29.1,
47.3,
11.5,
74.3,
56,
58.3,
61.8,
70.3,
62.1,
60.5,
62.9,
23.5,
47.7,
71,
48.7,
64.1,
68.6,
42.7,
65.9,
68.5,
17.7,
29.9,
26.6,
62.8,
31.7,
52.8,
65.4,
21.3,
67.1,
98.4,
46.5,
43.4,
45,
66.7,
36.9,
89.6,
33,
86.1,
95.9,
85.8,
67.2,
8.9,
37.5,
63.9,
44.6,
21.4,
40.2,
53.9,
72.5,
12.6,
45.2,
87.3,
48.9,
24.7,
68.3,
47.1,
72.9,
10.3,
68.7,
65,
25.2,
83.7,
48.6,
45.6,
66.5,
34.6,
6,
77.2,
59,
90,
28.3,
48,
58.7,
58,
67.6,
55.2,
68.2,
65.3,
74.4,
49.3,
38.4,
81.2,
64.5,
85.2,
13.1,
38,
15.4,
50,
32.5,
58.2,
98,
42.2,
95.9,
39.5,
11.7,
75,
52.9,
87.8,
92,
79.6,
45.4,
62.5,
26.5,
20.3,
89.2,
67.1,
84.6,
48.1,
70,
68.9,
50.6,
81.9,
94.6,
7.3,
37.8,
94.4,
20.8,
74.2,
35.8,
49.1,
31.9,
19.4,
66.7,
91,
64.4,
53.8,
36.6,
84.9,
0,
57.3,
15.8,
46.7,
59.6,
72.7,
86.7,
79.9,
40.1,
81,
41.2,
57.1,
9.6,
80.7,
71.6,
42.5,
41.5,
48.4,
41.2,
59.3,
83.9,
92,
37,
77.9,
62.8,
71.2,
72.3,
50.3,
38.5,
45.4,
89.2,
72,
57.3,
52.4,
68,
36.2,
60.9,
98.6,
59.5,
32.9,
34.4,
95.1,
57.5,
66.8,
60.2,
34.5,
56.4,
72.4,
8.9,
56.5,
20.1,
45.2,
60.1,
78.8,
64,
35.1,
51.7,
58.3,
83.2,
58.2,
18,
54.9,
45.1,
61.3,
79.2,
51.5,
98.8,
57.8,
44,
76.4,
24,
45,
41.3,
23.7,
54.2,
77.6,
42.6,
75.1,
54.7,
77.7,
71.7,
11.8,
40.1,
63.1,
60.4,
43,
46.9,
98.1,
56.8,
6.9,
42.2,
87.3,
43.7,
82.2,
100.5,
33,
45.9,
59.7,
66.6,
81.2,
75,
63.5,
44.8,
52.9,
89,
44.1,
33.2,
84.8,
3.3,
10,
56.7,
63,
43.2,
34.8,
56.3,
33.9,
35.9,
59.2,
74.6,
75.4,
82.9,
14.4,
78,
93,
37.1,
61,
29.3,
3.8,
44.9,
75.9,
73.7,
91.2,
53.7,
96.7,
65.1,
32.4,
37.2,
76.4,
87.4,
66.9,
48.8,
48.9,
11.2,
60.7,
81,
15.3,
74.1,
65.2,
70.9,
8.7,
61.6,
54.7,
89.6,
78,
11.7,
34.1,
66.1,
56,
36.4,
49.4,
72.7,
92.5,
40.7,
11.8,
24.2,
33,
75.5,
80.6,
84.7,
37,
20.6,
55.3,
97.5,
76.8,
68.5,
55,
89.4,
71.3,
68.3,
24.2,
98.1,
53.8,
69.2,
76.8,
1,
72,
41.3,
12,
34.7,
94.9,
44.8,
55.6,
32.9,
29.1,
86.3,
70,
30.1,
0,
53.5,
64.7,
19.8,
25.9,
40.4,
33.1,
64.3,
88.4,
54.2,
22.5,
73.2,
37.1,
75.2,
97.4,
90.8,
70.6,
23.6,
77.1,
33.1,
70.8,
49.2,
84,
58.6,
66.5,
71.3,
99.8,
15.7,
29.7,
69.2,
68.9,
45.7,
64.8,
70.7,
95.9,
62.7,
26.9,
56.5,
40.4,
19,
43.8,
88.1,
61.6,
56.2,
42.7,
47.9,
53.9,
29.5,
27.3,
61.3,
54,
85.7,
88.6,
49.7,
56.2,
29.2,
27.7,
57.2,
17.3,
24.1,
75.7,
38,
39.7,
21.2,
80,
43,
35.7,
46.6,
7.3,
39.9,
68,
105.9,
75.2,
53.3,
86.4,
8.8,
4,
7.3,
33.8,
25.4,
32.1,
12,
50.5,
64.7,
64,
72.5,
14.7,
75.4,
22.6,
88.5,
47.8,
71.6,
20.6,
64.8,
47.8,
7.7,
11.8,
32.4,
77.6,
56.4,
49.2,
87.7,
63.5,
28.2,
49,
61.6,
100,
67.7,
71.4,
13.2,
78.9,
91.7,
15.8,
54.1,
50.5,
27.9,
55.8,
38,
66,
85.2,
78.2,
77,
16.9,
51.9,
7.7,
63.2,
70,
71.4,
31.8,
18.1,
33,
38.7,
86,
49,
62,
59.3,
62.7,
30,
69.9,
49,
55.7,
32.8,
54.2,
46.8,
85.9,
29.5,
37.3,
85.1,
58.9,
4.6,
6.8,
67.6,
47.2,
60.8,
29.6,
74.9,
4.6,
72.2,
95.8,
38.4,
56.6,
65,
88.2,
49.7,
73.7,
24.1,
59.3,
62.1,
39.3,
41.5,
5,
30,
72.1,
93.5,
30.1,
60.8,
89,
92.1,
63.8,
41.8,
54.6,
91.1,
66.1,
36.1,
25.1,
87.1,
14.9,
122.8,
23.3,
68.8,
82.5,
70.3,
95.4,
29,
7.6,
60.2,
92.3,
55.2,
25.6,
54.5,
55.7,
94.5,
62,
28.8,
21,
65.9,
42.8,
55.6,
0,
36.8,
4.6,
76.6,
92.9,
7.5,
79.6,
34,
76.7,
35.7,
96.1,
2.2,
73,
85.7,
43,
81.4,
47.8,
55.9,
52,
28.9,
49.9,
59.5,
48,
70.8,
41.5,
57.8,
71.7,
39.7,
80.6,
58.5,
24.2,
50.1,
81,
58.8,
55.4,
96,
94.6,
83,
83.4,
100.9,
34.2,
44.9,
96.8,
68.6,
48.1,
24.1,
69.9,
46.7,
34.2,
58.2,
2.8,
91.7,
31.9,
33.6,
66.5,
26.7,
45.3,
49.4,
51.3,
58.8,
34.3,
77.8,
81.2,
38,
35.3,
65.3,
22.9,
75,
75.2,
60,
56.4,
38.8,
34,
82.2,
88,
15.9,
69.1,
40.7,
60.7,
59.4,
65.9,
21,
50.4,
95.9,
66.2,
9.9,
19,
54,
42.2,
56.2,
75.8,
76.2,
82.4,
80.2,
63,
49,
67.3,
79.1,
61.6,
45.5,
59.8,
27.7,
54.7,
75,
48.2,
36.1,
34,
63.8,
80.2,
59.6,
83.1,
88.8,
19.4,
71,
62.9,
3.4,
88.8,
12.1,
94.3,
86.2,
57.4,
92.4,
86,
66.9,
97.1,
63.9,
63.3,
51.6,
48.5,
63.4,
58.6,
36.4,
83.7,
87.5,
73,
60.8,
55,
78.8,
33.5,
27.5,
64,
63.2,
87.5,
24.6,
26.6,
37.6,
97.4,
54.5,
57.7,
29.8,
33.4,
43.4,
35.1,
78.6,
56.1,
61,
28.9,
96.8,
23.8,
49.4,
46.9,
75.4,
83.5,
53.4,
36.3,
82.7,
95.7,
19.8,
67.5,
17.3,
85,
61,
49,
33.2,
72.5,
23.5,
22.2,
17,
46.3,
16.3,
25.5,
71.9,
68.4,
43.5,
26.6,
40,
94.7,
67.5,
35.8,
77.4,
36.3,
15.2,
74.2,
63.8,
75.5,
22.4,
83.5,
37.9,
30.5,
83,
95.3,
47.3,
49.9,
49.5,
31.3,
36.2,
24.9,
22,
88.5,
11.9,
43.5,
66.3,
53,
21,
57,
38.6,
97.4,
66.3,
73,
92.4,
45.7,
50.3,
34.6,
59.2,
68.6,
24.3,
61.3,
43.8,
60,
61.7,
60.8,
71.7,
81.3,
10.5,
31.7,
50.9,
57,
83.7,
99.8,
31.6,
79.7,
73.5,
61.8,
47.1,
57,
56,
50.1,
62.8,
49,
94.2,
94.2,
85.9,
83.1,
81.3,
73.4,
94.5,
58,
76.7,
79.7,
15.7,
81,
92.3,
43.4,
66.9,
23.8,
31.2,
10.9,
59.4,
90.3,
74.2,
48.1,
38.1,
66.3,
58.2,
51.4,
79.6,
31.7,
69.7,
23.8,
17,
83.5,
37.5,
32.8,
66.7,
3.3,
82.4,
25.1,
73.9,
60.2,
7.7,
91.8,
33.2,
49.8,
90.9,
81.6,
67.2,
80.1,
16.5,
44.4,
26.4,
0,
37.1,
83.4,
16.3,
88.4,
42.2,
53.3,
52,
36.4,
79.3,
49.3,
19,
33.3,
3.6,
38.8,
75.5,
41.8,
89.4,
54.5,
84.8,
72,
51.7,
52.7,
85.8,
96.4,
65,
91.6,
86,
41.5,
83.2,
25.9,
49.5,
95.9,
58,
75.8,
48.6,
18.8,
52,
86,
39.2,
51.6,
19.3,
41.2,
53.8,
70.1,
33.6,
82.1,
43.5,
43.2,
52.3,
71.2,
60.3,
48.9,
64.3,
57.4,
55.9,
67.6,
79.1,
42.1,
62.8,
90,
16.3,
68.8,
36.7,
34.9,
47.8,
35.7,
26.8,
2.8,
78.8,
36.5,
81.1,
21.9,
89,
43.7,
0,
56.5,
81.3,
27,
64,
55.2,
20.1,
61.3,
39.2,
42.2,
45.9,
42.2,
20,
22.4,
56.2,
58.1,
49.3,
34,
72.1,
97,
68.6,
64.2,
24.6,
53.6,
66,
29,
78.9,
50.1,
69,
56.1,
58.7,
61.5,
1.2,
48.8,
45,
85.6,
57.8,
29.1,
77.5,
67.7,
32,
38.3,
73.8,
69.2,
66.9,
75.1,
12.6,
41.6,
46.8,
20.6,
4.1,
38,
74.3,
57.5,
79.1,
31.1,
43,
65.9,
31.2,
63.6,
55.2,
18.1,
36.8,
87.1,
66.6,
20.8,
7,
88,
9.4,
69.5,
40.9,
80.9,
44,
60.8,
94.5,
17.9,
66.6,
59.8,
40.2,
47.2,
97.1,
76,
65.1,
36.4,
75.3,
74,
81,
59,
68.1,
58.4,
29.6,
49.3,
84.7,
23.4,
64.3,
60.3,
55.7,
33.6,
58.9,
45.5,
66.7,
69.7,
92.3,
87.6,
28.3,
68.6,
39,
45.6,
60.5,
61.9,
64.7,
76.5,
83.2,
44.6,
68.4,
54,
105.2,
67.9,
69.4,
57.6,
83.4,
70.8,
59.1,
56.2,
88.6,
26.4,
85.5,
46.6,
65.7,
49.4,
62.9,
53.6,
50.2,
25,
80.8,
95.8,
86.8,
26.8,
19.9,
84.8,
31.8,
47.2,
37.5,
83,
76.2,
63.8,
61.2,
36.9,
68.6,
60.1,
59.7,
36.8,
74.9,
29.3,
80.5,
86.6,
59.9,
63.9,
57.1,
85.3,
29,
44,
72.2,
38.4,
58.8,
62.8,
44.2,
65.8,
59.5,
75.3,
38.1,
32.9,
41,
75.1,
34.9,
73.7,
88,
59,
74.5,
42.3,
30.4,
31.1,
98.6,
35.5,
44.4,
83.4,
34,
4.2,
81.8,
77.2,
68,
38.1,
34,
38.1,
19.1,
16.7,
38.2,
53.6,
82.5,
62.8,
66.2,
95.1,
62.1,
63,
95.5,
64.1,
18.4,
61.7,
44.2,
54.5,
31.2,
28.5,
45.7,
42.9,
74,
38.7,
62.1,
74.6,
22.7,
31.7,
40.8,
98.5,
64,
89.2,
15.9,
76.2,
52.8,
87,
21.3,
61.1,
55.2,
68.5,
43.8,
60.9,
81,
52.6,
72.8,
30.4,
63.6,
41.3,
19.6,
58.2,
48.1,
99.9,
46,
80.8,
89.3,
71,
40.1,
20.8,
70.3,
97.8,
91.7,
51.5,
84.1,
68.2,
93.4,
56.3,
67.8,
88.6,
61.6,
81.3,
15.5,
67.1,
51.4,
33.6,
67,
65.8,
59.2,
7.4,
1,
59.5,
72.5,
66.7,
40.7,
95.7,
95.1,
23.9,
43.5,
84.5,
48.6,
69.9,
32.7,
39.4,
68.5,
36.5,
45.4,
16.7,
85,
42.7,
39.3,
4.7,
92.8,
18.9,
98.9,
19.8,
62.8,
68,
36.5,
30.6,
57.7,
25.5,
18,
72.8,
24.2,
9.2,
36.3,
41.7,
82.5,
68,
34.4,
41.9,
89.1,
28.6,
70.9,
56.4,
8,
86.7,
4.8,
86.4,
90.9,
46.9,
69.6,
46.7,
36.8,
27.8,
50.3,
45.4,
74.9,
36.7,
25.3,
23,
28.7,
67,
71.1,
72.2,
79.9,
31.3,
90.6,
57.9,
38.2,
29,
52.5,
69.9,
59.6,
88.3,
16.3,
46.3,
42.4,
58.5,
47.6,
76.9,
47.3,
71.9,
68.2,
53,
64.9,
49.5,
21.1,
57.6,
59,
70.4,
30,
50.7,
54.3,
33,
25.2,
27.2,
11.5,
59.6,
97.7,
82.6,
85.6,
39.6,
86.8,
23.2,
44.2,
42.1,
66.2,
37.6,
70.1,
63.8,
21.5,
38.6,
58.6,
56,
80,
37.8,
12.1,
68.6,
81.9,
53.2,
36.2,
46.2,
75.6,
22.5,
63.8,
89.4,
85.3,
40.1,
80.1,
79.7,
78.6,
31.8,
96.6,
77.4,
79.5,
54.2,
66.3,
74.8,
27.8,
35,
19.3,
65.6,
52.5,
20.6,
38.5,
86.6,
75.2,
13.5,
53.2,
71.5,
23.6,
84.6,
48,
82.1,
52.9,
30,
96,
82.2,
77.9,
39.4,
70.5,
81.1,
98.5,
89.7,
55.7,
79.7,
62.7,
48.3,
20.8,
64.4,
81.9,
67.1,
80.7,
65.1,
34.4,
44,
47.8,
20.7,
73.1,
17.5,
43.8,
51.4,
50.6,
51.7,
72.8,
96.1,
65.5,
64.3,
2.5,
31.1,
11.3,
43.6,
13.8,
87.2,
46.2,
83.6,
49.2,
63.6,
31.6,
70.3,
88.8,
20,
32.4,
37.1,
43.4,
69,
65.2,
47.5,
57.2,
51.8,
50.2,
82.8,
3.6,
62.6,
83.7,
79,
61.3,
43.5,
81.4,
97.4,
95.6,
56.7,
65.6,
64,
43.8,
77.1,
97.1,
51.5,
96.9,
68.3,
50,
56.4,
24,
65.6,
67.1,
49.2,
39.8,
76.7,
44.3,
72.6,
31,
69,
58.9,
71.6,
95.9,
40.1,
64.6,
59,
38.2,
73.6,
4.8,
62.8,
27.5,
46.6,
36.5,
28.5,
88.1,
75.4,
50.6,
5.8,
57.4,
72.1,
76.9,
72.8,
57.7,
15,
59.4,
71.8,
46.3,
94.7,
27.3,
35.6,
71.7,
56.7,
36.5,
62.9,
50.9,
59.1,
83.7,
12.3,
36.5,
57.7,
84.2,
34.1,
60.9,
58.5,
31.9,
68.9,
46.6,
72.3,
66.1,
55.2,
57.4,
46.6,
26.3,
33.3,
72,
45,
68.7,
62.9,
92.8,
80.6,
55,
20.9,
48.1,
47.3,
48.7,
66.6,
84.4,
42.4,
45.4,
61.4,
37.2,
54.7,
93.7,
16,
51.3,
37,
57.5,
90,
38.9,
79.6,
55.4,
54.6,
32,
61.7,
61.9,
83.1,
0,
2.9,
90.6,
91.8,
61.8,
60.5,
38.4,
89.1,
87.2,
41.4,
52.5,
73.8,
95.8,
20.1,
26.6,
53.3,
68.4,
67.7,
17.8,
48.4,
37.3,
36.4,
87.5,
28.7,
58.5,
17,
30.5,
30,
34.9,
33.9,
68.8,
43,
55.6,
66.1,
27.6,
71.5,
61.9,
72.5,
76,
65.5,
78,
46.7,
30.4,
93,
83.3,
46,
84.2,
84.8,
17.8,
30,
97.7,
73.5,
41.2,
47.7,
54,
21.2,
85.1,
21.3,
51.7,
33.1,
14.8,
2.6,
77,
11.6,
81.1,
71,
47.1,
33,
68.2,
63.1,
70.1,
46.1,
21.7,
80.3,
98.3,
90,
79.9,
77.2,
82.5,
49.6,
82.2,
32,
13.1,
69.5,
82.6,
69.6,
90.2,
74.9,
67.3,
37.7,
40.3,
37.1,
90.3,
71.8,
24.9,
35.2,
65.2,
81.2,
92.8,
22.1,
78.8,
46.3,
2.9,
82,
65.5,
80.8,
29.3,
26.5,
56.1,
85.4,
80.4,
48.2,
59.5,
58.1,
90.7,
60,
92.5,
65.1,
87.9,
47.3,
93.2,
19.2,
89.1,
87.8,
73,
29.5,
7,
54.3,
84.9,
94.2,
41.5,
47,
45.2,
64.8,
22.1,
43.7,
47,
63.2,
54.2,
69.3,
48.9,
42.2,
63.2,
41.2,
68.8,
33.8,
55.6,
63.8,
36.8,
59.5,
67.3,
88.9,
55.9,
13.1,
61.9,
48.1,
69.1,
38.4,
20.2,
87.1,
17.3,
66.2,
76.9,
50.7,
90.5,
96.5,
54.7,
19.5,
51.8,
90.1,
37.7,
57.5,
35.5,
38.6,
51.8,
45.7,
39.6,
87.5,
50.5,
90.4,
79,
79.1,
80.1,
41.7,
39.7,
81,
52.2,
85.7,
27.7,
50.6,
63.3,
82,
78.9,
94.9,
56.2,
87.8,
53.3,
70.6,
73.8,
94.3,
41.3,
37.4,
32,
69.3,
27.4,
87.3,
57,
49.6,
58.3,
47.7,
57.5,
70,
84,
50.7,
60.4,
36.7,
72.1,
29.3,
25.7,
66.4,
35.3,
42.5,
38.5,
43.4,
64.6,
72.9,
84.3,
38.9,
50.8,
3.9,
58.5,
87,
4.5,
94.4,
18.6,
32.6,
61.5,
50.9,
69.4,
79,
71.3,
14.7,
92.7,
54.7,
84.5,
55.8,
53.3,
7.3,
96.3,
46,
66.7,
29.7,
94.2,
35.3,
82.6,
85.9,
89.8,
84.2,
49.3,
49.4,
20.1,
67.1,
70,
57.8,
69.1,
46.9,
58.5,
37.9,
58.5,
82.4,
47.8,
28.1,
57.1,
48.6,
51.6,
39.7,
6.8,
36.7,
56.8,
57.9,
18.8,
28.6,
32.6,
57.1,
84.2,
23.9,
22.5,
34.6,
70.9,
30.2,
62.8,
48.1,
35,
46.5,
73.5,
30.9,
37.3,
65.7,
80,
43.9,
63.1,
63,
51.7,
71.5,
79.6,
0,
92.7,
100.4,
46,
49.5,
89.7,
63.1,
52.5,
23.4,
44.6,
38.2,
99.7,
37.6,
80.7,
74.2,
100.8,
74,
70.1,
53.4,
13.8,
57.1,
0,
48.1,
74,
40.6,
32.3,
11.9,
5.6,
13.3,
71.8,
43,
46.4,
6.3,
14.2,
1.2,
64,
17,
66.9,
31.8,
37,
39.6,
54.2,
71.7,
61.6,
74.9,
72.8,
43.3,
25,
45.4,
23.2,
56.8,
69.6,
49,
68.3,
20.9,
89.1,
23,
59.1,
88.4,
46.8,
37.9,
66,
39.8,
88.6,
44.5,
40,
46.7,
61.2,
8.7,
74.6,
60.4,
70.9,
76.4,
88.6,
64.7,
36.5,
41.7,
25,
53.9,
64,
5.3,
48.4,
81.5,
17.8,
35.4,
57.5,
26.7,
96.3,
86.9,
63.5,
57.4,
86.5,
5.6,
56.3,
70.4,
47.2,
60.7,
51.4,
56.8,
18.1,
56.7,
30.4,
50,
48,
66.9,
97.2,
29,
87.6,
34,
61,
49.4,
69,
49.9,
66,
58.8,
59.4,
4.1,
55.3,
92.8,
60.1,
58.9,
79,
94.6,
12.5,
39,
12.2,
62,
47.3,
41.7,
86.5,
53.7,
61.8,
43.7,
38.9,
34.1,
24.8,
11,
44.6,
80.3,
21.4,
61.8,
41.9,
70.2,
57.7,
97.9,
91.1,
42.9,
49.5,
50.8,
37.6,
78.2,
14.9,
56.2,
69.1,
79.1,
83.7,
18.1,
80.9,
39.7,
60.5,
85.1,
83.9,
46.2,
82.7,
0.1,
19,
44.2,
55.6,
22,
23.8,
67.8,
65.2,
40.9,
66,
68.6,
90.3,
2.8,
94.6,
26.1,
31.2,
68.1,
70.3,
51.7,
44.7,
71.3,
86.8,
49.5,
50.8,
57,
34,
78.8,
5.7,
85.7,
82.6,
64.6,
27.5,
31.8,
54.3,
79.6,
96.9,
82.6,
65.8,
57.8,
22.9,
69.5,
89.1,
69.8,
36.3,
80.7,
24,
72.1,
59.3,
46,
77.6,
84.6,
89.5,
90.8,
38.4,
56.2,
30.4,
97.9,
36.3,
73.1,
49.7,
55.7,
65.9,
42.4,
64,
60.7,
32.6,
48.5,
31.9,
28.6,
3.7,
23,
39.4,
37.7,
65.9,
28.7,
29,
39,
84.4,
34.8,
38.6,
43.1,
55.3,
59.1,
48.3,
7.6,
51.7,
78,
71.9,
59.3,
52.2,
57.9,
63,
49.7,
15.3,
96.3,
78.5,
6.5,
63.1,
55.1,
56.2,
76.2,
70.5,
70.1,
37,
34.5,
83.5,
64.3,
72.8,
71.9,
35.5,
30.2,
47.6,
9.7,
49.7,
38.4,
17,
85.9,
66.3,
78.8,
96.2,
49.9,
33.4,
35.5,
57.9,
57.2,
54.3,
59.1,
27.5,
57.2,
65.4,
30.9,
98.9,
93.6,
27.8,
92.7,
6,
81.6,
73.5,
59.2,
38.6,
0,
66.3,
97,
37.7,
54.9,
79,
36.7,
19,
23.1,
60.6,
62.1,
28,
48.9,
90.6,
73.5,
57.5,
69.8,
85.9,
32.9,
87,
90,
46.4,
90.9,
60.5,
41.7,
37.5,
14.5,
36.5,
41.8,
28.2,
66.2,
76.6,
68,
1.6,
11.7,
64.6,
47,
44.1,
65.6,
58.6,
65.9,
51.3,
66.6,
1.9,
32.2,
69.5,
42,
50,
4.4,
54.4,
10.1,
57,
69.1,
80,
79.4,
72.7,
47.9,
56.6,
56.4,
41.8,
77.9,
18.7,
27.8,
47.1,
52,
35,
50,
35.5,
29.5,
1.9,
47,
95.3,
13.3,
50.9,
43.2,
56.4,
23.2,
25.9,
64.8,
33.9,
27.9,
13.2,
74,
70.8,
80,
40.2,
39.5,
96.1,
80.3,
72.1,
36.3,
76,
60.3,
36.7,
51.7,
61.2,
77.9,
59.2,
65.8,
76.7,
13.5,
86.3,
98.5,
62.3,
40.9,
56.4,
82.1,
80.1,
92.6,
27.3,
34.1,
61.9,
42.1,
61.2,
72.1,
36.3,
65,
64.4,
58.2,
38.6,
29.3,
70.2,
53.3,
82.3,
44.1,
68.7,
58.2,
83.8,
43.7,
29.1,
34,
81.8,
60.2,
60,
60.5,
76.6,
49,
85,
50.4,
52.8,
88.4,
62.1,
92,
52.7,
50.2,
67.9,
55,
53.9,
43.4,
55.2,
73.3,
63,
81.6,
75.4,
15,
88.6,
43.1,
53.2,
22.9,
25.6,
49.3,
36.4,
15.1,
63.9,
12.1,
87.7,
44.6,
81.8,
31.8,
18.9,
44.4,
94.2,
59.9,
83.2,
59,
80.6,
95.3,
36.8,
35.8,
57.8,
61.4,
94.4,
91.1,
56.9,
40.3,
37.1,
34.4,
70.4,
55,
65.7,
70.8,
67.8,
84.8,
53.5,
49.9,
63.1,
37.1,
68.8,
54.5,
92.5,
68.8,
65.1,
50.2,
21.9,
92.4,
25.5,
35.1,
49.3,
47.1,
17,
98.9,
42.4,
54,
24,
74.8,
80,
94.1,
30.8,
25.1,
66.6,
54.6,
15.5,
68.9,
60.8,
37,
69.7,
45.5,
87.9,
24.3,
54.2,
63.4,
15.2,
22.8,
60.9,
72.9,
68.9,
93.9,
36.4,
29.9,
36.7,
48.6,
0.9,
72.3,
35.6,
47.1,
91.2,
19,
22.4,
48.5,
72.3,
19.6,
28.6,
69.7,
46.2,
36.8,
55.2,
66.5,
25.9,
62.3,
18.8,
36.1,
73.6,
90.2,
55.8,
75.2,
67.7,
36.8,
26.1,
56.7,
91.6,
60.8,
31.1,
94.9,
47.9,
55,
84.6,
71.4,
72.2,
71,
97.1,
2,
87.5,
38,
95,
61,
46.3,
35.1,
7.9,
66.6,
89.2,
47.2,
94.4,
50.5,
84.2,
46.4,
17.4,
85.1,
65.8,
67,
64.4,
61.4,
86.8,
60.5,
48.8,
36.9,
50.4,
44.8,
95.2,
74.4,
7.8,
79.3,
52.3,
34.8,
75.5,
52.1,
65.8,
81.1,
21.5,
45.6,
52.9,
14.1,
42.6,
59.9,
71.1,
55,
40.4,
95.8,
59.8,
60.4,
80.3,
48,
52.6,
57.6,
90.9,
83.7,
16.8,
80.7,
85,
73.4,
66.7,
65.3,
76.2,
15.5,
89.8,
88.8,
51.8,
74.2,
70.6,
81.7,
44.9,
95.4,
52.2,
32.2,
96.6,
65.6,
76.2,
87,
64.6,
25.4,
93.9,
59.4,
20.3,
61.6,
4.7,
71.7,
96.9,
77.1,
67.3,
69.1,
64.9,
66.6,
32.8,
61.5,
55.9,
94.2,
25.9,
46.9,
11.5,
28,
40,
37.4,
60.4,
78.1,
47.9,
44.1,
26.5,
16.4,
8.7,
85.9,
79.3,
87,
65.9,
33.4,
60.7,
60.5,
25.5,
75.3,
59.1,
18.8,
54.3,
61,
27.4,
63.2,
54.6,
82,
52.5,
56.5,
59.1,
73.4,
30.2,
58.2,
87.4,
78.9,
101,
83.5,
38.2,
48.2,
81.5,
43,
81.1,
89.6,
73.1,
83.4,
10.7,
5.8,
86,
62,
35.7,
48.4,
97.7,
16.1,
24.8,
33,
56.1,
37.3,
23.3,
76.2,
97.4,
46.5,
48.7,
89.6,
45.5,
49.1,
43.5,
35.1,
62.4,
87.9,
17.6,
64.5,
94.3,
38.1,
59,
74.5,
68.4,
47.7,
49.8,
44,
55.9,
39.7,
41.4,
45.2,
14,
10.2,
69.5,
83.1,
23.3,
63.3,
86.6,
8.6,
17.2,
50.6,
54.1,
74.2,
31.5,
74.3,
89.4,
97.6,
15,
67.2,
53.5,
49.9,
89.1,
64.1,
78.2,
64.3,
79.5,
75.6,
32.3,
63.4,
38.8,
19,
88,
37.8,
49.3,
47.1,
27.4,
74.4,
86.1,
87,
43.6,
92.4,
28.3,
79.5,
89,
80.5,
86.2,
15.7,
90.2,
36,
66.3,
65,
75.8,
64.6,
66.8,
53.2,
78.5,
17,
49.6,
34.5,
94.8,
69.3,
32,
6.1,
44.6,
84.8,
49.7,
25.2,
46,
49.8,
49.6,
65.9,
58.4,
78.9,
38.8,
43.2,
84.3,
63.8,
35.1,
42.6,
67.1,
68.4,
20.7,
52.4,
76.7,
56.3,
68.6,
58,
53.9,
96,
65.3,
75.8,
68.1,
38.3,
41.1,
65.5,
79,
60,
2.7,
67.2,
40.9,
18.1,
41.2,
63.2,
19,
50.1,
75.2,
63.8,
41,
70.2,
32.4,
70.4,
23.4,
46.5,
31.1,
1.9,
11.2,
83.3,
41.3,
23.7,
89.2,
82.2,
81.5,
21.6,
66.2,
91.5,
29.1,
9.9,
66.4,
61.6,
33.3,
35.7,
49.7,
66.7,
91.8,
67.8,
15.4,
38.4,
48.3,
7.2,
85.7,
71.2,
40.6,
75,
37.6,
70.3,
26.2,
85,
71.7,
60.8,
44.2,
63.5,
72.8,
106.4,
8.6,
10.1,
50.6,
43.8,
74.7,
87.8,
38.5,
50.7,
63.7,
43.6,
74.5,
77.9,
60,
2.6,
93.2,
81.5,
78.5,
45.8,
53.4,
55.5,
61.5,
56.6,
65.9,
60,
88.9,
84.1,
9.7,
76,
72.8,
94.2,
57.2,
12.9,
27.7,
19.5,
86.4,
31.2,
81.2,
57.1,
56,
63,
62.5,
54.7,
73.6,
10.6,
50.1,
82.6,
17.2,
47,
55.9,
41.2,
83.4,
61,
79.3,
67.1,
11.6,
59.2,
51.6,
61,
41.8,
53.7,
62.6,
45,
65.1,
32.4,
34.8,
90.1,
98.3,
48.7,
50.3,
71.7,
54.5,
51.7,
40.6,
75.9,
92.3,
80.2,
52.9,
45.5,
90.7,
55.3,
24.7,
0.7,
49,
72,
43,
85.3,
14.5,
38.3,
34.9,
78.1,
4.8,
93.7,
1.7,
14.4,
47.6,
8.9,
43.9,
47.4,
38.9,
56.7,
63,
90.3,
66.1,
68.6,
56.5,
44.6,
37.3,
75.3,
55.1,
48.6,
70.7,
51,
52.9,
70.9,
26.8,
70,
42.6,
74.9,
37.6,
75.2,
54.7,
65.6,
66.8,
23.4,
77.1,
92.9,
89,
34,
46.9,
69.4,
72.8,
9.4,
61.1,
53.6,
14,
30.7,
50.6,
65.8,
57.5,
26.1,
36,
1.6,
79.9,
61,
64.9,
71.8,
35.4,
75.7,
22.4,
13.2,
80.3,
47.2,
78.3,
32.1,
79.3,
65.4,
48.2,
79.2,
40.2,
59.5,
45,
42.1,
72.4,
79.6,
59.9,
45.6,
69,
49.1,
70.8,
65.2,
65.9,
49.4,
51.6,
7.1,
29.9,
64.6,
41.1,
16,
77,
79.3,
46.6,
57.6,
81.3,
91.3,
56.9,
58.9,
52.4,
77.3,
48.9,
98.9,
68.3,
62.7,
34.8,
94.4,
50.5,
46.7,
70.1,
83,
44.4,
69.6,
45.5,
82.5,
74.2,
60.8,
81.8,
15.3,
22.7,
36.6,
89.5,
49.5,
89.5,
84.6,
60.8,
58,
44.8,
65.3,
87.8,
65,
89,
48.1,
62.7,
73.4,
77.8,
64.5,
49,
53.3,
25,
60,
77.4,
7.6,
81.9,
40.5,
58.2,
19.8,
1.4,
89.7,
17.3,
45.5,
50.3,
62.9,
39.5,
22.4,
49.3,
63.8,
68.9,
58.7,
61.5,
97.4,
32,
59,
73.1,
48.6,
64.6,
63.8,
20.6,
70.9,
29.5,
50.4,
47.9,
48.3,
72.3,
92,
38.9,
32.5,
26.6,
56.1,
79.9,
68.7,
86.5,
54.2,
53.5,
78,
34.3,
28.2,
68.9,
21.1,
85.7,
45.2,
72.8,
38.9,
34.3,
44.9,
35.7,
32.1,
29.7,
12.2,
76.6,
53.9,
64.4,
75.4,
54,
32.1,
84.3,
57.6,
0,
77.3,
33.7,
39.7,
76.7,
99.6,
13.2,
65.8,
36.9,
70,
101.5,
81.9,
98.4,
80.3,
93.4,
50.8,
77.5,
69.5,
67.2,
22.2,
61.5,
56.3,
13.1,
95.9,
43.1,
65,
32.5,
49.5,
61.7,
87.7,
42.3,
87.9,
12.7,
75.6,
59.4,
43.8,
96.1,
22.1,
66.1,
36.8,
50,
79,
69.4,
73.6,
43.3,
88,
88.8,
37.9,
45.5,
63.7,
69.9,
33.8,
15.1,
88.2,
2.3,
54,
85.1,
73.1,
53.5,
81.8,
52.9,
69.2,
91.9,
100.1,
21.7,
35.4,
96.9,
54.7,
82.6,
52.3,
97.3,
70.2,
64.5,
29.8,
61.1,
20.9,
65,
88.7,
82.1,
23.1,
48.5,
41.9,
62.2,
49.4,
45.6,
83.3,
84.1,
96.1,
38.8,
66.3,
49.5,
65.8,
86.3,
35.5,
26.3,
57.9,
43.5,
17,
96.9,
7.9,
85.9,
70,
86.7,
77.8,
66.8,
65.8,
71.4,
39.9,
25,
71.3,
25.7,
60.9,
90.1,
16.4,
77.8,
49,
19.6,
83.1,
39.2,
55.8,
74.1,
72.5,
23.2,
39.8,
64,
97.9,
36.6,
79.3,
41.4,
77.4,
71.7,
63.8,
26.5,
38,
55.3,
76.1,
55,
43.2,
19,
75.2,
68.3,
39,
72.8,
44.9,
49.9,
102.5,
54.1,
11.5,
59,
43.1,
95.1,
47,
42.2,
56.5,
41.1,
83.2,
0,
38,
1.2,
152.7,
65.2,
88.4,
49,
79.2,
31.9,
40.8,
43.8,
91.4,
79.4,
15.1,
72.2,
39.2,
79.6,
52.1,
92,
56.9,
53.9,
93,
47.9,
39.2,
62.8,
47,
100,
52.3,
50.7,
16.7,
84.3,
63.4,
49.2,
86.3,
73,
54.6,
92.4,
75.8,
73.3,
59.9,
31,
42.6,
55.7,
42,
46.3,
47.2,
91.1,
75.6,
62.9,
54,
48.1,
62,
81.1,
70,
53.1,
39.9,
75.9,
50.7,
30.2,
72.2,
7.3,
49.1,
72.3,
89.4,
81.3,
28.7,
22.3,
69,
90.2,
59.1,
74.7,
75.5,
93.2,
41.8,
79.4,
71.7,
42.9,
43.6,
0.5,
26.1,
49.4,
58.6,
31.1,
45.2,
63.6,
48.5,
8.7,
75.7,
62.1,
56.5,
19.2,
67,
43.1,
65.4,
83.3,
17,
92.3,
80.2,
59.4,
39,
48,
22.6,
29.2,
21.9,
49.1,
28.2,
93,
40.8,
53.1,
36.7,
65,
79,
81.9,
64.3,
79.5,
53.3,
76.8,
4.5,
19.7,
32.5,
45.5,
4.3,
35.7,
63.1,
58.6,
41.8,
27.8,
55.1,
23,
72,
86.5,
37.1,
30.5,
38.5,
42.1,
54.3,
30.5,
26.1,
45.5,
44.9,
52.9,
67.2,
55,
24.3,
48.1,
57,
38.3,
81,
68.8,
69.8,
30.2,
75.3,
64.2,
34.6,
19.8,
85.4,
69.6,
55.1,
61.4,
60.7,
66.7,
63.4,
33.7,
63.9,
41.4,
25.8,
82.6,
26.1,
91,
59,
71.7,
71.9,
44.4,
33.6,
14.9,
41.9,
38,
36.5,
57.3,
59.8,
44.4,
65.6,
42.3,
78.1,
17.6,
43.2,
52.6,
10.2,
80.3,
98.9,
79.3,
58,
22.3,
34.5,
49.6,
67.5,
93.7,
85.3,
77.1,
72.6,
10.7,
61,
29.1,
17.5,
13.2,
65,
13.6,
70.2,
76.8,
23.8,
50,
35.1,
52,
28.7,
72.3,
70.4,
44,
52.3,
79.3,
80.1,
42.3,
89.1,
27.9,
73.1,
96,
47.8,
56.3,
76.4,
61.3,
82.9,
97.3,
16.3,
95.4,
72.2,
90.8,
81.6,
61.7,
39.7,
17.2,
54.9,
20.3,
23,
55.1,
68.3,
82.5,
38.1,
14.1,
31.6,
56,
19.2,
63.7,
59.2,
76.3,
22.8,
90.4,
31.5,
70.3,
52.4,
54.3,
50,
55.5,
91.2,
84,
22.9,
57.1,
50.4,
78.2,
47.5,
74.6,
60.3,
22.2,
66,
21.6,
20.7,
73.1,
32.6,
37.6,
42.4,
84.9,
54.6,
46.9,
20.6,
22.7,
3,
45,
77.7,
86.5,
48.7,
33.6,
35.4,
79.5,
65.7,
68.5,
19.7,
38.1,
80.9,
79.3,
3.9,
45.4,
86.1,
47,
26.3,
47.2,
42.2,
42.2,
46.5,
55.2,
24.4,
85.9,
22.2,
45.7,
64.9,
93.9,
77.5,
59.9,
29.2,
87.2,
46.6,
53.3,
82.5,
72.9,
85,
18.5,
58.9,
61.3,
63.2,
50.3,
21.8,
86.6,
71.6,
91.1,
16.6,
54.6,
39.5,
77.6,
22.4,
93.3,
68.9,
87.6,
75,
10.2,
40.9,
90.6,
65,
90.9,
75.6,
54.2,
31.2,
72,
71.7,
12.6,
83.4,
70,
22.4,
47.6,
28.6,
68,
51.1,
88,
10.6,
40,
46.3,
40.1,
89.2,
57.8,
77.8,
46,
25.7,
53.6,
53,
78.9,
66.1,
24.1,
91.2,
90.6,
42.9,
65.6,
60,
92.3,
61.2,
15,
38.9,
61.6,
39,
86.8,
23.1,
24.6,
47.9,
67,
63.2,
93.2,
62.7,
4.5,
67.3,
68.9,
52,
73.2,
57.5,
77.5,
6.6,
34,
86.4,
66.8,
97.7,
42.8,
54.3,
83.1,
61.7,
75.1,
33.4,
67.3,
71.8,
70,
39,
58.5,
40.9,
58.8,
84,
85.8,
57.3,
53.8,
66.4,
53.4,
77.3,
34.5,
63.7,
38.2,
9.3,
59,
68.2,
53.2,
63,
55.7,
81.6,
24.6,
50,
92.2,
35.8,
48.4,
98.8,
83.1,
3.4,
53.6,
54.5,
77,
57.6,
69.1,
43.4,
66.1,
61.2,
81,
2.3,
75,
94.3,
88.6,
16.3,
54,
75,
71.6,
35.5,
21.6,
82.6,
49.8,
67,
38.9,
80.4,
36.9,
57.2,
38.7,
30.2,
62.9,
94.6,
41.8,
47.1,
85.2,
99.3,
35.2,
78,
21.5,
21.5,
85.4,
57.4,
35,
79.4,
21.8,
82.5,
68.6,
87.5,
83.3,
23.6,
36.6,
69.3,
52,
99.3,
44.4,
35.6,
73,
50.2,
46.7,
4.5,
65.2,
10.8,
46.4,
79,
92.9,
71.8,
94.3,
22.4,
53.4,
95,
85.8,
37.5,
30.2,
30,
38.9,
74.7,
33.2,
74.9,
49.9,
54.2,
87.1,
77.9,
52.5,
26.3,
60.4,
46.9,
31.7,
28.2,
22.9,
59.1,
30.7,
27,
86,
34.7,
39.1,
34.5,
36.1,
27.8,
39.8,
63.1,
1.3,
76.8,
36.5,
92.6,
47.2,
59.5,
74.2,
32,
13.5,
78.3,
16.3,
45.3,
39.7,
48.4,
23.9,
28.6,
23.3,
78.6,
34.2,
11.3,
20.3,
58.6,
71.5,
24.9,
41,
46.6,
53.5,
60.1,
17.3,
22.4,
20.1,
53.3,
12.4,
78.4,
41.5,
76.3,
38.4,
83.5,
26.9,
21.2,
23.5,
17.5,
75,
93.2,
49.5,
72.8,
67.7,
55.1,
22.2,
57,
39.2,
40.4,
77.2,
75.1,
85.3,
47.3,
44,
70.8,
34,
65.5,
19.5,
52.9,
33.7,
15.3,
32.5,
55.5,
67.8,
36.6,
96.2,
42,
87.3,
92.4,
85.9,
90.6,
52.1,
33.4,
32.2,
94.5,
43.1,
80.6,
29.4,
10.3,
66.7,
0,
53.9,
58.5,
62.7,
55.4,
66.9,
25.2,
56.9,
52.2,
63.2,
74,
1.6,
30.6,
48.5,
56.7,
3.2,
57.6,
28,
58.3,
54.6,
63.5,
52.7,
50.3,
81.1,
70.4,
66.7,
7.1,
4.5,
78.9,
35.7,
46.7,
96.7,
82,
13.8,
48.7,
57.8,
29.7,
57.4,
92.8,
38.8,
79.4,
62.6,
83.1,
45.1,
83.6,
43.3,
62.3,
35.9,
94.2,
58.2,
56.2,
56,
47,
73.2,
65.2,
52.9,
29.9,
72.7,
70.7,
70.1,
78,
50,
55.4,
61.6,
10.6,
58.3,
70.7,
33.3,
98.5,
42,
91.6,
41.3,
69.4,
43.5,
60.4,
73.7,
84.2,
51.5,
97,
47.6,
83.7,
38.4,
62.4,
39.6,
66.4,
16.3,
67.4,
65.3,
29.6,
82.8,
83,
82.2,
50.7,
0,
66.4,
47,
49.1,
56.2,
67.9,
55.2,
37.9,
19.9,
43.1,
6.2,
33.5,
44.3,
86.9,
40,
55,
43.7,
66.6,
92.9,
60.8,
46.6,
47,
70.9,
41.3,
65.7,
31.2,
0.5,
15.1,
50.1,
44.4,
55.6,
89.7,
34.4,
95.3,
84,
69.8,
80.5,
25.6,
34.9,
74,
60.7,
57.8,
89.3,
80.9,
101,
61.7,
56.5,
59.6,
55.2,
11.5,
41.9,
85.5,
16.2,
53.9,
81.8,
82.5,
0.1,
89.6,
29.4,
59.7,
88.2,
26.1,
52.6,
96.3,
11.2,
57.8,
31.7,
73.4,
20.7,
76.5,
21.9,
62.2,
75,
40,
72.1,
68.3,
66.1,
27.7,
54.8,
39.4,
86.9,
66.4,
32.4,
27.3,
52.2,
33.3,
30.8,
94,
34.3,
67.3,
38.3,
59,
87.3,
66.3,
34.6,
75.4,
59.8,
77,
64.3,
70.5,
26.7,
60.5,
76.1,
1.1,
70,
34.6,
83.8,
24,
98.7,
53.6,
28.9,
85,
25.6,
51.4,
80.6,
88,
85.3,
74.7,
57.1,
67.2,
53.5,
64.2,
35,
48.5,
81.4,
88.3,
22,
34.9,
40,
65.7,
16.6,
55,
30.2,
36.8,
21.4,
19.4,
66.7,
6.5,
76.6,
50.6,
20.4,
60.7,
44.5,
59.3,
0,
38.7,
88.9,
41.4,
70.3,
70.6,
78.3,
30.6,
69.7,
85.9,
84.2,
71.4,
42,
27.1,
82.1,
51.2,
55,
67.5,
67.1,
77.3,
58.3,
61.9,
46,
31.6,
41,
77.4,
91.1,
76.8,
61.1,
15.1,
74.3,
24.1,
92.9,
57.7,
96.4,
93.5,
74.1,
60.3,
98.3,
29.8,
57.4,
56.7,
4.5,
68.4,
47,
37.8,
83.5,
8.9,
81.1,
74.9,
64.1,
77.5,
8.8,
89,
37.8,
75.4,
58.4,
70,
50,
13,
58.9,
60.2,
101.5,
93.8,
61.3,
48,
9.5,
42.2,
95.5,
58.4,
59.3,
52.1,
28.9,
53,
62.6,
17.1,
42.5,
57.2,
89,
78.4,
60.4,
48.5,
22.2,
49.6,
21.5,
33.7,
55.7,
46,
54.7,
51.9,
69.4,
97.9,
31.5,
53.2,
57.5,
83,
60.4,
86.6,
71.5,
51.2,
80.7,
96,
1.4,
17.1,
51.4,
97.1,
81.8,
51.6,
40.5,
93,
44.5,
59.1,
44.1,
91.1,
89.8,
69.7,
63.5,
41.5,
68.7,
94.6,
39.9,
86.4,
54.4,
71.1,
64.8,
23.4,
29.7,
77.9,
37.6,
88.6,
73.7,
45.8,
84.6,
53.2,
59.9,
68.8,
86.5,
12,
82.3,
65.6,
84.8,
44.8,
51.9,
4.4,
42,
45.3,
54.2,
47.5,
15.5,
29.2,
23.7,
95,
20.5,
51.4,
59.5,
29.9,
86.7,
58,
68.7,
21.7,
89.9,
64.5,
51.4,
88.1,
16.2,
61.2,
38.6,
58.2,
65.7,
95.4,
80.4,
43.4,
45.5,
85.4,
36.3,
50,
45.4,
93.5,
70.4,
47.4,
52.2,
65.7,
26.5,
75.2,
66.9,
47.7,
66.4,
77,
51.2,
64,
93.7,
40.1,
83.6,
47,
42.6,
82.7,
84,
7.5,
88,
75,
43.5,
99.6,
40.1,
75.2,
25.4,
67.2,
0.5,
8.9,
76.8,
57.9,
28.6,
40.3,
47.8,
47.3,
47.2,
84.5,
31.5,
0,
58.2,
24,
39.7,
17,
83.4,
45.7,
68.8,
91.5,
52.1,
25.2,
38.2,
27.1,
46.3,
36.3,
31,
6,
50.4,
44.4,
45.4,
55.8,
31.7,
62.1,
92.4,
22.1,
45.6,
79.4,
80.7,
57.7,
64.8,
81.8,
0.2,
26.5,
59.5,
91.2,
39.2,
60.6,
62.9,
54,
92.1,
83,
59.8,
98,
52.6,
53.4,
35.9,
29.1,
61.9,
43.3,
64.8,
61.6,
9.2,
47,
60.8,
32.7,
62,
58.1,
90.6,
21.9,
50.3,
85,
56.3,
52,
63.2,
97.5,
78.5,
62.7,
26.6,
45.6,
55.1,
62.8,
76.7,
78.3,
56.9,
74,
25.6,
75.1,
58.6,
32.7,
37,
24.9,
31.3,
35.2,
67.4,
91.1,
39.7,
32.4,
96.2,
70.1,
59.7,
68.4,
14.9,
43.5,
98.6,
34.8,
24.5,
36.9,
35.8,
76.5,
53.2,
51.4,
16,
49.2,
23.1,
27.8,
37.6,
62.3,
34.6,
47.2,
25.9,
51,
82.6,
39.1,
78.5,
51.5,
84,
65.3,
69.1,
12.8,
97.8,
98.9,
0,
69.7,
69.9,
37.9,
48.4,
83,
63.6,
66.1,
57.3,
71.6,
52.5,
38.7,
85.6,
23.2,
62,
7,
42.1,
15.4,
8.8,
60.2,
40.8,
14.6,
33.9,
69.6,
75,
92.7,
95.6,
72.8,
28.3,
63.2,
98,
9,
37.1,
79,
85.9,
15.9,
86.5,
73,
67.4,
41,
49.9,
75.3,
15.5,
66.1,
63,
30.1,
73.1,
24.3,
70.7,
7.8,
27.4,
91.5,
33.9,
91.3,
75.1,
59.2,
75.1,
78.1,
65.3,
72.2,
84.4,
29.8,
51.8,
79.6,
26.8,
16.4,
46.2,
72.3,
47.7,
4.9,
26.9,
81.2,
48.1,
84.5,
32.7,
63.9,
74.6,
40.7,
86.7,
67.5,
68.2,
41.7,
45,
73,
88.8,
87.4,
23.4,
81.2,
58.5,
95.1,
55.1,
49.7,
54,
72,
82.4,
68.1,
54.4,
48.5,
77.5,
21.3,
92.1,
24.9,
75.1,
90.3,
72,
33.6,
86.8,
62.7,
68,
81,
96,
72.8,
60.1,
100,
46.7,
39.4,
81.3,
102,
59.3,
70.9,
65.9,
87.3,
73.6,
7.28,
46.9,
48.9,
88.4,
82,
62.3,
8.5,
34,
25.3,
62,
40.9,
36.7,
87.1,
33.1,
60.2,
58.6,
68.7,
59.5,
54.8,
63.1,
48.9,
23.5,
67.9,
54.1,
47.1,
9.2,
94.6,
74.6,
13.9,
40.3,
64.2,
82.4,
53,
73.6,
71.4,
78.9,
69.8,
60.3,
94.1,
76.7,
35.4,
37.1,
50.5,
0,
84.2,
5.3,
70.1,
69.6,
65.4,
55.3,
32.6,
52.8,
58,
31,
94.5,
32.8,
62.8,
41.8,
18.1,
10,
67.1,
74.2,
62.1,
84.7,
58.3,
10.4,
90.1,
81.1,
51,
50,
58,
58,
38.8,
93.4,
60,
48.9,
39.6,
29.3,
59.1,
13.7,
48.6,
96.6,
39.9,
78.3,
67.7,
12.4,
62,
73.1,
66,
85,
73.9,
31,
29.4,
46.4,
70.1,
82.4,
66,
52,
90.8,
84.4,
68.4,
59.5,
65.6,
87,
20.8,
71.2,
56.4,
26.2,
41.3,
54.4,
102.5,
10.8,
17.7,
78.7,
66.6,
48.8,
64.9,
62.3,
24.9,
71.9,
53,
79.9,
46.9,
0,
65.8,
51.2,
67.7,
62.4,
54.2,
37,
70.9,
75.2,
38.3,
81.7,
100.7,
72.8,
52.2,
56.3,
58.1,
74.1,
54.9,
0,
92.3,
50.1,
58.4,
82.9,
37.6,
14,
84.4,
80.7,
39.4,
55.4,
24.8,
94.4,
9.9,
52.3,
99.4,
87.4,
50.4,
51,
7.5,
52.4,
61.6,
79.2,
34.8,
13.1,
62,
77.3,
34.7,
75.3,
49.6,
53.8,
45.8,
63.1,
99.4,
67.9,
40.9,
20.7,
90.9,
56.6,
65.3,
43.5,
38.6,
29.5,
32.2,
29.6,
58.4,
70.7,
97.4,
74.6,
43.7,
59,
31.1,
67.3,
53,
64.3,
70.1,
30.2,
50.8,
59.2,
33.2,
46.5,
61.5,
57.9,
31.5,
39.3,
93.9,
27.2,
58.8,
58.3,
75.1,
44,
96,
35.1,
27.6,
31.8,
44.3,
10.4,
62,
42,
37.9,
39.3,
54.1,
34.3,
89.5,
31.9,
36.7,
92.5,
35.9,
82.7,
82,
58.9,
76.3,
47.1,
0,
31.6,
41.7,
29.8,
69.5,
10.5,
62.7,
83.1,
79.7,
42.6,
50.6,
49.5,
83.5,
44.4,
54.6,
11.6,
94,
51.8,
40,
71.8,
66.7,
93.7,
44,
44.9,
55.1,
52.8,
32.8,
64.6,
85.8,
43.7,
88.4,
10.2,
74.4,
59.3,
42.4,
3.4,
38.5,
46.9,
11.7,
54.6,
86.6,
32.3,
76.1,
90.5,
15.6,
87.4,
17,
37.1,
30.5,
66.5,
69.1,
71.3,
63.3,
82.3,
33.3,
90.3,
48.7,
79.8,
68.8,
30.7,
52.9,
69.8,
71.2,
50.1,
46.7,
4,
88.3,
34.5,
84.4,
44.8,
49.7,
7.6,
18.2,
88.2,
53.6,
20,
55.2,
45.2,
44.8,
74.5,
25.7,
41.3,
40.5,
87.1,
48.7,
83.8,
63.6,
87.7,
100.4,
96.7,
85.1,
97.7,
89.9,
35.4,
43.3,
28.9,
95,
25.8,
5.3,
66.8,
71.6,
79,
45.3,
5.7,
70.2,
56.9,
76.4,
28.4,
75.4,
79.6,
71.5,
97,
63,
53.6,
66.6,
92,
71.8,
73.3,
46.7,
39.2,
68.6,
18.8,
48.3,
51.8,
54,
24.8,
31.3,
17.8,
97,
87.2,
71.5,
63.6,
72.9,
85.8,
69,
56,
26.8,
96.9,
47.3,
96.4,
95.7,
58,
23,
83.6,
87.4,
39.6,
0.8,
47.7,
0,
31.7,
58,
70.1,
72.1,
43.6,
76.4,
82.2,
44.8,
10.9,
72.9,
15,
66.9,
50.9,
83.8,
77.2,
67.8,
74.4,
93.6,
49.4,
56.6,
52.4,
47.2,
44.6,
36.7,
77,
89.2,
48,
37,
56.5,
null,
63.7,
82.9,
52.2,
8.7,
107.4,
58.6,
52.4,
51.5,
71.7,
36.2,
63.5,
77.6,
50.7,
49.3,
27,
40.8,
83.1,
84.8,
37.9,
57.8,
76.5,
51.7,
50.7,
35,
40.8,
24,
88,
48.4,
71.7,
48,
58.1,
49.1,
11.8,
80.8,
12.8,
20.3,
90.8,
72.5,
59.9,
75.1,
33.9,
93.8,
66.1,
84.6,
61.6,
88.2,
39.7,
17.1,
67.8,
74.2,
1.6,
75,
51.3,
79.3,
40.9,
70.1,
13.3,
48.7,
71.3,
85,
60,
56.2,
74.8,
80.3,
81.8,
40.7,
80.3,
46.2,
46.8,
63.1,
39.9,
45.8,
74.9,
87.1,
24,
63.8,
32.1,
55.9,
32,
32.5,
66.4,
68.7,
72,
19.6,
57.9,
21.1,
36,
56.7,
64.8,
77.4,
37.2,
56.4,
71,
60.5,
22.8,
21.2,
77,
36.9,
62,
21.2,
42.8,
67.6,
39,
61,
49.6,
37.2,
8.8,
52.8,
91,
92.3,
33.9,
29.3,
72.6,
49.6,
40.4,
94.9,
79.9,
58.3,
57.9,
72.4,
94.9,
45.3,
66.7,
36.4,
55.8,
18.1,
59.9,
73.5,
49.6,
72.8,
62.3,
62,
15.2,
59.9,
86.6,
34.1,
58.8,
94.9,
47,
61.1,
56.9,
90.2,
69.4,
87.5,
41.5,
48.2,
57.3,
108,
9.6,
13.7,
88.7,
73.7,
99.2,
75.6,
59.6,
89.9,
60.5,
86,
48.6,
57.3,
72.9,
73.2,
34,
42.7,
39,
29,
5.3,
74,
126.4,
95.9,
82,
65,
71.1,
58,
1.1,
90.9,
26.7,
93.3,
63,
89,
91.2,
65,
54.4,
37.9,
48.4,
77.4,
54.9,
47.8,
71,
81,
12.5,
67.5,
17.8,
85.4,
82,
40.1,
95.2,
90,
65.9,
35.3,
65.3,
95.6,
0,
15.3,
49.5,
20.5,
36.8,
60.3,
72.5,
41.8,
26.7,
30.8,
59.3,
84.6,
78.5,
74.3,
69.7,
37.4,
67.9,
63,
78,
95.5,
46,
86.8,
72.5,
85.1,
66,
62.7,
32.8,
92,
68.8,
53.2,
88.1,
92.9,
21,
45.6,
63.1,
45.4,
49.8,
58.2,
68.9,
66.7,
16.4,
74.8,
71.3,
68.4,
72.2,
43.7,
57.2,
52,
43.8,
46.2,
67.3,
65.9,
19.7,
56,
53.8,
35.6,
65.7,
42.1,
82.2,
89.7,
37.2,
81,
28.3,
22.4,
20.5,
55,
32.6,
67.1,
59.2,
31.5,
64.7,
60,
29,
70,
93,
52.9,
96.3,
60.5,
91.9,
52.3,
53.6,
14.1,
88,
77.9,
89.1,
11.4,
76.1,
42.1,
58.8,
7.3,
52.2,
63.7,
27,
10.1,
21.5,
68.6,
57.1,
24.3,
33.9,
70.4,
9.2,
73.5,
64.4,
65.7,
4.3,
19.5,
31.2,
95.1,
27,
77.9,
67.8,
56.8,
94.5,
78.7,
50.6,
42.1,
65.3,
55.8,
74.2,
38.5,
70.6,
55.8,
73.8,
60.8,
51.1,
27.6,
31.9,
40.8,
37.4,
46.8,
72,
36,
93.5,
3.2,
17.3,
18.5,
50.1,
37,
27.8,
85.9,
89.7,
59.4,
38.2,
69,
50.8,
39,
51,
64.1,
61.9,
79.2,
30.9,
87,
23,
65.9,
67.9,
28,
36,
75,
34.4,
57.7,
9.6,
85.4,
35.3,
59,
41.1,
64.1,
34.7,
82.3,
82.8,
48.4,
85.1,
21.4,
48.3,
58.1,
86,
81.2,
52.1,
47.1,
81.6,
93,
77.5,
79.6,
33.4,
36.1,
69.3,
60.3,
29.1,
78,
30.6,
76.9,
74.2,
25,
82.3,
82.2,
94.1,
46.5,
27.3,
76,
37.8,
58.1,
72.7,
40.4,
37.3,
84.2,
54.8,
41.6,
61.4,
33.4,
48.5,
51.7,
8.5,
36.8,
78.7,
51.1,
84.6,
74.4,
32.8,
49.8,
82.2,
36.8,
56.5,
48.2,
49.1,
63.7,
74.4,
83.1,
72.1,
10.6,
45.3,
39,
95.7,
83.2,
72.7,
63.3,
82.9,
39.8,
48.1,
74,
56.8,
83.5,
56.2,
38.1,
50.8,
15.4,
88.8,
78.9,
64.9,
52,
30.7,
62.4,
67.6,
46.7,
67.4,
40.5,
50.2,
84.9,
72.4,
43.2,
14.6,
19,
78.1,
87.2,
36.1,
19.9,
73,
89,
41.6,
25.5,
90,
5.8,
28.4,
33,
58.5,
24,
23.9,
34,
78.7,
65.8,
52.3,
43.4,
28.5,
30.7,
79.7,
0,
21.9,
48.5,
89,
45.9,
25.1,
73.5,
9.5,
42.8,
40.2,
73.5,
69.5,
40.7,
8.8,
76.6,
31.6,
57.8,
36.1,
64.5,
69.9,
69.9,
92,
28.6,
19.1,
30.1,
26.8,
53.8,
27.9,
94.9,
80.7,
51.6,
22.1,
80.4,
55.3,
88.7,
52.3,
58.6,
24.2,
77.8,
65,
96.6,
18,
87.2,
75.8,
21.6,
21.2,
52,
33,
59,
79.1,
86.7,
69.1,
56.9,
78.8,
81,
47.7,
63.7,
55.2,
86.1,
27.8,
23.11,
53.1,
64.5,
26.5,
73.7,
91.9,
62.3,
18.3,
64,
65.7,
17.1,
48.9,
29.8,
56.3,
88.8,
52.6,
83.9,
76.8,
47.6,
69.2,
73.5,
57.6,
88.7,
87.7,
70.2,
36.7,
27.2,
79.9,
0.3,
88.5,
59.2,
88.2,
52.7,
89,
64.4,
100,
51.4,
10.6,
76.3,
38.6,
31.1,
85.6,
38.9,
69.7,
46.3,
48,
91.1,
91.4,
82,
53.1,
60.7,
16.9,
51.2,
49.9,
57.5,
12.7,
28.2,
67.3,
39.2,
35.8,
70.3,
33.8,
11,
58.2,
69.8,
26.2,
79.2,
58.9,
35.9,
24.7,
62.5,
45.3,
77,
56.6,
94.1,
43,
48,
53.5,
70.7,
61,
6.4,
99,
71.4,
61.6,
66,
56.2,
37.5,
49.6,
63.1,
62.3,
73.6,
69.6,
40.3,
12,
85.5,
43.8,
62.5,
41.7,
94.5,
68.3,
13.5,
21.1,
69,
67.8,
68.3,
44.3,
20.3,
51.6,
15.5,
36.2,
59.9,
47,
87,
13.6,
72.6,
41.7,
83.3,
36.7,
35.8,
61.8,
47.6,
31.5,
56.4,
37.6,
63.8,
87.6,
34.8,
79.4,
86.1,
40.8,
60.6,
57.3,
54.3,
53,
20.4,
55.5,
69.1,
70.6,
22.9,
63.2,
33.7,
29.5,
74.4,
26.6,
77.4,
70,
14.5,
81.4,
65.3,
53.3,
66.1,
81.8,
75,
69.9,
72,
51.5,
64.8,
57.4,
12.7,
92.3,
18.7,
94.7,
81.2,
44.2,
89.3,
77.2,
54,
40.1,
34.6,
80.6,
59,
21.3,
36.3,
80.8,
69.6,
49.9,
92.2,
15,
46.8,
56.2,
73,
61,
63.9,
56.5,
55.7,
91.8,
50,
86.9,
67.8,
7.5,
60.4,
39.7,
39.3,
87.8,
31,
91.5,
44.7,
56.7,
85,
34.1,
56.3,
84.9,
69.5,
67.8,
75.7,
50.1,
37.7,
75.2,
55,
49.3,
56.5,
73.7,
15.9,
48.2,
4.4,
31.5,
69.9,
86.8,
67,
9.3,
62.1,
73.5,
1.8,
10.3,
26.9,
33.9,
84.3,
57.6,
24.9,
63.2,
20.7,
34,
12.9,
14,
92.9,
71.5,
40.1,
97.8,
44.4,
93.9,
40.8,
87.1,
77.1,
31.4,
46.3,
46.3,
50.3,
56,
51.9,
48.9,
20.1,
77.2,
98.6,
8,
59.6,
66.1,
87.6,
78.4,
3.7,
83.2,
55.6,
65.1,
33.1,
52.8,
86.7,
35.7,
0,
58.9,
3.6,
33.6,
50.6,
35.7,
47.5,
24.8,
60.5,
30.9,
55.3,
73.8,
77.9,
63.4,
26.5,
79.1,
93.5,
49.7,
31,
49.1,
24.4,
89.9,
43.5,
49.3,
25.7,
34.7,
94.4,
42.2,
66,
73.5,
16.3,
61.1,
45.2,
60.3,
43,
70.6,
36.1,
41,
82.8,
19.7,
78.4,
48.9,
29.7,
55.4,
6.6,
83.6,
51.2,
50.6,
83.7,
85.2,
49.2,
56.3,
48.6,
96.3,
32.9,
92.7,
46.8,
47,
92.9,
57.8,
48.7,
27.7,
63,
74.5,
76.6,
48.8,
52,
44,
89.2,
67.9,
39.9,
27.9,
48.4,
96.5,
30.5,
68.5,
24.3,
66.3,
8.4,
56.8,
48.7,
37,
9.2,
75.3,
63.6,
14.5,
54.7,
23.1,
34.3,
63,
39.8,
34.8,
49.6,
58.6,
13.4,
50,
76.8,
83.8,
90.7,
69.7,
40,
88.9,
15.9,
55.6,
84.3,
81.9,
59.5,
81,
81.1,
56.4,
44,
80.1,
19.8,
27.5,
50.9,
83.6,
17.7,
40,
45,
88.3,
0.2,
45.6,
98,
80.5,
69.6,
39.2,
36.2,
82,
57.8,
79.1,
39.4,
59,
34.2,
56.5,
72.4,
85.6,
85,
24,
45.5,
53.6,
89.4,
29.5,
62.2,
37,
84,
9.6,
76.3,
33.9,
63.3,
45.8,
71.5,
51.2,
26.6,
69.5,
54.5,
21.3,
38,
23.1,
21.8,
53.7,
61.7,
65.9,
66.7,
38.3,
39,
18.3,
62.6,
37,
45.8,
76.9,
58.6,
84.8,
33.9,
50,
87.5,
99.1,
84.9,
36.2,
9.5,
89.9,
65.6,
65,
46.9,
55.4,
78.1,
23.1,
56.6,
88.4,
53.5,
73,
85.8,
84,
55.6,
46.8,
78.1,
94.1,
49.4,
55.2,
18.6,
87,
31.1,
83.9,
47,
49,
34.7,
32.4,
65.7,
88.2,
35.2,
97,
56.2,
68.4,
79.5,
40.6,
86,
3.1,
10.1,
48.8,
42.9,
40.6,
77.2,
40.9,
39.5,
39.9,
46.5,
47.1,
17.9,
74,
55.4,
64.9,
97,
80.3,
64.9,
46.1,
39.4,
69.8,
50.7,
69.1,
96.1,
64.7,
93.3,
28.8,
1.3,
74.7,
84.9,
49.3,
93.5,
58.4,
92.7,
71.2,
62.7,
45.3,
88,
67.3,
38.1,
59.1,
65.4,
64.9,
78,
48.1,
51.9,
72.7,
83,
74.6,
60.4,
79.6,
11.8,
83,
82.4,
14.7,
28.3,
58.6,
78.3,
49.1,
59.2,
71.1,
55.1,
70.1,
78.1,
73.4,
45.9,
70.3,
61.1,
37.3,
47.7,
82.3,
62.6,
50.3,
24.1,
61.2,
49.2,
66.2,
72.3,
40.7,
57,
80.2,
52.9,
60.4,
55.6,
57.4,
67.7,
91.7,
3.9,
35.3,
65.4,
87.4,
55.1,
66.6,
88.4,
0,
79,
25,
90.3,
18.9,
60.1,
73.1,
57.7,
65,
13.2,
39.1,
78.2,
69.9,
15.5,
93.6,
74.3,
27.8,
59.9,
28.6,
12.3,
59.5,
60.7,
44.4,
76,
8.6,
14.3,
36.2,
29.3,
57.5,
75.3,
40.6,
11.4,
65.9,
28.5,
52.7,
42.4,
78.4,
82,
39.6,
46.2,
67,
64.5,
50.3,
24.8,
80.9,
74.3,
37.6,
67.3,
55.4,
69.7,
61.3,
55.5,
57.7,
23.6,
25.4,
65.7,
93.9,
35,
62,
73,
32,
43,
22,
48.1,
61.3,
78,
60.5,
75,
36.7,
39,
77.4,
64.2,
56.7,
70.9,
74.1,
85.3,
76,
46,
32.3,
54.7,
77.8,
68,
46.6,
73,
40.3,
65.2,
73.4,
91.6,
55,
35.2,
65.1,
38.8,
24.9,
54.8,
32.2,
19,
33.6,
54.7,
62.2,
34.1,
86.4,
63.2,
83,
83.7,
12.9,
89.1,
29.9,
89.5,
82.3,
31.3,
66.8,
69,
36.5,
46.7,
75.9,
82.5,
70.7,
83.5,
97.2,
84.3,
11.4,
91.5,
39.9,
56,
54.8,
60,
53.2,
72,
117.5,
86,
71.7,
80.6,
19.1,
73.4,
82.2,
43.3,
64.1,
71.8,
54.2,
72.3,
23,
74.2,
56.1,
62.5,
48.1,
64.1,
34.4,
20.4,
80.6,
91.4,
36.5,
26.7,
23.8,
17.3,
55.5,
61.9,
12.8,
48.4,
79.2,
72.3,
44.7,
53,
70.8,
49.1,
65.9,
69.7,
59.2,
73.6,
31.4,
54.3,
61.3,
39,
67.6,
89.1,
85.3,
50,
48.3,
13.4,
82.5,
32.6,
21.6,
21,
36.2,
82.4,
29.1,
82.2,
32.4,
56.8,
63,
41.5,
88.3,
33.2,
19.6,
67.7,
64.9,
38.3,
55.9,
24.7,
78.9,
83.5,
91.4,
49.7,
65.6,
10.2,
79,
27.7,
25.3,
75,
64.6,
45.7,
36.4,
9.7,
76.5,
58.3,
40.2,
30.1,
59.6,
12,
84,
72.9,
52,
96.1,
72.5,
23.2,
43.1,
51.6,
38.5,
51.2,
47.7,
60.2,
89.9,
59.7,
46,
42.6,
63.6,
88.1,
73.2,
36.6,
96.9,
55.5,
37.5,
89.8,
82.7,
52.1,
91.4,
18.4,
31.2,
48.8,
56.5,
84.8,
35,
69.6,
38.8,
1.2,
50.4,
9.7,
50,
59.1,
26,
1.3,
90.2,
38.4,
59,
40.1,
35.9,
79.4,
86.9,
66.9,
44.4,
57.7,
54.5,
86,
87.1,
56.7,
66.5,
68.3,
87.2,
87.7,
25.9,
89.8,
37.6,
100.3,
65,
80.6,
34.4,
86.8,
77.8,
57,
63.7,
72.9,
91.4,
51.8,
37,
44.4,
96.4,
98.4,
91,
46.1,
28.6,
49.3,
91.8,
81.8,
27,
71.5,
92.3,
16.3,
33,
62.9,
64,
68.3,
50.6,
41.5,
99,
45.2,
67.6,
83.4,
85.6,
72.3,
70,
62.3,
72.3,
28,
45.5,
81,
90.2,
64.7,
26.1,
57.3,
66.8,
10.3,
17,
46.3,
41.1,
92,
65,
97,
59.7,
55.9,
34.8,
70.8,
76.9,
76.5,
73,
87.4,
69.4,
60,
63.7,
28.6,
41.8,
86.7,
73.5,
79.4,
80.2,
63.1,
64.8,
41.4,
39.7,
59.6,
52.5,
57.2,
79.5,
63.8,
68.5,
91,
69.9,
94,
71.3,
41.7,
49.3,
84.9,
50.8,
77,
78.9,
85.6,
85.8,
62.7,
52.3,
25.1,
94.1,
57.1,
29,
23.6,
4.7,
44.9,
57.1,
10.4,
86.8,
60.7,
30.9,
46,
64.9,
85.3,
71.1,
63.5,
61.3,
26,
96.5,
39.3,
20.7,
58,
18.6,
80.5,
40.4,
54.9,
27.5,
73.9,
2.2,
40.8,
42.5,
35.4,
70.9,
78.3,
52.5,
80.5,
88,
89.5,
58,
55.5,
2.1,
26.8,
39.1,
35.1,
16.1,
0,
64.6,
29,
40.6,
61.7,
68,
87.9,
22.2,
89.3,
21,
40.8,
28.5,
28.9,
65.3,
19.1,
58.4,
59.1,
116.1,
84.6,
70.5,
36.1,
88.9,
52.6,
75.9,
83.4,
30.2,
10,
57.4,
25.4,
15.2,
73.5,
40.9,
86.1,
97.3,
91.5,
75.7,
66.3,
68.2,
87.8,
21.5,
37.2,
90.8,
37,
54.1,
78.9,
93,
47.8,
96.3,
60.4,
74.3,
91.9,
20.3,
38.2,
61.3,
51.9,
32.3,
65.5,
96.7,
93.6,
39,
79.7,
96.9,
4.3,
72.3,
91.7,
95,
44.2,
87.3,
44.9,
20.4,
85.3,
55.7,
78.3,
48,
5.9,
55.2,
31.1,
95.9,
43.1,
26.9,
94.9,
79.3,
50.7,
17.6,
51.7,
53.7,
32.8,
90.3,
86.6,
27.1,
36.1,
28.5,
68.3,
40,
29.6,
70.1,
90.6,
28.3,
63.4,
83.8,
63,
89.5,
98.2,
44.9,
75.1,
78.3,
54.3,
35.7,
1.5,
81.9,
65.6,
47.7,
17.9,
65.2,
78.8,
51.2,
67.2,
61.8,
48.9,
11.1,
46,
45.3,
94.2,
66.4,
2.3,
59.3,
20.9,
46.7,
98,
50.2,
65.5,
95.1,
74,
89.9,
60.9,
38.5,
47.4,
99.5,
88.4,
34,
36.3,
92.7,
26.8,
52.6,
47.3,
31,
48.5,
89.7,
21.3,
38.1,
77.5,
55.7,
33.4,
36.6,
99.1,
74.7,
32.3,
78.7,
58.3,
78.6,
30,
43.1,
39.2,
56.4,
84,
52.6,
51.3,
77.4,
79.3,
0,
66.4,
56.8,
53.7,
91.6,
54.7,
29.5,
70.8,
12.1,
37,
25.5,
86.3,
61.9,
58,
14,
39.4,
77.3,
76.7,
57.8,
16,
63,
34.2,
96.2,
49.8,
28.6,
88.3,
80.5,
27.3,
51.4,
96.9,
46.8,
31.6,
37.6,
8.5,
52.2,
4.5,
69.2,
52.5,
4.6,
56.3,
82.2,
63.9,
53.9,
25.1,
33.9,
37.2,
42.8,
43.4,
78.4,
41,
86,
58.6,
59.9,
20.7,
13.4,
17.6,
41.2,
12.4,
42.7,
56.2,
67.9,
83.1,
49,
33,
61.5,
68.5,
26.1,
72.8,
12.1,
69,
52.6,
71.1,
67.6,
51.9,
37.3,
62,
52.8,
19.7,
88.7,
28.5,
51.6,
52.6,
69.8,
53.2,
46.3,
54.1,
17.5,
62.2,
5.7,
71.3,
63,
38.9,
91,
36.3,
12.6,
87.7,
32.6,
71,
52.9,
23.9,
62.7,
59.2,
78.4,
60,
7.8,
76.4,
81.7,
83.5,
72.7,
59,
69.9,
43.7,
43.7,
47.5,
88.3,
90.2,
39.9,
60.2,
55.3,
80.2,
33.2,
35.6,
68.8,
69.8,
92.8,
41.2,
73.5,
49.7,
17.5,
16.1,
55.9,
56.2,
90.1,
89.2,
62.2,
59.2,
47.7,
76.1,
81.5,
14.5,
40.4,
32.6,
50.3,
53,
41.1,
77.7,
93.6,
84.3,
91.7,
7.1,
77.8,
87.7,
84.8,
38.8,
43.7,
60.8,
70.6,
23.7,
61.8,
28.6,
18.5,
84.5,
55.8,
54.5,
28,
37.5,
91.4,
80.6,
47.4,
71.9,
14.3,
88.6,
29.5,
51.8,
55,
25.9,
100.2,
12.7,
82,
69.2,
84.3,
45.2,
74.2,
97.7,
80.9,
68.5,
61.1,
42.1,
97.5,
32.7,
64.8,
47.6,
14.7,
86.5,
79.9,
24.2,
83.8,
49.8,
61.3,
81.6,
73,
53.3,
37.1,
57.4,
72.1,
8.7,
50.3,
54,
22.9,
17,
41.5,
80.3,
16.6,
23,
79.9,
84.7,
40.4,
76.4,
74.3,
40.1,
7.6,
49,
44.8,
91.5,
8.6,
55.7,
21.6,
91.2,
56.4,
31.6,
71.6,
65,
79.8,
65.1,
71.6,
38.3,
75.8,
42.9,
56.3,
66.7,
34,
33.3,
71.8,
49.2,
80.5,
69,
10.5,
52.7,
50.1,
46.8,
84,
88.8,
64.9,
30.5,
88.4,
70.6,
75.6,
61.2,
34.6,
39.7,
41.4,
42.4,
90.1,
28,
59.5,
77.4,
70,
71.4,
45.4,
25.8,
33.4,
75,
48.8,
91.6,
75.5,
93,
32.8,
43.7,
43.1,
31.4,
79.5,
15.7,
41.4,
89.3,
47.1,
58.3,
90.5,
37.6,
84.3,
20.8,
52.2,
79.9,
18.6,
46.5,
53.3,
75.4,
27.9,
73.8,
97.6,
86.5,
77.6,
69.6,
52.4,
85,
81.6,
76.3,
97.7,
35.1,
20,
86.2,
49.1,
55,
75.1,
18.6,
63.2,
41.2,
48.8,
86.9,
62.1,
79.1,
65.4,
69.2,
43.1,
39.9,
48.8,
37.1,
18.5,
43.4,
21.9,
4.7,
76.4,
38,
45.3,
17.7,
20.1,
64,
93.3,
51.1,
58.7,
50,
82.8,
28.8,
53.4,
42.5,
50.9,
47.4,
26,
65.1,
35.6,
76,
62.4,
34.9,
35.5,
47.1,
71.1,
60.6,
13,
29.4,
26.4,
35.7,
63.4,
17,
59.2,
53,
59.9,
22.1,
93.6,
72.7,
69.1,
72.7,
47.3,
79.4,
78.7,
43.1,
39,
65.7,
89.9,
69.2,
5.4,
65.9,
74.1,
68,
17.2,
83.6,
89.9,
63.1,
70.1,
63.9,
12.2,
64.5,
62,
57.3,
37.3,
91,
74.8,
35.6,
67.9,
4.6,
41.4,
40.5,
73.9,
32,
78.3,
75.3,
25,
41.2,
68.1,
60.5,
42.6,
39.7,
2.7,
88.5,
55.1,
34.8,
57.6,
14.6,
20.3,
45.6,
36,
69,
32.5,
76.6,
81.1,
63.4,
67.9,
15.8,
79.1,
82.4,
60.2,
40.2,
66.1,
43.3,
68.6,
41.6,
41.2,
70.2,
85.1,
12.2,
20.2,
53.7,
46.3,
32.5,
68.6,
25.8,
73,
73.1,
43.5,
31.3,
76.6,
57.7,
72.9,
86,
15.5,
8.9,
66.5,
63.9,
59.1,
86.7,
71.1,
30.9,
15.6,
57.2,
0,
32.5,
57.3,
74,
76.3,
57.9,
13.4,
93.8,
36.6,
34,
83.2,
4.1,
89.4,
44.7,
35,
23.3,
82.7,
2.2,
58.6,
42.2,
23.6,
38.2,
82.5,
71.7,
46.5,
89.5,
76,
103.1,
67.2,
15.6,
60.4,
97.8,
53.4,
95.5,
58.8,
88,
53,
93.9,
45.6,
56.7,
51.8,
0,
75.4,
23.5,
53.5,
61.8,
13.1,
40,
94.3,
24.8,
49.4,
68.4,
75.4,
38.8,
67.6,
70.6,
33.9,
62,
84.6,
25.9,
36.8,
69.7,
58.8,
8.4,
38.5,
14.2,
67.6,
66.9,
55.4,
49.9,
50.6,
45.4,
48.4,
23.5,
56.3,
79.8,
52.8,
32,
68,
60.5,
42.5,
29.4,
95.3,
32.4,
51.2,
53,
35.1,
51.8,
75.5,
15.1,
55.7,
47,
15,
42,
38.8,
46.5,
22.9,
39.3,
88,
30.8,
62.8,
72.4,
76,
42.7,
78.7,
0,
47.1,
23.7,
20,
83.9,
58.4,
70.7,
53,
60.8,
94.8,
60,
43.8,
92.9,
97.9,
80.4,
35.7,
25.3,
74.4,
22.2,
61.8,
61.8,
33.8,
52.2,
21.7,
89.5,
72.6,
41.6,
58.9,
30.1,
84.8,
25.5,
54.6,
63.4,
56.6,
4,
9.7,
100.8,
59,
10.8,
66.5,
43.6,
61.2,
51.2,
44.3,
78.4,
51.8,
68.4,
36.5,
82.2,
85.1,
53.3,
42.3,
12,
69.9,
54.3,
53.9,
13.2,
54.9,
64.4,
50,
17.7,
40.8,
54.8,
97.7,
60,
57.3,
53.1,
39.9,
1,
35.9,
58.4,
37.5,
68.2,
36.9,
49.6,
1.3,
40.6,
0,
61.1,
61.3,
9.9,
49.4,
50.8,
58.2,
31,
44.8,
94,
74.9,
51.7,
67,
95.4,
34.9,
55.2,
30.4,
48,
42.1,
33.5,
52.8,
44.8,
57.7,
0.2,
41.8,
51.1,
41.2,
65.8,
99.7,
50,
44.6,
16.9,
23.7,
44.5,
34.5,
52.8,
52.8,
85.8,
5.5,
0,
59.2,
27.4,
19.1,
36.5,
79.5,
31.3,
55.8,
56.8,
58.7,
53.9,
38.3,
67.8,
34.5,
64.8,
64,
59.3,
41.7,
88.5,
25.5,
59.7,
65.1,
71,
27.2,
103.5,
24.8,
36.4,
87.6,
76,
38.4,
56.6,
4,
9.3,
28.6,
58.2,
33.3,
67.9,
66.9,
16.9,
46.3,
60,
33.5,
4.2,
27.7,
33.3,
58.7,
88.7,
33.7,
89.7,
56.3,
12.5,
57,
106.6,
49,
94.4,
47.8,
41.4,
38.3,
9.6,
60.8,
68.9,
63.8,
12.1,
71.6,
71.8,
10.5,
83.6,
50.2,
56,
55.4,
46,
80.1,
98.9,
61.5,
73.9,
67.4,
69.3,
67.3,
62.8,
40.7,
63,
16.2,
50.4,
67.9,
88,
62.8,
45,
49.1,
44,
68,
14.3,
60.7,
31.6,
48,
83.3,
0.3,
50.6,
58.5,
93.3,
55.6,
55.4,
34.6,
77.3,
46.9,
59.9,
80.5,
12.7,
89.4,
59.6,
64.5,
0,
57.6,
96.5,
2.7,
72.1,
65.4,
42.6,
46.7,
92.5,
99.1,
49.3,
28.8,
56.9,
77.1,
60.5,
88.5,
56.3,
60,
57.2,
22,
67.3,
79.3,
96,
50.8,
42.3,
37.7,
57.7,
42.4,
85.3,
73.1,
97.6,
39,
1.8,
44,
29,
63,
77.7,
19.8,
8.9,
65,
36,
50.8,
64.5,
65.8,
46.9,
21.6,
78.4,
67.8,
46,
30.8,
46.2,
79.2,
88.4,
101.2,
73.7,
9.5,
64.1,
25.1,
13.1,
54.4,
22.7,
69.1,
59.8,
73.4,
90.5,
66.9,
46.3,
97.6,
89.1,
74,
7.5,
49.8,
18.2,
62.6,
2.9,
35.1,
67.6,
46.1,
47,
23.4,
85.6,
31.9,
22.6,
8.3,
89,
25,
46.1,
37.6,
58.4,
48.8,
48,
95.4,
57.1,
37.3,
60,
50.1,
19.1,
37,
62.1,
30.7,
33.9,
94.3,
72.4,
28,
75.6,
53.4,
46.6,
42.5,
44.1,
61.9,
65.1,
48.7,
88.2,
46.7,
45.2,
56.6,
43.1,
21.2,
41.1,
50.3,
70.6,
96.7,
62.7,
42.7,
55.3,
70.6,
11,
84.4,
42.8,
60.9,
32.9,
84.4,
52.5,
47.2,
72.1,
71.3,
54.2,
52,
53.4,
88.8,
76.4,
28.5,
61.1,
61.8,
35.7,
73.6,
46.4,
31.2,
75,
64.8,
18.1,
57,
42.7,
97.2,
43.9,
40.7,
42.3,
81.7,
61.7,
41.2,
45.5,
59.5,
30,
20.4,
39.3,
22.4,
10.6,
77.5,
73.7,
42.2,
74,
63.5,
31.7,
17,
85.6,
62.5,
10.9,
71.9,
20.7,
75,
7.2,
60.7,
67.6,
46.2,
48.1,
93.3,
65.3,
12.6,
2.6,
79.4,
66.5,
56.7,
76,
67.8,
86.7,
64.9,
5.5,
95.6,
63.3,
30.6,
99.1,
90.2,
44.5,
33.3,
47.9,
31,
69.5,
24.4,
34.8,
54.1,
42.5,
53.6,
25.1,
65.2,
35.9,
68,
85.7,
53,
83.2,
77.3,
86.4,
82.6,
61.8,
53.9,
59.8,
79.5,
90.4,
65.2,
24.2,
93.6,
68,
61.1,
43.6,
100.3,
58.4,
49,
18.7,
46.7,
52.6,
90.3,
40.1,
70.3,
92.2,
74.7,
58.7,
84.3,
48.9,
82.8,
89.3,
71.2,
23.6,
72.6,
16.8,
69.9,
84.3,
29.9,
54.7,
27.1,
58.4,
35.4,
51,
7.2,
64,
81.8,
82.5,
67.4,
54.3,
57.1,
89,
50,
67,
23.5,
10,
28.4,
47.4,
87.7,
33.9,
72.4,
71.7,
59.5,
49.4,
87,
48.8,
11.7,
68.2,
47.1,
63.7,
52,
42.1,
48.1,
69.1,
82.9,
40.9,
51.9,
45.7,
74.5,
70.2,
76.2,
76.4,
46.1,
96.3,
68.4,
84.9,
32,
63.1,
52.1,
61.1,
17.7,
65.5,
70.5,
81.1,
55.7,
56.1,
35.4,
93.2,
96.3,
56.9,
56.3,
32.8,
93.4,
44.7,
41.3,
67.1,
40.6,
18.6,
29.2,
45,
60.7,
84.3,
26.7,
56.5,
38.7,
60.7,
57.8,
37.8,
89.6,
48.1,
1.3,
65.4,
51.2,
45.8,
17.6,
98.4,
98.4,
5.4,
28.6,
36.9,
96.1,
76.5,
85.1,
52.5,
37,
83,
14.4,
90.6,
14.5,
88.5,
82.3,
97.4,
80.4,
28.6,
43.3,
81.5,
5.6,
98.5,
47.5,
18.6,
74.5,
61.1,
47.2,
42.2,
0.4,
83.6,
64,
72.2,
82.8,
53.6,
60.1,
70.4,
79.5,
31.1,
16,
75.5,
75.4,
17.6,
50.1,
62.9,
63.6,
81.6,
46.6,
20.1,
56.5,
75.3,
83.5,
29,
75.5,
77.7,
68.3,
83.5,
72.1,
5.9,
87.1,
39.5,
61.8,
79.3,
67.2,
66.5,
68.9,
34.5,
102.7,
71.2,
49,
36.5,
43.3,
42.7,
93.5,
58.1,
85.9,
37.7,
96.7,
96.7,
44.7,
67.1,
47.7,
36.1,
85,
44.7,
43.1,
99.5,
53.7,
89.4,
49.9,
27.8,
24.1,
60,
58.8,
20.8,
77.1,
26.8,
58,
43,
53.9,
65,
95.9,
71.4,
55.5,
23.8,
80.4,
48.4,
30.4,
84.8,
39.2,
74.2,
55.6,
69.8,
55.5,
64.8,
46,
77.3,
63.1,
33.9,
5.4,
31.3,
44.3,
32.6,
40,
80.6,
56.4,
66.2,
81.3,
81.6,
37.4,
76.9,
36.6,
73.4,
14.3,
10.9,
74.7,
48.5,
53.3,
96.4,
59.4,
43.1,
92.3,
49,
87.9,
45.5,
37.5,
52.7,
60.4,
64.2,
68.9,
66.4,
59.4,
33.1,
39.3,
1.8,
81.1,
52.7,
50.2,
58.1,
85.1,
39.2,
94,
18.4,
40,
50.3,
31.2,
70.2,
71.2,
85.1,
25.5,
63.5,
86.5,
32.4,
45.4,
61.9,
91.6,
25.8,
38.9,
47,
57.5,
64.2,
70.4,
85,
38,
38.7,
13.6,
29.3,
93,
65.4,
64.9,
68.3,
47.6,
63.1,
94.1,
66.1,
75.8,
46.7,
74.9,
8.5,
23.9,
6.6,
64.8,
59.9,
46.3,
68.4,
43.8,
41.7,
67.2,
19.5,
49.9,
56,
49.4,
61.7,
32.9,
83,
53,
85.2,
86.8,
84.8,
74.1,
77.5,
67.4,
18,
54.1,
40.9,
41,
34.1,
78.3,
27.2,
42.9,
82.3,
63.3,
34.6,
67,
47.6,
4.7,
26.3,
66.1,
44.2,
73.2,
88.1,
76.2,
54,
53.9,
63.7,
95.2,
46.9,
85,
59.6,
29.2,
44.8,
45,
97.3,
51.6,
97.9,
61.1,
61.2,
45.4,
48.2,
38,
47.7,
47.5,
18.1,
51.1,
68.1,
74.9,
57.5,
69.5,
57.2,
11.6,
46.5,
54.6,
6.7,
68.1,
41.7,
86.1,
10,
13.5,
0.5,
39.8,
65.2,
84.4,
55.3,
3.8,
43.1,
14.6,
83.4,
72.2,
25,
17.4,
41.4,
38.6,
74.2,
93.6,
72.2,
61.7,
32.6,
82.1,
95.3,
24.7,
22.1,
83.1,
22.4,
43.6,
28.6,
65.2,
54.2,
39.6,
48.3,
85.6,
49.7,
31.3,
54.1,
37,
42.5,
87.3,
80.7,
56.3,
60.3,
61.6,
38.3,
27.6,
65.4,
61.8,
16,
63.7,
7.3,
75.1,
60.4,
67.5,
16.1,
57.6,
80.8,
69.9,
43.3,
54.8,
40.3,
52.1,
64.9,
73.3,
95.7,
83.8,
24.1,
32.1,
25,
61.6,
87,
78.1,
59.8,
56.9,
52.4,
5.79,
37.2,
74.2,
73.5,
50.5,
47.9,
42.3,
47.5,
80.1,
24.6,
46.3,
63,
77.2,
2,
0.5,
84.2,
32.5,
99.7,
75.8,
76.8,
38,
10.9,
29.4,
76.4,
88.4,
63.7,
90.8,
50.9,
18.6,
35,
51.7,
38.8,
90,
51.2,
42.9,
65.3,
75.9,
69.7,
72.5,
51.6,
74.4,
72.2,
101.3,
86.7,
70.6,
100.9,
33.4,
63.2,
57.7,
31.7,
72.9,
57.9,
63.2,
54.6,
58,
93.6,
91,
45.8,
68.3,
43.7,
18.5,
59.5,
85.4,
80,
32.1,
54.4,
86.9,
47.8,
86.3,
44.5,
37.7,
99,
52.9,
73,
30.6,
58.6,
19.7,
95.4,
84.2,
88.3,
80.3,
66.6,
78,
59.2,
32.9,
71.1,
99.2,
21.3,
25.7,
70.4,
56.6,
49.2,
57.9,
19.3,
57,
51,
48.6,
53.8,
54.4,
54.2,
24.3,
48.6,
16.4,
18.5,
53.4,
48.9,
21.8,
47.3,
50.6,
84.7,
51.1,
11,
87.7,
52.2,
57.3,
34.5,
48.4,
60.9,
15.6,
63.5,
21,
23.2,
52.6,
8.8,
74.1,
61.6,
43,
75.9,
43.8,
49.8,
28.2,
57.2,
50,
47,
27.3,
84.3,
22.6,
85,
53.8,
72.9,
53.4,
52.3,
47.9,
77.6,
79.5,
56.6,
67.6,
40.1,
58.6,
76.3,
38.9,
25,
69.1,
36.6,
47.8,
56.5,
45.2,
81.5,
53.8,
77.4,
57.3,
41.1,
28.1,
44.9,
74.1,
51.6,
58,
70.9,
63.2,
37.1,
47.8,
62.8,
67,
100.2,
47.4,
80.8,
92.2,
73.2,
67,
0.2,
60,
34.2,
56,
44.1,
31.2,
45.4,
34.8,
48.2,
41.7,
66.1,
70.1,
75.8,
0,
66.8,
46,
62,
28,
0,
52,
55.2,
84.2,
84.9,
83.1,
32.6,
82.8,
40.9,
25.8,
30.4,
58.2,
68.3,
94.6,
49.8,
17.9,
38.6,
49.9,
50.7,
77,
65.9,
97.4,
48.4,
91,
58.3,
57.5,
30.2,
7.5,
92.4,
58.1,
64.5,
15.1,
52.9,
79.7,
45.9,
48.2,
56.9,
34,
11.1,
23.9,
37.6,
37.2,
39.1,
43.5,
86.6,
54,
8.5,
34.7,
39.4,
69.4,
8.3,
86.8,
40.2,
59.3,
69.1,
86.8,
63,
42.6,
38.2,
56.1,
32.1,
34.9,
22.2,
82.1,
77.1,
47.1,
95.7,
47.6,
62.1,
62.1,
33.2,
85.4,
61.6,
41.7,
88.4,
52.3,
78.5,
95.9,
14.9,
51.7,
45.5,
23.7,
23.4,
70.2,
35.7,
67.3,
52.5,
31.8,
42.3,
43.5,
12.2,
10.6,
73.8,
31.1,
47.8,
29.4,
82.2,
37,
82.2,
25.1,
93.1,
85.9,
60.8,
89.2,
69.4,
79.9,
45.2,
54.2,
35,
53.8,
1.1,
30.8,
16,
55.4,
89.8,
76,
35.3,
30.9,
79.3,
35.5,
50.1,
92.2,
49.8,
88.3,
68.4,
79.7,
53,
84.9,
31.3,
75.9,
61.6,
67.7,
54.1,
61.6,
49.1,
62.9,
24.5,
62.8,
64.1,
45.2,
65.6,
7.1,
23.6,
93,
81.4,
15.6,
51.8,
95.9,
33.8,
68.4,
63.9,
44.9,
22.9,
48.7,
66.9,
67.2,
24.6,
53,
52.9,
61.4,
92.6,
19.6,
72.2,
69.6,
87.6,
64.3,
99.1,
89.1,
88.7,
70.5,
43,
74.8,
13.8,
50.2,
47.5,
81,
31.9,
48.4,
64.5,
40.9,
47.1,
83.4,
63.4,
44.7,
55.1,
65.6,
27.8,
75.6,
30.9,
47.7,
84.1,
49.2,
5.6,
53.8,
33.4,
49.2,
60.4,
33.3,
26,
39,
33.8,
6.3,
30.3,
96.8,
42.1,
74.7,
74.6,
74,
81,
33.5,
61.6,
10.8,
52.5,
82.5,
52,
47,
78,
43.4,
42.8,
25.5,
39.7,
42.8,
37,
5,
25.8,
42.3,
24,
59.9,
49.4,
35.8,
44.2,
77.1,
17.5,
71.7,
92.1,
92.2,
92.6,
98.4,
29.3,
69,
80,
82.9,
25.3,
86,
38.1,
100.4,
23.4,
52.1,
65.3,
16.9,
57,
54.1,
38.6,
69.4,
98.8,
37.9,
46.9,
55.7,
39.4,
50,
84.3,
69.9,
69.3,
56,
8.5,
52.7,
2,
26,
66.5,
83.7,
28.1,
23.1,
53.2,
91.7,
42.6,
16,
31.6,
69.2,
45,
6.1,
44.2,
76.1,
34.6,
60.5,
83.9,
42.4,
63.3,
51.2,
61.2,
84,
44.7,
54.2,
76.5,
80.4,
64.2,
83.6,
82.8,
82.9,
41.7,
61.6,
61.6,
83.2,
96.9,
41.2,
25.1,
45.3,
18.6,
77.6,
54.8,
31.9,
52.8,
54.6,
31.3,
45.3,
38.7,
69.2,
66.8,
13.9,
14,
68.7,
17,
46.3,
27.1,
55.3,
37.6,
30,
68.2,
22.5,
59.4,
81.1,
30.5,
51.8,
35.5,
34,
89.9,
70.2,
53.9,
61.2,
44.1,
42.9,
58.3,
78.4,
88,
18.2,
40,
63.6,
82.1,
46.5,
73.4,
31.7,
60.5,
70.3,
60,
33.8,
1,
98.5,
45.4,
17.9,
72.6,
59.5,
33.4,
17.6,
68.7,
9.8,
59.4,
49.6,
60,
48.4,
47.4,
52.8,
31.4,
55.7,
58.4,
100,
23.5,
38.3,
30.9,
39.4,
84.6,
67.1,
28.6,
52.2,
43.3,
74.8,
48.4,
81.5,
39.2,
47.6,
50.2,
89.4,
83,
44.4,
59.1,
85.4,
15.7,
91.7,
42,
73.5,
15.6,
36.4,
45.1,
34.1,
54.1,
37.4,
66.4,
37.8,
3.3,
51,
42,
68.8,
82.8,
48.3,
98.1,
56.2,
71.5,
66.1,
37.3,
47,
67.8,
46.8,
30,
60.7,
93.4,
74,
35.7,
37,
84.2,
73.7,
92.6,
84.1,
40,
40.9,
83.7,
73,
49.4,
35.2,
52.4,
47.3,
59.3,
64.4,
11.5,
50,
49.6,
50,
88.3,
72.8,
50.7,
65.1,
64.9,
22,
75.1,
59.2,
32,
58.3,
39,
31.5,
26.3,
64.1,
74.9,
55.7,
50,
60.3,
57.9,
70.2,
87.6,
43,
60.2,
51.8,
77,
33.4,
93.8,
63.2,
70.3,
25.8,
42.4,
53.4,
75.9,
54,
7.9,
71.2,
21.2,
86.3,
58.3,
76.2,
95.6,
48.6,
75,
77.7,
52,
41.7,
49,
35,
72.6,
60,
62.3,
60.3,
44.1,
19.1,
83.7,
88.5,
63.3,
81.2,
30.6,
51.7,
30.9,
50.5,
79.2,
56.3,
44.5,
41.8,
30,
58.8,
82.8,
67.9,
50.6,
47.5,
2.5,
40.1,
92.6,
21.3,
30,
40,
8.5,
83.4,
55.4,
92.8,
32.2,
84.6,
64.9,
59.6,
37.4,
47.4,
68.8,
53.3,
96.5,
34.4,
84.8,
82.3,
75.5,
68.1,
91.7,
83.7,
37.4,
29.1,
63.3,
47,
27.2,
48.3,
54.6,
52.1,
86.3,
65.9,
77.8,
54.9,
7,
94.7,
68.1,
6.8,
79.2,
34.7,
23.3,
49.2,
83.3,
1.1,
67.2,
11.5,
78.6,
72.3,
23.4,
19,
41.5,
60.6,
55.8,
51.1,
73.1,
61.6,
52,
39.5,
33.1,
65.5,
2,
44,
1.7,
40.4,
77.8,
56.2,
57.5,
27.9,
94.4,
74.5,
71.7,
53.5,
69.9,
62,
91,
40.2,
74.9,
40.1,
42.2,
98,
44.7,
50.6,
39.8,
3.9,
41.5,
25.8,
19.2,
78.2,
54.3,
44,
21.7,
94.9,
40.6,
60.8,
25.8,
34.9,
47.9,
11.9,
77.6,
26.8,
73.1,
66.8,
18.6,
66.9,
53.8,
50.8,
25.9,
7.9,
93.7,
67,
63.2,
27.8,
41,
69.9,
35,
60.1,
6.6,
59.3,
52.8,
70,
63.4,
34.5,
23.1,
39,
43.6,
87.7,
14.5,
80.5,
33.4,
19,
79.4,
0.7,
32.7,
84.5,
55.8,
51.9,
28.4,
56.4,
96.4,
64.6,
91.2,
45.2,
50.4,
68.5,
62.7,
72.2,
99.4,
69.5,
38,
44.4,
73.1,
57,
79,
79.2,
67,
58.5,
28.7,
0.7,
75,
86,
35,
31.9,
60.4,
56.2,
38,
61.5,
77.5,
54.9,
65.2,
26.3,
67.9,
16.2,
70.9,
33.2,
79.8,
76.7,
98.3,
24.4,
89.7,
62.7,
18.2,
92.4,
29.2,
50.1,
54.4,
57.1,
43.9,
40.7,
79,
74.8,
89.1,
95.7,
83.6,
15.5,
76.5,
95.6,
64.7,
72.6,
23.9,
62.6,
75,
62.8,
63.5,
60.4,
13.2,
37.9,
46.8,
83.8,
26,
55.1,
47.1,
53,
80.1,
62.7,
90.2,
41.6,
58.9,
41,
7.1,
42.6,
34.9,
16.7,
75.1,
90.2,
69.6,
50.5,
80.2,
15.6,
31.1,
9.1,
26.6,
67,
12.2,
96.2,
24.3,
66.9,
46,
21.2,
33.9,
37.7,
69.4,
84.7,
0.3,
67.6,
69.6,
60.9,
75.5,
49.9,
84.1,
93.6,
30.7,
67,
47.2,
0.6,
52,
50.2,
65.6,
71.5,
40,
98.5,
88.4,
91.4,
97.7,
46.3,
31.2,
17.4,
59.2,
97.9,
48.5,
0.5,
43.2,
44.9,
85,
57.2,
49.6,
60.4,
81.9,
37.2,
7,
50.5,
61.5,
89.3,
37.8,
70.2,
70.5,
22.8,
47.2,
38.1,
36.1,
92.1,
26,
28.8,
22.3,
71.8,
12.6,
13.9,
69.5,
43.1,
71.6,
49.7,
18,
49.8,
63.5,
63.6,
48.1,
47.5,
58.9,
68.2,
60,
97.2,
68.9,
67.7,
80.7,
81.6,
54.2,
73.3,
77.7,
29,
13.9,
67.7,
20.8,
17.5,
24.9,
85.8,
70.1,
90.6,
91.5,
84.8,
6.5,
92.5,
32.4,
35,
53.4,
25.9,
48.2,
56.3,
73.7,
49.7,
78.4,
69.2,
79.5,
44,
31,
49.8,
85.8,
65.8,
96.1,
36.6,
48.2,
13.2,
83.9,
85.2,
55,
74.6,
90.3,
43.9,
43,
60.2,
32,
null,
86.8,
47.3,
57.8,
46,
65.7,
65.9,
40.1,
68.8,
20,
63.7,
47.2,
8.8,
47.7,
66,
83.2,
79.8,
53.6,
67.1,
24.4,
59.4,
15.8,
96.9,
74.6,
33.8,
36,
70.2,
78.3,
90,
62,
44,
81.5,
41,
94.2,
79.3,
39.2,
15.2,
87.5,
14.3,
61.2,
79.5,
25.6,
22,
54.4,
35.8,
54,
25.8,
47.2,
76.3,
22.5,
80.2,
89.4,
43.9,
27.2,
60.4,
8.9,
5.6,
63.7,
29,
49,
33.6,
7.2,
56.9,
90.1,
79.1,
32.3,
84.8,
71.1,
62.6,
73.4,
15.6,
95.8,
57.1,
27.1,
55.7,
31.5,
67.2,
16.6,
29.9,
54.2,
60.4,
28.9,
61.7,
54.2,
25,
90.6,
72,
4.6,
73.1,
95,
66,
50.7,
35,
52,
43.9,
59.4,
59,
32.1,
54.2,
50.3,
34.2,
72.4,
2.2,
79.2,
24.4,
40.8,
44.6,
56.5,
59.8,
63.9,
43.3,
48.2,
34.5,
30.1,
52.9,
30.3,
93.4,
13.3,
81.6,
70.7,
90.8,
74,
9.4,
56,
68.9,
61.1,
49.8,
36.7,
64.6,
38.6,
73,
18.6,
39.7,
21.8,
49.8,
96.6,
80,
79.5,
87.6,
51.4,
95.8,
55.9,
82.2,
16.1,
65.6,
73,
37,
86.7,
88.9,
15.7,
69.6,
55.1,
38.9,
0,
16.9,
66.3,
81.9,
55.6,
49.7,
66.4,
37,
61.8,
34.5,
75.6,
26.3,
56.9,
58.7,
34.7,
45.6,
93.6,
50.8,
83.3,
38.2,
69.7,
49.8,
60.8,
54,
41.3,
28.9,
47.8,
100,
64.2,
66,
80.1,
96.1,
29.9,
23.4,
46.4,
75.4,
40.4,
22.9,
46,
42.4,
82.1,
61.1,
69.3,
94,
25.5,
20,
46,
35.3,
37.5,
26.8,
93.3,
44.5,
59.6,
29.5,
10,
63.6,
75.6,
29.8,
73.2,
3.7,
78.2,
41.6,
97,
72.1,
82.7,
82.3,
53.4,
26.2,
53.7,
55.7,
94.6,
69.6,
73.7,
72,
22.6,
43.3,
60.4,
86.3,
70.6,
29.6,
69.7,
71.9,
70.6,
60,
54.3,
57,
48.6,
26.9,
49.8,
71.4,
32.2,
15.6,
58.2,
99.8,
36.9,
68.4,
73.3,
59.4,
74,
82.3,
41,
41.2,
22,
57,
43.7,
63.5,
14.1,
70.2,
41.7,
50.4,
77.7,
53.2,
55.5,
48.7,
61.3,
78,
53.4,
45.6,
47.3,
5.1,
50.8,
61,
46.9,
43.7,
43.9,
35.8,
61.8,
71.2,
68.1,
40.1,
19.3,
48.6,
82.5,
91.2,
75.2,
51,
42.8,
23.4,
79.1,
45.8,
81.2,
38.3,
93,
78.2,
41.8,
64.4,
65.3,
21.7,
11.2,
26.2,
60.7,
8.8,
89.2,
38.6,
95.2,
47.9,
73.4,
30.6,
23,
68.6,
9.5,
83.6,
90.8,
76.3,
83.3,
66.5,
73.8,
92.7,
90.1,
69.1,
91.7,
83.3,
81.8,
58.8,
88.4,
47,
40,
4.5,
73.3,
58.8,
47.6,
52.9,
54.1,
59.3,
42.9,
50.7,
91.3,
97,
42.1,
29.5,
69.3,
53.5,
85,
38,
45.7,
47,
15.8,
59,
36,
20,
100.1,
54.3,
36.7,
10.3,
40.5,
37.1,
47.3,
86.4,
51.6,
74.5,
75.5,
55.7,
79.7,
57.7,
40.3,
44.6,
24.9,
39.4,
29.5,
71.7,
76.8,
76.7,
1,
82.5,
30.3,
9.4,
61.4,
73.6,
35,
73.5,
1.6,
29,
54.8,
8,
47,
63.1,
54.6,
26.6,
33.7,
53.9,
27.1,
86.2,
39,
76.1,
57.1,
66.6,
53.7,
34.1,
0,
46.2,
51.2,
49,
31.6,
84.3,
42.3,
21.2,
27.6,
83.8,
34.1,
22.4,
35.3,
34.4,
63,
76.6,
87.3,
16.1,
57.4,
49.4,
41,
61.3,
75.6,
40.4,
72.6,
70.5,
26.4,
83,
85.6,
76.7,
77.6,
78.5,
86.5,
64,
68,
87.6,
29.9,
38.9,
40.5,
75.3,
27.1,
88.5,
40.6,
80.7,
58.3,
48.7,
31.4,
92.4,
54.7,
45,
72.5,
62.6,
86.2,
95.5,
48.3,
29.7,
61.9,
61.9,
72.7,
28.9,
24.1,
64.3,
98.2,
13.8,
60.2,
47.7,
3.7,
32.6,
3.4,
68.4,
73.1,
61.5,
48.7,
52.4,
60.1,
29.8,
70.2,
64.3,
84.7,
41.8,
72,
63.6,
78,
23.2,
75.1,
24.7,
52.3,
87,
45.6,
30.5,
78,
22,
21,
58.9,
56.8,
95.7,
50.8,
53.6,
53,
98.6,
5.7,
37.8,
77.9,
56.7,
72,
23.4,
70,
72.3,
86.5,
45.9,
56.1,
84.9,
47.6,
20.7,
34.5,
52.8,
76,
5.4,
77.1,
5.6,
76.7,
41.5,
62.4,
86.6,
101,
81.9,
91.4,
74.4,
73.9,
66.7,
88.1,
68.8,
95.3,
23,
68.3,
51.4,
52.6,
49,
40.6,
43.4,
6.2,
41.7,
80.9,
58.4,
49.6,
5.3,
90.1,
0,
67.2,
99.3,
38.4,
2.2,
35.4,
94.1,
33.7,
64.7,
48.4,
62.7,
64.2,
87.4,
44.9,
99,
96.3,
67,
75.3,
51,
41.3,
94.5,
31.7,
67.3,
69.4,
83.1,
82.9,
60.7,
13.7,
54.4,
39.1,
46.4,
53.6,
84.5,
44.3,
25.4,
77.6,
67.2,
102.9,
27.1,
63.9,
39.7,
74.2,
86.2,
54,
51.6,
69.3,
70.5,
58.7,
77.8,
82.9,
39.1,
44.4,
57,
60,
66,
72.4,
36.2,
27.6,
15.6,
44.8,
69.4,
35.8,
46.8,
100.3,
7.5,
84.3,
64.4,
57.1,
76.9,
65,
73.2,
80.6,
83.3,
100,
34.9,
57.7,
61.7,
36.7,
58.9,
74.1,
61.3,
58.6,
76.5,
63.8,
49.3,
77.5,
59.8,
94,
47.5,
15.5,
37,
20.2,
22.8,
58,
45.9,
62,
39.5,
60.2,
53.5,
14.7,
38,
59.7,
58.7,
68.1,
49.6,
42.5,
53.6,
31.3,
92,
28.3,
72.4,
39.3,
71.7,
7.1,
76.1,
93.7,
38,
42.7,
96,
32.7,
58.3,
91.8,
53,
72.1,
86.4,
16.8,
20.7,
72.8,
44.1,
46.2,
65.8,
12.6,
51.6,
18,
68.2,
67.3,
45.9,
82.4,
84.4,
65.5,
81.4,
46.1,
53.4,
28.2,
87.3,
33.5,
76.8,
81.2,
65,
58.5,
81.6,
41.7,
14.3,
65.4,
17,
89.7,
65.1,
66.4,
79.5,
42.8,
32.8,
56.9,
63.3,
82.3,
50.9,
8.3,
37.2,
72,
16.3,
85.9,
47.2,
90.3,
26.4,
7.7,
49,
13.2,
78,
88.1,
18.9,
76.1,
13.7,
0.6,
84.2,
29.9,
23.9,
30.3,
43.4,
42.3,
66.8,
84.4,
93.8,
67.5,
72.5,
67.3,
64.6,
83.5,
67.1,
71,
63.1,
48.1,
71,
34.1,
51.8,
54.4,
38.2,
77.6,
95,
47.1,
59.5,
9.7,
53.5,
29.7,
56.8,
76.2,
37.7,
49.8,
33.7,
31.3,
57.9,
72,
61.6,
51.6,
94.7,
3.5,
67.2,
84.6,
42.3,
59.3,
3.5,
35.9,
94.6,
42.8,
58,
74,
21.4,
83.7,
34.6,
81.5,
80.5,
97.8,
38.2,
61.5,
62.6,
61.9,
12.1,
33.6,
49.1,
51.4,
52.8,
57.3,
81,
83.6,
41.2,
57.4,
3.2,
49.9,
65.5,
69.3,
57.4,
50.1,
31.3,
73,
63.8,
19.5,
64.1,
83.6,
66,
92.4,
43.4,
70.3,
65.8,
20.2,
51.5,
54.2,
37.3,
73.7,
39.2,
38.8,
39.1,
10.3,
45.7,
0,
71,
76.2,
60,
70.6,
96.4,
8.7,
54,
62.1,
94.8,
67.9,
48.2,
64,
71.8,
77.6,
49,
57.1,
41.7,
61.2,
94.8,
53.8,
49.1,
27.1,
43.5,
29.7,
66.5,
54.5,
38.3,
45,
59.8,
5.5,
12,
50.2,
57.1,
39.3,
59.7,
56.6,
30,
27.9,
57.1,
39.3,
82.2,
40.3,
68,
69.3,
47.3,
90.6,
56.7,
31.3,
36.5,
28.8,
27.6,
58.6,
91.6,
50,
51.7,
76.3,
74.9,
39.8,
83.5,
13,
53.4,
18.9,
59.8,
50.7,
33.1,
76.5,
55,
70.2,
67.9,
97.6,
40.2,
51.7,
42.2,
31.1,
94.1,
40.5,
55.7,
65,
25.1,
85.6,
63,
7.7,
50.7,
86.3,
70,
25.5,
10,
92.7,
73.4,
34.9,
55.5,
39.7,
56.5,
59.6,
89.7,
68.5,
37.2,
73,
82.1,
71.6,
57.3,
92.2,
23.3,
53.4,
87.2,
38,
64.7,
64.2,
86.5,
8.8,
75.7,
35.8,
38.7,
60.2,
37.6,
41.2,
55.3,
65.7,
59,
82.9,
79.4,
59.5,
98.6,
20.7,
56.4,
59.9,
90.9,
71.2,
80.2,
83.6,
20,
65.7,
9.8,
48.2,
44.7,
81.4,
29.9,
42.8,
21.8,
91.2,
32.6,
29.5,
76.6,
40.3,
95.1,
49.2,
35.3,
29.4,
34.7,
11.4,
54.1,
30.7,
91.4,
16.9,
33,
95.6,
47.5,
78.5,
47.3,
16.9,
38.3,
73.8,
87.2,
39.9,
34.2,
52.3,
36.8,
45.2,
47.7,
83.5,
29.8,
66.9,
50,
82.5,
95.1,
56.4,
48,
63.9,
49.7,
64.6,
47.2,
42.7,
94.1,
79,
29.9,
69.4,
61.9,
53.9,
54.1,
37,
32.5,
73.1,
11.7,
63.6,
88.8,
28.4,
73,
54.2,
40,
93.8,
95,
40.5,
28.1,
61,
44.8,
21.4,
24.5,
24.8,
62,
58.2,
64,
54.3,
73,
75.6,
23.8,
58.2,
87.9,
78.9,
41,
91.3,
83.8,
40.8,
33.4,
49.9,
12.3,
57.2,
69.3,
39.4,
43.5,
46.1,
53.3,
29.1,
82,
42.1,
4.1,
47.6,
38.8,
41.2,
33.1,
69,
87.9,
30.8,
31.9,
70.6,
60.2,
48.6,
88.2,
55.7,
55,
46.8,
66.9,
64,
36.9,
5.2,
38.7,
60.5,
61.4,
51.4,
40,
46.2,
84.1,
31,
81.2,
99.7,
70.7,
41.2,
59.9,
59,
74.9,
37.5,
47.2,
13.2,
30.8,
8.6,
46.4,
56.7,
74.7,
50.2,
77.8,
64.6,
35.2,
31.5,
49,
22.1,
82.2,
58.1,
44,
46.8,
40.6,
44.1,
83.7,
59.7,
59.9,
28.3,
48.2,
73.5,
24.3,
53.2,
40,
27.8,
71.6,
66.3,
60.6,
63.9,
67.7,
26,
13.3,
64,
35.2,
30.4,
95.4,
0,
10.8,
80.8,
49.3,
53.5,
40.8,
102.9,
65.5,
87.5,
33.7,
88.5,
54.7,
20.3,
68.6,
76.8,
0.4,
86.7,
69.9,
40.2,
97.5,
105.3,
92.7,
91.1,
33.3,
40.6,
69.8,
37,
97.4,
49,
47.1,
90.9,
43,
24.3,
11.7,
96.2,
54.4,
89,
85.2,
65.2,
57.8,
43.8,
56.7,
43.6,
51.2,
4.2,
58.8,
61.4,
88,
77.5,
56.9,
84.2,
44.2,
69.1,
55.2,
80.4,
14.4,
68.7,
53.3,
24.3,
36.6,
61.5,
76.5,
61.4,
28.3,
80.9,
47,
43.8,
45,
46,
37,
82.1,
36.7,
27.3,
15.1,
52,
34.2,
56.5,
79.7,
38.6,
57.3,
61.1,
38.2,
48.9,
62.1,
77.1,
55.4,
55.7,
56.6,
87.3,
96.8,
32.7,
81.5,
40.6,
85.9,
77.6,
48.5,
48.1,
71,
64.4,
53.8,
17,
51,
76.9,
69.1,
49.4,
47.3,
79.2,
22.8,
56.9,
50.4,
77.5,
30.2,
9.2,
71.4,
92.5,
14.3,
71.6,
87.3,
48.5,
31,
75.7,
36.5,
75.2,
96.1,
0.6,
100,
52.4,
65.1,
71,
59.7,
61.9,
64.7,
51.5,
64.3,
57.9,
70.4,
92.1,
58.8,
16.4,
65.3,
35.7,
92.8,
54.3,
20.1,
69,
54.1,
51.3,
72.8,
12.7,
80.8,
70,
71.6,
40,
74.7,
43.3,
84,
81,
60.6,
2.4,
45.7,
101.9,
15.1,
26.5,
31.2,
95.3,
38.8,
45.2,
66.3,
27.3,
93.9,
33.9,
50.5,
5.4,
63,
6.7,
68,
88.2,
64.3,
95.6,
42.9,
85.3,
75.5,
74,
51.6,
88.5,
57.7,
77.6,
41.9,
22.6,
12,
22.1,
27.7,
64,
57.2,
63.3,
68.2,
18.7,
58.1,
65.1,
66,
34.7,
62.1,
24.7,
86.5,
62.6,
49,
28.8,
50.4,
41.4,
58.5,
29,
64.8,
9.1,
38.7,
48.6,
64.5,
37.8,
30.5,
80,
88.4,
76.4,
20.3,
60.5,
64.1,
70.7,
41.4,
92.5,
41.2,
18.2,
25.5,
101.8,
43.5,
57.9,
17.6,
82.8,
91,
69.9,
69.9,
57.9,
46,
70.6,
93.9,
32,
0,
74.8,
28.1,
37.4,
56.1,
29.8,
80.6,
58.7,
22.3,
46.8,
58.1,
42.8,
45.4,
93.9,
25.3,
99.7,
48.5,
31.7,
47.2,
79.8,
36.1,
29.4,
58,
58.6,
79.7,
51.1,
44.5,
92.5,
68.2,
56.6,
25.9,
93.3,
63.5,
0.3,
79.9,
78.3,
89.4,
97.5,
0,
73.4,
37.9,
92.2,
59.4,
61.5,
42.2,
85.4,
20,
52.8,
43.5,
49.9,
92.9,
91.9,
69.4,
1.2,
80.3,
76.2,
47.4,
84.5,
39.5,
64.6,
51.2,
86.6,
46.1,
55.9,
41.5,
27,
33.9,
22.2,
37.6,
58.1,
59.3,
63.5,
37.8,
95.7,
74.7,
50.7,
72.3,
79,
39.2,
83.8,
51.5,
61.6,
40,
80.6,
75.6,
77.1,
70.5,
78,
98.2,
0.3,
69.6,
15.6,
78.3,
30.6,
92.4,
28.4,
12.3,
29.5,
98.5,
59,
64.5,
15.1,
53,
31.7,
65.7,
72.8,
28.4,
96.7,
75.3,
27.6,
63.1,
40.9,
43.6,
9.1,
16,
96.5,
43.8,
52.3,
70.3,
61.5,
38.1,
23.1,
30.7,
58,
65.6,
40,
50.7,
62.8,
31.9,
70.4,
47.5,
85.4,
44.8,
59.1,
53.5,
63.6,
61.3,
28.6,
29.8,
73.6,
84.4,
22.3,
71.9,
58,
47.4,
6.5,
20.8,
35,
46,
72.8,
43.3,
30.5,
61.6,
4.1,
44.6,
76.3,
86.5,
71.3,
76.2,
27.6,
47.7,
97.8,
67.3,
35.5,
20.6,
76.2,
46.1,
81.4,
46,
64.3,
70.4,
60.5,
28.5,
52.3,
43.8,
67.6,
26.4,
57.4,
67.8,
61.9,
52.7,
73.4,
72.3,
90.2,
74.2,
66.8,
48.8,
41.1,
7,
32.9,
41.1,
67.3,
47.6,
15.7,
42.7,
73.6,
16.8,
37.8,
39,
86,
63.6,
66.4,
82,
29.3,
44.2,
67.1,
52.8,
32.1,
60.4,
48.9,
4.7,
64.7,
55.6,
51.3,
16.7,
95.5,
68,
48.8,
26.2,
75.4,
91.2,
64.1,
89.2,
45.9,
12.6,
77.2,
42.7,
66,
60.4,
89,
86.1,
54.8,
78.7,
42.5,
65.4,
83.3,
55.7,
70.9,
49.3,
27.4,
38.7,
68.5,
55.1,
79.5,
30.3,
39.7,
50,
38,
54.8,
39.3,
76.1,
68.7,
31.4,
60.5,
40,
60.2,
40.9,
38.8,
70.7,
49,
71.7,
73.8,
96.9,
52.2,
37.4,
71.4,
66.9,
52.1,
85.8,
87,
66.7,
88.7,
56.1,
80.3,
97.7,
23.8,
72.3,
63,
10.4,
80.5,
63.8,
70.7,
12.9,
59.6,
61.4,
87,
47.8,
23.6,
63.9,
43,
68,
70.4,
76,
80.6,
61,
76.7,
70.7,
39.8,
42.3,
32.9,
24.4,
79.9,
88.6,
0.6,
13.4,
8.2,
93.7,
25.7,
71.5,
87.2,
40.3,
30.6,
81.5,
43,
78,
55.1,
65,
29.4,
38.9,
53.9,
42.4,
57.5,
38.1,
32.2,
74.7,
81.9,
58.7,
13.3,
61.5,
60.3,
91.3,
1.4,
54.3,
42,
47.8,
18.9,
83.1,
78.7,
13.5,
97.8,
23.8,
22.1,
61.6,
73,
77,
39.8,
31.5,
98.1,
84.5,
53,
59.1,
45.4,
29.5,
86.4,
18.2,
29.7,
55,
67.6,
84.2,
53.8,
43.6,
66.1,
52.4,
61.1,
83.1,
43.4,
37,
49.9,
20.1,
37.2,
37.1,
81.5,
29.9,
84,
72.6,
43,
73.1,
59.2,
26,
58,
53.6,
79.3,
68.9,
34.6,
84.8,
49.8,
30,
92.7,
81.9,
65.6,
44.9,
80.1,
87.7,
61.2,
72.2,
83.7,
15.1,
37,
52.9,
93.4,
31.1,
58.4,
98,
62.7,
49.3,
95.4,
19.9,
69.4,
76.6,
91.8,
70.8,
29.5,
81.9,
49.8,
53.5,
48.9,
13.3,
64.3,
40.8,
87.3,
56.3,
45.8,
53.7,
91,
68.1,
66.6,
58.7,
54.7,
15.3,
11.2,
22.3,
57.4,
52,
83.6,
98.8,
25.1,
43.7,
90.3,
92.5,
69.7,
91.6,
36.7,
60.5,
34.5,
77.8,
48.7,
61.2,
79,
70.1,
14.2,
48.2,
45.7,
68.8,
77.6,
51.4,
83.1,
20.2,
72.3,
78.5,
25.1,
91.2,
73.3,
41.1,
60.7,
92.6,
2.6,
64.7,
55.4,
94.9,
4.6,
22.8,
8.9,
47,
79.3,
16.3,
55,
57.9,
33.9,
95.5,
79,
91.3,
48.9,
54.2,
74.6,
78.3,
31.8,
85.5,
66.9,
83.9,
38.7,
28,
41.7,
76,
66.5,
86.1,
38.4,
58.8,
44.2,
80.8,
68.8,
58.8,
61.4,
50.1,
83.1,
0,
73.1,
71.5,
51.3,
76.4,
46.1,
64.6,
55.8,
48.9,
70,
18.9,
36.3,
21.2,
57.3,
63.2,
77.1,
73.6,
85.4,
82.5,
60.7,
98.3,
36.8,
93.6,
57.7,
14.3,
31.4,
47.3,
79.8,
28.8,
77.8,
79.5,
72.9,
20.7,
30,
59.4,
63.7,
58.4,
80.5,
49.7,
34.9,
57.5,
39.7,
55.1,
63.6,
25.8,
59.3,
66.7,
15.3,
38.8,
0,
63.7,
76.5,
13.5,
71.9,
36.4,
32.9,
76,
33.2,
48.4,
73.6,
50,
93.5,
79.9,
86.2,
40.4,
49.9,
81.2,
71.9,
62.8,
51.1,
95.7,
58.4,
41.7,
81.1,
79.5,
60.3,
43,
41.1,
45.4,
65.8,
77.3,
64.2,
54.8,
57,
42.2,
25.9,
10.7,
51.1,
42,
65.6,
89.3,
87.1,
null,
34.1,
67.1,
73.2,
41.1,
31.1,
1,
51.4,
75.4,
43.8,
64.1,
90.3,
54.7,
28,
26.2,
34.8,
30.3,
54,
26.5,
90.5,
50.3,
46.7,
5,
70.9,
93.6,
95.4,
43.1,
71.9,
32.2,
26.1,
80.4,
43.3,
61.5,
16.7,
66.2,
75.6,
96.7,
36.7,
61.2,
54.1,
32,
9.2,
70.3,
60.6,
43.7,
67.8,
60.3,
76.5,
75.6,
57.8,
84.2,
53.3,
92.2,
19.3,
71.5,
75.7,
37.6,
78.4,
11.3,
39.1,
43.3,
82.3,
60,
55.4,
71.3,
56.9,
19.9,
7,
62.5,
20.2,
64.4,
63.8,
16.2,
0,
36,
57.9,
21.6,
51,
83,
62,
70.9,
50.6,
34.9,
60,
96.9,
43.5,
36.2,
13.3,
21,
84,
39.6,
15.2,
11.4,
6.1,
78,
42.9,
56.8,
31.1,
80,
17.9,
41.7,
35.6,
53.1,
63.8,
16.2,
53.5,
76.2,
14.2,
91.4,
64.3,
31.8,
43.7,
43.4,
21.8,
40.9,
53.4,
79.2,
46.1,
29.2,
79.4,
80.7,
62.3,
59.9,
80.8,
6.3,
34.2,
0,
0,
53.5,
47.3,
68.6,
73,
52.1,
42.7,
39,
38.5,
52.4,
17.2,
87.5,
15.7,
74.5,
66.6,
62.6,
58.2,
21.4,
57.4,
60.4,
42.7,
26.2,
66.9,
94.1,
74.6,
81.6,
65.1,
85.6,
61.7,
72.2,
66.5,
76.1,
19.1,
64.2,
70.2,
26,
27.5,
73.4,
20.2,
25.7,
5.7,
96.8,
80.1,
5.1,
49.6,
54.1,
32,
58,
23.1,
59.1,
84.6,
58,
21.7,
56.1,
94.8,
54.9,
75,
37.8,
37,
36.7,
21,
62.8,
42.2,
95.1,
39,
62.4,
47.4,
36,
61.9,
87.9,
18.6,
66,
27.8,
21.5,
72.3,
31.8,
87.7,
55.8,
39.1,
50.1,
83.2,
44.1,
85.3,
11.3,
68,
68.8,
69.5,
65.9,
79.9,
42.9,
87.4,
94.8,
45.2,
45.1,
64.4,
62.5,
58.6,
42.6,
12.9,
89.4,
75.9,
80.5,
89,
1.5,
31.2,
42.2,
55,
7.1,
56.1,
36.1,
64,
62,
80.6,
33.3,
46.5,
47.8,
70.5,
59.6,
15.7,
79.5,
46,
20.8,
27.8,
50.9,
49.6,
62.4,
56,
86.1,
44.2,
13.3,
42.8,
61.6,
43.1,
79.7,
4.3,
6.1,
68.1,
70.2,
7.6,
22.1,
46.5,
89.2,
46,
64.3,
65.6,
61,
54.9,
83.6,
49.7,
51.3,
37,
68.1,
27.7,
44.7,
16.1,
43.1,
90.4,
77.4,
81.8,
9.4,
83.6,
37.5,
29.2,
50.4,
17.4,
80.8,
55.4,
70,
0,
56.1,
75.5,
34.6,
5.6,
84.4,
36,
46.5,
64.8,
52.6,
67.5,
26,
49.3,
42.8,
21.3,
51.1,
84.1,
35.6,
50.6,
55.6,
88.2,
57.7,
57.5,
56.4,
32.7,
23.6,
73.5,
89.1,
95,
47.4,
36.4,
50.5,
84.7,
79,
57.2,
46.5,
77.4,
12.8,
75.4,
64.2,
32.9,
85.6,
21.2,
58.4,
55.1,
43.3,
32.3,
59.5,
81.3,
32,
70,
91.6,
61,
49.5,
51.2,
36,
58.6,
94.1,
52.9,
43.4,
0,
27.3,
40.3,
87.9,
35.3,
64.5,
50.9,
21.6,
85.9,
9.8,
77.8,
90.5,
39.5,
97,
47.5,
39.7,
46.5,
28.7,
19.8,
62,
94.6,
74.1,
51.1,
57.4,
85.3,
73.3,
25.1,
64.8,
54.3,
48,
86.1,
73.5,
87.9,
62.8,
98.7,
94.8,
60.8,
56,
76,
80.1,
58.5,
33.2,
51.4,
10.7,
21.1,
78.2,
66.3,
23,
64.4,
57,
53.3,
53.7,
48.7,
30,
42.8,
8.8,
89.2,
53.3,
48.9,
78.1,
54.3,
36.9,
47.9,
51.3,
100.4,
72.8,
56.9,
25.7,
63.5,
76,
59,
51.6,
78.9,
58.2,
57.3,
28.6,
76,
62.3,
89.5,
85.1,
57.6,
33.9,
77.1,
97,
41.8,
56.6,
65.7,
33.4,
78.6,
48,
59,
34.8,
39.3,
62.5,
86.2,
41.9,
16,
26.4,
26.1,
24.1,
50.5,
42.4,
18.2,
73.1,
62.6,
80.8,
86.9,
42.9,
16.2,
67.9,
8.1,
50.4,
54.3,
49.8,
43.1,
68.6,
53.6,
73,
88.3,
0,
7.3,
73.4,
2.1,
41.5,
48,
8.7,
42.5,
64.2,
94.8,
85.4,
83.9,
38.5,
50,
33.9,
81.1,
84.3,
62.9,
39.1,
49.8,
98.1,
86.7,
47.4,
63.5,
34.8,
95.4,
37.1,
90,
78.9,
64.6,
63.5,
71.5,
69.8,
53.5,
88.5,
71.8,
43.3,
68.4,
49.9,
95.6,
43.2,
67.9,
19.3,
8.4,
24.8,
77.3,
81.3,
98.5,
54.9,
47.8,
54.9,
44.3,
96.6,
26.4,
48.1,
36.4,
41.5,
39,
67.2,
63.8,
64,
59.4,
23.3,
83.2,
64.5,
49.5,
51.6,
80.1,
35.7,
93,
92.8,
60.7,
42.8,
57.6,
14.7,
62.9,
67.9,
52.2,
53.2,
35.5,
62.7,
10.4,
22.5,
19.5,
44.6,
29.6,
23.4,
84.2,
45.4,
46.6,
29.8,
62.7,
99.2,
46.7,
54.4,
17.8,
73.1,
56.6,
50.4,
89.6,
32.9,
49.8,
24.3,
49.1,
69.7,
69.5,
33.4,
49.3,
90.5,
40.9,
71.3,
72.3,
30,
55.2,
50.7,
55,
54.5,
48.1,
45.8,
43.3,
53,
47.2,
80,
70.3,
37,
38.2,
41.2,
75.6,
76.7,
79.3,
94.3,
56.9,
28.8,
85.7,
66.7,
29.6,
23.1,
74.4,
43.2,
5.3,
30.8,
19.5,
58.6,
67.1,
91.2,
56.2,
74.5,
75.6,
23.2,
45.2,
60.7,
91.6,
65.9,
88.6,
56.1,
46,
100.1,
53.5,
49.1,
75.1,
6,
20.2,
0,
101.5,
50.3,
84.1,
45.9,
39.4,
55.1,
44.8,
81.6,
91.1,
61.8,
64.1,
69.2,
62.9,
6.3,
87,
82.4,
79.1,
94.7,
83.1,
11.8,
49.6,
44.9,
87.1,
67.9,
84.6,
59.2,
42,
28.2,
69.6,
38.4,
76.1,
28.7,
94.1,
23.7,
95,
55.1,
37.5,
86.6,
43.5,
71.5,
32.1,
93.7,
26.9,
41.2,
66.1,
18.2,
54.5,
12.2,
91.2,
54.7,
15.6,
21,
27.1,
45.6,
24.1,
54.9,
33.8,
0,
48.6,
38.3,
75.4,
40.6,
46.9,
36.3,
35.2,
73.5,
49.1,
26.3,
62,
64.6,
94.2,
49,
87,
32.1,
56.1,
77.3,
42.3,
20.4,
17,
87.9,
62.6,
57.7,
26.4,
37,
27.6,
54.9,
1.1,
55.4,
95.3,
21.8,
39.1,
69.7,
52.1,
94.2,
76.3,
15.2,
49.7,
87.7,
24,
38.2,
50.9,
47.5,
68.9,
87.2,
44.4,
78.3,
87.2,
91.6,
27.7,
97.1,
40.9,
71.1,
51.7,
87.3,
82.6,
67.6,
67.6,
51.7,
72.7,
42.1,
54,
12.3,
76.3,
72.3,
88.3,
32.4,
48.6,
0.8,
56.1,
81.2,
60.4,
64.4,
67.5,
32.7,
38.2,
79.2,
42.1,
79.4,
69.3,
66.6,
76.9,
1.5,
97.4,
78,
78.3,
81.3,
54.3,
60.9,
42.2,
48.7,
54.9,
19.9,
63.9,
76.5,
84,
92,
53.9,
68.9,
20.2,
81.8,
93.6,
11.2,
91,
86.2,
41.4,
63.9,
35.6,
87.7,
46.1,
64.5,
84.2,
2.1,
66.8,
33.7,
58.3,
76.7,
67.7,
84.4,
15.4,
74.3,
81.7,
24.3,
59.3,
82.3,
13.4,
81,
82.8,
18.2,
0,
41.5,
39.1,
27.5,
60,
56.9,
63.8,
78.2,
55.3,
84.6,
42.7,
98.9,
61.2,
38.8,
73.3,
23.9,
46.1,
58.3,
38.7,
73.6,
18.4,
86.8,
65.3,
92.8,
1.4,
89.6,
79.7,
31.6,
55.1,
59.1,
86.8,
33,
70.3,
88.2,
34.5,
6,
33,
39.7,
69.6,
56.3,
17,
82.1,
93.2,
56.5,
33.4,
31.1,
45.2,
69.6,
47.8,
66.4,
35.2,
64.4,
88.7,
76.9,
5.5,
64.4,
73.8,
76.4,
69.7,
49.2,
72.1,
38.1,
63,
83.1,
31.2,
20.1,
80.8,
44,
52,
15.7,
78.9,
37.7,
95.1,
23.9,
54.4,
33.4,
54.5,
52.2,
69.1,
83,
61.1,
11,
38.3,
67.8,
43.3,
38.2,
78.4,
27.3,
58.7,
5.9,
70.8,
38.7,
78.7,
94.5,
47.2,
44.8,
72.4,
68,
45.4,
40.7,
26.1,
85.2,
26.4,
70.9,
20.6,
86.7,
99.3,
72.3,
76.9,
3.6,
42,
30.4,
96,
62.6,
80.4,
74.7,
79.9,
57.2,
38.3,
64.1,
42,
46.1,
57.9,
46.7,
77.3,
82.1,
70.8,
79.6,
52.7,
15.4,
37.2,
71,
88.2,
34,
13.5,
44,
24.4,
73.8,
19.4,
10.1,
48.9,
59.9,
91.8,
55,
40.6,
61.1,
46.6,
56.1,
46.2,
31.1,
54,
44.2,
52.7,
45,
50.8,
45.2,
31.3,
82.9,
98,
91.3,
87.9,
69.5,
83.3,
30.8,
74,
60.8,
72.8,
13.6,
43.6,
95.7,
89.2,
48.1,
84.3,
13.9,
57.4,
81.2,
83.7,
81,
75.4,
56.2,
80.3,
88,
22.1,
53.3,
33.4,
88.5,
87.7,
28,
76.4,
68.5,
32.5,
31.5,
74.3,
21,
41.1,
58.7,
34.3,
84.4,
67.1,
75.5,
65.1,
45.5,
72.1,
49.8,
11.7,
69.3,
80.5,
79.7,
34.1,
71.4,
82.4,
46.6,
65.6,
83.4,
49.4,
42,
43.2,
24.8,
67.3,
59.9,
47.7,
88.8,
8.4,
39.5,
78.8,
74,
50.9,
91.8,
37.6,
82.6,
73.9,
71.2,
34.2,
51.1,
95.1,
68,
54.7,
72.1,
24.3,
39.1,
41.3,
93.6,
91.8,
48.1,
92,
87,
14.4,
66.2,
56.4,
57.6,
63.4,
44.9,
77.9,
60.9,
42.8,
21.4,
45.2,
73.1,
21,
80.8,
72.3,
56.6,
78.4,
18.2,
37.4,
14.2,
53.4,
63.2,
94.3,
36,
61.3,
55,
53.4,
47,
38.2,
50,
48.7,
42.4,
36.4,
87.4,
70.7,
79.8,
22.2,
36.9,
58.1,
30.2,
58.6,
63.4,
78.7,
70,
54.7,
45.3,
86.2,
35.8,
64.6,
22.9,
36.3,
37.1,
89.7,
71.2,
95.7,
28.7,
76.8,
71.3,
25,
76.5,
84.1,
55.3,
41.2,
19.9,
41.2,
81.6,
12.9,
15.9,
14.6,
81.5,
62.4,
23.9,
62.8,
65.7,
65,
40.5,
81.8,
91.2,
66.6,
35,
90.2,
27.2,
49.4,
27,
98.6,
58.4,
21.9,
90.8,
37.1,
48.3,
51.1,
65,
31.1,
57.9,
28,
37.1,
65.2,
87.2,
55.4,
52,
65.8,
35.8,
57.5,
59.5,
55.4,
72,
60.4,
75.5,
39.7,
65.9,
64.3,
74,
67,
72.3,
81.8,
64.8,
26.7,
75.1,
75.6,
62.7,
50.9,
87.6,
56.9,
38.2,
53.6,
21.1,
98.6,
88,
31.8,
66,
5,
41,
53,
12.2,
93,
27.8,
41.5,
21.9,
37.6,
59,
72,
41.4,
70.1,
69.7,
76.7,
45.3,
24.4,
4.5,
8.8,
48.9,
32.3,
67.9,
85.3,
76.6,
89.9,
76,
38,
38.2,
89.1,
50.1,
57.5,
42,
29.1,
79,
71.9,
86.2,
86.7,
38.5,
77.8,
68,
38.1,
20.8,
0,
59.5,
81.6,
97.4,
28,
37.8,
96.7,
36.3,
48.2,
94,
76.3,
83.1,
68.4,
52.9,
87.8,
46.7,
15.9,
77.8,
34.6,
41.6,
79.1,
58.2,
68.9,
46,
46,
52.1,
84.2,
22.2,
54,
35.3,
93.3,
97.1,
0,
26.9,
63.8,
64.7,
63.3,
54.7,
39.1,
50.3,
45.6,
57.3,
69.4,
36.6,
24.4,
16.6,
78.7,
10.8,
76.8,
80.9,
16.7,
50.6,
56.8,
38.2,
64.3,
72,
61.5,
72,
52.4,
48,
59,
82.5,
52.6,
50.4,
56.1,
82.9,
35.9,
20.7,
36.4,
58.7,
81.6,
47.8,
52.2,
53.9,
0.5,
25,
101.3,
31.5,
37.4,
49.8,
50.6,
22.6,
45.1,
17,
69.2,
87.7,
39.3,
41.8,
52.8,
58.7,
88.8,
65.8,
66.2,
43.9,
71.3,
10.5,
77.7,
71.1,
17.9,
92.6,
77.9,
33,
29.8,
82.2,
66.5,
47,
21.6,
51,
49.4,
5.2,
73.4,
35.6,
85.6,
48,
16.1,
35.9,
32.9,
54,
82.1,
25.7,
2.9,
69.2,
81.6,
75.8,
33.8,
65.4,
54.5,
77.8,
49.9,
47.3,
54.5,
94.6,
49.8,
95.4,
62.2,
60.1,
61.8,
40.6,
19.8,
31.9,
86.3,
33.7,
80.9,
24.4,
70.9,
83.2,
40.3,
27.7,
92.9,
75.1,
77.6,
30.1,
65.1,
32.4,
86.1,
75.7,
32,
63.5,
13.3,
17.1,
68.6,
60.2,
60.2,
79,
89.6,
79.3,
62.3,
35.7,
58.6,
57.3,
14,
72.7,
44.4,
33.3,
68.3,
9.7,
79.7,
51.1,
20.7,
90.3,
60.2,
16.2,
64.7,
68.1,
35.1,
74.5,
65.7,
75.5,
17.9,
61.4,
68.5,
21.4,
53.7,
7.7,
76.8,
70.2,
63.6,
67.9,
68.3,
79.1,
47.3,
60.4,
68.8,
50.1,
42.8,
48.3,
70.7,
65.2,
87.8,
74.7,
92.9,
86.6,
92.9,
65,
45,
35.5,
70.5,
49,
46.7,
17.4,
50.8,
79.6,
72.3,
33.1,
46.2,
35.4,
53.5,
40.5,
46.4,
78.5,
63.1,
51.8,
94.1,
32.6,
85.6,
81.3,
73.5,
58.3,
64.4,
55.1,
62.6,
45.2,
67.5,
46.2,
84.1,
60.1,
65.4,
52.7,
76.4,
93,
67.5,
35.2,
69.1,
74.3,
18.1,
72.4,
88.9,
55.7,
71.7,
53.2,
40,
57.4,
44,
65.9,
82.9,
83.5,
79.4,
42.8,
38,
31.8,
47.7,
53.7,
72.5,
73.4,
81.7,
36.3,
9,
76.4,
51.4,
79.5,
66.6,
73.6,
102,
36.6,
28.2,
61.4,
34.3,
29.9,
52.1,
65.9,
91.3,
31,
61.1,
59.5,
25.4,
64.1,
82.4,
67.8,
63.4,
29.8,
66.1,
24.2,
10.9,
46.9,
65.5,
19.6,
39,
58.9,
32.6,
37.3,
6,
21,
89.1,
30.1,
2.2,
49.7,
63.2,
83.7,
95.7,
27.9,
61.7,
82.9,
71.6,
66.2,
24.7,
27.5,
20.4,
16,
71.9,
47.6,
20.9,
87.4,
2.5,
49.9,
97.4,
54.9,
55.1,
61.1,
47.3,
69.4,
47.7,
83.5,
33.1,
58.2,
57.1,
54,
68.4,
49,
46.7,
71.4,
29.9,
36.3,
83.2,
56.2,
90,
39.1,
41.8,
58.8,
43,
58,
27.4,
60.1,
31.3,
72.3,
50.1,
50.3,
41.7,
52.7,
48.5,
75.7,
75.9,
72,
33.2,
64.4,
85.7,
68.5,
48,
42,
77.6,
55.1,
33.8,
90.5,
33.5,
18,
50.4,
49.6,
25.5,
60.7,
71.7,
71.4,
35.8,
33,
55.8,
92.5,
36.6,
43.1,
24.3,
79.7,
64.1,
53.7,
50.8,
79.2,
70.6,
50,
37.2,
33.1,
69.9,
87.4,
31.1,
85.8,
44.1,
86,
22.3,
84.7,
59.3,
79.9,
36.2,
8.5,
64.6,
7.1,
48,
51.9,
59.1,
56,
50.3,
86.5,
67,
62.8,
95.9,
77.5,
97.3,
83,
57.4,
83.8,
93.6,
43,
83,
45.6,
73.6,
60.6,
99.7,
39.8,
65,
79.1,
78.2,
85.7,
79.4,
74,
19.4,
82.6,
88.6,
53.8,
37.7,
34.8,
85.2,
12.4,
96.9,
79.9,
63.1,
64.6,
10.7,
62.7,
49,
86.1,
70.4,
9.1,
34.4,
72.5,
48.5,
22.3,
72.6,
54.4,
73.8,
62.9,
21.9,
67.3,
81.9,
48.6,
77,
75.7,
17.7,
30.1,
36.5,
76.9,
37.8,
66.1,
81,
69.6,
63.6,
65.7,
28.8,
84.5,
96.4,
48.6,
53.2,
38.8,
2.2,
65.2,
65.2,
52.3,
51.2,
40.7,
30.8,
96,
57.2,
61.9,
27.7,
82.9,
37.2,
69.5,
91,
67.6,
31.9,
58.5,
54.2,
71.5,
34,
62,
16.2,
84.1,
78.4,
89.1,
50.1,
37.1,
56.1,
27.1,
42.8,
69.5,
61.8,
44.8,
51.7,
40.8,
76.3,
34.2,
43.1,
64.7,
62,
95,
75.7,
28.2,
50.8,
38.5,
32,
34.3,
73.4,
35.7,
46.4,
85.5,
59.3,
20.6,
65.3,
72.6,
78.5,
75.4,
4,
32,
47,
86.7,
70.1,
57.5,
30.7,
62.2,
53.3,
56.4,
53.7,
40.8,
74.5,
41,
80,
74.5,
54.2,
76.5,
40.2,
60,
55.4,
68.2,
38.7,
10.1,
70.7,
94.9,
34,
37.9,
84.3,
37.4,
42.1,
57.6,
80.1,
56.4,
56,
31.9,
45.6,
40,
31.8,
83.1,
62.9,
36.4,
33.8,
80.4,
84.4,
32.2,
86.5,
56.6,
42.5,
39,
39.5,
80,
53.8,
54.2,
47.1,
61.9,
8.2,
80.6,
58.2,
47.5,
76.7,
42.1,
63.9,
85.8,
75,
1.2,
77.6,
62.7,
62.1,
80.3,
47.1,
14.7,
70.8,
95.1,
2.6,
66.8,
77.4,
34.5,
80.2,
42.3,
61.9,
85.2,
89.1,
76.8,
44.4,
71,
59.6,
64.7,
33,
22.3,
59.6,
17.5,
85.1,
85.9,
58.3,
47,
56.5,
43.9,
77.7,
51.6,
81.1,
82.9,
54.1,
21.8,
55.4,
7.4,
56.9,
66.1,
59.8,
40.1,
15.9,
93.3,
27.5,
31.9,
39.7,
57.6,
69,
60.9,
88,
89,
59.1,
60.8,
96,
17,
33.3,
45.7,
65.5,
86.1,
76.5,
17.3,
76.7,
33.8,
66.5,
73.9,
30.9,
26.9,
84.9,
60.8,
89.1,
19.2,
28.4,
91.3,
20.4,
32.3,
59,
85.1,
25.5,
98.1,
83.7,
89.4,
9.9,
31.6,
82.1,
62.5,
25.8,
24.8,
74.3,
28.7,
93.2,
56.5,
24.1,
49.1,
54.5,
38.2,
22,
37,
53.2,
25,
54,
80.5,
49.4,
20.4,
39.3,
15.2,
49.8,
41.7,
42.3,
80.9,
35.9,
36,
5.9,
80.2,
44.9,
32.6,
93,
86,
40.2,
78.7,
49.3,
65.4,
82.5,
89.1,
48.4,
65,
64.2,
88.3,
58.3,
25.2,
48.9,
87.7,
39.2,
59.5,
40.8,
24.8,
60.6,
87.5,
61.4,
85.7,
79.6,
10,
32.3,
65.2,
1.3,
78.9,
51,
47.6,
47.8,
76,
74.8,
55.9,
57.1,
43.8,
48.9,
20.9,
39.9,
44.5,
63.4,
6.1,
38.5,
83.5,
64.6,
80.1,
68.2,
61,
89.8,
7.4,
5.4,
60.3,
62.8,
53.5,
92.4,
67.5,
53.9,
70.7,
79.8,
57.8,
56.3,
75.9,
87.5,
74.8,
58.1,
21.9,
68.9,
26.6,
69.6,
51.7,
62.6,
75.5,
58.1,
42.7,
0,
40.6,
51.4,
99.2,
16.8,
74.9,
49.1,
98.3,
45.1,
83.3,
72.5,
41.2,
89.4,
73.7,
29.3,
66.7,
20.8,
12.3,
42,
61.6,
2.5,
63.5,
25.4,
88.3,
41,
37.7,
87.9,
83.2,
77.3,
6.4,
78.7,
95.3,
69.8,
30.1,
22.1,
61.2,
28.5,
31.8,
78.9,
54.2,
43.3,
89.9,
45.7,
98.4,
64,
51.1,
62,
47.6,
59.3,
98.1,
59.5,
84.6,
71,
55.9,
52.6,
93.4,
63.6,
96.1,
49.5,
28.8,
14,
33.2,
45.2,
57.6,
29,
33,
66.2,
74.4,
14.8,
16.9,
65.7,
55.3,
93.3,
50.6,
34.7,
10.2,
38,
59.6,
76.8,
46.2,
51.1,
59.8,
64.2,
73.1,
52,
95.3,
36.4,
71.1,
65.4,
82.7,
99.4,
72.5,
62.7,
40.8,
94,
51.2,
61.4,
18.7,
64,
24.2,
57.2,
85,
85.3,
8.2,
9.5,
62.8,
75.4,
73.9,
48.1,
84.3,
52.3,
40.3,
22.5,
55.2,
88.1,
53.7,
51.7,
74,
76.3,
65.4,
3.5,
66.4,
76.3,
59.8,
73.3,
86.2,
98.7,
57.1,
41.4,
91.2,
41.5,
76.7,
44.7,
39.5,
23.3,
38.2,
46,
64.1,
42.5,
70.8,
86.3,
94.2,
68.1,
36.4,
84.1,
35.8,
62.1,
79.8,
51.6,
90.9,
75.1,
41.9,
58.5,
25.2,
39,
65.7,
40.7,
85.1,
70.2,
30.8,
35.1,
43.8,
83.9,
69.4,
60.9,
79.9,
48.4,
44.7,
50.2,
24.3,
29.5,
60.4,
57.5,
49.1,
43.5,
26.5,
49.6,
91.1,
22.1,
46.8,
57.2,
2.2,
91.5,
30.5,
40.6,
63,
23.6,
63.1,
59.6,
31.1,
83.1,
33.8,
35.2,
84.2,
53.6,
74.2,
22.6,
66.3,
79.5,
85.6,
80.9,
89.5,
48.5,
84.7,
84,
31.7,
62.3,
36,
63.9,
55.4,
57.2,
68.4,
44.1,
38,
28.8,
60.3,
16.7,
49.6,
21.5,
36,
51.7,
59.6,
6.5,
13.8,
66.8,
41.8,
37.8,
83.3,
43.3,
44.3,
47.3,
26.8,
43.3,
66,
93.7,
39.6,
35.5,
28.9,
12.4,
39.1,
26.7,
53.2,
46.1,
68.9,
31.4,
93.2,
38.9,
87.8,
53.3,
48.1,
37,
64.7,
77,
74.1,
47.2,
25.3,
18,
30.9,
61.3,
55,
61.4,
67.5,
78,
48.5,
44.3,
54.6,
47.4,
5.4,
59.1,
4.9,
77.7,
27.9,
52.6,
58.9,
7.1,
40.6,
79.4,
28,
76.6,
89.6,
52.9,
8.4,
35.5,
94.3,
82.6,
67.5,
56.2,
61.9,
70.3,
44.1,
81,
55.2,
67.4,
73.9,
37.8,
95,
26,
62,
1.3,
62,
32.5,
54.5,
63,
50.9,
80.5,
4.9,
45.9,
50.7,
69.2,
0,
55.8,
74.4,
32.9,
0,
32.4,
40.8,
64,
84,
38.2,
80.7,
79.4,
29.8,
15.3,
42.8,
73.6,
79.9,
35.2,
26.1,
39.9,
79.4,
61.9,
61.1,
66.9,
19.5,
42.7,
100,
20.8,
69.3,
32.2,
68.2,
56,
81.3,
38.6,
18.7,
28.6,
67,
42.7,
50.8,
82.2,
34.6,
60.1,
46,
24.9,
85.7,
85.4,
95.3,
62.6,
86,
81.4,
46.4,
15.2,
37.8,
89.1,
97,
76.8,
46.1,
99.6,
59.7,
16.7,
74.1,
79.4,
34.5,
78.4,
52.4,
72.9,
35.4,
28.2,
48.4,
69,
46.8,
78.2,
69.5,
85.8,
38.4,
2.7,
73,
73.7,
7.1,
54,
50.9,
34.7,
93.3,
36.6,
29.1,
29.9,
58.6,
38.2,
45.5,
55.1,
41.5,
29.7,
16.6,
64.3,
75.4,
78.8,
56.9,
59.8,
56.6,
30.2,
42.4,
42.9,
69.6,
70.9,
89.5,
88,
67.1,
82.2,
17.9,
49.9,
26.2,
66.8,
11.6,
77.1,
54,
40.8,
78.7,
62.5,
85,
52.7,
80.6,
20.3,
29.7,
81.9,
68.6,
24.7,
68.1,
8,
82.8,
76.7,
43.8,
55.1,
19.1,
61.2,
46,
70.2,
64.6,
58,
48.7,
22,
37.7,
56.4,
76.5,
77.5,
55.9,
82.7,
23.2,
104.9,
23,
61,
91,
36.3,
5.4,
68.1,
91.9,
95.9,
90.5,
39.5,
35.1,
85,
24,
57.8,
100.7,
81.8,
94,
66.3,
45.6,
92,
29.8,
96,
17.9,
89.2,
81,
17,
75.3,
54,
25.4,
38,
38.9,
113.8,
97.9,
42.5,
13.8,
54,
8.4,
97.2,
32.4,
65.3,
73.5,
77.7,
42.9,
35.7,
36.1,
45,
42.4,
48.9,
61.6,
25.6,
73.7,
47.4,
61.6,
46.8,
46.1,
23.1,
55.2,
67.5,
65.5,
40.9,
33.1,
18.9,
64.3,
79,
60.4,
70.7,
77.9,
44,
48.1,
70.8,
5.8,
68.4,
36.2,
77.4,
41.8,
41.9,
6.7,
100,
27.9,
82.7,
68.6,
84,
72.9,
47.1,
35.4,
5.1,
69.9,
12,
100.2,
96.5,
38.2,
5.3,
58,
28.5,
46.4,
89,
20.6,
67.2,
94.9,
56.8,
66.9,
69.1,
1.8,
50.4,
93.5,
71.7,
65.5,
59.9,
76.2,
73.3,
67.1,
86.9,
39.2,
49,
77.8,
20.7,
18.7,
30.2,
48.7,
62.4,
95.9,
102.6,
21.2,
62.4,
7.2,
92,
37.2,
53.6,
50.2,
82.4,
71,
47,
60.5,
44.3,
38.6,
71.7,
100.9,
3.8,
62.3,
33.1,
9.7,
71.9,
75.2,
69.9,
28.7,
74.3,
59.8,
71,
41.3,
43.6,
70.2,
22.5,
63.5,
52.3,
52.1,
60.7,
55.5,
47.7,
13.3,
85.8,
80.8,
71.1,
67.2,
70.4,
40.1,
87.8,
45.7,
39.6,
91.4,
51.3,
54.3,
82.8,
50.5,
67.5,
40,
54.8,
93,
51.5,
58.7,
51.6,
39.5,
30.5,
15.9,
87.1,
70.4,
29.7,
15.3,
66.2,
23.7,
52.2,
59.7,
63.3,
58.1,
59.8,
74.1,
57.3,
62.9,
48.4,
53.9,
70.1,
72.7,
72.9,
31.4,
27.8,
46,
7.9,
45.2,
77.4,
81.8,
89.7,
69,
61.2,
47.6,
98.7,
43.9,
31.1,
11.9,
74.1,
28.8,
46.3,
68,
46.8,
78.1,
61.5,
62.2,
45.3,
12,
27.7,
17.5,
77.7,
28.3,
28.8,
48.7,
62.8,
48.9,
44,
39,
39.3,
45.3,
83.1,
61.8,
21.5,
54.8,
29.3,
67.4,
66.7,
53.2,
28.4,
89.7,
46.9,
27,
0.2,
59.4,
95,
40.1,
54,
77,
50,
58.7,
27.6,
7.7,
64.3,
57.1,
27,
62.2,
29.4,
39.1,
36.1,
48.5,
83.2,
38.3,
null,
73.8,
46.6,
71.9,
63.9,
80,
71.5,
78.3,
0,
85.7,
100.4,
48.8,
91.9,
37.9,
18.5,
65.3,
11.6,
46.4,
30.6,
34.6,
69.8,
58.8,
66.8,
64.2,
43.3,
68.1,
66.7,
46.7,
54.6,
61.7,
85.8,
83.4,
39,
92.5,
78,
39.8,
89,
42,
87.7,
54.1,
55.1,
62,
44.5,
92.5,
68.1,
85.2,
77.1,
63.4,
93.7,
63.9,
56,
8.8,
8.6,
41,
61.1,
31.7,
71.1,
68,
50.6,
30.3,
38,
62.4,
78,
76.6,
51.4,
13.6,
87,
53.2,
76,
81.2,
43.9,
71.1,
51.3,
54.5,
61,
53.9,
65.5,
37.3,
42.7,
58.3,
61.7,
37.3,
45.9,
32,
78.8,
37.6,
77.8,
70.4,
44.6,
74.4,
75.2,
86.3,
50.2,
19.8,
65.2,
49.8,
32.3,
75,
59.2,
43.7,
95.5,
68.5,
63.8,
19.8,
91.8,
89.3,
83.9,
71,
92.5,
27.9,
32.1,
40.1,
86.6,
84.2,
57.6,
85.2,
61.3,
88.9,
53.3,
57,
65.9,
58.3,
82.4,
66.9,
32.7,
41.5,
79.3,
30.2,
87.3,
99.3,
37,
90.8,
51.5,
62.7,
52.5,
66.2,
88,
71.7,
9.9,
10.4,
40.9,
43,
53.1,
71.1,
61.5,
10,
32.8,
75,
87.2,
81.8,
50,
41.7,
97.6,
71.8,
52.8,
89.1,
53,
56.2,
56.8,
22.8,
71.6,
76.7,
54.2,
10.3,
88.2,
43.4,
88,
36.5,
80.2,
78.5,
40.6,
82.7,
34,
63.5,
55.5,
44.6,
81.9,
22.4,
47.1,
83.8,
27,
54,
64.3,
63.2,
58,
80.2,
61,
87.9,
80.9,
25.3,
55.3,
43.2,
55.2,
29.6,
56.3,
10.6,
64.3,
96.2,
90.7,
71,
72.6,
26.6,
97.2,
98.5,
69.1,
61.2,
36.1,
46.4,
67.1,
98.9,
20.6,
72.1,
100.1,
85.4,
23,
0,
38,
66.4,
47.3,
53,
29.6,
50.2,
91,
56.3,
65.2,
34.2,
17.5,
16,
85.9,
61.3,
51.2,
70.8,
96.5,
8.2,
54.9,
82.3,
83,
76.4,
78.5,
75.9,
18.9,
29.2,
87.9,
53.2,
94,
38.8,
35.1,
37,
37.7,
55.5,
62.1,
45.8,
15.5,
8.8,
79.8,
74.8,
13,
75.3,
87,
21.2,
48.8,
86.8,
85.2,
5.2,
72.8,
58.7,
43.7,
98,
36,
37.9,
86.4,
26.4,
75.4,
56.1,
65.2,
59.2,
43.3,
45.4,
71,
48.4,
36.8,
92.3,
87.9,
35.9,
0.9,
34.1,
65.6,
90,
50.9,
55.6,
50.5,
53.1,
39.9,
61.9,
79.3,
69.6,
33.6,
26.5,
64.3,
53.1,
60.5,
44.9,
79.3,
80.7,
85.3,
45.8,
1.9,
47.6,
61.8,
49,
43,
68.7,
31.9,
28.9,
51.1,
55.1,
35.2,
85.5,
90.6,
69,
51.7,
31,
71.9,
40.4,
37.3,
39.1,
69,
24.8,
90,
100.9,
25.7,
39.4,
61.6,
63.7,
46.3,
41.2,
77,
68.7,
43.2,
86.2,
17,
95.7,
29.9,
93,
42.6,
76.6,
30.3,
72.9,
48.5,
43.3,
74.7,
67.7,
68.5,
30.4,
59.6,
30.4,
68.3,
44,
63.7,
72,
47,
53.2,
73.6,
68.4,
71.8,
43.9,
25.3,
39,
30.8,
54.3,
46,
27,
55.7,
92.6,
36.9,
43.5,
28.8,
98,
93,
73.4,
50.9,
28.2,
15,
98.9,
46.7,
80.8,
101,
77,
83.7,
34.8,
87.5,
42.4,
55.7,
48.2,
38.7,
80.9,
59.1,
30.6,
73.3,
62.3,
14.1,
86.6,
88.9,
36.3,
69.6,
56.8,
27.1,
95.7,
45.1,
32.8,
53.3,
38.7,
44.9,
47.1,
55.7,
54.2,
64.7,
4.2,
56.5,
94.2,
62.2,
87,
15.4,
31.9,
50.7,
64.8,
72,
16.1,
93.7,
89.3,
26.4,
81.2,
56.4,
16.4,
45,
74.6,
46,
84.4,
75.6,
63.7,
45,
17.3,
68.8,
82.6,
57.2,
72.5,
47,
52.1,
24.8,
77.1,
26.2,
48.2,
66.9,
97.8,
23.2,
32.9,
38.3,
60.6,
6.6,
25,
43.8,
86.3,
63.7,
63.9,
24.5,
22.2,
86,
92.8,
26,
39.4,
72.8,
30.1,
39.1,
69.2,
87.8,
60.1,
57.8,
36.8,
47.8,
11.5,
38.9,
50.5,
69.4,
12.3,
26.2,
85.9,
92.3,
61.8,
26.3,
23.1,
74.9,
62.8,
56.7,
67.5,
67.1,
42.3,
51.6,
87,
82.3,
74.4,
61,
34.3,
89.3,
1.1,
112,
80.1,
5,
39,
68.6,
75.9,
87.2,
39.1,
76,
83.9,
39.1,
92,
71.4,
98.3,
62.7,
63.1,
55,
60.2,
59.9,
41,
43.1,
34.8,
35,
58.3,
64.7,
54.9,
79.8,
52.1,
36.8,
87.9,
12.3,
36,
36.1,
62.9,
101.8,
40.9,
59.3,
71.7,
75.8,
83.8,
94.5,
72,
32.3,
45.9,
35.1,
45.6,
49.4,
68.3,
79,
12.9,
57.3,
44.4,
85.1,
1.4,
54.6,
50.1,
18.7,
78,
39.8,
58.4,
56.4,
54.9,
33.3,
67.3,
26.5,
28,
91.9,
75.3,
46.6,
68.4,
55.6,
85.4,
97,
41.6,
51.2,
31.1,
36.8,
50.4,
74,
33.4,
68.2,
76.8,
55,
88.5,
25.8,
63,
22.8,
62.7,
29.8,
32.2,
43.2,
64.8,
16.3,
94.8,
32.8,
72.3,
90.3,
47.1,
35.3,
90.5,
8.7,
65.6,
90.2,
65,
76.5,
97.4,
14.8,
49.4,
56.3,
27.1,
49.7,
41.9,
8.4,
79,
83.3,
67.6,
54,
79.3,
44.4,
50.6,
70,
57.4,
41.5,
50,
69.5,
28.5,
28.1,
20.5,
83.4,
59.5,
38.4,
52.4,
65.8,
81.7,
77.7,
56.5,
80.9,
52.6,
13.6,
76.7,
57.1,
65.7,
56.6,
51.9,
94,
95.8,
82.3,
91.6,
47.1,
98.8,
72,
69.8,
64.7,
49.1,
43.2,
52.2,
63.6,
56,
9.5,
28.7,
2.8,
59.5,
97.5,
89.4,
32,
38,
49.6,
26,
20.6,
29.4,
56.9,
68.9,
43,
75.6,
38.8,
63.4,
82.2,
29.6,
18.2,
28.3,
26.2,
26.2,
26.8,
9,
56.3,
51.6,
31.4,
62.3,
68.3,
56.6,
70.9,
78.8,
36.5,
68,
82.7,
18.6,
36,
48.3,
92.1,
86.3,
13.4,
22.2,
37.5,
31,
45.4,
40,
44.9,
73.2,
5.2,
18.1,
3.7,
60.5,
70.8,
61.2,
48.2,
39.6,
56.8,
39.8,
11.6,
82.4,
19.2,
41.7,
96.1,
29.6,
82.4,
61,
31.4,
31.3,
47.8,
24,
87.1,
95.9,
35.6,
20,
55,
24.1,
60.2,
59.9,
65.6,
40.1,
90.5,
68.6,
81,
51.5,
44.6,
2.4,
38.5,
79.2,
72.4,
50.8,
9,
99,
32.3,
51,
69.2,
61,
79,
65.9,
76.1,
58,
69.1,
62.8,
39.1,
87.8,
75.2,
27.9,
51.9,
32.8,
96.6,
23,
78.7,
88.3,
22.7,
67.7,
83.5,
52.2,
68.8,
43.7,
44.6,
52,
39.9,
98,
72.2,
19.6,
59.4,
59.9,
68.1,
63.1,
48.8,
47.4,
70.4,
49.5,
66.2,
62.7,
5.2,
97,
72.5,
65.8,
88.9,
77.2,
40.4,
46.3,
40.8,
36.1,
67.7,
48.5,
86.7,
58.1,
48.1,
30.8,
64.3,
18,
45.4,
40.1,
69.3,
58.6,
41.7,
62.5,
86.1,
80.2,
59.8,
52.4,
59.2,
54.9,
48.1,
49.1,
37.6,
80.6,
52.1,
52.7,
98.8,
87.9,
70.1,
99.8,
47,
1.8,
28.8,
55.2,
37.7,
66.7,
64,
79.6,
18.9,
82.7,
40.6,
38.3,
91.3,
62.9,
94.9,
98,
48.9,
38.6,
61,
51.3,
34.2,
35.4,
49.1,
32.7,
34.9,
44.5,
39.8,
41.2,
78.6,
95.1,
60.1,
28.1,
54.8,
2.5,
35.2,
70.7,
61.4,
22.2,
56.5,
36.8,
41.6,
24.3,
69.9,
45.1,
70.2,
30.6,
91.8,
82.7,
41.2,
49.3,
96.1,
45.5,
43.4,
55.2,
91.7,
16.1,
70.9,
66.6,
9.5,
28.4,
63.6,
67.2,
50,
67,
45.4,
39.2,
58,
87.5,
54.1,
30.7,
52,
73.3,
44.7,
7.9,
91,
98.5,
34.6,
54.8,
56.3,
31.8,
0.3,
85.9,
46,
21.8,
4.4,
44.6,
94.6,
42.5,
40.9,
32.6,
22.8,
27.5,
25.8,
41.5,
89.6,
41,
16.7,
57.9,
48.2,
82.1,
43.8,
54.9,
32.8,
31.9,
7.6,
41,
19.7,
53.4,
56.5,
40.7,
63.2,
6.3,
52.7,
37.9,
90.5,
33.8,
63.8,
75.9,
58.3,
50.5,
44,
70.9,
88.2,
84.2,
81,
55.2,
92.9,
88.1,
86.3,
10,
91.6,
56.3,
81.8,
35.5,
78,
53.3,
53.6,
78.2,
61.4,
59,
54.9,
66.1,
69.9,
42.8,
65.6,
59.9,
81.4,
20.4,
72.2,
22.4,
55.9,
52,
56.8,
37,
11.8,
59.8,
76.1,
21.9,
59.8,
89.5,
88,
88.1,
46.7,
73.8,
45.6,
82.2,
82.9,
52.3,
65.3,
43.1,
59.3,
33.4,
73.4,
81.9,
30.1,
98.5,
50.8,
29.1,
18.6,
43.3,
66.7,
13.7,
25.8,
61.7,
52.2,
76.7,
47.1,
74.3,
8.8,
86.5,
66.6,
74.2,
28,
48.3,
60.4,
43.2,
44.2,
52.7,
43.3,
74.2,
34,
16.8,
99.2,
13,
73.7,
77.7,
16.8,
86.1,
68.7,
53.2,
7.2,
60.7,
53.8,
48.2,
45.3,
97.4,
64.3,
44,
85.8,
93.5,
61.3,
71.4,
56.8,
82.6,
86.1,
51.1,
76.2,
70.5,
41.9,
45.8,
68.9,
46,
44.8,
56.6,
30.5,
56.3,
59.8,
44.6,
31.2,
92.1,
79.2,
73.4,
44.2,
88.9,
82.5,
52.3,
78.5,
41.3,
77.7,
82.5,
74.6,
25.7,
47.1,
24.6,
38.8,
35.5,
40.5,
44.8,
33.14,
68.9,
37.2,
49.3,
2.5,
83,
30.6,
89.8,
34.5,
84.7,
36.9,
56.8,
83.1,
24.4,
69,
95.6,
19.2,
75.5,
3.5,
95,
84.1,
52.3,
23.3,
46.2,
85.8,
87,
48.9,
60.2,
48.9,
43.1,
63.1,
77.2,
3.6,
64.8,
69.1,
47.4,
43.7,
55.4,
78.6,
66.9,
73.2,
32.4,
56.4,
57.4,
54.5,
87.1,
79.7,
61.6,
91.7,
71.8,
31.4,
45.4,
40.7,
35.8,
85,
59.9,
75,
24.6,
77.8,
11,
40.6,
85.7,
44.8,
39.1,
68.9,
76.8,
23.2,
67,
55.6,
32.1,
11.7,
39.5,
39.2,
42.5,
50.4,
54.8,
59.7,
42.2,
90.7,
73.8,
80.7,
27.5,
41.4,
91.9,
83.4,
94.9,
62.7,
24.1,
85.2,
72.3,
0,
18.9,
59.5,
44.9,
18.5,
57.5,
87.8,
60.3,
20.1,
77,
55,
64,
60.9,
82.3,
39.5,
74.4,
81.9,
75.2,
56.8,
39.5,
45.3,
37.5,
48.9,
79.7,
83.1,
47.7,
62.9,
50.5,
88.6,
67.4,
82.2,
68.8,
48,
54.1,
69.9,
50.2,
50.7,
57.4,
81.7,
81.6,
37.9,
35.8,
93.9,
80.3,
41.7,
50.3,
59.4,
88.8,
90.7,
95.2,
23.9,
33.3,
61.2,
77.3,
80.2,
69.5,
50.5,
49.6,
33.8,
18.8,
42.8,
29.9,
96.4,
25.7,
55.7,
54.2,
36.5,
37.5,
53.1,
56.3,
70.6,
65.1,
54.1,
52.4,
39.8,
93.9,
66.7,
47.8,
78,
60,
96.9,
90.6,
19.8,
34.9,
58.3,
18.4,
42,
72.8,
37,
48.6,
73.6,
42.4,
92.6,
38.9,
65.4,
75.4,
49.6,
43.5,
38.9,
78.6,
83.7,
62.2,
48.4,
98.6,
91.6,
61.9,
86.4,
72.2,
52.4,
88.1,
66.8,
88,
31.9,
40.8,
32.5,
17.7,
62.1,
75.1,
76,
66.2,
43.6,
41.4,
40.2,
77.2,
71.4,
41.9,
79.2,
91.8,
92.7,
39,
34.4,
82.3,
46.8,
44,
37.1,
71.1,
23.9,
68,
52,
48.1,
59.4,
49.3,
83.3,
39.7,
30.4,
31.5,
48.8,
30,
58.1,
64.7,
52,
58.8,
76.1,
73.5,
73.3,
87.3,
95.3,
55,
23.6,
39.3,
105.1,
80.2,
68.5,
44.2,
60.8,
18.7,
73.9,
78.2,
48,
62.5,
56.4,
14.2,
33.3,
85.3,
9.2,
95.2,
47.4,
66.4,
56.4,
28.3,
6,
20.1,
78.4,
25.5,
69.7,
48.9,
27.3,
5.3,
73.5,
50.9,
29.9,
31.3,
38.8,
96.7,
17.4,
38.3,
45.4,
52,
52.3,
79.8,
71,
25.1,
99,
48.2,
79.3,
17.5,
43.8,
53.9,
14.9,
62.4,
22,
71.9,
18.4,
4.2,
43.4,
87.2,
45.4,
100.8,
62.3,
92.4,
39.1,
41.2,
87.7,
31.6,
70.3,
65.9,
69.6,
30,
20,
5.1,
76.4,
60.6,
38.2,
90.3,
71.4,
92.2,
59,
22.8,
21.4,
17.2,
66.1,
35.9,
8.2,
38.7,
17.5,
57.4,
66.9,
58.8,
82.7,
73,
59.2,
13.7,
62.6,
49.3,
61.2,
25.3,
69.7,
49.6,
71.2,
94,
82.6,
83.9,
66.4,
23.4,
49.9,
82.4,
40.5,
62,
36.7,
52.4,
62,
71.9,
34.6,
22.9,
38.2,
59.5,
5.2,
88,
26.3,
29.9,
90.4,
46.6,
30.4,
41.5,
0.8,
57.7,
36.4,
26.7,
56.5,
69.2,
52.6,
77.9,
23.5,
41.5,
37.5,
23.8,
24.1,
35.7,
76.9,
36.5,
72.2,
88.2,
44.2,
20.8,
88.4,
63.9,
94.2,
70.9,
46.3,
21.2,
56.9,
57.4,
44.3,
74,
74.9,
56.7,
80.1,
54.1,
52.6,
46.4,
60.2,
87.8,
81.5,
65.3,
80.4,
28.9,
47.9,
63.1,
95,
57.4,
17,
71.2,
73,
26.9,
52.1,
61.7,
84.3,
83.4,
78.1,
28.8,
57.3,
39.1,
37.7,
90.9,
41.1,
62.1,
87.3,
36.9,
39.5,
68,
62.6,
46.5,
34.9,
77.7,
63.5,
53.6,
61.7,
59.3,
73.7,
31.6,
31.6,
55.7,
96.3,
85.9,
45.9,
9.2,
86.7,
54.2,
71.1,
60.4,
8.6,
51.5,
56.3,
44.8,
66.7,
75.1,
17.6,
53.9,
61.4,
76.5,
69.6,
14.1,
84.8,
34,
41.1,
49.3,
62,
85.6,
35.1,
74.3,
71,
10.6,
45.7,
62.8,
4.3,
34.5,
22.6,
84.4,
67.4,
3,
23.5,
63.5,
84.6,
49.1,
38.1,
50.2,
52.4,
34.1,
72.4,
51.1,
38.7,
84.7,
41.1,
44.1,
56,
30.5,
43.3,
92.7,
72,
67.8,
39.6,
48.1,
14.3,
61.4,
34.5,
69.4,
69.2,
63.8,
94.4,
97.1,
85.5,
33.3,
32.5,
87,
43.6,
45.2,
34.6,
86.7,
34.4,
55.4,
98,
21.1,
54.4,
24.3,
33.2,
46.1,
85.3,
57,
33.4,
65.8,
70.1,
81,
59.6,
82.7,
67.3,
70.2,
51.7,
95,
83.8,
93,
41.2,
8.4,
51.8,
37.5,
42.9,
67.8,
66,
37.2,
75.8,
64.2,
14.8,
63.7,
38.5,
49,
23.1,
66.9,
92.1,
29.1,
89.3,
68.6,
64.9,
90.1,
47.1,
59.4,
93.8,
27.6,
69.4,
19.7,
62.9,
33.8,
10,
85.3,
72.6,
25.3,
74.6,
77.8,
45.1,
32,
65.5,
40.3,
89.4,
66.1,
16.3,
79.1,
50.6,
62.7,
97.2,
59.9,
51,
39.8,
76.9,
51.9,
54.8,
35.7,
44,
52,
52.4,
71,
62.7,
52.3,
99.3,
79.1,
27.8,
31.2,
88.3,
37.1,
36,
73.2,
61.1,
84.2,
83.9,
21.5,
68.4,
66,
40.6,
45.4,
75.5,
39.9,
64,
85,
42,
24.6,
91.5,
31.2,
85.4,
103.8,
29,
44.6,
34.6,
51.3,
72.8,
82.7,
63.6,
89.3,
113.1,
70,
66.5,
25.2,
16.2,
29.3,
57,
67.5,
53.6,
23.7,
93.9,
63.1,
69.6,
6.6,
67.1,
23.4,
12.1,
54.4,
40.9,
78,
79.1,
83.1,
81.6,
94.9,
18.1,
76,
43.7,
38.7,
90.2,
66.1,
71.2,
28.1,
53.9,
33.7,
17.3,
31.4,
86.1,
54,
48.3,
51.4,
30,
null,
85.1,
54.5,
73.7,
72.8,
62.3,
18.2,
39.1,
84.6,
62.2,
76.7,
65.3,
33.1,
64.7,
27.1,
57.5,
43.8,
68.1,
5.6,
74.4,
0.4,
29.9,
39.7,
97.4,
68.2,
67.7,
32.5,
54.8,
79.6,
32.6,
72.7,
69.3,
57,
35.2,
93.5,
47.4,
14.8,
88,
85.1,
95.9,
88.7,
71.9,
80.9,
57.8,
61.8,
24.8,
78.9,
65.3,
94.7,
22.5,
72.3,
77.7,
81.2,
62.5,
62.7,
96.1,
57.9,
21.7,
88.5,
62.6,
53.5,
67.5,
75.7,
0.7,
47.4,
48,
67.2,
22.4,
67.3,
44.4,
77.9,
47.7,
67.2,
83.2,
70.4,
42.4,
54.3,
77.8,
39.9,
94.8,
54.9,
26.6,
45.2,
32.4,
28.4,
78.9,
7.7,
1.9,
47.3,
84.1,
88.1,
58.6,
6.3,
26.2,
37.7,
55.9,
42,
85.9,
15,
62.5,
42.5,
58.6,
65.5,
66.3,
79.7,
70.9,
14.4,
50,
29.7,
49.8,
50.1,
86.9,
76.3,
62.8,
52,
28.2,
59.5,
72,
82.8,
15,
76,
38.5,
73.1,
32.3,
36.2,
56.2,
73.2,
99.8,
58.7,
52,
71.9,
56,
41.5,
35,
79.3,
32.6,
53.7,
29.5,
37.9,
87.5,
56.9,
60.3,
79.1,
34,
75.1,
43.5,
81.2,
97,
38,
20.7,
33.7,
17.6,
67.6,
25,
0.6,
82.9,
32.9,
29.6,
4.3,
24,
15.1,
14.5,
82.4,
94.3,
98,
43.4,
70.8,
57.1,
51.3,
70.9,
54.2,
4.9,
77.1,
88.7,
58.7,
22,
19.2,
28.2,
73.7,
67.2,
0,
61.5,
43,
19.3,
33.4,
3,
68.2,
76.9,
66.8,
43.6,
71.8,
39.3,
66,
80.7,
52.8,
69,
90.2,
73,
32.1,
53.6,
49,
87.4,
17.8,
51,
82.8,
32.7,
34.1,
67.2,
55.1,
25.2,
50.1,
90.4,
52.6,
70.5,
23.3,
70.8,
35.2,
58.2,
32.3,
92.1,
80.4,
53.8,
39.7,
56.2,
78.7,
101.9,
56.6,
91.4,
33.4,
103.7,
40,
75.9,
56.9,
61.9,
67.9,
63,
0.5,
77.7,
37.8,
43.8,
3.1,
63,
70.1,
63,
56.6,
77,
82.1,
42,
47,
63.8,
18.8,
66.5,
86.4,
45.3,
69,
59.1,
36.4,
56.8,
70.9,
81.3,
72,
49.7,
46.1,
60.4,
47.8,
15.3,
11.1,
41.2,
31.5,
81.9,
66.6,
71.6,
46,
57.9,
61.1,
48,
50.7,
72.4,
44.9,
44,
7.4,
20.2,
20,
71.3,
11.9,
47.9,
72,
0.3,
80.4,
73.1,
31.3,
54.6,
83.8,
63.9,
51,
64.4,
12.1,
89.1,
39.7,
9.9,
40.6,
92.4,
38.6,
55.6,
78.5,
44.4,
80.7,
97.3,
65.5,
22.5,
23.2,
15.4,
74,
80.3,
28.8,
81,
48.4,
59.3,
72.1,
24.3,
68.5,
82.5,
77.4,
13.2,
69.6,
45.8,
22.4,
47.4,
73.4,
33.4,
68.6,
80,
43,
21.3,
74.2,
80.4,
28.3,
39.2,
35.4,
61.9,
55,
81.4,
65.4,
38.5,
12.5,
63,
60.2,
61,
73.5,
44,
56.3,
92.8,
93.6,
55.5,
6.6,
37.6,
63.5,
54,
42,
34,
83.5,
13.8,
45.8,
42.7,
91.3,
76.3,
67.6,
82.4,
93.3,
94.8,
86.5,
68,
96.2,
62,
51.7,
47.9,
82.8,
34.5,
31,
37.9,
40.9,
53.8,
92.2,
46.4,
20,
42.7,
81.3,
52.8,
81.1,
57.5,
79.5,
45.1,
52.2,
75.9,
43.1,
2.5,
60.1,
42.5,
41.5,
21.7,
94.1,
19.2,
70,
71.7,
37.5,
92.7,
91.4,
39.9,
23.1,
94.4,
64.5,
78.7,
50.5,
18.7,
29.7,
63,
39.9,
37.5,
97.5,
42,
64.7,
17.3,
8.4,
49.4,
91.9,
81.9,
46.3,
70.1,
52.7,
80.6,
34.6,
81,
70,
50.4,
49.8,
84.9,
75.8,
77,
50.6,
63.9,
36.4,
43.3,
47.1,
66.8,
75.2,
65.8,
58.3,
94.6,
65,
44.9,
45.3,
75,
39.1,
73.6,
58.2,
47.7,
39.1,
64,
71.8,
67.7,
72.4,
69.8,
75.6,
10,
40.9,
41.1,
51.1,
31.8,
83.1,
72.3,
79.8,
58.3,
69,
54.3,
71.9,
42.2,
83.4,
41,
88.4,
70,
21.7,
56.5,
9.8,
93.2,
35.6,
19.6,
56,
40.6,
61,
56,
65.4,
41,
62.8,
47.9,
59,
61,
90.1,
91.8,
60.9,
28.7,
36.2,
3.2,
87,
51.4,
33.7,
57.5,
21.8,
86.2,
67.5,
67.5,
24.2,
77.3,
77.3,
24.1,
51.6,
68.4,
91.6,
9.4,
61.4,
50.3,
53.4,
92.4,
27.7,
68.5,
20.9,
78.8,
84.1,
94.8,
43.6,
95,
50.5,
25.2,
19.2,
57.9,
82.9,
52.4,
52.3,
49,
65.5,
78,
74.8,
47.3,
62.3,
42.2,
60.2,
74,
58.8,
47.8,
89.3,
44.4,
42.9,
59,
96.7,
74.1,
37.2,
10.3,
18.3,
65.4,
57.2,
68.3,
68.9,
14.7,
66.2,
75.8,
23.7,
53.6,
22.1,
68.3,
32,
54.2,
70.9,
27.1,
50.2,
33.8,
39.2,
28.6,
60.4,
54.6,
82.2,
29.7,
43.7,
48.9,
74,
74.1,
42.1,
37.2,
70.7,
74.8,
81.2,
21.1,
74.6,
45.3,
68.8,
43.6,
66.8,
97.7,
72.1,
28.7,
68,
64.5,
24.4,
88.3,
85,
59.8,
54.3,
95.7,
67.9,
89.5,
71.7,
40.4,
32.1,
76,
70.1,
1.4,
92.8,
50.6,
37.7,
10.5,
63.8,
69,
50.5,
87.7,
53.4,
46.1,
80.7,
76.3,
14.3,
72.9,
35.8,
99.5,
66,
5.1,
70.2,
96.5,
50.4,
43,
82.8,
32.2,
13.7,
89.9,
2.5,
71.6,
23.2,
41.3,
78.8,
46,
10.5,
59.2,
45.7,
53,
57.5,
20.9,
7.2,
38.5,
30.8,
62.1,
98.9,
95.3,
15,
50,
53.1,
36,
34.4,
88.7,
29.7,
71.7,
61,
57.6,
75.7,
29.1,
49.2,
22,
58.4,
69.5,
51.1,
63.2,
26.1,
65.1,
25.9,
52.4,
11.6,
79.8,
49.5,
26.7,
58.2,
9.2,
22.4,
92.4,
47,
74.6,
48.9,
99,
82.6,
41.6,
9.8,
61.7,
80.3,
39.7,
88.9,
11.2,
95.5,
77.6,
78.7,
33.1,
38.1,
71.8,
100.7,
77.3,
50.9,
23.7,
31.1,
36.5,
51.4,
42.8,
52,
88.2,
59.9,
55,
79.6,
53.4,
4.8,
81.5,
80.8,
17.7,
68.7,
55,
77.4,
84.8,
16.3,
0.4,
60.9,
37.7,
55.8,
80.4,
83.8,
85.5,
27.3,
53.8,
57.9,
94.4,
82,
64.8,
0,
99,
84.4,
80.3,
24.4,
39.7,
0,
24,
51.3,
60.2,
77.1,
50.7,
62.4,
21.7,
22.5,
49.4,
0,
78.8,
13.6,
17.2,
62.8,
47.7,
62.9,
85.7,
92.1,
43.9,
68.4,
72.2,
60.8,
20.2,
85.5,
84.5,
36.8,
37.5,
77.2,
24.4,
21.1,
76,
51.9,
40.9,
45.4,
71.8,
49.9,
45.5,
36.4,
33.7,
95.5,
79.1,
60.6,
78.4,
86.1,
54.8,
91,
90.8,
84.7,
45,
56.6,
63.3,
73.5,
34.6,
18.2,
76.6,
66.8,
29.2,
75.6,
34.7,
62.9,
71.3,
47.5,
37.7,
78.9,
36.2,
62.4,
44.4,
79.1,
72.1,
16.3,
55.3,
73,
61.5,
41.8,
66.5,
27.9,
19.6,
80.3,
63.9,
58.3,
52.9,
71.1,
83.5,
51.7,
61.5,
80,
0,
67.6,
80.8,
56,
55.1,
15.5,
44,
2.4,
77.9,
100.5,
49.2,
67.3,
14.7,
52.7,
71.5,
35.4,
4.1,
87,
83.1,
81.1,
49.4,
79.7,
35.2,
41.9,
50.7,
23.8,
57.3,
46.9,
22.8,
33.6,
93.6,
33.5,
85.7,
72.5,
96.4,
64,
87.2,
63.8,
8.7,
65.9,
94.6,
35.3,
10.9,
42.7,
96,
88.7,
76.6,
57.1,
35.3,
46.4,
79,
115.3,
63.5,
82.4,
79.8,
53.2,
15.1,
19.6,
60,
29.7,
87.5,
53.3,
96.7,
77.5,
29.7,
32.2,
46.6,
47.5,
30.6,
25.1,
46.4,
26.8,
90.2,
69.7,
72,
63.9,
93.3,
16.8,
29.8,
45.9,
39.7,
78.7,
81.9,
44.7,
85.8,
34,
48.1,
58,
56.8,
44.2,
52.6,
59.9,
28.1,
57.2,
55.3,
37.7,
59.1,
79.7,
0,
85.7,
79.9,
59.9,
60,
60.1,
15.5,
60,
48.7,
70.5,
69.5,
56.9,
40.7,
55,
87.8,
20.2,
12.6,
59.2,
19.3,
87.6,
83.5,
62.9,
89.1,
68,
48.7,
78.5,
30.4,
86.1,
61,
31.8,
59,
46.1,
43.1,
45,
50.8,
78.2,
81.1,
48.8,
64.5,
52.1,
73,
73.4,
64.6,
74.7,
48.6,
78.3,
35.3,
53.4,
84.7,
71.6,
86.1,
25.8,
66.2,
45.7,
89.9,
59.5,
78.5,
49.3,
82.2,
73.8,
55.2,
25.5,
69.9,
67,
73.5,
101.3,
92.8,
78.6,
77.9,
8,
74.6,
65.6,
40.2,
93.1,
39.9,
99,
60.3,
70.4,
26.4,
46.8,
21.8,
75.5,
91.4,
39,
11.6,
91.5,
87.3,
9.9,
78.9,
54.6,
18.1,
21.5,
62,
57.3,
79.4,
50.8,
58,
62.6,
34.9,
43,
0.8,
77.9,
64.6,
99.5,
49.9,
75,
68.8,
15.5,
52.5,
90.4,
24.7,
63,
69.5,
66.6,
39.1,
88.2,
65,
67.1,
27,
76.6,
86,
73.3,
31.1,
77.2,
87,
72.4,
24.5,
84.5,
48.1,
72.5,
52.3,
18.9,
78.4,
78.9,
47.5,
77.2,
0,
87.9,
77.6,
61.3,
18.1,
25,
67.2,
52.6,
66.5,
21.5,
47.4,
87.5,
25,
89.4,
72.4,
69.5,
84.9,
39.6,
65,
43.3,
69.2,
52.6,
40.2,
66.6,
60.2,
87.1,
80.1,
68.2,
2.2,
23.1,
86.7,
82.4,
22.3,
81.2,
72.3,
57.7,
46.9,
90.4,
96.7,
94.3,
0,
96.7,
78.2,
17.6,
79,
55.2,
90.2,
74.8,
57.7,
55,
70.6,
76,
25,
33.5,
78.1,
45.3,
86.2,
36.1,
56.2,
70,
56.5,
55.4,
40.5,
91.8,
66,
63,
99.3,
44.2,
18.4,
38.6,
47.4,
56.3,
57.6,
91.7,
40.4,
45.6,
58,
57.4,
76,
85.8,
74.8,
87.3,
52.7,
74.2,
71,
68.2,
54.5,
74.5,
81.7,
74.9,
50.5,
80.5,
35.5,
57.7,
52,
62,
58,
42.7,
93.5,
87.1,
37.2,
52.3,
38.9,
25.2,
69.9,
42.8,
38.1,
26.6,
68.8,
50.7,
72.1,
34.8,
82.6,
42.8,
53.4,
82.3,
60.2,
39.9,
52.7,
64.8,
77.4,
61.9,
80.9,
34,
48,
29,
28.3,
54.7,
82.7,
28,
25.5,
67.9,
63.4,
48.2,
82.1,
83.5,
48.7,
56,
59.3,
65.7,
56.1,
32.8,
59.7,
45.9,
48.4,
75.4,
92.3,
33,
75.4,
33.2,
60.3,
8.7,
40.9,
50.4,
72.2,
20.3,
42.3,
88,
49.5,
92.9,
88.7,
56.6,
83.1,
98,
50.1,
1.3,
36,
85.5,
12,
39,
62,
4,
58.9,
52.4,
67.5,
41.7,
55.3,
97.6,
50.4,
75.8,
74,
16,
89.7,
58,
32.3,
58.5,
34.1,
47.5,
69.7,
60.3,
39.4,
68.3,
67.9,
52.7,
53,
23.7,
57,
61.7,
53.8,
16.6,
52,
39,
27.4,
91.8,
95.3,
20.3,
80,
53.9,
41.2,
38.4,
62.5,
72.3,
53.1,
50.7,
48.8,
59.9,
83.3,
33.8,
53.2,
77.8,
49.9,
49.3,
68.6,
13.2,
72.2,
60.9,
49.2,
16.1,
82.8,
58.5,
79.6,
32.3,
51.2,
88.6,
69.6,
59.7,
81.6,
47.1,
66.3,
67.2,
22,
80.7,
66.7,
55.6,
94.6,
18.5,
47.6,
58.7,
46.5,
84.2,
69.2,
13.9,
11.6,
14.5,
80.3,
53.9,
39.4,
52,
58,
71.1,
13,
40.7,
51.3,
43.1,
81,
27.1,
50,
86.3,
37,
36.2,
79.4,
35.4,
71.4,
98,
31.9,
33.9,
68.3,
36.8,
80.1,
32.7,
71.8,
18.7,
94.9,
18.3,
36.4,
59,
96.3,
11.2,
52.1,
63.2,
63.7,
97.4,
23.2,
45.5,
30.5,
2.3,
12,
83.9,
43.4,
72.6,
72.3,
59.4,
66.3,
80.2,
62.6,
49.7,
62.1,
28.3,
56.6,
80,
55,
56,
45.7,
86.4,
54,
50.8,
73.4,
14.3,
45.8,
97.5,
36.2,
0,
68.8,
8.8,
49.3,
49.8,
86.8,
41.5,
48,
75.8,
49.8,
93.9,
63.5,
92.8,
55.4,
57.2,
35,
42.6,
50.2,
62.5,
32.5,
62.2,
50.4,
52.2,
84.5,
71.7,
74.8,
26.1,
40,
61.5,
76.2,
39.3,
46.4,
86.9,
57.7,
45.1,
80.1,
64.1,
76.5,
54.8,
48.3,
52.6,
79.4,
12.2,
96.7,
87,
73.3,
10.1,
66.3,
71,
70,
77.5,
53.1,
78.7,
36.1,
42.2,
55,
56.3,
80.5,
64.8,
81.3,
61.9,
47.2,
73.6,
69.5,
23.8,
61,
53.6,
95.8,
75.2,
36.2,
79.1,
68,
96.3,
100.1,
9.7,
46.8,
76.2,
72.8,
30,
87,
77.7,
52,
72.2,
51.7,
38.4,
63.4,
55.3,
50.9,
82.9,
82,
72.4,
11.9,
41.2,
19.6,
83.9,
37.4,
76.8,
40.4,
6.5,
80.3,
49.8,
46.4,
78.7,
50,
20.4,
46,
33.7,
15.7,
71.4,
26.8,
27.1,
86.2,
64.4,
47.9,
71.2,
40.2,
83.9,
65.8,
84.6,
38.6,
60.3,
34.3,
36.3,
77.6,
69.6,
1.1,
7.7,
41.3,
66.2,
6.5,
28.8,
54.8,
84.4,
59.7,
79.3,
73,
78,
45.7,
52.3,
59.6,
70.9,
38.5,
64.2,
61.8,
40.9,
55.3,
25.4,
44.7,
41.8,
0.1,
72.2,
42.8,
64.4,
59.6,
60.1,
27.7,
83.6,
53.5,
86,
58.2,
24.8,
41.9,
26.1,
64.6,
35.2,
56.2,
35.7,
78.9,
67.9,
82.8,
45.6,
46,
29.8,
23.8,
26.9,
19.5,
56,
30.5,
76.1,
47.8,
69.6,
83.7,
45.6,
6.2,
67.3,
36.1,
56.7,
53.8,
89.6,
88.4,
35,
7.1,
72.2,
72.6,
44.9,
23.2,
96.9,
50.9,
66.5,
46.7,
62.2,
84.2,
57.5,
93.5,
69.1,
36.3,
35.7,
72.1,
80.2,
67,
49.7,
30.2,
40.3,
94.9,
29.6,
33.1,
82.2,
95.4,
36.4,
55.5,
65.2,
37.8,
47.3,
67.6,
10.4,
64.6,
66.6,
35.4,
51.3,
67.4,
42.2,
77.1,
54.3,
73,
54.6,
49.2,
62.2,
101.5,
89.9,
22.1,
21.4,
36.7,
90.1,
26.3,
22.4,
54,
36.2,
57.7,
55,
28.4,
62.9,
4.5,
50.8,
60.5,
65,
66.8,
94.6,
71.8,
9.7,
85,
86,
63.8,
31.3,
18.9,
85.8,
63.5,
28.2,
20.7,
24.3,
98.4,
23.7,
59.9,
62.7,
51.6,
66.5,
67.8,
62.5,
79.1,
38.6,
14.5,
81.7,
51.4,
60.1,
15.5,
74,
78.4,
64.5,
29,
37.9,
70.4,
24.3,
34.1,
67.5,
87.6,
15.8,
74,
67.7,
48.2,
78.2,
59.6,
50.2,
44.9,
49,
42,
44.3,
48,
68.7,
79.2,
68.3,
46.5,
66.6,
92.9,
65,
66.6,
26.5,
59.9,
93.8,
67.8,
63.2,
36,
63.8,
31.1,
43.7,
36.5,
56,
29.9,
16.3,
87.1,
53.8,
52.8,
61.9,
92.4,
67,
48.1,
61.2,
93,
90.5,
79.9,
11.1,
67.4,
100.1,
20.4,
15.7,
56.2,
8,
68.8,
85.3,
96.4,
73.3,
47.6,
10.7,
57.6,
18.7,
68.1,
79.4,
34.5,
78.4,
53.3,
25.3,
98.5,
25.3,
46.7,
45.3,
83.9,
60.3,
10.8,
70.4,
69.6,
49.4,
66.9,
58.2,
57.6,
92.8,
47.8,
58.8,
29.5,
53.5,
53.7,
81,
53.4,
76.4,
4.3,
80.1,
25.4,
67.5,
95,
98.6,
71.2,
78.3,
69.9,
67.3,
39.6,
53.2,
21.8,
55.3,
44.1,
42.4,
71.6,
52,
15.5,
78.6,
94.3,
49.6,
86,
70,
58.1,
24.6,
33,
33.5,
59.3,
52,
81.6,
62.5,
97.6,
80.4,
8,
81.7,
33.3,
64.1,
79.3,
83.4,
92.1,
5.7,
74.2,
98,
5,
3.8,
35,
92,
81.8,
74.9,
35,
59,
64.4,
68.4,
59.1,
44.3,
61.9,
72.9,
12.4,
69.9,
68.6,
61.4,
77.3,
77.7,
41.2,
56.2,
35.7,
20.9,
47.9,
63.8,
37.3,
39.4,
97.9,
43.3,
16.5,
7.6,
50.7,
59.1,
62,
69.3,
27.5,
81.7,
81.5,
44.8,
63.4,
100.7,
55.9,
92.8,
85.7,
38.5,
63.6,
56.5,
51.4,
34.7,
73.8,
7.5,
85.9,
41.1,
93.4,
67.1,
58.2,
65.9,
89.8,
73.5,
20.5,
98.1,
38.6,
24.6,
21.8,
57.2,
45.8,
92.6,
81.4,
79,
56,
91.8,
69.2,
83.9,
0.6,
90.7,
28.4,
18.1,
49.7,
51.4,
75.8,
35.5,
92.8,
47.7,
88,
70.2,
56.9,
31,
52.7,
0,
92.5,
71,
63.4,
82.3,
92.9,
59.7,
52.4,
42.1,
24.6,
22,
38.5,
82,
75,
60.3,
78,
59.8,
42.6,
41.9,
29.3,
70.7,
57.8,
46.8,
66.1,
67.9,
82,
92,
49.8,
36.9,
48.4,
93.4,
32.4,
87.2,
70.2,
89.2,
69.3,
16.3,
45.8,
77.7,
96,
56,
54.2,
65.2,
87,
42.4,
22.5,
21.4,
7.3,
55.2,
82.8,
78.2,
68.4,
94.3,
66.2,
59.5,
59.8,
93.9,
30.9,
44.3,
68.9,
44.5,
44.7,
98.9,
92.4,
32.6,
53.1,
21.4,
50.5,
29.7,
55.7,
26.4,
14.6,
70.6,
75.1,
67.4,
12.8,
52.4,
29.1,
56.4,
30,
23,
60.2,
79.1,
42.1,
34,
73,
20.5,
95.7,
33.2,
13,
93.9,
47.9,
2.3,
84.9,
86.5,
41.2,
41.3,
63,
53.9,
46.4,
23.2,
44.3,
77,
87.1,
49.3,
76.5,
10.3,
78.5,
55.2,
60.4,
81.6,
58.7,
36.7,
29.5,
56.4,
77.3,
43.4,
32.2,
39.6,
78.6,
79.9,
63.9,
64,
67.7,
47,
71.9,
76.2,
41.8,
4.4,
0.8,
37.4,
73.3,
79.8,
38.3,
58.6,
26,
76,
22.7,
64.3,
43.2,
37.7,
62.6,
73.1,
82.6,
52.4,
45,
43.1,
23.9,
38.6,
27.5,
54.4,
80,
88.2,
31.3,
90,
68.8,
65,
12.7,
77.6,
62.3,
83.1,
39.3,
40,
40.7,
38.1,
25.5,
39.4,
51.7,
46.8,
65.6,
80,
88.2,
38.8,
45.7,
69.4,
40,
93,
62.8,
39.4,
79.9,
71,
71,
56.8,
28.9,
68.2,
45.5,
8.4,
62,
95.9,
44,
53.6,
87,
69.9,
61.5,
57,
41.2,
53.4,
100.3,
96.7,
25.7,
68.9,
73.3,
91.5,
25.7,
64.2,
53.2,
62.8,
27.1,
39.8,
63.3,
42.6,
25.6,
20.3,
66.1,
55.1,
67.8,
63,
17.3,
64.8,
78.4,
94.3,
11.2,
91,
9,
74.6,
48.5,
50.8,
33.5,
2.2,
62,
66.8,
54.2,
54.7,
70.9,
62.4,
71,
83.2,
43.7,
47.5,
50.1,
55.8,
77.6,
52.8,
28.8,
83,
67.1,
87.6,
69.6,
46,
47.9,
91.9,
57.4,
35.7,
69.5,
33.3,
61.9,
5.7,
57.9,
39.4,
83.5,
80.8,
50.2,
71.3,
86.4,
73.7,
82,
97.3,
76.5,
41.4,
76.9,
93.8,
52.1,
47.2,
81.5,
71.9,
65.8,
26.3,
47.2,
60.6,
13.9,
51.3,
47.8,
72.3,
91.3,
59.4,
23.2,
77.6,
59.3,
31.7,
75.6,
95.3,
74.8,
35.3,
72.6,
39.8,
74.3,
69.6,
64.9,
48.7,
10.7,
59.7,
37.5,
84.5,
72.4,
90.8,
64.7,
78.4,
71,
6.5,
61.5,
25.9,
32.1,
77,
56.2,
23.7,
53.3,
27.3,
74.8,
43.1,
24.7,
29.2,
53.8,
42.4,
67.2,
77.9,
87.6,
86.7,
94.7,
25.6,
50.9,
43.9,
59.1,
94.3,
47.8,
76.7,
39,
42.5,
51.6,
58.9,
65.6,
93.5,
81.8,
69.7,
60.6,
62.9,
59,
28.8,
85.8,
86.4,
57.2,
44.4,
45.9,
32.5,
67.9,
87.8,
48.6,
82.5,
77.7,
59.2,
27.9,
7.9,
36.7,
76,
94.8,
22.5,
46.6,
60.3,
36.6,
31.9,
51,
99.3,
59.5,
71.1,
33.2,
27.9,
38.4,
38.5,
80.7,
70.1,
72.5,
69,
46.9,
48.6,
52.7,
78.6,
55.8,
77.4,
51.9,
15,
49.8,
37,
33.8,
37.3,
46.4,
63.6,
8.7,
62.2,
30.4,
35.5,
96.9,
53,
53.6,
74.4,
11.5,
97.8,
24.3,
57.3,
72.2,
46.6,
43.6,
85.2,
30.4,
62.4,
63,
55,
79.7,
14.4,
100.3,
61.5,
42.4,
59.2,
42.5,
29.8,
69.9,
37.1,
54,
54.3,
47.2,
80.4,
15.1,
39.1,
39.3,
6.2,
31.3,
91.1,
28.4,
56.5,
46.5,
66.5,
36.6,
67.6,
7.9,
52.2,
34.1,
15.9,
35.8,
58.4,
41,
33.7,
59.6,
68.5,
72.9,
53.5,
56.4,
73.6,
21.7,
55.5,
15.1,
42.8,
83.2,
62.7,
97.4,
39.1,
31.1,
44,
78.8,
55.3,
83.7,
13.3,
44.9,
67.7,
57.8,
63.6,
86.3,
91.6,
55.9,
42.9,
45.9,
49.1,
57.9,
68,
9.8,
18.9,
54.2,
9.1,
33.4,
96,
74.7,
51,
26.7,
61.6,
62.8,
27.6,
80.6,
26.3,
23.9,
68.6,
52,
32.6,
32.7,
96.7,
90.7,
20.7,
62.6,
59.4,
43.9,
66.5,
44.7,
10.3,
94.3,
41.6,
49.7,
97.8,
29.3,
42.1,
31,
14.2,
20.5,
44.8,
32.8,
89.1,
64.2,
34.3,
90,
54,
53.4,
39,
51.7,
26.5,
27.7,
86.1,
75.6,
54.7,
70.5,
77.4,
20.5,
80.8,
53,
88.5,
29.9,
53.5,
46.5,
33.2,
50.7,
75.4,
81.4,
52.3,
29.3,
22.6,
12.3,
45.3,
55.8,
67.9,
50.5,
68,
29.2,
84.1,
39.6,
82.4,
35.5,
12.2,
40.9,
69.9,
41.4,
47.2,
73.1,
50.6,
66.7,
29.8,
78.4,
93.8,
88.6,
11.7,
19,
42,
67,
29.7,
72.7,
59.6,
28.4,
61.1,
66.9,
44.7,
48.6,
53.1,
49.1,
35.6,
48.6,
97.7,
51.9,
39.7,
39.9,
31.3,
40.5,
50.9,
70.1,
50.8,
33.4,
75.7,
85.3,
63.2,
59.5,
44,
70.8,
13.1,
67.3,
39.6,
80,
60.4,
90,
22.7,
85.8,
71.7,
15.4,
25.8,
22,
39.6,
40.8,
39.3,
76.6,
76.3,
88.7,
84.7,
89.6,
35.6,
62.5,
22.9,
60,
48,
38,
80,
53.3,
61.2,
75.8,
65.3,
45.8,
52.5,
44.4,
66,
8,
36.3,
25.5,
64.1,
59.3,
61.6,
75.5,
62.2,
5.7,
92.5,
30,
17.5,
33.1,
45.3,
58.3,
74.8,
79,
80.5,
5.6,
60.5,
75,
74.3,
36.2,
66.7,
25.3,
58,
37.2,
56,
43.9,
17.6,
48.8,
39,
29,
45.7,
41.7,
69.7,
68.7,
31.3,
28.2,
66,
78.7,
57.1,
48.2,
30,
48.9,
39.9,
72.3,
60.1,
72.1,
21.3,
71.7,
23.8,
41.4,
62.5,
57,
58.3,
80.4,
67,
92,
7.4,
69.2,
65.3,
74,
51,
80.7,
96.3,
96.3,
61,
27.2,
73.9,
44.9,
83.9,
32.4,
61.5,
48.1,
62.6,
96.1,
66.3,
23.1,
56.9,
34.2,
92.9,
21.2,
79.8,
16.7,
19.8,
19.2,
26.7,
78,
52,
40.1,
65.9,
35.6,
62.5,
48.3,
60.7,
34.4,
55.1,
35.9,
10.1,
26.9,
19.6,
26.1,
70.1,
65.3,
67.7,
54.3,
65.7,
39.7,
38,
92.5,
98.8,
54.7,
34.4,
46.3,
25.6,
81.8,
75.3,
15.8,
67.3,
54.4,
34.9,
81.8,
97.1,
34.5,
94,
68.8,
70.6,
23.4,
16.7,
59.5,
32.8,
62.2,
81.4,
49.7,
70.2,
15.7,
28.9,
46.5,
51.3,
48.1,
81.4,
41.4,
28.2,
81.6,
51.1,
23.1,
91.3,
38.5,
71.1,
86.6,
71.1,
55.3,
56.6,
73.9,
30.1,
2.4,
33.8,
46.4,
81.1,
35.4,
70.7,
60.7,
22.1,
61.2,
92.2,
94.9,
63,
18.6,
29.8,
7.7,
76.5,
97,
68,
68,
29.7,
9.9,
33.8,
36.1,
95.4,
56,
75.5,
57.5,
48.8,
71.7,
96.7,
71.6,
82.9,
37.7,
47.9,
68.1,
19.5,
80.1,
35.6,
62.2,
17,
86.8,
74.7,
25.2,
62.6,
84.9,
64.7,
41.7,
82.8,
25.2,
68,
27,
69.1,
53.2,
24.9,
53.6,
46.6,
89.3,
81.4,
77.7,
76.7,
96.9,
51.9,
68.9,
55.8,
74.1,
73.1,
81.8,
55.3,
70.4,
18.8,
67.7,
81.9,
70,
34.5,
72.6,
58.8,
54.2,
53.6,
89.9,
38.2,
60.3,
88.5,
62.9,
29.4,
34.6,
40.9,
17.8,
46.3,
81.1,
70.1,
33.8,
85.4,
40.8,
63.1,
92.5,
37.7,
61.2,
63.2,
64.1,
47.4,
26.5,
90.4,
47,
47.2,
63.6,
36,
99.3,
87.9,
71.1,
90.2,
36.8,
12.1,
58.5,
30.5,
56.1,
24.9,
57.2,
45.7,
64.7,
65.6,
77.8,
24,
53.2,
4.7,
76.7,
63.4,
53.3,
63,
53.3,
81.3,
70.9,
95.2,
47.8,
14.8,
59.9,
90.8,
94.6,
10.8,
75.5,
42.1,
19.2,
48.4,
48.5,
51.9,
48.6,
66.1,
49.3,
6.1,
27.5,
77.7,
37.9,
90.6,
71,
56.7,
38.7,
51.6,
45,
49.3,
56.4,
60.8,
64,
86.2,
83.6,
36,
56.8,
79.7,
88,
32.2,
29.5,
58.3,
71.8,
63.2,
64.7,
13.1,
38.8,
101.9,
70.2,
16.8,
37.6,
78.1,
37.9,
20.1,
26.4,
91.2,
16.8,
53.8,
32.2,
40,
42.9,
71.7,
23.4,
0,
0.3,
75.2,
72.7,
53.7,
75.4,
66.6,
64,
50.3,
61.6,
43,
52.4,
40.8,
34.4,
62.2,
54.8,
46.2,
48.4,
64.3,
13.4,
41.8,
86.6,
44.6,
50.3,
84.1,
68.5,
60.2,
44,
46.5,
99.7,
12.4,
68.9,
41.8,
97.5,
78,
75.3,
60.4,
81,
36.2,
64,
59.1,
42.6,
33,
69.2,
97.8,
55.7,
45.2,
72.2,
71.9,
99,
7.8,
76.4,
87,
77,
44,
65.1,
35.9,
69.7,
20.9,
42.9,
28.1,
70.7,
69.1,
46.6,
42.4,
65.8,
23.9,
42.9,
75.2,
81.4,
66.7,
73.2,
83.5,
44,
83.4,
89,
60.4,
64.9,
58.2,
10.3,
60,
52.7,
35.3,
52.1,
94.6,
86.4,
61.1,
76.1,
65.6,
35.1,
30.3,
46.3,
29,
27.4,
40.9,
70.8,
50.8,
74.6,
31.8,
44,
73.9,
77.7,
34.3,
65.7,
62.3,
31,
30.7,
54.4,
83.8,
70.2,
73.3,
77.5,
55.9,
69.3,
61.3,
70,
82,
20.8,
72.5,
93.9,
37.8,
46.3,
75.5,
44.5,
73.6,
39.4,
36.8,
40.5,
47.5,
54.5,
22,
61.9,
49,
54.3,
28.2,
42.6,
36,
64.4,
53.8,
51.4,
64.2,
61.4,
61.1,
35.3,
79.6,
45.6,
0,
53.3,
58.3,
88.3,
52.9,
57.2,
48.2,
96.2,
12.6,
44,
81.6,
46,
50.3,
39.2,
15.7,
26.6,
72.7,
75,
35,
99.6,
84.4,
33.4,
99.7,
53.9,
36.8,
66.2,
82.2,
75.4,
51.6,
75.2,
60.4,
60.3,
95.3,
7,
94.3,
38.4,
42,
46.8,
63.2,
37,
80.1,
85.8,
49.2,
62.4,
0.2,
52,
29,
35.9,
81.2,
99,
28.4,
55.5,
31.9,
49,
21.7,
72.3,
31.2,
86.5,
64.4,
83.6,
29,
39.7,
30,
94.5,
54.6,
73.6,
53.5,
null,
79.3,
79.7,
73.2,
90.7,
24,
76,
87.8,
51.2,
24.5,
32.3,
80.4,
41.7,
76.5,
20,
37,
37.8,
58,
87.5,
11.8,
24.1,
88,
30.1,
30.7,
78.6,
80.4,
40.1,
68.5,
60.3,
75.1,
54.3,
85.3,
79.1,
33.3,
63.8,
76,
38.4,
79,
31.8,
31.5,
0.1,
73.2,
65.5,
68.6,
95.6,
44.1,
53.7,
60.5,
50.2,
56.7,
81.7,
59.3,
32.2,
40,
71.6,
37.1,
68.6,
44.3,
41.3,
24.6,
11,
20.9,
45.7,
54.3,
60.6,
40.6,
49.3,
17.1,
59.3,
37.8,
75.1,
80.7,
41.4,
32.1,
55.3,
10.6,
64.8,
63,
68.2,
46.2,
94.3,
49.7,
84.9,
20,
32.7,
85.8,
48.9,
52.9,
45.5,
73.7,
85.7,
63,
28,
97.3,
95.2,
52.4,
56.9,
77.3,
80.2,
40.6,
71.9,
15.4,
60,
32.3,
33.9,
77.5,
43.9,
56.5,
36,
19.3,
6.9,
70,
37.1,
20.7,
49.5,
43,
50.5,
78.6,
6.7,
47.8,
31.3,
60.3,
29.4,
83.5,
54.7,
57.5,
89.4,
16.1,
37.5,
80.9,
84.3,
64.9,
24.5,
91,
29.7,
17.3,
50.9,
43.8,
86.7,
59.5,
75.4,
33.3,
26.3,
49.1,
74.8,
63.1,
10.8,
65.4,
73,
21.1,
4.9,
70.3,
24,
0.1,
57.2,
38.2,
16.7,
30.1,
83,
14.5,
34,
65.2,
19.5,
30.7,
35,
51,
49.8,
77.4,
44.4,
43.4,
43,
7.9,
40,
65.7,
47.8,
52.5,
64.9,
26.8,
47.7,
89.7,
68,
4.9,
43.4,
64.9,
63.2,
70,
59.9,
13.2,
64,
10.2,
83.3,
43.6,
14.3,
64.3,
62.3,
45.9,
63.2,
54,
95.5,
88.5,
75.8,
50,
10.9,
44.4,
44.4,
35.8,
11.5,
73,
14.7,
86.6,
35.7,
28.6,
99.4,
38.5,
41.2,
42.3,
75.3,
28.5,
58,
54.8,
60.6,
54.8,
7,
72,
44.6,
49.1,
50.6,
50.3,
54.2,
29.6,
9.4,
56.3,
35.5,
10,
93.8,
18,
15.1,
85.3,
74.6,
51.1,
87.5,
70.1,
80.9,
74.3,
43.7,
78.9,
15.6,
53.6,
48.5,
68.6,
47.3,
26.9,
98.2,
51.2,
54.6,
79.7,
69.3,
48.8,
50.3,
24.9,
24.8,
96,
35.4,
66.3,
49.3,
35,
46.8,
40,
16.8,
33.8,
69.4,
55.2,
81.8,
38.4,
55.2,
61.6,
48.7,
38.6,
80.9,
21,
56.5,
53.8,
44.4,
54.6,
40.3,
76.8,
48.9,
53.1,
81.8,
44.2,
91.7,
39.8,
19.4,
91.4,
65,
51,
63.4,
47.8,
35.8,
60.6,
70.8,
64.9,
58.3,
60.7,
6.8,
51.1,
61.8,
77.8,
60.8,
65.5,
68.7,
72.5,
41.8,
74.2,
50.7,
88.7,
74.1,
51.5,
95.6,
55.7,
40.1,
55.4,
35.5,
24.2,
39.2,
45.6,
59.1,
60.5,
45,
94.6,
11.1,
37.3,
26,
90.5,
97.3,
39.7,
86.5,
25.4,
53.9,
63,
74.9,
61,
84,
58.1,
54.8,
81.4,
43.6,
76.2,
69.5,
23,
65,
67.8,
27.5,
51,
42.1,
56.2,
49,
92.4,
3,
42,
71,
18.9,
58.9,
89,
66,
41.3,
93.1,
13.2,
64.1,
61.6,
89.2,
102,
79.8,
38.5,
79.5,
70.3,
76.4,
8.8,
35.5,
80.6,
13.2,
36.9,
57.9,
61.3,
15.4,
23.3,
73.4,
15.3,
70.9,
37.9,
16.1,
47.1,
30,
88.6,
76.5,
31,
72.9,
37.4,
64,
94.8,
32.8,
39.4,
56.2,
40.4,
1.2,
87.8,
69.9,
56.4,
44.2,
59.4,
69.6,
32.1,
70.7,
18.5,
98.6,
50.7,
42.5,
33,
59.5,
76.7,
60.5,
62.3,
67,
98.1,
87.1,
51.3,
68.5,
85.6,
70.1,
74.4,
90.9,
27.3,
43.5,
57.2,
26.5,
37.5,
55.3,
99.4,
58,
50.5,
21.2,
1.1,
42.3,
91.4,
67.7,
62.6,
80.2,
48.4,
57.9,
60.1,
98.4,
67.4,
35.7,
72.6,
57.4,
83.9,
24.9,
94.8,
27.8,
60.9,
66.8,
86.5,
0.2,
51,
62.8,
40.8,
58.1,
11.4,
41.3,
46.9,
69.8,
19.1,
77.3,
78.3,
18.1,
50.9,
79.7,
23.7,
38.3,
37.3,
67.5,
20.9,
98.1,
81.2,
18.2,
95.5,
48.7,
62,
89.7,
77.1,
73.4,
43.9,
60.3,
41.2,
78.2,
30.8,
88.9,
57.1,
92.6,
49.5,
99.7,
42.8,
32.4,
36.8,
34.5,
16.2,
68.9,
18.9,
51.3,
62.9,
80.6,
87.3,
83.9,
63.3,
86.2,
62.3,
94.6,
62,
40.7,
56.6,
68.1,
34.4,
62.2,
60.7,
82.9,
72.4,
50,
74.7,
16,
4.2,
24.6,
43.5,
18.5,
44.2,
54,
41.1,
48.4,
19,
31.5,
77.1,
44.9,
61,
42.7,
27.9,
66.2,
63.3,
26.9,
78.1,
84,
21.6,
48.6,
33.6,
21.7,
64.4,
18.4,
43.9,
41.5,
54.3,
81.5,
50.4,
40.8,
79.2,
77,
56.1,
33.2,
62.6,
28.4,
26.7,
92.4,
53.8,
93.1,
31.4,
86.9,
34.4,
56.8,
61.6,
84.6,
67.4,
74.7,
34.3,
43.8,
33.5,
74.8,
68.4,
59.2,
68.8,
80.1,
80.8,
28.6,
63.9,
26.8,
49.7,
23.2,
43,
65.5,
66.4,
75.6,
17.9,
42.2,
55.5,
85.5,
85.9,
78,
94.1,
93.3,
23.8,
36,
38.8,
52.4,
68.6,
86.8,
36.4,
38.9,
36.7,
23.9,
93.8,
76.2,
55.5,
69.6,
55.1,
24.6,
38.6,
73.7,
29.8,
50.8,
78.8,
75.9,
67.3,
24,
62.8,
21.1,
54.3,
53.3,
52.4,
27.3,
85.7,
42.9,
43.9,
0.9,
46.2,
89.6,
74.3,
53,
78.2,
9.4,
46.4,
24.7,
24.7,
39.9,
1.2,
97.5,
76,
25.3,
85.8,
79.2,
71.1,
19.3,
80.6,
85.1,
71.8,
49.1,
92.6,
0,
34.2,
72.1,
48.7,
16.3,
86.9,
71.3,
41.6,
95.3,
62.1,
78.3,
75.9,
71.6,
66.4,
49.3,
71.1,
52.4,
33.7,
0.4,
69.5,
47.2,
54.2,
63.4,
12,
33.3,
46.8,
84.5,
37.4,
82.8,
32.4,
81.7,
46.3,
63.9,
47.8,
40.5,
60.9,
62.9,
74.4,
26.2,
27,
33.1,
85.8,
94.2,
8,
71.4,
47,
45.8,
22.5,
52.2,
63.2,
77.5,
79,
67.5,
15,
80.2,
38.2,
34,
53,
50.9,
39.1,
11.6,
74.4,
92.2,
88.3,
64.8,
54.7,
90.6,
41,
42.2,
39.5,
54.6,
30.2,
38.4,
86.3,
29.6,
34.3,
47.5,
55.8,
71.8,
56.9,
79.3,
53.5,
62.4,
54.5,
46.4,
23.1,
59.6,
51.6,
58.8,
19.1,
30.7,
4.6,
15.5,
73,
21.3,
71.2,
62.5,
49.8,
32,
57.4,
61.2,
74.6,
66.1,
34.9,
25.8,
61.8,
48.6,
33.9,
66.2,
72,
47.9,
100.5,
71.5,
70.6,
77.8,
81.3,
103.9,
57.3,
16.4,
82.9,
38,
81.3,
40.4,
16.3,
55.5,
22.1,
80,
55.1,
52.2,
49.1,
69.9,
64.8,
53.8,
65.5,
48.5,
9.9,
47,
35.4,
50.6,
22.3,
41,
29.6,
73.5,
85.2,
46.8,
88.7,
27.8,
64.3,
54.7,
50.7,
97.2,
29.5,
40.5,
47.3,
60.6,
41.1,
0.1,
63,
0,
35.3,
65.2,
98.1,
49.8,
86.1,
67.3,
73.1,
41.5,
45.1,
27.6,
16.8,
30.7,
57.7,
28.3,
40.8,
15.3,
98.5,
27.3,
45.2,
70.4,
73.8,
35,
27.5,
35.9,
62.8,
69.3,
27.1,
55.6,
97.6,
17.1,
74.8,
47.5,
42.9,
62.9,
94.3,
74.6,
81.5,
28.4,
81.4,
40.5,
78.3,
43.3,
60.9,
73.8,
39.9,
56.2,
57.6,
32.4,
14.6,
49.4,
70.1,
73.8,
18.6,
49.8,
12.3,
30.8,
96.6,
87.9,
50.2,
77,
40.4,
56.7,
72.5,
10.1,
56.6,
35.6,
40.8,
34.1,
81.3,
16.7,
78.8,
33.7,
9.3,
21,
16.5,
56,
43.8,
94.5,
57,
84.6,
81.4,
50.6,
32,
32.1,
33.2,
95.2,
14.9,
75.8,
93.3,
58.3,
52.4,
49.2,
44,
71.3,
49.3,
27.1,
58.1,
52.3,
57.6,
76.5,
77.7,
76.4,
33.7,
94.3,
72.5,
9,
87.5,
65.5,
61.8,
64.6,
40.9,
50.8,
30.3,
40,
31,
65.3,
49.4,
93.5,
61.2,
92.1,
28.5,
86.5,
61.2,
83.8,
37.7,
48.6,
25.9,
82,
56.3,
45.2,
49.8,
71.6,
73,
78.9,
69.7,
43.3,
53.8,
66.9,
80.6,
55.4,
2.4,
80.5,
4.1,
73.9,
83.2,
56.8,
23.8,
52,
59.2,
51.1,
54.6,
37.9,
60.7,
32.9,
26.6,
67.6,
71.7,
56,
59.9,
46.2,
41.3,
71.6,
31.2,
43.8,
86.5,
55,
42,
38.5,
69.2,
72.6,
79.4,
66.7,
71,
41.4,
75,
29.6,
84.8,
78.1,
54.9,
28.6,
41.1,
75.7,
12.7,
37.6,
97.1,
71.8,
38.4,
85.9,
58,
55.5,
35.9,
97.2,
59.7,
30.1,
80.7,
62,
98.3,
10.3,
51,
47.6,
81.5,
52,
67.5,
68.9,
78.8,
60.6,
76.6,
45.1,
20.2,
81.9,
49.1,
22.1,
58.7,
66.3,
34.9,
55.2,
90.1,
43.6,
40.4,
80.7,
35.2,
69,
73.2,
84.2,
13.9,
82.8,
54.1,
57.7,
59.7,
60.4,
17.2,
40.2,
47.5,
70.5,
46.4,
22,
64,
34.3,
30.1,
67.7,
43.6,
53.1,
87.7,
22.4,
68.7,
44.2,
70.7,
73.9,
85.5,
21,
61.7,
97.2,
69.2,
42.8,
79,
56.6,
64.4,
60.8,
87.6,
44.1,
95.8,
70.9,
60.7,
15.6,
39.9,
79.4,
65.6,
68.9,
78.6,
63.5,
30.4,
23.9,
63.1,
35.1,
22.1,
41,
88.9,
38.8,
62.8,
67.8,
72,
20.6,
46.6,
65.9,
33.2,
73.7,
45.5,
15.6,
69.7,
0,
15.7,
33.6,
66.6,
49.9,
31.7,
60,
49.8,
40.5,
8.4,
55.6,
79.3,
62.2,
16.3,
38.5,
57,
51.8,
18.5,
6,
90.5,
88.7,
32.7,
98.7,
43.6,
73.1,
83.3,
30,
81.2,
51.9,
30.2,
42.1,
51,
70.7,
36.9,
62.9,
68.7,
75.8,
81.4,
48.5,
105.1,
58.4,
54.4,
76.6,
75.1,
26.1,
26.7,
47.5,
89.8,
54.3,
75.6,
52.1,
92.3,
63.7,
57.5,
84.5,
16.5,
40.3,
47.1,
21.1,
29.7,
56.1,
21.4,
53,
5.9,
53.9,
45.3,
43.5,
43.3,
31.9,
53.8,
82,
97.1,
41.9,
29.8,
76.2,
84.8,
70.5,
35.4,
47,
34.3,
53.1,
71.3,
19.2,
49.2,
81,
70.8,
37.7,
35.9,
35.3,
50.4,
44,
72.1,
44.8,
56.2,
48.5,
47.2,
65.1,
50.1,
82.7,
38.8,
51.5,
76.4,
77.9,
55.8,
52.4,
24.9,
13,
98.3,
36.2,
75.5,
29.5,
84.2,
8.2,
44.6,
0,
78.2,
86.6,
67.9,
47.1,
53,
37,
60.8,
59.8,
32.7,
70.2,
21.8,
93,
76.9,
37.1,
87.1,
41.6,
46.7,
70.4,
36,
17.5,
97.5,
15.6,
81.3,
61.8,
56.5,
37,
60.7,
80,
42.7,
60.5,
64.3,
14.7,
46,
47.1,
70.2,
62.7,
42.4,
22.6,
61.2,
62.2,
78,
92.3,
11,
35.5,
44.7,
39.3,
54.4,
37.3,
74.6,
22.6,
98.2,
78.7,
82.1,
77.8,
28,
65.8,
97.2,
50.3,
68.5,
76,
85,
76.5,
23.5,
87.5,
51.4,
44.8,
57.6,
63.3,
15.2,
54,
39.3,
89.8,
35,
29.4,
106.2,
28.5,
54.4,
75,
20.3,
90.5,
65.2,
15.3,
55.7,
82.1,
21.7,
82.2,
3.4,
77.6,
64,
47,
50.5,
48.5,
47,
27.3,
57.1,
62,
51.2,
11.1,
86.6,
52.9,
51,
99,
63,
24.8,
26.2,
79.8,
42.6,
45.7,
72.6,
27.6,
61.7,
32.4,
48,
35,
87.6,
83.4,
45.2,
31,
41.3,
67.6,
60,
32.4,
82.2,
16.9,
94,
62.4,
78.1,
59.3,
70.7,
72.9,
71.6,
98.4,
65.3,
34.3,
69.5,
50,
58.2,
14.1,
51.1,
87.5,
52.8,
95.7,
37.1,
13.5,
10.8,
25.5,
99.3,
41.6,
11.8,
55.7,
32.6,
2.3,
48,
59.3,
73.6,
50.7,
21.1,
35.7,
48.5,
81.9,
85.9,
82.1,
73,
56.2,
88.8,
56.6,
81.1,
92.8,
41.2,
66.3,
71.7,
59.3,
88.6,
53.9,
33.8,
68.1,
27.5,
37.8,
65.4,
83,
14.7,
59.2,
71.5,
48.8,
9,
79.2,
81.5,
60.4,
93.3,
9.7,
62.9,
62.9,
88.2,
36.8,
61.8,
55.7,
52.3,
88.3,
74.1,
53.1,
18.8,
61.3,
48.4,
32.5,
55.5,
46,
69.8,
72.5,
57.2,
34,
38.7,
74.4,
20.3,
81.5,
33.4,
54.7,
57.2,
80.3,
29.1,
91.5,
62.2,
63.4,
34.4,
10.2,
65,
88.9,
51.3,
67.3,
52.5,
40.4,
26.9,
70,
56.5,
45.9,
19.6,
85.6,
46.7,
91.7,
54.8,
74.1,
49,
61.9,
45.7,
54.6,
45.8,
52.3,
49.7,
63,
67.1,
75.9,
41.3,
36.9,
4.7,
56.1,
10.3,
43.7,
97.2,
74,
41.5,
36.1,
93.5,
50.6,
69,
50,
77.3,
46.2,
70.5,
5,
66.7,
53,
20.4,
72.8,
58.9,
86.3,
92.2,
48,
38.5,
74.8,
87.8,
77.5,
86.3,
53.7,
72.9,
69.3,
36.8,
74,
47.5,
33.5,
45.9,
51.4,
91.4,
70,
69.2,
61.3,
65.1,
44.7,
66.4,
86.3,
6.1,
69,
16.7,
62.8,
70.7,
33.6,
60.7,
54.8,
73.2,
32.1,
58,
65.6,
65,
35.2,
92.4,
66.8,
50.4,
24.7,
27.6,
31.8,
55.2,
86.2,
79.3,
69.9,
83.9,
82.2,
35.5,
64,
82.7,
67.6,
80.5,
null,
36.3,
48,
37.9,
89.3,
66.6,
34,
41.1,
51.1,
45.4,
29.7,
50.1,
93.5,
35.7,
36.8,
42.2,
2.8,
74.2,
92.5,
95.1,
41,
16.3,
47.3,
66.5,
18.5,
68.2,
78.1,
40,
65.1,
27,
52.6,
97.4,
38.6,
66.5,
84.7,
51.9,
56.4,
32,
14.4,
60.9,
73.3,
76.9,
19.9,
60.2,
50.3,
34.5,
52.4,
81.8,
37.1,
47.7,
27.5,
90.7,
11.6,
42.7,
7.4,
64.8,
49.9,
48.1,
47.9,
82.8,
34.9,
65.3,
33.5,
49.1,
53,
49.9,
25.6,
52,
82.4,
47.7,
51.6,
98.6,
75.7,
78.8,
56.3,
16.9,
14.2,
15.4,
64.7,
78.7,
51.9,
21.6,
61.2,
17.7,
55.3,
26,
59.3,
66.7,
52.2,
1.5,
58.5,
87,
64.4,
54.7,
83.3,
73.9,
41.6,
62.9,
64.7,
11.5,
40.2,
59.8,
41.6,
91.7,
43,
50.3,
58.1,
46.3,
75.5,
69.2,
74.6,
44.2,
40.1,
63.1,
50.4,
55.8,
37.4,
72.4,
30.6,
49,
38.6,
25.3,
44.2,
7.6,
58.8,
60.6,
77,
55.8,
26,
58.8,
83.2,
83.7,
74.8,
50,
41.3,
51.8,
39.3,
83.9,
58.8,
66.1,
56.9,
49.2,
78.9,
40.8,
25,
57.6,
74.5,
49.9,
84.4,
72.3,
42.2,
79.6,
67,
49,
64.8,
42.9,
49.6,
47.6,
15.6,
82.7,
54.1,
67.9,
45.2,
29.7,
61.4,
13.3,
94.3,
48.4,
46.9,
9.9,
62.7,
49.2,
61.1,
58.7,
20.5,
47.2,
15.9,
73.8,
19,
61.8,
70,
86.1,
47.5,
0.7,
39.5,
41.2,
66.7,
68.3,
53.6,
10.2,
89.5,
49,
50.7,
22.6,
55,
64.2,
53.5,
67,
74.2,
64.7,
85,
42.4,
97.3,
61.2,
21.2,
46.2,
66.1,
78.2,
16.1,
45.8,
17.3,
49,
51,
94,
53.6,
9.6,
68.7,
64.1,
75.2,
0,
84.1,
60.6,
88.3,
53.2,
66.6,
33,
30.1,
40.9,
59.7,
32.5,
79.1,
53.2,
73.5,
70.8,
29.3,
46.1,
60.1,
96,
68,
24.2,
70.7,
47.9,
76.1,
18,
71.4,
17,
82.7,
27.4,
68,
15.1,
81.3,
84.3,
63.7,
50.6,
87.9,
26,
45.5,
9.6,
14.3,
62.7,
17.8,
7.4,
44.5,
76.9,
42.5,
57.2,
67.6,
67.5,
67.1,
4.1,
81.2,
28,
65.2,
47.5,
55.8,
19.6,
54.7,
9.9,
51.1,
50.7,
37.2,
50.1,
59.7,
70.7,
89.3,
60.1,
49.2,
91.8,
70.5,
53.5,
47.1,
11.5,
60,
76.5,
69.4,
84.2,
89,
64.5,
97,
10.1,
37.7,
53.1,
34,
41.7,
79.4,
40.9,
40,
44.1,
62.1,
35.4,
63.2,
98.5,
38.6,
25.4,
99.1,
32.5,
40.6,
13.3,
73.3,
20,
63.7,
58,
88.3,
67.1,
71.7,
74,
17.7,
56.3,
74.8,
77.8,
84.5,
40.5,
30,
0,
83.9,
45.4,
28.1,
65.1,
85.7,
20.5,
44.5,
66.4,
69.4,
88.5,
59.1,
12.3,
78.8,
50.5,
57.6,
84.7,
48.6,
56,
54.5,
29.9,
31.7,
46.8,
64.3,
42.7,
53.6,
56.5,
78.4,
34.4,
75.5,
39.8,
70.4,
99.7,
39.6,
44.9,
30.8,
8.3,
37.8,
63,
68.5,
33.2,
85.4,
66,
18.2,
61.5,
56.7,
25,
41.1,
42.4,
75,
62.9,
78,
52.2,
71.8,
49.3,
74.8,
87.6,
31.9,
70.5,
93.3,
65.8,
12.2,
64.4,
65.3,
19.8,
48.5,
50.5,
42.9,
93.3,
74.2,
15.4,
42.4,
44.8,
52.9,
40.9,
71.1,
43.1,
71.3,
31.5,
57,
95.1,
76.6,
27.4,
95.4,
16.1,
47.1,
56.6,
32.8,
59.2,
96.3,
37.7,
90.1,
5.3,
80.7,
76.5,
52.1,
14.4,
57.8,
79.6,
69.6,
25.6,
37.7,
14.7,
72.1,
78.5,
34.7,
38.1,
31,
38.3,
57.7,
20.2,
46.5,
24.8,
72.8,
98.1,
60.4,
92.2,
89.9,
64.6,
99,
55.8,
29.3,
47.9,
91.7,
69.7,
88.2,
33.9,
15.1,
75.5,
72.4,
30.5,
40.3,
88,
39.4,
20.9,
51.9,
46.1,
48.2,
62.9,
60.1,
22,
89.4,
78.8,
53.6,
71.4,
25.2,
82.2,
22.1,
30.1,
82.1,
49.5,
71.5,
69.2,
30.1,
47.4,
94.8,
72.1,
37.8,
81.5,
49.7,
73.4,
35.4,
104,
35.5,
35.6,
59.9,
69.2,
65.4,
61.2,
37.6,
49.1,
40.4,
62.7,
86.6,
67.6,
78.5,
72.8,
64.5,
36.7,
39.2,
50.9,
82.9,
88.9,
32,
80,
52.6,
9.4,
92.8,
65.1,
46.9,
54.4,
57.8,
60.4,
25.7,
30.5,
51.9,
34.1,
66.8,
18.9,
46,
36.4,
82.2,
89.3,
10.1,
44.2,
67.5,
42.3,
9.9,
86,
94.2,
62.7,
55,
52.5,
37.9,
54.9,
76.8,
59.4,
63.7,
21.5,
56.6,
32.4,
71.8,
58,
81.8,
66,
56.1,
49.7,
38.9,
73.4,
66.4,
48.7,
11.4,
7.1,
77.2,
52.7,
45.7,
60.1,
71.2,
15.2,
25.9,
44,
89,
65,
60,
12.4,
38.4,
95.3,
80.8,
81.5,
34.2,
29.5,
94,
71.3,
22.1,
17.6,
53.6,
30.1,
41.5,
82.8,
91.1,
13.1,
89.7,
35.1,
35.3,
43.2,
20.5,
70.4,
39.7,
10.3,
54.9,
49.3,
88.7,
43.7,
47.7,
74.9,
61.4,
44.8,
29,
47.1,
31.7,
1.9,
34,
86.4,
82.6,
39.8,
76.3,
20.1,
42.3,
77.6,
14.7,
58.9,
52,
52,
96.9,
62.6,
27,
40.3,
69.6,
63.3,
22.4,
84.2,
41.2,
58.9,
73.3,
75.1,
68.4,
43.5,
57.6,
27.6,
24.2,
31.2,
69.1,
47.9,
40.6,
66.8,
81.8,
60.5,
76.2,
39.4,
17.3,
25.3,
43.8,
65.4,
25.9,
34.9,
81.2,
42.2,
76.9,
77.8,
25.3,
89.9,
62.4,
48.9,
52.7,
48.5,
94.2,
79,
97.9,
61.2,
64.9,
8.4,
34.8,
50,
44.4,
75.4,
81.3,
54,
52.9,
52.6,
73.4,
47.9,
85.8,
72.7,
76.2,
72.9,
38.2,
53.2,
42.9,
47.9,
69.1,
53.9,
20.2,
72.4,
40.6,
27.7,
29.1,
37.2,
48.4,
74.7,
64.5,
30.8,
8.5,
92.2,
74.4,
88,
72.7,
88.5,
87.5,
74.1,
59.6,
39.7,
46.5,
59.3,
95.7,
40.4,
47.5,
64.3,
85.1,
24.1,
61.4,
20.7,
56,
53.6,
35.9,
101,
67.2,
80.5,
73.2,
49.6,
24.8,
71.2,
66.9,
62.6,
89.9,
48.7,
83.5,
92.6,
85.3,
37.2,
73.9,
90.4,
47.4,
81.9,
69.6,
52.1,
45.2,
73.6,
85,
25.2,
80.1,
86.1,
10.5,
60,
53.1,
20.9,
51.6,
70.1,
28.9,
33.7,
42.4,
22.4,
62.9,
50.8,
34.6,
22,
66.9,
97.5,
20,
47.9,
54.5,
57.5,
44.7,
87.6,
77.6,
0,
34.8,
45.2,
66,
70.6,
45.7,
85.2,
58.8,
1.9,
72.1,
37.1,
95.2,
46.7,
36.5,
75,
38.9,
48.9,
60.3,
84,
74,
80.2,
35.8,
63.8,
60.9,
94.5,
73.2,
72.7,
76.5,
79.5,
59.5,
6.2,
35.6,
72.5,
33.8,
54.2,
76.7,
52.7,
45.8,
50.8,
56,
60.4,
35.4,
48.3,
81,
33.3,
90.8,
61.6,
23.6,
40.7,
57.1,
41.4,
43.6,
62.9,
95,
25.8,
45.3,
94.5,
78.2,
92.9,
71.7,
47,
56.6,
79.3,
68.9,
82.5,
21.8,
40.6,
38.3,
27,
16.5,
77.1,
68.6,
9.1,
58.8,
24.9,
38.7,
62,
83.8,
65.2,
59.5,
80,
23.7,
80.9,
49.3,
23.1,
18.4,
44.5,
46.7,
48.6,
82,
88.5,
84.8,
34.1,
62.4,
73.9,
67.9,
75.6,
95.9,
45.9,
57.5,
75.1,
5.3,
50.5,
78.4,
73.6,
65.6,
70.2,
57.6,
57.4,
51.5,
60.7,
66.9,
81.5,
26.5,
57.2,
79.8,
4,
69.6,
18.5,
40.8,
63.3,
66,
56.4,
56.2,
32.4,
100,
16.1,
22.5,
31.3,
39.9,
69.4,
70.2,
62.3,
70.6,
90.7,
77.1,
95.2,
25,
73.1,
53,
60.9,
58,
99.7,
49.5,
83.4,
52.1,
24.4,
64.9,
48.6,
46.4,
71.1,
34.9,
33.3,
13.5,
61,
30.1,
42.3,
97.8,
46.9,
74.3,
29,
60.2,
30.5,
49.8,
40,
22.2,
57.5,
67.1,
11,
64.4,
52.6,
25.7,
82.6,
54,
51,
89.1,
83.8,
76.7,
61.4,
39.5,
84.4,
35.9,
34,
51.9,
50.3,
34.9,
56.1,
51.5,
56.6,
23.8,
96.8,
32.9,
46.9,
40.5,
66.5,
16.4,
66.4,
47.5,
50.4,
47.8,
97.1,
57.3,
39.9,
95.5,
11.8,
98.3,
82.3,
43.5,
7.9,
86.5,
83.7,
47.2,
96.4,
39.6,
74.9,
57.8,
22.6,
24.9,
70.6,
85.9,
72.1,
98.1,
59.4,
52.8,
52.4,
41.3,
76.3,
93.9,
84.7,
60,
59.3,
35.3,
1.8,
68,
91.9,
72.8,
20.3,
71.9,
38.3,
96.3,
29.8,
51.3,
99.1,
59.9,
43,
76.1,
62.7,
69.9,
55.1,
58.3,
78,
40.6,
14.6,
48.4,
11.4,
56.1,
54.6,
46.8,
80.4,
46.6,
55.3,
80.1,
28.4,
61.9,
70.4,
56.4,
81.2,
63.5,
72.6,
76,
79.3,
38.1,
71.7,
44.9,
45.9,
43.9,
82.6,
81.2,
74.3,
36,
88.1,
81.3,
54.9,
2.7,
26,
52.4,
31.2,
51.6,
59.2,
43.2,
17.2,
51.6,
32.6,
31.2,
18.7,
98.2,
51.2,
82.9,
15.4,
57.2,
85.1,
20.7,
79.4,
38.6,
100,
53.6,
64.9,
21,
76.7,
67.6,
53.5,
80.9,
63.5,
95.4,
34.2,
11.5,
56.9,
66.2,
52.5,
48.7,
35,
23.8,
57.6,
19.9,
78.9,
20.3,
85.9,
44.3,
57.6,
87.6,
62.9,
56.7,
62.6,
29.1,
39.4,
27.6,
62,
28.9,
99.7,
52.1,
42.6,
56.1,
34.6,
72.1,
22.4,
17.7,
43.3,
58.7,
76.7,
20.3,
57.1,
67,
36.4,
19,
72.3,
70.6,
38.7,
37.7,
73.1,
52,
74.4,
40,
86.5,
59.1,
48,
76.5,
44.7,
66.7,
54.6,
49.6,
25.3,
83.8,
64.7,
34.3,
29.9,
78.7,
84.7,
72.9,
61.1,
22,
64.9,
49.5,
93.7,
91.7,
41,
42.5,
81.7,
43.8,
0,
23.3,
70.5,
3.8,
14.7,
11.1,
96.9,
9.9,
60.5,
75.2,
55.4,
77.6,
73.6,
18.6,
36.5,
41,
62.6,
73.9,
25.7,
25.5,
41.2,
68.1,
61.2,
91.1,
17.7,
40.9,
88.7,
41.1,
46.5,
56.4,
43.3,
35.8,
58.5,
26.4,
32.8,
47.2,
53,
81.8,
71.4,
49.7,
34.7,
28.7,
17.4,
43.3,
49.4,
35.1,
97.4,
73.2,
69.3,
23.8,
66.2,
6.6,
102.4,
49.6,
47.2,
95.5,
2.1,
76.9,
29.8,
89.8,
55.8,
84.4,
74.1,
43.2,
92.5,
59.5,
25,
63,
80,
60.6,
54.3,
55.9,
91.9,
52.6,
38,
54.1,
41.5,
29,
66.2,
83.7,
43.8,
89.7,
57.3,
10.1,
7.5,
18.2,
99.7,
23.9,
92.8,
61.6,
76.6,
87.1,
78.7,
59.1,
93.3,
94,
39.1,
86.2,
34.7,
83.7,
77.2,
60.8,
54.6,
60.8,
42.7,
37,
38.5,
82.5,
59.2,
23.8,
68.8,
63.4,
72.2,
10.2,
96.1,
14.4,
76.6,
11.5,
51.7,
44.1,
88,
62.8,
39.4,
62.2,
53.4,
77,
48.1,
64.8,
47,
44,
1.5,
45.6,
57.4,
66.4,
39.5,
77.2,
35.7,
77.6,
89.5,
36.5,
67.2,
84.3,
72.5,
15.9,
54.2,
27.6,
72.1,
3.5,
90.3,
87.6,
57.8,
82.3,
57.9,
66.7,
88.7,
48.9,
69.7,
66.7,
39.4,
27.6,
36.7,
65.1,
66.1,
82.6,
90.7,
43.2,
6.7,
22.8,
40.4,
78.1,
36.8,
62.2,
79.5,
55.2,
42.5,
62.3,
16.3,
94.5,
77.6,
65.2,
53.3,
54.3,
71.3,
57.1,
31.3,
61.3,
0.3,
41.2,
64.4,
1.2,
69.8,
66.5,
44.7,
68.2,
50.6,
64.4,
67.3,
41.6,
47.8,
24,
26.9,
59.1,
55.4,
55.8,
16.2,
84.8,
33.6,
20.2,
53.8,
70,
90.8,
78.5,
88.2,
26.8,
45,
82.5,
30,
12.4,
71.3,
20.9,
68.6,
15.7,
42.5,
51.8,
90.7,
31.1,
91.1,
74.1,
44,
78.3,
73.4,
94.3,
90,
80,
59.1,
83.9,
54.7,
50,
33.7,
56.7,
63.1,
8.9,
94.5,
58.1,
16.7,
75,
47.3,
32.7,
26,
70.8,
76.4,
70.4,
73.4,
27,
83.3,
49.2,
36.2,
15.2,
81.4,
64.1,
49.3,
87,
43.7,
49.7,
9.6,
71,
54.8,
66.9,
90.2,
75.3,
68.3,
49.5,
79.4,
40.6,
8.3,
62.1,
8.5,
46.9,
39.2,
46.4,
66.5,
50.3,
63.7,
32.3,
78.2,
50,
51.6,
88.8,
31.9,
92.2,
78.1,
85.5,
87.2,
36.9,
95.8,
55.9,
100.6,
2.1,
53.9,
98.9,
58.4,
70.6,
73.8,
52.9,
90.6,
21.6,
0.8,
70.2,
56,
41.7,
80,
54.9,
40.3,
9.2,
28.5,
92,
19.8,
29.2,
27,
50.8,
56,
32.9,
71.3,
55.2,
73,
83.7,
41.2,
69.1,
84.6,
3.6,
58.8,
86.8,
77,
58.5,
4.6,
55.3,
67,
57.9,
96.7,
28,
0.3,
38,
45.2,
37.7,
59,
42.7,
99.1,
48.8,
34.1,
49.4,
76,
55.1,
91.1,
36.5,
88.2,
28.9,
48.5,
56.2,
62.7,
85.2,
70.2,
16.7,
56.4,
17,
68.8,
16.9,
51.1,
33.2,
27.5,
38.4,
80,
72.3,
99.7,
81.2,
53.2,
25.5,
20.3,
78.5,
60.6,
27.5,
42.7,
46,
68.9,
20,
90.1,
68.7,
62.4,
68.1,
34.1,
49.7,
67.5,
92.5,
94.1,
68.8,
85.7,
58.7,
95.8,
52.5,
47.9,
60.1,
66.3,
53.9,
83.3,
57.4,
5.5,
48.5,
69.4,
16.2,
96.1,
33.7,
9.5,
63.2,
57.8,
45.8,
94.7,
35.3,
68.3,
84.5,
64.3,
60.7,
17.7,
28.6,
54.6,
99.9,
44.2,
49.1,
87.4,
28.7,
39.2,
28.6,
85.6,
64.5,
74.1,
95.3,
52,
61.9,
49,
14,
59.9,
49.8,
12.4,
63.7,
36.6,
53.2,
7.5,
41.9,
70.9,
85.3,
52.5,
56,
28.3,
48,
94.4,
51.8,
23.4,
47.1,
51.3,
83.6,
58.2,
41.4,
91.7,
44,
30.3,
80.2,
35.6,
12.8,
82.5,
20.7,
49,
39.2,
58.5,
40.5,
90.8,
33.1,
48.3,
39.5,
34.9,
44.9,
22.8,
67.6,
0,
34.6,
4,
88.2,
77.6,
85,
74.5,
22.2,
62.1,
67.3,
72.1,
1.3,
55.7,
25,
29.7,
54.1,
82.3,
35.4,
85.8,
15,
56.3,
102.4,
12.9,
89.9,
75.6,
43.7,
43.3,
90.2,
64.1,
24.5,
75.1,
13.7,
55,
22.3,
67,
23.6,
80.8,
21.6,
48.7,
49.1,
39.2,
50.4,
68.3,
69.9,
87.4,
41.5,
88.7,
28.5,
27,
59.5,
82.9,
46.5,
0.2,
97.3,
87.9,
86.6,
12.2,
34.4,
48.7,
56.8,
79,
66.2,
27.9,
75.2,
66.7,
71.4,
35.2,
78.9,
87.3,
60.8,
68.6,
68.2,
7.8,
80,
5.5,
34.1,
43.4,
91.3,
20.5,
60,
29.7,
96,
82,
71.3,
55,
23.3,
88.4,
46.5,
70.5,
38.5,
78.1,
18.9,
79,
53.7,
50.3,
69.7,
103.3,
20.2,
64.9,
72,
49.5,
68.3,
40.4,
38.8,
52.6,
59.7,
51.9,
28.8,
57.5,
56.5,
77.7,
89.3,
86.1,
82.9,
44.8,
60.6,
39,
34.6,
59,
45,
85,
74.5,
74.2,
45.1,
72.2,
55.1,
84,
19.5,
76.3,
79.1,
28.2,
50,
68.8,
38.4,
81.8,
51.5,
53,
73.6,
32,
24.6,
50.8,
33.5,
39.3,
57.6,
67.4,
47,
54.2,
26.3,
25,
89.8,
20.2,
31.1,
51.1,
61.3,
57.3,
78.6,
64.7,
10.7,
65.2,
72.9,
59.9,
62,
67.5,
33.2,
74.7,
18.9,
43,
77.2,
56.3,
81.7,
48.8,
38.8,
37.8,
77,
69.1,
90.3,
111.4,
85.2,
37,
8.4,
54.2,
51.6,
34.1,
61.4,
67.3,
0,
57.7,
80.4,
78,
71,
52.2,
69,
94.3,
63.3,
63,
90.1,
45.8,
74.3,
68.8,
60.5,
102.7,
53.5,
23.5,
94.4,
21.9,
69.1,
76.7,
77.3,
90.5,
75.3,
35.3,
84.9,
62.9,
56.2,
59.1,
56.8,
22.4,
80.9,
53.3,
94.3,
30.9,
43,
40.2,
60.6,
68.2,
94.1,
73.7,
31,
51.9,
45.2,
16.9,
97.8,
62.8,
40.2,
75,
99.8,
29.6,
61.3,
81.9,
42.2,
76.9,
75.9,
84.5,
78.6,
21.8,
44.8,
50,
27.8,
71.5,
81.7,
26.4,
75,
63.9,
62.3,
28.8,
43.8,
46,
77.3,
67.9,
46.9,
69.9,
45.7,
68.7,
100,
84.3,
29.8,
45.7,
92.1,
46.6,
93.1,
59.8,
57.1,
68.9,
55.7,
47.7,
60.6,
86.1,
10,
57.5,
57.8,
50.6,
51.4,
92.1,
63.6,
78.1,
37,
56,
27.7,
71.2,
89.6,
51.5,
68.9,
66.8,
14.6,
78.4,
14.3,
65.5,
48.7,
35.5,
47.3,
84,
83.5,
53.1,
27,
44,
22.3,
86.5,
46.4,
14.5,
40.5,
53.2,
81,
69.3,
81.5,
81.4,
19.5,
54.9,
66.3,
29.4,
59,
46.3,
63,
77.3,
13.6,
55.3,
54,
55.2,
92.9,
37.6,
91.1,
4.6,
81.9,
51,
30.2,
49.5,
35.5,
50.4,
67.3,
62.9,
92.5,
36.3,
78.3,
34.2,
0,
44,
87.7,
22.5,
57.3,
77.5,
71.4,
32.5,
77.1,
43,
30.1,
98.6,
42.8,
30.6,
68.8,
83.7,
70.4,
83.1,
48.7,
16.2,
64.2,
58.6,
82.9,
72.8,
51.5,
30.4,
43.7,
52.1,
16.7,
78.4,
30.3,
89.5,
87.8,
26.4,
6.7,
47.4,
80.2,
93.6,
79.6,
76.1,
62.3,
35.1,
41,
71.9,
85.7,
54.3,
84,
90.9,
41.7,
86.6,
79.7,
82.5,
66.9,
37.4,
83.5,
49.6,
2,
63.2,
83.7,
72,
94.4,
61.9,
64.1,
49.5,
99,
33.5,
30.4,
42.5,
47.7,
64.6,
47.3,
33.2,
59.1,
85.8,
86.3,
97.4,
52,
22.5,
80.6,
34.5,
91.9,
61.3,
48.2,
79,
80.7,
48.5,
31.3,
93.3,
30.6,
75.3,
59.6,
44.9,
18.6,
14.6,
51.1,
74.1,
74.8,
58.5,
56.6,
73.7,
79.3,
40.9,
90.8,
86,
91.5,
46.1,
70.5,
49,
29.5,
68.9,
98.4,
61.5,
56.1,
40.5,
63.3,
89.3,
39.9,
54.6,
94.6,
57.1,
29.3,
19,
65.7,
84,
62.2,
86.1,
41.3,
68.9,
6.1,
68.5,
66.5,
48.5,
58.7,
82.6,
97.6,
89.9,
27.6,
38.4,
61.1,
91,
57.3,
10.8,
43.8,
43.6,
34.3,
54.6,
61.4,
61.5,
94.8,
57.7,
62.9,
59.3,
56.5,
88,
83.8,
82.1,
28.7,
4.6,
77.1,
97.7,
67.6,
41.1,
46.9,
74.7,
70.6,
56.3,
17.7,
81.4,
93.1,
50.3,
98.8,
54.9,
46.3,
31.8,
58.7,
63.5,
50.3,
55.5,
21.9,
38.3,
13.1,
61.9,
79.5,
20.2,
52.6,
49.4,
66.1,
56,
19.4,
56.9,
32,
9.7,
20.2,
77.7,
19.5,
44.6,
44.7,
83.8,
24.2,
77.9,
100.5,
71.8,
42,
32.4,
31.7,
84.8,
69.4,
0,
74.3,
50.5,
64.6,
46.5,
91.4,
60.9,
84.1,
79.8,
99.7,
70.6,
51.4,
54.6,
57.2,
60.5,
52.4,
75.3,
64.5,
87.1,
72.5,
36.4,
53.5,
80,
78.8,
39.7,
21.1,
63.6,
57,
62.7,
74.9,
50,
76.3,
58.8,
50.9,
39.7,
52.4,
75.3,
86.1,
93.8,
48.9,
40.5,
15.2,
41.7,
99.5,
49.3,
10,
60.9,
43.4,
25.5,
22.8,
88.1,
96.5,
0,
80,
21.8,
62.2,
54.6,
60.2,
37.8,
52.3,
94.4,
55.3,
56.4,
32.1,
65.7,
12.8,
99.9,
43,
46.9,
88.4,
22.9,
34.9,
88.4,
94.2,
84.2,
72.2,
34.7,
100.4,
55.6,
0,
70.9,
78.8,
89,
4.7,
69.2,
34.9,
90.1,
46.8,
70.1,
78.1,
22.1,
20.7,
36.9,
93.4,
70,
52.2,
68,
23.2,
82.6,
77.1,
90.3,
68.8,
90.8,
92.7,
72.4,
31.9,
69.3,
40.1,
93.8,
96.5,
34.5,
59.3,
23.8,
13.5,
77.8,
24.9,
66.3,
64.2,
41.2,
53.8,
42.4,
24.3,
58,
66,
11.5,
43.5,
40.1,
57.5,
35.5,
88.4,
49.4,
57.7,
34.4,
65.2,
21,
25.2,
84.3,
38.6,
64.9,
55,
58.1,
67.9,
78.9,
35,
46.5,
91.4,
93.7,
78.9,
37.6,
3.8,
70.5,
55.4,
61.2,
23.3,
86,
8.7,
53.4,
63.6,
35.9,
57,
69,
79,
101.1,
63.3,
55.6,
72.7,
86.6,
89.2,
54.7,
69.5,
25.2,
33.1,
38.8,
57.3,
81,
97.1,
16.2,
37.4,
38.2,
40.7,
27.2,
83.7,
84.9,
66.1,
35.8,
32.6,
61.3,
85.5,
38.9,
52.1,
65.2,
81.9,
51,
80,
26.9,
60.2,
47.1,
91.9,
23.2,
25.7,
71.6,
45,
50.3,
38,
46.9,
67.3,
35.9,
69.4,
36.7,
56.1,
60.1,
55.2,
70.5,
78.8,
62.3,
89.1,
58.9,
54.3,
11.6,
60.6,
66.6,
78.6,
87.3,
88.5,
18.3,
80.4,
68.3,
36.4,
39.1,
79.1,
100,
58.3,
82.5,
47.2,
42.9,
12.5,
25.5,
64.2,
67,
67.9,
60,
97.6,
45,
52.2,
68.2,
19.6,
43.9,
22.6,
48.1,
46.4,
61,
47.9,
59.7,
91,
76.3,
99,
17.3,
75.5,
66,
32.1,
76.1,
36.4,
29.8,
51.4,
25.8,
46.5,
25,
83.5,
60.1,
46.3,
28.7,
80.1,
71.4,
69.4,
36.7,
8.8,
57.3,
59.8,
44.5,
51.4,
41.1,
9.4,
38.2,
61.6,
77.3,
76.9,
104.2,
50.7,
49.5,
44,
80.9,
62.5,
34.2,
51.8,
58.5,
44.5,
86.4,
42.3,
58.6,
63.7,
13.7,
89.6,
20.2,
28.6,
68,
52.1,
26.8,
65.3,
52,
51.7,
58,
69.8,
2.1,
51.4,
64.4,
86.3,
43.1,
35,
85.7,
64.1,
84,
21.3,
49.8,
86.7,
47.5,
32.4,
67.4,
33.8,
42.2,
29.8,
95.4,
58.5,
22.2,
81.4,
58.3,
83.4,
3.7,
58.8,
70.1,
83.3,
49.4,
46.8,
25.2,
55.8,
55.6,
62.2,
52.9,
3.5,
96.6,
80.9,
13.9,
68.7,
40.4,
27.3,
52,
27.5,
41,
27.9,
61.9,
67.5,
64,
76.8,
94.5,
53.4,
79.4,
83.2,
83.7,
61.3,
39.8,
41.1,
81.8,
87.6,
70.6,
22.8,
56,
46,
76,
89.1,
60,
36.4,
25.6,
60,
71.8,
52.4,
46.7,
44.2,
28.4,
72.2,
72.3,
88.2,
31.7,
1.8,
94.9,
56.3,
22.7,
66.6,
83.1,
48,
53.9,
83.8,
30.9,
75.9,
71.9,
45,
67.1,
72.9,
65.3,
73.9,
43.4,
49.4,
44.8,
35.5,
78.2,
43.5,
82,
64.1,
36.2,
79.8,
81.9,
71.6,
41.5,
0,
4.5,
58.5,
79.4,
35.5,
93.5,
59,
33.1,
27.9,
51,
92,
21.9,
42.9,
79.8,
60,
63.6,
79.5,
72.5,
76,
45.8,
77.6,
29.4,
60,
65.3,
35.1,
85.3,
67.9,
50.9,
68.9,
99.2,
67.1,
88.8,
65.9,
32.4,
39.2,
85.2,
22.2,
7.8,
30.7,
60.5,
63.5,
50,
85.9,
51.1,
56.4,
62.7,
96.3,
55.9,
60.8,
62.6,
39.4,
21.5,
70.4,
17.7,
43.5,
60.6,
37.7,
16,
67.4,
24,
64.7,
46.3,
85.7,
77.3,
92.5,
49.3,
48.7,
40.9,
49,
90.4,
60,
42.7,
49.2,
34.4,
51.6,
39.6,
47.9,
33,
18.4,
69.2,
42.3,
39.9,
3,
93.6,
67.2,
84.2,
35.5,
33.7,
37.6,
92.9,
0,
69.2,
39.5,
29.4,
93.8,
73.3,
18.5,
86.2,
45.6,
23.8,
47.3,
49.3,
54.3,
50,
65.9,
15.3,
93.7,
73.3,
38.3,
94.6,
25.9,
88.3,
87.1,
95.4,
39.5,
78.3,
94.3,
53.3,
37.3,
62,
53.8,
94.2,
63,
57.2,
49.9,
72.6,
54,
36.1,
78.2,
68.2,
44.3,
32,
22.3,
8.5,
87,
84.3,
90.6,
61.8,
36.8,
17.8,
87.7,
43.7,
59.8,
46.8,
65,
7.7,
86,
39.4,
76.8,
4.8,
44.9,
38.6,
1.2,
66.4,
71.9,
85.2,
65,
28.5,
34.2,
46,
50.7,
61.5,
95.1,
75.7,
68.1,
91.3,
55.4,
85.9,
56,
42.8,
73.9,
77,
42.9,
13.7,
57.3,
48.9,
42.7,
46.3,
83.9,
44.8,
93.4,
60.7,
52.1,
19.8,
45.8,
43.7,
43.2,
45.9,
24.5,
57.7,
48.9,
97.1,
31.1,
34.9,
41.9,
92,
3.3,
17.7,
75.5,
64.4,
99.2,
66.1,
34.8,
71.2,
71,
25.6,
42,
78.6,
45.9,
83.3,
25.5,
51.8,
44.6,
43.4,
47.6,
65.4,
65.7,
69.2,
67.3,
52.5,
72.2,
54.7,
76,
33.7,
91.8,
41.7,
72.6,
69,
38.1,
46.2,
95.4,
51.2,
87,
59.2,
70.7,
35.3,
36.4,
61.2,
9.5,
32.8,
38.1,
13.7,
58.6,
77.8,
94.5,
74.1,
18.4,
75.5,
24.1,
51.2,
34,
32.9,
36.3,
44.4,
15.8,
12.4,
51,
56.5,
24.9,
93.2,
52.5,
82.2,
40.6,
58.4,
16.3,
88.2,
64,
78.8,
34.2,
53.1,
57.1,
58.5,
100.1,
69.3,
70.3,
5.2,
47.5,
72.7,
26.7,
43.6,
20.9,
34,
88.7,
28.9,
62,
68.2,
53.4,
60.4,
58,
60.6,
92.6,
81.3,
17.8,
17.2,
40.8,
76,
81.2,
68.5,
70.8,
36.8,
15.6,
63,
79.9,
36.5,
57.3,
37.6,
53.8,
36,
84,
0.6,
19.6,
46,
49.7,
57.6,
41.6,
86.9,
66,
44.7,
78,
90.9,
52.7,
61,
58.6,
74,
62.9,
71.3,
81.8,
51.5,
88.2,
42.5,
87,
49.1,
59.8,
9.2,
36.9,
69.8,
14,
31,
87,
64.7,
32.6,
49.5,
57.7,
78.5,
73.6,
49.7,
100.6,
25.9,
51.5,
37.2,
78.8,
60.6,
78.1,
45.5,
51.3,
92.5,
47.3,
81.8,
52.5,
110.4,
73.5,
97.3,
47.8,
61.6,
93.9,
21.6,
25.8,
60.3,
70.6,
61,
88.5,
36,
66,
9.2,
67.7,
58,
62.7,
56.4,
27.3,
60.6,
40.1,
40.3,
65.7,
54.5,
0,
101.1,
11.1,
47.9,
83.2,
65.9,
74.5,
76.5,
43.4,
35.7,
91.5,
74.4,
88,
6.7,
87.4,
95.1,
52,
47.3,
62.4,
64.4,
50.2,
71,
78,
98.4,
89.5,
44.2,
81.4,
69.2,
49.4,
37.1,
94.7,
44.9,
64.6,
50.4,
72.1,
94.7,
87.2,
79.3,
6.2,
70.6,
33.8,
12.1,
62.4,
81.9,
72.1,
68.2,
34.2,
56,
26.8,
88.3,
50.5,
79,
48.6,
79.3,
29.3,
68.7,
38,
24.1,
50,
62.7,
58.7,
42.7,
48.4,
57.9,
48.1,
79.2,
90.8,
49.3,
56.1,
24.8,
63.2,
54.1,
71.2,
62.7,
57.8,
95.4,
61.5,
62.6,
87.9,
68,
27.4,
67.4,
71.5,
99.6,
59.5,
68,
15.6,
44.7,
65.4,
31.8,
51.4,
77.5,
66.2,
31,
74.6,
83.4,
33,
73.8,
73.4,
43.2,
17,
72.1,
34.1,
33.5,
60.2,
45.9,
41.8,
38.7,
7.5,
44.8,
33.3,
89.1,
27,
53.8,
54.9,
46.6,
78.4,
28.9,
49,
61.7,
58.5,
83.6,
60.4,
43.1,
17.9,
88.3,
41.5,
42.6,
49.5,
89.4,
83.4,
41.9,
48.8,
66.5,
36.2,
96.2,
34,
33.1,
86.7,
57.8,
28.4,
49.9,
44.8,
51.5,
51.2,
63,
86.7,
92.9,
71.2,
17,
61.6,
56.1,
13.2,
27.8,
80.3,
64.9,
52.1,
69.7,
93.2,
10.5,
51,
77.9,
75.5,
3.6,
76.6,
81.2,
43.1,
45.4,
51.8,
67.9,
74.4,
44.5,
40.7,
60.9,
83.4,
57.1,
61.9,
68.2,
47.6,
89.7,
78.2,
50.5,
63.5,
48.2,
0,
62.3,
57.8,
78.6,
62.2,
27.1,
104.6,
86.5,
38.6,
38,
71.7,
93.3,
47.7,
88.8,
79.6,
57,
35.3,
75.3,
0,
63.8,
89.1,
56,
30.9,
55.2,
88.5,
94.8,
83.3,
41.1,
79.7,
48.5,
33.5,
41.9,
61.5,
29.6,
82.6,
48.8,
36.6,
90,
72.8,
46,
76.3,
67.6,
49.7,
31.3,
71,
33,
73,
58.5,
81.7,
39.1,
57.3,
17.3,
25.1,
44.9,
50.3,
77.2,
10.9,
52.8,
48.8,
36.7,
10.6,
61,
78,
41.2,
42,
91.5,
81.6,
31.8,
73.6,
26.5,
80.1,
62.6,
101.7,
4.3,
72.4,
1.5,
43.4,
45,
74.4,
64.3,
55.4,
64.3,
82.4,
51.2,
59.2,
71.2,
17.9,
77.2,
6.1,
75.6,
67.8,
49.8,
37.4,
79,
72.3,
58.3,
58.4,
13.8,
40.3,
59,
29.7,
70,
45.9,
38,
55.7,
62.3,
69.2,
74.1,
42.2,
71.8,
31.3,
98,
95.6,
29.1,
49.3,
77.4,
92.6,
75.7,
74.9,
27,
70.4,
30.5,
73.7,
38.3,
44.6,
32.3,
50.9,
64.3,
14.4,
55.5,
28,
7.6,
48.9,
64,
88.1,
30.4,
79.8,
87.8,
23.1,
8.6,
76.4,
56.3,
30,
79.6,
100.2,
73.2,
84.8,
15,
85.8,
65.4,
58.5,
81.4,
18.6,
73.2,
77.1,
57.7,
73.4,
60.7,
49,
37.6,
86.3,
62.1,
44.8,
38.7,
74.9,
71,
34.3,
70.3,
58.1,
51.7,
99.1,
55,
46.8,
50.2,
67.4,
18.1,
79.4,
70.8,
28.6,
47,
83.7,
47.4,
64,
75,
87.5,
43.4,
55.2,
67.4,
47.2,
15.6,
77,
38.4,
42.5,
56.4,
68.9,
66.4,
47.4,
88.3,
64.2,
91.9,
56.6,
52,
43.3,
60.8,
57.7,
60.3,
19.3,
48.5,
0,
35.4,
2,
36.2,
30.7,
86.4,
65.1,
60.1,
40.2,
49.1,
10.5,
39.7,
38,
43.7,
76.5,
32.7,
69.4,
88.1,
20.4,
62.9,
86.3,
51.7,
48.2,
57.5,
15.8,
54,
8.1,
94.2,
74.7,
6.9,
39.4,
53.6,
81.5,
59.3,
38.4,
77.1,
89.3,
59.8,
63.8,
32.1,
42.6,
37.4,
41.2,
21,
94.9,
82.1,
38.5,
61.6,
75.3,
34.4,
4.5,
33.3,
79.1,
66.1,
39.7,
69.1,
40,
75.5,
84.2,
41.4,
72.3,
55.5,
23.9,
79.6,
28.8,
38.1,
59.8,
58.5,
86.4,
66.3,
55,
70.5,
24,
25.7,
69.6,
55.3,
45.7,
78.3,
82.4,
91.7,
45.8,
0,
66.4,
95,
30.7,
10.5,
41.6,
59.3,
34.3,
96.2,
90.2,
73.3,
72.5,
75,
53.7,
59.5,
88.1,
27.9,
21.7,
84.9,
18.2,
58.2,
76.5,
0,
77.3,
54.4,
56.5,
54.6,
66,
7.4,
51.5,
76.2,
65.1,
70.1,
49.4,
70.4,
57.2,
30.9,
43.9,
44.3,
37.7,
70.3,
14.6,
64.4,
71.8,
23,
41.7,
19.5,
57.2,
55.5,
85.3,
22.8,
79.9,
87.2,
73.1,
75.2,
22.9,
35.7,
46.8,
17.2,
80,
44.9,
43.7,
24,
79.4,
37.8,
68.5,
17.5,
41.8,
88.2,
44.8,
87.1,
60.1,
40.7,
27.9,
61.2,
90.4,
27.8,
68.6,
69.8,
64.8,
95.6,
96.7,
8.3,
60.3,
78.2,
34,
96.5,
20,
39.6,
63.2,
91.4,
65.3,
70.6,
28.8,
40,
37.3,
37.6,
101.1,
28.9,
54,
48.2,
81.7,
51.7,
56.4,
24.9,
47,
33.2,
53.9,
46.1,
69.4,
86.1,
62.1,
18.3,
5.7,
60.9,
29.1,
56,
21.9,
69.5,
75.4,
88,
28.8,
26,
19.4,
69.1,
79.1,
67.5,
97.9,
93.6,
62.7,
80.6,
10.5,
56.8,
69.8,
69.3,
54,
25.5,
77.1,
82.4,
64.3,
77.3,
24.4,
33.4,
58.7,
95.8,
67,
34.9,
74.3,
94,
64,
83.2,
36.5,
101.1,
99.3,
70.1,
69.6,
11.3,
25.8,
81,
73.1,
89.5,
102.6,
19.5,
89.5,
51.8,
46.6,
56.8,
73.4,
80.1,
89.1,
21.8,
52.7,
17.8,
25.7,
52.3,
44,
72.9,
74.6,
73.5,
26.1,
91,
52.2,
84.7,
23,
61.7,
94.5,
51.6,
34.9,
88.3,
60,
26.4,
49,
59.2,
27.5,
46,
75.5,
60.7,
41,
75.6,
17.8,
48.8,
43.3,
79.1,
74.2,
29.2,
25.1,
26,
66.9,
91.6,
79.6,
15.9,
77.6,
57.2,
18.9,
63.4,
28.3,
51.5,
76,
52.6,
59,
52.5,
45.4,
84.9,
59.6,
82,
53.3,
44.7,
45.2,
83.5,
57.9,
63.3,
62.2,
50.3,
81.9,
5.3,
73.2,
0,
48.4,
60.2,
39.1,
95.2,
67,
53.5,
83.9,
81.3,
54.8,
44.4,
62.3,
22.9,
18.8,
36.1,
24.5,
92.3,
80.6,
92,
50.5,
79.9,
37.9,
25.2,
41.7,
60.7,
68,
44.9,
43.7,
61,
25.5,
15,
26,
78.4,
58.2,
27.3,
65.2,
57.3,
76.6,
94.6,
56.1,
61.8,
86.3,
47.7,
85.5,
62.9,
55.9,
84.8,
61.8,
89,
21,
38.5,
97.8,
42.9,
26.8,
69.1,
42.2,
78.1,
86.1,
65.8,
75.2,
70.6,
42.4,
15.1,
81.6,
15.4,
39.8,
7,
55.8,
76.1,
10,
57.3,
0.5,
60.3,
50.6,
83.8,
87.7,
49.1,
72.9,
66.9,
26.7,
77.1,
45.7,
34.3,
68.6,
86.2,
20.2,
45.7,
3.4,
29.9,
22.2,
42.6,
33.5,
80,
82.9,
32.4,
89.4,
77.6,
19.4,
68.1,
84.7,
49.9,
53.7,
30.3,
61.7,
68.3,
68.3,
26.1,
16.5,
80.3,
50.3,
70.4,
65,
33,
68.3,
34.9,
89.8,
28.2,
71.7,
75.5,
35,
40.5,
43.1,
50.5,
41.9,
58.7,
84.3,
42.8,
70.2,
null,
79.6,
64.2,
51.1,
68.9,
95.3,
42.1,
7.5,
67.9,
52.4,
11.2,
86.2,
53,
77.9,
12.4,
88.2,
49.1,
27,
69.4,
99.3,
84.4,
89.3,
2.7,
21.1,
47.9,
47.8,
97.4,
88.2,
43.8,
37.7,
22.4,
15.8,
87.3,
66.2,
47.2,
13.4,
74,
98.5,
40.9,
89.2,
74.5,
23.3,
61,
39.3,
12,
27.9,
25,
74.3,
42.6,
70.9,
62.5,
48.6,
55.8,
97.6,
34,
79.3,
5.5,
52.1,
49.3,
48.3,
60.6,
80.3,
38.4,
27.4,
90.9,
33.7,
9.2,
57.7,
61.3,
73,
33.2,
44.3,
92.7,
47.2,
28.2,
31.6,
71.1,
27.7,
14.9,
42.5,
44.7,
40.6,
97.6,
56.5,
54.2,
84.5,
61.7,
62.8,
27.9,
87.5,
91.7,
65.7,
57.8,
59.9,
33.6,
56.2,
14.6,
80,
53,
18,
50.4,
18.6,
49.3,
102.2,
33.6,
98.3,
2.9,
30.2,
32.4,
0,
0.8,
76.5,
50.8,
40.3,
10.7,
45.4,
34.5,
31.6,
51.6,
45,
13.1,
66.2,
78.9,
88.6,
62.3,
60.2,
49.5,
64.4,
70.7,
79,
70,
25.7,
20.8,
89.6,
35.5,
96.6,
38.3,
96,
49.9,
16.9,
31,
52.7,
24.3,
32.7,
10.3,
75,
68.6,
95.9,
53.7,
48,
41.2,
46.4,
26.7,
25.7,
65.1,
48.1,
38.3,
28.5,
33.2,
64,
70.3,
81.1,
15.8,
43.4,
63,
27.1,
70.4,
45.4,
88.7,
50.7,
74.8,
44.3,
30.1,
73.4,
85.7,
44,
42.1,
76.8,
31.2,
85,
50.6,
37.3,
47.4,
39.8,
36.2,
26,
20.5,
26.2,
65.6,
26,
31.2,
55.3,
99.8,
69.1,
59.8,
60.6,
41.7,
32.6,
84.8,
49.3,
61.5,
83.3,
31.4,
0,
85.1,
28.5,
66.9,
39.8,
61.4,
65.3,
38.1,
39.5,
33.2,
79.9,
86.1,
31.6,
37,
57.9,
68.8,
62.1,
86.1,
70.2,
71.1,
73.9,
21.8,
52.5,
66.4,
85.2,
53.4,
27.4,
29.4,
29.5,
69.6,
57.4,
48,
22.4,
83.5,
84.8,
34.2,
28.5,
70.6,
76.7,
88.3,
60.8,
63,
66.9,
90.5,
61.1,
60.7,
86.4,
67.1,
81.5,
42.2,
13.3,
66.4,
60.2,
75,
73.3,
40.7,
25.3,
82.7,
74.9,
52.8,
27.6,
37.3,
42.7,
50.4,
49.6,
35.9,
26.4,
79.1,
53.1,
75.4,
39,
33.8,
62.9,
69.6,
58.8,
53.3,
54.1,
72.8,
79.7,
61.2,
85.4,
100,
48.4,
81.1,
11.1,
97.4,
34,
37.8,
39.9,
70.1,
25,
81.6,
26.3,
22.8,
28.7,
49.9,
73,
76.1,
57.1,
54.9,
81.3,
47.9,
87.3,
78.4,
21.3,
65.7,
34.1,
79.4,
80.5,
52.3,
49,
81.8,
73.8,
46.5,
79.3,
76.6,
55.6,
18.9,
79,
63.7,
84.8,
62.8,
54.5,
33.6,
84.7,
80,
17.7,
36.5,
17.4,
53.5,
53.6,
52.3,
47,
18.3,
53.2,
93.1,
81,
84.8,
94.4,
51.4,
25.6,
30.2,
18.2,
27.6,
24.7,
53.5,
34.9,
96.2,
47.5,
84.7,
63.2,
22,
60.2,
54.3,
93.3,
69.2,
51.7,
4.6,
75.4,
14.7,
35.7,
31.1,
36.3,
59.5,
58.6,
40.4,
43.6,
20.6,
70.7,
52.3,
53.9,
61.6,
79.6,
82,
47.9,
91.5,
36.2,
0.2,
32.2,
26,
78.4,
11.1,
67.8,
47.7,
6.3,
19.8,
72.2,
45.5,
84.9,
73.7,
10.5,
61.8,
80.2,
42.3,
69,
11.4,
53.6,
80.9,
16.9,
42.3,
60,
97.8,
99,
25.5,
47.2,
58.9,
3.7,
57.1,
75,
27.6,
94.7,
54.8,
85.1,
84.2,
32.1,
18.3,
55.6,
79.7,
82.4,
45.7,
33.2,
51.6,
51.7,
68.1,
48.2,
76.3,
81.6,
69,
30.6,
27.9,
74,
49.3,
44,
81,
29.2,
63.7,
77.2,
38.4,
60,
66.1,
95.4,
31.6,
36.1,
52.9,
34.1,
84.2,
42,
73.8,
82.3,
40.2,
15.4,
87.3,
87.7,
82.1,
41.1,
75.2,
28,
23.1,
71.6,
53.7,
67.8,
90.3,
30.2,
50.7,
43.4,
27.8,
38.9,
67.3,
53.6,
27.3,
29.6,
16.6,
52.8,
13.4,
51.4,
75.2,
25.9,
38.8,
89.8,
62.7,
59.3,
31.1,
81.6,
13.2,
18.8,
44.3,
60.6,
66,
49.9,
63,
17,
81.7,
60.6,
69,
26.1,
53.8,
36.2,
60.8,
72.3,
56.3,
84,
73.7,
79.5,
17.6,
36,
35.5,
59,
83.4,
67,
19.9,
47.5,
52.4,
81.8,
78.6,
50.9,
21.8,
70.8,
55.7,
65.1,
39.6,
33.4,
99.9,
50,
33.3,
92.6,
22.6,
83.1,
73.8,
66.5,
58.2,
55.6,
67.5,
83.2,
42.1,
85.4,
79.7,
47.1,
71.1,
55.1,
100,
28.9,
92.9,
16.9,
47.7,
101.8,
82.2,
60,
64.7,
93.2,
19.9,
33.3,
34.9,
44.5,
86.9,
72.5,
37.8,
74.5,
43.6,
40,
91,
17,
67.8,
12.2,
30.5,
32.7,
66,
70.7,
29.2,
62.3,
28.2,
80.4,
60.1,
57.2,
57.4,
43.3,
93.4,
30.9,
84.4,
54.4,
91.6,
85.8,
67.5,
81.9,
78,
48,
83.6,
85.1,
42.2,
45.3,
76.6,
43.4,
50.9,
61.1,
56,
96.6,
70.1,
23,
79.5,
67.1,
58,
58.2,
39.2,
80.3,
54,
22.2,
30.8,
50.9,
79.9,
80.1,
57,
85.6,
34.5,
71.6,
53.6,
91.7,
50.4,
88.8,
40,
87.7,
60.5,
12.1,
60.5,
74.2,
62.9,
93.8,
30.9,
38.4,
56.9,
58.1,
58.8,
67.9,
14.4,
56.7,
43.2,
9.9,
90.9,
76.9,
48.3,
51.8,
48.9,
40.4,
65.4,
20.4,
45.5,
90,
44.2,
37.6,
66,
48,
63.4,
73.9,
27.8,
61.6,
10.7,
81.3,
45.4,
84.9,
41,
57.1,
20.9,
68,
12.3,
60.9,
94.9,
95.2,
50.5,
88.7,
95.1,
81.1,
91.6,
74.4,
63,
15.7,
51,
62.7,
14.4,
18,
40.7,
35.7,
66.6,
51.5,
52.9,
88.5,
93.1,
43.3,
81.4,
57.1,
73.2,
50.7,
2.2,
63.2,
63.4,
94.9,
28.7,
2,
7.6,
69.8,
32.6,
66.6,
88.6,
69.6,
89.4,
70.3,
50.2,
53.2,
33,
27,
80.2,
32,
1.3,
44.3,
36.3,
15.6,
31.8,
91,
25.7,
74.6,
28.2,
90.8,
72,
25.2,
68.1,
50.5,
51.3,
42.9,
59.9,
61.2,
25,
56.8,
71,
66.1,
14.9,
58.7,
86.3,
59.9,
75.6,
98.6,
40.3,
50.6,
5.7,
86.4,
41.1,
51.1,
26.2,
81.4,
12.4,
65.2,
63.5,
57.2,
61.9,
23.8,
30,
28,
54.7,
39.7,
92.3,
48,
58.9,
15.9,
33.6,
61.5,
68.5,
78.7,
46.2,
75.1,
77.1,
95.4,
57.2,
89.3,
30.1,
34.1,
31.4,
65.2,
41.3,
19.3,
40.1,
57,
89.6,
35.5,
33.8,
51.5,
87.8,
39,
68.7,
67.4,
65.9,
74.1,
25.6,
50.9,
77.8,
73.5,
37.3,
71.7,
30.9,
86.3,
84.4,
65.3,
55.8,
67.2,
4.9,
41.8,
73,
46.2,
97.3,
24.6,
73,
46.1,
85.3,
12.7,
49.3,
93.1,
29.5,
60.4,
70,
73.8,
87.1,
32.4,
70.8,
24.1,
72.3,
45.8,
24.7,
24.5,
70.8,
76.5,
52.1,
92.1,
60.6,
28.4,
33.2,
99.8,
35,
32.6,
58.3,
67.5,
72.7,
66.2,
64.4,
84.2,
54.9,
2.4,
80.4,
25.7,
51.4,
48.9,
82.4,
87,
27.6,
66.9,
52.9,
46.5,
77.5,
59.2,
31.7,
46.9,
20.6,
99.2,
54,
18.9,
69.5,
52.2,
24.3,
79.3,
36.6,
98.7,
90,
72.4,
56.5,
51.6,
62.8,
49,
59.6,
37.3,
55.4,
1.4,
30.9,
22.1,
77.3,
39.7,
68.8,
83.5,
50,
74.1,
34.6,
62.4,
77.2,
82.1,
35.4,
21.9,
8.5,
62,
73.7,
85.5,
58.3,
51.7,
43.1,
48.4,
86.2,
35.5,
57.6,
61.2,
72.3,
18.4,
63.6,
36,
51.7,
70.2,
77.5,
60.2,
78.6,
85.5,
15.2,
92.7,
71.6,
91.4,
85.1,
55.5,
80.7,
72.7,
44.1,
75.3,
67.5,
37.5,
75.7,
31.7,
38.6,
59.5,
26.2,
20.6,
88.8,
72.5,
11.8,
81.8,
43.1,
51.4,
38.5,
84.3,
61.2,
21.2,
48.4,
71.5,
38.2,
52.6,
43,
73.5,
83.2,
19.1,
58.4,
81.1,
22.1,
55.3,
48.4,
5.8,
73.3,
72.9,
28.2,
83.3,
79.1,
57.9,
73,
41.4,
72.9,
57.7,
78.8,
48.5,
76.1,
98,
47.7,
55.5,
5,
44.8,
38.4,
63.8,
18.5,
37.7,
76.2,
58.8,
42.5,
47,
87.7,
37.6,
55.8,
57.1,
43.3,
69.6,
92.4,
42.2,
65.1,
29.5,
77.1,
90.4,
67.7,
56.5,
90.2,
74.8,
79.9,
98.1,
24.4,
91.3,
59.7,
65,
30.2,
79.4,
100.7,
50.4,
87.6,
85.6,
36.5,
9,
5.9,
92.9,
75,
6.5,
84,
21.1,
62.2,
45.4,
37.9,
11.8,
77.5,
84.2,
65.3,
73.1,
30.5,
74.7,
77.2,
12.1,
69.4,
63.7,
79.5,
85.5,
61.4,
63.7,
95.8,
46,
101,
79.9,
59,
86.1,
94.6,
58.2,
34.4,
62.5,
44.1,
21.3,
91.8,
27.9,
76,
70.5,
17.5,
90.5,
65.7,
68.5,
90,
64.3,
65.7,
88.3,
94,
38.1,
36,
12.2,
52.8,
20.6,
14.3,
27.6,
43.9,
73.7,
49.2,
63.6,
20.8,
34.6,
22.6,
81.7,
74.1,
61.1,
87.5,
82.8,
53.6,
61.1,
40.8,
50,
87,
69.4,
29.7,
72.8,
36.2,
77.9,
66.9,
63,
44.3,
0.7,
56.5,
57.3,
33.8,
86.4,
65.2,
44,
66.6,
74.9,
46.1,
31.8,
50,
61.2,
77.9,
93.3,
68.8,
62.6,
10.8,
49.9,
79.6,
0,
24.2,
45,
77.9,
58.6,
67.9,
84.1,
41.1,
77,
31.1,
8.2,
42.2,
73,
86.9,
22.7,
50.3,
41,
3.7,
92.9,
78.2,
56.9,
66,
75.4,
87.7,
42.9,
38.4,
69.1,
37.8,
76.6,
58.1,
73.2,
48.3,
63,
72.9,
56.3,
38.7,
51.5,
80.7,
64.3,
55.6,
24.6,
44.8,
27.4,
82.8,
30.9,
57.2,
48.6,
49.9,
50.7,
64.2,
13.4,
33.3,
86.2,
30.6,
19.8,
77.4,
59.2,
87.6,
83.9,
46,
66.6,
61.5,
39.7,
82.6,
57.5,
85.7,
39.2,
59.4,
50.1,
77.5,
58.4,
77.1,
81.6,
46.7,
73.9,
40.3,
82.1,
82.3,
6,
44.4,
46.7,
63.6,
0.2,
16.4,
13.8,
92.3,
28.9,
75.8,
70.1,
33.5,
74.4,
83,
46.7,
44.4,
29.4,
49.7,
23,
58.9,
26.5,
3.5,
45.4,
30.8,
21.5,
70.2,
48,
44,
90.4,
17.3,
58.7,
56.3,
89.8,
41.8,
69.9,
54.9,
85.2,
84.7,
39.3,
72.1,
70.8,
36.3,
72.1,
9.5,
66.6,
68,
76.8,
60.4,
50.5,
73.4,
23.1,
37.4,
44.5,
85.1,
31.5,
78.2,
19.8,
45.5,
70.5,
77.9,
91.5,
54.6,
76.2,
45.7,
72.5,
36.1,
90.1,
41.5,
49.2,
52.1,
24.9,
58.8,
39.1,
89.3,
0.5,
7.2,
68.6,
31.7,
79.7,
39.6,
76.3,
72.7,
31.1,
35,
54.1,
70.7,
53,
70.1,
79.4,
69.8,
67.1,
41.6,
82.5,
71.1,
32.6,
20.5,
71.6,
79.1,
16.3,
91.5,
45.9,
92.2,
0,
55.1,
49,
25.6,
51.7,
45,
45,
32.8,
80.2,
74.4,
31.8,
46.8,
49,
32.1,
64,
47.8,
49.1,
65.1,
65,
56.8,
44,
65.1,
70.6,
34.4,
77,
72.9,
81.5,
57.6,
48.1,
51.6,
54,
61.2,
91.4,
47.1,
33.7,
28.5,
61.2,
32.9,
46,
67.7,
88,
4.9,
88.5,
73.3,
71.4,
60,
53.1,
70.7,
95.2,
39.1,
66.4,
87.4,
53.6,
84.5,
78.9,
77.1,
54.6,
57.3,
42.9,
98.4,
55,
25.7,
46.5,
74.8,
62.2,
46.6,
31.1,
40.1,
82.6,
59.9,
38.8,
71.6,
63,
26.1,
76.6,
41.1,
17,
22.9,
57.2,
36.4,
45.9,
49.3,
69.8,
83.8,
83.3,
54.3,
73.4,
56,
35.4,
87.9,
71,
94.3,
78.6,
0,
37.7,
23.6,
85.4,
38.9,
41.2,
5.1,
50.2,
79.8,
62.7,
32.1,
73.8,
73.2,
54.2,
73.1,
87.3,
50.2,
23.8,
30.2,
74.6,
40,
70,
23.8,
76,
86.1,
50,
58.6,
71.8,
26.4,
8.9,
55.5,
69.9,
45,
74.3,
35.4,
97.7,
26.4,
27.9,
79.7,
92.8,
63.6,
0,
43,
61.1,
14.1,
62,
39.2,
74.2,
55.3,
45.1,
74,
83.9,
77.9,
69.1,
27.3,
42.8,
0,
22.8,
33,
56,
14.1,
0,
56.4,
50.7,
79.4,
67.3,
87.2,
81.7,
46.3,
64.7,
84.9,
55.2,
68.7,
38.8,
48.7,
90.8,
51.4,
63.8,
29,
47.5,
0,
96,
26.8,
54.2,
17.7,
50.5,
24.8,
73.4,
7.6,
81.6,
41.4,
30.7,
53,
28.7,
21,
20.7,
64,
38.9,
65.3,
72.3,
27.7,
73.4,
83.3,
65,
80.7,
99.8,
98.5,
86.6,
72.1,
50,
44.4,
65.7,
48.9,
51.2,
72.5,
51,
85.3,
63.5,
39.5,
54.7,
45.3,
55.7,
97,
68.3,
55.5,
73.8,
84.1,
85.1,
46.3,
26.8,
28.8,
30.8,
49.4,
47.2,
54.9,
49.2,
43.7,
71.8,
99.2,
39.3,
82.5,
66,
21.7,
35,
90.5,
75.2,
69.3,
28,
88.9,
93.3,
87.6,
99.2,
55.5,
34,
43.3,
74.2,
60.9,
50.2,
49,
60.8,
17.4,
33.6,
25.3,
57.1,
56.3,
20,
45.7,
59.1,
34.9,
3.8,
73,
54.4,
39.9,
51.4,
39.1,
82.7,
6.2,
59.3,
63,
66.5,
76.9,
28.2,
57.7,
73.7,
49.7,
21.2,
63.9,
4.1,
11.5,
22,
38.2,
63.1,
45.5,
49.9,
34.2,
18.5,
70.8,
79.9,
76.1,
39.4,
9.8,
96.3,
32.2,
67.6,
58.2,
94.2,
86.3,
31.7,
40.6,
7.8,
76.7,
63.7,
24.7,
54.9,
63.7,
66.1,
79.8,
91.2,
102.4,
56.9,
86.9,
89.3,
51.3,
76.4,
21.5,
59.5,
40.8,
58.8,
41.3,
71.1,
55.5,
79,
62.8,
34.4,
78.7,
89.6,
10.6,
41.6,
26.9,
19,
62.5,
39.4,
86.9,
82.4,
39,
69.1,
74.3,
82.4,
91.6,
81,
40.5,
78.5,
84.3,
33.4,
95.5,
23.6,
36.2,
58.3,
64.7,
49.2,
44.2,
48.2,
80.5,
64.7,
28.3,
97.2,
78.6,
96,
97.3,
56,
84.5,
34.4,
25.7,
69.9,
64.6,
52.3,
128.4,
41.2,
64.7,
69.1,
54.7,
87.7,
64.2,
94.9,
43.6,
43.3,
58.6,
57.4,
88,
45.4,
57.8,
81.2,
50.5,
77,
60.3,
9.1,
47.8,
23.5,
10.5,
68.9,
38.6,
52,
53.9,
35.1,
48.6,
88.9,
57.7,
89,
71.9,
12.1,
10.5,
63,
76.7,
13.9,
27.1,
47.1,
77,
77.6,
56.8,
54.1,
59.1,
15.1,
55.6,
64.8,
21,
48.1,
73.4,
81.7,
41.6,
12.7,
50.9,
36.3,
21.7,
57.9,
30.8,
51.8,
30.3,
46.2,
16.4,
48.1,
17,
25.2,
54.3,
20.3,
90,
48.1,
4,
89.5,
22.5,
87.4,
65.1,
17.7,
97,
60.4,
61.8,
34,
27.6,
52,
64.9,
57.2,
71.2,
33.1,
73.7,
74.8,
84.1,
72.6,
45.5,
67.1,
48.3,
55.4,
14.6,
76.7,
80.8,
47.1,
70.3,
58.8,
33.5,
29.7,
79.2,
35.7,
21,
78.4,
76.4,
69.2,
82.7,
46.3,
22.1,
51.8,
36.8,
92.9,
78.9,
88.4,
44.6,
60.7,
71.8,
28.9,
58.3,
53,
33.4,
46.6,
41,
57.4,
54.3,
70.2,
40.3,
62.8,
97,
62.5,
34.7,
54.6,
38.2,
76.2,
64,
65.2,
56.4,
90.4,
63.6,
95.3,
69.1,
76.9,
51.2,
76,
24.5,
42.3,
37.7,
61.4,
92.5,
90.8,
56,
51.3,
82.7,
62.9,
53.5,
67,
61.8,
25.8,
98.5,
40,
71.7,
82.5,
66.1,
69.7,
26.8,
49.3,
86.1,
57.3,
27.6,
16.2,
95.9,
42.8,
66,
43.3,
44.8,
64.7,
78.3,
69,
36.4,
75,
95.7,
45.1,
24.9,
50.3,
73.2,
35.9,
101.9,
98.3,
65,
71.6,
78.2,
59.2,
42.2,
56.6,
83.8,
54,
63,
44.4,
94.6,
7.2,
32.9,
44.3,
60.3,
41.2,
79.1,
97,
10.2,
71.5,
13.7,
11.3,
45.1,
41.3,
33.8,
51.2,
92.1,
49.6,
58,
55.3,
2.7,
21.5,
35.2,
58.5,
45.6,
61.4,
89.8,
64.6,
54.5,
43.2,
33.7,
51.6,
86.7,
88.4,
54.2,
16.4,
0.8,
60.5,
69.7,
21.9,
70.2,
22.3,
39.9,
74.4,
53.3,
42.1,
46.7,
22.1,
63.6,
49.9,
19.9,
22.7,
76.9,
58.4,
38.9,
43.4,
73.8,
89.8,
53.3,
92.1,
65.6,
54.4,
64.8,
56.2,
56.9,
90,
19.7,
46.6,
26.7,
26.3,
48.6,
0,
17.9,
80.6,
71.1,
63.7,
0.4,
74.1,
73.9,
50.2,
38.6,
24.2,
31.7,
35.4,
64.2,
79.6,
65,
43.9,
20.1,
50,
29.9,
16.8,
28.1,
44.5,
28.7,
33.2,
17.2,
61.5,
23.6,
30.8,
38.4,
77.1,
63.1,
87.3,
14.7,
73.7,
70,
61.8,
51.1,
56.7,
26.8,
70.7,
38.1,
55.9,
55.1,
66.5,
84,
78.4,
77.3,
80.2,
59.8,
95.8,
42.4,
58.3,
52.3,
94.5,
97.3,
73.6,
60.2,
24.3,
46.1,
79.2,
39.3,
62.4,
40.7,
null,
60.8,
27.6,
85.4,
27.8,
71,
90.6,
42.8,
89.3,
64.8,
67.8,
33.2,
83.1,
59,
39.6,
81.8,
77.2,
32.2,
62.2,
27,
38.3,
78.8,
50.8,
87.4,
73.8,
91,
41.6,
91.1,
51.4,
46.9,
55.2,
79.3,
49.8,
49.7,
82.3,
69.9,
19,
47.3,
52.5,
75.9,
62.9,
67.5,
40.2,
85.2,
90.8,
86.3,
84.7,
21.5,
51.1,
72.2,
31.9,
64,
43.5,
59.3,
100.9,
2.3,
2.5,
58.1,
45,
33.9,
31.2,
31.3,
46.5,
94.2,
58.1,
51,
52.4,
65.6,
82.5,
21.9,
62.2,
38.2,
63.9,
57,
90.2,
93.1,
54.9,
56.4,
48.2,
60.8,
50.7,
55.4,
87.3,
96.4,
66.2,
13.4,
80.6,
73,
13.7,
21.2,
55.4,
66.9,
19.6,
70.6,
42.2,
64,
67.6,
11.8,
88.6,
79.4,
57.3,
76.6,
82.1,
45.2,
85.3,
90.8,
65.7,
86.8,
24.8,
99.3,
96.2,
40.3,
55.1,
52,
44.8,
13.9,
60.6,
99,
67.2,
90,
33.8,
59.8,
68.3,
90.1,
44,
57.2,
84.7,
58.6,
61.7,
52,
47.8,
72.5,
63.9,
16.4,
35.4,
42.1,
3.1,
62.6,
59.1,
17.6,
57.2,
67.1,
35.1,
77.7,
32.2,
36.9,
78.7,
79.4,
77.5,
48.3,
80.2,
47.5,
94.7,
50.8,
37,
55.7,
45.6,
93.6,
82.8,
63,
56.3,
46.1,
35.6,
47.4,
49.7,
96.2,
2.7,
65.4,
47.5,
74,
10.9,
51.9,
88.4,
50.7,
83.7,
44.7,
31.1,
76,
58.8,
83.9,
82,
45,
24.3,
48,
35.8,
56.2,
13.9,
20.2,
52,
55.1,
30.2,
35.9,
15.9,
65.6,
96.5,
13.5,
77,
42.4,
46,
77.6,
41.4,
44.4,
50,
55.8,
87.5,
96.2,
67,
40.8,
47.1,
16.2,
45.5,
68,
19.2,
94.8,
71.1,
24.4,
48.7,
84.4,
67.4,
62.9,
69.7,
88.6,
62.4,
70.9,
44.2,
79.8,
36.6,
57.5,
56.2,
22.4,
88.7,
54.7,
66.4,
59.3,
64.3,
69.7,
86.5,
61.1,
62.2,
55,
51.9,
19.3,
92.3,
43.5,
69.9,
58.1,
89.7,
94.1,
47.5,
46.8,
83.6,
54.2,
75.2,
67.5,
51.9,
77.7,
92.9,
80.5,
19.7,
97.4,
74,
45.6,
101,
4.7,
90.7,
64.6,
40.2,
49.7,
63.1,
92.6,
3.3,
34,
79.1,
59.5,
14,
0.8,
44.3,
57.2,
68.2,
5.8,
63.3,
60.3,
49.1,
67.9,
52.5,
87.2,
0,
17.7,
46.6,
65.5,
57.4,
83.6,
3.7,
53.4,
19.3,
83.8,
38.1,
78.1,
20.5,
52.4,
29.5,
82,
74.9,
74.6,
69.6,
65.3,
45.3,
72.6,
40.3,
20,
91.7,
45.6,
7.1,
35,
53.2,
44.1,
21.9,
39.1,
68.9,
48.1,
52.9,
34.2,
19,
47.1,
37.8,
38.7,
93.5,
77,
36.1,
53.4,
37,
55.3,
42.8,
29.5,
56.8,
67.3,
0,
80.7,
46.8,
54,
72.2,
98.7,
73,
59,
73.4,
35.3,
14,
9.7,
42.9,
61.8,
38,
66.2,
97.3,
41.1,
11.6,
56,
18.3,
28.9,
6.2,
71.7,
56.3,
81.1,
45.4,
48.8,
41.3,
66.4,
53.3,
86,
26.7,
59.8,
10.9,
77.2,
41,
72.1,
71.4,
null,
88.9,
50.7,
33.6,
4.9,
47,
26.5,
92.5,
50.4,
23.7,
45.5,
71,
24.8,
94.1,
13,
90.1,
33.7,
69.6,
43.5,
71.6,
76,
63.7,
49.7,
37.4,
64.2,
21.7,
8.5,
74.7,
48.1,
17.4,
52,
43.4,
29.8,
88.1,
65.4,
28.2,
78.3,
47.8,
65.1,
95.2,
27.4,
42.9,
80.2,
38.7,
68,
6.3,
55.9,
49,
47.7,
73.9,
38.6,
6.4,
52.7,
93.3,
64.4,
44.4,
73.2,
46.4,
99.1,
84.3,
33.1,
75.3,
84.9,
44.5,
66.8,
71.6,
66.2,
84.1,
93.5,
56.3,
42.2,
23,
66.1,
48.6,
63,
44.8,
77.7,
68.1,
59.8,
93,
32.7,
91.9,
83.6,
26.5,
66.2,
31.5,
36,
62.4,
57.2,
69.4,
36.8,
39.2,
59.4,
58.8,
46.2,
29.3,
101.4,
44.5,
59,
53,
6.8,
42.1,
82.6,
76.5,
27.4,
10.4,
27.4,
93.9,
37.4,
43.4,
50.7,
67.1,
60.1,
31,
39.4,
29.1,
67,
78.1,
56.1,
67.9,
90.1,
86.9,
39.5,
88.8,
65.2,
42.2,
70,
51.7,
34.7,
81.7,
25.1,
60.2,
32.8,
27.3,
34.8,
98.5,
54.9,
30.9,
82.1,
25,
78.8,
37.2,
89,
91.2,
40.5,
54.9,
67.7,
42.4,
53.4,
46.3,
34.8,
59.1,
80.6,
67.2,
83,
87.5,
13.2,
62.4,
67.5,
45.9,
76.1,
35.9,
54.4,
73.5,
15.3,
66.5,
73.2,
68.1,
48.7,
75.7,
70,
65.6,
73.2,
62.5,
48.5,
73.8,
79.4,
65.8,
44.2,
49.3,
67.4,
80.4,
64.8,
74.3,
54,
56.5,
97.2,
25.8,
52.3,
38.3,
88.6,
46.4,
82.7,
31.4,
36.1,
84.7,
44.7,
44.6,
56.3,
14.4,
83.7,
60.8,
48.9,
34.3,
29.3,
51.9,
87.6,
16.4,
42.2,
94.9,
69.1,
57.8,
44.5,
23.5,
75.6,
77.3,
39.6,
81.4,
97.5,
36.1,
37.4,
90.6,
60.1,
81.9,
85.4,
78.7,
66.9,
1.6,
46.9,
29.3,
85.2,
70.8,
8.7,
41.2,
44.2,
71.6,
75.4,
65.8,
37.1,
0,
32.9,
29.1,
32.1,
66.1,
37.4,
36.6,
44.8,
88.1,
21.6,
95.9,
55.6,
27.7,
37.4,
68.5,
52.7,
29.7,
10.2,
97.8,
49,
36.2,
18.7,
43,
55.8,
77.8,
53.4,
64,
36,
58.2,
38,
60.5,
75.1,
36.4,
82,
80.9,
55.8,
29.3,
83.6,
87.6,
50.4,
58.4,
1.5,
69.8,
118.4,
39.9,
20.7,
12.4,
59.8,
90.6,
23,
16.2,
26.9,
52.8,
33.4,
28.6,
57.1,
66.8,
53.5,
65.1,
59.4,
49,
90.6,
29.5,
46.6,
61.5,
74.1,
15.2,
7.3,
79.5,
59.6,
42.6,
24.7,
39.5,
71.1,
90.2,
41.1,
61.7,
32.7,
56.6,
8.1,
78.6,
77,
98.2,
47.9,
37,
84.1,
62.9,
78.2,
66.5,
53.8,
62.8,
51.2,
72.2,
64.8,
14.6,
34.8,
37.5,
75.6,
46.1,
37.5,
52.3,
6.4,
16,
41.4,
35.7,
10.9,
22.3,
53.4,
78.1,
40.4,
80.6,
70.9,
46.2,
97,
26.7,
86,
48.7,
86.3,
16.9,
64,
72,
62.6,
87.6,
57.6,
14.1,
84.8,
71.4,
22.3,
83,
77.1,
61.5,
54.9,
76.4,
51,
34,
62.3,
20.9,
72.3,
33.8,
57.6,
30.8,
67.5,
93.6,
26.8,
26.2,
52,
39.2,
27.1,
64.7,
93.6,
62.6,
91.8,
86.4,
41.5,
null,
58.2,
81,
68.1,
54.8,
23.1,
32,
29.8,
86.8,
67.5,
49.5,
86.9,
86.6,
38.5,
57.5,
51.8,
51.6,
24.2,
32.2,
40,
46.1,
73.5,
61.8,
62.2,
33.9,
72.9,
69.4,
57.3,
45.2,
26.6,
43.9,
66.5,
76,
97.2,
50.4,
31.7,
21.5,
78.4,
77,
13.6,
38.8,
86.9,
57.9,
83.7,
52.4,
31.9,
22.3,
67.7,
44.8,
41.9,
46.8,
40,
54.3,
72.6,
86.9,
74.7,
62.6,
50.5,
13.3,
39.7,
26.8,
19.4,
0.7,
62,
35.9,
30.5,
75.2,
78,
80.2,
52.3,
69.7,
69.8,
69.7,
8.2,
53.3,
38.7,
56.2,
73,
94.7,
66.6,
26.1,
58.1,
51.5,
80.8,
63.4,
85.3,
60.2,
13.4,
65.1,
24.3,
46.8,
34.3,
98,
81.2,
97.8,
70.9,
87.4,
57.9,
23.8,
31.3,
61.1,
49.9,
70.6,
93.3,
73.1,
15,
36.4,
44.1,
78.8,
65.8,
30.4,
82.4,
68.5,
71,
73.6,
19.9,
52.2,
52.8,
91,
89.2,
0.8,
65.2,
82.1,
72.6,
48.3,
75.3,
82,
67.2,
33.2,
37.2,
33.9,
52.4,
46.2,
36,
53.3,
71.8,
9.3,
73.6,
50.4,
95.3,
89.2,
64,
70.3,
18.5,
81.8,
31.5,
17.4,
null,
62,
50.9,
75.9,
29,
2.8,
48.7,
83.7,
23.9,
91.4,
47.7,
28.1,
83.7,
103.9,
47.6,
10,
57.6,
69.2,
55.1,
2.6,
37,
97.3,
35.5,
97.8,
31.3,
63.2,
16.3,
84.6,
77.2,
54.4,
69.4,
80,
73,
58.9,
7.4,
70.2,
95.3,
58.6,
68.1,
76.6,
72.8,
87.7,
67.6,
46.4,
65.8,
74.4,
66,
38.5,
31.1,
50.7,
32.9,
90.8,
66.6,
69.3,
95.1,
39,
19.3,
50.3,
69.7,
83.9,
87.1,
40.5,
64.8,
59.5,
55.9,
49.1,
81,
92.8,
78.9,
82,
1.3,
49.8,
33.5,
12.1,
0.6,
78.1,
87.5,
88.9,
36.3,
85.6,
78.5,
97.7,
61,
79.4,
37.3,
77.3,
3,
24.5,
79.9,
55.2,
45.1,
42,
45.9,
46.9,
74.3,
77.6,
57.7,
11.3,
40.8,
45,
43,
5.3,
85.4,
89.9,
69.3,
69.3,
88.9,
41,
97.9,
13.7,
39.6,
47.9,
5.7,
57.6,
48.2,
71.3,
20.2,
36.2,
28.7,
42.2,
63.4,
42.5,
51.8,
66.9,
30.4,
80.1,
12.2,
65.6,
51.5,
26.5,
101.6,
72.8,
28,
59.5,
83.2,
54.1,
82.7,
85.9,
79,
51.8,
80.4,
74.7,
32.6,
88.5,
53,
91.3,
37,
64.8,
34,
49.2,
46.7,
80.2,
58.1,
60.1,
47.9,
49.9,
29.7,
100.6,
16.7,
83.2,
83.9,
51.1,
30.9,
66,
94.3,
74.6,
56.6,
21,
39.1,
91.8,
39.2,
36,
34,
83.6,
83.1,
57.4,
100.4,
45.3,
77.5,
38.8,
12,
87.2,
39.2,
85,
56,
39.8,
37.3,
84.6,
46.2,
46.2,
45.1,
35.4,
69.7,
96,
73.3,
57.6,
79,
37.7,
32.7,
59.3,
46.9,
17.4,
58.7,
71.7,
67.7,
69.9,
45.4,
79.2,
17.7,
62.7,
80.3,
19.9,
69.6,
61.6,
79.1,
60.5,
41.9,
82.1,
85.9,
78.2,
81.1,
74.6,
76.6,
17.4,
56.9,
46.5,
33.4,
33.7,
58.9,
62.5,
62.8,
84,
85.1,
47.1,
77.9,
59.3,
94.7,
19.8,
48.9,
2.4,
37.3,
65.9,
59.1,
36,
65.1,
44.8,
30.5,
65.2,
28.4,
72.6,
74.9,
30.6,
38.2,
62.9,
41.9,
67.8,
66.1,
55.4,
5.7,
41.9,
75.3,
83.1,
45.5,
66.1,
44.3,
73.6,
70.1,
81.7,
8.1,
61.2,
89.5,
79.7,
74.7,
76.8,
45.8,
71.1,
98.7,
45.3,
75.8,
41.9,
65.7,
89,
11.4,
74.2,
48.3,
68,
69.1,
42.5,
70.7,
94.1,
21.8,
68.3,
22.9,
36.2,
87.1,
69,
52.9,
51.3,
93.8,
42.6,
31.8,
62.2,
47.2,
23.9,
null,
29.6,
37.3,
60.4,
29.3,
79.7,
51.4,
35,
59.2,
82.6,
69.9,
51.3,
53.8,
39.1,
53.7,
15.7,
68.8,
62,
78.5,
71.6,
87.1,
61.4,
93.7,
31.8,
75,
84.3,
62.7,
59.1,
29.5,
38.4,
49.7,
91,
70.6,
22,
59.6,
11.7,
74,
92.4,
43.8,
39.6,
33.6,
60.1,
61.7,
28,
80.8,
72.9,
60,
66.3,
41.7,
82.8,
41.8,
57.3,
22.7,
72.6,
10,
41.6,
40.4,
91.2,
48,
37.1,
55.7,
10.4,
6.5,
41.3,
78.4,
6.4,
98.3,
98.3,
97.5,
42.2,
52,
46.7,
88.4,
99.8,
53.7,
48.8,
63.9,
62.4,
46.5,
39.8,
94.7,
25.3,
15.7,
13.8,
9.4,
65.9,
47.9,
53,
85.7,
22.2,
72.8,
32.4,
51.2,
87.4,
42,
82.8,
78.8,
58.7,
59.9,
33.5,
26.5,
12,
27.8,
37.7,
31.1,
37.6,
86.7,
70.3,
51.8,
53.6,
37.1,
77.4,
25.8,
43.9,
96.4,
73,
21,
25.7,
44.3,
60.4,
56.4,
61.4,
38.5,
56.5,
43.9,
37.6,
15.4,
11,
10.7,
17.8,
52.8,
50,
66.4,
92.8,
71.9,
85.5,
49.8,
68.3,
85.6,
68.5,
56.9,
36,
85.8,
84,
87.7,
65,
53.6,
42.2,
38.2,
37,
88.4,
39,
58.7,
54.3,
81.2,
51.9,
75.3,
39.9,
95.2,
61.9,
51.5,
58.2,
53.2,
71,
18.4,
92.6,
40.6,
40.1,
59.2,
41.8,
50.9,
87.8,
58.7,
15.7,
52.6,
68.6,
24.4,
12.8,
40.8,
82,
70.5,
48.6,
78.2,
74.4,
43.1,
65.4,
63.6,
57.4,
27.8,
66.5,
47.8,
26.1,
41.8,
90.8,
28.8,
68,
60.4,
59,
33.4,
58.3,
44.9,
97.7,
61.7,
59.6,
44.4,
68.6,
22.4,
18.3,
86.1,
69.9,
80.3,
75.7,
90.9,
39.6,
86.9,
50.7,
80.2,
46.1,
21,
71.3,
94.6,
56.4,
39.9,
68.7,
85.3,
55.3,
57.4,
66.6,
47.7,
48.5,
67.2,
92.1,
61.8,
50.8,
68.5,
72.3,
6,
52.9,
70.4,
35.4,
68.2,
80.6,
69.5,
19.4,
38.4,
81.8,
63.7,
95.3,
52.5,
70.8,
69.6,
30.5,
82.5,
67.9,
25.4,
56.7,
47.3,
55.6,
36.4,
79.6,
24.2,
98.3,
94,
34.3,
91.7,
62.9,
43.4,
46,
64,
80.2,
55.4,
77.3,
71.2,
50.7,
68.7,
84.4,
60,
50.2,
36.5,
15.4,
79,
79.2,
92.6,
69.5,
71.2,
52.6,
34.7,
63.3,
97.2,
65.9,
97.2,
81.7,
91.3,
75.8,
66.8,
32.5,
41.4,
19,
68.9,
62.9,
44.7,
36.3,
43.7,
56.8,
79,
62.3,
37.9,
71.8,
28.2,
95.9,
87.4,
58.9,
16.3,
84.1,
51.3,
25.7,
40.7,
27.2,
57.4,
61,
87.2,
81.6,
22.5,
13.8,
93.9,
9.1,
7.7,
35.5,
71.9,
9.1,
70.9,
35.4,
40.6,
48.8,
57.7,
60.7,
34,
21.9,
7.1,
55.9,
92.6,
24.9,
35.6,
81.2,
88.6,
11.7,
65.9,
68.7,
81.4,
77.9,
64.3,
68.4,
0.1,
51.8,
69.2,
96.6,
65.3,
38.5,
27.7,
68.1,
44.6,
29.4,
38.2,
71.2,
51.4,
59.3,
72.4,
64.9,
81,
23.1,
68,
16.4,
95.1,
60.9,
23.5,
64.3,
66.8,
78.4,
85.7,
44.8,
21.7,
18.8,
56,
48.4,
18.5,
77.5,
58.2,
33.6,
72.4,
61.3,
77.8,
83.2,
32.7,
40.4,
51,
69,
54.8,
73.8,
43.6,
38.5,
54.4,
85.9,
10.2,
77.2,
77.4,
33.9,
55.2,
56.3,
53.8,
24.2,
40.2,
95.6,
97.8,
69.1,
81.5,
32.3,
34.7,
79,
25.4,
44.2,
31.5,
51.4,
100,
64.4,
65.6,
54.8,
42.7,
53.5,
66.9,
41.4,
37.9,
37.3,
80.2,
28.5,
5.4,
2.1,
95.4,
55.8,
87.6,
35.8,
47.9,
20.6,
82.2,
94.3,
32,
68,
34.4,
41,
57.1,
66.4,
30.9,
47.5,
51,
48.4,
62.6,
64.2,
88.9,
47,
21.4,
21.8,
68.9,
42.5,
5.6,
19.5,
55,
63.3,
24.8,
21.4,
31.9,
79.3,
34.9,
77.8,
40.7,
57.9,
10.8,
50,
67.7,
48.6,
63.4,
42.1,
68.2,
99.9,
20.5,
23.3,
64.8,
72.7,
68.1,
99,
51.3,
38.9,
44.7,
0.2,
27.6,
25,
62.1,
34.2,
78,
42.1,
81.2,
98.3,
14.7,
87.6,
91,
70.2,
90.2,
49.4,
77,
51.9,
42.8,
42,
66.9,
37.3,
55.8,
41.3,
42.9,
30.3,
40,
69.4,
81.6,
23.8,
9.8,
77.6,
25.4,
36.2,
87.7,
67.1,
24.5,
56.8,
26.1,
48.5,
23.7,
46.4,
81,
45.4,
80.9,
75.4,
55.1,
69.2,
49.3,
89.7,
20.4,
12.2,
25.4,
30,
40.8,
47.3,
78.8,
89.9,
48.1,
65.4,
67.5,
62.6,
96.7,
61.6,
0.5,
15.7,
47,
45,
65.8,
47.9,
78.8,
52.9,
85.8,
34.8,
36.2,
86.4,
31.3,
42.5,
89,
65.7,
43.3,
56.2,
58.2,
70,
73.8,
20.5,
76.3,
72,
27.5,
59.6,
54.8,
75.1,
57.7,
82.8,
66,
50.3,
75.4,
52.1,
7.7,
100.2,
32.3,
29,
50.2,
37.4,
39.5,
48,
0.2,
56.4,
58.6,
69.7,
78.2,
0,
47.2,
64.5,
64.7,
71.7,
61.8,
35.6,
26.7,
65.8,
33.9,
81.5,
0.1,
36,
81.1,
66.3,
49.2,
23.7,
36.7,
62.7,
44.1,
28.6,
43.5,
21,
49.5,
34.5,
72,
67,
86.2,
95.5,
2.2,
19.5,
39.3,
24.2,
67,
13.2,
27,
85,
22,
47.5,
87.8,
52.5,
40,
39.4,
31.4,
61.1,
90.1,
17.7,
24,
48.1,
30.7,
73.6,
75,
64.6,
54.5,
45.3,
59,
3.1,
28.9,
79.8,
63.9,
16.6,
30.8,
42.1,
47,
72.1,
68.8,
91.1,
69.2,
29.5,
57.6,
29.8,
33.9,
61.1,
21.7,
61.4,
67.8,
6.3,
84,
78.1,
23.2,
59.7,
49.5,
85.2,
27.8,
75.9,
73,
58.3,
71.4,
72.6,
30.1,
42.9,
46,
30,
35.4,
61,
63,
65.4,
42.8,
94.3,
74.5,
91.7,
51,
50.8,
28.2,
40.7,
59.8,
63.2,
56.9,
42.2,
57.3,
54.3,
74.3,
73.4,
36.9,
81.4,
56.8,
91.7,
53,
50.8,
24.3,
84.7,
91.2,
52.3,
65.6,
57.4,
49.6,
61.4,
64.7,
79.7,
69.7,
43.5,
92.9,
44.8,
42.5,
37.4,
49,
44.2,
84.2,
11.8,
59.5,
69.8,
33.9,
60,
62.2,
47.6,
27.4,
101.6,
68.9,
85.1,
54.6,
60.3,
62,
47.2,
8.7,
36,
67.3,
77.3,
23.6,
48.5,
92.3,
41.3,
94.8,
27.6,
46.7,
94.3,
3.7,
54.1,
41.4,
74.5,
53,
62.7,
96.9,
89.4,
91.3,
64.9,
54.9,
36.9,
74.5,
74,
49.8,
48.5,
96.2,
67.3,
34.4,
64.2,
89.8,
86.6,
35.8,
28,
82.6,
73.7,
27.1,
69.6,
52.1,
50.9,
36,
60.7,
42.5,
44.6,
36,
30.3,
43.6,
37.4,
55.3,
32.5,
53.8,
97.5,
23.3,
80,
56,
80.4,
98.6,
99.1,
62.6,
20.6,
65.3,
70.4,
80.8,
10.3,
69.1,
0,
47.6,
65.8,
86.7,
78.9,
60.6,
13.1,
15.2,
84.6,
28.3,
52.7,
35.6,
65.2,
72,
18.6,
26.1,
50.6,
50.7,
62.7,
55.6,
83.1,
51.1,
67.7,
10.3,
47.4,
43.9,
36.3,
20,
88.1,
41.6,
69.3,
83.1,
45.8,
69,
51.3,
63.8,
8.7,
40,
52.9,
51.4,
16.6,
53.4,
15.8,
70.9,
73,
28.2,
141.1,
89.6,
61.1,
46.4,
98.7,
88.2,
62.1,
94,
53.9,
49,
79.4,
38,
23.3,
88.4,
67.3,
31.1,
58.1,
61.7,
63.7,
67.5,
67.9,
11.6,
10.2,
86.7,
40.9,
59,
47.9,
54.4,
57,
56.7,
7.5,
35.8,
57.8,
79.5,
43.8,
41.7,
40,
45.6,
73.5,
90.9,
53.8,
72.3,
52.6,
34.1,
73.7,
1.7,
20.3,
48.8,
59.3,
41,
77.9,
48,
38.2,
74,
96.3,
42.3,
82.1,
40,
61.9,
68.8,
34.8,
34,
57.1,
64.6,
76.5,
45.9,
78.4,
66.3,
65,
81.2,
50.3,
69.7,
47.2,
62.6,
67.5,
56.1,
62.2,
11.7,
84.7,
65.5,
90.8,
99.1,
43,
78.7,
50.5,
46.3,
89.5,
1.4,
35.7,
65.4,
34.9,
23.2,
44.5,
31.4,
46.1,
60.5,
22.4,
94.4,
16.7,
1.1,
7.1,
45.7,
41.4,
18.1,
8.3,
36,
36.7,
61.2,
56.3,
75.5,
66.1,
54.9,
56,
46.3,
70.8,
64.3,
65.1,
30.8,
32.2,
94.7,
57.1,
72.7,
61,
82.8,
70.6,
3.1,
77.5,
82.5,
37.4,
72,
51.7,
45.8,
96.6,
24.3,
47.4,
78.7,
62.6,
31,
63.7,
56.8,
70.7,
87.2,
47.4,
23.5,
97.1,
34.4,
45.9,
36.9,
35.6,
21.9,
40.8,
58.3,
38.6,
28.8,
99.2,
83.8,
14.9,
35.5,
24.8,
42.8,
65,
15.3,
78,
95.4,
98.8,
76.7,
60.4,
85.7,
20,
71.7,
83.8,
79.5,
47.1,
63.7,
35.3,
49.4,
52.9,
83.9,
99.3,
34.3,
56.2,
47.8,
26,
94.3,
51.8,
45,
66.6,
53,
54.2,
95,
17.4,
54.1,
96.9,
64.6,
64.6,
64.7,
36,
74.2,
83.7,
93.8,
54.2,
57.2,
67,
95.9,
64.1,
83.1,
67.6,
61.3,
2,
97.5,
91.8,
13,
64.7,
40.2,
38.4,
43.2,
77.4,
59.1,
26.6,
36.4,
55.5,
41.4,
83.7,
36.7,
73.8,
29.2,
54.8,
58.5,
76,
69.2,
80.5,
67.9,
64.4,
73.5,
30.6,
46.6,
29.7,
51.3,
71,
88.5,
53.8,
60.7,
27.6,
71,
32.9,
5.5,
12,
28.5,
57,
21,
35.7,
86.5,
39.9,
55.8,
54.5,
32.4,
59.8,
77.1,
30.5,
58.5,
44.4,
63.5,
95,
51.6,
39.6,
74.9,
10.8,
22.8,
49.5,
53.3,
33.9,
59,
64.7,
57.8,
66.8,
13.9,
38.8,
47.2,
19.2,
31,
80.3,
78.1,
56.9,
34.3,
13.8,
88.8,
80.6,
17.9,
75.2,
10.6,
37.8,
60.8,
55.1,
16.8,
15.9,
51.2,
66.4,
74.8,
51.2,
91.9,
63.8,
51.6,
81.8,
52.1,
77.5,
41.7,
58.9,
65.6,
47.1,
29.2,
32.1,
92.8,
82.3,
87.8,
47.7,
69,
15.2,
39.7,
73.5,
48.1,
91.1,
40.5,
86.9,
57.3,
36,
67.3,
86.5,
60.3,
60.4,
52.3,
72.8,
82.4,
27.8,
54,
50.6,
57.9,
76.9,
74.5,
96.6,
45.9,
23.5,
49.3,
52.9,
60.1,
71.2,
57.2,
36.8,
53.5,
49.4,
62.7,
69.7,
32.7,
25.7,
58.2,
25.9,
59,
57,
83.6,
44,
72.7,
46.9,
83.2,
60.7,
53.9,
81,
86.9,
89.3,
18.9,
35,
47.3,
49.4,
28.4,
73.3,
99,
75.9,
69.7,
50.4,
57.8,
48.9,
69,
69.8,
50,
57.4,
70.4,
56.6,
55.1,
58.7,
13.9,
42.9,
92.1,
72.8,
75,
40,
73.2,
58.1,
17.9,
46.9,
50.9,
94,
41.5,
38.1,
57.3,
81.8,
62.9,
76.5,
45.5,
70,
28.4,
60.5,
74,
92.2,
93.8,
28.5,
17.1,
38.2,
89.8,
54.5,
50.8,
80.5,
60,
62.5,
37.8,
42,
2.2,
57.7,
39.8,
84.3,
25.5,
36,
30.1,
19.5,
36.5,
97.9,
29.9,
91.4,
9,
11.2,
41.1,
33,
84,
38.7,
90.7,
56.5,
66.9,
21.8,
43.5,
67.4,
49.9,
84.3,
58,
88.7,
51.3,
57.1,
11.9,
93.9,
44.9,
79.7,
3.2,
37,
37.7,
97.2,
87.4,
65.1,
60.3,
74.3,
34.5,
39,
13.2,
25.5,
37.4,
71.2,
81.2,
27.5,
78.7,
63.4,
63.1,
32,
69.3,
12.1,
65.7,
60.4,
71.2,
87.6,
66.3,
95,
24.8,
31.5,
89.8,
99.3,
39,
52.6,
80,
43.7,
59.1,
54.7,
47.8,
65.5,
39.4,
72.5,
85.5,
89.8,
72.1,
91,
46.7,
74,
61.8,
45.9,
36.3,
33.1,
1.2,
3.3,
14.1,
51.1,
63.2,
22.3,
35.8,
58.1,
92.7,
74.2,
56,
34.4,
79,
5.5,
68.1,
72.5,
83.6,
75,
70.2,
60.7,
61.1,
0.2,
41.2,
95.8,
53.9,
44.6,
72.7,
29.8,
57.8,
12.6,
76.2,
28.9,
59.1,
10.5,
54.5,
58.1,
43,
75,
53.4,
95.3,
57.3,
45.1,
78.6,
87.3,
54.8,
97.2,
51.8,
74.8,
92.7,
43.8,
31.3,
50.1,
48.7,
35.7,
7.4,
36.3,
66.8,
67.6,
46.7,
92.7,
27.6,
48.1,
9,
71.4,
90.7,
92.9,
75.9,
68.2,
68.7,
74.5,
47.5,
35.1,
17.7,
8.6,
0,
65.3,
45.1,
44.8,
69.2,
70.6,
48.5,
57.8,
52,
17.8,
92.3,
46.5,
44.4,
53.6,
49.9,
49.2,
66.7,
31.5,
29.4,
40,
52.4,
81.1,
23.9,
11.9,
25.5,
10.7,
59.3,
64.3,
26.8,
90.9,
51.9,
35.3,
58.7,
78.2,
66.2,
10.4,
77.5,
102.8,
56.2,
58.1,
9,
43.9,
26,
85,
34.1,
66.2,
61.6,
68,
44.8,
37.1,
73.7,
64.1,
75.3,
23.1,
14.9,
34.7,
51.5,
34.1,
38.2,
66.8,
56.1,
75,
63,
6.3,
39.5,
52.9,
32.7,
27.9,
84.4,
87.6,
39.5,
67.7,
64.4,
60.6,
79.8,
54.2,
62.9,
97.7,
71.3,
64.4,
18.4,
61.4,
38.2,
39.5,
58.3,
62.6,
51.7,
51.2,
97.8,
63.2,
57.8,
46.4,
38.4,
90.3,
68.9,
92.9,
88.9,
73,
21.6,
56.5,
63.4,
26.2,
70.3,
97.5,
81.3,
4.4,
25.8,
70.4,
23.8,
44.8,
19.9,
32.5,
65.5,
23.6,
4.4,
37.2,
83.2,
46.7,
54.4,
73.3,
65.6,
48.6,
57.4,
46.5,
60.4,
76.6,
64,
52.4,
61.2,
24.9,
86.5,
25,
97.1,
49.3,
81.3,
27.7,
23.2,
53.9,
41,
30.1,
5.6,
33.9,
70.3,
56,
64,
56.6,
71.2,
27,
39.9,
71.5,
30.4,
67.5,
53.9,
44.1,
48.8,
73.2,
47.5,
86.7,
56.4,
83.2,
28,
47.7,
14.4,
40.1,
55.3,
97.9,
36.1,
49.1,
40.5,
43.5,
44.3,
62.1,
83.1,
18.6,
22.1,
64.1,
60.7,
88,
59,
43.1,
35.4,
86.6,
73.1,
47.4,
94.2,
7.2,
71,
57.4,
33,
82.1,
38.8,
31.3,
77.8,
62.9,
34,
74.7,
84.6,
34.9,
79.4,
52.4,
32.3,
75,
10.7,
80.9,
20.5,
81.7,
56.1,
92.8,
63,
98.9,
62.6,
86,
46.4,
69.9,
48.8,
87.2,
51.8,
67.2,
32.9,
38.3,
81.5,
56.2,
77.9,
32.4,
66.7,
86.9,
41.5,
12,
59.6,
28.2,
57,
48.3,
56,
96.4,
31.8,
72,
93,
90.8,
35.6,
33.1,
75.2,
58.5,
47.3,
57.8,
60.1,
62.2,
57.2,
31.9,
88.6,
60.8,
82.6,
53.6,
99.1,
41.1,
90,
44.5,
68.1,
19.1,
90.4,
80.7,
58.9,
13.6,
16.3,
68.5,
92.8,
35.6,
68,
69.1,
19.7,
0,
91,
79.6,
19.3,
20,
81.8,
67.7,
62.7,
33,
55,
14.7,
55.8,
81.5,
11.9,
49,
47.8,
59,
87.1,
49.6,
35.7,
40.3,
49,
58.7,
78.9,
9.2,
54.8,
47.4,
50.1,
43.5,
72.2,
14.4,
69.3,
31.7,
44.1,
52.7,
55.3,
57.6,
19.1,
31.8,
46.6,
21,
22,
68.4,
16.1,
72,
31.7,
86.2,
81.3,
80.7,
45.1,
46,
70.1,
51.4,
48.4,
30.6,
77.8,
69.7,
88.5,
47.7,
81.9,
15.2,
35.6,
92.9,
48.1,
81.3,
67.2,
25.1,
41.1,
55.1,
24.5,
42.1,
69.6,
55.4,
40.2,
60.1,
35.6,
91,
97.7,
29.7,
84.8,
23.9,
68.6,
27.3,
19.3,
44.8,
98.5,
70.4,
84.5,
70,
94.1,
36.6,
43,
43.3,
49.7,
55,
43.6,
30.7,
84.1,
20,
53.1,
83.9,
94.8,
86.8,
69.3,
81.3,
47.8,
64,
43.1,
68.2,
44.4,
60.1,
10.9,
58,
52.1,
11.6,
52,
58.6,
29.4,
18.1,
96.2,
36.1,
27.9,
73.7,
75,
68.3,
24.7,
32.3,
101,
54.2,
47.5,
81.6,
77.4,
67.2,
79.1,
28.6,
92.6,
69.7,
60.7,
22.4,
87.7,
7.7,
86.9,
61.2,
93.6,
56.6,
48.7,
64.1,
80,
72.2,
44.9,
49.9,
58.9,
89,
57.1,
82.5,
32,
46.2,
64.9,
17.2,
36,
62.4,
36.2,
42.5,
33.2,
68.4,
38.8,
49,
37.8,
20.3,
46.1,
68.4,
72.6,
70.3,
17.7,
21.8,
75,
64.3,
48,
89.4,
42.7,
37.4,
43.9,
51.2,
62.1,
38.1,
97.2,
20.9,
48.4,
47.5,
76,
66.9,
53,
91.2,
34.1,
30.8,
68,
51.1,
84.8,
47.4,
38.3,
77.8,
76.4,
83.7,
83.8,
33.7,
2.3,
73,
51.6,
88.1,
55.3,
50.9,
55.7,
58.7,
89.1,
39.2,
63.3,
57,
59.9,
64.2,
47.7,
92.3,
24.6,
76.8,
18.8,
61.5,
23.7,
80.5,
78,
47,
50.5,
80.3,
79,
59.4,
94.9,
54.2,
99.6,
53.1,
0,
37.3,
51.5,
43.9,
36.7,
14.3,
31.8,
21.9,
30.2,
57.3,
55.3,
3.4,
31.1,
44,
32.5,
81.8,
54.8,
91.1,
82.3,
24.3,
51.3,
63.1,
82.9,
41,
75.2,
49.7,
60.2,
45.6,
30.1,
37.6,
91.5,
71.7,
70.9,
52.2,
85.6,
93.9,
80.3,
40.5,
81.7,
25.8,
0.3,
16.8,
17.2,
62.1,
30.6,
66,
85,
68.1,
51.2,
58.8,
101.6,
95.1,
55.5,
64.3,
93,
48.9,
59.6,
83.2,
86.9,
25,
67,
21.9,
33.6,
68.5,
63.1,
93.6,
67.4,
76.6,
29.6,
92.9,
27.2,
84.7,
67,
13.5,
58,
92.2,
71.5,
38.9,
54.4,
3.3,
58.2,
46.5,
87.9,
55.6,
82.4,
42.1,
43.7,
44.2,
83,
95,
63.5,
60.2,
51.9,
50.8,
59.7,
98.1,
41.1,
55.8,
78.7,
19.1,
7,
36.2,
93.4,
72.5,
51.6,
49,
8.2,
66.1,
36.78,
74.1,
49.8,
81.2,
41.5,
19.6,
39.2,
70.6,
42.4,
19.5,
56.9,
62.4,
56.8,
86.3,
23.3,
2.5,
30.4,
76.3,
29.8,
55,
23.6,
23.6,
62.6,
17.6,
76.7,
64.6,
9.5,
67.5,
59.7,
20.7,
48.5,
58,
11.1,
30.6,
15.1,
71,
99.7,
49.4,
38.5,
94.5,
9.5,
81.6,
40.1,
70,
70.5,
63.6,
53.9,
58.8,
15.2,
62.3,
62.6,
64.1,
60.7,
34.8,
69,
55.9,
26,
47.3,
71.9,
55,
54.7,
70,
45.5,
70.6,
25.3,
55.8,
64.6,
88,
44.3,
15.9,
20.2,
50.2,
26,
88.1,
56.6,
21.9,
9.6,
55.3,
73,
81.4,
91.4,
30.5,
43.1,
13.4,
91.5,
46.9,
3.2,
60.8,
14.6,
47.1,
33,
96.4,
88.8,
15,
61.4,
21.3,
33,
62.9,
27.6,
68.9,
40.6,
68.3,
77.8,
73.7,
55.8,
40.6,
52.6,
55.1,
33.2,
52.1,
71.1,
65.7,
63.1,
83,
44.1,
78.5,
93.5,
66.3,
101.2,
62.4,
78.8,
22.6,
36.9,
69,
67.3,
25.6,
70,
21.7,
18.4,
23.8,
26.7,
57.7,
30.9,
12.2,
86,
11.3,
41.2,
29.9,
69.9,
79.2,
86.2,
28.7,
20.7,
61.3,
41,
70.6,
63.3,
37.3,
67.9,
76.9,
20.6,
35.4,
82.4,
67.8,
89,
68.9,
70.6,
80.8,
90.6,
58.9,
87.4,
72,
26.2,
74.7,
62.8,
87.3,
47.2,
69.6,
49.7,
41.4,
65.9,
83.8,
59.5,
10,
51.9,
18.9,
34.1,
3.6,
38,
54.2,
79.3,
56.5,
34.7,
28.9,
50.7,
37.4,
26.7,
57.5,
48.6,
66.1,
10,
47.3,
75.4,
62.4,
56.1,
50.5,
50.7,
38.3,
52.4,
56.1,
58.1,
86.8,
46.4,
53.3,
40.1,
51.1,
60.9,
81.7,
0,
37.5,
45.3,
42.5,
70.8,
47,
61,
38,
35.9,
12.9,
29.3,
22.4,
76.7,
20.4,
68,
37.3,
65.8,
36.5,
76.1,
24.1,
48.6,
34.6,
34.7,
9.5,
74.2,
94.5,
10.4,
28.9,
81.2,
32,
69.7,
54.9,
32.9,
87.3,
92.4,
84.9,
66.7,
28.3,
51.7,
70.5,
77.4,
10,
41.3,
42.3,
57,
35.1,
72.8,
73.3,
62.2,
77.3,
68.9,
84.5,
65.1,
60.9,
45.9,
68.4,
59.3,
47.2,
25.5,
87.6,
77.4,
21.5,
57.6,
79.1,
32.4,
35.3,
77.9,
77.8,
59.8,
24.5,
25.3,
25,
88.1,
31.3,
44.9,
56.5,
73.4,
27.5,
80.4,
83.9,
44.4,
72.6,
46.5,
62.5,
46.5,
78.4,
36.9,
16.3,
49.1,
30.5,
91.8,
67.3,
43.9,
10.3,
25.7,
36.7,
86.7,
26.5,
93.3,
18.7,
60,
38.7,
48.8,
71.6,
22.9,
76.4,
23.1,
90.8,
37.4,
13,
1.8,
89.8,
89,
70.1,
83,
42.9,
76.7,
45.1,
83.9,
80.6,
59.2,
87,
93.2,
62.2,
48.2,
36.3,
48.1,
83.6,
81.3,
91.1,
8.8,
26.8,
110.4,
44.9,
67.7,
58.1,
92,
29.7,
73.7,
53.5,
15.4,
62.9,
91,
79.5,
42.2,
3.6,
5.3,
20.9,
33.8,
13.8,
43.1,
64.7,
57.7,
26.8,
18,
68.6,
45.7,
19.4,
59.4,
72.8,
22.8,
46.7,
92.1,
80.6,
54.2,
54.9,
76.4,
49.9,
0.5,
64,
64.2,
75.6,
80.2,
79.8,
69.5,
2,
95,
44,
55.7,
47.5,
50.2,
82.8,
49.6,
43.8,
41.9,
66.2,
54.2,
45,
67.9,
59.7,
66.3,
69.4,
33.9,
34.3,
20.8,
32.5,
19.2,
0,
54.2,
99.2,
92.7,
74,
54.4,
43.9,
81.2,
94,
61.7,
56.6,
40.4,
22.7,
40.2,
61.2,
69.7,
63.6,
19.8,
40.2,
14.6,
72.4,
76.2,
54.8,
35,
55.7,
74.7,
2.2,
19.3,
88.8,
63.3,
50.9,
71.5,
1.7,
17.1,
99.4,
79.4,
50.4,
71,
61.8,
65.9,
35.8,
21.5,
47.7,
76.5,
94.1,
29.3,
80.6,
62,
52.6,
91.1,
78.5,
81.4,
21.3,
46.3,
44.3,
66.2,
16,
77.4,
54.5,
63.2,
10.4,
12.3,
67.2,
84.6,
50.7,
33.7,
32.8,
63.8,
41.9,
67.7,
39.4,
58.9,
29.1,
26.1,
84.3,
65,
1.2,
77.3,
67.7,
60.2,
85.7,
78.8,
63.2,
49.1,
63.8,
35.9,
47.4,
59.3,
61.9,
85.1,
77.6,
75.3,
16.9,
24.7,
46.5,
47.6,
27.6,
62,
54.4,
42.6,
38.7,
39.1,
65.9,
87.8,
65.9,
59.6,
70.5,
22.8,
61.9,
76.4,
5.9,
31.8,
26.5,
13.1,
48.5,
82.5,
52.1,
60.3,
88.2,
65.6,
62.9,
82.8,
66,
24.2,
54,
62.8,
81.3,
17.7,
32.9,
4.6,
39,
28.9,
18,
72.1,
66.1,
69.6,
83.3,
47.7,
27.3,
57.7,
72.7,
84.7,
55.8,
70.6,
74.9,
33.9,
43.8,
67.3,
42.7,
67.2,
59.7,
22,
22.9,
82,
79.6,
42.8,
15.3,
25.9,
55.8,
91.6,
22,
84.9,
48.4,
85.6,
29.5,
73.4,
80.1,
72.1,
75.9,
90.5,
22.4,
45.6,
51.8,
90.7,
53,
31.6,
54,
14.6,
87,
102.2,
60.6,
73.7,
99.5,
44.3,
91.5,
45.2,
47.2,
84.2,
93.3,
31.6,
72.9,
21.7,
68.5,
69,
44.2,
30.3,
61.2,
98.6,
46.1,
33.7,
84.4,
96.7,
24.2,
73.2,
76.1,
54.2,
56.1,
27.8,
51.2,
24.3,
74.5,
55.4,
42.1,
50.9,
113,
47,
21.8,
89.4,
63.7,
8.3,
40,
68.1,
58,
42.9,
73.4,
37.7,
86.3,
79.7,
69,
81.9,
43.1,
82.1,
96.8,
50.4,
38.2,
29.9,
48.2,
43.7,
22,
37.9,
65,
77.6,
93.6,
57.9,
44.8,
67.3,
58,
61.6,
74.5,
63.1,
97.2,
33.6,
99.7,
30.4,
19.7,
49.3,
54.5,
25,
0.9,
48.3,
3.1,
21.4,
56.6,
79.2,
30.4,
82.6,
94,
84.5,
69.2,
21.5,
48.8,
47.2,
29.3,
19.5,
91.6,
68,
77.5,
65.6,
87,
31.8,
75.8,
60.6,
42.1,
63.9,
54.5,
41.9,
52.8,
2.8,
31.9,
90.4,
97.9,
85.7,
18.1,
72.7,
70,
44.2,
94.3,
86.1,
25.9,
78.7,
56.5,
40.8,
76.9,
84.1,
69.2,
90.6,
102.7,
89.6,
37.8,
56.4,
52,
55.5,
22.6,
51,
62.9,
62.7,
75.8,
54.2,
41.6,
40.1,
26,
33.3,
13.5,
23.5,
74.3,
35.7,
97.9,
45.8,
54.3,
49,
68.4,
64.7,
15.1,
34.9,
24.3,
37.6,
69.6,
40.7,
28.7,
65.7,
0,
67.8,
58,
55,
68.2,
59,
76.9,
60.1,
35.9,
31.4,
46.9,
48.1,
54.4,
11.4,
70.3,
93.2,
85.5,
57.4,
56.5,
42,
92.8,
58.6,
70.1,
25.4,
38,
62.9,
88,
25.2,
14,
91.4,
56.1,
38.3,
76.9,
16.1,
38.8,
63.2,
52.8,
28.9,
12.4,
24.1,
66.2,
57.8,
73.3,
65.4,
41.5,
69.1,
37.8,
63.5,
54.3,
10.6,
60.2,
49.7,
7.6,
38,
57.2,
45.4,
38.6,
31.7,
94.3,
80.6,
56.6,
42.7,
69.3,
94,
70.7,
83.8,
16.4,
35.5,
15.5,
38.6,
67.1,
60.2,
94.3,
62.3,
50.5,
15.5,
33.4,
67.7,
19.2,
7,
36.5,
68.1,
59,
71.8,
72.8,
5.4,
64.6,
54.9,
46.5,
80.2,
91.9,
64.6,
5.1,
44,
20.6,
91.3,
69.9,
56.3,
55.5,
95.2,
42.8,
48.7,
80.9,
40.2,
11.6,
19.1,
20,
54.7,
26.6,
95,
80,
86.8,
58.4,
48.7,
70.7,
48.7,
46.5,
92.5,
86.6,
62.9,
79.9,
74.7,
17.8,
49,
62.9,
27.4,
84.9,
97.6,
72.6,
42.7,
73.7,
70.7,
63.8,
79.7,
66.6,
85.4,
33.9,
45.3,
68.2,
67.1,
32.1,
83.4,
66.6,
69.9,
31.7,
10.7,
68.3,
45.4,
53.6,
92.9,
74.6,
55.4,
77.8,
73.3,
51.3,
45.6,
38.9,
87.7,
66.2,
34.2,
64,
78.1,
81.9,
68.9,
71,
68.6,
43.4,
63.4,
38.7,
72.1,
27.1,
37.2,
40.5,
19.2,
119.1,
53.4,
54.3,
33.3,
93.1,
79.9,
41.7,
33.2,
17.3,
36.7,
86.3,
77.6,
60.9,
39.6,
81.2,
54.7,
51.7,
60.2,
31.2,
80.3,
82.2,
80.3,
79.1,
26.5,
67.3,
92.3,
42.4,
76.5,
67,
66.8,
39.5,
58.8,
60.4,
58.6,
29.7,
17.5,
95,
18.2,
4.8,
86.7,
41.3,
23,
66.8,
53.4,
35.9,
10.4,
16.3,
50.5,
33.5,
66,
68.4,
33.8,
75.7,
38.5,
34.7,
79.1,
86.2,
83.9,
59.2,
80,
76.2,
89.1,
52.6,
77.8,
44.7,
51.9,
81.5,
33.9,
34.4,
85.2,
35.8,
34.8,
62.3,
70.4,
79.3,
18.6,
0,
61.5,
52.9,
53.3,
35.6,
27.9,
61.5,
88.8,
37.4,
73.2,
31.4,
45.1,
56.3,
48.1,
66.8,
82.2,
29.9,
14.5,
79.4,
45.9,
45.1,
35.9,
39.3,
99.4,
47,
34.7,
30.2,
71.1,
95.3,
74.3,
31.1,
80.6,
99.3,
78.2,
52.4,
94,
32.6,
38.3,
23.1,
19,
46.6,
127.6,
20,
62.7,
75,
28.3,
49,
70.7,
17.5,
13.4,
85.9,
54,
43.6,
8.4,
39.3,
50.3,
50.1,
89.3,
63.6,
55.1,
37.6,
29.8,
99.2,
67.6,
85.7,
51.4,
20.2,
75.4,
29.9,
50.1,
88.5,
53.7,
89.7,
23.6,
70,
78,
38,
40.6,
39.8,
70.1,
37.4,
74,
37.7,
62.2,
54.6,
24.8,
37,
12.3,
72.7,
29.3,
23.5,
52.8,
20.4,
17.1,
16.1,
53.6,
42,
27.3,
31.2,
78,
72.3,
57.3,
47.9,
89.3,
77.9,
57.5,
24.7,
46,
36,
57,
76.9,
38.6,
62,
84.2,
24.5,
73.3,
86.4,
82.5,
92.7,
59.6,
34.4,
20.9,
45.2,
96.6,
77.6,
51.1,
53.3,
66,
76.2,
88.9,
80.8,
52.6,
0,
83.2,
55.2,
20.5,
41,
81.9,
64.7,
85.9,
73,
21,
65.2,
37.5,
15.6,
38.3,
86.9,
66.5,
86.9,
35.2,
75.9,
39.1,
18.7,
11.2,
47.5,
36.8,
91.7,
45.7,
33.5,
61.5,
24.6,
61.9,
43.3,
75.5,
41.2,
87.7,
16.3,
62.9,
77.3,
90.2,
63.9,
63.6,
55.8,
35.1,
66.1,
58.8,
80.2,
40.1,
13.8,
45.5,
81.9,
71.3,
61.1,
59.6,
75.8,
48.2,
27.3,
80.8,
54.3,
29.1,
34.5,
58.7,
35.4,
24.6,
58.8,
30.6,
41.7,
53,
37,
12.4,
16.2,
57.7,
39.5,
42.5,
38.5,
92.6,
3.1,
54.1,
73.1,
86.5,
8.4,
74.4,
37.8,
54,
85.6,
39,
73.1,
70.3,
69,
0.5,
47.8,
30.9,
43.4,
65.8,
81.6,
17.2,
31,
76.5,
70.1,
91.8,
56.7,
31.9,
58.6,
32.8,
33.5,
38.4,
7.9,
97.7,
24.7,
27.3,
56,
61.9,
46.8,
97.8,
45.5,
88.4,
72.4,
16.8,
63.4,
20.3,
23.5,
28,
79,
64.1,
36.7,
18,
51.4,
50.9,
83.8,
80.3,
47,
94.1,
43.3,
91.8,
90,
68.5,
74.1,
99.1,
39.9,
52.2,
62.3,
26,
75.2,
31.8,
22.4,
69,
79.9,
77.4,
57.3,
59.6,
0.9,
20.8,
65.5,
70.7,
31,
45.9,
59.6,
66.3,
43.1,
48.1,
86.1,
51.7,
90.4,
87,
30.6,
95.4,
95.5,
38,
83,
5,
71.9,
45.9,
65.2,
21.4,
71.4,
45.3,
23.8,
74.5,
48.9,
35,
73,
19.1,
98.7,
25.1,
80.8,
55.3,
34.1,
94.9,
12.8,
7.2,
60.4,
46.1,
52.3,
52.6,
46.6,
76.5,
58.9,
63.7,
36,
70.7,
43.6,
41.5,
39.2,
21,
61.8,
29.4,
39.5,
64.1,
64.4,
75.5,
72.6,
15.6,
10.2,
29.2,
78.1,
85.5,
39.3,
24.4,
90,
50.1,
85.7,
14.7,
23.9,
12.5,
29,
15.6,
9,
14.8,
80,
18.6,
76.8,
73.5,
67.3,
29.9,
91.4,
16.8,
34.8,
37.4,
25.9,
77.9,
73.7,
39.3,
45.2,
56,
22.5,
100.4,
97.4,
60.2,
91.9,
37.1,
26.1,
76.4,
19.5,
64.6,
62.6,
43.1,
55.6,
50.9,
22.3,
74.3,
56.8,
61.1,
16.7,
40.3,
42.9,
76,
30.1,
36.6,
48.9,
58.5,
47.7,
75.8,
14.9,
41.2,
18.3,
25,
84.7,
54.5,
63.8,
87.6,
67.7,
79.1,
51.7,
85.9,
9.2,
87.8,
70,
89.5,
51.8,
42.7,
54.7,
84.7,
55.5,
18.4,
41.7,
30.9,
76.3,
35.7,
49,
16.1,
72.3,
70.5,
19.2,
33,
3.1,
41.8,
38.8,
51.6,
51.9,
49.3,
75.3,
77.8,
49.4,
85.5,
5.8,
90.5,
84.3,
81.7,
70.4,
46.9,
31,
30.1,
66.9,
54.7,
72.7,
38.9,
17.5,
66.5,
47.1,
45.7,
73.1,
71,
47.6,
64.6,
53.4,
71.9,
27,
56.2,
81.4,
72.4,
31.9,
100,
35.7,
38.1,
37.3,
34.7,
67.9,
90.3,
80.4,
28.8,
12.1,
27,
5.1,
61.9,
54.7,
32.5,
61.4,
45.3,
97.8,
88.2,
96.2,
94.9,
4,
22.4,
71.1,
64.6,
93.7,
90.1,
79.1,
91.7,
46.4,
44.4,
71.9,
18.1,
59.6,
75.6,
74.3,
57.6,
98.9,
33,
71,
87.6,
72.9,
33.6,
66,
83.8,
74.5,
91.2,
39.5,
44.4,
28.5,
40.6,
27.5,
48.6,
68.6,
88.5,
43.2,
61.9,
32.7,
26.8,
48.4,
49.6,
46,
63.7,
54.3,
80.6,
69.2,
39.5,
36.2,
64.8,
52.8,
49.4,
27.6,
73.9,
19.9,
48,
31,
69.7,
39.3,
97.7,
46,
78.3,
59.5,
57.6,
56.1,
40.5,
71.4,
13.4,
40.2,
33,
42,
30,
86.9,
53.6,
68.7,
88.9,
79.7,
22.1,
40.3,
64.4,
91.8,
37.8,
39,
51.9,
32.9,
84.8,
30.7,
67.5,
45.5,
28.5,
67.9,
56.6,
0,
55.1,
72.7,
95.1,
62.9,
43.6,
10.1,
80.6,
72.8,
26.7,
73.6,
36.9,
15.1,
84.8,
39.1,
75.2,
42.1,
34.4,
30.3,
64,
74.7,
98.3,
35.3,
83.4,
81.4,
96,
97.2,
78.6,
40.6,
47.3,
68.9,
90.6,
22.3,
21.5,
31.3,
36.5,
44.6,
54.1,
81.4,
35.5,
45.6,
8.6,
28.5,
61.7,
94.9,
66.5,
90.7,
77,
71.1,
69.1,
66.8,
37.4,
70.6,
44.1,
42.3,
62,
75.4,
76.9,
39.7,
25.1,
0,
75.8,
65.1,
46,
37.3,
54.1,
58.6,
15.1,
81.2,
47.6,
28.2,
77.6,
92.9,
63.9,
79.3,
98.1,
55,
86.5,
70.7,
42.8,
54,
85.5,
83.9,
44.4,
57.6,
19.7,
14.5,
95,
37.8,
60.7,
10.9,
74.6,
92.4,
84.5,
68.8,
66.4,
62.4,
35.5,
61.4,
80.7,
49.4,
69.4,
82.2,
31.3,
43.2,
64.1,
56.1,
50.9,
49.7,
51,
96,
92.3,
70.3,
46.9,
73,
46.9,
34.5,
73.6,
54.9,
74,
23,
46.3,
70.8,
88,
70.4,
21.4,
49,
93.8,
44.2,
94.6,
4,
77.5,
87.1,
93,
68.6,
3.9,
91.9,
63.3,
20.3,
45.7,
46.2,
58.4,
68,
90.4,
34.6,
73.1,
53.9,
83.9,
36.4,
85.1,
83.5,
3.8,
52.9,
59,
32.8,
85,
54.2,
76.6,
67.1,
35.9,
42.5,
20.3,
22.2,
84.9,
56,
48.3,
77.6,
77.7,
0,
76,
74.6,
55.2,
85.9,
68.5,
39.5,
20.4,
6.6,
62.2,
81.2,
35,
22.6,
40.4,
84,
65.8,
55.1,
97.5,
76.1,
77.7,
55.2,
62.3,
44.2,
50.2,
69.3,
7.1,
13.3,
79.8,
18.3,
26.5,
60.5,
67.5,
101.6,
70.5,
13.1,
34.4,
89.6,
4.1,
65.4,
66.5,
77.6,
28.4,
86.8,
58.6,
21.3,
55.8,
81.9,
73.3,
63.3,
50.6,
54.5,
51.6,
65.8,
20.5,
98.6,
98.1,
22.1,
76.2,
64.4,
37.8,
48.5,
34.3,
46.9,
75.5,
91.9,
34.4,
41.2,
45.8,
30.4,
60.1,
18,
59.4,
44.6,
38.3,
70,
63.2,
75.1,
60.4,
35.3,
64.3,
36.8,
68.2,
57.1,
89,
71.9,
12.3,
6.2,
49.6,
84.1,
85.5,
62.9,
13.6,
49.8,
49.7,
51.9,
64.1,
71.6,
18,
6.9,
53.9,
42,
55,
77.6,
25.9,
70.4,
78.1,
90.7,
86.8,
96.8,
1.8,
94.1,
72,
96.6,
54.7,
44.8,
37.8,
78,
7.6,
75,
93.7,
33,
50.6,
35.6,
28,
28.4,
75.3,
47.8,
54,
46.4,
45.5,
10.5,
17.3,
48.7,
30.3,
38.5,
70.7,
51.2,
82.2,
89.4,
59.9,
80.3,
3.1,
75.6,
75.5,
62.9,
34,
84.4,
77.8,
29.6,
15.2,
73.6,
73.3,
47,
85,
70.7,
84.5,
79.1,
68.8,
71.9,
35.9,
22,
46.1,
72.1,
97.7,
52.5,
70.2,
22.2,
36.2,
46.9,
59.4,
40.8,
86.2,
99,
66.5,
53.1,
65.3,
56.4,
40.6,
61.2,
28.3,
79.2,
63,
42.5,
67.9,
50,
58.7,
23.8,
64.1,
69,
35.6,
77.4,
33.4,
20.5,
64.7,
47.9,
94.7,
34.7,
27.2,
25.6,
73.6,
49,
8.2,
17.5,
72,
53.6,
69.1,
41.6,
29.3,
55,
80.2,
55.9,
1.3,
69.5,
51.3,
84.2,
90.8,
69.9,
54.8,
85.8,
83.7,
78.1,
53.3,
45.2,
48.3,
65.6,
28.5,
97,
14.5,
18.9,
79,
40.2,
74.4,
83.5,
37,
43,
71.1,
62.1,
61.2,
72.5,
45.9,
79.7,
69.6,
67.2,
56.5,
59.9,
52.7,
17.5,
32.6,
79.9,
27,
38.3,
98.4,
61.8,
23.6,
67.7,
92.4,
75.8,
19.9,
50.6,
24.8,
26.8,
67.6,
44.2,
59.6,
69.6,
46,
68.5,
26.6,
50.9,
69.1,
55.6,
26.3,
90.5,
47.9,
24,
60,
45.5,
37.8,
86,
85.4,
64.8,
60.5,
58.6,
37.7,
35.8,
81.2,
74.1,
80,
41.3,
84.8,
60.8,
91.1,
30.8,
78,
49.9,
65.8,
42,
75.9,
46.6,
21.1,
29.3,
56.6,
26.7,
24.7,
74.3,
79.5,
41.7,
94.5,
85.6,
28.5,
98.1,
13.2,
39.9,
56.9,
92.5,
31.9,
75,
3.4,
62.3,
46.4,
77.6,
40.3,
49.1,
44.7,
46,
28.8,
84.8,
40.4,
55,
3.3,
73.7,
94.4,
73.6,
71.3,
41.4,
49.2,
79.3,
61.8,
43.4,
64.2,
97,
48.5,
57.2,
76.5,
50.4,
56.3,
53.9,
43.1,
16.7,
73.9,
54.4,
88.7,
92.9,
98.7,
37.4,
51.1,
33.3,
81,
18.5,
69.5,
74.4,
51,
74.9,
30,
27.7,
52.7,
90.8,
54.4,
0,
77.4,
62.7,
80.3,
71.3,
43.4,
76.9,
42.2,
72.9,
22.4,
39.1,
82.3,
9.2,
94.6,
79.4,
27.5,
59.6,
36.5,
44.6,
49.6,
68,
65.7,
null,
18.6,
32.6,
76.6,
31.4,
19.9,
78.7,
80.5,
10.2,
58.3,
24.7,
111.2,
32.9,
28.2,
42.2,
71.3,
18,
35.6,
17.2,
40.8,
81.9,
15.6,
51.7,
78.1,
11.8,
30.5,
63.9,
23.8,
49.6,
52.7,
89.2,
55.5,
53.7,
24.5,
66.6,
79.8,
40.4,
48.9,
28.6,
15.1,
48.5,
28.6,
59.9,
50.6,
80.9,
19.6,
31,
61.6,
77.2,
70.8,
19.2,
38,
97.4,
46.5,
67.2,
93.6,
25,
32.1,
42.8,
42.9,
12.2,
73,
14,
51.8,
69.1,
63.8,
32.5,
21.2,
18.3,
22.8,
14.7,
55,
50.9,
82.3,
83,
52.1,
26.6,
71.4,
64.6,
49.8,
78.2,
88.3,
86.3,
80.2,
80.2,
38.1,
47.7,
24.3,
62,
4.1,
83.5,
70.2,
54,
23.8,
72.5,
20.6,
92.3,
78.1,
51.6,
89.4,
77.3,
75.4,
52.4,
28,
24.6,
56.5,
81.8,
17.3,
48.4,
55.2,
89.3,
29.3,
23,
96.4,
50.2,
58.3,
23.5,
64.6,
97.4,
95.2,
59.5,
19.2,
7,
69.4,
40.3,
86.9,
96,
46.1,
30.6,
73.7,
35.7,
41.8,
92,
15.7,
67.9,
82.9,
37.7,
84.5,
60.8,
91.5,
56,
42.9,
46.7,
99.3,
79.8,
38.3,
93.4,
57.2,
57,
72.1,
8,
58.6,
34.5,
102.3,
74.4,
46,
93.8,
95,
73,
86.9,
74,
63.9,
47.8,
16.3,
45.6,
28.4,
67.5,
65.1,
1.4,
57.1,
48.6,
25.1,
65.6,
43.7,
67,
96.5,
74.8,
58.2,
35,
94.1,
72.6,
17.3,
24.8,
47,
51.2,
43.2,
40.3,
83.6,
41.6,
86.5,
32.4,
34.2,
49.8,
58.3,
35.8,
76.2,
32.9,
71.7,
56.2,
33,
88.4,
64.6,
18.6,
91.2,
63.5,
40.8,
57.9,
65.5,
27.9,
61.3,
10.4,
12.9,
78.8,
69,
25.9,
26.8,
59.9,
0.1,
82.1,
60.2,
51.5,
6.9,
69.1,
31.7,
96.1,
75.4,
18.8,
70.1,
90.2,
37,
39.1,
59.1,
70,
25.9,
37.8,
84.2,
46.7,
73.6,
67.1,
47.3,
57.4,
54.7,
66.2,
53.1,
91.6,
59.6,
33.6,
62.5,
13.9,
22.7,
93,
44.8,
44.7,
73.4,
43.8,
50,
87.8,
13.5,
42.4,
53,
63,
85.2,
46.3,
1.4,
54,
16.9,
41.4,
36.8,
11.6,
79.6,
57.9,
61.7,
74.2,
76.8,
56,
33.1,
79.5,
72.4,
65.2,
44.2,
54.2,
70.2,
55.3,
93.5,
50.8,
87.2,
24.7,
52.4,
46.7,
93.6,
87.9,
43,
12.9,
57.3,
54.8,
27.4,
72.5,
42.7,
66.7,
81.3,
48.2,
66.1,
30.5,
14,
54.8,
80.4,
44.3,
87.4,
22.3,
65.7,
41.5,
37.9,
81.5,
52.9,
70.7,
25.6,
65.8,
74.8,
82.1,
53,
80.8,
28.4,
56.7,
16.3,
40,
47.2,
72.1,
96.2,
56.2,
21.8,
44,
16.1,
43.7,
64.2,
80,
66.9,
15.4,
28.9,
66.6,
66,
41.8,
27.3,
64.3,
26.4,
73,
61.8,
58.7,
29,
3.6,
20.6,
45.1,
90.4,
11.7,
20.1,
39.6,
37.1,
62.6,
11.9,
54.3,
6.2,
93,
57.6,
14.6,
8.2,
78.6,
41.2,
86.5,
90.2,
69.6,
7.4,
31.5,
71,
93.6,
50.5,
45.2,
0.4,
67.1,
66.1,
78.6,
53.9,
46.6,
73.9,
62.2,
75.7,
51.4,
56,
36.9,
83,
53.6,
54,
41.5,
93.7,
48,
15.1,
22,
87.4,
98.1,
60.7,
93,
94.2,
76.6,
19.1,
50.8,
32.3,
79.9,
62.3,
74.2,
9.2,
42.7,
82.9,
61,
88.8,
73.7,
60.4,
19.5,
68.1,
36.8,
57.1,
7.1,
7.6,
84,
66.4,
45.3,
81.5,
66.5,
60.6,
32.9,
85.8,
49.9,
78.4,
39.5,
44,
15,
76.6,
80.6,
68.4,
19.4,
75,
48.3,
46.6,
19,
35.4,
58.4,
75.3,
56.4,
79.6,
93.1,
48.5,
68.4,
86,
64.9,
55.1,
78.6,
76.8,
92.3,
74.5,
77.4,
13.4,
62.4,
77.2,
51.7,
67,
69.3,
51.7,
57.6,
98.6,
6.9,
78.1,
38.4,
86,
26.3,
51.2,
62,
92.4,
90.6,
77,
47.7,
34.6,
40.7,
93.8,
49.9,
85.5,
66.3,
76,
55.4,
68.6,
57.5,
21,
37.9,
78.4,
70,
44.5,
41.3,
49.4,
77.4,
63.9,
40,
38.8,
52.2,
62.2,
56.2,
62,
3,
67.4,
88,
71.8,
9.9,
62.3,
76,
25.5,
86.2,
76.1,
20.7,
0,
52.8,
50.3,
32.8,
84.9,
63.6,
43.4,
57.3,
72.1,
71.6,
26.1,
50.6,
82.5,
46.8,
72.9,
48.8,
75.8,
94.9,
92.3,
34,
76.6,
50.9,
67.8,
52.6,
71.1,
49.9,
74.9,
46.4,
95,
23.4,
76.5,
43.7,
44.3,
43.7,
70,
51.1,
75.6,
62.2,
86.7,
7.6,
32.5,
50.5,
41.5,
45.9,
80.9,
88.1,
59.8,
78.9,
88.5,
80,
56.8,
75.8,
89.9,
34.7,
53.4,
44.9,
85.8,
80.4,
58.7,
29.7,
18.6,
23.8,
72,
79.3,
43.7,
38.3,
67.6,
46.5,
95.2,
89,
13.5,
66.9,
0,
27.8,
83,
24.3,
5,
76.1,
77.3,
43.9,
83.1,
67.7,
69.7,
38.7,
95.4,
63.6,
13.4,
66.5,
25.2,
35.3,
38,
30.9,
63.2,
47.6,
40.7,
27.4,
96,
30,
39.4,
72.2,
32.4,
10.7,
61,
54.5,
40.5,
86.3,
58.9,
34.8,
84.1,
87.6,
90,
64.6,
82.3,
72.3,
49.2,
60.4,
5,
56.7,
11.7,
42.6,
78.1,
26.3,
73.6,
74.3,
62.3,
19.4,
37.6,
25.2,
63.6,
78.8,
55.8,
72.7,
52.2,
80.7,
35,
68.5,
94.4,
75.6,
34,
54.1,
57.1,
14.9,
50,
80.3,
71.8,
88.8,
39.3,
76.2,
52.7,
73.1,
44.8,
37.6,
63.9,
34.6,
93.7,
74.6,
80.8,
94.6,
71.6,
1.9,
29.5,
54.1,
65.8,
48.4,
56.2,
37,
72,
98.6,
79.4,
18.2,
92.9,
54.7,
33.1,
37.4,
87.9,
78.7,
33.8,
14.7,
50.6,
90.9,
76.3,
66.2,
22.9,
94.1,
33.9,
63.2,
46.4,
47.9,
71.2,
80.2,
47.9,
70.2,
63.3,
58.5,
92,
69.5,
80.5,
45.5,
73.6,
94.1,
86.6,
60.4,
61.9,
37,
3.4,
77.2,
65,
51.7,
55.4,
66.7,
83.4,
83.5,
47,
22.9,
81.1,
62.1,
32.9,
43.6,
72.9,
42.1,
6.6,
90.7,
53,
58.3,
40.2,
58.9,
28.7,
56.2,
70.3,
82,
89.5,
19.8,
23.7,
89.1,
77.8,
38.8,
59.8,
9,
84,
82.9,
61,
0,
27.6,
94.7,
64,
53.7,
63.5,
100.8,
64.3,
59,
62.5,
46.6,
37.9,
91.7,
61.6,
93.8,
40.4,
64.1,
7.4,
26.4,
71.8,
90.6,
59,
41.4,
67.5,
39.2,
63.3,
28.2,
95.5,
41.2,
80.7,
17.9,
79,
20.8,
62.7,
22.2,
73.3,
29.3,
44.2,
70.7,
23.5,
91.4,
42.1,
94.9,
18.4,
76,
76.4,
85.1,
76.1,
9.6,
60.5,
39.3,
21.7,
18.1,
42.7,
69,
67.1,
70.8,
10.6,
76.6,
85.6,
68.6,
5.6,
75,
9,
49.9,
78.9,
59.2,
25.9,
49.7,
82,
57.4,
59.1,
59.9,
22.3,
25.4,
22.1,
68.6,
38.1,
58.3,
16,
47.8,
63.7,
25.1,
76.5,
47.9,
39,
61.2,
66.2,
78.9,
87.8,
68.8,
70.3,
73.1,
64.2,
40.4,
10,
65.5,
67.5,
55.1,
48,
84,
86.2,
96.9,
80.5,
14.7,
51.8,
31.3,
46.6,
49.8,
72.4,
27.1,
57.2,
90.5,
0,
3.7,
35.2,
90.9,
10.9,
63,
45.7,
25.1,
20.5,
75,
70.5,
74.9,
19,
52.2,
47.1,
64.6,
58.4,
29.6,
67.1,
42.2,
39.1,
47.3,
28.4,
53.2,
64.3,
85.1,
81.3,
51.1,
78.8,
55,
31,
93.2,
56,
40.4,
0.8,
56,
80.1,
33.9,
52.8,
47.4,
53.3,
68.1,
56.7,
38.6,
73.2,
35.6,
71.2,
79.2,
51.5,
74.7,
58.9,
14.5,
28.3,
73.2,
91.1,
70,
35.3,
79.4,
35.4,
71.1,
55,
70.7,
56.7,
85.1,
38.4,
58.3,
80,
92.6,
23.2,
13.9,
80.3,
56.3,
40.5,
29.4,
55.1,
82.6,
28.7,
70.9,
38.6,
9.1,
16.2,
53.1,
21,
1.5,
35.4,
71,
49.3,
84.6,
83.7,
58.8,
58.9,
48.3,
62.9,
18.2,
8.2,
59.5,
67.3,
38.9,
22.8,
57.2,
33.4,
48.5,
50,
24.6,
58.4,
68.2,
54.7,
69.1,
52.1,
32.5,
60.9,
44.1,
59.8,
42.5,
35.6,
29.1,
83.3,
84.6,
70.2,
82.3,
77.1,
73.9,
42.4,
43.1,
67.2,
54.1,
44.2,
75,
66.3,
65.1,
21.2,
56.4,
97.3,
75,
59.4,
69.1,
61.6,
38.8,
77.4,
69.2,
71.1,
84.7,
58.2,
38.8,
69,
24.6,
57,
34,
43.1,
90.5,
55.6,
65.6,
56.2,
37.2,
25.3,
6.9,
56.1,
70.2,
41.5,
102,
43.9,
72,
48.3,
63.6,
49.2,
80.6,
60,
84,
83.7,
28.4,
81.2,
30.4,
83.7,
91.8,
65.8,
33,
52.3,
64,
44.5,
91,
48.7,
57.9,
61.6,
59.8,
58.1,
93.3,
60.8,
95.3,
39.2,
74.3,
28.4,
37.2,
25.5,
27,
13.8,
47.6,
65,
48.4,
43.4,
79,
29.2,
85.3,
63.4,
46.1,
80.7,
49.9,
92,
88.5,
64.5,
64.3,
7.4,
63.9,
44.8,
56.1,
49.3,
44,
57.7,
72.4,
59,
63.2,
52.8,
23.9,
60.6,
70,
47.1,
23.3,
62.9,
37.5,
69.4,
57.9,
63.7,
50.2,
79.6,
55.4,
54.6,
51.8,
44.4,
82.4,
57.4,
67.6,
53.8,
58.8,
36.7,
59.6,
39.5,
86,
4,
47.2,
61.1,
66.8,
58,
74.1,
91.7,
78.2,
61.7,
59.9,
18.4,
67.7,
17.4,
55.1,
28,
12.3,
86.7,
31.6,
60.1,
58,
68.8,
74.4,
66.3,
87.5,
45.1,
54.2,
35.9,
62.2,
78.5,
94.5,
68.7,
82.4,
69.6,
63.9,
96.8,
41.2,
0.2,
8.3,
83.1,
66.5,
43.3,
29.1,
29.7,
42.7,
84.7,
49.3,
71.8,
59.1,
56.1,
76.6,
66,
83,
49.5,
61.4,
72.3,
47.5,
80.3,
15.2,
73.9,
79.1,
88.1,
9.9,
67.5,
5.8,
94.7,
38.9,
null,
89.9,
36.7,
71.5,
25.8,
78.4,
96.7,
69.9,
83,
34.1,
65,
70.8,
27.6,
57.8,
98.6,
39.7,
62.3,
65.1,
52.6,
40.4,
58.1,
97.8,
59.4,
68,
88.4,
66.7,
20.9,
71.4,
43.2,
79.4,
63.9,
83,
77.8,
53.1,
97,
70.4,
61,
20,
73.7,
7,
91.2,
59,
39.5,
96,
68.9,
36.6,
24.2,
22.8,
77.9,
36.8,
49.4,
36.5,
56.8,
26.8,
76.4,
30.8,
0.9,
49.4,
83.7,
94.5,
54.9,
68.1,
59.5,
57.1,
52,
63.6,
89.7,
53,
86.3,
56.4,
45.5,
62.1,
67.5,
11.7,
48.1,
68,
57,
82.3,
57.5,
63.6,
52.9,
84.1,
82.8,
79.4,
28.1,
21.2,
40.6,
37,
94.4,
19.7,
74.7,
60.8,
24.8,
57.4,
52.3,
93.8,
68.6,
66.4,
41.7,
75.4,
44.4,
30.3,
60.7,
65.7,
85.5,
39.1,
93.3,
55.5,
80,
33.8,
84.6,
73.1,
95.7,
5.5,
53.4,
68.3,
49,
29.3,
66.8,
2.9,
68.9,
31.3,
56.5,
27.7,
91.9,
54,
63.7,
49,
35.3,
64.9,
67,
77,
83.6,
35.9,
37.8,
37.3,
9.7,
15.2,
24.2,
44.3,
85.1,
84.3,
72.9,
75.2,
44.9,
61.6,
1.7,
56.8,
65.6,
40.8,
44.3,
63.2,
75,
87.5,
12,
47.3,
83.5,
20.9,
33.7,
56.2,
68,
37.4,
78.5,
82.1,
87.4,
64.1,
52.6,
88.3,
32.5,
72.6,
0,
100,
86.3,
93.7,
23,
72.7,
47,
75.3,
18.1,
79.6,
61.2,
79.5,
45.7,
58.9,
75.2,
98.8,
38,
56.8,
45.2,
69.8,
44.6,
61.3,
61.2,
27.2,
56.1,
40.4,
53.7,
35.7,
87.9,
32.3,
48.3,
33.9,
98.7,
85.2,
61.4,
46.6,
29,
85.3,
76.7,
56.6,
49,
67.2,
60.4,
69,
82.3,
33.2,
8.7,
40.7,
89.1,
7.1,
74.9,
69.4,
19.9,
43.3,
78.7,
49.9,
58.5,
79.8,
72.2,
42.3,
32.9,
71.4,
56.4,
26.9,
88.1,
30.3,
68.2,
96.4,
44.7,
94.5,
70.9,
80.8,
46.4,
7.6,
70.7,
59.9,
14.1,
80.4,
28.4,
31.6,
36.7,
47.7,
31,
62.2,
59.3,
57.1,
96.3,
73.1,
22.3,
10.8,
75.5,
33.9,
41.3,
75.3,
17,
21.7,
77.8,
48.2,
86.1,
15.2,
26.5,
43,
47.9,
6.8,
19,
59.5,
55.5,
86.2,
77.7,
25.7,
47.6,
54,
50.1,
69.3,
80,
57.7,
42.3,
15.9,
61.2,
43.3,
49.1,
58.4,
39.4,
80.4,
37.9,
77.4,
8.6,
24,
76.4,
32.2,
45,
23.3,
10.5,
75.2,
53.2,
59.8,
78.9,
23.7,
45.5,
28.3,
25,
4.5,
51.9,
42.9,
96.6,
82,
12,
60.9,
38.9,
1.7,
20.6,
82,
42.7,
71.8,
66.4,
26.4,
76.2,
53.3,
6,
89.3,
54.5,
2.9,
98.5,
50,
46,
26.8,
69.9,
26.3,
36.4,
27.7,
19.9,
90.3,
38,
11.3,
62.1,
64.7,
73.6,
37.1,
75,
59,
27.3,
25,
60.6,
63.8,
25.5,
80,
74.7,
63.2,
89.4,
75.3,
29.9,
60.4,
78.3,
98.2,
43.1,
59.4,
24.4,
74.5,
25,
57.1,
63.6,
12.8,
32,
85.3,
39.8,
25.7,
56.8,
68.8,
71.5,
97.6,
37.6,
53.5,
28.4,
89.2,
90.1,
9.3,
43,
40.7,
57.8,
27.8,
32.1,
14.3,
39.2,
91.2,
26.6,
78.7,
96.1,
33.5,
41.1,
100.9,
81.7,
43.1,
77.2,
38.8,
21.2,
6.1,
17.4,
3.6,
31,
32.5,
73.4,
19.4,
82.2,
92.4,
83.3,
35.3,
63.3,
90.1,
22.1,
81.2,
13.6,
43.5,
26.1,
10.3,
72.6,
13.6,
23.4,
66.7,
45.3,
99,
97.6,
23.5,
62.9,
41.6,
97.5,
11.1,
82.5,
93.1,
12.3,
65.7,
41.5,
61.9,
77.6,
17.2,
27,
78.2,
61.3,
41.8,
89.3,
39,
97.9,
5.7,
92,
34.6,
14.3,
52.8,
93.7,
70.5,
82.4,
13.8,
42.3,
59.4,
75.7,
16.3,
67.2,
19.7,
34.9,
43.2,
77,
65,
37,
77.1,
66.9,
84,
74,
90.3,
27.1,
46.7,
46,
63.4,
18,
89.3,
45.4,
75.3,
74.1,
61.2,
96.7,
70.6,
62.4,
84.3,
49.4,
90.1,
68.7,
89.7,
58.6,
86.4,
77,
69.4,
57.1,
62,
57.4,
52.6,
96.6,
88.7,
31.7,
31.1,
96.6,
50,
72.1,
34.1,
58,
28.5,
82.7,
97.5,
78.5,
42,
44,
42.3,
7,
47.6,
49.6,
31.3,
30,
85.4,
82,
73.5,
90.7,
66.7,
91.2,
75.1,
46.2,
55.9,
57.4,
43.1,
33.3,
24.9,
48.8,
62,
49.4,
36.4,
42.6,
56,
29.7,
53.5,
0,
74.8,
63.5,
39.1,
70.5,
28.7,
50,
9.8,
87.2,
59.7,
62,
63.1,
68.7,
64.9,
30.3,
95.5,
28.7,
95.6,
48.4,
72.8,
88,
50,
25.8,
15.9,
46.1,
66.7,
81.6,
39.6,
82.6,
48.2,
62.8,
89,
0,
84.7,
64.9,
65.2,
18,
86.5,
33.7,
81.8,
67.1,
65.9,
4.1,
88.2,
52.3,
1.1,
45.1,
44.1,
78.7,
27.4,
86.1,
84.2,
70,
41.1,
53.7,
26.6,
19.8,
56.4,
57.6,
6.5,
76.4,
91.1,
84,
87.6,
82.1,
62,
84.4,
55.7,
42.4,
44.1,
78.9,
39,
65.5,
34.3,
59.5,
38.2,
70,
88.9,
83.7,
62.6,
71.4,
49,
24.6,
42.4,
41.6,
74.9,
62,
49.8,
80.2,
69.8,
86.4,
16.1,
30,
64.5,
78.7,
34.6,
68.9,
56.3,
38.6,
74.2,
90.1,
93.6,
56.4,
24.9,
41,
31.5,
34.6,
54.1,
70.5,
56.7,
63.5,
78.1,
25.5,
16.7,
51.3,
43.5,
49.7,
97.8,
42.6,
29.6,
49.6,
41.4,
95.1,
92.2,
59.4,
83.7,
31.7,
26.9,
89.2,
64.5,
33.2,
57.1,
2.3,
69.6,
94.6,
95.4,
51.6,
15.8,
57,
74.7,
92.7,
47.9,
31.1,
96.3,
29.3,
76.8,
41.7,
16.2,
55.3,
78.4,
36.1,
69.5,
82.2,
59.4,
63.4,
41.9,
79.7,
53,
12.8,
46.4,
100.4,
59.4,
98.7,
78.2,
89.5,
50,
47.8,
81.3,
77.3,
81.9,
71.2,
86.3,
83,
41,
70.3,
50.1,
77.5,
49.8,
69.9,
23.2,
70.8,
63.8,
65.9,
75.5,
59.4,
54,
53.5,
83.9,
1.3,
71.7,
12,
33.4,
19.6,
37.9,
59.5,
40.2,
78.7,
89.9,
60.2,
77.7,
48.4,
75.4,
72,
49.1,
63,
48.8,
31.8,
55.8,
1.8,
85.1,
33,
67.7,
97.5,
66.5,
21.5,
49.7,
59.7,
42.1,
35.9,
29.1,
51.5,
73.8,
33.2,
37.6,
60.2,
48.1,
30.4,
84.1,
63.7,
46.5,
34.2,
80.7,
4.6,
45.2,
93.3,
48,
53.6,
42.6,
53.4,
83.3,
49.3,
74.9,
60.6,
21.2,
28.4,
28.8,
76.5,
90.9,
81,
39.9,
37.4,
60.7,
86.7,
27.1,
59,
43.2,
95.1,
45.3,
31.7,
80.6,
27.8,
85.2,
102.8,
36.5,
31.7,
43,
52.6,
26.5,
6.3,
60.7,
75,
51.4,
52.9,
31.2,
74.2,
88.7,
14.5,
80.8,
79.2,
45,
57.1,
41.1,
45.5,
25.2,
73.9,
76,
93.9,
4.3,
0,
80.7,
55.3,
98,
53,
75.9,
44.3,
53.3,
61.4,
24.8,
67.8,
52.7,
63.4,
69.1,
13.9,
4,
23.7,
0,
29.8,
24.9,
42,
61,
6.3,
66.5,
21,
40,
10.5,
76.6,
38.9,
41.6,
36.8,
42.6,
61.6,
37.5,
66.7,
45.2,
67.9,
37.2,
62,
54.9,
30.1,
51,
0,
3.7,
52.4,
66.1,
54.3,
71,
58.4,
53.8,
62,
32.3,
37.3,
0.5,
71.5,
77.4,
78.3,
47.5,
50.1,
48.9,
57.9,
48.6,
8.8,
48.4,
72.2,
35.2,
97,
54.7,
42.6,
55,
98.4,
84.4,
68.7,
48,
97.3,
27,
54.4,
100.2,
28.8,
42.5,
5.8,
10.7,
58.5,
31.1,
39.1,
32.7,
26.3,
73,
88.1,
73.3,
86.4,
36,
55.2,
26.5,
75.2,
78.6,
65.9,
88.7,
60.7,
80,
38.4,
46.6,
28.8,
28.4,
80.2,
84.3,
61,
65,
98.4,
94.8,
76.4,
48.7,
80,
47.4,
29.9,
54.4,
55.6,
53.7,
45.3,
88.8,
64.8,
32.9,
100,
29,
48.5,
77.8,
58.2,
85.5,
18.9,
57.2,
54,
26,
39.6,
65.6,
14.1,
71.7,
67.4,
59.4,
71.5,
40.7,
68.3,
85.4,
36.5,
32.1,
51,
50.4,
92.7,
43.6,
30.7,
70.6,
64.7,
28.9,
36.4,
20.4,
17.3,
98.2,
69.1,
99.9,
50.3,
79.4,
22.4,
11.6,
69,
90,
57.4,
77.8,
55.9,
43.6,
45.2,
77.1,
50.9,
50.8,
0,
14.2,
90,
71.9,
52.7,
50.4,
25.2,
35.7,
76.1,
37.8,
28.3,
58,
72.9,
56.6,
50.4,
94.3,
80.6,
97.7,
68.1,
53.8,
72,
1.5,
64.3,
37.1,
13,
92.9,
41.7,
95.8,
94.4,
97.7,
84.5,
50.8,
49.3,
31.9,
69.7,
75.8,
72.3,
23.6,
0.12,
92.2,
82.3,
68.3,
78.5,
41.6,
67,
51.1,
11.4,
61.7,
68,
26.6,
95.3,
78,
59.2,
45.5,
23.5,
90.8,
38.9,
42.4,
35.6,
40.3,
67.6,
26.2,
41.4,
74,
28.8,
49.2,
23.1,
87.8,
68.4,
35.2,
83.6,
75.4,
54.3,
56.4,
59.9,
30.5,
36.7,
33.2,
12.9,
89.3,
19.2,
33.3,
62,
44.8,
71.4,
83.5,
42.5,
91.9,
23.1,
8,
62.5,
48.8,
52.5,
72.1,
90.2,
45.8,
53,
76.5,
64.1,
39.5,
35.9,
28.5,
58.3,
null,
53,
79.7,
119.8,
67.4,
54.9,
67.3,
63,
66.7,
67.2,
33.3,
43.5,
66,
93.7,
68,
85.5,
59.3,
54.2,
53.7,
94.5,
61.6,
25.8,
92.7,
49,
59.2,
96.9,
54.1,
95.9,
88.6,
65.8,
32.2,
3.2,
66.5,
65.1,
86.4,
100.5,
60.3,
70.4,
61.5,
34.1,
78,
80.3,
69.8,
94.1,
11.3,
23,
100.8,
45.4,
72,
80.4,
5,
66.1,
53.5,
25.9,
58,
40.6,
89.6,
66.1,
54.3,
39,
94.8,
78.3,
59.8,
98.7,
47.4,
59,
43.7,
63.9,
48.6,
26.2,
57.7,
53,
77.7,
63.3,
44.7,
3.9,
59.1,
85.9,
50.7,
23.4,
62.5,
46.2,
78.9,
61.4,
40.4,
73.1,
25.5,
38.8,
93.3,
43.6,
99.8,
41.2,
84.7,
53.7,
64.1,
100.9,
51.9,
1.8,
43.4,
45.5,
33.6,
19.9,
63.6,
97.3,
53.5,
59.5,
23.9,
45.9,
67.5,
40.3,
49.3,
0.8,
62.5,
34.7,
25.7,
51.4,
54.8,
48.5,
36.5,
67.9,
83.1,
98.9,
74.5,
57.9,
22.7,
98.4,
61.6,
43,
36.8,
66.7,
25.9,
48,
29.1,
10.4,
86,
50.8,
27.6,
68.1,
55,
52.2,
26.4,
73.3,
92.5,
23,
11.4,
49.4,
36.3,
63.3,
64.9,
38.8,
67.3,
26.1,
33.7,
30.6,
66.2,
97.3,
33,
69.1,
23.1,
41.1,
76.5,
81,
82.2,
57,
33.1,
48.8,
72.6,
26.6,
54.3,
53.1,
31.2,
9,
48.5,
24.6,
28.6,
68.3,
52.6,
29.5,
51.6,
45.2,
64.9,
35.1,
66.6,
42,
49,
42,
85.1,
100,
63,
91,
67.3,
0,
60.2,
46,
20.9,
31,
48.5,
96.6,
52.6,
86.3,
58.4,
14.5,
54.1,
84.2,
49.9,
60.9,
58.4,
8.1,
68.9,
37.4,
7.7,
41.1,
81.5,
10.4,
52.4,
90.8,
58.6,
50.4,
44.3,
87.1,
81,
87.1,
58.7,
47.1,
65.6,
36.2,
79.4,
50.4,
43,
68.5,
40.3,
40.6,
91.8,
70.9,
45.3,
22.2,
7.8,
24.7,
95.6,
25.9,
44.4,
71.4,
50.1,
70.8,
65.8,
48.7,
69.1,
25.9,
69,
36.8,
69.3,
27.4,
44.5,
75.5,
54,
31.3,
43.4,
70.5,
56.1,
55.5,
29.2,
75.2,
7.4,
20.6,
48.2,
15.1,
0.3,
32.4,
17.7,
40.9,
12.2,
54.1,
89.8,
48.7,
81,
46.3,
77.5,
61.6,
60.9,
82.3,
46.3,
35.9,
92.8,
56.8,
33,
45.4,
64.9,
24.6,
72.7,
77.2,
42.6,
7,
49.9,
74.5,
54.2,
49,
58.7,
34.8,
65.5,
72.9,
22.2,
77.2,
91.3,
10.1,
19,
44.2,
88.1,
79.9,
37.4,
79.9,
62.1,
87.7,
10.3,
60.7,
30.4,
40.2,
77.4,
17.8,
68.6,
53.1,
40.5,
42.9,
54,
9.2,
43.3,
5.2,
42.1,
81.1,
97.2,
69.1,
89,
62.6,
80.1,
63,
61.7,
69.2,
59.7,
70.2,
27.9,
80.9,
49,
54.1,
26.4,
16.2,
34.4,
63.7,
41.6,
68.1,
83.2,
61.2,
47.4,
72.6,
86.7,
24,
5.2,
21.1,
88.8,
7.9,
59,
70.2,
59.1,
86.8,
64,
50.7,
57.9,
70.4,
67,
56.9,
79.3,
30.3,
83.3,
26.4,
37.3,
79.3,
37.2,
41.5,
60.4,
88.3,
66.2,
89.3,
23.4,
48.5,
82.6,
94.1,
20.6,
83.3,
41.8,
41.5,
25.8,
53.9,
50,
60.3,
38.1,
19.3,
16,
36,
45.3,
98,
66.4,
83.5,
18,
81.3,
62,
51.3,
54.9,
41.9,
76.2,
33.8,
47.9,
26.6,
34.8,
28.1,
87.4,
27.6,
25.1,
46.7,
62.6,
37.8,
90.3,
68.4,
88.2,
61.6,
22.5,
61.1,
83.4,
71.1,
73.7,
52,
55.1,
49,
31,
87.4,
72,
47.5,
54.3,
19.6,
82.6,
50.9,
44,
51.9,
34.3,
69.5,
65.9,
71.4,
50.7,
56,
15.4,
95,
69.8,
62.7,
61.1,
78.8,
90.9,
84.3,
71,
47.9,
59.2,
40.4,
54.4,
71.7,
14.4,
76.3,
90.5,
70.5,
77,
101.5,
46.4,
16.6,
78.1,
61.1,
80.2,
57.1,
12.7,
59.6,
69.7,
54.1,
27.1,
32.1,
62.5,
71.4,
91.2,
45.3,
34.7,
45,
76.6,
30.9,
29.9,
66.2,
51.1,
68.3,
53.9,
38.4,
66.5,
51.7,
55.7,
56,
63.1,
26.1,
95.3,
96.3,
80.3,
35.1,
71.3,
61.4,
88.7,
38.9,
71.9,
66.4,
52.1,
53,
89,
86.9,
27.7,
83.3,
44.6,
71.1,
94.6,
22.6,
53.8,
43.5,
8.4,
32.9,
57.3,
40.8,
11.9,
93.7,
71,
20.7,
29.5,
58.8,
64,
76,
58.1,
91,
41.7,
42.6,
69.7,
85.8,
43.9,
62.6,
65.5,
38.5,
37.1,
65.9,
68.7,
35.3,
90.6,
49.4,
23.4,
31.1,
77.4,
30.4,
58.6,
68.5,
71.3,
85.8,
41.4,
67,
76.6,
53,
6,
71.8,
58,
78.5,
49.6,
58.5,
55.8,
17.1,
59.7,
45.9,
77.2,
32.9,
76.5,
21.8,
45.2,
54.7,
88.3,
84.7,
52.4,
38.3,
8.2,
82.3,
32.7,
46.9,
7.1,
51.6,
52,
61.2,
43.4,
42.4,
78.6,
81.8,
52.7,
67.3,
84.9,
73.1,
59.1,
35.1,
55,
14.5,
8.7,
56.3,
85,
71.6,
57.7,
49.7,
68,
65.8,
66.7,
93,
66.1,
84.7,
71.9,
85.5,
37.1,
49.2,
89.4,
65.7,
85.7,
40,
73.6,
42.5,
93.8,
50.4,
72.2,
25.4,
77.1,
57.1,
61.2,
28.3,
53,
46.9,
56.6,
50.9,
86.8,
72.6,
49.6,
79,
4.3,
56.4,
97,
62.5,
2.8,
35.7,
8.6,
52.1,
55,
77,
39.8,
30.8,
86,
37.8,
44.1,
36.1,
71.4,
44.5,
27.6,
22,
85.4,
85.8,
66,
89.1,
97.7,
50.8,
23.8,
72.5,
45.7,
76.3,
56.7,
76.8,
68,
75.9,
35.1,
33.6,
76.2,
66.8,
46.3,
65.1,
92.1,
38.8,
8.1,
73.5,
91.5,
40.3,
70.4,
68.3,
79.4,
25.6,
59.4,
32.4,
53.4,
61,
63.1,
25.5,
18.4,
78.7,
72.1,
27.3,
34.4,
56.6,
62.5,
74.8,
54.6,
71.8,
53.9,
62.1,
32.6,
52.7,
84.9,
22.4,
31.6,
26.8,
38.7,
72.4,
96.5,
37.5,
43.9,
0,
95.5,
48,
26,
32.2,
49.5,
37.9,
28.5,
89,
85.1,
37.1,
89.8,
64.5,
51.3,
55.7,
27.6,
29.9,
2.5,
62.1,
62.2,
83.9,
96.4,
15.7,
94,
56.4,
55.4,
56.6,
55.5,
48,
56.2,
43,
58,
50.8,
42.2,
50.5,
71.4,
56.6,
21.4,
66,
38.6,
44,
79,
56.6,
21.8,
60.6,
56.1,
24.3,
65.7,
54.3,
60.8,
58.7,
64,
7.5,
35,
20.1,
64.9,
56.8,
81.1,
3.4,
32.2,
8.6,
47.7,
70,
21,
7.6,
90.5,
78.1,
69,
39.2,
5.3,
47.5,
50.2,
18.6,
21.3,
21.3,
77.8,
66.2,
9.3,
48.8,
66,
31,
46.3,
98.1,
60.5,
53,
57.5,
14.9,
31,
71.5,
77.5,
22.4,
82.3,
28.8,
56.1,
65.6,
35.5,
74.7,
18.7,
29,
15,
50.5,
81,
42.9,
55.5,
48.2,
90.9,
77.4,
44.4,
19.5,
72.9,
42.2,
47.6,
45,
69.4,
84,
43.5,
92.4,
60.4,
44.6,
27.3,
35.9,
60.8,
87.8,
82.4,
77,
85,
46,
87.4,
66.4,
89.9,
47.6,
51.2,
78.4,
41.1,
59.4,
63,
35.7,
66.4,
96.5,
36,
74.4,
78.2,
67.1,
77,
27.7,
46.5,
45,
69.7,
67,
75.1,
49.7,
58.3,
45.4,
54.7,
28.8,
59.2,
66,
70.6,
51.1,
65.2,
86.7,
35.2,
75.8,
89.1,
52.3,
84.4,
9.3,
44.3,
31.4,
60.8,
65.1,
47.8,
64.5,
27.6,
74.1,
90.5,
35.7,
58.4,
31.1,
67.5,
30.2,
77.9,
49.9,
27.5,
36.1,
78,
10.6,
42.9,
30.8,
8.4,
34.3,
50.3,
59.3,
76.4,
46.9,
38.9,
84.8,
11.5,
60,
0.3,
53,
54.8,
57.8,
69.5,
69.1,
94.2,
32.7,
11.8,
77.9,
1,
61.7,
52.6,
59.2,
22.2,
95.7,
66.6,
73,
71.6,
71.3,
38.2,
11,
67.1,
66.7,
50,
90.4,
57.6,
58.7,
70,
42.6,
26.4,
61.2,
56.3,
95.8,
53.9,
12.8,
55.9,
16.3,
93.7,
74.9,
65,
12.2,
96.4,
59.4,
63.3,
59.7,
87.5,
88,
81.8,
72.6,
58.7,
61,
71.6,
16.5,
45.8,
67.8,
36,
81.7,
38.6,
75.9,
61.5,
5.3,
21.1,
8.3,
47.8,
90.9,
55.2,
66.2,
78.9,
56.4,
51.3,
52.2,
44.1,
86.8,
76.8,
41.3,
63.9,
53.8,
59.7,
13.4,
40,
69.5,
71.4,
92.5,
68.9,
64,
97.4,
76,
78.4,
62.3,
68.4,
10.6,
58.8,
66.6,
14.1,
46.2,
62.2,
51.3,
63,
88.7,
98.4,
58,
65.2,
40.1,
69,
43.5,
54.4,
26.4,
100,
5.8,
56.3,
36.5,
90.1,
30.5,
87.6,
67.4,
71.7,
66.2,
56.5,
72.5,
53.1,
32.7,
19.2,
90.7,
68.4,
68.2,
94.1,
30.3,
32.5,
90,
40.3,
86.4,
43.5,
41.4,
64,
46,
48.9,
32,
33.6,
67.6,
13.8,
81.3,
62.6,
60.3,
60.8,
25.1,
92.4,
83.1,
26.5,
37.4,
50.2,
73.6,
71.2,
50.3,
44,
49.5,
89.1,
67.2,
99.7,
59.8,
56.9,
50.6,
79.6,
96.3,
32.5,
85,
38.5,
54.5,
67.4,
22.7,
92.6,
80.8,
45.1,
86.2,
20.2,
49.7,
78.1,
72.3,
6.1,
37.6,
53.5,
34.7,
87.2,
77.9,
64.8,
80.5,
48.5,
31,
71.9,
73.3,
66.5,
58.9,
28.1,
74,
17.5,
16.4,
44.6,
81.3,
47.9,
68.9,
89.8,
57.9,
55.2,
48.4,
47.1,
71.4,
66.9,
44.2,
8.2,
12,
52.8,
43.3,
55.8,
59,
43.2,
58.5,
56.4,
65.7,
24.6,
65,
67.8,
19.7,
50.4,
0.7,
71.5,
76.2,
46.3,
50,
86.3,
55.4,
80.7,
56.6,
25,
16.6,
18.9,
53.4,
2.5,
90.1,
51.3,
90.4,
80.4,
12.2,
39.6,
14.6,
8,
99.4,
95.2,
73.7,
25.5,
57.9,
36.6,
25.7,
80.9,
58,
67.1,
49.3,
86.3,
79.6,
48.1,
37.7,
59.4,
71,
30.5,
2.5,
54.6,
34.7,
81.8,
95.2,
78.3,
62.5,
64.2,
62.4,
86.4,
81.7,
34.5,
5.1,
56.7,
55.2,
67.5,
14.5,
96.8,
18.4,
68.2,
57.7,
83.2,
87,
67.5,
93.6,
18,
37.7,
45.8,
97.6,
99.5,
80.6,
34,
63.5,
60,
45.1,
57,
29,
91.6,
87,
82.5,
42.3,
12,
93.5,
58.6,
66.6,
17,
48,
77.4,
56.2,
24.3,
66.3,
83.2,
53.7,
42.4,
92.4,
97.7,
7.9,
91.9,
9.2,
42.5,
0,
78.3,
2,
40.4,
29.4,
28.8,
75.1,
7.3,
64.6,
53.4,
70.5,
38.6,
43.8,
84.2,
71.4,
80,
47.3,
53.8,
72.8,
51.8,
86.6,
57.2,
50.3,
39.4,
55.6,
27.4,
55.8,
15.4,
62.6,
74.5,
43.1,
50,
55.5,
56.8,
65.1,
68.9,
8,
17.4,
60.9,
84.8,
63.3,
91.4,
52,
71.6,
71,
42.8,
57.4,
38.2,
49,
63,
100.6,
26.7,
33.2,
83.8,
27.9,
73,
72.9,
90.1,
29.9,
60.1,
37.9,
92.1,
30.8,
5.8,
73,
49.4,
81.3,
33.2,
75.6,
75,
73.4,
40,
36.5,
74.3,
68.6,
45.5,
63,
48.5,
75.6,
71.9,
47.8,
0,
12,
38.7,
31.7,
82.4,
58.1,
59,
56.6,
82.9,
16,
0.5,
60.6,
73.1,
4.6,
48.2,
28.8,
85.1,
70,
47.2,
82.9,
87.7,
71.4,
7.4,
38,
57.9,
39.6,
78,
44.4,
60.5,
51.9,
43.2,
72.3,
30.8,
35,
75.6,
66.9,
49,
65,
48.8,
44.6,
81.9,
78.3,
66.1,
86.6,
68.1,
74.6,
30.4,
12,
78.3,
67.9,
48.8,
40.5,
69.3,
69.9,
57.6,
5.7,
92.9,
66.4,
31.9,
65,
78.6,
57,
86.3,
81.3,
69,
33,
89.5,
29,
41.5,
72.6,
49.9,
41.3,
80.7,
48.8,
29.9,
94,
58,
55.9,
82,
2,
83.1,
56.5,
40.2,
55,
40.2,
61.4,
68.1,
74.4,
20.8,
12.4,
74.5,
71.7,
37.9,
86.2,
7.7,
3,
24.4,
42,
21.3,
73.6,
29,
71.6,
58.7,
38.7,
50.5,
69.5,
51.1,
43.5,
77.7,
67,
14.8,
90.9,
30.7,
37.9,
41.8,
75.2,
27,
38,
64.2,
39.6,
82.4,
39.5,
92.9,
20.3,
20.2,
28.3,
49.2,
60.9,
43.3,
60.9,
76.6,
32.1,
55,
53.3,
83.9,
23.9,
88.7,
58.7,
88.4,
47.4,
63.6,
65.2,
71.1,
61.9,
72.2,
60.6,
94.9,
19.9,
18,
41,
85.5,
30.8,
36.3,
42.7,
67.4,
78.6,
59.9,
56.8,
76.5,
74.6,
33,
37.7,
68.2,
23.1,
76.4,
6.6,
86.2,
28.3,
53.1,
37.3,
88.5,
83.2,
39,
78.3,
57.8,
89.7,
53,
84.7,
9.7,
31.1,
30.8,
71.5,
36.9,
91.1,
54.5,
78.9,
20.2,
69,
50.2,
48.3,
21.5,
60.5,
78.8,
14.1,
67.6,
48.8,
57,
61.3,
38.5,
65.4,
68.3,
0.1,
29.4,
57,
40.6,
67.9,
70,
57.8,
76,
63.2,
60.4,
51.8,
90.1,
54,
40.1,
78.7,
38.6,
34.3,
76.3,
84.5,
57.1,
55.8,
15.1,
55.3,
59.5,
44.9,
33.1,
61.8,
12.7,
74.1,
54.8,
61.2,
98,
45.3,
44.7,
39.3,
18.3,
79.4,
30.2,
42.7,
71.1,
47.6,
86.9,
68.3,
68.2,
52,
72,
64,
66.6,
14.2,
11.6,
37.4,
69.6,
67.3,
64,
96.9,
77.3,
60.1,
31.8,
57.2,
67.6,
27.4,
88.2,
62,
40.9,
98.3,
87,
72.6,
45.6,
60.8,
74.8,
44.5,
40.5,
51.2,
64.8,
83.6,
62.5,
43.2,
60.8,
2.8,
51.5,
61.9,
45,
65.1,
2,
52.7,
78.6,
13.3,
82.7,
65.3,
70.5,
82.4,
51.9,
90.8,
50.7,
74.3,
91.8,
61.1,
51.6,
90.9,
42.4,
81.7,
52.4,
88.1,
55.1,
70,
50.6,
71.1,
37.1,
63.1,
90.5,
40,
45.2,
29.5,
25,
41.5,
35.8,
25.5,
8.8,
0.6,
53.4,
46.2,
58.3,
59.6,
44,
80.7,
53.2,
82.7,
35,
63.3,
59.6,
52.1,
69.7,
70.6,
80.5,
41.5,
49.5,
43.2,
86.3,
69.7,
71.4,
50.2,
28.7,
66.5,
62.7,
38.2,
28.7,
49.5,
55.7,
12.3,
30.5,
89.7,
23.7,
95.2,
93.1,
26.1,
9.5,
36.1,
51.2,
84.2,
63.1,
92.2,
34.9,
56.7,
30.7,
93,
71,
89.4,
30.2,
85.8,
32.2,
56.1,
91.9,
32.7,
19.5,
64,
11.7,
90.2,
75.5,
20.2,
44,
58.2,
78.5,
43.4,
64.9,
71.3,
56.4,
41.7,
36.8,
91.1,
43.6,
61,
37,
39.7,
93.2,
26.4,
25,
25.2,
3.6,
32.7,
30.1,
31.2,
59,
43.2,
41.3,
52.5,
93.1,
59.8,
48.7,
46.1,
71.8,
53.7,
71.2,
106.5,
71.9,
87.9,
42.3,
62.1,
62.5,
73,
76,
96,
10.8,
97.4,
31.3,
50.7,
69.4,
59.8,
72.1,
61,
95.1,
22.2,
53.8,
80.1,
22.5,
93.3,
54,
66.4,
32.3,
90.9,
19.1,
50.7,
50.8,
10.4,
73.4,
12.8,
77.5,
20.4,
79,
53.4,
1.5,
17.5,
72.9,
35.8,
60.9,
64,
67.9,
74.4,
98.6,
40.7,
43,
78.4,
31.1,
44.5,
51.1,
64.8,
49.8,
49.5,
86.1,
11.3,
72.6,
21.9,
44.7,
49,
4.85,
52.1,
84.8,
35,
63.1,
43.8,
80.8,
41.4,
58.4,
41.7,
92.5,
49.7,
38.9,
36.9,
66.2,
19.6,
64.3,
39.6,
85.4,
41.5,
70.5,
92.2,
83.8,
65.4,
95.9,
66.2,
76.6,
84.5,
46.2,
80.9,
30.3,
74.4,
12,
52.5,
7.1,
67.9,
78.5,
59.5,
81.7,
36.2,
41.8,
79.8,
85.7,
88.7,
47,
21.4,
88.1,
40,
81.4,
89.3,
47.7,
76.4,
60.5,
78.9,
65.9,
56.6,
48.2,
91.3,
58.1,
83.8,
0.4,
70.6,
58.5,
51.7,
77.8,
92.5,
73.3,
77.5,
38.3,
63.5,
60.3,
9.4,
69.9,
41,
76.5,
13.4,
73.4,
70.3,
98.6,
21.1,
35.7,
65.7,
72.8,
55.3,
28.5,
70.6,
57.3,
77,
61.2,
19.3,
13.4,
21.6,
88.9,
63.6,
66.7,
25.9,
28.8,
30,
69.8,
83.9,
44.9,
70.7,
48.6,
66,
22,
46.6,
40.8,
35.1,
31.6,
84.9,
25.7,
52.2,
12,
32.8,
25.8,
66.9,
84.9,
57.8,
86.2,
85.3,
72.8,
72.8,
88.8,
55.4,
71.5,
68.3,
42,
53.9,
41,
59.9,
68.1,
81,
43.8,
7.6,
31.4,
36.4,
58.3,
24,
76.8,
54.6,
69.8,
80.8,
89.7,
13,
53.5,
7.1,
72.3,
56,
63,
4,
40.7,
43.4,
73.7,
76.3,
65.8,
93,
24.5,
70.3,
1,
58.9,
58.7,
67.4,
98.1,
93.2,
69.4,
97.7,
20.6,
59.7,
40.3,
20.7,
84,
44.6,
29.5,
43.9,
33,
79.3,
50.9,
72,
24.8,
50.7,
50.6,
83.6,
54.9,
60.2,
83.3,
68.2,
47.3,
19.9,
27.4,
70.3,
69.1,
99,
26.7,
49.1,
72.7,
63.4,
52.8,
54.3,
62.2,
54.5,
81.3,
55.3,
97.8,
21.8,
72.9,
40.5,
63.6,
68.4,
40.4,
100,
56.5,
75.5,
84.7,
81.5,
61.6,
47.8,
53.5,
28,
50.7,
70.6,
65.1,
52.8,
25.2,
26.7,
39.5,
59.1,
49.4,
60.2,
89.1,
48.1,
43,
88.7,
55.7,
53.7,
43.3,
91.6,
20.1,
96,
69.7,
53.7,
88.5,
74.6,
30,
58.7,
26.7,
85.2,
43.4,
24.9,
43.1,
98,
67.4,
79,
67.4,
null,
31,
72.8,
56,
28.4,
98.8,
74.3,
24.4,
68.7,
9.5,
25.8,
54.4,
79.7,
80.6,
26.6,
20.2,
0,
87.4,
60.7,
57.5,
53.3,
10.2,
48.2,
66.1,
31.3,
52.7,
56.5,
100.6,
84.8,
71.2,
94.6,
69.1,
64.6,
48,
0.9,
43.7,
75.4,
98.4,
27,
59.3,
32.7,
64.9,
77.5,
27.4,
47.1,
73,
1.5,
46.2,
63.8,
35.8,
16.6,
85.1,
84.1,
74.4,
80.9,
64,
63.5,
50.6,
60.1,
69,
61,
43,
92,
41.3,
30.4,
67.2,
9.1,
35.8,
37.4,
74.5,
74.1,
16.6,
48.6,
45.2,
64.4,
59.6,
68.6,
39.4,
12.2,
21.6,
38.3,
49.8,
77.7,
50.1,
37.5,
54,
98.1,
24.5,
4.7,
64.8,
34.2,
44.4,
87,
77.6,
58.4,
77.5,
63.8,
77.5,
48.9,
86.2,
45.7,
40.4,
57,
67.2,
29.8,
78.1,
74.2,
70.6,
50.3,
72.6,
29.6,
56.6,
70.2,
91,
21.7,
98.4,
25.4,
94.4,
64.3,
72.9,
36.6,
59.5,
40,
56.8,
96.3,
60.2,
47.6,
59.4,
88.4,
16.2,
68.8,
9.3,
43.8,
64.5,
51.8,
47.4,
81.1,
91.8,
93.6,
53.7,
89.8,
21.1,
43.1,
66.8,
84.4,
98,
62.6,
52.9,
97.9,
35.9,
74,
38.1,
19.2,
42.5,
59.2,
21.7,
47.9,
33.8,
62.4,
46.9,
50.6,
57.5,
40,
76.1,
57.5,
68.3,
44.1,
50.6,
83.3,
76.9,
75.9,
29.8,
92.9,
34,
76,
45.1,
88,
38.7,
78.3,
50.2,
33.5,
85.9,
87.5,
7,
31.5,
44.1,
38.2,
52.3,
32.8,
89.5,
26,
31.4,
41.6,
19.2,
55.5,
51.7,
49.3,
61.5,
19.6,
34.1,
18.7,
56.1,
37.8,
57.6,
47.5,
82,
63.6,
73,
38.5,
45.1,
78.8,
98.2,
18.4,
51.4,
9.7,
28.2,
33.6,
42.7,
85.2,
20.7,
80.4,
21.9,
38.6,
37.1,
20.4,
65.4,
56.2,
38.3,
57.5,
26.3,
17.5,
33.7,
78.4,
59.7,
51.7,
84.8,
32.5,
12.5,
92.2,
41.8,
75.8,
18.4,
67.8,
85.4,
48.4,
91,
79.8,
90.9,
55.5,
75.2,
51.2,
57.3,
76.3,
99.8,
48.4,
22.1,
44.1,
78,
28.2,
60.5,
57.6,
54.1,
6.5,
53.6,
48.2,
67.8,
71,
71.8,
22.2,
69.9,
91.8,
80,
33.1,
58.7,
78,
79,
39.5,
26,
70.1,
19.8,
63.3,
91.3,
55.1,
76.4,
53.2,
88.8,
56,
44.9,
67,
63.6,
52.7,
44.2,
36.3,
85,
49.4,
14,
72.6,
73.9,
3.9,
65.5,
63.6,
45.2,
40.3,
63.9,
31.3,
62.8,
8.9,
66.9,
86.7,
0,
63.4,
79.7,
17.7,
27.6,
98.6,
65.4,
29.4,
46.7,
56.3,
85.1,
69.7,
42.9,
89.7,
43.2,
85.5,
60.7,
72.4,
24,
63.3,
66.2,
71.8,
68.3,
9.4,
40.1,
60.7,
40,
76,
6,
89.4,
81.5,
56.2,
31.6,
68,
63.9,
73.9,
82.5,
69.7,
42.1,
78.6,
64.3,
32.6,
70.7,
63.5,
66.2,
47.1,
44,
34,
85.1,
78.8,
47.3,
41.9,
48.4,
24.5,
41,
74.4,
77.4,
74.5,
40.4,
72.5,
34,
64.7,
18.6,
50.5,
60,
43.5,
57.9,
30.3,
74,
32.2,
73.4,
51.8,
21,
29.8,
85.5,
46,
72.5,
70.2,
79.4,
43.4,
73.1,
45.8,
39.7,
34.1,
45.1,
61.5,
72.1,
85.6,
70.2,
24.2,
68.3,
50.1,
67,
60.8,
30.3,
20.9,
83.8,
16.3,
59.4,
48.4,
43.6,
48.5,
86.2,
83.6,
37.3,
101.9,
75.7,
100.3,
71.7,
72.7,
18.1,
36.8,
83.3,
43.2,
22.9,
91.3,
63,
69.6,
7,
61.9,
52.5,
95.3,
42.1,
65.5,
58.4,
59.4,
90.2,
30.1,
44.1,
12.1,
54.2,
62.4,
23.9,
84.6,
33.8,
47.2,
57.7,
9,
19.4,
84.7,
55.1,
53.2,
70.5,
62.2,
59.9,
65.6,
51.2,
40,
91.8,
49.5,
91.1,
101,
88.6,
33.4,
71.9,
14.8,
26.2,
75.3,
78.5,
57.4,
24.7,
64.5,
16.6,
89,
68.9,
48.6,
71.8,
54.5,
28.5,
41.2,
40.6,
52.7,
64,
19.4,
86.6,
54.2,
75,
87.5,
42.7,
78.8,
65.1,
76.2,
68.8,
24.4,
85.6,
28.1,
41.2,
41.3,
89.9,
72.8,
53.5,
35.2,
56.7,
66.2,
83.5,
68.7,
26.3,
67,
44.3,
75.1,
54.8,
30.9,
71.7,
85,
46.8,
47.7,
47.6,
75.1,
26.6,
75.1,
43,
43.9,
81.3,
44.9,
59.2,
75.6,
55.3,
32.2,
37,
48.1,
91.3,
69.5,
15,
2.9,
46.6,
53.1,
16.1,
91.2,
77.9,
51.8,
4.1,
27.4,
41.7,
50.1,
73.3,
43.1,
26.9,
29.4,
38,
53.3,
80,
57.3,
72.1,
77,
14.8,
36,
17.5,
40.8,
22.5,
75.7,
66.5,
6.2,
13.1,
43.7,
77,
16.7,
63.5,
26.6,
24.3,
84.7,
79.5,
61.8,
54.2,
85.2,
54.4,
58.5,
56,
95.9,
37.4,
44.9,
71.5,
49.9,
62.5,
80,
46,
39.9,
51.8,
44.1,
38.9,
98.1,
56.7,
41.9,
50.6,
45.8,
46.8,
69.4,
4.5,
16.3,
32.8,
59.1,
35.6,
35.8,
83.6,
15.1,
13.7,
12.4,
79.9,
33.1,
55.4,
24.6,
80.9,
76.5,
36.4,
92.1,
61,
81.8,
48,
78.1,
1.7,
25.5,
62.6,
63.8,
46.8,
41.8,
56.7,
21.6,
51.7,
94,
48.3,
66.3,
24.8,
65.7,
31.4,
95.4,
61.5,
14.9,
65.5,
17.7,
52.5,
36.9,
32,
41,
3,
89.4,
60.6,
82.7,
73.4,
21.2,
65.6,
56.8,
35.8,
50.5,
62.3,
65.9,
48.6,
39.5,
18.9,
45.3,
79.2,
46.4,
78.6,
3.5,
43.5,
79,
43.5,
44.2,
78.8,
83.3,
63.6,
57.4,
78.3,
45.6,
42.9,
37.7,
96.1,
61.4,
59.1,
16.3,
91.2,
64,
75,
25.6,
41.4,
68.5,
49.5,
68.4,
66.8,
67.2,
35.3,
60.9,
10.1,
35.2,
23.7,
47.8,
63.1,
84.7,
83.3,
61.2,
65.3,
46.1,
65.1,
89.9,
59.7,
33.8,
27.6,
5.7,
61.6,
74.3,
93.8,
72.2,
69.8,
74.8,
51.7,
66.6,
74.9,
64.3,
97.5,
45.8,
64.9,
80.7,
50,
33.5,
61.6,
45.5,
35.2,
47,
39.6,
33.8,
36.5,
55.8,
86.4,
69,
54.5,
66.8,
10.6,
21.9,
43.2,
64.8,
98,
90.6,
4.5,
29,
58,
40.3,
26.4,
66.6,
82.7,
92.2,
44.7,
21.5,
49.9,
47.5,
82.2,
36.8,
53.5,
42.1,
102,
89,
78.4,
94.9,
71,
72.3,
53.3,
87.1,
84.3,
80.6,
27.4,
52,
98,
0,
94.4,
30.1,
89.9,
39.9,
45.4,
52.5,
46.9,
14.2,
60,
62.6,
52.9,
24.6,
74,
20.7,
48.6,
76.6,
38,
90.4,
24.5,
46.5,
22.7,
47.8,
78.3,
57.6,
89.3,
22.1,
75,
40.9,
45.2,
58.5,
28.7,
40.7,
70.1,
72.9,
36,
58.9,
83.8,
83.9,
63.2,
67.8,
35.2,
74.3,
92.8,
88.8,
46.9,
58.3,
63,
60.5,
93.1,
54.6,
100.4,
63.8,
38,
26.7,
63.2,
89,
63.5,
86,
7.3,
77.8,
19.6,
25.3,
62.8,
58.5,
38.6,
8.2,
61.9,
78.1,
33.4,
30,
70.5,
0.3,
39.4,
79.8,
59.7,
34.7,
2.3,
48,
6,
85,
92,
58.5,
27.9,
96.3,
57.1,
27.6,
67.8,
98.3,
18.7,
84,
71.5,
76.2,
69.7,
62.6,
1,
72.8,
27.1,
51.2,
44,
40.9,
5.7,
91.5,
20.1,
88.3,
64.1,
60.4,
16.3,
100.4,
47.6,
54.7,
61.9,
84,
57.9,
76.1,
61.2,
67.3,
50.5,
98,
31.1,
51.1,
67.6,
75.8,
61,
40.9,
51.6,
54.2,
73.7,
92.8,
49.9,
75.3,
61.5,
21.6,
37.5,
89.9,
52.9,
68.9,
63.5,
60,
52.9,
65.5,
76.6,
86.8,
73.6,
53.7,
59.9,
67.6,
63,
41,
62.8,
71.7,
34.2,
2.5,
84.3,
31.7,
16,
57.8,
45.3,
59.7,
18.9,
46.7,
27.5,
64,
90,
23.3,
72.3,
2.4,
76.6,
91.7,
91,
21.5,
82.7,
49.1,
73.7,
76.2,
7.8,
33.5,
11.6,
70.9,
43.9,
47,
100.1,
37.5,
87.6,
78.6,
55.7,
28.2,
87.4,
87.8,
32.7,
89,
42.6,
30,
66.4,
84.1,
8.1,
56.1,
56.9,
7,
33.4,
0.3,
21.2,
36.3,
62.9,
16,
92.6,
71.6,
19.1,
71.7,
74.2,
42,
65.9,
39.3,
61.5,
43.9,
93.6,
47.7,
76.9,
45.6,
48,
48.8,
51.6,
77.5,
91.4,
77,
35.1,
38.5,
61.7,
64.3,
28.4,
53.1,
32.9,
43.7,
37.8,
28.7,
85.9,
81,
85.8,
59.4,
54.5,
35,
75.7,
91.3,
18.5,
65.7,
62.7,
33.2,
83.9,
88.5,
22,
90.2,
52.8,
51.7,
74.3,
7.4,
68.6,
91.9,
81,
71.8,
64.7,
35.1,
56.8,
0.5,
40.8,
67,
38.7,
61.4,
73.8,
85.5,
86.1,
78.1,
3.9,
84,
48.5,
63.8,
58,
94,
31.9,
79.4,
72.6,
0,
27.6,
49.2,
84.7,
69,
14.9,
43.5,
37.5,
59.7,
39.5,
72.1,
35.2,
95.4,
49.2,
75,
68.1,
57.2,
74.5,
52.9,
45.4,
25.3,
76.2,
91.7,
62.8,
92,
47.3,
34.7,
43.6,
31.6,
94.2,
56.8,
54,
25.2,
8.1,
23,
16.8,
62.6,
0.8,
54,
51.6,
30.3,
77.6,
72.7,
15.8,
81.6,
62.4,
39.2,
79.3,
28.2,
80,
42.3,
73.8,
33.6,
12.7,
61.2,
11.4,
75.5,
85,
95.8,
86,
100.8,
82.3,
54.9,
75.6,
38,
76.1,
49.4,
33.9,
53.4,
38.2,
24.4,
31.2,
39.8,
68.8,
85.6,
66.2,
86,
57.9,
90.7,
64.2,
22.4,
79.6,
22.4,
76.3,
47.9,
11.3,
62.7,
57.2,
31.7,
84.2,
35.4,
64.7,
78.9,
25.9,
70.8,
23.8,
62.9,
24.8,
37.6,
81.5,
28,
73.9,
71.5,
62.7,
92.1,
59.9,
68.2,
20.6,
69,
94.6,
9.2,
62,
52.2,
49.3,
33.9,
45.2,
65.8,
78.6,
11,
55.9,
94.8,
48.6,
61.9,
79,
67,
26.4,
54.4,
95.3,
29.5,
26.6,
85,
60,
33.2,
48.8,
62.6,
79.5,
53.5,
81.7,
10.5,
79.3,
98.6,
31.3,
37.2,
64.7,
54.8,
89.3,
31.1,
96.5,
63.1,
20.2,
60.3,
54.6,
53.8,
43.4,
11.6,
83.2,
77.4,
81,
112.9,
64.9,
70.9,
46.6,
27.6,
48.9,
63,
49.8,
56,
25.7,
48,
53.5,
67.8,
50.8,
58.9,
46.5,
51.5,
4,
45.7,
20.4,
92.9,
42.7,
42.5,
33,
86.4,
29.7,
27.4,
25.8,
60,
57.1,
65.1,
30.2,
32.4,
11.2,
44.5,
73.5,
48.8,
28.6,
78.2,
30,
83.3,
17.1,
28,
93.3,
36.7,
59.9,
69.8,
74,
70.4,
88.7,
81.9,
39,
12.7,
64.3,
78.4,
59.4,
27,
67.6,
77.4,
75.2,
32.8,
33,
55.2,
62.8,
45,
54.4,
50.7,
83.7,
70.7,
56.8,
66.7,
33.3,
50.2,
25.3,
70.9,
32.2,
45.5,
7,
31.5,
14.5,
62,
50.8,
43.9,
36.1,
26.7,
43,
73.8,
97,
69,
51.1,
21.9,
89.7,
61.2,
53.8,
60.4,
75,
45.6,
49.9,
31.4,
68.8,
63.7,
72.3,
55.1,
44.7,
0,
18.7,
49.5,
31.8,
30.2,
73.2,
37.7,
58.2,
54.8,
49.4,
26.2,
46.5,
79.9,
25,
51.3,
43.8,
66.9,
40.6,
28.6,
98.7,
61.8,
58,
80.9,
93.4,
43.4,
64.4,
64,
36,
5,
84.7,
11,
41.6,
25.4,
85,
96.7,
39,
24.9,
33.2,
25.8,
63.9,
60.9,
56.7,
63.3,
49.9,
79.2,
94.7,
84.2,
39.9,
8.6,
97.2,
30.8,
73.2,
53.3,
38.7,
26.6,
23.7,
35.9,
49.2,
72.5,
55.9,
36,
72,
97.4,
84.4,
35.1,
62.4,
83.2,
91.3,
24.2,
64.6,
9.7,
50.9,
86.9,
16.3,
32.4,
75.4,
65.8,
89.1,
84.6,
16,
77.1,
26.8,
42.2,
48.7,
38.2,
10.2,
78.1,
56.6,
77.9,
15,
63.2,
42.3,
86,
69.3,
40.6,
68.2,
49.7,
35.6,
87.7,
62.8,
0,
39.1,
57.6,
52.4,
60.6,
57.9,
42.7,
73.5,
64.4,
25,
63.9,
27.7,
95.4,
28.7,
2.3,
86.6,
53.6,
66.3,
61.2,
58.2,
37.9,
58.4,
71.8,
11.4,
9.5,
74,
37.8,
40.9,
86.9,
84.4,
44.1,
64.9,
58.7,
74.6,
80.1,
75,
68.9,
74.7,
40.7,
1.5,
36.2,
48.8,
45.7,
42.7,
29.7,
29.9,
4.2,
76,
83.9,
50,
62.4,
60.1,
17,
44.1,
56.8,
26.2,
86.6,
25.8,
47,
97.7,
35.9,
2.7,
20.4,
40.8,
66.9,
39.8,
59.1,
88.9,
16.4,
95.9,
44.4,
57.1,
50.2,
62.3,
19.4,
24,
27.2,
70.6,
10.7,
45.2,
84.4,
91.6,
36.9,
94.8,
3.8,
41.9,
64.6,
14.4,
29,
91,
86.6,
95.2,
40.6,
69.2,
5.7,
33.7,
59.7,
46.2,
101.8,
78.5,
88.9,
14,
35.6,
74.9,
50.3,
64.3,
8.5,
70.1,
65.2,
71.7,
61.1,
56.8,
37.1,
35.9,
95.4,
62.2,
57,
63,
53.9,
64.1,
85.7,
74.7,
97.6,
53.1,
62.4,
98.6,
25.8,
34.1,
84.1,
42,
59.3,
43.2,
54,
51,
48.3,
25.9,
90,
89.5,
67.8,
72,
44,
56,
50.2,
36,
70.8,
12.1,
36,
41.3,
97.8,
87.5,
36.7,
41.1,
46.5,
20.6,
60.7,
45.2,
37,
90.2,
72,
9.8,
81.1,
34.6,
52.3,
79.6,
36.7,
35.7,
48.9,
26.4,
13.6,
74.7,
67.1,
86,
66,
56,
75.1,
81.7,
10.6,
13.2,
26.5,
57.4,
12.7,
71.8,
49.7,
86.8,
63.9,
61.3,
85.4,
31.9,
54.7,
8.7,
23.1,
93.4,
51.5,
39.2,
95.3,
33.2,
73.3,
54.8,
55.4,
25.2,
63.8,
71.3,
72.9,
25,
37.3,
49.9,
43.1,
54.4,
52.9,
77.6,
16.9,
7.3,
36.1,
43.5,
50,
37.9,
55.3,
28.3,
69.9,
108.6,
74.6,
58,
14.1,
86.7,
27.6,
49,
7.5,
56.5,
95.5,
38.7,
60.4,
40.8,
37,
45.4,
72.2,
98.2,
96.4,
63,
70.4,
48.9,
72.3,
29.8,
58.7,
61,
97.2,
78.4,
41.4,
80.7,
52.5,
71.8,
63.4,
73.4,
11.2,
30.4,
45.5,
80.4,
46.1,
72.8,
8,
42,
43.4,
71.7,
48.1,
82.3,
44,
25,
35.8,
59,
14.1,
38.6,
64.9,
83.3,
67.4,
20.2,
16.7,
40,
77.2,
65.1,
69.4,
84.9,
51.7,
41.1,
7.4,
15.4,
26.3,
70.5,
93.5,
60,
54.7,
11.3,
48.8,
72.6,
9.3,
50.7,
78.5,
60.4,
55,
2.4,
65.5,
86.8,
50.8,
64.7,
44,
83.8,
46.6,
59,
50.5,
36.4,
54.2,
81.4,
58.9,
63.8,
79.8,
28.6,
10.6,
16.1,
74.8,
87,
58.2,
30,
64.7,
13.4,
39.5,
52.4,
81.4,
69.9,
89.9,
95.4,
58.3,
17.5,
67.8,
87.6,
60.5,
25.3,
71.2,
57.7,
94.3,
38.3,
62.4,
97.4,
36.2,
43.8,
41,
55.2,
47.3,
59.9,
100.7,
62,
93.3,
22.5,
43.3,
31.5,
83.5,
68,
20.9,
61.8,
79.1,
20.5,
48.9,
53,
69.1,
49.6,
62.6,
22.8,
46.5,
52.7,
36.3,
83,
75,
86.7,
26.6,
28.9,
44,
80.1,
46.5,
49.9,
36.1,
96.7,
70.9,
62.1,
35.6,
9.3,
62.2,
58.4,
33.2,
50.8,
74.5,
79.8,
17.7,
74.5,
15.4,
23.9,
74,
42.6,
64.6,
69.6,
50.5,
11,
49.1,
54.1,
68,
63.3,
30.9,
19.6,
85.1,
77.9,
81.9,
41.6,
56.7,
96.4,
64.6,
70.9,
28.4,
39.4,
66.7,
17.8,
79.3,
72.5,
58.1,
52.2,
41.9,
66.2,
40.7,
120.5,
92.4,
62,
26.9,
23.1,
84,
54.2,
54.2,
45.5,
67.4,
75,
94.2,
67.5,
22.7,
85.2,
29.3,
94.6,
79.2,
57,
59.9,
56.4,
90.9,
16.2,
28,
29.2,
85.3,
28.9,
72.4,
89.7,
56.2,
80,
47.3,
55.4,
55.3,
42.5,
44.8,
76.6,
17.2,
12.8,
29.2,
65.5,
3.4,
32.6,
8.4,
42.4,
45.3,
94.4,
91.7,
52.7,
77.9,
67.6,
80.2,
23.2,
31.3,
66.8,
93.9,
44.6,
56.6,
85.1,
16.7,
92.8,
45.4,
41.8,
51.5,
58.3,
18,
18.1,
63.9,
45.4,
0.2,
18,
21.9,
54.9,
87.3,
93.6,
10.5,
80.8,
22.6,
66.5,
47.1,
29.8,
35.4,
85,
23.6,
38.7,
90.5,
77.4,
59.9,
61.1,
59.5,
39.3,
92.5,
43,
92.7,
74.6,
34,
59.5,
70.6,
13.9,
74.7,
69.9,
68.1,
35.9,
67,
23,
71.1,
51.3,
11.9,
31.7,
22.4,
43.7,
96.9,
52.1,
57.7,
81.6,
74.2,
33.3,
95.3,
73.8,
73.8,
44.1,
42,
83.4,
37.7,
49.7,
27.2,
95.9,
92.7,
57,
64.6,
53.3,
44.9,
43.3,
25,
79.2,
57.7,
84.9,
75.1,
76,
46.9,
73.2,
31,
91.3,
42.8,
20.6,
49.5,
25.9,
78.8,
52.7,
37.8,
73.8,
59.6,
77.9,
38.1,
75.5,
37,
56.4,
18.9,
89.6,
74.8,
23.8,
58.8,
96.3,
56.2,
22.6,
21.1,
94.8,
57.4,
51,
33.9,
69.5,
81.1,
45.3,
98.9,
52.6,
59.4,
32,
4.1,
88.9,
68.2,
52.8,
70.3,
6.7,
7.2,
84,
58.9,
38.3,
92.5,
56,
85.7,
33.5,
50,
65.2,
25.2,
47.4,
57.3,
25.8,
60.9,
60.7,
3.6,
98.8,
87.3,
21.8,
48.1,
57.8,
83.5,
85.3,
36.6,
72.6,
65,
7.2,
57.3,
49.6,
64.5,
31.2,
69.9,
57,
62.1,
66.6,
49.5,
78.7,
74.1,
64.8,
95.9,
84.3,
42.7,
33.8,
87.3,
69.3,
57.2,
78,
42.4,
47.1,
14,
46,
20.7,
91.8,
27,
18.5,
81,
88.4,
83.1,
7.7,
90.7,
33.7,
24.1,
64.1,
92.5,
79.1,
24,
46.2,
66.1,
25.2,
90.7,
22.6,
27.7,
83.5,
80.6,
91.3,
8,
79.6,
72.2,
65.1,
48.6,
73.3,
85.3,
71.3,
40.7,
29,
14.4,
75.7,
93.9,
76.4,
73.8,
81.3,
68.2,
35.8,
85.3,
65,
63.6,
94.2,
54.3,
42.8,
56,
53.3,
60.7,
24.1,
83.3,
62.6,
83.9,
84.3,
13.9,
71.9,
34.9,
13.7,
45,
7.7
]
}
],
"layout": {
"legend": {
"bgcolor": "#F5F6F9",
"font": {
"color": "#4D5663"
}
},
"paper_bgcolor": "#F5F6F9",
"plot_bgcolor": "#F5F6F9",
"template": {
"data": {
"bar": [
{
"error_x": {
"color": "#2a3f5f"
},
"error_y": {
"color": "#2a3f5f"
},
"marker": {
"line": {
"color": "#E5ECF6",
"width": 0.5
}
},
"type": "bar"
}
],
"barpolar": [
{
"marker": {
"line": {
"color": "#E5ECF6",
"width": 0.5
}
},
"type": "barpolar"
}
],
"carpet": [
{
"aaxis": {
"endlinecolor": "#2a3f5f",
"gridcolor": "white",
"linecolor": "white",
"minorgridcolor": "white",
"startlinecolor": "#2a3f5f"
},
"baxis": {
"endlinecolor": "#2a3f5f",
"gridcolor": "white",
"linecolor": "white",
"minorgridcolor": "white",
"startlinecolor": "#2a3f5f"
},
"type": "carpet"
}
],
"choropleth": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "choropleth"
}
],
"contour": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "contour"
}
],
"contourcarpet": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "contourcarpet"
}
],
"heatmap": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "heatmap"
}
],
"heatmapgl": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "heatmapgl"
}
],
"histogram": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "histogram"
}
],
"histogram2d": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "histogram2d"
}
],
"histogram2dcontour": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "histogram2dcontour"
}
],
"mesh3d": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "mesh3d"
}
],
"parcoords": [
{
"line": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "parcoords"
}
],
"pie": [
{
"automargin": true,
"type": "pie"
}
],
"scatter": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatter"
}
],
"scatter3d": [
{
"line": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatter3d"
}
],
"scattercarpet": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattercarpet"
}
],
"scattergeo": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattergeo"
}
],
"scattergl": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattergl"
}
],
"scattermapbox": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattermapbox"
}
],
"scatterpolar": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterpolar"
}
],
"scatterpolargl": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterpolargl"
}
],
"scatterternary": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterternary"
}
],
"surface": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "surface"
}
],
"table": [
{
"cells": {
"fill": {
"color": "#EBF0F8"
},
"line": {
"color": "white"
}
},
"header": {
"fill": {
"color": "#C8D4E3"
},
"line": {
"color": "white"
}
},
"type": "table"
}
]
},
"layout": {
"annotationdefaults": {
"arrowcolor": "#2a3f5f",
"arrowhead": 0,
"arrowwidth": 1
},
"coloraxis": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"colorscale": {
"diverging": [
[
0,
"#8e0152"
],
[
0.1,
"#c51b7d"
],
[
0.2,
"#de77ae"
],
[
0.3,
"#f1b6da"
],
[
0.4,
"#fde0ef"
],
[
0.5,
"#f7f7f7"
],
[
0.6,
"#e6f5d0"
],
[
0.7,
"#b8e186"
],
[
0.8,
"#7fbc41"
],
[
0.9,
"#4d9221"
],
[
1,
"#276419"
]
],
"sequential": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"sequentialminus": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
]
},
"colorway": [
"#636efa",
"#EF553B",
"#00cc96",
"#ab63fa",
"#FFA15A",
"#19d3f3",
"#FF6692",
"#B6E880",
"#FF97FF",
"#FECB52"
],
"font": {
"color": "#2a3f5f"
},
"geo": {
"bgcolor": "white",
"lakecolor": "white",
"landcolor": "#E5ECF6",
"showlakes": true,
"showland": true,
"subunitcolor": "white"
},
"hoverlabel": {
"align": "left"
},
"hovermode": "closest",
"mapbox": {
"style": "light"
},
"paper_bgcolor": "white",
"plot_bgcolor": "#E5ECF6",
"polar": {
"angularaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"bgcolor": "#E5ECF6",
"radialaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
}
},
"scene": {
"xaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
},
"yaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
},
"zaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
}
},
"shapedefaults": {
"line": {
"color": "#2a3f5f"
}
},
"ternary": {
"aaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"baxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"bgcolor": "#E5ECF6",
"caxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
}
},
"title": {
"x": 0.05
},
"xaxis": {
"automargin": true,
"gridcolor": "white",
"linecolor": "white",
"ticks": "",
"title": {
"standoff": 15
},
"zerolinecolor": "white",
"zerolinewidth": 2
},
"yaxis": {
"automargin": true,
"gridcolor": "white",
"linecolor": "white",
"ticks": "",
"title": {
"standoff": 15
},
"zerolinecolor": "white",
"zerolinewidth": 2
}
}
},
"title": {
"font": {
"color": "#4D5663"
},
"text": "revol_util Box plot"
},
"xaxis": {
"gridcolor": "#E1E5ED",
"showgrid": true,
"tickfont": {
"color": "#4D5663"
},
"title": {
"font": {
"color": "#4D5663"
},
"text": ""
},
"zerolinecolor": "#E1E5ED"
},
"yaxis": {
"gridcolor": "#E1E5ED",
"showgrid": true,
"tickfont": {
"color": "#4D5663"
},
"title": {
"font": {
"color": "#4D5663"
},
"text": ""
},
"zerolinecolor": "#E1E5ED"
}
}
},
"text/html": [
"\n",
" \n",
" \n",
" \n",
" \n",
"
"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"application/vnd.plotly.v1+json": {
"config": {
"linkText": "Export to plot.ly",
"plotlyServerURL": "https://plot.ly",
"showLink": true
},
"data": [
{
"histfunc": "count",
"histnorm": "",
"marker": {
"color": "rgba(255, 153, 51, 1.0)",
"line": {
"color": "#4D5663",
"width": 1.3
}
},
"name": "tot_cur_bal",
"opacity": 0.8,
"orientation": "v",
"type": "histogram",
"x": [
28699,
9974,
38295,
55564,
47159,
350619,
13272,
272579,
281521,
76034,
72193,
39152,
194011,
165164,
39634,
48488,
71191,
221335,
34538,
125903,
66738,
null,
282808,
71697,
147448,
327930,
8589,
447388,
114298,
31445,
391749,
1385358,
68057,
6485,
23697,
4890,
5422,
176391,
10707,
141797,
53454,
229995,
13054,
42542,
624417,
38829,
28163,
null,
421664,
71646,
8312,
311014,
234697,
290962,
195008,
13166,
34752,
359326,
137019,
235231,
161107,
316510,
22198,
272177,
124248,
442155,
null,
null,
447154,
46867,
28862,
250586,
58396,
223151,
null,
103681,
123905,
405177,
77893,
22459,
174517,
244772,
23784,
28233,
27435,
275755,
142744,
37237,
15017,
408391,
106591,
35398,
24895,
null,
68650,
239603,
605585,
139788,
41237,
186934,
78372,
43807,
35449,
245928,
9943,
158699,
254138,
261143,
46625,
220405,
12172,
61294,
31225,
38746,
40749,
301791,
263725,
357941,
212529,
32825,
111460,
10163,
381787,
null,
618061,
58182,
23744,
105315,
31458,
14203,
null,
8328,
24353,
697738,
31254,
324254,
253332,
66287,
34248,
15736,
32296,
31773,
491917,
127882,
27519,
128115,
336159,
303569,
137534,
132687,
null,
57534,
null,
29284,
49328,
43998,
18955,
4161,
44318,
9687,
217361,
51448,
15567,
11346,
76398,
41374,
11900,
57897,
146182,
25315,
42886,
12743,
26807,
41719,
214384,
161474,
41019,
108745,
403512,
98749,
14677,
25608,
52348,
168733,
795423,
237669,
24110,
33335,
381762,
317022,
74344,
6557,
357373,
null,
207856,
null,
187785,
null,
45602,
20964,
23927,
74619,
18613,
36054,
28773,
2540,
209503,
null,
null,
189210,
12725,
67211,
31287,
141512,
17022,
38935,
397113,
268952,
30098,
null,
185010,
20974,
30163,
352644,
371710,
49447,
729286,
1275731,
369867,
10989,
142058,
109299,
419933,
236818,
230826,
197387,
38375,
21810,
null,
15550,
26955,
52359,
149955,
120660,
null,
59812,
21024,
130027,
10814,
315571,
2755,
null,
25885,
22363,
259654,
26566,
5713,
38691,
82172,
344169,
583364,
261450,
145255,
220734,
326635,
15925,
66547,
61199,
99488,
24981,
40106,
39636,
27105,
39497,
55926,
152124,
53692,
119007,
84473,
154943,
160755,
39752,
104546,
null,
35816,
32579,
61080,
329538,
33373,
178923,
37951,
256274,
162464,
347081,
216061,
295126,
null,
30235,
null,
13889,
351928,
300411,
38990,
null,
136956,
22720,
317207,
34706,
186750,
223548,
9657,
35975,
214793,
95565,
238017,
null,
50324,
394034,
20088,
20449,
130501,
164189,
13347,
179994,
17899,
39404,
287180,
56496,
41139,
10615,
658834,
63379,
68865,
354452,
30353,
null,
null,
411273,
46002,
55669,
53735,
99289,
180899,
18348,
747460,
25407,
43083,
236639,
29046,
35438,
34710,
14137,
23746,
146392,
214638,
312703,
28856,
56332,
6289,
9874,
93245,
null,
25218,
116274,
null,
144950,
13295,
43470,
81987,
198266,
41790,
null,
11304,
201921,
366823,
165886,
13288,
18299,
14262,
17403,
406681,
74413,
33086,
null,
61335,
60210,
35353,
null,
8183,
92860,
46894,
148501,
null,
57821,
170930,
15989,
233837,
244934,
240085,
211374,
103485,
139857,
22391,
184799,
264915,
57953,
129420,
111848,
327823,
26787,
64033,
254355,
101576,
556185,
23200,
null,
207625,
65485,
248611,
373534,
81863,
null,
14147,
null,
172831,
187073,
58250,
23287,
31369,
109651,
502944,
541157,
295656,
108124,
null,
33281,
216288,
106123,
34497,
41194,
56446,
19549,
180351,
40388,
70227,
258381,
27220,
24723,
22735,
14328,
151107,
468840,
4708,
122656,
19877,
263047,
71862,
124365,
21121,
148297,
32874,
75112,
376138,
5537,
24188,
69719,
159439,
40697,
8095,
366064,
213954,
210739,
null,
33582,
25085,
121160,
128656,
26913,
23672,
null,
203507,
163716,
165726,
183502,
15968,
54040,
278870,
92302,
152437,
16193,
230077,
131268,
135767,
154295,
48385,
210663,
124963,
34831,
null,
33079,
24878,
36930,
62949,
90030,
29880,
164515,
40347,
13177,
null,
447617,
177716,
12305,
null,
232601,
70078,
19900,
175950,
33874,
22444,
37039,
446278,
92948,
775376,
221904,
23696,
39890,
154730,
55151,
36726,
131678,
158221,
18632,
33280,
251220,
99581,
32863,
364241,
204018,
85343,
55869,
26448,
215033,
339858,
1234441,
141083,
15485,
102598,
158359,
24546,
180586,
58044,
17456,
50796,
20858,
16163,
372969,
64707,
271565,
185938,
null,
157226,
244426,
250201,
45336,
60407,
54924,
37839,
null,
18899,
202801,
null,
66981,
null,
27075,
60204,
175944,
32356,
212609,
161552,
17505,
null,
null,
15521,
215318,
76675,
20990,
31506,
15354,
null,
197356,
151870,
508277,
166089,
328730,
352961,
195109,
null,
null,
42394,
431407,
215895,
247430,
371149,
4185,
30496,
46613,
346859,
12438,
186158,
null,
195129,
45378,
255576,
14516,
98931,
77424,
301087,
204350,
20572,
43760,
230481,
64424,
35722,
130003,
569382,
129046,
100007,
338999,
34954,
179582,
15354,
31960,
43722,
53169,
47467,
277011,
39375,
70697,
459512,
10181,
288236,
40494,
1119620,
103771,
72539,
56368,
331686,
268631,
null,
21408,
18698,
160139,
751327,
61632,
25237,
144622,
11780,
1654,
177427,
null,
26847,
84876,
52458,
147071,
37677,
362232,
92482,
21099,
31232,
162622,
15685,
35217,
null,
13862,
171443,
40211,
47624,
17474,
41254,
69585,
4871,
262966,
33869,
2051680,
40168,
4780,
223359,
75802,
8822,
17695,
175182,
17870,
42759,
29655,
22696,
43035,
9621,
182034,
91870,
233656,
70569,
33436,
160967,
30480,
122956,
18235,
523816,
24449,
27678,
23189,
319370,
17448,
null,
143547,
165504,
331551,
16945,
145396,
7628,
16023,
334570,
27039,
300135,
null,
15441,
43020,
14267,
200947,
39517,
323104,
16238,
168329,
40044,
152851,
83950,
189558,
37026,
249444,
219679,
3917,
159744,
204239,
211916,
null,
649659,
248348,
13387,
61090,
39738,
108741,
183133,
28953,
2083,
null,
48858,
7641,
88149,
285279,
266350,
317918,
35547,
109845,
152573,
464373,
136494,
11589,
156615,
220896,
162212,
3455,
188825,
44121,
124109,
1332695,
257146,
332717,
532571,
99214,
null,
19856,
16862,
108141,
229954,
29900,
47451,
12041,
111218,
null,
18205,
73426,
8339,
238645,
269442,
55479,
353179,
50540,
48102,
103067,
39593,
35919,
31025,
97740,
159207,
111939,
149447,
7586,
25048,
74795,
null,
182475,
305232,
274663,
303129,
33624,
245780,
18149,
184455,
83420,
40938,
163459,
347024,
null,
33900,
11108,
24447,
null,
152177,
242499,
187876,
27377,
20078,
51845,
26433,
40217,
69090,
314302,
184109,
29714,
82175,
41940,
32048,
19750,
104870,
null,
177052,
12361,
130643,
39264,
120280,
24652,
104369,
141322,
27048,
74544,
157615,
229713,
102940,
283813,
20455,
24540,
200548,
30430,
453703,
40474,
1361016,
97388,
36910,
161786,
39954,
45661,
190690,
487234,
31397,
83891,
16998,
263086,
19968,
28757,
13052,
160096,
235173,
72132,
246771,
344875,
482448,
9398,
63337,
10688,
43421,
17370,
188555,
21189,
22481,
145197,
33175,
3926,
19542,
165551,
327709,
107965,
43369,
297064,
186147,
93547,
125549,
139951,
227205,
62735,
18094,
null,
416887,
46412,
125646,
null,
178347,
53034,
404034,
null,
293366,
29222,
8417,
260009,
7789,
44627,
89035,
195407,
293814,
53332,
79736,
195921,
106917,
441190,
41321,
198763,
241583,
6903,
44218,
215378,
221350,
736534,
199782,
179646,
21168,
220092,
72180,
285233,
null,
25505,
24617,
62296,
75364,
205002,
23046,
390172,
587516,
130805,
53443,
105006,
90903,
53434,
16338,
42889,
58161,
140595,
662752,
317097,
17831,
14924,
250749,
242372,
36937,
8246,
49249,
null,
13937,
190050,
39024,
null,
215143,
140054,
243071,
375143,
149073,
360615,
82230,
95921,
16222,
197496,
214187,
112820,
11707,
388146,
43745,
414011,
275721,
349168,
188142,
23505,
223350,
11279,
null,
121093,
38390,
39950,
25529,
4140,
35331,
135542,
44434,
189563,
156771,
390202,
null,
51434,
38587,
263842,
187006,
39707,
451200,
31468,
160563,
568085,
126705,
378709,
16774,
255080,
32348,
43492,
null,
45401,
183898,
294414,
839313,
null,
14519,
180375,
182819,
16927,
112677,
40710,
15706,
null,
19625,
12089,
53541,
null,
513741,
37126,
217490,
292718,
31749,
41969,
13425,
35085,
52898,
36175,
766037,
null,
13100,
185600,
29934,
372426,
32106,
69936,
35805,
null,
10770,
null,
24647,
178067,
65953,
322998,
null,
59736,
367936,
333261,
25027,
505867,
65182,
160399,
31577,
57566,
173610,
412881,
119411,
27884,
129321,
125016,
80937,
223263,
203705,
586647,
123495,
29786,
156212,
311958,
74497,
336577,
47861,
95506,
null,
38334,
280406,
14754,
17620,
39161,
123144,
361629,
347885,
213808,
124847,
46619,
528105,
9286,
21758,
55848,
117001,
36355,
30920,
29160,
173532,
17521,
30276,
10521,
414919,
252482,
157972,
89640,
65016,
53746,
217250,
52821,
119254,
133923,
187653,
215514,
28079,
24598,
191137,
37107,
55205,
156320,
null,
262786,
15650,
13148,
59362,
43873,
56882,
364366,
2951,
34868,
243513,
16285,
24372,
116276,
104112,
238341,
7971,
26043,
46525,
117800,
88498,
445227,
82287,
169664,
16378,
289657,
18637,
124490,
205685,
58759,
155187,
79634,
349560,
102449,
null,
39553,
37717,
3834,
162946,
209414,
42569,
161412,
15304,
58667,
76289,
24133,
null,
202599,
23320,
320292,
23866,
null,
385311,
122573,
20608,
319983,
null,
176240,
426261,
27852,
88451,
117411,
null,
36310,
8997,
576551,
267660,
14084,
341474,
66196,
34326,
null,
30589,
11373,
28241,
31879,
null,
101883,
12742,
1299833,
218018,
null,
44123,
30859,
357596,
14424,
5550,
29238,
139575,
5586,
53599,
null,
54459,
34634,
8951,
95828,
3068,
176068,
68241,
160416,
9583,
61841,
242955,
20408,
262383,
307991,
89473,
38055,
274980,
94191,
128468,
22540,
164164,
110677,
454209,
831171,
664011,
26766,
148132,
99391,
13366,
45624,
247677,
17151,
2054,
37908,
175814,
207044,
44825,
319276,
79233,
21395,
271011,
5498,
117477,
118844,
46116,
26437,
null,
293333,
224957,
null,
50096,
39734,
91806,
174888,
175085,
291528,
26258,
24889,
null,
220856,
null,
45196,
25625,
513291,
14181,
8501,
45642,
52658,
102677,
224552,
138025,
37736,
37288,
157472,
308045,
556906,
34662,
459505,
104325,
null,
234701,
27932,
56349,
57748,
104817,
17139,
2963,
272278,
null,
171835,
51680,
72649,
121215,
229613,
21493,
403165,
444914,
6856,
187261,
46013,
262923,
107379,
260335,
65038,
312245,
90268,
267052,
17676,
null,
5494,
27424,
102951,
9875,
424123,
176397,
23203,
54459,
67563,
106697,
23389,
9198,
33920,
34032,
103932,
185650,
129209,
97167,
null,
19299,
18332,
364168,
83437,
270092,
35769,
187305,
234095,
44392,
26364,
5619,
13095,
57182,
null,
null,
149090,
234080,
387297,
122672,
null,
82139,
264033,
16357,
804103,
168514,
29663,
24468,
84155,
70429,
192343,
24292,
69404,
52919,
234813,
387315,
45478,
null,
162380,
47648,
58390,
417928,
26485,
null,
21717,
202395,
75762,
null,
null,
62237,
28017,
206565,
359844,
17047,
null,
175620,
53940,
264836,
97845,
28124,
40233,
23859,
38349,
208745,
60489,
11852,
21366,
null,
45368,
null,
341561,
10238,
17176,
6643,
15162,
89264,
223596,
10241,
44838,
88258,
211338,
108213,
686794,
null,
178649,
335650,
24294,
null,
95096,
14741,
42209,
182366,
298929,
16862,
143117,
44064,
38384,
179761,
52351,
166311,
null,
291915,
40517,
99474,
455324,
8311,
109474,
100652,
73403,
31589,
163404,
null,
34623,
null,
49064,
218487,
60971,
349399,
191818,
137206,
17137,
20387,
341508,
356506,
16850,
126406,
35777,
44009,
15382,
null,
49889,
337240,
178172,
83087,
145334,
40584,
141749,
172682,
4296,
19605,
152319,
70369,
240658,
32280,
4595,
53430,
null,
201067,
16415,
32267,
32790,
408449,
198935,
403766,
23000,
7769,
63145,
53214,
232225,
null,
35481,
235408,
137246,
33368,
270069,
32240,
35143,
111602,
2982,
3258,
161352,
432949,
null,
18771,
35313,
22493,
187215,
569795,
31885,
360462,
47689,
10122,
475417,
445207,
66797,
34151,
33797,
33146,
211668,
34024,
null,
82279,
38433,
173726,
35478,
80550,
128762,
71736,
264016,
366882,
45453,
24199,
128111,
143073,
193880,
281967,
5032,
27566,
93031,
463860,
13530,
146633,
35252,
22585,
205560,
9374,
295344,
63503,
3437,
19906,
120133,
43435,
48595,
258284,
114869,
312731,
23541,
24092,
17511,
8093,
180805,
607673,
64746,
10005,
75671,
245623,
22723,
249170,
41661,
null,
85724,
106180,
411984,
55008,
250014,
88069,
13387,
217322,
239063,
149064,
19604,
89953,
24772,
41150,
172615,
377265,
22068,
48774,
46287,
405948,
41771,
234036,
89900,
27069,
38996,
45842,
218988,
17223,
16503,
null,
36960,
11194,
38185,
39166,
169984,
8630,
29369,
58396,
130734,
37248,
94562,
356299,
10112,
434862,
62696,
45710,
231330,
118221,
380990,
81845,
232212,
177204,
93032,
5113,
304632,
171628,
394150,
12911,
117003,
38560,
6310,
81696,
126067,
39064,
59522,
137647,
null,
100740,
38366,
null,
13460,
8678,
162780,
156847,
6471,
6064,
64169,
67493,
257173,
1167,
147027,
66755,
36013,
164454,
102165,
131125,
229172,
44094,
190750,
17261,
null,
81167,
15632,
222496,
210477,
80421,
183953,
208805,
253103,
10882,
39439,
442571,
157604,
121537,
30564,
20731,
238956,
326810,
416225,
56929,
295787,
null,
8170,
3357,
null,
405752,
82293,
null,
26325,
45819,
206121,
15867,
168705,
null,
61964,
433141,
49578,
182257,
158521,
8510,
629574,
37378,
26377,
120261,
87153,
8330,
321231,
43767,
null,
30171,
27146,
null,
126381,
22968,
304738,
495308,
163278,
40606,
15290,
30290,
25139,
11795,
null,
149849,
81651,
291641,
214563,
30031,
292038,
56415,
212243,
170208,
21491,
131867,
49872,
332464,
null,
102397,
26335,
48249,
122238,
null,
968125,
222822,
294971,
12770,
155016,
24979,
84125,
null,
65400,
241469,
34394,
165540,
18446,
44477,
56164,
250746,
31339,
6876,
65183,
22593,
54630,
538885,
16185,
352880,
10192,
175832,
126548,
200723,
42402,
22955,
269477,
362901,
470919,
51075,
19672,
163416,
33761,
49446,
53623,
214515,
484750,
185104,
451210,
731992,
234575,
null,
170461,
198520,
20669,
39989,
30928,
null,
33417,
5375,
24547,
388397,
25439,
23633,
57048,
376272,
36983,
113806,
29220,
17389,
83942,
131238,
392068,
254123,
52980,
24054,
6132,
980303,
28589,
22034,
254472,
100770,
15525,
null,
17751,
50934,
18115,
72219,
251142,
23685,
309298,
333386,
30462,
34028,
78060,
402250,
264969,
316581,
394245,
243030,
37667,
179121,
177912,
18413,
113166,
215831,
121835,
60434,
9883,
77925,
201308,
null,
12097,
283116,
142452,
37233,
172538,
467529,
9299,
201711,
210472,
64325,
157729,
37113,
188282,
538664,
89956,
46339,
17929,
260671,
283386,
13870,
105177,
254292,
313501,
343132,
53600,
156815,
7908,
414134,
390557,
3015,
470369,
59761,
139555,
152501,
121043,
324187,
10994,
12328,
null,
198708,
35139,
92846,
303010,
168090,
238734,
76009,
325499,
125555,
18310,
215660,
141000,
91448,
221476,
22142,
null,
283907,
158244,
85269,
58209,
324346,
8866,
56545,
129915,
45601,
58041,
482985,
48,
null,
337125,
197889,
138070,
130273,
16619,
18066,
153654,
458376,
42119,
78441,
259296,
209524,
35414,
160188,
1084326,
116035,
65064,
3848,
341365,
6417,
null,
91727,
106532,
37855,
225008,
6397,
132006,
225046,
54819,
null,
54587,
247424,
346819,
78450,
197933,
81052,
26678,
68622,
null,
null,
7078,
14626,
21978,
35059,
10195,
96531,
56502,
135637,
8283,
211335,
21696,
30608,
43797,
390085,
111519,
9639,
112937,
115485,
23294,
66833,
10291,
223730,
19454,
null,
null,
29567,
71118,
20104,
98280,
5765,
38547,
210355,
159793,
324151,
9409,
85607,
55878,
39199,
6311,
572434,
274477,
387876,
296683,
131135,
null,
101094,
null,
230588,
29682,
425774,
261176,
null,
211716,
11565,
21716,
386566,
42582,
141691,
131737,
196260,
188149,
2872,
204166,
198812,
8902,
50895,
109137,
8594,
339984,
25392,
45640,
368934,
196170,
211544,
195241,
96860,
104588,
48199,
17924,
344522,
717176,
13714,
null,
113964,
331514,
35226,
55692,
224252,
210875,
83186,
385993,
61091,
30571,
10831,
61242,
469787,
233600,
26903,
12113,
54356,
57296,
201289,
44216,
212442,
129417,
405277,
27397,
126177,
56944,
134854,
205914,
32620,
215936,
11190,
30137,
56335,
29466,
42498,
null,
39368,
184791,
6024,
252396,
25806,
null,
24192,
467700,
166000,
69541,
96198,
242582,
294141,
171366,
null,
72260,
163007,
155408,
291393,
209633,
107369,
20908,
121759,
190975,
58783,
161954,
72715,
293137,
null,
272909,
175440,
175530,
10563,
91801,
43687,
145497,
39518,
118090,
30421,
40606,
14894,
394342,
121656,
42623,
42422,
57098,
96355,
75289,
34624,
394894,
19350,
73401,
null,
194409,
212971,
7263,
34472,
6383,
15104,
156296,
33899,
196450,
null,
134310,
80385,
14163,
182726,
306792,
235773,
43143,
41714,
16403,
568845,
314293,
257401,
9066,
28293,
45704,
129161,
236646,
42997,
47301,
366365,
1303602,
283843,
36097,
68628,
46184,
null,
161430,
174295,
21056,
16652,
9312,
79549,
12989,
40137,
11928,
275922,
96614,
551318,
38910,
314926,
27965,
92293,
192801,
283662,
null,
98726,
238412,
24636,
208467,
284849,
84341,
249271,
39738,
54991,
345979,
null,
77555,
32171,
94692,
31427,
118928,
82920,
754414,
25733,
42456,
155332,
215553,
30150,
95117,
317765,
null,
38562,
436252,
226669,
25944,
22860,
12174,
57487,
113322,
189874,
52491,
41862,
null,
null,
null,
40275,
17755,
81518,
159950,
59699,
469053,
14153,
33832,
236699,
19800,
32343,
8115,
165760,
40136,
18212,
8233,
68619,
379952,
57374,
201205,
3608,
195767,
69833,
96771,
188727,
5919,
63034,
284610,
12252,
200626,
758189,
266569,
673419,
20743,
53068,
362147,
254705,
38934,
19881,
24244,
102326,
54135,
299011,
28788,
22709,
44260,
175207,
6422,
282736,
23519,
331651,
380681,
null,
237264,
213139,
25308,
7160,
191456,
31362,
187460,
3244,
null,
788382,
367577,
153979,
29752,
null,
183313,
9137,
61849,
213859,
215758,
211749,
265065,
189612,
171945,
null,
166535,
509708,
16911,
18418,
250087,
33279,
317034,
463385,
4740,
72620,
121266,
142013,
15759,
123088,
27361,
78998,
370612,
null,
13459,
null,
103157,
31378,
198672,
278376,
null,
79078,
null,
8470,
62515,
213463,
37632,
86183,
64638,
1826285,
null,
170438,
50579,
27665,
231941,
133545,
134858,
80185,
35496,
25119,
81007,
7190,
264260,
75340,
186164,
298938,
289560,
141733,
91626,
200277,
167584,
114121,
123917,
18761,
55569,
100588,
349028,
28482,
67472,
22570,
197665,
78342,
76541,
111399,
10411,
33697,
12862,
132552,
211105,
198590,
22458,
87842,
253479,
174456,
7000,
null,
158418,
319301,
280858,
36458,
125498,
31723,
329754,
null,
80325,
22231,
171550,
105643,
173796,
null,
8229,
330280,
71948,
106367,
8874,
362658,
177608,
39497,
128264,
33494,
110282,
null,
310434,
16128,
204188,
203458,
20162,
115455,
15558,
224654,
23723,
2780,
166975,
26147,
167992,
299056,
225522,
16793,
577172,
15057,
69159,
32305,
20029,
null,
23151,
null,
191416,
689956,
196115,
32851,
199438,
46711,
92286,
72536,
55119,
22304,
196324,
38363,
614368,
85680,
246340,
395264,
null,
null,
11676,
172703,
76226,
41701,
47667,
95830,
411457,
31445,
297988,
19799,
210829,
143576,
223450,
316448,
183477,
58692,
null,
15901,
332226,
394411,
21448,
331363,
42576,
470018,
18501,
6351,
189804,
136355,
193001,
56330,
43492,
30897,
278418,
336397,
22689,
29728,
132111,
21479,
11098,
34496,
43474,
256538,
24543,
17784,
210537,
null,
35769,
8801,
28182,
591644,
7689,
null,
2279,
368810,
13822,
null,
null,
4146,
207784,
27117,
34616,
48518,
134321,
260260,
746358,
244486,
80810,
254431,
121924,
null,
263495,
391729,
null,
203359,
15084,
72037,
378224,
251380,
171895,
40943,
146051,
147458,
126976,
12493,
117983,
32320,
null,
211401,
null,
72777,
5895,
533734,
23052,
350443,
45636,
20430,
439387,
33937,
null,
323610,
126367,
122399,
null,
628219,
null,
90720,
38642,
58988,
339878,
204449,
27286,
13870,
30044,
1042,
22532,
377861,
26479,
38754,
252269,
67395,
386016,
3431,
260145,
null,
22142,
14497,
63024,
41788,
321939,
null,
10028,
252647,
41359,
44403,
48945,
185887,
108102,
6929,
77574,
91415,
null,
12534,
63928,
22849,
45740,
87886,
35961,
224759,
367490,
154880,
334109,
198663,
154700,
47354,
139412,
94870,
171324,
120978,
31924,
168994,
128721,
43978,
46435,
131540,
65831,
34414,
40580,
199771,
107047,
39633,
218356,
26454,
23021,
36622,
310455,
45461,
13558,
18788,
91527,
null,
292879,
51127,
43140,
66066,
92389,
207447,
49313,
9250,
39642,
163465,
305620,
20795,
43057,
357477,
137104,
280422,
24349,
53574,
34568,
231788,
94305,
25154,
133195,
63881,
49095,
5551,
83173,
41320,
null,
30384,
29895,
18194,
236725,
402720,
145033,
133899,
10933,
null,
76918,
146441,
91640,
99500,
6315,
43865,
32831,
153525,
null,
59183,
356911,
19442,
9045,
null,
87950,
289056,
null,
69109,
null,
135972,
300548,
17403,
41716,
43910,
77022,
257338,
167989,
174814,
49830,
254707,
617363,
17195,
46548,
70950,
46618,
237326,
53624,
16907,
114717,
40920,
45076,
143051,
127990,
37385,
26636,
67145,
null,
140204,
163408,
230270,
11967,
159125,
57743,
18815,
369353,
194557,
170027,
323297,
79173,
318886,
53202,
12430,
null,
null,
35960,
94496,
33498,
207884,
53552,
134162,
169256,
null,
19433,
15284,
24444,
122182,
18907,
166058,
65787,
39910,
152435,
84199,
4014,
93547,
279562,
32752,
264236,
284462,
132000,
134405,
47508,
228780,
14265,
171645,
360160,
4859,
27292,
146256,
277431,
55470,
44981,
36795,
382802,
15678,
217205,
365770,
20473,
47199,
41213,
null,
null,
20373,
47344,
104135,
15973,
184154,
74905,
138322,
32818,
118836,
162308,
164530,
100357,
266195,
93821,
186819,
13238,
24235,
137167,
568141,
323160,
301293,
165507,
16717,
305320,
37279,
22148,
21723,
27950,
196911,
204374,
141033,
64443,
93024,
42674,
206850,
6476,
85602,
27631,
null,
174966,
92070,
38244,
240354,
132195,
20957,
22689,
119395,
295585,
6127,
113667,
214807,
310546,
161773,
33315,
164573,
390022,
73906,
195573,
205920,
8046,
51882,
49740,
58330,
32743,
209447,
15564,
28106,
152866,
51626,
183074,
61614,
59191,
261979,
6414,
78210,
439902,
25511,
13831,
58200,
33640,
241677,
5805,
91774,
336533,
21988,
38824,
190334,
71566,
379201,
15725,
162819,
594026,
545031,
123323,
338339,
71772,
28904,
226004,
33435,
65573,
62523,
8837,
186035,
52188,
11573,
90249,
261459,
41039,
116609,
385915,
6100,
49652,
13838,
13285,
78950,
null,
66344,
122942,
46432,
246197,
15308,
145789,
14536,
181273,
30462,
20641,
40305,
29354,
74140,
223624,
225071,
56406,
291405,
285644,
129075,
49340,
124692,
89279,
30842,
179109,
null,
110365,
34963,
178216,
null,
138736,
173881,
1718,
30599,
257269,
null,
88309,
226469,
30593,
null,
null,
24402,
136887,
72706,
null,
6702,
70046,
38370,
87756,
29620,
21419,
null,
112639,
369947,
22279,
21443,
69110,
7645,
18204,
347985,
32329,
4358,
25171,
null,
33144,
254218,
213630,
228339,
344979,
364449,
13158,
207373,
377128,
504441,
281198,
44409,
14150,
349386,
6702,
15156,
3938,
221251,
35873,
41643,
71389,
14518,
51906,
219145,
null,
null,
192525,
53016,
100117,
213535,
486757,
46611,
33276,
44690,
419006,
158704,
25543,
275286,
240909,
20185,
166283,
98601,
140532,
168605,
183672,
47555,
495423,
104278,
140928,
413188,
21419,
244781,
83575,
34348,
134708,
345050,
12230,
367907,
423946,
null,
59162,
393724,
26468,
17675,
74296,
305687,
124734,
205608,
157363,
252191,
27448,
369585,
224189,
14734,
315177,
12372,
298537,
129632,
8054,
null,
382701,
7511,
46666,
363291,
79322,
109705,
33122,
64187,
375777,
62007,
7311,
194947,
5862,
131819,
395676,
58225,
null,
190500,
465253,
29959,
283779,
167726,
189062,
337550,
108935,
29179,
14876,
400581,
129624,
4241,
42087,
155753,
237208,
null,
221140,
194586,
219563,
163701,
73044,
31700,
181481,
224335,
46746,
428522,
41875,
null,
224134,
39075,
41983,
22087,
36827,
209614,
135021,
30629,
343902,
40946,
65277,
184206,
50593,
55231,
35133,
350947,
302146,
18983,
40394,
87127,
26725,
182950,
279617,
21527,
277902,
11010,
164446,
303863,
43769,
185507,
32726,
253986,
28279,
246102,
298555,
311719,
null,
282661,
null,
null,
27573,
221429,
203646,
252406,
13207,
101395,
null,
420559,
140537,
34192,
56861,
9411,
73996,
338156,
13621,
47704,
392178,
22631,
27467,
16319,
18749,
36164,
200982,
null,
21076,
null,
23786,
null,
66576,
261270,
5954,
15456,
null,
215601,
null,
59015,
21000,
216134,
49909,
558723,
39428,
216000,
51579,
40203,
58437,
26226,
14487,
14571,
229562,
33787,
null,
487814,
30629,
17511,
32649,
99737,
43528,
354580,
62922,
24272,
338422,
165449,
43305,
null,
14176,
86242,
199901,
219311,
120251,
51468,
null,
78918,
3628,
37221,
150977,
366325,
28888,
15935,
340126,
41407,
185510,
78259,
37568,
96642,
36514,
45259,
259894,
null,
136029,
71306,
9698,
497222,
161516,
273093,
45024,
25119,
264498,
9057,
224222,
352980,
25193,
26029,
85640,
305410,
22768,
6589,
416103,
156239,
14656,
242922,
null,
14652,
175885,
107464,
47594,
160237,
null,
28944,
35379,
null,
321297,
null,
351228,
700336,
538256,
5633,
663937,
44218,
50919,
125950,
181617,
50368,
397625,
null,
40301,
191172,
null,
39082,
23925,
63842,
110289,
86092,
32036,
19137,
55665,
59003,
22402,
112662,
80895,
200792,
51434,
35875,
164658,
277228,
62200,
146539,
26204,
312208,
52352,
212366,
63022,
null,
105697,
124944,
24357,
10180,
45758,
55995,
170922,
null,
27033,
45546,
22713,
200179,
156212,
106832,
262327,
null,
501628,
160435,
660003,
1107,
210764,
37600,
68095,
42051,
66471,
null,
128710,
54505,
45996,
15844,
17204,
630340,
59901,
242717,
35262,
60790,
189237,
48785,
193893,
53675,
124114,
33629,
111384,
89445,
5088,
138396,
282176,
32952,
135225,
47283,
23776,
null,
161566,
432950,
4010,
213927,
null,
293144,
475197,
55532,
83782,
39006,
43676,
null,
11797,
null,
54294,
75528,
6001,
19865,
374264,
null,
23877,
8269,
45500,
545717,
428305,
136395,
36969,
226120,
30887,
15511,
314778,
4306,
172317,
178663,
16289,
51965,
null,
22907,
5132,
14165,
30611,
null,
null,
229078,
22676,
24547,
54925,
101914,
13456,
39481,
70449,
59448,
55667,
null,
9613,
244237,
null,
199809,
231907,
259334,
446611,
4204,
10061,
null,
19638,
117127,
449762,
36593,
113989,
9151,
39513,
28909,
114581,
228968,
14450,
155738,
227530,
200805,
260931,
22847,
22311,
null,
34946,
null,
20321,
144508,
321820,
172812,
423167,
201303,
547765,
30321,
11483,
null,
43230,
null,
278727,
162304,
153104,
86143,
444836,
212489,
136138,
176193,
null,
null,
63090,
125136,
664508,
325373,
170454,
286378,
26632,
22494,
56818,
73233,
254406,
null,
586934,
189210,
35634,
171622,
43447,
14413,
null,
7015,
151228,
24220,
170924,
52605,
226790,
null,
null,
161135,
219274,
30577,
183853,
272241,
null,
19033,
133501,
49966,
17045,
26927,
13210,
243454,
112949,
20458,
1393,
46910,
null,
369309,
25705,
16957,
1041916,
242012,
26994,
40128,
42975,
205820,
162233,
252462,
27166,
21477,
23467,
129487,
18984,
90687,
246224,
50448,
24209,
262925,
194886,
33360,
null,
27399,
104541,
87862,
290737,
401126,
81741,
123294,
222900,
109654,
372050,
17391,
181954,
15535,
19558,
66351,
54193,
178335,
131306,
127890,
244420,
18339,
178059,
84138,
271058,
159692,
77578,
75944,
178216,
404411,
438136,
4216,
270214,
49694,
21888,
723796,
null,
null,
54348,
48517,
135243,
53041,
null,
683078,
164696,
null,
null,
72271,
150053,
46556,
318675,
417746,
null,
68783,
64893,
98682,
30540,
57288,
44512,
875,
69440,
52096,
117689,
15750,
78102,
null,
63839,
64165,
389361,
17591,
28153,
482138,
225921,
73509,
null,
141355,
132399,
63097,
283427,
56790,
156532,
412800,
17054,
71658,
32416,
41692,
2643,
214958,
103828,
175148,
127867,
70942,
51837,
null,
39604,
137181,
32248,
null,
null,
97233,
96406,
10159,
13977,
118427,
10425,
71390,
116680,
168621,
322754,
28401,
17360,
12265,
342588,
30364,
57826,
114975,
31317,
177319,
175787,
159329,
22411,
4901,
98793,
318555,
162866,
8674,
null,
null,
9457,
null,
209165,
450574,
75503,
92036,
13861,
64217,
91663,
26474,
62944,
159888,
11529,
142925,
null,
210670,
63707,
458905,
69399,
114409,
4866,
181209,
91732,
97301,
116064,
112361,
114071,
156739,
165540,
null,
230306,
24857,
124422,
122903,
177550,
28736,
185289,
38444,
291673,
214551,
52892,
67163,
303878,
771664,
240971,
19406,
212015,
33028,
350719,
96205,
30233,
null,
75098,
22447,
201306,
12400,
64051,
null,
null,
17077,
15070,
null,
74833,
123969,
15497,
200314,
12813,
112191,
38943,
250522,
95149,
389790,
312236,
null,
18360,
78523,
137833,
288867,
234936,
13470,
748851,
null,
14809,
94815,
112075,
4415,
137207,
321104,
220316,
167327,
23670,
99012,
137664,
314518,
33562,
83186,
155247,
26571,
272348,
151687,
null,
5454,
292910,
13377,
333032,
13536,
71267,
15279,
22613,
86560,
490922,
152438,
21177,
34021,
87028,
27662,
25997,
27238,
138536,
108321,
300882,
33936,
23596,
126043,
27671,
158995,
294334,
15094,
8289,
42847,
null,
203259,
77765,
28093,
44863,
122458,
60717,
403122,
159180,
36079,
233129,
11694,
47125,
25413,
574594,
48705,
209291,
200280,
199612,
74410,
202752,
45217,
8098,
566959,
null,
46053,
48363,
337475,
256389,
9290,
466301,
61798,
168573,
null,
16829,
64995,
178226,
236626,
11720,
17404,
180222,
312198,
67257,
1010322,
311798,
null,
30065,
136131,
177566,
310748,
183149,
21915,
23884,
9003,
19462,
262371,
68173,
450736,
260261,
28973,
23669,
4909,
24603,
383631,
52231,
34689,
36075,
268285,
29104,
null,
251394,
15338,
132216,
37518,
134036,
31040,
386582,
262726,
356653,
154408,
132016,
22893,
28118,
349466,
244289,
13647,
8824,
107590,
159902,
10978,
8077,
112662,
32214,
31043,
8712,
12611,
32674,
125288,
27910,
179407,
530675,
21954,
null,
50047,
47996,
18809,
57982,
365072,
75521,
155485,
176521,
53865,
48647,
null,
55126,
41345,
null,
48408,
410422,
30008,
42119,
152385,
119414,
159259,
363890,
50259,
33369,
272306,
189232,
573300,
298776,
34642,
269301,
494167,
282374,
20714,
133163,
6262,
132882,
null,
253570,
341345,
163728,
42539,
307018,
null,
103344,
28451,
255828,
30055,
200722,
345780,
47400,
92926,
44983,
200311,
null,
37893,
46364,
298692,
282040,
84803,
13108,
135764,
280380,
141850,
720248,
435630,
159905,
31178,
251100,
19551,
271683,
159483,
37414,
246029,
407100,
166560,
185790,
90872,
11050,
182395,
72092,
144981,
463131,
27512,
36625,
null,
7530,
10239,
101140,
40119,
15439,
35701,
32306,
454547,
470814,
134646,
null,
48779,
8009,
464310,
10387,
189410,
272084,
57812,
145736,
164799,
25585,
5127,
18266,
363418,
null,
144765,
398427,
234664,
10596,
9303,
178297,
null,
12898,
24732,
54179,
426743,
13843,
387518,
317653,
219417,
237866,
226026,
null,
235349,
20327,
197020,
20747,
142758,
39619,
47202,
204145,
205875,
117882,
162151,
357144,
191042,
308369,
201361,
42246,
288683,
21982,
277271,
110179,
279011,
194964,
116523,
20532,
314873,
465156,
10977,
6624,
377383,
28824,
54375,
96425,
269898,
183709,
288408,
391757,
176367,
54366,
34755,
22418,
12396,
94712,
211442,
42470,
105965,
4817,
null,
24864,
181809,
28894,
146721,
3134,
26287,
22696,
9072,
7967,
34582,
62233,
17844,
101654,
342144,
27308,
361564,
589658,
23879,
59604,
45905,
14569,
102198,
28139,
105305,
254561,
null,
45854,
153039,
24618,
null,
37578,
70375,
401394,
110344,
60032,
136329,
247211,
318326,
59740,
85897,
50885,
273600,
73387,
37979,
null,
41791,
44311,
127394,
5483,
null,
428364,
9301,
31307,
103303,
24108,
209626,
117102,
263234,
22280,
236597,
3306,
59715,
264021,
354403,
31810,
31493,
348830,
167649,
377623,
32711,
26284,
24118,
83008,
90565,
24420,
4875,
null,
142432,
371175,
72936,
121664,
18920,
16017,
65744,
198850,
151858,
166794,
244372,
157395,
102672,
44071,
16605,
183739,
41790,
66571,
197798,
163085,
239734,
19074,
94238,
103212,
18876,
535847,
11033,
null,
30730,
207817,
68090,
157166,
8210,
654336,
97106,
null,
585824,
38384,
46596,
266568,
138427,
117370,
71620,
3246,
264659,
2742,
16962,
11057,
21065,
35580,
141953,
33617,
13373,
45911,
null,
104549,
31921,
46487,
13661,
45083,
20402,
359972,
84367,
164574,
335835,
76587,
7964,
556312,
207176,
50571,
522939,
207454,
320492,
33610,
null,
235846,
11424,
187804,
302417,
9692,
181959,
12074,
25131,
921640,
410156,
57250,
343079,
56201,
214391,
118438,
419082,
12243,
null,
219959,
162203,
null,
15951,
null,
55673,
305966,
170391,
61551,
375378,
175072,
34525,
14796,
311628,
171845,
112236,
36427,
356246,
92414,
358943,
15630,
292119,
38840,
402059,
7080,
189942,
599910,
5814,
115657,
252525,
123989,
null,
111586,
30191,
187741,
190044,
239548,
34487,
3031,
298384,
null,
218829,
29391,
8484,
24003,
7057,
16897,
160481,
56018,
402170,
76888,
33638,
51315,
170714,
55022,
null,
354466,
33952,
295879,
270006,
76073,
98224,
169334,
184720,
99383,
null,
197468,
103062,
25123,
357765,
186228,
62030,
null,
59656,
21227,
162790,
198040,
425734,
29502,
75203,
237273,
197199,
74047,
177883,
292439,
39595,
33364,
196414,
23368,
33959,
665264,
20410,
510968,
589272,
116226,
197043,
75465,
48537,
179251,
113566,
null,
20166,
292228,
null,
121453,
123626,
199594,
276618,
240437,
28460,
186766,
249909,
31406,
669956,
135402,
59441,
3616,
null,
90400,
264413,
120704,
5937,
208403,
46551,
24598,
206357,
417573,
24910,
69542,
267592,
258195,
346207,
257273,
53114,
4444,
423518,
147053,
183138,
19443,
23888,
361666,
216833,
154600,
89071,
237884,
28747,
92841,
31834,
76898,
115857,
20855,
63237,
292212,
14426,
148607,
9033,
291037,
4436,
null,
422373,
20221,
10442,
16461,
14400,
11603,
7875,
61439,
41042,
61205,
75838,
18151,
7887,
387996,
17276,
60180,
255052,
9144,
472675,
138071,
66108,
471787,
157676,
226085,
381154,
17402,
133182,
null,
309983,
14482,
52952,
433440,
8196,
50012,
24837,
null,
170087,
null,
617886,
31329,
23460,
20332,
162810,
33451,
120050,
138324,
162473,
257163,
18171,
157742,
24887,
null,
268462,
57513,
null,
null,
38955,
99267,
321911,
null,
224673,
238337,
108576,
430967,
371094,
9745,
258994,
9060,
122969,
395289,
298218,
77601,
132355,
243449,
34550,
28929,
52797,
228140,
225881,
42644,
null,
null,
292150,
95486,
179122,
null,
295042,
19304,
52056,
26987,
null,
33857,
41328,
null,
36967,
178871,
null,
201949,
485810,
null,
112875,
null,
234912,
7814,
385845,
200693,
27041,
84082,
2836,
182720,
67509,
742838,
120247,
97074,
69470,
8283,
28419,
60432,
253354,
204334,
22618,
34619,
24135,
23761,
485196,
null,
357950,
194181,
20115,
182825,
35010,
340594,
281065,
91584,
67050,
137444,
230533,
null,
287274,
207240,
6496,
23544,
27230,
254314,
644761,
209098,
121047,
17226,
111352,
31640,
241981,
25791,
703395,
312435,
38295,
209294,
23326,
8544,
147367,
1911,
83258,
163191,
17142,
275354,
496015,
null,
68265,
229145,
68411,
382822,
58159,
819319,
137880,
7707,
343426,
55163,
15254,
77250,
31457,
64623,
333774,
92787,
446584,
142603,
30360,
48581,
13357,
290621,
333382,
null,
null,
145611,
60466,
123776,
282340,
33108,
137781,
177450,
8773,
9790,
220697,
34901,
74533,
211805,
null,
61582,
308093,
14404,
27325,
466004,
289173,
878339,
189046,
175128,
23917,
11874,
137578,
null,
345012,
21716,
null,
34744,
26864,
null,
162671,
23550,
274228,
1537,
19034,
20939,
151126,
15604,
53865,
228520,
14511,
null,
73718,
98029,
null,
3540,
66045,
40317,
35670,
53314,
21807,
114517,
19729,
null,
1329807,
20835,
34952,
63001,
193582,
195037,
34736,
239798,
26532,
206540,
275255,
960818,
15169,
290429,
177262,
56673,
106404,
435469,
18199,
5727,
149795,
14926,
315280,
29599,
372031,
391914,
209844,
10135,
63727,
60982,
37443,
321980,
null,
12907,
22285,
172126,
42783,
186795,
28777,
226692,
27993,
6047,
14541,
170778,
98659,
20928,
57123,
9113,
232257,
198794,
47832,
63518,
43945,
24348,
51344,
17809,
null,
null,
null,
48929,
276795,
612298,
34975,
196303,
54226,
64748,
278944,
166432,
27972,
324490,
219063,
28805,
null,
361629,
65698,
26541,
282806,
53271,
127138,
33309,
46757,
113185,
90364,
17065,
192671,
23842,
22283,
280046,
null,
7784,
253373,
null,
61498,
361834,
134774,
13138,
217689,
309121,
50502,
131464,
301687,
229831,
147109,
235376,
233056,
39090,
20885,
36304,
12983,
192507,
67154,
null,
30206,
126607,
61495,
19369,
94424,
9262,
43847,
42809,
44914,
197961,
154604,
79534,
10712,
315761,
42108,
6195,
138599,
56724,
126379,
37541,
215836,
98491,
126922,
502915,
101104,
48996,
140214,
72305,
416272,
48813,
44933,
30845,
239907,
146547,
176739,
109488,
309294,
929860,
139642,
16025,
35036,
327910,
9772,
37388,
205143,
null,
45581,
23879,
187685,
108460,
374203,
null,
154684,
11443,
273546,
148866,
202877,
28802,
66005,
5959,
52096,
134091,
52012,
127959,
25104,
10755,
39950,
8988,
47939,
153842,
52084,
40475,
4573,
173634,
69081,
45894,
33040,
108720,
98278,
32838,
143490,
null,
708735,
21956,
45367,
27663,
20513,
153931,
230585,
7567,
37350,
176021,
7295,
57465,
38186,
241536,
15678,
172155,
27468,
6384,
79276,
null,
65092,
74578,
35722,
31828,
79306,
68660,
null,
443972,
26501,
24427,
266577,
15628,
33667,
314520,
54045,
146439,
18136,
42884,
121731,
308546,
308372,
152706,
46048,
569331,
40485,
82674,
217230,
31797,
18290,
1805,
30520,
21540,
25820,
31149,
3536,
47859,
55293,
33027,
241260,
69423,
180935,
41813,
465061,
174589,
148628,
48034,
30577,
313942,
428071,
320178,
527832,
69407,
19417,
23114,
39963,
110904,
168018,
38208,
null,
111949,
2274,
47393,
29624,
32447,
20765,
9482,
562627,
390053,
234319,
23790,
102263,
163898,
28028,
77282,
25298,
318888,
136240,
209556,
253209,
null,
167094,
471998,
5016,
16765,
130243,
140929,
28711,
292419,
37818,
286422,
232985,
55501,
102910,
16800,
188191,
622282,
249409,
170125,
191425,
18278,
null,
217805,
16041,
255946,
25804,
null,
109283,
null,
107458,
162402,
57397,
74400,
40721,
194693,
161198,
389663,
47232,
9769,
31012,
null,
15366,
255638,
131471,
null,
131471,
15354,
7482,
63541,
null,
234202,
77710,
212455,
21429,
161185,
301037,
401124,
18954,
19858,
553842,
192261,
410054,
109731,
168356,
546320,
20666,
213128,
48814,
79415,
39168,
211779,
61194,
483935,
226820,
5989,
13792,
235967,
null,
35422,
203267,
168996,
41987,
330177,
250484,
null,
304395,
132558,
55663,
223170,
18139,
32966,
174056,
71589,
21616,
16803,
199110,
610775,
null,
142447,
109492,
42286,
348903,
10118,
32812,
null,
91076,
125011,
55849,
169268,
97908,
230656,
755595,
92398,
16095,
5836,
22337,
90523,
122255,
41339,
156097,
null,
55975,
22723,
371359,
20674,
26700,
272214,
227005,
203905,
30033,
20962,
30683,
13409,
125503,
null,
189893,
30206,
70275,
319303,
92760,
62229,
18589,
278510,
146169,
327311,
391172,
null,
null,
101778,
15237,
406556,
53255,
20342,
89938,
286085,
167289,
59084,
11118,
41089,
117163,
244026,
248410,
15693,
23730,
263908,
38535,
33073,
133605,
27257,
29794,
null,
165206,
231406,
225828,
324912,
19030,
307713,
80154,
null,
579513,
23270,
22217,
46380,
41997,
65062,
95408,
37637,
11989,
33719,
62058,
null,
90005,
219950,
37028,
185514,
142250,
59003,
639918,
165806,
50202,
203827,
156714,
null,
27533,
297881,
null,
166190,
184998,
186501,
54009,
72821,
62613,
30317,
132493,
21100,
49140,
145197,
17219,
4397,
263094,
11906,
39883,
null,
160904,
30520,
295564,
49445,
487431,
233786,
23800,
586046,
279035,
26274,
51608,
null,
7652,
24024,
40229,
9577,
27539,
null,
16632,
82227,
507928,
134118,
49985,
186068,
44179,
28238,
7288,
202494,
44798,
208073,
140494,
237039,
50036,
20164,
413280,
19606,
21469,
70948,
255682,
3084,
157746,
330603,
340825,
70279,
54240,
36703,
141167,
147226,
null,
402012,
292396,
79074,
46804,
40256,
84239,
433796,
123244,
26564,
192490,
105466,
121708,
197470,
273001,
null,
48694,
null,
21592,
20673,
51255,
null,
6062,
23519,
29126,
119599,
35061,
270495,
181188,
154167,
null,
79241,
18820,
null,
417259,
87551,
130228,
430588,
8970,
131701,
40976,
null,
22709,
123897,
9540,
40477,
245664,
329033,
332221,
268725,
114959,
21551,
48537,
25618,
168877,
42709,
11915,
97700,
302021,
70719,
13859,
62604,
106834,
415050,
639211,
40720,
133244,
44964,
217813,
null,
15907,
null,
62866,
21018,
17890,
59251,
122722,
4726,
351755,
112068,
44532,
29723,
428498,
16725,
30146,
103201,
17441,
null,
85076,
42590,
399699,
307488,
22275,
232064,
69274,
51400,
null,
47179,
358529,
31799,
172993,
146749,
26922,
60212,
520225,
68813,
287943,
9842,
392270,
229860,
14029,
10928,
21362,
32109,
5435,
40758,
748170,
244439,
164908,
330492,
225314,
77532,
29610,
523282,
55374,
null,
185701,
227935,
86080,
12048,
40276,
25122,
160943,
49333,
153673,
9685,
null,
38253,
20,
16861,
273560,
29991,
78209,
81290,
193013,
140021,
53460,
47869,
67049,
130782,
385297,
38890,
143772,
15672,
23534,
37090,
103569,
72998,
15363,
425887,
22319,
49719,
9240,
17112,
73948,
11963,
16976,
591866,
77364,
null,
17214,
39654,
65154,
203519,
45923,
198094,
18051,
287671,
141752,
423294,
52121,
null,
68498,
196249,
20412,
371290,
512352,
17099,
20978,
46261,
16769,
43947,
101117,
21371,
26672,
null,
29031,
221269,
36047,
156996,
239891,
51427,
211152,
58603,
20556,
40083,
23027,
null,
88152,
29384,
14547,
48777,
26950,
40464,
182295,
384048,
288176,
78463,
10268,
null,
51625,
44808,
132935,
185859,
193323,
9751,
264756,
4896,
261318,
455855,
112050,
309246,
341353,
730276,
115435,
36250,
74797,
49652,
244767,
69922,
53013,
64270,
237326,
41757,
10899,
175390,
null,
31722,
null,
197396,
60154,
42489,
100267,
72929,
167461,
40288,
8792,
51209,
34093,
160690,
25762,
17393,
null,
20945,
47035,
186676,
30364,
null,
96663,
42113,
283976,
263336,
42572,
41835,
62927,
195204,
48224,
18746,
157953,
null,
3766,
53443,
324380,
20487,
74507,
19934,
51057,
77020,
234474,
36486,
175851,
6397,
null,
13720,
10132,
278062,
null,
27816,
88248,
14702,
216212,
null,
143016,
8921,
303922,
68898,
441571,
33274,
20029,
34213,
35358,
35267,
21482,
353248,
268054,
214270,
30984,
310649,
228861,
299962,
33232,
181744,
55849,
7452,
32860,
33230,
31100,
39057,
91607,
14292,
38209,
215128,
119933,
null,
201868,
59899,
null,
20004,
145048,
288304,
9506,
45584,
174315,
243723,
526048,
222758,
24083,
9081,
281251,
315249,
49983,
17437,
null,
541549,
372918,
493123,
196139,
30267,
null,
222608,
null,
22222,
32045,
8337,
44033,
56291,
10429,
101613,
220023,
26789,
13573,
112109,
132638,
23160,
24973,
null,
21483,
365899,
50372,
138434,
343952,
37497,
313044,
26882,
81328,
13619,
35917,
427731,
6832,
null,
78201,
33330,
53100,
4914,
109857,
258540,
null,
null,
60693,
null,
10079,
null,
380153,
14023,
382638,
513564,
15369,
94490,
300502,
null,
275466,
18652,
212775,
625580,
16064,
168314,
145703,
34888,
88779,
14848,
31925,
20854,
228116,
275725,
110407,
172116,
34628,
8756,
42838,
572512,
19941,
113624,
28520,
233763,
170216,
29554,
169065,
null,
82642,
114174,
118898,
260155,
3143,
768948,
173570,
12418,
31554,
null,
451209,
205147,
12734,
212786,
24635,
59104,
31967,
224635,
17854,
132953,
280088,
53654,
7868,
null,
166439,
22351,
527193,
296599,
17763,
24595,
31002,
760945,
149053,
44137,
70132,
40260,
76177,
6720,
162304,
66450,
659214,
24164,
275095,
null,
null,
10825,
22696,
108910,
49144,
128063,
37459,
49754,
120977,
61554,
140785,
187005,
14929,
29060,
null,
null,
59267,
98880,
7743,
null,
354632,
199151,
106643,
null,
214813,
214086,
198726,
422842,
224879,
12493,
48598,
204772,
279681,
57121,
154603,
100931,
242631,
189623,
177354,
108427,
16606,
315174,
565470,
4825,
63098,
125671,
11899,
47859,
10605,
371537,
130632,
246857,
194602,
138527,
7325,
138779,
76733,
32558,
4794,
9378,
null,
22023,
114661,
188910,
null,
39273,
15796,
214840,
292573,
36428,
39752,
305894,
39547,
26066,
378788,
158727,
111599,
171961,
594745,
63546,
521566,
65576,
25914,
166945,
45616,
52823,
448966,
100223,
35505,
136894,
20765,
320858,
258573,
23436,
60566,
76687,
158942,
12954,
79100,
4776,
267145,
195452,
216088,
35013,
119847,
115678,
null,
11128,
781456,
null,
null,
null,
15126,
null,
432679,
306403,
null,
233652,
286548,
9130,
14052,
34724,
19877,
13140,
27282,
null,
35075,
null,
253614,
174615,
53990,
196519,
145283,
267732,
142862,
327309,
83531,
699459,
14956,
11908,
111117,
426613,
null,
150657,
6006,
18597,
27594,
3845,
28443,
22191,
12429,
28563,
222130,
188229,
34351,
6816,
66307,
26651,
7120,
109245,
6707,
49840,
46691,
176861,
null,
75479,
328676,
7356,
275003,
34141,
271788,
193748,
150708,
213602,
136335,
306661,
63294,
56975,
54882,
208139,
183099,
112824,
287458,
10872,
309012,
32478,
null,
null,
null,
120182,
12708,
86110,
330121,
139653,
7461,
61626,
19205,
15843,
19696,
204243,
535756,
null,
20246,
145426,
23299,
144125,
249830,
213967,
16400,
254055,
292131,
741294,
252259,
218880,
22141,
9337,
25071,
66513,
null,
104022,
161400,
51534,
52697,
60562,
246481,
null,
15951,
19661,
75957,
392214,
282450,
22237,
384028,
30860,
544639,
20168,
6050,
989,
349126,
207475,
40615,
53289,
17004,
307151,
151422,
35219,
68428,
23366,
208579,
5956,
449193,
193155,
35800,
25128,
47260,
23340,
207090,
70900,
10054,
11045,
248688,
null,
null,
444429,
24615,
69982,
143875,
354289,
132430,
75274,
82577,
4024,
189038,
123800,
8982,
86717,
180951,
154615,
453602,
185823,
49572,
170851,
68891,
87829,
null,
132850,
59152,
318183,
248437,
62148,
737629,
24770,
69440,
229975,
136747,
615784,
443198,
28547,
19794,
166194,
159632,
107263,
14031,
58512,
223015,
15193,
44539,
341202,
265409,
262486,
223996,
147176,
131599,
46864,
371764,
584532,
null,
107974,
174607,
346852,
31966,
177122,
11526,
119968,
27057,
13959,
6513,
272341,
191402,
95092,
28035,
186706,
31088,
276363,
555807,
74938,
292342,
116538,
121524,
28124,
356286,
32048,
null,
6447,
315998,
null,
119734,
503448,
349183,
178110,
21004,
134017,
6800,
110034,
57238,
14194,
92642,
19510,
null,
73716,
21977,
153891,
31462,
321247,
109454,
49406,
345329,
null,
16882,
311967,
null,
292243,
133913,
121105,
14847,
27704,
269705,
335433,
9444,
42561,
111722,
585069,
21850,
246444,
28106,
12333,
38431,
420784,
9330,
246868,
null,
147254,
307795,
36741,
111290,
10728,
664776,
93105,
356934,
121599,
384544,
null,
5529,
null,
198717,
68326,
20926,
515632,
13258,
183052,
3333,
295335,
16146,
null,
28981,
13912,
28914,
26221,
371546,
272698,
24218,
212670,
9858,
42852,
327137,
220038,
115812,
344252,
43001,
null,
191181,
null,
77279,
34727,
390004,
null,
265034,
8743,
994739,
null,
14600,
null,
437974,
110334,
null,
null,
6049,
52416,
136300,
26052,
105329,
198712,
null,
78802,
8937,
39904,
181651,
63532,
null,
627549,
61170,
110731,
28977,
149265,
45227,
160354,
5053,
244986,
null,
36817,
131876,
132523,
39559,
null,
21451,
null,
null,
415590,
null,
null,
7397,
21113,
31550,
null,
243154,
30247,
165333,
261546,
null,
29259,
34010,
37340,
6116,
28328,
162609,
102758,
null,
167877,
2793,
22030,
114841,
107791,
179548,
null,
139487,
57680,
4498,
33940,
137287,
21364,
19942,
null,
419850,
578308,
145406,
260039,
106975,
4358,
35319,
267458,
null,
28850,
23518,
254371,
null,
null,
261022,
23074,
13699,
67650,
27537,
533992,
257600,
64977,
100465,
42365,
null,
68286,
null,
151733,
21703,
72430,
17563,
200951,
6355,
37538,
80415,
300833,
74020,
34132,
14403,
23771,
130430,
200989,
269809,
89321,
161458,
101170,
109573,
23135,
285497,
29407,
372662,
280525,
80427,
170707,
35763,
68317,
35545,
39903,
333627,
81191,
44939,
16501,
154083,
271885,
375927,
62834,
230444,
17596,
60890,
17889,
32713,
144622,
81444,
5500,
null,
40388,
41889,
46472,
74167,
333093,
38559,
28962,
98934,
244854,
99964,
75527,
294059,
254090,
13649,
306986,
null,
54908,
190772,
518560,
113031,
232046,
16391,
61389,
201092,
219010,
95871,
461564,
82909,
54115,
37887,
65472,
45006,
405338,
17272,
16266,
192073,
201529,
12879,
43471,
4856,
242237,
null,
238314,
55639,
40156,
331254,
42063,
18640,
null,
240432,
331044,
21678,
20425,
31686,
239605,
125288,
240751,
25541,
58392,
38941,
3776,
232784,
147045,
39556,
67168,
178732,
265677,
12291,
170823,
34021,
12234,
null,
30500,
234365,
287338,
563049,
24251,
95632,
44222,
284720,
12485,
183367,
23468,
null,
27248,
26763,
58991,
26337,
20516,
519706,
185713,
16623,
716836,
137436,
null,
559930,
440035,
145264,
65517,
138605,
449970,
218508,
193226,
23405,
138679,
213225,
52850,
2134998,
277356,
14777,
373708,
169987,
76694,
19717,
37454,
233281,
523640,
134100,
369532,
238096,
198740,
96777,
499760,
584204,
null,
138861,
54943,
31167,
null,
7006,
23576,
66354,
117509,
383750,
27982,
38203,
177193,
158694,
179632,
61750,
82353,
13709,
282244,
396257,
27061,
16409,
33163,
13218,
236550,
null,
149234,
51033,
373066,
96961,
68113,
261489,
49928,
121431,
39957,
153534,
305248,
19549,
254146,
118712,
195901,
5387,
336442,
267095,
185238,
61641,
159678,
208213,
26231,
219315,
307676,
null,
273822,
15876,
26277,
503511,
192625,
30500,
38288,
32274,
7270,
76654,
431952,
23866,
57953,
69189,
19289,
378638,
266930,
221768,
47451,
null,
49631,
15128,
7736,
135386,
246714,
55481,
113649,
169656,
126593,
17612,
27813,
43612,
83343,
66501,
304548,
140565,
91133,
289219,
15092,
19263,
null,
8891,
62606,
150702,
50072,
36055,
25395,
144676,
51233,
163301,
38566,
57544,
37853,
87164,
107503,
29675,
18522,
20684,
46352,
55209,
null,
183156,
23530,
31951,
17745,
34069,
47763,
48812,
84947,
47075,
17542,
223050,
53919,
334943,
370250,
335133,
69309,
24918,
83994,
null,
5157,
768976,
67414,
51390,
88427,
199200,
255628,
94191,
34259,
151242,
124572,
102794,
223774,
57977,
19603,
34006,
314800,
25894,
132790,
23302,
252752,
81867,
146180,
25413,
252668,
489096,
157533,
30253,
25424,
21272,
null,
8078,
323731,
31360,
57542,
92980,
50835,
45591,
457952,
304849,
358020,
185190,
62412,
142344,
221657,
46295,
27170,
25709,
11232,
13352,
39441,
100829,
8494,
118048,
77323,
304517,
224915,
55783,
32651,
205463,
27155,
120680,
18687,
157495,
606137,
28530,
225936,
100838,
null,
13237,
38987,
38607,
15592,
255390,
133458,
18430,
54228,
69580,
468950,
38806,
414671,
55819,
80992,
568245,
88903,
121504,
44647,
null,
161929,
23863,
820745,
34486,
114687,
11033,
145838,
12481,
7224,
48145,
735258,
null,
76720,
258147,
145210,
11103,
null,
35675,
202394,
83480,
460627,
17183,
68394,
158454,
85498,
64329,
135152,
79980,
14326,
168333,
15776,
null,
535395,
77144,
19048,
196454,
46762,
29657,
43791,
13677,
14417,
null,
148298,
151033,
53925,
12975,
334711,
75154,
104930,
14498,
null,
42788,
17940,
47589,
176315,
33103,
349206,
128262,
12708,
17499,
112382,
293100,
null,
161198,
154749,
4946,
60768,
46744,
36032,
453016,
319819,
152327,
47471,
59196,
34321,
23560,
22913,
214404,
99445,
174363,
243366,
30600,
203534,
173507,
81420,
32125,
16607,
26395,
19101,
30113,
80864,
52569,
63434,
null,
5748,
null,
25049,
174485,
26729,
259071,
69981,
162188,
120625,
294264,
61729,
198805,
439275,
44819,
195053,
25698,
423008,
198312,
26125,
254855,
7818,
80933,
272458,
86530,
165458,
null,
14803,
204222,
292762,
44543,
109006,
74986,
580866,
176800,
214321,
16158,
27372,
41174,
25744,
328280,
287711,
11683,
270441,
1620,
14757,
263198,
69423,
null,
37783,
129560,
528707,
38907,
112575,
14832,
35042,
233129,
200066,
125519,
240321,
107270,
4665,
17711,
419378,
null,
15988,
6674,
null,
142373,
426628,
179459,
39453,
175271,
217982,
36614,
18128,
null,
29690,
404596,
13848,
110992,
266959,
25129,
169691,
12430,
112383,
83824,
145257,
191689,
107568,
52478,
399475,
null,
199953,
10932,
100090,
10195,
138820,
260841,
313398,
45218,
176979,
158368,
25979,
353807,
4033,
24349,
226122,
4290,
331404,
17188,
37752,
17689,
51125,
50056,
207992,
722663,
189777,
67276,
314204,
113848,
null,
220204,
377020,
746402,
2739,
26958,
168870,
112499,
147090,
192886,
44137,
377688,
32662,
22342,
25130,
36716,
43996,
146729,
55399,
4191,
162961,
315816,
245690,
106687,
57164,
11430,
null,
123839,
72438,
139693,
92909,
25295,
41245,
32839,
18983,
24244,
172291,
177188,
239170,
43510,
57996,
34333,
188959,
208109,
6936,
43122,
null,
161914,
345298,
89006,
48894,
42818,
23550,
30519,
304408,
73150,
140013,
null,
26580,
67922,
null,
168527,
349896,
20187,
322598,
19635,
281071,
79744,
203673,
160321,
97968,
29371,
null,
null,
28175,
116657,
48110,
127132,
31968,
209886,
47477,
28058,
642004,
111925,
8833,
76803,
6335,
27965,
56866,
414407,
127342,
32243,
11329,
109965,
14580,
40650,
378770,
196342,
62739,
175049,
30670,
69744,
134463,
30755,
21301,
151190,
59201,
110929,
162632,
47652,
28488,
null,
55059,
21452,
28303,
31335,
null,
16994,
276462,
345336,
108414,
19630,
30402,
93089,
12651,
200311,
204551,
64115,
196622,
257753,
48371,
65090,
24738,
104389,
452644,
132526,
null,
27650,
33897,
172651,
31055,
31858,
24111,
138587,
null,
47643,
36937,
152766,
109808,
217073,
38334,
227668,
18186,
70626,
292848,
39923,
504628,
65260,
109424,
272569,
166637,
null,
138013,
76410,
225465,
360655,
321829,
62648,
28775,
106449,
168236,
10620,
42642,
16056,
40613,
43796,
null,
280689,
15196,
277516,
419070,
209704,
156893,
37575,
8348,
29297,
68100,
136416,
191039,
194645,
139689,
191238,
49965,
43162,
178097,
19289,
16784,
169473,
182429,
283880,
84978,
37822,
51571,
325114,
null,
25603,
29379,
458487,
23812,
null,
166396,
324551,
null,
88409,
34819,
384088,
243072,
66441,
253137,
131855,
116968,
35566,
421577,
27496,
34887,
26401,
118915,
22833,
42644,
36081,
354609,
47508,
157062,
270811,
7504,
6498,
75380,
29434,
41535,
null,
389723,
318271,
44043,
null,
11133,
null,
48633,
68943,
null,
221091,
344841,
122236,
12475,
140970,
29919,
60152,
5730,
null,
21540,
54120,
306956,
100332,
210861,
342581,
157383,
129757,
293089,
179158,
null,
81002,
272065,
164399,
30313,
234742,
82841,
223591,
211968,
188359,
344811,
304118,
37535,
320684,
35701,
37011,
36916,
10103,
7441,
39919,
259497,
23945,
3805,
13258,
18532,
31050,
94197,
12050,
270900,
364659,
84781,
15332,
296355,
54255,
113462,
null,
468677,
130489,
null,
37893,
null,
57776,
412901,
4814,
115408,
30317,
10447,
41046,
36712,
326925,
101117,
41005,
255609,
203527,
33268,
7364,
16732,
130926,
111233,
54595,
58726,
40734,
253999,
151115,
218588,
10629,
26512,
302389,
17952,
75971,
null,
31197,
15648,
7234,
289290,
180821,
20263,
43924,
63073,
283884,
6593,
null,
339238,
366921,
153258,
23191,
9023,
75891,
75883,
155992,
47010,
348128,
null,
148984,
84600,
338612,
341631,
134555,
115562,
325954,
154145,
43652,
156916,
27926,
44106,
214998,
234808,
33157,
21272,
183899,
305799,
439139,
264631,
102534,
157872,
23223,
76052,
244854,
126947,
217742,
680681,
31210,
379542,
null,
48983,
165251,
29012,
85383,
4551,
74937,
132432,
316258,
null,
38880,
208131,
200239,
184679,
175219,
191585,
18431,
108059,
26723,
1066302,
210119,
34873,
4425,
14459,
317477,
24090,
779859,
100307,
null,
39311,
223118,
16503,
161926,
null,
49659,
171019,
22884,
6836,
39837,
69600,
24616,
88099,
54507,
9275,
348808,
9123,
null,
22983,
null,
489138,
262751,
151685,
21178,
233723,
386286,
80076,
534969,
23001,
49792,
168389,
96890,
27705,
95697,
33972,
30292,
171998,
10815,
43154,
10520,
30338,
272714,
433144,
318161,
32284,
481172,
268190,
32734,
null,
325047,
20031,
null,
null,
240135,
149449,
242717,
421535,
5726,
236055,
null,
41291,
206235,
1765,
209598,
31540,
43416,
null,
70715,
211601,
194300,
null,
432768,
206462,
36048,
363960,
10994,
78655,
54712,
123116,
12142,
187096,
278586,
50603,
66973,
317434,
103436,
50201,
33444,
null,
null,
163244,
335891,
284191,
189438,
32754,
null,
452550,
621289,
26026,
221895,
39320,
37314,
290738,
null,
10576,
28413,
80425,
7938,
22482,
41241,
33036,
212098,
140633,
null,
112109,
275144,
13866,
85957,
250130,
234420,
298450,
null,
141781,
32759,
240899,
24189,
12687,
200165,
59602,
19031,
217888,
18377,
19745,
237776,
348564,
191258,
210890,
40204,
29431,
458904,
12802,
50548,
279104,
217750,
22370,
25663,
null,
null,
7086,
200154,
38088,
61387,
28491,
226959,
44755,
511253,
48215,
34914,
43440,
15824,
32685,
68536,
224099,
567894,
null,
104189,
63259,
null,
6018,
648725,
24021,
370739,
59997,
5915,
23444,
18214,
31594,
66960,
409442,
91350,
null,
509939,
69419,
17608,
357584,
435080,
101576,
38486,
176155,
193671,
17326,
208806,
255191,
79080,
136513,
39832,
45107,
30185,
243058,
9077,
7684,
327528,
86072,
25403,
13120,
150999,
28409,
239700,
166383,
8945,
16027,
84462,
160788,
200295,
189027,
54123,
146186,
17639,
18226,
32446,
230118,
null,
184166,
20774,
null,
223553,
67730,
400966,
6647,
30726,
86974,
21718,
120941,
164909,
208115,
34556,
67106,
null,
12122,
19661,
226542,
59344,
118740,
78460,
84691,
21111,
null,
79512,
130069,
36120,
52902,
57101,
30628,
130693,
64855,
3766,
801,
49668,
212779,
368922,
35294,
149280,
33570,
19568,
100295,
32572,
11064,
96398,
306431,
235682,
129162,
4439,
22384,
114165,
34081,
193959,
22114,
null,
179039,
115494,
null,
29671,
74953,
4897,
117759,
15242,
45255,
96842,
469458,
26641,
225924,
38672,
195933,
234062,
33110,
null,
52848,
13294,
430010,
332808,
232401,
16924,
241697,
143879,
381653,
431647,
257527,
56277,
null,
25811,
343806,
37037,
22573,
9509,
468691,
223013,
124154,
17708,
104229,
107261,
491984,
11642,
48254,
183689,
167673,
37198,
12247,
22077,
22581,
374153,
50234,
53560,
519513,
27536,
18706,
34267,
49972,
15471,
11103,
660012,
25788,
254978,
34673,
9344,
20124,
57066,
24767,
89117,
293275,
76147,
15976,
129523,
149280,
148919,
90779,
263547,
38926,
38097,
360022,
207067,
146657,
150772,
9346,
68139,
342965,
null,
328767,
216512,
13912,
325783,
264423,
25374,
56070,
269316,
23306,
116444,
null,
54035,
477725,
28190,
41543,
30615,
24225,
23972,
20760,
38012,
330707,
366858,
2815,
225205,
36224,
316421,
141481,
142442,
67466,
51676,
69752,
80857,
29649,
2599,
10761,
null,
28508,
9592,
30270,
23578,
15094,
166008,
179281,
42178,
38542,
27402,
109516,
112161,
56618,
7990,
621505,
17114,
281522,
531101,
11765,
1392,
36759,
212622,
21780,
233173,
48652,
101093,
311172,
19851,
null,
247971,
150363,
312243,
28640,
163821,
43863,
120899,
345604,
41685,
null,
52696,
null,
34910,
0,
18962,
42742,
69236,
25338,
162096,
108153,
27826,
47244,
226960,
14812,
61542,
44469,
76665,
72396,
null,
591017,
25482,
218343,
239078,
218573,
37716,
9993,
20317,
7461,
101355,
46265,
29853,
249207,
17251,
118839,
286062,
null,
292373,
326648,
105247,
null,
65498,
73254,
409318,
35665,
495216,
15354,
null,
45350,
46681,
26718,
11198,
174804,
14090,
52724,
3783,
193620,
320435,
29031,
139581,
141030,
19963,
91635,
97106,
96013,
80816,
24027,
343824,
32680,
130987,
135140,
28716,
315111,
347368,
40230,
58043,
52959,
293969,
661,
23512,
231695,
136464,
181563,
33910,
37943,
25935,
25119,
28926,
142470,
30851,
322740,
41080,
311888,
289910,
18092,
20654,
6938,
210437,
17286,
205747,
55482,
11488,
348824,
null,
178337,
299628,
84971,
259006,
190396,
null,
33171,
35781,
null,
200379,
133159,
null,
86874,
212290,
297117,
null,
25090,
131552,
5631,
null,
38811,
34851,
131780,
66048,
302908,
null,
225759,
159308,
124206,
38570,
27433,
99397,
19381,
189015,
336538,
16393,
106413,
127579,
292358,
104523,
161890,
162514,
48086,
278644,
null,
373293,
1787391,
249806,
29069,
19329,
32946,
445485,
205582,
214813,
8796,
21843,
27673,
null,
127143,
130943,
215609,
170461,
9820,
333292,
39139,
6130,
8912,
177568,
24158,
403221,
198389,
43012,
15019,
null,
95665,
89318,
31018,
821605,
245531,
131678,
187181,
180277,
343537,
36134,
109764,
29112,
13100,
17579,
234450,
11579,
50565,
64032,
2531,
2372,
155812,
98622,
468673,
270404,
37720,
80837,
30775,
19756,
199637,
49961,
78460,
13377,
126457,
16214,
177009,
24986,
129706,
13785,
18497,
211643,
23110,
68655,
30517,
372506,
24333,
518188,
129905,
13423,
583234,
264533,
null,
170765,
217940,
341906,
17015,
24224,
194754,
58652,
87783,
22209,
441460,
601146,
356216,
null,
205988,
108710,
60198,
438183,
59604,
null,
122488,
69087,
59899,
45437,
333521,
21731,
null,
44316,
56973,
3516,
2143,
141851,
5886,
225376,
6123,
222648,
230219,
178343,
448776,
155022,
42091,
353587,
24806,
32711,
32544,
22233,
27026,
89825,
190814,
39956,
10863,
197976,
196788,
125194,
145187,
23715,
null,
216807,
509534,
123894,
28191,
599198,
79273,
62319,
22349,
184059,
220467,
251839,
288852,
76419,
9631,
167580,
207117,
34984,
null,
null,
10396,
329306,
145986,
311603,
841012,
271662,
14764,
22661,
12508,
28282,
168458,
67907,
139998,
null,
null,
244081,
244229,
null,
223227,
208480,
null,
39741,
141643,
34482,
26377,
133051,
null,
174442,
140928,
206823,
25730,
null,
null,
38403,
53221,
29337,
91943,
91609,
52533,
90509,
1556,
53525,
185954,
60036,
147927,
28413,
16891,
38978,
305627,
148361,
133396,
287624,
37497,
129002,
12880,
30537,
349442,
19057,
203144,
264853,
null,
35665,
48944,
102483,
39733,
46060,
224115,
null,
277429,
208657,
26493,
36393,
215341,
16112,
355132,
7271,
35901,
3657,
null,
332568,
179584,
44576,
220594,
134998,
58296,
187380,
41326,
2308,
160550,
76027,
396271,
460038,
53579,
null,
null,
437724,
122600,
18052,
156280,
330926,
14065,
278220,
null,
150239,
122462,
24742,
18363,
69293,
192639,
35511,
45330,
154452,
266827,
28440,
null,
112875,
131606,
90299,
224188,
40557,
167923,
169896,
203955,
1273080,
93753,
336794,
22616,
208003,
60198,
219783,
null,
144405,
81748,
4914,
78239,
19714,
143505,
68731,
339675,
13683,
18070,
312915,
14989,
32274,
12808,
982076,
217582,
null,
72085,
153884,
219550,
18511,
99387,
7716,
9987,
246386,
174946,
30182,
96113,
191967,
251205,
278245,
57400,
156123,
36502,
60217,
180553,
25563,
10946,
123439,
219571,
7629,
64686,
12041,
253560,
54160,
7450,
221136,
30229,
38643,
122662,
317813,
125343,
79272,
40103,
9397,
38,
166435,
143073,
344131,
null,
null,
19862,
6184,
109470,
258526,
58168,
145007,
null,
170013,
290661,
154785,
30158,
67150,
11256,
21642,
378192,
123269,
8097,
22992,
124373,
9020,
202559,
44138,
19686,
218349,
110631,
12743,
5197,
615687,
265779,
64927,
171088,
343980,
9326,
201079,
6405,
33801,
161752,
35748,
77766,
207066,
69270,
33540,
187643,
95559,
63577,
null,
17499,
39201,
279008,
53924,
51982,
32821,
null,
20287,
64238,
132776,
37921,
78681,
null,
175042,
138989,
85020,
407421,
40701,
13751,
131583,
47807,
39516,
110237,
192455,
13459,
16650,
7754,
106944,
244119,
43941,
null,
228419,
27325,
208226,
269234,
32831,
100000,
256938,
146540,
null,
52415,
null,
166161,
39761,
21506,
54883,
null,
100379,
83871,
5346,
110255,
84149,
150711,
26558,
6735,
92344,
262707,
408136,
135040,
194001,
19079,
206447,
123367,
14837,
132343,
305229,
38040,
16979,
106377,
141030,
12768,
null,
358737,
958527,
30056,
46382,
5416,
214524,
168189,
436371,
8233,
103440,
204575,
178528,
22591,
176281,
49895,
14330,
63143,
207372,
30865,
243224,
71750,
674222,
46089,
68196,
111426,
226548,
276763,
null,
630539,
200325,
null,
22281,
263654,
null,
542565,
10382,
59606,
94167,
null,
62585,
100887,
null,
20000,
3125,
53331,
135469,
null,
81705,
209268,
184983,
81409,
23391,
20160,
30020,
430687,
23646,
40613,
13024,
204668,
null,
16398,
136966,
102783,
29957,
159206,
75237,
14812,
142142,
111493,
156869,
null,
417275,
291970,
52265,
44834,
3236,
null,
97744,
388785,
66723,
33138,
232760,
185485,
58663,
274741,
25112,
34152,
56782,
521659,
77206,
296588,
null,
200825,
22916,
92356,
24076,
171738,
20595,
140178,
8249,
null,
115557,
28318,
62388,
9593,
35204,
15517,
146929,
31413,
262518,
11409,
32491,
217658,
117882,
28785,
101077,
null,
342253,
null,
1063,
15948,
296698,
137366,
41719,
224308,
126434,
20499,
1080043,
188389,
30500,
50247,
247125,
374297,
12920,
73767,
346309,
null,
25873,
95111,
244817,
null,
null,
15049,
148100,
151948,
39018,
200853,
328987,
233854,
477666,
261998,
10648,
260285,
15557,
90566,
4301,
13156,
324773,
261763,
37739,
206538,
4966,
13223,
27571,
58875,
9934,
120659,
51573,
null,
53438,
34929,
48141,
43881,
420142,
46105,
269068,
73115,
424956,
140619,
39600,
8634,
21805,
8957,
39946,
64642,
97196,
354524,
252644,
150713,
10434,
680759,
90278,
148030,
165596,
73998,
191414,
44468,
141573,
141963,
213465,
361178,
47233,
41750,
null,
157051,
402620,
38249,
109664,
470984,
110668,
null,
244878,
168552,
825092,
149993,
214690,
151257,
92527,
9558,
80827,
44055,
31047,
204122,
103085,
259590,
84732,
328523,
758717,
149267,
238040,
null,
244693,
73881,
67297,
null,
27410,
175774,
32126,
14606,
501255,
13224,
32093,
397918,
127419,
49880,
133532,
126813,
90706,
106202,
8894,
165730,
30281,
161682,
373291,
484111,
214262,
364924,
null,
29201,
56962,
307116,
47774,
308718,
16118,
197487,
394719,
27230,
230304,
167878,
201387,
601523,
196818,
17299,
205157,
12111,
309317,
144864,
null,
197039,
null,
268270,
23440,
null,
147576,
155555,
90380,
150506,
44127,
50977,
190411,
20336,
30246,
266662,
46686,
219437,
149699,
30860,
31829,
18481,
180975,
19302,
24184,
527464,
28744,
86355,
129778,
130443,
387961,
141761,
192113,
201204,
63083,
15340,
68450,
15449,
43546,
15908,
30870,
178009,
11205,
64694,
53993,
299394,
null,
165900,
92773,
62208,
10256,
508052,
144671,
58577,
121317,
30539,
78986,
211548,
150626,
23169,
20628,
72912,
170301,
312333,
28585,
198042,
82162,
319489,
879838,
445062,
43508,
65117,
null,
67385,
375070,
1607,
409589,
76532,
25808,
222681,
287228,
17353,
115633,
21899,
29830,
166047,
247255,
null,
59751,
207753,
53653,
20415,
186857,
7631,
20031,
18444,
null,
16042,
218730,
181392,
6982,
280992,
54026,
56984,
null,
26848,
575314,
23467,
84439,
126248,
204316,
144071,
35552,
4089,
41374,
367016,
46171,
29165,
115110,
103669,
35678,
132550,
12499,
2307,
77401,
48784,
15806,
91909,
213766,
286547,
143250,
36699,
33167,
null,
null,
105825,
33249,
248350,
7463,
177758,
34061,
147570,
11586,
47657,
43989,
32891,
95002,
204305,
20699,
344159,
28509,
177778,
342970,
77569,
184292,
586196,
493205,
16264,
34869,
52690,
221555,
255994,
42941,
161021,
null,
32029,
null,
25362,
100906,
50701,
10603,
17001,
null,
211744,
68456,
62061,
52526,
296742,
42877,
542437,
20837,
374877,
59545,
19634,
241767,
22806,
433258,
36594,
29363,
798107,
60730,
257797,
307456,
18500,
18133,
null,
20940,
22902,
100638,
30556,
4258,
96512,
null,
56116,
47075,
42513,
109494,
null,
52972,
108534,
141171,
null,
176631,
150491,
15480,
5863,
14151,
28102,
83889,
15513,
357178,
131871,
32222,
316773,
50924,
83629,
74436,
577,
16468,
210271,
22995,
14878,
11833,
64169,
903,
4511,
7943,
73052,
131732,
50370,
3215,
32220,
240190,
3571,
128431,
124570,
432529,
25439,
127056,
25830,
54642,
140842,
383511,
881417,
60328,
262023,
263651,
53835,
160677,
31401,
23019,
null,
234511,
null,
223853,
342999,
154040,
277902,
48413,
195944,
198544,
11197,
25342,
121194,
151191,
84972,
26891,
null,
189437,
317831,
404433,
26327,
284890,
22034,
null,
1663,
46119,
15995,
185988,
36900,
149232,
33631,
153272,
47949,
50999,
null,
null,
null,
null,
144078,
595564,
8577,
112013,
35330,
37341,
3082,
143141,
35539,
23610,
170042,
null,
14186,
243905,
96564,
179915,
64959,
318554,
63348,
28640,
66931,
39527,
null,
551060,
51118,
22311,
43753,
38072,
63070,
null,
8250,
51467,
229635,
211712,
119386,
16999,
100591,
46290,
154822,
8014,
192810,
152507,
39073,
9779,
16196,
10151,
17262,
69992,
null,
6987,
196979,
null,
91152,
46069,
406753,
null,
52312,
99257,
5170,
25561,
161083,
null,
266654,
74330,
331152,
512994,
667730,
38073,
243258,
3744,
null,
12100,
236847,
80557,
17793,
303122,
null,
38642,
496126,
21105,
532839,
335356,
67116,
92443,
224397,
302065,
42838,
4904,
44499,
159758,
277591,
24439,
85166,
160811,
9008,
null,
12520,
241799,
102054,
69426,
15715,
265996,
27079,
326060,
147122,
8606,
31215,
100909,
184507,
88896,
18388,
405223,
286677,
4993,
317403,
24395,
172465,
48948,
706357,
21985,
42429,
24214,
17047,
41981,
10620,
124005,
30325,
17624,
36773,
731348,
null,
96428,
11232,
31805,
12633,
342418,
81047,
52213,
17776,
15302,
49062,
362662,
44590,
65433,
180015,
1110701,
49483,
null,
20022,
49009,
17939,
73712,
15048,
8407,
162171,
25527,
71295,
48387,
181449,
77726,
1191,
185544,
32933,
4354,
null,
191105,
160070,
22383,
198863,
9459,
7787,
453873,
149691,
31568,
31156,
122754,
null,
45391,
45077,
3291,
null,
177488,
6636,
52269,
30571,
24178,
21710,
157270,
175044,
8721,
42530,
48056,
null,
278837,
199652,
231357,
190429,
10464,
51737,
266136,
373228,
52623,
38674,
39227,
624896,
null,
16081,
71387,
51434,
147160,
16494,
414576,
5657,
42785,
41748,
19744,
57568,
492952,
129439,
19534,
27016,
48394,
177285,
60223,
275869,
80320,
53346,
179863,
8280,
145373,
null,
15084,
17710,
20505,
249120,
null,
53470,
115534,
108776,
35218,
170173,
116694,
250629,
30247,
6990,
143238,
63835,
6389,
null,
281723,
40704,
70440,
27192,
null,
284486,
29423,
61761,
168038,
72207,
109163,
47416,
334512,
144755,
261724,
179595,
null,
237487,
4213,
25490,
407985,
84658,
2318,
162967,
126032,
null,
215322,
240406,
708680,
548987,
21179,
118810,
10999,
19099,
730486,
11605,
39710,
288439,
33667,
28544,
35833,
null,
134361,
271672,
217064,
44727,
154535,
27527,
184034,
14333,
19222,
null,
191307,
37108,
54465,
74917,
118038,
43780,
176685,
269420,
null,
null,
54570,
618979,
28105,
104882,
67389,
255263,
370251,
161221,
19931,
14288,
247237,
24614,
6370,
81041,
112605,
51566,
56203,
194847,
5425,
270180,
13006,
126715,
383510,
161550,
201274,
127445,
272839,
34785,
37338,
368585,
28220,
31315,
226133,
5681,
196582,
126202,
67706,
141207,
311166,
299756,
104247,
376693,
97963,
28345,
169876,
194793,
1161200,
134432,
292515,
52232,
90055,
32588,
13751,
22644,
24903,
24353,
225925,
43502,
null,
301241,
214324,
93197,
275063,
281360,
81877,
null,
167214,
61534,
114474,
174652,
117129,
79672,
43615,
243663,
263165,
37672,
408928,
59713,
24636,
32329,
17688,
66903,
24917,
425405,
4428,
357189,
42981,
14137,
23957,
367963,
23498,
298846,
33789,
null,
31666,
15484,
249659,
114005,
null,
null,
49707,
262101,
112375,
662041,
134804,
null,
22535,
28940,
228483,
29149,
31891,
111610,
107938,
165581,
24094,
242949,
50999,
372984,
13190,
81115,
164121,
44861,
79392,
157388,
93455,
180226,
null,
40183,
9980,
320060,
177410,
43305,
2489,
28268,
122285,
9627,
null,
155713,
32016,
87423,
262356,
null,
16662,
123525,
128658,
97275,
5298,
49458,
24491,
29759,
107640,
163348,
null,
8806,
9203,
13176,
null,
163797,
28066,
320743,
17040,
29890,
156624,
500367,
65280,
192409,
107903,
250308,
322259,
305052,
141457,
70413,
128559,
227255,
365506,
300720,
989200,
240728,
634878,
288812,
null,
14649,
178581,
27948,
226135,
null,
115109,
null,
532415,
6577,
291098,
23414,
217164,
108803,
19824,
174466,
65997,
6816,
24177,
121502,
556429,
431404,
19018,
21915,
133029,
335697,
655046,
31160,
55956,
36262,
17783,
24528,
123570,
191121,
206816,
57465,
14146,
256446,
247784,
107941,
255197,
377306,
null,
76424,
43179,
232936,
428523,
383240,
165926,
14891,
213064,
107737,
96074,
360208,
264307,
253529,
24070,
267653,
47978,
57463,
240407,
76540,
26255,
null,
577568,
null,
20687,
null,
527786,
323933,
33756,
32373,
165103,
32766,
98530,
278028,
373679,
25330,
null,
null,
281788,
4423,
33439,
217397,
405573,
547036,
35098,
13416,
46971,
25109,
6694,
29771,
18994,
362207,
null,
66847,
295270,
278532,
366228,
65102,
73398,
45166,
222059,
146929,
33152,
437938,
108470,
234900,
183817,
402149,
null,
74528,
370142,
118051,
49460,
196913,
209491,
154118,
553926,
16335,
222416,
152710,
3808,
32391,
136311,
153314,
447925,
247103,
284717,
null,
51625,
350405,
104080,
11751,
140969,
28875,
56892,
267889,
225799,
612595,
79465,
19992,
41690,
47717,
259732,
118141,
263680,
36733,
267741,
150192,
282645,
200523,
83317,
7745,
19241,
11856,
18882,
9485,
39465,
572457,
21363,
null,
39684,
81463,
27916,
133551,
737989,
265998,
290464,
435418,
191741,
5414,
29329,
100881,
23504,
47250,
7401,
236009,
null,
180730,
null,
20501,
null,
68213,
null,
647323,
41160,
174230,
359660,
21605,
17143,
14209,
220382,
20105,
2018,
25388,
null,
null,
4074,
556428,
68349,
28375,
22913,
557890,
117725,
null,
23024,
61241,
79211,
68504,
74916,
219318,
181678,
100226,
242624,
80867,
43922,
132803,
285777,
107604,
36392,
34185,
433011,
114656,
4040,
5779,
41122,
14034,
74720,
34029,
5614,
33296,
16079,
171995,
522685,
60883,
98847,
6381,
166150,
222826,
20086,
353986,
264072,
322185,
null,
177441,
147926,
null,
null,
48391,
226704,
387726,
10497,
204393,
227580,
99461,
172126,
164036,
108830,
44773,
45413,
43307,
14575,
49605,
96336,
228160,
37026,
114655,
9591,
117041,
348502,
148923,
3461,
19857,
5715,
353872,
36630,
232696,
112981,
157919,
67597,
null,
47617,
17619,
18848,
null,
28231,
124336,
211098,
197506,
1348823,
236007,
78306,
334921,
54769,
17763,
43835,
20795,
null,
297361,
754500,
29284,
152262,
134618,
78732,
23836,
17793,
68224,
274916,
323343,
53495,
56947,
101558,
261356,
38264,
46845,
728964,
314028,
41552,
361818,
187664,
null,
65593,
64277,
8117,
39503,
331773,
46308,
24630,
149318,
53429,
null,
20364,
90241,
49847,
31723,
300568,
73485,
103653,
24576,
8319,
49156,
44664,
247918,
50221,
166275,
134321,
33290,
410189,
48712,
74769,
155048,
102572,
367696,
18400,
null,
50253,
6560,
68804,
598885,
22318,
23269,
267540,
18506,
118095,
17526,
null,
302520,
47923,
70191,
21628,
289810,
240933,
162218,
57166,
177811,
203338,
212496,
46561,
286510,
100760,
null,
74532,
null,
607002,
null,
283586,
34781,
207690,
134989,
7774,
22863,
463644,
27907,
214352,
165592,
32942,
429174,
24577,
219527,
493223,
254688,
66087,
158941,
25408,
24200,
18352,
157651,
38793,
null,
28416,
112819,
42248,
351829,
170525,
7115,
27885,
327705,
165449,
49593,
105672,
195495,
69087,
36835,
359284,
36971,
38755,
null,
12471,
684236,
14758,
33871,
92439,
112044,
57085,
null,
7188,
178093,
20460,
155893,
56844,
160836,
34826,
49544,
48215,
230535,
55574,
198659,
112682,
null,
null,
32764,
28530,
214049,
65560,
499758,
9985,
23875,
76341,
null,
291784,
241368,
null,
215700,
198088,
42753,
317104,
8448,
null,
149078,
25312,
312725,
33951,
144346,
5363,
449833,
29875,
75458,
323411,
103637,
38942,
56110,
154214,
1182474,
178109,
224250,
null,
419041,
187028,
31633,
101517,
47715,
210142,
39622,
100817,
48309,
487997,
28638,
351587,
15772,
160734,
20545,
151063,
303292,
51329,
208438,
285039,
327844,
184884,
554896,
31353,
null,
336155,
12762,
null,
92178,
68364,
20326,
43338,
123912,
13207,
121964,
150670,
341375,
105217,
296836,
251977,
298895,
31615,
315112,
55086,
5321,
238722,
47596,
284687,
5635,
26383,
164654,
201179,
182663,
35360,
221306,
74967,
227984,
390368,
69717,
5528,
null,
72615,
318185,
116131,
755579,
175017,
32690,
5097,
75089,
6449,
941851,
1247421,
null,
14650,
242866,
162140,
75878,
160069,
221920,
35852,
389327,
20485,
76482,
147173,
486937,
null,
109786,
78039,
2482331,
632725,
29712,
73412,
51916,
46693,
3594,
122078,
245648,
31435,
17823,
34658,
26422,
33404,
33449,
11403,
39856,
null,
31646,
35937,
490247,
23582,
28455,
null,
168857,
384828,
null,
14810,
8661,
25131,
60555,
240881,
116594,
166988,
254793,
38048,
88699,
126151,
14461,
100919,
130563,
251815,
146197,
126661,
59437,
278324,
13689,
null,
66077,
70074,
null,
407912,
169962,
116895,
27639,
202631,
12657,
137924,
30732,
121850,
null,
55553,
3779,
49931,
102969,
220121,
80927,
16994,
24341,
138718,
82386,
585365,
53118,
null,
null,
62243,
46392,
35948,
32647,
31364,
139546,
96921,
28532,
203619,
11410,
17194,
null,
231286,
18441,
231230,
39334,
35749,
204890,
32907,
30312,
130339,
74354,
65054,
21313,
298030,
148501,
45627,
473477,
null,
136114,
34619,
338103,
127489,
172177,
null,
91289,
575278,
null,
166555,
302760,
47254,
142498,
207210,
12147,
15887,
176207,
92718,
48450,
98318,
26055,
185766,
59820,
6272,
67024,
197109,
61436,
96322,
13907,
2823,
221542,
452544,
36255,
null,
39872,
76696,
230103,
406565,
88746,
null,
27047,
69530,
52062,
518338,
72652,
9791,
42588,
61049,
11409,
394307,
238180,
241764,
152095,
22661,
277174,
355081,
null,
383564,
9353,
185768,
33519,
294702,
75673,
391521,
68212,
null,
null,
1710232,
88782,
14373,
null,
50824,
22960,
44882,
92242,
225251,
187885,
146142,
22802,
26212,
52492,
null,
369531,
95907,
26749,
114949,
null,
41785,
329433,
35955,
11166,
48199,
65767,
46054,
313762,
180805,
57006,
39898,
87192,
null,
14264,
251345,
236818,
322310,
10901,
null,
11191,
33176,
49175,
55292,
337702,
108781,
null,
350620,
81211,
109945,
18244,
null,
55755,
8073,
130531,
18152,
371533,
25478,
138730,
36282,
413225,
129046,
75660,
6156,
15539,
23442,
62267,
26926,
null,
28140,
242362,
9801,
25357,
194192,
138764,
28142,
28907,
null,
321276,
189992,
14390,
359782,
190115,
588696,
56279,
6395,
22614,
196750,
163746,
181664,
221339,
362353,
154625,
357559,
34487,
null,
129786,
97113,
243948,
285989,
45549,
null,
403925,
2151,
208886,
93815,
519250,
45297,
92919,
406839,
15476,
1707,
233105,
189520,
116980,
24809,
24365,
162312,
2866,
891306,
151881,
176466,
15590,
37067,
205401,
28942,
null,
333529,
120894,
149624,
46102,
null,
497712,
null,
360031,
75367,
null,
182207,
291179,
null,
17644,
8124,
331019,
36164,
144728,
4157,
401534,
8930,
29921,
136139,
33594,
null,
45136,
28777,
28790,
174804,
30075,
null,
42962,
253631,
null,
365663,
189683,
61298,
166426,
40944,
null,
61443,
127345,
39679,
135942,
18577,
106784,
201074,
34530,
197147,
84760,
361382,
16732,
14222,
368773,
126124,
156390,
21598,
35491,
228800,
146395,
235156,
112466,
258812,
269781,
163536,
null,
null,
29808,
113128,
84490,
907858,
6397,
410365,
520017,
28019,
5007,
116669,
41361,
366556,
6714,
10549,
106240,
null,
104575,
75099,
52971,
432875,
258158,
256492,
7358,
103282,
91752,
177067,
34109,
15867,
59096,
null,
27299,
47561,
265113,
126798,
241309,
366679,
139859,
385274,
null,
747499,
272692,
372071,
95565,
null,
339816,
197713,
76522,
71028,
39312,
252816,
423970,
23629,
135724,
9980,
21478,
423664,
51006,
223183,
25268,
34684,
null,
123185,
5065,
37897,
26354,
37652,
63640,
35341,
95187,
134695,
243371,
28613,
183820,
22479,
40000,
21975,
149549,
297259,
362927,
19200,
31693,
158677,
71487,
34593,
167722,
52596,
258557,
215904,
177322,
8675,
null,
null,
122747,
33533,
163387,
270529,
49446,
339908,
93275,
340421,
685755,
181480,
216157,
4799,
50320,
4709,
317124,
7233,
237414,
128721,
42223,
33245,
33620,
71422,
50841,
33951,
280317,
36446,
217253,
13768,
200183,
364231,
149154,
1092523,
262440,
82641,
575328,
52140,
605550,
null,
712,
170055,
146374,
202278,
18296,
6182,
372510,
385745,
15057,
20324,
16342,
5957,
28623,
93104,
49508,
315702,
115724,
21111,
76485,
49737,
74143,
245940,
11530,
38344,
118524,
8067,
25586,
156739,
26347,
57919,
134287,
62593,
335416,
356611,
86749,
null,
220765,
344625,
92609,
51559,
183951,
39480,
176563,
20020,
null,
187741,
27783,
190373,
223673,
null,
72840,
262490,
417216,
137646,
374891,
17025,
267709,
103702,
84322,
29824,
15367,
57870,
29547,
18099,
303036,
22879,
400287,
49971,
302946,
51420,
5977,
154778,
13202,
null,
null,
7676,
17104,
264070,
424731,
70173,
363144,
69529,
34478,
61135,
236431,
279011,
15025,
25099,
23024,
161683,
26728,
25652,
198764,
753078,
94109,
44835,
146504,
526338,
null,
65585,
138142,
305208,
340222,
326362,
242664,
92066,
18317,
20209,
38247,
159104,
43121,
59610,
118085,
null,
6304,
295420,
20878,
13695,
148706,
93344,
46697,
10244,
32625,
45826,
null,
266401,
17366,
20996,
null,
287316,
15571,
162875,
30182,
25156,
35293,
108019,
44522,
268278,
41183,
171057,
35879,
315768,
272268,
null,
21097,
null,
250995,
216793,
36736,
254884,
37402,
398496,
123170,
13915,
88169,
198209,
254197,
21063,
null,
159942,
105270,
null,
7630,
21004,
257067,
63372,
40987,
162935,
144988,
21890,
74264,
125566,
null,
20562,
37834,
299936,
92181,
299643,
13480,
349908,
141544,
2881,
79700,
23918,
59803,
112031,
21530,
null,
55822,
184228,
29625,
270841,
215715,
21538,
349723,
30935,
263399,
74180,
62969,
170120,
293891,
197106,
189398,
371013,
30033,
192986,
40759,
6167,
50563,
55280,
13208,
58334,
229918,
160425,
58329,
81239,
85629,
27549,
99993,
311468,
56475,
15050,
174541,
89369,
12600,
318466,
295697,
29947,
10813,
195155,
18936,
39544,
485022,
25489,
370839,
18587,
200177,
4569,
65916,
22956,
7870,
3502,
258612,
265652,
null,
102123,
47610,
198833,
3031,
39288,
223011,
14914,
168642,
36193,
15608,
449220,
null,
28048,
714371,
273035,
88176,
188248,
180368,
17632,
324747,
75906,
63366,
29944,
228433,
36521,
303827,
174155,
21864,
70210,
44089,
122129,
5937,
439941,
73085,
26702,
43298,
38146,
207734,
150406,
37069,
126384,
12070,
158474,
null,
231712,
169903,
null,
138318,
694957,
280127,
359740,
95908,
null,
173782,
47561,
79331,
70048,
4986,
10936,
10460,
66889,
42421,
235952,
19894,
202093,
44823,
12066,
18173,
294880,
26785,
17115,
96723,
16962,
132477,
198182,
169307,
89142,
40096,
null,
51507,
220775,
250801,
19379,
205951,
150934,
19274,
null,
18119,
111356,
15973,
173302,
3008,
38175,
69363,
16950,
152568,
116940,
92880,
null,
null,
9946,
9438,
39233,
110922,
57536,
74087,
46358,
32362,
9865,
20817,
24562,
9420,
221281,
116767,
92423,
159041,
11211,
83293,
null,
192112,
16524,
12377,
107778,
23273,
79385,
20747,
88734,
39797,
41065,
13660,
64888,
25435,
190519,
215503,
73333,
122031,
54479,
24099,
100720,
64555,
223740,
6875,
230726,
59900,
209368,
16177,
100363,
10082,
39080,
99803,
573193,
109339,
141497,
159810,
52183,
21539,
27789,
9775,
25154,
332227,
11488,
null,
91186,
12045,
22664,
58449,
116531,
38986,
162705,
38066,
35431,
77534,
232932,
12931,
179519,
28380,
247169,
29548,
110873,
24428,
77290,
285578,
35330,
74545,
7448,
28877,
109057,
null,
193341,
null,
11734,
15022,
50676,
22451,
294867,
49101,
17929,
206785,
379275,
34594,
null,
14158,
1938,
284860,
73802,
74429,
5162,
8664,
56406,
121039,
null,
9715,
51783,
296858,
111430,
73299,
55544,
259057,
177385,
10406,
113120,
null,
209795,
158572,
368882,
125314,
6762,
42513,
null,
null,
155667,
281547,
34139,
41203,
106946,
56701,
null,
271635,
27691,
352845,
43865,
31949,
17920,
29440,
361749,
214868,
null,
234917,
13125,
311600,
103026,
259426,
192235,
158637,
37000,
19601,
38080,
369351,
172232,
81241,
11591,
305516,
84695,
166677,
75665,
43981,
164867,
14802,
null,
15205,
54971,
111179,
null,
441440,
427400,
350857,
83165,
null,
null,
236766,
160805,
41645,
167969,
16285,
null,
null,
367702,
38136,
67178,
176233,
11504,
313951,
214905,
181853,
126755,
11366,
64127,
null,
533159,
91063,
118544,
212952,
122208,
null,
77793,
153624,
null,
25134,
1859,
null,
39452,
16037,
362426,
68773,
null,
11592,
17008,
335295,
45612,
708475,
14526,
234866,
29898,
5797,
178397,
199495,
43223,
33884,
15874,
9039,
22111,
10624,
82587,
66456,
176199,
349435,
67097,
18934,
97689,
31632,
331079,
459123,
167225,
300255,
228413,
317300,
7962,
43294,
112214,
53190,
39179,
272358,
202022,
294227,
43348,
203004,
269123,
226147,
78054,
453989,
137243,
30521,
308711,
150816,
12726,
null,
132084,
108858,
76474,
14096,
273331,
105035,
124972,
18671,
379229,
60302,
73277,
143738,
280345,
147490,
38884,
28401,
null,
null,
155218,
475308,
34436,
355445,
109651,
416595,
351907,
188911,
37520,
36586,
51626,
61898,
3837,
149956,
174713,
425256,
15554,
214381,
257213,
116944,
null,
43083,
320499,
9938,
60439,
201776,
52386,
48511,
null,
27783,
99051,
355752,
248956,
248742,
607393,
43606,
16073,
22430,
22231,
123779,
165535,
212551,
336182,
117604,
365831,
11166,
null,
15218,
266330,
200717,
33990,
0,
2913,
41574,
8365,
56849,
40984,
234341,
350055,
62858,
null,
294285,
26778,
122311,
92657,
406379,
95744,
24633,
165111,
null,
337891,
7538,
27016,
28065,
47542,
74033,
null,
88705,
null,
162412,
201609,
201373,
152503,
84513,
10652,
37106,
6232,
154688,
387343,
31949,
null,
41737,
200067,
52178,
307568,
68218,
168090,
156224,
240969,
null,
250771,
69802,
32168,
199549,
27023,
null,
14059,
332500,
225032,
11758,
8023,
397661,
11980,
94724,
70545,
200521,
1286,
null,
92801,
56586,
148348,
35417,
104361,
415830,
15549,
43971,
176800,
244807,
172739,
21831,
48749,
196119,
29925,
42670,
5071,
12712,
156512,
363068,
38358,
236450,
30443,
3515,
112849,
null,
200832,
93430,
69857,
10438,
43703,
39316,
null,
16562,
null,
174938,
12661,
91,
4204,
269049,
241577,
225479,
11449,
46829,
397189,
18656,
18259,
13581,
92452,
190344,
184010,
147298,
6879,
25748,
64960,
44289,
null,
14498,
118916,
148694,
13923,
10368,
269281,
133037,
338336,
23020,
20857,
343181,
136306,
159068,
72963,
null,
133416,
227163,
132585,
22212,
284378,
354700,
41132,
61097,
254818,
null,
477692,
304634,
331836,
26006,
256894,
30775,
40949,
55929,
190811,
186107,
9847,
322775,
159773,
22318,
188488,
156764,
991484,
null,
12401,
null,
146323,
8803,
null,
27035,
5854,
348109,
97283,
123331,
224098,
191544,
205286,
366190,
15497,
83561,
303467,
null,
124145,
169701,
234057,
17109,
301909,
68501,
205305,
20120,
17670,
77700,
41090,
16826,
15024,
139883,
265687,
184641,
103960,
13943,
61973,
62210,
13154,
68205,
31710,
null,
65951,
202458,
46862,
252155,
null,
null,
null,
171462,
183292,
221938,
294611,
195402,
null,
38062,
13787,
192814,
63380,
108315,
9485,
98017,
122763,
159795,
128276,
6629,
26721,
189256,
187944,
421567,
38801,
281655,
9980,
null,
108551,
25910,
29180,
217991,
null,
3654,
95,
273305,
32026,
55995,
109216,
179312,
224645,
102487,
61161,
null,
215250,
100113,
31077,
57302,
42720,
148007,
15152,
196912,
85211,
440348,
789521,
222296,
4692,
122555,
10166,
null,
null,
null,
64612,
61594,
97734,
92080,
74414,
null,
238060,
null,
29338,
389743,
60456,
147238,
118382,
83863,
949,
81875,
69386,
205528,
18163,
51238,
42598,
70224,
127188,
114459,
84916,
112586,
null,
16067,
62794,
185978,
273847,
84861,
57364,
287131,
209841,
119591,
34106,
null,
10405,
128082,
12737,
54507,
9507,
31162,
67887,
12905,
263758,
146970,
283799,
92435,
130245,
49662,
199584,
187859,
14791,
180796,
192045,
167990,
132885,
14922,
300489,
39371,
20679,
80159,
10116,
9015,
361428,
33286,
173752,
71211,
585833,
130275,
321254,
12032,
518445,
328465,
114305,
null,
43808,
41324,
137079,
302586,
107160,
293733,
248883,
98454,
227966,
110720,
195559,
27735,
6420,
322617,
89981,
30063,
156833,
26817,
null,
317835,
48022,
14744,
245135,
15217,
76114,
179819,
370367,
53471,
32937,
167908,
133140,
23395,
24820,
16056,
150057,
309163,
5071,
63396,
395817,
22530,
29925,
192621,
200489,
252738,
null,
22217,
155070,
422071,
11952,
330037,
32716,
103770,
557315,
23233,
158553,
176969,
57208,
267448,
null,
41230,
197632,
71426,
480411,
42343,
26677,
45840,
56192,
452283,
null,
88363,
70074,
265021,
19748,
41063,
16516,
87230,
46618,
405642,
438822,
37094,
null,
19287,
16882,
414530,
14299,
311079,
65985,
39295,
151878,
null,
38532,
64309,
22358,
3333,
6810,
374493,
118765,
20297,
25818,
36356,
141737,
220077,
13751,
455627,
24109,
null,
386304,
null,
227435,
42161,
29867,
188902,
19423,
59098,
442732,
23807,
422096,
420223,
167023,
295018,
7676,
23629,
168478,
null,
343984,
225593,
310958,
218886,
228288,
459574,
33275,
55464,
231852,
31616,
139042,
21947,
21990,
304978,
null,
319248,
542086,
123895,
183481,
null,
280648,
168793,
415958,
40865,
30718,
null,
46162,
31399,
1172214,
null,
46269,
112473,
232888,
1362,
95132,
389440,
108333,
null,
38515,
31927,
107118,
12912,
290294,
155407,
null,
284333,
92535,
297872,
18150,
377786,
181162,
274508,
8258,
16983,
104277,
105060,
32014,
27696,
10481,
352295,
null,
301502,
146531,
380922,
12117,
82863,
26592,
16156,
31042,
20433,
null,
52269,
9896,
23558,
70406,
44882,
170556,
124940,
319827,
478290,
15281,
163080,
26061,
22702,
95071,
5654,
61358,
9975,
24937,
80880,
129298,
42506,
246780,
198186,
158224,
345543,
211142,
null,
174536,
6899,
67938,
100660,
199883,
337992,
59133,
141298,
3433,
29975,
204839,
35325,
246300,
25508,
49580,
25333,
17838,
62727,
14210,
28829,
276069,
12977,
276258,
13093,
59868,
137831,
264077,
23380,
156977,
209698,
217839,
null,
27509,
17488,
21117,
49722,
409195,
33554,
null,
91935,
29871,
170377,
18645,
328029,
62399,
158982,
25830,
262209,
495291,
53252,
107159,
27613,
176837,
35369,
292594,
561157,
42632,
4586,
35975,
190026,
135113,
88811,
null,
156487,
150296,
68025,
22683,
52979,
51857,
81178,
55091,
345110,
21376,
453905,
29678,
154508,
51963,
null,
16362,
null,
null,
6452,
188775,
229007,
230553,
76016,
207736,
34486,
50803,
196337,
48459,
155716,
748756,
null,
49873,
42449,
264689,
138753,
223388,
9028,
307368,
316923,
199659,
45933,
46566,
20371,
386703,
49122,
46952,
21000,
42219,
220848,
539868,
392846,
81638,
47189,
320172,
8839,
217783,
22557,
16652,
42655,
50123,
12704,
null,
71217,
465749,
64440,
64843,
255243,
213644,
183667,
38449,
null,
184243,
67199,
252431,
129408,
6710,
181964,
27135,
216132,
89087,
206476,
218715,
190475,
253778,
21359,
31024,
15233,
32924,
98835,
228428,
142276,
90728,
686857,
14305,
435092,
null,
61423,
204011,
235659,
51403,
13938,
36215,
247290,
103643,
162081,
120328,
27087,
170893,
44915,
null,
26505,
41361,
166599,
281571,
19750,
258694,
13778,
19674,
226547,
null,
8741,
26512,
18913,
290047,
41772,
40780,
null,
358858,
33913,
null,
326493,
75752,
86415,
52179,
null,
3005,
349441,
424118,
14878,
300537,
481922,
140155,
13312,
158436,
null,
null,
31589,
16545,
8263,
122290,
415733,
262646,
125523,
299916,
124824,
569245,
64345,
383496,
179572,
30080,
32649,
105520,
360583,
19982,
122405,
189426,
76925,
16291,
372771,
252102,
18514,
24002,
97215,
32306,
43664,
50312,
null,
7229,
null,
7562,
25017,
385738,
10408,
null,
127678,
null,
7033,
35178,
17153,
23235,
null,
232459,
15918,
77611,
26599,
13162,
169456,
37977,
49918,
141436,
155931,
null,
124248,
200627,
53102,
92575,
263752,
406061,
22993,
71913,
143714,
179956,
null,
null,
84205,
34373,
199161,
330398,
375634,
323225,
327640,
227582,
190951,
182011,
36873,
261349,
403435,
9204,
474697,
183090,
null,
57723,
22700,
167632,
302843,
32665,
189138,
null,
381537,
null,
89825,
42936,
230998,
139188,
123756,
166125,
62994,
35979,
36529,
44888,
56366,
233471,
106593,
330595,
353509,
14542,
139422,
47545,
31742,
48317,
139339,
11523,
79353,
5906,
null,
18489,
108069,
389113,
266556,
44042,
38850,
null,
15320,
3695,
52201,
558286,
null,
18188,
71719,
182729,
89425,
56225,
286599,
140050,
61744,
5605,
38941,
5437,
16486,
284815,
93056,
772341,
268146,
62268,
200459,
445209,
49465,
138788,
119643,
49595,
4201,
772475,
45866,
74983,
30593,
93769,
522410,
367097,
55235,
206796,
284245,
38051,
181139,
235683,
109446,
340225,
3874,
184503,
352002,
420969,
25218,
8001,
131938,
22167,
177975,
30117,
6581,
84063,
19567,
21079,
346484,
47343,
84895,
131263,
null,
106803,
null,
null,
145857,
125291,
24374,
69640,
43904,
66994,
null,
62928,
344054,
138610,
388470,
76411,
309871,
11159,
null,
36114,
389315,
77678,
182104,
37258,
3044,
18512,
246044,
396756,
31145,
5835,
41453,
167698,
3723,
210282,
18468,
15482,
270117,
3319,
219216,
356,
49659,
277404,
101489,
null,
381312,
20475,
2188,
12025,
69190,
202234,
37460,
91460,
212230,
186666,
42094,
646224,
9272,
23223,
397681,
20638,
60504,
37099,
23903,
293257,
13555,
262214,
82807,
21995,
215124,
32013,
7832,
23955,
184208,
27450,
13245,
18202,
25069,
null,
55306,
15733,
14301,
28053,
378915,
188819,
89770,
297474,
10605,
36932,
530376,
162975,
242271,
47954,
21281,
219196,
35700,
165146,
44147,
24846,
8850,
196389,
12892,
144094,
25880,
282569,
174642,
351757,
60264,
39353,
298863,
209542,
32857,
150921,
288345,
25565,
303425,
357700,
78938,
20628,
8922,
30539,
103683,
218981,
5017,
96236,
230085,
null,
7371,
132410,
8832,
332816,
null,
384026,
222345,
5410,
29752,
37830,
40550,
74619,
20155,
148451,
248300,
179354,
206160,
37342,
41006,
11257,
3198,
62982,
55653,
271114,
null,
461635,
8696,
223718,
241402,
null,
187668,
145558,
null,
73208,
272735,
241172,
58377,
47477,
30961,
9707,
38588,
34015,
9857,
349126,
140918,
151299,
142648,
34603,
240928,
287948,
14957,
9542,
270813,
41050,
29884,
43282,
10659,
35169,
8693,
219359,
null,
null,
169547,
443474,
390757,
15769,
691016,
372730,
134300,
null,
287652,
27372,
18273,
46618,
23861,
17559,
222717,
19206,
177265,
195697,
77035,
318344,
166836,
1386,
233068,
123695,
41052,
126843,
13784,
52289,
50369,
745510,
62310,
47402,
12828,
16580,
102197,
53686,
63776,
null,
21056,
49770,
null,
58058,
56504,
96909,
46647,
33011,
663911,
210239,
150076,
163586,
23136,
32378,
1926,
53886,
290257,
184280,
38943,
150368,
203384,
72998,
607283,
197595,
28187,
null,
364882,
40102,
null,
179742,
118729,
null,
131662,
115913,
35211,
50811,
475097,
107630,
13422,
408335,
44475,
13951,
46726,
19487,
42563,
12604,
218917,
23900,
34331,
21872,
36262,
144969,
233432,
6298,
2922,
204998,
324536,
160621,
444805,
304970,
147811,
237952,
88384,
14935,
23008,
64777,
104281,
4862,
294332,
15725,
27817,
170197,
23962,
224978,
45072,
192094,
221116,
4596,
57105,
433843,
127964,
47841,
40679,
330106,
81339,
29245,
279881,
913120,
93806,
51501,
367382,
169879,
11532,
141587,
44011,
701652,
33248,
13004,
10569,
76474,
58451,
49207,
70128,
26988,
526587,
44286,
145968,
115460,
266760,
994350,
25003,
15515,
18841,
34223,
426640,
59525,
10639,
51262,
27903,
351071,
22781,
110577,
61008,
59519,
280673,
27891,
28540,
237718,
156084,
97436,
96511,
191877,
72476,
57912,
304647,
212004,
78074,
767183,
70197,
100539,
26074,
103156,
8975,
165896,
90131,
249447,
127981,
152794,
126683,
159780,
61427,
747949,
161136,
14788,
21168,
233143,
34738,
91167,
null,
297771,
12040,
140368,
162727,
184991,
10464,
56821,
23783,
55449,
23501,
474695,
144988,
1800588,
192800,
69297,
149557,
null,
165688,
247962,
42162,
161834,
209547,
32870,
377833,
28831,
null,
6132,
20229,
283583,
16384,
47182,
20067,
205586,
104397,
128262,
null,
14580,
null,
343373,
74646,
23262,
339721,
53692,
24737,
93808,
19022,
63137,
13234,
3926,
354400,
36001,
83275,
316645,
59019,
339743,
16213,
704451,
null,
226296,
8609,
25915,
138919,
104140,
67434,
292009,
null,
21340,
18685,
72951,
7616,
114596,
19591,
27284,
220446,
255044,
313592,
19513,
23252,
221494,
107749,
75435,
8190,
3422,
167771,
328460,
90620,
165033,
134070,
31465,
331785,
null,
26227,
116393,
254046,
382912,
354244,
177831,
26741,
35775,
76171,
180596,
115360,
207196,
390302,
170585,
106718,
607205,
17488,
36520,
null,
36752,
21154,
79282,
504550,
230017,
77113,
182226,
38939,
21861,
282330,
28344,
53694,
25728,
18452,
7438,
265438,
224026,
null,
162610,
212702,
25269,
82441,
null,
200146,
245524,
315765,
293836,
12641,
33510,
159067,
13830,
171286,
null,
78368,
87187,
34044,
59385,
103747,
50274,
9722,
252856,
436916,
6957,
138671,
23700,
null,
198666,
165385,
3571,
323787,
20196,
367594,
46467,
80822,
329994,
84789,
157300,
389842,
27662,
8973,
21875,
187175,
9966,
69127,
124460,
27210,
202936,
null,
41589,
201752,
103867,
null,
null,
114811,
407761,
141632,
268069,
121948,
124918,
25134,
14191,
342132,
301497,
null,
null,
11234,
300859,
84236,
338119,
198673,
19362,
51379,
246323,
40437,
266645,
null,
null,
141821,
99039,
38484,
262527,
4352,
6835,
54690,
456229,
86327,
9181,
100864,
75794,
36178,
8189,
313853,
34618,
69325,
null,
163476,
66797,
4933,
79103,
157537,
138296,
208100,
58100,
20935,
232659,
16857,
126426,
152972,
null,
256758,
30376,
393622,
null,
29790,
25917,
22410,
319713,
96902,
29124,
80717,
94526,
98182,
232378,
null,
312788,
16307,
312373,
45248,
146814,
387310,
36129,
250969,
333882,
9156,
70307,
1557514,
151324,
508251,
15009,
171029,
380064,
185182,
96074,
12095,
177431,
11507,
55567,
145120,
216820,
141066,
185509,
6991,
17811,
17109,
null,
46981,
44139,
8230,
101678,
377267,
332526,
164968,
24868,
null,
41191,
77503,
226791,
31209,
179164,
null,
16813,
237899,
40524,
50621,
154379,
null,
null,
55179,
14942,
128374,
null,
115273,
39785,
16503,
135227,
90720,
27655,
89802,
440509,
742851,
81373,
207151,
30139,
154578,
139549,
171812,
24495,
118392,
201704,
66886,
209882,
314716,
322301,
23817,
20979,
209500,
45622,
212541,
119273,
311569,
230454,
26253,
377813,
22588,
313490,
310755,
124574,
4256,
302838,
51033,
120501,
70861,
301144,
null,
170234,
213050,
312901,
8270,
237296,
80874,
315622,
null,
null,
177226,
null,
67345,
146729,
78306,
181701,
64411,
930024,
25288,
72588,
11510,
383833,
499323,
411977,
303023,
37555,
50026,
32034,
245447,
645999,
61432,
61934,
23700,
26535,
363066,
193096,
null,
552725,
83669,
109193,
63961,
99852,
168937,
null,
14308,
388585,
238244,
344383,
56261,
6290,
45008,
143882,
27063,
133090,
98009,
6023,
91927,
50860,
141723,
35136,
10217,
204699,
92935,
20778,
null,
79904,
41662,
48322,
134298,
435234,
null,
38102,
31897,
262962,
352725,
221961,
122825,
49772,
153502,
360782,
101492,
27005,
95726,
166558,
312420,
271097,
38074,
144374,
19379,
268414,
99850,
348152,
63020,
31589,
29366,
24907,
24568,
44578,
489951,
238403,
null,
493938,
37665,
11753,
144157,
3440,
null,
170088,
396489,
19854,
257903,
103852,
70957,
71421,
57385,
197797,
56784,
null,
155996,
34770,
56649,
9134,
433604,
165830,
94796,
90687,
106025,
null,
64493,
null,
77286,
159436,
139851,
54740,
218322,
140288,
329014,
2024,
21942,
37069,
74415,
36434,
103046,
598694,
295277,
699798,
215228,
392273,
151841,
193798,
10456,
179355,
30402,
29650,
257499,
136677,
299546,
6477,
25639,
203660,
263344,
49337,
305382,
null,
119007,
60477,
18979,
346811,
33339,
38810,
75747,
26634,
6424,
39545,
41295,
null,
null,
155551,
42893,
null,
23901,
75436,
20408,
16406,
198982,
222143,
16334,
66841,
8216,
404742,
179222,
null,
269859,
null,
364129,
null,
278069,
310378,
178265,
58320,
8342,
125499,
735123,
63854,
40329,
24932,
null,
283950,
18761,
24198,
10361,
195095,
328562,
45710,
14751,
null,
23205,
22561,
156517,
271562,
52600,
31808,
16141,
10232,
63610,
377990,
302924,
105096,
78638,
135984,
214891,
527844,
null,
163146,
28567,
30443,
75864,
19359,
343466,
17856,
18379,
10603,
211184,
698801,
71124,
83723,
29480,
null,
73139,
47293,
29860,
22010,
82957,
137478,
26916,
null,
190499,
80343,
20649,
246872,
412207,
11468,
471954,
467019,
362103,
338160,
24923,
9637,
151859,
383398,
446381,
20699,
418654,
40453,
392453,
75386,
59218,
143155,
null,
146618,
30791,
null,
24240,
302015,
null,
18521,
426649,
12382,
null,
393776,
31721,
24277,
null,
293718,
29526,
100368,
53654,
16988,
89178,
78620,
34762,
null,
null,
24829,
245945,
78710,
null,
47561,
32832,
14965,
33767,
152535,
47118,
41519,
44371,
175458,
338551,
452158,
13257,
40928,
null,
350232,
14960,
24841,
13457,
184722,
55430,
308412,
8044,
60090,
66143,
null,
21281,
141879,
16041,
3549,
148515,
26150,
23286,
355758,
261925,
605012,
439865,
35520,
162597,
17621,
44803,
73450,
43382,
40657,
99804,
139257,
9470,
364549,
6991,
462000,
80321,
100734,
336927,
110652,
207259,
91704,
224640,
327492,
74832,
55493,
61128,
395948,
41311,
52001,
null,
50967,
122035,
260706,
366071,
12412,
11302,
114398,
11563,
33898,
490160,
494960,
99511,
318957,
19224,
75556,
58782,
173364,
337989,
268717,
29898,
81734,
200731,
6170,
10859,
130672,
331359,
730776,
null,
176059,
null,
null,
239695,
12262,
200035,
40535,
10180,
132862,
117703,
54229,
82578,
156093,
307141,
5772,
477103,
30013,
12505,
262338,
45592,
675544,
15790,
27086,
168120,
61237,
null,
60566,
35639,
44550,
264103,
94089,
30392,
435507,
11067,
44837,
208755,
12873,
19403,
33450,
22609,
440051,
97275,
197719,
41461,
202255,
307230,
51816,
312759,
745729,
11310,
11253,
341686,
18635,
265249,
39163,
null,
8019,
244850,
56511,
31596,
null,
90261,
260365,
197048,
547053,
196945,
51270,
319095,
32649,
183756,
554850,
511416,
null,
41219,
24778,
973451,
131318,
174087,
7522,
92958,
92013,
27954,
41811,
361061,
6655,
null,
42081,
187865,
45241,
224506,
95197,
112315,
1231,
168868,
289560,
123380,
25124,
null,
161465,
344684,
372681,
32107,
279504,
51687,
195402,
192681,
255607,
149148,
35877,
416681,
24020,
24918,
null,
172128,
246793,
158875,
31116,
37788,
149874,
84008,
123666,
50950,
null,
147052,
42530,
12121,
18399,
35313,
32776,
25208,
101707,
127190,
199382,
null,
null,
249463,
293747,
75682,
176977,
114237,
228230,
136007,
201190,
25149,
37545,
32194,
171811,
null,
80144,
270385,
337627,
154133,
370294,
172753,
null,
249296,
33786,
179650,
24966,
53283,
67321,
133232,
133106,
311312,
25199,
59066,
189850,
70802,
5667,
85776,
null,
47238,
185430,
357763,
184282,
73013,
14365,
222077,
9086,
124100,
15464,
null,
17143,
389152,
391979,
331274,
34135,
478205,
null,
45188,
130231,
479405,
61613,
296107,
26094,
6643,
197981,
16793,
17502,
489685,
90237,
null,
267239,
12914,
510739,
42245,
21214,
247830,
null,
39042,
17165,
81396,
45800,
180012,
54958,
285588,
6064,
21444,
34843,
437676,
276100,
7648,
14234,
null,
null,
7698,
92667,
255708,
134475,
null,
13000,
49825,
54933,
197255,
21285,
335062,
294489,
149686,
79529,
64311,
106677,
1263797,
60184,
null,
97433,
11584,
null,
61796,
257712,
145819,
45873,
326176,
null,
126393,
26296,
24170,
null,
42839,
344503,
18992,
85537,
null,
38073,
243212,
15793,
12622,
65604,
165943,
21198,
15138,
158753,
178311,
422052,
327564,
114020,
62589,
289956,
27682,
null,
36790,
46385,
30764,
314123,
369746,
17012,
395280,
78888,
193695,
null,
244699,
199199,
177430,
20927,
78348,
40554,
221516,
null,
30576,
387207,
24496,
72778,
254155,
239956,
517929,
10344,
374810,
3084,
56151,
42783,
31193,
116999,
300977,
6444,
200677,
16837,
358800,
48529,
172596,
17959,
310643,
121939,
20931,
38995,
274869,
179581,
38933,
914004,
24867,
139090,
106796,
147609,
178147,
297660,
177583,
37489,
26772,
31700,
30310,
17977,
121205,
11798,
31673,
105896,
305285,
197121,
17992,
173300,
38023,
198538,
108218,
null,
null,
28710,
54083,
28901,
41065,
null,
29930,
23257,
304794,
25968,
38323,
183367,
244203,
116765,
22827,
null,
null,
37143,
null,
137271,
281714,
106584,
60912,
null,
340057,
31733,
178224,
24773,
73722,
141228,
417699,
12175,
null,
171161,
371971,
147581,
16756,
453228,
15121,
277686,
9382,
33128,
35280,
53265,
79404,
53996,
15959,
240345,
35461,
33807,
4669,
248318,
12989,
17090,
28563,
44558,
111075,
41757,
127416,
30965,
196967,
32673,
86799,
297219,
384416,
219627,
171999,
null,
55267,
187027,
2402,
24909,
46486,
29004,
164466,
218456,
89388,
21013,
25193,
8175,
30549,
16101,
9749,
83195,
556130,
143114,
8735,
206847,
20336,
18408,
15478,
null,
30328,
363709,
21356,
176623,
3038,
30096,
148486,
89803,
198382,
21464,
90553,
36335,
5733,
379293,
93144,
234149,
null,
133630,
null,
50118,
17888,
31004,
76946,
147990,
75452,
253982,
13601,
6406,
37188,
41414,
36803,
180764,
159849,
85175,
30224,
71505,
38124,
23672,
4736,
195389,
null,
9710,
14511,
83041,
160696,
95856,
15972,
12703,
18047,
12443,
263942,
null,
96012,
90741,
349814,
77282,
7284,
44404,
44592,
56113,
171129,
176424,
47823,
18990,
22286,
29573,
23867,
35892,
200144,
26841,
192018,
213707,
166948,
29954,
8110,
160162,
29552,
18645,
60260,
89845,
227928,
71295,
17804,
227017,
138637,
32426,
40497,
38672,
null,
16774,
45530,
26593,
531508,
49073,
195412,
112112,
34453,
35433,
null,
207552,
62657,
173811,
18001,
166874,
90284,
217998,
8414,
null,
302391,
184309,
52327,
126135,
125061,
17918,
74335,
19885,
1092983,
18280,
50965,
40585,
351866,
45625,
263077,
35930,
245801,
6355,
222593,
null,
754474,
null,
null,
385865,
171430,
55127,
323702,
81906,
47666,
5868,
29164,
176409,
240290,
319704,
163546,
null,
233300,
18649,
3111,
180362,
43416,
37892,
422755,
26031,
202850,
219991,
257410,
34524,
217462,
159679,
26155,
27496,
17663,
164376,
30105,
90433,
263362,
9981,
17374,
25527,
296202,
7243,
13121,
81246,
289353,
37482,
13361,
14298,
233565,
10841,
85667,
296380,
164165,
45544,
76301,
23088,
362187,
232288,
22261,
12774,
166140,
36643,
83571,
null,
81645,
117908,
92925,
13309,
114781,
38446,
73177,
129428,
48702,
392988,
17039,
35649,
40596,
null,
225567,
133901,
null,
118653,
378765,
186121,
62204,
55503,
149107,
116096,
84365,
50305,
470734,
263851,
198245,
87235,
97940,
null,
187437,
151846,
null,
49079,
14086,
9297,
5684,
2919,
33345,
12598,
154068,
198024,
173044,
22666,
207253,
115792,
31242,
375702,
38152,
18350,
95581,
4837,
null,
null,
7691,
138745,
23175,
61353,
118946,
97168,
356001,
null,
65587,
72901,
27611,
21314,
6844,
515095,
229617,
148221,
256330,
37278,
292115,
171566,
null,
56327,
21422,
null,
252879,
177683,
600458,
57937,
9361,
74799,
79187,
186348,
344177,
78551,
239369,
39734,
223261,
19073,
266759,
11634,
191330,
21297,
13062,
48787,
250560,
26652,
326335,
193382,
15182,
262564,
20572,
82043,
11719,
28404,
57399,
8343,
25495,
49816,
292735,
23369,
50261,
41294,
42359,
54816,
3065,
224140,
null,
null,
null,
181388,
135952,
11264,
167877,
481022,
6778,
111060,
139501,
4417,
76805,
318075,
157898,
26355,
8964,
131700,
12498,
null,
157417,
12176,
31899,
4111,
27423,
null,
23373,
46852,
8523,
44444,
317529,
26886,
37794,
27439,
null,
351179,
206121,
28472,
19411,
48102,
74352,
null,
553484,
106805,
null,
265370,
56073,
127088,
46063,
81397,
62137,
21882,
83123,
null,
261154,
24633,
null,
27271,
386930,
196934,
140682,
20222,
8818,
1865,
161806,
177053,
27380,
null,
null,
97619,
39277,
59666,
null,
49656,
176216,
456283,
100587,
null,
35433,
11056,
8712,
315947,
40022,
94936,
26758,
476096,
380378,
null,
31759,
108777,
256032,
437149,
28918,
108914,
null,
293426,
404367,
9844,
null,
46883,
198831,
null,
167594,
26171,
29727,
null,
13951,
251883,
null,
17811,
259292,
159948,
191070,
118835,
195194,
179302,
null,
229333,
59372,
17793,
57287,
null,
283595,
269825,
46469,
10887,
99653,
12659,
377808,
null,
50656,
80253,
142042,
290901,
null,
44789,
307415,
38865,
89095,
288781,
8815,
359331,
310638,
254238,
230284,
289219,
59435,
113415,
25053,
218598,
14898,
266908,
52635,
172186,
214327,
457401,
237193,
231530,
112807,
348712,
81177,
59898,
null,
63774,
101933,
153641,
169047,
81048,
13504,
278871,
205520,
63437,
290874,
179344,
34144,
62217,
12366,
276515,
197152,
159652,
25965,
4897,
20485,
830130,
515844,
173537,
null,
107265,
null,
102189,
null,
58979,
126132,
29461,
146600,
331881,
277958,
199758,
45394,
24213,
19220,
139684,
20235,
6410,
225781,
262444,
20263,
161352,
21053,
145485,
350613,
368008,
178216,
6951,
162793,
34563,
273466,
54694,
217702,
23575,
149762,
40676,
358801,
27332,
358954,
50770,
32576,
150700,
null,
104639,
99551,
28295,
409799,
31991,
149594,
59022,
37804,
30889,
null,
7237,
220069,
163352,
280249,
59805,
30048,
318230,
null,
null,
361141,
389744,
207958,
17202,
188598,
244253,
294861,
61947,
52451,
470586,
322605,
null,
22486,
76888,
26417,
33614,
27399,
93591,
619563,
462390,
163772,
167935,
null,
23713,
318868,
123870,
56901,
5108,
52449,
282314,
18104,
null,
13214,
22955,
6683,
26652,
35569,
352478,
37128,
224386,
298888,
26765,
230343,
null,
63391,
226998,
27422,
240613,
null,
25297,
41583,
177867,
48824,
246957,
168990,
25169,
60843,
30281,
24733,
null,
215863,
2482,
407951,
180825,
33835,
152454,
22184,
47998,
16035,
96117,
249995,
38299,
278984,
1019644,
99484,
31357,
490875,
24655,
6853,
195933,
33841,
289424,
303598,
278598,
51673,
384458,
35621,
5457,
362949,
50999,
165914,
193766,
113901,
null,
16767,
334861,
50379,
37279,
33291,
45116,
132633,
22848,
106374,
214666,
231625,
6330,
null,
176093,
38030,
118948,
170985,
90792,
241045,
19261,
1087835,
152782,
103417,
134070,
60938,
99422,
280017,
48442,
11981,
529770,
149694,
120261,
310116,
36330,
189321,
3512,
21895,
24805,
395167,
25341,
60050,
null,
null,
52047,
267910,
50009,
13559,
30543,
316851,
217778,
30601,
23696,
6288,
358050,
63125,
138421,
297328,
69694,
111527,
204471,
null,
null,
226247,
null,
30561,
20068,
368656,
330933,
null,
42924,
548585,
323756,
20316,
17282,
281527,
938391,
6824,
39116,
58647,
113401,
15076,
248651,
281649,
39849,
null,
null,
398748,
755403,
6458,
null,
154741,
99753,
11626,
54031,
329978,
57553,
121744,
215002,
42513,
57289,
408664,
39598,
293223,
122283,
141648,
47823,
60905,
52948,
11488,
6679,
248347,
39210,
27353,
42778,
30601,
96523,
7526,
47127,
253891,
35553,
271084,
290630,
194651,
63109,
61542,
51532,
765950,
94379,
34060,
263729,
175337,
22303,
60590,
null,
8808,
38252,
386349,
120642,
212470,
407869,
140291,
null,
23285,
218271,
281474,
45171,
670509,
37817,
766371,
76613,
205109,
84760,
286512,
13600,
2645,
200235,
null,
285512,
326094,
417603,
513246,
126023,
291445,
22974,
436255,
65851,
47326,
5294,
24356,
24597,
null,
21366,
7367,
16830,
28846,
31846,
169527,
37059,
297535,
null,
254369,
231947,
148593,
28133,
37063,
339067,
29999,
95228,
56933,
30678,
57202,
13953,
null,
69494,
153982,
129325,
null,
76461,
302985,
53201,
58384,
37076,
444219,
63770,
307306,
125851,
224541,
244289,
206233,
99596,
832587,
86992,
370966,
272429,
70239,
62910,
250645,
370728,
231714,
64025,
150320,
195396,
54627,
397924,
420765,
66155,
703889,
242077,
218253,
7610,
20352,
27191,
205981,
175101,
32576,
null,
173320,
34032,
108232,
9937,
29531,
197546,
39782,
120493,
41891,
30142,
18077,
36096,
301959,
12087,
67583,
33068,
122111,
323113,
197126,
225828,
51580,
308094,
15919,
78410,
264997,
830972,
193547,
null,
25403,
154398,
15815,
266099,
235414,
73807,
33999,
25711,
236649,
24423,
217339,
154686,
346857,
64707,
109058,
116437,
70459,
227152,
74206,
143890,
16860,
19969,
39924,
174051,
null,
436143,
546966,
27218,
null,
227046,
153934,
412013,
44894,
34301,
29845,
14280,
33338,
177921,
446291,
null,
45333,
102052,
208567,
22312,
339909,
null,
76446,
235718,
181311,
9113,
50831,
13390,
18794,
351918,
268918,
237503,
51175,
91320,
114755,
null,
143477,
36641,
107707,
46065,
31184,
238189,
306489,
21590,
19659,
44035,
13866,
4914,
244386,
14014,
28026,
null,
9447,
86311,
109351,
null,
39171,
16061,
227839,
29871,
75813,
30214,
790616,
32693,
279979,
166490,
null,
13686,
30119,
283193,
179013,
212043,
12839,
22824,
923695,
34202,
18505,
143160,
23318,
216008,
34977,
null,
276816,
23277,
250807,
60259,
null,
122805,
184433,
27578,
null,
220117,
null,
30416,
433976,
24284,
192808,
395330,
15415,
207141,
null,
309701,
15125,
36927,
null,
98640,
120339,
17364,
9953,
287922,
314457,
47600,
11888,
null,
14464,
208820,
65760,
null,
35367,
19090,
268382,
164954,
16281,
81301,
29915,
54400,
267528,
70623,
131365,
33795,
25442,
39446,
108257,
245962,
390678,
91543,
1273619,
4755,
49821,
40679,
14245,
251208,
184456,
232705,
14354,
87362,
259771,
342079,
24381,
26840,
219229,
11567,
79504,
204177,
159512,
20856,
355726,
33760,
43462,
8435,
67126,
127847,
276109,
79988,
null,
426996,
268597,
53535,
26621,
106901,
21690,
294997,
21708,
115431,
20706,
254955,
129901,
62862,
15253,
37865,
15165,
227045,
31649,
325082,
3278,
null,
null,
43949,
430385,
238796,
166192,
210710,
127180,
178810,
9052,
510820,
null,
497802,
17375,
168225,
36375,
64034,
46126,
81877,
null,
164783,
13648,
163171,
42232,
72105,
7326,
51652,
146648,
291408,
5372,
210403,
52266,
263268,
4833,
185300,
197041,
346564,
null,
38246,
467569,
110721,
null,
262717,
43731,
23579,
32808,
31896,
207956,
47639,
19329,
212845,
68876,
12669,
82147,
26464,
73484,
361057,
52458,
65961,
322199,
86519,
73820,
null,
83130,
32370,
98102,
13802,
150425,
364006,
178179,
527428,
200792,
13430,
451063,
111399,
164319,
388157,
25716,
74396,
38006,
27675,
36875,
77871,
67164,
23338,
41060,
67422,
234963,
32102,
48993,
101294,
226214,
17643,
149179,
86016,
null,
32337,
108181,
346833,
null,
55684,
89764,
55450,
180181,
47648,
28190,
null,
38740,
24887,
121347,
31105,
99223,
10815,
17878,
45566,
null,
50607,
null,
11551,
297933,
70956,
12969,
37354,
23530,
39931,
192705,
52675,
114519,
4255,
61454,
38299,
34812,
36455,
41307,
25817,
318517,
274832,
43171,
344703,
92353,
186102,
1114,
15668,
181039,
418909,
280280,
147626,
13126,
263292,
27138,
912724,
29513,
34171,
12795,
32440,
14286,
130463,
null,
101915,
19526,
19015,
402580,
42371,
40837,
null,
319043,
12374,
null,
97347,
10136,
108979,
38270,
107772,
10822,
569871,
18389,
26098,
39435,
113631,
731689,
349703,
6492,
null,
194241,
17920,
533958,
114128,
13782,
116348,
44065,
169997,
304841,
28793,
506871,
33520,
193814,
198569,
148721,
21963,
18557,
260553,
325503,
24379,
40685,
17404,
19233,
440231,
157973,
320704,
46442,
402905,
301636,
407241,
16336,
318335,
103588,
10230,
195419,
22006,
46327,
140477,
427007,
245540,
598185,
154762,
11281,
null,
56384,
505996,
null,
453638,
41588,
17229,
56013,
52182,
91246,
43944,
13292,
29626,
null,
7885,
26869,
92161,
155021,
127261,
52789,
239381,
292085,
10827,
173510,
231923,
246246,
40737,
352694,
null,
147790,
98860,
82486,
115434,
7380,
12332,
305794,
24362,
70968,
30235,
203051,
32996,
20809,
3998,
4089,
89242,
null,
99754,
160288,
28979,
169218,
507525,
64044,
216431,
18260,
303393,
16531,
844969,
172685,
22750,
null,
68489,
null,
51289,
55090,
468122,
94945,
43433,
20190,
214866,
154683,
20030,
202855,
null,
257945,
144582,
117155,
164782,
41487,
null,
null,
133785,
32129,
34776,
151107,
435711,
22785,
null,
543072,
754095,
26371,
121550,
79794,
127299,
345435,
36721,
424147,
96755,
595168,
12179,
77890,
54629,
5319,
9868,
215152,
268077,
242156,
63679,
317190,
338549,
4265,
47424,
41051,
39442,
266563,
38010,
42976,
33779,
271897,
146994,
27408,
33764,
278813,
64446,
481816,
309044,
195392,
661354,
75423,
76479,
40258,
53657,
234911,
368411,
151584,
16159,
156554,
202077,
14628,
223249,
20026,
308090,
393453,
155740,
26386,
187833,
4952,
2689,
137814,
13052,
null,
66771,
339392,
179795,
54473,
143452,
17523,
27968,
136334,
1022,
null,
888738,
276262,
200758,
48528,
12714,
240744,
36083,
248100,
9267,
467917,
372024,
21415,
137793,
136746,
303383,
null,
57000,
146687,
42865,
197006,
54818,
50420,
193129,
149962,
193977,
null,
null,
270786,
142298,
59827,
354174,
226920,
672618,
null,
351343,
null,
32800,
211613,
25867,
383908,
19234,
158624,
163417,
66711,
1027321,
37023,
148164,
77531,
103947,
160965,
64202,
189338,
null,
29343,
15566,
null,
446790,
38737,
181461,
9179,
10901,
47805,
670265,
174164,
16760,
11910,
199341,
14994,
25209,
null,
401230,
18807,
31213,
27882,
26670,
41501,
null,
58759,
357741,
25637,
73292,
311133,
196787,
346548,
314949,
null,
212249,
null,
86085,
216261,
212708,
31067,
291380,
53680,
30011,
108051,
30225,
null,
36593,
60218,
null,
14994,
164901,
195069,
29495,
51436,
158902,
82563,
null,
null,
13860,
175147,
145514,
129182,
22634,
19203,
294989,
null,
68299,
25178,
74487,
67637,
218701,
null,
236668,
35568,
532034,
49523,
32623,
579600,
3517,
157415,
13671,
30959,
76709,
194704,
22653,
8750,
79016,
99214,
34344,
13537,
69475,
295751,
17152,
547369,
67114,
62073,
222446,
30568,
12103,
59209,
299926,
26264,
46366,
417086,
239613,
380926,
279715,
208215,
355082,
102604,
146537,
194595,
33158,
30875,
481492,
null,
31644,
24335,
371560,
12485,
129070,
39012,
14894,
8858,
20202,
null,
280668,
347244,
175544,
182132,
null,
4263,
271543,
374614,
null,
40955,
118996,
30761,
173557,
4338,
101855,
359988,
306823,
53618,
42442,
23937,
46779,
null,
null,
400957,
109867,
26721,
36506,
38460,
278472,
180298,
74045,
141745,
null,
145634,
22340,
32720,
33096,
49681,
125440,
116805,
426849,
187616,
332123,
null,
455170,
66142,
58670,
205463,
158465,
7934,
19359,
52155,
null,
46150,
9526,
212418,
154274,
143788,
203128,
48541,
219076,
120310,
453771,
284934,
53559,
279326,
972705,
37966,
438621,
8880,
264766,
84991,
48271,
null,
37976,
6493,
57482,
65294,
120658,
205036,
83812,
127250,
38293,
59782,
143715,
410074,
null,
39981,
null,
39543,
52997,
127755,
332043,
null,
496346,
null,
578219,
43693,
130697,
null,
111296,
98628,
11285,
9478,
17813,
119187,
283268,
101113,
1714681,
null,
234382,
28141,
707853,
269921,
24466,
35221,
47624,
32261,
36156,
48765,
35248,
10132,
16895,
9384,
66144,
136900,
12277,
189598,
22976,
104282,
15565,
86825,
null,
70535,
100502,
352919,
415119,
533259,
119844,
352988,
745191,
26607,
null,
254041,
74388,
10712,
18759,
252683,
58180,
238596,
null,
null,
91389,
17196,
34464,
329565,
21653,
260018,
179124,
395542,
10945,
33188,
34372,
18029,
null,
515482,
252884,
146066,
331934,
577138,
null,
36236,
266311,
27719,
null,
209988,
171467,
209145,
35613,
null,
25127,
138357,
28432,
30717,
217621,
26503,
208658,
122902,
211719,
49661,
60970,
234560,
18955,
39926,
70862,
448640,
33595,
47968,
12239,
39961,
27805,
157685,
289954,
null,
181460,
87113,
28476,
185283,
67948,
63699,
31883,
151655,
20255,
46540,
82779,
112464,
155177,
232910,
432073,
10454,
170830,
null,
95449,
108195,
33978,
54829,
210775,
16780,
7248,
null,
44241,
27892,
305578,
178270,
25623,
7865,
89197,
217671,
324164,
53291,
6135,
37350,
138673,
137036,
125060,
252269,
67998,
202066,
77140,
178428,
69674,
387939,
28742,
49706,
275606,
131244,
20112,
37084,
45871,
37594,
333001,
11934,
62749,
25081,
103290,
16213,
256417,
291275,
null,
404993,
89092,
31433,
null,
52489,
null,
188362,
null,
8124,
177011,
71000,
109086,
400909,
29985,
123259,
12941,
36463,
15723,
470057,
13107,
112597,
245195,
5249,
40824,
188737,
null,
21181,
6672,
27539,
11518,
1043178,
367979,
20706,
18707,
33370,
61388,
28664,
455637,
204736,
58657,
45149,
33365,
358888,
14259,
609758,
null,
49561,
null,
78055,
534788,
487671,
43965,
263543,
103237,
null,
24486,
35809,
281108,
17206,
226712,
95277,
27378,
93458,
222514,
null,
293446,
22183,
105696,
12289,
228325,
143989,
72861,
150769,
131335,
57194,
46217,
240953,
34436,
187190,
94269,
173366,
15058,
251903,
null,
568579,
388288,
null,
35171,
64364,
864809,
97005,
9765,
20862,
504944,
10320,
84064,
null,
218569,
null,
320493,
13823,
107879,
null,
279584,
77711,
146490,
27685,
20052,
144478,
132036,
249125,
150077,
120786,
null,
43586,
103590,
73948,
30435,
173081,
198498,
14534,
52323,
16378,
62211,
95964,
null,
null,
13488,
306523,
286230,
434605,
13826,
260788,
282773,
null,
41767,
212504,
25710,
191779,
80503,
114520,
206342,
281823,
135936,
12975,
72295,
195039,
206160,
240555,
22031,
null,
110597,
null,
169607,
20266,
253574,
61289,
29333,
184007,
216339,
13685,
123935,
11845,
46608,
141915,
22615,
null,
27380,
83117,
86773,
54312,
19648,
721440,
51344,
91345,
10920,
43479,
null,
157530,
89498,
22948,
106449,
415211,
269838,
null,
110980,
null,
403780,
143698,
249445,
322401,
21341,
23760,
49807,
21745,
65892,
229331,
20981,
7849,
260638,
153440,
31284,
11442,
229839,
301477,
36931,
19576,
19303,
210755,
null,
147423,
93642,
32983,
15480,
54168,
463458,
null,
433701,
null,
140309,
193651,
335000,
8930,
139660,
76795,
null,
305679,
57651,
97556,
54565,
71010,
220758,
412666,
101379,
113201,
411586,
22611,
165365,
26608,
585279,
162226,
40361,
null,
228742,
14351,
215129,
39413,
65660,
178270,
13335,
121480,
5944,
19634,
410161,
445532,
8747,
11335,
198059,
172061,
12662,
20444,
55924,
441068,
188136,
97135,
171424,
215733,
505701,
null,
24686,
13081,
null,
null,
454167,
null,
5463,
null,
299811,
186357,
37445,
15640,
258287,
44992,
28631,
355546,
296925,
10111,
101353,
11232,
210923,
43327,
null,
98395,
194146,
null,
590465,
null,
null,
43015,
22497,
401609,
147681,
56326,
103517,
35528,
261131,
178237,
35418,
3858,
368843,
null,
null,
300582,
67931,
175437,
31602,
113144,
44120,
null,
406436,
6539,
79751,
202918,
48917,
null,
163355,
null,
220056,
9746,
7386,
35419,
223080,
4195,
498040,
17350,
34605,
25443,
125697,
385363,
15182,
6302,
null,
55514,
336207,
32536,
426933,
273632,
62949,
95513,
39375,
4271,
38320,
336747,
45694,
218324,
73402,
499254,
14037,
28775,
32426,
312642,
57199,
114068,
62893,
237754,
30090,
49843,
203806,
43977,
21168,
44901,
407320,
16939,
151543,
213979,
23757,
71343,
368954,
28141,
21365,
80118,
39479,
4224,
9576,
89588,
40492,
5179,
14136,
15552,
5442,
456149,
317024,
167181,
123649,
316337,
154218,
14077,
57507,
91300,
37554,
31225,
4206,
41094,
263946,
6573,
327576,
37857,
59329,
176418,
19919,
210433,
17466,
3510,
113698,
104544,
810380,
158687,
72356,
null,
null,
43311,
null,
275501,
266360,
96218,
null,
72073,
59312,
393172,
10190,
243642,
72976,
10233,
22532,
254948,
230776,
172756,
45630,
112965,
42245,
64359,
23804,
43308,
null,
600651,
56107,
80143,
60297,
55407,
76497,
205447,
201168,
338897,
32736,
19299,
21300,
197474,
13222,
78544,
null,
188284,
null,
370051,
51517,
23195,
7811,
140452,
50275,
37994,
null,
163848,
66797,
42974,
522627,
216281,
27804,
25433,
437423,
244733,
null,
79857,
172250,
535832,
20865,
216366,
43010,
165678,
48950,
129773,
35588,
243614,
null,
230325,
349911,
243560,
180114,
23510,
777477,
282253,
176202,
482791,
289810,
144952,
18111,
13103,
92433,
189589,
24876,
217597,
13809,
34071,
26240,
48366,
152347,
48788,
46413,
6036,
706693,
55101,
32549,
174004,
62090,
66606,
162522,
172316,
360020,
152296,
141629,
140302,
null,
264736,
77661,
198676,
120365,
508423,
200697,
44059,
223684,
321610,
172452,
88006,
null,
14369,
5294,
339480,
108900,
20038,
21969,
172236,
263282,
14511,
55911,
17149,
23174,
9537,
153261,
52413,
289605,
22057,
61528,
null,
77090,
36203,
44088,
124683,
5636,
17378,
21431,
5496,
132106,
null,
4263,
163064,
155511,
11504,
563427,
135916,
83295,
44701,
null,
294593,
328745,
42222,
403178,
204528,
null,
342092,
46216,
null,
18229,
59690,
79083,
126316,
37378,
42605,
165039,
46148,
553173,
49614,
120762,
241675,
14224,
279873,
388074,
22496,
9889,
7436,
5125,
23901,
142490,
77983,
null,
null,
160907,
182698,
351959,
153384,
237464,
387199,
14469,
220725,
91114,
null,
127148,
400578,
100381,
45772,
44891,
null,
null,
123020,
null,
190722,
303979,
25238,
285154,
163787,
60558,
34092,
19839,
526699,
143198,
134789,
114448,
321617,
null,
261877,
12714,
108287,
null,
23688,
36569,
16002,
null,
351548,
null,
27526,
46488,
39197,
null,
94775,
null,
258596,
452811,
34719,
205370,
58484,
456571,
248161,
7075,
103990,
41830,
71287,
37758,
87343,
91817,
197573,
13402,
34924,
24569,
39942,
68110,
9575,
109234,
284936,
null,
241021,
null,
78118,
28897,
116057,
66409,
199580,
585917,
329600,
188944,
139669,
4083,
18523,
94427,
22156,
182112,
196261,
6017,
null,
112228,
71650,
37754,
211508,
47454,
201487,
null,
382176,
302484,
228625,
69323,
149723,
25267,
257779,
376437,
27692,
56094,
20938,
20704,
18434,
null,
362567,
13055,
56719,
86937,
56324,
51768,
26645,
102854,
30947,
287696,
null,
29526,
90225,
123743,
42880,
22764,
38679,
18431,
null,
129668,
14482,
224173,
170309,
787802,
103703,
70177,
null,
181744,
4301,
151386,
14003,
26389,
274071,
24772,
30055,
null,
180963,
42130,
48419,
151762,
343770,
28024,
null,
23297,
26720,
191807,
291510,
null,
443900,
46108,
36163,
3633,
86504,
39298,
224224,
373730,
148624,
75912,
96671,
2714,
15127,
306611,
720620,
420041,
null,
10173,
56888,
90686,
396842,
373578,
279319,
6978,
157992,
62485,
24219,
null,
221849,
null,
null,
231367,
69185,
11572,
27933,
56486,
232083,
238173,
38487,
43039,
19446,
12222,
46915,
11721,
26991,
23347,
37916,
28973,
23161,
27104,
10925,
518240,
129510,
197509,
50415,
57520,
212604,
null,
6442,
null,
24777,
null,
15941,
518403,
12720,
23715,
375583,
11482,
28135,
7525,
41246,
339173,
46706,
24704,
20386,
13639,
null,
94739,
308261,
250341,
133258,
162057,
null,
21557,
25006,
308467,
203837,
177014,
317971,
180569,
36815,
14633,
11580,
null,
99335,
404634,
27435,
null,
36933,
39596,
15335,
96659,
125932,
32640,
845854,
153808,
null,
24473,
null,
15705,
45804,
37135,
null,
323686,
51425,
215307,
202309,
null,
33449,
null,
111054,
4756,
206847,
236136,
321982,
39041,
27690,
18212,
314234,
71223,
387681,
125231,
234122,
83193,
213288,
31942,
112945,
77533,
null,
22652,
null,
294614,
228446,
27186,
46905,
44195,
23927,
31942,
137261,
null,
9141,
470800,
21168,
71372,
16784,
40310,
43614,
38041,
55700,
384172,
23097,
49880,
186102,
103959,
null,
150069,
293855,
null,
null,
49677,
16912,
41124,
18425,
82257,
30574,
158717,
82651,
181805,
157627,
167865,
21361,
26817,
89525,
183325,
6570,
10111,
27826,
106767,
122388,
33503,
44915,
53241,
100167,
23859,
426583,
170180,
12495,
null,
21855,
null,
407565,
141094,
19914,
181388,
null,
19017,
25992,
65160,
50684,
248492,
185186,
168586,
73920,
53606,
392194,
14756,
318609,
135251,
37971,
37583,
null,
31479,
48632,
558018,
390358,
52882,
121236,
8318,
260840,
175488,
41487,
16932,
476807,
135412,
51205,
8192,
147435,
null,
218451,
51711,
20317,
101790,
10708,
23314,
105414,
176124,
195628,
180777,
21657,
47277,
212973,
19762,
273165,
null,
null,
20242,
251344,
41954,
103918,
43131,
58612,
205626,
260747,
178090,
208253,
99623,
52304,
null,
496339,
null,
19625,
6475,
59855,
49803,
259924,
3010,
40365,
171010,
58373,
49305,
183451,
219015,
null,
8768,
265204,
286937,
77363,
51538,
17832,
793162,
115438,
null,
326008,
573393,
183912,
137854,
35192,
10419,
125768,
150814,
194933,
199535,
39591,
33378,
44368,
348875,
50884,
16552,
373254,
22846,
80438,
12055,
249451,
64139,
42073,
174290,
5240,
null,
212640,
25821,
616394,
92575,
30052,
498299,
459914,
8987,
301268,
null,
52505,
97376,
278729,
50991,
32635,
346281,
147786,
27821,
72924,
81046,
7516,
52491,
190907,
186862,
212035,
551642,
26226,
6601,
51233,
null,
43792,
194549,
122464,
75396,
57390,
20881,
39235,
332902,
26495,
10342,
6402,
52548,
null,
30587,
15316,
null,
46301,
14586,
54794,
51886,
279163,
118695,
140596,
32205,
211686,
46134,
103866,
160778,
57580,
119126,
206251,
59258,
320446,
51047,
269975,
321010,
275227,
234302,
76739,
null,
299201,
216336,
25911,
193207,
345390,
155918,
57746,
null,
443739,
22058,
47739,
null,
24011,
227619,
13927,
83704,
23793,
96339,
161708,
128688,
46663,
236294,
31359,
8121,
264584,
225853,
164234,
60648,
14544,
18962,
438216,
20615,
null,
131239,
406816,
332825,
130835,
203696,
21757,
3938,
155977,
508040,
49148,
219339,
180369,
20996,
663,
43697,
45547,
331145,
33394,
9793,
428,
302568,
15387,
null,
26264,
121643,
398843,
264065,
3690,
16473,
300310,
333237,
163704,
12377,
49510,
231283,
35856,
16044,
83144,
44698,
81572,
15060,
100776,
97795,
16134,
20436,
246026,
23553,
147157,
266039,
14619,
18672,
27657,
19419,
144114,
227063,
25361,
31612,
346386,
138901,
273643,
9843,
43705,
8910,
28002,
36802,
72487,
266614,
181002,
16115,
null,
127745,
25659,
10300,
303932,
198767,
20067,
49504,
34898,
15571,
21116,
30219,
109135,
482885,
11009,
61111,
198955,
298826,
22230,
9571,
49165,
36170,
198982,
136785,
61858,
32252,
39724,
204382,
40761,
122684,
34612,
196945,
369013,
313861,
163143,
null,
14132,
35507,
17317,
695603,
45377,
212685,
126500,
47738,
42914,
51610,
427117,
11718,
null,
102221,
249174,
25727,
239808,
null,
142413,
316450,
15307,
534297,
246401,
58617,
82451,
1246,
42361,
89272,
64613,
118159,
289230,
526698,
107241,
204307,
22471,
45710,
115785,
168488,
null,
121604,
314383,
22184,
148753,
265411,
102859,
4318,
342301,
28050,
null,
29069,
250864,
174359,
273234,
null,
null,
277969,
23600,
106121,
105767,
216840,
251846,
346686,
232948,
50312,
14395,
21504,
88148,
159359,
26253,
32345,
641633,
410022,
11644,
39240,
12080,
136003,
202246,
26407,
86388,
9967,
8772,
347915,
49471,
41449,
20069,
307670,
185439,
63508,
292464,
63810,
16887,
222861,
null,
158431,
316947,
135061,
57358,
null,
142211,
41001,
246861,
36008,
1153118,
5159,
292118,
410122,
7860,
18305,
35601,
101814,
81871,
261431,
35776,
84472,
17423,
null,
35844,
2168,
null,
382624,
441819,
351593,
289824,
35093,
351102,
29123,
159750,
24058,
235543,
76101,
208950,
null,
78030,
54842,
null,
null,
null,
16,
176260,
52618,
214048,
null,
175880,
176620,
447523,
385855,
22036,
null,
312143,
161598,
276985,
211878,
280692,
522834,
155450,
63098,
79931,
13652,
163617,
297458,
221556,
6682,
209884,
61645,
16560,
303081,
33352,
292036,
74041,
35667,
25069,
171981,
15910,
370336,
17825,
17493,
17432,
12273,
77018,
147093,
394950,
39333,
38017,
null,
23873,
21840,
141603,
5880,
null,
25491,
131056,
315432,
171307,
265447,
141828,
50959,
144329,
142548,
446634,
27431,
4541,
157676,
347894,
28832,
114668,
466918,
69946,
27901,
77551,
29336,
251919,
255879,
115308,
43109,
92279,
33130,
84230,
30789,
null,
39581,
null,
71922,
26902,
65208,
109598,
221020,
103228,
43421,
83168,
170067,
193004,
59214,
64129,
142979,
512257,
84666,
79656,
65417,
127745,
189648,
36607,
2266,
43566,
67386,
42642,
88685,
451127,
187788,
null,
75522,
71627,
149372,
260863,
223148,
178961,
43647,
222916,
123176,
326968,
6418,
124850,
null,
41920,
496261,
214722,
516090,
138384,
299480,
22740,
472257,
240427,
27717,
264701,
null,
24786,
549959,
345286,
74722,
14208,
30707,
49344,
99477,
214598,
null,
528033,
586572,
11929,
48644,
175330,
14868,
47135,
null,
19286,
140405,
103689,
170254,
180738,
453111,
40261,
null,
206690,
5402,
260212,
417525,
210938,
169682,
94694,
null,
33300,
91001,
21249,
6494,
56447,
37819,
567980,
310868,
44128,
40409,
222990,
10670,
35012,
335105,
129785,
138775,
29913,
141458,
66996,
39005,
180015,
29117,
14206,
40627,
22329,
63210,
290338,
643585,
9469,
127189,
null,
231014,
15290,
16266,
28098,
38586,
50979,
44727,
186396,
68124,
62481,
154373,
173516,
null,
17064,
54745,
443736,
16229,
43079,
312232,
124846,
33712,
190673,
254485,
289512,
null,
15114,
null,
153009,
null,
49521,
152562,
10828,
23963,
27214,
1181091,
58458,
15560,
43216,
403978,
250131,
10237,
34680,
46051,
522478,
14674,
30255,
101549,
null,
5003,
215062,
null,
null,
122310,
133519,
117292,
225672,
316589,
18791,
857304,
133996,
211594,
223694,
32143,
22029,
133089,
34802,
183847,
274455,
429987,
27766,
34284,
107685,
179200,
23822,
280723,
62044,
208517,
237762,
25122,
273326,
249459,
439308,
298797,
30290,
69874,
49844,
146660,
136900,
48679,
303547,
269735,
5673,
134720,
103329,
9410,
63142,
102416,
164561,
142688,
177587,
38301,
221138,
405264,
11151,
29269,
407279,
214574,
102289,
37953,
402364,
45684,
30998,
73675,
201281,
52907,
379869,
265392,
42253,
596894,
2138,
478772,
236013,
57539,
170076,
220517,
323278,
191782,
202038,
38045,
4587,
50525,
390951,
322531,
16620,
124099,
82215,
18768,
37500,
85909,
290987,
18569,
93350,
71787,
53043,
285608,
92231,
null,
290993,
null,
27155,
20004,
null,
66321,
23975,
162205,
106595,
271547,
247639,
23254,
153432,
39350,
112996,
25291,
156774,
208253,
null,
45994,
185055,
219740,
null,
163065,
153174,
211072,
32670,
309902,
19251,
null,
295969,
44317,
18985,
413295,
51332,
139130,
62584,
13262,
30826,
13305,
382015,
329971,
6405,
380464,
462513,
221983,
46076,
30969,
144385,
89065,
96841,
267175,
516473,
29622,
9925,
35099,
200558,
20270,
24692,
139036,
77284,
183465,
324799,
865398,
null,
8393,
267728,
66342,
302450,
null,
42851,
280548,
10245,
5631,
null,
284226,
43804,
194105,
36567,
22420,
194938,
145744,
86498,
320155,
94907,
31198,
413228,
6216,
192603,
13778,
139675,
53834,
null,
null,
51039,
218440,
127086,
null,
27928,
196203,
9142,
14038,
169002,
null,
9192,
264339,
143364,
null,
117721,
46517,
15556,
170932,
30021,
27633,
92363,
383152,
286321,
53509,
420242,
253033,
421096,
36542,
234020,
null,
381656,
107120,
13707,
39719,
37162,
119279,
null,
158733,
null,
225153,
130508,
132349,
23783,
6082,
81043,
null,
39613,
5799,
null,
1121630,
35430,
42847,
27481,
null,
23698,
471131,
7069,
3495,
161070,
21866,
115839,
null,
139816,
63075,
26485,
515171,
13904,
null,
185162,
35450,
46121,
42350,
null,
16940,
181669,
255318,
48617,
79097,
30108,
9175,
null,
285944,
193446,
null,
79529,
156742,
22628,
163319,
344156,
189494,
601355,
7571,
null,
null,
117469,
381977,
229989,
13706,
98692,
86123,
162399,
421709,
132553,
141534,
57458,
367323,
781553,
25551,
113775,
391867,
82579,
136969,
26755,
21035,
null,
38256,
348432,
44800,
33111,
514662,
15442,
404840,
263324,
49081,
27319,
114104,
140452,
14232,
167264,
18398,
212531,
16137,
35123,
363112,
223974,
159126,
630634,
113752,
40780,
27747,
null,
20480,
null,
381408,
399996,
248558,
13731,
177641,
201212,
436320,
191265,
7631,
50693,
null,
78590,
18503,
418279,
null,
48254,
117746,
276872,
16263,
null,
2736,
34418,
391030,
128525,
134581,
148797,
176202,
59553,
18672,
145383,
405248,
139158,
157330,
385839,
106269,
148807,
54916,
433911,
78218,
null,
null,
27885,
30501,
667175,
179850,
350453,
39174,
246093,
7922,
135339,
177345,
449149,
122180,
135301,
36314,
138155,
40226,
173479,
214905,
192458,
307492,
114896,
35823,
354819,
37346,
317073,
null,
74350,
null,
3709,
24928,
165522,
133909,
29913,
24518,
42065,
null,
61509,
294531,
146816,
231805,
205957,
57414,
116785,
141841,
27378,
206826,
47114,
147093,
5377,
121436,
6054,
20319,
14857,
126331,
435412,
101105,
56654,
322045,
49956,
397828,
72807,
32249,
80287,
44519,
224980,
144948,
142420,
null,
null,
71060,
100703,
12883,
98416,
43929,
null,
76762,
840845,
177241,
42149,
null,
26830,
87628,
409349,
49392,
36114,
78014,
null,
null,
482802,
null,
26578,
10934,
109599,
47423,
89444,
111441,
80450,
null,
87107,
139249,
19653,
240622,
43408,
44199,
10792,
380039,
111433,
172356,
355442,
178474,
304807,
68862,
284781,
39622,
null,
110305,
21865,
342923,
282669,
362469,
null,
8522,
278561,
54372,
63052,
4364,
null,
29087,
43791,
31885,
180658,
124475,
255922,
341446,
280056,
52451,
null,
55345,
21170,
29787,
91311,
170996,
40662,
18517,
222013,
29734,
37087,
36706,
89261,
null,
8021,
40535,
12410,
120818,
36541,
5525,
61016,
368998,
68854,
425770,
141342,
13479,
183773,
274278,
29891,
126338,
4564,
9812,
12400,
23170,
165563,
615821,
84412,
656906,
40552,
413849,
null,
137711,
48414,
null,
223117,
217506,
85091,
37850,
146667,
210222,
464234,
17179,
354810,
296138,
37816,
24735,
155566,
null,
298886,
138388,
68539,
28798,
18279,
294781,
33907,
44955,
7979,
null,
39996,
167103,
46156,
360507,
58146,
79220,
46008,
285754,
140801,
4889,
211609,
493641,
180875,
225773,
179140,
28557,
24109,
17080,
268130,
26215,
158328,
36062,
100779,
241322,
17728,
null,
15529,
34365,
278512,
773846,
117359,
38090,
467447,
98807,
334263,
32753,
313819,
61739,
40177,
null,
23444,
94506,
19136,
59269,
null,
74718,
79853,
null,
76231,
166855,
120443,
22104,
512662,
95884,
32401,
296336,
25583,
32508,
31293,
46243,
44927,
132033,
33050,
30436,
289711,
210619,
null,
34072,
null,
5763,
163325,
144532,
264306,
151507,
351842,
357236,
273288,
null,
186349,
12092,
420643,
80530,
352184,
152900,
228888,
6793,
93153,
241087,
119393,
168965,
27288,
67032,
365711,
146563,
387303,
501063,
60217,
156778,
14787,
30989,
151090,
10639,
null,
49366,
null,
15895,
121548,
210678,
19807,
16827,
481377,
82914,
203646,
174916,
7391,
165608,
null,
2556,
5547,
151825,
31953,
243736,
262319,
10702,
194579,
6688,
329058,
298782,
23143,
155753,
52779,
39930,
125452,
746460,
null,
98044,
229093,
398728,
76482,
34620,
12322,
9184,
337721,
102681,
411027,
117381,
31276,
71303,
210223,
12249,
15649,
18555,
31876,
246127,
248240,
248129,
9272,
32439,
27165,
243655,
75243,
202212,
227511,
25643,
2840,
46358,
92846,
null,
null,
13105,
6676,
89597,
191688,
266646,
371609,
113849,
44053,
346463,
8192,
633523,
37240,
120739,
null,
410564,
51784,
null,
19897,
76526,
257046,
56265,
178607,
514334,
378216,
43754,
98146,
20240,
217834,
235006,
106976,
28119,
29140,
91938,
202124,
null,
28742,
866133,
146645,
456376,
59954,
237657,
73726,
39755,
62766,
243885,
null,
14849,
375449,
233690,
283096,
242667,
227061,
414787,
51629,
31649,
15939,
19791,
101045,
241580,
335600,
28049,
476684,
326717,
59069,
255666,
339753,
95770,
34406,
null,
260852,
39396,
30183,
13481,
133782,
293885,
22193,
48753,
32300,
73221,
6449,
66401,
63859,
15566,
9869,
53448,
200035,
null,
67324,
57632,
95135,
19724,
32073,
41174,
null,
424699,
145204,
445491,
14608,
41844,
52532,
null,
85510,
157442,
130903,
46839,
35474,
125796,
199082,
203485,
21714,
30346,
57048,
65083,
207460,
10471,
32755,
13111,
6110,
1441,
306491,
330283,
212083,
30223,
14447,
69641,
null,
72048,
56432,
219200,
113201,
36964,
341668,
22100,
133412,
372327,
null,
70034,
270907,
181061,
1916,
172078,
null,
15322,
387051,
212382,
148535,
null,
117553,
16188,
236812,
60640,
33450,
302811,
65735,
4463,
121424,
75966,
21033,
119003,
19698,
27261,
12515,
19900,
52748,
31322,
291462,
108528,
59704,
9475,
183010,
68912,
58976,
100454,
2611,
542518,
null,
304510,
null,
322136,
17131,
115713,
93772,
91600,
232143,
309616,
111672,
685,
278565,
65694,
null,
15110,
48493,
360923,
197894,
346052,
115662,
26655,
10440,
376539,
316117,
118212,
41770,
null,
48951,
35946,
93743,
182550,
32857,
189009,
153411,
341376,
100891,
56025,
16377,
234099,
139998,
107858,
143211,
25054,
174507,
475669,
81185,
133888,
17782,
null,
215503,
209323,
7642,
102048,
44097,
126411,
284809,
67770,
32128,
43884,
51625,
null,
180910,
115839,
248190,
191413,
5269,
316953,
168239,
20766,
198186,
26523,
68616,
12560,
365178,
48852,
549699,
107730,
441737,
221459,
26291,
266943,
212931,
14323,
27846,
62066,
283660,
267780,
11811,
18685,
418919,
47761,
269284,
576989,
71648,
null,
43262,
null,
5939,
396048,
343914,
240727,
30059,
85407,
null,
10735,
661416,
9687,
171793,
null,
73516,
153921,
522992,
17226,
16638,
28474,
37942,
186318,
20277,
null,
2592,
31370,
130442,
169879,
171654,
17044,
22764,
223879,
101438,
608101,
null,
26861,
51105,
180173,
242342,
96934,
null,
29861,
135315,
237992,
277066,
35358,
46658,
27062,
47808,
630857,
77267,
29269,
158334,
157882,
234856,
205076,
59857,
26613,
8229,
388859,
66498,
165730,
55165,
91803,
153294,
30715,
53030,
309119,
390119,
16164,
22187,
null,
32009,
15847,
124684,
611600,
129825,
11216,
397547,
196899,
159517,
12547,
11951,
26048,
128220,
178934,
71944,
92353,
null,
11497,
405013,
308039,
22768,
197189,
238880,
87061,
236204,
7568,
23227,
173712,
91919,
71514,
6475,
null,
411103,
15067,
4518,
26940,
17185,
167500,
34922,
97354,
34635,
73313,
9988,
30181,
367775,
53428,
216879,
52809,
147895,
3472,
238143,
145811,
7191,
304691,
341299,
9035,
460186,
282572,
null,
185551,
233133,
378524,
21081,
15159,
260935,
245403,
153012,
25192,
658975,
443795,
60500,
309198,
160797,
null,
10841,
69937,
null,
46554,
34413,
241089,
414663,
131992,
109290,
117148,
94364,
97740,
141744,
null,
487934,
684136,
44632,
693499,
295489,
194798,
267692,
24749,
33273,
485988,
144596,
195348,
15690,
4477,
380136,
229975,
9907,
null,
253770,
272953,
18933,
288255,
65399,
94461,
179885,
27054,
809402,
218770,
173172,
256455,
215747,
228769,
45196,
64882,
93210,
7092,
28744,
22160,
151540,
231706,
41928,
null,
null,
25905,
256661,
403948,
19434,
2752,
26360,
79229,
4609,
29219,
30017,
7244,
253496,
210655,
1717,
158491,
247523,
17207,
284989,
24329,
91017,
158518,
103515,
519894,
352337,
455847,
15993,
315812,
25117,
17019,
207754,
248790,
194987,
null,
25153,
184323,
40127,
91075,
null,
48507,
null,
null,
47460,
38773,
37401,
11488,
107625,
291414,
29983,
486523,
90683,
32530,
72234,
253938,
40396,
43819,
330634,
50005,
null,
226954,
28881,
null,
456235,
12018,
97612,
17894,
39976,
243079,
95893,
34995,
68943,
52934,
153171,
86268,
163222,
198743,
22942,
232369,
340017,
43554,
681734,
20007,
56946,
201997,
38054,
8507,
32661,
42183,
302375,
null,
31321,
79273,
155582,
41245,
50566,
281224,
149831,
72402,
166964,
126531,
28710,
223623,
14677,
195194,
33753,
262910,
106763,
63956,
383916,
16338,
306370,
43070,
230504,
262521,
null,
6968,
337748,
53316,
17593,
304139,
151496,
253943,
439096,
38173,
15652,
77278,
null,
184659,
104583,
60058,
56732,
null,
20842,
263684,
151687,
149029,
191231,
245773,
33983,
null,
11333,
94943,
47497,
32329,
62649,
76464,
181860,
252988,
5082,
13599,
194410,
153899,
37595,
114567,
67992,
161078,
39757,
355801,
13765,
188139,
5440,
261787,
48903,
134656,
38306,
15644,
113370,
24805,
12775,
25058,
null,
381994,
50864,
41954,
503581,
39770,
16664,
171758,
19811,
null,
132325,
15838,
13694,
177572,
262411,
253076,
54069,
377837,
null,
27786,
13567,
139664,
680626,
null,
201338,
451338,
null,
254271,
208617,
5539,
129832,
19375,
55425,
null,
299666,
34394,
165167,
44278,
31990,
55393,
195256,
6303,
null,
98991,
224261,
451209,
229662,
91855,
674312,
24553,
281123,
408474,
14606,
79555,
26962,
42320,
57003,
5245,
233268,
135875,
368692,
45682,
4423,
50130,
291523,
223356,
259342,
62851,
null,
152148,
null,
253363,
229113,
45633,
18227,
103608,
40860,
41159,
210393,
26023,
null,
457612,
43148,
158779,
390403,
42702,
367585,
80735,
181764,
324157,
72932,
184937,
274372,
null,
217381,
17502,
474033,
101690,
18147,
23396,
34891,
289427,
103801,
30363,
21423,
503727,
19659,
52210,
22966,
242761,
25419,
255470,
27934,
10364,
4670,
29902,
27560,
284265,
279053,
183318,
46566,
34379,
40154,
38024,
13802,
276929,
18177,
16523,
32684,
433273,
369432,
292498,
566715,
3261,
279077,
97649,
310703,
146867,
62891,
214720,
33446,
134457,
59523,
261484,
null,
null,
179220,
null,
296448,
70726,
356571,
272227,
11538,
20842,
56313,
18008,
16700,
114924,
35694,
8004,
null,
117956,
null,
58195,
131302,
119164,
10772,
null,
29082,
297930,
162305,
13466,
45308,
null,
597185,
20916,
584674,
10128,
59992,
56803,
13494,
519654,
289674,
20031,
336577,
134099,
6860,
205987,
130277,
132006,
128555,
41365,
396724,
null,
9569,
null,
187199,
61732,
263503,
73049,
141070,
46840,
146737,
72525,
16582,
89694,
305388,
161649,
6235,
232850,
null,
158525,
37536,
null,
13912,
190821,
262433,
201633,
47745,
113825,
372151,
213918,
61847,
282220,
407879,
156988,
84090,
10825,
18716,
null,
222817,
26598,
383180,
179022,
285698,
42714,
40950,
48069,
48130,
47684,
null,
91489,
null,
262026,
211122,
65759,
40050,
null,
101215,
40261,
127163,
20073,
181811,
32375,
278107,
80589,
44987,
126071,
215834,
11712,
208166,
31351,
81542,
38085,
44352,
null,
29542,
32141,
52394,
209961,
128649,
196824,
65270,
461708,
209860,
500499,
114425,
282724,
387537,
258002,
9564,
37952,
335328,
178147,
33250,
26624,
454097,
47764,
31833,
32979,
35813,
18595,
8563,
null,
5433,
49665,
44865,
83001,
117922,
176239,
364535,
214672,
85480,
99327,
266224,
309281,
7481,
69887,
45364,
292298,
118370,
331687,
29441,
263211,
222162,
229808,
147622,
184226,
54039,
27806,
231253,
40442,
68009,
258310,
295996,
42433,
29098,
159236,
339605,
304727,
23035,
206871,
2150,
40561,
null,
469179,
314375,
28820,
21083,
273992,
176426,
5226,
304342,
34545,
16935,
82594,
36300,
42414,
760364,
43935,
149196,
302405,
6349,
60605,
56979,
null,
260320,
17658,
27850,
80142,
8100,
252277,
25019,
null,
107845,
26307,
127753,
20091,
266992,
275431,
1755,
222646,
173788,
232666,
247627,
197760,
null,
610775,
70222,
30296,
118318,
10099,
12257,
20335,
151063,
649928,
323982,
64073,
303308,
34772,
116180,
187392,
117735,
189834,
463955,
170326,
66212,
231471,
18058,
113395,
92736,
137663,
11956,
216861,
null,
64927,
412748,
20116,
332664,
370693,
85047,
19775,
19067,
297874,
22190,
263807,
37763,
46777,
23293,
235968,
98963,
8262,
170615,
775105,
180911,
45170,
162283,
87587,
192805,
112779,
246160,
null,
9421,
31315,
139443,
199883,
17669,
49422,
32502,
59359,
26978,
302690,
18235,
267446,
25542,
40830,
53821,
361886,
236155,
231529,
19788,
173580,
3841,
19314,
215712,
84223,
21934,
7062,
330529,
261370,
87788,
32446,
1584,
25997,
114926,
19156,
81323,
62121,
420843,
92294,
134934,
49171,
37214,
270135,
78936,
294070,
103692,
38029,
329445,
35578,
415002,
125954,
190763,
54338,
213946,
81179,
355834,
56459,
212062,
4537,
600969,
32301,
207207,
25640,
121665,
null,
25915,
20348,
102629,
45685,
20464,
null,
197792,
78188,
null,
5732,
321575,
27727,
101687,
44400,
177906,
37400,
133975,
24033,
124108,
135216,
25049,
32101,
166105,
228596,
70131,
null,
375436,
319697,
24387,
85877,
33983,
null,
724048,
62473,
95386,
33329,
221799,
166836,
20354,
42945,
13771,
37687,
44055,
21153,
3315,
201717,
148117,
null,
12985,
312315,
null,
47310,
140268,
286821,
null,
123768,
155696,
22870,
27061,
56492,
214387,
58416,
33043,
380205,
140889,
408128,
24924,
22441,
591480,
353550,
135142,
206688,
36554,
147445,
13958,
9923,
29693,
24395,
3633,
57366,
null,
140317,
30565,
416051,
56215,
416766,
41900,
93013,
241218,
334508,
173913,
206335,
72583,
17311,
300436,
43279,
25740,
91819,
136262,
58906,
42100,
null,
191830,
452589,
234678,
207793,
23867,
157051,
24545,
32549,
197183,
178545,
7820,
196017,
33981,
255711,
null,
131525,
27523,
195482,
123984,
138099,
44523,
null,
15,
68554,
46850,
280030,
161969,
24379,
null,
17355,
17287,
234067,
27245,
33568,
419181,
130215,
187179,
251283,
33637,
83646,
15239,
291072,
176400,
30542,
564700,
129806,
68730,
116313,
null,
15023,
31207,
120040,
54936,
138637,
29352,
76051,
192164,
164413,
136923,
73659,
53730,
null,
42697,
41748,
null,
360803,
154802,
578859,
235890,
9847,
null,
351650,
null,
161376,
6527,
196000,
61640,
157914,
12184,
315190,
37941,
175059,
78593,
63665,
64897,
270997,
10646,
23819,
91604,
83447,
17428,
344473,
43699,
183435,
45081,
137405,
76736,
239152,
153788,
318051,
428027,
null,
22566,
209715,
129406,
20353,
353306,
126928,
28527,
null,
274030,
178880,
13782,
7444,
83408,
237262,
18813,
36852,
28588,
59661,
420312,
71209,
365082,
116388,
56014,
32917,
30652,
24335,
9694,
219319,
123193,
19227,
null,
149965,
126659,
44877,
42535,
371372,
1242125,
805545,
178934,
244363,
28692,
337362,
302415,
null,
5584,
35389,
81956,
96067,
null,
272543,
164900,
375714,
27710,
209097,
328822,
45010,
39677,
56454,
662084,
null,
112620,
246182,
214795,
51528,
103865,
225151,
387926,
79819,
354631,
212966,
169668,
null,
180975,
163453,
61865,
221783,
93968,
319956,
147626,
102816,
32727,
69249,
623772,
35352,
223215,
137627,
null,
36369,
5015,
137805,
null,
36938,
594334,
13773,
105326,
123362,
61719,
null,
393810,
86651,
null,
23234,
32011,
18098,
30614,
270246,
195098,
11558,
307449,
169004,
47344,
154516,
150202,
null,
185586,
378786,
161661,
null,
68078,
3763,
15635,
18124,
150973,
299556,
46386,
260143,
25102,
146241,
16462,
55250,
29202,
21458,
84188,
null,
52144,
209617,
6504,
586379,
116753,
100537,
31187,
null,
174898,
328588,
87547,
48979,
10782,
66920,
77194,
382067,
471977,
38247,
94879,
17537,
217445,
48384,
328843,
379059,
148325,
42739,
26618,
247338,
22670,
471336,
null,
38302,
89119,
43523,
25524,
348124,
457196,
67975,
10686,
132805,
195490,
4775,
474667,
17151,
182981,
297978,
37404,
342996,
36755,
184999,
null,
209595,
259597,
257698,
152584,
333454,
356907,
22765,
84284,
99444,
6441,
28807,
431903,
149505,
41224,
8692,
178687,
79019,
175624,
null,
15891,
5764,
169259,
43951,
61804,
19963,
14367,
18427,
239791,
241015,
77205,
271376,
195041,
391209,
75962,
null,
114150,
31685,
484751,
11666,
317090,
365631,
210000,
18567,
174527,
120469,
42641,
229030,
250147,
29571,
362554,
468767,
290957,
37703,
179085,
null,
195185,
147989,
35060,
286649,
null,
8924,
170622,
322634,
30113,
65077,
129183,
272280,
103973,
17960,
289069,
115110,
101225,
128662,
277197,
31533,
99771,
null,
203921,
187799,
null,
185656,
409971,
115891,
23129,
128859,
75126,
12822,
186854,
329844,
40186,
476477,
16762,
72742,
12275,
null,
572941,
8116,
45865,
214280,
210995,
47281,
36284,
9185,
187646,
1318,
171558,
171927,
null,
194071,
15021,
6875,
306304,
33318,
13928,
509,
23846,
19977,
23611,
16082,
28566,
185594,
41319,
365885,
217179,
41464,
27292,
30581,
307342,
27100,
241606,
67454,
38350,
197227,
24440,
116324,
189147,
null,
308211,
25213,
185814,
378700,
11627,
20025,
687293,
74963,
3087,
213841,
530898,
118645,
167260,
243831,
305146,
14834,
23784,
167281,
218446,
52314,
34024,
16973,
39155,
7069,
53978,
214727,
63979,
213499,
158891,
83062,
19770,
13097,
3862,
293082,
22023,
94777,
74778,
7878,
31330,
56649,
159433,
67577,
202891,
146503,
18134,
22703,
517824,
33608,
150932,
34383,
364868,
57730,
23714,
206492,
14861,
117538,
2914,
30285,
285941,
112652,
311405,
17403,
325953,
2935,
24015,
49379,
157901,
179401,
null,
442621,
25273,
12221,
15172,
226467,
225474,
null,
236549,
12269,
131151,
31697,
22158,
null,
20116,
46635,
118640,
198994,
14089,
73215,
21853,
167986,
83224,
29741,
null,
56970,
26285,
38176,
45473,
46163,
null,
17725,
320746,
254038,
98537,
214388,
281349,
66441,
16473,
105756,
67680,
477838,
7370,
106973,
103277,
281844,
237408,
102151,
271990,
143479,
396186,
55092,
226831,
281083,
364943,
30267,
16072,
44178,
9624,
61326,
190195,
125983,
72062,
301109,
183991,
5741,
456545,
12747,
13647,
15743,
360883,
null,
280259,
64900,
48769,
328981,
1154,
420289,
268134,
58977,
64347,
18566,
65449,
105416,
41108,
39897,
42351,
25755,
323840,
28896,
44037,
90061,
68465,
242704,
370289,
15257,
74137,
24053,
57452,
110540,
15627,
29232,
76709,
42592,
387743,
null,
137652,
282981,
null,
420015,
16812,
526484,
20805,
119891,
30146,
2755,
7444,
6961,
301262,
95827,
60731,
399472,
56651,
25608,
482157,
203663,
null,
216567,
445612,
121268,
11109,
63366,
101804,
44410,
517803,
110518,
231050,
16171,
45132,
239551,
36517,
250875,
107503,
42192,
1086281,
165928,
211372,
167604,
25248,
430790,
null,
55845,
88122,
71886,
89863,
250637,
481258,
290287,
5259,
324754,
556945,
116523,
227956,
29884,
169084,
8936,
425128,
21780,
51380,
16605,
84497,
195389,
null,
24087,
47402,
8833,
14584,
379017,
15742,
337053,
null,
331284,
217824,
40391,
192018,
250089,
181449,
38325,
30024,
15398,
7312,
157008,
55208,
56142,
199725,
46198,
100232,
18855,
null,
690580,
52056,
30227,
23420,
45193,
144696,
31670,
398859,
25158,
11497,
193907,
115220,
362278,
17317,
286737,
211080,
496783,
43054,
201744,
284776,
46863,
286249,
290972,
65391,
246793,
49782,
327402,
37815,
252382,
33557,
94577,
698358,
46770,
108057,
58644,
25705,
28856,
178697,
140757,
129712,
57728,
95698,
65449,
757807,
115682,
178717,
null,
261124,
74395,
57519,
376527,
479304,
335398,
107813,
188339,
775958,
null,
38844,
23209,
185302,
69359,
177638,
323035,
37912,
338942,
474694,
27945,
51214,
67584,
1819,
33636,
394991,
54930,
45068,
10816,
15038,
null,
74277,
39475,
91864,
52467,
30153,
374709,
159504,
119349,
null,
null,
95387,
195531,
18008,
422759,
71790,
403606,
118665,
41888,
323527,
null,
44925,
30041,
313542,
31911,
6228,
149596,
null,
12223,
14353,
332571,
120064,
129903,
null,
368669,
193779,
21736,
37566,
31274,
11248,
30598,
60078,
201717,
141868,
160583,
14381,
125728,
null,
25849,
242119,
344871,
127154,
29282,
149719,
25841,
24624,
479302,
75723,
42276,
20944,
53158,
341817,
39552,
81587,
null,
35371,
196345,
268106,
74342,
393099,
87960,
40243,
272260,
121785,
542931,
87444,
133401,
69552,
69004,
286408,
20962,
31636,
282934,
77177,
439838,
33942,
63732,
50090,
30159,
11072,
40740,
285531,
240565,
302724,
18096,
192647,
6979,
30096,
8917,
69998,
96781,
null,
206830,
360020,
14465,
11751,
109199,
108141,
154762,
235086,
374411,
104053,
14543,
39469,
230269,
17181,
87709,
null,
38572,
388973,
54768,
18804,
35765,
23499,
44765,
6450,
null,
29745,
907,
74086,
25441,
42225,
24008,
151548,
57270,
4861,
89128,
100930,
273728,
94155,
281459,
405326,
95451,
88770,
58323,
13543,
6641,
28977,
143098,
403988,
276380,
630678,
134521,
18185,
200669,
89462,
9561,
197328,
55290,
12894,
15476,
18319,
280269,
435032,
12435,
57579,
91189,
null,
37358,
222158,
105486,
216628,
127627,
85302,
253262,
45439,
66079,
50052,
278631,
112335,
280245,
7076,
41663,
152558,
54870,
23257,
28381,
12236,
13560,
148260,
27712,
275328,
28463,
85809,
91445,
null,
14410,
41219,
40195,
221402,
40615,
35497,
132931,
358449,
51023,
null,
345844,
546935,
14765,
369365,
8800,
99587,
26141,
null,
129429,
4775,
33013,
6248,
178122,
19131,
196467,
127777,
470183,
183494,
89600,
828515,
241106,
296596,
13361,
125252,
null,
null,
634674,
210761,
39315,
126383,
164839,
212921,
44462,
387409,
null,
35132,
323859,
93542,
532476,
null,
36518,
213058,
607820,
107671,
183722,
111409,
20251,
142022,
null,
14326,
2128,
null,
24067,
179551,
103838,
null,
33832,
204203,
53535,
91818,
5868,
415211,
194145,
16777,
31770,
12897,
126681,
22165,
65296,
null,
2635,
252071,
25813,
19408,
49065,
37890,
67046,
337602,
34301,
217931,
167516,
526272,
268716,
5207,
358186,
90047,
62999,
null,
37151,
229013,
238048,
130456,
null,
202133,
8097,
38233,
277388,
101010,
449550,
175375,
613134,
22614,
125047,
118040,
null,
102448,
8241,
167684,
37919,
180246,
40212,
56469,
35627,
43765,
259060,
null,
44599,
null,
138764,
152124,
64116,
57985,
38360,
305198,
194352,
17706,
40696,
57383,
171358,
21824,
215226,
12278,
null,
null,
184783,
28362,
115113,
null,
11992,
42405,
310440,
619814,
18814,
373438,
254373,
181027,
5620,
null,
45864,
376975,
171260,
187679,
null,
22038,
464256,
15480,
null,
185726,
322378,
null,
160354,
226387,
81824,
33685,
25584,
133985,
46279,
104491,
24809,
205636,
389675,
null,
19121,
43209,
24602,
42086,
146460,
69440,
524723,
177133,
58489,
367997,
70795,
250735,
21118,
30679,
2285,
38532,
39691,
24673,
25354,
null,
4253,
38540,
43543,
311952,
126304,
36562,
14259,
218213,
156868,
338609,
296496,
269928,
212182,
170199,
37239,
182738,
163646,
452336,
37576,
36617,
42698,
12318,
11648,
null,
395862,
44414,
291261,
4572,
152885,
16865,
139530,
64220,
826111,
47365,
161842,
33009,
96496,
15429,
26264,
20050,
11176,
123391,
52325,
25182,
4710,
17249,
202129,
218088,
10853,
35857,
37920,
83069,
48117,
128370,
27991,
71209,
256799,
null,
295845,
354599,
143311,
18008,
69527,
null,
33186,
71567,
236303,
165906,
15952,
92049,
449,
72852,
218008,
35827,
69153,
58314,
200638,
75934,
16315,
null,
null,
14995,
282246,
12945,
75136,
29866,
269006,
51942,
49946,
134445,
209922,
9924,
null,
359551,
251195,
199426,
526344,
null,
29107,
27162,
null,
21993,
538269,
10148,
211008,
105910,
35084,
79119,
33871,
184736,
90951,
47946,
91196,
7856,
58686,
348923,
19564,
19248,
39264,
224069,
77511,
null,
343859,
16568,
78555,
162706,
39625,
null,
103172,
13495,
11812,
null,
259891,
null,
40268,
22013,
149545,
224669,
69194,
330227,
21890,
9216,
37342,
268214,
618366,
290579,
503557,
63770,
175227,
307789,
172467,
84713,
43714,
2136,
178671,
9870,
128785,
479339,
326896,
358745,
71600,
141740,
33890,
36343,
126657,
13012,
193479,
22174,
26394,
30511,
7622,
44200,
null,
121670,
38039,
169463,
167110,
null,
245218,
68981,
178849,
215980,
158018,
233555,
25625,
277082,
45722,
260538,
36337,
34130,
98256,
192842,
null,
212450,
118719,
46878,
3082,
176332,
194464,
46289,
null,
121120,
32472,
251523,
24256,
135628,
null,
315793,
18536,
null,
12328,
334576,
10011,
381217,
141643,
null,
680491,
294269,
218223,
30202,
217550,
8402,
12573,
401124,
102895,
23568,
12609,
73775,
32111,
379826,
null,
null,
126702,
80538,
369049,
64692,
39971,
326858,
72031,
379997,
152816,
128148,
26624,
7276,
444558,
344499,
45744,
21688,
46637,
45539,
35149,
18925,
44758,
85735,
26591,
357382,
13094,
178721,
195977,
27080,
393540,
229745,
403673,
213890,
340533,
null,
45917,
13406,
74203,
197991,
null,
387248,
null,
330678,
12311,
218507,
19388,
159477,
14425,
null,
39429,
174516,
260232,
70696,
70005,
36676,
381818,
397532,
37670,
null,
137028,
162971,
275445,
417028,
33649,
18164,
38763,
72916,
36966,
5174,
122816,
42762,
157023,
16740,
20556,
21233,
22405,
231503,
72910,
61246,
62992,
6274,
40876,
null,
393265,
362066,
39406,
null,
110776,
115983,
47647,
111296,
23656,
434462,
null,
24073,
null,
478253,
325051,
25260,
9432,
null,
32379,
18366,
94991,
46010,
167623,
39049,
93357,
277587,
70018,
229646,
223071,
309792,
17225,
33250,
43777,
402706,
286123,
77714,
49948,
293848,
11580,
548417,
null,
null,
119088,
15698,
null,
52098,
null,
668719,
23380,
79711,
117418,
47643,
274613,
72839,
41732,
30456,
24390,
211562,
60473,
106278,
22154,
109798,
379991,
9694,
55749,
7793,
18035,
132849,
519037,
142605,
45424,
62786,
254115,
7688,
218169,
198499,
160756,
496526,
null,
11055,
48132,
159567,
207407,
412209,
91710,
235544,
null,
453810,
163770,
54844,
161458,
85814,
118593,
159342,
58096,
257747,
297317,
null,
null,
261854,
583922,
178017,
14490,
101178,
22534,
223672,
324969,
211032,
33133,
604554,
39246,
35426,
7573,
262064,
13906,
219311,
72032,
26114,
283894,
311136,
294691,
376295,
33617,
53519,
82157,
63930,
199339,
19471,
33148,
33345,
16048,
50846,
201816,
null,
127753,
4337,
33343,
21145,
185834,
null,
213548,
230043,
null,
76230,
99366,
4190,
225724,
46595,
185697,
120162,
58289,
207250,
28353,
22902,
76756,
27895,
6289,
33240,
139254,
15798,
551581,
59437,
158718,
15734,
51667,
104398,
165564,
null,
83747,
4448,
null,
36869,
8029,
null,
null,
101254,
59640,
8672,
269686,
173944,
30945,
19466,
78949,
347747,
null,
296541,
28041,
33848,
40221,
68553,
6404,
13378,
58392,
8736,
null,
85901,
239199,
26270,
105873,
63989,
27920,
null,
43872,
78178,
83684,
113715,
6941,
254551,
6807,
16136,
7678,
21120,
null,
419918,
258618,
84664,
93900,
35986,
40951,
34247,
33499,
12057,
11350,
113417,
252272,
20567,
64074,
126567,
19723,
33087,
367627,
228960,
43424,
null,
7648,
33511,
105534,
56369,
167701,
29427,
16394,
86200,
92652,
null,
13739,
null,
243690,
7910,
47717,
311523,
80408,
25753,
36512,
39221,
101453,
169658,
35126,
42960,
76267,
39208,
245900,
118353,
58050,
212007,
117943,
49392,
328345,
62334,
211891,
34990,
17096,
454142,
66107,
89577,
42695,
101943,
118808,
391888,
81532,
200203,
120220,
195511,
null,
23478,
null,
198986,
27177,
339439,
null,
252019,
16189,
86753,
17474,
85712,
123108,
437948,
41603,
7280,
679390,
46174,
22735,
28890,
454248,
62450,
277092,
45902,
130123,
30962,
84238,
56431,
108555,
42939,
128775,
319165,
394631,
125320,
34908,
361899,
136401,
36560,
26169,
29193,
512580,
400640,
46717,
146202,
12220,
9991,
247188,
135652,
226374,
95711,
199035,
7304,
52836,
127056,
193358,
30753,
15122,
162438,
12007,
51353,
278991,
136608,
null,
530361,
2644,
4596,
84229,
140185,
10019,
null,
134696,
170969,
710392,
33705,
288264,
597573,
126996,
23077,
51668,
66576,
87871,
422948,
59754,
504748,
168866,
12413,
427503,
4610,
277014,
218301,
140732,
29075,
17660,
34800,
18985,
1716,
16956,
199733,
45909,
null,
22525,
144242,
71949,
497960,
84806,
142610,
135883,
10662,
12884,
null,
211413,
216680,
44847,
31172,
10892,
88868,
31844,
49074,
57800,
14364,
248350,
69140,
95042,
339472,
43697,
410022,
247575,
203800,
27595,
null,
24019,
35702,
70935,
59318,
18424,
111390,
141778,
19402,
63535,
37599,
243833,
253616,
193051,
71436,
12785,
67707,
44502,
29661,
178319,
null,
1843,
6190,
579225,
23639,
167997,
56862,
null,
102481,
9137,
28141,
59684,
169306,
229131,
95300,
512837,
41805,
20174,
31129,
175050,
165664,
48286,
386295,
null,
204872,
17445,
362916,
643024,
null,
null,
319609,
41817,
36432,
7970,
196864,
null,
10139,
41241,
null,
45981,
54101,
463694,
97683,
1036269,
55740,
166012,
116578,
712861,
null,
null,
222651,
12616,
259252,
323926,
42881,
415320,
2600,
4297,
25490,
231346,
12696,
254313,
107558,
188791,
15371,
13677,
485471,
266133,
189398,
61471,
290567,
73806,
26986,
49950,
55560,
226919,
null,
70683,
171539,
null,
4357,
72609,
150231,
1226768,
31279,
175688,
18374,
215073,
105595,
13102,
null,
26762,
300955,
302977,
null,
null,
51033,
194827,
238227,
107277,
38240,
320093,
45462,
73223,
null,
null,
12213,
174498,
39124,
351236,
77701,
227328,
421562,
502796,
13571,
null,
267454,
9045,
118693,
41000,
436808,
21766,
38259,
44841,
69059,
319155,
293864,
52864,
489795,
337710,
9847,
388358,
169662,
89428,
13471,
134135,
1745,
29470,
10950,
39575,
18704,
34102,
340403,
107902,
25829,
131965,
8720,
298660,
259751,
28250,
178657,
142977,
125527,
40189,
44555,
48610,
219829,
null,
140335,
290965,
111930,
35622,
62977,
3976,
93637,
264452,
53665,
23003,
null,
142169,
154983,
150303,
22110,
null,
52667,
33235,
null,
7844,
37097,
77422,
119722,
822589,
21245,
265265,
500796,
null,
6852,
73088,
31224,
164854,
399997,
13491,
55194,
41302,
695581,
208306,
18755,
220367,
11424,
205422,
null,
692275,
null,
31615,
212286,
327380,
18826,
187088,
44912,
24121,
94717,
31589,
529460,
15799,
23181,
145589,
368773,
20430,
43975,
52951,
267530,
388385,
84276,
24111,
68751,
164522,
598148,
467141,
230588,
147244,
169895,
72625,
533255,
27482,
29681,
40199,
259276,
242277,
13254,
18998,
274393,
60301,
null,
125270,
7837,
71294,
205005,
17693,
130793,
171998,
29481,
51497,
283330,
347836,
2145,
349331,
73127,
11097,
24880,
14030,
18360,
109938,
12537,
16473,
381704,
31615,
null,
236160,
128860,
46541,
46845,
null,
304749,
4841,
39752,
323803,
8042,
582279,
44904,
73871,
19511,
22016,
228646,
117610,
77819,
106591,
149903,
21850,
66885,
234618,
37380,
315395,
null,
25216,
214588,
15399,
48425,
328819,
127791,
176266,
null,
193333,
279847,
17543,
15341,
null,
12780,
133022,
139805,
238867,
33325,
11759,
210395,
50422,
79367,
31973,
182292,
null,
3583,
424680,
101563,
8546,
17610,
325939,
41026,
135579,
252344,
null,
25950,
33480,
408968,
14535,
7601,
67034,
112745,
38867,
7562,
886141,
14699,
48461,
342414,
72026,
null,
8844,
26323,
19035,
290775,
835,
39392,
176765,
78220,
17725,
430809,
250365,
699675,
31435,
140199,
331551,
55469,
null,
39474,
204067,
14224,
65506,
18628,
59365,
166116,
43821,
67058,
342719,
10993,
142218,
543168,
null,
69151,
269194,
165047,
27007,
null,
154317,
33919,
280608,
6989,
44117,
447067,
158984,
35975,
42538,
18083,
null,
81222,
null,
62715,
4998,
248165,
14854,
null,
74330,
421480,
33995,
424864,
null,
19707,
12921,
142010,
37263,
null,
44001,
null,
210717,
89534,
282645,
332258,
9193,
183217,
138373,
293317,
283361,
16930,
41430,
54201,
37880,
58693,
349005,
null,
65481,
2488,
127178,
124748,
443237,
60737,
26652,
301728,
29326,
845049,
22598,
33952,
49936,
322678,
523355,
182836,
64582,
320309,
10105,
308492,
265431,
null,
37236,
19392,
89926,
56077,
151752,
289149,
50855,
263761,
null,
99728,
168287,
45232,
null,
204495,
212945,
170556,
null,
299132,
160099,
21452,
null,
17379,
114233,
68444,
14594,
255689,
351293,
15193,
null,
59894,
46574,
311228,
null,
231858,
159692,
37557,
174465,
156586,
302426,
337930,
613808,
null,
8063,
952528,
265271,
25703,
16053,
170341,
272450,
73397,
46230,
1184,
292310,
175138,
219541,
11965,
177379,
9478,
55217,
41674,
36351,
5040,
42615,
6294,
132540,
52462,
16296,
112186,
301664,
198784,
null,
236575,
20181,
32922,
42404,
18417,
2750,
215439,
5899,
23357,
15455,
69457,
null,
195240,
3955,
268621,
443921,
null,
125355,
55998,
213451,
52280,
22205,
57761,
4185,
47318,
6436,
null,
null,
97144,
22881,
null,
355410,
14616,
133907,
234091,
86162,
417432,
71831,
6033,
372531,
37925,
11849,
487215,
61646,
388941,
73948,
90647,
9944,
34266,
2047,
9136,
188803,
9879,
109528,
97103,
298484,
180954,
368474,
112849,
239765,
45192,
37063,
328845,
103364,
347488,
13585,
326729,
4120,
679198,
359272,
356493,
null,
118973,
93080,
null,
7402,
86578,
220752,
44783,
167572,
138319,
94253,
401211,
10777,
282032,
29043,
null,
14606,
10436,
194351,
177595,
167062,
294812,
320590,
136941,
191477,
32297,
122137,
86593,
22103,
39284,
null,
247563,
315388,
121217,
null,
null,
20004,
null,
5497,
174585,
29688,
30113,
418538,
201698,
84130,
33521,
409612,
187468,
null,
51728,
225687,
330396,
167168,
37200,
null,
46140,
56551,
81890,
85799,
22177,
28865,
105073,
95363,
168230,
45754,
71412,
72478,
72764,
700880,
708222,
12692,
150675,
37009,
96630,
233617,
291500,
34611,
28189,
471938,
439005,
247309,
155187,
24246,
308091,
41633,
285468,
80847,
37974,
217462,
234824,
48346,
22604,
null,
41774,
149902,
242551,
154104,
411121,
59985,
57765,
10273,
16550,
473737,
113481,
366396,
220270,
155952,
29393,
346387,
9508,
29794,
287657,
242462,
170876,
103945,
null,
8543,
13973,
229666,
473579,
80039,
13604,
277749,
null,
47975,
27391,
230103,
19580,
60821,
112345,
26824,
null,
129216,
295391,
168789,
37572,
48730,
314620,
165186,
171813,
65005,
null,
325746,
69200,
299928,
20587,
4352,
54834,
470445,
424447,
359134,
19493,
180205,
2772,
13822,
165822,
null,
52665,
348442,
542044,
null,
111137,
null,
504836,
128221,
25466,
263636,
744007,
159279,
194768,
57329,
18968,
113684,
374235,
44969,
231876,
42427,
228542,
40430,
44993,
35398,
30305,
111101,
195352,
29834,
185126,
372123,
247734,
16319,
174222,
66898,
119786,
61194,
222788,
9277,
574277,
26490,
17382,
17709,
56996,
81572,
48776,
47809,
368302,
28361,
521432,
35096,
202224,
157308,
264201,
401190,
259270,
190399,
55088,
277023,
91675,
null,
32010,
176086,
132582,
118251,
386060,
14992,
24447,
240229,
134655,
6815,
104702,
34852,
116765,
32013,
151536,
28804,
369433,
182967,
48285,
null,
32379,
9816,
11034,
501293,
124564,
null,
null,
null,
312577,
41460,
20311,
158524,
null,
11559,
131306,
165663,
74692,
246583,
11107,
228128,
389004,
58085,
null,
48478,
141027,
308364,
235978,
165809,
75589,
15105,
80909,
81485,
46576,
207399,
21646,
437188,
19470,
null,
23218,
433021,
75262,
303761,
202362,
167784,
32652,
160963,
293619,
316951,
190407,
1568668,
91521,
3639,
2544,
null,
343756,
26855,
356651,
165419,
26860,
164387,
158729,
null,
48459,
203837,
35825,
29366,
62793,
36600,
null,
15797,
204176,
null,
124813,
44306,
358013,
33603,
367320,
26080,
39371,
165468,
24409,
350101,
333294,
null,
23000,
147480,
null,
345,
189554,
69087,
31583,
55799,
70232,
43447,
256347,
130944,
204849,
46690,
12392,
472835,
12847,
205037,
372627,
102516,
198493,
34246,
40047,
72148,
205505,
5175,
106122,
37001,
21921,
28607,
76575,
33356,
186388,
68248,
295643,
55164,
61375,
145738,
null,
238790,
280837,
117758,
20399,
189902,
395094,
285052,
13721,
811664,
162122,
11236,
133088,
231475,
231721,
23063,
114743,
21506,
29294,
18056,
272157,
357750,
129824,
27049,
32850,
427870,
17157,
21226,
6133,
38543,
22080,
28314,
358838,
194684,
283324,
67517,
170608,
37592,
null,
240566,
41377,
176849,
18693,
612831,
164631,
135506,
18943,
137650,
8827,
91637,
24028,
172871,
65974,
null,
162871,
262198,
78430,
337396,
32839,
10162,
null,
113898,
22864,
79445,
13710,
28167,
15863,
null,
164744,
25895,
47707,
45455,
214987,
21682,
200236,
279563,
23294,
11101,
28335,
609117,
403252,
19751,
null,
488263,
380931,
162355,
433943,
31489,
141865,
null,
32706,
232121,
98471,
142804,
137124,
163460,
null,
124026,
21469,
426130,
16073,
25555,
340966,
433958,
29942,
18727,
57902,
28634,
114896,
14270,
19813,
524857,
169043,
34028,
182526,
59971,
165224,
420003,
16217,
57914,
53680,
null,
2078,
46448,
190169,
24292,
353954,
null,
null,
26932,
155760,
20713,
16270,
137528,
52542,
6764,
17513,
145810,
18380,
278121,
132422,
327491,
79503,
39294,
144094,
66186,
null,
31410,
387805,
89571,
39941,
59826,
78123,
20362,
187197,
null,
33471,
63891,
1129,
3869,
241863,
37691,
404457,
99108,
12333,
65971,
397499,
15869,
27183,
202578,
151578,
217698,
33687,
126536,
89421,
117078,
51622,
76705,
null,
147231,
18337,
32344,
240683,
283020,
124946,
29178,
44157,
70662,
299451,
71849,
311351,
146652,
271144,
167359,
306496,
24654,
181590,
94256,
13237,
13115,
321536,
43648,
26536,
238426,
192214,
67599,
552793,
272677,
185434,
415936,
67677,
911561,
28035,
395175,
null,
459784,
52385,
null,
63564,
23489,
null,
13935,
45728,
434472,
33962,
141203,
303021,
31959,
55481,
29523,
24441,
368814,
116581,
61983,
145488,
3176,
279168,
168096,
315737,
46196,
136602,
89493,
181435,
35196,
null,
174968,
12083,
266018,
null,
313976,
36490,
null,
264132,
156884,
87053,
58046,
null,
39159,
26485,
399147,
32373,
432313,
187246,
16531,
52609,
659270,
782206,
13547,
7513,
69086,
null,
291028,
11646,
88459,
262072,
168990,
47699,
242591,
280561,
null,
9487,
117020,
191213,
442289,
299005,
44164,
356363,
205858,
117912,
105416,
89370,
null,
161310,
258715,
121337,
27735,
85254,
64978,
20917,
27959,
7831,
5247,
268532,
217337,
124186,
17253,
296091,
173339,
292041,
11457,
482789,
275351,
283812,
null,
271165,
269301,
215503,
null,
1580,
509021,
294692,
463027,
11438,
null,
31638,
286540,
12069,
274432,
43053,
492584,
81799,
115026,
39474,
18525,
334547,
28375,
37634,
429076,
null,
32516,
154091,
300637,
131014,
24629,
115826,
297135,
375203,
26755,
482632,
null,
422556,
null,
336125,
8183,
193503,
84391,
257216,
290632,
185759,
8262,
6309,
49679,
7025,
54932,
80194,
172953,
471211,
40824,
40482,
null,
265088,
118549,
null,
33518,
38695,
406634,
30345,
null,
24323,
221060,
220679,
475048,
137826,
57343,
141423,
228456,
27565,
21614,
null,
43036,
18079,
null,
53085,
45959,
216918,
299417,
13552,
81059,
59388,
151240,
467630,
17037,
11814,
24512,
null,
235082,
51636,
26882,
8945,
42251,
49838,
245877,
52037,
60075,
8844,
342882,
63711,
64644,
61758,
null,
27981,
43893,
94521,
29561,
53675,
15493,
75193,
18315,
172830,
19926,
43617,
28859,
25218,
23752,
102900,
183641,
123465,
142636,
151407,
107160,
174717,
35345,
150922,
110810,
287026,
50612,
11262,
31124,
123817,
21507,
431099,
null,
185820,
20350,
63130,
15418,
7454,
31966,
57659,
52438,
44958,
143493,
434238,
5626,
59038,
563050,
147247,
14270,
30704,
240502,
2708,
39503,
27799,
39175,
122973,
318562,
67047,
374826,
24355,
588744,
191557,
56999,
167563,
5266,
208061,
154809,
10879,
342728,
99191,
null,
99789,
237289,
112059,
299210,
161439,
4507,
372352,
14998,
87910,
null,
27865,
34788,
499350,
210124,
65166,
347225,
39065,
149660,
32038,
79481,
240019,
25790,
214921,
186714,
10951,
9859,
196722,
210468,
22942,
75493,
280717,
null,
null,
null,
23170,
50480,
73957,
3918,
98859,
75108,
149877,
null,
31134,
22363,
214329,
8962,
21488,
159846,
14365,
114684,
71638,
27020,
55859,
237180,
52852,
152369,
106657,
36475,
10692,
22583,
151103,
183747,
176138,
34851,
109179,
195929,
46639,
113268,
27748,
55223,
25276,
24421,
556098,
65241,
169752,
388737,
74255,
50455,
245861,
348938,
42084,
237730,
3061,
38034,
216691,
41149,
25438,
50053,
165696,
62919,
29345,
null,
563308,
185874,
275573,
74286,
212725,
139768,
19640,
22158,
285785,
371213,
657299,
28612,
17819,
144692,
195338,
29690,
57005,
183853,
53777,
64295,
8947,
49008,
64146,
321018,
127039,
229420,
39977,
278752,
468814,
55945,
118954,
120131,
25107,
186512,
55752,
25972,
27909,
118657,
255300,
2172,
17419,
289586,
44979,
208051,
61676,
87445,
null,
null,
309164,
15932,
71123,
449367,
121023,
67747,
55523,
51295,
882072,
308914,
115979,
98840,
39292,
88189,
175695,
57153,
25129,
101870,
39288,
15480,
404437,
113313,
24243,
289496,
757616,
400988,
325155,
52611,
43337,
569391,
28627,
234112,
48943,
42014,
38362,
18048,
94211,
36067,
61623,
220677,
220347,
414693,
379848,
30235,
153468,
328232,
71272,
null,
58039,
109670,
27073,
43948,
149205,
null,
399595,
1076751,
459261,
88752,
318690,
292598,
25402,
31156,
13885,
11391,
20282,
89149,
29434,
36039,
841214,
28048,
43270,
138668,
20904,
330187,
95404,
193372,
40169,
104907,
null,
29084,
344877,
196778,
470172,
174413,
33780,
19206,
81436,
37019,
245555,
null,
91703,
null,
8538,
20324,
254124,
44568,
17778,
20166,
215915,
10708,
189225,
76733,
14258,
100218,
76067,
null,
9417,
null,
61768,
307285,
341624,
44226,
115365,
63033,
83583,
13559,
627697,
48072,
400272,
121516,
35131,
22574,
38922,
105821,
295712,
21854,
59096,
356460,
33024,
34934,
36509,
77714,
444777,
178279,
null,
246725,
7329,
37082,
26419,
65240,
441030,
18688,
14844,
52084,
382670,
211783,
152139,
18445,
339323,
421260,
438467,
185976,
8782,
248476,
68084,
380074,
30031,
315461,
11989,
49421,
98165,
5282,
69198,
6804,
4139,
229369,
null,
12744,
356299,
null,
455065,
109386,
35625,
402406,
101367,
253353,
null,
139977,
17780,
92165,
303373,
50128,
42380,
null,
102982,
25378,
23970,
128566,
193980,
76621,
1863,
20997,
117392,
128362,
111380,
473919,
461002,
10387,
139270,
305383,
46558,
42794,
218488,
119383,
177717,
341598,
null,
423665,
44440,
14580,
222457,
134789,
null,
185749,
null,
null,
152134,
232058,
398861,
17360,
572571,
43437,
6418,
144464,
8759,
348441,
46591,
40896,
165679,
173126,
7114,
26816,
13338,
33799,
532737,
26762,
22836,
35927,
7663,
281393,
34026,
74656,
110346,
70644,
119690,
9280,
292147,
15594,
282849,
252152,
182857,
4214,
117335,
71623,
25556,
11624,
16314,
101914,
12145,
203650,
18485,
154457,
135306,
16755,
13483,
22607,
43677,
278450,
96866,
239,
19351,
34292,
36911,
19958,
518516,
49301,
15036,
170426,
61933,
78097,
492841,
158677,
260439,
166571,
10519,
64845,
87931,
168757,
27841,
385417,
101281,
295820,
28246,
35148,
450779,
212678,
46227,
5031,
9046,
209173,
12631,
11918,
40908,
132967,
39144,
33577,
207274,
null,
69036,
74117,
117264,
138427,
58602,
66635,
7756,
null,
368712,
235304,
47410,
9160,
197115,
8018,
null,
37955,
19914,
59616,
225916,
15323,
53883,
113415,
70084,
38923,
39263,
57168,
243809,
null,
75371,
215558,
91994,
7502,
31762,
34289,
34076,
125751,
116409,
88697,
null,
363127,
29332,
4020,
36151,
94241,
27703,
82796,
194819,
202395,
33284,
167859,
217436,
null,
35395,
33159,
12674,
51917,
380447,
174695,
140326,
10415,
395742,
28246,
146563,
16610,
38238,
272369,
175471,
16686,
45667,
21896,
114948,
124559,
22135,
59582,
216808,
196052,
58420,
null,
10421,
27778,
1893,
64514,
29903,
194448,
256799,
29517,
null,
9286,
134908,
390649,
26615,
222024,
119562,
19099,
49666,
418828,
424631,
141345,
283285,
46826,
111121,
null,
6644,
192477,
64727,
51677,
352008,
38322,
20522,
null,
20922,
341452,
14591,
43064,
14907,
352933,
38793,
20014,
340844,
41100,
174669,
256432,
31659,
47995,
203182,
24026,
6097,
208534,
79733,
42205,
33446,
82354,
144845,
null,
118815,
27296,
291332,
461012,
39221,
26489,
33037,
105961,
7476,
333566,
4230,
230171,
40098,
244145,
74647,
2670,
14461,
59662,
88773,
458096,
24520,
38306,
394294,
19765,
15284,
132406,
15502,
155555,
null,
409698,
26430,
310329,
15721,
20862,
43136,
89577,
30215,
495469,
32344,
25369,
43472,
null,
202062,
20951,
19830,
344285,
135317,
null,
7825,
136092,
null,
null,
null,
null,
231758,
40055,
32815,
null,
176798,
76213,
null,
10504,
10165,
25066,
132051,
47390,
39159,
215529,
196899,
61867,
27358,
590701,
332870,
null,
null,
312521,
371356,
1938,
19079,
333129,
26791,
510046,
275449,
9424,
174487,
380614,
308630,
24908,
41487,
49092,
92250,
54177,
207003,
16940,
14510,
63530,
63295,
357230,
5998,
25187,
219384,
null,
14090,
31281,
351466,
470463,
138006,
131233,
211852,
36991,
16662,
53281,
20031,
44716,
81011,
106744,
null,
30647,
null,
241730,
59618,
50456,
189723,
276709,
448612,
46509,
359600,
130685,
217221,
33811,
141494,
91188,
67555,
7399,
26065,
234035,
44199,
23418,
214823,
95991,
399672,
24719,
275317,
608364,
365915,
209765,
140918,
44136,
280655,
30561,
55064,
82128,
41154,
34581,
80065,
238215,
null,
170445,
34925,
81651,
12518,
79390,
179497,
21177,
34784,
20490,
29594,
346392,
29060,
22412,
272899,
40869,
44876,
14313,
283049,
227071,
235283,
390597,
5619,
240425,
259922,
12561,
600987,
37969,
273918,
148818,
11684,
184690,
32095,
123056,
270016,
69366,
14565,
48209,
136018,
null,
287263,
367843,
97776,
617,
4690,
37722,
198369,
120283,
191270,
502976,
197596,
26829,
200163,
null,
114949,
44079,
42336,
722659,
299248,
98840,
12094,
172100,
21749,
333103,
344238,
13606,
13368,
13221,
203988,
13296,
4252,
74376,
null,
64964,
109162,
57740,
126727,
198147,
7097,
231156,
34163,
122494,
227201,
91556,
58346,
21167,
67171,
30351,
292259,
338304,
11922,
74877,
24354,
null,
226929,
328998,
37628,
null,
194062,
144675,
34574,
29659,
19614,
181757,
null,
39120,
52757,
34857,
211548,
353913,
55766,
271572,
379455,
98904,
467849,
225740,
140402,
8083,
113868,
184045,
211238,
234522,
85762,
274805,
553627,
null,
null,
21738,
24680,
357909,
289001,
101030,
180511,
357400,
61107,
null,
19804,
35209,
121332,
null,
197004,
29958,
178632,
298972,
145704,
273542,
193349,
null,
46417,
144306,
null,
43445,
10171,
136740,
47593,
10896,
91960,
33699,
127243,
72476,
25862,
null,
120961,
156548,
27229,
109970,
296602,
312459,
207322,
33691,
83158,
31979,
325371,
null,
93374,
71876,
null,
115368,
207554,
237988,
264209,
258283,
158920,
226409,
39078,
68762,
122936,
10922,
null,
213095,
49153,
89313,
1105958,
null,
116910,
84276,
74910,
241133,
52796,
193900,
31955,
250825,
199841,
132425,
174653,
35803,
199917,
13165,
375805,
35166,
14056,
null,
53902,
80549,
35542,
null,
9317,
73152,
12155,
27426,
273430,
22034,
11086,
49571,
10161,
292893,
null,
34052,
216081,
10437,
57592,
189724,
26260,
216604,
328621,
435887,
282441,
378658,
27774,
7563,
36350,
12331,
299783,
104196,
126227,
372036,
null,
264375,
71764,
103176,
111832,
8352,
312323,
172826,
184124,
121823,
400683,
57353,
63470,
375571,
175274,
24765,
144833,
11656,
202048,
235634,
7933,
183044,
200393,
13449,
23845,
19847,
13821,
25625,
40234,
115582,
26209,
null,
139466,
null,
46404,
7928,
37967,
274344,
48352,
39482,
149918,
24627,
183890,
24289,
19341,
358976,
28601,
null,
69523,
77410,
35980,
260133,
47912,
6313,
437731,
38136,
323484,
23056,
32039,
44718,
9697,
null,
null,
55574,
59494,
19871,
83367,
162198,
17718,
80197,
18003,
88718,
180295,
275454,
451198,
213914,
13648,
221611,
96516,
566409,
473947,
123424,
6223,
219550,
289632,
42947,
40913,
15825,
29341,
243164,
177759,
73876,
7776,
24837,
31787,
33499,
131035,
187151,
57874,
244519,
76914,
94742,
null,
497242,
null,
211255,
20851,
506016,
120313,
109871,
276590,
30202,
170535,
36661,
147998,
380527,
31510,
115215,
515636,
57844,
180197,
9033,
18362,
112355,
14599,
173961,
38145,
175395,
24152,
6928,
null,
121347,
32943,
206624,
60344,
null,
185210,
10206,
272218,
148822,
17658,
444791,
null,
158213,
46500,
226918,
7585,
44471,
123742,
179480,
122629,
17446,
null,
347130,
191880,
95452,
85326,
104733,
26316,
41107,
57713,
7435,
432291,
46606,
10371,
56719,
111587,
205670,
173250,
22058,
224247,
296307,
8024,
5026,
41791,
18107,
null,
161533,
72004,
55279,
28386,
18170,
54078,
null,
43784,
133810,
178666,
160050,
null,
237379,
null,
null,
null,
162407,
8795,
183665,
201053,
148267,
228543,
7683,
291253,
22249,
247361,
136141,
38073,
44363,
306792,
118946,
348257,
54356,
46246,
603428,
425505,
41821,
13631,
217858,
285623,
253769,
135621,
23253,
16953,
44689,
514712,
30520,
35867,
79520,
1368650,
662606,
103579,
24607,
26860,
15328,
4479,
189853,
214319,
435048,
295380,
null,
12240,
12402,
null,
121437,
35047,
164766,
35506,
11848,
43119,
22049,
106511,
22351,
991025,
126565,
31837,
279274,
28865,
165226,
189970,
387590,
12165,
58580,
80871,
33359,
17887,
604388,
21346,
353799,
47729,
307034,
597555,
6861,
null,
20798,
30391,
32102,
74203,
158830,
57040,
7448,
197470,
135494,
124742,
568663,
8655,
25606,
332921,
309813,
71089,
null,
290918,
18441,
null,
50899,
9025,
36593,
55003,
400483,
8783,
216176,
187481,
39190,
201042,
85828,
186196,
34822,
455543,
31340,
144195,
116925,
54058,
266652,
null,
497312,
278931,
217274,
24334,
86174,
28821,
351271,
172693,
234958,
9220,
142180,
173234,
150121,
250494,
11267,
20176,
43835,
336704,
18997,
29311,
33057,
55628,
15793,
373773,
356557,
null,
18669,
12081,
172523,
141513,
342423,
99308,
172293,
11080,
444443,
176025,
7165,
137565,
23159,
15586,
181429,
27695,
114548,
42901,
13320,
42342,
39989,
20483,
325538,
50555,
136158,
150333,
318262,
30016,
319640,
31007,
91561,
318311,
31978,
762409,
94871,
48373,
17205,
155695,
61326,
200368,
9233,
107170,
20382,
246248,
409264,
4927,
203128,
32019,
null,
25810,
294643,
330755,
264126,
257554,
16424,
165857,
68005,
185731,
272983,
158793,
248457,
202256,
59963,
12963,
214426,
164733,
18185,
37710,
null,
174538,
30243,
291202,
764017,
3623,
29959,
38420,
351005,
50056,
null,
1667,
33824,
184568,
15353,
7751,
521078,
34554,
166318,
250800,
21021,
526202,
81607,
291585,
22065,
82141,
246032,
141003,
295889,
120667,
574461,
588091,
287870,
14018,
683993,
30462,
65609,
273724,
33444,
89617,
null,
190426,
205707,
343012,
41219,
56018,
19432,
10750,
null,
44036,
65794,
4427,
15061,
6761,
18029,
42027,
12762,
269198,
40734,
34016,
null,
565179,
323105,
13937,
149794,
91638,
567967,
null,
28241,
129567,
46305,
82760,
113263,
208827,
188202,
184007,
289999,
15362,
1526,
11452,
20918,
127101,
8614,
30784,
201404,
16182,
18302,
42473,
524912,
396657,
322077,
316109,
3015,
309340,
130441,
null,
13939,
458834,
4133,
37769,
267382,
279374,
357000,
null,
37064,
237115,
120943,
203435,
null,
null,
219935,
398103,
null,
29841,
330295,
24858,
96320,
15451,
2057,
13432,
34417,
214241,
29840,
44132,
34989,
94063,
46831,
187402,
183020,
29503,
71320,
27681,
47028,
18875,
9497,
3592,
471805,
499384,
10790,
17245,
50747,
39957,
255364,
117996,
177887,
null,
174780,
82619,
50464,
39755,
95754,
153443,
199728,
39599,
22414,
270352,
36502,
57638,
443360,
29584,
32759,
38705,
6637,
342270,
225841,
108462,
93328,
26969,
442942,
21020,
187756,
159203,
13455,
21398,
280989,
17884,
55081,
387154,
235199,
33198,
197686,
39259,
152635,
424062,
106989,
126836,
null,
157442,
null,
145741,
157364,
34409,
null,
42637,
325376,
45564,
421891,
206623,
50419,
47404,
15608,
318428,
360610,
352884,
212482,
11526,
63877,
12601,
33381,
77352,
121669,
163160,
40248,
129557,
374083,
712863,
307828,
25202,
29667,
38937,
36795,
53431,
38977,
40347,
61210,
81217,
22268,
252452,
41021,
9007,
null,
244021,
32932,
238174,
11895,
null,
null,
198534,
75257,
29542,
298309,
160602,
46816,
29913,
621591,
22823,
340542,
38493,
158144,
23460,
162630,
353355,
203378,
46390,
101115,
536105,
9074,
38864,
51024,
null,
13681,
26551,
null,
6624,
53689,
9706,
52171,
14225,
118136,
334282,
16211,
56842,
616041,
21361,
10662,
464925,
238268,
21907,
490860,
16946,
36764,
82132,
null,
26685,
null,
48147,
170482,
17389,
9571,
271402,
299408,
96529,
7251,
436652,
104374,
23888,
176391,
324138,
14206,
58375,
null,
17211,
13963,
631465,
null,
20090,
21076,
312895,
64977,
288736,
275614,
213827,
308147,
347734,
52591,
25693,
16697,
252931,
506589,
25477,
44060,
227085,
115652,
27511,
200956,
30312,
26871,
92976,
30239,
16136,
null,
51550,
132143,
38770,
31997,
17969,
119448,
407592,
8720,
23258,
51053,
191979,
64888,
95955,
108552,
19711,
416621,
181068,
344671,
250420,
23525,
78441,
null,
53731,
16624,
66111,
11396,
44267,
184172,
37379,
130253,
null,
209837,
248513,
35985,
282815,
194973,
193168,
70060,
null,
99251,
36266,
224014,
284914,
67993,
34135,
null,
254572,
21338,
14721,
146451,
104293,
24206,
9554,
155855,
5957,
121868,
31340,
60744,
36598,
119602,
259458,
345392,
262356,
null,
21674,
35499,
13524,
180351,
14616,
112765,
18470,
420484,
23213,
null,
128326,
28368,
29343,
281533,
184551,
60438,
298720,
176136,
93888,
57209,
14126,
221006,
38690,
38490,
233461,
196218,
26010,
35580,
7098,
157717,
73406,
62019,
5387,
43641,
267917,
22359,
135608,
179818,
61199,
574113,
389397,
62485,
29461,
16015,
21277,
22431,
116260,
121450,
368389,
32507,
150275,
19382,
16192,
5859,
175215,
239201,
39932,
13756,
305758,
304845,
416423,
47281,
232170,
314192,
492179,
238433,
100348,
20595,
214913,
35913,
null,
113203,
15742,
151953,
10378,
258195,
104999,
15958,
15909,
12950,
null,
19311,
58030,
146372,
41854,
148752,
79442,
16478,
23248,
54673,
294945,
42506,
130776,
316884,
165659,
126723,
null,
25869,
null,
371123,
26382,
86076,
140936,
null,
28840,
null,
31551,
164924,
187287,
194584,
21417,
61995,
22162,
25577,
7131,
null,
196717,
115336,
92336,
38966,
null,
5209,
14022,
7466,
29635,
316314,
21219,
null,
134321,
186806,
32377,
217501,
144502,
65606,
67797,
65757,
45525,
91751,
55685,
162703,
16821,
156532,
null,
8262,
30174,
32900,
4549,
455423,
14894,
83047,
182535,
111294,
137290,
15811,
180356,
377734,
180455,
87203,
580441,
428759,
43408,
350813,
154366,
5368,
100140,
74344,
17532,
38253,
60939,
556933,
27915,
null,
32867,
254358,
25790,
22374,
25381,
11982,
63131,
null,
201972,
44083,
83736,
284294,
433894,
148109,
278866,
65464,
34360,
null,
13145,
275678,
24719,
24884,
27219,
190781,
412130,
126392,
103480,
9338,
43469,
null,
146335,
9542,
39137,
64522,
null,
5538,
385098,
33006,
1207836,
307848,
309935,
null,
88134,
179164,
null,
178284,
201646,
1205797,
172058,
125831,
80845,
82381,
87958,
null,
457120,
298088,
85619,
144666,
37594,
26201,
231031,
56063,
73977,
17002,
60956,
9871,
176018,
282230,
240769,
4512,
183306,
97488,
65822,
44274,
98849,
156326,
56103,
110585,
29962,
137071,
null,
null,
189014,
236215,
308415,
null,
23778,
60057,
536428,
43624,
13146,
244074,
65128,
55938,
null,
46539,
197470,
2577,
66094,
null,
38118,
108832,
25619,
1015,
null,
262535,
235141,
16304,
139217,
253125,
167721,
96860,
null,
193576,
125669,
43730,
151388,
19285,
13605,
11763,
13903,
213714,
159899,
null,
322511,
199759,
null,
52251,
179360,
13509,
50884,
241005,
110734,
25837,
70431,
39966,
54348,
111705,
103694,
44690,
null,
114044,
212926,
315490,
22593,
75697,
205715,
299663,
30767,
290845,
303664,
165086,
null,
18997,
131953,
94535,
27226,
23972,
null,
18955,
28542,
null,
116968,
414877,
159431,
286602,
363912,
57822,
228199,
25409,
null,
290115,
49541,
327728,
75802,
39000,
40502,
7476,
28777,
48976,
47429,
53191,
48402,
null,
384232,
67423,
null,
null,
15179,
65087,
189973,
171748,
22993,
16256,
53168,
440590,
21962,
348454,
12100,
306700,
30746,
234218,
440987,
null,
104597,
null,
135122,
31093,
168135,
370536,
403154,
16485,
48857,
65803,
97167,
263744,
16260,
71532,
23806,
22954,
94880,
165556,
366404,
163429,
16490,
25242,
31785,
493939,
204168,
68527,
32084,
150047,
14649,
null,
40394,
1127,
null,
39406,
334843,
38096,
321607,
116803,
58674,
29597,
60982,
12315,
136357,
50445,
74936,
274474,
463301,
312784,
110645,
50215,
3780,
233302,
null,
61243,
318610,
87445,
269629,
17738,
67074,
21132,
513573,
null,
181754,
175794,
128216,
310523,
35924,
18452,
61733,
386429,
24268,
95147,
357962,
392614,
125770,
12459,
11159,
18071,
55731,
210826,
100957,
202245,
48536,
308928,
null,
798820,
2128434,
64348,
77711,
67732,
7768,
90654,
377097,
506020,
389969,
207721,
7858,
183436,
null,
5343,
30825,
null,
23180,
5549,
36331,
93966,
121915,
399446,
48190,
136332,
4094,
369057,
171144,
175437,
16568,
234468,
163931,
136151,
92385,
366092,
131961,
128536,
224634,
50678,
202868,
57996,
213674,
null,
26852,
129554,
11540,
46606,
20293,
278394,
8042,
163042,
385899,
331441,
355270,
228464,
53056,
143704,
36587,
412246,
218673,
36893,
312456,
38562,
134080,
447804,
36054,
null,
null,
10150,
23490,
161283,
70747,
251366,
12338,
243786,
172942,
null,
null,
203062,
45500,
41849,
50804,
37028,
433367,
247609,
55725,
119923,
300519,
591751,
130650,
17460,
81503,
221322,
37146,
null,
null,
179507,
28906,
345709,
45656,
65981,
194423,
16407,
83509,
51047,
248245,
170965,
23279,
36740,
326112,
131116,
23444,
104500,
32380,
28065,
74448,
150599,
310287,
5820,
61964,
21085,
52463,
59087,
154321,
150824,
126492,
63906,
22333,
144947,
217615,
300359,
49894,
312581,
128104,
32954,
16427,
477417,
44900,
13426,
null,
35903,
158113,
null,
358192,
598578,
44956,
134707,
6802,
24745,
9367,
13107,
72512,
136803,
36759,
118684,
23078,
10227,
468931,
397924,
19358,
49,
303898,
32416,
7042,
22958,
445498,
172455,
74801,
56524,
53521,
20376,
6391,
93465,
326529,
27511,
410228,
156528,
195263,
297172,
171786,
77359,
142317,
20632,
60070,
9990,
133195,
268367,
13163,
257404,
7101,
null,
118267,
422010,
174382,
42055,
18721,
166862,
216826,
534957,
122006,
null,
133108,
293324,
null,
183785,
297902,
261066,
null,
15877,
null,
91137,
null,
200570,
56307,
185882,
280043,
174558,
169139,
null,
45719,
172545,
71219,
33051,
7191,
409560,
46277,
45344,
99007,
268651,
192444,
110119,
28200,
15748,
26249,
49630,
205191,
13219,
13339,
69995,
37180,
216740,
27107,
null,
175224,
304693,
29067,
10767,
28628,
230134,
379757,
73382,
358731,
null,
498481,
21349,
337235,
634592,
7427,
17472,
null,
242920,
30109,
18253,
181737,
27354,
304951,
33756,
null,
94418,
244017,
53218,
169558,
42812,
493618,
37337,
513634,
70369,
19828,
97345,
275569,
29039,
873953,
16887,
249732,
210971,
81053,
245276,
311420,
217192,
82167,
84039,
473715,
310887,
257136,
53768,
89776,
467907,
11689,
651193,
23288,
432563,
141769,
86396,
49181,
250473,
30480,
null,
55613,
29184,
420658,
384384,
377830,
null,
287892,
281920,
39075,
44809,
null,
48738,
85079,
49015,
72166,
11748,
68055,
102701,
15106,
51969,
280513,
44745,
40064,
3562,
184285,
707939,
47885,
11769,
139173,
406293,
274014,
218871,
10779,
244930,
null,
115937,
140512,
1312,
1025728,
146577,
16595,
63446,
43110,
null,
21930,
83180,
202709,
null,
84323,
137149,
60088,
44074,
175686,
143739,
8442,
295970,
154175,
127379,
2491,
28452,
602838,
38534,
54762,
141975,
20052,
104175,
440300,
71814,
null,
27971,
49955,
143729,
426822,
201254,
null,
2847,
233406,
144905,
null,
39037,
61033,
20516,
null,
45167,
169417,
27489,
4790,
92638,
110271,
74245,
206735,
325487,
319636,
123329,
118887,
33524,
9424,
125671,
168022,
39428,
451872,
103026,
28260,
101838,
40844,
127714,
17376,
44240,
76247,
226922,
44970,
null,
320500,
237184,
223199,
18669,
282728,
45347,
173179,
19257,
166398,
236507,
168891,
99171,
680573,
153321,
176057,
44103,
68898,
351868,
48701,
34118,
173068,
16775,
3787,
131377,
74901,
133791,
17108,
28842,
36390,
54973,
26910,
295145,
234053,
19127,
21734,
null,
11798,
149097,
167197,
15400,
466071,
71971,
107135,
10318,
38104,
11135,
40124,
111824,
22005,
217332,
28057,
237944,
22304,
73980,
258060,
22380,
73721,
92908,
20255,
163780,
284427,
10096,
101648,
63086,
null,
220218,
50592,
24122,
51301,
603925,
62582,
97026,
117488,
9860,
58608,
null,
31347,
null,
271344,
415405,
400024,
113939,
60458,
29791,
107143,
29682,
14282,
98002,
30683,
169940,
103778,
39576,
35022,
199258,
105214,
33756,
null,
15148,
594954,
30069,
61349,
169323,
100130,
174161,
64751,
41784,
52173,
35448,
null,
561958,
49587,
107917,
32817,
293842,
439865,
41012,
247954,
35086,
79290,
394622,
336219,
306056,
57742,
262339,
122399,
47709,
162778,
177432,
146205,
633423,
339378,
168836,
456830,
75719,
380633,
24942,
266361,
43125,
104051,
null,
180930,
188954,
220924,
17846,
673615,
182431,
50784,
30002,
452932,
191989,
59392,
353563,
19229,
17942,
null,
131140,
21746,
44218,
31630,
42039,
35306,
14350,
3590,
297717,
24765,
53778,
182338,
null,
513265,
343017,
459552,
160047,
312918,
23196,
null,
15790,
19378,
481258,
66934,
29487,
70774,
224117,
211261,
352502,
235583,
null,
259463,
164745,
76177,
231486,
75846,
176987,
281297,
23989,
278820,
82299,
21963,
133442,
47008,
119654,
22900,
10240,
354014,
null,
16324,
39410,
246512,
186040,
77749,
403950,
101194,
135059,
219823,
112275,
23353,
58638,
161355,
168131,
20396,
90739,
24453,
86024,
25225,
137549,
12037,
60025,
null,
65619,
371733,
75227,
59297,
14624,
85011,
84582,
38225,
37723,
205398,
293097,
34477,
15871,
315899,
36559,
150571,
31444,
29668,
42191,
9669,
15356,
152190,
162234,
140418,
81464,
30289,
113291,
11784,
171692,
10000,
17350,
null,
115244,
20517,
393000,
122344,
210694,
20781,
97946,
276043,
15281,
170428,
156619,
null,
34920,
41628,
336304,
63068,
51311,
151131,
164259,
367016,
59463,
null,
137409,
28511,
136448,
204254,
32442,
5739,
20616,
25560,
309590,
81272,
240485,
80687,
120914,
47791,
40291,
21578,
40127,
122223,
172541,
88520,
28580,
5683,
51622,
537132,
6029,
264485,
38032,
26576,
55618,
45039,
150576,
null,
39452,
19632,
161650,
62510,
49398,
null,
120324,
269600,
181905,
423084,
73626,
13272,
39996,
10031,
68127,
41790,
56870,
123348,
94941,
null,
40133,
11430,
74201,
288927,
46057,
null,
146780,
27176,
262482,
406367,
29608,
307500,
70074,
48201,
56578,
263174,
51876,
6677,
null,
317847,
22018,
210737,
77752,
121640,
14518,
535570,
388266,
307348,
228418,
34373,
349033,
399928,
13290,
9287,
10316,
388435,
323986,
8613,
15119,
111927,
178546,
336014,
229179,
140959,
202837,
192515,
71157,
201740,
83506,
32304,
164688,
37713,
261055,
241593,
29019,
3762,
41724,
39380,
18724,
420462,
53606,
18876,
38695,
61547,
70273,
104370,
50319,
189828,
54917,
404759,
null,
122970,
238630,
22543,
313813,
51434,
47193,
76790,
656726,
306897,
147446,
31248,
271483,
null,
7931,
181885,
7153,
40561,
94617,
22452,
83537,
14992,
36017,
96562,
null,
64535,
258980,
9103,
17505,
11692,
6841,
1324818,
65522,
27170,
682618,
26880,
95557,
224565,
62817,
37335,
null,
8336,
37342,
16452,
33291,
51519,
110903,
317283,
291702,
348644,
236675,
138450,
186049,
25017,
29515,
16493,
6022,
140798,
99060,
20591,
54508,
41090,
240674,
152842,
358874,
40113,
null,
39675,
136140,
149652,
82756,
null,
286885,
315882,
30375,
18167,
10958,
96523,
79374,
31740,
23441,
153280,
154374,
58435,
321735,
299592,
58705,
13980,
24396,
8777,
32660,
155402,
49886,
14765,
19894,
52046,
37528,
null,
118758,
36142,
153922,
267206,
54544,
72584,
206628,
132037,
136314,
23361,
89258,
77894,
96402,
134009,
null,
374581,
775821,
263886,
308441,
159467,
21255,
22247,
39964,
26877,
25541,
151204,
null,
8288,
68506,
277799,
137373,
34573,
127274,
null,
272767,
182690,
42115,
32131,
314894,
23903,
45476,
240333,
31395,
106879,
25898,
249969,
226988,
193735,
35529,
272032,
null,
105767,
231624,
21392,
143458,
7505,
null,
12676,
38154,
26681,
11575,
495390,
135105,
31918,
45906,
654489,
26289,
24803,
183150,
42271,
11386,
192387,
null,
5803,
null,
180520,
212467,
197029,
189896,
144874,
null,
18762,
523919,
425472,
null,
96409,
20974,
44922,
69144,
36592,
105399,
84675,
87709,
12319,
15333,
14363,
39484,
65772,
270596,
239607,
42563,
182410,
20656,
5960,
117522,
80675,
33799,
23184,
71120,
13636,
186332,
61716,
29042,
56425,
63881,
257138,
240859,
180677,
148332,
43462,
18381,
4099,
52513,
124109,
338828,
90305,
136147,
null,
188588,
470568,
166205,
null,
39679,
103754,
17293,
130347,
208651,
753617,
504244,
2906,
31748,
231069,
199542,
7059,
394044,
null,
28266,
8805,
184888,
31907,
27425,
23747,
27265,
9041,
null,
117466,
57050,
71302,
9535,
56021,
100624,
444942,
46364,
299648,
421289,
288405,
80329,
17984,
50133,
53611,
null,
107876,
52276,
131138,
24897,
299344,
304748,
24092,
105426,
248857,
333935,
null,
244802,
null,
285325,
17003,
46721,
316802,
67186,
374926,
94571,
17006,
73976,
276829,
null,
22194,
238815,
211960,
38686,
38372,
21550,
223054,
292175,
40484,
232825,
18623,
248670,
345365,
174279,
307007,
34642,
93033,
50834,
53688,
180145,
27543,
29814,
43513,
185856,
23292,
548006,
52089,
94631,
76972,
186359,
null,
16590,
14558,
72204,
null,
5874,
132243,
6053,
307421,
47728,
237162,
15820,
360684,
43648,
9064,
227401,
null,
null,
40190,
16730,
50581,
183204,
198958,
58850,
25271,
352039,
32273,
122371,
80704,
77570,
44043,
79835,
25591,
611899,
33240,
9853,
595383,
25149,
null,
44084,
80741,
431561,
218891,
157794,
102339,
202020,
21231,
22487,
11623,
39607,
41414,
49697,
197529,
166451,
40804,
118297,
21622,
137025,
374146,
17724,
49140,
264777,
272283,
525030,
null,
33699,
null,
103386,
422732,
13359,
23806,
557847,
142735,
null,
226404,
337098,
21961,
191784,
32672,
68912,
280700,
51380,
115486,
332508,
15098,
123535,
24710,
26709,
183110,
89279,
33586,
61194,
9057,
null,
24211,
233287,
177885,
208969,
67791,
137285,
29321,
null,
27876,
17936,
42380,
75035,
163093,
10770,
38142,
63532,
15222,
14670,
null,
86452,
146514,
136684,
79819,
83281,
43364,
332264,
27302,
18348,
57864,
31023,
78680,
83630,
15739,
28796,
412974,
23779,
160198,
434844,
71631,
116196,
42467,
9928,
167511,
177115,
19590,
214629,
16859,
37395,
418043,
316453,
33941,
255327,
15598,
24572,
209799,
284227,
172947,
304054,
44501,
14389,
19299,
null,
132902,
266757,
44228,
null,
97461,
469649,
7094,
355893,
316800,
7679,
171045,
74080,
63032,
194170,
15934,
194469,
null,
14084,
199577,
26206,
245907,
252166,
108415,
267591,
156003,
231212,
null,
null,
14474,
484852,
104503,
null,
130815,
31106,
13102,
209030,
30214,
640526,
179717,
159499,
41536,
390680,
108835,
29639,
17232,
84513,
50274,
166951,
7453,
521944,
3183,
14732,
36738,
190028,
159517,
171011,
266810,
133838,
11237,
234156,
null,
588804,
174669,
32888,
41138,
103817,
15023,
40830,
17650,
21024,
22588,
50183,
80934,
5908,
40746,
5539,
196811,
230004,
52166,
19703,
308100,
14283,
135103,
null,
50729,
116126,
null,
260140,
56957,
28428,
66230,
139055,
24249,
23146,
7908,
409658,
319888,
209618,
24730,
357946,
152373,
237670,
null,
11702,
245687,
247983,
378054,
null,
312812,
261648,
243777,
45914,
15120,
41635,
143001,
158458,
35141,
68015,
null,
60130,
46886,
16954,
338917,
53709,
null,
798216,
null,
30296,
62356,
24463,
13884,
46963,
77489,
48991,
7120,
227697,
778056,
411219,
232616,
11620,
21945,
91088,
163542,
27650,
null,
142388,
3411,
131535,
163765,
null,
14583,
56852,
238455,
206441,
126738,
12707,
149179,
72753,
222101,
null,
null,
167388,
187965,
209971,
61244,
169390,
183682,
8772,
29296,
147221,
258011,
57165,
158072,
436670,
348455,
271836,
328507,
136655,
11200,
269511,
26944,
38843,
67497,
235352,
128215,
3139,
200388,
207925,
321430,
235666,
20761,
9780,
152335,
156241,
435423,
null,
72362,
43496,
null,
71978,
330319,
207836,
31440,
55987,
372811,
491278,
204283,
37678,
19468,
177104,
12939,
301153,
390879,
9199,
312082,
82685,
15621,
141539,
null,
53941,
37764,
31574,
323829,
166595,
61579,
143038,
40414,
111171,
399504,
5315,
14744,
51328,
38747,
233221,
32468,
134768,
15981,
523347,
null,
256837,
39597,
102522,
95794,
160671,
316426,
24445,
null,
null,
223175,
227732,
110955,
388152,
189370,
13537,
32982,
305330,
88350,
53071,
321304,
217267,
189162,
null,
375630,
4262,
140111,
null,
76116,
28142,
20039,
31988,
341833,
6813,
205467,
31567,
420096,
33457,
114641,
null,
232541,
327809,
152333,
123351,
23270,
291561,
75301,
314551,
3687,
456152,
null,
null,
227409,
21754,
39817,
19475,
200982,
26918,
247018,
86252,
14433,
38677,
18137,
272433,
14326,
18896,
186251,
1325807,
34166,
192990,
51786,
193543,
164249,
32539,
18017,
198324,
37880,
37085,
308482,
null,
79582,
33414,
32517,
31597,
28033,
null,
null,
44173,
295580,
134042,
466853,
181436,
54075,
110806,
null,
5089,
47427,
55878,
28520,
434695,
176775,
42129,
213551,
33501,
29027,
23895,
113701,
null,
null,
287458,
34025,
288723,
169144,
47415,
170142,
21783,
82062,
3377,
105037,
390655,
null,
51925,
65215,
25652,
92784,
10675,
72422,
207172,
347149,
23904,
22187,
36620,
308270,
18688,
171146,
53748,
7815,
27025,
151825,
171561,
29055,
166404,
null,
6235,
5157,
229560,
51992,
21154,
30450,
687470,
36030,
259694,
468251,
452396,
257165,
34480,
258503,
23591,
84992,
240109,
198503,
29539,
807885,
null,
424265,
294052,
17953,
250747,
20817,
163508,
49969,
21572,
394865,
1486126,
30777,
null,
null,
14007,
45383,
97200,
20946,
267492,
172811,
252221,
71522,
17002,
120502,
191321,
385091,
null,
44852,
516815,
279681,
9964,
17510,
42522,
251193,
37214,
21295,
336205,
24677,
290685,
442530,
35503,
77080,
null,
7462,
25853,
377176,
245417,
174748,
28588,
61746,
37032,
null,
67310,
92458,
632359,
44624,
272963,
30165,
32085,
415715,
68297,
253330,
863988,
60882,
145429,
null,
715576,
249430,
46977,
312245,
313071,
188349,
280590,
81643,
17971,
12782,
92272,
628560,
null,
23736,
66487,
364454,
163156,
72905,
9190,
25936,
91350,
106141,
15436,
465130,
9629,
157179,
451077,
112226,
68531,
244836,
43528,
23823,
551719,
53312,
119521,
4345,
247583,
null,
163705,
57533,
25502,
33196,
35950,
170113,
188928,
45718,
50785,
20716,
252258,
30664,
null,
null,
80206,
325209,
26118,
573076,
428588,
138808,
309439,
74134,
419862,
213768,
268321,
139291,
305649,
41659,
184767,
124860,
364347,
218834,
211725,
11269,
27444,
28230,
172489,
20933,
357635,
186508,
86496,
281674,
null,
155114,
78336,
18205,
16632,
120572,
11005,
11078,
532109,
null,
13412,
151075,
614417,
233682,
255532,
40536,
35811,
31084,
312514,
209961,
236585,
70572,
101011,
57307,
94292,
312630,
69668,
null,
217699,
89957,
116713,
277802,
232392,
336523,
7453,
108967,
34484,
15670,
null,
null,
262681,
53051,
182058,
null,
47603,
30925,
184272,
215490,
17666,
71064,
277521,
143096,
213173,
300229,
34693,
107349,
295449,
313761,
7277,
584602,
104366,
119783,
5389,
158293,
106663,
88368,
275173,
18193,
236964,
18285,
90406,
null,
651765,
null,
56038,
10921,
12595,
23337,
625413,
83073,
132826,
324880,
22148,
5574,
16302,
125524,
null,
854657,
160459,
96030,
28688,
282187,
47167,
19145,
null,
114885,
null,
74461,
122840,
175114,
155761,
null,
null,
53864,
9955,
164312,
206987,
167653,
165958,
647334,
229407,
14738,
297754,
42193,
9188,
223662,
50201,
192849,
229361,
17106,
221882,
20058,
37182,
198553,
332719,
677863,
6179,
null,
162971,
601299,
null,
11303,
229167,
231128,
42821,
35821,
30754,
33069,
135304,
6499,
231091,
123426,
426538,
81432,
null,
null,
68829,
55169,
12326,
72030,
173449,
18179,
31416,
25868,
23367,
9617,
43240,
532222,
38458,
41696,
7545,
null,
65431,
33688,
11409,
68658,
20976,
37483,
6403,
28781,
18267,
34479,
59226,
202079,
122138,
119812,
92796,
254163,
35173,
null,
26607,
null,
133612,
null,
8823,
150150,
93352,
280080,
40915,
308124,
295778,
64021,
39866,
21869,
161935,
128290,
239286,
3895,
12512,
149556,
51395,
38413,
193418,
424930,
203179,
41530,
null,
24704,
65846,
20470,
30104,
153641,
244541,
41214,
327521,
34502,
11166,
21448,
218556,
234227,
394299,
304493,
269090,
454818,
83997,
36379,
9378,
208926,
31359,
153541,
null,
10389,
393807,
25442,
10634,
43996,
28831,
26581,
144999,
412810,
28019,
null,
190625,
15400,
182516,
39364,
641383,
326309,
null,
134110,
151577,
98948,
348098,
28277,
125315,
24861,
46645,
79366,
154920,
25133,
38151,
379607,
88561,
50467,
30416,
51306,
117165,
223003,
null,
41794,
246931,
44232,
123532,
12617,
179292,
570342,
7758,
313343,
92641,
40738,
262230,
52450,
17928,
180223,
23348,
285153,
209545,
53838,
84962,
12026,
28674,
33904,
310987,
12290,
30865,
9638,
159891,
35178,
null,
235227,
61289,
15985,
null,
284364,
39656,
null,
295807,
31982,
39852,
null,
23420,
97881,
84410,
275759,
13143,
157280,
39643,
57422,
11099,
323865,
26435,
748357,
61192,
18807,
null,
317913,
277644,
507776,
890,
null,
8844,
132426,
20179,
32027,
94977,
5553,
195155,
440519,
null,
22985,
34764,
298714,
445573,
66417,
21954,
305470,
31693,
172744,
1114516,
20758,
401327,
229407,
209351,
null,
24092,
8424,
155165,
42186,
9161,
117004,
11411,
null,
13599,
24728,
152370,
485838,
240081,
162681,
182978,
19465,
38993,
21115,
40406,
525070,
null,
166614,
null,
3485,
139017,
37558,
null,
445821,
null,
351372,
236757,
247008,
212254,
64117,
72462,
10064,
160557,
10037,
5525,
8077,
97878,
147833,
146662,
null,
265148,
72937,
314700,
55002,
9991,
28842,
48482,
250384,
255971,
293777,
302975,
245854,
188502,
35733,
54956,
null,
18929,
78660,
49693,
117805,
242529,
22411,
354110,
3693,
100651,
361601,
523820,
199383,
74994,
52559,
13212,
62361,
38119,
247886,
254426,
null,
170583,
245932,
305662,
61773,
17449,
10339,
116486,
119003,
28716,
8201,
228774,
8499,
137635,
295131,
12543,
23148,
146692,
258828,
null,
153620,
258265,
18094,
49171,
284780,
18443,
159242,
348814,
28617,
16717,
329555,
18978,
40675,
175436,
21714,
515298,
218988,
251609,
325661,
391329,
null,
20965,
160558,
null,
225202,
17481,
208213,
14925,
153627,
32251,
170866,
73469,
144979,
138535,
120796,
602227,
54181,
81178,
36731,
17121,
259291,
169558,
187446,
69848,
2534,
24033,
52618,
123881,
534177,
168600,
162477,
18224,
null,
63648,
9108,
null,
552000,
237753,
186054,
24938,
26794,
100766,
221725,
174400,
125985,
3319,
null,
113775,
37186,
235979,
374614,
9736,
40496,
74089,
458599,
109714,
10021,
63326,
166079,
41840,
231441,
26820,
30061,
null,
100967,
27790,
65920,
4246,
323360,
90231,
157312,
83935,
27402,
98868,
28485,
31749,
27190,
186984,
null,
12973,
297939,
17459,
17309,
117818,
21354,
117095,
9187,
null,
202130,
266995,
100796,
479025,
56041,
109860,
48488,
17924,
50664,
118878,
null,
395019,
31930,
227311,
25189,
30780,
17583,
47524,
199671,
null,
383555,
29497,
8876,
5926,
92596,
35914,
299639,
12692,
154154,
161280,
32262,
319177,
204892,
134984,
330902,
50400,
235777,
114985,
133435,
138828,
191932,
307617,
null,
377961,
10306,
167510,
117053,
24325,
201384,
385377,
439907,
24038,
97994,
52358,
132377,
43773,
12533,
164088,
null,
326558,
null,
194286,
221461,
111600,
null,
52278,
19920,
14834,
78717,
16652,
577437,
236997,
37527,
null,
476739,
21573,
225580,
null,
3146,
228804,
305999,
49349,
87272,
394973,
168220,
179768,
127386,
16069,
251907,
222824,
32025,
480334,
6799,
141806,
null,
15996,
114732,
21247,
81880,
61320,
28509,
null,
239179,
130115,
16385,
190840,
521886,
84147,
112327,
null,
4238,
266433,
38866,
37052,
39361,
381386,
null,
167900,
44053,
461442,
null,
51071,
339144,
369998,
96613,
167282,
96324,
203045,
143007,
334404,
32369,
19964,
16405,
188584,
179189,
2806,
8021,
27347,
249014,
8637,
275744,
null,
119177,
199966,
55420,
266637,
33543,
62817,
33639,
178327,
292721,
34431,
39148,
28556,
144736,
385763,
37774,
2712,
null,
38677,
49467,
418427,
null,
32587,
null,
373944,
null,
65904,
42301,
38213,
179054,
131396,
30279,
222518,
20667,
105705,
14383,
null,
33714,
832125,
20349,
30032,
135394,
137801,
110852,
31283,
49936,
16080,
330651,
360682,
180986,
null,
73345,
159999,
207839,
92378,
10422,
186983,
30301,
81402,
22671,
185174,
18596,
9998,
21229,
124906,
122324,
23327,
189993,
207158,
115292,
43921,
13719,
214666,
24823,
20101,
51312,
85908,
55836,
129659,
null,
72132,
260821,
152605,
69284,
27391,
33710,
15866,
32854,
38812,
9245,
311503,
31209,
74707,
null,
33836,
414989,
122556,
95663,
416610,
7872,
50475,
108632,
36108,
29983,
187862,
31051,
144902,
199061,
81746,
58477,
33883,
256320,
14088,
28760,
227619,
31071,
null,
8985,
117362,
104907,
59946,
45786,
352317,
17848,
264637,
80908,
267850,
null,
214116,
133541,
null,
164659,
17396,
526397,
110845,
57712,
68002,
20598,
82406,
300409,
115361,
26606,
9202,
15899,
77255,
82383,
51391,
53818,
122857,
30512,
20565,
4518,
8753,
336360,
162408,
64663,
375373,
296251,
null,
33181,
49695,
84865,
418931,
878,
14908,
143112,
28484,
230879,
41073,
48795,
269690,
110467,
106914,
12979,
18174,
160859,
91055,
39270,
1533,
19721,
109018,
19899,
291532,
null,
13076,
186831,
188871,
15551,
15997,
null,
223419,
60576,
39136,
null,
281237,
365019,
47811,
60667,
319161,
46662,
221108,
41044,
152489,
18833,
62194,
395157,
156281,
335303,
7283,
33695,
17951,
198436,
278092,
18084,
40976,
61058,
49177,
9274,
null,
29561,
23160,
211758,
411242,
307272,
407704,
324977,
51205,
41080,
184541,
11226,
233910,
133135,
75125,
25487,
215448,
103884,
null,
8870,
41709,
22259,
23376,
400908,
189661,
null,
248561,
9735,
288759,
51689,
357313,
52127,
null,
315683,
356524,
23653,
6937,
32641,
33212,
46583,
176875,
387105,
39135,
186722,
161144,
52018,
22208,
20766,
107316,
344266,
63762,
11364,
494,
15177,
11440,
36707,
275790,
144899,
26541,
419414,
110628,
27884,
130375,
215836,
331665,
103339,
625125,
104150,
103322,
59739,
18917,
68786,
29291,
305631,
168319,
27800,
197563,
51951,
165324,
22780,
41527,
38717,
15272,
21790,
10510,
553354,
null,
170046,
93425,
90171,
434934,
null,
52527,
null,
102136,
null,
298266,
141045,
212175,
55863,
90476,
10458,
48698,
13070,
null,
298728,
641699,
7302,
131605,
77044,
38204,
18317,
224885,
62054,
116537,
48996,
166590,
46851,
14609,
292642,
193000,
360446,
null,
371433,
203279,
400194,
2109,
16482,
91287,
129456,
31267,
109985,
401446,
46290,
188945,
24475,
18280,
317525,
79652,
94254,
68640,
166104,
274170,
146166,
36799,
153944,
357569,
56137,
113185,
35297,
99689,
31490,
238991,
312352,
null,
133290,
289600,
195566,
303452,
167426,
95744,
63448,
310229,
267530,
45276,
33882,
10982,
211184,
17900,
277455,
33072,
184439,
23996,
20265,
20083,
20700,
54580,
30511,
128244,
324441,
null,
167882,
11,
40287,
24420,
92341,
151155,
3277,
49934,
30779,
18227,
147440,
176078,
90436,
148587,
null,
25861,
12307,
null,
63154,
343000,
83582,
24757,
62605,
35077,
18100,
25524,
21194,
20803,
2838,
220128,
97834,
165671,
1083902,
12413,
6746,
39029,
21143,
240262,
228915,
151291,
null,
138132,
23807,
438276,
99030,
237958,
152390,
114227,
64728,
163473,
170692,
41374,
222757,
23064,
78232,
10026,
28962,
282673,
205466,
73240,
18856,
9964,
135907,
486262,
31694,
330914,
12057,
106425,
301096,
158741,
152658,
111106,
null,
207847,
110582,
35190,
16269,
53938,
332264,
6509,
23784,
202904,
32501,
151941,
35274,
208331,
280864,
36907,
422908,
null,
5639,
412909,
441478,
11882,
332193,
38117,
354206,
223432,
524380,
494160,
289654,
145948,
20854,
77413,
184845,
183806,
19777,
24673,
221552,
740699,
23467,
17747,
182192,
18812,
32489,
36808,
57872,
37560,
130327,
254109,
165176,
440363,
15914,
166445,
21605,
null,
null,
225620,
67621,
111458,
94582,
383113,
316056,
58813,
null,
224147,
null,
351246,
53283,
287107,
644094,
191834,
83138,
38904,
null,
77353,
392250,
10584,
9364,
22022,
107412,
41048,
39426,
46639,
468698,
357922,
25253,
null,
309199,
205889,
43373,
116054,
224901,
210277,
428893,
60078,
49716,
3868,
122265,
179054,
32770,
52566,
279469,
12085,
13421,
132901,
58667,
467878,
13895,
167323,
null,
232811,
68891,
3454,
null,
6740,
38987,
53668,
214249,
null,
248188,
62688,
554512,
34522,
22877,
41227,
24002,
4693,
132719,
96531,
null,
248362,
444734,
642955,
22681,
36854,
21362,
86187,
26259,
28796,
690227,
8556,
190046,
271306,
13725,
70517,
455962,
19675,
33156,
338196,
44430,
96891,
66302,
105547,
35300,
265718,
20182,
59781,
88788,
103955,
49280,
154463,
null,
69107,
16322,
133567,
242016,
427540,
45127,
188122,
60044,
24568,
204726,
41888,
91804,
377414,
9695,
257312,
230684,
369355,
145890,
119703,
48483,
362675,
414285,
53318,
171042,
89312,
23265,
26275,
749079,
206995,
22930,
88423,
168487,
10838,
32478,
133669,
99227,
65719,
155237,
93521,
222000,
185682,
316697,
70649,
36140,
230675,
7058,
76707,
460965,
125887,
311237,
381294,
16715,
null,
36217,
260813,
8947,
11015,
null,
333934,
65958,
13277,
214266,
10544,
37081,
295340,
21930,
196686,
101349,
136520,
136235,
33619,
341173,
78802,
49385,
41699,
466647,
48435,
207033,
3910,
null,
223428,
418466,
359962,
31999,
45322,
110681,
45920,
47200,
42834,
131491,
474809,
12343,
330727,
null,
null,
479850,
38086,
128747,
8874,
67115,
31568,
38578,
438791,
140267,
3681,
19457,
46771,
558809,
259919,
23062,
175152,
468726,
null,
20253,
126135,
175508,
183869,
23872,
311388,
36469,
118679,
158500,
64751,
256491,
295896,
21359,
2961,
74444,
37483,
49752,
63140,
89307,
147504,
415995,
189316,
281817,
141103,
287569,
172137,
3515,
36941,
213617,
221013,
12816,
35474,
17779,
118626,
142493,
176722,
255241,
81574,
30985,
4470,
34610,
9372,
null,
338044,
43542,
30051,
107724,
13499,
285415,
9696,
203304,
100756,
29146,
227125,
173013,
268421,
133864,
177801,
35367,
5637,
6226,
616118,
36896,
477885,
327541,
14100,
13453,
25206,
25461,
14345,
22751,
781482,
87528,
43084,
18357,
76638,
17348,
245487,
68721,
156729,
97629,
8187,
12881,
111983,
74599,
42927,
250688,
74295,
null,
55020,
18474,
39058,
null,
3080,
22627,
182491,
340539,
545416,
377598,
86950,
58580,
63065,
62235,
224591,
12457,
78157,
54604,
14750,
221617,
20345,
50442,
550769,
115249,
15582,
39813,
265410,
290337,
73236,
457224,
11670,
8250,
76125,
null,
23574,
10398,
36667,
34104,
294665,
35901,
38847,
24563,
113446,
208098,
227422,
32968,
null,
null,
69891,
null,
null,
5301,
24363,
376417,
143491,
null,
346783,
256936,
68711,
72955,
1225,
7455,
67275,
108570,
9298,
251857,
247397,
7746,
163790,
308706,
58453,
196737,
210276,
421179,
19396,
207071,
null,
237171,
136834,
null,
79330,
null,
243892,
172699,
527535,
284658,
209844,
239938,
200942,
24209,
225087,
17118,
130768,
null,
578776,
4361,
400500,
111813,
36738,
321477,
26528,
233873,
327224,
122324,
14340,
91766,
264753,
6148,
19217,
212789,
467074,
5090,
12877,
12930,
53558,
252140,
33493,
48564,
219070,
365790,
299982,
167671,
123900,
null,
50469,
197645,
306431,
35873,
193326,
136330,
124697,
12916,
289832,
31945,
18812,
178457,
14676,
19173,
24740,
176045,
217118,
188057,
181168,
77621,
58553,
206539,
null,
39101,
25296,
null,
null,
290241,
599300,
19893,
160320,
40575,
null,
62731,
710495,
42930,
27667,
124911,
127936,
178793,
54930,
84313,
35022,
null,
137597,
10856,
18682,
29144,
null,
138921,
905596,
5213,
160365,
217805,
30208,
480673,
11164,
198542,
685918,
290030,
536396,
289749,
28369,
24126,
null,
85908,
308483,
null,
240795,
229154,
36739,
188189,
269846,
321460,
null,
241843,
44547,
15640,
15493,
229527,
49697,
263238,
221036,
332975,
12401,
60958,
34603,
202411,
13345,
249899,
7392,
137639,
52427,
189602,
239581,
280634,
32538,
420132,
293435,
72235,
400048,
219244,
6096,
376563,
167422,
420842,
87821,
33680,
43477,
417316,
22121,
345377,
116126,
18504,
null,
34863,
460750,
647520,
33044,
66374,
63646,
57059,
142654,
7517,
13988,
183716,
688729,
31124,
316009,
285192,
6522,
775070,
173653,
19530,
24949,
38460,
258630,
18046,
33049,
7928,
null,
258751,
8751,
8818,
202393,
21967,
13898,
185442,
99784,
14923,
19544,
84644,
638421,
10330,
16636,
217207,
19128,
226118,
45197,
21022,
58314,
null,
21300,
77546,
298085,
15292,
178011,
277878,
159380,
327367,
108266,
null,
51854,
16900,
106855,
39595,
76565,
95871,
12292,
28237,
7819,
216344,
28594,
2072,
200881,
41475,
30806,
81834,
63278,
349130,
19899,
260475,
261538,
97761,
137540,
233626,
23362,
23160,
42016,
49760,
25558,
20266,
28108,
310090,
228278,
null,
null,
30343,
165064,
232728,
null,
38897,
30871,
23718,
128731,
314396,
327336,
25841,
85921,
140977,
null,
10864,
90927,
29103,
24396,
5666,
null,
365831,
387180,
448238,
338909,
5916,
40719,
34414,
8191,
299840,
270261,
67006,
7837,
204046,
302349,
136993,
30828,
344398,
152080,
430474,
580246,
514118,
84646,
300005,
60133,
null,
32988,
58259,
100319,
29987,
93605,
134782,
null,
108889,
255175,
15824,
29985,
null,
92818,
78969,
null,
394441,
null,
114431,
null,
34691,
154606,
372297,
26023,
null,
null,
3038,
49143,
9098,
133326,
5724,
141691,
302326,
252895,
101254,
null,
null,
216493,
31716,
122155,
549702,
34627,
33691,
122330,
null,
257707,
179103,
null,
63932,
53795,
920517,
50921,
320780,
130524,
148292,
40538,
22473,
548547,
290413,
139375,
24362,
null,
111447,
34114,
217342,
null,
26418,
160102,
30804,
230567,
45328,
366804,
120136,
33792,
48462,
213001,
32349,
null,
149342,
null,
14053,
30899,
126130,
58282,
10180,
1894410,
null,
73665,
147435,
null,
14992,
126403,
51075,
251790,
37166,
66657,
26361,
298891,
171843,
133180,
192018,
243058,
5592,
54455,
45822,
77368,
121259,
25814,
31247,
33622,
25168,
218021,
250276,
24434,
436023,
91587,
7076,
239539,
18545,
40722,
347860,
172045,
164382,
null,
36279,
151769,
29279,
192071,
17189,
167672,
201719,
264924,
187150,
184654,
113632,
8774,
362094,
120310,
62395,
57809,
113267,
746503,
175785,
357486,
49422,
393562,
255144,
1641,
248064,
10694,
37211,
150100,
101621,
199940,
147137,
415537,
133879,
124856,
26718,
7839,
181805,
529068,
178193,
565661,
null,
15629,
119721,
51345,
314015,
239262,
205780,
140960,
90502,
48060,
514225,
46206,
7280,
12529,
343062,
294785,
null,
95226,
19024,
11658,
null,
115830,
null,
17224,
123412,
40855,
160581,
13818,
null,
57303,
129996,
27506,
49054,
25535,
1879,
31579,
115255,
20459,
281768,
237027,
80148,
49545,
35172,
163960,
433115,
419317,
18448,
315639,
461285,
185095,
604005,
null,
508570,
238893,
14488,
null,
318715,
14839,
55498,
32859,
null,
224677,
null,
23558,
70500,
294067,
137522,
144785,
289178,
198033,
78329,
36990,
17382,
78702,
63242,
25497,
56227,
459423,
375395,
178453,
46254,
72143,
79535,
290752,
29940,
288858,
765207,
53608,
323725,
165452,
375307,
83873,
175942,
22209,
11529,
318182,
261335,
140263,
66618,
26560,
34396,
229962,
null,
74084,
null,
257348,
20573,
501895,
154557,
41799,
225799,
9626,
11414,
9557,
null,
26317,
7076,
100165,
275673,
40961,
58786,
20065,
28900,
111141,
21835,
381507,
38911,
68338,
null,
53037,
159573,
123986,
18954,
31674,
154862,
15008,
null,
34273,
null,
226593,
300379,
136211,
241199,
132967,
20146,
35462,
35579,
105410,
39822,
111455,
161420,
null,
13872,
64333,
41497,
31616,
93613,
16122,
null,
308422,
506393,
7169,
16832,
null,
39446,
25708,
214488,
37454,
null,
23943,
66545,
19563,
707349,
229103,
504457,
26799,
null,
44709,
37164,
46620,
30732,
54492,
216530,
206509,
38301,
367964,
136491,
3965,
null,
485826,
94416,
12800,
42060,
58342,
126801,
275074,
52835,
228492,
19675,
26851,
187042,
328313,
21271,
28946,
43549,
18878,
31331,
427567,
460446,
94117,
102036,
8334,
null,
45194,
105067,
79552,
19694,
5031,
5915,
467666,
null,
191954,
54684,
24421,
30279,
189587,
29865,
10116,
149138,
102026,
null,
302911,
73723,
28797,
22239,
477744,
127568,
null,
19662,
74354,
72218,
152955,
62751,
105246,
184149,
37018,
237678,
10246,
22313,
47428,
43299,
54733,
106518,
220158,
11744,
24854,
166678,
15575,
16233,
321311,
47966,
29550,
40187,
47309,
93235,
299283,
50555,
46768,
278123,
74053,
8656,
25384,
null,
86813,
241082,
268671,
null,
244461,
152197,
12188,
362701,
59433,
200940,
22288,
null,
190142,
null,
30177,
42716,
169491,
6376,
31671,
622945,
72573,
301754,
null,
263208,
79744,
49043,
53152,
44156,
18906,
42441,
118149,
194653,
119248,
230540,
37542,
55619,
118831,
153669,
216137,
38914,
151996,
58173,
34568,
13139,
4761,
34273,
77237,
233871,
19438,
23161,
31163,
28492,
154567,
418081,
145615,
40988,
109862,
184637,
209399,
27912,
null,
150200,
null,
137518,
92589,
422405,
29843,
null,
240569,
62856,
133587,
34364,
56596,
210873,
8457,
13768,
138656,
196614,
628147,
null,
4288,
234380,
null,
null,
228479,
52984,
14769,
64061,
194643,
26408,
56483,
118710,
174362,
677571,
null,
104297,
null,
null,
195816,
174567,
125775,
null,
35175,
183516,
null,
167181,
6767,
null,
33997,
188174,
218557,
165002,
304332,
23210,
333738,
null,
240091,
75522,
204427,
267234,
288150,
345824,
3960,
12796,
null,
125181,
3389,
57564,
93716,
99871,
8317,
18818,
28301,
null,
12164,
9440,
127235,
55248,
103755,
127122,
null,
null,
6832,
37575,
137213,
null,
53030,
218819,
97966,
21762,
25394,
43142,
74335,
192810,
15083,
158328,
148604,
56053,
214380,
26489,
5589,
635,
49569,
45462,
105573,
191579,
26050,
372491,
278897,
131194,
34648,
55094,
23299,
8718,
162142,
119404,
132220,
23476,
109307,
null,
20978,
36149,
36680,
84933,
54693,
69262,
21073,
624229,
234927,
10915,
336638,
106124,
46781,
265378,
203781,
29505,
165464,
11067,
22918,
8599,
182902,
200225,
324258,
18930,
8497,
107022,
246775,
133814,
47750,
14154,
30293,
93415,
null,
197017,
34392,
17328,
134467,
104616,
139040,
48300,
116198,
70903,
23923,
19818,
247355,
null,
null,
9179,
172219,
26572,
164281,
48660,
null,
113661,
336986,
3140,
249413,
9387,
47471,
50345,
146815,
23893,
34845,
4067,
280559,
166098,
156498,
314249,
375374,
140238,
null,
151478,
154949,
520139,
1583,
319999,
3616,
26154,
3475,
34949,
32358,
156827,
290310,
224851,
135234,
27550,
142788,
477786,
247735,
84465,
386415,
126051,
280299,
818609,
13903,
13298,
909133,
211227,
38195,
3237,
218745,
294103,
76672,
31775,
115437,
137559,
21714,
25064,
9698,
33641,
57665,
268934,
33590,
57015,
290379,
118792,
16735,
50717,
112249,
293221,
7220,
37503,
23669,
219574,
159105,
34145,
51030,
38856,
24179,
154399,
19752,
161903,
12745,
22541,
7550,
276622,
null,
24803,
16167,
24619,
15704,
194791,
33104,
41675,
26060,
46128,
null,
472929,
88101,
458132,
null,
265058,
36618,
67330,
23238,
74334,
18938,
19578,
null,
28050,
233653,
null,
199245,
45985,
154070,
359694,
51621,
null,
183532,
65042,
216586,
41367,
45995,
18817,
32627,
172450,
147805,
null,
297136,
188051,
265657,
11126,
135434,
113686,
189862,
158384,
14368,
245657,
376392,
14985,
28695,
31089,
21016,
217055,
20333,
209723,
142668,
95388,
211872,
178867,
49798,
138805,
21046,
308887,
162215,
38958,
119432,
150287,
183072,
42245,
60268,
24784,
240728,
252856,
11645,
null,
36454,
88287,
null,
129087,
133718,
null,
36116,
32798,
176936,
13347,
40460,
63936,
648,
216432,
49301,
18957,
null,
231993,
336386,
311698,
172540,
47229,
34973,
172013,
91431,
111563,
7243,
121074,
233195,
25429,
18166,
32371,
11824,
44903,
null,
115053,
59804,
305177,
124469,
40247,
302955,
27656,
303908,
623483,
372272,
196430,
25146,
111664,
377664,
28398,
179674,
207644,
51846,
34668,
72261,
null,
169594,
142341,
null,
133024,
null,
3000,
null,
154184,
80287,
39084,
798541,
93165,
726757,
45400,
473115,
237951,
90771,
69004,
661104,
1791,
41268,
20855,
78411,
161075,
94615,
78644,
13137,
86128,
25475,
56295,
221330,
91484,
15559,
250194,
261965,
35361,
343339,
36869,
11672,
384253,
286315,
null,
193292,
217124,
8221,
null,
10384,
7734,
34271,
388138,
82146,
231006,
151614,
262156,
525806,
52838,
null,
1946,
null,
136056,
25671,
251580,
56709,
6775,
116489,
36522,
158371,
215224,
405747,
177679,
10906,
53985,
114500,
15921,
46045,
145679,
151887,
62225,
24572,
44396,
143619,
77373,
449060,
null,
66853,
133778,
48216,
182259,
115746,
436590,
654255,
313919,
27068,
null,
23858,
90941,
208472,
null,
7280,
88294,
9621,
79378,
68769,
33975,
181073,
103298,
40639,
46703,
null,
153663,
233387,
37010,
49030,
30070,
50021,
46078,
122376,
168363,
202828,
81606,
19524,
117439,
115795,
21994,
21851,
280640,
166057,
72246,
8276,
48354,
null,
365805,
344315,
21970,
164672,
null,
55156,
121578,
358843,
42722,
216050,
199543,
null,
229404,
138418,
3591,
255513,
226777,
24645,
1020895,
187876,
43815,
648169,
254317,
31287,
45774,
368902,
53003,
41521,
242311,
17465,
192558,
242091,
348116,
30428,
459333,
45979,
15567,
198221,
76180,
142274,
138034,
27478,
32440,
8784,
429073,
118762,
31188,
71910,
273455,
47277,
14712,
97434,
249369,
313737,
null,
327300,
151509,
57517,
100245,
170271,
39944,
36213,
41439,
12866,
61508,
192184,
null,
13058,
253427,
137977,
54222,
122343,
13875,
1064152,
222943,
2620,
12372,
null,
64814,
29328,
null,
98493,
8520,
213026,
390736,
371963,
117284,
75060,
354031,
321169,
null,
55080,
136816,
119553,
176096,
46551,
7170,
116819,
12148,
36191,
null,
271918,
17963,
16239,
210724,
270554,
239309,
552888,
152521,
21124,
27469,
179065,
19296,
5328,
20204,
7859,
null,
null,
90270,
40810,
35355,
null,
86359,
215603,
39779,
256812,
138084,
42003,
185888,
45379,
192604,
33407,
179998,
314914,
27407,
67096,
39537,
81049,
41401,
54621,
307986,
279760,
35224,
48684,
106837,
484744,
480363,
35092,
16899,
221129,
82677,
319155,
166638,
40817,
44541,
9992,
224733,
477285,
268827,
421856,
20122,
392042,
51389,
29307,
null,
null,
48676,
114902,
185526,
15984,
238105,
201417,
21477,
164443,
24091,
80291,
567006,
38382,
89107,
128203,
298615,
34527,
51123,
19904,
32122,
67228,
287256,
96542,
474487,
35787,
296444,
333736,
26761,
63529,
163324,
125087,
37692,
436747,
null,
72486,
27923,
23579,
262564,
60035,
112290,
6422,
317485,
178504,
63763,
163903,
38453,
187527,
185103,
17844,
248505,
218460,
60314,
22412,
303922,
102851,
8608,
11827,
11050,
40637,
347697,
32702,
7537,
16585,
202542,
82589,
12485,
325863,
309989,
41591,
127146,
467190,
339083,
63399,
333032,
27854,
12283,
51969,
39366,
134779,
426395,
126478,
368376,
115982,
71053,
null,
6809,
169929,
20899,
12283,
159712,
178676,
36797,
293080,
114816,
null,
56979,
35213,
261919,
234866,
40954,
255541,
410517,
46502,
25567,
282432,
247142,
182208,
90734,
null,
57930,
28656,
1026,
44693,
126830,
1135,
45599,
112676,
null,
25868,
203949,
38136,
858706,
128616,
485420,
32438,
214959,
null,
23956,
74675,
190429,
338097,
153416,
null,
184138,
45503,
76066,
6291,
null,
null,
91730,
160790,
51100,
283727,
31248,
422304,
28615,
154969,
143047,
346748,
31591,
94284,
9913,
29948,
null,
32107,
145592,
123081,
222129,
29426,
290290,
118964,
19605,
39740,
217226,
16109,
432688,
223658,
134676,
405009,
178527,
133426,
null,
162645,
14481,
388940,
11507,
42538,
397180,
78577,
33174,
206843,
93330,
31260,
132533,
242325,
166271,
7517,
null,
97851,
467616,
513862,
5194,
536761,
139023,
205122,
48683,
46980,
90818,
49623,
null,
265892,
119395,
115260,
23208,
20034,
826428,
18952,
68957,
160172,
206059,
null,
115242,
53767,
151778,
318328,
49664,
26783,
167434,
47895,
11641,
217614,
50105,
19444,
274353,
278963,
152138,
60761,
194198,
172134,
139860,
226234,
58560,
105693,
19755,
45915,
69809,
199262,
5786,
20994,
28391,
36370,
17772,
59334,
174079,
7271,
35811,
101502,
82256,
102564,
184572,
17177,
30970,
391542,
317748,
366875,
4248,
43080,
null,
9287,
144470,
10244,
270907,
347294,
28323,
53236,
156778,
1332,
309797,
229049,
10874,
225701,
47821,
15786,
329623,
258702,
17396,
191886,
4531,
14836,
84471,
129322,
7827,
323529,
1531324,
47305,
28172,
70628,
175043,
31374,
126742,
208996,
575032,
195074,
22492,
286897,
110329,
4615,
254715,
261829,
341501,
49105,
null,
28392,
107695,
13211,
176081,
382253,
149570,
272545,
37566,
43636,
16498,
264594,
304975,
119796,
null,
112620,
30286,
85349,
411164,
22093,
21594,
41911,
20963,
189856,
48669,
25830,
501653,
76140,
18709,
null,
37052,
389108,
130474,
36114,
290414,
406926,
288991,
27202,
180089,
null,
27432,
46025,
3081,
48269,
305720,
184990,
202912,
34510,
19746,
null,
40108,
29328,
85270,
31481,
412458,
117555,
74266,
25064,
40988,
null,
180100,
20416,
33245,
31688,
12079,
42141,
32923,
213335,
209476,
null,
8335,
128974,
5101,
27992,
44680,
361385,
44614,
null,
22112,
11167,
77602,
229866,
131780,
264415,
238224,
15672,
4689,
25123,
23890,
22188,
301865,
252095,
9584,
9285,
51961,
181498,
21279,
149731,
157608,
303019,
37631,
45780,
282289,
109406,
42575,
null,
null,
121798,
57417,
13705,
35084,
69381,
23871,
18564,
37105,
49169,
136637,
null,
289297,
52700,
219292,
29097,
null,
15218,
492226,
185416,
122897,
198698,
458391,
26237,
29621,
121619,
405974,
20088,
225877,
35829,
277514,
17832,
40571,
179778,
6100,
243192,
32602,
109389,
27906,
37158,
222607,
64378,
33337,
71468,
38647,
32424,
14100,
286928,
16065,
161125,
176271,
134831,
38391,
566094,
161966,
27095,
79646,
402841,
810472,
273634,
null,
390122,
95250,
158509,
19023,
37659,
159839,
226182,
13013,
30412,
89884,
null,
null,
113329,
307194,
272787,
143062,
270996,
17430,
77895,
47415,
176355,
104597,
159228,
315694,
null,
209692,
23413,
159356,
207387,
76163,
202201,
25392,
188672,
197973,
160599,
158275,
107900,
159380,
82817,
null,
493682,
47270,
243352,
198930,
504809,
325171,
24247,
11158,
236575,
43105,
14035,
166238,
152171,
null,
253938,
149387,
26775,
371734,
111125,
373753,
187682,
38082,
null,
240380,
18090,
18687,
304718,
50082,
311761,
8322,
23617,
70663,
30981,
18286,
154780,
291725,
161586,
245021,
375492,
24802,
196032,
275812,
67346,
293382,
171688,
42563,
296056,
6752,
188302,
233570,
6876,
327103,
26650,
480304,
51078,
225011,
null,
177069,
38830,
131856,
null,
43072,
82600,
107925,
33482,
11552,
38846,
139476,
19262,
60687,
140124,
290558,
8065,
95287,
58716,
262530,
184481,
282502,
235282,
25954,
363765,
16876,
22232,
160007,
24454,
121449,
35580,
12222,
103338,
37141,
50996,
86621,
21435,
36456,
null,
36852,
19854,
95121,
225734,
null,
100942,
392595,
437529,
192818,
10934,
23617,
250097,
280707,
143514,
233658,
145674,
12697,
191965,
29798,
24002,
60742,
34619,
108301,
190239,
408617,
179994,
null,
211279,
24529,
182649,
397123,
119737,
356961,
null,
19140,
296910,
147538,
164139,
22350,
40979,
60536,
204206,
10547,
72486,
null,
164668,
42003,
51977,
536130,
null,
1379,
null,
114298,
170954,
341173,
18814,
13530,
20460,
180730,
299799,
408706,
6141,
2331,
495939,
null,
145531,
157539,
621428,
null,
null,
194059,
85988,
null,
26422,
316795,
458380,
397832,
28404,
12571,
43012,
574806,
85827,
101782,
358872,
451892,
38723,
9547,
88900,
9844,
316889,
51825,
153427,
264562,
436297,
113626,
24289,
138910,
70634,
158943,
28536,
23656,
51344,
37554,
30194,
126160,
10000,
9283,
488064,
null,
33642,
52268,
11603,
25931,
991051,
73795,
64054,
163115,
243445,
165243,
82798,
133130,
18277,
31074,
103667,
503714,
168056,
642402,
10159,
169058,
47093,
93561,
null,
158400,
27524,
18852,
122179,
34801,
289986,
891296,
40925,
44781,
225141,
7272,
230614,
null,
32451,
25098,
35130,
null,
31675,
149961,
94159,
15895,
4767,
93748,
5353,
232975,
204720,
451868,
71724,
80646,
16689,
17510,
37828,
77470,
13815,
21263,
267869,
95229,
334687,
44882,
19419,
63109,
35300,
null,
363728,
149160,
9440,
238095,
268420,
183969,
9326,
119858,
65715,
50566,
19956,
296330,
143166,
330443,
197594,
243207,
163337,
166225,
289066,
10079,
71449,
45608,
17856,
77393,
null,
11483,
598300,
254568,
37458,
112489,
144209,
null,
10027,
168084,
167469,
58287,
23983,
182651,
154853,
136906,
808556,
46584,
262205,
857422,
69430,
32534,
48262,
345607,
53686,
202698,
79286,
257162,
382400,
148432,
187827,
295163,
191573,
1225,
10183,
29256,
45023,
4656,
58790,
22164,
22370,
34206,
62469,
15031,
83461,
56960,
449071,
72949,
227079,
10108,
33068,
555514,
185723,
152396,
253303,
null,
35842,
250853,
722094,
222682,
null,
16613,
null,
9654,
107816,
335893,
null,
181743,
67570,
363757,
248386,
42818,
40393,
276005,
59906,
25240,
30622,
215249,
302948,
30976,
208467,
152841,
31904,
626208,
22491,
45771,
410801,
9896,
40873,
258661,
47689,
258769,
205231,
52907,
null,
78885,
190232,
28408,
199959,
82629,
39079,
28927,
116577,
null,
274918,
null,
4720,
83449,
null,
492767,
null,
3806,
75280,
173100,
299657,
1179722,
322114,
31247,
42883,
12056,
null,
214469,
null,
41656,
318520,
197544,
365035,
271100,
6646,
127642,
250503,
19227,
48069,
11646,
17921,
214230,
300738,
20212,
429154,
172024,
27816,
55941,
300595,
4939,
110850,
350900,
17581,
33977,
15295,
343099,
617988,
10984,
20124,
10723,
71739,
198843,
37264,
237204,
364690,
53185,
16867,
12998,
171586,
20316,
230769,
526983,
44790,
203402,
112414,
18823,
null,
null,
383509,
12012,
null,
null,
4655,
67278,
30346,
206963,
56403,
35810,
190885,
300195,
144918,
56479,
166026,
34733,
37361,
358306,
28180,
23321,
95789,
87223,
29093,
161388,
null,
57788,
246149,
603184,
24542,
208717,
6072,
23290,
110962,
341243,
54841,
30929,
null,
58866,
29900,
7464,
13830,
272615,
31500,
12134,
5867,
44176,
11919,
null,
67537,
62262,
552631,
35820,
207793,
103221,
56398,
21314,
200945,
13058,
133399,
31365,
66767,
null,
null,
200082,
108099,
78873,
51967,
46712,
214179,
231699,
21715,
null,
19126,
29933,
26928,
1177,
7674,
115709,
218459,
13276,
458856,
33157,
283386,
209669,
329226,
364936,
296214,
90951,
36550,
47594,
333433,
31387,
163996,
44628,
254080,
239660,
9548,
null,
24661,
207014,
298539,
28249,
148647,
195493,
216873,
86148,
47399,
184701,
719676,
50171,
171574,
212506,
460763,
183856,
52383,
180078,
12632,
218337,
129572,
14531,
88991,
20644,
154566,
276277,
138414,
null,
115337,
91397,
81723,
154615,
369096,
190640,
363472,
11033,
188685,
8909,
54961,
119427,
136465,
361033,
385526,
18187,
23410,
61980,
57804,
206844,
288319,
32185,
227700,
223009,
356089,
25153,
21073,
166275,
13136,
105205,
8001,
13091,
322053,
null,
112419,
null,
141227,
276063,
8349,
240182,
285905,
28310,
32022,
390640,
136674,
null,
null,
132330,
60752,
null,
36652,
209755,
31785,
25525,
17392,
32706,
26378,
91912,
76517,
13039,
null,
205718,
53694,
69322,
9358,
23742,
139008,
30642,
90245,
104833,
31277,
173255,
198110,
208138,
39533,
105409,
121844,
29722,
261745,
38327,
160036,
160499,
222594,
11086,
86342,
2949,
40825,
398713,
702637,
168228,
28072,
42770,
42941,
135565,
28690,
264428,
18158,
9764,
509943,
87511,
168151,
6708,
31894,
87599,
188549,
38406,
null,
245126,
59254,
40525,
36307,
69261,
440927,
6043,
107151,
7763,
28361,
18350,
null,
206640,
null,
190567,
184514,
null,
21867,
481348,
124362,
233302,
735104,
74518,
11117,
185970,
626651,
37382,
null,
203839,
300011,
13569,
29638,
11518,
37009,
31193,
100470,
23304,
178572,
16024,
90360,
17628,
348927,
287932,
27876,
null,
149511,
80325,
105157,
213372,
216038,
287490,
353271,
18286,
530299,
9861,
null,
221873,
285808,
null,
70959,
358473,
8923,
35674,
11796,
322574,
35593,
null,
267664,
184227,
24199,
69723,
184017,
39360,
25202,
220150,
21854,
122635,
21136,
308128,
20924,
51031,
37937,
28175,
134991,
255098,
159272,
283916,
28118,
149653,
229404,
220948,
52368,
11684,
186201,
32502,
107982,
10613,
28488,
301685,
19305,
34979,
61676,
42913,
607411,
12763,
962183,
39147,
12407,
290989,
152891,
193174,
23050,
29272,
46810,
366958,
7582,
2043991,
450064,
60644,
237724,
null,
null,
236246,
58449,
51941,
59397,
171913,
null,
74008,
null,
34324,
46717,
204039,
null,
158986,
20637,
24841,
79029,
257724,
8443,
355888,
null,
140652,
97841,
324283,
22650,
241144,
274885,
344586,
null,
44030,
51832,
58110,
null,
210702,
30139,
120235,
18381,
26393,
253928,
79328,
256161,
200646,
365120,
97339,
3307,
null,
179966,
156695,
191826,
443433,
43235,
30610,
279954,
116019,
213339,
106847,
null,
164661,
10401,
118007,
16626,
78827,
214918,
181108,
622825,
38653,
259200,
77588,
212458,
54801,
31775,
361354,
21740,
188017,
25437,
null,
14431,
109081,
43156,
96746,
31674,
95594,
null,
254058,
4025,
115754,
12193,
4324,
10200,
194317,
130389,
4513,
256565,
364269,
8558,
18610,
null,
279078,
167881,
20848,
149097,
38268,
376716,
28296,
514692,
179341,
5069,
null,
265671,
61348,
317367,
92512,
6682,
13375,
43248,
11031,
10586,
61604,
11126,
73606,
23691,
null,
366548,
40167,
138691,
86886,
43791,
120117,
27589,
167269,
188239,
403249,
427900,
129294,
323021,
37610,
59845,
16881,
47810,
120363,
47935,
38945,
10459,
204919,
59644,
7513,
43025,
97334,
55998,
17640,
62358,
128463,
200773,
694698,
214828,
216781,
370534,
86650,
351773,
30484,
null,
243725,
56139,
24156,
9315,
138397,
352982,
325607,
579255,
16506,
34013,
251099,
41066,
7604,
49285,
10182,
280370,
323471,
11943,
294463,
258492,
4203,
252720,
41204,
330966,
18583,
13436,
45854,
48000,
639429,
20784,
163112,
44528,
427944,
18214,
39463,
null,
111753,
28915,
441962,
null,
85952,
153292,
22912,
68237,
160175,
399663,
103613,
96052,
14674,
252456,
6968,
22643,
12963,
189530,
409403,
null,
null,
55406,
60021,
null,
13885,
33601,
247855,
75855,
124917,
65821,
null,
32755,
237127,
86141,
7686,
null,
14697,
112138,
16323,
21991,
73042,
289701,
296103,
33548,
875664,
30480,
41884,
439778,
123020,
128783,
319195,
60757,
68509,
79749,
290902,
209569,
132019,
null,
25569,
57885,
272805,
50165,
114848,
5020,
38275,
102109,
73998,
null,
519897,
291244,
472365,
26119,
236057,
15454,
5396,
227451,
422331,
70053,
48088,
59443,
33075,
265554,
287740,
9995,
17916,
175067,
103056,
92950,
17255,
60872,
128195,
52863,
17888,
366830,
142159,
204162,
null,
271157,
141801,
102001,
27371,
142065,
273397,
33919,
256014,
33862,
17839,
107746,
358397,
477651,
17996,
262222,
null,
88551,
2127,
89385,
6362,
158073,
21021,
22493,
53405,
22904,
54694,
23865,
301737,
194162,
70151,
20976,
406776,
80735,
233646,
13785,
null,
115665,
308786,
10831,
13411,
243257,
5988,
35545,
41214,
null,
431282,
204353,
6938,
27927,
30797,
469091,
18539,
8507,
1158975,
47576,
null,
28089,
42830,
6016,
23220,
19658,
18887,
21905,
429739,
95339,
200437,
160267,
210103,
null,
null,
35765,
29639,
161968,
484041,
88139,
3599,
74531,
201940,
229749,
286511,
38874,
31144,
35564,
145456,
105553,
30679,
256315,
null,
7270,
260409,
38067,
33873,
105293,
145171,
340312,
94099,
133500,
34630,
24600,
22646,
16072,
371204,
155769,
323693,
267309,
240853,
9393,
268679,
39395,
236290,
46110,
60095,
34589,
7840,
198203,
178765,
null,
787933,
725616,
171893,
38184,
52891,
47580,
28206,
60705,
133225,
28471,
248297,
130169,
null,
31797,
156535,
23862,
403251,
612052,
33749,
23314,
120585,
237655,
null,
78130,
80471,
185572,
452903,
129846,
112798,
12004,
35468,
188507,
14425,
97023,
198204,
154402,
52474,
188030,
40802,
2873,
39805,
449252,
41711,
295625,
485735,
null,
110975,
49558,
24016,
43460,
35279,
67169,
192884,
36109,
48576,
161639,
193442,
null,
16881,
269792,
260654,
16162,
172737,
9722,
620670,
185448,
109484,
50506,
71133,
201403,
306007,
67936,
79657,
53490,
829578,
62095,
33587,
104945,
20912,
40296,
27406,
41907,
16114,
84833,
255467,
107198,
14999,
71960,
431646,
24320,
null,
324945,
81922,
17666,
314913,
28443,
68174,
4247,
16261,
243444,
400325,
49013,
null,
421562,
214441,
228129,
5573,
13345,
51688,
26380,
98006,
256490,
527739,
148124,
199128,
22255,
170331,
6686,
14785,
88905,
135199,
324859,
17998,
30903,
26131,
72839,
192391,
null,
28920,
66859,
45612,
43591,
361464,
41578,
24815,
18838,
17097,
321769,
158320,
null,
14977,
311121,
41424,
null,
76193,
86548,
28486,
108574,
142787,
30058,
38278,
15806,
133908,
19717,
4235,
141516,
160437,
212693,
7182,
309870,
224236,
222824,
224152,
301655,
39927,
177808,
14034,
43436,
59067,
112010,
153538,
40422,
17597,
null,
156838,
366771,
94290,
331366,
57349,
22058,
27740,
195924,
25701,
55999,
129774,
37742,
137841,
36987,
16125,
null,
null,
3737,
15942,
null,
43263,
12796,
5441,
14248,
180811,
17020,
12878,
154913,
71317,
291198,
441664,
221095,
47295,
280687,
343934,
19779,
46603,
417849,
36612,
48596,
256801,
262012,
24703,
23448,
41041,
323232,
431810,
null,
null,
184270,
76446,
14488,
36973,
153270,
31829,
7827,
181438,
168507,
469375,
29111,
96390,
40483,
103233,
17657,
35581,
253761,
208265,
10316,
68614,
null,
23179,
137857,
25523,
213110,
87496,
62147,
36538,
43722,
142817,
62944,
24998,
446710,
129715,
93756,
27962,
16455,
190680,
150102,
165558,
108813,
29857,
50420,
null,
531687,
83165,
143717,
48652,
358495,
348409,
374892,
30897,
464105,
72611,
null,
494595,
159409,
16804,
220530,
null,
364100,
28012,
82831,
9265,
136199,
308468,
206743,
null,
229459,
null,
325551,
360313,
126996,
27274,
83578,
23538,
581814,
109109,
38929,
259215,
25653,
36385,
300147,
21278,
67532,
138071,
59462,
68866,
null,
274891,
154320,
6807,
171270,
59002,
178439,
9365,
212082,
908655,
108642,
331759,
147382,
null,
64831,
29126,
258760,
1925,
126390,
182934,
231821,
null,
102736,
157497,
465710,
210156,
null,
279394,
264389,
137638,
29075,
24375,
55846,
192980,
233463,
151267,
363157,
null,
81149,
64634,
49163,
68389,
19740,
70937,
null,
null,
152246,
13856,
52128,
62094,
200614,
260600,
174210,
421308,
117057,
6696,
41107,
31093,
56840,
176419,
82893,
9664,
21683,
17276,
115973,
55872,
null,
210303,
19726,
108892,
5780,
324592,
71165,
240079,
26855,
99136,
77804,
204453,
68531,
14391,
138961,
27985,
40623,
326044,
2954,
124691,
37946,
156423,
161721,
68475,
349030,
40767,
48331,
41393,
210528,
211937,
279471,
45531,
147908,
121229,
175527,
162095,
167405,
365453,
9614,
21286,
122560,
86183,
22957,
193109,
162086,
197321,
14069,
5159,
19769,
149392,
196470,
34561,
28769,
9118,
22837,
30661,
196702,
10945,
203888,
681911,
null,
329528,
82883,
22133,
480070,
412503,
174947,
186689,
28662,
50884,
380783,
147113,
17214,
33402,
43333,
378356,
334100,
21335,
48305,
265642,
19620,
253843,
null,
21591,
22957,
37707,
157543,
11153,
52990,
55994,
19260,
205925,
431775,
120869,
291331,
23675,
37621,
892602,
17619,
59471,
13635,
120617,
243933,
10425,
null,
71927,
61268,
391009,
11026,
219390,
11823,
40157,
212175,
483122,
124549,
null,
312892,
156131,
38716,
29300,
63682,
15594,
122121,
192938,
374823,
16459,
259587,
140690,
14286,
86868,
27202,
473635,
null,
41258,
242897,
173706,
238525,
null,
268240,
9670,
64157,
93116,
20351,
322321,
13935,
null,
432149,
76175,
35881,
12919,
2700,
17805,
14457,
398402,
258751,
21771,
248001,
79587,
25701,
187021,
148174,
295784,
345037,
189309,
28588,
31850,
135397,
115225,
467607,
44778,
18605,
230549,
162469,
49193,
43547,
14272,
null,
171997,
13976,
21272,
70072,
77788,
5988,
92497,
399945,
67082,
431728,
42592,
125736,
20967,
310323,
null,
null,
10390,
32765,
627361,
139294,
25989,
10019,
136188,
39732,
25291,
15034,
8998,
30232,
109493,
5849,
50107,
24194,
225320,
100049,
251330,
null,
64969,
80496,
31792,
63418,
104595,
230658,
265994,
51022,
200461,
448679,
234588,
16100,
16512,
102114,
396470,
60836,
null,
48517,
426705,
78113,
321946,
176331,
268013,
317006,
32496,
null,
31100,
347954,
null,
null,
null,
12991,
154947,
241184,
46418,
772429,
null,
588207,
218499,
22840,
123553,
251939,
5379,
363063,
47397,
158942,
null,
86239,
28458,
null,
null,
23111,
24499,
78013,
67261,
207331,
null,
137869,
6132,
177720,
24769,
253747,
17524,
null,
37367,
48922,
null,
244085,
395739,
42321,
40073,
24545,
58113,
18047,
79277,
17698,
186607,
271984,
146957,
null,
38208,
301737,
14397,
312868,
106099,
3414,
31056,
305523,
49320,
null,
72482,
99567,
49850,
480495,
32264,
7899,
357902,
28237,
37291,
35966,
11485,
6624,
201206,
279328,
209618,
48614,
93008,
334184,
205425,
47590,
163066,
35516,
61506,
229635,
15419,
69687,
2393,
40327,
16084,
112578,
30698,
8502,
312701,
16743,
28268,
101242,
207335,
41945,
27934,
71628,
50490,
221986,
65563,
310738,
10238,
64770,
33466,
24887,
29390,
299265,
132301,
227825,
149535,
84415,
15103,
257955,
127379,
39050,
73436,
null,
225813,
264924,
null,
26160,
201270,
46845,
298928,
19801,
161408,
22894,
142762,
37823,
53653,
87242,
323587,
28413,
172698,
15683,
71268,
53949,
null,
17762,
412485,
181026,
200559,
275627,
121749,
305103,
44417,
6400,
49910,
37915,
30487,
25743,
240297,
241925,
45400,
355499,
1090199,
67489,
321432,
27359,
27604,
236269,
249011,
83921,
2408,
81552,
15344,
239125,
249324,
205751,
546178,
146598,
184862,
77051,
296234,
34067,
332694,
124163,
228907,
10524,
31270,
250334,
61500,
247415,
65349,
22968,
36861,
134375,
46262,
182962,
null,
304148,
33120,
337677,
null,
205002,
33625,
45624,
345779,
124787,
90114,
61722,
null,
16006,
4660,
27960,
63208,
221175,
42278,
486799,
259944,
365643,
408971,
195896,
212526,
31916,
7090,
7183,
19624,
17470,
11152,
25627,
81451,
30739,
420138,
14761,
192692,
null,
17171,
142190,
222139,
196977,
44847,
263503,
242268,
172329,
149799,
24061,
172513,
93730,
null,
251573,
174244,
145985,
10475,
424404,
null,
88830,
34500,
52126,
293255,
330365,
123386,
74017,
23223,
24591,
752026,
24803,
null,
26476,
295017,
17708,
291831,
26944,
55749,
141684,
98086,
272070,
27798,
174884,
419395,
null,
182398,
171355,
33004,
23796,
65600,
7049,
35655,
105918,
null,
65387,
65931,
null,
227504,
286902,
37055,
33891,
39134,
42295,
85559,
151105,
38611,
48696,
79839,
52415,
88835,
3630,
67599,
410026,
30432,
9277,
null,
78844,
549792,
120124,
115190,
112209,
449740,
19713,
71492,
null,
178791,
96224,
279558,
255792,
286823,
null,
4780,
60259,
31764,
253618,
10802,
339464,
42966,
4294,
10204,
64139,
62838,
235862,
80847,
21422,
44119,
3210,
92477,
228299,
38243,
24074,
18088,
304062,
153321,
40203,
55240,
43252,
null,
261529,
27515,
91427,
null,
5454,
33721,
247673,
101724,
43995,
66160,
124705,
54635,
68773,
44610,
38289,
62297,
381943,
null,
19054,
31874,
242202,
62197,
199602,
31506,
25928,
12854,
10713,
390918,
68207,
5884,
143269,
null,
9485,
72060,
97831,
215551,
227339,
8122,
72049,
303426,
22066,
248620,
51717,
42461,
83301,
31279,
178342,
32277,
33230,
25775,
203931,
23283,
17980,
324431,
101314,
null,
null,
106003,
null,
158834,
9736,
246104,
17953,
168211,
207116,
26709,
25736,
128163,
518370,
311160,
38298,
120566,
391619,
144688,
40148,
15853,
63811,
40063,
16178,
77338,
298006,
null,
34305,
96262,
339371,
252135,
14336,
null,
52401,
72777,
42179,
27588,
35544,
28125,
10686,
16062,
50610,
null,
46627,
64176,
54137,
75567,
30679,
183119,
40607,
43433,
190394,
224121,
53990,
114334,
249067,
67192,
12954,
49575,
1085912,
140760,
262666,
106583,
230731,
7204,
65944,
35704,
33752,
27192,
30945,
95537,
165707,
43584,
14285,
92556,
117643,
13285,
164611,
185263,
174286,
27100,
27138,
125838,
50009,
397655,
52627,
89005,
292743,
913925,
22964,
215585,
35069,
4104,
242942,
149838,
28696,
220751,
91352,
499564,
317943,
null,
3777,
203430,
58000,
145391,
38276,
287688,
30810,
388997,
220091,
26454,
96994,
218453,
95753,
30294,
234594,
null,
129997,
null,
340563,
44550,
51686,
70215,
null,
210515,
58565,
172049,
192971,
18779,
37425,
26375,
68849,
15206,
21729,
11860,
22482,
38458,
163926,
69887,
19049,
250500,
231080,
225127,
23986,
271194,
306669,
31408,
45372,
406900,
17528,
209310,
177332,
31367,
37367,
48194,
null,
null,
67736,
6251,
187039,
354311,
31544,
314869,
98274,
198400,
447953,
137505,
591919,
13129,
26959,
231530,
43406,
137545,
5656,
10573,
550404,
497889,
35666,
99085,
62549,
275690,
367743,
36393,
375189,
19096,
241001,
283124,
45527,
133919,
717036,
20925,
null,
418960,
21844,
null,
null,
291895,
1236650,
181690,
188895,
261171,
139236,
278189,
null,
356768,
47908,
1069743,
75671,
306718,
7900,
257864,
469971,
49714,
186010,
null,
23153,
52814,
181699,
32590,
199030,
144924,
11333,
87829,
2060,
190060,
13710,
279556,
199129,
null,
19033,
209827,
null,
71215,
65906,
35884,
10170,
30444,
342009,
248109,
98442,
36610,
115511,
191720,
233337,
200633,
289920,
58956,
290008,
197189,
19293,
24383,
null,
null,
151576,
6652,
null,
167615,
346460,
50586,
65942,
407473,
261671,
16771,
65974,
149216,
172584,
24599,
379202,
1727023,
24000,
448879,
null,
18847,
51766,
513530,
233460,
53077,
40748,
15648,
211275,
192971,
null,
34944,
32983,
null,
33509,
227199,
146594,
71178,
202339,
180957,
null,
78297,
null,
38935,
23188,
50192,
null,
55896,
6843,
null,
27199,
12205,
170420,
170217,
5667,
209905,
44518,
91991,
31825,
62544,
300641,
40470,
36235,
10589,
64240,
116188,
392394,
312137,
23346,
53693,
26835,
58508,
57331,
14151,
166378,
null,
278516,
182135,
null,
null,
241920,
24279,
50633,
137524,
209599,
831949,
13360,
40066,
2338,
17437,
10744,
244772,
48636,
22646,
74742,
140474,
123449,
null,
171643,
6678,
360650,
159249,
172494,
123936,
368990,
1217,
13906,
344875,
61446,
137380,
79504,
364515,
188467,
319961,
28223,
955426,
106017,
null,
21468,
27826,
100368,
431000,
155251,
13998,
16251,
null,
186667,
null,
62838,
160187,
14829,
6030,
272366,
166947,
3144,
112911,
null,
91182,
31524,
null,
225767,
324848,
40371,
51319,
292231,
null,
28060,
287452,
61146,
337075,
13320,
271303,
5633,
97195,
null,
70292,
12520,
18722,
7455,
null,
64445,
null,
157821,
4992,
3623,
13554,
32806,
51685,
5915,
51717,
34293,
51787,
70942,
401561,
51960,
61584,
null,
18494,
246798,
41136,
96377,
55286,
null,
106590,
901887,
28292,
null,
18395,
14014,
41560,
30705,
302592,
62817,
null,
5990,
36686,
null,
184141,
15905,
4033,
37390,
80160,
14409,
701862,
281024,
53625,
20764,
231807,
55238,
30765,
null,
37529,
7573,
11454,
196399,
36527,
231019,
7743,
40056,
66943,
62773,
20719,
146746,
17749,
24672,
121474,
151579,
null,
41140,
487315,
27223,
46755,
97086,
246595,
281263,
44806,
86363,
73576,
48865,
null,
49538,
433472,
133068,
39311,
31667,
45539,
217752,
52652,
70760,
50142,
137805,
300858,
350629,
354634,
266344,
29296,
5100,
4812,
50681,
200839,
238705,
50659,
5076,
21426,
57739,
25229,
239945,
34329,
3929,
367935,
114525,
79348,
39016,
84253,
8573,
24992,
59793,
62471,
null,
92011,
19137,
592283,
60192,
196423,
9703,
51354,
371395,
155683,
111097,
406376,
47712,
413531,
313269,
72038,
343851,
171356,
null,
105797,
26615,
28241,
385268,
24585,
57406,
185564,
462695,
31203,
25712,
null,
544037,
32567,
15258,
278247,
3321,
null,
59468,
325942,
17515,
274481,
123043,
20774,
134106,
25023,
70683,
23020,
52857,
154802,
null,
42112,
99763,
null,
26112,
29835,
48121,
111102,
15919,
13239,
83931,
22303,
370601,
30408,
487732,
326908,
36861,
null,
183481,
null,
22253,
null,
20023,
102639,
118506,
27790,
310507,
null,
35657,
43588,
329173,
28140,
302777,
217682,
4368,
32469,
29706,
598464,
69434,
108812,
25902,
160055,
349009,
131055,
20184,
43671,
20498,
214110,
252509,
53230,
23319,
148605,
29245,
52174,
null,
10525,
549700,
null,
33207,
56156,
36363,
77264,
14204,
54253,
510740,
214720,
292510,
35676,
null,
null,
17257,
37342,
null,
53847,
19999,
null,
90532,
20650,
23764,
671720,
142712,
3956,
230245,
697466,
130715,
28843,
53843,
48874,
146621,
428407,
355163,
129919,
341386,
21705,
20139,
38861,
307426,
303420,
57026,
156951,
null,
20604,
46951,
221898,
20870,
589479,
17891,
7507,
408625,
null,
138336,
59917,
null,
78902,
14010,
354927,
220044,
38314,
48961,
292492,
9670,
376788,
63359,
9483,
10794,
587691,
47145,
61395,
120473,
25436,
158062,
96255,
296472,
455778,
68545,
40219,
14359,
121974,
49936,
254385,
66447,
102197,
14737,
43736,
11146,
613119,
407876,
29551,
312262,
18622,
6922,
204667,
140436,
116078,
153286,
28613,
309518,
68870,
206976,
147361,
6194,
584365,
39418,
301598,
127751,
68112,
325651,
165040,
24729,
15530,
41387,
96518,
43447,
319032,
61455,
8962,
289002,
null,
203982,
665128,
null,
114602,
49876,
28940,
31374,
61763,
212107,
29720,
31332,
42100,
180587,
37370,
77777,
5040,
36950,
252005,
7881,
25612,
null,
73712,
247594,
null,
40655,
8524,
29081,
241001,
259349,
181399,
42800,
56103,
301178,
71138,
23846,
150142,
121472,
232387,
null,
225585,
12024,
10332,
15825,
14293,
128070,
null,
null,
55690,
100016,
10591,
26972,
null,
125851,
172926,
31590,
394086,
143211,
20513,
314227,
null,
46338,
47561,
4049,
24131,
135194,
28532,
39879,
242166,
null,
41966,
362279,
198926,
283287,
18917,
110543,
17246,
257458,
353998,
403081,
34460,
85834,
300465,
null,
263407,
4528,
59079,
217092,
18180,
49655,
208113,
10854,
50633,
330891,
178193,
114853,
null,
161511,
687429,
46811,
23782,
278223,
null,
291876,
17269,
157194,
38300,
203844,
166324,
58517,
8410,
4747,
612712,
42088,
168779,
70845,
236379,
17430,
11904,
140577,
188752,
185054,
353355,
25916,
586481,
194275,
214588,
105529,
75579,
14563,
206241,
237016,
null,
84572,
null,
154980,
null,
30478,
15442,
41099,
7016,
28151,
176441,
453695,
138554,
28990,
33851,
17342,
137734,
161012,
6682,
15820,
414981,
56328,
69803,
378185,
377214,
188534,
380834,
144791,
289426,
16897,
33392,
13847,
333979,
177033,
254346,
286559,
267803,
28394,
28281,
138943,
71155,
129734,
48524,
208929,
143930,
null,
42662,
17389,
19936,
28743,
null,
87989,
217391,
null,
19314,
46923,
344830,
null,
33159,
13519,
23496,
178592,
null,
24275,
108867,
null,
330662,
187783,
78516,
37078,
207418,
null,
40754,
53932,
259433,
162082,
239593,
null,
207990,
312393,
85844,
null,
16570,
39323,
235318,
391301,
340778,
205075,
25679,
null,
11782,
446087,
61941,
9178,
69039,
72566,
119870,
60201,
123112,
73747,
396131,
73894,
257949,
377279,
121051,
253057,
395751,
215164,
88904,
42714,
30991,
101797,
156659,
240498,
190572,
27305,
48785,
337746,
48055,
140977,
446918,
null,
2022,
277467,
null,
null,
515704,
39490,
340747,
92955,
13980,
37968,
303462,
45469,
184438,
37675,
210190,
57111,
19461,
35631,
566171,
86165,
16567,
206813,
8760,
2390,
36148,
76916,
45622,
192615,
267305,
47606,
10532,
20471,
80793,
3624,
1579,
9913,
24419,
169486,
591562,
118051,
148815,
171065,
140773,
null,
17874,
null,
5436,
208627,
77726,
426976,
1011,
291265,
657266,
15917,
587840,
16126,
385005,
225344,
220524,
21283,
77525,
7756,
23880,
212826,
348763,
273752,
97907,
104840,
30434,
null,
11891,
173940,
26415,
69407,
29984,
131521,
517002,
null,
102770,
241872,
222012,
11800,
207930,
20442,
72223,
22772,
65983,
null,
109981,
77692,
null,
23946,
242009,
19632,
25936,
49718,
474302,
167859,
56247,
97354,
187955,
8987,
479959,
187058,
173497,
486724,
14615,
294962,
126278,
null,
226321,
254121,
332360,
141026,
226663,
null,
7715,
null,
10342,
198942,
30392,
37216,
184852,
45990,
301393,
144642,
246074,
33534,
297264,
30794,
356629,
34089,
902750,
355591,
50418,
null,
42025,
354760,
198301,
5663,
86392,
61756,
28570,
64188,
117162,
48413,
198579,
13652,
238783,
null,
13852,
157437,
82513,
21781,
20061,
241803,
307451,
132621,
130117,
277762,
314325,
6254,
16609,
265791,
34089,
24155,
16286,
19532,
5496,
118794,
231849,
15724,
null,
22560,
76488,
126348,
51698,
263962,
8881,
216275,
null,
213561,
40914,
33059,
208206,
80845,
29426,
29982,
18443,
31051,
26049,
63820,
30885,
21388,
246476,
17997,
240854,
null,
195166,
125946,
13572,
81099,
20849,
260896,
3537,
19004,
31780,
72748,
565478,
167748,
236690,
266508,
24634,
33677,
147963,
21547,
334547,
259944,
91371,
null,
405490,
35949,
34559,
341480,
40786,
48833,
35988,
null,
17094,
77093,
30893,
474337,
13892,
166988,
1647,
4874,
276258,
175989,
null,
81555,
21031,
233207,
null,
1351,
38378,
47402,
141178,
14821,
89144,
261002,
189478,
14906,
228876,
241771,
33651,
174045,
206177,
49838,
null,
181147,
null,
8765,
26940,
88542,
178222,
11181,
33352,
null,
null,
144854,
283620,
47763,
14358,
700136,
85573,
13560,
127914,
2692,
76893,
4541,
26350,
48073,
42008,
321203,
50619,
225568,
79523,
60751,
215136,
29122,
213536,
28603,
363028,
17228,
null,
41536,
320770,
null,
3814,
null,
null,
23071,
212105,
66232,
19244,
202370,
242940,
379025,
25987,
86242,
10098,
43128,
100870,
189180,
69473,
250108,
404489,
224819,
40840,
6096,
129225,
59463,
137224,
314740,
42255,
null,
163076,
10904,
58607,
42946,
370333,
87481,
17902,
180599,
52057,
133464,
39159,
378746,
281556,
57310,
null,
193655,
241170,
325690,
47910,
27699,
50643,
403170,
null,
384342,
177810,
4570,
56655,
145199,
17478,
229554,
18170,
317001,
17231,
94684,
28528,
349903,
170775,
null,
4629,
18675,
79865,
172929,
95451,
151466,
150974,
178945,
null,
9652,
33977,
15725,
null,
34371,
45238,
57223,
287831,
186744,
17519,
219579,
379719,
null,
42952,
334378,
35876,
47473,
10424,
60468,
109071,
362364,
347497,
127841,
415482,
159897,
147526,
71105,
333237,
125437,
211486,
6679,
50384,
31265,
23391,
65866,
179923,
21477,
null,
225870,
280827,
651246,
45915,
39341,
502113,
2288155,
202482,
39024,
136562,
26870,
140952,
null,
23740,
337024,
170966,
49630,
26167,
172257,
279168,
38259,
39650,
374875,
43635,
140803,
30201,
239318,
30961,
30917,
28281,
56459,
124412,
443949,
172798,
20170,
29216,
null,
358595,
69793,
null,
498364,
178418,
27830,
null,
null,
115579,
39298,
33092,
21402,
93087,
35847,
45008,
197745,
11877,
142367,
99822,
142671,
null,
375279,
null,
142544,
null,
26233,
49720,
54087,
162411,
104997,
106703,
37268,
188447,
209500,
452353,
179582,
177489,
287096,
null,
16204,
104093,
49248,
177262,
30429,
19365,
75235,
184699,
173707,
26877,
52843,
283827,
169642,
397500,
89245,
128106,
44021,
6159,
18041,
445414,
65499,
203751,
29167,
58067,
202871,
177000,
61824,
214732,
20389,
17577,
186589,
31489,
353784,
141903,
5415,
294986,
22688,
38377,
43586,
46439,
54620,
309423,
579584,
45523,
6714,
null,
33262,
60914,
267869,
416052,
39748,
276640,
354430,
320894,
93598,
438779,
52725,
186382,
44217,
20681,
141700,
597718,
120307,
579795,
139100,
17759,
38672,
143800,
110209,
178341,
264578,
285419,
37995,
24530,
268026,
167318,
61761,
103425,
178539,
223093,
318019,
626677,
161934,
174528,
340052,
55182,
90811,
null,
351895,
231007,
247991,
638270,
13134,
33355,
18465,
null,
289722,
40611,
13495,
321040,
127905,
419475,
338833,
136994,
16932,
12502,
24367,
18396,
37312,
null,
345354,
63013,
235995,
64258,
7618,
null,
219593,
62081,
143819,
91962,
null,
null,
250900,
41805,
null,
27328,
30251,
77952,
2852,
null,
45129,
302276,
283899,
101696,
43192,
19090,
354806,
43184,
127944,
35365,
93447,
180891,
34971,
204856,
34962,
21941,
39799,
11406,
null,
116479,
230390,
90388,
156363,
61549,
17750,
427959,
11901,
23023,
163464,
315061,
3112,
null,
423367,
303228,
176155,
17070,
299808,
288259,
156649,
366361,
7576,
53102,
5288,
1332,
null,
81386,
277889,
426437,
44740,
4770,
26128,
13117,
85301,
29122,
null,
70909,
30913,
25564,
40742,
16552,
127728,
21144,
12596,
9499,
48253,
44208,
null,
38642,
169726,
66255,
426525,
29386,
306884,
95738,
252183,
208010,
34174,
196082,
205738,
308539,
6019,
null,
233342,
22588,
null,
286760,
280856,
16550,
169119,
8454,
339044,
29145,
308032,
265417,
169007,
49030,
108871,
12543,
867989,
306722,
300723,
47393,
578659,
37612,
23120,
32650,
249688,
216006,
16736,
252927,
204640,
34380,
274412,
25827,
113057,
281958,
26178,
162137,
15629,
173358,
44206,
31674,
20735,
41174,
8254,
17621,
142541,
85553,
22130,
65224,
85228,
30677,
10399,
302413,
45854,
200165,
null,
281572,
517837,
470102,
30370,
194178,
123709,
126399,
21064,
36342,
32976,
48397,
62833,
66122,
14477,
251805,
144725,
null,
26664,
230568,
25032,
429947,
143556,
null,
null,
150446,
608889,
144370,
154610,
436150,
255952,
null,
41885,
319872,
271546,
386417,
26739,
62771,
20781,
13189,
11511,
null,
null,
353496,
22325,
246454,
null,
null,
24989,
6810,
null,
120071,
144224,
528613,
181960,
223782,
215795,
15493,
668267,
33608,
24727,
61178,
39903,
151752,
12462,
54220,
206645,
17265,
null,
199302,
null,
37736,
126749,
69019,
19102,
361817,
247971,
54529,
33479,
23310,
37883,
155647,
19160,
344828,
224472,
524205,
363691,
40227,
20590,
108641,
null,
null,
5752,
21390,
14262,
35077,
62852,
25263,
301619,
54830,
29682,
371584,
83831,
52986,
16567,
56393,
355424,
383762,
313713,
251776,
110629,
270441,
421051,
32165,
11788,
430566,
953950,
172170,
26165,
419059,
null,
16652,
null,
276203,
87354,
12322,
276666,
null,
31914,
null,
53056,
267532,
143882,
11259,
37314,
73210,
21924,
381640,
219961,
50299,
null,
65712,
93708,
159684,
193990,
null,
22046,
18081,
null,
18619,
305052,
8999,
42866,
257432,
249550,
808833,
59629,
14275,
null,
null,
1212030,
166044,
191878,
117750,
460120,
333849,
29021,
18832,
79330,
42598,
295708,
18946,
null,
20436,
93872,
36440,
118412,
29743,
133286,
297249,
169553,
402010,
273535,
121850,
71787,
255101,
38766,
70287,
35621,
152640,
42805,
26339,
null,
386186,
183907,
196406,
10357,
39306,
8594,
130348,
11452,
17768,
301799,
943965,
null,
307238,
42116,
288261,
161802,
81575,
432577,
59107,
172287,
36834,
15288,
366619,
43804,
17337,
5685,
11207,
130547,
58069,
53504,
292248,
41504,
413469,
302803,
null,
40339,
null,
null,
152789,
160472,
331100,
201190,
237251,
24503,
497808,
138770,
6657,
5569,
236844,
74138,
null,
28122,
25027,
108781,
262754,
278822,
64710,
91127,
13197,
31071,
292185,
null,
49725,
31413,
271581,
161373,
176020,
268421,
184320,
null,
62695,
30242,
45705,
49399,
137573,
4988,
null,
48304,
172412,
45131,
352813,
26414,
36611,
26267,
49024,
62332,
42743,
null,
380315,
39402,
328260,
77743,
67655,
null,
null,
null,
521105,
48090,
570585,
85423,
67896,
236,
495507,
231620,
170684,
16198,
21100,
160444,
168950,
22820,
195613,
149281,
26487,
53233,
228956,
243420,
443662,
446434,
60537,
29663,
93676,
31640,
26874,
12782,
310681,
43586,
500657,
null,
251035,
295791,
348600,
null,
155720,
4466,
270587,
171312,
35577,
null,
173248,
null,
205379,
219677,
null,
1867,
44797,
31856,
7091,
278805,
56801,
14317,
null,
null,
25882,
39942,
240157,
18001,
47282,
263675,
155139,
21242,
27594,
77355,
246948,
null,
14401,
218195,
273756,
90734,
234087,
73117,
null,
null,
12754,
23898,
151190,
202144,
98153,
25123,
48850,
null,
38435,
42097,
201044,
18553,
14482,
66412,
273746,
47040,
21183,
28981,
51017,
309916,
15217,
37797,
20962,
137828,
109834,
14987,
22274,
41322,
40062,
10360,
188208,
222,
185663,
234554,
254784,
null,
279711,
76640,
321488,
76089,
238541,
37346,
24506,
94275,
37596,
46891,
32820,
54278,
36067,
null,
212546,
189131,
4049,
212537,
14323,
null,
215574,
286088,
96872,
122705,
53813,
163487,
35030,
29825,
14778,
201090,
254099,
32119,
null,
17959,
261940,
24025,
25836,
118021,
57360,
203627,
82887,
320298,
39449,
566847,
239296,
41782,
208600,
36439,
9188,
59736,
216488,
16642,
34359,
45905,
6091,
null,
14479,
36712,
509758,
null,
268508,
411167,
327514,
142164,
2443,
22166,
7139,
178465,
33173,
98287,
6597,
251438,
80674,
35288,
265678,
82671,
42111,
46189,
173486,
30510,
24897,
156522,
256340,
197301,
183101,
54527,
9877,
38486,
28424,
27674,
12001,
182202,
91976,
93839,
122646,
null,
13742,
142019,
189462,
135871,
45083,
116244,
24284,
49631,
5959,
303747,
33594,
573401,
39361,
418322,
null,
385985,
null,
37413,
3510,
77314,
72823,
null,
1477057,
387559,
23344,
172626,
338242,
102018,
null,
171167,
109620,
286434,
122543,
null,
157460,
75083,
79701,
28435,
114023,
34296,
31441,
44611,
93066,
31945,
33780,
132491,
562062,
48757,
292324,
340350,
74429,
33964,
null,
null,
266491,
101620,
93449,
231508,
28519,
32787,
118822,
626537,
299901,
null,
32798,
139670,
null,
117823,
null,
83180,
39331,
555965,
154189,
42659,
16516,
11333,
392945,
7809,
601954,
9719,
54047,
7771,
null,
24968,
88192,
183582,
10979,
35111,
51429,
35271,
404725,
127804,
null,
280210,
98533,
48148,
62966,
70554,
29581,
113949,
130328,
26556,
175787,
38034,
9731,
166779,
null,
280079,
null,
171463,
260569,
36401,
62634,
225679,
12655,
31114,
12618,
48165,
22859,
9465,
69154,
77524,
225757,
40222,
29829,
369343,
340793,
5457,
418621,
110580,
10148,
351701,
61970,
217816,
630226,
206485,
210481,
134221,
67932,
21138,
23889,
496816,
54851,
296824,
58518,
405339,
110042,
18968,
24008,
210250,
282152,
145353,
16769,
16075,
166909,
251368,
110820,
76093,
9877,
378072,
5289,
null,
24525,
88951,
16434,
35689,
265343,
36572,
15978,
null,
248251,
12976,
null,
491070,
104735,
503816,
30218,
170701,
8857,
103637,
28202,
66604,
3589,
7635,
47816,
377462,
36771,
null,
1004684,
50260,
149951,
42303,
8079,
8238,
null,
12136,
166225,
27894,
38739,
24860,
24514,
107467,
7146,
52550,
131231,
239559,
247772,
291702,
126808,
118826,
1810,
323391,
400558,
33558,
680045,
192198,
236102,
312106,
4038,
12434,
null,
49200,
725328,
107790,
251093,
null,
61631,
576293,
28717,
null,
178411,
333535,
143509,
63552,
37163,
44397,
22443,
65402,
21234,
16811,
32644,
37145,
21043,
13016,
8981,
62567,
70490,
187109,
null,
243721,
202730,
39138,
11579,
180601,
null,
146834,
264619,
37682,
12279,
77215,
41448,
81854,
91000,
null,
67859,
829762,
124459,
173732,
28774,
null,
29246,
119666,
null,
66439,
126224,
null,
8806,
19145,
null,
410345,
49532,
69697,
35079,
19482,
499207,
505,
16110,
171310,
283845,
37906,
223253,
81427,
191951,
446953,
62807,
11549,
null,
25100,
null,
8183,
null,
128174,
111568,
22135,
156248,
65024,
287295,
93544,
22001,
50686,
200102,
17365,
54396,
377631,
63491,
54223,
382863,
33651,
510904,
15621,
164616,
700259,
56229,
12595,
682324,
66363,
22307,
61153,
219622,
34405,
152292,
35204,
41324,
3866,
null,
null,
23293,
14867,
225537,
420162,
24013,
42097,
395102,
628260,
444712,
182219,
252714,
83635,
null,
23579,
182044,
164069,
46411,
23367,
17003,
45182,
505219,
170732,
36919,
9523,
12728,
353920,
33399,
163462,
159727,
329835,
248846,
18566,
334044,
45682,
378737,
null,
null,
9250,
158486,
429850,
88747,
424713,
33558,
76529,
59633,
223928,
null,
null,
116784,
96137,
25733,
38843,
23798,
359827,
837050,
23554,
5438,
232489,
108356,
57061,
12692,
null,
235928,
33298,
268238,
55268,
216246,
12104,
39451,
41264,
390059,
null,
248802,
39891,
134356,
34850,
241906,
54452,
null,
null,
67074,
99656,
23364,
57716,
18786,
18558,
254167,
508303,
15099,
42709,
52204,
218416,
201365,
284831,
31103,
26580,
28298,
289330,
30516,
75024,
62441,
23750,
345109,
25391,
37884,
174599,
80723,
263497,
32006,
42481,
122410,
14369,
15819,
75854,
195055,
305633,
26105,
15024,
8326,
37079,
29931,
14825,
156125,
7176,
52766,
459814,
27834,
42378,
null,
35308,
57866,
108808,
10453,
228899,
125079,
380459,
169902,
474215,
47204,
22872,
17911,
36032,
56898,
null,
25247,
41791,
45613,
47136,
43756,
null,
28570,
87149,
2954,
154842,
51906,
282206,
250349,
29954,
19677,
null,
184266,
226114,
4363,
2109,
20916,
150385,
113372,
47633,
185319,
null,
101880,
19647,
557647,
180484,
12833,
23113,
26573,
337049,
715277,
288601,
174227,
195204,
149800,
null,
40804,
346838,
196721,
27509,
157140,
20887,
11450,
70772,
144508,
101803,
265892,
43066,
2541,
241144,
30080,
14850,
35572,
9217,
240038,
51451,
93832,
40793,
18790,
30257,
107554,
326661,
68938,
19263,
67982,
100264,
20067,
85496,
318786,
55204,
19353,
38801,
90690,
20434,
null,
22959,
37408,
76245,
394536,
null,
null,
321277,
178098,
null,
217652,
38132,
370254,
22164,
466429,
355403,
13817,
129963,
16042,
47634,
519313,
56426,
237639,
126661,
50928,
216228,
null,
null,
136667,
14416,
436337,
null,
129010,
51534,
320477,
21930,
47816,
164649,
null,
41736,
202577,
null,
48027,
395283,
207601,
132306,
null,
148852,
6732,
34486,
22942,
325237,
64049,
317298,
6569,
17015,
167809,
246622,
237630,
293973,
149443,
null,
140104,
null,
15343,
45486,
28525,
154862,
7818,
18267,
201546,
282850,
320817,
15583,
190675,
null,
null,
7767,
35765,
456167,
294421,
323578,
null,
null,
361649,
25253,
325329,
65694,
26567,
112301,
495406,
323722,
324688,
58025,
105773,
52347,
57020,
198983,
26196,
88517,
null,
47974,
58133,
122595,
9774,
72292,
12025,
null,
138701,
null,
19190,
153455,
8211,
80212,
35767,
59044,
11656,
206765,
112599,
44350,
null,
581040,
113439,
21841,
18219,
40177,
157117,
5592,
253912,
39374,
8456,
309337,
null,
130945,
228493,
589573,
179064,
212144,
68750,
22642,
233740,
230,
52333,
71856,
32205,
168227,
207737,
null,
26692,
null,
16094,
521145,
null,
48839,
16895,
11196,
12369,
383595,
16901,
70814,
80062,
352831,
317179,
15775,
32445,
324248,
119920,
57353,
29133,
141035,
18659,
394025,
344760,
33608,
63479,
null,
4963,
203600,
36763,
233408,
21773,
null,
71773,
153350,
20272,
30768,
null,
25270,
222568,
23117,
30738,
29732,
317,
17699,
27047,
16786,
18009,
115440,
51860,
82042,
21131,
16060,
170860,
32793,
28663,
null,
26532,
359270,
20885,
238916,
4440,
209955,
283781,
null,
226026,
17987,
14068,
182951,
311725,
79019,
20354,
null,
274219,
47470,
366890,
10084,
64226,
270842,
44816,
null,
700335,
25111,
106441,
95715,
168251,
9514,
304999,
null,
80184,
22687,
40053,
181256,
234950,
450425,
226532,
9677,
442966,
82211,
269276,
40672,
713978,
121889,
22156,
197290,
48669,
67116,
null,
16589,
247963,
13131,
30839,
85991,
10910,
89229,
152890,
62186,
44681,
304052,
168557,
381518,
122344,
3501,
40078,
null,
260341,
67107,
11991,
273588,
null,
50287,
29724,
4774,
null,
31029,
223371,
62308,
177211,
154105,
858785,
386183,
203853,
49154,
170266,
84921,
698925,
235565,
177090,
100595,
277180,
252023,
105573,
null,
15336,
29649,
19674,
8197,
244098,
189180,
106174,
253193,
163195,
26746,
35453,
355148,
37318,
26016,
233444,
27619,
null,
160119,
35521,
46960,
23616,
472737,
11759,
160647,
null,
189235,
461421,
117869,
11277,
133375,
38867,
6758,
61316,
23665,
15050,
8779,
33744,
41882,
6140,
142506,
19689,
30677,
21192,
46031,
291510,
21121,
87672,
36143,
46689,
22023,
54793,
52427,
33963,
20862,
42538,
171312,
42167,
182527,
9310,
9042,
67318,
218443,
8350,
27909,
37131,
111453,
15710,
133749,
157219,
31467,
137096,
191038,
509729,
52611,
9999,
null,
null,
380957,
154951,
208146,
52268,
315366,
13535,
88514,
304844,
203881,
252447,
null,
284861,
200548,
159379,
303208,
9122,
110001,
14373,
166494,
360324,
236276,
273598,
206731,
20384,
10257,
null,
43501,
881284,
254064,
92367,
null,
81459,
16595,
290880,
null,
81886,
40323,
null,
null,
null,
46447,
171098,
133112,
null,
100146,
240727,
95160,
258779,
375536,
135566,
129984,
178284,
98777,
83873,
3830,
281791,
170058,
59894,
244675,
55699,
39686,
171410,
33527,
null,
95973,
51692,
60585,
28729,
180726,
null,
89098,
29685,
296981,
216408,
19007,
36366,
148998,
12586,
313656,
267467,
50961,
67987,
44714,
6757,
56010,
29244,
11551,
42894,
77677,
null,
null,
189529,
70604,
27086,
355226,
110279,
118929,
22390,
468978,
110060,
608145,
197716,
264430,
273298,
261161,
77735,
22949,
28701,
348426,
66545,
44231,
317058,
174324,
17265,
18274,
153347,
138256,
320422,
497706,
74505,
11874,
20366,
117720,
80826,
32780,
446419,
411512,
36234,
214265,
null,
34474,
31376,
287160,
38121,
210469,
231508,
156815,
340403,
null,
298482,
20392,
32756,
341918,
202083,
6896,
50602,
60296,
224353,
210702,
55584,
11440,
222689,
185811,
44489,
15545,
71024,
124506,
37280,
57133,
327012,
168171,
25990,
6462,
162854,
32808,
37196,
100756,
61932,
307948,
10051,
303353,
32765,
30052,
null,
35617,
114370,
31667,
null,
7453,
363230,
547924,
168738,
23695,
80610,
203802,
38141,
null,
216987,
52120,
35456,
32168,
32626,
23813,
166813,
17760,
127149,
103297,
94909,
247114,
127836,
366330,
10974,
61121,
238147,
188160,
286799,
null,
144689,
4711,
243520,
37245,
126966,
121945,
318692,
16774,
20903,
12227,
null,
31518,
163631,
51507,
6295,
null,
10733,
167837,
19815,
133048,
445544,
38058,
79229,
77982,
34161,
34264,
null,
null,
64607,
291737,
157819,
12662,
16337,
43942,
9230,
381792,
97117,
null,
6430,
8703,
128675,
39969,
49545,
12090,
251761,
23945,
141423,
91177,
387779,
null,
182793,
395524,
17415,
70371,
189323,
46563,
200962,
327013,
228477,
145860,
231681,
null,
285496,
38290,
26757,
47844,
48872,
286939,
221639,
261916,
315500,
92061,
49005,
102878,
223800,
376696,
30362,
200960,
148786,
392809,
39884,
32120,
121588,
null,
117243,
121821,
null,
177299,
89919,
27087,
38762,
14789,
211358,
null,
26839,
314643,
34648,
25572,
1222,
630413,
201255,
59935,
53428,
47423,
161597,
null,
452029,
99170,
7777,
28775,
126497,
15113,
268198,
40956,
456706,
75015,
430199,
184645,
166607,
null,
115500,
16390,
21075,
23547,
104763,
null,
15896,
19282,
28419,
278993,
null,
148706,
192561,
10198,
40876,
49367,
141678,
21174,
39771,
46218,
101397,
15968,
174808,
27280,
null,
366648,
336779,
9512,
67329,
33998,
242559,
41774,
75163,
164320,
134015,
11646,
244125,
55370,
19479,
40709,
78634,
229631,
323077,
109013,
59204,
9039,
16310,
21123,
244688,
94657,
233616,
192060,
14452,
262230,
16631,
12673,
null,
24989,
450293,
44976,
88775,
58889,
157241,
129037,
136950,
29268,
30004,
21508,
122836,
9323,
229977,
31065,
4047,
22885,
77007,
35059,
90911,
167615,
226511,
23455,
97723,
275042,
288126,
237851,
94448,
30443,
25628,
51451,
23977,
154554,
261121,
206239,
null,
38598,
5557,
395403,
23421,
250645,
61807,
128525,
3911,
13339,
10034,
375408,
183015,
153871,
null,
152217,
7547,
281804,
296249,
183339,
473118,
17652,
50340,
67467,
46020,
562128,
83244,
243216,
null,
32621,
null,
8218,
185988,
null,
30358,
287381,
274768,
32577,
138340,
287212,
175576,
64534,
12746,
81676,
41342,
14301,
51037,
271663,
47518,
49672,
248843,
623194,
25940,
11865,
7523,
36573,
25605,
148972,
259694,
418166,
167103,
153118,
234674,
263483,
170191,
261001,
37188,
12890,
25869,
172602,
242468,
273889,
246708,
23384,
213481,
34897,
27263,
7735,
12725,
6551,
15330,
238500,
97932,
50008,
30470,
null,
19702,
352395,
54490,
25139,
428703,
75059,
65457,
224978,
5520,
191855,
22343,
681608,
20057,
42096,
12042,
null,
36112,
361079,
12786,
262841,
385336,
73869,
75725,
43821,
228232,
69927,
5612,
10241,
18801,
351956,
24272,
158349,
43837,
null,
42458,
87772,
29588,
94722,
43051,
276766,
3437,
185578,
56060,
18349,
15719,
20686,
153891,
102644,
11390,
32603,
330956,
228255,
288558,
18392,
40336,
452932,
42322,
34830,
60447,
222635,
21677,
48848,
16599,
441397,
null,
178997,
238339,
39543,
105549,
49509,
59987,
null,
51334,
443653,
10357,
null,
32679,
64429,
33407,
341273,
42628,
62971,
235866,
101328,
13341,
12847,
null,
119699,
13818,
95426,
25857,
274663,
455124,
72282,
null,
159687,
7651,
245518,
304575,
87193,
40535,
520616,
23801,
121580,
132441,
262091,
10874,
23967,
231135,
54610,
17868,
277838,
25000,
74303,
72939,
237291,
15130,
250944,
10303,
207551,
50054,
null,
4416,
164877,
124397,
152691,
5904,
210248,
327698,
42251,
null,
34912,
21719,
72473,
70498,
28252,
210346,
228982,
103067,
317278,
null,
123550,
41682,
230758,
45183,
42112,
null,
239767,
188331,
30437,
61595,
100190,
7310,
137697,
88737,
108362,
35932,
180397,
35912,
71965,
163461,
36037,
57901,
90443,
281718,
59289,
57781,
40484,
33815,
20125,
21284,
10538,
7757,
15411,
27268,
137604,
null,
26741,
1129334,
262982,
38524,
369920,
null,
37500,
5023,
76575,
16938,
198515,
9271,
null,
307296,
184898,
218254,
92062,
358098,
10370,
506712,
259518,
168680,
700404,
505059,
15470,
14341,
517267,
null,
46422,
66246,
66727,
9567,
45771,
62004,
319170,
null,
76340,
93916,
148466,
14885,
138297,
364396,
50189,
242255,
765722,
60425,
38471,
142025,
50667,
79143,
299587,
86433,
298272,
7937,
326010,
12773,
41695,
35982,
251956,
31281,
198937,
99325,
55374,
484084,
222942,
444291,
9035,
35799,
null,
24256,
74699,
45702,
92245,
135609,
150256,
57081,
788,
615520,
73783,
127969,
286260,
172189,
144988,
144573,
7728,
13362,
2875,
165572,
155781,
176929,
9424,
10132,
110095,
18923,
380239,
15662,
19653,
480668,
201901,
37602,
17227,
6726,
141510,
565945,
null,
null,
248586,
190317,
103789,
370437,
4610,
290175,
399850,
14516,
205382,
232084,
194269,
33274,
449655,
241822,
20593,
212180,
16598,
38866,
338615,
7339,
43735,
283227,
null,
171488,
95911,
46126,
175801,
755824,
22944,
268878,
242181,
32310,
395591,
7003,
17744,
6248,
93381,
29378,
98004,
136550,
null,
55277,
28093,
78014,
212759,
null,
30592,
152351,
280902,
402386,
11854,
295927,
268095,
19194,
485174,
3787,
null,
58427,
8958,
842373,
682583,
18600,
85456,
39333,
217625,
11962,
344361,
365571,
137886,
43870,
36619,
8897,
21809,
195801,
120059,
27681,
261425,
67478,
230850,
243071,
119439,
188065,
161012,
37972,
186727,
45099,
41639,
null,
25780,
257267,
8582,
47367,
131286,
4842,
101523,
58227,
160245,
28926,
38075,
8267,
13032,
298065,
209523,
191743,
523793,
49092,
60698,
21396,
55341,
227995,
84688,
108220,
12705,
4783,
8546,
110448,
335454,
177502,
260484,
45286,
495453,
null,
203051,
18800,
10794,
115344,
null,
200551,
20257,
64260,
30404,
null,
33499,
23095,
25814,
39699,
98542,
408823,
46177,
65024,
11679,
48703,
200308,
157899,
255241,
219469,
5509,
182621,
172640,
50039,
32489,
973217,
24973,
108526,
133755,
9801,
null,
28702,
104919,
null,
247618,
445684,
997,
216487,
8703,
202870,
261783,
14676,
58231,
201465,
203186,
231188,
300517,
171003,
null,
null,
317951,
232088,
15295,
248283,
13201,
null,
201262,
495019,
2497,
17837,
117945,
343121,
11519,
63731,
null,
149091,
185647,
171357,
29728,
363696,
535445,
121919,
31907,
196187,
316147,
51516,
30676,
65422,
26717,
null,
65516,
38868,
58884,
9765,
37944,
194833,
321334,
254191,
43642,
281487,
38097,
11789,
391145,
16537,
53485,
41361,
16479,
60532,
28483,
666487,
721173,
19436,
654435,
214773,
null,
9730,
147706,
304110,
157476,
70089,
86895,
163459,
101418,
288962,
248241,
76691,
158585,
85087,
35401,
264271,
93073,
173282,
251864,
152262,
334399,
60097,
81565,
173911,
44293,
222696,
277707,
38716,
32995,
286395,
220290,
436161,
262294,
214562,
null,
153404,
79041,
56497,
277947,
null,
null,
217189,
107148,
84997,
8014,
24945,
416119,
null,
52498,
27000,
80905,
383036,
51014,
13952,
22158,
41508,
22931,
162842,
4875,
35469,
31594,
6421,
null,
132197,
27630,
26979,
649842,
7332,
138315,
223592,
182213,
15016,
224407,
464777,
844206,
null,
42827,
150487,
40646,
103329,
365195,
62028,
45572,
8666,
39377,
214054,
144527,
449165,
315345,
null,
15843,
null,
26035,
83914,
442978,
239828,
93117,
261054,
null,
null,
419361,
27931,
77500,
11411,
118858,
361108,
40855,
359356,
23666,
135711,
20508,
192189,
565490,
13170,
220176,
null,
264508,
6661,
69612,
288158,
null,
30920,
23991,
571504,
319548,
126371,
420353,
88923,
18568,
285359,
615394,
11319,
292365,
21735,
231668,
38911,
27659,
65767,
310163,
null,
13274,
34534,
105285,
40070,
null,
null,
9276,
319056,
418911,
221874,
220866,
199442,
13118,
29554,
12730,
138179,
24919,
257196,
178175,
null,
661566,
593463,
46909,
242831,
15101,
238708,
9873,
6745,
107442,
333885,
53881,
237093,
50080,
43389,
7571,
210032,
379762,
130492,
7263,
23903,
13876,
95636,
30773,
null,
64648,
24153,
199273,
24954,
227899,
94817,
null,
124189,
21030,
25492,
null,
21436,
231038,
29084,
255357,
41642,
13279,
13319,
327848,
8231,
135044,
26457,
11152,
42130,
29661,
142926,
249993,
26727,
215866,
750819,
26489,
496511,
280964,
463096,
76770,
143847,
17533,
154217,
154150,
10864,
494645,
245244,
47924,
322629,
null,
null,
56838,
278266,
17203,
278717,
292001,
218786,
17580,
27207,
361921,
null,
null,
397172,
241539,
null,
53926,
15784,
184638,
20894,
null,
439141,
64674,
22004,
31647,
278694,
68785,
301142,
8812,
71031,
212217,
45240,
511891,
21862,
303126,
null,
2774,
16401,
275783,
108483,
239090,
39315,
420297,
8104,
9764,
94417,
31236,
90415,
11296,
60854,
149992,
237109,
378899,
455206,
93181,
32064,
49110,
51659,
43360,
25703,
14887,
70057,
64436,
35827,
20071,
209616,
23214,
533284,
72950,
89626,
16495,
122960,
35355,
35945,
9817,
272351,
311992,
null,
204657,
14872,
18897,
48807,
31110,
116300,
5878,
263277,
14587,
412215,
392728,
15207,
null,
452387,
72791,
46934,
31977,
12160,
124167,
34926,
null,
181235,
23697,
182876,
145264,
10313,
8554,
26328,
332763,
44757,
66268,
195479,
145291,
195339,
192241,
225304,
113010,
168196,
null,
42051,
null,
22513,
61497,
50868,
null,
20504,
36249,
43305,
41045,
10272,
67376,
89611,
50486,
260421,
3155,
16413,
312735,
565901,
359168,
34718,
59529,
32275,
27889,
197809,
266503,
164050,
189483,
85209,
15433,
70481,
113714,
61705,
344905,
2742,
21394,
82088,
161722,
8411,
186057,
120662,
87176,
6372,
22269,
221400,
337014,
2517,
185538,
null,
22572,
123176,
683135,
46297,
356243,
214215,
286501,
305605,
10696,
28771,
432809,
223269,
9973,
197343,
7721,
21026,
63363,
50690,
27028,
251782,
53688,
57757,
425194,
16020,
134436,
51739,
346762,
5283,
9200,
250982,
48176,
58118,
null,
301936,
37459,
32709,
202911,
20564,
null,
144848,
75736,
355605,
126306,
38836,
305384,
49908,
151456,
127372,
36581,
386598,
74387,
34176,
20202,
181780,
100524,
83267,
308829,
558756,
null,
2685,
77434,
43568,
62837,
null,
180229,
119099,
75423,
203501,
294463,
null,
119872,
155460,
109073,
226455,
12201,
null,
4965,
2874,
null,
16772,
679058,
208574,
51000,
55929,
244083,
72274,
370597,
81185,
68511,
null,
158341,
26316,
90313,
423768,
337493,
34058,
111269,
476005,
1779,
333593,
146950,
null,
null,
216169,
null,
307236,
83955,
75229,
63029,
23401,
196087,
220118,
317801,
114692,
24778,
36627,
248611,
8845,
56589,
635168,
115604,
5902,
12631,
240063,
53953,
70143,
871810,
184560,
22583,
92341,
40990,
47466,
101541,
46526,
681502,
51487,
15722,
143764,
null,
20395,
280496,
21663,
21831,
265515,
66345,
262134,
null,
152953,
197623,
73535,
480530,
13101,
50307,
59436,
215291,
107027,
27343,
53049,
220236,
null,
65941,
7228,
299283,
283355,
211827,
37323,
50208,
61429,
26115,
67756,
57091,
5056,
374227,
186433,
56847,
227977,
196791,
411817,
7675,
18526,
108505,
34273,
289650,
33509,
null,
206529,
178006,
63266,
29199,
55224,
206288,
78318,
11593,
175062,
146703,
180637,
382424,
175367,
205502,
59945,
null,
308757,
291042,
37746,
89734,
149716,
60019,
null,
84928,
303863,
182502,
78836,
148740,
22918,
12694,
160462,
null,
441758,
27605,
209916,
11975,
176216,
7241,
53940,
22538,
59493,
39092,
163169,
5177,
161076,
44797,
40090,
39865,
32484,
282509,
273474,
147765,
231776,
362966,
20758,
206870,
null,
13302,
203131,
34283,
70637,
27163,
209287,
284906,
21327,
250039,
39940,
267029,
69113,
579717,
171851,
169536,
30747,
238868,
43101,
83151,
163701,
null,
271196,
37695,
44899,
56197,
null,
24124,
101174,
71091,
17146,
118646,
366913,
9362,
81034,
152900,
196841,
169536,
23843,
337411,
17545,
151038,
56399,
null,
28891,
null,
466108,
162884,
144195,
357099,
483569,
429429,
280368,
16911,
283323,
429401,
241121,
157982,
23402,
52897,
155677,
1303550,
205158,
6325,
22160,
null,
230352,
50164,
null,
13008,
12492,
null,
149028,
16385,
67640,
47408,
183563,
19317,
86302,
105118,
46993,
57718,
324305,
113176,
22401,
12889,
9799,
14908,
356531,
99456,
306559,
null,
205826,
195121,
29752,
16946,
null,
184672,
123769,
266251,
36134,
241562,
356443,
28356,
191752,
73199,
315766,
187180,
12601,
395174,
290204,
229351,
368347,
171543,
422643,
49340,
50410,
123461,
33184,
318684,
247991,
105867,
248324,
50344,
null,
360372,
141264,
11140,
42544,
148960,
157916,
216870,
42995,
113705,
106962,
686314,
18320,
112280,
428294,
25170,
33574,
17592,
324773,
9297,
21195,
20798,
46261,
77067,
35601,
39562,
62716,
13790,
1185111,
62665,
null,
28523,
392977,
52916,
89758,
108886,
654558,
111956,
90083,
342468,
23812,
179994,
null,
30763,
8828,
84942,
null,
26063,
34550,
26854,
198277,
42073,
17338,
94365,
342639,
16862,
61278,
225690,
183355,
24959,
15625,
248415,
null,
36093,
18976,
44479,
277022,
185807,
103479,
126653,
149551,
257072,
5470,
242897,
13296,
136748,
90740,
896,
55751,
null,
159586,
210143,
9302,
null,
12546,
11337,
37935,
77073,
106771,
301737,
79005,
12664,
null,
27669,
223573,
57145,
141420,
11940,
148425,
15594,
326276,
118870,
324090,
77723,
3787,
32014,
244301,
61870,
355299,
777538,
116218,
51563,
237762,
null,
14962,
37440,
426357,
74923,
31417,
89794,
5419,
249636,
51704,
46065,
136103,
493003,
null,
1138025,
199249,
743793,
4068,
114900,
28827,
374269,
null,
486949,
352172,
38212,
368266,
21453,
112755,
8286,
34944,
9065,
104567,
89969,
54424,
51046,
549117,
368478,
399963,
6839,
587999,
478988,
14254,
21303,
134980,
null,
180287,
26693,
15004,
36071,
null,
34357,
21152,
24516,
24227,
177721,
221533,
24471,
40430,
null,
30251,
250851,
10981,
30614,
null,
169388,
272055,
33966,
281040,
357571,
22218,
77055,
48059,
7496,
124446,
23197,
16693,
125407,
41581,
57515,
null,
52994,
254983,
10525,
71478,
22880,
378395,
7275,
28558,
42032,
56142,
85401,
null,
373996,
76000,
557765,
500570,
135564,
47306,
148092,
17568,
21033,
273586,
46391,
45467,
59064,
40003,
83011,
266153,
25826,
93964,
52846,
36808,
168084,
14198,
83520,
40490,
74350,
39166,
216805,
25062,
62153,
11619,
173563,
22978,
53292,
13181,
37905,
41145,
279232,
254,
401733,
331213,
28626,
35875,
133833,
25452,
10211,
411201,
29900,
4574,
18486,
null,
null,
17281,
25368,
84114,
37857,
15500,
49634,
null,
184696,
null,
57667,
null,
236856,
63815,
382827,
37507,
39985,
278572,
285425,
null,
32768,
246091,
143453,
81087,
20688,
23077,
118071,
144074,
29445,
47078,
361072,
10769,
52410,
24681,
291480,
123790,
167027,
256465,
5430,
11097,
null,
10632,
80877,
386023,
762669,
211839,
136167,
59409,
285220,
null,
40451,
86901,
50191,
22520,
57391,
134190,
38126,
169521,
132807,
101215,
345545,
18977,
122134,
140002,
null,
194161,
42502,
22163,
335894,
9207,
8827,
75692,
2992,
208619,
471138,
76550,
274646,
16616,
35483,
347481,
22760,
114346,
null,
57152,
1324144,
96643,
15818,
401540,
2198,
106801,
69846,
null,
248736,
321502,
29701,
27932,
18422,
62882,
298651,
null,
17585,
20136,
null,
2696,
null,
4942,
329230,
31429,
9465,
335258,
151748,
143852,
310911,
76344,
46898,
180443,
226681,
14838,
37296,
null,
125856,
105977,
28446,
28600,
6385,
243729,
167127,
38074,
156036,
18026,
35311,
469226,
78211,
40242,
42714,
21692,
6890,
410045,
53681,
57888,
129556,
87627,
67192,
null,
26055,
41569,
172272,
49937,
24958,
37416,
51445,
36770,
85212,
8980,
82481,
55852,
37648,
9249,
45140,
95440,
20021,
61514,
78421,
29671,
124328,
208212,
41666,
68280,
1765,
400396,
12006,
22784,
19142,
310538,
49435,
121852,
161945,
40383,
133823,
202866,
313342,
24165,
null,
null,
74840,
257096,
195530,
52998,
83230,
17201,
136235,
121492,
20394,
131119,
187251,
216613,
161602,
330058,
467725,
205601,
49280,
415294,
3941,
47697,
60299,
180897,
171289,
494724,
36640,
202559,
null,
19403,
28351,
469010,
null,
384325,
39104,
136875,
37367,
null,
26385,
74404,
180373,
359644,
8303,
212118,
229791,
15267,
327089,
323120,
344980,
20264,
245305,
133362,
10097,
35301,
4906,
33388,
5170,
null,
519576,
26626,
12277,
64193,
605383,
209464,
393851,
67401,
339847,
21544,
101760,
8451,
null,
null,
9722,
25817,
63335,
22453,
null,
36864,
251800,
868745,
197718,
52162,
16740,
12961,
40627,
148577,
18160,
61877,
152497,
72594,
22480,
353991,
196423,
34669,
38053,
230437,
37548,
276802,
101069,
467152,
104207,
365775,
219167,
68242,
554371,
22781,
116286,
197640,
29999,
180235,
254137,
2506,
73571,
11488,
72757,
22723,
207704,
null,
106480,
309719,
329915,
12818,
null,
98342,
81820,
20975,
null,
42418,
59991,
143713,
34641,
80538,
null,
null,
132950,
47558,
166156,
40927,
297412,
10407,
null,
27012,
22309,
72737,
null,
6373,
145422,
36971,
15380,
null,
207639,
281609,
null,
45297,
424695,
null,
3281,
90182,
33719,
402745,
363035,
40012,
321103,
362590,
22040,
null,
38665,
390496,
84282,
173797,
19761,
372912,
18133,
57719,
412635,
56766,
12183,
224543,
140526,
10276,
57272,
200342,
20122,
64697,
37194,
81735,
null,
217172,
69535,
39674,
null,
43777,
6255,
12002,
187650,
18152,
29615,
38838,
108623,
66707,
42976,
83656,
82270,
59557,
168044,
58948,
null,
182362,
150790,
40243,
22566,
184622,
179325,
34283,
104583,
16526,
10049,
333665,
176825,
77034,
210538,
33100,
203404,
23931,
null,
42599,
13017,
69492,
220339,
316403,
11975,
167741,
72759,
25669,
283279,
45600,
232366,
46166,
null,
51733,
82977,
191272,
172732,
192677,
null,
null,
229375,
30879,
145280,
null,
19567,
489776,
26571,
63106,
31172,
256195,
96145,
15521,
25455,
105673,
19383,
548340,
32251,
116652,
194294,
652224,
252059,
null,
61239,
12539,
19597,
373352,
161705,
258419,
20716,
46437,
167694,
56251,
137171,
28716,
24485,
22682,
420207,
76754,
40685,
174112,
53867,
391102,
45256,
29494,
25799,
240610,
37314,
62145,
214825,
11414,
44218,
36777,
null,
14572,
null,
133165,
10481,
15970,
28661,
34069,
303004,
135276,
265187,
44618,
6613,
31416,
36082,
40401,
281431,
26185,
138096,
41405,
54349,
203538,
43160,
210219,
null,
149729,
18891,
19225,
512315,
414452,
382804,
53414,
212627,
227261,
13352,
21380,
158812,
34035,
162217,
14860,
17821,
26463,
496248,
47239,
47794,
51321,
66917,
104750,
105889,
103750,
116337,
227619,
null,
17145,
44932,
23283,
28383,
135914,
70579,
9034,
null,
182852,
247800,
276501,
267258,
130319,
535811,
3451,
null,
58984,
10502,
82380,
62243,
12458,
373658,
143687,
17357,
100930,
466640,
153379,
32902,
14541,
50686,
200748,
168085,
72691,
35653,
80231,
null,
8448,
348046,
null,
null,
54817,
31698,
15760,
367343,
35431,
60513,
29631,
131236,
274126,
154856,
14634,
null,
20681,
null,
99655,
45243,
265511,
46569,
51461,
207705,
38144,
215884,
25660,
139920,
372967,
421722,
267022,
null,
317784,
181919,
26674,
17556,
274407,
28977,
404894,
14066,
80276,
24897,
null,
43117,
290484,
229424,
139521,
87883,
430246,
32437,
302444,
54785,
8586,
597521,
360227,
243992,
156284,
23238,
23355,
195012,
33101,
123424,
144300,
407029,
21534,
18718,
273485,
177717,
351838,
119299,
150589,
46484,
103532,
221732,
null,
40053,
null,
34047,
212124,
76092,
null,
37959,
43719,
105063,
230479,
null,
35528,
77743,
129918,
94577,
26801,
null,
62790,
23156,
77335,
99579,
46008,
31794,
68888,
279792,
272070,
7918,
423888,
30368,
119102,
null,
5394,
40165,
null,
295273,
9676,
11238,
374972,
41038,
30966,
196474,
5475,
124871,
null,
119163,
48724,
45629,
null,
188299,
57913,
61512,
43335,
52572,
285891,
312974,
91551,
145756,
242413,
784180,
51057,
null,
12636,
761166,
354545,
21171,
276730,
154399,
32149,
32038,
null,
15603,
203600,
47087,
33850,
33003,
87562,
null,
42681,
68261,
464338,
202637,
24107,
174047,
24347,
197533,
null,
572554,
187162,
135691,
33652,
127578,
51949,
325276,
138350,
29579,
170673,
376499,
54924,
324379,
116204,
158676,
296755,
245302,
201069,
181678,
133018,
92462,
49210,
null,
null,
204980,
null,
87303,
15364,
217086,
21935,
252067,
127264,
25728,
4412,
null,
264015,
16457,
444520,
171923,
154494,
292185,
135842,
22985,
72707,
16728,
305889,
13291,
22686,
11361,
17900,
283109,
43600,
164682,
43051,
27305,
50271,
34539,
23319,
2590,
244645,
44913,
79752,
20515,
93848,
154709,
110513,
37840,
16992,
232889,
257611,
null,
43001,
14068,
5114,
11312,
395394,
139934,
40488,
61015,
174726,
57137,
37227,
147426,
142640,
40068,
185017,
null,
82446,
15799,
219633,
16634,
7496,
15933,
31103,
null,
70115,
66364,
266127,
127426,
170860,
20896,
16120,
13712,
167848,
null,
181841,
10170,
266174,
294854,
16028,
234421,
null,
312778,
3960,
4350,
40231,
null,
146248,
35542,
63086,
118909,
148283,
156381,
544717,
142695,
15280,
138875,
39670,
328423,
null,
12813,
46826,
282619,
14294,
139361,
42197,
434955,
182280,
172947,
838923,
182375,
217972,
null,
15500,
103056,
166506,
181571,
132021,
54894,
230261,
null,
48519,
103478,
60975,
22933,
19270,
31309,
116460,
152864,
70492,
25399,
null,
null,
7277,
169033,
28399,
5239,
417075,
21976,
312627,
2343,
523468,
null,
18551,
110602,
170511,
35084,
65251,
122401,
155553,
22712,
133863,
335161,
452226,
256007,
31464,
12102,
214466,
103866,
20362,
6593,
306291,
81844,
51027,
718207,
125838,
96055,
52530,
116087,
42711,
215262,
203456,
189978,
148158,
199230,
24985,
184616,
5351,
246394,
112205,
7954,
36113,
28813,
21784,
264092,
57457,
195098,
40387,
null,
38617,
48036,
153981,
20254,
34450,
84442,
31042,
272590,
108610,
211553,
null,
null,
36783,
212392,
90713,
37945,
null,
28771,
185260,
276223,
285215,
14868,
573271,
407791,
null,
28668,
18871,
36911,
32355,
null,
53352,
70532,
264240,
35102,
232648,
237757,
68555,
296589,
54629,
18604,
338962,
27565,
308065,
29493,
91397,
53284,
14848,
195041,
41107,
215582,
84923,
119945,
233795,
108108,
61544,
147096,
135825,
2756,
4378,
186168,
216707,
279089,
79811,
47022,
null,
12978,
27261,
157121,
371229,
376591,
214587,
153753,
93217,
82806,
67831,
228415,
95732,
119862,
null,
104490,
76882,
644798,
8029,
47862,
91826,
59515,
375393,
null,
42444,
55168,
43188,
227910,
null,
33221,
275647,
56415,
8132,
109974,
2766,
92767,
75094,
168492,
263899,
48369,
36973,
266416,
null,
11781,
92783,
11995,
337839,
217058,
49563,
61646,
null,
114413,
178464,
259353,
null,
125035,
86303,
235061,
165720,
270294,
190794,
28052,
79849,
36431,
13814,
74003,
160351,
188995,
53929,
56173,
439241,
22260,
47830,
142017,
171087,
23570,
6606,
134512,
160703,
452383,
14822,
10065,
38863,
350537,
25521,
null,
108855,
58568,
115662,
80373,
23393,
17803,
null,
294289,
89186,
184335,
55824,
20594,
26525,
100149,
null,
null,
159942,
178145,
35315,
266454,
23616,
23469,
113299,
18479,
43820,
3960,
155591,
8990,
327561,
null,
37495,
23709,
27923,
14491,
323604,
145716,
18568,
55464,
62890,
3858,
47397,
511075,
40601,
null,
142538,
177632,
94396,
292952,
272097,
42920,
82587,
217323,
514077,
489229,
669993,
61931,
237945,
27271,
36877,
53257,
219511,
445265,
40380,
56528,
108174,
null,
427265,
26177,
59147,
157037,
264150,
12129,
49699,
245164,
150547,
null,
161833,
7758,
27639,
426234,
6051,
60161,
38921,
167188,
49311,
28882,
204112,
106893,
33168,
39807,
63301,
338195,
19446,
15045,
29920,
85944,
18197,
180688,
25240,
219648,
8468,
34380,
134604,
15552,
14994,
28013,
37937,
38152,
24351,
63856,
161341,
9270,
150692,
35653,
20350,
228458,
35690,
15827,
60083,
199056,
102882,
231815,
39113,
null,
353974,
106803,
22139,
165047,
145876,
null,
430466,
78557,
550651,
62657,
4680,
106793,
9976,
47704,
794972,
33434,
39874,
43380,
2267,
1354,
null,
20717,
36623,
58521,
19157,
8026,
60272,
null,
325074,
8731,
24054,
33977,
137400,
90476,
304275,
248169,
7619,
38281,
18165,
354538,
10199,
211417,
25812,
null,
null,
129448,
15776,
589189,
345724,
10719,
374451,
182268,
18487,
273886,
43136,
47307,
49170,
89346,
null,
43916,
9596,
57316,
40772,
16402,
36977,
100970,
213143,
39918,
null,
26096,
32087,
154983,
120185,
31544,
136857,
52634,
22584,
11138,
229670,
122375,
199842,
245651,
212386,
24679,
40524,
257485,
61135,
23194,
39338,
328910,
182708,
5931,
21915,
86063,
28632,
187513,
222444,
4790,
55932,
5086,
38241,
36754,
97266,
223741,
208217,
183980,
47787,
88594,
19101,
178193,
null,
null,
25160,
230102,
55493,
47286,
30147,
18833,
114723,
617190,
67099,
57401,
17709,
374307,
148878,
51755,
304482,
41161,
null,
382364,
175775,
45427,
35118,
null,
55296,
92576,
67519,
null,
25502,
57239,
71702,
32073,
85377,
101369,
339686,
36630,
63173,
21232,
227665,
40182,
288180,
28492,
175138,
243359,
85407,
101772,
213316,
166156,
22537,
51333,
340530,
21134,
19492,
851,
452478,
208300,
77259,
41764,
61304,
51734,
180267,
210969,
61567,
66120,
null,
63540,
44534,
266211,
151677,
142178,
101007,
null,
null,
132369,
334769,
238828,
279480,
10938,
18100,
null,
null,
120220,
41048,
137003,
258245,
55519,
23476,
156982,
21471,
361007,
243872,
389466,
127074,
9307,
57148,
343092,
157173,
91392,
215836,
28681,
19090,
45630,
102855,
31079,
161664,
15328,
372436,
60335,
1748,
18667,
15301,
null,
241978,
419159,
11649,
49430,
423286,
101915,
343009,
150692,
468481,
33350,
2128,
246146,
4759,
350087,
258917,
20139,
232041,
21405,
135049,
246913,
59785,
171098,
6618,
167699,
101926,
65389,
56417,
267220,
2154,
9912,
322827,
354223,
702988,
129776,
93822,
363823,
39099,
104913,
285269,
90836,
105724,
388668,
13095,
335433,
81630,
185775,
69112,
175361,
49926,
21618,
5627,
241547,
16655,
26732,
24061,
null,
227866,
176474,
10572,
260655,
39859,
32467,
24315,
410659,
37614,
10007,
93626,
35476,
40877,
48591,
29908,
232585,
81625,
12631,
217310,
14823,
89259,
34932,
395137,
20479,
596462,
118853,
23420,
198510,
411853,
99893,
72409,
238518,
null,
8459,
null,
16216,
294931,
126730,
119184,
null,
259438,
66428,
29811,
65220,
145769,
122511,
217770,
251088,
82872,
81720,
367886,
1109282,
143976,
19933,
50886,
359680,
31316,
9239,
129166,
154711,
104966,
230932,
161549,
null,
249002,
18847,
59765,
216415,
152502,
41484,
205229,
28284,
30956,
122972,
null,
39876,
94759,
null,
400455,
1650,
37746,
3929,
104130,
12189,
17273,
37371,
12929,
9849,
13473,
12772,
39280,
6439,
10938,
27631,
64524,
98343,
264471,
190103,
1871,
145512,
103533,
7802,
30491,
25908,
22986,
179426,
197797,
31165,
45002,
38216,
30199,
498181,
109755,
26676,
104474,
null,
16521,
24966,
null,
126193,
22740,
250765,
145106,
233836,
48069,
199675,
226577,
286079,
390490,
14358,
421626,
34172,
243350,
23181,
390637,
145238,
70730,
14747,
29234,
213351,
81180,
129282,
157285,
98442,
757512,
26088,
193782,
47021,
404184,
22133,
560749,
104162,
12629,
164156,
29769,
null,
172314,
null,
19134,
42935,
244142,
null,
null,
10849,
49293,
22140,
52032,
557664,
237733,
67850,
null,
12327,
32811,
6557,
87377,
95021,
262870,
null,
69606,
16723,
86943,
53810,
42442,
59912,
134638,
null,
13832,
199775,
73725,
38181,
38550,
null,
144177,
7432,
13169,
98288,
305687,
257157,
33206,
42995,
25387,
83429,
206210,
599703,
101815,
408925,
203869,
166177,
195397,
290499,
28247,
9337,
29128,
4965,
26598,
null,
116256,
152393,
27165,
94314,
11040,
27177,
129879,
54627,
140837,
403401,
362492,
41220,
null,
53398,
null,
13026,
202711,
191386,
47204,
23843,
48397,
384853,
558153,
62019,
172041,
62589,
49258,
24354,
326154,
37141,
30410,
489486,
242241,
null,
31119,
31433,
31560,
68678,
382431,
102498,
33648,
44244,
120417,
8419,
46146,
123482,
28910,
344147,
31264,
225026,
455643,
94311,
276391,
17883,
72993,
243176,
47090,
151624,
61365,
51025,
249876,
null,
29861,
5467,
228187,
260323,
48395,
113949,
34694,
294518,
103377,
170461,
125724,
32662,
null,
null,
null,
480820,
19090,
125598,
129845,
345206,
24500,
42252,
87237,
4217,
46358,
315743,
667844,
146148,
300606,
82351,
36099,
134679,
394592,
9703,
28686,
289711,
10401,
112458,
132337,
633392,
9166,
46374,
27525,
324759,
166799,
61998,
257788,
28099,
43916,
232257,
192577,
null,
288015,
90875,
577958,
193877,
171269,
8839,
47860,
null,
null,
283490,
206668,
253546,
310027,
316733,
22123,
27312,
165937,
27985,
12241,
119559,
9687,
10385,
368451,
250132,
111592,
17318,
41033,
49746,
91395,
28103,
7558,
13546,
228666,
32645,
163058,
7476,
129583,
439554,
101205,
45764,
172525,
496303,
308402,
539352,
75001,
107960,
192275,
109587,
146241,
32010,
33536,
55177,
103643,
259049,
299782,
12357,
6177,
103706,
134375,
28941,
284613,
61425,
null,
110740,
79607,
324627,
6282,
70482,
145339,
294544,
43678,
31965,
24183,
138034,
null,
150170,
null,
99875,
null,
50760,
null,
37727,
214927,
null,
242249,
167067,
65941,
256015,
273089,
40654,
193638,
129108,
24122,
67171,
8825,
46013,
76623,
32889,
133508,
42193,
15504,
31642,
254787,
62646,
32445,
null,
21455,
23085,
443714,
4741,
10807,
232084,
27795,
314823,
382897,
280057,
294739,
23006,
45887,
39032,
20456,
50632,
5694,
null,
50938,
89784,
100412,
399184,
9413,
324750,
21904,
null,
null,
null,
73145,
45991,
98601,
3334,
445091,
78765,
220645,
24136,
12792,
28726,
136161,
87510,
32392,
122213,
170885,
160462,
27963,
84534,
36073,
110944,
null,
null,
54367,
393670,
112020,
25702,
24875,
336879,
27881,
80761,
638994,
null,
10932,
165307,
21247,
355594,
157379,
565525,
233913,
342285,
41182,
115611,
173180,
317877,
33128,
51226,
null,
21938,
53021,
20935,
37219,
22116,
21007,
169566,
168623,
275219,
236210,
147285,
38394,
87914,
224048,
33149,
47033,
251087,
47841,
319599,
null,
41815,
117440,
21809,
50935,
37339,
263624,
28175,
273306,
59566,
103298,
37699,
74531,
97493,
73438,
20548,
232542,
14940,
13288,
239343,
24644,
220887,
129540,
242458,
33004,
11075,
94130,
105579,
32157,
16280,
25461,
16718,
109524,
24117,
628255,
127702,
163996,
17219,
81158,
17501,
163875,
8746,
23846,
168293,
151782,
88708,
26824,
null,
84888,
331540,
38561,
9100,
65282,
53240,
210192,
84320,
117446,
75247,
34124,
37607,
1016110,
352733,
243946,
31829,
21264,
160546,
129981,
150861,
61562,
32212,
62017,
36086,
40068,
320032,
305310,
292127,
58964,
22779,
12351,
88824,
59683,
37645,
120383,
37140,
129863,
53253,
244955,
246206,
241162,
240494,
515008,
null,
null,
35327,
87932,
510307,
4574,
403987,
37204,
35060,
659031,
162220,
null,
376156,
460761,
144337,
50416,
104766,
15015,
124231,
208403,
85668,
36826,
392016,
77696,
41339,
38759,
81270,
258360,
94724,
353272,
313976,
3905,
170564,
42570,
34334,
477263,
387067,
369910,
164799,
64561,
166944,
61176,
null,
39090,
35104,
433317,
31693,
33367,
184481,
32390,
8243,
152500,
25244,
91814,
34065,
null,
15411,
31366,
132016,
43250,
null,
8748,
19839,
18157,
56561,
9367,
35721,
198339,
16908,
43800,
12568,
56998,
440538,
23668,
211617,
94445,
56766,
60405,
164576,
26437,
177024,
393795,
17328,
841207,
24771,
42267,
48610,
null,
6181,
22362,
428362,
28709,
5183,
65116,
43701,
88073,
32439,
13722,
12409,
null,
376827,
268532,
33726,
20750,
141312,
11684,
34036,
null,
44161,
null,
null,
72602,
128612,
346701,
113163,
59009,
7246,
219225,
128363,
143292,
497119,
133306,
273565,
243642,
45478,
26884,
32998,
223564,
134088,
null,
23483,
191376,
18004,
257945,
31196,
3174,
46751,
93647,
32182,
270656,
27511,
39718,
474076,
62108,
459844,
217276,
115669,
208470,
157017,
59708,
97692,
96937,
14707,
455055,
315999,
24205,
null,
141495,
37675,
137542,
22682,
17444,
69388,
14669,
19664,
33035,
71514,
147092,
359718,
15661,
18355,
366635,
90875,
178426,
41226,
24613,
5290,
138736,
19860,
98050,
265886,
33956,
13587,
86462,
36300,
38308,
null,
18688,
68869,
33995,
null,
28975,
null,
30940,
null,
42886,
26672,
33640,
274623,
24803,
71567,
86171,
185106,
28146,
14746,
null,
50206,
75599,
477484,
null,
23734,
42396,
null,
182096,
151308,
349829,
206107,
183682,
13656,
34183,
200688,
222637,
263503,
359896,
268831,
260302,
9396,
52467,
394383,
209224,
467037,
407811,
79197,
332671,
54690,
28049,
15060,
18363,
24078,
32289,
89357,
96809,
435274,
125135,
197018,
341353,
17411,
6747,
55807,
73300,
232199,
44978,
null,
242690,
32549,
119165,
410617,
31125,
364316,
42462,
27817,
433703,
null,
482470,
191798,
56483,
138490,
20335,
191356,
123345,
41660,
25828,
264703,
51880,
82395,
2722,
30200,
77060,
14306,
318320,
44207,
1870,
22994,
39287,
58464,
265873,
37643,
117297,
361688,
null,
21996,
76596,
41103,
264887,
211012,
11942,
208868,
9077,
null,
3124,
87891,
108601,
455321,
70243,
28362,
209543,
416882,
21728,
28230,
22343,
129863,
46000,
144963,
248109,
319611,
154488,
461213,
17007,
164462,
null,
161439,
21123,
132540,
41397,
null,
549802,
null,
18532,
176069,
521954,
105471,
46985,
158692,
20689,
null,
272222,
316631,
89080,
null,
149368,
358199,
173517,
16516,
89609,
null,
87040,
328374,
284620,
99469,
13830,
26482,
189862,
224556,
288677,
28109,
null,
15922,
48295,
156010,
46414,
210635,
34279,
169255,
34388,
128405,
205420,
null,
147300,
53045,
214925,
19495,
201274,
23737,
2571,
12318,
1214,
16020,
143985,
547207,
27794,
473899,
139339,
153211,
null,
35422,
102697,
40025,
28583,
106916,
204869,
292549,
128458,
186355,
250640,
24176,
230403,
211909,
null,
23497,
7240,
378324,
167949,
223471,
14281,
41382,
103267,
21788,
72024,
86010,
26864,
146318,
521528,
11368,
212659,
226463,
14046,
null,
null,
17235,
217801,
459759,
47496,
null,
14920,
860702,
null,
7998,
62810,
87457,
57109,
150707,
331303,
94584,
110492,
43544,
9475,
409322,
186168,
146939,
50867,
44007,
39736,
51570,
34356,
288095,
375095,
299516,
null,
129492,
87961,
107401,
79977,
20145,
14363,
32668,
383404,
152618,
18227,
25382,
null,
126979,
20971,
263530,
5330,
220026,
45703,
53067,
4730,
97531,
null,
11264,
18438,
6412,
322655,
279748,
302551,
54695,
113897,
48068,
3978,
130036,
53383,
289119,
26074,
null,
8866,
56158,
null,
19077,
49251,
322768,
154249,
56507,
83356,
226778,
894728,
54557,
87774,
11123,
64685,
153016,
202206,
17955,
35071,
187625,
265047,
205257,
261997,
7628,
null,
35968,
65859,
93880,
null,
51711,
139164,
259434,
412835,
12288,
null,
null,
60090,
null,
380685,
444992,
null,
52526,
658879,
509027,
129896,
9787,
58041,
74998,
628119,
132771,
62840,
13895,
12037,
224388,
29068,
238453,
31646,
38339,
43726,
6803,
80677,
126080,
19643,
33330,
2647,
153235,
134592,
286242,
247295,
124102,
53131,
151764,
77236,
null,
null,
192117,
55586,
526044,
8657,
58130,
15510,
149013,
78905,
null,
61204,
105080,
21543,
59072,
106894,
20603,
159396,
14809,
139487,
197216,
38573,
356123,
31782,
168006,
326186,
null,
18766,
235244,
353515,
122905,
174867,
13543,
370258,
295701,
131937,
null,
325362,
156421,
175236,
82078,
26577,
221642,
23526,
12286,
311573,
68071,
16217,
224209,
76150,
21278,
116611,
97394,
41743,
24813,
44850,
429678,
129609,
19766,
37325,
null,
100397,
null,
92073,
35615,
273828,
101317,
376208,
null,
316020,
null,
113818,
159966,
138839,
null,
50552,
30878,
7589,
30641,
26963,
44978,
null,
null,
42638,
240558,
30563,
37503,
83006,
16307,
340967,
299154,
93428,
36436,
504723,
133745,
31943,
238504,
178052,
56554,
195967,
125528,
85390,
302016,
227166,
145541,
6751,
29898,
310771,
181689,
288989,
178908,
14786,
36767,
131744,
56587,
202907,
49787,
26843,
86020,
51466,
20483,
144123,
78804,
251754,
38541,
108940,
13514,
78899,
54607,
3174,
165328,
87907,
6238,
74143,
33866,
202774,
607412,
74825,
188304,
15725,
92267,
56711,
9522,
42279,
56810,
28714,
137608,
192389,
99276,
212744,
90039,
218072,
36020,
7847,
null,
168296,
12432,
318744,
15035,
32432,
149990,
252621,
83279,
39933,
259104,
51340,
137748,
322425,
25712,
57182,
64863,
27297,
53582,
25460,
null,
7817,
37605,
null,
67021,
47520,
342276,
301493,
389096,
162360,
null,
1020,
null,
41228,
256788,
165345,
null,
171172,
428143,
163203,
23346,
null,
297636,
448556,
null,
114054,
38824,
197469,
286281,
127522,
null,
5236,
28890,
44443,
147351,
null,
10607,
65861,
49163,
171568,
293788,
238692,
6356,
80218,
81298,
93897,
22441,
null,
28350,
45426,
117878,
21223,
33729,
39010,
26322,
50015,
48727,
106002,
null,
141475,
12376,
null,
27346,
408745,
286870,
31923,
203050,
169106,
54692,
12406,
219809,
15522,
14585,
74387,
687213,
67798,
308853,
7140,
66123,
90568,
333107,
35625,
43741,
2829,
214009,
292136,
184753,
126716,
59453,
378755,
184663,
15922,
288956,
9383,
174725,
52612,
182813,
128172,
240062,
null,
null,
93027,
1457,
15635,
9682,
null,
645050,
336269,
106814,
18520,
202091,
70505,
335837,
67948,
39151,
33046,
1053484,
101449,
439734,
61694,
41083,
66755,
19868,
13726,
133752,
177020,
333582,
20273,
193742,
157041,
587954,
15685,
231457,
40198,
35277,
189672,
137412,
95220,
54129,
28295,
33528,
161855,
280120,
277094,
109699,
38702,
236248,
320708,
null,
484581,
218396,
596153,
22835,
58669,
249016,
82973,
19475,
190016,
372539,
234276,
1239155,
351014,
137056,
null,
238425,
160667,
null,
51842,
16208,
203055,
23670,
216937,
147543,
22407,
10265,
49281,
186194,
null,
120790,
33213,
37536,
15269,
144371,
19430,
12325,
29284,
11401,
108249,
587179,
244550,
9368,
365816,
230819,
452539,
59240,
217326,
18376,
268716,
23173,
133383,
99039,
12874,
69638,
257914,
51467,
null,
null,
null,
37758,
271377,
198709,
50368,
29760,
138067,
20980,
119384,
39071,
206890,
44479,
211801,
11873,
35759,
null,
50833,
166954,
38045,
259769,
93724,
213785,
234432,
290623,
55408,
310346,
436120,
123925,
154675,
null,
null,
299319,
16419,
6405,
31787,
34194,
18432,
23315,
297121,
213322,
19463,
9476,
537890,
174718,
209199,
208783,
219101,
null,
224545,
305762,
null,
67154,
45324,
544861,
30441,
359646,
167133,
366723,
32314,
102255,
17169,
158030,
215631,
21896,
31403,
49638,
7089,
null,
36204,
19320,
43246,
431448,
34540,
307067,
null,
576048,
315008,
129979,
29798,
29187,
null,
46110,
34408,
101921,
11078,
298535,
6613,
235800,
37968,
208789,
292760,
197267,
280535,
17510,
41501,
184745,
36833,
66485,
24153,
181247,
135555,
33487,
502970,
287702,
47899,
40317,
25894,
42483,
34436,
250109,
108698,
32006,
44456,
419625,
55048,
22200,
120716,
null,
12890,
38801,
102678,
208579,
130137,
118774,
47300,
68782,
41426,
34063,
59833,
21277,
254499,
89884,
400017,
2170,
96997,
17027,
538191,
21498,
27671,
47640,
10218,
26587,
13613,
124182,
27714,
60589,
92660,
33629,
177294,
43224,
329804,
86340,
67965,
28945,
28130,
252932,
54538,
520243,
263462,
10744,
null,
35641,
284806,
36075,
357138,
217672,
139628,
69343,
26605,
114339,
327313,
18051,
318423,
184264,
null,
43401,
527773,
221930,
15964,
16291,
54720,
169054,
13898,
14096,
77739,
26600,
null,
21533,
34307,
null,
50359,
14348,
18492,
null,
338006,
211676,
80131,
31062,
72634,
87526,
34852,
8593,
86633,
null,
14164,
230001,
15787,
59476,
113952,
102360,
209677,
170494,
38503,
402149,
null,
9822,
148108,
5909,
160908,
179401,
null,
167660,
67925,
15873,
42126,
20285,
34070,
7697,
135619,
29306,
26690,
63909,
12140,
15888,
15709,
9293,
181763,
76911,
281988,
6625,
null,
48614,
7260,
34066,
293109,
241045,
46363,
187454,
2571,
172349,
171364,
null,
12181,
32872,
14731,
235687,
40804,
245461,
77617,
172376,
52395,
61238,
67212,
48823,
20027,
57954,
128763,
260542,
38805,
248678,
390469,
85896,
42360,
450270,
61207,
59262,
20539,
7110,
12395,
240073,
72818,
60402,
69422,
20052,
1825,
4862,
241288,
41292,
70889,
130103,
47650,
225312,
189324,
4351,
347692,
169400,
216113,
null,
174604,
26662,
52290,
69767,
28937,
16765,
22131,
57820,
33981,
32169,
52278,
null,
23663,
24968,
261897,
74181,
18155,
14931,
121855,
6641,
11325,
347688,
112629,
55790,
190815,
276217,
267647,
105938,
null,
29662,
23569,
5880,
133263,
411110,
248068,
264204,
56771,
39721,
9982,
187975,
50642,
15553,
109445,
111557,
192017,
34422,
162788,
null,
6692,
4403,
5665,
null,
256235,
155309,
58302,
352690,
481990,
23908,
219434,
539049,
234999,
18051,
214137,
80597,
5919,
20934,
154807,
258659,
7168,
188602,
43679,
31172,
null,
26635,
217781,
282155,
19619,
208182,
25374,
570199,
45032,
226737,
65748,
3783,
57607,
19291,
17299,
9813,
390747,
null,
75534,
348445,
172654,
25738,
310604,
168005,
18747,
326168,
88805,
35237,
147179,
324186,
15033,
10984,
52952,
25205,
11374,
null,
4798,
167828,
118061,
15405,
196917,
23124,
22960,
11066,
241931,
null,
null,
293350,
125436,
153711,
13208,
269121,
null,
385183,
25895,
312880,
null,
null,
159378,
584792,
275560,
253328,
136399,
15759,
71045,
304087,
204076,
16716,
12565,
76754,
153835,
131176,
259475,
36961,
24937,
315619,
3154,
468958,
582869,
236967,
12895,
26381,
298453,
93165,
352967,
179394,
27777,
27362,
194608,
138587,
224944,
134412,
211118,
519903,
205614,
163110,
16096,
21478,
256806,
401039,
40494,
44494,
null,
142477,
267941,
108654,
142719,
58708,
70526,
58290,
16151,
41165,
358186,
8911,
null,
220572,
84176,
517655,
81325,
14645,
80691,
121956,
51560,
28514,
12520,
15307,
167978,
94460,
140757,
212477,
66559,
380199,
131746,
199365,
18057,
196261,
19927,
54967,
null,
51481,
64686,
56657,
148085,
null,
180276,
144203,
148165,
426157,
237703,
null,
null,
269154,
57162,
161303,
275602,
27346,
18790,
80697,
29120,
3981,
17880,
89403,
250538,
37131,
21650,
17917,
15390,
157807,
28381,
101915,
156744,
null,
650180,
79187,
196069,
294737,
51794,
261902,
48939,
56037,
12975,
4010,
35616,
123866,
174281,
185362,
710543,
23450,
25106,
413308,
null,
58767,
26805,
34128,
267116,
18176,
37442,
171777,
69692,
null,
33541,
235590,
99335,
31086,
455199,
null,
612744,
208428,
347002,
184649,
917,
32640,
28860,
83612,
84906,
25747,
null,
30509,
19502,
160626,
212984,
495902,
14364,
27727,
11839,
171198,
49181,
33945,
469898,
207614,
38252,
39432,
255067,
null,
364717,
235376,
25139,
103255,
161440,
2546,
630054,
8977,
28514,
null,
500573,
21670,
41782,
40156,
16826,
240072,
245734,
299281,
383282,
5973,
265457,
null,
122232,
19071,
150564,
40242,
12180,
374617,
151558,
14576,
425635,
60978,
102573,
11087,
12491,
398045,
39802,
75187,
15930,
null,
59565,
260758,
7178,
149385,
53311,
43729,
172230,
27563,
295424,
49818,
48421,
162859,
42533,
50456,
22060,
329328,
30582,
87652,
61140,
3757,
9343,
45027,
177741,
261429,
432546,
167871,
50232,
74417,
70514,
372648,
23470,
92073,
178418,
167657,
42081,
24916,
37402,
12115,
null,
21536,
6450,
108938,
146252,
324808,
19585,
105501,
35163,
null,
123560,
65896,
18958,
null,
56017,
266589,
227530,
87506,
null,
22136,
232685,
143478,
20430,
null,
123817,
102193,
411637,
291476,
null,
23072,
147038,
26145,
209970,
14725,
44675,
581107,
146941,
45884,
41279,
null,
30000,
13076,
64376,
326287,
249294,
227252,
172353,
44156,
20982,
41528,
217923,
26012,
3032,
375226,
115269,
81333,
214724,
245757,
24508,
199279,
97443,
169517,
null,
19436,
188888,
7801,
41944,
39492,
81368,
40297,
59779,
140854,
29053,
139918,
131278,
28718,
421799,
5129,
39342,
41330,
95094,
5187,
101989,
96695,
342654,
442816,
null,
null,
234030,
129454,
141418,
348041,
412024,
149197,
30399,
10777,
151895,
150095,
38276,
10481,
249223,
null,
9583,
87267,
52135,
85868,
219179,
97284,
153511,
324435,
14041,
77094,
183077,
203714,
11580,
108418,
31427,
33581,
1832,
2108,
null,
143778,
81508,
73704,
null,
160851,
27634,
302016,
13323,
16748,
42467,
10343,
307686,
179015,
205405,
205038,
56274,
69713,
36109,
13731,
null,
9224,
21867,
null,
83576,
308063,
9819,
null,
8534,
49442,
506140,
176512,
562519,
51917,
84007,
21021,
211987,
66465,
75962,
958850,
38451,
23410,
154035,
17540,
null,
415777,
494163,
18087,
38914,
22111,
335938,
9902,
54064,
246100,
null,
87928,
187202,
5175,
222858,
78233,
199923,
169892,
16284,
191651,
73267,
264651,
468,
113495,
18441,
235830,
4902,
141646,
217778,
81012,
47574,
9833,
18769,
7623,
175890,
95764,
28811,
null,
18496,
149292,
341692,
194931,
129314,
26582,
304615,
474187,
549128,
57999,
null,
41519,
282770,
16944,
28978,
3189,
208826,
271273,
32713,
23801,
612171,
13970,
287565,
9122,
222495,
332526,
null,
20037,
14836,
20107,
65497,
28105,
3023,
46482,
160097,
71022,
26433,
136904,
71396,
274914,
223126,
178054,
306921,
47832,
null,
20099,
13016,
261642,
14136,
null,
365730,
null,
null,
175059,
865280,
812007,
27939,
168233,
null,
21083,
17736,
304462,
58675,
33993,
171306,
148369,
11105,
621936,
23082,
34529,
446218,
190531,
254804,
8375,
103000,
812487,
23446,
null,
165450,
141668,
102848,
402901,
17938,
36247,
18784,
22966,
30226,
399083,
39636,
188605,
50908,
13311,
51379,
284780,
165049,
null,
25166,
31733,
5460,
769817,
85686,
68078,
31259,
196713,
51337,
28114,
23122,
94834,
148147,
125316,
13789,
147275,
26586,
8727,
null,
201922,
132585,
160341,
371131,
20276,
124584,
39648,
55959,
40585,
118751,
135185,
null,
17847,
350610,
49279,
118763,
25317,
404906,
null,
563431,
47366,
19238,
18288,
59345,
28326,
91387,
260485,
149863,
36876,
23433,
349890,
9154,
24326,
234722,
173953,
117375,
26331,
261881,
255380,
68252,
340793,
481153,
295063,
433065,
55885,
745883,
65365,
10309,
194934,
4820,
182584,
90983,
202713,
193520,
277774,
21471,
128638,
244907,
3543,
215584,
null,
64567,
452934,
30802,
8446,
170906,
32772,
null,
42081,
8835,
79390,
20246,
164867,
60506,
22403,
88642,
119867,
221469,
null,
432742,
63561,
20682,
299008,
null,
416766,
null,
4781,
94676,
175828,
358982,
48153,
62608,
210471,
77040,
49904,
53274,
181627,
51323,
154511,
3338,
51950,
281945,
40515,
null,
214986,
256968,
832318,
83482,
37503,
20391,
851,
194806,
144712,
null,
14168,
395941,
35455,
463389,
25861,
200875,
308393,
67023,
28839,
172784,
270929,
null,
346714,
263511,
11451,
31270,
35535,
330372,
41643,
27672,
161518,
62716,
181630,
null,
46645,
null,
412519,
189241,
22053,
116398,
null,
27480,
12545,
21682,
160788,
632457,
127024,
218106,
413770,
77343,
198134,
null,
14033,
7635,
22786,
69156,
61218,
36294,
209700,
122568,
338708,
169902,
17730,
371554,
238911,
164242,
33851,
47178,
93817,
83997,
null,
22230,
14772,
63612,
540,
195767,
107998,
21399,
5537,
32737,
29315,
11178,
37606,
9198,
17586,
640945,
76452,
164479,
38866,
128502,
83945,
189644,
34617,
243246,
54370,
9041,
179900,
242295,
196701,
166630,
7554,
70775,
null,
73610,
9244,
null,
32724,
27756,
255242,
21650,
21339,
12064,
272743,
20509,
885735,
29631,
11402,
140612,
193391,
170739,
46473,
312173,
161847,
17925,
10200,
33394,
62930,
7419,
20713,
17272,
24251,
85522,
99034,
191758,
38893,
58716,
299736,
21607,
221010,
23108,
25228,
59099,
28310,
32598,
153617,
747628,
70941,
249723,
113343,
334198,
100405,
32460,
53480,
39894,
77939,
35959,
16832,
493148,
null,
83577,
6707,
14314,
143523,
57237,
22581,
205174,
263503,
153161,
9201,
6346,
194189,
338956,
null,
80500,
130684,
70755,
62436,
223348,
188198,
19186,
31455,
32758,
34136,
101195,
90095,
133204,
7329,
44593,
309356,
82080,
289910,
164025,
null,
272406,
71977,
22842,
85195,
131025,
67106,
450028,
60063,
38030,
27089,
37852,
31324,
49449,
222720,
348875,
11027,
241569,
50880,
21861,
127257,
332941,
184450,
30129,
81268,
34978,
152218,
42277,
33215,
26704,
374326,
169391,
102501,
130782,
29351,
37827,
153231,
16993,
377190,
52926,
82122,
177526,
419149,
62743,
12215,
187971,
324194,
186360,
89204,
45968,
640108,
34027,
null,
144480,
275738,
189154,
11402,
5479,
991366,
45105,
37098,
39405,
7882,
16475,
62116,
271437,
436490,
173176,
83959,
201444,
23966,
260794,
105506,
39750,
199997,
20393,
158600,
2187,
131910,
53614,
580473,
29894,
70326,
16091,
39520,
413349,
112621,
153092,
408900,
31937,
92344,
365478,
315585,
45549,
47005,
424944,
229424,
17763,
38697,
21539,
88882,
98282,
8274,
323910,
null,
13271,
139336,
43242,
109044,
2053,
786752,
97973,
18214,
124257,
484782,
292607,
null,
10227,
6403,
25769,
58135,
125602,
19014,
312872,
23975,
83085,
591976,
null,
null,
70918,
46108,
316337,
null,
56326,
407709,
61671,
209472,
null,
413316,
null,
28534,
null,
12616,
283637,
13929,
64893,
181236,
2185,
348598,
37128,
34789,
null,
123995,
180560,
270668,
275862,
134795,
12290,
34580,
198585,
27884,
161688,
null,
28192,
104721,
3776,
201899,
201290,
36029,
168257,
9689,
36445,
69003,
null,
343336,
4404,
83114,
20582,
8394,
121171,
19136,
497023,
113580,
231867,
null,
21864,
33828,
120768,
42553,
86427,
239154,
35601,
81671,
null,
182324,
19227,
91119,
25429,
173478,
24108,
50226,
1177682,
67525,
48351,
20097,
237068,
147345,
null,
73293,
null,
30733,
296626,
15302,
399794,
231171,
22875,
39208,
null,
406896,
211330,
175794,
74996,
197187,
24613,
126404,
15343,
133360,
45054,
328500,
145416,
31520,
400176,
166977,
341585,
125019,
61931,
15917,
109378,
32099,
299981,
675688,
192221,
null,
18068,
225781,
24370,
234457,
117916,
87145,
43123,
181960,
438883,
262107,
45553,
null,
224435,
375639,
24712,
199311,
null,
167140,
30939,
218766,
166951,
16273,
102297,
5766,
20112,
20591,
241741,
null,
7481,
15702,
33616,
30774,
48367,
null,
304897,
269947,
148361,
33627,
44055,
59074,
123512,
325302,
223496,
26971,
48335,
229576,
null,
18173,
69508,
227508,
105061,
77838,
201770,
37488,
44706,
16391,
182715,
null,
27471,
112555,
310432,
299939,
468199,
12970,
53787,
496886,
261225,
445763,
169680,
56636,
19332,
9624,
null,
31281,
25949,
230751,
793174,
120627,
322225,
485613,
206951,
185544,
10069,
null,
29024,
247241,
14632,
null,
185157,
41108,
18286,
8171,
162969,
97852,
160620,
236039,
5719,
51798,
304830,
55011,
96323,
180315,
28536,
315047,
151227,
259851,
16236,
294534,
58369,
null,
13089,
20866,
null,
5699,
6195,
50250,
14852,
208362,
155302,
281533,
49591,
14527,
168112,
93081,
null,
14961,
58259,
78009,
213898,
155329,
50555,
34420,
174030,
45843,
175185,
38704,
null,
61024,
108220,
45436,
97396,
33003,
null,
271508,
30295,
null,
30912,
150405,
46838,
13195,
197772,
null,
62443,
670654,
5943,
8054,
266348,
117945,
91240,
27298,
339622,
30306,
21000,
338617,
22480,
41098,
354173,
205334,
89528,
17728,
40637,
39780,
179413,
45688,
14483,
306809,
35077,
null,
191348,
289299,
114513,
13752,
109431,
6944,
128420,
29528,
129573,
3091,
142982,
52999,
19259,
70886,
75215,
1321,
201245,
345735,
219385,
144090,
20187,
11025,
89934,
44434,
110059,
331002,
38049,
78719,
352112,
36707,
15768,
53835,
61192,
50616,
null,
90610,
384405,
57235,
7946,
26657,
175615,
null,
52552,
14437,
329686,
368774,
363403,
41318,
233306,
11781,
25707,
1150307,
181635,
199881,
null,
28882,
27958,
329024,
48236,
13056,
154202,
46984,
null,
20175,
73438,
60149,
152696,
267534,
null,
19422,
130067,
86826,
112146,
35279,
18034,
726480,
13541,
37243,
22400,
46061,
64588,
305693,
501500,
194744,
593512,
226051,
218197,
324809,
172061,
null,
24768,
109856,
75919,
256191,
25566,
232098,
34348,
42965,
142398,
384218,
39058,
14748,
165580,
378382,
276598,
321772,
325436,
191103,
41896,
241890,
10601,
411794,
35492,
164501,
38784,
98663,
195691,
235828,
255907,
84715,
43317,
64800,
172817,
21342,
null,
206503,
299638,
28121,
52925,
125535,
467099,
68670,
274508,
236453,
161756,
242469,
111352,
166796,
179373,
14181,
491376,
408314,
181779,
261998,
41973,
37445,
33514,
174069,
186128,
150413,
29875,
null,
22506,
6339,
70045,
72947,
56260,
127014,
5074,
238729,
175865,
181363,
50072,
83512,
111720,
90395,
121133,
null,
249694,
188733,
34916,
227780,
304088,
19238,
163365,
106301,
225120,
43414,
339058,
88651,
379283,
36499,
58224,
309526,
36699,
61391,
17689,
192496,
43256,
null,
11715,
49967,
239408,
23412,
17100,
null,
null,
1684,
43675,
202378,
113863,
55484,
null,
50347,
108327,
35792,
76328,
227828,
null,
null,
222950,
266893,
375424,
201066,
206581,
174394,
8689,
101006,
286635,
17184,
30743,
138630,
129145,
138236,
209103,
231156,
331060,
257496,
590043,
353586,
91866,
32283,
363674,
124296,
27287,
313900,
144911,
null,
32722,
226313,
33015,
291057,
191866,
11220,
41822,
47588,
273607,
139656,
8593,
68066,
262902,
198750,
188134,
58382,
275858,
398124,
null,
287544,
27253,
35073,
2582,
7789,
118357,
220748,
28860,
31035,
88662,
259508,
265363,
1179,
535522,
234110,
91821,
339476,
210972,
48798,
153255,
35116,
27938,
207281,
260460,
22546,
13821,
null,
43874,
149415,
607787,
null,
296498,
95007,
null,
165871,
181368,
307787,
50826,
30009,
31278,
238130,
25021,
30294,
110735,
197453,
37510,
67796,
4572,
177810,
106659,
7712,
61301,
85069,
46916,
37542,
6744,
null,
47933,
null,
3537,
39578,
157995,
197513,
164566,
184803,
40619,
326039,
21221,
14964,
225529,
259865,
null,
163068,
19523,
null,
120223,
39083,
66465,
7648,
79525,
null,
153785,
109705,
21289,
39052,
97152,
10306,
4309,
118980,
97538,
246414,
46936,
78704,
34056,
11061,
170059,
null,
10357,
192586,
17561,
52262,
129657,
21831,
566332,
null,
11125,
143752,
37630,
131627,
30497,
245691,
null,
59043,
44323,
null,
115222,
146617,
1643,
null,
152348,
58453,
118655,
23550,
96954,
236002,
96672,
126669,
240392,
216917,
57590,
77063,
94026,
19120,
19115,
21832,
2836,
251882,
null,
135797,
77544,
82840,
72497,
5141,
258212,
116553,
34009,
166804,
182255,
59320,
272825,
33113,
447076,
50427,
107796,
802109,
75029,
60263,
95616,
163098,
37391,
88344,
247668,
88400,
389112,
7974,
180547,
null,
35469,
75532,
207868,
131062,
39731,
34669,
3823,
164458,
123381,
null,
7163,
215593,
18133,
38129,
204907,
34571,
85686,
null,
68195,
43818,
265655,
123164,
57099,
18779,
37307,
36202,
34644,
281757,
316415,
15684,
9439,
224161,
585925,
3978,
219431,
167488,
341467,
245000,
10927,
11983,
29883,
21670,
3827,
309800,
53407,
19243,
747919,
100990,
338813,
207975,
404580,
28320,
null,
48095,
15067,
201211,
111018,
7596,
null,
176236,
211692,
null,
45896,
49444,
59151,
48824,
43857,
21586,
null,
12539,
null,
4766,
59354,
201713,
217607,
139080,
15590,
195737,
70316,
16058,
13515,
17023,
327041,
93230,
342564,
40511,
36760,
38428,
52303,
610738,
13467,
50797,
154803,
4293,
162144,
null,
63313,
114765,
null,
21728,
780937,
26466,
10479,
14574,
19560,
111249,
21515,
203766,
61422,
71825,
10611,
150431,
34042,
null,
308295,
31368,
34082,
248497,
10936,
219095,
null,
112023,
452517,
343864,
null,
219839,
26348,
32755,
372919,
454179,
90172,
343159,
225287,
15176,
202393,
19193,
8038,
36942,
186161,
138500,
68759,
32169,
null,
13473,
206945,
null,
15830,
215748,
87427,
169519,
60644,
11005,
39436,
67326,
125071,
319878,
202978,
null,
78206,
48863,
8407,
null,
23809,
12106,
216678,
46549,
31791,
null,
60802,
492684,
null,
172725,
13149,
48691,
12614,
3537,
32519,
14360,
9510,
55055,
342226,
null,
189298,
502802,
167367,
46677,
144945,
11021,
16804,
155459,
9660,
220083,
69398,
240789,
55999,
44092,
72414,
215902,
28899,
29370,
177451,
7104,
12528,
34110,
9471,
16317,
58276,
11170,
285390,
316625,
13125,
420593,
239770,
168355,
105505,
null,
20565,
3451,
26908,
113501,
214523,
268976,
196334,
45692,
318684,
null,
293961,
416078,
297054,
12323,
39906,
229255,
13835,
207128,
14872,
33335,
98119,
35186,
null,
286873,
202638,
46841,
4897,
209614,
351168,
519299,
440531,
273093,
93914,
21610,
292191,
166662,
239295,
null,
null,
426516,
50271,
136989,
null,
346294,
245772,
144175,
197195,
89616,
29748,
21328,
316739,
158867,
23692,
99736,
54737,
439965,
253993,
143601,
61451,
128704,
36050,
139403,
344815,
333421,
19062,
99485,
76418,
23280,
18485,
null,
244489,
36589,
120886,
682328,
318801,
188065,
15611,
122220,
552645,
42799,
null,
331273,
184792,
206363,
13970,
158779,
100521,
98788,
457759,
310539,
157182,
32438,
239551,
125056,
null,
45355,
180487,
null,
211553,
127552,
272989,
48525,
265579,
98595,
36933,
79632,
348846,
28675,
48615,
183266,
101449,
null,
null,
null,
127390,
15707,
214911,
348893,
34226,
30892,
33596,
208388,
206991,
6407,
440339,
604219,
287965,
null,
16815,
null,
null,
38553,
133697,
124760,
114951,
435859,
67544,
58793,
152377,
358940,
26420,
11347,
412124,
46849,
15304,
30617,
187743,
387816,
394634,
15902,
512776,
null,
309950,
28549,
3152,
16669,
5087,
172467,
11593,
31930,
21356,
null,
205454,
80402,
37570,
16448,
40206,
138546,
82961,
406262,
240655,
212542,
137855,
321132,
201881,
490565,
25886,
65067,
179244,
139715,
321738,
25796,
225672,
null,
213994,
232779,
63388,
42369,
22785,
177954,
213654,
225646,
null,
5811,
363988,
229868,
null,
215623,
97697,
465716,
494754,
41780,
273392,
null,
null,
26772,
560786,
23528,
20015,
154948,
181339,
287156,
null,
142068,
11454,
92392,
301160,
60239,
58754,
97886,
110074,
459726,
160829,
378093,
11691,
156290,
16365,
233118,
177713,
137816,
381376,
25647,
37839,
195704,
196251,
50532,
null,
126595,
32873,
62149,
15558,
149861,
30770,
18752,
20036,
null,
90568,
85023,
91486,
284780,
42799,
153601,
94856,
144778,
null,
33794,
181798,
543845,
7654,
143911,
55924,
null,
49654,
21678,
24068,
24563,
42557,
5112,
78993,
210620,
54474,
37376,
800946,
179344,
301630,
37250,
107061,
265426,
28695,
34771,
22838,
27838,
null,
33211,
133438,
147628,
60389,
573142,
8742,
23001,
46777,
70812,
26420,
249174,
245370,
66377,
null,
32204,
5214,
291926,
17024,
55107,
30835,
100838,
121029,
156557,
96790,
1864,
30660,
33282,
43278,
59374,
26540,
462524,
28670,
174773,
214992,
394171,
90301,
19287,
38031,
286720,
41075,
61355,
29926,
null,
228827,
167756,
43230,
17579,
182237,
209200,
10537,
74485,
124107,
null,
423271,
67355,
22093,
150814,
98598,
16545,
1867,
64061,
29268,
91486,
57848,
272632,
26128,
15595,
52618,
2073,
448348,
30466,
26422,
317787,
null,
220798,
54302,
30500,
31895,
27860,
128918,
35347,
null,
48292,
40992,
60991,
305898,
33669,
364177,
289224,
121931,
145525,
40305,
122332,
90235,
198232,
526225,
299516,
119929,
187267,
319553,
16241,
28500,
214969,
210281,
668261,
492495,
5091,
236875,
251938,
78205,
199237,
272535,
212617,
179837,
22141,
855238,
59393,
74954,
91520,
121374,
356703,
322018,
43052,
54352,
23232,
100655,
5459,
11404,
16080,
22459,
387712,
75021,
21516,
475467,
38083,
29495,
100261,
82820,
30972,
163450,
5780,
null,
null,
41652,
24275,
20938,
182715,
278597,
214296,
78678,
null,
null,
40767,
36584,
182323,
77038,
null,
322953,
144998,
257148,
117987,
197067,
44548,
406035,
null,
11730,
13285,
335462,
220392,
190295,
177747,
301329,
400291,
195168,
31614,
14894,
29065,
145640,
405920,
16502,
21357,
21686,
37640,
31795,
245421,
157511,
166013,
75700,
51133,
5370,
202761,
24600,
103825,
12982,
10310,
155273,
239576,
31687,
42423,
38476,
25364,
328792,
149931,
17416,
321377,
251479,
19178,
10876,
35260,
null,
215064,
10199,
210525,
247845,
60019,
null,
493907,
9784,
212125,
241586,
139555,
288703,
3512,
198277,
195783,
26265,
248933,
23998,
76677,
507040,
95996,
277412,
287954,
262402,
242754,
152519,
34417,
14869,
318053,
170056,
57164,
12553,
51596,
22179,
517413,
42983,
null,
139623,
45777,
378361,
285073,
364585,
236222,
75158,
279079,
267523,
558382,
177368,
5686,
399072,
15386,
35915,
69160,
85465,
31324,
72462,
47164,
null,
268500,
143597,
61569,
306936,
42088,
88664,
75018,
144930,
25523,
698720,
25063,
99502,
10421,
325119,
10795,
28969,
221123,
140938,
72975,
323402,
198007,
262832,
281169,
155558,
312190,
19807,
null,
27473,
null,
375605,
null,
74152,
222604,
144146,
227386,
544777,
435656,
33277,
43295,
47475,
33139,
192537,
89312,
177990,
23209,
153666,
9386,
309961,
115000,
229099,
29374,
null,
36822,
null,
145535,
324550,
179354,
126562,
673448,
283569,
104937,
187565,
143324,
10588,
13649,
218226,
186915,
100926,
235739,
409797,
44721,
373100,
28275,
536103,
31854,
52388,
4947,
227007,
94141,
10912,
null,
111793,
87090,
2879,
181967,
164284,
61855,
55438,
72696,
702741,
288238,
80481,
567151,
10494,
48221,
7179,
207208,
27429,
349552,
4851,
133837,
82950,
64844,
13884,
27308,
72902,
214847,
203771,
148606,
632420,
256762,
42692,
46994,
286099,
null,
160412,
17225,
150550,
286229,
9740,
72654,
31924,
327335,
34550,
420405,
null,
110633,
17190,
267572,
140196,
116090,
28307,
444141,
null,
254827,
7305,
87285,
237635,
26652,
55545,
560505,
7840,
101567,
214471,
19505,
527980,
22859,
309098,
138014,
164205,
null,
null,
120995,
5485,
381517,
136136,
89526,
336017,
40033,
460896,
30173,
242281,
311206,
23932,
8289,
226102,
333874,
135350,
163088,
111735,
298886,
57293,
6184,
43260,
87120,
13914,
110208,
null,
46671,
109713,
40397,
165136,
70547,
16731,
197563,
59263,
75921,
190967,
76528,
null,
65573,
325217,
156625,
4317,
376448,
22601,
10527,
374868,
247799,
105561,
141699,
11094,
374461,
null,
49547,
78420,
null,
325169,
101134,
12983,
28847,
199990,
440974,
9189,
431724,
162203,
8745,
133611,
64195,
194831,
295288,
183591,
404193,
214986,
171839,
46601,
36033,
394142,
31175,
18800,
19869,
38556,
72881,
37122,
1157584,
264353,
153318,
387868,
188374,
164039,
38254,
191539,
30127,
207603,
20285,
96133,
62840,
98684,
17471,
116031,
170417,
30604,
50287,
237319,
272731,
4221,
170447,
207075,
10125,
5842,
4978,
13022,
519003,
90819,
11535,
106125,
20513,
135787,
89561,
490680,
32461,
486086,
49137,
179476,
11911,
56811,
192739,
61094,
36909,
162599,
229265,
177265,
358290,
655202,
82116,
170464,
24285,
108699,
85313,
36401,
237483,
150335,
17108,
24414,
397677,
102002,
588302,
73416,
120203,
108482,
30562,
153193,
41959,
46150,
50445,
179450,
213494,
15677,
53243,
29184,
275008,
35363,
123168,
67092,
50997,
null,
205817,
138035,
655905,
11717,
null,
null,
238506,
24832,
null,
20842,
255040,
43880,
23528,
10821,
36667,
121423,
136162,
86696,
34885,
42733,
72965,
241163,
13021,
210001,
227060,
822323,
132216,
253747,
152386,
25550,
24295,
61295,
16212,
205999,
1441,
36207,
185889,
42304,
204369,
39080,
126707,
212959,
null,
null,
68017,
11078,
104214,
70713,
232421,
3741,
128982,
29995,
19960,
398153,
21313,
409318,
50270,
485217,
208418,
23069,
14445,
175427,
140219,
41264,
88325,
null,
36180,
4549,
457011,
237260,
266650,
129717,
491431,
23218,
104658,
524579,
532419,
155760,
22901,
28989,
29016,
17821,
44018,
270600,
189617,
44985,
12754,
290670,
29092,
39583,
4341,
180978,
62052,
368293,
426483,
13316,
119840,
42010,
12757,
26658,
14293,
361039,
117915,
141522,
null,
52002,
270713,
370047,
407668,
241176,
null,
195032,
267861,
133678,
47518,
368805,
7736,
47443,
27316,
26993,
188492,
154333,
252276,
130478,
41998,
11732,
220603,
44724,
255474,
142029,
13427,
22907,
10422,
15369,
10085,
14293,
287897,
null,
483877,
338678,
101414,
122362,
29061,
74873,
13651,
137202,
17757,
33506,
19016,
142401,
43680,
14465,
820,
28838,
39947,
18464,
9085,
9472,
299703,
62529,
196342,
24494,
94834,
90751,
159108,
43415,
null,
234570,
35621,
33588,
null,
151929,
369360,
21853,
37162,
74646,
8454,
190955,
9752,
367585,
337422,
38367,
165364,
21830,
40941,
338280,
42235,
170905,
null,
230411,
422388,
null,
381402,
15365,
25247,
45973,
null,
33443,
256238,
72202,
135886,
250541,
22043,
77350,
231708,
195852,
176847,
186005,
32343,
932680,
12429,
178358,
48156,
20858,
null,
36623,
16011,
4002,
32199,
53182,
232541,
37434,
123561,
59102,
202787,
131431,
34858,
23184,
175325,
77565,
83860,
158437,
227980,
337874,
455039,
31577,
12289,
475336,
56036,
33668,
84576,
139037,
296287,
288958,
38839,
null,
12235,
null,
382770,
41389,
328850,
87787,
88993,
141226,
46243,
14649,
28255,
47702,
19165,
206928,
118615,
27356,
125229,
36278,
null,
195402,
273273,
322832,
52061,
415899,
46271,
166629,
210174,
null,
11232,
7190,
19395,
458806,
8315,
91345,
112484,
145461,
94961,
649152,
352751,
175430,
206326,
71646,
178942,
181591,
43103,
null,
35996,
18220,
28099,
17553,
364852,
239555,
321376,
49462,
236960,
null,
229962,
273396,
null,
520366,
159947,
284498,
543500,
250766,
251019,
134640,
6243,
69276,
217482,
166796,
530782,
488248,
28380,
11130,
11681,
46737,
4587,
280078,
69356,
null,
135660,
247749,
127823,
57612,
33442,
34879,
136684,
27484,
215705,
22184,
null,
51388,
189199,
19261,
18007,
null,
54123,
36109,
61066,
314273,
48217,
12759,
212583,
null,
144489,
315551,
null,
20136,
39999,
35931,
536675,
null,
58368,
146856,
299894,
27925,
126150,
337526,
66530,
94476,
32319,
225486,
63104,
99377,
320886,
546642,
null,
24034,
15009,
25341,
12802,
131554,
58909,
32556,
82228,
null,
16179,
14748,
125449,
null,
314524,
94140,
237342,
244140,
13775,
null,
33687,
410309,
219657,
116488,
64927,
25855,
40272,
83483,
189446,
13040,
16145,
null,
22462,
null,
322109,
140949,
9656,
291435,
62024,
null,
395425,
213474,
55088,
36947,
77497,
31684,
292416,
75453,
403328,
10341,
27955,
454892,
94959,
86208,
84121,
45234,
254639,
271517,
140121,
8008,
403107,
35673,
19393,
293871,
38699,
8739,
19417,
25492,
523453,
8366,
589303,
186081,
16707,
28576,
502564,
60178,
272005,
49131,
106508,
282240,
null,
143564,
232350,
206148,
776984,
395571,
166321,
32171,
19706,
34432,
409578,
310876,
307166,
26602,
196381,
247171,
null,
240246,
287421,
113378,
49112,
19923,
4690,
429186,
122083,
179400,
16388,
8518,
5290,
94075,
229394,
44362,
5515,
null,
191732,
122055,
null,
109388,
51386,
28642,
164972,
46288,
22362,
78066,
248412,
157792,
6748,
43418,
277796,
12294,
46837,
null,
175725,
10582,
null,
296768,
271170,
13880,
null,
129844,
155062,
374626,
141736,
9962,
22882,
207117,
361518,
60808,
3856,
127293,
50073,
75171,
79010,
19397,
447333,
null,
null,
32137,
47394,
87371,
28609,
274214,
53865,
20413,
182824,
21004,
40194,
73276,
83637,
158912,
72139,
35963,
195840,
221998,
14960,
42738,
18716,
36568,
null,
253265,
182877,
245545,
576471,
16096,
278754,
269481,
69725,
69931,
10560,
1061100,
263695,
93604,
43639,
232266,
8703,
554525,
44271,
510443,
249076,
145405,
48513,
34638,
161153,
22810,
9401,
7428,
134381,
36413,
226549,
173307,
142814,
80780,
36836,
6380,
15824,
202672,
7464,
278508,
17666,
91580,
null,
26092,
789224,
25925,
325262,
43671,
35190,
3938,
9652,
38377,
228345,
386895,
158803,
144213,
127547,
7678,
40368,
19746,
38331,
320174,
214461,
93501,
428612,
202481,
20328,
20386,
175802,
121891,
180375,
485292,
null,
null,
22211,
21753,
33773,
null,
null,
30761,
25909,
288190,
4541,
13311,
273462,
97819,
362834,
106208,
51168,
26127,
30559,
202503,
150653,
6861,
55052,
51959,
162510,
97219,
303824,
24039,
192337,
381792,
30838,
360773,
null,
141760,
48371,
14994,
7909,
212737,
374244,
138950,
22840,
50174,
143391,
17588,
176574,
41015,
16368,
34815,
37241,
89504,
245572,
197246,
null,
223704,
109626,
3468,
5947,
200920,
120389,
277899,
22349,
236712,
42863,
147200,
4031,
18535,
89562,
12552,
22575,
321938,
198900,
21406,
41424,
238024,
32157,
null,
97022,
144711,
97606,
11417,
54979,
20142,
2068,
104033,
59550,
81121,
114983,
146087,
58762,
195142,
108736,
7020,
16766,
196084,
null,
101889,
18221,
94791,
30753,
344975,
4086,
400741,
100862,
480442,
47345,
18317,
87305,
37936,
513925,
40702,
188315,
258425,
98889,
208117,
7708,
72432,
18776,
17246,
210044,
22087,
221537,
28555,
380233,
524240,
135478,
26796,
49662,
9943,
null,
47756,
121506,
512305,
60624,
193196,
26342,
24470,
73240,
3322,
21651,
38854,
140394,
137186,
68057,
44493,
42149,
10790,
257001,
64960,
null,
8607,
135256,
258795,
27694,
57257,
3951,
143171,
26615,
47005,
16227,
15830,
110873,
null,
244262,
100922,
505896,
39664,
375667,
28913,
null,
31640,
47225,
254462,
246933,
153926,
415546,
336537,
35848,
584890,
33313,
414117,
44737,
378179,
231006,
94622,
182646,
27728,
354544,
null,
127264,
245144,
180644,
10237,
268168,
259962,
null,
76569,
20988,
null,
45117,
101068,
198930,
7192,
null,
83737,
123334,
20179,
17253,
21477,
28836,
190497,
280296,
46313,
338033,
null,
11483,
85081,
88158,
44226,
23409,
611067,
33613,
815086,
436928,
491880,
125764,
null,
132410,
270330,
16508,
76272,
214795,
278719,
12285,
175283,
17902,
63001,
439164,
7170,
252977,
13838,
98697,
86837,
10579,
170098,
42364,
344560,
11346,
2956,
133904,
68603,
96621,
18320,
309731,
36993,
279359,
10322,
54419,
194722,
null,
48088,
17326,
22525,
30566,
47668,
11988,
null,
35982,
282483,
193641,
18146,
305569,
76150,
149222,
12228,
21407,
231244,
143297,
50479,
18041,
null,
18834,
19876,
481575,
40819,
16400,
399764,
292289,
35577,
24137,
39728,
null,
160602,
21782,
null,
48184,
13756,
15191,
235296,
19234,
121599,
40283,
463041,
null,
84299,
57845,
278603,
23053,
5478,
174585,
211000,
449602,
69331,
475212,
237498,
225055,
214905,
158275,
431446,
73963,
32593,
9805,
16764,
236034,
177165,
23655,
640149,
679908,
44399,
34827,
34873,
9657,
336833,
36432,
200013,
null,
421182,
17620,
231924,
316910,
5818,
269599,
10106,
89609,
44534,
null,
454663,
75995,
135860,
null,
21984,
null,
419183,
50012,
138559,
5311,
null,
159649,
218115,
72155,
203446,
22479,
52614,
241777,
66131,
218928,
null,
73730,
28191,
220989,
117053,
24198,
374873,
345401,
6729,
19334,
39763,
178774,
69630,
63803,
5753,
180064,
37460,
72169,
34558,
213326,
158838,
371514,
222531,
159203,
33404,
333540,
null,
256576,
17205,
null,
134576,
150198,
88507,
239501,
null,
222300,
63351,
212634,
12791,
163569,
190182,
11166,
20395,
38572,
45029,
212969,
6916,
33818,
90159,
29724,
21718,
20737,
179840,
125259,
168263,
14695,
132315,
26470,
49824,
347914,
31474,
295578,
122777,
7320,
70087,
null,
319808,
427114,
160595,
5,
41856,
1006121,
146635,
232127,
209484,
11328,
10411,
32098,
52724,
50311,
467086,
22320,
394278,
415926,
174861,
17865,
76924,
49400,
133543,
227185,
43150,
23674,
11465,
86806,
86761,
232627,
46522,
38216,
18296,
37127,
276657,
303040,
228537,
171485,
34219,
9419,
152441,
205504,
144392,
17278,
563844,
227979,
3120,
54893,
84820,
226413,
26989,
81259,
47488,
203547,
66298,
59413,
null,
32729,
234044,
445104,
18785,
7561,
null,
11132,
105254,
25413,
41485,
53752,
75051,
205291,
118,
424909,
52048,
24083,
54558,
127706,
25560,
7504,
387969,
2392,
23999,
20623,
224601,
11336,
153676,
58908,
310403,
21615,
173169,
21843,
115465,
568853,
134882,
25438,
245768,
365754,
290998,
212029,
27695,
86527,
null,
41350,
45336,
203983,
null,
207541,
276032,
57414,
180464,
228106,
277538,
414883,
98236,
317457,
30968,
38947,
218852,
148882,
88552,
30464,
115349,
27608,
null,
51676,
35939,
138880,
283669,
16982,
215717,
21741,
126131,
null,
33114,
null,
466550,
157250,
39065,
224369,
null,
46341,
123336,
null,
330245,
299098,
1942171,
150474,
92186,
15883,
null,
156065,
26158,
23178,
56404,
254736,
32194,
18107,
47908,
18286,
247606,
26752,
18473,
45692,
49603,
73848,
228782,
66115,
46199,
105803,
177078,
27803,
249898,
30659,
36711,
165306,
35816,
35259,
19287,
167884,
30514,
179690,
186470,
null,
80436,
51019,
47927,
93501,
206393,
295437,
141457,
130712,
2743,
302553,
11452,
27770,
275904,
null,
292047,
33408,
83305,
346034,
276397,
462097,
209210,
null,
21414,
84744,
51433,
90189,
39445,
100242,
79094,
266382,
8216,
57244,
141447,
360384,
66367,
247010,
333862,
null,
107374,
null,
148197,
61513,
93697,
52444,
326147,
128882,
93242,
542590,
277160,
47012,
86186,
66923,
130678,
180511,
165629,
195704,
35423,
191601,
22543,
459371,
68036,
59486,
21819,
323760,
7929,
null,
23189,
27816,
null,
60719,
184057,
47885,
230866,
375630,
23068,
66297,
153423,
32442,
39952,
25960,
19755,
null,
27806,
149570,
23717,
175879,
83626,
7065,
234605,
null,
280476,
18006,
123634,
null,
null,
331435,
26679,
null,
39784,
50079,
26689,
null,
842264,
260800,
74520,
16476,
290598,
262208,
316049,
106570,
363826,
9606,
null,
161371,
764451,
64593,
213795,
117145,
26992,
14975,
319286,
375809,
31098,
53830,
19236,
273210,
274529,
648329,
93168,
217827,
30855,
181100,
321651,
208057,
27506,
12918,
66701,
null,
299470,
20448,
499317,
411751,
45597,
21590,
92044,
null,
28821,
92970,
28874,
58229,
121843,
68547,
131283,
198070,
60661,
30280,
23701,
10415,
43117,
81798,
14951,
461422,
11421,
16921,
128285,
46316,
null,
35187,
95551,
33168,
53745,
133336,
4359,
464856,
24977,
179775,
117040,
null,
79306,
340688,
null,
142844,
88218,
135617,
576586,
21735,
15765,
154518,
269224,
3833,
73312,
25138,
111881,
222327,
382826,
2366,
64573,
53160,
161193,
138908,
198448,
4685,
245523,
null,
25704,
49507,
143760,
277260,
null,
null,
30455,
324057,
17053,
null,
3772,
31761,
380274,
null,
null,
546902,
12975,
null,
125597,
120668,
173360,
172092,
117638,
67143,
9086,
48782,
75862,
114739,
18506,
75454,
20366,
36003,
21468,
38779,
59589,
53174,
6792,
192519,
163061,
null,
31956,
197937,
228154,
25257,
336485,
18734,
213799,
21636,
6264,
27580,
288031,
88826,
312354,
236744,
9862,
null,
86787,
15235,
54767,
317755,
40035,
165009,
34276,
74720,
218580,
33128,
32696,
18381,
42226,
null,
304314,
53385,
46070,
19525,
17087,
32548,
154715,
27375,
15176,
164056,
11864,
13901,
140996,
224943,
323675,
null,
25707,
6455,
29479,
135873,
423901,
null,
91397,
414558,
54538,
30408,
172583,
37239,
373790,
46521,
478629,
92971,
null,
349953,
151994,
167804,
30184,
92421,
249491,
366417,
232856,
43139,
21716,
27133,
null,
22245,
31968,
337368,
335974,
167867,
87717,
333766,
148528,
30258,
62713,
384804,
220056,
49672,
231810,
376544,
505816,
39247,
137418,
13113,
245821,
487718,
22280,
23064,
6388,
15892,
273334,
21313,
54783,
66382,
60173,
18154,
439931,
228039,
40050,
440077,
208732,
350664,
270973,
57263,
56133,
19542,
52822,
94730,
null,
32809,
475642,
133942,
149577,
267105,
250243,
10703,
195721,
5348,
9436,
87390,
98465,
141791,
187534,
6300,
13966,
166695,
null,
119904,
35353,
277063,
12318,
8058,
183277,
364508,
205124,
259843,
154162,
102959,
26596,
59560,
174439,
134180,
275050,
181777,
null,
null,
251355,
313676,
4320,
110992,
87548,
265857,
52677,
88125,
71269,
475017,
13081,
16707,
273681,
15496,
134889,
28158,
66383,
181856,
93918,
13230,
176684,
21709,
323338,
null,
24915,
386109,
null,
236450,
14641,
33949,
68292,
333421,
56613,
95449,
154623,
95228,
74389,
209942,
37309,
170928,
13508,
135034,
155939,
127737,
30077,
506449,
32591,
368452,
13516,
null,
114466,
13153,
334919,
227613,
46912,
119814,
734106,
91103,
9517,
217880,
36477,
4466,
null,
121461,
30334,
106988,
31762,
176033,
633003,
0,
54639,
77816,
null,
640105,
43861,
45870,
51149,
43083,
18915,
127212,
91099,
93292,
160006,
42843,
34858,
34730,
47355,
20416,
671981,
104645,
12424,
296389,
27370,
28050,
203396,
11542,
223671,
36689,
66385,
358766,
42924,
195959,
146102,
118142,
166609,
165366,
47291,
43375,
74382,
111361,
null,
26930,
26932,
347202,
52625,
305755,
322460,
160676,
66405,
27711,
63524,
33948,
10465,
22426,
41223,
12150,
205050,
null,
56483,
14947,
193434,
75170,
37122,
36390,
110889,
217101,
22549,
27734,
58054,
34854,
154513,
133934,
241030,
16461,
332381,
196514,
30642,
356807,
19579,
72741,
134744,
24772,
337142,
146644,
60674,
86491,
22479,
339998,
39531,
253274,
210918,
9625,
11908,
122412,
31721,
328642,
266063,
11002,
42741,
null,
22939,
151065,
11999,
352038,
277285,
345401,
236915,
13656,
36308,
153618,
24653,
413240,
33316,
303608,
191774,
69426,
231895,
17545,
256287,
33935,
4680,
598165,
9459,
79155,
17164,
144494,
85031,
124893,
73119,
330975,
170016,
396512,
24615,
null,
23305,
208487,
29528,
28306,
41678,
12648,
3154,
348405,
1689,
55764,
15067,
22950,
247905,
288763,
331340,
14671,
39605,
3895,
25463,
39355,
116112,
67010,
69263,
227903,
43828,
217077,
109185,
219283,
18573,
207290,
122775,
172714,
null,
9919,
176625,
67541,
83947,
291268,
34985,
527849,
93065,
98360,
390006,
null,
77382,
13115,
326394,
31163,
null,
26670,
23692,
80285,
36295,
256738,
227590,
45686,
null,
281929,
196393,
420292,
209432,
2577,
7922,
37403,
null,
124639,
103885,
32611,
110321,
35308,
30893,
132156,
39175,
4785,
4225,
107347,
93483,
122525,
48860,
174810,
98206,
null,
205743,
9335,
135929,
72569,
3282,
801630,
22716,
61565,
82752,
153516,
4578,
51988,
24972,
29516,
108094,
36697,
27374,
160070,
null,
273371,
47218,
55415,
256953,
18031,
23678,
45869,
286154,
null,
389119,
75818,
37227,
39631,
64550,
30722,
11758,
76663,
22223,
127954,
165675,
64420,
41217,
23697,
144239,
45130,
290086,
98286,
13018,
248124,
null,
33486,
23656,
167290,
null,
8585,
58958,
102323,
165499,
234442,
19908,
379421,
78528,
211408,
504057,
300208,
377964,
183700,
204642,
16858,
185380,
14514,
74079,
17397,
51113,
195975,
19938,
null,
92674,
147914,
236339,
35161,
null,
34424,
21591,
31635,
84009,
289402,
298172,
17709,
87639,
25728,
51583,
29263,
147800,
7574,
40358,
155286,
144375,
436447,
12720,
22982,
512913,
27748,
97693,
26011,
null,
187098,
44224,
16877,
397817,
31310,
150516,
579989,
179894,
19625,
272467,
31681,
161628,
297438,
310904,
355421,
14051,
171973,
574148,
82587,
137595,
28909,
413873,
188633,
44765,
null,
11794,
2389,
12278,
32546,
115758,
66342,
336771,
27761,
19485,
204997,
70330,
16135,
124105,
181610,
null,
283144,
12959,
44857,
254042,
52732,
257082,
70851,
402777,
34192,
null,
45741,
253265,
333197,
null,
260345,
87982,
273998,
326786,
55133,
null,
75952,
13734,
12930,
204768,
162158,
211393,
45831,
115521,
38640,
123261,
212501,
288080,
59509,
41067,
63841,
223225,
140906,
144908,
486750,
38271,
26080,
152020,
31966,
70984,
34619,
147428,
159886,
39066,
11805,
31490,
23891,
13464,
67595,
16937,
62438,
null,
137413,
null,
73139,
160299,
10235,
28959,
166249,
17969,
88844,
160006,
167558,
111324,
141572,
110254,
207444,
165942,
201234,
286204,
207687,
159665,
166906,
193630,
256410,
246491,
392483,
27316,
419418,
5743,
348153,
73899,
40263,
93777,
286554,
19178,
13996,
24191,
null,
80320,
69447,
37393,
27960,
13869,
null,
119365,
221959,
168914,
91426,
15721,
11123,
126055,
39970,
464976,
61783,
59642,
76188,
216501,
27519,
64735,
null,
346472,
33663,
229247,
189631,
501121,
null,
11740,
46936,
108228,
183428,
104656,
121378,
62998,
235037,
139839,
11273,
22438,
39854,
48149,
6575,
32792,
73527,
16004,
9829,
354902,
299655,
244399,
59627,
null,
25843,
153969,
618236,
58071,
258422,
347263,
255634,
22625,
21084,
33818,
17162,
477646,
85179,
29744,
151765,
38075,
116797,
153678,
279849,
55841,
205378,
86247,
69329,
78919,
39188,
122612,
57230,
161115,
322169,
62524,
207363,
236772,
70011,
198703,
null,
417009,
224199,
272754,
300108,
304515,
41705,
10553,
11432,
34689,
158339,
11215,
null,
43429,
232579,
213845,
33049,
48390,
168422,
13415,
45131,
162655,
33633,
46502,
8514,
17867,
235331,
120327,
38039,
211702,
25035,
187230,
152030,
53892,
48718,
null,
44231,
27892,
47730,
63526,
240552,
277258,
null,
50232,
597042,
null,
26399,
103438,
55078,
278320,
83387,
59465,
752428,
393847,
null,
12277,
81786,
863497,
303095,
2018,
13226,
325972,
134836,
274092,
null,
172824,
10485,
18945,
23624,
null,
110924,
19836,
33823,
408871,
22771,
24885,
null,
208732,
11035,
25844,
490914,
40969,
256731,
228711,
13030,
35331,
146522,
35395,
29258,
66065,
23761,
312773,
68169,
1248,
342204,
72191,
26713,
161331,
26683,
14775,
138113,
163952,
45592,
214355,
30337,
11489,
572019,
51304,
null,
150553,
230542,
50564,
140794,
111005,
210367,
164626,
156457,
null,
145671,
170305,
223292,
null,
null,
43207,
102054,
261240,
27125,
19892,
8329,
5187,
33840,
82006,
null,
null,
22706,
12025,
546680,
null,
28067,
13701,
null,
327799,
9692,
232112,
null,
25641,
242348,
105331,
582627,
52609,
324801,
36351,
31534,
165859,
42520,
359720,
21846,
27857,
213896,
420784,
15764,
21269,
66313,
115821,
7889,
813,
244992,
null,
290172,
101665,
26407,
211210,
39254,
null,
24625,
43005,
209171,
362545,
73064,
86628,
13214,
111070,
240881,
59693,
57064,
114774,
32618,
217812,
66380,
80563,
8214,
172194,
62438,
384525,
18199,
43871,
229181,
35611,
51563,
null,
85825,
263247,
12322,
30489,
9614,
42284,
27429,
171044,
70352,
36745,
43852,
289734,
21689,
188302,
162710,
154991,
4362,
104434,
58436,
171249,
5414,
null,
43078,
60732,
16111,
null,
434348,
15615,
46090,
73925,
168073,
12270,
41603,
null,
70797,
54012,
11397,
null,
141743,
177335,
3986,
18270,
229032,
558652,
30296,
42931,
66999,
440144,
null,
81632,
27730,
41301,
28321,
63076,
585519,
101917,
225114,
133982,
120729,
293291,
null,
28525,
47380,
49553,
121370,
368520,
93765,
null,
69636,
32735,
63748,
9070,
85601,
null,
43594,
95312,
56700,
9859,
39648,
6164,
319883,
null,
null,
342156,
469455,
17434,
65619,
207040,
7194,
null,
33800,
283527,
162992,
35517,
14622,
null,
63240,
33672,
null,
21281,
38650,
146243,
8733,
136865,
62505,
null,
26441,
53522,
451563,
97469,
12109,
424214,
81571,
50130,
20707,
9284,
null,
185361,
267750,
147820,
230803,
null,
239936,
192192,
44201,
85336,
213818,
18061,
220542,
80526,
363088,
435854,
37441,
111436,
null,
458194,
null,
20296,
24166,
58434,
110073,
34521,
185326,
null,
63545,
139935,
513450,
59779,
274286,
null,
32137,
52981,
null,
61632,
null,
409826,
31833,
42576,
16281,
245389,
452712,
79555,
186560,
6786,
301488,
9796,
243963,
17755,
29147,
11474,
166263,
215261,
27563,
42504,
32306,
39792,
16689,
6050,
487603,
37938,
6025,
20694,
25640,
78490,
10192,
71264,
63231,
16746,
378858,
33921,
288417,
177287,
4361,
54993,
126895,
24620,
null,
225565,
92230,
19038,
100621,
74963,
346189,
null,
24189,
62166,
33026,
null,
299796,
124589,
null,
52127,
8396,
919563,
17621,
433383,
209074,
134572,
25963,
771805,
15665,
344653,
38719,
55218,
216435,
29409,
106677,
48538,
297273,
229781,
12737,
85715,
183607,
217320,
298047,
16246,
24491,
69701,
191835,
38645,
48584,
8045,
189174,
72288,
18583,
90892,
362196,
79663,
null,
14340,
12772,
62621,
23472,
31985,
18836,
19122,
46072,
44057,
68070,
null,
508983,
271194,
538310,
67616,
82911,
18558,
164146,
251229,
57891,
434833,
218671,
49340,
23667,
162607,
339819,
160202,
93880,
78805,
394260,
268931,
39950,
36306,
5451,
122145,
284810,
8721,
144169,
40283,
14182,
34577,
66407,
null,
182017,
null,
321167,
56580,
145130,
5255,
282341,
28830,
276413,
96161,
19275,
48261,
10874,
179324,
null,
29239,
143152,
17938,
4578,
419519,
62810,
146808,
180300,
null,
11819,
155040,
null,
45596,
309550,
66937,
null,
85528,
19660,
null,
117934,
50007,
136278,
538687,
50667,
41823,
19670,
66042,
65360,
167313,
57896,
206370,
159800,
115476,
224625,
77772,
229872,
23427,
18915,
null,
240844,
24710,
73434,
29075,
22767,
47568,
642921,
17436,
413564,
4964,
5097,
null,
20168,
279682,
17275,
184614,
113574,
330056,
97905,
351907,
174107,
829825,
50449,
30285,
164318,
132862,
36743,
17663,
38439,
162679,
12393,
7259,
11089,
204332,
153086,
77215,
190533,
61424,
8196,
57217,
75707,
231565,
31488,
274781,
20269,
197888,
271898,
35787,
28971,
62342,
440850,
18431,
384316,
51039,
15336,
47154,
7259,
387061,
16937,
82297,
434276,
23291,
37768,
null,
16719,
349162,
216633,
420169,
70745,
27682,
203180,
null,
362011,
228461,
79080,
15392,
223213,
191871,
390575,
177889,
null,
13624,
null,
null,
80647,
493966,
196027,
147624,
22076,
43456,
272615,
189260,
50665,
138697,
23541,
372271,
146848,
null,
22095,
null,
78937,
419282,
13271,
25942,
128597,
20272,
153072,
7946,
55532,
36376,
596918,
96952,
166252,
null,
14040,
26700,
171248,
54617,
10615,
15178,
32342,
28213,
107675,
287144,
311334,
70145,
null,
null,
34557,
8102,
137171,
7589,
328647,
159361,
13661,
122296,
125007,
190021,
388757,
19549,
60778,
32173,
210996,
16082,
72184,
null,
45421,
151774,
22244,
33532,
353468,
233112,
49949,
309500,
47973,
164376,
77006,
36850,
156165,
null,
102822,
27023,
143306,
138752,
147702,
17749,
140232,
null,
507679,
31318,
200902,
335552,
161391,
35877,
15796,
204086,
48498,
78652,
20002,
3860,
21238,
394102,
280516,
null,
55014,
112946,
9146,
319502,
null,
158147,
24615,
287430,
null,
251513,
5446,
11975,
42599,
134793,
41507,
null,
147720,
10210,
11181,
48695,
159427,
334694,
226521,
18053,
266167,
4026,
16736,
99444,
101450,
12387,
16233,
25896,
43360,
133216,
265564,
10382,
17121,
46319,
24317,
69653,
205290,
299028,
639604,
23623,
8679,
275541,
94101,
73916,
23117,
231427,
null,
91327,
null,
218253,
57902,
48941,
111636,
251136,
321950,
409407,
109465,
138904,
76290,
220646,
35962,
238922,
68048,
30796,
23021,
66555,
4279,
18110,
214913,
192847,
3989,
33434,
211796,
47493,
36900,
33508,
204744,
346203,
null,
49537,
176272,
362968,
35397,
501809,
31045,
21987,
5884,
190549,
664658,
null,
72865,
152447,
68386,
12512,
1130217,
33426,
46702,
112796,
5443,
7849,
251593,
43113,
248450,
122633,
null,
125684,
null,
18504,
342967,
10730,
4835,
22657,
276995,
51172,
133877,
8913,
550953,
219590,
134917,
404818,
89926,
21647,
99300,
39212,
63770,
412915,
5806,
184737,
50835,
25615,
27080,
291027,
27123,
77658,
19915,
442061,
36979,
26697,
8151,
61021,
7979,
250969,
347095,
62389,
208666,
232320,
null,
110055,
158232,
399057,
127169,
399462,
45094,
145830,
225692,
44361,
233750,
null,
100549,
313787,
29318,
46887,
6688,
23580,
null,
39152,
null,
199700,
349271,
189575,
60779,
17852,
59755,
232067,
17337,
null,
143734,
117065,
365929,
53012,
746647,
47084,
386739,
6592,
null,
31525,
647150,
121609,
6613,
205671,
23537,
477505,
210826,
10390,
34773,
50780,
103512,
29163,
12402,
11796,
119515,
null,
36229,
207393,
216254,
125947,
18061,
null,
17238,
110647,
248489,
165869,
133836,
168996,
257623,
null,
73576,
26163,
11346,
179397,
291662,
19247,
54067,
31266,
50226,
39296,
241897,
34246,
83098,
26815,
457,
33189,
72281,
154711,
135614,
25182,
26642,
57241,
108522,
20133,
49778,
143628,
54408,
535737,
319493,
174306,
23918,
65357,
60606,
22386,
59944,
12996,
199561,
50095,
148003,
191221,
228024,
32080,
40374,
144802,
34048,
4539,
467352,
392651,
285848,
29219,
12257,
102099,
null,
29924,
88393,
34059,
469214,
6699,
228784,
39825,
245486,
159778,
177623,
53569,
4074,
16557,
30330,
53370,
147727,
109765,
41432,
369065,
471587,
50926,
45911,
8143,
12543,
34753,
24725,
169516,
249316,
359670,
80775,
390243,
130040,
24569,
39814,
612156,
13971,
29700,
13515,
48043,
11113,
null,
111004,
12996,
36592,
17750,
94797,
119141,
null,
80843,
208045,
338594,
10202,
225195,
178108,
35563,
39558,
287559,
33861,
153545,
2524,
50695,
211360,
239459,
322479,
21890,
29654,
22931,
66154,
77744,
10214,
127656,
27909,
151047,
62628,
51925,
301056,
8038,
260191,
324106,
157310,
245347,
22578,
136513,
39496,
27781,
247806,
41153,
241685,
151521,
608705,
64380,
288342,
175088,
372618,
62947,
33224,
97189,
44904,
null,
72972,
null,
null,
22767,
16902,
47244,
320160,
443707,
29193,
178822,
314357,
12554,
319490,
58122,
null,
188415,
371631,
444192,
251234,
35139,
234682,
38385,
135676,
114643,
81302,
92474,
8274,
19229,
3881,
263171,
60315,
154591,
32184,
165791,
30940,
223706,
24102,
21226,
205802,
231058,
36673,
189333,
222743,
24166,
348786,
52424,
15493,
15371,
341056,
56059,
450438,
163160,
18042,
37989,
317543,
18105,
76248,
56955,
20930,
14091,
null,
16007,
186861,
25181,
null,
25567,
164193,
140166,
44862,
158206,
187066,
4356,
26957,
32532,
null,
127377,
21300,
82500,
79682,
437175,
142078,
64377,
221634,
164209,
23073,
12708,
129424,
70246,
null,
null,
43422,
107735,
456152,
122266,
177590,
179131,
37639,
12814,
63052,
null,
4980,
27226,
141672,
32255,
null,
146277,
412145,
null,
48395,
211706,
7142,
369276,
14395,
34676,
89180,
233908,
52695,
null,
25048,
51990,
9801,
45215,
4306,
142114,
159446,
186879,
59964,
676621,
null,
34443,
null,
188989,
215369,
233688,
8907,
145803,
116489,
9966,
80508,
71601,
190417,
87664,
null,
197044,
26470,
20209,
204774,
336044,
23420,
9766,
73073,
14232,
240595,
411,
73790,
376563,
65899,
378149,
126278,
121748,
null,
87579,
6869,
265944,
49684,
108463,
183648,
172351,
5907,
35429,
27828,
64455,
10652,
127601,
5980,
295407,
203627,
380794,
4394,
52245,
134230,
5356,
37278,
266083,
470925,
220637,
66553,
47738,
null,
86713,
14031,
251202,
13729,
null,
842241,
110039,
348589,
288712,
65780,
113849,
97878,
51313,
45941,
208042,
70536,
293112,
95783,
16070,
null,
81810,
34543,
156002,
102994,
143883,
194195,
67926,
47070,
296058,
48226,
176926,
null,
110602,
40106,
304490,
172692,
13268,
48808,
41165,
25874,
115787,
888029,
1801,
152689,
9753,
11663,
30920,
12656,
614213,
456180,
54745,
9873,
10786,
74494,
128435,
16903,
35832,
10903,
100817,
9900,
94971,
124780,
479833,
208234,
22088,
99410,
61967,
44043,
216167,
240457,
96387,
367322,
364346,
13163,
60077,
394286,
258688,
17021,
29836,
62007,
35147,
23568,
null,
184144,
9534,
21731,
14955,
278541,
19888,
220179,
143919,
77968,
15930,
44530,
null,
50253,
44994,
52247,
24978,
15157,
38841,
59137,
180392,
38556,
218439,
386869,
262639,
198796,
243464,
135435,
240192,
32585,
14392,
464467,
257208,
8972,
33108,
189581,
122913,
450298,
17223,
9772,
11676,
426399,
168627,
6686,
312841,
256586,
183911,
null,
30247,
null,
7515,
53480,
160052,
418119,
362823,
180613,
null,
17159,
61678,
333964,
269204,
547924,
65853,
221666,
22434,
43137,
329838,
32045,
243966,
95266,
25172,
48419,
9837,
null,
17790,
137035,
178519,
53062,
466907,
30901,
21353,
48253,
null,
null,
429189,
31854,
350864,
25203,
null,
267424,
46199,
10781,
261996,
184858,
15481,
315647,
162812,
12297,
202930,
26172,
null,
97231,
25953,
11229,
126870,
60116,
2056,
207412,
71700,
35883,
445283,
115875,
154720,
118686,
100303,
167017,
25003,
339546,
13100,
11289,
277373,
37211,
null,
17507,
18034,
null,
15156,
26202,
321842,
150419,
24134,
56779,
24309,
23730,
34629,
23313,
21969,
35888,
35564,
92734,
160530,
163057,
null,
41577,
31938,
7795,
50699,
50375,
null,
18012,
null,
41025,
306136,
13300,
450759,
240067,
108717,
30327,
54193,
38164,
118964,
164505,
479234,
33073,
176306,
15152,
134412,
161431,
null,
8304,
35829,
12219,
216713,
128357,
254733,
15397,
null,
221053,
968,
170274,
184676,
143663,
37540,
90283,
185711,
525530,
null,
75098,
50977,
38016,
7045,
295896,
232591,
126599,
null,
84454,
6166,
165714,
41598,
23242,
61241,
32040,
null,
137888,
14618,
null,
208953,
325042,
127582,
8497,
162791,
17066,
20853,
32419,
38293,
172789,
32172,
199282,
21239,
134716,
null,
255781,
71288,
36486,
236530,
43404,
null,
148865,
123086,
199377,
44735,
53978,
48662,
null,
16776,
274646,
10852,
51674,
311178,
25552,
299483,
286870,
235881,
12787,
8646,
56439,
143739,
330124,
19932,
24226,
18555,
44068,
131422,
362078,
32754,
335856,
43217,
1105509,
294628,
35444,
296389,
381071,
10076,
42445,
28734,
316763,
370157,
392028,
13771,
214891,
237625,
401760,
313652,
324360,
64742,
31143,
34808,
null,
112326,
126164,
286064,
18005,
30183,
339783,
null,
40560,
176814,
28618,
251039,
348126,
148309,
106688,
130998,
32953,
28233,
492524,
380177,
163547,
262530,
100842,
438980,
32933,
321631,
240116,
186782,
474440,
17979,
232857,
28974,
168653,
168285,
101781,
356100,
125989,
83515,
40829,
115571,
169858,
792818,
125264,
317134,
190079,
201572,
83044,
6996,
296466,
62240,
322850,
21605,
43896,
18396,
null,
89380,
156949,
434404,
172314,
277455,
316187,
18429,
145909,
32321,
30999,
null,
289647,
null,
102412,
58952,
243208,
111830,
28905,
295403,
142411,
24394,
65390,
4103,
18276,
null,
51811,
38866,
216108,
53541,
null,
3116,
310735,
107945,
13319,
218446,
121556,
250801,
281120,
288660,
10012,
540688,
349456,
41560,
9184,
15302,
140724,
247588,
null,
142650,
209422,
98475,
12903,
null,
87990,
125995,
56146,
7932,
350995,
13913,
119716,
239100,
10816,
34175,
391437,
44293,
25995,
null,
203050,
74496,
253418,
23083,
null,
282529,
29705,
406338,
54054,
128313,
9873,
85000,
58148,
208491,
404188,
221948,
100240,
548248,
140916,
123793,
670200,
595712,
331746,
34989,
17916,
264807,
6615,
28639,
44502,
89849,
504288,
9505,
22887,
151580,
29104,
38195,
51969,
173823,
107564,
49374,
49643,
216450,
149903,
null,
28309,
29584,
62269,
280182,
33378,
256209,
277464,
19218,
288160,
32839,
113781,
84407,
243360,
20184,
247545,
179562,
51757,
127035,
253219,
40917,
364976,
257787,
24668,
187373,
50861,
15884,
34345,
48223,
132807,
358518,
559952,
33159,
14107,
41269,
45336,
32200,
204637,
54582,
67571,
null,
321215,
281197,
123458,
350455,
72580,
243768,
408916,
32910,
171456,
757673,
62203,
22740,
24211,
387488,
253172,
835947,
83248,
null,
28103,
24485,
59783,
616829,
75661,
68790,
null,
247870,
324347,
129494,
10105,
43450,
49974,
null,
64460,
22584,
null,
217988,
419205,
9795,
166983,
218521,
16394,
10284,
44374,
29120,
25504,
147514,
7613,
154313,
92939,
83641,
20085,
null,
35533,
24466,
298955,
null,
61550,
7553,
32407,
284660,
67758,
138224,
57339,
408419,
44859,
392971,
null,
179949,
127392,
5781,
153141,
279416,
254287,
54810,
34775,
232880,
40765,
57075,
151624,
13958,
156806,
37306,
17220,
null,
390933,
252272,
17146,
120613,
7426,
26869,
null,
419099,
80412,
11956,
16079,
15652,
19391,
541955,
154261,
742153,
26589,
33981,
187097,
7274,
203800,
161363,
39478,
60257,
56456,
53785,
76392,
12349,
189519,
165913,
33177,
243597,
123168,
62472,
14306,
176681,
140921,
173280,
null,
335000,
282180,
4970,
28694,
22612,
282894,
212560,
134932,
8368,
76078,
19352,
187592,
638741,
227221,
null,
13252,
88423,
271558,
23626,
60238,
46771,
17752,
63310,
20291,
420182,
81663,
61507,
6651,
104633,
137795,
null,
6149,
283253,
14056,
12478,
12014,
252204,
97442,
155572,
24001,
46115,
548787,
108341,
141596,
124663,
null,
9414,
76043,
179265,
31067,
323494,
null,
77965,
437212,
15624,
315706,
148216,
null,
35670,
85048,
14813,
134890,
118397,
230799,
165748,
312399,
null,
24370,
13752,
21670,
352862,
47655,
10292,
61793,
227941,
64442,
27201,
20481,
21184,
82167,
199614,
411303,
19321,
99726,
97726,
null,
191585,
18491,
60899,
48497,
25288,
18012,
246600,
19554,
null,
40521,
226859,
358155,
49326,
59212,
7523,
7368,
277503,
56741,
66086,
123972,
15867,
305409,
348127,
314109,
30415,
159943,
18817,
298635,
161899,
301580,
15808,
87089,
15079,
325857,
null,
43578,
null,
26528,
10975,
30954,
193438,
86345,
60133,
50981,
93110,
167542,
12262,
79222,
12551,
84858,
null,
71968,
74681,
123281,
170056,
151328,
407860,
74960,
355436,
153068,
160918,
61967,
59227,
286995,
null,
86312,
30309,
129276,
59068,
18104,
960484,
186664,
306122,
79080,
32159,
21356,
13680,
42004,
43826,
21077,
34499,
236437,
631554,
129836,
28438,
290826,
106741,
27296,
15361,
90583,
19911,
308161,
24564,
154274,
15017,
16689,
47824,
324636,
112160,
511459,
43299,
null,
228271,
112861,
30551,
36260,
233972,
23363,
122915,
75778,
282657,
296025,
429666,
null,
24878,
344877,
405338,
null,
180780,
57473,
30572,
275769,
198772,
164914,
7586,
null,
286020,
null,
41567,
115132,
53357,
53169,
52594,
null,
109750,
302488,
38148,
9825,
66194,
89976,
null,
181774,
22698,
45242,
170454,
414960,
31091,
10449,
492378,
63971,
45966,
265726,
27547,
null,
19357,
156160,
31303,
37855,
36943,
null,
387281,
96784,
86591,
null,
188416,
94684,
255334,
null,
52103,
35551,
49900,
9210,
61074,
28203,
247639,
289575,
26868,
66084,
26849,
100618,
430406,
48341,
598839,
null,
290168,
12761,
109477,
177073,
775773,
155411,
10578,
null,
47151,
12122,
27846,
64330,
216301,
21352,
44306,
47241,
40959,
null,
241594,
18510,
21438,
374254,
null,
18206,
644130,
32972,
15944,
41941,
114708,
null,
45783,
33226,
190046,
30187,
59688,
38957,
670231,
null,
26796,
31366,
17690,
229770,
6831,
568444,
175622,
30613,
4383,
160933,
9118,
28334,
16825,
null,
14337,
417237,
4294,
348380,
7167,
95351,
null,
34867,
null,
16315,
33004,
28352,
16133,
35899,
16588,
42045,
515821,
36967,
294899,
33590,
null,
19327,
152204,
356876,
426594,
14251,
97958,
42546,
475841,
31869,
62741,
397615,
null,
49086,
20156,
15611,
329803,
37568,
283393,
110361,
78979,
118276,
258440,
417409,
49117,
23566,
15060,
57643,
32791,
37010,
null,
38774,
415201,
10837,
401533,
283334,
111550,
35120,
95860,
59484,
38219,
286242,
150774,
9801,
35889,
176235,
56719,
226525,
24083,
null,
130037,
21695,
270259,
null,
28835,
10805,
null,
122526,
40179,
182631,
6235,
23744,
78076,
null,
150155,
14503,
26097,
30860,
57965,
140549,
82444,
268373,
43758,
null,
15727,
121326,
180071,
79081,
37087,
233959,
null,
94784,
13084,
50281,
521050,
124088,
169820,
233892,
136115,
32464,
9285,
401510,
313667,
391716,
360329,
35183,
254242,
234494,
421901,
340751,
29605,
124873,
101000,
19805,
24900,
35560,
177704,
120600,
43889,
35513,
635837,
284670,
14753,
296405,
935931,
27466,
350435,
222955,
46216,
18878,
200092,
80119,
304791,
13965,
102663,
249476,
21455,
54942,
13611,
336010,
44771,
50653,
43519,
119213,
171892,
20205,
68658,
308563,
28284,
33287,
null,
41891,
13479,
223079,
193339,
17620,
null,
147707,
486435,
null,
null,
180782,
217014,
18367,
11327,
6507,
354217,
87863,
226339,
271110,
159674,
61150,
125909,
29884,
79412,
147351,
62396,
254711,
46661,
7567,
null,
27245,
83174,
null,
null,
35754,
null,
40861,
65971,
38705,
34573,
34786,
63061,
27980,
153727,
572316,
null,
102497,
210263,
23575,
320751,
17281,
43664,
34538,
11375,
21376,
24467,
17409,
177916,
30223,
null,
55033,
1119115,
20222,
395806,
479500,
51463,
214986,
15016,
159963,
90908,
328356,
158768,
7498,
16342,
22388,
51311,
127658,
33404,
73406,
35119,
64745,
45077,
509592,
283089,
255538,
null,
125729,
109415,
37459,
null,
16427,
40163,
24387,
310689,
192601,
400735,
61759,
309006,
29859,
299110,
67008,
null,
184632,
12418,
10781,
385849,
null,
67033,
18522,
217701,
261431,
166557,
88606,
55250,
28992,
null,
32234,
180087,
4545,
275532,
null,
52943,
null,
16711,
23794,
32232,
499783,
6988,
8377,
4439,
12147,
118818,
19018,
15925,
13003,
null,
156978,
373559,
213097,
34833,
53913,
33525,
57009,
530937,
359203,
114113,
333188,
172566,
34985,
167318,
4738,
12003,
115577,
220807,
77853,
357683,
19651,
588409,
116555,
211023,
291546,
326063,
47242,
399247,
null,
75847,
15147,
null,
55985,
35048,
null,
199649,
68232,
144127,
312588,
134211,
195212,
73565,
389625,
35289,
156879,
null,
14084,
359505,
202470,
306337,
124145,
261985,
284747,
110993,
6044,
550387,
79514,
null,
63992,
78324,
55130,
18782,
115859,
7678,
288329,
213046,
10654,
null,
28397,
61021,
169739,
172023,
279958,
260166,
56753,
26562,
176891,
35953,
392669,
89529,
179926,
196558,
80009,
410286,
53718,
122325,
272584,
774224,
158838,
23183,
38880,
47848,
48821,
18363,
235942,
null,
234636,
38113,
31652,
3336,
267993,
51977,
35399,
245146,
157984,
5720,
33621,
316405,
43297,
60023,
618679,
416262,
202525,
16801,
268820,
274389,
308161,
122535,
12644,
null,
121687,
null,
65939,
18757,
319204,
104731,
198652,
461426,
23300,
27835,
39446,
265700,
5481,
211343,
118891,
137952,
105362,
305027,
451762,
24742,
30332,
30167,
114462,
192235,
35614,
22410,
153699,
21315,
23746,
25770,
366482,
27363,
233206,
65448,
214792,
30202,
106733,
488637,
46522,
238579,
null,
346840,
89612,
84647,
245714,
243038,
234310,
151266,
64836,
31206,
21320,
381289,
19962,
30845,
173349,
41078,
161466,
320641,
159002,
null,
269907,
22085,
71194,
null,
5071,
120159,
329037,
220210,
306003,
63555,
335922,
143228,
34206,
290138,
505436,
null,
null,
null,
20711,
48448,
8845,
5410,
178271,
62822,
327160,
null,
6425,
233923,
131373,
null,
44658,
334557,
99284,
435707,
null,
16012,
426998,
6155,
43414,
151619,
79991,
185022,
190576,
86235,
254770,
12697,
106886,
11554,
148690,
12279,
78021,
12991,
155662,
28484,
70057,
284255,
74798,
432748,
7020,
275078,
255779,
11656,
55020,
141527,
505045,
29801,
27656,
350930,
87027,
5042,
7940,
324215,
95849,
42464,
67409,
117499,
14811,
303367,
5063,
196873,
5483,
560359,
null,
87800,
182836,
null,
301802,
213613,
25247,
38267,
43812,
50636,
44015,
139061,
206357,
31178,
125178,
191140,
64436,
26516,
11214,
57780,
158837,
null,
41043,
39336,
130799,
71685,
15377,
187817,
13423,
179326,
12822,
6948,
294874,
18790,
194861,
26896,
27750,
102923,
466263,
17809,
1100864,
80063,
202265,
240146,
11627,
124025,
148812,
333274,
38984,
157649,
null,
40865,
74244,
196006,
57062,
53083,
32983,
43845,
165714,
230118,
16186,
16837,
23947,
null,
23549,
null,
293461,
440547,
59555,
25240,
17221,
7539,
72838,
86655,
162459,
145723,
243847,
3830,
174184,
16104,
179481,
45791,
330650,
533906,
65751,
298473,
7923,
null,
69464,
65634,
7881,
56254,
43336,
14767,
279268,
28332,
194846,
303709,
38309,
116773,
28841,
36236,
26703,
176148,
null,
80461,
134311,
61341,
null,
213091,
512739,
229672,
284623,
180038,
null,
null,
166146,
171418,
175948,
88109,
340874,
37625,
35806,
356456,
274580,
139084,
34155,
27598,
null,
63661,
27503,
14435,
4907,
118308,
60682,
133790,
13607,
23619,
72191,
171045,
29119,
468149,
212919,
null,
29805,
31518,
280549,
464236,
87369,
44957,
582466,
46960,
43934,
164462,
239354,
33092,
111310,
419786,
20953,
27642,
100697,
58595,
40103,
11160,
27863,
31188,
179645,
62916,
null,
190444,
null,
42348,
61603,
92959,
70516,
304895,
12096,
431382,
17180,
301016,
67363,
385136,
31717,
35721,
198888,
145329,
137977,
93951,
125957,
344035,
46160,
null,
260314,
19280,
211986,
192456,
430666,
38183,
90876,
null,
153695,
136852,
401796,
null,
27095,
null,
67300,
113,
15541,
313326,
51993,
85907,
51698,
294209,
259945,
31162,
552779,
34136,
38278,
null,
195073,
26465,
107271,
125282,
271068,
29129,
26925,
438770,
72737,
123330,
472332,
134083,
163388,
170511,
84926,
254524,
17975,
868690,
45996,
552475,
201533,
23589,
6367,
29479,
309930,
818415,
336377,
406760,
265073,
303826,
49130,
7726,
70494,
786977,
120227,
8505,
157826,
41841,
35806,
203584,
35557,
202646,
154296,
35264,
402371,
12756,
7354,
66788,
381550,
93842,
187664,
288247,
14910,
25086,
273740,
32001,
261315,
20966,
434543,
1109,
null,
null,
61004,
29100,
77529,
17952,
306516,
18785,
2757,
31386,
244159,
252697,
37907,
261458,
291964,
39532,
610996,
null,
231112,
235500,
61771,
28965,
null,
null,
30705,
25059,
20623,
122783,
146441,
163576,
null,
23798,
122569,
11161,
60104,
342896,
21774,
null,
273174,
11234,
15584,
175743,
377287,
224969,
444647,
42795,
20969,
55256,
93137,
116040,
49281,
17142,
183135,
null,
28134,
69922,
26857,
40483,
30662,
155498,
140135,
18968,
330813,
272741,
61032,
149413,
469637,
30500,
25444,
null,
117870,
144995,
109164,
128076,
65115,
188349,
34157,
140468,
23714,
50504,
29961,
69786,
100064,
201283,
22406,
351045,
12355,
24386,
76269,
358383,
41597,
57987,
59730,
177761,
107058,
306732,
106673,
32178,
591111,
27814,
19530,
82564,
10412,
null,
274237,
18837,
176678,
134510,
342611,
35050,
340937,
268474,
12723,
17588,
244307,
30775,
728295,
188156,
24190,
19056,
null,
33922,
50536,
42337,
151496,
10021,
100080,
302162,
83083,
317859,
156984,
145601,
210104,
238905,
null,
137042,
95307,
26537,
20298,
67070,
146424,
484939,
32413,
10638,
108432,
85733,
3084,
56356,
114056,
23650,
26838,
358108,
256585,
135947,
69242,
217656,
null,
225405,
116467,
25942,
34884,
28664,
14385,
17781,
72081,
400127,
199175,
102885,
28064,
38378,
43304,
4802,
40701,
725132,
13618,
223181,
475332,
null,
271745,
60225,
159930,
40023,
4578,
66351,
59039,
79503,
138134,
150984,
241498,
39537,
3762,
84734,
103440,
68006,
26741,
90104,
192911,
17600,
31772,
39038,
306686,
11514,
277116,
87020,
43233,
87801,
null,
null,
147312,
34198,
46384,
24276,
null,
48361,
14232,
60236,
48299,
11556,
45979,
515773,
5651,
47689,
38791,
19998,
16026,
null,
34839,
219162,
20937,
32889,
null,
354844,
148702,
46834,
270109,
103336,
23144,
null,
69617,
214657,
311065,
70977,
122285,
93565,
31411,
null,
122456,
18689,
19565,
353551,
235508,
null,
null,
31488,
null,
298077,
333920,
39142,
146555,
null,
189365,
278187,
147511,
173878,
28731,
50340,
512660,
51793,
174175,
359125,
142950,
21990,
306437,
160060,
null,
213509,
164713,
86911,
349077,
null,
27282,
25430,
39138,
33196,
null,
79232,
null,
158307,
14419,
33502,
31590,
83660,
415261,
null,
17673,
65942,
140785,
271135,
177382,
398760,
359154,
140426,
549498,
null,
248407,
585905,
597000,
462344,
209477,
null,
126379,
337559,
350831,
25597,
null,
28199,
117212,
32741,
16928,
1457,
217900,
30863,
557755,
null,
21646,
656367,
227985,
251063,
17539,
25196,
33350,
25909,
179589,
34433,
93264,
206007,
268333,
203528,
43337,
191794,
18167,
4261,
236851,
48080,
221612,
64560,
31458,
201764,
null,
31954,
208733,
41317,
257223,
104989,
19377,
210092,
137610,
61363,
34297,
221325,
null,
53164,
177677,
307787,
68249,
null,
28888,
49924,
null,
6143,
318112,
370115,
164500,
4534,
53802,
22037,
159971,
41408,
100684,
351074,
313709,
55879,
66427,
18870,
140815,
null,
43564,
33557,
null,
278807,
3474,
131464,
239233,
null,
24746,
60367,
56466,
395742,
1020893,
12195,
482359,
430988,
86369,
95025,
327379,
157635,
16449,
200650,
112239,
142789,
null,
12070,
32717,
25164,
13731,
435128,
84540,
165748,
182238,
12961,
61834,
3577,
152875,
265580,
12842,
33327,
58353,
54305,
278909,
27584,
null,
null,
31782,
237353,
34932,
45400,
257522,
224276,
295195,
228718,
58036,
50591,
194968,
64106,
19536,
434628,
73303,
136352,
41721,
270952,
27354,
37402,
232405,
33779,
284834,
null,
29873,
82390,
197981,
73205,
19463,
146375,
54256,
16410,
115618,
66043,
139705,
118094,
415864,
785063,
232939,
302330,
149237,
17126,
308755,
92576,
21231,
null,
417579,
24899,
null,
318327,
25768,
34464,
299507,
403849,
317891,
5814,
15610,
59383,
137432,
7451,
29817,
89129,
13629,
11589,
96905,
8241,
12583,
299769,
210338,
49721,
538718,
186749,
118647,
86139,
46888,
250162,
117139,
116278,
288058,
240703,
281299,
578806,
45302,
296294,
552654,
null,
195091,
47377,
18951,
229916,
322865,
20993,
169256,
52035,
243263,
43379,
null,
130002,
null,
435550,
null,
23751,
9615,
273275,
239023,
7580,
18336,
1813,
98755,
14455,
205492,
12192,
13462,
13521,
39663,
269073,
91181,
41681,
null,
null,
24105,
38707,
10391,
205768,
13029,
9312,
7025,
38917,
316,
6099,
79227,
352157,
45907,
null,
null,
6934,
11564,
64629,
42093,
178791,
252451,
27851,
19757,
98933,
26255,
182712,
18881,
70104,
44882,
168896,
201481,
215588,
211944,
281790,
17431,
9902,
332015,
62594,
25419,
23860,
27280,
3787,
230103,
228870,
56886,
29706,
128620,
40173,
284833,
49058,
185448,
320327,
84952,
270212,
103165,
600215,
62320,
18470,
179510,
186198,
88051,
43959,
667596,
23943,
46394,
300255,
144681,
null,
185622,
144432,
69189,
205846,
242646,
47852,
41048,
null,
null,
413757,
null,
null,
28997,
96652,
127051,
33810,
264481,
243558,
20315,
316266,
117204,
315841,
257026,
169882,
163363,
26858,
22814,
20336,
377370,
33023,
225619,
109894,
68413,
null,
152934,
94009,
11206,
null,
21445,
17290,
27762,
32136,
216541,
263162,
313700,
231395,
18953,
67324,
388912,
8351,
326324,
160509,
30890,
199127,
501903,
348759,
89339,
29386,
30996,
9045,
177482,
113671,
141920,
137851,
8028,
18291,
38021,
52509,
25684,
38992,
657945,
59236,
36601,
16300,
21308,
24626,
96963,
null,
331433,
184773,
30493,
42952,
4092,
18283,
243424,
272344,
86117,
134926,
9506,
46339,
204668,
null,
110009,
25017,
232023,
2727,
98510,
261438,
71247,
20657,
18418,
193225,
60540,
45041,
49459,
187531,
88813,
28978,
159608,
67365,
260125,
11237,
39795,
7209,
84933,
17641,
176225,
273976,
null,
291612,
37421,
3229,
17632,
14728,
15323,
3404,
62344,
36218,
32612,
247809,
31487,
null,
118229,
11736,
309658,
294392,
41517,
43363,
49467,
14980,
317929,
36026,
157969,
41655,
527184,
71635,
286358,
null,
132555,
471407,
190545,
38887,
70944,
134789,
31931,
364568,
450856,
31013,
68182,
6419,
514534,
65623,
157719,
219727,
148313,
22529,
34670,
82543,
290333,
37034,
15730,
8743,
35580,
null,
546465,
186051,
53121,
28001,
36308,
168084,
184378,
665974,
57124,
3990,
null,
65659,
127738,
151978,
31949,
418395,
157596,
24011,
35155,
392090,
18200,
28510,
156490,
41247,
64089,
122662,
120539,
null,
52897,
175265,
null,
30282,
93111,
169590,
351506,
78749,
60177,
239721,
20462,
268316,
109176,
23593,
22430,
null,
22986,
null,
376006,
456043,
11043,
174456,
134235,
33512,
42642,
33863,
229252,
171189,
155961,
222468,
424118,
160853,
22322,
362741,
305571,
96851,
357849,
null,
26858,
26944,
134478,
186590,
468818,
134445,
233721,
33940,
265865,
461645,
84662,
79409,
348989,
126496,
345885,
444457,
40281,
173663,
52898,
159319,
394916,
43743,
270668,
163212,
222184,
12868,
174753,
171865,
18885,
680973,
295554,
287982,
168394,
283708,
19188,
471351,
170624,
8681,
33375,
137153,
269889,
149898,
25886,
213653,
77551,
34524,
53109,
29054,
86001,
182514,
37124,
19214,
89477,
72701,
130139,
null,
64364,
244598,
46391,
null,
152649,
42084,
170542,
17035,
21597,
null,
76453,
58498,
9399,
315425,
null,
142926,
80958,
116879,
18965,
114277,
373090,
33944,
173807,
175008,
13511,
204665,
84286,
71718,
null,
36989,
201497,
275507,
70896,
386605,
162994,
315155,
77094,
152548,
68372,
77697,
20110,
62772,
117812,
126436,
12820,
34424,
57275,
20980,
18327,
458914,
14096,
59833,
128666,
8364,
157619,
143811,
52560,
37723,
31192,
30929,
41888,
347277,
58705,
249706,
null,
null,
289592,
179016,
12617,
50882,
63630,
187121,
46685,
38376,
487848,
null,
95621,
66002,
12486,
26286,
50087,
31526,
null,
108608,
43727,
109662,
148631,
27997,
11409,
null,
128036,
10923,
53976,
44554,
86754,
220110,
194771,
10925,
null,
61358,
412321,
243174,
15590,
40107,
267058,
110524,
192755,
38940,
126555,
252656,
459309,
247007,
290444,
142632,
232431,
27927,
216923,
282415,
237651,
93787,
202096,
207311,
7535,
389113,
70695,
189806,
4532,
133635,
123476,
53884,
19869,
162684,
128306,
38330,
25925,
40826,
135348,
34096,
192470,
203061,
104289,
null,
211609,
28408,
52796,
32946,
34327,
59814,
391620,
218434,
25773,
172561,
19930,
62380,
273365,
14779,
88057,
184517,
8499,
null,
21737,
288053,
148514,
51456,
75500,
null,
278186,
25505,
35826,
241385,
59320,
190740,
12307,
34915,
41526,
19214,
48156,
16563,
4227,
36873,
284973,
267608,
166382,
219391,
16315,
41662,
38011,
164680,
null,
null,
297682,
30882,
9545,
26570,
642828,
31496,
25561,
113520,
204452,
22114,
460115,
47424,
286319,
22910,
81019,
390559,
27709,
null,
27565,
32362,
63230,
15826,
16501,
287602,
671550,
62547,
369703,
53399,
null,
51767,
null,
273868,
null,
171203,
279909,
10031,
13834,
45512,
149092,
236451,
277407,
137903,
42009,
440608,
46982,
null,
288398,
null,
41862,
9587,
11528,
25309,
66212,
null,
88353,
60263,
null,
782877,
157664,
61521,
null,
170254,
13508,
222117,
477433,
61338,
19384,
31120,
149499,
43171,
null,
265686,
63336,
222683,
30813,
30703,
15677,
272433,
354010,
22108,
177482,
308880,
264167,
49187,
526027,
52094,
119624,
null,
16272,
45472,
null,
41201,
293416,
71176,
40156,
36294,
146567,
2261,
168575,
236050,
194322,
39054,
37901,
61049,
44496,
163197,
174560,
23676,
72048,
29728,
116205,
265684,
148452,
2015,
345354,
707133,
147607,
103864,
305953,
112339,
39180,
558361,
66977,
433315,
12873,
16443,
27783,
17114,
12391,
28778,
41810,
186371,
190279,
70279,
314476,
57872,
527215,
2590,
411284,
161432,
149872,
17689,
655802,
11123,
123123,
261622,
169229,
39148,
104850,
18304,
null,
529185,
276017,
25609,
32565,
175047,
24340,
null,
30997,
84538,
49748,
365983,
43613,
123358,
23472,
25808,
41403,
35696,
179699,
96059,
23508,
169591,
26695,
28792,
9953,
9147,
null,
136452,
286261,
29678,
63850,
284351,
171461,
116064,
182321,
48607,
266942,
68834,
18700,
31443,
50412,
246487,
658,
null,
224256,
342862,
11052,
312663,
135816,
51168,
37722,
34016,
27731,
221433,
41622,
83938,
35973,
84076,
155195,
42155,
252055,
95913,
179014,
14211,
281144,
236577,
166883,
41557,
null,
null,
180469,
350679,
36392,
189081,
205404,
7876,
105506,
14186,
24562,
183903,
37395,
null,
156073,
null,
null,
29580,
90463,
94977,
340638,
3669,
53494,
368802,
184652,
254873,
185348,
48773,
36921,
1294903,
66982,
144955,
30060,
188966,
204657,
30372,
336710,
177950,
18763,
417861,
197585,
19386,
25881,
199222,
149274,
176968,
19980,
178341,
93246,
112810,
328588,
35864,
36410,
61827,
98856,
24178,
138367,
476582,
null,
319557,
134669,
501363,
56566,
181533,
26054,
373795,
30519,
49300,
41111,
143244,
217626,
644332,
231754,
null,
9582,
141499,
13366,
26690,
195190,
null,
257169,
24101,
51233,
196624,
603295,
13620,
115859,
158088,
null,
81262,
16631,
4714,
685496,
76468,
null,
209533,
null,
16123,
270869,
119530,
56806,
6838,
17829,
200248,
35540,
22935,
123455,
null,
null,
146440,
19281,
19726,
196131,
213776,
null,
80032,
null,
201502,
505541,
14932,
23434,
296953,
401432,
50510,
null,
82747,
null,
7767,
15902,
52121,
86393,
170315,
20787,
11910,
180661,
212442,
97204,
144444,
30962,
320829,
199706,
17018,
53948,
25191,
5732,
31269,
213723,
303128,
29386,
98345,
285857,
353419,
25414,
160567,
null,
19893,
20399,
474368,
465934,
27144,
412146,
null,
342305,
10368,
191049,
null,
81556,
73152,
37660,
460588,
25187,
14302,
15373,
455975,
112740,
219458,
138779,
null,
80876,
112264,
271086,
9762,
71404,
138505,
76784,
71124,
179031,
15137,
15684,
191464,
11378,
21039,
107160,
42506,
67212,
217214,
30216,
159233,
null,
null,
74895,
645838,
33363,
146804,
29210,
26112,
45425,
239901,
74413,
56694,
28866,
371889,
117259,
87307,
67882,
271286,
null,
182649,
29569,
241819,
12252,
59667,
368108,
null,
258533,
166017,
null,
290942,
79390,
52322,
60110,
14104,
8392,
31132,
431805,
42280,
89053,
null,
43770,
368583,
2152,
403687,
72230,
88070,
15684,
185623,
143526,
263315,
null,
210418,
137500,
167526,
470945,
51179,
41091,
332695,
158735,
281481,
37292,
42169,
23405,
273514,
19398,
null,
8581,
null,
21149,
42843,
12163,
878127,
463633,
10362,
107945,
279224,
120046,
563031,
281933,
101997,
null,
101318,
92102,
337737,
212966,
149711,
21823,
171507,
329689,
117600,
318191,
12391,
229079,
191293,
6493,
51535,
81695,
8979,
216666,
5815,
315109,
55208,
182289,
141561,
21783,
361836,
17042,
31490,
10684,
147874,
61353,
45116,
28161,
54992,
358891,
165809,
null,
49345,
30968,
29155,
null,
309129,
33525,
278111,
16824,
null,
4200,
47444,
23319,
11324,
134277,
null,
165140,
36571,
8061,
460000,
8875,
null,
60421,
22659,
2784,
24639,
null,
null,
57020,
27910,
228964,
null,
244393,
null,
155641,
47768,
19179,
36868,
19849,
175691,
60018,
66758,
44602,
274395,
415891,
136695,
95672,
38120,
124735,
17214,
22392,
13200,
301843,
207326,
27310,
207166,
529738,
471383,
8018,
418439,
279923,
107355,
21269,
242463,
27464,
15563,
209467,
401101,
26009,
24939,
31809,
177345,
31397,
4209,
22062,
133642,
null,
34561,
29182,
175052,
144446,
212204,
61749,
303338,
274176,
5293,
18495,
15430,
37326,
null,
66971,
37002,
28891,
76486,
222940,
354440,
197868,
null,
154917,
929765,
26836,
5912,
231640,
17968,
44570,
4763,
346691,
214531,
525424,
16769,
145991,
145903,
30190,
83584,
477034,
376008,
121843,
160141,
44609,
48220,
31964,
48472,
27088,
31512,
null,
47975,
21679,
50186,
223627,
257369,
4605,
189821,
40333,
null,
325856,
16162,
91009,
431968,
238815,
null,
82687,
19469,
412695,
396328,
75668,
79654,
24449,
null,
87465,
29987,
32231,
null,
29734,
29470,
null,
8434,
75380,
15591,
313733,
6910,
82740,
5171,
null,
55274,
38236,
69354,
264554,
763089,
35299,
353236,
178017,
85990,
7435,
32605,
null,
9544,
58308,
109443,
418069,
20653,
307958,
45238,
86823,
9907,
331240,
37049,
67152,
175732,
102991,
154218,
276204,
129401,
108443,
25555,
162519,
519684,
140756,
191853,
94027,
324819,
319122,
288226,
35865,
419583,
null,
19029,
4008,
113898,
49701,
21113,
542454,
13699,
611969,
473122,
24020,
210839,
null,
138530,
41684,
34739,
406022,
11311,
220023,
55045,
86685,
135552,
217460,
244312,
85756,
70509,
39597,
null,
null,
132933,
62750,
61033,
135864,
5525,
184944,
null,
134379,
221014,
287480,
57829,
null,
8201,
185044,
56602,
590803,
52827,
12727,
160740,
77460,
103554,
17422,
null,
null,
102425,
110819,
45160,
21918,
46015,
null,
16354,
32828,
114057,
43688,
86425,
82215,
33323,
57064,
4167,
null,
275588,
70686,
91397,
446738,
3384,
462631,
24700,
39876,
124312,
46562,
278207,
47440,
45737,
229439,
39412,
null,
822095,
73010,
261523,
19180,
334538,
45390,
68517,
43136,
null,
29059,
193167,
25804,
38041,
null,
187551,
null,
125355,
9701,
135853,
24478,
34216,
280754,
82604,
140956,
34494,
305863,
157653,
65124,
249409,
25437,
122415,
288643,
null,
248356,
238898,
123522,
548880,
230909,
278277,
49483,
315899,
22255,
39063,
191581,
124011,
238330,
185764,
63610,
213487,
172646,
38598,
49069,
4560,
392617,
112867,
137023,
30156,
29809,
157739,
974449,
316666,
18613,
27261,
326831,
240250,
284292,
30743,
24093,
111311,
45835,
26072,
118171,
189469,
164500,
194668,
443160,
48206,
17401,
15118,
118619,
34225,
211950,
384040,
33810,
123344,
283896,
100149,
173859,
167956,
null,
317951,
77530,
398322,
42214,
381151,
57163,
145940,
2007,
235788,
125676,
20051,
4598,
57139,
198787,
38164,
129382,
9378,
251277,
71484,
526028,
15188,
217832,
130493,
247181,
13470,
9018,
15494,
166797,
132411,
141123,
null,
null,
58329,
148161,
268662,
53840,
457310,
60420,
202263,
31198,
10169,
6841,
null,
282783,
167457,
null,
157120,
217145,
147300,
378467,
100701,
null,
70972,
143221,
302404,
228588,
26690,
8775,
80103,
null,
45677,
251432,
227948,
53687,
9786,
273428,
590420,
236908,
316139,
23860,
12234,
24326,
288552,
315953,
21115,
163578,
722392,
240418,
29435,
150487,
492197,
20685,
132018,
72200,
296617,
20712,
287692,
195471,
5576,
162777,
63882,
82609,
50328,
226932,
338019,
779972,
190074,
null,
364293,
547560,
null,
172182,
251709,
552587,
292508,
130619,
50112,
22446,
164192,
13559,
24701,
179321,
2686,
95322,
212115,
37510,
null,
861063,
162834,
12841,
54492,
115544,
193940,
10690,
62474,
253889,
251556,
363842,
null,
76734,
155509,
22761,
128847,
null,
66730,
26770,
20379,
133445,
236349,
10449,
160501,
7503,
53253,
192511,
83010,
204729,
20450,
164634,
45737,
150830,
9925,
111668,
37408,
13858,
319317,
171413,
139746,
14835,
543641,
null,
386082,
216877,
null,
23818,
8094,
11047,
34371,
199623,
null,
377800,
35536,
39774,
187508,
13287,
24785,
null,
null,
10240,
409268,
23253,
27027,
30677,
332521,
392611,
29909,
42941,
28901,
null,
144966,
39547,
33896,
83997,
null,
383426,
329788,
237710,
8046,
11756,
276169,
33074,
null,
19430,
687955,
35687,
null,
653655,
34034,
13331,
34922,
102069,
123627,
168377,
66633,
333501,
7374,
20219,
37809,
73657,
56968,
27184,
56831,
405381,
null,
87402,
70643,
20340,
8815,
240628,
39604,
326513,
190053,
38756,
234033,
15072,
557401,
98203,
273206,
66603,
441186,
182531,
174656,
22927,
20436,
251048,
40406,
342876,
15531,
144448,
221578,
400319,
42458,
983839,
254281,
3798,
167198,
73182,
53052,
30934,
16395,
359169,
54711,
null,
93238,
null,
16222,
184201,
323063,
75770,
232995,
155584,
null,
83876,
4015,
49965,
113082,
19564,
530074,
103781,
99493,
null,
null,
40021,
53422,
33604,
279973,
17149,
107871,
239629,
50223,
194722,
null,
null,
75643,
16292,
141504,
42616,
143112,
237181,
8659,
321021,
54250,
64568,
46096,
null,
15489,
80818,
15529,
209210,
216484,
34861,
66482,
212934,
35068,
140508,
105032,
110883,
152574,
168188,
74840,
397630,
5081,
234515,
154871,
191472,
217484,
39867,
24787,
39341,
175429,
88248,
null,
141221,
106639,
67067,
72431,
602762,
227133,
56972,
9129,
58236,
23465,
160405,
20960,
194058,
30286,
16072,
18118,
18391,
613657,
5453,
26390,
76028,
36474,
51214,
397647,
141509,
163930,
8401,
37822,
139177,
12527,
237517,
40737,
23147,
234422,
179723,
129820,
26021,
58520,
33124,
245017,
69129,
53077,
134033,
156800,
18754,
429728,
47449,
400550,
289344,
15956,
541465,
12809,
331327,
13660,
29058,
44677,
null,
18965,
31540,
389985,
201250,
333629,
12331,
32577,
441799,
146751,
303716,
6545,
210096,
162031,
null,
195846,
327264,
40076,
240364,
6991,
65267,
462441,
348648,
null,
42205,
43627,
62276,
339852,
null,
11871,
null,
193722,
95568,
7392,
59178,
126665,
18646,
88721,
44181,
null,
null,
null,
170689,
13611,
20131,
309625,
40430,
401227,
null,
122423,
10743,
87171,
317969,
40519,
177345,
624158,
29513,
81046,
12859,
196760,
null,
187620,
27563,
53029,
7040,
34834,
75278,
92499,
108263,
977415,
null,
74725,
3759,
198675,
66534,
109870,
32306,
39444,
500324,
4442,
58906,
369240,
14502,
102853,
75522,
null,
29919,
56753,
8160,
193792,
54965,
11018,
31827,
40081,
64529,
36963,
47585,
211683,
31542,
3231,
179187,
40689,
28059,
19236,
11290,
9636,
393945,
33502,
165093,
461542,
13481,
21472,
33860,
57049,
54920,
21042,
68326,
33640,
68028,
60058,
47769,
131742,
40550,
257350,
172657,
null,
435648,
276268,
23041,
155029,
29367,
null,
144908,
17643,
206520,
97727,
26207,
30557,
23503,
4770,
28498,
440415,
205785,
39075,
36674,
257154,
100554,
10687,
182917,
328136,
27429,
18920,
626685,
8990,
137510,
32950,
166973,
90326,
293704,
212225,
23235,
336125,
177116,
14975,
14975,
196092,
44082,
69482,
60999,
17072,
109631,
28990,
19017,
135710,
21071,
431107,
112232,
31078,
116624,
40435,
33643,
62533,
124103,
116604,
555875,
188094,
3238,
24214,
15034,
48239,
245758,
7816,
184653,
185123,
32986,
565934,
32295,
174332,
266483,
52147,
174753,
428310,
347880,
25337,
12914,
77543,
242216,
36321,
31988,
86249,
249232,
105194,
null,
188230,
16816,
null,
350077,
252720,
142812,
223155,
51232,
688108,
311155,
445036,
48380,
226279,
220994,
44399,
254685,
439927,
18975,
null,
25859,
120289,
166586,
168542,
353556,
285704,
14326,
81058,
32284,
241193,
307284,
44679,
13306,
264721,
279959,
null,
14597,
65429,
34982,
null,
276683,
342766,
28649,
25214,
273508,
82540,
59095,
28054,
15641,
181044,
161188,
30658,
40029,
28488,
211453,
12020,
19206,
126114,
25769,
60552,
140250,
529907,
303696,
260722,
null,
76272,
126226,
207512,
105357,
115245,
321958,
443589,
44723,
170351,
9450,
343442,
137907,
459588,
819257,
20064,
79502,
null,
187869,
106839,
null,
39161,
330700,
317097,
324448,
56523,
null,
209638,
11971,
38626,
54578,
null,
402170,
258975,
310620,
200326,
11163,
70070,
127544,
null,
31274,
26881,
null,
24374,
63795,
9201,
27370,
253894,
28517,
26308,
366373,
42416,
214757,
233849,
1154527,
222277,
155087,
18562,
null,
15110,
90149,
30719,
88177,
24830,
174705,
282732,
40428,
125667,
299696,
325428,
26696,
22011,
43907,
null,
223992,
232020,
5360,
240528,
286441,
11664,
213548,
187341,
7967,
185291,
20372,
51705,
null,
413949,
237897,
176792,
140996,
183928,
153773,
135261,
57042,
84087,
121578,
143105,
107950,
14700,
116374,
75635,
null,
18897,
207977,
221235,
23379,
43644,
526516,
24662,
233467,
422026,
86887,
108300,
277290,
125065,
140851,
474410,
17802,
32258,
124681,
112166,
169054,
250710,
117674,
90564,
154515,
2579,
10899,
320517,
91189,
26842,
30645,
247100,
4381,
null,
37597,
4783,
167082,
263835,
27998,
41885,
51747,
56487,
63924,
19082,
189699,
215814,
389615,
99824,
55652,
null,
116280,
47163,
19070,
26861,
286663,
70629,
11102,
166540,
116763,
122438,
133116,
63626,
12203,
66095,
214494,
439250,
357503,
62175,
575907,
198066,
27616,
29908,
268874,
209982,
166660,
24659,
191187,
10298,
79223,
23566,
25589,
30398,
403776,
619532,
59938,
null,
552878,
28941,
76365,
709217,
22346,
150042,
17965,
502264,
null,
354609,
74638,
87648,
86753,
246285,
60771,
5059,
195985,
36100,
20949,
139670,
63465,
146218,
241244,
8865,
14968,
232867,
8228,
16291,
40374,
269032,
35172,
341879,
43797,
37915,
14606,
332739,
372255,
414330,
29248,
6573,
164076,
146150,
31543,
46415,
26902,
29187,
381957,
22143,
18497,
27005,
191169,
null,
9436,
304637,
11972,
63364,
23971,
83481,
45086,
39741,
17119,
null,
417852,
24520,
52022,
73127,
776453,
672414,
39035,
7889,
255245,
517481,
45075,
39822,
9250,
243249,
76547,
17574,
35008,
239621,
284599,
37791,
289037,
17651,
12513,
4815,
19234,
34839,
null,
91919,
20266,
31080,
42921,
267879,
74855,
495228,
47813,
511572,
248810,
290588,
53370,
14980,
120051,
93713,
102555,
5527,
null,
20023,
37821,
914,
19242,
null,
129774,
null,
3680,
10147,
467424,
61102,
76677,
25331,
364447,
4383,
37709,
22445,
478989,
39720,
301671,
52335,
34123,
296948,
5181,
19185,
null,
39256,
18239,
245112,
41143,
29852,
92527,
28892,
107157,
217248,
282099,
138140,
39206,
null,
null,
36740,
30206,
172829,
146541,
22661,
20054,
65159,
34363,
29648,
104843,
null,
209598,
113869,
17950,
223584,
25266,
45573,
null,
null,
206151,
217587,
625273,
24704,
78083,
55007,
56107,
18944,
387365,
222066,
121781,
217214,
68608,
290200,
17240,
241099,
8507,
130341,
99323,
15644,
22502,
563248,
47785,
106973,
48554,
1802,
73772,
15055,
null,
144267,
27521,
null,
48426,
14180,
141143,
481528,
21192,
262495,
121780,
625,
22219,
330737,
217706,
97131,
33193,
288590,
null,
131388,
101017,
148342,
null,
196871,
20153,
394341,
286342,
181592,
null,
39182,
115608,
320705,
55229,
63579,
286839,
13887,
44712,
60030,
131721,
17220,
267111,
22299,
392723,
409013,
293527,
46787,
382551,
103496,
166963,
67705,
12241,
216705,
null,
19725,
180584,
30753,
283485,
34530,
186373,
245449,
315908,
183721,
177901,
70477,
55206,
410024,
311297,
145673,
6927,
36316,
254143,
8755,
null,
21394,
577941,
17488,
63118,
30898,
10353,
null,
24427,
null,
100571,
303610,
298208,
118636,
185065,
69013,
162735,
18091,
37157,
null,
3235,
313007,
12772,
25810,
null,
296566,
40658,
34280,
6544,
98936,
67620,
null,
25277,
64579,
363237,
82005,
181215,
284518,
null,
122726,
471310,
426585,
76124,
294722,
5855,
26714,
195543,
26853,
103634,
357494,
274153,
100936,
10392,
22664,
53467,
185205,
11315,
134333,
37714,
null,
223734,
74189,
121573,
265572,
216957,
117764,
null,
461086,
3716,
35157,
46881,
71222,
220416,
114995,
65191,
263084,
50323,
313156,
0,
26286,
199809,
340419,
74210,
12820,
77434,
495421,
null,
128434,
1630,
247743,
199402,
617055,
27186,
155415,
613013,
32214,
11935,
42225,
21631,
96075,
79896,
40674,
33958,
37812,
244431,
35021,
24546,
73387,
41531,
421756,
null,
null,
203568,
83191,
23453,
175892,
32828,
11893,
308182,
null,
48396,
44476,
56279,
18687,
null,
134662,
null,
10725,
29612,
89626,
9505,
48817,
116756,
17462,
187216,
224195,
192021,
null,
290672,
319344,
161794,
421927,
361866,
375147,
34753,
7537,
23823,
71231,
156220,
42805,
55137,
39607,
15302,
64418,
7738,
49186,
251239,
185230,
93580,
null,
170022,
null,
508256,
17637,
159165,
14848,
378299,
93440,
91908,
42653,
null,
10944,
146112,
11385,
264595,
94115,
134074,
43802,
63782,
11322,
27853,
210323,
30144,
272502,
null,
269652,
29056,
87236,
18147,
75431,
96772,
250518,
30260,
21096,
45402,
82985,
8447,
204531,
2970,
29901,
81216,
237741,
377652,
622133,
17540,
86638,
106807,
88550,
95197,
311477,
203812,
232090,
6940,
321106,
19812,
28668,
null,
130266,
7736,
183627,
28346,
5125,
1335,
401619,
23868,
102412,
165559,
46789,
43710,
206874,
9581,
246566,
67346,
215755,
152400,
76690,
12944,
161468,
15454,
21462,
526823,
35813,
154678,
80294,
560545,
91878,
394589,
45112,
150233,
54835,
83096,
25675,
97554,
59829,
43187,
29678,
3699,
268368,
16658,
15278,
249141,
102228,
50475,
null,
5597,
223186,
null,
88735,
342519,
6428,
104895,
21818,
null,
214943,
26545,
104358,
24901,
17128,
221571,
252065,
16356,
12987,
191308,
51244,
93581,
null,
58878,
null,
121649,
27593,
null,
null,
66150,
8437,
58033,
19343,
328810,
27505,
27807,
27497,
null,
203910,
208668,
null,
296628,
6079,
5704,
2247,
149099,
260009,
null,
314547,
31759,
41174,
null,
null,
47883,
96490,
162302,
12883,
234515,
498624,
33233,
31605,
237992,
24567,
46602,
178759,
137022,
137308,
397275,
39063,
421339,
86924,
155335,
335728,
15710,
41418,
81439,
36436,
null,
216415,
40951,
257428,
9998,
32981,
null,
14133,
115984,
778258,
21354,
96993,
63875,
267235,
52898,
372649,
142021,
270733,
272419,
346265,
21012,
215365,
24030,
39437,
55958,
44130,
32763,
47725,
189650,
79671,
71310,
119515,
160034,
49003,
30499,
403124,
76811,
318791,
207104,
69874,
45028,
17844,
60113,
321280,
21056,
39227,
43623,
15696,
247672,
119425,
106695,
199663,
21938,
508919,
868,
12051,
null,
2753,
430506,
236591,
29096,
297908,
null,
10951,
4297,
23443,
313671,
51316,
17337,
63279,
102435,
364621,
139052,
35254,
302785,
155860,
60355,
18788,
63328,
4224,
268741,
319499,
117381,
213326,
null,
43599,
288836,
222843,
17343,
81100,
7896,
41038,
25784,
288938,
319763,
64095,
null,
72229,
309180,
17509,
26396,
26950,
55840,
33373,
70773,
805611,
43218,
348986,
80192,
54623,
198650,
351839,
null,
490363,
42052,
365928,
290128,
23269,
317345,
47558,
92095,
24284,
null,
128428,
10676,
45309,
9990,
31695,
18701,
62550,
null,
172443,
9291,
317110,
10204,
18007,
764686,
11333,
87454,
108685,
167595,
176346,
null,
25675,
73046,
241236,
38072,
45250,
338140,
61458,
502292,
null,
50442,
18800,
219045,
124727,
8390,
152243,
328043,
75120,
404969,
74496,
63686,
61658,
94831,
137332,
14265,
315815,
196450,
64245,
145781,
17570,
110261,
11538,
16116,
214696,
203215,
542080,
6538,
62900,
189176,
161826,
115630,
239598,
57253,
147522,
17151,
262410,
37152,
30790,
76561,
17234,
49075,
23983,
16758,
10765,
66435,
17774,
106836,
25277,
184712,
54512,
167789,
23749,
28579,
141576,
334240,
338700,
198607,
35964,
48020,
10947,
78627,
383111,
66397,
15630,
436876,
201384,
166429,
50426,
29847,
62580,
48388,
94942,
355966,
12712,
136036,
396277,
89112,
107358,
287689,
22498,
129015,
19828,
275531,
72951,
null,
3302,
181597,
23719,
176377,
28190,
44809,
33967,
108338,
102365,
45148,
6733,
null,
272875,
8967,
22975,
237556,
33078,
30410,
5325,
16104,
79551,
352913,
115877,
215565,
37254,
135371,
null,
26040,
20625,
7573,
40428,
80046,
203244,
19687,
42573,
92203,
554318,
122155,
286415,
117804,
375626,
null,
120279,
null,
199023,
300486,
20698,
13466,
274720,
30009,
39577,
13502,
175732,
5083,
191312,
39663,
3637,
49274,
183141,
270097,
14740,
202041,
14290,
74244,
16844,
null,
null,
null,
63296,
null,
4076,
292054,
46212,
110076,
230042,
13742,
29260,
41772,
325086,
110455,
382001,
237782,
45471,
278811,
299357,
411014,
355119,
246095,
11256,
112955,
254511,
158050,
73806,
null,
108063,
214801,
215354,
281486,
57400,
38431,
334551,
376939,
306912,
186698,
55830,
419190,
779978,
59624,
36383,
270958,
38115,
551941,
48228,
178012,
33400,
88799,
237712,
17467,
280424,
174862,
141881,
162191,
61325,
15273,
3925,
286533,
442671,
114668,
21645,
189556,
51409,
219193,
73610,
529465,
51728,
20336,
52684,
124851,
32601,
175390,
19404,
50759,
316568,
213849,
43129,
6765,
75545,
38716,
297714,
102858,
190643,
131733,
217565,
42107,
138180,
42968,
83286,
8885,
28100,
644435,
2902,
18056,
9509,
null,
61134,
111659,
137479,
223565,
null,
171537,
382912,
134041,
43873,
62253,
44988,
3378,
null,
180012,
24562,
326725,
544533,
16555,
90109,
329164,
118858,
17103,
179600,
421756,
455987,
35936,
154180,
164380,
42633,
49016,
null,
418977,
251845,
300882,
115018,
59721,
289269,
367571,
484114,
51276,
198035,
null,
179802,
4842,
17038,
29903,
154930,
144136,
53988,
42517,
9376,
55043,
124168,
197007,
130868,
244595,
191696,
43322,
156529,
null,
173740,
16128,
710070,
null,
60697,
232173,
143271,
33225,
60161,
15263,
55209,
null,
97533,
197063,
37848,
null,
45194,
336447,
32352,
28715,
94636,
24561,
56361,
12412,
228608,
12519,
null,
211474,
230605,
32986,
36519,
35913,
134250,
11035,
22980,
null,
131663,
198219,
119527,
26552,
36133,
918956,
13927,
45316,
106411,
8310,
null,
12790,
220747,
313470,
52198,
7016,
251106,
293982,
144465,
4225,
32832,
18258,
24992,
null,
240105,
203177,
130343,
180892,
10707,
null,
8748,
132858,
24351,
75853,
17888,
435608,
8276,
4355,
382590,
21587,
null,
247490,
1162719,
295724,
13008,
140361,
110461,
540036,
216939,
113310,
53913,
190124,
95249,
222110,
20917,
14599,
54668,
105351,
150429,
34647,
42164,
33709,
241156,
44694,
null,
68873,
10886,
79894,
12134,
23865,
null,
21710,
133256,
303919,
196439,
39811,
154666,
76108,
14780,
41002,
363618,
439201,
null,
74010,
139003,
166975,
null,
58348,
469680,
49601,
312851,
131268,
55863,
83944,
28158,
14646,
254060,
66541,
25725,
null,
25910,
75869,
30190,
51098,
234491,
302332,
28842,
18703,
150398,
25078,
null,
15097,
118174,
210552,
57343,
32233,
50633,
9737,
107275,
null,
23047,
null,
33235,
19433,
64293,
16522,
3949,
32807,
null,
15369,
62585,
62038,
null,
36659,
304045,
498625,
99154,
80811,
192028,
28155,
248672,
16767,
23913,
241362,
88970,
89229,
23326,
186208,
45151,
4146,
308240,
42898,
11028,
326835,
3579,
null,
47101,
68295,
413646,
649227,
102709,
168873,
193064,
176426,
153425,
110489,
null,
234484,
null,
83227,
null,
150577,
9289,
186472,
606442,
null,
null,
5421,
18097,
30289,
29097,
90130,
195281,
1358606,
59905,
511103,
240247,
12877,
152925,
39677,
153802,
237915,
270054,
189174,
null,
420584,
9423,
135654,
24013,
16343,
105375,
279090,
31916,
null,
412342,
47138,
23453,
27411,
26061,
389727,
5296,
29033,
472358,
341168,
425201,
2264,
52318,
201737,
503199,
48696,
134827,
146464,
41181,
29374,
null,
20183,
124006,
18773,
91358,
95392,
null,
34551,
15869,
12781,
297155,
25271,
37443,
153111,
380221,
null,
18272,
null,
161822,
430276,
174444,
115952,
null,
35737,
null,
218110,
49066,
81625,
40447,
81784,
27718,
30469,
391193,
150733,
33455,
145007,
162739,
41084,
197884,
200841,
463888,
null,
58280,
74055,
210281,
31970,
null,
60428,
null,
11127,
279936,
198506,
null,
99644,
250032,
119113,
16021,
8886,
18212,
131558,
83183,
17103,
4215,
164921,
75601,
156519,
23880,
203500,
370103,
361595,
22378,
346741,
16935,
232820,
240495,
null,
7948,
377221,
null,
36666,
41581,
251904,
120243,
null,
477825,
null,
17163,
null,
54663,
187273,
41041,
100181,
124534,
47072,
385680,
16714,
null,
27474,
408857,
90178,
137311,
344964,
262449,
279124,
26942,
255591,
null,
363103,
334087,
null,
20281,
18608,
256260,
122099,
18487,
171646,
21486,
41492,
43591,
162739,
190362,
275460,
25256,
3242,
143328,
108555,
54382,
31177,
68487,
16545,
null,
382097,
211490,
168410,
199479,
null,
13263,
310507,
285179,
null,
123695,
3544,
56644,
49652,
242000,
30619,
58531,
28767,
28555,
306437,
93345,
58901,
370683,
39815,
36708,
55918,
20129,
51898,
71223,
225432,
31679,
177207,
3081,
6927,
null,
239504,
15985,
548403,
151808,
295304,
306693,
176871,
51740,
492587,
37070,
225814,
null,
466692,
27702,
3862,
8753,
162897,
145681,
44136,
36671,
null,
249513,
87431,
76700,
131620,
28156,
null,
92444,
250160,
6398,
212656,
null,
16552,
21965,
112995,
null,
23526,
null,
32762,
9582,
394008,
307494,
40658,
4424,
107621,
7611,
498306,
162239,
220331,
15763,
66175,
71043,
64060,
null,
499669,
259897,
63155,
15607,
178897,
385868,
121905,
55085,
324270,
null,
25019,
115148,
7411,
27597,
null,
271149,
70915,
28824,
361567,
null,
null,
13742,
17774,
318751,
32579,
21736,
94272,
22333,
12944,
85324,
54423,
293638,
279755,
null,
306911,
85034,
38507,
42896,
8117,
300950,
469775,
null,
67114,
122150,
24662,
333192,
null,
36785,
38862,
98149,
27370,
179322,
16602,
75391,
90849,
null,
null,
174116,
393276,
30867,
205817,
132379,
null,
755510,
8121,
102602,
401751,
143759,
34770,
197386,
153597,
64907,
119197,
42510,
203918,
230572,
215234,
202647,
189616,
365791,
15758,
76417,
26558,
41326,
267921,
59440,
130395,
113921,
289827,
null,
25303,
93219,
426506,
52775,
41204,
265035,
6323,
45555,
114883,
51792,
251242,
63814,
17438,
23532,
51811,
244038,
786030,
11045,
49982,
null,
134384,
27465,
8779,
266053,
72776,
55042,
15646,
25752,
63468,
null,
353372,
110976,
18003,
406674,
50570,
49643,
440531,
13142,
73492,
54175,
40476,
11911,
289435,
248808,
66568,
161245,
115612,
43762,
144512,
7397,
295752,
35604,
23085,
637603,
165747,
33446,
14058,
25829,
174890,
53531,
277917,
126326,
18893,
25289,
338997,
null,
173492,
36581,
31762,
26721,
13602,
211959,
41303,
41756,
null,
49696,
299278,
120306,
563888,
387807,
102664,
33568,
284339,
37517,
94865,
365495,
232840,
null,
9281,
24113,
11352,
null,
154773,
42472,
125776,
124892,
220843,
116921,
92233,
310189,
80242,
36527,
33059,
27467,
218991,
174228,
24638,
299971,
191361,
19316,
219477,
167650,
13644,
118060,
32382,
22746,
27399,
322314,
17504,
50129,
21643,
40126,
214720,
113433,
16761,
910509,
272252,
141237,
55986,
38661,
59449,
75750,
300051,
609966,
217937,
175737,
55603,
325881,
233540,
20817,
359587,
382687,
99452,
229371,
36239,
51050,
238203,
17934,
28100,
370110,
14912,
28397,
65341,
null,
34008,
195364,
259752,
9961,
266009,
149344,
23648,
null,
117065,
173538,
24643,
38455,
24711,
12504,
77359,
62132,
14412,
19762,
135930,
36317,
125946,
64227,
46096,
39413,
123434,
163825,
231106,
11950,
60618,
439794,
119470,
46491,
27129,
330216,
59965,
342452,
56881,
26867,
142417,
73722,
429439,
10305,
82672,
231685,
355543,
290684,
54279,
21854,
25869,
361059,
10545,
61891,
20212,
14139,
46047,
12189,
107449,
18443,
41299,
35034,
35634,
37487,
181172,
43264,
32913,
26904,
71479,
37876,
null,
111044,
297846,
null,
271862,
83598,
40170,
74604,
161296,
27833,
40081,
28683,
null,
198517,
93686,
4443,
156104,
405165,
31333,
577250,
null,
31549,
70339,
21272,
158064,
48605,
250741,
159662,
15541,
284039,
289744,
null,
60670,
43470,
76281,
19339,
492563,
156858,
116678,
34065,
230505,
38339,
8640,
188431,
94263,
32882,
67952,
20856,
315464,
5163,
168463,
105785,
17476,
314104,
95351,
57079,
15413,
163646,
254067,
91964,
17857,
72325,
null,
6223,
13995,
16859,
31675,
265224,
128500,
296372,
58174,
263968,
155951,
293339,
363189,
130292,
41179,
28101,
54729,
26364,
36319,
47354,
313986,
13343,
157467,
null,
627557,
350661,
7803,
52860,
382680,
17719,
389438,
null,
32952,
null,
518915,
3746,
162873,
432385,
62995,
39038,
18063,
143221,
30028,
417397,
276692,
null,
442603,
702371,
122127,
162109,
51195,
17367,
93551,
232118,
106848,
354004,
200174,
43539,
30723,
144865,
68382,
null,
177665,
28086,
144316,
33789,
33120,
54128,
83652,
215819,
8535,
135695,
500346,
241504,
24953,
328594,
66196,
14926,
null,
15124,
29329,
12919,
80766,
19000,
31951,
169132,
13476,
121477,
189863,
448710,
34491,
156405,
33098,
335025,
119211,
606082,
16820,
null,
338387,
17602,
null,
63454,
157912,
9934,
23148,
559022,
375802,
4419,
204788,
8921,
null,
338005,
17653,
38684,
82669,
7386,
142413,
27838,
17595,
36120,
89556,
214502,
47795,
72387,
18695,
5879,
214289,
51866,
5858,
69522,
31106,
209606,
271909,
156861,
102737,
464271,
417462,
80642,
396122,
35432,
372356,
40168,
5662,
305594,
30461,
19166,
228856,
15057,
398069,
34157,
57484,
38439,
55215,
46206,
68601,
6495,
182317,
49747,
139052,
95816,
37187,
222758,
222034,
3377,
20160,
62660,
297056,
21723,
824165,
37666,
215273,
104139,
31217,
42057,
615883,
93319,
252348,
278678,
36038,
292451,
82680,
256132,
102024,
3672,
88163,
7843,
262203,
655154,
93619,
797943,
25189,
58367,
null,
82308,
312123,
439471,
301165,
91979,
21438,
11363,
10040,
204618,
265220,
163910,
null,
67500,
153444,
31255,
510120,
260139,
157857,
253992,
null,
16711,
null,
247482,
25669,
359552,
336968,
137441,
283762,
null,
750468,
242129,
8515,
148766,
25655,
407690,
72839,
19442,
336774,
null,
142322,
215009,
25212,
25311,
33523,
47432,
43165,
293359,
294960,
401873,
263045,
14990,
188437,
123732,
161196,
437678,
6765,
158036,
20468,
279468,
55376,
62651,
49187,
286398,
162803,
265479,
66430,
21583,
467532,
521808,
42105,
17089,
31141,
35071,
null,
17795,
433981,
369608,
176481,
23145,
227938,
154023,
39560,
28587,
28210,
58962,
12703,
257135,
43432,
201438,
293761,
45921,
19673,
27027,
315498,
55036,
414863,
57799,
66156,
48079,
7010,
17785,
215091,
20511,
9230,
169910,
57039,
215264,
37175,
17611,
45840,
null,
null,
194447,
273998,
19522,
35236,
34073,
11972,
147676,
60297,
24008,
309536,
264166,
76792,
38370,
null,
10084,
118779,
58826,
33449,
70582,
null,
166981,
8559,
40982,
158119,
null,
78802,
16440,
359295,
null,
195197,
24912,
4301,
24512,
36958,
null,
108407,
115748,
41227,
43161,
null,
20528,
8962,
218485,
27705,
null,
75107,
242332,
187223,
null,
257395,
249338,
183274,
null,
221578,
16207,
205451,
null,
61869,
153781,
24207,
216046,
210143,
140390,
106131,
19180,
31269,
161874,
16134,
150266,
40435,
109411,
38279,
193487,
12630,
228218,
416879,
100756,
122916,
257712,
38145,
27414,
4285,
519107,
185766,
373657,
57871,
38391,
57212,
29733,
33985,
234903,
263774,
239336,
75287,
231054,
546864,
null,
22913,
226212,
25413,
2870,
1201215,
210773,
55546,
27865,
50688,
36680,
null,
38852,
95290,
186088,
128739,
285875,
505442,
212189,
9208,
198771,
281644,
62145,
131055,
542627,
25259,
173575,
90228,
11674,
53464,
46208,
612463,
279107,
10022,
null,
128422,
36566,
166510,
null,
26543,
9810,
181777,
29548,
26501,
394955,
52404,
98289,
310361,
9976,
34730,
null,
265647,
39135,
492017,
210693,
66332,
53719,
330880,
84381,
160991,
97779,
17131,
425773,
29269,
123664,
329095,
54786,
230250,
195803,
122206,
null,
117390,
45035,
276844,
131525,
298531,
16254,
null,
null,
751921,
61850,
204614,
435631,
348689,
600234,
189171,
64280,
null,
468043,
65142,
112168,
252493,
150010,
137016,
335122,
219494,
29969,
43046,
138672,
30174,
30505,
481366,
30107,
5304,
null,
117218,
279828,
88154,
122933,
9267,
312875,
622516,
11048,
45540,
158504,
2673,
178962,
175862,
4891,
193990,
104380,
336535,
3291,
39701,
327641,
180764,
36557,
110671,
24806,
37157,
628800,
237485,
29178,
3469,
43641,
129826,
46186,
56707,
307544,
89490,
176578,
16709,
91291,
26069,
13738,
146805,
398424,
42555,
45868,
null,
337620,
304572,
30725,
352121,
216283,
43075,
3706,
55042,
260232,
null,
185939,
82755,
214335,
61174,
6870,
75884,
77079,
null,
null,
348511,
229334,
574244,
43719,
16240,
null,
478349,
236697,
193581,
50430,
null,
102970,
20006,
349892,
80695,
19142,
12748,
17544,
86466,
28629,
25194,
234564,
9811,
201448,
20068,
null,
211341,
33464,
245207,
21924,
null,
96240,
null,
152464,
26293,
169890,
92566,
82414,
45689,
19238,
2885,
143005,
315558,
792145,
421030,
1761299,
222162,
33407,
19513,
null,
24309,
25420,
18300,
138944,
76536,
100044,
56820,
50296,
81106,
35656,
25678,
287700,
148728,
226131,
4978,
53670,
291905,
null,
77266,
124936,
26768,
11608,
197228,
26758,
42020,
21672,
133607,
15059,
22436,
16787,
329985,
62106,
18940,
22853,
339150,
null,
229438,
null,
54775,
199585,
null,
26659,
95094,
133700,
281499,
29930,
108053,
133954,
1064933,
98287,
97824,
16489,
9875,
172083,
194686,
197121,
null,
441457,
19860,
null,
112811,
203300,
97878,
72538,
469522,
24351,
273515,
29165,
120404,
8573,
19559,
418002,
7838,
188734,
58235,
227590,
309449,
null,
4156,
136066,
329635,
16550,
26918,
21930,
10772,
162144,
60231,
27692,
null,
329307,
8122,
7334,
191737,
71475,
57463,
42848,
123846,
165427,
17243,
163426,
258179,
22949,
348938,
201870,
10372,
152866,
97627,
42223,
343603,
277257,
40849,
101732,
9390,
8069,
3070,
25207,
null,
254428,
43987,
134974,
17625,
111688,
231904,
25255,
null,
35459,
26782,
12901,
30600,
72685,
29447,
26210,
532763,
286436,
54800,
35138,
33656,
54133,
421290,
239332,
45917,
3806,
94338,
21216,
255423,
27618,
425380,
149736,
null,
22068,
6161,
539560,
20985,
16592,
14720,
528647,
54145,
242045,
32443,
392685,
152780,
195678,
342064,
55507,
77612,
260285,
12816,
193393,
18357,
34259,
37509,
16559,
18642,
68207,
198084,
434698,
44068,
345727,
65296,
393848,
43632,
187417,
13434,
79282,
241837,
659530,
229884,
27457,
108825,
564881,
21835,
30262,
46396,
426530,
16801,
null,
29931,
265958,
281051,
27039,
24315,
93315,
527558,
540840,
141443,
508516,
24946,
265279,
10096,
19118,
96563,
103218,
9182,
146988,
212491,
18368,
531676,
606772,
386553,
150772,
183254,
30438,
142673,
63596,
160706,
562060,
16758,
14879,
368242,
596781,
14846,
82016,
8613,
306378,
69492,
115714,
34755,
null,
null,
214210,
19078,
458329,
8564,
18719,
20012,
264204,
45749,
152052,
14033,
29993,
43631,
268110,
511073,
152925,
275145,
138662,
null,
11825,
49719,
15316,
211861,
9567,
48560,
63246,
178677,
112028,
109896,
21387,
17648,
42210,
248464,
55688,
53904,
23828,
84189,
562404,
17908,
null,
42302,
69311,
20354,
209885,
142150,
39246,
58219,
null,
5815,
52120,
56405,
6444,
97072,
34794,
null,
13234,
58054,
166596,
5391,
9226,
286009,
89122,
null,
6276,
96245,
209779,
433159,
1042355,
369030,
49857,
212549,
488578,
19635,
18704,
9485,
49047,
172955,
69677,
15378,
26265,
335377,
172334,
25334,
14462,
15226,
171390,
27634,
null,
23885,
14674,
205134,
438240,
231442,
78946,
67593,
480,
31601,
66527,
237697,
317783,
null,
144910,
28958,
30567,
349283,
31401,
222502,
144937,
54796,
48647,
771955,
98747,
null,
6952,
113738,
49420,
58631,
147502,
12238,
96362,
521773,
26083,
11291,
149026,
45536,
25537,
58461,
54929,
10350,
23545,
204543,
null,
36563,
102083,
null,
33136,
227576,
160197,
277453,
83338,
19828,
157217,
21467,
322400,
null,
null,
30169,
22367,
37912,
95563,
101826,
186419,
29449,
274879,
198347,
15568,
23116,
48577,
27679,
21187,
587278,
356808,
51663,
39631,
21530,
43938,
33347,
null,
150986,
25633,
134043,
422689,
223829,
16036,
69308,
17047,
10898,
38427,
271998,
91825,
9902,
57224,
63659,
74248,
null,
170424,
10384,
null,
17286,
78945,
111513,
28960,
57416,
434048,
139692,
11339,
null,
258718,
71221,
235823,
213195,
59686,
756292,
217892,
378917,
null,
510,
null,
12375,
84803,
48093,
237875,
21343,
104844,
171409,
65797,
null,
221999,
10889,
100017,
275686,
27820,
258655,
120171,
104496,
343268,
2153,
931,
29165,
213428,
179437,
49864,
49624,
363988,
10045,
null,
323720,
216189,
146267,
141202,
142182,
16424,
112773,
113681,
150762,
68062,
19954,
null,
14334,
41358,
275177,
192743,
108510,
26082,
14792,
267530,
170468,
144066,
247826,
146313,
52268,
14033,
237363,
201297,
120262,
118866,
27857,
7669,
269871,
179868,
9169,
158619,
32141,
22093,
46894,
null,
34859,
102000,
37796,
43673,
236725,
14175,
42007,
270628,
314452,
101144,
211967,
94303,
203237,
348229,
null,
7069,
3595,
66609,
16448,
39900,
297505,
77059,
11151,
4066,
null,
85814,
238627,
423931,
223434,
7365,
345485,
4891,
387470,
651511,
45644,
null,
30410,
70959,
12292,
33073,
124839,
489844,
null,
145969,
191278,
211326,
286961,
61671,
378182,
437745,
79337,
148011,
153843,
38762,
113090,
28181,
47678,
null,
26582,
174644,
373318,
null,
37236,
23709,
118835,
172206,
229786,
121976,
225330,
null,
74846,
null,
189115,
667410,
26236,
334615,
405241,
18217,
302472,
32993,
106854,
20554,
18889,
27967,
33477,
40380,
161057,
6083,
73485,
35165,
131020,
185813,
224045,
98221,
25981,
251735,
14535,
341543,
null,
20458,
27197,
164200,
273218,
98044,
248418,
6580,
null,
370532,
201701,
253262,
167648,
76779,
13440,
null,
124286,
25165,
360599,
661539,
37935,
191096,
379991,
28176,
51425,
49059,
42448,
72192,
null,
376281,
13159,
556593,
712228,
18870,
127965,
112803,
132015,
259166,
128045,
39096,
21853,
9964,
86202,
25572,
62819,
18973,
209152,
298862,
null,
16527,
19495,
80695,
192792,
444016,
null,
20152,
287161,
252320,
31426,
null,
35211,
78490,
4675,
null,
126838,
204661,
39163,
105832,
314280,
28583,
141598,
33234,
41431,
178267,
15637,
14880,
8775,
23792,
781949,
174290,
46438,
124569,
132045,
30679,
24086,
25825,
77419,
83391,
419129,
79440,
9425,
373981,
25922,
14760,
202565,
16111,
305478,
289867,
26823,
511386,
295995,
34982,
181818,
283050,
174004,
7861,
7027,
215146,
18830,
35525,
26185,
300801,
null,
78202,
36142,
37886,
17293,
34555,
30314,
13629,
13688,
79421,
276343,
206101,
103494,
null,
63851,
320401,
573203,
null,
184856,
260142,
73553,
179800,
143795,
162585,
22461,
255287,
166127,
221913,
6917,
35176,
6112,
397178,
49131,
27930,
818308,
38846,
77773,
157518,
70689,
null,
38024,
17168,
28746,
null,
37673,
152878,
121248,
383155,
163628,
143593,
15402,
30721,
73658,
136597,
281365,
null,
null,
554181,
32787,
10730,
139795,
364383,
90394,
154236,
66941,
502109,
22878,
null,
360832,
170381,
210567,
13034,
101569,
17634,
4102,
94894,
null,
470032,
146855,
154151,
54057,
44047,
39724,
141276,
26945,
298100,
85963,
333,
756144,
31591,
70850,
23931,
68451,
26791,
187848,
105724,
44424,
34136,
321753,
71190,
34664,
175817,
5490,
230528,
57284,
141891,
133534,
270560,
142440,
null,
18955,
10162,
17654,
90138,
206867,
57727,
71038,
87936,
33743,
39921,
471935,
212424,
238434,
118169,
29141,
305101,
62396,
27790,
406510,
81095,
171926,
null,
679,
33742,
1034284,
null,
134311,
56571,
null,
27577,
null,
16401,
103357,
352438,
11585,
184765,
221538,
62661,
474463,
35129,
null,
null,
65354,
21364,
735462,
380263,
279892,
19066,
248853,
51219,
64679,
322580,
21432,
67604,
194476,
311165,
46347,
125697,
21807,
329429,
116630,
22859,
null,
136574,
259676,
140908,
433704,
42872,
70024,
231779,
447048,
11192,
22373,
9302,
605293,
556745,
293043,
39970,
null,
204209,
311447,
83543,
169502,
50556,
236900,
15556,
null,
24785,
49276,
109780,
58637,
178241,
16710,
60095,
77298,
179383,
82921,
52707,
176218,
270138,
15479,
51597,
79402,
41161,
479312,
202407,
null,
5610,
9397,
132162,
15802,
460750,
44727,
47110,
300408,
91664,
null,
423148,
111401,
138101,
277061,
191461,
84768,
37161,
95824,
308871,
32114,
42506,
141590,
71970,
27629,
null,
41828,
188534,
207710,
165521,
279732,
202755,
null,
345366,
1489,
62765,
null,
155981,
37719,
33425,
199601,
606672,
15312,
12838,
36938,
46926,
60842,
292525,
4398,
32798,
12857,
244446,
null,
4539,
52017,
215169,
20311,
147875,
166906,
295523,
57722,
97868,
100725,
23175,
13985,
611509,
109907,
346644,
10185,
43149,
44843,
212012,
106276,
null,
34751,
41472,
278767,
73110,
266449,
48337,
213181,
12076,
325415,
104940,
27913,
228902,
16114,
410303,
null,
35910,
25248,
61570,
315399,
222224,
18914,
null,
48811,
125427,
28275,
200289,
229855,
149020,
6284,
51134,
7321,
114511,
217751,
24497,
4881,
132984,
407402,
30945,
281494,
99690,
213510,
null,
249065,
288242,
99221,
null,
259052,
105810,
343010,
89690,
5711,
35373,
151385,
210607,
374391,
693660,
107413,
21509,
33717,
49732,
25512,
219579,
null,
94491,
35038,
369226,
47991,
155101,
52603,
269141,
107239,
37602,
null,
3711,
38466,
55988,
24050,
231773,
329705,
null,
345272,
255298,
138560,
1990,
161298,
321745,
540173,
19873,
142993,
null,
null,
24150,
34234,
93683,
93213,
124496,
null,
14325,
17529,
172077,
404119,
4549,
241013,
38866,
222439,
67814,
48254,
null,
67518,
49299,
40538,
347624,
349043,
15501,
231429,
170435,
354668,
55488,
158482,
112886,
142059,
603166,
null,
104845,
null,
625053,
90764,
115733,
310901,
30866,
59644,
null,
12684,
5113,
41768,
30366,
4190,
41917,
47926,
196771,
153950,
22244,
66242,
null,
56146,
3516,
330417,
6264,
325037,
165163,
187562,
null,
33643,
31386,
null,
14135,
6939,
1034998,
424481,
26536,
38972,
56559,
40684,
33818,
142377,
17595,
324890,
401006,
144893,
null,
186851,
475488,
15933,
511056,
36885,
24945,
17778,
131292,
null,
70252,
59532,
461858,
142249,
null,
71289,
55977,
20311,
156549,
255869,
5966,
26173,
12682,
null,
202839,
26814,
237621,
14099,
184293,
126519,
null,
291286,
20570,
11430,
5057,
null,
6580,
67040,
15709,
23167,
16824,
20180,
232285,
22430,
12664,
430615,
11257,
152769,
7172,
151136,
353109,
55904,
104697,
34612,
18139,
53918,
115506,
332125,
2716,
318856,
286629,
97410,
4580,
null,
263854,
167096,
56797,
141105,
127131,
150231,
24143,
579688,
506250,
27929,
29737,
217354,
29211,
178402,
372294,
10413,
35475,
378503,
null,
6624,
38664,
16504,
237309,
23456,
225109,
42540,
56693,
30004,
10372,
234313,
34872,
null,
75170,
30511,
10989,
13681,
186837,
307765,
372090,
68469,
40340,
77348,
267245,
742740,
242951,
364069,
2596,
315974,
182908,
41979,
6059,
25134,
45846,
210542,
46033,
192122,
10252,
38352,
null,
36345,
153663,
500744,
189117,
11996,
195998,
391014,
57646,
697813,
158645,
177600,
537050,
null,
245976,
129779,
19172,
36218,
11900,
5683,
34403,
119345,
223676,
null,
291796,
381961,
24712,
311634,
null,
null,
15077,
232404,
38166,
23640,
187873,
157530,
352173,
8246,
19759,
19884,
428870,
585778,
12327,
318282,
37884,
18832,
16329,
461525,
98108,
null,
71845,
55468,
43452,
218189,
19946,
31837,
36974,
null,
58245,
242179,
61360,
22156,
12826,
140608,
66071,
149903,
231621,
413954,
109696,
65784,
145039,
null,
13490,
29626,
7730,
985639,
167428,
547360,
29673,
89856,
49172,
193198,
453686,
null,
470428,
65326,
38030,
42713,
358395,
null,
null,
253491,
176604,
52326,
252238,
562714,
48927,
193151,
null,
43103,
132572,
102481,
22846,
18278,
101384,
2621,
347812,
69738,
239951,
290054,
9716,
165611,
416262,
30328,
15762,
10784,
34503,
31001,
56479,
103641,
39466,
153795,
null,
null,
14204,
5241,
84835,
30752,
59397,
507265,
29008,
23945,
null,
11567,
null,
367127,
133469,
264582,
313669,
216849,
120205,
103618,
454805,
63988,
456758,
null,
15344,
188308,
30441,
43662,
73615,
13490,
282511,
121265,
259649,
64156,
135223,
132149,
19436,
46479,
108610,
174275,
53619,
15201,
53026,
234671,
178973,
69867,
445120,
56048,
8293,
16964,
206094,
10330,
63221,
26762,
8710,
28893,
25243,
20069,
107969,
15480,
3674,
67270,
43703,
381273,
null,
129896,
5571,
11995,
203330,
298050,
32226,
32616,
688875,
221651,
23674,
67603,
28774,
37960,
221480,
288416,
133450,
121755,
341274,
80280,
38861,
null,
24550,
23868,
86324,
null,
106884,
44066,
194237,
164829,
11040,
178163,
null,
157436,
244607,
38056,
35682,
5829,
null,
190081,
240448,
19347,
178172,
18341,
23870,
19417,
72964,
227083,
307139,
203019,
15253,
581150,
39160,
45488,
90189,
22910,
43324,
68481,
53835,
120304,
19816,
null,
357883,
289803,
173467,
148677,
568814,
103890,
15834,
33433,
60224,
1855,
54833,
112592,
296019,
16656,
29801,
131702,
147499,
343448,
null,
243441,
25259,
null,
176602,
19010,
38231,
176375,
16938,
285543,
242301,
33531,
287409,
457075,
166115,
8341,
223386,
35975,
null,
273538,
null,
74369,
389410,
24517,
51960,
464381,
20525,
43199,
173631,
null,
47511,
26403,
62017,
26139,
109203,
79461,
163781,
113116,
92242,
331167,
262310,
967,
38580,
71593,
41499,
142004,
5146,
243126,
410235,
55016,
null,
259454,
10047,
408641,
102603,
145419,
98169,
33643,
119034,
4198,
202156,
null,
116528,
51408,
30390,
25787,
185300,
425217,
128786,
6221,
18302,
70070,
921885,
655372,
58532,
62535,
80142,
160641,
18940,
26144,
47450,
221182,
42824,
389974,
399436,
30415,
164959,
null,
20622,
69822,
85851,
66762,
null,
313883,
30247,
335023,
415614,
117160,
164926,
145076,
131028,
162544,
291759,
7352,
180313,
901113,
401761,
108941,
144026,
45416,
120112,
49314,
132043,
13409,
28760,
10366,
11171,
89591,
16036,
22511,
199832,
70054,
34234,
61292,
142964,
109391,
199498,
10465,
8057,
78520,
148200,
257865,
220942,
null,
16426,
378978,
null,
163736,
324345,
11881,
22407,
31797,
348061,
53793,
10649,
237682,
163995,
20636,
47422,
null,
351474,
113005,
21079,
116133,
79507,
391871,
169450,
249732,
185568,
165596,
18304,
95338,
385290,
198279,
null,
114059,
118866,
23691,
16188,
31811,
178989,
null,
187805,
316440,
675058,
74362,
145881,
null,
5449,
292579,
37319,
15327,
13094,
30709,
358754,
6579,
24471,
36418,
88995,
129817,
112373,
4043,
83805,
30799,
null,
319782,
10070,
32474,
65419,
113699,
81800,
23614,
267831,
21765,
null,
183041,
163976,
159625,
23503,
341825,
277417,
39266,
35128,
214360,
27897,
45207,
null,
44056,
433315,
24518,
null,
27729,
38817,
6479,
61219,
37970,
74361,
73413,
208283,
116939,
40557,
null,
469464,
211224,
267418,
186159,
34674,
46370,
3661,
45469,
261834,
null,
250895,
228486,
256352,
26500,
69564,
160035,
41611,
null,
255399,
55009,
9453,
27024,
19736,
35818,
null,
14432,
458681,
null,
283995,
null,
215887,
25910,
48397,
125642,
33846,
309709,
300298,
127333,
277959,
137917,
279131,
720201,
24828,
143320,
22894,
12263,
10466,
9490,
36252,
200103,
335150,
93397,
22429,
32747,
44353,
null,
46517,
278947,
284530,
93279,
193379,
17236,
154962,
95900,
14678,
75651,
255399,
541811,
13150,
55336,
5658,
147708,
249829,
99353,
418345,
39949,
261645,
423570,
186546,
null,
26829,
102676,
193857,
385676,
124478,
207512,
152941,
295009,
null,
122161,
null,
178732,
177646,
82628,
103643,
26825,
28341,
82097,
33893,
6410,
147256,
6137,
48891,
30461,
211835,
null,
8742,
181799,
76468,
53437,
207510,
null,
347032,
46118,
16095,
169290,
5598,
17039,
72449,
302955,
310714,
23884,
291003,
476439,
62709,
126958,
13591,
null,
20606,
42960,
36594,
82995,
108023,
89743,
331118,
null,
124608,
164974,
4535,
45846,
33476,
155262,
365322,
167542,
102110,
93988,
127436,
171071,
75546,
null,
35608,
39777,
25435,
51267,
null,
null,
375696,
62911,
246312,
395281,
null,
153346,
222037,
103808,
14856,
10856,
40220,
27030,
115838,
443374,
111419,
110979,
40491,
269108,
45867,
19709,
19727,
136841,
316132,
71235,
15639,
57439,
270273,
31701,
28067,
56772,
155830,
194803,
320154,
449285,
409867,
148187,
40171,
220850,
34860,
189663,
34695,
39539,
10168,
null,
244858,
17248,
26974,
144113,
120047,
34497,
61177,
178983,
43380,
null,
101188,
15910,
181286,
24408,
337041,
31440,
68816,
60327,
40422,
22598,
56760,
134091,
null,
46931,
50062,
102333,
354398,
389019,
21003,
null,
167685,
48870,
77011,
22885,
201795,
653630,
6779,
10105,
357843,
26885,
null,
6580,
86578,
197485,
56599,
29325,
84608,
null,
484417,
186204,
336160,
null,
30553,
6115,
117071,
null,
42793,
null,
null,
218860,
56545,
38270,
82400,
9630,
null,
333229,
595588,
198284,
null,
30659,
282983,
348253,
86161,
247622,
26026,
82904,
290634,
15771,
293913,
234998,
5056,
277961,
9948,
83503,
211097,
249751,
192774,
47495,
4637,
380449,
96401,
32407,
28768,
18145,
94626,
337373,
19905,
142397,
87199,
63617,
12657,
229705,
39147,
17264,
3847,
114856,
243447,
128983,
124976,
220717,
170943,
578521,
80387,
null,
8503,
null,
118022,
110851,
248685,
406870,
75274,
23071,
null,
27626,
270427,
48160,
12131,
null,
406923,
333363,
67337,
127763,
59731,
250181,
106981,
235830,
16945,
160114,
328265,
null,
299020,
51664,
83336,
225598,
276896,
208008,
18639,
18505,
27289,
33042,
null,
173949,
22618,
294857,
35419,
96489,
79508,
163499,
92639,
13805,
48238,
636154,
352299,
140008,
367153,
37849,
201909,
20764,
7947,
39007,
29414,
199928,
11535,
5406,
183364,
102970,
33027,
139528,
244311,
213481,
774532,
26988,
540072,
147810,
176683,
62224,
33377,
30392,
20496,
213615,
18261,
24382,
53683,
23293,
136644,
150219,
94272,
108950,
null,
173865,
14346,
26688,
37319,
142059,
1378,
226881,
306494,
19880,
117800,
52143,
51195,
337948,
8303,
363527,
14605,
44712,
null,
55190,
25954,
40230,
21403,
9035,
175516,
25645,
329802,
188914,
36255,
206257,
197597,
68520,
56639,
118155,
182314,
182068,
265480,
202722,
null,
null,
42565,
46782,
24898,
8053,
null,
113950,
297771,
596060,
107876,
90541,
140081,
784,
null,
137178,
118050,
139212,
706394,
237491,
38396,
13548,
37222,
122063,
111387,
1027562,
142383,
25076,
14906,
140323,
267843,
205851,
3286,
154757,
1153375,
150237,
47987,
143950,
240185,
102581,
14474,
66417,
235214,
86705,
152081,
44387,
74075,
3886,
19372,
9597,
75538,
99198,
215735,
8765,
12745,
328048,
77450,
140088,
460516,
265575,
186182,
214155,
144161,
63224,
17389,
32134,
16874,
576013,
87314,
491885,
140744,
594519,
28122,
266713,
96993,
76327,
13806,
176843,
313340,
95798,
19589,
7454,
75209,
166278,
205834,
33408,
718836,
37654,
906895,
36110,
533938,
416241,
25123,
39351,
57047,
26843,
100007,
12051,
538424,
132354,
43574,
null,
22015,
18165,
205838,
65583,
222242,
11432,
285416,
114955,
59272,
350951,
148298,
40865,
24525,
346199,
40183,
138646,
262295,
227982,
75527,
333418,
750820,
19966,
25889,
46875,
null,
214754,
34574,
80804,
288353,
99939,
null,
198756,
19198,
59808,
43773,
39646,
null,
386280,
2813,
204180,
41589,
null,
52534,
25066,
33089,
70964,
261830,
18471,
27178,
20119,
187145,
82480,
126177,
36471,
23471,
259557,
null,
53348,
27430,
17958,
null,
5911,
243908,
31187,
55871,
1587483,
143411,
143648,
24176,
29060,
167023,
null,
523014,
60342,
1223,
322686,
31431,
679983,
105704,
325785,
24042,
222562,
15058,
229611,
1191276,
282057,
207920,
36453,
1834,
324865,
114334,
35709,
null,
387137,
226861,
null,
259096,
178181,
37376,
162025,
89811,
42699,
453858,
104072,
481662,
160041,
32144,
45124,
36185,
336582,
91755,
154781,
93354,
7139,
null,
508544,
20172,
43258,
24891,
21539,
27376,
118825,
154603,
51375,
6196,
137452,
60417,
214466,
80610,
226582,
3611,
36086,
385020,
null,
14627,
29303,
89199,
7454,
213669,
18641,
23148,
8404,
27125,
97640,
40295,
39355,
223803,
190636,
55606,
366559,
null,
31603,
100874,
37300,
10917,
6276,
225457,
38364,
11478,
91746,
9204,
294219,
1950,
284554,
437118,
373890,
177360,
24848,
188142,
369812,
20468,
186618,
165018,
173391,
45406,
35792,
18823,
178722,
null,
8418,
null,
416785,
41804,
83188,
193882,
15668,
454633,
1138612,
59332,
29391,
null,
null,
305081,
114639,
109898,
10675,
26930,
10011,
4677,
14619,
null,
24949,
125790,
78456,
169562,
94357,
null,
174387,
43574,
431859,
222378,
247827,
294521,
262709,
21358,
61778,
177816,
68306,
null,
255620,
26139,
null,
26195,
null,
35330,
983,
105622,
261236,
146266,
61644,
47192,
26408,
23955,
53989,
8283,
3002,
56396,
13938,
15908,
23757,
128159,
null,
111399,
36580,
47708,
12613,
null,
16303,
null,
295711,
94360,
34495,
115527,
38509,
9045,
244745,
205574,
35567,
154369,
53330,
null,
52578,
47021,
null,
19372,
230753,
68322,
42424,
37383,
null,
322858,
26821,
121463,
125585,
71528,
41101,
7573,
58129,
58854,
68216,
322963,
18148,
233397,
3466,
15937,
103658,
227098,
357965,
23182,
11700,
26324,
29006,
115025,
100379,
4257,
168531,
28253,
262768,
226992,
82709,
9264,
21141,
181872,
14889,
215505,
84606,
null,
42309,
9312,
231455,
20364,
14985,
46882,
96615,
146458,
42419,
344032,
77488,
41046,
27932,
147195,
21958,
134263,
292009,
8467,
55500,
295775,
25943,
190137,
20118,
50694,
null,
221764,
11836,
199517,
95181,
32622,
64092,
340630,
4278,
66229,
433150,
269733,
218651,
10766,
158200,
15332,
182400,
55975,
735513,
19562,
325292,
9508,
102601,
115882,
159988,
null,
113067,
341827,
31130,
58369,
162314,
140866,
347724,
42777,
23455,
224610,
42771,
79993,
110587,
1289,
229828,
29926,
31167,
11657,
85035,
178722,
17861,
64302,
802250,
58137,
15456,
336001,
15044,
167639,
45184,
359065,
223439,
null,
225667,
303437,
285012,
51463,
419690,
27768,
41779,
362644,
56035,
19636,
717970,
164757,
76069,
5388,
13544,
63846,
36261,
185866,
147281,
24147,
10146,
17488,
56524,
52922,
192677,
68355,
19010,
238223,
35981,
76072,
458897,
19651,
15373,
277716,
48281,
169544,
178370,
172965,
564333,
437927,
419257,
264202,
30558,
7537,
33480,
20008,
21987,
53177,
null,
null,
227368,
49309,
70885,
null,
27923,
40802,
26030,
null,
57493,
114844,
12635,
55033,
20489,
40416,
5150,
55454,
28240,
190660,
263645,
50017,
15580,
49433,
22071,
36356,
54564,
96740,
14462,
38715,
97734,
215990,
75737,
null,
108858,
71229,
8689,
281422,
2487,
null,
234990,
12522,
null,
40521,
173324,
132508,
243757,
5745,
273458,
19988,
54108,
27642,
null,
62914,
62556,
506461,
160103,
74396,
85976,
83772,
null,
71672,
62475,
22631,
227947,
30265,
276004,
114147,
37428,
18723,
23894,
27363,
20098,
108741,
537529,
98412,
228300,
50325,
178731,
259168,
299375,
281586,
130399,
null,
31889,
181962,
149763,
26793,
289267,
14195,
267620,
335217,
238427,
null,
29534,
18296,
11969,
315381,
260449,
40489,
115968,
191934,
220566,
165346,
7447,
538391,
131640,
202998,
23861,
23962,
254704,
null,
32397,
null,
195143,
14522,
648024,
107075,
324087,
170999,
44067,
36662,
401950,
161835,
23578,
44030,
271629,
169502,
377532,
189524,
340020,
15762,
35229,
208192,
30630,
154001,
100681,
87242,
52673,
234356,
60045,
27498,
null,
null,
180115,
210687,
130729,
24165,
45643,
144009,
23111,
114562,
206549,
106844,
42219,
359871,
41941,
7502,
195591,
260084,
15983,
149719,
78177,
264673,
null,
50589,
null,
45227,
87458,
75043,
12901,
13846,
139572,
217279,
185835,
43579,
10221,
21710,
243935,
224569,
50433,
280166,
374321,
8997,
27962,
138777,
107112,
13564,
65272,
41145,
854422,
403134,
215741,
null,
210120,
220605,
null,
439128,
139089,
118357,
23336,
null,
86688,
13127,
229869,
3461,
53938,
40463,
336103,
193699,
6432,
238325,
205521,
59718,
430191,
11262,
36359,
176960,
null,
104557,
75384,
116729,
62690,
149819,
123599,
8694,
656458,
null,
68210,
72410,
24073,
43264,
8026,
332037,
360718,
36387,
33630,
109956,
445111,
278661,
259890,
133458,
195781,
131319,
null,
37185,
null,
131472,
53842,
85616,
45503,
10860,
487605,
433379,
70217,
11593,
218858,
35678,
238261,
70262,
37942,
401740,
238389,
28628,
14267,
29285,
37690,
84400,
197252,
20699,
128401,
33395,
45443,
113095,
129407,
213097,
317541,
25708,
null,
39583,
44748,
174563,
421315,
105833,
57704,
12175,
99177,
182944,
531076,
18403,
null,
358776,
243267,
131306,
8675,
102468,
298431,
7425,
125787,
474046,
124368,
39940,
115664,
8177,
30910,
81809,
8987,
4013,
96935,
211731,
385991,
204068,
47332,
31348,
12853,
64409,
17130,
156240,
35328,
null,
124352,
139306,
34879,
28966,
71878,
49577,
82971,
52153,
37970,
75898,
296153,
351847,
232634,
69530,
503350,
191553,
4579,
190953,
23649,
12791,
null,
296180,
39963,
53744,
427261,
29785,
37674,
4073,
454311,
79442,
118233,
18738,
22297,
79986,
240674,
145319,
100916,
178310,
29063,
356244,
54355,
null,
138986,
361727,
222534,
155798,
21103,
53852,
46878,
28918,
105352,
478365,
194530,
46782,
null,
170151,
5355,
138277,
68125,
284651,
164785,
418650,
14413,
105594,
17104,
313791,
43794,
234215,
142711,
null,
81689,
57214,
null,
42041,
null,
null,
45522,
8280,
185245,
351187,
32223,
172682,
23116,
363640,
54741,
null,
54134,
10012,
188136,
65563,
41772,
17417,
155858,
17497,
null,
45686,
46857,
147190,
95167,
56892,
26804,
285699,
21440,
154107,
224360,
74395,
5102,
389597,
642283,
58145,
7107,
22510,
72662,
29679,
94459,
358974,
null,
47243,
29268,
255752,
25639,
237277,
null,
null,
null,
269081,
232502,
20441,
331150,
24281,
170627,
395732,
114292,
38086,
215324,
77786,
176148,
22413,
27196,
20357,
45951,
28566,
36794,
111779,
136681,
213057,
38644,
151881,
83119,
null,
164306,
42558,
36644,
12119,
24010,
36977,
61499,
14700,
24416,
275725,
null,
12058,
216030,
74318,
13296,
null,
42014,
25305,
17332,
21404,
55571,
27267,
287326,
15238,
197206,
208840,
35324,
85956,
111342,
158592,
46260,
141387,
406800,
57659,
9357,
8882,
131628,
100833,
41602,
26187,
322322,
29184,
56255,
106782,
180039,
297513,
42245,
28730,
25941,
154690,
180077,
120613,
27446,
90430,
54713,
144736,
36055,
21432,
105064,
50596,
19958,
154199,
300146,
28012,
217248,
77869,
7131,
46741,
null,
17070,
201669,
21046,
496511,
56759,
113329,
25745,
106281,
346946,
44906,
55860,
189919,
9362,
317909,
199616,
547197,
35125,
130351,
48475,
98519,
360120,
36375,
285937,
89732,
91181,
334824,
38378,
13129,
26122,
204451,
162760,
445261,
29210,
10002,
274824,
16365,
317061,
139984,
83714,
128994,
34749,
7982,
172857,
28425,
439361,
96995,
74718,
350985,
65890,
316472,
83224,
143267,
308572,
17175,
456705,
10303,
340391,
null,
255776,
120876,
null,
328060,
129046,
null,
83917,
null,
11618,
298655,
24918,
40457,
33482,
15557,
17836,
52375,
5944,
77025,
41070,
360835,
33965,
99741,
288225,
86962,
81696,
114600,
25571,
257651,
220119,
182512,
9203,
19986,
288118,
105394,
243297,
1028190,
23552,
625680,
29342,
110098,
152338,
89924,
156476,
238035,
81252,
323314,
108381,
188768,
91194,
42728,
261085,
45899,
null,
46052,
274646,
null,
445972,
null,
226697,
47089,
null,
null,
8640,
46276,
264440,
51034,
126425,
21018,
13928,
28994,
32975,
null,
316571,
7285,
33299,
9236,
37161,
24768,
107372,
378661,
303957,
383926,
177409,
28163,
166830,
78655,
13424,
32832,
null,
107451,
49458,
153652,
168784,
75254,
19921,
48866,
50870,
31152,
552710,
12133,
37621,
34055,
21594,
403359,
8732,
308507,
285505,
40558,
33288,
713912,
34978,
205004,
155074,
28579,
820114,
20205,
49252,
9760,
37779,
null,
225467,
380254,
112644,
285774,
51903,
98872,
144882,
null,
null,
213063,
39353,
125243,
37992,
41308,
140203,
15823,
null,
190750,
78978,
137610,
72164,
582211,
80677,
234836,
14756,
37726,
25900,
94732,
194808,
31132,
null,
124971,
12585,
237689,
67581,
230093,
169873,
63448,
40770,
71672,
331964,
36595,
51904,
104998,
142149,
88985,
33167,
173356,
23911,
64702,
37113,
57186,
36182,
53957,
146804,
128236,
148176,
null,
21516,
110578,
2587,
9452,
82169,
372181,
267221,
174911,
24678,
52347,
169043,
203866,
187369,
30900,
19266,
null,
null,
4997,
241694,
306142,
14578,
216905,
441526,
31010,
19565,
55095,
28241,
7425,
322777,
null,
152063,
3084,
58906,
19096,
208522,
19570,
16417,
null,
147460,
213953,
216959,
17285,
248554,
246069,
411240,
232704,
356696,
494009,
320433,
118140,
254116,
266704,
11133,
27709,
54422,
null,
8657,
271562,
339341,
49874,
24008,
14898,
70779,
403544,
19894,
84685,
99628,
371368,
3304,
31471,
47197,
57758,
16280,
113622,
null,
17876,
null,
57758,
261749,
197889,
521007,
30792,
241640,
37631,
171782,
24786,
4186,
42361,
30252,
129260,
4269,
522470,
199053,
10482,
739969,
null,
150032,
164575,
398961,
210528,
60544,
196522,
175598,
117509,
20834,
76421,
116492,
24496,
32728,
46291,
54302,
null,
89134,
29546,
33723,
131822,
59430,
18195,
23417,
482156,
13818,
null,
127191,
60778,
651059,
117809,
442774,
47697,
537461,
147392,
32048,
4311,
231996,
434834,
null,
271056,
132363,
120456,
66855,
68628,
15216,
165839,
30125,
151190,
34896,
50610,
23909,
15704,
37951,
348968,
136108,
12613,
410691,
241029,
21342,
23420,
23984,
308928,
26146,
77095,
16464,
202925,
22565,
14992,
127499,
35672,
85729,
20936,
null,
28499,
null,
14251,
208892,
147510,
473728,
202760,
66706,
75797,
13821,
146628,
136394,
81166,
366824,
887579,
null,
7969,
228102,
126032,
165480,
43696,
303252,
30939,
129060,
30392,
33796,
139923,
49387,
153203,
53678,
43964,
null,
145390,
195174,
77960,
null,
216056,
323811,
534727,
null,
28654,
20968,
40187,
238486,
20295,
155141,
99575,
null,
256311,
334950,
507550,
157558,
564465,
29233,
356108,
73722,
13021,
309517,
252077,
55272,
226487,
79094,
209131,
10128,
9966,
148225,
93422,
26215,
36252,
52125,
179183,
220748,
170672,
169210,
282493,
32332,
null,
140980,
15862,
16278,
16516,
20812,
26656,
272202,
10730,
39142,
20557,
10859,
100013,
104413,
96370,
341059,
307619,
27410,
64781,
77828,
12712,
29645,
125013,
34202,
163377,
116584,
3853,
41771,
172703,
264683,
32504,
67453,
274829,
24957,
99499,
44936,
78364,
12537,
366381,
75825,
145220,
null,
28264,
24987,
17711,
324309,
84394,
null,
191438,
573054,
19077,
55487,
313047,
16126,
257676,
110615,
84372,
187195,
446347,
87796,
59822,
12655,
188144,
25818,
485199,
208235,
204854,
14976,
236825,
97947,
41449,
330657,
217933,
31290,
165789,
7160,
15778,
11497,
7825,
562340,
270618,
60441,
211804,
392737,
315677,
null,
268620,
null,
624699,
25173,
265392,
38420,
10116,
6413,
4615,
250168,
151771,
83343,
22697,
null,
null,
75462,
95365,
99331,
363022,
108808,
24491,
48103,
11349,
39849,
301742,
4670,
98011,
20999,
15199,
258658,
20452,
54303,
78262,
12787,
101358,
77286,
397025,
33031,
211221,
13213,
42769,
51293,
43834,
102639,
21756,
436667,
181023,
126199,
120310,
572843,
18732,
26641,
8315,
21286,
80550,
10581,
93139,
274264,
31951,
7956,
17073,
15570,
27643,
123824,
36016,
221936,
209089,
245941,
null,
70766,
444527,
36320,
318209,
null,
259050,
112926,
64904,
83409,
156321,
11911,
314241,
25946,
258979,
185916,
92773,
32522,
31823,
51674,
42967,
null,
492095,
11348,
338274,
12209,
177998,
22162,
null,
25729,
13966,
2741,
33382,
18894,
147833,
272941,
101306,
317793,
165924,
75178,
null,
48380,
84932,
417426,
182407,
278876,
37272,
113168,
88503,
184719,
272419,
null,
null,
164333,
19337,
88337,
null,
679763,
13991,
67130,
233579,
210370,
282862,
22523,
80050,
247804,
40981,
190635,
21120,
57082,
25037,
54814,
20413,
29011,
550891,
232313,
339110,
11488,
null,
249039,
9556,
273003,
43780,
25567,
194528,
null,
15393,
289424,
248395,
27402,
21003,
173040,
288328,
254737,
20281,
27919,
95703,
246214,
31370,
22154,
197141,
null,
44353,
294180,
365590,
12801,
59422,
25696,
null,
2312,
146415,
6214,
null,
22999,
258997,
13949,
14083,
438693,
134641,
190615,
315515,
30526,
6493,
23140,
46407,
382759,
49462,
12461,
218159,
269841,
60342,
null,
25043,
14563,
26372,
113817,
36618,
77927,
254026,
40854,
25991,
59090,
19076,
167592,
57536,
252547,
1072,
64948,
269961,
18925,
8483,
234056,
247376,
151293,
24904,
11667,
240749,
164265,
34274,
181205,
69676,
73682,
34532,
25051,
407007,
45007,
200423,
52524,
null,
202949,
5536,
397816,
46956,
3163,
401268,
66908,
38938,
26553,
9158,
356321,
null,
33647,
97841,
4723,
25898,
273661,
29315,
165943,
169709,
16917,
428352,
85767,
19498,
38232,
33799,
10099,
37052,
85467,
133392,
113570,
162706,
null,
264130,
277659,
193774,
21065,
197744,
13405,
443884,
59395,
149907,
41660,
225239,
156173,
171381,
177338,
96665,
34141,
18050,
39074,
5009,
14680,
51751,
267604,
5864,
209437,
55257,
196568,
42097,
72628,
9771,
30955,
240955,
18557,
34648,
30046,
244685,
269527,
132932,
2504,
30617,
135359,
14460,
180369,
311036,
10727,
49440,
null,
null,
52239,
31685,
23853,
302783,
2362,
null,
52523,
15619,
58544,
48996,
60666,
72796,
229861,
398535,
176512,
null,
124534,
null,
472553,
163033,
74429,
17127,
212357,
216309,
23864,
43688,
null,
279205,
283426,
269073,
259564,
424553,
13721,
6478,
323284,
35529,
515897,
209913,
28480,
274044,
null,
31250,
32521,
190709,
null,
64551,
33249,
null,
58711,
138752,
198106,
42348,
21635,
7469,
135713,
27965,
286599,
45672,
180695,
408952,
18347,
69032,
214699,
12087,
20361,
39765,
139681,
43697,
34277,
14758,
343772,
80470,
130859,
117801,
335101,
26793,
190266,
104504,
29173,
181134,
120988,
9676,
104842,
86616,
279583,
42925,
126592,
43820,
39452,
null,
153893,
83825,
431445,
136688,
49058,
44187,
230046,
328194,
96685,
26419,
42952,
20623,
31393,
74182,
41217,
null,
47940,
null,
20780,
214141,
77649,
421547,
28702,
null,
209020,
41178,
27485,
174522,
193655,
81227,
85146,
53473,
111251,
262349,
23950,
277014,
10107,
null,
111503,
251588,
0,
166127,
214776,
35737,
259244,
10463,
343093,
null,
116593,
64180,
26703,
20359,
218293,
25323,
29404,
238201,
61833,
67467,
200006,
108767,
77528,
150317,
400565,
316179,
23131,
10577,
38717,
120448,
133731,
38155,
208157,
31186,
24202,
290863,
104693,
12984,
5921,
25384,
56249,
82527,
140710,
99862,
null,
355729,
263970,
213115,
35300,
24289,
52746,
21095,
188942,
null,
190868,
250448,
78079,
167783,
628934,
187078,
15504,
27274,
47021,
185205,
370352,
30316,
null,
181649,
38965,
49683,
66371,
23902,
37647,
19328,
33443,
70585,
99738,
38585,
9309,
560908,
56826,
42556,
128868,
7614,
35533,
4115,
77489,
68191,
97220,
206364,
74485,
12075,
84190,
10196,
223867,
null,
92598,
18712,
28884,
88288,
12637,
382141,
145402,
68996,
95985,
5369,
136317,
6424,
195950,
13206,
null,
22030,
9657,
501783,
48865,
null,
387312,
46407,
28999,
null,
10307,
48809,
16252,
3312,
32115,
null,
364486,
33907,
232905,
40475,
22208,
56544,
26311,
19899,
236024,
317696,
70892,
114963,
49414,
215077,
null,
270417,
4823,
145774,
22400,
24179,
15373,
null,
277408,
13129,
48660,
45384,
245006,
198825,
146437,
119515,
11646,
128302,
34693,
556627,
28479,
50788,
23199,
52638,
null,
106529,
20237,
376742,
238719,
7157,
8958,
null,
178694,
null,
462660,
8124,
217177,
26052,
76319,
38486,
331276,
17216,
260945,
23197,
5866,
77141,
298395,
7448,
17058,
43043,
8622,
28773,
36471,
12748,
44236,
null,
333362,
347475,
114814,
163233,
28014,
209017,
13980,
38895,
103632,
null,
224527,
468477,
30899,
233439,
null,
545283,
33475,
41700,
282597,
27436,
321714,
21656,
61273,
57028,
30833,
26457,
248171,
118431,
null,
142071,
185664,
292524,
392980,
367235,
27618,
192593,
80285,
12986,
null,
58549,
107820,
233229,
264951,
49028,
159215,
550831,
246532,
73312,
113715,
388516,
8668,
422321,
167306,
47068,
45596,
null,
88306,
31223,
140524,
48792,
2838,
110610,
null,
209972,
30952,
null,
12724,
14319,
77063,
23367,
4273,
435222,
null,
185074,
62312,
192061,
157413,
16240,
34207,
324347,
59753,
41174,
81660,
110734,
20581,
null,
22489,
null,
98649,
46455,
45017,
173112,
581986,
25692,
227551,
30848,
41843,
569799,
60332,
null,
118985,
192840,
21872,
185715,
38085,
232340,
72748,
7620,
90625,
409782,
12549,
60953,
412672,
null,
22455,
56306,
288346,
390802,
34890,
18722,
3601,
20538,
119357,
161398,
5644,
48537,
42427,
34839,
231176,
15812,
null,
226699,
186143,
188117,
302386,
71948,
478049,
202,
142066,
242846,
12166,
39908,
5669,
262140,
69700,
11264,
22411,
350843,
51196,
29834,
227115,
38041,
20530,
85498,
212207,
60707,
27242,
38087,
11524,
144597,
59821,
181225,
154750,
157529,
41538,
284790,
272308,
123470,
278673,
null,
321572,
262023,
17213,
349327,
50581,
21707,
98563,
44548,
32049,
2420,
64573,
53578,
60058,
null,
null,
192710,
31594,
6343,
48711,
68472,
209180,
450758,
null,
54614,
36621,
217017,
212736,
181409,
93652,
47810,
74709,
362238,
204808,
46432,
72239,
43838,
19907,
39099,
21072,
208008,
90818,
218596,
23328,
27159,
124192,
107417,
355723,
36027,
179201,
80655,
33036,
95308,
214827,
287177,
96414,
20901,
462705,
129717,
1606,
56476,
45952,
55471,
17613,
35664,
61771,
203164,
121874,
84776,
57236,
3529,
null,
13025,
16832,
35624,
27856,
16034,
94419,
72451,
225431,
16324,
79847,
22872,
285255,
219337,
176990,
74010,
50562,
115662,
268975,
56584,
236326,
48247,
128142,
120671,
85432,
27661,
null,
3892,
28009,
49167,
91814,
null,
65871,
162673,
161242,
12832,
40583,
179859,
111035,
null,
321099,
184040,
283405,
39959,
44696,
19811,
14264,
192046,
127102,
192769,
54219,
47129,
203808,
49640,
33082,
743894,
13613,
298728,
null,
98080,
null,
47115,
119968,
63756,
null,
15495,
23086,
332663,
215127,
14188,
26788,
59141,
122542,
180215,
163809,
258351,
72223,
335007,
125449,
38692,
6694,
18690,
null,
186959,
20714,
4155,
52851,
70580,
265642,
null,
318446,
13493,
null,
378293,
124319,
null,
26085,
9050,
20568,
45128,
269435,
null,
48078,
256326,
69639,
10037,
61182,
33087,
788024,
188302,
null,
34320,
39027,
169371,
55151,
null,
310386,
47200,
81161,
79721,
25797,
731133,
9487,
21505,
393132,
9520,
44969,
295435,
189580,
null,
286199,
44170,
107321,
264765,
31924,
16461,
361740,
113694,
79399,
null,
107903,
19309,
167921,
458992,
24950,
24102,
7051,
58768,
null,
409271,
18023,
23415,
75057,
31624,
27934,
69056,
18933,
173989,
7176,
113443,
291748,
10779,
72841,
111635,
59272,
186453,
202998,
600905,
176690,
70841,
24225,
154435,
265995,
93524,
22203,
25833,
330153,
3242,
36767,
24972,
251566,
42310,
52748,
31977,
202519,
242994,
20605,
365388,
508912,
24844,
55028,
51523,
46493,
15621,
null,
840772,
126151,
202751,
234748,
516806,
143500,
120143,
56860,
362153,
29097,
44856,
31781,
207080,
301018,
null,
22823,
146886,
79289,
234958,
19920,
29776,
155965,
80863,
289442,
154330,
260294,
85784,
68334,
67007,
216494,
203633,
297109,
215239,
286291,
153968,
11953,
31856,
264078,
87862,
31545,
273102,
9566,
346901,
18692,
35217,
166980,
92486,
48375,
58777,
16609,
120280,
41604,
31540,
99101,
52019,
null,
453548,
491108,
535856,
null,
17384,
212568,
45639,
117657,
115480,
5220,
273106,
83552,
34097,
11898,
92582,
282117,
8971,
102262,
98400,
null,
96865,
208046,
75132,
629623,
4464,
null,
282448,
24834,
369198,
124811,
15083,
160185,
275872,
19367,
233246,
264878,
null,
52649,
127882,
358611,
33075,
175223,
16759,
65177,
184930,
36669,
null,
73867,
17384,
357079,
314633,
57688,
179156,
249587,
63228,
153769,
234539,
21552,
11298,
42688,
17172,
194187,
47169,
65498,
202030,
354516,
174776,
149771,
48472,
313044,
250163,
83278,
16834,
97987,
18712,
318229,
26974,
16525,
49008,
540190,
21424,
248929,
13418,
27450,
62361,
55508,
27487,
226421,
46478,
280023,
267290,
null,
20822,
74304,
23023,
158276,
189925,
37420,
38721,
225134,
189360,
170718,
54617,
15010,
111676,
9880,
482397,
145708,
36033,
81856,
43289,
291302,
36273,
65325,
25722,
13991,
108426,
308581,
9631,
17374,
17875,
20247,
27177,
52023,
68366,
3183,
182052,
77757,
39843,
255309,
22777,
222548,
69822,
null,
21676,
205529,
782108,
77202,
145413,
220470,
null,
284056,
219064,
257069,
44308,
67638,
182505,
382018,
58751,
18998,
359109,
null,
null,
72122,
null,
217517,
53236,
null,
8758,
82411,
52885,
59410,
107038,
154957,
232102,
67413,
186789,
38086,
176017,
177654,
340082,
381585,
216982,
277256,
7806,
165643,
121191,
492773,
27640,
22894,
32403,
319665,
null,
null,
27812,
37103,
155919,
433649,
203594,
217766,
500183,
20320,
216962,
105793,
197957,
4894,
120571,
49750,
24712,
167313,
88949,
null,
342161,
10782,
16832,
16240,
82328,
42015,
63718,
179496,
34715,
7860,
222034,
293405,
177116,
118327,
282719,
14944,
174035,
14830,
3717,
27042,
62730,
95493,
102127,
6401,
18465,
564461,
14807,
241813,
79284,
42939,
null,
31452,
null,
173663,
168037,
327195,
13349,
60118,
7805,
226598,
33629,
19639,
24021,
46055,
67690,
53199,
93692,
199873,
396407,
22772,
81758,
310760,
37892,
149102,
14031,
26265,
41745,
250813,
590731,
41831,
44430,
64155,
160817,
4568,
154002,
323301,
null,
null,
21503,
212842,
9067,
null,
139797,
745617,
320794,
null,
14900,
182697,
32769,
null,
24774,
305032,
51161,
303825,
23564,
378443,
38794,
74624,
318347,
119506,
345426,
184034,
null,
123553,
252389,
53465,
17420,
13673,
23630,
10884,
351395,
65356,
485726,
null,
10904,
476496,
108025,
22180,
20487,
255701,
409353,
7580,
532532,
32433,
73149,
35518,
41640,
144361,
null,
330599,
6521,
39028,
9993,
174643,
30227,
293237,
79656,
433405,
137999,
77025,
284859,
4070,
37622,
106673,
121469,
224017,
20103,
49859,
22878,
71022,
24100,
8829,
78552,
400399,
67924,
125026,
236716,
2513,
4177,
null,
32784,
22863,
164042,
84139,
246046,
186501,
44431,
29150,
15940,
31689,
63579,
793270,
54462,
169097,
342623,
147247,
5823,
19300,
13511,
86208,
41752,
98257,
null,
270867,
258699,
259454,
53828,
31279,
12124,
63226,
45081,
293458,
181069,
19300,
45935,
68993,
null,
20858,
86967,
24462,
40969,
null,
33515,
null,
298614,
265295,
629859,
477880,
75649,
66030,
4691,
190325,
263022,
748276,
11136,
28222,
305067,
35059,
172297,
12560,
66477,
3965,
11602,
289187,
39991,
29001,
49321,
12738,
138622,
48184,
432718,
24040,
159574,
33678,
141959,
36196,
75176,
12178,
24498,
198267,
347936,
100438,
null,
37939,
211243,
21345,
21367,
51354,
492441,
22013,
343364,
70324,
61690,
330510,
77284,
88419,
260156,
7902,
35002,
41630,
167818,
46070,
541305,
305616,
321438,
20426,
33990,
null,
6157,
16072,
40371,
206258,
25913,
365926,
44286,
16547,
1420912,
144903,
36569,
null,
24397,
9976,
217884,
226030,
237703,
316417,
null,
21547,
14023,
55965,
43816,
210709,
47700,
68191,
792357,
321711,
426650,
273508,
145038,
131709,
27532,
168225,
72037,
43357,
117850,
458633,
301355,
216204,
93206,
160630,
453946,
83932,
null,
57566,
103284,
21056,
276598,
27465,
144174,
221969,
32739,
453418,
296160,
47058,
520250,
18151,
322814,
186587,
22527,
47189,
7611,
452752,
343441,
90654,
3978,
72056,
33204,
56875,
46866,
41935,
358502,
null,
395568,
173726,
283855,
26743,
31136,
null,
113996,
null,
6957,
86452,
102620,
184481,
430452,
147668,
38659,
12325,
114819,
85903,
158303,
191746,
18393,
18229,
18444,
19220,
null,
63677,
4759,
415346,
57687,
278734,
875487,
20577,
244390,
300589,
54550,
338838,
12246,
46128,
31244,
295865,
346467,
36987,
6974,
36858,
168791,
173725,
347322,
11074,
39167,
165408,
83874,
335492,
170761,
1992,
40858,
244894,
240715,
57706,
16868,
187390,
66951,
null,
null,
125307,
4955,
294228,
332699,
null,
22920,
28317,
248294,
136299,
19891,
48737,
8678,
466481,
121611,
37171,
199545,
149050,
6150,
43274,
195578,
384089,
21183,
62691,
174839,
44785,
44239,
19905,
425048,
11364,
230121,
48716,
223238,
42453,
48507,
358421,
17635,
350707,
10826,
33332,
29318,
208896,
389535,
217214,
13268,
12640,
118533,
47385,
383542,
285406,
97913,
9973,
258113,
19274,
60995,
239780,
90194,
16917,
249399,
26571,
129101,
20161,
85599,
105239,
32835,
4294,
null,
35228,
26710,
16728,
447096,
4041,
155457,
226507,
76859,
30963,
172885,
51950,
166457,
127488,
102382,
145013,
42763,
31267,
16718,
8792,
37401,
204849,
null,
672236,
32975,
96731,
306553,
152244,
34445,
213748,
104022,
16847,
436908,
192851,
40714,
420422,
7378,
11229,
237278,
33268,
119429,
89418,
14041,
409073,
144974,
60657,
317668,
321028,
46782,
209580,
33868,
4458,
64800,
390689,
229634,
260482,
237273,
18676,
36727,
null,
688463,
38270,
411532,
122640,
null,
165573,
null,
64989,
573213,
44484,
39943,
188888,
13368,
null,
38613,
29612,
24318,
7986,
148657,
375958,
null,
370309,
17504,
259792,
202747,
null,
24373,
174640,
9022,
8575,
285290,
383191,
140609,
303136,
84910,
252076,
185185,
668681,
11031,
null,
35778,
34196,
18241,
133313,
27144,
56653,
582310,
35228,
null,
49266,
328734,
32655,
130647,
20477,
22477,
98746,
null,
42804,
382170,
198304,
19578,
11422,
53155,
361227,
158812,
null,
692763,
23733,
153315,
301791,
203441,
119760,
null,
187714,
240377,
43644,
null,
53560,
191927,
21498,
115839,
71136,
15400,
675709,
71552,
143699,
18907,
26505,
355672,
50329,
98395,
37900,
34713,
10410,
531222,
276238,
104869,
20784,
317703,
4991,
29260,
31185,
11419,
5632,
26632,
62777,
48322,
49039,
42658,
95627,
341523,
133002,
316015,
190660,
null,
323857,
11917,
31235,
35134,
386239,
243836,
274701,
15846,
30897,
23693,
208156,
287918,
192398,
171553,
115345,
155681,
34168,
41148,
null,
14200,
null,
81347,
83274,
62204,
21551,
51004,
41690,
158766,
37822,
176060,
46920,
67251,
71358,
71222,
10484,
212674,
26278,
52653,
77030,
68738,
253742,
94711,
123896,
28656,
12380,
43977,
412406,
21378,
45136,
37112,
null,
43177,
115782,
357827,
71338,
227960,
260559,
46447,
188308,
26424,
310230,
27533,
159360,
149089,
null,
56097,
null,
17055,
605251,
17016,
14788,
113801,
255003,
88879,
224739,
35601,
49555,
18269,
164571,
46535,
37351,
13146,
360405,
255517,
null,
36849,
524205,
130390,
276456,
null,
60890,
363214,
336139,
15202,
18835,
29393,
139352,
null,
326315,
10202,
141748,
152333,
26289,
7761,
null,
27312,
29267,
305568,
336414,
325579,
30704,
130877,
58165,
245390,
58175,
317888,
9032,
499265,
138117,
31144,
33669,
253211,
13556,
25017,
207343,
124625,
67124,
103216,
283348,
31819,
221313,
64401,
43163,
130827,
32510,
143864,
160078,
32599,
89837,
37802,
17832,
18329,
289671,
24562,
29750,
215954,
429390,
14880,
396254,
null,
417718,
50318,
113336,
1919,
182740,
209313,
191521,
null,
45349,
13047,
329940,
129166,
57154,
103133,
8124,
10807,
337519,
74856,
40773,
308636,
35880,
3633,
14033,
9306,
238134,
8767,
39031,
13166,
32298,
13061,
250449,
329061,
134619,
114530,
246586,
177240,
567649,
37660,
214871,
232748,
427937,
75474,
154228,
31120,
500519,
166318,
240356,
13862,
80971,
97374,
66130,
48398,
213342,
146461,
25150,
17958,
28024,
5850,
2471,
206847,
1433115,
96055,
210416,
129209,
645331,
366794,
181431,
54687,
17597,
18440,
30222,
58198,
13153,
null,
58522,
295608,
84331,
47245,
92024,
23471,
185537,
30131,
null,
175229,
107487,
275831,
44003,
171695,
null,
15845,
34402,
125508,
133141,
26939,
51066,
295788,
15991,
null,
356255,
134475,
430602,
166475,
113883,
30497,
null,
39133,
23223,
834566,
259776,
173753,
28016,
null,
72813,
3455,
217441,
31705,
9307,
381541,
120942,
5532,
null,
135675,
null,
14571,
228610,
852059,
234681,
236181,
null,
83924,
null,
451496,
82556,
12100,
50020,
25818,
15637,
null,
152419,
197028,
154453,
154777,
140320,
271995,
228999,
255755,
340368,
26026,
26905,
223789,
5199,
82030,
243947,
171280,
50322,
69584,
null,
12157,
276812,
null,
81344,
152101,
18788,
305141,
161519,
null,
9547,
6628,
7823,
54480,
49450,
304582,
34093,
373867,
79902,
58406,
163353,
32488,
19866,
110486,
26762,
522980,
24279,
35571,
160368,
157370,
74435,
94250,
61066,
37884,
25284,
269393,
25170,
312854,
138189,
null,
334572,
null,
95310,
275474,
null,
309030,
25341,
14217,
null,
201268,
157977,
279535,
22764,
70143,
258159,
3394,
14828,
19408,
90624,
185544,
30663,
239230,
168421,
202864,
118208,
null,
57357,
176636,
78568,
175901,
3980,
null,
null,
8828,
650319,
63704,
85619,
62249,
97424,
32385,
526744,
38435,
66848,
29327,
185665,
284120,
188144,
66789,
9381,
36855,
100091,
43268,
94953,
27923,
248030,
170505,
314458,
30010,
103263,
41161,
245671,
240742,
21348,
31790,
82769,
43196,
5951,
150455,
20928,
52962,
39730,
32904,
30198,
307383,
5530,
null,
294771,
31159,
68277,
372260,
null,
26852,
193983,
126041,
90819,
5339,
200845,
40000,
151936,
28955,
253762,
162005,
5199,
118556,
224201,
170469,
21400,
5473,
108923,
303124,
13827,
309954,
109366,
88462,
43620,
57807,
18987,
363615,
12847,
174922,
116405,
null,
54636,
6801,
36066,
145611,
41183,
27989,
300949,
19189,
122265,
469709,
null,
288458,
11362,
33298,
null,
10810,
42838,
62204,
36563,
130387,
29319,
12972,
null,
277663,
51298,
52875,
56930,
65090,
21738,
230183,
24950,
874918,
46349,
285883,
15527,
16400,
17123,
12918,
273661,
163923,
54829,
11494,
120818,
4449,
4954,
null,
302486,
192679,
10698,
29783,
42626,
13939,
12895,
68799,
null,
426863,
90887,
192811,
24448,
1019,
188509,
26094,
123029,
68246,
432951,
9203,
415289,
169185,
268986,
320429,
292694,
310581,
105937,
211557,
39046,
376226,
273646,
237427,
32032,
null,
226422,
null,
4952,
144875,
360787,
null,
640343,
150034,
91113,
29185,
46573,
19296,
null,
234102,
24198,
82926,
11262,
510840,
339971,
113080,
71645,
41519,
603772,
68702,
236145,
303025,
61591,
428569,
27980,
762656,
50507,
23012,
137199,
142307,
105384,
191867,
38796,
290728,
23610,
22235,
null,
209658,
147254,
40060,
39201,
186773,
59636,
108631,
35302,
35734,
473813,
110607,
37847,
293817,
77516,
507066,
43215,
5862,
190336,
37790,
51299,
20118,
106779,
37687,
230114,
37881,
445828,
20747,
178216,
269015,
null,
null,
24964,
28370,
86263,
null,
163017,
35155,
66610,
67800,
65111,
4677,
183484,
145444,
51867,
297922,
66142,
28575,
368327,
127772,
null,
227071,
419418,
25385,
324351,
15669,
null,
190846,
64762,
40375,
29504,
7726,
1581,
537789,
204867,
206705,
69107,
86754,
305941,
109724,
205159,
111159,
503933,
141316,
56651,
19700,
25501,
null,
521905,
202352,
120486,
742028,
135250,
229526,
113394,
63622,
174759,
138913,
20180,
null,
null,
332658,
56004,
23987,
6077,
347817,
139268,
26023,
46185,
42351,
151256,
null,
null,
213606,
329356,
360258,
259080,
22797,
24868,
48970,
75722,
134921,
180291,
52320,
166401,
69015,
10451,
223326,
22711,
34124,
22945,
143257,
75273,
602592,
70682,
407684,
283059,
55492,
269292,
31102,
24046,
194728,
48451,
null,
47785,
71542,
24880,
49573,
209030,
169416,
16191,
49878,
41220,
218476,
160004,
4820,
30902,
173138,
93925,
276627,
null,
22593,
37068,
20718,
null,
62412,
44869,
171371,
32748,
76554,
234482,
7548,
102839,
83257,
70274,
23018,
246470,
566964,
126630,
37940,
86803,
9053,
42838,
564218,
46002,
93074,
214945,
156106,
165861,
112779,
218587,
11721,
17129,
251127,
25027,
80756,
46675,
101707,
45293,
315054,
33465,
37694,
115148,
40733,
33422,
51669,
174279,
30725,
280455,
27075,
20079,
8809,
49754,
77011,
4285,
147748,
41103,
11454,
396136,
79782,
98389,
41528,
146742,
26508,
379552,
28323,
null,
240212,
156180,
127969,
77287,
104429,
null,
22410,
209822,
18314,
57792,
119794,
30209,
168630,
null,
162933,
57489,
13582,
null,
245670,
75194,
943654,
250081,
117150,
166030,
172910,
30469,
24924,
21459,
185946,
23705,
70792,
351649,
8467,
107510,
19567,
421830,
485305,
33100,
7865,
91738,
null,
444152,
152475,
23561,
null,
19668,
523570,
null,
43025,
15650,
236077,
71944,
20914,
90417,
53384,
9305,
256582,
279405,
27757,
4486,
229916,
150190,
182601,
14376,
197305,
410657,
87185,
null,
35417,
125387,
88386,
42589,
14357,
95185,
18727,
59610,
32465,
null,
101616,
148372,
13226,
87215,
284688,
21823,
355264,
198457,
203232,
30638,
325047,
495417,
null,
198115,
4354,
24655,
19995,
142996,
null,
304122,
null,
217361,
null,
207336,
25189,
171905,
348478,
142801,
31661,
767219,
270460,
null,
5365,
57794,
167950,
198917,
571673,
56952,
24044,
20062,
34543,
63496,
72093,
41882,
59239,
259486,
12367,
243165,
9482,
359297,
34729,
31634,
497,
null,
null,
203365,
91993,
18871,
null,
71350,
52177,
21207,
319014,
39359,
8896,
410068,
252001,
237764,
10277,
145207,
219527,
59013,
127223,
112750,
54824,
8988,
11314,
1206312,
53747,
null,
286058,
56529,
161551,
26206,
7013,
68204,
null,
10797,
13484,
47422,
99807,
82131,
298872,
350790,
215818,
null,
25737,
8088,
307423,
263388,
118577,
438767,
242695,
47578,
46010,
414094,
256280,
202052,
160920,
19769,
242565,
null,
64888,
null,
304549,
24805,
230048,
34385,
218187,
54442,
null,
25843,
23111,
8373,
144137,
166526,
528870,
50386,
243847,
167450,
80379,
17254,
17102,
26884,
14884,
26447,
18654,
193321,
34005,
340835,
15570,
401877,
103178,
190601,
103617,
39235,
115628,
269396,
62114,
40322,
68256,
44386,
492320,
4257,
null,
110114,
25903,
199873,
61194,
175822,
137852,
181356,
222691,
258298,
33314,
297289,
65318,
72438,
18772,
214638,
null,
50754,
357553,
63652,
194819,
150054,
69544,
217489,
6733,
96243,
38865,
353632,
5537,
72955,
105509,
171811,
24696,
60136,
51550,
364524,
null,
null,
24505,
31524,
372505,
25664,
13807,
62827,
180416,
11994,
8781,
39914,
123935,
57322,
269164,
null,
112374,
128184,
380718,
14466,
null,
53653,
240882,
16094,
276576,
22921,
6540,
174522,
23394,
29014,
241059,
448214,
14733,
20957,
281471,
4701,
134443,
null,
36039,
94316,
319019,
226149,
337626,
570521,
113976,
385155,
118536,
146074,
4167,
18703,
34121,
337507,
227192,
10851,
50797,
144196,
37374,
18850,
34081,
null,
330958,
31950,
294346,
12864,
193087,
18883,
11620,
113769,
311166,
653612,
253619,
184176,
19933,
19597,
435087,
47144,
null,
212949,
13620,
22703,
276017,
85347,
17037,
228734,
220480,
132604,
43438,
71258,
49767,
52067,
50483,
2576,
237799,
46963,
42241,
187416,
282455,
196700,
55259,
13126,
11873,
172034,
53474,
127888,
36646,
229092,
102347,
198135,
67930,
37427,
204353,
null,
33813,
64758,
43318,
23502,
16104,
187292,
502616,
12907,
40436,
209001,
19851,
null,
299771,
107790,
106299,
108111,
46125,
null,
147997,
77623,
225726,
279976,
257077,
268643,
191558,
133192,
7111,
26124,
48744,
null,
35926,
null,
321630,
474584,
51932,
265241,
257343,
75735,
296168,
305253,
267258,
248546,
null,
217345,
10375,
5919,
238574,
225248,
120904,
456431,
26085,
225187,
null,
null,
null,
211010,
226934,
82357,
11370,
13847,
null,
24872,
66361,
111068,
12045,
124560,
39752,
127448,
377468,
64988,
427058,
48389,
92907,
227647,
339794,
178211,
14016,
195750,
400957,
66753,
17017,
190658,
27660,
111568,
39814,
53484,
23588,
111522,
28912,
21692,
113710,
419565,
91668,
69989,
194566,
20037,
43085,
47923,
14073,
18373,
null,
30821,
null,
7437,
94029,
53777,
32772,
207562,
24534,
504633,
424345,
982,
16219,
42588,
271644,
31528,
45715,
32492,
211012,
387748,
25839,
137160,
317496,
40356,
33476,
66472,
null,
null,
65714,
69612,
264190,
389931,
37966,
142110,
73796,
366133,
21072,
10973,
16444,
28217,
null,
59136,
269747,
2629,
3709,
11525,
340431,
29396,
366878,
180979,
432449,
178537,
14671,
446441,
102592,
93651,
50050,
18397,
25112,
361933,
299034,
142634,
670525,
28204,
437123,
7954,
null,
23963,
null,
47565,
31499,
24744,
29638,
75133,
20580,
217479,
447640,
154128,
193042,
24972,
150367,
44285,
597577,
19583,
42398,
303326,
19467,
316990,
221851,
11451,
4570,
6448,
330916,
176673,
72250,
199207,
196274,
72876,
null,
295213,
51455,
54437,
99046,
138705,
471634,
null,
200945,
206710,
127046,
354842,
220643,
26090,
26805,
74317,
74258,
137868,
46433,
207248,
734726,
142981,
35846,
112665,
47128,
null,
45892,
218537,
10587,
518558,
292717,
37854,
14869,
20770,
253275,
155610,
104721,
60658,
10757,
21395,
60157,
55085,
null,
7395,
null,
138574,
224981,
43253,
6780,
56011,
329620,
29447,
13215,
26868,
217393,
145953,
11876,
21911,
301850,
29665,
318063,
null,
330356,
null,
80163,
89666,
33084,
56527,
32413,
31153,
118846,
34711,
214907,
449962,
215537,
107094,
38437,
17635,
63215,
316314,
205377,
391759,
40774,
62356,
147587,
340196,
null,
178107,
376612,
13480,
38960,
217950,
35183,
239215,
29510,
62510,
14180,
104787,
17822,
376671,
389706,
184063,
null,
22121,
null,
61865,
42834,
136138,
40068,
134152,
326017,
20621,
494783,
57701,
63362,
198030,
7773,
968006,
5727,
324550,
309132,
133618,
9964,
217003,
64014,
56871,
54750,
241839,
301262,
20121,
81152,
15050,
178489,
81914,
80027,
136052,
181651,
127405,
27235,
null,
12910,
26453,
183920,
428957,
360557,
41299,
464033,
229864,
7575,
40646,
139494,
383939,
17776,
33884,
60865,
277391,
167873,
11265,
580802,
21671,
22108,
359533,
22205,
573769,
55605,
19452,
458489,
34120,
11267,
320846,
null,
64160,
143463,
7520,
215924,
1776628,
329607,
215046,
306306,
29791,
31243,
46465,
78420,
95696,
21277,
216758,
226828,
21137,
31743,
324836,
22012,
421673,
203692,
67523,
64682,
4950,
231478,
41217,
564818,
41550,
53719,
299477,
null,
34184,
null,
83796,
48059,
2933,
30016,
68305,
10879,
43192,
241974,
183465,
95879,
162155,
87366,
8100,
20151,
99975,
199914,
116370,
486053,
570029,
119466,
186572,
858946,
74106,
13148,
263165,
126899,
null,
10003,
52605,
38770,
163119,
35799,
17943,
33404,
143116,
null,
186368,
36510,
180104,
47108,
18891,
null,
79226,
28384,
68494,
16155,
48583,
167879,
75390,
38381,
12895,
3629,
34357,
84592,
17002,
12475,
26532,
30044,
26691,
33432,
49842,
38836,
46553,
96929,
77930,
87922,
70497,
null,
94446,
116327,
75315,
223114,
9547,
116899,
38394,
15556,
149736,
13060,
478258,
394905,
329697,
77792,
106429,
232931,
154918,
31211,
null,
31918,
232996,
39022,
103037,
51803,
42627,
10083,
400288,
6164,
54212,
40764,
268281,
584588,
188200,
344315,
null,
154602,
65949,
85005,
9420,
108841,
131669,
15810,
153139,
305968,
711052,
null,
32928,
110312,
25759,
26052,
212914,
675846,
108497,
38020,
158240,
13761,
201940,
8908,
58193,
269493,
179408,
null,
19179,
55569,
303634,
288608,
176337,
58060,
49940,
100862,
9228,
172460,
100509,
null,
97939,
22013,
26809,
18430,
null,
184929,
27601,
25496,
154377,
23743,
42562,
278187,
260029,
33283,
31685,
214186,
51256,
256555,
31101,
242748,
19725,
195155,
98148,
32142,
379303,
311748,
449580,
38405,
null,
59585,
224732,
170460,
64236,
174737,
202864,
318521,
9130,
259931,
40849,
28737,
36991,
185439,
32398,
160173,
266731,
212628,
131459,
157105,
477524,
28107,
3765,
123207,
134344,
100011,
4841,
8876,
85936,
182507,
43473,
30409,
153994,
321386,
331383,
155278,
25068,
28187,
292528,
196722,
226322,
241336,
108080,
17600,
72799,
null,
258180,
64438,
422333,
143150,
109469,
44808,
22791,
15732,
22110,
286872,
102158,
455455,
61444,
null,
207991,
44266,
264677,
null,
18938,
38650,
177606,
78734,
24763,
131065,
17595,
null,
180477,
3297,
211228,
null,
19055,
19551,
48247,
781,
246976,
149242,
12718,
61001,
73159,
22490,
73396,
237047,
61166,
175419,
493450,
49983,
124007,
22637,
5267,
171765,
34005,
49826,
163799,
434733,
41729,
267087,
16778,
28803,
910045,
11689,
270025,
30041,
null,
null,
19029,
422856,
38905,
25027,
29801,
243150,
31520,
282302,
131423,
50691,
338955,
50196,
190579,
117191,
99562,
8232,
36047,
31154,
183459,
82265,
null,
206648,
8277,
115000,
364318,
283655,
300927,
124835,
29345,
34022,
119750,
62941,
134587,
26647,
200985,
143697,
172437,
null,
352196,
46923,
19025,
28087,
251143,
8203,
16907,
465833,
77523,
27035,
18821,
634167,
129185,
109890,
null,
294841,
178779,
58860,
135962,
100988,
367159,
635213,
80179,
173920,
24261,
248890,
34948,
14085,
37125,
165909,
9330,
31554,
218807,
615691,
57719,
16925,
19651,
null,
13854,
372509,
247006,
17083,
119872,
65187,
21990,
137283,
31307,
119752,
637515,
295240,
709249,
394719,
252119,
26469,
332219,
191883,
368577,
21399,
197654,
35595,
25593,
220017,
null,
26114,
26726,
47824,
318270,
31204,
11148,
73263,
16722,
35528,
359876,
266444,
136022,
30559,
39652,
25102,
321387,
12554,
29838,
58143,
163798,
72069,
274235,
40850,
341114,
52733,
58987,
null,
22972,
380093,
31859,
669815,
198614,
29294,
274253,
138500,
28848,
32504,
218678,
20683,
613571,
48062,
93814,
92274,
231743,
82386,
43840,
174144,
160637,
55642,
144046,
225521,
189011,
138336,
35997,
226419,
null,
134727,
15163,
71245,
13116,
61505,
16488,
56557,
null,
112921,
30339,
43602,
185584,
458560,
11830,
null,
8000,
256450,
null,
23872,
74076,
140242,
59014,
213536,
39496,
206879,
447430,
35088,
63757,
8482,
159718,
185647,
251502,
292819,
24999,
80463,
28948,
68578,
129524,
391495,
4402,
54318,
464095,
12127,
70949,
261966,
336024,
72557,
212076,
101594,
217939,
155581,
39863,
289032,
23083,
90104,
5663,
69968,
117069,
null,
null,
409038,
20333,
29428,
521133,
250064,
154003,
11970,
44195,
53054,
115256,
27565,
362403,
44576,
19087,
15701,
12890,
20126,
36290,
341257,
17927,
null,
22482,
369912,
117596,
73890,
25433,
55913,
117851,
28674,
76225,
3277,
74724,
102125,
244553,
49636,
null,
24666,
309055,
244609,
63674,
195759,
19275,
15790,
24226,
132834,
73670,
164300,
159773,
59048,
323830,
22341,
197611,
65602,
15577,
28725,
26650,
265432,
349259,
33255,
230139,
277388,
null,
174537,
17771,
48256,
190222,
17441,
31443,
238650,
64993,
139863,
38527,
141648,
430225,
179666,
277709,
173094,
null,
161616,
9315,
null,
31777,
165153,
68648,
53901,
17941,
76392,
68858,
7598,
181464,
37065,
20121,
279816,
328981,
112371,
247418,
169128,
147598,
null,
136076,
null,
101054,
27251,
20351,
110515,
198240,
120584,
287259,
35105,
31558,
20811,
62784,
17255,
273437,
193002,
196430,
null,
16765,
141918,
46020,
440317,
237332,
156101,
47970,
18485,
3481,
622280,
33736,
28292,
34425,
12818,
157363,
39913,
90609,
247979,
9828,
65280,
424722,
135209,
40788,
160979,
20440,
399251,
null,
70820,
287496,
45575,
259812,
95696,
211505,
74427,
157518,
489056,
null,
294481,
307265,
12392,
360330,
23732,
16735,
256400,
33212,
238005,
22440,
894817,
57696,
762459,
117138,
null,
63643,
94335,
126606,
27578,
107213,
456942,
43568,
169806,
24602,
27527,
9440,
null,
null,
56150,
231963,
53631,
378510,
313882,
444537,
null,
null,
23883,
78990,
304459,
null,
53649,
null,
170595,
16145,
19291,
43401,
142113,
895389,
24690,
9232,
40087,
37939,
null,
61404,
25471,
34028,
49998,
36973,
99111,
124448,
27329,
5445,
23533,
659988,
156966,
343383,
74597,
34383,
219189,
320298,
89905,
99503,
181217,
126433,
20405,
6036,
null,
31664,
231726,
107309,
13815,
12969,
13236,
347943,
88654,
102574,
28338,
116851,
28016,
298488,
19960,
164848,
33163,
64659,
169031,
44415,
248807,
16040,
461010,
11160,
737898,
62355,
3838,
42358,
8770,
148277,
234525,
395138,
12457,
10824,
57977,
64053,
268534,
182447,
null,
249901,
12783,
45462,
15359,
327468,
357096,
141986,
310712,
11415,
null,
138266,
27785,
77739,
32746,
90845,
68636,
40823,
null,
418605,
13353,
117707,
392625,
null,
53057,
28262,
184817,
47141,
null,
157628,
null,
120529,
null,
18611,
456286,
null,
354366,
32936,
54101,
82263,
40814,
50476,
91962,
68650,
294896,
null,
182415,
84519,
11878,
238944,
49367,
151537,
412062,
62059,
280023,
15853,
294683,
194773,
null,
146204,
128499,
224001,
319543,
138916,
35696,
null,
204143,
93528,
11764,
557641,
110124,
37514,
381443,
29611,
439622,
192077,
18144,
147236,
260920,
179398,
50090,
325775,
27869,
364905,
127831,
23642,
19407,
153372,
1050877,
34638,
157014,
93297,
10826,
25371,
206383,
null,
456903,
298283,
37955,
57261,
407848,
115462,
null,
null,
null,
44583,
51889,
340059,
181774,
33645,
null,
195146,
138698,
44327,
406949,
200236,
160388,
null,
42409,
36831,
300675,
47737,
18899,
117462,
32090,
219826,
20118,
91009,
183436,
14389,
37326,
null,
144975,
null,
6201,
null,
136471,
47630,
756758,
302321,
184023,
180090,
67555,
212736,
46739,
145888,
9666,
116909,
237640,
177263,
63659,
223251,
6167,
144345,
48543,
12060,
138999,
38970,
42082,
382324,
18471,
11867,
64565,
86910,
17689,
8181,
19135,
34283,
21474,
null,
262668,
32674,
9215,
121073,
46575,
34873,
160575,
23373,
3185,
9441,
529008,
321422,
21709,
29316,
95864,
17901,
31666,
9951,
18211,
174527,
5578,
338739,
281648,
151223,
958,
24622,
null,
8424,
15037,
32470,
73934,
31175,
69301,
102064,
23671,
32706,
7747,
9389,
122341,
382780,
175773,
185687,
49362,
156413,
68062,
null,
null,
null,
39983,
16466,
433296,
36283,
151344,
4891,
56720,
249510,
132444,
6425,
102139,
21457,
110098,
611197,
231453,
296964,
98010,
121730,
64247,
155387,
264187,
null,
188710,
190534,
58219,
50660,
217186,
92167,
229003,
35234,
3598,
null,
22093,
189735,
49020,
16592,
244668,
76005,
2114,
93418,
15057,
17348,
98290,
37099,
27489,
126986,
34259,
340517,
167595,
240183,
55713,
14776,
209807,
38739,
41234,
15593,
156085,
158374,
null,
58187,
17613,
8113,
22493,
33956,
75677,
161515,
23296,
23935,
72103,
63842,
171518,
572614,
39568,
398638,
67184,
74550,
205667,
53476,
44235,
null,
360657,
95528,
3552,
8199,
82674,
68810,
524501,
33137,
386837,
10400,
26024,
28407,
87729,
54401,
77943,
41198,
31877,
70633,
120322,
472277,
56238,
58400,
null,
40823,
22792,
74310,
23683,
21348,
103643,
195987,
346894,
9235,
null,
49191,
83425,
49447,
247649,
65122,
372855,
20411,
365873,
36506,
30929,
94753,
17858,
19491,
40877,
41227,
null,
30056,
56738,
106965,
47401,
226700,
197654,
14422,
null,
109075,
55838,
299184,
26601,
12455,
115738,
41607,
11000,
49735,
167148,
42104,
null,
null,
76416,
163161,
133477,
25127,
null,
421485,
47300,
241494,
39738,
null,
34156,
71394,
5392,
55727,
197173,
202562,
141441,
126484,
266095,
39592,
398485,
6494,
null,
37779,
101821,
22744,
204523,
29655,
15331,
4637,
52908,
423857,
369445,
379535,
114261,
110137,
19820,
161693,
393251,
4502,
308479,
26937,
28072,
50981,
41924,
202398,
251496,
42470,
185486,
97756,
null,
20695,
137258,
66668,
50771,
10317,
160478,
null,
49728,
68029,
174833,
341422,
14902,
26818,
27582,
45463,
31578,
27628,
50817,
null,
null,
30437,
275669,
32331,
6480,
9032,
36028,
74657,
4789,
137272,
246882,
36300,
299576,
30323,
544926,
189935,
22663,
39295,
22184,
null,
160258,
17371,
null,
397543,
364139,
84628,
40351,
180464,
25163,
50809,
223552,
281480,
null,
299190,
null,
63584,
null,
31747,
22547,
60077,
136612,
33234,
255293,
407561,
101714,
254349,
null,
152935,
21544,
83448,
13678,
232660,
342698,
300458,
65407,
52198,
52124,
389274,
37660,
23713,
14302,
46710,
201992,
48872,
147463,
399091,
93709,
30302,
460456,
167232,
115671,
null,
70081,
113466,
41870,
152542,
65469,
262550,
34684,
315833,
153449,
17978,
40396,
12573,
676003,
170171,
26674,
7601,
19468,
53227,
34254,
13159,
217691,
132099,
32247,
36619,
579207,
82728,
333591,
188453,
250853,
null,
null,
6138,
49594,
83487,
224500,
268939,
49019,
18350,
2942,
null,
44947,
19371,
309631,
605232,
144842,
170289,
22401,
34907,
11599,
311969,
338245,
8272,
18630,
150327,
62018,
24165,
243053,
12774,
97421,
33761,
162104,
6754,
20525,
232767,
14249,
37989,
311556,
240648,
567888,
174501,
null,
93625,
107674,
328717,
80216,
95976,
328459,
27701,
55172,
439583,
150742,
51014,
174864,
16620,
260311,
17342,
31665,
14502,
278976,
10000,
175369,
12593,
185103,
226044,
35998,
153363,
39244,
174193,
20086,
2886,
459880,
13009,
null,
36083,
192889,
24724,
17838,
140934,
3732,
2746,
null,
3075,
222329,
332524,
116668,
37555,
209217,
254641,
128157,
19470,
54917,
378659,
77368,
null,
150657,
374867,
null,
98623,
72109,
35617,
77175,
37199,
371974,
135864,
1715,
16803,
209825,
null,
42508,
8142,
49850,
246292,
3839,
147663,
191327,
115059,
null,
405495,
196195,
276568,
91313,
157485,
3719,
29961,
277380,
56765,
16220,
269817,
27929,
74731,
203758,
75321,
46058,
200895,
284342,
179136,
20550,
69246,
249571,
132249,
769107,
170271,
null,
38708,
59979,
188684,
104417,
33950,
201857,
245597,
52059,
182025,
35556,
69421,
85274,
100871,
49693,
13859,
12800,
18128,
255903,
70882,
43019,
45712,
80110,
241821,
256124,
63483,
437781,
44315,
315918,
634376,
102181,
10615,
79514,
46264,
132123,
291024,
183219,
327641,
null,
37282,
null,
63101,
144359,
null,
380166,
171826,
null,
6023,
29218,
361423,
447134,
23117,
36084,
27664,
24281,
101234,
109355,
10406,
54402,
134607,
96535,
null,
92652,
94468,
55589,
32283,
27101,
58817,
192535,
48480,
19644,
180245,
5206,
100082,
429799,
28315,
147346,
46996,
215029,
null,
563610,
33975,
15397,
null,
164486,
248381,
43724,
74428,
555863,
295885,
215397,
141083,
52288,
283026,
238911,
null,
41397,
338539,
310407,
147400,
27089,
39634,
26344,
3848,
123695,
28552,
21562,
18911,
51938,
351734,
17704,
286099,
19800,
105440,
446846,
92766,
69089,
24081,
53478,
99787,
49553,
87285,
378775,
25690,
174492,
224678,
35566,
null,
375290,
111842,
145172,
127626,
230356,
607896,
null,
538143,
null,
21359,
56815,
195596,
47732,
281096,
334371,
194699,
98660,
null,
null,
100402,
334388,
67055,
16851,
157013,
744813,
174535,
119870,
20767,
34125,
23817,
28827,
93269,
null,
273712,
45283,
157141,
296940,
294013,
150815,
632686,
43946,
231063,
57125,
88497,
223720,
40418,
26144,
30253,
28156,
229007,
19572,
26926,
36695,
7891,
null,
null,
271843,
21772,
35430,
31906,
28561,
null,
34544,
21061,
3148
]
}
],
"layout": {
"barmode": "overlay",
"legend": {
"bgcolor": "#F5F6F9",
"font": {
"color": "#4D5663"
}
},
"paper_bgcolor": "#F5F6F9",
"plot_bgcolor": "#F5F6F9",
"template": {
"data": {
"bar": [
{
"error_x": {
"color": "#2a3f5f"
},
"error_y": {
"color": "#2a3f5f"
},
"marker": {
"line": {
"color": "#E5ECF6",
"width": 0.5
}
},
"type": "bar"
}
],
"barpolar": [
{
"marker": {
"line": {
"color": "#E5ECF6",
"width": 0.5
}
},
"type": "barpolar"
}
],
"carpet": [
{
"aaxis": {
"endlinecolor": "#2a3f5f",
"gridcolor": "white",
"linecolor": "white",
"minorgridcolor": "white",
"startlinecolor": "#2a3f5f"
},
"baxis": {
"endlinecolor": "#2a3f5f",
"gridcolor": "white",
"linecolor": "white",
"minorgridcolor": "white",
"startlinecolor": "#2a3f5f"
},
"type": "carpet"
}
],
"choropleth": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "choropleth"
}
],
"contour": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "contour"
}
],
"contourcarpet": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "contourcarpet"
}
],
"heatmap": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "heatmap"
}
],
"heatmapgl": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "heatmapgl"
}
],
"histogram": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "histogram"
}
],
"histogram2d": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "histogram2d"
}
],
"histogram2dcontour": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "histogram2dcontour"
}
],
"mesh3d": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "mesh3d"
}
],
"parcoords": [
{
"line": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "parcoords"
}
],
"pie": [
{
"automargin": true,
"type": "pie"
}
],
"scatter": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatter"
}
],
"scatter3d": [
{
"line": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatter3d"
}
],
"scattercarpet": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattercarpet"
}
],
"scattergeo": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattergeo"
}
],
"scattergl": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattergl"
}
],
"scattermapbox": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattermapbox"
}
],
"scatterpolar": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterpolar"
}
],
"scatterpolargl": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterpolargl"
}
],
"scatterternary": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterternary"
}
],
"surface": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "surface"
}
],
"table": [
{
"cells": {
"fill": {
"color": "#EBF0F8"
},
"line": {
"color": "white"
}
},
"header": {
"fill": {
"color": "#C8D4E3"
},
"line": {
"color": "white"
}
},
"type": "table"
}
]
},
"layout": {
"annotationdefaults": {
"arrowcolor": "#2a3f5f",
"arrowhead": 0,
"arrowwidth": 1
},
"coloraxis": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"colorscale": {
"diverging": [
[
0,
"#8e0152"
],
[
0.1,
"#c51b7d"
],
[
0.2,
"#de77ae"
],
[
0.3,
"#f1b6da"
],
[
0.4,
"#fde0ef"
],
[
0.5,
"#f7f7f7"
],
[
0.6,
"#e6f5d0"
],
[
0.7,
"#b8e186"
],
[
0.8,
"#7fbc41"
],
[
0.9,
"#4d9221"
],
[
1,
"#276419"
]
],
"sequential": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"sequentialminus": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
]
},
"colorway": [
"#636efa",
"#EF553B",
"#00cc96",
"#ab63fa",
"#FFA15A",
"#19d3f3",
"#FF6692",
"#B6E880",
"#FF97FF",
"#FECB52"
],
"font": {
"color": "#2a3f5f"
},
"geo": {
"bgcolor": "white",
"lakecolor": "white",
"landcolor": "#E5ECF6",
"showlakes": true,
"showland": true,
"subunitcolor": "white"
},
"hoverlabel": {
"align": "left"
},
"hovermode": "closest",
"mapbox": {
"style": "light"
},
"paper_bgcolor": "white",
"plot_bgcolor": "#E5ECF6",
"polar": {
"angularaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"bgcolor": "#E5ECF6",
"radialaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
}
},
"scene": {
"xaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
},
"yaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
},
"zaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
}
},
"shapedefaults": {
"line": {
"color": "#2a3f5f"
}
},
"ternary": {
"aaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"baxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"bgcolor": "#E5ECF6",
"caxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
}
},
"title": {
"x": 0.05
},
"xaxis": {
"automargin": true,
"gridcolor": "white",
"linecolor": "white",
"ticks": "",
"title": {
"standoff": 15
},
"zerolinecolor": "white",
"zerolinewidth": 2
},
"yaxis": {
"automargin": true,
"gridcolor": "white",
"linecolor": "white",
"ticks": "",
"title": {
"standoff": 15
},
"zerolinecolor": "white",
"zerolinewidth": 2
}
}
},
"title": {
"font": {
"color": "#4D5663"
},
"text": "tot_cur_bal Distribution"
},
"xaxis": {
"gridcolor": "#E1E5ED",
"showgrid": true,
"tickfont": {
"color": "#4D5663"
},
"title": {
"font": {
"color": "#4D5663"
},
"text": ""
},
"zerolinecolor": "#E1E5ED"
},
"yaxis": {
"gridcolor": "#E1E5ED",
"showgrid": true,
"tickfont": {
"color": "#4D5663"
},
"title": {
"font": {
"color": "#4D5663"
},
"text": ""
},
"zerolinecolor": "#E1E5ED"
}
}
},
"text/html": [
"\n",
" \n",
" \n",
" \n",
" \n",
"
"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"application/vnd.plotly.v1+json": {
"config": {
"linkText": "Export to plot.ly",
"plotlyServerURL": "https://plot.ly",
"showLink": true
},
"data": [
{
"boxpoints": false,
"line": {
"width": 1.3
},
"marker": {
"color": "rgba(255, 153, 51, 1.0)"
},
"name": "tot_cur_bal",
"orientation": "v",
"type": "box",
"y": [
28699,
9974,
38295,
55564,
47159,
350619,
13272,
272579,
281521,
76034,
72193,
39152,
194011,
165164,
39634,
48488,
71191,
221335,
34538,
125903,
66738,
null,
282808,
71697,
147448,
327930,
8589,
447388,
114298,
31445,
391749,
1385358,
68057,
6485,
23697,
4890,
5422,
176391,
10707,
141797,
53454,
229995,
13054,
42542,
624417,
38829,
28163,
null,
421664,
71646,
8312,
311014,
234697,
290962,
195008,
13166,
34752,
359326,
137019,
235231,
161107,
316510,
22198,
272177,
124248,
442155,
null,
null,
447154,
46867,
28862,
250586,
58396,
223151,
null,
103681,
123905,
405177,
77893,
22459,
174517,
244772,
23784,
28233,
27435,
275755,
142744,
37237,
15017,
408391,
106591,
35398,
24895,
null,
68650,
239603,
605585,
139788,
41237,
186934,
78372,
43807,
35449,
245928,
9943,
158699,
254138,
261143,
46625,
220405,
12172,
61294,
31225,
38746,
40749,
301791,
263725,
357941,
212529,
32825,
111460,
10163,
381787,
null,
618061,
58182,
23744,
105315,
31458,
14203,
null,
8328,
24353,
697738,
31254,
324254,
253332,
66287,
34248,
15736,
32296,
31773,
491917,
127882,
27519,
128115,
336159,
303569,
137534,
132687,
null,
57534,
null,
29284,
49328,
43998,
18955,
4161,
44318,
9687,
217361,
51448,
15567,
11346,
76398,
41374,
11900,
57897,
146182,
25315,
42886,
12743,
26807,
41719,
214384,
161474,
41019,
108745,
403512,
98749,
14677,
25608,
52348,
168733,
795423,
237669,
24110,
33335,
381762,
317022,
74344,
6557,
357373,
null,
207856,
null,
187785,
null,
45602,
20964,
23927,
74619,
18613,
36054,
28773,
2540,
209503,
null,
null,
189210,
12725,
67211,
31287,
141512,
17022,
38935,
397113,
268952,
30098,
null,
185010,
20974,
30163,
352644,
371710,
49447,
729286,
1275731,
369867,
10989,
142058,
109299,
419933,
236818,
230826,
197387,
38375,
21810,
null,
15550,
26955,
52359,
149955,
120660,
null,
59812,
21024,
130027,
10814,
315571,
2755,
null,
25885,
22363,
259654,
26566,
5713,
38691,
82172,
344169,
583364,
261450,
145255,
220734,
326635,
15925,
66547,
61199,
99488,
24981,
40106,
39636,
27105,
39497,
55926,
152124,
53692,
119007,
84473,
154943,
160755,
39752,
104546,
null,
35816,
32579,
61080,
329538,
33373,
178923,
37951,
256274,
162464,
347081,
216061,
295126,
null,
30235,
null,
13889,
351928,
300411,
38990,
null,
136956,
22720,
317207,
34706,
186750,
223548,
9657,
35975,
214793,
95565,
238017,
null,
50324,
394034,
20088,
20449,
130501,
164189,
13347,
179994,
17899,
39404,
287180,
56496,
41139,
10615,
658834,
63379,
68865,
354452,
30353,
null,
null,
411273,
46002,
55669,
53735,
99289,
180899,
18348,
747460,
25407,
43083,
236639,
29046,
35438,
34710,
14137,
23746,
146392,
214638,
312703,
28856,
56332,
6289,
9874,
93245,
null,
25218,
116274,
null,
144950,
13295,
43470,
81987,
198266,
41790,
null,
11304,
201921,
366823,
165886,
13288,
18299,
14262,
17403,
406681,
74413,
33086,
null,
61335,
60210,
35353,
null,
8183,
92860,
46894,
148501,
null,
57821,
170930,
15989,
233837,
244934,
240085,
211374,
103485,
139857,
22391,
184799,
264915,
57953,
129420,
111848,
327823,
26787,
64033,
254355,
101576,
556185,
23200,
null,
207625,
65485,
248611,
373534,
81863,
null,
14147,
null,
172831,
187073,
58250,
23287,
31369,
109651,
502944,
541157,
295656,
108124,
null,
33281,
216288,
106123,
34497,
41194,
56446,
19549,
180351,
40388,
70227,
258381,
27220,
24723,
22735,
14328,
151107,
468840,
4708,
122656,
19877,
263047,
71862,
124365,
21121,
148297,
32874,
75112,
376138,
5537,
24188,
69719,
159439,
40697,
8095,
366064,
213954,
210739,
null,
33582,
25085,
121160,
128656,
26913,
23672,
null,
203507,
163716,
165726,
183502,
15968,
54040,
278870,
92302,
152437,
16193,
230077,
131268,
135767,
154295,
48385,
210663,
124963,
34831,
null,
33079,
24878,
36930,
62949,
90030,
29880,
164515,
40347,
13177,
null,
447617,
177716,
12305,
null,
232601,
70078,
19900,
175950,
33874,
22444,
37039,
446278,
92948,
775376,
221904,
23696,
39890,
154730,
55151,
36726,
131678,
158221,
18632,
33280,
251220,
99581,
32863,
364241,
204018,
85343,
55869,
26448,
215033,
339858,
1234441,
141083,
15485,
102598,
158359,
24546,
180586,
58044,
17456,
50796,
20858,
16163,
372969,
64707,
271565,
185938,
null,
157226,
244426,
250201,
45336,
60407,
54924,
37839,
null,
18899,
202801,
null,
66981,
null,
27075,
60204,
175944,
32356,
212609,
161552,
17505,
null,
null,
15521,
215318,
76675,
20990,
31506,
15354,
null,
197356,
151870,
508277,
166089,
328730,
352961,
195109,
null,
null,
42394,
431407,
215895,
247430,
371149,
4185,
30496,
46613,
346859,
12438,
186158,
null,
195129,
45378,
255576,
14516,
98931,
77424,
301087,
204350,
20572,
43760,
230481,
64424,
35722,
130003,
569382,
129046,
100007,
338999,
34954,
179582,
15354,
31960,
43722,
53169,
47467,
277011,
39375,
70697,
459512,
10181,
288236,
40494,
1119620,
103771,
72539,
56368,
331686,
268631,
null,
21408,
18698,
160139,
751327,
61632,
25237,
144622,
11780,
1654,
177427,
null,
26847,
84876,
52458,
147071,
37677,
362232,
92482,
21099,
31232,
162622,
15685,
35217,
null,
13862,
171443,
40211,
47624,
17474,
41254,
69585,
4871,
262966,
33869,
2051680,
40168,
4780,
223359,
75802,
8822,
17695,
175182,
17870,
42759,
29655,
22696,
43035,
9621,
182034,
91870,
233656,
70569,
33436,
160967,
30480,
122956,
18235,
523816,
24449,
27678,
23189,
319370,
17448,
null,
143547,
165504,
331551,
16945,
145396,
7628,
16023,
334570,
27039,
300135,
null,
15441,
43020,
14267,
200947,
39517,
323104,
16238,
168329,
40044,
152851,
83950,
189558,
37026,
249444,
219679,
3917,
159744,
204239,
211916,
null,
649659,
248348,
13387,
61090,
39738,
108741,
183133,
28953,
2083,
null,
48858,
7641,
88149,
285279,
266350,
317918,
35547,
109845,
152573,
464373,
136494,
11589,
156615,
220896,
162212,
3455,
188825,
44121,
124109,
1332695,
257146,
332717,
532571,
99214,
null,
19856,
16862,
108141,
229954,
29900,
47451,
12041,
111218,
null,
18205,
73426,
8339,
238645,
269442,
55479,
353179,
50540,
48102,
103067,
39593,
35919,
31025,
97740,
159207,
111939,
149447,
7586,
25048,
74795,
null,
182475,
305232,
274663,
303129,
33624,
245780,
18149,
184455,
83420,
40938,
163459,
347024,
null,
33900,
11108,
24447,
null,
152177,
242499,
187876,
27377,
20078,
51845,
26433,
40217,
69090,
314302,
184109,
29714,
82175,
41940,
32048,
19750,
104870,
null,
177052,
12361,
130643,
39264,
120280,
24652,
104369,
141322,
27048,
74544,
157615,
229713,
102940,
283813,
20455,
24540,
200548,
30430,
453703,
40474,
1361016,
97388,
36910,
161786,
39954,
45661,
190690,
487234,
31397,
83891,
16998,
263086,
19968,
28757,
13052,
160096,
235173,
72132,
246771,
344875,
482448,
9398,
63337,
10688,
43421,
17370,
188555,
21189,
22481,
145197,
33175,
3926,
19542,
165551,
327709,
107965,
43369,
297064,
186147,
93547,
125549,
139951,
227205,
62735,
18094,
null,
416887,
46412,
125646,
null,
178347,
53034,
404034,
null,
293366,
29222,
8417,
260009,
7789,
44627,
89035,
195407,
293814,
53332,
79736,
195921,
106917,
441190,
41321,
198763,
241583,
6903,
44218,
215378,
221350,
736534,
199782,
179646,
21168,
220092,
72180,
285233,
null,
25505,
24617,
62296,
75364,
205002,
23046,
390172,
587516,
130805,
53443,
105006,
90903,
53434,
16338,
42889,
58161,
140595,
662752,
317097,
17831,
14924,
250749,
242372,
36937,
8246,
49249,
null,
13937,
190050,
39024,
null,
215143,
140054,
243071,
375143,
149073,
360615,
82230,
95921,
16222,
197496,
214187,
112820,
11707,
388146,
43745,
414011,
275721,
349168,
188142,
23505,
223350,
11279,
null,
121093,
38390,
39950,
25529,
4140,
35331,
135542,
44434,
189563,
156771,
390202,
null,
51434,
38587,
263842,
187006,
39707,
451200,
31468,
160563,
568085,
126705,
378709,
16774,
255080,
32348,
43492,
null,
45401,
183898,
294414,
839313,
null,
14519,
180375,
182819,
16927,
112677,
40710,
15706,
null,
19625,
12089,
53541,
null,
513741,
37126,
217490,
292718,
31749,
41969,
13425,
35085,
52898,
36175,
766037,
null,
13100,
185600,
29934,
372426,
32106,
69936,
35805,
null,
10770,
null,
24647,
178067,
65953,
322998,
null,
59736,
367936,
333261,
25027,
505867,
65182,
160399,
31577,
57566,
173610,
412881,
119411,
27884,
129321,
125016,
80937,
223263,
203705,
586647,
123495,
29786,
156212,
311958,
74497,
336577,
47861,
95506,
null,
38334,
280406,
14754,
17620,
39161,
123144,
361629,
347885,
213808,
124847,
46619,
528105,
9286,
21758,
55848,
117001,
36355,
30920,
29160,
173532,
17521,
30276,
10521,
414919,
252482,
157972,
89640,
65016,
53746,
217250,
52821,
119254,
133923,
187653,
215514,
28079,
24598,
191137,
37107,
55205,
156320,
null,
262786,
15650,
13148,
59362,
43873,
56882,
364366,
2951,
34868,
243513,
16285,
24372,
116276,
104112,
238341,
7971,
26043,
46525,
117800,
88498,
445227,
82287,
169664,
16378,
289657,
18637,
124490,
205685,
58759,
155187,
79634,
349560,
102449,
null,
39553,
37717,
3834,
162946,
209414,
42569,
161412,
15304,
58667,
76289,
24133,
null,
202599,
23320,
320292,
23866,
null,
385311,
122573,
20608,
319983,
null,
176240,
426261,
27852,
88451,
117411,
null,
36310,
8997,
576551,
267660,
14084,
341474,
66196,
34326,
null,
30589,
11373,
28241,
31879,
null,
101883,
12742,
1299833,
218018,
null,
44123,
30859,
357596,
14424,
5550,
29238,
139575,
5586,
53599,
null,
54459,
34634,
8951,
95828,
3068,
176068,
68241,
160416,
9583,
61841,
242955,
20408,
262383,
307991,
89473,
38055,
274980,
94191,
128468,
22540,
164164,
110677,
454209,
831171,
664011,
26766,
148132,
99391,
13366,
45624,
247677,
17151,
2054,
37908,
175814,
207044,
44825,
319276,
79233,
21395,
271011,
5498,
117477,
118844,
46116,
26437,
null,
293333,
224957,
null,
50096,
39734,
91806,
174888,
175085,
291528,
26258,
24889,
null,
220856,
null,
45196,
25625,
513291,
14181,
8501,
45642,
52658,
102677,
224552,
138025,
37736,
37288,
157472,
308045,
556906,
34662,
459505,
104325,
null,
234701,
27932,
56349,
57748,
104817,
17139,
2963,
272278,
null,
171835,
51680,
72649,
121215,
229613,
21493,
403165,
444914,
6856,
187261,
46013,
262923,
107379,
260335,
65038,
312245,
90268,
267052,
17676,
null,
5494,
27424,
102951,
9875,
424123,
176397,
23203,
54459,
67563,
106697,
23389,
9198,
33920,
34032,
103932,
185650,
129209,
97167,
null,
19299,
18332,
364168,
83437,
270092,
35769,
187305,
234095,
44392,
26364,
5619,
13095,
57182,
null,
null,
149090,
234080,
387297,
122672,
null,
82139,
264033,
16357,
804103,
168514,
29663,
24468,
84155,
70429,
192343,
24292,
69404,
52919,
234813,
387315,
45478,
null,
162380,
47648,
58390,
417928,
26485,
null,
21717,
202395,
75762,
null,
null,
62237,
28017,
206565,
359844,
17047,
null,
175620,
53940,
264836,
97845,
28124,
40233,
23859,
38349,
208745,
60489,
11852,
21366,
null,
45368,
null,
341561,
10238,
17176,
6643,
15162,
89264,
223596,
10241,
44838,
88258,
211338,
108213,
686794,
null,
178649,
335650,
24294,
null,
95096,
14741,
42209,
182366,
298929,
16862,
143117,
44064,
38384,
179761,
52351,
166311,
null,
291915,
40517,
99474,
455324,
8311,
109474,
100652,
73403,
31589,
163404,
null,
34623,
null,
49064,
218487,
60971,
349399,
191818,
137206,
17137,
20387,
341508,
356506,
16850,
126406,
35777,
44009,
15382,
null,
49889,
337240,
178172,
83087,
145334,
40584,
141749,
172682,
4296,
19605,
152319,
70369,
240658,
32280,
4595,
53430,
null,
201067,
16415,
32267,
32790,
408449,
198935,
403766,
23000,
7769,
63145,
53214,
232225,
null,
35481,
235408,
137246,
33368,
270069,
32240,
35143,
111602,
2982,
3258,
161352,
432949,
null,
18771,
35313,
22493,
187215,
569795,
31885,
360462,
47689,
10122,
475417,
445207,
66797,
34151,
33797,
33146,
211668,
34024,
null,
82279,
38433,
173726,
35478,
80550,
128762,
71736,
264016,
366882,
45453,
24199,
128111,
143073,
193880,
281967,
5032,
27566,
93031,
463860,
13530,
146633,
35252,
22585,
205560,
9374,
295344,
63503,
3437,
19906,
120133,
43435,
48595,
258284,
114869,
312731,
23541,
24092,
17511,
8093,
180805,
607673,
64746,
10005,
75671,
245623,
22723,
249170,
41661,
null,
85724,
106180,
411984,
55008,
250014,
88069,
13387,
217322,
239063,
149064,
19604,
89953,
24772,
41150,
172615,
377265,
22068,
48774,
46287,
405948,
41771,
234036,
89900,
27069,
38996,
45842,
218988,
17223,
16503,
null,
36960,
11194,
38185,
39166,
169984,
8630,
29369,
58396,
130734,
37248,
94562,
356299,
10112,
434862,
62696,
45710,
231330,
118221,
380990,
81845,
232212,
177204,
93032,
5113,
304632,
171628,
394150,
12911,
117003,
38560,
6310,
81696,
126067,
39064,
59522,
137647,
null,
100740,
38366,
null,
13460,
8678,
162780,
156847,
6471,
6064,
64169,
67493,
257173,
1167,
147027,
66755,
36013,
164454,
102165,
131125,
229172,
44094,
190750,
17261,
null,
81167,
15632,
222496,
210477,
80421,
183953,
208805,
253103,
10882,
39439,
442571,
157604,
121537,
30564,
20731,
238956,
326810,
416225,
56929,
295787,
null,
8170,
3357,
null,
405752,
82293,
null,
26325,
45819,
206121,
15867,
168705,
null,
61964,
433141,
49578,
182257,
158521,
8510,
629574,
37378,
26377,
120261,
87153,
8330,
321231,
43767,
null,
30171,
27146,
null,
126381,
22968,
304738,
495308,
163278,
40606,
15290,
30290,
25139,
11795,
null,
149849,
81651,
291641,
214563,
30031,
292038,
56415,
212243,
170208,
21491,
131867,
49872,
332464,
null,
102397,
26335,
48249,
122238,
null,
968125,
222822,
294971,
12770,
155016,
24979,
84125,
null,
65400,
241469,
34394,
165540,
18446,
44477,
56164,
250746,
31339,
6876,
65183,
22593,
54630,
538885,
16185,
352880,
10192,
175832,
126548,
200723,
42402,
22955,
269477,
362901,
470919,
51075,
19672,
163416,
33761,
49446,
53623,
214515,
484750,
185104,
451210,
731992,
234575,
null,
170461,
198520,
20669,
39989,
30928,
null,
33417,
5375,
24547,
388397,
25439,
23633,
57048,
376272,
36983,
113806,
29220,
17389,
83942,
131238,
392068,
254123,
52980,
24054,
6132,
980303,
28589,
22034,
254472,
100770,
15525,
null,
17751,
50934,
18115,
72219,
251142,
23685,
309298,
333386,
30462,
34028,
78060,
402250,
264969,
316581,
394245,
243030,
37667,
179121,
177912,
18413,
113166,
215831,
121835,
60434,
9883,
77925,
201308,
null,
12097,
283116,
142452,
37233,
172538,
467529,
9299,
201711,
210472,
64325,
157729,
37113,
188282,
538664,
89956,
46339,
17929,
260671,
283386,
13870,
105177,
254292,
313501,
343132,
53600,
156815,
7908,
414134,
390557,
3015,
470369,
59761,
139555,
152501,
121043,
324187,
10994,
12328,
null,
198708,
35139,
92846,
303010,
168090,
238734,
76009,
325499,
125555,
18310,
215660,
141000,
91448,
221476,
22142,
null,
283907,
158244,
85269,
58209,
324346,
8866,
56545,
129915,
45601,
58041,
482985,
48,
null,
337125,
197889,
138070,
130273,
16619,
18066,
153654,
458376,
42119,
78441,
259296,
209524,
35414,
160188,
1084326,
116035,
65064,
3848,
341365,
6417,
null,
91727,
106532,
37855,
225008,
6397,
132006,
225046,
54819,
null,
54587,
247424,
346819,
78450,
197933,
81052,
26678,
68622,
null,
null,
7078,
14626,
21978,
35059,
10195,
96531,
56502,
135637,
8283,
211335,
21696,
30608,
43797,
390085,
111519,
9639,
112937,
115485,
23294,
66833,
10291,
223730,
19454,
null,
null,
29567,
71118,
20104,
98280,
5765,
38547,
210355,
159793,
324151,
9409,
85607,
55878,
39199,
6311,
572434,
274477,
387876,
296683,
131135,
null,
101094,
null,
230588,
29682,
425774,
261176,
null,
211716,
11565,
21716,
386566,
42582,
141691,
131737,
196260,
188149,
2872,
204166,
198812,
8902,
50895,
109137,
8594,
339984,
25392,
45640,
368934,
196170,
211544,
195241,
96860,
104588,
48199,
17924,
344522,
717176,
13714,
null,
113964,
331514,
35226,
55692,
224252,
210875,
83186,
385993,
61091,
30571,
10831,
61242,
469787,
233600,
26903,
12113,
54356,
57296,
201289,
44216,
212442,
129417,
405277,
27397,
126177,
56944,
134854,
205914,
32620,
215936,
11190,
30137,
56335,
29466,
42498,
null,
39368,
184791,
6024,
252396,
25806,
null,
24192,
467700,
166000,
69541,
96198,
242582,
294141,
171366,
null,
72260,
163007,
155408,
291393,
209633,
107369,
20908,
121759,
190975,
58783,
161954,
72715,
293137,
null,
272909,
175440,
175530,
10563,
91801,
43687,
145497,
39518,
118090,
30421,
40606,
14894,
394342,
121656,
42623,
42422,
57098,
96355,
75289,
34624,
394894,
19350,
73401,
null,
194409,
212971,
7263,
34472,
6383,
15104,
156296,
33899,
196450,
null,
134310,
80385,
14163,
182726,
306792,
235773,
43143,
41714,
16403,
568845,
314293,
257401,
9066,
28293,
45704,
129161,
236646,
42997,
47301,
366365,
1303602,
283843,
36097,
68628,
46184,
null,
161430,
174295,
21056,
16652,
9312,
79549,
12989,
40137,
11928,
275922,
96614,
551318,
38910,
314926,
27965,
92293,
192801,
283662,
null,
98726,
238412,
24636,
208467,
284849,
84341,
249271,
39738,
54991,
345979,
null,
77555,
32171,
94692,
31427,
118928,
82920,
754414,
25733,
42456,
155332,
215553,
30150,
95117,
317765,
null,
38562,
436252,
226669,
25944,
22860,
12174,
57487,
113322,
189874,
52491,
41862,
null,
null,
null,
40275,
17755,
81518,
159950,
59699,
469053,
14153,
33832,
236699,
19800,
32343,
8115,
165760,
40136,
18212,
8233,
68619,
379952,
57374,
201205,
3608,
195767,
69833,
96771,
188727,
5919,
63034,
284610,
12252,
200626,
758189,
266569,
673419,
20743,
53068,
362147,
254705,
38934,
19881,
24244,
102326,
54135,
299011,
28788,
22709,
44260,
175207,
6422,
282736,
23519,
331651,
380681,
null,
237264,
213139,
25308,
7160,
191456,
31362,
187460,
3244,
null,
788382,
367577,
153979,
29752,
null,
183313,
9137,
61849,
213859,
215758,
211749,
265065,
189612,
171945,
null,
166535,
509708,
16911,
18418,
250087,
33279,
317034,
463385,
4740,
72620,
121266,
142013,
15759,
123088,
27361,
78998,
370612,
null,
13459,
null,
103157,
31378,
198672,
278376,
null,
79078,
null,
8470,
62515,
213463,
37632,
86183,
64638,
1826285,
null,
170438,
50579,
27665,
231941,
133545,
134858,
80185,
35496,
25119,
81007,
7190,
264260,
75340,
186164,
298938,
289560,
141733,
91626,
200277,
167584,
114121,
123917,
18761,
55569,
100588,
349028,
28482,
67472,
22570,
197665,
78342,
76541,
111399,
10411,
33697,
12862,
132552,
211105,
198590,
22458,
87842,
253479,
174456,
7000,
null,
158418,
319301,
280858,
36458,
125498,
31723,
329754,
null,
80325,
22231,
171550,
105643,
173796,
null,
8229,
330280,
71948,
106367,
8874,
362658,
177608,
39497,
128264,
33494,
110282,
null,
310434,
16128,
204188,
203458,
20162,
115455,
15558,
224654,
23723,
2780,
166975,
26147,
167992,
299056,
225522,
16793,
577172,
15057,
69159,
32305,
20029,
null,
23151,
null,
191416,
689956,
196115,
32851,
199438,
46711,
92286,
72536,
55119,
22304,
196324,
38363,
614368,
85680,
246340,
395264,
null,
null,
11676,
172703,
76226,
41701,
47667,
95830,
411457,
31445,
297988,
19799,
210829,
143576,
223450,
316448,
183477,
58692,
null,
15901,
332226,
394411,
21448,
331363,
42576,
470018,
18501,
6351,
189804,
136355,
193001,
56330,
43492,
30897,
278418,
336397,
22689,
29728,
132111,
21479,
11098,
34496,
43474,
256538,
24543,
17784,
210537,
null,
35769,
8801,
28182,
591644,
7689,
null,
2279,
368810,
13822,
null,
null,
4146,
207784,
27117,
34616,
48518,
134321,
260260,
746358,
244486,
80810,
254431,
121924,
null,
263495,
391729,
null,
203359,
15084,
72037,
378224,
251380,
171895,
40943,
146051,
147458,
126976,
12493,
117983,
32320,
null,
211401,
null,
72777,
5895,
533734,
23052,
350443,
45636,
20430,
439387,
33937,
null,
323610,
126367,
122399,
null,
628219,
null,
90720,
38642,
58988,
339878,
204449,
27286,
13870,
30044,
1042,
22532,
377861,
26479,
38754,
252269,
67395,
386016,
3431,
260145,
null,
22142,
14497,
63024,
41788,
321939,
null,
10028,
252647,
41359,
44403,
48945,
185887,
108102,
6929,
77574,
91415,
null,
12534,
63928,
22849,
45740,
87886,
35961,
224759,
367490,
154880,
334109,
198663,
154700,
47354,
139412,
94870,
171324,
120978,
31924,
168994,
128721,
43978,
46435,
131540,
65831,
34414,
40580,
199771,
107047,
39633,
218356,
26454,
23021,
36622,
310455,
45461,
13558,
18788,
91527,
null,
292879,
51127,
43140,
66066,
92389,
207447,
49313,
9250,
39642,
163465,
305620,
20795,
43057,
357477,
137104,
280422,
24349,
53574,
34568,
231788,
94305,
25154,
133195,
63881,
49095,
5551,
83173,
41320,
null,
30384,
29895,
18194,
236725,
402720,
145033,
133899,
10933,
null,
76918,
146441,
91640,
99500,
6315,
43865,
32831,
153525,
null,
59183,
356911,
19442,
9045,
null,
87950,
289056,
null,
69109,
null,
135972,
300548,
17403,
41716,
43910,
77022,
257338,
167989,
174814,
49830,
254707,
617363,
17195,
46548,
70950,
46618,
237326,
53624,
16907,
114717,
40920,
45076,
143051,
127990,
37385,
26636,
67145,
null,
140204,
163408,
230270,
11967,
159125,
57743,
18815,
369353,
194557,
170027,
323297,
79173,
318886,
53202,
12430,
null,
null,
35960,
94496,
33498,
207884,
53552,
134162,
169256,
null,
19433,
15284,
24444,
122182,
18907,
166058,
65787,
39910,
152435,
84199,
4014,
93547,
279562,
32752,
264236,
284462,
132000,
134405,
47508,
228780,
14265,
171645,
360160,
4859,
27292,
146256,
277431,
55470,
44981,
36795,
382802,
15678,
217205,
365770,
20473,
47199,
41213,
null,
null,
20373,
47344,
104135,
15973,
184154,
74905,
138322,
32818,
118836,
162308,
164530,
100357,
266195,
93821,
186819,
13238,
24235,
137167,
568141,
323160,
301293,
165507,
16717,
305320,
37279,
22148,
21723,
27950,
196911,
204374,
141033,
64443,
93024,
42674,
206850,
6476,
85602,
27631,
null,
174966,
92070,
38244,
240354,
132195,
20957,
22689,
119395,
295585,
6127,
113667,
214807,
310546,
161773,
33315,
164573,
390022,
73906,
195573,
205920,
8046,
51882,
49740,
58330,
32743,
209447,
15564,
28106,
152866,
51626,
183074,
61614,
59191,
261979,
6414,
78210,
439902,
25511,
13831,
58200,
33640,
241677,
5805,
91774,
336533,
21988,
38824,
190334,
71566,
379201,
15725,
162819,
594026,
545031,
123323,
338339,
71772,
28904,
226004,
33435,
65573,
62523,
8837,
186035,
52188,
11573,
90249,
261459,
41039,
116609,
385915,
6100,
49652,
13838,
13285,
78950,
null,
66344,
122942,
46432,
246197,
15308,
145789,
14536,
181273,
30462,
20641,
40305,
29354,
74140,
223624,
225071,
56406,
291405,
285644,
129075,
49340,
124692,
89279,
30842,
179109,
null,
110365,
34963,
178216,
null,
138736,
173881,
1718,
30599,
257269,
null,
88309,
226469,
30593,
null,
null,
24402,
136887,
72706,
null,
6702,
70046,
38370,
87756,
29620,
21419,
null,
112639,
369947,
22279,
21443,
69110,
7645,
18204,
347985,
32329,
4358,
25171,
null,
33144,
254218,
213630,
228339,
344979,
364449,
13158,
207373,
377128,
504441,
281198,
44409,
14150,
349386,
6702,
15156,
3938,
221251,
35873,
41643,
71389,
14518,
51906,
219145,
null,
null,
192525,
53016,
100117,
213535,
486757,
46611,
33276,
44690,
419006,
158704,
25543,
275286,
240909,
20185,
166283,
98601,
140532,
168605,
183672,
47555,
495423,
104278,
140928,
413188,
21419,
244781,
83575,
34348,
134708,
345050,
12230,
367907,
423946,
null,
59162,
393724,
26468,
17675,
74296,
305687,
124734,
205608,
157363,
252191,
27448,
369585,
224189,
14734,
315177,
12372,
298537,
129632,
8054,
null,
382701,
7511,
46666,
363291,
79322,
109705,
33122,
64187,
375777,
62007,
7311,
194947,
5862,
131819,
395676,
58225,
null,
190500,
465253,
29959,
283779,
167726,
189062,
337550,
108935,
29179,
14876,
400581,
129624,
4241,
42087,
155753,
237208,
null,
221140,
194586,
219563,
163701,
73044,
31700,
181481,
224335,
46746,
428522,
41875,
null,
224134,
39075,
41983,
22087,
36827,
209614,
135021,
30629,
343902,
40946,
65277,
184206,
50593,
55231,
35133,
350947,
302146,
18983,
40394,
87127,
26725,
182950,
279617,
21527,
277902,
11010,
164446,
303863,
43769,
185507,
32726,
253986,
28279,
246102,
298555,
311719,
null,
282661,
null,
null,
27573,
221429,
203646,
252406,
13207,
101395,
null,
420559,
140537,
34192,
56861,
9411,
73996,
338156,
13621,
47704,
392178,
22631,
27467,
16319,
18749,
36164,
200982,
null,
21076,
null,
23786,
null,
66576,
261270,
5954,
15456,
null,
215601,
null,
59015,
21000,
216134,
49909,
558723,
39428,
216000,
51579,
40203,
58437,
26226,
14487,
14571,
229562,
33787,
null,
487814,
30629,
17511,
32649,
99737,
43528,
354580,
62922,
24272,
338422,
165449,
43305,
null,
14176,
86242,
199901,
219311,
120251,
51468,
null,
78918,
3628,
37221,
150977,
366325,
28888,
15935,
340126,
41407,
185510,
78259,
37568,
96642,
36514,
45259,
259894,
null,
136029,
71306,
9698,
497222,
161516,
273093,
45024,
25119,
264498,
9057,
224222,
352980,
25193,
26029,
85640,
305410,
22768,
6589,
416103,
156239,
14656,
242922,
null,
14652,
175885,
107464,
47594,
160237,
null,
28944,
35379,
null,
321297,
null,
351228,
700336,
538256,
5633,
663937,
44218,
50919,
125950,
181617,
50368,
397625,
null,
40301,
191172,
null,
39082,
23925,
63842,
110289,
86092,
32036,
19137,
55665,
59003,
22402,
112662,
80895,
200792,
51434,
35875,
164658,
277228,
62200,
146539,
26204,
312208,
52352,
212366,
63022,
null,
105697,
124944,
24357,
10180,
45758,
55995,
170922,
null,
27033,
45546,
22713,
200179,
156212,
106832,
262327,
null,
501628,
160435,
660003,
1107,
210764,
37600,
68095,
42051,
66471,
null,
128710,
54505,
45996,
15844,
17204,
630340,
59901,
242717,
35262,
60790,
189237,
48785,
193893,
53675,
124114,
33629,
111384,
89445,
5088,
138396,
282176,
32952,
135225,
47283,
23776,
null,
161566,
432950,
4010,
213927,
null,
293144,
475197,
55532,
83782,
39006,
43676,
null,
11797,
null,
54294,
75528,
6001,
19865,
374264,
null,
23877,
8269,
45500,
545717,
428305,
136395,
36969,
226120,
30887,
15511,
314778,
4306,
172317,
178663,
16289,
51965,
null,
22907,
5132,
14165,
30611,
null,
null,
229078,
22676,
24547,
54925,
101914,
13456,
39481,
70449,
59448,
55667,
null,
9613,
244237,
null,
199809,
231907,
259334,
446611,
4204,
10061,
null,
19638,
117127,
449762,
36593,
113989,
9151,
39513,
28909,
114581,
228968,
14450,
155738,
227530,
200805,
260931,
22847,
22311,
null,
34946,
null,
20321,
144508,
321820,
172812,
423167,
201303,
547765,
30321,
11483,
null,
43230,
null,
278727,
162304,
153104,
86143,
444836,
212489,
136138,
176193,
null,
null,
63090,
125136,
664508,
325373,
170454,
286378,
26632,
22494,
56818,
73233,
254406,
null,
586934,
189210,
35634,
171622,
43447,
14413,
null,
7015,
151228,
24220,
170924,
52605,
226790,
null,
null,
161135,
219274,
30577,
183853,
272241,
null,
19033,
133501,
49966,
17045,
26927,
13210,
243454,
112949,
20458,
1393,
46910,
null,
369309,
25705,
16957,
1041916,
242012,
26994,
40128,
42975,
205820,
162233,
252462,
27166,
21477,
23467,
129487,
18984,
90687,
246224,
50448,
24209,
262925,
194886,
33360,
null,
27399,
104541,
87862,
290737,
401126,
81741,
123294,
222900,
109654,
372050,
17391,
181954,
15535,
19558,
66351,
54193,
178335,
131306,
127890,
244420,
18339,
178059,
84138,
271058,
159692,
77578,
75944,
178216,
404411,
438136,
4216,
270214,
49694,
21888,
723796,
null,
null,
54348,
48517,
135243,
53041,
null,
683078,
164696,
null,
null,
72271,
150053,
46556,
318675,
417746,
null,
68783,
64893,
98682,
30540,
57288,
44512,
875,
69440,
52096,
117689,
15750,
78102,
null,
63839,
64165,
389361,
17591,
28153,
482138,
225921,
73509,
null,
141355,
132399,
63097,
283427,
56790,
156532,
412800,
17054,
71658,
32416,
41692,
2643,
214958,
103828,
175148,
127867,
70942,
51837,
null,
39604,
137181,
32248,
null,
null,
97233,
96406,
10159,
13977,
118427,
10425,
71390,
116680,
168621,
322754,
28401,
17360,
12265,
342588,
30364,
57826,
114975,
31317,
177319,
175787,
159329,
22411,
4901,
98793,
318555,
162866,
8674,
null,
null,
9457,
null,
209165,
450574,
75503,
92036,
13861,
64217,
91663,
26474,
62944,
159888,
11529,
142925,
null,
210670,
63707,
458905,
69399,
114409,
4866,
181209,
91732,
97301,
116064,
112361,
114071,
156739,
165540,
null,
230306,
24857,
124422,
122903,
177550,
28736,
185289,
38444,
291673,
214551,
52892,
67163,
303878,
771664,
240971,
19406,
212015,
33028,
350719,
96205,
30233,
null,
75098,
22447,
201306,
12400,
64051,
null,
null,
17077,
15070,
null,
74833,
123969,
15497,
200314,
12813,
112191,
38943,
250522,
95149,
389790,
312236,
null,
18360,
78523,
137833,
288867,
234936,
13470,
748851,
null,
14809,
94815,
112075,
4415,
137207,
321104,
220316,
167327,
23670,
99012,
137664,
314518,
33562,
83186,
155247,
26571,
272348,
151687,
null,
5454,
292910,
13377,
333032,
13536,
71267,
15279,
22613,
86560,
490922,
152438,
21177,
34021,
87028,
27662,
25997,
27238,
138536,
108321,
300882,
33936,
23596,
126043,
27671,
158995,
294334,
15094,
8289,
42847,
null,
203259,
77765,
28093,
44863,
122458,
60717,
403122,
159180,
36079,
233129,
11694,
47125,
25413,
574594,
48705,
209291,
200280,
199612,
74410,
202752,
45217,
8098,
566959,
null,
46053,
48363,
337475,
256389,
9290,
466301,
61798,
168573,
null,
16829,
64995,
178226,
236626,
11720,
17404,
180222,
312198,
67257,
1010322,
311798,
null,
30065,
136131,
177566,
310748,
183149,
21915,
23884,
9003,
19462,
262371,
68173,
450736,
260261,
28973,
23669,
4909,
24603,
383631,
52231,
34689,
36075,
268285,
29104,
null,
251394,
15338,
132216,
37518,
134036,
31040,
386582,
262726,
356653,
154408,
132016,
22893,
28118,
349466,
244289,
13647,
8824,
107590,
159902,
10978,
8077,
112662,
32214,
31043,
8712,
12611,
32674,
125288,
27910,
179407,
530675,
21954,
null,
50047,
47996,
18809,
57982,
365072,
75521,
155485,
176521,
53865,
48647,
null,
55126,
41345,
null,
48408,
410422,
30008,
42119,
152385,
119414,
159259,
363890,
50259,
33369,
272306,
189232,
573300,
298776,
34642,
269301,
494167,
282374,
20714,
133163,
6262,
132882,
null,
253570,
341345,
163728,
42539,
307018,
null,
103344,
28451,
255828,
30055,
200722,
345780,
47400,
92926,
44983,
200311,
null,
37893,
46364,
298692,
282040,
84803,
13108,
135764,
280380,
141850,
720248,
435630,
159905,
31178,
251100,
19551,
271683,
159483,
37414,
246029,
407100,
166560,
185790,
90872,
11050,
182395,
72092,
144981,
463131,
27512,
36625,
null,
7530,
10239,
101140,
40119,
15439,
35701,
32306,
454547,
470814,
134646,
null,
48779,
8009,
464310,
10387,
189410,
272084,
57812,
145736,
164799,
25585,
5127,
18266,
363418,
null,
144765,
398427,
234664,
10596,
9303,
178297,
null,
12898,
24732,
54179,
426743,
13843,
387518,
317653,
219417,
237866,
226026,
null,
235349,
20327,
197020,
20747,
142758,
39619,
47202,
204145,
205875,
117882,
162151,
357144,
191042,
308369,
201361,
42246,
288683,
21982,
277271,
110179,
279011,
194964,
116523,
20532,
314873,
465156,
10977,
6624,
377383,
28824,
54375,
96425,
269898,
183709,
288408,
391757,
176367,
54366,
34755,
22418,
12396,
94712,
211442,
42470,
105965,
4817,
null,
24864,
181809,
28894,
146721,
3134,
26287,
22696,
9072,
7967,
34582,
62233,
17844,
101654,
342144,
27308,
361564,
589658,
23879,
59604,
45905,
14569,
102198,
28139,
105305,
254561,
null,
45854,
153039,
24618,
null,
37578,
70375,
401394,
110344,
60032,
136329,
247211,
318326,
59740,
85897,
50885,
273600,
73387,
37979,
null,
41791,
44311,
127394,
5483,
null,
428364,
9301,
31307,
103303,
24108,
209626,
117102,
263234,
22280,
236597,
3306,
59715,
264021,
354403,
31810,
31493,
348830,
167649,
377623,
32711,
26284,
24118,
83008,
90565,
24420,
4875,
null,
142432,
371175,
72936,
121664,
18920,
16017,
65744,
198850,
151858,
166794,
244372,
157395,
102672,
44071,
16605,
183739,
41790,
66571,
197798,
163085,
239734,
19074,
94238,
103212,
18876,
535847,
11033,
null,
30730,
207817,
68090,
157166,
8210,
654336,
97106,
null,
585824,
38384,
46596,
266568,
138427,
117370,
71620,
3246,
264659,
2742,
16962,
11057,
21065,
35580,
141953,
33617,
13373,
45911,
null,
104549,
31921,
46487,
13661,
45083,
20402,
359972,
84367,
164574,
335835,
76587,
7964,
556312,
207176,
50571,
522939,
207454,
320492,
33610,
null,
235846,
11424,
187804,
302417,
9692,
181959,
12074,
25131,
921640,
410156,
57250,
343079,
56201,
214391,
118438,
419082,
12243,
null,
219959,
162203,
null,
15951,
null,
55673,
305966,
170391,
61551,
375378,
175072,
34525,
14796,
311628,
171845,
112236,
36427,
356246,
92414,
358943,
15630,
292119,
38840,
402059,
7080,
189942,
599910,
5814,
115657,
252525,
123989,
null,
111586,
30191,
187741,
190044,
239548,
34487,
3031,
298384,
null,
218829,
29391,
8484,
24003,
7057,
16897,
160481,
56018,
402170,
76888,
33638,
51315,
170714,
55022,
null,
354466,
33952,
295879,
270006,
76073,
98224,
169334,
184720,
99383,
null,
197468,
103062,
25123,
357765,
186228,
62030,
null,
59656,
21227,
162790,
198040,
425734,
29502,
75203,
237273,
197199,
74047,
177883,
292439,
39595,
33364,
196414,
23368,
33959,
665264,
20410,
510968,
589272,
116226,
197043,
75465,
48537,
179251,
113566,
null,
20166,
292228,
null,
121453,
123626,
199594,
276618,
240437,
28460,
186766,
249909,
31406,
669956,
135402,
59441,
3616,
null,
90400,
264413,
120704,
5937,
208403,
46551,
24598,
206357,
417573,
24910,
69542,
267592,
258195,
346207,
257273,
53114,
4444,
423518,
147053,
183138,
19443,
23888,
361666,
216833,
154600,
89071,
237884,
28747,
92841,
31834,
76898,
115857,
20855,
63237,
292212,
14426,
148607,
9033,
291037,
4436,
null,
422373,
20221,
10442,
16461,
14400,
11603,
7875,
61439,
41042,
61205,
75838,
18151,
7887,
387996,
17276,
60180,
255052,
9144,
472675,
138071,
66108,
471787,
157676,
226085,
381154,
17402,
133182,
null,
309983,
14482,
52952,
433440,
8196,
50012,
24837,
null,
170087,
null,
617886,
31329,
23460,
20332,
162810,
33451,
120050,
138324,
162473,
257163,
18171,
157742,
24887,
null,
268462,
57513,
null,
null,
38955,
99267,
321911,
null,
224673,
238337,
108576,
430967,
371094,
9745,
258994,
9060,
122969,
395289,
298218,
77601,
132355,
243449,
34550,
28929,
52797,
228140,
225881,
42644,
null,
null,
292150,
95486,
179122,
null,
295042,
19304,
52056,
26987,
null,
33857,
41328,
null,
36967,
178871,
null,
201949,
485810,
null,
112875,
null,
234912,
7814,
385845,
200693,
27041,
84082,
2836,
182720,
67509,
742838,
120247,
97074,
69470,
8283,
28419,
60432,
253354,
204334,
22618,
34619,
24135,
23761,
485196,
null,
357950,
194181,
20115,
182825,
35010,
340594,
281065,
91584,
67050,
137444,
230533,
null,
287274,
207240,
6496,
23544,
27230,
254314,
644761,
209098,
121047,
17226,
111352,
31640,
241981,
25791,
703395,
312435,
38295,
209294,
23326,
8544,
147367,
1911,
83258,
163191,
17142,
275354,
496015,
null,
68265,
229145,
68411,
382822,
58159,
819319,
137880,
7707,
343426,
55163,
15254,
77250,
31457,
64623,
333774,
92787,
446584,
142603,
30360,
48581,
13357,
290621,
333382,
null,
null,
145611,
60466,
123776,
282340,
33108,
137781,
177450,
8773,
9790,
220697,
34901,
74533,
211805,
null,
61582,
308093,
14404,
27325,
466004,
289173,
878339,
189046,
175128,
23917,
11874,
137578,
null,
345012,
21716,
null,
34744,
26864,
null,
162671,
23550,
274228,
1537,
19034,
20939,
151126,
15604,
53865,
228520,
14511,
null,
73718,
98029,
null,
3540,
66045,
40317,
35670,
53314,
21807,
114517,
19729,
null,
1329807,
20835,
34952,
63001,
193582,
195037,
34736,
239798,
26532,
206540,
275255,
960818,
15169,
290429,
177262,
56673,
106404,
435469,
18199,
5727,
149795,
14926,
315280,
29599,
372031,
391914,
209844,
10135,
63727,
60982,
37443,
321980,
null,
12907,
22285,
172126,
42783,
186795,
28777,
226692,
27993,
6047,
14541,
170778,
98659,
20928,
57123,
9113,
232257,
198794,
47832,
63518,
43945,
24348,
51344,
17809,
null,
null,
null,
48929,
276795,
612298,
34975,
196303,
54226,
64748,
278944,
166432,
27972,
324490,
219063,
28805,
null,
361629,
65698,
26541,
282806,
53271,
127138,
33309,
46757,
113185,
90364,
17065,
192671,
23842,
22283,
280046,
null,
7784,
253373,
null,
61498,
361834,
134774,
13138,
217689,
309121,
50502,
131464,
301687,
229831,
147109,
235376,
233056,
39090,
20885,
36304,
12983,
192507,
67154,
null,
30206,
126607,
61495,
19369,
94424,
9262,
43847,
42809,
44914,
197961,
154604,
79534,
10712,
315761,
42108,
6195,
138599,
56724,
126379,
37541,
215836,
98491,
126922,
502915,
101104,
48996,
140214,
72305,
416272,
48813,
44933,
30845,
239907,
146547,
176739,
109488,
309294,
929860,
139642,
16025,
35036,
327910,
9772,
37388,
205143,
null,
45581,
23879,
187685,
108460,
374203,
null,
154684,
11443,
273546,
148866,
202877,
28802,
66005,
5959,
52096,
134091,
52012,
127959,
25104,
10755,
39950,
8988,
47939,
153842,
52084,
40475,
4573,
173634,
69081,
45894,
33040,
108720,
98278,
32838,
143490,
null,
708735,
21956,
45367,
27663,
20513,
153931,
230585,
7567,
37350,
176021,
7295,
57465,
38186,
241536,
15678,
172155,
27468,
6384,
79276,
null,
65092,
74578,
35722,
31828,
79306,
68660,
null,
443972,
26501,
24427,
266577,
15628,
33667,
314520,
54045,
146439,
18136,
42884,
121731,
308546,
308372,
152706,
46048,
569331,
40485,
82674,
217230,
31797,
18290,
1805,
30520,
21540,
25820,
31149,
3536,
47859,
55293,
33027,
241260,
69423,
180935,
41813,
465061,
174589,
148628,
48034,
30577,
313942,
428071,
320178,
527832,
69407,
19417,
23114,
39963,
110904,
168018,
38208,
null,
111949,
2274,
47393,
29624,
32447,
20765,
9482,
562627,
390053,
234319,
23790,
102263,
163898,
28028,
77282,
25298,
318888,
136240,
209556,
253209,
null,
167094,
471998,
5016,
16765,
130243,
140929,
28711,
292419,
37818,
286422,
232985,
55501,
102910,
16800,
188191,
622282,
249409,
170125,
191425,
18278,
null,
217805,
16041,
255946,
25804,
null,
109283,
null,
107458,
162402,
57397,
74400,
40721,
194693,
161198,
389663,
47232,
9769,
31012,
null,
15366,
255638,
131471,
null,
131471,
15354,
7482,
63541,
null,
234202,
77710,
212455,
21429,
161185,
301037,
401124,
18954,
19858,
553842,
192261,
410054,
109731,
168356,
546320,
20666,
213128,
48814,
79415,
39168,
211779,
61194,
483935,
226820,
5989,
13792,
235967,
null,
35422,
203267,
168996,
41987,
330177,
250484,
null,
304395,
132558,
55663,
223170,
18139,
32966,
174056,
71589,
21616,
16803,
199110,
610775,
null,
142447,
109492,
42286,
348903,
10118,
32812,
null,
91076,
125011,
55849,
169268,
97908,
230656,
755595,
92398,
16095,
5836,
22337,
90523,
122255,
41339,
156097,
null,
55975,
22723,
371359,
20674,
26700,
272214,
227005,
203905,
30033,
20962,
30683,
13409,
125503,
null,
189893,
30206,
70275,
319303,
92760,
62229,
18589,
278510,
146169,
327311,
391172,
null,
null,
101778,
15237,
406556,
53255,
20342,
89938,
286085,
167289,
59084,
11118,
41089,
117163,
244026,
248410,
15693,
23730,
263908,
38535,
33073,
133605,
27257,
29794,
null,
165206,
231406,
225828,
324912,
19030,
307713,
80154,
null,
579513,
23270,
22217,
46380,
41997,
65062,
95408,
37637,
11989,
33719,
62058,
null,
90005,
219950,
37028,
185514,
142250,
59003,
639918,
165806,
50202,
203827,
156714,
null,
27533,
297881,
null,
166190,
184998,
186501,
54009,
72821,
62613,
30317,
132493,
21100,
49140,
145197,
17219,
4397,
263094,
11906,
39883,
null,
160904,
30520,
295564,
49445,
487431,
233786,
23800,
586046,
279035,
26274,
51608,
null,
7652,
24024,
40229,
9577,
27539,
null,
16632,
82227,
507928,
134118,
49985,
186068,
44179,
28238,
7288,
202494,
44798,
208073,
140494,
237039,
50036,
20164,
413280,
19606,
21469,
70948,
255682,
3084,
157746,
330603,
340825,
70279,
54240,
36703,
141167,
147226,
null,
402012,
292396,
79074,
46804,
40256,
84239,
433796,
123244,
26564,
192490,
105466,
121708,
197470,
273001,
null,
48694,
null,
21592,
20673,
51255,
null,
6062,
23519,
29126,
119599,
35061,
270495,
181188,
154167,
null,
79241,
18820,
null,
417259,
87551,
130228,
430588,
8970,
131701,
40976,
null,
22709,
123897,
9540,
40477,
245664,
329033,
332221,
268725,
114959,
21551,
48537,
25618,
168877,
42709,
11915,
97700,
302021,
70719,
13859,
62604,
106834,
415050,
639211,
40720,
133244,
44964,
217813,
null,
15907,
null,
62866,
21018,
17890,
59251,
122722,
4726,
351755,
112068,
44532,
29723,
428498,
16725,
30146,
103201,
17441,
null,
85076,
42590,
399699,
307488,
22275,
232064,
69274,
51400,
null,
47179,
358529,
31799,
172993,
146749,
26922,
60212,
520225,
68813,
287943,
9842,
392270,
229860,
14029,
10928,
21362,
32109,
5435,
40758,
748170,
244439,
164908,
330492,
225314,
77532,
29610,
523282,
55374,
null,
185701,
227935,
86080,
12048,
40276,
25122,
160943,
49333,
153673,
9685,
null,
38253,
20,
16861,
273560,
29991,
78209,
81290,
193013,
140021,
53460,
47869,
67049,
130782,
385297,
38890,
143772,
15672,
23534,
37090,
103569,
72998,
15363,
425887,
22319,
49719,
9240,
17112,
73948,
11963,
16976,
591866,
77364,
null,
17214,
39654,
65154,
203519,
45923,
198094,
18051,
287671,
141752,
423294,
52121,
null,
68498,
196249,
20412,
371290,
512352,
17099,
20978,
46261,
16769,
43947,
101117,
21371,
26672,
null,
29031,
221269,
36047,
156996,
239891,
51427,
211152,
58603,
20556,
40083,
23027,
null,
88152,
29384,
14547,
48777,
26950,
40464,
182295,
384048,
288176,
78463,
10268,
null,
51625,
44808,
132935,
185859,
193323,
9751,
264756,
4896,
261318,
455855,
112050,
309246,
341353,
730276,
115435,
36250,
74797,
49652,
244767,
69922,
53013,
64270,
237326,
41757,
10899,
175390,
null,
31722,
null,
197396,
60154,
42489,
100267,
72929,
167461,
40288,
8792,
51209,
34093,
160690,
25762,
17393,
null,
20945,
47035,
186676,
30364,
null,
96663,
42113,
283976,
263336,
42572,
41835,
62927,
195204,
48224,
18746,
157953,
null,
3766,
53443,
324380,
20487,
74507,
19934,
51057,
77020,
234474,
36486,
175851,
6397,
null,
13720,
10132,
278062,
null,
27816,
88248,
14702,
216212,
null,
143016,
8921,
303922,
68898,
441571,
33274,
20029,
34213,
35358,
35267,
21482,
353248,
268054,
214270,
30984,
310649,
228861,
299962,
33232,
181744,
55849,
7452,
32860,
33230,
31100,
39057,
91607,
14292,
38209,
215128,
119933,
null,
201868,
59899,
null,
20004,
145048,
288304,
9506,
45584,
174315,
243723,
526048,
222758,
24083,
9081,
281251,
315249,
49983,
17437,
null,
541549,
372918,
493123,
196139,
30267,
null,
222608,
null,
22222,
32045,
8337,
44033,
56291,
10429,
101613,
220023,
26789,
13573,
112109,
132638,
23160,
24973,
null,
21483,
365899,
50372,
138434,
343952,
37497,
313044,
26882,
81328,
13619,
35917,
427731,
6832,
null,
78201,
33330,
53100,
4914,
109857,
258540,
null,
null,
60693,
null,
10079,
null,
380153,
14023,
382638,
513564,
15369,
94490,
300502,
null,
275466,
18652,
212775,
625580,
16064,
168314,
145703,
34888,
88779,
14848,
31925,
20854,
228116,
275725,
110407,
172116,
34628,
8756,
42838,
572512,
19941,
113624,
28520,
233763,
170216,
29554,
169065,
null,
82642,
114174,
118898,
260155,
3143,
768948,
173570,
12418,
31554,
null,
451209,
205147,
12734,
212786,
24635,
59104,
31967,
224635,
17854,
132953,
280088,
53654,
7868,
null,
166439,
22351,
527193,
296599,
17763,
24595,
31002,
760945,
149053,
44137,
70132,
40260,
76177,
6720,
162304,
66450,
659214,
24164,
275095,
null,
null,
10825,
22696,
108910,
49144,
128063,
37459,
49754,
120977,
61554,
140785,
187005,
14929,
29060,
null,
null,
59267,
98880,
7743,
null,
354632,
199151,
106643,
null,
214813,
214086,
198726,
422842,
224879,
12493,
48598,
204772,
279681,
57121,
154603,
100931,
242631,
189623,
177354,
108427,
16606,
315174,
565470,
4825,
63098,
125671,
11899,
47859,
10605,
371537,
130632,
246857,
194602,
138527,
7325,
138779,
76733,
32558,
4794,
9378,
null,
22023,
114661,
188910,
null,
39273,
15796,
214840,
292573,
36428,
39752,
305894,
39547,
26066,
378788,
158727,
111599,
171961,
594745,
63546,
521566,
65576,
25914,
166945,
45616,
52823,
448966,
100223,
35505,
136894,
20765,
320858,
258573,
23436,
60566,
76687,
158942,
12954,
79100,
4776,
267145,
195452,
216088,
35013,
119847,
115678,
null,
11128,
781456,
null,
null,
null,
15126,
null,
432679,
306403,
null,
233652,
286548,
9130,
14052,
34724,
19877,
13140,
27282,
null,
35075,
null,
253614,
174615,
53990,
196519,
145283,
267732,
142862,
327309,
83531,
699459,
14956,
11908,
111117,
426613,
null,
150657,
6006,
18597,
27594,
3845,
28443,
22191,
12429,
28563,
222130,
188229,
34351,
6816,
66307,
26651,
7120,
109245,
6707,
49840,
46691,
176861,
null,
75479,
328676,
7356,
275003,
34141,
271788,
193748,
150708,
213602,
136335,
306661,
63294,
56975,
54882,
208139,
183099,
112824,
287458,
10872,
309012,
32478,
null,
null,
null,
120182,
12708,
86110,
330121,
139653,
7461,
61626,
19205,
15843,
19696,
204243,
535756,
null,
20246,
145426,
23299,
144125,
249830,
213967,
16400,
254055,
292131,
741294,
252259,
218880,
22141,
9337,
25071,
66513,
null,
104022,
161400,
51534,
52697,
60562,
246481,
null,
15951,
19661,
75957,
392214,
282450,
22237,
384028,
30860,
544639,
20168,
6050,
989,
349126,
207475,
40615,
53289,
17004,
307151,
151422,
35219,
68428,
23366,
208579,
5956,
449193,
193155,
35800,
25128,
47260,
23340,
207090,
70900,
10054,
11045,
248688,
null,
null,
444429,
24615,
69982,
143875,
354289,
132430,
75274,
82577,
4024,
189038,
123800,
8982,
86717,
180951,
154615,
453602,
185823,
49572,
170851,
68891,
87829,
null,
132850,
59152,
318183,
248437,
62148,
737629,
24770,
69440,
229975,
136747,
615784,
443198,
28547,
19794,
166194,
159632,
107263,
14031,
58512,
223015,
15193,
44539,
341202,
265409,
262486,
223996,
147176,
131599,
46864,
371764,
584532,
null,
107974,
174607,
346852,
31966,
177122,
11526,
119968,
27057,
13959,
6513,
272341,
191402,
95092,
28035,
186706,
31088,
276363,
555807,
74938,
292342,
116538,
121524,
28124,
356286,
32048,
null,
6447,
315998,
null,
119734,
503448,
349183,
178110,
21004,
134017,
6800,
110034,
57238,
14194,
92642,
19510,
null,
73716,
21977,
153891,
31462,
321247,
109454,
49406,
345329,
null,
16882,
311967,
null,
292243,
133913,
121105,
14847,
27704,
269705,
335433,
9444,
42561,
111722,
585069,
21850,
246444,
28106,
12333,
38431,
420784,
9330,
246868,
null,
147254,
307795,
36741,
111290,
10728,
664776,
93105,
356934,
121599,
384544,
null,
5529,
null,
198717,
68326,
20926,
515632,
13258,
183052,
3333,
295335,
16146,
null,
28981,
13912,
28914,
26221,
371546,
272698,
24218,
212670,
9858,
42852,
327137,
220038,
115812,
344252,
43001,
null,
191181,
null,
77279,
34727,
390004,
null,
265034,
8743,
994739,
null,
14600,
null,
437974,
110334,
null,
null,
6049,
52416,
136300,
26052,
105329,
198712,
null,
78802,
8937,
39904,
181651,
63532,
null,
627549,
61170,
110731,
28977,
149265,
45227,
160354,
5053,
244986,
null,
36817,
131876,
132523,
39559,
null,
21451,
null,
null,
415590,
null,
null,
7397,
21113,
31550,
null,
243154,
30247,
165333,
261546,
null,
29259,
34010,
37340,
6116,
28328,
162609,
102758,
null,
167877,
2793,
22030,
114841,
107791,
179548,
null,
139487,
57680,
4498,
33940,
137287,
21364,
19942,
null,
419850,
578308,
145406,
260039,
106975,
4358,
35319,
267458,
null,
28850,
23518,
254371,
null,
null,
261022,
23074,
13699,
67650,
27537,
533992,
257600,
64977,
100465,
42365,
null,
68286,
null,
151733,
21703,
72430,
17563,
200951,
6355,
37538,
80415,
300833,
74020,
34132,
14403,
23771,
130430,
200989,
269809,
89321,
161458,
101170,
109573,
23135,
285497,
29407,
372662,
280525,
80427,
170707,
35763,
68317,
35545,
39903,
333627,
81191,
44939,
16501,
154083,
271885,
375927,
62834,
230444,
17596,
60890,
17889,
32713,
144622,
81444,
5500,
null,
40388,
41889,
46472,
74167,
333093,
38559,
28962,
98934,
244854,
99964,
75527,
294059,
254090,
13649,
306986,
null,
54908,
190772,
518560,
113031,
232046,
16391,
61389,
201092,
219010,
95871,
461564,
82909,
54115,
37887,
65472,
45006,
405338,
17272,
16266,
192073,
201529,
12879,
43471,
4856,
242237,
null,
238314,
55639,
40156,
331254,
42063,
18640,
null,
240432,
331044,
21678,
20425,
31686,
239605,
125288,
240751,
25541,
58392,
38941,
3776,
232784,
147045,
39556,
67168,
178732,
265677,
12291,
170823,
34021,
12234,
null,
30500,
234365,
287338,
563049,
24251,
95632,
44222,
284720,
12485,
183367,
23468,
null,
27248,
26763,
58991,
26337,
20516,
519706,
185713,
16623,
716836,
137436,
null,
559930,
440035,
145264,
65517,
138605,
449970,
218508,
193226,
23405,
138679,
213225,
52850,
2134998,
277356,
14777,
373708,
169987,
76694,
19717,
37454,
233281,
523640,
134100,
369532,
238096,
198740,
96777,
499760,
584204,
null,
138861,
54943,
31167,
null,
7006,
23576,
66354,
117509,
383750,
27982,
38203,
177193,
158694,
179632,
61750,
82353,
13709,
282244,
396257,
27061,
16409,
33163,
13218,
236550,
null,
149234,
51033,
373066,
96961,
68113,
261489,
49928,
121431,
39957,
153534,
305248,
19549,
254146,
118712,
195901,
5387,
336442,
267095,
185238,
61641,
159678,
208213,
26231,
219315,
307676,
null,
273822,
15876,
26277,
503511,
192625,
30500,
38288,
32274,
7270,
76654,
431952,
23866,
57953,
69189,
19289,
378638,
266930,
221768,
47451,
null,
49631,
15128,
7736,
135386,
246714,
55481,
113649,
169656,
126593,
17612,
27813,
43612,
83343,
66501,
304548,
140565,
91133,
289219,
15092,
19263,
null,
8891,
62606,
150702,
50072,
36055,
25395,
144676,
51233,
163301,
38566,
57544,
37853,
87164,
107503,
29675,
18522,
20684,
46352,
55209,
null,
183156,
23530,
31951,
17745,
34069,
47763,
48812,
84947,
47075,
17542,
223050,
53919,
334943,
370250,
335133,
69309,
24918,
83994,
null,
5157,
768976,
67414,
51390,
88427,
199200,
255628,
94191,
34259,
151242,
124572,
102794,
223774,
57977,
19603,
34006,
314800,
25894,
132790,
23302,
252752,
81867,
146180,
25413,
252668,
489096,
157533,
30253,
25424,
21272,
null,
8078,
323731,
31360,
57542,
92980,
50835,
45591,
457952,
304849,
358020,
185190,
62412,
142344,
221657,
46295,
27170,
25709,
11232,
13352,
39441,
100829,
8494,
118048,
77323,
304517,
224915,
55783,
32651,
205463,
27155,
120680,
18687,
157495,
606137,
28530,
225936,
100838,
null,
13237,
38987,
38607,
15592,
255390,
133458,
18430,
54228,
69580,
468950,
38806,
414671,
55819,
80992,
568245,
88903,
121504,
44647,
null,
161929,
23863,
820745,
34486,
114687,
11033,
145838,
12481,
7224,
48145,
735258,
null,
76720,
258147,
145210,
11103,
null,
35675,
202394,
83480,
460627,
17183,
68394,
158454,
85498,
64329,
135152,
79980,
14326,
168333,
15776,
null,
535395,
77144,
19048,
196454,
46762,
29657,
43791,
13677,
14417,
null,
148298,
151033,
53925,
12975,
334711,
75154,
104930,
14498,
null,
42788,
17940,
47589,
176315,
33103,
349206,
128262,
12708,
17499,
112382,
293100,
null,
161198,
154749,
4946,
60768,
46744,
36032,
453016,
319819,
152327,
47471,
59196,
34321,
23560,
22913,
214404,
99445,
174363,
243366,
30600,
203534,
173507,
81420,
32125,
16607,
26395,
19101,
30113,
80864,
52569,
63434,
null,
5748,
null,
25049,
174485,
26729,
259071,
69981,
162188,
120625,
294264,
61729,
198805,
439275,
44819,
195053,
25698,
423008,
198312,
26125,
254855,
7818,
80933,
272458,
86530,
165458,
null,
14803,
204222,
292762,
44543,
109006,
74986,
580866,
176800,
214321,
16158,
27372,
41174,
25744,
328280,
287711,
11683,
270441,
1620,
14757,
263198,
69423,
null,
37783,
129560,
528707,
38907,
112575,
14832,
35042,
233129,
200066,
125519,
240321,
107270,
4665,
17711,
419378,
null,
15988,
6674,
null,
142373,
426628,
179459,
39453,
175271,
217982,
36614,
18128,
null,
29690,
404596,
13848,
110992,
266959,
25129,
169691,
12430,
112383,
83824,
145257,
191689,
107568,
52478,
399475,
null,
199953,
10932,
100090,
10195,
138820,
260841,
313398,
45218,
176979,
158368,
25979,
353807,
4033,
24349,
226122,
4290,
331404,
17188,
37752,
17689,
51125,
50056,
207992,
722663,
189777,
67276,
314204,
113848,
null,
220204,
377020,
746402,
2739,
26958,
168870,
112499,
147090,
192886,
44137,
377688,
32662,
22342,
25130,
36716,
43996,
146729,
55399,
4191,
162961,
315816,
245690,
106687,
57164,
11430,
null,
123839,
72438,
139693,
92909,
25295,
41245,
32839,
18983,
24244,
172291,
177188,
239170,
43510,
57996,
34333,
188959,
208109,
6936,
43122,
null,
161914,
345298,
89006,
48894,
42818,
23550,
30519,
304408,
73150,
140013,
null,
26580,
67922,
null,
168527,
349896,
20187,
322598,
19635,
281071,
79744,
203673,
160321,
97968,
29371,
null,
null,
28175,
116657,
48110,
127132,
31968,
209886,
47477,
28058,
642004,
111925,
8833,
76803,
6335,
27965,
56866,
414407,
127342,
32243,
11329,
109965,
14580,
40650,
378770,
196342,
62739,
175049,
30670,
69744,
134463,
30755,
21301,
151190,
59201,
110929,
162632,
47652,
28488,
null,
55059,
21452,
28303,
31335,
null,
16994,
276462,
345336,
108414,
19630,
30402,
93089,
12651,
200311,
204551,
64115,
196622,
257753,
48371,
65090,
24738,
104389,
452644,
132526,
null,
27650,
33897,
172651,
31055,
31858,
24111,
138587,
null,
47643,
36937,
152766,
109808,
217073,
38334,
227668,
18186,
70626,
292848,
39923,
504628,
65260,
109424,
272569,
166637,
null,
138013,
76410,
225465,
360655,
321829,
62648,
28775,
106449,
168236,
10620,
42642,
16056,
40613,
43796,
null,
280689,
15196,
277516,
419070,
209704,
156893,
37575,
8348,
29297,
68100,
136416,
191039,
194645,
139689,
191238,
49965,
43162,
178097,
19289,
16784,
169473,
182429,
283880,
84978,
37822,
51571,
325114,
null,
25603,
29379,
458487,
23812,
null,
166396,
324551,
null,
88409,
34819,
384088,
243072,
66441,
253137,
131855,
116968,
35566,
421577,
27496,
34887,
26401,
118915,
22833,
42644,
36081,
354609,
47508,
157062,
270811,
7504,
6498,
75380,
29434,
41535,
null,
389723,
318271,
44043,
null,
11133,
null,
48633,
68943,
null,
221091,
344841,
122236,
12475,
140970,
29919,
60152,
5730,
null,
21540,
54120,
306956,
100332,
210861,
342581,
157383,
129757,
293089,
179158,
null,
81002,
272065,
164399,
30313,
234742,
82841,
223591,
211968,
188359,
344811,
304118,
37535,
320684,
35701,
37011,
36916,
10103,
7441,
39919,
259497,
23945,
3805,
13258,
18532,
31050,
94197,
12050,
270900,
364659,
84781,
15332,
296355,
54255,
113462,
null,
468677,
130489,
null,
37893,
null,
57776,
412901,
4814,
115408,
30317,
10447,
41046,
36712,
326925,
101117,
41005,
255609,
203527,
33268,
7364,
16732,
130926,
111233,
54595,
58726,
40734,
253999,
151115,
218588,
10629,
26512,
302389,
17952,
75971,
null,
31197,
15648,
7234,
289290,
180821,
20263,
43924,
63073,
283884,
6593,
null,
339238,
366921,
153258,
23191,
9023,
75891,
75883,
155992,
47010,
348128,
null,
148984,
84600,
338612,
341631,
134555,
115562,
325954,
154145,
43652,
156916,
27926,
44106,
214998,
234808,
33157,
21272,
183899,
305799,
439139,
264631,
102534,
157872,
23223,
76052,
244854,
126947,
217742,
680681,
31210,
379542,
null,
48983,
165251,
29012,
85383,
4551,
74937,
132432,
316258,
null,
38880,
208131,
200239,
184679,
175219,
191585,
18431,
108059,
26723,
1066302,
210119,
34873,
4425,
14459,
317477,
24090,
779859,
100307,
null,
39311,
223118,
16503,
161926,
null,
49659,
171019,
22884,
6836,
39837,
69600,
24616,
88099,
54507,
9275,
348808,
9123,
null,
22983,
null,
489138,
262751,
151685,
21178,
233723,
386286,
80076,
534969,
23001,
49792,
168389,
96890,
27705,
95697,
33972,
30292,
171998,
10815,
43154,
10520,
30338,
272714,
433144,
318161,
32284,
481172,
268190,
32734,
null,
325047,
20031,
null,
null,
240135,
149449,
242717,
421535,
5726,
236055,
null,
41291,
206235,
1765,
209598,
31540,
43416,
null,
70715,
211601,
194300,
null,
432768,
206462,
36048,
363960,
10994,
78655,
54712,
123116,
12142,
187096,
278586,
50603,
66973,
317434,
103436,
50201,
33444,
null,
null,
163244,
335891,
284191,
189438,
32754,
null,
452550,
621289,
26026,
221895,
39320,
37314,
290738,
null,
10576,
28413,
80425,
7938,
22482,
41241,
33036,
212098,
140633,
null,
112109,
275144,
13866,
85957,
250130,
234420,
298450,
null,
141781,
32759,
240899,
24189,
12687,
200165,
59602,
19031,
217888,
18377,
19745,
237776,
348564,
191258,
210890,
40204,
29431,
458904,
12802,
50548,
279104,
217750,
22370,
25663,
null,
null,
7086,
200154,
38088,
61387,
28491,
226959,
44755,
511253,
48215,
34914,
43440,
15824,
32685,
68536,
224099,
567894,
null,
104189,
63259,
null,
6018,
648725,
24021,
370739,
59997,
5915,
23444,
18214,
31594,
66960,
409442,
91350,
null,
509939,
69419,
17608,
357584,
435080,
101576,
38486,
176155,
193671,
17326,
208806,
255191,
79080,
136513,
39832,
45107,
30185,
243058,
9077,
7684,
327528,
86072,
25403,
13120,
150999,
28409,
239700,
166383,
8945,
16027,
84462,
160788,
200295,
189027,
54123,
146186,
17639,
18226,
32446,
230118,
null,
184166,
20774,
null,
223553,
67730,
400966,
6647,
30726,
86974,
21718,
120941,
164909,
208115,
34556,
67106,
null,
12122,
19661,
226542,
59344,
118740,
78460,
84691,
21111,
null,
79512,
130069,
36120,
52902,
57101,
30628,
130693,
64855,
3766,
801,
49668,
212779,
368922,
35294,
149280,
33570,
19568,
100295,
32572,
11064,
96398,
306431,
235682,
129162,
4439,
22384,
114165,
34081,
193959,
22114,
null,
179039,
115494,
null,
29671,
74953,
4897,
117759,
15242,
45255,
96842,
469458,
26641,
225924,
38672,
195933,
234062,
33110,
null,
52848,
13294,
430010,
332808,
232401,
16924,
241697,
143879,
381653,
431647,
257527,
56277,
null,
25811,
343806,
37037,
22573,
9509,
468691,
223013,
124154,
17708,
104229,
107261,
491984,
11642,
48254,
183689,
167673,
37198,
12247,
22077,
22581,
374153,
50234,
53560,
519513,
27536,
18706,
34267,
49972,
15471,
11103,
660012,
25788,
254978,
34673,
9344,
20124,
57066,
24767,
89117,
293275,
76147,
15976,
129523,
149280,
148919,
90779,
263547,
38926,
38097,
360022,
207067,
146657,
150772,
9346,
68139,
342965,
null,
328767,
216512,
13912,
325783,
264423,
25374,
56070,
269316,
23306,
116444,
null,
54035,
477725,
28190,
41543,
30615,
24225,
23972,
20760,
38012,
330707,
366858,
2815,
225205,
36224,
316421,
141481,
142442,
67466,
51676,
69752,
80857,
29649,
2599,
10761,
null,
28508,
9592,
30270,
23578,
15094,
166008,
179281,
42178,
38542,
27402,
109516,
112161,
56618,
7990,
621505,
17114,
281522,
531101,
11765,
1392,
36759,
212622,
21780,
233173,
48652,
101093,
311172,
19851,
null,
247971,
150363,
312243,
28640,
163821,
43863,
120899,
345604,
41685,
null,
52696,
null,
34910,
0,
18962,
42742,
69236,
25338,
162096,
108153,
27826,
47244,
226960,
14812,
61542,
44469,
76665,
72396,
null,
591017,
25482,
218343,
239078,
218573,
37716,
9993,
20317,
7461,
101355,
46265,
29853,
249207,
17251,
118839,
286062,
null,
292373,
326648,
105247,
null,
65498,
73254,
409318,
35665,
495216,
15354,
null,
45350,
46681,
26718,
11198,
174804,
14090,
52724,
3783,
193620,
320435,
29031,
139581,
141030,
19963,
91635,
97106,
96013,
80816,
24027,
343824,
32680,
130987,
135140,
28716,
315111,
347368,
40230,
58043,
52959,
293969,
661,
23512,
231695,
136464,
181563,
33910,
37943,
25935,
25119,
28926,
142470,
30851,
322740,
41080,
311888,
289910,
18092,
20654,
6938,
210437,
17286,
205747,
55482,
11488,
348824,
null,
178337,
299628,
84971,
259006,
190396,
null,
33171,
35781,
null,
200379,
133159,
null,
86874,
212290,
297117,
null,
25090,
131552,
5631,
null,
38811,
34851,
131780,
66048,
302908,
null,
225759,
159308,
124206,
38570,
27433,
99397,
19381,
189015,
336538,
16393,
106413,
127579,
292358,
104523,
161890,
162514,
48086,
278644,
null,
373293,
1787391,
249806,
29069,
19329,
32946,
445485,
205582,
214813,
8796,
21843,
27673,
null,
127143,
130943,
215609,
170461,
9820,
333292,
39139,
6130,
8912,
177568,
24158,
403221,
198389,
43012,
15019,
null,
95665,
89318,
31018,
821605,
245531,
131678,
187181,
180277,
343537,
36134,
109764,
29112,
13100,
17579,
234450,
11579,
50565,
64032,
2531,
2372,
155812,
98622,
468673,
270404,
37720,
80837,
30775,
19756,
199637,
49961,
78460,
13377,
126457,
16214,
177009,
24986,
129706,
13785,
18497,
211643,
23110,
68655,
30517,
372506,
24333,
518188,
129905,
13423,
583234,
264533,
null,
170765,
217940,
341906,
17015,
24224,
194754,
58652,
87783,
22209,
441460,
601146,
356216,
null,
205988,
108710,
60198,
438183,
59604,
null,
122488,
69087,
59899,
45437,
333521,
21731,
null,
44316,
56973,
3516,
2143,
141851,
5886,
225376,
6123,
222648,
230219,
178343,
448776,
155022,
42091,
353587,
24806,
32711,
32544,
22233,
27026,
89825,
190814,
39956,
10863,
197976,
196788,
125194,
145187,
23715,
null,
216807,
509534,
123894,
28191,
599198,
79273,
62319,
22349,
184059,
220467,
251839,
288852,
76419,
9631,
167580,
207117,
34984,
null,
null,
10396,
329306,
145986,
311603,
841012,
271662,
14764,
22661,
12508,
28282,
168458,
67907,
139998,
null,
null,
244081,
244229,
null,
223227,
208480,
null,
39741,
141643,
34482,
26377,
133051,
null,
174442,
140928,
206823,
25730,
null,
null,
38403,
53221,
29337,
91943,
91609,
52533,
90509,
1556,
53525,
185954,
60036,
147927,
28413,
16891,
38978,
305627,
148361,
133396,
287624,
37497,
129002,
12880,
30537,
349442,
19057,
203144,
264853,
null,
35665,
48944,
102483,
39733,
46060,
224115,
null,
277429,
208657,
26493,
36393,
215341,
16112,
355132,
7271,
35901,
3657,
null,
332568,
179584,
44576,
220594,
134998,
58296,
187380,
41326,
2308,
160550,
76027,
396271,
460038,
53579,
null,
null,
437724,
122600,
18052,
156280,
330926,
14065,
278220,
null,
150239,
122462,
24742,
18363,
69293,
192639,
35511,
45330,
154452,
266827,
28440,
null,
112875,
131606,
90299,
224188,
40557,
167923,
169896,
203955,
1273080,
93753,
336794,
22616,
208003,
60198,
219783,
null,
144405,
81748,
4914,
78239,
19714,
143505,
68731,
339675,
13683,
18070,
312915,
14989,
32274,
12808,
982076,
217582,
null,
72085,
153884,
219550,
18511,
99387,
7716,
9987,
246386,
174946,
30182,
96113,
191967,
251205,
278245,
57400,
156123,
36502,
60217,
180553,
25563,
10946,
123439,
219571,
7629,
64686,
12041,
253560,
54160,
7450,
221136,
30229,
38643,
122662,
317813,
125343,
79272,
40103,
9397,
38,
166435,
143073,
344131,
null,
null,
19862,
6184,
109470,
258526,
58168,
145007,
null,
170013,
290661,
154785,
30158,
67150,
11256,
21642,
378192,
123269,
8097,
22992,
124373,
9020,
202559,
44138,
19686,
218349,
110631,
12743,
5197,
615687,
265779,
64927,
171088,
343980,
9326,
201079,
6405,
33801,
161752,
35748,
77766,
207066,
69270,
33540,
187643,
95559,
63577,
null,
17499,
39201,
279008,
53924,
51982,
32821,
null,
20287,
64238,
132776,
37921,
78681,
null,
175042,
138989,
85020,
407421,
40701,
13751,
131583,
47807,
39516,
110237,
192455,
13459,
16650,
7754,
106944,
244119,
43941,
null,
228419,
27325,
208226,
269234,
32831,
100000,
256938,
146540,
null,
52415,
null,
166161,
39761,
21506,
54883,
null,
100379,
83871,
5346,
110255,
84149,
150711,
26558,
6735,
92344,
262707,
408136,
135040,
194001,
19079,
206447,
123367,
14837,
132343,
305229,
38040,
16979,
106377,
141030,
12768,
null,
358737,
958527,
30056,
46382,
5416,
214524,
168189,
436371,
8233,
103440,
204575,
178528,
22591,
176281,
49895,
14330,
63143,
207372,
30865,
243224,
71750,
674222,
46089,
68196,
111426,
226548,
276763,
null,
630539,
200325,
null,
22281,
263654,
null,
542565,
10382,
59606,
94167,
null,
62585,
100887,
null,
20000,
3125,
53331,
135469,
null,
81705,
209268,
184983,
81409,
23391,
20160,
30020,
430687,
23646,
40613,
13024,
204668,
null,
16398,
136966,
102783,
29957,
159206,
75237,
14812,
142142,
111493,
156869,
null,
417275,
291970,
52265,
44834,
3236,
null,
97744,
388785,
66723,
33138,
232760,
185485,
58663,
274741,
25112,
34152,
56782,
521659,
77206,
296588,
null,
200825,
22916,
92356,
24076,
171738,
20595,
140178,
8249,
null,
115557,
28318,
62388,
9593,
35204,
15517,
146929,
31413,
262518,
11409,
32491,
217658,
117882,
28785,
101077,
null,
342253,
null,
1063,
15948,
296698,
137366,
41719,
224308,
126434,
20499,
1080043,
188389,
30500,
50247,
247125,
374297,
12920,
73767,
346309,
null,
25873,
95111,
244817,
null,
null,
15049,
148100,
151948,
39018,
200853,
328987,
233854,
477666,
261998,
10648,
260285,
15557,
90566,
4301,
13156,
324773,
261763,
37739,
206538,
4966,
13223,
27571,
58875,
9934,
120659,
51573,
null,
53438,
34929,
48141,
43881,
420142,
46105,
269068,
73115,
424956,
140619,
39600,
8634,
21805,
8957,
39946,
64642,
97196,
354524,
252644,
150713,
10434,
680759,
90278,
148030,
165596,
73998,
191414,
44468,
141573,
141963,
213465,
361178,
47233,
41750,
null,
157051,
402620,
38249,
109664,
470984,
110668,
null,
244878,
168552,
825092,
149993,
214690,
151257,
92527,
9558,
80827,
44055,
31047,
204122,
103085,
259590,
84732,
328523,
758717,
149267,
238040,
null,
244693,
73881,
67297,
null,
27410,
175774,
32126,
14606,
501255,
13224,
32093,
397918,
127419,
49880,
133532,
126813,
90706,
106202,
8894,
165730,
30281,
161682,
373291,
484111,
214262,
364924,
null,
29201,
56962,
307116,
47774,
308718,
16118,
197487,
394719,
27230,
230304,
167878,
201387,
601523,
196818,
17299,
205157,
12111,
309317,
144864,
null,
197039,
null,
268270,
23440,
null,
147576,
155555,
90380,
150506,
44127,
50977,
190411,
20336,
30246,
266662,
46686,
219437,
149699,
30860,
31829,
18481,
180975,
19302,
24184,
527464,
28744,
86355,
129778,
130443,
387961,
141761,
192113,
201204,
63083,
15340,
68450,
15449,
43546,
15908,
30870,
178009,
11205,
64694,
53993,
299394,
null,
165900,
92773,
62208,
10256,
508052,
144671,
58577,
121317,
30539,
78986,
211548,
150626,
23169,
20628,
72912,
170301,
312333,
28585,
198042,
82162,
319489,
879838,
445062,
43508,
65117,
null,
67385,
375070,
1607,
409589,
76532,
25808,
222681,
287228,
17353,
115633,
21899,
29830,
166047,
247255,
null,
59751,
207753,
53653,
20415,
186857,
7631,
20031,
18444,
null,
16042,
218730,
181392,
6982,
280992,
54026,
56984,
null,
26848,
575314,
23467,
84439,
126248,
204316,
144071,
35552,
4089,
41374,
367016,
46171,
29165,
115110,
103669,
35678,
132550,
12499,
2307,
77401,
48784,
15806,
91909,
213766,
286547,
143250,
36699,
33167,
null,
null,
105825,
33249,
248350,
7463,
177758,
34061,
147570,
11586,
47657,
43989,
32891,
95002,
204305,
20699,
344159,
28509,
177778,
342970,
77569,
184292,
586196,
493205,
16264,
34869,
52690,
221555,
255994,
42941,
161021,
null,
32029,
null,
25362,
100906,
50701,
10603,
17001,
null,
211744,
68456,
62061,
52526,
296742,
42877,
542437,
20837,
374877,
59545,
19634,
241767,
22806,
433258,
36594,
29363,
798107,
60730,
257797,
307456,
18500,
18133,
null,
20940,
22902,
100638,
30556,
4258,
96512,
null,
56116,
47075,
42513,
109494,
null,
52972,
108534,
141171,
null,
176631,
150491,
15480,
5863,
14151,
28102,
83889,
15513,
357178,
131871,
32222,
316773,
50924,
83629,
74436,
577,
16468,
210271,
22995,
14878,
11833,
64169,
903,
4511,
7943,
73052,
131732,
50370,
3215,
32220,
240190,
3571,
128431,
124570,
432529,
25439,
127056,
25830,
54642,
140842,
383511,
881417,
60328,
262023,
263651,
53835,
160677,
31401,
23019,
null,
234511,
null,
223853,
342999,
154040,
277902,
48413,
195944,
198544,
11197,
25342,
121194,
151191,
84972,
26891,
null,
189437,
317831,
404433,
26327,
284890,
22034,
null,
1663,
46119,
15995,
185988,
36900,
149232,
33631,
153272,
47949,
50999,
null,
null,
null,
null,
144078,
595564,
8577,
112013,
35330,
37341,
3082,
143141,
35539,
23610,
170042,
null,
14186,
243905,
96564,
179915,
64959,
318554,
63348,
28640,
66931,
39527,
null,
551060,
51118,
22311,
43753,
38072,
63070,
null,
8250,
51467,
229635,
211712,
119386,
16999,
100591,
46290,
154822,
8014,
192810,
152507,
39073,
9779,
16196,
10151,
17262,
69992,
null,
6987,
196979,
null,
91152,
46069,
406753,
null,
52312,
99257,
5170,
25561,
161083,
null,
266654,
74330,
331152,
512994,
667730,
38073,
243258,
3744,
null,
12100,
236847,
80557,
17793,
303122,
null,
38642,
496126,
21105,
532839,
335356,
67116,
92443,
224397,
302065,
42838,
4904,
44499,
159758,
277591,
24439,
85166,
160811,
9008,
null,
12520,
241799,
102054,
69426,
15715,
265996,
27079,
326060,
147122,
8606,
31215,
100909,
184507,
88896,
18388,
405223,
286677,
4993,
317403,
24395,
172465,
48948,
706357,
21985,
42429,
24214,
17047,
41981,
10620,
124005,
30325,
17624,
36773,
731348,
null,
96428,
11232,
31805,
12633,
342418,
81047,
52213,
17776,
15302,
49062,
362662,
44590,
65433,
180015,
1110701,
49483,
null,
20022,
49009,
17939,
73712,
15048,
8407,
162171,
25527,
71295,
48387,
181449,
77726,
1191,
185544,
32933,
4354,
null,
191105,
160070,
22383,
198863,
9459,
7787,
453873,
149691,
31568,
31156,
122754,
null,
45391,
45077,
3291,
null,
177488,
6636,
52269,
30571,
24178,
21710,
157270,
175044,
8721,
42530,
48056,
null,
278837,
199652,
231357,
190429,
10464,
51737,
266136,
373228,
52623,
38674,
39227,
624896,
null,
16081,
71387,
51434,
147160,
16494,
414576,
5657,
42785,
41748,
19744,
57568,
492952,
129439,
19534,
27016,
48394,
177285,
60223,
275869,
80320,
53346,
179863,
8280,
145373,
null,
15084,
17710,
20505,
249120,
null,
53470,
115534,
108776,
35218,
170173,
116694,
250629,
30247,
6990,
143238,
63835,
6389,
null,
281723,
40704,
70440,
27192,
null,
284486,
29423,
61761,
168038,
72207,
109163,
47416,
334512,
144755,
261724,
179595,
null,
237487,
4213,
25490,
407985,
84658,
2318,
162967,
126032,
null,
215322,
240406,
708680,
548987,
21179,
118810,
10999,
19099,
730486,
11605,
39710,
288439,
33667,
28544,
35833,
null,
134361,
271672,
217064,
44727,
154535,
27527,
184034,
14333,
19222,
null,
191307,
37108,
54465,
74917,
118038,
43780,
176685,
269420,
null,
null,
54570,
618979,
28105,
104882,
67389,
255263,
370251,
161221,
19931,
14288,
247237,
24614,
6370,
81041,
112605,
51566,
56203,
194847,
5425,
270180,
13006,
126715,
383510,
161550,
201274,
127445,
272839,
34785,
37338,
368585,
28220,
31315,
226133,
5681,
196582,
126202,
67706,
141207,
311166,
299756,
104247,
376693,
97963,
28345,
169876,
194793,
1161200,
134432,
292515,
52232,
90055,
32588,
13751,
22644,
24903,
24353,
225925,
43502,
null,
301241,
214324,
93197,
275063,
281360,
81877,
null,
167214,
61534,
114474,
174652,
117129,
79672,
43615,
243663,
263165,
37672,
408928,
59713,
24636,
32329,
17688,
66903,
24917,
425405,
4428,
357189,
42981,
14137,
23957,
367963,
23498,
298846,
33789,
null,
31666,
15484,
249659,
114005,
null,
null,
49707,
262101,
112375,
662041,
134804,
null,
22535,
28940,
228483,
29149,
31891,
111610,
107938,
165581,
24094,
242949,
50999,
372984,
13190,
81115,
164121,
44861,
79392,
157388,
93455,
180226,
null,
40183,
9980,
320060,
177410,
43305,
2489,
28268,
122285,
9627,
null,
155713,
32016,
87423,
262356,
null,
16662,
123525,
128658,
97275,
5298,
49458,
24491,
29759,
107640,
163348,
null,
8806,
9203,
13176,
null,
163797,
28066,
320743,
17040,
29890,
156624,
500367,
65280,
192409,
107903,
250308,
322259,
305052,
141457,
70413,
128559,
227255,
365506,
300720,
989200,
240728,
634878,
288812,
null,
14649,
178581,
27948,
226135,
null,
115109,
null,
532415,
6577,
291098,
23414,
217164,
108803,
19824,
174466,
65997,
6816,
24177,
121502,
556429,
431404,
19018,
21915,
133029,
335697,
655046,
31160,
55956,
36262,
17783,
24528,
123570,
191121,
206816,
57465,
14146,
256446,
247784,
107941,
255197,
377306,
null,
76424,
43179,
232936,
428523,
383240,
165926,
14891,
213064,
107737,
96074,
360208,
264307,
253529,
24070,
267653,
47978,
57463,
240407,
76540,
26255,
null,
577568,
null,
20687,
null,
527786,
323933,
33756,
32373,
165103,
32766,
98530,
278028,
373679,
25330,
null,
null,
281788,
4423,
33439,
217397,
405573,
547036,
35098,
13416,
46971,
25109,
6694,
29771,
18994,
362207,
null,
66847,
295270,
278532,
366228,
65102,
73398,
45166,
222059,
146929,
33152,
437938,
108470,
234900,
183817,
402149,
null,
74528,
370142,
118051,
49460,
196913,
209491,
154118,
553926,
16335,
222416,
152710,
3808,
32391,
136311,
153314,
447925,
247103,
284717,
null,
51625,
350405,
104080,
11751,
140969,
28875,
56892,
267889,
225799,
612595,
79465,
19992,
41690,
47717,
259732,
118141,
263680,
36733,
267741,
150192,
282645,
200523,
83317,
7745,
19241,
11856,
18882,
9485,
39465,
572457,
21363,
null,
39684,
81463,
27916,
133551,
737989,
265998,
290464,
435418,
191741,
5414,
29329,
100881,
23504,
47250,
7401,
236009,
null,
180730,
null,
20501,
null,
68213,
null,
647323,
41160,
174230,
359660,
21605,
17143,
14209,
220382,
20105,
2018,
25388,
null,
null,
4074,
556428,
68349,
28375,
22913,
557890,
117725,
null,
23024,
61241,
79211,
68504,
74916,
219318,
181678,
100226,
242624,
80867,
43922,
132803,
285777,
107604,
36392,
34185,
433011,
114656,
4040,
5779,
41122,
14034,
74720,
34029,
5614,
33296,
16079,
171995,
522685,
60883,
98847,
6381,
166150,
222826,
20086,
353986,
264072,
322185,
null,
177441,
147926,
null,
null,
48391,
226704,
387726,
10497,
204393,
227580,
99461,
172126,
164036,
108830,
44773,
45413,
43307,
14575,
49605,
96336,
228160,
37026,
114655,
9591,
117041,
348502,
148923,
3461,
19857,
5715,
353872,
36630,
232696,
112981,
157919,
67597,
null,
47617,
17619,
18848,
null,
28231,
124336,
211098,
197506,
1348823,
236007,
78306,
334921,
54769,
17763,
43835,
20795,
null,
297361,
754500,
29284,
152262,
134618,
78732,
23836,
17793,
68224,
274916,
323343,
53495,
56947,
101558,
261356,
38264,
46845,
728964,
314028,
41552,
361818,
187664,
null,
65593,
64277,
8117,
39503,
331773,
46308,
24630,
149318,
53429,
null,
20364,
90241,
49847,
31723,
300568,
73485,
103653,
24576,
8319,
49156,
44664,
247918,
50221,
166275,
134321,
33290,
410189,
48712,
74769,
155048,
102572,
367696,
18400,
null,
50253,
6560,
68804,
598885,
22318,
23269,
267540,
18506,
118095,
17526,
null,
302520,
47923,
70191,
21628,
289810,
240933,
162218,
57166,
177811,
203338,
212496,
46561,
286510,
100760,
null,
74532,
null,
607002,
null,
283586,
34781,
207690,
134989,
7774,
22863,
463644,
27907,
214352,
165592,
32942,
429174,
24577,
219527,
493223,
254688,
66087,
158941,
25408,
24200,
18352,
157651,
38793,
null,
28416,
112819,
42248,
351829,
170525,
7115,
27885,
327705,
165449,
49593,
105672,
195495,
69087,
36835,
359284,
36971,
38755,
null,
12471,
684236,
14758,
33871,
92439,
112044,
57085,
null,
7188,
178093,
20460,
155893,
56844,
160836,
34826,
49544,
48215,
230535,
55574,
198659,
112682,
null,
null,
32764,
28530,
214049,
65560,
499758,
9985,
23875,
76341,
null,
291784,
241368,
null,
215700,
198088,
42753,
317104,
8448,
null,
149078,
25312,
312725,
33951,
144346,
5363,
449833,
29875,
75458,
323411,
103637,
38942,
56110,
154214,
1182474,
178109,
224250,
null,
419041,
187028,
31633,
101517,
47715,
210142,
39622,
100817,
48309,
487997,
28638,
351587,
15772,
160734,
20545,
151063,
303292,
51329,
208438,
285039,
327844,
184884,
554896,
31353,
null,
336155,
12762,
null,
92178,
68364,
20326,
43338,
123912,
13207,
121964,
150670,
341375,
105217,
296836,
251977,
298895,
31615,
315112,
55086,
5321,
238722,
47596,
284687,
5635,
26383,
164654,
201179,
182663,
35360,
221306,
74967,
227984,
390368,
69717,
5528,
null,
72615,
318185,
116131,
755579,
175017,
32690,
5097,
75089,
6449,
941851,
1247421,
null,
14650,
242866,
162140,
75878,
160069,
221920,
35852,
389327,
20485,
76482,
147173,
486937,
null,
109786,
78039,
2482331,
632725,
29712,
73412,
51916,
46693,
3594,
122078,
245648,
31435,
17823,
34658,
26422,
33404,
33449,
11403,
39856,
null,
31646,
35937,
490247,
23582,
28455,
null,
168857,
384828,
null,
14810,
8661,
25131,
60555,
240881,
116594,
166988,
254793,
38048,
88699,
126151,
14461,
100919,
130563,
251815,
146197,
126661,
59437,
278324,
13689,
null,
66077,
70074,
null,
407912,
169962,
116895,
27639,
202631,
12657,
137924,
30732,
121850,
null,
55553,
3779,
49931,
102969,
220121,
80927,
16994,
24341,
138718,
82386,
585365,
53118,
null,
null,
62243,
46392,
35948,
32647,
31364,
139546,
96921,
28532,
203619,
11410,
17194,
null,
231286,
18441,
231230,
39334,
35749,
204890,
32907,
30312,
130339,
74354,
65054,
21313,
298030,
148501,
45627,
473477,
null,
136114,
34619,
338103,
127489,
172177,
null,
91289,
575278,
null,
166555,
302760,
47254,
142498,
207210,
12147,
15887,
176207,
92718,
48450,
98318,
26055,
185766,
59820,
6272,
67024,
197109,
61436,
96322,
13907,
2823,
221542,
452544,
36255,
null,
39872,
76696,
230103,
406565,
88746,
null,
27047,
69530,
52062,
518338,
72652,
9791,
42588,
61049,
11409,
394307,
238180,
241764,
152095,
22661,
277174,
355081,
null,
383564,
9353,
185768,
33519,
294702,
75673,
391521,
68212,
null,
null,
1710232,
88782,
14373,
null,
50824,
22960,
44882,
92242,
225251,
187885,
146142,
22802,
26212,
52492,
null,
369531,
95907,
26749,
114949,
null,
41785,
329433,
35955,
11166,
48199,
65767,
46054,
313762,
180805,
57006,
39898,
87192,
null,
14264,
251345,
236818,
322310,
10901,
null,
11191,
33176,
49175,
55292,
337702,
108781,
null,
350620,
81211,
109945,
18244,
null,
55755,
8073,
130531,
18152,
371533,
25478,
138730,
36282,
413225,
129046,
75660,
6156,
15539,
23442,
62267,
26926,
null,
28140,
242362,
9801,
25357,
194192,
138764,
28142,
28907,
null,
321276,
189992,
14390,
359782,
190115,
588696,
56279,
6395,
22614,
196750,
163746,
181664,
221339,
362353,
154625,
357559,
34487,
null,
129786,
97113,
243948,
285989,
45549,
null,
403925,
2151,
208886,
93815,
519250,
45297,
92919,
406839,
15476,
1707,
233105,
189520,
116980,
24809,
24365,
162312,
2866,
891306,
151881,
176466,
15590,
37067,
205401,
28942,
null,
333529,
120894,
149624,
46102,
null,
497712,
null,
360031,
75367,
null,
182207,
291179,
null,
17644,
8124,
331019,
36164,
144728,
4157,
401534,
8930,
29921,
136139,
33594,
null,
45136,
28777,
28790,
174804,
30075,
null,
42962,
253631,
null,
365663,
189683,
61298,
166426,
40944,
null,
61443,
127345,
39679,
135942,
18577,
106784,
201074,
34530,
197147,
84760,
361382,
16732,
14222,
368773,
126124,
156390,
21598,
35491,
228800,
146395,
235156,
112466,
258812,
269781,
163536,
null,
null,
29808,
113128,
84490,
907858,
6397,
410365,
520017,
28019,
5007,
116669,
41361,
366556,
6714,
10549,
106240,
null,
104575,
75099,
52971,
432875,
258158,
256492,
7358,
103282,
91752,
177067,
34109,
15867,
59096,
null,
27299,
47561,
265113,
126798,
241309,
366679,
139859,
385274,
null,
747499,
272692,
372071,
95565,
null,
339816,
197713,
76522,
71028,
39312,
252816,
423970,
23629,
135724,
9980,
21478,
423664,
51006,
223183,
25268,
34684,
null,
123185,
5065,
37897,
26354,
37652,
63640,
35341,
95187,
134695,
243371,
28613,
183820,
22479,
40000,
21975,
149549,
297259,
362927,
19200,
31693,
158677,
71487,
34593,
167722,
52596,
258557,
215904,
177322,
8675,
null,
null,
122747,
33533,
163387,
270529,
49446,
339908,
93275,
340421,
685755,
181480,
216157,
4799,
50320,
4709,
317124,
7233,
237414,
128721,
42223,
33245,
33620,
71422,
50841,
33951,
280317,
36446,
217253,
13768,
200183,
364231,
149154,
1092523,
262440,
82641,
575328,
52140,
605550,
null,
712,
170055,
146374,
202278,
18296,
6182,
372510,
385745,
15057,
20324,
16342,
5957,
28623,
93104,
49508,
315702,
115724,
21111,
76485,
49737,
74143,
245940,
11530,
38344,
118524,
8067,
25586,
156739,
26347,
57919,
134287,
62593,
335416,
356611,
86749,
null,
220765,
344625,
92609,
51559,
183951,
39480,
176563,
20020,
null,
187741,
27783,
190373,
223673,
null,
72840,
262490,
417216,
137646,
374891,
17025,
267709,
103702,
84322,
29824,
15367,
57870,
29547,
18099,
303036,
22879,
400287,
49971,
302946,
51420,
5977,
154778,
13202,
null,
null,
7676,
17104,
264070,
424731,
70173,
363144,
69529,
34478,
61135,
236431,
279011,
15025,
25099,
23024,
161683,
26728,
25652,
198764,
753078,
94109,
44835,
146504,
526338,
null,
65585,
138142,
305208,
340222,
326362,
242664,
92066,
18317,
20209,
38247,
159104,
43121,
59610,
118085,
null,
6304,
295420,
20878,
13695,
148706,
93344,
46697,
10244,
32625,
45826,
null,
266401,
17366,
20996,
null,
287316,
15571,
162875,
30182,
25156,
35293,
108019,
44522,
268278,
41183,
171057,
35879,
315768,
272268,
null,
21097,
null,
250995,
216793,
36736,
254884,
37402,
398496,
123170,
13915,
88169,
198209,
254197,
21063,
null,
159942,
105270,
null,
7630,
21004,
257067,
63372,
40987,
162935,
144988,
21890,
74264,
125566,
null,
20562,
37834,
299936,
92181,
299643,
13480,
349908,
141544,
2881,
79700,
23918,
59803,
112031,
21530,
null,
55822,
184228,
29625,
270841,
215715,
21538,
349723,
30935,
263399,
74180,
62969,
170120,
293891,
197106,
189398,
371013,
30033,
192986,
40759,
6167,
50563,
55280,
13208,
58334,
229918,
160425,
58329,
81239,
85629,
27549,
99993,
311468,
56475,
15050,
174541,
89369,
12600,
318466,
295697,
29947,
10813,
195155,
18936,
39544,
485022,
25489,
370839,
18587,
200177,
4569,
65916,
22956,
7870,
3502,
258612,
265652,
null,
102123,
47610,
198833,
3031,
39288,
223011,
14914,
168642,
36193,
15608,
449220,
null,
28048,
714371,
273035,
88176,
188248,
180368,
17632,
324747,
75906,
63366,
29944,
228433,
36521,
303827,
174155,
21864,
70210,
44089,
122129,
5937,
439941,
73085,
26702,
43298,
38146,
207734,
150406,
37069,
126384,
12070,
158474,
null,
231712,
169903,
null,
138318,
694957,
280127,
359740,
95908,
null,
173782,
47561,
79331,
70048,
4986,
10936,
10460,
66889,
42421,
235952,
19894,
202093,
44823,
12066,
18173,
294880,
26785,
17115,
96723,
16962,
132477,
198182,
169307,
89142,
40096,
null,
51507,
220775,
250801,
19379,
205951,
150934,
19274,
null,
18119,
111356,
15973,
173302,
3008,
38175,
69363,
16950,
152568,
116940,
92880,
null,
null,
9946,
9438,
39233,
110922,
57536,
74087,
46358,
32362,
9865,
20817,
24562,
9420,
221281,
116767,
92423,
159041,
11211,
83293,
null,
192112,
16524,
12377,
107778,
23273,
79385,
20747,
88734,
39797,
41065,
13660,
64888,
25435,
190519,
215503,
73333,
122031,
54479,
24099,
100720,
64555,
223740,
6875,
230726,
59900,
209368,
16177,
100363,
10082,
39080,
99803,
573193,
109339,
141497,
159810,
52183,
21539,
27789,
9775,
25154,
332227,
11488,
null,
91186,
12045,
22664,
58449,
116531,
38986,
162705,
38066,
35431,
77534,
232932,
12931,
179519,
28380,
247169,
29548,
110873,
24428,
77290,
285578,
35330,
74545,
7448,
28877,
109057,
null,
193341,
null,
11734,
15022,
50676,
22451,
294867,
49101,
17929,
206785,
379275,
34594,
null,
14158,
1938,
284860,
73802,
74429,
5162,
8664,
56406,
121039,
null,
9715,
51783,
296858,
111430,
73299,
55544,
259057,
177385,
10406,
113120,
null,
209795,
158572,
368882,
125314,
6762,
42513,
null,
null,
155667,
281547,
34139,
41203,
106946,
56701,
null,
271635,
27691,
352845,
43865,
31949,
17920,
29440,
361749,
214868,
null,
234917,
13125,
311600,
103026,
259426,
192235,
158637,
37000,
19601,
38080,
369351,
172232,
81241,
11591,
305516,
84695,
166677,
75665,
43981,
164867,
14802,
null,
15205,
54971,
111179,
null,
441440,
427400,
350857,
83165,
null,
null,
236766,
160805,
41645,
167969,
16285,
null,
null,
367702,
38136,
67178,
176233,
11504,
313951,
214905,
181853,
126755,
11366,
64127,
null,
533159,
91063,
118544,
212952,
122208,
null,
77793,
153624,
null,
25134,
1859,
null,
39452,
16037,
362426,
68773,
null,
11592,
17008,
335295,
45612,
708475,
14526,
234866,
29898,
5797,
178397,
199495,
43223,
33884,
15874,
9039,
22111,
10624,
82587,
66456,
176199,
349435,
67097,
18934,
97689,
31632,
331079,
459123,
167225,
300255,
228413,
317300,
7962,
43294,
112214,
53190,
39179,
272358,
202022,
294227,
43348,
203004,
269123,
226147,
78054,
453989,
137243,
30521,
308711,
150816,
12726,
null,
132084,
108858,
76474,
14096,
273331,
105035,
124972,
18671,
379229,
60302,
73277,
143738,
280345,
147490,
38884,
28401,
null,
null,
155218,
475308,
34436,
355445,
109651,
416595,
351907,
188911,
37520,
36586,
51626,
61898,
3837,
149956,
174713,
425256,
15554,
214381,
257213,
116944,
null,
43083,
320499,
9938,
60439,
201776,
52386,
48511,
null,
27783,
99051,
355752,
248956,
248742,
607393,
43606,
16073,
22430,
22231,
123779,
165535,
212551,
336182,
117604,
365831,
11166,
null,
15218,
266330,
200717,
33990,
0,
2913,
41574,
8365,
56849,
40984,
234341,
350055,
62858,
null,
294285,
26778,
122311,
92657,
406379,
95744,
24633,
165111,
null,
337891,
7538,
27016,
28065,
47542,
74033,
null,
88705,
null,
162412,
201609,
201373,
152503,
84513,
10652,
37106,
6232,
154688,
387343,
31949,
null,
41737,
200067,
52178,
307568,
68218,
168090,
156224,
240969,
null,
250771,
69802,
32168,
199549,
27023,
null,
14059,
332500,
225032,
11758,
8023,
397661,
11980,
94724,
70545,
200521,
1286,
null,
92801,
56586,
148348,
35417,
104361,
415830,
15549,
43971,
176800,
244807,
172739,
21831,
48749,
196119,
29925,
42670,
5071,
12712,
156512,
363068,
38358,
236450,
30443,
3515,
112849,
null,
200832,
93430,
69857,
10438,
43703,
39316,
null,
16562,
null,
174938,
12661,
91,
4204,
269049,
241577,
225479,
11449,
46829,
397189,
18656,
18259,
13581,
92452,
190344,
184010,
147298,
6879,
25748,
64960,
44289,
null,
14498,
118916,
148694,
13923,
10368,
269281,
133037,
338336,
23020,
20857,
343181,
136306,
159068,
72963,
null,
133416,
227163,
132585,
22212,
284378,
354700,
41132,
61097,
254818,
null,
477692,
304634,
331836,
26006,
256894,
30775,
40949,
55929,
190811,
186107,
9847,
322775,
159773,
22318,
188488,
156764,
991484,
null,
12401,
null,
146323,
8803,
null,
27035,
5854,
348109,
97283,
123331,
224098,
191544,
205286,
366190,
15497,
83561,
303467,
null,
124145,
169701,
234057,
17109,
301909,
68501,
205305,
20120,
17670,
77700,
41090,
16826,
15024,
139883,
265687,
184641,
103960,
13943,
61973,
62210,
13154,
68205,
31710,
null,
65951,
202458,
46862,
252155,
null,
null,
null,
171462,
183292,
221938,
294611,
195402,
null,
38062,
13787,
192814,
63380,
108315,
9485,
98017,
122763,
159795,
128276,
6629,
26721,
189256,
187944,
421567,
38801,
281655,
9980,
null,
108551,
25910,
29180,
217991,
null,
3654,
95,
273305,
32026,
55995,
109216,
179312,
224645,
102487,
61161,
null,
215250,
100113,
31077,
57302,
42720,
148007,
15152,
196912,
85211,
440348,
789521,
222296,
4692,
122555,
10166,
null,
null,
null,
64612,
61594,
97734,
92080,
74414,
null,
238060,
null,
29338,
389743,
60456,
147238,
118382,
83863,
949,
81875,
69386,
205528,
18163,
51238,
42598,
70224,
127188,
114459,
84916,
112586,
null,
16067,
62794,
185978,
273847,
84861,
57364,
287131,
209841,
119591,
34106,
null,
10405,
128082,
12737,
54507,
9507,
31162,
67887,
12905,
263758,
146970,
283799,
92435,
130245,
49662,
199584,
187859,
14791,
180796,
192045,
167990,
132885,
14922,
300489,
39371,
20679,
80159,
10116,
9015,
361428,
33286,
173752,
71211,
585833,
130275,
321254,
12032,
518445,
328465,
114305,
null,
43808,
41324,
137079,
302586,
107160,
293733,
248883,
98454,
227966,
110720,
195559,
27735,
6420,
322617,
89981,
30063,
156833,
26817,
null,
317835,
48022,
14744,
245135,
15217,
76114,
179819,
370367,
53471,
32937,
167908,
133140,
23395,
24820,
16056,
150057,
309163,
5071,
63396,
395817,
22530,
29925,
192621,
200489,
252738,
null,
22217,
155070,
422071,
11952,
330037,
32716,
103770,
557315,
23233,
158553,
176969,
57208,
267448,
null,
41230,
197632,
71426,
480411,
42343,
26677,
45840,
56192,
452283,
null,
88363,
70074,
265021,
19748,
41063,
16516,
87230,
46618,
405642,
438822,
37094,
null,
19287,
16882,
414530,
14299,
311079,
65985,
39295,
151878,
null,
38532,
64309,
22358,
3333,
6810,
374493,
118765,
20297,
25818,
36356,
141737,
220077,
13751,
455627,
24109,
null,
386304,
null,
227435,
42161,
29867,
188902,
19423,
59098,
442732,
23807,
422096,
420223,
167023,
295018,
7676,
23629,
168478,
null,
343984,
225593,
310958,
218886,
228288,
459574,
33275,
55464,
231852,
31616,
139042,
21947,
21990,
304978,
null,
319248,
542086,
123895,
183481,
null,
280648,
168793,
415958,
40865,
30718,
null,
46162,
31399,
1172214,
null,
46269,
112473,
232888,
1362,
95132,
389440,
108333,
null,
38515,
31927,
107118,
12912,
290294,
155407,
null,
284333,
92535,
297872,
18150,
377786,
181162,
274508,
8258,
16983,
104277,
105060,
32014,
27696,
10481,
352295,
null,
301502,
146531,
380922,
12117,
82863,
26592,
16156,
31042,
20433,
null,
52269,
9896,
23558,
70406,
44882,
170556,
124940,
319827,
478290,
15281,
163080,
26061,
22702,
95071,
5654,
61358,
9975,
24937,
80880,
129298,
42506,
246780,
198186,
158224,
345543,
211142,
null,
174536,
6899,
67938,
100660,
199883,
337992,
59133,
141298,
3433,
29975,
204839,
35325,
246300,
25508,
49580,
25333,
17838,
62727,
14210,
28829,
276069,
12977,
276258,
13093,
59868,
137831,
264077,
23380,
156977,
209698,
217839,
null,
27509,
17488,
21117,
49722,
409195,
33554,
null,
91935,
29871,
170377,
18645,
328029,
62399,
158982,
25830,
262209,
495291,
53252,
107159,
27613,
176837,
35369,
292594,
561157,
42632,
4586,
35975,
190026,
135113,
88811,
null,
156487,
150296,
68025,
22683,
52979,
51857,
81178,
55091,
345110,
21376,
453905,
29678,
154508,
51963,
null,
16362,
null,
null,
6452,
188775,
229007,
230553,
76016,
207736,
34486,
50803,
196337,
48459,
155716,
748756,
null,
49873,
42449,
264689,
138753,
223388,
9028,
307368,
316923,
199659,
45933,
46566,
20371,
386703,
49122,
46952,
21000,
42219,
220848,
539868,
392846,
81638,
47189,
320172,
8839,
217783,
22557,
16652,
42655,
50123,
12704,
null,
71217,
465749,
64440,
64843,
255243,
213644,
183667,
38449,
null,
184243,
67199,
252431,
129408,
6710,
181964,
27135,
216132,
89087,
206476,
218715,
190475,
253778,
21359,
31024,
15233,
32924,
98835,
228428,
142276,
90728,
686857,
14305,
435092,
null,
61423,
204011,
235659,
51403,
13938,
36215,
247290,
103643,
162081,
120328,
27087,
170893,
44915,
null,
26505,
41361,
166599,
281571,
19750,
258694,
13778,
19674,
226547,
null,
8741,
26512,
18913,
290047,
41772,
40780,
null,
358858,
33913,
null,
326493,
75752,
86415,
52179,
null,
3005,
349441,
424118,
14878,
300537,
481922,
140155,
13312,
158436,
null,
null,
31589,
16545,
8263,
122290,
415733,
262646,
125523,
299916,
124824,
569245,
64345,
383496,
179572,
30080,
32649,
105520,
360583,
19982,
122405,
189426,
76925,
16291,
372771,
252102,
18514,
24002,
97215,
32306,
43664,
50312,
null,
7229,
null,
7562,
25017,
385738,
10408,
null,
127678,
null,
7033,
35178,
17153,
23235,
null,
232459,
15918,
77611,
26599,
13162,
169456,
37977,
49918,
141436,
155931,
null,
124248,
200627,
53102,
92575,
263752,
406061,
22993,
71913,
143714,
179956,
null,
null,
84205,
34373,
199161,
330398,
375634,
323225,
327640,
227582,
190951,
182011,
36873,
261349,
403435,
9204,
474697,
183090,
null,
57723,
22700,
167632,
302843,
32665,
189138,
null,
381537,
null,
89825,
42936,
230998,
139188,
123756,
166125,
62994,
35979,
36529,
44888,
56366,
233471,
106593,
330595,
353509,
14542,
139422,
47545,
31742,
48317,
139339,
11523,
79353,
5906,
null,
18489,
108069,
389113,
266556,
44042,
38850,
null,
15320,
3695,
52201,
558286,
null,
18188,
71719,
182729,
89425,
56225,
286599,
140050,
61744,
5605,
38941,
5437,
16486,
284815,
93056,
772341,
268146,
62268,
200459,
445209,
49465,
138788,
119643,
49595,
4201,
772475,
45866,
74983,
30593,
93769,
522410,
367097,
55235,
206796,
284245,
38051,
181139,
235683,
109446,
340225,
3874,
184503,
352002,
420969,
25218,
8001,
131938,
22167,
177975,
30117,
6581,
84063,
19567,
21079,
346484,
47343,
84895,
131263,
null,
106803,
null,
null,
145857,
125291,
24374,
69640,
43904,
66994,
null,
62928,
344054,
138610,
388470,
76411,
309871,
11159,
null,
36114,
389315,
77678,
182104,
37258,
3044,
18512,
246044,
396756,
31145,
5835,
41453,
167698,
3723,
210282,
18468,
15482,
270117,
3319,
219216,
356,
49659,
277404,
101489,
null,
381312,
20475,
2188,
12025,
69190,
202234,
37460,
91460,
212230,
186666,
42094,
646224,
9272,
23223,
397681,
20638,
60504,
37099,
23903,
293257,
13555,
262214,
82807,
21995,
215124,
32013,
7832,
23955,
184208,
27450,
13245,
18202,
25069,
null,
55306,
15733,
14301,
28053,
378915,
188819,
89770,
297474,
10605,
36932,
530376,
162975,
242271,
47954,
21281,
219196,
35700,
165146,
44147,
24846,
8850,
196389,
12892,
144094,
25880,
282569,
174642,
351757,
60264,
39353,
298863,
209542,
32857,
150921,
288345,
25565,
303425,
357700,
78938,
20628,
8922,
30539,
103683,
218981,
5017,
96236,
230085,
null,
7371,
132410,
8832,
332816,
null,
384026,
222345,
5410,
29752,
37830,
40550,
74619,
20155,
148451,
248300,
179354,
206160,
37342,
41006,
11257,
3198,
62982,
55653,
271114,
null,
461635,
8696,
223718,
241402,
null,
187668,
145558,
null,
73208,
272735,
241172,
58377,
47477,
30961,
9707,
38588,
34015,
9857,
349126,
140918,
151299,
142648,
34603,
240928,
287948,
14957,
9542,
270813,
41050,
29884,
43282,
10659,
35169,
8693,
219359,
null,
null,
169547,
443474,
390757,
15769,
691016,
372730,
134300,
null,
287652,
27372,
18273,
46618,
23861,
17559,
222717,
19206,
177265,
195697,
77035,
318344,
166836,
1386,
233068,
123695,
41052,
126843,
13784,
52289,
50369,
745510,
62310,
47402,
12828,
16580,
102197,
53686,
63776,
null,
21056,
49770,
null,
58058,
56504,
96909,
46647,
33011,
663911,
210239,
150076,
163586,
23136,
32378,
1926,
53886,
290257,
184280,
38943,
150368,
203384,
72998,
607283,
197595,
28187,
null,
364882,
40102,
null,
179742,
118729,
null,
131662,
115913,
35211,
50811,
475097,
107630,
13422,
408335,
44475,
13951,
46726,
19487,
42563,
12604,
218917,
23900,
34331,
21872,
36262,
144969,
233432,
6298,
2922,
204998,
324536,
160621,
444805,
304970,
147811,
237952,
88384,
14935,
23008,
64777,
104281,
4862,
294332,
15725,
27817,
170197,
23962,
224978,
45072,
192094,
221116,
4596,
57105,
433843,
127964,
47841,
40679,
330106,
81339,
29245,
279881,
913120,
93806,
51501,
367382,
169879,
11532,
141587,
44011,
701652,
33248,
13004,
10569,
76474,
58451,
49207,
70128,
26988,
526587,
44286,
145968,
115460,
266760,
994350,
25003,
15515,
18841,
34223,
426640,
59525,
10639,
51262,
27903,
351071,
22781,
110577,
61008,
59519,
280673,
27891,
28540,
237718,
156084,
97436,
96511,
191877,
72476,
57912,
304647,
212004,
78074,
767183,
70197,
100539,
26074,
103156,
8975,
165896,
90131,
249447,
127981,
152794,
126683,
159780,
61427,
747949,
161136,
14788,
21168,
233143,
34738,
91167,
null,
297771,
12040,
140368,
162727,
184991,
10464,
56821,
23783,
55449,
23501,
474695,
144988,
1800588,
192800,
69297,
149557,
null,
165688,
247962,
42162,
161834,
209547,
32870,
377833,
28831,
null,
6132,
20229,
283583,
16384,
47182,
20067,
205586,
104397,
128262,
null,
14580,
null,
343373,
74646,
23262,
339721,
53692,
24737,
93808,
19022,
63137,
13234,
3926,
354400,
36001,
83275,
316645,
59019,
339743,
16213,
704451,
null,
226296,
8609,
25915,
138919,
104140,
67434,
292009,
null,
21340,
18685,
72951,
7616,
114596,
19591,
27284,
220446,
255044,
313592,
19513,
23252,
221494,
107749,
75435,
8190,
3422,
167771,
328460,
90620,
165033,
134070,
31465,
331785,
null,
26227,
116393,
254046,
382912,
354244,
177831,
26741,
35775,
76171,
180596,
115360,
207196,
390302,
170585,
106718,
607205,
17488,
36520,
null,
36752,
21154,
79282,
504550,
230017,
77113,
182226,
38939,
21861,
282330,
28344,
53694,
25728,
18452,
7438,
265438,
224026,
null,
162610,
212702,
25269,
82441,
null,
200146,
245524,
315765,
293836,
12641,
33510,
159067,
13830,
171286,
null,
78368,
87187,
34044,
59385,
103747,
50274,
9722,
252856,
436916,
6957,
138671,
23700,
null,
198666,
165385,
3571,
323787,
20196,
367594,
46467,
80822,
329994,
84789,
157300,
389842,
27662,
8973,
21875,
187175,
9966,
69127,
124460,
27210,
202936,
null,
41589,
201752,
103867,
null,
null,
114811,
407761,
141632,
268069,
121948,
124918,
25134,
14191,
342132,
301497,
null,
null,
11234,
300859,
84236,
338119,
198673,
19362,
51379,
246323,
40437,
266645,
null,
null,
141821,
99039,
38484,
262527,
4352,
6835,
54690,
456229,
86327,
9181,
100864,
75794,
36178,
8189,
313853,
34618,
69325,
null,
163476,
66797,
4933,
79103,
157537,
138296,
208100,
58100,
20935,
232659,
16857,
126426,
152972,
null,
256758,
30376,
393622,
null,
29790,
25917,
22410,
319713,
96902,
29124,
80717,
94526,
98182,
232378,
null,
312788,
16307,
312373,
45248,
146814,
387310,
36129,
250969,
333882,
9156,
70307,
1557514,
151324,
508251,
15009,
171029,
380064,
185182,
96074,
12095,
177431,
11507,
55567,
145120,
216820,
141066,
185509,
6991,
17811,
17109,
null,
46981,
44139,
8230,
101678,
377267,
332526,
164968,
24868,
null,
41191,
77503,
226791,
31209,
179164,
null,
16813,
237899,
40524,
50621,
154379,
null,
null,
55179,
14942,
128374,
null,
115273,
39785,
16503,
135227,
90720,
27655,
89802,
440509,
742851,
81373,
207151,
30139,
154578,
139549,
171812,
24495,
118392,
201704,
66886,
209882,
314716,
322301,
23817,
20979,
209500,
45622,
212541,
119273,
311569,
230454,
26253,
377813,
22588,
313490,
310755,
124574,
4256,
302838,
51033,
120501,
70861,
301144,
null,
170234,
213050,
312901,
8270,
237296,
80874,
315622,
null,
null,
177226,
null,
67345,
146729,
78306,
181701,
64411,
930024,
25288,
72588,
11510,
383833,
499323,
411977,
303023,
37555,
50026,
32034,
245447,
645999,
61432,
61934,
23700,
26535,
363066,
193096,
null,
552725,
83669,
109193,
63961,
99852,
168937,
null,
14308,
388585,
238244,
344383,
56261,
6290,
45008,
143882,
27063,
133090,
98009,
6023,
91927,
50860,
141723,
35136,
10217,
204699,
92935,
20778,
null,
79904,
41662,
48322,
134298,
435234,
null,
38102,
31897,
262962,
352725,
221961,
122825,
49772,
153502,
360782,
101492,
27005,
95726,
166558,
312420,
271097,
38074,
144374,
19379,
268414,
99850,
348152,
63020,
31589,
29366,
24907,
24568,
44578,
489951,
238403,
null,
493938,
37665,
11753,
144157,
3440,
null,
170088,
396489,
19854,
257903,
103852,
70957,
71421,
57385,
197797,
56784,
null,
155996,
34770,
56649,
9134,
433604,
165830,
94796,
90687,
106025,
null,
64493,
null,
77286,
159436,
139851,
54740,
218322,
140288,
329014,
2024,
21942,
37069,
74415,
36434,
103046,
598694,
295277,
699798,
215228,
392273,
151841,
193798,
10456,
179355,
30402,
29650,
257499,
136677,
299546,
6477,
25639,
203660,
263344,
49337,
305382,
null,
119007,
60477,
18979,
346811,
33339,
38810,
75747,
26634,
6424,
39545,
41295,
null,
null,
155551,
42893,
null,
23901,
75436,
20408,
16406,
198982,
222143,
16334,
66841,
8216,
404742,
179222,
null,
269859,
null,
364129,
null,
278069,
310378,
178265,
58320,
8342,
125499,
735123,
63854,
40329,
24932,
null,
283950,
18761,
24198,
10361,
195095,
328562,
45710,
14751,
null,
23205,
22561,
156517,
271562,
52600,
31808,
16141,
10232,
63610,
377990,
302924,
105096,
78638,
135984,
214891,
527844,
null,
163146,
28567,
30443,
75864,
19359,
343466,
17856,
18379,
10603,
211184,
698801,
71124,
83723,
29480,
null,
73139,
47293,
29860,
22010,
82957,
137478,
26916,
null,
190499,
80343,
20649,
246872,
412207,
11468,
471954,
467019,
362103,
338160,
24923,
9637,
151859,
383398,
446381,
20699,
418654,
40453,
392453,
75386,
59218,
143155,
null,
146618,
30791,
null,
24240,
302015,
null,
18521,
426649,
12382,
null,
393776,
31721,
24277,
null,
293718,
29526,
100368,
53654,
16988,
89178,
78620,
34762,
null,
null,
24829,
245945,
78710,
null,
47561,
32832,
14965,
33767,
152535,
47118,
41519,
44371,
175458,
338551,
452158,
13257,
40928,
null,
350232,
14960,
24841,
13457,
184722,
55430,
308412,
8044,
60090,
66143,
null,
21281,
141879,
16041,
3549,
148515,
26150,
23286,
355758,
261925,
605012,
439865,
35520,
162597,
17621,
44803,
73450,
43382,
40657,
99804,
139257,
9470,
364549,
6991,
462000,
80321,
100734,
336927,
110652,
207259,
91704,
224640,
327492,
74832,
55493,
61128,
395948,
41311,
52001,
null,
50967,
122035,
260706,
366071,
12412,
11302,
114398,
11563,
33898,
490160,
494960,
99511,
318957,
19224,
75556,
58782,
173364,
337989,
268717,
29898,
81734,
200731,
6170,
10859,
130672,
331359,
730776,
null,
176059,
null,
null,
239695,
12262,
200035,
40535,
10180,
132862,
117703,
54229,
82578,
156093,
307141,
5772,
477103,
30013,
12505,
262338,
45592,
675544,
15790,
27086,
168120,
61237,
null,
60566,
35639,
44550,
264103,
94089,
30392,
435507,
11067,
44837,
208755,
12873,
19403,
33450,
22609,
440051,
97275,
197719,
41461,
202255,
307230,
51816,
312759,
745729,
11310,
11253,
341686,
18635,
265249,
39163,
null,
8019,
244850,
56511,
31596,
null,
90261,
260365,
197048,
547053,
196945,
51270,
319095,
32649,
183756,
554850,
511416,
null,
41219,
24778,
973451,
131318,
174087,
7522,
92958,
92013,
27954,
41811,
361061,
6655,
null,
42081,
187865,
45241,
224506,
95197,
112315,
1231,
168868,
289560,
123380,
25124,
null,
161465,
344684,
372681,
32107,
279504,
51687,
195402,
192681,
255607,
149148,
35877,
416681,
24020,
24918,
null,
172128,
246793,
158875,
31116,
37788,
149874,
84008,
123666,
50950,
null,
147052,
42530,
12121,
18399,
35313,
32776,
25208,
101707,
127190,
199382,
null,
null,
249463,
293747,
75682,
176977,
114237,
228230,
136007,
201190,
25149,
37545,
32194,
171811,
null,
80144,
270385,
337627,
154133,
370294,
172753,
null,
249296,
33786,
179650,
24966,
53283,
67321,
133232,
133106,
311312,
25199,
59066,
189850,
70802,
5667,
85776,
null,
47238,
185430,
357763,
184282,
73013,
14365,
222077,
9086,
124100,
15464,
null,
17143,
389152,
391979,
331274,
34135,
478205,
null,
45188,
130231,
479405,
61613,
296107,
26094,
6643,
197981,
16793,
17502,
489685,
90237,
null,
267239,
12914,
510739,
42245,
21214,
247830,
null,
39042,
17165,
81396,
45800,
180012,
54958,
285588,
6064,
21444,
34843,
437676,
276100,
7648,
14234,
null,
null,
7698,
92667,
255708,
134475,
null,
13000,
49825,
54933,
197255,
21285,
335062,
294489,
149686,
79529,
64311,
106677,
1263797,
60184,
null,
97433,
11584,
null,
61796,
257712,
145819,
45873,
326176,
null,
126393,
26296,
24170,
null,
42839,
344503,
18992,
85537,
null,
38073,
243212,
15793,
12622,
65604,
165943,
21198,
15138,
158753,
178311,
422052,
327564,
114020,
62589,
289956,
27682,
null,
36790,
46385,
30764,
314123,
369746,
17012,
395280,
78888,
193695,
null,
244699,
199199,
177430,
20927,
78348,
40554,
221516,
null,
30576,
387207,
24496,
72778,
254155,
239956,
517929,
10344,
374810,
3084,
56151,
42783,
31193,
116999,
300977,
6444,
200677,
16837,
358800,
48529,
172596,
17959,
310643,
121939,
20931,
38995,
274869,
179581,
38933,
914004,
24867,
139090,
106796,
147609,
178147,
297660,
177583,
37489,
26772,
31700,
30310,
17977,
121205,
11798,
31673,
105896,
305285,
197121,
17992,
173300,
38023,
198538,
108218,
null,
null,
28710,
54083,
28901,
41065,
null,
29930,
23257,
304794,
25968,
38323,
183367,
244203,
116765,
22827,
null,
null,
37143,
null,
137271,
281714,
106584,
60912,
null,
340057,
31733,
178224,
24773,
73722,
141228,
417699,
12175,
null,
171161,
371971,
147581,
16756,
453228,
15121,
277686,
9382,
33128,
35280,
53265,
79404,
53996,
15959,
240345,
35461,
33807,
4669,
248318,
12989,
17090,
28563,
44558,
111075,
41757,
127416,
30965,
196967,
32673,
86799,
297219,
384416,
219627,
171999,
null,
55267,
187027,
2402,
24909,
46486,
29004,
164466,
218456,
89388,
21013,
25193,
8175,
30549,
16101,
9749,
83195,
556130,
143114,
8735,
206847,
20336,
18408,
15478,
null,
30328,
363709,
21356,
176623,
3038,
30096,
148486,
89803,
198382,
21464,
90553,
36335,
5733,
379293,
93144,
234149,
null,
133630,
null,
50118,
17888,
31004,
76946,
147990,
75452,
253982,
13601,
6406,
37188,
41414,
36803,
180764,
159849,
85175,
30224,
71505,
38124,
23672,
4736,
195389,
null,
9710,
14511,
83041,
160696,
95856,
15972,
12703,
18047,
12443,
263942,
null,
96012,
90741,
349814,
77282,
7284,
44404,
44592,
56113,
171129,
176424,
47823,
18990,
22286,
29573,
23867,
35892,
200144,
26841,
192018,
213707,
166948,
29954,
8110,
160162,
29552,
18645,
60260,
89845,
227928,
71295,
17804,
227017,
138637,
32426,
40497,
38672,
null,
16774,
45530,
26593,
531508,
49073,
195412,
112112,
34453,
35433,
null,
207552,
62657,
173811,
18001,
166874,
90284,
217998,
8414,
null,
302391,
184309,
52327,
126135,
125061,
17918,
74335,
19885,
1092983,
18280,
50965,
40585,
351866,
45625,
263077,
35930,
245801,
6355,
222593,
null,
754474,
null,
null,
385865,
171430,
55127,
323702,
81906,
47666,
5868,
29164,
176409,
240290,
319704,
163546,
null,
233300,
18649,
3111,
180362,
43416,
37892,
422755,
26031,
202850,
219991,
257410,
34524,
217462,
159679,
26155,
27496,
17663,
164376,
30105,
90433,
263362,
9981,
17374,
25527,
296202,
7243,
13121,
81246,
289353,
37482,
13361,
14298,
233565,
10841,
85667,
296380,
164165,
45544,
76301,
23088,
362187,
232288,
22261,
12774,
166140,
36643,
83571,
null,
81645,
117908,
92925,
13309,
114781,
38446,
73177,
129428,
48702,
392988,
17039,
35649,
40596,
null,
225567,
133901,
null,
118653,
378765,
186121,
62204,
55503,
149107,
116096,
84365,
50305,
470734,
263851,
198245,
87235,
97940,
null,
187437,
151846,
null,
49079,
14086,
9297,
5684,
2919,
33345,
12598,
154068,
198024,
173044,
22666,
207253,
115792,
31242,
375702,
38152,
18350,
95581,
4837,
null,
null,
7691,
138745,
23175,
61353,
118946,
97168,
356001,
null,
65587,
72901,
27611,
21314,
6844,
515095,
229617,
148221,
256330,
37278,
292115,
171566,
null,
56327,
21422,
null,
252879,
177683,
600458,
57937,
9361,
74799,
79187,
186348,
344177,
78551,
239369,
39734,
223261,
19073,
266759,
11634,
191330,
21297,
13062,
48787,
250560,
26652,
326335,
193382,
15182,
262564,
20572,
82043,
11719,
28404,
57399,
8343,
25495,
49816,
292735,
23369,
50261,
41294,
42359,
54816,
3065,
224140,
null,
null,
null,
181388,
135952,
11264,
167877,
481022,
6778,
111060,
139501,
4417,
76805,
318075,
157898,
26355,
8964,
131700,
12498,
null,
157417,
12176,
31899,
4111,
27423,
null,
23373,
46852,
8523,
44444,
317529,
26886,
37794,
27439,
null,
351179,
206121,
28472,
19411,
48102,
74352,
null,
553484,
106805,
null,
265370,
56073,
127088,
46063,
81397,
62137,
21882,
83123,
null,
261154,
24633,
null,
27271,
386930,
196934,
140682,
20222,
8818,
1865,
161806,
177053,
27380,
null,
null,
97619,
39277,
59666,
null,
49656,
176216,
456283,
100587,
null,
35433,
11056,
8712,
315947,
40022,
94936,
26758,
476096,
380378,
null,
31759,
108777,
256032,
437149,
28918,
108914,
null,
293426,
404367,
9844,
null,
46883,
198831,
null,
167594,
26171,
29727,
null,
13951,
251883,
null,
17811,
259292,
159948,
191070,
118835,
195194,
179302,
null,
229333,
59372,
17793,
57287,
null,
283595,
269825,
46469,
10887,
99653,
12659,
377808,
null,
50656,
80253,
142042,
290901,
null,
44789,
307415,
38865,
89095,
288781,
8815,
359331,
310638,
254238,
230284,
289219,
59435,
113415,
25053,
218598,
14898,
266908,
52635,
172186,
214327,
457401,
237193,
231530,
112807,
348712,
81177,
59898,
null,
63774,
101933,
153641,
169047,
81048,
13504,
278871,
205520,
63437,
290874,
179344,
34144,
62217,
12366,
276515,
197152,
159652,
25965,
4897,
20485,
830130,
515844,
173537,
null,
107265,
null,
102189,
null,
58979,
126132,
29461,
146600,
331881,
277958,
199758,
45394,
24213,
19220,
139684,
20235,
6410,
225781,
262444,
20263,
161352,
21053,
145485,
350613,
368008,
178216,
6951,
162793,
34563,
273466,
54694,
217702,
23575,
149762,
40676,
358801,
27332,
358954,
50770,
32576,
150700,
null,
104639,
99551,
28295,
409799,
31991,
149594,
59022,
37804,
30889,
null,
7237,
220069,
163352,
280249,
59805,
30048,
318230,
null,
null,
361141,
389744,
207958,
17202,
188598,
244253,
294861,
61947,
52451,
470586,
322605,
null,
22486,
76888,
26417,
33614,
27399,
93591,
619563,
462390,
163772,
167935,
null,
23713,
318868,
123870,
56901,
5108,
52449,
282314,
18104,
null,
13214,
22955,
6683,
26652,
35569,
352478,
37128,
224386,
298888,
26765,
230343,
null,
63391,
226998,
27422,
240613,
null,
25297,
41583,
177867,
48824,
246957,
168990,
25169,
60843,
30281,
24733,
null,
215863,
2482,
407951,
180825,
33835,
152454,
22184,
47998,
16035,
96117,
249995,
38299,
278984,
1019644,
99484,
31357,
490875,
24655,
6853,
195933,
33841,
289424,
303598,
278598,
51673,
384458,
35621,
5457,
362949,
50999,
165914,
193766,
113901,
null,
16767,
334861,
50379,
37279,
33291,
45116,
132633,
22848,
106374,
214666,
231625,
6330,
null,
176093,
38030,
118948,
170985,
90792,
241045,
19261,
1087835,
152782,
103417,
134070,
60938,
99422,
280017,
48442,
11981,
529770,
149694,
120261,
310116,
36330,
189321,
3512,
21895,
24805,
395167,
25341,
60050,
null,
null,
52047,
267910,
50009,
13559,
30543,
316851,
217778,
30601,
23696,
6288,
358050,
63125,
138421,
297328,
69694,
111527,
204471,
null,
null,
226247,
null,
30561,
20068,
368656,
330933,
null,
42924,
548585,
323756,
20316,
17282,
281527,
938391,
6824,
39116,
58647,
113401,
15076,
248651,
281649,
39849,
null,
null,
398748,
755403,
6458,
null,
154741,
99753,
11626,
54031,
329978,
57553,
121744,
215002,
42513,
57289,
408664,
39598,
293223,
122283,
141648,
47823,
60905,
52948,
11488,
6679,
248347,
39210,
27353,
42778,
30601,
96523,
7526,
47127,
253891,
35553,
271084,
290630,
194651,
63109,
61542,
51532,
765950,
94379,
34060,
263729,
175337,
22303,
60590,
null,
8808,
38252,
386349,
120642,
212470,
407869,
140291,
null,
23285,
218271,
281474,
45171,
670509,
37817,
766371,
76613,
205109,
84760,
286512,
13600,
2645,
200235,
null,
285512,
326094,
417603,
513246,
126023,
291445,
22974,
436255,
65851,
47326,
5294,
24356,
24597,
null,
21366,
7367,
16830,
28846,
31846,
169527,
37059,
297535,
null,
254369,
231947,
148593,
28133,
37063,
339067,
29999,
95228,
56933,
30678,
57202,
13953,
null,
69494,
153982,
129325,
null,
76461,
302985,
53201,
58384,
37076,
444219,
63770,
307306,
125851,
224541,
244289,
206233,
99596,
832587,
86992,
370966,
272429,
70239,
62910,
250645,
370728,
231714,
64025,
150320,
195396,
54627,
397924,
420765,
66155,
703889,
242077,
218253,
7610,
20352,
27191,
205981,
175101,
32576,
null,
173320,
34032,
108232,
9937,
29531,
197546,
39782,
120493,
41891,
30142,
18077,
36096,
301959,
12087,
67583,
33068,
122111,
323113,
197126,
225828,
51580,
308094,
15919,
78410,
264997,
830972,
193547,
null,
25403,
154398,
15815,
266099,
235414,
73807,
33999,
25711,
236649,
24423,
217339,
154686,
346857,
64707,
109058,
116437,
70459,
227152,
74206,
143890,
16860,
19969,
39924,
174051,
null,
436143,
546966,
27218,
null,
227046,
153934,
412013,
44894,
34301,
29845,
14280,
33338,
177921,
446291,
null,
45333,
102052,
208567,
22312,
339909,
null,
76446,
235718,
181311,
9113,
50831,
13390,
18794,
351918,
268918,
237503,
51175,
91320,
114755,
null,
143477,
36641,
107707,
46065,
31184,
238189,
306489,
21590,
19659,
44035,
13866,
4914,
244386,
14014,
28026,
null,
9447,
86311,
109351,
null,
39171,
16061,
227839,
29871,
75813,
30214,
790616,
32693,
279979,
166490,
null,
13686,
30119,
283193,
179013,
212043,
12839,
22824,
923695,
34202,
18505,
143160,
23318,
216008,
34977,
null,
276816,
23277,
250807,
60259,
null,
122805,
184433,
27578,
null,
220117,
null,
30416,
433976,
24284,
192808,
395330,
15415,
207141,
null,
309701,
15125,
36927,
null,
98640,
120339,
17364,
9953,
287922,
314457,
47600,
11888,
null,
14464,
208820,
65760,
null,
35367,
19090,
268382,
164954,
16281,
81301,
29915,
54400,
267528,
70623,
131365,
33795,
25442,
39446,
108257,
245962,
390678,
91543,
1273619,
4755,
49821,
40679,
14245,
251208,
184456,
232705,
14354,
87362,
259771,
342079,
24381,
26840,
219229,
11567,
79504,
204177,
159512,
20856,
355726,
33760,
43462,
8435,
67126,
127847,
276109,
79988,
null,
426996,
268597,
53535,
26621,
106901,
21690,
294997,
21708,
115431,
20706,
254955,
129901,
62862,
15253,
37865,
15165,
227045,
31649,
325082,
3278,
null,
null,
43949,
430385,
238796,
166192,
210710,
127180,
178810,
9052,
510820,
null,
497802,
17375,
168225,
36375,
64034,
46126,
81877,
null,
164783,
13648,
163171,
42232,
72105,
7326,
51652,
146648,
291408,
5372,
210403,
52266,
263268,
4833,
185300,
197041,
346564,
null,
38246,
467569,
110721,
null,
262717,
43731,
23579,
32808,
31896,
207956,
47639,
19329,
212845,
68876,
12669,
82147,
26464,
73484,
361057,
52458,
65961,
322199,
86519,
73820,
null,
83130,
32370,
98102,
13802,
150425,
364006,
178179,
527428,
200792,
13430,
451063,
111399,
164319,
388157,
25716,
74396,
38006,
27675,
36875,
77871,
67164,
23338,
41060,
67422,
234963,
32102,
48993,
101294,
226214,
17643,
149179,
86016,
null,
32337,
108181,
346833,
null,
55684,
89764,
55450,
180181,
47648,
28190,
null,
38740,
24887,
121347,
31105,
99223,
10815,
17878,
45566,
null,
50607,
null,
11551,
297933,
70956,
12969,
37354,
23530,
39931,
192705,
52675,
114519,
4255,
61454,
38299,
34812,
36455,
41307,
25817,
318517,
274832,
43171,
344703,
92353,
186102,
1114,
15668,
181039,
418909,
280280,
147626,
13126,
263292,
27138,
912724,
29513,
34171,
12795,
32440,
14286,
130463,
null,
101915,
19526,
19015,
402580,
42371,
40837,
null,
319043,
12374,
null,
97347,
10136,
108979,
38270,
107772,
10822,
569871,
18389,
26098,
39435,
113631,
731689,
349703,
6492,
null,
194241,
17920,
533958,
114128,
13782,
116348,
44065,
169997,
304841,
28793,
506871,
33520,
193814,
198569,
148721,
21963,
18557,
260553,
325503,
24379,
40685,
17404,
19233,
440231,
157973,
320704,
46442,
402905,
301636,
407241,
16336,
318335,
103588,
10230,
195419,
22006,
46327,
140477,
427007,
245540,
598185,
154762,
11281,
null,
56384,
505996,
null,
453638,
41588,
17229,
56013,
52182,
91246,
43944,
13292,
29626,
null,
7885,
26869,
92161,
155021,
127261,
52789,
239381,
292085,
10827,
173510,
231923,
246246,
40737,
352694,
null,
147790,
98860,
82486,
115434,
7380,
12332,
305794,
24362,
70968,
30235,
203051,
32996,
20809,
3998,
4089,
89242,
null,
99754,
160288,
28979,
169218,
507525,
64044,
216431,
18260,
303393,
16531,
844969,
172685,
22750,
null,
68489,
null,
51289,
55090,
468122,
94945,
43433,
20190,
214866,
154683,
20030,
202855,
null,
257945,
144582,
117155,
164782,
41487,
null,
null,
133785,
32129,
34776,
151107,
435711,
22785,
null,
543072,
754095,
26371,
121550,
79794,
127299,
345435,
36721,
424147,
96755,
595168,
12179,
77890,
54629,
5319,
9868,
215152,
268077,
242156,
63679,
317190,
338549,
4265,
47424,
41051,
39442,
266563,
38010,
42976,
33779,
271897,
146994,
27408,
33764,
278813,
64446,
481816,
309044,
195392,
661354,
75423,
76479,
40258,
53657,
234911,
368411,
151584,
16159,
156554,
202077,
14628,
223249,
20026,
308090,
393453,
155740,
26386,
187833,
4952,
2689,
137814,
13052,
null,
66771,
339392,
179795,
54473,
143452,
17523,
27968,
136334,
1022,
null,
888738,
276262,
200758,
48528,
12714,
240744,
36083,
248100,
9267,
467917,
372024,
21415,
137793,
136746,
303383,
null,
57000,
146687,
42865,
197006,
54818,
50420,
193129,
149962,
193977,
null,
null,
270786,
142298,
59827,
354174,
226920,
672618,
null,
351343,
null,
32800,
211613,
25867,
383908,
19234,
158624,
163417,
66711,
1027321,
37023,
148164,
77531,
103947,
160965,
64202,
189338,
null,
29343,
15566,
null,
446790,
38737,
181461,
9179,
10901,
47805,
670265,
174164,
16760,
11910,
199341,
14994,
25209,
null,
401230,
18807,
31213,
27882,
26670,
41501,
null,
58759,
357741,
25637,
73292,
311133,
196787,
346548,
314949,
null,
212249,
null,
86085,
216261,
212708,
31067,
291380,
53680,
30011,
108051,
30225,
null,
36593,
60218,
null,
14994,
164901,
195069,
29495,
51436,
158902,
82563,
null,
null,
13860,
175147,
145514,
129182,
22634,
19203,
294989,
null,
68299,
25178,
74487,
67637,
218701,
null,
236668,
35568,
532034,
49523,
32623,
579600,
3517,
157415,
13671,
30959,
76709,
194704,
22653,
8750,
79016,
99214,
34344,
13537,
69475,
295751,
17152,
547369,
67114,
62073,
222446,
30568,
12103,
59209,
299926,
26264,
46366,
417086,
239613,
380926,
279715,
208215,
355082,
102604,
146537,
194595,
33158,
30875,
481492,
null,
31644,
24335,
371560,
12485,
129070,
39012,
14894,
8858,
20202,
null,
280668,
347244,
175544,
182132,
null,
4263,
271543,
374614,
null,
40955,
118996,
30761,
173557,
4338,
101855,
359988,
306823,
53618,
42442,
23937,
46779,
null,
null,
400957,
109867,
26721,
36506,
38460,
278472,
180298,
74045,
141745,
null,
145634,
22340,
32720,
33096,
49681,
125440,
116805,
426849,
187616,
332123,
null,
455170,
66142,
58670,
205463,
158465,
7934,
19359,
52155,
null,
46150,
9526,
212418,
154274,
143788,
203128,
48541,
219076,
120310,
453771,
284934,
53559,
279326,
972705,
37966,
438621,
8880,
264766,
84991,
48271,
null,
37976,
6493,
57482,
65294,
120658,
205036,
83812,
127250,
38293,
59782,
143715,
410074,
null,
39981,
null,
39543,
52997,
127755,
332043,
null,
496346,
null,
578219,
43693,
130697,
null,
111296,
98628,
11285,
9478,
17813,
119187,
283268,
101113,
1714681,
null,
234382,
28141,
707853,
269921,
24466,
35221,
47624,
32261,
36156,
48765,
35248,
10132,
16895,
9384,
66144,
136900,
12277,
189598,
22976,
104282,
15565,
86825,
null,
70535,
100502,
352919,
415119,
533259,
119844,
352988,
745191,
26607,
null,
254041,
74388,
10712,
18759,
252683,
58180,
238596,
null,
null,
91389,
17196,
34464,
329565,
21653,
260018,
179124,
395542,
10945,
33188,
34372,
18029,
null,
515482,
252884,
146066,
331934,
577138,
null,
36236,
266311,
27719,
null,
209988,
171467,
209145,
35613,
null,
25127,
138357,
28432,
30717,
217621,
26503,
208658,
122902,
211719,
49661,
60970,
234560,
18955,
39926,
70862,
448640,
33595,
47968,
12239,
39961,
27805,
157685,
289954,
null,
181460,
87113,
28476,
185283,
67948,
63699,
31883,
151655,
20255,
46540,
82779,
112464,
155177,
232910,
432073,
10454,
170830,
null,
95449,
108195,
33978,
54829,
210775,
16780,
7248,
null,
44241,
27892,
305578,
178270,
25623,
7865,
89197,
217671,
324164,
53291,
6135,
37350,
138673,
137036,
125060,
252269,
67998,
202066,
77140,
178428,
69674,
387939,
28742,
49706,
275606,
131244,
20112,
37084,
45871,
37594,
333001,
11934,
62749,
25081,
103290,
16213,
256417,
291275,
null,
404993,
89092,
31433,
null,
52489,
null,
188362,
null,
8124,
177011,
71000,
109086,
400909,
29985,
123259,
12941,
36463,
15723,
470057,
13107,
112597,
245195,
5249,
40824,
188737,
null,
21181,
6672,
27539,
11518,
1043178,
367979,
20706,
18707,
33370,
61388,
28664,
455637,
204736,
58657,
45149,
33365,
358888,
14259,
609758,
null,
49561,
null,
78055,
534788,
487671,
43965,
263543,
103237,
null,
24486,
35809,
281108,
17206,
226712,
95277,
27378,
93458,
222514,
null,
293446,
22183,
105696,
12289,
228325,
143989,
72861,
150769,
131335,
57194,
46217,
240953,
34436,
187190,
94269,
173366,
15058,
251903,
null,
568579,
388288,
null,
35171,
64364,
864809,
97005,
9765,
20862,
504944,
10320,
84064,
null,
218569,
null,
320493,
13823,
107879,
null,
279584,
77711,
146490,
27685,
20052,
144478,
132036,
249125,
150077,
120786,
null,
43586,
103590,
73948,
30435,
173081,
198498,
14534,
52323,
16378,
62211,
95964,
null,
null,
13488,
306523,
286230,
434605,
13826,
260788,
282773,
null,
41767,
212504,
25710,
191779,
80503,
114520,
206342,
281823,
135936,
12975,
72295,
195039,
206160,
240555,
22031,
null,
110597,
null,
169607,
20266,
253574,
61289,
29333,
184007,
216339,
13685,
123935,
11845,
46608,
141915,
22615,
null,
27380,
83117,
86773,
54312,
19648,
721440,
51344,
91345,
10920,
43479,
null,
157530,
89498,
22948,
106449,
415211,
269838,
null,
110980,
null,
403780,
143698,
249445,
322401,
21341,
23760,
49807,
21745,
65892,
229331,
20981,
7849,
260638,
153440,
31284,
11442,
229839,
301477,
36931,
19576,
19303,
210755,
null,
147423,
93642,
32983,
15480,
54168,
463458,
null,
433701,
null,
140309,
193651,
335000,
8930,
139660,
76795,
null,
305679,
57651,
97556,
54565,
71010,
220758,
412666,
101379,
113201,
411586,
22611,
165365,
26608,
585279,
162226,
40361,
null,
228742,
14351,
215129,
39413,
65660,
178270,
13335,
121480,
5944,
19634,
410161,
445532,
8747,
11335,
198059,
172061,
12662,
20444,
55924,
441068,
188136,
97135,
171424,
215733,
505701,
null,
24686,
13081,
null,
null,
454167,
null,
5463,
null,
299811,
186357,
37445,
15640,
258287,
44992,
28631,
355546,
296925,
10111,
101353,
11232,
210923,
43327,
null,
98395,
194146,
null,
590465,
null,
null,
43015,
22497,
401609,
147681,
56326,
103517,
35528,
261131,
178237,
35418,
3858,
368843,
null,
null,
300582,
67931,
175437,
31602,
113144,
44120,
null,
406436,
6539,
79751,
202918,
48917,
null,
163355,
null,
220056,
9746,
7386,
35419,
223080,
4195,
498040,
17350,
34605,
25443,
125697,
385363,
15182,
6302,
null,
55514,
336207,
32536,
426933,
273632,
62949,
95513,
39375,
4271,
38320,
336747,
45694,
218324,
73402,
499254,
14037,
28775,
32426,
312642,
57199,
114068,
62893,
237754,
30090,
49843,
203806,
43977,
21168,
44901,
407320,
16939,
151543,
213979,
23757,
71343,
368954,
28141,
21365,
80118,
39479,
4224,
9576,
89588,
40492,
5179,
14136,
15552,
5442,
456149,
317024,
167181,
123649,
316337,
154218,
14077,
57507,
91300,
37554,
31225,
4206,
41094,
263946,
6573,
327576,
37857,
59329,
176418,
19919,
210433,
17466,
3510,
113698,
104544,
810380,
158687,
72356,
null,
null,
43311,
null,
275501,
266360,
96218,
null,
72073,
59312,
393172,
10190,
243642,
72976,
10233,
22532,
254948,
230776,
172756,
45630,
112965,
42245,
64359,
23804,
43308,
null,
600651,
56107,
80143,
60297,
55407,
76497,
205447,
201168,
338897,
32736,
19299,
21300,
197474,
13222,
78544,
null,
188284,
null,
370051,
51517,
23195,
7811,
140452,
50275,
37994,
null,
163848,
66797,
42974,
522627,
216281,
27804,
25433,
437423,
244733,
null,
79857,
172250,
535832,
20865,
216366,
43010,
165678,
48950,
129773,
35588,
243614,
null,
230325,
349911,
243560,
180114,
23510,
777477,
282253,
176202,
482791,
289810,
144952,
18111,
13103,
92433,
189589,
24876,
217597,
13809,
34071,
26240,
48366,
152347,
48788,
46413,
6036,
706693,
55101,
32549,
174004,
62090,
66606,
162522,
172316,
360020,
152296,
141629,
140302,
null,
264736,
77661,
198676,
120365,
508423,
200697,
44059,
223684,
321610,
172452,
88006,
null,
14369,
5294,
339480,
108900,
20038,
21969,
172236,
263282,
14511,
55911,
17149,
23174,
9537,
153261,
52413,
289605,
22057,
61528,
null,
77090,
36203,
44088,
124683,
5636,
17378,
21431,
5496,
132106,
null,
4263,
163064,
155511,
11504,
563427,
135916,
83295,
44701,
null,
294593,
328745,
42222,
403178,
204528,
null,
342092,
46216,
null,
18229,
59690,
79083,
126316,
37378,
42605,
165039,
46148,
553173,
49614,
120762,
241675,
14224,
279873,
388074,
22496,
9889,
7436,
5125,
23901,
142490,
77983,
null,
null,
160907,
182698,
351959,
153384,
237464,
387199,
14469,
220725,
91114,
null,
127148,
400578,
100381,
45772,
44891,
null,
null,
123020,
null,
190722,
303979,
25238,
285154,
163787,
60558,
34092,
19839,
526699,
143198,
134789,
114448,
321617,
null,
261877,
12714,
108287,
null,
23688,
36569,
16002,
null,
351548,
null,
27526,
46488,
39197,
null,
94775,
null,
258596,
452811,
34719,
205370,
58484,
456571,
248161,
7075,
103990,
41830,
71287,
37758,
87343,
91817,
197573,
13402,
34924,
24569,
39942,
68110,
9575,
109234,
284936,
null,
241021,
null,
78118,
28897,
116057,
66409,
199580,
585917,
329600,
188944,
139669,
4083,
18523,
94427,
22156,
182112,
196261,
6017,
null,
112228,
71650,
37754,
211508,
47454,
201487,
null,
382176,
302484,
228625,
69323,
149723,
25267,
257779,
376437,
27692,
56094,
20938,
20704,
18434,
null,
362567,
13055,
56719,
86937,
56324,
51768,
26645,
102854,
30947,
287696,
null,
29526,
90225,
123743,
42880,
22764,
38679,
18431,
null,
129668,
14482,
224173,
170309,
787802,
103703,
70177,
null,
181744,
4301,
151386,
14003,
26389,
274071,
24772,
30055,
null,
180963,
42130,
48419,
151762,
343770,
28024,
null,
23297,
26720,
191807,
291510,
null,
443900,
46108,
36163,
3633,
86504,
39298,
224224,
373730,
148624,
75912,
96671,
2714,
15127,
306611,
720620,
420041,
null,
10173,
56888,
90686,
396842,
373578,
279319,
6978,
157992,
62485,
24219,
null,
221849,
null,
null,
231367,
69185,
11572,
27933,
56486,
232083,
238173,
38487,
43039,
19446,
12222,
46915,
11721,
26991,
23347,
37916,
28973,
23161,
27104,
10925,
518240,
129510,
197509,
50415,
57520,
212604,
null,
6442,
null,
24777,
null,
15941,
518403,
12720,
23715,
375583,
11482,
28135,
7525,
41246,
339173,
46706,
24704,
20386,
13639,
null,
94739,
308261,
250341,
133258,
162057,
null,
21557,
25006,
308467,
203837,
177014,
317971,
180569,
36815,
14633,
11580,
null,
99335,
404634,
27435,
null,
36933,
39596,
15335,
96659,
125932,
32640,
845854,
153808,
null,
24473,
null,
15705,
45804,
37135,
null,
323686,
51425,
215307,
202309,
null,
33449,
null,
111054,
4756,
206847,
236136,
321982,
39041,
27690,
18212,
314234,
71223,
387681,
125231,
234122,
83193,
213288,
31942,
112945,
77533,
null,
22652,
null,
294614,
228446,
27186,
46905,
44195,
23927,
31942,
137261,
null,
9141,
470800,
21168,
71372,
16784,
40310,
43614,
38041,
55700,
384172,
23097,
49880,
186102,
103959,
null,
150069,
293855,
null,
null,
49677,
16912,
41124,
18425,
82257,
30574,
158717,
82651,
181805,
157627,
167865,
21361,
26817,
89525,
183325,
6570,
10111,
27826,
106767,
122388,
33503,
44915,
53241,
100167,
23859,
426583,
170180,
12495,
null,
21855,
null,
407565,
141094,
19914,
181388,
null,
19017,
25992,
65160,
50684,
248492,
185186,
168586,
73920,
53606,
392194,
14756,
318609,
135251,
37971,
37583,
null,
31479,
48632,
558018,
390358,
52882,
121236,
8318,
260840,
175488,
41487,
16932,
476807,
135412,
51205,
8192,
147435,
null,
218451,
51711,
20317,
101790,
10708,
23314,
105414,
176124,
195628,
180777,
21657,
47277,
212973,
19762,
273165,
null,
null,
20242,
251344,
41954,
103918,
43131,
58612,
205626,
260747,
178090,
208253,
99623,
52304,
null,
496339,
null,
19625,
6475,
59855,
49803,
259924,
3010,
40365,
171010,
58373,
49305,
183451,
219015,
null,
8768,
265204,
286937,
77363,
51538,
17832,
793162,
115438,
null,
326008,
573393,
183912,
137854,
35192,
10419,
125768,
150814,
194933,
199535,
39591,
33378,
44368,
348875,
50884,
16552,
373254,
22846,
80438,
12055,
249451,
64139,
42073,
174290,
5240,
null,
212640,
25821,
616394,
92575,
30052,
498299,
459914,
8987,
301268,
null,
52505,
97376,
278729,
50991,
32635,
346281,
147786,
27821,
72924,
81046,
7516,
52491,
190907,
186862,
212035,
551642,
26226,
6601,
51233,
null,
43792,
194549,
122464,
75396,
57390,
20881,
39235,
332902,
26495,
10342,
6402,
52548,
null,
30587,
15316,
null,
46301,
14586,
54794,
51886,
279163,
118695,
140596,
32205,
211686,
46134,
103866,
160778,
57580,
119126,
206251,
59258,
320446,
51047,
269975,
321010,
275227,
234302,
76739,
null,
299201,
216336,
25911,
193207,
345390,
155918,
57746,
null,
443739,
22058,
47739,
null,
24011,
227619,
13927,
83704,
23793,
96339,
161708,
128688,
46663,
236294,
31359,
8121,
264584,
225853,
164234,
60648,
14544,
18962,
438216,
20615,
null,
131239,
406816,
332825,
130835,
203696,
21757,
3938,
155977,
508040,
49148,
219339,
180369,
20996,
663,
43697,
45547,
331145,
33394,
9793,
428,
302568,
15387,
null,
26264,
121643,
398843,
264065,
3690,
16473,
300310,
333237,
163704,
12377,
49510,
231283,
35856,
16044,
83144,
44698,
81572,
15060,
100776,
97795,
16134,
20436,
246026,
23553,
147157,
266039,
14619,
18672,
27657,
19419,
144114,
227063,
25361,
31612,
346386,
138901,
273643,
9843,
43705,
8910,
28002,
36802,
72487,
266614,
181002,
16115,
null,
127745,
25659,
10300,
303932,
198767,
20067,
49504,
34898,
15571,
21116,
30219,
109135,
482885,
11009,
61111,
198955,
298826,
22230,
9571,
49165,
36170,
198982,
136785,
61858,
32252,
39724,
204382,
40761,
122684,
34612,
196945,
369013,
313861,
163143,
null,
14132,
35507,
17317,
695603,
45377,
212685,
126500,
47738,
42914,
51610,
427117,
11718,
null,
102221,
249174,
25727,
239808,
null,
142413,
316450,
15307,
534297,
246401,
58617,
82451,
1246,
42361,
89272,
64613,
118159,
289230,
526698,
107241,
204307,
22471,
45710,
115785,
168488,
null,
121604,
314383,
22184,
148753,
265411,
102859,
4318,
342301,
28050,
null,
29069,
250864,
174359,
273234,
null,
null,
277969,
23600,
106121,
105767,
216840,
251846,
346686,
232948,
50312,
14395,
21504,
88148,
159359,
26253,
32345,
641633,
410022,
11644,
39240,
12080,
136003,
202246,
26407,
86388,
9967,
8772,
347915,
49471,
41449,
20069,
307670,
185439,
63508,
292464,
63810,
16887,
222861,
null,
158431,
316947,
135061,
57358,
null,
142211,
41001,
246861,
36008,
1153118,
5159,
292118,
410122,
7860,
18305,
35601,
101814,
81871,
261431,
35776,
84472,
17423,
null,
35844,
2168,
null,
382624,
441819,
351593,
289824,
35093,
351102,
29123,
159750,
24058,
235543,
76101,
208950,
null,
78030,
54842,
null,
null,
null,
16,
176260,
52618,
214048,
null,
175880,
176620,
447523,
385855,
22036,
null,
312143,
161598,
276985,
211878,
280692,
522834,
155450,
63098,
79931,
13652,
163617,
297458,
221556,
6682,
209884,
61645,
16560,
303081,
33352,
292036,
74041,
35667,
25069,
171981,
15910,
370336,
17825,
17493,
17432,
12273,
77018,
147093,
394950,
39333,
38017,
null,
23873,
21840,
141603,
5880,
null,
25491,
131056,
315432,
171307,
265447,
141828,
50959,
144329,
142548,
446634,
27431,
4541,
157676,
347894,
28832,
114668,
466918,
69946,
27901,
77551,
29336,
251919,
255879,
115308,
43109,
92279,
33130,
84230,
30789,
null,
39581,
null,
71922,
26902,
65208,
109598,
221020,
103228,
43421,
83168,
170067,
193004,
59214,
64129,
142979,
512257,
84666,
79656,
65417,
127745,
189648,
36607,
2266,
43566,
67386,
42642,
88685,
451127,
187788,
null,
75522,
71627,
149372,
260863,
223148,
178961,
43647,
222916,
123176,
326968,
6418,
124850,
null,
41920,
496261,
214722,
516090,
138384,
299480,
22740,
472257,
240427,
27717,
264701,
null,
24786,
549959,
345286,
74722,
14208,
30707,
49344,
99477,
214598,
null,
528033,
586572,
11929,
48644,
175330,
14868,
47135,
null,
19286,
140405,
103689,
170254,
180738,
453111,
40261,
null,
206690,
5402,
260212,
417525,
210938,
169682,
94694,
null,
33300,
91001,
21249,
6494,
56447,
37819,
567980,
310868,
44128,
40409,
222990,
10670,
35012,
335105,
129785,
138775,
29913,
141458,
66996,
39005,
180015,
29117,
14206,
40627,
22329,
63210,
290338,
643585,
9469,
127189,
null,
231014,
15290,
16266,
28098,
38586,
50979,
44727,
186396,
68124,
62481,
154373,
173516,
null,
17064,
54745,
443736,
16229,
43079,
312232,
124846,
33712,
190673,
254485,
289512,
null,
15114,
null,
153009,
null,
49521,
152562,
10828,
23963,
27214,
1181091,
58458,
15560,
43216,
403978,
250131,
10237,
34680,
46051,
522478,
14674,
30255,
101549,
null,
5003,
215062,
null,
null,
122310,
133519,
117292,
225672,
316589,
18791,
857304,
133996,
211594,
223694,
32143,
22029,
133089,
34802,
183847,
274455,
429987,
27766,
34284,
107685,
179200,
23822,
280723,
62044,
208517,
237762,
25122,
273326,
249459,
439308,
298797,
30290,
69874,
49844,
146660,
136900,
48679,
303547,
269735,
5673,
134720,
103329,
9410,
63142,
102416,
164561,
142688,
177587,
38301,
221138,
405264,
11151,
29269,
407279,
214574,
102289,
37953,
402364,
45684,
30998,
73675,
201281,
52907,
379869,
265392,
42253,
596894,
2138,
478772,
236013,
57539,
170076,
220517,
323278,
191782,
202038,
38045,
4587,
50525,
390951,
322531,
16620,
124099,
82215,
18768,
37500,
85909,
290987,
18569,
93350,
71787,
53043,
285608,
92231,
null,
290993,
null,
27155,
20004,
null,
66321,
23975,
162205,
106595,
271547,
247639,
23254,
153432,
39350,
112996,
25291,
156774,
208253,
null,
45994,
185055,
219740,
null,
163065,
153174,
211072,
32670,
309902,
19251,
null,
295969,
44317,
18985,
413295,
51332,
139130,
62584,
13262,
30826,
13305,
382015,
329971,
6405,
380464,
462513,
221983,
46076,
30969,
144385,
89065,
96841,
267175,
516473,
29622,
9925,
35099,
200558,
20270,
24692,
139036,
77284,
183465,
324799,
865398,
null,
8393,
267728,
66342,
302450,
null,
42851,
280548,
10245,
5631,
null,
284226,
43804,
194105,
36567,
22420,
194938,
145744,
86498,
320155,
94907,
31198,
413228,
6216,
192603,
13778,
139675,
53834,
null,
null,
51039,
218440,
127086,
null,
27928,
196203,
9142,
14038,
169002,
null,
9192,
264339,
143364,
null,
117721,
46517,
15556,
170932,
30021,
27633,
92363,
383152,
286321,
53509,
420242,
253033,
421096,
36542,
234020,
null,
381656,
107120,
13707,
39719,
37162,
119279,
null,
158733,
null,
225153,
130508,
132349,
23783,
6082,
81043,
null,
39613,
5799,
null,
1121630,
35430,
42847,
27481,
null,
23698,
471131,
7069,
3495,
161070,
21866,
115839,
null,
139816,
63075,
26485,
515171,
13904,
null,
185162,
35450,
46121,
42350,
null,
16940,
181669,
255318,
48617,
79097,
30108,
9175,
null,
285944,
193446,
null,
79529,
156742,
22628,
163319,
344156,
189494,
601355,
7571,
null,
null,
117469,
381977,
229989,
13706,
98692,
86123,
162399,
421709,
132553,
141534,
57458,
367323,
781553,
25551,
113775,
391867,
82579,
136969,
26755,
21035,
null,
38256,
348432,
44800,
33111,
514662,
15442,
404840,
263324,
49081,
27319,
114104,
140452,
14232,
167264,
18398,
212531,
16137,
35123,
363112,
223974,
159126,
630634,
113752,
40780,
27747,
null,
20480,
null,
381408,
399996,
248558,
13731,
177641,
201212,
436320,
191265,
7631,
50693,
null,
78590,
18503,
418279,
null,
48254,
117746,
276872,
16263,
null,
2736,
34418,
391030,
128525,
134581,
148797,
176202,
59553,
18672,
145383,
405248,
139158,
157330,
385839,
106269,
148807,
54916,
433911,
78218,
null,
null,
27885,
30501,
667175,
179850,
350453,
39174,
246093,
7922,
135339,
177345,
449149,
122180,
135301,
36314,
138155,
40226,
173479,
214905,
192458,
307492,
114896,
35823,
354819,
37346,
317073,
null,
74350,
null,
3709,
24928,
165522,
133909,
29913,
24518,
42065,
null,
61509,
294531,
146816,
231805,
205957,
57414,
116785,
141841,
27378,
206826,
47114,
147093,
5377,
121436,
6054,
20319,
14857,
126331,
435412,
101105,
56654,
322045,
49956,
397828,
72807,
32249,
80287,
44519,
224980,
144948,
142420,
null,
null,
71060,
100703,
12883,
98416,
43929,
null,
76762,
840845,
177241,
42149,
null,
26830,
87628,
409349,
49392,
36114,
78014,
null,
null,
482802,
null,
26578,
10934,
109599,
47423,
89444,
111441,
80450,
null,
87107,
139249,
19653,
240622,
43408,
44199,
10792,
380039,
111433,
172356,
355442,
178474,
304807,
68862,
284781,
39622,
null,
110305,
21865,
342923,
282669,
362469,
null,
8522,
278561,
54372,
63052,
4364,
null,
29087,
43791,
31885,
180658,
124475,
255922,
341446,
280056,
52451,
null,
55345,
21170,
29787,
91311,
170996,
40662,
18517,
222013,
29734,
37087,
36706,
89261,
null,
8021,
40535,
12410,
120818,
36541,
5525,
61016,
368998,
68854,
425770,
141342,
13479,
183773,
274278,
29891,
126338,
4564,
9812,
12400,
23170,
165563,
615821,
84412,
656906,
40552,
413849,
null,
137711,
48414,
null,
223117,
217506,
85091,
37850,
146667,
210222,
464234,
17179,
354810,
296138,
37816,
24735,
155566,
null,
298886,
138388,
68539,
28798,
18279,
294781,
33907,
44955,
7979,
null,
39996,
167103,
46156,
360507,
58146,
79220,
46008,
285754,
140801,
4889,
211609,
493641,
180875,
225773,
179140,
28557,
24109,
17080,
268130,
26215,
158328,
36062,
100779,
241322,
17728,
null,
15529,
34365,
278512,
773846,
117359,
38090,
467447,
98807,
334263,
32753,
313819,
61739,
40177,
null,
23444,
94506,
19136,
59269,
null,
74718,
79853,
null,
76231,
166855,
120443,
22104,
512662,
95884,
32401,
296336,
25583,
32508,
31293,
46243,
44927,
132033,
33050,
30436,
289711,
210619,
null,
34072,
null,
5763,
163325,
144532,
264306,
151507,
351842,
357236,
273288,
null,
186349,
12092,
420643,
80530,
352184,
152900,
228888,
6793,
93153,
241087,
119393,
168965,
27288,
67032,
365711,
146563,
387303,
501063,
60217,
156778,
14787,
30989,
151090,
10639,
null,
49366,
null,
15895,
121548,
210678,
19807,
16827,
481377,
82914,
203646,
174916,
7391,
165608,
null,
2556,
5547,
151825,
31953,
243736,
262319,
10702,
194579,
6688,
329058,
298782,
23143,
155753,
52779,
39930,
125452,
746460,
null,
98044,
229093,
398728,
76482,
34620,
12322,
9184,
337721,
102681,
411027,
117381,
31276,
71303,
210223,
12249,
15649,
18555,
31876,
246127,
248240,
248129,
9272,
32439,
27165,
243655,
75243,
202212,
227511,
25643,
2840,
46358,
92846,
null,
null,
13105,
6676,
89597,
191688,
266646,
371609,
113849,
44053,
346463,
8192,
633523,
37240,
120739,
null,
410564,
51784,
null,
19897,
76526,
257046,
56265,
178607,
514334,
378216,
43754,
98146,
20240,
217834,
235006,
106976,
28119,
29140,
91938,
202124,
null,
28742,
866133,
146645,
456376,
59954,
237657,
73726,
39755,
62766,
243885,
null,
14849,
375449,
233690,
283096,
242667,
227061,
414787,
51629,
31649,
15939,
19791,
101045,
241580,
335600,
28049,
476684,
326717,
59069,
255666,
339753,
95770,
34406,
null,
260852,
39396,
30183,
13481,
133782,
293885,
22193,
48753,
32300,
73221,
6449,
66401,
63859,
15566,
9869,
53448,
200035,
null,
67324,
57632,
95135,
19724,
32073,
41174,
null,
424699,
145204,
445491,
14608,
41844,
52532,
null,
85510,
157442,
130903,
46839,
35474,
125796,
199082,
203485,
21714,
30346,
57048,
65083,
207460,
10471,
32755,
13111,
6110,
1441,
306491,
330283,
212083,
30223,
14447,
69641,
null,
72048,
56432,
219200,
113201,
36964,
341668,
22100,
133412,
372327,
null,
70034,
270907,
181061,
1916,
172078,
null,
15322,
387051,
212382,
148535,
null,
117553,
16188,
236812,
60640,
33450,
302811,
65735,
4463,
121424,
75966,
21033,
119003,
19698,
27261,
12515,
19900,
52748,
31322,
291462,
108528,
59704,
9475,
183010,
68912,
58976,
100454,
2611,
542518,
null,
304510,
null,
322136,
17131,
115713,
93772,
91600,
232143,
309616,
111672,
685,
278565,
65694,
null,
15110,
48493,
360923,
197894,
346052,
115662,
26655,
10440,
376539,
316117,
118212,
41770,
null,
48951,
35946,
93743,
182550,
32857,
189009,
153411,
341376,
100891,
56025,
16377,
234099,
139998,
107858,
143211,
25054,
174507,
475669,
81185,
133888,
17782,
null,
215503,
209323,
7642,
102048,
44097,
126411,
284809,
67770,
32128,
43884,
51625,
null,
180910,
115839,
248190,
191413,
5269,
316953,
168239,
20766,
198186,
26523,
68616,
12560,
365178,
48852,
549699,
107730,
441737,
221459,
26291,
266943,
212931,
14323,
27846,
62066,
283660,
267780,
11811,
18685,
418919,
47761,
269284,
576989,
71648,
null,
43262,
null,
5939,
396048,
343914,
240727,
30059,
85407,
null,
10735,
661416,
9687,
171793,
null,
73516,
153921,
522992,
17226,
16638,
28474,
37942,
186318,
20277,
null,
2592,
31370,
130442,
169879,
171654,
17044,
22764,
223879,
101438,
608101,
null,
26861,
51105,
180173,
242342,
96934,
null,
29861,
135315,
237992,
277066,
35358,
46658,
27062,
47808,
630857,
77267,
29269,
158334,
157882,
234856,
205076,
59857,
26613,
8229,
388859,
66498,
165730,
55165,
91803,
153294,
30715,
53030,
309119,
390119,
16164,
22187,
null,
32009,
15847,
124684,
611600,
129825,
11216,
397547,
196899,
159517,
12547,
11951,
26048,
128220,
178934,
71944,
92353,
null,
11497,
405013,
308039,
22768,
197189,
238880,
87061,
236204,
7568,
23227,
173712,
91919,
71514,
6475,
null,
411103,
15067,
4518,
26940,
17185,
167500,
34922,
97354,
34635,
73313,
9988,
30181,
367775,
53428,
216879,
52809,
147895,
3472,
238143,
145811,
7191,
304691,
341299,
9035,
460186,
282572,
null,
185551,
233133,
378524,
21081,
15159,
260935,
245403,
153012,
25192,
658975,
443795,
60500,
309198,
160797,
null,
10841,
69937,
null,
46554,
34413,
241089,
414663,
131992,
109290,
117148,
94364,
97740,
141744,
null,
487934,
684136,
44632,
693499,
295489,
194798,
267692,
24749,
33273,
485988,
144596,
195348,
15690,
4477,
380136,
229975,
9907,
null,
253770,
272953,
18933,
288255,
65399,
94461,
179885,
27054,
809402,
218770,
173172,
256455,
215747,
228769,
45196,
64882,
93210,
7092,
28744,
22160,
151540,
231706,
41928,
null,
null,
25905,
256661,
403948,
19434,
2752,
26360,
79229,
4609,
29219,
30017,
7244,
253496,
210655,
1717,
158491,
247523,
17207,
284989,
24329,
91017,
158518,
103515,
519894,
352337,
455847,
15993,
315812,
25117,
17019,
207754,
248790,
194987,
null,
25153,
184323,
40127,
91075,
null,
48507,
null,
null,
47460,
38773,
37401,
11488,
107625,
291414,
29983,
486523,
90683,
32530,
72234,
253938,
40396,
43819,
330634,
50005,
null,
226954,
28881,
null,
456235,
12018,
97612,
17894,
39976,
243079,
95893,
34995,
68943,
52934,
153171,
86268,
163222,
198743,
22942,
232369,
340017,
43554,
681734,
20007,
56946,
201997,
38054,
8507,
32661,
42183,
302375,
null,
31321,
79273,
155582,
41245,
50566,
281224,
149831,
72402,
166964,
126531,
28710,
223623,
14677,
195194,
33753,
262910,
106763,
63956,
383916,
16338,
306370,
43070,
230504,
262521,
null,
6968,
337748,
53316,
17593,
304139,
151496,
253943,
439096,
38173,
15652,
77278,
null,
184659,
104583,
60058,
56732,
null,
20842,
263684,
151687,
149029,
191231,
245773,
33983,
null,
11333,
94943,
47497,
32329,
62649,
76464,
181860,
252988,
5082,
13599,
194410,
153899,
37595,
114567,
67992,
161078,
39757,
355801,
13765,
188139,
5440,
261787,
48903,
134656,
38306,
15644,
113370,
24805,
12775,
25058,
null,
381994,
50864,
41954,
503581,
39770,
16664,
171758,
19811,
null,
132325,
15838,
13694,
177572,
262411,
253076,
54069,
377837,
null,
27786,
13567,
139664,
680626,
null,
201338,
451338,
null,
254271,
208617,
5539,
129832,
19375,
55425,
null,
299666,
34394,
165167,
44278,
31990,
55393,
195256,
6303,
null,
98991,
224261,
451209,
229662,
91855,
674312,
24553,
281123,
408474,
14606,
79555,
26962,
42320,
57003,
5245,
233268,
135875,
368692,
45682,
4423,
50130,
291523,
223356,
259342,
62851,
null,
152148,
null,
253363,
229113,
45633,
18227,
103608,
40860,
41159,
210393,
26023,
null,
457612,
43148,
158779,
390403,
42702,
367585,
80735,
181764,
324157,
72932,
184937,
274372,
null,
217381,
17502,
474033,
101690,
18147,
23396,
34891,
289427,
103801,
30363,
21423,
503727,
19659,
52210,
22966,
242761,
25419,
255470,
27934,
10364,
4670,
29902,
27560,
284265,
279053,
183318,
46566,
34379,
40154,
38024,
13802,
276929,
18177,
16523,
32684,
433273,
369432,
292498,
566715,
3261,
279077,
97649,
310703,
146867,
62891,
214720,
33446,
134457,
59523,
261484,
null,
null,
179220,
null,
296448,
70726,
356571,
272227,
11538,
20842,
56313,
18008,
16700,
114924,
35694,
8004,
null,
117956,
null,
58195,
131302,
119164,
10772,
null,
29082,
297930,
162305,
13466,
45308,
null,
597185,
20916,
584674,
10128,
59992,
56803,
13494,
519654,
289674,
20031,
336577,
134099,
6860,
205987,
130277,
132006,
128555,
41365,
396724,
null,
9569,
null,
187199,
61732,
263503,
73049,
141070,
46840,
146737,
72525,
16582,
89694,
305388,
161649,
6235,
232850,
null,
158525,
37536,
null,
13912,
190821,
262433,
201633,
47745,
113825,
372151,
213918,
61847,
282220,
407879,
156988,
84090,
10825,
18716,
null,
222817,
26598,
383180,
179022,
285698,
42714,
40950,
48069,
48130,
47684,
null,
91489,
null,
262026,
211122,
65759,
40050,
null,
101215,
40261,
127163,
20073,
181811,
32375,
278107,
80589,
44987,
126071,
215834,
11712,
208166,
31351,
81542,
38085,
44352,
null,
29542,
32141,
52394,
209961,
128649,
196824,
65270,
461708,
209860,
500499,
114425,
282724,
387537,
258002,
9564,
37952,
335328,
178147,
33250,
26624,
454097,
47764,
31833,
32979,
35813,
18595,
8563,
null,
5433,
49665,
44865,
83001,
117922,
176239,
364535,
214672,
85480,
99327,
266224,
309281,
7481,
69887,
45364,
292298,
118370,
331687,
29441,
263211,
222162,
229808,
147622,
184226,
54039,
27806,
231253,
40442,
68009,
258310,
295996,
42433,
29098,
159236,
339605,
304727,
23035,
206871,
2150,
40561,
null,
469179,
314375,
28820,
21083,
273992,
176426,
5226,
304342,
34545,
16935,
82594,
36300,
42414,
760364,
43935,
149196,
302405,
6349,
60605,
56979,
null,
260320,
17658,
27850,
80142,
8100,
252277,
25019,
null,
107845,
26307,
127753,
20091,
266992,
275431,
1755,
222646,
173788,
232666,
247627,
197760,
null,
610775,
70222,
30296,
118318,
10099,
12257,
20335,
151063,
649928,
323982,
64073,
303308,
34772,
116180,
187392,
117735,
189834,
463955,
170326,
66212,
231471,
18058,
113395,
92736,
137663,
11956,
216861,
null,
64927,
412748,
20116,
332664,
370693,
85047,
19775,
19067,
297874,
22190,
263807,
37763,
46777,
23293,
235968,
98963,
8262,
170615,
775105,
180911,
45170,
162283,
87587,
192805,
112779,
246160,
null,
9421,
31315,
139443,
199883,
17669,
49422,
32502,
59359,
26978,
302690,
18235,
267446,
25542,
40830,
53821,
361886,
236155,
231529,
19788,
173580,
3841,
19314,
215712,
84223,
21934,
7062,
330529,
261370,
87788,
32446,
1584,
25997,
114926,
19156,
81323,
62121,
420843,
92294,
134934,
49171,
37214,
270135,
78936,
294070,
103692,
38029,
329445,
35578,
415002,
125954,
190763,
54338,
213946,
81179,
355834,
56459,
212062,
4537,
600969,
32301,
207207,
25640,
121665,
null,
25915,
20348,
102629,
45685,
20464,
null,
197792,
78188,
null,
5732,
321575,
27727,
101687,
44400,
177906,
37400,
133975,
24033,
124108,
135216,
25049,
32101,
166105,
228596,
70131,
null,
375436,
319697,
24387,
85877,
33983,
null,
724048,
62473,
95386,
33329,
221799,
166836,
20354,
42945,
13771,
37687,
44055,
21153,
3315,
201717,
148117,
null,
12985,
312315,
null,
47310,
140268,
286821,
null,
123768,
155696,
22870,
27061,
56492,
214387,
58416,
33043,
380205,
140889,
408128,
24924,
22441,
591480,
353550,
135142,
206688,
36554,
147445,
13958,
9923,
29693,
24395,
3633,
57366,
null,
140317,
30565,
416051,
56215,
416766,
41900,
93013,
241218,
334508,
173913,
206335,
72583,
17311,
300436,
43279,
25740,
91819,
136262,
58906,
42100,
null,
191830,
452589,
234678,
207793,
23867,
157051,
24545,
32549,
197183,
178545,
7820,
196017,
33981,
255711,
null,
131525,
27523,
195482,
123984,
138099,
44523,
null,
15,
68554,
46850,
280030,
161969,
24379,
null,
17355,
17287,
234067,
27245,
33568,
419181,
130215,
187179,
251283,
33637,
83646,
15239,
291072,
176400,
30542,
564700,
129806,
68730,
116313,
null,
15023,
31207,
120040,
54936,
138637,
29352,
76051,
192164,
164413,
136923,
73659,
53730,
null,
42697,
41748,
null,
360803,
154802,
578859,
235890,
9847,
null,
351650,
null,
161376,
6527,
196000,
61640,
157914,
12184,
315190,
37941,
175059,
78593,
63665,
64897,
270997,
10646,
23819,
91604,
83447,
17428,
344473,
43699,
183435,
45081,
137405,
76736,
239152,
153788,
318051,
428027,
null,
22566,
209715,
129406,
20353,
353306,
126928,
28527,
null,
274030,
178880,
13782,
7444,
83408,
237262,
18813,
36852,
28588,
59661,
420312,
71209,
365082,
116388,
56014,
32917,
30652,
24335,
9694,
219319,
123193,
19227,
null,
149965,
126659,
44877,
42535,
371372,
1242125,
805545,
178934,
244363,
28692,
337362,
302415,
null,
5584,
35389,
81956,
96067,
null,
272543,
164900,
375714,
27710,
209097,
328822,
45010,
39677,
56454,
662084,
null,
112620,
246182,
214795,
51528,
103865,
225151,
387926,
79819,
354631,
212966,
169668,
null,
180975,
163453,
61865,
221783,
93968,
319956,
147626,
102816,
32727,
69249,
623772,
35352,
223215,
137627,
null,
36369,
5015,
137805,
null,
36938,
594334,
13773,
105326,
123362,
61719,
null,
393810,
86651,
null,
23234,
32011,
18098,
30614,
270246,
195098,
11558,
307449,
169004,
47344,
154516,
150202,
null,
185586,
378786,
161661,
null,
68078,
3763,
15635,
18124,
150973,
299556,
46386,
260143,
25102,
146241,
16462,
55250,
29202,
21458,
84188,
null,
52144,
209617,
6504,
586379,
116753,
100537,
31187,
null,
174898,
328588,
87547,
48979,
10782,
66920,
77194,
382067,
471977,
38247,
94879,
17537,
217445,
48384,
328843,
379059,
148325,
42739,
26618,
247338,
22670,
471336,
null,
38302,
89119,
43523,
25524,
348124,
457196,
67975,
10686,
132805,
195490,
4775,
474667,
17151,
182981,
297978,
37404,
342996,
36755,
184999,
null,
209595,
259597,
257698,
152584,
333454,
356907,
22765,
84284,
99444,
6441,
28807,
431903,
149505,
41224,
8692,
178687,
79019,
175624,
null,
15891,
5764,
169259,
43951,
61804,
19963,
14367,
18427,
239791,
241015,
77205,
271376,
195041,
391209,
75962,
null,
114150,
31685,
484751,
11666,
317090,
365631,
210000,
18567,
174527,
120469,
42641,
229030,
250147,
29571,
362554,
468767,
290957,
37703,
179085,
null,
195185,
147989,
35060,
286649,
null,
8924,
170622,
322634,
30113,
65077,
129183,
272280,
103973,
17960,
289069,
115110,
101225,
128662,
277197,
31533,
99771,
null,
203921,
187799,
null,
185656,
409971,
115891,
23129,
128859,
75126,
12822,
186854,
329844,
40186,
476477,
16762,
72742,
12275,
null,
572941,
8116,
45865,
214280,
210995,
47281,
36284,
9185,
187646,
1318,
171558,
171927,
null,
194071,
15021,
6875,
306304,
33318,
13928,
509,
23846,
19977,
23611,
16082,
28566,
185594,
41319,
365885,
217179,
41464,
27292,
30581,
307342,
27100,
241606,
67454,
38350,
197227,
24440,
116324,
189147,
null,
308211,
25213,
185814,
378700,
11627,
20025,
687293,
74963,
3087,
213841,
530898,
118645,
167260,
243831,
305146,
14834,
23784,
167281,
218446,
52314,
34024,
16973,
39155,
7069,
53978,
214727,
63979,
213499,
158891,
83062,
19770,
13097,
3862,
293082,
22023,
94777,
74778,
7878,
31330,
56649,
159433,
67577,
202891,
146503,
18134,
22703,
517824,
33608,
150932,
34383,
364868,
57730,
23714,
206492,
14861,
117538,
2914,
30285,
285941,
112652,
311405,
17403,
325953,
2935,
24015,
49379,
157901,
179401,
null,
442621,
25273,
12221,
15172,
226467,
225474,
null,
236549,
12269,
131151,
31697,
22158,
null,
20116,
46635,
118640,
198994,
14089,
73215,
21853,
167986,
83224,
29741,
null,
56970,
26285,
38176,
45473,
46163,
null,
17725,
320746,
254038,
98537,
214388,
281349,
66441,
16473,
105756,
67680,
477838,
7370,
106973,
103277,
281844,
237408,
102151,
271990,
143479,
396186,
55092,
226831,
281083,
364943,
30267,
16072,
44178,
9624,
61326,
190195,
125983,
72062,
301109,
183991,
5741,
456545,
12747,
13647,
15743,
360883,
null,
280259,
64900,
48769,
328981,
1154,
420289,
268134,
58977,
64347,
18566,
65449,
105416,
41108,
39897,
42351,
25755,
323840,
28896,
44037,
90061,
68465,
242704,
370289,
15257,
74137,
24053,
57452,
110540,
15627,
29232,
76709,
42592,
387743,
null,
137652,
282981,
null,
420015,
16812,
526484,
20805,
119891,
30146,
2755,
7444,
6961,
301262,
95827,
60731,
399472,
56651,
25608,
482157,
203663,
null,
216567,
445612,
121268,
11109,
63366,
101804,
44410,
517803,
110518,
231050,
16171,
45132,
239551,
36517,
250875,
107503,
42192,
1086281,
165928,
211372,
167604,
25248,
430790,
null,
55845,
88122,
71886,
89863,
250637,
481258,
290287,
5259,
324754,
556945,
116523,
227956,
29884,
169084,
8936,
425128,
21780,
51380,
16605,
84497,
195389,
null,
24087,
47402,
8833,
14584,
379017,
15742,
337053,
null,
331284,
217824,
40391,
192018,
250089,
181449,
38325,
30024,
15398,
7312,
157008,
55208,
56142,
199725,
46198,
100232,
18855,
null,
690580,
52056,
30227,
23420,
45193,
144696,
31670,
398859,
25158,
11497,
193907,
115220,
362278,
17317,
286737,
211080,
496783,
43054,
201744,
284776,
46863,
286249,
290972,
65391,
246793,
49782,
327402,
37815,
252382,
33557,
94577,
698358,
46770,
108057,
58644,
25705,
28856,
178697,
140757,
129712,
57728,
95698,
65449,
757807,
115682,
178717,
null,
261124,
74395,
57519,
376527,
479304,
335398,
107813,
188339,
775958,
null,
38844,
23209,
185302,
69359,
177638,
323035,
37912,
338942,
474694,
27945,
51214,
67584,
1819,
33636,
394991,
54930,
45068,
10816,
15038,
null,
74277,
39475,
91864,
52467,
30153,
374709,
159504,
119349,
null,
null,
95387,
195531,
18008,
422759,
71790,
403606,
118665,
41888,
323527,
null,
44925,
30041,
313542,
31911,
6228,
149596,
null,
12223,
14353,
332571,
120064,
129903,
null,
368669,
193779,
21736,
37566,
31274,
11248,
30598,
60078,
201717,
141868,
160583,
14381,
125728,
null,
25849,
242119,
344871,
127154,
29282,
149719,
25841,
24624,
479302,
75723,
42276,
20944,
53158,
341817,
39552,
81587,
null,
35371,
196345,
268106,
74342,
393099,
87960,
40243,
272260,
121785,
542931,
87444,
133401,
69552,
69004,
286408,
20962,
31636,
282934,
77177,
439838,
33942,
63732,
50090,
30159,
11072,
40740,
285531,
240565,
302724,
18096,
192647,
6979,
30096,
8917,
69998,
96781,
null,
206830,
360020,
14465,
11751,
109199,
108141,
154762,
235086,
374411,
104053,
14543,
39469,
230269,
17181,
87709,
null,
38572,
388973,
54768,
18804,
35765,
23499,
44765,
6450,
null,
29745,
907,
74086,
25441,
42225,
24008,
151548,
57270,
4861,
89128,
100930,
273728,
94155,
281459,
405326,
95451,
88770,
58323,
13543,
6641,
28977,
143098,
403988,
276380,
630678,
134521,
18185,
200669,
89462,
9561,
197328,
55290,
12894,
15476,
18319,
280269,
435032,
12435,
57579,
91189,
null,
37358,
222158,
105486,
216628,
127627,
85302,
253262,
45439,
66079,
50052,
278631,
112335,
280245,
7076,
41663,
152558,
54870,
23257,
28381,
12236,
13560,
148260,
27712,
275328,
28463,
85809,
91445,
null,
14410,
41219,
40195,
221402,
40615,
35497,
132931,
358449,
51023,
null,
345844,
546935,
14765,
369365,
8800,
99587,
26141,
null,
129429,
4775,
33013,
6248,
178122,
19131,
196467,
127777,
470183,
183494,
89600,
828515,
241106,
296596,
13361,
125252,
null,
null,
634674,
210761,
39315,
126383,
164839,
212921,
44462,
387409,
null,
35132,
323859,
93542,
532476,
null,
36518,
213058,
607820,
107671,
183722,
111409,
20251,
142022,
null,
14326,
2128,
null,
24067,
179551,
103838,
null,
33832,
204203,
53535,
91818,
5868,
415211,
194145,
16777,
31770,
12897,
126681,
22165,
65296,
null,
2635,
252071,
25813,
19408,
49065,
37890,
67046,
337602,
34301,
217931,
167516,
526272,
268716,
5207,
358186,
90047,
62999,
null,
37151,
229013,
238048,
130456,
null,
202133,
8097,
38233,
277388,
101010,
449550,
175375,
613134,
22614,
125047,
118040,
null,
102448,
8241,
167684,
37919,
180246,
40212,
56469,
35627,
43765,
259060,
null,
44599,
null,
138764,
152124,
64116,
57985,
38360,
305198,
194352,
17706,
40696,
57383,
171358,
21824,
215226,
12278,
null,
null,
184783,
28362,
115113,
null,
11992,
42405,
310440,
619814,
18814,
373438,
254373,
181027,
5620,
null,
45864,
376975,
171260,
187679,
null,
22038,
464256,
15480,
null,
185726,
322378,
null,
160354,
226387,
81824,
33685,
25584,
133985,
46279,
104491,
24809,
205636,
389675,
null,
19121,
43209,
24602,
42086,
146460,
69440,
524723,
177133,
58489,
367997,
70795,
250735,
21118,
30679,
2285,
38532,
39691,
24673,
25354,
null,
4253,
38540,
43543,
311952,
126304,
36562,
14259,
218213,
156868,
338609,
296496,
269928,
212182,
170199,
37239,
182738,
163646,
452336,
37576,
36617,
42698,
12318,
11648,
null,
395862,
44414,
291261,
4572,
152885,
16865,
139530,
64220,
826111,
47365,
161842,
33009,
96496,
15429,
26264,
20050,
11176,
123391,
52325,
25182,
4710,
17249,
202129,
218088,
10853,
35857,
37920,
83069,
48117,
128370,
27991,
71209,
256799,
null,
295845,
354599,
143311,
18008,
69527,
null,
33186,
71567,
236303,
165906,
15952,
92049,
449,
72852,
218008,
35827,
69153,
58314,
200638,
75934,
16315,
null,
null,
14995,
282246,
12945,
75136,
29866,
269006,
51942,
49946,
134445,
209922,
9924,
null,
359551,
251195,
199426,
526344,
null,
29107,
27162,
null,
21993,
538269,
10148,
211008,
105910,
35084,
79119,
33871,
184736,
90951,
47946,
91196,
7856,
58686,
348923,
19564,
19248,
39264,
224069,
77511,
null,
343859,
16568,
78555,
162706,
39625,
null,
103172,
13495,
11812,
null,
259891,
null,
40268,
22013,
149545,
224669,
69194,
330227,
21890,
9216,
37342,
268214,
618366,
290579,
503557,
63770,
175227,
307789,
172467,
84713,
43714,
2136,
178671,
9870,
128785,
479339,
326896,
358745,
71600,
141740,
33890,
36343,
126657,
13012,
193479,
22174,
26394,
30511,
7622,
44200,
null,
121670,
38039,
169463,
167110,
null,
245218,
68981,
178849,
215980,
158018,
233555,
25625,
277082,
45722,
260538,
36337,
34130,
98256,
192842,
null,
212450,
118719,
46878,
3082,
176332,
194464,
46289,
null,
121120,
32472,
251523,
24256,
135628,
null,
315793,
18536,
null,
12328,
334576,
10011,
381217,
141643,
null,
680491,
294269,
218223,
30202,
217550,
8402,
12573,
401124,
102895,
23568,
12609,
73775,
32111,
379826,
null,
null,
126702,
80538,
369049,
64692,
39971,
326858,
72031,
379997,
152816,
128148,
26624,
7276,
444558,
344499,
45744,
21688,
46637,
45539,
35149,
18925,
44758,
85735,
26591,
357382,
13094,
178721,
195977,
27080,
393540,
229745,
403673,
213890,
340533,
null,
45917,
13406,
74203,
197991,
null,
387248,
null,
330678,
12311,
218507,
19388,
159477,
14425,
null,
39429,
174516,
260232,
70696,
70005,
36676,
381818,
397532,
37670,
null,
137028,
162971,
275445,
417028,
33649,
18164,
38763,
72916,
36966,
5174,
122816,
42762,
157023,
16740,
20556,
21233,
22405,
231503,
72910,
61246,
62992,
6274,
40876,
null,
393265,
362066,
39406,
null,
110776,
115983,
47647,
111296,
23656,
434462,
null,
24073,
null,
478253,
325051,
25260,
9432,
null,
32379,
18366,
94991,
46010,
167623,
39049,
93357,
277587,
70018,
229646,
223071,
309792,
17225,
33250,
43777,
402706,
286123,
77714,
49948,
293848,
11580,
548417,
null,
null,
119088,
15698,
null,
52098,
null,
668719,
23380,
79711,
117418,
47643,
274613,
72839,
41732,
30456,
24390,
211562,
60473,
106278,
22154,
109798,
379991,
9694,
55749,
7793,
18035,
132849,
519037,
142605,
45424,
62786,
254115,
7688,
218169,
198499,
160756,
496526,
null,
11055,
48132,
159567,
207407,
412209,
91710,
235544,
null,
453810,
163770,
54844,
161458,
85814,
118593,
159342,
58096,
257747,
297317,
null,
null,
261854,
583922,
178017,
14490,
101178,
22534,
223672,
324969,
211032,
33133,
604554,
39246,
35426,
7573,
262064,
13906,
219311,
72032,
26114,
283894,
311136,
294691,
376295,
33617,
53519,
82157,
63930,
199339,
19471,
33148,
33345,
16048,
50846,
201816,
null,
127753,
4337,
33343,
21145,
185834,
null,
213548,
230043,
null,
76230,
99366,
4190,
225724,
46595,
185697,
120162,
58289,
207250,
28353,
22902,
76756,
27895,
6289,
33240,
139254,
15798,
551581,
59437,
158718,
15734,
51667,
104398,
165564,
null,
83747,
4448,
null,
36869,
8029,
null,
null,
101254,
59640,
8672,
269686,
173944,
30945,
19466,
78949,
347747,
null,
296541,
28041,
33848,
40221,
68553,
6404,
13378,
58392,
8736,
null,
85901,
239199,
26270,
105873,
63989,
27920,
null,
43872,
78178,
83684,
113715,
6941,
254551,
6807,
16136,
7678,
21120,
null,
419918,
258618,
84664,
93900,
35986,
40951,
34247,
33499,
12057,
11350,
113417,
252272,
20567,
64074,
126567,
19723,
33087,
367627,
228960,
43424,
null,
7648,
33511,
105534,
56369,
167701,
29427,
16394,
86200,
92652,
null,
13739,
null,
243690,
7910,
47717,
311523,
80408,
25753,
36512,
39221,
101453,
169658,
35126,
42960,
76267,
39208,
245900,
118353,
58050,
212007,
117943,
49392,
328345,
62334,
211891,
34990,
17096,
454142,
66107,
89577,
42695,
101943,
118808,
391888,
81532,
200203,
120220,
195511,
null,
23478,
null,
198986,
27177,
339439,
null,
252019,
16189,
86753,
17474,
85712,
123108,
437948,
41603,
7280,
679390,
46174,
22735,
28890,
454248,
62450,
277092,
45902,
130123,
30962,
84238,
56431,
108555,
42939,
128775,
319165,
394631,
125320,
34908,
361899,
136401,
36560,
26169,
29193,
512580,
400640,
46717,
146202,
12220,
9991,
247188,
135652,
226374,
95711,
199035,
7304,
52836,
127056,
193358,
30753,
15122,
162438,
12007,
51353,
278991,
136608,
null,
530361,
2644,
4596,
84229,
140185,
10019,
null,
134696,
170969,
710392,
33705,
288264,
597573,
126996,
23077,
51668,
66576,
87871,
422948,
59754,
504748,
168866,
12413,
427503,
4610,
277014,
218301,
140732,
29075,
17660,
34800,
18985,
1716,
16956,
199733,
45909,
null,
22525,
144242,
71949,
497960,
84806,
142610,
135883,
10662,
12884,
null,
211413,
216680,
44847,
31172,
10892,
88868,
31844,
49074,
57800,
14364,
248350,
69140,
95042,
339472,
43697,
410022,
247575,
203800,
27595,
null,
24019,
35702,
70935,
59318,
18424,
111390,
141778,
19402,
63535,
37599,
243833,
253616,
193051,
71436,
12785,
67707,
44502,
29661,
178319,
null,
1843,
6190,
579225,
23639,
167997,
56862,
null,
102481,
9137,
28141,
59684,
169306,
229131,
95300,
512837,
41805,
20174,
31129,
175050,
165664,
48286,
386295,
null,
204872,
17445,
362916,
643024,
null,
null,
319609,
41817,
36432,
7970,
196864,
null,
10139,
41241,
null,
45981,
54101,
463694,
97683,
1036269,
55740,
166012,
116578,
712861,
null,
null,
222651,
12616,
259252,
323926,
42881,
415320,
2600,
4297,
25490,
231346,
12696,
254313,
107558,
188791,
15371,
13677,
485471,
266133,
189398,
61471,
290567,
73806,
26986,
49950,
55560,
226919,
null,
70683,
171539,
null,
4357,
72609,
150231,
1226768,
31279,
175688,
18374,
215073,
105595,
13102,
null,
26762,
300955,
302977,
null,
null,
51033,
194827,
238227,
107277,
38240,
320093,
45462,
73223,
null,
null,
12213,
174498,
39124,
351236,
77701,
227328,
421562,
502796,
13571,
null,
267454,
9045,
118693,
41000,
436808,
21766,
38259,
44841,
69059,
319155,
293864,
52864,
489795,
337710,
9847,
388358,
169662,
89428,
13471,
134135,
1745,
29470,
10950,
39575,
18704,
34102,
340403,
107902,
25829,
131965,
8720,
298660,
259751,
28250,
178657,
142977,
125527,
40189,
44555,
48610,
219829,
null,
140335,
290965,
111930,
35622,
62977,
3976,
93637,
264452,
53665,
23003,
null,
142169,
154983,
150303,
22110,
null,
52667,
33235,
null,
7844,
37097,
77422,
119722,
822589,
21245,
265265,
500796,
null,
6852,
73088,
31224,
164854,
399997,
13491,
55194,
41302,
695581,
208306,
18755,
220367,
11424,
205422,
null,
692275,
null,
31615,
212286,
327380,
18826,
187088,
44912,
24121,
94717,
31589,
529460,
15799,
23181,
145589,
368773,
20430,
43975,
52951,
267530,
388385,
84276,
24111,
68751,
164522,
598148,
467141,
230588,
147244,
169895,
72625,
533255,
27482,
29681,
40199,
259276,
242277,
13254,
18998,
274393,
60301,
null,
125270,
7837,
71294,
205005,
17693,
130793,
171998,
29481,
51497,
283330,
347836,
2145,
349331,
73127,
11097,
24880,
14030,
18360,
109938,
12537,
16473,
381704,
31615,
null,
236160,
128860,
46541,
46845,
null,
304749,
4841,
39752,
323803,
8042,
582279,
44904,
73871,
19511,
22016,
228646,
117610,
77819,
106591,
149903,
21850,
66885,
234618,
37380,
315395,
null,
25216,
214588,
15399,
48425,
328819,
127791,
176266,
null,
193333,
279847,
17543,
15341,
null,
12780,
133022,
139805,
238867,
33325,
11759,
210395,
50422,
79367,
31973,
182292,
null,
3583,
424680,
101563,
8546,
17610,
325939,
41026,
135579,
252344,
null,
25950,
33480,
408968,
14535,
7601,
67034,
112745,
38867,
7562,
886141,
14699,
48461,
342414,
72026,
null,
8844,
26323,
19035,
290775,
835,
39392,
176765,
78220,
17725,
430809,
250365,
699675,
31435,
140199,
331551,
55469,
null,
39474,
204067,
14224,
65506,
18628,
59365,
166116,
43821,
67058,
342719,
10993,
142218,
543168,
null,
69151,
269194,
165047,
27007,
null,
154317,
33919,
280608,
6989,
44117,
447067,
158984,
35975,
42538,
18083,
null,
81222,
null,
62715,
4998,
248165,
14854,
null,
74330,
421480,
33995,
424864,
null,
19707,
12921,
142010,
37263,
null,
44001,
null,
210717,
89534,
282645,
332258,
9193,
183217,
138373,
293317,
283361,
16930,
41430,
54201,
37880,
58693,
349005,
null,
65481,
2488,
127178,
124748,
443237,
60737,
26652,
301728,
29326,
845049,
22598,
33952,
49936,
322678,
523355,
182836,
64582,
320309,
10105,
308492,
265431,
null,
37236,
19392,
89926,
56077,
151752,
289149,
50855,
263761,
null,
99728,
168287,
45232,
null,
204495,
212945,
170556,
null,
299132,
160099,
21452,
null,
17379,
114233,
68444,
14594,
255689,
351293,
15193,
null,
59894,
46574,
311228,
null,
231858,
159692,
37557,
174465,
156586,
302426,
337930,
613808,
null,
8063,
952528,
265271,
25703,
16053,
170341,
272450,
73397,
46230,
1184,
292310,
175138,
219541,
11965,
177379,
9478,
55217,
41674,
36351,
5040,
42615,
6294,
132540,
52462,
16296,
112186,
301664,
198784,
null,
236575,
20181,
32922,
42404,
18417,
2750,
215439,
5899,
23357,
15455,
69457,
null,
195240,
3955,
268621,
443921,
null,
125355,
55998,
213451,
52280,
22205,
57761,
4185,
47318,
6436,
null,
null,
97144,
22881,
null,
355410,
14616,
133907,
234091,
86162,
417432,
71831,
6033,
372531,
37925,
11849,
487215,
61646,
388941,
73948,
90647,
9944,
34266,
2047,
9136,
188803,
9879,
109528,
97103,
298484,
180954,
368474,
112849,
239765,
45192,
37063,
328845,
103364,
347488,
13585,
326729,
4120,
679198,
359272,
356493,
null,
118973,
93080,
null,
7402,
86578,
220752,
44783,
167572,
138319,
94253,
401211,
10777,
282032,
29043,
null,
14606,
10436,
194351,
177595,
167062,
294812,
320590,
136941,
191477,
32297,
122137,
86593,
22103,
39284,
null,
247563,
315388,
121217,
null,
null,
20004,
null,
5497,
174585,
29688,
30113,
418538,
201698,
84130,
33521,
409612,
187468,
null,
51728,
225687,
330396,
167168,
37200,
null,
46140,
56551,
81890,
85799,
22177,
28865,
105073,
95363,
168230,
45754,
71412,
72478,
72764,
700880,
708222,
12692,
150675,
37009,
96630,
233617,
291500,
34611,
28189,
471938,
439005,
247309,
155187,
24246,
308091,
41633,
285468,
80847,
37974,
217462,
234824,
48346,
22604,
null,
41774,
149902,
242551,
154104,
411121,
59985,
57765,
10273,
16550,
473737,
113481,
366396,
220270,
155952,
29393,
346387,
9508,
29794,
287657,
242462,
170876,
103945,
null,
8543,
13973,
229666,
473579,
80039,
13604,
277749,
null,
47975,
27391,
230103,
19580,
60821,
112345,
26824,
null,
129216,
295391,
168789,
37572,
48730,
314620,
165186,
171813,
65005,
null,
325746,
69200,
299928,
20587,
4352,
54834,
470445,
424447,
359134,
19493,
180205,
2772,
13822,
165822,
null,
52665,
348442,
542044,
null,
111137,
null,
504836,
128221,
25466,
263636,
744007,
159279,
194768,
57329,
18968,
113684,
374235,
44969,
231876,
42427,
228542,
40430,
44993,
35398,
30305,
111101,
195352,
29834,
185126,
372123,
247734,
16319,
174222,
66898,
119786,
61194,
222788,
9277,
574277,
26490,
17382,
17709,
56996,
81572,
48776,
47809,
368302,
28361,
521432,
35096,
202224,
157308,
264201,
401190,
259270,
190399,
55088,
277023,
91675,
null,
32010,
176086,
132582,
118251,
386060,
14992,
24447,
240229,
134655,
6815,
104702,
34852,
116765,
32013,
151536,
28804,
369433,
182967,
48285,
null,
32379,
9816,
11034,
501293,
124564,
null,
null,
null,
312577,
41460,
20311,
158524,
null,
11559,
131306,
165663,
74692,
246583,
11107,
228128,
389004,
58085,
null,
48478,
141027,
308364,
235978,
165809,
75589,
15105,
80909,
81485,
46576,
207399,
21646,
437188,
19470,
null,
23218,
433021,
75262,
303761,
202362,
167784,
32652,
160963,
293619,
316951,
190407,
1568668,
91521,
3639,
2544,
null,
343756,
26855,
356651,
165419,
26860,
164387,
158729,
null,
48459,
203837,
35825,
29366,
62793,
36600,
null,
15797,
204176,
null,
124813,
44306,
358013,
33603,
367320,
26080,
39371,
165468,
24409,
350101,
333294,
null,
23000,
147480,
null,
345,
189554,
69087,
31583,
55799,
70232,
43447,
256347,
130944,
204849,
46690,
12392,
472835,
12847,
205037,
372627,
102516,
198493,
34246,
40047,
72148,
205505,
5175,
106122,
37001,
21921,
28607,
76575,
33356,
186388,
68248,
295643,
55164,
61375,
145738,
null,
238790,
280837,
117758,
20399,
189902,
395094,
285052,
13721,
811664,
162122,
11236,
133088,
231475,
231721,
23063,
114743,
21506,
29294,
18056,
272157,
357750,
129824,
27049,
32850,
427870,
17157,
21226,
6133,
38543,
22080,
28314,
358838,
194684,
283324,
67517,
170608,
37592,
null,
240566,
41377,
176849,
18693,
612831,
164631,
135506,
18943,
137650,
8827,
91637,
24028,
172871,
65974,
null,
162871,
262198,
78430,
337396,
32839,
10162,
null,
113898,
22864,
79445,
13710,
28167,
15863,
null,
164744,
25895,
47707,
45455,
214987,
21682,
200236,
279563,
23294,
11101,
28335,
609117,
403252,
19751,
null,
488263,
380931,
162355,
433943,
31489,
141865,
null,
32706,
232121,
98471,
142804,
137124,
163460,
null,
124026,
21469,
426130,
16073,
25555,
340966,
433958,
29942,
18727,
57902,
28634,
114896,
14270,
19813,
524857,
169043,
34028,
182526,
59971,
165224,
420003,
16217,
57914,
53680,
null,
2078,
46448,
190169,
24292,
353954,
null,
null,
26932,
155760,
20713,
16270,
137528,
52542,
6764,
17513,
145810,
18380,
278121,
132422,
327491,
79503,
39294,
144094,
66186,
null,
31410,
387805,
89571,
39941,
59826,
78123,
20362,
187197,
null,
33471,
63891,
1129,
3869,
241863,
37691,
404457,
99108,
12333,
65971,
397499,
15869,
27183,
202578,
151578,
217698,
33687,
126536,
89421,
117078,
51622,
76705,
null,
147231,
18337,
32344,
240683,
283020,
124946,
29178,
44157,
70662,
299451,
71849,
311351,
146652,
271144,
167359,
306496,
24654,
181590,
94256,
13237,
13115,
321536,
43648,
26536,
238426,
192214,
67599,
552793,
272677,
185434,
415936,
67677,
911561,
28035,
395175,
null,
459784,
52385,
null,
63564,
23489,
null,
13935,
45728,
434472,
33962,
141203,
303021,
31959,
55481,
29523,
24441,
368814,
116581,
61983,
145488,
3176,
279168,
168096,
315737,
46196,
136602,
89493,
181435,
35196,
null,
174968,
12083,
266018,
null,
313976,
36490,
null,
264132,
156884,
87053,
58046,
null,
39159,
26485,
399147,
32373,
432313,
187246,
16531,
52609,
659270,
782206,
13547,
7513,
69086,
null,
291028,
11646,
88459,
262072,
168990,
47699,
242591,
280561,
null,
9487,
117020,
191213,
442289,
299005,
44164,
356363,
205858,
117912,
105416,
89370,
null,
161310,
258715,
121337,
27735,
85254,
64978,
20917,
27959,
7831,
5247,
268532,
217337,
124186,
17253,
296091,
173339,
292041,
11457,
482789,
275351,
283812,
null,
271165,
269301,
215503,
null,
1580,
509021,
294692,
463027,
11438,
null,
31638,
286540,
12069,
274432,
43053,
492584,
81799,
115026,
39474,
18525,
334547,
28375,
37634,
429076,
null,
32516,
154091,
300637,
131014,
24629,
115826,
297135,
375203,
26755,
482632,
null,
422556,
null,
336125,
8183,
193503,
84391,
257216,
290632,
185759,
8262,
6309,
49679,
7025,
54932,
80194,
172953,
471211,
40824,
40482,
null,
265088,
118549,
null,
33518,
38695,
406634,
30345,
null,
24323,
221060,
220679,
475048,
137826,
57343,
141423,
228456,
27565,
21614,
null,
43036,
18079,
null,
53085,
45959,
216918,
299417,
13552,
81059,
59388,
151240,
467630,
17037,
11814,
24512,
null,
235082,
51636,
26882,
8945,
42251,
49838,
245877,
52037,
60075,
8844,
342882,
63711,
64644,
61758,
null,
27981,
43893,
94521,
29561,
53675,
15493,
75193,
18315,
172830,
19926,
43617,
28859,
25218,
23752,
102900,
183641,
123465,
142636,
151407,
107160,
174717,
35345,
150922,
110810,
287026,
50612,
11262,
31124,
123817,
21507,
431099,
null,
185820,
20350,
63130,
15418,
7454,
31966,
57659,
52438,
44958,
143493,
434238,
5626,
59038,
563050,
147247,
14270,
30704,
240502,
2708,
39503,
27799,
39175,
122973,
318562,
67047,
374826,
24355,
588744,
191557,
56999,
167563,
5266,
208061,
154809,
10879,
342728,
99191,
null,
99789,
237289,
112059,
299210,
161439,
4507,
372352,
14998,
87910,
null,
27865,
34788,
499350,
210124,
65166,
347225,
39065,
149660,
32038,
79481,
240019,
25790,
214921,
186714,
10951,
9859,
196722,
210468,
22942,
75493,
280717,
null,
null,
null,
23170,
50480,
73957,
3918,
98859,
75108,
149877,
null,
31134,
22363,
214329,
8962,
21488,
159846,
14365,
114684,
71638,
27020,
55859,
237180,
52852,
152369,
106657,
36475,
10692,
22583,
151103,
183747,
176138,
34851,
109179,
195929,
46639,
113268,
27748,
55223,
25276,
24421,
556098,
65241,
169752,
388737,
74255,
50455,
245861,
348938,
42084,
237730,
3061,
38034,
216691,
41149,
25438,
50053,
165696,
62919,
29345,
null,
563308,
185874,
275573,
74286,
212725,
139768,
19640,
22158,
285785,
371213,
657299,
28612,
17819,
144692,
195338,
29690,
57005,
183853,
53777,
64295,
8947,
49008,
64146,
321018,
127039,
229420,
39977,
278752,
468814,
55945,
118954,
120131,
25107,
186512,
55752,
25972,
27909,
118657,
255300,
2172,
17419,
289586,
44979,
208051,
61676,
87445,
null,
null,
309164,
15932,
71123,
449367,
121023,
67747,
55523,
51295,
882072,
308914,
115979,
98840,
39292,
88189,
175695,
57153,
25129,
101870,
39288,
15480,
404437,
113313,
24243,
289496,
757616,
400988,
325155,
52611,
43337,
569391,
28627,
234112,
48943,
42014,
38362,
18048,
94211,
36067,
61623,
220677,
220347,
414693,
379848,
30235,
153468,
328232,
71272,
null,
58039,
109670,
27073,
43948,
149205,
null,
399595,
1076751,
459261,
88752,
318690,
292598,
25402,
31156,
13885,
11391,
20282,
89149,
29434,
36039,
841214,
28048,
43270,
138668,
20904,
330187,
95404,
193372,
40169,
104907,
null,
29084,
344877,
196778,
470172,
174413,
33780,
19206,
81436,
37019,
245555,
null,
91703,
null,
8538,
20324,
254124,
44568,
17778,
20166,
215915,
10708,
189225,
76733,
14258,
100218,
76067,
null,
9417,
null,
61768,
307285,
341624,
44226,
115365,
63033,
83583,
13559,
627697,
48072,
400272,
121516,
35131,
22574,
38922,
105821,
295712,
21854,
59096,
356460,
33024,
34934,
36509,
77714,
444777,
178279,
null,
246725,
7329,
37082,
26419,
65240,
441030,
18688,
14844,
52084,
382670,
211783,
152139,
18445,
339323,
421260,
438467,
185976,
8782,
248476,
68084,
380074,
30031,
315461,
11989,
49421,
98165,
5282,
69198,
6804,
4139,
229369,
null,
12744,
356299,
null,
455065,
109386,
35625,
402406,
101367,
253353,
null,
139977,
17780,
92165,
303373,
50128,
42380,
null,
102982,
25378,
23970,
128566,
193980,
76621,
1863,
20997,
117392,
128362,
111380,
473919,
461002,
10387,
139270,
305383,
46558,
42794,
218488,
119383,
177717,
341598,
null,
423665,
44440,
14580,
222457,
134789,
null,
185749,
null,
null,
152134,
232058,
398861,
17360,
572571,
43437,
6418,
144464,
8759,
348441,
46591,
40896,
165679,
173126,
7114,
26816,
13338,
33799,
532737,
26762,
22836,
35927,
7663,
281393,
34026,
74656,
110346,
70644,
119690,
9280,
292147,
15594,
282849,
252152,
182857,
4214,
117335,
71623,
25556,
11624,
16314,
101914,
12145,
203650,
18485,
154457,
135306,
16755,
13483,
22607,
43677,
278450,
96866,
239,
19351,
34292,
36911,
19958,
518516,
49301,
15036,
170426,
61933,
78097,
492841,
158677,
260439,
166571,
10519,
64845,
87931,
168757,
27841,
385417,
101281,
295820,
28246,
35148,
450779,
212678,
46227,
5031,
9046,
209173,
12631,
11918,
40908,
132967,
39144,
33577,
207274,
null,
69036,
74117,
117264,
138427,
58602,
66635,
7756,
null,
368712,
235304,
47410,
9160,
197115,
8018,
null,
37955,
19914,
59616,
225916,
15323,
53883,
113415,
70084,
38923,
39263,
57168,
243809,
null,
75371,
215558,
91994,
7502,
31762,
34289,
34076,
125751,
116409,
88697,
null,
363127,
29332,
4020,
36151,
94241,
27703,
82796,
194819,
202395,
33284,
167859,
217436,
null,
35395,
33159,
12674,
51917,
380447,
174695,
140326,
10415,
395742,
28246,
146563,
16610,
38238,
272369,
175471,
16686,
45667,
21896,
114948,
124559,
22135,
59582,
216808,
196052,
58420,
null,
10421,
27778,
1893,
64514,
29903,
194448,
256799,
29517,
null,
9286,
134908,
390649,
26615,
222024,
119562,
19099,
49666,
418828,
424631,
141345,
283285,
46826,
111121,
null,
6644,
192477,
64727,
51677,
352008,
38322,
20522,
null,
20922,
341452,
14591,
43064,
14907,
352933,
38793,
20014,
340844,
41100,
174669,
256432,
31659,
47995,
203182,
24026,
6097,
208534,
79733,
42205,
33446,
82354,
144845,
null,
118815,
27296,
291332,
461012,
39221,
26489,
33037,
105961,
7476,
333566,
4230,
230171,
40098,
244145,
74647,
2670,
14461,
59662,
88773,
458096,
24520,
38306,
394294,
19765,
15284,
132406,
15502,
155555,
null,
409698,
26430,
310329,
15721,
20862,
43136,
89577,
30215,
495469,
32344,
25369,
43472,
null,
202062,
20951,
19830,
344285,
135317,
null,
7825,
136092,
null,
null,
null,
null,
231758,
40055,
32815,
null,
176798,
76213,
null,
10504,
10165,
25066,
132051,
47390,
39159,
215529,
196899,
61867,
27358,
590701,
332870,
null,
null,
312521,
371356,
1938,
19079,
333129,
26791,
510046,
275449,
9424,
174487,
380614,
308630,
24908,
41487,
49092,
92250,
54177,
207003,
16940,
14510,
63530,
63295,
357230,
5998,
25187,
219384,
null,
14090,
31281,
351466,
470463,
138006,
131233,
211852,
36991,
16662,
53281,
20031,
44716,
81011,
106744,
null,
30647,
null,
241730,
59618,
50456,
189723,
276709,
448612,
46509,
359600,
130685,
217221,
33811,
141494,
91188,
67555,
7399,
26065,
234035,
44199,
23418,
214823,
95991,
399672,
24719,
275317,
608364,
365915,
209765,
140918,
44136,
280655,
30561,
55064,
82128,
41154,
34581,
80065,
238215,
null,
170445,
34925,
81651,
12518,
79390,
179497,
21177,
34784,
20490,
29594,
346392,
29060,
22412,
272899,
40869,
44876,
14313,
283049,
227071,
235283,
390597,
5619,
240425,
259922,
12561,
600987,
37969,
273918,
148818,
11684,
184690,
32095,
123056,
270016,
69366,
14565,
48209,
136018,
null,
287263,
367843,
97776,
617,
4690,
37722,
198369,
120283,
191270,
502976,
197596,
26829,
200163,
null,
114949,
44079,
42336,
722659,
299248,
98840,
12094,
172100,
21749,
333103,
344238,
13606,
13368,
13221,
203988,
13296,
4252,
74376,
null,
64964,
109162,
57740,
126727,
198147,
7097,
231156,
34163,
122494,
227201,
91556,
58346,
21167,
67171,
30351,
292259,
338304,
11922,
74877,
24354,
null,
226929,
328998,
37628,
null,
194062,
144675,
34574,
29659,
19614,
181757,
null,
39120,
52757,
34857,
211548,
353913,
55766,
271572,
379455,
98904,
467849,
225740,
140402,
8083,
113868,
184045,
211238,
234522,
85762,
274805,
553627,
null,
null,
21738,
24680,
357909,
289001,
101030,
180511,
357400,
61107,
null,
19804,
35209,
121332,
null,
197004,
29958,
178632,
298972,
145704,
273542,
193349,
null,
46417,
144306,
null,
43445,
10171,
136740,
47593,
10896,
91960,
33699,
127243,
72476,
25862,
null,
120961,
156548,
27229,
109970,
296602,
312459,
207322,
33691,
83158,
31979,
325371,
null,
93374,
71876,
null,
115368,
207554,
237988,
264209,
258283,
158920,
226409,
39078,
68762,
122936,
10922,
null,
213095,
49153,
89313,
1105958,
null,
116910,
84276,
74910,
241133,
52796,
193900,
31955,
250825,
199841,
132425,
174653,
35803,
199917,
13165,
375805,
35166,
14056,
null,
53902,
80549,
35542,
null,
9317,
73152,
12155,
27426,
273430,
22034,
11086,
49571,
10161,
292893,
null,
34052,
216081,
10437,
57592,
189724,
26260,
216604,
328621,
435887,
282441,
378658,
27774,
7563,
36350,
12331,
299783,
104196,
126227,
372036,
null,
264375,
71764,
103176,
111832,
8352,
312323,
172826,
184124,
121823,
400683,
57353,
63470,
375571,
175274,
24765,
144833,
11656,
202048,
235634,
7933,
183044,
200393,
13449,
23845,
19847,
13821,
25625,
40234,
115582,
26209,
null,
139466,
null,
46404,
7928,
37967,
274344,
48352,
39482,
149918,
24627,
183890,
24289,
19341,
358976,
28601,
null,
69523,
77410,
35980,
260133,
47912,
6313,
437731,
38136,
323484,
23056,
32039,
44718,
9697,
null,
null,
55574,
59494,
19871,
83367,
162198,
17718,
80197,
18003,
88718,
180295,
275454,
451198,
213914,
13648,
221611,
96516,
566409,
473947,
123424,
6223,
219550,
289632,
42947,
40913,
15825,
29341,
243164,
177759,
73876,
7776,
24837,
31787,
33499,
131035,
187151,
57874,
244519,
76914,
94742,
null,
497242,
null,
211255,
20851,
506016,
120313,
109871,
276590,
30202,
170535,
36661,
147998,
380527,
31510,
115215,
515636,
57844,
180197,
9033,
18362,
112355,
14599,
173961,
38145,
175395,
24152,
6928,
null,
121347,
32943,
206624,
60344,
null,
185210,
10206,
272218,
148822,
17658,
444791,
null,
158213,
46500,
226918,
7585,
44471,
123742,
179480,
122629,
17446,
null,
347130,
191880,
95452,
85326,
104733,
26316,
41107,
57713,
7435,
432291,
46606,
10371,
56719,
111587,
205670,
173250,
22058,
224247,
296307,
8024,
5026,
41791,
18107,
null,
161533,
72004,
55279,
28386,
18170,
54078,
null,
43784,
133810,
178666,
160050,
null,
237379,
null,
null,
null,
162407,
8795,
183665,
201053,
148267,
228543,
7683,
291253,
22249,
247361,
136141,
38073,
44363,
306792,
118946,
348257,
54356,
46246,
603428,
425505,
41821,
13631,
217858,
285623,
253769,
135621,
23253,
16953,
44689,
514712,
30520,
35867,
79520,
1368650,
662606,
103579,
24607,
26860,
15328,
4479,
189853,
214319,
435048,
295380,
null,
12240,
12402,
null,
121437,
35047,
164766,
35506,
11848,
43119,
22049,
106511,
22351,
991025,
126565,
31837,
279274,
28865,
165226,
189970,
387590,
12165,
58580,
80871,
33359,
17887,
604388,
21346,
353799,
47729,
307034,
597555,
6861,
null,
20798,
30391,
32102,
74203,
158830,
57040,
7448,
197470,
135494,
124742,
568663,
8655,
25606,
332921,
309813,
71089,
null,
290918,
18441,
null,
50899,
9025,
36593,
55003,
400483,
8783,
216176,
187481,
39190,
201042,
85828,
186196,
34822,
455543,
31340,
144195,
116925,
54058,
266652,
null,
497312,
278931,
217274,
24334,
86174,
28821,
351271,
172693,
234958,
9220,
142180,
173234,
150121,
250494,
11267,
20176,
43835,
336704,
18997,
29311,
33057,
55628,
15793,
373773,
356557,
null,
18669,
12081,
172523,
141513,
342423,
99308,
172293,
11080,
444443,
176025,
7165,
137565,
23159,
15586,
181429,
27695,
114548,
42901,
13320,
42342,
39989,
20483,
325538,
50555,
136158,
150333,
318262,
30016,
319640,
31007,
91561,
318311,
31978,
762409,
94871,
48373,
17205,
155695,
61326,
200368,
9233,
107170,
20382,
246248,
409264,
4927,
203128,
32019,
null,
25810,
294643,
330755,
264126,
257554,
16424,
165857,
68005,
185731,
272983,
158793,
248457,
202256,
59963,
12963,
214426,
164733,
18185,
37710,
null,
174538,
30243,
291202,
764017,
3623,
29959,
38420,
351005,
50056,
null,
1667,
33824,
184568,
15353,
7751,
521078,
34554,
166318,
250800,
21021,
526202,
81607,
291585,
22065,
82141,
246032,
141003,
295889,
120667,
574461,
588091,
287870,
14018,
683993,
30462,
65609,
273724,
33444,
89617,
null,
190426,
205707,
343012,
41219,
56018,
19432,
10750,
null,
44036,
65794,
4427,
15061,
6761,
18029,
42027,
12762,
269198,
40734,
34016,
null,
565179,
323105,
13937,
149794,
91638,
567967,
null,
28241,
129567,
46305,
82760,
113263,
208827,
188202,
184007,
289999,
15362,
1526,
11452,
20918,
127101,
8614,
30784,
201404,
16182,
18302,
42473,
524912,
396657,
322077,
316109,
3015,
309340,
130441,
null,
13939,
458834,
4133,
37769,
267382,
279374,
357000,
null,
37064,
237115,
120943,
203435,
null,
null,
219935,
398103,
null,
29841,
330295,
24858,
96320,
15451,
2057,
13432,
34417,
214241,
29840,
44132,
34989,
94063,
46831,
187402,
183020,
29503,
71320,
27681,
47028,
18875,
9497,
3592,
471805,
499384,
10790,
17245,
50747,
39957,
255364,
117996,
177887,
null,
174780,
82619,
50464,
39755,
95754,
153443,
199728,
39599,
22414,
270352,
36502,
57638,
443360,
29584,
32759,
38705,
6637,
342270,
225841,
108462,
93328,
26969,
442942,
21020,
187756,
159203,
13455,
21398,
280989,
17884,
55081,
387154,
235199,
33198,
197686,
39259,
152635,
424062,
106989,
126836,
null,
157442,
null,
145741,
157364,
34409,
null,
42637,
325376,
45564,
421891,
206623,
50419,
47404,
15608,
318428,
360610,
352884,
212482,
11526,
63877,
12601,
33381,
77352,
121669,
163160,
40248,
129557,
374083,
712863,
307828,
25202,
29667,
38937,
36795,
53431,
38977,
40347,
61210,
81217,
22268,
252452,
41021,
9007,
null,
244021,
32932,
238174,
11895,
null,
null,
198534,
75257,
29542,
298309,
160602,
46816,
29913,
621591,
22823,
340542,
38493,
158144,
23460,
162630,
353355,
203378,
46390,
101115,
536105,
9074,
38864,
51024,
null,
13681,
26551,
null,
6624,
53689,
9706,
52171,
14225,
118136,
334282,
16211,
56842,
616041,
21361,
10662,
464925,
238268,
21907,
490860,
16946,
36764,
82132,
null,
26685,
null,
48147,
170482,
17389,
9571,
271402,
299408,
96529,
7251,
436652,
104374,
23888,
176391,
324138,
14206,
58375,
null,
17211,
13963,
631465,
null,
20090,
21076,
312895,
64977,
288736,
275614,
213827,
308147,
347734,
52591,
25693,
16697,
252931,
506589,
25477,
44060,
227085,
115652,
27511,
200956,
30312,
26871,
92976,
30239,
16136,
null,
51550,
132143,
38770,
31997,
17969,
119448,
407592,
8720,
23258,
51053,
191979,
64888,
95955,
108552,
19711,
416621,
181068,
344671,
250420,
23525,
78441,
null,
53731,
16624,
66111,
11396,
44267,
184172,
37379,
130253,
null,
209837,
248513,
35985,
282815,
194973,
193168,
70060,
null,
99251,
36266,
224014,
284914,
67993,
34135,
null,
254572,
21338,
14721,
146451,
104293,
24206,
9554,
155855,
5957,
121868,
31340,
60744,
36598,
119602,
259458,
345392,
262356,
null,
21674,
35499,
13524,
180351,
14616,
112765,
18470,
420484,
23213,
null,
128326,
28368,
29343,
281533,
184551,
60438,
298720,
176136,
93888,
57209,
14126,
221006,
38690,
38490,
233461,
196218,
26010,
35580,
7098,
157717,
73406,
62019,
5387,
43641,
267917,
22359,
135608,
179818,
61199,
574113,
389397,
62485,
29461,
16015,
21277,
22431,
116260,
121450,
368389,
32507,
150275,
19382,
16192,
5859,
175215,
239201,
39932,
13756,
305758,
304845,
416423,
47281,
232170,
314192,
492179,
238433,
100348,
20595,
214913,
35913,
null,
113203,
15742,
151953,
10378,
258195,
104999,
15958,
15909,
12950,
null,
19311,
58030,
146372,
41854,
148752,
79442,
16478,
23248,
54673,
294945,
42506,
130776,
316884,
165659,
126723,
null,
25869,
null,
371123,
26382,
86076,
140936,
null,
28840,
null,
31551,
164924,
187287,
194584,
21417,
61995,
22162,
25577,
7131,
null,
196717,
115336,
92336,
38966,
null,
5209,
14022,
7466,
29635,
316314,
21219,
null,
134321,
186806,
32377,
217501,
144502,
65606,
67797,
65757,
45525,
91751,
55685,
162703,
16821,
156532,
null,
8262,
30174,
32900,
4549,
455423,
14894,
83047,
182535,
111294,
137290,
15811,
180356,
377734,
180455,
87203,
580441,
428759,
43408,
350813,
154366,
5368,
100140,
74344,
17532,
38253,
60939,
556933,
27915,
null,
32867,
254358,
25790,
22374,
25381,
11982,
63131,
null,
201972,
44083,
83736,
284294,
433894,
148109,
278866,
65464,
34360,
null,
13145,
275678,
24719,
24884,
27219,
190781,
412130,
126392,
103480,
9338,
43469,
null,
146335,
9542,
39137,
64522,
null,
5538,
385098,
33006,
1207836,
307848,
309935,
null,
88134,
179164,
null,
178284,
201646,
1205797,
172058,
125831,
80845,
82381,
87958,
null,
457120,
298088,
85619,
144666,
37594,
26201,
231031,
56063,
73977,
17002,
60956,
9871,
176018,
282230,
240769,
4512,
183306,
97488,
65822,
44274,
98849,
156326,
56103,
110585,
29962,
137071,
null,
null,
189014,
236215,
308415,
null,
23778,
60057,
536428,
43624,
13146,
244074,
65128,
55938,
null,
46539,
197470,
2577,
66094,
null,
38118,
108832,
25619,
1015,
null,
262535,
235141,
16304,
139217,
253125,
167721,
96860,
null,
193576,
125669,
43730,
151388,
19285,
13605,
11763,
13903,
213714,
159899,
null,
322511,
199759,
null,
52251,
179360,
13509,
50884,
241005,
110734,
25837,
70431,
39966,
54348,
111705,
103694,
44690,
null,
114044,
212926,
315490,
22593,
75697,
205715,
299663,
30767,
290845,
303664,
165086,
null,
18997,
131953,
94535,
27226,
23972,
null,
18955,
28542,
null,
116968,
414877,
159431,
286602,
363912,
57822,
228199,
25409,
null,
290115,
49541,
327728,
75802,
39000,
40502,
7476,
28777,
48976,
47429,
53191,
48402,
null,
384232,
67423,
null,
null,
15179,
65087,
189973,
171748,
22993,
16256,
53168,
440590,
21962,
348454,
12100,
306700,
30746,
234218,
440987,
null,
104597,
null,
135122,
31093,
168135,
370536,
403154,
16485,
48857,
65803,
97167,
263744,
16260,
71532,
23806,
22954,
94880,
165556,
366404,
163429,
16490,
25242,
31785,
493939,
204168,
68527,
32084,
150047,
14649,
null,
40394,
1127,
null,
39406,
334843,
38096,
321607,
116803,
58674,
29597,
60982,
12315,
136357,
50445,
74936,
274474,
463301,
312784,
110645,
50215,
3780,
233302,
null,
61243,
318610,
87445,
269629,
17738,
67074,
21132,
513573,
null,
181754,
175794,
128216,
310523,
35924,
18452,
61733,
386429,
24268,
95147,
357962,
392614,
125770,
12459,
11159,
18071,
55731,
210826,
100957,
202245,
48536,
308928,
null,
798820,
2128434,
64348,
77711,
67732,
7768,
90654,
377097,
506020,
389969,
207721,
7858,
183436,
null,
5343,
30825,
null,
23180,
5549,
36331,
93966,
121915,
399446,
48190,
136332,
4094,
369057,
171144,
175437,
16568,
234468,
163931,
136151,
92385,
366092,
131961,
128536,
224634,
50678,
202868,
57996,
213674,
null,
26852,
129554,
11540,
46606,
20293,
278394,
8042,
163042,
385899,
331441,
355270,
228464,
53056,
143704,
36587,
412246,
218673,
36893,
312456,
38562,
134080,
447804,
36054,
null,
null,
10150,
23490,
161283,
70747,
251366,
12338,
243786,
172942,
null,
null,
203062,
45500,
41849,
50804,
37028,
433367,
247609,
55725,
119923,
300519,
591751,
130650,
17460,
81503,
221322,
37146,
null,
null,
179507,
28906,
345709,
45656,
65981,
194423,
16407,
83509,
51047,
248245,
170965,
23279,
36740,
326112,
131116,
23444,
104500,
32380,
28065,
74448,
150599,
310287,
5820,
61964,
21085,
52463,
59087,
154321,
150824,
126492,
63906,
22333,
144947,
217615,
300359,
49894,
312581,
128104,
32954,
16427,
477417,
44900,
13426,
null,
35903,
158113,
null,
358192,
598578,
44956,
134707,
6802,
24745,
9367,
13107,
72512,
136803,
36759,
118684,
23078,
10227,
468931,
397924,
19358,
49,
303898,
32416,
7042,
22958,
445498,
172455,
74801,
56524,
53521,
20376,
6391,
93465,
326529,
27511,
410228,
156528,
195263,
297172,
171786,
77359,
142317,
20632,
60070,
9990,
133195,
268367,
13163,
257404,
7101,
null,
118267,
422010,
174382,
42055,
18721,
166862,
216826,
534957,
122006,
null,
133108,
293324,
null,
183785,
297902,
261066,
null,
15877,
null,
91137,
null,
200570,
56307,
185882,
280043,
174558,
169139,
null,
45719,
172545,
71219,
33051,
7191,
409560,
46277,
45344,
99007,
268651,
192444,
110119,
28200,
15748,
26249,
49630,
205191,
13219,
13339,
69995,
37180,
216740,
27107,
null,
175224,
304693,
29067,
10767,
28628,
230134,
379757,
73382,
358731,
null,
498481,
21349,
337235,
634592,
7427,
17472,
null,
242920,
30109,
18253,
181737,
27354,
304951,
33756,
null,
94418,
244017,
53218,
169558,
42812,
493618,
37337,
513634,
70369,
19828,
97345,
275569,
29039,
873953,
16887,
249732,
210971,
81053,
245276,
311420,
217192,
82167,
84039,
473715,
310887,
257136,
53768,
89776,
467907,
11689,
651193,
23288,
432563,
141769,
86396,
49181,
250473,
30480,
null,
55613,
29184,
420658,
384384,
377830,
null,
287892,
281920,
39075,
44809,
null,
48738,
85079,
49015,
72166,
11748,
68055,
102701,
15106,
51969,
280513,
44745,
40064,
3562,
184285,
707939,
47885,
11769,
139173,
406293,
274014,
218871,
10779,
244930,
null,
115937,
140512,
1312,
1025728,
146577,
16595,
63446,
43110,
null,
21930,
83180,
202709,
null,
84323,
137149,
60088,
44074,
175686,
143739,
8442,
295970,
154175,
127379,
2491,
28452,
602838,
38534,
54762,
141975,
20052,
104175,
440300,
71814,
null,
27971,
49955,
143729,
426822,
201254,
null,
2847,
233406,
144905,
null,
39037,
61033,
20516,
null,
45167,
169417,
27489,
4790,
92638,
110271,
74245,
206735,
325487,
319636,
123329,
118887,
33524,
9424,
125671,
168022,
39428,
451872,
103026,
28260,
101838,
40844,
127714,
17376,
44240,
76247,
226922,
44970,
null,
320500,
237184,
223199,
18669,
282728,
45347,
173179,
19257,
166398,
236507,
168891,
99171,
680573,
153321,
176057,
44103,
68898,
351868,
48701,
34118,
173068,
16775,
3787,
131377,
74901,
133791,
17108,
28842,
36390,
54973,
26910,
295145,
234053,
19127,
21734,
null,
11798,
149097,
167197,
15400,
466071,
71971,
107135,
10318,
38104,
11135,
40124,
111824,
22005,
217332,
28057,
237944,
22304,
73980,
258060,
22380,
73721,
92908,
20255,
163780,
284427,
10096,
101648,
63086,
null,
220218,
50592,
24122,
51301,
603925,
62582,
97026,
117488,
9860,
58608,
null,
31347,
null,
271344,
415405,
400024,
113939,
60458,
29791,
107143,
29682,
14282,
98002,
30683,
169940,
103778,
39576,
35022,
199258,
105214,
33756,
null,
15148,
594954,
30069,
61349,
169323,
100130,
174161,
64751,
41784,
52173,
35448,
null,
561958,
49587,
107917,
32817,
293842,
439865,
41012,
247954,
35086,
79290,
394622,
336219,
306056,
57742,
262339,
122399,
47709,
162778,
177432,
146205,
633423,
339378,
168836,
456830,
75719,
380633,
24942,
266361,
43125,
104051,
null,
180930,
188954,
220924,
17846,
673615,
182431,
50784,
30002,
452932,
191989,
59392,
353563,
19229,
17942,
null,
131140,
21746,
44218,
31630,
42039,
35306,
14350,
3590,
297717,
24765,
53778,
182338,
null,
513265,
343017,
459552,
160047,
312918,
23196,
null,
15790,
19378,
481258,
66934,
29487,
70774,
224117,
211261,
352502,
235583,
null,
259463,
164745,
76177,
231486,
75846,
176987,
281297,
23989,
278820,
82299,
21963,
133442,
47008,
119654,
22900,
10240,
354014,
null,
16324,
39410,
246512,
186040,
77749,
403950,
101194,
135059,
219823,
112275,
23353,
58638,
161355,
168131,
20396,
90739,
24453,
86024,
25225,
137549,
12037,
60025,
null,
65619,
371733,
75227,
59297,
14624,
85011,
84582,
38225,
37723,
205398,
293097,
34477,
15871,
315899,
36559,
150571,
31444,
29668,
42191,
9669,
15356,
152190,
162234,
140418,
81464,
30289,
113291,
11784,
171692,
10000,
17350,
null,
115244,
20517,
393000,
122344,
210694,
20781,
97946,
276043,
15281,
170428,
156619,
null,
34920,
41628,
336304,
63068,
51311,
151131,
164259,
367016,
59463,
null,
137409,
28511,
136448,
204254,
32442,
5739,
20616,
25560,
309590,
81272,
240485,
80687,
120914,
47791,
40291,
21578,
40127,
122223,
172541,
88520,
28580,
5683,
51622,
537132,
6029,
264485,
38032,
26576,
55618,
45039,
150576,
null,
39452,
19632,
161650,
62510,
49398,
null,
120324,
269600,
181905,
423084,
73626,
13272,
39996,
10031,
68127,
41790,
56870,
123348,
94941,
null,
40133,
11430,
74201,
288927,
46057,
null,
146780,
27176,
262482,
406367,
29608,
307500,
70074,
48201,
56578,
263174,
51876,
6677,
null,
317847,
22018,
210737,
77752,
121640,
14518,
535570,
388266,
307348,
228418,
34373,
349033,
399928,
13290,
9287,
10316,
388435,
323986,
8613,
15119,
111927,
178546,
336014,
229179,
140959,
202837,
192515,
71157,
201740,
83506,
32304,
164688,
37713,
261055,
241593,
29019,
3762,
41724,
39380,
18724,
420462,
53606,
18876,
38695,
61547,
70273,
104370,
50319,
189828,
54917,
404759,
null,
122970,
238630,
22543,
313813,
51434,
47193,
76790,
656726,
306897,
147446,
31248,
271483,
null,
7931,
181885,
7153,
40561,
94617,
22452,
83537,
14992,
36017,
96562,
null,
64535,
258980,
9103,
17505,
11692,
6841,
1324818,
65522,
27170,
682618,
26880,
95557,
224565,
62817,
37335,
null,
8336,
37342,
16452,
33291,
51519,
110903,
317283,
291702,
348644,
236675,
138450,
186049,
25017,
29515,
16493,
6022,
140798,
99060,
20591,
54508,
41090,
240674,
152842,
358874,
40113,
null,
39675,
136140,
149652,
82756,
null,
286885,
315882,
30375,
18167,
10958,
96523,
79374,
31740,
23441,
153280,
154374,
58435,
321735,
299592,
58705,
13980,
24396,
8777,
32660,
155402,
49886,
14765,
19894,
52046,
37528,
null,
118758,
36142,
153922,
267206,
54544,
72584,
206628,
132037,
136314,
23361,
89258,
77894,
96402,
134009,
null,
374581,
775821,
263886,
308441,
159467,
21255,
22247,
39964,
26877,
25541,
151204,
null,
8288,
68506,
277799,
137373,
34573,
127274,
null,
272767,
182690,
42115,
32131,
314894,
23903,
45476,
240333,
31395,
106879,
25898,
249969,
226988,
193735,
35529,
272032,
null,
105767,
231624,
21392,
143458,
7505,
null,
12676,
38154,
26681,
11575,
495390,
135105,
31918,
45906,
654489,
26289,
24803,
183150,
42271,
11386,
192387,
null,
5803,
null,
180520,
212467,
197029,
189896,
144874,
null,
18762,
523919,
425472,
null,
96409,
20974,
44922,
69144,
36592,
105399,
84675,
87709,
12319,
15333,
14363,
39484,
65772,
270596,
239607,
42563,
182410,
20656,
5960,
117522,
80675,
33799,
23184,
71120,
13636,
186332,
61716,
29042,
56425,
63881,
257138,
240859,
180677,
148332,
43462,
18381,
4099,
52513,
124109,
338828,
90305,
136147,
null,
188588,
470568,
166205,
null,
39679,
103754,
17293,
130347,
208651,
753617,
504244,
2906,
31748,
231069,
199542,
7059,
394044,
null,
28266,
8805,
184888,
31907,
27425,
23747,
27265,
9041,
null,
117466,
57050,
71302,
9535,
56021,
100624,
444942,
46364,
299648,
421289,
288405,
80329,
17984,
50133,
53611,
null,
107876,
52276,
131138,
24897,
299344,
304748,
24092,
105426,
248857,
333935,
null,
244802,
null,
285325,
17003,
46721,
316802,
67186,
374926,
94571,
17006,
73976,
276829,
null,
22194,
238815,
211960,
38686,
38372,
21550,
223054,
292175,
40484,
232825,
18623,
248670,
345365,
174279,
307007,
34642,
93033,
50834,
53688,
180145,
27543,
29814,
43513,
185856,
23292,
548006,
52089,
94631,
76972,
186359,
null,
16590,
14558,
72204,
null,
5874,
132243,
6053,
307421,
47728,
237162,
15820,
360684,
43648,
9064,
227401,
null,
null,
40190,
16730,
50581,
183204,
198958,
58850,
25271,
352039,
32273,
122371,
80704,
77570,
44043,
79835,
25591,
611899,
33240,
9853,
595383,
25149,
null,
44084,
80741,
431561,
218891,
157794,
102339,
202020,
21231,
22487,
11623,
39607,
41414,
49697,
197529,
166451,
40804,
118297,
21622,
137025,
374146,
17724,
49140,
264777,
272283,
525030,
null,
33699,
null,
103386,
422732,
13359,
23806,
557847,
142735,
null,
226404,
337098,
21961,
191784,
32672,
68912,
280700,
51380,
115486,
332508,
15098,
123535,
24710,
26709,
183110,
89279,
33586,
61194,
9057,
null,
24211,
233287,
177885,
208969,
67791,
137285,
29321,
null,
27876,
17936,
42380,
75035,
163093,
10770,
38142,
63532,
15222,
14670,
null,
86452,
146514,
136684,
79819,
83281,
43364,
332264,
27302,
18348,
57864,
31023,
78680,
83630,
15739,
28796,
412974,
23779,
160198,
434844,
71631,
116196,
42467,
9928,
167511,
177115,
19590,
214629,
16859,
37395,
418043,
316453,
33941,
255327,
15598,
24572,
209799,
284227,
172947,
304054,
44501,
14389,
19299,
null,
132902,
266757,
44228,
null,
97461,
469649,
7094,
355893,
316800,
7679,
171045,
74080,
63032,
194170,
15934,
194469,
null,
14084,
199577,
26206,
245907,
252166,
108415,
267591,
156003,
231212,
null,
null,
14474,
484852,
104503,
null,
130815,
31106,
13102,
209030,
30214,
640526,
179717,
159499,
41536,
390680,
108835,
29639,
17232,
84513,
50274,
166951,
7453,
521944,
3183,
14732,
36738,
190028,
159517,
171011,
266810,
133838,
11237,
234156,
null,
588804,
174669,
32888,
41138,
103817,
15023,
40830,
17650,
21024,
22588,
50183,
80934,
5908,
40746,
5539,
196811,
230004,
52166,
19703,
308100,
14283,
135103,
null,
50729,
116126,
null,
260140,
56957,
28428,
66230,
139055,
24249,
23146,
7908,
409658,
319888,
209618,
24730,
357946,
152373,
237670,
null,
11702,
245687,
247983,
378054,
null,
312812,
261648,
243777,
45914,
15120,
41635,
143001,
158458,
35141,
68015,
null,
60130,
46886,
16954,
338917,
53709,
null,
798216,
null,
30296,
62356,
24463,
13884,
46963,
77489,
48991,
7120,
227697,
778056,
411219,
232616,
11620,
21945,
91088,
163542,
27650,
null,
142388,
3411,
131535,
163765,
null,
14583,
56852,
238455,
206441,
126738,
12707,
149179,
72753,
222101,
null,
null,
167388,
187965,
209971,
61244,
169390,
183682,
8772,
29296,
147221,
258011,
57165,
158072,
436670,
348455,
271836,
328507,
136655,
11200,
269511,
26944,
38843,
67497,
235352,
128215,
3139,
200388,
207925,
321430,
235666,
20761,
9780,
152335,
156241,
435423,
null,
72362,
43496,
null,
71978,
330319,
207836,
31440,
55987,
372811,
491278,
204283,
37678,
19468,
177104,
12939,
301153,
390879,
9199,
312082,
82685,
15621,
141539,
null,
53941,
37764,
31574,
323829,
166595,
61579,
143038,
40414,
111171,
399504,
5315,
14744,
51328,
38747,
233221,
32468,
134768,
15981,
523347,
null,
256837,
39597,
102522,
95794,
160671,
316426,
24445,
null,
null,
223175,
227732,
110955,
388152,
189370,
13537,
32982,
305330,
88350,
53071,
321304,
217267,
189162,
null,
375630,
4262,
140111,
null,
76116,
28142,
20039,
31988,
341833,
6813,
205467,
31567,
420096,
33457,
114641,
null,
232541,
327809,
152333,
123351,
23270,
291561,
75301,
314551,
3687,
456152,
null,
null,
227409,
21754,
39817,
19475,
200982,
26918,
247018,
86252,
14433,
38677,
18137,
272433,
14326,
18896,
186251,
1325807,
34166,
192990,
51786,
193543,
164249,
32539,
18017,
198324,
37880,
37085,
308482,
null,
79582,
33414,
32517,
31597,
28033,
null,
null,
44173,
295580,
134042,
466853,
181436,
54075,
110806,
null,
5089,
47427,
55878,
28520,
434695,
176775,
42129,
213551,
33501,
29027,
23895,
113701,
null,
null,
287458,
34025,
288723,
169144,
47415,
170142,
21783,
82062,
3377,
105037,
390655,
null,
51925,
65215,
25652,
92784,
10675,
72422,
207172,
347149,
23904,
22187,
36620,
308270,
18688,
171146,
53748,
7815,
27025,
151825,
171561,
29055,
166404,
null,
6235,
5157,
229560,
51992,
21154,
30450,
687470,
36030,
259694,
468251,
452396,
257165,
34480,
258503,
23591,
84992,
240109,
198503,
29539,
807885,
null,
424265,
294052,
17953,
250747,
20817,
163508,
49969,
21572,
394865,
1486126,
30777,
null,
null,
14007,
45383,
97200,
20946,
267492,
172811,
252221,
71522,
17002,
120502,
191321,
385091,
null,
44852,
516815,
279681,
9964,
17510,
42522,
251193,
37214,
21295,
336205,
24677,
290685,
442530,
35503,
77080,
null,
7462,
25853,
377176,
245417,
174748,
28588,
61746,
37032,
null,
67310,
92458,
632359,
44624,
272963,
30165,
32085,
415715,
68297,
253330,
863988,
60882,
145429,
null,
715576,
249430,
46977,
312245,
313071,
188349,
280590,
81643,
17971,
12782,
92272,
628560,
null,
23736,
66487,
364454,
163156,
72905,
9190,
25936,
91350,
106141,
15436,
465130,
9629,
157179,
451077,
112226,
68531,
244836,
43528,
23823,
551719,
53312,
119521,
4345,
247583,
null,
163705,
57533,
25502,
33196,
35950,
170113,
188928,
45718,
50785,
20716,
252258,
30664,
null,
null,
80206,
325209,
26118,
573076,
428588,
138808,
309439,
74134,
419862,
213768,
268321,
139291,
305649,
41659,
184767,
124860,
364347,
218834,
211725,
11269,
27444,
28230,
172489,
20933,
357635,
186508,
86496,
281674,
null,
155114,
78336,
18205,
16632,
120572,
11005,
11078,
532109,
null,
13412,
151075,
614417,
233682,
255532,
40536,
35811,
31084,
312514,
209961,
236585,
70572,
101011,
57307,
94292,
312630,
69668,
null,
217699,
89957,
116713,
277802,
232392,
336523,
7453,
108967,
34484,
15670,
null,
null,
262681,
53051,
182058,
null,
47603,
30925,
184272,
215490,
17666,
71064,
277521,
143096,
213173,
300229,
34693,
107349,
295449,
313761,
7277,
584602,
104366,
119783,
5389,
158293,
106663,
88368,
275173,
18193,
236964,
18285,
90406,
null,
651765,
null,
56038,
10921,
12595,
23337,
625413,
83073,
132826,
324880,
22148,
5574,
16302,
125524,
null,
854657,
160459,
96030,
28688,
282187,
47167,
19145,
null,
114885,
null,
74461,
122840,
175114,
155761,
null,
null,
53864,
9955,
164312,
206987,
167653,
165958,
647334,
229407,
14738,
297754,
42193,
9188,
223662,
50201,
192849,
229361,
17106,
221882,
20058,
37182,
198553,
332719,
677863,
6179,
null,
162971,
601299,
null,
11303,
229167,
231128,
42821,
35821,
30754,
33069,
135304,
6499,
231091,
123426,
426538,
81432,
null,
null,
68829,
55169,
12326,
72030,
173449,
18179,
31416,
25868,
23367,
9617,
43240,
532222,
38458,
41696,
7545,
null,
65431,
33688,
11409,
68658,
20976,
37483,
6403,
28781,
18267,
34479,
59226,
202079,
122138,
119812,
92796,
254163,
35173,
null,
26607,
null,
133612,
null,
8823,
150150,
93352,
280080,
40915,
308124,
295778,
64021,
39866,
21869,
161935,
128290,
239286,
3895,
12512,
149556,
51395,
38413,
193418,
424930,
203179,
41530,
null,
24704,
65846,
20470,
30104,
153641,
244541,
41214,
327521,
34502,
11166,
21448,
218556,
234227,
394299,
304493,
269090,
454818,
83997,
36379,
9378,
208926,
31359,
153541,
null,
10389,
393807,
25442,
10634,
43996,
28831,
26581,
144999,
412810,
28019,
null,
190625,
15400,
182516,
39364,
641383,
326309,
null,
134110,
151577,
98948,
348098,
28277,
125315,
24861,
46645,
79366,
154920,
25133,
38151,
379607,
88561,
50467,
30416,
51306,
117165,
223003,
null,
41794,
246931,
44232,
123532,
12617,
179292,
570342,
7758,
313343,
92641,
40738,
262230,
52450,
17928,
180223,
23348,
285153,
209545,
53838,
84962,
12026,
28674,
33904,
310987,
12290,
30865,
9638,
159891,
35178,
null,
235227,
61289,
15985,
null,
284364,
39656,
null,
295807,
31982,
39852,
null,
23420,
97881,
84410,
275759,
13143,
157280,
39643,
57422,
11099,
323865,
26435,
748357,
61192,
18807,
null,
317913,
277644,
507776,
890,
null,
8844,
132426,
20179,
32027,
94977,
5553,
195155,
440519,
null,
22985,
34764,
298714,
445573,
66417,
21954,
305470,
31693,
172744,
1114516,
20758,
401327,
229407,
209351,
null,
24092,
8424,
155165,
42186,
9161,
117004,
11411,
null,
13599,
24728,
152370,
485838,
240081,
162681,
182978,
19465,
38993,
21115,
40406,
525070,
null,
166614,
null,
3485,
139017,
37558,
null,
445821,
null,
351372,
236757,
247008,
212254,
64117,
72462,
10064,
160557,
10037,
5525,
8077,
97878,
147833,
146662,
null,
265148,
72937,
314700,
55002,
9991,
28842,
48482,
250384,
255971,
293777,
302975,
245854,
188502,
35733,
54956,
null,
18929,
78660,
49693,
117805,
242529,
22411,
354110,
3693,
100651,
361601,
523820,
199383,
74994,
52559,
13212,
62361,
38119,
247886,
254426,
null,
170583,
245932,
305662,
61773,
17449,
10339,
116486,
119003,
28716,
8201,
228774,
8499,
137635,
295131,
12543,
23148,
146692,
258828,
null,
153620,
258265,
18094,
49171,
284780,
18443,
159242,
348814,
28617,
16717,
329555,
18978,
40675,
175436,
21714,
515298,
218988,
251609,
325661,
391329,
null,
20965,
160558,
null,
225202,
17481,
208213,
14925,
153627,
32251,
170866,
73469,
144979,
138535,
120796,
602227,
54181,
81178,
36731,
17121,
259291,
169558,
187446,
69848,
2534,
24033,
52618,
123881,
534177,
168600,
162477,
18224,
null,
63648,
9108,
null,
552000,
237753,
186054,
24938,
26794,
100766,
221725,
174400,
125985,
3319,
null,
113775,
37186,
235979,
374614,
9736,
40496,
74089,
458599,
109714,
10021,
63326,
166079,
41840,
231441,
26820,
30061,
null,
100967,
27790,
65920,
4246,
323360,
90231,
157312,
83935,
27402,
98868,
28485,
31749,
27190,
186984,
null,
12973,
297939,
17459,
17309,
117818,
21354,
117095,
9187,
null,
202130,
266995,
100796,
479025,
56041,
109860,
48488,
17924,
50664,
118878,
null,
395019,
31930,
227311,
25189,
30780,
17583,
47524,
199671,
null,
383555,
29497,
8876,
5926,
92596,
35914,
299639,
12692,
154154,
161280,
32262,
319177,
204892,
134984,
330902,
50400,
235777,
114985,
133435,
138828,
191932,
307617,
null,
377961,
10306,
167510,
117053,
24325,
201384,
385377,
439907,
24038,
97994,
52358,
132377,
43773,
12533,
164088,
null,
326558,
null,
194286,
221461,
111600,
null,
52278,
19920,
14834,
78717,
16652,
577437,
236997,
37527,
null,
476739,
21573,
225580,
null,
3146,
228804,
305999,
49349,
87272,
394973,
168220,
179768,
127386,
16069,
251907,
222824,
32025,
480334,
6799,
141806,
null,
15996,
114732,
21247,
81880,
61320,
28509,
null,
239179,
130115,
16385,
190840,
521886,
84147,
112327,
null,
4238,
266433,
38866,
37052,
39361,
381386,
null,
167900,
44053,
461442,
null,
51071,
339144,
369998,
96613,
167282,
96324,
203045,
143007,
334404,
32369,
19964,
16405,
188584,
179189,
2806,
8021,
27347,
249014,
8637,
275744,
null,
119177,
199966,
55420,
266637,
33543,
62817,
33639,
178327,
292721,
34431,
39148,
28556,
144736,
385763,
37774,
2712,
null,
38677,
49467,
418427,
null,
32587,
null,
373944,
null,
65904,
42301,
38213,
179054,
131396,
30279,
222518,
20667,
105705,
14383,
null,
33714,
832125,
20349,
30032,
135394,
137801,
110852,
31283,
49936,
16080,
330651,
360682,
180986,
null,
73345,
159999,
207839,
92378,
10422,
186983,
30301,
81402,
22671,
185174,
18596,
9998,
21229,
124906,
122324,
23327,
189993,
207158,
115292,
43921,
13719,
214666,
24823,
20101,
51312,
85908,
55836,
129659,
null,
72132,
260821,
152605,
69284,
27391,
33710,
15866,
32854,
38812,
9245,
311503,
31209,
74707,
null,
33836,
414989,
122556,
95663,
416610,
7872,
50475,
108632,
36108,
29983,
187862,
31051,
144902,
199061,
81746,
58477,
33883,
256320,
14088,
28760,
227619,
31071,
null,
8985,
117362,
104907,
59946,
45786,
352317,
17848,
264637,
80908,
267850,
null,
214116,
133541,
null,
164659,
17396,
526397,
110845,
57712,
68002,
20598,
82406,
300409,
115361,
26606,
9202,
15899,
77255,
82383,
51391,
53818,
122857,
30512,
20565,
4518,
8753,
336360,
162408,
64663,
375373,
296251,
null,
33181,
49695,
84865,
418931,
878,
14908,
143112,
28484,
230879,
41073,
48795,
269690,
110467,
106914,
12979,
18174,
160859,
91055,
39270,
1533,
19721,
109018,
19899,
291532,
null,
13076,
186831,
188871,
15551,
15997,
null,
223419,
60576,
39136,
null,
281237,
365019,
47811,
60667,
319161,
46662,
221108,
41044,
152489,
18833,
62194,
395157,
156281,
335303,
7283,
33695,
17951,
198436,
278092,
18084,
40976,
61058,
49177,
9274,
null,
29561,
23160,
211758,
411242,
307272,
407704,
324977,
51205,
41080,
184541,
11226,
233910,
133135,
75125,
25487,
215448,
103884,
null,
8870,
41709,
22259,
23376,
400908,
189661,
null,
248561,
9735,
288759,
51689,
357313,
52127,
null,
315683,
356524,
23653,
6937,
32641,
33212,
46583,
176875,
387105,
39135,
186722,
161144,
52018,
22208,
20766,
107316,
344266,
63762,
11364,
494,
15177,
11440,
36707,
275790,
144899,
26541,
419414,
110628,
27884,
130375,
215836,
331665,
103339,
625125,
104150,
103322,
59739,
18917,
68786,
29291,
305631,
168319,
27800,
197563,
51951,
165324,
22780,
41527,
38717,
15272,
21790,
10510,
553354,
null,
170046,
93425,
90171,
434934,
null,
52527,
null,
102136,
null,
298266,
141045,
212175,
55863,
90476,
10458,
48698,
13070,
null,
298728,
641699,
7302,
131605,
77044,
38204,
18317,
224885,
62054,
116537,
48996,
166590,
46851,
14609,
292642,
193000,
360446,
null,
371433,
203279,
400194,
2109,
16482,
91287,
129456,
31267,
109985,
401446,
46290,
188945,
24475,
18280,
317525,
79652,
94254,
68640,
166104,
274170,
146166,
36799,
153944,
357569,
56137,
113185,
35297,
99689,
31490,
238991,
312352,
null,
133290,
289600,
195566,
303452,
167426,
95744,
63448,
310229,
267530,
45276,
33882,
10982,
211184,
17900,
277455,
33072,
184439,
23996,
20265,
20083,
20700,
54580,
30511,
128244,
324441,
null,
167882,
11,
40287,
24420,
92341,
151155,
3277,
49934,
30779,
18227,
147440,
176078,
90436,
148587,
null,
25861,
12307,
null,
63154,
343000,
83582,
24757,
62605,
35077,
18100,
25524,
21194,
20803,
2838,
220128,
97834,
165671,
1083902,
12413,
6746,
39029,
21143,
240262,
228915,
151291,
null,
138132,
23807,
438276,
99030,
237958,
152390,
114227,
64728,
163473,
170692,
41374,
222757,
23064,
78232,
10026,
28962,
282673,
205466,
73240,
18856,
9964,
135907,
486262,
31694,
330914,
12057,
106425,
301096,
158741,
152658,
111106,
null,
207847,
110582,
35190,
16269,
53938,
332264,
6509,
23784,
202904,
32501,
151941,
35274,
208331,
280864,
36907,
422908,
null,
5639,
412909,
441478,
11882,
332193,
38117,
354206,
223432,
524380,
494160,
289654,
145948,
20854,
77413,
184845,
183806,
19777,
24673,
221552,
740699,
23467,
17747,
182192,
18812,
32489,
36808,
57872,
37560,
130327,
254109,
165176,
440363,
15914,
166445,
21605,
null,
null,
225620,
67621,
111458,
94582,
383113,
316056,
58813,
null,
224147,
null,
351246,
53283,
287107,
644094,
191834,
83138,
38904,
null,
77353,
392250,
10584,
9364,
22022,
107412,
41048,
39426,
46639,
468698,
357922,
25253,
null,
309199,
205889,
43373,
116054,
224901,
210277,
428893,
60078,
49716,
3868,
122265,
179054,
32770,
52566,
279469,
12085,
13421,
132901,
58667,
467878,
13895,
167323,
null,
232811,
68891,
3454,
null,
6740,
38987,
53668,
214249,
null,
248188,
62688,
554512,
34522,
22877,
41227,
24002,
4693,
132719,
96531,
null,
248362,
444734,
642955,
22681,
36854,
21362,
86187,
26259,
28796,
690227,
8556,
190046,
271306,
13725,
70517,
455962,
19675,
33156,
338196,
44430,
96891,
66302,
105547,
35300,
265718,
20182,
59781,
88788,
103955,
49280,
154463,
null,
69107,
16322,
133567,
242016,
427540,
45127,
188122,
60044,
24568,
204726,
41888,
91804,
377414,
9695,
257312,
230684,
369355,
145890,
119703,
48483,
362675,
414285,
53318,
171042,
89312,
23265,
26275,
749079,
206995,
22930,
88423,
168487,
10838,
32478,
133669,
99227,
65719,
155237,
93521,
222000,
185682,
316697,
70649,
36140,
230675,
7058,
76707,
460965,
125887,
311237,
381294,
16715,
null,
36217,
260813,
8947,
11015,
null,
333934,
65958,
13277,
214266,
10544,
37081,
295340,
21930,
196686,
101349,
136520,
136235,
33619,
341173,
78802,
49385,
41699,
466647,
48435,
207033,
3910,
null,
223428,
418466,
359962,
31999,
45322,
110681,
45920,
47200,
42834,
131491,
474809,
12343,
330727,
null,
null,
479850,
38086,
128747,
8874,
67115,
31568,
38578,
438791,
140267,
3681,
19457,
46771,
558809,
259919,
23062,
175152,
468726,
null,
20253,
126135,
175508,
183869,
23872,
311388,
36469,
118679,
158500,
64751,
256491,
295896,
21359,
2961,
74444,
37483,
49752,
63140,
89307,
147504,
415995,
189316,
281817,
141103,
287569,
172137,
3515,
36941,
213617,
221013,
12816,
35474,
17779,
118626,
142493,
176722,
255241,
81574,
30985,
4470,
34610,
9372,
null,
338044,
43542,
30051,
107724,
13499,
285415,
9696,
203304,
100756,
29146,
227125,
173013,
268421,
133864,
177801,
35367,
5637,
6226,
616118,
36896,
477885,
327541,
14100,
13453,
25206,
25461,
14345,
22751,
781482,
87528,
43084,
18357,
76638,
17348,
245487,
68721,
156729,
97629,
8187,
12881,
111983,
74599,
42927,
250688,
74295,
null,
55020,
18474,
39058,
null,
3080,
22627,
182491,
340539,
545416,
377598,
86950,
58580,
63065,
62235,
224591,
12457,
78157,
54604,
14750,
221617,
20345,
50442,
550769,
115249,
15582,
39813,
265410,
290337,
73236,
457224,
11670,
8250,
76125,
null,
23574,
10398,
36667,
34104,
294665,
35901,
38847,
24563,
113446,
208098,
227422,
32968,
null,
null,
69891,
null,
null,
5301,
24363,
376417,
143491,
null,
346783,
256936,
68711,
72955,
1225,
7455,
67275,
108570,
9298,
251857,
247397,
7746,
163790,
308706,
58453,
196737,
210276,
421179,
19396,
207071,
null,
237171,
136834,
null,
79330,
null,
243892,
172699,
527535,
284658,
209844,
239938,
200942,
24209,
225087,
17118,
130768,
null,
578776,
4361,
400500,
111813,
36738,
321477,
26528,
233873,
327224,
122324,
14340,
91766,
264753,
6148,
19217,
212789,
467074,
5090,
12877,
12930,
53558,
252140,
33493,
48564,
219070,
365790,
299982,
167671,
123900,
null,
50469,
197645,
306431,
35873,
193326,
136330,
124697,
12916,
289832,
31945,
18812,
178457,
14676,
19173,
24740,
176045,
217118,
188057,
181168,
77621,
58553,
206539,
null,
39101,
25296,
null,
null,
290241,
599300,
19893,
160320,
40575,
null,
62731,
710495,
42930,
27667,
124911,
127936,
178793,
54930,
84313,
35022,
null,
137597,
10856,
18682,
29144,
null,
138921,
905596,
5213,
160365,
217805,
30208,
480673,
11164,
198542,
685918,
290030,
536396,
289749,
28369,
24126,
null,
85908,
308483,
null,
240795,
229154,
36739,
188189,
269846,
321460,
null,
241843,
44547,
15640,
15493,
229527,
49697,
263238,
221036,
332975,
12401,
60958,
34603,
202411,
13345,
249899,
7392,
137639,
52427,
189602,
239581,
280634,
32538,
420132,
293435,
72235,
400048,
219244,
6096,
376563,
167422,
420842,
87821,
33680,
43477,
417316,
22121,
345377,
116126,
18504,
null,
34863,
460750,
647520,
33044,
66374,
63646,
57059,
142654,
7517,
13988,
183716,
688729,
31124,
316009,
285192,
6522,
775070,
173653,
19530,
24949,
38460,
258630,
18046,
33049,
7928,
null,
258751,
8751,
8818,
202393,
21967,
13898,
185442,
99784,
14923,
19544,
84644,
638421,
10330,
16636,
217207,
19128,
226118,
45197,
21022,
58314,
null,
21300,
77546,
298085,
15292,
178011,
277878,
159380,
327367,
108266,
null,
51854,
16900,
106855,
39595,
76565,
95871,
12292,
28237,
7819,
216344,
28594,
2072,
200881,
41475,
30806,
81834,
63278,
349130,
19899,
260475,
261538,
97761,
137540,
233626,
23362,
23160,
42016,
49760,
25558,
20266,
28108,
310090,
228278,
null,
null,
30343,
165064,
232728,
null,
38897,
30871,
23718,
128731,
314396,
327336,
25841,
85921,
140977,
null,
10864,
90927,
29103,
24396,
5666,
null,
365831,
387180,
448238,
338909,
5916,
40719,
34414,
8191,
299840,
270261,
67006,
7837,
204046,
302349,
136993,
30828,
344398,
152080,
430474,
580246,
514118,
84646,
300005,
60133,
null,
32988,
58259,
100319,
29987,
93605,
134782,
null,
108889,
255175,
15824,
29985,
null,
92818,
78969,
null,
394441,
null,
114431,
null,
34691,
154606,
372297,
26023,
null,
null,
3038,
49143,
9098,
133326,
5724,
141691,
302326,
252895,
101254,
null,
null,
216493,
31716,
122155,
549702,
34627,
33691,
122330,
null,
257707,
179103,
null,
63932,
53795,
920517,
50921,
320780,
130524,
148292,
40538,
22473,
548547,
290413,
139375,
24362,
null,
111447,
34114,
217342,
null,
26418,
160102,
30804,
230567,
45328,
366804,
120136,
33792,
48462,
213001,
32349,
null,
149342,
null,
14053,
30899,
126130,
58282,
10180,
1894410,
null,
73665,
147435,
null,
14992,
126403,
51075,
251790,
37166,
66657,
26361,
298891,
171843,
133180,
192018,
243058,
5592,
54455,
45822,
77368,
121259,
25814,
31247,
33622,
25168,
218021,
250276,
24434,
436023,
91587,
7076,
239539,
18545,
40722,
347860,
172045,
164382,
null,
36279,
151769,
29279,
192071,
17189,
167672,
201719,
264924,
187150,
184654,
113632,
8774,
362094,
120310,
62395,
57809,
113267,
746503,
175785,
357486,
49422,
393562,
255144,
1641,
248064,
10694,
37211,
150100,
101621,
199940,
147137,
415537,
133879,
124856,
26718,
7839,
181805,
529068,
178193,
565661,
null,
15629,
119721,
51345,
314015,
239262,
205780,
140960,
90502,
48060,
514225,
46206,
7280,
12529,
343062,
294785,
null,
95226,
19024,
11658,
null,
115830,
null,
17224,
123412,
40855,
160581,
13818,
null,
57303,
129996,
27506,
49054,
25535,
1879,
31579,
115255,
20459,
281768,
237027,
80148,
49545,
35172,
163960,
433115,
419317,
18448,
315639,
461285,
185095,
604005,
null,
508570,
238893,
14488,
null,
318715,
14839,
55498,
32859,
null,
224677,
null,
23558,
70500,
294067,
137522,
144785,
289178,
198033,
78329,
36990,
17382,
78702,
63242,
25497,
56227,
459423,
375395,
178453,
46254,
72143,
79535,
290752,
29940,
288858,
765207,
53608,
323725,
165452,
375307,
83873,
175942,
22209,
11529,
318182,
261335,
140263,
66618,
26560,
34396,
229962,
null,
74084,
null,
257348,
20573,
501895,
154557,
41799,
225799,
9626,
11414,
9557,
null,
26317,
7076,
100165,
275673,
40961,
58786,
20065,
28900,
111141,
21835,
381507,
38911,
68338,
null,
53037,
159573,
123986,
18954,
31674,
154862,
15008,
null,
34273,
null,
226593,
300379,
136211,
241199,
132967,
20146,
35462,
35579,
105410,
39822,
111455,
161420,
null,
13872,
64333,
41497,
31616,
93613,
16122,
null,
308422,
506393,
7169,
16832,
null,
39446,
25708,
214488,
37454,
null,
23943,
66545,
19563,
707349,
229103,
504457,
26799,
null,
44709,
37164,
46620,
30732,
54492,
216530,
206509,
38301,
367964,
136491,
3965,
null,
485826,
94416,
12800,
42060,
58342,
126801,
275074,
52835,
228492,
19675,
26851,
187042,
328313,
21271,
28946,
43549,
18878,
31331,
427567,
460446,
94117,
102036,
8334,
null,
45194,
105067,
79552,
19694,
5031,
5915,
467666,
null,
191954,
54684,
24421,
30279,
189587,
29865,
10116,
149138,
102026,
null,
302911,
73723,
28797,
22239,
477744,
127568,
null,
19662,
74354,
72218,
152955,
62751,
105246,
184149,
37018,
237678,
10246,
22313,
47428,
43299,
54733,
106518,
220158,
11744,
24854,
166678,
15575,
16233,
321311,
47966,
29550,
40187,
47309,
93235,
299283,
50555,
46768,
278123,
74053,
8656,
25384,
null,
86813,
241082,
268671,
null,
244461,
152197,
12188,
362701,
59433,
200940,
22288,
null,
190142,
null,
30177,
42716,
169491,
6376,
31671,
622945,
72573,
301754,
null,
263208,
79744,
49043,
53152,
44156,
18906,
42441,
118149,
194653,
119248,
230540,
37542,
55619,
118831,
153669,
216137,
38914,
151996,
58173,
34568,
13139,
4761,
34273,
77237,
233871,
19438,
23161,
31163,
28492,
154567,
418081,
145615,
40988,
109862,
184637,
209399,
27912,
null,
150200,
null,
137518,
92589,
422405,
29843,
null,
240569,
62856,
133587,
34364,
56596,
210873,
8457,
13768,
138656,
196614,
628147,
null,
4288,
234380,
null,
null,
228479,
52984,
14769,
64061,
194643,
26408,
56483,
118710,
174362,
677571,
null,
104297,
null,
null,
195816,
174567,
125775,
null,
35175,
183516,
null,
167181,
6767,
null,
33997,
188174,
218557,
165002,
304332,
23210,
333738,
null,
240091,
75522,
204427,
267234,
288150,
345824,
3960,
12796,
null,
125181,
3389,
57564,
93716,
99871,
8317,
18818,
28301,
null,
12164,
9440,
127235,
55248,
103755,
127122,
null,
null,
6832,
37575,
137213,
null,
53030,
218819,
97966,
21762,
25394,
43142,
74335,
192810,
15083,
158328,
148604,
56053,
214380,
26489,
5589,
635,
49569,
45462,
105573,
191579,
26050,
372491,
278897,
131194,
34648,
55094,
23299,
8718,
162142,
119404,
132220,
23476,
109307,
null,
20978,
36149,
36680,
84933,
54693,
69262,
21073,
624229,
234927,
10915,
336638,
106124,
46781,
265378,
203781,
29505,
165464,
11067,
22918,
8599,
182902,
200225,
324258,
18930,
8497,
107022,
246775,
133814,
47750,
14154,
30293,
93415,
null,
197017,
34392,
17328,
134467,
104616,
139040,
48300,
116198,
70903,
23923,
19818,
247355,
null,
null,
9179,
172219,
26572,
164281,
48660,
null,
113661,
336986,
3140,
249413,
9387,
47471,
50345,
146815,
23893,
34845,
4067,
280559,
166098,
156498,
314249,
375374,
140238,
null,
151478,
154949,
520139,
1583,
319999,
3616,
26154,
3475,
34949,
32358,
156827,
290310,
224851,
135234,
27550,
142788,
477786,
247735,
84465,
386415,
126051,
280299,
818609,
13903,
13298,
909133,
211227,
38195,
3237,
218745,
294103,
76672,
31775,
115437,
137559,
21714,
25064,
9698,
33641,
57665,
268934,
33590,
57015,
290379,
118792,
16735,
50717,
112249,
293221,
7220,
37503,
23669,
219574,
159105,
34145,
51030,
38856,
24179,
154399,
19752,
161903,
12745,
22541,
7550,
276622,
null,
24803,
16167,
24619,
15704,
194791,
33104,
41675,
26060,
46128,
null,
472929,
88101,
458132,
null,
265058,
36618,
67330,
23238,
74334,
18938,
19578,
null,
28050,
233653,
null,
199245,
45985,
154070,
359694,
51621,
null,
183532,
65042,
216586,
41367,
45995,
18817,
32627,
172450,
147805,
null,
297136,
188051,
265657,
11126,
135434,
113686,
189862,
158384,
14368,
245657,
376392,
14985,
28695,
31089,
21016,
217055,
20333,
209723,
142668,
95388,
211872,
178867,
49798,
138805,
21046,
308887,
162215,
38958,
119432,
150287,
183072,
42245,
60268,
24784,
240728,
252856,
11645,
null,
36454,
88287,
null,
129087,
133718,
null,
36116,
32798,
176936,
13347,
40460,
63936,
648,
216432,
49301,
18957,
null,
231993,
336386,
311698,
172540,
47229,
34973,
172013,
91431,
111563,
7243,
121074,
233195,
25429,
18166,
32371,
11824,
44903,
null,
115053,
59804,
305177,
124469,
40247,
302955,
27656,
303908,
623483,
372272,
196430,
25146,
111664,
377664,
28398,
179674,
207644,
51846,
34668,
72261,
null,
169594,
142341,
null,
133024,
null,
3000,
null,
154184,
80287,
39084,
798541,
93165,
726757,
45400,
473115,
237951,
90771,
69004,
661104,
1791,
41268,
20855,
78411,
161075,
94615,
78644,
13137,
86128,
25475,
56295,
221330,
91484,
15559,
250194,
261965,
35361,
343339,
36869,
11672,
384253,
286315,
null,
193292,
217124,
8221,
null,
10384,
7734,
34271,
388138,
82146,
231006,
151614,
262156,
525806,
52838,
null,
1946,
null,
136056,
25671,
251580,
56709,
6775,
116489,
36522,
158371,
215224,
405747,
177679,
10906,
53985,
114500,
15921,
46045,
145679,
151887,
62225,
24572,
44396,
143619,
77373,
449060,
null,
66853,
133778,
48216,
182259,
115746,
436590,
654255,
313919,
27068,
null,
23858,
90941,
208472,
null,
7280,
88294,
9621,
79378,
68769,
33975,
181073,
103298,
40639,
46703,
null,
153663,
233387,
37010,
49030,
30070,
50021,
46078,
122376,
168363,
202828,
81606,
19524,
117439,
115795,
21994,
21851,
280640,
166057,
72246,
8276,
48354,
null,
365805,
344315,
21970,
164672,
null,
55156,
121578,
358843,
42722,
216050,
199543,
null,
229404,
138418,
3591,
255513,
226777,
24645,
1020895,
187876,
43815,
648169,
254317,
31287,
45774,
368902,
53003,
41521,
242311,
17465,
192558,
242091,
348116,
30428,
459333,
45979,
15567,
198221,
76180,
142274,
138034,
27478,
32440,
8784,
429073,
118762,
31188,
71910,
273455,
47277,
14712,
97434,
249369,
313737,
null,
327300,
151509,
57517,
100245,
170271,
39944,
36213,
41439,
12866,
61508,
192184,
null,
13058,
253427,
137977,
54222,
122343,
13875,
1064152,
222943,
2620,
12372,
null,
64814,
29328,
null,
98493,
8520,
213026,
390736,
371963,
117284,
75060,
354031,
321169,
null,
55080,
136816,
119553,
176096,
46551,
7170,
116819,
12148,
36191,
null,
271918,
17963,
16239,
210724,
270554,
239309,
552888,
152521,
21124,
27469,
179065,
19296,
5328,
20204,
7859,
null,
null,
90270,
40810,
35355,
null,
86359,
215603,
39779,
256812,
138084,
42003,
185888,
45379,
192604,
33407,
179998,
314914,
27407,
67096,
39537,
81049,
41401,
54621,
307986,
279760,
35224,
48684,
106837,
484744,
480363,
35092,
16899,
221129,
82677,
319155,
166638,
40817,
44541,
9992,
224733,
477285,
268827,
421856,
20122,
392042,
51389,
29307,
null,
null,
48676,
114902,
185526,
15984,
238105,
201417,
21477,
164443,
24091,
80291,
567006,
38382,
89107,
128203,
298615,
34527,
51123,
19904,
32122,
67228,
287256,
96542,
474487,
35787,
296444,
333736,
26761,
63529,
163324,
125087,
37692,
436747,
null,
72486,
27923,
23579,
262564,
60035,
112290,
6422,
317485,
178504,
63763,
163903,
38453,
187527,
185103,
17844,
248505,
218460,
60314,
22412,
303922,
102851,
8608,
11827,
11050,
40637,
347697,
32702,
7537,
16585,
202542,
82589,
12485,
325863,
309989,
41591,
127146,
467190,
339083,
63399,
333032,
27854,
12283,
51969,
39366,
134779,
426395,
126478,
368376,
115982,
71053,
null,
6809,
169929,
20899,
12283,
159712,
178676,
36797,
293080,
114816,
null,
56979,
35213,
261919,
234866,
40954,
255541,
410517,
46502,
25567,
282432,
247142,
182208,
90734,
null,
57930,
28656,
1026,
44693,
126830,
1135,
45599,
112676,
null,
25868,
203949,
38136,
858706,
128616,
485420,
32438,
214959,
null,
23956,
74675,
190429,
338097,
153416,
null,
184138,
45503,
76066,
6291,
null,
null,
91730,
160790,
51100,
283727,
31248,
422304,
28615,
154969,
143047,
346748,
31591,
94284,
9913,
29948,
null,
32107,
145592,
123081,
222129,
29426,
290290,
118964,
19605,
39740,
217226,
16109,
432688,
223658,
134676,
405009,
178527,
133426,
null,
162645,
14481,
388940,
11507,
42538,
397180,
78577,
33174,
206843,
93330,
31260,
132533,
242325,
166271,
7517,
null,
97851,
467616,
513862,
5194,
536761,
139023,
205122,
48683,
46980,
90818,
49623,
null,
265892,
119395,
115260,
23208,
20034,
826428,
18952,
68957,
160172,
206059,
null,
115242,
53767,
151778,
318328,
49664,
26783,
167434,
47895,
11641,
217614,
50105,
19444,
274353,
278963,
152138,
60761,
194198,
172134,
139860,
226234,
58560,
105693,
19755,
45915,
69809,
199262,
5786,
20994,
28391,
36370,
17772,
59334,
174079,
7271,
35811,
101502,
82256,
102564,
184572,
17177,
30970,
391542,
317748,
366875,
4248,
43080,
null,
9287,
144470,
10244,
270907,
347294,
28323,
53236,
156778,
1332,
309797,
229049,
10874,
225701,
47821,
15786,
329623,
258702,
17396,
191886,
4531,
14836,
84471,
129322,
7827,
323529,
1531324,
47305,
28172,
70628,
175043,
31374,
126742,
208996,
575032,
195074,
22492,
286897,
110329,
4615,
254715,
261829,
341501,
49105,
null,
28392,
107695,
13211,
176081,
382253,
149570,
272545,
37566,
43636,
16498,
264594,
304975,
119796,
null,
112620,
30286,
85349,
411164,
22093,
21594,
41911,
20963,
189856,
48669,
25830,
501653,
76140,
18709,
null,
37052,
389108,
130474,
36114,
290414,
406926,
288991,
27202,
180089,
null,
27432,
46025,
3081,
48269,
305720,
184990,
202912,
34510,
19746,
null,
40108,
29328,
85270,
31481,
412458,
117555,
74266,
25064,
40988,
null,
180100,
20416,
33245,
31688,
12079,
42141,
32923,
213335,
209476,
null,
8335,
128974,
5101,
27992,
44680,
361385,
44614,
null,
22112,
11167,
77602,
229866,
131780,
264415,
238224,
15672,
4689,
25123,
23890,
22188,
301865,
252095,
9584,
9285,
51961,
181498,
21279,
149731,
157608,
303019,
37631,
45780,
282289,
109406,
42575,
null,
null,
121798,
57417,
13705,
35084,
69381,
23871,
18564,
37105,
49169,
136637,
null,
289297,
52700,
219292,
29097,
null,
15218,
492226,
185416,
122897,
198698,
458391,
26237,
29621,
121619,
405974,
20088,
225877,
35829,
277514,
17832,
40571,
179778,
6100,
243192,
32602,
109389,
27906,
37158,
222607,
64378,
33337,
71468,
38647,
32424,
14100,
286928,
16065,
161125,
176271,
134831,
38391,
566094,
161966,
27095,
79646,
402841,
810472,
273634,
null,
390122,
95250,
158509,
19023,
37659,
159839,
226182,
13013,
30412,
89884,
null,
null,
113329,
307194,
272787,
143062,
270996,
17430,
77895,
47415,
176355,
104597,
159228,
315694,
null,
209692,
23413,
159356,
207387,
76163,
202201,
25392,
188672,
197973,
160599,
158275,
107900,
159380,
82817,
null,
493682,
47270,
243352,
198930,
504809,
325171,
24247,
11158,
236575,
43105,
14035,
166238,
152171,
null,
253938,
149387,
26775,
371734,
111125,
373753,
187682,
38082,
null,
240380,
18090,
18687,
304718,
50082,
311761,
8322,
23617,
70663,
30981,
18286,
154780,
291725,
161586,
245021,
375492,
24802,
196032,
275812,
67346,
293382,
171688,
42563,
296056,
6752,
188302,
233570,
6876,
327103,
26650,
480304,
51078,
225011,
null,
177069,
38830,
131856,
null,
43072,
82600,
107925,
33482,
11552,
38846,
139476,
19262,
60687,
140124,
290558,
8065,
95287,
58716,
262530,
184481,
282502,
235282,
25954,
363765,
16876,
22232,
160007,
24454,
121449,
35580,
12222,
103338,
37141,
50996,
86621,
21435,
36456,
null,
36852,
19854,
95121,
225734,
null,
100942,
392595,
437529,
192818,
10934,
23617,
250097,
280707,
143514,
233658,
145674,
12697,
191965,
29798,
24002,
60742,
34619,
108301,
190239,
408617,
179994,
null,
211279,
24529,
182649,
397123,
119737,
356961,
null,
19140,
296910,
147538,
164139,
22350,
40979,
60536,
204206,
10547,
72486,
null,
164668,
42003,
51977,
536130,
null,
1379,
null,
114298,
170954,
341173,
18814,
13530,
20460,
180730,
299799,
408706,
6141,
2331,
495939,
null,
145531,
157539,
621428,
null,
null,
194059,
85988,
null,
26422,
316795,
458380,
397832,
28404,
12571,
43012,
574806,
85827,
101782,
358872,
451892,
38723,
9547,
88900,
9844,
316889,
51825,
153427,
264562,
436297,
113626,
24289,
138910,
70634,
158943,
28536,
23656,
51344,
37554,
30194,
126160,
10000,
9283,
488064,
null,
33642,
52268,
11603,
25931,
991051,
73795,
64054,
163115,
243445,
165243,
82798,
133130,
18277,
31074,
103667,
503714,
168056,
642402,
10159,
169058,
47093,
93561,
null,
158400,
27524,
18852,
122179,
34801,
289986,
891296,
40925,
44781,
225141,
7272,
230614,
null,
32451,
25098,
35130,
null,
31675,
149961,
94159,
15895,
4767,
93748,
5353,
232975,
204720,
451868,
71724,
80646,
16689,
17510,
37828,
77470,
13815,
21263,
267869,
95229,
334687,
44882,
19419,
63109,
35300,
null,
363728,
149160,
9440,
238095,
268420,
183969,
9326,
119858,
65715,
50566,
19956,
296330,
143166,
330443,
197594,
243207,
163337,
166225,
289066,
10079,
71449,
45608,
17856,
77393,
null,
11483,
598300,
254568,
37458,
112489,
144209,
null,
10027,
168084,
167469,
58287,
23983,
182651,
154853,
136906,
808556,
46584,
262205,
857422,
69430,
32534,
48262,
345607,
53686,
202698,
79286,
257162,
382400,
148432,
187827,
295163,
191573,
1225,
10183,
29256,
45023,
4656,
58790,
22164,
22370,
34206,
62469,
15031,
83461,
56960,
449071,
72949,
227079,
10108,
33068,
555514,
185723,
152396,
253303,
null,
35842,
250853,
722094,
222682,
null,
16613,
null,
9654,
107816,
335893,
null,
181743,
67570,
363757,
248386,
42818,
40393,
276005,
59906,
25240,
30622,
215249,
302948,
30976,
208467,
152841,
31904,
626208,
22491,
45771,
410801,
9896,
40873,
258661,
47689,
258769,
205231,
52907,
null,
78885,
190232,
28408,
199959,
82629,
39079,
28927,
116577,
null,
274918,
null,
4720,
83449,
null,
492767,
null,
3806,
75280,
173100,
299657,
1179722,
322114,
31247,
42883,
12056,
null,
214469,
null,
41656,
318520,
197544,
365035,
271100,
6646,
127642,
250503,
19227,
48069,
11646,
17921,
214230,
300738,
20212,
429154,
172024,
27816,
55941,
300595,
4939,
110850,
350900,
17581,
33977,
15295,
343099,
617988,
10984,
20124,
10723,
71739,
198843,
37264,
237204,
364690,
53185,
16867,
12998,
171586,
20316,
230769,
526983,
44790,
203402,
112414,
18823,
null,
null,
383509,
12012,
null,
null,
4655,
67278,
30346,
206963,
56403,
35810,
190885,
300195,
144918,
56479,
166026,
34733,
37361,
358306,
28180,
23321,
95789,
87223,
29093,
161388,
null,
57788,
246149,
603184,
24542,
208717,
6072,
23290,
110962,
341243,
54841,
30929,
null,
58866,
29900,
7464,
13830,
272615,
31500,
12134,
5867,
44176,
11919,
null,
67537,
62262,
552631,
35820,
207793,
103221,
56398,
21314,
200945,
13058,
133399,
31365,
66767,
null,
null,
200082,
108099,
78873,
51967,
46712,
214179,
231699,
21715,
null,
19126,
29933,
26928,
1177,
7674,
115709,
218459,
13276,
458856,
33157,
283386,
209669,
329226,
364936,
296214,
90951,
36550,
47594,
333433,
31387,
163996,
44628,
254080,
239660,
9548,
null,
24661,
207014,
298539,
28249,
148647,
195493,
216873,
86148,
47399,
184701,
719676,
50171,
171574,
212506,
460763,
183856,
52383,
180078,
12632,
218337,
129572,
14531,
88991,
20644,
154566,
276277,
138414,
null,
115337,
91397,
81723,
154615,
369096,
190640,
363472,
11033,
188685,
8909,
54961,
119427,
136465,
361033,
385526,
18187,
23410,
61980,
57804,
206844,
288319,
32185,
227700,
223009,
356089,
25153,
21073,
166275,
13136,
105205,
8001,
13091,
322053,
null,
112419,
null,
141227,
276063,
8349,
240182,
285905,
28310,
32022,
390640,
136674,
null,
null,
132330,
60752,
null,
36652,
209755,
31785,
25525,
17392,
32706,
26378,
91912,
76517,
13039,
null,
205718,
53694,
69322,
9358,
23742,
139008,
30642,
90245,
104833,
31277,
173255,
198110,
208138,
39533,
105409,
121844,
29722,
261745,
38327,
160036,
160499,
222594,
11086,
86342,
2949,
40825,
398713,
702637,
168228,
28072,
42770,
42941,
135565,
28690,
264428,
18158,
9764,
509943,
87511,
168151,
6708,
31894,
87599,
188549,
38406,
null,
245126,
59254,
40525,
36307,
69261,
440927,
6043,
107151,
7763,
28361,
18350,
null,
206640,
null,
190567,
184514,
null,
21867,
481348,
124362,
233302,
735104,
74518,
11117,
185970,
626651,
37382,
null,
203839,
300011,
13569,
29638,
11518,
37009,
31193,
100470,
23304,
178572,
16024,
90360,
17628,
348927,
287932,
27876,
null,
149511,
80325,
105157,
213372,
216038,
287490,
353271,
18286,
530299,
9861,
null,
221873,
285808,
null,
70959,
358473,
8923,
35674,
11796,
322574,
35593,
null,
267664,
184227,
24199,
69723,
184017,
39360,
25202,
220150,
21854,
122635,
21136,
308128,
20924,
51031,
37937,
28175,
134991,
255098,
159272,
283916,
28118,
149653,
229404,
220948,
52368,
11684,
186201,
32502,
107982,
10613,
28488,
301685,
19305,
34979,
61676,
42913,
607411,
12763,
962183,
39147,
12407,
290989,
152891,
193174,
23050,
29272,
46810,
366958,
7582,
2043991,
450064,
60644,
237724,
null,
null,
236246,
58449,
51941,
59397,
171913,
null,
74008,
null,
34324,
46717,
204039,
null,
158986,
20637,
24841,
79029,
257724,
8443,
355888,
null,
140652,
97841,
324283,
22650,
241144,
274885,
344586,
null,
44030,
51832,
58110,
null,
210702,
30139,
120235,
18381,
26393,
253928,
79328,
256161,
200646,
365120,
97339,
3307,
null,
179966,
156695,
191826,
443433,
43235,
30610,
279954,
116019,
213339,
106847,
null,
164661,
10401,
118007,
16626,
78827,
214918,
181108,
622825,
38653,
259200,
77588,
212458,
54801,
31775,
361354,
21740,
188017,
25437,
null,
14431,
109081,
43156,
96746,
31674,
95594,
null,
254058,
4025,
115754,
12193,
4324,
10200,
194317,
130389,
4513,
256565,
364269,
8558,
18610,
null,
279078,
167881,
20848,
149097,
38268,
376716,
28296,
514692,
179341,
5069,
null,
265671,
61348,
317367,
92512,
6682,
13375,
43248,
11031,
10586,
61604,
11126,
73606,
23691,
null,
366548,
40167,
138691,
86886,
43791,
120117,
27589,
167269,
188239,
403249,
427900,
129294,
323021,
37610,
59845,
16881,
47810,
120363,
47935,
38945,
10459,
204919,
59644,
7513,
43025,
97334,
55998,
17640,
62358,
128463,
200773,
694698,
214828,
216781,
370534,
86650,
351773,
30484,
null,
243725,
56139,
24156,
9315,
138397,
352982,
325607,
579255,
16506,
34013,
251099,
41066,
7604,
49285,
10182,
280370,
323471,
11943,
294463,
258492,
4203,
252720,
41204,
330966,
18583,
13436,
45854,
48000,
639429,
20784,
163112,
44528,
427944,
18214,
39463,
null,
111753,
28915,
441962,
null,
85952,
153292,
22912,
68237,
160175,
399663,
103613,
96052,
14674,
252456,
6968,
22643,
12963,
189530,
409403,
null,
null,
55406,
60021,
null,
13885,
33601,
247855,
75855,
124917,
65821,
null,
32755,
237127,
86141,
7686,
null,
14697,
112138,
16323,
21991,
73042,
289701,
296103,
33548,
875664,
30480,
41884,
439778,
123020,
128783,
319195,
60757,
68509,
79749,
290902,
209569,
132019,
null,
25569,
57885,
272805,
50165,
114848,
5020,
38275,
102109,
73998,
null,
519897,
291244,
472365,
26119,
236057,
15454,
5396,
227451,
422331,
70053,
48088,
59443,
33075,
265554,
287740,
9995,
17916,
175067,
103056,
92950,
17255,
60872,
128195,
52863,
17888,
366830,
142159,
204162,
null,
271157,
141801,
102001,
27371,
142065,
273397,
33919,
256014,
33862,
17839,
107746,
358397,
477651,
17996,
262222,
null,
88551,
2127,
89385,
6362,
158073,
21021,
22493,
53405,
22904,
54694,
23865,
301737,
194162,
70151,
20976,
406776,
80735,
233646,
13785,
null,
115665,
308786,
10831,
13411,
243257,
5988,
35545,
41214,
null,
431282,
204353,
6938,
27927,
30797,
469091,
18539,
8507,
1158975,
47576,
null,
28089,
42830,
6016,
23220,
19658,
18887,
21905,
429739,
95339,
200437,
160267,
210103,
null,
null,
35765,
29639,
161968,
484041,
88139,
3599,
74531,
201940,
229749,
286511,
38874,
31144,
35564,
145456,
105553,
30679,
256315,
null,
7270,
260409,
38067,
33873,
105293,
145171,
340312,
94099,
133500,
34630,
24600,
22646,
16072,
371204,
155769,
323693,
267309,
240853,
9393,
268679,
39395,
236290,
46110,
60095,
34589,
7840,
198203,
178765,
null,
787933,
725616,
171893,
38184,
52891,
47580,
28206,
60705,
133225,
28471,
248297,
130169,
null,
31797,
156535,
23862,
403251,
612052,
33749,
23314,
120585,
237655,
null,
78130,
80471,
185572,
452903,
129846,
112798,
12004,
35468,
188507,
14425,
97023,
198204,
154402,
52474,
188030,
40802,
2873,
39805,
449252,
41711,
295625,
485735,
null,
110975,
49558,
24016,
43460,
35279,
67169,
192884,
36109,
48576,
161639,
193442,
null,
16881,
269792,
260654,
16162,
172737,
9722,
620670,
185448,
109484,
50506,
71133,
201403,
306007,
67936,
79657,
53490,
829578,
62095,
33587,
104945,
20912,
40296,
27406,
41907,
16114,
84833,
255467,
107198,
14999,
71960,
431646,
24320,
null,
324945,
81922,
17666,
314913,
28443,
68174,
4247,
16261,
243444,
400325,
49013,
null,
421562,
214441,
228129,
5573,
13345,
51688,
26380,
98006,
256490,
527739,
148124,
199128,
22255,
170331,
6686,
14785,
88905,
135199,
324859,
17998,
30903,
26131,
72839,
192391,
null,
28920,
66859,
45612,
43591,
361464,
41578,
24815,
18838,
17097,
321769,
158320,
null,
14977,
311121,
41424,
null,
76193,
86548,
28486,
108574,
142787,
30058,
38278,
15806,
133908,
19717,
4235,
141516,
160437,
212693,
7182,
309870,
224236,
222824,
224152,
301655,
39927,
177808,
14034,
43436,
59067,
112010,
153538,
40422,
17597,
null,
156838,
366771,
94290,
331366,
57349,
22058,
27740,
195924,
25701,
55999,
129774,
37742,
137841,
36987,
16125,
null,
null,
3737,
15942,
null,
43263,
12796,
5441,
14248,
180811,
17020,
12878,
154913,
71317,
291198,
441664,
221095,
47295,
280687,
343934,
19779,
46603,
417849,
36612,
48596,
256801,
262012,
24703,
23448,
41041,
323232,
431810,
null,
null,
184270,
76446,
14488,
36973,
153270,
31829,
7827,
181438,
168507,
469375,
29111,
96390,
40483,
103233,
17657,
35581,
253761,
208265,
10316,
68614,
null,
23179,
137857,
25523,
213110,
87496,
62147,
36538,
43722,
142817,
62944,
24998,
446710,
129715,
93756,
27962,
16455,
190680,
150102,
165558,
108813,
29857,
50420,
null,
531687,
83165,
143717,
48652,
358495,
348409,
374892,
30897,
464105,
72611,
null,
494595,
159409,
16804,
220530,
null,
364100,
28012,
82831,
9265,
136199,
308468,
206743,
null,
229459,
null,
325551,
360313,
126996,
27274,
83578,
23538,
581814,
109109,
38929,
259215,
25653,
36385,
300147,
21278,
67532,
138071,
59462,
68866,
null,
274891,
154320,
6807,
171270,
59002,
178439,
9365,
212082,
908655,
108642,
331759,
147382,
null,
64831,
29126,
258760,
1925,
126390,
182934,
231821,
null,
102736,
157497,
465710,
210156,
null,
279394,
264389,
137638,
29075,
24375,
55846,
192980,
233463,
151267,
363157,
null,
81149,
64634,
49163,
68389,
19740,
70937,
null,
null,
152246,
13856,
52128,
62094,
200614,
260600,
174210,
421308,
117057,
6696,
41107,
31093,
56840,
176419,
82893,
9664,
21683,
17276,
115973,
55872,
null,
210303,
19726,
108892,
5780,
324592,
71165,
240079,
26855,
99136,
77804,
204453,
68531,
14391,
138961,
27985,
40623,
326044,
2954,
124691,
37946,
156423,
161721,
68475,
349030,
40767,
48331,
41393,
210528,
211937,
279471,
45531,
147908,
121229,
175527,
162095,
167405,
365453,
9614,
21286,
122560,
86183,
22957,
193109,
162086,
197321,
14069,
5159,
19769,
149392,
196470,
34561,
28769,
9118,
22837,
30661,
196702,
10945,
203888,
681911,
null,
329528,
82883,
22133,
480070,
412503,
174947,
186689,
28662,
50884,
380783,
147113,
17214,
33402,
43333,
378356,
334100,
21335,
48305,
265642,
19620,
253843,
null,
21591,
22957,
37707,
157543,
11153,
52990,
55994,
19260,
205925,
431775,
120869,
291331,
23675,
37621,
892602,
17619,
59471,
13635,
120617,
243933,
10425,
null,
71927,
61268,
391009,
11026,
219390,
11823,
40157,
212175,
483122,
124549,
null,
312892,
156131,
38716,
29300,
63682,
15594,
122121,
192938,
374823,
16459,
259587,
140690,
14286,
86868,
27202,
473635,
null,
41258,
242897,
173706,
238525,
null,
268240,
9670,
64157,
93116,
20351,
322321,
13935,
null,
432149,
76175,
35881,
12919,
2700,
17805,
14457,
398402,
258751,
21771,
248001,
79587,
25701,
187021,
148174,
295784,
345037,
189309,
28588,
31850,
135397,
115225,
467607,
44778,
18605,
230549,
162469,
49193,
43547,
14272,
null,
171997,
13976,
21272,
70072,
77788,
5988,
92497,
399945,
67082,
431728,
42592,
125736,
20967,
310323,
null,
null,
10390,
32765,
627361,
139294,
25989,
10019,
136188,
39732,
25291,
15034,
8998,
30232,
109493,
5849,
50107,
24194,
225320,
100049,
251330,
null,
64969,
80496,
31792,
63418,
104595,
230658,
265994,
51022,
200461,
448679,
234588,
16100,
16512,
102114,
396470,
60836,
null,
48517,
426705,
78113,
321946,
176331,
268013,
317006,
32496,
null,
31100,
347954,
null,
null,
null,
12991,
154947,
241184,
46418,
772429,
null,
588207,
218499,
22840,
123553,
251939,
5379,
363063,
47397,
158942,
null,
86239,
28458,
null,
null,
23111,
24499,
78013,
67261,
207331,
null,
137869,
6132,
177720,
24769,
253747,
17524,
null,
37367,
48922,
null,
244085,
395739,
42321,
40073,
24545,
58113,
18047,
79277,
17698,
186607,
271984,
146957,
null,
38208,
301737,
14397,
312868,
106099,
3414,
31056,
305523,
49320,
null,
72482,
99567,
49850,
480495,
32264,
7899,
357902,
28237,
37291,
35966,
11485,
6624,
201206,
279328,
209618,
48614,
93008,
334184,
205425,
47590,
163066,
35516,
61506,
229635,
15419,
69687,
2393,
40327,
16084,
112578,
30698,
8502,
312701,
16743,
28268,
101242,
207335,
41945,
27934,
71628,
50490,
221986,
65563,
310738,
10238,
64770,
33466,
24887,
29390,
299265,
132301,
227825,
149535,
84415,
15103,
257955,
127379,
39050,
73436,
null,
225813,
264924,
null,
26160,
201270,
46845,
298928,
19801,
161408,
22894,
142762,
37823,
53653,
87242,
323587,
28413,
172698,
15683,
71268,
53949,
null,
17762,
412485,
181026,
200559,
275627,
121749,
305103,
44417,
6400,
49910,
37915,
30487,
25743,
240297,
241925,
45400,
355499,
1090199,
67489,
321432,
27359,
27604,
236269,
249011,
83921,
2408,
81552,
15344,
239125,
249324,
205751,
546178,
146598,
184862,
77051,
296234,
34067,
332694,
124163,
228907,
10524,
31270,
250334,
61500,
247415,
65349,
22968,
36861,
134375,
46262,
182962,
null,
304148,
33120,
337677,
null,
205002,
33625,
45624,
345779,
124787,
90114,
61722,
null,
16006,
4660,
27960,
63208,
221175,
42278,
486799,
259944,
365643,
408971,
195896,
212526,
31916,
7090,
7183,
19624,
17470,
11152,
25627,
81451,
30739,
420138,
14761,
192692,
null,
17171,
142190,
222139,
196977,
44847,
263503,
242268,
172329,
149799,
24061,
172513,
93730,
null,
251573,
174244,
145985,
10475,
424404,
null,
88830,
34500,
52126,
293255,
330365,
123386,
74017,
23223,
24591,
752026,
24803,
null,
26476,
295017,
17708,
291831,
26944,
55749,
141684,
98086,
272070,
27798,
174884,
419395,
null,
182398,
171355,
33004,
23796,
65600,
7049,
35655,
105918,
null,
65387,
65931,
null,
227504,
286902,
37055,
33891,
39134,
42295,
85559,
151105,
38611,
48696,
79839,
52415,
88835,
3630,
67599,
410026,
30432,
9277,
null,
78844,
549792,
120124,
115190,
112209,
449740,
19713,
71492,
null,
178791,
96224,
279558,
255792,
286823,
null,
4780,
60259,
31764,
253618,
10802,
339464,
42966,
4294,
10204,
64139,
62838,
235862,
80847,
21422,
44119,
3210,
92477,
228299,
38243,
24074,
18088,
304062,
153321,
40203,
55240,
43252,
null,
261529,
27515,
91427,
null,
5454,
33721,
247673,
101724,
43995,
66160,
124705,
54635,
68773,
44610,
38289,
62297,
381943,
null,
19054,
31874,
242202,
62197,
199602,
31506,
25928,
12854,
10713,
390918,
68207,
5884,
143269,
null,
9485,
72060,
97831,
215551,
227339,
8122,
72049,
303426,
22066,
248620,
51717,
42461,
83301,
31279,
178342,
32277,
33230,
25775,
203931,
23283,
17980,
324431,
101314,
null,
null,
106003,
null,
158834,
9736,
246104,
17953,
168211,
207116,
26709,
25736,
128163,
518370,
311160,
38298,
120566,
391619,
144688,
40148,
15853,
63811,
40063,
16178,
77338,
298006,
null,
34305,
96262,
339371,
252135,
14336,
null,
52401,
72777,
42179,
27588,
35544,
28125,
10686,
16062,
50610,
null,
46627,
64176,
54137,
75567,
30679,
183119,
40607,
43433,
190394,
224121,
53990,
114334,
249067,
67192,
12954,
49575,
1085912,
140760,
262666,
106583,
230731,
7204,
65944,
35704,
33752,
27192,
30945,
95537,
165707,
43584,
14285,
92556,
117643,
13285,
164611,
185263,
174286,
27100,
27138,
125838,
50009,
397655,
52627,
89005,
292743,
913925,
22964,
215585,
35069,
4104,
242942,
149838,
28696,
220751,
91352,
499564,
317943,
null,
3777,
203430,
58000,
145391,
38276,
287688,
30810,
388997,
220091,
26454,
96994,
218453,
95753,
30294,
234594,
null,
129997,
null,
340563,
44550,
51686,
70215,
null,
210515,
58565,
172049,
192971,
18779,
37425,
26375,
68849,
15206,
21729,
11860,
22482,
38458,
163926,
69887,
19049,
250500,
231080,
225127,
23986,
271194,
306669,
31408,
45372,
406900,
17528,
209310,
177332,
31367,
37367,
48194,
null,
null,
67736,
6251,
187039,
354311,
31544,
314869,
98274,
198400,
447953,
137505,
591919,
13129,
26959,
231530,
43406,
137545,
5656,
10573,
550404,
497889,
35666,
99085,
62549,
275690,
367743,
36393,
375189,
19096,
241001,
283124,
45527,
133919,
717036,
20925,
null,
418960,
21844,
null,
null,
291895,
1236650,
181690,
188895,
261171,
139236,
278189,
null,
356768,
47908,
1069743,
75671,
306718,
7900,
257864,
469971,
49714,
186010,
null,
23153,
52814,
181699,
32590,
199030,
144924,
11333,
87829,
2060,
190060,
13710,
279556,
199129,
null,
19033,
209827,
null,
71215,
65906,
35884,
10170,
30444,
342009,
248109,
98442,
36610,
115511,
191720,
233337,
200633,
289920,
58956,
290008,
197189,
19293,
24383,
null,
null,
151576,
6652,
null,
167615,
346460,
50586,
65942,
407473,
261671,
16771,
65974,
149216,
172584,
24599,
379202,
1727023,
24000,
448879,
null,
18847,
51766,
513530,
233460,
53077,
40748,
15648,
211275,
192971,
null,
34944,
32983,
null,
33509,
227199,
146594,
71178,
202339,
180957,
null,
78297,
null,
38935,
23188,
50192,
null,
55896,
6843,
null,
27199,
12205,
170420,
170217,
5667,
209905,
44518,
91991,
31825,
62544,
300641,
40470,
36235,
10589,
64240,
116188,
392394,
312137,
23346,
53693,
26835,
58508,
57331,
14151,
166378,
null,
278516,
182135,
null,
null,
241920,
24279,
50633,
137524,
209599,
831949,
13360,
40066,
2338,
17437,
10744,
244772,
48636,
22646,
74742,
140474,
123449,
null,
171643,
6678,
360650,
159249,
172494,
123936,
368990,
1217,
13906,
344875,
61446,
137380,
79504,
364515,
188467,
319961,
28223,
955426,
106017,
null,
21468,
27826,
100368,
431000,
155251,
13998,
16251,
null,
186667,
null,
62838,
160187,
14829,
6030,
272366,
166947,
3144,
112911,
null,
91182,
31524,
null,
225767,
324848,
40371,
51319,
292231,
null,
28060,
287452,
61146,
337075,
13320,
271303,
5633,
97195,
null,
70292,
12520,
18722,
7455,
null,
64445,
null,
157821,
4992,
3623,
13554,
32806,
51685,
5915,
51717,
34293,
51787,
70942,
401561,
51960,
61584,
null,
18494,
246798,
41136,
96377,
55286,
null,
106590,
901887,
28292,
null,
18395,
14014,
41560,
30705,
302592,
62817,
null,
5990,
36686,
null,
184141,
15905,
4033,
37390,
80160,
14409,
701862,
281024,
53625,
20764,
231807,
55238,
30765,
null,
37529,
7573,
11454,
196399,
36527,
231019,
7743,
40056,
66943,
62773,
20719,
146746,
17749,
24672,
121474,
151579,
null,
41140,
487315,
27223,
46755,
97086,
246595,
281263,
44806,
86363,
73576,
48865,
null,
49538,
433472,
133068,
39311,
31667,
45539,
217752,
52652,
70760,
50142,
137805,
300858,
350629,
354634,
266344,
29296,
5100,
4812,
50681,
200839,
238705,
50659,
5076,
21426,
57739,
25229,
239945,
34329,
3929,
367935,
114525,
79348,
39016,
84253,
8573,
24992,
59793,
62471,
null,
92011,
19137,
592283,
60192,
196423,
9703,
51354,
371395,
155683,
111097,
406376,
47712,
413531,
313269,
72038,
343851,
171356,
null,
105797,
26615,
28241,
385268,
24585,
57406,
185564,
462695,
31203,
25712,
null,
544037,
32567,
15258,
278247,
3321,
null,
59468,
325942,
17515,
274481,
123043,
20774,
134106,
25023,
70683,
23020,
52857,
154802,
null,
42112,
99763,
null,
26112,
29835,
48121,
111102,
15919,
13239,
83931,
22303,
370601,
30408,
487732,
326908,
36861,
null,
183481,
null,
22253,
null,
20023,
102639,
118506,
27790,
310507,
null,
35657,
43588,
329173,
28140,
302777,
217682,
4368,
32469,
29706,
598464,
69434,
108812,
25902,
160055,
349009,
131055,
20184,
43671,
20498,
214110,
252509,
53230,
23319,
148605,
29245,
52174,
null,
10525,
549700,
null,
33207,
56156,
36363,
77264,
14204,
54253,
510740,
214720,
292510,
35676,
null,
null,
17257,
37342,
null,
53847,
19999,
null,
90532,
20650,
23764,
671720,
142712,
3956,
230245,
697466,
130715,
28843,
53843,
48874,
146621,
428407,
355163,
129919,
341386,
21705,
20139,
38861,
307426,
303420,
57026,
156951,
null,
20604,
46951,
221898,
20870,
589479,
17891,
7507,
408625,
null,
138336,
59917,
null,
78902,
14010,
354927,
220044,
38314,
48961,
292492,
9670,
376788,
63359,
9483,
10794,
587691,
47145,
61395,
120473,
25436,
158062,
96255,
296472,
455778,
68545,
40219,
14359,
121974,
49936,
254385,
66447,
102197,
14737,
43736,
11146,
613119,
407876,
29551,
312262,
18622,
6922,
204667,
140436,
116078,
153286,
28613,
309518,
68870,
206976,
147361,
6194,
584365,
39418,
301598,
127751,
68112,
325651,
165040,
24729,
15530,
41387,
96518,
43447,
319032,
61455,
8962,
289002,
null,
203982,
665128,
null,
114602,
49876,
28940,
31374,
61763,
212107,
29720,
31332,
42100,
180587,
37370,
77777,
5040,
36950,
252005,
7881,
25612,
null,
73712,
247594,
null,
40655,
8524,
29081,
241001,
259349,
181399,
42800,
56103,
301178,
71138,
23846,
150142,
121472,
232387,
null,
225585,
12024,
10332,
15825,
14293,
128070,
null,
null,
55690,
100016,
10591,
26972,
null,
125851,
172926,
31590,
394086,
143211,
20513,
314227,
null,
46338,
47561,
4049,
24131,
135194,
28532,
39879,
242166,
null,
41966,
362279,
198926,
283287,
18917,
110543,
17246,
257458,
353998,
403081,
34460,
85834,
300465,
null,
263407,
4528,
59079,
217092,
18180,
49655,
208113,
10854,
50633,
330891,
178193,
114853,
null,
161511,
687429,
46811,
23782,
278223,
null,
291876,
17269,
157194,
38300,
203844,
166324,
58517,
8410,
4747,
612712,
42088,
168779,
70845,
236379,
17430,
11904,
140577,
188752,
185054,
353355,
25916,
586481,
194275,
214588,
105529,
75579,
14563,
206241,
237016,
null,
84572,
null,
154980,
null,
30478,
15442,
41099,
7016,
28151,
176441,
453695,
138554,
28990,
33851,
17342,
137734,
161012,
6682,
15820,
414981,
56328,
69803,
378185,
377214,
188534,
380834,
144791,
289426,
16897,
33392,
13847,
333979,
177033,
254346,
286559,
267803,
28394,
28281,
138943,
71155,
129734,
48524,
208929,
143930,
null,
42662,
17389,
19936,
28743,
null,
87989,
217391,
null,
19314,
46923,
344830,
null,
33159,
13519,
23496,
178592,
null,
24275,
108867,
null,
330662,
187783,
78516,
37078,
207418,
null,
40754,
53932,
259433,
162082,
239593,
null,
207990,
312393,
85844,
null,
16570,
39323,
235318,
391301,
340778,
205075,
25679,
null,
11782,
446087,
61941,
9178,
69039,
72566,
119870,
60201,
123112,
73747,
396131,
73894,
257949,
377279,
121051,
253057,
395751,
215164,
88904,
42714,
30991,
101797,
156659,
240498,
190572,
27305,
48785,
337746,
48055,
140977,
446918,
null,
2022,
277467,
null,
null,
515704,
39490,
340747,
92955,
13980,
37968,
303462,
45469,
184438,
37675,
210190,
57111,
19461,
35631,
566171,
86165,
16567,
206813,
8760,
2390,
36148,
76916,
45622,
192615,
267305,
47606,
10532,
20471,
80793,
3624,
1579,
9913,
24419,
169486,
591562,
118051,
148815,
171065,
140773,
null,
17874,
null,
5436,
208627,
77726,
426976,
1011,
291265,
657266,
15917,
587840,
16126,
385005,
225344,
220524,
21283,
77525,
7756,
23880,
212826,
348763,
273752,
97907,
104840,
30434,
null,
11891,
173940,
26415,
69407,
29984,
131521,
517002,
null,
102770,
241872,
222012,
11800,
207930,
20442,
72223,
22772,
65983,
null,
109981,
77692,
null,
23946,
242009,
19632,
25936,
49718,
474302,
167859,
56247,
97354,
187955,
8987,
479959,
187058,
173497,
486724,
14615,
294962,
126278,
null,
226321,
254121,
332360,
141026,
226663,
null,
7715,
null,
10342,
198942,
30392,
37216,
184852,
45990,
301393,
144642,
246074,
33534,
297264,
30794,
356629,
34089,
902750,
355591,
50418,
null,
42025,
354760,
198301,
5663,
86392,
61756,
28570,
64188,
117162,
48413,
198579,
13652,
238783,
null,
13852,
157437,
82513,
21781,
20061,
241803,
307451,
132621,
130117,
277762,
314325,
6254,
16609,
265791,
34089,
24155,
16286,
19532,
5496,
118794,
231849,
15724,
null,
22560,
76488,
126348,
51698,
263962,
8881,
216275,
null,
213561,
40914,
33059,
208206,
80845,
29426,
29982,
18443,
31051,
26049,
63820,
30885,
21388,
246476,
17997,
240854,
null,
195166,
125946,
13572,
81099,
20849,
260896,
3537,
19004,
31780,
72748,
565478,
167748,
236690,
266508,
24634,
33677,
147963,
21547,
334547,
259944,
91371,
null,
405490,
35949,
34559,
341480,
40786,
48833,
35988,
null,
17094,
77093,
30893,
474337,
13892,
166988,
1647,
4874,
276258,
175989,
null,
81555,
21031,
233207,
null,
1351,
38378,
47402,
141178,
14821,
89144,
261002,
189478,
14906,
228876,
241771,
33651,
174045,
206177,
49838,
null,
181147,
null,
8765,
26940,
88542,
178222,
11181,
33352,
null,
null,
144854,
283620,
47763,
14358,
700136,
85573,
13560,
127914,
2692,
76893,
4541,
26350,
48073,
42008,
321203,
50619,
225568,
79523,
60751,
215136,
29122,
213536,
28603,
363028,
17228,
null,
41536,
320770,
null,
3814,
null,
null,
23071,
212105,
66232,
19244,
202370,
242940,
379025,
25987,
86242,
10098,
43128,
100870,
189180,
69473,
250108,
404489,
224819,
40840,
6096,
129225,
59463,
137224,
314740,
42255,
null,
163076,
10904,
58607,
42946,
370333,
87481,
17902,
180599,
52057,
133464,
39159,
378746,
281556,
57310,
null,
193655,
241170,
325690,
47910,
27699,
50643,
403170,
null,
384342,
177810,
4570,
56655,
145199,
17478,
229554,
18170,
317001,
17231,
94684,
28528,
349903,
170775,
null,
4629,
18675,
79865,
172929,
95451,
151466,
150974,
178945,
null,
9652,
33977,
15725,
null,
34371,
45238,
57223,
287831,
186744,
17519,
219579,
379719,
null,
42952,
334378,
35876,
47473,
10424,
60468,
109071,
362364,
347497,
127841,
415482,
159897,
147526,
71105,
333237,
125437,
211486,
6679,
50384,
31265,
23391,
65866,
179923,
21477,
null,
225870,
280827,
651246,
45915,
39341,
502113,
2288155,
202482,
39024,
136562,
26870,
140952,
null,
23740,
337024,
170966,
49630,
26167,
172257,
279168,
38259,
39650,
374875,
43635,
140803,
30201,
239318,
30961,
30917,
28281,
56459,
124412,
443949,
172798,
20170,
29216,
null,
358595,
69793,
null,
498364,
178418,
27830,
null,
null,
115579,
39298,
33092,
21402,
93087,
35847,
45008,
197745,
11877,
142367,
99822,
142671,
null,
375279,
null,
142544,
null,
26233,
49720,
54087,
162411,
104997,
106703,
37268,
188447,
209500,
452353,
179582,
177489,
287096,
null,
16204,
104093,
49248,
177262,
30429,
19365,
75235,
184699,
173707,
26877,
52843,
283827,
169642,
397500,
89245,
128106,
44021,
6159,
18041,
445414,
65499,
203751,
29167,
58067,
202871,
177000,
61824,
214732,
20389,
17577,
186589,
31489,
353784,
141903,
5415,
294986,
22688,
38377,
43586,
46439,
54620,
309423,
579584,
45523,
6714,
null,
33262,
60914,
267869,
416052,
39748,
276640,
354430,
320894,
93598,
438779,
52725,
186382,
44217,
20681,
141700,
597718,
120307,
579795,
139100,
17759,
38672,
143800,
110209,
178341,
264578,
285419,
37995,
24530,
268026,
167318,
61761,
103425,
178539,
223093,
318019,
626677,
161934,
174528,
340052,
55182,
90811,
null,
351895,
231007,
247991,
638270,
13134,
33355,
18465,
null,
289722,
40611,
13495,
321040,
127905,
419475,
338833,
136994,
16932,
12502,
24367,
18396,
37312,
null,
345354,
63013,
235995,
64258,
7618,
null,
219593,
62081,
143819,
91962,
null,
null,
250900,
41805,
null,
27328,
30251,
77952,
2852,
null,
45129,
302276,
283899,
101696,
43192,
19090,
354806,
43184,
127944,
35365,
93447,
180891,
34971,
204856,
34962,
21941,
39799,
11406,
null,
116479,
230390,
90388,
156363,
61549,
17750,
427959,
11901,
23023,
163464,
315061,
3112,
null,
423367,
303228,
176155,
17070,
299808,
288259,
156649,
366361,
7576,
53102,
5288,
1332,
null,
81386,
277889,
426437,
44740,
4770,
26128,
13117,
85301,
29122,
null,
70909,
30913,
25564,
40742,
16552,
127728,
21144,
12596,
9499,
48253,
44208,
null,
38642,
169726,
66255,
426525,
29386,
306884,
95738,
252183,
208010,
34174,
196082,
205738,
308539,
6019,
null,
233342,
22588,
null,
286760,
280856,
16550,
169119,
8454,
339044,
29145,
308032,
265417,
169007,
49030,
108871,
12543,
867989,
306722,
300723,
47393,
578659,
37612,
23120,
32650,
249688,
216006,
16736,
252927,
204640,
34380,
274412,
25827,
113057,
281958,
26178,
162137,
15629,
173358,
44206,
31674,
20735,
41174,
8254,
17621,
142541,
85553,
22130,
65224,
85228,
30677,
10399,
302413,
45854,
200165,
null,
281572,
517837,
470102,
30370,
194178,
123709,
126399,
21064,
36342,
32976,
48397,
62833,
66122,
14477,
251805,
144725,
null,
26664,
230568,
25032,
429947,
143556,
null,
null,
150446,
608889,
144370,
154610,
436150,
255952,
null,
41885,
319872,
271546,
386417,
26739,
62771,
20781,
13189,
11511,
null,
null,
353496,
22325,
246454,
null,
null,
24989,
6810,
null,
120071,
144224,
528613,
181960,
223782,
215795,
15493,
668267,
33608,
24727,
61178,
39903,
151752,
12462,
54220,
206645,
17265,
null,
199302,
null,
37736,
126749,
69019,
19102,
361817,
247971,
54529,
33479,
23310,
37883,
155647,
19160,
344828,
224472,
524205,
363691,
40227,
20590,
108641,
null,
null,
5752,
21390,
14262,
35077,
62852,
25263,
301619,
54830,
29682,
371584,
83831,
52986,
16567,
56393,
355424,
383762,
313713,
251776,
110629,
270441,
421051,
32165,
11788,
430566,
953950,
172170,
26165,
419059,
null,
16652,
null,
276203,
87354,
12322,
276666,
null,
31914,
null,
53056,
267532,
143882,
11259,
37314,
73210,
21924,
381640,
219961,
50299,
null,
65712,
93708,
159684,
193990,
null,
22046,
18081,
null,
18619,
305052,
8999,
42866,
257432,
249550,
808833,
59629,
14275,
null,
null,
1212030,
166044,
191878,
117750,
460120,
333849,
29021,
18832,
79330,
42598,
295708,
18946,
null,
20436,
93872,
36440,
118412,
29743,
133286,
297249,
169553,
402010,
273535,
121850,
71787,
255101,
38766,
70287,
35621,
152640,
42805,
26339,
null,
386186,
183907,
196406,
10357,
39306,
8594,
130348,
11452,
17768,
301799,
943965,
null,
307238,
42116,
288261,
161802,
81575,
432577,
59107,
172287,
36834,
15288,
366619,
43804,
17337,
5685,
11207,
130547,
58069,
53504,
292248,
41504,
413469,
302803,
null,
40339,
null,
null,
152789,
160472,
331100,
201190,
237251,
24503,
497808,
138770,
6657,
5569,
236844,
74138,
null,
28122,
25027,
108781,
262754,
278822,
64710,
91127,
13197,
31071,
292185,
null,
49725,
31413,
271581,
161373,
176020,
268421,
184320,
null,
62695,
30242,
45705,
49399,
137573,
4988,
null,
48304,
172412,
45131,
352813,
26414,
36611,
26267,
49024,
62332,
42743,
null,
380315,
39402,
328260,
77743,
67655,
null,
null,
null,
521105,
48090,
570585,
85423,
67896,
236,
495507,
231620,
170684,
16198,
21100,
160444,
168950,
22820,
195613,
149281,
26487,
53233,
228956,
243420,
443662,
446434,
60537,
29663,
93676,
31640,
26874,
12782,
310681,
43586,
500657,
null,
251035,
295791,
348600,
null,
155720,
4466,
270587,
171312,
35577,
null,
173248,
null,
205379,
219677,
null,
1867,
44797,
31856,
7091,
278805,
56801,
14317,
null,
null,
25882,
39942,
240157,
18001,
47282,
263675,
155139,
21242,
27594,
77355,
246948,
null,
14401,
218195,
273756,
90734,
234087,
73117,
null,
null,
12754,
23898,
151190,
202144,
98153,
25123,
48850,
null,
38435,
42097,
201044,
18553,
14482,
66412,
273746,
47040,
21183,
28981,
51017,
309916,
15217,
37797,
20962,
137828,
109834,
14987,
22274,
41322,
40062,
10360,
188208,
222,
185663,
234554,
254784,
null,
279711,
76640,
321488,
76089,
238541,
37346,
24506,
94275,
37596,
46891,
32820,
54278,
36067,
null,
212546,
189131,
4049,
212537,
14323,
null,
215574,
286088,
96872,
122705,
53813,
163487,
35030,
29825,
14778,
201090,
254099,
32119,
null,
17959,
261940,
24025,
25836,
118021,
57360,
203627,
82887,
320298,
39449,
566847,
239296,
41782,
208600,
36439,
9188,
59736,
216488,
16642,
34359,
45905,
6091,
null,
14479,
36712,
509758,
null,
268508,
411167,
327514,
142164,
2443,
22166,
7139,
178465,
33173,
98287,
6597,
251438,
80674,
35288,
265678,
82671,
42111,
46189,
173486,
30510,
24897,
156522,
256340,
197301,
183101,
54527,
9877,
38486,
28424,
27674,
12001,
182202,
91976,
93839,
122646,
null,
13742,
142019,
189462,
135871,
45083,
116244,
24284,
49631,
5959,
303747,
33594,
573401,
39361,
418322,
null,
385985,
null,
37413,
3510,
77314,
72823,
null,
1477057,
387559,
23344,
172626,
338242,
102018,
null,
171167,
109620,
286434,
122543,
null,
157460,
75083,
79701,
28435,
114023,
34296,
31441,
44611,
93066,
31945,
33780,
132491,
562062,
48757,
292324,
340350,
74429,
33964,
null,
null,
266491,
101620,
93449,
231508,
28519,
32787,
118822,
626537,
299901,
null,
32798,
139670,
null,
117823,
null,
83180,
39331,
555965,
154189,
42659,
16516,
11333,
392945,
7809,
601954,
9719,
54047,
7771,
null,
24968,
88192,
183582,
10979,
35111,
51429,
35271,
404725,
127804,
null,
280210,
98533,
48148,
62966,
70554,
29581,
113949,
130328,
26556,
175787,
38034,
9731,
166779,
null,
280079,
null,
171463,
260569,
36401,
62634,
225679,
12655,
31114,
12618,
48165,
22859,
9465,
69154,
77524,
225757,
40222,
29829,
369343,
340793,
5457,
418621,
110580,
10148,
351701,
61970,
217816,
630226,
206485,
210481,
134221,
67932,
21138,
23889,
496816,
54851,
296824,
58518,
405339,
110042,
18968,
24008,
210250,
282152,
145353,
16769,
16075,
166909,
251368,
110820,
76093,
9877,
378072,
5289,
null,
24525,
88951,
16434,
35689,
265343,
36572,
15978,
null,
248251,
12976,
null,
491070,
104735,
503816,
30218,
170701,
8857,
103637,
28202,
66604,
3589,
7635,
47816,
377462,
36771,
null,
1004684,
50260,
149951,
42303,
8079,
8238,
null,
12136,
166225,
27894,
38739,
24860,
24514,
107467,
7146,
52550,
131231,
239559,
247772,
291702,
126808,
118826,
1810,
323391,
400558,
33558,
680045,
192198,
236102,
312106,
4038,
12434,
null,
49200,
725328,
107790,
251093,
null,
61631,
576293,
28717,
null,
178411,
333535,
143509,
63552,
37163,
44397,
22443,
65402,
21234,
16811,
32644,
37145,
21043,
13016,
8981,
62567,
70490,
187109,
null,
243721,
202730,
39138,
11579,
180601,
null,
146834,
264619,
37682,
12279,
77215,
41448,
81854,
91000,
null,
67859,
829762,
124459,
173732,
28774,
null,
29246,
119666,
null,
66439,
126224,
null,
8806,
19145,
null,
410345,
49532,
69697,
35079,
19482,
499207,
505,
16110,
171310,
283845,
37906,
223253,
81427,
191951,
446953,
62807,
11549,
null,
25100,
null,
8183,
null,
128174,
111568,
22135,
156248,
65024,
287295,
93544,
22001,
50686,
200102,
17365,
54396,
377631,
63491,
54223,
382863,
33651,
510904,
15621,
164616,
700259,
56229,
12595,
682324,
66363,
22307,
61153,
219622,
34405,
152292,
35204,
41324,
3866,
null,
null,
23293,
14867,
225537,
420162,
24013,
42097,
395102,
628260,
444712,
182219,
252714,
83635,
null,
23579,
182044,
164069,
46411,
23367,
17003,
45182,
505219,
170732,
36919,
9523,
12728,
353920,
33399,
163462,
159727,
329835,
248846,
18566,
334044,
45682,
378737,
null,
null,
9250,
158486,
429850,
88747,
424713,
33558,
76529,
59633,
223928,
null,
null,
116784,
96137,
25733,
38843,
23798,
359827,
837050,
23554,
5438,
232489,
108356,
57061,
12692,
null,
235928,
33298,
268238,
55268,
216246,
12104,
39451,
41264,
390059,
null,
248802,
39891,
134356,
34850,
241906,
54452,
null,
null,
67074,
99656,
23364,
57716,
18786,
18558,
254167,
508303,
15099,
42709,
52204,
218416,
201365,
284831,
31103,
26580,
28298,
289330,
30516,
75024,
62441,
23750,
345109,
25391,
37884,
174599,
80723,
263497,
32006,
42481,
122410,
14369,
15819,
75854,
195055,
305633,
26105,
15024,
8326,
37079,
29931,
14825,
156125,
7176,
52766,
459814,
27834,
42378,
null,
35308,
57866,
108808,
10453,
228899,
125079,
380459,
169902,
474215,
47204,
22872,
17911,
36032,
56898,
null,
25247,
41791,
45613,
47136,
43756,
null,
28570,
87149,
2954,
154842,
51906,
282206,
250349,
29954,
19677,
null,
184266,
226114,
4363,
2109,
20916,
150385,
113372,
47633,
185319,
null,
101880,
19647,
557647,
180484,
12833,
23113,
26573,
337049,
715277,
288601,
174227,
195204,
149800,
null,
40804,
346838,
196721,
27509,
157140,
20887,
11450,
70772,
144508,
101803,
265892,
43066,
2541,
241144,
30080,
14850,
35572,
9217,
240038,
51451,
93832,
40793,
18790,
30257,
107554,
326661,
68938,
19263,
67982,
100264,
20067,
85496,
318786,
55204,
19353,
38801,
90690,
20434,
null,
22959,
37408,
76245,
394536,
null,
null,
321277,
178098,
null,
217652,
38132,
370254,
22164,
466429,
355403,
13817,
129963,
16042,
47634,
519313,
56426,
237639,
126661,
50928,
216228,
null,
null,
136667,
14416,
436337,
null,
129010,
51534,
320477,
21930,
47816,
164649,
null,
41736,
202577,
null,
48027,
395283,
207601,
132306,
null,
148852,
6732,
34486,
22942,
325237,
64049,
317298,
6569,
17015,
167809,
246622,
237630,
293973,
149443,
null,
140104,
null,
15343,
45486,
28525,
154862,
7818,
18267,
201546,
282850,
320817,
15583,
190675,
null,
null,
7767,
35765,
456167,
294421,
323578,
null,
null,
361649,
25253,
325329,
65694,
26567,
112301,
495406,
323722,
324688,
58025,
105773,
52347,
57020,
198983,
26196,
88517,
null,
47974,
58133,
122595,
9774,
72292,
12025,
null,
138701,
null,
19190,
153455,
8211,
80212,
35767,
59044,
11656,
206765,
112599,
44350,
null,
581040,
113439,
21841,
18219,
40177,
157117,
5592,
253912,
39374,
8456,
309337,
null,
130945,
228493,
589573,
179064,
212144,
68750,
22642,
233740,
230,
52333,
71856,
32205,
168227,
207737,
null,
26692,
null,
16094,
521145,
null,
48839,
16895,
11196,
12369,
383595,
16901,
70814,
80062,
352831,
317179,
15775,
32445,
324248,
119920,
57353,
29133,
141035,
18659,
394025,
344760,
33608,
63479,
null,
4963,
203600,
36763,
233408,
21773,
null,
71773,
153350,
20272,
30768,
null,
25270,
222568,
23117,
30738,
29732,
317,
17699,
27047,
16786,
18009,
115440,
51860,
82042,
21131,
16060,
170860,
32793,
28663,
null,
26532,
359270,
20885,
238916,
4440,
209955,
283781,
null,
226026,
17987,
14068,
182951,
311725,
79019,
20354,
null,
274219,
47470,
366890,
10084,
64226,
270842,
44816,
null,
700335,
25111,
106441,
95715,
168251,
9514,
304999,
null,
80184,
22687,
40053,
181256,
234950,
450425,
226532,
9677,
442966,
82211,
269276,
40672,
713978,
121889,
22156,
197290,
48669,
67116,
null,
16589,
247963,
13131,
30839,
85991,
10910,
89229,
152890,
62186,
44681,
304052,
168557,
381518,
122344,
3501,
40078,
null,
260341,
67107,
11991,
273588,
null,
50287,
29724,
4774,
null,
31029,
223371,
62308,
177211,
154105,
858785,
386183,
203853,
49154,
170266,
84921,
698925,
235565,
177090,
100595,
277180,
252023,
105573,
null,
15336,
29649,
19674,
8197,
244098,
189180,
106174,
253193,
163195,
26746,
35453,
355148,
37318,
26016,
233444,
27619,
null,
160119,
35521,
46960,
23616,
472737,
11759,
160647,
null,
189235,
461421,
117869,
11277,
133375,
38867,
6758,
61316,
23665,
15050,
8779,
33744,
41882,
6140,
142506,
19689,
30677,
21192,
46031,
291510,
21121,
87672,
36143,
46689,
22023,
54793,
52427,
33963,
20862,
42538,
171312,
42167,
182527,
9310,
9042,
67318,
218443,
8350,
27909,
37131,
111453,
15710,
133749,
157219,
31467,
137096,
191038,
509729,
52611,
9999,
null,
null,
380957,
154951,
208146,
52268,
315366,
13535,
88514,
304844,
203881,
252447,
null,
284861,
200548,
159379,
303208,
9122,
110001,
14373,
166494,
360324,
236276,
273598,
206731,
20384,
10257,
null,
43501,
881284,
254064,
92367,
null,
81459,
16595,
290880,
null,
81886,
40323,
null,
null,
null,
46447,
171098,
133112,
null,
100146,
240727,
95160,
258779,
375536,
135566,
129984,
178284,
98777,
83873,
3830,
281791,
170058,
59894,
244675,
55699,
39686,
171410,
33527,
null,
95973,
51692,
60585,
28729,
180726,
null,
89098,
29685,
296981,
216408,
19007,
36366,
148998,
12586,
313656,
267467,
50961,
67987,
44714,
6757,
56010,
29244,
11551,
42894,
77677,
null,
null,
189529,
70604,
27086,
355226,
110279,
118929,
22390,
468978,
110060,
608145,
197716,
264430,
273298,
261161,
77735,
22949,
28701,
348426,
66545,
44231,
317058,
174324,
17265,
18274,
153347,
138256,
320422,
497706,
74505,
11874,
20366,
117720,
80826,
32780,
446419,
411512,
36234,
214265,
null,
34474,
31376,
287160,
38121,
210469,
231508,
156815,
340403,
null,
298482,
20392,
32756,
341918,
202083,
6896,
50602,
60296,
224353,
210702,
55584,
11440,
222689,
185811,
44489,
15545,
71024,
124506,
37280,
57133,
327012,
168171,
25990,
6462,
162854,
32808,
37196,
100756,
61932,
307948,
10051,
303353,
32765,
30052,
null,
35617,
114370,
31667,
null,
7453,
363230,
547924,
168738,
23695,
80610,
203802,
38141,
null,
216987,
52120,
35456,
32168,
32626,
23813,
166813,
17760,
127149,
103297,
94909,
247114,
127836,
366330,
10974,
61121,
238147,
188160,
286799,
null,
144689,
4711,
243520,
37245,
126966,
121945,
318692,
16774,
20903,
12227,
null,
31518,
163631,
51507,
6295,
null,
10733,
167837,
19815,
133048,
445544,
38058,
79229,
77982,
34161,
34264,
null,
null,
64607,
291737,
157819,
12662,
16337,
43942,
9230,
381792,
97117,
null,
6430,
8703,
128675,
39969,
49545,
12090,
251761,
23945,
141423,
91177,
387779,
null,
182793,
395524,
17415,
70371,
189323,
46563,
200962,
327013,
228477,
145860,
231681,
null,
285496,
38290,
26757,
47844,
48872,
286939,
221639,
261916,
315500,
92061,
49005,
102878,
223800,
376696,
30362,
200960,
148786,
392809,
39884,
32120,
121588,
null,
117243,
121821,
null,
177299,
89919,
27087,
38762,
14789,
211358,
null,
26839,
314643,
34648,
25572,
1222,
630413,
201255,
59935,
53428,
47423,
161597,
null,
452029,
99170,
7777,
28775,
126497,
15113,
268198,
40956,
456706,
75015,
430199,
184645,
166607,
null,
115500,
16390,
21075,
23547,
104763,
null,
15896,
19282,
28419,
278993,
null,
148706,
192561,
10198,
40876,
49367,
141678,
21174,
39771,
46218,
101397,
15968,
174808,
27280,
null,
366648,
336779,
9512,
67329,
33998,
242559,
41774,
75163,
164320,
134015,
11646,
244125,
55370,
19479,
40709,
78634,
229631,
323077,
109013,
59204,
9039,
16310,
21123,
244688,
94657,
233616,
192060,
14452,
262230,
16631,
12673,
null,
24989,
450293,
44976,
88775,
58889,
157241,
129037,
136950,
29268,
30004,
21508,
122836,
9323,
229977,
31065,
4047,
22885,
77007,
35059,
90911,
167615,
226511,
23455,
97723,
275042,
288126,
237851,
94448,
30443,
25628,
51451,
23977,
154554,
261121,
206239,
null,
38598,
5557,
395403,
23421,
250645,
61807,
128525,
3911,
13339,
10034,
375408,
183015,
153871,
null,
152217,
7547,
281804,
296249,
183339,
473118,
17652,
50340,
67467,
46020,
562128,
83244,
243216,
null,
32621,
null,
8218,
185988,
null,
30358,
287381,
274768,
32577,
138340,
287212,
175576,
64534,
12746,
81676,
41342,
14301,
51037,
271663,
47518,
49672,
248843,
623194,
25940,
11865,
7523,
36573,
25605,
148972,
259694,
418166,
167103,
153118,
234674,
263483,
170191,
261001,
37188,
12890,
25869,
172602,
242468,
273889,
246708,
23384,
213481,
34897,
27263,
7735,
12725,
6551,
15330,
238500,
97932,
50008,
30470,
null,
19702,
352395,
54490,
25139,
428703,
75059,
65457,
224978,
5520,
191855,
22343,
681608,
20057,
42096,
12042,
null,
36112,
361079,
12786,
262841,
385336,
73869,
75725,
43821,
228232,
69927,
5612,
10241,
18801,
351956,
24272,
158349,
43837,
null,
42458,
87772,
29588,
94722,
43051,
276766,
3437,
185578,
56060,
18349,
15719,
20686,
153891,
102644,
11390,
32603,
330956,
228255,
288558,
18392,
40336,
452932,
42322,
34830,
60447,
222635,
21677,
48848,
16599,
441397,
null,
178997,
238339,
39543,
105549,
49509,
59987,
null,
51334,
443653,
10357,
null,
32679,
64429,
33407,
341273,
42628,
62971,
235866,
101328,
13341,
12847,
null,
119699,
13818,
95426,
25857,
274663,
455124,
72282,
null,
159687,
7651,
245518,
304575,
87193,
40535,
520616,
23801,
121580,
132441,
262091,
10874,
23967,
231135,
54610,
17868,
277838,
25000,
74303,
72939,
237291,
15130,
250944,
10303,
207551,
50054,
null,
4416,
164877,
124397,
152691,
5904,
210248,
327698,
42251,
null,
34912,
21719,
72473,
70498,
28252,
210346,
228982,
103067,
317278,
null,
123550,
41682,
230758,
45183,
42112,
null,
239767,
188331,
30437,
61595,
100190,
7310,
137697,
88737,
108362,
35932,
180397,
35912,
71965,
163461,
36037,
57901,
90443,
281718,
59289,
57781,
40484,
33815,
20125,
21284,
10538,
7757,
15411,
27268,
137604,
null,
26741,
1129334,
262982,
38524,
369920,
null,
37500,
5023,
76575,
16938,
198515,
9271,
null,
307296,
184898,
218254,
92062,
358098,
10370,
506712,
259518,
168680,
700404,
505059,
15470,
14341,
517267,
null,
46422,
66246,
66727,
9567,
45771,
62004,
319170,
null,
76340,
93916,
148466,
14885,
138297,
364396,
50189,
242255,
765722,
60425,
38471,
142025,
50667,
79143,
299587,
86433,
298272,
7937,
326010,
12773,
41695,
35982,
251956,
31281,
198937,
99325,
55374,
484084,
222942,
444291,
9035,
35799,
null,
24256,
74699,
45702,
92245,
135609,
150256,
57081,
788,
615520,
73783,
127969,
286260,
172189,
144988,
144573,
7728,
13362,
2875,
165572,
155781,
176929,
9424,
10132,
110095,
18923,
380239,
15662,
19653,
480668,
201901,
37602,
17227,
6726,
141510,
565945,
null,
null,
248586,
190317,
103789,
370437,
4610,
290175,
399850,
14516,
205382,
232084,
194269,
33274,
449655,
241822,
20593,
212180,
16598,
38866,
338615,
7339,
43735,
283227,
null,
171488,
95911,
46126,
175801,
755824,
22944,
268878,
242181,
32310,
395591,
7003,
17744,
6248,
93381,
29378,
98004,
136550,
null,
55277,
28093,
78014,
212759,
null,
30592,
152351,
280902,
402386,
11854,
295927,
268095,
19194,
485174,
3787,
null,
58427,
8958,
842373,
682583,
18600,
85456,
39333,
217625,
11962,
344361,
365571,
137886,
43870,
36619,
8897,
21809,
195801,
120059,
27681,
261425,
67478,
230850,
243071,
119439,
188065,
161012,
37972,
186727,
45099,
41639,
null,
25780,
257267,
8582,
47367,
131286,
4842,
101523,
58227,
160245,
28926,
38075,
8267,
13032,
298065,
209523,
191743,
523793,
49092,
60698,
21396,
55341,
227995,
84688,
108220,
12705,
4783,
8546,
110448,
335454,
177502,
260484,
45286,
495453,
null,
203051,
18800,
10794,
115344,
null,
200551,
20257,
64260,
30404,
null,
33499,
23095,
25814,
39699,
98542,
408823,
46177,
65024,
11679,
48703,
200308,
157899,
255241,
219469,
5509,
182621,
172640,
50039,
32489,
973217,
24973,
108526,
133755,
9801,
null,
28702,
104919,
null,
247618,
445684,
997,
216487,
8703,
202870,
261783,
14676,
58231,
201465,
203186,
231188,
300517,
171003,
null,
null,
317951,
232088,
15295,
248283,
13201,
null,
201262,
495019,
2497,
17837,
117945,
343121,
11519,
63731,
null,
149091,
185647,
171357,
29728,
363696,
535445,
121919,
31907,
196187,
316147,
51516,
30676,
65422,
26717,
null,
65516,
38868,
58884,
9765,
37944,
194833,
321334,
254191,
43642,
281487,
38097,
11789,
391145,
16537,
53485,
41361,
16479,
60532,
28483,
666487,
721173,
19436,
654435,
214773,
null,
9730,
147706,
304110,
157476,
70089,
86895,
163459,
101418,
288962,
248241,
76691,
158585,
85087,
35401,
264271,
93073,
173282,
251864,
152262,
334399,
60097,
81565,
173911,
44293,
222696,
277707,
38716,
32995,
286395,
220290,
436161,
262294,
214562,
null,
153404,
79041,
56497,
277947,
null,
null,
217189,
107148,
84997,
8014,
24945,
416119,
null,
52498,
27000,
80905,
383036,
51014,
13952,
22158,
41508,
22931,
162842,
4875,
35469,
31594,
6421,
null,
132197,
27630,
26979,
649842,
7332,
138315,
223592,
182213,
15016,
224407,
464777,
844206,
null,
42827,
150487,
40646,
103329,
365195,
62028,
45572,
8666,
39377,
214054,
144527,
449165,
315345,
null,
15843,
null,
26035,
83914,
442978,
239828,
93117,
261054,
null,
null,
419361,
27931,
77500,
11411,
118858,
361108,
40855,
359356,
23666,
135711,
20508,
192189,
565490,
13170,
220176,
null,
264508,
6661,
69612,
288158,
null,
30920,
23991,
571504,
319548,
126371,
420353,
88923,
18568,
285359,
615394,
11319,
292365,
21735,
231668,
38911,
27659,
65767,
310163,
null,
13274,
34534,
105285,
40070,
null,
null,
9276,
319056,
418911,
221874,
220866,
199442,
13118,
29554,
12730,
138179,
24919,
257196,
178175,
null,
661566,
593463,
46909,
242831,
15101,
238708,
9873,
6745,
107442,
333885,
53881,
237093,
50080,
43389,
7571,
210032,
379762,
130492,
7263,
23903,
13876,
95636,
30773,
null,
64648,
24153,
199273,
24954,
227899,
94817,
null,
124189,
21030,
25492,
null,
21436,
231038,
29084,
255357,
41642,
13279,
13319,
327848,
8231,
135044,
26457,
11152,
42130,
29661,
142926,
249993,
26727,
215866,
750819,
26489,
496511,
280964,
463096,
76770,
143847,
17533,
154217,
154150,
10864,
494645,
245244,
47924,
322629,
null,
null,
56838,
278266,
17203,
278717,
292001,
218786,
17580,
27207,
361921,
null,
null,
397172,
241539,
null,
53926,
15784,
184638,
20894,
null,
439141,
64674,
22004,
31647,
278694,
68785,
301142,
8812,
71031,
212217,
45240,
511891,
21862,
303126,
null,
2774,
16401,
275783,
108483,
239090,
39315,
420297,
8104,
9764,
94417,
31236,
90415,
11296,
60854,
149992,
237109,
378899,
455206,
93181,
32064,
49110,
51659,
43360,
25703,
14887,
70057,
64436,
35827,
20071,
209616,
23214,
533284,
72950,
89626,
16495,
122960,
35355,
35945,
9817,
272351,
311992,
null,
204657,
14872,
18897,
48807,
31110,
116300,
5878,
263277,
14587,
412215,
392728,
15207,
null,
452387,
72791,
46934,
31977,
12160,
124167,
34926,
null,
181235,
23697,
182876,
145264,
10313,
8554,
26328,
332763,
44757,
66268,
195479,
145291,
195339,
192241,
225304,
113010,
168196,
null,
42051,
null,
22513,
61497,
50868,
null,
20504,
36249,
43305,
41045,
10272,
67376,
89611,
50486,
260421,
3155,
16413,
312735,
565901,
359168,
34718,
59529,
32275,
27889,
197809,
266503,
164050,
189483,
85209,
15433,
70481,
113714,
61705,
344905,
2742,
21394,
82088,
161722,
8411,
186057,
120662,
87176,
6372,
22269,
221400,
337014,
2517,
185538,
null,
22572,
123176,
683135,
46297,
356243,
214215,
286501,
305605,
10696,
28771,
432809,
223269,
9973,
197343,
7721,
21026,
63363,
50690,
27028,
251782,
53688,
57757,
425194,
16020,
134436,
51739,
346762,
5283,
9200,
250982,
48176,
58118,
null,
301936,
37459,
32709,
202911,
20564,
null,
144848,
75736,
355605,
126306,
38836,
305384,
49908,
151456,
127372,
36581,
386598,
74387,
34176,
20202,
181780,
100524,
83267,
308829,
558756,
null,
2685,
77434,
43568,
62837,
null,
180229,
119099,
75423,
203501,
294463,
null,
119872,
155460,
109073,
226455,
12201,
null,
4965,
2874,
null,
16772,
679058,
208574,
51000,
55929,
244083,
72274,
370597,
81185,
68511,
null,
158341,
26316,
90313,
423768,
337493,
34058,
111269,
476005,
1779,
333593,
146950,
null,
null,
216169,
null,
307236,
83955,
75229,
63029,
23401,
196087,
220118,
317801,
114692,
24778,
36627,
248611,
8845,
56589,
635168,
115604,
5902,
12631,
240063,
53953,
70143,
871810,
184560,
22583,
92341,
40990,
47466,
101541,
46526,
681502,
51487,
15722,
143764,
null,
20395,
280496,
21663,
21831,
265515,
66345,
262134,
null,
152953,
197623,
73535,
480530,
13101,
50307,
59436,
215291,
107027,
27343,
53049,
220236,
null,
65941,
7228,
299283,
283355,
211827,
37323,
50208,
61429,
26115,
67756,
57091,
5056,
374227,
186433,
56847,
227977,
196791,
411817,
7675,
18526,
108505,
34273,
289650,
33509,
null,
206529,
178006,
63266,
29199,
55224,
206288,
78318,
11593,
175062,
146703,
180637,
382424,
175367,
205502,
59945,
null,
308757,
291042,
37746,
89734,
149716,
60019,
null,
84928,
303863,
182502,
78836,
148740,
22918,
12694,
160462,
null,
441758,
27605,
209916,
11975,
176216,
7241,
53940,
22538,
59493,
39092,
163169,
5177,
161076,
44797,
40090,
39865,
32484,
282509,
273474,
147765,
231776,
362966,
20758,
206870,
null,
13302,
203131,
34283,
70637,
27163,
209287,
284906,
21327,
250039,
39940,
267029,
69113,
579717,
171851,
169536,
30747,
238868,
43101,
83151,
163701,
null,
271196,
37695,
44899,
56197,
null,
24124,
101174,
71091,
17146,
118646,
366913,
9362,
81034,
152900,
196841,
169536,
23843,
337411,
17545,
151038,
56399,
null,
28891,
null,
466108,
162884,
144195,
357099,
483569,
429429,
280368,
16911,
283323,
429401,
241121,
157982,
23402,
52897,
155677,
1303550,
205158,
6325,
22160,
null,
230352,
50164,
null,
13008,
12492,
null,
149028,
16385,
67640,
47408,
183563,
19317,
86302,
105118,
46993,
57718,
324305,
113176,
22401,
12889,
9799,
14908,
356531,
99456,
306559,
null,
205826,
195121,
29752,
16946,
null,
184672,
123769,
266251,
36134,
241562,
356443,
28356,
191752,
73199,
315766,
187180,
12601,
395174,
290204,
229351,
368347,
171543,
422643,
49340,
50410,
123461,
33184,
318684,
247991,
105867,
248324,
50344,
null,
360372,
141264,
11140,
42544,
148960,
157916,
216870,
42995,
113705,
106962,
686314,
18320,
112280,
428294,
25170,
33574,
17592,
324773,
9297,
21195,
20798,
46261,
77067,
35601,
39562,
62716,
13790,
1185111,
62665,
null,
28523,
392977,
52916,
89758,
108886,
654558,
111956,
90083,
342468,
23812,
179994,
null,
30763,
8828,
84942,
null,
26063,
34550,
26854,
198277,
42073,
17338,
94365,
342639,
16862,
61278,
225690,
183355,
24959,
15625,
248415,
null,
36093,
18976,
44479,
277022,
185807,
103479,
126653,
149551,
257072,
5470,
242897,
13296,
136748,
90740,
896,
55751,
null,
159586,
210143,
9302,
null,
12546,
11337,
37935,
77073,
106771,
301737,
79005,
12664,
null,
27669,
223573,
57145,
141420,
11940,
148425,
15594,
326276,
118870,
324090,
77723,
3787,
32014,
244301,
61870,
355299,
777538,
116218,
51563,
237762,
null,
14962,
37440,
426357,
74923,
31417,
89794,
5419,
249636,
51704,
46065,
136103,
493003,
null,
1138025,
199249,
743793,
4068,
114900,
28827,
374269,
null,
486949,
352172,
38212,
368266,
21453,
112755,
8286,
34944,
9065,
104567,
89969,
54424,
51046,
549117,
368478,
399963,
6839,
587999,
478988,
14254,
21303,
134980,
null,
180287,
26693,
15004,
36071,
null,
34357,
21152,
24516,
24227,
177721,
221533,
24471,
40430,
null,
30251,
250851,
10981,
30614,
null,
169388,
272055,
33966,
281040,
357571,
22218,
77055,
48059,
7496,
124446,
23197,
16693,
125407,
41581,
57515,
null,
52994,
254983,
10525,
71478,
22880,
378395,
7275,
28558,
42032,
56142,
85401,
null,
373996,
76000,
557765,
500570,
135564,
47306,
148092,
17568,
21033,
273586,
46391,
45467,
59064,
40003,
83011,
266153,
25826,
93964,
52846,
36808,
168084,
14198,
83520,
40490,
74350,
39166,
216805,
25062,
62153,
11619,
173563,
22978,
53292,
13181,
37905,
41145,
279232,
254,
401733,
331213,
28626,
35875,
133833,
25452,
10211,
411201,
29900,
4574,
18486,
null,
null,
17281,
25368,
84114,
37857,
15500,
49634,
null,
184696,
null,
57667,
null,
236856,
63815,
382827,
37507,
39985,
278572,
285425,
null,
32768,
246091,
143453,
81087,
20688,
23077,
118071,
144074,
29445,
47078,
361072,
10769,
52410,
24681,
291480,
123790,
167027,
256465,
5430,
11097,
null,
10632,
80877,
386023,
762669,
211839,
136167,
59409,
285220,
null,
40451,
86901,
50191,
22520,
57391,
134190,
38126,
169521,
132807,
101215,
345545,
18977,
122134,
140002,
null,
194161,
42502,
22163,
335894,
9207,
8827,
75692,
2992,
208619,
471138,
76550,
274646,
16616,
35483,
347481,
22760,
114346,
null,
57152,
1324144,
96643,
15818,
401540,
2198,
106801,
69846,
null,
248736,
321502,
29701,
27932,
18422,
62882,
298651,
null,
17585,
20136,
null,
2696,
null,
4942,
329230,
31429,
9465,
335258,
151748,
143852,
310911,
76344,
46898,
180443,
226681,
14838,
37296,
null,
125856,
105977,
28446,
28600,
6385,
243729,
167127,
38074,
156036,
18026,
35311,
469226,
78211,
40242,
42714,
21692,
6890,
410045,
53681,
57888,
129556,
87627,
67192,
null,
26055,
41569,
172272,
49937,
24958,
37416,
51445,
36770,
85212,
8980,
82481,
55852,
37648,
9249,
45140,
95440,
20021,
61514,
78421,
29671,
124328,
208212,
41666,
68280,
1765,
400396,
12006,
22784,
19142,
310538,
49435,
121852,
161945,
40383,
133823,
202866,
313342,
24165,
null,
null,
74840,
257096,
195530,
52998,
83230,
17201,
136235,
121492,
20394,
131119,
187251,
216613,
161602,
330058,
467725,
205601,
49280,
415294,
3941,
47697,
60299,
180897,
171289,
494724,
36640,
202559,
null,
19403,
28351,
469010,
null,
384325,
39104,
136875,
37367,
null,
26385,
74404,
180373,
359644,
8303,
212118,
229791,
15267,
327089,
323120,
344980,
20264,
245305,
133362,
10097,
35301,
4906,
33388,
5170,
null,
519576,
26626,
12277,
64193,
605383,
209464,
393851,
67401,
339847,
21544,
101760,
8451,
null,
null,
9722,
25817,
63335,
22453,
null,
36864,
251800,
868745,
197718,
52162,
16740,
12961,
40627,
148577,
18160,
61877,
152497,
72594,
22480,
353991,
196423,
34669,
38053,
230437,
37548,
276802,
101069,
467152,
104207,
365775,
219167,
68242,
554371,
22781,
116286,
197640,
29999,
180235,
254137,
2506,
73571,
11488,
72757,
22723,
207704,
null,
106480,
309719,
329915,
12818,
null,
98342,
81820,
20975,
null,
42418,
59991,
143713,
34641,
80538,
null,
null,
132950,
47558,
166156,
40927,
297412,
10407,
null,
27012,
22309,
72737,
null,
6373,
145422,
36971,
15380,
null,
207639,
281609,
null,
45297,
424695,
null,
3281,
90182,
33719,
402745,
363035,
40012,
321103,
362590,
22040,
null,
38665,
390496,
84282,
173797,
19761,
372912,
18133,
57719,
412635,
56766,
12183,
224543,
140526,
10276,
57272,
200342,
20122,
64697,
37194,
81735,
null,
217172,
69535,
39674,
null,
43777,
6255,
12002,
187650,
18152,
29615,
38838,
108623,
66707,
42976,
83656,
82270,
59557,
168044,
58948,
null,
182362,
150790,
40243,
22566,
184622,
179325,
34283,
104583,
16526,
10049,
333665,
176825,
77034,
210538,
33100,
203404,
23931,
null,
42599,
13017,
69492,
220339,
316403,
11975,
167741,
72759,
25669,
283279,
45600,
232366,
46166,
null,
51733,
82977,
191272,
172732,
192677,
null,
null,
229375,
30879,
145280,
null,
19567,
489776,
26571,
63106,
31172,
256195,
96145,
15521,
25455,
105673,
19383,
548340,
32251,
116652,
194294,
652224,
252059,
null,
61239,
12539,
19597,
373352,
161705,
258419,
20716,
46437,
167694,
56251,
137171,
28716,
24485,
22682,
420207,
76754,
40685,
174112,
53867,
391102,
45256,
29494,
25799,
240610,
37314,
62145,
214825,
11414,
44218,
36777,
null,
14572,
null,
133165,
10481,
15970,
28661,
34069,
303004,
135276,
265187,
44618,
6613,
31416,
36082,
40401,
281431,
26185,
138096,
41405,
54349,
203538,
43160,
210219,
null,
149729,
18891,
19225,
512315,
414452,
382804,
53414,
212627,
227261,
13352,
21380,
158812,
34035,
162217,
14860,
17821,
26463,
496248,
47239,
47794,
51321,
66917,
104750,
105889,
103750,
116337,
227619,
null,
17145,
44932,
23283,
28383,
135914,
70579,
9034,
null,
182852,
247800,
276501,
267258,
130319,
535811,
3451,
null,
58984,
10502,
82380,
62243,
12458,
373658,
143687,
17357,
100930,
466640,
153379,
32902,
14541,
50686,
200748,
168085,
72691,
35653,
80231,
null,
8448,
348046,
null,
null,
54817,
31698,
15760,
367343,
35431,
60513,
29631,
131236,
274126,
154856,
14634,
null,
20681,
null,
99655,
45243,
265511,
46569,
51461,
207705,
38144,
215884,
25660,
139920,
372967,
421722,
267022,
null,
317784,
181919,
26674,
17556,
274407,
28977,
404894,
14066,
80276,
24897,
null,
43117,
290484,
229424,
139521,
87883,
430246,
32437,
302444,
54785,
8586,
597521,
360227,
243992,
156284,
23238,
23355,
195012,
33101,
123424,
144300,
407029,
21534,
18718,
273485,
177717,
351838,
119299,
150589,
46484,
103532,
221732,
null,
40053,
null,
34047,
212124,
76092,
null,
37959,
43719,
105063,
230479,
null,
35528,
77743,
129918,
94577,
26801,
null,
62790,
23156,
77335,
99579,
46008,
31794,
68888,
279792,
272070,
7918,
423888,
30368,
119102,
null,
5394,
40165,
null,
295273,
9676,
11238,
374972,
41038,
30966,
196474,
5475,
124871,
null,
119163,
48724,
45629,
null,
188299,
57913,
61512,
43335,
52572,
285891,
312974,
91551,
145756,
242413,
784180,
51057,
null,
12636,
761166,
354545,
21171,
276730,
154399,
32149,
32038,
null,
15603,
203600,
47087,
33850,
33003,
87562,
null,
42681,
68261,
464338,
202637,
24107,
174047,
24347,
197533,
null,
572554,
187162,
135691,
33652,
127578,
51949,
325276,
138350,
29579,
170673,
376499,
54924,
324379,
116204,
158676,
296755,
245302,
201069,
181678,
133018,
92462,
49210,
null,
null,
204980,
null,
87303,
15364,
217086,
21935,
252067,
127264,
25728,
4412,
null,
264015,
16457,
444520,
171923,
154494,
292185,
135842,
22985,
72707,
16728,
305889,
13291,
22686,
11361,
17900,
283109,
43600,
164682,
43051,
27305,
50271,
34539,
23319,
2590,
244645,
44913,
79752,
20515,
93848,
154709,
110513,
37840,
16992,
232889,
257611,
null,
43001,
14068,
5114,
11312,
395394,
139934,
40488,
61015,
174726,
57137,
37227,
147426,
142640,
40068,
185017,
null,
82446,
15799,
219633,
16634,
7496,
15933,
31103,
null,
70115,
66364,
266127,
127426,
170860,
20896,
16120,
13712,
167848,
null,
181841,
10170,
266174,
294854,
16028,
234421,
null,
312778,
3960,
4350,
40231,
null,
146248,
35542,
63086,
118909,
148283,
156381,
544717,
142695,
15280,
138875,
39670,
328423,
null,
12813,
46826,
282619,
14294,
139361,
42197,
434955,
182280,
172947,
838923,
182375,
217972,
null,
15500,
103056,
166506,
181571,
132021,
54894,
230261,
null,
48519,
103478,
60975,
22933,
19270,
31309,
116460,
152864,
70492,
25399,
null,
null,
7277,
169033,
28399,
5239,
417075,
21976,
312627,
2343,
523468,
null,
18551,
110602,
170511,
35084,
65251,
122401,
155553,
22712,
133863,
335161,
452226,
256007,
31464,
12102,
214466,
103866,
20362,
6593,
306291,
81844,
51027,
718207,
125838,
96055,
52530,
116087,
42711,
215262,
203456,
189978,
148158,
199230,
24985,
184616,
5351,
246394,
112205,
7954,
36113,
28813,
21784,
264092,
57457,
195098,
40387,
null,
38617,
48036,
153981,
20254,
34450,
84442,
31042,
272590,
108610,
211553,
null,
null,
36783,
212392,
90713,
37945,
null,
28771,
185260,
276223,
285215,
14868,
573271,
407791,
null,
28668,
18871,
36911,
32355,
null,
53352,
70532,
264240,
35102,
232648,
237757,
68555,
296589,
54629,
18604,
338962,
27565,
308065,
29493,
91397,
53284,
14848,
195041,
41107,
215582,
84923,
119945,
233795,
108108,
61544,
147096,
135825,
2756,
4378,
186168,
216707,
279089,
79811,
47022,
null,
12978,
27261,
157121,
371229,
376591,
214587,
153753,
93217,
82806,
67831,
228415,
95732,
119862,
null,
104490,
76882,
644798,
8029,
47862,
91826,
59515,
375393,
null,
42444,
55168,
43188,
227910,
null,
33221,
275647,
56415,
8132,
109974,
2766,
92767,
75094,
168492,
263899,
48369,
36973,
266416,
null,
11781,
92783,
11995,
337839,
217058,
49563,
61646,
null,
114413,
178464,
259353,
null,
125035,
86303,
235061,
165720,
270294,
190794,
28052,
79849,
36431,
13814,
74003,
160351,
188995,
53929,
56173,
439241,
22260,
47830,
142017,
171087,
23570,
6606,
134512,
160703,
452383,
14822,
10065,
38863,
350537,
25521,
null,
108855,
58568,
115662,
80373,
23393,
17803,
null,
294289,
89186,
184335,
55824,
20594,
26525,
100149,
null,
null,
159942,
178145,
35315,
266454,
23616,
23469,
113299,
18479,
43820,
3960,
155591,
8990,
327561,
null,
37495,
23709,
27923,
14491,
323604,
145716,
18568,
55464,
62890,
3858,
47397,
511075,
40601,
null,
142538,
177632,
94396,
292952,
272097,
42920,
82587,
217323,
514077,
489229,
669993,
61931,
237945,
27271,
36877,
53257,
219511,
445265,
40380,
56528,
108174,
null,
427265,
26177,
59147,
157037,
264150,
12129,
49699,
245164,
150547,
null,
161833,
7758,
27639,
426234,
6051,
60161,
38921,
167188,
49311,
28882,
204112,
106893,
33168,
39807,
63301,
338195,
19446,
15045,
29920,
85944,
18197,
180688,
25240,
219648,
8468,
34380,
134604,
15552,
14994,
28013,
37937,
38152,
24351,
63856,
161341,
9270,
150692,
35653,
20350,
228458,
35690,
15827,
60083,
199056,
102882,
231815,
39113,
null,
353974,
106803,
22139,
165047,
145876,
null,
430466,
78557,
550651,
62657,
4680,
106793,
9976,
47704,
794972,
33434,
39874,
43380,
2267,
1354,
null,
20717,
36623,
58521,
19157,
8026,
60272,
null,
325074,
8731,
24054,
33977,
137400,
90476,
304275,
248169,
7619,
38281,
18165,
354538,
10199,
211417,
25812,
null,
null,
129448,
15776,
589189,
345724,
10719,
374451,
182268,
18487,
273886,
43136,
47307,
49170,
89346,
null,
43916,
9596,
57316,
40772,
16402,
36977,
100970,
213143,
39918,
null,
26096,
32087,
154983,
120185,
31544,
136857,
52634,
22584,
11138,
229670,
122375,
199842,
245651,
212386,
24679,
40524,
257485,
61135,
23194,
39338,
328910,
182708,
5931,
21915,
86063,
28632,
187513,
222444,
4790,
55932,
5086,
38241,
36754,
97266,
223741,
208217,
183980,
47787,
88594,
19101,
178193,
null,
null,
25160,
230102,
55493,
47286,
30147,
18833,
114723,
617190,
67099,
57401,
17709,
374307,
148878,
51755,
304482,
41161,
null,
382364,
175775,
45427,
35118,
null,
55296,
92576,
67519,
null,
25502,
57239,
71702,
32073,
85377,
101369,
339686,
36630,
63173,
21232,
227665,
40182,
288180,
28492,
175138,
243359,
85407,
101772,
213316,
166156,
22537,
51333,
340530,
21134,
19492,
851,
452478,
208300,
77259,
41764,
61304,
51734,
180267,
210969,
61567,
66120,
null,
63540,
44534,
266211,
151677,
142178,
101007,
null,
null,
132369,
334769,
238828,
279480,
10938,
18100,
null,
null,
120220,
41048,
137003,
258245,
55519,
23476,
156982,
21471,
361007,
243872,
389466,
127074,
9307,
57148,
343092,
157173,
91392,
215836,
28681,
19090,
45630,
102855,
31079,
161664,
15328,
372436,
60335,
1748,
18667,
15301,
null,
241978,
419159,
11649,
49430,
423286,
101915,
343009,
150692,
468481,
33350,
2128,
246146,
4759,
350087,
258917,
20139,
232041,
21405,
135049,
246913,
59785,
171098,
6618,
167699,
101926,
65389,
56417,
267220,
2154,
9912,
322827,
354223,
702988,
129776,
93822,
363823,
39099,
104913,
285269,
90836,
105724,
388668,
13095,
335433,
81630,
185775,
69112,
175361,
49926,
21618,
5627,
241547,
16655,
26732,
24061,
null,
227866,
176474,
10572,
260655,
39859,
32467,
24315,
410659,
37614,
10007,
93626,
35476,
40877,
48591,
29908,
232585,
81625,
12631,
217310,
14823,
89259,
34932,
395137,
20479,
596462,
118853,
23420,
198510,
411853,
99893,
72409,
238518,
null,
8459,
null,
16216,
294931,
126730,
119184,
null,
259438,
66428,
29811,
65220,
145769,
122511,
217770,
251088,
82872,
81720,
367886,
1109282,
143976,
19933,
50886,
359680,
31316,
9239,
129166,
154711,
104966,
230932,
161549,
null,
249002,
18847,
59765,
216415,
152502,
41484,
205229,
28284,
30956,
122972,
null,
39876,
94759,
null,
400455,
1650,
37746,
3929,
104130,
12189,
17273,
37371,
12929,
9849,
13473,
12772,
39280,
6439,
10938,
27631,
64524,
98343,
264471,
190103,
1871,
145512,
103533,
7802,
30491,
25908,
22986,
179426,
197797,
31165,
45002,
38216,
30199,
498181,
109755,
26676,
104474,
null,
16521,
24966,
null,
126193,
22740,
250765,
145106,
233836,
48069,
199675,
226577,
286079,
390490,
14358,
421626,
34172,
243350,
23181,
390637,
145238,
70730,
14747,
29234,
213351,
81180,
129282,
157285,
98442,
757512,
26088,
193782,
47021,
404184,
22133,
560749,
104162,
12629,
164156,
29769,
null,
172314,
null,
19134,
42935,
244142,
null,
null,
10849,
49293,
22140,
52032,
557664,
237733,
67850,
null,
12327,
32811,
6557,
87377,
95021,
262870,
null,
69606,
16723,
86943,
53810,
42442,
59912,
134638,
null,
13832,
199775,
73725,
38181,
38550,
null,
144177,
7432,
13169,
98288,
305687,
257157,
33206,
42995,
25387,
83429,
206210,
599703,
101815,
408925,
203869,
166177,
195397,
290499,
28247,
9337,
29128,
4965,
26598,
null,
116256,
152393,
27165,
94314,
11040,
27177,
129879,
54627,
140837,
403401,
362492,
41220,
null,
53398,
null,
13026,
202711,
191386,
47204,
23843,
48397,
384853,
558153,
62019,
172041,
62589,
49258,
24354,
326154,
37141,
30410,
489486,
242241,
null,
31119,
31433,
31560,
68678,
382431,
102498,
33648,
44244,
120417,
8419,
46146,
123482,
28910,
344147,
31264,
225026,
455643,
94311,
276391,
17883,
72993,
243176,
47090,
151624,
61365,
51025,
249876,
null,
29861,
5467,
228187,
260323,
48395,
113949,
34694,
294518,
103377,
170461,
125724,
32662,
null,
null,
null,
480820,
19090,
125598,
129845,
345206,
24500,
42252,
87237,
4217,
46358,
315743,
667844,
146148,
300606,
82351,
36099,
134679,
394592,
9703,
28686,
289711,
10401,
112458,
132337,
633392,
9166,
46374,
27525,
324759,
166799,
61998,
257788,
28099,
43916,
232257,
192577,
null,
288015,
90875,
577958,
193877,
171269,
8839,
47860,
null,
null,
283490,
206668,
253546,
310027,
316733,
22123,
27312,
165937,
27985,
12241,
119559,
9687,
10385,
368451,
250132,
111592,
17318,
41033,
49746,
91395,
28103,
7558,
13546,
228666,
32645,
163058,
7476,
129583,
439554,
101205,
45764,
172525,
496303,
308402,
539352,
75001,
107960,
192275,
109587,
146241,
32010,
33536,
55177,
103643,
259049,
299782,
12357,
6177,
103706,
134375,
28941,
284613,
61425,
null,
110740,
79607,
324627,
6282,
70482,
145339,
294544,
43678,
31965,
24183,
138034,
null,
150170,
null,
99875,
null,
50760,
null,
37727,
214927,
null,
242249,
167067,
65941,
256015,
273089,
40654,
193638,
129108,
24122,
67171,
8825,
46013,
76623,
32889,
133508,
42193,
15504,
31642,
254787,
62646,
32445,
null,
21455,
23085,
443714,
4741,
10807,
232084,
27795,
314823,
382897,
280057,
294739,
23006,
45887,
39032,
20456,
50632,
5694,
null,
50938,
89784,
100412,
399184,
9413,
324750,
21904,
null,
null,
null,
73145,
45991,
98601,
3334,
445091,
78765,
220645,
24136,
12792,
28726,
136161,
87510,
32392,
122213,
170885,
160462,
27963,
84534,
36073,
110944,
null,
null,
54367,
393670,
112020,
25702,
24875,
336879,
27881,
80761,
638994,
null,
10932,
165307,
21247,
355594,
157379,
565525,
233913,
342285,
41182,
115611,
173180,
317877,
33128,
51226,
null,
21938,
53021,
20935,
37219,
22116,
21007,
169566,
168623,
275219,
236210,
147285,
38394,
87914,
224048,
33149,
47033,
251087,
47841,
319599,
null,
41815,
117440,
21809,
50935,
37339,
263624,
28175,
273306,
59566,
103298,
37699,
74531,
97493,
73438,
20548,
232542,
14940,
13288,
239343,
24644,
220887,
129540,
242458,
33004,
11075,
94130,
105579,
32157,
16280,
25461,
16718,
109524,
24117,
628255,
127702,
163996,
17219,
81158,
17501,
163875,
8746,
23846,
168293,
151782,
88708,
26824,
null,
84888,
331540,
38561,
9100,
65282,
53240,
210192,
84320,
117446,
75247,
34124,
37607,
1016110,
352733,
243946,
31829,
21264,
160546,
129981,
150861,
61562,
32212,
62017,
36086,
40068,
320032,
305310,
292127,
58964,
22779,
12351,
88824,
59683,
37645,
120383,
37140,
129863,
53253,
244955,
246206,
241162,
240494,
515008,
null,
null,
35327,
87932,
510307,
4574,
403987,
37204,
35060,
659031,
162220,
null,
376156,
460761,
144337,
50416,
104766,
15015,
124231,
208403,
85668,
36826,
392016,
77696,
41339,
38759,
81270,
258360,
94724,
353272,
313976,
3905,
170564,
42570,
34334,
477263,
387067,
369910,
164799,
64561,
166944,
61176,
null,
39090,
35104,
433317,
31693,
33367,
184481,
32390,
8243,
152500,
25244,
91814,
34065,
null,
15411,
31366,
132016,
43250,
null,
8748,
19839,
18157,
56561,
9367,
35721,
198339,
16908,
43800,
12568,
56998,
440538,
23668,
211617,
94445,
56766,
60405,
164576,
26437,
177024,
393795,
17328,
841207,
24771,
42267,
48610,
null,
6181,
22362,
428362,
28709,
5183,
65116,
43701,
88073,
32439,
13722,
12409,
null,
376827,
268532,
33726,
20750,
141312,
11684,
34036,
null,
44161,
null,
null,
72602,
128612,
346701,
113163,
59009,
7246,
219225,
128363,
143292,
497119,
133306,
273565,
243642,
45478,
26884,
32998,
223564,
134088,
null,
23483,
191376,
18004,
257945,
31196,
3174,
46751,
93647,
32182,
270656,
27511,
39718,
474076,
62108,
459844,
217276,
115669,
208470,
157017,
59708,
97692,
96937,
14707,
455055,
315999,
24205,
null,
141495,
37675,
137542,
22682,
17444,
69388,
14669,
19664,
33035,
71514,
147092,
359718,
15661,
18355,
366635,
90875,
178426,
41226,
24613,
5290,
138736,
19860,
98050,
265886,
33956,
13587,
86462,
36300,
38308,
null,
18688,
68869,
33995,
null,
28975,
null,
30940,
null,
42886,
26672,
33640,
274623,
24803,
71567,
86171,
185106,
28146,
14746,
null,
50206,
75599,
477484,
null,
23734,
42396,
null,
182096,
151308,
349829,
206107,
183682,
13656,
34183,
200688,
222637,
263503,
359896,
268831,
260302,
9396,
52467,
394383,
209224,
467037,
407811,
79197,
332671,
54690,
28049,
15060,
18363,
24078,
32289,
89357,
96809,
435274,
125135,
197018,
341353,
17411,
6747,
55807,
73300,
232199,
44978,
null,
242690,
32549,
119165,
410617,
31125,
364316,
42462,
27817,
433703,
null,
482470,
191798,
56483,
138490,
20335,
191356,
123345,
41660,
25828,
264703,
51880,
82395,
2722,
30200,
77060,
14306,
318320,
44207,
1870,
22994,
39287,
58464,
265873,
37643,
117297,
361688,
null,
21996,
76596,
41103,
264887,
211012,
11942,
208868,
9077,
null,
3124,
87891,
108601,
455321,
70243,
28362,
209543,
416882,
21728,
28230,
22343,
129863,
46000,
144963,
248109,
319611,
154488,
461213,
17007,
164462,
null,
161439,
21123,
132540,
41397,
null,
549802,
null,
18532,
176069,
521954,
105471,
46985,
158692,
20689,
null,
272222,
316631,
89080,
null,
149368,
358199,
173517,
16516,
89609,
null,
87040,
328374,
284620,
99469,
13830,
26482,
189862,
224556,
288677,
28109,
null,
15922,
48295,
156010,
46414,
210635,
34279,
169255,
34388,
128405,
205420,
null,
147300,
53045,
214925,
19495,
201274,
23737,
2571,
12318,
1214,
16020,
143985,
547207,
27794,
473899,
139339,
153211,
null,
35422,
102697,
40025,
28583,
106916,
204869,
292549,
128458,
186355,
250640,
24176,
230403,
211909,
null,
23497,
7240,
378324,
167949,
223471,
14281,
41382,
103267,
21788,
72024,
86010,
26864,
146318,
521528,
11368,
212659,
226463,
14046,
null,
null,
17235,
217801,
459759,
47496,
null,
14920,
860702,
null,
7998,
62810,
87457,
57109,
150707,
331303,
94584,
110492,
43544,
9475,
409322,
186168,
146939,
50867,
44007,
39736,
51570,
34356,
288095,
375095,
299516,
null,
129492,
87961,
107401,
79977,
20145,
14363,
32668,
383404,
152618,
18227,
25382,
null,
126979,
20971,
263530,
5330,
220026,
45703,
53067,
4730,
97531,
null,
11264,
18438,
6412,
322655,
279748,
302551,
54695,
113897,
48068,
3978,
130036,
53383,
289119,
26074,
null,
8866,
56158,
null,
19077,
49251,
322768,
154249,
56507,
83356,
226778,
894728,
54557,
87774,
11123,
64685,
153016,
202206,
17955,
35071,
187625,
265047,
205257,
261997,
7628,
null,
35968,
65859,
93880,
null,
51711,
139164,
259434,
412835,
12288,
null,
null,
60090,
null,
380685,
444992,
null,
52526,
658879,
509027,
129896,
9787,
58041,
74998,
628119,
132771,
62840,
13895,
12037,
224388,
29068,
238453,
31646,
38339,
43726,
6803,
80677,
126080,
19643,
33330,
2647,
153235,
134592,
286242,
247295,
124102,
53131,
151764,
77236,
null,
null,
192117,
55586,
526044,
8657,
58130,
15510,
149013,
78905,
null,
61204,
105080,
21543,
59072,
106894,
20603,
159396,
14809,
139487,
197216,
38573,
356123,
31782,
168006,
326186,
null,
18766,
235244,
353515,
122905,
174867,
13543,
370258,
295701,
131937,
null,
325362,
156421,
175236,
82078,
26577,
221642,
23526,
12286,
311573,
68071,
16217,
224209,
76150,
21278,
116611,
97394,
41743,
24813,
44850,
429678,
129609,
19766,
37325,
null,
100397,
null,
92073,
35615,
273828,
101317,
376208,
null,
316020,
null,
113818,
159966,
138839,
null,
50552,
30878,
7589,
30641,
26963,
44978,
null,
null,
42638,
240558,
30563,
37503,
83006,
16307,
340967,
299154,
93428,
36436,
504723,
133745,
31943,
238504,
178052,
56554,
195967,
125528,
85390,
302016,
227166,
145541,
6751,
29898,
310771,
181689,
288989,
178908,
14786,
36767,
131744,
56587,
202907,
49787,
26843,
86020,
51466,
20483,
144123,
78804,
251754,
38541,
108940,
13514,
78899,
54607,
3174,
165328,
87907,
6238,
74143,
33866,
202774,
607412,
74825,
188304,
15725,
92267,
56711,
9522,
42279,
56810,
28714,
137608,
192389,
99276,
212744,
90039,
218072,
36020,
7847,
null,
168296,
12432,
318744,
15035,
32432,
149990,
252621,
83279,
39933,
259104,
51340,
137748,
322425,
25712,
57182,
64863,
27297,
53582,
25460,
null,
7817,
37605,
null,
67021,
47520,
342276,
301493,
389096,
162360,
null,
1020,
null,
41228,
256788,
165345,
null,
171172,
428143,
163203,
23346,
null,
297636,
448556,
null,
114054,
38824,
197469,
286281,
127522,
null,
5236,
28890,
44443,
147351,
null,
10607,
65861,
49163,
171568,
293788,
238692,
6356,
80218,
81298,
93897,
22441,
null,
28350,
45426,
117878,
21223,
33729,
39010,
26322,
50015,
48727,
106002,
null,
141475,
12376,
null,
27346,
408745,
286870,
31923,
203050,
169106,
54692,
12406,
219809,
15522,
14585,
74387,
687213,
67798,
308853,
7140,
66123,
90568,
333107,
35625,
43741,
2829,
214009,
292136,
184753,
126716,
59453,
378755,
184663,
15922,
288956,
9383,
174725,
52612,
182813,
128172,
240062,
null,
null,
93027,
1457,
15635,
9682,
null,
645050,
336269,
106814,
18520,
202091,
70505,
335837,
67948,
39151,
33046,
1053484,
101449,
439734,
61694,
41083,
66755,
19868,
13726,
133752,
177020,
333582,
20273,
193742,
157041,
587954,
15685,
231457,
40198,
35277,
189672,
137412,
95220,
54129,
28295,
33528,
161855,
280120,
277094,
109699,
38702,
236248,
320708,
null,
484581,
218396,
596153,
22835,
58669,
249016,
82973,
19475,
190016,
372539,
234276,
1239155,
351014,
137056,
null,
238425,
160667,
null,
51842,
16208,
203055,
23670,
216937,
147543,
22407,
10265,
49281,
186194,
null,
120790,
33213,
37536,
15269,
144371,
19430,
12325,
29284,
11401,
108249,
587179,
244550,
9368,
365816,
230819,
452539,
59240,
217326,
18376,
268716,
23173,
133383,
99039,
12874,
69638,
257914,
51467,
null,
null,
null,
37758,
271377,
198709,
50368,
29760,
138067,
20980,
119384,
39071,
206890,
44479,
211801,
11873,
35759,
null,
50833,
166954,
38045,
259769,
93724,
213785,
234432,
290623,
55408,
310346,
436120,
123925,
154675,
null,
null,
299319,
16419,
6405,
31787,
34194,
18432,
23315,
297121,
213322,
19463,
9476,
537890,
174718,
209199,
208783,
219101,
null,
224545,
305762,
null,
67154,
45324,
544861,
30441,
359646,
167133,
366723,
32314,
102255,
17169,
158030,
215631,
21896,
31403,
49638,
7089,
null,
36204,
19320,
43246,
431448,
34540,
307067,
null,
576048,
315008,
129979,
29798,
29187,
null,
46110,
34408,
101921,
11078,
298535,
6613,
235800,
37968,
208789,
292760,
197267,
280535,
17510,
41501,
184745,
36833,
66485,
24153,
181247,
135555,
33487,
502970,
287702,
47899,
40317,
25894,
42483,
34436,
250109,
108698,
32006,
44456,
419625,
55048,
22200,
120716,
null,
12890,
38801,
102678,
208579,
130137,
118774,
47300,
68782,
41426,
34063,
59833,
21277,
254499,
89884,
400017,
2170,
96997,
17027,
538191,
21498,
27671,
47640,
10218,
26587,
13613,
124182,
27714,
60589,
92660,
33629,
177294,
43224,
329804,
86340,
67965,
28945,
28130,
252932,
54538,
520243,
263462,
10744,
null,
35641,
284806,
36075,
357138,
217672,
139628,
69343,
26605,
114339,
327313,
18051,
318423,
184264,
null,
43401,
527773,
221930,
15964,
16291,
54720,
169054,
13898,
14096,
77739,
26600,
null,
21533,
34307,
null,
50359,
14348,
18492,
null,
338006,
211676,
80131,
31062,
72634,
87526,
34852,
8593,
86633,
null,
14164,
230001,
15787,
59476,
113952,
102360,
209677,
170494,
38503,
402149,
null,
9822,
148108,
5909,
160908,
179401,
null,
167660,
67925,
15873,
42126,
20285,
34070,
7697,
135619,
29306,
26690,
63909,
12140,
15888,
15709,
9293,
181763,
76911,
281988,
6625,
null,
48614,
7260,
34066,
293109,
241045,
46363,
187454,
2571,
172349,
171364,
null,
12181,
32872,
14731,
235687,
40804,
245461,
77617,
172376,
52395,
61238,
67212,
48823,
20027,
57954,
128763,
260542,
38805,
248678,
390469,
85896,
42360,
450270,
61207,
59262,
20539,
7110,
12395,
240073,
72818,
60402,
69422,
20052,
1825,
4862,
241288,
41292,
70889,
130103,
47650,
225312,
189324,
4351,
347692,
169400,
216113,
null,
174604,
26662,
52290,
69767,
28937,
16765,
22131,
57820,
33981,
32169,
52278,
null,
23663,
24968,
261897,
74181,
18155,
14931,
121855,
6641,
11325,
347688,
112629,
55790,
190815,
276217,
267647,
105938,
null,
29662,
23569,
5880,
133263,
411110,
248068,
264204,
56771,
39721,
9982,
187975,
50642,
15553,
109445,
111557,
192017,
34422,
162788,
null,
6692,
4403,
5665,
null,
256235,
155309,
58302,
352690,
481990,
23908,
219434,
539049,
234999,
18051,
214137,
80597,
5919,
20934,
154807,
258659,
7168,
188602,
43679,
31172,
null,
26635,
217781,
282155,
19619,
208182,
25374,
570199,
45032,
226737,
65748,
3783,
57607,
19291,
17299,
9813,
390747,
null,
75534,
348445,
172654,
25738,
310604,
168005,
18747,
326168,
88805,
35237,
147179,
324186,
15033,
10984,
52952,
25205,
11374,
null,
4798,
167828,
118061,
15405,
196917,
23124,
22960,
11066,
241931,
null,
null,
293350,
125436,
153711,
13208,
269121,
null,
385183,
25895,
312880,
null,
null,
159378,
584792,
275560,
253328,
136399,
15759,
71045,
304087,
204076,
16716,
12565,
76754,
153835,
131176,
259475,
36961,
24937,
315619,
3154,
468958,
582869,
236967,
12895,
26381,
298453,
93165,
352967,
179394,
27777,
27362,
194608,
138587,
224944,
134412,
211118,
519903,
205614,
163110,
16096,
21478,
256806,
401039,
40494,
44494,
null,
142477,
267941,
108654,
142719,
58708,
70526,
58290,
16151,
41165,
358186,
8911,
null,
220572,
84176,
517655,
81325,
14645,
80691,
121956,
51560,
28514,
12520,
15307,
167978,
94460,
140757,
212477,
66559,
380199,
131746,
199365,
18057,
196261,
19927,
54967,
null,
51481,
64686,
56657,
148085,
null,
180276,
144203,
148165,
426157,
237703,
null,
null,
269154,
57162,
161303,
275602,
27346,
18790,
80697,
29120,
3981,
17880,
89403,
250538,
37131,
21650,
17917,
15390,
157807,
28381,
101915,
156744,
null,
650180,
79187,
196069,
294737,
51794,
261902,
48939,
56037,
12975,
4010,
35616,
123866,
174281,
185362,
710543,
23450,
25106,
413308,
null,
58767,
26805,
34128,
267116,
18176,
37442,
171777,
69692,
null,
33541,
235590,
99335,
31086,
455199,
null,
612744,
208428,
347002,
184649,
917,
32640,
28860,
83612,
84906,
25747,
null,
30509,
19502,
160626,
212984,
495902,
14364,
27727,
11839,
171198,
49181,
33945,
469898,
207614,
38252,
39432,
255067,
null,
364717,
235376,
25139,
103255,
161440,
2546,
630054,
8977,
28514,
null,
500573,
21670,
41782,
40156,
16826,
240072,
245734,
299281,
383282,
5973,
265457,
null,
122232,
19071,
150564,
40242,
12180,
374617,
151558,
14576,
425635,
60978,
102573,
11087,
12491,
398045,
39802,
75187,
15930,
null,
59565,
260758,
7178,
149385,
53311,
43729,
172230,
27563,
295424,
49818,
48421,
162859,
42533,
50456,
22060,
329328,
30582,
87652,
61140,
3757,
9343,
45027,
177741,
261429,
432546,
167871,
50232,
74417,
70514,
372648,
23470,
92073,
178418,
167657,
42081,
24916,
37402,
12115,
null,
21536,
6450,
108938,
146252,
324808,
19585,
105501,
35163,
null,
123560,
65896,
18958,
null,
56017,
266589,
227530,
87506,
null,
22136,
232685,
143478,
20430,
null,
123817,
102193,
411637,
291476,
null,
23072,
147038,
26145,
209970,
14725,
44675,
581107,
146941,
45884,
41279,
null,
30000,
13076,
64376,
326287,
249294,
227252,
172353,
44156,
20982,
41528,
217923,
26012,
3032,
375226,
115269,
81333,
214724,
245757,
24508,
199279,
97443,
169517,
null,
19436,
188888,
7801,
41944,
39492,
81368,
40297,
59779,
140854,
29053,
139918,
131278,
28718,
421799,
5129,
39342,
41330,
95094,
5187,
101989,
96695,
342654,
442816,
null,
null,
234030,
129454,
141418,
348041,
412024,
149197,
30399,
10777,
151895,
150095,
38276,
10481,
249223,
null,
9583,
87267,
52135,
85868,
219179,
97284,
153511,
324435,
14041,
77094,
183077,
203714,
11580,
108418,
31427,
33581,
1832,
2108,
null,
143778,
81508,
73704,
null,
160851,
27634,
302016,
13323,
16748,
42467,
10343,
307686,
179015,
205405,
205038,
56274,
69713,
36109,
13731,
null,
9224,
21867,
null,
83576,
308063,
9819,
null,
8534,
49442,
506140,
176512,
562519,
51917,
84007,
21021,
211987,
66465,
75962,
958850,
38451,
23410,
154035,
17540,
null,
415777,
494163,
18087,
38914,
22111,
335938,
9902,
54064,
246100,
null,
87928,
187202,
5175,
222858,
78233,
199923,
169892,
16284,
191651,
73267,
264651,
468,
113495,
18441,
235830,
4902,
141646,
217778,
81012,
47574,
9833,
18769,
7623,
175890,
95764,
28811,
null,
18496,
149292,
341692,
194931,
129314,
26582,
304615,
474187,
549128,
57999,
null,
41519,
282770,
16944,
28978,
3189,
208826,
271273,
32713,
23801,
612171,
13970,
287565,
9122,
222495,
332526,
null,
20037,
14836,
20107,
65497,
28105,
3023,
46482,
160097,
71022,
26433,
136904,
71396,
274914,
223126,
178054,
306921,
47832,
null,
20099,
13016,
261642,
14136,
null,
365730,
null,
null,
175059,
865280,
812007,
27939,
168233,
null,
21083,
17736,
304462,
58675,
33993,
171306,
148369,
11105,
621936,
23082,
34529,
446218,
190531,
254804,
8375,
103000,
812487,
23446,
null,
165450,
141668,
102848,
402901,
17938,
36247,
18784,
22966,
30226,
399083,
39636,
188605,
50908,
13311,
51379,
284780,
165049,
null,
25166,
31733,
5460,
769817,
85686,
68078,
31259,
196713,
51337,
28114,
23122,
94834,
148147,
125316,
13789,
147275,
26586,
8727,
null,
201922,
132585,
160341,
371131,
20276,
124584,
39648,
55959,
40585,
118751,
135185,
null,
17847,
350610,
49279,
118763,
25317,
404906,
null,
563431,
47366,
19238,
18288,
59345,
28326,
91387,
260485,
149863,
36876,
23433,
349890,
9154,
24326,
234722,
173953,
117375,
26331,
261881,
255380,
68252,
340793,
481153,
295063,
433065,
55885,
745883,
65365,
10309,
194934,
4820,
182584,
90983,
202713,
193520,
277774,
21471,
128638,
244907,
3543,
215584,
null,
64567,
452934,
30802,
8446,
170906,
32772,
null,
42081,
8835,
79390,
20246,
164867,
60506,
22403,
88642,
119867,
221469,
null,
432742,
63561,
20682,
299008,
null,
416766,
null,
4781,
94676,
175828,
358982,
48153,
62608,
210471,
77040,
49904,
53274,
181627,
51323,
154511,
3338,
51950,
281945,
40515,
null,
214986,
256968,
832318,
83482,
37503,
20391,
851,
194806,
144712,
null,
14168,
395941,
35455,
463389,
25861,
200875,
308393,
67023,
28839,
172784,
270929,
null,
346714,
263511,
11451,
31270,
35535,
330372,
41643,
27672,
161518,
62716,
181630,
null,
46645,
null,
412519,
189241,
22053,
116398,
null,
27480,
12545,
21682,
160788,
632457,
127024,
218106,
413770,
77343,
198134,
null,
14033,
7635,
22786,
69156,
61218,
36294,
209700,
122568,
338708,
169902,
17730,
371554,
238911,
164242,
33851,
47178,
93817,
83997,
null,
22230,
14772,
63612,
540,
195767,
107998,
21399,
5537,
32737,
29315,
11178,
37606,
9198,
17586,
640945,
76452,
164479,
38866,
128502,
83945,
189644,
34617,
243246,
54370,
9041,
179900,
242295,
196701,
166630,
7554,
70775,
null,
73610,
9244,
null,
32724,
27756,
255242,
21650,
21339,
12064,
272743,
20509,
885735,
29631,
11402,
140612,
193391,
170739,
46473,
312173,
161847,
17925,
10200,
33394,
62930,
7419,
20713,
17272,
24251,
85522,
99034,
191758,
38893,
58716,
299736,
21607,
221010,
23108,
25228,
59099,
28310,
32598,
153617,
747628,
70941,
249723,
113343,
334198,
100405,
32460,
53480,
39894,
77939,
35959,
16832,
493148,
null,
83577,
6707,
14314,
143523,
57237,
22581,
205174,
263503,
153161,
9201,
6346,
194189,
338956,
null,
80500,
130684,
70755,
62436,
223348,
188198,
19186,
31455,
32758,
34136,
101195,
90095,
133204,
7329,
44593,
309356,
82080,
289910,
164025,
null,
272406,
71977,
22842,
85195,
131025,
67106,
450028,
60063,
38030,
27089,
37852,
31324,
49449,
222720,
348875,
11027,
241569,
50880,
21861,
127257,
332941,
184450,
30129,
81268,
34978,
152218,
42277,
33215,
26704,
374326,
169391,
102501,
130782,
29351,
37827,
153231,
16993,
377190,
52926,
82122,
177526,
419149,
62743,
12215,
187971,
324194,
186360,
89204,
45968,
640108,
34027,
null,
144480,
275738,
189154,
11402,
5479,
991366,
45105,
37098,
39405,
7882,
16475,
62116,
271437,
436490,
173176,
83959,
201444,
23966,
260794,
105506,
39750,
199997,
20393,
158600,
2187,
131910,
53614,
580473,
29894,
70326,
16091,
39520,
413349,
112621,
153092,
408900,
31937,
92344,
365478,
315585,
45549,
47005,
424944,
229424,
17763,
38697,
21539,
88882,
98282,
8274,
323910,
null,
13271,
139336,
43242,
109044,
2053,
786752,
97973,
18214,
124257,
484782,
292607,
null,
10227,
6403,
25769,
58135,
125602,
19014,
312872,
23975,
83085,
591976,
null,
null,
70918,
46108,
316337,
null,
56326,
407709,
61671,
209472,
null,
413316,
null,
28534,
null,
12616,
283637,
13929,
64893,
181236,
2185,
348598,
37128,
34789,
null,
123995,
180560,
270668,
275862,
134795,
12290,
34580,
198585,
27884,
161688,
null,
28192,
104721,
3776,
201899,
201290,
36029,
168257,
9689,
36445,
69003,
null,
343336,
4404,
83114,
20582,
8394,
121171,
19136,
497023,
113580,
231867,
null,
21864,
33828,
120768,
42553,
86427,
239154,
35601,
81671,
null,
182324,
19227,
91119,
25429,
173478,
24108,
50226,
1177682,
67525,
48351,
20097,
237068,
147345,
null,
73293,
null,
30733,
296626,
15302,
399794,
231171,
22875,
39208,
null,
406896,
211330,
175794,
74996,
197187,
24613,
126404,
15343,
133360,
45054,
328500,
145416,
31520,
400176,
166977,
341585,
125019,
61931,
15917,
109378,
32099,
299981,
675688,
192221,
null,
18068,
225781,
24370,
234457,
117916,
87145,
43123,
181960,
438883,
262107,
45553,
null,
224435,
375639,
24712,
199311,
null,
167140,
30939,
218766,
166951,
16273,
102297,
5766,
20112,
20591,
241741,
null,
7481,
15702,
33616,
30774,
48367,
null,
304897,
269947,
148361,
33627,
44055,
59074,
123512,
325302,
223496,
26971,
48335,
229576,
null,
18173,
69508,
227508,
105061,
77838,
201770,
37488,
44706,
16391,
182715,
null,
27471,
112555,
310432,
299939,
468199,
12970,
53787,
496886,
261225,
445763,
169680,
56636,
19332,
9624,
null,
31281,
25949,
230751,
793174,
120627,
322225,
485613,
206951,
185544,
10069,
null,
29024,
247241,
14632,
null,
185157,
41108,
18286,
8171,
162969,
97852,
160620,
236039,
5719,
51798,
304830,
55011,
96323,
180315,
28536,
315047,
151227,
259851,
16236,
294534,
58369,
null,
13089,
20866,
null,
5699,
6195,
50250,
14852,
208362,
155302,
281533,
49591,
14527,
168112,
93081,
null,
14961,
58259,
78009,
213898,
155329,
50555,
34420,
174030,
45843,
175185,
38704,
null,
61024,
108220,
45436,
97396,
33003,
null,
271508,
30295,
null,
30912,
150405,
46838,
13195,
197772,
null,
62443,
670654,
5943,
8054,
266348,
117945,
91240,
27298,
339622,
30306,
21000,
338617,
22480,
41098,
354173,
205334,
89528,
17728,
40637,
39780,
179413,
45688,
14483,
306809,
35077,
null,
191348,
289299,
114513,
13752,
109431,
6944,
128420,
29528,
129573,
3091,
142982,
52999,
19259,
70886,
75215,
1321,
201245,
345735,
219385,
144090,
20187,
11025,
89934,
44434,
110059,
331002,
38049,
78719,
352112,
36707,
15768,
53835,
61192,
50616,
null,
90610,
384405,
57235,
7946,
26657,
175615,
null,
52552,
14437,
329686,
368774,
363403,
41318,
233306,
11781,
25707,
1150307,
181635,
199881,
null,
28882,
27958,
329024,
48236,
13056,
154202,
46984,
null,
20175,
73438,
60149,
152696,
267534,
null,
19422,
130067,
86826,
112146,
35279,
18034,
726480,
13541,
37243,
22400,
46061,
64588,
305693,
501500,
194744,
593512,
226051,
218197,
324809,
172061,
null,
24768,
109856,
75919,
256191,
25566,
232098,
34348,
42965,
142398,
384218,
39058,
14748,
165580,
378382,
276598,
321772,
325436,
191103,
41896,
241890,
10601,
411794,
35492,
164501,
38784,
98663,
195691,
235828,
255907,
84715,
43317,
64800,
172817,
21342,
null,
206503,
299638,
28121,
52925,
125535,
467099,
68670,
274508,
236453,
161756,
242469,
111352,
166796,
179373,
14181,
491376,
408314,
181779,
261998,
41973,
37445,
33514,
174069,
186128,
150413,
29875,
null,
22506,
6339,
70045,
72947,
56260,
127014,
5074,
238729,
175865,
181363,
50072,
83512,
111720,
90395,
121133,
null,
249694,
188733,
34916,
227780,
304088,
19238,
163365,
106301,
225120,
43414,
339058,
88651,
379283,
36499,
58224,
309526,
36699,
61391,
17689,
192496,
43256,
null,
11715,
49967,
239408,
23412,
17100,
null,
null,
1684,
43675,
202378,
113863,
55484,
null,
50347,
108327,
35792,
76328,
227828,
null,
null,
222950,
266893,
375424,
201066,
206581,
174394,
8689,
101006,
286635,
17184,
30743,
138630,
129145,
138236,
209103,
231156,
331060,
257496,
590043,
353586,
91866,
32283,
363674,
124296,
27287,
313900,
144911,
null,
32722,
226313,
33015,
291057,
191866,
11220,
41822,
47588,
273607,
139656,
8593,
68066,
262902,
198750,
188134,
58382,
275858,
398124,
null,
287544,
27253,
35073,
2582,
7789,
118357,
220748,
28860,
31035,
88662,
259508,
265363,
1179,
535522,
234110,
91821,
339476,
210972,
48798,
153255,
35116,
27938,
207281,
260460,
22546,
13821,
null,
43874,
149415,
607787,
null,
296498,
95007,
null,
165871,
181368,
307787,
50826,
30009,
31278,
238130,
25021,
30294,
110735,
197453,
37510,
67796,
4572,
177810,
106659,
7712,
61301,
85069,
46916,
37542,
6744,
null,
47933,
null,
3537,
39578,
157995,
197513,
164566,
184803,
40619,
326039,
21221,
14964,
225529,
259865,
null,
163068,
19523,
null,
120223,
39083,
66465,
7648,
79525,
null,
153785,
109705,
21289,
39052,
97152,
10306,
4309,
118980,
97538,
246414,
46936,
78704,
34056,
11061,
170059,
null,
10357,
192586,
17561,
52262,
129657,
21831,
566332,
null,
11125,
143752,
37630,
131627,
30497,
245691,
null,
59043,
44323,
null,
115222,
146617,
1643,
null,
152348,
58453,
118655,
23550,
96954,
236002,
96672,
126669,
240392,
216917,
57590,
77063,
94026,
19120,
19115,
21832,
2836,
251882,
null,
135797,
77544,
82840,
72497,
5141,
258212,
116553,
34009,
166804,
182255,
59320,
272825,
33113,
447076,
50427,
107796,
802109,
75029,
60263,
95616,
163098,
37391,
88344,
247668,
88400,
389112,
7974,
180547,
null,
35469,
75532,
207868,
131062,
39731,
34669,
3823,
164458,
123381,
null,
7163,
215593,
18133,
38129,
204907,
34571,
85686,
null,
68195,
43818,
265655,
123164,
57099,
18779,
37307,
36202,
34644,
281757,
316415,
15684,
9439,
224161,
585925,
3978,
219431,
167488,
341467,
245000,
10927,
11983,
29883,
21670,
3827,
309800,
53407,
19243,
747919,
100990,
338813,
207975,
404580,
28320,
null,
48095,
15067,
201211,
111018,
7596,
null,
176236,
211692,
null,
45896,
49444,
59151,
48824,
43857,
21586,
null,
12539,
null,
4766,
59354,
201713,
217607,
139080,
15590,
195737,
70316,
16058,
13515,
17023,
327041,
93230,
342564,
40511,
36760,
38428,
52303,
610738,
13467,
50797,
154803,
4293,
162144,
null,
63313,
114765,
null,
21728,
780937,
26466,
10479,
14574,
19560,
111249,
21515,
203766,
61422,
71825,
10611,
150431,
34042,
null,
308295,
31368,
34082,
248497,
10936,
219095,
null,
112023,
452517,
343864,
null,
219839,
26348,
32755,
372919,
454179,
90172,
343159,
225287,
15176,
202393,
19193,
8038,
36942,
186161,
138500,
68759,
32169,
null,
13473,
206945,
null,
15830,
215748,
87427,
169519,
60644,
11005,
39436,
67326,
125071,
319878,
202978,
null,
78206,
48863,
8407,
null,
23809,
12106,
216678,
46549,
31791,
null,
60802,
492684,
null,
172725,
13149,
48691,
12614,
3537,
32519,
14360,
9510,
55055,
342226,
null,
189298,
502802,
167367,
46677,
144945,
11021,
16804,
155459,
9660,
220083,
69398,
240789,
55999,
44092,
72414,
215902,
28899,
29370,
177451,
7104,
12528,
34110,
9471,
16317,
58276,
11170,
285390,
316625,
13125,
420593,
239770,
168355,
105505,
null,
20565,
3451,
26908,
113501,
214523,
268976,
196334,
45692,
318684,
null,
293961,
416078,
297054,
12323,
39906,
229255,
13835,
207128,
14872,
33335,
98119,
35186,
null,
286873,
202638,
46841,
4897,
209614,
351168,
519299,
440531,
273093,
93914,
21610,
292191,
166662,
239295,
null,
null,
426516,
50271,
136989,
null,
346294,
245772,
144175,
197195,
89616,
29748,
21328,
316739,
158867,
23692,
99736,
54737,
439965,
253993,
143601,
61451,
128704,
36050,
139403,
344815,
333421,
19062,
99485,
76418,
23280,
18485,
null,
244489,
36589,
120886,
682328,
318801,
188065,
15611,
122220,
552645,
42799,
null,
331273,
184792,
206363,
13970,
158779,
100521,
98788,
457759,
310539,
157182,
32438,
239551,
125056,
null,
45355,
180487,
null,
211553,
127552,
272989,
48525,
265579,
98595,
36933,
79632,
348846,
28675,
48615,
183266,
101449,
null,
null,
null,
127390,
15707,
214911,
348893,
34226,
30892,
33596,
208388,
206991,
6407,
440339,
604219,
287965,
null,
16815,
null,
null,
38553,
133697,
124760,
114951,
435859,
67544,
58793,
152377,
358940,
26420,
11347,
412124,
46849,
15304,
30617,
187743,
387816,
394634,
15902,
512776,
null,
309950,
28549,
3152,
16669,
5087,
172467,
11593,
31930,
21356,
null,
205454,
80402,
37570,
16448,
40206,
138546,
82961,
406262,
240655,
212542,
137855,
321132,
201881,
490565,
25886,
65067,
179244,
139715,
321738,
25796,
225672,
null,
213994,
232779,
63388,
42369,
22785,
177954,
213654,
225646,
null,
5811,
363988,
229868,
null,
215623,
97697,
465716,
494754,
41780,
273392,
null,
null,
26772,
560786,
23528,
20015,
154948,
181339,
287156,
null,
142068,
11454,
92392,
301160,
60239,
58754,
97886,
110074,
459726,
160829,
378093,
11691,
156290,
16365,
233118,
177713,
137816,
381376,
25647,
37839,
195704,
196251,
50532,
null,
126595,
32873,
62149,
15558,
149861,
30770,
18752,
20036,
null,
90568,
85023,
91486,
284780,
42799,
153601,
94856,
144778,
null,
33794,
181798,
543845,
7654,
143911,
55924,
null,
49654,
21678,
24068,
24563,
42557,
5112,
78993,
210620,
54474,
37376,
800946,
179344,
301630,
37250,
107061,
265426,
28695,
34771,
22838,
27838,
null,
33211,
133438,
147628,
60389,
573142,
8742,
23001,
46777,
70812,
26420,
249174,
245370,
66377,
null,
32204,
5214,
291926,
17024,
55107,
30835,
100838,
121029,
156557,
96790,
1864,
30660,
33282,
43278,
59374,
26540,
462524,
28670,
174773,
214992,
394171,
90301,
19287,
38031,
286720,
41075,
61355,
29926,
null,
228827,
167756,
43230,
17579,
182237,
209200,
10537,
74485,
124107,
null,
423271,
67355,
22093,
150814,
98598,
16545,
1867,
64061,
29268,
91486,
57848,
272632,
26128,
15595,
52618,
2073,
448348,
30466,
26422,
317787,
null,
220798,
54302,
30500,
31895,
27860,
128918,
35347,
null,
48292,
40992,
60991,
305898,
33669,
364177,
289224,
121931,
145525,
40305,
122332,
90235,
198232,
526225,
299516,
119929,
187267,
319553,
16241,
28500,
214969,
210281,
668261,
492495,
5091,
236875,
251938,
78205,
199237,
272535,
212617,
179837,
22141,
855238,
59393,
74954,
91520,
121374,
356703,
322018,
43052,
54352,
23232,
100655,
5459,
11404,
16080,
22459,
387712,
75021,
21516,
475467,
38083,
29495,
100261,
82820,
30972,
163450,
5780,
null,
null,
41652,
24275,
20938,
182715,
278597,
214296,
78678,
null,
null,
40767,
36584,
182323,
77038,
null,
322953,
144998,
257148,
117987,
197067,
44548,
406035,
null,
11730,
13285,
335462,
220392,
190295,
177747,
301329,
400291,
195168,
31614,
14894,
29065,
145640,
405920,
16502,
21357,
21686,
37640,
31795,
245421,
157511,
166013,
75700,
51133,
5370,
202761,
24600,
103825,
12982,
10310,
155273,
239576,
31687,
42423,
38476,
25364,
328792,
149931,
17416,
321377,
251479,
19178,
10876,
35260,
null,
215064,
10199,
210525,
247845,
60019,
null,
493907,
9784,
212125,
241586,
139555,
288703,
3512,
198277,
195783,
26265,
248933,
23998,
76677,
507040,
95996,
277412,
287954,
262402,
242754,
152519,
34417,
14869,
318053,
170056,
57164,
12553,
51596,
22179,
517413,
42983,
null,
139623,
45777,
378361,
285073,
364585,
236222,
75158,
279079,
267523,
558382,
177368,
5686,
399072,
15386,
35915,
69160,
85465,
31324,
72462,
47164,
null,
268500,
143597,
61569,
306936,
42088,
88664,
75018,
144930,
25523,
698720,
25063,
99502,
10421,
325119,
10795,
28969,
221123,
140938,
72975,
323402,
198007,
262832,
281169,
155558,
312190,
19807,
null,
27473,
null,
375605,
null,
74152,
222604,
144146,
227386,
544777,
435656,
33277,
43295,
47475,
33139,
192537,
89312,
177990,
23209,
153666,
9386,
309961,
115000,
229099,
29374,
null,
36822,
null,
145535,
324550,
179354,
126562,
673448,
283569,
104937,
187565,
143324,
10588,
13649,
218226,
186915,
100926,
235739,
409797,
44721,
373100,
28275,
536103,
31854,
52388,
4947,
227007,
94141,
10912,
null,
111793,
87090,
2879,
181967,
164284,
61855,
55438,
72696,
702741,
288238,
80481,
567151,
10494,
48221,
7179,
207208,
27429,
349552,
4851,
133837,
82950,
64844,
13884,
27308,
72902,
214847,
203771,
148606,
632420,
256762,
42692,
46994,
286099,
null,
160412,
17225,
150550,
286229,
9740,
72654,
31924,
327335,
34550,
420405,
null,
110633,
17190,
267572,
140196,
116090,
28307,
444141,
null,
254827,
7305,
87285,
237635,
26652,
55545,
560505,
7840,
101567,
214471,
19505,
527980,
22859,
309098,
138014,
164205,
null,
null,
120995,
5485,
381517,
136136,
89526,
336017,
40033,
460896,
30173,
242281,
311206,
23932,
8289,
226102,
333874,
135350,
163088,
111735,
298886,
57293,
6184,
43260,
87120,
13914,
110208,
null,
46671,
109713,
40397,
165136,
70547,
16731,
197563,
59263,
75921,
190967,
76528,
null,
65573,
325217,
156625,
4317,
376448,
22601,
10527,
374868,
247799,
105561,
141699,
11094,
374461,
null,
49547,
78420,
null,
325169,
101134,
12983,
28847,
199990,
440974,
9189,
431724,
162203,
8745,
133611,
64195,
194831,
295288,
183591,
404193,
214986,
171839,
46601,
36033,
394142,
31175,
18800,
19869,
38556,
72881,
37122,
1157584,
264353,
153318,
387868,
188374,
164039,
38254,
191539,
30127,
207603,
20285,
96133,
62840,
98684,
17471,
116031,
170417,
30604,
50287,
237319,
272731,
4221,
170447,
207075,
10125,
5842,
4978,
13022,
519003,
90819,
11535,
106125,
20513,
135787,
89561,
490680,
32461,
486086,
49137,
179476,
11911,
56811,
192739,
61094,
36909,
162599,
229265,
177265,
358290,
655202,
82116,
170464,
24285,
108699,
85313,
36401,
237483,
150335,
17108,
24414,
397677,
102002,
588302,
73416,
120203,
108482,
30562,
153193,
41959,
46150,
50445,
179450,
213494,
15677,
53243,
29184,
275008,
35363,
123168,
67092,
50997,
null,
205817,
138035,
655905,
11717,
null,
null,
238506,
24832,
null,
20842,
255040,
43880,
23528,
10821,
36667,
121423,
136162,
86696,
34885,
42733,
72965,
241163,
13021,
210001,
227060,
822323,
132216,
253747,
152386,
25550,
24295,
61295,
16212,
205999,
1441,
36207,
185889,
42304,
204369,
39080,
126707,
212959,
null,
null,
68017,
11078,
104214,
70713,
232421,
3741,
128982,
29995,
19960,
398153,
21313,
409318,
50270,
485217,
208418,
23069,
14445,
175427,
140219,
41264,
88325,
null,
36180,
4549,
457011,
237260,
266650,
129717,
491431,
23218,
104658,
524579,
532419,
155760,
22901,
28989,
29016,
17821,
44018,
270600,
189617,
44985,
12754,
290670,
29092,
39583,
4341,
180978,
62052,
368293,
426483,
13316,
119840,
42010,
12757,
26658,
14293,
361039,
117915,
141522,
null,
52002,
270713,
370047,
407668,
241176,
null,
195032,
267861,
133678,
47518,
368805,
7736,
47443,
27316,
26993,
188492,
154333,
252276,
130478,
41998,
11732,
220603,
44724,
255474,
142029,
13427,
22907,
10422,
15369,
10085,
14293,
287897,
null,
483877,
338678,
101414,
122362,
29061,
74873,
13651,
137202,
17757,
33506,
19016,
142401,
43680,
14465,
820,
28838,
39947,
18464,
9085,
9472,
299703,
62529,
196342,
24494,
94834,
90751,
159108,
43415,
null,
234570,
35621,
33588,
null,
151929,
369360,
21853,
37162,
74646,
8454,
190955,
9752,
367585,
337422,
38367,
165364,
21830,
40941,
338280,
42235,
170905,
null,
230411,
422388,
null,
381402,
15365,
25247,
45973,
null,
33443,
256238,
72202,
135886,
250541,
22043,
77350,
231708,
195852,
176847,
186005,
32343,
932680,
12429,
178358,
48156,
20858,
null,
36623,
16011,
4002,
32199,
53182,
232541,
37434,
123561,
59102,
202787,
131431,
34858,
23184,
175325,
77565,
83860,
158437,
227980,
337874,
455039,
31577,
12289,
475336,
56036,
33668,
84576,
139037,
296287,
288958,
38839,
null,
12235,
null,
382770,
41389,
328850,
87787,
88993,
141226,
46243,
14649,
28255,
47702,
19165,
206928,
118615,
27356,
125229,
36278,
null,
195402,
273273,
322832,
52061,
415899,
46271,
166629,
210174,
null,
11232,
7190,
19395,
458806,
8315,
91345,
112484,
145461,
94961,
649152,
352751,
175430,
206326,
71646,
178942,
181591,
43103,
null,
35996,
18220,
28099,
17553,
364852,
239555,
321376,
49462,
236960,
null,
229962,
273396,
null,
520366,
159947,
284498,
543500,
250766,
251019,
134640,
6243,
69276,
217482,
166796,
530782,
488248,
28380,
11130,
11681,
46737,
4587,
280078,
69356,
null,
135660,
247749,
127823,
57612,
33442,
34879,
136684,
27484,
215705,
22184,
null,
51388,
189199,
19261,
18007,
null,
54123,
36109,
61066,
314273,
48217,
12759,
212583,
null,
144489,
315551,
null,
20136,
39999,
35931,
536675,
null,
58368,
146856,
299894,
27925,
126150,
337526,
66530,
94476,
32319,
225486,
63104,
99377,
320886,
546642,
null,
24034,
15009,
25341,
12802,
131554,
58909,
32556,
82228,
null,
16179,
14748,
125449,
null,
314524,
94140,
237342,
244140,
13775,
null,
33687,
410309,
219657,
116488,
64927,
25855,
40272,
83483,
189446,
13040,
16145,
null,
22462,
null,
322109,
140949,
9656,
291435,
62024,
null,
395425,
213474,
55088,
36947,
77497,
31684,
292416,
75453,
403328,
10341,
27955,
454892,
94959,
86208,
84121,
45234,
254639,
271517,
140121,
8008,
403107,
35673,
19393,
293871,
38699,
8739,
19417,
25492,
523453,
8366,
589303,
186081,
16707,
28576,
502564,
60178,
272005,
49131,
106508,
282240,
null,
143564,
232350,
206148,
776984,
395571,
166321,
32171,
19706,
34432,
409578,
310876,
307166,
26602,
196381,
247171,
null,
240246,
287421,
113378,
49112,
19923,
4690,
429186,
122083,
179400,
16388,
8518,
5290,
94075,
229394,
44362,
5515,
null,
191732,
122055,
null,
109388,
51386,
28642,
164972,
46288,
22362,
78066,
248412,
157792,
6748,
43418,
277796,
12294,
46837,
null,
175725,
10582,
null,
296768,
271170,
13880,
null,
129844,
155062,
374626,
141736,
9962,
22882,
207117,
361518,
60808,
3856,
127293,
50073,
75171,
79010,
19397,
447333,
null,
null,
32137,
47394,
87371,
28609,
274214,
53865,
20413,
182824,
21004,
40194,
73276,
83637,
158912,
72139,
35963,
195840,
221998,
14960,
42738,
18716,
36568,
null,
253265,
182877,
245545,
576471,
16096,
278754,
269481,
69725,
69931,
10560,
1061100,
263695,
93604,
43639,
232266,
8703,
554525,
44271,
510443,
249076,
145405,
48513,
34638,
161153,
22810,
9401,
7428,
134381,
36413,
226549,
173307,
142814,
80780,
36836,
6380,
15824,
202672,
7464,
278508,
17666,
91580,
null,
26092,
789224,
25925,
325262,
43671,
35190,
3938,
9652,
38377,
228345,
386895,
158803,
144213,
127547,
7678,
40368,
19746,
38331,
320174,
214461,
93501,
428612,
202481,
20328,
20386,
175802,
121891,
180375,
485292,
null,
null,
22211,
21753,
33773,
null,
null,
30761,
25909,
288190,
4541,
13311,
273462,
97819,
362834,
106208,
51168,
26127,
30559,
202503,
150653,
6861,
55052,
51959,
162510,
97219,
303824,
24039,
192337,
381792,
30838,
360773,
null,
141760,
48371,
14994,
7909,
212737,
374244,
138950,
22840,
50174,
143391,
17588,
176574,
41015,
16368,
34815,
37241,
89504,
245572,
197246,
null,
223704,
109626,
3468,
5947,
200920,
120389,
277899,
22349,
236712,
42863,
147200,
4031,
18535,
89562,
12552,
22575,
321938,
198900,
21406,
41424,
238024,
32157,
null,
97022,
144711,
97606,
11417,
54979,
20142,
2068,
104033,
59550,
81121,
114983,
146087,
58762,
195142,
108736,
7020,
16766,
196084,
null,
101889,
18221,
94791,
30753,
344975,
4086,
400741,
100862,
480442,
47345,
18317,
87305,
37936,
513925,
40702,
188315,
258425,
98889,
208117,
7708,
72432,
18776,
17246,
210044,
22087,
221537,
28555,
380233,
524240,
135478,
26796,
49662,
9943,
null,
47756,
121506,
512305,
60624,
193196,
26342,
24470,
73240,
3322,
21651,
38854,
140394,
137186,
68057,
44493,
42149,
10790,
257001,
64960,
null,
8607,
135256,
258795,
27694,
57257,
3951,
143171,
26615,
47005,
16227,
15830,
110873,
null,
244262,
100922,
505896,
39664,
375667,
28913,
null,
31640,
47225,
254462,
246933,
153926,
415546,
336537,
35848,
584890,
33313,
414117,
44737,
378179,
231006,
94622,
182646,
27728,
354544,
null,
127264,
245144,
180644,
10237,
268168,
259962,
null,
76569,
20988,
null,
45117,
101068,
198930,
7192,
null,
83737,
123334,
20179,
17253,
21477,
28836,
190497,
280296,
46313,
338033,
null,
11483,
85081,
88158,
44226,
23409,
611067,
33613,
815086,
436928,
491880,
125764,
null,
132410,
270330,
16508,
76272,
214795,
278719,
12285,
175283,
17902,
63001,
439164,
7170,
252977,
13838,
98697,
86837,
10579,
170098,
42364,
344560,
11346,
2956,
133904,
68603,
96621,
18320,
309731,
36993,
279359,
10322,
54419,
194722,
null,
48088,
17326,
22525,
30566,
47668,
11988,
null,
35982,
282483,
193641,
18146,
305569,
76150,
149222,
12228,
21407,
231244,
143297,
50479,
18041,
null,
18834,
19876,
481575,
40819,
16400,
399764,
292289,
35577,
24137,
39728,
null,
160602,
21782,
null,
48184,
13756,
15191,
235296,
19234,
121599,
40283,
463041,
null,
84299,
57845,
278603,
23053,
5478,
174585,
211000,
449602,
69331,
475212,
237498,
225055,
214905,
158275,
431446,
73963,
32593,
9805,
16764,
236034,
177165,
23655,
640149,
679908,
44399,
34827,
34873,
9657,
336833,
36432,
200013,
null,
421182,
17620,
231924,
316910,
5818,
269599,
10106,
89609,
44534,
null,
454663,
75995,
135860,
null,
21984,
null,
419183,
50012,
138559,
5311,
null,
159649,
218115,
72155,
203446,
22479,
52614,
241777,
66131,
218928,
null,
73730,
28191,
220989,
117053,
24198,
374873,
345401,
6729,
19334,
39763,
178774,
69630,
63803,
5753,
180064,
37460,
72169,
34558,
213326,
158838,
371514,
222531,
159203,
33404,
333540,
null,
256576,
17205,
null,
134576,
150198,
88507,
239501,
null,
222300,
63351,
212634,
12791,
163569,
190182,
11166,
20395,
38572,
45029,
212969,
6916,
33818,
90159,
29724,
21718,
20737,
179840,
125259,
168263,
14695,
132315,
26470,
49824,
347914,
31474,
295578,
122777,
7320,
70087,
null,
319808,
427114,
160595,
5,
41856,
1006121,
146635,
232127,
209484,
11328,
10411,
32098,
52724,
50311,
467086,
22320,
394278,
415926,
174861,
17865,
76924,
49400,
133543,
227185,
43150,
23674,
11465,
86806,
86761,
232627,
46522,
38216,
18296,
37127,
276657,
303040,
228537,
171485,
34219,
9419,
152441,
205504,
144392,
17278,
563844,
227979,
3120,
54893,
84820,
226413,
26989,
81259,
47488,
203547,
66298,
59413,
null,
32729,
234044,
445104,
18785,
7561,
null,
11132,
105254,
25413,
41485,
53752,
75051,
205291,
118,
424909,
52048,
24083,
54558,
127706,
25560,
7504,
387969,
2392,
23999,
20623,
224601,
11336,
153676,
58908,
310403,
21615,
173169,
21843,
115465,
568853,
134882,
25438,
245768,
365754,
290998,
212029,
27695,
86527,
null,
41350,
45336,
203983,
null,
207541,
276032,
57414,
180464,
228106,
277538,
414883,
98236,
317457,
30968,
38947,
218852,
148882,
88552,
30464,
115349,
27608,
null,
51676,
35939,
138880,
283669,
16982,
215717,
21741,
126131,
null,
33114,
null,
466550,
157250,
39065,
224369,
null,
46341,
123336,
null,
330245,
299098,
1942171,
150474,
92186,
15883,
null,
156065,
26158,
23178,
56404,
254736,
32194,
18107,
47908,
18286,
247606,
26752,
18473,
45692,
49603,
73848,
228782,
66115,
46199,
105803,
177078,
27803,
249898,
30659,
36711,
165306,
35816,
35259,
19287,
167884,
30514,
179690,
186470,
null,
80436,
51019,
47927,
93501,
206393,
295437,
141457,
130712,
2743,
302553,
11452,
27770,
275904,
null,
292047,
33408,
83305,
346034,
276397,
462097,
209210,
null,
21414,
84744,
51433,
90189,
39445,
100242,
79094,
266382,
8216,
57244,
141447,
360384,
66367,
247010,
333862,
null,
107374,
null,
148197,
61513,
93697,
52444,
326147,
128882,
93242,
542590,
277160,
47012,
86186,
66923,
130678,
180511,
165629,
195704,
35423,
191601,
22543,
459371,
68036,
59486,
21819,
323760,
7929,
null,
23189,
27816,
null,
60719,
184057,
47885,
230866,
375630,
23068,
66297,
153423,
32442,
39952,
25960,
19755,
null,
27806,
149570,
23717,
175879,
83626,
7065,
234605,
null,
280476,
18006,
123634,
null,
null,
331435,
26679,
null,
39784,
50079,
26689,
null,
842264,
260800,
74520,
16476,
290598,
262208,
316049,
106570,
363826,
9606,
null,
161371,
764451,
64593,
213795,
117145,
26992,
14975,
319286,
375809,
31098,
53830,
19236,
273210,
274529,
648329,
93168,
217827,
30855,
181100,
321651,
208057,
27506,
12918,
66701,
null,
299470,
20448,
499317,
411751,
45597,
21590,
92044,
null,
28821,
92970,
28874,
58229,
121843,
68547,
131283,
198070,
60661,
30280,
23701,
10415,
43117,
81798,
14951,
461422,
11421,
16921,
128285,
46316,
null,
35187,
95551,
33168,
53745,
133336,
4359,
464856,
24977,
179775,
117040,
null,
79306,
340688,
null,
142844,
88218,
135617,
576586,
21735,
15765,
154518,
269224,
3833,
73312,
25138,
111881,
222327,
382826,
2366,
64573,
53160,
161193,
138908,
198448,
4685,
245523,
null,
25704,
49507,
143760,
277260,
null,
null,
30455,
324057,
17053,
null,
3772,
31761,
380274,
null,
null,
546902,
12975,
null,
125597,
120668,
173360,
172092,
117638,
67143,
9086,
48782,
75862,
114739,
18506,
75454,
20366,
36003,
21468,
38779,
59589,
53174,
6792,
192519,
163061,
null,
31956,
197937,
228154,
25257,
336485,
18734,
213799,
21636,
6264,
27580,
288031,
88826,
312354,
236744,
9862,
null,
86787,
15235,
54767,
317755,
40035,
165009,
34276,
74720,
218580,
33128,
32696,
18381,
42226,
null,
304314,
53385,
46070,
19525,
17087,
32548,
154715,
27375,
15176,
164056,
11864,
13901,
140996,
224943,
323675,
null,
25707,
6455,
29479,
135873,
423901,
null,
91397,
414558,
54538,
30408,
172583,
37239,
373790,
46521,
478629,
92971,
null,
349953,
151994,
167804,
30184,
92421,
249491,
366417,
232856,
43139,
21716,
27133,
null,
22245,
31968,
337368,
335974,
167867,
87717,
333766,
148528,
30258,
62713,
384804,
220056,
49672,
231810,
376544,
505816,
39247,
137418,
13113,
245821,
487718,
22280,
23064,
6388,
15892,
273334,
21313,
54783,
66382,
60173,
18154,
439931,
228039,
40050,
440077,
208732,
350664,
270973,
57263,
56133,
19542,
52822,
94730,
null,
32809,
475642,
133942,
149577,
267105,
250243,
10703,
195721,
5348,
9436,
87390,
98465,
141791,
187534,
6300,
13966,
166695,
null,
119904,
35353,
277063,
12318,
8058,
183277,
364508,
205124,
259843,
154162,
102959,
26596,
59560,
174439,
134180,
275050,
181777,
null,
null,
251355,
313676,
4320,
110992,
87548,
265857,
52677,
88125,
71269,
475017,
13081,
16707,
273681,
15496,
134889,
28158,
66383,
181856,
93918,
13230,
176684,
21709,
323338,
null,
24915,
386109,
null,
236450,
14641,
33949,
68292,
333421,
56613,
95449,
154623,
95228,
74389,
209942,
37309,
170928,
13508,
135034,
155939,
127737,
30077,
506449,
32591,
368452,
13516,
null,
114466,
13153,
334919,
227613,
46912,
119814,
734106,
91103,
9517,
217880,
36477,
4466,
null,
121461,
30334,
106988,
31762,
176033,
633003,
0,
54639,
77816,
null,
640105,
43861,
45870,
51149,
43083,
18915,
127212,
91099,
93292,
160006,
42843,
34858,
34730,
47355,
20416,
671981,
104645,
12424,
296389,
27370,
28050,
203396,
11542,
223671,
36689,
66385,
358766,
42924,
195959,
146102,
118142,
166609,
165366,
47291,
43375,
74382,
111361,
null,
26930,
26932,
347202,
52625,
305755,
322460,
160676,
66405,
27711,
63524,
33948,
10465,
22426,
41223,
12150,
205050,
null,
56483,
14947,
193434,
75170,
37122,
36390,
110889,
217101,
22549,
27734,
58054,
34854,
154513,
133934,
241030,
16461,
332381,
196514,
30642,
356807,
19579,
72741,
134744,
24772,
337142,
146644,
60674,
86491,
22479,
339998,
39531,
253274,
210918,
9625,
11908,
122412,
31721,
328642,
266063,
11002,
42741,
null,
22939,
151065,
11999,
352038,
277285,
345401,
236915,
13656,
36308,
153618,
24653,
413240,
33316,
303608,
191774,
69426,
231895,
17545,
256287,
33935,
4680,
598165,
9459,
79155,
17164,
144494,
85031,
124893,
73119,
330975,
170016,
396512,
24615,
null,
23305,
208487,
29528,
28306,
41678,
12648,
3154,
348405,
1689,
55764,
15067,
22950,
247905,
288763,
331340,
14671,
39605,
3895,
25463,
39355,
116112,
67010,
69263,
227903,
43828,
217077,
109185,
219283,
18573,
207290,
122775,
172714,
null,
9919,
176625,
67541,
83947,
291268,
34985,
527849,
93065,
98360,
390006,
null,
77382,
13115,
326394,
31163,
null,
26670,
23692,
80285,
36295,
256738,
227590,
45686,
null,
281929,
196393,
420292,
209432,
2577,
7922,
37403,
null,
124639,
103885,
32611,
110321,
35308,
30893,
132156,
39175,
4785,
4225,
107347,
93483,
122525,
48860,
174810,
98206,
null,
205743,
9335,
135929,
72569,
3282,
801630,
22716,
61565,
82752,
153516,
4578,
51988,
24972,
29516,
108094,
36697,
27374,
160070,
null,
273371,
47218,
55415,
256953,
18031,
23678,
45869,
286154,
null,
389119,
75818,
37227,
39631,
64550,
30722,
11758,
76663,
22223,
127954,
165675,
64420,
41217,
23697,
144239,
45130,
290086,
98286,
13018,
248124,
null,
33486,
23656,
167290,
null,
8585,
58958,
102323,
165499,
234442,
19908,
379421,
78528,
211408,
504057,
300208,
377964,
183700,
204642,
16858,
185380,
14514,
74079,
17397,
51113,
195975,
19938,
null,
92674,
147914,
236339,
35161,
null,
34424,
21591,
31635,
84009,
289402,
298172,
17709,
87639,
25728,
51583,
29263,
147800,
7574,
40358,
155286,
144375,
436447,
12720,
22982,
512913,
27748,
97693,
26011,
null,
187098,
44224,
16877,
397817,
31310,
150516,
579989,
179894,
19625,
272467,
31681,
161628,
297438,
310904,
355421,
14051,
171973,
574148,
82587,
137595,
28909,
413873,
188633,
44765,
null,
11794,
2389,
12278,
32546,
115758,
66342,
336771,
27761,
19485,
204997,
70330,
16135,
124105,
181610,
null,
283144,
12959,
44857,
254042,
52732,
257082,
70851,
402777,
34192,
null,
45741,
253265,
333197,
null,
260345,
87982,
273998,
326786,
55133,
null,
75952,
13734,
12930,
204768,
162158,
211393,
45831,
115521,
38640,
123261,
212501,
288080,
59509,
41067,
63841,
223225,
140906,
144908,
486750,
38271,
26080,
152020,
31966,
70984,
34619,
147428,
159886,
39066,
11805,
31490,
23891,
13464,
67595,
16937,
62438,
null,
137413,
null,
73139,
160299,
10235,
28959,
166249,
17969,
88844,
160006,
167558,
111324,
141572,
110254,
207444,
165942,
201234,
286204,
207687,
159665,
166906,
193630,
256410,
246491,
392483,
27316,
419418,
5743,
348153,
73899,
40263,
93777,
286554,
19178,
13996,
24191,
null,
80320,
69447,
37393,
27960,
13869,
null,
119365,
221959,
168914,
91426,
15721,
11123,
126055,
39970,
464976,
61783,
59642,
76188,
216501,
27519,
64735,
null,
346472,
33663,
229247,
189631,
501121,
null,
11740,
46936,
108228,
183428,
104656,
121378,
62998,
235037,
139839,
11273,
22438,
39854,
48149,
6575,
32792,
73527,
16004,
9829,
354902,
299655,
244399,
59627,
null,
25843,
153969,
618236,
58071,
258422,
347263,
255634,
22625,
21084,
33818,
17162,
477646,
85179,
29744,
151765,
38075,
116797,
153678,
279849,
55841,
205378,
86247,
69329,
78919,
39188,
122612,
57230,
161115,
322169,
62524,
207363,
236772,
70011,
198703,
null,
417009,
224199,
272754,
300108,
304515,
41705,
10553,
11432,
34689,
158339,
11215,
null,
43429,
232579,
213845,
33049,
48390,
168422,
13415,
45131,
162655,
33633,
46502,
8514,
17867,
235331,
120327,
38039,
211702,
25035,
187230,
152030,
53892,
48718,
null,
44231,
27892,
47730,
63526,
240552,
277258,
null,
50232,
597042,
null,
26399,
103438,
55078,
278320,
83387,
59465,
752428,
393847,
null,
12277,
81786,
863497,
303095,
2018,
13226,
325972,
134836,
274092,
null,
172824,
10485,
18945,
23624,
null,
110924,
19836,
33823,
408871,
22771,
24885,
null,
208732,
11035,
25844,
490914,
40969,
256731,
228711,
13030,
35331,
146522,
35395,
29258,
66065,
23761,
312773,
68169,
1248,
342204,
72191,
26713,
161331,
26683,
14775,
138113,
163952,
45592,
214355,
30337,
11489,
572019,
51304,
null,
150553,
230542,
50564,
140794,
111005,
210367,
164626,
156457,
null,
145671,
170305,
223292,
null,
null,
43207,
102054,
261240,
27125,
19892,
8329,
5187,
33840,
82006,
null,
null,
22706,
12025,
546680,
null,
28067,
13701,
null,
327799,
9692,
232112,
null,
25641,
242348,
105331,
582627,
52609,
324801,
36351,
31534,
165859,
42520,
359720,
21846,
27857,
213896,
420784,
15764,
21269,
66313,
115821,
7889,
813,
244992,
null,
290172,
101665,
26407,
211210,
39254,
null,
24625,
43005,
209171,
362545,
73064,
86628,
13214,
111070,
240881,
59693,
57064,
114774,
32618,
217812,
66380,
80563,
8214,
172194,
62438,
384525,
18199,
43871,
229181,
35611,
51563,
null,
85825,
263247,
12322,
30489,
9614,
42284,
27429,
171044,
70352,
36745,
43852,
289734,
21689,
188302,
162710,
154991,
4362,
104434,
58436,
171249,
5414,
null,
43078,
60732,
16111,
null,
434348,
15615,
46090,
73925,
168073,
12270,
41603,
null,
70797,
54012,
11397,
null,
141743,
177335,
3986,
18270,
229032,
558652,
30296,
42931,
66999,
440144,
null,
81632,
27730,
41301,
28321,
63076,
585519,
101917,
225114,
133982,
120729,
293291,
null,
28525,
47380,
49553,
121370,
368520,
93765,
null,
69636,
32735,
63748,
9070,
85601,
null,
43594,
95312,
56700,
9859,
39648,
6164,
319883,
null,
null,
342156,
469455,
17434,
65619,
207040,
7194,
null,
33800,
283527,
162992,
35517,
14622,
null,
63240,
33672,
null,
21281,
38650,
146243,
8733,
136865,
62505,
null,
26441,
53522,
451563,
97469,
12109,
424214,
81571,
50130,
20707,
9284,
null,
185361,
267750,
147820,
230803,
null,
239936,
192192,
44201,
85336,
213818,
18061,
220542,
80526,
363088,
435854,
37441,
111436,
null,
458194,
null,
20296,
24166,
58434,
110073,
34521,
185326,
null,
63545,
139935,
513450,
59779,
274286,
null,
32137,
52981,
null,
61632,
null,
409826,
31833,
42576,
16281,
245389,
452712,
79555,
186560,
6786,
301488,
9796,
243963,
17755,
29147,
11474,
166263,
215261,
27563,
42504,
32306,
39792,
16689,
6050,
487603,
37938,
6025,
20694,
25640,
78490,
10192,
71264,
63231,
16746,
378858,
33921,
288417,
177287,
4361,
54993,
126895,
24620,
null,
225565,
92230,
19038,
100621,
74963,
346189,
null,
24189,
62166,
33026,
null,
299796,
124589,
null,
52127,
8396,
919563,
17621,
433383,
209074,
134572,
25963,
771805,
15665,
344653,
38719,
55218,
216435,
29409,
106677,
48538,
297273,
229781,
12737,
85715,
183607,
217320,
298047,
16246,
24491,
69701,
191835,
38645,
48584,
8045,
189174,
72288,
18583,
90892,
362196,
79663,
null,
14340,
12772,
62621,
23472,
31985,
18836,
19122,
46072,
44057,
68070,
null,
508983,
271194,
538310,
67616,
82911,
18558,
164146,
251229,
57891,
434833,
218671,
49340,
23667,
162607,
339819,
160202,
93880,
78805,
394260,
268931,
39950,
36306,
5451,
122145,
284810,
8721,
144169,
40283,
14182,
34577,
66407,
null,
182017,
null,
321167,
56580,
145130,
5255,
282341,
28830,
276413,
96161,
19275,
48261,
10874,
179324,
null,
29239,
143152,
17938,
4578,
419519,
62810,
146808,
180300,
null,
11819,
155040,
null,
45596,
309550,
66937,
null,
85528,
19660,
null,
117934,
50007,
136278,
538687,
50667,
41823,
19670,
66042,
65360,
167313,
57896,
206370,
159800,
115476,
224625,
77772,
229872,
23427,
18915,
null,
240844,
24710,
73434,
29075,
22767,
47568,
642921,
17436,
413564,
4964,
5097,
null,
20168,
279682,
17275,
184614,
113574,
330056,
97905,
351907,
174107,
829825,
50449,
30285,
164318,
132862,
36743,
17663,
38439,
162679,
12393,
7259,
11089,
204332,
153086,
77215,
190533,
61424,
8196,
57217,
75707,
231565,
31488,
274781,
20269,
197888,
271898,
35787,
28971,
62342,
440850,
18431,
384316,
51039,
15336,
47154,
7259,
387061,
16937,
82297,
434276,
23291,
37768,
null,
16719,
349162,
216633,
420169,
70745,
27682,
203180,
null,
362011,
228461,
79080,
15392,
223213,
191871,
390575,
177889,
null,
13624,
null,
null,
80647,
493966,
196027,
147624,
22076,
43456,
272615,
189260,
50665,
138697,
23541,
372271,
146848,
null,
22095,
null,
78937,
419282,
13271,
25942,
128597,
20272,
153072,
7946,
55532,
36376,
596918,
96952,
166252,
null,
14040,
26700,
171248,
54617,
10615,
15178,
32342,
28213,
107675,
287144,
311334,
70145,
null,
null,
34557,
8102,
137171,
7589,
328647,
159361,
13661,
122296,
125007,
190021,
388757,
19549,
60778,
32173,
210996,
16082,
72184,
null,
45421,
151774,
22244,
33532,
353468,
233112,
49949,
309500,
47973,
164376,
77006,
36850,
156165,
null,
102822,
27023,
143306,
138752,
147702,
17749,
140232,
null,
507679,
31318,
200902,
335552,
161391,
35877,
15796,
204086,
48498,
78652,
20002,
3860,
21238,
394102,
280516,
null,
55014,
112946,
9146,
319502,
null,
158147,
24615,
287430,
null,
251513,
5446,
11975,
42599,
134793,
41507,
null,
147720,
10210,
11181,
48695,
159427,
334694,
226521,
18053,
266167,
4026,
16736,
99444,
101450,
12387,
16233,
25896,
43360,
133216,
265564,
10382,
17121,
46319,
24317,
69653,
205290,
299028,
639604,
23623,
8679,
275541,
94101,
73916,
23117,
231427,
null,
91327,
null,
218253,
57902,
48941,
111636,
251136,
321950,
409407,
109465,
138904,
76290,
220646,
35962,
238922,
68048,
30796,
23021,
66555,
4279,
18110,
214913,
192847,
3989,
33434,
211796,
47493,
36900,
33508,
204744,
346203,
null,
49537,
176272,
362968,
35397,
501809,
31045,
21987,
5884,
190549,
664658,
null,
72865,
152447,
68386,
12512,
1130217,
33426,
46702,
112796,
5443,
7849,
251593,
43113,
248450,
122633,
null,
125684,
null,
18504,
342967,
10730,
4835,
22657,
276995,
51172,
133877,
8913,
550953,
219590,
134917,
404818,
89926,
21647,
99300,
39212,
63770,
412915,
5806,
184737,
50835,
25615,
27080,
291027,
27123,
77658,
19915,
442061,
36979,
26697,
8151,
61021,
7979,
250969,
347095,
62389,
208666,
232320,
null,
110055,
158232,
399057,
127169,
399462,
45094,
145830,
225692,
44361,
233750,
null,
100549,
313787,
29318,
46887,
6688,
23580,
null,
39152,
null,
199700,
349271,
189575,
60779,
17852,
59755,
232067,
17337,
null,
143734,
117065,
365929,
53012,
746647,
47084,
386739,
6592,
null,
31525,
647150,
121609,
6613,
205671,
23537,
477505,
210826,
10390,
34773,
50780,
103512,
29163,
12402,
11796,
119515,
null,
36229,
207393,
216254,
125947,
18061,
null,
17238,
110647,
248489,
165869,
133836,
168996,
257623,
null,
73576,
26163,
11346,
179397,
291662,
19247,
54067,
31266,
50226,
39296,
241897,
34246,
83098,
26815,
457,
33189,
72281,
154711,
135614,
25182,
26642,
57241,
108522,
20133,
49778,
143628,
54408,
535737,
319493,
174306,
23918,
65357,
60606,
22386,
59944,
12996,
199561,
50095,
148003,
191221,
228024,
32080,
40374,
144802,
34048,
4539,
467352,
392651,
285848,
29219,
12257,
102099,
null,
29924,
88393,
34059,
469214,
6699,
228784,
39825,
245486,
159778,
177623,
53569,
4074,
16557,
30330,
53370,
147727,
109765,
41432,
369065,
471587,
50926,
45911,
8143,
12543,
34753,
24725,
169516,
249316,
359670,
80775,
390243,
130040,
24569,
39814,
612156,
13971,
29700,
13515,
48043,
11113,
null,
111004,
12996,
36592,
17750,
94797,
119141,
null,
80843,
208045,
338594,
10202,
225195,
178108,
35563,
39558,
287559,
33861,
153545,
2524,
50695,
211360,
239459,
322479,
21890,
29654,
22931,
66154,
77744,
10214,
127656,
27909,
151047,
62628,
51925,
301056,
8038,
260191,
324106,
157310,
245347,
22578,
136513,
39496,
27781,
247806,
41153,
241685,
151521,
608705,
64380,
288342,
175088,
372618,
62947,
33224,
97189,
44904,
null,
72972,
null,
null,
22767,
16902,
47244,
320160,
443707,
29193,
178822,
314357,
12554,
319490,
58122,
null,
188415,
371631,
444192,
251234,
35139,
234682,
38385,
135676,
114643,
81302,
92474,
8274,
19229,
3881,
263171,
60315,
154591,
32184,
165791,
30940,
223706,
24102,
21226,
205802,
231058,
36673,
189333,
222743,
24166,
348786,
52424,
15493,
15371,
341056,
56059,
450438,
163160,
18042,
37989,
317543,
18105,
76248,
56955,
20930,
14091,
null,
16007,
186861,
25181,
null,
25567,
164193,
140166,
44862,
158206,
187066,
4356,
26957,
32532,
null,
127377,
21300,
82500,
79682,
437175,
142078,
64377,
221634,
164209,
23073,
12708,
129424,
70246,
null,
null,
43422,
107735,
456152,
122266,
177590,
179131,
37639,
12814,
63052,
null,
4980,
27226,
141672,
32255,
null,
146277,
412145,
null,
48395,
211706,
7142,
369276,
14395,
34676,
89180,
233908,
52695,
null,
25048,
51990,
9801,
45215,
4306,
142114,
159446,
186879,
59964,
676621,
null,
34443,
null,
188989,
215369,
233688,
8907,
145803,
116489,
9966,
80508,
71601,
190417,
87664,
null,
197044,
26470,
20209,
204774,
336044,
23420,
9766,
73073,
14232,
240595,
411,
73790,
376563,
65899,
378149,
126278,
121748,
null,
87579,
6869,
265944,
49684,
108463,
183648,
172351,
5907,
35429,
27828,
64455,
10652,
127601,
5980,
295407,
203627,
380794,
4394,
52245,
134230,
5356,
37278,
266083,
470925,
220637,
66553,
47738,
null,
86713,
14031,
251202,
13729,
null,
842241,
110039,
348589,
288712,
65780,
113849,
97878,
51313,
45941,
208042,
70536,
293112,
95783,
16070,
null,
81810,
34543,
156002,
102994,
143883,
194195,
67926,
47070,
296058,
48226,
176926,
null,
110602,
40106,
304490,
172692,
13268,
48808,
41165,
25874,
115787,
888029,
1801,
152689,
9753,
11663,
30920,
12656,
614213,
456180,
54745,
9873,
10786,
74494,
128435,
16903,
35832,
10903,
100817,
9900,
94971,
124780,
479833,
208234,
22088,
99410,
61967,
44043,
216167,
240457,
96387,
367322,
364346,
13163,
60077,
394286,
258688,
17021,
29836,
62007,
35147,
23568,
null,
184144,
9534,
21731,
14955,
278541,
19888,
220179,
143919,
77968,
15930,
44530,
null,
50253,
44994,
52247,
24978,
15157,
38841,
59137,
180392,
38556,
218439,
386869,
262639,
198796,
243464,
135435,
240192,
32585,
14392,
464467,
257208,
8972,
33108,
189581,
122913,
450298,
17223,
9772,
11676,
426399,
168627,
6686,
312841,
256586,
183911,
null,
30247,
null,
7515,
53480,
160052,
418119,
362823,
180613,
null,
17159,
61678,
333964,
269204,
547924,
65853,
221666,
22434,
43137,
329838,
32045,
243966,
95266,
25172,
48419,
9837,
null,
17790,
137035,
178519,
53062,
466907,
30901,
21353,
48253,
null,
null,
429189,
31854,
350864,
25203,
null,
267424,
46199,
10781,
261996,
184858,
15481,
315647,
162812,
12297,
202930,
26172,
null,
97231,
25953,
11229,
126870,
60116,
2056,
207412,
71700,
35883,
445283,
115875,
154720,
118686,
100303,
167017,
25003,
339546,
13100,
11289,
277373,
37211,
null,
17507,
18034,
null,
15156,
26202,
321842,
150419,
24134,
56779,
24309,
23730,
34629,
23313,
21969,
35888,
35564,
92734,
160530,
163057,
null,
41577,
31938,
7795,
50699,
50375,
null,
18012,
null,
41025,
306136,
13300,
450759,
240067,
108717,
30327,
54193,
38164,
118964,
164505,
479234,
33073,
176306,
15152,
134412,
161431,
null,
8304,
35829,
12219,
216713,
128357,
254733,
15397,
null,
221053,
968,
170274,
184676,
143663,
37540,
90283,
185711,
525530,
null,
75098,
50977,
38016,
7045,
295896,
232591,
126599,
null,
84454,
6166,
165714,
41598,
23242,
61241,
32040,
null,
137888,
14618,
null,
208953,
325042,
127582,
8497,
162791,
17066,
20853,
32419,
38293,
172789,
32172,
199282,
21239,
134716,
null,
255781,
71288,
36486,
236530,
43404,
null,
148865,
123086,
199377,
44735,
53978,
48662,
null,
16776,
274646,
10852,
51674,
311178,
25552,
299483,
286870,
235881,
12787,
8646,
56439,
143739,
330124,
19932,
24226,
18555,
44068,
131422,
362078,
32754,
335856,
43217,
1105509,
294628,
35444,
296389,
381071,
10076,
42445,
28734,
316763,
370157,
392028,
13771,
214891,
237625,
401760,
313652,
324360,
64742,
31143,
34808,
null,
112326,
126164,
286064,
18005,
30183,
339783,
null,
40560,
176814,
28618,
251039,
348126,
148309,
106688,
130998,
32953,
28233,
492524,
380177,
163547,
262530,
100842,
438980,
32933,
321631,
240116,
186782,
474440,
17979,
232857,
28974,
168653,
168285,
101781,
356100,
125989,
83515,
40829,
115571,
169858,
792818,
125264,
317134,
190079,
201572,
83044,
6996,
296466,
62240,
322850,
21605,
43896,
18396,
null,
89380,
156949,
434404,
172314,
277455,
316187,
18429,
145909,
32321,
30999,
null,
289647,
null,
102412,
58952,
243208,
111830,
28905,
295403,
142411,
24394,
65390,
4103,
18276,
null,
51811,
38866,
216108,
53541,
null,
3116,
310735,
107945,
13319,
218446,
121556,
250801,
281120,
288660,
10012,
540688,
349456,
41560,
9184,
15302,
140724,
247588,
null,
142650,
209422,
98475,
12903,
null,
87990,
125995,
56146,
7932,
350995,
13913,
119716,
239100,
10816,
34175,
391437,
44293,
25995,
null,
203050,
74496,
253418,
23083,
null,
282529,
29705,
406338,
54054,
128313,
9873,
85000,
58148,
208491,
404188,
221948,
100240,
548248,
140916,
123793,
670200,
595712,
331746,
34989,
17916,
264807,
6615,
28639,
44502,
89849,
504288,
9505,
22887,
151580,
29104,
38195,
51969,
173823,
107564,
49374,
49643,
216450,
149903,
null,
28309,
29584,
62269,
280182,
33378,
256209,
277464,
19218,
288160,
32839,
113781,
84407,
243360,
20184,
247545,
179562,
51757,
127035,
253219,
40917,
364976,
257787,
24668,
187373,
50861,
15884,
34345,
48223,
132807,
358518,
559952,
33159,
14107,
41269,
45336,
32200,
204637,
54582,
67571,
null,
321215,
281197,
123458,
350455,
72580,
243768,
408916,
32910,
171456,
757673,
62203,
22740,
24211,
387488,
253172,
835947,
83248,
null,
28103,
24485,
59783,
616829,
75661,
68790,
null,
247870,
324347,
129494,
10105,
43450,
49974,
null,
64460,
22584,
null,
217988,
419205,
9795,
166983,
218521,
16394,
10284,
44374,
29120,
25504,
147514,
7613,
154313,
92939,
83641,
20085,
null,
35533,
24466,
298955,
null,
61550,
7553,
32407,
284660,
67758,
138224,
57339,
408419,
44859,
392971,
null,
179949,
127392,
5781,
153141,
279416,
254287,
54810,
34775,
232880,
40765,
57075,
151624,
13958,
156806,
37306,
17220,
null,
390933,
252272,
17146,
120613,
7426,
26869,
null,
419099,
80412,
11956,
16079,
15652,
19391,
541955,
154261,
742153,
26589,
33981,
187097,
7274,
203800,
161363,
39478,
60257,
56456,
53785,
76392,
12349,
189519,
165913,
33177,
243597,
123168,
62472,
14306,
176681,
140921,
173280,
null,
335000,
282180,
4970,
28694,
22612,
282894,
212560,
134932,
8368,
76078,
19352,
187592,
638741,
227221,
null,
13252,
88423,
271558,
23626,
60238,
46771,
17752,
63310,
20291,
420182,
81663,
61507,
6651,
104633,
137795,
null,
6149,
283253,
14056,
12478,
12014,
252204,
97442,
155572,
24001,
46115,
548787,
108341,
141596,
124663,
null,
9414,
76043,
179265,
31067,
323494,
null,
77965,
437212,
15624,
315706,
148216,
null,
35670,
85048,
14813,
134890,
118397,
230799,
165748,
312399,
null,
24370,
13752,
21670,
352862,
47655,
10292,
61793,
227941,
64442,
27201,
20481,
21184,
82167,
199614,
411303,
19321,
99726,
97726,
null,
191585,
18491,
60899,
48497,
25288,
18012,
246600,
19554,
null,
40521,
226859,
358155,
49326,
59212,
7523,
7368,
277503,
56741,
66086,
123972,
15867,
305409,
348127,
314109,
30415,
159943,
18817,
298635,
161899,
301580,
15808,
87089,
15079,
325857,
null,
43578,
null,
26528,
10975,
30954,
193438,
86345,
60133,
50981,
93110,
167542,
12262,
79222,
12551,
84858,
null,
71968,
74681,
123281,
170056,
151328,
407860,
74960,
355436,
153068,
160918,
61967,
59227,
286995,
null,
86312,
30309,
129276,
59068,
18104,
960484,
186664,
306122,
79080,
32159,
21356,
13680,
42004,
43826,
21077,
34499,
236437,
631554,
129836,
28438,
290826,
106741,
27296,
15361,
90583,
19911,
308161,
24564,
154274,
15017,
16689,
47824,
324636,
112160,
511459,
43299,
null,
228271,
112861,
30551,
36260,
233972,
23363,
122915,
75778,
282657,
296025,
429666,
null,
24878,
344877,
405338,
null,
180780,
57473,
30572,
275769,
198772,
164914,
7586,
null,
286020,
null,
41567,
115132,
53357,
53169,
52594,
null,
109750,
302488,
38148,
9825,
66194,
89976,
null,
181774,
22698,
45242,
170454,
414960,
31091,
10449,
492378,
63971,
45966,
265726,
27547,
null,
19357,
156160,
31303,
37855,
36943,
null,
387281,
96784,
86591,
null,
188416,
94684,
255334,
null,
52103,
35551,
49900,
9210,
61074,
28203,
247639,
289575,
26868,
66084,
26849,
100618,
430406,
48341,
598839,
null,
290168,
12761,
109477,
177073,
775773,
155411,
10578,
null,
47151,
12122,
27846,
64330,
216301,
21352,
44306,
47241,
40959,
null,
241594,
18510,
21438,
374254,
null,
18206,
644130,
32972,
15944,
41941,
114708,
null,
45783,
33226,
190046,
30187,
59688,
38957,
670231,
null,
26796,
31366,
17690,
229770,
6831,
568444,
175622,
30613,
4383,
160933,
9118,
28334,
16825,
null,
14337,
417237,
4294,
348380,
7167,
95351,
null,
34867,
null,
16315,
33004,
28352,
16133,
35899,
16588,
42045,
515821,
36967,
294899,
33590,
null,
19327,
152204,
356876,
426594,
14251,
97958,
42546,
475841,
31869,
62741,
397615,
null,
49086,
20156,
15611,
329803,
37568,
283393,
110361,
78979,
118276,
258440,
417409,
49117,
23566,
15060,
57643,
32791,
37010,
null,
38774,
415201,
10837,
401533,
283334,
111550,
35120,
95860,
59484,
38219,
286242,
150774,
9801,
35889,
176235,
56719,
226525,
24083,
null,
130037,
21695,
270259,
null,
28835,
10805,
null,
122526,
40179,
182631,
6235,
23744,
78076,
null,
150155,
14503,
26097,
30860,
57965,
140549,
82444,
268373,
43758,
null,
15727,
121326,
180071,
79081,
37087,
233959,
null,
94784,
13084,
50281,
521050,
124088,
169820,
233892,
136115,
32464,
9285,
401510,
313667,
391716,
360329,
35183,
254242,
234494,
421901,
340751,
29605,
124873,
101000,
19805,
24900,
35560,
177704,
120600,
43889,
35513,
635837,
284670,
14753,
296405,
935931,
27466,
350435,
222955,
46216,
18878,
200092,
80119,
304791,
13965,
102663,
249476,
21455,
54942,
13611,
336010,
44771,
50653,
43519,
119213,
171892,
20205,
68658,
308563,
28284,
33287,
null,
41891,
13479,
223079,
193339,
17620,
null,
147707,
486435,
null,
null,
180782,
217014,
18367,
11327,
6507,
354217,
87863,
226339,
271110,
159674,
61150,
125909,
29884,
79412,
147351,
62396,
254711,
46661,
7567,
null,
27245,
83174,
null,
null,
35754,
null,
40861,
65971,
38705,
34573,
34786,
63061,
27980,
153727,
572316,
null,
102497,
210263,
23575,
320751,
17281,
43664,
34538,
11375,
21376,
24467,
17409,
177916,
30223,
null,
55033,
1119115,
20222,
395806,
479500,
51463,
214986,
15016,
159963,
90908,
328356,
158768,
7498,
16342,
22388,
51311,
127658,
33404,
73406,
35119,
64745,
45077,
509592,
283089,
255538,
null,
125729,
109415,
37459,
null,
16427,
40163,
24387,
310689,
192601,
400735,
61759,
309006,
29859,
299110,
67008,
null,
184632,
12418,
10781,
385849,
null,
67033,
18522,
217701,
261431,
166557,
88606,
55250,
28992,
null,
32234,
180087,
4545,
275532,
null,
52943,
null,
16711,
23794,
32232,
499783,
6988,
8377,
4439,
12147,
118818,
19018,
15925,
13003,
null,
156978,
373559,
213097,
34833,
53913,
33525,
57009,
530937,
359203,
114113,
333188,
172566,
34985,
167318,
4738,
12003,
115577,
220807,
77853,
357683,
19651,
588409,
116555,
211023,
291546,
326063,
47242,
399247,
null,
75847,
15147,
null,
55985,
35048,
null,
199649,
68232,
144127,
312588,
134211,
195212,
73565,
389625,
35289,
156879,
null,
14084,
359505,
202470,
306337,
124145,
261985,
284747,
110993,
6044,
550387,
79514,
null,
63992,
78324,
55130,
18782,
115859,
7678,
288329,
213046,
10654,
null,
28397,
61021,
169739,
172023,
279958,
260166,
56753,
26562,
176891,
35953,
392669,
89529,
179926,
196558,
80009,
410286,
53718,
122325,
272584,
774224,
158838,
23183,
38880,
47848,
48821,
18363,
235942,
null,
234636,
38113,
31652,
3336,
267993,
51977,
35399,
245146,
157984,
5720,
33621,
316405,
43297,
60023,
618679,
416262,
202525,
16801,
268820,
274389,
308161,
122535,
12644,
null,
121687,
null,
65939,
18757,
319204,
104731,
198652,
461426,
23300,
27835,
39446,
265700,
5481,
211343,
118891,
137952,
105362,
305027,
451762,
24742,
30332,
30167,
114462,
192235,
35614,
22410,
153699,
21315,
23746,
25770,
366482,
27363,
233206,
65448,
214792,
30202,
106733,
488637,
46522,
238579,
null,
346840,
89612,
84647,
245714,
243038,
234310,
151266,
64836,
31206,
21320,
381289,
19962,
30845,
173349,
41078,
161466,
320641,
159002,
null,
269907,
22085,
71194,
null,
5071,
120159,
329037,
220210,
306003,
63555,
335922,
143228,
34206,
290138,
505436,
null,
null,
null,
20711,
48448,
8845,
5410,
178271,
62822,
327160,
null,
6425,
233923,
131373,
null,
44658,
334557,
99284,
435707,
null,
16012,
426998,
6155,
43414,
151619,
79991,
185022,
190576,
86235,
254770,
12697,
106886,
11554,
148690,
12279,
78021,
12991,
155662,
28484,
70057,
284255,
74798,
432748,
7020,
275078,
255779,
11656,
55020,
141527,
505045,
29801,
27656,
350930,
87027,
5042,
7940,
324215,
95849,
42464,
67409,
117499,
14811,
303367,
5063,
196873,
5483,
560359,
null,
87800,
182836,
null,
301802,
213613,
25247,
38267,
43812,
50636,
44015,
139061,
206357,
31178,
125178,
191140,
64436,
26516,
11214,
57780,
158837,
null,
41043,
39336,
130799,
71685,
15377,
187817,
13423,
179326,
12822,
6948,
294874,
18790,
194861,
26896,
27750,
102923,
466263,
17809,
1100864,
80063,
202265,
240146,
11627,
124025,
148812,
333274,
38984,
157649,
null,
40865,
74244,
196006,
57062,
53083,
32983,
43845,
165714,
230118,
16186,
16837,
23947,
null,
23549,
null,
293461,
440547,
59555,
25240,
17221,
7539,
72838,
86655,
162459,
145723,
243847,
3830,
174184,
16104,
179481,
45791,
330650,
533906,
65751,
298473,
7923,
null,
69464,
65634,
7881,
56254,
43336,
14767,
279268,
28332,
194846,
303709,
38309,
116773,
28841,
36236,
26703,
176148,
null,
80461,
134311,
61341,
null,
213091,
512739,
229672,
284623,
180038,
null,
null,
166146,
171418,
175948,
88109,
340874,
37625,
35806,
356456,
274580,
139084,
34155,
27598,
null,
63661,
27503,
14435,
4907,
118308,
60682,
133790,
13607,
23619,
72191,
171045,
29119,
468149,
212919,
null,
29805,
31518,
280549,
464236,
87369,
44957,
582466,
46960,
43934,
164462,
239354,
33092,
111310,
419786,
20953,
27642,
100697,
58595,
40103,
11160,
27863,
31188,
179645,
62916,
null,
190444,
null,
42348,
61603,
92959,
70516,
304895,
12096,
431382,
17180,
301016,
67363,
385136,
31717,
35721,
198888,
145329,
137977,
93951,
125957,
344035,
46160,
null,
260314,
19280,
211986,
192456,
430666,
38183,
90876,
null,
153695,
136852,
401796,
null,
27095,
null,
67300,
113,
15541,
313326,
51993,
85907,
51698,
294209,
259945,
31162,
552779,
34136,
38278,
null,
195073,
26465,
107271,
125282,
271068,
29129,
26925,
438770,
72737,
123330,
472332,
134083,
163388,
170511,
84926,
254524,
17975,
868690,
45996,
552475,
201533,
23589,
6367,
29479,
309930,
818415,
336377,
406760,
265073,
303826,
49130,
7726,
70494,
786977,
120227,
8505,
157826,
41841,
35806,
203584,
35557,
202646,
154296,
35264,
402371,
12756,
7354,
66788,
381550,
93842,
187664,
288247,
14910,
25086,
273740,
32001,
261315,
20966,
434543,
1109,
null,
null,
61004,
29100,
77529,
17952,
306516,
18785,
2757,
31386,
244159,
252697,
37907,
261458,
291964,
39532,
610996,
null,
231112,
235500,
61771,
28965,
null,
null,
30705,
25059,
20623,
122783,
146441,
163576,
null,
23798,
122569,
11161,
60104,
342896,
21774,
null,
273174,
11234,
15584,
175743,
377287,
224969,
444647,
42795,
20969,
55256,
93137,
116040,
49281,
17142,
183135,
null,
28134,
69922,
26857,
40483,
30662,
155498,
140135,
18968,
330813,
272741,
61032,
149413,
469637,
30500,
25444,
null,
117870,
144995,
109164,
128076,
65115,
188349,
34157,
140468,
23714,
50504,
29961,
69786,
100064,
201283,
22406,
351045,
12355,
24386,
76269,
358383,
41597,
57987,
59730,
177761,
107058,
306732,
106673,
32178,
591111,
27814,
19530,
82564,
10412,
null,
274237,
18837,
176678,
134510,
342611,
35050,
340937,
268474,
12723,
17588,
244307,
30775,
728295,
188156,
24190,
19056,
null,
33922,
50536,
42337,
151496,
10021,
100080,
302162,
83083,
317859,
156984,
145601,
210104,
238905,
null,
137042,
95307,
26537,
20298,
67070,
146424,
484939,
32413,
10638,
108432,
85733,
3084,
56356,
114056,
23650,
26838,
358108,
256585,
135947,
69242,
217656,
null,
225405,
116467,
25942,
34884,
28664,
14385,
17781,
72081,
400127,
199175,
102885,
28064,
38378,
43304,
4802,
40701,
725132,
13618,
223181,
475332,
null,
271745,
60225,
159930,
40023,
4578,
66351,
59039,
79503,
138134,
150984,
241498,
39537,
3762,
84734,
103440,
68006,
26741,
90104,
192911,
17600,
31772,
39038,
306686,
11514,
277116,
87020,
43233,
87801,
null,
null,
147312,
34198,
46384,
24276,
null,
48361,
14232,
60236,
48299,
11556,
45979,
515773,
5651,
47689,
38791,
19998,
16026,
null,
34839,
219162,
20937,
32889,
null,
354844,
148702,
46834,
270109,
103336,
23144,
null,
69617,
214657,
311065,
70977,
122285,
93565,
31411,
null,
122456,
18689,
19565,
353551,
235508,
null,
null,
31488,
null,
298077,
333920,
39142,
146555,
null,
189365,
278187,
147511,
173878,
28731,
50340,
512660,
51793,
174175,
359125,
142950,
21990,
306437,
160060,
null,
213509,
164713,
86911,
349077,
null,
27282,
25430,
39138,
33196,
null,
79232,
null,
158307,
14419,
33502,
31590,
83660,
415261,
null,
17673,
65942,
140785,
271135,
177382,
398760,
359154,
140426,
549498,
null,
248407,
585905,
597000,
462344,
209477,
null,
126379,
337559,
350831,
25597,
null,
28199,
117212,
32741,
16928,
1457,
217900,
30863,
557755,
null,
21646,
656367,
227985,
251063,
17539,
25196,
33350,
25909,
179589,
34433,
93264,
206007,
268333,
203528,
43337,
191794,
18167,
4261,
236851,
48080,
221612,
64560,
31458,
201764,
null,
31954,
208733,
41317,
257223,
104989,
19377,
210092,
137610,
61363,
34297,
221325,
null,
53164,
177677,
307787,
68249,
null,
28888,
49924,
null,
6143,
318112,
370115,
164500,
4534,
53802,
22037,
159971,
41408,
100684,
351074,
313709,
55879,
66427,
18870,
140815,
null,
43564,
33557,
null,
278807,
3474,
131464,
239233,
null,
24746,
60367,
56466,
395742,
1020893,
12195,
482359,
430988,
86369,
95025,
327379,
157635,
16449,
200650,
112239,
142789,
null,
12070,
32717,
25164,
13731,
435128,
84540,
165748,
182238,
12961,
61834,
3577,
152875,
265580,
12842,
33327,
58353,
54305,
278909,
27584,
null,
null,
31782,
237353,
34932,
45400,
257522,
224276,
295195,
228718,
58036,
50591,
194968,
64106,
19536,
434628,
73303,
136352,
41721,
270952,
27354,
37402,
232405,
33779,
284834,
null,
29873,
82390,
197981,
73205,
19463,
146375,
54256,
16410,
115618,
66043,
139705,
118094,
415864,
785063,
232939,
302330,
149237,
17126,
308755,
92576,
21231,
null,
417579,
24899,
null,
318327,
25768,
34464,
299507,
403849,
317891,
5814,
15610,
59383,
137432,
7451,
29817,
89129,
13629,
11589,
96905,
8241,
12583,
299769,
210338,
49721,
538718,
186749,
118647,
86139,
46888,
250162,
117139,
116278,
288058,
240703,
281299,
578806,
45302,
296294,
552654,
null,
195091,
47377,
18951,
229916,
322865,
20993,
169256,
52035,
243263,
43379,
null,
130002,
null,
435550,
null,
23751,
9615,
273275,
239023,
7580,
18336,
1813,
98755,
14455,
205492,
12192,
13462,
13521,
39663,
269073,
91181,
41681,
null,
null,
24105,
38707,
10391,
205768,
13029,
9312,
7025,
38917,
316,
6099,
79227,
352157,
45907,
null,
null,
6934,
11564,
64629,
42093,
178791,
252451,
27851,
19757,
98933,
26255,
182712,
18881,
70104,
44882,
168896,
201481,
215588,
211944,
281790,
17431,
9902,
332015,
62594,
25419,
23860,
27280,
3787,
230103,
228870,
56886,
29706,
128620,
40173,
284833,
49058,
185448,
320327,
84952,
270212,
103165,
600215,
62320,
18470,
179510,
186198,
88051,
43959,
667596,
23943,
46394,
300255,
144681,
null,
185622,
144432,
69189,
205846,
242646,
47852,
41048,
null,
null,
413757,
null,
null,
28997,
96652,
127051,
33810,
264481,
243558,
20315,
316266,
117204,
315841,
257026,
169882,
163363,
26858,
22814,
20336,
377370,
33023,
225619,
109894,
68413,
null,
152934,
94009,
11206,
null,
21445,
17290,
27762,
32136,
216541,
263162,
313700,
231395,
18953,
67324,
388912,
8351,
326324,
160509,
30890,
199127,
501903,
348759,
89339,
29386,
30996,
9045,
177482,
113671,
141920,
137851,
8028,
18291,
38021,
52509,
25684,
38992,
657945,
59236,
36601,
16300,
21308,
24626,
96963,
null,
331433,
184773,
30493,
42952,
4092,
18283,
243424,
272344,
86117,
134926,
9506,
46339,
204668,
null,
110009,
25017,
232023,
2727,
98510,
261438,
71247,
20657,
18418,
193225,
60540,
45041,
49459,
187531,
88813,
28978,
159608,
67365,
260125,
11237,
39795,
7209,
84933,
17641,
176225,
273976,
null,
291612,
37421,
3229,
17632,
14728,
15323,
3404,
62344,
36218,
32612,
247809,
31487,
null,
118229,
11736,
309658,
294392,
41517,
43363,
49467,
14980,
317929,
36026,
157969,
41655,
527184,
71635,
286358,
null,
132555,
471407,
190545,
38887,
70944,
134789,
31931,
364568,
450856,
31013,
68182,
6419,
514534,
65623,
157719,
219727,
148313,
22529,
34670,
82543,
290333,
37034,
15730,
8743,
35580,
null,
546465,
186051,
53121,
28001,
36308,
168084,
184378,
665974,
57124,
3990,
null,
65659,
127738,
151978,
31949,
418395,
157596,
24011,
35155,
392090,
18200,
28510,
156490,
41247,
64089,
122662,
120539,
null,
52897,
175265,
null,
30282,
93111,
169590,
351506,
78749,
60177,
239721,
20462,
268316,
109176,
23593,
22430,
null,
22986,
null,
376006,
456043,
11043,
174456,
134235,
33512,
42642,
33863,
229252,
171189,
155961,
222468,
424118,
160853,
22322,
362741,
305571,
96851,
357849,
null,
26858,
26944,
134478,
186590,
468818,
134445,
233721,
33940,
265865,
461645,
84662,
79409,
348989,
126496,
345885,
444457,
40281,
173663,
52898,
159319,
394916,
43743,
270668,
163212,
222184,
12868,
174753,
171865,
18885,
680973,
295554,
287982,
168394,
283708,
19188,
471351,
170624,
8681,
33375,
137153,
269889,
149898,
25886,
213653,
77551,
34524,
53109,
29054,
86001,
182514,
37124,
19214,
89477,
72701,
130139,
null,
64364,
244598,
46391,
null,
152649,
42084,
170542,
17035,
21597,
null,
76453,
58498,
9399,
315425,
null,
142926,
80958,
116879,
18965,
114277,
373090,
33944,
173807,
175008,
13511,
204665,
84286,
71718,
null,
36989,
201497,
275507,
70896,
386605,
162994,
315155,
77094,
152548,
68372,
77697,
20110,
62772,
117812,
126436,
12820,
34424,
57275,
20980,
18327,
458914,
14096,
59833,
128666,
8364,
157619,
143811,
52560,
37723,
31192,
30929,
41888,
347277,
58705,
249706,
null,
null,
289592,
179016,
12617,
50882,
63630,
187121,
46685,
38376,
487848,
null,
95621,
66002,
12486,
26286,
50087,
31526,
null,
108608,
43727,
109662,
148631,
27997,
11409,
null,
128036,
10923,
53976,
44554,
86754,
220110,
194771,
10925,
null,
61358,
412321,
243174,
15590,
40107,
267058,
110524,
192755,
38940,
126555,
252656,
459309,
247007,
290444,
142632,
232431,
27927,
216923,
282415,
237651,
93787,
202096,
207311,
7535,
389113,
70695,
189806,
4532,
133635,
123476,
53884,
19869,
162684,
128306,
38330,
25925,
40826,
135348,
34096,
192470,
203061,
104289,
null,
211609,
28408,
52796,
32946,
34327,
59814,
391620,
218434,
25773,
172561,
19930,
62380,
273365,
14779,
88057,
184517,
8499,
null,
21737,
288053,
148514,
51456,
75500,
null,
278186,
25505,
35826,
241385,
59320,
190740,
12307,
34915,
41526,
19214,
48156,
16563,
4227,
36873,
284973,
267608,
166382,
219391,
16315,
41662,
38011,
164680,
null,
null,
297682,
30882,
9545,
26570,
642828,
31496,
25561,
113520,
204452,
22114,
460115,
47424,
286319,
22910,
81019,
390559,
27709,
null,
27565,
32362,
63230,
15826,
16501,
287602,
671550,
62547,
369703,
53399,
null,
51767,
null,
273868,
null,
171203,
279909,
10031,
13834,
45512,
149092,
236451,
277407,
137903,
42009,
440608,
46982,
null,
288398,
null,
41862,
9587,
11528,
25309,
66212,
null,
88353,
60263,
null,
782877,
157664,
61521,
null,
170254,
13508,
222117,
477433,
61338,
19384,
31120,
149499,
43171,
null,
265686,
63336,
222683,
30813,
30703,
15677,
272433,
354010,
22108,
177482,
308880,
264167,
49187,
526027,
52094,
119624,
null,
16272,
45472,
null,
41201,
293416,
71176,
40156,
36294,
146567,
2261,
168575,
236050,
194322,
39054,
37901,
61049,
44496,
163197,
174560,
23676,
72048,
29728,
116205,
265684,
148452,
2015,
345354,
707133,
147607,
103864,
305953,
112339,
39180,
558361,
66977,
433315,
12873,
16443,
27783,
17114,
12391,
28778,
41810,
186371,
190279,
70279,
314476,
57872,
527215,
2590,
411284,
161432,
149872,
17689,
655802,
11123,
123123,
261622,
169229,
39148,
104850,
18304,
null,
529185,
276017,
25609,
32565,
175047,
24340,
null,
30997,
84538,
49748,
365983,
43613,
123358,
23472,
25808,
41403,
35696,
179699,
96059,
23508,
169591,
26695,
28792,
9953,
9147,
null,
136452,
286261,
29678,
63850,
284351,
171461,
116064,
182321,
48607,
266942,
68834,
18700,
31443,
50412,
246487,
658,
null,
224256,
342862,
11052,
312663,
135816,
51168,
37722,
34016,
27731,
221433,
41622,
83938,
35973,
84076,
155195,
42155,
252055,
95913,
179014,
14211,
281144,
236577,
166883,
41557,
null,
null,
180469,
350679,
36392,
189081,
205404,
7876,
105506,
14186,
24562,
183903,
37395,
null,
156073,
null,
null,
29580,
90463,
94977,
340638,
3669,
53494,
368802,
184652,
254873,
185348,
48773,
36921,
1294903,
66982,
144955,
30060,
188966,
204657,
30372,
336710,
177950,
18763,
417861,
197585,
19386,
25881,
199222,
149274,
176968,
19980,
178341,
93246,
112810,
328588,
35864,
36410,
61827,
98856,
24178,
138367,
476582,
null,
319557,
134669,
501363,
56566,
181533,
26054,
373795,
30519,
49300,
41111,
143244,
217626,
644332,
231754,
null,
9582,
141499,
13366,
26690,
195190,
null,
257169,
24101,
51233,
196624,
603295,
13620,
115859,
158088,
null,
81262,
16631,
4714,
685496,
76468,
null,
209533,
null,
16123,
270869,
119530,
56806,
6838,
17829,
200248,
35540,
22935,
123455,
null,
null,
146440,
19281,
19726,
196131,
213776,
null,
80032,
null,
201502,
505541,
14932,
23434,
296953,
401432,
50510,
null,
82747,
null,
7767,
15902,
52121,
86393,
170315,
20787,
11910,
180661,
212442,
97204,
144444,
30962,
320829,
199706,
17018,
53948,
25191,
5732,
31269,
213723,
303128,
29386,
98345,
285857,
353419,
25414,
160567,
null,
19893,
20399,
474368,
465934,
27144,
412146,
null,
342305,
10368,
191049,
null,
81556,
73152,
37660,
460588,
25187,
14302,
15373,
455975,
112740,
219458,
138779,
null,
80876,
112264,
271086,
9762,
71404,
138505,
76784,
71124,
179031,
15137,
15684,
191464,
11378,
21039,
107160,
42506,
67212,
217214,
30216,
159233,
null,
null,
74895,
645838,
33363,
146804,
29210,
26112,
45425,
239901,
74413,
56694,
28866,
371889,
117259,
87307,
67882,
271286,
null,
182649,
29569,
241819,
12252,
59667,
368108,
null,
258533,
166017,
null,
290942,
79390,
52322,
60110,
14104,
8392,
31132,
431805,
42280,
89053,
null,
43770,
368583,
2152,
403687,
72230,
88070,
15684,
185623,
143526,
263315,
null,
210418,
137500,
167526,
470945,
51179,
41091,
332695,
158735,
281481,
37292,
42169,
23405,
273514,
19398,
null,
8581,
null,
21149,
42843,
12163,
878127,
463633,
10362,
107945,
279224,
120046,
563031,
281933,
101997,
null,
101318,
92102,
337737,
212966,
149711,
21823,
171507,
329689,
117600,
318191,
12391,
229079,
191293,
6493,
51535,
81695,
8979,
216666,
5815,
315109,
55208,
182289,
141561,
21783,
361836,
17042,
31490,
10684,
147874,
61353,
45116,
28161,
54992,
358891,
165809,
null,
49345,
30968,
29155,
null,
309129,
33525,
278111,
16824,
null,
4200,
47444,
23319,
11324,
134277,
null,
165140,
36571,
8061,
460000,
8875,
null,
60421,
22659,
2784,
24639,
null,
null,
57020,
27910,
228964,
null,
244393,
null,
155641,
47768,
19179,
36868,
19849,
175691,
60018,
66758,
44602,
274395,
415891,
136695,
95672,
38120,
124735,
17214,
22392,
13200,
301843,
207326,
27310,
207166,
529738,
471383,
8018,
418439,
279923,
107355,
21269,
242463,
27464,
15563,
209467,
401101,
26009,
24939,
31809,
177345,
31397,
4209,
22062,
133642,
null,
34561,
29182,
175052,
144446,
212204,
61749,
303338,
274176,
5293,
18495,
15430,
37326,
null,
66971,
37002,
28891,
76486,
222940,
354440,
197868,
null,
154917,
929765,
26836,
5912,
231640,
17968,
44570,
4763,
346691,
214531,
525424,
16769,
145991,
145903,
30190,
83584,
477034,
376008,
121843,
160141,
44609,
48220,
31964,
48472,
27088,
31512,
null,
47975,
21679,
50186,
223627,
257369,
4605,
189821,
40333,
null,
325856,
16162,
91009,
431968,
238815,
null,
82687,
19469,
412695,
396328,
75668,
79654,
24449,
null,
87465,
29987,
32231,
null,
29734,
29470,
null,
8434,
75380,
15591,
313733,
6910,
82740,
5171,
null,
55274,
38236,
69354,
264554,
763089,
35299,
353236,
178017,
85990,
7435,
32605,
null,
9544,
58308,
109443,
418069,
20653,
307958,
45238,
86823,
9907,
331240,
37049,
67152,
175732,
102991,
154218,
276204,
129401,
108443,
25555,
162519,
519684,
140756,
191853,
94027,
324819,
319122,
288226,
35865,
419583,
null,
19029,
4008,
113898,
49701,
21113,
542454,
13699,
611969,
473122,
24020,
210839,
null,
138530,
41684,
34739,
406022,
11311,
220023,
55045,
86685,
135552,
217460,
244312,
85756,
70509,
39597,
null,
null,
132933,
62750,
61033,
135864,
5525,
184944,
null,
134379,
221014,
287480,
57829,
null,
8201,
185044,
56602,
590803,
52827,
12727,
160740,
77460,
103554,
17422,
null,
null,
102425,
110819,
45160,
21918,
46015,
null,
16354,
32828,
114057,
43688,
86425,
82215,
33323,
57064,
4167,
null,
275588,
70686,
91397,
446738,
3384,
462631,
24700,
39876,
124312,
46562,
278207,
47440,
45737,
229439,
39412,
null,
822095,
73010,
261523,
19180,
334538,
45390,
68517,
43136,
null,
29059,
193167,
25804,
38041,
null,
187551,
null,
125355,
9701,
135853,
24478,
34216,
280754,
82604,
140956,
34494,
305863,
157653,
65124,
249409,
25437,
122415,
288643,
null,
248356,
238898,
123522,
548880,
230909,
278277,
49483,
315899,
22255,
39063,
191581,
124011,
238330,
185764,
63610,
213487,
172646,
38598,
49069,
4560,
392617,
112867,
137023,
30156,
29809,
157739,
974449,
316666,
18613,
27261,
326831,
240250,
284292,
30743,
24093,
111311,
45835,
26072,
118171,
189469,
164500,
194668,
443160,
48206,
17401,
15118,
118619,
34225,
211950,
384040,
33810,
123344,
283896,
100149,
173859,
167956,
null,
317951,
77530,
398322,
42214,
381151,
57163,
145940,
2007,
235788,
125676,
20051,
4598,
57139,
198787,
38164,
129382,
9378,
251277,
71484,
526028,
15188,
217832,
130493,
247181,
13470,
9018,
15494,
166797,
132411,
141123,
null,
null,
58329,
148161,
268662,
53840,
457310,
60420,
202263,
31198,
10169,
6841,
null,
282783,
167457,
null,
157120,
217145,
147300,
378467,
100701,
null,
70972,
143221,
302404,
228588,
26690,
8775,
80103,
null,
45677,
251432,
227948,
53687,
9786,
273428,
590420,
236908,
316139,
23860,
12234,
24326,
288552,
315953,
21115,
163578,
722392,
240418,
29435,
150487,
492197,
20685,
132018,
72200,
296617,
20712,
287692,
195471,
5576,
162777,
63882,
82609,
50328,
226932,
338019,
779972,
190074,
null,
364293,
547560,
null,
172182,
251709,
552587,
292508,
130619,
50112,
22446,
164192,
13559,
24701,
179321,
2686,
95322,
212115,
37510,
null,
861063,
162834,
12841,
54492,
115544,
193940,
10690,
62474,
253889,
251556,
363842,
null,
76734,
155509,
22761,
128847,
null,
66730,
26770,
20379,
133445,
236349,
10449,
160501,
7503,
53253,
192511,
83010,
204729,
20450,
164634,
45737,
150830,
9925,
111668,
37408,
13858,
319317,
171413,
139746,
14835,
543641,
null,
386082,
216877,
null,
23818,
8094,
11047,
34371,
199623,
null,
377800,
35536,
39774,
187508,
13287,
24785,
null,
null,
10240,
409268,
23253,
27027,
30677,
332521,
392611,
29909,
42941,
28901,
null,
144966,
39547,
33896,
83997,
null,
383426,
329788,
237710,
8046,
11756,
276169,
33074,
null,
19430,
687955,
35687,
null,
653655,
34034,
13331,
34922,
102069,
123627,
168377,
66633,
333501,
7374,
20219,
37809,
73657,
56968,
27184,
56831,
405381,
null,
87402,
70643,
20340,
8815,
240628,
39604,
326513,
190053,
38756,
234033,
15072,
557401,
98203,
273206,
66603,
441186,
182531,
174656,
22927,
20436,
251048,
40406,
342876,
15531,
144448,
221578,
400319,
42458,
983839,
254281,
3798,
167198,
73182,
53052,
30934,
16395,
359169,
54711,
null,
93238,
null,
16222,
184201,
323063,
75770,
232995,
155584,
null,
83876,
4015,
49965,
113082,
19564,
530074,
103781,
99493,
null,
null,
40021,
53422,
33604,
279973,
17149,
107871,
239629,
50223,
194722,
null,
null,
75643,
16292,
141504,
42616,
143112,
237181,
8659,
321021,
54250,
64568,
46096,
null,
15489,
80818,
15529,
209210,
216484,
34861,
66482,
212934,
35068,
140508,
105032,
110883,
152574,
168188,
74840,
397630,
5081,
234515,
154871,
191472,
217484,
39867,
24787,
39341,
175429,
88248,
null,
141221,
106639,
67067,
72431,
602762,
227133,
56972,
9129,
58236,
23465,
160405,
20960,
194058,
30286,
16072,
18118,
18391,
613657,
5453,
26390,
76028,
36474,
51214,
397647,
141509,
163930,
8401,
37822,
139177,
12527,
237517,
40737,
23147,
234422,
179723,
129820,
26021,
58520,
33124,
245017,
69129,
53077,
134033,
156800,
18754,
429728,
47449,
400550,
289344,
15956,
541465,
12809,
331327,
13660,
29058,
44677,
null,
18965,
31540,
389985,
201250,
333629,
12331,
32577,
441799,
146751,
303716,
6545,
210096,
162031,
null,
195846,
327264,
40076,
240364,
6991,
65267,
462441,
348648,
null,
42205,
43627,
62276,
339852,
null,
11871,
null,
193722,
95568,
7392,
59178,
126665,
18646,
88721,
44181,
null,
null,
null,
170689,
13611,
20131,
309625,
40430,
401227,
null,
122423,
10743,
87171,
317969,
40519,
177345,
624158,
29513,
81046,
12859,
196760,
null,
187620,
27563,
53029,
7040,
34834,
75278,
92499,
108263,
977415,
null,
74725,
3759,
198675,
66534,
109870,
32306,
39444,
500324,
4442,
58906,
369240,
14502,
102853,
75522,
null,
29919,
56753,
8160,
193792,
54965,
11018,
31827,
40081,
64529,
36963,
47585,
211683,
31542,
3231,
179187,
40689,
28059,
19236,
11290,
9636,
393945,
33502,
165093,
461542,
13481,
21472,
33860,
57049,
54920,
21042,
68326,
33640,
68028,
60058,
47769,
131742,
40550,
257350,
172657,
null,
435648,
276268,
23041,
155029,
29367,
null,
144908,
17643,
206520,
97727,
26207,
30557,
23503,
4770,
28498,
440415,
205785,
39075,
36674,
257154,
100554,
10687,
182917,
328136,
27429,
18920,
626685,
8990,
137510,
32950,
166973,
90326,
293704,
212225,
23235,
336125,
177116,
14975,
14975,
196092,
44082,
69482,
60999,
17072,
109631,
28990,
19017,
135710,
21071,
431107,
112232,
31078,
116624,
40435,
33643,
62533,
124103,
116604,
555875,
188094,
3238,
24214,
15034,
48239,
245758,
7816,
184653,
185123,
32986,
565934,
32295,
174332,
266483,
52147,
174753,
428310,
347880,
25337,
12914,
77543,
242216,
36321,
31988,
86249,
249232,
105194,
null,
188230,
16816,
null,
350077,
252720,
142812,
223155,
51232,
688108,
311155,
445036,
48380,
226279,
220994,
44399,
254685,
439927,
18975,
null,
25859,
120289,
166586,
168542,
353556,
285704,
14326,
81058,
32284,
241193,
307284,
44679,
13306,
264721,
279959,
null,
14597,
65429,
34982,
null,
276683,
342766,
28649,
25214,
273508,
82540,
59095,
28054,
15641,
181044,
161188,
30658,
40029,
28488,
211453,
12020,
19206,
126114,
25769,
60552,
140250,
529907,
303696,
260722,
null,
76272,
126226,
207512,
105357,
115245,
321958,
443589,
44723,
170351,
9450,
343442,
137907,
459588,
819257,
20064,
79502,
null,
187869,
106839,
null,
39161,
330700,
317097,
324448,
56523,
null,
209638,
11971,
38626,
54578,
null,
402170,
258975,
310620,
200326,
11163,
70070,
127544,
null,
31274,
26881,
null,
24374,
63795,
9201,
27370,
253894,
28517,
26308,
366373,
42416,
214757,
233849,
1154527,
222277,
155087,
18562,
null,
15110,
90149,
30719,
88177,
24830,
174705,
282732,
40428,
125667,
299696,
325428,
26696,
22011,
43907,
null,
223992,
232020,
5360,
240528,
286441,
11664,
213548,
187341,
7967,
185291,
20372,
51705,
null,
413949,
237897,
176792,
140996,
183928,
153773,
135261,
57042,
84087,
121578,
143105,
107950,
14700,
116374,
75635,
null,
18897,
207977,
221235,
23379,
43644,
526516,
24662,
233467,
422026,
86887,
108300,
277290,
125065,
140851,
474410,
17802,
32258,
124681,
112166,
169054,
250710,
117674,
90564,
154515,
2579,
10899,
320517,
91189,
26842,
30645,
247100,
4381,
null,
37597,
4783,
167082,
263835,
27998,
41885,
51747,
56487,
63924,
19082,
189699,
215814,
389615,
99824,
55652,
null,
116280,
47163,
19070,
26861,
286663,
70629,
11102,
166540,
116763,
122438,
133116,
63626,
12203,
66095,
214494,
439250,
357503,
62175,
575907,
198066,
27616,
29908,
268874,
209982,
166660,
24659,
191187,
10298,
79223,
23566,
25589,
30398,
403776,
619532,
59938,
null,
552878,
28941,
76365,
709217,
22346,
150042,
17965,
502264,
null,
354609,
74638,
87648,
86753,
246285,
60771,
5059,
195985,
36100,
20949,
139670,
63465,
146218,
241244,
8865,
14968,
232867,
8228,
16291,
40374,
269032,
35172,
341879,
43797,
37915,
14606,
332739,
372255,
414330,
29248,
6573,
164076,
146150,
31543,
46415,
26902,
29187,
381957,
22143,
18497,
27005,
191169,
null,
9436,
304637,
11972,
63364,
23971,
83481,
45086,
39741,
17119,
null,
417852,
24520,
52022,
73127,
776453,
672414,
39035,
7889,
255245,
517481,
45075,
39822,
9250,
243249,
76547,
17574,
35008,
239621,
284599,
37791,
289037,
17651,
12513,
4815,
19234,
34839,
null,
91919,
20266,
31080,
42921,
267879,
74855,
495228,
47813,
511572,
248810,
290588,
53370,
14980,
120051,
93713,
102555,
5527,
null,
20023,
37821,
914,
19242,
null,
129774,
null,
3680,
10147,
467424,
61102,
76677,
25331,
364447,
4383,
37709,
22445,
478989,
39720,
301671,
52335,
34123,
296948,
5181,
19185,
null,
39256,
18239,
245112,
41143,
29852,
92527,
28892,
107157,
217248,
282099,
138140,
39206,
null,
null,
36740,
30206,
172829,
146541,
22661,
20054,
65159,
34363,
29648,
104843,
null,
209598,
113869,
17950,
223584,
25266,
45573,
null,
null,
206151,
217587,
625273,
24704,
78083,
55007,
56107,
18944,
387365,
222066,
121781,
217214,
68608,
290200,
17240,
241099,
8507,
130341,
99323,
15644,
22502,
563248,
47785,
106973,
48554,
1802,
73772,
15055,
null,
144267,
27521,
null,
48426,
14180,
141143,
481528,
21192,
262495,
121780,
625,
22219,
330737,
217706,
97131,
33193,
288590,
null,
131388,
101017,
148342,
null,
196871,
20153,
394341,
286342,
181592,
null,
39182,
115608,
320705,
55229,
63579,
286839,
13887,
44712,
60030,
131721,
17220,
267111,
22299,
392723,
409013,
293527,
46787,
382551,
103496,
166963,
67705,
12241,
216705,
null,
19725,
180584,
30753,
283485,
34530,
186373,
245449,
315908,
183721,
177901,
70477,
55206,
410024,
311297,
145673,
6927,
36316,
254143,
8755,
null,
21394,
577941,
17488,
63118,
30898,
10353,
null,
24427,
null,
100571,
303610,
298208,
118636,
185065,
69013,
162735,
18091,
37157,
null,
3235,
313007,
12772,
25810,
null,
296566,
40658,
34280,
6544,
98936,
67620,
null,
25277,
64579,
363237,
82005,
181215,
284518,
null,
122726,
471310,
426585,
76124,
294722,
5855,
26714,
195543,
26853,
103634,
357494,
274153,
100936,
10392,
22664,
53467,
185205,
11315,
134333,
37714,
null,
223734,
74189,
121573,
265572,
216957,
117764,
null,
461086,
3716,
35157,
46881,
71222,
220416,
114995,
65191,
263084,
50323,
313156,
0,
26286,
199809,
340419,
74210,
12820,
77434,
495421,
null,
128434,
1630,
247743,
199402,
617055,
27186,
155415,
613013,
32214,
11935,
42225,
21631,
96075,
79896,
40674,
33958,
37812,
244431,
35021,
24546,
73387,
41531,
421756,
null,
null,
203568,
83191,
23453,
175892,
32828,
11893,
308182,
null,
48396,
44476,
56279,
18687,
null,
134662,
null,
10725,
29612,
89626,
9505,
48817,
116756,
17462,
187216,
224195,
192021,
null,
290672,
319344,
161794,
421927,
361866,
375147,
34753,
7537,
23823,
71231,
156220,
42805,
55137,
39607,
15302,
64418,
7738,
49186,
251239,
185230,
93580,
null,
170022,
null,
508256,
17637,
159165,
14848,
378299,
93440,
91908,
42653,
null,
10944,
146112,
11385,
264595,
94115,
134074,
43802,
63782,
11322,
27853,
210323,
30144,
272502,
null,
269652,
29056,
87236,
18147,
75431,
96772,
250518,
30260,
21096,
45402,
82985,
8447,
204531,
2970,
29901,
81216,
237741,
377652,
622133,
17540,
86638,
106807,
88550,
95197,
311477,
203812,
232090,
6940,
321106,
19812,
28668,
null,
130266,
7736,
183627,
28346,
5125,
1335,
401619,
23868,
102412,
165559,
46789,
43710,
206874,
9581,
246566,
67346,
215755,
152400,
76690,
12944,
161468,
15454,
21462,
526823,
35813,
154678,
80294,
560545,
91878,
394589,
45112,
150233,
54835,
83096,
25675,
97554,
59829,
43187,
29678,
3699,
268368,
16658,
15278,
249141,
102228,
50475,
null,
5597,
223186,
null,
88735,
342519,
6428,
104895,
21818,
null,
214943,
26545,
104358,
24901,
17128,
221571,
252065,
16356,
12987,
191308,
51244,
93581,
null,
58878,
null,
121649,
27593,
null,
null,
66150,
8437,
58033,
19343,
328810,
27505,
27807,
27497,
null,
203910,
208668,
null,
296628,
6079,
5704,
2247,
149099,
260009,
null,
314547,
31759,
41174,
null,
null,
47883,
96490,
162302,
12883,
234515,
498624,
33233,
31605,
237992,
24567,
46602,
178759,
137022,
137308,
397275,
39063,
421339,
86924,
155335,
335728,
15710,
41418,
81439,
36436,
null,
216415,
40951,
257428,
9998,
32981,
null,
14133,
115984,
778258,
21354,
96993,
63875,
267235,
52898,
372649,
142021,
270733,
272419,
346265,
21012,
215365,
24030,
39437,
55958,
44130,
32763,
47725,
189650,
79671,
71310,
119515,
160034,
49003,
30499,
403124,
76811,
318791,
207104,
69874,
45028,
17844,
60113,
321280,
21056,
39227,
43623,
15696,
247672,
119425,
106695,
199663,
21938,
508919,
868,
12051,
null,
2753,
430506,
236591,
29096,
297908,
null,
10951,
4297,
23443,
313671,
51316,
17337,
63279,
102435,
364621,
139052,
35254,
302785,
155860,
60355,
18788,
63328,
4224,
268741,
319499,
117381,
213326,
null,
43599,
288836,
222843,
17343,
81100,
7896,
41038,
25784,
288938,
319763,
64095,
null,
72229,
309180,
17509,
26396,
26950,
55840,
33373,
70773,
805611,
43218,
348986,
80192,
54623,
198650,
351839,
null,
490363,
42052,
365928,
290128,
23269,
317345,
47558,
92095,
24284,
null,
128428,
10676,
45309,
9990,
31695,
18701,
62550,
null,
172443,
9291,
317110,
10204,
18007,
764686,
11333,
87454,
108685,
167595,
176346,
null,
25675,
73046,
241236,
38072,
45250,
338140,
61458,
502292,
null,
50442,
18800,
219045,
124727,
8390,
152243,
328043,
75120,
404969,
74496,
63686,
61658,
94831,
137332,
14265,
315815,
196450,
64245,
145781,
17570,
110261,
11538,
16116,
214696,
203215,
542080,
6538,
62900,
189176,
161826,
115630,
239598,
57253,
147522,
17151,
262410,
37152,
30790,
76561,
17234,
49075,
23983,
16758,
10765,
66435,
17774,
106836,
25277,
184712,
54512,
167789,
23749,
28579,
141576,
334240,
338700,
198607,
35964,
48020,
10947,
78627,
383111,
66397,
15630,
436876,
201384,
166429,
50426,
29847,
62580,
48388,
94942,
355966,
12712,
136036,
396277,
89112,
107358,
287689,
22498,
129015,
19828,
275531,
72951,
null,
3302,
181597,
23719,
176377,
28190,
44809,
33967,
108338,
102365,
45148,
6733,
null,
272875,
8967,
22975,
237556,
33078,
30410,
5325,
16104,
79551,
352913,
115877,
215565,
37254,
135371,
null,
26040,
20625,
7573,
40428,
80046,
203244,
19687,
42573,
92203,
554318,
122155,
286415,
117804,
375626,
null,
120279,
null,
199023,
300486,
20698,
13466,
274720,
30009,
39577,
13502,
175732,
5083,
191312,
39663,
3637,
49274,
183141,
270097,
14740,
202041,
14290,
74244,
16844,
null,
null,
null,
63296,
null,
4076,
292054,
46212,
110076,
230042,
13742,
29260,
41772,
325086,
110455,
382001,
237782,
45471,
278811,
299357,
411014,
355119,
246095,
11256,
112955,
254511,
158050,
73806,
null,
108063,
214801,
215354,
281486,
57400,
38431,
334551,
376939,
306912,
186698,
55830,
419190,
779978,
59624,
36383,
270958,
38115,
551941,
48228,
178012,
33400,
88799,
237712,
17467,
280424,
174862,
141881,
162191,
61325,
15273,
3925,
286533,
442671,
114668,
21645,
189556,
51409,
219193,
73610,
529465,
51728,
20336,
52684,
124851,
32601,
175390,
19404,
50759,
316568,
213849,
43129,
6765,
75545,
38716,
297714,
102858,
190643,
131733,
217565,
42107,
138180,
42968,
83286,
8885,
28100,
644435,
2902,
18056,
9509,
null,
61134,
111659,
137479,
223565,
null,
171537,
382912,
134041,
43873,
62253,
44988,
3378,
null,
180012,
24562,
326725,
544533,
16555,
90109,
329164,
118858,
17103,
179600,
421756,
455987,
35936,
154180,
164380,
42633,
49016,
null,
418977,
251845,
300882,
115018,
59721,
289269,
367571,
484114,
51276,
198035,
null,
179802,
4842,
17038,
29903,
154930,
144136,
53988,
42517,
9376,
55043,
124168,
197007,
130868,
244595,
191696,
43322,
156529,
null,
173740,
16128,
710070,
null,
60697,
232173,
143271,
33225,
60161,
15263,
55209,
null,
97533,
197063,
37848,
null,
45194,
336447,
32352,
28715,
94636,
24561,
56361,
12412,
228608,
12519,
null,
211474,
230605,
32986,
36519,
35913,
134250,
11035,
22980,
null,
131663,
198219,
119527,
26552,
36133,
918956,
13927,
45316,
106411,
8310,
null,
12790,
220747,
313470,
52198,
7016,
251106,
293982,
144465,
4225,
32832,
18258,
24992,
null,
240105,
203177,
130343,
180892,
10707,
null,
8748,
132858,
24351,
75853,
17888,
435608,
8276,
4355,
382590,
21587,
null,
247490,
1162719,
295724,
13008,
140361,
110461,
540036,
216939,
113310,
53913,
190124,
95249,
222110,
20917,
14599,
54668,
105351,
150429,
34647,
42164,
33709,
241156,
44694,
null,
68873,
10886,
79894,
12134,
23865,
null,
21710,
133256,
303919,
196439,
39811,
154666,
76108,
14780,
41002,
363618,
439201,
null,
74010,
139003,
166975,
null,
58348,
469680,
49601,
312851,
131268,
55863,
83944,
28158,
14646,
254060,
66541,
25725,
null,
25910,
75869,
30190,
51098,
234491,
302332,
28842,
18703,
150398,
25078,
null,
15097,
118174,
210552,
57343,
32233,
50633,
9737,
107275,
null,
23047,
null,
33235,
19433,
64293,
16522,
3949,
32807,
null,
15369,
62585,
62038,
null,
36659,
304045,
498625,
99154,
80811,
192028,
28155,
248672,
16767,
23913,
241362,
88970,
89229,
23326,
186208,
45151,
4146,
308240,
42898,
11028,
326835,
3579,
null,
47101,
68295,
413646,
649227,
102709,
168873,
193064,
176426,
153425,
110489,
null,
234484,
null,
83227,
null,
150577,
9289,
186472,
606442,
null,
null,
5421,
18097,
30289,
29097,
90130,
195281,
1358606,
59905,
511103,
240247,
12877,
152925,
39677,
153802,
237915,
270054,
189174,
null,
420584,
9423,
135654,
24013,
16343,
105375,
279090,
31916,
null,
412342,
47138,
23453,
27411,
26061,
389727,
5296,
29033,
472358,
341168,
425201,
2264,
52318,
201737,
503199,
48696,
134827,
146464,
41181,
29374,
null,
20183,
124006,
18773,
91358,
95392,
null,
34551,
15869,
12781,
297155,
25271,
37443,
153111,
380221,
null,
18272,
null,
161822,
430276,
174444,
115952,
null,
35737,
null,
218110,
49066,
81625,
40447,
81784,
27718,
30469,
391193,
150733,
33455,
145007,
162739,
41084,
197884,
200841,
463888,
null,
58280,
74055,
210281,
31970,
null,
60428,
null,
11127,
279936,
198506,
null,
99644,
250032,
119113,
16021,
8886,
18212,
131558,
83183,
17103,
4215,
164921,
75601,
156519,
23880,
203500,
370103,
361595,
22378,
346741,
16935,
232820,
240495,
null,
7948,
377221,
null,
36666,
41581,
251904,
120243,
null,
477825,
null,
17163,
null,
54663,
187273,
41041,
100181,
124534,
47072,
385680,
16714,
null,
27474,
408857,
90178,
137311,
344964,
262449,
279124,
26942,
255591,
null,
363103,
334087,
null,
20281,
18608,
256260,
122099,
18487,
171646,
21486,
41492,
43591,
162739,
190362,
275460,
25256,
3242,
143328,
108555,
54382,
31177,
68487,
16545,
null,
382097,
211490,
168410,
199479,
null,
13263,
310507,
285179,
null,
123695,
3544,
56644,
49652,
242000,
30619,
58531,
28767,
28555,
306437,
93345,
58901,
370683,
39815,
36708,
55918,
20129,
51898,
71223,
225432,
31679,
177207,
3081,
6927,
null,
239504,
15985,
548403,
151808,
295304,
306693,
176871,
51740,
492587,
37070,
225814,
null,
466692,
27702,
3862,
8753,
162897,
145681,
44136,
36671,
null,
249513,
87431,
76700,
131620,
28156,
null,
92444,
250160,
6398,
212656,
null,
16552,
21965,
112995,
null,
23526,
null,
32762,
9582,
394008,
307494,
40658,
4424,
107621,
7611,
498306,
162239,
220331,
15763,
66175,
71043,
64060,
null,
499669,
259897,
63155,
15607,
178897,
385868,
121905,
55085,
324270,
null,
25019,
115148,
7411,
27597,
null,
271149,
70915,
28824,
361567,
null,
null,
13742,
17774,
318751,
32579,
21736,
94272,
22333,
12944,
85324,
54423,
293638,
279755,
null,
306911,
85034,
38507,
42896,
8117,
300950,
469775,
null,
67114,
122150,
24662,
333192,
null,
36785,
38862,
98149,
27370,
179322,
16602,
75391,
90849,
null,
null,
174116,
393276,
30867,
205817,
132379,
null,
755510,
8121,
102602,
401751,
143759,
34770,
197386,
153597,
64907,
119197,
42510,
203918,
230572,
215234,
202647,
189616,
365791,
15758,
76417,
26558,
41326,
267921,
59440,
130395,
113921,
289827,
null,
25303,
93219,
426506,
52775,
41204,
265035,
6323,
45555,
114883,
51792,
251242,
63814,
17438,
23532,
51811,
244038,
786030,
11045,
49982,
null,
134384,
27465,
8779,
266053,
72776,
55042,
15646,
25752,
63468,
null,
353372,
110976,
18003,
406674,
50570,
49643,
440531,
13142,
73492,
54175,
40476,
11911,
289435,
248808,
66568,
161245,
115612,
43762,
144512,
7397,
295752,
35604,
23085,
637603,
165747,
33446,
14058,
25829,
174890,
53531,
277917,
126326,
18893,
25289,
338997,
null,
173492,
36581,
31762,
26721,
13602,
211959,
41303,
41756,
null,
49696,
299278,
120306,
563888,
387807,
102664,
33568,
284339,
37517,
94865,
365495,
232840,
null,
9281,
24113,
11352,
null,
154773,
42472,
125776,
124892,
220843,
116921,
92233,
310189,
80242,
36527,
33059,
27467,
218991,
174228,
24638,
299971,
191361,
19316,
219477,
167650,
13644,
118060,
32382,
22746,
27399,
322314,
17504,
50129,
21643,
40126,
214720,
113433,
16761,
910509,
272252,
141237,
55986,
38661,
59449,
75750,
300051,
609966,
217937,
175737,
55603,
325881,
233540,
20817,
359587,
382687,
99452,
229371,
36239,
51050,
238203,
17934,
28100,
370110,
14912,
28397,
65341,
null,
34008,
195364,
259752,
9961,
266009,
149344,
23648,
null,
117065,
173538,
24643,
38455,
24711,
12504,
77359,
62132,
14412,
19762,
135930,
36317,
125946,
64227,
46096,
39413,
123434,
163825,
231106,
11950,
60618,
439794,
119470,
46491,
27129,
330216,
59965,
342452,
56881,
26867,
142417,
73722,
429439,
10305,
82672,
231685,
355543,
290684,
54279,
21854,
25869,
361059,
10545,
61891,
20212,
14139,
46047,
12189,
107449,
18443,
41299,
35034,
35634,
37487,
181172,
43264,
32913,
26904,
71479,
37876,
null,
111044,
297846,
null,
271862,
83598,
40170,
74604,
161296,
27833,
40081,
28683,
null,
198517,
93686,
4443,
156104,
405165,
31333,
577250,
null,
31549,
70339,
21272,
158064,
48605,
250741,
159662,
15541,
284039,
289744,
null,
60670,
43470,
76281,
19339,
492563,
156858,
116678,
34065,
230505,
38339,
8640,
188431,
94263,
32882,
67952,
20856,
315464,
5163,
168463,
105785,
17476,
314104,
95351,
57079,
15413,
163646,
254067,
91964,
17857,
72325,
null,
6223,
13995,
16859,
31675,
265224,
128500,
296372,
58174,
263968,
155951,
293339,
363189,
130292,
41179,
28101,
54729,
26364,
36319,
47354,
313986,
13343,
157467,
null,
627557,
350661,
7803,
52860,
382680,
17719,
389438,
null,
32952,
null,
518915,
3746,
162873,
432385,
62995,
39038,
18063,
143221,
30028,
417397,
276692,
null,
442603,
702371,
122127,
162109,
51195,
17367,
93551,
232118,
106848,
354004,
200174,
43539,
30723,
144865,
68382,
null,
177665,
28086,
144316,
33789,
33120,
54128,
83652,
215819,
8535,
135695,
500346,
241504,
24953,
328594,
66196,
14926,
null,
15124,
29329,
12919,
80766,
19000,
31951,
169132,
13476,
121477,
189863,
448710,
34491,
156405,
33098,
335025,
119211,
606082,
16820,
null,
338387,
17602,
null,
63454,
157912,
9934,
23148,
559022,
375802,
4419,
204788,
8921,
null,
338005,
17653,
38684,
82669,
7386,
142413,
27838,
17595,
36120,
89556,
214502,
47795,
72387,
18695,
5879,
214289,
51866,
5858,
69522,
31106,
209606,
271909,
156861,
102737,
464271,
417462,
80642,
396122,
35432,
372356,
40168,
5662,
305594,
30461,
19166,
228856,
15057,
398069,
34157,
57484,
38439,
55215,
46206,
68601,
6495,
182317,
49747,
139052,
95816,
37187,
222758,
222034,
3377,
20160,
62660,
297056,
21723,
824165,
37666,
215273,
104139,
31217,
42057,
615883,
93319,
252348,
278678,
36038,
292451,
82680,
256132,
102024,
3672,
88163,
7843,
262203,
655154,
93619,
797943,
25189,
58367,
null,
82308,
312123,
439471,
301165,
91979,
21438,
11363,
10040,
204618,
265220,
163910,
null,
67500,
153444,
31255,
510120,
260139,
157857,
253992,
null,
16711,
null,
247482,
25669,
359552,
336968,
137441,
283762,
null,
750468,
242129,
8515,
148766,
25655,
407690,
72839,
19442,
336774,
null,
142322,
215009,
25212,
25311,
33523,
47432,
43165,
293359,
294960,
401873,
263045,
14990,
188437,
123732,
161196,
437678,
6765,
158036,
20468,
279468,
55376,
62651,
49187,
286398,
162803,
265479,
66430,
21583,
467532,
521808,
42105,
17089,
31141,
35071,
null,
17795,
433981,
369608,
176481,
23145,
227938,
154023,
39560,
28587,
28210,
58962,
12703,
257135,
43432,
201438,
293761,
45921,
19673,
27027,
315498,
55036,
414863,
57799,
66156,
48079,
7010,
17785,
215091,
20511,
9230,
169910,
57039,
215264,
37175,
17611,
45840,
null,
null,
194447,
273998,
19522,
35236,
34073,
11972,
147676,
60297,
24008,
309536,
264166,
76792,
38370,
null,
10084,
118779,
58826,
33449,
70582,
null,
166981,
8559,
40982,
158119,
null,
78802,
16440,
359295,
null,
195197,
24912,
4301,
24512,
36958,
null,
108407,
115748,
41227,
43161,
null,
20528,
8962,
218485,
27705,
null,
75107,
242332,
187223,
null,
257395,
249338,
183274,
null,
221578,
16207,
205451,
null,
61869,
153781,
24207,
216046,
210143,
140390,
106131,
19180,
31269,
161874,
16134,
150266,
40435,
109411,
38279,
193487,
12630,
228218,
416879,
100756,
122916,
257712,
38145,
27414,
4285,
519107,
185766,
373657,
57871,
38391,
57212,
29733,
33985,
234903,
263774,
239336,
75287,
231054,
546864,
null,
22913,
226212,
25413,
2870,
1201215,
210773,
55546,
27865,
50688,
36680,
null,
38852,
95290,
186088,
128739,
285875,
505442,
212189,
9208,
198771,
281644,
62145,
131055,
542627,
25259,
173575,
90228,
11674,
53464,
46208,
612463,
279107,
10022,
null,
128422,
36566,
166510,
null,
26543,
9810,
181777,
29548,
26501,
394955,
52404,
98289,
310361,
9976,
34730,
null,
265647,
39135,
492017,
210693,
66332,
53719,
330880,
84381,
160991,
97779,
17131,
425773,
29269,
123664,
329095,
54786,
230250,
195803,
122206,
null,
117390,
45035,
276844,
131525,
298531,
16254,
null,
null,
751921,
61850,
204614,
435631,
348689,
600234,
189171,
64280,
null,
468043,
65142,
112168,
252493,
150010,
137016,
335122,
219494,
29969,
43046,
138672,
30174,
30505,
481366,
30107,
5304,
null,
117218,
279828,
88154,
122933,
9267,
312875,
622516,
11048,
45540,
158504,
2673,
178962,
175862,
4891,
193990,
104380,
336535,
3291,
39701,
327641,
180764,
36557,
110671,
24806,
37157,
628800,
237485,
29178,
3469,
43641,
129826,
46186,
56707,
307544,
89490,
176578,
16709,
91291,
26069,
13738,
146805,
398424,
42555,
45868,
null,
337620,
304572,
30725,
352121,
216283,
43075,
3706,
55042,
260232,
null,
185939,
82755,
214335,
61174,
6870,
75884,
77079,
null,
null,
348511,
229334,
574244,
43719,
16240,
null,
478349,
236697,
193581,
50430,
null,
102970,
20006,
349892,
80695,
19142,
12748,
17544,
86466,
28629,
25194,
234564,
9811,
201448,
20068,
null,
211341,
33464,
245207,
21924,
null,
96240,
null,
152464,
26293,
169890,
92566,
82414,
45689,
19238,
2885,
143005,
315558,
792145,
421030,
1761299,
222162,
33407,
19513,
null,
24309,
25420,
18300,
138944,
76536,
100044,
56820,
50296,
81106,
35656,
25678,
287700,
148728,
226131,
4978,
53670,
291905,
null,
77266,
124936,
26768,
11608,
197228,
26758,
42020,
21672,
133607,
15059,
22436,
16787,
329985,
62106,
18940,
22853,
339150,
null,
229438,
null,
54775,
199585,
null,
26659,
95094,
133700,
281499,
29930,
108053,
133954,
1064933,
98287,
97824,
16489,
9875,
172083,
194686,
197121,
null,
441457,
19860,
null,
112811,
203300,
97878,
72538,
469522,
24351,
273515,
29165,
120404,
8573,
19559,
418002,
7838,
188734,
58235,
227590,
309449,
null,
4156,
136066,
329635,
16550,
26918,
21930,
10772,
162144,
60231,
27692,
null,
329307,
8122,
7334,
191737,
71475,
57463,
42848,
123846,
165427,
17243,
163426,
258179,
22949,
348938,
201870,
10372,
152866,
97627,
42223,
343603,
277257,
40849,
101732,
9390,
8069,
3070,
25207,
null,
254428,
43987,
134974,
17625,
111688,
231904,
25255,
null,
35459,
26782,
12901,
30600,
72685,
29447,
26210,
532763,
286436,
54800,
35138,
33656,
54133,
421290,
239332,
45917,
3806,
94338,
21216,
255423,
27618,
425380,
149736,
null,
22068,
6161,
539560,
20985,
16592,
14720,
528647,
54145,
242045,
32443,
392685,
152780,
195678,
342064,
55507,
77612,
260285,
12816,
193393,
18357,
34259,
37509,
16559,
18642,
68207,
198084,
434698,
44068,
345727,
65296,
393848,
43632,
187417,
13434,
79282,
241837,
659530,
229884,
27457,
108825,
564881,
21835,
30262,
46396,
426530,
16801,
null,
29931,
265958,
281051,
27039,
24315,
93315,
527558,
540840,
141443,
508516,
24946,
265279,
10096,
19118,
96563,
103218,
9182,
146988,
212491,
18368,
531676,
606772,
386553,
150772,
183254,
30438,
142673,
63596,
160706,
562060,
16758,
14879,
368242,
596781,
14846,
82016,
8613,
306378,
69492,
115714,
34755,
null,
null,
214210,
19078,
458329,
8564,
18719,
20012,
264204,
45749,
152052,
14033,
29993,
43631,
268110,
511073,
152925,
275145,
138662,
null,
11825,
49719,
15316,
211861,
9567,
48560,
63246,
178677,
112028,
109896,
21387,
17648,
42210,
248464,
55688,
53904,
23828,
84189,
562404,
17908,
null,
42302,
69311,
20354,
209885,
142150,
39246,
58219,
null,
5815,
52120,
56405,
6444,
97072,
34794,
null,
13234,
58054,
166596,
5391,
9226,
286009,
89122,
null,
6276,
96245,
209779,
433159,
1042355,
369030,
49857,
212549,
488578,
19635,
18704,
9485,
49047,
172955,
69677,
15378,
26265,
335377,
172334,
25334,
14462,
15226,
171390,
27634,
null,
23885,
14674,
205134,
438240,
231442,
78946,
67593,
480,
31601,
66527,
237697,
317783,
null,
144910,
28958,
30567,
349283,
31401,
222502,
144937,
54796,
48647,
771955,
98747,
null,
6952,
113738,
49420,
58631,
147502,
12238,
96362,
521773,
26083,
11291,
149026,
45536,
25537,
58461,
54929,
10350,
23545,
204543,
null,
36563,
102083,
null,
33136,
227576,
160197,
277453,
83338,
19828,
157217,
21467,
322400,
null,
null,
30169,
22367,
37912,
95563,
101826,
186419,
29449,
274879,
198347,
15568,
23116,
48577,
27679,
21187,
587278,
356808,
51663,
39631,
21530,
43938,
33347,
null,
150986,
25633,
134043,
422689,
223829,
16036,
69308,
17047,
10898,
38427,
271998,
91825,
9902,
57224,
63659,
74248,
null,
170424,
10384,
null,
17286,
78945,
111513,
28960,
57416,
434048,
139692,
11339,
null,
258718,
71221,
235823,
213195,
59686,
756292,
217892,
378917,
null,
510,
null,
12375,
84803,
48093,
237875,
21343,
104844,
171409,
65797,
null,
221999,
10889,
100017,
275686,
27820,
258655,
120171,
104496,
343268,
2153,
931,
29165,
213428,
179437,
49864,
49624,
363988,
10045,
null,
323720,
216189,
146267,
141202,
142182,
16424,
112773,
113681,
150762,
68062,
19954,
null,
14334,
41358,
275177,
192743,
108510,
26082,
14792,
267530,
170468,
144066,
247826,
146313,
52268,
14033,
237363,
201297,
120262,
118866,
27857,
7669,
269871,
179868,
9169,
158619,
32141,
22093,
46894,
null,
34859,
102000,
37796,
43673,
236725,
14175,
42007,
270628,
314452,
101144,
211967,
94303,
203237,
348229,
null,
7069,
3595,
66609,
16448,
39900,
297505,
77059,
11151,
4066,
null,
85814,
238627,
423931,
223434,
7365,
345485,
4891,
387470,
651511,
45644,
null,
30410,
70959,
12292,
33073,
124839,
489844,
null,
145969,
191278,
211326,
286961,
61671,
378182,
437745,
79337,
148011,
153843,
38762,
113090,
28181,
47678,
null,
26582,
174644,
373318,
null,
37236,
23709,
118835,
172206,
229786,
121976,
225330,
null,
74846,
null,
189115,
667410,
26236,
334615,
405241,
18217,
302472,
32993,
106854,
20554,
18889,
27967,
33477,
40380,
161057,
6083,
73485,
35165,
131020,
185813,
224045,
98221,
25981,
251735,
14535,
341543,
null,
20458,
27197,
164200,
273218,
98044,
248418,
6580,
null,
370532,
201701,
253262,
167648,
76779,
13440,
null,
124286,
25165,
360599,
661539,
37935,
191096,
379991,
28176,
51425,
49059,
42448,
72192,
null,
376281,
13159,
556593,
712228,
18870,
127965,
112803,
132015,
259166,
128045,
39096,
21853,
9964,
86202,
25572,
62819,
18973,
209152,
298862,
null,
16527,
19495,
80695,
192792,
444016,
null,
20152,
287161,
252320,
31426,
null,
35211,
78490,
4675,
null,
126838,
204661,
39163,
105832,
314280,
28583,
141598,
33234,
41431,
178267,
15637,
14880,
8775,
23792,
781949,
174290,
46438,
124569,
132045,
30679,
24086,
25825,
77419,
83391,
419129,
79440,
9425,
373981,
25922,
14760,
202565,
16111,
305478,
289867,
26823,
511386,
295995,
34982,
181818,
283050,
174004,
7861,
7027,
215146,
18830,
35525,
26185,
300801,
null,
78202,
36142,
37886,
17293,
34555,
30314,
13629,
13688,
79421,
276343,
206101,
103494,
null,
63851,
320401,
573203,
null,
184856,
260142,
73553,
179800,
143795,
162585,
22461,
255287,
166127,
221913,
6917,
35176,
6112,
397178,
49131,
27930,
818308,
38846,
77773,
157518,
70689,
null,
38024,
17168,
28746,
null,
37673,
152878,
121248,
383155,
163628,
143593,
15402,
30721,
73658,
136597,
281365,
null,
null,
554181,
32787,
10730,
139795,
364383,
90394,
154236,
66941,
502109,
22878,
null,
360832,
170381,
210567,
13034,
101569,
17634,
4102,
94894,
null,
470032,
146855,
154151,
54057,
44047,
39724,
141276,
26945,
298100,
85963,
333,
756144,
31591,
70850,
23931,
68451,
26791,
187848,
105724,
44424,
34136,
321753,
71190,
34664,
175817,
5490,
230528,
57284,
141891,
133534,
270560,
142440,
null,
18955,
10162,
17654,
90138,
206867,
57727,
71038,
87936,
33743,
39921,
471935,
212424,
238434,
118169,
29141,
305101,
62396,
27790,
406510,
81095,
171926,
null,
679,
33742,
1034284,
null,
134311,
56571,
null,
27577,
null,
16401,
103357,
352438,
11585,
184765,
221538,
62661,
474463,
35129,
null,
null,
65354,
21364,
735462,
380263,
279892,
19066,
248853,
51219,
64679,
322580,
21432,
67604,
194476,
311165,
46347,
125697,
21807,
329429,
116630,
22859,
null,
136574,
259676,
140908,
433704,
42872,
70024,
231779,
447048,
11192,
22373,
9302,
605293,
556745,
293043,
39970,
null,
204209,
311447,
83543,
169502,
50556,
236900,
15556,
null,
24785,
49276,
109780,
58637,
178241,
16710,
60095,
77298,
179383,
82921,
52707,
176218,
270138,
15479,
51597,
79402,
41161,
479312,
202407,
null,
5610,
9397,
132162,
15802,
460750,
44727,
47110,
300408,
91664,
null,
423148,
111401,
138101,
277061,
191461,
84768,
37161,
95824,
308871,
32114,
42506,
141590,
71970,
27629,
null,
41828,
188534,
207710,
165521,
279732,
202755,
null,
345366,
1489,
62765,
null,
155981,
37719,
33425,
199601,
606672,
15312,
12838,
36938,
46926,
60842,
292525,
4398,
32798,
12857,
244446,
null,
4539,
52017,
215169,
20311,
147875,
166906,
295523,
57722,
97868,
100725,
23175,
13985,
611509,
109907,
346644,
10185,
43149,
44843,
212012,
106276,
null,
34751,
41472,
278767,
73110,
266449,
48337,
213181,
12076,
325415,
104940,
27913,
228902,
16114,
410303,
null,
35910,
25248,
61570,
315399,
222224,
18914,
null,
48811,
125427,
28275,
200289,
229855,
149020,
6284,
51134,
7321,
114511,
217751,
24497,
4881,
132984,
407402,
30945,
281494,
99690,
213510,
null,
249065,
288242,
99221,
null,
259052,
105810,
343010,
89690,
5711,
35373,
151385,
210607,
374391,
693660,
107413,
21509,
33717,
49732,
25512,
219579,
null,
94491,
35038,
369226,
47991,
155101,
52603,
269141,
107239,
37602,
null,
3711,
38466,
55988,
24050,
231773,
329705,
null,
345272,
255298,
138560,
1990,
161298,
321745,
540173,
19873,
142993,
null,
null,
24150,
34234,
93683,
93213,
124496,
null,
14325,
17529,
172077,
404119,
4549,
241013,
38866,
222439,
67814,
48254,
null,
67518,
49299,
40538,
347624,
349043,
15501,
231429,
170435,
354668,
55488,
158482,
112886,
142059,
603166,
null,
104845,
null,
625053,
90764,
115733,
310901,
30866,
59644,
null,
12684,
5113,
41768,
30366,
4190,
41917,
47926,
196771,
153950,
22244,
66242,
null,
56146,
3516,
330417,
6264,
325037,
165163,
187562,
null,
33643,
31386,
null,
14135,
6939,
1034998,
424481,
26536,
38972,
56559,
40684,
33818,
142377,
17595,
324890,
401006,
144893,
null,
186851,
475488,
15933,
511056,
36885,
24945,
17778,
131292,
null,
70252,
59532,
461858,
142249,
null,
71289,
55977,
20311,
156549,
255869,
5966,
26173,
12682,
null,
202839,
26814,
237621,
14099,
184293,
126519,
null,
291286,
20570,
11430,
5057,
null,
6580,
67040,
15709,
23167,
16824,
20180,
232285,
22430,
12664,
430615,
11257,
152769,
7172,
151136,
353109,
55904,
104697,
34612,
18139,
53918,
115506,
332125,
2716,
318856,
286629,
97410,
4580,
null,
263854,
167096,
56797,
141105,
127131,
150231,
24143,
579688,
506250,
27929,
29737,
217354,
29211,
178402,
372294,
10413,
35475,
378503,
null,
6624,
38664,
16504,
237309,
23456,
225109,
42540,
56693,
30004,
10372,
234313,
34872,
null,
75170,
30511,
10989,
13681,
186837,
307765,
372090,
68469,
40340,
77348,
267245,
742740,
242951,
364069,
2596,
315974,
182908,
41979,
6059,
25134,
45846,
210542,
46033,
192122,
10252,
38352,
null,
36345,
153663,
500744,
189117,
11996,
195998,
391014,
57646,
697813,
158645,
177600,
537050,
null,
245976,
129779,
19172,
36218,
11900,
5683,
34403,
119345,
223676,
null,
291796,
381961,
24712,
311634,
null,
null,
15077,
232404,
38166,
23640,
187873,
157530,
352173,
8246,
19759,
19884,
428870,
585778,
12327,
318282,
37884,
18832,
16329,
461525,
98108,
null,
71845,
55468,
43452,
218189,
19946,
31837,
36974,
null,
58245,
242179,
61360,
22156,
12826,
140608,
66071,
149903,
231621,
413954,
109696,
65784,
145039,
null,
13490,
29626,
7730,
985639,
167428,
547360,
29673,
89856,
49172,
193198,
453686,
null,
470428,
65326,
38030,
42713,
358395,
null,
null,
253491,
176604,
52326,
252238,
562714,
48927,
193151,
null,
43103,
132572,
102481,
22846,
18278,
101384,
2621,
347812,
69738,
239951,
290054,
9716,
165611,
416262,
30328,
15762,
10784,
34503,
31001,
56479,
103641,
39466,
153795,
null,
null,
14204,
5241,
84835,
30752,
59397,
507265,
29008,
23945,
null,
11567,
null,
367127,
133469,
264582,
313669,
216849,
120205,
103618,
454805,
63988,
456758,
null,
15344,
188308,
30441,
43662,
73615,
13490,
282511,
121265,
259649,
64156,
135223,
132149,
19436,
46479,
108610,
174275,
53619,
15201,
53026,
234671,
178973,
69867,
445120,
56048,
8293,
16964,
206094,
10330,
63221,
26762,
8710,
28893,
25243,
20069,
107969,
15480,
3674,
67270,
43703,
381273,
null,
129896,
5571,
11995,
203330,
298050,
32226,
32616,
688875,
221651,
23674,
67603,
28774,
37960,
221480,
288416,
133450,
121755,
341274,
80280,
38861,
null,
24550,
23868,
86324,
null,
106884,
44066,
194237,
164829,
11040,
178163,
null,
157436,
244607,
38056,
35682,
5829,
null,
190081,
240448,
19347,
178172,
18341,
23870,
19417,
72964,
227083,
307139,
203019,
15253,
581150,
39160,
45488,
90189,
22910,
43324,
68481,
53835,
120304,
19816,
null,
357883,
289803,
173467,
148677,
568814,
103890,
15834,
33433,
60224,
1855,
54833,
112592,
296019,
16656,
29801,
131702,
147499,
343448,
null,
243441,
25259,
null,
176602,
19010,
38231,
176375,
16938,
285543,
242301,
33531,
287409,
457075,
166115,
8341,
223386,
35975,
null,
273538,
null,
74369,
389410,
24517,
51960,
464381,
20525,
43199,
173631,
null,
47511,
26403,
62017,
26139,
109203,
79461,
163781,
113116,
92242,
331167,
262310,
967,
38580,
71593,
41499,
142004,
5146,
243126,
410235,
55016,
null,
259454,
10047,
408641,
102603,
145419,
98169,
33643,
119034,
4198,
202156,
null,
116528,
51408,
30390,
25787,
185300,
425217,
128786,
6221,
18302,
70070,
921885,
655372,
58532,
62535,
80142,
160641,
18940,
26144,
47450,
221182,
42824,
389974,
399436,
30415,
164959,
null,
20622,
69822,
85851,
66762,
null,
313883,
30247,
335023,
415614,
117160,
164926,
145076,
131028,
162544,
291759,
7352,
180313,
901113,
401761,
108941,
144026,
45416,
120112,
49314,
132043,
13409,
28760,
10366,
11171,
89591,
16036,
22511,
199832,
70054,
34234,
61292,
142964,
109391,
199498,
10465,
8057,
78520,
148200,
257865,
220942,
null,
16426,
378978,
null,
163736,
324345,
11881,
22407,
31797,
348061,
53793,
10649,
237682,
163995,
20636,
47422,
null,
351474,
113005,
21079,
116133,
79507,
391871,
169450,
249732,
185568,
165596,
18304,
95338,
385290,
198279,
null,
114059,
118866,
23691,
16188,
31811,
178989,
null,
187805,
316440,
675058,
74362,
145881,
null,
5449,
292579,
37319,
15327,
13094,
30709,
358754,
6579,
24471,
36418,
88995,
129817,
112373,
4043,
83805,
30799,
null,
319782,
10070,
32474,
65419,
113699,
81800,
23614,
267831,
21765,
null,
183041,
163976,
159625,
23503,
341825,
277417,
39266,
35128,
214360,
27897,
45207,
null,
44056,
433315,
24518,
null,
27729,
38817,
6479,
61219,
37970,
74361,
73413,
208283,
116939,
40557,
null,
469464,
211224,
267418,
186159,
34674,
46370,
3661,
45469,
261834,
null,
250895,
228486,
256352,
26500,
69564,
160035,
41611,
null,
255399,
55009,
9453,
27024,
19736,
35818,
null,
14432,
458681,
null,
283995,
null,
215887,
25910,
48397,
125642,
33846,
309709,
300298,
127333,
277959,
137917,
279131,
720201,
24828,
143320,
22894,
12263,
10466,
9490,
36252,
200103,
335150,
93397,
22429,
32747,
44353,
null,
46517,
278947,
284530,
93279,
193379,
17236,
154962,
95900,
14678,
75651,
255399,
541811,
13150,
55336,
5658,
147708,
249829,
99353,
418345,
39949,
261645,
423570,
186546,
null,
26829,
102676,
193857,
385676,
124478,
207512,
152941,
295009,
null,
122161,
null,
178732,
177646,
82628,
103643,
26825,
28341,
82097,
33893,
6410,
147256,
6137,
48891,
30461,
211835,
null,
8742,
181799,
76468,
53437,
207510,
null,
347032,
46118,
16095,
169290,
5598,
17039,
72449,
302955,
310714,
23884,
291003,
476439,
62709,
126958,
13591,
null,
20606,
42960,
36594,
82995,
108023,
89743,
331118,
null,
124608,
164974,
4535,
45846,
33476,
155262,
365322,
167542,
102110,
93988,
127436,
171071,
75546,
null,
35608,
39777,
25435,
51267,
null,
null,
375696,
62911,
246312,
395281,
null,
153346,
222037,
103808,
14856,
10856,
40220,
27030,
115838,
443374,
111419,
110979,
40491,
269108,
45867,
19709,
19727,
136841,
316132,
71235,
15639,
57439,
270273,
31701,
28067,
56772,
155830,
194803,
320154,
449285,
409867,
148187,
40171,
220850,
34860,
189663,
34695,
39539,
10168,
null,
244858,
17248,
26974,
144113,
120047,
34497,
61177,
178983,
43380,
null,
101188,
15910,
181286,
24408,
337041,
31440,
68816,
60327,
40422,
22598,
56760,
134091,
null,
46931,
50062,
102333,
354398,
389019,
21003,
null,
167685,
48870,
77011,
22885,
201795,
653630,
6779,
10105,
357843,
26885,
null,
6580,
86578,
197485,
56599,
29325,
84608,
null,
484417,
186204,
336160,
null,
30553,
6115,
117071,
null,
42793,
null,
null,
218860,
56545,
38270,
82400,
9630,
null,
333229,
595588,
198284,
null,
30659,
282983,
348253,
86161,
247622,
26026,
82904,
290634,
15771,
293913,
234998,
5056,
277961,
9948,
83503,
211097,
249751,
192774,
47495,
4637,
380449,
96401,
32407,
28768,
18145,
94626,
337373,
19905,
142397,
87199,
63617,
12657,
229705,
39147,
17264,
3847,
114856,
243447,
128983,
124976,
220717,
170943,
578521,
80387,
null,
8503,
null,
118022,
110851,
248685,
406870,
75274,
23071,
null,
27626,
270427,
48160,
12131,
null,
406923,
333363,
67337,
127763,
59731,
250181,
106981,
235830,
16945,
160114,
328265,
null,
299020,
51664,
83336,
225598,
276896,
208008,
18639,
18505,
27289,
33042,
null,
173949,
22618,
294857,
35419,
96489,
79508,
163499,
92639,
13805,
48238,
636154,
352299,
140008,
367153,
37849,
201909,
20764,
7947,
39007,
29414,
199928,
11535,
5406,
183364,
102970,
33027,
139528,
244311,
213481,
774532,
26988,
540072,
147810,
176683,
62224,
33377,
30392,
20496,
213615,
18261,
24382,
53683,
23293,
136644,
150219,
94272,
108950,
null,
173865,
14346,
26688,
37319,
142059,
1378,
226881,
306494,
19880,
117800,
52143,
51195,
337948,
8303,
363527,
14605,
44712,
null,
55190,
25954,
40230,
21403,
9035,
175516,
25645,
329802,
188914,
36255,
206257,
197597,
68520,
56639,
118155,
182314,
182068,
265480,
202722,
null,
null,
42565,
46782,
24898,
8053,
null,
113950,
297771,
596060,
107876,
90541,
140081,
784,
null,
137178,
118050,
139212,
706394,
237491,
38396,
13548,
37222,
122063,
111387,
1027562,
142383,
25076,
14906,
140323,
267843,
205851,
3286,
154757,
1153375,
150237,
47987,
143950,
240185,
102581,
14474,
66417,
235214,
86705,
152081,
44387,
74075,
3886,
19372,
9597,
75538,
99198,
215735,
8765,
12745,
328048,
77450,
140088,
460516,
265575,
186182,
214155,
144161,
63224,
17389,
32134,
16874,
576013,
87314,
491885,
140744,
594519,
28122,
266713,
96993,
76327,
13806,
176843,
313340,
95798,
19589,
7454,
75209,
166278,
205834,
33408,
718836,
37654,
906895,
36110,
533938,
416241,
25123,
39351,
57047,
26843,
100007,
12051,
538424,
132354,
43574,
null,
22015,
18165,
205838,
65583,
222242,
11432,
285416,
114955,
59272,
350951,
148298,
40865,
24525,
346199,
40183,
138646,
262295,
227982,
75527,
333418,
750820,
19966,
25889,
46875,
null,
214754,
34574,
80804,
288353,
99939,
null,
198756,
19198,
59808,
43773,
39646,
null,
386280,
2813,
204180,
41589,
null,
52534,
25066,
33089,
70964,
261830,
18471,
27178,
20119,
187145,
82480,
126177,
36471,
23471,
259557,
null,
53348,
27430,
17958,
null,
5911,
243908,
31187,
55871,
1587483,
143411,
143648,
24176,
29060,
167023,
null,
523014,
60342,
1223,
322686,
31431,
679983,
105704,
325785,
24042,
222562,
15058,
229611,
1191276,
282057,
207920,
36453,
1834,
324865,
114334,
35709,
null,
387137,
226861,
null,
259096,
178181,
37376,
162025,
89811,
42699,
453858,
104072,
481662,
160041,
32144,
45124,
36185,
336582,
91755,
154781,
93354,
7139,
null,
508544,
20172,
43258,
24891,
21539,
27376,
118825,
154603,
51375,
6196,
137452,
60417,
214466,
80610,
226582,
3611,
36086,
385020,
null,
14627,
29303,
89199,
7454,
213669,
18641,
23148,
8404,
27125,
97640,
40295,
39355,
223803,
190636,
55606,
366559,
null,
31603,
100874,
37300,
10917,
6276,
225457,
38364,
11478,
91746,
9204,
294219,
1950,
284554,
437118,
373890,
177360,
24848,
188142,
369812,
20468,
186618,
165018,
173391,
45406,
35792,
18823,
178722,
null,
8418,
null,
416785,
41804,
83188,
193882,
15668,
454633,
1138612,
59332,
29391,
null,
null,
305081,
114639,
109898,
10675,
26930,
10011,
4677,
14619,
null,
24949,
125790,
78456,
169562,
94357,
null,
174387,
43574,
431859,
222378,
247827,
294521,
262709,
21358,
61778,
177816,
68306,
null,
255620,
26139,
null,
26195,
null,
35330,
983,
105622,
261236,
146266,
61644,
47192,
26408,
23955,
53989,
8283,
3002,
56396,
13938,
15908,
23757,
128159,
null,
111399,
36580,
47708,
12613,
null,
16303,
null,
295711,
94360,
34495,
115527,
38509,
9045,
244745,
205574,
35567,
154369,
53330,
null,
52578,
47021,
null,
19372,
230753,
68322,
42424,
37383,
null,
322858,
26821,
121463,
125585,
71528,
41101,
7573,
58129,
58854,
68216,
322963,
18148,
233397,
3466,
15937,
103658,
227098,
357965,
23182,
11700,
26324,
29006,
115025,
100379,
4257,
168531,
28253,
262768,
226992,
82709,
9264,
21141,
181872,
14889,
215505,
84606,
null,
42309,
9312,
231455,
20364,
14985,
46882,
96615,
146458,
42419,
344032,
77488,
41046,
27932,
147195,
21958,
134263,
292009,
8467,
55500,
295775,
25943,
190137,
20118,
50694,
null,
221764,
11836,
199517,
95181,
32622,
64092,
340630,
4278,
66229,
433150,
269733,
218651,
10766,
158200,
15332,
182400,
55975,
735513,
19562,
325292,
9508,
102601,
115882,
159988,
null,
113067,
341827,
31130,
58369,
162314,
140866,
347724,
42777,
23455,
224610,
42771,
79993,
110587,
1289,
229828,
29926,
31167,
11657,
85035,
178722,
17861,
64302,
802250,
58137,
15456,
336001,
15044,
167639,
45184,
359065,
223439,
null,
225667,
303437,
285012,
51463,
419690,
27768,
41779,
362644,
56035,
19636,
717970,
164757,
76069,
5388,
13544,
63846,
36261,
185866,
147281,
24147,
10146,
17488,
56524,
52922,
192677,
68355,
19010,
238223,
35981,
76072,
458897,
19651,
15373,
277716,
48281,
169544,
178370,
172965,
564333,
437927,
419257,
264202,
30558,
7537,
33480,
20008,
21987,
53177,
null,
null,
227368,
49309,
70885,
null,
27923,
40802,
26030,
null,
57493,
114844,
12635,
55033,
20489,
40416,
5150,
55454,
28240,
190660,
263645,
50017,
15580,
49433,
22071,
36356,
54564,
96740,
14462,
38715,
97734,
215990,
75737,
null,
108858,
71229,
8689,
281422,
2487,
null,
234990,
12522,
null,
40521,
173324,
132508,
243757,
5745,
273458,
19988,
54108,
27642,
null,
62914,
62556,
506461,
160103,
74396,
85976,
83772,
null,
71672,
62475,
22631,
227947,
30265,
276004,
114147,
37428,
18723,
23894,
27363,
20098,
108741,
537529,
98412,
228300,
50325,
178731,
259168,
299375,
281586,
130399,
null,
31889,
181962,
149763,
26793,
289267,
14195,
267620,
335217,
238427,
null,
29534,
18296,
11969,
315381,
260449,
40489,
115968,
191934,
220566,
165346,
7447,
538391,
131640,
202998,
23861,
23962,
254704,
null,
32397,
null,
195143,
14522,
648024,
107075,
324087,
170999,
44067,
36662,
401950,
161835,
23578,
44030,
271629,
169502,
377532,
189524,
340020,
15762,
35229,
208192,
30630,
154001,
100681,
87242,
52673,
234356,
60045,
27498,
null,
null,
180115,
210687,
130729,
24165,
45643,
144009,
23111,
114562,
206549,
106844,
42219,
359871,
41941,
7502,
195591,
260084,
15983,
149719,
78177,
264673,
null,
50589,
null,
45227,
87458,
75043,
12901,
13846,
139572,
217279,
185835,
43579,
10221,
21710,
243935,
224569,
50433,
280166,
374321,
8997,
27962,
138777,
107112,
13564,
65272,
41145,
854422,
403134,
215741,
null,
210120,
220605,
null,
439128,
139089,
118357,
23336,
null,
86688,
13127,
229869,
3461,
53938,
40463,
336103,
193699,
6432,
238325,
205521,
59718,
430191,
11262,
36359,
176960,
null,
104557,
75384,
116729,
62690,
149819,
123599,
8694,
656458,
null,
68210,
72410,
24073,
43264,
8026,
332037,
360718,
36387,
33630,
109956,
445111,
278661,
259890,
133458,
195781,
131319,
null,
37185,
null,
131472,
53842,
85616,
45503,
10860,
487605,
433379,
70217,
11593,
218858,
35678,
238261,
70262,
37942,
401740,
238389,
28628,
14267,
29285,
37690,
84400,
197252,
20699,
128401,
33395,
45443,
113095,
129407,
213097,
317541,
25708,
null,
39583,
44748,
174563,
421315,
105833,
57704,
12175,
99177,
182944,
531076,
18403,
null,
358776,
243267,
131306,
8675,
102468,
298431,
7425,
125787,
474046,
124368,
39940,
115664,
8177,
30910,
81809,
8987,
4013,
96935,
211731,
385991,
204068,
47332,
31348,
12853,
64409,
17130,
156240,
35328,
null,
124352,
139306,
34879,
28966,
71878,
49577,
82971,
52153,
37970,
75898,
296153,
351847,
232634,
69530,
503350,
191553,
4579,
190953,
23649,
12791,
null,
296180,
39963,
53744,
427261,
29785,
37674,
4073,
454311,
79442,
118233,
18738,
22297,
79986,
240674,
145319,
100916,
178310,
29063,
356244,
54355,
null,
138986,
361727,
222534,
155798,
21103,
53852,
46878,
28918,
105352,
478365,
194530,
46782,
null,
170151,
5355,
138277,
68125,
284651,
164785,
418650,
14413,
105594,
17104,
313791,
43794,
234215,
142711,
null,
81689,
57214,
null,
42041,
null,
null,
45522,
8280,
185245,
351187,
32223,
172682,
23116,
363640,
54741,
null,
54134,
10012,
188136,
65563,
41772,
17417,
155858,
17497,
null,
45686,
46857,
147190,
95167,
56892,
26804,
285699,
21440,
154107,
224360,
74395,
5102,
389597,
642283,
58145,
7107,
22510,
72662,
29679,
94459,
358974,
null,
47243,
29268,
255752,
25639,
237277,
null,
null,
null,
269081,
232502,
20441,
331150,
24281,
170627,
395732,
114292,
38086,
215324,
77786,
176148,
22413,
27196,
20357,
45951,
28566,
36794,
111779,
136681,
213057,
38644,
151881,
83119,
null,
164306,
42558,
36644,
12119,
24010,
36977,
61499,
14700,
24416,
275725,
null,
12058,
216030,
74318,
13296,
null,
42014,
25305,
17332,
21404,
55571,
27267,
287326,
15238,
197206,
208840,
35324,
85956,
111342,
158592,
46260,
141387,
406800,
57659,
9357,
8882,
131628,
100833,
41602,
26187,
322322,
29184,
56255,
106782,
180039,
297513,
42245,
28730,
25941,
154690,
180077,
120613,
27446,
90430,
54713,
144736,
36055,
21432,
105064,
50596,
19958,
154199,
300146,
28012,
217248,
77869,
7131,
46741,
null,
17070,
201669,
21046,
496511,
56759,
113329,
25745,
106281,
346946,
44906,
55860,
189919,
9362,
317909,
199616,
547197,
35125,
130351,
48475,
98519,
360120,
36375,
285937,
89732,
91181,
334824,
38378,
13129,
26122,
204451,
162760,
445261,
29210,
10002,
274824,
16365,
317061,
139984,
83714,
128994,
34749,
7982,
172857,
28425,
439361,
96995,
74718,
350985,
65890,
316472,
83224,
143267,
308572,
17175,
456705,
10303,
340391,
null,
255776,
120876,
null,
328060,
129046,
null,
83917,
null,
11618,
298655,
24918,
40457,
33482,
15557,
17836,
52375,
5944,
77025,
41070,
360835,
33965,
99741,
288225,
86962,
81696,
114600,
25571,
257651,
220119,
182512,
9203,
19986,
288118,
105394,
243297,
1028190,
23552,
625680,
29342,
110098,
152338,
89924,
156476,
238035,
81252,
323314,
108381,
188768,
91194,
42728,
261085,
45899,
null,
46052,
274646,
null,
445972,
null,
226697,
47089,
null,
null,
8640,
46276,
264440,
51034,
126425,
21018,
13928,
28994,
32975,
null,
316571,
7285,
33299,
9236,
37161,
24768,
107372,
378661,
303957,
383926,
177409,
28163,
166830,
78655,
13424,
32832,
null,
107451,
49458,
153652,
168784,
75254,
19921,
48866,
50870,
31152,
552710,
12133,
37621,
34055,
21594,
403359,
8732,
308507,
285505,
40558,
33288,
713912,
34978,
205004,
155074,
28579,
820114,
20205,
49252,
9760,
37779,
null,
225467,
380254,
112644,
285774,
51903,
98872,
144882,
null,
null,
213063,
39353,
125243,
37992,
41308,
140203,
15823,
null,
190750,
78978,
137610,
72164,
582211,
80677,
234836,
14756,
37726,
25900,
94732,
194808,
31132,
null,
124971,
12585,
237689,
67581,
230093,
169873,
63448,
40770,
71672,
331964,
36595,
51904,
104998,
142149,
88985,
33167,
173356,
23911,
64702,
37113,
57186,
36182,
53957,
146804,
128236,
148176,
null,
21516,
110578,
2587,
9452,
82169,
372181,
267221,
174911,
24678,
52347,
169043,
203866,
187369,
30900,
19266,
null,
null,
4997,
241694,
306142,
14578,
216905,
441526,
31010,
19565,
55095,
28241,
7425,
322777,
null,
152063,
3084,
58906,
19096,
208522,
19570,
16417,
null,
147460,
213953,
216959,
17285,
248554,
246069,
411240,
232704,
356696,
494009,
320433,
118140,
254116,
266704,
11133,
27709,
54422,
null,
8657,
271562,
339341,
49874,
24008,
14898,
70779,
403544,
19894,
84685,
99628,
371368,
3304,
31471,
47197,
57758,
16280,
113622,
null,
17876,
null,
57758,
261749,
197889,
521007,
30792,
241640,
37631,
171782,
24786,
4186,
42361,
30252,
129260,
4269,
522470,
199053,
10482,
739969,
null,
150032,
164575,
398961,
210528,
60544,
196522,
175598,
117509,
20834,
76421,
116492,
24496,
32728,
46291,
54302,
null,
89134,
29546,
33723,
131822,
59430,
18195,
23417,
482156,
13818,
null,
127191,
60778,
651059,
117809,
442774,
47697,
537461,
147392,
32048,
4311,
231996,
434834,
null,
271056,
132363,
120456,
66855,
68628,
15216,
165839,
30125,
151190,
34896,
50610,
23909,
15704,
37951,
348968,
136108,
12613,
410691,
241029,
21342,
23420,
23984,
308928,
26146,
77095,
16464,
202925,
22565,
14992,
127499,
35672,
85729,
20936,
null,
28499,
null,
14251,
208892,
147510,
473728,
202760,
66706,
75797,
13821,
146628,
136394,
81166,
366824,
887579,
null,
7969,
228102,
126032,
165480,
43696,
303252,
30939,
129060,
30392,
33796,
139923,
49387,
153203,
53678,
43964,
null,
145390,
195174,
77960,
null,
216056,
323811,
534727,
null,
28654,
20968,
40187,
238486,
20295,
155141,
99575,
null,
256311,
334950,
507550,
157558,
564465,
29233,
356108,
73722,
13021,
309517,
252077,
55272,
226487,
79094,
209131,
10128,
9966,
148225,
93422,
26215,
36252,
52125,
179183,
220748,
170672,
169210,
282493,
32332,
null,
140980,
15862,
16278,
16516,
20812,
26656,
272202,
10730,
39142,
20557,
10859,
100013,
104413,
96370,
341059,
307619,
27410,
64781,
77828,
12712,
29645,
125013,
34202,
163377,
116584,
3853,
41771,
172703,
264683,
32504,
67453,
274829,
24957,
99499,
44936,
78364,
12537,
366381,
75825,
145220,
null,
28264,
24987,
17711,
324309,
84394,
null,
191438,
573054,
19077,
55487,
313047,
16126,
257676,
110615,
84372,
187195,
446347,
87796,
59822,
12655,
188144,
25818,
485199,
208235,
204854,
14976,
236825,
97947,
41449,
330657,
217933,
31290,
165789,
7160,
15778,
11497,
7825,
562340,
270618,
60441,
211804,
392737,
315677,
null,
268620,
null,
624699,
25173,
265392,
38420,
10116,
6413,
4615,
250168,
151771,
83343,
22697,
null,
null,
75462,
95365,
99331,
363022,
108808,
24491,
48103,
11349,
39849,
301742,
4670,
98011,
20999,
15199,
258658,
20452,
54303,
78262,
12787,
101358,
77286,
397025,
33031,
211221,
13213,
42769,
51293,
43834,
102639,
21756,
436667,
181023,
126199,
120310,
572843,
18732,
26641,
8315,
21286,
80550,
10581,
93139,
274264,
31951,
7956,
17073,
15570,
27643,
123824,
36016,
221936,
209089,
245941,
null,
70766,
444527,
36320,
318209,
null,
259050,
112926,
64904,
83409,
156321,
11911,
314241,
25946,
258979,
185916,
92773,
32522,
31823,
51674,
42967,
null,
492095,
11348,
338274,
12209,
177998,
22162,
null,
25729,
13966,
2741,
33382,
18894,
147833,
272941,
101306,
317793,
165924,
75178,
null,
48380,
84932,
417426,
182407,
278876,
37272,
113168,
88503,
184719,
272419,
null,
null,
164333,
19337,
88337,
null,
679763,
13991,
67130,
233579,
210370,
282862,
22523,
80050,
247804,
40981,
190635,
21120,
57082,
25037,
54814,
20413,
29011,
550891,
232313,
339110,
11488,
null,
249039,
9556,
273003,
43780,
25567,
194528,
null,
15393,
289424,
248395,
27402,
21003,
173040,
288328,
254737,
20281,
27919,
95703,
246214,
31370,
22154,
197141,
null,
44353,
294180,
365590,
12801,
59422,
25696,
null,
2312,
146415,
6214,
null,
22999,
258997,
13949,
14083,
438693,
134641,
190615,
315515,
30526,
6493,
23140,
46407,
382759,
49462,
12461,
218159,
269841,
60342,
null,
25043,
14563,
26372,
113817,
36618,
77927,
254026,
40854,
25991,
59090,
19076,
167592,
57536,
252547,
1072,
64948,
269961,
18925,
8483,
234056,
247376,
151293,
24904,
11667,
240749,
164265,
34274,
181205,
69676,
73682,
34532,
25051,
407007,
45007,
200423,
52524,
null,
202949,
5536,
397816,
46956,
3163,
401268,
66908,
38938,
26553,
9158,
356321,
null,
33647,
97841,
4723,
25898,
273661,
29315,
165943,
169709,
16917,
428352,
85767,
19498,
38232,
33799,
10099,
37052,
85467,
133392,
113570,
162706,
null,
264130,
277659,
193774,
21065,
197744,
13405,
443884,
59395,
149907,
41660,
225239,
156173,
171381,
177338,
96665,
34141,
18050,
39074,
5009,
14680,
51751,
267604,
5864,
209437,
55257,
196568,
42097,
72628,
9771,
30955,
240955,
18557,
34648,
30046,
244685,
269527,
132932,
2504,
30617,
135359,
14460,
180369,
311036,
10727,
49440,
null,
null,
52239,
31685,
23853,
302783,
2362,
null,
52523,
15619,
58544,
48996,
60666,
72796,
229861,
398535,
176512,
null,
124534,
null,
472553,
163033,
74429,
17127,
212357,
216309,
23864,
43688,
null,
279205,
283426,
269073,
259564,
424553,
13721,
6478,
323284,
35529,
515897,
209913,
28480,
274044,
null,
31250,
32521,
190709,
null,
64551,
33249,
null,
58711,
138752,
198106,
42348,
21635,
7469,
135713,
27965,
286599,
45672,
180695,
408952,
18347,
69032,
214699,
12087,
20361,
39765,
139681,
43697,
34277,
14758,
343772,
80470,
130859,
117801,
335101,
26793,
190266,
104504,
29173,
181134,
120988,
9676,
104842,
86616,
279583,
42925,
126592,
43820,
39452,
null,
153893,
83825,
431445,
136688,
49058,
44187,
230046,
328194,
96685,
26419,
42952,
20623,
31393,
74182,
41217,
null,
47940,
null,
20780,
214141,
77649,
421547,
28702,
null,
209020,
41178,
27485,
174522,
193655,
81227,
85146,
53473,
111251,
262349,
23950,
277014,
10107,
null,
111503,
251588,
0,
166127,
214776,
35737,
259244,
10463,
343093,
null,
116593,
64180,
26703,
20359,
218293,
25323,
29404,
238201,
61833,
67467,
200006,
108767,
77528,
150317,
400565,
316179,
23131,
10577,
38717,
120448,
133731,
38155,
208157,
31186,
24202,
290863,
104693,
12984,
5921,
25384,
56249,
82527,
140710,
99862,
null,
355729,
263970,
213115,
35300,
24289,
52746,
21095,
188942,
null,
190868,
250448,
78079,
167783,
628934,
187078,
15504,
27274,
47021,
185205,
370352,
30316,
null,
181649,
38965,
49683,
66371,
23902,
37647,
19328,
33443,
70585,
99738,
38585,
9309,
560908,
56826,
42556,
128868,
7614,
35533,
4115,
77489,
68191,
97220,
206364,
74485,
12075,
84190,
10196,
223867,
null,
92598,
18712,
28884,
88288,
12637,
382141,
145402,
68996,
95985,
5369,
136317,
6424,
195950,
13206,
null,
22030,
9657,
501783,
48865,
null,
387312,
46407,
28999,
null,
10307,
48809,
16252,
3312,
32115,
null,
364486,
33907,
232905,
40475,
22208,
56544,
26311,
19899,
236024,
317696,
70892,
114963,
49414,
215077,
null,
270417,
4823,
145774,
22400,
24179,
15373,
null,
277408,
13129,
48660,
45384,
245006,
198825,
146437,
119515,
11646,
128302,
34693,
556627,
28479,
50788,
23199,
52638,
null,
106529,
20237,
376742,
238719,
7157,
8958,
null,
178694,
null,
462660,
8124,
217177,
26052,
76319,
38486,
331276,
17216,
260945,
23197,
5866,
77141,
298395,
7448,
17058,
43043,
8622,
28773,
36471,
12748,
44236,
null,
333362,
347475,
114814,
163233,
28014,
209017,
13980,
38895,
103632,
null,
224527,
468477,
30899,
233439,
null,
545283,
33475,
41700,
282597,
27436,
321714,
21656,
61273,
57028,
30833,
26457,
248171,
118431,
null,
142071,
185664,
292524,
392980,
367235,
27618,
192593,
80285,
12986,
null,
58549,
107820,
233229,
264951,
49028,
159215,
550831,
246532,
73312,
113715,
388516,
8668,
422321,
167306,
47068,
45596,
null,
88306,
31223,
140524,
48792,
2838,
110610,
null,
209972,
30952,
null,
12724,
14319,
77063,
23367,
4273,
435222,
null,
185074,
62312,
192061,
157413,
16240,
34207,
324347,
59753,
41174,
81660,
110734,
20581,
null,
22489,
null,
98649,
46455,
45017,
173112,
581986,
25692,
227551,
30848,
41843,
569799,
60332,
null,
118985,
192840,
21872,
185715,
38085,
232340,
72748,
7620,
90625,
409782,
12549,
60953,
412672,
null,
22455,
56306,
288346,
390802,
34890,
18722,
3601,
20538,
119357,
161398,
5644,
48537,
42427,
34839,
231176,
15812,
null,
226699,
186143,
188117,
302386,
71948,
478049,
202,
142066,
242846,
12166,
39908,
5669,
262140,
69700,
11264,
22411,
350843,
51196,
29834,
227115,
38041,
20530,
85498,
212207,
60707,
27242,
38087,
11524,
144597,
59821,
181225,
154750,
157529,
41538,
284790,
272308,
123470,
278673,
null,
321572,
262023,
17213,
349327,
50581,
21707,
98563,
44548,
32049,
2420,
64573,
53578,
60058,
null,
null,
192710,
31594,
6343,
48711,
68472,
209180,
450758,
null,
54614,
36621,
217017,
212736,
181409,
93652,
47810,
74709,
362238,
204808,
46432,
72239,
43838,
19907,
39099,
21072,
208008,
90818,
218596,
23328,
27159,
124192,
107417,
355723,
36027,
179201,
80655,
33036,
95308,
214827,
287177,
96414,
20901,
462705,
129717,
1606,
56476,
45952,
55471,
17613,
35664,
61771,
203164,
121874,
84776,
57236,
3529,
null,
13025,
16832,
35624,
27856,
16034,
94419,
72451,
225431,
16324,
79847,
22872,
285255,
219337,
176990,
74010,
50562,
115662,
268975,
56584,
236326,
48247,
128142,
120671,
85432,
27661,
null,
3892,
28009,
49167,
91814,
null,
65871,
162673,
161242,
12832,
40583,
179859,
111035,
null,
321099,
184040,
283405,
39959,
44696,
19811,
14264,
192046,
127102,
192769,
54219,
47129,
203808,
49640,
33082,
743894,
13613,
298728,
null,
98080,
null,
47115,
119968,
63756,
null,
15495,
23086,
332663,
215127,
14188,
26788,
59141,
122542,
180215,
163809,
258351,
72223,
335007,
125449,
38692,
6694,
18690,
null,
186959,
20714,
4155,
52851,
70580,
265642,
null,
318446,
13493,
null,
378293,
124319,
null,
26085,
9050,
20568,
45128,
269435,
null,
48078,
256326,
69639,
10037,
61182,
33087,
788024,
188302,
null,
34320,
39027,
169371,
55151,
null,
310386,
47200,
81161,
79721,
25797,
731133,
9487,
21505,
393132,
9520,
44969,
295435,
189580,
null,
286199,
44170,
107321,
264765,
31924,
16461,
361740,
113694,
79399,
null,
107903,
19309,
167921,
458992,
24950,
24102,
7051,
58768,
null,
409271,
18023,
23415,
75057,
31624,
27934,
69056,
18933,
173989,
7176,
113443,
291748,
10779,
72841,
111635,
59272,
186453,
202998,
600905,
176690,
70841,
24225,
154435,
265995,
93524,
22203,
25833,
330153,
3242,
36767,
24972,
251566,
42310,
52748,
31977,
202519,
242994,
20605,
365388,
508912,
24844,
55028,
51523,
46493,
15621,
null,
840772,
126151,
202751,
234748,
516806,
143500,
120143,
56860,
362153,
29097,
44856,
31781,
207080,
301018,
null,
22823,
146886,
79289,
234958,
19920,
29776,
155965,
80863,
289442,
154330,
260294,
85784,
68334,
67007,
216494,
203633,
297109,
215239,
286291,
153968,
11953,
31856,
264078,
87862,
31545,
273102,
9566,
346901,
18692,
35217,
166980,
92486,
48375,
58777,
16609,
120280,
41604,
31540,
99101,
52019,
null,
453548,
491108,
535856,
null,
17384,
212568,
45639,
117657,
115480,
5220,
273106,
83552,
34097,
11898,
92582,
282117,
8971,
102262,
98400,
null,
96865,
208046,
75132,
629623,
4464,
null,
282448,
24834,
369198,
124811,
15083,
160185,
275872,
19367,
233246,
264878,
null,
52649,
127882,
358611,
33075,
175223,
16759,
65177,
184930,
36669,
null,
73867,
17384,
357079,
314633,
57688,
179156,
249587,
63228,
153769,
234539,
21552,
11298,
42688,
17172,
194187,
47169,
65498,
202030,
354516,
174776,
149771,
48472,
313044,
250163,
83278,
16834,
97987,
18712,
318229,
26974,
16525,
49008,
540190,
21424,
248929,
13418,
27450,
62361,
55508,
27487,
226421,
46478,
280023,
267290,
null,
20822,
74304,
23023,
158276,
189925,
37420,
38721,
225134,
189360,
170718,
54617,
15010,
111676,
9880,
482397,
145708,
36033,
81856,
43289,
291302,
36273,
65325,
25722,
13991,
108426,
308581,
9631,
17374,
17875,
20247,
27177,
52023,
68366,
3183,
182052,
77757,
39843,
255309,
22777,
222548,
69822,
null,
21676,
205529,
782108,
77202,
145413,
220470,
null,
284056,
219064,
257069,
44308,
67638,
182505,
382018,
58751,
18998,
359109,
null,
null,
72122,
null,
217517,
53236,
null,
8758,
82411,
52885,
59410,
107038,
154957,
232102,
67413,
186789,
38086,
176017,
177654,
340082,
381585,
216982,
277256,
7806,
165643,
121191,
492773,
27640,
22894,
32403,
319665,
null,
null,
27812,
37103,
155919,
433649,
203594,
217766,
500183,
20320,
216962,
105793,
197957,
4894,
120571,
49750,
24712,
167313,
88949,
null,
342161,
10782,
16832,
16240,
82328,
42015,
63718,
179496,
34715,
7860,
222034,
293405,
177116,
118327,
282719,
14944,
174035,
14830,
3717,
27042,
62730,
95493,
102127,
6401,
18465,
564461,
14807,
241813,
79284,
42939,
null,
31452,
null,
173663,
168037,
327195,
13349,
60118,
7805,
226598,
33629,
19639,
24021,
46055,
67690,
53199,
93692,
199873,
396407,
22772,
81758,
310760,
37892,
149102,
14031,
26265,
41745,
250813,
590731,
41831,
44430,
64155,
160817,
4568,
154002,
323301,
null,
null,
21503,
212842,
9067,
null,
139797,
745617,
320794,
null,
14900,
182697,
32769,
null,
24774,
305032,
51161,
303825,
23564,
378443,
38794,
74624,
318347,
119506,
345426,
184034,
null,
123553,
252389,
53465,
17420,
13673,
23630,
10884,
351395,
65356,
485726,
null,
10904,
476496,
108025,
22180,
20487,
255701,
409353,
7580,
532532,
32433,
73149,
35518,
41640,
144361,
null,
330599,
6521,
39028,
9993,
174643,
30227,
293237,
79656,
433405,
137999,
77025,
284859,
4070,
37622,
106673,
121469,
224017,
20103,
49859,
22878,
71022,
24100,
8829,
78552,
400399,
67924,
125026,
236716,
2513,
4177,
null,
32784,
22863,
164042,
84139,
246046,
186501,
44431,
29150,
15940,
31689,
63579,
793270,
54462,
169097,
342623,
147247,
5823,
19300,
13511,
86208,
41752,
98257,
null,
270867,
258699,
259454,
53828,
31279,
12124,
63226,
45081,
293458,
181069,
19300,
45935,
68993,
null,
20858,
86967,
24462,
40969,
null,
33515,
null,
298614,
265295,
629859,
477880,
75649,
66030,
4691,
190325,
263022,
748276,
11136,
28222,
305067,
35059,
172297,
12560,
66477,
3965,
11602,
289187,
39991,
29001,
49321,
12738,
138622,
48184,
432718,
24040,
159574,
33678,
141959,
36196,
75176,
12178,
24498,
198267,
347936,
100438,
null,
37939,
211243,
21345,
21367,
51354,
492441,
22013,
343364,
70324,
61690,
330510,
77284,
88419,
260156,
7902,
35002,
41630,
167818,
46070,
541305,
305616,
321438,
20426,
33990,
null,
6157,
16072,
40371,
206258,
25913,
365926,
44286,
16547,
1420912,
144903,
36569,
null,
24397,
9976,
217884,
226030,
237703,
316417,
null,
21547,
14023,
55965,
43816,
210709,
47700,
68191,
792357,
321711,
426650,
273508,
145038,
131709,
27532,
168225,
72037,
43357,
117850,
458633,
301355,
216204,
93206,
160630,
453946,
83932,
null,
57566,
103284,
21056,
276598,
27465,
144174,
221969,
32739,
453418,
296160,
47058,
520250,
18151,
322814,
186587,
22527,
47189,
7611,
452752,
343441,
90654,
3978,
72056,
33204,
56875,
46866,
41935,
358502,
null,
395568,
173726,
283855,
26743,
31136,
null,
113996,
null,
6957,
86452,
102620,
184481,
430452,
147668,
38659,
12325,
114819,
85903,
158303,
191746,
18393,
18229,
18444,
19220,
null,
63677,
4759,
415346,
57687,
278734,
875487,
20577,
244390,
300589,
54550,
338838,
12246,
46128,
31244,
295865,
346467,
36987,
6974,
36858,
168791,
173725,
347322,
11074,
39167,
165408,
83874,
335492,
170761,
1992,
40858,
244894,
240715,
57706,
16868,
187390,
66951,
null,
null,
125307,
4955,
294228,
332699,
null,
22920,
28317,
248294,
136299,
19891,
48737,
8678,
466481,
121611,
37171,
199545,
149050,
6150,
43274,
195578,
384089,
21183,
62691,
174839,
44785,
44239,
19905,
425048,
11364,
230121,
48716,
223238,
42453,
48507,
358421,
17635,
350707,
10826,
33332,
29318,
208896,
389535,
217214,
13268,
12640,
118533,
47385,
383542,
285406,
97913,
9973,
258113,
19274,
60995,
239780,
90194,
16917,
249399,
26571,
129101,
20161,
85599,
105239,
32835,
4294,
null,
35228,
26710,
16728,
447096,
4041,
155457,
226507,
76859,
30963,
172885,
51950,
166457,
127488,
102382,
145013,
42763,
31267,
16718,
8792,
37401,
204849,
null,
672236,
32975,
96731,
306553,
152244,
34445,
213748,
104022,
16847,
436908,
192851,
40714,
420422,
7378,
11229,
237278,
33268,
119429,
89418,
14041,
409073,
144974,
60657,
317668,
321028,
46782,
209580,
33868,
4458,
64800,
390689,
229634,
260482,
237273,
18676,
36727,
null,
688463,
38270,
411532,
122640,
null,
165573,
null,
64989,
573213,
44484,
39943,
188888,
13368,
null,
38613,
29612,
24318,
7986,
148657,
375958,
null,
370309,
17504,
259792,
202747,
null,
24373,
174640,
9022,
8575,
285290,
383191,
140609,
303136,
84910,
252076,
185185,
668681,
11031,
null,
35778,
34196,
18241,
133313,
27144,
56653,
582310,
35228,
null,
49266,
328734,
32655,
130647,
20477,
22477,
98746,
null,
42804,
382170,
198304,
19578,
11422,
53155,
361227,
158812,
null,
692763,
23733,
153315,
301791,
203441,
119760,
null,
187714,
240377,
43644,
null,
53560,
191927,
21498,
115839,
71136,
15400,
675709,
71552,
143699,
18907,
26505,
355672,
50329,
98395,
37900,
34713,
10410,
531222,
276238,
104869,
20784,
317703,
4991,
29260,
31185,
11419,
5632,
26632,
62777,
48322,
49039,
42658,
95627,
341523,
133002,
316015,
190660,
null,
323857,
11917,
31235,
35134,
386239,
243836,
274701,
15846,
30897,
23693,
208156,
287918,
192398,
171553,
115345,
155681,
34168,
41148,
null,
14200,
null,
81347,
83274,
62204,
21551,
51004,
41690,
158766,
37822,
176060,
46920,
67251,
71358,
71222,
10484,
212674,
26278,
52653,
77030,
68738,
253742,
94711,
123896,
28656,
12380,
43977,
412406,
21378,
45136,
37112,
null,
43177,
115782,
357827,
71338,
227960,
260559,
46447,
188308,
26424,
310230,
27533,
159360,
149089,
null,
56097,
null,
17055,
605251,
17016,
14788,
113801,
255003,
88879,
224739,
35601,
49555,
18269,
164571,
46535,
37351,
13146,
360405,
255517,
null,
36849,
524205,
130390,
276456,
null,
60890,
363214,
336139,
15202,
18835,
29393,
139352,
null,
326315,
10202,
141748,
152333,
26289,
7761,
null,
27312,
29267,
305568,
336414,
325579,
30704,
130877,
58165,
245390,
58175,
317888,
9032,
499265,
138117,
31144,
33669,
253211,
13556,
25017,
207343,
124625,
67124,
103216,
283348,
31819,
221313,
64401,
43163,
130827,
32510,
143864,
160078,
32599,
89837,
37802,
17832,
18329,
289671,
24562,
29750,
215954,
429390,
14880,
396254,
null,
417718,
50318,
113336,
1919,
182740,
209313,
191521,
null,
45349,
13047,
329940,
129166,
57154,
103133,
8124,
10807,
337519,
74856,
40773,
308636,
35880,
3633,
14033,
9306,
238134,
8767,
39031,
13166,
32298,
13061,
250449,
329061,
134619,
114530,
246586,
177240,
567649,
37660,
214871,
232748,
427937,
75474,
154228,
31120,
500519,
166318,
240356,
13862,
80971,
97374,
66130,
48398,
213342,
146461,
25150,
17958,
28024,
5850,
2471,
206847,
1433115,
96055,
210416,
129209,
645331,
366794,
181431,
54687,
17597,
18440,
30222,
58198,
13153,
null,
58522,
295608,
84331,
47245,
92024,
23471,
185537,
30131,
null,
175229,
107487,
275831,
44003,
171695,
null,
15845,
34402,
125508,
133141,
26939,
51066,
295788,
15991,
null,
356255,
134475,
430602,
166475,
113883,
30497,
null,
39133,
23223,
834566,
259776,
173753,
28016,
null,
72813,
3455,
217441,
31705,
9307,
381541,
120942,
5532,
null,
135675,
null,
14571,
228610,
852059,
234681,
236181,
null,
83924,
null,
451496,
82556,
12100,
50020,
25818,
15637,
null,
152419,
197028,
154453,
154777,
140320,
271995,
228999,
255755,
340368,
26026,
26905,
223789,
5199,
82030,
243947,
171280,
50322,
69584,
null,
12157,
276812,
null,
81344,
152101,
18788,
305141,
161519,
null,
9547,
6628,
7823,
54480,
49450,
304582,
34093,
373867,
79902,
58406,
163353,
32488,
19866,
110486,
26762,
522980,
24279,
35571,
160368,
157370,
74435,
94250,
61066,
37884,
25284,
269393,
25170,
312854,
138189,
null,
334572,
null,
95310,
275474,
null,
309030,
25341,
14217,
null,
201268,
157977,
279535,
22764,
70143,
258159,
3394,
14828,
19408,
90624,
185544,
30663,
239230,
168421,
202864,
118208,
null,
57357,
176636,
78568,
175901,
3980,
null,
null,
8828,
650319,
63704,
85619,
62249,
97424,
32385,
526744,
38435,
66848,
29327,
185665,
284120,
188144,
66789,
9381,
36855,
100091,
43268,
94953,
27923,
248030,
170505,
314458,
30010,
103263,
41161,
245671,
240742,
21348,
31790,
82769,
43196,
5951,
150455,
20928,
52962,
39730,
32904,
30198,
307383,
5530,
null,
294771,
31159,
68277,
372260,
null,
26852,
193983,
126041,
90819,
5339,
200845,
40000,
151936,
28955,
253762,
162005,
5199,
118556,
224201,
170469,
21400,
5473,
108923,
303124,
13827,
309954,
109366,
88462,
43620,
57807,
18987,
363615,
12847,
174922,
116405,
null,
54636,
6801,
36066,
145611,
41183,
27989,
300949,
19189,
122265,
469709,
null,
288458,
11362,
33298,
null,
10810,
42838,
62204,
36563,
130387,
29319,
12972,
null,
277663,
51298,
52875,
56930,
65090,
21738,
230183,
24950,
874918,
46349,
285883,
15527,
16400,
17123,
12918,
273661,
163923,
54829,
11494,
120818,
4449,
4954,
null,
302486,
192679,
10698,
29783,
42626,
13939,
12895,
68799,
null,
426863,
90887,
192811,
24448,
1019,
188509,
26094,
123029,
68246,
432951,
9203,
415289,
169185,
268986,
320429,
292694,
310581,
105937,
211557,
39046,
376226,
273646,
237427,
32032,
null,
226422,
null,
4952,
144875,
360787,
null,
640343,
150034,
91113,
29185,
46573,
19296,
null,
234102,
24198,
82926,
11262,
510840,
339971,
113080,
71645,
41519,
603772,
68702,
236145,
303025,
61591,
428569,
27980,
762656,
50507,
23012,
137199,
142307,
105384,
191867,
38796,
290728,
23610,
22235,
null,
209658,
147254,
40060,
39201,
186773,
59636,
108631,
35302,
35734,
473813,
110607,
37847,
293817,
77516,
507066,
43215,
5862,
190336,
37790,
51299,
20118,
106779,
37687,
230114,
37881,
445828,
20747,
178216,
269015,
null,
null,
24964,
28370,
86263,
null,
163017,
35155,
66610,
67800,
65111,
4677,
183484,
145444,
51867,
297922,
66142,
28575,
368327,
127772,
null,
227071,
419418,
25385,
324351,
15669,
null,
190846,
64762,
40375,
29504,
7726,
1581,
537789,
204867,
206705,
69107,
86754,
305941,
109724,
205159,
111159,
503933,
141316,
56651,
19700,
25501,
null,
521905,
202352,
120486,
742028,
135250,
229526,
113394,
63622,
174759,
138913,
20180,
null,
null,
332658,
56004,
23987,
6077,
347817,
139268,
26023,
46185,
42351,
151256,
null,
null,
213606,
329356,
360258,
259080,
22797,
24868,
48970,
75722,
134921,
180291,
52320,
166401,
69015,
10451,
223326,
22711,
34124,
22945,
143257,
75273,
602592,
70682,
407684,
283059,
55492,
269292,
31102,
24046,
194728,
48451,
null,
47785,
71542,
24880,
49573,
209030,
169416,
16191,
49878,
41220,
218476,
160004,
4820,
30902,
173138,
93925,
276627,
null,
22593,
37068,
20718,
null,
62412,
44869,
171371,
32748,
76554,
234482,
7548,
102839,
83257,
70274,
23018,
246470,
566964,
126630,
37940,
86803,
9053,
42838,
564218,
46002,
93074,
214945,
156106,
165861,
112779,
218587,
11721,
17129,
251127,
25027,
80756,
46675,
101707,
45293,
315054,
33465,
37694,
115148,
40733,
33422,
51669,
174279,
30725,
280455,
27075,
20079,
8809,
49754,
77011,
4285,
147748,
41103,
11454,
396136,
79782,
98389,
41528,
146742,
26508,
379552,
28323,
null,
240212,
156180,
127969,
77287,
104429,
null,
22410,
209822,
18314,
57792,
119794,
30209,
168630,
null,
162933,
57489,
13582,
null,
245670,
75194,
943654,
250081,
117150,
166030,
172910,
30469,
24924,
21459,
185946,
23705,
70792,
351649,
8467,
107510,
19567,
421830,
485305,
33100,
7865,
91738,
null,
444152,
152475,
23561,
null,
19668,
523570,
null,
43025,
15650,
236077,
71944,
20914,
90417,
53384,
9305,
256582,
279405,
27757,
4486,
229916,
150190,
182601,
14376,
197305,
410657,
87185,
null,
35417,
125387,
88386,
42589,
14357,
95185,
18727,
59610,
32465,
null,
101616,
148372,
13226,
87215,
284688,
21823,
355264,
198457,
203232,
30638,
325047,
495417,
null,
198115,
4354,
24655,
19995,
142996,
null,
304122,
null,
217361,
null,
207336,
25189,
171905,
348478,
142801,
31661,
767219,
270460,
null,
5365,
57794,
167950,
198917,
571673,
56952,
24044,
20062,
34543,
63496,
72093,
41882,
59239,
259486,
12367,
243165,
9482,
359297,
34729,
31634,
497,
null,
null,
203365,
91993,
18871,
null,
71350,
52177,
21207,
319014,
39359,
8896,
410068,
252001,
237764,
10277,
145207,
219527,
59013,
127223,
112750,
54824,
8988,
11314,
1206312,
53747,
null,
286058,
56529,
161551,
26206,
7013,
68204,
null,
10797,
13484,
47422,
99807,
82131,
298872,
350790,
215818,
null,
25737,
8088,
307423,
263388,
118577,
438767,
242695,
47578,
46010,
414094,
256280,
202052,
160920,
19769,
242565,
null,
64888,
null,
304549,
24805,
230048,
34385,
218187,
54442,
null,
25843,
23111,
8373,
144137,
166526,
528870,
50386,
243847,
167450,
80379,
17254,
17102,
26884,
14884,
26447,
18654,
193321,
34005,
340835,
15570,
401877,
103178,
190601,
103617,
39235,
115628,
269396,
62114,
40322,
68256,
44386,
492320,
4257,
null,
110114,
25903,
199873,
61194,
175822,
137852,
181356,
222691,
258298,
33314,
297289,
65318,
72438,
18772,
214638,
null,
50754,
357553,
63652,
194819,
150054,
69544,
217489,
6733,
96243,
38865,
353632,
5537,
72955,
105509,
171811,
24696,
60136,
51550,
364524,
null,
null,
24505,
31524,
372505,
25664,
13807,
62827,
180416,
11994,
8781,
39914,
123935,
57322,
269164,
null,
112374,
128184,
380718,
14466,
null,
53653,
240882,
16094,
276576,
22921,
6540,
174522,
23394,
29014,
241059,
448214,
14733,
20957,
281471,
4701,
134443,
null,
36039,
94316,
319019,
226149,
337626,
570521,
113976,
385155,
118536,
146074,
4167,
18703,
34121,
337507,
227192,
10851,
50797,
144196,
37374,
18850,
34081,
null,
330958,
31950,
294346,
12864,
193087,
18883,
11620,
113769,
311166,
653612,
253619,
184176,
19933,
19597,
435087,
47144,
null,
212949,
13620,
22703,
276017,
85347,
17037,
228734,
220480,
132604,
43438,
71258,
49767,
52067,
50483,
2576,
237799,
46963,
42241,
187416,
282455,
196700,
55259,
13126,
11873,
172034,
53474,
127888,
36646,
229092,
102347,
198135,
67930,
37427,
204353,
null,
33813,
64758,
43318,
23502,
16104,
187292,
502616,
12907,
40436,
209001,
19851,
null,
299771,
107790,
106299,
108111,
46125,
null,
147997,
77623,
225726,
279976,
257077,
268643,
191558,
133192,
7111,
26124,
48744,
null,
35926,
null,
321630,
474584,
51932,
265241,
257343,
75735,
296168,
305253,
267258,
248546,
null,
217345,
10375,
5919,
238574,
225248,
120904,
456431,
26085,
225187,
null,
null,
null,
211010,
226934,
82357,
11370,
13847,
null,
24872,
66361,
111068,
12045,
124560,
39752,
127448,
377468,
64988,
427058,
48389,
92907,
227647,
339794,
178211,
14016,
195750,
400957,
66753,
17017,
190658,
27660,
111568,
39814,
53484,
23588,
111522,
28912,
21692,
113710,
419565,
91668,
69989,
194566,
20037,
43085,
47923,
14073,
18373,
null,
30821,
null,
7437,
94029,
53777,
32772,
207562,
24534,
504633,
424345,
982,
16219,
42588,
271644,
31528,
45715,
32492,
211012,
387748,
25839,
137160,
317496,
40356,
33476,
66472,
null,
null,
65714,
69612,
264190,
389931,
37966,
142110,
73796,
366133,
21072,
10973,
16444,
28217,
null,
59136,
269747,
2629,
3709,
11525,
340431,
29396,
366878,
180979,
432449,
178537,
14671,
446441,
102592,
93651,
50050,
18397,
25112,
361933,
299034,
142634,
670525,
28204,
437123,
7954,
null,
23963,
null,
47565,
31499,
24744,
29638,
75133,
20580,
217479,
447640,
154128,
193042,
24972,
150367,
44285,
597577,
19583,
42398,
303326,
19467,
316990,
221851,
11451,
4570,
6448,
330916,
176673,
72250,
199207,
196274,
72876,
null,
295213,
51455,
54437,
99046,
138705,
471634,
null,
200945,
206710,
127046,
354842,
220643,
26090,
26805,
74317,
74258,
137868,
46433,
207248,
734726,
142981,
35846,
112665,
47128,
null,
45892,
218537,
10587,
518558,
292717,
37854,
14869,
20770,
253275,
155610,
104721,
60658,
10757,
21395,
60157,
55085,
null,
7395,
null,
138574,
224981,
43253,
6780,
56011,
329620,
29447,
13215,
26868,
217393,
145953,
11876,
21911,
301850,
29665,
318063,
null,
330356,
null,
80163,
89666,
33084,
56527,
32413,
31153,
118846,
34711,
214907,
449962,
215537,
107094,
38437,
17635,
63215,
316314,
205377,
391759,
40774,
62356,
147587,
340196,
null,
178107,
376612,
13480,
38960,
217950,
35183,
239215,
29510,
62510,
14180,
104787,
17822,
376671,
389706,
184063,
null,
22121,
null,
61865,
42834,
136138,
40068,
134152,
326017,
20621,
494783,
57701,
63362,
198030,
7773,
968006,
5727,
324550,
309132,
133618,
9964,
217003,
64014,
56871,
54750,
241839,
301262,
20121,
81152,
15050,
178489,
81914,
80027,
136052,
181651,
127405,
27235,
null,
12910,
26453,
183920,
428957,
360557,
41299,
464033,
229864,
7575,
40646,
139494,
383939,
17776,
33884,
60865,
277391,
167873,
11265,
580802,
21671,
22108,
359533,
22205,
573769,
55605,
19452,
458489,
34120,
11267,
320846,
null,
64160,
143463,
7520,
215924,
1776628,
329607,
215046,
306306,
29791,
31243,
46465,
78420,
95696,
21277,
216758,
226828,
21137,
31743,
324836,
22012,
421673,
203692,
67523,
64682,
4950,
231478,
41217,
564818,
41550,
53719,
299477,
null,
34184,
null,
83796,
48059,
2933,
30016,
68305,
10879,
43192,
241974,
183465,
95879,
162155,
87366,
8100,
20151,
99975,
199914,
116370,
486053,
570029,
119466,
186572,
858946,
74106,
13148,
263165,
126899,
null,
10003,
52605,
38770,
163119,
35799,
17943,
33404,
143116,
null,
186368,
36510,
180104,
47108,
18891,
null,
79226,
28384,
68494,
16155,
48583,
167879,
75390,
38381,
12895,
3629,
34357,
84592,
17002,
12475,
26532,
30044,
26691,
33432,
49842,
38836,
46553,
96929,
77930,
87922,
70497,
null,
94446,
116327,
75315,
223114,
9547,
116899,
38394,
15556,
149736,
13060,
478258,
394905,
329697,
77792,
106429,
232931,
154918,
31211,
null,
31918,
232996,
39022,
103037,
51803,
42627,
10083,
400288,
6164,
54212,
40764,
268281,
584588,
188200,
344315,
null,
154602,
65949,
85005,
9420,
108841,
131669,
15810,
153139,
305968,
711052,
null,
32928,
110312,
25759,
26052,
212914,
675846,
108497,
38020,
158240,
13761,
201940,
8908,
58193,
269493,
179408,
null,
19179,
55569,
303634,
288608,
176337,
58060,
49940,
100862,
9228,
172460,
100509,
null,
97939,
22013,
26809,
18430,
null,
184929,
27601,
25496,
154377,
23743,
42562,
278187,
260029,
33283,
31685,
214186,
51256,
256555,
31101,
242748,
19725,
195155,
98148,
32142,
379303,
311748,
449580,
38405,
null,
59585,
224732,
170460,
64236,
174737,
202864,
318521,
9130,
259931,
40849,
28737,
36991,
185439,
32398,
160173,
266731,
212628,
131459,
157105,
477524,
28107,
3765,
123207,
134344,
100011,
4841,
8876,
85936,
182507,
43473,
30409,
153994,
321386,
331383,
155278,
25068,
28187,
292528,
196722,
226322,
241336,
108080,
17600,
72799,
null,
258180,
64438,
422333,
143150,
109469,
44808,
22791,
15732,
22110,
286872,
102158,
455455,
61444,
null,
207991,
44266,
264677,
null,
18938,
38650,
177606,
78734,
24763,
131065,
17595,
null,
180477,
3297,
211228,
null,
19055,
19551,
48247,
781,
246976,
149242,
12718,
61001,
73159,
22490,
73396,
237047,
61166,
175419,
493450,
49983,
124007,
22637,
5267,
171765,
34005,
49826,
163799,
434733,
41729,
267087,
16778,
28803,
910045,
11689,
270025,
30041,
null,
null,
19029,
422856,
38905,
25027,
29801,
243150,
31520,
282302,
131423,
50691,
338955,
50196,
190579,
117191,
99562,
8232,
36047,
31154,
183459,
82265,
null,
206648,
8277,
115000,
364318,
283655,
300927,
124835,
29345,
34022,
119750,
62941,
134587,
26647,
200985,
143697,
172437,
null,
352196,
46923,
19025,
28087,
251143,
8203,
16907,
465833,
77523,
27035,
18821,
634167,
129185,
109890,
null,
294841,
178779,
58860,
135962,
100988,
367159,
635213,
80179,
173920,
24261,
248890,
34948,
14085,
37125,
165909,
9330,
31554,
218807,
615691,
57719,
16925,
19651,
null,
13854,
372509,
247006,
17083,
119872,
65187,
21990,
137283,
31307,
119752,
637515,
295240,
709249,
394719,
252119,
26469,
332219,
191883,
368577,
21399,
197654,
35595,
25593,
220017,
null,
26114,
26726,
47824,
318270,
31204,
11148,
73263,
16722,
35528,
359876,
266444,
136022,
30559,
39652,
25102,
321387,
12554,
29838,
58143,
163798,
72069,
274235,
40850,
341114,
52733,
58987,
null,
22972,
380093,
31859,
669815,
198614,
29294,
274253,
138500,
28848,
32504,
218678,
20683,
613571,
48062,
93814,
92274,
231743,
82386,
43840,
174144,
160637,
55642,
144046,
225521,
189011,
138336,
35997,
226419,
null,
134727,
15163,
71245,
13116,
61505,
16488,
56557,
null,
112921,
30339,
43602,
185584,
458560,
11830,
null,
8000,
256450,
null,
23872,
74076,
140242,
59014,
213536,
39496,
206879,
447430,
35088,
63757,
8482,
159718,
185647,
251502,
292819,
24999,
80463,
28948,
68578,
129524,
391495,
4402,
54318,
464095,
12127,
70949,
261966,
336024,
72557,
212076,
101594,
217939,
155581,
39863,
289032,
23083,
90104,
5663,
69968,
117069,
null,
null,
409038,
20333,
29428,
521133,
250064,
154003,
11970,
44195,
53054,
115256,
27565,
362403,
44576,
19087,
15701,
12890,
20126,
36290,
341257,
17927,
null,
22482,
369912,
117596,
73890,
25433,
55913,
117851,
28674,
76225,
3277,
74724,
102125,
244553,
49636,
null,
24666,
309055,
244609,
63674,
195759,
19275,
15790,
24226,
132834,
73670,
164300,
159773,
59048,
323830,
22341,
197611,
65602,
15577,
28725,
26650,
265432,
349259,
33255,
230139,
277388,
null,
174537,
17771,
48256,
190222,
17441,
31443,
238650,
64993,
139863,
38527,
141648,
430225,
179666,
277709,
173094,
null,
161616,
9315,
null,
31777,
165153,
68648,
53901,
17941,
76392,
68858,
7598,
181464,
37065,
20121,
279816,
328981,
112371,
247418,
169128,
147598,
null,
136076,
null,
101054,
27251,
20351,
110515,
198240,
120584,
287259,
35105,
31558,
20811,
62784,
17255,
273437,
193002,
196430,
null,
16765,
141918,
46020,
440317,
237332,
156101,
47970,
18485,
3481,
622280,
33736,
28292,
34425,
12818,
157363,
39913,
90609,
247979,
9828,
65280,
424722,
135209,
40788,
160979,
20440,
399251,
null,
70820,
287496,
45575,
259812,
95696,
211505,
74427,
157518,
489056,
null,
294481,
307265,
12392,
360330,
23732,
16735,
256400,
33212,
238005,
22440,
894817,
57696,
762459,
117138,
null,
63643,
94335,
126606,
27578,
107213,
456942,
43568,
169806,
24602,
27527,
9440,
null,
null,
56150,
231963,
53631,
378510,
313882,
444537,
null,
null,
23883,
78990,
304459,
null,
53649,
null,
170595,
16145,
19291,
43401,
142113,
895389,
24690,
9232,
40087,
37939,
null,
61404,
25471,
34028,
49998,
36973,
99111,
124448,
27329,
5445,
23533,
659988,
156966,
343383,
74597,
34383,
219189,
320298,
89905,
99503,
181217,
126433,
20405,
6036,
null,
31664,
231726,
107309,
13815,
12969,
13236,
347943,
88654,
102574,
28338,
116851,
28016,
298488,
19960,
164848,
33163,
64659,
169031,
44415,
248807,
16040,
461010,
11160,
737898,
62355,
3838,
42358,
8770,
148277,
234525,
395138,
12457,
10824,
57977,
64053,
268534,
182447,
null,
249901,
12783,
45462,
15359,
327468,
357096,
141986,
310712,
11415,
null,
138266,
27785,
77739,
32746,
90845,
68636,
40823,
null,
418605,
13353,
117707,
392625,
null,
53057,
28262,
184817,
47141,
null,
157628,
null,
120529,
null,
18611,
456286,
null,
354366,
32936,
54101,
82263,
40814,
50476,
91962,
68650,
294896,
null,
182415,
84519,
11878,
238944,
49367,
151537,
412062,
62059,
280023,
15853,
294683,
194773,
null,
146204,
128499,
224001,
319543,
138916,
35696,
null,
204143,
93528,
11764,
557641,
110124,
37514,
381443,
29611,
439622,
192077,
18144,
147236,
260920,
179398,
50090,
325775,
27869,
364905,
127831,
23642,
19407,
153372,
1050877,
34638,
157014,
93297,
10826,
25371,
206383,
null,
456903,
298283,
37955,
57261,
407848,
115462,
null,
null,
null,
44583,
51889,
340059,
181774,
33645,
null,
195146,
138698,
44327,
406949,
200236,
160388,
null,
42409,
36831,
300675,
47737,
18899,
117462,
32090,
219826,
20118,
91009,
183436,
14389,
37326,
null,
144975,
null,
6201,
null,
136471,
47630,
756758,
302321,
184023,
180090,
67555,
212736,
46739,
145888,
9666,
116909,
237640,
177263,
63659,
223251,
6167,
144345,
48543,
12060,
138999,
38970,
42082,
382324,
18471,
11867,
64565,
86910,
17689,
8181,
19135,
34283,
21474,
null,
262668,
32674,
9215,
121073,
46575,
34873,
160575,
23373,
3185,
9441,
529008,
321422,
21709,
29316,
95864,
17901,
31666,
9951,
18211,
174527,
5578,
338739,
281648,
151223,
958,
24622,
null,
8424,
15037,
32470,
73934,
31175,
69301,
102064,
23671,
32706,
7747,
9389,
122341,
382780,
175773,
185687,
49362,
156413,
68062,
null,
null,
null,
39983,
16466,
433296,
36283,
151344,
4891,
56720,
249510,
132444,
6425,
102139,
21457,
110098,
611197,
231453,
296964,
98010,
121730,
64247,
155387,
264187,
null,
188710,
190534,
58219,
50660,
217186,
92167,
229003,
35234,
3598,
null,
22093,
189735,
49020,
16592,
244668,
76005,
2114,
93418,
15057,
17348,
98290,
37099,
27489,
126986,
34259,
340517,
167595,
240183,
55713,
14776,
209807,
38739,
41234,
15593,
156085,
158374,
null,
58187,
17613,
8113,
22493,
33956,
75677,
161515,
23296,
23935,
72103,
63842,
171518,
572614,
39568,
398638,
67184,
74550,
205667,
53476,
44235,
null,
360657,
95528,
3552,
8199,
82674,
68810,
524501,
33137,
386837,
10400,
26024,
28407,
87729,
54401,
77943,
41198,
31877,
70633,
120322,
472277,
56238,
58400,
null,
40823,
22792,
74310,
23683,
21348,
103643,
195987,
346894,
9235,
null,
49191,
83425,
49447,
247649,
65122,
372855,
20411,
365873,
36506,
30929,
94753,
17858,
19491,
40877,
41227,
null,
30056,
56738,
106965,
47401,
226700,
197654,
14422,
null,
109075,
55838,
299184,
26601,
12455,
115738,
41607,
11000,
49735,
167148,
42104,
null,
null,
76416,
163161,
133477,
25127,
null,
421485,
47300,
241494,
39738,
null,
34156,
71394,
5392,
55727,
197173,
202562,
141441,
126484,
266095,
39592,
398485,
6494,
null,
37779,
101821,
22744,
204523,
29655,
15331,
4637,
52908,
423857,
369445,
379535,
114261,
110137,
19820,
161693,
393251,
4502,
308479,
26937,
28072,
50981,
41924,
202398,
251496,
42470,
185486,
97756,
null,
20695,
137258,
66668,
50771,
10317,
160478,
null,
49728,
68029,
174833,
341422,
14902,
26818,
27582,
45463,
31578,
27628,
50817,
null,
null,
30437,
275669,
32331,
6480,
9032,
36028,
74657,
4789,
137272,
246882,
36300,
299576,
30323,
544926,
189935,
22663,
39295,
22184,
null,
160258,
17371,
null,
397543,
364139,
84628,
40351,
180464,
25163,
50809,
223552,
281480,
null,
299190,
null,
63584,
null,
31747,
22547,
60077,
136612,
33234,
255293,
407561,
101714,
254349,
null,
152935,
21544,
83448,
13678,
232660,
342698,
300458,
65407,
52198,
52124,
389274,
37660,
23713,
14302,
46710,
201992,
48872,
147463,
399091,
93709,
30302,
460456,
167232,
115671,
null,
70081,
113466,
41870,
152542,
65469,
262550,
34684,
315833,
153449,
17978,
40396,
12573,
676003,
170171,
26674,
7601,
19468,
53227,
34254,
13159,
217691,
132099,
32247,
36619,
579207,
82728,
333591,
188453,
250853,
null,
null,
6138,
49594,
83487,
224500,
268939,
49019,
18350,
2942,
null,
44947,
19371,
309631,
605232,
144842,
170289,
22401,
34907,
11599,
311969,
338245,
8272,
18630,
150327,
62018,
24165,
243053,
12774,
97421,
33761,
162104,
6754,
20525,
232767,
14249,
37989,
311556,
240648,
567888,
174501,
null,
93625,
107674,
328717,
80216,
95976,
328459,
27701,
55172,
439583,
150742,
51014,
174864,
16620,
260311,
17342,
31665,
14502,
278976,
10000,
175369,
12593,
185103,
226044,
35998,
153363,
39244,
174193,
20086,
2886,
459880,
13009,
null,
36083,
192889,
24724,
17838,
140934,
3732,
2746,
null,
3075,
222329,
332524,
116668,
37555,
209217,
254641,
128157,
19470,
54917,
378659,
77368,
null,
150657,
374867,
null,
98623,
72109,
35617,
77175,
37199,
371974,
135864,
1715,
16803,
209825,
null,
42508,
8142,
49850,
246292,
3839,
147663,
191327,
115059,
null,
405495,
196195,
276568,
91313,
157485,
3719,
29961,
277380,
56765,
16220,
269817,
27929,
74731,
203758,
75321,
46058,
200895,
284342,
179136,
20550,
69246,
249571,
132249,
769107,
170271,
null,
38708,
59979,
188684,
104417,
33950,
201857,
245597,
52059,
182025,
35556,
69421,
85274,
100871,
49693,
13859,
12800,
18128,
255903,
70882,
43019,
45712,
80110,
241821,
256124,
63483,
437781,
44315,
315918,
634376,
102181,
10615,
79514,
46264,
132123,
291024,
183219,
327641,
null,
37282,
null,
63101,
144359,
null,
380166,
171826,
null,
6023,
29218,
361423,
447134,
23117,
36084,
27664,
24281,
101234,
109355,
10406,
54402,
134607,
96535,
null,
92652,
94468,
55589,
32283,
27101,
58817,
192535,
48480,
19644,
180245,
5206,
100082,
429799,
28315,
147346,
46996,
215029,
null,
563610,
33975,
15397,
null,
164486,
248381,
43724,
74428,
555863,
295885,
215397,
141083,
52288,
283026,
238911,
null,
41397,
338539,
310407,
147400,
27089,
39634,
26344,
3848,
123695,
28552,
21562,
18911,
51938,
351734,
17704,
286099,
19800,
105440,
446846,
92766,
69089,
24081,
53478,
99787,
49553,
87285,
378775,
25690,
174492,
224678,
35566,
null,
375290,
111842,
145172,
127626,
230356,
607896,
null,
538143,
null,
21359,
56815,
195596,
47732,
281096,
334371,
194699,
98660,
null,
null,
100402,
334388,
67055,
16851,
157013,
744813,
174535,
119870,
20767,
34125,
23817,
28827,
93269,
null,
273712,
45283,
157141,
296940,
294013,
150815,
632686,
43946,
231063,
57125,
88497,
223720,
40418,
26144,
30253,
28156,
229007,
19572,
26926,
36695,
7891,
null,
null,
271843,
21772,
35430,
31906,
28561,
null,
34544,
21061,
3148
]
}
],
"layout": {
"legend": {
"bgcolor": "#F5F6F9",
"font": {
"color": "#4D5663"
}
},
"paper_bgcolor": "#F5F6F9",
"plot_bgcolor": "#F5F6F9",
"template": {
"data": {
"bar": [
{
"error_x": {
"color": "#2a3f5f"
},
"error_y": {
"color": "#2a3f5f"
},
"marker": {
"line": {
"color": "#E5ECF6",
"width": 0.5
}
},
"type": "bar"
}
],
"barpolar": [
{
"marker": {
"line": {
"color": "#E5ECF6",
"width": 0.5
}
},
"type": "barpolar"
}
],
"carpet": [
{
"aaxis": {
"endlinecolor": "#2a3f5f",
"gridcolor": "white",
"linecolor": "white",
"minorgridcolor": "white",
"startlinecolor": "#2a3f5f"
},
"baxis": {
"endlinecolor": "#2a3f5f",
"gridcolor": "white",
"linecolor": "white",
"minorgridcolor": "white",
"startlinecolor": "#2a3f5f"
},
"type": "carpet"
}
],
"choropleth": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "choropleth"
}
],
"contour": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "contour"
}
],
"contourcarpet": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "contourcarpet"
}
],
"heatmap": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "heatmap"
}
],
"heatmapgl": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "heatmapgl"
}
],
"histogram": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "histogram"
}
],
"histogram2d": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "histogram2d"
}
],
"histogram2dcontour": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "histogram2dcontour"
}
],
"mesh3d": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "mesh3d"
}
],
"parcoords": [
{
"line": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "parcoords"
}
],
"pie": [
{
"automargin": true,
"type": "pie"
}
],
"scatter": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatter"
}
],
"scatter3d": [
{
"line": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatter3d"
}
],
"scattercarpet": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattercarpet"
}
],
"scattergeo": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattergeo"
}
],
"scattergl": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattergl"
}
],
"scattermapbox": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattermapbox"
}
],
"scatterpolar": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterpolar"
}
],
"scatterpolargl": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterpolargl"
}
],
"scatterternary": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterternary"
}
],
"surface": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "surface"
}
],
"table": [
{
"cells": {
"fill": {
"color": "#EBF0F8"
},
"line": {
"color": "white"
}
},
"header": {
"fill": {
"color": "#C8D4E3"
},
"line": {
"color": "white"
}
},
"type": "table"
}
]
},
"layout": {
"annotationdefaults": {
"arrowcolor": "#2a3f5f",
"arrowhead": 0,
"arrowwidth": 1
},
"coloraxis": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"colorscale": {
"diverging": [
[
0,
"#8e0152"
],
[
0.1,
"#c51b7d"
],
[
0.2,
"#de77ae"
],
[
0.3,
"#f1b6da"
],
[
0.4,
"#fde0ef"
],
[
0.5,
"#f7f7f7"
],
[
0.6,
"#e6f5d0"
],
[
0.7,
"#b8e186"
],
[
0.8,
"#7fbc41"
],
[
0.9,
"#4d9221"
],
[
1,
"#276419"
]
],
"sequential": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"sequentialminus": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
]
},
"colorway": [
"#636efa",
"#EF553B",
"#00cc96",
"#ab63fa",
"#FFA15A",
"#19d3f3",
"#FF6692",
"#B6E880",
"#FF97FF",
"#FECB52"
],
"font": {
"color": "#2a3f5f"
},
"geo": {
"bgcolor": "white",
"lakecolor": "white",
"landcolor": "#E5ECF6",
"showlakes": true,
"showland": true,
"subunitcolor": "white"
},
"hoverlabel": {
"align": "left"
},
"hovermode": "closest",
"mapbox": {
"style": "light"
},
"paper_bgcolor": "white",
"plot_bgcolor": "#E5ECF6",
"polar": {
"angularaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"bgcolor": "#E5ECF6",
"radialaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
}
},
"scene": {
"xaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
},
"yaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
},
"zaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
}
},
"shapedefaults": {
"line": {
"color": "#2a3f5f"
}
},
"ternary": {
"aaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"baxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"bgcolor": "#E5ECF6",
"caxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
}
},
"title": {
"x": 0.05
},
"xaxis": {
"automargin": true,
"gridcolor": "white",
"linecolor": "white",
"ticks": "",
"title": {
"standoff": 15
},
"zerolinecolor": "white",
"zerolinewidth": 2
},
"yaxis": {
"automargin": true,
"gridcolor": "white",
"linecolor": "white",
"ticks": "",
"title": {
"standoff": 15
},
"zerolinecolor": "white",
"zerolinewidth": 2
}
}
},
"title": {
"font": {
"color": "#4D5663"
},
"text": "tot_cur_bal Box plot"
},
"xaxis": {
"gridcolor": "#E1E5ED",
"showgrid": true,
"tickfont": {
"color": "#4D5663"
},
"title": {
"font": {
"color": "#4D5663"
},
"text": ""
},
"zerolinecolor": "#E1E5ED"
},
"yaxis": {
"gridcolor": "#E1E5ED",
"showgrid": true,
"tickfont": {
"color": "#4D5663"
},
"title": {
"font": {
"color": "#4D5663"
},
"text": ""
},
"zerolinecolor": "#E1E5ED"
}
}
},
"text/html": [
"\n",
" \n",
" \n",
" \n",
" \n",
"
"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"application/vnd.plotly.v1+json": {
"config": {
"linkText": "Export to plot.ly",
"plotlyServerURL": "https://plot.ly",
"showLink": true
},
"data": [
{
"histfunc": "count",
"histnorm": "",
"marker": {
"color": "rgba(255, 153, 51, 1.0)",
"line": {
"color": "#4D5663",
"width": 1.3
}
},
"name": "total_rev_hi_lim",
"opacity": 0.8,
"orientation": "v",
"type": "histogram",
"x": [
30800,
32900,
34900,
24700,
47033,
29500,
55500,
11800,
62100,
33200,
47000,
19600,
139900,
43000,
41200,
18500,
15900,
17400,
17000,
31000,
27200,
null,
25700,
14300,
41400,
43400,
19800,
33100,
49900,
10900,
94100,
69000,
4900,
12300,
30200,
8900,
6600,
37100,
16700,
62400,
5500,
46500,
26600,
32400,
57300,
9400,
72900,
null,
22500,
20100,
18200,
74000,
43300,
13000,
33600,
18800,
90600,
32900,
5600,
72600,
62800,
87000,
54500,
22100,
20000,
63700,
null,
null,
14400,
62200,
8300,
15700,
3000,
17300,
null,
33300,
10500,
40200,
34400,
26400,
15550,
118600,
23300,
27500,
43900,
12950,
16200,
23700,
23800,
8700,
46800,
19000,
0,
null,
44200,
5800,
22300,
16900,
84500,
31200,
14800,
31900,
67600,
71207,
6000,
6500,
23800,
130300,
24000,
31000,
48900,
64700,
54000,
5800,
43300,
70000,
34900,
7300,
45600,
15600,
22800,
12600,
92000,
null,
47400,
8800,
27500,
46000,
25300,
10800,
null,
8000,
7900,
46400,
67700,
13507,
60100,
33100,
31100,
15200,
19500,
37900,
33700,
22500,
7500,
12900,
57600,
38800,
95900,
59600,
null,
7800,
null,
14900,
37500,
12300,
46000,
41600,
27000,
12000,
18600,
19900,
28700,
11400,
46100,
26000,
5800,
49500,
25100,
19900,
14800,
21600,
110500,
48900,
143100,
17800,
47100,
62300,
11500,
31100,
11200,
15200,
22500,
22500,
28900,
19700,
16600,
16300,
47700,
4700,
68200,
13200,
29600,
null,
35800,
null,
38700,
null,
24500,
13500,
41100,
81300,
38050,
10700,
12700,
1000,
16200,
null,
null,
37000,
4850,
40800,
11500,
41300,
17400,
12700,
19100,
72300,
30800,
null,
50900,
8400,
25800,
25100,
17000,
3300,
149900,
16500,
95100,
28700,
18500,
5300,
60300,
99000,
28800,
47000,
38800,
18900,
null,
22800,
36400,
38900,
11700,
88197,
null,
5500,
20600,
36500,
10700,
33300,
9600,
null,
33500,
19000,
33000,
21300,
34900,
16100,
11610,
28500,
30900,
42600,
32500,
2600,
48600,
18800,
21900,
9300,
23900,
36000,
23000,
36800,
18600,
27500,
12900,
50200,
38600,
21100,
12400,
5700,
19600,
29500,
11500,
null,
37250,
18100,
32800,
7700,
19900,
24800,
6100,
75500,
19100,
56200,
81000,
12000,
null,
13500,
null,
17700,
58200,
78600,
5800,
null,
25100,
10300,
52200,
32800,
24800,
24900,
32500,
27900,
35800,
55400,
23500,
null,
25800,
241600,
32400,
39800,
184100,
53700,
6800,
23100,
32100,
32100,
26900,
14400,
23500,
4500,
47800,
44300,
15100,
45900,
24800,
null,
null,
31200,
3500,
27400,
49200,
27600,
13200,
62600,
54423,
15500,
22000,
70700,
22300,
20300,
7000,
11100,
12600,
28300,
31600,
37500,
10500,
74400,
23500,
14500,
64000,
null,
22200,
72600,
null,
20700,
5900,
33300,
11200,
41500,
32400,
null,
8800,
41400,
7500,
35500,
12600,
31400,
32300,
20000,
75000,
41245,
25500,
null,
21800,
26000,
24000,
null,
5900,
23500,
14000,
11800,
null,
24600,
46600,
20200,
1000,
81600,
19000,
1800,
11100,
11200,
18500,
44500,
24700,
13900,
56900,
3600,
27100,
13900,
26900,
65700,
41400,
66400,
30200,
null,
8400,
2300,
5300,
49700,
27300,
null,
2800,
null,
18500,
26000,
53800,
16600,
28000,
29600,
111400,
66100,
50100,
31600,
null,
11300,
51600,
21000,
27400,
14500,
20000,
19800,
27100,
10500,
29800,
57800,
12200,
8300,
23800,
14800,
12800,
28500,
17900,
16600,
16100,
35800,
24000,
62600,
16900,
86700,
33400,
44900,
30900,
20600,
6600,
13600,
43700,
43200,
6500,
25500,
30300,
45500,
null,
5700,
7600,
44000,
32400,
31400,
13300,
null,
13700,
31400,
19700,
15300,
26400,
30100,
48100,
11300,
27200,
12700,
16200,
79500,
35400,
30500,
4000,
8700,
20300,
4600,
null,
9700,
11300,
18900,
73400,
62100,
25300,
35200,
15200,
16900,
null,
11900,
16000,
28500,
null,
17700,
40800,
37900,
73800,
12500,
27700,
52200,
41500,
6300,
62100,
21200,
20600,
14800,
20600,
27400,
63700,
38500,
40300,
23500,
53100,
41700,
18100,
38500,
96300,
28500,
97700,
6800,
31600,
14500,
31700,
78200,
21500,
13100,
52800,
38000,
15100,
28700,
6400,
16800,
23400,
14700,
19000,
21500,
55300,
11900,
17000,
null,
68700,
46800,
22900,
18100,
9000,
56900,
26400,
null,
45000,
9800,
null,
20800,
null,
18400,
30500,
26800,
38400,
12800,
79700,
37000,
null,
null,
21200,
44000,
23800,
25100,
57800,
9700,
null,
26800,
18600,
27000,
14200,
26100,
21500,
90600,
null,
null,
49100,
17300,
9200,
22500,
76400,
32000,
10000,
9400,
20700,
16700,
30800,
null,
22300,
25000,
35600,
4500,
29000,
23000,
11900,
27400,
7000,
90000,
21200,
47400,
12500,
15300,
90300,
36900,
24100,
5100,
7800,
17900,
20500,
9100,
44200,
19700,
15300,
99800,
24600,
18900,
68000,
29000,
59300,
12900,
122400,
33200,
13750,
8100,
27400,
5751,
null,
33800,
15700,
21200,
51500,
53100,
6500,
53000,
20300,
5500,
52000,
null,
20600,
28400,
1700,
11200,
33500,
62000,
36200,
35400,
15200,
9500,
24000,
18300,
null,
24900,
23400,
68800,
28700,
48000,
26800,
35300,
21300,
2700,
48700,
371700,
8900,
5200,
10500,
15900,
8700,
23000,
17700,
16600,
3100,
15600,
13600,
17200,
17300,
21500,
13700,
50200,
25000,
35600,
25400,
49300,
9900,
50000,
50100,
15400,
34100,
13500,
28700,
31800,
null,
35100,
34600,
63400,
60900,
4800,
6750,
50800,
42000,
33000,
15100,
null,
30700,
22800,
20600,
32300,
23300,
60900,
53100,
23700,
22500,
15000,
20600,
25200,
34500,
28300,
76800,
4300,
63300,
25800,
14000,
null,
112900,
20800,
5200,
10300,
38300,
39200,
13700,
15200,
4200,
null,
44500,
3800,
22000,
70900,
42900,
53100,
31500,
36200,
41900,
78000,
21600,
10600,
10000,
32100,
31300,
6900,
12168,
10700,
30500,
188400,
25600,
100600,
34200,
20900,
null,
26400,
12100,
10400,
49600,
10500,
11200,
16400,
16000,
null,
10600,
45000,
12600,
139000,
26200,
17800,
22700,
14000,
12604,
7200,
23900,
8700,
27100,
16800,
7000,
27300,
30100,
6300,
12500,
35800,
null,
19100,
47700,
33900,
13800,
32000,
14300,
24100,
25200,
30800,
6500,
37500,
81000,
null,
19600,
13600,
34500,
null,
16000,
22800,
7500,
4600,
9100,
38700,
8300,
39800,
25100,
19500,
34900,
27000,
24300,
45700,
12500,
43500,
54400,
null,
36070,
5100,
14700,
41100,
18400,
11300,
29500,
50900,
14700,
21000,
63500,
55800,
4300,
35100,
8900,
18300,
16800,
13800,
59000,
18200,
41700,
23000,
28600,
25700,
0,
18100,
3200,
106000,
19300,
13500,
13200,
55300,
52922,
10200,
21800,
23900,
41600,
36300,
53700,
49600,
37500,
10300,
9900,
12000,
33700,
12200,
24800,
27000,
22800,
15300,
51100,
6900,
4500,
12000,
22700,
8000,
28800,
19100,
25000,
26800,
33700,
45500,
11600,
20600,
23800,
null,
122400,
41100,
6100,
null,
71100,
25600,
19700,
null,
51300,
15200,
14900,
33700,
11200,
25600,
74300,
30400,
21800,
20600,
33500,
47300,
43800,
53600,
28600,
31200,
56500,
9400,
10700,
69300,
23200,
71900,
37500,
49200,
26900,
15600,
8000,
41500,
null,
18700,
11500,
48100,
18000,
12900,
7400,
22000,
200100,
29200,
14500,
9300,
48700,
32100,
16700,
52900,
11100,
4500,
17500,
38300,
34500,
58900,
25100,
73525,
58700,
6800,
11500,
null,
15000,
33800,
14900,
null,
15200,
12800,
10500,
95300,
4800,
44400,
12600,
20000,
16500,
23300,
51400,
16950,
23800,
8100,
24900,
29500,
35000,
19800,
52100,
38300,
55500,
14800,
null,
24000,
37000,
45600,
31300,
5300,
26500,
97000,
10500,
27900,
20900,
27500,
null,
29700,
3700,
12840,
6900,
8200,
30000,
35400,
22300,
17600,
20100,
9600,
28000,
21300,
44100,
4800,
null,
35900,
31000,
9000,
10900,
null,
15200,
34600,
23700,
27500,
10400,
18300,
32700,
null,
27900,
25000,
7200,
null,
46900,
9500,
46400,
45000,
13500,
86000,
55700,
45800,
18200,
23800,
270900,
null,
21300,
29400,
9700,
30300,
18600,
29400,
28700,
null,
3700,
null,
22300,
16100,
25400,
29300,
null,
23700,
20400,
23900,
21100,
86700,
26300,
38200,
21500,
8000,
25700,
101900,
10100,
33200,
8500,
15900,
22400,
9100,
26800,
11000,
25100,
7900,
21000,
64600,
18800,
46000,
14600,
22200,
null,
25000,
13400,
7800,
15800,
29200,
39600,
51700,
43000,
27400,
36500,
24300,
62700,
3700,
20000,
27700,
19600,
35400,
18000,
31700,
10200,
17000,
41256,
18300,
52900,
72900,
51800,
11400,
43400,
37100,
15800,
51300,
75700,
20300,
56200,
7000,
13900,
19600,
23800,
52500,
22800,
31900,
null,
23600,
18800,
16400,
20100,
9500,
20200,
37700,
138300,
44405,
80500,
13000,
17300,
20700,
61600,
32000,
7300,
41500,
17700,
25000,
17600,
88300,
19700,
6900,
12900,
33000,
15200,
27100,
27200,
42100,
31700,
43700,
12000,
21500,
null,
76000,
7300,
8900,
97798,
22200,
6100,
37900,
24800,
12000,
48400,
15100,
null,
101100,
21700,
28900,
47900,
null,
41000,
25200,
49000,
32600,
null,
10110,
21200,
5400,
18600,
63400,
null,
11200,
35200,
14400,
19200,
14700,
66600,
56000,
17200,
null,
10200,
24900,
22700,
13200,
null,
27400,
16300,
165300,
35800,
null,
30119,
28042,
22300,
21800,
8500,
21600,
26100,
4300,
30000,
null,
12000,
24300,
4200,
27126,
9000,
35700,
22500,
29400,
10200,
22900,
61400,
15200,
14600,
19100,
37100,
26900,
23300,
18800,
9850,
22300,
7300,
13200,
40400,
111700,
113700,
21500,
36400,
24800,
26600,
25300,
16400,
17800,
14100,
28900,
31100,
4300,
13700,
72100,
33400,
12400,
53200,
14400,
30900,
22100,
15000,
31300,
null,
17000,
7300,
null,
67300,
28900,
8800,
30900,
19100,
17950,
17300,
8500,
null,
17700,
null,
17200,
7600,
24900,
36400,
12200,
32100,
48900,
12000,
20700,
246400,
8900,
31200,
13700,
19800,
30700,
11400,
127800,
14400,
null,
60500,
33600,
60100,
36100,
22200,
7500,
28100,
171600,
null,
19200,
16000,
18700,
11000,
166000,
12300,
51500,
84100,
20600,
17450,
6900,
66800,
34800,
29100,
26900,
68800,
23000,
42000,
21600,
null,
11600,
15100,
19100,
15700,
21700,
6000,
45300,
101500,
26800,
11500,
15300,
16900,
40700,
21200,
4650,
15100,
9900,
3100,
null,
28500,
17100,
33400,
24400,
78924,
36900,
40300,
71800,
40000,
102000,
14000,
29500,
13300,
null,
null,
17500,
17800,
85800,
42900,
null,
14800,
26400,
2900,
49500,
33500,
14500,
16900,
57800,
31100,
26800,
17500,
7000,
20700,
9000,
14300,
58500,
null,
34900,
37700,
52100,
122900,
9000,
null,
13800,
110000,
20500,
null,
null,
16100,
12200,
46400,
57000,
14700,
null,
33800,
38300,
20100,
7300,
23600,
34400,
6700,
80500,
41700,
9700,
10100,
10400,
null,
15500,
null,
30000,
7000,
10900,
12900,
18000,
27100,
18300,
40200,
5700,
34800,
11500,
30150,
64300,
null,
28500,
7100,
9900,
null,
106500,
22000,
20200,
106100,
10400,
37000,
30800,
15700,
21900,
16700,
78100,
20500,
null,
25700,
44900,
50600,
8800,
14000,
11500,
24500,
40800,
59500,
14100,
null,
57500,
null,
33800,
13000,
42800,
25700,
25100,
56600,
12600,
15200,
28800,
129900,
24700,
30300,
25500,
4900,
10800,
null,
61547,
24000,
42600,
17700,
48500,
59300,
42800,
15300,
16600,
11900,
9100,
2900,
60300,
13500,
40000,
38900,
null,
29000,
9900,
20500,
28000,
64000,
34000,
74635,
47900,
22400,
119900,
7100,
49100,
null,
40500,
24700,
22700,
7000,
12200,
18100,
5900,
34400,
86000,
14100,
38000,
72500,
null,
43189,
10010,
25200,
30000,
28700,
8300,
18400,
8700,
9000,
125900,
8700,
6700,
14400,
24300,
97800,
25222,
39200,
null,
22100,
39400,
41300,
17500,
45700,
48700,
15500,
7600,
27600,
25300,
5700,
15709,
21700,
23800,
34700,
10100,
14100,
21400,
69500,
18100,
42200,
28400,
21600,
13100,
14600,
11700,
15000,
6800,
23100,
9200,
17800,
15200,
11900,
21200,
73800,
29100,
25500,
20900,
97900,
25200,
28100,
11800,
10200,
26500,
40000,
16500,
23900,
17400,
null,
14700,
14500,
155700,
27000,
55700,
8300,
9800,
17100,
17700,
43500,
7700,
26900,
28700,
14600,
18700,
66000,
15300,
7900,
24400,
46600,
51500,
69400,
3500,
8700,
27600,
58500,
16900,
14600,
27345,
null,
19900,
29300,
33200,
33000,
15000,
2500,
34600,
17000,
77100,
22100,
32600,
158000,
8300,
20700,
144800,
41500,
24700,
26800,
38900,
22000,
64500,
33500,
35700,
3800,
6400,
18600,
18500,
12300,
21500,
9700,
5200,
13300,
8700,
34600,
114600,
23500,
null,
50000,
43400,
null,
16800,
23200,
8800,
21500,
12000,
10750,
18700,
43500,
26500,
17000,
144800,
22100,
53646,
14100,
26060,
79900,
204100,
43200,
13100,
38400,
null,
34800,
17200,
16300,
46700,
38800,
108100,
50400,
14400,
7100,
22300,
10700,
7000,
40100,
28900,
42400,
68500,
30100,
47100,
7400,
48800,
null,
41700,
4200,
null,
41500,
48000,
null,
13500,
25903,
29000,
6500,
32300,
null,
85700,
75300,
26400,
25400,
38800,
5000,
7400,
73000,
20625,
26600,
26000,
8200,
50800,
24000,
null,
41300,
38300,
null,
32200,
27500,
21400,
119700,
93700,
12700,
35300,
18400,
5100,
10300,
null,
57600,
19000,
17400,
17500,
5800,
54600,
45900,
43000,
19600,
36000,
36700,
21200,
32200,
null,
10800,
28400,
13400,
32400,
null,
133100,
71900,
78500,
12000,
36000,
25300,
19700,
null,
10900,
56200,
11100,
29400,
5800,
49700,
10600,
37300,
5900,
3000,
19600,
24000,
15400,
45300,
23300,
71100,
10800,
84500,
16900,
14800,
17300,
12600,
17700,
37700,
10300,
15000,
44800,
99200,
18700,
18200,
14800,
15800,
66247,
49900,
28300,
88100,
40000,
null,
16300,
53300,
13200,
15000,
12950,
null,
14400,
7900,
13500,
33700,
40600,
29000,
30000,
5100,
11500,
10800,
11500,
14700,
57400,
50900,
13000,
29800,
50700,
25167,
27800,
199200,
12300,
268100,
39900,
24200,
19700,
null,
66400,
14500,
13800,
19800,
45200,
9800,
67900,
52350,
28800,
15400,
19300,
22700,
26300,
62900,
44700,
54400,
8650,
56500,
7500,
28700,
37474,
39000,
9000,
10700,
21100,
17000,
41700,
null,
12300,
61800,
28200,
33000,
16700,
37600,
23000,
75500,
13400,
14000,
19000,
20000,
9000,
118850,
31200,
64800,
30400,
33800,
122400,
15600,
13400,
41700,
95100,
39100,
32000,
27300,
5700,
16300,
39300,
10600,
12000,
25800,
24500,
41900,
53000,
12000,
18600,
2800,
null,
43500,
21300,
43700,
44800,
12050,
21500,
10700,
35000,
9000,
28000,
51200,
43900,
27000,
35400,
35600,
null,
52500,
49500,
26900,
26300,
7000,
8200,
34000,
5700,
46900,
17500,
71000,
111100,
null,
39500,
34300,
62200,
51400,
18400,
19900,
40100,
66400,
68200,
37000,
30700,
40400,
12000,
35200,
44800,
5500,
22800,
13500,
57500,
24400,
null,
13000,
43400,
38000,
72500,
12900,
20500,
3000,
15300,
null,
54700,
43100,
25100,
17800,
22300,
13600,
7700,
8600,
null,
null,
13300,
12200,
3300,
37200,
11600,
17900,
32300,
31500,
25000,
92500,
2300,
9200,
34000,
55850,
34400,
33240,
31300,
15900,
23500,
43200,
26400,
26600,
23600,
null,
null,
12300,
12300,
9100,
20500,
16300,
39400,
1200,
8100,
42100,
10800,
25800,
19500,
20000,
23600,
24700,
24500,
65143,
58100,
14900,
null,
82800,
null,
52300,
38800,
42600,
110100,
null,
43500,
8600,
48000,
158300,
10000,
13800,
80100,
42800,
36500,
17600,
25700,
6000,
5100,
23300,
89600,
23600,
25500,
48290,
14600,
15300,
21600,
40900,
63100,
36400,
21200,
8100,
33800,
22500,
150160,
12100,
null,
61500,
27200,
62300,
20800,
47600,
22600,
13600,
49100,
25700,
9800,
6300,
14000,
23200,
20000,
26100,
18900,
43400,
18100,
27800,
36700,
60000,
39900,
62400,
25400,
24100,
3700,
27200,
9800,
12900,
17600,
14000,
12750,
19000,
11700,
28900,
null,
9900,
30500,
23800,
77100,
8100,
null,
19400,
90008,
11800,
22300,
6300,
69900,
73700,
36300,
null,
42700,
35400,
53800,
10500,
54300,
12100,
17800,
46400,
10800,
17200,
33900,
33400,
66500,
null,
36800,
49500,
10800,
25100,
34000,
48200,
6000,
29800,
14900,
22500,
43600,
12300,
56300,
9900,
40900,
25200,
28744,
24500,
34300,
2600,
16200,
5000,
29500,
null,
13200,
77400,
15500,
87600,
22900,
18100,
35000,
53600,
5500,
null,
18000,
6100,
13430,
14700,
22500,
13400,
44600,
7600,
29400,
111700,
10200,
83300,
17200,
22300,
39400,
9700,
58800,
40700,
11500,
14300,
769000,
60400,
14500,
64200,
26500,
null,
20800,
33900,
16400,
23100,
6800,
3100,
23100,
14800,
13900,
15100,
11500,
102700,
17100,
31600,
133400,
21200,
78200,
28428,
null,
9400,
73300,
29500,
91200,
18500,
8500,
36300,
87000,
32000,
143000,
null,
29300,
47300,
69100,
16400,
40700,
11200,
274560,
7800,
31100,
6400,
38400,
26700,
33800,
16400,
null,
18200,
17400,
17100,
6100,
5600,
21500,
20100,
11300,
117900,
18700,
12500,
null,
null,
null,
74400,
23400,
15800,
42900,
28200,
60900,
11500,
76244,
114100,
26600,
25000,
7200,
117900,
50300,
7500,
5500,
47200,
66000,
20800,
26800,
7700,
16700,
16200,
27200,
15500,
6000,
7500,
30800,
10500,
22500,
81200,
13000,
19700,
11200,
23000,
13200,
128400,
12000,
23600,
8800,
34800,
47888,
24500,
30800,
14600,
49600,
8900,
11300,
32600,
41500,
31600,
80300,
null,
37800,
50600,
34500,
5900,
46300,
4500,
23600,
4300,
null,
80500,
29900,
16200,
33200,
null,
24700,
10900,
21200,
30200,
9500,
16100,
44100,
42996,
16100,
null,
68500,
20100,
18400,
6700,
184200,
42600,
59100,
24100,
7200,
15900,
33800,
3100,
17200,
45800,
20600,
13300,
5900,
null,
9400,
null,
75200,
14400,
86300,
24500,
null,
39500,
null,
73815,
65700,
20800,
38200,
25900,
10400,
154700,
null,
51400,
61400,
38900,
48600,
5510,
24800,
14200,
17700,
15500,
40400,
14000,
30700,
46800,
64100,
35600,
5400,
59900,
16700,
45300,
43000,
21800,
41600,
48900,
11900,
11600,
50900,
37200,
50800,
16900,
51600,
77200,
28200,
374500,
11900,
22500,
21700,
15000,
28050,
52400,
5100,
86500,
18400,
10200,
13600,
null,
36700,
38300,
28400,
10600,
19700,
24600,
25800,
null,
70700,
7400,
29300,
7900,
58500,
null,
17000,
13500,
27600,
11600,
25700,
48800,
89000,
24200,
21400,
30500,
39200,
null,
32400,
38800,
122300,
12600,
14000,
7400,
32300,
17400,
49400,
128500,
64700,
8600,
38200,
55000,
38700,
10900,
44200,
27400,
4900,
41500,
16100,
null,
5200,
null,
26800,
3000,
46300,
25700,
24200,
22600,
32900,
12000,
33800,
5100,
52700,
40100,
109400,
11500,
12000,
39200,
null,
null,
16650,
16600,
3000,
42000,
1600,
27100,
38800,
17100,
16500,
80500,
29000,
39500,
27500,
49600,
21600,
57700,
null,
500,
48500,
17500,
18100,
34100,
10200,
28500,
41100,
56400,
4000,
8000,
67200,
40100,
11100,
21200,
43100,
23400,
14300,
8400,
6500,
32700,
20200,
22100,
23200,
36400,
13800,
30100,
27500,
null,
32800,
9500,
7200,
175700,
15200,
null,
5100,
41400,
10300,
null,
null,
3800,
17000,
1300,
14800,
10800,
6500,
56100,
93600,
106800,
66600,
77200,
23410,
null,
30600,
123900,
null,
12300,
34500,
52300,
61200,
7400,
83600,
13500,
24500,
9100,
8900,
13000,
50500,
14800,
null,
9000,
null,
17300,
10100,
69500,
9730,
73500,
19000,
8600,
61500,
20500,
null,
30300,
10400,
37700,
null,
40200,
null,
7000,
12300,
31400,
11500,
25500,
13200,
19600,
44400,
10500,
23700,
60000,
45400,
24800,
51500,
21800,
15800,
10400,
28200,
null,
32200,
59500,
8200,
17200,
51000,
null,
19700,
81300,
5500,
7600,
47300,
8400,
12800,
22500,
27200,
21200,
null,
23400,
44900,
21700,
22100,
56400,
10000,
38500,
100500,
32900,
22200,
16300,
9300,
21400,
30500,
5500,
63500,
35500,
17600,
46400,
20600,
30200,
35400,
33400,
7400,
15800,
17300,
27800,
24500,
10100,
39700,
13700,
21600,
30600,
7400,
45400,
13400,
12200,
16600,
null,
21000,
15600,
46900,
29000,
9200,
46000,
18400,
19600,
27900,
31900,
63600,
11200,
48700,
36300,
23900,
52600,
4900,
11500,
14900,
64300,
71700,
25100,
19700,
10200,
10600,
9300,
83000,
14000,
null,
9800,
65100,
9100,
30500,
44800,
21400,
11100,
6300,
null,
23700,
19200,
15600,
32800,
19900,
81900,
8400,
32200,
null,
7000,
51400,
12800,
14800,
null,
21300,
74100,
null,
10300,
null,
17700,
79100,
6100,
19500,
7400,
39900,
8800,
18400,
51400,
37000,
41100,
24100,
34600,
38200,
8400,
28200,
5900,
23800,
14000,
55900,
58100,
23200,
58000,
117400,
43100,
31800,
29500,
null,
17600,
30100,
29800,
11000,
63500,
47500,
14000,
16000,
30500,
10800,
21300,
9800,
19900,
29800,
12500,
null,
null,
11500,
7800,
20500,
47600,
25600,
66600,
12100,
null,
6200,
8700,
6000,
22200,
27100,
50300,
44700,
19000,
13700,
36500,
10100,
13200,
54800,
11100,
28600,
63100,
54600,
8400,
28800,
34900,
16800,
44400,
200500,
7500,
28600,
27300,
41200,
9400,
15600,
24600,
90100,
9200,
32700,
120700,
22100,
10400,
26200,
null,
null,
33100,
26000,
13100,
99300,
30000,
22000,
27200,
27400,
27900,
24500,
49800,
14300,
35500,
17500,
65800,
10500,
18200,
7800,
41700,
47800,
7300,
9500,
12000,
26900,
38500,
34200,
4600,
11000,
18100,
18400,
24100,
5200,
17500,
36200,
67000,
6000,
38300,
53300,
null,
18000,
37600,
31400,
21600,
25300,
15700,
8000,
108800,
56800,
8500,
14200,
20300,
26000,
30100,
9900,
21300,
30300,
6000,
7000,
13100,
5500,
9800,
6000,
53047,
42100,
9200,
41200,
18100,
3500,
11400,
26600,
4300,
23600,
20800,
12300,
30600,
28600,
16800,
40100,
62300,
20100,
46900,
10100,
15500,
51300,
11400,
5700,
23900,
14800,
41889,
14100,
26600,
156300,
55500,
4800,
34600,
6700,
9200,
97900,
9400,
53464,
20700,
7100,
8600,
21300,
12800,
31900,
19200,
9800,
22600,
33600,
6700,
50300,
29700,
18070,
7000,
null,
15800,
37200,
11300,
22800,
9700,
21600,
11700,
37400,
7500,
16500,
12500,
31800,
23000,
16800,
17800,
57600,
50300,
51400,
46000,
24400,
34500,
37700,
19500,
19600,
null,
51700,
23700,
32600,
null,
32900,
114300,
17000,
42350,
19300,
null,
8000,
54200,
37400,
null,
null,
11200,
33700,
24300,
null,
70400,
29300,
29800,
34400,
6900,
13000,
null,
29800,
23500,
56900,
8700,
8500,
8100,
3500,
102700,
22300,
7900,
137600,
null,
20500,
44000,
12700,
63300,
70300,
59400,
7800,
18100,
65300,
6500,
25800,
29300,
16900,
34500,
13100,
11400,
13900,
4100,
18900,
31100,
36000,
9300,
28300,
23300,
null,
null,
18600,
14800,
9600,
11100,
25700,
4300,
47400,
52100,
33100,
57400,
47200,
48700,
22800,
6600,
17300,
20100,
42500,
84200,
17500,
60000,
46600,
28600,
33800,
24300,
8700,
79200,
6200,
30300,
7000,
149500,
45100,
21200,
29400,
null,
31400,
21200,
7000,
25600,
8000,
32500,
38200,
10800,
10600,
34700,
8100,
103500,
9000,
37200,
20000,
28100,
30400,
12500,
5300,
null,
30500,
7400,
16000,
25200,
22400,
28800,
28800,
13900,
124100,
18200,
8800,
43800,
3100,
30000,
38137,
23200,
null,
22400,
33900,
32900,
39300,
89745,
23900,
80900,
15000,
4600,
30600,
24900,
25900,
9500,
12800,
32800,
51200,
null,
52400,
16900,
22700,
31800,
32800,
8600,
31500,
21200,
18300,
62800,
7000,
null,
37400,
48900,
33700,
22000,
3200,
15700,
19100,
47000,
38500,
16100,
24500,
20900,
9200,
51500,
46600,
44300,
53500,
19000,
18500,
36700,
16700,
15600,
59800,
9900,
25700,
15800,
4200,
51400,
5100,
28900,
35800,
21000,
4300,
33800,
92800,
29800,
null,
57300,
null,
null,
12700,
67200,
36900,
40900,
17200,
31900,
null,
40038,
32400,
13300,
28000,
5800,
34318,
84315,
10200,
10100,
15800,
21000,
7100,
21900,
10700,
26300,
56300,
null,
18200,
null,
9400,
null,
15400,
42850,
17400,
26500,
null,
15900,
null,
33000,
20900,
18900,
21600,
29600,
30800,
37900,
5100,
21500,
29400,
10000,
29000,
7200,
35200,
30100,
null,
54340,
10700,
5800,
19300,
17100,
8100,
78600,
43900,
13000,
69500,
9900,
67400,
null,
15000,
41600,
41200,
24900,
40300,
14300,
null,
53000,
6200,
16200,
39000,
25900,
17700,
13800,
94700,
33000,
9700,
50800,
23900,
17000,
39600,
43900,
16500,
null,
15900,
27600,
6300,
34700,
21700,
16400,
8000,
32300,
82200,
20800,
7600,
42400,
74500,
24300,
77500,
15500,
21800,
43100,
201800,
96000,
3250,
53200,
null,
3700,
17800,
46900,
28500,
51100,
null,
15600,
9200,
null,
78900,
null,
130400,
166100,
90300,
44100,
93100,
40700,
18300,
39600,
30900,
20600,
118400,
null,
3300,
34200,
null,
18800,
16400,
57500,
25300,
23800,
24000,
29117,
6300,
16800,
16500,
13900,
20100,
19000,
53000,
29000,
4500,
33800,
76800,
64700,
18100,
18700,
15300,
36300,
68400,
null,
126300,
29800,
67300,
20100,
36200,
49700,
54700,
null,
19300,
64200,
7500,
86700,
12600,
60700,
20200,
null,
23900,
6700,
102200,
5100,
39000,
21300,
69400,
17700,
13000,
null,
40500,
20500,
20200,
23700,
12000,
72400,
24900,
13100,
11400,
66500,
13700,
13300,
86600,
41300,
21600,
13800,
16900,
14500,
5300,
17100,
90100,
10100,
21500,
33000,
9900,
null,
33100,
33000,
9200,
38400,
null,
29950,
222600,
43300,
58300,
21500,
18000,
null,
11550,
null,
36700,
20200,
9300,
20300,
18400,
null,
7900,
13693,
12900,
19500,
31600,
34300,
7500,
9700,
11000,
49600,
101800,
6000,
23700,
52900,
25900,
25898,
null,
29200,
8400,
16400,
33600,
null,
null,
17300,
22400,
16100,
7100,
21800,
24100,
20900,
42000,
36800,
26200,
null,
8700,
15300,
null,
11700,
41700,
7800,
17500,
9600,
14000,
null,
35200,
11500,
36900,
6600,
16700,
13200,
74200,
15100,
16600,
21200,
11900,
39900,
10000,
65300,
50400,
18100,
8300,
null,
11400,
null,
20800,
12500,
49500,
8500,
49600,
10500,
25300,
18000,
5600,
null,
57400,
null,
64800,
9415,
23400,
28900,
38562,
45600,
45900,
15600,
null,
null,
5300,
30500,
124200,
99500,
8450,
11900,
11850,
8100,
26100,
26000,
43500,
null,
127300,
14100,
56400,
39000,
16500,
18100,
null,
10600,
54900,
41700,
132000,
7700,
13300,
null,
null,
100400,
72600,
11800,
13700,
42700,
null,
16100,
40900,
24800,
10500,
20500,
17300,
38000,
25900,
15700,
14300,
35400,
null,
20000,
30400,
23500,
112700,
14500,
6400,
18900,
25800,
33500,
50000,
38000,
2950,
17800,
1200,
34900,
20700,
48800,
30700,
77700,
25200,
44500,
9600,
19600,
null,
67600,
51800,
67200,
55300,
52900,
40300,
79100,
20300,
7950,
30600,
13500,
20500,
3900,
12900,
13300,
7500,
47800,
12400,
28400,
28700,
31400,
26300,
48500,
11200,
48100,
16500,
4500,
88750,
38300,
18100,
8200,
24300,
21900,
16000,
114500,
null,
null,
38000,
21600,
34800,
48000,
null,
47600,
8800,
null,
null,
31900,
20600,
30900,
40500,
37900,
null,
6700,
37400,
8300,
5700,
15600,
15317,
15000,
36800,
47000,
42200,
19500,
55600,
null,
9700,
33700,
99400,
6000,
1700,
41800,
15200,
12500,
null,
26700,
7800,
62900,
38296,
12900,
118200,
25400,
27100,
8100,
24400,
18300,
6800,
22000,
29174,
112900,
12900,
36000,
23000,
null,
52700,
58700,
12500,
null,
null,
19700,
10400,
31800,
16300,
6800,
23500,
49100,
8000,
15500,
18300,
43100,
9353,
8000,
113500,
51700,
27200,
5200,
26000,
28100,
25000,
30600,
44300,
15900,
8200,
27300,
63500,
13000,
null,
null,
23100,
null,
28100,
6000,
22000,
18300,
6000,
17500,
20400,
8200,
42400,
51100,
11200,
12800,
null,
8300,
14800,
54400,
13700,
34300,
9000,
27500,
26700,
32500,
8100,
12700,
49200,
19700,
8900,
null,
112000,
44400,
17000,
22800,
45000,
61600,
24400,
20000,
57000,
22500,
5600,
18000,
22200,
258700,
49900,
15600,
25700,
14900,
41500,
18800,
18700,
null,
29900,
24900,
16800,
12900,
27200,
null,
null,
60300,
15800,
null,
2600,
35300,
23400,
42300,
24000,
34400,
2100,
2700,
3390,
16700,
54300,
null,
3600,
33100,
25200,
57700,
28000,
4000,
47600,
null,
19800,
17700,
43300,
4500,
22200,
34000,
26400,
24400,
12100,
35700,
20000,
46200,
14800,
6400,
19600,
29100,
110700,
12300,
null,
11300,
33200,
11200,
38700,
11900,
26300,
26400,
35800,
71100,
26100,
180800,
17700,
28200,
62700,
12500,
34900,
15100,
45100,
42900,
29300,
15500,
13200,
36800,
11000,
15100,
33700,
4375,
28500,
12600,
null,
47400,
10500,
25450,
12700,
21000,
11400,
125800,
28900,
10450,
39600,
19500,
30900,
49900,
34400,
27500,
29100,
76300,
53400,
13800,
47000,
109100,
9245,
193700,
null,
10800,
17600,
7000,
32800,
18800,
40700,
89400,
5200,
null,
7800,
33200,
16100,
14350,
47700,
24600,
33200,
10900,
25400,
128400,
74300,
null,
15900,
7600,
26200,
14400,
55900,
27200,
20600,
9500,
24200,
44700,
42200,
32200,
37100,
7150,
14600,
12300,
29400,
8500,
27700,
28900,
18300,
43700,
105100,
null,
36800,
29900,
30200,
8300,
34000,
43600,
45100,
90100,
181600,
5800,
20300,
18400,
44500,
25600,
23500,
10100,
18000,
5000,
10400,
6200,
24100,
25300,
39000,
22000,
10700,
13600,
23300,
49800,
11700,
16400,
95800,
29100,
null,
31500,
28400,
17700,
39600,
5400,
33900,
25200,
23600,
13200,
600,
null,
20600,
36450,
null,
37700,
34000,
22200,
143500,
29000,
41900,
16700,
9300,
50600,
5900,
53400,
51455,
46000,
55400,
31400,
77900,
156900,
56800,
19200,
242400,
2000,
20200,
null,
44501,
21800,
33300,
27500,
40200,
null,
64400,
11200,
45200,
14000,
101500,
37700,
11000,
40900,
25500,
41500,
null,
54800,
42459,
36900,
67700,
124000,
19400,
36600,
23000,
14700,
75300,
21800,
30600,
13400,
9400,
15600,
3100,
91100,
17500,
68100,
8000,
29500,
31200,
54484,
12300,
38900,
9300,
78400,
22600,
24100,
20250,
null,
7850,
11800,
19900,
10800,
7000,
30700,
25700,
32000,
63200,
14900,
null,
49600,
9100,
158600,
12600,
43800,
28600,
19400,
21600,
14900,
64300,
6500,
10500,
4500,
null,
22600,
36700,
55400,
5300,
8600,
30600,
null,
11100,
15800,
30000,
51000,
31700,
110900,
22200,
38200,
17800,
42400,
null,
37400,
82500,
36000,
25000,
14600,
37400,
7800,
42100,
51300,
6300,
5400,
110800,
10700,
42500,
71400,
11700,
29676,
22900,
13350,
27700,
11460,
78700,
30000,
5000,
17000,
24200,
17000,
10600,
16700,
6200,
14600,
19300,
39100,
14100,
3600,
86800,
76100,
22100,
8800,
17800,
11500,
36600,
41700,
12200,
48122,
7200,
null,
34000,
110200,
13500,
23800,
17000,
64900,
5400,
14400,
13000,
17300,
34300,
18900,
32500,
34400,
4600,
58300,
194600,
22300,
43000,
13500,
12900,
81600,
10100,
4800,
9300,
null,
19500,
5700,
18100,
null,
40400,
27700,
66700,
26400,
60500,
4000,
19800,
171400,
28200,
26500,
126500,
14100,
41300,
27100,
null,
31600,
6000,
24700,
19300,
null,
76300,
31900,
52800,
22800,
38800,
36800,
14400,
16300,
23100,
55310,
8400,
9100,
8800,
31800,
21000,
18700,
55500,
10900,
112400,
43600,
18600,
23700,
23600,
18200,
14300,
8800,
null,
39700,
8600,
79500,
18400,
20400,
11500,
45000,
14900,
23400,
16400,
43400,
80900,
128900,
50500,
16000,
57800,
5500,
5400,
15100,
63400,
27200,
13000,
42300,
39600,
16700,
4900,
35300,
null,
14800,
45500,
34300,
36600,
5700,
114900,
6700,
null,
40500,
23100,
26100,
54800,
36800,
37200,
38800,
49700,
64171,
5400,
12500,
30500,
21100,
21100,
9400,
2300,
12400,
4200,
null,
27200,
40300,
37100,
33550,
30300,
18200,
28000,
55400,
11400,
77900,
40200,
22200,
54600,
13500,
43300,
48100,
22600,
38900,
13100,
null,
11500,
12400,
60100,
39700,
18500,
51000,
10900,
21700,
61000,
36100,
34400,
30100,
26100,
38800,
11700,
23000,
8900,
null,
229700,
53300,
null,
14300,
null,
16100,
19900,
43500,
50000,
21800,
21400,
30900,
23900,
81800,
15000,
23600,
5500,
111900,
24400,
57000,
8400,
65000,
21100,
63000,
18800,
12100,
206200,
14700,
69000,
32800,
31300,
null,
28700,
7860,
101767,
130900,
16100,
28810,
22400,
23800,
null,
6700,
23500,
6800,
14400,
11800,
3300,
22700,
16600,
74400,
11600,
32300,
46200,
22900,
19000,
null,
25800,
38100,
2800,
10400,
24700,
26200,
17800,
15500,
34700,
null,
48800,
80500,
30200,
88700,
44800,
9600,
null,
47300,
3500,
29000,
41300,
2500,
28300,
20400,
25700,
78000,
20500,
55500,
36100,
50358,
18400,
13500,
9200,
32000,
20700,
3160,
18000,
51800,
23300,
23000,
15586,
17000,
58200,
5050,
null,
48100,
42400,
null,
17700,
15900,
29000,
62000,
144800,
52658,
12100,
30800,
30700,
22500,
20700,
47700,
10700,
null,
12300,
24800,
23800,
25200,
17200,
32300,
4600,
13700,
58500,
52300,
27500,
9200,
18800,
10800,
56000,
28000,
9100,
53700,
32300,
12100,
10200,
24300,
42100,
53500,
22700,
60600,
156800,
24400,
21100,
16300,
48400,
28800,
16400,
42500,
186100,
51000,
17500,
20300,
9000,
23900,
null,
3500,
1000,
12000,
22400,
27600,
17600,
4800,
25000,
8500,
5300,
28100,
13900,
17700,
24700,
12900,
18800,
29100,
9500,
55700,
53800,
21349,
85400,
19900,
39100,
65000,
31000,
9000,
null,
43100,
16200,
60000,
13800,
15300,
49300,
8900,
null,
43200,
null,
64900,
28400,
29600,
8100,
16000,
7200,
10200,
31300,
11900,
39000,
4300,
33500,
25400,
null,
53900,
61900,
null,
null,
19600,
25200,
32400,
null,
14094,
37600,
13800,
60300,
26500,
16800,
45300,
10600,
61500,
97800,
47500,
14400,
9900,
68000,
5800,
51200,
17000,
71700,
37900,
10200,
null,
null,
19400,
44300,
12100,
null,
125400,
9600,
29500,
8000,
null,
21350,
124043,
null,
49800,
21300,
null,
69600,
201900,
null,
165500,
null,
20700,
15700,
58600,
50800,
14600,
13800,
9100,
37500,
16000,
81500,
9600,
22800,
23800,
41700,
50500,
83100,
9700,
36741,
21100,
9500,
27100,
14500,
80600,
null,
7950,
24900,
41800,
27404,
6900,
4500,
20000,
35000,
80200,
30900,
36800,
null,
101700,
16300,
12600,
7100,
50200,
19700,
17508,
95500,
32200,
9200,
44100,
30300,
28400,
32300,
41200,
53400,
26300,
15300,
11600,
15700,
28900,
47500,
25400,
26250,
4900,
99400,
39700,
null,
36200,
35000,
38800,
60487,
20000,
84500,
21600,
22500,
64600,
13500,
13100,
56900,
10200,
6200,
63400,
102300,
125800,
21400,
14400,
17500,
6669,
35600,
59250,
null,
null,
17300,
40700,
16700,
10800,
47400,
17700,
257200,
12200,
24000,
57200,
33700,
12700,
23800,
null,
30400,
50800,
24500,
21800,
182100,
86200,
51500,
23000,
29000,
25300,
11600,
17500,
null,
22200,
10900,
null,
32500,
48100,
null,
49000,
21700,
9100,
7900,
6900,
34100,
10900,
6000,
68400,
43200,
16300,
null,
34200,
71100,
null,
4200,
21700,
15800,
16160,
14000,
21400,
17700,
7900,
null,
57000,
45500,
41500,
16700,
29000,
33000,
4100,
45100,
46500,
34500,
39200,
291100,
19600,
95000,
20300,
48200,
10700,
21600,
13600,
1700,
13100,
15600,
6000,
76900,
12700,
27600,
63500,
56900,
16400,
57362,
52300,
32000,
null,
18400,
13300,
22000,
21300,
10500,
15800,
49900,
38200,
47400,
105500,
7700,
7100,
13900,
42700,
28700,
93400,
49800,
4200,
79200,
17400,
25200,
18794,
32100,
null,
null,
null,
38400,
95100,
29400,
16900,
28500,
53200,
27500,
53700,
36500,
42200,
34800,
38100,
26400,
null,
35000,
14800,
18800,
20900,
31200,
45600,
13900,
19300,
21700,
37000,
13300,
18600,
20100,
18500,
45900,
null,
7100,
31600,
null,
46400,
37100,
10500,
18900,
70600,
42700,
61700,
10200,
64100,
13500,
5100,
14000,
7800,
17900,
21200,
56700,
9800,
27800,
28200,
null,
40300,
42000,
105300,
11200,
28200,
33800,
34000,
25500,
28100,
10500,
76000,
26500,
6900,
33500,
22100,
14700,
40700,
38900,
29600,
27700,
12900,
21700,
39700,
409600,
96400,
35800,
62600,
39200,
19875,
67100,
2300,
1000,
32600,
24100,
19000,
7250,
54400,
86100,
13900,
8100,
14800,
48800,
8600,
36100,
42400,
null,
16700,
25000,
32700,
30900,
46100,
null,
5000,
5300,
62600,
9600,
14600,
6000,
12200,
57900,
19400,
37900,
27100,
8400,
18600,
18100,
56400,
10700,
21200,
22200,
37900,
20052,
5100,
77600,
52800,
18900,
63600,
53800,
19400,
21200,
34100,
null,
83400,
11000,
14200,
9800,
6800,
19800,
15500,
8400,
30500,
22700,
21500,
27000,
34700,
13200,
19600,
40300,
21700,
6600,
88500,
null,
4800,
28900,
36000,
13000,
2600,
500,
null,
95700,
12500,
53400,
37700,
7000,
39300,
21900,
32200,
33600,
8900,
12700,
28400,
42500,
23600,
20000,
13300,
57600,
46500,
10800,
23900,
7500,
20600,
6200,
49200,
21600,
8900,
66600,
4800,
29400,
19700,
18800,
30600,
74800,
11700,
3900,
48800,
19500,
29100,
24700,
34300,
64400,
99400,
115000,
6900,
28900,
54200,
21800,
21700,
33800,
28500,
24200,
null,
15900,
4200,
51100,
17200,
30500,
21300,
27900,
56200,
20000,
62500,
9300,
20900,
59100,
67500,
11200,
51600,
44300,
27200,
39700,
6900,
null,
19000,
37300,
36100,
41200,
19900,
78400,
32000,
23700,
8400,
18300,
12800,
38600,
55800,
41600,
16400,
73100,
54600,
11500,
38900,
22000,
null,
27700,
6300,
114800,
10500,
null,
10800,
null,
21800,
29500,
29900,
16900,
16000,
53500,
31900,
58300,
57100,
14800,
26600,
null,
10500,
30300,
9100,
null,
38100,
6000,
17100,
41700,
null,
37200,
16800,
54300,
4500,
17100,
119800,
34750,
18000,
26100,
32200,
52000,
46400,
18900,
10900,
33500,
37500,
5000,
15000,
8400,
27200,
58000,
14300,
7600,
26200,
19600,
13700,
61000,
null,
15200,
68800,
10500,
75000,
27500,
90300,
null,
18600,
41700,
29300,
31900,
17300,
13900,
40700,
41900,
13200,
46700,
26500,
12800,
null,
10000,
23500,
3600,
23600,
4990,
27000,
null,
13350,
23400,
7900,
75600,
24100,
29266,
68300,
20900,
38300,
10500,
14100,
11000,
43000,
16400,
153400,
null,
29700,
11400,
57805,
31800,
71800,
27800,
35000,
23700,
41400,
19900,
52200,
18300,
8700,
null,
17500,
66000,
9700,
8300,
6400,
3000,
17700,
26100,
60200,
28800,
57200,
null,
null,
118960,
22800,
38600,
32800,
6700,
25900,
19967,
40600,
31100,
9600,
43200,
32700,
9800,
26300,
12100,
58660,
93000,
33400,
23900,
24700,
9000,
19000,
null,
36600,
22600,
12300,
62100,
3100,
22200,
57900,
null,
230500,
59700,
10600,
12700,
26400,
7500,
65000,
36300,
14500,
19400,
19800,
null,
75262,
21700,
18400,
44400,
22100,
20224,
31500,
30300,
4500,
21300,
35500,
null,
9800,
65200,
null,
18000,
12300,
6000,
60200,
10100,
8200,
20800,
27800,
10300,
6600,
132600,
22600,
5500,
20600,
35000,
44000,
null,
4600,
27100,
57400,
30900,
26200,
60100,
13900,
37100,
35300,
22500,
36200,
null,
26900,
13800,
28800,
24400,
27300,
null,
16200,
15700,
48900,
10900,
16100,
32100,
28900,
29000,
32000,
34600,
12300,
72900,
1800,
8800,
11200,
6000,
101600,
26700,
12900,
35100,
18000,
6500,
15900,
30000,
16300,
51800,
9400,
18900,
61500,
41900,
null,
71900,
38800,
32200,
32300,
35800,
38600,
58400,
3900,
8600,
22200,
23200,
29800,
10900,
34800,
null,
22400,
null,
27600,
19100,
55800,
null,
11500,
12000,
38500,
38000,
22900,
23600,
29200,
3500,
null,
31400,
15500,
null,
225300,
18400,
64700,
37400,
16700,
22000,
22700,
null,
10700,
15600,
31600,
7300,
155413,
20500,
29900,
43800,
13400,
23700,
15900,
54900,
62970,
30000,
17690,
16900,
71400,
18300,
1000,
1500,
87900,
60000,
77400,
6600,
7900,
5300,
70900,
null,
17600,
null,
95600,
18600,
8700,
24600,
10000,
14400,
60700,
6500,
18700,
19000,
47900,
41000,
24800,
5000,
7600,
null,
117300,
9400,
22200,
30700,
30900,
5800,
18400,
38000,
null,
35800,
57400,
14200,
48900,
69200,
46400,
16000,
16700,
39000,
33600,
15900,
15800,
157000,
12000,
11400,
24500,
3950,
1850,
15700,
56200,
30700,
31000,
74400,
56000,
45700,
11400,
34200,
5600,
null,
23400,
15300,
74750,
19700,
30300,
25700,
18700,
23300,
17540,
72200,
null,
16400,
6500,
17000,
43600,
20000,
14900,
22300,
21900,
12300,
25600,
69000,
27300,
16000,
18800,
38800,
17600,
21000,
10100,
18800,
9900,
15300,
2700,
30200,
23400,
27700,
10900,
5000,
1500,
3800,
27100,
55000,
19800,
null,
10600,
14900,
16600,
30300,
16400,
76100,
5900,
6900,
25600,
60000,
9800,
null,
31800,
5500,
30000,
39800,
37300,
17300,
11000,
30400,
25300,
22800,
20500,
33400,
1800,
null,
42800,
54200,
19400,
12100,
23900,
13800,
12000,
7500,
17700,
22100,
36400,
null,
51900,
24900,
20800,
21800,
19550,
6200,
47500,
62000,
19700,
28400,
17600,
null,
11500,
37600,
300,
23900,
23900,
19000,
47500,
10100,
31000,
55700,
11000,
51600,
38600,
3400,
36200,
17100,
4900,
8400,
59200,
14900,
143200,
500,
20200,
8800,
38800,
38700,
null,
9700,
null,
17000,
30900,
23900,
24800,
21600,
10000,
24000,
13900,
38100,
22600,
15900,
15900,
33100,
null,
20700,
78500,
53800,
26200,
null,
19200,
57200,
10400,
19900,
10900,
37800,
53200,
15600,
13500,
26800,
13800,
null,
9800,
4400,
39900,
15400,
10200,
12800,
45000,
14350,
10300,
41200,
17000,
14400,
null,
32500,
11000,
35700,
null,
19500,
9400,
21000,
34000,
null,
9800,
15900,
31900,
39100,
34100,
24900,
8400,
6700,
48700,
40300,
10700,
7600,
40300,
85500,
29100,
21300,
64800,
42800,
33100,
23200,
18800,
18500,
4500,
40500,
79100,
1300,
19500,
14100,
13400,
43500,
41500,
null,
81200,
75800,
null,
30800,
21600,
38700,
7000,
19700,
10900,
37900,
23700,
33500,
31700,
18600,
34000,
18400,
25200,
19400,
null,
39500,
28000,
67000,
35200,
43100,
null,
21700,
null,
19600,
76500,
12500,
18500,
26500,
26600,
2800,
27500,
17500,
9900,
49200,
13800,
35500,
15200,
null,
22400,
50800,
8800,
5600,
116100,
26900,
22700,
17600,
19500,
13400,
27300,
16836,
12600,
null,
59800,
13600,
22100,
5700,
28500,
120200,
null,
null,
18500,
null,
28800,
null,
150657,
7818,
17400,
71600,
9500,
21200,
67300,
null,
40200,
18900,
15000,
245000,
17510,
26900,
30700,
52700,
15400,
4000,
21800,
16100,
111800,
34100,
86000,
97500,
22800,
11900,
9500,
14400,
15700,
25200,
37600,
40450,
132500,
16400,
34400,
null,
43700,
7600,
39500,
13400,
7800,
26100,
18500,
13100,
81900,
null,
94400,
42400,
18600,
54000,
16600,
4000,
50600,
22700,
23000,
50600,
38100,
57700,
16700,
null,
27200,
28200,
49800,
13200,
6600,
10000,
60000,
292600,
3800,
11700,
78000,
28700,
83400,
3800,
21400,
52261,
211100,
13800,
22900,
null,
null,
32800,
37600,
22400,
40700,
21300,
39200,
8500,
16600,
33600,
9000,
28300,
33400,
102400,
null,
null,
22400,
21700,
34800,
null,
40000,
28900,
37000,
null,
5700,
43500,
20500,
51800,
20600,
43500,
17400,
27700,
40650,
21140,
51100,
70000,
33000,
33000,
30000,
8700,
49700,
36500,
79400,
7100,
53500,
83700,
24500,
8800,
15800,
20000,
46200,
31800,
49100,
7900,
9200,
18500,
5800,
56700,
8100,
17600,
null,
32900,
8800,
39000,
null,
8700,
12800,
8900,
17900,
19000,
24500,
73800,
31000,
15300,
31900,
30400,
22100,
10600,
72700,
15500,
24400,
39000,
18900,
30700,
39200,
103200,
13100,
42700,
28500,
28500,
12300,
50800,
46600,
12300,
22400,
41500,
12600,
16800,
36100,
6600,
23600,
67500,
32600,
44900,
19400,
38300,
null,
37700,
155000,
null,
null,
null,
13600,
null,
18900,
17800,
null,
60300,
8600,
10000,
6100,
16400,
10300,
17700,
24300,
null,
27500,
null,
53500,
16100,
10100,
10500,
30900,
44200,
51600,
52000,
10700,
65200,
8700,
3500,
42800,
60000,
null,
25800,
14900,
15500,
22900,
4600,
21600,
24500,
5600,
11100,
8700,
32077,
13600,
24600,
10600,
7400,
15900,
39300,
9500,
25700,
118400,
4400,
null,
12900,
9200,
13200,
37000,
30000,
25400,
42000,
18700,
88300,
46300,
19800,
13800,
30500,
27200,
72900,
38800,
37900,
37400,
15800,
13200,
42480,
null,
null,
null,
12000,
12700,
8500,
25000,
18600,
7300,
38200,
65600,
46000,
16000,
16300,
14400,
null,
16100,
64200,
7100,
10000,
7700,
26700,
33500,
9800,
67500,
59100,
121825,
38300,
43016,
9630,
16800,
100700,
null,
17300,
22800,
25800,
26300,
41800,
5000,
null,
29300,
30300,
10400,
37000,
93600,
41200,
28700,
40100,
107330,
19900,
11800,
6100,
45600,
16600,
3900,
23200,
10100,
11500,
56800,
28600,
49100,
22700,
20700,
23000,
163574,
19900,
15600,
5300,
11400,
34700,
43400,
3800,
14300,
9100,
74300,
null,
null,
82100,
19200,
40800,
25300,
65200,
65400,
29900,
13800,
37900,
35000,
13400,
10935,
87000,
27500,
8550,
40400,
41600,
38300,
18500,
128600,
21200,
null,
6800,
77300,
70700,
73900,
3900,
14900,
25800,
63600,
27200,
18200,
49200,
94800,
22200,
25300,
50300,
6900,
31900,
10000,
7300,
16800,
22600,
39200,
36300,
132400,
48400,
60300,
21000,
40300,
10900,
16700,
60200,
null,
59300,
9600,
39300,
49700,
31900,
26000,
12400,
37400,
15400,
10600,
20000,
30100,
12100,
16900,
37700,
35400,
35100,
34600,
1000,
5900,
17200,
6000,
9700,
83500,
33900,
null,
9600,
24500,
null,
12000,
32600,
12900,
33100,
39300,
10800,
38100,
37700,
44300,
23300,
15200,
4900,
null,
20400,
18400,
4700,
31500,
26800,
14200,
45100,
43000,
null,
12400,
11975,
null,
39700,
35000,
48000,
20900,
16000,
21900,
50200,
26443,
39700,
10900,
238500,
9700,
34400,
20600,
61700,
18900,
148300,
22100,
31500,
null,
11500,
18200,
25600,
13300,
13200,
38400,
19200,
47500,
57000,
21500,
null,
10800,
null,
49300,
37500,
6300,
16100,
25800,
39200,
9200,
33100,
13600,
null,
3300,
16600,
22080,
22100,
19200,
48900,
19700,
39000,
8000,
6300,
24700,
36300,
43300,
68400,
7900,
null,
22500,
null,
38400,
20100,
46200,
null,
105100,
14100,
70511,
null,
2600,
null,
109300,
59300,
null,
null,
21900,
27900,
13500,
14700,
31500,
23500,
null,
3400,
11000,
36100,
25400,
23200,
null,
63600,
19100,
32400,
37600,
54200,
67200,
33100,
8100,
64200,
null,
8100,
26100,
35300,
14800,
null,
10100,
null,
null,
88700,
null,
null,
19500,
8100,
5200,
null,
16600,
32200,
25300,
31000,
null,
23200,
9000,
14800,
6100,
18650,
6500,
2200,
null,
37700,
21300,
9300,
26800,
50800,
18800,
null,
51400,
20300,
15550,
19500,
6320,
12300,
30100,
null,
53100,
111300,
11600,
25700,
57200,
8200,
11400,
18900,
null,
53700,
22700,
18274,
null,
null,
24600,
23200,
16100,
23500,
19700,
51670,
22500,
63800,
42500,
46800,
null,
43400,
null,
50100,
5400,
11000,
9500,
15500,
4400,
18100,
20800,
71700,
26400,
33600,
7600,
57300,
18000,
24800,
69685,
10600,
15700,
7150,
90900,
8200,
18100,
23400,
31000,
33000,
12200,
30000,
58600,
14600,
40100,
52800,
34000,
38200,
17800,
9150,
16600,
17000,
22200,
55700,
66700,
11700,
28200,
47400,
19200,
30900,
42500,
6100,
null,
55300,
22300,
21600,
22700,
13900,
16500,
32800,
13200,
22700,
6400,
3250,
34100,
61800,
19400,
75474,
null,
4800,
40200,
17400,
36700,
47100,
7500,
56100,
28700,
32500,
58000,
105800,
27000,
17300,
33000,
10800,
15800,
52500,
7400,
7100,
60500,
44500,
34200,
45600,
9400,
40400,
null,
23500,
27200,
124900,
3500,
42800,
9300,
null,
8500,
80100,
23300,
10500,
13500,
51600,
25400,
55000,
19300,
63200,
9000,
15700,
62600,
26700,
34400,
42600,
36700,
12900,
5900,
9900,
3600,
8600,
null,
32400,
41200,
38500,
71800,
28600,
4500,
13800,
29200,
8200,
37000,
23600,
null,
26400,
10900,
13400,
10200,
18700,
57100,
65600,
16800,
66900,
56400,
null,
67200,
17700,
23100,
61400,
89800,
121600,
20900,
19600,
10000,
39100,
41100,
62600,
260000,
72700,
16695,
14900,
27700,
35400,
9500,
54000,
59800,
205200,
39300,
87700,
35300,
17000,
11500,
118100,
292300,
null,
55300,
28300,
2900,
null,
8300,
32750,
34600,
28800,
51400,
17750,
4400,
14200,
23800,
66200,
10600,
70300,
17600,
31300,
36600,
30200,
8000,
39000,
5100,
12300,
null,
38500,
34200,
36300,
109600,
48050,
41900,
27200,
7500,
13900,
9400,
25800,
30900,
66100,
6900,
20900,
45400,
30800,
31200,
30400,
38800,
34000,
16700,
6800,
52900,
48700,
null,
35600,
21000,
27100,
25600,
45100,
15900,
21600,
13000,
7600,
62000,
30300,
5600,
67600,
8300,
57800,
31500,
41800,
6100,
17200,
null,
30900,
27300,
25100,
29800,
57100,
74800,
122500,
37000,
45900,
23300,
28600,
22400,
14400,
12800,
50800,
18800,
17300,
16300,
20800,
19300,
null,
16700,
25200,
13000,
25000,
23900,
23300,
42600,
18500,
9300,
25800,
53100,
4000,
12100,
3500,
35800,
44000,
7500,
13000,
17200,
null,
12400,
24200,
3800,
36400,
27700,
13500,
7200,
82900,
23900,
39100,
11000,
26700,
48800,
74200,
26300,
16900,
5000,
12100,
null,
6000,
79059,
27700,
20600,
5800,
15500,
30700,
22900,
33600,
19200,
28600,
22000,
14200,
51300,
12150,
19100,
10000,
19700,
16000,
25300,
50800,
47400,
15000,
7200,
21900,
18700,
33800,
24200,
10500,
27100,
null,
8600,
129815,
67600,
17500,
39300,
13800,
11800,
96500,
36000,
27500,
18800,
81600,
15850,
34400,
35400,
100500,
33500,
29300,
18100,
35500,
42000,
13500,
10500,
8100,
95400,
28000,
53200,
33400,
15500,
69500,
36200,
19200,
78153,
128800,
9600,
16700,
20100,
null,
15100,
29200,
40900,
4400,
201600,
13300,
35100,
22600,
52800,
42400,
5800,
22800,
43500,
4800,
90848,
43500,
23300,
23100,
null,
36200,
10100,
372000,
9900,
16200,
14000,
8200,
9000,
28500,
12400,
8800,
null,
22900,
34100,
22000,
15100,
null,
12100,
39600,
18700,
7200,
50800,
4000,
14600,
15200,
17100,
32600,
5800,
8100,
25098,
24400,
null,
36600,
29000,
4500,
26400,
11900,
28300,
41400,
8300,
9900,
null,
71400,
95500,
22700,
13600,
59600,
20100,
22300,
8300,
null,
55700,
33700,
58200,
22700,
54800,
20000,
25200,
22600,
3400,
40500,
46400,
null,
13500,
38400,
11900,
18000,
19200,
27000,
42800,
71900,
62300,
70600,
7400,
15800,
27000,
5700,
22000,
88600,
5500,
3000,
6800,
240598,
15600,
29000,
7400,
37700,
16000,
14800,
17300,
9800,
20400,
12900,
null,
14800,
null,
27400,
22700,
27000,
64000,
34100,
33500,
57300,
162000,
22100,
22900,
230010,
6900,
12600,
14600,
24900,
16000,
17000,
68900,
20200,
23300,
19400,
17000,
45200,
null,
12800,
35100,
26400,
8900,
14000,
29200,
24500,
19700,
5500,
12500,
42000,
7209,
33400,
59700,
10500,
18100,
28500,
9800,
17200,
44600,
41000,
null,
24600,
14600,
15900,
13300,
58400,
18800,
17400,
34400,
12600,
43800,
9200,
36800,
9800,
18700,
102200,
null,
25450,
15300,
null,
9300,
31800,
41600,
8600,
17000,
46500,
16400,
40100,
null,
7500,
44300,
14700,
8400,
67500,
13900,
28300,
12600,
12200,
72559,
12300,
48600,
49600,
17400,
4000,
null,
6800,
12650,
50800,
5900,
65800,
66400,
12000,
16300,
50200,
3900,
22000,
38800,
16000,
19400,
57900,
17200,
31900,
27500,
24200,
22300,
49100,
58100,
16000,
33800,
6450,
23000,
43100,
30100,
null,
18900,
66000,
286500,
4400,
11900,
42500,
29800,
9600,
26000,
12000,
86400,
20000,
34300,
19100,
44200,
31300,
9600,
22100,
8300,
34800,
47700,
25400,
37400,
29000,
24300,
null,
4200,
70100,
35600,
36600,
7000,
19800,
4200,
10000,
27900,
7100,
66100,
25500,
34300,
90100,
38300,
27600,
39300,
4600,
12300,
null,
138900,
23600,
14500,
32950,
8750,
48200,
14577,
36300,
8500,
50500,
null,
12800,
87600,
null,
45000,
106700,
3000,
29900,
27900,
49000,
21300,
11015,
17000,
37000,
30900,
null,
null,
31800,
32700,
12200,
11000,
20700,
8400,
18200,
37600,
10100,
26400,
23000,
60200,
17000,
18400,
72900,
46200,
24700,
15100,
6300,
17500,
40700,
40900,
23100,
45700,
17200,
39000,
7600,
14500,
92700,
13300,
19600,
29000,
20000,
37500,
19700,
5900,
16240,
null,
28300,
8300,
14900,
16700,
null,
11000,
98501,
71700,
20000,
13600,
9800,
23900,
12700,
28700,
61000,
6100,
56000,
46300,
21100,
47600,
14500,
19300,
94200,
37800,
null,
39200,
20800,
74400,
40300,
22100,
23600,
29200,
null,
53000,
17000,
73149,
21700,
17900,
4900,
48000,
90600,
12000,
32300,
19300,
22400,
24800,
6200,
36600,
42100,
null,
39800,
86700,
38200,
21400,
59357,
9200,
16000,
19700,
20800,
22900,
6100,
1800,
43000,
33200,
null,
28200,
11400,
74600,
43300,
37300,
140000,
17000,
18200,
33200,
45000,
109300,
19500,
38300,
84200,
88900,
17000,
15100,
41431,
13600,
12000,
29000,
47000,
25100,
47800,
39300,
81100,
52900,
null,
14800,
9700,
51000,
11100,
null,
18000,
29300,
null,
61100,
20700,
32700,
24400,
24800,
61500,
46400,
25900,
9800,
109900,
12000,
6300,
44600,
20200,
6500,
13100,
13600,
19800,
58800,
33500,
78600,
13500,
6000,
45100,
12300,
8500,
null,
49900,
61100,
9700,
null,
11400,
null,
14700,
41300,
null,
87900,
69000,
50600,
8300,
38300,
22500,
41800,
25500,
null,
40800,
27600,
14500,
11200,
41500,
6000,
89400,
27700,
32600,
55800,
null,
43900,
43900,
12800,
7300,
17500,
37900,
71100,
35400,
15700,
42200,
6500,
15800,
100300,
15700,
3300,
5900,
13100,
13900,
5000,
71200,
17800,
34300,
18400,
8800,
39800,
59400,
28400,
61900,
7300,
37600,
15000,
83800,
16600,
15200,
null,
16800,
66700,
null,
8500,
null,
12000,
3300,
19900,
44200,
17900,
30000,
22900,
130000,
57800,
2770,
67600,
38500,
33500,
15200,
15400,
21100,
60000,
3700,
8700,
24300,
15400,
39300,
13900,
19700,
23900,
17200,
42500,
40000,
16800,
null,
33200,
30200,
28760,
57400,
41200,
26700,
10300,
23600,
44800,
14900,
null,
24600,
62100,
78500,
17900,
26000,
28800,
18200,
25100,
28400,
49000,
null,
17900,
2600,
75100,
46424,
22000,
12300,
18400,
28100,
7050,
29500,
83600,
12200,
55000,
37300,
6700,
45100,
19400,
44900,
34700,
55600,
50700,
67000,
5900,
44300,
13200,
31100,
8600,
34000,
84300,
13300,
null,
14500,
17300,
18200,
45900,
12900,
10700,
38800,
93700,
null,
61400,
12000,
45700,
101600,
7900,
56900,
13900,
12500,
7400,
71000,
21000,
48100,
9800,
15600,
53800,
34800,
147200,
27900,
null,
47500,
30400,
13900,
26000,
null,
23700,
39900,
33300,
9900,
14400,
78300,
24100,
11100,
21500,
12400,
24800,
16900,
null,
19200,
null,
133500,
22400,
11700,
38500,
13200,
56700,
23800,
30500,
7000,
48500,
35600,
32500,
32000,
66100,
23900,
16300,
17800,
12900,
15100,
72900,
26700,
12800,
68608,
43800,
13800,
51700,
17300,
20000,
null,
50700,
8500,
null,
null,
30500,
13800,
37400,
49300,
11600,
133000,
null,
15300,
46400,
26800,
59000,
22800,
22400,
null,
13900,
4600,
33200,
null,
57000,
21800,
30200,
39200,
15700,
18900,
74500,
8500,
3500,
50300,
23300,
7500,
15100,
8700,
70700,
13900,
11100,
null,
null,
15600,
82000,
28900,
5400,
29400,
null,
44000,
82500,
20700,
27100,
15900,
11500,
21100,
null,
19300,
27900,
11300,
12900,
16400,
66300,
54400,
11700,
17500,
null,
21900,
34800,
20700,
73000,
40300,
13800,
72500,
null,
33100,
31900,
21900,
15200,
7900,
19700,
21600,
13700,
16500,
25300,
7800,
29500,
14600,
39000,
56300,
19100,
18200,
33600,
16100,
37300,
7500,
31700,
9900,
21800,
null,
null,
22100,
9300,
24600,
100900,
15800,
7400,
11200,
9400,
7600,
25200,
15900,
6200,
25900,
36500,
25800,
95200,
null,
40100,
17000,
null,
26000,
44300,
29100,
27800,
47400,
19900,
14700,
16000,
15100,
32550,
74900,
75900,
null,
48400,
38400,
12600,
32000,
70000,
21500,
45300,
35800,
16600,
27000,
12800,
4500,
14200,
18495,
7500,
59100,
41900,
49100,
12600,
15800,
11700,
76400,
16700,
23600,
30700,
13800,
46600,
42400,
42300,
31200,
2300,
18700,
47900,
33900,
32806,
52800,
30900,
15000,
18500,
45200,
null,
12000,
30400,
null,
41600,
29400,
124400,
19000,
6500,
29700,
14700,
9700,
66100,
6600,
10400,
10500,
null,
26000,
28000,
18900,
43200,
9500,
70000,
54400,
12100,
null,
33200,
27100,
26800,
18500,
66500,
32000,
39900,
14600,
25000,
6000,
20100,
34800,
84900,
28800,
26400,
7500,
19300,
48700,
41200,
17000,
28700,
6700,
30700,
53600,
6000,
66400,
13700,
14600,
31400,
31800,
null,
20400,
45844,
null,
31674,
20100,
12500,
230800,
21700,
43300,
14800,
18800,
28400,
32900,
19100,
68100,
36000,
40800,
null,
52700,
24500,
56800,
29700,
40000,
32800,
36900,
23545,
32700,
10400,
34700,
49200,
null,
35600,
18500,
19200,
13000,
14200,
28200,
45400,
24900,
19400,
33000,
35000,
24200,
16400,
19900,
11200,
11100,
25500,
15800,
46800,
10600,
7600,
32200,
12100,
85200,
3900,
21700,
41900,
15100,
11200,
14300,
109400,
19100,
22000,
19700,
6200,
10917,
53700,
22000,
16000,
42200,
10900,
22100,
12000,
4700,
20100,
8200,
69800,
26100,
12300,
45500,
66600,
46900,
75800,
12500,
30000,
59800,
null,
20300,
45000,
15600,
43000,
31300,
14500,
27200,
99600,
44900,
19000,
null,
11000,
67800,
18500,
16000,
33600,
5800,
6800,
40900,
16700,
11000,
17200,
7300,
20500,
22100,
39800,
16200,
19700,
16100,
7400,
14100,
15600,
22800,
25900,
19500,
null,
19200,
15600,
12800,
29200,
17000,
54900,
18300,
23600,
12800,
37600,
12700,
11500,
15800,
13900,
46200,
7300,
5900,
37300,
12100,
47800,
8500,
16500,
13100,
10700,
17100,
600,
14900,
13100,
null,
57000,
16300,
20100,
22000,
39100,
24000,
12900,
62100,
22900,
null,
27600,
null,
14100,
5300,
28000,
23300,
33200,
27000,
22800,
78600,
13800,
31700,
7300,
16800,
10600,
38000,
23800,
3300,
null,
71900,
15600,
21800,
25900,
19700,
9700,
12300,
41700,
12700,
27770,
7800,
14000,
45500,
16500,
25600,
77000,
null,
15300,
13400,
18300,
null,
13700,
78800,
43000,
16200,
34960,
17400,
null,
4400,
125300,
39000,
11700,
28400,
1600,
212400,
19400,
123691,
50100,
44300,
18900,
30600,
31200,
21000,
4700,
797,
11000,
33600,
11600,
20500,
14000,
48600,
5600,
22000,
31800,
16400,
8000,
10700,
20400,
16400,
13400,
18100,
60000,
10300,
16300,
23700,
10200,
20800,
29500,
19300,
5200,
35800,
12600,
31400,
71300,
6100,
18900,
13100,
23500,
24400,
11900,
9200,
6700,
16100,
null,
6000,
16700,
97500,
35600,
20000,
null,
55100,
29000,
null,
25000,
12000,
null,
10800,
11800,
33000,
null,
13700,
11200,
10400,
null,
61300,
14100,
10200,
25400,
20600,
null,
162100,
8100,
9900,
19500,
44800,
10700,
10000,
43300,
26400,
14100,
26700,
45600,
38500,
16900,
18500,
216800,
26100,
81740,
null,
19100,
193800,
5300,
12500,
16700,
16300,
41000,
83000,
31100,
16300,
18300,
16100,
null,
33000,
48400,
27400,
34200,
34000,
27900,
16000,
13300,
7700,
8900,
33800,
19100,
27600,
30300,
20200,
null,
42100,
69500,
13700,
158500,
57400,
20100,
37900,
17900,
35800,
53200,
48600,
11200,
4000,
35500,
23500,
12400,
41500,
22700,
18200,
4900,
10200,
47700,
9600,
37800,
13600,
4704,
21000,
17800,
25300,
73800,
26300,
17300,
24600,
15300,
32000,
3300,
24800,
20300,
6200,
24600,
6000,
14900,
11500,
79000,
7900,
66900,
47600,
3300,
43500,
60400,
null,
37900,
66825,
65700,
31400,
65100,
33400,
18600,
18600,
15400,
27800,
108400,
30100,
null,
8700,
38300,
87800,
52200,
15600,
null,
18250,
19800,
58700,
19300,
31800,
21850,
null,
26500,
10300,
8200,
32100,
46000,
42000,
33200,
11300,
18900,
37900,
55800,
22600,
15751,
12300,
52700,
25300,
13600,
25000,
18600,
92700,
26800,
32900,
19900,
16000,
7600,
29000,
36100,
27800,
4500,
null,
52100,
51600,
29200,
6900,
25700,
16000,
50300,
15900,
14100,
5300,
42800,
13600,
40800,
20600,
7200,
227600,
13900,
null,
null,
1800,
31000,
10900,
224150,
144400,
25700,
11600,
12600,
16700,
19200,
17500,
27400,
18100,
null,
null,
61800,
25900,
null,
10500,
65900,
null,
18800,
42400,
43100,
64900,
28700,
null,
59554,
40700,
22800,
66900,
null,
null,
5500,
45700,
16600,
52500,
23900,
31500,
65700,
4400,
9400,
48850,
73400,
131400,
30600,
20000,
59600,
18200,
17700,
16300,
20875,
42912,
16200,
12400,
25200,
2800,
45278,
54900,
18300,
null,
30300,
20100,
103600,
42200,
47400,
11000,
null,
43700,
34200,
13200,
35900,
32000,
5500,
32800,
11200,
17300,
7900,
null,
6300,
16600,
16800,
78700,
150200,
24200,
11300,
19000,
17800,
90693,
54200,
54300,
37400,
9500,
null,
null,
28800,
53600,
15800,
23600,
36800,
15100,
31500,
null,
20000,
10000,
11100,
22500,
37500,
55600,
7700,
7800,
85800,
22100,
23300,
null,
17200,
42200,
30500,
36500,
23500,
61300,
36168,
17300,
633200,
14100,
38100,
15100,
22300,
53100,
17700,
null,
23400,
17700,
8300,
5700,
13500,
6500,
41400,
39800,
13100,
7700,
13000,
19000,
26200,
8300,
40200,
31900,
null,
56595,
21000,
38800,
8000,
13000,
4000,
9600,
63500,
74000,
31600,
55123,
33000,
80200,
84500,
19900,
8000,
34400,
62000,
30700,
18800,
19000,
42900,
300500,
79700,
15500,
14500,
35500,
38200,
20700,
11300,
20000,
16400,
7300,
12000,
2800,
26900,
25700,
11400,
50000,
22450,
5300,
56400,
null,
null,
14600,
7600,
12300,
71000,
49600,
16700,
null,
68481,
41000,
25500,
13400,
45000,
13600,
17200,
99200,
9600,
7400,
9100,
26300,
11700,
33900,
18500,
21900,
66200,
20500,
25200,
7200,
131100,
23000,
29400,
34500,
117000,
11600,
8100,
8300,
4500,
15500,
47300,
49600,
23300,
47400,
30500,
67600,
25100,
33000,
null,
36000,
35600,
23700,
35400,
21700,
10100,
null,
16900,
25700,
38600,
25500,
23200,
null,
7750,
75030,
15000,
34600,
10500,
13300,
6500,
10600,
44500,
50200,
23200,
64000,
14600,
19900,
83900,
45300,
6400,
null,
17000,
17000,
13100,
81700,
3900,
27700,
34000,
15600,
null,
18300,
null,
17200,
19500,
15000,
6400,
null,
15900,
15200,
13200,
26000,
23700,
85300,
31200,
10300,
17500,
32500,
30900,
41800,
40900,
17600,
29400,
36500,
22900,
35600,
70200,
32500,
41800,
21100,
36000,
8000,
null,
6500,
162800,
9500,
22700,
2900,
36100,
34100,
34700,
11300,
7500,
90300,
18200,
28300,
28300,
7900,
16200,
14000,
44700,
13100,
34400,
17600,
246200,
21300,
47400,
17300,
10100,
24200,
null,
87500,
30000,
null,
33000,
73900,
null,
32300,
8100,
65500,
27800,
null,
9000,
27000,
null,
12500,
100700,
25700,
14500,
null,
14300,
24500,
32100,
25500,
76800,
22100,
43000,
6950,
11700,
29600,
6800,
4000,
null,
9900,
58600,
16600,
104300,
21100,
8100,
10900,
201500,
24000,
51000,
null,
101300,
59900,
79400,
18200,
5700,
null,
8000,
8000,
61500,
9300,
52700,
21100,
44200,
7600,
15000,
7200,
98300,
39400,
17400,
84100,
null,
17100,
3800,
46235,
10033,
18000,
25500,
4000,
11000,
null,
27200,
49300,
50200,
7000,
11700,
14800,
18400,
23500,
15400,
19800,
9000,
21400,
39900,
16800,
37000,
null,
26700,
null,
6000,
15000,
11700,
31300,
33400,
20100,
58600,
34200,
33400,
21300,
51300,
4500,
6000,
15700,
37800,
9200,
13600,
null,
19800,
6450,
39600,
null,
null,
28100,
9400,
64000,
29000,
42200,
39800,
39300,
93500,
33400,
13600,
46600,
5500,
40500,
8100,
15100,
29600,
56600,
47100,
48600,
20100,
8200,
41300,
32000,
11400,
26600,
14700,
null,
26700,
20200,
39400,
21000,
47900,
13300,
19900,
17700,
36500,
23500,
3500,
9800,
10400,
9800,
13700,
49800,
21400,
19000,
20000,
20900,
4100,
30900,
65800,
40300,
109900,
92900,
41700,
11300,
15200,
5900,
30500,
28800,
18400,
50000,
null,
21700,
25000,
13500,
13700,
34700,
62500,
null,
64600,
0,
117800,
24700,
22000,
31100,
20100,
19800,
37500,
9700,
37400,
43000,
10600,
21099,
44800,
36200,
27800,
28200,
21000,
null,
29400,
19900,
14100,
null,
15700,
29000,
13248,
25240,
88000,
6800,
15900,
169518,
32900,
46800,
23200,
21300,
54400,
42000,
57500,
10500,
116000,
112900,
74600,
50700,
53200,
28800,
null,
20600,
26500,
23500,
38000,
42900,
11000,
45100,
19700,
30000,
26000,
48900,
89600,
108400,
34100,
9500,
28000,
17700,
20000,
47800,
null,
65000,
null,
53500,
18900,
null,
23500,
38000,
91500,
29500,
3100,
67800,
13900,
21100,
16900,
163700,
16000,
26900,
8200,
12900,
30800,
19300,
8900,
39700,
47700,
208800,
11900,
24600,
33100,
13400,
28600,
26100,
17400,
6800,
44100,
57100,
26400,
22192,
8100,
24200,
17500,
53000,
36000,
44500,
29800,
32800,
null,
12600,
14500,
12000,
25900,
28600,
43200,
74800,
14500,
14100,
4100,
23000,
7000,
38400,
14100,
12200,
9200,
29700,
32400,
16900,
29900,
20500,
61900,
73500,
29100,
24000,
null,
25400,
84200,
19400,
55500,
36300,
23100,
91900,
81000,
31600,
19800,
40400,
11200,
17000,
11600,
null,
14600,
99800,
44100,
34300,
20000,
9200,
21200,
10200,
null,
7600,
52400,
48900,
8640,
53200,
17400,
25700,
null,
38000,
64300,
24300,
36500,
17400,
24600,
22900,
22500,
19100,
13900,
15700,
20500,
14600,
118700,
61700,
33100,
28100,
10600,
6600,
20100,
14200,
15700,
15600,
61000,
23600,
31900,
21200,
33200,
null,
null,
17300,
27300,
16700,
32100,
39000,
21600,
17800,
5200,
6400,
28600,
19300,
29300,
7100,
25100,
52500,
19300,
30900,
47200,
50200,
43300,
326700,
72000,
10300,
14500,
12400,
10000,
56000,
19000,
20200,
null,
11800,
null,
15000,
29200,
10900,
34100,
15500,
null,
62100,
14300,
30200,
7800,
22100,
58200,
35800,
20300,
53900,
49000,
35700,
23500,
28100,
23400,
31700,
13300,
65800,
67200,
39500,
35700,
16000,
6600,
null,
20800,
29300,
23500,
18100,
11000,
33700,
null,
9000,
46600,
6500,
17500,
null,
23000,
9000,
11700,
null,
8600,
10000,
4000,
16600,
33500,
47701,
33900,
19300,
29500,
13000,
21200,
31200,
25500,
19300,
8100,
7500,
6600,
23600,
23100,
24700,
4600,
17950,
7100,
11700,
27900,
12100,
46200,
27400,
17300,
13300,
17700,
6400,
28900,
90600,
58200,
11200,
16500,
21400,
29200,
18100,
80000,
267900,
40400,
4000,
12000,
74600,
99700,
22900,
13200,
null,
88600,
null,
33500,
23000,
20100,
63000,
13900,
22000,
47300,
9100,
13000,
42500,
90100,
38200,
36700,
null,
26100,
51100,
39500,
12200,
43700,
5600,
null,
2500,
6900,
5600,
18600,
7200,
21000,
11100,
26000,
16800,
31300,
null,
null,
null,
null,
16700,
9000,
17800,
19600,
16000,
27300,
7400,
22300,
37900,
27600,
19900,
null,
16300,
58900,
32500,
7500,
26000,
62207,
60600,
26800,
41500,
32600,
null,
38800,
1500,
30900,
23900,
40200,
22300,
null,
56700,
6000,
78500,
31200,
53300,
40400,
58905,
48500,
53800,
3200,
14500,
16100,
11300,
9250,
18600,
46100,
7200,
66600,
null,
5900,
15000,
null,
44600,
40964,
35000,
null,
60500,
11200,
8800,
80800,
50300,
null,
47600,
63600,
27900,
10800,
11800,
11000,
22000,
14400,
null,
4100,
8200,
18300,
17800,
15400,
null,
81700,
132500,
13800,
35800,
30300,
41700,
9000,
48100,
12400,
8000,
16300,
30200,
5900,
34100,
20700,
5400,
14000,
3600,
null,
7200,
63700,
6900,
12700,
15300,
87800,
11800,
73300,
30400,
23500,
61800,
73840,
14400,
34200,
4100,
22500,
20000,
7900,
29900,
24300,
2400,
1700,
23900,
20600,
16800,
11800,
18425,
6200,
32900,
8600,
51300,
74500,
14600,
178100,
null,
69200,
24700,
7600,
13800,
54900,
22300,
13500,
29500,
10200,
11200,
12000,
20100,
54200,
27800,
58600,
39300,
null,
25000,
14500,
2200,
32800,
19400,
7900,
59500,
18500,
28100,
12900,
49300,
18000,
9200,
45400,
10900,
16000,
null,
51900,
38000,
27700,
39000,
6900,
16100,
56400,
19700,
12100,
8800,
43300,
null,
13500,
34800,
6400,
null,
33900,
21200,
47000,
34000,
6800,
8400,
40100,
19000,
16500,
3500,
40400,
null,
17500,
39000,
100200,
53000,
23800,
36800,
69200,
48100,
9600,
9575,
18000,
6200,
null,
14500,
4400,
42400,
40700,
12500,
32000,
25900,
12800,
45900,
16400,
9800,
72600,
35800,
17500,
13300,
44600,
58500,
21400,
28000,
40900,
51900,
64200,
30700,
25400,
null,
20300,
21500,
19500,
50100,
null,
13800,
18600,
26900,
25200,
14300,
15200,
11500,
23400,
11400,
25300,
23000,
12500,
null,
63100,
19300,
33600,
16300,
null,
13500,
14700,
19200,
152400,
22100,
26700,
6100,
31700,
41900,
32600,
13800,
null,
36200,
2800,
8700,
19300,
47700,
5500,
35600,
23700,
null,
47500,
21900,
26000,
24500,
10100,
20700,
15700,
35100,
130209,
43600,
22100,
24400,
6800,
18500,
23600,
null,
66700,
150900,
34400,
54500,
36700,
79800,
18200,
38000,
16000,
null,
66100,
43100,
53300,
15700,
23950,
32100,
44400,
18200,
null,
null,
56400,
174600,
1100,
37000,
34700,
62700,
40800,
34900,
33100,
8700,
40600,
21100,
24300,
25100,
27100,
12600,
28900,
7800,
19100,
55700,
6100,
11500,
45119,
67400,
26700,
25900,
38200,
12500,
26100,
73300,
22000,
9700,
12000,
12700,
41100,
11200,
9000,
35300,
30600,
36400,
28900,
32500,
12300,
74700,
16100,
61000,
50800,
5700,
36600,
24200,
12100,
8100,
17800,
5400,
5900,
42700,
20600,
28500,
null,
27100,
59900,
13300,
12100,
16500,
94400,
null,
30600,
9600,
11300,
72400,
29400,
10900,
15100,
17300,
10100,
49000,
68700,
93400,
17300,
36600,
21700,
36700,
37900,
27600,
38700,
58600,
18200,
6700,
11100,
25700,
29100,
141100,
4000,
null,
66900,
9100,
0,
56700,
null,
null,
28900,
19100,
39700,
40700,
53400,
null,
18100,
25500,
6700,
25200,
23300,
39300,
13500,
16200,
14500,
68200,
23600,
41700,
36900,
31900,
47600,
14300,
22800,
16600,
58600,
25100,
null,
19300,
12100,
62600,
29500,
56400,
5900,
30200,
87100,
20100,
null,
15900,
37100,
42000,
76200,
null,
12400,
165500,
15300,
33100,
21300,
11900,
6600,
69500,
31800,
13900,
null,
78500,
21600,
11300,
null,
16500,
37800,
58250,
53300,
6500,
9100,
35200,
31700,
11600,
5500,
54300,
53600,
14400,
14400,
6300,
25600,
4800,
9600,
52500,
104474,
17300,
61200,
23300,
null,
19000,
18800,
27800,
38700,
null,
20000,
null,
13900,
14300,
44700,
20700,
64000,
17400,
39600,
43800,
9300,
11200,
41300,
15100,
44600,
8600,
11200,
23600,
16100,
40500,
75500,
5400,
38700,
800,
23100,
14000,
30800,
16300,
56900,
31500,
14800,
35400,
68800,
6700,
24200,
41200,
null,
29000,
44500,
17600,
76200,
10100,
7800,
14600,
33300,
24500,
19700,
40600,
37300,
64900,
38500,
13500,
16000,
28800,
31500,
18400,
5100,
null,
32800,
null,
45800,
null,
49400,
18000,
33600,
29900,
35600,
13100,
33500,
16700,
142500,
11900,
null,
null,
11400,
16800,
35400,
34900,
47000,
57100,
14000,
14400,
57500,
30600,
6600,
46200,
12900,
112500,
null,
11300,
15700,
67900,
113300,
32100,
46400,
30700,
49100,
22800,
74600,
19200,
144900,
59200,
2900,
73100,
null,
51700,
72100,
29200,
15800,
22800,
31600,
35500,
63800,
17100,
21600,
45800,
15600,
22900,
5000,
68200,
20900,
37500,
8800,
null,
8300,
44703,
12300,
12000,
20000,
48300,
47500,
23100,
25900,
7000,
77500,
10900,
14000,
47400,
32500,
26700,
38700,
21800,
79700,
16000,
41940,
23000,
77800,
16900,
16900,
17700,
20400,
7000,
41900,
8900,
22500,
null,
9492,
24600,
25300,
12500,
36600,
44900,
78500,
53383,
29100,
7900,
22000,
65900,
15100,
33700,
14600,
57300,
null,
45600,
null,
17300,
null,
26500,
null,
38400,
8600,
42700,
240700,
26700,
32520,
70800,
57700,
15600,
12780,
36200,
null,
null,
5800,
22000,
21500,
33200,
40700,
99000,
27900,
null,
30300,
37700,
12200,
75700,
65700,
19900,
30200,
22800,
4200,
23400,
32200,
79100,
28700,
37900,
25600,
24400,
189300,
7100,
5000,
11400,
30500,
29100,
79600,
47200,
20500,
26100,
17200,
16400,
43600,
21400,
13700,
10050,
37000,
48200,
20100,
41000,
12000,
5900,
null,
14300,
18500,
null,
null,
59900,
17450,
45300,
17000,
19800,
23000,
21400,
26400,
126500,
28700,
6500,
40000,
7700,
6600,
500,
27700,
44300,
14100,
27000,
9000,
24500,
120400,
46610,
7400,
16100,
6300,
81500,
15500,
28200,
39000,
34500,
9600,
null,
42000,
16600,
17500,
null,
13300,
16200,
10300,
19600,
39600,
10000,
15700,
63400,
18500,
37500,
25400,
19300,
null,
14000,
39700,
29500,
13600,
40500,
29000,
16700,
23700,
20800,
78700,
29400,
23600,
12600,
7000,
22800,
25400,
10400,
17200,
33100,
13000,
19400,
14100,
null,
52000,
56100,
1500,
27300,
32200,
3200,
28300,
11900,
74600,
null,
32400,
14400,
53200,
24514,
74600,
13100,
11300,
39400,
2200,
28200,
19000,
34400,
20600,
24700,
31600,
8200,
25500,
56100,
47500,
32400,
39100,
90000,
20300,
null,
27600,
7400,
40300,
115100,
35800,
18900,
30200,
21300,
50400,
7000,
null,
44300,
10200,
204900,
17500,
32000,
24455,
12500,
73900,
65400,
97400,
11400,
37100,
89900,
47200,
null,
47700,
null,
59700,
null,
1500,
52584,
46000,
59600,
16500,
15200,
29700,
10100,
39100,
34200,
14300,
107500,
8900,
19000,
36600,
22400,
18600,
9600,
41400,
73800,
8000,
12900,
33500,
null,
25700,
27800,
28400,
51000,
43300,
35100,
103900,
90100,
31800,
15100,
19700,
42754,
10400,
7100,
17600,
66600,
59500,
null,
16200,
98521,
14500,
10900,
25700,
64800,
30000,
null,
1600,
101400,
5500,
13900,
8300,
19800,
33500,
39280,
20000,
17600,
16900,
20600,
54600,
null,
null,
30100,
11800,
66100,
45300,
38500,
5200,
17900,
6200,
null,
23400,
55700,
null,
149400,
58200,
46900,
16000,
25700,
null,
51500,
40600,
102000,
20600,
26000,
12400,
75683,
13600,
54900,
35200,
25300,
21800,
13300,
32700,
76200,
31100,
29400,
null,
37800,
46100,
31200,
20800,
22810,
26900,
29500,
27600,
51900,
49000,
46100,
127200,
47800,
22500,
63200,
100900,
16200,
18500,
35700,
33600,
70400,
5700,
43600,
39400,
null,
74100,
14800,
null,
22700,
16900,
22800,
16200,
39900,
16100,
43400,
15800,
21400,
10800,
29400,
21500,
53200,
53800,
103000,
30700,
29900,
20500,
21400,
36000,
18500,
21100,
43200,
65800,
24700,
24800,
17800,
102800,
39700,
80600,
33900,
21400,
null,
25200,
46600,
2800,
54000,
95400,
26200,
8000,
34700,
16500,
65300,
367400,
null,
26600,
9600,
10800,
48000,
21000,
44700,
53100,
15000,
14500,
36700,
32900,
19400,
null,
33300,
19100,
678400,
10700,
31400,
8900,
25800,
48600,
9700,
9900,
32900,
20400,
10700,
5800,
91100,
6100,
15400,
1400,
14900,
null,
8600,
30900,
20300,
23400,
6700,
null,
24800,
41600,
null,
17500,
33100,
26100,
10500,
8500,
39300,
29200,
44700,
11600,
50300,
11800,
30500,
30800,
27400,
16000,
59700,
8600,
52400,
41500,
17900,
null,
57000,
22300,
null,
16300,
23400,
18700,
12500,
14300,
22800,
31900,
4250,
22400,
null,
13900,
16100,
64500,
5700,
22800,
28015,
33670,
8400,
14900,
9800,
20000,
27400,
null,
null,
94700,
16900,
37100,
20700,
15700,
32400,
13750,
12200,
54800,
64400,
29100,
null,
16000,
9200,
48700,
21700,
14600,
14000,
45100,
13500,
6600,
12200,
33000,
8300,
37700,
44800,
9500,
102300,
null,
30000,
32071,
116100,
28800,
13700,
null,
63800,
133000,
null,
22600,
34600,
90700,
120900,
22100,
17600,
25000,
68800,
27100,
48500,
15800,
34400,
21500,
40400,
8300,
32900,
32500,
59600,
144300,
10350,
32100,
17500,
57300,
35000,
null,
28000,
27100,
3400,
40400,
15700,
null,
46500,
28397,
42000,
60300,
13300,
10600,
13800,
53300,
11600,
86000,
53400,
19700,
21100,
9600,
17600,
68900,
null,
7400,
9200,
3500,
42700,
26200,
15600,
74600,
4900,
null,
null,
1314900,
33400,
13900,
null,
31000,
59100,
26300,
38100,
23500,
23500,
22900,
27500,
32300,
57900,
null,
17500,
25800,
14100,
17000,
null,
21400,
26000,
43100,
16000,
42600,
33000,
25400,
50900,
112400,
55100,
4400,
19900,
null,
42400,
86300,
45000,
77700,
12900,
null,
12700,
2000,
21400,
17700,
63800,
36900,
null,
49900,
6400,
31100,
8500,
null,
31000,
15200,
10300,
26500,
84800,
40200,
27100,
22300,
25600,
75800,
22000,
7300,
13500,
22700,
70200,
30100,
null,
29600,
35400,
12100,
19700,
38900,
9930,
23500,
21900,
null,
15800,
50300,
13400,
28700,
5800,
31500,
155400,
9600,
8600,
45151,
27400,
70600,
39600,
59260,
35300,
17700,
36100,
null,
10600,
13430,
5500,
26400,
39400,
null,
109800,
8600,
10900,
16200,
79800,
16300,
30100,
40400,
7400,
13000,
80400,
8300,
60700,
2400,
13100,
42000,
4900,
154500,
184185,
23000,
13600,
37600,
67700,
27400,
null,
18800,
6900,
13626,
1200,
null,
18900,
null,
29400,
26600,
null,
90000,
42600,
null,
8400,
24600,
36600,
9800,
25200,
3400,
64600,
15600,
22000,
15600,
14600,
null,
29800,
33600,
49800,
39300,
15000,
null,
2000,
15200,
null,
68400,
40400,
15900,
19500,
12600,
null,
8400,
11900,
21800,
41400,
27836,
27400,
24200,
31100,
11600,
24900,
65400,
9800,
16500,
62552,
47400,
32000,
16400,
11700,
104900,
22200,
15600,
51300,
8500,
20500,
38800,
null,
null,
36000,
37300,
78500,
328800,
17200,
59961,
385880,
76200,
19900,
22800,
60300,
21600,
10800,
14500,
59300,
null,
43700,
7300,
7800,
44400,
43200,
26500,
23400,
45100,
20000,
27032,
13800,
22200,
20200,
null,
11500,
54000,
30100,
11800,
8100,
49808,
5600,
39700,
null,
351000,
74771,
32600,
55200,
null,
19600,
16500,
31600,
22400,
16700,
15000,
13000,
72000,
17500,
24100,
20700,
51400,
50300,
30300,
31600,
9400,
null,
61500,
6000,
52100,
19800,
20700,
51700,
50500,
73600,
12500,
30700,
10700,
26500,
19700,
12700,
22200,
15100,
30200,
29800,
21000,
7200,
19300,
33300,
16500,
49300,
57400,
24300,
11100,
18600,
12400,
null,
null,
14900,
53000,
2500,
23500,
24700,
27100,
23100,
40900,
145900,
1600,
24700,
7200,
47600,
15800,
27200,
6500,
21300,
33300,
21400,
30919,
15000,
53000,
16600,
26300,
44400,
14800,
14000,
29500,
16700,
63000,
38300,
136200,
15500,
51900,
43400,
7300,
271000,
null,
18996,
18600,
13800,
39800,
21089,
8700,
98811,
6600,
82200,
22000,
17600,
8600,
25200,
57200,
36400,
39400,
12100,
42400,
31400,
25700,
27200,
40000,
15900,
15100,
56700,
14700,
15400,
40300,
36700,
12000,
35900,
49300,
31300,
53900,
9400,
null,
51000,
37200,
25600,
55300,
3100,
56100,
20600,
15900,
null,
64900,
30500,
20000,
45300,
null,
38800,
44000,
96000,
55600,
17700,
20400,
77000,
34800,
54700,
15100,
41500,
33900,
15500,
25000,
53000,
21300,
40000,
46200,
5500,
20000,
8600,
94600,
10200,
null,
null,
11400,
38600,
28600,
151900,
103600,
16000,
47200,
32900,
36600,
18700,
69900,
34300,
10700,
32800,
15800,
12500,
34600,
15400,
59500,
17700,
36300,
19300,
72900,
null,
27300,
8100,
22800,
15600,
21600,
17600,
16100,
34200,
28000,
15300,
12200,
48000,
50700,
48000,
null,
20000,
32700,
15600,
9700,
14900,
11400,
17200,
23950,
21900,
18900,
null,
48600,
8200,
11100,
null,
19100,
10800,
23521,
7700,
27800,
29100,
38600,
11200,
73800,
27000,
13200,
23600,
56900,
68114,
null,
26800,
null,
21200,
36300,
50900,
43800,
23300,
19600,
22950,
19800,
22300,
28200,
10200,
66000,
null,
50100,
30600,
null,
9000,
34400,
41200,
58200,
49300,
8300,
24500,
4900,
89400,
69100,
null,
15800,
11900,
23000,
29900,
26500,
6100,
56900,
18900,
21800,
93150,
16900,
13100,
20800,
11500,
null,
21700,
66232,
10800,
39100,
65100,
15500,
15500,
8500,
43500,
9900,
21400,
10300,
41700,
8800,
10900,
36900,
22000,
38000,
32500,
16800,
24400,
12200,
20500,
11700,
9200,
56500,
3000,
32300,
49200,
77000,
6400,
50400,
40800,
15800,
29201,
51000,
22000,
13000,
46500,
37800,
19600,
43500,
10800,
20600,
95300,
24554,
36200,
18800,
65600,
36700,
34100,
4200,
9400,
6900,
42600,
32000,
null,
54900,
30300,
22400,
5100,
25900,
39500,
11100,
47500,
45100,
16700,
53100,
null,
46500,
30100,
37050,
44200,
39700,
45800,
31100,
31500,
23900,
65500,
15000,
17600,
44300,
20700,
36100,
43400,
13600,
27400,
9200,
10200,
38700,
14900,
9500,
59700,
34100,
13600,
22100,
35800,
34600,
17100,
6400,
null,
81062,
57000,
null,
20300,
195600,
38900,
37600,
52300,
null,
55300,
37500,
58100,
62400,
10000,
10300,
34000,
27300,
8000,
20400,
21600,
16200,
34600,
15500,
48861,
37400,
13400,
16000,
32700,
19700,
17700,
25497,
27400,
25001,
54400,
null,
19800,
23500,
32200,
8600,
33603,
67900,
19000,
null,
30500,
16200,
26600,
4400,
4800,
34100,
18900,
25200,
28300,
28200,
31600,
null,
null,
14900,
17300,
17400,
20600,
32600,
23600,
57200,
22000,
34400,
17800,
12100,
14700,
102800,
46000,
36000,
53500,
17000,
9000,
null,
47300,
22200,
30600,
14400,
45000,
12900,
11200,
82900,
14700,
22800,
22860,
82400,
14700,
25500,
40100,
18900,
19500,
15300,
13900,
17800,
34000,
29800,
15200,
53400,
39700,
37300,
16400,
75000,
8900,
24600,
56100,
14200,
52500,
43700,
13300,
36500,
11200,
38900,
13100,
43500,
11200,
54000,
null,
29600,
15900,
24500,
31000,
43300,
45900,
22800,
28300,
30600,
21600,
64700,
24400,
67900,
30300,
33400,
10500,
49900,
7300,
74400,
19000,
35700,
27500,
33400,
32400,
13300,
null,
34000,
null,
4200,
21100,
27000,
11300,
50300,
5500,
19800,
62600,
4700,
13000,
null,
17700,
5700,
122500,
5500,
17400,
19200,
22600,
15800,
22300,
null,
26600,
33200,
12800,
6100,
5400,
42500,
35100,
8700,
13900,
9200,
null,
22300,
39400,
61300,
71300,
12600,
32000,
null,
null,
8000,
28800,
300500,
10200,
44222,
28900,
null,
23500,
19500,
38300,
15000,
19000,
6400,
11200,
47100,
37500,
null,
28000,
32800,
63300,
17900,
20200,
11100,
14700,
18700,
16100,
36800,
15000,
8500,
28800,
13100,
43900,
18500,
12400,
22200,
29600,
18700,
3000,
null,
109500,
42100,
15900,
null,
32000,
40100,
83700,
63100,
null,
null,
15600,
20900,
24600,
29900,
23100,
null,
null,
50200,
32000,
9400,
25000,
15200,
53200,
16300,
5900,
50800,
28400,
35000,
null,
56200,
25100,
52900,
30300,
8900,
null,
37400,
15400,
null,
89900,
15500,
null,
11100,
30800,
57600,
43000,
null,
34500,
24600,
10900,
46200,
85800,
800,
40500,
39800,
15200,
55400,
14700,
40700,
20600,
1000,
15800,
12000,
22100,
18600,
6300,
21100,
57200,
8500,
15800,
54800,
41200,
32400,
39700,
20500,
26000,
17300,
7800,
10600,
101300,
23100,
27800,
36900,
36000,
16000,
109300,
2500,
10300,
11500,
94500,
51000,
97600,
26500,
7000,
45500,
22400,
3000,
null,
5900,
44200,
8500,
10100,
49000,
7200,
31700,
11900,
44900,
37200,
107800,
52000,
6000,
19440,
18200,
8000,
null,
null,
37000,
72400,
3500,
41700,
14500,
112700,
52300,
26400,
36300,
27500,
17600,
36400,
13000,
40100,
18200,
46500,
13200,
6800,
69433,
32500,
null,
11200,
14200,
9900,
38500,
4500,
36200,
28400,
null,
9300,
40400,
24300,
26400,
50300,
31500,
35801,
12800,
23300,
12400,
14600,
29600,
57900,
50000,
46032,
100500,
61800,
null,
33400,
15600,
32800,
82300,
5000,
6500,
18800,
10300,
13800,
23200,
42200,
7700,
5600,
null,
91500,
39500,
8200,
18700,
54501,
7700,
16200,
33400,
null,
10700,
2700,
20600,
13400,
43100,
29100,
null,
8300,
null,
16200,
11800,
56900,
25200,
19000,
13300,
52300,
8100,
22800,
74300,
43600,
null,
9800,
63000,
29600,
19400,
150400,
12700,
27500,
44100,
null,
22100,
14400,
66900,
37700,
38800,
null,
12500,
34700,
50700,
28800,
5000,
92600,
32800,
27000,
18600,
57700,
3200,
null,
17900,
14300,
22700,
14900,
13200,
13000,
8600,
20700,
38400,
83900,
49900,
5900,
24700,
30100,
57178,
27000,
7300,
21300,
17900,
5500,
24400,
29000,
12400,
10000,
7250,
null,
47100,
10400,
44100,
19200,
42800,
20400,
null,
14600,
null,
48100,
15200,
7000,
6300,
26900,
63100,
53900,
13600,
24500,
27800,
66500,
12200,
19900,
28200,
16200,
19200,
19600,
25400,
14700,
116200,
9300,
null,
15900,
11200,
22400,
26800,
3350,
36000,
30000,
42965,
21025,
19700,
24000,
21600,
16700,
15700,
null,
64200,
57700,
5600,
17600,
17700,
20100,
3100,
86800,
18451,
null,
33000,
43200,
15100,
9000,
14800,
12100,
11800,
24200,
24300,
13900,
17600,
23000,
30500,
5400,
10600,
51700,
206449,
null,
17425,
null,
25500,
16500,
null,
76800,
28300,
24900,
64200,
20900,
21500,
32200,
48300,
3800,
38650,
10390,
80200,
null,
12500,
14000,
26500,
3500,
11700,
0,
26100,
26300,
18700,
10200,
9300,
19100,
22400,
18100,
124400,
17900,
28300,
9400,
9700,
7840,
9900,
35800,
50900,
null,
19000,
22100,
41800,
13000,
null,
null,
null,
45900,
10300,
46700,
20300,
12300,
null,
30800,
18200,
17700,
5150,
49300,
15000,
13900,
23100,
46800,
6850,
116700,
26845,
26000,
22300,
20300,
18400,
50200,
7400,
null,
66000,
15200,
21200,
7500,
null,
6400,
3400,
47100,
21600,
34800,
77735,
27200,
25500,
22600,
63000,
null,
32400,
9800,
26900,
41000,
34700,
15300,
10000,
29100,
15400,
53400,
234800,
19700,
21900,
6700,
17400,
null,
null,
null,
19200,
31000,
81300,
64400,
15300,
null,
28100,
null,
21600,
23500,
29300,
33400,
37600,
29900,
5100,
34200,
57200,
61900,
46000,
60500,
15000,
44300,
20500,
16600,
9700,
16000,
null,
22700,
19700,
53700,
88100,
30400,
21500,
102900,
14500,
17000,
68400,
null,
13400,
35700,
10050,
6200,
15100,
41400,
6600,
22500,
56700,
19197,
111700,
116920,
16100,
15300,
26200,
25100,
10424,
23700,
6900,
25800,
5700,
21400,
49200,
12000,
13800,
2100,
7300,
12700,
29000,
30300,
17300,
3100,
267100,
21900,
43300,
11000,
60000,
24900,
30300,
null,
10600,
44800,
19500,
14500,
13600,
45400,
51700,
20100,
4800,
73100,
153800,
26500,
9800,
56900,
70000,
25900,
3500,
13500,
null,
79800,
7500,
18400,
20600,
24000,
12900,
9800,
39700,
49702,
25500,
14100,
25923,
8200,
10100,
13000,
80900,
20900,
6500,
18700,
16900,
20800,
18600,
102400,
52900,
29200,
null,
23500,
23800,
55500,
28100,
61100,
10900,
17500,
67800,
24300,
33600,
44100,
37800,
53200,
null,
16200,
22500,
34500,
162000,
13700,
14800,
26700,
45600,
43500,
null,
31100,
70900,
48400,
44000,
16800,
19600,
45200,
14700,
48100,
26100,
9000,
null,
26000,
15100,
90000,
12100,
28400,
11900,
83800,
20856,
null,
35400,
43100,
3000,
11700,
20100,
38100,
47700,
30400,
56100,
28100,
21900,
50900,
9600,
33200,
40600,
null,
46800,
null,
18400,
11000,
18100,
19500,
22200,
6300,
67100,
53500,
70200,
33800,
5100,
7700,
1000,
37900,
18200,
null,
28100,
59200,
116200,
28800,
132000,
55300,
9300,
56000,
23000,
18600,
29400,
15200,
23900,
145900,
null,
28913,
82500,
2500,
12800,
null,
30800,
46200,
96200,
13750,
48300,
null,
15900,
15100,
309900,
null,
61100,
30800,
12200,
1900,
12200,
146100,
16900,
null,
14800,
25600,
88200,
11400,
54100,
31100,
null,
18800,
15100,
46200,
5100,
38200,
63300,
87373,
14900,
72000,
32200,
10500,
17100,
7600,
25000,
69200,
null,
12100,
20700,
21911,
22900,
49700,
17600,
16200,
11400,
24100,
null,
19900,
13800,
20900,
51500,
20400,
36200,
12100,
35100,
68300,
25800,
12100,
9850,
42100,
13900,
9400,
15500,
16200,
23700,
32600,
21000,
36200,
63700,
43700,
46873,
79300,
103305,
null,
19100,
11700,
47000,
52500,
48400,
132600,
42200,
23500,
25526,
18900,
13000,
28900,
28500,
21300,
18300,
8800,
19100,
27200,
18900,
14300,
42800,
14200,
4600,
25500,
21400,
16800,
28100,
14000,
31600,
123600,
4300,
null,
12100,
28000,
17300,
7300,
67200,
17400,
null,
26900,
8000,
5800,
17300,
37137,
7700,
184050,
24600,
50600,
60500,
16900,
20600,
22300,
27900,
16500,
42700,
62640,
17500,
15750,
8800,
8300,
4500,
11600,
null,
30600,
44900,
27500,
19500,
29600,
61600,
60800,
21900,
54000,
7900,
29300,
26000,
38300,
12600,
null,
34300,
null,
null,
12400,
16900,
55800,
18600,
7900,
22400,
13000,
20400,
40600,
13000,
12400,
42100,
null,
31400,
18000,
75500,
7100,
42300,
11200,
31500,
44400,
17000,
62644,
28700,
17100,
73000,
48400,
18500,
28100,
11200,
21500,
73000,
124750,
23400,
4900,
158100,
16500,
19500,
27800,
9900,
13700,
42100,
9100,
null,
12400,
57100,
56100,
29500,
60500,
60700,
14632,
17600,
null,
52900,
66500,
14900,
38500,
8800,
29200,
34200,
8900,
7700,
25000,
7236,
11000,
47400,
16700,
7800,
40100,
20300,
53620,
35700,
17700,
43300,
86300,
25400,
75100,
null,
165900,
50200,
18100,
8700,
19345,
10000,
35200,
19400,
46500,
74100,
48100,
32500,
55900,
null,
11600,
24600,
12600,
60900,
11000,
35600,
39600,
34400,
20900,
null,
13300,
6300,
15800,
36900,
16500,
41900,
null,
8700,
32800,
null,
29800,
40000,
19400,
27700,
null,
6000,
95400,
193500,
24300,
102100,
45000,
14800,
19300,
8300,
null,
null,
121200,
31900,
32900,
40600,
36700,
11200,
82200,
10700,
30000,
32200,
15200,
29200,
26200,
30300,
14100,
26200,
72100,
31417,
16200,
110200,
49286,
3700,
31500,
130400,
17600,
66700,
17000,
19700,
35700,
12800,
null,
3700,
null,
11100,
18900,
53600,
16000,
null,
32400,
null,
16700,
99200,
21900,
14300,
null,
63600,
6100,
69100,
14800,
22700,
13100,
8900,
34750,
29900,
5900,
null,
20500,
49100,
29600,
50500,
49600,
11000,
96095,
15200,
6400,
38500,
null,
null,
38600,
29900,
67600,
46400,
34000,
72800,
30800,
33500,
49600,
39800,
7300,
28000,
10700,
9400,
43000,
47100,
null,
33700,
28500,
72500,
31200,
35000,
5300,
null,
41900,
null,
14600,
17300,
38300,
26800,
39300,
4900,
6600,
75300,
15000,
17500,
17200,
38900,
20900,
35500,
202100,
12800,
15700,
22100,
13600,
20700,
14400,
18100,
4100,
12400,
null,
16000,
27500,
27300,
66650,
6300,
13800,
null,
19100,
6900,
17300,
10201,
null,
13100,
80400,
15100,
50700,
46200,
48600,
32700,
25742,
2700,
11000,
7600,
4900,
36900,
2200,
57800,
28500,
24100,
53400,
92100,
12200,
7800,
14500,
56100,
18600,
46900,
7200,
18000,
41300,
27900,
32800,
16500,
45200,
33100,
236200,
60900,
33000,
17600,
21900,
51700,
4300,
25700,
63300,
147000,
16000,
5700,
62300,
9700,
9500,
24400,
15900,
32900,
30000,
6300,
63500,
140200,
6800,
32000,
null,
10000,
null,
null,
83400,
53500,
35300,
39000,
35000,
56900,
null,
13500,
7900,
8600,
29700,
79700,
52000,
6500,
null,
47700,
38300,
61500,
43600,
17800,
7000,
14400,
19400,
27700,
2700,
8900,
6900,
25100,
8500,
28100,
26500,
28700,
90500,
11400,
51700,
29800,
49900,
77900,
30100,
null,
46100,
13100,
13900,
15700,
13000,
31900,
42200,
64700,
17300,
15200,
11900,
88700,
16900,
28600,
103200,
26700,
36600,
15100,
31700,
38000,
14200,
25000,
12300,
9400,
16700,
36940,
7100,
27700,
22400,
24100,
53100,
13900,
11100,
null,
60300,
9600,
49900,
78300,
36500,
11300,
14500,
19900,
15700,
10000,
48600,
36800,
56000,
55600,
28400,
8300,
15900,
18100,
20900,
26800,
15400,
23000,
16000,
20840,
25500,
117300,
16900,
23100,
33300,
31900,
30000,
6900,
33800,
2500,
53900,
18000,
18600,
16900,
12400,
17600,
10900,
6500,
15100,
33200,
18000,
12000,
139100,
null,
12100,
104200,
50400,
42800,
null,
24100,
26600,
35900,
7900,
21800,
10700,
169100,
36500,
30200,
25600,
38200,
27000,
20700,
12100,
29900,
10300,
14200,
14901,
87500,
null,
9800,
14030,
16000,
90350,
null,
46800,
16800,
null,
50300,
44700,
12700,
38700,
31100,
15600,
19100,
9500,
17300,
12300,
15200,
8500,
14400,
63500,
7400,
29700,
27900,
26800,
7700,
70200,
4200,
16300,
23000,
12600,
5600,
20900,
16800,
null,
null,
29200,
84700,
30200,
9000,
83300,
40400,
61300,
null,
56900,
13200,
14000,
48500,
8300,
21500,
900,
10100,
29000,
20600,
16000,
16600,
3700,
15000,
78300,
54600,
38700,
23700,
12900,
34300,
29400,
110000,
23500,
28200,
6100,
20700,
15900,
25800,
39800,
null,
54200,
19400,
null,
23900,
9900,
22600,
40300,
57100,
224800,
7000,
29300,
24700,
21500,
25900,
2500,
64400,
21600,
12500,
50500,
23100,
43500,
19500,
203500,
15900,
14500,
null,
67900,
25500,
null,
40700,
9600,
null,
28300,
9300,
35900,
23100,
107400,
24470,
18000,
52900,
17800,
7200,
21300,
36550,
56300,
24000,
12900,
24200,
25600,
15000,
24500,
27400,
21700,
10600,
3100,
52400,
31000,
8200,
137100,
137400,
21600,
43300,
18300,
12800,
7800,
47600,
14700,
8500,
23900,
21400,
8000,
14400,
29500,
29400,
23100,
5800,
50400,
8250,
6100,
61600,
19400,
14000,
38000,
39200,
7900,
38000,
17100,
2750,
11000,
11600,
54000,
53100,
11350,
38700,
17000,
28300,
3800,
17700,
37500,
22300,
47700,
21400,
43500,
38500,
69300,
48500,
29100,
32200,
97625,
103350,
49400,
25100,
20500,
35300,
33400,
19800,
17800,
51100,
21000,
28300,
39400,
31800,
47700,
15600,
7600,
64300,
10100,
16600,
58200,
11700,
11200,
26300,
47400,
15400,
36500,
13200,
8900,
25200,
11800,
34700,
26800,
47000,
18500,
7100,
8000,
9500,
74400,
8800,
40500,
19100,
96100,
14100,
53700,
36500,
41200,
5400,
16100,
21600,
null,
106100,
2900,
22600,
28800,
61100,
12700,
92585,
14200,
34900,
61900,
36900,
84500,
258000,
36600,
57600,
18300,
null,
10600,
42500,
29900,
40400,
23500,
22000,
16000,
31800,
null,
13200,
12000,
40050,
7600,
27200,
18900,
79900,
23400,
28800,
null,
16600,
null,
40400,
17000,
31300,
23100,
32900,
67100,
40500,
42300,
151000,
14005,
12700,
179100,
30200,
17300,
88400,
15100,
61500,
17500,
74500,
null,
36900,
13200,
8300,
48300,
18200,
88200,
40900,
null,
35000,
14000,
33500,
18600,
12200,
16800,
19900,
20700,
45800,
12800,
17200,
40600,
15600,
34300,
11000,
5600,
7200,
85200,
27700,
23400,
25100,
54500,
18600,
68400,
null,
18100,
59000,
73599,
69500,
35500,
21600,
40700,
38400,
12600,
22200,
1800,
46000,
55000,
36000,
12500,
41600,
79070,
12600,
null,
21300,
16100,
22600,
157800,
41300,
15000,
12600,
28800,
8800,
22700,
55500,
39700,
25400,
17301,
14500,
42500,
14000,
null,
39083,
38700,
4300,
11700,
null,
47800,
23000,
5000,
30000,
9000,
7400,
27700,
15300,
20800,
null,
29300,
11700,
29600,
4200,
43700,
26700,
7600,
52300,
37900,
11800,
16600,
22500,
null,
13800,
7900,
22000,
52700,
20400,
22000,
13200,
69200,
45800,
8100,
40100,
46600,
27900,
13300,
25400,
36600,
17000,
38700,
33400,
20800,
21900,
null,
41300,
17950,
6100,
null,
null,
24600,
44100,
27400,
23400,
24300,
18700,
1100,
21800,
51264,
18200,
null,
null,
5800,
16700,
19700,
34200,
18200,
15000,
23000,
23900,
14700,
17400,
null,
null,
34400,
23700,
11100,
17200,
8300,
12800,
57200,
42400,
29100,
12900,
20000,
87400,
38000,
14000,
45700,
46200,
24700,
null,
35400,
3400,
5900,
33400,
10900,
40000,
34400,
17300,
18800,
35400,
34900,
70496,
16200,
null,
32600,
15100,
17200,
null,
10900,
17100,
9300,
58200,
30400,
23000,
5000,
11400,
7700,
74100,
null,
21800,
9500,
31300,
20400,
15300,
80100,
33700,
11200,
115600,
12800,
47200,
202900,
38300,
31000,
136500,
46400,
44100,
22800,
12700,
16800,
38700,
11500,
53800,
18000,
19000,
49300,
31100,
24600,
23500,
24500,
null,
24500,
21000,
16600,
17450,
53100,
75800,
25300,
28600,
null,
58400,
18400,
31500,
16800,
38000,
null,
29200,
8200,
28640,
12600,
32000,
null,
null,
33400,
51500,
18600,
null,
6200,
13000,
13000,
8200,
166900,
23000,
64700,
9500,
125900,
33200,
11000,
30400,
13000,
93900,
23900,
14000,
15300,
43500,
14700,
4750,
51600,
43300,
11300,
33900,
10000,
7800,
62100,
53700,
19700,
12400,
9700,
39000,
29025,
39000,
101800,
27500,
51300,
120600,
23200,
18600,
17100,
40193,
null,
31900,
31500,
7000,
26600,
11200,
10700,
18500,
null,
null,
40537,
null,
18200,
4000,
31600,
33700,
31000,
69400,
4200,
24800,
17233,
2400,
20100,
47600,
30100,
32700,
4400,
16200,
110600,
45300,
16000,
8400,
7500,
26200,
105600,
73400,
null,
104100,
3000,
22900,
8700,
128900,
12100,
null,
26500,
50400,
17200,
77400,
6000,
27500,
49500,
3500,
22100,
20700,
28700,
22000,
10300,
43300,
6800,
8800,
9300,
38600,
36000,
9500,
null,
57300,
24050,
27200,
45200,
41800,
null,
28400,
25300,
55000,
16800,
18500,
18000,
56300,
11200,
23900,
23200,
19200,
49200,
64100,
32200,
76600,
24400,
36300,
10400,
29100,
10200,
12100,
33000,
16200,
19700,
32000,
21300,
14500,
48800,
190700,
null,
17400,
43800,
6700,
28500,
12600,
null,
19909,
49100,
8800,
49700,
22099,
30200,
13000,
36600,
19000,
13400,
null,
39400,
18000,
33800,
11100,
27400,
3800,
36700,
7300,
47663,
null,
61400,
null,
13700,
45400,
52000,
42200,
35800,
68900,
43600,
31379,
63100,
18000,
12200,
14500,
35500,
35200,
25600,
259500,
8900,
116100,
17800,
13500,
5200,
42100,
34000,
16300,
60400,
44800,
221300,
17300,
12600,
19900,
90500,
24600,
34500,
null,
11900,
59400,
114500,
25700,
52300,
56700,
76300,
10000,
5700,
17000,
17100,
null,
null,
36100,
12000,
null,
23300,
49600,
7500,
17500,
21900,
15000,
17400,
10600,
7500,
68900,
29100,
null,
51400,
null,
128100,
null,
34600,
38200,
14800,
21900,
22000,
45900,
87700,
42100,
18500,
18200,
null,
72900,
5500,
15200,
42300,
8600,
47800,
50300,
23900,
null,
24300,
8800,
13400,
69300,
43330,
74200,
20600,
19300,
22000,
147600,
35300,
9700,
17400,
42800,
38800,
14700,
null,
51600,
8900,
14600,
34100,
36000,
71500,
22300,
19900,
2800,
75400,
151860,
17000,
15900,
27400,
null,
10700,
31200,
80700,
20200,
27600,
37500,
32800,
null,
53800,
66600,
22200,
33000,
13600,
13600,
92100,
29900,
13400,
65100,
8900,
14600,
16100,
39400,
63200,
13900,
31800,
29800,
30090,
24000,
10400,
28800,
null,
39000,
9400,
null,
10500,
107600,
null,
19900,
22900,
15000,
null,
27300,
17700,
48400,
null,
20000,
26200,
37900,
29500,
11300,
6009,
56000,
19400,
null,
null,
27700,
9100,
18800,
null,
5700,
12900,
17100,
29100,
35300,
45200,
42400,
22500,
6900,
99700,
82000,
18600,
16900,
null,
41300,
13200,
43200,
10700,
41900,
8500,
37400,
2700,
6000,
57800,
null,
5050,
36600,
26100,
9100,
7400,
33000,
31100,
112000,
45800,
170700,
59000,
13400,
9800,
13700,
20700,
60000,
26300,
34000,
38600,
14500,
14300,
34900,
18100,
113500,
19600,
14500,
81400,
24100,
26700,
28400,
50600,
66800,
54800,
36400,
54700,
33400,
20500,
29900,
null,
46300,
10700,
19800,
60300,
3100,
17900,
50900,
12700,
47700,
58900,
26600,
15500,
4900,
5000,
41600,
14500,
56500,
45800,
18600,
28400,
23800,
61400,
11900,
31700,
9500,
30700,
71100,
null,
43200,
null,
null,
30300,
8500,
36100,
38300,
18300,
47900,
13200,
34800,
47300,
14800,
239800,
12400,
41000,
17700,
19500,
43700,
9300,
91200,
14600,
13100,
8900,
39500,
null,
50900,
31650,
40100,
30400,
11000,
35500,
50500,
12200,
29300,
55500,
50100,
12700,
30000,
13100,
31100,
20700,
46100,
7400,
11800,
40800,
31700,
37900,
85600,
20800,
25600,
12000,
21300,
7000,
6500,
null,
28800,
22900,
9800,
9000,
null,
31500,
29300,
58600,
57700,
22300,
5700,
63600,
28700,
12000,
73700,
18700,
null,
29500,
3800,
39000,
28000,
40200,
11600,
17600,
24380,
19400,
10300,
49500,
10900,
null,
21700,
128200,
27700,
10000,
57000,
19900,
18400,
41600,
85000,
50900,
10000,
null,
55000,
32400,
47900,
5400,
5900,
39000,
20800,
64900,
39600,
36200,
35900,
115100,
11700,
29400,
null,
31500,
19309,
78100,
36900,
19100,
37600,
16900,
10400,
10300,
null,
17800,
5300,
8100,
11100,
21000,
40900,
43200,
12200,
7600,
14300,
null,
null,
34900,
22400,
15400,
55000,
27200,
67100,
18200,
13500,
25500,
26100,
38600,
25500,
null,
30700,
47600,
20300,
38500,
21000,
53700,
null,
52600,
32300,
22400,
19400,
28400,
6100,
35800,
51500,
35000,
39800,
48700,
8500,
41900,
17200,
87900,
null,
32100,
43300,
12000,
17100,
23100,
7700,
27400,
8200,
17700,
11000,
null,
21600,
18000,
34900,
37300,
23100,
72400,
null,
23500,
151395,
92000,
18100,
31800,
18800,
8100,
48700,
8500,
3500,
68000,
58800,
null,
34300,
38700,
41000,
29000,
9300,
16700,
null,
10000,
13500,
12100,
23000,
3900,
10400,
41400,
13400,
18000,
25900,
100300,
6700,
3600,
28500,
null,
null,
17200,
13600,
69190,
27700,
null,
12900,
25300,
33200,
52500,
26600,
5400,
14400,
54000,
27100,
69100,
57400,
43000,
8000,
null,
3100,
14400,
null,
22100,
50300,
7300,
52900,
26700,
null,
10300,
26700,
10500,
null,
6600,
37000,
14800,
43800,
null,
14700,
13900,
20800,
31500,
19500,
23500,
22000,
16950,
21400,
55700,
20700,
12800,
12800,
38700,
30900,
40200,
null,
19600,
27300,
9475,
21000,
126500,
22200,
34700,
19800,
4400,
null,
14400,
39800,
29100,
19400,
28100,
15700,
42100,
null,
19100,
39600,
32400,
11200,
21600,
6500,
57400,
13500,
19000,
10400,
7700,
28000,
32900,
8500,
93100,
3000,
25700,
25000,
43600,
26400,
28400,
24900,
34800,
13200,
5400,
8800,
53200,
37000,
67300,
20100,
30800,
3100,
23600,
153800,
50400,
18900,
47700,
16500,
29500,
64600,
8700,
59200,
29000,
39800,
12900,
57964,
7900,
12300,
10400,
13700,
29500,
20500,
13800,
null,
null,
23100,
9600,
28200,
67700,
null,
28000,
52400,
62100,
8300,
34100,
13100,
6600,
38500,
12800,
null,
null,
18500,
null,
36800,
55800,
27100,
14300,
null,
20500,
22200,
35600,
31600,
18800,
13450,
57100,
31300,
null,
44400,
75300,
29700,
22600,
91400,
9000,
19200,
30500,
12900,
10000,
14600,
15800,
56300,
20400,
5900,
7700,
51200,
41800,
46900,
21500,
5400,
13100,
46200,
83400,
28570,
12300,
83000,
31000,
26700,
13700,
7800,
49000,
31900,
12500,
null,
24700,
45400,
3900,
66800,
5500,
16900,
103000,
22000,
15800,
10800,
11700,
12000,
33500,
44000,
15500,
14500,
41200,
30900,
6200,
15300,
11200,
8200,
24700,
null,
14100,
29600,
10700,
57900,
10500,
15700,
9700,
8100,
48100,
31100,
67600,
42700,
16600,
17000,
9600,
25300,
null,
25500,
null,
17800,
20000,
7600,
12000,
38700,
47200,
12000,
14800,
15300,
45200,
52400,
44100,
40200,
30500,
142500,
17900,
26600,
28100,
21400,
10100,
17100,
null,
27400,
22700,
15500,
38000,
15400,
13500,
5000,
3800,
13500,
35300,
null,
25200,
21800,
26400,
36100,
29500,
8800,
24600,
9600,
32900,
67300,
38200,
6000,
32400,
30331,
19100,
52700,
21600,
13700,
10900,
14800,
56700,
15600,
16500,
112000,
12200,
21000,
7500,
41200,
43200,
44700,
24700,
22800,
46300,
13700,
9000,
7000,
null,
17200,
24300,
24700,
95300,
49900,
19800,
12100,
21200,
20300,
null,
60700,
17000,
17600,
5150,
25000,
13300,
46900,
9200,
null,
10600,
56000,
27000,
28700,
13600,
25000,
41200,
45300,
377400,
17000,
36500,
11300,
7200,
13700,
30300,
9600,
69500,
6800,
59500,
null,
89450,
null,
null,
31700,
5400,
41000,
33600,
8800,
9300,
16200,
26900,
5500,
16900,
64600,
28400,
null,
11100,
20300,
8300,
59200,
51800,
36300,
14300,
17895,
31200,
21500,
55100,
37500,
57200,
52000,
12600,
16300,
9700,
35900,
3900,
26800,
58100,
21600,
26100,
10500,
47700,
8400,
33800,
16300,
38900,
42500,
36400,
13700,
122200,
15300,
20400,
22900,
71896,
26000,
6500,
14800,
46100,
11000,
24500,
8100,
41100,
11100,
19100,
null,
12700,
57900,
9000,
12000,
17100,
127200,
45900,
13500,
7400,
17800,
26300,
17800,
53700,
null,
39100,
49600,
null,
32400,
35500,
58500,
39700,
35200,
33500,
20900,
49800,
34500,
33700,
117700,
25000,
13700,
12900,
null,
13400,
42100,
null,
26463,
14800,
31300,
19200,
12500,
28400,
16600,
6300,
43200,
8600,
19500,
6000,
37800,
26500,
41000,
56500,
41800,
18600,
11100,
null,
null,
23800,
3800,
8400,
9800,
13300,
53200,
25400,
null,
34500,
55600,
17100,
56100,
21800,
29700,
27000,
64900,
44426,
45300,
26700,
35700,
null,
22200,
15000,
null,
17800,
16000,
54400,
21600,
1500,
26000,
46400,
19000,
24800,
16800,
31900,
40700,
64500,
16200,
19500,
50300,
19300,
26300,
8000,
10800,
14700,
27100,
19100,
35400,
39400,
21700,
6300,
36700,
7900,
17500,
8500,
18400,
32100,
4300,
48150,
13500,
54700,
15800,
72300,
77100,
5200,
22000,
null,
null,
null,
8000,
7100,
9800,
26800,
23800,
10500,
6300,
23000,
6900,
8800,
33000,
54100,
21600,
14900,
66200,
17100,
null,
13600,
11700,
33600,
9000,
9100,
null,
15500,
60000,
19800,
45100,
53400,
56100,
44600,
6800,
null,
66300,
48200,
15500,
17000,
8100,
7400,
null,
69300,
26900,
null,
5800,
68000,
11300,
56800,
14200,
22800,
45800,
22600,
null,
18100,
24700,
null,
13200,
97600,
6300,
14100,
44800,
20600,
11500,
14300,
22200,
86600,
null,
null,
11800,
11100,
40100,
null,
36200,
5600,
30300,
4300,
null,
23800,
37900,
40500,
11500,
35000,
48700,
14600,
20400,
58000,
null,
32400,
28400,
6800,
24100,
15400,
29900,
null,
84900,
13300,
69600,
null,
5600,
39200,
null,
17400,
7700,
62800,
null,
8200,
42500,
null,
13300,
8500,
13700,
35800,
1500,
27800,
6169,
null,
20600,
27300,
32600,
37200,
null,
74500,
39900,
11100,
12500,
6400,
14900,
65100,
null,
16800,
35700,
22100,
21600,
null,
42900,
71300,
87900,
23100,
8300,
13100,
11500,
18400,
72200,
20400,
24600,
41000,
26100,
9500,
52000,
11900,
12800,
30900,
54300,
30900,
34400,
22300,
71700,
14200,
17200,
35000,
64300,
null,
5500,
20800,
28200,
26300,
11400,
24800,
15100,
45283,
15900,
44200,
24400,
28300,
18100,
21000,
33300,
141400,
6400,
12400,
4300,
19600,
124900,
70000,
66251,
null,
72800,
null,
20800,
null,
5300,
16700,
32950,
27200,
22000,
84400,
25800,
32200,
18300,
7300,
54000,
8700,
6500,
20800,
15400,
17900,
37300,
22900,
5200,
35200,
95467,
62000,
11900,
8800,
74500,
17100,
92500,
6300,
42000,
64600,
15200,
44100,
19200,
23200,
35300,
41800,
18800,
null,
8700,
13100,
8500,
85500,
23400,
36800,
20800,
20800,
29700,
null,
18100,
79500,
18000,
30400,
13500,
19400,
37500,
null,
null,
5000,
82500,
6000,
7300,
32000,
48700,
18900,
21600,
22100,
44100,
55500,
null,
23500,
11600,
54200,
31200,
43300,
22600,
30400,
71000,
46900,
29000,
null,
48900,
71200,
29300,
15400,
5400,
43900,
45500,
9700,
null,
10600,
43100,
4600,
20200,
11800,
16700,
7800,
38800,
8900,
15000,
11200,
null,
47200,
14300,
7600,
9100,
null,
9700,
12800,
22100,
15000,
9200,
27400,
8300,
49100,
14600,
33500,
null,
73100,
23800,
34000,
27000,
46600,
30100,
1700,
4000,
6600,
49000,
53900,
60800,
44700,
69600,
22000,
25400,
361000,
8800,
14300,
19600,
35700,
37800,
27800,
10900,
5000,
98400,
12900,
5900,
50900,
9100,
21600,
29700,
3100,
null,
15500,
10000,
21700,
3300,
47400,
71400,
7600,
23400,
19500,
39200,
35900,
10900,
null,
12300,
27200,
27500,
15600,
1100,
41900,
20900,
16300,
11100,
35900,
17200,
37700,
23400,
40700,
11800,
14100,
148100,
13400,
111900,
60100,
10000,
71100,
6300,
19000,
7800,
22200,
35100,
73000,
null,
null,
32500,
31700,
22000,
18400,
32000,
28400,
59500,
34900,
17500,
13000,
25700,
62200,
75700,
15800,
3500,
3600,
22000,
null,
null,
30100,
null,
131300,
43500,
54900,
29700,
null,
42500,
20000,
30100,
7100,
33300,
19500,
84600,
10500,
7600,
49700,
17600,
9000,
12000,
29200,
13200,
null,
null,
28300,
17400,
8100,
null,
28700,
10000,
9900,
15300,
20700,
68200,
50300,
18700,
8005,
18900,
158000,
18700,
13200,
9150,
21162,
12500,
38700,
17700,
10500,
20400,
10500,
43800,
9400,
10900,
45300,
18100,
11500,
9200,
38500,
6100,
27700,
27100,
55100,
16800,
26500,
33650,
211100,
5350,
14200,
9700,
39500,
14100,
14000,
null,
13900,
40000,
130800,
23500,
46300,
21700,
18900,
null,
15100,
27700,
28600,
16900,
38400,
47600,
47600,
116600,
20200,
27400,
55400,
14000,
7500,
27800,
null,
22000,
8200,
39800,
10000,
22500,
9300,
36600,
107600,
58800,
22600,
11000,
21900,
32550,
null,
26400,
8400,
22400,
13200,
20500,
23800,
61000,
78300,
null,
49200,
24200,
29500,
31900,
16400,
45300,
41000,
20200,
9500,
26300,
12800,
13000,
null,
65900,
14200,
19700,
null,
14000,
30600,
18300,
37600,
19800,
27300,
31400,
85100,
10200,
39100,
14100,
16500,
46700,
69200,
16600,
9300,
27100,
30400,
63200,
17700,
32700,
42969,
41400,
23700,
57200,
11500,
1200,
46800,
17500,
105170,
48700,
48100,
12900,
19000,
19600,
40300,
6200,
23100,
null,
28700,
27200,
29800,
26800,
35600,
29800,
26200,
6190,
24600,
16200,
17700,
29800,
49100,
15200,
23800,
18800,
33900,
83500,
88900,
27500,
37500,
134300,
21000,
40600,
20800,
81100,
32800,
null,
11000,
21500,
10800,
40300,
18200,
13400,
152516,
36400,
16800,
38300,
11200,
11500,
6500,
16300,
57200,
5200,
17600,
31300,
40800,
12600,
22700,
18200,
35400,
6400,
null,
85700,
39200,
52800,
null,
27600,
33800,
41400,
28300,
56500,
4300,
6500,
13400,
16000,
38000,
null,
27000,
17400,
32100,
16300,
18200,
null,
8000,
26900,
131300,
13500,
28500,
9000,
14700,
36400,
5500,
20700,
96500,
22300,
16200,
null,
7500,
68700,
8400,
20400,
13900,
12200,
60900,
3500,
14100,
54700,
26400,
19500,
172100,
12500,
30700,
null,
11200,
32000,
12000,
null,
38900,
57300,
9400,
27300,
24100,
36900,
9900,
37700,
39600,
27400,
null,
24700,
6100,
17700,
101400,
7300,
23600,
8500,
147200,
18500,
4200,
17700,
14100,
28500,
21400,
null,
26600,
7600,
25000,
40400,
null,
28500,
9900,
19000,
null,
11600,
null,
22300,
31600,
34100,
15100,
21000,
9300,
8500,
null,
27500,
12600,
9000,
null,
9300,
53300,
12400,
14400,
59605,
53700,
53000,
13700,
null,
31600,
72700,
13300,
null,
36300,
16400,
21200,
65600,
8600,
23900,
18900,
30700,
10500,
13800,
45500,
16900,
53600,
16700,
25000,
64800,
91441,
54600,
128000,
7300,
35800,
51700,
14100,
28500,
24000,
42600,
37100,
26600,
7600,
44800,
18100,
25700,
122200,
14900,
24700,
74700,
41820,
1100,
62300,
35300,
7900,
12500,
37100,
73700,
45213,
52200,
null,
40141,
16400,
44300,
52500,
43032,
31800,
14400,
98700,
2600,
20300,
22500,
64400,
49000,
14800,
3000,
15500,
27700,
15900,
86600,
7700,
null,
null,
25800,
141800,
55100,
136900,
31800,
25500,
30500,
3600,
23300,
null,
84400,
15200,
47200,
27500,
16100,
11300,
10200,
null,
43500,
800,
13100,
27800,
13200,
9900,
53900,
24800,
27500,
8700,
69500,
38800,
91000,
13950,
19500,
15900,
29700,
null,
16700,
24600,
15000,
null,
45500,
20100,
23800,
25100,
142600,
12832,
24500,
4400,
94500,
61400,
7500,
28600,
34900,
17800,
52500,
46200,
35700,
25100,
25500,
9000,
null,
48600,
29800,
9450,
18900,
16000,
21500,
15200,
95000,
32300,
12900,
38000,
48100,
25200,
73200,
14500,
77200,
14700,
15500,
11000,
23100,
2300,
33964,
30300,
62290,
20700,
31800,
17400,
75700,
10100,
23700,
31400,
1200,
null,
17300,
32800,
15500,
null,
18500,
8200,
20900,
66100,
53900,
5000,
null,
24700,
21300,
15500,
16700,
8800,
22300,
7900,
26100,
null,
62500,
null,
12500,
22100,
24300,
17900,
16500,
14900,
27300,
23700,
18500,
4700,
5200,
27800,
8200,
26700,
12400,
24100,
19800,
55000,
33900,
33600,
14200,
85100,
19500,
5900,
14800,
25200,
63300,
11800,
11800,
46000,
118500,
6200,
46300,
6500,
22600,
20200,
62500,
25600,
15100,
null,
24900,
58800,
5400,
97305,
44700,
41600,
null,
24300,
7000,
null,
20700,
16700,
13000,
48400,
28900,
5900,
85400,
6600,
15200,
24000,
37500,
38700,
144300,
13800,
null,
13200,
44700,
144800,
111100,
26200,
10300,
14000,
39000,
12100,
20400,
19700,
43000,
40500,
85700,
38543,
37200,
25800,
21700,
64700,
30200,
32700,
73900,
7800,
210100,
19200,
14300,
25500,
123400,
11100,
54800,
12227,
35400,
86500,
21000,
53300,
7700,
31800,
21900,
59500,
1000,
33600,
30300,
17500,
null,
11200,
58400,
null,
27500,
41500,
12000,
12500,
50500,
36100,
7500,
33400,
32100,
null,
38400,
24100,
6900,
20700,
35200,
7600,
24800,
50100,
18100,
33800,
93900,
35500,
78800,
85800,
null,
9600,
9600,
43200,
21700,
11900,
13000,
32900,
76000,
56700,
9300,
22500,
36400,
92400,
4100,
11300,
18300,
null,
7800,
22000,
20200,
23000,
39900,
20800,
11400,
36800,
23500,
10369,
15800,
36900,
700,
null,
6500,
null,
30200,
44300,
28800,
46600,
30000,
6100,
26400,
11700,
6500,
62300,
null,
35400,
33400,
20500,
31300,
11300,
null,
null,
44400,
14200,
11200,
43900,
18900,
9700,
null,
24700,
177900,
9400,
10300,
11500,
71700,
48000,
24800,
41400,
31700,
232300,
54800,
22000,
10900,
9000,
13100,
39600,
71400,
42400,
14500,
30800,
6500,
11300,
6700,
22500,
60200,
50200,
15300,
20800,
20000,
17100,
20000,
17700,
12000,
34900,
10100,
40500,
40000,
21800,
137600,
32500,
24700,
1900,
11100,
39000,
42300,
23300,
13000,
22900,
7800,
26700,
12200,
14300,
101700,
59700,
11000,
16800,
29600,
14500,
4500,
18800,
11100,
null,
53500,
60800,
8145,
17100,
29400,
10990,
12600,
18300,
21900,
null,
283300,
35500,
13100,
35300,
12850,
55900,
22300,
43800,
12200,
47300,
14000,
27700,
18900,
4100,
133800,
null,
48000,
25300,
20600,
22100,
14800,
56900,
56500,
19800,
46200,
null,
null,
44400,
19700,
18400,
63800,
46500,
61100,
null,
103400,
null,
78100,
15700,
73900,
72400,
15800,
11300,
95300,
38100,
77500,
22700,
19500,
26000,
36400,
16100,
20800,
41800,
null,
11300,
5000,
null,
42800,
3900,
55800,
4000,
13800,
11900,
38800,
27100,
18600,
13200,
21400,
21700,
7200,
null,
15600,
21200,
54500,
22800,
31600,
58800,
null,
20800,
13000,
12500,
35400,
35600,
35900,
153100,
68300,
null,
23800,
null,
21600,
7300,
29600,
23600,
27400,
6200,
19500,
27100,
10500,
null,
13900,
15000,
null,
13900,
5400,
54100,
34400,
33600,
15700,
12400,
null,
null,
29200,
62600,
35300,
6800,
8400,
12600,
60400,
null,
70600,
15700,
63100,
20300,
19800,
null,
30300,
23300,
50200,
9500,
23900,
37700,
5000,
35500,
20500,
1000,
29800,
93600,
4400,
21200,
3800,
31400,
46600,
8750,
52500,
43100,
24200,
19300,
10500,
46100,
19800,
16300,
28400,
25600,
104900,
18000,
50600,
27700,
14100,
40700,
37500,
23900,
53200,
20000,
18200,
57900,
28800,
22700,
46000,
null,
13000,
6500,
60800,
21500,
40100,
21300,
105600,
10700,
17600,
null,
36500,
21500,
48500,
50100,
null,
1400,
42900,
25200,
null,
8000,
13200,
18500,
49900,
4900,
21300,
103500,
20200,
5300,
12700,
32900,
18200,
null,
null,
79900,
31100,
23700,
10700,
16400,
20100,
39300,
53500,
6000,
null,
4600,
17900,
75600,
14600,
16400,
15500,
16000,
64700,
16500,
102700,
null,
57300,
85600,
20409,
17300,
17800,
5200,
8200,
15100,
null,
9900,
11700,
62400,
27800,
72300,
57600,
14400,
46600,
9700,
121600,
7600,
21300,
40850,
89000,
38100,
44200,
15800,
23100,
2300,
20500,
null,
18300,
22500,
63900,
25100,
25800,
11400,
14900,
19000,
2900,
10900,
16300,
34400,
null,
16100,
null,
9200,
44000,
27300,
53900,
null,
119440,
null,
129200,
35000,
56200,
null,
42900,
21000,
44800,
4300,
13800,
7500,
34600,
11300,
132300,
null,
9500,
29000,
161300,
52700,
22700,
36500,
38600,
43800,
60600,
8900,
12100,
9500,
16100,
5500,
8300,
53600,
51300,
55500,
8900,
12300,
30000,
33100,
null,
29700,
89200,
68100,
22500,
16700,
35800,
109500,
114600,
45000,
null,
19600,
52100,
12000,
17800,
94100,
2800,
6500,
null,
null,
45800,
22200,
19800,
28200,
39300,
31400,
6200,
50300,
12800,
12150,
9900,
12900,
null,
6800,
31500,
3400,
24700,
41300,
null,
21700,
35300,
19100,
null,
12840,
66900,
31400,
33500,
null,
52000,
27300,
83800,
31900,
13500,
8000,
58600,
28000,
16600,
25300,
35300,
29900,
34400,
30100,
25500,
20000,
27400,
19600,
12600,
21500,
54300,
20500,
85200,
null,
58300,
19200,
16400,
34700,
26600,
27900,
10700,
39600,
4500,
11200,
19700,
12700,
28600,
32900,
27400,
5200,
22100,
null,
15500,
62500,
17100,
12800,
23433,
20000,
9800,
null,
39400,
61330,
109900,
38600,
3600,
16700,
52000,
28700,
12500,
20900,
6100,
80700,
20900,
7700,
1850,
57200,
8800,
29400,
30200,
37400,
35700,
1900,
13000,
38200,
51200,
35200,
11500,
18900,
10000,
39700,
30600,
16000,
15300,
19400,
9700,
13000,
21700,
54000,
null,
25600,
15900,
9700,
null,
53200,
null,
30200,
null,
4300,
42800,
17100,
14600,
44800,
35700,
13200,
21100,
24900,
9900,
67400,
16300,
44800,
90700,
11494,
6300,
25800,
null,
28100,
14800,
5500,
20200,
72100,
17700,
20600,
38100,
11700,
8500,
17555,
31200,
41300,
13800,
41000,
8200,
84000,
7800,
45400,
null,
45000,
null,
18900,
37600,
47500,
20800,
40800,
30300,
null,
23400,
22600,
20200,
14700,
7300,
53700,
74800,
17800,
20000,
null,
11500,
28400,
90500,
14200,
18200,
7700,
16600,
32400,
21700,
27300,
21100,
75000,
8050,
34300,
18600,
25200,
18600,
34000,
null,
33500,
44300,
null,
23600,
22800,
47000,
6100,
11551,
39400,
74100,
15000,
25100,
null,
19800,
null,
55000,
8300,
43300,
null,
36900,
11200,
5400,
26500,
11500,
7300,
85000,
36300,
10400,
23700,
null,
7100,
13100,
33800,
11700,
58700,
9000,
11700,
6800,
45800,
60300,
19800,
null,
null,
9000,
33700,
29700,
61600,
12150,
173600,
19700,
null,
91600,
10900,
12800,
41100,
27000,
14900,
13400,
36000,
28700,
8800,
34900,
22800,
39500,
39400,
24600,
null,
23000,
null,
22300,
29800,
25800,
13600,
18400,
31900,
25400,
12700,
21000,
13400,
22500,
31600,
13400,
null,
7600,
25000,
24700,
6000,
2600,
98600,
13400,
30400,
16800,
20300,
null,
17700,
11500,
21800,
40600,
76700,
63300,
null,
84500,
null,
71700,
15300,
31400,
38200,
6000,
11500,
31200,
13000,
18600,
45600,
65500,
9200,
129500,
10900,
35800,
9500,
81400,
30800,
23500,
11300,
13500,
28900,
null,
26500,
6200,
9350,
14000,
42200,
22100,
null,
24300,
null,
21800,
68500,
23100,
23000,
33400,
79000,
null,
25000,
52100,
3900,
29700,
80300,
31500,
31600,
12800,
27200,
6200,
17700,
40900,
15000,
50000,
8300,
27100,
null,
13200,
21700,
7000,
34900,
35500,
61000,
20200,
12300,
8900,
32000,
47700,
56400,
11500,
21100,
12300,
14800,
3700,
37100,
44500,
59500,
22200,
12000,
21300,
53400,
5800,
null,
12900,
14600,
null,
null,
60400,
null,
8000,
null,
16400,
12300,
17255,
4500,
12000,
55600,
23500,
103100,
900,
17800,
57700,
13400,
35700,
42200,
null,
35700,
9450,
null,
35400,
null,
null,
23600,
24500,
32000,
34300,
24100,
5700,
20200,
95700,
20100,
14200,
14000,
40000,
null,
null,
143000,
57200,
37100,
17400,
8300,
14700,
null,
6600,
16500,
131400,
31600,
14400,
null,
21500,
null,
41700,
9255,
10600,
34500,
56600,
15100,
55900,
17800,
16300,
26900,
16300,
93300,
11700,
14700,
null,
14400,
56710,
44500,
38300,
24200,
33900,
10700,
10300,
15600,
39800,
49700,
10900,
16100,
20600,
65900,
7200,
36200,
19800,
12800,
22800,
20000,
35500,
40400,
30400,
20400,
24000,
32300,
12250,
4300,
85700,
19400,
19600,
61900,
7300,
4550,
20000,
17300,
22400,
25000,
40500,
8500,
6000,
43800,
25700,
6600,
21600,
30400,
18800,
21500,
16000,
7200,
7800,
16600,
10800,
9000,
17000,
28900,
14800,
22900,
7500,
48500,
27500,
11600,
18100,
30400,
23800,
8000,
22500,
13900,
13300,
15300,
28200,
34700,
98400,
49500,
23900,
null,
null,
58800,
null,
19400,
88000,
52400,
null,
22200,
26800,
91100,
10600,
82800,
10500,
14200,
6300,
12000,
29100,
38900,
19800,
41700,
25800,
7500,
13400,
37600,
null,
35900,
5900,
112900,
78000,
18600,
41300,
17000,
28000,
42800,
6600,
24300,
26500,
22200,
26100,
68500,
null,
40000,
null,
3500,
18700,
5200,
8500,
18100,
32400,
14300,
null,
19600,
6500,
17500,
37100,
12900,
27400,
31500,
27700,
13800,
null,
40500,
55200,
252100,
18200,
41000,
16960,
1900,
5900,
4900,
21400,
12100,
null,
10600,
24900,
34300,
39300,
30900,
107300,
61000,
85600,
50000,
41800,
42200,
17200,
16500,
81300,
49700,
33100,
28000,
10000,
20000,
24100,
19300,
22700,
49400,
4100,
10800,
318300,
14000,
27400,
13800,
16800,
9700,
7500,
26500,
33050,
21000,
29800,
19700,
null,
72800,
46000,
49000,
42200,
43600,
42500,
48100,
11400,
21500,
24200,
29800,
null,
8100,
35500,
10200,
12700,
11900,
8700,
32200,
209800,
12900,
30600,
14850,
12800,
13900,
12300,
27200,
77500,
17800,
25900,
null,
28500,
15500,
23400,
44100,
7500,
15800,
3400,
6500,
30600,
null,
7600,
44800,
48400,
2900,
87900,
35300,
44800,
52100,
null,
22100,
57600,
20600,
67500,
97300,
null,
39500,
84000,
null,
202800,
11000,
52600,
8100,
17300,
13300,
54000,
33348,
2900,
7200,
44700,
53600,
13100,
70800,
44200,
27490,
9700,
15400,
14300,
4200,
62000,
7100,
null,
null,
42200,
24900,
111800,
20500,
30600,
83900,
14900,
50800,
32600,
null,
15000,
18500,
11200,
32500,
43100,
null,
null,
15100,
null,
75800,
58400,
15500,
19300,
19100,
39300,
4400,
14700,
22500,
67800,
6500,
3200,
37500,
null,
33600,
9000,
44400,
null,
4100,
9900,
23600,
null,
141600,
null,
8400,
7600,
31100,
null,
49900,
null,
23400,
61400,
13900,
54300,
43400,
77700,
112700,
6400,
9100,
37200,
18900,
13400,
5800,
69100,
32700,
6500,
6900,
13200,
16486,
48300,
23400,
42400,
72965,
null,
54300,
null,
15500,
54750,
37700,
27400,
11235,
83800,
67100,
13700,
32800,
24400,
54100,
5100,
28000,
33500,
3700,
29800,
null,
32100,
15900,
49900,
44200,
17600,
22700,
null,
27500,
33300,
25100,
69400,
51400,
7600,
17900,
21000,
16300,
19300,
7900,
7800,
17300,
null,
19000,
16800,
3100,
77800,
31100,
3000,
24900,
16400,
41200,
7500,
null,
24600,
15800,
19000,
5280,
19500,
45700,
21000,
null,
24200,
10600,
53800,
21300,
152200,
11700,
18900,
null,
21400,
6200,
5850,
17200,
13400,
21000,
62700,
7200,
null,
42800,
17600,
65300,
25100,
4600,
8000,
null,
33200,
35800,
61500,
9000,
null,
40700,
30000,
23600,
16500,
23900,
41500,
32200,
194000,
14000,
29250,
16500,
3800,
13300,
3300,
50400,
40900,
null,
21800,
22800,
13800,
62300,
49500,
31100,
15600,
56700,
7400,
21900,
null,
18800,
null,
null,
36700,
55400,
15400,
16100,
60000,
15000,
48500,
20200,
26200,
18900,
4500,
34300,
22500,
34100,
11400,
1700,
29200,
14300,
15390,
50200,
19300,
18900,
11600,
12200,
17500,
76800,
null,
8300,
null,
17700,
null,
15300,
71500,
16100,
26900,
11900,
6800,
66700,
26500,
6200,
32600,
3000,
9900,
34100,
17600,
null,
25400,
20600,
36300,
36100,
9000,
null,
13300,
28200,
58655,
31200,
18600,
27900,
7800,
27600,
9900,
47300,
null,
25700,
94200,
38900,
null,
18800,
24700,
4700,
26600,
33600,
9500,
78100,
19900,
null,
21100,
null,
31000,
28600,
88200,
null,
98900,
26000,
27600,
45900,
null,
26300,
null,
50200,
5500,
33300,
35400,
59100,
40200,
12100,
34100,
56600,
7000,
56200,
31500,
9000,
12600,
62000,
13000,
33100,
29500,
null,
62100,
null,
42800,
68000,
3400,
16300,
18500,
12200,
14600,
11400,
null,
32200,
31800,
9400,
71400,
7200,
38300,
10000,
8500,
4900,
20700,
18500,
44300,
55400,
43400,
null,
13000,
39800,
null,
null,
31600,
9600,
22600,
49100,
91600,
24500,
47000,
7400,
35400,
59200,
17500,
13700,
28500,
21100,
38200,
32800,
11200,
25200,
8000,
5300,
18000,
23400,
27700,
80710,
8600,
259900,
22600,
15400,
null,
13200,
null,
18200,
4300,
23800,
9900,
null,
18700,
22100,
25700,
29000,
10000,
16900,
17700,
4700,
12400,
21000,
14600,
19700,
68300,
18900,
34300,
null,
30800,
12800,
18700,
34800,
41400,
16500,
19100,
105100,
23600,
27400,
18500,
28000,
62900,
28200,
35000,
68900,
null,
22000,
58700,
24200,
41200,
12300,
6900,
9300,
49732,
20300,
37400,
6900,
27800,
121200,
8600,
18700,
null,
null,
3100,
50000,
32000,
37200,
8000,
57600,
21300,
13100,
33500,
16400,
34100,
32600,
null,
123800,
null,
24300,
6700,
20400,
26000,
18500,
9400,
18800,
32800,
16600,
13100,
45500,
22000,
null,
14200,
49600,
28800,
29400,
9200,
3300,
53800,
24600,
null,
50400,
10800,
24900,
42800,
12800,
15100,
51200,
22500,
34200,
6300,
86200,
19600,
5300,
113300,
45100,
15500,
40100,
25200,
5600,
62400,
16900,
33500,
21200,
15200,
6500,
null,
15500,
12900,
66500,
37600,
7000,
66100,
12400,
17200,
18900,
null,
13400,
27600,
18400,
32200,
15500,
40000,
24500,
18700,
2300,
45900,
17600,
30600,
38400,
22300,
50900,
66000,
13400,
8900,
24600,
null,
47810,
20500,
14700,
34400,
22200,
36500,
15800,
97900,
12300,
10200,
7000,
28400,
null,
25900,
15600,
null,
28200,
4300,
36900,
31200,
18500,
28588,
19900,
14500,
7300,
30890,
17400,
18900,
14200,
54300,
38200,
37000,
42800,
28100,
14500,
50400,
34500,
5100,
12200,
null,
29500,
57300,
14600,
19500,
43600,
20000,
7000,
null,
91300,
12800,
6000,
null,
30100,
14700,
14100,
36800,
25500,
25700,
17300,
41500,
88900,
15300,
6000,
17800,
7300,
41300,
21600,
39900,
20500,
10500,
86300,
24300,
null,
12400,
44700,
88300,
20800,
28200,
7700,
13100,
17100,
28300,
29400,
29000,
37086,
6800,
2900,
10900,
44300,
42100,
30500,
14700,
17100,
149800,
18500,
null,
6400,
25700,
32500,
27200,
7000,
16300,
44400,
21100,
14000,
18800,
25000,
11700,
6400,
45900,
3100,
42300,
51200,
46000,
39000,
7400,
36363,
11300,
48900,
9300,
9900,
25400,
8800,
35800,
44900,
39700,
55400,
38300,
31800,
7500,
57700,
10500,
23700,
34800,
65900,
9600,
8300,
15300,
39400,
36800,
27200,
25700,
null,
23400,
39400,
14300,
101300,
175500,
7000,
12000,
44900,
25200,
30200,
10600,
30600,
128300,
8100,
17500,
32100,
39900,
28000,
8000,
29900,
19700,
38000,
23160,
40700,
22800,
4100,
48400,
8900,
21800,
38900,
21100,
174400,
69800,
88500,
null,
22800,
26400,
33100,
92200,
14000,
21600,
10600,
57100,
16600,
13100,
9500,
13000,
null,
28700,
38200,
8500,
28800,
null,
22900,
47500,
2600,
40800,
103600,
35400,
30500,
3900,
5700,
7403,
11400,
26470,
55600,
23100,
41600,
85600,
10300,
8500,
79300,
14900,
null,
23200,
20000,
27200,
35200,
2800,
31400,
14600,
38100,
50500,
null,
9800,
63049,
79700,
8100,
null,
null,
16000,
8800,
53100,
13100,
43525,
197800,
25500,
9400,
13300,
15500,
15800,
29800,
43000,
16700,
27700,
116400,
35800,
4600,
57500,
18900,
84000,
14800,
34900,
90100,
86800,
8900,
103500,
16300,
10200,
20100,
44400,
34600,
11200,
13300,
22000,
22400,
12700,
null,
36770,
39000,
25716,
10200,
null,
33200,
82400,
299800,
55100,
383400,
29400,
22100,
17200,
13100,
4200,
45100,
32600,
21000,
42200,
45000,
12300,
34000,
null,
61500,
5900,
null,
40500,
76900,
31700,
57600,
29300,
139700,
17600,
19400,
10200,
10200,
3900,
13300,
null,
47000,
15300,
null,
null,
null,
6200,
56400,
41200,
28500,
null,
5000,
4600,
54400,
33500,
27700,
null,
54700,
18000,
29900,
72800,
67300,
78000,
11200,
12400,
30000,
24800,
31400,
21700,
18100,
6300,
10750,
5100,
22400,
203900,
28500,
8700,
22200,
16400,
34400,
33800,
27000,
41600,
16600,
29200,
47800,
26600,
13500,
25900,
51900,
31000,
8500,
null,
15900,
11900,
23600,
9900,
null,
14400,
52200,
71000,
4000,
45300,
40300,
14400,
29800,
20100,
97920,
7500,
6400,
16200,
58700,
26400,
19700,
9000,
21900,
18700,
40600,
38100,
23800,
30700,
39000,
5600,
19200,
237100,
75500,
23900,
null,
7700,
null,
10700,
16200,
30900,
14500,
72800,
63500,
23800,
26700,
43900,
17500,
28800,
15900,
42400,
35300,
24600,
13200,
25800,
8500,
43500,
21300,
5100,
22100,
7750,
73000,
2500,
49800,
16400,
null,
12500,
8100,
41900,
48100,
51500,
46900,
28300,
26000,
14800,
54700,
21800,
17300,
null,
3400,
25400,
8900,
70000,
21800,
13900,
16000,
45100,
52300,
16100,
19800,
null,
18400,
24500,
71400,
30900,
15000,
8000,
11400,
3800,
55400,
null,
52800,
10900,
8600,
26200,
100500,
22200,
25600,
null,
28200,
5600,
28900,
50300,
21800,
153600,
22500,
null,
12400,
2000,
47000,
13500,
34600,
18800,
21100,
null,
12800,
39700,
20800,
5600,
25400,
41900,
32700,
35700,
28400,
12400,
16400,
8600,
11600,
25100,
8700,
28500,
39300,
28100,
73500,
21900,
49300,
19000,
10700,
7300,
18900,
8500,
26700,
135600,
7100,
5000,
null,
38100,
15400,
10600,
7800,
27200,
66000,
18200,
76200,
51700,
38900,
22900,
12500,
null,
15000,
11800,
62800,
14200,
113400,
71300,
54500,
9200,
33900,
43850,
22700,
null,
11000,
null,
24500,
null,
19400,
37800,
23500,
12900,
47500,
5000,
18500,
14000,
46700,
77900,
15300,
30900,
37300,
25500,
106100,
23600,
19000,
21400,
null,
26300,
19100,
null,
null,
72700,
18100,
61400,
25200,
34700,
10700,
10500,
8700,
12600,
79300,
20500,
16900,
20300,
28100,
44700,
16100,
91200,
19500,
65700,
18200,
79700,
17900,
79200,
58900,
46500,
46500,
25900,
34600,
36400,
39700,
25400,
6000,
11300,
53900,
41800,
112200,
62400,
28700,
33900,
13800,
18400,
44800,
17400,
48800,
14800,
6900,
13100,
34900,
45000,
80387,
85500,
10600,
15300,
16200,
65500,
19200,
51400,
42400,
53300,
23600,
28700,
70300,
5900,
14200,
31600,
22600,
49800,
4150,
63000,
30400,
19400,
20200,
63000,
48500,
15900,
31200,
34700,
9600,
23200,
30700,
67200,
54700,
39850,
10200,
33900,
43000,
66400,
74900,
12600,
50700,
20000,
12900,
35700,
17900,
null,
20100,
null,
53700,
11082,
null,
12400,
32600,
106700,
10400,
24500,
158900,
16600,
47400,
11700,
17900,
29600,
8900,
8200,
null,
11800,
23000,
24000,
null,
38900,
52900,
23000,
26000,
15900,
15100,
null,
28200,
15200,
17000,
17000,
12700,
19500,
29700,
17200,
9780,
24000,
52700,
28700,
5900,
43300,
60600,
13900,
15300,
19900,
13600,
16900,
15400,
30200,
81700,
24300,
18000,
19000,
17600,
16400,
17400,
27000,
15900,
36100,
19700,
118100,
null,
13900,
69500,
15900,
9200,
null,
30400,
9900,
24200,
29500,
null,
25800,
29900,
29900,
14700,
11500,
70800,
7800,
24800,
29100,
11600,
13400,
8100,
18500,
44500,
14400,
32800,
27600,
null,
null,
8200,
13800,
19800,
null,
59400,
52700,
18000,
11500,
22049,
null,
14500,
61000,
31700,
null,
14400,
11900,
25700,
34300,
20600,
17100,
52700,
14600,
7500,
9200,
59100,
6550,
55600,
11500,
17700,
null,
59000,
26800,
7600,
19600,
37300,
16100,
null,
57000,
null,
24400,
35800,
14600,
21500,
13400,
23700,
null,
31500,
19800,
null,
137500,
15900,
14800,
39400,
null,
24100,
19300,
9600,
6500,
60220,
11440,
10500,
null,
38600,
43300,
8300,
236900,
26200,
null,
10900,
36000,
17100,
29300,
null,
2000,
20700,
64100,
21900,
15000,
35000,
6000,
null,
15800,
20800,
null,
81600,
31000,
10800,
42500,
27000,
17600,
17800,
14100,
null,
null,
17500,
61400,
56100,
17800,
61300,
12000,
48200,
33300,
37500,
35500,
30600,
66100,
38324,
16900,
38700,
18900,
23800,
117000,
34400,
14600,
null,
32700,
26100,
30500,
31000,
12900,
6600,
18500,
44100,
51700,
7100,
3500,
26100,
31500,
43500,
19200,
32700,
17800,
32500,
11600,
5500,
27100,
121800,
24800,
21400,
11900,
null,
16000,
null,
46300,
30700,
15700,
5400,
35300,
39500,
30900,
38500,
25300,
8300,
null,
78600,
37500,
34400,
null,
36400,
33400,
19180,
63100,
null,
8800,
4000,
43400,
13100,
16200,
11700,
42000,
73900,
24800,
18700,
31800,
10700,
20900,
24300,
15900,
31500,
29600,
26700,
36400,
null,
null,
38500,
13300,
49755,
55000,
28700,
34800,
71900,
6600,
40500,
2900,
5600,
8000,
42800,
45900,
14400,
27000,
30400,
30700,
20900,
33500,
13550,
6500,
43100,
21400,
135900,
null,
32100,
null,
23400,
15200,
5700,
13800,
9000,
21200,
19000,
null,
15200,
57500,
25200,
7300,
26000,
24100,
14100,
13600,
10630,
17700,
23300,
39800,
11900,
25900,
6400,
16600,
7400,
4500,
5900,
23600,
17000,
54700,
29500,
17000,
20300,
17900,
84400,
27500,
28100,
34800,
6600,
null,
null,
37700,
21300,
36500,
14700,
27400,
null,
49200,
485900,
3100,
64800,
null,
21200,
20900,
80400,
33000,
30800,
25700,
null,
null,
117800,
null,
8200,
68000,
17550,
49000,
47200,
13200,
24900,
null,
24100,
14400,
10500,
55000,
14400,
15000,
24700,
44700,
26500,
14000,
36500,
81700,
49700,
39400,
29700,
14550,
null,
31500,
36900,
121200,
38400,
62100,
null,
24800,
43100,
31100,
13900,
7100,
null,
28700,
9900,
15900,
15100,
16400,
32400,
74400,
24200,
20600,
null,
8400,
19700,
29200,
47500,
28400,
12600,
23000,
12300,
23200,
20000,
7700,
21300,
null,
27501,
33900,
20400,
18500,
34600,
6000,
12600,
66700,
16500,
19500,
41700,
7500,
39200,
74300,
33400,
49200,
6700,
7100,
9500,
31700,
100427,
74400,
51800,
99300,
38200,
58000,
null,
15500,
11900,
null,
44000,
26100,
10600,
18100,
19900,
46800,
121000,
32700,
44400,
83400,
19300,
52300,
119200,
null,
24500,
6400,
37100,
27900,
11000,
52200,
22500,
16000,
9811,
null,
24100,
22700,
12500,
15500,
28900,
21900,
22500,
13000,
19600,
25100,
58600,
32800,
18900,
22300,
72300,
14700,
36700,
18300,
30500,
10400,
30600,
31800,
29700,
52300,
34800,
null,
20400,
17500,
41100,
41500,
16400,
10000,
48300,
12100,
170500,
40600,
87000,
26100,
42700,
null,
22800,
23400,
1500,
10100,
null,
82708,
34800,
null,
24900,
2500,
35200,
39600,
52600,
57900,
10700,
16000,
12600,
65100,
30100,
64500,
12500,
11500,
11100,
14300,
41300,
16850,
null,
94900,
null,
10300,
7600,
24000,
13900,
9800,
46000,
31600,
65900,
null,
8600,
26500,
34100,
48600,
43000,
13300,
21400,
21000,
12000,
9400,
25600,
15800,
45800,
22400,
171500,
50600,
48300,
36800,
64600,
16600,
20600,
11100,
25900,
13700,
null,
25500,
null,
12200,
12900,
43700,
34700,
17000,
45600,
3800,
46700,
29400,
12700,
23800,
null,
8500,
33200,
28600,
87300,
41000,
26700,
13500,
55100,
16000,
63600,
13800,
30300,
15800,
21500,
50900,
12600,
41400,
null,
14200,
14300,
40100,
58400,
8500,
9000,
17000,
18500,
15900,
39300,
39300,
23400,
13800,
49600,
15000,
9700,
59200,
22000,
7800,
38900,
26900,
13800,
20600,
10600,
26000,
16300,
21500,
46000,
28300,
34500,
74550,
14200,
null,
null,
60400,
12300,
23000,
48600,
15000,
10700,
24200,
44400,
70700,
9800,
133300,
23500,
25200,
null,
69900,
12300,
null,
21000,
6900,
19400,
10500,
26300,
16700,
36100,
9000,
19000,
15500,
29600,
7750,
58400,
15800,
12600,
20700,
3400,
null,
13200,
173521,
8000,
25100,
78900,
48000,
19300,
58500,
124500,
34800,
null,
93500,
43200,
61600,
28000,
4200,
52200,
30100,
45000,
30200,
53114,
36300,
24900,
21000,
9500,
14000,
61300,
14300,
11000,
47100,
87000,
16700,
5400,
null,
38700,
18300,
16700,
22600,
39600,
12100,
34500,
38500,
10300,
10938,
6800,
5800,
20100,
13900,
16900,
40700,
10700,
null,
8400,
39100,
29100,
39400,
12000,
21300,
null,
8900,
42300,
8200,
14300,
39800,
37800,
null,
14100,
39600,
35900,
29500,
20400,
27500,
13200,
56400,
12900,
31600,
11900,
28700,
22000,
9900,
17500,
13400,
10200,
6500,
43800,
47700,
40000,
21150,
10500,
38400,
null,
49200,
30000,
17900,
39600,
21900,
47800,
26600,
20500,
39900,
null,
19400,
4600,
23700,
7800,
13800,
null,
13800,
15600,
77400,
11300,
null,
74400,
40000,
92800,
15900,
11500,
15100,
50100,
25900,
15900,
19400,
13100,
11600,
17800,
22300,
12300,
14200,
54800,
77788,
17800,
19000,
31500,
12500,
18200,
50900,
21200,
1300,
5600,
65300,
null,
78116,
null,
19900,
22200,
38300,
18100,
17200,
22200,
57300,
39800,
50500,
54200,
17700,
null,
19700,
63997,
64100,
26200,
21200,
3900,
18500,
9100,
20700,
38000,
7200,
19300,
null,
21600,
11600,
21200,
30200,
6700,
24800,
64100,
111600,
16200,
30700,
23700,
51500,
25600,
57300,
12900,
17000,
23900,
81000,
53200,
56900,
17300,
null,
92800,
10800,
17400,
14600,
27600,
30200,
32200,
37700,
17700,
34900,
21600,
null,
21600,
61300,
69300,
6600,
5100,
10900,
35600,
5800,
3600,
13000,
16000,
28500,
83400,
11600,
88000,
22800,
98200,
53200,
16300,
24500,
28700,
5800,
17100,
17000,
33800,
51300,
8400,
27000,
81500,
31600,
17200,
66900,
79800,
null,
12000,
null,
10300,
41500,
72900,
27600,
14700,
7650,
null,
17500,
144600,
19000,
33400,
null,
2000,
14500,
32800,
17100,
22000,
33900,
10000,
65900,
5400,
null,
31200,
18900,
10076,
45000,
42200,
61600,
40300,
12700,
4500,
9400,
null,
21700,
16000,
42600,
10100,
18400,
null,
10700,
70200,
67100,
34900,
13200,
26000,
18600,
31300,
184600,
165700,
27400,
28000,
65500,
33200,
26300,
28000,
26100,
15700,
14200,
43000,
18600,
44200,
29500,
26700,
56300,
21000,
53100,
48700,
53100,
16358,
null,
45300,
15500,
7400,
57000,
10200,
5400,
25500,
57000,
12900,
4000,
20400,
32800,
20200,
18900,
25700,
7700,
null,
16900,
18000,
81600,
18800,
4200,
24000,
28900,
20000,
15300,
36100,
38000,
63400,
40900,
26600,
null,
46400,
12300,
11000,
18300,
22100,
9500,
5500,
19300,
21600,
11200,
5800,
5700,
67500,
21500,
36100,
70300,
4300,
10300,
10400,
40800,
7370,
77700,
35200,
24700,
91500,
89000,
null,
102600,
115800,
26000,
18800,
10700,
38100,
18600,
86600,
13400,
94900,
42100,
44700,
12100,
27400,
null,
19200,
30500,
null,
11300,
21900,
26600,
22174,
29700,
25700,
24400,
46500,
6700,
16300,
null,
17100,
63700,
10400,
8600,
8100,
22800,
175400,
21900,
6900,
222800,
25800,
23500,
18500,
14700,
62700,
71700,
10900,
null,
39100,
48900,
16200,
49500,
26900,
8300,
29900,
6900,
5000,
19900,
63500,
37100,
22900,
16900,
15600,
57700,
43300,
9500,
22700,
6200,
34800,
19400,
6200,
null,
null,
9900,
21000,
20000,
6800,
3200,
9500,
1100,
20300,
15700,
22600,
15600,
31600,
12400,
9200,
130400,
59300,
3950,
39000,
23900,
14900,
10100,
19100,
256700,
30100,
48500,
13200,
65500,
57900,
8300,
19600,
26500,
91500,
null,
18400,
41500,
61900,
53700,
null,
23100,
null,
null,
23000,
28800,
29400,
27400,
8000,
9200,
21400,
70900,
6990,
3300,
14100,
50400,
58100,
21000,
29300,
6800,
null,
16000,
15300,
null,
30000,
45200,
19000,
18000,
16400,
13400,
41300,
81000,
2000,
50700,
41500,
19500,
13900,
30100,
20500,
56400,
60000,
23200,
45700,
18300,
36500,
9400,
20700,
9000,
23200,
9600,
24300,
null,
18700,
13700,
23200,
25000,
48400,
19800,
30600,
25731,
37800,
26200,
32800,
15400,
5200,
32700,
10700,
80800,
33800,
25900,
38100,
42000,
118800,
9500,
4300,
3500,
null,
7000,
175044,
35300,
20760,
35000,
5300,
66200,
69300,
41900,
16200,
11500,
null,
54700,
57400,
41000,
9400,
null,
18400,
10800,
36500,
23300,
7300,
11600,
13400,
null,
15900,
21500,
10800,
36700,
32800,
27600,
37700,
29000,
19800,
11500,
10300,
92900,
16400,
12700,
48500,
31100,
20500,
17500,
18800,
19000,
6400,
23300,
58365,
11000,
8200,
11200,
28500,
18800,
23700,
14300,
null,
62100,
16200,
22900,
131300,
55100,
11600,
16100,
39200,
null,
16700,
11100,
23700,
11200,
18200,
10700,
11100,
47400,
null,
6850,
12600,
26400,
159900,
null,
20900,
132700,
null,
8100,
51500,
19050,
53900,
40900,
24800,
null,
30700,
31400,
23400,
54200,
16100,
18700,
62500,
60300,
null,
11700,
28300,
39000,
17800,
38700,
12500,
12800,
69700,
59100,
24000,
12900,
18300,
48900,
7400,
12400,
13300,
79900,
10600,
35400,
16800,
12300,
31200,
31000,
61800,
33900,
null,
19500,
null,
60600,
19200,
28400,
14100,
16100,
49200,
24200,
15500,
50200,
null,
453500,
23800,
20000,
45500,
14900,
54200,
11500,
21000,
18100,
5300,
46900,
84000,
null,
10300,
55400,
47600,
15400,
10354,
12250,
26454,
36100,
11100,
10700,
94800,
23600,
9500,
10800,
27400,
5800,
17100,
123200,
29100,
6800,
8900,
21400,
4000,
33500,
20200,
32800,
34000,
45200,
13000,
23300,
17900,
34500,
38600,
9000,
25100,
125500,
23300,
9000,
68000,
8700,
74500,
17700,
22000,
52200,
36300,
22900,
18000,
83300,
54400,
18100,
null,
null,
11900,
null,
13800,
40500,
50300,
64300,
14000,
13700,
105600,
10700,
41900,
21200,
99100,
5300,
null,
15400,
null,
16600,
37400,
17000,
62200,
null,
11400,
101400,
22900,
17000,
43300,
null,
117900,
19600,
66600,
26100,
32000,
65800,
12700,
51000,
7800,
29800,
139900,
38500,
9500,
60400,
21000,
5500,
26100,
4600,
46300,
null,
12900,
null,
35900,
26000,
22100,
77200,
8000,
38998,
74280,
23300,
15900,
27600,
14700,
43739,
11100,
51800,
null,
16300,
39100,
null,
17600,
9300,
38900,
39100,
3550,
36700,
97900,
36600,
42600,
67600,
29400,
11000,
42100,
32500,
22000,
null,
33800,
21300,
35200,
11100,
51400,
70900,
11800,
27400,
13100,
32600,
null,
7200,
null,
30400,
21400,
32200,
42000,
null,
36300,
17400,
9800,
34000,
43600,
13700,
20800,
35600,
60800,
37800,
29100,
21500,
6600,
18400,
41700,
10700,
6700,
null,
21400,
31200,
49400,
110200,
23000,
53200,
77500,
63800,
51800,
31100,
14100,
37100,
11200,
26600,
17100,
5000,
49100,
15700,
62300,
35000,
27800,
60500,
42600,
6700,
12000,
9200,
54000,
null,
12700,
41400,
21000,
5100,
9000,
18300,
21800,
20000,
96400,
8000,
90800,
70200,
15300,
53000,
37800,
42300,
3100,
102400,
26600,
31200,
38200,
37200,
10300,
58300,
9600,
20100,
103900,
59100,
49600,
118600,
73000,
28300,
16700,
34400,
27500,
52400,
31000,
7500,
8900,
5300,
null,
12100,
3400,
5500,
16900,
12600,
13600,
7200,
52750,
28700,
17300,
11000,
29400,
16600,
90600,
34600,
17200,
42500,
26400,
51900,
40500,
null,
10100,
45300,
7100,
37600,
4400,
32700,
24300,
null,
44100,
16800,
20900,
17800,
23500,
11000,
5600,
16400,
19800,
27061,
16100,
59900,
null,
146400,
59200,
4200,
40700,
52500,
12000,
22000,
45000,
13700,
15000,
13400,
18100,
19100,
66500,
14300,
26800,
30400,
16900,
94200,
35200,
25500,
10100,
58800,
11800,
44600,
25625,
52900,
null,
31400,
38600,
14800,
49000,
130400,
14600,
5800,
15300,
76200,
33200,
9400,
41700,
46500,
24200,
75500,
51800,
9300,
53600,
75900,
27100,
44200,
64100,
33100,
61800,
5800,
21500,
null,
17000,
21400,
47000,
20100,
24200,
18500,
33500,
11500,
13800,
37600,
24100,
75400,
31900,
41000,
47100,
79300,
26100,
14100,
42000,
3700,
17500,
17500,
46000,
14000,
13100,
9100,
40300,
6800,
13600,
3000,
4400,
23100,
37700,
1500,
9400,
66500,
125800,
23600,
38900,
53770,
8200,
20600,
11500,
27100,
109900,
69500,
19500,
21200,
74800,
41300,
24200,
4100,
40900,
7700,
62900,
33200,
19700,
69100,
42500,
12000,
36700,
47100,
80900,
null,
6000,
22900,
29300,
47200,
45700,
null,
17000,
69200,
null,
11900,
38400,
26000,
34800,
14300,
55600,
25100,
22200,
64400,
15600,
17300,
16300,
37900,
17900,
42100,
41700,
null,
64200,
63400,
35500,
32600,
5200,
null,
85900,
40500,
11700,
31100,
55800,
11300,
17000,
21000,
19200,
7500,
38600,
38800,
3900,
182600,
32200,
null,
12500,
147800,
null,
4700,
5800,
30000,
null,
40700,
14700,
13000,
3800,
25400,
17200,
37200,
18100,
10400,
20200,
26900,
9200,
14700,
47500,
31900,
27700,
24900,
18300,
8500,
20400,
39300,
44700,
9300,
7800,
48200,
null,
52600,
30900,
50500,
13100,
27100,
21500,
53500,
53500,
13400,
38400,
9700,
21500,
24100,
57600,
102200,
6700,
3000,
22800,
6500,
59800,
null,
42800,
82300,
5700,
70300,
13100,
35800,
15700,
32500,
24400,
13600,
6500,
76800,
32400,
75500,
null,
25100,
36900,
5300,
17100,
16700,
46700,
null,
600,
6500,
6800,
31500,
39200,
24700,
null,
26200,
22400,
48000,
19600,
6300,
46300,
29800,
24150,
27300,
38000,
4400,
27000,
35100,
12800,
32800,
27200,
28300,
5100,
44700,
null,
12600,
14800,
31600,
25100,
83100,
4300,
31000,
44200,
51000,
48100,
12000,
23000,
null,
33200,
35000,
null,
58400,
3800,
91400,
16300,
23500,
null,
64700,
null,
23400,
31800,
36700,
31600,
45700,
11300,
9800,
14650,
12700,
168200,
10500,
22500,
37500,
5800,
26600,
29700,
34100,
49600,
19800,
9300,
100500,
23200,
22200,
37100,
7000,
43500,
75700,
21100,
null,
23700,
37000,
6900,
17600,
41800,
17300,
31000,
null,
55500,
43700,
45900,
4800,
16500,
19600,
9045,
29350,
41900,
16900,
37100,
12400,
78400,
41700,
40900,
58400,
15600,
78900,
5300,
47700,
34800,
34600,
null,
18400,
13600,
12900,
21600,
85500,
42200,
40500,
32700,
63400,
31600,
30700,
71000,
null,
8800,
16000,
81300,
24900,
null,
28400,
19200,
55900,
16500,
11800,
53700,
31000,
43600,
29300,
12100,
null,
20800,
9700,
14300,
21400,
12000,
32000,
13000,
44100,
39900,
20400,
43400,
null,
12800,
32600,
3200,
114200,
12100,
29100,
23500,
14900,
20800,
18500,
136400,
3400,
7000,
12300,
null,
28100,
27700,
33100,
null,
42900,
86300,
7400,
45400,
16900,
19700,
null,
69300,
22900,
null,
15500,
7000,
7500,
15900,
9100,
35300,
6000,
27800,
26700,
13300,
45000,
21900,
null,
13800,
106370,
64200,
null,
25900,
25400,
31900,
6700,
67300,
70500,
37800,
19500,
23100,
5000,
7900,
31500,
11300,
9600,
28500,
null,
51700,
51600,
32500,
46300,
118100,
26500,
11200,
null,
21500,
46000,
16000,
27600,
15500,
12900,
95200,
61400,
131200,
25400,
29100,
18500,
29200,
15400,
31200,
19100,
35900,
2700,
17000,
70500,
17400,
48000,
null,
32300,
79600,
42218,
25300,
24200,
91300,
10700,
6000,
58400,
12100,
3500,
61700,
8400,
20600,
23300,
48300,
42500,
1400,
20600,
null,
32800,
20300,
48100,
27300,
75000,
0,
18400,
57800,
8600,
19300,
19720,
79700,
29600,
14000,
34900,
15800,
8300,
20500,
null,
14700,
9600,
28200,
1900,
11900,
25450,
17600,
10500,
17200,
83600,
12300,
38900,
5200,
8000,
49669,
null,
24500,
13900,
151900,
43400,
20200,
29200,
13500,
6600,
41200,
8800,
37800,
197900,
40100,
17900,
23600,
60500,
51320,
23200,
17500,
null,
25600,
97300,
39900,
48100,
null,
11100,
25100,
37600,
11400,
16500,
33000,
8100,
18800,
8400,
15900,
29800,
15500,
18100,
60500,
17500,
47000,
null,
32900,
26600,
null,
91100,
101300,
116900,
11200,
8700,
10400,
36500,
18300,
62900,
16800,
40000,
4600,
25100,
13900,
null,
9900,
40300,
60400,
35800,
58300,
15800,
19500,
19400,
32600,
51100,
17000,
13200,
null,
12600,
22600,
20100,
55000,
12500,
14600,
12300,
6300,
12500,
11100,
31000,
32600,
14100,
19000,
58500,
23000,
64900,
34050,
13500,
10600,
11900,
32300,
47800,
41200,
40300,
23600,
38900,
18700,
null,
13000,
11300,
97000,
53500,
10100,
12200,
77600,
16100,
10900,
45200,
91500,
49700,
37100,
28800,
17000,
29600,
18800,
42900,
26700,
38200,
12100,
11700,
7761,
9000,
30600,
51200,
31600,
310200,
22500,
22000,
25000,
6400,
2700,
45300,
15500,
40100,
12500,
14700,
8900,
52500,
61700,
11700,
45900,
6900,
14600,
10100,
24000,
83800,
12600,
6500,
46700,
13400,
22200,
37100,
34400,
51300,
92700,
70000,
65000,
30400,
66500,
13900,
16400,
8100,
4650,
37800,
43600,
68400,
null,
22500,
38000,
24700,
31610,
50500,
94800,
null,
24300,
13400,
37200,
21800,
10100,
null,
14200,
56000,
18600,
18400,
26600,
13900,
15900,
11800,
70200,
8500,
null,
22400,
14600,
17000,
14800,
6500,
null,
26900,
27400,
36800,
20400,
36400,
28700,
27300,
19587,
8800,
54900,
24700,
26500,
55300,
26900,
35600,
19500,
37200,
13200,
7000,
158900,
28500,
8800,
25900,
78300,
16600,
29700,
40500,
20500,
31900,
66900,
25200,
38500,
9100,
86600,
7200,
134100,
13400,
13700,
11200,
54900,
null,
20900,
20600,
25400,
87800,
1400,
143200,
98500,
76400,
103900,
40200,
10400,
17800,
45000,
51900,
24600,
14100,
51600,
59400,
23200,
42000,
17200,
17400,
42300,
20200,
18700,
36300,
31000,
16300,
44900,
71500,
28600,
22400,
55770,
null,
34500,
29000,
null,
10700,
60600,
53200,
11100,
48800,
21900,
9600,
24900,
21800,
61000,
18700,
77800,
6700,
12700,
26700,
55300,
34500,
null,
19500,
4700,
111711,
19400,
30900,
16300,
37300,
115000,
13900,
26800,
20400,
54100,
68200,
1750,
141788,
20300,
17300,
55200,
85800,
63800,
17200,
30200,
129000,
null,
35000,
40200,
72800,
55250,
71000,
40500,
91800,
23900,
33900,
93900,
45100,
63400,
15800,
51800,
13100,
64300,
28100,
25000,
5500,
83000,
8600,
null,
33400,
63900,
18500,
29100,
62700,
24400,
18900,
null,
21900,
67300,
13200,
98500,
48500,
48600,
32700,
40300,
18400,
14900,
24900,
53085,
30600,
42506,
75800,
17100,
37500,
null,
59800,
37100,
24800,
26700,
29700,
14000,
15200,
30800,
22700,
14100,
13000,
117700,
72285,
27400,
56900,
51500,
17400,
14500,
41600,
254800,
18200,
57500,
53300,
39800,
78900,
75600,
111000,
28100,
39400,
28500,
41100,
229900,
45300,
40200,
48300,
27400,
34600,
70405,
9809,
50800,
7500,
46600,
26500,
24500,
16300,
25500,
null,
11200,
26400,
2100,
69800,
153300,
26800,
23900,
85500,
138800,
null,
67100,
11100,
197500,
79800,
17400,
65200,
9700,
236600,
83700,
31600,
29800,
29800,
24600,
15000,
50300,
23200,
13800,
8400,
29300,
null,
20600,
5200,
11400,
34600,
32300,
95430,
30600,
17900,
null,
null,
19400,
75600,
19900,
27800,
12500,
39000,
40100,
42900,
23100,
null,
11300,
31200,
35000,
38200,
8500,
76500,
null,
17800,
10900,
42000,
11200,
27500,
null,
30100,
42000,
20501,
25600,
16100,
12800,
13500,
28300,
51400,
20200,
38100,
35800,
36900,
null,
57700,
175900,
4600,
16000,
7700,
62600,
6900,
23000,
38700,
18500,
30000,
9500,
73700,
47400,
8000,
63600,
null,
12500,
32400,
23000,
27633,
97800,
45400,
38300,
125300,
41500,
24200,
27100,
33500,
41800,
37500,
48500,
37700,
19800,
125800,
49700,
89300,
24600,
3200,
77900,
35400,
15400,
11600,
22900,
45000,
16300,
36300,
17700,
15000,
9400,
17300,
99000,
11300,
null,
24900,
45100,
18500,
4400,
34700,
15000,
99800,
26600,
64550,
7800,
23100,
2100,
11200,
37200,
3500,
null,
34600,
17500,
25100,
13200,
15200,
8600,
11600,
7000,
null,
18000,
6800,
59800,
5500,
47600,
84000,
8600,
18600,
6500,
12200,
31600,
26000,
74600,
21700,
75500,
24400,
41800,
15900,
20300,
30000,
21300,
12600,
100900,
26300,
50700,
24300,
9600,
18500,
7900,
20000,
26500,
33500,
21000,
20500,
34800,
21400,
32900,
11700,
41000,
54400,
null,
34600,
72200,
52200,
42100,
46300,
16600,
22100,
39800,
6000,
24500,
39700,
33800,
103000,
27800,
41800,
45800,
81000,
29700,
42100,
29400,
15800,
53200,
30700,
15300,
8700,
27700,
25500,
null,
22000,
41300,
23100,
69300,
16700,
30100,
69300,
22600,
57800,
null,
42900,
115000,
28100,
18300,
13100,
27900,
32800,
null,
16400,
7500,
26100,
8600,
98000,
23600,
13000,
9100,
21600,
12400,
3800,
217600,
19900,
55500,
42700,
29500,
null,
null,
35200,
57600,
14600,
20700,
35300,
24900,
50200,
40900,
null,
40100,
81900,
55400,
38000,
null,
9600,
6900,
333400,
30100,
11100,
15600,
25830,
33200,
null,
7700,
22500,
null,
25400,
20800,
34100,
null,
9800,
30500,
22000,
40500,
20400,
67000,
141600,
11700,
21400,
12300,
23000,
1600,
24500,
null,
16500,
57800,
29100,
10400,
19100,
7300,
38900,
33500,
6700,
13100,
26000,
39500,
104700,
8950,
53400,
22100,
30700,
null,
28600,
15500,
21900,
26400,
null,
24700,
17000,
9900,
89300,
4500,
39000,
105420,
29000,
70200,
23100,
47100,
null,
63800,
9200,
88800,
22900,
78000,
28900,
34300,
12900,
56300,
16800,
null,
100400,
null,
13500,
4600,
25100,
75200,
21300,
21100,
21100,
6800,
34300,
88000,
13200,
2600,
27600,
29800,
null,
null,
42700,
16900,
28800,
null,
10600,
18700,
36100,
30400,
9000,
65900,
68700,
25700,
12200,
null,
3700,
45900,
17500,
9500,
null,
26200,
57900,
13600,
null,
16800,
98800,
null,
8300,
53600,
7700,
8900,
12900,
82600,
35200,
48600,
16500,
14200,
11000,
null,
10700,
23100,
132300,
31100,
174500,
38000,
43200,
15800,
10200,
12000,
18800,
30400,
14100,
35300,
4700,
30900,
22500,
17900,
6800,
null,
3600,
23200,
14600,
49400,
25400,
34900,
14000,
12400,
6400,
107700,
102400,
24100,
9300,
37600,
26300,
31600,
66400,
39300,
49700,
53600,
35900,
22100,
21800,
null,
32500,
55600,
36600,
6400,
15700,
8500,
34700,
41300,
12200,
52900,
13900,
35600,
29600,
8900,
26200,
66700,
5900,
18400,
16800,
31400,
17200,
2800,
81300,
28300,
36900,
19200,
53000,
11000,
12100,
37800,
29300,
18500,
19300,
null,
27200,
19600,
12700,
19000,
22400,
null,
24000,
26400,
19400,
23500,
35700,
12200,
2700,
44000,
26500,
22000,
18900,
8200,
115600,
34800,
32200,
null,
null,
9100,
22700,
14800,
13000,
74900,
6500,
18000,
28100,
11100,
21400,
10900,
null,
52500,
98700,
155900,
146700,
null,
4800,
27800,
null,
17200,
104000,
16800,
11800,
11000,
22300,
20000,
36000,
53232,
11000,
30300,
48400,
15700,
12800,
26800,
35900,
16000,
29400,
20600,
56700,
null,
40100,
16500,
30600,
57600,
18000,
null,
16700,
5700,
7300,
null,
28500,
null,
9000,
20432,
44200,
20200,
32300,
17300,
25300,
16300,
24700,
23400,
30200,
84800,
21500,
79500,
33200,
38700,
25000,
15200,
22000,
4400,
36800,
14700,
9750,
344500,
11400,
38800,
37300,
10300,
11200,
14500,
5400,
9000,
18900,
13500,
29400,
21400,
15100,
3000,
null,
22300,
56100,
26000,
43800,
null,
61400,
11300,
70800,
22100,
41100,
159200,
13800,
20100,
15800,
50200,
40400,
23131,
12300,
40000,
null,
27800,
12400,
24100,
2200,
7200,
31300,
8350,
null,
7500,
155400,
43100,
13300,
166800,
null,
10100,
121000,
null,
12952,
16600,
24400,
17200,
30500,
null,
201200,
68200,
87500,
32600,
89200,
24400,
3000,
41500,
47900,
10400,
9300,
18700,
20100,
111900,
null,
null,
12100,
9900,
28600,
5700,
19500,
84500,
6400,
51700,
16300,
18200,
22100,
19300,
42900,
34400,
43900,
9700,
42200,
19900,
62100,
32600,
14600,
6600,
10100,
15900,
18000,
29200,
37700,
31900,
24400,
78800,
55500,
30000,
56100,
null,
12500,
19400,
41100,
27100,
null,
37500,
null,
11000,
14500,
60800,
34900,
90000,
18000,
null,
59500,
59800,
19000,
24900,
39500,
27700,
70100,
53000,
27200,
null,
9400,
32200,
12200,
104900,
28700,
18500,
49400,
53500,
18900,
8200,
24000,
54800,
30100,
11300,
12300,
18300,
18100,
19500,
20000,
24300,
16400,
19300,
24700,
null,
12000,
174100,
14900,
null,
19400,
45200,
10600,
131100,
26800,
50900,
null,
16000,
null,
17400,
34700,
38900,
9300,
null,
22700,
33900,
38600,
6000,
29900,
15400,
78500,
54500,
47200,
77900,
50700,
9600,
16100,
41283,
43200,
34717,
50500,
28900,
71300,
83700,
14300,
24900,
null,
null,
10700,
14900,
null,
6500,
null,
6800,
21200,
1600,
11400,
28400,
42200,
60900,
19600,
44800,
22100,
57500,
78100,
16400,
27100,
58500,
33200,
19900,
5800,
9600,
37200,
52000,
81600,
30700,
21900,
31700,
16300,
10400,
26300,
31700,
47500,
28800,
null,
28600,
15600,
24100,
19100,
7700,
98200,
18300,
null,
17800,
9600,
5900,
24300,
26000,
26100,
20053,
19900,
10300,
27100,
null,
null,
66200,
31400,
15900,
1800,
24200,
28700,
58000,
60200,
59100,
16800,
32900,
38400,
26100,
23000,
40600,
20700,
51500,
38200,
38500,
29900,
47000,
67700,
31500,
13800,
11400,
22100,
9900,
22800,
5500,
12100,
15800,
38000,
6900,
31200,
null,
15300,
17600,
38400,
18400,
11100,
null,
40700,
40600,
null,
13200,
13500,
15700,
26500,
38200,
37500,
16100,
26100,
3500,
31600,
14800,
18700,
23000,
14500,
29300,
18000,
2500,
81200,
76300,
9700,
23500,
11900,
70300,
31150,
null,
16900,
19700,
null,
16600,
49700,
null,
null,
27250,
32300,
8800,
105500,
8300,
10000,
45200,
9700,
48000,
null,
24800,
27600,
15100,
19600,
11700,
16400,
21100,
17500,
10200,
null,
10000,
16800,
25100,
15100,
14900,
20400,
null,
8500,
42200,
13300,
11500,
13500,
47100,
13500,
11600,
13450,
7300,
null,
178400,
28300,
6700,
15500,
48500,
25800,
26600,
23300,
6600,
13500,
19900,
24600,
15800,
30800,
25600,
36900,
12700,
13700,
28800,
11800,
null,
21100,
45200,
9100,
3900,
80300,
8300,
4900,
14500,
30100,
null,
12500,
null,
20200,
13000,
48700,
91400,
14900,
118100,
22700,
8500,
40600,
28500,
42000,
19796,
15250,
16700,
40900,
8900,
28900,
12900,
58200,
28000,
21700,
15500,
22300,
3900,
29000,
28000,
45300,
23700,
19500,
63500,
10100,
24300,
48400,
20539,
68800,
47600,
null,
6300,
null,
14500,
36200,
44000,
null,
38800,
21300,
31700,
35600,
49100,
18300,
35500,
31500,
15010,
17000,
19000,
33000,
31550,
39300,
31500,
5500,
17100,
54800,
33500,
26500,
30700,
9300,
15400,
46800,
34100,
66200,
69700,
43400,
31400,
15700,
10400,
21900,
27100,
58400,
67900,
16400,
19200,
16400,
9600,
17300,
32200,
48900,
67600,
153300,
12000,
35500,
11800,
20800,
17400,
22300,
38500,
15600,
35500,
41400,
8800,
null,
54800,
2800,
5600,
40400,
9800,
14500,
null,
19000,
18400,
26100,
26400,
6500,
77300,
32900,
10500,
36400,
48300,
45200,
45900,
9800,
57100,
12700,
9400,
58900,
48000,
28000,
53700,
41600,
5100,
20950,
12000,
12000,
2400,
24500,
6500,
13600,
null,
24400,
14800,
4700,
45500,
7000,
12000,
38900,
13000,
37000,
null,
16500,
16100,
13000,
2200,
9400,
17200,
22100,
14454,
36800,
38800,
36000,
44300,
14400,
47800,
15200,
12600,
64700,
31000,
16000,
null,
5080,
25100,
3100,
69500,
18600,
29600,
19400,
34200,
8100,
21700,
119800,
31700,
13300,
15500,
3900,
22200,
46900,
17600,
9800,
null,
10700,
15500,
116700,
12500,
14000,
15200,
null,
37900,
11800,
25800,
16000,
34800,
51300,
54700,
24600,
53900,
21675,
6700,
31300,
82600,
25100,
73300,
null,
27900,
45400,
39700,
28279,
null,
null,
116700,
33200,
35500,
9300,
31200,
null,
25700,
21000,
null,
12400,
15100,
26500,
77500,
178000,
3775,
12000,
15000,
306600,
null,
null,
45400,
31300,
21700,
21600,
23100,
108800,
7300,
7400,
4800,
17700,
24600,
20200,
18600,
45400,
20300,
2000,
15300,
13100,
14700,
47600,
29400,
5900,
43000,
8100,
52700,
41701,
null,
20100,
25400,
null,
8300,
46000,
42900,
51800,
39600,
21700,
28700,
103200,
55900,
5000,
null,
17500,
27100,
24200,
null,
null,
203300,
42900,
23800,
21500,
22100,
89800,
38100,
7200,
null,
null,
5600,
40300,
23500,
39200,
4500,
49700,
2300,
27800,
14400,
null,
36800,
6200,
20000,
21500,
109400,
55600,
13000,
85000,
8500,
78200,
27700,
14900,
53200,
16600,
11100,
39200,
23900,
12700,
5400,
5500,
5500,
34400,
9400,
29200,
18400,
5500,
31100,
39100,
25700,
11700,
13500,
59600,
69000,
26600,
16800,
26100,
15900,
3300,
7500,
105500,
67300,
null,
9000,
37200,
25200,
14900,
17200,
5800,
15400,
60400,
40400,
18100,
null,
61900,
13800,
53800,
15000,
null,
18000,
13400,
null,
2600,
1900,
68000,
30079,
318800,
12700,
19800,
60000,
null,
5300,
50700,
10000,
8700,
37200,
15300,
15400,
23100,
253000,
20200,
10000,
87500,
30200,
34400,
null,
89400,
null,
42800,
17000,
107200,
25600,
34400,
14800,
25310,
24500,
14200,
107200,
30900,
27800,
28200,
32000,
16700,
19900,
41700,
63500,
39200,
22500,
23900,
66200,
29300,
9500,
44200,
30400,
68900,
22300,
57500,
50700,
19600,
81900,
53800,
35600,
6400,
21000,
17607,
27700,
16200,
null,
22100,
16500,
21200,
41000,
39700,
9900,
82159,
79750,
37600,
28300,
57100,
14200,
24700,
6500,
19500,
19800,
7200,
8400,
27200,
14300,
6500,
63400,
9800,
null,
25100,
22000,
8700,
55000,
null,
13900,
10800,
29800,
108200,
25100,
77800,
29500,
42500,
18600,
3700,
19900,
7000,
16501,
26900,
44900,
29800,
3600,
78700,
29500,
57200,
null,
40400,
10500,
39600,
34500,
9500,
8000,
21200,
null,
63000,
8018,
64300,
13200,
null,
10700,
10200,
7700,
54800,
19900,
8679,
10500,
53000,
15000,
35500,
50400,
null,
7800,
16500,
35100,
23100,
36500,
60200,
31300,
21700,
15400,
null,
11600,
26000,
44900,
11500,
8400,
19900,
107100,
11500,
3300,
53100,
17800,
66900,
1800,
3300,
null,
31800,
22700,
41900,
67500,
67300,
25700,
87500,
35700,
18700,
37000,
73200,
146100,
38200,
22500,
29900,
52500,
null,
27200,
63400,
16100,
47900,
27800,
9900,
46000,
21600,
76600,
117200,
15100,
28700,
231200,
null,
14700,
34400,
41200,
26000,
null,
39600,
8900,
5500,
17400,
11800,
15100,
59300,
14300,
16800,
11100,
null,
12250,
null,
51700,
12000,
10700,
19500,
null,
30200,
59100,
18000,
10300,
null,
53000,
38000,
49800,
12100,
null,
17500,
null,
24200,
21500,
14800,
67000,
28300,
16600,
19200,
64200,
172400,
24900,
32600,
21300,
35100,
33000,
101400,
null,
54300,
5600,
12000,
112800,
8600,
49610,
17800,
20200,
38000,
130000,
17500,
31100,
17200,
98100,
35200,
14600,
47800,
26700,
17700,
19500,
15800,
null,
43542,
4000,
18100,
13000,
34000,
40200,
163202,
46400,
null,
24900,
38700,
22200,
null,
12400,
24200,
34900,
null,
29102,
58000,
25400,
null,
32200,
29600,
12023,
8000,
48500,
58316,
11800,
null,
195592,
17900,
176300,
null,
25700,
80400,
14500,
57800,
65200,
15700,
43803,
80200,
null,
8600,
51300,
56800,
109000,
31600,
36200,
47700,
33600,
23300,
14900,
5100,
11700,
166600,
19900,
27500,
11000,
24400,
18500,
31200,
6500,
16650,
28900,
44200,
32800,
6920,
12900,
61900,
37700,
null,
22800,
17800,
28300,
13500,
18300,
7325,
33800,
19100,
45900,
26000,
34400,
null,
14300,
17100,
20700,
183400,
null,
9900,
20100,
9800,
54100,
9700,
38500,
4700,
53251,
7400,
null,
null,
66100,
27100,
null,
22200,
8800,
16900,
41600,
11600,
41100,
10000,
7795,
48900,
42800,
13100,
32500,
26100,
39200,
25700,
26100,
7800,
56100,
5100,
8500,
5400,
27400,
9200,
33400,
76600,
15200,
39700,
24700,
10600,
45300,
3900,
18200,
14200,
45700,
7300,
33100,
26400,
109100,
53800,
68600,
null,
13400,
18300,
null,
24700,
38500,
29300,
17300,
16200,
4700,
23300,
234800,
12800,
61200,
9400,
null,
6300,
12000,
47400,
6000,
27900,
14300,
77600,
35600,
35900,
26400,
4700,
14200,
29500,
5000,
null,
60000,
8700,
58300,
null,
null,
21200,
null,
12300,
9000,
26200,
9300,
31000,
12800,
19900,
23800,
3400,
5300,
null,
34301,
51800,
14300,
16000,
11400,
null,
5800,
43000,
6400,
2800,
41100,
10600,
51800,
33800,
24100,
23600,
13500,
31400,
42100,
131100,
134300,
13700,
54900,
15500,
187600,
57002,
14600,
17800,
40800,
53300,
25700,
24600,
31300,
7500,
22400,
50400,
79200,
59500,
28000,
75500,
82300,
11400,
13100,
null,
37100,
21000,
42750,
16300,
147100,
12800,
49200,
40000,
40100,
28300,
62000,
131100,
16500,
41800,
14700,
22000,
18400,
33700,
17500,
2400,
35700,
30000,
null,
7200,
14400,
14400,
32900,
26400,
22200,
31500,
null,
41100,
9000,
108100,
39600,
30900,
10200,
29100,
null,
21200,
25500,
29000,
42900,
28600,
71700,
61400,
58800,
15100,
null,
10300,
19100,
27600,
19700,
9200,
6800,
41900,
128500,
34100,
26600,
20300,
7200,
9700,
46900,
null,
21500,
49100,
54000,
null,
20900,
null,
94800,
37700,
10200,
25400,
143800,
43700,
29200,
13000,
19500,
76700,
60600,
35800,
23500,
10600,
109700,
85000,
51400,
71700,
8700,
26100,
45100,
7800,
28500,
6800,
22000,
24100,
42700,
18400,
34900,
7300,
55700,
5500,
56400,
25200,
33200,
18400,
62300,
17100,
74700,
53600,
39900,
34000,
47700,
20000,
24300,
44500,
43200,
67900,
47000,
51100,
13400,
22100,
13200,
null,
3800,
58200,
27800,
20100,
34000,
36300,
17600,
83700,
29600,
7500,
36300,
11800,
26600,
21300,
44500,
34800,
21800,
264600,
28700,
null,
40300,
36300,
25000,
46500,
15300,
null,
null,
null,
37300,
12600,
42900,
52500,
null,
6400,
13500,
15800,
79800,
18900,
15400,
41400,
43300,
27598,
null,
61900,
19600,
29000,
27800,
21300,
34600,
13400,
23900,
93400,
26800,
47800,
29300,
34250,
39000,
null,
9800,
150900,
24100,
18900,
22700,
22500,
29000,
35800,
46000,
42900,
42100,
148400,
27400,
5400,
21800,
null,
122600,
31600,
6300,
94700,
20400,
35919,
5900,
null,
31600,
19800,
59400,
45300,
34200,
29900,
null,
70200,
74000,
null,
24300,
30600,
38400,
33900,
7900,
15300,
52847,
25500,
17200,
61965,
44000,
null,
15200,
24600,
null,
16500,
18300,
10900,
35100,
9400,
38100,
15500,
27000,
64400,
10500,
12200,
10800,
4500,
18800,
41000,
50300,
16300,
65300,
10900,
43000,
10500,
64200,
11800,
32100,
19800,
41400,
27400,
23900,
24000,
22400,
10100,
30500,
31200,
6600,
39800,
null,
188200,
21200,
17100,
41766,
27700,
61400,
49500,
34300,
23300,
15900,
20200,
21200,
12900,
10100,
13800,
2400,
23400,
31600,
19500,
34300,
14800,
15700,
67800,
33700,
44900,
17700,
2850,
14100,
68800,
17400,
6300,
31500,
34800,
22000,
75400,
47400,
36000,
null,
21300,
11800,
17300,
13000,
64800,
8600,
38200,
10900,
700,
4700,
94200,
20500,
6100,
18200,
null,
37800,
87200,
32900,
12200,
34800,
26100,
null,
60200,
27000,
51000,
2500,
20100,
27800,
null,
11000,
12300,
24500,
108400,
37400,
20300,
19400,
15400,
26900,
11000,
14900,
107100,
40400,
23100,
null,
216000,
92200,
6500,
40100,
25800,
10000,
null,
38036,
24000,
10400,
19000,
17300,
27500,
null,
91000,
24200,
52800,
23800,
25100,
60400,
38018,
23900,
28900,
13200,
31600,
12900,
16000,
5200,
55900,
12100,
44100,
17300,
26500,
27700,
70900,
37500,
10300,
19500,
null,
14300,
31300,
46000,
32100,
44300,
null,
null,
22800,
26300,
37900,
21400,
27700,
21100,
24600,
14000,
19400,
30100,
75400,
13100,
27100,
54600,
15000,
56000,
40600,
null,
15000,
16300,
14800,
34000,
34500,
71500,
31100,
10300,
null,
15800,
19500,
2000,
7500,
33800,
11600,
131000,
42600,
12100,
61500,
13000,
14300,
72820,
20775,
25800,
30700,
25900,
7800,
14900,
49100,
28300,
60700,
null,
13300,
7500,
15800,
15500,
27100,
11900,
14700,
31300,
22700,
40400,
33800,
35100,
177350,
34800,
20800,
81800,
25800,
35800,
26500,
15377,
24600,
81400,
60800,
44200,
21100,
8300,
12300,
101000,
13800,
25000,
35800,
28600,
30400,
17150,
8700,
null,
22400,
85100,
null,
33400,
22700,
null,
21300,
18600,
46100,
6000,
15100,
49800,
7300,
23300,
24600,
40500,
16500,
27500,
25700,
12200,
11000,
25800,
66000,
61300,
22400,
6300,
18800,
55805,
12400,
null,
71000,
2600,
46600,
null,
12300,
24100,
null,
32241,
43300,
30200,
78500,
null,
4800,
65100,
36600,
8100,
18800,
23500,
19400,
13100,
155300,
323800,
6700,
12200,
66400,
null,
21100,
11300,
40700,
6300,
19900,
51900,
23600,
24600,
null,
10000,
6500,
18600,
43000,
33000,
9300,
41500,
110200,
188500,
10800,
13300,
null,
10500,
26600,
20300,
18200,
113500,
5000,
12200,
10900,
17500,
14400,
8100,
37100,
31200,
8100,
76700,
35000,
30200,
10300,
33900,
12800,
37000,
null,
32500,
11600,
28200,
null,
8700,
122500,
32600,
10200,
6600,
null,
13900,
82600,
18500,
21300,
15363,
90300,
20600,
35800,
20100,
22300,
71100,
19300,
35000,
68900,
null,
75700,
11300,
57500,
7900,
24800,
17000,
16300,
7300,
12200,
31200,
null,
51400,
null,
10800,
17800,
22500,
22800,
43100,
39500,
29000,
6500,
10800,
19000,
11300,
11500,
94500,
5900,
161000,
28700,
16300,
null,
43600,
7900,
null,
37600,
32700,
40900,
11500,
null,
25800,
45900,
29400,
62000,
169400,
13100,
55000,
9450,
32500,
28900,
null,
16400,
29400,
null,
77600,
37250,
36700,
57300,
16900,
16200,
28900,
5100,
116000,
20000,
29000,
8100,
null,
25900,
26900,
12700,
1000,
27900,
33400,
23100,
24300,
22760,
5200,
19200,
64600,
27000,
58300,
null,
8800,
28700,
51900,
59100,
11000,
21000,
33000,
7900,
104800,
17100,
15700,
15500,
27800,
19000,
18300,
34900,
21800,
89200,
12300,
44600,
26200,
76600,
37600,
7100,
40800,
34500,
26100,
21000,
13500,
45400,
85400,
null,
18500,
34400,
31200,
22100,
22500,
38500,
52500,
6300,
2400,
42600,
8600,
34100,
23300,
61800,
24500,
22900,
12400,
43000,
14000,
10500,
15400,
6900,
22500,
43400,
73200,
32800,
10800,
206000,
45500,
57800,
28300,
6000,
19300,
24100,
12500,
22900,
38500,
null,
19700,
91600,
35700,
53200,
12900,
5000,
61100,
22100,
20100,
null,
30300,
33200,
37900,
24800,
17600,
29000,
8100,
17600,
15500,
27200,
36450,
13500,
22700,
40200,
3500,
15400,
36900,
16300,
8500,
30300,
55400,
null,
null,
null,
26500,
33400,
40900,
11900,
17900,
62800,
51400,
null,
11600,
23300,
36300,
10100,
37100,
65700,
16100,
9000,
31700,
35300,
25100,
63900,
33990,
18200,
59500,
45200,
28100,
12500,
18300,
13800,
52597,
5600,
49500,
12500,
29600,
10500,
2600,
18400,
7500,
13800,
43000,
15300,
16700,
6500,
16900,
29600,
50100,
39100,
7100,
36600,
3900,
34700,
21400,
2400,
12800,
45800,
46400,
28900,
15600,
null,
31700,
1200,
44900,
17700,
62000,
23700,
20800,
12700,
24200,
19700,
73900,
25500,
23000,
48900,
18300,
17700,
32000,
52300,
28200,
30000,
15100,
16300,
4000,
34900,
22000,
18400,
42000,
41300,
36600,
34300,
15000,
65000,
11950,
17800,
20400,
6400,
26400,
25300,
53000,
5100,
17700,
10600,
12100,
23000,
40700,
12000,
null,
null,
35209,
27300,
21200,
69400,
22500,
39600,
18500,
17600,
20100,
23800,
8400,
28100,
16300,
45100,
49000,
11700,
5500,
7100,
36900,
10300,
52500,
7800,
5500,
26900,
149100,
37200,
29100,
59500,
8400,
29700,
35600,
16500,
42600,
14500,
6400,
9300,
23400,
26900,
111150,
46200,
2500,
72000,
39600,
22100,
23400,
8300,
8400,
null,
11600,
29900,
21600,
12600,
34700,
null,
153000,
106800,
54000,
10100,
76200,
39100,
29800,
4300,
8100,
6300,
16300,
10200,
22700,
15400,
283600,
6600,
45900,
5000,
47200,
41500,
67300,
26600,
8100,
50000,
null,
23800,
33000,
32600,
4350,
86800,
12500,
38900,
35800,
21600,
11800,
null,
5600,
null,
5500,
16300,
41400,
46300,
38200,
3300,
156900,
5500,
91600,
35900,
14200,
31600,
10300,
null,
8200,
null,
18100,
97000,
26500,
24200,
18400,
27700,
32700,
42100,
31500,
35200,
18000,
14200,
13100,
29100,
14900,
47100,
30600,
26000,
26900,
15400,
51000,
17500,
48000,
10300,
71600,
28100,
null,
33100,
7800,
3500,
51500,
62700,
52680,
10200,
31300,
56400,
51800,
32400,
29700,
29500,
27400,
25900,
12100,
58400,
25500,
62200,
61200,
103000,
9400,
86700,
8100,
17900,
65900,
15200,
18700,
17900,
22600,
15600,
null,
17700,
49300,
null,
75000,
37400,
9300,
42100,
28700,
13400,
null,
41300,
23900,
8600,
37900,
10500,
43200,
null,
45000,
32000,
18100,
18700,
69400,
5500,
6800,
26300,
44900,
250300,
24200,
188000,
19800,
14500,
31500,
25400,
2900,
22600,
13100,
33100,
44400,
21600,
null,
30000,
55000,
28100,
38900,
26900,
null,
26200,
null,
null,
45800,
59900,
92200,
17300,
49100,
4100,
10200,
29757,
13700,
43100,
13300,
59800,
34000,
81500,
8800,
6550,
35900,
9100,
84900,
40700,
8600,
49400,
9000,
24800,
28700,
38800,
55100,
21800,
34600,
5600,
45700,
25700,
13200,
12700,
26400,
67900,
21300,
14100,
22800,
16900,
12600,
11500,
19400,
28000,
17600,
29300,
15900,
13900,
14000,
15400,
31100,
55000,
55800,
9100,
15300,
8600,
9900,
25500,
286800,
15300,
16300,
41500,
8300,
20800,
46500,
18000,
18800,
93249,
7100,
38100,
7600,
6500,
21400,
46100,
9900,
16400,
21500,
7000,
107000,
46800,
23750,
7100,
11200,
5500,
65068,
23500,
19100,
18600,
26900,
23300,
18300,
null,
32900,
8100,
25900,
6500,
10900,
3000,
20800,
null,
58500,
26900,
9600,
5200,
77900,
28800,
null,
14500,
20850,
18700,
9800,
12100,
15500,
31300,
25700,
13700,
30500,
17900,
34200,
null,
34900,
49500,
73600,
11200,
24200,
12400,
16300,
12200,
24500,
13000,
null,
42900,
23500,
16700,
14200,
9200,
2300,
11100,
8900,
41200,
27000,
12800,
6600,
null,
3700,
9600,
2500,
42200,
82900,
68200,
7500,
18000,
48100,
16100,
19600,
13900,
20700,
32000,
31500,
43500,
30400,
39100,
13500,
8400,
12800,
10200,
47500,
20800,
13000,
null,
12300,
21800,
2800,
20500,
13000,
20500,
14200,
16100,
null,
10500,
9900,
74000,
18100,
25500,
21500,
6000,
16000,
107600,
19300,
21800,
34100,
5100,
62700,
null,
10300,
27500,
3500,
41600,
116700,
31800,
2900,
null,
33000,
13700,
16900,
32800,
22900,
38300,
23200,
35800,
26000,
19000,
36400,
52400,
8500,
15600,
10000,
5500,
6400,
6000,
35700,
20900,
14200,
8300,
14000,
null,
17600,
28600,
20700,
263500,
25600,
7000,
12500,
43600,
8400,
46600,
17100,
70800,
7400,
48800,
44700,
2500,
31400,
39500,
24300,
54500,
18700,
122700,
7200,
16300,
7300,
5300,
14300,
30400,
null,
20900,
21200,
50000,
4800,
23600,
38300,
28400,
28800,
105100,
46900,
10100,
21800,
null,
16800,
27600,
18400,
37300,
10000,
null,
12000,
25800,
null,
null,
null,
null,
19000,
27200,
27200,
null,
15000,
36900,
null,
12300,
12000,
21900,
14112,
5900,
26300,
43300,
53500,
36700,
30900,
6700,
27800,
null,
null,
40000,
4100,
21100,
35200,
26000,
9100,
107400,
15300,
10200,
159800,
41800,
21100,
24200,
12300,
24800,
1100,
30100,
52500,
12100,
22600,
54900,
11700,
5700,
16000,
16000,
110400,
null,
37100,
7600,
7600,
43100,
21900,
10800,
11000,
20200,
5200,
20100,
12100,
33100,
8500,
71400,
null,
11900,
null,
36700,
56900,
11900,
52700,
33600,
67200,
50300,
44200,
12610,
28100,
18400,
49200,
9100,
9600,
8500,
34800,
10700,
68300,
24900,
17600,
7900,
35100,
28200,
44100,
16300,
49000,
87700,
55900,
14400,
33500,
11500,
32000,
20400,
19500,
22200,
10600,
30600,
null,
31400,
19300,
34200,
21535,
60300,
43800,
10800,
21100,
10400,
23700,
21300,
15700,
27400,
57000,
6700,
37000,
4800,
10700,
61100,
34000,
22800,
9900,
51000,
8455,
16400,
72000,
13500,
75100,
52800,
46900,
46100,
17500,
9300,
22400,
15600,
14000,
25600,
16700,
null,
25600,
21900,
147700,
25300,
21600,
9900,
27300,
22200,
47600,
15200,
50725,
13600,
15700,
null,
18700,
7100,
18700,
25300,
43500,
15700,
6800,
14200,
33000,
27400,
53400,
14300,
20500,
7200,
18300,
7700,
11700,
21400,
null,
8600,
13100,
1800,
26600,
47500,
9900,
8700,
19200,
37400,
39600,
29800,
12300,
4100,
51100,
54200,
30500,
38500,
34700,
52500,
10200,
null,
42000,
21800,
16600,
null,
37200,
34400,
7600,
42511,
6700,
53000,
null,
22100,
11600,
7000,
30600,
50800,
59700,
29600,
41300,
20800,
83200,
30000,
10700,
26700,
9100,
16500,
12300,
176600,
32000,
25300,
107200,
null,
null,
28700,
27700,
48800,
125400,
17400,
15400,
33600,
63000,
null,
17900,
75700,
114800,
null,
21900,
28300,
21700,
24300,
41200,
38900,
20700,
null,
24300,
33700,
null,
38900,
24500,
67500,
27700,
10900,
45700,
28400,
7300,
10400,
40200,
null,
11600,
13300,
11900,
7000,
22300,
21300,
21500,
8300,
58700,
28400,
43900,
null,
26500,
13300,
null,
5800,
48000,
73600,
21400,
30150,
37400,
46600,
22100,
30400,
6700,
20000,
null,
19300,
36200,
56900,
105600,
null,
57200,
15100,
40200,
20300,
16100,
23800,
18000,
147600,
17500,
15600,
23800,
23000,
38700,
18700,
101200,
12600,
3700,
null,
14000,
6900,
16100,
null,
18200,
62700,
23600,
10600,
26800,
18600,
31000,
15300,
5300,
14950,
null,
26900,
20400,
13300,
32100,
41300,
52300,
13400,
28000,
105600,
33000,
31100,
27500,
19300,
83100,
13500,
22500,
4500,
6600,
47100,
null,
9300,
54700,
15600,
16500,
24500,
63282,
47300,
30376,
8900,
23900,
60200,
9300,
18800,
23500,
24100,
10500,
7500,
17400,
7400,
52700,
70900,
18800,
5600,
28900,
26700,
25810,
56900,
40600,
15600,
22050,
null,
2400,
null,
27400,
11700,
6400,
12300,
10200,
67000,
25600,
24300,
16900,
16300,
33100,
36200,
25300,
null,
37800,
31200,
18500,
15050,
15700,
6300,
36400,
5200,
23700,
21500,
31500,
9200,
33700,
null,
null,
30100,
44800,
24200,
15500,
34500,
10700,
26300,
5600,
103700,
37400,
30800,
49800,
2700,
7700,
22900,
44400,
191351,
54500,
26800,
18000,
37300,
36100,
37500,
21700,
31700,
9300,
24200,
27800,
21000,
12100,
35400,
35200,
18700,
15600,
18600,
5100,
56800,
7600,
55825,
null,
19100,
null,
31500,
10800,
24200,
15800,
40100,
42300,
46500,
84150,
14500,
49100,
45000,
24200,
22600,
45000,
30600,
27600,
10300,
23900,
22300,
7100,
10600,
7900,
25900,
7000,
11200,
null,
60300,
12300,
29800,
61700,
null,
74400,
7400,
41300,
73300,
14400,
59500,
null,
59500,
70600,
65900,
8100,
11600,
35100,
23800,
37500,
7400,
null,
15100,
17100,
26700,
8600,
19200,
15100,
22700,
1800,
31000,
46900,
18200,
13700,
24500,
14000,
10300,
18600,
29500,
18900,
41400,
10700,
11800,
35800,
12800,
null,
36600,
2000,
8000,
14500,
13800,
37000,
null,
34400,
43400,
55700,
70200,
null,
38000,
null,
null,
null,
132200,
8900,
33700,
20600,
26900,
10100,
18600,
6600,
41300,
98400,
7700,
31900,
17100,
68400,
4800,
24400,
14200,
13900,
53200,
95700,
18800,
37000,
39700,
30600,
62100,
7400,
23000,
15700,
23400,
34300,
7000,
22100,
39800,
237800,
140000,
10700,
17700,
4650,
26000,
9100,
40800,
41300,
147800,
34700,
null,
31900,
11200,
null,
0,
32100,
59000,
22700,
14100,
11200,
42400,
12600,
30500,
132599,
26500,
52900,
21200,
43600,
18200,
14600,
64500,
17500,
35400,
31900,
20100,
12000,
66800,
14500,
18300,
13200,
41700,
4000,
19700,
null,
33400,
12900,
13060,
62300,
63600,
19300,
39800,
64400,
9400,
19700,
87200,
26600,
4800,
3400,
13000,
15600,
null,
18200,
66900,
null,
5800,
14900,
85600,
97300,
29300,
12300,
6400,
32100,
27900,
43100,
17000,
46900,
20700,
102300,
12200,
121900,
12500,
27600,
36800,
null,
101400,
11100,
269399,
17400,
23000,
26500,
72700,
20900,
25700,
22600,
17800,
35600,
23500,
12600,
20200,
12700,
41200,
82800,
24700,
26500,
33100,
29000,
19000,
31800,
15000,
null,
3000,
9000,
72200,
48900,
14300,
15800,
18300,
13900,
26250,
40700,
16100,
33600,
24200,
47200,
33500,
30100,
19900,
10900,
19000,
11700,
8000,
16800,
47300,
108600,
38559,
28900,
24600,
10400,
100500,
12100,
44700,
81900,
19900,
125200,
18300,
32700,
50400,
15500,
27200,
40500,
19200,
6500,
36400,
14500,
66300,
23900,
15600,
22100,
null,
9500,
43300,
105700,
13300,
41700,
33200,
18700,
21300,
26800,
9400,
17300,
33800,
40600,
35600,
56200,
71186,
34000,
9300,
27200,
null,
47800,
31700,
35600,
315300,
39296,
27000,
68200,
123200,
22300,
null,
19200,
25400,
21400,
48400,
16800,
53300,
25500,
2000,
98100,
11800,
10000,
101300,
15000,
18500,
11700,
206700,
33300,
30300,
6000,
144900,
49300,
16700,
13200,
134800,
3100,
8000,
28600,
31300,
22500,
null,
31800,
17900,
55500,
24700,
46300,
23300,
15200,
null,
41100,
25900,
5700,
31800,
8600,
9600,
22100,
18600,
12600,
30700,
29400,
null,
40200,
50600,
23500,
21500,
21400,
3700,
null,
9000,
38200,
8700,
18900,
41500,
22100,
64500,
23100,
33300,
10000,
71500,
29200,
8050,
74700,
14500,
17400,
29700,
52400,
12300,
500,
69600,
55849,
12300,
50800,
8300,
59200,
24900,
null,
4900,
125800,
6700,
9800,
39200,
126000,
53158,
null,
41800,
25700,
45500,
26400,
null,
null,
29700,
4900,
null,
500,
36900,
11500,
18000,
6100,
6700,
14700,
9100,
54500,
17600,
6100,
35200,
51000,
8700,
14000,
15700,
53100,
15500,
34800,
18400,
6100,
49360,
3700,
39773,
106150,
19000,
7200,
47000,
24600,
28100,
34500,
34300,
null,
45000,
24600,
11900,
17600,
10700,
68500,
83500,
40500,
36600,
19100,
34700,
32100,
34000,
15500,
31000,
15600,
17500,
40800,
48300,
13900,
44100,
12800,
146300,
7900,
37200,
25600,
18500,
8800,
60900,
30800,
30200,
50300,
19900,
14400,
36300,
13900,
55500,
42500,
57900,
32900,
null,
18700,
null,
53700,
49800,
21400,
null,
5100,
17900,
46400,
40000,
18400,
30500,
46100,
18900,
37600,
9200,
31500,
53500,
12200,
29300,
9500,
25300,
21900,
40700,
30100,
17100,
32800,
21700,
27900,
90200,
12700,
7900,
43600,
21000,
60300,
23000,
19100,
54900,
28700,
1200,
25100,
31600,
11900,
null,
31500,
19600,
14000,
27800,
null,
null,
58100,
41700,
11200,
25400,
103800,
7800,
18100,
10600,
25200,
42900,
22500,
26500,
22000,
40890,
75900,
20200,
28600,
11000,
16600,
11200,
38100,
33700,
null,
9700,
57300,
null,
24300,
106600,
19400,
16500,
7300,
39000,
59300,
19500,
13400,
56200,
18100,
24000,
64400,
20800,
8400,
65300,
33200,
32000,
39300,
null,
5300,
null,
21900,
110100,
28400,
2400,
43200,
22000,
26100,
15000,
18900,
41200,
7200,
8600,
9400,
5900,
20900,
null,
20500,
8309,
49600,
null,
117500,
34300,
34400,
50500,
54900,
24600,
7800,
55700,
3300,
12600,
10100,
13100,
31400,
118200,
33800,
33400,
45600,
65900,
44200,
38300,
29400,
12400,
48300,
16450,
9700,
null,
73400,
14200,
21400,
19600,
27000,
10000,
46200,
13400,
8800,
8200,
22300,
35700,
18000,
23100,
14100,
45823,
22600,
70000,
25900,
14000,
18500,
null,
62700,
11650,
14000,
3400,
32500,
57200,
10500,
11100,
null,
16500,
51200,
15500,
27500,
28400,
37700,
15250,
null,
82100,
55300,
60700,
42900,
99600,
25100,
null,
15400,
35000,
13300,
37200,
25300,
28500,
13700,
5500,
11000,
70400,
21800,
36600,
24300,
21900,
50500,
37200,
12100,
null,
21800,
11500,
37400,
68500,
29700,
15800,
54600,
31100,
26400,
null,
17800,
12600,
25900,
44800,
28600,
51000,
40997,
79400,
7500,
29800,
27500,
22600,
14900,
34100,
25400,
7800,
24100,
63000,
19300,
23700,
20100,
81900,
11600,
27400,
63100,
21200,
63600,
24400,
41500,
87300,
75300,
17570,
16100,
1800,
21500,
25000,
21700,
13500,
49100,
20600,
33700,
8500,
26100,
22800,
21100,
9500,
7100,
9300,
68400,
53200,
45300,
28900,
13200,
22100,
41700,
9800,
104200,
12500,
65200,
86200,
null,
40500,
12700,
79000,
16100,
41500,
37500,
19200,
7300,
18400,
null,
14600,
26100,
81600,
36700,
19400,
22800,
12400,
10100,
22700,
50900,
20100,
31300,
30800,
99300,
20800,
null,
8500,
null,
14500,
66400,
98500,
9500,
null,
12200,
null,
8500,
26700,
45800,
38155,
18200,
24200,
9700,
27300,
9300,
null,
23800,
29700,
41800,
43600,
null,
18700,
8700,
23300,
17000,
19100,
27800,
null,
15600,
27100,
30800,
38100,
50600,
81764,
39300,
11800,
18900,
36400,
21500,
7500,
12300,
7400,
null,
21100,
32000,
38000,
11400,
161300,
30200,
9600,
8600,
19400,
36000,
21700,
64500,
60300,
34600,
17000,
64100,
23100,
47000,
21100,
28200,
5500,
14700,
46200,
71600,
34000,
34200,
5500,
23400,
null,
24500,
33500,
19400,
16400,
14000,
17800,
13220,
null,
7800,
46900,
20000,
29500,
91500,
36809,
63191,
28200,
22200,
null,
20100,
20000,
32100,
40500,
15800,
25900,
16500,
27200,
19000,
7700,
29700,
null,
27000,
5600,
24800,
42000,
null,
8600,
43200,
37600,
75300,
28800,
46500,
null,
29000,
155400,
null,
97300,
20000,
69200,
8400,
36100,
23300,
18800,
14800,
null,
126200,
37400,
32300,
23500,
24700,
27000,
35100,
30500,
15400,
24600,
8400,
4500,
9100,
66400,
77600,
25600,
41600,
7200,
12000,
15000,
31000,
45600,
3100,
4300,
36700,
21800,
null,
null,
16300,
35900,
97200,
null,
34700,
10900,
9200,
35800,
35200,
9000,
76600,
24000,
null,
7600,
19500,
14800,
42400,
null,
74380,
17500,
13200,
8500,
null,
2200,
38200,
3000,
33600,
55600,
70400,
51100,
null,
32000,
111500,
17900,
13500,
32900,
8100,
8700,
11500,
150100,
109800,
null,
63800,
21500,
null,
10800,
32000,
19700,
3000,
15100,
167300,
21100,
13000,
33600,
22700,
39600,
27100,
26100,
null,
22600,
50200,
67900,
12500,
19800,
16900,
20700,
70600,
47500,
19900,
45400,
null,
60200,
16300,
111500,
10600,
11900,
null,
34500,
15000,
null,
44700,
15500,
14300,
26700,
26300,
28600,
12100,
18900,
null,
154700,
9500,
13200,
56000,
36900,
20800,
8900,
29700,
43500,
16700,
60800,
18100,
null,
43700,
7400,
null,
null,
29800,
20400,
74000,
6200,
30200,
26000,
13700,
25200,
27400,
15300,
16600,
15400,
26200,
75700,
142600,
null,
11400,
null,
65700,
22600,
33700,
47500,
25200,
27000,
80700,
27100,
25900,
23200,
18100,
26600,
17500,
8200,
23500,
41000,
144800,
14700,
31200,
13300,
20600,
21400,
16200,
16000,
12100,
63500,
19100,
null,
20500,
20300,
null,
11300,
26900,
5900,
81800,
11500,
13900,
23100,
52700,
16000,
11700,
43600,
20300,
43100,
67400,
44400,
59000,
65700,
9500,
50900,
null,
900,
88600,
9400,
39400,
36600,
62100,
13900,
22700,
null,
26600,
9100,
11300,
42000,
15800,
11600,
27200,
60200,
20700,
52400,
175200,
51100,
26400,
13200,
13600,
31400,
21700,
25400,
3900,
31600,
23700,
18800,
null,
52100,
112000,
51600,
47000,
70225,
14800,
3500,
49800,
29400,
22100,
39600,
13700,
29800,
null,
8400,
20200,
null,
37900,
9300,
23300,
12800,
29100,
36400,
10700,
41200,
11200,
95900,
27400,
3000,
12400,
41400,
33300,
7500,
76000,
8900,
9300,
42900,
48800,
28600,
42700,
32000,
20800,
null,
10500,
26900,
17200,
20100,
12100,
27200,
3700,
22300,
157700,
35200,
46300,
19100,
24400,
71600,
18900,
15600,
21000,
20500,
100800,
57800,
9600,
194300,
21800,
null,
null,
10600,
4800,
12100,
44500,
8500,
3000,
29500,
35800,
null,
null,
34500,
27400,
32200,
13800,
22700,
39800,
16100,
17100,
33000,
50800,
125300,
24600,
3800,
23200,
24700,
41000,
null,
null,
16100,
15500,
37400,
9800,
15100,
147700,
11100,
12500,
13200,
29800,
43400,
3200,
15500,
33800,
14400,
11300,
116006,
27000,
26600,
24900,
54100,
17600,
11400,
21400,
11500,
23300,
23000,
53000,
17900,
22800,
19200,
11000,
46300,
60700,
42100,
18700,
43100,
18200,
13900,
2700,
30900,
22400,
22500,
null,
44600,
26500,
null,
83000,
160500,
18700,
36600,
21000,
6300,
15300,
18200,
15300,
16900,
18000,
18500,
44400,
8300,
33300,
138500,
19900,
12700,
18500,
30000,
11400,
19200,
94700,
41000,
15700,
59500,
43800,
18600,
9100,
61800,
81700,
38000,
8200,
25200,
38100,
74600,
5600,
39300,
64600,
53000,
22700,
27200,
9000,
33900,
18000,
68100,
19700,
null,
47300,
32400,
50010,
30900,
65400,
42400,
35900,
123400,
12500,
null,
23000,
21700,
null,
34400,
7000,
21000,
null,
56300,
null,
32600,
null,
51500,
27100,
25700,
69000,
41500,
27600,
null,
10600,
20300,
33500,
79900,
9600,
52800,
3200,
34500,
25300,
165100,
18000,
6000,
10800,
9200,
38400,
13200,
23100,
7900,
6900,
37200,
26700,
113400,
46200,
null,
28400,
31400,
84100,
14500,
22000,
27000,
65800,
51410,
31100,
null,
34900,
16400,
26000,
9900,
14000,
19300,
null,
90000,
3400,
28800,
103000,
25000,
18400,
36300,
null,
20400,
9100,
19600,
11600,
10700,
74100,
22100,
28700,
63900,
17700,
13500,
31200,
6400,
29500,
9800,
51800,
37200,
13600,
34383,
33100,
45000,
18500,
5500,
51900,
31400,
32700,
18000,
24100,
40600,
56500,
89300,
7500,
57700,
6500,
25000,
63300,
93700,
31000,
null,
20600,
21800,
46200,
17900,
42800,
null,
13300,
12600,
14800,
27300,
null,
43600,
17900,
17100,
11600,
11900,
59000,
18100,
13700,
32500,
49300,
43500,
23900,
4200,
25300,
21300,
28300,
15700,
24600,
143670,
24400,
72900,
38000,
52800,
null,
13200,
14700,
10800,
162100,
5800,
8400,
20500,
43900,
null,
16400,
67100,
70400,
null,
10800,
49300,
98800,
34500,
60300,
19500,
11800,
12100,
11500,
28700,
11500,
19200,
62200,
30500,
4700,
116700,
11370,
47000,
61450,
32700,
null,
4200,
11500,
16400,
66600,
39000,
null,
9800,
31600,
21100,
null,
25800,
19300,
35300,
null,
20600,
69700,
22800,
4900,
16700,
16400,
27200,
40000,
64100,
12500,
34400,
16700,
46400,
10700,
21200,
22800,
10900,
71900,
94000,
10200,
16000,
20600,
19400,
42100,
32700,
32000,
14800,
36200,
null,
112558,
53700,
23000,
11800,
213500,
6000,
20000,
16400,
20900,
48700,
16200,
30300,
17900,
28800,
42600,
17300,
90500,
33100,
49100,
28300,
262100,
51500,
12300,
30600,
16400,
35300,
10000,
25200,
6100,
4098,
16000,
27800,
12500,
3200,
10000,
null,
5700,
29600,
57700,
23000,
34700,
23900,
22400,
9500,
12100,
39000,
26700,
114600,
42900,
38000,
24100,
31000,
21300,
26000,
43000,
39900,
5300,
49700,
9850,
29200,
88200,
13800,
10500,
16500,
null,
43100,
6100,
11700,
53200,
80689,
24200,
14600,
16900,
14600,
27300,
null,
7100,
null,
22500,
74200,
13900,
15300,
8400,
76100,
14700,
13200,
13500,
10800,
19500,
18600,
11000,
33300,
46600,
41400,
19200,
24900,
null,
14200,
313000,
8700,
37000,
30000,
25800,
36000,
25000,
16900,
54900,
21100,
null,
7500,
8700,
16800,
14200,
35800,
17300,
46300,
10000,
10800,
16000,
23300,
83900,
14200,
10300,
28300,
17100,
17300,
18900,
42700,
4600,
54522,
52900,
107500,
42500,
16200,
98600,
13000,
37700,
20900,
26600,
null,
11300,
8400,
44500,
83000,
205700,
26100,
68700,
50700,
12700,
20500,
77500,
12500,
14000,
29600,
null,
55600,
30400,
23800,
30600,
14200,
36200,
7900,
5400,
38600,
31800,
5500,
27700,
null,
37800,
10400,
57800,
36300,
32300,
12800,
null,
19100,
2800,
35100,
14400,
9400,
9500,
37100,
26300,
50700,
19200,
null,
29300,
95400,
4700,
46300,
28100,
40000,
58500,
27300,
39000,
7945,
19700,
103000,
31900,
39300,
26700,
24700,
32800,
null,
15800,
37175,
12000,
6600,
32300,
38800,
6400,
10900,
14200,
12200,
19300,
32800,
60000,
5200,
10700,
66500,
10400,
21000,
53900,
12300,
33300,
8877,
null,
23900,
15300,
4500,
14700,
58300,
10500,
13500,
132300,
28700,
74900,
16600,
14700,
17500,
22197,
20300,
14300,
14900,
12900,
15300,
15800,
22800,
53300,
108700,
69400,
32200,
15800,
20000,
13300,
8600,
13600,
17900,
null,
22500,
9200,
52400,
3100,
10300,
6100,
113600,
78100,
10100,
5600,
44861,
null,
15600,
15500,
16800,
29000,
103400,
66700,
45800,
30900,
87100,
null,
32700,
16000,
18500,
38900,
38600,
10500,
14100,
15900,
57600,
41000,
118700,
22900,
34400,
11600,
21500,
27800,
15500,
20300,
43600,
12700,
33600,
6200,
34690,
43300,
14000,
22500,
20700,
30195,
17200,
57000,
22800,
null,
19400,
21100,
5200,
8600,
32400,
null,
18400,
63600,
6100,
46400,
13400,
8100,
16500,
5800,
17400,
12800,
39100,
34700,
48800,
null,
30900,
10600,
65600,
40624,
11700,
null,
16600,
18200,
100300,
70500,
33100,
52800,
31500,
102100,
15000,
33100,
21700,
11200,
null,
69800,
66338,
36200,
23600,
7000,
3500,
135900,
44300,
57935,
40500,
14400,
15600,
15800,
17500,
11400,
12400,
45800,
36035,
16300,
31600,
26750,
27300,
29000,
56200,
73700,
16600,
33000,
34000,
9000,
42100,
34100,
13900,
23500,
9200,
16000,
17500,
5900,
6600,
17900,
11400,
32000,
20500,
10800,
14400,
26000,
22100,
14300,
47200,
20000,
42000,
19700,
null,
21000,
15700,
11800,
66400,
37800,
3000,
40000,
26900,
44300,
31000,
7400,
36800,
null,
13200,
42700,
8600,
34700,
28800,
4500,
45069,
23900,
17400,
46200,
null,
7900,
26900,
19100,
23100,
19300,
4600,
93500,
15500,
16940,
20100,
46200,
14500,
39500,
13500,
32500,
null,
10300,
91600,
16600,
47500,
16700,
32900,
70400,
16000,
88300,
115100,
20900,
25600,
15300,
15500,
4500,
13600,
18300,
20000,
13800,
18300,
14400,
58400,
23200,
68400,
7200,
null,
21500,
15800,
54600,
35800,
null,
31900,
52900,
24200,
15800,
16200,
81900,
7000,
18100,
50800,
10000,
4500,
27700,
29200,
10000,
16500,
19100,
22800,
12000,
23700,
45700,
10800,
56000,
6400,
32900,
40900,
null,
13500,
17100,
9700,
32400,
60432,
16400,
12500,
11200,
22900,
14500,
33300,
10100,
18500,
23000,
null,
22200,
14600,
13600,
10900,
13600,
18700,
2600,
41100,
15900,
19900,
22400,
null,
15900,
62200,
30100,
23300,
15700,
11900,
null,
70700,
56600,
8900,
15000,
43000,
8300,
15300,
18800,
15400,
15100,
108600,
16300,
22700,
9100,
18700,
31000,
null,
22000,
22380,
16700,
12600,
29600,
null,
9250,
20100,
43200,
12900,
66386,
44700,
23400,
49200,
36600,
14000,
58716,
67400,
6500,
21200,
28000,
null,
21800,
null,
71400,
46100,
26400,
62800,
39300,
null,
15500,
11500,
21900,
null,
24100,
21400,
1900,
18300,
62357,
4500,
7100,
11700,
11200,
7300,
5000,
28600,
24800,
110700,
32900,
14000,
14800,
57300,
13200,
37200,
19400,
24700,
16400,
43000,
11000,
15000,
26800,
24500,
21200,
16000,
52500,
73000,
24000,
7600,
7900,
23800,
6962,
13500,
101700,
71200,
4300,
10200,
null,
30800,
237000,
29900,
null,
74000,
32600,
6000,
20100,
44100,
31100,
11500,
18900,
17000,
52100,
22600,
7200,
109800,
null,
15100,
28300,
24700,
13100,
19700,
18425,
22600,
19900,
null,
9200,
67600,
42200,
14200,
14300,
19700,
19900,
26400,
12900,
13800,
48300,
18000,
9800,
8100,
12300,
null,
170300,
36700,
48900,
17200,
8300,
23100,
26300,
43500,
31600,
27100,
null,
12300,
null,
27900,
6400,
42000,
16900,
16700,
102927,
21900,
41300,
9700,
37600,
null,
4500,
51800,
26500,
40000,
18400,
18200,
7000,
73850,
25400,
8700,
7600,
31700,
62400,
28400,
138100,
15300,
2300,
25300,
40800,
24100,
15800,
21600,
10700,
23000,
10600,
35700,
29700,
33900,
29100,
33100,
null,
24800,
20800,
6400,
null,
10400,
18300,
13400,
35300,
12000,
17400,
29400,
19300,
8200,
10900,
28200,
null,
null,
9200,
27300,
36300,
29100,
3500,
18700,
24500,
41200,
19510,
69500,
10700,
104300,
15100,
17000,
27500,
29300,
36500,
6400,
14000,
68000,
null,
35300,
56100,
25000,
3200,
17800,
37700,
20000,
10600,
19500,
12200,
28000,
23500,
40500,
70800,
25200,
22600,
13100,
19300,
38800,
16200,
14900,
26300,
50900,
46700,
61600,
null,
40500,
null,
11800,
82500,
33400,
13400,
28800,
18800,
null,
51600,
25300,
16300,
68800,
11800,
8570,
23000,
9050,
18600,
108800,
30500,
24700,
10600,
29300,
61800,
20800,
23600,
24600,
6000,
null,
19000,
23600,
28100,
51900,
26200,
35300,
5500,
null,
4700,
27500,
6300,
156500,
18000,
19700,
31810,
36000,
13000,
8600,
null,
19900,
27400,
8600,
20400,
76600,
31800,
15300,
17500,
20100,
25300,
38500,
11700,
52200,
19300,
16400,
46900,
13300,
13700,
83200,
29900,
23500,
18100,
41000,
7500,
25400,
24500,
5700,
18600,
26400,
163700,
6400,
20700,
3800,
24800,
31600,
41800,
35400,
42900,
22100,
93900,
8500,
36100,
null,
10000,
99100,
96700,
null,
38600,
22100,
13100,
19500,
46700,
20700,
23100,
5000,
47600,
20100,
36300,
14200,
null,
19900,
23500,
31200,
18900,
74700,
10300,
22500,
36770,
35200,
null,
null,
31684,
44200,
8800,
null,
66800,
34800,
23200,
75929,
14300,
114800,
26800,
57500,
27800,
35500,
26900,
21500,
38800,
44900,
20445,
14400,
8700,
42300,
6400,
26200,
28600,
18100,
34800,
11500,
25700,
52200,
29600,
15700,
null,
32200,
12450,
10600,
88300,
6600,
11400,
37600,
7700,
16800,
10000,
9800,
32500,
23600,
37800,
16400,
199600,
114600,
48500,
21500,
16600,
22300,
33800,
null,
45300,
7400,
null,
13800,
43800,
10000,
48500,
80100,
9000,
14500,
11700,
5000,
51600,
10800,
28200,
14500,
68900,
16000,
null,
11700,
88800,
67800,
1500,
null,
32600,
143500,
10500,
14600,
8600,
21900,
35200,
37601,
30100,
69000,
null,
36000,
49300,
18500,
38300,
57700,
null,
106700,
null,
6400,
13900,
15500,
13970,
33475,
17200,
52500,
18100,
57100,
35400,
21600,
26100,
12800,
5500,
26700,
16700,
23900,
null,
15300,
73900,
70100,
18200,
null,
24000,
30400,
47700,
108000,
18500,
6500,
34700,
31000,
39000,
null,
null,
19500,
79700,
20600,
61900,
11400,
8300,
9300,
7200,
5000,
12400,
125700,
10300,
22700,
21200,
25900,
25900,
14200,
12300,
47600,
16000,
22600,
33900,
42800,
25800,
13500,
65800,
28300,
63300,
13700,
9850,
14200,
24200,
16800,
30400,
null,
20700,
4300,
null,
5000,
49900,
26800,
16200,
64200,
11100,
12300,
84000,
42700,
10000,
23600,
13500,
51900,
42600,
12000,
46700,
45500,
6800,
17000,
null,
64300,
26300,
10600,
46900,
36900,
99100,
14500,
34400,
9200,
72100,
12800,
25500,
10800,
74140,
46900,
6300,
6000,
31900,
30600,
null,
313500,
30900,
32400,
81000,
43200,
33900,
27400,
null,
null,
27471,
6700,
5800,
23200,
25500,
21500,
9500,
26700,
14100,
12800,
30300,
27700,
35200,
null,
21400,
8300,
34100,
null,
17500,
24300,
12200,
23500,
24500,
21700,
6000,
4200,
9900,
59300,
102200,
null,
53900,
26000,
41600,
9600,
5500,
53600,
21700,
47700,
17350,
11800,
null,
null,
7500,
19900,
12500,
42700,
5800,
15500,
40900,
6500,
18000,
29400,
9400,
48400,
16000,
30000,
24000,
183800,
24900,
70200,
1500,
17700,
8700,
26100,
9300,
54700,
9200,
5100,
8900,
null,
19837,
23600,
39500,
12300,
14900,
null,
null,
14500,
23500,
37550,
55600,
18900,
36200,
18300,
null,
10500,
9500,
5900,
78400,
30900,
20600,
15200,
71300,
12000,
19600,
10700,
25300,
null,
null,
44400,
60200,
900,
15800,
48700,
45900,
15400,
85900,
10100,
138900,
37500,
null,
59800,
18800,
46300,
14600,
39400,
14300,
40900,
125900,
17300,
13700,
16800,
43200,
4400,
20400,
18000,
7800,
27600,
19400,
14800,
16900,
22800,
null,
28100,
30400,
19900,
55500,
7400,
41600,
97500,
29100,
32500,
25700,
11800,
37300,
16000,
29200,
32300,
58400,
10445,
36300,
6400,
45900,
null,
48000,
55100,
5500,
30612,
21300,
23800,
9500,
53900,
69700,
42600,
11580,
null,
null,
25200,
25100,
30700,
16600,
24680,
17600,
27600,
13200,
7050,
12400,
26900,
123700,
null,
15900,
28100,
30300,
7000,
17300,
30600,
30500,
27400,
11700,
15500,
24500,
87800,
52300,
23800,
33200,
null,
7500,
13700,
103600,
27400,
53700,
12900,
118500,
20200,
null,
30800,
6500,
135300,
11800,
23400,
37100,
15300,
15200,
35500,
20800,
26100,
42500,
12300,
null,
129800,
18100,
33600,
45500,
8600,
30300,
17100,
4500,
23800,
11500,
23800,
45900,
null,
14300,
45000,
29700,
40400,
117400,
8000,
17900,
40300,
1800,
30200,
195500,
12800,
17100,
83700,
23700,
41800,
10200,
12600,
26200,
50400,
10300,
40000,
12900,
28100,
null,
28400,
59100,
15100,
33800,
23100,
24700,
50300,
24100,
6900,
13100,
24700,
10500,
null,
null,
48100,
43200,
21100,
8000,
78100,
19300,
19100,
18200,
28300,
23300,
6300,
32600,
13400,
6175,
49100,
46700,
26500,
34600,
39900,
4000,
36700,
34400,
113300,
16000,
42400,
94200,
28500,
6200,
null,
85700,
23600,
19100,
15963,
29700,
25500,
21200,
1800,
null,
16000,
18500,
39200,
80800,
18500,
11900,
16700,
40600,
39200,
19700,
76600,
58700,
32300,
40000,
66700,
99800,
96300,
null,
54800,
3800,
122200,
18800,
38000,
11800,
8300,
15200,
4200,
24500,
null,
null,
5800,
62700,
25800,
null,
32700,
38200,
87430,
50200,
15100,
26200,
38100,
43100,
37340,
36400,
29300,
27300,
34400,
100200,
25100,
55300,
47300,
20800,
9600,
34400,
39300,
9600,
14100,
40400,
20700,
21400,
21600,
null,
20100,
null,
17200,
13300,
18200,
10600,
114900,
30000,
58800,
38500,
28700,
9500,
4300,
15200,
null,
8700,
20100,
29500,
15200,
75700,
68200,
14400,
null,
16000,
null,
27900,
75900,
15900,
9300,
null,
null,
25400,
12300,
53600,
8300,
36400,
33200,
51520,
24900,
7000,
53800,
8100,
3700,
14400,
8300,
6100,
53410,
15500,
9050,
23300,
40000,
15800,
79200,
345000,
24500,
null,
16800,
109600,
null,
18900,
27700,
32900,
35100,
20500,
53700,
35400,
23700,
7000,
21200,
50100,
73400,
54200,
null,
null,
28700,
22000,
11300,
27100,
46800,
16800,
21100,
19900,
10000,
11300,
15100,
37000,
10600,
2700,
16200,
null,
33000,
36800,
21300,
11600,
23900,
46400,
4000,
11300,
8500,
34200,
40300,
8100,
18900,
15600,
14800,
7600,
22300,
null,
72200,
null,
16200,
null,
24000,
5100,
11000,
12200,
25450,
30000,
52400,
15200,
20000,
34300,
42100,
28300,
9700,
4200,
17000,
17500,
42600,
17000,
50000,
57500,
31700,
18700,
null,
31200,
29500,
10400,
5700,
11200,
67400,
35900,
55600,
17700,
22300,
48300,
54600,
34300,
67300,
51300,
45800,
23500,
40000,
25900,
24600,
10500,
45500,
19900,
null,
12600,
59100,
36500,
5800,
25300,
19500,
7800,
10500,
139800,
32200,
null,
53900,
24800,
43300,
21300,
157400,
43100,
null,
27600,
16500,
19100,
83500,
19400,
2000,
6600,
8200,
17900,
15000,
30500,
21900,
61500,
11100,
17900,
44400,
16700,
24800,
11600,
null,
56700,
36000,
20700,
31700,
64300,
56100,
53700,
3800,
25000,
38500,
28600,
11750,
74000,
13200,
54900,
22900,
20800,
70653,
17900,
23600,
11700,
7100,
50000,
26300,
13200,
30162,
9800,
12400,
17500,
null,
13800,
29000,
12100,
null,
12500,
22100,
null,
12562,
33600,
23700,
null,
20900,
39500,
18900,
27000,
10200,
36500,
6300,
37500,
21200,
24600,
11300,
32800,
30100,
17500,
null,
19500,
68800,
248900,
4500,
null,
5200,
34200,
26500,
26100,
12400,
30900,
54100,
50000,
null,
10800,
25800,
50600,
39000,
73900,
35500,
24400,
84000,
13300,
105200,
9800,
14100,
5300,
11400,
null,
10100,
12100,
48400,
44734,
33000,
7000,
12700,
null,
7400,
16600,
120100,
46500,
30200,
35100,
27600,
11400,
17700,
4600,
9300,
111100,
null,
35200,
null,
4800,
15200,
30500,
null,
87300,
null,
78100,
19500,
29500,
64000,
47500,
19600,
15500,
25300,
33300,
7700,
13700,
41700,
8200,
122700,
null,
22800,
72600,
48100,
18100,
13100,
8600,
36900,
44900,
34100,
19500,
40800,
55800,
16500,
19800,
13000,
null,
8900,
71300,
11400,
16400,
57300,
9700,
31600,
17800,
44800,
43900,
58100,
18500,
9300,
15400,
15900,
18400,
41800,
29600,
99000,
null,
37500,
11900,
47400,
27400,
13500,
13000,
4800,
35900,
20600,
29500,
53800,
23800,
15000,
63300,
60900,
51300,
19400,
98400,
null,
26000,
32400,
32500,
1600,
44535,
20000,
66500,
9300,
4000,
8300,
60800,
25100,
24100,
23000,
3000,
75300,
44900,
28000,
90500,
21900,
null,
22600,
24200,
null,
17000,
13100,
24000,
33900,
29000,
97500,
11000,
73600,
51600,
16700,
29400,
23000,
51800,
7800,
28500,
16400,
3000,
94900,
25200,
70800,
18300,
22800,
9900,
17200,
19700,
18400,
171600,
13800,
null,
37000,
21400,
null,
75100,
22300,
21000,
26300,
14400,
31700,
57700,
22100,
50600,
5300,
null,
18300,
16100,
162200,
22500,
5000,
12700,
16500,
46000,
15500,
22900,
18800,
21100,
34200,
28800,
15300,
28505,
null,
15260,
5900,
28000,
6700,
53600,
19100,
64600,
19400,
52074,
20400,
7200,
14800,
10800,
8300,
null,
2150,
50700,
9400,
39900,
51900,
77600,
56000,
25200,
null,
12900,
52100,
13300,
21600,
20600,
37000,
10800,
14700,
19100,
71800,
null,
123400,
63000,
35000,
46400,
27100,
6300,
33200,
68500,
null,
31800,
31100,
9500,
21200,
26600,
13000,
42500,
19200,
33900,
29600,
24200,
42000,
47100,
32100,
61000,
17200,
63200,
54900,
27500,
68800,
26200,
54875,
null,
30400,
11100,
32500,
57500,
31100,
15500,
40300,
55100,
24000,
16100,
19600,
45200,
8100,
25100,
18700,
null,
166000,
null,
28500,
27100,
107000,
null,
7600,
14900,
17200,
41900,
27000,
36000,
49800,
2500,
null,
11200,
23500,
46900,
null,
8200,
18000,
37900,
12600,
69100,
23600,
18500,
67900,
28200,
16700,
39000,
44300,
16100,
25089,
16000,
26700,
null,
36500,
19700,
34400,
61100,
103100,
76874,
null,
36000,
38480,
26200,
6500,
126400,
30400,
84800,
null,
4300,
53500,
14450,
35900,
14100,
7800,
null,
22000,
4300,
19600,
null,
18600,
27600,
42900,
35800,
18700,
17600,
36700,
3500,
19000,
5600,
19600,
30400,
22100,
53800,
24100,
5700,
38500,
36800,
26200,
7500,
null,
29800,
51700,
51417,
33600,
30000,
69388,
33000,
8800,
19300,
22500,
21600,
30400,
36700,
160200,
10200,
1500,
null,
33600,
12800,
83300,
null,
22400,
null,
31600,
null,
79200,
24500,
18000,
10000,
52900,
9300,
86700,
96800,
14900,
7300,
null,
23600,
68200,
11300,
15700,
12800,
20000,
80200,
15300,
30200,
26800,
11000,
37300,
20100,
null,
32100,
47100,
32800,
39800,
14200,
48800,
16400,
11300,
8100,
32300,
20200,
9200,
8200,
37500,
11700,
30000,
56300,
7800,
58300,
22500,
7600,
32100,
32400,
20400,
43000,
12900,
23600,
12400,
null,
69700,
49700,
27800,
25300,
32100,
15200,
13400,
18200,
22500,
9600,
43600,
46600,
7400,
null,
12100,
41400,
14700,
16600,
69500,
15200,
30200,
41000,
22700,
35500,
23900,
21700,
84400,
25900,
12800,
63200,
7000,
29400,
17800,
14100,
43300,
26500,
null,
12500,
16000,
55700,
17000,
17300,
40500,
15200,
16300,
20600,
26100,
null,
25100,
15600,
null,
40100,
8800,
121300,
26300,
35800,
4300,
24800,
14500,
75300,
10100,
19200,
7566,
11100,
52500,
48000,
13700,
30700,
16600,
19800,
14300,
12200,
8200,
26400,
81600,
39500,
24200,
53600,
null,
52900,
1600,
8200,
44400,
19500,
15800,
36500,
35900,
51254,
51000,
29900,
12000,
49100,
23600,
14000,
20300,
19700,
29500,
18900,
20900,
4000,
18500,
24500,
12200,
null,
26100,
22000,
43600,
4300,
19000,
null,
46500,
83000,
19600,
null,
28600,
11600,
30800,
6500,
107700,
37900,
20200,
14200,
96700,
33000,
89300,
26700,
32200,
73700,
7100,
28600,
31000,
63300,
64600,
27700,
43600,
29600,
34900,
41300,
null,
7600,
26300,
7400,
23200,
95700,
42300,
11300,
9300,
24000,
8600,
11700,
47100,
39600,
37500,
17000,
15200,
7800,
null,
6800,
11200,
19900,
40000,
14200,
26480,
null,
74400,
17000,
24000,
24800,
123000,
29000,
null,
7300,
70800,
13700,
13000,
12100,
17400,
7500,
18000,
54000,
11300,
84100,
91800,
35300,
36500,
16000,
14450,
42600,
32900,
37900,
42600,
8050,
39700,
16400,
70800,
12600,
7300,
47500,
21700,
15700,
19900,
38500,
181400,
58800,
61380,
18100,
21600,
50900,
16000,
24600,
14800,
51400,
19100,
47000,
25400,
62100,
27100,
7900,
15100,
41900,
33000,
17100,
5000,
21400,
null,
26600,
43900,
30400,
16400,
null,
48800,
null,
22400,
null,
64600,
13690,
112500,
32000,
10500,
14700,
14400,
9600,
null,
26400,
198700,
11500,
14000,
21600,
11700,
14800,
11500,
11900,
37400,
53400,
17500,
33300,
9100,
99300,
121200,
95600,
null,
32300,
24200,
19500,
6200,
19400,
36100,
39000,
21400,
6300,
41900,
27800,
15200,
13100,
19700,
83900,
6400,
87600,
13800,
88800,
43500,
36100,
59400,
51600,
48400,
3800,
33300,
10900,
66200,
5300,
17600,
46900,
null,
36700,
70000,
8400,
26000,
30100,
50200,
46000,
12700,
45000,
14200,
68400,
21600,
74800,
12500,
43900,
17400,
60700,
21100,
17000,
30500,
10500,
16600,
12400,
12500,
64300,
null,
21300,
11000,
14600,
10300,
31000,
45400,
6400,
14500,
15100,
29500,
76400,
26800,
8900,
89300,
null,
41600,
14800,
null,
6000,
28800,
12300,
17100,
9500,
10700,
11700,
33577,
6500,
26400,
49700,
14800,
42300,
9400,
93200,
15100,
11300,
11700,
18300,
22600,
35900,
5200,
null,
29000,
8600,
44200,
38800,
40400,
23263,
22300,
26900,
25100,
28700,
18300,
40900,
14500,
14500,
8500,
34900,
37600,
22100,
30800,
13700,
17900,
15600,
43000,
33800,
58800,
21300,
23400,
17800,
24600,
23700,
35100,
null,
38100,
14800,
32600,
37300,
34100,
26300,
18700,
16200,
29600,
35500,
21900,
24400,
8300,
22500,
8500,
53100,
null,
10800,
23900,
89800,
6500,
49800,
25000,
13300,
22500,
30600,
42500,
54100,
34200,
23400,
54300,
51200,
111200,
8600,
23200,
26600,
91900,
44000,
31000,
15900,
18300,
10800,
26900,
19350,
7100,
7400,
38900,
21600,
9300,
27900,
24100,
37300,
null,
null,
26300,
75800,
49600,
10700,
439100,
35500,
10400,
null,
14700,
null,
29100,
48000,
6500,
80700,
14000,
13000,
9400,
null,
45000,
17200,
28800,
21250,
31500,
55500,
65200,
23100,
30900,
27400,
17600,
13700,
null,
9800,
31457,
15000,
117103,
100900,
4800,
48000,
6900,
16000,
26600,
22900,
29400,
31300,
26000,
12800,
7400,
69500,
31300,
10900,
54900,
31500,
14100,
null,
40700,
15600,
5100,
null,
20900,
35086,
36500,
11200,
null,
48100,
18000,
61300,
10000,
22000,
28300,
14600,
9800,
12200,
22800,
null,
8700,
122200,
106800,
1500,
14800,
30700,
20500,
3900,
21200,
121500,
9500,
44800,
20000,
16700,
15600,
144000,
36900,
25800,
23900,
48700,
50500,
66700,
22900,
28800,
12800,
35300,
32300,
17600,
18200,
41900,
9100,
null,
51600,
13600,
27700,
50800,
44600,
7500,
22100,
10500,
3300,
24700,
3900,
55900,
43000,
17200,
25800,
23500,
27600,
47300,
45100,
16400,
36700,
51100,
39800,
32100,
78800,
24300,
41200,
21800,
57400,
14600,
39500,
17000,
24600,
13800,
27500,
22400,
23200,
9100,
133400,
27500,
34700,
19200,
43700,
25300,
22450,
8300,
19100,
37900,
15500,
35300,
25200,
31700,
null,
35800,
36200,
16600,
25400,
null,
18300,
74995,
10100,
5400,
36700,
29600,
14900,
33200,
14000,
108200,
7500,
13300,
14200,
20300,
1300,
27800,
5500,
129900,
25300,
139000,
8800,
null,
16000,
23900,
60200,
22700,
36300,
142500,
41000,
19100,
60438,
6200,
10000,
15400,
149300,
null,
null,
57600,
28700,
20400,
72500,
9300,
22600,
17900,
55100,
12600,
6000,
3700,
18700,
181500,
47000,
20800,
12800,
9700,
null,
53000,
14600,
14700,
13000,
36800,
13600,
19300,
121100,
9500,
25400,
18400,
22000,
11900,
11800,
18400,
27700,
31800,
8300,
9100,
34600,
38300,
22100,
80500,
43100,
25400,
3600,
23200,
11500,
78000,
6400,
7500,
15000,
27000,
22100,
34200,
7800,
31012,
37900,
1000,
9500,
7200,
42800,
null,
36400,
22000,
37400,
19200,
9900,
35500,
21400,
21700,
5300,
28000,
79100,
59400,
35700,
52100,
2300,
39600,
7500,
9200,
26400,
28300,
36900,
14300,
11700,
8300,
10500,
53100,
4500,
5700,
23100,
88600,
51600,
6300,
7000,
11900,
81100,
14800,
113200,
58300,
23300,
4500,
43700,
35400,
15600,
49600,
35200,
null,
24900,
39800,
32100,
null,
4600,
26400,
33300,
11600,
10400,
28200,
24000,
32600,
21600,
55700,
15300,
14200,
14700,
19700,
42400,
5300,
27100,
36400,
11300,
28200,
34200,
19300,
44500,
16900,
14800,
23500,
19100,
20400,
36100,
null,
25500,
10900,
11000,
51400,
20900,
20900,
19900,
23300,
25500,
27800,
32000,
17400,
null,
null,
226400,
null,
null,
6600,
16500,
30000,
7500,
null,
20900,
23300,
44800,
7000,
1000,
4900,
20200,
32700,
31300,
16300,
17900,
6200,
6800,
55400,
19300,
40200,
39600,
34200,
13400,
39100,
null,
14500,
37200,
null,
8300,
null,
39300,
48500,
13100,
43400,
86200,
25000,
64800,
41900,
59800,
17400,
42100,
null,
26600,
5500,
111300,
26100,
30800,
79400,
19900,
114200,
48200,
22400,
18800,
110300,
47400,
22400,
30400,
25600,
5800,
9700,
22800,
13500,
10500,
37100,
20300,
14400,
48200,
35700,
24300,
26000,
1500,
null,
45800,
39000,
18100,
4300,
9700,
293500,
5000,
11500,
33550,
12800,
11400,
34500,
70200,
34000,
23600,
25900,
59300,
17600,
29300,
23500,
95900,
56300,
null,
33100,
5200,
null,
null,
14500,
4500,
7200,
11300,
19500,
null,
33000,
58600,
33600,
11300,
37400,
47500,
42300,
30100,
28317,
32100,
null,
91600,
11200,
14800,
34400,
null,
91000,
177870,
4400,
60000,
33900,
21913,
103100,
6500,
53123,
16800,
122900,
77000,
91200,
48000,
7600,
null,
12100,
43100,
null,
17400,
142900,
20100,
8100,
17100,
10800,
null,
16400,
17200,
22500,
8400,
50900,
13100,
41400,
5000,
26000,
15600,
24010,
22600,
40400,
30051,
23500,
20518,
29900,
51300,
82400,
21000,
37500,
23900,
68000,
33800,
19900,
41100,
14800,
8800,
37545,
171600,
26100,
26900,
18900,
44900,
5850,
10100,
68100,
65600,
13600,
null,
32100,
30600,
42300,
29300,
57800,
84900,
14700,
68528,
22900,
26700,
39100,
46800,
45400,
16700,
16700,
6400,
55500,
2900,
7547,
19000,
70200,
22200,
20800,
13200,
7700,
null,
32000,
20400,
20600,
43900,
37200,
4200,
20900,
6500,
23500,
7700,
7900,
119500,
44100,
11300,
144300,
8200,
28700,
14000,
7600,
40700,
null,
18300,
16100,
95100,
7400,
39500,
19400,
48400,
27700,
23200,
null,
14800,
14400,
11600,
4500,
23700,
94700,
5700,
8400,
133600,
24700,
22000,
5100,
14200,
110200,
16100,
26400,
36800,
24800,
5300,
39800,
39600,
17900,
5100,
28400,
37800,
29600,
96000,
21500,
29100,
26600,
19200,
21500,
19000,
null,
null,
11750,
22000,
39000,
null,
9500,
10300,
35200,
19800,
58400,
45600,
22300,
24950,
8200,
null,
12600,
27500,
6000,
25900,
9900,
null,
154000,
105900,
23700,
66300,
7200,
41600,
61500,
13000,
60000,
50300,
43000,
73800,
30462,
14100,
18400,
45100,
19100,
7600,
10600,
33200,
28300,
27500,
129600,
60700,
null,
37100,
39800,
36000,
24000,
9600,
15400,
null,
50100,
41674,
4100,
10100,
null,
30700,
33500,
null,
85900,
null,
2800,
null,
39500,
12700,
20000,
12000,
null,
null,
2000,
13430,
16400,
23400,
39500,
16200,
28300,
21900,
15100,
null,
null,
52300,
29000,
16200,
96000,
18300,
48900,
31200,
null,
35400,
55500,
null,
46800,
28300,
92200,
54500,
17100,
22300,
26700,
3200,
10957,
15300,
102125,
16700,
48500,
null,
21200,
43000,
20200,
null,
9700,
83900,
9600,
40100,
35800,
16900,
4300,
19300,
37100,
21600,
23400,
null,
14500,
null,
10100,
31100,
41800,
59300,
28300,
914900,
null,
19000,
16800,
null,
33000,
35120,
92400,
135000,
10800,
155800,
6500,
76000,
17900,
34200,
53100,
27700,
13900,
27800,
100940,
31600,
10000,
21200,
41300,
17300,
36500,
14000,
81400,
4500,
46200,
19200,
10100,
68701,
12000,
12100,
18100,
100500,
57200,
null,
77800,
9100,
8600,
7800,
25200,
26000,
13500,
26000,
45900,
12800,
11700,
9800,
78200,
13400,
34600,
35600,
5700,
157000,
36500,
8500,
38600,
38400,
13800,
2700,
31200,
36100,
101900,
127500,
11200,
37300,
29300,
33400,
21600,
18300,
52300,
12006,
30800,
59700,
10700,
119600,
null,
21300,
36900,
12600,
10400,
11000,
13400,
27900,
8600,
26600,
45900,
41000,
12500,
27800,
79200,
22800,
null,
26500,
37800,
9000,
null,
16300,
null,
18300,
24900,
34000,
40500,
7000,
null,
17300,
32900,
21900,
23500,
11800,
9100,
22200,
96700,
14300,
37500,
24000,
15600,
18660,
17400,
16600,
74000,
32500,
14800,
19700,
50400,
20100,
56600,
null,
86100,
41500,
9300,
null,
41000,
32800,
22700,
17500,
null,
27300,
null,
20500,
62300,
41700,
18400,
22454,
109300,
22100,
103200,
19100,
8500,
41700,
32900,
25400,
42200,
34300,
23500,
25000,
11600,
52200,
16200,
136600,
29500,
32500,
555800,
5000,
20600,
9500,
53900,
29200,
12900,
22600,
5600,
90100,
33200,
18600,
21000,
15550,
42700,
56200,
null,
17849,
null,
56075,
41900,
15100,
26200,
7500,
39300,
29900,
14000,
26000,
null,
26800,
10200,
40700,
10800,
17500,
18500,
15400,
19000,
3200,
21600,
98300,
3600,
26604,
null,
36000,
25500,
41500,
35400,
9800,
12300,
3600,
null,
27600,
null,
63300,
47300,
14900,
36500,
21000,
20700,
11100,
46000,
74000,
14700,
36700,
54500,
null,
6800,
25200,
26100,
51300,
57100,
15700,
null,
37808,
44600,
6600,
10900,
null,
35900,
25200,
12300,
40100,
null,
15900,
15600,
54900,
13500,
9000,
56800,
38400,
null,
15000,
15400,
12500,
22500,
18100,
67200,
17400,
85500,
53400,
3500,
24200,
null,
29800,
27200,
4600,
81400,
19900,
19200,
48900,
68500,
12700,
14900,
18100,
28600,
13600,
2900,
24100,
27600,
25000,
25100,
28400,
74600,
30500,
5105,
19300,
null,
11700,
7000,
15600,
12300,
11200,
11600,
23800,
null,
29900,
68500,
27000,
4500,
31000,
15700,
17900,
16000,
6300,
null,
74200,
15500,
6000,
12000,
15600,
35900,
null,
19500,
96100,
39900,
21100,
3000,
62500,
16500,
23400,
20600,
17500,
5300,
13100,
49300,
6100,
28800,
25400,
18700,
15000,
15700,
24400,
13600,
39200,
42000,
3400,
19600,
34100,
4500,
51100,
12100,
37000,
42000,
18100,
177900,
18800,
null,
6450,
12100,
36200,
null,
11200,
32100,
17000,
26000,
56130,
26800,
4350,
null,
9200,
null,
8400,
6700,
42600,
20900,
7600,
65000,
27000,
58700,
null,
16800,
32400,
51600,
64000,
20500,
10800,
28700,
20100,
20100,
20700,
76300,
36600,
21900,
22400,
14200,
44937,
3800,
42000,
23400,
6700,
49200,
5300,
24800,
93700,
7800,
29000,
53700,
16300,
34200,
19600,
4700,
13200,
28000,
8950,
27300,
25500,
36000,
null,
88500,
null,
5100,
39100,
7500,
44400,
null,
35800,
6100,
66800,
13200,
34200,
79600,
12500,
69900,
13500,
15800,
94900,
null,
6800,
12500,
null,
null,
176500,
15300,
1600,
11300,
30200,
86500,
22200,
39800,
23400,
131300,
null,
37900,
null,
null,
27200,
53103,
157200,
null,
36400,
25300,
null,
10500,
9700,
null,
23600,
14800,
15300,
124600,
18300,
17700,
67300,
null,
40000,
49200,
68600,
58000,
41700,
85100,
10900,
15500,
null,
42900,
5740,
25600,
59000,
9000,
18600,
35000,
50300,
null,
5700,
8300,
48000,
32400,
26700,
11300,
null,
null,
15800,
30300,
54200,
null,
4800,
33787,
29400,
14700,
18800,
68500,
32000,
22800,
8200,
7200,
21400,
45200,
39400,
50200,
31900,
4800,
7100,
179500,
31400,
13700,
34900,
57300,
71600,
146500,
28200,
56800,
33100,
19800,
21000,
18300,
27300,
55500,
7400,
null,
28700,
8800,
27300,
22700,
20100,
7400,
5600,
68500,
8300,
3300,
17000,
16700,
16000,
52800,
13600,
30100,
9000,
39700,
45600,
15600,
31300,
7000,
73700,
20400,
17800,
9000,
35100,
7100,
47500,
15400,
12800,
47900,
null,
19700,
28400,
31900,
144900,
31100,
56400,
23000,
3700,
35900,
8000,
7700,
14100,
null,
null,
41300,
28700,
67000,
5200,
18500,
null,
21800,
25200,
3700,
23500,
9200,
35900,
36300,
24700,
37060,
11700,
4700,
20300,
43500,
19300,
43200,
15600,
34000,
null,
36400,
54200,
41700,
40700,
23600,
4200,
19900,
13200,
28000,
11700,
79400,
100200,
35400,
21000,
7700,
4400,
23800,
19700,
17600,
41500,
24900,
60900,
28800,
8047,
17100,
12500,
25100,
2600,
17500,
61200,
27500,
3800,
63200,
19900,
8700,
20000,
9800,
22600,
15200,
87300,
128800,
26200,
12600,
42800,
37000,
18591,
58700,
30600,
34100,
11100,
11400,
6600,
37200,
24900,
12300,
24300,
8800,
18600,
24600,
88200,
52800,
13600,
12300,
7200,
39200,
null,
40700,
34900,
23400,
17600,
87300,
23700,
18900,
33400,
41400,
null,
24400,
20900,
26100,
null,
30200,
21600,
19900,
4100,
28500,
11200,
10500,
null,
12200,
119200,
null,
55500,
9800,
34400,
20200,
29400,
null,
68200,
55900,
23800,
11300,
88050,
25700,
13600,
11000,
17800,
null,
7300,
36700,
22800,
26000,
15100,
4100,
44700,
4600,
28100,
24400,
31700,
21400,
14300,
12500,
12800,
28500,
24200,
8100,
40100,
24000,
38800,
25800,
54300,
32700,
21300,
52500,
13800,
12275,
22700,
16500,
24500,
31200,
31995,
14800,
59000,
47900,
32500,
null,
24800,
34100,
null,
24400,
10300,
null,
19100,
47100,
73600,
15500,
48400,
13400,
27900,
10000,
28900,
16200,
null,
27500,
16600,
15400,
37300,
19200,
6300,
8300,
11650,
39700,
8000,
31900,
69200,
8100,
6200,
7800,
12500,
13300,
null,
14600,
17900,
116400,
15900,
89500,
29400,
24100,
27400,
65500,
29200,
82300,
3600,
31292,
72500,
25900,
48400,
44800,
53800,
32300,
30000,
null,
97400,
35300,
null,
60400,
null,
4600,
null,
14000,
24800,
4600,
23877,
30100,
105400,
25200,
61850,
27600,
39900,
9900,
10500,
4600,
19400,
27500,
15600,
19400,
17800,
10100,
7600,
56200,
29100,
32721,
39900,
50500,
19000,
21500,
37500,
20600,
27900,
2800,
33600,
26000,
31300,
null,
43900,
13400,
9700,
null,
10900,
21200,
25300,
118000,
24400,
45300,
22800,
39900,
244800,
41800,
null,
4900,
null,
88200,
32200,
12600,
35200,
19300,
81200,
29900,
22400,
58200,
7500,
40200,
6800,
27600,
15800,
40200,
39500,
25200,
4500,
24800,
24500,
29900,
9600,
13900,
13900,
null,
60800,
41700,
21000,
10900,
7700,
153600,
154500,
23900,
40700,
null,
3000,
20100,
91400,
null,
9700,
10200,
13400,
38100,
40300,
3150,
24300,
29600,
19000,
83700,
null,
27200,
31500,
20200,
34000,
25100,
11800,
9400,
21200,
15600,
25145,
41900,
41300,
2000,
18200,
28600,
15900,
37700,
31300,
14500,
35800,
24700,
null,
65500,
4200,
7000,
59100,
null,
7100,
17900,
19700,
12700,
35800,
22800,
null,
122900,
8500,
14800,
40100,
51268,
26400,
117200,
197800,
45100,
159900,
20600,
53600,
148100,
35900,
51300,
36900,
80900,
15000,
42600,
7200,
56400,
16700,
24000,
5000,
80600,
8200,
48900,
47000,
11500,
12600,
22800,
7700,
23900,
14200,
36000,
22500,
52350,
6500,
7300,
13400,
56000,
120900,
null,
22800,
34700,
34100,
15170,
26000,
42700,
11900,
50619,
18200,
39300,
27000,
null,
2700,
41500,
26500,
33900,
52500,
12400,
51700,
35200,
2700,
26000,
null,
58300,
33100,
null,
62400,
52300,
18200,
26400,
13000,
52200,
10700,
23100,
21500,
null,
18600,
23000,
46500,
43200,
14100,
7600,
10100,
12000,
28200,
null,
33600,
25000,
15400,
19300,
21300,
59100,
6800,
7700,
14100,
36800,
11250,
13500,
12900,
19000,
24800,
null,
null,
32200,
56334,
8200,
null,
18000,
20200,
6700,
6500,
5100,
10400,
41600,
23500,
48200,
13900,
47800,
16100,
2200,
18500,
42000,
28700,
26500,
111300,
13500,
17000,
27200,
21600,
13100,
18500,
15500,
10600,
57480,
53200,
4000,
32400,
6900,
17200,
43400,
17300,
36000,
68900,
72900,
48800,
19200,
27500,
4250,
42350,
null,
null,
27500,
16000,
41300,
12700,
16100,
26600,
59700,
26800,
37500,
51200,
48700,
12000,
29300,
2000,
7500,
1600,
11000,
6700,
12700,
6600,
33800,
48300,
23800,
27700,
53100,
39900,
31400,
35285,
26300,
19500,
11100,
23700,
null,
85500,
17300,
15300,
31400,
89700,
15100,
7300,
39909,
18200,
24600,
40000,
24800,
27900,
13900,
11300,
1500,
25400,
30800,
3600,
92600,
17000,
19400,
13000,
18800,
22300,
78000,
59500,
10400,
56200,
17000,
60000,
19000,
24500,
35300,
17800,
500,
88700,
44419,
33200,
20600,
11800,
10000,
27700,
7000,
4500,
62000,
13700,
74500,
12600,
22400,
null,
12300,
44100,
14100,
15900,
33400,
12000,
28300,
40300,
29600,
null,
41600,
22500,
125200,
38400,
9000,
94500,
26300,
15600,
18600,
15200,
12300,
3000,
13000,
null,
6200,
20700,
22600,
10500,
30900,
3000,
35900,
153400,
null,
7400,
12300,
19200,
391000,
9000,
87400,
27600,
21500,
null,
14000,
69200,
19384,
14600,
7000,
null,
75100,
88800,
76500,
14900,
null,
null,
31000,
30500,
40700,
23000,
24400,
104600,
27800,
21800,
27900,
54900,
25000,
42200,
44700,
16300,
null,
220200,
3800,
25000,
27200,
40700,
26000,
19600,
26300,
38200,
30700,
4450,
28600,
8300,
8100,
54600,
16000,
35300,
null,
133300,
15700,
11000,
11100,
14500,
26000,
26800,
53700,
36700,
37900,
34300,
25300,
53400,
15900,
18100,
null,
29200,
167700,
26400,
8300,
49800,
43900,
115200,
67800,
9700,
29300,
12400,
null,
15700,
10100,
36100,
20000,
9300,
138400,
45700,
15400,
16500,
16100,
null,
7500,
80600,
33000,
4300,
5900,
10300,
87000,
24400,
49200,
17800,
94200,
13700,
46400,
19400,
33700,
17400,
11200,
104400,
6400,
18800,
42700,
62100,
49000,
22100,
32032,
64000,
8800,
22000,
35300,
56700,
25600,
14700,
24000,
6500,
9000,
23600,
16200,
9000,
11400,
25300,
30400,
28200,
10100,
12700,
6400,
11500,
null,
6650,
4900,
3000,
13700,
34000,
29300,
20300,
20400,
17700,
81700,
38900,
12100,
15500,
34500,
21000,
38600,
27600,
21700,
44700,
5900,
7900,
15400,
54800,
11900,
58100,
291200,
15100,
89400,
26500,
44000,
46000,
13900,
13500,
21900,
44900,
5100,
28200,
17300,
18300,
12800,
130500,
20200,
38300,
null,
57200,
32900,
4700,
19200,
26200,
36000,
35800,
22000,
17100,
16700,
24400,
31900,
25600,
null,
37700,
43100,
23600,
118700,
16000,
13900,
11900,
13600,
22475,
24800,
11700,
35100,
4400,
4900,
null,
31400,
26900,
26000,
5200,
12000,
44600,
80000,
33900,
20900,
null,
31900,
61096,
3400,
30100,
14400,
108551,
24000,
20400,
11700,
null,
1500,
8300,
19600,
20000,
27300,
28000,
14100,
3400,
27100,
null,
28300,
25700,
39000,
19700,
14500,
13500,
15700,
43100,
36480,
null,
17500,
50668,
5300,
5900,
6400,
57900,
19000,
null,
11100,
31800,
23100,
12300,
62800,
43700,
34900,
9800,
29300,
27200,
26300,
20200,
56800,
12200,
9900,
11400,
42400,
16300,
3900,
42500,
28700,
91400,
12500,
14500,
33500,
27900,
11000,
null,
null,
81100,
19000,
15900,
11200,
27480,
31900,
13200,
20100,
34200,
4500,
null,
52800,
34200,
23375,
41303,
null,
76300,
183700,
47200,
32300,
60500,
125300,
29200,
26450,
12100,
29000,
15000,
40200,
33200,
43300,
11100,
16800,
23800,
7100,
35300,
30400,
45900,
10200,
13600,
23400,
12400,
5900,
38700,
20150,
35100,
19300,
140190,
5400,
22300,
98600,
16100,
36400,
33000,
50400,
21400,
29200,
18900,
30200,
2800,
null,
22600,
23700,
21800,
24600,
143800,
60200,
14700,
27300,
16200,
21200,
null,
null,
2400,
45200,
38900,
19300,
32200,
20100,
31300,
18100,
178025,
15700,
27300,
36700,
null,
67000,
8500,
17200,
17300,
28400,
25100,
22800,
15300,
8400,
15300,
58400,
18700,
13500,
18400,
null,
23500,
19800,
26100,
13500,
71800,
5700,
18200,
7500,
17300,
44900,
8900,
28800,
5500,
null,
11400,
10200,
19000,
41800,
61500,
57300,
54000,
6100,
null,
20900,
7300,
10800,
108572,
31862,
35300,
24500,
28700,
37300,
49300,
23900,
30100,
27900,
26100,
70500,
44500,
21200,
22000,
55200,
43800,
51400,
45300,
47900,
50000,
36700,
17100,
64000,
48900,
12100,
41500,
50200,
9700,
68100,
null,
12900,
18500,
6700,
null,
19600,
92500,
7900,
41100,
7800,
26200,
9100,
7200,
30700,
22400,
74900,
22200,
38100,
18600,
73950,
29400,
96700,
57100,
17700,
70400,
8800,
8800,
43500,
32000,
22300,
22900,
20700,
13300,
22900,
68800,
27900,
17700,
23900,
null,
25300,
33100,
23500,
30500,
null,
10800,
73000,
73600,
16300,
8600,
15300,
55800,
98200,
16000,
35600,
17200,
14700,
6700,
23000,
42700,
42300,
10300,
12800,
15000,
70024,
24800,
null,
48100,
9500,
32900,
32600,
53400,
23500,
null,
18500,
28900,
13700,
42500,
44900,
27200,
6000,
36100,
14000,
25500,
null,
54100,
27400,
15800,
48700,
null,
61500,
null,
29600,
19100,
23900,
18800,
10000,
23900,
48900,
346600,
47900,
6100,
3200,
67500,
null,
18400,
48200,
55000,
null,
null,
72300,
23200,
null,
64300,
41000,
18500,
40000,
42200,
12800,
197900,
18200,
10500,
15600,
40200,
44300,
14100,
13200,
53700,
18800,
65900,
9600,
13500,
42200,
37600,
12700,
11100,
59500,
23800,
71856,
53900,
37500,
27400,
7300,
22800,
177900,
11000,
16400,
22900,
null,
14700,
7500,
36000,
6000,
34400,
52100,
9000,
21600,
30700,
52900,
49110,
29200,
34500,
19100,
90600,
34600,
27100,
96800,
17400,
11200,
58400,
20200,
null,
28400,
15800,
14300,
39300,
16400,
12700,
151624,
14600,
17000,
39100,
22900,
53900,
null,
22300,
13400,
32800,
null,
9500,
41300,
11300,
19100,
13000,
23300,
14900,
33900,
5400,
55600,
32200,
45500,
10000,
21800,
31400,
43502,
14900,
53600,
7500,
66200,
41200,
24200,
11900,
53000,
8900,
null,
38200,
30000,
800,
41300,
51600,
17500,
2400,
97300,
27500,
15000,
25800,
32800,
6600,
44800,
37900,
21400,
12200,
46600,
77100,
10400,
22300,
23100,
32000,
46400,
null,
9800,
41700,
30300,
36300,
30100,
18100,
null,
13200,
40800,
8300,
19500,
14100,
18900,
24100,
31600,
32701,
22500,
25200,
119500,
28100,
14100,
29500,
47800,
32000,
45500,
97400,
34000,
32400,
55700,
27300,
17200,
12700,
16200,
9000,
10800,
16900,
23300,
19500,
8800,
18200,
35400,
19800,
12500,
5100,
14400,
94100,
87100,
23500,
10029,
13600,
32000,
13600,
6400,
23200,
null,
13300,
15700,
39400,
117300,
null,
20000,
null,
6050,
15500,
67600,
null,
17900,
6800,
34300,
11900,
9300,
6500,
38900,
20700,
17700,
16600,
16800,
28700,
15300,
24900,
42900,
15300,
183900,
29200,
58400,
69200,
19800,
33500,
44500,
22000,
15900,
44500,
9700,
null,
13600,
8800,
10688,
20100,
24900,
46200,
20300,
13800,
null,
10700,
null,
5400,
156200,
null,
17300,
null,
5100,
4300,
54870,
23400,
296700,
17500,
10600,
38100,
18900,
null,
18900,
null,
9600,
18500,
14100,
36700,
23200,
7100,
151700,
5300,
20300,
23800,
26100,
48800,
13000,
40000,
31000,
39100,
47800,
0,
11700,
11300,
6900,
300,
8700,
13700,
14100,
10400,
13300,
89100,
15300,
7500,
14500,
11800,
41900,
16300,
22300,
3500,
13400,
16900,
16000,
25000,
17700,
4800,
261500,
32689,
6900,
12900,
12800,
null,
null,
67800,
14500,
null,
null,
22900,
35300,
27300,
7400,
24100,
15900,
19400,
62900,
14900,
10900,
11300,
8300,
16800,
37200,
31800,
5200,
11400,
64100,
36700,
54000,
null,
69400,
4600,
29600,
5500,
37800,
10800,
13600,
73900,
69100,
14100,
17200,
null,
68100,
8500,
18700,
4600,
11700,
28300,
16500,
9200,
46600,
18200,
null,
21900,
19300,
68600,
17350,
17100,
11500,
20400,
8300,
2000,
20100,
8400,
42100,
38800,
null,
null,
22500,
74300,
10200,
43600,
3000,
107000,
47700,
16000,
null,
7800,
21900,
15600,
13400,
13400,
48000,
29400,
13900,
32300,
10900,
22200,
112500,
43700,
31500,
20500,
10800,
7700,
24100,
81127,
6500,
12400,
35600,
34300,
40100,
10400,
null,
13400,
30000,
7400,
27400,
13000,
13400,
30000,
18500,
25700,
14700,
93200,
54900,
26200,
18000,
14600,
76500,
6500,
24600,
1200,
66400,
24100,
4500,
25200,
20800,
17000,
48400,
20000,
null,
2400,
10200,
34500,
35100,
205553,
25200,
54600,
28300,
11200,
26000,
32700,
4500,
8100,
11750,
88400,
11100,
14500,
69900,
2000,
82300,
52600,
23400,
47500,
5500,
17400,
20000,
12600,
20900,
8200,
19200,
12600,
4100,
38000,
null,
45500,
null,
47300,
19900,
20800,
77600,
156150,
3900,
37700,
24100,
6800,
null,
null,
37769,
25800,
null,
11300,
13300,
25500,
21400,
50000,
7400,
27500,
4200,
35900,
18700,
null,
71700,
84800,
28175,
9800,
9600,
7000,
17000,
5100,
50600,
33400,
10900,
23250,
23300,
22100,
28900,
37287,
51000,
76400,
25100,
25000,
26300,
29400,
16100,
11500,
18000,
25300,
12700,
63300,
10900,
20900,
24000,
62400,
8000,
18400,
7800,
10000,
13900,
177811,
35700,
204900,
7600,
3800,
21300,
78000,
14400,
null,
25500,
76900,
16400,
25300,
44100,
63100,
10200,
845,
12000,
12900,
10800,
null,
4000,
null,
26800,
9400,
null,
13900,
86761,
48900,
34900,
145300,
7600,
10300,
41100,
46000,
45800,
null,
7700,
48200,
14011,
68100,
5700,
30100,
19000,
25900,
11600,
24200,
8900,
33000,
12200,
20300,
22200,
8900,
null,
13500,
16200,
7200,
4700,
27100,
54000,
35500,
22200,
27000,
15100,
null,
22500,
32600,
null,
6500,
19500,
5500,
41200,
42800,
150000,
13400,
null,
20600,
46700,
7500,
23800,
47500,
55500,
36529,
67800,
10100,
23400,
10400,
29900,
19300,
26900,
41600,
13100,
76727,
10050,
6300,
12700,
27100,
9000,
23900,
104300,
15400,
17200,
10500,
43500,
27600,
26000,
31900,
89668,
22600,
4500,
64001,
26500,
94600,
28000,
441100,
22200,
18100,
29600,
38400,
27800,
31300,
6000,
30000,
75000,
16100,
420500,
86950,
17400,
32400,
null,
null,
28500,
61200,
26200,
7000,
18800,
null,
31500,
null,
41000,
15300,
6500,
null,
52600,
6800,
8200,
16400,
34300,
20900,
29000,
null,
22700,
26800,
16700,
9400,
16500,
70700,
59400,
null,
25800,
22100,
40400,
null,
72200,
60500,
33800,
40900,
4300,
23500,
45400,
12000,
39200,
39300,
2800,
31200,
null,
57314,
101300,
27000,
32800,
16200,
20300,
18100,
40500,
92110,
19700,
null,
34000,
12400,
28000,
47600,
12900,
11600,
24300,
67500,
35000,
24900,
8200,
80100,
37600,
31400,
81600,
23500,
52100,
16300,
null,
21600,
14600,
18500,
26400,
46300,
64730,
null,
13500,
15800,
24900,
5800,
15200,
30900,
63300,
16650,
13200,
47850,
14100,
13000,
13400,
null,
36400,
22200,
20000,
5300,
18100,
56000,
24100,
289470,
94400,
6900,
null,
43600,
18600,
60500,
8100,
15200,
16900,
17600,
15800,
18300,
9700,
10700,
6700,
19100,
null,
12600,
63000,
27900,
8700,
81400,
16200,
14900,
41700,
19200,
47600,
61300,
20900,
26600,
45500,
28900,
69800,
54900,
9000,
27200,
6700,
12000,
24300,
9400,
35400,
26600,
113300,
15300,
22300,
13600,
40700,
60400,
71100,
13400,
37000,
11600,
9700,
11600,
18700,
null,
70200,
38900,
21200,
9300,
16500,
57700,
6700,
1350,
22600,
92600,
55600,
68400,
13500,
6700,
4100,
134500,
41300,
12300,
57000,
27939,
7300,
14200,
47000,
42700,
33600,
25500,
23400,
110200,
35400,
25800,
23400,
19900,
264000,
15500,
17400,
null,
101700,
37900,
63500,
null,
11700,
12200,
21500,
15700,
54500,
40500,
13000,
19800,
8300,
46000,
41300,
9800,
26000,
31700,
16700,
null,
null,
56500,
24900,
null,
11700,
27600,
7800,
23100,
23800,
19900,
null,
24300,
15000,
13900,
16200,
null,
19400,
2800,
38000,
12990,
27100,
25175,
32400,
24700,
182200,
33800,
52500,
23860,
31500,
24100,
21400,
24200,
7800,
17303,
25500,
64600,
11200,
null,
37100,
17300,
56200,
36100,
45200,
8100,
9500,
114900,
21200,
null,
80600,
47300,
80800,
18400,
34400,
16400,
10250,
24100,
96900,
7600,
57300,
28000,
35000,
52000,
20200,
21000,
36700,
33000,
47900,
29400,
19700,
35900,
20400,
23900,
28100,
3300,
10900,
45900,
null,
38400,
15500,
12900,
7400,
45600,
18800,
44000,
36000,
14400,
34800,
40700,
11100,
70600,
22100,
19700,
null,
64900,
2600,
37700,
9100,
27500,
12000,
28400,
52100,
30400,
5900,
51500,
48100,
20400,
33400,
5600,
77200,
29600,
15700,
4000,
null,
13600,
77100,
15200,
14500,
16100,
12000,
10500,
50225,
null,
37700,
40960,
7700,
6000,
9900,
5500,
10600,
5000,
30200,
33900,
null,
40300,
17400,
15300,
5300,
51300,
12300,
9700,
37300,
16400,
41300,
10700,
14300,
null,
null,
28500,
31000,
50200,
65900,
32800,
7300,
46400,
45200,
66700,
64100,
11900,
13500,
15200,
3000,
20500,
15000,
38600,
null,
15900,
32300,
5700,
56100,
22700,
5000,
61800,
21800,
75100,
33100,
41500,
53200,
17300,
9000,
47300,
23200,
36900,
178600,
23000,
64100,
21500,
18300,
16000,
13900,
10900,
14000,
27800,
17800,
null,
13900,
47300,
4600,
21300,
50300,
54300,
34600,
15500,
8100,
4600,
31800,
35200,
null,
17800,
21000,
7700,
53300,
17900,
14000,
21800,
83300,
34800,
null,
8900,
15600,
47900,
39700,
29300,
8000,
24800,
8200,
54400,
18600,
51600,
29300,
57300,
14100,
7300,
30400,
11200,
40000,
15000,
23800,
38600,
108900,
null,
23300,
48600,
35500,
13040,
21900,
59900,
41800,
5900,
30400,
25300,
11300,
null,
16200,
32300,
18300,
6200,
8200,
51600,
36200,
35000,
41900,
32200,
16000,
28700,
14400,
10500,
97070,
18400,
248900,
30700,
69900,
47500,
14300,
52600,
37800,
22700,
15000,
31000,
23600,
11200,
11100,
17800,
35973,
9300,
null,
13700,
22700,
8800,
54718,
4800,
35800,
46000,
21600,
2500,
57700,
22100,
null,
47400,
23600,
8400,
16000,
24500,
28100,
45000,
2816,
13000,
71100,
10500,
6500,
8537,
28300,
42000,
26600,
23000,
20200,
33700,
12700,
18500,
18600,
17400,
29700,
null,
26500,
29600,
33300,
53300,
63000,
15600,
28100,
17000,
22100,
14000,
32500,
null,
26000,
60000,
35400,
null,
25700,
26700,
29585,
22700,
46100,
22900,
16000,
3750,
17300,
3100,
7900,
13400,
10800,
50800,
5900,
39700,
85000,
18700,
18500,
24200,
22000,
27900,
7500,
106500,
15400,
46800,
71100,
61800,
76300,
null,
37600,
19400,
41200,
75000,
12000,
33600,
10000,
43000,
25500,
26400,
46600,
11900,
17800,
68100,
29500,
null,
null,
4400,
66100,
null,
25500,
19500,
8350,
30400,
50000,
4500,
25200,
57400,
43700,
23500,
16500,
57200,
28800,
41900,
33400,
21300,
21400,
92800,
27600,
22800,
30200,
42900,
20500,
15600,
18400,
136300,
30000,
null,
null,
28400,
8100,
11300,
2700,
63000,
52300,
9100,
38800,
21000,
89600,
35000,
12700,
11500,
41700,
15000,
52100,
91300,
32400,
55500,
35200,
null,
24100,
53140,
9000,
31900,
42800,
16400,
18900,
11800,
20500,
15700,
3600,
30500,
28900,
70600,
14200,
13000,
26300,
12500,
44300,
6000,
11400,
34400,
null,
21000,
19800,
53400,
11300,
13700,
12200,
46800,
60700,
35000,
28800,
null,
3100,
22900,
21100,
38000,
null,
47800,
45100,
28000,
10800,
10000,
12600,
23700,
null,
47100,
null,
23900,
23200,
16500,
38800,
13100,
12300,
50200,
66700,
13200,
71100,
17900,
6500,
36500,
4000,
28100,
23600,
26809,
27900,
null,
47800,
17200,
3000,
35500,
10700,
20400,
7500,
40400,
110600,
6400,
106800,
1500,
null,
8300,
33950,
41300,
10200,
15800,
22300,
18900,
null,
68800,
83000,
168400,
9100,
null,
19700,
32900,
6400,
17000,
85300,
37000,
16300,
49400,
27400,
41700,
null,
57500,
128500,
24500,
20300,
26200,
84300,
null,
null,
13800,
6100,
74500,
6100,
5700,
12800,
48600,
63100,
30600,
6100,
82000,
16900,
14700,
51500,
44100,
5500,
18700,
19300,
39600,
18100,
null,
14000,
16700,
65600,
6900,
33100,
34400,
41300,
9800,
35500,
16700,
70400,
20400,
23800,
67300,
30500,
12800,
91100,
4600,
56100,
42300,
25300,
58200,
71000,
26600,
43700,
14200,
53200,
25550,
6500,
4100,
33500,
15300,
25300,
3300,
29200,
22100,
58200,
24800,
22500,
10900,
19400,
64000,
86600,
19000,
14100,
41300,
3300,
23500,
13600,
20700,
56300,
32300,
15000,
11500,
35300,
86200,
12900,
23300,
131900,
null,
100100,
57000,
18400,
14300,
31300,
54400,
33500,
6200,
19300,
47400,
6300,
12000,
27100,
44900,
37100,
139900,
16500,
9300,
22100,
11300,
45700,
null,
31700,
12600,
17400,
10300,
48500,
32500,
29200,
9300,
20800,
40800,
53400,
9200,
11500,
20000,
16500,
66000,
20900,
25500,
20200,
45100,
13300,
null,
10300,
45600,
10100,
20800,
37000,
16300,
10200,
30100,
36500,
10000,
null,
40400,
6000,
20250,
28900,
24900,
7300,
22500,
18600,
107900,
12900,
42200,
19600,
28000,
85000,
30700,
89600,
null,
127400,
56600,
22550,
48000,
null,
106200,
1400,
41700,
15300,
53100,
34700,
10800,
null,
40400,
29300,
35900,
19700,
8600,
3950,
12100,
113600,
36800,
17000,
18200,
54200,
74200,
27100,
40100,
17200,
37100,
19500,
19900,
10500,
32900,
41300,
33700,
23286,
55800,
14900,
71800,
83888,
30000,
29900,
null,
28100,
10300,
46200,
11100,
78900,
6800,
67100,
137500,
6000,
12600,
20900,
16000,
16700,
73700,
null,
null,
27300,
12400,
55600,
6200,
6050,
14400,
12500,
8400,
49400,
24200,
18130,
27800,
39662,
27000,
20500,
7500,
48950,
34900,
34000,
null,
30000,
15900,
26700,
13800,
25600,
41000,
25200,
35000,
12500,
32800,
17600,
8300,
6500,
26700,
22000,
14700,
null,
22200,
91000,
44800,
27400,
42300,
43800,
15500,
11700,
null,
33700,
38700,
null,
null,
null,
24800,
5400,
41200,
3700,
72100,
null,
30500,
8500,
13500,
72600,
13000,
8400,
55300,
19100,
20000,
null,
65000,
39700,
null,
null,
14500,
1400,
48200,
6700,
24450,
null,
15600,
6800,
19800,
52300,
49700,
4600,
null,
22200,
49500,
null,
15900,
58100,
14500,
17400,
43900,
50100,
8300,
19300,
11500,
38200,
31000,
45400,
null,
23600,
70800,
18800,
74500,
50000,
4300,
24600,
8500,
11900,
null,
30300,
28200,
47200,
71500,
10400,
6600,
55000,
2600,
31000,
11400,
16100,
15900,
7700,
38700,
31900,
39700,
21000,
34000,
13800,
35500,
50200,
127800,
5900,
64100,
27200,
37300,
50800,
24500,
15300,
12300,
16600,
14000,
15700,
12100,
19500,
16400,
25400,
16500,
27200,
45200,
12600,
50700,
27700,
71600,
4400,
36400,
32800,
17500,
32700,
17700,
20800,
99800,
17800,
20600,
9700,
24000,
80300,
19100,
23500,
null,
9150,
48400,
null,
35700,
34400,
40700,
48000,
6010,
51300,
32900,
32400,
7100,
25000,
9400,
25100,
7500,
79500,
30983,
18900,
24400,
null,
15000,
8400,
81800,
2100,
39300,
65000,
12500,
16900,
6800,
18500,
13000,
35300,
6400,
19600,
110700,
15300,
95000,
629900,
59400,
20700,
29900,
16800,
39800,
19600,
17600,
11200,
37400,
16900,
65000,
53000,
11500,
24020,
9400,
51608,
73100,
48400,
26500,
40300,
17200,
62600,
14300,
49900,
21000,
13800,
14900,
49400,
25400,
9600,
31200,
27000,
11800,
null,
81600,
19200,
79800,
null,
42700,
16200,
17600,
13300,
27000,
42544,
22000,
null,
27000,
17200,
7900,
16000,
49100,
51100,
31700,
33500,
26900,
11400,
32600,
9100,
33900,
12900,
9200,
17150,
27600,
14300,
28300,
19500,
17600,
29200,
23500,
26300,
null,
5400,
13900,
58300,
71000,
67300,
53700,
58300,
18500,
17300,
5000,
14800,
36500,
null,
22800,
11200,
3900,
28800,
30600,
null,
15700,
51977,
15200,
74800,
26000,
53600,
63400,
18300,
5300,
25500,
13985,
null,
21400,
46900,
12500,
19000,
3100,
7100,
17700,
2300,
58200,
10600,
18700,
33500,
null,
12600,
58600,
22600,
30700,
53900,
13600,
68900,
2200,
null,
68000,
18200,
null,
27900,
57400,
20500,
22400,
38700,
14500,
26800,
18100,
37100,
28000,
39800,
21200,
18700,
4300,
23900,
51000,
7800,
13100,
null,
52000,
36800,
29800,
6200,
5050,
22400,
19700,
5400,
null,
19100,
47100,
12710,
61200,
38800,
null,
16700,
3300,
6400,
24800,
21000,
27800,
37700,
13600,
12200,
39500,
25500,
50600,
12800,
9400,
46200,
5800,
14500,
29500,
32300,
14200,
41021,
30900,
21400,
12800,
12300,
25000,
null,
66500,
45900,
17600,
null,
20100,
63600,
6700,
7100,
5400,
14700,
47200,
71400,
12300,
53309,
38200,
63100,
16500,
null,
20500,
62100,
15700,
6600,
49200,
25700,
7100,
17500,
54300,
47000,
98100,
11400,
40700,
null,
13000,
25000,
25200,
51500,
34600,
19700,
19500,
40860,
13026,
29828,
10200,
12100,
13000,
15900,
61100,
8100,
41600,
24900,
46400,
8300,
14900,
43400,
9500,
null,
null,
38400,
null,
50100,
22100,
56300,
8200,
34700,
17700,
18100,
30000,
18100,
41300,
55000,
26800,
49381,
34900,
10200,
44400,
12500,
17800,
4200,
27900,
12200,
38100,
null,
8200,
34900,
17200,
51000,
10500,
null,
26800,
10700,
11500,
11600,
35800,
23700,
9000,
5800,
13300,
null,
2800,
3000,
11200,
31700,
18400,
64400,
45100,
24800,
50100,
63300,
26300,
45200,
33400,
24800,
20200,
9600,
130300,
4100,
6200,
12800,
11400,
30900,
29600,
37700,
18800,
6200,
27600,
32500,
5100,
6000,
13800,
31000,
38800,
17900,
32500,
17400,
27300,
27100,
9200,
31000,
41000,
50900,
14300,
15100,
19000,
87200,
70000,
20300,
6600,
6700,
13100,
11250,
24300,
26200,
24200,
25600,
17300,
null,
7000,
62700,
9300,
4500,
31400,
29500,
51510,
62200,
34900,
27600,
6800,
63600,
8400,
97900,
52200,
null,
36200,
null,
65500,
16200,
15400,
6600,
null,
3600,
43300,
15100,
33400,
22800,
6200,
7000,
4800,
12900,
32600,
15500,
51600,
46800,
6600,
24800,
4650,
116000,
21600,
42700,
9700,
16890,
13600,
13600,
19000,
35000,
3600,
31000,
21100,
38900,
11000,
7500,
null,
null,
20400,
10000,
55300,
42200,
14700,
52600,
35100,
40400,
100100,
15700,
20100,
17400,
25300,
39700,
30500,
60100,
18000,
11700,
86000,
27200,
31900,
34000,
8800,
63300,
78000,
19000,
52200,
31800,
13400,
40000,
12400,
41500,
104700,
74900,
null,
1500,
19800,
null,
null,
20800,
5400,
3100,
26100,
3000,
24600,
53000,
null,
33500,
19825,
149500,
21900,
13600,
8500,
20000,
20700,
34900,
18433,
null,
28600,
11800,
47300,
66200,
15900,
33200,
26100,
109800,
43500,
41300,
21400,
14500,
68700,
null,
7500,
16400,
null,
16600,
123827,
15200,
11100,
8400,
44000,
41600,
47100,
42600,
118600,
13000,
52700,
20700,
15800,
20000,
54100,
29300,
10500,
105550,
null,
null,
28500,
10500,
null,
48600,
25200,
30700,
16100,
39800,
16600,
11300,
6000,
12700,
27500,
12600,
45400,
212000,
12700,
13600,
null,
75400,
21400,
236300,
56400,
36600,
14800,
17400,
11700,
26100,
null,
23800,
30000,
null,
42500,
27700,
36700,
9100,
26100,
22700,
null,
50700,
null,
13300,
72400,
17000,
null,
86800,
16600,
null,
28100,
25100,
30400,
30100,
6400,
31500,
32200,
24200,
96600,
36600,
87800,
4600,
7100,
14100,
22500,
40500,
56300,
44000,
98200,
12700,
20500,
22400,
45400,
21400,
34500,
null,
49300,
19400,
null,
null,
101000,
14500,
19600,
15200,
60600,
36200,
51700,
54900,
3200,
16300,
34300,
14000,
46100,
21200,
20000,
39200,
17800,
null,
7500,
11300,
24000,
5400,
10100,
15500,
69300,
2000,
12200,
31200,
21100,
35800,
17900,
26300,
15800,
48900,
7600,
281300,
69100,
null,
42700,
5300,
84500,
39100,
47200,
23900,
11000,
null,
52800,
null,
15400,
36000,
14100,
4700,
17800,
33000,
9500,
48900,
null,
21800,
21000,
null,
21000,
73200,
43000,
65000,
89300,
null,
141300,
112000,
43938,
62300,
12900,
9200,
14100,
18500,
null,
48100,
18300,
20600,
19200,
null,
44000,
null,
25400,
5900,
14000,
6200,
29900,
48400,
9900,
9900,
26400,
16000,
45300,
71000,
9600,
11700,
null,
20600,
143500,
18300,
5100,
55400,
null,
49800,
168400,
12500,
null,
19300,
43300,
15800,
26850,
43400,
17800,
null,
39700,
15300,
null,
27000,
37900,
10400,
23400,
74700,
36700,
100543,
13900,
44900,
10200,
283600,
14800,
11000,
null,
9600,
31900,
57400,
5500,
16400,
19900,
14600,
32000,
25700,
19900,
8500,
35500,
9800,
30700,
60300,
21700,
null,
22700,
32000,
14900,
44700,
31800,
8200,
21000,
29600,
24500,
6000,
11400,
null,
48000,
97300,
37300,
27100,
127886,
29200,
3000,
11900,
28200,
13500,
20700,
49300,
38100,
95400,
38800,
12100,
3800,
13200,
44300,
51900,
32600,
97100,
42400,
20600,
20200,
12300,
27300,
13700,
6100,
25800,
44600,
19500,
12300,
48300,
14300,
25300,
20900,
79800,
null,
37100,
9300,
71000,
18100,
129100,
9900,
11500,
39000,
9500,
79100,
51400,
33700,
73000,
43100,
8600,
17900,
21400,
null,
13700,
51500,
18900,
57800,
6900,
7800,
122000,
83400,
21900,
23400,
null,
70800,
3800,
11500,
33300,
5100,
null,
95000,
13200,
13800,
75500,
1000,
33900,
22600,
47600,
8500,
13100,
9300,
60000,
null,
21600,
31500,
null,
18100,
22100,
37800,
9600,
13796,
22537,
66900,
9900,
49400,
19700,
96600,
38300,
16400,
null,
7300,
null,
18300,
null,
7500,
87700,
4200,
55400,
38900,
null,
46900,
18500,
23600,
4750,
116600,
56300,
7500,
25000,
13400,
22300,
30700,
26300,
20100,
108800,
61800,
44000,
25300,
112500,
8000,
62000,
15700,
47400,
11700,
50366,
11200,
26600,
null,
20100,
16200,
null,
1400,
29000,
52800,
35600,
33728,
12700,
45500,
143600,
44800,
23300,
null,
null,
16000,
16600,
null,
16900,
14500,
null,
56600,
30700,
31100,
47000,
3700,
24400,
27900,
151600,
36600,
38700,
8800,
17200,
21400,
6400,
33000,
49100,
48100,
37800,
19900,
72200,
43000,
14000,
68500,
43100,
null,
10400,
12000,
25900,
24400,
51700,
20900,
8400,
29500,
null,
7100,
26700,
null,
8600,
4600,
77800,
124400,
16800,
8200,
20000,
19600,
25500,
46100,
12300,
13700,
66400,
19800,
5200,
27900,
12500,
50900,
27600,
3000,
52300,
22500,
43200,
24900,
80700,
17900,
67700,
14800,
11200,
5700,
25400,
38400,
18100,
27200,
43500,
166900,
23800,
19000,
26700,
9600,
25300,
28200,
34100,
40500,
21200,
5000,
24100,
9800,
51300,
12300,
5900,
29500,
54000,
33400,
2900,
19000,
11100,
77900,
30800,
18300,
5500,
9700,
13400,
59300,
null,
12500,
103500,
null,
18800,
7300,
17900,
12400,
44100,
13800,
23300,
6200,
19400,
12800,
45700,
18100,
61000,
28500,
65800,
7300,
25500,
null,
44600,
59600,
null,
18900,
12200,
6200,
55800,
28900,
14700,
26600,
55100,
59600,
34200,
8000,
48200,
49900,
21100,
null,
28800,
18200,
15200,
18100,
20500,
57300,
null,
null,
67700,
13500,
14700,
67800,
null,
23100,
7400,
6000,
106000,
44200,
1600,
74600,
null,
33600,
27300,
7600,
28600,
103400,
41000,
32500,
15500,
null,
47500,
96600,
47000,
17200,
14700,
19500,
27900,
45500,
47400,
21000,
13300,
46500,
79700,
null,
42600,
10600,
31900,
26100,
32300,
17100,
6600,
17600,
9300,
44500,
31600,
22900,
null,
17600,
88000,
104000,
25200,
39000,
null,
10100,
27200,
4700,
103100,
21800,
12800,
44800,
7800,
22900,
79300,
10400,
31100,
37100,
75400,
7100,
7200,
2700,
16300,
38100,
52300,
7900,
66700,
1400,
37000,
24000,
16100,
30300,
12900,
14500,
null,
12400,
null,
22400,
null,
8000,
18000,
22600,
16500,
12600,
64700,
34500,
30500,
39300,
13500,
35500,
6400,
23600,
12600,
6900,
36700,
11600,
20500,
37700,
24100,
4600,
56507,
30300,
13700,
14500,
6000,
4700,
45000,
79100,
35700,
3700,
13400,
7100,
41200,
16100,
25100,
27300,
21500,
12500,
4100,
null,
29500,
16900,
16400,
10400,
null,
20800,
1100,
null,
17500,
17700,
47400,
null,
28700,
17200,
65200,
34800,
null,
9200,
10000,
null,
17700,
22600,
12100,
36200,
62500,
null,
44200,
12741,
134400,
34400,
14900,
null,
9000,
19500,
22000,
null,
5000,
20800,
25900,
21000,
50100,
34800,
5500,
null,
24500,
12300,
13500,
18000,
29000,
21400,
16700,
38300,
15100,
7100,
48500,
22600,
32500,
36400,
37100,
41900,
34600,
186500,
29200,
15500,
9900,
33600,
17200,
26100,
28000,
29300,
6700,
37900,
24800,
52500,
24200,
null,
4900,
25900,
null,
null,
35800,
14800,
50300,
17000,
9300,
67200,
99500,
39500,
35300,
27200,
11800,
10000,
2900,
9700,
46300,
84000,
8600,
23600,
8900,
44100,
48600,
47100,
28000,
38400,
51800,
46300,
13800,
17850,
109200,
4000,
10900,
11200,
4800,
35000,
33700,
13900,
12000,
16900,
3500,
null,
16500,
null,
7300,
27200,
45300,
25700,
249400,
44000,
103570,
9700,
21600,
3400,
7890,
4200,
15200,
42200,
69200,
9900,
22500,
56300,
93500,
24900,
29000,
15300,
20100,
null,
11900,
36000,
19200,
29500,
3400,
43500,
49100,
null,
21600,
20800,
18100,
15900,
9700,
19100,
48800,
9000,
10200,
null,
39000,
7400,
null,
37900,
4300,
17100,
8600,
29900,
83600,
42600,
8900,
24000,
15500,
13400,
112100,
26500,
28000,
50900,
33900,
10800,
33600,
null,
31400,
32700,
26000,
18000,
42800,
null,
10000,
null,
11300,
58700,
30700,
48800,
32300,
33400,
21500,
32100,
143128,
27700,
15500,
9500,
23500,
16700,
104500,
21300,
27700,
null,
21700,
56300,
29800,
8800,
2500,
15200,
30600,
3000,
7550,
25500,
14200,
14200,
40500,
null,
12500,
33950,
11900,
13900,
30153,
16600,
18500,
16600,
31100,
49000,
101000,
14700,
18000,
45900,
2300,
15700,
18800,
24900,
9100,
35600,
10000,
14600,
null,
11500,
10600,
38500,
6800,
34700,
4300,
44000,
null,
64500,
18300,
36800,
30900,
35100,
6800,
23300,
1300,
4300,
38200,
30800,
17400,
15600,
6800,
18000,
14500,
null,
30200,
61251,
15200,
14900,
29600,
16500,
9500,
16800,
15900,
42400,
147160,
17900,
30900,
27800,
36200,
39600,
18300,
28300,
13200,
109800,
71000,
null,
59000,
19500,
8900,
24500,
35500,
11900,
74900,
null,
15700,
28800,
42100,
100100,
27700,
6900,
5000,
1300,
26100,
6700,
null,
13600,
12800,
54600,
null,
7500,
28782,
9300,
32000,
25100,
13000,
127200,
63000,
10700,
19400,
14400,
14900,
16300,
36300,
21500,
null,
20200,
null,
2600,
10000,
19000,
33900,
12100,
32000,
null,
null,
35200,
20500,
13100,
23000,
8500,
80000,
10500,
29100,
4400,
7300,
8300,
19800,
61000,
32300,
32200,
12300,
42600,
24300,
5000,
12600,
9800,
89800,
2900,
56300,
19400,
null,
28800,
43400,
null,
18300,
null,
null,
35400,
24000,
25400,
12200,
58700,
33900,
4300,
30800,
7600,
31700,
24400,
11000,
55400,
6300,
14900,
93900,
80300,
7600,
4300,
30900,
96800,
92100,
18600,
43500,
null,
44800,
20100,
42600,
61100,
13900,
22400,
9800,
38500,
11800,
21000,
7700,
17000,
217500,
17200,
null,
8000,
35900,
16400,
26900,
53200,
43100,
39500,
null,
99200,
15600,
28400,
10000,
19400,
24200,
15800,
10700,
11400,
16400,
67000,
38900,
81800,
22000,
null,
14400,
9100,
23800,
28100,
62300,
31300,
20400,
15500,
null,
10100,
27400,
21400,
null,
2100,
7700,
15600,
33700,
19000,
23800,
30000,
26400,
null,
106500,
71100,
27500,
31200,
9900,
16800,
12800,
53600,
7700,
17900,
22100,
31100,
16500,
9700,
27500,
16300,
9200,
17200,
16100,
14900,
21800,
32800,
14400,
30800,
null,
23700,
27300,
150600,
13800,
2600,
57800,
55000,
29600,
23000,
30700,
37000,
18000,
null,
13600,
97300,
4300,
13900,
12200,
54400,
76300,
38200,
38300,
13800,
45000,
14900,
24200,
58800,
31600,
17800,
16600,
50500,
21400,
14300,
44800,
24800,
25400,
null,
66900,
11500,
null,
25500,
52700,
41800,
null,
null,
22800,
55300,
16900,
2300,
75900,
39300,
14100,
20900,
20500,
38900,
11200,
14100,
null,
43100,
null,
31000,
null,
50800,
66200,
51600,
82300,
26300,
62300,
5500,
13100,
9200,
147400,
33800,
33500,
14300,
null,
8600,
22000,
14000,
110500,
15000,
50300,
23200,
14200,
122500,
27600,
7800,
23800,
5800,
53400,
27200,
14900,
11100,
12275,
6400,
47000,
24100,
47181,
12000,
56200,
42200,
37400,
12400,
13400,
19400,
21800,
44200,
17200,
48700,
22800,
7100,
23300,
14500,
14000,
43500,
24300,
9000,
23500,
22900,
21100,
6100,
null,
21000,
49300,
29300,
65100,
6400,
19300,
94200,
122500,
152100,
93500,
61500,
12400,
21400,
42300,
34300,
39200,
16200,
20500,
11300,
29600,
94800,
6750,
32400,
15800,
30100,
110100,
33800,
25500,
39600,
11300,
53300,
29800,
65400,
9250,
23850,
59100,
3100,
22040,
19300,
15900,
32300,
null,
33800,
79400,
57100,
65800,
10700,
19400,
12900,
null,
29600,
19700,
30700,
32800,
84300,
99700,
95200,
27500,
35000,
8400,
39000,
24000,
61800,
null,
34900,
38900,
33100,
42100,
14400,
null,
35531,
29000,
30600,
2400,
null,
null,
43700,
13400,
null,
11400,
30000,
21800,
33600,
null,
43800,
49400,
17900,
7600,
29400,
32200,
78600,
14100,
6750,
56300,
16600,
17000,
56700,
23400,
16500,
17500,
30100,
24200,
null,
35900,
7400,
9000,
48500,
19600,
17700,
22600,
8400,
15400,
18500,
56900,
11800,
null,
65000,
19700,
27500,
24300,
48100,
71300,
42600,
14300,
17900,
18100,
6000,
12600,
null,
37400,
39100,
91800,
38900,
12900,
4000,
23500,
3600,
12800,
null,
35200,
8500,
32000,
32800,
16300,
29100,
27700,
17300,
8200,
4100,
32600,
null,
21100,
9500,
75200,
51400,
11000,
51300,
17100,
13300,
11500,
2700,
13500,
55800,
25200,
19200,
null,
15900,
6400,
null,
62300,
14000,
26300,
4800,
9000,
38000,
11000,
38370,
7700,
13400,
21300,
69500,
23000,
64000,
19000,
64400,
18100,
1000,
46100,
14100,
12500,
6800,
56100,
13900,
6600,
12500,
28000,
39300,
84000,
8100,
113900,
19200,
18600,
7900,
29751,
29700,
6400,
47950,
13700,
13900,
35100,
14500,
12400,
10000,
31300,
7200,
17686,
22100,
39400,
25200,
47100,
null,
17200,
61900,
22700,
5700,
39900,
9800,
26400,
24000,
14300,
56600,
45600,
15200,
15200,
17200,
7300,
58500,
null,
86244,
17000,
16100,
38100,
13000,
null,
null,
58000,
50600,
13300,
19000,
57000,
76000,
null,
49400,
13800,
48200,
92200,
67300,
29400,
35100,
5400,
44600,
null,
null,
21100,
17400,
23700,
null,
null,
5600,
9500,
null,
15800,
8400,
40900,
25400,
32750,
179551,
18700,
13300,
3800,
7900,
18100,
29700,
21800,
17000,
38700,
29400,
13600,
null,
29700,
null,
28900,
66300,
21000,
48500,
42500,
41600,
21800,
35953,
21600,
28900,
33300,
10500,
12700,
42200,
157900,
15700,
15400,
6500,
26400,
null,
null,
18200,
11600,
16200,
83000,
23400,
24900,
16400,
6500,
20200,
69200,
41300,
66700,
23100,
7800,
70700,
23300,
43900,
25000,
17500,
28300,
18900,
31000,
12000,
44500,
195700,
56400,
7000,
37100,
null,
34300,
null,
26000,
7000,
3700,
106400,
null,
67940,
null,
21400,
24100,
64500,
55000,
16400,
6400,
8700,
65100,
130700,
20000,
null,
50600,
4600,
19600,
14500,
null,
38900,
14700,
null,
24030,
11100,
12700,
42500,
69600,
34100,
65700,
19700,
18200,
null,
null,
148200,
29100,
42600,
21500,
43100,
96300,
18200,
18300,
6800,
36400,
40300,
11900,
null,
39600,
21300,
10000,
54300,
62875,
17800,
45700,
8500,
82000,
33950,
23400,
36200,
64600,
34000,
21500,
31700,
29900,
34500,
23500,
null,
25700,
6800,
11200,
36200,
27900,
10600,
28300,
20000,
18300,
112200,
33995,
null,
37400,
31300,
28800,
21100,
49800,
108100,
11800,
24100,
45200,
42100,
12900,
36700,
26800,
13100,
5200,
15900,
7100,
63900,
52200,
32000,
82600,
33500,
null,
27100,
null,
null,
34600,
61500,
40194,
24700,
76900,
29500,
45000,
17800,
7500,
15600,
68330,
47500,
null,
15400,
4400,
54089,
53200,
5000,
6900,
35300,
4500,
38100,
16500,
null,
20900,
30600,
26000,
23200,
64200,
34200,
23400,
null,
35000,
9800,
37800,
3500,
37700,
15600,
null,
21100,
26400,
86200,
69000,
14000,
9600,
4300,
27500,
19000,
32900,
null,
39900,
29700,
21800,
6000,
22100,
null,
null,
null,
114300,
19200,
281700,
17500,
28100,
3000,
26500,
26400,
16200,
17500,
27700,
15800,
29200,
12050,
39100,
18400,
27400,
56600,
31800,
3100,
34000,
30000,
13100,
15200,
43400,
9900,
10100,
6600,
56500,
21600,
49500,
null,
34800,
22300,
42100,
null,
15400,
14900,
36100,
22700,
52400,
null,
12700,
null,
44500,
21933,
null,
6300,
73600,
17800,
8500,
25000,
24000,
15000,
null,
null,
8000,
23000,
5100,
16800,
33900,
23500,
17100,
12400,
18600,
19500,
56700,
null,
12100,
10300,
22100,
56500,
49200,
20900,
null,
null,
2000,
27700,
20200,
52900,
10400,
400,
18500,
null,
70400,
32100,
28600,
11800,
22700,
66500,
12100,
9800,
26400,
13000,
37600,
40800,
12400,
33800,
20600,
6500,
34000,
20500,
10100,
93100,
76000,
19400,
96200,
10900,
11600,
48500,
28200,
null,
28700,
89200,
30100,
6100,
34300,
12800,
18300,
3300,
13250,
8000,
10400,
3000,
21500,
null,
42100,
53200,
8000,
30500,
60100,
null,
15500,
49600,
56800,
19600,
13650,
48100,
36900,
73400,
14300,
60500,
45600,
17300,
null,
7400,
87500,
10800,
11700,
50900,
48100,
42968,
9600,
13300,
19700,
63400,
66000,
29700,
94300,
19200,
9400,
57900,
72800,
50300,
11100,
15100,
8700,
null,
18800,
27600,
202400,
null,
19500,
185600,
11100,
4000,
12700,
27900,
300,
47200,
15200,
21700,
12700,
43439,
21900,
10300,
3400,
52400,
47200,
64000,
15800,
26300,
29600,
17800,
9500,
13400,
21500,
52500,
17200,
42900,
29600,
22300,
5800,
26100,
23800,
6700,
12150,
null,
33700,
12500,
35300,
47200,
51200,
32500,
6900,
61800,
14500,
27600,
21800,
42200,
37000,
44500,
null,
11100,
null,
30100,
5600,
23100,
3600,
null,
66100,
35400,
40900,
32300,
13900,
53100,
null,
12200,
9000,
164200,
76400,
null,
4500,
41300,
10900,
10600,
17100,
27900,
41200,
11800,
15200,
27200,
25500,
21000,
31600,
40100,
16300,
43600,
29000,
26700,
null,
null,
43600,
43500,
16700,
9200,
33700,
52100,
40300,
206200,
79400,
null,
10100,
6000,
null,
39000,
null,
30200,
9800,
256300,
24100,
2000,
22400,
22800,
51100,
23500,
155300,
13500,
12300,
17200,
null,
24600,
13400,
37000,
22000,
20700,
14500,
21900,
44600,
18600,
null,
43664,
17200,
19600,
4400,
78455,
7200,
32900,
47000,
4500,
16300,
32500,
19900,
27100,
null,
22500,
null,
49088,
78900,
8500,
17700,
42400,
12500,
36600,
15400,
28866,
20500,
8500,
4000,
30500,
36400,
26000,
25200,
101000,
114200,
15100,
20500,
22700,
19500,
116000,
14200,
25000,
81200,
78100,
81400,
8000,
99900,
5475,
42100,
51600,
35200,
46100,
28100,
77100,
115600,
23500,
5700,
26200,
11000,
37500,
2200,
24000,
39000,
113300,
39500,
120100,
14600,
67000,
30200,
null,
12400,
19700,
13900,
33000,
54800,
88300,
13000,
null,
70400,
16500,
null,
58300,
38400,
45000,
5900,
29300,
12800,
12400,
28600,
49500,
7200,
8900,
14600,
47000,
32800,
null,
322000,
40200,
19700,
5600,
5000,
7300,
null,
24435,
20200,
15700,
0,
6300,
33900,
13100,
15500,
13100,
9500,
87900,
20900,
11020,
1600,
36100,
20600,
80800,
158800,
23400,
319300,
11700,
36800,
47200,
6800,
36400,
null,
9700,
146500,
13000,
51600,
null,
48700,
119600,
10400,
null,
6850,
121700,
20200,
12200,
8000,
19600,
24600,
8700,
19500,
65600,
19500,
5600,
22500,
18000,
11400,
47600,
14800,
12600,
null,
16000,
45100,
22100,
11900,
36200,
null,
33200,
59680,
45950,
36500,
28000,
56100,
9000,
17400,
null,
37300,
27400,
22500,
34100,
101700,
null,
24300,
11200,
null,
17700,
14300,
null,
6000,
15200,
null,
108500,
13800,
4600,
29100,
21500,
19450,
50000,
76500,
20600,
69100,
8200,
40100,
28800,
18700,
57500,
4300,
32000,
null,
62400,
null,
11300,
null,
19300,
18300,
15000,
26800,
27000,
29200,
14700,
22300,
15600,
70400,
44361,
11000,
5500,
35700,
38300,
16100,
21900,
89600,
13800,
38700,
194951,
6800,
20600,
178700,
34300,
28600,
4900,
8000,
19100,
1300,
34700,
39000,
4000,
null,
null,
9200,
5700,
5800,
92200,
29200,
44600,
42488,
152600,
26600,
3200,
31000,
41400,
null,
4400,
68900,
4200,
100600,
10500,
10600,
12500,
34000,
5900,
15200,
15400,
17600,
39000,
23600,
61700,
18000,
42300,
22400,
8400,
25600,
20900,
64600,
null,
null,
10800,
82000,
21700,
30900,
21700,
10400,
33600,
36400,
19800,
null,
null,
52800,
18100,
33200,
8800,
8000,
13600,
328800,
6700,
8900,
46000,
18000,
22200,
46500,
null,
92100,
25600,
45000,
30000,
41600,
20300,
15800,
37200,
21800,
null,
12800,
27600,
15700,
18300,
20200,
47800,
null,
null,
39400,
38800,
8700,
8500,
18100,
17800,
17100,
126200,
8600,
36200,
7800,
26200,
46200,
48000,
25000,
17300,
12400,
49300,
18000,
98100,
26000,
20600,
22900,
5900,
20200,
94400,
3300,
22100,
18500,
40700,
2000,
19600,
17700,
23600,
29000,
62000,
15500,
33050,
6700,
20100,
2200,
29000,
16300,
17200,
104700,
29800,
11600,
27700,
null,
19800,
7100,
27200,
22900,
65200,
38700,
79600,
44860,
105900,
74200,
11200,
27500,
8200,
10800,
null,
63000,
79923,
12200,
14100,
26200,
null,
12900,
13200,
12600,
28700,
36900,
8700,
21700,
11000,
21000,
null,
4800,
18100,
18600,
18900,
79900,
37300,
26300,
9900,
22800,
null,
65600,
25100,
37300,
300,
3300,
11500,
6800,
64000,
227500,
39200,
13400,
19200,
36000,
null,
17600,
26800,
12000,
6300,
16400,
15500,
10550,
22150,
31300,
35300,
100100,
62600,
4800,
39400,
29100,
14100,
25800,
10100,
19200,
24900,
95800,
5000,
17500,
35600,
15000,
46900,
13800,
9800,
89951,
16800,
30800,
15100,
88500,
26100,
4300,
6700,
48800,
43200,
null,
20700,
8000,
21400,
40194,
null,
null,
9000,
97700,
null,
9400,
24500,
41000,
14300,
11000,
74200,
4800,
20100,
21000,
46800,
20000,
31750,
8800,
54000,
21800,
55200,
null,
null,
13500,
26100,
96900,
null,
29900,
84200,
19900,
38600,
15300,
27700,
null,
9300,
24400,
null,
56300,
77200,
18400,
20000,
null,
26300,
31700,
28600,
15500,
47900,
24900,
15800,
10000,
27000,
29500,
37800,
101800,
50300,
26500,
null,
19900,
null,
16300,
26800,
21400,
8300,
8600,
6800,
15000,
26200,
37200,
7200,
23300,
null,
null,
26000,
91300,
32500,
30000,
49500,
null,
null,
27800,
43300,
55400,
26000,
4800,
6500,
88200,
48700,
21100,
9700,
34100,
68200,
63900,
6400,
5900,
22700,
null,
15300,
65900,
19800,
21700,
18600,
25200,
null,
14400,
null,
5800,
18200,
12600,
75800,
36300,
5500,
11500,
30000,
8200,
18900,
null,
69200,
22600,
15400,
19300,
12600,
29000,
10700,
141500,
13700,
27700,
38300,
null,
79400,
21000,
82000,
13100,
7700,
7400,
10700,
10000,
4000,
24700,
25200,
8700,
31800,
9500,
null,
12200,
null,
28000,
228200,
null,
52900,
3900,
16200,
19200,
44600,
118600,
10000,
7900,
59800,
58900,
13800,
4400,
46100,
48900,
48500,
25300,
51700,
17100,
75100,
54000,
6500,
59440,
null,
8600,
6400,
37000,
119000,
50200,
null,
33600,
15700,
15100,
13300,
null,
15100,
2200,
34400,
5800,
13500,
14200,
32400,
7300,
8200,
11700,
25600,
13000,
24500,
12600,
35800,
165600,
16400,
19400,
null,
7070,
26900,
14300,
27100,
6600,
10100,
30800,
null,
33000,
13900,
9300,
29000,
43300,
18200,
24100,
null,
98500,
3700,
41900,
9800,
15700,
49400,
48400,
null,
92000,
7100,
12900,
37000,
23600,
16200,
10400,
null,
41500,
31100,
40400,
16700,
26200,
16900,
52500,
22500,
14300,
21500,
24100,
35800,
284400,
18700,
6600,
16800,
13700,
34800,
null,
12700,
49300,
16300,
37000,
8300,
31300,
8300,
5500,
16400,
31600,
70600,
76300,
45600,
23400,
4200,
81300,
null,
29100,
31600,
15200,
35800,
null,
11600,
28000,
8250,
null,
4750,
37400,
20600,
25300,
82800,
100600,
30700,
28600,
21000,
14600,
14400,
66200,
29700,
2000,
45000,
19200,
29200,
37900,
null,
4200,
14900,
6600,
19200,
2500,
7400,
52900,
10400,
43000,
31800,
6600,
47100,
86200,
11900,
35200,
27400,
null,
58300,
30100,
74400,
10000,
43643,
25600,
9200,
null,
36600,
39300,
34700,
21100,
22100,
9500,
20200,
77800,
10400,
14600,
7800,
4500,
18800,
38500,
20700,
115600,
29900,
10400,
66100,
25800,
37400,
34900,
27500,
19100,
16900,
37900,
85900,
26100,
15900,
18400,
11600,
21400,
33700,
35200,
17000,
28745,
19700,
4600,
7300,
159500,
15600,
46700,
65234,
13500,
34800,
23500,
23753,
49500,
19000,
14500,
null,
null,
15500,
13200,
25200,
10500,
38400,
9700,
9500,
13400,
32000,
25900,
null,
7500,
14500,
10500,
13000,
9600,
32600,
22100,
5400,
46700,
96800,
85000,
19900,
4500,
6500,
null,
20100,
65900,
21150,
28800,
null,
13100,
87900,
14400,
null,
66600,
41100,
null,
null,
null,
29400,
29900,
21100,
null,
18300,
49200,
55000,
42200,
22000,
22800,
75600,
23100,
12600,
82000,
11400,
44800,
84800,
8800,
57928,
33805,
29400,
15700,
14900,
null,
12100,
20000,
15400,
12800,
43600,
null,
2050,
46500,
57200,
50800,
19800,
6750,
24600,
14500,
31300,
43300,
51100,
13000,
11600,
16500,
22800,
20400,
10500,
58900,
29000,
null,
null,
226300,
29900,
14000,
14900,
7500,
38500,
9800,
69200,
17700,
61400,
39500,
10900,
35200,
91500,
90600,
40200,
18100,
74500,
28500,
27100,
63700,
83300,
12800,
31500,
26800,
52000,
46000,
26400,
48800,
34900,
42400,
39000,
14900,
18000,
74400,
27900,
49860,
19100,
null,
50000,
21300,
18700,
41200,
77300,
14500,
8700,
8300,
null,
41100,
28000,
5900,
67900,
16300,
13800,
21100,
28900,
36700,
38500,
30300,
17800,
16300,
14300,
13800,
12200,
28300,
25800,
25600,
35800,
20500,
29600,
14000,
12500,
40600,
12900,
29100,
37000,
11700,
38800,
25100,
27800,
26400,
18000,
null,
6000,
18450,
13600,
null,
3200,
58100,
52100,
39200,
14000,
4300,
30500,
13900,
null,
37300,
26300,
29200,
37665,
7600,
12900,
41900,
8100,
45100,
88100,
39800,
52900,
36500,
26600,
14500,
13500,
51400,
40700,
43300,
null,
37900,
6000,
74400,
5300,
36400,
34500,
23200,
15000,
23000,
20400,
null,
24200,
19400,
52700,
31400,
null,
47700,
47700,
11900,
26500,
63900,
17000,
18300,
12800,
71900,
20600,
null,
null,
23700,
30100,
62500,
5300,
13200,
36200,
5000,
24500,
12400,
null,
19400,
9100,
41104,
33800,
30600,
29700,
62504,
20200,
16800,
33500,
92400,
null,
59600,
12500,
11300,
35400,
17100,
33000,
25300,
57700,
22100,
36600,
15250,
null,
63500,
52300,
16900,
30300,
22000,
19900,
102200,
39100,
43900,
87500,
15100,
16300,
20700,
56818,
25900,
8400,
25200,
18100,
3500,
600,
19900,
null,
13200,
19400,
null,
8400,
15000,
48600,
28200,
7200,
6800,
null,
15780,
43200,
24700,
17000,
5000,
109500,
38900,
27300,
33400,
11000,
6200,
null,
34400,
80300,
31400,
16100,
7300,
7300,
30200,
18100,
10000,
17300,
101300,
49000,
4500,
null,
17600,
17300,
11000,
26000,
15000,
null,
3300,
27300,
47200,
14100,
null,
37900,
13500,
14700,
30200,
31651,
29500,
37800,
27100,
21000,
8500,
16400,
40500,
36700,
null,
83500,
20600,
7000,
13200,
46200,
50300,
25600,
13900,
11200,
26800,
13800,
20300,
18300,
5100,
22200,
10700,
50200,
67700,
32700,
39700,
9700,
4600,
46400,
19500,
13400,
19400,
37400,
10700,
12300,
6000,
7400,
null,
23600,
52800,
15200,
37300,
32200,
8800,
25900,
39500,
66200,
22300,
14700,
17300,
35800,
146100,
17275,
11500,
23600,
8100,
10400,
22700,
33800,
37900,
11800,
3300,
10000,
38800,
22900,
14400,
11811,
12000,
39600,
9100,
50300,
6700,
33600,
null,
38400,
5700,
3500,
11700,
5800,
17100,
41988,
5600,
16300,
10300,
18400,
24900,
7800,
null,
77000,
64300,
35000,
116100,
14600,
20700,
7500,
7700,
17900,
15200,
49700,
30100,
55000,
null,
9800,
null,
10600,
32100,
null,
13800,
24500,
104500,
40500,
11500,
92500,
52300,
40400,
14800,
23000,
29900,
20800,
33600,
54700,
9800,
37600,
79500,
32200,
35900,
9400,
20500,
76800,
29600,
21900,
31100,
34000,
34600,
55500,
32800,
22200,
11200,
30000,
53500,
11000,
24700,
16800,
27700,
40800,
27400,
20300,
8700,
12600,
11900,
8000,
18600,
3800,
18000,
47300,
11400,
37900,
16100,
null,
28500,
14600,
6600,
13000,
89900,
4600,
9400,
14100,
7300,
56200,
31300,
46400,
41400,
11800,
13800,
null,
21100,
160700,
22200,
19700,
25200,
13300,
14200,
65100,
34500,
67700,
9400,
5700,
17400,
63700,
6700,
25500,
6700,
null,
25100,
63500,
1300,
36100,
21000,
25100,
17100,
54100,
23100,
27500,
21600,
28000,
40500,
63900,
15900,
2500,
10900,
10900,
5700,
20700,
61400,
27800,
34900,
13500,
33000,
86800,
17800,
16200,
22700,
52900,
null,
33200,
9500,
62900,
40500,
10100,
4000,
null,
6450,
41900,
5100,
null,
15900,
22100,
14100,
12300,
21300,
26100,
23100,
10300,
18500,
12900,
null,
13000,
49800,
149860,
8200,
24600,
49400,
158500,
null,
11100,
11600,
13900,
49800,
88000,
14500,
40900,
48400,
16300,
37600,
41200,
18600,
54400,
34600,
36200,
46200,
48200,
20000,
31500,
23800,
9700,
8700,
35300,
35100,
25100,
15300,
null,
4700,
5800,
37100,
10700,
14700,
30000,
36200,
31800,
null,
1300,
18100,
12000,
15900,
14300,
59300,
52500,
40000,
13310,
null,
16700,
24900,
39900,
25300,
50300,
null,
45800,
51800,
39400,
29200,
30000,
16100,
18500,
132200,
5700,
9800,
61400,
20500,
37100,
41000,
24800,
58710,
18500,
14200,
24100,
15800,
36500,
16600,
19100,
3700,
9600,
3800,
2500,
16700,
18200,
null,
16700,
69500,
16500,
27300,
48100,
null,
26900,
7700,
28500,
26800,
101700,
21300,
null,
25900,
45900,
14000,
1800,
26300,
13600,
71200,
18700,
8700,
21200,
133700,
5400,
31100,
123300,
null,
22400,
38700,
10100,
11300,
26200,
53200,
53700,
null,
11700,
45600,
48300,
2000,
13300,
30100,
6000,
15100,
29700,
19900,
16000,
31600,
23100,
36400,
23300,
8300,
7500,
11400,
117400,
12200,
43200,
27700,
83600,
18200,
30400,
19000,
13700,
25500,
14800,
72700,
16600,
45000,
null,
29600,
40200,
20500,
10500,
29900,
92600,
36200,
8700,
62100,
31500,
20300,
31300,
28700,
22900,
43700,
10500,
43500,
5000,
20900,
38500,
23500,
15000,
19400,
11900,
39800,
10000,
18600,
18400,
55300,
10500,
49400,
27000,
22600,
11900,
57100,
null,
null,
30100,
14200,
119898,
48000,
12600,
21300,
71100,
4600,
30000,
86000,
78300,
8500,
42500,
46900,
28900,
57800,
14600,
16700,
23200,
10900,
31900,
23600,
null,
35600,
30300,
35500,
23600,
15200,
37900,
46700,
20200,
21100,
30100,
26500,
19900,
6200,
19700,
33700,
11400,
18600,
null,
27200,
17200,
27700,
31500,
null,
76100,
54000,
25000,
136700,
17000,
23300,
33700,
26900,
17200,
9700,
null,
18800,
13500,
64600,
29600,
21600,
20400,
26600,
73500,
19800,
99700,
12100,
17400,
27900,
10300,
53200,
18100,
14400,
6000,
24600,
55000,
12100,
34700,
44500,
21100,
52800,
35400,
34400,
20200,
32900,
46800,
null,
39000,
39000,
5700,
55100,
37900,
8700,
31100,
45600,
45400,
53800,
16700,
15000,
16400,
48400,
28600,
48821,
46574,
25100,
17900,
28100,
34400,
32300,
41900,
46700,
21100,
10900,
12400,
54100,
42300,
23500,
12900,
11700,
102500,
null,
19200,
18500,
20700,
37500,
null,
14800,
6600,
35000,
16900,
null,
58700,
14700,
19100,
23000,
16400,
51200,
49200,
20500,
19600,
23400,
7045,
41400,
32300,
56000,
12300,
51000,
16800,
17300,
40200,
108500,
9800,
26000,
19000,
16500,
null,
36900,
36400,
null,
38200,
39400,
12200,
5500,
33800,
21300,
16300,
11800,
14800,
14400,
113400,
13000,
8400,
31690,
null,
null,
52000,
65500,
24500,
67700,
18900,
null,
23300,
47800,
7800,
24900,
9000,
18400,
12600,
63400,
null,
42400,
64000,
15300,
19200,
35300,
127600,
26800,
44114,
17100,
66600,
28200,
48900,
11600,
3800,
null,
6750,
12700,
15100,
13100,
6700,
7900,
72400,
22600,
30300,
45000,
43100,
11400,
62900,
21300,
3900,
4700,
10300,
21600,
17200,
59400,
15000,
52400,
112500,
84200,
null,
13400,
23200,
39100,
16200,
18700,
28100,
25000,
24300,
19400,
24900,
16400,
49300,
3750,
21100,
49400,
29600,
28500,
22400,
15000,
61300,
36900,
97500,
19100,
52600,
32500,
14500,
73900,
19300,
30300,
7000,
18800,
33100,
16100,
null,
14900,
36500,
64800,
20600,
null,
null,
19400,
17700,
37600,
9300,
11900,
28500,
null,
8600,
21600,
55000,
31700,
22600,
9800,
15900,
17300,
9300,
24400,
2700,
13300,
23100,
6500,
null,
12700,
12500,
15000,
20900,
8000,
57300,
22500,
20700,
19300,
37600,
58000,
38610,
null,
21900,
59800,
4000,
12100,
43500,
18500,
49000,
7200,
15600,
31300,
97621,
30100,
41600,
null,
26100,
null,
70800,
25000,
17100,
17000,
25200,
62397,
null,
null,
58600,
29400,
40209,
19700,
29100,
49000,
17700,
38300,
25700,
45300,
27500,
15100,
71100,
9700,
26500,
null,
6700,
6700,
86800,
35400,
null,
14600,
28600,
23500,
16000,
24900,
16900,
16600,
28100,
16600,
84800,
13100,
27500,
5100,
58900,
34700,
5000,
50400,
48094,
null,
10840,
5600,
16900,
64300,
null,
null,
9500,
64400,
20200,
25000,
42600,
21700,
35600,
8800,
17800,
6800,
9000,
27500,
21200,
null,
47000,
49300,
39900,
30200,
18000,
13368,
15500,
8200,
13400,
84500,
48800,
54300,
28500,
32300,
11900,
18500,
2800,
11500,
18100,
31900,
200,
10000,
15100,
null,
36000,
11500,
44000,
3525,
9400,
71100,
null,
15750,
2600,
18400,
null,
24200,
13500,
8000,
21700,
33500,
10500,
12700,
33100,
7900,
17100,
15700,
18400,
3800,
15500,
51800,
19100,
23000,
32400,
23500,
5800,
42000,
34900,
6600,
82100,
42500,
15800,
73200,
31100,
0,
130100,
23200,
19700,
68000,
null,
null,
18600,
24300,
26900,
12500,
40700,
29400,
8950,
59200,
18000,
null,
null,
91500,
15100,
null,
10000,
7500,
52700,
15900,
null,
56500,
8800,
15000,
20700,
38300,
12400,
19100,
10500,
2800,
28800,
24400,
25200,
13700,
18000,
null,
30000,
17200,
6500,
27400,
16500,
41200,
40900,
6700,
16900,
26100,
20500,
23600,
28400,
22500,
37400,
102600,
21700,
19537,
10200,
32300,
12400,
22600,
12100,
29100,
19700,
25300,
10900,
8000,
7900,
34300,
36400,
6500,
3300,
13500,
28500,
6500,
17800,
21600,
9100,
44400,
31600,
null,
83400,
10900,
7000,
27300,
36800,
24300,
7000,
22800,
13300,
65900,
24600,
19500,
null,
78800,
49100,
29900,
71400,
9200,
29500,
16700,
null,
119500,
27000,
18400,
43300,
10800,
13300,
44100,
91200,
62800,
12300,
32200,
9800,
36000,
25000,
87300,
7800,
12800,
null,
45900,
null,
10700,
24400,
27600,
null,
16600,
10600,
34800,
18900,
19700,
11800,
37900,
12900,
74700,
18300,
6500,
35000,
79000,
95900,
14400,
14700,
71200,
12300,
33700,
28500,
83500,
6200,
25900,
20700,
6500,
4200,
9500,
75700,
3800,
20900,
55500,
18800,
13100,
43200,
14100,
15400,
5400,
16700,
48400,
8800,
2600,
34800,
null,
24700,
76600,
46100,
27700,
89300,
68700,
32800,
32200,
49400,
17000,
7000,
31600,
4100,
48000,
15550,
20300,
27400,
19300,
6400,
22000,
69325,
42300,
19100,
44500,
19700,
2800,
31200,
8000,
16500,
88800,
21100,
55700,
null,
19300,
44900,
16700,
101200,
10500,
null,
105300,
60000,
47200,
72500,
23100,
46800,
16600,
15200,
6800,
17600,
37500,
45900,
37500,
34500,
11900,
29200,
31300,
13400,
60300,
null,
4400,
5400,
59400,
38100,
null,
14800,
2900,
13100,
22700,
47000,
null,
24100,
16300,
43400,
21800,
11500,
null,
10800,
13800,
null,
15000,
73000,
21300,
39800,
59800,
26700,
26300,
106300,
23600,
34800,
null,
10400,
25500,
14000,
44200,
12100,
37900,
5200,
27600,
3900,
25700,
17600,
null,
null,
55100,
null,
68500,
6100,
23400,
11300,
9900,
54700,
24900,
38100,
15000,
21100,
7300,
38000,
13700,
187300,
115600,
49500,
7300,
22800,
10300,
27000,
92400,
77500,
35700,
13500,
27200,
11400,
45200,
11400,
28100,
27800,
25900,
18600,
9100,
null,
20100,
36900,
25700,
21100,
42700,
24600,
33200,
null,
36400,
34000,
24700,
51400,
10800,
23900,
12800,
28500,
57500,
32300,
12900,
85700,
null,
61400,
26700,
44000,
68700,
71900,
23800,
22400,
26100,
19400,
23600,
21200,
8500,
40500,
4300,
52300,
54100,
21100,
27600,
15000,
51500,
30900,
17300,
51200,
29300,
null,
191100,
19100,
3500,
34200,
26500,
33200,
67900,
13500,
21800,
30000,
7000,
83400,
41300,
24214,
41500,
null,
37000,
93300,
13400,
50000,
52700,
21200,
null,
33000,
62600,
44800,
8300,
20800,
23600,
6000,
52100,
null,
27800,
14300,
20300,
19700,
24200,
5500,
26000,
12500,
9000,
29800,
16100,
9600,
10000,
14700,
5300,
5400,
31500,
61900,
37300,
34800,
52300,
8200,
26300,
23100,
null,
27200,
22100,
27300,
39200,
15300,
17400,
59500,
29300,
12700,
70300,
21500,
90905,
94700,
17500,
9500,
29100,
700,
7200,
30309,
20300,
null,
31600,
13400,
33300,
50200,
null,
7900,
60000,
71400,
13700,
33212,
34200,
5500,
16500,
28500,
18000,
28000,
56952,
105300,
6800,
79500,
153400,
null,
25600,
null,
49400,
12500,
21300,
28800,
17000,
69400,
59700,
97900,
53900,
54628,
11900,
20400,
17300,
30800,
24100,
3300,
15900,
87000,
30200,
null,
13000,
29300,
null,
17000,
15200,
null,
27100,
10300,
59500,
18650,
27100,
14300,
4800,
15000,
16200,
17000,
13800,
10100,
24800,
17800,
17400,
11900,
27600,
14400,
37100,
null,
26600,
15700,
24900,
19200,
null,
29400,
25400,
39600,
14800,
21000,
50200,
6000,
27400,
15500,
26800,
12500,
15500,
55600,
22000,
17600,
148300,
42000,
13200,
23700,
5500,
24900,
28300,
66900,
25600,
12400,
85460,
20600,
null,
20900,
14000,
4200,
22400,
20100,
47900,
12400,
5100,
16300,
26100,
54000,
22000,
17300,
42100,
27700,
13200,
14700,
32200,
11900,
45000,
1900,
24300,
49600,
32500,
12700,
13700,
11400,
51942,
60300,
null,
33900,
84600,
10000,
15400,
42900,
40200,
49800,
93700,
77900,
41500,
18200,
null,
27300,
26400,
20400,
null,
14200,
9000,
8000,
14100,
43100,
31700,
6100,
30100,
23100,
9700,
76500,
8400,
18000,
2550,
55000,
null,
29800,
18000,
21600,
34800,
62300,
58100,
22800,
18600,
21529,
8200,
27300,
14600,
2200,
30100,
16800,
44700,
null,
5100,
41900,
10200,
null,
5000,
15000,
19900,
22700,
10400,
24900,
37600,
14300,
null,
16200,
31200,
13600,
20100,
15900,
27400,
33200,
8100,
8800,
123300,
4000,
6100,
6600,
9500,
15500,
30300,
59300,
24700,
22700,
18900,
null,
24100,
32400,
51634,
17500,
9400,
16000,
46000,
16800,
23500,
6800,
42300,
73800,
null,
12900,
11400,
120500,
10600,
16100,
13500,
70100,
null,
108200,
53900,
54300,
51000,
17300,
27600,
15200,
8800,
12800,
18400,
24000,
75800,
19500,
175700,
12400,
62400,
12600,
49700,
53700,
27100,
8900,
26200,
null,
1000,
15400,
23300,
44400,
null,
29600,
31600,
34400,
9300,
35700,
7600,
29500,
17200,
null,
13400,
29400,
18500,
10800,
null,
67400,
38700,
27400,
16500,
10700,
38500,
31500,
32300,
19700,
14600,
25400,
10600,
19800,
27700,
43900,
null,
17000,
11700,
5100,
45400,
15600,
39300,
10500,
57400,
19300,
38400,
16000,
null,
106400,
6300,
85400,
47200,
25300,
47000,
49200,
24700,
11100,
2300,
26800,
11500,
33500,
30000,
4500,
44700,
9400,
21400,
9200,
38300,
24400,
8500,
87200,
36000,
18500,
16900,
28800,
32100,
26500,
16100,
15000,
6500,
23000,
16600,
22800,
5700,
25000,
17200,
86000,
10000,
7900,
15700,
13000,
11000,
24200,
20600,
31900,
15400,
7300,
null,
null,
17100,
47100,
69900,
53200,
16000,
17500,
null,
3900,
null,
4000,
null,
24700,
33000,
48700,
50700,
25400,
68700,
36400,
null,
14700,
57200,
64200,
13200,
12000,
9600,
21700,
13600,
29000,
24100,
27200,
13300,
15200,
16200,
32000,
10100,
23500,
63400,
9100,
14000,
null,
13600,
19800,
28000,
67700,
20200,
21000,
31200,
34500,
null,
15400,
39500,
10800,
10600,
19000,
23700,
31900,
18100,
3900,
28900,
52400,
7900,
10900,
54800,
null,
5600,
19700,
24600,
128512,
16750,
7850,
106300,
4300,
14000,
143300,
17700,
21000,
29400,
18500,
303900,
38100,
12700,
null,
7800,
334500,
15400,
16600,
102400,
40000,
22000,
26100,
null,
62600,
46200,
23900,
12600,
24600,
4100,
26900,
null,
18400,
6009,
null,
17200,
null,
13100,
24100,
13600,
17400,
45600,
40000,
69000,
63000,
13300,
15900,
2500,
32500,
12100,
13200,
null,
22300,
40800,
5600,
67900,
7400,
31400,
7800,
18700,
12400,
22200,
24900,
281400,
13500,
84300,
15500,
5900,
24700,
61600,
65200,
51100,
10100,
11900,
5900,
null,
26800,
66400,
19700,
16100,
20400,
50100,
37200,
56500,
28500,
14000,
34700,
29800,
36000,
19800,
50500,
6900,
13300,
9200,
27700,
63800,
20000,
44900,
16000,
80500,
13100,
60050,
49200,
18800,
21000,
27100,
5200,
17400,
3100,
33100,
9600,
35000,
112000,
15100,
null,
null,
52600,
46100,
20500,
6770,
31200,
16800,
33000,
17000,
20800,
100300,
78100,
37800,
45400,
26900,
2052,
9300,
10500,
119500,
5400,
20300,
7600,
5800,
36900,
48900,
8800,
6800,
null,
13000,
37600,
35100,
null,
12400,
61700,
93000,
37400,
null,
14600,
9350,
34800,
17400,
8600,
48989,
53500,
23600,
15500,
79900,
34500,
18700,
57000,
51300,
15500,
19000,
6800,
29600,
7100,
null,
29000,
22300,
36000,
20300,
16900,
17400,
96800,
5500,
10000,
13200,
32100,
34100,
null,
null,
20400,
27000,
20000,
22000,
null,
21700,
27300,
11000,
46700,
17000,
20600,
18200,
74300,
11200,
19100,
12100,
8900,
67300,
25800,
62500,
56700,
7900,
7500,
40100,
17300,
39000,
18500,
57100,
4000,
64200,
38600,
107500,
5500,
37400,
64100,
34300,
35500,
10500,
45931,
3100,
51100,
7000,
15000,
57500,
32100,
null,
69100,
14100,
16700,
17700,
null,
16900,
24300,
9600,
null,
7000,
32200,
55500,
7200,
9200,
null,
null,
25800,
35800,
24100,
36900,
27500,
8300,
null,
3600,
27300,
10100,
null,
17400,
28600,
16400,
17200,
null,
14300,
44900,
null,
46000,
25600,
null,
13250,
17000,
16600,
16800,
29500,
59700,
63800,
21700,
26600,
null,
23100,
45500,
20400,
32000,
6200,
35600,
18500,
31200,
45700,
26700,
10300,
26200,
28300,
37800,
22700,
6600,
8000,
17100,
10900,
78000,
null,
24800,
17700,
11000,
null,
13500,
22250,
23800,
44600,
9000,
44700,
14400,
11300,
19200,
36100,
36200,
21500,
24050,
40900,
25700,
null,
38200,
11500,
8300,
4500,
34900,
18100,
22000,
337400,
10600,
13300,
11200,
48300,
10100,
16000,
13700,
24900,
12200,
null,
37200,
25000,
31080,
112600,
10500,
9500,
71000,
22600,
8300,
108900,
38900,
27800,
10900,
null,
12400,
18600,
23500,
23100,
6700,
null,
null,
47900,
15500,
21100,
null,
10500,
46200,
7800,
49920,
5500,
6000,
45800,
7600,
23800,
25900,
11700,
192200,
23100,
10200,
6200,
116200,
7600,
null,
27700,
6300,
18700,
45000,
31300,
16600,
44450,
43800,
19300,
23300,
32200,
12100,
32100,
27300,
58300,
36400,
32200,
70500,
67100,
64100,
21000,
24800,
31000,
34300,
23000,
51800,
22349,
21900,
5000,
58000,
null,
41300,
null,
5700,
4700,
19000,
41600,
14400,
44300,
17900,
21100,
57100,
14500,
27000,
19100,
17000,
6000,
22500,
149200,
20500,
16900,
12900,
68900,
86200,
null,
19000,
20500,
26700,
140800,
51000,
15100,
22700,
18900,
32300,
25400,
34100,
10600,
22500,
29700,
71700,
49000,
45100,
48600,
29100,
14100,
24600,
8700,
26800,
10900,
19000,
14900,
55700,
null,
25400,
14700,
35490,
14600,
10000,
71500,
21600,
null,
36200,
15000,
22600,
24500,
28300,
50300,
31400,
null,
26400,
47400,
6900,
16300,
37700,
165500,
24200,
26100,
103200,
40200,
7200,
24400,
78400,
20000,
12200,
17500,
3500,
64100,
61500,
null,
15550,
32900,
null,
null,
15200,
21500,
13500,
31100,
54200,
16600,
29800,
175500,
39100,
24600,
6900,
null,
6500,
null,
12000,
40900,
50500,
42200,
45000,
30700,
41700,
13900,
38400,
30300,
21300,
17000,
92800,
null,
35100,
12200,
23100,
14200,
49100,
18500,
33000,
43900,
73500,
18500,
null,
26500,
33200,
58500,
21800,
23000,
38400,
24300,
66000,
13100,
13200,
73600,
58100,
26000,
62200,
6800,
19900,
22300,
19100,
65100,
20800,
54200,
65400,
6300,
33100,
62400,
18100,
14500,
11500,
20600,
25400,
34900,
null,
36700,
null,
11900,
18900,
45100,
null,
1900,
34400,
86700,
13400,
null,
29000,
9900,
21500,
41400,
26300,
null,
29500,
24200,
5900,
49200,
28500,
14000,
34200,
55800,
34100,
6600,
64800,
19800,
24800,
null,
16300,
86900,
null,
16300,
23900,
24200,
33000,
17900,
12900,
12500,
16800,
17800,
null,
12100,
12800,
22100,
null,
19100,
19100,
20400,
24900,
13300,
3300,
17900,
16000,
21500,
14000,
4800,
14200,
null,
17000,
69900,
17600,
8700,
36700,
15500,
60400,
21500,
null,
35500,
10900,
9900,
21800,
10000,
14400,
null,
12500,
29700,
12800,
26200,
15900,
14300,
43200,
24400,
null,
135200,
67700,
28400,
13300,
5000,
42500,
71300,
18800,
10600,
3500,
94800,
32000,
42000,
10500,
9200,
10400,
32100,
49600,
84500,
39700,
106800,
92300,
null,
null,
53600,
null,
21300,
19800,
44100,
8500,
29900,
24200,
14600,
21100,
null,
47600,
103800,
152900,
10700,
50600,
20800,
46900,
13000,
31500,
10700,
57600,
53800,
11000,
25500,
21100,
24900,
91600,
34000,
14000,
25800,
60100,
19300,
42500,
4700,
61300,
11100,
17800,
15200,
6100,
16400,
32500,
5500,
19400,
41400,
22200,
null,
30200,
47000,
14100,
12400,
39900,
21300,
42400,
53200,
15900,
42650,
55000,
21800,
60400,
25300,
36800,
null,
17500,
19400,
15900,
12700,
5600,
21000,
22600,
null,
16900,
27100,
22500,
9700,
16700,
1900,
11200,
38200,
7500,
null,
34200,
4700,
35000,
35700,
12100,
10800,
null,
85100,
12000,
7800,
23500,
null,
8400,
100200,
4300,
14100,
32300,
21700,
17600,
49700,
10100,
27900,
24800,
30700,
null,
38300,
24200,
168700,
13900,
44600,
15900,
47700,
41500,
63900,
27000,
32500,
24000,
null,
19200,
25900,
76400,
19600,
4700,
24505,
26000,
null,
39300,
10300,
14500,
10400,
23000,
14600,
18000,
23900,
32300,
34500,
null,
null,
5500,
32000,
22700,
6700,
64100,
25700,
29200,
12100,
17200,
null,
33300,
23000,
129700,
41200,
16000,
32500,
51800,
17300,
17400,
82200,
23300,
70200,
8800,
17200,
99600,
109200,
28100,
12800,
7400,
29900,
28300,
33300,
23200,
36300,
8000,
26800,
8100,
23600,
16900,
14600,
51000,
19600,
11300,
27800,
8100,
14700,
28400,
12500,
13500,
8100,
10000,
24200,
49700,
35300,
18100,
null,
16100,
41100,
40000,
26600,
10900,
23700,
8900,
19500,
31300,
26600,
null,
null,
8500,
43300,
14700,
16500,
null,
28000,
19900,
25100,
31800,
23700,
39000,
4300,
null,
21500,
21200,
38600,
28400,
null,
14800,
45300,
14800,
8400,
20900,
64800,
35200,
19400,
27600,
30000,
61600,
32700,
33300,
29700,
15300,
103000,
43300,
11600,
18700,
10200,
20500,
67100,
7300,
15800,
53100,
8000,
25900,
2200,
7300,
26700,
15200,
15400,
4900,
34500,
null,
12000,
43800,
71000,
17400,
32400,
17500,
7500,
5100,
50100,
34400,
38000,
30400,
11217,
null,
54300,
11200,
17300,
8000,
41600,
60700,
6100,
31092,
null,
8500,
18800,
35300,
34200,
null,
9300,
71660,
51000,
9100,
44200,
7600,
88900,
8900,
57400,
73700,
20200,
41800,
111700,
null,
29800,
42001,
22300,
42600,
52000,
12800,
105600,
null,
11500,
4000,
55900,
null,
30200,
4000,
53500,
84266,
4700,
64300,
11700,
14100,
13600,
4800,
20700,
6200,
6800,
23700,
18500,
55900,
15000,
51800,
17600,
18500,
10300,
8600,
20000,
10100,
94900,
22900,
30500,
32200,
51100,
48600,
null,
12500,
58900,
25500,
19800,
14900,
10100,
null,
19200,
13100,
21900,
46700,
22200,
13300,
28400,
null,
null,
10700,
8200,
9500,
19700,
11100,
26600,
17400,
26800,
25800,
4500,
41400,
15200,
50200,
null,
52550,
22800,
20700,
2800,
15500,
66500,
15000,
18900,
14500,
5800,
39500,
61000,
15200,
null,
6500,
39400,
50500,
43000,
9200,
18700,
47700,
18100,
48300,
38200,
31300,
25000,
3500,
3000,
53000,
18300,
17400,
33300,
26100,
13900,
26700,
null,
13900,
46800,
69500,
28300,
22700,
26201,
26600,
47300,
36000,
null,
38100,
15700,
135700,
181300,
39900,
18600,
19800,
17800,
29900,
20300,
82300,
94900,
13400,
37200,
23400,
45400,
22600,
37400,
38000,
27300,
20000,
22900,
18600,
21600,
13000,
12800,
10700,
17500,
19000,
24700,
9200,
10600,
27300,
24100,
19400,
10600,
32200,
11300,
23700,
26300,
40800,
27600,
18400,
41300,
16400,
9700,
17100,
null,
130060,
23000,
3900,
12500,
25100,
null,
17600,
22600,
25300,
20100,
6500,
17900,
11952,
19700,
62900,
14300,
63700,
13600,
30600,
25300,
null,
33000,
8400,
13100,
17900,
7200,
13600,
null,
14500,
15500,
11700,
24100,
137200,
7000,
42800,
48500,
28600,
48600,
14100,
327700,
13500,
10600,
41000,
null,
null,
26600,
15900,
86500,
50700,
16600,
73100,
28200,
22200,
40400,
13300,
30800,
37700,
57400,
null,
40100,
9600,
55000,
18000,
25000,
11400,
21800,
29900,
46200,
null,
26200,
23000,
17900,
11100,
3700,
8800,
30300,
31600,
50400,
27300,
19200,
58400,
39300,
21400,
21300,
15500,
11200,
14000,
3100,
22100,
56300,
29800,
10000,
10700,
29600,
22800,
41200,
64400,
9100,
39500,
8000,
25200,
30400,
59100,
22200,
63200,
26400,
23500,
19800,
52500,
42200,
null,
null,
17000,
14000,
60200,
14000,
23200,
29100,
24700,
48400,
44600,
31100,
6000,
23900,
30500,
40300,
37900,
13700,
null,
47200,
44300,
4400,
27000,
null,
16600,
33800,
27300,
null,
26400,
34400,
26500,
38700,
22400,
11200,
161000,
18000,
29500,
11500,
9100,
37328,
73200,
28100,
17200,
50600,
44800,
40300,
20900,
10300,
13500,
57900,
73300,
9200,
7700,
24100,
40100,
15400,
19900,
7500,
6700,
20200,
25600,
13300,
16500,
84000,
null,
31600,
37700,
12500,
74500,
14400,
16200,
null,
null,
21500,
32100,
52200,
48700,
13000,
50600,
null,
null,
37200,
35500,
22600,
93800,
30100,
8100,
29600,
32700,
27400,
26100,
30500,
55200,
18000,
41500,
21500,
16200,
7500,
36500,
7300,
16600,
55800,
36400,
41600,
22000,
14400,
112800,
24800,
6600,
37600,
16800,
null,
41100,
26800,
13800,
18700,
115100,
20400,
34275,
15800,
32600,
49500,
4500,
32400,
14100,
35200,
33500,
7400,
34100,
40100,
41300,
17345,
34300,
42400,
5500,
8500,
7900,
12500,
19200,
29800,
6050,
5800,
21700,
3300,
25000,
45600,
35400,
103800,
86000,
23100,
33600,
18700,
8100,
24200,
1500,
70100,
56300,
22800,
33400,
16400,
47600,
20400,
12700,
49100,
9900,
29000,
3500,
null,
111100,
39800,
36600,
11800,
33900,
29000,
17200,
32200,
30800,
31900,
9800,
27200,
35600,
6400,
37400,
26200,
13000,
12400,
15100,
31400,
21300,
24600,
70000,
6357,
153300,
25700,
14200,
14400,
15100,
32900,
11100,
14800,
null,
13800,
null,
15200,
59000,
29600,
21300,
null,
17600,
8800,
3000,
19700,
14500,
21800,
20000,
25600,
31200,
17000,
17100,
341900,
34200,
8900,
14800,
15600,
38100,
13700,
21700,
106500,
24700,
77956,
31500,
null,
59500,
46600,
11100,
10900,
12200,
37100,
170600,
20800,
18200,
15400,
null,
48400,
7200,
null,
9000,
5100,
19400,
5650,
12700,
11000,
21400,
37300,
10700,
35800,
31500,
12600,
23300,
18300,
38100,
30000,
10900,
41400,
30800,
42600,
9800,
13900,
12800,
12600,
35900,
41606,
30900,
90100,
9400,
25900,
55200,
39049,
25700,
37800,
44400,
7300,
46300,
null,
8000,
23600,
null,
29300,
23900,
29400,
56300,
13900,
31500,
15700,
44300,
38900,
23000,
18700,
115100,
9400,
34900,
32300,
46900,
50800,
23000,
18800,
8500,
15000,
18200,
35200,
31300,
7550,
68200,
24400,
29300,
34000,
69200,
72400,
276300,
5500,
2800,
33600,
30800,
null,
58200,
null,
19500,
8800,
75700,
null,
null,
19700,
63600,
46200,
37000,
41100,
8500,
8500,
null,
20600,
18700,
21700,
30900,
25500,
26900,
null,
40300,
13500,
7300,
23700,
73000,
10500,
52100,
null,
37600,
30200,
6600,
11700,
23700,
null,
8800,
14100,
6600,
79000,
107400,
30600,
57700,
35000,
9200,
46700,
15400,
180700,
46500,
82000,
48600,
76600,
50800,
31400,
31300,
16100,
25400,
22600,
3500,
null,
22800,
28200,
38700,
38300,
4200,
4200,
24800,
23000,
16100,
89600,
137300,
15500,
null,
50700,
null,
33000,
42900,
14600,
9700,
30900,
13600,
81600,
60550,
18800,
11800,
25200,
1900,
18696,
70869,
24900,
10900,
148700,
14500,
null,
37700,
56700,
22600,
3000,
21100,
42500,
27800,
42400,
43100,
6600,
2900,
32500,
20100,
27700,
40300,
67300,
48200,
18600,
160000,
10100,
7800,
38600,
36500,
91600,
20300,
11500,
19600,
null,
44100,
8100,
45400,
85400,
78900,
18400,
25900,
11400,
65800,
49200,
21300,
12900,
null,
null,
null,
36600,
15200,
32800,
111800,
40000,
32100,
20500,
30900,
5100,
21100,
43500,
30600,
14900,
66600,
18600,
13800,
34700,
30200,
6400,
75000,
152500,
5705,
19100,
6600,
38200,
44500,
19000,
29000,
49800,
78700,
26800,
74000,
5300,
12600,
20300,
51100,
null,
63500,
55200,
42900,
10300,
130100,
6600,
15700,
null,
null,
34600,
7100,
29000,
17900,
8500,
58000,
15000,
119500,
24800,
24900,
36800,
19300,
12600,
113930,
38800,
10600,
37800,
21600,
43600,
29100,
36900,
11400,
20600,
38400,
21500,
33400,
10700,
36400,
53600,
52800,
16400,
11400,
80500,
8100,
146400,
40700,
19800,
65700,
5300,
46500,
11100,
25600,
48400,
41456,
45700,
13500,
7400,
15400,
69500,
145800,
23000,
170900,
25500,
null,
14900,
41000,
41900,
15700,
15600,
10400,
8400,
7700,
19600,
11500,
81300,
null,
19200,
null,
67800,
null,
12000,
null,
20000,
17200,
null,
26500,
42000,
16800,
55700,
78422,
24800,
15200,
39000,
33200,
26000,
28100,
18300,
14500,
46300,
30000,
29000,
9100,
8500,
10400,
19300,
22600,
null,
7700,
43900,
29800,
6400,
3000,
43800,
27600,
92900,
43500,
65900,
34300,
6100,
27700,
15100,
4400,
13800,
20100,
null,
58900,
3600,
19900,
17200,
24100,
67400,
48300,
null,
null,
null,
8200,
42700,
13800,
2000,
16100,
56700,
33700,
46200,
47400,
22700,
20800,
6700,
15300,
55800,
10800,
40500,
30300,
12500,
25700,
5800,
null,
null,
15900,
26600,
30600,
21600,
14300,
42500,
31800,
0,
99500,
null,
15200,
11800,
7600,
114100,
31500,
2500,
5100,
7300,
50500,
21200,
110510,
34600,
50700,
38900,
null,
14400,
15800,
18900,
9400,
20600,
32700,
49500,
19100,
41900,
47200,
8300,
52800,
22100,
12300,
36600,
9500,
21600,
20600,
84400,
null,
9200,
24800,
20300,
13200,
13000,
12100,
38300,
8600,
27200,
136100,
24900,
12700,
36700,
23400,
7300,
9500,
18800,
16900,
15700,
32900,
70900,
32000,
230400,
5000,
14200,
5700,
51000,
76100,
7400,
17000,
17000,
19900,
19100,
17700,
32200,
9100,
11000,
14000,
5700,
81000,
20500,
28700,
33700,
11300,
6800,
55000,
null,
9400,
30400,
73800,
12500,
8400,
27600,
41800,
71400,
32800,
21900,
9800,
11200,
248100,
43300,
35500,
12000,
6200,
13200,
55600,
9900,
7000,
11700,
39100,
13800,
45400,
9200,
31900,
8500,
22300,
15900,
9200,
41600,
13600,
41500,
8100,
44000,
44000,
14500,
19000,
41500,
21500,
43000,
101700,
null,
null,
85500,
17500,
50100,
7300,
41500,
6900,
13100,
66900,
43400,
null,
43000,
1000,
21200,
19800,
47400,
64600,
42500,
12100,
9200,
23100,
40000,
8000,
25400,
19700,
13000,
32200,
5000,
15600,
53500,
6400,
29900,
16700,
27600,
25600,
27100,
71188,
16400,
18100,
32500,
26300,
null,
33100,
50900,
30900,
20100,
15800,
16000,
20500,
17500,
29100,
6900,
35800,
17200,
null,
2900,
5000,
9000,
23900,
null,
15600,
15600,
5500,
13800,
31600,
21700,
175700,
26300,
15000,
5600,
48350,
5900,
30500,
11300,
20700,
29800,
55500,
28000,
10200,
17800,
21600,
20100,
21700,
20600,
13000,
12000,
null,
15000,
33700,
20800,
14150,
17500,
24600,
29000,
22700,
24100,
11900,
21700,
null,
26900,
5500,
30000,
19800,
35800,
7200,
15000,
null,
10200,
null,
null,
10600,
94100,
67700,
28500,
27800,
2000,
38900,
40300,
57900,
23000,
10200,
23900,
70400,
52000,
34300,
30400,
10900,
33000,
null,
10600,
39500,
16800,
13100,
36600,
121600,
48700,
19400,
16000,
11800,
21300,
24500,
49700,
41800,
157600,
32600,
20995,
84000,
11800,
19900,
8200,
103500,
40000,
88800,
14600,
33300,
null,
34300,
32000,
13700,
19300,
16400,
63300,
19900,
16400,
15700,
25600,
14800,
17300,
42600,
58900,
23200,
10100,
7100,
33000,
27200,
6200,
91200,
7300,
25900,
52700,
46300,
19000,
21200,
15700,
35400,
null,
17200,
17369,
4000,
null,
41700,
null,
42400,
null,
57900,
28600,
5100,
24700,
19500,
34900,
26400,
59100,
29200,
13100,
null,
41800,
45800,
17500,
null,
8200,
10800,
null,
10500,
14400,
51900,
60300,
32500,
17500,
10300,
39900,
12900,
13300,
27000,
83700,
18300,
5800,
23800,
19600,
23580,
29300,
62800,
52400,
41700,
52400,
10400,
20600,
10900,
46000,
13000,
73900,
7500,
36600,
23700,
18200,
36000,
11600,
15500,
63700,
40100,
33500,
7900,
null,
25000,
27700,
10000,
28400,
19600,
19700,
19100,
15100,
42900,
null,
41100,
26900,
65400,
17100,
12800,
16800,
24200,
15700,
14200,
44100,
14700,
11200,
7500,
9200,
15100,
52700,
45200,
13100,
5700,
10000,
37800,
17700,
103200,
5000,
30800,
105000,
null,
38900,
17000,
27000,
29400,
94900,
7600,
42300,
14000,
null,
19390,
11000,
23700,
21200,
13900,
26200,
46600,
32600,
19200,
20700,
23800,
9300,
68900,
36500,
26500,
20500,
28000,
64800,
12200,
12000,
null,
45800,
1600,
34800,
14900,
null,
81200,
null,
30000,
97200,
53400,
106400,
28800,
83400,
7300,
null,
65900,
25300,
41600,
null,
30000,
94447,
35000,
5000,
79700,
null,
39100,
140800,
53400,
36900,
17600,
14300,
21000,
27800,
52900,
35100,
null,
55000,
27000,
21400,
10500,
66000,
28600,
24600,
14000,
6800,
46400,
null,
73800,
28900,
22900,
23700,
17700,
18700,
7500,
13800,
109100,
14300,
29500,
133600,
22200,
154900,
33800,
5700,
null,
32500,
34400,
48700,
8400,
40500,
12300,
20500,
24700,
16900,
64400,
10200,
26300,
17300,
null,
12700,
10500,
130600,
12500,
35800,
11000,
10200,
36100,
15000,
19625,
27000,
16700,
40100,
74500,
8800,
23700,
26600,
13000,
null,
null,
10500,
85600,
59400,
83200,
null,
18200,
24400,
null,
6500,
101400,
7000,
12500,
12200,
23600,
114700,
141550,
13500,
15200,
57600,
57000,
16500,
34200,
89800,
53705,
16200,
7800,
42600,
41600,
24900,
null,
18400,
14600,
22800,
66800,
30800,
28500,
6700,
32000,
11000,
16500,
11450,
null,
18000,
12700,
60200,
8500,
41100,
19700,
26500,
7300,
16000,
null,
34300,
22700,
7100,
58000,
55200,
76804,
32800,
65000,
48500,
6150,
5000,
10800,
79600,
13900,
null,
15800,
89500,
null,
22400,
12100,
24200,
15500,
31700,
22400,
31600,
104100,
77900,
27100,
26800,
10400,
61100,
29000,
48000,
41200,
25000,
30400,
70500,
38100,
11600,
null,
20100,
25200,
4200,
null,
127100,
11400,
67700,
64500,
10300,
null,
null,
5800,
null,
37400,
94600,
null,
12400,
48600,
56200,
20700,
16200,
80700,
51600,
194800,
17300,
120900,
15400,
6200,
19100,
13800,
23700,
9400,
10700,
27600,
24900,
9600,
18000,
6600,
23500,
3500,
12400,
19300,
23000,
33600,
3200,
44200,
56600,
39800,
null,
null,
23254,
71300,
252300,
7500,
47800,
27400,
34500,
22800,
null,
2500,
13500,
116100,
39800,
19000,
17100,
17500,
54600,
72900,
9200,
16700,
64900,
17000,
20100,
31400,
null,
25500,
75300,
42000,
9400,
9600,
15200,
22400,
79400,
82300,
null,
68500,
41300,
171300,
32900,
27000,
14900,
12400,
26300,
192100,
74400,
22600,
23100,
9000,
27300,
11200,
10500,
84500,
22300,
22100,
31200,
9600,
3300,
42100,
null,
26700,
null,
15000,
29200,
11300,
8100,
46800,
null,
84800,
null,
37700,
5500,
48100,
null,
39400,
14900,
13050,
7400,
28000,
20300,
null,
null,
84600,
31000,
17700,
3700,
15600,
11600,
26900,
120000,
33000,
11000,
29800,
19400,
36100,
78600,
16300,
8400,
7500,
8900,
34800,
29000,
8265,
25600,
10700,
52400,
73200,
28700,
16500,
24200,
8600,
10200,
95055,
13900,
11100,
21500,
11000,
29500,
72100,
18100,
117900,
6700,
48000,
12300,
66894,
28100,
9800,
23900,
17600,
27300,
48300,
9000,
18600,
2900,
61200,
42500,
21700,
26000,
16000,
14000,
79100,
19800,
62600,
27700,
34400,
14000,
52300,
41900,
17017,
13400,
23600,
24200,
21200,
null,
16500,
33000,
24500,
23500,
20200,
25300,
23600,
35600,
18200,
33800,
8600,
5100,
84200,
29800,
16000,
3100,
25600,
38200,
36500,
null,
23900,
47200,
null,
27100,
41600,
33200,
11300,
39800,
9000,
null,
41015,
null,
1500,
13500,
48000,
null,
11200,
49000,
7900,
33400,
null,
5000,
153900,
null,
15000,
35700,
25500,
17500,
48200,
null,
6100,
16600,
69900,
19300,
null,
16500,
40300,
19300,
16000,
17500,
42050,
14000,
60800,
10100,
11700,
26300,
null,
5600,
12400,
9800,
29600,
9500,
38200,
15800,
37900,
18900,
59500,
null,
28400,
15000,
null,
15400,
63000,
21500,
36900,
57600,
57900,
9600,
41200,
43200,
37400,
15700,
51600,
71300,
31400,
29100,
8700,
25800,
12800,
27500,
10100,
9700,
6950,
219700,
36000,
40000,
26400,
14000,
17100,
14900,
42000,
35500,
27800,
11300,
19200,
16200,
43700,
47726,
null,
null,
18500,
1800,
14700,
3500,
null,
94100,
31000,
33000,
32900,
6000,
96500,
34200,
47300,
15500,
9500,
211400,
9500,
25500,
30100,
30900,
15700,
16866,
22900,
12100,
37500,
28500,
13700,
38000,
14400,
54500,
21410,
45700,
28200,
27500,
17300,
15700,
17100,
10000,
8600,
20800,
42400,
29600,
26200,
39100,
15700,
8000,
18900,
null,
40000,
35400,
63200,
77300,
78400,
35200,
82200,
21800,
203100,
48700,
5100,
510200,
46100,
29100,
null,
52100,
26300,
null,
46400,
12300,
47700,
2300,
36300,
49900,
6600,
23200,
8000,
26100,
null,
43400,
6200,
18700,
7000,
9000,
13700,
16300,
18100,
16600,
49200,
69400,
101100,
17400,
21900,
38000,
19200,
10300,
36725,
6400,
5500,
32100,
61800,
9600,
11600,
24100,
10500,
29600,
null,
null,
null,
29200,
22800,
34700,
17100,
41900,
42700,
12800,
137800,
35000,
17900,
17100,
9900,
21000,
31900,
null,
54771,
19300,
11700,
20200,
49900,
31500,
51600,
21965,
46100,
72400,
18400,
32700,
90600,
null,
null,
36300,
23900,
9300,
22900,
10900,
21200,
20900,
55600,
27000,
26100,
11400,
132400,
42900,
43600,
62800,
41600,
null,
105700,
39100,
null,
53718,
51900,
72300,
27800,
42200,
17700,
31300,
34000,
64000,
12700,
18500,
22600,
25000,
66200,
12300,
12800,
null,
28400,
26400,
10400,
10500,
20200,
24700,
null,
46700,
36300,
11200,
6200,
25600,
null,
38500,
13800,
8200,
18500,
22900,
8000,
231400,
33300,
19800,
17800,
11900,
14400,
16700,
43400,
76600,
25700,
30100,
15900,
11500,
25800,
30200,
64900,
23700,
24400,
17300,
8300,
23500,
19500,
38000,
84500,
12500,
21000,
15829,
21700,
30400,
25000,
null,
6900,
57300,
170200,
2100,
13500,
10100,
61500,
20300,
23600,
33800,
2300,
15900,
33400,
12900,
8800,
5500,
32600,
7500,
61600,
16200,
41200,
9500,
8500,
37400,
6000,
10900,
13900,
22300,
41301,
9500,
33500,
21900,
41200,
25000,
23800,
22400,
53900,
7700,
11400,
53700,
60100,
27400,
null,
36400,
188800,
23900,
5000,
45800,
11200,
9500,
15700,
36100,
68000,
14700,
40100,
21400,
null,
39300,
81000,
31000,
11400,
22800,
13200,
106000,
25500,
25300,
11500,
19700,
null,
16300,
12500,
null,
9800,
26500,
23500,
null,
20900,
18300,
28800,
12700,
6100,
5000,
16100,
39800,
32300,
null,
18500,
22500,
7800,
28500,
26200,
21000,
95500,
37300,
31400,
21000,
null,
19800,
21500,
15200,
12900,
14100,
null,
16500,
47300,
3300,
12300,
22300,
14000,
14700,
6000,
37500,
10000,
69100,
23700,
32600,
26600,
9200,
20100,
4900,
5600,
15200,
null,
42300,
9400,
47700,
42200,
26800,
30600,
25800,
6600,
61000,
33200,
null,
27700,
44500,
14300,
36900,
4000,
20200,
89500,
47300,
12000,
19000,
41900,
29300,
28400,
118100,
43127,
68200,
16700,
45800,
49000,
39300,
19300,
48600,
15800,
17100,
5800,
15000,
31500,
1900,
12400,
8700,
17700,
17700,
15300,
3300,
55100,
8025,
38200,
18600,
128100,
99400,
20500,
47500,
24300,
53800,
32400,
null,
27900,
52600,
37500,
23100,
5600,
8400,
11400,
24200,
6000,
32600,
34700,
null,
61800,
22600,
4800,
27800,
4000,
32900,
29200,
12700,
14200,
10700,
29000,
15400,
33600,
30500,
58500,
12800,
null,
33200,
37800,
26650,
150400,
39900,
63500,
17800,
3600,
15200,
9900,
18300,
13500,
24300,
51600,
29300,
108800,
10100,
19215,
null,
22300,
21985,
25800,
null,
27800,
30000,
11200,
18500,
22700,
32600,
67700,
89800,
57000,
27300,
26900,
73700,
15300,
33500,
62700,
8700,
12200,
52500,
28700,
6200,
null,
7700,
11100,
20100,
15000,
35500,
33900,
53800,
10100,
34600,
27800,
5700,
64600,
8900,
6100,
9100,
225805,
null,
11200,
24900,
9700,
9700,
27900,
25300,
19000,
49200,
45630,
13200,
16700,
28900,
13300,
31400,
25500,
17700,
16900,
null,
900,
22800,
37000,
8900,
37000,
58400,
16000,
29500,
22400,
null,
null,
28000,
14900,
7500,
5500,
14200,
null,
50700,
15000,
15300,
null,
null,
74500,
44100,
24300,
15400,
5100,
11700,
18800,
33600,
37000,
19900,
15100,
24700,
3300,
7100,
36100,
40700,
30300,
18600,
5000,
18100,
71500,
19700,
14900,
33400,
43800,
13500,
23700,
24900,
27500,
9300,
25200,
16000,
39300,
25100,
21900,
29900,
18800,
24500,
31400,
17300,
37800,
8000,
9400,
28800,
null,
26200,
56600,
59500,
8100,
36100,
44300,
138800,
29000,
14507,
26100,
19400,
null,
49200,
20300,
70800,
21700,
20300,
18700,
30200,
62100,
31400,
14400,
35400,
36100,
5600,
20600,
24400,
77000,
64900,
19800,
135400,
5600,
21900,
10800,
22200,
null,
9600,
19300,
21500,
19300,
null,
28800,
32500,
6700,
75500,
59200,
null,
null,
52100,
29900,
14200,
65000,
24900,
16400,
18600,
22700,
10300,
21100,
24000,
110400,
10300,
38300,
19100,
11400,
27500,
31700,
16500,
15000,
null,
7400,
14200,
23800,
64500,
21000,
25800,
47800,
46700,
22300,
11800,
16500,
26700,
42000,
98100,
34600,
21200,
9100,
35620,
null,
43400,
31800,
30900,
20400,
21300,
15600,
70300,
39600,
null,
28220,
55100,
28100,
34300,
95900,
null,
34150,
3000,
17700,
33100,
10900,
46100,
14500,
36000,
12700,
8800,
null,
18600,
30400,
27000,
13200,
58500,
18200,
27000,
5200,
10500,
36000,
25100,
47900,
29400,
9600,
66300,
36700,
null,
36500,
33200,
57000,
72300,
23500,
13100,
248400,
9800,
15600,
null,
49439,
15600,
56701,
23600,
41800,
37400,
21400,
81100,
58100,
12300,
21600,
null,
27900,
14000,
8100,
24000,
9500,
10500,
12900,
5550,
51100,
22000,
7600,
14400,
20900,
15400,
7000,
25800,
9600,
null,
7500,
9200,
9800,
50900,
30500,
38800,
35800,
40300,
30900,
16400,
13700,
92100,
23900,
10200,
4000,
44400,
16300,
28800,
11300,
4400,
3700,
21980,
7700,
59600,
64600,
34100,
34700,
15300,
28400,
42200,
18200,
27600,
60200,
10000,
22000,
7750,
14700,
22600,
null,
4500,
7900,
67000,
70200,
33700,
25700,
132100,
16300,
null,
13150,
8200,
22800,
null,
30700,
46000,
36270,
22000,
null,
13200,
49200,
32200,
4300,
null,
21500,
25400,
77200,
20300,
null,
34300,
42600,
8600,
0,
17300,
35400,
53000,
32900,
19100,
42500,
null,
6500,
9300,
32100,
66900,
35300,
39700,
42100,
22700,
15000,
27800,
112800,
18800,
25400,
72806,
38500,
29200,
7800,
34800,
28100,
26500,
12100,
123600,
null,
15800,
81250,
11300,
17300,
23400,
64300,
12900,
7600,
4900,
9500,
16800,
32600,
47100,
110100,
20700,
2400,
10400,
36300,
15700,
11900,
15600,
7100,
70100,
null,
null,
11200,
30900,
10400,
17400,
37700,
31600,
6000,
28200,
16500,
24100,
15900,
46800,
35000,
null,
2600,
7500,
18500,
69300,
24400,
59700,
45600,
12500,
7900,
19700,
30000,
5500,
18800,
75400,
5500,
13100,
23800,
35100,
null,
10000,
5700,
15300,
null,
22300,
39300,
43700,
12000,
19500,
68100,
15500,
19600,
15700,
56000,
17400,
6600,
16600,
45000,
8450,
null,
16500,
30600,
null,
63100,
30000,
7200,
null,
3700,
22600,
56100,
117600,
40300,
59700,
41100,
19600,
18700,
14600,
18200,
25000,
28800,
27800,
68800,
23100,
null,
106800,
30500,
13200,
23600,
20500,
70300,
11300,
32100,
61000,
null,
64600,
50600,
11900,
46600,
30830,
27200,
21200,
23400,
6000,
16700,
5500,
30200,
11000,
56000,
26700,
13600,
102300,
36100,
138700,
14600,
6200,
13700,
9000,
19900,
10800,
19700,
null,
21400,
27900,
41100,
30100,
39800,
33250,
40400,
65800,
64400,
16900,
null,
27500,
98200,
29400,
11300,
10500,
34600,
15700,
19000,
18200,
91400,
20300,
80220,
11300,
14100,
65700,
null,
18100,
17000,
37500,
36000,
5900,
17000,
27600,
25700,
151600,
26800,
33400,
47800,
35500,
13900,
17300,
80800,
13300,
null,
20500,
8900,
53200,
24900,
null,
30900,
null,
null,
18600,
313000,
19800,
11200,
10600,
null,
3400,
26100,
38500,
30400,
25100,
16900,
2800,
27600,
15300,
50700,
17600,
77000,
42000,
43200,
13300,
30400,
17600,
19600,
null,
55300,
22000,
32000,
73300,
11200,
29200,
22200,
20700,
14600,
43600,
25400,
15900,
44800,
10900,
20000,
27600,
4600,
null,
13700,
48200,
6000,
58600,
11000,
36600,
7500,
56700,
34000,
19900,
32700,
10500,
21800,
21100,
13300,
27600,
89000,
8100,
null,
23100,
33830,
167500,
54200,
21300,
29100,
21800,
15300,
13000,
81200,
38900,
null,
7100,
41300,
24800,
65500,
10400,
16800,
null,
22300,
16700,
17300,
4200,
28900,
22300,
17500,
52200,
8250,
30200,
5700,
56500,
18900,
41000,
20200,
56200,
10800,
10500,
31100,
83800,
39500,
12400,
230200,
22100,
23300,
37600,
53000,
9600,
6950,
51100,
6500,
104500,
16400,
55500,
21100,
9200,
4100,
17700,
22000,
9200,
8500,
null,
25000,
47700,
26000,
19200,
34100,
2500,
null,
13500,
60300,
23400,
31900,
26000,
83124,
26400,
40200,
163000,
28000,
null,
18900,
9500,
12300,
22700,
null,
52800,
null,
4700,
7000,
19300,
28900,
12900,
10200,
19600,
47100,
22100,
22200,
8500,
17800,
35700,
16700,
39600,
53100,
16200,
null,
60300,
46800,
278200,
14100,
21700,
37100,
33500,
16900,
38385,
null,
50600,
45900,
15100,
53900,
14800,
72900,
21700,
40500,
37500,
22800,
61800,
null,
13700,
42400,
20100,
20600,
7637,
74300,
57400,
15700,
4450,
22200,
39274,
null,
25600,
null,
10700,
20100,
24500,
19400,
null,
36600,
6200,
12500,
9300,
132900,
23900,
22000,
22700,
40900,
52500,
null,
19400,
16200,
14000,
27700,
28800,
27300,
37700,
49700,
8600,
73100,
1500,
35600,
24400,
84000,
27100,
27700,
56600,
8500,
null,
30700,
10800,
18700,
5400,
23500,
16900,
41900,
17400,
39400,
8000,
14000,
50500,
13400,
29900,
17600,
7300,
23600,
28000,
25600,
92400,
197100,
4200,
37000,
7300,
6500,
32700,
6400,
11900,
18900,
4700,
12900,
null,
28000,
19300,
null,
27450,
24900,
13900,
17800,
13200,
18700,
21700,
2538,
53900,
35400,
11000,
21800,
22900,
23600,
44500,
15000,
8500,
24700,
42400,
21800,
4800,
8100,
5100,
25400,
9800,
1000,
28200,
146800,
52500,
20200,
41400,
12500,
32000,
9000,
5000,
66600,
31300,
26300,
13800,
68600,
38900,
71400,
38900,
88100,
35950,
43400,
26600,
15200,
15400,
20500,
8100,
68700,
null,
16800,
15100,
9800,
19500,
11300,
7300,
33600,
80600,
11100,
8700,
11100,
26400,
103500,
null,
96300,
18800,
65500,
37100,
52600,
10700,
7100,
30300,
40600,
29900,
34800,
23100,
85100,
12400,
43900,
5300,
11900,
16800,
15200,
null,
49600,
55200,
24000,
8800,
21000,
18000,
42900,
44400,
11100,
21300,
38200,
4400,
49400,
24500,
33400,
19200,
55300,
14100,
42900,
27300,
58020,
47600,
14700,
10800,
16000,
15700,
15400,
15500,
7400,
74850,
18300,
47000,
43400,
18700,
19100,
29000,
7800,
4000,
8200,
11800,
34700,
16500,
28000,
16000,
20800,
28200,
71100,
7200,
17100,
19000,
48500,
null,
156700,
47600,
17800,
7700,
19800,
41700,
67800,
13700,
14800,
12100,
13100,
13100,
8500,
15600,
39900,
53300,
29600,
36700,
46300,
122900,
28900,
22300,
19400,
6300,
14600,
21700,
20200,
48500,
36000,
17500,
52000,
55100,
94900,
68800,
33600,
44200,
40000,
3100,
60100,
35600,
25300,
23800,
52900,
45300,
68600,
16000,
14900,
29100,
17500,
22000,
17500,
null,
19100,
11500,
52100,
32700,
4200,
227150,
45000,
6100,
11400,
79800,
38700,
null,
7500,
57100,
3600,
39100,
8000,
57400,
62300,
33400,
10200,
80200,
null,
null,
28900,
19800,
55700,
null,
10100,
31300,
27500,
54100,
null,
17300,
null,
29800,
null,
42400,
43000,
17300,
47600,
20600,
7900,
64700,
11100,
44500,
null,
55600,
25200,
27100,
15400,
15800,
10900,
29300,
8200,
32900,
17800,
null,
33400,
16000,
15500,
18600,
15700,
45400,
25600,
16100,
6200,
46500,
null,
4600,
11400,
85000,
7500,
6300,
140700,
16500,
12200,
42900,
35700,
null,
6600,
14200,
8700,
19800,
11800,
42000,
13800,
40000,
null,
7100,
24900,
29000,
55600,
36200,
10800,
13200,
343500,
8700,
22200,
13100,
16700,
13000,
null,
14500,
null,
5400,
10800,
27900,
113168,
9200,
8600,
33356,
null,
33000,
24800,
9800,
14800,
19400,
29400,
147400,
10100,
22400,
27000,
39300,
101900,
14600,
21100,
33000,
44800,
35500,
68300,
17000,
27700,
17100,
41600,
85100,
50200,
null,
17600,
45600,
9500,
21200,
47500,
22000,
12300,
33500,
23600,
12100,
36800,
null,
59400,
28100,
22650,
27300,
null,
8850,
11800,
49300,
16100,
15200,
24700,
25600,
28700,
28800,
214100,
null,
8600,
12700,
11800,
11200,
21500,
null,
32800,
28100,
30500,
21400,
16100,
12300,
50800,
35900,
79300,
11700,
60800,
14500,
null,
10600,
7500,
112700,
13400,
16500,
26000,
56000,
8700,
51200,
28300,
null,
20500,
50600,
59700,
18000,
15700,
20300,
32700,
17700,
11200,
14900,
18500,
55500,
14600,
11000,
null,
14400,
12200,
64400,
103700,
42500,
19900,
170500,
23900,
118900,
37600,
null,
24900,
59500,
7300,
null,
13200,
126245,
7000,
20600,
29800,
38400,
11300,
12700,
16800,
17000,
25500,
21800,
23500,
17000,
43000,
86300,
15700,
62500,
9700,
115000,
16584,
null,
2500,
26100,
null,
9500,
10300,
19700,
6550,
35298,
24000,
33500,
18000,
15700,
11500,
22400,
null,
22000,
13600,
58700,
8300,
35500,
29000,
11200,
12300,
15500,
27500,
18400,
null,
42400,
15900,
54425,
13300,
13300,
null,
33700,
5300,
null,
27300,
4800,
22100,
6010,
21900,
null,
21400,
79100,
6900,
16100,
25100,
49100,
25172,
31700,
65200,
21700,
7400,
13200,
37800,
22900,
33800,
30600,
48500,
25000,
97600,
23700,
21780,
26600,
2900,
10000,
37000,
null,
32600,
25100,
19500,
17500,
58400,
17400,
10000,
12500,
37200,
11700,
48000,
48800,
19500,
13700,
68000,
11400,
36500,
10700,
84600,
8700,
19700,
11400,
18800,
16200,
52300,
8500,
13800,
15000,
59800,
23600,
25400,
27900,
25200,
29000,
null,
26300,
42300,
52000,
51300,
50800,
47100,
null,
15200,
8100,
63700,
36500,
4100,
47325,
25300,
23200,
14900,
231200,
44200,
54700,
null,
13500,
20400,
49200,
34700,
16800,
14000,
20500,
null,
22700,
9700,
52400,
7600,
3000,
null,
24800,
14300,
19300,
80951,
17900,
3500,
47600,
63100,
60100,
8300,
22700,
74200,
45200,
15700,
40300,
220000,
28400,
46100,
66700,
8800,
null,
3400,
15100,
23200,
42300,
27300,
21600,
33000,
46200,
11200,
89100,
23100,
10800,
9500,
7100,
43800,
42600,
14300,
47800,
1000,
42600,
14200,
58100,
8700,
24700,
26100,
24000,
12100,
18500,
18000,
11400,
26600,
30800,
29000,
6400,
null,
19900,
2400,
18600,
22400,
43100,
6600,
93700,
13900,
24700,
25300,
34300,
35600,
36100,
35300,
16500,
37400,
87000,
40500,
61850,
30700,
12400,
14900,
22400,
91400,
43000,
13400,
null,
17900,
9900,
47100,
18300,
11300,
37600,
6300,
33600,
35500,
101600,
15500,
39300,
61700,
42100,
48800,
null,
14900,
18500,
67400,
30700,
7400,
44200,
32400,
20400,
110200,
60200,
116300,
49500,
31400,
21600,
7800,
35700,
29900,
23200,
27300,
7300,
36500,
null,
34200,
56200,
25700,
5000,
26800,
null,
null,
6600,
40600,
10400,
70000,
51500,
null,
2700,
22300,
38100,
15500,
18300,
null,
null,
34400,
26100,
51600,
25800,
69400,
30300,
26200,
37800,
79000,
14000,
30600,
10928,
13600,
53500,
8400,
24700,
44900,
54200,
11600,
5300,
16000,
51181,
115600,
38400,
13300,
184200,
17800,
null,
35600,
24900,
20600,
32500,
35700,
20300,
8400,
29600,
47600,
4300,
53600,
7100,
21305,
157300,
69400,
54200,
61900,
10800,
null,
27600,
39900,
3000,
4900,
14700,
29300,
28900,
33400,
12400,
70000,
35300,
113000,
4300,
32400,
43600,
75300,
35400,
14500,
52400,
34300,
13500,
65200,
41100,
15800,
2000,
11200,
null,
3500,
27000,
163000,
null,
19800,
23400,
null,
53100,
12200,
28100,
9100,
7900,
9400,
42400,
34500,
12300,
56100,
51200,
25500,
11700,
9700,
35100,
32800,
13800,
41000,
19700,
33300,
22200,
17400,
null,
43900,
null,
4200,
2000,
13600,
37100,
16600,
27400,
75300,
27400,
6000,
10100,
38100,
20200,
null,
31400,
28700,
null,
6500,
18820,
21000,
18080,
57300,
null,
119700,
20400,
14300,
29400,
41300,
15100,
11700,
36100,
29000,
22700,
60300,
21600,
35500,
30400,
16300,
null,
28100,
30000,
7900,
24300,
6000,
13100,
104400,
null,
5200,
27200,
39500,
9600,
13300,
36800,
null,
22300,
12400,
null,
25500,
31500,
5800,
null,
12000,
44200,
10800,
25800,
26073,
70203,
13900,
43600,
65300,
21400,
43000,
83300,
7900,
12600,
36000,
16400,
5700,
16900,
null,
17400,
41100,
38000,
8200,
8100,
2000,
31500,
46700,
16700,
17000,
41500,
7800,
21000,
52900,
21300,
20800,
132300,
21200,
5300,
89400,
49400,
13100,
40600,
12000,
119300,
28700,
9300,
36700,
null,
32200,
15600,
11200,
15500,
75534,
20800,
31300,
1400,
13900,
null,
10800,
24800,
25500,
27890,
28100,
20000,
24100,
null,
38200,
3600,
59300,
17300,
6500,
23100,
29200,
45100,
13700,
23900,
36086,
25550,
7800,
26000,
38000,
11000,
48400,
37000,
57800,
9000,
26300,
25600,
6800,
30000,
12970,
87800,
1600,
16400,
24400,
19600,
38100,
20400,
22000,
16800,
null,
58200,
20800,
6000,
32500,
9900,
null,
24900,
59200,
null,
118900,
23400,
43900,
33400,
26200,
11200,
null,
24100,
null,
15200,
10100,
45400,
54500,
20800,
11800,
19200,
68300,
10300,
16100,
4600,
5700,
28100,
118400,
25300,
26600,
15400,
54500,
301800,
28500,
5400,
29600,
66100,
36500,
null,
36000,
18700,
null,
7300,
42400,
14100,
6300,
13600,
16200,
79800,
33500,
50700,
7100,
32700,
5100,
30900,
20500,
null,
39500,
29700,
12200,
35600,
5500,
10500,
null,
64500,
98730,
121400,
null,
7200,
27800,
42800,
83200,
84200,
11200,
43600,
15300,
7900,
37800,
26100,
27000,
47200,
61000,
22200,
32600,
17500,
null,
14800,
15900,
null,
26700,
23200,
13800,
78800,
39000,
13600,
22800,
24500,
23000,
35700,
31100,
null,
54800,
16100,
8676,
null,
11100,
15500,
24900,
2500,
16800,
null,
28700,
10600,
null,
60900,
16400,
21300,
25100,
11700,
19500,
14200,
32100,
20600,
15000,
null,
31900,
17500,
56400,
50400,
16200,
16300,
6800,
28400,
14500,
63900,
11000,
45200,
65400,
23700,
41900,
33200,
35600,
27900,
42300,
7000,
4100,
13300,
44300,
30600,
40400,
48200,
30500,
14100,
36300,
39900,
21800,
10400,
37100,
null,
5100,
5700,
15200,
8500,
10800,
81100,
74000,
21100,
20000,
null,
140700,
164400,
27400,
19400,
15300,
70700,
12000,
20500,
31800,
9000,
14000,
16800,
null,
49900,
67300,
6600,
12700,
31000,
5300,
27800,
20800,
119200,
26600,
22700,
44300,
16700,
71400,
null,
null,
3200,
26000,
13400,
null,
38000,
42100,
34400,
39700,
21200,
31500,
7200,
30700,
77850,
19700,
140270,
24800,
91600,
34800,
9500,
7900,
28200,
10500,
16500,
61700,
25100,
12400,
52800,
12400,
64700,
22400,
null,
15900,
21186,
48200,
116100,
12200,
46500,
19300,
24800,
12800,
6900,
null,
25400,
13800,
10800,
13600,
34700,
4300,
10200,
20000,
46700,
8500,
18600,
80503,
56000,
null,
31700,
55200,
null,
51800,
16700,
20800,
44600,
31500,
24500,
2200,
21600,
28000,
29100,
59100,
30600,
30100,
null,
null,
null,
9100,
13000,
40300,
31500,
16700,
34000,
28400,
29100,
24400,
21700,
95400,
71300,
25800,
null,
8100,
null,
null,
32600,
47000,
25100,
1300,
72200,
22300,
4400,
78900,
136200,
28200,
36200,
17600,
6700,
10200,
21300,
25300,
61800,
25100,
12100,
62500,
null,
14950,
23200,
12800,
37100,
15200,
26200,
22300,
14500,
5100,
null,
28100,
19150,
21500,
21400,
47500,
35300,
11400,
33100,
11200,
44100,
7000,
21300,
179800,
30000,
16400,
13500,
12800,
20600,
46700,
15200,
15400,
null,
53200,
35300,
9700,
26800,
9700,
47300,
33100,
9500,
null,
14100,
73000,
22300,
null,
39900,
4300,
27500,
13000,
13400,
8300,
null,
null,
24700,
88300,
18900,
28900,
10300,
36400,
60000,
null,
36700,
4000,
26000,
25500,
15800,
16100,
16800,
46100,
63300,
73200,
32000,
82500,
12700,
19500,
230000,
7300,
12200,
54600,
15800,
17600,
74500,
17900,
22500,
null,
26000,
36200,
16600,
13100,
22900,
21500,
13250,
14700,
null,
10700,
4900,
44400,
67100,
92800,
37200,
53200,
11000,
null,
13300,
34500,
48499,
10300,
44200,
26700,
null,
400,
3100,
12300,
21100,
7400,
5500,
23100,
37200,
28700,
27014,
181900,
12300,
6900,
41900,
12700,
29700,
24500,
44900,
10400,
14700,
null,
16600,
13500,
57700,
14300,
75150,
9500,
4300,
14500,
20300,
28300,
54700,
45300,
11000,
null,
10800,
4000,
50600,
21900,
55400,
31300,
50400,
13200,
9600,
16100,
8300,
22600,
35100,
32300,
29200,
18200,
69600,
9000,
26100,
18000,
1300,
27500,
56100,
8000,
6800,
9200,
22100,
11300,
null,
35000,
8000,
66600,
29700,
43500,
22600,
7300,
45300,
53800,
null,
24000,
32300,
17500,
17400,
2900,
700,
8100,
23600,
18700,
21200,
17200,
36700,
47000,
15900,
11000,
15900,
15100,
53130,
92000,
59800,
null,
23300,
39100,
14500,
4000,
3100,
21900,
29300,
null,
17100,
32000,
14600,
12200,
30640,
57000,
25200,
38000,
22600,
4900,
83100,
14200,
8400,
54400,
70000,
13400,
14300,
16500,
12500,
7600,
30900,
82300,
43200,
21600,
7400,
20500,
66500,
23500,
34100,
8100,
129400,
7000,
85200,
34000,
44700,
49100,
10700,
13400,
46400,
41000,
43500,
72700,
11100,
23300,
22800,
23100,
21300,
20500,
116425,
11600,
49500,
50100,
19700,
14500,
47500,
35600,
10400,
14500,
14700,
null,
null,
59100,
31100,
24100,
65533,
59600,
25800,
16300,
null,
null,
24300,
10000,
15800,
26900,
null,
15200,
66400,
19675,
6200,
47400,
30500,
15800,
null,
54200,
11400,
48600,
51300,
13200,
35300,
52000,
41200,
27600,
14900,
24700,
3500,
15900,
68400,
16700,
11100,
5000,
41200,
18200,
15200,
46100,
63000,
9800,
19600,
12600,
11100,
15300,
17300,
13400,
15200,
7825,
31500,
29000,
12700,
11300,
161100,
77920,
22900,
17800,
36200,
36500,
13900,
30700,
16600,
null,
17300,
16000,
43600,
15800,
7300,
null,
34900,
14000,
26400,
69929,
6400,
65000,
12200,
46000,
32000,
10000,
51000,
31000,
11800,
56600,
37600,
50800,
78300,
11500,
34800,
10200,
30000,
13600,
83300,
14600,
23200,
8900,
19600,
22400,
42400,
8500,
null,
73800,
18300,
5800,
36600,
30800,
16300,
4600,
54400,
88200,
84300,
16200,
33500,
25300,
9400,
11700,
41000,
6800,
19500,
12700,
14400,
null,
46300,
12300,
47200,
30100,
34300,
78700,
27000,
39000,
26100,
75700,
3300,
23500,
8300,
3800,
14900,
31900,
35900,
25200,
37500,
129500,
30600,
26000,
8500,
23700,
33600,
21000,
null,
24100,
null,
9700,
null,
62900,
25600,
48900,
42800,
64800,
15800,
23500,
15600,
41000,
34800,
52900,
40500,
16700,
42600,
15000,
9200,
20000,
23700,
27900,
44300,
null,
20400,
null,
37600,
10600,
18800,
14500,
76400,
16300,
7300,
70000,
26100,
21700,
20100,
26600,
24700,
15500,
43300,
88200,
83600,
63100,
7800,
178100,
20300,
15200,
6800,
23200,
7100,
34200,
null,
46300,
13700,
8800,
37400,
41600,
31800,
29500,
19300,
355000,
39400,
12802,
82800,
21600,
37200,
7400,
32900,
11900,
45500,
31000,
13500,
6200,
38600,
25800,
9000,
8900,
77100,
67500,
32000,
163700,
6400,
10700,
14500,
34700,
null,
115500,
70100,
26000,
19800,
20900,
39600,
20700,
72200,
6600,
10500,
null,
43700,
29800,
2600,
12200,
42700,
16800,
65400,
null,
23200,
17600,
12500,
27900,
16700,
17300,
200800,
9700,
30200,
24100,
62300,
10100,
14500,
105200,
42800,
13600,
null,
null,
92200,
10500,
69600,
12400,
151100,
15700,
50000,
24800,
24600,
47600,
48900,
33000,
14700,
14900,
17400,
48800,
40000,
40400,
24700,
12585,
6300,
22800,
94900,
31910,
14600,
null,
12600,
33100,
9900,
13300,
18300,
26300,
14300,
9800,
65400,
33200,
81700,
null,
23400,
63200,
31300,
7900,
59600,
18500,
31000,
52800,
54215,
90100,
74500,
18000,
68700,
null,
13200,
13500,
null,
37700,
75700,
8500,
51800,
9500,
110300,
14800,
45200,
8700,
5600,
11900,
15800,
55300,
32500,
6900,
19900,
11000,
13500,
3700,
35500,
110600,
69400,
17000,
44800,
16700,
4700,
12600,
160000,
17600,
87700,
53700,
52700,
51800,
6500,
58300,
17900,
5800,
29600,
7500,
15600,
28600,
11100,
7200,
58000,
36900,
44400,
30700,
28700,
5600,
32200,
15900,
15300,
13900,
26800,
11500,
46500,
40000,
7400,
10500,
34600,
5500,
50500,
67500,
25100,
128500,
2800,
8500,
28800,
24600,
23600,
39300,
7100,
5100,
26600,
24300,
58000,
40100,
12450,
16600,
16300,
20900,
9300,
8500,
26800,
161500,
16000,
8700,
33500,
8600,
60500,
8900,
47700,
108500,
56800,
17700,
16500,
56300,
98600,
36600,
24711,
9300,
24200,
22800,
16800,
16600,
35600,
133105,
72000,
null,
22900,
23900,
14800,
17000,
null,
null,
33100,
21300,
null,
37800,
29300,
110900,
26600,
26500,
16400,
24700,
16600,
41300,
20200,
21000,
30100,
38000,
21700,
26100,
17200,
41000,
22240,
22100,
25800,
10200,
23000,
34600,
36500,
19800,
11400,
19400,
71600,
25600,
31400,
63400,
16400,
11500,
null,
null,
35200,
4000,
22800,
21000,
24700,
5000,
9350,
4900,
7000,
10700,
9000,
62400,
15200,
59100,
14500,
28500,
12700,
67000,
13200,
20700,
19600,
null,
42000,
7500,
175600,
33200,
61200,
45600,
155600,
14400,
60000,
23500,
6900,
12700,
26300,
18500,
33700,
19100,
3200,
69500,
15500,
35300,
30800,
25400,
51000,
31800,
5400,
41500,
18900,
19000,
59900,
20400,
15900,
40500,
8100,
23500,
8200,
50682,
17000,
36000,
null,
12227,
18800,
106300,
28700,
40500,
null,
28000,
82000,
12300,
18300,
19900,
36500,
15400,
37200,
18800,
41100,
17000,
12800,
58700,
26100,
17800,
57000,
16500,
31100,
21900,
21700,
11600,
25800,
3300,
10700,
24000,
43500,
null,
118400,
55700,
30733,
32800,
9800,
71745,
8500,
4300,
26700,
83600,
13400,
78762,
12800,
19200,
5200,
30415,
2500,
20800,
11100,
5800,
47200,
11200,
6500,
7500,
30300,
156700,
28600,
12900,
null,
22100,
7300,
9800,
null,
20300,
32600,
10000,
46200,
69900,
20400,
53800,
11300,
51500,
33500,
22400,
7100,
30700,
9700,
32800,
22000,
11000,
null,
102100,
62100,
null,
54200,
8300,
28800,
28500,
null,
22600,
20500,
18400,
19700,
24400,
8300,
124900,
17800,
31600,
13300,
24700,
7200,
331000,
26700,
50400,
19200,
20700,
null,
10500,
6600,
8200,
6800,
40500,
27000,
26100,
24500,
9700,
35500,
95900,
15100,
12500,
33700,
119806,
8700,
19500,
16900,
65600,
8900,
30000,
25800,
16800,
30800,
9800,
24800,
13500,
86100,
10800,
1900,
null,
13700,
null,
98200,
11500,
44500,
42200,
31500,
18700,
29900,
15200,
12500,
31300,
10000,
22700,
30800,
18047,
7000,
14300,
null,
41300,
64100,
58000,
44101,
20600,
23400,
37000,
11300,
null,
25400,
10800,
70200,
46100,
7700,
29500,
25700,
19200,
60100,
80100,
35900,
67200,
39500,
16600,
44200,
8100,
25200,
null,
76600,
12200,
13900,
19300,
17500,
26400,
45400,
38100,
12200,
null,
19300,
16200,
null,
45600,
28000,
39700,
43200,
20300,
15100,
45000,
5700,
24100,
7800,
15100,
95800,
54800,
22300,
13600,
4800,
27000,
9600,
41600,
8500,
null,
12800,
31600,
52100,
14000,
36700,
66500,
26200,
28512,
14800,
5200,
null,
100400,
39000,
24800,
22177,
null,
21300,
26500,
53400,
42100,
39000,
5500,
43300,
null,
16300,
15900,
null,
55900,
11000,
16076,
79415,
null,
14900,
4900,
10700,
20600,
34600,
122000,
50300,
13000,
28800,
124300,
33900,
26400,
13700,
145500,
null,
17600,
31300,
6600,
11100,
49300,
31900,
14200,
2700,
null,
21100,
19600,
8500,
null,
21900,
51400,
27000,
13000,
17100,
null,
39800,
48900,
27700,
15000,
18200,
14200,
10800,
41200,
15300,
17700,
11600,
null,
14100,
null,
43200,
16600,
22100,
35500,
25200,
null,
94100,
48200,
22600,
22400,
83383,
19100,
11800,
46300,
41900,
17500,
20300,
38700,
26700,
5300,
10700,
35200,
30200,
45600,
11000,
15900,
10600,
18000,
25090,
19300,
14300,
7300,
22800,
16600,
60400,
6700,
67290,
33200,
32000,
17300,
67700,
11400,
103900,
13500,
17700,
33800,
null,
3300,
2800,
52700,
107000,
55400,
23100,
50300,
53500,
38300,
68000,
35400,
19300,
5000,
19600,
67000,
null,
19400,
5500,
58500,
22500,
27200,
17100,
37200,
54700,
34500,
9900,
26800,
12100,
25800,
36800,
40800,
8400,
null,
30800,
27000,
null,
24000,
24200,
8000,
14400,
21000,
5300,
45100,
19700,
20600,
21500,
20800,
19000,
22000,
15400,
null,
22700,
8500,
null,
92000,
12500,
17900,
null,
75300,
22100,
19700,
19300,
21200,
53700,
58300,
37000,
17000,
7500,
3000,
21600,
18900,
55800,
7300,
130600,
null,
null,
13100,
17300,
41800,
16600,
15600,
16500,
26300,
32900,
9000,
7200,
10800,
3600,
47800,
81500,
25000,
29800,
65400,
2800,
34500,
26000,
14200,
null,
31800,
22000,
52000,
32200,
26800,
4600,
34300,
73600,
27000,
17200,
170900,
22400,
6400,
46400,
21500,
23750,
56100,
10500,
96600,
97900,
42900,
15000,
57800,
22300,
24800,
9500,
12100,
47100,
17900,
56010,
6900,
27100,
18000,
5900,
9900,
4300,
35300,
18800,
52200,
8300,
28100,
null,
17200,
150000,
17600,
24300,
41100,
9800,
16300,
12700,
24800,
24100,
14900,
30000,
12600,
24400,
7000,
109200,
14700,
20100,
29000,
9000,
6900,
9100,
84500,
45300,
66300,
10200,
15500,
40900,
37900,
null,
null,
34900,
10100,
42700,
null,
null,
17200,
67500,
191875,
11100,
27000,
77000,
5400,
11200,
27800,
31500,
59300,
54000,
49600,
68700,
12100,
19600,
28700,
105100,
45500,
78200,
64800,
56800,
38600,
18500,
52200,
null,
6800,
44600,
27600,
12600,
31500,
29600,
45500,
5500,
26000,
30500,
21800,
25300,
80926,
25400,
67100,
57500,
6600,
125700,
16700,
null,
9900,
3500,
17300,
18200,
50000,
5700,
20600,
3700,
12000,
14000,
7100,
11100,
2300,
29500,
13300,
8600,
22800,
13100,
15300,
18800,
32300,
18600,
null,
27500,
57600,
57200,
20200,
18900,
20100,
30000,
39000,
12400,
20900,
77500,
55100,
18200,
16900,
12000,
14700,
7400,
15000,
null,
14700,
33300,
15700,
34400,
27400,
10900,
14800,
70300,
36600,
21400,
3100,
27600,
21000,
51800,
7200,
9300,
36400,
16000,
15400,
29300,
15400,
25100,
9000,
28000,
18200,
5400,
10000,
3100,
42900,
64100,
37700,
44478,
5400,
null,
38600,
29200,
56700,
12300,
12200,
49600,
68800,
117900,
6550,
22500,
18300,
20300,
34600,
10150,
17800,
18650,
5200,
32500,
59700,
null,
14600,
12800,
52100,
24300,
73700,
9100,
7100,
15500,
28300,
27100,
42000,
16100,
null,
32100,
6300,
61100,
16300,
34500,
33000,
null,
12800,
8600,
45700,
31400,
37300,
53800,
22000,
21900,
49500,
35700,
24700,
23200,
70000,
36300,
27200,
24800,
72100,
145200,
null,
13700,
41000,
34400,
8800,
31500,
35400,
null,
14932,
15700,
null,
12500,
42800,
24000,
16800,
null,
47400,
32700,
12100,
8000,
7950,
16300,
29600,
16900,
29000,
69900,
null,
14200,
1000,
101000,
18600,
36400,
200800,
33800,
23300,
57500,
46000,
15700,
null,
50500,
43200,
15900,
17400,
18000,
54700,
19900,
13700,
20300,
15400,
38500,
14600,
19100,
34600,
17600,
18000,
6300,
28700,
38300,
75900,
12000,
4800,
51400,
3300,
4600,
37900,
58400,
50100,
101992,
5900,
31900,
59000,
null,
18200,
12900,
17400,
6100,
48200,
43500,
null,
1700,
62400,
52400,
38000,
19200,
16900,
36000,
7300,
16300,
26100,
96400,
8800,
12300,
null,
11400,
7900,
18400,
28700,
11200,
18000,
29600,
21600,
9800,
6100,
null,
26300,
40100,
null,
22300,
12700,
22300,
13200,
9400,
31100,
33600,
120800,
null,
27100,
23200,
12800,
12600,
13800,
9800,
182300,
36600,
16500,
54920,
19400,
9850,
22100,
14000,
52000,
75100,
23000,
14100,
20100,
21400,
44900,
37700,
488400,
37600,
35800,
54300,
18800,
82000,
39050,
51300,
35300,
null,
38200,
7900,
103400,
16100,
44000,
49600,
16400,
7900,
34000,
null,
149300,
6400,
25800,
null,
39900,
null,
48000,
41000,
28300,
5600,
null,
46000,
98600,
54000,
95400,
21700,
30100,
2900,
48000,
49500,
null,
72400,
11400,
47800,
27900,
2500,
30600,
82500,
17100,
34400,
18400,
36000,
12700,
34500,
10200,
20600,
18100,
14700,
13400,
12000,
51500,
51400,
46500,
14000,
8300,
62000,
null,
87500,
27600,
null,
24100,
29600,
13200,
27300,
null,
10300,
26300,
38500,
46800,
102300,
10800,
8800,
52300,
23500,
31400,
38800,
13700,
21700,
20100,
30500,
15100,
16700,
59100,
48300,
68900,
6500,
25500,
10000,
19700,
60000,
7000,
57200,
14300,
24700,
31900,
null,
59800,
28700,
5000,
2800,
19800,
105600,
22100,
25500,
31800,
19000,
7800,
22500,
38600,
9700,
23700,
31700,
27900,
5500,
15900,
14000,
28100,
32600,
16400,
38000,
4400,
35400,
10000,
20300,
10150,
16500,
58500,
11700,
19500,
38100,
16800,
10000,
174175,
5600,
10900,
6900,
80400,
10100,
19700,
22700,
15000,
46600,
19200,
21400,
29500,
49000,
19300,
35645,
21400,
25400,
51789,
7300,
null,
34600,
18400,
21500,
16000,
11100,
null,
14900,
31400,
9900,
25000,
64400,
22200,
138500,
2800,
19600,
26000,
2000,
30900,
25000,
38700,
15500,
30600,
7600,
12600,
15300,
11800,
6500,
12000,
26900,
78500,
23900,
39000,
8900,
18600,
38600,
34200,
25200,
5800,
125100,
29900,
63400,
14200,
26000,
null,
12000,
27300,
26100,
null,
33700,
20500,
51600,
78300,
30600,
18500,
49900,
4000,
34800,
71900,
53200,
44600,
15700,
25200,
11600,
23600,
7500,
null,
45000,
26000,
10100,
10000,
21200,
52200,
13559,
6900,
null,
40200,
null,
64100,
30000,
5800,
4800,
null,
43500,
5500,
null,
28600,
70100,
607200,
2400,
27000,
35500,
null,
36400,
26500,
18300,
22100,
91600,
41000,
9800,
13100,
13300,
53500,
11800,
17300,
3400,
36500,
24500,
43800,
68100,
10100,
19700,
7500,
11240,
29200,
58800,
25400,
15800,
31900,
21200,
8500,
27800,
39200,
13700,
35600,
null,
9500,
29700,
13900,
15900,
79800,
64100,
49100,
38700,
17500,
23100,
13100,
75200,
19600,
null,
65900,
40100,
48700,
91800,
24700,
27700,
78500,
null,
25900,
22200,
36200,
17000,
20000,
15100,
38300,
32200,
5500,
40500,
17000,
114900,
50700,
26600,
19400,
null,
36500,
null,
19700,
9700,
11800,
18800,
131800,
12300,
22100,
16900,
63300,
19500,
57500,
18700,
24500,
19000,
54900,
56300,
23800,
53300,
9600,
96700,
28100,
95200,
10200,
22500,
47500,
null,
6900,
20700,
null,
9400,
22300,
35900,
16600,
59400,
48000,
2500,
23000,
16100,
23400,
21000,
21800,
null,
15300,
4700,
5800,
59300,
28500,
7800,
7500,
null,
27800,
23400,
7700,
null,
null,
55300,
19300,
null,
17800,
23700,
25500,
null,
178000,
40400,
19800,
35500,
3300,
36000,
46800,
23700,
57000,
20900,
null,
49200,
56200,
24000,
36600,
15500,
45100,
46601,
226500,
58100,
12100,
19300,
34300,
26800,
9900,
51100,
22400,
15500,
57800,
25900,
5500,
21200,
10900,
16600,
16300,
null,
51500,
42300,
17900,
37500,
39600,
24900,
60400,
null,
7900,
4700,
7200,
42100,
14100,
34900,
18200,
39000,
84000,
18300,
16800,
12600,
10200,
19600,
8400,
37700,
38600,
15100,
23200,
28900,
null,
25700,
35700,
3500,
106100,
14700,
14800,
67600,
34800,
21200,
7400,
null,
20300,
1000,
null,
77900,
16900,
11100,
19500,
32300,
8700,
19600,
41300,
13900,
28500,
9600,
9200,
11500,
72900,
15500,
15900,
47700,
22100,
10500,
7000,
13400,
33100,
null,
7100,
12800,
68986,
37000,
null,
null,
40700,
97900,
3400,
null,
4000,
15800,
24400,
null,
null,
53300,
8100,
null,
5300,
56000,
36500,
22200,
54400,
13500,
34000,
20800,
49100,
14900,
12900,
33800,
24300,
55900,
5000,
44100,
27600,
7500,
15800,
40600,
25100,
null,
7300,
14500,
22600,
66400,
23300,
34900,
21900,
17900,
21100,
23400,
50900,
22100,
41600,
47500,
4600,
null,
4600,
30100,
20600,
30000,
28000,
46100,
38900,
11600,
32171,
18300,
27200,
12000,
37600,
null,
69900,
34200,
52600,
22100,
12636,
19600,
15500,
8900,
13200,
5700,
13300,
17000,
5000,
52800,
48100,
null,
31600,
12700,
4200,
30000,
134800,
null,
10900,
35200,
32600,
17700,
58800,
18600,
68400,
8300,
195800,
27200,
null,
81000,
16900,
11500,
13600,
23800,
7000,
122600,
63700,
35800,
11400,
9100,
null,
18700,
17000,
29800,
5200,
51200,
40500,
59500,
32300,
35700,
16300,
41400,
15400,
28400,
3000,
75600,
63200,
8500,
29700,
12200,
23700,
89600,
9600,
21400,
20500,
12300,
33200,
27600,
8100,
27900,
38500,
8400,
32900,
22800,
28200,
134900,
1200,
101500,
20700,
7400,
22700,
59800,
44100,
12100,
null,
26500,
35800,
23700,
81700,
13600,
29200,
10300,
8300,
5500,
15800,
72600,
13100,
24000,
37500,
45700,
27400,
45500,
null,
82000,
6700,
54100,
15000,
13300,
34800,
84100,
12000,
49000,
19900,
33900,
6600,
48000,
81100,
6000,
13700,
20800,
null,
null,
52400,
20300,
5900,
16000,
4200,
48300,
23900,
27100,
15000,
56800,
30200,
35600,
56500,
13700,
11900,
10700,
54200,
13600,
45800,
17400,
47700,
40900,
16900,
null,
6800,
21300,
null,
37200,
6200,
13200,
38300,
44200,
25800,
14900,
57300,
40200,
39500,
30300,
42600,
94900,
14100,
8800,
19200,
9500,
7300,
16600,
15600,
28500,
4700,
null,
166200,
35900,
15400,
6700,
55400,
18700,
368900,
40500,
14200,
15700,
17200,
21700,
null,
5600,
36700,
26500,
22000,
14200,
22500,
2500,
58800,
47500,
null,
69000,
17200,
15500,
53800,
21300,
18000,
26100,
61800,
16700,
45100,
11600,
8600,
22700,
17100,
5950,
49700,
22500,
18500,
37900,
43200,
25400,
32200,
5500,
27200,
11100,
95800,
6400,
7300,
14600,
15400,
42200,
52200,
25500,
42300,
38700,
13500,
30100,
null,
14200,
24700,
124300,
26300,
51300,
40000,
21500,
31400,
20100,
10000,
8700,
5600,
5100,
4500,
22800,
39500,
null,
51100,
19300,
24700,
11000,
700,
12500,
37600,
18300,
52100,
11900,
26800,
19500,
16100,
113000,
55200,
7000,
29000,
84100,
11500,
37500,
55600,
63268,
5900,
68216,
29100,
16800,
23600,
11100,
16400,
44300,
28300,
17400,
27700,
21500,
16400,
25200,
20600,
38900,
18900,
13300,
39800,
null,
7500,
89742,
16900,
26000,
66300,
21200,
12300,
18400,
16700,
12800,
10100,
32800,
7700,
11900,
45300,
5900,
51300,
17500,
28800,
36800,
7700,
18500,
11600,
21400,
39000,
12100,
63200,
50100,
64100,
104500,
15400,
37700,
11100,
null,
23900,
41400,
10600,
25500,
15600,
10000,
5200,
85100,
1700,
64600,
14800,
20000,
35300,
44400,
30900,
23400,
29900,
17200,
19200,
26300,
19600,
49000,
37500,
71000,
9800,
34300,
32600,
17000,
24900,
49700,
45400,
19200,
null,
3500,
263100,
28500,
12200,
43500,
47000,
27650,
16500,
42400,
116700,
null,
11300,
29300,
17800,
13900,
null,
20800,
20500,
20900,
7200,
61500,
28500,
17800,
null,
32100,
100100,
181100,
8200,
16800,
4000,
42700,
null,
8000,
33200,
26300,
6600,
25200,
19800,
7600,
15500,
17500,
7400,
50762,
18900,
39600,
21600,
14500,
33720,
null,
28300,
22000,
181700,
60900,
7700,
77500,
11700,
29300,
6900,
22200,
9520,
37500,
28500,
35400,
24000,
21900,
7500,
18000,
null,
103700,
22100,
4500,
28200,
10900,
13300,
39500,
18600,
null,
24800,
42700,
23252,
19500,
74800,
22200,
20200,
7200,
21000,
23300,
27700,
14700,
58200,
40400,
34200,
33800,
16500,
11300,
59300,
24300,
null,
14629,
20600,
65100,
null,
9300,
150700,
29100,
34500,
33400,
6400,
24400,
40100,
59267,
80100,
22600,
28000,
52900,
14900,
18100,
13900,
23300,
11900,
32300,
7500,
38300,
15600,
null,
32500,
17600,
64900,
13000,
null,
34500,
900,
16100,
30500,
35000,
13200,
7500,
13400,
24600,
9600,
68000,
14400,
13600,
7100,
8600,
27700,
55900,
27300,
37500,
11700,
20800,
16300,
27900,
null,
39300,
58800,
27400,
14600,
25700,
11100,
224600,
145300,
9300,
31300,
23500,
14300,
51800,
17600,
19200,
15000,
24000,
29470,
28500,
37200,
12100,
30700,
21700,
77500,
null,
16000,
5200,
15500,
34300,
31900,
14300,
52400,
28500,
11800,
17000,
43500,
1400,
25400,
4200,
null,
48100,
14600,
10800,
36100,
25300,
54700,
13000,
17200,
50500,
null,
33200,
31300,
28900,
null,
48100,
49500,
6500,
48500,
23500,
null,
21300,
20000,
16500,
37700,
25900,
52600,
27500,
31300,
15500,
45800,
26000,
46200,
9000,
47600,
24100,
17400,
34200,
39200,
41300,
17000,
77900,
101100,
13800,
8200,
9300,
56200,
34300,
45800,
26400,
8100,
20200,
25200,
13900,
15200,
21300,
null,
42900,
null,
12000,
33000,
16500,
21300,
23100,
2600,
76700,
50600,
23200,
10800,
13000,
7900,
17800,
35300,
22100,
11500,
32800,
25300,
19000,
65700,
158400,
28300,
39800,
23300,
0,
15800,
70800,
11600,
25400,
30800,
8000,
14800,
10400,
18700,
null,
26400,
22100,
15800,
32400,
20200,
null,
6800,
10100,
36300,
14100,
56100,
23500,
55900,
60000,
56100,
8100,
27000,
1500,
4900,
36900,
23000,
null,
51800,
15100,
27900,
22000,
140500,
null,
11600,
38800,
48200,
49400,
47200,
25700,
10400,
18800,
1500,
21000,
14700,
46300,
16200,
28000,
12800,
1000,
24700,
19700,
88800,
34200,
44700,
24700,
null,
27000,
26500,
60300,
16900,
98200,
22600,
36500,
28300,
40900,
25400,
14500,
22600,
73400,
24300,
11100,
21800,
38700,
60000,
31300,
7500,
31100,
100400,
4500,
23200,
25300,
24100,
38800,
28000,
50700,
22100,
20200,
31600,
10400,
23900,
null,
53000,
16900,
114700,
26500,
17600,
10800,
8300,
25700,
7100,
32200,
18700,
null,
19600,
48000,
29800,
14200,
30200,
17100,
17300,
8700,
23900,
58300,
43873,
11100,
26600,
33000,
43800,
52300,
31000,
6300,
64700,
89258,
36500,
21600,
null,
9800,
20700,
27400,
12300,
19300,
57700,
null,
7200,
75100,
null,
10300,
20100,
40400,
87600,
27700,
2000,
357900,
38500,
null,
8900,
26900,
31300,
8400,
4700,
14300,
18400,
38200,
16200,
null,
40300,
6700,
63800,
17700,
null,
16100,
14400,
29800,
61000,
16100,
16200,
null,
41700,
19300,
14800,
73000,
6300,
45900,
25000,
8600,
33500,
42300,
13800,
59100,
22400,
18000,
45300,
18100,
12200,
38400,
147550,
9200,
25900,
14200,
23100,
30400,
60600,
25300,
27100,
14900,
6800,
24900,
28200,
null,
12400,
50200,
46600,
55500,
20400,
49000,
44806,
20710,
null,
4500,
20000,
14800,
null,
null,
3500,
32500,
106900,
12100,
37400,
12500,
15700,
23600,
22200,
null,
null,
800,
22600,
51100,
null,
35200,
29700,
null,
20000,
2850,
102400,
null,
30400,
38900,
45000,
26400,
50100,
28900,
22300,
34800,
29000,
33800,
87000,
23800,
18600,
41600,
54100,
13400,
69000,
10200,
56300,
44200,
9500,
77500,
null,
84500,
27100,
22100,
27000,
5800,
null,
23300,
42700,
71000,
38916,
16500,
75400,
10500,
7200,
19200,
11200,
26300,
16300,
40700,
83400,
19500,
17000,
16700,
8200,
42300,
27500,
5400,
6600,
16500,
15700,
42900,
null,
38500,
12300,
12700,
47400,
15400,
17500,
63700,
12100,
24100,
33100,
33600,
25000,
16700,
14400,
61000,
21000,
11300,
99600,
32900,
106300,
7500,
null,
14000,
73600,
25300,
null,
36600,
6900,
11300,
19100,
66500,
4200,
17800,
null,
46300,
19800,
24400,
null,
42900,
34800,
14200,
13100,
40300,
140800,
36100,
42900,
7500,
20300,
null,
49800,
10400,
24100,
35500,
23900,
110000,
56047,
44000,
28400,
15300,
51700,
null,
3600,
28200,
10500,
15800,
25500,
13500,
null,
18200,
26300,
18800,
17800,
21300,
null,
78600,
14750,
34200,
29700,
29900,
9350,
122300,
null,
null,
63900,
47300,
25700,
65700,
22400,
4900,
null,
31000,
147200,
28100,
7600,
21200,
null,
41700,
27800,
null,
7800,
29300,
47200,
17500,
35500,
52600,
null,
14100,
26500,
38100,
18100,
22900,
76300,
91900,
21500,
11600,
29500,
null,
5300,
13100,
63000,
48800,
null,
63400,
13600,
22100,
35300,
13300,
5600,
17500,
93000,
137600,
60600,
28000,
19300,
null,
26200,
null,
11700,
17500,
162900,
21200,
9200,
24000,
null,
9600,
60600,
61800,
50200,
120000,
null,
33900,
17900,
null,
12700,
null,
14200,
9200,
14500,
21100,
26100,
30700,
25000,
46100,
20000,
14500,
9400,
9000,
58100,
15400,
5600,
55800,
58300,
15600,
40800,
19500,
63300,
15100,
2100,
11500,
16000,
9200,
15900,
34700,
46800,
34500,
34300,
11700,
8200,
28500,
14200,
108000,
34700,
4600,
25600,
55900,
19700,
null,
4700,
15200,
18300,
30300,
35700,
58000,
null,
5600,
29400,
27200,
null,
91000,
21400,
null,
10600,
10700,
123300,
13600,
47100,
51300,
32100,
2700,
43100,
14800,
90250,
34600,
22300,
23300,
10600,
4500,
16100,
18300,
13500,
27000,
56300,
23200,
22000,
31100,
2500,
33300,
17300,
76300,
31300,
13400,
18200,
23700,
56300,
30100,
54200,
48600,
29400,
null,
18000,
15600,
30000,
14500,
11200,
16600,
16800,
11600,
86200,
36200,
null,
19500,
93950,
39600,
68400,
62500,
25300,
31500,
78000,
51300,
134300,
22800,
14100,
8200,
27300,
28500,
34600,
55100,
33000,
7725,
41900,
66573,
10500,
14200,
16100,
48600,
400,
12300,
32300,
300,
16300,
72526,
null,
46300,
null,
33900,
4900,
87000,
40000,
40200,
29000,
30100,
26700,
28900,
5900,
7500,
48700,
null,
26600,
9100,
15300,
9600,
27300,
18300,
21000,
83100,
null,
11900,
49000,
null,
24700,
9000,
10600,
null,
31700,
19400,
null,
65100,
28300,
21300,
39990,
52300,
24900,
14700,
13600,
8300,
55000,
37900,
6100,
33200,
125000,
19500,
10300,
29900,
53900,
9600,
null,
34300,
38600,
10732,
21800,
56100,
49000,
15000,
16800,
59600,
12600,
6800,
null,
22900,
26100,
41200,
35100,
34500,
72200,
41000,
19600,
11800,
40600,
47600,
21200,
3000,
14500,
39000,
18800,
10800,
26900,
19600,
86000,
31900,
28000,
41500,
40000,
66100,
22300,
15500,
24000,
20900,
27000,
14500,
55600,
11200,
42200,
126500,
19800,
25300,
24800,
58200,
8800,
20700,
10800,
37800,
75200,
12600,
118600,
35000,
49700,
22600,
22600,
43700,
null,
10100,
74100,
36000,
88200,
52000,
11300,
9000,
null,
166700,
54200,
13100,
7700,
21900,
28800,
39000,
87600,
null,
65900,
null,
null,
7600,
108100,
24200,
17500,
11600,
15200,
92400,
23000,
50000,
18500,
19600,
16400,
26900,
null,
25900,
null,
46200,
52100,
7800,
12000,
16300,
2300,
36900,
10800,
42900,
75200,
17000,
10900,
45100,
null,
21700,
75000,
60800,
25900,
14700,
22300,
43100,
69100,
17500,
57200,
32100,
12700,
null,
null,
5500,
6500,
29900,
13200,
57800,
34900,
17600,
2500,
4700,
41200,
49000,
6500,
51400,
16700,
37300,
11400,
13800,
null,
14700,
26800,
12400,
33306,
53000,
40700,
44100,
41000,
13900,
24400,
25500,
25800,
19700,
null,
7400,
23600,
8800,
16200,
12300,
55000,
31500,
null,
60700,
36700,
16800,
54200,
35000,
31200,
7200,
49700,
28200,
35300,
24680,
11600,
23400,
38900,
114800,
null,
13800,
15300,
17500,
57900,
null,
18100,
31000,
16300,
null,
5400,
7600,
25600,
9500,
48300,
18800,
null,
29400,
22100,
29200,
25100,
48200,
18400,
30900,
60100,
39700,
16200,
17600,
8250,
16800,
19000,
2400,
25706,
67800,
20700,
61200,
33400,
15000,
15500,
19500,
44000,
14300,
20700,
294600,
12000,
13900,
8000,
9700,
20800,
6600,
14700,
null,
87500,
null,
14500,
41800,
6800,
14700,
147200,
11600,
89100,
37100,
22500,
23100,
16400,
18800,
9800,
33900,
4300,
26300,
23900,
10500,
5800,
18100,
24400,
7100,
17100,
47100,
25700,
14600,
78500,
50200,
22800,
null,
6800,
34000,
38100,
13400,
24700,
45944,
5700,
11100,
21500,
9005,
null,
60400,
12100,
43400,
21400,
29000,
23100,
33000,
29622,
15600,
23600,
46200,
10400,
99200,
17400,
null,
26000,
null,
25200,
29500,
4100,
9700,
19400,
31700,
34000,
22200,
16000,
69800,
18400,
24200,
15100,
18070,
24425,
29400,
12500,
23700,
58200,
14700,
30400,
28300,
20830,
22800,
110800,
16100,
10900,
38700,
63200,
43700,
16000,
23600,
94300,
17200,
68700,
59800,
39600,
39400,
25100,
null,
19300,
6300,
11945,
18500,
9400,
6700,
14800,
47300,
60200,
38200,
null,
2400,
43500,
13100,
42500,
11100,
21500,
null,
17500,
null,
61000,
51700,
49600,
9300,
15200,
5900,
23000,
9400,
null,
14800,
41400,
12600,
27000,
96901,
19000,
32200,
15000,
null,
15000,
86200,
34600,
12900,
17200,
14500,
118450,
24100,
11800,
18300,
104100,
15300,
16900,
24600,
3400,
23700,
null,
9700,
16400,
57300,
32700,
17400,
null,
18800,
37000,
38700,
20800,
44400,
10000,
25600,
null,
6900,
13100,
29800,
134600,
46800,
11000,
28300,
7000,
11800,
29800,
29700,
14100,
22647,
48800,
17100,
105000,
12500,
34800,
64300,
13500,
61700,
52800,
50100,
32100,
55800,
12100,
25300,
77500,
33200,
30100,
29100,
21300,
1000,
28200,
58500,
13000,
49600,
42400,
91300,
39600,
60400,
59926,
18100,
11900,
35700,
12600,
12500,
18300,
49300,
32500,
18500,
85700,
null,
29800,
69800,
27400,
17100,
7800,
20900,
41800,
39400,
15200,
29600,
73000,
14000,
42048,
15700,
23542,
21200,
42900,
8300,
22200,
24700,
29900,
12500,
71500,
6600,
38000,
14600,
197700,
76200,
53300,
4900,
39600,
5600,
17900,
17700,
24600,
10800,
22700,
19700,
48100,
24200,
null,
11600,
27300,
23500,
21200,
75100,
26800,
null,
24100,
47000,
45800,
11900,
69400,
31700,
16700,
8600,
55404,
35950,
69000,
5100,
28000,
20300,
33250,
51600,
26800,
56500,
7300,
56800,
56800,
39500,
103000,
16600,
39600,
18100,
13800,
232500,
14500,
38900,
134900,
20500,
40200,
12000,
49723,
32900,
38600,
54300,
41500,
69600,
13100,
2000,
65100,
26100,
16800,
40200,
35300,
1600,
15300,
137800,
null,
30300,
null,
null,
7400,
17400,
13800,
3200,
52300,
5900,
104800,
72300,
25400,
43000,
24500,
null,
21300,
124700,
72000,
14400,
11900,
22800,
34100,
53300,
5100,
31700,
82000,
4600,
19900,
4600,
24400,
41600,
9200,
11600,
9300,
17500,
22300,
8100,
30500,
36100,
8800,
7600,
46579,
8900,
11500,
17800,
49400,
18500,
35100,
24600,
13000,
75500,
37200,
2800,
6500,
94900,
19500,
13000,
23200,
10200,
17900,
null,
9600,
42800,
13700,
null,
18000,
20300,
92900,
22500,
33400,
21700,
10200,
30400,
20400,
null,
87100,
22200,
15400,
22300,
58000,
119600,
8800,
61600,
24300,
20200,
24600,
34700,
46700,
null,
null,
7100,
13900,
6300,
9600,
15300,
25010,
6600,
2400,
7900,
null,
7500,
39000,
6600,
16000,
null,
14200,
62300,
null,
31600,
18200,
30400,
16100,
52100,
25400,
31500,
48000,
15800,
null,
11300,
9000,
14700,
8700,
8800,
21600,
20400,
40000,
45100,
27000,
null,
21500,
null,
21500,
13200,
216700,
32400,
30800,
55200,
27100,
26500,
11400,
12000,
31000,
null,
85047,
17200,
10700,
44300,
20700,
6900,
13700,
94500,
35200,
18800,
5200,
35600,
33700,
67500,
9000,
11200,
14900,
null,
28400,
5500,
40400,
43100,
24200,
29200,
28300,
10000,
19500,
33300,
27000,
8200,
22700,
15000,
58800,
20500,
48600,
5600,
24300,
38100,
12000,
9900,
53500,
26100,
32900,
30700,
11400,
null,
27600,
27100,
26900,
31900,
null,
3600,
16105,
30800,
13200,
6000,
18600,
13100,
16500,
22200,
7800,
68100,
59800,
14100,
4900,
null,
70167,
23200,
10300,
32750,
26700,
24600,
34600,
17100,
9400,
17300,
34100,
null,
18000,
13800,
52100,
24900,
16300,
19000,
51200,
18300,
15500,
31400,
18700,
52500,
8500,
8300,
9300,
16800,
9300,
38300,
19200,
7800,
57900,
64500,
49700,
29700,
5500,
23500,
8700,
9700,
71400,
29500,
78400,
31100,
24000,
26100,
52700,
5300,
23700,
13800,
22000,
58864,
4900,
14300,
42500,
117500,
42300,
6400,
12500,
20400,
28000,
19500,
null,
15000,
18500,
10800,
13700,
25800,
8900,
45500,
47100,
67200,
14100,
31900,
null,
22900,
30200,
16700,
3400,
6700,
15900,
7000,
17000,
31600,
6300,
56364,
136000,
63700,
24900,
11300,
19900,
55700,
3000,
54900,
23400,
15500,
6200,
37300,
60000,
81100,
38100,
25900,
19800,
91600,
10300,
13700,
43600,
34600,
44100,
null,
28600,
null,
7600,
56400,
11500,
54100,
9000,
12700,
null,
25900,
34000,
49593,
49000,
121900,
40200,
62900,
22800,
18500,
174700,
21800,
54900,
20200,
15200,
27600,
21800,
null,
29200,
20000,
44300,
17000,
15800,
32600,
14300,
21300,
null,
null,
23500,
27400,
16300,
19100,
null,
25500,
16300,
10300,
15200,
27600,
13000,
47200,
46900,
8820,
31900,
18400,
null,
59900,
9300,
14100,
14800,
77300,
21700,
21300,
16100,
18800,
45300,
26300,
21800,
6100,
36000,
44800,
35100,
27100,
16000,
11300,
19100,
16400,
null,
26600,
35300,
null,
17700,
13000,
20686,
8000,
9100,
37800,
16000,
14900,
4500,
11400,
33900,
13500,
13400,
30800,
23500,
10300,
null,
39400,
20200,
13000,
74200,
52000,
null,
21500,
null,
17900,
53600,
15900,
58300,
16900,
11800,
21350,
53300,
47600,
45000,
7800,
49100,
65800,
27400,
38700,
27900,
79400,
null,
25100,
32600,
19000,
9900,
16800,
13300,
18500,
null,
11200,
27350,
8200,
7700,
22000,
50400,
75000,
66600,
17000,
null,
65700,
9100,
17600,
21000,
40100,
36600,
11200,
null,
4000,
8200,
31800,
46500,
15100,
31800,
36000,
null,
12600,
20600,
null,
30200,
55400,
4700,
5000,
113020,
24700,
17400,
57000,
5600,
68000,
11900,
24200,
20600,
10300,
null,
22700,
11100,
16300,
11200,
42600,
null,
137800,
4300,
9000,
23700,
8000,
51700,
null,
23000,
38084,
3200,
25561,
108900,
33977,
36900,
39300,
56900,
14500,
9900,
16800,
48000,
38700,
24973,
23400,
67000,
23100,
32800,
28900,
54900,
19170,
296100,
55000,
76125,
7100,
17400,
111400,
11400,
22000,
20500,
96600,
42600,
93100,
9700,
80700,
70000,
67200,
6500,
110300,
12500,
19200,
70300,
null,
17200,
13200,
18700,
7500,
6400,
33600,
null,
30000,
13500,
7100,
30600,
44900,
25200,
6500,
31400,
16300,
42750,
19800,
45900,
33800,
51100,
24500,
98100,
22300,
46600,
39000,
87900,
14600,
33000,
12900,
14500,
36900,
3000,
4200,
45000,
49800,
6700,
16600,
29700,
22100,
95500,
15400,
58000,
11700,
51500,
15400,
10500,
21100,
48100,
21200,
7800,
13800,
4300,
null,
35900,
91100,
23400,
26000,
21300,
101200,
27300,
36300,
34300,
37800,
null,
20800,
null,
33000,
18800,
21500,
89600,
19976,
24500,
27300,
16300,
19100,
11100,
22600,
null,
28600,
31100,
26100,
20200,
null,
5400,
45300,
34100,
9900,
126800,
68300,
26600,
35600,
57250,
5300,
16000,
53500,
25500,
14300,
14900,
20900,
62100,
null,
29000,
17500,
12900,
6200,
null,
13500,
34100,
8500,
1800,
16500,
5900,
30000,
115200,
11300,
16400,
11500,
38100,
60500,
null,
49600,
7500,
20000,
11500,
null,
75600,
5800,
34600,
38900,
15500,
14100,
37200,
12500,
14700,
29100,
34800,
16100,
69000,
19100,
30000,
17500,
59100,
103700,
7300,
34000,
37981,
8100,
13500,
29061,
20400,
4300,
33000,
12000,
22600,
22400,
50800,
20500,
21900,
18500,
25100,
27700,
9000,
22400,
null,
20500,
30800,
42200,
330900,
17200,
29500,
88000,
34900,
22800,
4600,
14500,
11400,
25800,
33800,
62400,
23200,
54500,
12400,
20550,
6900,
128000,
30500,
6600,
6600,
55400,
15600,
22700,
10200,
92200,
26000,
42000,
13100,
29800,
9450,
30900,
44000,
20000,
48300,
119100,
null,
60000,
110000,
32300,
5400,
22000,
50400,
28600,
11000,
188800,
18600,
41700,
44900,
8900,
54600,
30400,
63200,
34000,
null,
52450,
17900,
24900,
17100,
31100,
78900,
null,
16050,
13600,
16500,
18500,
82500,
40100,
null,
6000,
3500,
null,
68200,
2000,
9500,
68700,
15200,
28600,
3700,
18500,
20600,
7800,
32500,
1300,
33100,
53000,
34400,
29200,
null,
43100,
14700,
45200,
null,
55300,
12900,
6200,
32700,
15800,
66000,
15200,
160500,
28600,
29800,
null,
20800,
42500,
21900,
174000,
63500,
76000,
20000,
6200,
60400,
35600,
24500,
24100,
19400,
50300,
7600,
20620,
null,
40100,
137000,
9400,
20900,
11100,
26600,
null,
37100,
17500,
11500,
19200,
13000,
11500,
24300,
31600,
63500,
4600,
8000,
19500,
17100,
28400,
25200,
16000,
40500,
7300,
45100,
4700,
8200,
52900,
75400,
6600,
44200,
9000,
12300,
29700,
16700,
38100,
40700,
null,
42400,
24100,
6600,
10500,
27800,
41900,
25500,
61500,
11300,
35900,
33100,
54700,
82900,
9900,
null,
14600,
37800,
53400,
51300,
22700,
2900,
33770,
90800,
4000,
44500,
22200,
37100,
10500,
10400,
86400,
null,
6500,
38637,
28800,
15300,
18300,
23700,
29600,
9700,
23500,
75100,
72500,
7200,
21000,
24500,
null,
11400,
35800,
110234,
16100,
19200,
null,
20700,
51300,
45900,
35100,
43300,
null,
17100,
28277,
24100,
65600,
14100,
55700,
27400,
31400,
null,
7300,
12500,
6000,
68000,
14700,
4600,
41500,
20400,
22200,
9400,
16400,
15300,
38000,
37500,
13400,
27900,
14300,
43700,
null,
60200,
17000,
22000,
26000,
20300,
19900,
30800,
38000,
null,
8500,
25400,
35900,
33200,
12600,
13500,
37900,
27400,
64800,
53000,
55800,
7400,
105300,
47900,
6400,
29600,
65934,
10800,
20100,
31800,
27100,
27100,
18400,
7700,
23900,
null,
44700,
null,
8800,
6000,
17400,
29300,
14700,
30000,
28100,
21900,
52000,
6700,
15800,
1600,
4500,
null,
21300,
43300,
25600,
20700,
20400,
31600,
12400,
26600,
75500,
7500,
19540,
69200,
59600,
null,
79000,
21100,
71300,
82700,
25000,
90200,
53900,
18100,
1000,
24000,
30000,
24600,
42200,
30000,
5400,
10300,
41100,
105900,
22200,
5400,
36400,
13800,
34100,
13800,
20200,
13500,
18600,
15900,
28900,
15900,
14500,
20500,
50800,
25300,
43100,
8200,
null,
26000,
39200,
14900,
27400,
39900,
7000,
28600,
13500,
22100,
12500,
50700,
null,
25900,
41800,
75900,
null,
42600,
28600,
15800,
43300,
17800,
33900,
22700,
null,
31300,
null,
8300,
45200,
33500,
55200,
30700,
null,
46600,
72900,
19200,
10600,
37600,
16000,
null,
8400,
16600,
7000,
22100,
45800,
40400,
77500,
12700,
56000,
27400,
100000,
15400,
null,
22900,
28300,
22800,
12900,
65000,
null,
28700,
16500,
13000,
null,
28500,
41600,
52400,
null,
116800,
7200,
10900,
15600,
17000,
14800,
28200,
11200,
16500,
68600,
37900,
27500,
90500,
13500,
22700,
null,
18600,
17700,
33800,
63304,
76600,
61300,
9800,
null,
85200,
9000,
9750,
15400,
6100,
22100,
31600,
41700,
47300,
null,
11400,
7500,
46700,
185100,
null,
12400,
145400,
17100,
35100,
25100,
35800,
null,
63200,
9400,
15844,
45700,
31700,
51500,
56700,
null,
68500,
32000,
15800,
28700,
8000,
151700,
5100,
37300,
9300,
46700,
7500,
26100,
23500,
null,
14300,
32000,
8700,
69000,
10200,
14600,
null,
6700,
null,
7000,
9500,
21000,
17100,
24800,
21700,
12600,
91800,
25800,
19700,
24300,
null,
7000,
27900,
32700,
92900,
39200,
21100,
12900,
24500,
7100,
45600,
9300,
null,
133100,
57400,
12400,
44600,
64400,
106900,
50900,
126850,
19100,
53500,
109600,
51000,
79300,
31300,
22100,
36090,
46700,
null,
24450,
22000,
2750,
27400,
30500,
13551,
5500,
69100,
25000,
15100,
43300,
36300,
21100,
35900,
26300,
8900,
18500,
19300,
null,
11500,
10500,
70200,
null,
19900,
13500,
null,
34374,
28100,
107500,
15600,
33800,
36300,
null,
21600,
15100,
23300,
11900,
27000,
18800,
27500,
22600,
3800,
null,
18200,
20500,
5800,
24000,
20800,
58000,
null,
7300,
15000,
72500,
100900,
9300,
54600,
22900,
73680,
31100,
22200,
56100,
17200,
30400,
24400,
27900,
18800,
34200,
19150,
97400,
46200,
34500,
27900,
6300,
10600,
38900,
39200,
39600,
28100,
10800,
49400,
66200,
8200,
45200,
28000,
12000,
30100,
28000,
47000,
24800,
35500,
14100,
70800,
9100,
9700,
11700,
6500,
13000,
15500,
69300,
45600,
10700,
12500,
22200,
34900,
13800,
18900,
52500,
26300,
29600,
null,
78500,
11100,
4000,
27500,
16500,
null,
35900,
14400,
null,
null,
111100,
34200,
25800,
14900,
7300,
127500,
74800,
96500,
7300,
24100,
23500,
29900,
63700,
25700,
9000,
6500,
24300,
25600,
8400,
null,
48400,
41800,
null,
null,
29674,
null,
46500,
89200,
12200,
3700,
34500,
10000,
20400,
4300,
100300,
null,
18000,
35500,
15800,
30500,
11100,
53300,
9700,
12300,
26800,
15300,
24300,
71800,
24400,
null,
17000,
367800,
40100,
47400,
96900,
16800,
19500,
19900,
43500,
43400,
23100,
22100,
12500,
25700,
6300,
13300,
19400,
34400,
8800,
12700,
16200,
36900,
31600,
11300,
132600,
null,
16500,
15800,
9100,
null,
10700,
10700,
41600,
13400,
67400,
15800,
25807,
17700,
18400,
93000,
12100,
null,
46700,
19800,
11200,
53900,
null,
7000,
36100,
79100,
8200,
26300,
21700,
22600,
20700,
null,
10700,
45200,
3900,
45800,
null,
11400,
null,
33900,
26200,
17900,
110800,
6800,
13850,
10400,
24700,
24100,
28300,
11300,
16800,
null,
16200,
31200,
86500,
5000,
13300,
40800,
46400,
49900,
61200,
13500,
17200,
35300,
300,
39800,
12000,
8900,
8900,
21500,
24200,
4600,
10100,
91800,
51200,
111800,
84900,
13400,
36500,
50600,
null,
45400,
12400,
null,
5800,
3000,
null,
12500,
26300,
15200,
2100,
17200,
11000,
33900,
104300,
22400,
25900,
null,
28200,
12500,
13000,
18300,
14500,
15300,
48400,
10720,
27100,
52000,
13800,
null,
18189,
14500,
12400,
34600,
10100,
8800,
13700,
10300,
16400,
null,
13700,
18000,
10300,
108900,
50300,
39300,
14700,
26500,
17300,
7900,
44200,
16900,
34800,
50300,
7000,
8696,
15200,
8200,
46400,
24700,
25500,
27000,
13700,
56100,
6400,
17400,
15200,
null,
45300,
14300,
21510,
7200,
10800,
28300,
37900,
13300,
56100,
26600,
40600,
189000,
47300,
34300,
37100,
21700,
33800,
17300,
73800,
47400,
61900,
33300,
29300,
null,
8800,
null,
16000,
7800,
13000,
42800,
48000,
39000,
17400,
13600,
20000,
36200,
21500,
34100,
60342,
23300,
19100,
43500,
52700,
15600,
35900,
57500,
26037,
15800,
26950,
10100,
23600,
14600,
20200,
18300,
152700,
11800,
24700,
10500,
16600,
18200,
35920,
185100,
25300,
14000,
null,
16600,
22400,
21800,
24100,
22500,
27500,
89300,
60200,
14500,
32700,
186200,
14200,
53100,
42900,
16200,
63800,
23200,
11650,
null,
49500,
23700,
23100,
null,
12500,
27600,
75000,
45100,
22400,
8500,
50100,
20700,
44200,
71000,
117800,
null,
null,
null,
13000,
28500,
19600,
12400,
28400,
22100,
64900,
null,
10400,
35700,
26400,
null,
8610,
27600,
18500,
58700,
null,
18500,
2700,
8100,
28400,
28500,
66600,
31700,
59000,
43300,
42300,
34800,
4300,
7500,
61000,
34550,
73900,
17100,
28100,
19700,
7500,
38700,
9900,
14700,
10600,
38700,
31900,
11900,
104400,
54300,
47300,
20100,
25100,
41200,
7700,
6600,
9000,
49500,
12500,
43800,
68300,
55900,
17300,
27300,
36100,
86700,
6300,
42100,
null,
65000,
41500,
null,
37700,
53600,
5500,
112900,
22400,
27600,
53500,
16800,
38968,
23100,
5400,
12200,
43400,
23600,
5500,
4100,
11900,
null,
22000,
36200,
45800,
8800,
59700,
40400,
19000,
28700,
9400,
19551,
56600,
204000,
11100,
46400,
41600,
19300,
105700,
29400,
140300,
4300,
22600,
17500,
3600,
13000,
74800,
30400,
16000,
27800,
null,
20300,
69800,
27300,
21700,
9000,
8500,
47500,
8000,
34100,
23400,
30700,
16900,
null,
46900,
null,
17750,
43000,
4200,
11500,
14500,
10900,
22200,
24800,
34700,
8700,
26700,
7600,
21100,
6400,
16200,
14100,
63400,
28600,
11800,
25400,
12700,
null,
23200,
51700,
17600,
39900,
18100,
8800,
17600,
20800,
21800,
32700,
28200,
22300,
12000,
30200,
20800,
54400,
null,
48600,
23200,
27500,
null,
12200,
16300,
89900,
79400,
110400,
null,
null,
102200,
23000,
30600,
46300,
11800,
9900,
27700,
145015,
43500,
14100,
37200,
13100,
null,
14800,
38143,
16600,
7500,
19500,
57200,
56300,
10300,
46351,
18900,
3000,
41100,
32000,
27800,
null,
87500,
41000,
94600,
55500,
53900,
20700,
41600,
45100,
25200,
59800,
23200,
11400,
105300,
93000,
22000,
13800,
36600,
31200,
68900,
18100,
29200,
12885,
32000,
15100,
null,
41100,
null,
51600,
22000,
11800,
16200,
28000,
24800,
27600,
43300,
12300,
23100,
13500,
18200,
15700,
28100,
32700,
13800,
23100,
11100,
39600,
12200,
null,
38300,
4350,
68600,
62800,
58900,
5300,
3900,
null,
36156,
24900,
77400,
null,
30170,
null,
33400,
3100,
20300,
22400,
18700,
12500,
16900,
17400,
27400,
49700,
52000,
13300,
28200,
null,
20400,
20400,
20200,
17300,
51700,
15900,
28000,
33700,
500,
82500,
30400,
31300,
23100,
57000,
2200,
23300,
20000,
49000,
31000,
28100,
47700,
3800,
8000,
18925,
59200,
121300,
79400,
82500,
20200,
39000,
6300,
14000,
11000,
55200,
29100,
20700,
33700,
36000,
48200,
3300,
6200,
53900,
22400,
19000,
21500,
14200,
10100,
25400,
44600,
16400,
15500,
52300,
3900,
22700,
16000,
8800,
16000,
31500,
42000,
6400,
null,
null,
47540,
26300,
78500,
25200,
45300,
7000,
26100,
29000,
29400,
20800,
10050,
70000,
92300,
70400,
59100,
null,
53300,
12500,
45900,
68500,
null,
null,
10800,
5600,
21400,
18900,
20300,
25800,
null,
46500,
14800,
9000,
41600,
22700,
5200,
null,
67200,
18900,
18100,
28327,
61800,
20700,
98300,
12000,
34700,
32100,
60900,
22100,
14800,
58300,
19500,
null,
10000,
22400,
31300,
4500,
43200,
7300,
8700,
41600,
20300,
12000,
7400,
16100,
63000,
25500,
14900,
null,
39000,
68200,
15400,
36400,
9300,
21300,
62400,
21300,
14100,
22100,
25500,
7800,
10600,
21400,
5600,
17600,
53500,
12600,
9000,
192400,
4800,
49900,
29900,
31500,
29000,
16900,
37800,
49200,
51700,
13900,
8600,
27300,
13500,
null,
16700,
11500,
57924,
81200,
14400,
33900,
39500,
12200,
12800,
6300,
44300,
43300,
307600,
71000,
13500,
18100,
null,
17300,
18600,
11900,
18600,
11900,
20500,
43210,
2300,
66300,
20800,
22100,
38700,
22000,
null,
15100,
64801,
23100,
4200,
29400,
28200,
46100,
30000,
12600,
77600,
22167,
4800,
5300,
45400,
10700,
17800,
68200,
26900,
48000,
30700,
28000,
null,
36700,
25500,
21700,
20400,
25300,
22100,
20300,
43400,
33300,
44000,
42100,
9450,
19600,
38600,
14700,
4000,
18800,
500,
59600,
45400,
null,
75500,
19600,
13600,
27550,
56500,
12200,
41700,
33600,
10800,
26600,
29600,
29200,
9800,
92800,
49400,
14600,
22200,
22800,
49400,
34700,
12400,
24500,
11200,
6600,
48400,
26700,
57400,
3200,
null,
null,
19300,
19300,
29800,
22000,
null,
15600,
16900,
63400,
30100,
13400,
31600,
13800,
5200,
59900,
25400,
29400,
8800,
null,
6600,
26600,
23400,
13800,
null,
9000,
12800,
44900,
10800,
29000,
25800,
null,
55700,
7900,
103700,
58000,
13200,
19600,
5900,
null,
104000,
25500,
15500,
38900,
30400,
null,
null,
24100,
null,
28200,
205400,
24500,
41700,
null,
33200,
70900,
39200,
11300,
10290,
3600,
93700,
11700,
34900,
26100,
21600,
14000,
14500,
8100,
null,
7700,
9100,
28400,
62900,
null,
38000,
14100,
74500,
23900,
null,
11700,
null,
19700,
6300,
19100,
15900,
23600,
32900,
null,
12500,
27000,
13500,
22400,
37300,
62000,
20600,
37700,
69800,
null,
50100,
44500,
65100,
55500,
28700,
null,
47900,
95700,
53641,
46200,
null,
34971,
29100,
10800,
17500,
17500,
14500,
31100,
27400,
null,
12000,
28100,
23000,
8600,
11600,
22400,
17300,
34200,
30700,
31600,
5000,
46800,
21500,
16400,
45100,
8400,
25500,
7700,
13050,
31600,
3200,
47300,
34000,
6600,
null,
12600,
19600,
13200,
34800,
16650,
5100,
28000,
64600,
4700,
7800,
20400,
null,
19700,
21700,
26100,
5800,
null,
20500,
55000,
null,
10200,
27900,
68000,
11400,
11000,
12200,
6200,
25900,
2500,
6700,
15300,
28000,
8700,
8700,
47700,
5700,
null,
40200,
13400,
null,
16400,
3500,
11700,
30000,
null,
16100,
14100,
9800,
56200,
14800,
25300,
41500,
26600,
29400,
16800,
91700,
68900,
8600,
2100,
14800,
42600,
null,
7000,
10150,
34500,
18400,
48700,
58400,
35900,
25800,
15300,
18200,
5800,
6800,
11200,
14600,
20700,
32900,
63200,
4550,
44100,
null,
null,
42100,
36400,
15800,
15500,
21800,
64900,
68093,
48100,
16200,
35500,
66700,
13200,
29200,
7000,
19100,
16100,
5400,
43500,
45200,
15800,
36500,
21800,
62000,
null,
13200,
126300,
46800,
11600,
25900,
18800,
13100,
23600,
24400,
28900,
194600,
14700,
13100,
45800,
48000,
71400,
17700,
1200,
102700,
10400,
24600,
null,
44600,
13100,
null,
68100,
8300,
4300,
8700,
65300,
28400,
16100,
37000,
10000,
22000,
8100,
17000,
24600,
43900,
11300,
12500,
13400,
18500,
42700,
19000,
44400,
37500,
131500,
49700,
31000,
15500,
43500,
8233,
16000,
44900,
36700,
46800,
50700,
17300,
65600,
45700,
null,
42900,
7800,
18100,
26300,
4600,
54500,
21000,
29300,
8400,
46900,
null,
33200,
null,
107100,
null,
24300,
22700,
70500,
77900,
49300,
18100,
25800,
33900,
19000,
22200,
10700,
14500,
15500,
27400,
37200,
8800,
13600,
null,
null,
28400,
24400,
5100,
13500,
14600,
10800,
26400,
42400,
9200,
19300,
4200,
23500,
600,
null,
null,
21400,
11900,
28000,
55100,
38500,
59539,
37200,
21900,
36600,
24000,
21600,
21000,
48200,
49800,
98900,
38400,
21600,
42300,
13100,
9600,
28400,
41300,
33900,
6100,
11200,
17450,
9600,
20400,
44100,
8900,
12100,
36900,
36600,
63900,
0,
25300,
66900,
47000,
35500,
28400,
195500,
24600,
27200,
46900,
28200,
26600,
36800,
40248,
74200,
37700,
213000,
3500,
null,
46700,
23300,
10400,
29500,
77900,
38600,
85800,
null,
null,
73500,
null,
null,
19700,
77500,
18900,
19900,
24400,
23700,
12400,
92000,
22600,
74800,
70300,
37100,
18800,
89300,
60600,
37800,
28900,
24600,
46100,
34700,
6200,
null,
21000,
65300,
11600,
null,
36800,
10300,
14300,
23000,
44100,
47600,
27200,
46900,
56300,
62400,
65100,
7900,
10200,
37900,
22400,
5400,
83900,
24000,
21500,
10100,
14300,
47600,
49100,
21500,
8600,
19800,
14200,
8900,
32300,
24800,
8700,
73800,
112700,
11700,
17800,
13100,
10900,
8200,
8500,
null,
23400,
39100,
10800,
7900,
22000,
17800,
5700,
15600,
15700,
26600,
31500,
73400,
2800,
null,
16500,
11700,
139600,
25500,
7600,
67300,
17400,
11000,
37900,
56500,
5300,
25100,
15500,
28700,
40841,
49400,
23300,
34900,
42600,
13800,
23800,
34700,
7900,
33600,
7300,
10300,
null,
45300,
8200,
10475,
15500,
26200,
71000,
32900,
23300,
23100,
14600,
83300,
37300,
null,
132560,
7900,
56700,
53900,
17100,
34300,
85100,
26100,
86200,
21100,
38700,
130300,
63000,
3500,
20800,
null,
35403,
76000,
18400,
22400,
30500,
175500,
29300,
29300,
141700,
30700,
8800,
20600,
56800,
129565,
9800,
68700,
63000,
15300,
34274,
11900,
47300,
6500,
49300,
28000,
37200,
null,
40300,
25700,
5800,
13300,
17000,
34800,
25300,
86900,
3900,
12700,
null,
21500,
23000,
8600,
50600,
50000,
33400,
25100,
56300,
50100,
22400,
8500,
10700,
28404,
33200,
8700,
15500,
null,
44900,
26300,
null,
53900,
17600,
14200,
36600,
16900,
72700,
89200,
69300,
56100,
24500,
8400,
21600,
null,
10800,
null,
55400,
19200,
14400,
16000,
18800,
25600,
14000,
37400,
42200,
28100,
44200,
30600,
11100,
74100,
22600,
5700,
102400,
9000,
25300,
null,
17500,
16700,
23100,
21600,
45000,
59300,
73300,
15100,
32800,
101200,
36700,
32000,
12500,
12500,
128700,
48300,
8600,
46200,
48400,
45176,
38500,
9800,
71800,
51900,
21800,
5700,
14600,
33300,
7000,
16600,
20800,
69400,
24300,
37600,
14050,
22900,
63200,
11600,
15100,
6000,
73650,
15000,
12000,
8500,
8000,
26400,
34300,
8500,
39300,
24700,
29600,
24200,
10300,
102200,
14200,
null,
26600,
12400,
51100,
null,
36800,
12300,
7000,
23300,
17500,
null,
21000,
11500,
11100,
32200,
null,
14000,
66500,
13500,
35400,
25900,
100000,
6200,
50600,
31100,
10300,
16600,
9300,
94000,
null,
22700,
29000,
17600,
106800,
129800,
50700,
44100,
67300,
24900,
12200,
4800,
16100,
64900,
15800,
27800,
24800,
28300,
18500,
28500,
12600,
36800,
14400,
8200,
19900,
20700,
15600,
12700,
12900,
14700,
42600,
7700,
2500,
21300,
14300,
15900,
null,
null,
38200,
17400,
5500,
28248,
77800,
15500,
58100,
4900,
19400,
null,
13800,
23000,
6300,
25100,
34200,
17300,
null,
23600,
47100,
30400,
28100,
10200,
19000,
null,
6500,
14500,
68800,
12900,
35500,
68700,
101240,
16700,
null,
26500,
25224,
30500,
10000,
162017,
42500,
25400,
48600,
38600,
34400,
100700,
35000,
12500,
23500,
14500,
23300,
15100,
14800,
29400,
84970,
7500,
54100,
97267,
21300,
10200,
12700,
38200,
7549,
25300,
32900,
64900,
6600,
42200,
37900,
45500,
32800,
16120,
20500,
15200,
61500,
22500,
21200,
null,
32200,
35200,
44600,
14900,
14100,
21300,
12300,
32000,
27700,
58700,
10900,
23400,
31800,
13300,
29600,
16000,
28700,
null,
6100,
14400,
14200,
19400,
78442,
null,
29600,
27000,
43600,
75000,
59300,
85100,
26900,
27000,
13600,
6800,
26600,
26300,
24800,
8500,
54200,
16600,
16400,
19700,
20700,
68548,
18300,
9500,
null,
null,
43400,
12200,
26500,
13000,
223800,
22500,
9950,
76600,
9600,
9600,
8500,
34300,
64000,
14700,
24200,
89600,
22100,
null,
22100,
15700,
62200,
34600,
7000,
134000,
48500,
40500,
31400,
61600,
null,
45100,
null,
30600,
null,
3300,
12200,
14100,
13500,
10700,
11300,
6700,
45500,
8400,
15000,
39300,
23300,
null,
55100,
null,
54500,
27500,
21500,
23600,
19500,
null,
57200,
88200,
null,
54100,
52300,
16900,
null,
60500,
41300,
37700,
16700,
18200,
29700,
19800,
13500,
5500,
null,
12400,
24300,
13900,
67600,
15400,
6800,
26680,
30200,
6600,
16300,
28250,
40100,
31800,
38700,
10030,
14000,
null,
13800,
72000,
null,
16700,
11500,
8500,
138900,
10000,
18500,
3900,
24600,
60700,
20800,
24100,
58800,
3900,
24400,
2200,
33796,
31400,
16800,
23000,
46900,
5800,
23900,
4000,
85900,
23300,
23000,
70797,
5300,
67900,
23700,
109900,
12000,
100800,
5600,
16200,
47800,
9200,
9700,
83700,
10500,
14800,
15900,
29300,
70100,
81100,
127800,
5300,
109200,
10300,
59100,
6000,
35300,
19000,
35300,
14500,
23600,
33000,
15700,
14700,
null,
43100,
82600,
24709,
7500,
5700,
42600,
null,
6900,
14900,
31900,
17500,
16200,
16700,
8400,
18400,
15200,
29200,
10200,
5800,
78800,
10250,
22600,
11800,
6600,
22500,
null,
8000,
56100,
56100,
40800,
29300,
26600,
1900,
31300,
26500,
6900,
59000,
18200,
14800,
27900,
44600,
32200,
null,
13600,
72200,
16600,
61300,
7600,
28000,
19900,
12100,
10500,
28600,
35400,
26200,
8400,
23300,
25000,
61300,
4400,
23500,
15800,
21800,
100509,
44700,
41100,
22200,
null,
null,
50700,
31481,
22100,
19700,
33000,
31500,
38100,
17300,
24300,
39390,
9800,
null,
28800,
null,
null,
41400,
10600,
37700,
57400,
8900,
18000,
56400,
8200,
42900,
33800,
29100,
3800,
182000,
9900,
56500,
26000,
26500,
52800,
9500,
12100,
37600,
33700,
87200,
15000,
21400,
7300,
95300,
56500,
24000,
4200,
32700,
7500,
7400,
52700,
20700,
19300,
4000,
54580,
22300,
34800,
27300,
null,
33700,
17300,
166100,
24000,
34600,
7700,
8200,
41200,
21700,
34600,
10800,
25523,
144800,
33600,
null,
7300,
15900,
10600,
21200,
82100,
null,
30500,
3400,
27000,
30500,
13600,
11100,
76500,
23900,
null,
60600,
15400,
16000,
31000,
18500,
null,
27000,
null,
5600,
29600,
35500,
17000,
39300,
39900,
27200,
13800,
14400,
54400,
null,
null,
19900,
10500,
14500,
22000,
33000,
null,
33900,
null,
14000,
56400,
27200,
14800,
29000,
93400,
14300,
null,
25900,
null,
28100,
20900,
28500,
17900,
22900,
17200,
6000,
38900,
18700,
45200,
14800,
17900,
42700,
53800,
47045,
15400,
4100,
2800,
34600,
80000,
14400,
41100,
35700,
23500,
46500,
20000,
39400,
null,
21700,
44000,
11800,
49100,
9600,
86700,
null,
28400,
25300,
25300,
null,
3900,
51400,
28400,
71000,
11000,
9500,
9300,
24600,
15900,
32400,
32100,
null,
14300,
27000,
46100,
13500,
54900,
16300,
33300,
40700,
10400,
6200,
57200,
25200,
13300,
100900,
57500,
11000,
27700,
13700,
26800,
13100,
null,
null,
22800,
20300,
46600,
20400,
15600,
10800,
11200,
18200,
17100,
25400,
26200,
63200,
7000,
48200,
33400,
6000,
null,
64400,
31700,
45100,
13500,
40100,
160100,
null,
3500,
33700,
null,
73000,
19200,
58900,
37700,
12700,
66700,
15900,
28800,
29400,
44500,
null,
18000,
31000,
5200,
87100,
19400,
46600,
11900,
24300,
25600,
70000,
null,
142500,
19000,
59400,
46700,
60300,
32400,
51800,
14000,
42100,
15900,
10000,
26300,
43200,
12600,
null,
10700,
null,
18800,
32900,
23300,
79000,
50200,
5200,
15900,
54600,
27200,
31700,
55400,
54900,
null,
19400,
62500,
127500,
60600,
14600,
13200,
7300,
41800,
21300,
19150,
1400,
12900,
22900,
33300,
39000,
40600,
7700,
27200,
11500,
42300,
43500,
24200,
19900,
5900,
137000,
10500,
13600,
1000,
27900,
42500,
29800,
8500,
33700,
50200,
17900,
null,
11500,
10600,
9800,
null,
14300,
15600,
18500,
26900,
null,
19700,
19200,
5000,
9700,
9400,
null,
11200,
10000,
5500,
43700,
13800,
null,
12500,
24100,
7300,
18300,
null,
null,
24900,
12000,
37000,
null,
10000,
null,
35600,
28700,
12800,
23900,
9500,
25600,
20400,
33800,
6500,
29400,
76500,
46100,
27000,
9600,
39100,
55500,
22600,
31500,
25500,
22300,
33900,
51700,
5500,
27700,
14000,
70100,
34500,
25300,
31700,
61500,
9100,
20500,
79500,
21100,
19900,
19500,
22000,
27200,
38200,
39000,
14700,
21700,
null,
14800,
26900,
11900,
26800,
43000,
7600,
14100,
16500,
17000,
25800,
23500,
13600,
null,
29000,
16000,
15100,
57100,
28900,
47545,
49300,
null,
20700,
218000,
5000,
15400,
32100,
47500,
14300,
8200,
31000,
7500,
137550,
10500,
52800,
25400,
34500,
32200,
144300,
33100,
35500,
63700,
37100,
3000,
20700,
15000,
14100,
17500,
null,
36300,
22200,
57900,
13300,
28500,
23300,
37900,
15500,
null,
29600,
10375,
40600,
10400,
25900,
null,
30900,
7700,
135200,
29600,
39000,
44800,
21300,
null,
17000,
38600,
23300,
null,
36200,
35800,
null,
12300,
24000,
24000,
22500,
15900,
104200,
5600,
null,
34000,
22400,
16000,
40500,
25900,
25700,
20800,
35400,
18100,
31867,
34800,
null,
14100,
15800,
12000,
154507,
29400,
72500,
18530,
6300,
33900,
35300,
45900,
8800,
26100,
11100,
23700,
36400,
44800,
64600,
10800,
10300,
49700,
22400,
27600,
22000,
19800,
37600,
8900,
19400,
65800,
null,
34200,
9000,
31676,
24600,
12300,
60900,
10800,
41900,
25700,
15100,
23800,
null,
35200,
28700,
9800,
45400,
26200,
42200,
14300,
52200,
8100,
12000,
9900,
47400,
24000,
14500,
null,
null,
21100,
14600,
28700,
34500,
15800,
20700,
null,
17500,
27200,
36600,
19300,
null,
19700,
13800,
31300,
48900,
48300,
9700,
37500,
8000,
46200,
14700,
null,
null,
17300,
22800,
77400,
42400,
48300,
null,
12300,
19200,
15700,
95100,
12100,
16970,
11400,
48500,
4700,
null,
30400,
14500,
29900,
12700,
5200,
39700,
23800,
12575,
31900,
19200,
60100,
41300,
10200,
20400,
28000,
null,
512600,
32600,
51400,
27600,
44200,
7750,
13700,
14100,
null,
12300,
11200,
13800,
8500,
null,
44745,
null,
42000,
14600,
23800,
45700,
9500,
85100,
17300,
29100,
48900,
52500,
3800,
26500,
24200,
20100,
48200,
19500,
null,
46900,
26000,
34700,
69100,
43200,
41500,
21800,
17400,
11900,
70300,
38000,
27456,
72000,
85300,
52100,
28800,
12000,
7500,
10900,
8400,
62300,
27600,
24700,
15200,
13600,
9500,
230142,
3500,
28200,
28200,
37600,
26700,
44600,
21100,
30500,
37300,
31900,
27700,
23700,
16800,
12500,
38600,
31600,
39900,
12200,
12300,
25995,
30900,
59200,
33500,
17900,
8400,
18200,
15500,
45299,
42800,
null,
22534,
57300,
69100,
10600,
49700,
6600,
17159,
7200,
37500,
41800,
17800,
1000,
18000,
29200,
25900,
76200,
23900,
9500,
14500,
88300,
11000,
39500,
22900,
65938,
49400,
14800,
21700,
16700,
6550,
15300,
null,
null,
13000,
24100,
41400,
9400,
33900,
43000,
52900,
14300,
8900,
12400,
null,
13700,
71800,
null,
35900,
81000,
39300,
41300,
17400,
null,
31500,
76200,
20000,
34000,
45000,
12200,
58700,
null,
26100,
83400,
28600,
37800,
20700,
62800,
61800,
32500,
55700,
18000,
30200,
8100,
37400,
27624,
12900,
13100,
33300,
48300,
20800,
17400,
24000,
9200,
35200,
54800,
27200,
1800,
65000,
10500,
14100,
28400,
82700,
8700,
51900,
33000,
16567,
397300,
12400,
null,
9200,
48400,
null,
37400,
107400,
8800,
46900,
46900,
62000,
14300,
11400,
34500,
13400,
45300,
12400,
27350,
29300,
26400,
null,
92400,
21600,
8300,
19900,
8300,
42800,
31620,
23400,
167000,
19800,
25000,
null,
66100,
84100,
38100,
45400,
null,
39700,
30600,
22700,
7800,
10300,
10600,
27820,
13800,
9700,
56100,
30500,
12600,
39700,
29300,
53200,
10200,
10900,
20000,
7000,
18800,
39900,
22900,
17300,
61200,
71500,
null,
89500,
34800,
null,
23200,
23700,
17400,
7800,
4000,
null,
16300,
47500,
10000,
47900,
9400,
21800,
null,
null,
32300,
40500,
15900,
10000,
9400,
141400,
68700,
42500,
15000,
29200,
null,
9100,
17800,
39000,
3800,
null,
47500,
82000,
14700,
19700,
20000,
28100,
37000,
null,
13300,
24800,
15700,
null,
7800,
48600,
14700,
33200,
10050,
20300,
60100,
50100,
29400,
18900,
15200,
40200,
15400,
34100,
13500,
26000,
59500,
null,
21000,
14800,
54400,
19000,
17400,
42400,
26100,
54700,
28300,
46200,
4400,
50500,
17600,
19500,
12100,
34100,
23700,
21900,
23900,
25600,
38900,
23500,
16200,
12100,
71700,
36400,
14000,
50100,
52800,
36400,
4000,
28000,
34300,
26100,
22100,
15900,
108600,
17900,
null,
38300,
null,
26900,
22900,
66700,
71900,
17300,
19300,
null,
31700,
6100,
18300,
2400,
22000,
124800,
11700,
27700,
null,
null,
37600,
10900,
11600,
45200,
36400,
4500,
15500,
12100,
32500,
null,
null,
33500,
20400,
34800,
10300,
14800,
39400,
20800,
44500,
33200,
8900,
19900,
null,
32800,
19100,
27800,
43400,
68700,
22000,
36700,
68100,
32400,
18100,
11800,
24000,
119000,
34600,
3200,
39300,
7800,
105500,
6600,
23300,
44500,
14800,
22200,
36700,
31600,
19000,
null,
15400,
12000,
5000,
19300,
29500,
40300,
11200,
18900,
28700,
28900,
33200,
3100,
30800,
7700,
16100,
49900,
62000,
19800,
9000,
20100,
87800,
18700,
26800,
20400,
23700,
44700,
7800,
47600,
13600,
6800,
51800,
12400,
9600,
19400,
62200,
21800,
18700,
40893,
33400,
44600,
34700,
16000,
12600,
40200,
24900,
42700,
15100,
18300,
6400,
15000,
83214,
20000,
57300,
14800,
27700,
47400,
null,
6700,
8600,
69300,
27500,
73300,
17800,
23800,
24900,
32200,
27600,
8100,
84000,
11600,
null,
42800,
16200,
19500,
35700,
7100,
15600,
28900,
22900,
null,
13500,
69600,
14400,
23500,
null,
15000,
null,
14000,
16300,
11200,
25900,
62000,
28800,
11900,
29700,
null,
null,
null,
24300,
9700,
14300,
54500,
38300,
151100,
null,
63400,
11200,
18900,
38200,
29400,
23331,
25600,
46200,
24780,
12200,
10000,
null,
48200,
33000,
29300,
9100,
9200,
500,
8200,
8300,
302700,
null,
48000,
9100,
33800,
82600,
13600,
36800,
28200,
74500,
60800,
2200,
23500,
12900,
23600,
1400,
null,
9100,
22900,
18900,
24100,
30400,
8900,
21500,
18000,
30300,
36500,
47900,
29700,
49200,
4600,
90000,
35600,
37700,
29300,
26800,
11800,
43000,
52700,
30900,
101500,
15500,
6200,
24200,
56100,
71400,
23500,
4800,
28600,
21000,
5600,
45000,
44700,
47400,
45400,
18400,
null,
29500,
33700,
49600,
32200,
21000,
null,
25600,
12000,
58600,
21900,
15500,
13700,
14100,
11000,
14900,
85100,
42700,
60900,
12900,
34800,
12800,
18500,
53100,
79200,
3000,
9500,
28200,
31300,
24800,
101900,
32400,
42000,
12700,
23200,
24200,
30300,
34300,
36600,
8200,
31600,
16500,
44600,
6300,
63800,
20200,
23400,
15900,
31500,
16400,
57307,
29800,
14400,
28400,
50400,
35100,
48300,
48500,
47600,
23900,
27200,
4400,
12700,
15000,
9000,
5200,
19900,
11400,
19600,
0,
80500,
38000,
20400,
36600,
45300,
32600,
13800,
71300,
17500,
18800,
33300,
32800,
24800,
5400,
45100,
33700,
28700,
null,
55000,
19900,
null,
31400,
16600,
19100,
18500,
12100,
30200,
102300,
44000,
37300,
19000,
38400,
19100,
34200,
175600,
16850,
null,
14500,
2800,
44000,
54500,
56700,
12700,
11700,
4000,
19400,
6800,
28300,
12400,
41300,
18800,
83100,
null,
12800,
16500,
13100,
null,
54800,
62000,
23300,
61700,
60000,
41400,
12100,
21500,
6400,
27500,
27600,
18000,
34100,
32900,
15000,
21100,
21300,
10900,
10500,
28700,
70000,
25700,
12600,
31400,
null,
5900,
25700,
75700,
20000,
5200,
56500,
49500,
21060,
30800,
48100,
29800,
9000,
45470,
231600,
95900,
19800,
null,
45100,
52100,
null,
26400,
52700,
23900,
48900,
17500,
null,
11000,
6000,
14000,
24500,
null,
16700,
78600,
13300,
203300,
16600,
28000,
139900,
null,
29600,
2000,
null,
10200,
18800,
15700,
7500,
4000,
27700,
22600,
13500,
32100,
48500,
32400,
183500,
33300,
15700,
56600,
null,
17200,
13600,
19300,
45600,
22200,
21300,
32400,
17800,
26300,
13000,
24200,
10700,
6900,
28300,
null,
33900,
21800,
4500,
20200,
35200,
25300,
15500,
34300,
12200,
11200,
28800,
18600,
null,
37650,
99400,
73100,
23400,
31100,
51400,
55900,
31900,
42681,
4300,
13200,
32200,
15800,
17600,
8520,
null,
27700,
30100,
108000,
45000,
7800,
77900,
5900,
15300,
4000,
57000,
12100,
41100,
59600,
21800,
23500,
19400,
18700,
68050,
27100,
5700,
76800,
9050,
36900,
62400,
10400,
13300,
51830,
25800,
28300,
10700,
3200,
9000,
null,
7500,
7600,
12600,
78800,
13000,
23200,
27400,
9700,
11700,
5300,
14000,
88900,
56300,
15800,
32000,
null,
39400,
1200,
9200,
14200,
61600,
6550,
21400,
117900,
15000,
12100,
21900,
43300,
13600,
36800,
75100,
46700,
41600,
11600,
211000,
19400,
23000,
7600,
16900,
18200,
39900,
3400,
15100,
21400,
38400,
20500,
11400,
17000,
65800,
66500,
7800,
null,
88700,
52600,
16400,
80300,
10300,
10700,
30500,
57800,
null,
26500,
4800,
16400,
19600,
24800,
25300,
5800,
33700,
26300,
17500,
26200,
43000,
24100,
25100,
16600,
26800,
58200,
21600,
11500,
32600,
36000,
36900,
10100,
7300,
24300,
11900,
31100,
74900,
329000,
9300,
26450,
32400,
54900,
49700,
13800,
18900,
43000,
30200,
21200,
10800,
27600,
16000,
null,
49600,
60900,
6400,
23300,
5300,
108230,
21900,
12400,
5200,
null,
14700,
26000,
24500,
36300,
251000,
21500,
8900,
14600,
16200,
17700,
2800,
21500,
12600,
41100,
22100,
18900,
9900,
18800,
29300,
22900,
126300,
28800,
24900,
8600,
16300,
81900,
null,
23800,
27100,
37500,
6500,
47900,
43600,
42100,
24400,
129020,
62700,
19300,
14300,
13000,
20400,
84600,
74600,
0,
null,
21700,
59400,
18500,
18598,
null,
16100,
null,
15500,
22300,
65500,
42500,
7500,
8900,
299100,
13000,
13400,
3600,
73400,
7000,
7800,
17600,
4700,
32500,
23900,
41700,
null,
28500,
13000,
48200,
17000,
59500,
27100,
12500,
35800,
52500,
19800,
45127,
26400,
null,
null,
22200,
23500,
31650,
35300,
10100,
9050,
17300,
20300,
12900,
21000,
null,
15000,
25000,
40400,
35500,
3500,
25200,
null,
null,
6200,
64700,
172198,
9900,
22400,
53300,
28400,
10800,
88900,
5000,
25500,
8000,
19300,
55800,
12500,
14800,
12500,
19600,
28300,
9100,
3600,
26200,
14600,
27200,
6700,
5000,
12700,
9000,
null,
79400,
15300,
null,
10600,
30700,
77800,
25400,
14600,
10250,
8700,
9200,
42200,
44700,
12700,
32000,
9300,
7600,
null,
20700,
19900,
69200,
null,
7500,
40700,
4600,
134900,
35800,
null,
33500,
46300,
11600,
20100,
27100,
7800,
21300,
16500,
18225,
21300,
27400,
32300,
25000,
21200,
32800,
31200,
17400,
13074,
32400,
46200,
17300,
49000,
14700,
null,
15200,
35200,
32400,
47600,
14000,
84800,
26700,
33600,
57700,
21300,
28000,
26600,
15400,
10000,
11700,
11100,
14200,
28600,
11500,
null,
19700,
69000,
23000,
8900,
30700,
15200,
null,
14000,
null,
54400,
22000,
19000,
71716,
18800,
42900,
23800,
28300,
24100,
null,
2900,
45300,
17200,
20250,
null,
2400,
14500,
24800,
17100,
24200,
13600,
null,
80400,
48100,
8600,
20600,
18700,
34200,
null,
20400,
7100,
85500,
20057,
28300,
7100,
15000,
11500,
14400,
72000,
33900,
32600,
18500,
34700,
6300,
19200,
69400,
13900,
22600,
10200,
null,
20600,
29000,
21500,
38600,
123100,
62400,
null,
123100,
12700,
10600,
29400,
153800,
7800,
29300,
9300,
12700,
34800,
65300,
2500,
29000,
49500,
100800,
11900,
34300,
32100,
45500,
null,
14400,
1700,
17300,
38500,
74800,
10900,
15400,
121300,
45000,
12200,
2700,
1800,
41900,
18470,
72900,
19900,
26500,
43700,
25300,
29800,
26500,
23300,
47200,
null,
null,
45400,
92800,
10600,
17800,
15200,
17900,
34100,
null,
5800,
1100,
41300,
11400,
null,
25600,
null,
46600,
30600,
7100,
18000,
39500,
32300,
30600,
31400,
11300,
5100,
null,
48900,
16800,
118600,
36462,
47800,
19100,
88700,
8600,
9200,
31100,
36900,
19200,
59900,
39200,
6800,
13600,
7600,
22500,
18100,
38200,
40500,
null,
19600,
null,
121300,
6600,
49300,
17500,
46100,
12400,
29500,
23900,
null,
16900,
51500,
18000,
12200,
12300,
49800,
16300,
15900,
111400,
101100,
10500,
16000,
51300,
null,
38600,
17700,
20300,
4500,
9800,
56900,
30600,
36400,
9300,
39675,
17000,
5300,
25200,
4100,
69700,
49600,
44500,
20500,
57000,
21900,
29600,
25770,
53800,
2400,
116400,
13000,
52800,
8450,
14800,
42900,
20700,
null,
17000,
8200,
32164,
30300,
19100,
5100,
37000,
15300,
25300,
23500,
12500,
51700,
33500,
5800,
33200,
0,
14200,
16500,
89100,
9000,
15500,
48300,
13000,
32200,
10300,
26200,
33100,
45300,
24700,
26000,
12100,
35000,
54300,
25200,
28000,
41700,
4400,
2000,
13700,
10900,
16000,
24000,
16400,
146100,
71800,
37300,
null,
8191,
18100,
null,
43338,
65900,
500,
52600,
34200,
null,
53300,
25800,
9000,
47500,
5900,
66280,
33700,
6200,
25600,
70900,
85500,
40500,
null,
27300,
null,
5200,
28000,
null,
null,
116100,
43400,
11000,
9750,
28900,
36900,
14200,
20885,
null,
13900,
16400,
null,
27600,
27500,
10700,
5800,
7200,
2960,
null,
31400,
19600,
44000,
null,
null,
27100,
16900,
42000,
12200,
58900,
15600,
28400,
20600,
11900,
14700,
40800,
40100,
27200,
68700,
26200,
20700,
37300,
73000,
4500,
38300,
16500,
52700,
27200,
16100,
null,
16000,
13600,
48300,
14600,
36200,
null,
49400,
30500,
18000,
8300,
12800,
29600,
32800,
5700,
41900,
45000,
28100,
53500,
27000,
13900,
5600,
15700,
25400,
5900,
9900,
22525,
21200,
35600,
26300,
17600,
7800,
10300,
9900,
29000,
106700,
27000,
17800,
92200,
0,
26200,
12700,
15300,
21000,
15000,
16300,
33100,
26600,
17100,
23200,
8900,
28600,
3800,
64900,
8700,
16600,
null,
5000,
35400,
22300,
26800,
37200,
null,
35000,
6800,
59500,
56400,
8800,
13000,
32300,
9700,
22700,
69900,
95800,
55700,
22400,
50800,
26800,
17100,
5800,
84500,
26300,
38000,
21500,
null,
15400,
54400,
85100,
34200,
6400,
8700,
24000,
37100,
13600,
48200,
39900,
null,
21880,
24900,
20100,
46621,
41600,
17200,
31500,
36300,
135400,
25400,
37700,
19800,
17800,
29600,
43500,
null,
3000,
15781,
83600,
20500,
24500,
38900,
17600,
11400,
18900,
null,
38789,
4300,
25900,
13200,
5300,
18100,
31000,
null,
26110,
19800,
115400,
3000,
23900,
19700,
10600,
8600,
7150,
81800,
31800,
null,
11000,
69500,
33800,
23200,
3900,
51900,
35500,
83600,
null,
45300,
9100,
43600,
21500,
6200,
12500,
37800,
6800,
23700,
40500,
19100,
11500,
33200,
13800,
11900,
39300,
52800,
10000,
20200,
22000,
8200,
12200,
27000,
58800,
34600,
41639,
12000,
8100,
38200,
18400,
34000,
18200,
3700,
5800,
20600,
92000,
31200,
12100,
8600,
18600,
41600,
32100,
33600,
36200,
16600,
22800,
20400,
17000,
22600,
3600,
36500,
16300,
38300,
16900,
83400,
79800,
17000,
51400,
45100,
17390,
45100,
6500,
13300,
9200,
105500,
34000,
29600,
74600,
20000,
30000,
47000,
39200,
54100,
8400,
9100,
127300,
27800,
28800,
54500,
32300,
18600,
9900,
80800,
29000,
null,
10100,
14600,
21000,
16000,
7400,
41900,
6000,
12100,
38100,
19000,
31600,
null,
3800,
14900,
3400,
26100,
16000,
11900,
12700,
18400,
41500,
28500,
20800,
15200,
20000,
32600,
null,
20800,
14000,
22500,
23900,
19100,
50600,
15500,
28000,
11500,
97900,
5800,
14100,
59500,
27800,
null,
55300,
null,
32400,
23000,
15700,
15600,
53800,
11900,
30500,
18600,
60300,
11100,
19700,
11800,
8400,
16800,
64000,
72500,
31500,
8800,
6500,
5200,
37039,
null,
null,
null,
15600,
null,
13100,
57300,
31500,
15400,
15200,
17900,
29100,
7600,
152500,
64103,
45700,
42900,
12900,
19700,
32700,
22200,
73500,
24600,
16300,
7400,
52500,
17800,
39500,
null,
163600,
42600,
16800,
93441,
32400,
24500,
8500,
17900,
64500,
22100,
18700,
12500,
35000,
36700,
23400,
82600,
89300,
87100,
17400,
61600,
28700,
106600,
41700,
25500,
35100,
19700,
8000,
106400,
30600,
20400,
5000,
13400,
4700,
7200,
23100,
83900,
23700,
33300,
28300,
22800,
16000,
30600,
17300,
7600,
22600,
58300,
8200,
91900,
14800,
17000,
50900,
17100,
13300,
43400,
49000,
31500,
28600,
27500,
42417,
19000,
10800,
24700,
21400,
15500,
27400,
194700,
28100,
1800,
14900,
null,
9900,
66500,
6000,
18700,
null,
27800,
22300,
13900,
17900,
8500,
14700,
8000,
null,
6000,
21700,
72800,
210500,
10300,
45500,
38100,
47600,
11000,
4700,
57200,
28200,
25100,
23400,
22700,
10200,
29946,
null,
99700,
43300,
120000,
20000,
16100,
34080,
106500,
54000,
11200,
55500,
null,
54400,
18300,
61366,
17000,
36200,
40200,
22700,
13900,
12300,
18200,
10200,
13500,
72100,
15900,
30000,
17900,
24400,
null,
51400,
16800,
43500,
null,
19900,
23300,
34500,
30900,
27800,
115100,
44300,
null,
24600,
45900,
11300,
null,
42400,
29300,
9300,
10100,
52400,
7300,
34500,
34500,
47800,
12200,
null,
15200,
28000,
49300,
21600,
53600,
37000,
28300,
24400,
null,
11400,
110600,
9400,
5000,
27300,
57800,
7200,
10800,
43800,
11700,
null,
11500,
25000,
30900,
28500,
16800,
49400,
28500,
35800,
26900,
17900,
26600,
43600,
null,
53600,
49100,
13800,
36000,
13700,
null,
7900,
45600,
14800,
21600,
41400,
31600,
17300,
11200,
14200,
2100,
null,
32400,
126100,
23300,
12100,
27100,
16900,
37000,
30400,
27000,
53612,
53900,
15200,
70500,
24300,
20900,
47200,
9000,
22000,
21800,
8300,
66500,
14000,
29000,
null,
45100,
9800,
17600,
30400,
10400,
null,
22800,
19700,
17700,
43400,
33100,
37911,
7800,
23900,
23600,
39500,
60800,
null,
6000,
17400,
19700,
null,
20100,
49600,
19900,
18500,
37400,
18000,
16400,
37800,
20700,
32200,
25000,
15400,
null,
23500,
27900,
27700,
66200,
61000,
51400,
54300,
4900,
31000,
33400,
null,
12400,
15100,
48300,
7700,
21548,
48900,
8100,
6500,
null,
25000,
null,
15300,
12400,
38300,
15600,
5000,
18900,
null,
22100,
58400,
11900,
null,
37400,
11500,
75500,
17600,
19400,
40700,
18400,
49700,
23200,
37500,
107100,
13700,
60600,
6800,
62000,
6400,
7300,
74400,
21000,
29100,
78100,
12700,
null,
40900,
8100,
5400,
121700,
15000,
30100,
8600,
34900,
15200,
20100,
null,
26900,
null,
163600,
null,
45900,
31900,
16300,
6100,
null,
null,
15300,
44600,
2100,
22800,
8000,
42450,
86000,
11700,
13600,
19400,
15100,
55300,
39000,
24500,
117800,
49400,
19200,
null,
65100,
12500,
139300,
30000,
6200,
2900,
7100,
3100,
null,
59080,
26700,
15032,
19700,
17500,
63100,
10300,
18100,
75600,
20700,
15494,
9800,
29700,
42800,
21600,
33700,
68500,
20000,
22900,
37000,
null,
35100,
26600,
20500,
15700,
44400,
null,
38600,
21800,
6800,
33100,
8100,
29200,
68100,
17100,
null,
21600,
null,
41600,
37600,
23200,
15700,
null,
32200,
null,
12200,
14400,
13300,
5900,
16700,
11100,
167600,
80100,
8800,
4000,
17000,
12700,
35300,
46400,
21000,
61500,
null,
208600,
12100,
17700,
16300,
null,
20500,
null,
20800,
48000,
9900,
null,
13600,
11500,
12700,
32800,
15300,
19100,
5800,
12700,
18900,
8800,
28300,
11100,
10100,
12900,
32300,
47900,
51000,
15800,
36000,
6700,
6600,
33160,
null,
12700,
58100,
null,
24000,
60500,
23100,
47500,
null,
56400,
null,
30600,
null,
46000,
89200,
63500,
14900,
88200,
5500,
37000,
20500,
null,
3810,
41100,
12600,
32800,
21200,
15500,
96800,
10200,
97500,
null,
74100,
28600,
null,
39500,
10000,
35200,
20700,
21600,
5700,
12000,
18100,
7800,
33300,
51200,
37900,
38500,
3700,
45500,
10300,
2100,
29100,
15700,
12900,
null,
32000,
31500,
24500,
27800,
null,
15100,
17800,
68400,
null,
19400,
14900,
11800,
10500,
6900,
27400,
6000,
42900,
30600,
36100,
15700,
23100,
187100,
12900,
45300,
6600,
15800,
38300,
24800,
44000,
29300,
22300,
15100,
56700,
null,
19425,
24500,
56900,
38300,
16200,
52200,
25300,
23000,
10300,
15500,
26100,
null,
108600,
13350,
8650,
13300,
14600,
8600,
29900,
25500,
null,
97500,
20200,
25100,
26100,
10500,
null,
48800,
61400,
11000,
13600,
null,
30400,
13300,
11450,
null,
21100,
null,
13400,
16600,
34400,
36200,
20000,
4100,
5300,
42900,
23400,
12000,
18500,
21500,
33900,
57900,
73600,
null,
53200,
19500,
26200,
18800,
44000,
66700,
29400,
11800,
33800,
null,
25500,
10100,
5800,
18800,
null,
35200,
12900,
19300,
12500,
null,
null,
17600,
20900,
19600,
7700,
50000,
12600,
20200,
14700,
71200,
47300,
12200,
22700,
null,
24900,
62200,
15500,
11300,
61300,
88200,
60100,
null,
39600,
11700,
36700,
27500,
null,
51200,
18600,
12200,
26300,
16100,
25900,
16300,
36200,
null,
null,
26300,
43800,
7300,
74300,
21600,
null,
61900,
29000,
44266,
161300,
19100,
21300,
19100,
11000,
17300,
31700,
20400,
44000,
39400,
59700,
57800,
37000,
23200,
26700,
19500,
22900,
13800,
14600,
14100,
3600,
29800,
19500,
null,
26200,
15700,
13800,
19100,
10300,
12600,
12300,
24800,
18200,
6600,
60900,
35600,
18500,
11700,
8200,
63380,
52096,
39100,
33700,
null,
14100,
25600,
14100,
52300,
11313,
5000,
18000,
52700,
5500,
null,
41200,
11800,
22500,
19500,
40900,
2100,
48500,
8400,
28000,
9100,
32300,
12700,
45700,
57400,
25400,
15800,
8400,
23200,
42700,
15100,
40700,
22500,
57600,
100700,
41100,
16900,
18600,
20700,
39300,
19700,
8700,
50700,
22200,
14400,
19900,
null,
42800,
20700,
28800,
10500,
17600,
83800,
14900,
1500,
null,
32100,
32700,
68100,
38500,
5800,
50000,
18200,
29800,
34586,
7100,
161300,
23500,
null,
14300,
9100,
14700,
null,
24000,
35400,
28600,
28500,
25500,
42400,
46900,
29400,
11700,
28600,
31100,
5000,
47000,
17000,
35400,
65100,
33600,
13250,
43600,
11100,
19400,
68100,
17300,
9500,
22000,
42500,
34200,
9200,
14800,
17800,
39700,
38100,
14000,
142300,
15700,
70000,
23800,
22700,
16800,
29000,
53900,
71300,
10200,
45600,
8600,
23300,
29100,
16000,
23800,
64600,
16100,
33100,
10000,
25700,
19000,
11500,
49200,
20000,
9200,
14800,
36200,
null,
5200,
41300,
28900,
18300,
12800,
5800,
5000,
null,
22200,
7200,
16000,
35500,
12500,
8700,
14600,
39900,
9800,
39700,
15000,
19400,
61500,
4700,
5900,
44200,
53900,
59900,
10800,
11300,
46100,
29800,
12700,
41500,
12300,
18650,
54800,
27500,
50400,
6500,
25300,
28000,
79300,
16300,
17700,
23700,
96600,
10600,
29300,
64200,
31400,
36500,
23032,
18500,
7100,
16800,
11650,
12900,
51400,
34400,
33600,
35100,
20100,
24500,
25800,
5300,
16600,
8900,
33500,
41200,
null,
37300,
9800,
null,
14500,
49300,
24231,
10000,
9800,
40900,
12000,
14200,
null,
52400,
19000,
11100,
40678,
12700,
34300,
74100,
null,
11900,
22700,
15000,
30900,
9500,
7100,
4700,
30900,
4300,
15100,
null,
13100,
25800,
43700,
39200,
120100,
62600,
43100,
6500,
47100,
16100,
17100,
195800,
7900,
7000,
15300,
13800,
38900,
22300,
45200,
29200,
1500,
72600,
65700,
9300,
17700,
23600,
50500,
7200,
1000,
27600,
null,
17100,
12300,
24500,
27600,
44000,
31400,
11900,
44530,
55500,
20600,
23400,
16200,
37600,
51700,
3200,
18300,
13700,
52600,
15700,
14600,
16500,
10000,
null,
159500,
31600,
3900,
4100,
33100,
36800,
92300,
null,
52600,
null,
28400,
6600,
7600,
37600,
28100,
16000,
8400,
17600,
19700,
41139,
76400,
null,
88600,
151900,
46229,
39100,
44100,
20731,
8500,
59400,
7800,
41900,
34900,
15000,
11453,
2500,
17000,
null,
36200,
14000,
32200,
23800,
9100,
6300,
22700,
22500,
24200,
27000,
131400,
29400,
19700,
4000,
26900,
23400,
null,
11300,
28100,
28474,
7700,
14000,
58900,
10500,
49500,
28900,
26600,
25700,
39400,
17400,
65900,
17000,
29000,
77500,
9200,
null,
24400,
5700,
null,
3800,
4300,
9600,
24600,
800,
13800,
34000,
31800,
22200,
null,
111300,
22800,
9500,
18200,
20500,
10300,
50400,
3500,
3000,
38300,
12000,
8900,
42300,
8100,
8500,
31100,
7500,
6300,
6600,
16400,
8000,
38700,
47700,
21000,
28200,
56100,
14300,
23200,
11700,
47800,
115145,
47100,
91667,
15981,
50800,
39396,
17400,
66900,
15900,
29600,
18400,
16100,
39300,
52100,
11100,
21800,
48500,
3900,
22300,
94000,
6200,
7000,
14800,
9600,
26200,
68700,
12400,
177800,
17400,
54700,
92300,
8000,
27000,
100000,
77600,
27400,
3300,
5500,
16100,
29500,
41200,
20200,
20500,
45400,
6200,
40000,
60000,
50000,
75600,
50400,
47100,
null,
48600,
49200,
28800,
19200,
22200,
16100,
21800,
4300,
11200,
31010,
49000,
null,
33200,
41500,
19500,
14800,
61800,
17100,
32200,
null,
22200,
null,
23000,
16600,
56700,
38800,
57300,
6800,
null,
36000,
143900,
14100,
25200,
21100,
30000,
30200,
18300,
24500,
null,
10200,
13700,
26100,
42700,
7300,
7600,
15700,
26700,
18700,
74600,
47200,
28000,
8500,
2000,
35700,
29700,
17500,
28500,
25500,
48750,
40000,
45900,
66500,
32800,
36800,
41300,
8600,
7300,
42600,
70900,
9800,
17400,
32600,
28300,
null,
21400,
18000,
16800,
22200,
33200,
86600,
20200,
12200,
13800,
24800,
118000,
9500,
77200,
12100,
42300,
56200,
36700,
34200,
16400,
48900,
3725,
25700,
10300,
15900,
6400,
8400,
17900,
52100,
11000,
24200,
24600,
11300,
39100,
24900,
25900,
32400,
null,
null,
31009,
15000,
4300,
67400,
34300,
1700,
10600,
17900,
13600,
47807,
14900,
15700,
15200,
null,
11800,
26500,
37600,
13000,
25000,
null,
38400,
43800,
3900,
10800,
null,
16000,
19150,
49800,
null,
2200,
22600,
11100,
17600,
65400,
null,
21600,
20400,
9000,
24300,
null,
5400,
10100,
8200,
48500,
null,
55400,
22700,
33400,
null,
13400,
16700,
24000,
null,
87900,
16100,
15200,
null,
48600,
26100,
38500,
114000,
27400,
18500,
16000,
20400,
30000,
13200,
12600,
55700,
12000,
55800,
35100,
27100,
9400,
22800,
15500,
22700,
5900,
13800,
3200,
55800,
7700,
25900,
56900,
57700,
20800,
7700,
44300,
19200,
18700,
57800,
30000,
42200,
8000,
29600,
48000,
null,
10100,
24300,
15200,
20700,
33600,
23400,
12000,
44100,
59500,
26400,
null,
21200,
17600,
23700,
29000,
13500,
17000,
21000,
7800,
27100,
19700,
14500,
18100,
84600,
28600,
40000,
13400,
8800,
22600,
38700,
77700,
14800,
42300,
null,
12800,
47400,
11300,
null,
25900,
3000,
46700,
55300,
4200,
73700,
46745,
6700,
39000,
18200,
14400,
null,
5068,
7300,
95100,
17400,
50800,
32300,
38800,
82400,
20700,
7400,
14000,
44900,
5200,
21200,
23200,
4000,
25900,
3600,
25200,
null,
30400,
32000,
20700,
39500,
84900,
8400,
null,
null,
50594,
31200,
65300,
21200,
70900,
78600,
54700,
12100,
null,
40900,
34900,
9800,
79900,
94800,
42200,
46100,
47400,
54600,
18100,
28400,
8500,
61500,
94000,
19000,
12900,
null,
4200,
54200,
39300,
25100,
5300,
36500,
28400,
16700,
31800,
29700,
2600,
16200,
82200,
54200,
80600,
40600,
25600,
9500,
9500,
72700,
26400,
17600,
34800,
32900,
8000,
26400,
29900,
52500,
8900,
42700,
10200,
7600,
14900,
27400,
24600,
27700,
8000,
38400,
32400,
15700,
68500,
17700,
12500,
14800,
null,
84300,
20200,
15500,
44100,
34821,
16400,
5200,
25100,
32500,
null,
29700,
48900,
27500,
18100,
13300,
37877,
37902,
null,
null,
127200,
44900,
28700,
16000,
8600,
null,
29500,
51800,
52800,
17300,
null,
18100,
10600,
31000,
27400,
30000,
18100,
8400,
20600,
28000,
12700,
16600,
41600,
24800,
12100,
null,
24400,
10800,
65000,
33400,
null,
12600,
null,
43000,
21700,
23410,
35000,
18900,
7500,
16200,
11510,
75900,
18200,
158000,
114300,
1119200,
16600,
43950,
16500,
null,
46500,
23400,
20000,
45200,
41900,
14000,
29650,
84600,
28900,
83400,
23000,
23100,
15500,
48200,
6800,
28600,
26900,
null,
18600,
40500,
5000,
13200,
47800,
22900,
34500,
6300,
74000,
27200,
14600,
37900,
31700,
28000,
56256,
35500,
72400,
null,
15700,
null,
13500,
26500,
null,
15500,
28800,
6900,
24600,
6600,
11800,
16100,
538900,
41900,
27400,
19600,
15700,
16400,
15000,
26700,
null,
87100,
22000,
null,
18180,
82200,
20200,
144400,
79300,
34400,
12500,
37000,
1500,
13700,
22200,
11000,
8100,
15400,
31500,
60800,
31300,
null,
8500,
9800,
36300,
14000,
20300,
10900,
2500,
87900,
28300,
46500,
null,
70600,
12700,
13100,
4500,
23200,
51300,
14600,
85800,
22300,
36500,
33300,
11300,
43700,
34900,
13500,
10400,
16012,
45900,
17600,
56700,
43600,
10900,
5000,
22700,
3300,
6900,
20600,
null,
500,
11200,
63000,
53000,
43400,
9600,
10100,
null,
7150,
18800,
38900,
1200,
48300,
37000,
17700,
94500,
56600,
57600,
5500,
90300,
28100,
91200,
11700,
23300,
32100,
35000,
8800,
66900,
15200,
73200,
27500,
null,
13350,
10500,
69600,
22300,
30300,
23400,
17400,
5700,
18100,
22200,
13400,
65000,
9200,
10000,
64800,
9900,
90600,
40300,
13300,
25150,
80000,
29500,
27200,
25900,
39200,
19300,
49400,
32400,
20700,
28400,
82400,
28400,
25900,
21000,
45900,
43000,
26700,
22964,
13000,
36300,
36900,
23500,
31700,
20100,
41700,
7800,
null,
10500,
70800,
61100,
11600,
17900,
11800,
102600,
58200,
38600,
87900,
17900,
19800,
42200,
12700,
29400,
13300,
20500,
10500,
48600,
16800,
55500,
27100,
27400,
14300,
40300,
24300,
24300,
35500,
8400,
38800,
17500,
28000,
92500,
19800,
6600,
17400,
10600,
24700,
7000,
15100,
13500,
null,
null,
12800,
15650,
16900,
6000,
7830,
28000,
79900,
4800,
11200,
16200,
24900,
42600,
97400,
135200,
48400,
65900,
18100,
null,
16600,
33900,
13900,
18500,
12100,
84100,
9900,
14900,
20400,
45200,
24400,
39300,
24700,
18800,
27900,
15300,
10800,
26200,
61700,
23400,
null,
21800,
23900,
15800,
231400,
26300,
89500,
11300,
null,
5300,
12800,
16700,
17800,
46200,
26700,
null,
8800,
19800,
13000,
26600,
6300,
32700,
9700,
null,
17800,
65900,
52700,
12400,
76480,
39900,
15200,
24600,
58700,
11700,
10300,
14500,
7600,
19600,
34100,
32400,
11000,
23600,
39300,
11400,
42400,
17900,
19550,
10600,
null,
18200,
34300,
19400,
40600,
22100,
77200,
20900,
15900,
31500,
41400,
15800,
44000,
null,
18700,
36300,
34300,
65600,
9500,
45000,
24600,
16800,
51600,
241700,
23700,
null,
36900,
19200,
72300,
30000,
22800,
9800,
44300,
78100,
10600,
6000,
13900,
37900,
8100,
30500,
2100,
12000,
24500,
40000,
null,
32200,
51100,
null,
21100,
55000,
37500,
257300,
26600,
38200,
23500,
9200,
22700,
null,
null,
35100,
38600,
23200,
21500,
89200,
21300,
27200,
21600,
37500,
45500,
21400,
20200,
10600,
4500,
66000,
17700,
36800,
6000,
23400,
53800,
15800,
null,
41300,
10000,
27800,
83500,
27200,
3500,
10900,
33300,
10200,
8300,
15900,
56100,
15400,
31500,
35800,
16400,
null,
5000,
8400,
null,
5500,
41100,
22900,
28700,
37000,
85000,
37500,
19300,
null,
70400,
12700,
9300,
5700,
17000,
35500,
45500,
68200,
null,
15400,
null,
26600,
17800,
12200,
88800,
25900,
8500,
106100,
6050,
null,
28300,
18100,
42100,
45900,
28100,
29500,
35800,
17800,
18300,
14800,
13300,
17800,
48300,
52700,
1700,
58900,
151800,
15200,
null,
21200,
44400,
20700,
49100,
23500,
26600,
35700,
18500,
44900,
5600,
33000,
null,
16600,
78500,
34500,
26900,
37800,
41600,
12300,
48200,
23400,
32900,
38600,
57600,
23300,
72300,
69600,
32600,
31500,
11000,
14500,
11300,
56700,
13600,
12950,
17300,
18700,
43200,
16400,
null,
7700,
26500,
15700,
10600,
20900,
26300,
16000,
93200,
25200,
6000,
40500,
15200,
29400,
16000,
null,
26950,
7600,
36500,
21700,
25500,
23800,
33300,
12200,
16100,
null,
18700,
47500,
63500,
22600,
36400,
43100,
18800,
27100,
45200,
45900,
null,
17400,
14000,
15100,
2700,
66300,
45300,
null,
45400,
51400,
36800,
33800,
45800,
16500,
52010,
19000,
71400,
48200,
58300,
28200,
10450,
15400,
null,
3300,
18200,
74500,
null,
49700,
9100,
32000,
49800,
68300,
72700,
15300,
null,
25900,
null,
24200,
14100,
19500,
18500,
23100,
18000,
24600,
22700,
25600,
8500,
5400,
16300,
5600,
14500,
10600,
31800,
23200,
53300,
16700,
22400,
100000,
8200,
9800,
97000,
38200,
34200,
null,
21000,
6800,
14900,
11500,
23900,
65100,
10400,
null,
48500,
44200,
55700,
60400,
49300,
11500,
null,
10400,
8200,
131300,
18000,
3600,
25300,
23400,
1900,
5400,
51000,
16800,
65900,
null,
89900,
10400,
27000,
32100,
31700,
21000,
48500,
26900,
69400,
41500,
10600,
17000,
8200,
57200,
47300,
5700,
5700,
116567,
102500,
null,
34000,
16500,
41500,
22600,
64300,
null,
20100,
15700,
14800,
37400,
null,
29600,
51900,
1700,
null,
9300,
34600,
15500,
16700,
159300,
4000,
35900,
23700,
41900,
14100,
24500,
24400,
23100,
66300,
151200,
79300,
38300,
17700,
36300,
27400,
20300,
14000,
11300,
88800,
63600,
46100,
8600,
42200,
22900,
19900,
21600,
16500,
28100,
25900,
18600,
31900,
12000,
63300,
34700,
22600,
8100,
5500,
8500,
23600,
22100,
4800,
19100,
30500,
null,
28000,
25200,
37400,
23600,
11900,
30100,
15600,
5100,
21500,
13000,
24200,
23600,
null,
61200,
20500,
36500,
null,
26600,
31600,
59800,
4700,
46000,
31700,
16400,
66200,
24500,
60800,
7552,
11400,
9000,
69900,
48100,
10400,
38400,
19800,
10000,
56500,
5900,
null,
31400,
9300,
12300,
null,
17800,
137400,
31600,
31800,
33400,
64700,
41100,
19300,
38600,
24800,
28100,
null,
null,
39800,
73900,
22000,
24000,
30300,
7300,
37400,
57300,
50300,
26800,
null,
80300,
42600,
34100,
7300,
13437,
23000,
9100,
15000,
null,
47900,
125895,
8700,
59200,
11000,
67000,
13800,
30000,
43800,
39900,
3800,
38000,
16300,
30200,
20000,
18900,
4200,
48300,
8900,
15600,
36800,
43564,
13100,
7000,
21900,
4300,
29300,
82400,
61800,
41600,
14100,
18600,
null,
13600,
44100,
24400,
44100,
55800,
43000,
27000,
45700,
16800,
6700,
83600,
28600,
55800,
13800,
32900,
13000,
16100,
10600,
54100,
15700,
4600,
null,
34800,
6600,
106069,
null,
56700,
35100,
null,
11300,
null,
39100,
5300,
89700,
18000,
13400,
40200,
22500,
43900,
18400,
null,
null,
13000,
45100,
105000,
56300,
16900,
14400,
81200,
19400,
40100,
58400,
6900,
23500,
26900,
46700,
19300,
21700,
9300,
38000,
39000,
9800,
null,
27700,
73500,
35800,
12300,
27800,
21400,
11200,
9800,
35100,
22500,
14700,
111300,
40200,
59500,
9200,
null,
122700,
32943,
44500,
26800,
23200,
55900,
13700,
null,
7100,
15800,
109426,
42800,
15200,
14800,
8000,
21200,
15300,
43764,
30800,
37800,
70600,
43000,
6400,
17500,
46700,
37500,
27900,
null,
3800,
11300,
18300,
11300,
29800,
17300,
9900,
54500,
3900,
null,
33200,
44300,
29800,
21200,
24200,
12500,
30100,
23000,
21600,
46300,
12300,
67300,
27000,
34100,
null,
8700,
50200,
41500,
26600,
4600,
60200,
null,
55300,
5400,
34300,
null,
40100,
12400,
14900,
41600,
60800,
19000,
12900,
17500,
20200,
15800,
12700,
59300,
65300,
14700,
10700,
null,
5500,
24200,
22200,
9500,
33000,
18800,
3000,
2050,
120300,
8400,
20000,
17200,
120250,
13962,
142800,
21200,
12200,
45000,
18300,
32300,
null,
17900,
52500,
7900,
4100,
81400,
38600,
18900,
9500,
17100,
37713,
7700,
30900,
34700,
25000,
null,
15100,
92900,
34400,
17900,
54300,
64500,
null,
44100,
6700,
64350,
39800,
49800,
16000,
21300,
37500,
8400,
10300,
47000,
26900,
21800,
28600,
84100,
11500,
44700,
4100,
25300,
null,
25300,
17000,
15700,
null,
39000,
61000,
13900,
18300,
12100,
21000,
12300,
54500,
64600,
60100,
13600,
17700,
22500,
60100,
19800,
4000,
null,
9100,
16800,
5200,
10400,
2600,
14300,
10500,
27500,
16900,
null,
15300,
35564,
22400,
18800,
33300,
16700,
null,
11100,
6000,
39100,
23900,
76300,
20500,
22000,
24500,
9800,
null,
null,
12100,
38600,
37200,
17100,
25087,
null,
15800,
39900,
89900,
84000,
10400,
41200,
22200,
46948,
33822,
15500,
null,
19200,
6100,
41000,
16400,
60100,
19200,
62400,
40700,
9900,
67400,
26200,
18900,
6900,
19500,
null,
22200,
null,
85100,
12300,
17400,
86000,
25098,
10100,
null,
12600,
23800,
23600,
41700,
14300,
80700,
30500,
82350,
28200,
33900,
15800,
null,
58100,
5800,
44900,
9800,
21200,
45100,
1700,
null,
13500,
22300,
null,
16500,
38400,
334100,
66500,
19100,
10800,
65700,
76200,
19100,
17200,
9300,
39600,
29000,
8900,
null,
56200,
138600,
8700,
86900,
51900,
26100,
11100,
54700,
null,
25500,
56200,
65400,
31200,
null,
41300,
63200,
20700,
45400,
38500,
16700,
3200,
27700,
null,
34210,
6000,
45400,
10600,
28000,
43700,
null,
29400,
16200,
33500,
7700,
null,
9700,
25100,
15300,
16200,
17900,
12200,
33300,
9100,
40300,
17900,
23400,
35400,
20300,
26500,
112900,
17400,
29600,
23500,
43050,
6500,
20200,
55600,
10700,
53000,
158400,
5100,
18700,
null,
15200,
15300,
25900,
7800,
28100,
15200,
33500,
50500,
26300,
48200,
17700,
91800,
14500,
15800,
24100,
14500,
40100,
55300,
null,
12200,
18900,
27400,
86200,
42500,
59900,
19900,
28300,
54000,
20600,
34500,
39100,
null,
27400,
21300,
8600,
15300,
38100,
57000,
205700,
64700,
89600,
64700,
88800,
72600,
20500,
72300,
16800,
110000,
40300,
23300,
36700,
68900,
13500,
48400,
27300,
40400,
18100,
19800,
null,
33100,
6800,
45500,
25500,
31000,
22573,
26000,
1500,
48900,
49600,
19313,
192700,
null,
6600,
11000,
10000,
32100,
36000,
23000,
22700,
82800,
14700,
null,
81000,
13000,
16400,
19900,
null,
null,
16300,
21300,
27200,
15500,
32100,
28700,
26560,
13100,
25800,
21200,
37900,
8900,
24700,
13300,
26500,
29500,
20500,
36300,
10300,
null,
51700,
3800,
16400,
49800,
13300,
5700,
8500,
null,
72900,
108100,
25000,
22800,
13800,
24700,
13500,
25181,
8200,
56400,
9800,
11700,
21600,
null,
15300,
13650,
9900,
231600,
17800,
126080,
9700,
31600,
18700,
3200,
19800,
null,
52437,
12100,
50600,
4800,
22600,
null,
null,
29500,
67000,
30800,
70500,
40500,
61300,
10400,
null,
26900,
16000,
6500,
41800,
17500,
21600,
8400,
20100,
34900,
18000,
6900,
14100,
39400,
56400,
50144,
17800,
13500,
11200,
13400,
28300,
31500,
28600,
53800,
null,
null,
15300,
36700,
52400,
10600,
62800,
77300,
18300,
9600,
null,
17500,
null,
42800,
214400,
43600,
26700,
42800,
45500,
23800,
66000,
37500,
43700,
null,
16600,
21900,
28300,
24000,
90600,
12000,
32400,
19000,
86700,
44400,
24900,
45000,
32600,
74553,
10100,
50700,
6000,
5000,
19200,
88500,
11400,
35200,
53900,
52500,
6100,
8600,
42300,
32900,
55900,
34200,
18100,
5500,
13200,
58100,
70000,
9400,
8000,
24700,
28300,
45100,
null,
44800,
10600,
17600,
10800,
4200,
28700,
9600,
72600,
13700,
9100,
24700,
17000,
7100,
55000,
57100,
65500,
47800,
6000,
43200,
7500,
null,
24600,
15700,
68800,
null,
20300,
12900,
18772,
24500,
10300,
16200,
null,
19500,
53400,
26600,
14100,
15500,
null,
32700,
16000,
15200,
26100,
36900,
20200,
16900,
20700,
30200,
43700,
11700,
17800,
281634,
11500,
29200,
97200,
28100,
25900,
17800,
21500,
26200,
8900,
null,
54100,
26000,
48200,
13000,
72300,
16800,
8500,
38800,
94800,
11500,
9400,
107100,
50100,
11700,
8700,
19100,
22500,
74900,
null,
190600,
21100,
null,
13400,
5800,
34300,
16800,
7300,
107600,
18800,
36100,
13500,
40300,
11700,
9000,
14700,
17500,
null,
28200,
null,
33100,
80100,
8000,
19300,
14800,
12500,
27900,
7800,
null,
27800,
13800,
28500,
49400,
121500,
18100,
14100,
38200,
21400,
73500,
8000,
6200,
31600,
32900,
16600,
8100,
14600,
7100,
8300,
18800,
null,
71800,
27300,
69900,
14100,
45700,
25500,
34800,
8200,
9700,
6200,
null,
21100,
23100,
20500,
31500,
6600,
59100,
27900,
10800,
52100,
40300,
237700,
41500,
104100,
20800,
15600,
78400,
19700,
10300,
21800,
47100,
17500,
73200,
44100,
9300,
26000,
null,
15100,
55900,
19300,
7400,
null,
14100,
12400,
56600,
28100,
15500,
34500,
65300,
114700,
79463,
19500,
56500,
17000,
34500,
66500,
34400,
43800,
17500,
35200,
12100,
12800,
6500,
5900,
15100,
20500,
39600,
26200,
34500,
17300,
10800,
79600,
16800,
41400,
16200,
32000,
7600,
14800,
40300,
37100,
68800,
35100,
null,
14000,
9500,
null,
45000,
15000,
25400,
17700,
10300,
22600,
25400,
10500,
70800,
49200,
10600,
25300,
null,
34500,
12300,
48700,
117100,
6800,
93200,
19700,
70200,
6900,
16700,
10300,
14800,
27600,
13600,
null,
7300,
84400,
8400,
32600,
5800,
16300,
null,
25600,
7500,
37800,
41100,
15400,
null,
24600,
48400,
23200,
30000,
28500,
51500,
18900,
9800,
15500,
5400,
18600,
122100,
16100,
13200,
19400,
15000,
null,
13800,
28300,
10000,
41300,
80500,
34100,
19400,
32200,
6100,
null,
56400,
27000,
21600,
9500,
7100,
52700,
48600,
6700,
22200,
29400,
14100,
null,
39500,
49600,
30000,
null,
12700,
29000,
11000,
134700,
19850,
12100,
24300,
27000,
22700,
53000,
null,
18900,
21600,
20600,
19200,
12300,
21900,
12800,
17900,
45100,
null,
45800,
15300,
44900,
16900,
8500,
39300,
9800,
null,
51800,
10800,
25800,
11800,
19600,
13100,
null,
6500,
29500,
null,
33600,
null,
67800,
74400,
42800,
44100,
28300,
13900,
32500,
24000,
15600,
8500,
15300,
8800,
39000,
28100,
8300,
26700,
13700,
48600,
12500,
24900,
63000,
21100,
11000,
48100,
24300,
null,
45200,
69100,
4500,
75400,
32100,
10500,
5300,
16900,
9400,
7200,
44500,
36000,
156900,
94800,
22975,
27000,
60800,
8000,
46000,
22200,
45300,
5700,
16800,
null,
23000,
16800,
18200,
80300,
14000,
26000,
39300,
56200,
null,
8500,
null,
27600,
73500,
28100,
85800,
25200,
25100,
31300,
23000,
71800,
22000,
15800,
73400,
16500,
11100,
null,
7200,
8300,
2800,
33200,
53600,
null,
21800,
11600,
12100,
15800,
14800,
13600,
22200,
36800,
58700,
21700,
38800,
15600,
22400,
57000,
6500,
null,
31900,
11500,
20200,
46890,
7300,
10000,
21000,
null,
8300,
11000,
11900,
10600,
28300,
28000,
36900,
30300,
47000,
65000,
32600,
7600,
61400,
null,
27200,
10500,
18900,
6000,
null,
null,
56700,
11600,
9200,
72800,
null,
6700,
10600,
33300,
16200,
9900,
13700,
37600,
5200,
30400,
73900,
5500,
52200,
11200,
29400,
21400,
10000,
26600,
97147,
61400,
15500,
15500,
49600,
27400,
22900,
30400,
72800,
60000,
47400,
19300,
56900,
34600,
36700,
67700,
36100,
57200,
45600,
14000,
3600,
null,
21200,
20000,
19200,
5100,
7200,
42600,
17800,
43400,
14000,
null,
23200,
14300,
28900,
22700,
39000,
37300,
17900,
5000,
16800,
40300,
41900,
12500,
null,
35900,
70924,
15900,
32500,
18200,
12000,
null,
20400,
18900,
40000,
28800,
25700,
42300,
7000,
19450,
46400,
4200,
null,
21400,
29700,
11000,
27700,
43200,
30400,
null,
14900,
25500,
24000,
null,
9200,
34200,
15900,
null,
23200,
null,
null,
7900,
12800,
21500,
14300,
22900,
null,
23000,
46000,
14400,
null,
29400,
46700,
40200,
47800,
29200,
33100,
20600,
103000,
21539,
39000,
44400,
21600,
15000,
9300,
14900,
20400,
37300,
31400,
35700,
16400,
51300,
20137,
8600,
9800,
12000,
10100,
24200,
8300,
16800,
10500,
10500,
4600,
68600,
36200,
8900,
5000,
45400,
29900,
16500,
17800,
42900,
46100,
83300,
32400,
null,
26100,
null,
22900,
16100,
11600,
14200,
59300,
4400,
null,
17500,
13200,
29800,
17800,
null,
22200,
6600,
26600,
33900,
55300,
12400,
49200,
74700,
27900,
54000,
8200,
null,
39700,
82700,
24400,
14100,
10000,
7500,
23100,
10900,
7300,
14700,
null,
46400,
33500,
52400,
22800,
60400,
16900,
15690,
13300,
11300,
5800,
24900,
29500,
23200,
32300,
13900,
6800,
8400,
10100,
26700,
33550,
16500,
53900,
11110,
17500,
19700,
12300,
700,
18400,
27700,
113400,
13100,
59600,
7500,
34000,
40100,
38800,
16700,
17200,
35200,
20200,
10200,
26800,
8300,
31400,
39400,
22500,
36200,
null,
11200,
14700,
26200,
10500,
28400,
1800,
20900,
53700,
38900,
65200,
7900,
7300,
27700,
13400,
4700,
8600,
3800,
null,
10800,
16800,
11000,
15600,
22900,
60500,
9000,
16300,
53700,
63500,
14200,
63700,
81650,
36800,
33900,
32500,
19500,
10200,
26000,
null,
null,
11500,
6300,
23300,
31100,
null,
26200,
33700,
257500,
17300,
7900,
42600,
6000,
null,
39100,
15900,
17300,
33300,
23200,
123300,
15600,
16200,
53100,
32800,
657000,
11500,
16100,
13800,
7200,
39200,
55300,
16000,
29600,
485300,
71700,
12400,
41260,
83600,
102400,
83400,
18300,
42800,
24400,
20100,
32400,
39000,
12800,
24400,
15690,
77000,
33100,
43700,
9900,
10200,
65800,
60094,
4600,
19800,
31000,
43300,
11700,
25300,
22100,
22300,
87300,
34000,
27100,
15900,
16600,
82200,
118500,
24400,
29200,
53600,
10000,
6399,
28900,
172100,
14800,
15600,
9600,
52200,
35000,
14200,
9000,
41000,
26000,
110500,
11600,
74600,
54200,
8000,
16500,
40400,
25900,
36500,
3250,
13500,
74900,
5200,
null,
26200,
13800,
34700,
20200,
27700,
20600,
38400,
30600,
47200,
17700,
71400,
13100,
29700,
44800,
11500,
34900,
41000,
43500,
1300,
57800,
47300,
9600,
11900,
31300,
null,
63200,
8200,
66200,
27100,
8200,
null,
26200,
20900,
11000,
37000,
13300,
null,
16300,
6100,
28200,
6600,
null,
7000,
82300,
34700,
17000,
38400,
31300,
15700,
10000,
25300,
5200,
19400,
25000,
28300,
86500,
null,
8200,
15300,
28200,
null,
10800,
76300,
19100,
24000,
83724,
40000,
10600,
41500,
63600,
29600,
null,
18200,
19800,
4500,
27400,
14300,
28550,
17800,
4700,
10900,
25800,
21800,
26800,
332300,
18700,
2000,
21400,
143500,
56100,
33500,
16600,
null,
15200,
79500,
null,
75300,
26700,
47000,
34900,
27000,
33800,
86000,
85800,
77100,
29100,
13000,
54300,
15500,
40200,
19700,
23800,
16700,
11500,
null,
49900,
20400,
28200,
27000,
26500,
17900,
26500,
30800,
37200,
19000,
34100,
20800,
25400,
53400,
35800,
15300,
6000,
44300,
null,
6700,
11700,
54500,
27800,
21800,
11900,
23800,
5500,
15200,
39400,
16300,
8500,
46300,
8300,
48800,
47800,
null,
23950,
20500,
23700,
8000,
7300,
12700,
33500,
5900,
25800,
12800,
44500,
2400,
34900,
158555,
109800,
39800,
28800,
20300,
83300,
15500,
41000,
10900,
17250,
9300,
26700,
27800,
53221,
null,
9800,
null,
41400,
36200,
53500,
22600,
18300,
75000,
43600,
65300,
62900,
null,
null,
50200,
66200,
63900,
11000,
13300,
12900,
11600,
11400,
null,
38300,
18800,
10800,
40700,
38200,
null,
76300,
8700,
13500,
6500,
28900,
8400,
56400,
21000,
3000,
15400,
7500,
null,
53000,
13600,
null,
14000,
null,
29400,
5900,
15800,
37000,
20500,
20400,
23600,
12800,
11700,
52000,
8300,
16200,
27800,
9900,
30900,
31700,
88900,
null,
26600,
21900,
27900,
12500,
null,
22500,
null,
31900,
13900,
13400,
30100,
45600,
40400,
38300,
11600,
68600,
20800,
10400,
null,
19900,
37400,
null,
8300,
25500,
89300,
0,
99500,
null,
6500,
25900,
27300,
8600,
34900,
21800,
13000,
40600,
45000,
11700,
99000,
43000,
100400,
19700,
44800,
31000,
31900,
50500,
20800,
10600,
23100,
22400,
19800,
27400,
17900,
39900,
14700,
18800,
6500,
17400,
36500,
18700,
9500,
10300,
72300,
64000,
null,
31200,
9500,
53400,
25100,
18525,
19100,
52800,
28900,
12100,
70400,
33700,
7775,
11800,
11300,
25200,
22400,
197300,
26400,
30200,
76300,
10600,
24400,
22800,
31300,
null,
50400,
6900,
53600,
39800,
26000,
56600,
51400,
8400,
16900,
9800,
81200,
23600,
11700,
25600,
20400,
34900,
15200,
23300,
13200,
60900,
22700,
71500,
16000,
23700,
null,
10500,
9400,
7700,
37400,
38000,
50000,
48200,
18900,
13100,
12400,
11500,
23800,
34400,
4600,
51300,
9000,
11900,
30200,
36300,
27100,
20000,
171000,
359000,
20600,
16000,
62400,
40000,
43700,
15000,
31000,
91600,
null,
33500,
29200,
15500,
28500,
6400,
21600,
33000,
109400,
24300,
24800,
166800,
76400,
20300,
6500,
11900,
30300,
18900,
37400,
18000,
23100,
10800,
4800,
38500,
32100,
30200,
91100,
13400,
59800,
5750,
13800,
58400,
47000,
8800,
22900,
7800,
31700,
17100,
50296,
319600,
33500,
68900,
34200,
38700,
26500,
15200,
8900,
53400,
23500,
null,
null,
32200,
3300,
23950,
null,
8300,
35400,
25600,
null,
31000,
8300,
16100,
85100,
40000,
61200,
10000,
24100,
34400,
24000,
12800,
14700,
16600,
38500,
30600,
14300,
40300,
49300,
13600,
54400,
13200,
37400,
17600,
null,
31900,
31200,
15000,
24300,
8900,
null,
30700,
4000,
null,
22200,
47300,
5600,
47800,
6800,
18800,
20500,
105000,
36400,
null,
75900,
27100,
34500,
67000,
10000,
4300,
22000,
null,
40200,
22200,
8900,
33500,
17000,
17300,
6500,
30000,
39600,
11800,
20100,
15800,
12300,
39600,
13500,
23900,
24900,
56900,
42500,
32783,
52600,
63400,
null,
35800,
79900,
27100,
26100,
39600,
26800,
28300,
4674,
25900,
null,
14800,
43500,
28900,
45200,
72300,
13700,
14300,
14700,
12700,
4800,
13300,
141500,
29600,
14500,
36600,
29400,
17700,
null,
8700,
null,
11600,
4700,
114000,
5700,
82000,
19900,
27900,
16800,
35900,
31800,
5900,
4200,
24200,
23200,
85700,
45900,
73700,
17400,
19100,
47500,
12900,
12300,
38600,
6300,
19800,
44000,
10700,
8700,
null,
null,
45800,
55100,
34653,
19700,
31300,
40070,
6000,
67400,
14700,
20800,
30880,
252000,
38900,
7600,
14000,
110300,
10000,
22200,
38600,
57800,
null,
14700,
null,
34700,
20400,
55100,
21500,
27100,
21100,
53500,
14100,
16000,
17400,
10900,
17600,
10500,
24500,
27300,
182100,
23700,
8800,
44300,
17200,
26000,
21300,
159900,
149550,
36900,
58800,
null,
26300,
21700,
null,
8000,
24000,
4900,
8400,
null,
23400,
26000,
58300,
6300,
30600,
33300,
20000,
10100,
13800,
31500,
59700,
38900,
44500,
20100,
71300,
7200,
null,
66800,
17100,
5600,
41000,
72400,
22700,
7600,
36100,
null,
9100,
13500,
5700,
56400,
15800,
31300,
92400,
24100,
21300,
21000,
66600,
36100,
37702,
11300,
19300,
16800,
null,
19500,
null,
68000,
20460,
11100,
9500,
7500,
49400,
90400,
18127,
12200,
34300,
21500,
5500,
9700,
31700,
42700,
31100,
11000,
17700,
4500,
73500,
73000,
55200,
16200,
61400,
17400,
11700,
7700,
24900,
28500,
22000,
17000,
null,
9900,
8200,
71800,
58900,
8400,
35100,
8400,
17300,
11200,
20300,
7300,
null,
11100,
41500,
28700,
1700,
61400,
37500,
3900,
27800,
46700,
17200,
17000,
38700,
9000,
11100,
37400,
6600,
11600,
14800,
13000,
67000,
19700,
25100,
4250,
23200,
38700,
22000,
38600,
59300,
null,
7250,
28700,
19800,
45600,
51600,
15800,
10850,
24200,
25100,
18400,
51800,
7050,
27800,
80000,
40800,
17100,
9700,
26400,
4600,
30500,
null,
27500,
79500,
1500,
32100,
21624,
22300,
4800,
31200,
78200,
36300,
24200,
17100,
8700,
116600,
22200,
51400,
31900,
43300,
30900,
24800,
null,
37950,
33900,
80800,
27600,
24000,
17100,
14000,
4500,
28200,
13400,
46100,
43700,
null,
22400,
2300,
29300,
37600,
14300,
25300,
53600,
9000,
39000,
16600,
7500,
15400,
36000,
9000,
null,
47600,
10600,
null,
4300,
null,
null,
34400,
15500,
15800,
24100,
17400,
48100,
26300,
110700,
52600,
null,
7300,
22900,
76300,
19000,
29500,
16500,
37100,
14500,
null,
4000,
17000,
37800,
49500,
77100,
25100,
46400,
800,
38500,
30700,
10600,
13200,
53000,
29300,
30600,
6800,
8200,
21000,
34900,
47000,
70500,
null,
116000,
11000,
26800,
5000,
43300,
null,
null,
null,
6100,
8700,
20400,
28400,
16900,
48800,
125200,
6300,
11400,
12500,
11800,
39300,
45600,
27300,
25150,
11600,
18100,
22600,
37524,
24400,
49700,
16100,
82200,
50500,
null,
29500,
13300,
46500,
21700,
13800,
40800,
30600,
10200,
13700,
35500,
null,
23800,
17600,
36500,
25100,
null,
19200,
26500,
8500,
54500,
11000,
13000,
14500,
14000,
22600,
13700,
57000,
12500,
30600,
7900,
20400,
17300,
13100,
27600,
10300,
13500,
29000,
63300,
66300,
19330,
37500,
10500,
49600,
11900,
10200,
2500,
24800,
21600,
24200,
30500,
34300,
4400,
30200,
71000,
11500,
59500,
24200,
40200,
46200,
16700,
12600,
68800,
4800,
39200,
20900,
8700,
12200,
50800,
null,
21200,
41700,
28600,
76300,
11100,
50600,
4900,
14400,
42800,
53100,
34200,
28000,
16900,
17600,
17700,
49600,
13500,
22900,
12600,
14200,
32700,
11400,
39700,
9500,
12400,
18400,
2500,
11500,
42400,
15900,
75300,
58900,
5300,
12200,
16600,
32700,
24900,
37200,
15100,
62900,
43600,
89500,
31200,
34300,
14400,
64000,
27900,
18000,
2500,
41652,
29100,
6500,
44500,
6500,
24300,
18400,
12100,
null,
56400,
29400,
null,
16100,
191000,
null,
49600,
null,
19700,
46600,
7600,
28000,
15400,
6700,
4800,
33500,
4900,
5000,
7400,
51900,
43900,
4900,
19100,
53700,
4400,
9700,
26700,
42400,
23300,
16000,
50100,
26300,
7900,
29500,
17700,
5600,
11100,
89400,
89400,
22300,
17900,
18500,
31000,
7500,
105300,
7900,
4700,
46800,
40100,
20800,
2000,
37800,
null,
32100,
34100,
null,
67700,
null,
4700,
21200,
null,
null,
33200,
23700,
40700,
25000,
91600,
13300,
20300,
21700,
13300,
null,
59800,
11900,
30000,
11700,
22300,
19100,
7200,
34300,
20200,
72100,
46600,
3500,
45100,
54800,
20750,
39100,
null,
34900,
15600,
16800,
18800,
29400,
21000,
49500,
14700,
24900,
84600,
13400,
26300,
15800,
61300,
42400,
58900,
144700,
46800,
31600,
27800,
28200,
24000,
31600,
26600,
16200,
73100,
31300,
13900,
33000,
56300,
null,
41400,
41700,
27100,
25400,
76600,
32300,
16500,
null,
null,
20000,
18500,
14700,
67800,
20500,
37900,
13000,
null,
54200,
10900,
58800,
38200,
20100,
41100,
173300,
7900,
25500,
12600,
13100,
47300,
41700,
null,
109900,
44400,
45300,
14800,
2300,
17500,
19300,
8500,
8700,
42000,
2500,
33500,
9800,
8900,
22700,
19700,
5800,
18800,
5400,
900,
9600,
16900,
19100,
120400,
17600,
59000,
null,
24500,
76700,
16000,
17800,
38700,
5300,
40800,
12500,
15200,
11200,
9300,
44100,
17900,
23000,
13600,
null,
null,
8400,
71500,
38700,
51100,
9600,
57300,
64000,
5150,
18600,
39400,
9800,
48400,
null,
18800,
9500,
13700,
8500,
66700,
20700,
40400,
null,
20200,
25500,
27100,
5200,
13800,
11500,
57400,
21500,
43500,
78600,
82700,
10100,
40200,
26600,
52400,
11800,
19200,
null,
9800,
24900,
54401,
24500,
26100,
9700,
32400,
23600,
34200,
204300,
65700,
80600,
5800,
23500,
25800,
37100,
29300,
9900,
null,
48100,
null,
79000,
45200,
71700,
195400,
11100,
28500,
19600,
60900,
6600,
8500,
40400,
8499,
50800,
5100,
53200,
59700,
13100,
45200,
null,
47600,
24100,
50000,
16500,
23000,
14800,
23800,
34700,
18800,
17500,
51700,
13000,
37200,
26400,
34600,
null,
16500,
13600,
88435,
42700,
23800,
3900,
12100,
31100,
18300,
null,
13800,
42100,
29800,
12200,
44200,
54100,
96300,
13100,
12700,
6700,
47200,
23700,
null,
29100,
8200,
17700,
12300,
26700,
17250,
20500,
39100,
9100,
12000,
2800,
34600,
11500,
21300,
69400,
21700,
21800,
29000,
20100,
26800,
42300,
20000,
49300,
44600,
26172,
20300,
46400,
16300,
25500,
48700,
18300,
5500,
10900,
null,
60400,
null,
19000,
50000,
10800,
22400,
13400,
54400,
16100,
57500,
3100,
36500,
24800,
7200,
24000,
null,
13500,
14900,
15700,
12205,
15700,
12400,
18400,
15100,
28900,
19300,
11700,
23800,
11700,
50200,
7600,
null,
15000,
19700,
60600,
null,
14200,
22800,
25100,
null,
76300,
13600,
81200,
9700,
24300,
12900,
20600,
null,
40500,
56300,
114700,
61300,
45700,
24800,
76400,
54800,
40200,
49400,
27200,
22800,
13700,
24900,
56200,
10700,
25600,
55000,
15000,
71400,
21200,
23100,
17700,
12700,
14800,
15500,
61100,
8000,
null,
37400,
20300,
7700,
22700,
23000,
33800,
5400,
13200,
25200,
8700,
10600,
108566,
27700,
22200,
31000,
42700,
19000,
17300,
8400,
10805,
20300,
8800,
32830,
23500,
18500,
19300,
41100,
38100,
10500,
51700,
11400,
9400,
9500,
21100,
39500,
10600,
16100,
42200,
35100,
12500,
null,
23800,
18100,
15000,
13300,
30800,
null,
21000,
71900,
18800,
24100,
37400,
31000,
94700,
50800,
107592,
45900,
66500,
56000,
46100,
15878,
126700,
34200,
24900,
31500,
11500,
8900,
12000,
16000,
14400,
13508,
35700,
71700,
21600,
11600,
11675,
9900,
39700,
24300,
24900,
39100,
9600,
25000,
37000,
null,
73400,
null,
13700,
31200,
33100,
24200,
5300,
7500,
11800,
23400,
6500,
30400,
33800,
null,
null,
3500,
57700,
45100,
19500,
11300,
19000,
18000,
6700,
11300,
29200,
7900,
13400,
10800,
4350,
41400,
12000,
12700,
31700,
9400,
18200,
31700,
24900,
17200,
16700,
9300,
76400,
33600,
71200,
13000,
23800,
45800,
22200,
16300,
19100,
105400,
33000,
15300,
20400,
48100,
13200,
9100,
12400,
6300,
67600,
7100,
38200,
9700,
49200,
4700,
27000,
9400,
38100,
37000,
null,
21500,
22200,
44900,
31400,
null,
26600,
13500,
9500,
21800,
16400,
25100,
56100,
15600,
27300,
29400,
27800,
11900,
10900,
29500,
21500,
null,
22700,
25100,
8800,
12000,
29800,
24026,
null,
24600,
7200,
5100,
31300,
7600,
6000,
20400,
52500,
22100,
30000,
45900,
null,
62800,
31600,
60200,
16900,
69100,
8300,
15500,
11500,
5900,
43100,
null,
null,
19300,
20100,
19400,
null,
128200,
32300,
45800,
24000,
64300,
32300,
6800,
12700,
51600,
6000,
22400,
78400,
9500,
18200,
18600,
9200,
17600,
31440,
39700,
18700,
11000,
null,
32300,
6300,
146000,
12400,
17300,
36104,
null,
21900,
26300,
63700,
16700,
9200,
44000,
29300,
38300,
41500,
37000,
15500,
20900,
16500,
20600,
22200,
null,
15000,
40800,
76700,
3300,
8000,
17900,
null,
12338,
14000,
11200,
null,
24700,
90600,
7300,
26300,
53800,
27000,
20300,
25700,
39300,
28600,
25000,
67100,
33100,
26800,
31600,
27600,
49900,
11300,
null,
38300,
16300,
44200,
42100,
43200,
12300,
61100,
9300,
12800,
16000,
24100,
24600,
48900,
92500,
23900,
18200,
34400,
19600,
10400,
14500,
26100,
42000,
24000,
15800,
32300,
19700,
24300,
17100,
14300,
12600,
13500,
29200,
41200,
29000,
62564,
51100,
null,
21000,
14200,
40600,
4000,
8700,
38800,
81800,
28400,
32200,
12200,
76400,
null,
10800,
13500,
6300,
27500,
80300,
24300,
27900,
35400,
19800,
43600,
6000,
23600,
44600,
17700,
22900,
58000,
29500,
28300,
7200,
14300,
null,
14800,
17200,
30900,
33100,
81700,
20100,
78500,
11400,
100600,
13000,
36300,
38400,
27500,
66800,
8000,
24300,
14300,
11200,
16300,
24618,
21900,
49500,
8600,
11500,
37800,
40300,
3200,
23100,
5400,
8500,
21400,
15100,
20300,
11800,
32700,
87800,
8400,
11800,
50100,
55001,
9100,
24300,
43600,
10300,
49200,
null,
null,
20600,
3000,
34100,
33300,
10700,
null,
42000,
22000,
58900,
17200,
33500,
83900,
56600,
33200,
76800,
null,
6900,
null,
45400,
19200,
70900,
10900,
36800,
46800,
26000,
42100,
null,
50900,
24800,
20000,
12900,
46500,
22400,
15500,
37600,
20100,
13200,
88700,
17700,
54800,
null,
18400,
22500,
17600,
null,
31100,
61600,
null,
38452,
16200,
33900,
26100,
23600,
17300,
30300,
12100,
34400,
6600,
53300,
63300,
24800,
38000,
46900,
9200,
23700,
4900,
16500,
7000,
45600,
19600,
16400,
31000,
800,
25600,
61200,
31800,
53200,
6400,
22600,
63100,
24300,
11200,
37900,
41500,
44800,
48610,
19000,
33000,
14100,
null,
5600,
12600,
46000,
36100,
17700,
15000,
3000,
42100,
39000,
17000,
9800,
10810,
9600,
40300,
22800,
null,
26800,
null,
18850,
66100,
22200,
41600,
22100,
null,
12100,
24900,
51900,
42900,
12800,
35800,
82490,
25900,
18900,
49300,
17100,
51800,
23700,
null,
24700,
28500,
10300,
21500,
14400,
31200,
7000,
36400,
62800,
null,
21500,
29500,
5900,
9900,
17100,
26700,
61500,
64500,
17700,
10200,
41800,
11200,
18250,
103500,
20000,
110600,
29900,
9400,
18800,
28900,
43200,
6100,
26313,
35055,
800,
13400,
12900,
19900,
26200,
4600,
87500,
33600,
45600,
72900,
null,
22400,
28500,
48300,
28400,
14900,
15100,
39300,
58900,
null,
40100,
27900,
11000,
129400,
65600,
41300,
26900,
17600,
25500,
40300,
61900,
18100,
null,
48800,
19900,
17400,
17600,
51100,
53900,
44800,
11900,
85200,
13500,
9600,
13300,
38200,
27700,
45700,
61800,
9200,
16100,
9700,
25400,
45700,
14580,
18500,
18700,
11000,
18500,
26600,
17200,
null,
14900,
12400,
33900,
16700,
16700,
42600,
15800,
21500,
101200,
21600,
29600,
6400,
33100,
11700,
null,
15100,
7500,
20200,
25100,
null,
36052,
22900,
14700,
null,
24200,
13600,
15800,
8000,
23400,
null,
40100,
14100,
14100,
37600,
18500,
8600,
3000,
27800,
129200,
28400,
13400,
14000,
62200,
58900,
null,
31700,
5200,
3800,
11800,
22600,
16400,
null,
44500,
21300,
17800,
19500,
15600,
4200,
27300,
27900,
11000,
36000,
8700,
63800,
18000,
11700,
11800,
25700,
null,
13300,
7900,
32750,
49500,
8800,
5200,
null,
42300,
null,
71237,
19800,
41500,
12700,
24200,
30300,
31700,
35500,
53300,
83800,
8900,
15900,
17500,
13800,
31900,
8000,
42900,
26600,
19300,
29400,
36400,
null,
18100,
66900,
20400,
35500,
24000,
14900,
16500,
500,
93700,
null,
51800,
55981,
94500,
28000,
null,
101400,
11900,
12100,
9000,
11200,
107100,
29600,
4200,
25900,
11700,
17900,
72300,
21500,
null,
26400,
17500,
44600,
30000,
43200,
8800,
20700,
41900,
16100,
null,
19900,
24200,
36300,
39100,
81800,
28100,
27900,
17900,
21000,
14200,
8300,
24900,
59200,
22900,
10800,
17200,
null,
9900,
23000,
40800,
76500,
4800,
16000,
null,
8300,
40900,
null,
45800,
16800,
12100,
32800,
13500,
71800,
null,
33000,
50800,
9700,
52000,
23000,
21700,
17700,
9200,
46400,
9800,
56100,
26000,
null,
8000,
null,
23400,
35100,
24400,
28500,
13100,
70900,
2500,
9800,
7500,
174400,
70600,
null,
63400,
37400,
27100,
7500,
20500,
72200,
49300,
3700,
3300,
6500,
13100,
3600,
25700,
null,
15800,
8000,
36000,
14600,
19100,
26250,
34200,
26800,
9400,
19200,
10900,
54100,
14600,
10000,
39700,
29500,
null,
68800,
29900,
128700,
111000,
81145,
5500,
5500,
30500,
45700,
22400,
11350,
7600,
14900,
15400,
10600,
7500,
203400,
6100,
27200,
27700,
38200,
25200,
30700,
16900,
15300,
3400,
16200,
10800,
71000,
14900,
17900,
35500,
74200,
17600,
22100,
25300,
38650,
5300,
null,
9100,
33600,
33800,
63900,
12500,
10100,
36300,
87400,
35200,
7400,
22500,
14500,
29200,
null,
null,
50100,
11200,
22400,
27500,
17100,
50300,
32000,
null,
30200,
17300,
47400,
50200,
55000,
13200,
25200,
29800,
185100,
8500,
8100,
21800,
25400,
13900,
32200,
13500,
18900,
23800,
15200,
15000,
30600,
23900,
127000,
12200,
40300,
46900,
77400,
11700,
30900,
35500,
41100,
78400,
10000,
41500,
19100,
11300,
40300,
45100,
44500,
14500,
31600,
24600,
39200,
77500,
116500,
25000,
7000,
null,
8300,
19700,
40100,
2300,
55400,
88500,
36500,
28600,
15100,
32700,
22900,
46900,
39400,
19000,
50400,
23600,
65700,
14700,
9800,
16300,
11800,
35500,
26500,
23400,
16400,
null,
28300,
11300,
12900,
21700,
null,
35000,
63800,
18700,
24400,
4300,
24300,
23500,
null,
95500,
34400,
23000,
9700,
49700,
29400,
19800,
84300,
21000,
17900,
17700,
36300,
40300,
5400,
16500,
38200,
13600,
20000,
null,
23900,
null,
3100,
25700,
102200,
null,
16800,
20200,
56200,
13600,
34100,
17150,
7100,
21600,
6600,
6700,
80100,
8600,
82100,
23300,
31400,
28500,
15500,
null,
44700,
18000,
10300,
11400,
28500,
30200,
null,
15000,
11800,
null,
39700,
32100,
null,
25500,
12000,
17800,
35400,
58100,
null,
23300,
97300,
18200,
7500,
16600,
25500,
39200,
57000,
null,
26600,
24800,
9100,
22100,
null,
74000,
44200,
52700,
19800,
21000,
351200,
18000,
23400,
58600,
11000,
7300,
15000,
28300,
null,
180400,
45000,
40100,
51951,
28500,
6800,
46400,
6100,
28300,
null,
129100,
25300,
4500,
10900,
14600,
13000,
13000,
13900,
null,
39600,
21100,
11800,
31800,
53400,
5000,
28400,
5000,
23000,
10900,
31100,
211600,
16200,
7400,
8700,
34500,
25200,
46000,
100800,
54800,
13140,
8100,
16600,
25900,
70800,
12400,
3200,
83500,
4500,
16600,
45600,
8800,
33600,
49700,
5750,
96800,
3400,
23200,
48300,
11200,
12100,
6400,
26000,
15400,
21300,
null,
53500,
49200,
15600,
76800,
51500,
21600,
17300,
43300,
66400,
4300,
38100,
11100,
33700,
121100,
null,
30300,
20900,
94600,
22400,
16800,
56200,
26500,
23200,
14400,
22700,
131558,
16800,
22000,
33900,
27700,
34400,
6300,
52300,
29400,
12300,
16900,
14300,
11600,
28500,
13400,
38100,
19900,
39085,
29300,
39600,
20200,
36300,
97100,
24100,
10800,
15000,
38500,
38300,
9500,
22700,
null,
53800,
71100,
128400,
null,
28200,
37700,
50800,
41800,
68000,
10930,
36700,
19400,
23500,
12000,
46900,
9200,
16300,
10700,
21300,
null,
22800,
27800,
37400,
26200,
12300,
null,
28200,
3800,
39000,
114300,
13100,
19700,
23500,
7000,
22400,
24600,
null,
23900,
63800,
61400,
19000,
20100,
5900,
12500,
37700,
29100,
null,
52533,
16900,
27500,
23700,
16500,
72400,
18100,
30600,
29700,
84800,
8100,
17400,
23700,
25800,
105500,
39100,
53600,
31500,
6700,
39700,
7200,
53300,
2000,
19100,
14600,
18500,
49600,
17500,
14100,
16500,
14000,
23500,
73300,
39600,
21000,
19200,
19100,
19700,
2100,
39900,
45300,
82400,
50200,
12000,
null,
15000,
29800,
24300,
26200,
76800,
20600,
8150,
21800,
28900,
18300,
15200,
22400,
14400,
10100,
150700,
11500,
22600,
32000,
19700,
52100,
20100,
56000,
29800,
56600,
71000,
4700,
13200,
12500,
15200,
5200,
13400,
28600,
111000,
12800,
34000,
15800,
6300,
29600,
13700,
102700,
27600,
null,
36300,
80900,
171800,
24000,
49100,
40100,
null,
55400,
39800,
33800,
2600,
34300,
92100,
48400,
34300,
3500,
26500,
null,
null,
18100,
null,
9900,
14300,
null,
18900,
26400,
7000,
26700,
38300,
19900,
41302,
33500,
24100,
17500,
21900,
14000,
54300,
7500,
10700,
77200,
10200,
40800,
12000,
66804,
57900,
11800,
12600,
69200,
null,
null,
13100,
28700,
18900,
29100,
36100,
51400,
63600,
10500,
109100,
19100,
45900,
15000,
65000,
24900,
11800,
26500,
24800,
null,
101100,
21800,
40000,
7500,
14800,
33400,
44100,
60000,
21700,
5100,
18400,
32300,
12700,
29300,
107900,
18400,
12600,
19700,
14100,
16100,
12500,
56900,
22500,
9400,
10800,
33600,
18200,
47900,
42700,
34000,
null,
61600,
null,
94200,
66100,
28800,
12900,
40200,
12200,
38500,
30000,
15200,
18700,
34900,
9000,
37500,
53500,
86700,
132900,
25000,
65000,
66400,
22400,
1600,
21200,
29400,
15700,
85000,
50400,
6600,
19600,
71700,
16800,
11000,
9400,
96500,
null,
null,
34400,
41200,
6100,
null,
13200,
14300,
55993,
null,
24000,
117900,
13600,
null,
45126,
40800,
17700,
81400,
33600,
75200,
50600,
25300,
39900,
28900,
8600,
59700,
null,
67400,
28300,
19300,
11100,
22200,
51900,
12500,
32200,
11500,
27600,
null,
13700,
105300,
71000,
7900,
18000,
63200,
40800,
12400,
48200,
21900,
5200,
11500,
27200,
27600,
null,
25900,
9600,
22575,
9500,
27000,
13300,
32500,
18700,
73600,
10400,
23477,
57810,
3000,
40848,
18900,
15000,
21300,
139800,
13300,
16200,
57500,
16200,
8700,
13000,
46500,
31500,
34700,
22800,
4400,
32013,
null,
31300,
16700,
56200,
35653,
25600,
52200,
4300,
20700,
12800,
22450,
14200,
62500,
5600,
14500,
52200,
42100,
10800,
6700,
13500,
29900,
36700,
9400,
null,
64700,
17700,
10400,
49600,
36500,
17000,
64100,
14100,
62500,
22900,
20800,
12400,
10400,
null,
24000,
15100,
17600,
53200,
null,
23800,
null,
14500,
18100,
92000,
187000,
40300,
12800,
13600,
12500,
10100,
89000,
11100,
38200,
40400,
31200,
24600,
8600,
31200,
9300,
8600,
40800,
44500,
20700,
22900,
33100,
6700,
28900,
32400,
14300,
24900,
29300,
20600,
16700,
36300,
17600,
41800,
18500,
12200,
20300,
null,
31950,
109200,
40300,
37800,
9800,
105800,
15600,
63900,
9800,
16700,
18500,
11900,
23500,
39600,
17100,
7000,
196400,
23200,
34100,
9100,
75208,
80500,
22800,
30500,
null,
18800,
34300,
23100,
39400,
8300,
66100,
35000,
31600,
112400,
21900,
50900,
null,
13600,
13646,
18100,
11200,
31000,
62600,
null,
16000,
16500,
10100,
67400,
55200,
39100,
55400,
160200,
7900,
40600,
29100,
11200,
33500,
20000,
26700,
26200,
43500,
18300,
58610,
32800,
39100,
7500,
55800,
55400,
41800,
null,
22700,
6600,
62900,
67780,
23700,
40900,
7500,
32600,
43500,
22000,
16300,
50800,
30800,
72800,
53000,
10400,
9400,
88100,
36900,
49100,
34000,
10000,
64900,
10800,
58100,
20200,
51400,
50702,
null,
166800,
155426,
35200,
19000,
16340,
null,
11400,
null,
5300,
46000,
10700,
23700,
53600,
17400,
20200,
3600,
14200,
100300,
37900,
31200,
20100,
20000,
17000,
20753,
null,
66500,
5200,
22200,
19100,
7300,
510100,
23500,
44300,
46400,
42300,
56400,
19400,
74400,
17800,
18700,
16000,
19600,
20300,
17300,
33700,
17500,
43900,
12500,
22300,
25700,
44100,
101200,
15000,
8900,
14000,
23500,
68300,
2900,
7500,
57200,
16700,
null,
null,
47600,
9160,
12300,
70318,
null,
15200,
31800,
17700,
35400,
4400,
41100,
16900,
7400,
8600,
66900,
55900,
50400,
3300,
26900,
14100,
132600,
5300,
25000,
50400,
26800,
19100,
19600,
37400,
21900,
12000,
19500,
13700,
8500,
14300,
82000,
73500,
112200,
9100,
16300,
9600,
20400,
23200,
8600,
19200,
20600,
49400,
45200,
28400,
43600,
70000,
7900,
20900,
11200,
20400,
1500,
11200,
25500,
62200,
20900,
54700,
7300,
33000,
18300,
10100,
5500,
null,
32600,
10100,
35200,
33200,
21700,
38000,
13000,
2000,
12100,
97100,
66800,
7450,
17600,
8300,
3500,
17900,
17800,
29100,
35600,
27003,
25800,
null,
112900,
22800,
18800,
28800,
21300,
25000,
7600,
86000,
22000,
13800,
32700,
29900,
51800,
13300,
23300,
18300,
39000,
31400,
14900,
16500,
67300,
10400,
45100,
18200,
22200,
10900,
58100,
19400,
7300,
14000,
259000,
27800,
7200,
13600,
17300,
12900,
null,
138900,
46900,
17600,
19900,
null,
25000,
null,
39800,
28200,
20300,
15600,
13000,
36800,
null,
32200,
2200,
21300,
7400,
26800,
19900,
null,
7000,
23300,
29800,
57900,
null,
25200,
17200,
8500,
13000,
29800,
26900,
22400,
25300,
44100,
103000,
20900,
63200,
8800,
null,
33100,
17800,
17900,
28200,
19474,
15900,
117800,
24800,
null,
40900,
50500,
9100,
15800,
23800,
12400,
12800,
null,
24400,
27300,
20600,
43100,
17900,
31000,
97700,
67200,
null,
96700,
12800,
46800,
33900,
48800,
28500,
null,
19000,
30700,
21600,
null,
28900,
9200,
4600,
19800,
48800,
20400,
61600,
40700,
42600,
24700,
11400,
104700,
13100,
22900,
27500,
16500,
25400,
32400,
21600,
13200,
10200,
34400,
8500,
15300,
9300,
43200,
9200,
27900,
17600,
6700,
100200,
40200,
50900,
13800,
13100,
15100,
19400,
null,
21900,
9500,
2800,
11600,
43100,
47100,
46000,
27000,
24500,
27200,
28500,
5300,
17800,
25600,
28300,
8100,
24600,
23500,
null,
67400,
null,
47600,
23100,
34400,
6800,
16200,
7200,
18300,
41700,
19200,
30400,
39500,
58800,
33000,
19500,
24400,
8200,
8910,
36100,
14900,
19100,
25100,
14500,
7400,
16300,
8100,
58900,
13300,
15800,
24500,
null,
30100,
17000,
23200,
15300,
35200,
53800,
5200,
61200,
28700,
21900,
15255,
18400,
6200,
null,
24700,
null,
26100,
65600,
6200,
26100,
23700,
36200,
48000,
11800,
11300,
23500,
15800,
27300,
49700,
10600,
16300,
38600,
35600,
null,
23700,
6300,
29200,
75400,
null,
19800,
62900,
26800,
11300,
20900,
12100,
21900,
null,
2600,
16300,
14700,
16300,
15000,
8400,
null,
20300,
19900,
17600,
24500,
56200,
30800,
63400,
53600,
42600,
14754,
101500,
15100,
70000,
55800,
36500,
11800,
81700,
9600,
9200,
29900,
21900,
35400,
7453,
33400,
55900,
40500,
71600,
63100,
45100,
14200,
53800,
43700,
13400,
11500,
9900,
22900,
16400,
7500,
43300,
34500,
15700,
68900,
3200,
38300,
null,
10830,
101100,
78100,
4300,
16300,
33400,
57500,
null,
19200,
6800,
10900,
18800,
24700,
6900,
7100,
16100,
127500,
18000,
14000,
6000,
60730,
8400,
7400,
15500,
68600,
23300,
19200,
4700,
86000,
16800,
2700,
41400,
8400,
6400,
36800,
13800,
202000,
11700,
33300,
6000,
97800,
25300,
29200,
101700,
32597,
20800,
1900,
6800,
64500,
82800,
93600,
16900,
21700,
12800,
9700,
42200,
24300,
16000,
9600,
50100,
260900,
31200,
80700,
25100,
51900,
27800,
6600,
13500,
2000,
44500,
8200,
25300,
9300,
null,
8100,
121300,
28000,
19700,
10900,
20100,
24700,
6800,
null,
17400,
19500,
34100,
36800,
13200,
null,
18100,
11500,
18300,
11000,
5800,
31800,
68400,
40000,
null,
12700,
47600,
37600,
14100,
17500,
16500,
null,
5400,
4800,
25500,
20500,
27500,
27000,
null,
14700,
5900,
19400,
16150,
19400,
26300,
27100,
22800,
null,
10900,
null,
14100,
19200,
114900,
78400,
35286,
null,
45900,
null,
45800,
2600,
22700,
5400,
40300,
13500,
null,
22303,
26000,
42300,
14500,
17500,
55500,
44000,
33000,
86500,
18800,
7700,
63795,
6000,
87900,
17200,
49500,
11800,
29100,
null,
25100,
10900,
null,
10700,
13600,
33000,
11600,
3100,
null,
36100,
20200,
9200,
36300,
9300,
48600,
19000,
49500,
37700,
21400,
38200,
23900,
16800,
22300,
26600,
4800,
19500,
28600,
17800,
16300,
17900,
5300,
50819,
16300,
10900,
15500,
50700,
86500,
6500,
null,
18900,
null,
37500,
26600,
null,
126300,
11200,
15400,
null,
55600,
33700,
52500,
30100,
41200,
30000,
200,
80915,
14400,
34600,
24900,
19400,
12100,
3800,
24700,
11000,
null,
23400,
31700,
29800,
15900,
13800,
null,
null,
18700,
25800,
17400,
7200,
13500,
46400,
31400,
20500,
34800,
31600,
15300,
28300,
36700,
7300,
6500,
26700,
31900,
4900,
52200,
12800,
11200,
54100,
15900,
10100,
14500,
98000,
9500,
80300,
38000,
44500,
9200,
78400,
44300,
14700,
11800,
13800,
15500,
26500,
35400,
43000,
43100,
5650,
null,
12300,
36100,
8600,
26100,
null,
1300,
8900,
73200,
12900,
10700,
90700,
19600,
62500,
18400,
54255,
14500,
9300,
21500,
45100,
16400,
11400,
13600,
12700,
22700,
17400,
23400,
31800,
19100,
25700,
12400,
10400,
54200,
14900,
13200,
107100,
null,
30500,
32000,
31900,
19400,
57500,
14100,
51200,
10900,
25000,
80500,
null,
21400,
16990,
40100,
null,
35200,
12200,
64100,
41800,
18700,
13400,
20200,
null,
24400,
9600,
34800,
74200,
2300,
24900,
13100,
17100,
677800,
7300,
39700,
24900,
12800,
14300,
15400,
61000,
31100,
13100,
13000,
23400,
1900,
7600,
null,
13000,
21100,
5100,
16900,
43700,
5900,
12900,
31400,
null,
51800,
35900,
70600,
7400,
1700,
28500,
13100,
22400,
44600,
74500,
13500,
24900,
19500,
88900,
50700,
47700,
55200,
11800,
37700,
9600,
18630,
48100,
10900,
35700,
null,
23500,
null,
12700,
15500,
34900,
null,
100800,
27300,
77400,
16200,
14050,
19800,
null,
109200,
18000,
59900,
55700,
31200,
10000,
76500,
17400,
41000,
142600,
6500,
54300,
117600,
19100,
38500,
7700,
116550,
35100,
7350,
18600,
28700,
12800,
40400,
34200,
49300,
26800,
21900,
null,
58100,
19800,
15800,
9300,
16800,
12800,
34900,
78600,
76200,
19600,
24400,
16300,
58500,
38700,
186955,
24000,
13100,
81700,
8400,
18000,
46800,
58200,
17680,
60300,
7500,
39200,
15900,
25100,
54000,
null,
null,
36600,
41900,
16400,
null,
18800,
16900,
53400,
60600,
54500,
14700,
41600,
12000,
17800,
41800,
24100,
61600,
54500,
29500,
null,
60600,
64000,
23900,
65500,
20400,
null,
22600,
27700,
25500,
50000,
12700,
56300,
291600,
35600,
30450,
13700,
217600,
113500,
10700,
71600,
54100,
53000,
17700,
30500,
12000,
28100,
null,
57300,
6300,
10300,
105200,
5800,
30000,
3700,
16700,
13500,
23700,
13700,
null,
null,
218100,
20400,
26500,
15200,
28700,
27500,
42300,
32500,
16600,
36900,
null,
null,
28700,
122900,
22500,
53600,
21000,
30800,
9500,
22400,
68574,
17300,
17500,
66200,
69200,
5900,
4900,
37400,
10500,
25700,
24100,
20000,
53500,
46600,
18400,
33000,
37100,
36400,
14800,
24900,
32217,
10600,
null,
19500,
27200,
16600,
10600,
13800,
103900,
20200,
41800,
10000,
27100,
21000,
13800,
12000,
32600,
44800,
49300,
null,
37000,
22500,
8300,
null,
34700,
100118,
68300,
21900,
13400,
21300,
10000,
14500,
14200,
17100,
14400,
36200,
34000,
23300,
33600,
84600,
12200,
11600,
345300,
18300,
14400,
27200,
25800,
73410,
9000,
20400,
90100,
23000,
29800,
5000,
1500,
42300,
43400,
23900,
38400,
6400,
18700,
44300,
22500,
13800,
5200,
6000,
22300,
31500,
11000,
15400,
14100,
14900,
28300,
1500,
117700,
42200,
36600,
69500,
28300,
6300,
21800,
9000,
12200,
17700,
6300,
null,
29900,
4300,
16430,
12800,
30800,
null,
6000,
12600,
10300,
34100,
39900,
8000,
12100,
null,
57700,
41500,
1200,
null,
49900,
30100,
176700,
56350,
16200,
16200,
4500,
20700,
16700,
20500,
27000,
6900,
9100,
74900,
17000,
30000,
7700,
47800,
22600,
2400,
12700,
15600,
null,
85400,
23000,
44100,
null,
44900,
124100,
null,
25700,
37500,
17100,
9600,
20800,
60300,
12100,
9500,
17600,
12000,
31200,
10800,
32900,
10100,
3100,
14900,
9700,
71300,
54400,
null,
53200,
15500,
33100,
27400,
42700,
40400,
22800,
23500,
15900,
null,
5000,
30800,
20100,
9800,
11400,
5300,
48100,
41800,
30800,
13800,
21300,
22400,
null,
20200,
7200,
13100,
30359,
25300,
null,
19000,
null,
14000,
null,
68600,
29100,
10200,
41700,
14000,
24700,
381900,
23400,
null,
8900,
28100,
29900,
47400,
52600,
19500,
6100,
18900,
7400,
9600,
8500,
26100,
44100,
29400,
33900,
40600,
12900,
12400,
20400,
7500,
3700,
null,
null,
63200,
32500,
72200,
null,
6150,
26000,
6000,
30300,
15300,
9100,
36300,
20600,
66338,
25200,
24600,
17100,
15600,
31000,
41300,
18500,
25600,
23400,
135000,
61900,
null,
29400,
37900,
58500,
31000,
7900,
35900,
null,
15800,
13200,
53700,
14600,
31700,
26000,
44500,
14200,
null,
28800,
20100,
57400,
13100,
27400,
75000,
21500,
3000,
1500,
93600,
26800,
45000,
7900,
21100,
23300,
null,
5800,
null,
15000,
31600,
26800,
10500,
62700,
38600,
null,
22000,
10200,
8300,
5700,
19200,
12800,
3800,
98900,
800,
71309,
27400,
11100,
29700,
18900,
5900,
12400,
49400,
13600,
49700,
62800,
63100,
67900,
18400,
50100,
21000,
9900,
36800,
4800,
42900,
11500,
43500,
44600,
4300,
null,
36200,
20900,
29200,
24800,
26500,
58000,
11900,
75000,
41900,
9600,
69400,
36900,
72800,
20400,
65300,
null,
7300,
23800,
24100,
109300,
43200,
33700,
31800,
12000,
40700,
25000,
17300,
8500,
24900,
9300,
21200,
62500,
40400,
33700,
25700,
null,
null,
21300,
31400,
105200,
24500,
31900,
2800,
24500,
12500,
7700,
37300,
13400,
27600,
34800,
null,
28200,
33900,
50100,
20300,
null,
35800,
40500,
8250,
39700,
0,
21100,
17500,
20500,
21200,
63600,
42000,
19100,
6800,
20900,
4500,
35300,
null,
8300,
16100,
46900,
600,
29100,
62900,
17200,
20900,
34100,
38200,
7300,
56900,
64800,
51000,
7500,
12800,
35400,
4800,
13500,
29200,
2850,
null,
12600,
31200,
6000,
33100,
22000,
29500,
5900,
36400,
40700,
34000,
21000,
21900,
13100,
16700,
68300,
53700,
null,
20700,
15200,
17800,
48600,
17100,
13500,
20400,
38900,
18100,
27800,
14100,
27500,
35548,
30900,
20900,
44800,
54900,
19600,
36500,
74900,
50600,
38600,
8500,
10000,
80900,
82500,
48500,
53300,
44400,
20500,
25500,
54466,
23900,
110100,
null,
12300,
50500,
6200,
13700,
5600,
26610,
210200,
22100,
30300,
9700,
17000,
null,
17200,
38000,
9800,
17600,
11500,
null,
22000,
26300,
16000,
42200,
6000,
27300,
13300,
7400,
5500,
32300,
3600,
null,
19600,
null,
22400,
51500,
10800,
37800,
77200,
36500,
30000,
70400,
32900,
43600,
null,
13000,
23500,
13500,
40100,
16600,
40300,
12600,
22600,
25000,
null,
null,
null,
20200,
11300,
40800,
11600,
15300,
null,
1800,
25800,
54200,
19900,
51000,
7000,
92097,
28400,
27900,
33400,
45200,
25800,
73700,
28900,
34200,
15700,
30400,
47200,
37500,
14600,
58000,
16200,
16800,
40300,
12600,
8820,
53600,
22900,
15300,
42600,
28900,
20900,
15400,
14300,
2900,
150400,
15400,
31900,
35700,
null,
94700,
null,
4400,
16200,
16800,
34400,
22200,
22900,
111900,
15600,
5000,
47600,
40500,
52600,
20600,
9600,
13600,
7300,
42300,
24700,
19900,
53700,
34400,
14500,
65400,
null,
null,
22000,
13100,
59100,
40800,
36300,
19100,
47100,
8700,
29100,
53800,
14700,
50200,
null,
23600,
40200,
15000,
11000,
12300,
38500,
22000,
62900,
22600,
18200,
36400,
35100,
36400,
48400,
30200,
19900,
32300,
27600,
37800,
31500,
15200,
46600,
35900,
96700,
9100,
null,
25400,
null,
40000,
14900,
3000,
1600,
13000,
23400,
71600,
43600,
21800,
38500,
35405,
42000,
61500,
84300,
17000,
15550,
34800,
4600,
107100,
24700,
17700,
17600,
9200,
43400,
11600,
11800,
34700,
30600,
22000,
null,
28500,
19000,
68771,
11900,
21000,
33300,
null,
15600,
32800,
18800,
14300,
33900,
206600,
40900,
5000,
37300,
18400,
25800,
3200,
70200,
41200,
11400,
28200,
15200,
null,
18900,
14000,
19800,
35100,
48000,
15600,
6100,
17400,
7200,
12800,
20900,
11500,
15500,
15100,
21200,
37800,
null,
10800,
null,
54300,
31600,
17600,
16900,
12000,
10200,
15300,
31100,
21700,
11300,
19600,
37600,
26700,
10400,
24600,
43800,
null,
47900,
null,
5800,
3900,
22600,
20800,
8100,
18400,
13000,
52500,
19500,
12900,
17000,
27900,
16100,
35000,
40100,
26900,
45800,
15400,
28500,
31800,
16200,
74000,
null,
15700,
10000,
16300,
23900,
13900,
10100,
16900,
40200,
11100,
13450,
78600,
13100,
86800,
60000,
43500,
null,
32200,
null,
17400,
39800,
55000,
8100,
38100,
135100,
24100,
80000,
8700,
26400,
31800,
11590,
4300,
18900,
42100,
39300,
21700,
3700,
9400,
8100,
10100,
33500,
34600,
67100,
4500,
42100,
15000,
11200,
14500,
19500,
27500,
25700,
100100,
118800,
null,
8000,
38000,
94000,
23900,
22200,
10800,
19600,
8500,
10100,
36200,
24500,
18400,
26800,
28700,
61500,
13600,
25100,
6500,
310800,
41200,
29900,
23900,
9700,
238800,
22100,
27700,
36076,
20300,
18800,
69500,
null,
45700,
33500,
14800,
12300,
888800,
57700,
78800,
32500,
32300,
68600,
23500,
47600,
12200,
86300,
56100,
89400,
21200,
46043,
17900,
14600,
47400,
40300,
31592,
19600,
9400,
24100,
77400,
14500,
25700,
16600,
46800,
null,
20000,
null,
10400,
60600,
12100,
7500,
23500,
26400,
18200,
28100,
34700,
16200,
133700,
27800,
11700,
18500,
17600,
32100,
62500,
79600,
69800,
55800,
67300,
98300,
15800,
25000,
48800,
27500,
null,
23100,
18300,
28300,
29600,
10200,
40000,
45400,
37800,
null,
23800,
19800,
28300,
80100,
20000,
null,
11500,
13000,
40200,
70800,
7700,
8400,
34200,
104535,
15700,
8700,
26600,
75700,
14500,
10500,
33200,
11300,
19500,
41800,
29000,
53300,
36400,
27300,
86400,
51900,
41000,
null,
19400,
23100,
3800,
100300,
15600,
9000,
49000,
14200,
18100,
27146,
28300,
12800,
19600,
102400,
7500,
31500,
27700,
11900,
null,
36300,
15900,
54600,
18300,
13600,
16700,
6100,
25200,
11900,
63000,
8800,
10000,
8800,
118688,
85500,
null,
17300,
20400,
12200,
22300,
45000,
23000,
24300,
40600,
47000,
262100,
null,
60900,
13000,
56800,
19900,
12700,
17000,
37400,
12500,
26200,
7600,
35600,
17700,
45500,
33300,
15800,
null,
16700,
10500,
36100,
17700,
29500,
44000,
14500,
12600,
7700,
20200,
41100,
null,
13400,
23200,
18700,
7200,
null,
57600,
5600,
25660,
24250,
62500,
7500,
41700,
50300,
16300,
33100,
68900,
19800,
33600,
61600,
8000,
16400,
27300,
14200,
43600,
14900,
12500,
159300,
24240,
null,
13700,
4400,
27900,
11300,
21200,
34200,
64800,
12000,
25700,
24300,
14800,
2200,
22900,
27000,
12500,
105900,
42200,
30000,
70400,
91300,
8200,
5500,
17400,
25900,
35000,
7200,
25125,
158400,
2800,
16500,
14800,
18000,
5500,
33900,
7700,
32300,
17600,
281000,
15900,
35900,
19500,
59800,
11100,
20200,
null,
27200,
30000,
47900,
33800,
9800,
11800,
34200,
14200,
34400,
50600,
83800,
31700,
20000,
null,
24400,
35600,
62500,
null,
11000,
11100,
13500,
53900,
21100,
14700,
25500,
null,
27300,
18200,
18200,
null,
5100,
12600,
47400,
17400,
20600,
14400,
4700,
5800,
24500,
14500,
5200,
84800,
32900,
28800,
58342,
40800,
26300,
9600,
5900,
22800,
22600,
21400,
16400,
55100,
28300,
34200,
10000,
6600,
92360,
9200,
22400,
4100,
null,
null,
15400,
58100,
10000,
9500,
52300,
24700,
42800,
19800,
6700,
31800,
59100,
34300,
92000,
18900,
6900,
21800,
29700,
77100,
53600,
53498,
null,
25600,
13900,
41300,
34100,
52300,
39800,
10000,
18500,
60600,
36899,
16000,
22800,
68600,
29600,
32300,
9800,
null,
17300,
4400,
25600,
21500,
14800,
17500,
14900,
45400,
47300,
5000,
10600,
206300,
9100,
26900,
null,
29800,
17900,
61700,
63200,
26400,
38900,
53400,
38800,
58100,
26100,
35200,
11200,
14400,
17100,
13600,
31100,
12800,
58500,
126800,
54900,
7600,
56700,
null,
17050,
84600,
28500,
8300,
17000,
27200,
18100,
14500,
51800,
37500,
46100,
40700,
53600,
6400,
20500,
15800,
23400,
6900,
76900,
26800,
21400,
8100,
14000,
42400,
null,
35400,
17900,
18500,
29300,
15800,
11100,
22500,
9800,
25000,
13300,
19700,
24900,
32100,
10000,
31000,
33400,
33800,
30300,
63000,
34800,
41200,
13100,
11900,
9600,
19000,
23600,
null,
14900,
42800,
21500,
126900,
43500,
12500,
26600,
18200,
48100,
26600,
34100,
20100,
21800,
62800,
20600,
33200,
33600,
43000,
39800,
27800,
30600,
43600,
7200,
6300,
109500,
50000,
25600,
46200,
null,
97800,
11700,
39600,
20500,
30100,
45000,
15800,
null,
10100,
8600,
15300,
68700,
52900,
24100,
null,
10500,
31400,
null,
9200,
34000,
11800,
31600,
7000,
17700,
16400,
40600,
14900,
39500,
9700,
32500,
23400,
10300,
69600,
22800,
34500,
19000,
36200,
13000,
18100,
46700,
10500,
25500,
20200,
39673,
44200,
27000,
37600,
46900,
28600,
22300,
10600,
50000,
47100,
36200,
34500,
7200,
13500,
23600,
null,
null,
14600,
18800,
8300,
18700,
120200,
28400,
24300,
12300,
56800,
15100,
43400,
19600,
44800,
16600,
11600,
44900,
4200,
36600,
19200,
30200,
null,
26200,
119300,
21100,
7900,
12500,
14400,
11400,
24900,
14400,
14900,
30800,
8900,
56400,
6100,
null,
13200,
16000,
51400,
22500,
52500,
21800,
27800,
12600,
58900,
21300,
25300,
16400,
6200,
33400,
16000,
53300,
34200,
11400,
32200,
29500,
15300,
96800,
32200,
15100,
26100,
null,
15100,
25400,
35000,
36200,
28400,
29100,
10200,
18700,
15300,
63800,
12900,
49700,
74900,
92450,
7800,
null,
33600,
17600,
null,
17100,
27200,
74900,
48000,
19500,
28700,
31600,
11900,
7400,
18700,
19700,
16000,
128431,
72500,
70800,
37000,
19600,
null,
15300,
null,
11000,
11200,
28000,
47600,
16200,
12100,
73800,
11900,
23700,
12400,
9000,
21100,
39100,
77800,
27000,
null,
22200,
16900,
10800,
115900,
24200,
11000,
9600,
23100,
9250,
28600,
50600,
51100,
2800,
11500,
25700,
46400,
14800,
20605,
7700,
20400,
3500,
35700,
40800,
26100,
32100,
8600,
null,
22000,
121000,
9100,
18100,
29800,
10100,
4800,
43600,
47400,
null,
12800,
44000,
15700,
16600,
29300,
22200,
56311,
54700,
12600,
18000,
9100,
50000,
29600,
6400,
null,
11700,
20200,
152700,
15300,
8200,
76600,
25200,
70500,
24100,
10600,
14500,
null,
null,
12000,
85900,
32670,
39700,
53200,
41000,
null,
null,
27200,
25000,
143800,
null,
57600,
null,
24500,
26600,
23600,
83400,
15800,
5000,
29600,
24800,
12600,
55500,
null,
44600,
9600,
20500,
29800,
61300,
41500,
37100,
23500,
8100,
28300,
35200,
12750,
12000,
16100,
10400,
58300,
29400,
18400,
12700,
44056,
18900,
34800,
12600,
null,
11200,
18300,
9000,
8400,
24400,
26200,
18100,
91200,
24500,
11300,
34300,
29100,
82000,
1200,
33400,
7400,
47506,
12100,
24100,
20900,
20500,
57800,
15500,
57300,
20900,
13400,
53600,
29100,
76700,
45000,
112600,
9200,
29500,
34000,
17600,
20900,
63800,
null,
48400,
16000,
57800,
23900,
32500,
26700,
43200,
74000,
6000,
null,
63200,
46400,
11900,
43500,
21800,
4500,
41200,
null,
34700,
12400,
102300,
13100,
null,
17400,
27500,
25300,
34700,
null,
22700,
null,
19000,
null,
14500,
29500,
null,
85600,
6900,
23000,
18900,
17000,
28000,
7000,
9700,
44600,
null,
25050,
33400,
23800,
22200,
23000,
55700,
36900,
9700,
21500,
500,
21700,
45800,
null,
28900,
12900,
7500,
43100,
37000,
12500,
null,
80800,
16500,
21850,
105200,
41000,
14500,
12100,
40137,
35500,
18300,
30500,
11300,
52500,
8300,
9000,
61500,
14850,
19100,
25600,
25900,
22600,
51800,
442736,
3800,
30100,
6900,
19900,
69400,
22100,
null,
208800,
25600,
48000,
8800,
13900,
17400,
null,
null,
null,
27700,
13900,
42700,
86600,
22400,
null,
20600,
26700,
20300,
6400,
13050,
19800,
null,
41100,
28100,
39900,
20656,
7800,
47000,
16500,
27600,
13900,
19900,
35700,
14600,
18100,
null,
25800,
null,
9500,
null,
13800,
47300,
20800,
120400,
9100,
15800,
30500,
37600,
31500,
18600,
22200,
43300,
29000,
2500,
29600,
40800,
17300,
19100,
7100,
5500,
18400,
34200,
16700,
14300,
6700,
16100,
27000,
18100,
31200,
3800,
7800,
25000,
39900,
null,
55500,
10000,
13900,
11500,
26600,
49800,
17900,
24700,
27900,
36500,
114400,
21700,
20400,
12600,
10600,
8700,
46800,
8600,
24400,
35500,
2400,
41100,
37400,
57400,
63900,
68100,
null,
17200,
21200,
57100,
67900,
77000,
12600,
32200,
8100,
50100,
5500,
20300,
108200,
18000,
57200,
25400,
23900,
3630,
9400,
null,
null,
null,
60200,
24598,
133000,
9700,
13500,
29900,
20100,
67300,
29300,
12800,
29500,
40700,
35500,
100100,
64600,
16900,
33200,
5800,
1300,
17300,
25700,
null,
110600,
17100,
81300,
62800,
7000,
17500,
22900,
25800,
3900,
null,
8600,
25500,
14100,
16300,
44100,
33200,
16500,
25200,
20100,
12100,
60300,
64400,
14200,
6100,
21300,
16700,
16000,
13600,
37600,
5200,
27400,
27900,
14200,
10100,
17000,
35400,
null,
24400,
33200,
6000,
3800,
45900,
27300,
36400,
7800,
19600,
65700,
60100,
21400,
33500,
52000,
8000,
28900,
4800,
26500,
87300,
14500,
null,
20100,
28500,
3900,
10100,
19300,
8700,
11500,
36600,
73900,
10900,
32100,
18300,
43300,
13300,
14800,
6800,
71733,
15900,
42200,
53500,
50300,
14900,
null,
38300,
13000,
18500,
9400,
17600,
25750,
24800,
10500,
12300,
null,
1000,
106900,
36100,
28200,
7600,
4500,
41100,
152000,
6200,
27300,
25000,
43400,
12700,
86561,
13000,
null,
8000,
30400,
6000,
9200,
42300,
27600,
13100,
null,
10400,
11700,
20300,
58800,
12800,
60100,
19600,
15300,
22900,
1000,
15300,
null,
null,
16900,
19600,
36100,
19100,
null,
30100,
43000,
27600,
8360,
null,
39400,
46900,
11000,
10400,
33900,
40400,
24700,
7000,
21600,
14300,
68300,
9000,
null,
39200,
29200,
32300,
28600,
4700,
51500,
7900,
18300,
8000,
24000,
106300,
39100,
21900,
27800,
42100,
70300,
40200,
20800,
22900,
26800,
43400,
20300,
13400,
51100,
21000,
103500,
45000,
null,
14600,
18900,
45200,
15700,
45200,
36336,
null,
9900,
40200,
56600,
6300,
37300,
13800,
12800,
30500,
20200,
15400,
20500,
null,
null,
14800,
11000,
6300,
10800,
16500,
32800,
107800,
6600,
6100,
3900,
25600,
40500,
55100,
117600,
51500,
6800,
19800,
12500,
null,
27000,
11600,
null,
17900,
30200,
17300,
9400,
44000,
17200,
24200,
24000,
37600,
null,
78400,
null,
15500,
null,
33200,
11000,
91100,
44600,
29500,
41000,
50100,
9000,
8500,
null,
18100,
4300,
47992,
48600,
30550,
55800,
15800,
37500,
2500,
32600,
40500,
13100,
21000,
15900,
47000,
70900,
14500,
35100,
31000,
9100,
24000,
22600,
26100,
16250,
null,
67100,
6800,
15200,
24000,
7600,
16400,
22000,
99600,
38000,
38700,
8900,
2500,
60500,
14000,
29900,
28600,
14000,
27700,
21500,
28300,
25200,
25900,
5000,
26600,
31100,
6200,
50700,
19400,
60500,
null,
null,
6700,
81100,
37100,
48600,
30900,
122300,
24800,
6900,
null,
6900,
6300,
60700,
19600,
14700,
39310,
35372,
27700,
15100,
44500,
14700,
10100,
44800,
18500,
26400,
25100,
27400,
20700,
27800,
7400,
20400,
6200,
6200,
21800,
27300,
21400,
16100,
96000,
47100,
36800,
null,
70900,
10000,
68570,
47600,
48100,
54800,
8200,
12900,
16800,
16300,
10200,
5300,
26500,
23800,
13000,
32200,
24200,
35300,
11000,
12979,
9900,
47800,
23100,
35300,
18100,
10800,
32900,
17700,
6100,
17300,
5300,
null,
13100,
19000,
14800,
76000,
8100,
4500,
81900,
null,
36500,
21100,
34500,
11300,
16400,
17300,
10500,
31700,
11400,
34200,
9200,
31407,
null,
28600,
25643,
null,
11900,
22000,
15600,
34100,
29900,
19300,
35380,
9500,
26300,
32600,
null,
5400,
16500,
10900,
51100,
4100,
22000,
6200,
18600,
null,
60300,
38900,
20200,
30500,
14900,
9600,
6800,
39300,
31900,
5100,
46400,
32700,
16200,
52300,
8700,
44800,
22400,
74437,
26800,
96300,
35200,
70100,
22100,
14000,
20500,
null,
22700,
68800,
33500,
6900,
52400,
56300,
35400,
10300,
61000,
31900,
45100,
17900,
8500,
12900,
4600,
5200,
37600,
45500,
8300,
23700,
22600,
7100,
29800,
36900,
2700,
218200,
5300,
76100,
107350,
17900,
13700,
14200,
7600,
29800,
19900,
32000,
43400,
null,
24000,
null,
25000,
26200,
null,
59800,
73551,
null,
3800,
37500,
64600,
154100,
3900,
64000,
44800,
27103,
5600,
40400,
17700,
2300,
83000,
120300,
null,
35300,
47500,
20100,
9400,
14000,
12941,
18500,
13900,
14100,
24200,
5300,
42400,
22500,
15600,
13500,
9000,
22600,
null,
205730,
39400,
11900,
null,
36200,
12600,
21700,
14500,
17400,
24300,
13100,
19900,
43300,
7000,
31400,
null,
9100,
59900,
33400,
52300,
13200,
24200,
30900,
10500,
23400,
9500,
23700,
3000,
67600,
90100,
11100,
9800,
6950,
27600,
54300,
27100,
27000,
15100,
22500,
34000,
30700,
38800,
58600,
11300,
35800,
50900,
21500,
null,
41200,
10300,
24800,
14300,
28100,
220860,
null,
27600,
null,
25700,
167418,
36700,
25500,
73900,
48000,
34100,
14100,
null,
null,
43100,
59300,
2600,
74500,
37200,
20200,
25400,
4900,
5250,
25600,
7100,
15100,
95300,
null,
38300,
16200,
47200,
7600,
67100,
29300,
32400,
46702,
24400,
9000,
11700,
20100,
23900,
8100,
47600,
20500,
40300,
39300,
48100,
16500,
6900,
null,
null,
42000,
12800,
31700,
2900,
39700,
null,
51200,
23500,
40988
]
}
],
"layout": {
"barmode": "overlay",
"legend": {
"bgcolor": "#F5F6F9",
"font": {
"color": "#4D5663"
}
},
"paper_bgcolor": "#F5F6F9",
"plot_bgcolor": "#F5F6F9",
"template": {
"data": {
"bar": [
{
"error_x": {
"color": "#2a3f5f"
},
"error_y": {
"color": "#2a3f5f"
},
"marker": {
"line": {
"color": "#E5ECF6",
"width": 0.5
}
},
"type": "bar"
}
],
"barpolar": [
{
"marker": {
"line": {
"color": "#E5ECF6",
"width": 0.5
}
},
"type": "barpolar"
}
],
"carpet": [
{
"aaxis": {
"endlinecolor": "#2a3f5f",
"gridcolor": "white",
"linecolor": "white",
"minorgridcolor": "white",
"startlinecolor": "#2a3f5f"
},
"baxis": {
"endlinecolor": "#2a3f5f",
"gridcolor": "white",
"linecolor": "white",
"minorgridcolor": "white",
"startlinecolor": "#2a3f5f"
},
"type": "carpet"
}
],
"choropleth": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "choropleth"
}
],
"contour": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "contour"
}
],
"contourcarpet": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "contourcarpet"
}
],
"heatmap": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "heatmap"
}
],
"heatmapgl": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "heatmapgl"
}
],
"histogram": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "histogram"
}
],
"histogram2d": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "histogram2d"
}
],
"histogram2dcontour": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "histogram2dcontour"
}
],
"mesh3d": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "mesh3d"
}
],
"parcoords": [
{
"line": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "parcoords"
}
],
"pie": [
{
"automargin": true,
"type": "pie"
}
],
"scatter": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatter"
}
],
"scatter3d": [
{
"line": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatter3d"
}
],
"scattercarpet": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattercarpet"
}
],
"scattergeo": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattergeo"
}
],
"scattergl": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattergl"
}
],
"scattermapbox": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattermapbox"
}
],
"scatterpolar": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterpolar"
}
],
"scatterpolargl": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterpolargl"
}
],
"scatterternary": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterternary"
}
],
"surface": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "surface"
}
],
"table": [
{
"cells": {
"fill": {
"color": "#EBF0F8"
},
"line": {
"color": "white"
}
},
"header": {
"fill": {
"color": "#C8D4E3"
},
"line": {
"color": "white"
}
},
"type": "table"
}
]
},
"layout": {
"annotationdefaults": {
"arrowcolor": "#2a3f5f",
"arrowhead": 0,
"arrowwidth": 1
},
"coloraxis": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"colorscale": {
"diverging": [
[
0,
"#8e0152"
],
[
0.1,
"#c51b7d"
],
[
0.2,
"#de77ae"
],
[
0.3,
"#f1b6da"
],
[
0.4,
"#fde0ef"
],
[
0.5,
"#f7f7f7"
],
[
0.6,
"#e6f5d0"
],
[
0.7,
"#b8e186"
],
[
0.8,
"#7fbc41"
],
[
0.9,
"#4d9221"
],
[
1,
"#276419"
]
],
"sequential": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"sequentialminus": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
]
},
"colorway": [
"#636efa",
"#EF553B",
"#00cc96",
"#ab63fa",
"#FFA15A",
"#19d3f3",
"#FF6692",
"#B6E880",
"#FF97FF",
"#FECB52"
],
"font": {
"color": "#2a3f5f"
},
"geo": {
"bgcolor": "white",
"lakecolor": "white",
"landcolor": "#E5ECF6",
"showlakes": true,
"showland": true,
"subunitcolor": "white"
},
"hoverlabel": {
"align": "left"
},
"hovermode": "closest",
"mapbox": {
"style": "light"
},
"paper_bgcolor": "white",
"plot_bgcolor": "#E5ECF6",
"polar": {
"angularaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"bgcolor": "#E5ECF6",
"radialaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
}
},
"scene": {
"xaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
},
"yaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
},
"zaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
}
},
"shapedefaults": {
"line": {
"color": "#2a3f5f"
}
},
"ternary": {
"aaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"baxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"bgcolor": "#E5ECF6",
"caxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
}
},
"title": {
"x": 0.05
},
"xaxis": {
"automargin": true,
"gridcolor": "white",
"linecolor": "white",
"ticks": "",
"title": {
"standoff": 15
},
"zerolinecolor": "white",
"zerolinewidth": 2
},
"yaxis": {
"automargin": true,
"gridcolor": "white",
"linecolor": "white",
"ticks": "",
"title": {
"standoff": 15
},
"zerolinecolor": "white",
"zerolinewidth": 2
}
}
},
"title": {
"font": {
"color": "#4D5663"
},
"text": "total_rev_hi_lim Distribution"
},
"xaxis": {
"gridcolor": "#E1E5ED",
"showgrid": true,
"tickfont": {
"color": "#4D5663"
},
"title": {
"font": {
"color": "#4D5663"
},
"text": ""
},
"zerolinecolor": "#E1E5ED"
},
"yaxis": {
"gridcolor": "#E1E5ED",
"showgrid": true,
"tickfont": {
"color": "#4D5663"
},
"title": {
"font": {
"color": "#4D5663"
},
"text": ""
},
"zerolinecolor": "#E1E5ED"
}
}
},
"text/html": [
"\n",
" \n",
" \n",
" \n",
" \n",
"
"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"application/vnd.plotly.v1+json": {
"config": {
"linkText": "Export to plot.ly",
"plotlyServerURL": "https://plot.ly",
"showLink": true
},
"data": [
{
"boxpoints": false,
"line": {
"width": 1.3
},
"marker": {
"color": "rgba(255, 153, 51, 1.0)"
},
"name": "total_rev_hi_lim",
"orientation": "v",
"type": "box",
"y": [
30800,
32900,
34900,
24700,
47033,
29500,
55500,
11800,
62100,
33200,
47000,
19600,
139900,
43000,
41200,
18500,
15900,
17400,
17000,
31000,
27200,
null,
25700,
14300,
41400,
43400,
19800,
33100,
49900,
10900,
94100,
69000,
4900,
12300,
30200,
8900,
6600,
37100,
16700,
62400,
5500,
46500,
26600,
32400,
57300,
9400,
72900,
null,
22500,
20100,
18200,
74000,
43300,
13000,
33600,
18800,
90600,
32900,
5600,
72600,
62800,
87000,
54500,
22100,
20000,
63700,
null,
null,
14400,
62200,
8300,
15700,
3000,
17300,
null,
33300,
10500,
40200,
34400,
26400,
15550,
118600,
23300,
27500,
43900,
12950,
16200,
23700,
23800,
8700,
46800,
19000,
0,
null,
44200,
5800,
22300,
16900,
84500,
31200,
14800,
31900,
67600,
71207,
6000,
6500,
23800,
130300,
24000,
31000,
48900,
64700,
54000,
5800,
43300,
70000,
34900,
7300,
45600,
15600,
22800,
12600,
92000,
null,
47400,
8800,
27500,
46000,
25300,
10800,
null,
8000,
7900,
46400,
67700,
13507,
60100,
33100,
31100,
15200,
19500,
37900,
33700,
22500,
7500,
12900,
57600,
38800,
95900,
59600,
null,
7800,
null,
14900,
37500,
12300,
46000,
41600,
27000,
12000,
18600,
19900,
28700,
11400,
46100,
26000,
5800,
49500,
25100,
19900,
14800,
21600,
110500,
48900,
143100,
17800,
47100,
62300,
11500,
31100,
11200,
15200,
22500,
22500,
28900,
19700,
16600,
16300,
47700,
4700,
68200,
13200,
29600,
null,
35800,
null,
38700,
null,
24500,
13500,
41100,
81300,
38050,
10700,
12700,
1000,
16200,
null,
null,
37000,
4850,
40800,
11500,
41300,
17400,
12700,
19100,
72300,
30800,
null,
50900,
8400,
25800,
25100,
17000,
3300,
149900,
16500,
95100,
28700,
18500,
5300,
60300,
99000,
28800,
47000,
38800,
18900,
null,
22800,
36400,
38900,
11700,
88197,
null,
5500,
20600,
36500,
10700,
33300,
9600,
null,
33500,
19000,
33000,
21300,
34900,
16100,
11610,
28500,
30900,
42600,
32500,
2600,
48600,
18800,
21900,
9300,
23900,
36000,
23000,
36800,
18600,
27500,
12900,
50200,
38600,
21100,
12400,
5700,
19600,
29500,
11500,
null,
37250,
18100,
32800,
7700,
19900,
24800,
6100,
75500,
19100,
56200,
81000,
12000,
null,
13500,
null,
17700,
58200,
78600,
5800,
null,
25100,
10300,
52200,
32800,
24800,
24900,
32500,
27900,
35800,
55400,
23500,
null,
25800,
241600,
32400,
39800,
184100,
53700,
6800,
23100,
32100,
32100,
26900,
14400,
23500,
4500,
47800,
44300,
15100,
45900,
24800,
null,
null,
31200,
3500,
27400,
49200,
27600,
13200,
62600,
54423,
15500,
22000,
70700,
22300,
20300,
7000,
11100,
12600,
28300,
31600,
37500,
10500,
74400,
23500,
14500,
64000,
null,
22200,
72600,
null,
20700,
5900,
33300,
11200,
41500,
32400,
null,
8800,
41400,
7500,
35500,
12600,
31400,
32300,
20000,
75000,
41245,
25500,
null,
21800,
26000,
24000,
null,
5900,
23500,
14000,
11800,
null,
24600,
46600,
20200,
1000,
81600,
19000,
1800,
11100,
11200,
18500,
44500,
24700,
13900,
56900,
3600,
27100,
13900,
26900,
65700,
41400,
66400,
30200,
null,
8400,
2300,
5300,
49700,
27300,
null,
2800,
null,
18500,
26000,
53800,
16600,
28000,
29600,
111400,
66100,
50100,
31600,
null,
11300,
51600,
21000,
27400,
14500,
20000,
19800,
27100,
10500,
29800,
57800,
12200,
8300,
23800,
14800,
12800,
28500,
17900,
16600,
16100,
35800,
24000,
62600,
16900,
86700,
33400,
44900,
30900,
20600,
6600,
13600,
43700,
43200,
6500,
25500,
30300,
45500,
null,
5700,
7600,
44000,
32400,
31400,
13300,
null,
13700,
31400,
19700,
15300,
26400,
30100,
48100,
11300,
27200,
12700,
16200,
79500,
35400,
30500,
4000,
8700,
20300,
4600,
null,
9700,
11300,
18900,
73400,
62100,
25300,
35200,
15200,
16900,
null,
11900,
16000,
28500,
null,
17700,
40800,
37900,
73800,
12500,
27700,
52200,
41500,
6300,
62100,
21200,
20600,
14800,
20600,
27400,
63700,
38500,
40300,
23500,
53100,
41700,
18100,
38500,
96300,
28500,
97700,
6800,
31600,
14500,
31700,
78200,
21500,
13100,
52800,
38000,
15100,
28700,
6400,
16800,
23400,
14700,
19000,
21500,
55300,
11900,
17000,
null,
68700,
46800,
22900,
18100,
9000,
56900,
26400,
null,
45000,
9800,
null,
20800,
null,
18400,
30500,
26800,
38400,
12800,
79700,
37000,
null,
null,
21200,
44000,
23800,
25100,
57800,
9700,
null,
26800,
18600,
27000,
14200,
26100,
21500,
90600,
null,
null,
49100,
17300,
9200,
22500,
76400,
32000,
10000,
9400,
20700,
16700,
30800,
null,
22300,
25000,
35600,
4500,
29000,
23000,
11900,
27400,
7000,
90000,
21200,
47400,
12500,
15300,
90300,
36900,
24100,
5100,
7800,
17900,
20500,
9100,
44200,
19700,
15300,
99800,
24600,
18900,
68000,
29000,
59300,
12900,
122400,
33200,
13750,
8100,
27400,
5751,
null,
33800,
15700,
21200,
51500,
53100,
6500,
53000,
20300,
5500,
52000,
null,
20600,
28400,
1700,
11200,
33500,
62000,
36200,
35400,
15200,
9500,
24000,
18300,
null,
24900,
23400,
68800,
28700,
48000,
26800,
35300,
21300,
2700,
48700,
371700,
8900,
5200,
10500,
15900,
8700,
23000,
17700,
16600,
3100,
15600,
13600,
17200,
17300,
21500,
13700,
50200,
25000,
35600,
25400,
49300,
9900,
50000,
50100,
15400,
34100,
13500,
28700,
31800,
null,
35100,
34600,
63400,
60900,
4800,
6750,
50800,
42000,
33000,
15100,
null,
30700,
22800,
20600,
32300,
23300,
60900,
53100,
23700,
22500,
15000,
20600,
25200,
34500,
28300,
76800,
4300,
63300,
25800,
14000,
null,
112900,
20800,
5200,
10300,
38300,
39200,
13700,
15200,
4200,
null,
44500,
3800,
22000,
70900,
42900,
53100,
31500,
36200,
41900,
78000,
21600,
10600,
10000,
32100,
31300,
6900,
12168,
10700,
30500,
188400,
25600,
100600,
34200,
20900,
null,
26400,
12100,
10400,
49600,
10500,
11200,
16400,
16000,
null,
10600,
45000,
12600,
139000,
26200,
17800,
22700,
14000,
12604,
7200,
23900,
8700,
27100,
16800,
7000,
27300,
30100,
6300,
12500,
35800,
null,
19100,
47700,
33900,
13800,
32000,
14300,
24100,
25200,
30800,
6500,
37500,
81000,
null,
19600,
13600,
34500,
null,
16000,
22800,
7500,
4600,
9100,
38700,
8300,
39800,
25100,
19500,
34900,
27000,
24300,
45700,
12500,
43500,
54400,
null,
36070,
5100,
14700,
41100,
18400,
11300,
29500,
50900,
14700,
21000,
63500,
55800,
4300,
35100,
8900,
18300,
16800,
13800,
59000,
18200,
41700,
23000,
28600,
25700,
0,
18100,
3200,
106000,
19300,
13500,
13200,
55300,
52922,
10200,
21800,
23900,
41600,
36300,
53700,
49600,
37500,
10300,
9900,
12000,
33700,
12200,
24800,
27000,
22800,
15300,
51100,
6900,
4500,
12000,
22700,
8000,
28800,
19100,
25000,
26800,
33700,
45500,
11600,
20600,
23800,
null,
122400,
41100,
6100,
null,
71100,
25600,
19700,
null,
51300,
15200,
14900,
33700,
11200,
25600,
74300,
30400,
21800,
20600,
33500,
47300,
43800,
53600,
28600,
31200,
56500,
9400,
10700,
69300,
23200,
71900,
37500,
49200,
26900,
15600,
8000,
41500,
null,
18700,
11500,
48100,
18000,
12900,
7400,
22000,
200100,
29200,
14500,
9300,
48700,
32100,
16700,
52900,
11100,
4500,
17500,
38300,
34500,
58900,
25100,
73525,
58700,
6800,
11500,
null,
15000,
33800,
14900,
null,
15200,
12800,
10500,
95300,
4800,
44400,
12600,
20000,
16500,
23300,
51400,
16950,
23800,
8100,
24900,
29500,
35000,
19800,
52100,
38300,
55500,
14800,
null,
24000,
37000,
45600,
31300,
5300,
26500,
97000,
10500,
27900,
20900,
27500,
null,
29700,
3700,
12840,
6900,
8200,
30000,
35400,
22300,
17600,
20100,
9600,
28000,
21300,
44100,
4800,
null,
35900,
31000,
9000,
10900,
null,
15200,
34600,
23700,
27500,
10400,
18300,
32700,
null,
27900,
25000,
7200,
null,
46900,
9500,
46400,
45000,
13500,
86000,
55700,
45800,
18200,
23800,
270900,
null,
21300,
29400,
9700,
30300,
18600,
29400,
28700,
null,
3700,
null,
22300,
16100,
25400,
29300,
null,
23700,
20400,
23900,
21100,
86700,
26300,
38200,
21500,
8000,
25700,
101900,
10100,
33200,
8500,
15900,
22400,
9100,
26800,
11000,
25100,
7900,
21000,
64600,
18800,
46000,
14600,
22200,
null,
25000,
13400,
7800,
15800,
29200,
39600,
51700,
43000,
27400,
36500,
24300,
62700,
3700,
20000,
27700,
19600,
35400,
18000,
31700,
10200,
17000,
41256,
18300,
52900,
72900,
51800,
11400,
43400,
37100,
15800,
51300,
75700,
20300,
56200,
7000,
13900,
19600,
23800,
52500,
22800,
31900,
null,
23600,
18800,
16400,
20100,
9500,
20200,
37700,
138300,
44405,
80500,
13000,
17300,
20700,
61600,
32000,
7300,
41500,
17700,
25000,
17600,
88300,
19700,
6900,
12900,
33000,
15200,
27100,
27200,
42100,
31700,
43700,
12000,
21500,
null,
76000,
7300,
8900,
97798,
22200,
6100,
37900,
24800,
12000,
48400,
15100,
null,
101100,
21700,
28900,
47900,
null,
41000,
25200,
49000,
32600,
null,
10110,
21200,
5400,
18600,
63400,
null,
11200,
35200,
14400,
19200,
14700,
66600,
56000,
17200,
null,
10200,
24900,
22700,
13200,
null,
27400,
16300,
165300,
35800,
null,
30119,
28042,
22300,
21800,
8500,
21600,
26100,
4300,
30000,
null,
12000,
24300,
4200,
27126,
9000,
35700,
22500,
29400,
10200,
22900,
61400,
15200,
14600,
19100,
37100,
26900,
23300,
18800,
9850,
22300,
7300,
13200,
40400,
111700,
113700,
21500,
36400,
24800,
26600,
25300,
16400,
17800,
14100,
28900,
31100,
4300,
13700,
72100,
33400,
12400,
53200,
14400,
30900,
22100,
15000,
31300,
null,
17000,
7300,
null,
67300,
28900,
8800,
30900,
19100,
17950,
17300,
8500,
null,
17700,
null,
17200,
7600,
24900,
36400,
12200,
32100,
48900,
12000,
20700,
246400,
8900,
31200,
13700,
19800,
30700,
11400,
127800,
14400,
null,
60500,
33600,
60100,
36100,
22200,
7500,
28100,
171600,
null,
19200,
16000,
18700,
11000,
166000,
12300,
51500,
84100,
20600,
17450,
6900,
66800,
34800,
29100,
26900,
68800,
23000,
42000,
21600,
null,
11600,
15100,
19100,
15700,
21700,
6000,
45300,
101500,
26800,
11500,
15300,
16900,
40700,
21200,
4650,
15100,
9900,
3100,
null,
28500,
17100,
33400,
24400,
78924,
36900,
40300,
71800,
40000,
102000,
14000,
29500,
13300,
null,
null,
17500,
17800,
85800,
42900,
null,
14800,
26400,
2900,
49500,
33500,
14500,
16900,
57800,
31100,
26800,
17500,
7000,
20700,
9000,
14300,
58500,
null,
34900,
37700,
52100,
122900,
9000,
null,
13800,
110000,
20500,
null,
null,
16100,
12200,
46400,
57000,
14700,
null,
33800,
38300,
20100,
7300,
23600,
34400,
6700,
80500,
41700,
9700,
10100,
10400,
null,
15500,
null,
30000,
7000,
10900,
12900,
18000,
27100,
18300,
40200,
5700,
34800,
11500,
30150,
64300,
null,
28500,
7100,
9900,
null,
106500,
22000,
20200,
106100,
10400,
37000,
30800,
15700,
21900,
16700,
78100,
20500,
null,
25700,
44900,
50600,
8800,
14000,
11500,
24500,
40800,
59500,
14100,
null,
57500,
null,
33800,
13000,
42800,
25700,
25100,
56600,
12600,
15200,
28800,
129900,
24700,
30300,
25500,
4900,
10800,
null,
61547,
24000,
42600,
17700,
48500,
59300,
42800,
15300,
16600,
11900,
9100,
2900,
60300,
13500,
40000,
38900,
null,
29000,
9900,
20500,
28000,
64000,
34000,
74635,
47900,
22400,
119900,
7100,
49100,
null,
40500,
24700,
22700,
7000,
12200,
18100,
5900,
34400,
86000,
14100,
38000,
72500,
null,
43189,
10010,
25200,
30000,
28700,
8300,
18400,
8700,
9000,
125900,
8700,
6700,
14400,
24300,
97800,
25222,
39200,
null,
22100,
39400,
41300,
17500,
45700,
48700,
15500,
7600,
27600,
25300,
5700,
15709,
21700,
23800,
34700,
10100,
14100,
21400,
69500,
18100,
42200,
28400,
21600,
13100,
14600,
11700,
15000,
6800,
23100,
9200,
17800,
15200,
11900,
21200,
73800,
29100,
25500,
20900,
97900,
25200,
28100,
11800,
10200,
26500,
40000,
16500,
23900,
17400,
null,
14700,
14500,
155700,
27000,
55700,
8300,
9800,
17100,
17700,
43500,
7700,
26900,
28700,
14600,
18700,
66000,
15300,
7900,
24400,
46600,
51500,
69400,
3500,
8700,
27600,
58500,
16900,
14600,
27345,
null,
19900,
29300,
33200,
33000,
15000,
2500,
34600,
17000,
77100,
22100,
32600,
158000,
8300,
20700,
144800,
41500,
24700,
26800,
38900,
22000,
64500,
33500,
35700,
3800,
6400,
18600,
18500,
12300,
21500,
9700,
5200,
13300,
8700,
34600,
114600,
23500,
null,
50000,
43400,
null,
16800,
23200,
8800,
21500,
12000,
10750,
18700,
43500,
26500,
17000,
144800,
22100,
53646,
14100,
26060,
79900,
204100,
43200,
13100,
38400,
null,
34800,
17200,
16300,
46700,
38800,
108100,
50400,
14400,
7100,
22300,
10700,
7000,
40100,
28900,
42400,
68500,
30100,
47100,
7400,
48800,
null,
41700,
4200,
null,
41500,
48000,
null,
13500,
25903,
29000,
6500,
32300,
null,
85700,
75300,
26400,
25400,
38800,
5000,
7400,
73000,
20625,
26600,
26000,
8200,
50800,
24000,
null,
41300,
38300,
null,
32200,
27500,
21400,
119700,
93700,
12700,
35300,
18400,
5100,
10300,
null,
57600,
19000,
17400,
17500,
5800,
54600,
45900,
43000,
19600,
36000,
36700,
21200,
32200,
null,
10800,
28400,
13400,
32400,
null,
133100,
71900,
78500,
12000,
36000,
25300,
19700,
null,
10900,
56200,
11100,
29400,
5800,
49700,
10600,
37300,
5900,
3000,
19600,
24000,
15400,
45300,
23300,
71100,
10800,
84500,
16900,
14800,
17300,
12600,
17700,
37700,
10300,
15000,
44800,
99200,
18700,
18200,
14800,
15800,
66247,
49900,
28300,
88100,
40000,
null,
16300,
53300,
13200,
15000,
12950,
null,
14400,
7900,
13500,
33700,
40600,
29000,
30000,
5100,
11500,
10800,
11500,
14700,
57400,
50900,
13000,
29800,
50700,
25167,
27800,
199200,
12300,
268100,
39900,
24200,
19700,
null,
66400,
14500,
13800,
19800,
45200,
9800,
67900,
52350,
28800,
15400,
19300,
22700,
26300,
62900,
44700,
54400,
8650,
56500,
7500,
28700,
37474,
39000,
9000,
10700,
21100,
17000,
41700,
null,
12300,
61800,
28200,
33000,
16700,
37600,
23000,
75500,
13400,
14000,
19000,
20000,
9000,
118850,
31200,
64800,
30400,
33800,
122400,
15600,
13400,
41700,
95100,
39100,
32000,
27300,
5700,
16300,
39300,
10600,
12000,
25800,
24500,
41900,
53000,
12000,
18600,
2800,
null,
43500,
21300,
43700,
44800,
12050,
21500,
10700,
35000,
9000,
28000,
51200,
43900,
27000,
35400,
35600,
null,
52500,
49500,
26900,
26300,
7000,
8200,
34000,
5700,
46900,
17500,
71000,
111100,
null,
39500,
34300,
62200,
51400,
18400,
19900,
40100,
66400,
68200,
37000,
30700,
40400,
12000,
35200,
44800,
5500,
22800,
13500,
57500,
24400,
null,
13000,
43400,
38000,
72500,
12900,
20500,
3000,
15300,
null,
54700,
43100,
25100,
17800,
22300,
13600,
7700,
8600,
null,
null,
13300,
12200,
3300,
37200,
11600,
17900,
32300,
31500,
25000,
92500,
2300,
9200,
34000,
55850,
34400,
33240,
31300,
15900,
23500,
43200,
26400,
26600,
23600,
null,
null,
12300,
12300,
9100,
20500,
16300,
39400,
1200,
8100,
42100,
10800,
25800,
19500,
20000,
23600,
24700,
24500,
65143,
58100,
14900,
null,
82800,
null,
52300,
38800,
42600,
110100,
null,
43500,
8600,
48000,
158300,
10000,
13800,
80100,
42800,
36500,
17600,
25700,
6000,
5100,
23300,
89600,
23600,
25500,
48290,
14600,
15300,
21600,
40900,
63100,
36400,
21200,
8100,
33800,
22500,
150160,
12100,
null,
61500,
27200,
62300,
20800,
47600,
22600,
13600,
49100,
25700,
9800,
6300,
14000,
23200,
20000,
26100,
18900,
43400,
18100,
27800,
36700,
60000,
39900,
62400,
25400,
24100,
3700,
27200,
9800,
12900,
17600,
14000,
12750,
19000,
11700,
28900,
null,
9900,
30500,
23800,
77100,
8100,
null,
19400,
90008,
11800,
22300,
6300,
69900,
73700,
36300,
null,
42700,
35400,
53800,
10500,
54300,
12100,
17800,
46400,
10800,
17200,
33900,
33400,
66500,
null,
36800,
49500,
10800,
25100,
34000,
48200,
6000,
29800,
14900,
22500,
43600,
12300,
56300,
9900,
40900,
25200,
28744,
24500,
34300,
2600,
16200,
5000,
29500,
null,
13200,
77400,
15500,
87600,
22900,
18100,
35000,
53600,
5500,
null,
18000,
6100,
13430,
14700,
22500,
13400,
44600,
7600,
29400,
111700,
10200,
83300,
17200,
22300,
39400,
9700,
58800,
40700,
11500,
14300,
769000,
60400,
14500,
64200,
26500,
null,
20800,
33900,
16400,
23100,
6800,
3100,
23100,
14800,
13900,
15100,
11500,
102700,
17100,
31600,
133400,
21200,
78200,
28428,
null,
9400,
73300,
29500,
91200,
18500,
8500,
36300,
87000,
32000,
143000,
null,
29300,
47300,
69100,
16400,
40700,
11200,
274560,
7800,
31100,
6400,
38400,
26700,
33800,
16400,
null,
18200,
17400,
17100,
6100,
5600,
21500,
20100,
11300,
117900,
18700,
12500,
null,
null,
null,
74400,
23400,
15800,
42900,
28200,
60900,
11500,
76244,
114100,
26600,
25000,
7200,
117900,
50300,
7500,
5500,
47200,
66000,
20800,
26800,
7700,
16700,
16200,
27200,
15500,
6000,
7500,
30800,
10500,
22500,
81200,
13000,
19700,
11200,
23000,
13200,
128400,
12000,
23600,
8800,
34800,
47888,
24500,
30800,
14600,
49600,
8900,
11300,
32600,
41500,
31600,
80300,
null,
37800,
50600,
34500,
5900,
46300,
4500,
23600,
4300,
null,
80500,
29900,
16200,
33200,
null,
24700,
10900,
21200,
30200,
9500,
16100,
44100,
42996,
16100,
null,
68500,
20100,
18400,
6700,
184200,
42600,
59100,
24100,
7200,
15900,
33800,
3100,
17200,
45800,
20600,
13300,
5900,
null,
9400,
null,
75200,
14400,
86300,
24500,
null,
39500,
null,
73815,
65700,
20800,
38200,
25900,
10400,
154700,
null,
51400,
61400,
38900,
48600,
5510,
24800,
14200,
17700,
15500,
40400,
14000,
30700,
46800,
64100,
35600,
5400,
59900,
16700,
45300,
43000,
21800,
41600,
48900,
11900,
11600,
50900,
37200,
50800,
16900,
51600,
77200,
28200,
374500,
11900,
22500,
21700,
15000,
28050,
52400,
5100,
86500,
18400,
10200,
13600,
null,
36700,
38300,
28400,
10600,
19700,
24600,
25800,
null,
70700,
7400,
29300,
7900,
58500,
null,
17000,
13500,
27600,
11600,
25700,
48800,
89000,
24200,
21400,
30500,
39200,
null,
32400,
38800,
122300,
12600,
14000,
7400,
32300,
17400,
49400,
128500,
64700,
8600,
38200,
55000,
38700,
10900,
44200,
27400,
4900,
41500,
16100,
null,
5200,
null,
26800,
3000,
46300,
25700,
24200,
22600,
32900,
12000,
33800,
5100,
52700,
40100,
109400,
11500,
12000,
39200,
null,
null,
16650,
16600,
3000,
42000,
1600,
27100,
38800,
17100,
16500,
80500,
29000,
39500,
27500,
49600,
21600,
57700,
null,
500,
48500,
17500,
18100,
34100,
10200,
28500,
41100,
56400,
4000,
8000,
67200,
40100,
11100,
21200,
43100,
23400,
14300,
8400,
6500,
32700,
20200,
22100,
23200,
36400,
13800,
30100,
27500,
null,
32800,
9500,
7200,
175700,
15200,
null,
5100,
41400,
10300,
null,
null,
3800,
17000,
1300,
14800,
10800,
6500,
56100,
93600,
106800,
66600,
77200,
23410,
null,
30600,
123900,
null,
12300,
34500,
52300,
61200,
7400,
83600,
13500,
24500,
9100,
8900,
13000,
50500,
14800,
null,
9000,
null,
17300,
10100,
69500,
9730,
73500,
19000,
8600,
61500,
20500,
null,
30300,
10400,
37700,
null,
40200,
null,
7000,
12300,
31400,
11500,
25500,
13200,
19600,
44400,
10500,
23700,
60000,
45400,
24800,
51500,
21800,
15800,
10400,
28200,
null,
32200,
59500,
8200,
17200,
51000,
null,
19700,
81300,
5500,
7600,
47300,
8400,
12800,
22500,
27200,
21200,
null,
23400,
44900,
21700,
22100,
56400,
10000,
38500,
100500,
32900,
22200,
16300,
9300,
21400,
30500,
5500,
63500,
35500,
17600,
46400,
20600,
30200,
35400,
33400,
7400,
15800,
17300,
27800,
24500,
10100,
39700,
13700,
21600,
30600,
7400,
45400,
13400,
12200,
16600,
null,
21000,
15600,
46900,
29000,
9200,
46000,
18400,
19600,
27900,
31900,
63600,
11200,
48700,
36300,
23900,
52600,
4900,
11500,
14900,
64300,
71700,
25100,
19700,
10200,
10600,
9300,
83000,
14000,
null,
9800,
65100,
9100,
30500,
44800,
21400,
11100,
6300,
null,
23700,
19200,
15600,
32800,
19900,
81900,
8400,
32200,
null,
7000,
51400,
12800,
14800,
null,
21300,
74100,
null,
10300,
null,
17700,
79100,
6100,
19500,
7400,
39900,
8800,
18400,
51400,
37000,
41100,
24100,
34600,
38200,
8400,
28200,
5900,
23800,
14000,
55900,
58100,
23200,
58000,
117400,
43100,
31800,
29500,
null,
17600,
30100,
29800,
11000,
63500,
47500,
14000,
16000,
30500,
10800,
21300,
9800,
19900,
29800,
12500,
null,
null,
11500,
7800,
20500,
47600,
25600,
66600,
12100,
null,
6200,
8700,
6000,
22200,
27100,
50300,
44700,
19000,
13700,
36500,
10100,
13200,
54800,
11100,
28600,
63100,
54600,
8400,
28800,
34900,
16800,
44400,
200500,
7500,
28600,
27300,
41200,
9400,
15600,
24600,
90100,
9200,
32700,
120700,
22100,
10400,
26200,
null,
null,
33100,
26000,
13100,
99300,
30000,
22000,
27200,
27400,
27900,
24500,
49800,
14300,
35500,
17500,
65800,
10500,
18200,
7800,
41700,
47800,
7300,
9500,
12000,
26900,
38500,
34200,
4600,
11000,
18100,
18400,
24100,
5200,
17500,
36200,
67000,
6000,
38300,
53300,
null,
18000,
37600,
31400,
21600,
25300,
15700,
8000,
108800,
56800,
8500,
14200,
20300,
26000,
30100,
9900,
21300,
30300,
6000,
7000,
13100,
5500,
9800,
6000,
53047,
42100,
9200,
41200,
18100,
3500,
11400,
26600,
4300,
23600,
20800,
12300,
30600,
28600,
16800,
40100,
62300,
20100,
46900,
10100,
15500,
51300,
11400,
5700,
23900,
14800,
41889,
14100,
26600,
156300,
55500,
4800,
34600,
6700,
9200,
97900,
9400,
53464,
20700,
7100,
8600,
21300,
12800,
31900,
19200,
9800,
22600,
33600,
6700,
50300,
29700,
18070,
7000,
null,
15800,
37200,
11300,
22800,
9700,
21600,
11700,
37400,
7500,
16500,
12500,
31800,
23000,
16800,
17800,
57600,
50300,
51400,
46000,
24400,
34500,
37700,
19500,
19600,
null,
51700,
23700,
32600,
null,
32900,
114300,
17000,
42350,
19300,
null,
8000,
54200,
37400,
null,
null,
11200,
33700,
24300,
null,
70400,
29300,
29800,
34400,
6900,
13000,
null,
29800,
23500,
56900,
8700,
8500,
8100,
3500,
102700,
22300,
7900,
137600,
null,
20500,
44000,
12700,
63300,
70300,
59400,
7800,
18100,
65300,
6500,
25800,
29300,
16900,
34500,
13100,
11400,
13900,
4100,
18900,
31100,
36000,
9300,
28300,
23300,
null,
null,
18600,
14800,
9600,
11100,
25700,
4300,
47400,
52100,
33100,
57400,
47200,
48700,
22800,
6600,
17300,
20100,
42500,
84200,
17500,
60000,
46600,
28600,
33800,
24300,
8700,
79200,
6200,
30300,
7000,
149500,
45100,
21200,
29400,
null,
31400,
21200,
7000,
25600,
8000,
32500,
38200,
10800,
10600,
34700,
8100,
103500,
9000,
37200,
20000,
28100,
30400,
12500,
5300,
null,
30500,
7400,
16000,
25200,
22400,
28800,
28800,
13900,
124100,
18200,
8800,
43800,
3100,
30000,
38137,
23200,
null,
22400,
33900,
32900,
39300,
89745,
23900,
80900,
15000,
4600,
30600,
24900,
25900,
9500,
12800,
32800,
51200,
null,
52400,
16900,
22700,
31800,
32800,
8600,
31500,
21200,
18300,
62800,
7000,
null,
37400,
48900,
33700,
22000,
3200,
15700,
19100,
47000,
38500,
16100,
24500,
20900,
9200,
51500,
46600,
44300,
53500,
19000,
18500,
36700,
16700,
15600,
59800,
9900,
25700,
15800,
4200,
51400,
5100,
28900,
35800,
21000,
4300,
33800,
92800,
29800,
null,
57300,
null,
null,
12700,
67200,
36900,
40900,
17200,
31900,
null,
40038,
32400,
13300,
28000,
5800,
34318,
84315,
10200,
10100,
15800,
21000,
7100,
21900,
10700,
26300,
56300,
null,
18200,
null,
9400,
null,
15400,
42850,
17400,
26500,
null,
15900,
null,
33000,
20900,
18900,
21600,
29600,
30800,
37900,
5100,
21500,
29400,
10000,
29000,
7200,
35200,
30100,
null,
54340,
10700,
5800,
19300,
17100,
8100,
78600,
43900,
13000,
69500,
9900,
67400,
null,
15000,
41600,
41200,
24900,
40300,
14300,
null,
53000,
6200,
16200,
39000,
25900,
17700,
13800,
94700,
33000,
9700,
50800,
23900,
17000,
39600,
43900,
16500,
null,
15900,
27600,
6300,
34700,
21700,
16400,
8000,
32300,
82200,
20800,
7600,
42400,
74500,
24300,
77500,
15500,
21800,
43100,
201800,
96000,
3250,
53200,
null,
3700,
17800,
46900,
28500,
51100,
null,
15600,
9200,
null,
78900,
null,
130400,
166100,
90300,
44100,
93100,
40700,
18300,
39600,
30900,
20600,
118400,
null,
3300,
34200,
null,
18800,
16400,
57500,
25300,
23800,
24000,
29117,
6300,
16800,
16500,
13900,
20100,
19000,
53000,
29000,
4500,
33800,
76800,
64700,
18100,
18700,
15300,
36300,
68400,
null,
126300,
29800,
67300,
20100,
36200,
49700,
54700,
null,
19300,
64200,
7500,
86700,
12600,
60700,
20200,
null,
23900,
6700,
102200,
5100,
39000,
21300,
69400,
17700,
13000,
null,
40500,
20500,
20200,
23700,
12000,
72400,
24900,
13100,
11400,
66500,
13700,
13300,
86600,
41300,
21600,
13800,
16900,
14500,
5300,
17100,
90100,
10100,
21500,
33000,
9900,
null,
33100,
33000,
9200,
38400,
null,
29950,
222600,
43300,
58300,
21500,
18000,
null,
11550,
null,
36700,
20200,
9300,
20300,
18400,
null,
7900,
13693,
12900,
19500,
31600,
34300,
7500,
9700,
11000,
49600,
101800,
6000,
23700,
52900,
25900,
25898,
null,
29200,
8400,
16400,
33600,
null,
null,
17300,
22400,
16100,
7100,
21800,
24100,
20900,
42000,
36800,
26200,
null,
8700,
15300,
null,
11700,
41700,
7800,
17500,
9600,
14000,
null,
35200,
11500,
36900,
6600,
16700,
13200,
74200,
15100,
16600,
21200,
11900,
39900,
10000,
65300,
50400,
18100,
8300,
null,
11400,
null,
20800,
12500,
49500,
8500,
49600,
10500,
25300,
18000,
5600,
null,
57400,
null,
64800,
9415,
23400,
28900,
38562,
45600,
45900,
15600,
null,
null,
5300,
30500,
124200,
99500,
8450,
11900,
11850,
8100,
26100,
26000,
43500,
null,
127300,
14100,
56400,
39000,
16500,
18100,
null,
10600,
54900,
41700,
132000,
7700,
13300,
null,
null,
100400,
72600,
11800,
13700,
42700,
null,
16100,
40900,
24800,
10500,
20500,
17300,
38000,
25900,
15700,
14300,
35400,
null,
20000,
30400,
23500,
112700,
14500,
6400,
18900,
25800,
33500,
50000,
38000,
2950,
17800,
1200,
34900,
20700,
48800,
30700,
77700,
25200,
44500,
9600,
19600,
null,
67600,
51800,
67200,
55300,
52900,
40300,
79100,
20300,
7950,
30600,
13500,
20500,
3900,
12900,
13300,
7500,
47800,
12400,
28400,
28700,
31400,
26300,
48500,
11200,
48100,
16500,
4500,
88750,
38300,
18100,
8200,
24300,
21900,
16000,
114500,
null,
null,
38000,
21600,
34800,
48000,
null,
47600,
8800,
null,
null,
31900,
20600,
30900,
40500,
37900,
null,
6700,
37400,
8300,
5700,
15600,
15317,
15000,
36800,
47000,
42200,
19500,
55600,
null,
9700,
33700,
99400,
6000,
1700,
41800,
15200,
12500,
null,
26700,
7800,
62900,
38296,
12900,
118200,
25400,
27100,
8100,
24400,
18300,
6800,
22000,
29174,
112900,
12900,
36000,
23000,
null,
52700,
58700,
12500,
null,
null,
19700,
10400,
31800,
16300,
6800,
23500,
49100,
8000,
15500,
18300,
43100,
9353,
8000,
113500,
51700,
27200,
5200,
26000,
28100,
25000,
30600,
44300,
15900,
8200,
27300,
63500,
13000,
null,
null,
23100,
null,
28100,
6000,
22000,
18300,
6000,
17500,
20400,
8200,
42400,
51100,
11200,
12800,
null,
8300,
14800,
54400,
13700,
34300,
9000,
27500,
26700,
32500,
8100,
12700,
49200,
19700,
8900,
null,
112000,
44400,
17000,
22800,
45000,
61600,
24400,
20000,
57000,
22500,
5600,
18000,
22200,
258700,
49900,
15600,
25700,
14900,
41500,
18800,
18700,
null,
29900,
24900,
16800,
12900,
27200,
null,
null,
60300,
15800,
null,
2600,
35300,
23400,
42300,
24000,
34400,
2100,
2700,
3390,
16700,
54300,
null,
3600,
33100,
25200,
57700,
28000,
4000,
47600,
null,
19800,
17700,
43300,
4500,
22200,
34000,
26400,
24400,
12100,
35700,
20000,
46200,
14800,
6400,
19600,
29100,
110700,
12300,
null,
11300,
33200,
11200,
38700,
11900,
26300,
26400,
35800,
71100,
26100,
180800,
17700,
28200,
62700,
12500,
34900,
15100,
45100,
42900,
29300,
15500,
13200,
36800,
11000,
15100,
33700,
4375,
28500,
12600,
null,
47400,
10500,
25450,
12700,
21000,
11400,
125800,
28900,
10450,
39600,
19500,
30900,
49900,
34400,
27500,
29100,
76300,
53400,
13800,
47000,
109100,
9245,
193700,
null,
10800,
17600,
7000,
32800,
18800,
40700,
89400,
5200,
null,
7800,
33200,
16100,
14350,
47700,
24600,
33200,
10900,
25400,
128400,
74300,
null,
15900,
7600,
26200,
14400,
55900,
27200,
20600,
9500,
24200,
44700,
42200,
32200,
37100,
7150,
14600,
12300,
29400,
8500,
27700,
28900,
18300,
43700,
105100,
null,
36800,
29900,
30200,
8300,
34000,
43600,
45100,
90100,
181600,
5800,
20300,
18400,
44500,
25600,
23500,
10100,
18000,
5000,
10400,
6200,
24100,
25300,
39000,
22000,
10700,
13600,
23300,
49800,
11700,
16400,
95800,
29100,
null,
31500,
28400,
17700,
39600,
5400,
33900,
25200,
23600,
13200,
600,
null,
20600,
36450,
null,
37700,
34000,
22200,
143500,
29000,
41900,
16700,
9300,
50600,
5900,
53400,
51455,
46000,
55400,
31400,
77900,
156900,
56800,
19200,
242400,
2000,
20200,
null,
44501,
21800,
33300,
27500,
40200,
null,
64400,
11200,
45200,
14000,
101500,
37700,
11000,
40900,
25500,
41500,
null,
54800,
42459,
36900,
67700,
124000,
19400,
36600,
23000,
14700,
75300,
21800,
30600,
13400,
9400,
15600,
3100,
91100,
17500,
68100,
8000,
29500,
31200,
54484,
12300,
38900,
9300,
78400,
22600,
24100,
20250,
null,
7850,
11800,
19900,
10800,
7000,
30700,
25700,
32000,
63200,
14900,
null,
49600,
9100,
158600,
12600,
43800,
28600,
19400,
21600,
14900,
64300,
6500,
10500,
4500,
null,
22600,
36700,
55400,
5300,
8600,
30600,
null,
11100,
15800,
30000,
51000,
31700,
110900,
22200,
38200,
17800,
42400,
null,
37400,
82500,
36000,
25000,
14600,
37400,
7800,
42100,
51300,
6300,
5400,
110800,
10700,
42500,
71400,
11700,
29676,
22900,
13350,
27700,
11460,
78700,
30000,
5000,
17000,
24200,
17000,
10600,
16700,
6200,
14600,
19300,
39100,
14100,
3600,
86800,
76100,
22100,
8800,
17800,
11500,
36600,
41700,
12200,
48122,
7200,
null,
34000,
110200,
13500,
23800,
17000,
64900,
5400,
14400,
13000,
17300,
34300,
18900,
32500,
34400,
4600,
58300,
194600,
22300,
43000,
13500,
12900,
81600,
10100,
4800,
9300,
null,
19500,
5700,
18100,
null,
40400,
27700,
66700,
26400,
60500,
4000,
19800,
171400,
28200,
26500,
126500,
14100,
41300,
27100,
null,
31600,
6000,
24700,
19300,
null,
76300,
31900,
52800,
22800,
38800,
36800,
14400,
16300,
23100,
55310,
8400,
9100,
8800,
31800,
21000,
18700,
55500,
10900,
112400,
43600,
18600,
23700,
23600,
18200,
14300,
8800,
null,
39700,
8600,
79500,
18400,
20400,
11500,
45000,
14900,
23400,
16400,
43400,
80900,
128900,
50500,
16000,
57800,
5500,
5400,
15100,
63400,
27200,
13000,
42300,
39600,
16700,
4900,
35300,
null,
14800,
45500,
34300,
36600,
5700,
114900,
6700,
null,
40500,
23100,
26100,
54800,
36800,
37200,
38800,
49700,
64171,
5400,
12500,
30500,
21100,
21100,
9400,
2300,
12400,
4200,
null,
27200,
40300,
37100,
33550,
30300,
18200,
28000,
55400,
11400,
77900,
40200,
22200,
54600,
13500,
43300,
48100,
22600,
38900,
13100,
null,
11500,
12400,
60100,
39700,
18500,
51000,
10900,
21700,
61000,
36100,
34400,
30100,
26100,
38800,
11700,
23000,
8900,
null,
229700,
53300,
null,
14300,
null,
16100,
19900,
43500,
50000,
21800,
21400,
30900,
23900,
81800,
15000,
23600,
5500,
111900,
24400,
57000,
8400,
65000,
21100,
63000,
18800,
12100,
206200,
14700,
69000,
32800,
31300,
null,
28700,
7860,
101767,
130900,
16100,
28810,
22400,
23800,
null,
6700,
23500,
6800,
14400,
11800,
3300,
22700,
16600,
74400,
11600,
32300,
46200,
22900,
19000,
null,
25800,
38100,
2800,
10400,
24700,
26200,
17800,
15500,
34700,
null,
48800,
80500,
30200,
88700,
44800,
9600,
null,
47300,
3500,
29000,
41300,
2500,
28300,
20400,
25700,
78000,
20500,
55500,
36100,
50358,
18400,
13500,
9200,
32000,
20700,
3160,
18000,
51800,
23300,
23000,
15586,
17000,
58200,
5050,
null,
48100,
42400,
null,
17700,
15900,
29000,
62000,
144800,
52658,
12100,
30800,
30700,
22500,
20700,
47700,
10700,
null,
12300,
24800,
23800,
25200,
17200,
32300,
4600,
13700,
58500,
52300,
27500,
9200,
18800,
10800,
56000,
28000,
9100,
53700,
32300,
12100,
10200,
24300,
42100,
53500,
22700,
60600,
156800,
24400,
21100,
16300,
48400,
28800,
16400,
42500,
186100,
51000,
17500,
20300,
9000,
23900,
null,
3500,
1000,
12000,
22400,
27600,
17600,
4800,
25000,
8500,
5300,
28100,
13900,
17700,
24700,
12900,
18800,
29100,
9500,
55700,
53800,
21349,
85400,
19900,
39100,
65000,
31000,
9000,
null,
43100,
16200,
60000,
13800,
15300,
49300,
8900,
null,
43200,
null,
64900,
28400,
29600,
8100,
16000,
7200,
10200,
31300,
11900,
39000,
4300,
33500,
25400,
null,
53900,
61900,
null,
null,
19600,
25200,
32400,
null,
14094,
37600,
13800,
60300,
26500,
16800,
45300,
10600,
61500,
97800,
47500,
14400,
9900,
68000,
5800,
51200,
17000,
71700,
37900,
10200,
null,
null,
19400,
44300,
12100,
null,
125400,
9600,
29500,
8000,
null,
21350,
124043,
null,
49800,
21300,
null,
69600,
201900,
null,
165500,
null,
20700,
15700,
58600,
50800,
14600,
13800,
9100,
37500,
16000,
81500,
9600,
22800,
23800,
41700,
50500,
83100,
9700,
36741,
21100,
9500,
27100,
14500,
80600,
null,
7950,
24900,
41800,
27404,
6900,
4500,
20000,
35000,
80200,
30900,
36800,
null,
101700,
16300,
12600,
7100,
50200,
19700,
17508,
95500,
32200,
9200,
44100,
30300,
28400,
32300,
41200,
53400,
26300,
15300,
11600,
15700,
28900,
47500,
25400,
26250,
4900,
99400,
39700,
null,
36200,
35000,
38800,
60487,
20000,
84500,
21600,
22500,
64600,
13500,
13100,
56900,
10200,
6200,
63400,
102300,
125800,
21400,
14400,
17500,
6669,
35600,
59250,
null,
null,
17300,
40700,
16700,
10800,
47400,
17700,
257200,
12200,
24000,
57200,
33700,
12700,
23800,
null,
30400,
50800,
24500,
21800,
182100,
86200,
51500,
23000,
29000,
25300,
11600,
17500,
null,
22200,
10900,
null,
32500,
48100,
null,
49000,
21700,
9100,
7900,
6900,
34100,
10900,
6000,
68400,
43200,
16300,
null,
34200,
71100,
null,
4200,
21700,
15800,
16160,
14000,
21400,
17700,
7900,
null,
57000,
45500,
41500,
16700,
29000,
33000,
4100,
45100,
46500,
34500,
39200,
291100,
19600,
95000,
20300,
48200,
10700,
21600,
13600,
1700,
13100,
15600,
6000,
76900,
12700,
27600,
63500,
56900,
16400,
57362,
52300,
32000,
null,
18400,
13300,
22000,
21300,
10500,
15800,
49900,
38200,
47400,
105500,
7700,
7100,
13900,
42700,
28700,
93400,
49800,
4200,
79200,
17400,
25200,
18794,
32100,
null,
null,
null,
38400,
95100,
29400,
16900,
28500,
53200,
27500,
53700,
36500,
42200,
34800,
38100,
26400,
null,
35000,
14800,
18800,
20900,
31200,
45600,
13900,
19300,
21700,
37000,
13300,
18600,
20100,
18500,
45900,
null,
7100,
31600,
null,
46400,
37100,
10500,
18900,
70600,
42700,
61700,
10200,
64100,
13500,
5100,
14000,
7800,
17900,
21200,
56700,
9800,
27800,
28200,
null,
40300,
42000,
105300,
11200,
28200,
33800,
34000,
25500,
28100,
10500,
76000,
26500,
6900,
33500,
22100,
14700,
40700,
38900,
29600,
27700,
12900,
21700,
39700,
409600,
96400,
35800,
62600,
39200,
19875,
67100,
2300,
1000,
32600,
24100,
19000,
7250,
54400,
86100,
13900,
8100,
14800,
48800,
8600,
36100,
42400,
null,
16700,
25000,
32700,
30900,
46100,
null,
5000,
5300,
62600,
9600,
14600,
6000,
12200,
57900,
19400,
37900,
27100,
8400,
18600,
18100,
56400,
10700,
21200,
22200,
37900,
20052,
5100,
77600,
52800,
18900,
63600,
53800,
19400,
21200,
34100,
null,
83400,
11000,
14200,
9800,
6800,
19800,
15500,
8400,
30500,
22700,
21500,
27000,
34700,
13200,
19600,
40300,
21700,
6600,
88500,
null,
4800,
28900,
36000,
13000,
2600,
500,
null,
95700,
12500,
53400,
37700,
7000,
39300,
21900,
32200,
33600,
8900,
12700,
28400,
42500,
23600,
20000,
13300,
57600,
46500,
10800,
23900,
7500,
20600,
6200,
49200,
21600,
8900,
66600,
4800,
29400,
19700,
18800,
30600,
74800,
11700,
3900,
48800,
19500,
29100,
24700,
34300,
64400,
99400,
115000,
6900,
28900,
54200,
21800,
21700,
33800,
28500,
24200,
null,
15900,
4200,
51100,
17200,
30500,
21300,
27900,
56200,
20000,
62500,
9300,
20900,
59100,
67500,
11200,
51600,
44300,
27200,
39700,
6900,
null,
19000,
37300,
36100,
41200,
19900,
78400,
32000,
23700,
8400,
18300,
12800,
38600,
55800,
41600,
16400,
73100,
54600,
11500,
38900,
22000,
null,
27700,
6300,
114800,
10500,
null,
10800,
null,
21800,
29500,
29900,
16900,
16000,
53500,
31900,
58300,
57100,
14800,
26600,
null,
10500,
30300,
9100,
null,
38100,
6000,
17100,
41700,
null,
37200,
16800,
54300,
4500,
17100,
119800,
34750,
18000,
26100,
32200,
52000,
46400,
18900,
10900,
33500,
37500,
5000,
15000,
8400,
27200,
58000,
14300,
7600,
26200,
19600,
13700,
61000,
null,
15200,
68800,
10500,
75000,
27500,
90300,
null,
18600,
41700,
29300,
31900,
17300,
13900,
40700,
41900,
13200,
46700,
26500,
12800,
null,
10000,
23500,
3600,
23600,
4990,
27000,
null,
13350,
23400,
7900,
75600,
24100,
29266,
68300,
20900,
38300,
10500,
14100,
11000,
43000,
16400,
153400,
null,
29700,
11400,
57805,
31800,
71800,
27800,
35000,
23700,
41400,
19900,
52200,
18300,
8700,
null,
17500,
66000,
9700,
8300,
6400,
3000,
17700,
26100,
60200,
28800,
57200,
null,
null,
118960,
22800,
38600,
32800,
6700,
25900,
19967,
40600,
31100,
9600,
43200,
32700,
9800,
26300,
12100,
58660,
93000,
33400,
23900,
24700,
9000,
19000,
null,
36600,
22600,
12300,
62100,
3100,
22200,
57900,
null,
230500,
59700,
10600,
12700,
26400,
7500,
65000,
36300,
14500,
19400,
19800,
null,
75262,
21700,
18400,
44400,
22100,
20224,
31500,
30300,
4500,
21300,
35500,
null,
9800,
65200,
null,
18000,
12300,
6000,
60200,
10100,
8200,
20800,
27800,
10300,
6600,
132600,
22600,
5500,
20600,
35000,
44000,
null,
4600,
27100,
57400,
30900,
26200,
60100,
13900,
37100,
35300,
22500,
36200,
null,
26900,
13800,
28800,
24400,
27300,
null,
16200,
15700,
48900,
10900,
16100,
32100,
28900,
29000,
32000,
34600,
12300,
72900,
1800,
8800,
11200,
6000,
101600,
26700,
12900,
35100,
18000,
6500,
15900,
30000,
16300,
51800,
9400,
18900,
61500,
41900,
null,
71900,
38800,
32200,
32300,
35800,
38600,
58400,
3900,
8600,
22200,
23200,
29800,
10900,
34800,
null,
22400,
null,
27600,
19100,
55800,
null,
11500,
12000,
38500,
38000,
22900,
23600,
29200,
3500,
null,
31400,
15500,
null,
225300,
18400,
64700,
37400,
16700,
22000,
22700,
null,
10700,
15600,
31600,
7300,
155413,
20500,
29900,
43800,
13400,
23700,
15900,
54900,
62970,
30000,
17690,
16900,
71400,
18300,
1000,
1500,
87900,
60000,
77400,
6600,
7900,
5300,
70900,
null,
17600,
null,
95600,
18600,
8700,
24600,
10000,
14400,
60700,
6500,
18700,
19000,
47900,
41000,
24800,
5000,
7600,
null,
117300,
9400,
22200,
30700,
30900,
5800,
18400,
38000,
null,
35800,
57400,
14200,
48900,
69200,
46400,
16000,
16700,
39000,
33600,
15900,
15800,
157000,
12000,
11400,
24500,
3950,
1850,
15700,
56200,
30700,
31000,
74400,
56000,
45700,
11400,
34200,
5600,
null,
23400,
15300,
74750,
19700,
30300,
25700,
18700,
23300,
17540,
72200,
null,
16400,
6500,
17000,
43600,
20000,
14900,
22300,
21900,
12300,
25600,
69000,
27300,
16000,
18800,
38800,
17600,
21000,
10100,
18800,
9900,
15300,
2700,
30200,
23400,
27700,
10900,
5000,
1500,
3800,
27100,
55000,
19800,
null,
10600,
14900,
16600,
30300,
16400,
76100,
5900,
6900,
25600,
60000,
9800,
null,
31800,
5500,
30000,
39800,
37300,
17300,
11000,
30400,
25300,
22800,
20500,
33400,
1800,
null,
42800,
54200,
19400,
12100,
23900,
13800,
12000,
7500,
17700,
22100,
36400,
null,
51900,
24900,
20800,
21800,
19550,
6200,
47500,
62000,
19700,
28400,
17600,
null,
11500,
37600,
300,
23900,
23900,
19000,
47500,
10100,
31000,
55700,
11000,
51600,
38600,
3400,
36200,
17100,
4900,
8400,
59200,
14900,
143200,
500,
20200,
8800,
38800,
38700,
null,
9700,
null,
17000,
30900,
23900,
24800,
21600,
10000,
24000,
13900,
38100,
22600,
15900,
15900,
33100,
null,
20700,
78500,
53800,
26200,
null,
19200,
57200,
10400,
19900,
10900,
37800,
53200,
15600,
13500,
26800,
13800,
null,
9800,
4400,
39900,
15400,
10200,
12800,
45000,
14350,
10300,
41200,
17000,
14400,
null,
32500,
11000,
35700,
null,
19500,
9400,
21000,
34000,
null,
9800,
15900,
31900,
39100,
34100,
24900,
8400,
6700,
48700,
40300,
10700,
7600,
40300,
85500,
29100,
21300,
64800,
42800,
33100,
23200,
18800,
18500,
4500,
40500,
79100,
1300,
19500,
14100,
13400,
43500,
41500,
null,
81200,
75800,
null,
30800,
21600,
38700,
7000,
19700,
10900,
37900,
23700,
33500,
31700,
18600,
34000,
18400,
25200,
19400,
null,
39500,
28000,
67000,
35200,
43100,
null,
21700,
null,
19600,
76500,
12500,
18500,
26500,
26600,
2800,
27500,
17500,
9900,
49200,
13800,
35500,
15200,
null,
22400,
50800,
8800,
5600,
116100,
26900,
22700,
17600,
19500,
13400,
27300,
16836,
12600,
null,
59800,
13600,
22100,
5700,
28500,
120200,
null,
null,
18500,
null,
28800,
null,
150657,
7818,
17400,
71600,
9500,
21200,
67300,
null,
40200,
18900,
15000,
245000,
17510,
26900,
30700,
52700,
15400,
4000,
21800,
16100,
111800,
34100,
86000,
97500,
22800,
11900,
9500,
14400,
15700,
25200,
37600,
40450,
132500,
16400,
34400,
null,
43700,
7600,
39500,
13400,
7800,
26100,
18500,
13100,
81900,
null,
94400,
42400,
18600,
54000,
16600,
4000,
50600,
22700,
23000,
50600,
38100,
57700,
16700,
null,
27200,
28200,
49800,
13200,
6600,
10000,
60000,
292600,
3800,
11700,
78000,
28700,
83400,
3800,
21400,
52261,
211100,
13800,
22900,
null,
null,
32800,
37600,
22400,
40700,
21300,
39200,
8500,
16600,
33600,
9000,
28300,
33400,
102400,
null,
null,
22400,
21700,
34800,
null,
40000,
28900,
37000,
null,
5700,
43500,
20500,
51800,
20600,
43500,
17400,
27700,
40650,
21140,
51100,
70000,
33000,
33000,
30000,
8700,
49700,
36500,
79400,
7100,
53500,
83700,
24500,
8800,
15800,
20000,
46200,
31800,
49100,
7900,
9200,
18500,
5800,
56700,
8100,
17600,
null,
32900,
8800,
39000,
null,
8700,
12800,
8900,
17900,
19000,
24500,
73800,
31000,
15300,
31900,
30400,
22100,
10600,
72700,
15500,
24400,
39000,
18900,
30700,
39200,
103200,
13100,
42700,
28500,
28500,
12300,
50800,
46600,
12300,
22400,
41500,
12600,
16800,
36100,
6600,
23600,
67500,
32600,
44900,
19400,
38300,
null,
37700,
155000,
null,
null,
null,
13600,
null,
18900,
17800,
null,
60300,
8600,
10000,
6100,
16400,
10300,
17700,
24300,
null,
27500,
null,
53500,
16100,
10100,
10500,
30900,
44200,
51600,
52000,
10700,
65200,
8700,
3500,
42800,
60000,
null,
25800,
14900,
15500,
22900,
4600,
21600,
24500,
5600,
11100,
8700,
32077,
13600,
24600,
10600,
7400,
15900,
39300,
9500,
25700,
118400,
4400,
null,
12900,
9200,
13200,
37000,
30000,
25400,
42000,
18700,
88300,
46300,
19800,
13800,
30500,
27200,
72900,
38800,
37900,
37400,
15800,
13200,
42480,
null,
null,
null,
12000,
12700,
8500,
25000,
18600,
7300,
38200,
65600,
46000,
16000,
16300,
14400,
null,
16100,
64200,
7100,
10000,
7700,
26700,
33500,
9800,
67500,
59100,
121825,
38300,
43016,
9630,
16800,
100700,
null,
17300,
22800,
25800,
26300,
41800,
5000,
null,
29300,
30300,
10400,
37000,
93600,
41200,
28700,
40100,
107330,
19900,
11800,
6100,
45600,
16600,
3900,
23200,
10100,
11500,
56800,
28600,
49100,
22700,
20700,
23000,
163574,
19900,
15600,
5300,
11400,
34700,
43400,
3800,
14300,
9100,
74300,
null,
null,
82100,
19200,
40800,
25300,
65200,
65400,
29900,
13800,
37900,
35000,
13400,
10935,
87000,
27500,
8550,
40400,
41600,
38300,
18500,
128600,
21200,
null,
6800,
77300,
70700,
73900,
3900,
14900,
25800,
63600,
27200,
18200,
49200,
94800,
22200,
25300,
50300,
6900,
31900,
10000,
7300,
16800,
22600,
39200,
36300,
132400,
48400,
60300,
21000,
40300,
10900,
16700,
60200,
null,
59300,
9600,
39300,
49700,
31900,
26000,
12400,
37400,
15400,
10600,
20000,
30100,
12100,
16900,
37700,
35400,
35100,
34600,
1000,
5900,
17200,
6000,
9700,
83500,
33900,
null,
9600,
24500,
null,
12000,
32600,
12900,
33100,
39300,
10800,
38100,
37700,
44300,
23300,
15200,
4900,
null,
20400,
18400,
4700,
31500,
26800,
14200,
45100,
43000,
null,
12400,
11975,
null,
39700,
35000,
48000,
20900,
16000,
21900,
50200,
26443,
39700,
10900,
238500,
9700,
34400,
20600,
61700,
18900,
148300,
22100,
31500,
null,
11500,
18200,
25600,
13300,
13200,
38400,
19200,
47500,
57000,
21500,
null,
10800,
null,
49300,
37500,
6300,
16100,
25800,
39200,
9200,
33100,
13600,
null,
3300,
16600,
22080,
22100,
19200,
48900,
19700,
39000,
8000,
6300,
24700,
36300,
43300,
68400,
7900,
null,
22500,
null,
38400,
20100,
46200,
null,
105100,
14100,
70511,
null,
2600,
null,
109300,
59300,
null,
null,
21900,
27900,
13500,
14700,
31500,
23500,
null,
3400,
11000,
36100,
25400,
23200,
null,
63600,
19100,
32400,
37600,
54200,
67200,
33100,
8100,
64200,
null,
8100,
26100,
35300,
14800,
null,
10100,
null,
null,
88700,
null,
null,
19500,
8100,
5200,
null,
16600,
32200,
25300,
31000,
null,
23200,
9000,
14800,
6100,
18650,
6500,
2200,
null,
37700,
21300,
9300,
26800,
50800,
18800,
null,
51400,
20300,
15550,
19500,
6320,
12300,
30100,
null,
53100,
111300,
11600,
25700,
57200,
8200,
11400,
18900,
null,
53700,
22700,
18274,
null,
null,
24600,
23200,
16100,
23500,
19700,
51670,
22500,
63800,
42500,
46800,
null,
43400,
null,
50100,
5400,
11000,
9500,
15500,
4400,
18100,
20800,
71700,
26400,
33600,
7600,
57300,
18000,
24800,
69685,
10600,
15700,
7150,
90900,
8200,
18100,
23400,
31000,
33000,
12200,
30000,
58600,
14600,
40100,
52800,
34000,
38200,
17800,
9150,
16600,
17000,
22200,
55700,
66700,
11700,
28200,
47400,
19200,
30900,
42500,
6100,
null,
55300,
22300,
21600,
22700,
13900,
16500,
32800,
13200,
22700,
6400,
3250,
34100,
61800,
19400,
75474,
null,
4800,
40200,
17400,
36700,
47100,
7500,
56100,
28700,
32500,
58000,
105800,
27000,
17300,
33000,
10800,
15800,
52500,
7400,
7100,
60500,
44500,
34200,
45600,
9400,
40400,
null,
23500,
27200,
124900,
3500,
42800,
9300,
null,
8500,
80100,
23300,
10500,
13500,
51600,
25400,
55000,
19300,
63200,
9000,
15700,
62600,
26700,
34400,
42600,
36700,
12900,
5900,
9900,
3600,
8600,
null,
32400,
41200,
38500,
71800,
28600,
4500,
13800,
29200,
8200,
37000,
23600,
null,
26400,
10900,
13400,
10200,
18700,
57100,
65600,
16800,
66900,
56400,
null,
67200,
17700,
23100,
61400,
89800,
121600,
20900,
19600,
10000,
39100,
41100,
62600,
260000,
72700,
16695,
14900,
27700,
35400,
9500,
54000,
59800,
205200,
39300,
87700,
35300,
17000,
11500,
118100,
292300,
null,
55300,
28300,
2900,
null,
8300,
32750,
34600,
28800,
51400,
17750,
4400,
14200,
23800,
66200,
10600,
70300,
17600,
31300,
36600,
30200,
8000,
39000,
5100,
12300,
null,
38500,
34200,
36300,
109600,
48050,
41900,
27200,
7500,
13900,
9400,
25800,
30900,
66100,
6900,
20900,
45400,
30800,
31200,
30400,
38800,
34000,
16700,
6800,
52900,
48700,
null,
35600,
21000,
27100,
25600,
45100,
15900,
21600,
13000,
7600,
62000,
30300,
5600,
67600,
8300,
57800,
31500,
41800,
6100,
17200,
null,
30900,
27300,
25100,
29800,
57100,
74800,
122500,
37000,
45900,
23300,
28600,
22400,
14400,
12800,
50800,
18800,
17300,
16300,
20800,
19300,
null,
16700,
25200,
13000,
25000,
23900,
23300,
42600,
18500,
9300,
25800,
53100,
4000,
12100,
3500,
35800,
44000,
7500,
13000,
17200,
null,
12400,
24200,
3800,
36400,
27700,
13500,
7200,
82900,
23900,
39100,
11000,
26700,
48800,
74200,
26300,
16900,
5000,
12100,
null,
6000,
79059,
27700,
20600,
5800,
15500,
30700,
22900,
33600,
19200,
28600,
22000,
14200,
51300,
12150,
19100,
10000,
19700,
16000,
25300,
50800,
47400,
15000,
7200,
21900,
18700,
33800,
24200,
10500,
27100,
null,
8600,
129815,
67600,
17500,
39300,
13800,
11800,
96500,
36000,
27500,
18800,
81600,
15850,
34400,
35400,
100500,
33500,
29300,
18100,
35500,
42000,
13500,
10500,
8100,
95400,
28000,
53200,
33400,
15500,
69500,
36200,
19200,
78153,
128800,
9600,
16700,
20100,
null,
15100,
29200,
40900,
4400,
201600,
13300,
35100,
22600,
52800,
42400,
5800,
22800,
43500,
4800,
90848,
43500,
23300,
23100,
null,
36200,
10100,
372000,
9900,
16200,
14000,
8200,
9000,
28500,
12400,
8800,
null,
22900,
34100,
22000,
15100,
null,
12100,
39600,
18700,
7200,
50800,
4000,
14600,
15200,
17100,
32600,
5800,
8100,
25098,
24400,
null,
36600,
29000,
4500,
26400,
11900,
28300,
41400,
8300,
9900,
null,
71400,
95500,
22700,
13600,
59600,
20100,
22300,
8300,
null,
55700,
33700,
58200,
22700,
54800,
20000,
25200,
22600,
3400,
40500,
46400,
null,
13500,
38400,
11900,
18000,
19200,
27000,
42800,
71900,
62300,
70600,
7400,
15800,
27000,
5700,
22000,
88600,
5500,
3000,
6800,
240598,
15600,
29000,
7400,
37700,
16000,
14800,
17300,
9800,
20400,
12900,
null,
14800,
null,
27400,
22700,
27000,
64000,
34100,
33500,
57300,
162000,
22100,
22900,
230010,
6900,
12600,
14600,
24900,
16000,
17000,
68900,
20200,
23300,
19400,
17000,
45200,
null,
12800,
35100,
26400,
8900,
14000,
29200,
24500,
19700,
5500,
12500,
42000,
7209,
33400,
59700,
10500,
18100,
28500,
9800,
17200,
44600,
41000,
null,
24600,
14600,
15900,
13300,
58400,
18800,
17400,
34400,
12600,
43800,
9200,
36800,
9800,
18700,
102200,
null,
25450,
15300,
null,
9300,
31800,
41600,
8600,
17000,
46500,
16400,
40100,
null,
7500,
44300,
14700,
8400,
67500,
13900,
28300,
12600,
12200,
72559,
12300,
48600,
49600,
17400,
4000,
null,
6800,
12650,
50800,
5900,
65800,
66400,
12000,
16300,
50200,
3900,
22000,
38800,
16000,
19400,
57900,
17200,
31900,
27500,
24200,
22300,
49100,
58100,
16000,
33800,
6450,
23000,
43100,
30100,
null,
18900,
66000,
286500,
4400,
11900,
42500,
29800,
9600,
26000,
12000,
86400,
20000,
34300,
19100,
44200,
31300,
9600,
22100,
8300,
34800,
47700,
25400,
37400,
29000,
24300,
null,
4200,
70100,
35600,
36600,
7000,
19800,
4200,
10000,
27900,
7100,
66100,
25500,
34300,
90100,
38300,
27600,
39300,
4600,
12300,
null,
138900,
23600,
14500,
32950,
8750,
48200,
14577,
36300,
8500,
50500,
null,
12800,
87600,
null,
45000,
106700,
3000,
29900,
27900,
49000,
21300,
11015,
17000,
37000,
30900,
null,
null,
31800,
32700,
12200,
11000,
20700,
8400,
18200,
37600,
10100,
26400,
23000,
60200,
17000,
18400,
72900,
46200,
24700,
15100,
6300,
17500,
40700,
40900,
23100,
45700,
17200,
39000,
7600,
14500,
92700,
13300,
19600,
29000,
20000,
37500,
19700,
5900,
16240,
null,
28300,
8300,
14900,
16700,
null,
11000,
98501,
71700,
20000,
13600,
9800,
23900,
12700,
28700,
61000,
6100,
56000,
46300,
21100,
47600,
14500,
19300,
94200,
37800,
null,
39200,
20800,
74400,
40300,
22100,
23600,
29200,
null,
53000,
17000,
73149,
21700,
17900,
4900,
48000,
90600,
12000,
32300,
19300,
22400,
24800,
6200,
36600,
42100,
null,
39800,
86700,
38200,
21400,
59357,
9200,
16000,
19700,
20800,
22900,
6100,
1800,
43000,
33200,
null,
28200,
11400,
74600,
43300,
37300,
140000,
17000,
18200,
33200,
45000,
109300,
19500,
38300,
84200,
88900,
17000,
15100,
41431,
13600,
12000,
29000,
47000,
25100,
47800,
39300,
81100,
52900,
null,
14800,
9700,
51000,
11100,
null,
18000,
29300,
null,
61100,
20700,
32700,
24400,
24800,
61500,
46400,
25900,
9800,
109900,
12000,
6300,
44600,
20200,
6500,
13100,
13600,
19800,
58800,
33500,
78600,
13500,
6000,
45100,
12300,
8500,
null,
49900,
61100,
9700,
null,
11400,
null,
14700,
41300,
null,
87900,
69000,
50600,
8300,
38300,
22500,
41800,
25500,
null,
40800,
27600,
14500,
11200,
41500,
6000,
89400,
27700,
32600,
55800,
null,
43900,
43900,
12800,
7300,
17500,
37900,
71100,
35400,
15700,
42200,
6500,
15800,
100300,
15700,
3300,
5900,
13100,
13900,
5000,
71200,
17800,
34300,
18400,
8800,
39800,
59400,
28400,
61900,
7300,
37600,
15000,
83800,
16600,
15200,
null,
16800,
66700,
null,
8500,
null,
12000,
3300,
19900,
44200,
17900,
30000,
22900,
130000,
57800,
2770,
67600,
38500,
33500,
15200,
15400,
21100,
60000,
3700,
8700,
24300,
15400,
39300,
13900,
19700,
23900,
17200,
42500,
40000,
16800,
null,
33200,
30200,
28760,
57400,
41200,
26700,
10300,
23600,
44800,
14900,
null,
24600,
62100,
78500,
17900,
26000,
28800,
18200,
25100,
28400,
49000,
null,
17900,
2600,
75100,
46424,
22000,
12300,
18400,
28100,
7050,
29500,
83600,
12200,
55000,
37300,
6700,
45100,
19400,
44900,
34700,
55600,
50700,
67000,
5900,
44300,
13200,
31100,
8600,
34000,
84300,
13300,
null,
14500,
17300,
18200,
45900,
12900,
10700,
38800,
93700,
null,
61400,
12000,
45700,
101600,
7900,
56900,
13900,
12500,
7400,
71000,
21000,
48100,
9800,
15600,
53800,
34800,
147200,
27900,
null,
47500,
30400,
13900,
26000,
null,
23700,
39900,
33300,
9900,
14400,
78300,
24100,
11100,
21500,
12400,
24800,
16900,
null,
19200,
null,
133500,
22400,
11700,
38500,
13200,
56700,
23800,
30500,
7000,
48500,
35600,
32500,
32000,
66100,
23900,
16300,
17800,
12900,
15100,
72900,
26700,
12800,
68608,
43800,
13800,
51700,
17300,
20000,
null,
50700,
8500,
null,
null,
30500,
13800,
37400,
49300,
11600,
133000,
null,
15300,
46400,
26800,
59000,
22800,
22400,
null,
13900,
4600,
33200,
null,
57000,
21800,
30200,
39200,
15700,
18900,
74500,
8500,
3500,
50300,
23300,
7500,
15100,
8700,
70700,
13900,
11100,
null,
null,
15600,
82000,
28900,
5400,
29400,
null,
44000,
82500,
20700,
27100,
15900,
11500,
21100,
null,
19300,
27900,
11300,
12900,
16400,
66300,
54400,
11700,
17500,
null,
21900,
34800,
20700,
73000,
40300,
13800,
72500,
null,
33100,
31900,
21900,
15200,
7900,
19700,
21600,
13700,
16500,
25300,
7800,
29500,
14600,
39000,
56300,
19100,
18200,
33600,
16100,
37300,
7500,
31700,
9900,
21800,
null,
null,
22100,
9300,
24600,
100900,
15800,
7400,
11200,
9400,
7600,
25200,
15900,
6200,
25900,
36500,
25800,
95200,
null,
40100,
17000,
null,
26000,
44300,
29100,
27800,
47400,
19900,
14700,
16000,
15100,
32550,
74900,
75900,
null,
48400,
38400,
12600,
32000,
70000,
21500,
45300,
35800,
16600,
27000,
12800,
4500,
14200,
18495,
7500,
59100,
41900,
49100,
12600,
15800,
11700,
76400,
16700,
23600,
30700,
13800,
46600,
42400,
42300,
31200,
2300,
18700,
47900,
33900,
32806,
52800,
30900,
15000,
18500,
45200,
null,
12000,
30400,
null,
41600,
29400,
124400,
19000,
6500,
29700,
14700,
9700,
66100,
6600,
10400,
10500,
null,
26000,
28000,
18900,
43200,
9500,
70000,
54400,
12100,
null,
33200,
27100,
26800,
18500,
66500,
32000,
39900,
14600,
25000,
6000,
20100,
34800,
84900,
28800,
26400,
7500,
19300,
48700,
41200,
17000,
28700,
6700,
30700,
53600,
6000,
66400,
13700,
14600,
31400,
31800,
null,
20400,
45844,
null,
31674,
20100,
12500,
230800,
21700,
43300,
14800,
18800,
28400,
32900,
19100,
68100,
36000,
40800,
null,
52700,
24500,
56800,
29700,
40000,
32800,
36900,
23545,
32700,
10400,
34700,
49200,
null,
35600,
18500,
19200,
13000,
14200,
28200,
45400,
24900,
19400,
33000,
35000,
24200,
16400,
19900,
11200,
11100,
25500,
15800,
46800,
10600,
7600,
32200,
12100,
85200,
3900,
21700,
41900,
15100,
11200,
14300,
109400,
19100,
22000,
19700,
6200,
10917,
53700,
22000,
16000,
42200,
10900,
22100,
12000,
4700,
20100,
8200,
69800,
26100,
12300,
45500,
66600,
46900,
75800,
12500,
30000,
59800,
null,
20300,
45000,
15600,
43000,
31300,
14500,
27200,
99600,
44900,
19000,
null,
11000,
67800,
18500,
16000,
33600,
5800,
6800,
40900,
16700,
11000,
17200,
7300,
20500,
22100,
39800,
16200,
19700,
16100,
7400,
14100,
15600,
22800,
25900,
19500,
null,
19200,
15600,
12800,
29200,
17000,
54900,
18300,
23600,
12800,
37600,
12700,
11500,
15800,
13900,
46200,
7300,
5900,
37300,
12100,
47800,
8500,
16500,
13100,
10700,
17100,
600,
14900,
13100,
null,
57000,
16300,
20100,
22000,
39100,
24000,
12900,
62100,
22900,
null,
27600,
null,
14100,
5300,
28000,
23300,
33200,
27000,
22800,
78600,
13800,
31700,
7300,
16800,
10600,
38000,
23800,
3300,
null,
71900,
15600,
21800,
25900,
19700,
9700,
12300,
41700,
12700,
27770,
7800,
14000,
45500,
16500,
25600,
77000,
null,
15300,
13400,
18300,
null,
13700,
78800,
43000,
16200,
34960,
17400,
null,
4400,
125300,
39000,
11700,
28400,
1600,
212400,
19400,
123691,
50100,
44300,
18900,
30600,
31200,
21000,
4700,
797,
11000,
33600,
11600,
20500,
14000,
48600,
5600,
22000,
31800,
16400,
8000,
10700,
20400,
16400,
13400,
18100,
60000,
10300,
16300,
23700,
10200,
20800,
29500,
19300,
5200,
35800,
12600,
31400,
71300,
6100,
18900,
13100,
23500,
24400,
11900,
9200,
6700,
16100,
null,
6000,
16700,
97500,
35600,
20000,
null,
55100,
29000,
null,
25000,
12000,
null,
10800,
11800,
33000,
null,
13700,
11200,
10400,
null,
61300,
14100,
10200,
25400,
20600,
null,
162100,
8100,
9900,
19500,
44800,
10700,
10000,
43300,
26400,
14100,
26700,
45600,
38500,
16900,
18500,
216800,
26100,
81740,
null,
19100,
193800,
5300,
12500,
16700,
16300,
41000,
83000,
31100,
16300,
18300,
16100,
null,
33000,
48400,
27400,
34200,
34000,
27900,
16000,
13300,
7700,
8900,
33800,
19100,
27600,
30300,
20200,
null,
42100,
69500,
13700,
158500,
57400,
20100,
37900,
17900,
35800,
53200,
48600,
11200,
4000,
35500,
23500,
12400,
41500,
22700,
18200,
4900,
10200,
47700,
9600,
37800,
13600,
4704,
21000,
17800,
25300,
73800,
26300,
17300,
24600,
15300,
32000,
3300,
24800,
20300,
6200,
24600,
6000,
14900,
11500,
79000,
7900,
66900,
47600,
3300,
43500,
60400,
null,
37900,
66825,
65700,
31400,
65100,
33400,
18600,
18600,
15400,
27800,
108400,
30100,
null,
8700,
38300,
87800,
52200,
15600,
null,
18250,
19800,
58700,
19300,
31800,
21850,
null,
26500,
10300,
8200,
32100,
46000,
42000,
33200,
11300,
18900,
37900,
55800,
22600,
15751,
12300,
52700,
25300,
13600,
25000,
18600,
92700,
26800,
32900,
19900,
16000,
7600,
29000,
36100,
27800,
4500,
null,
52100,
51600,
29200,
6900,
25700,
16000,
50300,
15900,
14100,
5300,
42800,
13600,
40800,
20600,
7200,
227600,
13900,
null,
null,
1800,
31000,
10900,
224150,
144400,
25700,
11600,
12600,
16700,
19200,
17500,
27400,
18100,
null,
null,
61800,
25900,
null,
10500,
65900,
null,
18800,
42400,
43100,
64900,
28700,
null,
59554,
40700,
22800,
66900,
null,
null,
5500,
45700,
16600,
52500,
23900,
31500,
65700,
4400,
9400,
48850,
73400,
131400,
30600,
20000,
59600,
18200,
17700,
16300,
20875,
42912,
16200,
12400,
25200,
2800,
45278,
54900,
18300,
null,
30300,
20100,
103600,
42200,
47400,
11000,
null,
43700,
34200,
13200,
35900,
32000,
5500,
32800,
11200,
17300,
7900,
null,
6300,
16600,
16800,
78700,
150200,
24200,
11300,
19000,
17800,
90693,
54200,
54300,
37400,
9500,
null,
null,
28800,
53600,
15800,
23600,
36800,
15100,
31500,
null,
20000,
10000,
11100,
22500,
37500,
55600,
7700,
7800,
85800,
22100,
23300,
null,
17200,
42200,
30500,
36500,
23500,
61300,
36168,
17300,
633200,
14100,
38100,
15100,
22300,
53100,
17700,
null,
23400,
17700,
8300,
5700,
13500,
6500,
41400,
39800,
13100,
7700,
13000,
19000,
26200,
8300,
40200,
31900,
null,
56595,
21000,
38800,
8000,
13000,
4000,
9600,
63500,
74000,
31600,
55123,
33000,
80200,
84500,
19900,
8000,
34400,
62000,
30700,
18800,
19000,
42900,
300500,
79700,
15500,
14500,
35500,
38200,
20700,
11300,
20000,
16400,
7300,
12000,
2800,
26900,
25700,
11400,
50000,
22450,
5300,
56400,
null,
null,
14600,
7600,
12300,
71000,
49600,
16700,
null,
68481,
41000,
25500,
13400,
45000,
13600,
17200,
99200,
9600,
7400,
9100,
26300,
11700,
33900,
18500,
21900,
66200,
20500,
25200,
7200,
131100,
23000,
29400,
34500,
117000,
11600,
8100,
8300,
4500,
15500,
47300,
49600,
23300,
47400,
30500,
67600,
25100,
33000,
null,
36000,
35600,
23700,
35400,
21700,
10100,
null,
16900,
25700,
38600,
25500,
23200,
null,
7750,
75030,
15000,
34600,
10500,
13300,
6500,
10600,
44500,
50200,
23200,
64000,
14600,
19900,
83900,
45300,
6400,
null,
17000,
17000,
13100,
81700,
3900,
27700,
34000,
15600,
null,
18300,
null,
17200,
19500,
15000,
6400,
null,
15900,
15200,
13200,
26000,
23700,
85300,
31200,
10300,
17500,
32500,
30900,
41800,
40900,
17600,
29400,
36500,
22900,
35600,
70200,
32500,
41800,
21100,
36000,
8000,
null,
6500,
162800,
9500,
22700,
2900,
36100,
34100,
34700,
11300,
7500,
90300,
18200,
28300,
28300,
7900,
16200,
14000,
44700,
13100,
34400,
17600,
246200,
21300,
47400,
17300,
10100,
24200,
null,
87500,
30000,
null,
33000,
73900,
null,
32300,
8100,
65500,
27800,
null,
9000,
27000,
null,
12500,
100700,
25700,
14500,
null,
14300,
24500,
32100,
25500,
76800,
22100,
43000,
6950,
11700,
29600,
6800,
4000,
null,
9900,
58600,
16600,
104300,
21100,
8100,
10900,
201500,
24000,
51000,
null,
101300,
59900,
79400,
18200,
5700,
null,
8000,
8000,
61500,
9300,
52700,
21100,
44200,
7600,
15000,
7200,
98300,
39400,
17400,
84100,
null,
17100,
3800,
46235,
10033,
18000,
25500,
4000,
11000,
null,
27200,
49300,
50200,
7000,
11700,
14800,
18400,
23500,
15400,
19800,
9000,
21400,
39900,
16800,
37000,
null,
26700,
null,
6000,
15000,
11700,
31300,
33400,
20100,
58600,
34200,
33400,
21300,
51300,
4500,
6000,
15700,
37800,
9200,
13600,
null,
19800,
6450,
39600,
null,
null,
28100,
9400,
64000,
29000,
42200,
39800,
39300,
93500,
33400,
13600,
46600,
5500,
40500,
8100,
15100,
29600,
56600,
47100,
48600,
20100,
8200,
41300,
32000,
11400,
26600,
14700,
null,
26700,
20200,
39400,
21000,
47900,
13300,
19900,
17700,
36500,
23500,
3500,
9800,
10400,
9800,
13700,
49800,
21400,
19000,
20000,
20900,
4100,
30900,
65800,
40300,
109900,
92900,
41700,
11300,
15200,
5900,
30500,
28800,
18400,
50000,
null,
21700,
25000,
13500,
13700,
34700,
62500,
null,
64600,
0,
117800,
24700,
22000,
31100,
20100,
19800,
37500,
9700,
37400,
43000,
10600,
21099,
44800,
36200,
27800,
28200,
21000,
null,
29400,
19900,
14100,
null,
15700,
29000,
13248,
25240,
88000,
6800,
15900,
169518,
32900,
46800,
23200,
21300,
54400,
42000,
57500,
10500,
116000,
112900,
74600,
50700,
53200,
28800,
null,
20600,
26500,
23500,
38000,
42900,
11000,
45100,
19700,
30000,
26000,
48900,
89600,
108400,
34100,
9500,
28000,
17700,
20000,
47800,
null,
65000,
null,
53500,
18900,
null,
23500,
38000,
91500,
29500,
3100,
67800,
13900,
21100,
16900,
163700,
16000,
26900,
8200,
12900,
30800,
19300,
8900,
39700,
47700,
208800,
11900,
24600,
33100,
13400,
28600,
26100,
17400,
6800,
44100,
57100,
26400,
22192,
8100,
24200,
17500,
53000,
36000,
44500,
29800,
32800,
null,
12600,
14500,
12000,
25900,
28600,
43200,
74800,
14500,
14100,
4100,
23000,
7000,
38400,
14100,
12200,
9200,
29700,
32400,
16900,
29900,
20500,
61900,
73500,
29100,
24000,
null,
25400,
84200,
19400,
55500,
36300,
23100,
91900,
81000,
31600,
19800,
40400,
11200,
17000,
11600,
null,
14600,
99800,
44100,
34300,
20000,
9200,
21200,
10200,
null,
7600,
52400,
48900,
8640,
53200,
17400,
25700,
null,
38000,
64300,
24300,
36500,
17400,
24600,
22900,
22500,
19100,
13900,
15700,
20500,
14600,
118700,
61700,
33100,
28100,
10600,
6600,
20100,
14200,
15700,
15600,
61000,
23600,
31900,
21200,
33200,
null,
null,
17300,
27300,
16700,
32100,
39000,
21600,
17800,
5200,
6400,
28600,
19300,
29300,
7100,
25100,
52500,
19300,
30900,
47200,
50200,
43300,
326700,
72000,
10300,
14500,
12400,
10000,
56000,
19000,
20200,
null,
11800,
null,
15000,
29200,
10900,
34100,
15500,
null,
62100,
14300,
30200,
7800,
22100,
58200,
35800,
20300,
53900,
49000,
35700,
23500,
28100,
23400,
31700,
13300,
65800,
67200,
39500,
35700,
16000,
6600,
null,
20800,
29300,
23500,
18100,
11000,
33700,
null,
9000,
46600,
6500,
17500,
null,
23000,
9000,
11700,
null,
8600,
10000,
4000,
16600,
33500,
47701,
33900,
19300,
29500,
13000,
21200,
31200,
25500,
19300,
8100,
7500,
6600,
23600,
23100,
24700,
4600,
17950,
7100,
11700,
27900,
12100,
46200,
27400,
17300,
13300,
17700,
6400,
28900,
90600,
58200,
11200,
16500,
21400,
29200,
18100,
80000,
267900,
40400,
4000,
12000,
74600,
99700,
22900,
13200,
null,
88600,
null,
33500,
23000,
20100,
63000,
13900,
22000,
47300,
9100,
13000,
42500,
90100,
38200,
36700,
null,
26100,
51100,
39500,
12200,
43700,
5600,
null,
2500,
6900,
5600,
18600,
7200,
21000,
11100,
26000,
16800,
31300,
null,
null,
null,
null,
16700,
9000,
17800,
19600,
16000,
27300,
7400,
22300,
37900,
27600,
19900,
null,
16300,
58900,
32500,
7500,
26000,
62207,
60600,
26800,
41500,
32600,
null,
38800,
1500,
30900,
23900,
40200,
22300,
null,
56700,
6000,
78500,
31200,
53300,
40400,
58905,
48500,
53800,
3200,
14500,
16100,
11300,
9250,
18600,
46100,
7200,
66600,
null,
5900,
15000,
null,
44600,
40964,
35000,
null,
60500,
11200,
8800,
80800,
50300,
null,
47600,
63600,
27900,
10800,
11800,
11000,
22000,
14400,
null,
4100,
8200,
18300,
17800,
15400,
null,
81700,
132500,
13800,
35800,
30300,
41700,
9000,
48100,
12400,
8000,
16300,
30200,
5900,
34100,
20700,
5400,
14000,
3600,
null,
7200,
63700,
6900,
12700,
15300,
87800,
11800,
73300,
30400,
23500,
61800,
73840,
14400,
34200,
4100,
22500,
20000,
7900,
29900,
24300,
2400,
1700,
23900,
20600,
16800,
11800,
18425,
6200,
32900,
8600,
51300,
74500,
14600,
178100,
null,
69200,
24700,
7600,
13800,
54900,
22300,
13500,
29500,
10200,
11200,
12000,
20100,
54200,
27800,
58600,
39300,
null,
25000,
14500,
2200,
32800,
19400,
7900,
59500,
18500,
28100,
12900,
49300,
18000,
9200,
45400,
10900,
16000,
null,
51900,
38000,
27700,
39000,
6900,
16100,
56400,
19700,
12100,
8800,
43300,
null,
13500,
34800,
6400,
null,
33900,
21200,
47000,
34000,
6800,
8400,
40100,
19000,
16500,
3500,
40400,
null,
17500,
39000,
100200,
53000,
23800,
36800,
69200,
48100,
9600,
9575,
18000,
6200,
null,
14500,
4400,
42400,
40700,
12500,
32000,
25900,
12800,
45900,
16400,
9800,
72600,
35800,
17500,
13300,
44600,
58500,
21400,
28000,
40900,
51900,
64200,
30700,
25400,
null,
20300,
21500,
19500,
50100,
null,
13800,
18600,
26900,
25200,
14300,
15200,
11500,
23400,
11400,
25300,
23000,
12500,
null,
63100,
19300,
33600,
16300,
null,
13500,
14700,
19200,
152400,
22100,
26700,
6100,
31700,
41900,
32600,
13800,
null,
36200,
2800,
8700,
19300,
47700,
5500,
35600,
23700,
null,
47500,
21900,
26000,
24500,
10100,
20700,
15700,
35100,
130209,
43600,
22100,
24400,
6800,
18500,
23600,
null,
66700,
150900,
34400,
54500,
36700,
79800,
18200,
38000,
16000,
null,
66100,
43100,
53300,
15700,
23950,
32100,
44400,
18200,
null,
null,
56400,
174600,
1100,
37000,
34700,
62700,
40800,
34900,
33100,
8700,
40600,
21100,
24300,
25100,
27100,
12600,
28900,
7800,
19100,
55700,
6100,
11500,
45119,
67400,
26700,
25900,
38200,
12500,
26100,
73300,
22000,
9700,
12000,
12700,
41100,
11200,
9000,
35300,
30600,
36400,
28900,
32500,
12300,
74700,
16100,
61000,
50800,
5700,
36600,
24200,
12100,
8100,
17800,
5400,
5900,
42700,
20600,
28500,
null,
27100,
59900,
13300,
12100,
16500,
94400,
null,
30600,
9600,
11300,
72400,
29400,
10900,
15100,
17300,
10100,
49000,
68700,
93400,
17300,
36600,
21700,
36700,
37900,
27600,
38700,
58600,
18200,
6700,
11100,
25700,
29100,
141100,
4000,
null,
66900,
9100,
0,
56700,
null,
null,
28900,
19100,
39700,
40700,
53400,
null,
18100,
25500,
6700,
25200,
23300,
39300,
13500,
16200,
14500,
68200,
23600,
41700,
36900,
31900,
47600,
14300,
22800,
16600,
58600,
25100,
null,
19300,
12100,
62600,
29500,
56400,
5900,
30200,
87100,
20100,
null,
15900,
37100,
42000,
76200,
null,
12400,
165500,
15300,
33100,
21300,
11900,
6600,
69500,
31800,
13900,
null,
78500,
21600,
11300,
null,
16500,
37800,
58250,
53300,
6500,
9100,
35200,
31700,
11600,
5500,
54300,
53600,
14400,
14400,
6300,
25600,
4800,
9600,
52500,
104474,
17300,
61200,
23300,
null,
19000,
18800,
27800,
38700,
null,
20000,
null,
13900,
14300,
44700,
20700,
64000,
17400,
39600,
43800,
9300,
11200,
41300,
15100,
44600,
8600,
11200,
23600,
16100,
40500,
75500,
5400,
38700,
800,
23100,
14000,
30800,
16300,
56900,
31500,
14800,
35400,
68800,
6700,
24200,
41200,
null,
29000,
44500,
17600,
76200,
10100,
7800,
14600,
33300,
24500,
19700,
40600,
37300,
64900,
38500,
13500,
16000,
28800,
31500,
18400,
5100,
null,
32800,
null,
45800,
null,
49400,
18000,
33600,
29900,
35600,
13100,
33500,
16700,
142500,
11900,
null,
null,
11400,
16800,
35400,
34900,
47000,
57100,
14000,
14400,
57500,
30600,
6600,
46200,
12900,
112500,
null,
11300,
15700,
67900,
113300,
32100,
46400,
30700,
49100,
22800,
74600,
19200,
144900,
59200,
2900,
73100,
null,
51700,
72100,
29200,
15800,
22800,
31600,
35500,
63800,
17100,
21600,
45800,
15600,
22900,
5000,
68200,
20900,
37500,
8800,
null,
8300,
44703,
12300,
12000,
20000,
48300,
47500,
23100,
25900,
7000,
77500,
10900,
14000,
47400,
32500,
26700,
38700,
21800,
79700,
16000,
41940,
23000,
77800,
16900,
16900,
17700,
20400,
7000,
41900,
8900,
22500,
null,
9492,
24600,
25300,
12500,
36600,
44900,
78500,
53383,
29100,
7900,
22000,
65900,
15100,
33700,
14600,
57300,
null,
45600,
null,
17300,
null,
26500,
null,
38400,
8600,
42700,
240700,
26700,
32520,
70800,
57700,
15600,
12780,
36200,
null,
null,
5800,
22000,
21500,
33200,
40700,
99000,
27900,
null,
30300,
37700,
12200,
75700,
65700,
19900,
30200,
22800,
4200,
23400,
32200,
79100,
28700,
37900,
25600,
24400,
189300,
7100,
5000,
11400,
30500,
29100,
79600,
47200,
20500,
26100,
17200,
16400,
43600,
21400,
13700,
10050,
37000,
48200,
20100,
41000,
12000,
5900,
null,
14300,
18500,
null,
null,
59900,
17450,
45300,
17000,
19800,
23000,
21400,
26400,
126500,
28700,
6500,
40000,
7700,
6600,
500,
27700,
44300,
14100,
27000,
9000,
24500,
120400,
46610,
7400,
16100,
6300,
81500,
15500,
28200,
39000,
34500,
9600,
null,
42000,
16600,
17500,
null,
13300,
16200,
10300,
19600,
39600,
10000,
15700,
63400,
18500,
37500,
25400,
19300,
null,
14000,
39700,
29500,
13600,
40500,
29000,
16700,
23700,
20800,
78700,
29400,
23600,
12600,
7000,
22800,
25400,
10400,
17200,
33100,
13000,
19400,
14100,
null,
52000,
56100,
1500,
27300,
32200,
3200,
28300,
11900,
74600,
null,
32400,
14400,
53200,
24514,
74600,
13100,
11300,
39400,
2200,
28200,
19000,
34400,
20600,
24700,
31600,
8200,
25500,
56100,
47500,
32400,
39100,
90000,
20300,
null,
27600,
7400,
40300,
115100,
35800,
18900,
30200,
21300,
50400,
7000,
null,
44300,
10200,
204900,
17500,
32000,
24455,
12500,
73900,
65400,
97400,
11400,
37100,
89900,
47200,
null,
47700,
null,
59700,
null,
1500,
52584,
46000,
59600,
16500,
15200,
29700,
10100,
39100,
34200,
14300,
107500,
8900,
19000,
36600,
22400,
18600,
9600,
41400,
73800,
8000,
12900,
33500,
null,
25700,
27800,
28400,
51000,
43300,
35100,
103900,
90100,
31800,
15100,
19700,
42754,
10400,
7100,
17600,
66600,
59500,
null,
16200,
98521,
14500,
10900,
25700,
64800,
30000,
null,
1600,
101400,
5500,
13900,
8300,
19800,
33500,
39280,
20000,
17600,
16900,
20600,
54600,
null,
null,
30100,
11800,
66100,
45300,
38500,
5200,
17900,
6200,
null,
23400,
55700,
null,
149400,
58200,
46900,
16000,
25700,
null,
51500,
40600,
102000,
20600,
26000,
12400,
75683,
13600,
54900,
35200,
25300,
21800,
13300,
32700,
76200,
31100,
29400,
null,
37800,
46100,
31200,
20800,
22810,
26900,
29500,
27600,
51900,
49000,
46100,
127200,
47800,
22500,
63200,
100900,
16200,
18500,
35700,
33600,
70400,
5700,
43600,
39400,
null,
74100,
14800,
null,
22700,
16900,
22800,
16200,
39900,
16100,
43400,
15800,
21400,
10800,
29400,
21500,
53200,
53800,
103000,
30700,
29900,
20500,
21400,
36000,
18500,
21100,
43200,
65800,
24700,
24800,
17800,
102800,
39700,
80600,
33900,
21400,
null,
25200,
46600,
2800,
54000,
95400,
26200,
8000,
34700,
16500,
65300,
367400,
null,
26600,
9600,
10800,
48000,
21000,
44700,
53100,
15000,
14500,
36700,
32900,
19400,
null,
33300,
19100,
678400,
10700,
31400,
8900,
25800,
48600,
9700,
9900,
32900,
20400,
10700,
5800,
91100,
6100,
15400,
1400,
14900,
null,
8600,
30900,
20300,
23400,
6700,
null,
24800,
41600,
null,
17500,
33100,
26100,
10500,
8500,
39300,
29200,
44700,
11600,
50300,
11800,
30500,
30800,
27400,
16000,
59700,
8600,
52400,
41500,
17900,
null,
57000,
22300,
null,
16300,
23400,
18700,
12500,
14300,
22800,
31900,
4250,
22400,
null,
13900,
16100,
64500,
5700,
22800,
28015,
33670,
8400,
14900,
9800,
20000,
27400,
null,
null,
94700,
16900,
37100,
20700,
15700,
32400,
13750,
12200,
54800,
64400,
29100,
null,
16000,
9200,
48700,
21700,
14600,
14000,
45100,
13500,
6600,
12200,
33000,
8300,
37700,
44800,
9500,
102300,
null,
30000,
32071,
116100,
28800,
13700,
null,
63800,
133000,
null,
22600,
34600,
90700,
120900,
22100,
17600,
25000,
68800,
27100,
48500,
15800,
34400,
21500,
40400,
8300,
32900,
32500,
59600,
144300,
10350,
32100,
17500,
57300,
35000,
null,
28000,
27100,
3400,
40400,
15700,
null,
46500,
28397,
42000,
60300,
13300,
10600,
13800,
53300,
11600,
86000,
53400,
19700,
21100,
9600,
17600,
68900,
null,
7400,
9200,
3500,
42700,
26200,
15600,
74600,
4900,
null,
null,
1314900,
33400,
13900,
null,
31000,
59100,
26300,
38100,
23500,
23500,
22900,
27500,
32300,
57900,
null,
17500,
25800,
14100,
17000,
null,
21400,
26000,
43100,
16000,
42600,
33000,
25400,
50900,
112400,
55100,
4400,
19900,
null,
42400,
86300,
45000,
77700,
12900,
null,
12700,
2000,
21400,
17700,
63800,
36900,
null,
49900,
6400,
31100,
8500,
null,
31000,
15200,
10300,
26500,
84800,
40200,
27100,
22300,
25600,
75800,
22000,
7300,
13500,
22700,
70200,
30100,
null,
29600,
35400,
12100,
19700,
38900,
9930,
23500,
21900,
null,
15800,
50300,
13400,
28700,
5800,
31500,
155400,
9600,
8600,
45151,
27400,
70600,
39600,
59260,
35300,
17700,
36100,
null,
10600,
13430,
5500,
26400,
39400,
null,
109800,
8600,
10900,
16200,
79800,
16300,
30100,
40400,
7400,
13000,
80400,
8300,
60700,
2400,
13100,
42000,
4900,
154500,
184185,
23000,
13600,
37600,
67700,
27400,
null,
18800,
6900,
13626,
1200,
null,
18900,
null,
29400,
26600,
null,
90000,
42600,
null,
8400,
24600,
36600,
9800,
25200,
3400,
64600,
15600,
22000,
15600,
14600,
null,
29800,
33600,
49800,
39300,
15000,
null,
2000,
15200,
null,
68400,
40400,
15900,
19500,
12600,
null,
8400,
11900,
21800,
41400,
27836,
27400,
24200,
31100,
11600,
24900,
65400,
9800,
16500,
62552,
47400,
32000,
16400,
11700,
104900,
22200,
15600,
51300,
8500,
20500,
38800,
null,
null,
36000,
37300,
78500,
328800,
17200,
59961,
385880,
76200,
19900,
22800,
60300,
21600,
10800,
14500,
59300,
null,
43700,
7300,
7800,
44400,
43200,
26500,
23400,
45100,
20000,
27032,
13800,
22200,
20200,
null,
11500,
54000,
30100,
11800,
8100,
49808,
5600,
39700,
null,
351000,
74771,
32600,
55200,
null,
19600,
16500,
31600,
22400,
16700,
15000,
13000,
72000,
17500,
24100,
20700,
51400,
50300,
30300,
31600,
9400,
null,
61500,
6000,
52100,
19800,
20700,
51700,
50500,
73600,
12500,
30700,
10700,
26500,
19700,
12700,
22200,
15100,
30200,
29800,
21000,
7200,
19300,
33300,
16500,
49300,
57400,
24300,
11100,
18600,
12400,
null,
null,
14900,
53000,
2500,
23500,
24700,
27100,
23100,
40900,
145900,
1600,
24700,
7200,
47600,
15800,
27200,
6500,
21300,
33300,
21400,
30919,
15000,
53000,
16600,
26300,
44400,
14800,
14000,
29500,
16700,
63000,
38300,
136200,
15500,
51900,
43400,
7300,
271000,
null,
18996,
18600,
13800,
39800,
21089,
8700,
98811,
6600,
82200,
22000,
17600,
8600,
25200,
57200,
36400,
39400,
12100,
42400,
31400,
25700,
27200,
40000,
15900,
15100,
56700,
14700,
15400,
40300,
36700,
12000,
35900,
49300,
31300,
53900,
9400,
null,
51000,
37200,
25600,
55300,
3100,
56100,
20600,
15900,
null,
64900,
30500,
20000,
45300,
null,
38800,
44000,
96000,
55600,
17700,
20400,
77000,
34800,
54700,
15100,
41500,
33900,
15500,
25000,
53000,
21300,
40000,
46200,
5500,
20000,
8600,
94600,
10200,
null,
null,
11400,
38600,
28600,
151900,
103600,
16000,
47200,
32900,
36600,
18700,
69900,
34300,
10700,
32800,
15800,
12500,
34600,
15400,
59500,
17700,
36300,
19300,
72900,
null,
27300,
8100,
22800,
15600,
21600,
17600,
16100,
34200,
28000,
15300,
12200,
48000,
50700,
48000,
null,
20000,
32700,
15600,
9700,
14900,
11400,
17200,
23950,
21900,
18900,
null,
48600,
8200,
11100,
null,
19100,
10800,
23521,
7700,
27800,
29100,
38600,
11200,
73800,
27000,
13200,
23600,
56900,
68114,
null,
26800,
null,
21200,
36300,
50900,
43800,
23300,
19600,
22950,
19800,
22300,
28200,
10200,
66000,
null,
50100,
30600,
null,
9000,
34400,
41200,
58200,
49300,
8300,
24500,
4900,
89400,
69100,
null,
15800,
11900,
23000,
29900,
26500,
6100,
56900,
18900,
21800,
93150,
16900,
13100,
20800,
11500,
null,
21700,
66232,
10800,
39100,
65100,
15500,
15500,
8500,
43500,
9900,
21400,
10300,
41700,
8800,
10900,
36900,
22000,
38000,
32500,
16800,
24400,
12200,
20500,
11700,
9200,
56500,
3000,
32300,
49200,
77000,
6400,
50400,
40800,
15800,
29201,
51000,
22000,
13000,
46500,
37800,
19600,
43500,
10800,
20600,
95300,
24554,
36200,
18800,
65600,
36700,
34100,
4200,
9400,
6900,
42600,
32000,
null,
54900,
30300,
22400,
5100,
25900,
39500,
11100,
47500,
45100,
16700,
53100,
null,
46500,
30100,
37050,
44200,
39700,
45800,
31100,
31500,
23900,
65500,
15000,
17600,
44300,
20700,
36100,
43400,
13600,
27400,
9200,
10200,
38700,
14900,
9500,
59700,
34100,
13600,
22100,
35800,
34600,
17100,
6400,
null,
81062,
57000,
null,
20300,
195600,
38900,
37600,
52300,
null,
55300,
37500,
58100,
62400,
10000,
10300,
34000,
27300,
8000,
20400,
21600,
16200,
34600,
15500,
48861,
37400,
13400,
16000,
32700,
19700,
17700,
25497,
27400,
25001,
54400,
null,
19800,
23500,
32200,
8600,
33603,
67900,
19000,
null,
30500,
16200,
26600,
4400,
4800,
34100,
18900,
25200,
28300,
28200,
31600,
null,
null,
14900,
17300,
17400,
20600,
32600,
23600,
57200,
22000,
34400,
17800,
12100,
14700,
102800,
46000,
36000,
53500,
17000,
9000,
null,
47300,
22200,
30600,
14400,
45000,
12900,
11200,
82900,
14700,
22800,
22860,
82400,
14700,
25500,
40100,
18900,
19500,
15300,
13900,
17800,
34000,
29800,
15200,
53400,
39700,
37300,
16400,
75000,
8900,
24600,
56100,
14200,
52500,
43700,
13300,
36500,
11200,
38900,
13100,
43500,
11200,
54000,
null,
29600,
15900,
24500,
31000,
43300,
45900,
22800,
28300,
30600,
21600,
64700,
24400,
67900,
30300,
33400,
10500,
49900,
7300,
74400,
19000,
35700,
27500,
33400,
32400,
13300,
null,
34000,
null,
4200,
21100,
27000,
11300,
50300,
5500,
19800,
62600,
4700,
13000,
null,
17700,
5700,
122500,
5500,
17400,
19200,
22600,
15800,
22300,
null,
26600,
33200,
12800,
6100,
5400,
42500,
35100,
8700,
13900,
9200,
null,
22300,
39400,
61300,
71300,
12600,
32000,
null,
null,
8000,
28800,
300500,
10200,
44222,
28900,
null,
23500,
19500,
38300,
15000,
19000,
6400,
11200,
47100,
37500,
null,
28000,
32800,
63300,
17900,
20200,
11100,
14700,
18700,
16100,
36800,
15000,
8500,
28800,
13100,
43900,
18500,
12400,
22200,
29600,
18700,
3000,
null,
109500,
42100,
15900,
null,
32000,
40100,
83700,
63100,
null,
null,
15600,
20900,
24600,
29900,
23100,
null,
null,
50200,
32000,
9400,
25000,
15200,
53200,
16300,
5900,
50800,
28400,
35000,
null,
56200,
25100,
52900,
30300,
8900,
null,
37400,
15400,
null,
89900,
15500,
null,
11100,
30800,
57600,
43000,
null,
34500,
24600,
10900,
46200,
85800,
800,
40500,
39800,
15200,
55400,
14700,
40700,
20600,
1000,
15800,
12000,
22100,
18600,
6300,
21100,
57200,
8500,
15800,
54800,
41200,
32400,
39700,
20500,
26000,
17300,
7800,
10600,
101300,
23100,
27800,
36900,
36000,
16000,
109300,
2500,
10300,
11500,
94500,
51000,
97600,
26500,
7000,
45500,
22400,
3000,
null,
5900,
44200,
8500,
10100,
49000,
7200,
31700,
11900,
44900,
37200,
107800,
52000,
6000,
19440,
18200,
8000,
null,
null,
37000,
72400,
3500,
41700,
14500,
112700,
52300,
26400,
36300,
27500,
17600,
36400,
13000,
40100,
18200,
46500,
13200,
6800,
69433,
32500,
null,
11200,
14200,
9900,
38500,
4500,
36200,
28400,
null,
9300,
40400,
24300,
26400,
50300,
31500,
35801,
12800,
23300,
12400,
14600,
29600,
57900,
50000,
46032,
100500,
61800,
null,
33400,
15600,
32800,
82300,
5000,
6500,
18800,
10300,
13800,
23200,
42200,
7700,
5600,
null,
91500,
39500,
8200,
18700,
54501,
7700,
16200,
33400,
null,
10700,
2700,
20600,
13400,
43100,
29100,
null,
8300,
null,
16200,
11800,
56900,
25200,
19000,
13300,
52300,
8100,
22800,
74300,
43600,
null,
9800,
63000,
29600,
19400,
150400,
12700,
27500,
44100,
null,
22100,
14400,
66900,
37700,
38800,
null,
12500,
34700,
50700,
28800,
5000,
92600,
32800,
27000,
18600,
57700,
3200,
null,
17900,
14300,
22700,
14900,
13200,
13000,
8600,
20700,
38400,
83900,
49900,
5900,
24700,
30100,
57178,
27000,
7300,
21300,
17900,
5500,
24400,
29000,
12400,
10000,
7250,
null,
47100,
10400,
44100,
19200,
42800,
20400,
null,
14600,
null,
48100,
15200,
7000,
6300,
26900,
63100,
53900,
13600,
24500,
27800,
66500,
12200,
19900,
28200,
16200,
19200,
19600,
25400,
14700,
116200,
9300,
null,
15900,
11200,
22400,
26800,
3350,
36000,
30000,
42965,
21025,
19700,
24000,
21600,
16700,
15700,
null,
64200,
57700,
5600,
17600,
17700,
20100,
3100,
86800,
18451,
null,
33000,
43200,
15100,
9000,
14800,
12100,
11800,
24200,
24300,
13900,
17600,
23000,
30500,
5400,
10600,
51700,
206449,
null,
17425,
null,
25500,
16500,
null,
76800,
28300,
24900,
64200,
20900,
21500,
32200,
48300,
3800,
38650,
10390,
80200,
null,
12500,
14000,
26500,
3500,
11700,
0,
26100,
26300,
18700,
10200,
9300,
19100,
22400,
18100,
124400,
17900,
28300,
9400,
9700,
7840,
9900,
35800,
50900,
null,
19000,
22100,
41800,
13000,
null,
null,
null,
45900,
10300,
46700,
20300,
12300,
null,
30800,
18200,
17700,
5150,
49300,
15000,
13900,
23100,
46800,
6850,
116700,
26845,
26000,
22300,
20300,
18400,
50200,
7400,
null,
66000,
15200,
21200,
7500,
null,
6400,
3400,
47100,
21600,
34800,
77735,
27200,
25500,
22600,
63000,
null,
32400,
9800,
26900,
41000,
34700,
15300,
10000,
29100,
15400,
53400,
234800,
19700,
21900,
6700,
17400,
null,
null,
null,
19200,
31000,
81300,
64400,
15300,
null,
28100,
null,
21600,
23500,
29300,
33400,
37600,
29900,
5100,
34200,
57200,
61900,
46000,
60500,
15000,
44300,
20500,
16600,
9700,
16000,
null,
22700,
19700,
53700,
88100,
30400,
21500,
102900,
14500,
17000,
68400,
null,
13400,
35700,
10050,
6200,
15100,
41400,
6600,
22500,
56700,
19197,
111700,
116920,
16100,
15300,
26200,
25100,
10424,
23700,
6900,
25800,
5700,
21400,
49200,
12000,
13800,
2100,
7300,
12700,
29000,
30300,
17300,
3100,
267100,
21900,
43300,
11000,
60000,
24900,
30300,
null,
10600,
44800,
19500,
14500,
13600,
45400,
51700,
20100,
4800,
73100,
153800,
26500,
9800,
56900,
70000,
25900,
3500,
13500,
null,
79800,
7500,
18400,
20600,
24000,
12900,
9800,
39700,
49702,
25500,
14100,
25923,
8200,
10100,
13000,
80900,
20900,
6500,
18700,
16900,
20800,
18600,
102400,
52900,
29200,
null,
23500,
23800,
55500,
28100,
61100,
10900,
17500,
67800,
24300,
33600,
44100,
37800,
53200,
null,
16200,
22500,
34500,
162000,
13700,
14800,
26700,
45600,
43500,
null,
31100,
70900,
48400,
44000,
16800,
19600,
45200,
14700,
48100,
26100,
9000,
null,
26000,
15100,
90000,
12100,
28400,
11900,
83800,
20856,
null,
35400,
43100,
3000,
11700,
20100,
38100,
47700,
30400,
56100,
28100,
21900,
50900,
9600,
33200,
40600,
null,
46800,
null,
18400,
11000,
18100,
19500,
22200,
6300,
67100,
53500,
70200,
33800,
5100,
7700,
1000,
37900,
18200,
null,
28100,
59200,
116200,
28800,
132000,
55300,
9300,
56000,
23000,
18600,
29400,
15200,
23900,
145900,
null,
28913,
82500,
2500,
12800,
null,
30800,
46200,
96200,
13750,
48300,
null,
15900,
15100,
309900,
null,
61100,
30800,
12200,
1900,
12200,
146100,
16900,
null,
14800,
25600,
88200,
11400,
54100,
31100,
null,
18800,
15100,
46200,
5100,
38200,
63300,
87373,
14900,
72000,
32200,
10500,
17100,
7600,
25000,
69200,
null,
12100,
20700,
21911,
22900,
49700,
17600,
16200,
11400,
24100,
null,
19900,
13800,
20900,
51500,
20400,
36200,
12100,
35100,
68300,
25800,
12100,
9850,
42100,
13900,
9400,
15500,
16200,
23700,
32600,
21000,
36200,
63700,
43700,
46873,
79300,
103305,
null,
19100,
11700,
47000,
52500,
48400,
132600,
42200,
23500,
25526,
18900,
13000,
28900,
28500,
21300,
18300,
8800,
19100,
27200,
18900,
14300,
42800,
14200,
4600,
25500,
21400,
16800,
28100,
14000,
31600,
123600,
4300,
null,
12100,
28000,
17300,
7300,
67200,
17400,
null,
26900,
8000,
5800,
17300,
37137,
7700,
184050,
24600,
50600,
60500,
16900,
20600,
22300,
27900,
16500,
42700,
62640,
17500,
15750,
8800,
8300,
4500,
11600,
null,
30600,
44900,
27500,
19500,
29600,
61600,
60800,
21900,
54000,
7900,
29300,
26000,
38300,
12600,
null,
34300,
null,
null,
12400,
16900,
55800,
18600,
7900,
22400,
13000,
20400,
40600,
13000,
12400,
42100,
null,
31400,
18000,
75500,
7100,
42300,
11200,
31500,
44400,
17000,
62644,
28700,
17100,
73000,
48400,
18500,
28100,
11200,
21500,
73000,
124750,
23400,
4900,
158100,
16500,
19500,
27800,
9900,
13700,
42100,
9100,
null,
12400,
57100,
56100,
29500,
60500,
60700,
14632,
17600,
null,
52900,
66500,
14900,
38500,
8800,
29200,
34200,
8900,
7700,
25000,
7236,
11000,
47400,
16700,
7800,
40100,
20300,
53620,
35700,
17700,
43300,
86300,
25400,
75100,
null,
165900,
50200,
18100,
8700,
19345,
10000,
35200,
19400,
46500,
74100,
48100,
32500,
55900,
null,
11600,
24600,
12600,
60900,
11000,
35600,
39600,
34400,
20900,
null,
13300,
6300,
15800,
36900,
16500,
41900,
null,
8700,
32800,
null,
29800,
40000,
19400,
27700,
null,
6000,
95400,
193500,
24300,
102100,
45000,
14800,
19300,
8300,
null,
null,
121200,
31900,
32900,
40600,
36700,
11200,
82200,
10700,
30000,
32200,
15200,
29200,
26200,
30300,
14100,
26200,
72100,
31417,
16200,
110200,
49286,
3700,
31500,
130400,
17600,
66700,
17000,
19700,
35700,
12800,
null,
3700,
null,
11100,
18900,
53600,
16000,
null,
32400,
null,
16700,
99200,
21900,
14300,
null,
63600,
6100,
69100,
14800,
22700,
13100,
8900,
34750,
29900,
5900,
null,
20500,
49100,
29600,
50500,
49600,
11000,
96095,
15200,
6400,
38500,
null,
null,
38600,
29900,
67600,
46400,
34000,
72800,
30800,
33500,
49600,
39800,
7300,
28000,
10700,
9400,
43000,
47100,
null,
33700,
28500,
72500,
31200,
35000,
5300,
null,
41900,
null,
14600,
17300,
38300,
26800,
39300,
4900,
6600,
75300,
15000,
17500,
17200,
38900,
20900,
35500,
202100,
12800,
15700,
22100,
13600,
20700,
14400,
18100,
4100,
12400,
null,
16000,
27500,
27300,
66650,
6300,
13800,
null,
19100,
6900,
17300,
10201,
null,
13100,
80400,
15100,
50700,
46200,
48600,
32700,
25742,
2700,
11000,
7600,
4900,
36900,
2200,
57800,
28500,
24100,
53400,
92100,
12200,
7800,
14500,
56100,
18600,
46900,
7200,
18000,
41300,
27900,
32800,
16500,
45200,
33100,
236200,
60900,
33000,
17600,
21900,
51700,
4300,
25700,
63300,
147000,
16000,
5700,
62300,
9700,
9500,
24400,
15900,
32900,
30000,
6300,
63500,
140200,
6800,
32000,
null,
10000,
null,
null,
83400,
53500,
35300,
39000,
35000,
56900,
null,
13500,
7900,
8600,
29700,
79700,
52000,
6500,
null,
47700,
38300,
61500,
43600,
17800,
7000,
14400,
19400,
27700,
2700,
8900,
6900,
25100,
8500,
28100,
26500,
28700,
90500,
11400,
51700,
29800,
49900,
77900,
30100,
null,
46100,
13100,
13900,
15700,
13000,
31900,
42200,
64700,
17300,
15200,
11900,
88700,
16900,
28600,
103200,
26700,
36600,
15100,
31700,
38000,
14200,
25000,
12300,
9400,
16700,
36940,
7100,
27700,
22400,
24100,
53100,
13900,
11100,
null,
60300,
9600,
49900,
78300,
36500,
11300,
14500,
19900,
15700,
10000,
48600,
36800,
56000,
55600,
28400,
8300,
15900,
18100,
20900,
26800,
15400,
23000,
16000,
20840,
25500,
117300,
16900,
23100,
33300,
31900,
30000,
6900,
33800,
2500,
53900,
18000,
18600,
16900,
12400,
17600,
10900,
6500,
15100,
33200,
18000,
12000,
139100,
null,
12100,
104200,
50400,
42800,
null,
24100,
26600,
35900,
7900,
21800,
10700,
169100,
36500,
30200,
25600,
38200,
27000,
20700,
12100,
29900,
10300,
14200,
14901,
87500,
null,
9800,
14030,
16000,
90350,
null,
46800,
16800,
null,
50300,
44700,
12700,
38700,
31100,
15600,
19100,
9500,
17300,
12300,
15200,
8500,
14400,
63500,
7400,
29700,
27900,
26800,
7700,
70200,
4200,
16300,
23000,
12600,
5600,
20900,
16800,
null,
null,
29200,
84700,
30200,
9000,
83300,
40400,
61300,
null,
56900,
13200,
14000,
48500,
8300,
21500,
900,
10100,
29000,
20600,
16000,
16600,
3700,
15000,
78300,
54600,
38700,
23700,
12900,
34300,
29400,
110000,
23500,
28200,
6100,
20700,
15900,
25800,
39800,
null,
54200,
19400,
null,
23900,
9900,
22600,
40300,
57100,
224800,
7000,
29300,
24700,
21500,
25900,
2500,
64400,
21600,
12500,
50500,
23100,
43500,
19500,
203500,
15900,
14500,
null,
67900,
25500,
null,
40700,
9600,
null,
28300,
9300,
35900,
23100,
107400,
24470,
18000,
52900,
17800,
7200,
21300,
36550,
56300,
24000,
12900,
24200,
25600,
15000,
24500,
27400,
21700,
10600,
3100,
52400,
31000,
8200,
137100,
137400,
21600,
43300,
18300,
12800,
7800,
47600,
14700,
8500,
23900,
21400,
8000,
14400,
29500,
29400,
23100,
5800,
50400,
8250,
6100,
61600,
19400,
14000,
38000,
39200,
7900,
38000,
17100,
2750,
11000,
11600,
54000,
53100,
11350,
38700,
17000,
28300,
3800,
17700,
37500,
22300,
47700,
21400,
43500,
38500,
69300,
48500,
29100,
32200,
97625,
103350,
49400,
25100,
20500,
35300,
33400,
19800,
17800,
51100,
21000,
28300,
39400,
31800,
47700,
15600,
7600,
64300,
10100,
16600,
58200,
11700,
11200,
26300,
47400,
15400,
36500,
13200,
8900,
25200,
11800,
34700,
26800,
47000,
18500,
7100,
8000,
9500,
74400,
8800,
40500,
19100,
96100,
14100,
53700,
36500,
41200,
5400,
16100,
21600,
null,
106100,
2900,
22600,
28800,
61100,
12700,
92585,
14200,
34900,
61900,
36900,
84500,
258000,
36600,
57600,
18300,
null,
10600,
42500,
29900,
40400,
23500,
22000,
16000,
31800,
null,
13200,
12000,
40050,
7600,
27200,
18900,
79900,
23400,
28800,
null,
16600,
null,
40400,
17000,
31300,
23100,
32900,
67100,
40500,
42300,
151000,
14005,
12700,
179100,
30200,
17300,
88400,
15100,
61500,
17500,
74500,
null,
36900,
13200,
8300,
48300,
18200,
88200,
40900,
null,
35000,
14000,
33500,
18600,
12200,
16800,
19900,
20700,
45800,
12800,
17200,
40600,
15600,
34300,
11000,
5600,
7200,
85200,
27700,
23400,
25100,
54500,
18600,
68400,
null,
18100,
59000,
73599,
69500,
35500,
21600,
40700,
38400,
12600,
22200,
1800,
46000,
55000,
36000,
12500,
41600,
79070,
12600,
null,
21300,
16100,
22600,
157800,
41300,
15000,
12600,
28800,
8800,
22700,
55500,
39700,
25400,
17301,
14500,
42500,
14000,
null,
39083,
38700,
4300,
11700,
null,
47800,
23000,
5000,
30000,
9000,
7400,
27700,
15300,
20800,
null,
29300,
11700,
29600,
4200,
43700,
26700,
7600,
52300,
37900,
11800,
16600,
22500,
null,
13800,
7900,
22000,
52700,
20400,
22000,
13200,
69200,
45800,
8100,
40100,
46600,
27900,
13300,
25400,
36600,
17000,
38700,
33400,
20800,
21900,
null,
41300,
17950,
6100,
null,
null,
24600,
44100,
27400,
23400,
24300,
18700,
1100,
21800,
51264,
18200,
null,
null,
5800,
16700,
19700,
34200,
18200,
15000,
23000,
23900,
14700,
17400,
null,
null,
34400,
23700,
11100,
17200,
8300,
12800,
57200,
42400,
29100,
12900,
20000,
87400,
38000,
14000,
45700,
46200,
24700,
null,
35400,
3400,
5900,
33400,
10900,
40000,
34400,
17300,
18800,
35400,
34900,
70496,
16200,
null,
32600,
15100,
17200,
null,
10900,
17100,
9300,
58200,
30400,
23000,
5000,
11400,
7700,
74100,
null,
21800,
9500,
31300,
20400,
15300,
80100,
33700,
11200,
115600,
12800,
47200,
202900,
38300,
31000,
136500,
46400,
44100,
22800,
12700,
16800,
38700,
11500,
53800,
18000,
19000,
49300,
31100,
24600,
23500,
24500,
null,
24500,
21000,
16600,
17450,
53100,
75800,
25300,
28600,
null,
58400,
18400,
31500,
16800,
38000,
null,
29200,
8200,
28640,
12600,
32000,
null,
null,
33400,
51500,
18600,
null,
6200,
13000,
13000,
8200,
166900,
23000,
64700,
9500,
125900,
33200,
11000,
30400,
13000,
93900,
23900,
14000,
15300,
43500,
14700,
4750,
51600,
43300,
11300,
33900,
10000,
7800,
62100,
53700,
19700,
12400,
9700,
39000,
29025,
39000,
101800,
27500,
51300,
120600,
23200,
18600,
17100,
40193,
null,
31900,
31500,
7000,
26600,
11200,
10700,
18500,
null,
null,
40537,
null,
18200,
4000,
31600,
33700,
31000,
69400,
4200,
24800,
17233,
2400,
20100,
47600,
30100,
32700,
4400,
16200,
110600,
45300,
16000,
8400,
7500,
26200,
105600,
73400,
null,
104100,
3000,
22900,
8700,
128900,
12100,
null,
26500,
50400,
17200,
77400,
6000,
27500,
49500,
3500,
22100,
20700,
28700,
22000,
10300,
43300,
6800,
8800,
9300,
38600,
36000,
9500,
null,
57300,
24050,
27200,
45200,
41800,
null,
28400,
25300,
55000,
16800,
18500,
18000,
56300,
11200,
23900,
23200,
19200,
49200,
64100,
32200,
76600,
24400,
36300,
10400,
29100,
10200,
12100,
33000,
16200,
19700,
32000,
21300,
14500,
48800,
190700,
null,
17400,
43800,
6700,
28500,
12600,
null,
19909,
49100,
8800,
49700,
22099,
30200,
13000,
36600,
19000,
13400,
null,
39400,
18000,
33800,
11100,
27400,
3800,
36700,
7300,
47663,
null,
61400,
null,
13700,
45400,
52000,
42200,
35800,
68900,
43600,
31379,
63100,
18000,
12200,
14500,
35500,
35200,
25600,
259500,
8900,
116100,
17800,
13500,
5200,
42100,
34000,
16300,
60400,
44800,
221300,
17300,
12600,
19900,
90500,
24600,
34500,
null,
11900,
59400,
114500,
25700,
52300,
56700,
76300,
10000,
5700,
17000,
17100,
null,
null,
36100,
12000,
null,
23300,
49600,
7500,
17500,
21900,
15000,
17400,
10600,
7500,
68900,
29100,
null,
51400,
null,
128100,
null,
34600,
38200,
14800,
21900,
22000,
45900,
87700,
42100,
18500,
18200,
null,
72900,
5500,
15200,
42300,
8600,
47800,
50300,
23900,
null,
24300,
8800,
13400,
69300,
43330,
74200,
20600,
19300,
22000,
147600,
35300,
9700,
17400,
42800,
38800,
14700,
null,
51600,
8900,
14600,
34100,
36000,
71500,
22300,
19900,
2800,
75400,
151860,
17000,
15900,
27400,
null,
10700,
31200,
80700,
20200,
27600,
37500,
32800,
null,
53800,
66600,
22200,
33000,
13600,
13600,
92100,
29900,
13400,
65100,
8900,
14600,
16100,
39400,
63200,
13900,
31800,
29800,
30090,
24000,
10400,
28800,
null,
39000,
9400,
null,
10500,
107600,
null,
19900,
22900,
15000,
null,
27300,
17700,
48400,
null,
20000,
26200,
37900,
29500,
11300,
6009,
56000,
19400,
null,
null,
27700,
9100,
18800,
null,
5700,
12900,
17100,
29100,
35300,
45200,
42400,
22500,
6900,
99700,
82000,
18600,
16900,
null,
41300,
13200,
43200,
10700,
41900,
8500,
37400,
2700,
6000,
57800,
null,
5050,
36600,
26100,
9100,
7400,
33000,
31100,
112000,
45800,
170700,
59000,
13400,
9800,
13700,
20700,
60000,
26300,
34000,
38600,
14500,
14300,
34900,
18100,
113500,
19600,
14500,
81400,
24100,
26700,
28400,
50600,
66800,
54800,
36400,
54700,
33400,
20500,
29900,
null,
46300,
10700,
19800,
60300,
3100,
17900,
50900,
12700,
47700,
58900,
26600,
15500,
4900,
5000,
41600,
14500,
56500,
45800,
18600,
28400,
23800,
61400,
11900,
31700,
9500,
30700,
71100,
null,
43200,
null,
null,
30300,
8500,
36100,
38300,
18300,
47900,
13200,
34800,
47300,
14800,
239800,
12400,
41000,
17700,
19500,
43700,
9300,
91200,
14600,
13100,
8900,
39500,
null,
50900,
31650,
40100,
30400,
11000,
35500,
50500,
12200,
29300,
55500,
50100,
12700,
30000,
13100,
31100,
20700,
46100,
7400,
11800,
40800,
31700,
37900,
85600,
20800,
25600,
12000,
21300,
7000,
6500,
null,
28800,
22900,
9800,
9000,
null,
31500,
29300,
58600,
57700,
22300,
5700,
63600,
28700,
12000,
73700,
18700,
null,
29500,
3800,
39000,
28000,
40200,
11600,
17600,
24380,
19400,
10300,
49500,
10900,
null,
21700,
128200,
27700,
10000,
57000,
19900,
18400,
41600,
85000,
50900,
10000,
null,
55000,
32400,
47900,
5400,
5900,
39000,
20800,
64900,
39600,
36200,
35900,
115100,
11700,
29400,
null,
31500,
19309,
78100,
36900,
19100,
37600,
16900,
10400,
10300,
null,
17800,
5300,
8100,
11100,
21000,
40900,
43200,
12200,
7600,
14300,
null,
null,
34900,
22400,
15400,
55000,
27200,
67100,
18200,
13500,
25500,
26100,
38600,
25500,
null,
30700,
47600,
20300,
38500,
21000,
53700,
null,
52600,
32300,
22400,
19400,
28400,
6100,
35800,
51500,
35000,
39800,
48700,
8500,
41900,
17200,
87900,
null,
32100,
43300,
12000,
17100,
23100,
7700,
27400,
8200,
17700,
11000,
null,
21600,
18000,
34900,
37300,
23100,
72400,
null,
23500,
151395,
92000,
18100,
31800,
18800,
8100,
48700,
8500,
3500,
68000,
58800,
null,
34300,
38700,
41000,
29000,
9300,
16700,
null,
10000,
13500,
12100,
23000,
3900,
10400,
41400,
13400,
18000,
25900,
100300,
6700,
3600,
28500,
null,
null,
17200,
13600,
69190,
27700,
null,
12900,
25300,
33200,
52500,
26600,
5400,
14400,
54000,
27100,
69100,
57400,
43000,
8000,
null,
3100,
14400,
null,
22100,
50300,
7300,
52900,
26700,
null,
10300,
26700,
10500,
null,
6600,
37000,
14800,
43800,
null,
14700,
13900,
20800,
31500,
19500,
23500,
22000,
16950,
21400,
55700,
20700,
12800,
12800,
38700,
30900,
40200,
null,
19600,
27300,
9475,
21000,
126500,
22200,
34700,
19800,
4400,
null,
14400,
39800,
29100,
19400,
28100,
15700,
42100,
null,
19100,
39600,
32400,
11200,
21600,
6500,
57400,
13500,
19000,
10400,
7700,
28000,
32900,
8500,
93100,
3000,
25700,
25000,
43600,
26400,
28400,
24900,
34800,
13200,
5400,
8800,
53200,
37000,
67300,
20100,
30800,
3100,
23600,
153800,
50400,
18900,
47700,
16500,
29500,
64600,
8700,
59200,
29000,
39800,
12900,
57964,
7900,
12300,
10400,
13700,
29500,
20500,
13800,
null,
null,
23100,
9600,
28200,
67700,
null,
28000,
52400,
62100,
8300,
34100,
13100,
6600,
38500,
12800,
null,
null,
18500,
null,
36800,
55800,
27100,
14300,
null,
20500,
22200,
35600,
31600,
18800,
13450,
57100,
31300,
null,
44400,
75300,
29700,
22600,
91400,
9000,
19200,
30500,
12900,
10000,
14600,
15800,
56300,
20400,
5900,
7700,
51200,
41800,
46900,
21500,
5400,
13100,
46200,
83400,
28570,
12300,
83000,
31000,
26700,
13700,
7800,
49000,
31900,
12500,
null,
24700,
45400,
3900,
66800,
5500,
16900,
103000,
22000,
15800,
10800,
11700,
12000,
33500,
44000,
15500,
14500,
41200,
30900,
6200,
15300,
11200,
8200,
24700,
null,
14100,
29600,
10700,
57900,
10500,
15700,
9700,
8100,
48100,
31100,
67600,
42700,
16600,
17000,
9600,
25300,
null,
25500,
null,
17800,
20000,
7600,
12000,
38700,
47200,
12000,
14800,
15300,
45200,
52400,
44100,
40200,
30500,
142500,
17900,
26600,
28100,
21400,
10100,
17100,
null,
27400,
22700,
15500,
38000,
15400,
13500,
5000,
3800,
13500,
35300,
null,
25200,
21800,
26400,
36100,
29500,
8800,
24600,
9600,
32900,
67300,
38200,
6000,
32400,
30331,
19100,
52700,
21600,
13700,
10900,
14800,
56700,
15600,
16500,
112000,
12200,
21000,
7500,
41200,
43200,
44700,
24700,
22800,
46300,
13700,
9000,
7000,
null,
17200,
24300,
24700,
95300,
49900,
19800,
12100,
21200,
20300,
null,
60700,
17000,
17600,
5150,
25000,
13300,
46900,
9200,
null,
10600,
56000,
27000,
28700,
13600,
25000,
41200,
45300,
377400,
17000,
36500,
11300,
7200,
13700,
30300,
9600,
69500,
6800,
59500,
null,
89450,
null,
null,
31700,
5400,
41000,
33600,
8800,
9300,
16200,
26900,
5500,
16900,
64600,
28400,
null,
11100,
20300,
8300,
59200,
51800,
36300,
14300,
17895,
31200,
21500,
55100,
37500,
57200,
52000,
12600,
16300,
9700,
35900,
3900,
26800,
58100,
21600,
26100,
10500,
47700,
8400,
33800,
16300,
38900,
42500,
36400,
13700,
122200,
15300,
20400,
22900,
71896,
26000,
6500,
14800,
46100,
11000,
24500,
8100,
41100,
11100,
19100,
null,
12700,
57900,
9000,
12000,
17100,
127200,
45900,
13500,
7400,
17800,
26300,
17800,
53700,
null,
39100,
49600,
null,
32400,
35500,
58500,
39700,
35200,
33500,
20900,
49800,
34500,
33700,
117700,
25000,
13700,
12900,
null,
13400,
42100,
null,
26463,
14800,
31300,
19200,
12500,
28400,
16600,
6300,
43200,
8600,
19500,
6000,
37800,
26500,
41000,
56500,
41800,
18600,
11100,
null,
null,
23800,
3800,
8400,
9800,
13300,
53200,
25400,
null,
34500,
55600,
17100,
56100,
21800,
29700,
27000,
64900,
44426,
45300,
26700,
35700,
null,
22200,
15000,
null,
17800,
16000,
54400,
21600,
1500,
26000,
46400,
19000,
24800,
16800,
31900,
40700,
64500,
16200,
19500,
50300,
19300,
26300,
8000,
10800,
14700,
27100,
19100,
35400,
39400,
21700,
6300,
36700,
7900,
17500,
8500,
18400,
32100,
4300,
48150,
13500,
54700,
15800,
72300,
77100,
5200,
22000,
null,
null,
null,
8000,
7100,
9800,
26800,
23800,
10500,
6300,
23000,
6900,
8800,
33000,
54100,
21600,
14900,
66200,
17100,
null,
13600,
11700,
33600,
9000,
9100,
null,
15500,
60000,
19800,
45100,
53400,
56100,
44600,
6800,
null,
66300,
48200,
15500,
17000,
8100,
7400,
null,
69300,
26900,
null,
5800,
68000,
11300,
56800,
14200,
22800,
45800,
22600,
null,
18100,
24700,
null,
13200,
97600,
6300,
14100,
44800,
20600,
11500,
14300,
22200,
86600,
null,
null,
11800,
11100,
40100,
null,
36200,
5600,
30300,
4300,
null,
23800,
37900,
40500,
11500,
35000,
48700,
14600,
20400,
58000,
null,
32400,
28400,
6800,
24100,
15400,
29900,
null,
84900,
13300,
69600,
null,
5600,
39200,
null,
17400,
7700,
62800,
null,
8200,
42500,
null,
13300,
8500,
13700,
35800,
1500,
27800,
6169,
null,
20600,
27300,
32600,
37200,
null,
74500,
39900,
11100,
12500,
6400,
14900,
65100,
null,
16800,
35700,
22100,
21600,
null,
42900,
71300,
87900,
23100,
8300,
13100,
11500,
18400,
72200,
20400,
24600,
41000,
26100,
9500,
52000,
11900,
12800,
30900,
54300,
30900,
34400,
22300,
71700,
14200,
17200,
35000,
64300,
null,
5500,
20800,
28200,
26300,
11400,
24800,
15100,
45283,
15900,
44200,
24400,
28300,
18100,
21000,
33300,
141400,
6400,
12400,
4300,
19600,
124900,
70000,
66251,
null,
72800,
null,
20800,
null,
5300,
16700,
32950,
27200,
22000,
84400,
25800,
32200,
18300,
7300,
54000,
8700,
6500,
20800,
15400,
17900,
37300,
22900,
5200,
35200,
95467,
62000,
11900,
8800,
74500,
17100,
92500,
6300,
42000,
64600,
15200,
44100,
19200,
23200,
35300,
41800,
18800,
null,
8700,
13100,
8500,
85500,
23400,
36800,
20800,
20800,
29700,
null,
18100,
79500,
18000,
30400,
13500,
19400,
37500,
null,
null,
5000,
82500,
6000,
7300,
32000,
48700,
18900,
21600,
22100,
44100,
55500,
null,
23500,
11600,
54200,
31200,
43300,
22600,
30400,
71000,
46900,
29000,
null,
48900,
71200,
29300,
15400,
5400,
43900,
45500,
9700,
null,
10600,
43100,
4600,
20200,
11800,
16700,
7800,
38800,
8900,
15000,
11200,
null,
47200,
14300,
7600,
9100,
null,
9700,
12800,
22100,
15000,
9200,
27400,
8300,
49100,
14600,
33500,
null,
73100,
23800,
34000,
27000,
46600,
30100,
1700,
4000,
6600,
49000,
53900,
60800,
44700,
69600,
22000,
25400,
361000,
8800,
14300,
19600,
35700,
37800,
27800,
10900,
5000,
98400,
12900,
5900,
50900,
9100,
21600,
29700,
3100,
null,
15500,
10000,
21700,
3300,
47400,
71400,
7600,
23400,
19500,
39200,
35900,
10900,
null,
12300,
27200,
27500,
15600,
1100,
41900,
20900,
16300,
11100,
35900,
17200,
37700,
23400,
40700,
11800,
14100,
148100,
13400,
111900,
60100,
10000,
71100,
6300,
19000,
7800,
22200,
35100,
73000,
null,
null,
32500,
31700,
22000,
18400,
32000,
28400,
59500,
34900,
17500,
13000,
25700,
62200,
75700,
15800,
3500,
3600,
22000,
null,
null,
30100,
null,
131300,
43500,
54900,
29700,
null,
42500,
20000,
30100,
7100,
33300,
19500,
84600,
10500,
7600,
49700,
17600,
9000,
12000,
29200,
13200,
null,
null,
28300,
17400,
8100,
null,
28700,
10000,
9900,
15300,
20700,
68200,
50300,
18700,
8005,
18900,
158000,
18700,
13200,
9150,
21162,
12500,
38700,
17700,
10500,
20400,
10500,
43800,
9400,
10900,
45300,
18100,
11500,
9200,
38500,
6100,
27700,
27100,
55100,
16800,
26500,
33650,
211100,
5350,
14200,
9700,
39500,
14100,
14000,
null,
13900,
40000,
130800,
23500,
46300,
21700,
18900,
null,
15100,
27700,
28600,
16900,
38400,
47600,
47600,
116600,
20200,
27400,
55400,
14000,
7500,
27800,
null,
22000,
8200,
39800,
10000,
22500,
9300,
36600,
107600,
58800,
22600,
11000,
21900,
32550,
null,
26400,
8400,
22400,
13200,
20500,
23800,
61000,
78300,
null,
49200,
24200,
29500,
31900,
16400,
45300,
41000,
20200,
9500,
26300,
12800,
13000,
null,
65900,
14200,
19700,
null,
14000,
30600,
18300,
37600,
19800,
27300,
31400,
85100,
10200,
39100,
14100,
16500,
46700,
69200,
16600,
9300,
27100,
30400,
63200,
17700,
32700,
42969,
41400,
23700,
57200,
11500,
1200,
46800,
17500,
105170,
48700,
48100,
12900,
19000,
19600,
40300,
6200,
23100,
null,
28700,
27200,
29800,
26800,
35600,
29800,
26200,
6190,
24600,
16200,
17700,
29800,
49100,
15200,
23800,
18800,
33900,
83500,
88900,
27500,
37500,
134300,
21000,
40600,
20800,
81100,
32800,
null,
11000,
21500,
10800,
40300,
18200,
13400,
152516,
36400,
16800,
38300,
11200,
11500,
6500,
16300,
57200,
5200,
17600,
31300,
40800,
12600,
22700,
18200,
35400,
6400,
null,
85700,
39200,
52800,
null,
27600,
33800,
41400,
28300,
56500,
4300,
6500,
13400,
16000,
38000,
null,
27000,
17400,
32100,
16300,
18200,
null,
8000,
26900,
131300,
13500,
28500,
9000,
14700,
36400,
5500,
20700,
96500,
22300,
16200,
null,
7500,
68700,
8400,
20400,
13900,
12200,
60900,
3500,
14100,
54700,
26400,
19500,
172100,
12500,
30700,
null,
11200,
32000,
12000,
null,
38900,
57300,
9400,
27300,
24100,
36900,
9900,
37700,
39600,
27400,
null,
24700,
6100,
17700,
101400,
7300,
23600,
8500,
147200,
18500,
4200,
17700,
14100,
28500,
21400,
null,
26600,
7600,
25000,
40400,
null,
28500,
9900,
19000,
null,
11600,
null,
22300,
31600,
34100,
15100,
21000,
9300,
8500,
null,
27500,
12600,
9000,
null,
9300,
53300,
12400,
14400,
59605,
53700,
53000,
13700,
null,
31600,
72700,
13300,
null,
36300,
16400,
21200,
65600,
8600,
23900,
18900,
30700,
10500,
13800,
45500,
16900,
53600,
16700,
25000,
64800,
91441,
54600,
128000,
7300,
35800,
51700,
14100,
28500,
24000,
42600,
37100,
26600,
7600,
44800,
18100,
25700,
122200,
14900,
24700,
74700,
41820,
1100,
62300,
35300,
7900,
12500,
37100,
73700,
45213,
52200,
null,
40141,
16400,
44300,
52500,
43032,
31800,
14400,
98700,
2600,
20300,
22500,
64400,
49000,
14800,
3000,
15500,
27700,
15900,
86600,
7700,
null,
null,
25800,
141800,
55100,
136900,
31800,
25500,
30500,
3600,
23300,
null,
84400,
15200,
47200,
27500,
16100,
11300,
10200,
null,
43500,
800,
13100,
27800,
13200,
9900,
53900,
24800,
27500,
8700,
69500,
38800,
91000,
13950,
19500,
15900,
29700,
null,
16700,
24600,
15000,
null,
45500,
20100,
23800,
25100,
142600,
12832,
24500,
4400,
94500,
61400,
7500,
28600,
34900,
17800,
52500,
46200,
35700,
25100,
25500,
9000,
null,
48600,
29800,
9450,
18900,
16000,
21500,
15200,
95000,
32300,
12900,
38000,
48100,
25200,
73200,
14500,
77200,
14700,
15500,
11000,
23100,
2300,
33964,
30300,
62290,
20700,
31800,
17400,
75700,
10100,
23700,
31400,
1200,
null,
17300,
32800,
15500,
null,
18500,
8200,
20900,
66100,
53900,
5000,
null,
24700,
21300,
15500,
16700,
8800,
22300,
7900,
26100,
null,
62500,
null,
12500,
22100,
24300,
17900,
16500,
14900,
27300,
23700,
18500,
4700,
5200,
27800,
8200,
26700,
12400,
24100,
19800,
55000,
33900,
33600,
14200,
85100,
19500,
5900,
14800,
25200,
63300,
11800,
11800,
46000,
118500,
6200,
46300,
6500,
22600,
20200,
62500,
25600,
15100,
null,
24900,
58800,
5400,
97305,
44700,
41600,
null,
24300,
7000,
null,
20700,
16700,
13000,
48400,
28900,
5900,
85400,
6600,
15200,
24000,
37500,
38700,
144300,
13800,
null,
13200,
44700,
144800,
111100,
26200,
10300,
14000,
39000,
12100,
20400,
19700,
43000,
40500,
85700,
38543,
37200,
25800,
21700,
64700,
30200,
32700,
73900,
7800,
210100,
19200,
14300,
25500,
123400,
11100,
54800,
12227,
35400,
86500,
21000,
53300,
7700,
31800,
21900,
59500,
1000,
33600,
30300,
17500,
null,
11200,
58400,
null,
27500,
41500,
12000,
12500,
50500,
36100,
7500,
33400,
32100,
null,
38400,
24100,
6900,
20700,
35200,
7600,
24800,
50100,
18100,
33800,
93900,
35500,
78800,
85800,
null,
9600,
9600,
43200,
21700,
11900,
13000,
32900,
76000,
56700,
9300,
22500,
36400,
92400,
4100,
11300,
18300,
null,
7800,
22000,
20200,
23000,
39900,
20800,
11400,
36800,
23500,
10369,
15800,
36900,
700,
null,
6500,
null,
30200,
44300,
28800,
46600,
30000,
6100,
26400,
11700,
6500,
62300,
null,
35400,
33400,
20500,
31300,
11300,
null,
null,
44400,
14200,
11200,
43900,
18900,
9700,
null,
24700,
177900,
9400,
10300,
11500,
71700,
48000,
24800,
41400,
31700,
232300,
54800,
22000,
10900,
9000,
13100,
39600,
71400,
42400,
14500,
30800,
6500,
11300,
6700,
22500,
60200,
50200,
15300,
20800,
20000,
17100,
20000,
17700,
12000,
34900,
10100,
40500,
40000,
21800,
137600,
32500,
24700,
1900,
11100,
39000,
42300,
23300,
13000,
22900,
7800,
26700,
12200,
14300,
101700,
59700,
11000,
16800,
29600,
14500,
4500,
18800,
11100,
null,
53500,
60800,
8145,
17100,
29400,
10990,
12600,
18300,
21900,
null,
283300,
35500,
13100,
35300,
12850,
55900,
22300,
43800,
12200,
47300,
14000,
27700,
18900,
4100,
133800,
null,
48000,
25300,
20600,
22100,
14800,
56900,
56500,
19800,
46200,
null,
null,
44400,
19700,
18400,
63800,
46500,
61100,
null,
103400,
null,
78100,
15700,
73900,
72400,
15800,
11300,
95300,
38100,
77500,
22700,
19500,
26000,
36400,
16100,
20800,
41800,
null,
11300,
5000,
null,
42800,
3900,
55800,
4000,
13800,
11900,
38800,
27100,
18600,
13200,
21400,
21700,
7200,
null,
15600,
21200,
54500,
22800,
31600,
58800,
null,
20800,
13000,
12500,
35400,
35600,
35900,
153100,
68300,
null,
23800,
null,
21600,
7300,
29600,
23600,
27400,
6200,
19500,
27100,
10500,
null,
13900,
15000,
null,
13900,
5400,
54100,
34400,
33600,
15700,
12400,
null,
null,
29200,
62600,
35300,
6800,
8400,
12600,
60400,
null,
70600,
15700,
63100,
20300,
19800,
null,
30300,
23300,
50200,
9500,
23900,
37700,
5000,
35500,
20500,
1000,
29800,
93600,
4400,
21200,
3800,
31400,
46600,
8750,
52500,
43100,
24200,
19300,
10500,
46100,
19800,
16300,
28400,
25600,
104900,
18000,
50600,
27700,
14100,
40700,
37500,
23900,
53200,
20000,
18200,
57900,
28800,
22700,
46000,
null,
13000,
6500,
60800,
21500,
40100,
21300,
105600,
10700,
17600,
null,
36500,
21500,
48500,
50100,
null,
1400,
42900,
25200,
null,
8000,
13200,
18500,
49900,
4900,
21300,
103500,
20200,
5300,
12700,
32900,
18200,
null,
null,
79900,
31100,
23700,
10700,
16400,
20100,
39300,
53500,
6000,
null,
4600,
17900,
75600,
14600,
16400,
15500,
16000,
64700,
16500,
102700,
null,
57300,
85600,
20409,
17300,
17800,
5200,
8200,
15100,
null,
9900,
11700,
62400,
27800,
72300,
57600,
14400,
46600,
9700,
121600,
7600,
21300,
40850,
89000,
38100,
44200,
15800,
23100,
2300,
20500,
null,
18300,
22500,
63900,
25100,
25800,
11400,
14900,
19000,
2900,
10900,
16300,
34400,
null,
16100,
null,
9200,
44000,
27300,
53900,
null,
119440,
null,
129200,
35000,
56200,
null,
42900,
21000,
44800,
4300,
13800,
7500,
34600,
11300,
132300,
null,
9500,
29000,
161300,
52700,
22700,
36500,
38600,
43800,
60600,
8900,
12100,
9500,
16100,
5500,
8300,
53600,
51300,
55500,
8900,
12300,
30000,
33100,
null,
29700,
89200,
68100,
22500,
16700,
35800,
109500,
114600,
45000,
null,
19600,
52100,
12000,
17800,
94100,
2800,
6500,
null,
null,
45800,
22200,
19800,
28200,
39300,
31400,
6200,
50300,
12800,
12150,
9900,
12900,
null,
6800,
31500,
3400,
24700,
41300,
null,
21700,
35300,
19100,
null,
12840,
66900,
31400,
33500,
null,
52000,
27300,
83800,
31900,
13500,
8000,
58600,
28000,
16600,
25300,
35300,
29900,
34400,
30100,
25500,
20000,
27400,
19600,
12600,
21500,
54300,
20500,
85200,
null,
58300,
19200,
16400,
34700,
26600,
27900,
10700,
39600,
4500,
11200,
19700,
12700,
28600,
32900,
27400,
5200,
22100,
null,
15500,
62500,
17100,
12800,
23433,
20000,
9800,
null,
39400,
61330,
109900,
38600,
3600,
16700,
52000,
28700,
12500,
20900,
6100,
80700,
20900,
7700,
1850,
57200,
8800,
29400,
30200,
37400,
35700,
1900,
13000,
38200,
51200,
35200,
11500,
18900,
10000,
39700,
30600,
16000,
15300,
19400,
9700,
13000,
21700,
54000,
null,
25600,
15900,
9700,
null,
53200,
null,
30200,
null,
4300,
42800,
17100,
14600,
44800,
35700,
13200,
21100,
24900,
9900,
67400,
16300,
44800,
90700,
11494,
6300,
25800,
null,
28100,
14800,
5500,
20200,
72100,
17700,
20600,
38100,
11700,
8500,
17555,
31200,
41300,
13800,
41000,
8200,
84000,
7800,
45400,
null,
45000,
null,
18900,
37600,
47500,
20800,
40800,
30300,
null,
23400,
22600,
20200,
14700,
7300,
53700,
74800,
17800,
20000,
null,
11500,
28400,
90500,
14200,
18200,
7700,
16600,
32400,
21700,
27300,
21100,
75000,
8050,
34300,
18600,
25200,
18600,
34000,
null,
33500,
44300,
null,
23600,
22800,
47000,
6100,
11551,
39400,
74100,
15000,
25100,
null,
19800,
null,
55000,
8300,
43300,
null,
36900,
11200,
5400,
26500,
11500,
7300,
85000,
36300,
10400,
23700,
null,
7100,
13100,
33800,
11700,
58700,
9000,
11700,
6800,
45800,
60300,
19800,
null,
null,
9000,
33700,
29700,
61600,
12150,
173600,
19700,
null,
91600,
10900,
12800,
41100,
27000,
14900,
13400,
36000,
28700,
8800,
34900,
22800,
39500,
39400,
24600,
null,
23000,
null,
22300,
29800,
25800,
13600,
18400,
31900,
25400,
12700,
21000,
13400,
22500,
31600,
13400,
null,
7600,
25000,
24700,
6000,
2600,
98600,
13400,
30400,
16800,
20300,
null,
17700,
11500,
21800,
40600,
76700,
63300,
null,
84500,
null,
71700,
15300,
31400,
38200,
6000,
11500,
31200,
13000,
18600,
45600,
65500,
9200,
129500,
10900,
35800,
9500,
81400,
30800,
23500,
11300,
13500,
28900,
null,
26500,
6200,
9350,
14000,
42200,
22100,
null,
24300,
null,
21800,
68500,
23100,
23000,
33400,
79000,
null,
25000,
52100,
3900,
29700,
80300,
31500,
31600,
12800,
27200,
6200,
17700,
40900,
15000,
50000,
8300,
27100,
null,
13200,
21700,
7000,
34900,
35500,
61000,
20200,
12300,
8900,
32000,
47700,
56400,
11500,
21100,
12300,
14800,
3700,
37100,
44500,
59500,
22200,
12000,
21300,
53400,
5800,
null,
12900,
14600,
null,
null,
60400,
null,
8000,
null,
16400,
12300,
17255,
4500,
12000,
55600,
23500,
103100,
900,
17800,
57700,
13400,
35700,
42200,
null,
35700,
9450,
null,
35400,
null,
null,
23600,
24500,
32000,
34300,
24100,
5700,
20200,
95700,
20100,
14200,
14000,
40000,
null,
null,
143000,
57200,
37100,
17400,
8300,
14700,
null,
6600,
16500,
131400,
31600,
14400,
null,
21500,
null,
41700,
9255,
10600,
34500,
56600,
15100,
55900,
17800,
16300,
26900,
16300,
93300,
11700,
14700,
null,
14400,
56710,
44500,
38300,
24200,
33900,
10700,
10300,
15600,
39800,
49700,
10900,
16100,
20600,
65900,
7200,
36200,
19800,
12800,
22800,
20000,
35500,
40400,
30400,
20400,
24000,
32300,
12250,
4300,
85700,
19400,
19600,
61900,
7300,
4550,
20000,
17300,
22400,
25000,
40500,
8500,
6000,
43800,
25700,
6600,
21600,
30400,
18800,
21500,
16000,
7200,
7800,
16600,
10800,
9000,
17000,
28900,
14800,
22900,
7500,
48500,
27500,
11600,
18100,
30400,
23800,
8000,
22500,
13900,
13300,
15300,
28200,
34700,
98400,
49500,
23900,
null,
null,
58800,
null,
19400,
88000,
52400,
null,
22200,
26800,
91100,
10600,
82800,
10500,
14200,
6300,
12000,
29100,
38900,
19800,
41700,
25800,
7500,
13400,
37600,
null,
35900,
5900,
112900,
78000,
18600,
41300,
17000,
28000,
42800,
6600,
24300,
26500,
22200,
26100,
68500,
null,
40000,
null,
3500,
18700,
5200,
8500,
18100,
32400,
14300,
null,
19600,
6500,
17500,
37100,
12900,
27400,
31500,
27700,
13800,
null,
40500,
55200,
252100,
18200,
41000,
16960,
1900,
5900,
4900,
21400,
12100,
null,
10600,
24900,
34300,
39300,
30900,
107300,
61000,
85600,
50000,
41800,
42200,
17200,
16500,
81300,
49700,
33100,
28000,
10000,
20000,
24100,
19300,
22700,
49400,
4100,
10800,
318300,
14000,
27400,
13800,
16800,
9700,
7500,
26500,
33050,
21000,
29800,
19700,
null,
72800,
46000,
49000,
42200,
43600,
42500,
48100,
11400,
21500,
24200,
29800,
null,
8100,
35500,
10200,
12700,
11900,
8700,
32200,
209800,
12900,
30600,
14850,
12800,
13900,
12300,
27200,
77500,
17800,
25900,
null,
28500,
15500,
23400,
44100,
7500,
15800,
3400,
6500,
30600,
null,
7600,
44800,
48400,
2900,
87900,
35300,
44800,
52100,
null,
22100,
57600,
20600,
67500,
97300,
null,
39500,
84000,
null,
202800,
11000,
52600,
8100,
17300,
13300,
54000,
33348,
2900,
7200,
44700,
53600,
13100,
70800,
44200,
27490,
9700,
15400,
14300,
4200,
62000,
7100,
null,
null,
42200,
24900,
111800,
20500,
30600,
83900,
14900,
50800,
32600,
null,
15000,
18500,
11200,
32500,
43100,
null,
null,
15100,
null,
75800,
58400,
15500,
19300,
19100,
39300,
4400,
14700,
22500,
67800,
6500,
3200,
37500,
null,
33600,
9000,
44400,
null,
4100,
9900,
23600,
null,
141600,
null,
8400,
7600,
31100,
null,
49900,
null,
23400,
61400,
13900,
54300,
43400,
77700,
112700,
6400,
9100,
37200,
18900,
13400,
5800,
69100,
32700,
6500,
6900,
13200,
16486,
48300,
23400,
42400,
72965,
null,
54300,
null,
15500,
54750,
37700,
27400,
11235,
83800,
67100,
13700,
32800,
24400,
54100,
5100,
28000,
33500,
3700,
29800,
null,
32100,
15900,
49900,
44200,
17600,
22700,
null,
27500,
33300,
25100,
69400,
51400,
7600,
17900,
21000,
16300,
19300,
7900,
7800,
17300,
null,
19000,
16800,
3100,
77800,
31100,
3000,
24900,
16400,
41200,
7500,
null,
24600,
15800,
19000,
5280,
19500,
45700,
21000,
null,
24200,
10600,
53800,
21300,
152200,
11700,
18900,
null,
21400,
6200,
5850,
17200,
13400,
21000,
62700,
7200,
null,
42800,
17600,
65300,
25100,
4600,
8000,
null,
33200,
35800,
61500,
9000,
null,
40700,
30000,
23600,
16500,
23900,
41500,
32200,
194000,
14000,
29250,
16500,
3800,
13300,
3300,
50400,
40900,
null,
21800,
22800,
13800,
62300,
49500,
31100,
15600,
56700,
7400,
21900,
null,
18800,
null,
null,
36700,
55400,
15400,
16100,
60000,
15000,
48500,
20200,
26200,
18900,
4500,
34300,
22500,
34100,
11400,
1700,
29200,
14300,
15390,
50200,
19300,
18900,
11600,
12200,
17500,
76800,
null,
8300,
null,
17700,
null,
15300,
71500,
16100,
26900,
11900,
6800,
66700,
26500,
6200,
32600,
3000,
9900,
34100,
17600,
null,
25400,
20600,
36300,
36100,
9000,
null,
13300,
28200,
58655,
31200,
18600,
27900,
7800,
27600,
9900,
47300,
null,
25700,
94200,
38900,
null,
18800,
24700,
4700,
26600,
33600,
9500,
78100,
19900,
null,
21100,
null,
31000,
28600,
88200,
null,
98900,
26000,
27600,
45900,
null,
26300,
null,
50200,
5500,
33300,
35400,
59100,
40200,
12100,
34100,
56600,
7000,
56200,
31500,
9000,
12600,
62000,
13000,
33100,
29500,
null,
62100,
null,
42800,
68000,
3400,
16300,
18500,
12200,
14600,
11400,
null,
32200,
31800,
9400,
71400,
7200,
38300,
10000,
8500,
4900,
20700,
18500,
44300,
55400,
43400,
null,
13000,
39800,
null,
null,
31600,
9600,
22600,
49100,
91600,
24500,
47000,
7400,
35400,
59200,
17500,
13700,
28500,
21100,
38200,
32800,
11200,
25200,
8000,
5300,
18000,
23400,
27700,
80710,
8600,
259900,
22600,
15400,
null,
13200,
null,
18200,
4300,
23800,
9900,
null,
18700,
22100,
25700,
29000,
10000,
16900,
17700,
4700,
12400,
21000,
14600,
19700,
68300,
18900,
34300,
null,
30800,
12800,
18700,
34800,
41400,
16500,
19100,
105100,
23600,
27400,
18500,
28000,
62900,
28200,
35000,
68900,
null,
22000,
58700,
24200,
41200,
12300,
6900,
9300,
49732,
20300,
37400,
6900,
27800,
121200,
8600,
18700,
null,
null,
3100,
50000,
32000,
37200,
8000,
57600,
21300,
13100,
33500,
16400,
34100,
32600,
null,
123800,
null,
24300,
6700,
20400,
26000,
18500,
9400,
18800,
32800,
16600,
13100,
45500,
22000,
null,
14200,
49600,
28800,
29400,
9200,
3300,
53800,
24600,
null,
50400,
10800,
24900,
42800,
12800,
15100,
51200,
22500,
34200,
6300,
86200,
19600,
5300,
113300,
45100,
15500,
40100,
25200,
5600,
62400,
16900,
33500,
21200,
15200,
6500,
null,
15500,
12900,
66500,
37600,
7000,
66100,
12400,
17200,
18900,
null,
13400,
27600,
18400,
32200,
15500,
40000,
24500,
18700,
2300,
45900,
17600,
30600,
38400,
22300,
50900,
66000,
13400,
8900,
24600,
null,
47810,
20500,
14700,
34400,
22200,
36500,
15800,
97900,
12300,
10200,
7000,
28400,
null,
25900,
15600,
null,
28200,
4300,
36900,
31200,
18500,
28588,
19900,
14500,
7300,
30890,
17400,
18900,
14200,
54300,
38200,
37000,
42800,
28100,
14500,
50400,
34500,
5100,
12200,
null,
29500,
57300,
14600,
19500,
43600,
20000,
7000,
null,
91300,
12800,
6000,
null,
30100,
14700,
14100,
36800,
25500,
25700,
17300,
41500,
88900,
15300,
6000,
17800,
7300,
41300,
21600,
39900,
20500,
10500,
86300,
24300,
null,
12400,
44700,
88300,
20800,
28200,
7700,
13100,
17100,
28300,
29400,
29000,
37086,
6800,
2900,
10900,
44300,
42100,
30500,
14700,
17100,
149800,
18500,
null,
6400,
25700,
32500,
27200,
7000,
16300,
44400,
21100,
14000,
18800,
25000,
11700,
6400,
45900,
3100,
42300,
51200,
46000,
39000,
7400,
36363,
11300,
48900,
9300,
9900,
25400,
8800,
35800,
44900,
39700,
55400,
38300,
31800,
7500,
57700,
10500,
23700,
34800,
65900,
9600,
8300,
15300,
39400,
36800,
27200,
25700,
null,
23400,
39400,
14300,
101300,
175500,
7000,
12000,
44900,
25200,
30200,
10600,
30600,
128300,
8100,
17500,
32100,
39900,
28000,
8000,
29900,
19700,
38000,
23160,
40700,
22800,
4100,
48400,
8900,
21800,
38900,
21100,
174400,
69800,
88500,
null,
22800,
26400,
33100,
92200,
14000,
21600,
10600,
57100,
16600,
13100,
9500,
13000,
null,
28700,
38200,
8500,
28800,
null,
22900,
47500,
2600,
40800,
103600,
35400,
30500,
3900,
5700,
7403,
11400,
26470,
55600,
23100,
41600,
85600,
10300,
8500,
79300,
14900,
null,
23200,
20000,
27200,
35200,
2800,
31400,
14600,
38100,
50500,
null,
9800,
63049,
79700,
8100,
null,
null,
16000,
8800,
53100,
13100,
43525,
197800,
25500,
9400,
13300,
15500,
15800,
29800,
43000,
16700,
27700,
116400,
35800,
4600,
57500,
18900,
84000,
14800,
34900,
90100,
86800,
8900,
103500,
16300,
10200,
20100,
44400,
34600,
11200,
13300,
22000,
22400,
12700,
null,
36770,
39000,
25716,
10200,
null,
33200,
82400,
299800,
55100,
383400,
29400,
22100,
17200,
13100,
4200,
45100,
32600,
21000,
42200,
45000,
12300,
34000,
null,
61500,
5900,
null,
40500,
76900,
31700,
57600,
29300,
139700,
17600,
19400,
10200,
10200,
3900,
13300,
null,
47000,
15300,
null,
null,
null,
6200,
56400,
41200,
28500,
null,
5000,
4600,
54400,
33500,
27700,
null,
54700,
18000,
29900,
72800,
67300,
78000,
11200,
12400,
30000,
24800,
31400,
21700,
18100,
6300,
10750,
5100,
22400,
203900,
28500,
8700,
22200,
16400,
34400,
33800,
27000,
41600,
16600,
29200,
47800,
26600,
13500,
25900,
51900,
31000,
8500,
null,
15900,
11900,
23600,
9900,
null,
14400,
52200,
71000,
4000,
45300,
40300,
14400,
29800,
20100,
97920,
7500,
6400,
16200,
58700,
26400,
19700,
9000,
21900,
18700,
40600,
38100,
23800,
30700,
39000,
5600,
19200,
237100,
75500,
23900,
null,
7700,
null,
10700,
16200,
30900,
14500,
72800,
63500,
23800,
26700,
43900,
17500,
28800,
15900,
42400,
35300,
24600,
13200,
25800,
8500,
43500,
21300,
5100,
22100,
7750,
73000,
2500,
49800,
16400,
null,
12500,
8100,
41900,
48100,
51500,
46900,
28300,
26000,
14800,
54700,
21800,
17300,
null,
3400,
25400,
8900,
70000,
21800,
13900,
16000,
45100,
52300,
16100,
19800,
null,
18400,
24500,
71400,
30900,
15000,
8000,
11400,
3800,
55400,
null,
52800,
10900,
8600,
26200,
100500,
22200,
25600,
null,
28200,
5600,
28900,
50300,
21800,
153600,
22500,
null,
12400,
2000,
47000,
13500,
34600,
18800,
21100,
null,
12800,
39700,
20800,
5600,
25400,
41900,
32700,
35700,
28400,
12400,
16400,
8600,
11600,
25100,
8700,
28500,
39300,
28100,
73500,
21900,
49300,
19000,
10700,
7300,
18900,
8500,
26700,
135600,
7100,
5000,
null,
38100,
15400,
10600,
7800,
27200,
66000,
18200,
76200,
51700,
38900,
22900,
12500,
null,
15000,
11800,
62800,
14200,
113400,
71300,
54500,
9200,
33900,
43850,
22700,
null,
11000,
null,
24500,
null,
19400,
37800,
23500,
12900,
47500,
5000,
18500,
14000,
46700,
77900,
15300,
30900,
37300,
25500,
106100,
23600,
19000,
21400,
null,
26300,
19100,
null,
null,
72700,
18100,
61400,
25200,
34700,
10700,
10500,
8700,
12600,
79300,
20500,
16900,
20300,
28100,
44700,
16100,
91200,
19500,
65700,
18200,
79700,
17900,
79200,
58900,
46500,
46500,
25900,
34600,
36400,
39700,
25400,
6000,
11300,
53900,
41800,
112200,
62400,
28700,
33900,
13800,
18400,
44800,
17400,
48800,
14800,
6900,
13100,
34900,
45000,
80387,
85500,
10600,
15300,
16200,
65500,
19200,
51400,
42400,
53300,
23600,
28700,
70300,
5900,
14200,
31600,
22600,
49800,
4150,
63000,
30400,
19400,
20200,
63000,
48500,
15900,
31200,
34700,
9600,
23200,
30700,
67200,
54700,
39850,
10200,
33900,
43000,
66400,
74900,
12600,
50700,
20000,
12900,
35700,
17900,
null,
20100,
null,
53700,
11082,
null,
12400,
32600,
106700,
10400,
24500,
158900,
16600,
47400,
11700,
17900,
29600,
8900,
8200,
null,
11800,
23000,
24000,
null,
38900,
52900,
23000,
26000,
15900,
15100,
null,
28200,
15200,
17000,
17000,
12700,
19500,
29700,
17200,
9780,
24000,
52700,
28700,
5900,
43300,
60600,
13900,
15300,
19900,
13600,
16900,
15400,
30200,
81700,
24300,
18000,
19000,
17600,
16400,
17400,
27000,
15900,
36100,
19700,
118100,
null,
13900,
69500,
15900,
9200,
null,
30400,
9900,
24200,
29500,
null,
25800,
29900,
29900,
14700,
11500,
70800,
7800,
24800,
29100,
11600,
13400,
8100,
18500,
44500,
14400,
32800,
27600,
null,
null,
8200,
13800,
19800,
null,
59400,
52700,
18000,
11500,
22049,
null,
14500,
61000,
31700,
null,
14400,
11900,
25700,
34300,
20600,
17100,
52700,
14600,
7500,
9200,
59100,
6550,
55600,
11500,
17700,
null,
59000,
26800,
7600,
19600,
37300,
16100,
null,
57000,
null,
24400,
35800,
14600,
21500,
13400,
23700,
null,
31500,
19800,
null,
137500,
15900,
14800,
39400,
null,
24100,
19300,
9600,
6500,
60220,
11440,
10500,
null,
38600,
43300,
8300,
236900,
26200,
null,
10900,
36000,
17100,
29300,
null,
2000,
20700,
64100,
21900,
15000,
35000,
6000,
null,
15800,
20800,
null,
81600,
31000,
10800,
42500,
27000,
17600,
17800,
14100,
null,
null,
17500,
61400,
56100,
17800,
61300,
12000,
48200,
33300,
37500,
35500,
30600,
66100,
38324,
16900,
38700,
18900,
23800,
117000,
34400,
14600,
null,
32700,
26100,
30500,
31000,
12900,
6600,
18500,
44100,
51700,
7100,
3500,
26100,
31500,
43500,
19200,
32700,
17800,
32500,
11600,
5500,
27100,
121800,
24800,
21400,
11900,
null,
16000,
null,
46300,
30700,
15700,
5400,
35300,
39500,
30900,
38500,
25300,
8300,
null,
78600,
37500,
34400,
null,
36400,
33400,
19180,
63100,
null,
8800,
4000,
43400,
13100,
16200,
11700,
42000,
73900,
24800,
18700,
31800,
10700,
20900,
24300,
15900,
31500,
29600,
26700,
36400,
null,
null,
38500,
13300,
49755,
55000,
28700,
34800,
71900,
6600,
40500,
2900,
5600,
8000,
42800,
45900,
14400,
27000,
30400,
30700,
20900,
33500,
13550,
6500,
43100,
21400,
135900,
null,
32100,
null,
23400,
15200,
5700,
13800,
9000,
21200,
19000,
null,
15200,
57500,
25200,
7300,
26000,
24100,
14100,
13600,
10630,
17700,
23300,
39800,
11900,
25900,
6400,
16600,
7400,
4500,
5900,
23600,
17000,
54700,
29500,
17000,
20300,
17900,
84400,
27500,
28100,
34800,
6600,
null,
null,
37700,
21300,
36500,
14700,
27400,
null,
49200,
485900,
3100,
64800,
null,
21200,
20900,
80400,
33000,
30800,
25700,
null,
null,
117800,
null,
8200,
68000,
17550,
49000,
47200,
13200,
24900,
null,
24100,
14400,
10500,
55000,
14400,
15000,
24700,
44700,
26500,
14000,
36500,
81700,
49700,
39400,
29700,
14550,
null,
31500,
36900,
121200,
38400,
62100,
null,
24800,
43100,
31100,
13900,
7100,
null,
28700,
9900,
15900,
15100,
16400,
32400,
74400,
24200,
20600,
null,
8400,
19700,
29200,
47500,
28400,
12600,
23000,
12300,
23200,
20000,
7700,
21300,
null,
27501,
33900,
20400,
18500,
34600,
6000,
12600,
66700,
16500,
19500,
41700,
7500,
39200,
74300,
33400,
49200,
6700,
7100,
9500,
31700,
100427,
74400,
51800,
99300,
38200,
58000,
null,
15500,
11900,
null,
44000,
26100,
10600,
18100,
19900,
46800,
121000,
32700,
44400,
83400,
19300,
52300,
119200,
null,
24500,
6400,
37100,
27900,
11000,
52200,
22500,
16000,
9811,
null,
24100,
22700,
12500,
15500,
28900,
21900,
22500,
13000,
19600,
25100,
58600,
32800,
18900,
22300,
72300,
14700,
36700,
18300,
30500,
10400,
30600,
31800,
29700,
52300,
34800,
null,
20400,
17500,
41100,
41500,
16400,
10000,
48300,
12100,
170500,
40600,
87000,
26100,
42700,
null,
22800,
23400,
1500,
10100,
null,
82708,
34800,
null,
24900,
2500,
35200,
39600,
52600,
57900,
10700,
16000,
12600,
65100,
30100,
64500,
12500,
11500,
11100,
14300,
41300,
16850,
null,
94900,
null,
10300,
7600,
24000,
13900,
9800,
46000,
31600,
65900,
null,
8600,
26500,
34100,
48600,
43000,
13300,
21400,
21000,
12000,
9400,
25600,
15800,
45800,
22400,
171500,
50600,
48300,
36800,
64600,
16600,
20600,
11100,
25900,
13700,
null,
25500,
null,
12200,
12900,
43700,
34700,
17000,
45600,
3800,
46700,
29400,
12700,
23800,
null,
8500,
33200,
28600,
87300,
41000,
26700,
13500,
55100,
16000,
63600,
13800,
30300,
15800,
21500,
50900,
12600,
41400,
null,
14200,
14300,
40100,
58400,
8500,
9000,
17000,
18500,
15900,
39300,
39300,
23400,
13800,
49600,
15000,
9700,
59200,
22000,
7800,
38900,
26900,
13800,
20600,
10600,
26000,
16300,
21500,
46000,
28300,
34500,
74550,
14200,
null,
null,
60400,
12300,
23000,
48600,
15000,
10700,
24200,
44400,
70700,
9800,
133300,
23500,
25200,
null,
69900,
12300,
null,
21000,
6900,
19400,
10500,
26300,
16700,
36100,
9000,
19000,
15500,
29600,
7750,
58400,
15800,
12600,
20700,
3400,
null,
13200,
173521,
8000,
25100,
78900,
48000,
19300,
58500,
124500,
34800,
null,
93500,
43200,
61600,
28000,
4200,
52200,
30100,
45000,
30200,
53114,
36300,
24900,
21000,
9500,
14000,
61300,
14300,
11000,
47100,
87000,
16700,
5400,
null,
38700,
18300,
16700,
22600,
39600,
12100,
34500,
38500,
10300,
10938,
6800,
5800,
20100,
13900,
16900,
40700,
10700,
null,
8400,
39100,
29100,
39400,
12000,
21300,
null,
8900,
42300,
8200,
14300,
39800,
37800,
null,
14100,
39600,
35900,
29500,
20400,
27500,
13200,
56400,
12900,
31600,
11900,
28700,
22000,
9900,
17500,
13400,
10200,
6500,
43800,
47700,
40000,
21150,
10500,
38400,
null,
49200,
30000,
17900,
39600,
21900,
47800,
26600,
20500,
39900,
null,
19400,
4600,
23700,
7800,
13800,
null,
13800,
15600,
77400,
11300,
null,
74400,
40000,
92800,
15900,
11500,
15100,
50100,
25900,
15900,
19400,
13100,
11600,
17800,
22300,
12300,
14200,
54800,
77788,
17800,
19000,
31500,
12500,
18200,
50900,
21200,
1300,
5600,
65300,
null,
78116,
null,
19900,
22200,
38300,
18100,
17200,
22200,
57300,
39800,
50500,
54200,
17700,
null,
19700,
63997,
64100,
26200,
21200,
3900,
18500,
9100,
20700,
38000,
7200,
19300,
null,
21600,
11600,
21200,
30200,
6700,
24800,
64100,
111600,
16200,
30700,
23700,
51500,
25600,
57300,
12900,
17000,
23900,
81000,
53200,
56900,
17300,
null,
92800,
10800,
17400,
14600,
27600,
30200,
32200,
37700,
17700,
34900,
21600,
null,
21600,
61300,
69300,
6600,
5100,
10900,
35600,
5800,
3600,
13000,
16000,
28500,
83400,
11600,
88000,
22800,
98200,
53200,
16300,
24500,
28700,
5800,
17100,
17000,
33800,
51300,
8400,
27000,
81500,
31600,
17200,
66900,
79800,
null,
12000,
null,
10300,
41500,
72900,
27600,
14700,
7650,
null,
17500,
144600,
19000,
33400,
null,
2000,
14500,
32800,
17100,
22000,
33900,
10000,
65900,
5400,
null,
31200,
18900,
10076,
45000,
42200,
61600,
40300,
12700,
4500,
9400,
null,
21700,
16000,
42600,
10100,
18400,
null,
10700,
70200,
67100,
34900,
13200,
26000,
18600,
31300,
184600,
165700,
27400,
28000,
65500,
33200,
26300,
28000,
26100,
15700,
14200,
43000,
18600,
44200,
29500,
26700,
56300,
21000,
53100,
48700,
53100,
16358,
null,
45300,
15500,
7400,
57000,
10200,
5400,
25500,
57000,
12900,
4000,
20400,
32800,
20200,
18900,
25700,
7700,
null,
16900,
18000,
81600,
18800,
4200,
24000,
28900,
20000,
15300,
36100,
38000,
63400,
40900,
26600,
null,
46400,
12300,
11000,
18300,
22100,
9500,
5500,
19300,
21600,
11200,
5800,
5700,
67500,
21500,
36100,
70300,
4300,
10300,
10400,
40800,
7370,
77700,
35200,
24700,
91500,
89000,
null,
102600,
115800,
26000,
18800,
10700,
38100,
18600,
86600,
13400,
94900,
42100,
44700,
12100,
27400,
null,
19200,
30500,
null,
11300,
21900,
26600,
22174,
29700,
25700,
24400,
46500,
6700,
16300,
null,
17100,
63700,
10400,
8600,
8100,
22800,
175400,
21900,
6900,
222800,
25800,
23500,
18500,
14700,
62700,
71700,
10900,
null,
39100,
48900,
16200,
49500,
26900,
8300,
29900,
6900,
5000,
19900,
63500,
37100,
22900,
16900,
15600,
57700,
43300,
9500,
22700,
6200,
34800,
19400,
6200,
null,
null,
9900,
21000,
20000,
6800,
3200,
9500,
1100,
20300,
15700,
22600,
15600,
31600,
12400,
9200,
130400,
59300,
3950,
39000,
23900,
14900,
10100,
19100,
256700,
30100,
48500,
13200,
65500,
57900,
8300,
19600,
26500,
91500,
null,
18400,
41500,
61900,
53700,
null,
23100,
null,
null,
23000,
28800,
29400,
27400,
8000,
9200,
21400,
70900,
6990,
3300,
14100,
50400,
58100,
21000,
29300,
6800,
null,
16000,
15300,
null,
30000,
45200,
19000,
18000,
16400,
13400,
41300,
81000,
2000,
50700,
41500,
19500,
13900,
30100,
20500,
56400,
60000,
23200,
45700,
18300,
36500,
9400,
20700,
9000,
23200,
9600,
24300,
null,
18700,
13700,
23200,
25000,
48400,
19800,
30600,
25731,
37800,
26200,
32800,
15400,
5200,
32700,
10700,
80800,
33800,
25900,
38100,
42000,
118800,
9500,
4300,
3500,
null,
7000,
175044,
35300,
20760,
35000,
5300,
66200,
69300,
41900,
16200,
11500,
null,
54700,
57400,
41000,
9400,
null,
18400,
10800,
36500,
23300,
7300,
11600,
13400,
null,
15900,
21500,
10800,
36700,
32800,
27600,
37700,
29000,
19800,
11500,
10300,
92900,
16400,
12700,
48500,
31100,
20500,
17500,
18800,
19000,
6400,
23300,
58365,
11000,
8200,
11200,
28500,
18800,
23700,
14300,
null,
62100,
16200,
22900,
131300,
55100,
11600,
16100,
39200,
null,
16700,
11100,
23700,
11200,
18200,
10700,
11100,
47400,
null,
6850,
12600,
26400,
159900,
null,
20900,
132700,
null,
8100,
51500,
19050,
53900,
40900,
24800,
null,
30700,
31400,
23400,
54200,
16100,
18700,
62500,
60300,
null,
11700,
28300,
39000,
17800,
38700,
12500,
12800,
69700,
59100,
24000,
12900,
18300,
48900,
7400,
12400,
13300,
79900,
10600,
35400,
16800,
12300,
31200,
31000,
61800,
33900,
null,
19500,
null,
60600,
19200,
28400,
14100,
16100,
49200,
24200,
15500,
50200,
null,
453500,
23800,
20000,
45500,
14900,
54200,
11500,
21000,
18100,
5300,
46900,
84000,
null,
10300,
55400,
47600,
15400,
10354,
12250,
26454,
36100,
11100,
10700,
94800,
23600,
9500,
10800,
27400,
5800,
17100,
123200,
29100,
6800,
8900,
21400,
4000,
33500,
20200,
32800,
34000,
45200,
13000,
23300,
17900,
34500,
38600,
9000,
25100,
125500,
23300,
9000,
68000,
8700,
74500,
17700,
22000,
52200,
36300,
22900,
18000,
83300,
54400,
18100,
null,
null,
11900,
null,
13800,
40500,
50300,
64300,
14000,
13700,
105600,
10700,
41900,
21200,
99100,
5300,
null,
15400,
null,
16600,
37400,
17000,
62200,
null,
11400,
101400,
22900,
17000,
43300,
null,
117900,
19600,
66600,
26100,
32000,
65800,
12700,
51000,
7800,
29800,
139900,
38500,
9500,
60400,
21000,
5500,
26100,
4600,
46300,
null,
12900,
null,
35900,
26000,
22100,
77200,
8000,
38998,
74280,
23300,
15900,
27600,
14700,
43739,
11100,
51800,
null,
16300,
39100,
null,
17600,
9300,
38900,
39100,
3550,
36700,
97900,
36600,
42600,
67600,
29400,
11000,
42100,
32500,
22000,
null,
33800,
21300,
35200,
11100,
51400,
70900,
11800,
27400,
13100,
32600,
null,
7200,
null,
30400,
21400,
32200,
42000,
null,
36300,
17400,
9800,
34000,
43600,
13700,
20800,
35600,
60800,
37800,
29100,
21500,
6600,
18400,
41700,
10700,
6700,
null,
21400,
31200,
49400,
110200,
23000,
53200,
77500,
63800,
51800,
31100,
14100,
37100,
11200,
26600,
17100,
5000,
49100,
15700,
62300,
35000,
27800,
60500,
42600,
6700,
12000,
9200,
54000,
null,
12700,
41400,
21000,
5100,
9000,
18300,
21800,
20000,
96400,
8000,
90800,
70200,
15300,
53000,
37800,
42300,
3100,
102400,
26600,
31200,
38200,
37200,
10300,
58300,
9600,
20100,
103900,
59100,
49600,
118600,
73000,
28300,
16700,
34400,
27500,
52400,
31000,
7500,
8900,
5300,
null,
12100,
3400,
5500,
16900,
12600,
13600,
7200,
52750,
28700,
17300,
11000,
29400,
16600,
90600,
34600,
17200,
42500,
26400,
51900,
40500,
null,
10100,
45300,
7100,
37600,
4400,
32700,
24300,
null,
44100,
16800,
20900,
17800,
23500,
11000,
5600,
16400,
19800,
27061,
16100,
59900,
null,
146400,
59200,
4200,
40700,
52500,
12000,
22000,
45000,
13700,
15000,
13400,
18100,
19100,
66500,
14300,
26800,
30400,
16900,
94200,
35200,
25500,
10100,
58800,
11800,
44600,
25625,
52900,
null,
31400,
38600,
14800,
49000,
130400,
14600,
5800,
15300,
76200,
33200,
9400,
41700,
46500,
24200,
75500,
51800,
9300,
53600,
75900,
27100,
44200,
64100,
33100,
61800,
5800,
21500,
null,
17000,
21400,
47000,
20100,
24200,
18500,
33500,
11500,
13800,
37600,
24100,
75400,
31900,
41000,
47100,
79300,
26100,
14100,
42000,
3700,
17500,
17500,
46000,
14000,
13100,
9100,
40300,
6800,
13600,
3000,
4400,
23100,
37700,
1500,
9400,
66500,
125800,
23600,
38900,
53770,
8200,
20600,
11500,
27100,
109900,
69500,
19500,
21200,
74800,
41300,
24200,
4100,
40900,
7700,
62900,
33200,
19700,
69100,
42500,
12000,
36700,
47100,
80900,
null,
6000,
22900,
29300,
47200,
45700,
null,
17000,
69200,
null,
11900,
38400,
26000,
34800,
14300,
55600,
25100,
22200,
64400,
15600,
17300,
16300,
37900,
17900,
42100,
41700,
null,
64200,
63400,
35500,
32600,
5200,
null,
85900,
40500,
11700,
31100,
55800,
11300,
17000,
21000,
19200,
7500,
38600,
38800,
3900,
182600,
32200,
null,
12500,
147800,
null,
4700,
5800,
30000,
null,
40700,
14700,
13000,
3800,
25400,
17200,
37200,
18100,
10400,
20200,
26900,
9200,
14700,
47500,
31900,
27700,
24900,
18300,
8500,
20400,
39300,
44700,
9300,
7800,
48200,
null,
52600,
30900,
50500,
13100,
27100,
21500,
53500,
53500,
13400,
38400,
9700,
21500,
24100,
57600,
102200,
6700,
3000,
22800,
6500,
59800,
null,
42800,
82300,
5700,
70300,
13100,
35800,
15700,
32500,
24400,
13600,
6500,
76800,
32400,
75500,
null,
25100,
36900,
5300,
17100,
16700,
46700,
null,
600,
6500,
6800,
31500,
39200,
24700,
null,
26200,
22400,
48000,
19600,
6300,
46300,
29800,
24150,
27300,
38000,
4400,
27000,
35100,
12800,
32800,
27200,
28300,
5100,
44700,
null,
12600,
14800,
31600,
25100,
83100,
4300,
31000,
44200,
51000,
48100,
12000,
23000,
null,
33200,
35000,
null,
58400,
3800,
91400,
16300,
23500,
null,
64700,
null,
23400,
31800,
36700,
31600,
45700,
11300,
9800,
14650,
12700,
168200,
10500,
22500,
37500,
5800,
26600,
29700,
34100,
49600,
19800,
9300,
100500,
23200,
22200,
37100,
7000,
43500,
75700,
21100,
null,
23700,
37000,
6900,
17600,
41800,
17300,
31000,
null,
55500,
43700,
45900,
4800,
16500,
19600,
9045,
29350,
41900,
16900,
37100,
12400,
78400,
41700,
40900,
58400,
15600,
78900,
5300,
47700,
34800,
34600,
null,
18400,
13600,
12900,
21600,
85500,
42200,
40500,
32700,
63400,
31600,
30700,
71000,
null,
8800,
16000,
81300,
24900,
null,
28400,
19200,
55900,
16500,
11800,
53700,
31000,
43600,
29300,
12100,
null,
20800,
9700,
14300,
21400,
12000,
32000,
13000,
44100,
39900,
20400,
43400,
null,
12800,
32600,
3200,
114200,
12100,
29100,
23500,
14900,
20800,
18500,
136400,
3400,
7000,
12300,
null,
28100,
27700,
33100,
null,
42900,
86300,
7400,
45400,
16900,
19700,
null,
69300,
22900,
null,
15500,
7000,
7500,
15900,
9100,
35300,
6000,
27800,
26700,
13300,
45000,
21900,
null,
13800,
106370,
64200,
null,
25900,
25400,
31900,
6700,
67300,
70500,
37800,
19500,
23100,
5000,
7900,
31500,
11300,
9600,
28500,
null,
51700,
51600,
32500,
46300,
118100,
26500,
11200,
null,
21500,
46000,
16000,
27600,
15500,
12900,
95200,
61400,
131200,
25400,
29100,
18500,
29200,
15400,
31200,
19100,
35900,
2700,
17000,
70500,
17400,
48000,
null,
32300,
79600,
42218,
25300,
24200,
91300,
10700,
6000,
58400,
12100,
3500,
61700,
8400,
20600,
23300,
48300,
42500,
1400,
20600,
null,
32800,
20300,
48100,
27300,
75000,
0,
18400,
57800,
8600,
19300,
19720,
79700,
29600,
14000,
34900,
15800,
8300,
20500,
null,
14700,
9600,
28200,
1900,
11900,
25450,
17600,
10500,
17200,
83600,
12300,
38900,
5200,
8000,
49669,
null,
24500,
13900,
151900,
43400,
20200,
29200,
13500,
6600,
41200,
8800,
37800,
197900,
40100,
17900,
23600,
60500,
51320,
23200,
17500,
null,
25600,
97300,
39900,
48100,
null,
11100,
25100,
37600,
11400,
16500,
33000,
8100,
18800,
8400,
15900,
29800,
15500,
18100,
60500,
17500,
47000,
null,
32900,
26600,
null,
91100,
101300,
116900,
11200,
8700,
10400,
36500,
18300,
62900,
16800,
40000,
4600,
25100,
13900,
null,
9900,
40300,
60400,
35800,
58300,
15800,
19500,
19400,
32600,
51100,
17000,
13200,
null,
12600,
22600,
20100,
55000,
12500,
14600,
12300,
6300,
12500,
11100,
31000,
32600,
14100,
19000,
58500,
23000,
64900,
34050,
13500,
10600,
11900,
32300,
47800,
41200,
40300,
23600,
38900,
18700,
null,
13000,
11300,
97000,
53500,
10100,
12200,
77600,
16100,
10900,
45200,
91500,
49700,
37100,
28800,
17000,
29600,
18800,
42900,
26700,
38200,
12100,
11700,
7761,
9000,
30600,
51200,
31600,
310200,
22500,
22000,
25000,
6400,
2700,
45300,
15500,
40100,
12500,
14700,
8900,
52500,
61700,
11700,
45900,
6900,
14600,
10100,
24000,
83800,
12600,
6500,
46700,
13400,
22200,
37100,
34400,
51300,
92700,
70000,
65000,
30400,
66500,
13900,
16400,
8100,
4650,
37800,
43600,
68400,
null,
22500,
38000,
24700,
31610,
50500,
94800,
null,
24300,
13400,
37200,
21800,
10100,
null,
14200,
56000,
18600,
18400,
26600,
13900,
15900,
11800,
70200,
8500,
null,
22400,
14600,
17000,
14800,
6500,
null,
26900,
27400,
36800,
20400,
36400,
28700,
27300,
19587,
8800,
54900,
24700,
26500,
55300,
26900,
35600,
19500,
37200,
13200,
7000,
158900,
28500,
8800,
25900,
78300,
16600,
29700,
40500,
20500,
31900,
66900,
25200,
38500,
9100,
86600,
7200,
134100,
13400,
13700,
11200,
54900,
null,
20900,
20600,
25400,
87800,
1400,
143200,
98500,
76400,
103900,
40200,
10400,
17800,
45000,
51900,
24600,
14100,
51600,
59400,
23200,
42000,
17200,
17400,
42300,
20200,
18700,
36300,
31000,
16300,
44900,
71500,
28600,
22400,
55770,
null,
34500,
29000,
null,
10700,
60600,
53200,
11100,
48800,
21900,
9600,
24900,
21800,
61000,
18700,
77800,
6700,
12700,
26700,
55300,
34500,
null,
19500,
4700,
111711,
19400,
30900,
16300,
37300,
115000,
13900,
26800,
20400,
54100,
68200,
1750,
141788,
20300,
17300,
55200,
85800,
63800,
17200,
30200,
129000,
null,
35000,
40200,
72800,
55250,
71000,
40500,
91800,
23900,
33900,
93900,
45100,
63400,
15800,
51800,
13100,
64300,
28100,
25000,
5500,
83000,
8600,
null,
33400,
63900,
18500,
29100,
62700,
24400,
18900,
null,
21900,
67300,
13200,
98500,
48500,
48600,
32700,
40300,
18400,
14900,
24900,
53085,
30600,
42506,
75800,
17100,
37500,
null,
59800,
37100,
24800,
26700,
29700,
14000,
15200,
30800,
22700,
14100,
13000,
117700,
72285,
27400,
56900,
51500,
17400,
14500,
41600,
254800,
18200,
57500,
53300,
39800,
78900,
75600,
111000,
28100,
39400,
28500,
41100,
229900,
45300,
40200,
48300,
27400,
34600,
70405,
9809,
50800,
7500,
46600,
26500,
24500,
16300,
25500,
null,
11200,
26400,
2100,
69800,
153300,
26800,
23900,
85500,
138800,
null,
67100,
11100,
197500,
79800,
17400,
65200,
9700,
236600,
83700,
31600,
29800,
29800,
24600,
15000,
50300,
23200,
13800,
8400,
29300,
null,
20600,
5200,
11400,
34600,
32300,
95430,
30600,
17900,
null,
null,
19400,
75600,
19900,
27800,
12500,
39000,
40100,
42900,
23100,
null,
11300,
31200,
35000,
38200,
8500,
76500,
null,
17800,
10900,
42000,
11200,
27500,
null,
30100,
42000,
20501,
25600,
16100,
12800,
13500,
28300,
51400,
20200,
38100,
35800,
36900,
null,
57700,
175900,
4600,
16000,
7700,
62600,
6900,
23000,
38700,
18500,
30000,
9500,
73700,
47400,
8000,
63600,
null,
12500,
32400,
23000,
27633,
97800,
45400,
38300,
125300,
41500,
24200,
27100,
33500,
41800,
37500,
48500,
37700,
19800,
125800,
49700,
89300,
24600,
3200,
77900,
35400,
15400,
11600,
22900,
45000,
16300,
36300,
17700,
15000,
9400,
17300,
99000,
11300,
null,
24900,
45100,
18500,
4400,
34700,
15000,
99800,
26600,
64550,
7800,
23100,
2100,
11200,
37200,
3500,
null,
34600,
17500,
25100,
13200,
15200,
8600,
11600,
7000,
null,
18000,
6800,
59800,
5500,
47600,
84000,
8600,
18600,
6500,
12200,
31600,
26000,
74600,
21700,
75500,
24400,
41800,
15900,
20300,
30000,
21300,
12600,
100900,
26300,
50700,
24300,
9600,
18500,
7900,
20000,
26500,
33500,
21000,
20500,
34800,
21400,
32900,
11700,
41000,
54400,
null,
34600,
72200,
52200,
42100,
46300,
16600,
22100,
39800,
6000,
24500,
39700,
33800,
103000,
27800,
41800,
45800,
81000,
29700,
42100,
29400,
15800,
53200,
30700,
15300,
8700,
27700,
25500,
null,
22000,
41300,
23100,
69300,
16700,
30100,
69300,
22600,
57800,
null,
42900,
115000,
28100,
18300,
13100,
27900,
32800,
null,
16400,
7500,
26100,
8600,
98000,
23600,
13000,
9100,
21600,
12400,
3800,
217600,
19900,
55500,
42700,
29500,
null,
null,
35200,
57600,
14600,
20700,
35300,
24900,
50200,
40900,
null,
40100,
81900,
55400,
38000,
null,
9600,
6900,
333400,
30100,
11100,
15600,
25830,
33200,
null,
7700,
22500,
null,
25400,
20800,
34100,
null,
9800,
30500,
22000,
40500,
20400,
67000,
141600,
11700,
21400,
12300,
23000,
1600,
24500,
null,
16500,
57800,
29100,
10400,
19100,
7300,
38900,
33500,
6700,
13100,
26000,
39500,
104700,
8950,
53400,
22100,
30700,
null,
28600,
15500,
21900,
26400,
null,
24700,
17000,
9900,
89300,
4500,
39000,
105420,
29000,
70200,
23100,
47100,
null,
63800,
9200,
88800,
22900,
78000,
28900,
34300,
12900,
56300,
16800,
null,
100400,
null,
13500,
4600,
25100,
75200,
21300,
21100,
21100,
6800,
34300,
88000,
13200,
2600,
27600,
29800,
null,
null,
42700,
16900,
28800,
null,
10600,
18700,
36100,
30400,
9000,
65900,
68700,
25700,
12200,
null,
3700,
45900,
17500,
9500,
null,
26200,
57900,
13600,
null,
16800,
98800,
null,
8300,
53600,
7700,
8900,
12900,
82600,
35200,
48600,
16500,
14200,
11000,
null,
10700,
23100,
132300,
31100,
174500,
38000,
43200,
15800,
10200,
12000,
18800,
30400,
14100,
35300,
4700,
30900,
22500,
17900,
6800,
null,
3600,
23200,
14600,
49400,
25400,
34900,
14000,
12400,
6400,
107700,
102400,
24100,
9300,
37600,
26300,
31600,
66400,
39300,
49700,
53600,
35900,
22100,
21800,
null,
32500,
55600,
36600,
6400,
15700,
8500,
34700,
41300,
12200,
52900,
13900,
35600,
29600,
8900,
26200,
66700,
5900,
18400,
16800,
31400,
17200,
2800,
81300,
28300,
36900,
19200,
53000,
11000,
12100,
37800,
29300,
18500,
19300,
null,
27200,
19600,
12700,
19000,
22400,
null,
24000,
26400,
19400,
23500,
35700,
12200,
2700,
44000,
26500,
22000,
18900,
8200,
115600,
34800,
32200,
null,
null,
9100,
22700,
14800,
13000,
74900,
6500,
18000,
28100,
11100,
21400,
10900,
null,
52500,
98700,
155900,
146700,
null,
4800,
27800,
null,
17200,
104000,
16800,
11800,
11000,
22300,
20000,
36000,
53232,
11000,
30300,
48400,
15700,
12800,
26800,
35900,
16000,
29400,
20600,
56700,
null,
40100,
16500,
30600,
57600,
18000,
null,
16700,
5700,
7300,
null,
28500,
null,
9000,
20432,
44200,
20200,
32300,
17300,
25300,
16300,
24700,
23400,
30200,
84800,
21500,
79500,
33200,
38700,
25000,
15200,
22000,
4400,
36800,
14700,
9750,
344500,
11400,
38800,
37300,
10300,
11200,
14500,
5400,
9000,
18900,
13500,
29400,
21400,
15100,
3000,
null,
22300,
56100,
26000,
43800,
null,
61400,
11300,
70800,
22100,
41100,
159200,
13800,
20100,
15800,
50200,
40400,
23131,
12300,
40000,
null,
27800,
12400,
24100,
2200,
7200,
31300,
8350,
null,
7500,
155400,
43100,
13300,
166800,
null,
10100,
121000,
null,
12952,
16600,
24400,
17200,
30500,
null,
201200,
68200,
87500,
32600,
89200,
24400,
3000,
41500,
47900,
10400,
9300,
18700,
20100,
111900,
null,
null,
12100,
9900,
28600,
5700,
19500,
84500,
6400,
51700,
16300,
18200,
22100,
19300,
42900,
34400,
43900,
9700,
42200,
19900,
62100,
32600,
14600,
6600,
10100,
15900,
18000,
29200,
37700,
31900,
24400,
78800,
55500,
30000,
56100,
null,
12500,
19400,
41100,
27100,
null,
37500,
null,
11000,
14500,
60800,
34900,
90000,
18000,
null,
59500,
59800,
19000,
24900,
39500,
27700,
70100,
53000,
27200,
null,
9400,
32200,
12200,
104900,
28700,
18500,
49400,
53500,
18900,
8200,
24000,
54800,
30100,
11300,
12300,
18300,
18100,
19500,
20000,
24300,
16400,
19300,
24700,
null,
12000,
174100,
14900,
null,
19400,
45200,
10600,
131100,
26800,
50900,
null,
16000,
null,
17400,
34700,
38900,
9300,
null,
22700,
33900,
38600,
6000,
29900,
15400,
78500,
54500,
47200,
77900,
50700,
9600,
16100,
41283,
43200,
34717,
50500,
28900,
71300,
83700,
14300,
24900,
null,
null,
10700,
14900,
null,
6500,
null,
6800,
21200,
1600,
11400,
28400,
42200,
60900,
19600,
44800,
22100,
57500,
78100,
16400,
27100,
58500,
33200,
19900,
5800,
9600,
37200,
52000,
81600,
30700,
21900,
31700,
16300,
10400,
26300,
31700,
47500,
28800,
null,
28600,
15600,
24100,
19100,
7700,
98200,
18300,
null,
17800,
9600,
5900,
24300,
26000,
26100,
20053,
19900,
10300,
27100,
null,
null,
66200,
31400,
15900,
1800,
24200,
28700,
58000,
60200,
59100,
16800,
32900,
38400,
26100,
23000,
40600,
20700,
51500,
38200,
38500,
29900,
47000,
67700,
31500,
13800,
11400,
22100,
9900,
22800,
5500,
12100,
15800,
38000,
6900,
31200,
null,
15300,
17600,
38400,
18400,
11100,
null,
40700,
40600,
null,
13200,
13500,
15700,
26500,
38200,
37500,
16100,
26100,
3500,
31600,
14800,
18700,
23000,
14500,
29300,
18000,
2500,
81200,
76300,
9700,
23500,
11900,
70300,
31150,
null,
16900,
19700,
null,
16600,
49700,
null,
null,
27250,
32300,
8800,
105500,
8300,
10000,
45200,
9700,
48000,
null,
24800,
27600,
15100,
19600,
11700,
16400,
21100,
17500,
10200,
null,
10000,
16800,
25100,
15100,
14900,
20400,
null,
8500,
42200,
13300,
11500,
13500,
47100,
13500,
11600,
13450,
7300,
null,
178400,
28300,
6700,
15500,
48500,
25800,
26600,
23300,
6600,
13500,
19900,
24600,
15800,
30800,
25600,
36900,
12700,
13700,
28800,
11800,
null,
21100,
45200,
9100,
3900,
80300,
8300,
4900,
14500,
30100,
null,
12500,
null,
20200,
13000,
48700,
91400,
14900,
118100,
22700,
8500,
40600,
28500,
42000,
19796,
15250,
16700,
40900,
8900,
28900,
12900,
58200,
28000,
21700,
15500,
22300,
3900,
29000,
28000,
45300,
23700,
19500,
63500,
10100,
24300,
48400,
20539,
68800,
47600,
null,
6300,
null,
14500,
36200,
44000,
null,
38800,
21300,
31700,
35600,
49100,
18300,
35500,
31500,
15010,
17000,
19000,
33000,
31550,
39300,
31500,
5500,
17100,
54800,
33500,
26500,
30700,
9300,
15400,
46800,
34100,
66200,
69700,
43400,
31400,
15700,
10400,
21900,
27100,
58400,
67900,
16400,
19200,
16400,
9600,
17300,
32200,
48900,
67600,
153300,
12000,
35500,
11800,
20800,
17400,
22300,
38500,
15600,
35500,
41400,
8800,
null,
54800,
2800,
5600,
40400,
9800,
14500,
null,
19000,
18400,
26100,
26400,
6500,
77300,
32900,
10500,
36400,
48300,
45200,
45900,
9800,
57100,
12700,
9400,
58900,
48000,
28000,
53700,
41600,
5100,
20950,
12000,
12000,
2400,
24500,
6500,
13600,
null,
24400,
14800,
4700,
45500,
7000,
12000,
38900,
13000,
37000,
null,
16500,
16100,
13000,
2200,
9400,
17200,
22100,
14454,
36800,
38800,
36000,
44300,
14400,
47800,
15200,
12600,
64700,
31000,
16000,
null,
5080,
25100,
3100,
69500,
18600,
29600,
19400,
34200,
8100,
21700,
119800,
31700,
13300,
15500,
3900,
22200,
46900,
17600,
9800,
null,
10700,
15500,
116700,
12500,
14000,
15200,
null,
37900,
11800,
25800,
16000,
34800,
51300,
54700,
24600,
53900,
21675,
6700,
31300,
82600,
25100,
73300,
null,
27900,
45400,
39700,
28279,
null,
null,
116700,
33200,
35500,
9300,
31200,
null,
25700,
21000,
null,
12400,
15100,
26500,
77500,
178000,
3775,
12000,
15000,
306600,
null,
null,
45400,
31300,
21700,
21600,
23100,
108800,
7300,
7400,
4800,
17700,
24600,
20200,
18600,
45400,
20300,
2000,
15300,
13100,
14700,
47600,
29400,
5900,
43000,
8100,
52700,
41701,
null,
20100,
25400,
null,
8300,
46000,
42900,
51800,
39600,
21700,
28700,
103200,
55900,
5000,
null,
17500,
27100,
24200,
null,
null,
203300,
42900,
23800,
21500,
22100,
89800,
38100,
7200,
null,
null,
5600,
40300,
23500,
39200,
4500,
49700,
2300,
27800,
14400,
null,
36800,
6200,
20000,
21500,
109400,
55600,
13000,
85000,
8500,
78200,
27700,
14900,
53200,
16600,
11100,
39200,
23900,
12700,
5400,
5500,
5500,
34400,
9400,
29200,
18400,
5500,
31100,
39100,
25700,
11700,
13500,
59600,
69000,
26600,
16800,
26100,
15900,
3300,
7500,
105500,
67300,
null,
9000,
37200,
25200,
14900,
17200,
5800,
15400,
60400,
40400,
18100,
null,
61900,
13800,
53800,
15000,
null,
18000,
13400,
null,
2600,
1900,
68000,
30079,
318800,
12700,
19800,
60000,
null,
5300,
50700,
10000,
8700,
37200,
15300,
15400,
23100,
253000,
20200,
10000,
87500,
30200,
34400,
null,
89400,
null,
42800,
17000,
107200,
25600,
34400,
14800,
25310,
24500,
14200,
107200,
30900,
27800,
28200,
32000,
16700,
19900,
41700,
63500,
39200,
22500,
23900,
66200,
29300,
9500,
44200,
30400,
68900,
22300,
57500,
50700,
19600,
81900,
53800,
35600,
6400,
21000,
17607,
27700,
16200,
null,
22100,
16500,
21200,
41000,
39700,
9900,
82159,
79750,
37600,
28300,
57100,
14200,
24700,
6500,
19500,
19800,
7200,
8400,
27200,
14300,
6500,
63400,
9800,
null,
25100,
22000,
8700,
55000,
null,
13900,
10800,
29800,
108200,
25100,
77800,
29500,
42500,
18600,
3700,
19900,
7000,
16501,
26900,
44900,
29800,
3600,
78700,
29500,
57200,
null,
40400,
10500,
39600,
34500,
9500,
8000,
21200,
null,
63000,
8018,
64300,
13200,
null,
10700,
10200,
7700,
54800,
19900,
8679,
10500,
53000,
15000,
35500,
50400,
null,
7800,
16500,
35100,
23100,
36500,
60200,
31300,
21700,
15400,
null,
11600,
26000,
44900,
11500,
8400,
19900,
107100,
11500,
3300,
53100,
17800,
66900,
1800,
3300,
null,
31800,
22700,
41900,
67500,
67300,
25700,
87500,
35700,
18700,
37000,
73200,
146100,
38200,
22500,
29900,
52500,
null,
27200,
63400,
16100,
47900,
27800,
9900,
46000,
21600,
76600,
117200,
15100,
28700,
231200,
null,
14700,
34400,
41200,
26000,
null,
39600,
8900,
5500,
17400,
11800,
15100,
59300,
14300,
16800,
11100,
null,
12250,
null,
51700,
12000,
10700,
19500,
null,
30200,
59100,
18000,
10300,
null,
53000,
38000,
49800,
12100,
null,
17500,
null,
24200,
21500,
14800,
67000,
28300,
16600,
19200,
64200,
172400,
24900,
32600,
21300,
35100,
33000,
101400,
null,
54300,
5600,
12000,
112800,
8600,
49610,
17800,
20200,
38000,
130000,
17500,
31100,
17200,
98100,
35200,
14600,
47800,
26700,
17700,
19500,
15800,
null,
43542,
4000,
18100,
13000,
34000,
40200,
163202,
46400,
null,
24900,
38700,
22200,
null,
12400,
24200,
34900,
null,
29102,
58000,
25400,
null,
32200,
29600,
12023,
8000,
48500,
58316,
11800,
null,
195592,
17900,
176300,
null,
25700,
80400,
14500,
57800,
65200,
15700,
43803,
80200,
null,
8600,
51300,
56800,
109000,
31600,
36200,
47700,
33600,
23300,
14900,
5100,
11700,
166600,
19900,
27500,
11000,
24400,
18500,
31200,
6500,
16650,
28900,
44200,
32800,
6920,
12900,
61900,
37700,
null,
22800,
17800,
28300,
13500,
18300,
7325,
33800,
19100,
45900,
26000,
34400,
null,
14300,
17100,
20700,
183400,
null,
9900,
20100,
9800,
54100,
9700,
38500,
4700,
53251,
7400,
null,
null,
66100,
27100,
null,
22200,
8800,
16900,
41600,
11600,
41100,
10000,
7795,
48900,
42800,
13100,
32500,
26100,
39200,
25700,
26100,
7800,
56100,
5100,
8500,
5400,
27400,
9200,
33400,
76600,
15200,
39700,
24700,
10600,
45300,
3900,
18200,
14200,
45700,
7300,
33100,
26400,
109100,
53800,
68600,
null,
13400,
18300,
null,
24700,
38500,
29300,
17300,
16200,
4700,
23300,
234800,
12800,
61200,
9400,
null,
6300,
12000,
47400,
6000,
27900,
14300,
77600,
35600,
35900,
26400,
4700,
14200,
29500,
5000,
null,
60000,
8700,
58300,
null,
null,
21200,
null,
12300,
9000,
26200,
9300,
31000,
12800,
19900,
23800,
3400,
5300,
null,
34301,
51800,
14300,
16000,
11400,
null,
5800,
43000,
6400,
2800,
41100,
10600,
51800,
33800,
24100,
23600,
13500,
31400,
42100,
131100,
134300,
13700,
54900,
15500,
187600,
57002,
14600,
17800,
40800,
53300,
25700,
24600,
31300,
7500,
22400,
50400,
79200,
59500,
28000,
75500,
82300,
11400,
13100,
null,
37100,
21000,
42750,
16300,
147100,
12800,
49200,
40000,
40100,
28300,
62000,
131100,
16500,
41800,
14700,
22000,
18400,
33700,
17500,
2400,
35700,
30000,
null,
7200,
14400,
14400,
32900,
26400,
22200,
31500,
null,
41100,
9000,
108100,
39600,
30900,
10200,
29100,
null,
21200,
25500,
29000,
42900,
28600,
71700,
61400,
58800,
15100,
null,
10300,
19100,
27600,
19700,
9200,
6800,
41900,
128500,
34100,
26600,
20300,
7200,
9700,
46900,
null,
21500,
49100,
54000,
null,
20900,
null,
94800,
37700,
10200,
25400,
143800,
43700,
29200,
13000,
19500,
76700,
60600,
35800,
23500,
10600,
109700,
85000,
51400,
71700,
8700,
26100,
45100,
7800,
28500,
6800,
22000,
24100,
42700,
18400,
34900,
7300,
55700,
5500,
56400,
25200,
33200,
18400,
62300,
17100,
74700,
53600,
39900,
34000,
47700,
20000,
24300,
44500,
43200,
67900,
47000,
51100,
13400,
22100,
13200,
null,
3800,
58200,
27800,
20100,
34000,
36300,
17600,
83700,
29600,
7500,
36300,
11800,
26600,
21300,
44500,
34800,
21800,
264600,
28700,
null,
40300,
36300,
25000,
46500,
15300,
null,
null,
null,
37300,
12600,
42900,
52500,
null,
6400,
13500,
15800,
79800,
18900,
15400,
41400,
43300,
27598,
null,
61900,
19600,
29000,
27800,
21300,
34600,
13400,
23900,
93400,
26800,
47800,
29300,
34250,
39000,
null,
9800,
150900,
24100,
18900,
22700,
22500,
29000,
35800,
46000,
42900,
42100,
148400,
27400,
5400,
21800,
null,
122600,
31600,
6300,
94700,
20400,
35919,
5900,
null,
31600,
19800,
59400,
45300,
34200,
29900,
null,
70200,
74000,
null,
24300,
30600,
38400,
33900,
7900,
15300,
52847,
25500,
17200,
61965,
44000,
null,
15200,
24600,
null,
16500,
18300,
10900,
35100,
9400,
38100,
15500,
27000,
64400,
10500,
12200,
10800,
4500,
18800,
41000,
50300,
16300,
65300,
10900,
43000,
10500,
64200,
11800,
32100,
19800,
41400,
27400,
23900,
24000,
22400,
10100,
30500,
31200,
6600,
39800,
null,
188200,
21200,
17100,
41766,
27700,
61400,
49500,
34300,
23300,
15900,
20200,
21200,
12900,
10100,
13800,
2400,
23400,
31600,
19500,
34300,
14800,
15700,
67800,
33700,
44900,
17700,
2850,
14100,
68800,
17400,
6300,
31500,
34800,
22000,
75400,
47400,
36000,
null,
21300,
11800,
17300,
13000,
64800,
8600,
38200,
10900,
700,
4700,
94200,
20500,
6100,
18200,
null,
37800,
87200,
32900,
12200,
34800,
26100,
null,
60200,
27000,
51000,
2500,
20100,
27800,
null,
11000,
12300,
24500,
108400,
37400,
20300,
19400,
15400,
26900,
11000,
14900,
107100,
40400,
23100,
null,
216000,
92200,
6500,
40100,
25800,
10000,
null,
38036,
24000,
10400,
19000,
17300,
27500,
null,
91000,
24200,
52800,
23800,
25100,
60400,
38018,
23900,
28900,
13200,
31600,
12900,
16000,
5200,
55900,
12100,
44100,
17300,
26500,
27700,
70900,
37500,
10300,
19500,
null,
14300,
31300,
46000,
32100,
44300,
null,
null,
22800,
26300,
37900,
21400,
27700,
21100,
24600,
14000,
19400,
30100,
75400,
13100,
27100,
54600,
15000,
56000,
40600,
null,
15000,
16300,
14800,
34000,
34500,
71500,
31100,
10300,
null,
15800,
19500,
2000,
7500,
33800,
11600,
131000,
42600,
12100,
61500,
13000,
14300,
72820,
20775,
25800,
30700,
25900,
7800,
14900,
49100,
28300,
60700,
null,
13300,
7500,
15800,
15500,
27100,
11900,
14700,
31300,
22700,
40400,
33800,
35100,
177350,
34800,
20800,
81800,
25800,
35800,
26500,
15377,
24600,
81400,
60800,
44200,
21100,
8300,
12300,
101000,
13800,
25000,
35800,
28600,
30400,
17150,
8700,
null,
22400,
85100,
null,
33400,
22700,
null,
21300,
18600,
46100,
6000,
15100,
49800,
7300,
23300,
24600,
40500,
16500,
27500,
25700,
12200,
11000,
25800,
66000,
61300,
22400,
6300,
18800,
55805,
12400,
null,
71000,
2600,
46600,
null,
12300,
24100,
null,
32241,
43300,
30200,
78500,
null,
4800,
65100,
36600,
8100,
18800,
23500,
19400,
13100,
155300,
323800,
6700,
12200,
66400,
null,
21100,
11300,
40700,
6300,
19900,
51900,
23600,
24600,
null,
10000,
6500,
18600,
43000,
33000,
9300,
41500,
110200,
188500,
10800,
13300,
null,
10500,
26600,
20300,
18200,
113500,
5000,
12200,
10900,
17500,
14400,
8100,
37100,
31200,
8100,
76700,
35000,
30200,
10300,
33900,
12800,
37000,
null,
32500,
11600,
28200,
null,
8700,
122500,
32600,
10200,
6600,
null,
13900,
82600,
18500,
21300,
15363,
90300,
20600,
35800,
20100,
22300,
71100,
19300,
35000,
68900,
null,
75700,
11300,
57500,
7900,
24800,
17000,
16300,
7300,
12200,
31200,
null,
51400,
null,
10800,
17800,
22500,
22800,
43100,
39500,
29000,
6500,
10800,
19000,
11300,
11500,
94500,
5900,
161000,
28700,
16300,
null,
43600,
7900,
null,
37600,
32700,
40900,
11500,
null,
25800,
45900,
29400,
62000,
169400,
13100,
55000,
9450,
32500,
28900,
null,
16400,
29400,
null,
77600,
37250,
36700,
57300,
16900,
16200,
28900,
5100,
116000,
20000,
29000,
8100,
null,
25900,
26900,
12700,
1000,
27900,
33400,
23100,
24300,
22760,
5200,
19200,
64600,
27000,
58300,
null,
8800,
28700,
51900,
59100,
11000,
21000,
33000,
7900,
104800,
17100,
15700,
15500,
27800,
19000,
18300,
34900,
21800,
89200,
12300,
44600,
26200,
76600,
37600,
7100,
40800,
34500,
26100,
21000,
13500,
45400,
85400,
null,
18500,
34400,
31200,
22100,
22500,
38500,
52500,
6300,
2400,
42600,
8600,
34100,
23300,
61800,
24500,
22900,
12400,
43000,
14000,
10500,
15400,
6900,
22500,
43400,
73200,
32800,
10800,
206000,
45500,
57800,
28300,
6000,
19300,
24100,
12500,
22900,
38500,
null,
19700,
91600,
35700,
53200,
12900,
5000,
61100,
22100,
20100,
null,
30300,
33200,
37900,
24800,
17600,
29000,
8100,
17600,
15500,
27200,
36450,
13500,
22700,
40200,
3500,
15400,
36900,
16300,
8500,
30300,
55400,
null,
null,
null,
26500,
33400,
40900,
11900,
17900,
62800,
51400,
null,
11600,
23300,
36300,
10100,
37100,
65700,
16100,
9000,
31700,
35300,
25100,
63900,
33990,
18200,
59500,
45200,
28100,
12500,
18300,
13800,
52597,
5600,
49500,
12500,
29600,
10500,
2600,
18400,
7500,
13800,
43000,
15300,
16700,
6500,
16900,
29600,
50100,
39100,
7100,
36600,
3900,
34700,
21400,
2400,
12800,
45800,
46400,
28900,
15600,
null,
31700,
1200,
44900,
17700,
62000,
23700,
20800,
12700,
24200,
19700,
73900,
25500,
23000,
48900,
18300,
17700,
32000,
52300,
28200,
30000,
15100,
16300,
4000,
34900,
22000,
18400,
42000,
41300,
36600,
34300,
15000,
65000,
11950,
17800,
20400,
6400,
26400,
25300,
53000,
5100,
17700,
10600,
12100,
23000,
40700,
12000,
null,
null,
35209,
27300,
21200,
69400,
22500,
39600,
18500,
17600,
20100,
23800,
8400,
28100,
16300,
45100,
49000,
11700,
5500,
7100,
36900,
10300,
52500,
7800,
5500,
26900,
149100,
37200,
29100,
59500,
8400,
29700,
35600,
16500,
42600,
14500,
6400,
9300,
23400,
26900,
111150,
46200,
2500,
72000,
39600,
22100,
23400,
8300,
8400,
null,
11600,
29900,
21600,
12600,
34700,
null,
153000,
106800,
54000,
10100,
76200,
39100,
29800,
4300,
8100,
6300,
16300,
10200,
22700,
15400,
283600,
6600,
45900,
5000,
47200,
41500,
67300,
26600,
8100,
50000,
null,
23800,
33000,
32600,
4350,
86800,
12500,
38900,
35800,
21600,
11800,
null,
5600,
null,
5500,
16300,
41400,
46300,
38200,
3300,
156900,
5500,
91600,
35900,
14200,
31600,
10300,
null,
8200,
null,
18100,
97000,
26500,
24200,
18400,
27700,
32700,
42100,
31500,
35200,
18000,
14200,
13100,
29100,
14900,
47100,
30600,
26000,
26900,
15400,
51000,
17500,
48000,
10300,
71600,
28100,
null,
33100,
7800,
3500,
51500,
62700,
52680,
10200,
31300,
56400,
51800,
32400,
29700,
29500,
27400,
25900,
12100,
58400,
25500,
62200,
61200,
103000,
9400,
86700,
8100,
17900,
65900,
15200,
18700,
17900,
22600,
15600,
null,
17700,
49300,
null,
75000,
37400,
9300,
42100,
28700,
13400,
null,
41300,
23900,
8600,
37900,
10500,
43200,
null,
45000,
32000,
18100,
18700,
69400,
5500,
6800,
26300,
44900,
250300,
24200,
188000,
19800,
14500,
31500,
25400,
2900,
22600,
13100,
33100,
44400,
21600,
null,
30000,
55000,
28100,
38900,
26900,
null,
26200,
null,
null,
45800,
59900,
92200,
17300,
49100,
4100,
10200,
29757,
13700,
43100,
13300,
59800,
34000,
81500,
8800,
6550,
35900,
9100,
84900,
40700,
8600,
49400,
9000,
24800,
28700,
38800,
55100,
21800,
34600,
5600,
45700,
25700,
13200,
12700,
26400,
67900,
21300,
14100,
22800,
16900,
12600,
11500,
19400,
28000,
17600,
29300,
15900,
13900,
14000,
15400,
31100,
55000,
55800,
9100,
15300,
8600,
9900,
25500,
286800,
15300,
16300,
41500,
8300,
20800,
46500,
18000,
18800,
93249,
7100,
38100,
7600,
6500,
21400,
46100,
9900,
16400,
21500,
7000,
107000,
46800,
23750,
7100,
11200,
5500,
65068,
23500,
19100,
18600,
26900,
23300,
18300,
null,
32900,
8100,
25900,
6500,
10900,
3000,
20800,
null,
58500,
26900,
9600,
5200,
77900,
28800,
null,
14500,
20850,
18700,
9800,
12100,
15500,
31300,
25700,
13700,
30500,
17900,
34200,
null,
34900,
49500,
73600,
11200,
24200,
12400,
16300,
12200,
24500,
13000,
null,
42900,
23500,
16700,
14200,
9200,
2300,
11100,
8900,
41200,
27000,
12800,
6600,
null,
3700,
9600,
2500,
42200,
82900,
68200,
7500,
18000,
48100,
16100,
19600,
13900,
20700,
32000,
31500,
43500,
30400,
39100,
13500,
8400,
12800,
10200,
47500,
20800,
13000,
null,
12300,
21800,
2800,
20500,
13000,
20500,
14200,
16100,
null,
10500,
9900,
74000,
18100,
25500,
21500,
6000,
16000,
107600,
19300,
21800,
34100,
5100,
62700,
null,
10300,
27500,
3500,
41600,
116700,
31800,
2900,
null,
33000,
13700,
16900,
32800,
22900,
38300,
23200,
35800,
26000,
19000,
36400,
52400,
8500,
15600,
10000,
5500,
6400,
6000,
35700,
20900,
14200,
8300,
14000,
null,
17600,
28600,
20700,
263500,
25600,
7000,
12500,
43600,
8400,
46600,
17100,
70800,
7400,
48800,
44700,
2500,
31400,
39500,
24300,
54500,
18700,
122700,
7200,
16300,
7300,
5300,
14300,
30400,
null,
20900,
21200,
50000,
4800,
23600,
38300,
28400,
28800,
105100,
46900,
10100,
21800,
null,
16800,
27600,
18400,
37300,
10000,
null,
12000,
25800,
null,
null,
null,
null,
19000,
27200,
27200,
null,
15000,
36900,
null,
12300,
12000,
21900,
14112,
5900,
26300,
43300,
53500,
36700,
30900,
6700,
27800,
null,
null,
40000,
4100,
21100,
35200,
26000,
9100,
107400,
15300,
10200,
159800,
41800,
21100,
24200,
12300,
24800,
1100,
30100,
52500,
12100,
22600,
54900,
11700,
5700,
16000,
16000,
110400,
null,
37100,
7600,
7600,
43100,
21900,
10800,
11000,
20200,
5200,
20100,
12100,
33100,
8500,
71400,
null,
11900,
null,
36700,
56900,
11900,
52700,
33600,
67200,
50300,
44200,
12610,
28100,
18400,
49200,
9100,
9600,
8500,
34800,
10700,
68300,
24900,
17600,
7900,
35100,
28200,
44100,
16300,
49000,
87700,
55900,
14400,
33500,
11500,
32000,
20400,
19500,
22200,
10600,
30600,
null,
31400,
19300,
34200,
21535,
60300,
43800,
10800,
21100,
10400,
23700,
21300,
15700,
27400,
57000,
6700,
37000,
4800,
10700,
61100,
34000,
22800,
9900,
51000,
8455,
16400,
72000,
13500,
75100,
52800,
46900,
46100,
17500,
9300,
22400,
15600,
14000,
25600,
16700,
null,
25600,
21900,
147700,
25300,
21600,
9900,
27300,
22200,
47600,
15200,
50725,
13600,
15700,
null,
18700,
7100,
18700,
25300,
43500,
15700,
6800,
14200,
33000,
27400,
53400,
14300,
20500,
7200,
18300,
7700,
11700,
21400,
null,
8600,
13100,
1800,
26600,
47500,
9900,
8700,
19200,
37400,
39600,
29800,
12300,
4100,
51100,
54200,
30500,
38500,
34700,
52500,
10200,
null,
42000,
21800,
16600,
null,
37200,
34400,
7600,
42511,
6700,
53000,
null,
22100,
11600,
7000,
30600,
50800,
59700,
29600,
41300,
20800,
83200,
30000,
10700,
26700,
9100,
16500,
12300,
176600,
32000,
25300,
107200,
null,
null,
28700,
27700,
48800,
125400,
17400,
15400,
33600,
63000,
null,
17900,
75700,
114800,
null,
21900,
28300,
21700,
24300,
41200,
38900,
20700,
null,
24300,
33700,
null,
38900,
24500,
67500,
27700,
10900,
45700,
28400,
7300,
10400,
40200,
null,
11600,
13300,
11900,
7000,
22300,
21300,
21500,
8300,
58700,
28400,
43900,
null,
26500,
13300,
null,
5800,
48000,
73600,
21400,
30150,
37400,
46600,
22100,
30400,
6700,
20000,
null,
19300,
36200,
56900,
105600,
null,
57200,
15100,
40200,
20300,
16100,
23800,
18000,
147600,
17500,
15600,
23800,
23000,
38700,
18700,
101200,
12600,
3700,
null,
14000,
6900,
16100,
null,
18200,
62700,
23600,
10600,
26800,
18600,
31000,
15300,
5300,
14950,
null,
26900,
20400,
13300,
32100,
41300,
52300,
13400,
28000,
105600,
33000,
31100,
27500,
19300,
83100,
13500,
22500,
4500,
6600,
47100,
null,
9300,
54700,
15600,
16500,
24500,
63282,
47300,
30376,
8900,
23900,
60200,
9300,
18800,
23500,
24100,
10500,
7500,
17400,
7400,
52700,
70900,
18800,
5600,
28900,
26700,
25810,
56900,
40600,
15600,
22050,
null,
2400,
null,
27400,
11700,
6400,
12300,
10200,
67000,
25600,
24300,
16900,
16300,
33100,
36200,
25300,
null,
37800,
31200,
18500,
15050,
15700,
6300,
36400,
5200,
23700,
21500,
31500,
9200,
33700,
null,
null,
30100,
44800,
24200,
15500,
34500,
10700,
26300,
5600,
103700,
37400,
30800,
49800,
2700,
7700,
22900,
44400,
191351,
54500,
26800,
18000,
37300,
36100,
37500,
21700,
31700,
9300,
24200,
27800,
21000,
12100,
35400,
35200,
18700,
15600,
18600,
5100,
56800,
7600,
55825,
null,
19100,
null,
31500,
10800,
24200,
15800,
40100,
42300,
46500,
84150,
14500,
49100,
45000,
24200,
22600,
45000,
30600,
27600,
10300,
23900,
22300,
7100,
10600,
7900,
25900,
7000,
11200,
null,
60300,
12300,
29800,
61700,
null,
74400,
7400,
41300,
73300,
14400,
59500,
null,
59500,
70600,
65900,
8100,
11600,
35100,
23800,
37500,
7400,
null,
15100,
17100,
26700,
8600,
19200,
15100,
22700,
1800,
31000,
46900,
18200,
13700,
24500,
14000,
10300,
18600,
29500,
18900,
41400,
10700,
11800,
35800,
12800,
null,
36600,
2000,
8000,
14500,
13800,
37000,
null,
34400,
43400,
55700,
70200,
null,
38000,
null,
null,
null,
132200,
8900,
33700,
20600,
26900,
10100,
18600,
6600,
41300,
98400,
7700,
31900,
17100,
68400,
4800,
24400,
14200,
13900,
53200,
95700,
18800,
37000,
39700,
30600,
62100,
7400,
23000,
15700,
23400,
34300,
7000,
22100,
39800,
237800,
140000,
10700,
17700,
4650,
26000,
9100,
40800,
41300,
147800,
34700,
null,
31900,
11200,
null,
0,
32100,
59000,
22700,
14100,
11200,
42400,
12600,
30500,
132599,
26500,
52900,
21200,
43600,
18200,
14600,
64500,
17500,
35400,
31900,
20100,
12000,
66800,
14500,
18300,
13200,
41700,
4000,
19700,
null,
33400,
12900,
13060,
62300,
63600,
19300,
39800,
64400,
9400,
19700,
87200,
26600,
4800,
3400,
13000,
15600,
null,
18200,
66900,
null,
5800,
14900,
85600,
97300,
29300,
12300,
6400,
32100,
27900,
43100,
17000,
46900,
20700,
102300,
12200,
121900,
12500,
27600,
36800,
null,
101400,
11100,
269399,
17400,
23000,
26500,
72700,
20900,
25700,
22600,
17800,
35600,
23500,
12600,
20200,
12700,
41200,
82800,
24700,
26500,
33100,
29000,
19000,
31800,
15000,
null,
3000,
9000,
72200,
48900,
14300,
15800,
18300,
13900,
26250,
40700,
16100,
33600,
24200,
47200,
33500,
30100,
19900,
10900,
19000,
11700,
8000,
16800,
47300,
108600,
38559,
28900,
24600,
10400,
100500,
12100,
44700,
81900,
19900,
125200,
18300,
32700,
50400,
15500,
27200,
40500,
19200,
6500,
36400,
14500,
66300,
23900,
15600,
22100,
null,
9500,
43300,
105700,
13300,
41700,
33200,
18700,
21300,
26800,
9400,
17300,
33800,
40600,
35600,
56200,
71186,
34000,
9300,
27200,
null,
47800,
31700,
35600,
315300,
39296,
27000,
68200,
123200,
22300,
null,
19200,
25400,
21400,
48400,
16800,
53300,
25500,
2000,
98100,
11800,
10000,
101300,
15000,
18500,
11700,
206700,
33300,
30300,
6000,
144900,
49300,
16700,
13200,
134800,
3100,
8000,
28600,
31300,
22500,
null,
31800,
17900,
55500,
24700,
46300,
23300,
15200,
null,
41100,
25900,
5700,
31800,
8600,
9600,
22100,
18600,
12600,
30700,
29400,
null,
40200,
50600,
23500,
21500,
21400,
3700,
null,
9000,
38200,
8700,
18900,
41500,
22100,
64500,
23100,
33300,
10000,
71500,
29200,
8050,
74700,
14500,
17400,
29700,
52400,
12300,
500,
69600,
55849,
12300,
50800,
8300,
59200,
24900,
null,
4900,
125800,
6700,
9800,
39200,
126000,
53158,
null,
41800,
25700,
45500,
26400,
null,
null,
29700,
4900,
null,
500,
36900,
11500,
18000,
6100,
6700,
14700,
9100,
54500,
17600,
6100,
35200,
51000,
8700,
14000,
15700,
53100,
15500,
34800,
18400,
6100,
49360,
3700,
39773,
106150,
19000,
7200,
47000,
24600,
28100,
34500,
34300,
null,
45000,
24600,
11900,
17600,
10700,
68500,
83500,
40500,
36600,
19100,
34700,
32100,
34000,
15500,
31000,
15600,
17500,
40800,
48300,
13900,
44100,
12800,
146300,
7900,
37200,
25600,
18500,
8800,
60900,
30800,
30200,
50300,
19900,
14400,
36300,
13900,
55500,
42500,
57900,
32900,
null,
18700,
null,
53700,
49800,
21400,
null,
5100,
17900,
46400,
40000,
18400,
30500,
46100,
18900,
37600,
9200,
31500,
53500,
12200,
29300,
9500,
25300,
21900,
40700,
30100,
17100,
32800,
21700,
27900,
90200,
12700,
7900,
43600,
21000,
60300,
23000,
19100,
54900,
28700,
1200,
25100,
31600,
11900,
null,
31500,
19600,
14000,
27800,
null,
null,
58100,
41700,
11200,
25400,
103800,
7800,
18100,
10600,
25200,
42900,
22500,
26500,
22000,
40890,
75900,
20200,
28600,
11000,
16600,
11200,
38100,
33700,
null,
9700,
57300,
null,
24300,
106600,
19400,
16500,
7300,
39000,
59300,
19500,
13400,
56200,
18100,
24000,
64400,
20800,
8400,
65300,
33200,
32000,
39300,
null,
5300,
null,
21900,
110100,
28400,
2400,
43200,
22000,
26100,
15000,
18900,
41200,
7200,
8600,
9400,
5900,
20900,
null,
20500,
8309,
49600,
null,
117500,
34300,
34400,
50500,
54900,
24600,
7800,
55700,
3300,
12600,
10100,
13100,
31400,
118200,
33800,
33400,
45600,
65900,
44200,
38300,
29400,
12400,
48300,
16450,
9700,
null,
73400,
14200,
21400,
19600,
27000,
10000,
46200,
13400,
8800,
8200,
22300,
35700,
18000,
23100,
14100,
45823,
22600,
70000,
25900,
14000,
18500,
null,
62700,
11650,
14000,
3400,
32500,
57200,
10500,
11100,
null,
16500,
51200,
15500,
27500,
28400,
37700,
15250,
null,
82100,
55300,
60700,
42900,
99600,
25100,
null,
15400,
35000,
13300,
37200,
25300,
28500,
13700,
5500,
11000,
70400,
21800,
36600,
24300,
21900,
50500,
37200,
12100,
null,
21800,
11500,
37400,
68500,
29700,
15800,
54600,
31100,
26400,
null,
17800,
12600,
25900,
44800,
28600,
51000,
40997,
79400,
7500,
29800,
27500,
22600,
14900,
34100,
25400,
7800,
24100,
63000,
19300,
23700,
20100,
81900,
11600,
27400,
63100,
21200,
63600,
24400,
41500,
87300,
75300,
17570,
16100,
1800,
21500,
25000,
21700,
13500,
49100,
20600,
33700,
8500,
26100,
22800,
21100,
9500,
7100,
9300,
68400,
53200,
45300,
28900,
13200,
22100,
41700,
9800,
104200,
12500,
65200,
86200,
null,
40500,
12700,
79000,
16100,
41500,
37500,
19200,
7300,
18400,
null,
14600,
26100,
81600,
36700,
19400,
22800,
12400,
10100,
22700,
50900,
20100,
31300,
30800,
99300,
20800,
null,
8500,
null,
14500,
66400,
98500,
9500,
null,
12200,
null,
8500,
26700,
45800,
38155,
18200,
24200,
9700,
27300,
9300,
null,
23800,
29700,
41800,
43600,
null,
18700,
8700,
23300,
17000,
19100,
27800,
null,
15600,
27100,
30800,
38100,
50600,
81764,
39300,
11800,
18900,
36400,
21500,
7500,
12300,
7400,
null,
21100,
32000,
38000,
11400,
161300,
30200,
9600,
8600,
19400,
36000,
21700,
64500,
60300,
34600,
17000,
64100,
23100,
47000,
21100,
28200,
5500,
14700,
46200,
71600,
34000,
34200,
5500,
23400,
null,
24500,
33500,
19400,
16400,
14000,
17800,
13220,
null,
7800,
46900,
20000,
29500,
91500,
36809,
63191,
28200,
22200,
null,
20100,
20000,
32100,
40500,
15800,
25900,
16500,
27200,
19000,
7700,
29700,
null,
27000,
5600,
24800,
42000,
null,
8600,
43200,
37600,
75300,
28800,
46500,
null,
29000,
155400,
null,
97300,
20000,
69200,
8400,
36100,
23300,
18800,
14800,
null,
126200,
37400,
32300,
23500,
24700,
27000,
35100,
30500,
15400,
24600,
8400,
4500,
9100,
66400,
77600,
25600,
41600,
7200,
12000,
15000,
31000,
45600,
3100,
4300,
36700,
21800,
null,
null,
16300,
35900,
97200,
null,
34700,
10900,
9200,
35800,
35200,
9000,
76600,
24000,
null,
7600,
19500,
14800,
42400,
null,
74380,
17500,
13200,
8500,
null,
2200,
38200,
3000,
33600,
55600,
70400,
51100,
null,
32000,
111500,
17900,
13500,
32900,
8100,
8700,
11500,
150100,
109800,
null,
63800,
21500,
null,
10800,
32000,
19700,
3000,
15100,
167300,
21100,
13000,
33600,
22700,
39600,
27100,
26100,
null,
22600,
50200,
67900,
12500,
19800,
16900,
20700,
70600,
47500,
19900,
45400,
null,
60200,
16300,
111500,
10600,
11900,
null,
34500,
15000,
null,
44700,
15500,
14300,
26700,
26300,
28600,
12100,
18900,
null,
154700,
9500,
13200,
56000,
36900,
20800,
8900,
29700,
43500,
16700,
60800,
18100,
null,
43700,
7400,
null,
null,
29800,
20400,
74000,
6200,
30200,
26000,
13700,
25200,
27400,
15300,
16600,
15400,
26200,
75700,
142600,
null,
11400,
null,
65700,
22600,
33700,
47500,
25200,
27000,
80700,
27100,
25900,
23200,
18100,
26600,
17500,
8200,
23500,
41000,
144800,
14700,
31200,
13300,
20600,
21400,
16200,
16000,
12100,
63500,
19100,
null,
20500,
20300,
null,
11300,
26900,
5900,
81800,
11500,
13900,
23100,
52700,
16000,
11700,
43600,
20300,
43100,
67400,
44400,
59000,
65700,
9500,
50900,
null,
900,
88600,
9400,
39400,
36600,
62100,
13900,
22700,
null,
26600,
9100,
11300,
42000,
15800,
11600,
27200,
60200,
20700,
52400,
175200,
51100,
26400,
13200,
13600,
31400,
21700,
25400,
3900,
31600,
23700,
18800,
null,
52100,
112000,
51600,
47000,
70225,
14800,
3500,
49800,
29400,
22100,
39600,
13700,
29800,
null,
8400,
20200,
null,
37900,
9300,
23300,
12800,
29100,
36400,
10700,
41200,
11200,
95900,
27400,
3000,
12400,
41400,
33300,
7500,
76000,
8900,
9300,
42900,
48800,
28600,
42700,
32000,
20800,
null,
10500,
26900,
17200,
20100,
12100,
27200,
3700,
22300,
157700,
35200,
46300,
19100,
24400,
71600,
18900,
15600,
21000,
20500,
100800,
57800,
9600,
194300,
21800,
null,
null,
10600,
4800,
12100,
44500,
8500,
3000,
29500,
35800,
null,
null,
34500,
27400,
32200,
13800,
22700,
39800,
16100,
17100,
33000,
50800,
125300,
24600,
3800,
23200,
24700,
41000,
null,
null,
16100,
15500,
37400,
9800,
15100,
147700,
11100,
12500,
13200,
29800,
43400,
3200,
15500,
33800,
14400,
11300,
116006,
27000,
26600,
24900,
54100,
17600,
11400,
21400,
11500,
23300,
23000,
53000,
17900,
22800,
19200,
11000,
46300,
60700,
42100,
18700,
43100,
18200,
13900,
2700,
30900,
22400,
22500,
null,
44600,
26500,
null,
83000,
160500,
18700,
36600,
21000,
6300,
15300,
18200,
15300,
16900,
18000,
18500,
44400,
8300,
33300,
138500,
19900,
12700,
18500,
30000,
11400,
19200,
94700,
41000,
15700,
59500,
43800,
18600,
9100,
61800,
81700,
38000,
8200,
25200,
38100,
74600,
5600,
39300,
64600,
53000,
22700,
27200,
9000,
33900,
18000,
68100,
19700,
null,
47300,
32400,
50010,
30900,
65400,
42400,
35900,
123400,
12500,
null,
23000,
21700,
null,
34400,
7000,
21000,
null,
56300,
null,
32600,
null,
51500,
27100,
25700,
69000,
41500,
27600,
null,
10600,
20300,
33500,
79900,
9600,
52800,
3200,
34500,
25300,
165100,
18000,
6000,
10800,
9200,
38400,
13200,
23100,
7900,
6900,
37200,
26700,
113400,
46200,
null,
28400,
31400,
84100,
14500,
22000,
27000,
65800,
51410,
31100,
null,
34900,
16400,
26000,
9900,
14000,
19300,
null,
90000,
3400,
28800,
103000,
25000,
18400,
36300,
null,
20400,
9100,
19600,
11600,
10700,
74100,
22100,
28700,
63900,
17700,
13500,
31200,
6400,
29500,
9800,
51800,
37200,
13600,
34383,
33100,
45000,
18500,
5500,
51900,
31400,
32700,
18000,
24100,
40600,
56500,
89300,
7500,
57700,
6500,
25000,
63300,
93700,
31000,
null,
20600,
21800,
46200,
17900,
42800,
null,
13300,
12600,
14800,
27300,
null,
43600,
17900,
17100,
11600,
11900,
59000,
18100,
13700,
32500,
49300,
43500,
23900,
4200,
25300,
21300,
28300,
15700,
24600,
143670,
24400,
72900,
38000,
52800,
null,
13200,
14700,
10800,
162100,
5800,
8400,
20500,
43900,
null,
16400,
67100,
70400,
null,
10800,
49300,
98800,
34500,
60300,
19500,
11800,
12100,
11500,
28700,
11500,
19200,
62200,
30500,
4700,
116700,
11370,
47000,
61450,
32700,
null,
4200,
11500,
16400,
66600,
39000,
null,
9800,
31600,
21100,
null,
25800,
19300,
35300,
null,
20600,
69700,
22800,
4900,
16700,
16400,
27200,
40000,
64100,
12500,
34400,
16700,
46400,
10700,
21200,
22800,
10900,
71900,
94000,
10200,
16000,
20600,
19400,
42100,
32700,
32000,
14800,
36200,
null,
112558,
53700,
23000,
11800,
213500,
6000,
20000,
16400,
20900,
48700,
16200,
30300,
17900,
28800,
42600,
17300,
90500,
33100,
49100,
28300,
262100,
51500,
12300,
30600,
16400,
35300,
10000,
25200,
6100,
4098,
16000,
27800,
12500,
3200,
10000,
null,
5700,
29600,
57700,
23000,
34700,
23900,
22400,
9500,
12100,
39000,
26700,
114600,
42900,
38000,
24100,
31000,
21300,
26000,
43000,
39900,
5300,
49700,
9850,
29200,
88200,
13800,
10500,
16500,
null,
43100,
6100,
11700,
53200,
80689,
24200,
14600,
16900,
14600,
27300,
null,
7100,
null,
22500,
74200,
13900,
15300,
8400,
76100,
14700,
13200,
13500,
10800,
19500,
18600,
11000,
33300,
46600,
41400,
19200,
24900,
null,
14200,
313000,
8700,
37000,
30000,
25800,
36000,
25000,
16900,
54900,
21100,
null,
7500,
8700,
16800,
14200,
35800,
17300,
46300,
10000,
10800,
16000,
23300,
83900,
14200,
10300,
28300,
17100,
17300,
18900,
42700,
4600,
54522,
52900,
107500,
42500,
16200,
98600,
13000,
37700,
20900,
26600,
null,
11300,
8400,
44500,
83000,
205700,
26100,
68700,
50700,
12700,
20500,
77500,
12500,
14000,
29600,
null,
55600,
30400,
23800,
30600,
14200,
36200,
7900,
5400,
38600,
31800,
5500,
27700,
null,
37800,
10400,
57800,
36300,
32300,
12800,
null,
19100,
2800,
35100,
14400,
9400,
9500,
37100,
26300,
50700,
19200,
null,
29300,
95400,
4700,
46300,
28100,
40000,
58500,
27300,
39000,
7945,
19700,
103000,
31900,
39300,
26700,
24700,
32800,
null,
15800,
37175,
12000,
6600,
32300,
38800,
6400,
10900,
14200,
12200,
19300,
32800,
60000,
5200,
10700,
66500,
10400,
21000,
53900,
12300,
33300,
8877,
null,
23900,
15300,
4500,
14700,
58300,
10500,
13500,
132300,
28700,
74900,
16600,
14700,
17500,
22197,
20300,
14300,
14900,
12900,
15300,
15800,
22800,
53300,
108700,
69400,
32200,
15800,
20000,
13300,
8600,
13600,
17900,
null,
22500,
9200,
52400,
3100,
10300,
6100,
113600,
78100,
10100,
5600,
44861,
null,
15600,
15500,
16800,
29000,
103400,
66700,
45800,
30900,
87100,
null,
32700,
16000,
18500,
38900,
38600,
10500,
14100,
15900,
57600,
41000,
118700,
22900,
34400,
11600,
21500,
27800,
15500,
20300,
43600,
12700,
33600,
6200,
34690,
43300,
14000,
22500,
20700,
30195,
17200,
57000,
22800,
null,
19400,
21100,
5200,
8600,
32400,
null,
18400,
63600,
6100,
46400,
13400,
8100,
16500,
5800,
17400,
12800,
39100,
34700,
48800,
null,
30900,
10600,
65600,
40624,
11700,
null,
16600,
18200,
100300,
70500,
33100,
52800,
31500,
102100,
15000,
33100,
21700,
11200,
null,
69800,
66338,
36200,
23600,
7000,
3500,
135900,
44300,
57935,
40500,
14400,
15600,
15800,
17500,
11400,
12400,
45800,
36035,
16300,
31600,
26750,
27300,
29000,
56200,
73700,
16600,
33000,
34000,
9000,
42100,
34100,
13900,
23500,
9200,
16000,
17500,
5900,
6600,
17900,
11400,
32000,
20500,
10800,
14400,
26000,
22100,
14300,
47200,
20000,
42000,
19700,
null,
21000,
15700,
11800,
66400,
37800,
3000,
40000,
26900,
44300,
31000,
7400,
36800,
null,
13200,
42700,
8600,
34700,
28800,
4500,
45069,
23900,
17400,
46200,
null,
7900,
26900,
19100,
23100,
19300,
4600,
93500,
15500,
16940,
20100,
46200,
14500,
39500,
13500,
32500,
null,
10300,
91600,
16600,
47500,
16700,
32900,
70400,
16000,
88300,
115100,
20900,
25600,
15300,
15500,
4500,
13600,
18300,
20000,
13800,
18300,
14400,
58400,
23200,
68400,
7200,
null,
21500,
15800,
54600,
35800,
null,
31900,
52900,
24200,
15800,
16200,
81900,
7000,
18100,
50800,
10000,
4500,
27700,
29200,
10000,
16500,
19100,
22800,
12000,
23700,
45700,
10800,
56000,
6400,
32900,
40900,
null,
13500,
17100,
9700,
32400,
60432,
16400,
12500,
11200,
22900,
14500,
33300,
10100,
18500,
23000,
null,
22200,
14600,
13600,
10900,
13600,
18700,
2600,
41100,
15900,
19900,
22400,
null,
15900,
62200,
30100,
23300,
15700,
11900,
null,
70700,
56600,
8900,
15000,
43000,
8300,
15300,
18800,
15400,
15100,
108600,
16300,
22700,
9100,
18700,
31000,
null,
22000,
22380,
16700,
12600,
29600,
null,
9250,
20100,
43200,
12900,
66386,
44700,
23400,
49200,
36600,
14000,
58716,
67400,
6500,
21200,
28000,
null,
21800,
null,
71400,
46100,
26400,
62800,
39300,
null,
15500,
11500,
21900,
null,
24100,
21400,
1900,
18300,
62357,
4500,
7100,
11700,
11200,
7300,
5000,
28600,
24800,
110700,
32900,
14000,
14800,
57300,
13200,
37200,
19400,
24700,
16400,
43000,
11000,
15000,
26800,
24500,
21200,
16000,
52500,
73000,
24000,
7600,
7900,
23800,
6962,
13500,
101700,
71200,
4300,
10200,
null,
30800,
237000,
29900,
null,
74000,
32600,
6000,
20100,
44100,
31100,
11500,
18900,
17000,
52100,
22600,
7200,
109800,
null,
15100,
28300,
24700,
13100,
19700,
18425,
22600,
19900,
null,
9200,
67600,
42200,
14200,
14300,
19700,
19900,
26400,
12900,
13800,
48300,
18000,
9800,
8100,
12300,
null,
170300,
36700,
48900,
17200,
8300,
23100,
26300,
43500,
31600,
27100,
null,
12300,
null,
27900,
6400,
42000,
16900,
16700,
102927,
21900,
41300,
9700,
37600,
null,
4500,
51800,
26500,
40000,
18400,
18200,
7000,
73850,
25400,
8700,
7600,
31700,
62400,
28400,
138100,
15300,
2300,
25300,
40800,
24100,
15800,
21600,
10700,
23000,
10600,
35700,
29700,
33900,
29100,
33100,
null,
24800,
20800,
6400,
null,
10400,
18300,
13400,
35300,
12000,
17400,
29400,
19300,
8200,
10900,
28200,
null,
null,
9200,
27300,
36300,
29100,
3500,
18700,
24500,
41200,
19510,
69500,
10700,
104300,
15100,
17000,
27500,
29300,
36500,
6400,
14000,
68000,
null,
35300,
56100,
25000,
3200,
17800,
37700,
20000,
10600,
19500,
12200,
28000,
23500,
40500,
70800,
25200,
22600,
13100,
19300,
38800,
16200,
14900,
26300,
50900,
46700,
61600,
null,
40500,
null,
11800,
82500,
33400,
13400,
28800,
18800,
null,
51600,
25300,
16300,
68800,
11800,
8570,
23000,
9050,
18600,
108800,
30500,
24700,
10600,
29300,
61800,
20800,
23600,
24600,
6000,
null,
19000,
23600,
28100,
51900,
26200,
35300,
5500,
null,
4700,
27500,
6300,
156500,
18000,
19700,
31810,
36000,
13000,
8600,
null,
19900,
27400,
8600,
20400,
76600,
31800,
15300,
17500,
20100,
25300,
38500,
11700,
52200,
19300,
16400,
46900,
13300,
13700,
83200,
29900,
23500,
18100,
41000,
7500,
25400,
24500,
5700,
18600,
26400,
163700,
6400,
20700,
3800,
24800,
31600,
41800,
35400,
42900,
22100,
93900,
8500,
36100,
null,
10000,
99100,
96700,
null,
38600,
22100,
13100,
19500,
46700,
20700,
23100,
5000,
47600,
20100,
36300,
14200,
null,
19900,
23500,
31200,
18900,
74700,
10300,
22500,
36770,
35200,
null,
null,
31684,
44200,
8800,
null,
66800,
34800,
23200,
75929,
14300,
114800,
26800,
57500,
27800,
35500,
26900,
21500,
38800,
44900,
20445,
14400,
8700,
42300,
6400,
26200,
28600,
18100,
34800,
11500,
25700,
52200,
29600,
15700,
null,
32200,
12450,
10600,
88300,
6600,
11400,
37600,
7700,
16800,
10000,
9800,
32500,
23600,
37800,
16400,
199600,
114600,
48500,
21500,
16600,
22300,
33800,
null,
45300,
7400,
null,
13800,
43800,
10000,
48500,
80100,
9000,
14500,
11700,
5000,
51600,
10800,
28200,
14500,
68900,
16000,
null,
11700,
88800,
67800,
1500,
null,
32600,
143500,
10500,
14600,
8600,
21900,
35200,
37601,
30100,
69000,
null,
36000,
49300,
18500,
38300,
57700,
null,
106700,
null,
6400,
13900,
15500,
13970,
33475,
17200,
52500,
18100,
57100,
35400,
21600,
26100,
12800,
5500,
26700,
16700,
23900,
null,
15300,
73900,
70100,
18200,
null,
24000,
30400,
47700,
108000,
18500,
6500,
34700,
31000,
39000,
null,
null,
19500,
79700,
20600,
61900,
11400,
8300,
9300,
7200,
5000,
12400,
125700,
10300,
22700,
21200,
25900,
25900,
14200,
12300,
47600,
16000,
22600,
33900,
42800,
25800,
13500,
65800,
28300,
63300,
13700,
9850,
14200,
24200,
16800,
30400,
null,
20700,
4300,
null,
5000,
49900,
26800,
16200,
64200,
11100,
12300,
84000,
42700,
10000,
23600,
13500,
51900,
42600,
12000,
46700,
45500,
6800,
17000,
null,
64300,
26300,
10600,
46900,
36900,
99100,
14500,
34400,
9200,
72100,
12800,
25500,
10800,
74140,
46900,
6300,
6000,
31900,
30600,
null,
313500,
30900,
32400,
81000,
43200,
33900,
27400,
null,
null,
27471,
6700,
5800,
23200,
25500,
21500,
9500,
26700,
14100,
12800,
30300,
27700,
35200,
null,
21400,
8300,
34100,
null,
17500,
24300,
12200,
23500,
24500,
21700,
6000,
4200,
9900,
59300,
102200,
null,
53900,
26000,
41600,
9600,
5500,
53600,
21700,
47700,
17350,
11800,
null,
null,
7500,
19900,
12500,
42700,
5800,
15500,
40900,
6500,
18000,
29400,
9400,
48400,
16000,
30000,
24000,
183800,
24900,
70200,
1500,
17700,
8700,
26100,
9300,
54700,
9200,
5100,
8900,
null,
19837,
23600,
39500,
12300,
14900,
null,
null,
14500,
23500,
37550,
55600,
18900,
36200,
18300,
null,
10500,
9500,
5900,
78400,
30900,
20600,
15200,
71300,
12000,
19600,
10700,
25300,
null,
null,
44400,
60200,
900,
15800,
48700,
45900,
15400,
85900,
10100,
138900,
37500,
null,
59800,
18800,
46300,
14600,
39400,
14300,
40900,
125900,
17300,
13700,
16800,
43200,
4400,
20400,
18000,
7800,
27600,
19400,
14800,
16900,
22800,
null,
28100,
30400,
19900,
55500,
7400,
41600,
97500,
29100,
32500,
25700,
11800,
37300,
16000,
29200,
32300,
58400,
10445,
36300,
6400,
45900,
null,
48000,
55100,
5500,
30612,
21300,
23800,
9500,
53900,
69700,
42600,
11580,
null,
null,
25200,
25100,
30700,
16600,
24680,
17600,
27600,
13200,
7050,
12400,
26900,
123700,
null,
15900,
28100,
30300,
7000,
17300,
30600,
30500,
27400,
11700,
15500,
24500,
87800,
52300,
23800,
33200,
null,
7500,
13700,
103600,
27400,
53700,
12900,
118500,
20200,
null,
30800,
6500,
135300,
11800,
23400,
37100,
15300,
15200,
35500,
20800,
26100,
42500,
12300,
null,
129800,
18100,
33600,
45500,
8600,
30300,
17100,
4500,
23800,
11500,
23800,
45900,
null,
14300,
45000,
29700,
40400,
117400,
8000,
17900,
40300,
1800,
30200,
195500,
12800,
17100,
83700,
23700,
41800,
10200,
12600,
26200,
50400,
10300,
40000,
12900,
28100,
null,
28400,
59100,
15100,
33800,
23100,
24700,
50300,
24100,
6900,
13100,
24700,
10500,
null,
null,
48100,
43200,
21100,
8000,
78100,
19300,
19100,
18200,
28300,
23300,
6300,
32600,
13400,
6175,
49100,
46700,
26500,
34600,
39900,
4000,
36700,
34400,
113300,
16000,
42400,
94200,
28500,
6200,
null,
85700,
23600,
19100,
15963,
29700,
25500,
21200,
1800,
null,
16000,
18500,
39200,
80800,
18500,
11900,
16700,
40600,
39200,
19700,
76600,
58700,
32300,
40000,
66700,
99800,
96300,
null,
54800,
3800,
122200,
18800,
38000,
11800,
8300,
15200,
4200,
24500,
null,
null,
5800,
62700,
25800,
null,
32700,
38200,
87430,
50200,
15100,
26200,
38100,
43100,
37340,
36400,
29300,
27300,
34400,
100200,
25100,
55300,
47300,
20800,
9600,
34400,
39300,
9600,
14100,
40400,
20700,
21400,
21600,
null,
20100,
null,
17200,
13300,
18200,
10600,
114900,
30000,
58800,
38500,
28700,
9500,
4300,
15200,
null,
8700,
20100,
29500,
15200,
75700,
68200,
14400,
null,
16000,
null,
27900,
75900,
15900,
9300,
null,
null,
25400,
12300,
53600,
8300,
36400,
33200,
51520,
24900,
7000,
53800,
8100,
3700,
14400,
8300,
6100,
53410,
15500,
9050,
23300,
40000,
15800,
79200,
345000,
24500,
null,
16800,
109600,
null,
18900,
27700,
32900,
35100,
20500,
53700,
35400,
23700,
7000,
21200,
50100,
73400,
54200,
null,
null,
28700,
22000,
11300,
27100,
46800,
16800,
21100,
19900,
10000,
11300,
15100,
37000,
10600,
2700,
16200,
null,
33000,
36800,
21300,
11600,
23900,
46400,
4000,
11300,
8500,
34200,
40300,
8100,
18900,
15600,
14800,
7600,
22300,
null,
72200,
null,
16200,
null,
24000,
5100,
11000,
12200,
25450,
30000,
52400,
15200,
20000,
34300,
42100,
28300,
9700,
4200,
17000,
17500,
42600,
17000,
50000,
57500,
31700,
18700,
null,
31200,
29500,
10400,
5700,
11200,
67400,
35900,
55600,
17700,
22300,
48300,
54600,
34300,
67300,
51300,
45800,
23500,
40000,
25900,
24600,
10500,
45500,
19900,
null,
12600,
59100,
36500,
5800,
25300,
19500,
7800,
10500,
139800,
32200,
null,
53900,
24800,
43300,
21300,
157400,
43100,
null,
27600,
16500,
19100,
83500,
19400,
2000,
6600,
8200,
17900,
15000,
30500,
21900,
61500,
11100,
17900,
44400,
16700,
24800,
11600,
null,
56700,
36000,
20700,
31700,
64300,
56100,
53700,
3800,
25000,
38500,
28600,
11750,
74000,
13200,
54900,
22900,
20800,
70653,
17900,
23600,
11700,
7100,
50000,
26300,
13200,
30162,
9800,
12400,
17500,
null,
13800,
29000,
12100,
null,
12500,
22100,
null,
12562,
33600,
23700,
null,
20900,
39500,
18900,
27000,
10200,
36500,
6300,
37500,
21200,
24600,
11300,
32800,
30100,
17500,
null,
19500,
68800,
248900,
4500,
null,
5200,
34200,
26500,
26100,
12400,
30900,
54100,
50000,
null,
10800,
25800,
50600,
39000,
73900,
35500,
24400,
84000,
13300,
105200,
9800,
14100,
5300,
11400,
null,
10100,
12100,
48400,
44734,
33000,
7000,
12700,
null,
7400,
16600,
120100,
46500,
30200,
35100,
27600,
11400,
17700,
4600,
9300,
111100,
null,
35200,
null,
4800,
15200,
30500,
null,
87300,
null,
78100,
19500,
29500,
64000,
47500,
19600,
15500,
25300,
33300,
7700,
13700,
41700,
8200,
122700,
null,
22800,
72600,
48100,
18100,
13100,
8600,
36900,
44900,
34100,
19500,
40800,
55800,
16500,
19800,
13000,
null,
8900,
71300,
11400,
16400,
57300,
9700,
31600,
17800,
44800,
43900,
58100,
18500,
9300,
15400,
15900,
18400,
41800,
29600,
99000,
null,
37500,
11900,
47400,
27400,
13500,
13000,
4800,
35900,
20600,
29500,
53800,
23800,
15000,
63300,
60900,
51300,
19400,
98400,
null,
26000,
32400,
32500,
1600,
44535,
20000,
66500,
9300,
4000,
8300,
60800,
25100,
24100,
23000,
3000,
75300,
44900,
28000,
90500,
21900,
null,
22600,
24200,
null,
17000,
13100,
24000,
33900,
29000,
97500,
11000,
73600,
51600,
16700,
29400,
23000,
51800,
7800,
28500,
16400,
3000,
94900,
25200,
70800,
18300,
22800,
9900,
17200,
19700,
18400,
171600,
13800,
null,
37000,
21400,
null,
75100,
22300,
21000,
26300,
14400,
31700,
57700,
22100,
50600,
5300,
null,
18300,
16100,
162200,
22500,
5000,
12700,
16500,
46000,
15500,
22900,
18800,
21100,
34200,
28800,
15300,
28505,
null,
15260,
5900,
28000,
6700,
53600,
19100,
64600,
19400,
52074,
20400,
7200,
14800,
10800,
8300,
null,
2150,
50700,
9400,
39900,
51900,
77600,
56000,
25200,
null,
12900,
52100,
13300,
21600,
20600,
37000,
10800,
14700,
19100,
71800,
null,
123400,
63000,
35000,
46400,
27100,
6300,
33200,
68500,
null,
31800,
31100,
9500,
21200,
26600,
13000,
42500,
19200,
33900,
29600,
24200,
42000,
47100,
32100,
61000,
17200,
63200,
54900,
27500,
68800,
26200,
54875,
null,
30400,
11100,
32500,
57500,
31100,
15500,
40300,
55100,
24000,
16100,
19600,
45200,
8100,
25100,
18700,
null,
166000,
null,
28500,
27100,
107000,
null,
7600,
14900,
17200,
41900,
27000,
36000,
49800,
2500,
null,
11200,
23500,
46900,
null,
8200,
18000,
37900,
12600,
69100,
23600,
18500,
67900,
28200,
16700,
39000,
44300,
16100,
25089,
16000,
26700,
null,
36500,
19700,
34400,
61100,
103100,
76874,
null,
36000,
38480,
26200,
6500,
126400,
30400,
84800,
null,
4300,
53500,
14450,
35900,
14100,
7800,
null,
22000,
4300,
19600,
null,
18600,
27600,
42900,
35800,
18700,
17600,
36700,
3500,
19000,
5600,
19600,
30400,
22100,
53800,
24100,
5700,
38500,
36800,
26200,
7500,
null,
29800,
51700,
51417,
33600,
30000,
69388,
33000,
8800,
19300,
22500,
21600,
30400,
36700,
160200,
10200,
1500,
null,
33600,
12800,
83300,
null,
22400,
null,
31600,
null,
79200,
24500,
18000,
10000,
52900,
9300,
86700,
96800,
14900,
7300,
null,
23600,
68200,
11300,
15700,
12800,
20000,
80200,
15300,
30200,
26800,
11000,
37300,
20100,
null,
32100,
47100,
32800,
39800,
14200,
48800,
16400,
11300,
8100,
32300,
20200,
9200,
8200,
37500,
11700,
30000,
56300,
7800,
58300,
22500,
7600,
32100,
32400,
20400,
43000,
12900,
23600,
12400,
null,
69700,
49700,
27800,
25300,
32100,
15200,
13400,
18200,
22500,
9600,
43600,
46600,
7400,
null,
12100,
41400,
14700,
16600,
69500,
15200,
30200,
41000,
22700,
35500,
23900,
21700,
84400,
25900,
12800,
63200,
7000,
29400,
17800,
14100,
43300,
26500,
null,
12500,
16000,
55700,
17000,
17300,
40500,
15200,
16300,
20600,
26100,
null,
25100,
15600,
null,
40100,
8800,
121300,
26300,
35800,
4300,
24800,
14500,
75300,
10100,
19200,
7566,
11100,
52500,
48000,
13700,
30700,
16600,
19800,
14300,
12200,
8200,
26400,
81600,
39500,
24200,
53600,
null,
52900,
1600,
8200,
44400,
19500,
15800,
36500,
35900,
51254,
51000,
29900,
12000,
49100,
23600,
14000,
20300,
19700,
29500,
18900,
20900,
4000,
18500,
24500,
12200,
null,
26100,
22000,
43600,
4300,
19000,
null,
46500,
83000,
19600,
null,
28600,
11600,
30800,
6500,
107700,
37900,
20200,
14200,
96700,
33000,
89300,
26700,
32200,
73700,
7100,
28600,
31000,
63300,
64600,
27700,
43600,
29600,
34900,
41300,
null,
7600,
26300,
7400,
23200,
95700,
42300,
11300,
9300,
24000,
8600,
11700,
47100,
39600,
37500,
17000,
15200,
7800,
null,
6800,
11200,
19900,
40000,
14200,
26480,
null,
74400,
17000,
24000,
24800,
123000,
29000,
null,
7300,
70800,
13700,
13000,
12100,
17400,
7500,
18000,
54000,
11300,
84100,
91800,
35300,
36500,
16000,
14450,
42600,
32900,
37900,
42600,
8050,
39700,
16400,
70800,
12600,
7300,
47500,
21700,
15700,
19900,
38500,
181400,
58800,
61380,
18100,
21600,
50900,
16000,
24600,
14800,
51400,
19100,
47000,
25400,
62100,
27100,
7900,
15100,
41900,
33000,
17100,
5000,
21400,
null,
26600,
43900,
30400,
16400,
null,
48800,
null,
22400,
null,
64600,
13690,
112500,
32000,
10500,
14700,
14400,
9600,
null,
26400,
198700,
11500,
14000,
21600,
11700,
14800,
11500,
11900,
37400,
53400,
17500,
33300,
9100,
99300,
121200,
95600,
null,
32300,
24200,
19500,
6200,
19400,
36100,
39000,
21400,
6300,
41900,
27800,
15200,
13100,
19700,
83900,
6400,
87600,
13800,
88800,
43500,
36100,
59400,
51600,
48400,
3800,
33300,
10900,
66200,
5300,
17600,
46900,
null,
36700,
70000,
8400,
26000,
30100,
50200,
46000,
12700,
45000,
14200,
68400,
21600,
74800,
12500,
43900,
17400,
60700,
21100,
17000,
30500,
10500,
16600,
12400,
12500,
64300,
null,
21300,
11000,
14600,
10300,
31000,
45400,
6400,
14500,
15100,
29500,
76400,
26800,
8900,
89300,
null,
41600,
14800,
null,
6000,
28800,
12300,
17100,
9500,
10700,
11700,
33577,
6500,
26400,
49700,
14800,
42300,
9400,
93200,
15100,
11300,
11700,
18300,
22600,
35900,
5200,
null,
29000,
8600,
44200,
38800,
40400,
23263,
22300,
26900,
25100,
28700,
18300,
40900,
14500,
14500,
8500,
34900,
37600,
22100,
30800,
13700,
17900,
15600,
43000,
33800,
58800,
21300,
23400,
17800,
24600,
23700,
35100,
null,
38100,
14800,
32600,
37300,
34100,
26300,
18700,
16200,
29600,
35500,
21900,
24400,
8300,
22500,
8500,
53100,
null,
10800,
23900,
89800,
6500,
49800,
25000,
13300,
22500,
30600,
42500,
54100,
34200,
23400,
54300,
51200,
111200,
8600,
23200,
26600,
91900,
44000,
31000,
15900,
18300,
10800,
26900,
19350,
7100,
7400,
38900,
21600,
9300,
27900,
24100,
37300,
null,
null,
26300,
75800,
49600,
10700,
439100,
35500,
10400,
null,
14700,
null,
29100,
48000,
6500,
80700,
14000,
13000,
9400,
null,
45000,
17200,
28800,
21250,
31500,
55500,
65200,
23100,
30900,
27400,
17600,
13700,
null,
9800,
31457,
15000,
117103,
100900,
4800,
48000,
6900,
16000,
26600,
22900,
29400,
31300,
26000,
12800,
7400,
69500,
31300,
10900,
54900,
31500,
14100,
null,
40700,
15600,
5100,
null,
20900,
35086,
36500,
11200,
null,
48100,
18000,
61300,
10000,
22000,
28300,
14600,
9800,
12200,
22800,
null,
8700,
122200,
106800,
1500,
14800,
30700,
20500,
3900,
21200,
121500,
9500,
44800,
20000,
16700,
15600,
144000,
36900,
25800,
23900,
48700,
50500,
66700,
22900,
28800,
12800,
35300,
32300,
17600,
18200,
41900,
9100,
null,
51600,
13600,
27700,
50800,
44600,
7500,
22100,
10500,
3300,
24700,
3900,
55900,
43000,
17200,
25800,
23500,
27600,
47300,
45100,
16400,
36700,
51100,
39800,
32100,
78800,
24300,
41200,
21800,
57400,
14600,
39500,
17000,
24600,
13800,
27500,
22400,
23200,
9100,
133400,
27500,
34700,
19200,
43700,
25300,
22450,
8300,
19100,
37900,
15500,
35300,
25200,
31700,
null,
35800,
36200,
16600,
25400,
null,
18300,
74995,
10100,
5400,
36700,
29600,
14900,
33200,
14000,
108200,
7500,
13300,
14200,
20300,
1300,
27800,
5500,
129900,
25300,
139000,
8800,
null,
16000,
23900,
60200,
22700,
36300,
142500,
41000,
19100,
60438,
6200,
10000,
15400,
149300,
null,
null,
57600,
28700,
20400,
72500,
9300,
22600,
17900,
55100,
12600,
6000,
3700,
18700,
181500,
47000,
20800,
12800,
9700,
null,
53000,
14600,
14700,
13000,
36800,
13600,
19300,
121100,
9500,
25400,
18400,
22000,
11900,
11800,
18400,
27700,
31800,
8300,
9100,
34600,
38300,
22100,
80500,
43100,
25400,
3600,
23200,
11500,
78000,
6400,
7500,
15000,
27000,
22100,
34200,
7800,
31012,
37900,
1000,
9500,
7200,
42800,
null,
36400,
22000,
37400,
19200,
9900,
35500,
21400,
21700,
5300,
28000,
79100,
59400,
35700,
52100,
2300,
39600,
7500,
9200,
26400,
28300,
36900,
14300,
11700,
8300,
10500,
53100,
4500,
5700,
23100,
88600,
51600,
6300,
7000,
11900,
81100,
14800,
113200,
58300,
23300,
4500,
43700,
35400,
15600,
49600,
35200,
null,
24900,
39800,
32100,
null,
4600,
26400,
33300,
11600,
10400,
28200,
24000,
32600,
21600,
55700,
15300,
14200,
14700,
19700,
42400,
5300,
27100,
36400,
11300,
28200,
34200,
19300,
44500,
16900,
14800,
23500,
19100,
20400,
36100,
null,
25500,
10900,
11000,
51400,
20900,
20900,
19900,
23300,
25500,
27800,
32000,
17400,
null,
null,
226400,
null,
null,
6600,
16500,
30000,
7500,
null,
20900,
23300,
44800,
7000,
1000,
4900,
20200,
32700,
31300,
16300,
17900,
6200,
6800,
55400,
19300,
40200,
39600,
34200,
13400,
39100,
null,
14500,
37200,
null,
8300,
null,
39300,
48500,
13100,
43400,
86200,
25000,
64800,
41900,
59800,
17400,
42100,
null,
26600,
5500,
111300,
26100,
30800,
79400,
19900,
114200,
48200,
22400,
18800,
110300,
47400,
22400,
30400,
25600,
5800,
9700,
22800,
13500,
10500,
37100,
20300,
14400,
48200,
35700,
24300,
26000,
1500,
null,
45800,
39000,
18100,
4300,
9700,
293500,
5000,
11500,
33550,
12800,
11400,
34500,
70200,
34000,
23600,
25900,
59300,
17600,
29300,
23500,
95900,
56300,
null,
33100,
5200,
null,
null,
14500,
4500,
7200,
11300,
19500,
null,
33000,
58600,
33600,
11300,
37400,
47500,
42300,
30100,
28317,
32100,
null,
91600,
11200,
14800,
34400,
null,
91000,
177870,
4400,
60000,
33900,
21913,
103100,
6500,
53123,
16800,
122900,
77000,
91200,
48000,
7600,
null,
12100,
43100,
null,
17400,
142900,
20100,
8100,
17100,
10800,
null,
16400,
17200,
22500,
8400,
50900,
13100,
41400,
5000,
26000,
15600,
24010,
22600,
40400,
30051,
23500,
20518,
29900,
51300,
82400,
21000,
37500,
23900,
68000,
33800,
19900,
41100,
14800,
8800,
37545,
171600,
26100,
26900,
18900,
44900,
5850,
10100,
68100,
65600,
13600,
null,
32100,
30600,
42300,
29300,
57800,
84900,
14700,
68528,
22900,
26700,
39100,
46800,
45400,
16700,
16700,
6400,
55500,
2900,
7547,
19000,
70200,
22200,
20800,
13200,
7700,
null,
32000,
20400,
20600,
43900,
37200,
4200,
20900,
6500,
23500,
7700,
7900,
119500,
44100,
11300,
144300,
8200,
28700,
14000,
7600,
40700,
null,
18300,
16100,
95100,
7400,
39500,
19400,
48400,
27700,
23200,
null,
14800,
14400,
11600,
4500,
23700,
94700,
5700,
8400,
133600,
24700,
22000,
5100,
14200,
110200,
16100,
26400,
36800,
24800,
5300,
39800,
39600,
17900,
5100,
28400,
37800,
29600,
96000,
21500,
29100,
26600,
19200,
21500,
19000,
null,
null,
11750,
22000,
39000,
null,
9500,
10300,
35200,
19800,
58400,
45600,
22300,
24950,
8200,
null,
12600,
27500,
6000,
25900,
9900,
null,
154000,
105900,
23700,
66300,
7200,
41600,
61500,
13000,
60000,
50300,
43000,
73800,
30462,
14100,
18400,
45100,
19100,
7600,
10600,
33200,
28300,
27500,
129600,
60700,
null,
37100,
39800,
36000,
24000,
9600,
15400,
null,
50100,
41674,
4100,
10100,
null,
30700,
33500,
null,
85900,
null,
2800,
null,
39500,
12700,
20000,
12000,
null,
null,
2000,
13430,
16400,
23400,
39500,
16200,
28300,
21900,
15100,
null,
null,
52300,
29000,
16200,
96000,
18300,
48900,
31200,
null,
35400,
55500,
null,
46800,
28300,
92200,
54500,
17100,
22300,
26700,
3200,
10957,
15300,
102125,
16700,
48500,
null,
21200,
43000,
20200,
null,
9700,
83900,
9600,
40100,
35800,
16900,
4300,
19300,
37100,
21600,
23400,
null,
14500,
null,
10100,
31100,
41800,
59300,
28300,
914900,
null,
19000,
16800,
null,
33000,
35120,
92400,
135000,
10800,
155800,
6500,
76000,
17900,
34200,
53100,
27700,
13900,
27800,
100940,
31600,
10000,
21200,
41300,
17300,
36500,
14000,
81400,
4500,
46200,
19200,
10100,
68701,
12000,
12100,
18100,
100500,
57200,
null,
77800,
9100,
8600,
7800,
25200,
26000,
13500,
26000,
45900,
12800,
11700,
9800,
78200,
13400,
34600,
35600,
5700,
157000,
36500,
8500,
38600,
38400,
13800,
2700,
31200,
36100,
101900,
127500,
11200,
37300,
29300,
33400,
21600,
18300,
52300,
12006,
30800,
59700,
10700,
119600,
null,
21300,
36900,
12600,
10400,
11000,
13400,
27900,
8600,
26600,
45900,
41000,
12500,
27800,
79200,
22800,
null,
26500,
37800,
9000,
null,
16300,
null,
18300,
24900,
34000,
40500,
7000,
null,
17300,
32900,
21900,
23500,
11800,
9100,
22200,
96700,
14300,
37500,
24000,
15600,
18660,
17400,
16600,
74000,
32500,
14800,
19700,
50400,
20100,
56600,
null,
86100,
41500,
9300,
null,
41000,
32800,
22700,
17500,
null,
27300,
null,
20500,
62300,
41700,
18400,
22454,
109300,
22100,
103200,
19100,
8500,
41700,
32900,
25400,
42200,
34300,
23500,
25000,
11600,
52200,
16200,
136600,
29500,
32500,
555800,
5000,
20600,
9500,
53900,
29200,
12900,
22600,
5600,
90100,
33200,
18600,
21000,
15550,
42700,
56200,
null,
17849,
null,
56075,
41900,
15100,
26200,
7500,
39300,
29900,
14000,
26000,
null,
26800,
10200,
40700,
10800,
17500,
18500,
15400,
19000,
3200,
21600,
98300,
3600,
26604,
null,
36000,
25500,
41500,
35400,
9800,
12300,
3600,
null,
27600,
null,
63300,
47300,
14900,
36500,
21000,
20700,
11100,
46000,
74000,
14700,
36700,
54500,
null,
6800,
25200,
26100,
51300,
57100,
15700,
null,
37808,
44600,
6600,
10900,
null,
35900,
25200,
12300,
40100,
null,
15900,
15600,
54900,
13500,
9000,
56800,
38400,
null,
15000,
15400,
12500,
22500,
18100,
67200,
17400,
85500,
53400,
3500,
24200,
null,
29800,
27200,
4600,
81400,
19900,
19200,
48900,
68500,
12700,
14900,
18100,
28600,
13600,
2900,
24100,
27600,
25000,
25100,
28400,
74600,
30500,
5105,
19300,
null,
11700,
7000,
15600,
12300,
11200,
11600,
23800,
null,
29900,
68500,
27000,
4500,
31000,
15700,
17900,
16000,
6300,
null,
74200,
15500,
6000,
12000,
15600,
35900,
null,
19500,
96100,
39900,
21100,
3000,
62500,
16500,
23400,
20600,
17500,
5300,
13100,
49300,
6100,
28800,
25400,
18700,
15000,
15700,
24400,
13600,
39200,
42000,
3400,
19600,
34100,
4500,
51100,
12100,
37000,
42000,
18100,
177900,
18800,
null,
6450,
12100,
36200,
null,
11200,
32100,
17000,
26000,
56130,
26800,
4350,
null,
9200,
null,
8400,
6700,
42600,
20900,
7600,
65000,
27000,
58700,
null,
16800,
32400,
51600,
64000,
20500,
10800,
28700,
20100,
20100,
20700,
76300,
36600,
21900,
22400,
14200,
44937,
3800,
42000,
23400,
6700,
49200,
5300,
24800,
93700,
7800,
29000,
53700,
16300,
34200,
19600,
4700,
13200,
28000,
8950,
27300,
25500,
36000,
null,
88500,
null,
5100,
39100,
7500,
44400,
null,
35800,
6100,
66800,
13200,
34200,
79600,
12500,
69900,
13500,
15800,
94900,
null,
6800,
12500,
null,
null,
176500,
15300,
1600,
11300,
30200,
86500,
22200,
39800,
23400,
131300,
null,
37900,
null,
null,
27200,
53103,
157200,
null,
36400,
25300,
null,
10500,
9700,
null,
23600,
14800,
15300,
124600,
18300,
17700,
67300,
null,
40000,
49200,
68600,
58000,
41700,
85100,
10900,
15500,
null,
42900,
5740,
25600,
59000,
9000,
18600,
35000,
50300,
null,
5700,
8300,
48000,
32400,
26700,
11300,
null,
null,
15800,
30300,
54200,
null,
4800,
33787,
29400,
14700,
18800,
68500,
32000,
22800,
8200,
7200,
21400,
45200,
39400,
50200,
31900,
4800,
7100,
179500,
31400,
13700,
34900,
57300,
71600,
146500,
28200,
56800,
33100,
19800,
21000,
18300,
27300,
55500,
7400,
null,
28700,
8800,
27300,
22700,
20100,
7400,
5600,
68500,
8300,
3300,
17000,
16700,
16000,
52800,
13600,
30100,
9000,
39700,
45600,
15600,
31300,
7000,
73700,
20400,
17800,
9000,
35100,
7100,
47500,
15400,
12800,
47900,
null,
19700,
28400,
31900,
144900,
31100,
56400,
23000,
3700,
35900,
8000,
7700,
14100,
null,
null,
41300,
28700,
67000,
5200,
18500,
null,
21800,
25200,
3700,
23500,
9200,
35900,
36300,
24700,
37060,
11700,
4700,
20300,
43500,
19300,
43200,
15600,
34000,
null,
36400,
54200,
41700,
40700,
23600,
4200,
19900,
13200,
28000,
11700,
79400,
100200,
35400,
21000,
7700,
4400,
23800,
19700,
17600,
41500,
24900,
60900,
28800,
8047,
17100,
12500,
25100,
2600,
17500,
61200,
27500,
3800,
63200,
19900,
8700,
20000,
9800,
22600,
15200,
87300,
128800,
26200,
12600,
42800,
37000,
18591,
58700,
30600,
34100,
11100,
11400,
6600,
37200,
24900,
12300,
24300,
8800,
18600,
24600,
88200,
52800,
13600,
12300,
7200,
39200,
null,
40700,
34900,
23400,
17600,
87300,
23700,
18900,
33400,
41400,
null,
24400,
20900,
26100,
null,
30200,
21600,
19900,
4100,
28500,
11200,
10500,
null,
12200,
119200,
null,
55500,
9800,
34400,
20200,
29400,
null,
68200,
55900,
23800,
11300,
88050,
25700,
13600,
11000,
17800,
null,
7300,
36700,
22800,
26000,
15100,
4100,
44700,
4600,
28100,
24400,
31700,
21400,
14300,
12500,
12800,
28500,
24200,
8100,
40100,
24000,
38800,
25800,
54300,
32700,
21300,
52500,
13800,
12275,
22700,
16500,
24500,
31200,
31995,
14800,
59000,
47900,
32500,
null,
24800,
34100,
null,
24400,
10300,
null,
19100,
47100,
73600,
15500,
48400,
13400,
27900,
10000,
28900,
16200,
null,
27500,
16600,
15400,
37300,
19200,
6300,
8300,
11650,
39700,
8000,
31900,
69200,
8100,
6200,
7800,
12500,
13300,
null,
14600,
17900,
116400,
15900,
89500,
29400,
24100,
27400,
65500,
29200,
82300,
3600,
31292,
72500,
25900,
48400,
44800,
53800,
32300,
30000,
null,
97400,
35300,
null,
60400,
null,
4600,
null,
14000,
24800,
4600,
23877,
30100,
105400,
25200,
61850,
27600,
39900,
9900,
10500,
4600,
19400,
27500,
15600,
19400,
17800,
10100,
7600,
56200,
29100,
32721,
39900,
50500,
19000,
21500,
37500,
20600,
27900,
2800,
33600,
26000,
31300,
null,
43900,
13400,
9700,
null,
10900,
21200,
25300,
118000,
24400,
45300,
22800,
39900,
244800,
41800,
null,
4900,
null,
88200,
32200,
12600,
35200,
19300,
81200,
29900,
22400,
58200,
7500,
40200,
6800,
27600,
15800,
40200,
39500,
25200,
4500,
24800,
24500,
29900,
9600,
13900,
13900,
null,
60800,
41700,
21000,
10900,
7700,
153600,
154500,
23900,
40700,
null,
3000,
20100,
91400,
null,
9700,
10200,
13400,
38100,
40300,
3150,
24300,
29600,
19000,
83700,
null,
27200,
31500,
20200,
34000,
25100,
11800,
9400,
21200,
15600,
25145,
41900,
41300,
2000,
18200,
28600,
15900,
37700,
31300,
14500,
35800,
24700,
null,
65500,
4200,
7000,
59100,
null,
7100,
17900,
19700,
12700,
35800,
22800,
null,
122900,
8500,
14800,
40100,
51268,
26400,
117200,
197800,
45100,
159900,
20600,
53600,
148100,
35900,
51300,
36900,
80900,
15000,
42600,
7200,
56400,
16700,
24000,
5000,
80600,
8200,
48900,
47000,
11500,
12600,
22800,
7700,
23900,
14200,
36000,
22500,
52350,
6500,
7300,
13400,
56000,
120900,
null,
22800,
34700,
34100,
15170,
26000,
42700,
11900,
50619,
18200,
39300,
27000,
null,
2700,
41500,
26500,
33900,
52500,
12400,
51700,
35200,
2700,
26000,
null,
58300,
33100,
null,
62400,
52300,
18200,
26400,
13000,
52200,
10700,
23100,
21500,
null,
18600,
23000,
46500,
43200,
14100,
7600,
10100,
12000,
28200,
null,
33600,
25000,
15400,
19300,
21300,
59100,
6800,
7700,
14100,
36800,
11250,
13500,
12900,
19000,
24800,
null,
null,
32200,
56334,
8200,
null,
18000,
20200,
6700,
6500,
5100,
10400,
41600,
23500,
48200,
13900,
47800,
16100,
2200,
18500,
42000,
28700,
26500,
111300,
13500,
17000,
27200,
21600,
13100,
18500,
15500,
10600,
57480,
53200,
4000,
32400,
6900,
17200,
43400,
17300,
36000,
68900,
72900,
48800,
19200,
27500,
4250,
42350,
null,
null,
27500,
16000,
41300,
12700,
16100,
26600,
59700,
26800,
37500,
51200,
48700,
12000,
29300,
2000,
7500,
1600,
11000,
6700,
12700,
6600,
33800,
48300,
23800,
27700,
53100,
39900,
31400,
35285,
26300,
19500,
11100,
23700,
null,
85500,
17300,
15300,
31400,
89700,
15100,
7300,
39909,
18200,
24600,
40000,
24800,
27900,
13900,
11300,
1500,
25400,
30800,
3600,
92600,
17000,
19400,
13000,
18800,
22300,
78000,
59500,
10400,
56200,
17000,
60000,
19000,
24500,
35300,
17800,
500,
88700,
44419,
33200,
20600,
11800,
10000,
27700,
7000,
4500,
62000,
13700,
74500,
12600,
22400,
null,
12300,
44100,
14100,
15900,
33400,
12000,
28300,
40300,
29600,
null,
41600,
22500,
125200,
38400,
9000,
94500,
26300,
15600,
18600,
15200,
12300,
3000,
13000,
null,
6200,
20700,
22600,
10500,
30900,
3000,
35900,
153400,
null,
7400,
12300,
19200,
391000,
9000,
87400,
27600,
21500,
null,
14000,
69200,
19384,
14600,
7000,
null,
75100,
88800,
76500,
14900,
null,
null,
31000,
30500,
40700,
23000,
24400,
104600,
27800,
21800,
27900,
54900,
25000,
42200,
44700,
16300,
null,
220200,
3800,
25000,
27200,
40700,
26000,
19600,
26300,
38200,
30700,
4450,
28600,
8300,
8100,
54600,
16000,
35300,
null,
133300,
15700,
11000,
11100,
14500,
26000,
26800,
53700,
36700,
37900,
34300,
25300,
53400,
15900,
18100,
null,
29200,
167700,
26400,
8300,
49800,
43900,
115200,
67800,
9700,
29300,
12400,
null,
15700,
10100,
36100,
20000,
9300,
138400,
45700,
15400,
16500,
16100,
null,
7500,
80600,
33000,
4300,
5900,
10300,
87000,
24400,
49200,
17800,
94200,
13700,
46400,
19400,
33700,
17400,
11200,
104400,
6400,
18800,
42700,
62100,
49000,
22100,
32032,
64000,
8800,
22000,
35300,
56700,
25600,
14700,
24000,
6500,
9000,
23600,
16200,
9000,
11400,
25300,
30400,
28200,
10100,
12700,
6400,
11500,
null,
6650,
4900,
3000,
13700,
34000,
29300,
20300,
20400,
17700,
81700,
38900,
12100,
15500,
34500,
21000,
38600,
27600,
21700,
44700,
5900,
7900,
15400,
54800,
11900,
58100,
291200,
15100,
89400,
26500,
44000,
46000,
13900,
13500,
21900,
44900,
5100,
28200,
17300,
18300,
12800,
130500,
20200,
38300,
null,
57200,
32900,
4700,
19200,
26200,
36000,
35800,
22000,
17100,
16700,
24400,
31900,
25600,
null,
37700,
43100,
23600,
118700,
16000,
13900,
11900,
13600,
22475,
24800,
11700,
35100,
4400,
4900,
null,
31400,
26900,
26000,
5200,
12000,
44600,
80000,
33900,
20900,
null,
31900,
61096,
3400,
30100,
14400,
108551,
24000,
20400,
11700,
null,
1500,
8300,
19600,
20000,
27300,
28000,
14100,
3400,
27100,
null,
28300,
25700,
39000,
19700,
14500,
13500,
15700,
43100,
36480,
null,
17500,
50668,
5300,
5900,
6400,
57900,
19000,
null,
11100,
31800,
23100,
12300,
62800,
43700,
34900,
9800,
29300,
27200,
26300,
20200,
56800,
12200,
9900,
11400,
42400,
16300,
3900,
42500,
28700,
91400,
12500,
14500,
33500,
27900,
11000,
null,
null,
81100,
19000,
15900,
11200,
27480,
31900,
13200,
20100,
34200,
4500,
null,
52800,
34200,
23375,
41303,
null,
76300,
183700,
47200,
32300,
60500,
125300,
29200,
26450,
12100,
29000,
15000,
40200,
33200,
43300,
11100,
16800,
23800,
7100,
35300,
30400,
45900,
10200,
13600,
23400,
12400,
5900,
38700,
20150,
35100,
19300,
140190,
5400,
22300,
98600,
16100,
36400,
33000,
50400,
21400,
29200,
18900,
30200,
2800,
null,
22600,
23700,
21800,
24600,
143800,
60200,
14700,
27300,
16200,
21200,
null,
null,
2400,
45200,
38900,
19300,
32200,
20100,
31300,
18100,
178025,
15700,
27300,
36700,
null,
67000,
8500,
17200,
17300,
28400,
25100,
22800,
15300,
8400,
15300,
58400,
18700,
13500,
18400,
null,
23500,
19800,
26100,
13500,
71800,
5700,
18200,
7500,
17300,
44900,
8900,
28800,
5500,
null,
11400,
10200,
19000,
41800,
61500,
57300,
54000,
6100,
null,
20900,
7300,
10800,
108572,
31862,
35300,
24500,
28700,
37300,
49300,
23900,
30100,
27900,
26100,
70500,
44500,
21200,
22000,
55200,
43800,
51400,
45300,
47900,
50000,
36700,
17100,
64000,
48900,
12100,
41500,
50200,
9700,
68100,
null,
12900,
18500,
6700,
null,
19600,
92500,
7900,
41100,
7800,
26200,
9100,
7200,
30700,
22400,
74900,
22200,
38100,
18600,
73950,
29400,
96700,
57100,
17700,
70400,
8800,
8800,
43500,
32000,
22300,
22900,
20700,
13300,
22900,
68800,
27900,
17700,
23900,
null,
25300,
33100,
23500,
30500,
null,
10800,
73000,
73600,
16300,
8600,
15300,
55800,
98200,
16000,
35600,
17200,
14700,
6700,
23000,
42700,
42300,
10300,
12800,
15000,
70024,
24800,
null,
48100,
9500,
32900,
32600,
53400,
23500,
null,
18500,
28900,
13700,
42500,
44900,
27200,
6000,
36100,
14000,
25500,
null,
54100,
27400,
15800,
48700,
null,
61500,
null,
29600,
19100,
23900,
18800,
10000,
23900,
48900,
346600,
47900,
6100,
3200,
67500,
null,
18400,
48200,
55000,
null,
null,
72300,
23200,
null,
64300,
41000,
18500,
40000,
42200,
12800,
197900,
18200,
10500,
15600,
40200,
44300,
14100,
13200,
53700,
18800,
65900,
9600,
13500,
42200,
37600,
12700,
11100,
59500,
23800,
71856,
53900,
37500,
27400,
7300,
22800,
177900,
11000,
16400,
22900,
null,
14700,
7500,
36000,
6000,
34400,
52100,
9000,
21600,
30700,
52900,
49110,
29200,
34500,
19100,
90600,
34600,
27100,
96800,
17400,
11200,
58400,
20200,
null,
28400,
15800,
14300,
39300,
16400,
12700,
151624,
14600,
17000,
39100,
22900,
53900,
null,
22300,
13400,
32800,
null,
9500,
41300,
11300,
19100,
13000,
23300,
14900,
33900,
5400,
55600,
32200,
45500,
10000,
21800,
31400,
43502,
14900,
53600,
7500,
66200,
41200,
24200,
11900,
53000,
8900,
null,
38200,
30000,
800,
41300,
51600,
17500,
2400,
97300,
27500,
15000,
25800,
32800,
6600,
44800,
37900,
21400,
12200,
46600,
77100,
10400,
22300,
23100,
32000,
46400,
null,
9800,
41700,
30300,
36300,
30100,
18100,
null,
13200,
40800,
8300,
19500,
14100,
18900,
24100,
31600,
32701,
22500,
25200,
119500,
28100,
14100,
29500,
47800,
32000,
45500,
97400,
34000,
32400,
55700,
27300,
17200,
12700,
16200,
9000,
10800,
16900,
23300,
19500,
8800,
18200,
35400,
19800,
12500,
5100,
14400,
94100,
87100,
23500,
10029,
13600,
32000,
13600,
6400,
23200,
null,
13300,
15700,
39400,
117300,
null,
20000,
null,
6050,
15500,
67600,
null,
17900,
6800,
34300,
11900,
9300,
6500,
38900,
20700,
17700,
16600,
16800,
28700,
15300,
24900,
42900,
15300,
183900,
29200,
58400,
69200,
19800,
33500,
44500,
22000,
15900,
44500,
9700,
null,
13600,
8800,
10688,
20100,
24900,
46200,
20300,
13800,
null,
10700,
null,
5400,
156200,
null,
17300,
null,
5100,
4300,
54870,
23400,
296700,
17500,
10600,
38100,
18900,
null,
18900,
null,
9600,
18500,
14100,
36700,
23200,
7100,
151700,
5300,
20300,
23800,
26100,
48800,
13000,
40000,
31000,
39100,
47800,
0,
11700,
11300,
6900,
300,
8700,
13700,
14100,
10400,
13300,
89100,
15300,
7500,
14500,
11800,
41900,
16300,
22300,
3500,
13400,
16900,
16000,
25000,
17700,
4800,
261500,
32689,
6900,
12900,
12800,
null,
null,
67800,
14500,
null,
null,
22900,
35300,
27300,
7400,
24100,
15900,
19400,
62900,
14900,
10900,
11300,
8300,
16800,
37200,
31800,
5200,
11400,
64100,
36700,
54000,
null,
69400,
4600,
29600,
5500,
37800,
10800,
13600,
73900,
69100,
14100,
17200,
null,
68100,
8500,
18700,
4600,
11700,
28300,
16500,
9200,
46600,
18200,
null,
21900,
19300,
68600,
17350,
17100,
11500,
20400,
8300,
2000,
20100,
8400,
42100,
38800,
null,
null,
22500,
74300,
10200,
43600,
3000,
107000,
47700,
16000,
null,
7800,
21900,
15600,
13400,
13400,
48000,
29400,
13900,
32300,
10900,
22200,
112500,
43700,
31500,
20500,
10800,
7700,
24100,
81127,
6500,
12400,
35600,
34300,
40100,
10400,
null,
13400,
30000,
7400,
27400,
13000,
13400,
30000,
18500,
25700,
14700,
93200,
54900,
26200,
18000,
14600,
76500,
6500,
24600,
1200,
66400,
24100,
4500,
25200,
20800,
17000,
48400,
20000,
null,
2400,
10200,
34500,
35100,
205553,
25200,
54600,
28300,
11200,
26000,
32700,
4500,
8100,
11750,
88400,
11100,
14500,
69900,
2000,
82300,
52600,
23400,
47500,
5500,
17400,
20000,
12600,
20900,
8200,
19200,
12600,
4100,
38000,
null,
45500,
null,
47300,
19900,
20800,
77600,
156150,
3900,
37700,
24100,
6800,
null,
null,
37769,
25800,
null,
11300,
13300,
25500,
21400,
50000,
7400,
27500,
4200,
35900,
18700,
null,
71700,
84800,
28175,
9800,
9600,
7000,
17000,
5100,
50600,
33400,
10900,
23250,
23300,
22100,
28900,
37287,
51000,
76400,
25100,
25000,
26300,
29400,
16100,
11500,
18000,
25300,
12700,
63300,
10900,
20900,
24000,
62400,
8000,
18400,
7800,
10000,
13900,
177811,
35700,
204900,
7600,
3800,
21300,
78000,
14400,
null,
25500,
76900,
16400,
25300,
44100,
63100,
10200,
845,
12000,
12900,
10800,
null,
4000,
null,
26800,
9400,
null,
13900,
86761,
48900,
34900,
145300,
7600,
10300,
41100,
46000,
45800,
null,
7700,
48200,
14011,
68100,
5700,
30100,
19000,
25900,
11600,
24200,
8900,
33000,
12200,
20300,
22200,
8900,
null,
13500,
16200,
7200,
4700,
27100,
54000,
35500,
22200,
27000,
15100,
null,
22500,
32600,
null,
6500,
19500,
5500,
41200,
42800,
150000,
13400,
null,
20600,
46700,
7500,
23800,
47500,
55500,
36529,
67800,
10100,
23400,
10400,
29900,
19300,
26900,
41600,
13100,
76727,
10050,
6300,
12700,
27100,
9000,
23900,
104300,
15400,
17200,
10500,
43500,
27600,
26000,
31900,
89668,
22600,
4500,
64001,
26500,
94600,
28000,
441100,
22200,
18100,
29600,
38400,
27800,
31300,
6000,
30000,
75000,
16100,
420500,
86950,
17400,
32400,
null,
null,
28500,
61200,
26200,
7000,
18800,
null,
31500,
null,
41000,
15300,
6500,
null,
52600,
6800,
8200,
16400,
34300,
20900,
29000,
null,
22700,
26800,
16700,
9400,
16500,
70700,
59400,
null,
25800,
22100,
40400,
null,
72200,
60500,
33800,
40900,
4300,
23500,
45400,
12000,
39200,
39300,
2800,
31200,
null,
57314,
101300,
27000,
32800,
16200,
20300,
18100,
40500,
92110,
19700,
null,
34000,
12400,
28000,
47600,
12900,
11600,
24300,
67500,
35000,
24900,
8200,
80100,
37600,
31400,
81600,
23500,
52100,
16300,
null,
21600,
14600,
18500,
26400,
46300,
64730,
null,
13500,
15800,
24900,
5800,
15200,
30900,
63300,
16650,
13200,
47850,
14100,
13000,
13400,
null,
36400,
22200,
20000,
5300,
18100,
56000,
24100,
289470,
94400,
6900,
null,
43600,
18600,
60500,
8100,
15200,
16900,
17600,
15800,
18300,
9700,
10700,
6700,
19100,
null,
12600,
63000,
27900,
8700,
81400,
16200,
14900,
41700,
19200,
47600,
61300,
20900,
26600,
45500,
28900,
69800,
54900,
9000,
27200,
6700,
12000,
24300,
9400,
35400,
26600,
113300,
15300,
22300,
13600,
40700,
60400,
71100,
13400,
37000,
11600,
9700,
11600,
18700,
null,
70200,
38900,
21200,
9300,
16500,
57700,
6700,
1350,
22600,
92600,
55600,
68400,
13500,
6700,
4100,
134500,
41300,
12300,
57000,
27939,
7300,
14200,
47000,
42700,
33600,
25500,
23400,
110200,
35400,
25800,
23400,
19900,
264000,
15500,
17400,
null,
101700,
37900,
63500,
null,
11700,
12200,
21500,
15700,
54500,
40500,
13000,
19800,
8300,
46000,
41300,
9800,
26000,
31700,
16700,
null,
null,
56500,
24900,
null,
11700,
27600,
7800,
23100,
23800,
19900,
null,
24300,
15000,
13900,
16200,
null,
19400,
2800,
38000,
12990,
27100,
25175,
32400,
24700,
182200,
33800,
52500,
23860,
31500,
24100,
21400,
24200,
7800,
17303,
25500,
64600,
11200,
null,
37100,
17300,
56200,
36100,
45200,
8100,
9500,
114900,
21200,
null,
80600,
47300,
80800,
18400,
34400,
16400,
10250,
24100,
96900,
7600,
57300,
28000,
35000,
52000,
20200,
21000,
36700,
33000,
47900,
29400,
19700,
35900,
20400,
23900,
28100,
3300,
10900,
45900,
null,
38400,
15500,
12900,
7400,
45600,
18800,
44000,
36000,
14400,
34800,
40700,
11100,
70600,
22100,
19700,
null,
64900,
2600,
37700,
9100,
27500,
12000,
28400,
52100,
30400,
5900,
51500,
48100,
20400,
33400,
5600,
77200,
29600,
15700,
4000,
null,
13600,
77100,
15200,
14500,
16100,
12000,
10500,
50225,
null,
37700,
40960,
7700,
6000,
9900,
5500,
10600,
5000,
30200,
33900,
null,
40300,
17400,
15300,
5300,
51300,
12300,
9700,
37300,
16400,
41300,
10700,
14300,
null,
null,
28500,
31000,
50200,
65900,
32800,
7300,
46400,
45200,
66700,
64100,
11900,
13500,
15200,
3000,
20500,
15000,
38600,
null,
15900,
32300,
5700,
56100,
22700,
5000,
61800,
21800,
75100,
33100,
41500,
53200,
17300,
9000,
47300,
23200,
36900,
178600,
23000,
64100,
21500,
18300,
16000,
13900,
10900,
14000,
27800,
17800,
null,
13900,
47300,
4600,
21300,
50300,
54300,
34600,
15500,
8100,
4600,
31800,
35200,
null,
17800,
21000,
7700,
53300,
17900,
14000,
21800,
83300,
34800,
null,
8900,
15600,
47900,
39700,
29300,
8000,
24800,
8200,
54400,
18600,
51600,
29300,
57300,
14100,
7300,
30400,
11200,
40000,
15000,
23800,
38600,
108900,
null,
23300,
48600,
35500,
13040,
21900,
59900,
41800,
5900,
30400,
25300,
11300,
null,
16200,
32300,
18300,
6200,
8200,
51600,
36200,
35000,
41900,
32200,
16000,
28700,
14400,
10500,
97070,
18400,
248900,
30700,
69900,
47500,
14300,
52600,
37800,
22700,
15000,
31000,
23600,
11200,
11100,
17800,
35973,
9300,
null,
13700,
22700,
8800,
54718,
4800,
35800,
46000,
21600,
2500,
57700,
22100,
null,
47400,
23600,
8400,
16000,
24500,
28100,
45000,
2816,
13000,
71100,
10500,
6500,
8537,
28300,
42000,
26600,
23000,
20200,
33700,
12700,
18500,
18600,
17400,
29700,
null,
26500,
29600,
33300,
53300,
63000,
15600,
28100,
17000,
22100,
14000,
32500,
null,
26000,
60000,
35400,
null,
25700,
26700,
29585,
22700,
46100,
22900,
16000,
3750,
17300,
3100,
7900,
13400,
10800,
50800,
5900,
39700,
85000,
18700,
18500,
24200,
22000,
27900,
7500,
106500,
15400,
46800,
71100,
61800,
76300,
null,
37600,
19400,
41200,
75000,
12000,
33600,
10000,
43000,
25500,
26400,
46600,
11900,
17800,
68100,
29500,
null,
null,
4400,
66100,
null,
25500,
19500,
8350,
30400,
50000,
4500,
25200,
57400,
43700,
23500,
16500,
57200,
28800,
41900,
33400,
21300,
21400,
92800,
27600,
22800,
30200,
42900,
20500,
15600,
18400,
136300,
30000,
null,
null,
28400,
8100,
11300,
2700,
63000,
52300,
9100,
38800,
21000,
89600,
35000,
12700,
11500,
41700,
15000,
52100,
91300,
32400,
55500,
35200,
null,
24100,
53140,
9000,
31900,
42800,
16400,
18900,
11800,
20500,
15700,
3600,
30500,
28900,
70600,
14200,
13000,
26300,
12500,
44300,
6000,
11400,
34400,
null,
21000,
19800,
53400,
11300,
13700,
12200,
46800,
60700,
35000,
28800,
null,
3100,
22900,
21100,
38000,
null,
47800,
45100,
28000,
10800,
10000,
12600,
23700,
null,
47100,
null,
23900,
23200,
16500,
38800,
13100,
12300,
50200,
66700,
13200,
71100,
17900,
6500,
36500,
4000,
28100,
23600,
26809,
27900,
null,
47800,
17200,
3000,
35500,
10700,
20400,
7500,
40400,
110600,
6400,
106800,
1500,
null,
8300,
33950,
41300,
10200,
15800,
22300,
18900,
null,
68800,
83000,
168400,
9100,
null,
19700,
32900,
6400,
17000,
85300,
37000,
16300,
49400,
27400,
41700,
null,
57500,
128500,
24500,
20300,
26200,
84300,
null,
null,
13800,
6100,
74500,
6100,
5700,
12800,
48600,
63100,
30600,
6100,
82000,
16900,
14700,
51500,
44100,
5500,
18700,
19300,
39600,
18100,
null,
14000,
16700,
65600,
6900,
33100,
34400,
41300,
9800,
35500,
16700,
70400,
20400,
23800,
67300,
30500,
12800,
91100,
4600,
56100,
42300,
25300,
58200,
71000,
26600,
43700,
14200,
53200,
25550,
6500,
4100,
33500,
15300,
25300,
3300,
29200,
22100,
58200,
24800,
22500,
10900,
19400,
64000,
86600,
19000,
14100,
41300,
3300,
23500,
13600,
20700,
56300,
32300,
15000,
11500,
35300,
86200,
12900,
23300,
131900,
null,
100100,
57000,
18400,
14300,
31300,
54400,
33500,
6200,
19300,
47400,
6300,
12000,
27100,
44900,
37100,
139900,
16500,
9300,
22100,
11300,
45700,
null,
31700,
12600,
17400,
10300,
48500,
32500,
29200,
9300,
20800,
40800,
53400,
9200,
11500,
20000,
16500,
66000,
20900,
25500,
20200,
45100,
13300,
null,
10300,
45600,
10100,
20800,
37000,
16300,
10200,
30100,
36500,
10000,
null,
40400,
6000,
20250,
28900,
24900,
7300,
22500,
18600,
107900,
12900,
42200,
19600,
28000,
85000,
30700,
89600,
null,
127400,
56600,
22550,
48000,
null,
106200,
1400,
41700,
15300,
53100,
34700,
10800,
null,
40400,
29300,
35900,
19700,
8600,
3950,
12100,
113600,
36800,
17000,
18200,
54200,
74200,
27100,
40100,
17200,
37100,
19500,
19900,
10500,
32900,
41300,
33700,
23286,
55800,
14900,
71800,
83888,
30000,
29900,
null,
28100,
10300,
46200,
11100,
78900,
6800,
67100,
137500,
6000,
12600,
20900,
16000,
16700,
73700,
null,
null,
27300,
12400,
55600,
6200,
6050,
14400,
12500,
8400,
49400,
24200,
18130,
27800,
39662,
27000,
20500,
7500,
48950,
34900,
34000,
null,
30000,
15900,
26700,
13800,
25600,
41000,
25200,
35000,
12500,
32800,
17600,
8300,
6500,
26700,
22000,
14700,
null,
22200,
91000,
44800,
27400,
42300,
43800,
15500,
11700,
null,
33700,
38700,
null,
null,
null,
24800,
5400,
41200,
3700,
72100,
null,
30500,
8500,
13500,
72600,
13000,
8400,
55300,
19100,
20000,
null,
65000,
39700,
null,
null,
14500,
1400,
48200,
6700,
24450,
null,
15600,
6800,
19800,
52300,
49700,
4600,
null,
22200,
49500,
null,
15900,
58100,
14500,
17400,
43900,
50100,
8300,
19300,
11500,
38200,
31000,
45400,
null,
23600,
70800,
18800,
74500,
50000,
4300,
24600,
8500,
11900,
null,
30300,
28200,
47200,
71500,
10400,
6600,
55000,
2600,
31000,
11400,
16100,
15900,
7700,
38700,
31900,
39700,
21000,
34000,
13800,
35500,
50200,
127800,
5900,
64100,
27200,
37300,
50800,
24500,
15300,
12300,
16600,
14000,
15700,
12100,
19500,
16400,
25400,
16500,
27200,
45200,
12600,
50700,
27700,
71600,
4400,
36400,
32800,
17500,
32700,
17700,
20800,
99800,
17800,
20600,
9700,
24000,
80300,
19100,
23500,
null,
9150,
48400,
null,
35700,
34400,
40700,
48000,
6010,
51300,
32900,
32400,
7100,
25000,
9400,
25100,
7500,
79500,
30983,
18900,
24400,
null,
15000,
8400,
81800,
2100,
39300,
65000,
12500,
16900,
6800,
18500,
13000,
35300,
6400,
19600,
110700,
15300,
95000,
629900,
59400,
20700,
29900,
16800,
39800,
19600,
17600,
11200,
37400,
16900,
65000,
53000,
11500,
24020,
9400,
51608,
73100,
48400,
26500,
40300,
17200,
62600,
14300,
49900,
21000,
13800,
14900,
49400,
25400,
9600,
31200,
27000,
11800,
null,
81600,
19200,
79800,
null,
42700,
16200,
17600,
13300,
27000,
42544,
22000,
null,
27000,
17200,
7900,
16000,
49100,
51100,
31700,
33500,
26900,
11400,
32600,
9100,
33900,
12900,
9200,
17150,
27600,
14300,
28300,
19500,
17600,
29200,
23500,
26300,
null,
5400,
13900,
58300,
71000,
67300,
53700,
58300,
18500,
17300,
5000,
14800,
36500,
null,
22800,
11200,
3900,
28800,
30600,
null,
15700,
51977,
15200,
74800,
26000,
53600,
63400,
18300,
5300,
25500,
13985,
null,
21400,
46900,
12500,
19000,
3100,
7100,
17700,
2300,
58200,
10600,
18700,
33500,
null,
12600,
58600,
22600,
30700,
53900,
13600,
68900,
2200,
null,
68000,
18200,
null,
27900,
57400,
20500,
22400,
38700,
14500,
26800,
18100,
37100,
28000,
39800,
21200,
18700,
4300,
23900,
51000,
7800,
13100,
null,
52000,
36800,
29800,
6200,
5050,
22400,
19700,
5400,
null,
19100,
47100,
12710,
61200,
38800,
null,
16700,
3300,
6400,
24800,
21000,
27800,
37700,
13600,
12200,
39500,
25500,
50600,
12800,
9400,
46200,
5800,
14500,
29500,
32300,
14200,
41021,
30900,
21400,
12800,
12300,
25000,
null,
66500,
45900,
17600,
null,
20100,
63600,
6700,
7100,
5400,
14700,
47200,
71400,
12300,
53309,
38200,
63100,
16500,
null,
20500,
62100,
15700,
6600,
49200,
25700,
7100,
17500,
54300,
47000,
98100,
11400,
40700,
null,
13000,
25000,
25200,
51500,
34600,
19700,
19500,
40860,
13026,
29828,
10200,
12100,
13000,
15900,
61100,
8100,
41600,
24900,
46400,
8300,
14900,
43400,
9500,
null,
null,
38400,
null,
50100,
22100,
56300,
8200,
34700,
17700,
18100,
30000,
18100,
41300,
55000,
26800,
49381,
34900,
10200,
44400,
12500,
17800,
4200,
27900,
12200,
38100,
null,
8200,
34900,
17200,
51000,
10500,
null,
26800,
10700,
11500,
11600,
35800,
23700,
9000,
5800,
13300,
null,
2800,
3000,
11200,
31700,
18400,
64400,
45100,
24800,
50100,
63300,
26300,
45200,
33400,
24800,
20200,
9600,
130300,
4100,
6200,
12800,
11400,
30900,
29600,
37700,
18800,
6200,
27600,
32500,
5100,
6000,
13800,
31000,
38800,
17900,
32500,
17400,
27300,
27100,
9200,
31000,
41000,
50900,
14300,
15100,
19000,
87200,
70000,
20300,
6600,
6700,
13100,
11250,
24300,
26200,
24200,
25600,
17300,
null,
7000,
62700,
9300,
4500,
31400,
29500,
51510,
62200,
34900,
27600,
6800,
63600,
8400,
97900,
52200,
null,
36200,
null,
65500,
16200,
15400,
6600,
null,
3600,
43300,
15100,
33400,
22800,
6200,
7000,
4800,
12900,
32600,
15500,
51600,
46800,
6600,
24800,
4650,
116000,
21600,
42700,
9700,
16890,
13600,
13600,
19000,
35000,
3600,
31000,
21100,
38900,
11000,
7500,
null,
null,
20400,
10000,
55300,
42200,
14700,
52600,
35100,
40400,
100100,
15700,
20100,
17400,
25300,
39700,
30500,
60100,
18000,
11700,
86000,
27200,
31900,
34000,
8800,
63300,
78000,
19000,
52200,
31800,
13400,
40000,
12400,
41500,
104700,
74900,
null,
1500,
19800,
null,
null,
20800,
5400,
3100,
26100,
3000,
24600,
53000,
null,
33500,
19825,
149500,
21900,
13600,
8500,
20000,
20700,
34900,
18433,
null,
28600,
11800,
47300,
66200,
15900,
33200,
26100,
109800,
43500,
41300,
21400,
14500,
68700,
null,
7500,
16400,
null,
16600,
123827,
15200,
11100,
8400,
44000,
41600,
47100,
42600,
118600,
13000,
52700,
20700,
15800,
20000,
54100,
29300,
10500,
105550,
null,
null,
28500,
10500,
null,
48600,
25200,
30700,
16100,
39800,
16600,
11300,
6000,
12700,
27500,
12600,
45400,
212000,
12700,
13600,
null,
75400,
21400,
236300,
56400,
36600,
14800,
17400,
11700,
26100,
null,
23800,
30000,
null,
42500,
27700,
36700,
9100,
26100,
22700,
null,
50700,
null,
13300,
72400,
17000,
null,
86800,
16600,
null,
28100,
25100,
30400,
30100,
6400,
31500,
32200,
24200,
96600,
36600,
87800,
4600,
7100,
14100,
22500,
40500,
56300,
44000,
98200,
12700,
20500,
22400,
45400,
21400,
34500,
null,
49300,
19400,
null,
null,
101000,
14500,
19600,
15200,
60600,
36200,
51700,
54900,
3200,
16300,
34300,
14000,
46100,
21200,
20000,
39200,
17800,
null,
7500,
11300,
24000,
5400,
10100,
15500,
69300,
2000,
12200,
31200,
21100,
35800,
17900,
26300,
15800,
48900,
7600,
281300,
69100,
null,
42700,
5300,
84500,
39100,
47200,
23900,
11000,
null,
52800,
null,
15400,
36000,
14100,
4700,
17800,
33000,
9500,
48900,
null,
21800,
21000,
null,
21000,
73200,
43000,
65000,
89300,
null,
141300,
112000,
43938,
62300,
12900,
9200,
14100,
18500,
null,
48100,
18300,
20600,
19200,
null,
44000,
null,
25400,
5900,
14000,
6200,
29900,
48400,
9900,
9900,
26400,
16000,
45300,
71000,
9600,
11700,
null,
20600,
143500,
18300,
5100,
55400,
null,
49800,
168400,
12500,
null,
19300,
43300,
15800,
26850,
43400,
17800,
null,
39700,
15300,
null,
27000,
37900,
10400,
23400,
74700,
36700,
100543,
13900,
44900,
10200,
283600,
14800,
11000,
null,
9600,
31900,
57400,
5500,
16400,
19900,
14600,
32000,
25700,
19900,
8500,
35500,
9800,
30700,
60300,
21700,
null,
22700,
32000,
14900,
44700,
31800,
8200,
21000,
29600,
24500,
6000,
11400,
null,
48000,
97300,
37300,
27100,
127886,
29200,
3000,
11900,
28200,
13500,
20700,
49300,
38100,
95400,
38800,
12100,
3800,
13200,
44300,
51900,
32600,
97100,
42400,
20600,
20200,
12300,
27300,
13700,
6100,
25800,
44600,
19500,
12300,
48300,
14300,
25300,
20900,
79800,
null,
37100,
9300,
71000,
18100,
129100,
9900,
11500,
39000,
9500,
79100,
51400,
33700,
73000,
43100,
8600,
17900,
21400,
null,
13700,
51500,
18900,
57800,
6900,
7800,
122000,
83400,
21900,
23400,
null,
70800,
3800,
11500,
33300,
5100,
null,
95000,
13200,
13800,
75500,
1000,
33900,
22600,
47600,
8500,
13100,
9300,
60000,
null,
21600,
31500,
null,
18100,
22100,
37800,
9600,
13796,
22537,
66900,
9900,
49400,
19700,
96600,
38300,
16400,
null,
7300,
null,
18300,
null,
7500,
87700,
4200,
55400,
38900,
null,
46900,
18500,
23600,
4750,
116600,
56300,
7500,
25000,
13400,
22300,
30700,
26300,
20100,
108800,
61800,
44000,
25300,
112500,
8000,
62000,
15700,
47400,
11700,
50366,
11200,
26600,
null,
20100,
16200,
null,
1400,
29000,
52800,
35600,
33728,
12700,
45500,
143600,
44800,
23300,
null,
null,
16000,
16600,
null,
16900,
14500,
null,
56600,
30700,
31100,
47000,
3700,
24400,
27900,
151600,
36600,
38700,
8800,
17200,
21400,
6400,
33000,
49100,
48100,
37800,
19900,
72200,
43000,
14000,
68500,
43100,
null,
10400,
12000,
25900,
24400,
51700,
20900,
8400,
29500,
null,
7100,
26700,
null,
8600,
4600,
77800,
124400,
16800,
8200,
20000,
19600,
25500,
46100,
12300,
13700,
66400,
19800,
5200,
27900,
12500,
50900,
27600,
3000,
52300,
22500,
43200,
24900,
80700,
17900,
67700,
14800,
11200,
5700,
25400,
38400,
18100,
27200,
43500,
166900,
23800,
19000,
26700,
9600,
25300,
28200,
34100,
40500,
21200,
5000,
24100,
9800,
51300,
12300,
5900,
29500,
54000,
33400,
2900,
19000,
11100,
77900,
30800,
18300,
5500,
9700,
13400,
59300,
null,
12500,
103500,
null,
18800,
7300,
17900,
12400,
44100,
13800,
23300,
6200,
19400,
12800,
45700,
18100,
61000,
28500,
65800,
7300,
25500,
null,
44600,
59600,
null,
18900,
12200,
6200,
55800,
28900,
14700,
26600,
55100,
59600,
34200,
8000,
48200,
49900,
21100,
null,
28800,
18200,
15200,
18100,
20500,
57300,
null,
null,
67700,
13500,
14700,
67800,
null,
23100,
7400,
6000,
106000,
44200,
1600,
74600,
null,
33600,
27300,
7600,
28600,
103400,
41000,
32500,
15500,
null,
47500,
96600,
47000,
17200,
14700,
19500,
27900,
45500,
47400,
21000,
13300,
46500,
79700,
null,
42600,
10600,
31900,
26100,
32300,
17100,
6600,
17600,
9300,
44500,
31600,
22900,
null,
17600,
88000,
104000,
25200,
39000,
null,
10100,
27200,
4700,
103100,
21800,
12800,
44800,
7800,
22900,
79300,
10400,
31100,
37100,
75400,
7100,
7200,
2700,
16300,
38100,
52300,
7900,
66700,
1400,
37000,
24000,
16100,
30300,
12900,
14500,
null,
12400,
null,
22400,
null,
8000,
18000,
22600,
16500,
12600,
64700,
34500,
30500,
39300,
13500,
35500,
6400,
23600,
12600,
6900,
36700,
11600,
20500,
37700,
24100,
4600,
56507,
30300,
13700,
14500,
6000,
4700,
45000,
79100,
35700,
3700,
13400,
7100,
41200,
16100,
25100,
27300,
21500,
12500,
4100,
null,
29500,
16900,
16400,
10400,
null,
20800,
1100,
null,
17500,
17700,
47400,
null,
28700,
17200,
65200,
34800,
null,
9200,
10000,
null,
17700,
22600,
12100,
36200,
62500,
null,
44200,
12741,
134400,
34400,
14900,
null,
9000,
19500,
22000,
null,
5000,
20800,
25900,
21000,
50100,
34800,
5500,
null,
24500,
12300,
13500,
18000,
29000,
21400,
16700,
38300,
15100,
7100,
48500,
22600,
32500,
36400,
37100,
41900,
34600,
186500,
29200,
15500,
9900,
33600,
17200,
26100,
28000,
29300,
6700,
37900,
24800,
52500,
24200,
null,
4900,
25900,
null,
null,
35800,
14800,
50300,
17000,
9300,
67200,
99500,
39500,
35300,
27200,
11800,
10000,
2900,
9700,
46300,
84000,
8600,
23600,
8900,
44100,
48600,
47100,
28000,
38400,
51800,
46300,
13800,
17850,
109200,
4000,
10900,
11200,
4800,
35000,
33700,
13900,
12000,
16900,
3500,
null,
16500,
null,
7300,
27200,
45300,
25700,
249400,
44000,
103570,
9700,
21600,
3400,
7890,
4200,
15200,
42200,
69200,
9900,
22500,
56300,
93500,
24900,
29000,
15300,
20100,
null,
11900,
36000,
19200,
29500,
3400,
43500,
49100,
null,
21600,
20800,
18100,
15900,
9700,
19100,
48800,
9000,
10200,
null,
39000,
7400,
null,
37900,
4300,
17100,
8600,
29900,
83600,
42600,
8900,
24000,
15500,
13400,
112100,
26500,
28000,
50900,
33900,
10800,
33600,
null,
31400,
32700,
26000,
18000,
42800,
null,
10000,
null,
11300,
58700,
30700,
48800,
32300,
33400,
21500,
32100,
143128,
27700,
15500,
9500,
23500,
16700,
104500,
21300,
27700,
null,
21700,
56300,
29800,
8800,
2500,
15200,
30600,
3000,
7550,
25500,
14200,
14200,
40500,
null,
12500,
33950,
11900,
13900,
30153,
16600,
18500,
16600,
31100,
49000,
101000,
14700,
18000,
45900,
2300,
15700,
18800,
24900,
9100,
35600,
10000,
14600,
null,
11500,
10600,
38500,
6800,
34700,
4300,
44000,
null,
64500,
18300,
36800,
30900,
35100,
6800,
23300,
1300,
4300,
38200,
30800,
17400,
15600,
6800,
18000,
14500,
null,
30200,
61251,
15200,
14900,
29600,
16500,
9500,
16800,
15900,
42400,
147160,
17900,
30900,
27800,
36200,
39600,
18300,
28300,
13200,
109800,
71000,
null,
59000,
19500,
8900,
24500,
35500,
11900,
74900,
null,
15700,
28800,
42100,
100100,
27700,
6900,
5000,
1300,
26100,
6700,
null,
13600,
12800,
54600,
null,
7500,
28782,
9300,
32000,
25100,
13000,
127200,
63000,
10700,
19400,
14400,
14900,
16300,
36300,
21500,
null,
20200,
null,
2600,
10000,
19000,
33900,
12100,
32000,
null,
null,
35200,
20500,
13100,
23000,
8500,
80000,
10500,
29100,
4400,
7300,
8300,
19800,
61000,
32300,
32200,
12300,
42600,
24300,
5000,
12600,
9800,
89800,
2900,
56300,
19400,
null,
28800,
43400,
null,
18300,
null,
null,
35400,
24000,
25400,
12200,
58700,
33900,
4300,
30800,
7600,
31700,
24400,
11000,
55400,
6300,
14900,
93900,
80300,
7600,
4300,
30900,
96800,
92100,
18600,
43500,
null,
44800,
20100,
42600,
61100,
13900,
22400,
9800,
38500,
11800,
21000,
7700,
17000,
217500,
17200,
null,
8000,
35900,
16400,
26900,
53200,
43100,
39500,
null,
99200,
15600,
28400,
10000,
19400,
24200,
15800,
10700,
11400,
16400,
67000,
38900,
81800,
22000,
null,
14400,
9100,
23800,
28100,
62300,
31300,
20400,
15500,
null,
10100,
27400,
21400,
null,
2100,
7700,
15600,
33700,
19000,
23800,
30000,
26400,
null,
106500,
71100,
27500,
31200,
9900,
16800,
12800,
53600,
7700,
17900,
22100,
31100,
16500,
9700,
27500,
16300,
9200,
17200,
16100,
14900,
21800,
32800,
14400,
30800,
null,
23700,
27300,
150600,
13800,
2600,
57800,
55000,
29600,
23000,
30700,
37000,
18000,
null,
13600,
97300,
4300,
13900,
12200,
54400,
76300,
38200,
38300,
13800,
45000,
14900,
24200,
58800,
31600,
17800,
16600,
50500,
21400,
14300,
44800,
24800,
25400,
null,
66900,
11500,
null,
25500,
52700,
41800,
null,
null,
22800,
55300,
16900,
2300,
75900,
39300,
14100,
20900,
20500,
38900,
11200,
14100,
null,
43100,
null,
31000,
null,
50800,
66200,
51600,
82300,
26300,
62300,
5500,
13100,
9200,
147400,
33800,
33500,
14300,
null,
8600,
22000,
14000,
110500,
15000,
50300,
23200,
14200,
122500,
27600,
7800,
23800,
5800,
53400,
27200,
14900,
11100,
12275,
6400,
47000,
24100,
47181,
12000,
56200,
42200,
37400,
12400,
13400,
19400,
21800,
44200,
17200,
48700,
22800,
7100,
23300,
14500,
14000,
43500,
24300,
9000,
23500,
22900,
21100,
6100,
null,
21000,
49300,
29300,
65100,
6400,
19300,
94200,
122500,
152100,
93500,
61500,
12400,
21400,
42300,
34300,
39200,
16200,
20500,
11300,
29600,
94800,
6750,
32400,
15800,
30100,
110100,
33800,
25500,
39600,
11300,
53300,
29800,
65400,
9250,
23850,
59100,
3100,
22040,
19300,
15900,
32300,
null,
33800,
79400,
57100,
65800,
10700,
19400,
12900,
null,
29600,
19700,
30700,
32800,
84300,
99700,
95200,
27500,
35000,
8400,
39000,
24000,
61800,
null,
34900,
38900,
33100,
42100,
14400,
null,
35531,
29000,
30600,
2400,
null,
null,
43700,
13400,
null,
11400,
30000,
21800,
33600,
null,
43800,
49400,
17900,
7600,
29400,
32200,
78600,
14100,
6750,
56300,
16600,
17000,
56700,
23400,
16500,
17500,
30100,
24200,
null,
35900,
7400,
9000,
48500,
19600,
17700,
22600,
8400,
15400,
18500,
56900,
11800,
null,
65000,
19700,
27500,
24300,
48100,
71300,
42600,
14300,
17900,
18100,
6000,
12600,
null,
37400,
39100,
91800,
38900,
12900,
4000,
23500,
3600,
12800,
null,
35200,
8500,
32000,
32800,
16300,
29100,
27700,
17300,
8200,
4100,
32600,
null,
21100,
9500,
75200,
51400,
11000,
51300,
17100,
13300,
11500,
2700,
13500,
55800,
25200,
19200,
null,
15900,
6400,
null,
62300,
14000,
26300,
4800,
9000,
38000,
11000,
38370,
7700,
13400,
21300,
69500,
23000,
64000,
19000,
64400,
18100,
1000,
46100,
14100,
12500,
6800,
56100,
13900,
6600,
12500,
28000,
39300,
84000,
8100,
113900,
19200,
18600,
7900,
29751,
29700,
6400,
47950,
13700,
13900,
35100,
14500,
12400,
10000,
31300,
7200,
17686,
22100,
39400,
25200,
47100,
null,
17200,
61900,
22700,
5700,
39900,
9800,
26400,
24000,
14300,
56600,
45600,
15200,
15200,
17200,
7300,
58500,
null,
86244,
17000,
16100,
38100,
13000,
null,
null,
58000,
50600,
13300,
19000,
57000,
76000,
null,
49400,
13800,
48200,
92200,
67300,
29400,
35100,
5400,
44600,
null,
null,
21100,
17400,
23700,
null,
null,
5600,
9500,
null,
15800,
8400,
40900,
25400,
32750,
179551,
18700,
13300,
3800,
7900,
18100,
29700,
21800,
17000,
38700,
29400,
13600,
null,
29700,
null,
28900,
66300,
21000,
48500,
42500,
41600,
21800,
35953,
21600,
28900,
33300,
10500,
12700,
42200,
157900,
15700,
15400,
6500,
26400,
null,
null,
18200,
11600,
16200,
83000,
23400,
24900,
16400,
6500,
20200,
69200,
41300,
66700,
23100,
7800,
70700,
23300,
43900,
25000,
17500,
28300,
18900,
31000,
12000,
44500,
195700,
56400,
7000,
37100,
null,
34300,
null,
26000,
7000,
3700,
106400,
null,
67940,
null,
21400,
24100,
64500,
55000,
16400,
6400,
8700,
65100,
130700,
20000,
null,
50600,
4600,
19600,
14500,
null,
38900,
14700,
null,
24030,
11100,
12700,
42500,
69600,
34100,
65700,
19700,
18200,
null,
null,
148200,
29100,
42600,
21500,
43100,
96300,
18200,
18300,
6800,
36400,
40300,
11900,
null,
39600,
21300,
10000,
54300,
62875,
17800,
45700,
8500,
82000,
33950,
23400,
36200,
64600,
34000,
21500,
31700,
29900,
34500,
23500,
null,
25700,
6800,
11200,
36200,
27900,
10600,
28300,
20000,
18300,
112200,
33995,
null,
37400,
31300,
28800,
21100,
49800,
108100,
11800,
24100,
45200,
42100,
12900,
36700,
26800,
13100,
5200,
15900,
7100,
63900,
52200,
32000,
82600,
33500,
null,
27100,
null,
null,
34600,
61500,
40194,
24700,
76900,
29500,
45000,
17800,
7500,
15600,
68330,
47500,
null,
15400,
4400,
54089,
53200,
5000,
6900,
35300,
4500,
38100,
16500,
null,
20900,
30600,
26000,
23200,
64200,
34200,
23400,
null,
35000,
9800,
37800,
3500,
37700,
15600,
null,
21100,
26400,
86200,
69000,
14000,
9600,
4300,
27500,
19000,
32900,
null,
39900,
29700,
21800,
6000,
22100,
null,
null,
null,
114300,
19200,
281700,
17500,
28100,
3000,
26500,
26400,
16200,
17500,
27700,
15800,
29200,
12050,
39100,
18400,
27400,
56600,
31800,
3100,
34000,
30000,
13100,
15200,
43400,
9900,
10100,
6600,
56500,
21600,
49500,
null,
34800,
22300,
42100,
null,
15400,
14900,
36100,
22700,
52400,
null,
12700,
null,
44500,
21933,
null,
6300,
73600,
17800,
8500,
25000,
24000,
15000,
null,
null,
8000,
23000,
5100,
16800,
33900,
23500,
17100,
12400,
18600,
19500,
56700,
null,
12100,
10300,
22100,
56500,
49200,
20900,
null,
null,
2000,
27700,
20200,
52900,
10400,
400,
18500,
null,
70400,
32100,
28600,
11800,
22700,
66500,
12100,
9800,
26400,
13000,
37600,
40800,
12400,
33800,
20600,
6500,
34000,
20500,
10100,
93100,
76000,
19400,
96200,
10900,
11600,
48500,
28200,
null,
28700,
89200,
30100,
6100,
34300,
12800,
18300,
3300,
13250,
8000,
10400,
3000,
21500,
null,
42100,
53200,
8000,
30500,
60100,
null,
15500,
49600,
56800,
19600,
13650,
48100,
36900,
73400,
14300,
60500,
45600,
17300,
null,
7400,
87500,
10800,
11700,
50900,
48100,
42968,
9600,
13300,
19700,
63400,
66000,
29700,
94300,
19200,
9400,
57900,
72800,
50300,
11100,
15100,
8700,
null,
18800,
27600,
202400,
null,
19500,
185600,
11100,
4000,
12700,
27900,
300,
47200,
15200,
21700,
12700,
43439,
21900,
10300,
3400,
52400,
47200,
64000,
15800,
26300,
29600,
17800,
9500,
13400,
21500,
52500,
17200,
42900,
29600,
22300,
5800,
26100,
23800,
6700,
12150,
null,
33700,
12500,
35300,
47200,
51200,
32500,
6900,
61800,
14500,
27600,
21800,
42200,
37000,
44500,
null,
11100,
null,
30100,
5600,
23100,
3600,
null,
66100,
35400,
40900,
32300,
13900,
53100,
null,
12200,
9000,
164200,
76400,
null,
4500,
41300,
10900,
10600,
17100,
27900,
41200,
11800,
15200,
27200,
25500,
21000,
31600,
40100,
16300,
43600,
29000,
26700,
null,
null,
43600,
43500,
16700,
9200,
33700,
52100,
40300,
206200,
79400,
null,
10100,
6000,
null,
39000,
null,
30200,
9800,
256300,
24100,
2000,
22400,
22800,
51100,
23500,
155300,
13500,
12300,
17200,
null,
24600,
13400,
37000,
22000,
20700,
14500,
21900,
44600,
18600,
null,
43664,
17200,
19600,
4400,
78455,
7200,
32900,
47000,
4500,
16300,
32500,
19900,
27100,
null,
22500,
null,
49088,
78900,
8500,
17700,
42400,
12500,
36600,
15400,
28866,
20500,
8500,
4000,
30500,
36400,
26000,
25200,
101000,
114200,
15100,
20500,
22700,
19500,
116000,
14200,
25000,
81200,
78100,
81400,
8000,
99900,
5475,
42100,
51600,
35200,
46100,
28100,
77100,
115600,
23500,
5700,
26200,
11000,
37500,
2200,
24000,
39000,
113300,
39500,
120100,
14600,
67000,
30200,
null,
12400,
19700,
13900,
33000,
54800,
88300,
13000,
null,
70400,
16500,
null,
58300,
38400,
45000,
5900,
29300,
12800,
12400,
28600,
49500,
7200,
8900,
14600,
47000,
32800,
null,
322000,
40200,
19700,
5600,
5000,
7300,
null,
24435,
20200,
15700,
0,
6300,
33900,
13100,
15500,
13100,
9500,
87900,
20900,
11020,
1600,
36100,
20600,
80800,
158800,
23400,
319300,
11700,
36800,
47200,
6800,
36400,
null,
9700,
146500,
13000,
51600,
null,
48700,
119600,
10400,
null,
6850,
121700,
20200,
12200,
8000,
19600,
24600,
8700,
19500,
65600,
19500,
5600,
22500,
18000,
11400,
47600,
14800,
12600,
null,
16000,
45100,
22100,
11900,
36200,
null,
33200,
59680,
45950,
36500,
28000,
56100,
9000,
17400,
null,
37300,
27400,
22500,
34100,
101700,
null,
24300,
11200,
null,
17700,
14300,
null,
6000,
15200,
null,
108500,
13800,
4600,
29100,
21500,
19450,
50000,
76500,
20600,
69100,
8200,
40100,
28800,
18700,
57500,
4300,
32000,
null,
62400,
null,
11300,
null,
19300,
18300,
15000,
26800,
27000,
29200,
14700,
22300,
15600,
70400,
44361,
11000,
5500,
35700,
38300,
16100,
21900,
89600,
13800,
38700,
194951,
6800,
20600,
178700,
34300,
28600,
4900,
8000,
19100,
1300,
34700,
39000,
4000,
null,
null,
9200,
5700,
5800,
92200,
29200,
44600,
42488,
152600,
26600,
3200,
31000,
41400,
null,
4400,
68900,
4200,
100600,
10500,
10600,
12500,
34000,
5900,
15200,
15400,
17600,
39000,
23600,
61700,
18000,
42300,
22400,
8400,
25600,
20900,
64600,
null,
null,
10800,
82000,
21700,
30900,
21700,
10400,
33600,
36400,
19800,
null,
null,
52800,
18100,
33200,
8800,
8000,
13600,
328800,
6700,
8900,
46000,
18000,
22200,
46500,
null,
92100,
25600,
45000,
30000,
41600,
20300,
15800,
37200,
21800,
null,
12800,
27600,
15700,
18300,
20200,
47800,
null,
null,
39400,
38800,
8700,
8500,
18100,
17800,
17100,
126200,
8600,
36200,
7800,
26200,
46200,
48000,
25000,
17300,
12400,
49300,
18000,
98100,
26000,
20600,
22900,
5900,
20200,
94400,
3300,
22100,
18500,
40700,
2000,
19600,
17700,
23600,
29000,
62000,
15500,
33050,
6700,
20100,
2200,
29000,
16300,
17200,
104700,
29800,
11600,
27700,
null,
19800,
7100,
27200,
22900,
65200,
38700,
79600,
44860,
105900,
74200,
11200,
27500,
8200,
10800,
null,
63000,
79923,
12200,
14100,
26200,
null,
12900,
13200,
12600,
28700,
36900,
8700,
21700,
11000,
21000,
null,
4800,
18100,
18600,
18900,
79900,
37300,
26300,
9900,
22800,
null,
65600,
25100,
37300,
300,
3300,
11500,
6800,
64000,
227500,
39200,
13400,
19200,
36000,
null,
17600,
26800,
12000,
6300,
16400,
15500,
10550,
22150,
31300,
35300,
100100,
62600,
4800,
39400,
29100,
14100,
25800,
10100,
19200,
24900,
95800,
5000,
17500,
35600,
15000,
46900,
13800,
9800,
89951,
16800,
30800,
15100,
88500,
26100,
4300,
6700,
48800,
43200,
null,
20700,
8000,
21400,
40194,
null,
null,
9000,
97700,
null,
9400,
24500,
41000,
14300,
11000,
74200,
4800,
20100,
21000,
46800,
20000,
31750,
8800,
54000,
21800,
55200,
null,
null,
13500,
26100,
96900,
null,
29900,
84200,
19900,
38600,
15300,
27700,
null,
9300,
24400,
null,
56300,
77200,
18400,
20000,
null,
26300,
31700,
28600,
15500,
47900,
24900,
15800,
10000,
27000,
29500,
37800,
101800,
50300,
26500,
null,
19900,
null,
16300,
26800,
21400,
8300,
8600,
6800,
15000,
26200,
37200,
7200,
23300,
null,
null,
26000,
91300,
32500,
30000,
49500,
null,
null,
27800,
43300,
55400,
26000,
4800,
6500,
88200,
48700,
21100,
9700,
34100,
68200,
63900,
6400,
5900,
22700,
null,
15300,
65900,
19800,
21700,
18600,
25200,
null,
14400,
null,
5800,
18200,
12600,
75800,
36300,
5500,
11500,
30000,
8200,
18900,
null,
69200,
22600,
15400,
19300,
12600,
29000,
10700,
141500,
13700,
27700,
38300,
null,
79400,
21000,
82000,
13100,
7700,
7400,
10700,
10000,
4000,
24700,
25200,
8700,
31800,
9500,
null,
12200,
null,
28000,
228200,
null,
52900,
3900,
16200,
19200,
44600,
118600,
10000,
7900,
59800,
58900,
13800,
4400,
46100,
48900,
48500,
25300,
51700,
17100,
75100,
54000,
6500,
59440,
null,
8600,
6400,
37000,
119000,
50200,
null,
33600,
15700,
15100,
13300,
null,
15100,
2200,
34400,
5800,
13500,
14200,
32400,
7300,
8200,
11700,
25600,
13000,
24500,
12600,
35800,
165600,
16400,
19400,
null,
7070,
26900,
14300,
27100,
6600,
10100,
30800,
null,
33000,
13900,
9300,
29000,
43300,
18200,
24100,
null,
98500,
3700,
41900,
9800,
15700,
49400,
48400,
null,
92000,
7100,
12900,
37000,
23600,
16200,
10400,
null,
41500,
31100,
40400,
16700,
26200,
16900,
52500,
22500,
14300,
21500,
24100,
35800,
284400,
18700,
6600,
16800,
13700,
34800,
null,
12700,
49300,
16300,
37000,
8300,
31300,
8300,
5500,
16400,
31600,
70600,
76300,
45600,
23400,
4200,
81300,
null,
29100,
31600,
15200,
35800,
null,
11600,
28000,
8250,
null,
4750,
37400,
20600,
25300,
82800,
100600,
30700,
28600,
21000,
14600,
14400,
66200,
29700,
2000,
45000,
19200,
29200,
37900,
null,
4200,
14900,
6600,
19200,
2500,
7400,
52900,
10400,
43000,
31800,
6600,
47100,
86200,
11900,
35200,
27400,
null,
58300,
30100,
74400,
10000,
43643,
25600,
9200,
null,
36600,
39300,
34700,
21100,
22100,
9500,
20200,
77800,
10400,
14600,
7800,
4500,
18800,
38500,
20700,
115600,
29900,
10400,
66100,
25800,
37400,
34900,
27500,
19100,
16900,
37900,
85900,
26100,
15900,
18400,
11600,
21400,
33700,
35200,
17000,
28745,
19700,
4600,
7300,
159500,
15600,
46700,
65234,
13500,
34800,
23500,
23753,
49500,
19000,
14500,
null,
null,
15500,
13200,
25200,
10500,
38400,
9700,
9500,
13400,
32000,
25900,
null,
7500,
14500,
10500,
13000,
9600,
32600,
22100,
5400,
46700,
96800,
85000,
19900,
4500,
6500,
null,
20100,
65900,
21150,
28800,
null,
13100,
87900,
14400,
null,
66600,
41100,
null,
null,
null,
29400,
29900,
21100,
null,
18300,
49200,
55000,
42200,
22000,
22800,
75600,
23100,
12600,
82000,
11400,
44800,
84800,
8800,
57928,
33805,
29400,
15700,
14900,
null,
12100,
20000,
15400,
12800,
43600,
null,
2050,
46500,
57200,
50800,
19800,
6750,
24600,
14500,
31300,
43300,
51100,
13000,
11600,
16500,
22800,
20400,
10500,
58900,
29000,
null,
null,
226300,
29900,
14000,
14900,
7500,
38500,
9800,
69200,
17700,
61400,
39500,
10900,
35200,
91500,
90600,
40200,
18100,
74500,
28500,
27100,
63700,
83300,
12800,
31500,
26800,
52000,
46000,
26400,
48800,
34900,
42400,
39000,
14900,
18000,
74400,
27900,
49860,
19100,
null,
50000,
21300,
18700,
41200,
77300,
14500,
8700,
8300,
null,
41100,
28000,
5900,
67900,
16300,
13800,
21100,
28900,
36700,
38500,
30300,
17800,
16300,
14300,
13800,
12200,
28300,
25800,
25600,
35800,
20500,
29600,
14000,
12500,
40600,
12900,
29100,
37000,
11700,
38800,
25100,
27800,
26400,
18000,
null,
6000,
18450,
13600,
null,
3200,
58100,
52100,
39200,
14000,
4300,
30500,
13900,
null,
37300,
26300,
29200,
37665,
7600,
12900,
41900,
8100,
45100,
88100,
39800,
52900,
36500,
26600,
14500,
13500,
51400,
40700,
43300,
null,
37900,
6000,
74400,
5300,
36400,
34500,
23200,
15000,
23000,
20400,
null,
24200,
19400,
52700,
31400,
null,
47700,
47700,
11900,
26500,
63900,
17000,
18300,
12800,
71900,
20600,
null,
null,
23700,
30100,
62500,
5300,
13200,
36200,
5000,
24500,
12400,
null,
19400,
9100,
41104,
33800,
30600,
29700,
62504,
20200,
16800,
33500,
92400,
null,
59600,
12500,
11300,
35400,
17100,
33000,
25300,
57700,
22100,
36600,
15250,
null,
63500,
52300,
16900,
30300,
22000,
19900,
102200,
39100,
43900,
87500,
15100,
16300,
20700,
56818,
25900,
8400,
25200,
18100,
3500,
600,
19900,
null,
13200,
19400,
null,
8400,
15000,
48600,
28200,
7200,
6800,
null,
15780,
43200,
24700,
17000,
5000,
109500,
38900,
27300,
33400,
11000,
6200,
null,
34400,
80300,
31400,
16100,
7300,
7300,
30200,
18100,
10000,
17300,
101300,
49000,
4500,
null,
17600,
17300,
11000,
26000,
15000,
null,
3300,
27300,
47200,
14100,
null,
37900,
13500,
14700,
30200,
31651,
29500,
37800,
27100,
21000,
8500,
16400,
40500,
36700,
null,
83500,
20600,
7000,
13200,
46200,
50300,
25600,
13900,
11200,
26800,
13800,
20300,
18300,
5100,
22200,
10700,
50200,
67700,
32700,
39700,
9700,
4600,
46400,
19500,
13400,
19400,
37400,
10700,
12300,
6000,
7400,
null,
23600,
52800,
15200,
37300,
32200,
8800,
25900,
39500,
66200,
22300,
14700,
17300,
35800,
146100,
17275,
11500,
23600,
8100,
10400,
22700,
33800,
37900,
11800,
3300,
10000,
38800,
22900,
14400,
11811,
12000,
39600,
9100,
50300,
6700,
33600,
null,
38400,
5700,
3500,
11700,
5800,
17100,
41988,
5600,
16300,
10300,
18400,
24900,
7800,
null,
77000,
64300,
35000,
116100,
14600,
20700,
7500,
7700,
17900,
15200,
49700,
30100,
55000,
null,
9800,
null,
10600,
32100,
null,
13800,
24500,
104500,
40500,
11500,
92500,
52300,
40400,
14800,
23000,
29900,
20800,
33600,
54700,
9800,
37600,
79500,
32200,
35900,
9400,
20500,
76800,
29600,
21900,
31100,
34000,
34600,
55500,
32800,
22200,
11200,
30000,
53500,
11000,
24700,
16800,
27700,
40800,
27400,
20300,
8700,
12600,
11900,
8000,
18600,
3800,
18000,
47300,
11400,
37900,
16100,
null,
28500,
14600,
6600,
13000,
89900,
4600,
9400,
14100,
7300,
56200,
31300,
46400,
41400,
11800,
13800,
null,
21100,
160700,
22200,
19700,
25200,
13300,
14200,
65100,
34500,
67700,
9400,
5700,
17400,
63700,
6700,
25500,
6700,
null,
25100,
63500,
1300,
36100,
21000,
25100,
17100,
54100,
23100,
27500,
21600,
28000,
40500,
63900,
15900,
2500,
10900,
10900,
5700,
20700,
61400,
27800,
34900,
13500,
33000,
86800,
17800,
16200,
22700,
52900,
null,
33200,
9500,
62900,
40500,
10100,
4000,
null,
6450,
41900,
5100,
null,
15900,
22100,
14100,
12300,
21300,
26100,
23100,
10300,
18500,
12900,
null,
13000,
49800,
149860,
8200,
24600,
49400,
158500,
null,
11100,
11600,
13900,
49800,
88000,
14500,
40900,
48400,
16300,
37600,
41200,
18600,
54400,
34600,
36200,
46200,
48200,
20000,
31500,
23800,
9700,
8700,
35300,
35100,
25100,
15300,
null,
4700,
5800,
37100,
10700,
14700,
30000,
36200,
31800,
null,
1300,
18100,
12000,
15900,
14300,
59300,
52500,
40000,
13310,
null,
16700,
24900,
39900,
25300,
50300,
null,
45800,
51800,
39400,
29200,
30000,
16100,
18500,
132200,
5700,
9800,
61400,
20500,
37100,
41000,
24800,
58710,
18500,
14200,
24100,
15800,
36500,
16600,
19100,
3700,
9600,
3800,
2500,
16700,
18200,
null,
16700,
69500,
16500,
27300,
48100,
null,
26900,
7700,
28500,
26800,
101700,
21300,
null,
25900,
45900,
14000,
1800,
26300,
13600,
71200,
18700,
8700,
21200,
133700,
5400,
31100,
123300,
null,
22400,
38700,
10100,
11300,
26200,
53200,
53700,
null,
11700,
45600,
48300,
2000,
13300,
30100,
6000,
15100,
29700,
19900,
16000,
31600,
23100,
36400,
23300,
8300,
7500,
11400,
117400,
12200,
43200,
27700,
83600,
18200,
30400,
19000,
13700,
25500,
14800,
72700,
16600,
45000,
null,
29600,
40200,
20500,
10500,
29900,
92600,
36200,
8700,
62100,
31500,
20300,
31300,
28700,
22900,
43700,
10500,
43500,
5000,
20900,
38500,
23500,
15000,
19400,
11900,
39800,
10000,
18600,
18400,
55300,
10500,
49400,
27000,
22600,
11900,
57100,
null,
null,
30100,
14200,
119898,
48000,
12600,
21300,
71100,
4600,
30000,
86000,
78300,
8500,
42500,
46900,
28900,
57800,
14600,
16700,
23200,
10900,
31900,
23600,
null,
35600,
30300,
35500,
23600,
15200,
37900,
46700,
20200,
21100,
30100,
26500,
19900,
6200,
19700,
33700,
11400,
18600,
null,
27200,
17200,
27700,
31500,
null,
76100,
54000,
25000,
136700,
17000,
23300,
33700,
26900,
17200,
9700,
null,
18800,
13500,
64600,
29600,
21600,
20400,
26600,
73500,
19800,
99700,
12100,
17400,
27900,
10300,
53200,
18100,
14400,
6000,
24600,
55000,
12100,
34700,
44500,
21100,
52800,
35400,
34400,
20200,
32900,
46800,
null,
39000,
39000,
5700,
55100,
37900,
8700,
31100,
45600,
45400,
53800,
16700,
15000,
16400,
48400,
28600,
48821,
46574,
25100,
17900,
28100,
34400,
32300,
41900,
46700,
21100,
10900,
12400,
54100,
42300,
23500,
12900,
11700,
102500,
null,
19200,
18500,
20700,
37500,
null,
14800,
6600,
35000,
16900,
null,
58700,
14700,
19100,
23000,
16400,
51200,
49200,
20500,
19600,
23400,
7045,
41400,
32300,
56000,
12300,
51000,
16800,
17300,
40200,
108500,
9800,
26000,
19000,
16500,
null,
36900,
36400,
null,
38200,
39400,
12200,
5500,
33800,
21300,
16300,
11800,
14800,
14400,
113400,
13000,
8400,
31690,
null,
null,
52000,
65500,
24500,
67700,
18900,
null,
23300,
47800,
7800,
24900,
9000,
18400,
12600,
63400,
null,
42400,
64000,
15300,
19200,
35300,
127600,
26800,
44114,
17100,
66600,
28200,
48900,
11600,
3800,
null,
6750,
12700,
15100,
13100,
6700,
7900,
72400,
22600,
30300,
45000,
43100,
11400,
62900,
21300,
3900,
4700,
10300,
21600,
17200,
59400,
15000,
52400,
112500,
84200,
null,
13400,
23200,
39100,
16200,
18700,
28100,
25000,
24300,
19400,
24900,
16400,
49300,
3750,
21100,
49400,
29600,
28500,
22400,
15000,
61300,
36900,
97500,
19100,
52600,
32500,
14500,
73900,
19300,
30300,
7000,
18800,
33100,
16100,
null,
14900,
36500,
64800,
20600,
null,
null,
19400,
17700,
37600,
9300,
11900,
28500,
null,
8600,
21600,
55000,
31700,
22600,
9800,
15900,
17300,
9300,
24400,
2700,
13300,
23100,
6500,
null,
12700,
12500,
15000,
20900,
8000,
57300,
22500,
20700,
19300,
37600,
58000,
38610,
null,
21900,
59800,
4000,
12100,
43500,
18500,
49000,
7200,
15600,
31300,
97621,
30100,
41600,
null,
26100,
null,
70800,
25000,
17100,
17000,
25200,
62397,
null,
null,
58600,
29400,
40209,
19700,
29100,
49000,
17700,
38300,
25700,
45300,
27500,
15100,
71100,
9700,
26500,
null,
6700,
6700,
86800,
35400,
null,
14600,
28600,
23500,
16000,
24900,
16900,
16600,
28100,
16600,
84800,
13100,
27500,
5100,
58900,
34700,
5000,
50400,
48094,
null,
10840,
5600,
16900,
64300,
null,
null,
9500,
64400,
20200,
25000,
42600,
21700,
35600,
8800,
17800,
6800,
9000,
27500,
21200,
null,
47000,
49300,
39900,
30200,
18000,
13368,
15500,
8200,
13400,
84500,
48800,
54300,
28500,
32300,
11900,
18500,
2800,
11500,
18100,
31900,
200,
10000,
15100,
null,
36000,
11500,
44000,
3525,
9400,
71100,
null,
15750,
2600,
18400,
null,
24200,
13500,
8000,
21700,
33500,
10500,
12700,
33100,
7900,
17100,
15700,
18400,
3800,
15500,
51800,
19100,
23000,
32400,
23500,
5800,
42000,
34900,
6600,
82100,
42500,
15800,
73200,
31100,
0,
130100,
23200,
19700,
68000,
null,
null,
18600,
24300,
26900,
12500,
40700,
29400,
8950,
59200,
18000,
null,
null,
91500,
15100,
null,
10000,
7500,
52700,
15900,
null,
56500,
8800,
15000,
20700,
38300,
12400,
19100,
10500,
2800,
28800,
24400,
25200,
13700,
18000,
null,
30000,
17200,
6500,
27400,
16500,
41200,
40900,
6700,
16900,
26100,
20500,
23600,
28400,
22500,
37400,
102600,
21700,
19537,
10200,
32300,
12400,
22600,
12100,
29100,
19700,
25300,
10900,
8000,
7900,
34300,
36400,
6500,
3300,
13500,
28500,
6500,
17800,
21600,
9100,
44400,
31600,
null,
83400,
10900,
7000,
27300,
36800,
24300,
7000,
22800,
13300,
65900,
24600,
19500,
null,
78800,
49100,
29900,
71400,
9200,
29500,
16700,
null,
119500,
27000,
18400,
43300,
10800,
13300,
44100,
91200,
62800,
12300,
32200,
9800,
36000,
25000,
87300,
7800,
12800,
null,
45900,
null,
10700,
24400,
27600,
null,
16600,
10600,
34800,
18900,
19700,
11800,
37900,
12900,
74700,
18300,
6500,
35000,
79000,
95900,
14400,
14700,
71200,
12300,
33700,
28500,
83500,
6200,
25900,
20700,
6500,
4200,
9500,
75700,
3800,
20900,
55500,
18800,
13100,
43200,
14100,
15400,
5400,
16700,
48400,
8800,
2600,
34800,
null,
24700,
76600,
46100,
27700,
89300,
68700,
32800,
32200,
49400,
17000,
7000,
31600,
4100,
48000,
15550,
20300,
27400,
19300,
6400,
22000,
69325,
42300,
19100,
44500,
19700,
2800,
31200,
8000,
16500,
88800,
21100,
55700,
null,
19300,
44900,
16700,
101200,
10500,
null,
105300,
60000,
47200,
72500,
23100,
46800,
16600,
15200,
6800,
17600,
37500,
45900,
37500,
34500,
11900,
29200,
31300,
13400,
60300,
null,
4400,
5400,
59400,
38100,
null,
14800,
2900,
13100,
22700,
47000,
null,
24100,
16300,
43400,
21800,
11500,
null,
10800,
13800,
null,
15000,
73000,
21300,
39800,
59800,
26700,
26300,
106300,
23600,
34800,
null,
10400,
25500,
14000,
44200,
12100,
37900,
5200,
27600,
3900,
25700,
17600,
null,
null,
55100,
null,
68500,
6100,
23400,
11300,
9900,
54700,
24900,
38100,
15000,
21100,
7300,
38000,
13700,
187300,
115600,
49500,
7300,
22800,
10300,
27000,
92400,
77500,
35700,
13500,
27200,
11400,
45200,
11400,
28100,
27800,
25900,
18600,
9100,
null,
20100,
36900,
25700,
21100,
42700,
24600,
33200,
null,
36400,
34000,
24700,
51400,
10800,
23900,
12800,
28500,
57500,
32300,
12900,
85700,
null,
61400,
26700,
44000,
68700,
71900,
23800,
22400,
26100,
19400,
23600,
21200,
8500,
40500,
4300,
52300,
54100,
21100,
27600,
15000,
51500,
30900,
17300,
51200,
29300,
null,
191100,
19100,
3500,
34200,
26500,
33200,
67900,
13500,
21800,
30000,
7000,
83400,
41300,
24214,
41500,
null,
37000,
93300,
13400,
50000,
52700,
21200,
null,
33000,
62600,
44800,
8300,
20800,
23600,
6000,
52100,
null,
27800,
14300,
20300,
19700,
24200,
5500,
26000,
12500,
9000,
29800,
16100,
9600,
10000,
14700,
5300,
5400,
31500,
61900,
37300,
34800,
52300,
8200,
26300,
23100,
null,
27200,
22100,
27300,
39200,
15300,
17400,
59500,
29300,
12700,
70300,
21500,
90905,
94700,
17500,
9500,
29100,
700,
7200,
30309,
20300,
null,
31600,
13400,
33300,
50200,
null,
7900,
60000,
71400,
13700,
33212,
34200,
5500,
16500,
28500,
18000,
28000,
56952,
105300,
6800,
79500,
153400,
null,
25600,
null,
49400,
12500,
21300,
28800,
17000,
69400,
59700,
97900,
53900,
54628,
11900,
20400,
17300,
30800,
24100,
3300,
15900,
87000,
30200,
null,
13000,
29300,
null,
17000,
15200,
null,
27100,
10300,
59500,
18650,
27100,
14300,
4800,
15000,
16200,
17000,
13800,
10100,
24800,
17800,
17400,
11900,
27600,
14400,
37100,
null,
26600,
15700,
24900,
19200,
null,
29400,
25400,
39600,
14800,
21000,
50200,
6000,
27400,
15500,
26800,
12500,
15500,
55600,
22000,
17600,
148300,
42000,
13200,
23700,
5500,
24900,
28300,
66900,
25600,
12400,
85460,
20600,
null,
20900,
14000,
4200,
22400,
20100,
47900,
12400,
5100,
16300,
26100,
54000,
22000,
17300,
42100,
27700,
13200,
14700,
32200,
11900,
45000,
1900,
24300,
49600,
32500,
12700,
13700,
11400,
51942,
60300,
null,
33900,
84600,
10000,
15400,
42900,
40200,
49800,
93700,
77900,
41500,
18200,
null,
27300,
26400,
20400,
null,
14200,
9000,
8000,
14100,
43100,
31700,
6100,
30100,
23100,
9700,
76500,
8400,
18000,
2550,
55000,
null,
29800,
18000,
21600,
34800,
62300,
58100,
22800,
18600,
21529,
8200,
27300,
14600,
2200,
30100,
16800,
44700,
null,
5100,
41900,
10200,
null,
5000,
15000,
19900,
22700,
10400,
24900,
37600,
14300,
null,
16200,
31200,
13600,
20100,
15900,
27400,
33200,
8100,
8800,
123300,
4000,
6100,
6600,
9500,
15500,
30300,
59300,
24700,
22700,
18900,
null,
24100,
32400,
51634,
17500,
9400,
16000,
46000,
16800,
23500,
6800,
42300,
73800,
null,
12900,
11400,
120500,
10600,
16100,
13500,
70100,
null,
108200,
53900,
54300,
51000,
17300,
27600,
15200,
8800,
12800,
18400,
24000,
75800,
19500,
175700,
12400,
62400,
12600,
49700,
53700,
27100,
8900,
26200,
null,
1000,
15400,
23300,
44400,
null,
29600,
31600,
34400,
9300,
35700,
7600,
29500,
17200,
null,
13400,
29400,
18500,
10800,
null,
67400,
38700,
27400,
16500,
10700,
38500,
31500,
32300,
19700,
14600,
25400,
10600,
19800,
27700,
43900,
null,
17000,
11700,
5100,
45400,
15600,
39300,
10500,
57400,
19300,
38400,
16000,
null,
106400,
6300,
85400,
47200,
25300,
47000,
49200,
24700,
11100,
2300,
26800,
11500,
33500,
30000,
4500,
44700,
9400,
21400,
9200,
38300,
24400,
8500,
87200,
36000,
18500,
16900,
28800,
32100,
26500,
16100,
15000,
6500,
23000,
16600,
22800,
5700,
25000,
17200,
86000,
10000,
7900,
15700,
13000,
11000,
24200,
20600,
31900,
15400,
7300,
null,
null,
17100,
47100,
69900,
53200,
16000,
17500,
null,
3900,
null,
4000,
null,
24700,
33000,
48700,
50700,
25400,
68700,
36400,
null,
14700,
57200,
64200,
13200,
12000,
9600,
21700,
13600,
29000,
24100,
27200,
13300,
15200,
16200,
32000,
10100,
23500,
63400,
9100,
14000,
null,
13600,
19800,
28000,
67700,
20200,
21000,
31200,
34500,
null,
15400,
39500,
10800,
10600,
19000,
23700,
31900,
18100,
3900,
28900,
52400,
7900,
10900,
54800,
null,
5600,
19700,
24600,
128512,
16750,
7850,
106300,
4300,
14000,
143300,
17700,
21000,
29400,
18500,
303900,
38100,
12700,
null,
7800,
334500,
15400,
16600,
102400,
40000,
22000,
26100,
null,
62600,
46200,
23900,
12600,
24600,
4100,
26900,
null,
18400,
6009,
null,
17200,
null,
13100,
24100,
13600,
17400,
45600,
40000,
69000,
63000,
13300,
15900,
2500,
32500,
12100,
13200,
null,
22300,
40800,
5600,
67900,
7400,
31400,
7800,
18700,
12400,
22200,
24900,
281400,
13500,
84300,
15500,
5900,
24700,
61600,
65200,
51100,
10100,
11900,
5900,
null,
26800,
66400,
19700,
16100,
20400,
50100,
37200,
56500,
28500,
14000,
34700,
29800,
36000,
19800,
50500,
6900,
13300,
9200,
27700,
63800,
20000,
44900,
16000,
80500,
13100,
60050,
49200,
18800,
21000,
27100,
5200,
17400,
3100,
33100,
9600,
35000,
112000,
15100,
null,
null,
52600,
46100,
20500,
6770,
31200,
16800,
33000,
17000,
20800,
100300,
78100,
37800,
45400,
26900,
2052,
9300,
10500,
119500,
5400,
20300,
7600,
5800,
36900,
48900,
8800,
6800,
null,
13000,
37600,
35100,
null,
12400,
61700,
93000,
37400,
null,
14600,
9350,
34800,
17400,
8600,
48989,
53500,
23600,
15500,
79900,
34500,
18700,
57000,
51300,
15500,
19000,
6800,
29600,
7100,
null,
29000,
22300,
36000,
20300,
16900,
17400,
96800,
5500,
10000,
13200,
32100,
34100,
null,
null,
20400,
27000,
20000,
22000,
null,
21700,
27300,
11000,
46700,
17000,
20600,
18200,
74300,
11200,
19100,
12100,
8900,
67300,
25800,
62500,
56700,
7900,
7500,
40100,
17300,
39000,
18500,
57100,
4000,
64200,
38600,
107500,
5500,
37400,
64100,
34300,
35500,
10500,
45931,
3100,
51100,
7000,
15000,
57500,
32100,
null,
69100,
14100,
16700,
17700,
null,
16900,
24300,
9600,
null,
7000,
32200,
55500,
7200,
9200,
null,
null,
25800,
35800,
24100,
36900,
27500,
8300,
null,
3600,
27300,
10100,
null,
17400,
28600,
16400,
17200,
null,
14300,
44900,
null,
46000,
25600,
null,
13250,
17000,
16600,
16800,
29500,
59700,
63800,
21700,
26600,
null,
23100,
45500,
20400,
32000,
6200,
35600,
18500,
31200,
45700,
26700,
10300,
26200,
28300,
37800,
22700,
6600,
8000,
17100,
10900,
78000,
null,
24800,
17700,
11000,
null,
13500,
22250,
23800,
44600,
9000,
44700,
14400,
11300,
19200,
36100,
36200,
21500,
24050,
40900,
25700,
null,
38200,
11500,
8300,
4500,
34900,
18100,
22000,
337400,
10600,
13300,
11200,
48300,
10100,
16000,
13700,
24900,
12200,
null,
37200,
25000,
31080,
112600,
10500,
9500,
71000,
22600,
8300,
108900,
38900,
27800,
10900,
null,
12400,
18600,
23500,
23100,
6700,
null,
null,
47900,
15500,
21100,
null,
10500,
46200,
7800,
49920,
5500,
6000,
45800,
7600,
23800,
25900,
11700,
192200,
23100,
10200,
6200,
116200,
7600,
null,
27700,
6300,
18700,
45000,
31300,
16600,
44450,
43800,
19300,
23300,
32200,
12100,
32100,
27300,
58300,
36400,
32200,
70500,
67100,
64100,
21000,
24800,
31000,
34300,
23000,
51800,
22349,
21900,
5000,
58000,
null,
41300,
null,
5700,
4700,
19000,
41600,
14400,
44300,
17900,
21100,
57100,
14500,
27000,
19100,
17000,
6000,
22500,
149200,
20500,
16900,
12900,
68900,
86200,
null,
19000,
20500,
26700,
140800,
51000,
15100,
22700,
18900,
32300,
25400,
34100,
10600,
22500,
29700,
71700,
49000,
45100,
48600,
29100,
14100,
24600,
8700,
26800,
10900,
19000,
14900,
55700,
null,
25400,
14700,
35490,
14600,
10000,
71500,
21600,
null,
36200,
15000,
22600,
24500,
28300,
50300,
31400,
null,
26400,
47400,
6900,
16300,
37700,
165500,
24200,
26100,
103200,
40200,
7200,
24400,
78400,
20000,
12200,
17500,
3500,
64100,
61500,
null,
15550,
32900,
null,
null,
15200,
21500,
13500,
31100,
54200,
16600,
29800,
175500,
39100,
24600,
6900,
null,
6500,
null,
12000,
40900,
50500,
42200,
45000,
30700,
41700,
13900,
38400,
30300,
21300,
17000,
92800,
null,
35100,
12200,
23100,
14200,
49100,
18500,
33000,
43900,
73500,
18500,
null,
26500,
33200,
58500,
21800,
23000,
38400,
24300,
66000,
13100,
13200,
73600,
58100,
26000,
62200,
6800,
19900,
22300,
19100,
65100,
20800,
54200,
65400,
6300,
33100,
62400,
18100,
14500,
11500,
20600,
25400,
34900,
null,
36700,
null,
11900,
18900,
45100,
null,
1900,
34400,
86700,
13400,
null,
29000,
9900,
21500,
41400,
26300,
null,
29500,
24200,
5900,
49200,
28500,
14000,
34200,
55800,
34100,
6600,
64800,
19800,
24800,
null,
16300,
86900,
null,
16300,
23900,
24200,
33000,
17900,
12900,
12500,
16800,
17800,
null,
12100,
12800,
22100,
null,
19100,
19100,
20400,
24900,
13300,
3300,
17900,
16000,
21500,
14000,
4800,
14200,
null,
17000,
69900,
17600,
8700,
36700,
15500,
60400,
21500,
null,
35500,
10900,
9900,
21800,
10000,
14400,
null,
12500,
29700,
12800,
26200,
15900,
14300,
43200,
24400,
null,
135200,
67700,
28400,
13300,
5000,
42500,
71300,
18800,
10600,
3500,
94800,
32000,
42000,
10500,
9200,
10400,
32100,
49600,
84500,
39700,
106800,
92300,
null,
null,
53600,
null,
21300,
19800,
44100,
8500,
29900,
24200,
14600,
21100,
null,
47600,
103800,
152900,
10700,
50600,
20800,
46900,
13000,
31500,
10700,
57600,
53800,
11000,
25500,
21100,
24900,
91600,
34000,
14000,
25800,
60100,
19300,
42500,
4700,
61300,
11100,
17800,
15200,
6100,
16400,
32500,
5500,
19400,
41400,
22200,
null,
30200,
47000,
14100,
12400,
39900,
21300,
42400,
53200,
15900,
42650,
55000,
21800,
60400,
25300,
36800,
null,
17500,
19400,
15900,
12700,
5600,
21000,
22600,
null,
16900,
27100,
22500,
9700,
16700,
1900,
11200,
38200,
7500,
null,
34200,
4700,
35000,
35700,
12100,
10800,
null,
85100,
12000,
7800,
23500,
null,
8400,
100200,
4300,
14100,
32300,
21700,
17600,
49700,
10100,
27900,
24800,
30700,
null,
38300,
24200,
168700,
13900,
44600,
15900,
47700,
41500,
63900,
27000,
32500,
24000,
null,
19200,
25900,
76400,
19600,
4700,
24505,
26000,
null,
39300,
10300,
14500,
10400,
23000,
14600,
18000,
23900,
32300,
34500,
null,
null,
5500,
32000,
22700,
6700,
64100,
25700,
29200,
12100,
17200,
null,
33300,
23000,
129700,
41200,
16000,
32500,
51800,
17300,
17400,
82200,
23300,
70200,
8800,
17200,
99600,
109200,
28100,
12800,
7400,
29900,
28300,
33300,
23200,
36300,
8000,
26800,
8100,
23600,
16900,
14600,
51000,
19600,
11300,
27800,
8100,
14700,
28400,
12500,
13500,
8100,
10000,
24200,
49700,
35300,
18100,
null,
16100,
41100,
40000,
26600,
10900,
23700,
8900,
19500,
31300,
26600,
null,
null,
8500,
43300,
14700,
16500,
null,
28000,
19900,
25100,
31800,
23700,
39000,
4300,
null,
21500,
21200,
38600,
28400,
null,
14800,
45300,
14800,
8400,
20900,
64800,
35200,
19400,
27600,
30000,
61600,
32700,
33300,
29700,
15300,
103000,
43300,
11600,
18700,
10200,
20500,
67100,
7300,
15800,
53100,
8000,
25900,
2200,
7300,
26700,
15200,
15400,
4900,
34500,
null,
12000,
43800,
71000,
17400,
32400,
17500,
7500,
5100,
50100,
34400,
38000,
30400,
11217,
null,
54300,
11200,
17300,
8000,
41600,
60700,
6100,
31092,
null,
8500,
18800,
35300,
34200,
null,
9300,
71660,
51000,
9100,
44200,
7600,
88900,
8900,
57400,
73700,
20200,
41800,
111700,
null,
29800,
42001,
22300,
42600,
52000,
12800,
105600,
null,
11500,
4000,
55900,
null,
30200,
4000,
53500,
84266,
4700,
64300,
11700,
14100,
13600,
4800,
20700,
6200,
6800,
23700,
18500,
55900,
15000,
51800,
17600,
18500,
10300,
8600,
20000,
10100,
94900,
22900,
30500,
32200,
51100,
48600,
null,
12500,
58900,
25500,
19800,
14900,
10100,
null,
19200,
13100,
21900,
46700,
22200,
13300,
28400,
null,
null,
10700,
8200,
9500,
19700,
11100,
26600,
17400,
26800,
25800,
4500,
41400,
15200,
50200,
null,
52550,
22800,
20700,
2800,
15500,
66500,
15000,
18900,
14500,
5800,
39500,
61000,
15200,
null,
6500,
39400,
50500,
43000,
9200,
18700,
47700,
18100,
48300,
38200,
31300,
25000,
3500,
3000,
53000,
18300,
17400,
33300,
26100,
13900,
26700,
null,
13900,
46800,
69500,
28300,
22700,
26201,
26600,
47300,
36000,
null,
38100,
15700,
135700,
181300,
39900,
18600,
19800,
17800,
29900,
20300,
82300,
94900,
13400,
37200,
23400,
45400,
22600,
37400,
38000,
27300,
20000,
22900,
18600,
21600,
13000,
12800,
10700,
17500,
19000,
24700,
9200,
10600,
27300,
24100,
19400,
10600,
32200,
11300,
23700,
26300,
40800,
27600,
18400,
41300,
16400,
9700,
17100,
null,
130060,
23000,
3900,
12500,
25100,
null,
17600,
22600,
25300,
20100,
6500,
17900,
11952,
19700,
62900,
14300,
63700,
13600,
30600,
25300,
null,
33000,
8400,
13100,
17900,
7200,
13600,
null,
14500,
15500,
11700,
24100,
137200,
7000,
42800,
48500,
28600,
48600,
14100,
327700,
13500,
10600,
41000,
null,
null,
26600,
15900,
86500,
50700,
16600,
73100,
28200,
22200,
40400,
13300,
30800,
37700,
57400,
null,
40100,
9600,
55000,
18000,
25000,
11400,
21800,
29900,
46200,
null,
26200,
23000,
17900,
11100,
3700,
8800,
30300,
31600,
50400,
27300,
19200,
58400,
39300,
21400,
21300,
15500,
11200,
14000,
3100,
22100,
56300,
29800,
10000,
10700,
29600,
22800,
41200,
64400,
9100,
39500,
8000,
25200,
30400,
59100,
22200,
63200,
26400,
23500,
19800,
52500,
42200,
null,
null,
17000,
14000,
60200,
14000,
23200,
29100,
24700,
48400,
44600,
31100,
6000,
23900,
30500,
40300,
37900,
13700,
null,
47200,
44300,
4400,
27000,
null,
16600,
33800,
27300,
null,
26400,
34400,
26500,
38700,
22400,
11200,
161000,
18000,
29500,
11500,
9100,
37328,
73200,
28100,
17200,
50600,
44800,
40300,
20900,
10300,
13500,
57900,
73300,
9200,
7700,
24100,
40100,
15400,
19900,
7500,
6700,
20200,
25600,
13300,
16500,
84000,
null,
31600,
37700,
12500,
74500,
14400,
16200,
null,
null,
21500,
32100,
52200,
48700,
13000,
50600,
null,
null,
37200,
35500,
22600,
93800,
30100,
8100,
29600,
32700,
27400,
26100,
30500,
55200,
18000,
41500,
21500,
16200,
7500,
36500,
7300,
16600,
55800,
36400,
41600,
22000,
14400,
112800,
24800,
6600,
37600,
16800,
null,
41100,
26800,
13800,
18700,
115100,
20400,
34275,
15800,
32600,
49500,
4500,
32400,
14100,
35200,
33500,
7400,
34100,
40100,
41300,
17345,
34300,
42400,
5500,
8500,
7900,
12500,
19200,
29800,
6050,
5800,
21700,
3300,
25000,
45600,
35400,
103800,
86000,
23100,
33600,
18700,
8100,
24200,
1500,
70100,
56300,
22800,
33400,
16400,
47600,
20400,
12700,
49100,
9900,
29000,
3500,
null,
111100,
39800,
36600,
11800,
33900,
29000,
17200,
32200,
30800,
31900,
9800,
27200,
35600,
6400,
37400,
26200,
13000,
12400,
15100,
31400,
21300,
24600,
70000,
6357,
153300,
25700,
14200,
14400,
15100,
32900,
11100,
14800,
null,
13800,
null,
15200,
59000,
29600,
21300,
null,
17600,
8800,
3000,
19700,
14500,
21800,
20000,
25600,
31200,
17000,
17100,
341900,
34200,
8900,
14800,
15600,
38100,
13700,
21700,
106500,
24700,
77956,
31500,
null,
59500,
46600,
11100,
10900,
12200,
37100,
170600,
20800,
18200,
15400,
null,
48400,
7200,
null,
9000,
5100,
19400,
5650,
12700,
11000,
21400,
37300,
10700,
35800,
31500,
12600,
23300,
18300,
38100,
30000,
10900,
41400,
30800,
42600,
9800,
13900,
12800,
12600,
35900,
41606,
30900,
90100,
9400,
25900,
55200,
39049,
25700,
37800,
44400,
7300,
46300,
null,
8000,
23600,
null,
29300,
23900,
29400,
56300,
13900,
31500,
15700,
44300,
38900,
23000,
18700,
115100,
9400,
34900,
32300,
46900,
50800,
23000,
18800,
8500,
15000,
18200,
35200,
31300,
7550,
68200,
24400,
29300,
34000,
69200,
72400,
276300,
5500,
2800,
33600,
30800,
null,
58200,
null,
19500,
8800,
75700,
null,
null,
19700,
63600,
46200,
37000,
41100,
8500,
8500,
null,
20600,
18700,
21700,
30900,
25500,
26900,
null,
40300,
13500,
7300,
23700,
73000,
10500,
52100,
null,
37600,
30200,
6600,
11700,
23700,
null,
8800,
14100,
6600,
79000,
107400,
30600,
57700,
35000,
9200,
46700,
15400,
180700,
46500,
82000,
48600,
76600,
50800,
31400,
31300,
16100,
25400,
22600,
3500,
null,
22800,
28200,
38700,
38300,
4200,
4200,
24800,
23000,
16100,
89600,
137300,
15500,
null,
50700,
null,
33000,
42900,
14600,
9700,
30900,
13600,
81600,
60550,
18800,
11800,
25200,
1900,
18696,
70869,
24900,
10900,
148700,
14500,
null,
37700,
56700,
22600,
3000,
21100,
42500,
27800,
42400,
43100,
6600,
2900,
32500,
20100,
27700,
40300,
67300,
48200,
18600,
160000,
10100,
7800,
38600,
36500,
91600,
20300,
11500,
19600,
null,
44100,
8100,
45400,
85400,
78900,
18400,
25900,
11400,
65800,
49200,
21300,
12900,
null,
null,
null,
36600,
15200,
32800,
111800,
40000,
32100,
20500,
30900,
5100,
21100,
43500,
30600,
14900,
66600,
18600,
13800,
34700,
30200,
6400,
75000,
152500,
5705,
19100,
6600,
38200,
44500,
19000,
29000,
49800,
78700,
26800,
74000,
5300,
12600,
20300,
51100,
null,
63500,
55200,
42900,
10300,
130100,
6600,
15700,
null,
null,
34600,
7100,
29000,
17900,
8500,
58000,
15000,
119500,
24800,
24900,
36800,
19300,
12600,
113930,
38800,
10600,
37800,
21600,
43600,
29100,
36900,
11400,
20600,
38400,
21500,
33400,
10700,
36400,
53600,
52800,
16400,
11400,
80500,
8100,
146400,
40700,
19800,
65700,
5300,
46500,
11100,
25600,
48400,
41456,
45700,
13500,
7400,
15400,
69500,
145800,
23000,
170900,
25500,
null,
14900,
41000,
41900,
15700,
15600,
10400,
8400,
7700,
19600,
11500,
81300,
null,
19200,
null,
67800,
null,
12000,
null,
20000,
17200,
null,
26500,
42000,
16800,
55700,
78422,
24800,
15200,
39000,
33200,
26000,
28100,
18300,
14500,
46300,
30000,
29000,
9100,
8500,
10400,
19300,
22600,
null,
7700,
43900,
29800,
6400,
3000,
43800,
27600,
92900,
43500,
65900,
34300,
6100,
27700,
15100,
4400,
13800,
20100,
null,
58900,
3600,
19900,
17200,
24100,
67400,
48300,
null,
null,
null,
8200,
42700,
13800,
2000,
16100,
56700,
33700,
46200,
47400,
22700,
20800,
6700,
15300,
55800,
10800,
40500,
30300,
12500,
25700,
5800,
null,
null,
15900,
26600,
30600,
21600,
14300,
42500,
31800,
0,
99500,
null,
15200,
11800,
7600,
114100,
31500,
2500,
5100,
7300,
50500,
21200,
110510,
34600,
50700,
38900,
null,
14400,
15800,
18900,
9400,
20600,
32700,
49500,
19100,
41900,
47200,
8300,
52800,
22100,
12300,
36600,
9500,
21600,
20600,
84400,
null,
9200,
24800,
20300,
13200,
13000,
12100,
38300,
8600,
27200,
136100,
24900,
12700,
36700,
23400,
7300,
9500,
18800,
16900,
15700,
32900,
70900,
32000,
230400,
5000,
14200,
5700,
51000,
76100,
7400,
17000,
17000,
19900,
19100,
17700,
32200,
9100,
11000,
14000,
5700,
81000,
20500,
28700,
33700,
11300,
6800,
55000,
null,
9400,
30400,
73800,
12500,
8400,
27600,
41800,
71400,
32800,
21900,
9800,
11200,
248100,
43300,
35500,
12000,
6200,
13200,
55600,
9900,
7000,
11700,
39100,
13800,
45400,
9200,
31900,
8500,
22300,
15900,
9200,
41600,
13600,
41500,
8100,
44000,
44000,
14500,
19000,
41500,
21500,
43000,
101700,
null,
null,
85500,
17500,
50100,
7300,
41500,
6900,
13100,
66900,
43400,
null,
43000,
1000,
21200,
19800,
47400,
64600,
42500,
12100,
9200,
23100,
40000,
8000,
25400,
19700,
13000,
32200,
5000,
15600,
53500,
6400,
29900,
16700,
27600,
25600,
27100,
71188,
16400,
18100,
32500,
26300,
null,
33100,
50900,
30900,
20100,
15800,
16000,
20500,
17500,
29100,
6900,
35800,
17200,
null,
2900,
5000,
9000,
23900,
null,
15600,
15600,
5500,
13800,
31600,
21700,
175700,
26300,
15000,
5600,
48350,
5900,
30500,
11300,
20700,
29800,
55500,
28000,
10200,
17800,
21600,
20100,
21700,
20600,
13000,
12000,
null,
15000,
33700,
20800,
14150,
17500,
24600,
29000,
22700,
24100,
11900,
21700,
null,
26900,
5500,
30000,
19800,
35800,
7200,
15000,
null,
10200,
null,
null,
10600,
94100,
67700,
28500,
27800,
2000,
38900,
40300,
57900,
23000,
10200,
23900,
70400,
52000,
34300,
30400,
10900,
33000,
null,
10600,
39500,
16800,
13100,
36600,
121600,
48700,
19400,
16000,
11800,
21300,
24500,
49700,
41800,
157600,
32600,
20995,
84000,
11800,
19900,
8200,
103500,
40000,
88800,
14600,
33300,
null,
34300,
32000,
13700,
19300,
16400,
63300,
19900,
16400,
15700,
25600,
14800,
17300,
42600,
58900,
23200,
10100,
7100,
33000,
27200,
6200,
91200,
7300,
25900,
52700,
46300,
19000,
21200,
15700,
35400,
null,
17200,
17369,
4000,
null,
41700,
null,
42400,
null,
57900,
28600,
5100,
24700,
19500,
34900,
26400,
59100,
29200,
13100,
null,
41800,
45800,
17500,
null,
8200,
10800,
null,
10500,
14400,
51900,
60300,
32500,
17500,
10300,
39900,
12900,
13300,
27000,
83700,
18300,
5800,
23800,
19600,
23580,
29300,
62800,
52400,
41700,
52400,
10400,
20600,
10900,
46000,
13000,
73900,
7500,
36600,
23700,
18200,
36000,
11600,
15500,
63700,
40100,
33500,
7900,
null,
25000,
27700,
10000,
28400,
19600,
19700,
19100,
15100,
42900,
null,
41100,
26900,
65400,
17100,
12800,
16800,
24200,
15700,
14200,
44100,
14700,
11200,
7500,
9200,
15100,
52700,
45200,
13100,
5700,
10000,
37800,
17700,
103200,
5000,
30800,
105000,
null,
38900,
17000,
27000,
29400,
94900,
7600,
42300,
14000,
null,
19390,
11000,
23700,
21200,
13900,
26200,
46600,
32600,
19200,
20700,
23800,
9300,
68900,
36500,
26500,
20500,
28000,
64800,
12200,
12000,
null,
45800,
1600,
34800,
14900,
null,
81200,
null,
30000,
97200,
53400,
106400,
28800,
83400,
7300,
null,
65900,
25300,
41600,
null,
30000,
94447,
35000,
5000,
79700,
null,
39100,
140800,
53400,
36900,
17600,
14300,
21000,
27800,
52900,
35100,
null,
55000,
27000,
21400,
10500,
66000,
28600,
24600,
14000,
6800,
46400,
null,
73800,
28900,
22900,
23700,
17700,
18700,
7500,
13800,
109100,
14300,
29500,
133600,
22200,
154900,
33800,
5700,
null,
32500,
34400,
48700,
8400,
40500,
12300,
20500,
24700,
16900,
64400,
10200,
26300,
17300,
null,
12700,
10500,
130600,
12500,
35800,
11000,
10200,
36100,
15000,
19625,
27000,
16700,
40100,
74500,
8800,
23700,
26600,
13000,
null,
null,
10500,
85600,
59400,
83200,
null,
18200,
24400,
null,
6500,
101400,
7000,
12500,
12200,
23600,
114700,
141550,
13500,
15200,
57600,
57000,
16500,
34200,
89800,
53705,
16200,
7800,
42600,
41600,
24900,
null,
18400,
14600,
22800,
66800,
30800,
28500,
6700,
32000,
11000,
16500,
11450,
null,
18000,
12700,
60200,
8500,
41100,
19700,
26500,
7300,
16000,
null,
34300,
22700,
7100,
58000,
55200,
76804,
32800,
65000,
48500,
6150,
5000,
10800,
79600,
13900,
null,
15800,
89500,
null,
22400,
12100,
24200,
15500,
31700,
22400,
31600,
104100,
77900,
27100,
26800,
10400,
61100,
29000,
48000,
41200,
25000,
30400,
70500,
38100,
11600,
null,
20100,
25200,
4200,
null,
127100,
11400,
67700,
64500,
10300,
null,
null,
5800,
null,
37400,
94600,
null,
12400,
48600,
56200,
20700,
16200,
80700,
51600,
194800,
17300,
120900,
15400,
6200,
19100,
13800,
23700,
9400,
10700,
27600,
24900,
9600,
18000,
6600,
23500,
3500,
12400,
19300,
23000,
33600,
3200,
44200,
56600,
39800,
null,
null,
23254,
71300,
252300,
7500,
47800,
27400,
34500,
22800,
null,
2500,
13500,
116100,
39800,
19000,
17100,
17500,
54600,
72900,
9200,
16700,
64900,
17000,
20100,
31400,
null,
25500,
75300,
42000,
9400,
9600,
15200,
22400,
79400,
82300,
null,
68500,
41300,
171300,
32900,
27000,
14900,
12400,
26300,
192100,
74400,
22600,
23100,
9000,
27300,
11200,
10500,
84500,
22300,
22100,
31200,
9600,
3300,
42100,
null,
26700,
null,
15000,
29200,
11300,
8100,
46800,
null,
84800,
null,
37700,
5500,
48100,
null,
39400,
14900,
13050,
7400,
28000,
20300,
null,
null,
84600,
31000,
17700,
3700,
15600,
11600,
26900,
120000,
33000,
11000,
29800,
19400,
36100,
78600,
16300,
8400,
7500,
8900,
34800,
29000,
8265,
25600,
10700,
52400,
73200,
28700,
16500,
24200,
8600,
10200,
95055,
13900,
11100,
21500,
11000,
29500,
72100,
18100,
117900,
6700,
48000,
12300,
66894,
28100,
9800,
23900,
17600,
27300,
48300,
9000,
18600,
2900,
61200,
42500,
21700,
26000,
16000,
14000,
79100,
19800,
62600,
27700,
34400,
14000,
52300,
41900,
17017,
13400,
23600,
24200,
21200,
null,
16500,
33000,
24500,
23500,
20200,
25300,
23600,
35600,
18200,
33800,
8600,
5100,
84200,
29800,
16000,
3100,
25600,
38200,
36500,
null,
23900,
47200,
null,
27100,
41600,
33200,
11300,
39800,
9000,
null,
41015,
null,
1500,
13500,
48000,
null,
11200,
49000,
7900,
33400,
null,
5000,
153900,
null,
15000,
35700,
25500,
17500,
48200,
null,
6100,
16600,
69900,
19300,
null,
16500,
40300,
19300,
16000,
17500,
42050,
14000,
60800,
10100,
11700,
26300,
null,
5600,
12400,
9800,
29600,
9500,
38200,
15800,
37900,
18900,
59500,
null,
28400,
15000,
null,
15400,
63000,
21500,
36900,
57600,
57900,
9600,
41200,
43200,
37400,
15700,
51600,
71300,
31400,
29100,
8700,
25800,
12800,
27500,
10100,
9700,
6950,
219700,
36000,
40000,
26400,
14000,
17100,
14900,
42000,
35500,
27800,
11300,
19200,
16200,
43700,
47726,
null,
null,
18500,
1800,
14700,
3500,
null,
94100,
31000,
33000,
32900,
6000,
96500,
34200,
47300,
15500,
9500,
211400,
9500,
25500,
30100,
30900,
15700,
16866,
22900,
12100,
37500,
28500,
13700,
38000,
14400,
54500,
21410,
45700,
28200,
27500,
17300,
15700,
17100,
10000,
8600,
20800,
42400,
29600,
26200,
39100,
15700,
8000,
18900,
null,
40000,
35400,
63200,
77300,
78400,
35200,
82200,
21800,
203100,
48700,
5100,
510200,
46100,
29100,
null,
52100,
26300,
null,
46400,
12300,
47700,
2300,
36300,
49900,
6600,
23200,
8000,
26100,
null,
43400,
6200,
18700,
7000,
9000,
13700,
16300,
18100,
16600,
49200,
69400,
101100,
17400,
21900,
38000,
19200,
10300,
36725,
6400,
5500,
32100,
61800,
9600,
11600,
24100,
10500,
29600,
null,
null,
null,
29200,
22800,
34700,
17100,
41900,
42700,
12800,
137800,
35000,
17900,
17100,
9900,
21000,
31900,
null,
54771,
19300,
11700,
20200,
49900,
31500,
51600,
21965,
46100,
72400,
18400,
32700,
90600,
null,
null,
36300,
23900,
9300,
22900,
10900,
21200,
20900,
55600,
27000,
26100,
11400,
132400,
42900,
43600,
62800,
41600,
null,
105700,
39100,
null,
53718,
51900,
72300,
27800,
42200,
17700,
31300,
34000,
64000,
12700,
18500,
22600,
25000,
66200,
12300,
12800,
null,
28400,
26400,
10400,
10500,
20200,
24700,
null,
46700,
36300,
11200,
6200,
25600,
null,
38500,
13800,
8200,
18500,
22900,
8000,
231400,
33300,
19800,
17800,
11900,
14400,
16700,
43400,
76600,
25700,
30100,
15900,
11500,
25800,
30200,
64900,
23700,
24400,
17300,
8300,
23500,
19500,
38000,
84500,
12500,
21000,
15829,
21700,
30400,
25000,
null,
6900,
57300,
170200,
2100,
13500,
10100,
61500,
20300,
23600,
33800,
2300,
15900,
33400,
12900,
8800,
5500,
32600,
7500,
61600,
16200,
41200,
9500,
8500,
37400,
6000,
10900,
13900,
22300,
41301,
9500,
33500,
21900,
41200,
25000,
23800,
22400,
53900,
7700,
11400,
53700,
60100,
27400,
null,
36400,
188800,
23900,
5000,
45800,
11200,
9500,
15700,
36100,
68000,
14700,
40100,
21400,
null,
39300,
81000,
31000,
11400,
22800,
13200,
106000,
25500,
25300,
11500,
19700,
null,
16300,
12500,
null,
9800,
26500,
23500,
null,
20900,
18300,
28800,
12700,
6100,
5000,
16100,
39800,
32300,
null,
18500,
22500,
7800,
28500,
26200,
21000,
95500,
37300,
31400,
21000,
null,
19800,
21500,
15200,
12900,
14100,
null,
16500,
47300,
3300,
12300,
22300,
14000,
14700,
6000,
37500,
10000,
69100,
23700,
32600,
26600,
9200,
20100,
4900,
5600,
15200,
null,
42300,
9400,
47700,
42200,
26800,
30600,
25800,
6600,
61000,
33200,
null,
27700,
44500,
14300,
36900,
4000,
20200,
89500,
47300,
12000,
19000,
41900,
29300,
28400,
118100,
43127,
68200,
16700,
45800,
49000,
39300,
19300,
48600,
15800,
17100,
5800,
15000,
31500,
1900,
12400,
8700,
17700,
17700,
15300,
3300,
55100,
8025,
38200,
18600,
128100,
99400,
20500,
47500,
24300,
53800,
32400,
null,
27900,
52600,
37500,
23100,
5600,
8400,
11400,
24200,
6000,
32600,
34700,
null,
61800,
22600,
4800,
27800,
4000,
32900,
29200,
12700,
14200,
10700,
29000,
15400,
33600,
30500,
58500,
12800,
null,
33200,
37800,
26650,
150400,
39900,
63500,
17800,
3600,
15200,
9900,
18300,
13500,
24300,
51600,
29300,
108800,
10100,
19215,
null,
22300,
21985,
25800,
null,
27800,
30000,
11200,
18500,
22700,
32600,
67700,
89800,
57000,
27300,
26900,
73700,
15300,
33500,
62700,
8700,
12200,
52500,
28700,
6200,
null,
7700,
11100,
20100,
15000,
35500,
33900,
53800,
10100,
34600,
27800,
5700,
64600,
8900,
6100,
9100,
225805,
null,
11200,
24900,
9700,
9700,
27900,
25300,
19000,
49200,
45630,
13200,
16700,
28900,
13300,
31400,
25500,
17700,
16900,
null,
900,
22800,
37000,
8900,
37000,
58400,
16000,
29500,
22400,
null,
null,
28000,
14900,
7500,
5500,
14200,
null,
50700,
15000,
15300,
null,
null,
74500,
44100,
24300,
15400,
5100,
11700,
18800,
33600,
37000,
19900,
15100,
24700,
3300,
7100,
36100,
40700,
30300,
18600,
5000,
18100,
71500,
19700,
14900,
33400,
43800,
13500,
23700,
24900,
27500,
9300,
25200,
16000,
39300,
25100,
21900,
29900,
18800,
24500,
31400,
17300,
37800,
8000,
9400,
28800,
null,
26200,
56600,
59500,
8100,
36100,
44300,
138800,
29000,
14507,
26100,
19400,
null,
49200,
20300,
70800,
21700,
20300,
18700,
30200,
62100,
31400,
14400,
35400,
36100,
5600,
20600,
24400,
77000,
64900,
19800,
135400,
5600,
21900,
10800,
22200,
null,
9600,
19300,
21500,
19300,
null,
28800,
32500,
6700,
75500,
59200,
null,
null,
52100,
29900,
14200,
65000,
24900,
16400,
18600,
22700,
10300,
21100,
24000,
110400,
10300,
38300,
19100,
11400,
27500,
31700,
16500,
15000,
null,
7400,
14200,
23800,
64500,
21000,
25800,
47800,
46700,
22300,
11800,
16500,
26700,
42000,
98100,
34600,
21200,
9100,
35620,
null,
43400,
31800,
30900,
20400,
21300,
15600,
70300,
39600,
null,
28220,
55100,
28100,
34300,
95900,
null,
34150,
3000,
17700,
33100,
10900,
46100,
14500,
36000,
12700,
8800,
null,
18600,
30400,
27000,
13200,
58500,
18200,
27000,
5200,
10500,
36000,
25100,
47900,
29400,
9600,
66300,
36700,
null,
36500,
33200,
57000,
72300,
23500,
13100,
248400,
9800,
15600,
null,
49439,
15600,
56701,
23600,
41800,
37400,
21400,
81100,
58100,
12300,
21600,
null,
27900,
14000,
8100,
24000,
9500,
10500,
12900,
5550,
51100,
22000,
7600,
14400,
20900,
15400,
7000,
25800,
9600,
null,
7500,
9200,
9800,
50900,
30500,
38800,
35800,
40300,
30900,
16400,
13700,
92100,
23900,
10200,
4000,
44400,
16300,
28800,
11300,
4400,
3700,
21980,
7700,
59600,
64600,
34100,
34700,
15300,
28400,
42200,
18200,
27600,
60200,
10000,
22000,
7750,
14700,
22600,
null,
4500,
7900,
67000,
70200,
33700,
25700,
132100,
16300,
null,
13150,
8200,
22800,
null,
30700,
46000,
36270,
22000,
null,
13200,
49200,
32200,
4300,
null,
21500,
25400,
77200,
20300,
null,
34300,
42600,
8600,
0,
17300,
35400,
53000,
32900,
19100,
42500,
null,
6500,
9300,
32100,
66900,
35300,
39700,
42100,
22700,
15000,
27800,
112800,
18800,
25400,
72806,
38500,
29200,
7800,
34800,
28100,
26500,
12100,
123600,
null,
15800,
81250,
11300,
17300,
23400,
64300,
12900,
7600,
4900,
9500,
16800,
32600,
47100,
110100,
20700,
2400,
10400,
36300,
15700,
11900,
15600,
7100,
70100,
null,
null,
11200,
30900,
10400,
17400,
37700,
31600,
6000,
28200,
16500,
24100,
15900,
46800,
35000,
null,
2600,
7500,
18500,
69300,
24400,
59700,
45600,
12500,
7900,
19700,
30000,
5500,
18800,
75400,
5500,
13100,
23800,
35100,
null,
10000,
5700,
15300,
null,
22300,
39300,
43700,
12000,
19500,
68100,
15500,
19600,
15700,
56000,
17400,
6600,
16600,
45000,
8450,
null,
16500,
30600,
null,
63100,
30000,
7200,
null,
3700,
22600,
56100,
117600,
40300,
59700,
41100,
19600,
18700,
14600,
18200,
25000,
28800,
27800,
68800,
23100,
null,
106800,
30500,
13200,
23600,
20500,
70300,
11300,
32100,
61000,
null,
64600,
50600,
11900,
46600,
30830,
27200,
21200,
23400,
6000,
16700,
5500,
30200,
11000,
56000,
26700,
13600,
102300,
36100,
138700,
14600,
6200,
13700,
9000,
19900,
10800,
19700,
null,
21400,
27900,
41100,
30100,
39800,
33250,
40400,
65800,
64400,
16900,
null,
27500,
98200,
29400,
11300,
10500,
34600,
15700,
19000,
18200,
91400,
20300,
80220,
11300,
14100,
65700,
null,
18100,
17000,
37500,
36000,
5900,
17000,
27600,
25700,
151600,
26800,
33400,
47800,
35500,
13900,
17300,
80800,
13300,
null,
20500,
8900,
53200,
24900,
null,
30900,
null,
null,
18600,
313000,
19800,
11200,
10600,
null,
3400,
26100,
38500,
30400,
25100,
16900,
2800,
27600,
15300,
50700,
17600,
77000,
42000,
43200,
13300,
30400,
17600,
19600,
null,
55300,
22000,
32000,
73300,
11200,
29200,
22200,
20700,
14600,
43600,
25400,
15900,
44800,
10900,
20000,
27600,
4600,
null,
13700,
48200,
6000,
58600,
11000,
36600,
7500,
56700,
34000,
19900,
32700,
10500,
21800,
21100,
13300,
27600,
89000,
8100,
null,
23100,
33830,
167500,
54200,
21300,
29100,
21800,
15300,
13000,
81200,
38900,
null,
7100,
41300,
24800,
65500,
10400,
16800,
null,
22300,
16700,
17300,
4200,
28900,
22300,
17500,
52200,
8250,
30200,
5700,
56500,
18900,
41000,
20200,
56200,
10800,
10500,
31100,
83800,
39500,
12400,
230200,
22100,
23300,
37600,
53000,
9600,
6950,
51100,
6500,
104500,
16400,
55500,
21100,
9200,
4100,
17700,
22000,
9200,
8500,
null,
25000,
47700,
26000,
19200,
34100,
2500,
null,
13500,
60300,
23400,
31900,
26000,
83124,
26400,
40200,
163000,
28000,
null,
18900,
9500,
12300,
22700,
null,
52800,
null,
4700,
7000,
19300,
28900,
12900,
10200,
19600,
47100,
22100,
22200,
8500,
17800,
35700,
16700,
39600,
53100,
16200,
null,
60300,
46800,
278200,
14100,
21700,
37100,
33500,
16900,
38385,
null,
50600,
45900,
15100,
53900,
14800,
72900,
21700,
40500,
37500,
22800,
61800,
null,
13700,
42400,
20100,
20600,
7637,
74300,
57400,
15700,
4450,
22200,
39274,
null,
25600,
null,
10700,
20100,
24500,
19400,
null,
36600,
6200,
12500,
9300,
132900,
23900,
22000,
22700,
40900,
52500,
null,
19400,
16200,
14000,
27700,
28800,
27300,
37700,
49700,
8600,
73100,
1500,
35600,
24400,
84000,
27100,
27700,
56600,
8500,
null,
30700,
10800,
18700,
5400,
23500,
16900,
41900,
17400,
39400,
8000,
14000,
50500,
13400,
29900,
17600,
7300,
23600,
28000,
25600,
92400,
197100,
4200,
37000,
7300,
6500,
32700,
6400,
11900,
18900,
4700,
12900,
null,
28000,
19300,
null,
27450,
24900,
13900,
17800,
13200,
18700,
21700,
2538,
53900,
35400,
11000,
21800,
22900,
23600,
44500,
15000,
8500,
24700,
42400,
21800,
4800,
8100,
5100,
25400,
9800,
1000,
28200,
146800,
52500,
20200,
41400,
12500,
32000,
9000,
5000,
66600,
31300,
26300,
13800,
68600,
38900,
71400,
38900,
88100,
35950,
43400,
26600,
15200,
15400,
20500,
8100,
68700,
null,
16800,
15100,
9800,
19500,
11300,
7300,
33600,
80600,
11100,
8700,
11100,
26400,
103500,
null,
96300,
18800,
65500,
37100,
52600,
10700,
7100,
30300,
40600,
29900,
34800,
23100,
85100,
12400,
43900,
5300,
11900,
16800,
15200,
null,
49600,
55200,
24000,
8800,
21000,
18000,
42900,
44400,
11100,
21300,
38200,
4400,
49400,
24500,
33400,
19200,
55300,
14100,
42900,
27300,
58020,
47600,
14700,
10800,
16000,
15700,
15400,
15500,
7400,
74850,
18300,
47000,
43400,
18700,
19100,
29000,
7800,
4000,
8200,
11800,
34700,
16500,
28000,
16000,
20800,
28200,
71100,
7200,
17100,
19000,
48500,
null,
156700,
47600,
17800,
7700,
19800,
41700,
67800,
13700,
14800,
12100,
13100,
13100,
8500,
15600,
39900,
53300,
29600,
36700,
46300,
122900,
28900,
22300,
19400,
6300,
14600,
21700,
20200,
48500,
36000,
17500,
52000,
55100,
94900,
68800,
33600,
44200,
40000,
3100,
60100,
35600,
25300,
23800,
52900,
45300,
68600,
16000,
14900,
29100,
17500,
22000,
17500,
null,
19100,
11500,
52100,
32700,
4200,
227150,
45000,
6100,
11400,
79800,
38700,
null,
7500,
57100,
3600,
39100,
8000,
57400,
62300,
33400,
10200,
80200,
null,
null,
28900,
19800,
55700,
null,
10100,
31300,
27500,
54100,
null,
17300,
null,
29800,
null,
42400,
43000,
17300,
47600,
20600,
7900,
64700,
11100,
44500,
null,
55600,
25200,
27100,
15400,
15800,
10900,
29300,
8200,
32900,
17800,
null,
33400,
16000,
15500,
18600,
15700,
45400,
25600,
16100,
6200,
46500,
null,
4600,
11400,
85000,
7500,
6300,
140700,
16500,
12200,
42900,
35700,
null,
6600,
14200,
8700,
19800,
11800,
42000,
13800,
40000,
null,
7100,
24900,
29000,
55600,
36200,
10800,
13200,
343500,
8700,
22200,
13100,
16700,
13000,
null,
14500,
null,
5400,
10800,
27900,
113168,
9200,
8600,
33356,
null,
33000,
24800,
9800,
14800,
19400,
29400,
147400,
10100,
22400,
27000,
39300,
101900,
14600,
21100,
33000,
44800,
35500,
68300,
17000,
27700,
17100,
41600,
85100,
50200,
null,
17600,
45600,
9500,
21200,
47500,
22000,
12300,
33500,
23600,
12100,
36800,
null,
59400,
28100,
22650,
27300,
null,
8850,
11800,
49300,
16100,
15200,
24700,
25600,
28700,
28800,
214100,
null,
8600,
12700,
11800,
11200,
21500,
null,
32800,
28100,
30500,
21400,
16100,
12300,
50800,
35900,
79300,
11700,
60800,
14500,
null,
10600,
7500,
112700,
13400,
16500,
26000,
56000,
8700,
51200,
28300,
null,
20500,
50600,
59700,
18000,
15700,
20300,
32700,
17700,
11200,
14900,
18500,
55500,
14600,
11000,
null,
14400,
12200,
64400,
103700,
42500,
19900,
170500,
23900,
118900,
37600,
null,
24900,
59500,
7300,
null,
13200,
126245,
7000,
20600,
29800,
38400,
11300,
12700,
16800,
17000,
25500,
21800,
23500,
17000,
43000,
86300,
15700,
62500,
9700,
115000,
16584,
null,
2500,
26100,
null,
9500,
10300,
19700,
6550,
35298,
24000,
33500,
18000,
15700,
11500,
22400,
null,
22000,
13600,
58700,
8300,
35500,
29000,
11200,
12300,
15500,
27500,
18400,
null,
42400,
15900,
54425,
13300,
13300,
null,
33700,
5300,
null,
27300,
4800,
22100,
6010,
21900,
null,
21400,
79100,
6900,
16100,
25100,
49100,
25172,
31700,
65200,
21700,
7400,
13200,
37800,
22900,
33800,
30600,
48500,
25000,
97600,
23700,
21780,
26600,
2900,
10000,
37000,
null,
32600,
25100,
19500,
17500,
58400,
17400,
10000,
12500,
37200,
11700,
48000,
48800,
19500,
13700,
68000,
11400,
36500,
10700,
84600,
8700,
19700,
11400,
18800,
16200,
52300,
8500,
13800,
15000,
59800,
23600,
25400,
27900,
25200,
29000,
null,
26300,
42300,
52000,
51300,
50800,
47100,
null,
15200,
8100,
63700,
36500,
4100,
47325,
25300,
23200,
14900,
231200,
44200,
54700,
null,
13500,
20400,
49200,
34700,
16800,
14000,
20500,
null,
22700,
9700,
52400,
7600,
3000,
null,
24800,
14300,
19300,
80951,
17900,
3500,
47600,
63100,
60100,
8300,
22700,
74200,
45200,
15700,
40300,
220000,
28400,
46100,
66700,
8800,
null,
3400,
15100,
23200,
42300,
27300,
21600,
33000,
46200,
11200,
89100,
23100,
10800,
9500,
7100,
43800,
42600,
14300,
47800,
1000,
42600,
14200,
58100,
8700,
24700,
26100,
24000,
12100,
18500,
18000,
11400,
26600,
30800,
29000,
6400,
null,
19900,
2400,
18600,
22400,
43100,
6600,
93700,
13900,
24700,
25300,
34300,
35600,
36100,
35300,
16500,
37400,
87000,
40500,
61850,
30700,
12400,
14900,
22400,
91400,
43000,
13400,
null,
17900,
9900,
47100,
18300,
11300,
37600,
6300,
33600,
35500,
101600,
15500,
39300,
61700,
42100,
48800,
null,
14900,
18500,
67400,
30700,
7400,
44200,
32400,
20400,
110200,
60200,
116300,
49500,
31400,
21600,
7800,
35700,
29900,
23200,
27300,
7300,
36500,
null,
34200,
56200,
25700,
5000,
26800,
null,
null,
6600,
40600,
10400,
70000,
51500,
null,
2700,
22300,
38100,
15500,
18300,
null,
null,
34400,
26100,
51600,
25800,
69400,
30300,
26200,
37800,
79000,
14000,
30600,
10928,
13600,
53500,
8400,
24700,
44900,
54200,
11600,
5300,
16000,
51181,
115600,
38400,
13300,
184200,
17800,
null,
35600,
24900,
20600,
32500,
35700,
20300,
8400,
29600,
47600,
4300,
53600,
7100,
21305,
157300,
69400,
54200,
61900,
10800,
null,
27600,
39900,
3000,
4900,
14700,
29300,
28900,
33400,
12400,
70000,
35300,
113000,
4300,
32400,
43600,
75300,
35400,
14500,
52400,
34300,
13500,
65200,
41100,
15800,
2000,
11200,
null,
3500,
27000,
163000,
null,
19800,
23400,
null,
53100,
12200,
28100,
9100,
7900,
9400,
42400,
34500,
12300,
56100,
51200,
25500,
11700,
9700,
35100,
32800,
13800,
41000,
19700,
33300,
22200,
17400,
null,
43900,
null,
4200,
2000,
13600,
37100,
16600,
27400,
75300,
27400,
6000,
10100,
38100,
20200,
null,
31400,
28700,
null,
6500,
18820,
21000,
18080,
57300,
null,
119700,
20400,
14300,
29400,
41300,
15100,
11700,
36100,
29000,
22700,
60300,
21600,
35500,
30400,
16300,
null,
28100,
30000,
7900,
24300,
6000,
13100,
104400,
null,
5200,
27200,
39500,
9600,
13300,
36800,
null,
22300,
12400,
null,
25500,
31500,
5800,
null,
12000,
44200,
10800,
25800,
26073,
70203,
13900,
43600,
65300,
21400,
43000,
83300,
7900,
12600,
36000,
16400,
5700,
16900,
null,
17400,
41100,
38000,
8200,
8100,
2000,
31500,
46700,
16700,
17000,
41500,
7800,
21000,
52900,
21300,
20800,
132300,
21200,
5300,
89400,
49400,
13100,
40600,
12000,
119300,
28700,
9300,
36700,
null,
32200,
15600,
11200,
15500,
75534,
20800,
31300,
1400,
13900,
null,
10800,
24800,
25500,
27890,
28100,
20000,
24100,
null,
38200,
3600,
59300,
17300,
6500,
23100,
29200,
45100,
13700,
23900,
36086,
25550,
7800,
26000,
38000,
11000,
48400,
37000,
57800,
9000,
26300,
25600,
6800,
30000,
12970,
87800,
1600,
16400,
24400,
19600,
38100,
20400,
22000,
16800,
null,
58200,
20800,
6000,
32500,
9900,
null,
24900,
59200,
null,
118900,
23400,
43900,
33400,
26200,
11200,
null,
24100,
null,
15200,
10100,
45400,
54500,
20800,
11800,
19200,
68300,
10300,
16100,
4600,
5700,
28100,
118400,
25300,
26600,
15400,
54500,
301800,
28500,
5400,
29600,
66100,
36500,
null,
36000,
18700,
null,
7300,
42400,
14100,
6300,
13600,
16200,
79800,
33500,
50700,
7100,
32700,
5100,
30900,
20500,
null,
39500,
29700,
12200,
35600,
5500,
10500,
null,
64500,
98730,
121400,
null,
7200,
27800,
42800,
83200,
84200,
11200,
43600,
15300,
7900,
37800,
26100,
27000,
47200,
61000,
22200,
32600,
17500,
null,
14800,
15900,
null,
26700,
23200,
13800,
78800,
39000,
13600,
22800,
24500,
23000,
35700,
31100,
null,
54800,
16100,
8676,
null,
11100,
15500,
24900,
2500,
16800,
null,
28700,
10600,
null,
60900,
16400,
21300,
25100,
11700,
19500,
14200,
32100,
20600,
15000,
null,
31900,
17500,
56400,
50400,
16200,
16300,
6800,
28400,
14500,
63900,
11000,
45200,
65400,
23700,
41900,
33200,
35600,
27900,
42300,
7000,
4100,
13300,
44300,
30600,
40400,
48200,
30500,
14100,
36300,
39900,
21800,
10400,
37100,
null,
5100,
5700,
15200,
8500,
10800,
81100,
74000,
21100,
20000,
null,
140700,
164400,
27400,
19400,
15300,
70700,
12000,
20500,
31800,
9000,
14000,
16800,
null,
49900,
67300,
6600,
12700,
31000,
5300,
27800,
20800,
119200,
26600,
22700,
44300,
16700,
71400,
null,
null,
3200,
26000,
13400,
null,
38000,
42100,
34400,
39700,
21200,
31500,
7200,
30700,
77850,
19700,
140270,
24800,
91600,
34800,
9500,
7900,
28200,
10500,
16500,
61700,
25100,
12400,
52800,
12400,
64700,
22400,
null,
15900,
21186,
48200,
116100,
12200,
46500,
19300,
24800,
12800,
6900,
null,
25400,
13800,
10800,
13600,
34700,
4300,
10200,
20000,
46700,
8500,
18600,
80503,
56000,
null,
31700,
55200,
null,
51800,
16700,
20800,
44600,
31500,
24500,
2200,
21600,
28000,
29100,
59100,
30600,
30100,
null,
null,
null,
9100,
13000,
40300,
31500,
16700,
34000,
28400,
29100,
24400,
21700,
95400,
71300,
25800,
null,
8100,
null,
null,
32600,
47000,
25100,
1300,
72200,
22300,
4400,
78900,
136200,
28200,
36200,
17600,
6700,
10200,
21300,
25300,
61800,
25100,
12100,
62500,
null,
14950,
23200,
12800,
37100,
15200,
26200,
22300,
14500,
5100,
null,
28100,
19150,
21500,
21400,
47500,
35300,
11400,
33100,
11200,
44100,
7000,
21300,
179800,
30000,
16400,
13500,
12800,
20600,
46700,
15200,
15400,
null,
53200,
35300,
9700,
26800,
9700,
47300,
33100,
9500,
null,
14100,
73000,
22300,
null,
39900,
4300,
27500,
13000,
13400,
8300,
null,
null,
24700,
88300,
18900,
28900,
10300,
36400,
60000,
null,
36700,
4000,
26000,
25500,
15800,
16100,
16800,
46100,
63300,
73200,
32000,
82500,
12700,
19500,
230000,
7300,
12200,
54600,
15800,
17600,
74500,
17900,
22500,
null,
26000,
36200,
16600,
13100,
22900,
21500,
13250,
14700,
null,
10700,
4900,
44400,
67100,
92800,
37200,
53200,
11000,
null,
13300,
34500,
48499,
10300,
44200,
26700,
null,
400,
3100,
12300,
21100,
7400,
5500,
23100,
37200,
28700,
27014,
181900,
12300,
6900,
41900,
12700,
29700,
24500,
44900,
10400,
14700,
null,
16600,
13500,
57700,
14300,
75150,
9500,
4300,
14500,
20300,
28300,
54700,
45300,
11000,
null,
10800,
4000,
50600,
21900,
55400,
31300,
50400,
13200,
9600,
16100,
8300,
22600,
35100,
32300,
29200,
18200,
69600,
9000,
26100,
18000,
1300,
27500,
56100,
8000,
6800,
9200,
22100,
11300,
null,
35000,
8000,
66600,
29700,
43500,
22600,
7300,
45300,
53800,
null,
24000,
32300,
17500,
17400,
2900,
700,
8100,
23600,
18700,
21200,
17200,
36700,
47000,
15900,
11000,
15900,
15100,
53130,
92000,
59800,
null,
23300,
39100,
14500,
4000,
3100,
21900,
29300,
null,
17100,
32000,
14600,
12200,
30640,
57000,
25200,
38000,
22600,
4900,
83100,
14200,
8400,
54400,
70000,
13400,
14300,
16500,
12500,
7600,
30900,
82300,
43200,
21600,
7400,
20500,
66500,
23500,
34100,
8100,
129400,
7000,
85200,
34000,
44700,
49100,
10700,
13400,
46400,
41000,
43500,
72700,
11100,
23300,
22800,
23100,
21300,
20500,
116425,
11600,
49500,
50100,
19700,
14500,
47500,
35600,
10400,
14500,
14700,
null,
null,
59100,
31100,
24100,
65533,
59600,
25800,
16300,
null,
null,
24300,
10000,
15800,
26900,
null,
15200,
66400,
19675,
6200,
47400,
30500,
15800,
null,
54200,
11400,
48600,
51300,
13200,
35300,
52000,
41200,
27600,
14900,
24700,
3500,
15900,
68400,
16700,
11100,
5000,
41200,
18200,
15200,
46100,
63000,
9800,
19600,
12600,
11100,
15300,
17300,
13400,
15200,
7825,
31500,
29000,
12700,
11300,
161100,
77920,
22900,
17800,
36200,
36500,
13900,
30700,
16600,
null,
17300,
16000,
43600,
15800,
7300,
null,
34900,
14000,
26400,
69929,
6400,
65000,
12200,
46000,
32000,
10000,
51000,
31000,
11800,
56600,
37600,
50800,
78300,
11500,
34800,
10200,
30000,
13600,
83300,
14600,
23200,
8900,
19600,
22400,
42400,
8500,
null,
73800,
18300,
5800,
36600,
30800,
16300,
4600,
54400,
88200,
84300,
16200,
33500,
25300,
9400,
11700,
41000,
6800,
19500,
12700,
14400,
null,
46300,
12300,
47200,
30100,
34300,
78700,
27000,
39000,
26100,
75700,
3300,
23500,
8300,
3800,
14900,
31900,
35900,
25200,
37500,
129500,
30600,
26000,
8500,
23700,
33600,
21000,
null,
24100,
null,
9700,
null,
62900,
25600,
48900,
42800,
64800,
15800,
23500,
15600,
41000,
34800,
52900,
40500,
16700,
42600,
15000,
9200,
20000,
23700,
27900,
44300,
null,
20400,
null,
37600,
10600,
18800,
14500,
76400,
16300,
7300,
70000,
26100,
21700,
20100,
26600,
24700,
15500,
43300,
88200,
83600,
63100,
7800,
178100,
20300,
15200,
6800,
23200,
7100,
34200,
null,
46300,
13700,
8800,
37400,
41600,
31800,
29500,
19300,
355000,
39400,
12802,
82800,
21600,
37200,
7400,
32900,
11900,
45500,
31000,
13500,
6200,
38600,
25800,
9000,
8900,
77100,
67500,
32000,
163700,
6400,
10700,
14500,
34700,
null,
115500,
70100,
26000,
19800,
20900,
39600,
20700,
72200,
6600,
10500,
null,
43700,
29800,
2600,
12200,
42700,
16800,
65400,
null,
23200,
17600,
12500,
27900,
16700,
17300,
200800,
9700,
30200,
24100,
62300,
10100,
14500,
105200,
42800,
13600,
null,
null,
92200,
10500,
69600,
12400,
151100,
15700,
50000,
24800,
24600,
47600,
48900,
33000,
14700,
14900,
17400,
48800,
40000,
40400,
24700,
12585,
6300,
22800,
94900,
31910,
14600,
null,
12600,
33100,
9900,
13300,
18300,
26300,
14300,
9800,
65400,
33200,
81700,
null,
23400,
63200,
31300,
7900,
59600,
18500,
31000,
52800,
54215,
90100,
74500,
18000,
68700,
null,
13200,
13500,
null,
37700,
75700,
8500,
51800,
9500,
110300,
14800,
45200,
8700,
5600,
11900,
15800,
55300,
32500,
6900,
19900,
11000,
13500,
3700,
35500,
110600,
69400,
17000,
44800,
16700,
4700,
12600,
160000,
17600,
87700,
53700,
52700,
51800,
6500,
58300,
17900,
5800,
29600,
7500,
15600,
28600,
11100,
7200,
58000,
36900,
44400,
30700,
28700,
5600,
32200,
15900,
15300,
13900,
26800,
11500,
46500,
40000,
7400,
10500,
34600,
5500,
50500,
67500,
25100,
128500,
2800,
8500,
28800,
24600,
23600,
39300,
7100,
5100,
26600,
24300,
58000,
40100,
12450,
16600,
16300,
20900,
9300,
8500,
26800,
161500,
16000,
8700,
33500,
8600,
60500,
8900,
47700,
108500,
56800,
17700,
16500,
56300,
98600,
36600,
24711,
9300,
24200,
22800,
16800,
16600,
35600,
133105,
72000,
null,
22900,
23900,
14800,
17000,
null,
null,
33100,
21300,
null,
37800,
29300,
110900,
26600,
26500,
16400,
24700,
16600,
41300,
20200,
21000,
30100,
38000,
21700,
26100,
17200,
41000,
22240,
22100,
25800,
10200,
23000,
34600,
36500,
19800,
11400,
19400,
71600,
25600,
31400,
63400,
16400,
11500,
null,
null,
35200,
4000,
22800,
21000,
24700,
5000,
9350,
4900,
7000,
10700,
9000,
62400,
15200,
59100,
14500,
28500,
12700,
67000,
13200,
20700,
19600,
null,
42000,
7500,
175600,
33200,
61200,
45600,
155600,
14400,
60000,
23500,
6900,
12700,
26300,
18500,
33700,
19100,
3200,
69500,
15500,
35300,
30800,
25400,
51000,
31800,
5400,
41500,
18900,
19000,
59900,
20400,
15900,
40500,
8100,
23500,
8200,
50682,
17000,
36000,
null,
12227,
18800,
106300,
28700,
40500,
null,
28000,
82000,
12300,
18300,
19900,
36500,
15400,
37200,
18800,
41100,
17000,
12800,
58700,
26100,
17800,
57000,
16500,
31100,
21900,
21700,
11600,
25800,
3300,
10700,
24000,
43500,
null,
118400,
55700,
30733,
32800,
9800,
71745,
8500,
4300,
26700,
83600,
13400,
78762,
12800,
19200,
5200,
30415,
2500,
20800,
11100,
5800,
47200,
11200,
6500,
7500,
30300,
156700,
28600,
12900,
null,
22100,
7300,
9800,
null,
20300,
32600,
10000,
46200,
69900,
20400,
53800,
11300,
51500,
33500,
22400,
7100,
30700,
9700,
32800,
22000,
11000,
null,
102100,
62100,
null,
54200,
8300,
28800,
28500,
null,
22600,
20500,
18400,
19700,
24400,
8300,
124900,
17800,
31600,
13300,
24700,
7200,
331000,
26700,
50400,
19200,
20700,
null,
10500,
6600,
8200,
6800,
40500,
27000,
26100,
24500,
9700,
35500,
95900,
15100,
12500,
33700,
119806,
8700,
19500,
16900,
65600,
8900,
30000,
25800,
16800,
30800,
9800,
24800,
13500,
86100,
10800,
1900,
null,
13700,
null,
98200,
11500,
44500,
42200,
31500,
18700,
29900,
15200,
12500,
31300,
10000,
22700,
30800,
18047,
7000,
14300,
null,
41300,
64100,
58000,
44101,
20600,
23400,
37000,
11300,
null,
25400,
10800,
70200,
46100,
7700,
29500,
25700,
19200,
60100,
80100,
35900,
67200,
39500,
16600,
44200,
8100,
25200,
null,
76600,
12200,
13900,
19300,
17500,
26400,
45400,
38100,
12200,
null,
19300,
16200,
null,
45600,
28000,
39700,
43200,
20300,
15100,
45000,
5700,
24100,
7800,
15100,
95800,
54800,
22300,
13600,
4800,
27000,
9600,
41600,
8500,
null,
12800,
31600,
52100,
14000,
36700,
66500,
26200,
28512,
14800,
5200,
null,
100400,
39000,
24800,
22177,
null,
21300,
26500,
53400,
42100,
39000,
5500,
43300,
null,
16300,
15900,
null,
55900,
11000,
16076,
79415,
null,
14900,
4900,
10700,
20600,
34600,
122000,
50300,
13000,
28800,
124300,
33900,
26400,
13700,
145500,
null,
17600,
31300,
6600,
11100,
49300,
31900,
14200,
2700,
null,
21100,
19600,
8500,
null,
21900,
51400,
27000,
13000,
17100,
null,
39800,
48900,
27700,
15000,
18200,
14200,
10800,
41200,
15300,
17700,
11600,
null,
14100,
null,
43200,
16600,
22100,
35500,
25200,
null,
94100,
48200,
22600,
22400,
83383,
19100,
11800,
46300,
41900,
17500,
20300,
38700,
26700,
5300,
10700,
35200,
30200,
45600,
11000,
15900,
10600,
18000,
25090,
19300,
14300,
7300,
22800,
16600,
60400,
6700,
67290,
33200,
32000,
17300,
67700,
11400,
103900,
13500,
17700,
33800,
null,
3300,
2800,
52700,
107000,
55400,
23100,
50300,
53500,
38300,
68000,
35400,
19300,
5000,
19600,
67000,
null,
19400,
5500,
58500,
22500,
27200,
17100,
37200,
54700,
34500,
9900,
26800,
12100,
25800,
36800,
40800,
8400,
null,
30800,
27000,
null,
24000,
24200,
8000,
14400,
21000,
5300,
45100,
19700,
20600,
21500,
20800,
19000,
22000,
15400,
null,
22700,
8500,
null,
92000,
12500,
17900,
null,
75300,
22100,
19700,
19300,
21200,
53700,
58300,
37000,
17000,
7500,
3000,
21600,
18900,
55800,
7300,
130600,
null,
null,
13100,
17300,
41800,
16600,
15600,
16500,
26300,
32900,
9000,
7200,
10800,
3600,
47800,
81500,
25000,
29800,
65400,
2800,
34500,
26000,
14200,
null,
31800,
22000,
52000,
32200,
26800,
4600,
34300,
73600,
27000,
17200,
170900,
22400,
6400,
46400,
21500,
23750,
56100,
10500,
96600,
97900,
42900,
15000,
57800,
22300,
24800,
9500,
12100,
47100,
17900,
56010,
6900,
27100,
18000,
5900,
9900,
4300,
35300,
18800,
52200,
8300,
28100,
null,
17200,
150000,
17600,
24300,
41100,
9800,
16300,
12700,
24800,
24100,
14900,
30000,
12600,
24400,
7000,
109200,
14700,
20100,
29000,
9000,
6900,
9100,
84500,
45300,
66300,
10200,
15500,
40900,
37900,
null,
null,
34900,
10100,
42700,
null,
null,
17200,
67500,
191875,
11100,
27000,
77000,
5400,
11200,
27800,
31500,
59300,
54000,
49600,
68700,
12100,
19600,
28700,
105100,
45500,
78200,
64800,
56800,
38600,
18500,
52200,
null,
6800,
44600,
27600,
12600,
31500,
29600,
45500,
5500,
26000,
30500,
21800,
25300,
80926,
25400,
67100,
57500,
6600,
125700,
16700,
null,
9900,
3500,
17300,
18200,
50000,
5700,
20600,
3700,
12000,
14000,
7100,
11100,
2300,
29500,
13300,
8600,
22800,
13100,
15300,
18800,
32300,
18600,
null,
27500,
57600,
57200,
20200,
18900,
20100,
30000,
39000,
12400,
20900,
77500,
55100,
18200,
16900,
12000,
14700,
7400,
15000,
null,
14700,
33300,
15700,
34400,
27400,
10900,
14800,
70300,
36600,
21400,
3100,
27600,
21000,
51800,
7200,
9300,
36400,
16000,
15400,
29300,
15400,
25100,
9000,
28000,
18200,
5400,
10000,
3100,
42900,
64100,
37700,
44478,
5400,
null,
38600,
29200,
56700,
12300,
12200,
49600,
68800,
117900,
6550,
22500,
18300,
20300,
34600,
10150,
17800,
18650,
5200,
32500,
59700,
null,
14600,
12800,
52100,
24300,
73700,
9100,
7100,
15500,
28300,
27100,
42000,
16100,
null,
32100,
6300,
61100,
16300,
34500,
33000,
null,
12800,
8600,
45700,
31400,
37300,
53800,
22000,
21900,
49500,
35700,
24700,
23200,
70000,
36300,
27200,
24800,
72100,
145200,
null,
13700,
41000,
34400,
8800,
31500,
35400,
null,
14932,
15700,
null,
12500,
42800,
24000,
16800,
null,
47400,
32700,
12100,
8000,
7950,
16300,
29600,
16900,
29000,
69900,
null,
14200,
1000,
101000,
18600,
36400,
200800,
33800,
23300,
57500,
46000,
15700,
null,
50500,
43200,
15900,
17400,
18000,
54700,
19900,
13700,
20300,
15400,
38500,
14600,
19100,
34600,
17600,
18000,
6300,
28700,
38300,
75900,
12000,
4800,
51400,
3300,
4600,
37900,
58400,
50100,
101992,
5900,
31900,
59000,
null,
18200,
12900,
17400,
6100,
48200,
43500,
null,
1700,
62400,
52400,
38000,
19200,
16900,
36000,
7300,
16300,
26100,
96400,
8800,
12300,
null,
11400,
7900,
18400,
28700,
11200,
18000,
29600,
21600,
9800,
6100,
null,
26300,
40100,
null,
22300,
12700,
22300,
13200,
9400,
31100,
33600,
120800,
null,
27100,
23200,
12800,
12600,
13800,
9800,
182300,
36600,
16500,
54920,
19400,
9850,
22100,
14000,
52000,
75100,
23000,
14100,
20100,
21400,
44900,
37700,
488400,
37600,
35800,
54300,
18800,
82000,
39050,
51300,
35300,
null,
38200,
7900,
103400,
16100,
44000,
49600,
16400,
7900,
34000,
null,
149300,
6400,
25800,
null,
39900,
null,
48000,
41000,
28300,
5600,
null,
46000,
98600,
54000,
95400,
21700,
30100,
2900,
48000,
49500,
null,
72400,
11400,
47800,
27900,
2500,
30600,
82500,
17100,
34400,
18400,
36000,
12700,
34500,
10200,
20600,
18100,
14700,
13400,
12000,
51500,
51400,
46500,
14000,
8300,
62000,
null,
87500,
27600,
null,
24100,
29600,
13200,
27300,
null,
10300,
26300,
38500,
46800,
102300,
10800,
8800,
52300,
23500,
31400,
38800,
13700,
21700,
20100,
30500,
15100,
16700,
59100,
48300,
68900,
6500,
25500,
10000,
19700,
60000,
7000,
57200,
14300,
24700,
31900,
null,
59800,
28700,
5000,
2800,
19800,
105600,
22100,
25500,
31800,
19000,
7800,
22500,
38600,
9700,
23700,
31700,
27900,
5500,
15900,
14000,
28100,
32600,
16400,
38000,
4400,
35400,
10000,
20300,
10150,
16500,
58500,
11700,
19500,
38100,
16800,
10000,
174175,
5600,
10900,
6900,
80400,
10100,
19700,
22700,
15000,
46600,
19200,
21400,
29500,
49000,
19300,
35645,
21400,
25400,
51789,
7300,
null,
34600,
18400,
21500,
16000,
11100,
null,
14900,
31400,
9900,
25000,
64400,
22200,
138500,
2800,
19600,
26000,
2000,
30900,
25000,
38700,
15500,
30600,
7600,
12600,
15300,
11800,
6500,
12000,
26900,
78500,
23900,
39000,
8900,
18600,
38600,
34200,
25200,
5800,
125100,
29900,
63400,
14200,
26000,
null,
12000,
27300,
26100,
null,
33700,
20500,
51600,
78300,
30600,
18500,
49900,
4000,
34800,
71900,
53200,
44600,
15700,
25200,
11600,
23600,
7500,
null,
45000,
26000,
10100,
10000,
21200,
52200,
13559,
6900,
null,
40200,
null,
64100,
30000,
5800,
4800,
null,
43500,
5500,
null,
28600,
70100,
607200,
2400,
27000,
35500,
null,
36400,
26500,
18300,
22100,
91600,
41000,
9800,
13100,
13300,
53500,
11800,
17300,
3400,
36500,
24500,
43800,
68100,
10100,
19700,
7500,
11240,
29200,
58800,
25400,
15800,
31900,
21200,
8500,
27800,
39200,
13700,
35600,
null,
9500,
29700,
13900,
15900,
79800,
64100,
49100,
38700,
17500,
23100,
13100,
75200,
19600,
null,
65900,
40100,
48700,
91800,
24700,
27700,
78500,
null,
25900,
22200,
36200,
17000,
20000,
15100,
38300,
32200,
5500,
40500,
17000,
114900,
50700,
26600,
19400,
null,
36500,
null,
19700,
9700,
11800,
18800,
131800,
12300,
22100,
16900,
63300,
19500,
57500,
18700,
24500,
19000,
54900,
56300,
23800,
53300,
9600,
96700,
28100,
95200,
10200,
22500,
47500,
null,
6900,
20700,
null,
9400,
22300,
35900,
16600,
59400,
48000,
2500,
23000,
16100,
23400,
21000,
21800,
null,
15300,
4700,
5800,
59300,
28500,
7800,
7500,
null,
27800,
23400,
7700,
null,
null,
55300,
19300,
null,
17800,
23700,
25500,
null,
178000,
40400,
19800,
35500,
3300,
36000,
46800,
23700,
57000,
20900,
null,
49200,
56200,
24000,
36600,
15500,
45100,
46601,
226500,
58100,
12100,
19300,
34300,
26800,
9900,
51100,
22400,
15500,
57800,
25900,
5500,
21200,
10900,
16600,
16300,
null,
51500,
42300,
17900,
37500,
39600,
24900,
60400,
null,
7900,
4700,
7200,
42100,
14100,
34900,
18200,
39000,
84000,
18300,
16800,
12600,
10200,
19600,
8400,
37700,
38600,
15100,
23200,
28900,
null,
25700,
35700,
3500,
106100,
14700,
14800,
67600,
34800,
21200,
7400,
null,
20300,
1000,
null,
77900,
16900,
11100,
19500,
32300,
8700,
19600,
41300,
13900,
28500,
9600,
9200,
11500,
72900,
15500,
15900,
47700,
22100,
10500,
7000,
13400,
33100,
null,
7100,
12800,
68986,
37000,
null,
null,
40700,
97900,
3400,
null,
4000,
15800,
24400,
null,
null,
53300,
8100,
null,
5300,
56000,
36500,
22200,
54400,
13500,
34000,
20800,
49100,
14900,
12900,
33800,
24300,
55900,
5000,
44100,
27600,
7500,
15800,
40600,
25100,
null,
7300,
14500,
22600,
66400,
23300,
34900,
21900,
17900,
21100,
23400,
50900,
22100,
41600,
47500,
4600,
null,
4600,
30100,
20600,
30000,
28000,
46100,
38900,
11600,
32171,
18300,
27200,
12000,
37600,
null,
69900,
34200,
52600,
22100,
12636,
19600,
15500,
8900,
13200,
5700,
13300,
17000,
5000,
52800,
48100,
null,
31600,
12700,
4200,
30000,
134800,
null,
10900,
35200,
32600,
17700,
58800,
18600,
68400,
8300,
195800,
27200,
null,
81000,
16900,
11500,
13600,
23800,
7000,
122600,
63700,
35800,
11400,
9100,
null,
18700,
17000,
29800,
5200,
51200,
40500,
59500,
32300,
35700,
16300,
41400,
15400,
28400,
3000,
75600,
63200,
8500,
29700,
12200,
23700,
89600,
9600,
21400,
20500,
12300,
33200,
27600,
8100,
27900,
38500,
8400,
32900,
22800,
28200,
134900,
1200,
101500,
20700,
7400,
22700,
59800,
44100,
12100,
null,
26500,
35800,
23700,
81700,
13600,
29200,
10300,
8300,
5500,
15800,
72600,
13100,
24000,
37500,
45700,
27400,
45500,
null,
82000,
6700,
54100,
15000,
13300,
34800,
84100,
12000,
49000,
19900,
33900,
6600,
48000,
81100,
6000,
13700,
20800,
null,
null,
52400,
20300,
5900,
16000,
4200,
48300,
23900,
27100,
15000,
56800,
30200,
35600,
56500,
13700,
11900,
10700,
54200,
13600,
45800,
17400,
47700,
40900,
16900,
null,
6800,
21300,
null,
37200,
6200,
13200,
38300,
44200,
25800,
14900,
57300,
40200,
39500,
30300,
42600,
94900,
14100,
8800,
19200,
9500,
7300,
16600,
15600,
28500,
4700,
null,
166200,
35900,
15400,
6700,
55400,
18700,
368900,
40500,
14200,
15700,
17200,
21700,
null,
5600,
36700,
26500,
22000,
14200,
22500,
2500,
58800,
47500,
null,
69000,
17200,
15500,
53800,
21300,
18000,
26100,
61800,
16700,
45100,
11600,
8600,
22700,
17100,
5950,
49700,
22500,
18500,
37900,
43200,
25400,
32200,
5500,
27200,
11100,
95800,
6400,
7300,
14600,
15400,
42200,
52200,
25500,
42300,
38700,
13500,
30100,
null,
14200,
24700,
124300,
26300,
51300,
40000,
21500,
31400,
20100,
10000,
8700,
5600,
5100,
4500,
22800,
39500,
null,
51100,
19300,
24700,
11000,
700,
12500,
37600,
18300,
52100,
11900,
26800,
19500,
16100,
113000,
55200,
7000,
29000,
84100,
11500,
37500,
55600,
63268,
5900,
68216,
29100,
16800,
23600,
11100,
16400,
44300,
28300,
17400,
27700,
21500,
16400,
25200,
20600,
38900,
18900,
13300,
39800,
null,
7500,
89742,
16900,
26000,
66300,
21200,
12300,
18400,
16700,
12800,
10100,
32800,
7700,
11900,
45300,
5900,
51300,
17500,
28800,
36800,
7700,
18500,
11600,
21400,
39000,
12100,
63200,
50100,
64100,
104500,
15400,
37700,
11100,
null,
23900,
41400,
10600,
25500,
15600,
10000,
5200,
85100,
1700,
64600,
14800,
20000,
35300,
44400,
30900,
23400,
29900,
17200,
19200,
26300,
19600,
49000,
37500,
71000,
9800,
34300,
32600,
17000,
24900,
49700,
45400,
19200,
null,
3500,
263100,
28500,
12200,
43500,
47000,
27650,
16500,
42400,
116700,
null,
11300,
29300,
17800,
13900,
null,
20800,
20500,
20900,
7200,
61500,
28500,
17800,
null,
32100,
100100,
181100,
8200,
16800,
4000,
42700,
null,
8000,
33200,
26300,
6600,
25200,
19800,
7600,
15500,
17500,
7400,
50762,
18900,
39600,
21600,
14500,
33720,
null,
28300,
22000,
181700,
60900,
7700,
77500,
11700,
29300,
6900,
22200,
9520,
37500,
28500,
35400,
24000,
21900,
7500,
18000,
null,
103700,
22100,
4500,
28200,
10900,
13300,
39500,
18600,
null,
24800,
42700,
23252,
19500,
74800,
22200,
20200,
7200,
21000,
23300,
27700,
14700,
58200,
40400,
34200,
33800,
16500,
11300,
59300,
24300,
null,
14629,
20600,
65100,
null,
9300,
150700,
29100,
34500,
33400,
6400,
24400,
40100,
59267,
80100,
22600,
28000,
52900,
14900,
18100,
13900,
23300,
11900,
32300,
7500,
38300,
15600,
null,
32500,
17600,
64900,
13000,
null,
34500,
900,
16100,
30500,
35000,
13200,
7500,
13400,
24600,
9600,
68000,
14400,
13600,
7100,
8600,
27700,
55900,
27300,
37500,
11700,
20800,
16300,
27900,
null,
39300,
58800,
27400,
14600,
25700,
11100,
224600,
145300,
9300,
31300,
23500,
14300,
51800,
17600,
19200,
15000,
24000,
29470,
28500,
37200,
12100,
30700,
21700,
77500,
null,
16000,
5200,
15500,
34300,
31900,
14300,
52400,
28500,
11800,
17000,
43500,
1400,
25400,
4200,
null,
48100,
14600,
10800,
36100,
25300,
54700,
13000,
17200,
50500,
null,
33200,
31300,
28900,
null,
48100,
49500,
6500,
48500,
23500,
null,
21300,
20000,
16500,
37700,
25900,
52600,
27500,
31300,
15500,
45800,
26000,
46200,
9000,
47600,
24100,
17400,
34200,
39200,
41300,
17000,
77900,
101100,
13800,
8200,
9300,
56200,
34300,
45800,
26400,
8100,
20200,
25200,
13900,
15200,
21300,
null,
42900,
null,
12000,
33000,
16500,
21300,
23100,
2600,
76700,
50600,
23200,
10800,
13000,
7900,
17800,
35300,
22100,
11500,
32800,
25300,
19000,
65700,
158400,
28300,
39800,
23300,
0,
15800,
70800,
11600,
25400,
30800,
8000,
14800,
10400,
18700,
null,
26400,
22100,
15800,
32400,
20200,
null,
6800,
10100,
36300,
14100,
56100,
23500,
55900,
60000,
56100,
8100,
27000,
1500,
4900,
36900,
23000,
null,
51800,
15100,
27900,
22000,
140500,
null,
11600,
38800,
48200,
49400,
47200,
25700,
10400,
18800,
1500,
21000,
14700,
46300,
16200,
28000,
12800,
1000,
24700,
19700,
88800,
34200,
44700,
24700,
null,
27000,
26500,
60300,
16900,
98200,
22600,
36500,
28300,
40900,
25400,
14500,
22600,
73400,
24300,
11100,
21800,
38700,
60000,
31300,
7500,
31100,
100400,
4500,
23200,
25300,
24100,
38800,
28000,
50700,
22100,
20200,
31600,
10400,
23900,
null,
53000,
16900,
114700,
26500,
17600,
10800,
8300,
25700,
7100,
32200,
18700,
null,
19600,
48000,
29800,
14200,
30200,
17100,
17300,
8700,
23900,
58300,
43873,
11100,
26600,
33000,
43800,
52300,
31000,
6300,
64700,
89258,
36500,
21600,
null,
9800,
20700,
27400,
12300,
19300,
57700,
null,
7200,
75100,
null,
10300,
20100,
40400,
87600,
27700,
2000,
357900,
38500,
null,
8900,
26900,
31300,
8400,
4700,
14300,
18400,
38200,
16200,
null,
40300,
6700,
63800,
17700,
null,
16100,
14400,
29800,
61000,
16100,
16200,
null,
41700,
19300,
14800,
73000,
6300,
45900,
25000,
8600,
33500,
42300,
13800,
59100,
22400,
18000,
45300,
18100,
12200,
38400,
147550,
9200,
25900,
14200,
23100,
30400,
60600,
25300,
27100,
14900,
6800,
24900,
28200,
null,
12400,
50200,
46600,
55500,
20400,
49000,
44806,
20710,
null,
4500,
20000,
14800,
null,
null,
3500,
32500,
106900,
12100,
37400,
12500,
15700,
23600,
22200,
null,
null,
800,
22600,
51100,
null,
35200,
29700,
null,
20000,
2850,
102400,
null,
30400,
38900,
45000,
26400,
50100,
28900,
22300,
34800,
29000,
33800,
87000,
23800,
18600,
41600,
54100,
13400,
69000,
10200,
56300,
44200,
9500,
77500,
null,
84500,
27100,
22100,
27000,
5800,
null,
23300,
42700,
71000,
38916,
16500,
75400,
10500,
7200,
19200,
11200,
26300,
16300,
40700,
83400,
19500,
17000,
16700,
8200,
42300,
27500,
5400,
6600,
16500,
15700,
42900,
null,
38500,
12300,
12700,
47400,
15400,
17500,
63700,
12100,
24100,
33100,
33600,
25000,
16700,
14400,
61000,
21000,
11300,
99600,
32900,
106300,
7500,
null,
14000,
73600,
25300,
null,
36600,
6900,
11300,
19100,
66500,
4200,
17800,
null,
46300,
19800,
24400,
null,
42900,
34800,
14200,
13100,
40300,
140800,
36100,
42900,
7500,
20300,
null,
49800,
10400,
24100,
35500,
23900,
110000,
56047,
44000,
28400,
15300,
51700,
null,
3600,
28200,
10500,
15800,
25500,
13500,
null,
18200,
26300,
18800,
17800,
21300,
null,
78600,
14750,
34200,
29700,
29900,
9350,
122300,
null,
null,
63900,
47300,
25700,
65700,
22400,
4900,
null,
31000,
147200,
28100,
7600,
21200,
null,
41700,
27800,
null,
7800,
29300,
47200,
17500,
35500,
52600,
null,
14100,
26500,
38100,
18100,
22900,
76300,
91900,
21500,
11600,
29500,
null,
5300,
13100,
63000,
48800,
null,
63400,
13600,
22100,
35300,
13300,
5600,
17500,
93000,
137600,
60600,
28000,
19300,
null,
26200,
null,
11700,
17500,
162900,
21200,
9200,
24000,
null,
9600,
60600,
61800,
50200,
120000,
null,
33900,
17900,
null,
12700,
null,
14200,
9200,
14500,
21100,
26100,
30700,
25000,
46100,
20000,
14500,
9400,
9000,
58100,
15400,
5600,
55800,
58300,
15600,
40800,
19500,
63300,
15100,
2100,
11500,
16000,
9200,
15900,
34700,
46800,
34500,
34300,
11700,
8200,
28500,
14200,
108000,
34700,
4600,
25600,
55900,
19700,
null,
4700,
15200,
18300,
30300,
35700,
58000,
null,
5600,
29400,
27200,
null,
91000,
21400,
null,
10600,
10700,
123300,
13600,
47100,
51300,
32100,
2700,
43100,
14800,
90250,
34600,
22300,
23300,
10600,
4500,
16100,
18300,
13500,
27000,
56300,
23200,
22000,
31100,
2500,
33300,
17300,
76300,
31300,
13400,
18200,
23700,
56300,
30100,
54200,
48600,
29400,
null,
18000,
15600,
30000,
14500,
11200,
16600,
16800,
11600,
86200,
36200,
null,
19500,
93950,
39600,
68400,
62500,
25300,
31500,
78000,
51300,
134300,
22800,
14100,
8200,
27300,
28500,
34600,
55100,
33000,
7725,
41900,
66573,
10500,
14200,
16100,
48600,
400,
12300,
32300,
300,
16300,
72526,
null,
46300,
null,
33900,
4900,
87000,
40000,
40200,
29000,
30100,
26700,
28900,
5900,
7500,
48700,
null,
26600,
9100,
15300,
9600,
27300,
18300,
21000,
83100,
null,
11900,
49000,
null,
24700,
9000,
10600,
null,
31700,
19400,
null,
65100,
28300,
21300,
39990,
52300,
24900,
14700,
13600,
8300,
55000,
37900,
6100,
33200,
125000,
19500,
10300,
29900,
53900,
9600,
null,
34300,
38600,
10732,
21800,
56100,
49000,
15000,
16800,
59600,
12600,
6800,
null,
22900,
26100,
41200,
35100,
34500,
72200,
41000,
19600,
11800,
40600,
47600,
21200,
3000,
14500,
39000,
18800,
10800,
26900,
19600,
86000,
31900,
28000,
41500,
40000,
66100,
22300,
15500,
24000,
20900,
27000,
14500,
55600,
11200,
42200,
126500,
19800,
25300,
24800,
58200,
8800,
20700,
10800,
37800,
75200,
12600,
118600,
35000,
49700,
22600,
22600,
43700,
null,
10100,
74100,
36000,
88200,
52000,
11300,
9000,
null,
166700,
54200,
13100,
7700,
21900,
28800,
39000,
87600,
null,
65900,
null,
null,
7600,
108100,
24200,
17500,
11600,
15200,
92400,
23000,
50000,
18500,
19600,
16400,
26900,
null,
25900,
null,
46200,
52100,
7800,
12000,
16300,
2300,
36900,
10800,
42900,
75200,
17000,
10900,
45100,
null,
21700,
75000,
60800,
25900,
14700,
22300,
43100,
69100,
17500,
57200,
32100,
12700,
null,
null,
5500,
6500,
29900,
13200,
57800,
34900,
17600,
2500,
4700,
41200,
49000,
6500,
51400,
16700,
37300,
11400,
13800,
null,
14700,
26800,
12400,
33306,
53000,
40700,
44100,
41000,
13900,
24400,
25500,
25800,
19700,
null,
7400,
23600,
8800,
16200,
12300,
55000,
31500,
null,
60700,
36700,
16800,
54200,
35000,
31200,
7200,
49700,
28200,
35300,
24680,
11600,
23400,
38900,
114800,
null,
13800,
15300,
17500,
57900,
null,
18100,
31000,
16300,
null,
5400,
7600,
25600,
9500,
48300,
18800,
null,
29400,
22100,
29200,
25100,
48200,
18400,
30900,
60100,
39700,
16200,
17600,
8250,
16800,
19000,
2400,
25706,
67800,
20700,
61200,
33400,
15000,
15500,
19500,
44000,
14300,
20700,
294600,
12000,
13900,
8000,
9700,
20800,
6600,
14700,
null,
87500,
null,
14500,
41800,
6800,
14700,
147200,
11600,
89100,
37100,
22500,
23100,
16400,
18800,
9800,
33900,
4300,
26300,
23900,
10500,
5800,
18100,
24400,
7100,
17100,
47100,
25700,
14600,
78500,
50200,
22800,
null,
6800,
34000,
38100,
13400,
24700,
45944,
5700,
11100,
21500,
9005,
null,
60400,
12100,
43400,
21400,
29000,
23100,
33000,
29622,
15600,
23600,
46200,
10400,
99200,
17400,
null,
26000,
null,
25200,
29500,
4100,
9700,
19400,
31700,
34000,
22200,
16000,
69800,
18400,
24200,
15100,
18070,
24425,
29400,
12500,
23700,
58200,
14700,
30400,
28300,
20830,
22800,
110800,
16100,
10900,
38700,
63200,
43700,
16000,
23600,
94300,
17200,
68700,
59800,
39600,
39400,
25100,
null,
19300,
6300,
11945,
18500,
9400,
6700,
14800,
47300,
60200,
38200,
null,
2400,
43500,
13100,
42500,
11100,
21500,
null,
17500,
null,
61000,
51700,
49600,
9300,
15200,
5900,
23000,
9400,
null,
14800,
41400,
12600,
27000,
96901,
19000,
32200,
15000,
null,
15000,
86200,
34600,
12900,
17200,
14500,
118450,
24100,
11800,
18300,
104100,
15300,
16900,
24600,
3400,
23700,
null,
9700,
16400,
57300,
32700,
17400,
null,
18800,
37000,
38700,
20800,
44400,
10000,
25600,
null,
6900,
13100,
29800,
134600,
46800,
11000,
28300,
7000,
11800,
29800,
29700,
14100,
22647,
48800,
17100,
105000,
12500,
34800,
64300,
13500,
61700,
52800,
50100,
32100,
55800,
12100,
25300,
77500,
33200,
30100,
29100,
21300,
1000,
28200,
58500,
13000,
49600,
42400,
91300,
39600,
60400,
59926,
18100,
11900,
35700,
12600,
12500,
18300,
49300,
32500,
18500,
85700,
null,
29800,
69800,
27400,
17100,
7800,
20900,
41800,
39400,
15200,
29600,
73000,
14000,
42048,
15700,
23542,
21200,
42900,
8300,
22200,
24700,
29900,
12500,
71500,
6600,
38000,
14600,
197700,
76200,
53300,
4900,
39600,
5600,
17900,
17700,
24600,
10800,
22700,
19700,
48100,
24200,
null,
11600,
27300,
23500,
21200,
75100,
26800,
null,
24100,
47000,
45800,
11900,
69400,
31700,
16700,
8600,
55404,
35950,
69000,
5100,
28000,
20300,
33250,
51600,
26800,
56500,
7300,
56800,
56800,
39500,
103000,
16600,
39600,
18100,
13800,
232500,
14500,
38900,
134900,
20500,
40200,
12000,
49723,
32900,
38600,
54300,
41500,
69600,
13100,
2000,
65100,
26100,
16800,
40200,
35300,
1600,
15300,
137800,
null,
30300,
null,
null,
7400,
17400,
13800,
3200,
52300,
5900,
104800,
72300,
25400,
43000,
24500,
null,
21300,
124700,
72000,
14400,
11900,
22800,
34100,
53300,
5100,
31700,
82000,
4600,
19900,
4600,
24400,
41600,
9200,
11600,
9300,
17500,
22300,
8100,
30500,
36100,
8800,
7600,
46579,
8900,
11500,
17800,
49400,
18500,
35100,
24600,
13000,
75500,
37200,
2800,
6500,
94900,
19500,
13000,
23200,
10200,
17900,
null,
9600,
42800,
13700,
null,
18000,
20300,
92900,
22500,
33400,
21700,
10200,
30400,
20400,
null,
87100,
22200,
15400,
22300,
58000,
119600,
8800,
61600,
24300,
20200,
24600,
34700,
46700,
null,
null,
7100,
13900,
6300,
9600,
15300,
25010,
6600,
2400,
7900,
null,
7500,
39000,
6600,
16000,
null,
14200,
62300,
null,
31600,
18200,
30400,
16100,
52100,
25400,
31500,
48000,
15800,
null,
11300,
9000,
14700,
8700,
8800,
21600,
20400,
40000,
45100,
27000,
null,
21500,
null,
21500,
13200,
216700,
32400,
30800,
55200,
27100,
26500,
11400,
12000,
31000,
null,
85047,
17200,
10700,
44300,
20700,
6900,
13700,
94500,
35200,
18800,
5200,
35600,
33700,
67500,
9000,
11200,
14900,
null,
28400,
5500,
40400,
43100,
24200,
29200,
28300,
10000,
19500,
33300,
27000,
8200,
22700,
15000,
58800,
20500,
48600,
5600,
24300,
38100,
12000,
9900,
53500,
26100,
32900,
30700,
11400,
null,
27600,
27100,
26900,
31900,
null,
3600,
16105,
30800,
13200,
6000,
18600,
13100,
16500,
22200,
7800,
68100,
59800,
14100,
4900,
null,
70167,
23200,
10300,
32750,
26700,
24600,
34600,
17100,
9400,
17300,
34100,
null,
18000,
13800,
52100,
24900,
16300,
19000,
51200,
18300,
15500,
31400,
18700,
52500,
8500,
8300,
9300,
16800,
9300,
38300,
19200,
7800,
57900,
64500,
49700,
29700,
5500,
23500,
8700,
9700,
71400,
29500,
78400,
31100,
24000,
26100,
52700,
5300,
23700,
13800,
22000,
58864,
4900,
14300,
42500,
117500,
42300,
6400,
12500,
20400,
28000,
19500,
null,
15000,
18500,
10800,
13700,
25800,
8900,
45500,
47100,
67200,
14100,
31900,
null,
22900,
30200,
16700,
3400,
6700,
15900,
7000,
17000,
31600,
6300,
56364,
136000,
63700,
24900,
11300,
19900,
55700,
3000,
54900,
23400,
15500,
6200,
37300,
60000,
81100,
38100,
25900,
19800,
91600,
10300,
13700,
43600,
34600,
44100,
null,
28600,
null,
7600,
56400,
11500,
54100,
9000,
12700,
null,
25900,
34000,
49593,
49000,
121900,
40200,
62900,
22800,
18500,
174700,
21800,
54900,
20200,
15200,
27600,
21800,
null,
29200,
20000,
44300,
17000,
15800,
32600,
14300,
21300,
null,
null,
23500,
27400,
16300,
19100,
null,
25500,
16300,
10300,
15200,
27600,
13000,
47200,
46900,
8820,
31900,
18400,
null,
59900,
9300,
14100,
14800,
77300,
21700,
21300,
16100,
18800,
45300,
26300,
21800,
6100,
36000,
44800,
35100,
27100,
16000,
11300,
19100,
16400,
null,
26600,
35300,
null,
17700,
13000,
20686,
8000,
9100,
37800,
16000,
14900,
4500,
11400,
33900,
13500,
13400,
30800,
23500,
10300,
null,
39400,
20200,
13000,
74200,
52000,
null,
21500,
null,
17900,
53600,
15900,
58300,
16900,
11800,
21350,
53300,
47600,
45000,
7800,
49100,
65800,
27400,
38700,
27900,
79400,
null,
25100,
32600,
19000,
9900,
16800,
13300,
18500,
null,
11200,
27350,
8200,
7700,
22000,
50400,
75000,
66600,
17000,
null,
65700,
9100,
17600,
21000,
40100,
36600,
11200,
null,
4000,
8200,
31800,
46500,
15100,
31800,
36000,
null,
12600,
20600,
null,
30200,
55400,
4700,
5000,
113020,
24700,
17400,
57000,
5600,
68000,
11900,
24200,
20600,
10300,
null,
22700,
11100,
16300,
11200,
42600,
null,
137800,
4300,
9000,
23700,
8000,
51700,
null,
23000,
38084,
3200,
25561,
108900,
33977,
36900,
39300,
56900,
14500,
9900,
16800,
48000,
38700,
24973,
23400,
67000,
23100,
32800,
28900,
54900,
19170,
296100,
55000,
76125,
7100,
17400,
111400,
11400,
22000,
20500,
96600,
42600,
93100,
9700,
80700,
70000,
67200,
6500,
110300,
12500,
19200,
70300,
null,
17200,
13200,
18700,
7500,
6400,
33600,
null,
30000,
13500,
7100,
30600,
44900,
25200,
6500,
31400,
16300,
42750,
19800,
45900,
33800,
51100,
24500,
98100,
22300,
46600,
39000,
87900,
14600,
33000,
12900,
14500,
36900,
3000,
4200,
45000,
49800,
6700,
16600,
29700,
22100,
95500,
15400,
58000,
11700,
51500,
15400,
10500,
21100,
48100,
21200,
7800,
13800,
4300,
null,
35900,
91100,
23400,
26000,
21300,
101200,
27300,
36300,
34300,
37800,
null,
20800,
null,
33000,
18800,
21500,
89600,
19976,
24500,
27300,
16300,
19100,
11100,
22600,
null,
28600,
31100,
26100,
20200,
null,
5400,
45300,
34100,
9900,
126800,
68300,
26600,
35600,
57250,
5300,
16000,
53500,
25500,
14300,
14900,
20900,
62100,
null,
29000,
17500,
12900,
6200,
null,
13500,
34100,
8500,
1800,
16500,
5900,
30000,
115200,
11300,
16400,
11500,
38100,
60500,
null,
49600,
7500,
20000,
11500,
null,
75600,
5800,
34600,
38900,
15500,
14100,
37200,
12500,
14700,
29100,
34800,
16100,
69000,
19100,
30000,
17500,
59100,
103700,
7300,
34000,
37981,
8100,
13500,
29061,
20400,
4300,
33000,
12000,
22600,
22400,
50800,
20500,
21900,
18500,
25100,
27700,
9000,
22400,
null,
20500,
30800,
42200,
330900,
17200,
29500,
88000,
34900,
22800,
4600,
14500,
11400,
25800,
33800,
62400,
23200,
54500,
12400,
20550,
6900,
128000,
30500,
6600,
6600,
55400,
15600,
22700,
10200,
92200,
26000,
42000,
13100,
29800,
9450,
30900,
44000,
20000,
48300,
119100,
null,
60000,
110000,
32300,
5400,
22000,
50400,
28600,
11000,
188800,
18600,
41700,
44900,
8900,
54600,
30400,
63200,
34000,
null,
52450,
17900,
24900,
17100,
31100,
78900,
null,
16050,
13600,
16500,
18500,
82500,
40100,
null,
6000,
3500,
null,
68200,
2000,
9500,
68700,
15200,
28600,
3700,
18500,
20600,
7800,
32500,
1300,
33100,
53000,
34400,
29200,
null,
43100,
14700,
45200,
null,
55300,
12900,
6200,
32700,
15800,
66000,
15200,
160500,
28600,
29800,
null,
20800,
42500,
21900,
174000,
63500,
76000,
20000,
6200,
60400,
35600,
24500,
24100,
19400,
50300,
7600,
20620,
null,
40100,
137000,
9400,
20900,
11100,
26600,
null,
37100,
17500,
11500,
19200,
13000,
11500,
24300,
31600,
63500,
4600,
8000,
19500,
17100,
28400,
25200,
16000,
40500,
7300,
45100,
4700,
8200,
52900,
75400,
6600,
44200,
9000,
12300,
29700,
16700,
38100,
40700,
null,
42400,
24100,
6600,
10500,
27800,
41900,
25500,
61500,
11300,
35900,
33100,
54700,
82900,
9900,
null,
14600,
37800,
53400,
51300,
22700,
2900,
33770,
90800,
4000,
44500,
22200,
37100,
10500,
10400,
86400,
null,
6500,
38637,
28800,
15300,
18300,
23700,
29600,
9700,
23500,
75100,
72500,
7200,
21000,
24500,
null,
11400,
35800,
110234,
16100,
19200,
null,
20700,
51300,
45900,
35100,
43300,
null,
17100,
28277,
24100,
65600,
14100,
55700,
27400,
31400,
null,
7300,
12500,
6000,
68000,
14700,
4600,
41500,
20400,
22200,
9400,
16400,
15300,
38000,
37500,
13400,
27900,
14300,
43700,
null,
60200,
17000,
22000,
26000,
20300,
19900,
30800,
38000,
null,
8500,
25400,
35900,
33200,
12600,
13500,
37900,
27400,
64800,
53000,
55800,
7400,
105300,
47900,
6400,
29600,
65934,
10800,
20100,
31800,
27100,
27100,
18400,
7700,
23900,
null,
44700,
null,
8800,
6000,
17400,
29300,
14700,
30000,
28100,
21900,
52000,
6700,
15800,
1600,
4500,
null,
21300,
43300,
25600,
20700,
20400,
31600,
12400,
26600,
75500,
7500,
19540,
69200,
59600,
null,
79000,
21100,
71300,
82700,
25000,
90200,
53900,
18100,
1000,
24000,
30000,
24600,
42200,
30000,
5400,
10300,
41100,
105900,
22200,
5400,
36400,
13800,
34100,
13800,
20200,
13500,
18600,
15900,
28900,
15900,
14500,
20500,
50800,
25300,
43100,
8200,
null,
26000,
39200,
14900,
27400,
39900,
7000,
28600,
13500,
22100,
12500,
50700,
null,
25900,
41800,
75900,
null,
42600,
28600,
15800,
43300,
17800,
33900,
22700,
null,
31300,
null,
8300,
45200,
33500,
55200,
30700,
null,
46600,
72900,
19200,
10600,
37600,
16000,
null,
8400,
16600,
7000,
22100,
45800,
40400,
77500,
12700,
56000,
27400,
100000,
15400,
null,
22900,
28300,
22800,
12900,
65000,
null,
28700,
16500,
13000,
null,
28500,
41600,
52400,
null,
116800,
7200,
10900,
15600,
17000,
14800,
28200,
11200,
16500,
68600,
37900,
27500,
90500,
13500,
22700,
null,
18600,
17700,
33800,
63304,
76600,
61300,
9800,
null,
85200,
9000,
9750,
15400,
6100,
22100,
31600,
41700,
47300,
null,
11400,
7500,
46700,
185100,
null,
12400,
145400,
17100,
35100,
25100,
35800,
null,
63200,
9400,
15844,
45700,
31700,
51500,
56700,
null,
68500,
32000,
15800,
28700,
8000,
151700,
5100,
37300,
9300,
46700,
7500,
26100,
23500,
null,
14300,
32000,
8700,
69000,
10200,
14600,
null,
6700,
null,
7000,
9500,
21000,
17100,
24800,
21700,
12600,
91800,
25800,
19700,
24300,
null,
7000,
27900,
32700,
92900,
39200,
21100,
12900,
24500,
7100,
45600,
9300,
null,
133100,
57400,
12400,
44600,
64400,
106900,
50900,
126850,
19100,
53500,
109600,
51000,
79300,
31300,
22100,
36090,
46700,
null,
24450,
22000,
2750,
27400,
30500,
13551,
5500,
69100,
25000,
15100,
43300,
36300,
21100,
35900,
26300,
8900,
18500,
19300,
null,
11500,
10500,
70200,
null,
19900,
13500,
null,
34374,
28100,
107500,
15600,
33800,
36300,
null,
21600,
15100,
23300,
11900,
27000,
18800,
27500,
22600,
3800,
null,
18200,
20500,
5800,
24000,
20800,
58000,
null,
7300,
15000,
72500,
100900,
9300,
54600,
22900,
73680,
31100,
22200,
56100,
17200,
30400,
24400,
27900,
18800,
34200,
19150,
97400,
46200,
34500,
27900,
6300,
10600,
38900,
39200,
39600,
28100,
10800,
49400,
66200,
8200,
45200,
28000,
12000,
30100,
28000,
47000,
24800,
35500,
14100,
70800,
9100,
9700,
11700,
6500,
13000,
15500,
69300,
45600,
10700,
12500,
22200,
34900,
13800,
18900,
52500,
26300,
29600,
null,
78500,
11100,
4000,
27500,
16500,
null,
35900,
14400,
null,
null,
111100,
34200,
25800,
14900,
7300,
127500,
74800,
96500,
7300,
24100,
23500,
29900,
63700,
25700,
9000,
6500,
24300,
25600,
8400,
null,
48400,
41800,
null,
null,
29674,
null,
46500,
89200,
12200,
3700,
34500,
10000,
20400,
4300,
100300,
null,
18000,
35500,
15800,
30500,
11100,
53300,
9700,
12300,
26800,
15300,
24300,
71800,
24400,
null,
17000,
367800,
40100,
47400,
96900,
16800,
19500,
19900,
43500,
43400,
23100,
22100,
12500,
25700,
6300,
13300,
19400,
34400,
8800,
12700,
16200,
36900,
31600,
11300,
132600,
null,
16500,
15800,
9100,
null,
10700,
10700,
41600,
13400,
67400,
15800,
25807,
17700,
18400,
93000,
12100,
null,
46700,
19800,
11200,
53900,
null,
7000,
36100,
79100,
8200,
26300,
21700,
22600,
20700,
null,
10700,
45200,
3900,
45800,
null,
11400,
null,
33900,
26200,
17900,
110800,
6800,
13850,
10400,
24700,
24100,
28300,
11300,
16800,
null,
16200,
31200,
86500,
5000,
13300,
40800,
46400,
49900,
61200,
13500,
17200,
35300,
300,
39800,
12000,
8900,
8900,
21500,
24200,
4600,
10100,
91800,
51200,
111800,
84900,
13400,
36500,
50600,
null,
45400,
12400,
null,
5800,
3000,
null,
12500,
26300,
15200,
2100,
17200,
11000,
33900,
104300,
22400,
25900,
null,
28200,
12500,
13000,
18300,
14500,
15300,
48400,
10720,
27100,
52000,
13800,
null,
18189,
14500,
12400,
34600,
10100,
8800,
13700,
10300,
16400,
null,
13700,
18000,
10300,
108900,
50300,
39300,
14700,
26500,
17300,
7900,
44200,
16900,
34800,
50300,
7000,
8696,
15200,
8200,
46400,
24700,
25500,
27000,
13700,
56100,
6400,
17400,
15200,
null,
45300,
14300,
21510,
7200,
10800,
28300,
37900,
13300,
56100,
26600,
40600,
189000,
47300,
34300,
37100,
21700,
33800,
17300,
73800,
47400,
61900,
33300,
29300,
null,
8800,
null,
16000,
7800,
13000,
42800,
48000,
39000,
17400,
13600,
20000,
36200,
21500,
34100,
60342,
23300,
19100,
43500,
52700,
15600,
35900,
57500,
26037,
15800,
26950,
10100,
23600,
14600,
20200,
18300,
152700,
11800,
24700,
10500,
16600,
18200,
35920,
185100,
25300,
14000,
null,
16600,
22400,
21800,
24100,
22500,
27500,
89300,
60200,
14500,
32700,
186200,
14200,
53100,
42900,
16200,
63800,
23200,
11650,
null,
49500,
23700,
23100,
null,
12500,
27600,
75000,
45100,
22400,
8500,
50100,
20700,
44200,
71000,
117800,
null,
null,
null,
13000,
28500,
19600,
12400,
28400,
22100,
64900,
null,
10400,
35700,
26400,
null,
8610,
27600,
18500,
58700,
null,
18500,
2700,
8100,
28400,
28500,
66600,
31700,
59000,
43300,
42300,
34800,
4300,
7500,
61000,
34550,
73900,
17100,
28100,
19700,
7500,
38700,
9900,
14700,
10600,
38700,
31900,
11900,
104400,
54300,
47300,
20100,
25100,
41200,
7700,
6600,
9000,
49500,
12500,
43800,
68300,
55900,
17300,
27300,
36100,
86700,
6300,
42100,
null,
65000,
41500,
null,
37700,
53600,
5500,
112900,
22400,
27600,
53500,
16800,
38968,
23100,
5400,
12200,
43400,
23600,
5500,
4100,
11900,
null,
22000,
36200,
45800,
8800,
59700,
40400,
19000,
28700,
9400,
19551,
56600,
204000,
11100,
46400,
41600,
19300,
105700,
29400,
140300,
4300,
22600,
17500,
3600,
13000,
74800,
30400,
16000,
27800,
null,
20300,
69800,
27300,
21700,
9000,
8500,
47500,
8000,
34100,
23400,
30700,
16900,
null,
46900,
null,
17750,
43000,
4200,
11500,
14500,
10900,
22200,
24800,
34700,
8700,
26700,
7600,
21100,
6400,
16200,
14100,
63400,
28600,
11800,
25400,
12700,
null,
23200,
51700,
17600,
39900,
18100,
8800,
17600,
20800,
21800,
32700,
28200,
22300,
12000,
30200,
20800,
54400,
null,
48600,
23200,
27500,
null,
12200,
16300,
89900,
79400,
110400,
null,
null,
102200,
23000,
30600,
46300,
11800,
9900,
27700,
145015,
43500,
14100,
37200,
13100,
null,
14800,
38143,
16600,
7500,
19500,
57200,
56300,
10300,
46351,
18900,
3000,
41100,
32000,
27800,
null,
87500,
41000,
94600,
55500,
53900,
20700,
41600,
45100,
25200,
59800,
23200,
11400,
105300,
93000,
22000,
13800,
36600,
31200,
68900,
18100,
29200,
12885,
32000,
15100,
null,
41100,
null,
51600,
22000,
11800,
16200,
28000,
24800,
27600,
43300,
12300,
23100,
13500,
18200,
15700,
28100,
32700,
13800,
23100,
11100,
39600,
12200,
null,
38300,
4350,
68600,
62800,
58900,
5300,
3900,
null,
36156,
24900,
77400,
null,
30170,
null,
33400,
3100,
20300,
22400,
18700,
12500,
16900,
17400,
27400,
49700,
52000,
13300,
28200,
null,
20400,
20400,
20200,
17300,
51700,
15900,
28000,
33700,
500,
82500,
30400,
31300,
23100,
57000,
2200,
23300,
20000,
49000,
31000,
28100,
47700,
3800,
8000,
18925,
59200,
121300,
79400,
82500,
20200,
39000,
6300,
14000,
11000,
55200,
29100,
20700,
33700,
36000,
48200,
3300,
6200,
53900,
22400,
19000,
21500,
14200,
10100,
25400,
44600,
16400,
15500,
52300,
3900,
22700,
16000,
8800,
16000,
31500,
42000,
6400,
null,
null,
47540,
26300,
78500,
25200,
45300,
7000,
26100,
29000,
29400,
20800,
10050,
70000,
92300,
70400,
59100,
null,
53300,
12500,
45900,
68500,
null,
null,
10800,
5600,
21400,
18900,
20300,
25800,
null,
46500,
14800,
9000,
41600,
22700,
5200,
null,
67200,
18900,
18100,
28327,
61800,
20700,
98300,
12000,
34700,
32100,
60900,
22100,
14800,
58300,
19500,
null,
10000,
22400,
31300,
4500,
43200,
7300,
8700,
41600,
20300,
12000,
7400,
16100,
63000,
25500,
14900,
null,
39000,
68200,
15400,
36400,
9300,
21300,
62400,
21300,
14100,
22100,
25500,
7800,
10600,
21400,
5600,
17600,
53500,
12600,
9000,
192400,
4800,
49900,
29900,
31500,
29000,
16900,
37800,
49200,
51700,
13900,
8600,
27300,
13500,
null,
16700,
11500,
57924,
81200,
14400,
33900,
39500,
12200,
12800,
6300,
44300,
43300,
307600,
71000,
13500,
18100,
null,
17300,
18600,
11900,
18600,
11900,
20500,
43210,
2300,
66300,
20800,
22100,
38700,
22000,
null,
15100,
64801,
23100,
4200,
29400,
28200,
46100,
30000,
12600,
77600,
22167,
4800,
5300,
45400,
10700,
17800,
68200,
26900,
48000,
30700,
28000,
null,
36700,
25500,
21700,
20400,
25300,
22100,
20300,
43400,
33300,
44000,
42100,
9450,
19600,
38600,
14700,
4000,
18800,
500,
59600,
45400,
null,
75500,
19600,
13600,
27550,
56500,
12200,
41700,
33600,
10800,
26600,
29600,
29200,
9800,
92800,
49400,
14600,
22200,
22800,
49400,
34700,
12400,
24500,
11200,
6600,
48400,
26700,
57400,
3200,
null,
null,
19300,
19300,
29800,
22000,
null,
15600,
16900,
63400,
30100,
13400,
31600,
13800,
5200,
59900,
25400,
29400,
8800,
null,
6600,
26600,
23400,
13800,
null,
9000,
12800,
44900,
10800,
29000,
25800,
null,
55700,
7900,
103700,
58000,
13200,
19600,
5900,
null,
104000,
25500,
15500,
38900,
30400,
null,
null,
24100,
null,
28200,
205400,
24500,
41700,
null,
33200,
70900,
39200,
11300,
10290,
3600,
93700,
11700,
34900,
26100,
21600,
14000,
14500,
8100,
null,
7700,
9100,
28400,
62900,
null,
38000,
14100,
74500,
23900,
null,
11700,
null,
19700,
6300,
19100,
15900,
23600,
32900,
null,
12500,
27000,
13500,
22400,
37300,
62000,
20600,
37700,
69800,
null,
50100,
44500,
65100,
55500,
28700,
null,
47900,
95700,
53641,
46200,
null,
34971,
29100,
10800,
17500,
17500,
14500,
31100,
27400,
null,
12000,
28100,
23000,
8600,
11600,
22400,
17300,
34200,
30700,
31600,
5000,
46800,
21500,
16400,
45100,
8400,
25500,
7700,
13050,
31600,
3200,
47300,
34000,
6600,
null,
12600,
19600,
13200,
34800,
16650,
5100,
28000,
64600,
4700,
7800,
20400,
null,
19700,
21700,
26100,
5800,
null,
20500,
55000,
null,
10200,
27900,
68000,
11400,
11000,
12200,
6200,
25900,
2500,
6700,
15300,
28000,
8700,
8700,
47700,
5700,
null,
40200,
13400,
null,
16400,
3500,
11700,
30000,
null,
16100,
14100,
9800,
56200,
14800,
25300,
41500,
26600,
29400,
16800,
91700,
68900,
8600,
2100,
14800,
42600,
null,
7000,
10150,
34500,
18400,
48700,
58400,
35900,
25800,
15300,
18200,
5800,
6800,
11200,
14600,
20700,
32900,
63200,
4550,
44100,
null,
null,
42100,
36400,
15800,
15500,
21800,
64900,
68093,
48100,
16200,
35500,
66700,
13200,
29200,
7000,
19100,
16100,
5400,
43500,
45200,
15800,
36500,
21800,
62000,
null,
13200,
126300,
46800,
11600,
25900,
18800,
13100,
23600,
24400,
28900,
194600,
14700,
13100,
45800,
48000,
71400,
17700,
1200,
102700,
10400,
24600,
null,
44600,
13100,
null,
68100,
8300,
4300,
8700,
65300,
28400,
16100,
37000,
10000,
22000,
8100,
17000,
24600,
43900,
11300,
12500,
13400,
18500,
42700,
19000,
44400,
37500,
131500,
49700,
31000,
15500,
43500,
8233,
16000,
44900,
36700,
46800,
50700,
17300,
65600,
45700,
null,
42900,
7800,
18100,
26300,
4600,
54500,
21000,
29300,
8400,
46900,
null,
33200,
null,
107100,
null,
24300,
22700,
70500,
77900,
49300,
18100,
25800,
33900,
19000,
22200,
10700,
14500,
15500,
27400,
37200,
8800,
13600,
null,
null,
28400,
24400,
5100,
13500,
14600,
10800,
26400,
42400,
9200,
19300,
4200,
23500,
600,
null,
null,
21400,
11900,
28000,
55100,
38500,
59539,
37200,
21900,
36600,
24000,
21600,
21000,
48200,
49800,
98900,
38400,
21600,
42300,
13100,
9600,
28400,
41300,
33900,
6100,
11200,
17450,
9600,
20400,
44100,
8900,
12100,
36900,
36600,
63900,
0,
25300,
66900,
47000,
35500,
28400,
195500,
24600,
27200,
46900,
28200,
26600,
36800,
40248,
74200,
37700,
213000,
3500,
null,
46700,
23300,
10400,
29500,
77900,
38600,
85800,
null,
null,
73500,
null,
null,
19700,
77500,
18900,
19900,
24400,
23700,
12400,
92000,
22600,
74800,
70300,
37100,
18800,
89300,
60600,
37800,
28900,
24600,
46100,
34700,
6200,
null,
21000,
65300,
11600,
null,
36800,
10300,
14300,
23000,
44100,
47600,
27200,
46900,
56300,
62400,
65100,
7900,
10200,
37900,
22400,
5400,
83900,
24000,
21500,
10100,
14300,
47600,
49100,
21500,
8600,
19800,
14200,
8900,
32300,
24800,
8700,
73800,
112700,
11700,
17800,
13100,
10900,
8200,
8500,
null,
23400,
39100,
10800,
7900,
22000,
17800,
5700,
15600,
15700,
26600,
31500,
73400,
2800,
null,
16500,
11700,
139600,
25500,
7600,
67300,
17400,
11000,
37900,
56500,
5300,
25100,
15500,
28700,
40841,
49400,
23300,
34900,
42600,
13800,
23800,
34700,
7900,
33600,
7300,
10300,
null,
45300,
8200,
10475,
15500,
26200,
71000,
32900,
23300,
23100,
14600,
83300,
37300,
null,
132560,
7900,
56700,
53900,
17100,
34300,
85100,
26100,
86200,
21100,
38700,
130300,
63000,
3500,
20800,
null,
35403,
76000,
18400,
22400,
30500,
175500,
29300,
29300,
141700,
30700,
8800,
20600,
56800,
129565,
9800,
68700,
63000,
15300,
34274,
11900,
47300,
6500,
49300,
28000,
37200,
null,
40300,
25700,
5800,
13300,
17000,
34800,
25300,
86900,
3900,
12700,
null,
21500,
23000,
8600,
50600,
50000,
33400,
25100,
56300,
50100,
22400,
8500,
10700,
28404,
33200,
8700,
15500,
null,
44900,
26300,
null,
53900,
17600,
14200,
36600,
16900,
72700,
89200,
69300,
56100,
24500,
8400,
21600,
null,
10800,
null,
55400,
19200,
14400,
16000,
18800,
25600,
14000,
37400,
42200,
28100,
44200,
30600,
11100,
74100,
22600,
5700,
102400,
9000,
25300,
null,
17500,
16700,
23100,
21600,
45000,
59300,
73300,
15100,
32800,
101200,
36700,
32000,
12500,
12500,
128700,
48300,
8600,
46200,
48400,
45176,
38500,
9800,
71800,
51900,
21800,
5700,
14600,
33300,
7000,
16600,
20800,
69400,
24300,
37600,
14050,
22900,
63200,
11600,
15100,
6000,
73650,
15000,
12000,
8500,
8000,
26400,
34300,
8500,
39300,
24700,
29600,
24200,
10300,
102200,
14200,
null,
26600,
12400,
51100,
null,
36800,
12300,
7000,
23300,
17500,
null,
21000,
11500,
11100,
32200,
null,
14000,
66500,
13500,
35400,
25900,
100000,
6200,
50600,
31100,
10300,
16600,
9300,
94000,
null,
22700,
29000,
17600,
106800,
129800,
50700,
44100,
67300,
24900,
12200,
4800,
16100,
64900,
15800,
27800,
24800,
28300,
18500,
28500,
12600,
36800,
14400,
8200,
19900,
20700,
15600,
12700,
12900,
14700,
42600,
7700,
2500,
21300,
14300,
15900,
null,
null,
38200,
17400,
5500,
28248,
77800,
15500,
58100,
4900,
19400,
null,
13800,
23000,
6300,
25100,
34200,
17300,
null,
23600,
47100,
30400,
28100,
10200,
19000,
null,
6500,
14500,
68800,
12900,
35500,
68700,
101240,
16700,
null,
26500,
25224,
30500,
10000,
162017,
42500,
25400,
48600,
38600,
34400,
100700,
35000,
12500,
23500,
14500,
23300,
15100,
14800,
29400,
84970,
7500,
54100,
97267,
21300,
10200,
12700,
38200,
7549,
25300,
32900,
64900,
6600,
42200,
37900,
45500,
32800,
16120,
20500,
15200,
61500,
22500,
21200,
null,
32200,
35200,
44600,
14900,
14100,
21300,
12300,
32000,
27700,
58700,
10900,
23400,
31800,
13300,
29600,
16000,
28700,
null,
6100,
14400,
14200,
19400,
78442,
null,
29600,
27000,
43600,
75000,
59300,
85100,
26900,
27000,
13600,
6800,
26600,
26300,
24800,
8500,
54200,
16600,
16400,
19700,
20700,
68548,
18300,
9500,
null,
null,
43400,
12200,
26500,
13000,
223800,
22500,
9950,
76600,
9600,
9600,
8500,
34300,
64000,
14700,
24200,
89600,
22100,
null,
22100,
15700,
62200,
34600,
7000,
134000,
48500,
40500,
31400,
61600,
null,
45100,
null,
30600,
null,
3300,
12200,
14100,
13500,
10700,
11300,
6700,
45500,
8400,
15000,
39300,
23300,
null,
55100,
null,
54500,
27500,
21500,
23600,
19500,
null,
57200,
88200,
null,
54100,
52300,
16900,
null,
60500,
41300,
37700,
16700,
18200,
29700,
19800,
13500,
5500,
null,
12400,
24300,
13900,
67600,
15400,
6800,
26680,
30200,
6600,
16300,
28250,
40100,
31800,
38700,
10030,
14000,
null,
13800,
72000,
null,
16700,
11500,
8500,
138900,
10000,
18500,
3900,
24600,
60700,
20800,
24100,
58800,
3900,
24400,
2200,
33796,
31400,
16800,
23000,
46900,
5800,
23900,
4000,
85900,
23300,
23000,
70797,
5300,
67900,
23700,
109900,
12000,
100800,
5600,
16200,
47800,
9200,
9700,
83700,
10500,
14800,
15900,
29300,
70100,
81100,
127800,
5300,
109200,
10300,
59100,
6000,
35300,
19000,
35300,
14500,
23600,
33000,
15700,
14700,
null,
43100,
82600,
24709,
7500,
5700,
42600,
null,
6900,
14900,
31900,
17500,
16200,
16700,
8400,
18400,
15200,
29200,
10200,
5800,
78800,
10250,
22600,
11800,
6600,
22500,
null,
8000,
56100,
56100,
40800,
29300,
26600,
1900,
31300,
26500,
6900,
59000,
18200,
14800,
27900,
44600,
32200,
null,
13600,
72200,
16600,
61300,
7600,
28000,
19900,
12100,
10500,
28600,
35400,
26200,
8400,
23300,
25000,
61300,
4400,
23500,
15800,
21800,
100509,
44700,
41100,
22200,
null,
null,
50700,
31481,
22100,
19700,
33000,
31500,
38100,
17300,
24300,
39390,
9800,
null,
28800,
null,
null,
41400,
10600,
37700,
57400,
8900,
18000,
56400,
8200,
42900,
33800,
29100,
3800,
182000,
9900,
56500,
26000,
26500,
52800,
9500,
12100,
37600,
33700,
87200,
15000,
21400,
7300,
95300,
56500,
24000,
4200,
32700,
7500,
7400,
52700,
20700,
19300,
4000,
54580,
22300,
34800,
27300,
null,
33700,
17300,
166100,
24000,
34600,
7700,
8200,
41200,
21700,
34600,
10800,
25523,
144800,
33600,
null,
7300,
15900,
10600,
21200,
82100,
null,
30500,
3400,
27000,
30500,
13600,
11100,
76500,
23900,
null,
60600,
15400,
16000,
31000,
18500,
null,
27000,
null,
5600,
29600,
35500,
17000,
39300,
39900,
27200,
13800,
14400,
54400,
null,
null,
19900,
10500,
14500,
22000,
33000,
null,
33900,
null,
14000,
56400,
27200,
14800,
29000,
93400,
14300,
null,
25900,
null,
28100,
20900,
28500,
17900,
22900,
17200,
6000,
38900,
18700,
45200,
14800,
17900,
42700,
53800,
47045,
15400,
4100,
2800,
34600,
80000,
14400,
41100,
35700,
23500,
46500,
20000,
39400,
null,
21700,
44000,
11800,
49100,
9600,
86700,
null,
28400,
25300,
25300,
null,
3900,
51400,
28400,
71000,
11000,
9500,
9300,
24600,
15900,
32400,
32100,
null,
14300,
27000,
46100,
13500,
54900,
16300,
33300,
40700,
10400,
6200,
57200,
25200,
13300,
100900,
57500,
11000,
27700,
13700,
26800,
13100,
null,
null,
22800,
20300,
46600,
20400,
15600,
10800,
11200,
18200,
17100,
25400,
26200,
63200,
7000,
48200,
33400,
6000,
null,
64400,
31700,
45100,
13500,
40100,
160100,
null,
3500,
33700,
null,
73000,
19200,
58900,
37700,
12700,
66700,
15900,
28800,
29400,
44500,
null,
18000,
31000,
5200,
87100,
19400,
46600,
11900,
24300,
25600,
70000,
null,
142500,
19000,
59400,
46700,
60300,
32400,
51800,
14000,
42100,
15900,
10000,
26300,
43200,
12600,
null,
10700,
null,
18800,
32900,
23300,
79000,
50200,
5200,
15900,
54600,
27200,
31700,
55400,
54900,
null,
19400,
62500,
127500,
60600,
14600,
13200,
7300,
41800,
21300,
19150,
1400,
12900,
22900,
33300,
39000,
40600,
7700,
27200,
11500,
42300,
43500,
24200,
19900,
5900,
137000,
10500,
13600,
1000,
27900,
42500,
29800,
8500,
33700,
50200,
17900,
null,
11500,
10600,
9800,
null,
14300,
15600,
18500,
26900,
null,
19700,
19200,
5000,
9700,
9400,
null,
11200,
10000,
5500,
43700,
13800,
null,
12500,
24100,
7300,
18300,
null,
null,
24900,
12000,
37000,
null,
10000,
null,
35600,
28700,
12800,
23900,
9500,
25600,
20400,
33800,
6500,
29400,
76500,
46100,
27000,
9600,
39100,
55500,
22600,
31500,
25500,
22300,
33900,
51700,
5500,
27700,
14000,
70100,
34500,
25300,
31700,
61500,
9100,
20500,
79500,
21100,
19900,
19500,
22000,
27200,
38200,
39000,
14700,
21700,
null,
14800,
26900,
11900,
26800,
43000,
7600,
14100,
16500,
17000,
25800,
23500,
13600,
null,
29000,
16000,
15100,
57100,
28900,
47545,
49300,
null,
20700,
218000,
5000,
15400,
32100,
47500,
14300,
8200,
31000,
7500,
137550,
10500,
52800,
25400,
34500,
32200,
144300,
33100,
35500,
63700,
37100,
3000,
20700,
15000,
14100,
17500,
null,
36300,
22200,
57900,
13300,
28500,
23300,
37900,
15500,
null,
29600,
10375,
40600,
10400,
25900,
null,
30900,
7700,
135200,
29600,
39000,
44800,
21300,
null,
17000,
38600,
23300,
null,
36200,
35800,
null,
12300,
24000,
24000,
22500,
15900,
104200,
5600,
null,
34000,
22400,
16000,
40500,
25900,
25700,
20800,
35400,
18100,
31867,
34800,
null,
14100,
15800,
12000,
154507,
29400,
72500,
18530,
6300,
33900,
35300,
45900,
8800,
26100,
11100,
23700,
36400,
44800,
64600,
10800,
10300,
49700,
22400,
27600,
22000,
19800,
37600,
8900,
19400,
65800,
null,
34200,
9000,
31676,
24600,
12300,
60900,
10800,
41900,
25700,
15100,
23800,
null,
35200,
28700,
9800,
45400,
26200,
42200,
14300,
52200,
8100,
12000,
9900,
47400,
24000,
14500,
null,
null,
21100,
14600,
28700,
34500,
15800,
20700,
null,
17500,
27200,
36600,
19300,
null,
19700,
13800,
31300,
48900,
48300,
9700,
37500,
8000,
46200,
14700,
null,
null,
17300,
22800,
77400,
42400,
48300,
null,
12300,
19200,
15700,
95100,
12100,
16970,
11400,
48500,
4700,
null,
30400,
14500,
29900,
12700,
5200,
39700,
23800,
12575,
31900,
19200,
60100,
41300,
10200,
20400,
28000,
null,
512600,
32600,
51400,
27600,
44200,
7750,
13700,
14100,
null,
12300,
11200,
13800,
8500,
null,
44745,
null,
42000,
14600,
23800,
45700,
9500,
85100,
17300,
29100,
48900,
52500,
3800,
26500,
24200,
20100,
48200,
19500,
null,
46900,
26000,
34700,
69100,
43200,
41500,
21800,
17400,
11900,
70300,
38000,
27456,
72000,
85300,
52100,
28800,
12000,
7500,
10900,
8400,
62300,
27600,
24700,
15200,
13600,
9500,
230142,
3500,
28200,
28200,
37600,
26700,
44600,
21100,
30500,
37300,
31900,
27700,
23700,
16800,
12500,
38600,
31600,
39900,
12200,
12300,
25995,
30900,
59200,
33500,
17900,
8400,
18200,
15500,
45299,
42800,
null,
22534,
57300,
69100,
10600,
49700,
6600,
17159,
7200,
37500,
41800,
17800,
1000,
18000,
29200,
25900,
76200,
23900,
9500,
14500,
88300,
11000,
39500,
22900,
65938,
49400,
14800,
21700,
16700,
6550,
15300,
null,
null,
13000,
24100,
41400,
9400,
33900,
43000,
52900,
14300,
8900,
12400,
null,
13700,
71800,
null,
35900,
81000,
39300,
41300,
17400,
null,
31500,
76200,
20000,
34000,
45000,
12200,
58700,
null,
26100,
83400,
28600,
37800,
20700,
62800,
61800,
32500,
55700,
18000,
30200,
8100,
37400,
27624,
12900,
13100,
33300,
48300,
20800,
17400,
24000,
9200,
35200,
54800,
27200,
1800,
65000,
10500,
14100,
28400,
82700,
8700,
51900,
33000,
16567,
397300,
12400,
null,
9200,
48400,
null,
37400,
107400,
8800,
46900,
46900,
62000,
14300,
11400,
34500,
13400,
45300,
12400,
27350,
29300,
26400,
null,
92400,
21600,
8300,
19900,
8300,
42800,
31620,
23400,
167000,
19800,
25000,
null,
66100,
84100,
38100,
45400,
null,
39700,
30600,
22700,
7800,
10300,
10600,
27820,
13800,
9700,
56100,
30500,
12600,
39700,
29300,
53200,
10200,
10900,
20000,
7000,
18800,
39900,
22900,
17300,
61200,
71500,
null,
89500,
34800,
null,
23200,
23700,
17400,
7800,
4000,
null,
16300,
47500,
10000,
47900,
9400,
21800,
null,
null,
32300,
40500,
15900,
10000,
9400,
141400,
68700,
42500,
15000,
29200,
null,
9100,
17800,
39000,
3800,
null,
47500,
82000,
14700,
19700,
20000,
28100,
37000,
null,
13300,
24800,
15700,
null,
7800,
48600,
14700,
33200,
10050,
20300,
60100,
50100,
29400,
18900,
15200,
40200,
15400,
34100,
13500,
26000,
59500,
null,
21000,
14800,
54400,
19000,
17400,
42400,
26100,
54700,
28300,
46200,
4400,
50500,
17600,
19500,
12100,
34100,
23700,
21900,
23900,
25600,
38900,
23500,
16200,
12100,
71700,
36400,
14000,
50100,
52800,
36400,
4000,
28000,
34300,
26100,
22100,
15900,
108600,
17900,
null,
38300,
null,
26900,
22900,
66700,
71900,
17300,
19300,
null,
31700,
6100,
18300,
2400,
22000,
124800,
11700,
27700,
null,
null,
37600,
10900,
11600,
45200,
36400,
4500,
15500,
12100,
32500,
null,
null,
33500,
20400,
34800,
10300,
14800,
39400,
20800,
44500,
33200,
8900,
19900,
null,
32800,
19100,
27800,
43400,
68700,
22000,
36700,
68100,
32400,
18100,
11800,
24000,
119000,
34600,
3200,
39300,
7800,
105500,
6600,
23300,
44500,
14800,
22200,
36700,
31600,
19000,
null,
15400,
12000,
5000,
19300,
29500,
40300,
11200,
18900,
28700,
28900,
33200,
3100,
30800,
7700,
16100,
49900,
62000,
19800,
9000,
20100,
87800,
18700,
26800,
20400,
23700,
44700,
7800,
47600,
13600,
6800,
51800,
12400,
9600,
19400,
62200,
21800,
18700,
40893,
33400,
44600,
34700,
16000,
12600,
40200,
24900,
42700,
15100,
18300,
6400,
15000,
83214,
20000,
57300,
14800,
27700,
47400,
null,
6700,
8600,
69300,
27500,
73300,
17800,
23800,
24900,
32200,
27600,
8100,
84000,
11600,
null,
42800,
16200,
19500,
35700,
7100,
15600,
28900,
22900,
null,
13500,
69600,
14400,
23500,
null,
15000,
null,
14000,
16300,
11200,
25900,
62000,
28800,
11900,
29700,
null,
null,
null,
24300,
9700,
14300,
54500,
38300,
151100,
null,
63400,
11200,
18900,
38200,
29400,
23331,
25600,
46200,
24780,
12200,
10000,
null,
48200,
33000,
29300,
9100,
9200,
500,
8200,
8300,
302700,
null,
48000,
9100,
33800,
82600,
13600,
36800,
28200,
74500,
60800,
2200,
23500,
12900,
23600,
1400,
null,
9100,
22900,
18900,
24100,
30400,
8900,
21500,
18000,
30300,
36500,
47900,
29700,
49200,
4600,
90000,
35600,
37700,
29300,
26800,
11800,
43000,
52700,
30900,
101500,
15500,
6200,
24200,
56100,
71400,
23500,
4800,
28600,
21000,
5600,
45000,
44700,
47400,
45400,
18400,
null,
29500,
33700,
49600,
32200,
21000,
null,
25600,
12000,
58600,
21900,
15500,
13700,
14100,
11000,
14900,
85100,
42700,
60900,
12900,
34800,
12800,
18500,
53100,
79200,
3000,
9500,
28200,
31300,
24800,
101900,
32400,
42000,
12700,
23200,
24200,
30300,
34300,
36600,
8200,
31600,
16500,
44600,
6300,
63800,
20200,
23400,
15900,
31500,
16400,
57307,
29800,
14400,
28400,
50400,
35100,
48300,
48500,
47600,
23900,
27200,
4400,
12700,
15000,
9000,
5200,
19900,
11400,
19600,
0,
80500,
38000,
20400,
36600,
45300,
32600,
13800,
71300,
17500,
18800,
33300,
32800,
24800,
5400,
45100,
33700,
28700,
null,
55000,
19900,
null,
31400,
16600,
19100,
18500,
12100,
30200,
102300,
44000,
37300,
19000,
38400,
19100,
34200,
175600,
16850,
null,
14500,
2800,
44000,
54500,
56700,
12700,
11700,
4000,
19400,
6800,
28300,
12400,
41300,
18800,
83100,
null,
12800,
16500,
13100,
null,
54800,
62000,
23300,
61700,
60000,
41400,
12100,
21500,
6400,
27500,
27600,
18000,
34100,
32900,
15000,
21100,
21300,
10900,
10500,
28700,
70000,
25700,
12600,
31400,
null,
5900,
25700,
75700,
20000,
5200,
56500,
49500,
21060,
30800,
48100,
29800,
9000,
45470,
231600,
95900,
19800,
null,
45100,
52100,
null,
26400,
52700,
23900,
48900,
17500,
null,
11000,
6000,
14000,
24500,
null,
16700,
78600,
13300,
203300,
16600,
28000,
139900,
null,
29600,
2000,
null,
10200,
18800,
15700,
7500,
4000,
27700,
22600,
13500,
32100,
48500,
32400,
183500,
33300,
15700,
56600,
null,
17200,
13600,
19300,
45600,
22200,
21300,
32400,
17800,
26300,
13000,
24200,
10700,
6900,
28300,
null,
33900,
21800,
4500,
20200,
35200,
25300,
15500,
34300,
12200,
11200,
28800,
18600,
null,
37650,
99400,
73100,
23400,
31100,
51400,
55900,
31900,
42681,
4300,
13200,
32200,
15800,
17600,
8520,
null,
27700,
30100,
108000,
45000,
7800,
77900,
5900,
15300,
4000,
57000,
12100,
41100,
59600,
21800,
23500,
19400,
18700,
68050,
27100,
5700,
76800,
9050,
36900,
62400,
10400,
13300,
51830,
25800,
28300,
10700,
3200,
9000,
null,
7500,
7600,
12600,
78800,
13000,
23200,
27400,
9700,
11700,
5300,
14000,
88900,
56300,
15800,
32000,
null,
39400,
1200,
9200,
14200,
61600,
6550,
21400,
117900,
15000,
12100,
21900,
43300,
13600,
36800,
75100,
46700,
41600,
11600,
211000,
19400,
23000,
7600,
16900,
18200,
39900,
3400,
15100,
21400,
38400,
20500,
11400,
17000,
65800,
66500,
7800,
null,
88700,
52600,
16400,
80300,
10300,
10700,
30500,
57800,
null,
26500,
4800,
16400,
19600,
24800,
25300,
5800,
33700,
26300,
17500,
26200,
43000,
24100,
25100,
16600,
26800,
58200,
21600,
11500,
32600,
36000,
36900,
10100,
7300,
24300,
11900,
31100,
74900,
329000,
9300,
26450,
32400,
54900,
49700,
13800,
18900,
43000,
30200,
21200,
10800,
27600,
16000,
null,
49600,
60900,
6400,
23300,
5300,
108230,
21900,
12400,
5200,
null,
14700,
26000,
24500,
36300,
251000,
21500,
8900,
14600,
16200,
17700,
2800,
21500,
12600,
41100,
22100,
18900,
9900,
18800,
29300,
22900,
126300,
28800,
24900,
8600,
16300,
81900,
null,
23800,
27100,
37500,
6500,
47900,
43600,
42100,
24400,
129020,
62700,
19300,
14300,
13000,
20400,
84600,
74600,
0,
null,
21700,
59400,
18500,
18598,
null,
16100,
null,
15500,
22300,
65500,
42500,
7500,
8900,
299100,
13000,
13400,
3600,
73400,
7000,
7800,
17600,
4700,
32500,
23900,
41700,
null,
28500,
13000,
48200,
17000,
59500,
27100,
12500,
35800,
52500,
19800,
45127,
26400,
null,
null,
22200,
23500,
31650,
35300,
10100,
9050,
17300,
20300,
12900,
21000,
null,
15000,
25000,
40400,
35500,
3500,
25200,
null,
null,
6200,
64700,
172198,
9900,
22400,
53300,
28400,
10800,
88900,
5000,
25500,
8000,
19300,
55800,
12500,
14800,
12500,
19600,
28300,
9100,
3600,
26200,
14600,
27200,
6700,
5000,
12700,
9000,
null,
79400,
15300,
null,
10600,
30700,
77800,
25400,
14600,
10250,
8700,
9200,
42200,
44700,
12700,
32000,
9300,
7600,
null,
20700,
19900,
69200,
null,
7500,
40700,
4600,
134900,
35800,
null,
33500,
46300,
11600,
20100,
27100,
7800,
21300,
16500,
18225,
21300,
27400,
32300,
25000,
21200,
32800,
31200,
17400,
13074,
32400,
46200,
17300,
49000,
14700,
null,
15200,
35200,
32400,
47600,
14000,
84800,
26700,
33600,
57700,
21300,
28000,
26600,
15400,
10000,
11700,
11100,
14200,
28600,
11500,
null,
19700,
69000,
23000,
8900,
30700,
15200,
null,
14000,
null,
54400,
22000,
19000,
71716,
18800,
42900,
23800,
28300,
24100,
null,
2900,
45300,
17200,
20250,
null,
2400,
14500,
24800,
17100,
24200,
13600,
null,
80400,
48100,
8600,
20600,
18700,
34200,
null,
20400,
7100,
85500,
20057,
28300,
7100,
15000,
11500,
14400,
72000,
33900,
32600,
18500,
34700,
6300,
19200,
69400,
13900,
22600,
10200,
null,
20600,
29000,
21500,
38600,
123100,
62400,
null,
123100,
12700,
10600,
29400,
153800,
7800,
29300,
9300,
12700,
34800,
65300,
2500,
29000,
49500,
100800,
11900,
34300,
32100,
45500,
null,
14400,
1700,
17300,
38500,
74800,
10900,
15400,
121300,
45000,
12200,
2700,
1800,
41900,
18470,
72900,
19900,
26500,
43700,
25300,
29800,
26500,
23300,
47200,
null,
null,
45400,
92800,
10600,
17800,
15200,
17900,
34100,
null,
5800,
1100,
41300,
11400,
null,
25600,
null,
46600,
30600,
7100,
18000,
39500,
32300,
30600,
31400,
11300,
5100,
null,
48900,
16800,
118600,
36462,
47800,
19100,
88700,
8600,
9200,
31100,
36900,
19200,
59900,
39200,
6800,
13600,
7600,
22500,
18100,
38200,
40500,
null,
19600,
null,
121300,
6600,
49300,
17500,
46100,
12400,
29500,
23900,
null,
16900,
51500,
18000,
12200,
12300,
49800,
16300,
15900,
111400,
101100,
10500,
16000,
51300,
null,
38600,
17700,
20300,
4500,
9800,
56900,
30600,
36400,
9300,
39675,
17000,
5300,
25200,
4100,
69700,
49600,
44500,
20500,
57000,
21900,
29600,
25770,
53800,
2400,
116400,
13000,
52800,
8450,
14800,
42900,
20700,
null,
17000,
8200,
32164,
30300,
19100,
5100,
37000,
15300,
25300,
23500,
12500,
51700,
33500,
5800,
33200,
0,
14200,
16500,
89100,
9000,
15500,
48300,
13000,
32200,
10300,
26200,
33100,
45300,
24700,
26000,
12100,
35000,
54300,
25200,
28000,
41700,
4400,
2000,
13700,
10900,
16000,
24000,
16400,
146100,
71800,
37300,
null,
8191,
18100,
null,
43338,
65900,
500,
52600,
34200,
null,
53300,
25800,
9000,
47500,
5900,
66280,
33700,
6200,
25600,
70900,
85500,
40500,
null,
27300,
null,
5200,
28000,
null,
null,
116100,
43400,
11000,
9750,
28900,
36900,
14200,
20885,
null,
13900,
16400,
null,
27600,
27500,
10700,
5800,
7200,
2960,
null,
31400,
19600,
44000,
null,
null,
27100,
16900,
42000,
12200,
58900,
15600,
28400,
20600,
11900,
14700,
40800,
40100,
27200,
68700,
26200,
20700,
37300,
73000,
4500,
38300,
16500,
52700,
27200,
16100,
null,
16000,
13600,
48300,
14600,
36200,
null,
49400,
30500,
18000,
8300,
12800,
29600,
32800,
5700,
41900,
45000,
28100,
53500,
27000,
13900,
5600,
15700,
25400,
5900,
9900,
22525,
21200,
35600,
26300,
17600,
7800,
10300,
9900,
29000,
106700,
27000,
17800,
92200,
0,
26200,
12700,
15300,
21000,
15000,
16300,
33100,
26600,
17100,
23200,
8900,
28600,
3800,
64900,
8700,
16600,
null,
5000,
35400,
22300,
26800,
37200,
null,
35000,
6800,
59500,
56400,
8800,
13000,
32300,
9700,
22700,
69900,
95800,
55700,
22400,
50800,
26800,
17100,
5800,
84500,
26300,
38000,
21500,
null,
15400,
54400,
85100,
34200,
6400,
8700,
24000,
37100,
13600,
48200,
39900,
null,
21880,
24900,
20100,
46621,
41600,
17200,
31500,
36300,
135400,
25400,
37700,
19800,
17800,
29600,
43500,
null,
3000,
15781,
83600,
20500,
24500,
38900,
17600,
11400,
18900,
null,
38789,
4300,
25900,
13200,
5300,
18100,
31000,
null,
26110,
19800,
115400,
3000,
23900,
19700,
10600,
8600,
7150,
81800,
31800,
null,
11000,
69500,
33800,
23200,
3900,
51900,
35500,
83600,
null,
45300,
9100,
43600,
21500,
6200,
12500,
37800,
6800,
23700,
40500,
19100,
11500,
33200,
13800,
11900,
39300,
52800,
10000,
20200,
22000,
8200,
12200,
27000,
58800,
34600,
41639,
12000,
8100,
38200,
18400,
34000,
18200,
3700,
5800,
20600,
92000,
31200,
12100,
8600,
18600,
41600,
32100,
33600,
36200,
16600,
22800,
20400,
17000,
22600,
3600,
36500,
16300,
38300,
16900,
83400,
79800,
17000,
51400,
45100,
17390,
45100,
6500,
13300,
9200,
105500,
34000,
29600,
74600,
20000,
30000,
47000,
39200,
54100,
8400,
9100,
127300,
27800,
28800,
54500,
32300,
18600,
9900,
80800,
29000,
null,
10100,
14600,
21000,
16000,
7400,
41900,
6000,
12100,
38100,
19000,
31600,
null,
3800,
14900,
3400,
26100,
16000,
11900,
12700,
18400,
41500,
28500,
20800,
15200,
20000,
32600,
null,
20800,
14000,
22500,
23900,
19100,
50600,
15500,
28000,
11500,
97900,
5800,
14100,
59500,
27800,
null,
55300,
null,
32400,
23000,
15700,
15600,
53800,
11900,
30500,
18600,
60300,
11100,
19700,
11800,
8400,
16800,
64000,
72500,
31500,
8800,
6500,
5200,
37039,
null,
null,
null,
15600,
null,
13100,
57300,
31500,
15400,
15200,
17900,
29100,
7600,
152500,
64103,
45700,
42900,
12900,
19700,
32700,
22200,
73500,
24600,
16300,
7400,
52500,
17800,
39500,
null,
163600,
42600,
16800,
93441,
32400,
24500,
8500,
17900,
64500,
22100,
18700,
12500,
35000,
36700,
23400,
82600,
89300,
87100,
17400,
61600,
28700,
106600,
41700,
25500,
35100,
19700,
8000,
106400,
30600,
20400,
5000,
13400,
4700,
7200,
23100,
83900,
23700,
33300,
28300,
22800,
16000,
30600,
17300,
7600,
22600,
58300,
8200,
91900,
14800,
17000,
50900,
17100,
13300,
43400,
49000,
31500,
28600,
27500,
42417,
19000,
10800,
24700,
21400,
15500,
27400,
194700,
28100,
1800,
14900,
null,
9900,
66500,
6000,
18700,
null,
27800,
22300,
13900,
17900,
8500,
14700,
8000,
null,
6000,
21700,
72800,
210500,
10300,
45500,
38100,
47600,
11000,
4700,
57200,
28200,
25100,
23400,
22700,
10200,
29946,
null,
99700,
43300,
120000,
20000,
16100,
34080,
106500,
54000,
11200,
55500,
null,
54400,
18300,
61366,
17000,
36200,
40200,
22700,
13900,
12300,
18200,
10200,
13500,
72100,
15900,
30000,
17900,
24400,
null,
51400,
16800,
43500,
null,
19900,
23300,
34500,
30900,
27800,
115100,
44300,
null,
24600,
45900,
11300,
null,
42400,
29300,
9300,
10100,
52400,
7300,
34500,
34500,
47800,
12200,
null,
15200,
28000,
49300,
21600,
53600,
37000,
28300,
24400,
null,
11400,
110600,
9400,
5000,
27300,
57800,
7200,
10800,
43800,
11700,
null,
11500,
25000,
30900,
28500,
16800,
49400,
28500,
35800,
26900,
17900,
26600,
43600,
null,
53600,
49100,
13800,
36000,
13700,
null,
7900,
45600,
14800,
21600,
41400,
31600,
17300,
11200,
14200,
2100,
null,
32400,
126100,
23300,
12100,
27100,
16900,
37000,
30400,
27000,
53612,
53900,
15200,
70500,
24300,
20900,
47200,
9000,
22000,
21800,
8300,
66500,
14000,
29000,
null,
45100,
9800,
17600,
30400,
10400,
null,
22800,
19700,
17700,
43400,
33100,
37911,
7800,
23900,
23600,
39500,
60800,
null,
6000,
17400,
19700,
null,
20100,
49600,
19900,
18500,
37400,
18000,
16400,
37800,
20700,
32200,
25000,
15400,
null,
23500,
27900,
27700,
66200,
61000,
51400,
54300,
4900,
31000,
33400,
null,
12400,
15100,
48300,
7700,
21548,
48900,
8100,
6500,
null,
25000,
null,
15300,
12400,
38300,
15600,
5000,
18900,
null,
22100,
58400,
11900,
null,
37400,
11500,
75500,
17600,
19400,
40700,
18400,
49700,
23200,
37500,
107100,
13700,
60600,
6800,
62000,
6400,
7300,
74400,
21000,
29100,
78100,
12700,
null,
40900,
8100,
5400,
121700,
15000,
30100,
8600,
34900,
15200,
20100,
null,
26900,
null,
163600,
null,
45900,
31900,
16300,
6100,
null,
null,
15300,
44600,
2100,
22800,
8000,
42450,
86000,
11700,
13600,
19400,
15100,
55300,
39000,
24500,
117800,
49400,
19200,
null,
65100,
12500,
139300,
30000,
6200,
2900,
7100,
3100,
null,
59080,
26700,
15032,
19700,
17500,
63100,
10300,
18100,
75600,
20700,
15494,
9800,
29700,
42800,
21600,
33700,
68500,
20000,
22900,
37000,
null,
35100,
26600,
20500,
15700,
44400,
null,
38600,
21800,
6800,
33100,
8100,
29200,
68100,
17100,
null,
21600,
null,
41600,
37600,
23200,
15700,
null,
32200,
null,
12200,
14400,
13300,
5900,
16700,
11100,
167600,
80100,
8800,
4000,
17000,
12700,
35300,
46400,
21000,
61500,
null,
208600,
12100,
17700,
16300,
null,
20500,
null,
20800,
48000,
9900,
null,
13600,
11500,
12700,
32800,
15300,
19100,
5800,
12700,
18900,
8800,
28300,
11100,
10100,
12900,
32300,
47900,
51000,
15800,
36000,
6700,
6600,
33160,
null,
12700,
58100,
null,
24000,
60500,
23100,
47500,
null,
56400,
null,
30600,
null,
46000,
89200,
63500,
14900,
88200,
5500,
37000,
20500,
null,
3810,
41100,
12600,
32800,
21200,
15500,
96800,
10200,
97500,
null,
74100,
28600,
null,
39500,
10000,
35200,
20700,
21600,
5700,
12000,
18100,
7800,
33300,
51200,
37900,
38500,
3700,
45500,
10300,
2100,
29100,
15700,
12900,
null,
32000,
31500,
24500,
27800,
null,
15100,
17800,
68400,
null,
19400,
14900,
11800,
10500,
6900,
27400,
6000,
42900,
30600,
36100,
15700,
23100,
187100,
12900,
45300,
6600,
15800,
38300,
24800,
44000,
29300,
22300,
15100,
56700,
null,
19425,
24500,
56900,
38300,
16200,
52200,
25300,
23000,
10300,
15500,
26100,
null,
108600,
13350,
8650,
13300,
14600,
8600,
29900,
25500,
null,
97500,
20200,
25100,
26100,
10500,
null,
48800,
61400,
11000,
13600,
null,
30400,
13300,
11450,
null,
21100,
null,
13400,
16600,
34400,
36200,
20000,
4100,
5300,
42900,
23400,
12000,
18500,
21500,
33900,
57900,
73600,
null,
53200,
19500,
26200,
18800,
44000,
66700,
29400,
11800,
33800,
null,
25500,
10100,
5800,
18800,
null,
35200,
12900,
19300,
12500,
null,
null,
17600,
20900,
19600,
7700,
50000,
12600,
20200,
14700,
71200,
47300,
12200,
22700,
null,
24900,
62200,
15500,
11300,
61300,
88200,
60100,
null,
39600,
11700,
36700,
27500,
null,
51200,
18600,
12200,
26300,
16100,
25900,
16300,
36200,
null,
null,
26300,
43800,
7300,
74300,
21600,
null,
61900,
29000,
44266,
161300,
19100,
21300,
19100,
11000,
17300,
31700,
20400,
44000,
39400,
59700,
57800,
37000,
23200,
26700,
19500,
22900,
13800,
14600,
14100,
3600,
29800,
19500,
null,
26200,
15700,
13800,
19100,
10300,
12600,
12300,
24800,
18200,
6600,
60900,
35600,
18500,
11700,
8200,
63380,
52096,
39100,
33700,
null,
14100,
25600,
14100,
52300,
11313,
5000,
18000,
52700,
5500,
null,
41200,
11800,
22500,
19500,
40900,
2100,
48500,
8400,
28000,
9100,
32300,
12700,
45700,
57400,
25400,
15800,
8400,
23200,
42700,
15100,
40700,
22500,
57600,
100700,
41100,
16900,
18600,
20700,
39300,
19700,
8700,
50700,
22200,
14400,
19900,
null,
42800,
20700,
28800,
10500,
17600,
83800,
14900,
1500,
null,
32100,
32700,
68100,
38500,
5800,
50000,
18200,
29800,
34586,
7100,
161300,
23500,
null,
14300,
9100,
14700,
null,
24000,
35400,
28600,
28500,
25500,
42400,
46900,
29400,
11700,
28600,
31100,
5000,
47000,
17000,
35400,
65100,
33600,
13250,
43600,
11100,
19400,
68100,
17300,
9500,
22000,
42500,
34200,
9200,
14800,
17800,
39700,
38100,
14000,
142300,
15700,
70000,
23800,
22700,
16800,
29000,
53900,
71300,
10200,
45600,
8600,
23300,
29100,
16000,
23800,
64600,
16100,
33100,
10000,
25700,
19000,
11500,
49200,
20000,
9200,
14800,
36200,
null,
5200,
41300,
28900,
18300,
12800,
5800,
5000,
null,
22200,
7200,
16000,
35500,
12500,
8700,
14600,
39900,
9800,
39700,
15000,
19400,
61500,
4700,
5900,
44200,
53900,
59900,
10800,
11300,
46100,
29800,
12700,
41500,
12300,
18650,
54800,
27500,
50400,
6500,
25300,
28000,
79300,
16300,
17700,
23700,
96600,
10600,
29300,
64200,
31400,
36500,
23032,
18500,
7100,
16800,
11650,
12900,
51400,
34400,
33600,
35100,
20100,
24500,
25800,
5300,
16600,
8900,
33500,
41200,
null,
37300,
9800,
null,
14500,
49300,
24231,
10000,
9800,
40900,
12000,
14200,
null,
52400,
19000,
11100,
40678,
12700,
34300,
74100,
null,
11900,
22700,
15000,
30900,
9500,
7100,
4700,
30900,
4300,
15100,
null,
13100,
25800,
43700,
39200,
120100,
62600,
43100,
6500,
47100,
16100,
17100,
195800,
7900,
7000,
15300,
13800,
38900,
22300,
45200,
29200,
1500,
72600,
65700,
9300,
17700,
23600,
50500,
7200,
1000,
27600,
null,
17100,
12300,
24500,
27600,
44000,
31400,
11900,
44530,
55500,
20600,
23400,
16200,
37600,
51700,
3200,
18300,
13700,
52600,
15700,
14600,
16500,
10000,
null,
159500,
31600,
3900,
4100,
33100,
36800,
92300,
null,
52600,
null,
28400,
6600,
7600,
37600,
28100,
16000,
8400,
17600,
19700,
41139,
76400,
null,
88600,
151900,
46229,
39100,
44100,
20731,
8500,
59400,
7800,
41900,
34900,
15000,
11453,
2500,
17000,
null,
36200,
14000,
32200,
23800,
9100,
6300,
22700,
22500,
24200,
27000,
131400,
29400,
19700,
4000,
26900,
23400,
null,
11300,
28100,
28474,
7700,
14000,
58900,
10500,
49500,
28900,
26600,
25700,
39400,
17400,
65900,
17000,
29000,
77500,
9200,
null,
24400,
5700,
null,
3800,
4300,
9600,
24600,
800,
13800,
34000,
31800,
22200,
null,
111300,
22800,
9500,
18200,
20500,
10300,
50400,
3500,
3000,
38300,
12000,
8900,
42300,
8100,
8500,
31100,
7500,
6300,
6600,
16400,
8000,
38700,
47700,
21000,
28200,
56100,
14300,
23200,
11700,
47800,
115145,
47100,
91667,
15981,
50800,
39396,
17400,
66900,
15900,
29600,
18400,
16100,
39300,
52100,
11100,
21800,
48500,
3900,
22300,
94000,
6200,
7000,
14800,
9600,
26200,
68700,
12400,
177800,
17400,
54700,
92300,
8000,
27000,
100000,
77600,
27400,
3300,
5500,
16100,
29500,
41200,
20200,
20500,
45400,
6200,
40000,
60000,
50000,
75600,
50400,
47100,
null,
48600,
49200,
28800,
19200,
22200,
16100,
21800,
4300,
11200,
31010,
49000,
null,
33200,
41500,
19500,
14800,
61800,
17100,
32200,
null,
22200,
null,
23000,
16600,
56700,
38800,
57300,
6800,
null,
36000,
143900,
14100,
25200,
21100,
30000,
30200,
18300,
24500,
null,
10200,
13700,
26100,
42700,
7300,
7600,
15700,
26700,
18700,
74600,
47200,
28000,
8500,
2000,
35700,
29700,
17500,
28500,
25500,
48750,
40000,
45900,
66500,
32800,
36800,
41300,
8600,
7300,
42600,
70900,
9800,
17400,
32600,
28300,
null,
21400,
18000,
16800,
22200,
33200,
86600,
20200,
12200,
13800,
24800,
118000,
9500,
77200,
12100,
42300,
56200,
36700,
34200,
16400,
48900,
3725,
25700,
10300,
15900,
6400,
8400,
17900,
52100,
11000,
24200,
24600,
11300,
39100,
24900,
25900,
32400,
null,
null,
31009,
15000,
4300,
67400,
34300,
1700,
10600,
17900,
13600,
47807,
14900,
15700,
15200,
null,
11800,
26500,
37600,
13000,
25000,
null,
38400,
43800,
3900,
10800,
null,
16000,
19150,
49800,
null,
2200,
22600,
11100,
17600,
65400,
null,
21600,
20400,
9000,
24300,
null,
5400,
10100,
8200,
48500,
null,
55400,
22700,
33400,
null,
13400,
16700,
24000,
null,
87900,
16100,
15200,
null,
48600,
26100,
38500,
114000,
27400,
18500,
16000,
20400,
30000,
13200,
12600,
55700,
12000,
55800,
35100,
27100,
9400,
22800,
15500,
22700,
5900,
13800,
3200,
55800,
7700,
25900,
56900,
57700,
20800,
7700,
44300,
19200,
18700,
57800,
30000,
42200,
8000,
29600,
48000,
null,
10100,
24300,
15200,
20700,
33600,
23400,
12000,
44100,
59500,
26400,
null,
21200,
17600,
23700,
29000,
13500,
17000,
21000,
7800,
27100,
19700,
14500,
18100,
84600,
28600,
40000,
13400,
8800,
22600,
38700,
77700,
14800,
42300,
null,
12800,
47400,
11300,
null,
25900,
3000,
46700,
55300,
4200,
73700,
46745,
6700,
39000,
18200,
14400,
null,
5068,
7300,
95100,
17400,
50800,
32300,
38800,
82400,
20700,
7400,
14000,
44900,
5200,
21200,
23200,
4000,
25900,
3600,
25200,
null,
30400,
32000,
20700,
39500,
84900,
8400,
null,
null,
50594,
31200,
65300,
21200,
70900,
78600,
54700,
12100,
null,
40900,
34900,
9800,
79900,
94800,
42200,
46100,
47400,
54600,
18100,
28400,
8500,
61500,
94000,
19000,
12900,
null,
4200,
54200,
39300,
25100,
5300,
36500,
28400,
16700,
31800,
29700,
2600,
16200,
82200,
54200,
80600,
40600,
25600,
9500,
9500,
72700,
26400,
17600,
34800,
32900,
8000,
26400,
29900,
52500,
8900,
42700,
10200,
7600,
14900,
27400,
24600,
27700,
8000,
38400,
32400,
15700,
68500,
17700,
12500,
14800,
null,
84300,
20200,
15500,
44100,
34821,
16400,
5200,
25100,
32500,
null,
29700,
48900,
27500,
18100,
13300,
37877,
37902,
null,
null,
127200,
44900,
28700,
16000,
8600,
null,
29500,
51800,
52800,
17300,
null,
18100,
10600,
31000,
27400,
30000,
18100,
8400,
20600,
28000,
12700,
16600,
41600,
24800,
12100,
null,
24400,
10800,
65000,
33400,
null,
12600,
null,
43000,
21700,
23410,
35000,
18900,
7500,
16200,
11510,
75900,
18200,
158000,
114300,
1119200,
16600,
43950,
16500,
null,
46500,
23400,
20000,
45200,
41900,
14000,
29650,
84600,
28900,
83400,
23000,
23100,
15500,
48200,
6800,
28600,
26900,
null,
18600,
40500,
5000,
13200,
47800,
22900,
34500,
6300,
74000,
27200,
14600,
37900,
31700,
28000,
56256,
35500,
72400,
null,
15700,
null,
13500,
26500,
null,
15500,
28800,
6900,
24600,
6600,
11800,
16100,
538900,
41900,
27400,
19600,
15700,
16400,
15000,
26700,
null,
87100,
22000,
null,
18180,
82200,
20200,
144400,
79300,
34400,
12500,
37000,
1500,
13700,
22200,
11000,
8100,
15400,
31500,
60800,
31300,
null,
8500,
9800,
36300,
14000,
20300,
10900,
2500,
87900,
28300,
46500,
null,
70600,
12700,
13100,
4500,
23200,
51300,
14600,
85800,
22300,
36500,
33300,
11300,
43700,
34900,
13500,
10400,
16012,
45900,
17600,
56700,
43600,
10900,
5000,
22700,
3300,
6900,
20600,
null,
500,
11200,
63000,
53000,
43400,
9600,
10100,
null,
7150,
18800,
38900,
1200,
48300,
37000,
17700,
94500,
56600,
57600,
5500,
90300,
28100,
91200,
11700,
23300,
32100,
35000,
8800,
66900,
15200,
73200,
27500,
null,
13350,
10500,
69600,
22300,
30300,
23400,
17400,
5700,
18100,
22200,
13400,
65000,
9200,
10000,
64800,
9900,
90600,
40300,
13300,
25150,
80000,
29500,
27200,
25900,
39200,
19300,
49400,
32400,
20700,
28400,
82400,
28400,
25900,
21000,
45900,
43000,
26700,
22964,
13000,
36300,
36900,
23500,
31700,
20100,
41700,
7800,
null,
10500,
70800,
61100,
11600,
17900,
11800,
102600,
58200,
38600,
87900,
17900,
19800,
42200,
12700,
29400,
13300,
20500,
10500,
48600,
16800,
55500,
27100,
27400,
14300,
40300,
24300,
24300,
35500,
8400,
38800,
17500,
28000,
92500,
19800,
6600,
17400,
10600,
24700,
7000,
15100,
13500,
null,
null,
12800,
15650,
16900,
6000,
7830,
28000,
79900,
4800,
11200,
16200,
24900,
42600,
97400,
135200,
48400,
65900,
18100,
null,
16600,
33900,
13900,
18500,
12100,
84100,
9900,
14900,
20400,
45200,
24400,
39300,
24700,
18800,
27900,
15300,
10800,
26200,
61700,
23400,
null,
21800,
23900,
15800,
231400,
26300,
89500,
11300,
null,
5300,
12800,
16700,
17800,
46200,
26700,
null,
8800,
19800,
13000,
26600,
6300,
32700,
9700,
null,
17800,
65900,
52700,
12400,
76480,
39900,
15200,
24600,
58700,
11700,
10300,
14500,
7600,
19600,
34100,
32400,
11000,
23600,
39300,
11400,
42400,
17900,
19550,
10600,
null,
18200,
34300,
19400,
40600,
22100,
77200,
20900,
15900,
31500,
41400,
15800,
44000,
null,
18700,
36300,
34300,
65600,
9500,
45000,
24600,
16800,
51600,
241700,
23700,
null,
36900,
19200,
72300,
30000,
22800,
9800,
44300,
78100,
10600,
6000,
13900,
37900,
8100,
30500,
2100,
12000,
24500,
40000,
null,
32200,
51100,
null,
21100,
55000,
37500,
257300,
26600,
38200,
23500,
9200,
22700,
null,
null,
35100,
38600,
23200,
21500,
89200,
21300,
27200,
21600,
37500,
45500,
21400,
20200,
10600,
4500,
66000,
17700,
36800,
6000,
23400,
53800,
15800,
null,
41300,
10000,
27800,
83500,
27200,
3500,
10900,
33300,
10200,
8300,
15900,
56100,
15400,
31500,
35800,
16400,
null,
5000,
8400,
null,
5500,
41100,
22900,
28700,
37000,
85000,
37500,
19300,
null,
70400,
12700,
9300,
5700,
17000,
35500,
45500,
68200,
null,
15400,
null,
26600,
17800,
12200,
88800,
25900,
8500,
106100,
6050,
null,
28300,
18100,
42100,
45900,
28100,
29500,
35800,
17800,
18300,
14800,
13300,
17800,
48300,
52700,
1700,
58900,
151800,
15200,
null,
21200,
44400,
20700,
49100,
23500,
26600,
35700,
18500,
44900,
5600,
33000,
null,
16600,
78500,
34500,
26900,
37800,
41600,
12300,
48200,
23400,
32900,
38600,
57600,
23300,
72300,
69600,
32600,
31500,
11000,
14500,
11300,
56700,
13600,
12950,
17300,
18700,
43200,
16400,
null,
7700,
26500,
15700,
10600,
20900,
26300,
16000,
93200,
25200,
6000,
40500,
15200,
29400,
16000,
null,
26950,
7600,
36500,
21700,
25500,
23800,
33300,
12200,
16100,
null,
18700,
47500,
63500,
22600,
36400,
43100,
18800,
27100,
45200,
45900,
null,
17400,
14000,
15100,
2700,
66300,
45300,
null,
45400,
51400,
36800,
33800,
45800,
16500,
52010,
19000,
71400,
48200,
58300,
28200,
10450,
15400,
null,
3300,
18200,
74500,
null,
49700,
9100,
32000,
49800,
68300,
72700,
15300,
null,
25900,
null,
24200,
14100,
19500,
18500,
23100,
18000,
24600,
22700,
25600,
8500,
5400,
16300,
5600,
14500,
10600,
31800,
23200,
53300,
16700,
22400,
100000,
8200,
9800,
97000,
38200,
34200,
null,
21000,
6800,
14900,
11500,
23900,
65100,
10400,
null,
48500,
44200,
55700,
60400,
49300,
11500,
null,
10400,
8200,
131300,
18000,
3600,
25300,
23400,
1900,
5400,
51000,
16800,
65900,
null,
89900,
10400,
27000,
32100,
31700,
21000,
48500,
26900,
69400,
41500,
10600,
17000,
8200,
57200,
47300,
5700,
5700,
116567,
102500,
null,
34000,
16500,
41500,
22600,
64300,
null,
20100,
15700,
14800,
37400,
null,
29600,
51900,
1700,
null,
9300,
34600,
15500,
16700,
159300,
4000,
35900,
23700,
41900,
14100,
24500,
24400,
23100,
66300,
151200,
79300,
38300,
17700,
36300,
27400,
20300,
14000,
11300,
88800,
63600,
46100,
8600,
42200,
22900,
19900,
21600,
16500,
28100,
25900,
18600,
31900,
12000,
63300,
34700,
22600,
8100,
5500,
8500,
23600,
22100,
4800,
19100,
30500,
null,
28000,
25200,
37400,
23600,
11900,
30100,
15600,
5100,
21500,
13000,
24200,
23600,
null,
61200,
20500,
36500,
null,
26600,
31600,
59800,
4700,
46000,
31700,
16400,
66200,
24500,
60800,
7552,
11400,
9000,
69900,
48100,
10400,
38400,
19800,
10000,
56500,
5900,
null,
31400,
9300,
12300,
null,
17800,
137400,
31600,
31800,
33400,
64700,
41100,
19300,
38600,
24800,
28100,
null,
null,
39800,
73900,
22000,
24000,
30300,
7300,
37400,
57300,
50300,
26800,
null,
80300,
42600,
34100,
7300,
13437,
23000,
9100,
15000,
null,
47900,
125895,
8700,
59200,
11000,
67000,
13800,
30000,
43800,
39900,
3800,
38000,
16300,
30200,
20000,
18900,
4200,
48300,
8900,
15600,
36800,
43564,
13100,
7000,
21900,
4300,
29300,
82400,
61800,
41600,
14100,
18600,
null,
13600,
44100,
24400,
44100,
55800,
43000,
27000,
45700,
16800,
6700,
83600,
28600,
55800,
13800,
32900,
13000,
16100,
10600,
54100,
15700,
4600,
null,
34800,
6600,
106069,
null,
56700,
35100,
null,
11300,
null,
39100,
5300,
89700,
18000,
13400,
40200,
22500,
43900,
18400,
null,
null,
13000,
45100,
105000,
56300,
16900,
14400,
81200,
19400,
40100,
58400,
6900,
23500,
26900,
46700,
19300,
21700,
9300,
38000,
39000,
9800,
null,
27700,
73500,
35800,
12300,
27800,
21400,
11200,
9800,
35100,
22500,
14700,
111300,
40200,
59500,
9200,
null,
122700,
32943,
44500,
26800,
23200,
55900,
13700,
null,
7100,
15800,
109426,
42800,
15200,
14800,
8000,
21200,
15300,
43764,
30800,
37800,
70600,
43000,
6400,
17500,
46700,
37500,
27900,
null,
3800,
11300,
18300,
11300,
29800,
17300,
9900,
54500,
3900,
null,
33200,
44300,
29800,
21200,
24200,
12500,
30100,
23000,
21600,
46300,
12300,
67300,
27000,
34100,
null,
8700,
50200,
41500,
26600,
4600,
60200,
null,
55300,
5400,
34300,
null,
40100,
12400,
14900,
41600,
60800,
19000,
12900,
17500,
20200,
15800,
12700,
59300,
65300,
14700,
10700,
null,
5500,
24200,
22200,
9500,
33000,
18800,
3000,
2050,
120300,
8400,
20000,
17200,
120250,
13962,
142800,
21200,
12200,
45000,
18300,
32300,
null,
17900,
52500,
7900,
4100,
81400,
38600,
18900,
9500,
17100,
37713,
7700,
30900,
34700,
25000,
null,
15100,
92900,
34400,
17900,
54300,
64500,
null,
44100,
6700,
64350,
39800,
49800,
16000,
21300,
37500,
8400,
10300,
47000,
26900,
21800,
28600,
84100,
11500,
44700,
4100,
25300,
null,
25300,
17000,
15700,
null,
39000,
61000,
13900,
18300,
12100,
21000,
12300,
54500,
64600,
60100,
13600,
17700,
22500,
60100,
19800,
4000,
null,
9100,
16800,
5200,
10400,
2600,
14300,
10500,
27500,
16900,
null,
15300,
35564,
22400,
18800,
33300,
16700,
null,
11100,
6000,
39100,
23900,
76300,
20500,
22000,
24500,
9800,
null,
null,
12100,
38600,
37200,
17100,
25087,
null,
15800,
39900,
89900,
84000,
10400,
41200,
22200,
46948,
33822,
15500,
null,
19200,
6100,
41000,
16400,
60100,
19200,
62400,
40700,
9900,
67400,
26200,
18900,
6900,
19500,
null,
22200,
null,
85100,
12300,
17400,
86000,
25098,
10100,
null,
12600,
23800,
23600,
41700,
14300,
80700,
30500,
82350,
28200,
33900,
15800,
null,
58100,
5800,
44900,
9800,
21200,
45100,
1700,
null,
13500,
22300,
null,
16500,
38400,
334100,
66500,
19100,
10800,
65700,
76200,
19100,
17200,
9300,
39600,
29000,
8900,
null,
56200,
138600,
8700,
86900,
51900,
26100,
11100,
54700,
null,
25500,
56200,
65400,
31200,
null,
41300,
63200,
20700,
45400,
38500,
16700,
3200,
27700,
null,
34210,
6000,
45400,
10600,
28000,
43700,
null,
29400,
16200,
33500,
7700,
null,
9700,
25100,
15300,
16200,
17900,
12200,
33300,
9100,
40300,
17900,
23400,
35400,
20300,
26500,
112900,
17400,
29600,
23500,
43050,
6500,
20200,
55600,
10700,
53000,
158400,
5100,
18700,
null,
15200,
15300,
25900,
7800,
28100,
15200,
33500,
50500,
26300,
48200,
17700,
91800,
14500,
15800,
24100,
14500,
40100,
55300,
null,
12200,
18900,
27400,
86200,
42500,
59900,
19900,
28300,
54000,
20600,
34500,
39100,
null,
27400,
21300,
8600,
15300,
38100,
57000,
205700,
64700,
89600,
64700,
88800,
72600,
20500,
72300,
16800,
110000,
40300,
23300,
36700,
68900,
13500,
48400,
27300,
40400,
18100,
19800,
null,
33100,
6800,
45500,
25500,
31000,
22573,
26000,
1500,
48900,
49600,
19313,
192700,
null,
6600,
11000,
10000,
32100,
36000,
23000,
22700,
82800,
14700,
null,
81000,
13000,
16400,
19900,
null,
null,
16300,
21300,
27200,
15500,
32100,
28700,
26560,
13100,
25800,
21200,
37900,
8900,
24700,
13300,
26500,
29500,
20500,
36300,
10300,
null,
51700,
3800,
16400,
49800,
13300,
5700,
8500,
null,
72900,
108100,
25000,
22800,
13800,
24700,
13500,
25181,
8200,
56400,
9800,
11700,
21600,
null,
15300,
13650,
9900,
231600,
17800,
126080,
9700,
31600,
18700,
3200,
19800,
null,
52437,
12100,
50600,
4800,
22600,
null,
null,
29500,
67000,
30800,
70500,
40500,
61300,
10400,
null,
26900,
16000,
6500,
41800,
17500,
21600,
8400,
20100,
34900,
18000,
6900,
14100,
39400,
56400,
50144,
17800,
13500,
11200,
13400,
28300,
31500,
28600,
53800,
null,
null,
15300,
36700,
52400,
10600,
62800,
77300,
18300,
9600,
null,
17500,
null,
42800,
214400,
43600,
26700,
42800,
45500,
23800,
66000,
37500,
43700,
null,
16600,
21900,
28300,
24000,
90600,
12000,
32400,
19000,
86700,
44400,
24900,
45000,
32600,
74553,
10100,
50700,
6000,
5000,
19200,
88500,
11400,
35200,
53900,
52500,
6100,
8600,
42300,
32900,
55900,
34200,
18100,
5500,
13200,
58100,
70000,
9400,
8000,
24700,
28300,
45100,
null,
44800,
10600,
17600,
10800,
4200,
28700,
9600,
72600,
13700,
9100,
24700,
17000,
7100,
55000,
57100,
65500,
47800,
6000,
43200,
7500,
null,
24600,
15700,
68800,
null,
20300,
12900,
18772,
24500,
10300,
16200,
null,
19500,
53400,
26600,
14100,
15500,
null,
32700,
16000,
15200,
26100,
36900,
20200,
16900,
20700,
30200,
43700,
11700,
17800,
281634,
11500,
29200,
97200,
28100,
25900,
17800,
21500,
26200,
8900,
null,
54100,
26000,
48200,
13000,
72300,
16800,
8500,
38800,
94800,
11500,
9400,
107100,
50100,
11700,
8700,
19100,
22500,
74900,
null,
190600,
21100,
null,
13400,
5800,
34300,
16800,
7300,
107600,
18800,
36100,
13500,
40300,
11700,
9000,
14700,
17500,
null,
28200,
null,
33100,
80100,
8000,
19300,
14800,
12500,
27900,
7800,
null,
27800,
13800,
28500,
49400,
121500,
18100,
14100,
38200,
21400,
73500,
8000,
6200,
31600,
32900,
16600,
8100,
14600,
7100,
8300,
18800,
null,
71800,
27300,
69900,
14100,
45700,
25500,
34800,
8200,
9700,
6200,
null,
21100,
23100,
20500,
31500,
6600,
59100,
27900,
10800,
52100,
40300,
237700,
41500,
104100,
20800,
15600,
78400,
19700,
10300,
21800,
47100,
17500,
73200,
44100,
9300,
26000,
null,
15100,
55900,
19300,
7400,
null,
14100,
12400,
56600,
28100,
15500,
34500,
65300,
114700,
79463,
19500,
56500,
17000,
34500,
66500,
34400,
43800,
17500,
35200,
12100,
12800,
6500,
5900,
15100,
20500,
39600,
26200,
34500,
17300,
10800,
79600,
16800,
41400,
16200,
32000,
7600,
14800,
40300,
37100,
68800,
35100,
null,
14000,
9500,
null,
45000,
15000,
25400,
17700,
10300,
22600,
25400,
10500,
70800,
49200,
10600,
25300,
null,
34500,
12300,
48700,
117100,
6800,
93200,
19700,
70200,
6900,
16700,
10300,
14800,
27600,
13600,
null,
7300,
84400,
8400,
32600,
5800,
16300,
null,
25600,
7500,
37800,
41100,
15400,
null,
24600,
48400,
23200,
30000,
28500,
51500,
18900,
9800,
15500,
5400,
18600,
122100,
16100,
13200,
19400,
15000,
null,
13800,
28300,
10000,
41300,
80500,
34100,
19400,
32200,
6100,
null,
56400,
27000,
21600,
9500,
7100,
52700,
48600,
6700,
22200,
29400,
14100,
null,
39500,
49600,
30000,
null,
12700,
29000,
11000,
134700,
19850,
12100,
24300,
27000,
22700,
53000,
null,
18900,
21600,
20600,
19200,
12300,
21900,
12800,
17900,
45100,
null,
45800,
15300,
44900,
16900,
8500,
39300,
9800,
null,
51800,
10800,
25800,
11800,
19600,
13100,
null,
6500,
29500,
null,
33600,
null,
67800,
74400,
42800,
44100,
28300,
13900,
32500,
24000,
15600,
8500,
15300,
8800,
39000,
28100,
8300,
26700,
13700,
48600,
12500,
24900,
63000,
21100,
11000,
48100,
24300,
null,
45200,
69100,
4500,
75400,
32100,
10500,
5300,
16900,
9400,
7200,
44500,
36000,
156900,
94800,
22975,
27000,
60800,
8000,
46000,
22200,
45300,
5700,
16800,
null,
23000,
16800,
18200,
80300,
14000,
26000,
39300,
56200,
null,
8500,
null,
27600,
73500,
28100,
85800,
25200,
25100,
31300,
23000,
71800,
22000,
15800,
73400,
16500,
11100,
null,
7200,
8300,
2800,
33200,
53600,
null,
21800,
11600,
12100,
15800,
14800,
13600,
22200,
36800,
58700,
21700,
38800,
15600,
22400,
57000,
6500,
null,
31900,
11500,
20200,
46890,
7300,
10000,
21000,
null,
8300,
11000,
11900,
10600,
28300,
28000,
36900,
30300,
47000,
65000,
32600,
7600,
61400,
null,
27200,
10500,
18900,
6000,
null,
null,
56700,
11600,
9200,
72800,
null,
6700,
10600,
33300,
16200,
9900,
13700,
37600,
5200,
30400,
73900,
5500,
52200,
11200,
29400,
21400,
10000,
26600,
97147,
61400,
15500,
15500,
49600,
27400,
22900,
30400,
72800,
60000,
47400,
19300,
56900,
34600,
36700,
67700,
36100,
57200,
45600,
14000,
3600,
null,
21200,
20000,
19200,
5100,
7200,
42600,
17800,
43400,
14000,
null,
23200,
14300,
28900,
22700,
39000,
37300,
17900,
5000,
16800,
40300,
41900,
12500,
null,
35900,
70924,
15900,
32500,
18200,
12000,
null,
20400,
18900,
40000,
28800,
25700,
42300,
7000,
19450,
46400,
4200,
null,
21400,
29700,
11000,
27700,
43200,
30400,
null,
14900,
25500,
24000,
null,
9200,
34200,
15900,
null,
23200,
null,
null,
7900,
12800,
21500,
14300,
22900,
null,
23000,
46000,
14400,
null,
29400,
46700,
40200,
47800,
29200,
33100,
20600,
103000,
21539,
39000,
44400,
21600,
15000,
9300,
14900,
20400,
37300,
31400,
35700,
16400,
51300,
20137,
8600,
9800,
12000,
10100,
24200,
8300,
16800,
10500,
10500,
4600,
68600,
36200,
8900,
5000,
45400,
29900,
16500,
17800,
42900,
46100,
83300,
32400,
null,
26100,
null,
22900,
16100,
11600,
14200,
59300,
4400,
null,
17500,
13200,
29800,
17800,
null,
22200,
6600,
26600,
33900,
55300,
12400,
49200,
74700,
27900,
54000,
8200,
null,
39700,
82700,
24400,
14100,
10000,
7500,
23100,
10900,
7300,
14700,
null,
46400,
33500,
52400,
22800,
60400,
16900,
15690,
13300,
11300,
5800,
24900,
29500,
23200,
32300,
13900,
6800,
8400,
10100,
26700,
33550,
16500,
53900,
11110,
17500,
19700,
12300,
700,
18400,
27700,
113400,
13100,
59600,
7500,
34000,
40100,
38800,
16700,
17200,
35200,
20200,
10200,
26800,
8300,
31400,
39400,
22500,
36200,
null,
11200,
14700,
26200,
10500,
28400,
1800,
20900,
53700,
38900,
65200,
7900,
7300,
27700,
13400,
4700,
8600,
3800,
null,
10800,
16800,
11000,
15600,
22900,
60500,
9000,
16300,
53700,
63500,
14200,
63700,
81650,
36800,
33900,
32500,
19500,
10200,
26000,
null,
null,
11500,
6300,
23300,
31100,
null,
26200,
33700,
257500,
17300,
7900,
42600,
6000,
null,
39100,
15900,
17300,
33300,
23200,
123300,
15600,
16200,
53100,
32800,
657000,
11500,
16100,
13800,
7200,
39200,
55300,
16000,
29600,
485300,
71700,
12400,
41260,
83600,
102400,
83400,
18300,
42800,
24400,
20100,
32400,
39000,
12800,
24400,
15690,
77000,
33100,
43700,
9900,
10200,
65800,
60094,
4600,
19800,
31000,
43300,
11700,
25300,
22100,
22300,
87300,
34000,
27100,
15900,
16600,
82200,
118500,
24400,
29200,
53600,
10000,
6399,
28900,
172100,
14800,
15600,
9600,
52200,
35000,
14200,
9000,
41000,
26000,
110500,
11600,
74600,
54200,
8000,
16500,
40400,
25900,
36500,
3250,
13500,
74900,
5200,
null,
26200,
13800,
34700,
20200,
27700,
20600,
38400,
30600,
47200,
17700,
71400,
13100,
29700,
44800,
11500,
34900,
41000,
43500,
1300,
57800,
47300,
9600,
11900,
31300,
null,
63200,
8200,
66200,
27100,
8200,
null,
26200,
20900,
11000,
37000,
13300,
null,
16300,
6100,
28200,
6600,
null,
7000,
82300,
34700,
17000,
38400,
31300,
15700,
10000,
25300,
5200,
19400,
25000,
28300,
86500,
null,
8200,
15300,
28200,
null,
10800,
76300,
19100,
24000,
83724,
40000,
10600,
41500,
63600,
29600,
null,
18200,
19800,
4500,
27400,
14300,
28550,
17800,
4700,
10900,
25800,
21800,
26800,
332300,
18700,
2000,
21400,
143500,
56100,
33500,
16600,
null,
15200,
79500,
null,
75300,
26700,
47000,
34900,
27000,
33800,
86000,
85800,
77100,
29100,
13000,
54300,
15500,
40200,
19700,
23800,
16700,
11500,
null,
49900,
20400,
28200,
27000,
26500,
17900,
26500,
30800,
37200,
19000,
34100,
20800,
25400,
53400,
35800,
15300,
6000,
44300,
null,
6700,
11700,
54500,
27800,
21800,
11900,
23800,
5500,
15200,
39400,
16300,
8500,
46300,
8300,
48800,
47800,
null,
23950,
20500,
23700,
8000,
7300,
12700,
33500,
5900,
25800,
12800,
44500,
2400,
34900,
158555,
109800,
39800,
28800,
20300,
83300,
15500,
41000,
10900,
17250,
9300,
26700,
27800,
53221,
null,
9800,
null,
41400,
36200,
53500,
22600,
18300,
75000,
43600,
65300,
62900,
null,
null,
50200,
66200,
63900,
11000,
13300,
12900,
11600,
11400,
null,
38300,
18800,
10800,
40700,
38200,
null,
76300,
8700,
13500,
6500,
28900,
8400,
56400,
21000,
3000,
15400,
7500,
null,
53000,
13600,
null,
14000,
null,
29400,
5900,
15800,
37000,
20500,
20400,
23600,
12800,
11700,
52000,
8300,
16200,
27800,
9900,
30900,
31700,
88900,
null,
26600,
21900,
27900,
12500,
null,
22500,
null,
31900,
13900,
13400,
30100,
45600,
40400,
38300,
11600,
68600,
20800,
10400,
null,
19900,
37400,
null,
8300,
25500,
89300,
0,
99500,
null,
6500,
25900,
27300,
8600,
34900,
21800,
13000,
40600,
45000,
11700,
99000,
43000,
100400,
19700,
44800,
31000,
31900,
50500,
20800,
10600,
23100,
22400,
19800,
27400,
17900,
39900,
14700,
18800,
6500,
17400,
36500,
18700,
9500,
10300,
72300,
64000,
null,
31200,
9500,
53400,
25100,
18525,
19100,
52800,
28900,
12100,
70400,
33700,
7775,
11800,
11300,
25200,
22400,
197300,
26400,
30200,
76300,
10600,
24400,
22800,
31300,
null,
50400,
6900,
53600,
39800,
26000,
56600,
51400,
8400,
16900,
9800,
81200,
23600,
11700,
25600,
20400,
34900,
15200,
23300,
13200,
60900,
22700,
71500,
16000,
23700,
null,
10500,
9400,
7700,
37400,
38000,
50000,
48200,
18900,
13100,
12400,
11500,
23800,
34400,
4600,
51300,
9000,
11900,
30200,
36300,
27100,
20000,
171000,
359000,
20600,
16000,
62400,
40000,
43700,
15000,
31000,
91600,
null,
33500,
29200,
15500,
28500,
6400,
21600,
33000,
109400,
24300,
24800,
166800,
76400,
20300,
6500,
11900,
30300,
18900,
37400,
18000,
23100,
10800,
4800,
38500,
32100,
30200,
91100,
13400,
59800,
5750,
13800,
58400,
47000,
8800,
22900,
7800,
31700,
17100,
50296,
319600,
33500,
68900,
34200,
38700,
26500,
15200,
8900,
53400,
23500,
null,
null,
32200,
3300,
23950,
null,
8300,
35400,
25600,
null,
31000,
8300,
16100,
85100,
40000,
61200,
10000,
24100,
34400,
24000,
12800,
14700,
16600,
38500,
30600,
14300,
40300,
49300,
13600,
54400,
13200,
37400,
17600,
null,
31900,
31200,
15000,
24300,
8900,
null,
30700,
4000,
null,
22200,
47300,
5600,
47800,
6800,
18800,
20500,
105000,
36400,
null,
75900,
27100,
34500,
67000,
10000,
4300,
22000,
null,
40200,
22200,
8900,
33500,
17000,
17300,
6500,
30000,
39600,
11800,
20100,
15800,
12300,
39600,
13500,
23900,
24900,
56900,
42500,
32783,
52600,
63400,
null,
35800,
79900,
27100,
26100,
39600,
26800,
28300,
4674,
25900,
null,
14800,
43500,
28900,
45200,
72300,
13700,
14300,
14700,
12700,
4800,
13300,
141500,
29600,
14500,
36600,
29400,
17700,
null,
8700,
null,
11600,
4700,
114000,
5700,
82000,
19900,
27900,
16800,
35900,
31800,
5900,
4200,
24200,
23200,
85700,
45900,
73700,
17400,
19100,
47500,
12900,
12300,
38600,
6300,
19800,
44000,
10700,
8700,
null,
null,
45800,
55100,
34653,
19700,
31300,
40070,
6000,
67400,
14700,
20800,
30880,
252000,
38900,
7600,
14000,
110300,
10000,
22200,
38600,
57800,
null,
14700,
null,
34700,
20400,
55100,
21500,
27100,
21100,
53500,
14100,
16000,
17400,
10900,
17600,
10500,
24500,
27300,
182100,
23700,
8800,
44300,
17200,
26000,
21300,
159900,
149550,
36900,
58800,
null,
26300,
21700,
null,
8000,
24000,
4900,
8400,
null,
23400,
26000,
58300,
6300,
30600,
33300,
20000,
10100,
13800,
31500,
59700,
38900,
44500,
20100,
71300,
7200,
null,
66800,
17100,
5600,
41000,
72400,
22700,
7600,
36100,
null,
9100,
13500,
5700,
56400,
15800,
31300,
92400,
24100,
21300,
21000,
66600,
36100,
37702,
11300,
19300,
16800,
null,
19500,
null,
68000,
20460,
11100,
9500,
7500,
49400,
90400,
18127,
12200,
34300,
21500,
5500,
9700,
31700,
42700,
31100,
11000,
17700,
4500,
73500,
73000,
55200,
16200,
61400,
17400,
11700,
7700,
24900,
28500,
22000,
17000,
null,
9900,
8200,
71800,
58900,
8400,
35100,
8400,
17300,
11200,
20300,
7300,
null,
11100,
41500,
28700,
1700,
61400,
37500,
3900,
27800,
46700,
17200,
17000,
38700,
9000,
11100,
37400,
6600,
11600,
14800,
13000,
67000,
19700,
25100,
4250,
23200,
38700,
22000,
38600,
59300,
null,
7250,
28700,
19800,
45600,
51600,
15800,
10850,
24200,
25100,
18400,
51800,
7050,
27800,
80000,
40800,
17100,
9700,
26400,
4600,
30500,
null,
27500,
79500,
1500,
32100,
21624,
22300,
4800,
31200,
78200,
36300,
24200,
17100,
8700,
116600,
22200,
51400,
31900,
43300,
30900,
24800,
null,
37950,
33900,
80800,
27600,
24000,
17100,
14000,
4500,
28200,
13400,
46100,
43700,
null,
22400,
2300,
29300,
37600,
14300,
25300,
53600,
9000,
39000,
16600,
7500,
15400,
36000,
9000,
null,
47600,
10600,
null,
4300,
null,
null,
34400,
15500,
15800,
24100,
17400,
48100,
26300,
110700,
52600,
null,
7300,
22900,
76300,
19000,
29500,
16500,
37100,
14500,
null,
4000,
17000,
37800,
49500,
77100,
25100,
46400,
800,
38500,
30700,
10600,
13200,
53000,
29300,
30600,
6800,
8200,
21000,
34900,
47000,
70500,
null,
116000,
11000,
26800,
5000,
43300,
null,
null,
null,
6100,
8700,
20400,
28400,
16900,
48800,
125200,
6300,
11400,
12500,
11800,
39300,
45600,
27300,
25150,
11600,
18100,
22600,
37524,
24400,
49700,
16100,
82200,
50500,
null,
29500,
13300,
46500,
21700,
13800,
40800,
30600,
10200,
13700,
35500,
null,
23800,
17600,
36500,
25100,
null,
19200,
26500,
8500,
54500,
11000,
13000,
14500,
14000,
22600,
13700,
57000,
12500,
30600,
7900,
20400,
17300,
13100,
27600,
10300,
13500,
29000,
63300,
66300,
19330,
37500,
10500,
49600,
11900,
10200,
2500,
24800,
21600,
24200,
30500,
34300,
4400,
30200,
71000,
11500,
59500,
24200,
40200,
46200,
16700,
12600,
68800,
4800,
39200,
20900,
8700,
12200,
50800,
null,
21200,
41700,
28600,
76300,
11100,
50600,
4900,
14400,
42800,
53100,
34200,
28000,
16900,
17600,
17700,
49600,
13500,
22900,
12600,
14200,
32700,
11400,
39700,
9500,
12400,
18400,
2500,
11500,
42400,
15900,
75300,
58900,
5300,
12200,
16600,
32700,
24900,
37200,
15100,
62900,
43600,
89500,
31200,
34300,
14400,
64000,
27900,
18000,
2500,
41652,
29100,
6500,
44500,
6500,
24300,
18400,
12100,
null,
56400,
29400,
null,
16100,
191000,
null,
49600,
null,
19700,
46600,
7600,
28000,
15400,
6700,
4800,
33500,
4900,
5000,
7400,
51900,
43900,
4900,
19100,
53700,
4400,
9700,
26700,
42400,
23300,
16000,
50100,
26300,
7900,
29500,
17700,
5600,
11100,
89400,
89400,
22300,
17900,
18500,
31000,
7500,
105300,
7900,
4700,
46800,
40100,
20800,
2000,
37800,
null,
32100,
34100,
null,
67700,
null,
4700,
21200,
null,
null,
33200,
23700,
40700,
25000,
91600,
13300,
20300,
21700,
13300,
null,
59800,
11900,
30000,
11700,
22300,
19100,
7200,
34300,
20200,
72100,
46600,
3500,
45100,
54800,
20750,
39100,
null,
34900,
15600,
16800,
18800,
29400,
21000,
49500,
14700,
24900,
84600,
13400,
26300,
15800,
61300,
42400,
58900,
144700,
46800,
31600,
27800,
28200,
24000,
31600,
26600,
16200,
73100,
31300,
13900,
33000,
56300,
null,
41400,
41700,
27100,
25400,
76600,
32300,
16500,
null,
null,
20000,
18500,
14700,
67800,
20500,
37900,
13000,
null,
54200,
10900,
58800,
38200,
20100,
41100,
173300,
7900,
25500,
12600,
13100,
47300,
41700,
null,
109900,
44400,
45300,
14800,
2300,
17500,
19300,
8500,
8700,
42000,
2500,
33500,
9800,
8900,
22700,
19700,
5800,
18800,
5400,
900,
9600,
16900,
19100,
120400,
17600,
59000,
null,
24500,
76700,
16000,
17800,
38700,
5300,
40800,
12500,
15200,
11200,
9300,
44100,
17900,
23000,
13600,
null,
null,
8400,
71500,
38700,
51100,
9600,
57300,
64000,
5150,
18600,
39400,
9800,
48400,
null,
18800,
9500,
13700,
8500,
66700,
20700,
40400,
null,
20200,
25500,
27100,
5200,
13800,
11500,
57400,
21500,
43500,
78600,
82700,
10100,
40200,
26600,
52400,
11800,
19200,
null,
9800,
24900,
54401,
24500,
26100,
9700,
32400,
23600,
34200,
204300,
65700,
80600,
5800,
23500,
25800,
37100,
29300,
9900,
null,
48100,
null,
79000,
45200,
71700,
195400,
11100,
28500,
19600,
60900,
6600,
8500,
40400,
8499,
50800,
5100,
53200,
59700,
13100,
45200,
null,
47600,
24100,
50000,
16500,
23000,
14800,
23800,
34700,
18800,
17500,
51700,
13000,
37200,
26400,
34600,
null,
16500,
13600,
88435,
42700,
23800,
3900,
12100,
31100,
18300,
null,
13800,
42100,
29800,
12200,
44200,
54100,
96300,
13100,
12700,
6700,
47200,
23700,
null,
29100,
8200,
17700,
12300,
26700,
17250,
20500,
39100,
9100,
12000,
2800,
34600,
11500,
21300,
69400,
21700,
21800,
29000,
20100,
26800,
42300,
20000,
49300,
44600,
26172,
20300,
46400,
16300,
25500,
48700,
18300,
5500,
10900,
null,
60400,
null,
19000,
50000,
10800,
22400,
13400,
54400,
16100,
57500,
3100,
36500,
24800,
7200,
24000,
null,
13500,
14900,
15700,
12205,
15700,
12400,
18400,
15100,
28900,
19300,
11700,
23800,
11700,
50200,
7600,
null,
15000,
19700,
60600,
null,
14200,
22800,
25100,
null,
76300,
13600,
81200,
9700,
24300,
12900,
20600,
null,
40500,
56300,
114700,
61300,
45700,
24800,
76400,
54800,
40200,
49400,
27200,
22800,
13700,
24900,
56200,
10700,
25600,
55000,
15000,
71400,
21200,
23100,
17700,
12700,
14800,
15500,
61100,
8000,
null,
37400,
20300,
7700,
22700,
23000,
33800,
5400,
13200,
25200,
8700,
10600,
108566,
27700,
22200,
31000,
42700,
19000,
17300,
8400,
10805,
20300,
8800,
32830,
23500,
18500,
19300,
41100,
38100,
10500,
51700,
11400,
9400,
9500,
21100,
39500,
10600,
16100,
42200,
35100,
12500,
null,
23800,
18100,
15000,
13300,
30800,
null,
21000,
71900,
18800,
24100,
37400,
31000,
94700,
50800,
107592,
45900,
66500,
56000,
46100,
15878,
126700,
34200,
24900,
31500,
11500,
8900,
12000,
16000,
14400,
13508,
35700,
71700,
21600,
11600,
11675,
9900,
39700,
24300,
24900,
39100,
9600,
25000,
37000,
null,
73400,
null,
13700,
31200,
33100,
24200,
5300,
7500,
11800,
23400,
6500,
30400,
33800,
null,
null,
3500,
57700,
45100,
19500,
11300,
19000,
18000,
6700,
11300,
29200,
7900,
13400,
10800,
4350,
41400,
12000,
12700,
31700,
9400,
18200,
31700,
24900,
17200,
16700,
9300,
76400,
33600,
71200,
13000,
23800,
45800,
22200,
16300,
19100,
105400,
33000,
15300,
20400,
48100,
13200,
9100,
12400,
6300,
67600,
7100,
38200,
9700,
49200,
4700,
27000,
9400,
38100,
37000,
null,
21500,
22200,
44900,
31400,
null,
26600,
13500,
9500,
21800,
16400,
25100,
56100,
15600,
27300,
29400,
27800,
11900,
10900,
29500,
21500,
null,
22700,
25100,
8800,
12000,
29800,
24026,
null,
24600,
7200,
5100,
31300,
7600,
6000,
20400,
52500,
22100,
30000,
45900,
null,
62800,
31600,
60200,
16900,
69100,
8300,
15500,
11500,
5900,
43100,
null,
null,
19300,
20100,
19400,
null,
128200,
32300,
45800,
24000,
64300,
32300,
6800,
12700,
51600,
6000,
22400,
78400,
9500,
18200,
18600,
9200,
17600,
31440,
39700,
18700,
11000,
null,
32300,
6300,
146000,
12400,
17300,
36104,
null,
21900,
26300,
63700,
16700,
9200,
44000,
29300,
38300,
41500,
37000,
15500,
20900,
16500,
20600,
22200,
null,
15000,
40800,
76700,
3300,
8000,
17900,
null,
12338,
14000,
11200,
null,
24700,
90600,
7300,
26300,
53800,
27000,
20300,
25700,
39300,
28600,
25000,
67100,
33100,
26800,
31600,
27600,
49900,
11300,
null,
38300,
16300,
44200,
42100,
43200,
12300,
61100,
9300,
12800,
16000,
24100,
24600,
48900,
92500,
23900,
18200,
34400,
19600,
10400,
14500,
26100,
42000,
24000,
15800,
32300,
19700,
24300,
17100,
14300,
12600,
13500,
29200,
41200,
29000,
62564,
51100,
null,
21000,
14200,
40600,
4000,
8700,
38800,
81800,
28400,
32200,
12200,
76400,
null,
10800,
13500,
6300,
27500,
80300,
24300,
27900,
35400,
19800,
43600,
6000,
23600,
44600,
17700,
22900,
58000,
29500,
28300,
7200,
14300,
null,
14800,
17200,
30900,
33100,
81700,
20100,
78500,
11400,
100600,
13000,
36300,
38400,
27500,
66800,
8000,
24300,
14300,
11200,
16300,
24618,
21900,
49500,
8600,
11500,
37800,
40300,
3200,
23100,
5400,
8500,
21400,
15100,
20300,
11800,
32700,
87800,
8400,
11800,
50100,
55001,
9100,
24300,
43600,
10300,
49200,
null,
null,
20600,
3000,
34100,
33300,
10700,
null,
42000,
22000,
58900,
17200,
33500,
83900,
56600,
33200,
76800,
null,
6900,
null,
45400,
19200,
70900,
10900,
36800,
46800,
26000,
42100,
null,
50900,
24800,
20000,
12900,
46500,
22400,
15500,
37600,
20100,
13200,
88700,
17700,
54800,
null,
18400,
22500,
17600,
null,
31100,
61600,
null,
38452,
16200,
33900,
26100,
23600,
17300,
30300,
12100,
34400,
6600,
53300,
63300,
24800,
38000,
46900,
9200,
23700,
4900,
16500,
7000,
45600,
19600,
16400,
31000,
800,
25600,
61200,
31800,
53200,
6400,
22600,
63100,
24300,
11200,
37900,
41500,
44800,
48610,
19000,
33000,
14100,
null,
5600,
12600,
46000,
36100,
17700,
15000,
3000,
42100,
39000,
17000,
9800,
10810,
9600,
40300,
22800,
null,
26800,
null,
18850,
66100,
22200,
41600,
22100,
null,
12100,
24900,
51900,
42900,
12800,
35800,
82490,
25900,
18900,
49300,
17100,
51800,
23700,
null,
24700,
28500,
10300,
21500,
14400,
31200,
7000,
36400,
62800,
null,
21500,
29500,
5900,
9900,
17100,
26700,
61500,
64500,
17700,
10200,
41800,
11200,
18250,
103500,
20000,
110600,
29900,
9400,
18800,
28900,
43200,
6100,
26313,
35055,
800,
13400,
12900,
19900,
26200,
4600,
87500,
33600,
45600,
72900,
null,
22400,
28500,
48300,
28400,
14900,
15100,
39300,
58900,
null,
40100,
27900,
11000,
129400,
65600,
41300,
26900,
17600,
25500,
40300,
61900,
18100,
null,
48800,
19900,
17400,
17600,
51100,
53900,
44800,
11900,
85200,
13500,
9600,
13300,
38200,
27700,
45700,
61800,
9200,
16100,
9700,
25400,
45700,
14580,
18500,
18700,
11000,
18500,
26600,
17200,
null,
14900,
12400,
33900,
16700,
16700,
42600,
15800,
21500,
101200,
21600,
29600,
6400,
33100,
11700,
null,
15100,
7500,
20200,
25100,
null,
36052,
22900,
14700,
null,
24200,
13600,
15800,
8000,
23400,
null,
40100,
14100,
14100,
37600,
18500,
8600,
3000,
27800,
129200,
28400,
13400,
14000,
62200,
58900,
null,
31700,
5200,
3800,
11800,
22600,
16400,
null,
44500,
21300,
17800,
19500,
15600,
4200,
27300,
27900,
11000,
36000,
8700,
63800,
18000,
11700,
11800,
25700,
null,
13300,
7900,
32750,
49500,
8800,
5200,
null,
42300,
null,
71237,
19800,
41500,
12700,
24200,
30300,
31700,
35500,
53300,
83800,
8900,
15900,
17500,
13800,
31900,
8000,
42900,
26600,
19300,
29400,
36400,
null,
18100,
66900,
20400,
35500,
24000,
14900,
16500,
500,
93700,
null,
51800,
55981,
94500,
28000,
null,
101400,
11900,
12100,
9000,
11200,
107100,
29600,
4200,
25900,
11700,
17900,
72300,
21500,
null,
26400,
17500,
44600,
30000,
43200,
8800,
20700,
41900,
16100,
null,
19900,
24200,
36300,
39100,
81800,
28100,
27900,
17900,
21000,
14200,
8300,
24900,
59200,
22900,
10800,
17200,
null,
9900,
23000,
40800,
76500,
4800,
16000,
null,
8300,
40900,
null,
45800,
16800,
12100,
32800,
13500,
71800,
null,
33000,
50800,
9700,
52000,
23000,
21700,
17700,
9200,
46400,
9800,
56100,
26000,
null,
8000,
null,
23400,
35100,
24400,
28500,
13100,
70900,
2500,
9800,
7500,
174400,
70600,
null,
63400,
37400,
27100,
7500,
20500,
72200,
49300,
3700,
3300,
6500,
13100,
3600,
25700,
null,
15800,
8000,
36000,
14600,
19100,
26250,
34200,
26800,
9400,
19200,
10900,
54100,
14600,
10000,
39700,
29500,
null,
68800,
29900,
128700,
111000,
81145,
5500,
5500,
30500,
45700,
22400,
11350,
7600,
14900,
15400,
10600,
7500,
203400,
6100,
27200,
27700,
38200,
25200,
30700,
16900,
15300,
3400,
16200,
10800,
71000,
14900,
17900,
35500,
74200,
17600,
22100,
25300,
38650,
5300,
null,
9100,
33600,
33800,
63900,
12500,
10100,
36300,
87400,
35200,
7400,
22500,
14500,
29200,
null,
null,
50100,
11200,
22400,
27500,
17100,
50300,
32000,
null,
30200,
17300,
47400,
50200,
55000,
13200,
25200,
29800,
185100,
8500,
8100,
21800,
25400,
13900,
32200,
13500,
18900,
23800,
15200,
15000,
30600,
23900,
127000,
12200,
40300,
46900,
77400,
11700,
30900,
35500,
41100,
78400,
10000,
41500,
19100,
11300,
40300,
45100,
44500,
14500,
31600,
24600,
39200,
77500,
116500,
25000,
7000,
null,
8300,
19700,
40100,
2300,
55400,
88500,
36500,
28600,
15100,
32700,
22900,
46900,
39400,
19000,
50400,
23600,
65700,
14700,
9800,
16300,
11800,
35500,
26500,
23400,
16400,
null,
28300,
11300,
12900,
21700,
null,
35000,
63800,
18700,
24400,
4300,
24300,
23500,
null,
95500,
34400,
23000,
9700,
49700,
29400,
19800,
84300,
21000,
17900,
17700,
36300,
40300,
5400,
16500,
38200,
13600,
20000,
null,
23900,
null,
3100,
25700,
102200,
null,
16800,
20200,
56200,
13600,
34100,
17150,
7100,
21600,
6600,
6700,
80100,
8600,
82100,
23300,
31400,
28500,
15500,
null,
44700,
18000,
10300,
11400,
28500,
30200,
null,
15000,
11800,
null,
39700,
32100,
null,
25500,
12000,
17800,
35400,
58100,
null,
23300,
97300,
18200,
7500,
16600,
25500,
39200,
57000,
null,
26600,
24800,
9100,
22100,
null,
74000,
44200,
52700,
19800,
21000,
351200,
18000,
23400,
58600,
11000,
7300,
15000,
28300,
null,
180400,
45000,
40100,
51951,
28500,
6800,
46400,
6100,
28300,
null,
129100,
25300,
4500,
10900,
14600,
13000,
13000,
13900,
null,
39600,
21100,
11800,
31800,
53400,
5000,
28400,
5000,
23000,
10900,
31100,
211600,
16200,
7400,
8700,
34500,
25200,
46000,
100800,
54800,
13140,
8100,
16600,
25900,
70800,
12400,
3200,
83500,
4500,
16600,
45600,
8800,
33600,
49700,
5750,
96800,
3400,
23200,
48300,
11200,
12100,
6400,
26000,
15400,
21300,
null,
53500,
49200,
15600,
76800,
51500,
21600,
17300,
43300,
66400,
4300,
38100,
11100,
33700,
121100,
null,
30300,
20900,
94600,
22400,
16800,
56200,
26500,
23200,
14400,
22700,
131558,
16800,
22000,
33900,
27700,
34400,
6300,
52300,
29400,
12300,
16900,
14300,
11600,
28500,
13400,
38100,
19900,
39085,
29300,
39600,
20200,
36300,
97100,
24100,
10800,
15000,
38500,
38300,
9500,
22700,
null,
53800,
71100,
128400,
null,
28200,
37700,
50800,
41800,
68000,
10930,
36700,
19400,
23500,
12000,
46900,
9200,
16300,
10700,
21300,
null,
22800,
27800,
37400,
26200,
12300,
null,
28200,
3800,
39000,
114300,
13100,
19700,
23500,
7000,
22400,
24600,
null,
23900,
63800,
61400,
19000,
20100,
5900,
12500,
37700,
29100,
null,
52533,
16900,
27500,
23700,
16500,
72400,
18100,
30600,
29700,
84800,
8100,
17400,
23700,
25800,
105500,
39100,
53600,
31500,
6700,
39700,
7200,
53300,
2000,
19100,
14600,
18500,
49600,
17500,
14100,
16500,
14000,
23500,
73300,
39600,
21000,
19200,
19100,
19700,
2100,
39900,
45300,
82400,
50200,
12000,
null,
15000,
29800,
24300,
26200,
76800,
20600,
8150,
21800,
28900,
18300,
15200,
22400,
14400,
10100,
150700,
11500,
22600,
32000,
19700,
52100,
20100,
56000,
29800,
56600,
71000,
4700,
13200,
12500,
15200,
5200,
13400,
28600,
111000,
12800,
34000,
15800,
6300,
29600,
13700,
102700,
27600,
null,
36300,
80900,
171800,
24000,
49100,
40100,
null,
55400,
39800,
33800,
2600,
34300,
92100,
48400,
34300,
3500,
26500,
null,
null,
18100,
null,
9900,
14300,
null,
18900,
26400,
7000,
26700,
38300,
19900,
41302,
33500,
24100,
17500,
21900,
14000,
54300,
7500,
10700,
77200,
10200,
40800,
12000,
66804,
57900,
11800,
12600,
69200,
null,
null,
13100,
28700,
18900,
29100,
36100,
51400,
63600,
10500,
109100,
19100,
45900,
15000,
65000,
24900,
11800,
26500,
24800,
null,
101100,
21800,
40000,
7500,
14800,
33400,
44100,
60000,
21700,
5100,
18400,
32300,
12700,
29300,
107900,
18400,
12600,
19700,
14100,
16100,
12500,
56900,
22500,
9400,
10800,
33600,
18200,
47900,
42700,
34000,
null,
61600,
null,
94200,
66100,
28800,
12900,
40200,
12200,
38500,
30000,
15200,
18700,
34900,
9000,
37500,
53500,
86700,
132900,
25000,
65000,
66400,
22400,
1600,
21200,
29400,
15700,
85000,
50400,
6600,
19600,
71700,
16800,
11000,
9400,
96500,
null,
null,
34400,
41200,
6100,
null,
13200,
14300,
55993,
null,
24000,
117900,
13600,
null,
45126,
40800,
17700,
81400,
33600,
75200,
50600,
25300,
39900,
28900,
8600,
59700,
null,
67400,
28300,
19300,
11100,
22200,
51900,
12500,
32200,
11500,
27600,
null,
13700,
105300,
71000,
7900,
18000,
63200,
40800,
12400,
48200,
21900,
5200,
11500,
27200,
27600,
null,
25900,
9600,
22575,
9500,
27000,
13300,
32500,
18700,
73600,
10400,
23477,
57810,
3000,
40848,
18900,
15000,
21300,
139800,
13300,
16200,
57500,
16200,
8700,
13000,
46500,
31500,
34700,
22800,
4400,
32013,
null,
31300,
16700,
56200,
35653,
25600,
52200,
4300,
20700,
12800,
22450,
14200,
62500,
5600,
14500,
52200,
42100,
10800,
6700,
13500,
29900,
36700,
9400,
null,
64700,
17700,
10400,
49600,
36500,
17000,
64100,
14100,
62500,
22900,
20800,
12400,
10400,
null,
24000,
15100,
17600,
53200,
null,
23800,
null,
14500,
18100,
92000,
187000,
40300,
12800,
13600,
12500,
10100,
89000,
11100,
38200,
40400,
31200,
24600,
8600,
31200,
9300,
8600,
40800,
44500,
20700,
22900,
33100,
6700,
28900,
32400,
14300,
24900,
29300,
20600,
16700,
36300,
17600,
41800,
18500,
12200,
20300,
null,
31950,
109200,
40300,
37800,
9800,
105800,
15600,
63900,
9800,
16700,
18500,
11900,
23500,
39600,
17100,
7000,
196400,
23200,
34100,
9100,
75208,
80500,
22800,
30500,
null,
18800,
34300,
23100,
39400,
8300,
66100,
35000,
31600,
112400,
21900,
50900,
null,
13600,
13646,
18100,
11200,
31000,
62600,
null,
16000,
16500,
10100,
67400,
55200,
39100,
55400,
160200,
7900,
40600,
29100,
11200,
33500,
20000,
26700,
26200,
43500,
18300,
58610,
32800,
39100,
7500,
55800,
55400,
41800,
null,
22700,
6600,
62900,
67780,
23700,
40900,
7500,
32600,
43500,
22000,
16300,
50800,
30800,
72800,
53000,
10400,
9400,
88100,
36900,
49100,
34000,
10000,
64900,
10800,
58100,
20200,
51400,
50702,
null,
166800,
155426,
35200,
19000,
16340,
null,
11400,
null,
5300,
46000,
10700,
23700,
53600,
17400,
20200,
3600,
14200,
100300,
37900,
31200,
20100,
20000,
17000,
20753,
null,
66500,
5200,
22200,
19100,
7300,
510100,
23500,
44300,
46400,
42300,
56400,
19400,
74400,
17800,
18700,
16000,
19600,
20300,
17300,
33700,
17500,
43900,
12500,
22300,
25700,
44100,
101200,
15000,
8900,
14000,
23500,
68300,
2900,
7500,
57200,
16700,
null,
null,
47600,
9160,
12300,
70318,
null,
15200,
31800,
17700,
35400,
4400,
41100,
16900,
7400,
8600,
66900,
55900,
50400,
3300,
26900,
14100,
132600,
5300,
25000,
50400,
26800,
19100,
19600,
37400,
21900,
12000,
19500,
13700,
8500,
14300,
82000,
73500,
112200,
9100,
16300,
9600,
20400,
23200,
8600,
19200,
20600,
49400,
45200,
28400,
43600,
70000,
7900,
20900,
11200,
20400,
1500,
11200,
25500,
62200,
20900,
54700,
7300,
33000,
18300,
10100,
5500,
null,
32600,
10100,
35200,
33200,
21700,
38000,
13000,
2000,
12100,
97100,
66800,
7450,
17600,
8300,
3500,
17900,
17800,
29100,
35600,
27003,
25800,
null,
112900,
22800,
18800,
28800,
21300,
25000,
7600,
86000,
22000,
13800,
32700,
29900,
51800,
13300,
23300,
18300,
39000,
31400,
14900,
16500,
67300,
10400,
45100,
18200,
22200,
10900,
58100,
19400,
7300,
14000,
259000,
27800,
7200,
13600,
17300,
12900,
null,
138900,
46900,
17600,
19900,
null,
25000,
null,
39800,
28200,
20300,
15600,
13000,
36800,
null,
32200,
2200,
21300,
7400,
26800,
19900,
null,
7000,
23300,
29800,
57900,
null,
25200,
17200,
8500,
13000,
29800,
26900,
22400,
25300,
44100,
103000,
20900,
63200,
8800,
null,
33100,
17800,
17900,
28200,
19474,
15900,
117800,
24800,
null,
40900,
50500,
9100,
15800,
23800,
12400,
12800,
null,
24400,
27300,
20600,
43100,
17900,
31000,
97700,
67200,
null,
96700,
12800,
46800,
33900,
48800,
28500,
null,
19000,
30700,
21600,
null,
28900,
9200,
4600,
19800,
48800,
20400,
61600,
40700,
42600,
24700,
11400,
104700,
13100,
22900,
27500,
16500,
25400,
32400,
21600,
13200,
10200,
34400,
8500,
15300,
9300,
43200,
9200,
27900,
17600,
6700,
100200,
40200,
50900,
13800,
13100,
15100,
19400,
null,
21900,
9500,
2800,
11600,
43100,
47100,
46000,
27000,
24500,
27200,
28500,
5300,
17800,
25600,
28300,
8100,
24600,
23500,
null,
67400,
null,
47600,
23100,
34400,
6800,
16200,
7200,
18300,
41700,
19200,
30400,
39500,
58800,
33000,
19500,
24400,
8200,
8910,
36100,
14900,
19100,
25100,
14500,
7400,
16300,
8100,
58900,
13300,
15800,
24500,
null,
30100,
17000,
23200,
15300,
35200,
53800,
5200,
61200,
28700,
21900,
15255,
18400,
6200,
null,
24700,
null,
26100,
65600,
6200,
26100,
23700,
36200,
48000,
11800,
11300,
23500,
15800,
27300,
49700,
10600,
16300,
38600,
35600,
null,
23700,
6300,
29200,
75400,
null,
19800,
62900,
26800,
11300,
20900,
12100,
21900,
null,
2600,
16300,
14700,
16300,
15000,
8400,
null,
20300,
19900,
17600,
24500,
56200,
30800,
63400,
53600,
42600,
14754,
101500,
15100,
70000,
55800,
36500,
11800,
81700,
9600,
9200,
29900,
21900,
35400,
7453,
33400,
55900,
40500,
71600,
63100,
45100,
14200,
53800,
43700,
13400,
11500,
9900,
22900,
16400,
7500,
43300,
34500,
15700,
68900,
3200,
38300,
null,
10830,
101100,
78100,
4300,
16300,
33400,
57500,
null,
19200,
6800,
10900,
18800,
24700,
6900,
7100,
16100,
127500,
18000,
14000,
6000,
60730,
8400,
7400,
15500,
68600,
23300,
19200,
4700,
86000,
16800,
2700,
41400,
8400,
6400,
36800,
13800,
202000,
11700,
33300,
6000,
97800,
25300,
29200,
101700,
32597,
20800,
1900,
6800,
64500,
82800,
93600,
16900,
21700,
12800,
9700,
42200,
24300,
16000,
9600,
50100,
260900,
31200,
80700,
25100,
51900,
27800,
6600,
13500,
2000,
44500,
8200,
25300,
9300,
null,
8100,
121300,
28000,
19700,
10900,
20100,
24700,
6800,
null,
17400,
19500,
34100,
36800,
13200,
null,
18100,
11500,
18300,
11000,
5800,
31800,
68400,
40000,
null,
12700,
47600,
37600,
14100,
17500,
16500,
null,
5400,
4800,
25500,
20500,
27500,
27000,
null,
14700,
5900,
19400,
16150,
19400,
26300,
27100,
22800,
null,
10900,
null,
14100,
19200,
114900,
78400,
35286,
null,
45900,
null,
45800,
2600,
22700,
5400,
40300,
13500,
null,
22303,
26000,
42300,
14500,
17500,
55500,
44000,
33000,
86500,
18800,
7700,
63795,
6000,
87900,
17200,
49500,
11800,
29100,
null,
25100,
10900,
null,
10700,
13600,
33000,
11600,
3100,
null,
36100,
20200,
9200,
36300,
9300,
48600,
19000,
49500,
37700,
21400,
38200,
23900,
16800,
22300,
26600,
4800,
19500,
28600,
17800,
16300,
17900,
5300,
50819,
16300,
10900,
15500,
50700,
86500,
6500,
null,
18900,
null,
37500,
26600,
null,
126300,
11200,
15400,
null,
55600,
33700,
52500,
30100,
41200,
30000,
200,
80915,
14400,
34600,
24900,
19400,
12100,
3800,
24700,
11000,
null,
23400,
31700,
29800,
15900,
13800,
null,
null,
18700,
25800,
17400,
7200,
13500,
46400,
31400,
20500,
34800,
31600,
15300,
28300,
36700,
7300,
6500,
26700,
31900,
4900,
52200,
12800,
11200,
54100,
15900,
10100,
14500,
98000,
9500,
80300,
38000,
44500,
9200,
78400,
44300,
14700,
11800,
13800,
15500,
26500,
35400,
43000,
43100,
5650,
null,
12300,
36100,
8600,
26100,
null,
1300,
8900,
73200,
12900,
10700,
90700,
19600,
62500,
18400,
54255,
14500,
9300,
21500,
45100,
16400,
11400,
13600,
12700,
22700,
17400,
23400,
31800,
19100,
25700,
12400,
10400,
54200,
14900,
13200,
107100,
null,
30500,
32000,
31900,
19400,
57500,
14100,
51200,
10900,
25000,
80500,
null,
21400,
16990,
40100,
null,
35200,
12200,
64100,
41800,
18700,
13400,
20200,
null,
24400,
9600,
34800,
74200,
2300,
24900,
13100,
17100,
677800,
7300,
39700,
24900,
12800,
14300,
15400,
61000,
31100,
13100,
13000,
23400,
1900,
7600,
null,
13000,
21100,
5100,
16900,
43700,
5900,
12900,
31400,
null,
51800,
35900,
70600,
7400,
1700,
28500,
13100,
22400,
44600,
74500,
13500,
24900,
19500,
88900,
50700,
47700,
55200,
11800,
37700,
9600,
18630,
48100,
10900,
35700,
null,
23500,
null,
12700,
15500,
34900,
null,
100800,
27300,
77400,
16200,
14050,
19800,
null,
109200,
18000,
59900,
55700,
31200,
10000,
76500,
17400,
41000,
142600,
6500,
54300,
117600,
19100,
38500,
7700,
116550,
35100,
7350,
18600,
28700,
12800,
40400,
34200,
49300,
26800,
21900,
null,
58100,
19800,
15800,
9300,
16800,
12800,
34900,
78600,
76200,
19600,
24400,
16300,
58500,
38700,
186955,
24000,
13100,
81700,
8400,
18000,
46800,
58200,
17680,
60300,
7500,
39200,
15900,
25100,
54000,
null,
null,
36600,
41900,
16400,
null,
18800,
16900,
53400,
60600,
54500,
14700,
41600,
12000,
17800,
41800,
24100,
61600,
54500,
29500,
null,
60600,
64000,
23900,
65500,
20400,
null,
22600,
27700,
25500,
50000,
12700,
56300,
291600,
35600,
30450,
13700,
217600,
113500,
10700,
71600,
54100,
53000,
17700,
30500,
12000,
28100,
null,
57300,
6300,
10300,
105200,
5800,
30000,
3700,
16700,
13500,
23700,
13700,
null,
null,
218100,
20400,
26500,
15200,
28700,
27500,
42300,
32500,
16600,
36900,
null,
null,
28700,
122900,
22500,
53600,
21000,
30800,
9500,
22400,
68574,
17300,
17500,
66200,
69200,
5900,
4900,
37400,
10500,
25700,
24100,
20000,
53500,
46600,
18400,
33000,
37100,
36400,
14800,
24900,
32217,
10600,
null,
19500,
27200,
16600,
10600,
13800,
103900,
20200,
41800,
10000,
27100,
21000,
13800,
12000,
32600,
44800,
49300,
null,
37000,
22500,
8300,
null,
34700,
100118,
68300,
21900,
13400,
21300,
10000,
14500,
14200,
17100,
14400,
36200,
34000,
23300,
33600,
84600,
12200,
11600,
345300,
18300,
14400,
27200,
25800,
73410,
9000,
20400,
90100,
23000,
29800,
5000,
1500,
42300,
43400,
23900,
38400,
6400,
18700,
44300,
22500,
13800,
5200,
6000,
22300,
31500,
11000,
15400,
14100,
14900,
28300,
1500,
117700,
42200,
36600,
69500,
28300,
6300,
21800,
9000,
12200,
17700,
6300,
null,
29900,
4300,
16430,
12800,
30800,
null,
6000,
12600,
10300,
34100,
39900,
8000,
12100,
null,
57700,
41500,
1200,
null,
49900,
30100,
176700,
56350,
16200,
16200,
4500,
20700,
16700,
20500,
27000,
6900,
9100,
74900,
17000,
30000,
7700,
47800,
22600,
2400,
12700,
15600,
null,
85400,
23000,
44100,
null,
44900,
124100,
null,
25700,
37500,
17100,
9600,
20800,
60300,
12100,
9500,
17600,
12000,
31200,
10800,
32900,
10100,
3100,
14900,
9700,
71300,
54400,
null,
53200,
15500,
33100,
27400,
42700,
40400,
22800,
23500,
15900,
null,
5000,
30800,
20100,
9800,
11400,
5300,
48100,
41800,
30800,
13800,
21300,
22400,
null,
20200,
7200,
13100,
30359,
25300,
null,
19000,
null,
14000,
null,
68600,
29100,
10200,
41700,
14000,
24700,
381900,
23400,
null,
8900,
28100,
29900,
47400,
52600,
19500,
6100,
18900,
7400,
9600,
8500,
26100,
44100,
29400,
33900,
40600,
12900,
12400,
20400,
7500,
3700,
null,
null,
63200,
32500,
72200,
null,
6150,
26000,
6000,
30300,
15300,
9100,
36300,
20600,
66338,
25200,
24600,
17100,
15600,
31000,
41300,
18500,
25600,
23400,
135000,
61900,
null,
29400,
37900,
58500,
31000,
7900,
35900,
null,
15800,
13200,
53700,
14600,
31700,
26000,
44500,
14200,
null,
28800,
20100,
57400,
13100,
27400,
75000,
21500,
3000,
1500,
93600,
26800,
45000,
7900,
21100,
23300,
null,
5800,
null,
15000,
31600,
26800,
10500,
62700,
38600,
null,
22000,
10200,
8300,
5700,
19200,
12800,
3800,
98900,
800,
71309,
27400,
11100,
29700,
18900,
5900,
12400,
49400,
13600,
49700,
62800,
63100,
67900,
18400,
50100,
21000,
9900,
36800,
4800,
42900,
11500,
43500,
44600,
4300,
null,
36200,
20900,
29200,
24800,
26500,
58000,
11900,
75000,
41900,
9600,
69400,
36900,
72800,
20400,
65300,
null,
7300,
23800,
24100,
109300,
43200,
33700,
31800,
12000,
40700,
25000,
17300,
8500,
24900,
9300,
21200,
62500,
40400,
33700,
25700,
null,
null,
21300,
31400,
105200,
24500,
31900,
2800,
24500,
12500,
7700,
37300,
13400,
27600,
34800,
null,
28200,
33900,
50100,
20300,
null,
35800,
40500,
8250,
39700,
0,
21100,
17500,
20500,
21200,
63600,
42000,
19100,
6800,
20900,
4500,
35300,
null,
8300,
16100,
46900,
600,
29100,
62900,
17200,
20900,
34100,
38200,
7300,
56900,
64800,
51000,
7500,
12800,
35400,
4800,
13500,
29200,
2850,
null,
12600,
31200,
6000,
33100,
22000,
29500,
5900,
36400,
40700,
34000,
21000,
21900,
13100,
16700,
68300,
53700,
null,
20700,
15200,
17800,
48600,
17100,
13500,
20400,
38900,
18100,
27800,
14100,
27500,
35548,
30900,
20900,
44800,
54900,
19600,
36500,
74900,
50600,
38600,
8500,
10000,
80900,
82500,
48500,
53300,
44400,
20500,
25500,
54466,
23900,
110100,
null,
12300,
50500,
6200,
13700,
5600,
26610,
210200,
22100,
30300,
9700,
17000,
null,
17200,
38000,
9800,
17600,
11500,
null,
22000,
26300,
16000,
42200,
6000,
27300,
13300,
7400,
5500,
32300,
3600,
null,
19600,
null,
22400,
51500,
10800,
37800,
77200,
36500,
30000,
70400,
32900,
43600,
null,
13000,
23500,
13500,
40100,
16600,
40300,
12600,
22600,
25000,
null,
null,
null,
20200,
11300,
40800,
11600,
15300,
null,
1800,
25800,
54200,
19900,
51000,
7000,
92097,
28400,
27900,
33400,
45200,
25800,
73700,
28900,
34200,
15700,
30400,
47200,
37500,
14600,
58000,
16200,
16800,
40300,
12600,
8820,
53600,
22900,
15300,
42600,
28900,
20900,
15400,
14300,
2900,
150400,
15400,
31900,
35700,
null,
94700,
null,
4400,
16200,
16800,
34400,
22200,
22900,
111900,
15600,
5000,
47600,
40500,
52600,
20600,
9600,
13600,
7300,
42300,
24700,
19900,
53700,
34400,
14500,
65400,
null,
null,
22000,
13100,
59100,
40800,
36300,
19100,
47100,
8700,
29100,
53800,
14700,
50200,
null,
23600,
40200,
15000,
11000,
12300,
38500,
22000,
62900,
22600,
18200,
36400,
35100,
36400,
48400,
30200,
19900,
32300,
27600,
37800,
31500,
15200,
46600,
35900,
96700,
9100,
null,
25400,
null,
40000,
14900,
3000,
1600,
13000,
23400,
71600,
43600,
21800,
38500,
35405,
42000,
61500,
84300,
17000,
15550,
34800,
4600,
107100,
24700,
17700,
17600,
9200,
43400,
11600,
11800,
34700,
30600,
22000,
null,
28500,
19000,
68771,
11900,
21000,
33300,
null,
15600,
32800,
18800,
14300,
33900,
206600,
40900,
5000,
37300,
18400,
25800,
3200,
70200,
41200,
11400,
28200,
15200,
null,
18900,
14000,
19800,
35100,
48000,
15600,
6100,
17400,
7200,
12800,
20900,
11500,
15500,
15100,
21200,
37800,
null,
10800,
null,
54300,
31600,
17600,
16900,
12000,
10200,
15300,
31100,
21700,
11300,
19600,
37600,
26700,
10400,
24600,
43800,
null,
47900,
null,
5800,
3900,
22600,
20800,
8100,
18400,
13000,
52500,
19500,
12900,
17000,
27900,
16100,
35000,
40100,
26900,
45800,
15400,
28500,
31800,
16200,
74000,
null,
15700,
10000,
16300,
23900,
13900,
10100,
16900,
40200,
11100,
13450,
78600,
13100,
86800,
60000,
43500,
null,
32200,
null,
17400,
39800,
55000,
8100,
38100,
135100,
24100,
80000,
8700,
26400,
31800,
11590,
4300,
18900,
42100,
39300,
21700,
3700,
9400,
8100,
10100,
33500,
34600,
67100,
4500,
42100,
15000,
11200,
14500,
19500,
27500,
25700,
100100,
118800,
null,
8000,
38000,
94000,
23900,
22200,
10800,
19600,
8500,
10100,
36200,
24500,
18400,
26800,
28700,
61500,
13600,
25100,
6500,
310800,
41200,
29900,
23900,
9700,
238800,
22100,
27700,
36076,
20300,
18800,
69500,
null,
45700,
33500,
14800,
12300,
888800,
57700,
78800,
32500,
32300,
68600,
23500,
47600,
12200,
86300,
56100,
89400,
21200,
46043,
17900,
14600,
47400,
40300,
31592,
19600,
9400,
24100,
77400,
14500,
25700,
16600,
46800,
null,
20000,
null,
10400,
60600,
12100,
7500,
23500,
26400,
18200,
28100,
34700,
16200,
133700,
27800,
11700,
18500,
17600,
32100,
62500,
79600,
69800,
55800,
67300,
98300,
15800,
25000,
48800,
27500,
null,
23100,
18300,
28300,
29600,
10200,
40000,
45400,
37800,
null,
23800,
19800,
28300,
80100,
20000,
null,
11500,
13000,
40200,
70800,
7700,
8400,
34200,
104535,
15700,
8700,
26600,
75700,
14500,
10500,
33200,
11300,
19500,
41800,
29000,
53300,
36400,
27300,
86400,
51900,
41000,
null,
19400,
23100,
3800,
100300,
15600,
9000,
49000,
14200,
18100,
27146,
28300,
12800,
19600,
102400,
7500,
31500,
27700,
11900,
null,
36300,
15900,
54600,
18300,
13600,
16700,
6100,
25200,
11900,
63000,
8800,
10000,
8800,
118688,
85500,
null,
17300,
20400,
12200,
22300,
45000,
23000,
24300,
40600,
47000,
262100,
null,
60900,
13000,
56800,
19900,
12700,
17000,
37400,
12500,
26200,
7600,
35600,
17700,
45500,
33300,
15800,
null,
16700,
10500,
36100,
17700,
29500,
44000,
14500,
12600,
7700,
20200,
41100,
null,
13400,
23200,
18700,
7200,
null,
57600,
5600,
25660,
24250,
62500,
7500,
41700,
50300,
16300,
33100,
68900,
19800,
33600,
61600,
8000,
16400,
27300,
14200,
43600,
14900,
12500,
159300,
24240,
null,
13700,
4400,
27900,
11300,
21200,
34200,
64800,
12000,
25700,
24300,
14800,
2200,
22900,
27000,
12500,
105900,
42200,
30000,
70400,
91300,
8200,
5500,
17400,
25900,
35000,
7200,
25125,
158400,
2800,
16500,
14800,
18000,
5500,
33900,
7700,
32300,
17600,
281000,
15900,
35900,
19500,
59800,
11100,
20200,
null,
27200,
30000,
47900,
33800,
9800,
11800,
34200,
14200,
34400,
50600,
83800,
31700,
20000,
null,
24400,
35600,
62500,
null,
11000,
11100,
13500,
53900,
21100,
14700,
25500,
null,
27300,
18200,
18200,
null,
5100,
12600,
47400,
17400,
20600,
14400,
4700,
5800,
24500,
14500,
5200,
84800,
32900,
28800,
58342,
40800,
26300,
9600,
5900,
22800,
22600,
21400,
16400,
55100,
28300,
34200,
10000,
6600,
92360,
9200,
22400,
4100,
null,
null,
15400,
58100,
10000,
9500,
52300,
24700,
42800,
19800,
6700,
31800,
59100,
34300,
92000,
18900,
6900,
21800,
29700,
77100,
53600,
53498,
null,
25600,
13900,
41300,
34100,
52300,
39800,
10000,
18500,
60600,
36899,
16000,
22800,
68600,
29600,
32300,
9800,
null,
17300,
4400,
25600,
21500,
14800,
17500,
14900,
45400,
47300,
5000,
10600,
206300,
9100,
26900,
null,
29800,
17900,
61700,
63200,
26400,
38900,
53400,
38800,
58100,
26100,
35200,
11200,
14400,
17100,
13600,
31100,
12800,
58500,
126800,
54900,
7600,
56700,
null,
17050,
84600,
28500,
8300,
17000,
27200,
18100,
14500,
51800,
37500,
46100,
40700,
53600,
6400,
20500,
15800,
23400,
6900,
76900,
26800,
21400,
8100,
14000,
42400,
null,
35400,
17900,
18500,
29300,
15800,
11100,
22500,
9800,
25000,
13300,
19700,
24900,
32100,
10000,
31000,
33400,
33800,
30300,
63000,
34800,
41200,
13100,
11900,
9600,
19000,
23600,
null,
14900,
42800,
21500,
126900,
43500,
12500,
26600,
18200,
48100,
26600,
34100,
20100,
21800,
62800,
20600,
33200,
33600,
43000,
39800,
27800,
30600,
43600,
7200,
6300,
109500,
50000,
25600,
46200,
null,
97800,
11700,
39600,
20500,
30100,
45000,
15800,
null,
10100,
8600,
15300,
68700,
52900,
24100,
null,
10500,
31400,
null,
9200,
34000,
11800,
31600,
7000,
17700,
16400,
40600,
14900,
39500,
9700,
32500,
23400,
10300,
69600,
22800,
34500,
19000,
36200,
13000,
18100,
46700,
10500,
25500,
20200,
39673,
44200,
27000,
37600,
46900,
28600,
22300,
10600,
50000,
47100,
36200,
34500,
7200,
13500,
23600,
null,
null,
14600,
18800,
8300,
18700,
120200,
28400,
24300,
12300,
56800,
15100,
43400,
19600,
44800,
16600,
11600,
44900,
4200,
36600,
19200,
30200,
null,
26200,
119300,
21100,
7900,
12500,
14400,
11400,
24900,
14400,
14900,
30800,
8900,
56400,
6100,
null,
13200,
16000,
51400,
22500,
52500,
21800,
27800,
12600,
58900,
21300,
25300,
16400,
6200,
33400,
16000,
53300,
34200,
11400,
32200,
29500,
15300,
96800,
32200,
15100,
26100,
null,
15100,
25400,
35000,
36200,
28400,
29100,
10200,
18700,
15300,
63800,
12900,
49700,
74900,
92450,
7800,
null,
33600,
17600,
null,
17100,
27200,
74900,
48000,
19500,
28700,
31600,
11900,
7400,
18700,
19700,
16000,
128431,
72500,
70800,
37000,
19600,
null,
15300,
null,
11000,
11200,
28000,
47600,
16200,
12100,
73800,
11900,
23700,
12400,
9000,
21100,
39100,
77800,
27000,
null,
22200,
16900,
10800,
115900,
24200,
11000,
9600,
23100,
9250,
28600,
50600,
51100,
2800,
11500,
25700,
46400,
14800,
20605,
7700,
20400,
3500,
35700,
40800,
26100,
32100,
8600,
null,
22000,
121000,
9100,
18100,
29800,
10100,
4800,
43600,
47400,
null,
12800,
44000,
15700,
16600,
29300,
22200,
56311,
54700,
12600,
18000,
9100,
50000,
29600,
6400,
null,
11700,
20200,
152700,
15300,
8200,
76600,
25200,
70500,
24100,
10600,
14500,
null,
null,
12000,
85900,
32670,
39700,
53200,
41000,
null,
null,
27200,
25000,
143800,
null,
57600,
null,
24500,
26600,
23600,
83400,
15800,
5000,
29600,
24800,
12600,
55500,
null,
44600,
9600,
20500,
29800,
61300,
41500,
37100,
23500,
8100,
28300,
35200,
12750,
12000,
16100,
10400,
58300,
29400,
18400,
12700,
44056,
18900,
34800,
12600,
null,
11200,
18300,
9000,
8400,
24400,
26200,
18100,
91200,
24500,
11300,
34300,
29100,
82000,
1200,
33400,
7400,
47506,
12100,
24100,
20900,
20500,
57800,
15500,
57300,
20900,
13400,
53600,
29100,
76700,
45000,
112600,
9200,
29500,
34000,
17600,
20900,
63800,
null,
48400,
16000,
57800,
23900,
32500,
26700,
43200,
74000,
6000,
null,
63200,
46400,
11900,
43500,
21800,
4500,
41200,
null,
34700,
12400,
102300,
13100,
null,
17400,
27500,
25300,
34700,
null,
22700,
null,
19000,
null,
14500,
29500,
null,
85600,
6900,
23000,
18900,
17000,
28000,
7000,
9700,
44600,
null,
25050,
33400,
23800,
22200,
23000,
55700,
36900,
9700,
21500,
500,
21700,
45800,
null,
28900,
12900,
7500,
43100,
37000,
12500,
null,
80800,
16500,
21850,
105200,
41000,
14500,
12100,
40137,
35500,
18300,
30500,
11300,
52500,
8300,
9000,
61500,
14850,
19100,
25600,
25900,
22600,
51800,
442736,
3800,
30100,
6900,
19900,
69400,
22100,
null,
208800,
25600,
48000,
8800,
13900,
17400,
null,
null,
null,
27700,
13900,
42700,
86600,
22400,
null,
20600,
26700,
20300,
6400,
13050,
19800,
null,
41100,
28100,
39900,
20656,
7800,
47000,
16500,
27600,
13900,
19900,
35700,
14600,
18100,
null,
25800,
null,
9500,
null,
13800,
47300,
20800,
120400,
9100,
15800,
30500,
37600,
31500,
18600,
22200,
43300,
29000,
2500,
29600,
40800,
17300,
19100,
7100,
5500,
18400,
34200,
16700,
14300,
6700,
16100,
27000,
18100,
31200,
3800,
7800,
25000,
39900,
null,
55500,
10000,
13900,
11500,
26600,
49800,
17900,
24700,
27900,
36500,
114400,
21700,
20400,
12600,
10600,
8700,
46800,
8600,
24400,
35500,
2400,
41100,
37400,
57400,
63900,
68100,
null,
17200,
21200,
57100,
67900,
77000,
12600,
32200,
8100,
50100,
5500,
20300,
108200,
18000,
57200,
25400,
23900,
3630,
9400,
null,
null,
null,
60200,
24598,
133000,
9700,
13500,
29900,
20100,
67300,
29300,
12800,
29500,
40700,
35500,
100100,
64600,
16900,
33200,
5800,
1300,
17300,
25700,
null,
110600,
17100,
81300,
62800,
7000,
17500,
22900,
25800,
3900,
null,
8600,
25500,
14100,
16300,
44100,
33200,
16500,
25200,
20100,
12100,
60300,
64400,
14200,
6100,
21300,
16700,
16000,
13600,
37600,
5200,
27400,
27900,
14200,
10100,
17000,
35400,
null,
24400,
33200,
6000,
3800,
45900,
27300,
36400,
7800,
19600,
65700,
60100,
21400,
33500,
52000,
8000,
28900,
4800,
26500,
87300,
14500,
null,
20100,
28500,
3900,
10100,
19300,
8700,
11500,
36600,
73900,
10900,
32100,
18300,
43300,
13300,
14800,
6800,
71733,
15900,
42200,
53500,
50300,
14900,
null,
38300,
13000,
18500,
9400,
17600,
25750,
24800,
10500,
12300,
null,
1000,
106900,
36100,
28200,
7600,
4500,
41100,
152000,
6200,
27300,
25000,
43400,
12700,
86561,
13000,
null,
8000,
30400,
6000,
9200,
42300,
27600,
13100,
null,
10400,
11700,
20300,
58800,
12800,
60100,
19600,
15300,
22900,
1000,
15300,
null,
null,
16900,
19600,
36100,
19100,
null,
30100,
43000,
27600,
8360,
null,
39400,
46900,
11000,
10400,
33900,
40400,
24700,
7000,
21600,
14300,
68300,
9000,
null,
39200,
29200,
32300,
28600,
4700,
51500,
7900,
18300,
8000,
24000,
106300,
39100,
21900,
27800,
42100,
70300,
40200,
20800,
22900,
26800,
43400,
20300,
13400,
51100,
21000,
103500,
45000,
null,
14600,
18900,
45200,
15700,
45200,
36336,
null,
9900,
40200,
56600,
6300,
37300,
13800,
12800,
30500,
20200,
15400,
20500,
null,
null,
14800,
11000,
6300,
10800,
16500,
32800,
107800,
6600,
6100,
3900,
25600,
40500,
55100,
117600,
51500,
6800,
19800,
12500,
null,
27000,
11600,
null,
17900,
30200,
17300,
9400,
44000,
17200,
24200,
24000,
37600,
null,
78400,
null,
15500,
null,
33200,
11000,
91100,
44600,
29500,
41000,
50100,
9000,
8500,
null,
18100,
4300,
47992,
48600,
30550,
55800,
15800,
37500,
2500,
32600,
40500,
13100,
21000,
15900,
47000,
70900,
14500,
35100,
31000,
9100,
24000,
22600,
26100,
16250,
null,
67100,
6800,
15200,
24000,
7600,
16400,
22000,
99600,
38000,
38700,
8900,
2500,
60500,
14000,
29900,
28600,
14000,
27700,
21500,
28300,
25200,
25900,
5000,
26600,
31100,
6200,
50700,
19400,
60500,
null,
null,
6700,
81100,
37100,
48600,
30900,
122300,
24800,
6900,
null,
6900,
6300,
60700,
19600,
14700,
39310,
35372,
27700,
15100,
44500,
14700,
10100,
44800,
18500,
26400,
25100,
27400,
20700,
27800,
7400,
20400,
6200,
6200,
21800,
27300,
21400,
16100,
96000,
47100,
36800,
null,
70900,
10000,
68570,
47600,
48100,
54800,
8200,
12900,
16800,
16300,
10200,
5300,
26500,
23800,
13000,
32200,
24200,
35300,
11000,
12979,
9900,
47800,
23100,
35300,
18100,
10800,
32900,
17700,
6100,
17300,
5300,
null,
13100,
19000,
14800,
76000,
8100,
4500,
81900,
null,
36500,
21100,
34500,
11300,
16400,
17300,
10500,
31700,
11400,
34200,
9200,
31407,
null,
28600,
25643,
null,
11900,
22000,
15600,
34100,
29900,
19300,
35380,
9500,
26300,
32600,
null,
5400,
16500,
10900,
51100,
4100,
22000,
6200,
18600,
null,
60300,
38900,
20200,
30500,
14900,
9600,
6800,
39300,
31900,
5100,
46400,
32700,
16200,
52300,
8700,
44800,
22400,
74437,
26800,
96300,
35200,
70100,
22100,
14000,
20500,
null,
22700,
68800,
33500,
6900,
52400,
56300,
35400,
10300,
61000,
31900,
45100,
17900,
8500,
12900,
4600,
5200,
37600,
45500,
8300,
23700,
22600,
7100,
29800,
36900,
2700,
218200,
5300,
76100,
107350,
17900,
13700,
14200,
7600,
29800,
19900,
32000,
43400,
null,
24000,
null,
25000,
26200,
null,
59800,
73551,
null,
3800,
37500,
64600,
154100,
3900,
64000,
44800,
27103,
5600,
40400,
17700,
2300,
83000,
120300,
null,
35300,
47500,
20100,
9400,
14000,
12941,
18500,
13900,
14100,
24200,
5300,
42400,
22500,
15600,
13500,
9000,
22600,
null,
205730,
39400,
11900,
null,
36200,
12600,
21700,
14500,
17400,
24300,
13100,
19900,
43300,
7000,
31400,
null,
9100,
59900,
33400,
52300,
13200,
24200,
30900,
10500,
23400,
9500,
23700,
3000,
67600,
90100,
11100,
9800,
6950,
27600,
54300,
27100,
27000,
15100,
22500,
34000,
30700,
38800,
58600,
11300,
35800,
50900,
21500,
null,
41200,
10300,
24800,
14300,
28100,
220860,
null,
27600,
null,
25700,
167418,
36700,
25500,
73900,
48000,
34100,
14100,
null,
null,
43100,
59300,
2600,
74500,
37200,
20200,
25400,
4900,
5250,
25600,
7100,
15100,
95300,
null,
38300,
16200,
47200,
7600,
67100,
29300,
32400,
46702,
24400,
9000,
11700,
20100,
23900,
8100,
47600,
20500,
40300,
39300,
48100,
16500,
6900,
null,
null,
42000,
12800,
31700,
2900,
39700,
null,
51200,
23500,
40988
]
}
],
"layout": {
"legend": {
"bgcolor": "#F5F6F9",
"font": {
"color": "#4D5663"
}
},
"paper_bgcolor": "#F5F6F9",
"plot_bgcolor": "#F5F6F9",
"template": {
"data": {
"bar": [
{
"error_x": {
"color": "#2a3f5f"
},
"error_y": {
"color": "#2a3f5f"
},
"marker": {
"line": {
"color": "#E5ECF6",
"width": 0.5
}
},
"type": "bar"
}
],
"barpolar": [
{
"marker": {
"line": {
"color": "#E5ECF6",
"width": 0.5
}
},
"type": "barpolar"
}
],
"carpet": [
{
"aaxis": {
"endlinecolor": "#2a3f5f",
"gridcolor": "white",
"linecolor": "white",
"minorgridcolor": "white",
"startlinecolor": "#2a3f5f"
},
"baxis": {
"endlinecolor": "#2a3f5f",
"gridcolor": "white",
"linecolor": "white",
"minorgridcolor": "white",
"startlinecolor": "#2a3f5f"
},
"type": "carpet"
}
],
"choropleth": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "choropleth"
}
],
"contour": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "contour"
}
],
"contourcarpet": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "contourcarpet"
}
],
"heatmap": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "heatmap"
}
],
"heatmapgl": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "heatmapgl"
}
],
"histogram": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "histogram"
}
],
"histogram2d": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "histogram2d"
}
],
"histogram2dcontour": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "histogram2dcontour"
}
],
"mesh3d": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "mesh3d"
}
],
"parcoords": [
{
"line": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "parcoords"
}
],
"pie": [
{
"automargin": true,
"type": "pie"
}
],
"scatter": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatter"
}
],
"scatter3d": [
{
"line": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatter3d"
}
],
"scattercarpet": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattercarpet"
}
],
"scattergeo": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattergeo"
}
],
"scattergl": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattergl"
}
],
"scattermapbox": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattermapbox"
}
],
"scatterpolar": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterpolar"
}
],
"scatterpolargl": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterpolargl"
}
],
"scatterternary": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterternary"
}
],
"surface": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "surface"
}
],
"table": [
{
"cells": {
"fill": {
"color": "#EBF0F8"
},
"line": {
"color": "white"
}
},
"header": {
"fill": {
"color": "#C8D4E3"
},
"line": {
"color": "white"
}
},
"type": "table"
}
]
},
"layout": {
"annotationdefaults": {
"arrowcolor": "#2a3f5f",
"arrowhead": 0,
"arrowwidth": 1
},
"coloraxis": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"colorscale": {
"diverging": [
[
0,
"#8e0152"
],
[
0.1,
"#c51b7d"
],
[
0.2,
"#de77ae"
],
[
0.3,
"#f1b6da"
],
[
0.4,
"#fde0ef"
],
[
0.5,
"#f7f7f7"
],
[
0.6,
"#e6f5d0"
],
[
0.7,
"#b8e186"
],
[
0.8,
"#7fbc41"
],
[
0.9,
"#4d9221"
],
[
1,
"#276419"
]
],
"sequential": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"sequentialminus": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
]
},
"colorway": [
"#636efa",
"#EF553B",
"#00cc96",
"#ab63fa",
"#FFA15A",
"#19d3f3",
"#FF6692",
"#B6E880",
"#FF97FF",
"#FECB52"
],
"font": {
"color": "#2a3f5f"
},
"geo": {
"bgcolor": "white",
"lakecolor": "white",
"landcolor": "#E5ECF6",
"showlakes": true,
"showland": true,
"subunitcolor": "white"
},
"hoverlabel": {
"align": "left"
},
"hovermode": "closest",
"mapbox": {
"style": "light"
},
"paper_bgcolor": "white",
"plot_bgcolor": "#E5ECF6",
"polar": {
"angularaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"bgcolor": "#E5ECF6",
"radialaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
}
},
"scene": {
"xaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
},
"yaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
},
"zaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
}
},
"shapedefaults": {
"line": {
"color": "#2a3f5f"
}
},
"ternary": {
"aaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"baxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"bgcolor": "#E5ECF6",
"caxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
}
},
"title": {
"x": 0.05
},
"xaxis": {
"automargin": true,
"gridcolor": "white",
"linecolor": "white",
"ticks": "",
"title": {
"standoff": 15
},
"zerolinecolor": "white",
"zerolinewidth": 2
},
"yaxis": {
"automargin": true,
"gridcolor": "white",
"linecolor": "white",
"ticks": "",
"title": {
"standoff": 15
},
"zerolinecolor": "white",
"zerolinewidth": 2
}
}
},
"title": {
"font": {
"color": "#4D5663"
},
"text": "total_rev_hi_lim Box plot"
},
"xaxis": {
"gridcolor": "#E1E5ED",
"showgrid": true,
"tickfont": {
"color": "#4D5663"
},
"title": {
"font": {
"color": "#4D5663"
},
"text": ""
},
"zerolinecolor": "#E1E5ED"
},
"yaxis": {
"gridcolor": "#E1E5ED",
"showgrid": true,
"tickfont": {
"color": "#4D5663"
},
"title": {
"font": {
"color": "#4D5663"
},
"text": ""
},
"zerolinecolor": "#E1E5ED"
}
}
},
"text/html": [
"\n",
" \n",
" \n",
" \n",
" \n",
"
"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"\n",
"columns inputed with : mean are ['revol_util', 'tot_cur_bal', 'total_rev_hi_lim']\n",
"revol_util filled with: 55.045863060809744\n",
"tot_cur_bal filled with: 139812.53492993632\n",
"total_rev_hi_lim filled with: 32223.922038216562\n",
"\n",
"columns label encoded\n",
" Index(['term', 'grade', 'sub_grade', 'emp_title', 'emp_length',\n",
" 'home_ownership', 'verification_status', 'purpose', 'title', 'zip_code',\n",
" 'addr_state', 'initial_list_status', 'application_type',\n",
" 'last_week_pay'],\n",
" dtype='object')\n"
]
},
{
"data": {
"application/vnd.plotly.v1+json": {
"config": {
"plotlyServerURL": "https://plot.ly"
},
"data": [
{
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"reversescale": false,
"showscale": true,
"type": "heatmap",
"x": [
"loan_amnt",
"funded_amnt",
"funded_amnt_inv",
"term",
"int_rate",
"grade",
"sub_grade",
"emp_title",
"emp_length",
"home_ownership",
"annual_inc",
"verification_status",
"purpose",
"title",
"zip_code",
"addr_state",
"dti",
"delinq_2yrs",
"inq_last_6mths",
"open_acc",
"pub_rec",
"revol_bal",
"revol_util",
"total_acc",
"initial_list_status",
"total_rec_int",
"total_rec_late_fee",
"recoveries",
"collection_recovery_fee",
"collections_12_mths_ex_med",
"application_type",
"last_week_pay",
"acc_now_delinq",
"tot_cur_bal",
"total_rev_hi_lim",
"loan_status"
],
"y": [
"loan_amnt",
"funded_amnt",
"funded_amnt_inv",
"term",
"int_rate",
"grade",
"sub_grade",
"emp_title",
"emp_length",
"home_ownership",
"annual_inc",
"verification_status",
"purpose",
"title",
"zip_code",
"addr_state",
"dti",
"delinq_2yrs",
"inq_last_6mths",
"open_acc",
"pub_rec",
"revol_bal",
"revol_util",
"total_acc",
"initial_list_status",
"total_rec_int",
"total_rec_late_fee",
"recoveries",
"collection_recovery_fee",
"collections_12_mths_ex_med",
"application_type",
"last_week_pay",
"acc_now_delinq",
"tot_cur_bal",
"total_rev_hi_lim",
"loan_status"
],
"z": [
[
1,
0.9993673107070573,
0.9973949825265475,
0.41311371953604037,
0.14366943710400248,
0.15123445239190716,
0.15536725259812714,
-0.05673961933312235,
-0.06308131688329331,
-0.2019158715910581,
0.40108540920753716,
0.2737970376550767,
-0.16068862997246122,
-0.13425640681305548,
-0.00507487327949772,
0.014357096225740723,
0.04160853225294765,
0.0007415367106552037,
-0.03400768276149403,
0.19332376596788578,
-0.0816999635971703,
0.34149699703986486,
0.1230515269517587,
0.22199995958283308,
0.08229056535555854,
0.5323758319755684,
0.03039699981128343,
0.0755662292629318,
0.05456576387485704,
-0.015887925632336142,
0.00537034555863025,
0.022006609114648416,
0.0004827152903769945,
0.3214379296704683,
0.3469448299096464,
-0.09806066158604641
],
[
0.9993673107070573,
1,
0.9981704288031574,
0.412339652004089,
0.14379252375822307,
0.15107359569631804,
0.15509596609179319,
-0.056446660003662,
-0.06291062598972043,
-0.2018326352785139,
0.40087176939356634,
0.2731419955737419,
-0.16138750772421034,
-0.13500421435162355,
-0.00517543484882429,
0.01446970373805114,
0.04232391258958052,
0.0010547673276096636,
-0.03452233482826037,
0.1935251707354553,
-0.0814461770879756,
0.3413116909130855,
0.12341263209434497,
0.22157396955347955,
0.08378860902113754,
0.5314657533019836,
0.030269633683367422,
0.07543904480895032,
0.054488650595454505,
-0.015726918732288136,
0.005404500361503288,
0.022646819725312677,
0.0005841390999188,
0.321611053068661,
0.3471316910806371,
-0.09974063517361584
],
[
0.9973949825265475,
0.9981704288031574,
1,
0.41290376483488955,
0.14394478670358515,
0.14940628867128436,
0.15339121987627705,
-0.05538084917111292,
-0.061882506224260926,
-0.2015453711610762,
0.39994608406008947,
0.2741103680435304,
-0.16352652242173563,
-0.13749931253022543,
-0.005417715817851578,
0.014472860465228195,
0.04439172279281363,
0.0015324685071629318,
-0.03866603173524088,
0.1941822791080103,
-0.08061178508457131,
0.339649030440468,
0.12392080589216109,
0.22173133490096522,
0.08787930617565409,
0.5292283263940617,
0.026987296260350367,
0.0734694212367801,
0.051602719267371436,
-0.015296932487366122,
0.0054739591017863775,
0.02449943082066455,
0.0004408390208968079,
0.3210757354942176,
0.3465968857344195,
-0.10368158647050939
],
[
0.41311371953604037,
0.412339652004089,
0.41290376483488955,
1,
0.4277873334938889,
0.4423558955036647,
0.45202147295116846,
-0.026528122521823187,
-0.033802765736630484,
-0.10380357604396363,
0.07558694303098122,
0.16758167815281758,
-0.05839364427570224,
-0.0632057798737132,
-0.029624717714176636,
0.02436666095721477,
0.10730932533245617,
0.0007659632105278963,
-0.0007276146170709287,
0.08853665094524413,
-0.023698233348671688,
0.09521153970092615,
0.0882227390403947,
0.10510958357225778,
0.12848024309665088,
0.38653366117227445,
0.005894751256496635,
0.06230716598495562,
0.039043197714352496,
-0.0013881705983337703,
0.012339505523841695,
0.03296842706856984,
0.005923374315533706,
0.10989707632923694,
0.07583482299734122,
-0.1314544468506384
],
[
0.14366943710400248,
0.14379252375822307,
0.14394478670358515,
0.4277873334938889,
1,
0.9535737112910263,
0.9769146297008081,
0.02169564790117714,
0.013380584294397252,
0.06633301052504133,
-0.07568113658436114,
0.2499537419998286,
0.15113729552332306,
0.09364436618277527,
0.0007001602988473001,
0.008100369802086492,
0.15789622187463925,
0.05506105904294921,
0.23028709311292908,
-0.0077782473446677694,
0.05702890617850652,
-0.03542229297624434,
0.2713516886712768,
-0.033447633685265134,
-0.11415670051317652,
0.44807241953966465,
0.05059996085209665,
0.11253201737516652,
0.0694149647782059,
0.013964592160664847,
0.007174505406334653,
-0.023394941410067434,
0.02531738684242965,
-0.08760582484385757,
-0.18303223766351773,
0.001315715105046892
],
[
0.15123445239190716,
0.15107359569631804,
0.14940628867128436,
0.4423558955036647,
0.9535737112910263,
1,
0.9764644961761394,
0.022024054326508734,
0.009289495708890953,
0.06537746822995874,
-0.06549187393939643,
0.22903340191862673,
0.15171332806631785,
0.053369691121970986,
-0.002022135809065368,
0.009447616977660677,
0.16554426481598802,
0.060681948093255916,
0.21859411405363868,
0.004608563914233126,
0.06639976104248572,
-0.02810499380157885,
0.24839279175837192,
-0.026212002732536065,
-0.0714167395414081,
0.3778210686601146,
0.04587727350190705,
0.09522884945324374,
0.06395382244989364,
0.02200069409636774,
0.010719897959057688,
0.025224964290838536,
0.0262133129357894,
-0.07927942053537479,
-0.16346685445001832,
-0.05842830898633616
],
[
0.15536725259812714,
0.15509596609179319,
0.15339121987627705,
0.45202147295116846,
0.9769146297008081,
0.9764644961761394,
1,
0.02240755755220031,
0.009626479243445736,
0.06814367868219676,
-0.06853616970854917,
0.24063454524081382,
0.15545522292123395,
0.05471932554746991,
-0.0022399910656615857,
0.009516955532873407,
0.1716199024286485,
0.06183474618339236,
0.22460573730587255,
0.0031617682901269196,
0.0670626523143616,
-0.028723472772034003,
0.2590168538347546,
-0.028710384582010504,
-0.06682686863767658,
0.3888325382656363,
0.04631111290164317,
0.09759050588479604,
0.0653599491919464,
0.021704450136974866,
0.010804005313944208,
0.025549773424498573,
0.027855172810561185,
-0.08300776878706932,
-0.17099740460608218,
-0.05729791014263772
],
[
-0.05673961933312235,
-0.056446660003662,
-0.05538084917111292,
-0.026528122521823187,
0.02169564790117714,
0.022024054326508734,
0.02240755755220031,
1,
0.18144202307584517,
-0.008263794158526726,
-0.06209924217529195,
0.05846964248451429,
0.020798856679962313,
0.08029298153311334,
-0.006686383150673372,
0.0075940206348329995,
0.015824119915088496,
0.0001333279948853352,
0.0015097664673913243,
-0.0515308210974667,
0.04137749167349271,
-0.03623594058065723,
-0.027383105883524696,
-0.036178856247907724,
-0.0010246656340571671,
-0.026362634357548657,
0.005936576934344635,
0.0036308115645922335,
0.007072288972627666,
0.013407638485743775,
-0.003331560851945194,
0.0067456219276319,
0.0015094721747491195,
-0.05026705594493313,
-0.03272903963528642,
-0.036046910279810475
],
[
-0.06308131688329331,
-0.06291062598972043,
-0.061882506224260926,
-0.033802765736630484,
0.013380584294397252,
0.009289495708890953,
0.009626479243445736,
0.18144202307584517,
1,
-0.0006562355291177585,
-0.06803881613030116,
0.08334061150694358,
0.007907050977030938,
0.01814969911058476,
0.0016449886098510234,
-0.003741104513591542,
0.026991125089876163,
-0.026786863693399318,
-0.0032947760836769986,
-0.04146233602712595,
0.030841454907430236,
-0.04252827491856082,
-0.023925010310720883,
-0.04337915466801065,
-0.013676609292509388,
-0.026182606822821832,
-0.0033834219667489523,
0.006559616342723415,
0.0038612858505641225,
-3.638296436917112e-05,
0.00029247265744294747,
-0.002723463176442134,
-0.010314795530514705,
-0.04104551735009645,
-0.03920916331672977,
-0.006294912291385543
],
[
-0.2019158715910581,
-0.2018326352785139,
-0.2015453711610762,
-0.10380357604396363,
0.06633301052504133,
0.06537746822995874,
0.06814367868219676,
-0.008263794158526726,
-0.0006562355291177585,
1,
-0.18483117718102926,
-0.0345023641605532,
0.0337984861944795,
0.0036708446150360246,
0.01529191761546139,
-0.06740060904395742,
0.014071761469811669,
-0.05255823619001008,
-0.036371871475244434,
-0.13106315818290842,
0.010074780311283886,
-0.16784768447422393,
-0.018615295017250816,
-0.21471441255940335,
-0.026552318247412224,
-0.10295309187685193,
-0.0043236572276293414,
-0.00875991306974773,
-0.008606677552553283,
0.004395076043852439,
-0.00010662964918016358,
0.00582070910628204,
-0.01682702954559417,
-0.4938532067528801,
-0.17435976358907318,
-0.008417080510053349
],
[
0.40108540920753716,
0.40087176939356634,
0.39994608406008947,
0.07558694303098122,
-0.07568113658436114,
-0.06549187393939643,
-0.06853616970854917,
-0.06209924217529195,
-0.06803881613030116,
-0.18483117718102926,
1,
0.08192131136654758,
0.006430029735015196,
-0.031234879280442707,
-0.015439174112058827,
-0.003952337172149827,
-0.20860517481450574,
0.05586758573498273,
0.039720857750799234,
0.1561661847581233,
-0.009555280504687002,
0.3529061023310094,
0.041811059093469424,
0.2193065184763861,
0.04575758892406839,
0.1606931503806069,
0.01417862241455744,
0.006552077985370611,
0.006751696947288823,
-0.005112151418505477,
-0.006289245567748207,
0.017414227537550456,
0.02230982529097467,
0.4768413759531402,
0.34182754393774584,
-0.005600004657288227
],
[
0.2737970376550767,
0.2731419955737419,
0.2741103680435304,
0.16758167815281758,
0.2499537419998286,
0.22903340191862673,
0.24063454524081382,
0.05846964248451429,
0.08334061150694358,
-0.0345023641605532,
0.08192131136654758,
1,
0.012701615229108211,
0.007900988943574362,
0.001166926419317222,
-0.003009362948922437,
0.09837099957973558,
0.0033209380373541457,
0.0729302811147864,
0.04603212753302003,
0.039724424930923784,
0.08989391307183653,
0.08462927510827067,
0.06406415580219664,
-0.034538559231869326,
0.26760334159587096,
0.013422384867226342,
0.05006620059727212,
0.02938127689085275,
0.012941042166460179,
0.004872166169305358,
-0.04295672830300664,
0.007586400642540934,
0.06139975588774038,
0.05116657756902476,
-0.02661784839361224
],
[
-0.16068862997246122,
-0.16138750772421034,
-0.16352652242173563,
-0.05839364427570224,
0.15113729552332306,
0.15171332806631785,
0.15545522292123395,
0.020798856679962313,
0.007907050977030938,
0.0337984861944795,
0.006430029735015196,
0.012701615229108211,
1,
0.41751295336363037,
-0.011285153016651232,
-0.0040111077904582985,
-0.08990901398991973,
0.017449799245961788,
0.05189253323562731,
-0.07852834685162759,
0.019167439718075406,
-0.07800272081085825,
-0.1067868440081956,
-0.061511148758259554,
-0.06914102669124954,
-0.034450076060040746,
0.025660757149675535,
0.017536225346724128,
0.011132642431576807,
0.00678373092690319,
0.0010118822324284358,
-0.0214607567958376,
0.008531885664845716,
-0.027290053564699837,
-0.05936139744964515,
0.05696551253971207
],
[
-0.13425640681305548,
-0.13500421435162355,
-0.13749931253022543,
-0.0632057798737132,
0.09364436618277527,
0.053369691121970986,
0.05471932554746991,
0.08029298153311334,
0.01814969911058476,
0.0036708446150360246,
-0.031234879280442707,
0.007900988943574362,
0.41751295336363037,
1,
-0.006805577445327398,
-0.0047158148873595925,
-0.07645939273115507,
-0.018143656921564236,
0.05604090676832486,
-0.07787494493535581,
-0.01883872075323851,
-0.06471104835823145,
-0.04328088508219377,
-0.05940083429340112,
-0.15550183125608844,
0.06749152386272105,
0.029753084053691675,
0.04076494881688665,
0.024636053362644045,
-0.01811070084174997,
-0.0021504504245727753,
-0.1735758892551564,
0.0008111386605700343,
-0.028545090351875455,
-0.055351025295872214,
0.1710336867954722
],
[
-0.00507487327949772,
-0.00517543484882429,
-0.005417715817851578,
-0.029624717714176636,
0.0007001602988473001,
-0.002022135809065368,
-0.0022399910656615857,
-0.006686383150673372,
0.0016449886098510234,
0.01529191761546139,
-0.015439174112058827,
0.001166926419317222,
-0.011285153016651232,
-0.006805577445327398,
1,
-0.2637121981089354,
0.0021985731510732807,
-0.03246170020848946,
0.00014251621358845064,
-0.05459778777075654,
-0.0012874684195429982,
-0.027087322901021522,
0.01817575740524541,
-0.02378191562538043,
-0.01012453949849028,
-0.00808468034770711,
-0.003279678719922463,
0.0028110682936848155,
0.006795583967923758,
-0.0005492985501828694,
0.0007560843314131327,
-0.008318446541552485,
-0.0026600218666307527,
-0.004858219884591405,
-0.03594356420102614,
0.018249726101813062
],
[
0.014357096225740723,
0.01446970373805114,
0.014472860465228195,
0.02436666095721477,
0.008100369802086492,
0.009447616977660677,
0.009516955532873407,
0.0075940206348329995,
-0.003741104513591542,
-0.06740060904395742,
-0.003952337172149827,
-0.003009362948922437,
-0.0040111077904582985,
-0.0047158148873595925,
-0.2637121981089354,
1,
0.03843233639050731,
0.019538735058602343,
0.0053724801882894585,
0.036955421535015215,
-0.009460322071780942,
-0.00641658612807751,
0.0029847625607689744,
0.04594385517357497,
0.01701193489995595,
0.0093732114563079,
-0.00031587719371388944,
-0.005739695653081888,
-0.001773515467238366,
0.007243743988879271,
0.0027959414778755886,
0.011460765823582738,
0.009037407873233157,
-0.005982905081269974,
-0.0005637893461752431,
-0.020198474342035685
],
[
0.04160853225294765,
0.04232391258958052,
0.04439172279281363,
0.10730932533245617,
0.15789622187463925,
0.16554426481598802,
0.1716199024286485,
0.015824119915088496,
0.026991125089876163,
0.014071761469811669,
-0.20860517481450574,
0.09837099957973558,
-0.08990901398991973,
-0.07645939273115507,
0.0021985731510732807,
0.03843233639050731,
1,
-0.004306565723081028,
-0.01647472597217059,
0.2985305829222179,
-0.04459167911769544,
0.13991221742431906,
0.17132147035400355,
0.22204282167014028,
0.05110386522772334,
0.01671088814410185,
-0.006292770123648165,
0.0034653042211982617,
0.0036727057841006226,
0.0033788540311453833,
0.025256662744338958,
0.0407586315913094,
0.013712516532054077,
-0.01818752150691596,
0.0824519602024066,
-0.1343557063926868
],
[
0.0007415367106552037,
0.0010547673276096636,
0.0015324685071629318,
0.0007659632105278963,
0.05506105904294921,
0.060681948093255916,
0.06183474618339236,
0.0001333279948853352,
-0.026786863693399318,
-0.05255823619001008,
0.05586758573498273,
0.0033209380373541457,
0.017449799245961788,
-0.018143656921564236,
-0.03246170020848946,
0.019538735058602343,
-0.004306565723081028,
1,
0.020384034504745612,
0.05550346075276047,
-0.01067849965464546,
-0.03243883558798766,
-0.011997274915568491,
0.12489130033898062,
0.015743819721073016,
-0.0021257926522072128,
0.01798692632914995,
-0.0023232066061796572,
-0.0008419453977416289,
0.0658318099856898,
-0.0007549075432580317,
0.027770547906924115,
0.13013020308737916,
0.06509155070255052,
-0.045356838682710184,
-0.04467080853930925
],
[
-0.03400768276149403,
-0.03452233482826037,
-0.03866603173524088,
-0.0007276146170709287,
0.23028709311292908,
0.21859411405363868,
0.22460573730587255,
0.0015097664673913243,
-0.0032947760836769986,
-0.036371871475244434,
0.039720857750799234,
0.0729302811147864,
0.05189253323562731,
0.05604090676832486,
0.00014251621358845064,
0.0053724801882894585,
-0.01647472597217059,
0.020384034504745612,
1,
0.11339725191786394,
0.050194605668322706,
-0.02391365988845393,
-0.09094808528856578,
0.13622335666530158,
-0.08677399964492707,
0.08725949814981891,
0.02098680794852601,
0.04480882234369649,
0.03640581684262851,
0.006046808767780671,
-0.006416705957685335,
-0.010084465041148372,
-0.005410403954381636,
0.029620923728497763,
0.004312386499570435,
0.08851260689281325
],
[
0.19332376596788578,
0.1935251707354553,
0.1941822791080103,
0.08853665094524413,
-0.0077782473446677694,
0.004608563914233126,
0.0031617682901269196,
-0.0515308210974667,
-0.04146233602712595,
-0.13106315818290842,
0.1561661847581233,
0.04603212753302003,
-0.07852834685162759,
-0.07787494493535581,
-0.05459778777075654,
0.036955421535015215,
0.2985305829222179,
0.05550346075276047,
0.11339725191786394,
1,
-0.03423327020670189,
0.2196085500870657,
-0.1515926659905363,
0.6980956657110625,
0.06495306513072319,
0.06446598079600936,
-0.007397402362062316,
-0.00025758601801110094,
0.0015986210424646448,
0.011836146009475114,
-0.004514816219778578,
0.037521371007512364,
0.017524817385453865,
0.23600303267186948,
0.35866222790091923,
-0.06503025859446773
],
[
-0.0816999635971703,
-0.0814461770879756,
-0.08061178508457131,
-0.023698233348671688,
0.05702890617850652,
0.06639976104248572,
0.0670626523143616,
0.04137749167349271,
0.030841454907430236,
0.010074780311283886,
-0.009555280504687002,
0.039724424930923784,
0.019167439718075406,
-0.01883872075323851,
-0.0012874684195429982,
-0.009460322071780942,
-0.04459167911769544,
-0.01067849965464546,
0.050194605668322706,
-0.03423327020670189,
1,
-0.10333969996810113,
-0.07789160638163083,
0.008906053136261595,
0.021823003590788845,
-0.05560786537046778,
-0.01438426181210534,
-0.014396798491525835,
-0.006055711509509304,
0.027307640924854687,
0.003649835399042438,
0.05220987126693662,
0.007607311659102293,
-0.07610300243421696,
-0.11896927858944512,
-0.047414324415988945
],
[
0.34149699703986486,
0.3413116909130855,
0.339649030440468,
0.09521153970092615,
-0.03542229297624434,
-0.02810499380157885,
-0.028723472772034003,
-0.03623594058065723,
-0.04252827491856082,
-0.16784768447422393,
0.3529061023310094,
0.08989391307183653,
-0.07800272081085825,
-0.06471104835823145,
-0.027087322901021522,
-0.00641658612807751,
0.13991221742431906,
-0.03243883558798766,
-0.02391365988845393,
0.2196085500870657,
-0.10333969996810113,
1,
0.21728161263631166,
0.18215744606752643,
0.04107106988798885,
0.1449897777501001,
0.003473770726778378,
0.00977871689914861,
0.006674213517660574,
-0.02688637728505219,
-0.0013534661309447867,
0.0035753748752334075,
0.00018477323219028436,
0.43869659815013035,
0.8217569136566378,
-0.04166450720175678
],
[
0.1230515269517587,
0.12341263209434497,
0.12392080589216109,
0.0882227390403947,
0.2713516886712768,
0.24839279175837192,
0.2590168538347546,
-0.027383105883524696,
-0.023925010310720883,
-0.018615295017250816,
0.041811059093469424,
0.08462927510827067,
-0.1067868440081956,
-0.04328088508219377,
0.01817575740524541,
0.0029847625607689744,
0.17132147035400355,
-0.011997274915568491,
-0.09094808528856578,
-0.1515926659905363,
-0.07789160638163083,
0.21728161263631166,
1,
-0.1182951904571059,
-0.03594143376279657,
0.18295627318848992,
0.01690915539961196,
0.0332996326637299,
0.021104638711206016,
-0.03833373650277318,
0.009465679760186837,
-0.02071095807745041,
-0.028518925798846892,
0.07892105439026302,
-0.13194931484096498,
-0.04767002019513653
],
[
0.22199995958283308,
0.22157396955347955,
0.22173133490096522,
0.10510958357225778,
-0.033447633685265134,
-0.026212002732536065,
-0.028710384582010504,
-0.036178856247907724,
-0.04337915466801065,
-0.21471441255940335,
0.2193065184763861,
0.06406415580219664,
-0.061511148758259554,
-0.05940083429340112,
-0.02378191562538043,
0.04594385517357497,
0.22204282167014028,
0.12489130033898062,
0.13622335666530158,
0.6980956657110625,
0.008906053136261595,
0.18215744606752643,
-0.1182951904571059,
1,
0.04964627996646787,
0.09451252723266558,
-0.004425509244874343,
0.008567785983567751,
0.007105454883750359,
0.010017137747474446,
-0.0049636867294269825,
0.034853511246596795,
0.02429861728758495,
0.2979801075033031,
0.27875469771835226,
-0.0022069144086347145
],
[
0.08229056535555854,
0.08378860902113754,
0.08787930617565409,
0.12848024309665088,
-0.11415670051317652,
-0.0714167395414081,
-0.06682686863767658,
-0.0010246656340571671,
-0.013676609292509388,
-0.026552318247412224,
0.04575758892406839,
-0.034538559231869326,
-0.06914102669124954,
-0.15550183125608844,
-0.01012453949849028,
0.01701193489995595,
0.05110386522772334,
0.015743819721073016,
-0.08677399964492707,
0.06495306513072319,
0.021823003590788845,
0.04107106988798885,
-0.03594143376279657,
0.04964627996646787,
1,
-0.1621818346204736,
-0.03269411815607662,
-0.06470581516264627,
-0.046648226131306744,
0.02698604874907086,
0.014030351773278445,
0.17460355812768374,
0.005386865361166284,
0.02967428849718705,
0.06462589394318119,
-0.2263849321958786
],
[
0.5323758319755684,
0.5314657533019836,
0.5292283263940617,
0.38653366117227445,
0.44807241953966465,
0.3778210686601146,
0.3888325382656363,
-0.026362634357548657,
-0.026182606822821832,
-0.10295309187685193,
0.1606931503806069,
0.26760334159587096,
-0.034450076060040746,
0.06749152386272105,
-0.00808468034770711,
0.0093732114563079,
0.01671088814410185,
-0.0021257926522072128,
0.08725949814981891,
0.06446598079600936,
-0.05560786537046778,
0.1449897777501001,
0.18295627318848992,
0.09451252723266558,
-0.1621818346204736,
1,
0.0852835608756438,
0.07280709975574022,
0.05849546777900835,
-0.029296428214199727,
-0.015166449011570104,
-0.1709003017123901,
0.00015138319789988005,
0.12931663184671807,
0.08087666752344008,
0.03804778658884139
],
[
0.03039699981128343,
0.030269633683367422,
0.026987296260350367,
0.005894751256496635,
0.05059996085209665,
0.04587727350190705,
0.04631111290164317,
0.005936576934344635,
-0.0033834219667489523,
-0.0043236572276293414,
0.01417862241455744,
0.013422384867226342,
0.025660757149675535,
0.029753084053691675,
-0.003279678719922463,
-0.00031587719371388944,
-0.006292770123648165,
0.01798692632914995,
0.02098680794852601,
-0.007397402362062316,
-0.01438426181210534,
0.003473770726778378,
0.01690915539961196,
-0.004425509244874343,
-0.03269411815607662,
0.0852835608756438,
1,
0.08606644247307588,
0.06398867272896556,
-0.006113794354628054,
0.0007952716495211405,
-0.023818356347927644,
0.0048827428487531275,
0.007895156726208084,
-0.0031219181236287357,
-0.002616490770933299
],
[
0.0755662292629318,
0.07543904480895032,
0.0734694212367801,
0.06230716598495562,
0.11253201737516652,
0.09522884945324374,
0.09759050588479604,
0.0036308115645922335,
0.006559616342723415,
-0.00875991306974773,
0.006552077985370611,
0.05006620059727212,
0.017536225346724128,
0.04076494881688665,
0.0028110682936848155,
-0.005739695653081888,
0.0034653042211982617,
-0.0023232066061796572,
0.04480882234369649,
-0.00025758601801110094,
-0.014396798491525835,
0.00977871689914861,
0.0332996326637299,
0.008567785983567751,
-0.06470581516264627,
0.07280709975574022,
0.08606644247307588,
1,
0.7980052100207572,
-0.0016024388724498715,
-0.0024309625494929373,
0.014068203826042265,
-0.0002289659087295931,
-0.001887419417588788,
0.0016162289829809635,
-0.0648411851145522
],
[
0.05456576387485704,
0.054488650595454505,
0.051602719267371436,
0.039043197714352496,
0.0694149647782059,
0.06395382244989364,
0.0653599491919464,
0.007072288972627666,
0.0038612858505641225,
-0.008606677552553283,
0.006751696947288823,
0.02938127689085275,
0.011132642431576807,
0.024636053362644045,
0.006795583967923758,
-0.001773515467238366,
0.0036727057841006226,
-0.0008419453977416289,
0.03640581684262851,
0.0015986210424646448,
-0.006055711509509304,
0.006674213517660574,
0.021104638711206016,
0.007105454883750359,
-0.046648226131306744,
0.05849546777900835,
0.06398867272896556,
0.7980052100207572,
1,
0.002665874005773007,
-0.0015445884852588862,
0.0058878558864206305,
-0.0020990966362222055,
0.0015573305013247298,
0.002716171101254757,
-0.04119888556874379
],
[
-0.015887925632336142,
-0.015726918732288136,
-0.015296932487366122,
-0.0013881705983337703,
0.013964592160664847,
0.02200069409636774,
0.021704450136974866,
0.013407638485743775,
-3.638296436917112e-05,
0.004395076043852439,
-0.005112151418505477,
0.012941042166460179,
0.00678373092690319,
-0.01811070084174997,
-0.0005492985501828694,
0.007243743988879271,
0.0033788540311453833,
0.0658318099856898,
0.006046808767780671,
0.011836146009475114,
0.027307640924854687,
-0.02688637728505219,
-0.03833373650277318,
0.010017137747474446,
0.02698604874907086,
-0.029296428214199727,
-0.006113794354628054,
-0.0016024388724498715,
0.002665874005773007,
1,
-0.0023738717767656514,
0.01955040770797248,
0.017389460249368206,
-0.015476179404925185,
-0.02340160057083718,
-0.036778701612293505
],
[
0.00537034555863025,
0.005404500361503288,
0.0054739591017863775,
0.012339505523841695,
0.007174505406334653,
0.010719897959057688,
0.010804005313944208,
-0.003331560851945194,
0.00029247265744294747,
-0.00010662964918016358,
-0.006289245567748207,
0.004872166169305358,
0.0010118822324284358,
-0.0021504504245727753,
0.0007560843314131327,
0.0027959414778755886,
0.025256662744338958,
-0.0007549075432580317,
-0.006416705957685335,
-0.004514816219778578,
0.003649835399042438,
-0.0013534661309447867,
0.009465679760186837,
-0.0049636867294269825,
0.014030351773278445,
-0.015166449011570104,
0.0007952716495211405,
-0.0024309625494929373,
-0.0015445884852588862,
-0.0023738717767656514,
1,
0.017579517381095262,
-0.0014163741952864593,
-0.0009449880330908882,
-0.0055088770832310546,
-0.011674749402946619
],
[
0.022006609114648416,
0.022646819725312677,
0.02449943082066455,
0.03296842706856984,
-0.023394941410067434,
0.025224964290838536,
0.025549773424498573,
0.0067456219276319,
-0.002723463176442134,
0.00582070910628204,
0.017414227537550456,
-0.04295672830300664,
-0.0214607567958376,
-0.1735758892551564,
-0.008318446541552485,
0.011460765823582738,
0.0407586315913094,
0.027770547906924115,
-0.010084465041148372,
0.037521371007512364,
0.05220987126693662,
0.0035753748752334075,
-0.02071095807745041,
0.034853511246596795,
0.17460355812768374,
-0.1709003017123901,
-0.023818356347927644,
0.014068203826042265,
0.0058878558864206305,
0.01955040770797248,
0.017579517381095262,
1,
0.006485493601996285,
-0.004241175184069997,
0.004339542182509757,
-0.11455446404926434
],
[
0.0004827152903769945,
0.0005841390999188,
0.0004408390208968079,
0.005923374315533706,
0.02531738684242965,
0.0262133129357894,
0.027855172810561185,
0.0015094721747491195,
-0.010314795530514705,
-0.01682702954559417,
0.02230982529097467,
0.007586400642540934,
0.008531885664845716,
0.0008111386605700343,
-0.0026600218666307527,
0.009037407873233157,
0.013712516532054077,
0.13013020308737916,
-0.005410403954381636,
0.017524817385453865,
0.007607311659102293,
0.00018477323219028436,
-0.028518925798846892,
0.02429861728758495,
0.005386865361166284,
0.00015138319789988005,
0.0048827428487531275,
-0.0002289659087295931,
-0.0020990966362222055,
0.017389460249368206,
-0.0014163741952864593,
0.006485493601996285,
1,
0.025502908944671734,
0.009807676666848494,
-0.013868266555449984
],
[
0.3214379296704683,
0.321611053068661,
0.3210757354942176,
0.10989707632923694,
-0.08760582484385757,
-0.07927942053537479,
-0.08300776878706932,
-0.05026705594493313,
-0.04104551735009645,
-0.4938532067528801,
0.4768413759531402,
0.06139975588774038,
-0.027290053564699837,
-0.028545090351875455,
-0.004858219884591405,
-0.005982905081269974,
-0.01818752150691596,
0.06509155070255052,
0.029620923728497763,
0.23600303267186948,
-0.07610300243421696,
0.43869659815013035,
0.07892105439026302,
0.2979801075033031,
0.02967428849718705,
0.12931663184671807,
0.007895156726208084,
-0.001887419417588788,
0.0015573305013247298,
-0.015476179404925185,
-0.0009449880330908882,
-0.004241175184069997,
0.025502908944671734,
1,
0.42756299169797507,
0.016235464993980004
],
[
0.3469448299096464,
0.3471316910806371,
0.3465968857344195,
0.07583482299734122,
-0.18303223766351773,
-0.16346685445001832,
-0.17099740460608218,
-0.03272903963528642,
-0.03920916331672977,
-0.17435976358907318,
0.34182754393774584,
0.05116657756902476,
-0.05936139744964515,
-0.055351025295872214,
-0.03594356420102614,
-0.0005637893461752431,
0.0824519602024066,
-0.045356838682710184,
0.004312386499570435,
0.35866222790091923,
-0.11896927858944512,
0.8217569136566378,
-0.13194931484096498,
0.27875469771835226,
0.06462589394318119,
0.08087666752344008,
-0.0031219181236287357,
0.0016162289829809635,
0.002716171101254757,
-0.02340160057083718,
-0.0055088770832310546,
0.004339542182509757,
0.009807676666848494,
0.42756299169797507,
1,
-0.023938271700324212
],
[
-0.09806066158604641,
-0.09974063517361584,
-0.10368158647050939,
-0.1314544468506384,
0.001315715105046892,
-0.05842830898633616,
-0.05729791014263772,
-0.036046910279810475,
-0.006294912291385543,
-0.008417080510053349,
-0.005600004657288227,
-0.02661784839361224,
0.05696551253971207,
0.1710336867954722,
0.018249726101813062,
-0.020198474342035685,
-0.1343557063926868,
-0.04467080853930925,
0.08851260689281325,
-0.06503025859446773,
-0.047414324415988945,
-0.04166450720175678,
-0.04767002019513653,
-0.0022069144086347145,
-0.2263849321958786,
0.03804778658884139,
-0.002616490770933299,
-0.0648411851145522,
-0.04119888556874379,
-0.036778701612293505,
-0.011674749402946619,
-0.11455446404926434,
-0.013868266555449984,
0.016235464993980004,
-0.023938271700324212,
1
]
]
}
],
"layout": {
"annotations": [
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "loan_amnt",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "funded_amnt",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "funded_amnt_inv",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.41",
"x": "term",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.14",
"x": "int_rate",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.15",
"x": "grade",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.16",
"x": "sub_grade",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "emp_title",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "emp_length",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.2",
"x": "home_ownership",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.4",
"x": "annual_inc",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.27",
"x": "verification_status",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.16",
"x": "purpose",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.13",
"x": "title",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "zip_code",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "addr_state",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "dti",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "delinq_2yrs",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "inq_last_6mths",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.19",
"x": "open_acc",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "pub_rec",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.34",
"x": "revol_bal",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "revol_util",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.22",
"x": "total_acc",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "initial_list_status",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.53",
"x": "total_rec_int",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "total_rec_late_fee",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "recoveries",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "collection_recovery_fee",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "application_type",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "last_week_pay",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "acc_now_delinq",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.32",
"x": "tot_cur_bal",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.35",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "loan_status",
"xref": "x",
"y": "loan_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "loan_amnt",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "funded_amnt",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "funded_amnt_inv",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.41",
"x": "term",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.14",
"x": "int_rate",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.15",
"x": "grade",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.16",
"x": "sub_grade",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "emp_title",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "emp_length",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.2",
"x": "home_ownership",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.4",
"x": "annual_inc",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.27",
"x": "verification_status",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.16",
"x": "purpose",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.14",
"x": "title",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "zip_code",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "addr_state",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "dti",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "delinq_2yrs",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "inq_last_6mths",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.19",
"x": "open_acc",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "pub_rec",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.34",
"x": "revol_bal",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "revol_util",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.22",
"x": "total_acc",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "initial_list_status",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.53",
"x": "total_rec_int",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "total_rec_late_fee",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "recoveries",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "collection_recovery_fee",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "application_type",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "last_week_pay",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "acc_now_delinq",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.32",
"x": "tot_cur_bal",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.35",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "loan_status",
"xref": "x",
"y": "funded_amnt",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "loan_amnt",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "funded_amnt",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "funded_amnt_inv",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.41",
"x": "term",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.14",
"x": "int_rate",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.15",
"x": "grade",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.15",
"x": "sub_grade",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "emp_title",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "emp_length",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.2",
"x": "home_ownership",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.4",
"x": "annual_inc",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.27",
"x": "verification_status",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.16",
"x": "purpose",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.14",
"x": "title",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "zip_code",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "addr_state",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "dti",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "delinq_2yrs",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "inq_last_6mths",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.19",
"x": "open_acc",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "pub_rec",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.34",
"x": "revol_bal",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "revol_util",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.22",
"x": "total_acc",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "initial_list_status",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.53",
"x": "total_rec_int",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "total_rec_late_fee",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "recoveries",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "collection_recovery_fee",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "application_type",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "last_week_pay",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "acc_now_delinq",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.32",
"x": "tot_cur_bal",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.35",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "loan_status",
"xref": "x",
"y": "funded_amnt_inv",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.41",
"x": "loan_amnt",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.41",
"x": "funded_amnt",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.41",
"x": "funded_amnt_inv",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "term",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.43",
"x": "int_rate",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.44",
"x": "grade",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.45",
"x": "sub_grade",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "emp_title",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "emp_length",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "home_ownership",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "annual_inc",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.17",
"x": "verification_status",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "purpose",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "title",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "zip_code",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "addr_state",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.11",
"x": "dti",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "delinq_2yrs",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "inq_last_6mths",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "open_acc",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "pub_rec",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "revol_bal",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "revol_util",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.11",
"x": "total_acc",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.13",
"x": "initial_list_status",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.39",
"x": "total_rec_int",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "total_rec_late_fee",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "recoveries",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "collection_recovery_fee",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "application_type",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "last_week_pay",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "acc_now_delinq",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.11",
"x": "tot_cur_bal",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.13",
"x": "loan_status",
"xref": "x",
"y": "term",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.14",
"x": "loan_amnt",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.14",
"x": "funded_amnt",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.14",
"x": "funded_amnt_inv",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.43",
"x": "term",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "int_rate",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.95",
"x": "grade",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.98",
"x": "sub_grade",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "emp_title",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "emp_length",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "home_ownership",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "annual_inc",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.25",
"x": "verification_status",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.15",
"x": "purpose",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "title",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "zip_code",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "addr_state",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.16",
"x": "dti",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "delinq_2yrs",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.23",
"x": "inq_last_6mths",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "open_acc",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "pub_rec",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "revol_bal",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.27",
"x": "revol_util",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "total_acc",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.11",
"x": "initial_list_status",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.45",
"x": "total_rec_int",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "total_rec_late_fee",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.11",
"x": "recoveries",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "collection_recovery_fee",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "application_type",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "last_week_pay",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "acc_now_delinq",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.09",
"x": "tot_cur_bal",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.18",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "loan_status",
"xref": "x",
"y": "int_rate",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.15",
"x": "loan_amnt",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.15",
"x": "funded_amnt",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.15",
"x": "funded_amnt_inv",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.44",
"x": "term",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.95",
"x": "int_rate",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "grade",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.98",
"x": "sub_grade",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "emp_title",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "emp_length",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "home_ownership",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "annual_inc",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.23",
"x": "verification_status",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.15",
"x": "purpose",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "title",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "zip_code",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "addr_state",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.17",
"x": "dti",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "delinq_2yrs",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.22",
"x": "inq_last_6mths",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "open_acc",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "pub_rec",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "revol_bal",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.25",
"x": "revol_util",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "total_acc",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "initial_list_status",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.38",
"x": "total_rec_int",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "total_rec_late_fee",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "recoveries",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "collection_recovery_fee",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "application_type",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "last_week_pay",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "acc_now_delinq",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "tot_cur_bal",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.16",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "loan_status",
"xref": "x",
"y": "grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.16",
"x": "loan_amnt",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.16",
"x": "funded_amnt",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.15",
"x": "funded_amnt_inv",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.45",
"x": "term",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.98",
"x": "int_rate",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.98",
"x": "grade",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "sub_grade",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "emp_title",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "emp_length",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "home_ownership",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "annual_inc",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.24",
"x": "verification_status",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.16",
"x": "purpose",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "title",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "zip_code",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "addr_state",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.17",
"x": "dti",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "delinq_2yrs",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.22",
"x": "inq_last_6mths",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "open_acc",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "pub_rec",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "revol_bal",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.26",
"x": "revol_util",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "total_acc",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "initial_list_status",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.39",
"x": "total_rec_int",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "total_rec_late_fee",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "recoveries",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "collection_recovery_fee",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "application_type",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "last_week_pay",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "acc_now_delinq",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "tot_cur_bal",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.17",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "loan_status",
"xref": "x",
"y": "sub_grade",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "loan_amnt",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "funded_amnt",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "funded_amnt_inv",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "term",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "int_rate",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "grade",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "sub_grade",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "emp_title",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.18",
"x": "emp_length",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "home_ownership",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "annual_inc",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "verification_status",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "purpose",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "title",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "zip_code",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "addr_state",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "dti",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "delinq_2yrs",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "inq_last_6mths",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "open_acc",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "pub_rec",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "revol_bal",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "revol_util",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "total_acc",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "initial_list_status",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "total_rec_int",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "total_rec_late_fee",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "recoveries",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "collection_recovery_fee",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "application_type",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "last_week_pay",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "acc_now_delinq",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "tot_cur_bal",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "loan_status",
"xref": "x",
"y": "emp_title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "loan_amnt",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "funded_amnt",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "funded_amnt_inv",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "term",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "int_rate",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "grade",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "sub_grade",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.18",
"x": "emp_title",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "emp_length",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "home_ownership",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "annual_inc",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "verification_status",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "purpose",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "title",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "zip_code",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "addr_state",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "dti",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "delinq_2yrs",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "inq_last_6mths",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "open_acc",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "pub_rec",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "revol_bal",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "revol_util",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "total_acc",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "initial_list_status",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "total_rec_int",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "total_rec_late_fee",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "recoveries",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "collection_recovery_fee",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "application_type",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "last_week_pay",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "acc_now_delinq",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "tot_cur_bal",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "loan_status",
"xref": "x",
"y": "emp_length",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.2",
"x": "loan_amnt",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.2",
"x": "funded_amnt",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.2",
"x": "funded_amnt_inv",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "term",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "int_rate",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "grade",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "sub_grade",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "emp_title",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "emp_length",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "home_ownership",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.18",
"x": "annual_inc",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "verification_status",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "purpose",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "title",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "zip_code",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "addr_state",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "dti",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "delinq_2yrs",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "inq_last_6mths",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.13",
"x": "open_acc",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "pub_rec",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.17",
"x": "revol_bal",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "revol_util",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.21",
"x": "total_acc",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "initial_list_status",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "total_rec_int",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "total_rec_late_fee",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "recoveries",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "collection_recovery_fee",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "application_type",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "last_week_pay",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "acc_now_delinq",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.49",
"x": "tot_cur_bal",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.17",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "loan_status",
"xref": "x",
"y": "home_ownership",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.4",
"x": "loan_amnt",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.4",
"x": "funded_amnt",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.4",
"x": "funded_amnt_inv",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "term",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "int_rate",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "grade",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "sub_grade",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "emp_title",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "emp_length",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.18",
"x": "home_ownership",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "annual_inc",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "verification_status",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "purpose",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "title",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "zip_code",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "addr_state",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.21",
"x": "dti",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "delinq_2yrs",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "inq_last_6mths",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.16",
"x": "open_acc",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "pub_rec",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.35",
"x": "revol_bal",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "revol_util",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.22",
"x": "total_acc",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "initial_list_status",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.16",
"x": "total_rec_int",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "total_rec_late_fee",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "recoveries",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "collection_recovery_fee",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "application_type",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "last_week_pay",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "acc_now_delinq",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.48",
"x": "tot_cur_bal",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.34",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "loan_status",
"xref": "x",
"y": "annual_inc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.27",
"x": "loan_amnt",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.27",
"x": "funded_amnt",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.27",
"x": "funded_amnt_inv",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.17",
"x": "term",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.25",
"x": "int_rate",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.23",
"x": "grade",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.24",
"x": "sub_grade",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "emp_title",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "emp_length",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "home_ownership",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "annual_inc",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "verification_status",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "purpose",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "title",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "zip_code",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "addr_state",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "dti",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "delinq_2yrs",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "inq_last_6mths",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "open_acc",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "pub_rec",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "revol_bal",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "revol_util",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "total_acc",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "initial_list_status",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.27",
"x": "total_rec_int",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "total_rec_late_fee",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "recoveries",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "collection_recovery_fee",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "application_type",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "last_week_pay",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "acc_now_delinq",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "tot_cur_bal",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "loan_status",
"xref": "x",
"y": "verification_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.16",
"x": "loan_amnt",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.16",
"x": "funded_amnt",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.16",
"x": "funded_amnt_inv",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "term",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.15",
"x": "int_rate",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.15",
"x": "grade",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.16",
"x": "sub_grade",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "emp_title",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "emp_length",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "home_ownership",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "annual_inc",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "verification_status",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "purpose",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.42",
"x": "title",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "zip_code",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "addr_state",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.09",
"x": "dti",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "delinq_2yrs",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "inq_last_6mths",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "open_acc",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "pub_rec",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "revol_bal",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.11",
"x": "revol_util",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "total_acc",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "initial_list_status",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "total_rec_int",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "total_rec_late_fee",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "recoveries",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "collection_recovery_fee",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "application_type",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "last_week_pay",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "acc_now_delinq",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "tot_cur_bal",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "loan_status",
"xref": "x",
"y": "purpose",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.13",
"x": "loan_amnt",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.14",
"x": "funded_amnt",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.14",
"x": "funded_amnt_inv",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "term",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "int_rate",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "grade",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "sub_grade",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "emp_title",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "emp_length",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "home_ownership",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "annual_inc",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "verification_status",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.42",
"x": "purpose",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "title",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "zip_code",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "addr_state",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "dti",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "delinq_2yrs",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "inq_last_6mths",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "open_acc",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "pub_rec",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "revol_bal",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "revol_util",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "total_acc",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.16",
"x": "initial_list_status",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "total_rec_int",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "total_rec_late_fee",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "recoveries",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "collection_recovery_fee",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "application_type",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.17",
"x": "last_week_pay",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "acc_now_delinq",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "tot_cur_bal",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.17",
"x": "loan_status",
"xref": "x",
"y": "title",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "loan_amnt",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "funded_amnt",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "funded_amnt_inv",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "term",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "int_rate",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "grade",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "sub_grade",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "emp_title",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "emp_length",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "home_ownership",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "annual_inc",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "verification_status",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "purpose",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "title",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "zip_code",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.26",
"x": "addr_state",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "dti",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "delinq_2yrs",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "inq_last_6mths",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "open_acc",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "pub_rec",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "revol_bal",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "revol_util",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "total_acc",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "initial_list_status",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "total_rec_int",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "total_rec_late_fee",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "recoveries",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "collection_recovery_fee",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "application_type",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "last_week_pay",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "acc_now_delinq",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "tot_cur_bal",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "loan_status",
"xref": "x",
"y": "zip_code",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "loan_amnt",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "funded_amnt",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "funded_amnt_inv",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "term",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "int_rate",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "grade",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "sub_grade",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "emp_title",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "emp_length",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "home_ownership",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "annual_inc",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "verification_status",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "purpose",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "title",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.26",
"x": "zip_code",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "addr_state",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "dti",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "delinq_2yrs",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "inq_last_6mths",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "open_acc",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "pub_rec",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "revol_bal",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "revol_util",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "total_acc",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "initial_list_status",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "total_rec_int",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "total_rec_late_fee",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "recoveries",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "collection_recovery_fee",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "application_type",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "last_week_pay",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "acc_now_delinq",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "tot_cur_bal",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "loan_status",
"xref": "x",
"y": "addr_state",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "loan_amnt",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "funded_amnt",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "funded_amnt_inv",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.11",
"x": "term",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.16",
"x": "int_rate",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.17",
"x": "grade",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.17",
"x": "sub_grade",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "emp_title",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "emp_length",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "home_ownership",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.21",
"x": "annual_inc",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "verification_status",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.09",
"x": "purpose",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "title",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "zip_code",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "addr_state",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "dti",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "delinq_2yrs",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "inq_last_6mths",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.3",
"x": "open_acc",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "pub_rec",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.14",
"x": "revol_bal",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.17",
"x": "revol_util",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.22",
"x": "total_acc",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "initial_list_status",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "total_rec_int",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "total_rec_late_fee",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "recoveries",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "collection_recovery_fee",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "application_type",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "last_week_pay",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "acc_now_delinq",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "tot_cur_bal",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.13",
"x": "loan_status",
"xref": "x",
"y": "dti",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "loan_amnt",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "funded_amnt",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "funded_amnt_inv",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "term",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "int_rate",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "grade",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "sub_grade",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "emp_title",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "emp_length",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "home_ownership",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "annual_inc",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "verification_status",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "purpose",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "title",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "zip_code",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "addr_state",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "dti",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "delinq_2yrs",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "inq_last_6mths",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "open_acc",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "pub_rec",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "revol_bal",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "revol_util",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "total_acc",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "initial_list_status",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "total_rec_int",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "total_rec_late_fee",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "recoveries",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "collection_recovery_fee",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "application_type",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "last_week_pay",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.13",
"x": "acc_now_delinq",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "tot_cur_bal",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "loan_status",
"xref": "x",
"y": "delinq_2yrs",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "loan_amnt",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "funded_amnt",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "funded_amnt_inv",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "term",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.23",
"x": "int_rate",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.22",
"x": "grade",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.22",
"x": "sub_grade",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "emp_title",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "emp_length",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "home_ownership",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "annual_inc",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "verification_status",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "purpose",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "title",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "zip_code",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "addr_state",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "dti",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "delinq_2yrs",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "inq_last_6mths",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.11",
"x": "open_acc",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "pub_rec",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "revol_bal",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.09",
"x": "revol_util",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.14",
"x": "total_acc",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.09",
"x": "initial_list_status",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "total_rec_int",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "total_rec_late_fee",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "recoveries",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "collection_recovery_fee",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "application_type",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "last_week_pay",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "acc_now_delinq",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "tot_cur_bal",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "loan_status",
"xref": "x",
"y": "inq_last_6mths",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.19",
"x": "loan_amnt",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.19",
"x": "funded_amnt",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.19",
"x": "funded_amnt_inv",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "term",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "int_rate",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "grade",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "sub_grade",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "emp_title",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "emp_length",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.13",
"x": "home_ownership",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.16",
"x": "annual_inc",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "verification_status",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "purpose",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "title",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "zip_code",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "addr_state",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.3",
"x": "dti",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "delinq_2yrs",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.11",
"x": "inq_last_6mths",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "open_acc",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "pub_rec",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.22",
"x": "revol_bal",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.15",
"x": "revol_util",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.7",
"x": "total_acc",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "initial_list_status",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "total_rec_int",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "total_rec_late_fee",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "recoveries",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "collection_recovery_fee",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "application_type",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "last_week_pay",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "acc_now_delinq",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.24",
"x": "tot_cur_bal",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.36",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "loan_status",
"xref": "x",
"y": "open_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "loan_amnt",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "funded_amnt",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "funded_amnt_inv",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "term",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "int_rate",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "grade",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "sub_grade",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "emp_title",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "emp_length",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "home_ownership",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "annual_inc",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "verification_status",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "purpose",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "title",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "zip_code",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "addr_state",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "dti",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "delinq_2yrs",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "inq_last_6mths",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "open_acc",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "pub_rec",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "revol_bal",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "revol_util",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "total_acc",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "initial_list_status",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "total_rec_int",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "total_rec_late_fee",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "recoveries",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "collection_recovery_fee",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "application_type",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "last_week_pay",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "acc_now_delinq",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "tot_cur_bal",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.12",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "loan_status",
"xref": "x",
"y": "pub_rec",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.34",
"x": "loan_amnt",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.34",
"x": "funded_amnt",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.34",
"x": "funded_amnt_inv",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "term",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "int_rate",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "grade",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "sub_grade",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "emp_title",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "emp_length",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.17",
"x": "home_ownership",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.35",
"x": "annual_inc",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "verification_status",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "purpose",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "title",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "zip_code",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "addr_state",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.14",
"x": "dti",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "delinq_2yrs",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "inq_last_6mths",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.22",
"x": "open_acc",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "pub_rec",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "revol_bal",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.22",
"x": "revol_util",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.18",
"x": "total_acc",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "initial_list_status",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.14",
"x": "total_rec_int",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "total_rec_late_fee",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "recoveries",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "collection_recovery_fee",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "application_type",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "last_week_pay",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "acc_now_delinq",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.44",
"x": "tot_cur_bal",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.82",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "loan_status",
"xref": "x",
"y": "revol_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "loan_amnt",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "funded_amnt",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "funded_amnt_inv",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "term",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.27",
"x": "int_rate",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.25",
"x": "grade",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.26",
"x": "sub_grade",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "emp_title",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "emp_length",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "home_ownership",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "annual_inc",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "verification_status",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.11",
"x": "purpose",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "title",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "zip_code",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "addr_state",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.17",
"x": "dti",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "delinq_2yrs",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.09",
"x": "inq_last_6mths",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.15",
"x": "open_acc",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "pub_rec",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.22",
"x": "revol_bal",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "revol_util",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.12",
"x": "total_acc",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "initial_list_status",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.18",
"x": "total_rec_int",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "total_rec_late_fee",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "recoveries",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "collection_recovery_fee",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "application_type",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "last_week_pay",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "acc_now_delinq",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "tot_cur_bal",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.13",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "loan_status",
"xref": "x",
"y": "revol_util",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.22",
"x": "loan_amnt",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.22",
"x": "funded_amnt",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.22",
"x": "funded_amnt_inv",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.11",
"x": "term",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "int_rate",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "grade",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "sub_grade",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "emp_title",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "emp_length",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.21",
"x": "home_ownership",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.22",
"x": "annual_inc",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "verification_status",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "purpose",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "title",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "zip_code",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "addr_state",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.22",
"x": "dti",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "delinq_2yrs",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.14",
"x": "inq_last_6mths",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.7",
"x": "open_acc",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "pub_rec",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.18",
"x": "revol_bal",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.12",
"x": "revol_util",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "total_acc",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "initial_list_status",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "total_rec_int",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "total_rec_late_fee",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "recoveries",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "collection_recovery_fee",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "application_type",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "last_week_pay",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "acc_now_delinq",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.3",
"x": "tot_cur_bal",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.28",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "loan_status",
"xref": "x",
"y": "total_acc",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "loan_amnt",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "funded_amnt",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "funded_amnt_inv",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.13",
"x": "term",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.11",
"x": "int_rate",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "grade",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "sub_grade",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "emp_title",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "emp_length",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "home_ownership",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "annual_inc",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "verification_status",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "purpose",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.16",
"x": "title",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "zip_code",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "addr_state",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "dti",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "delinq_2yrs",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.09",
"x": "inq_last_6mths",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "open_acc",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "pub_rec",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "revol_bal",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "revol_util",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "total_acc",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "initial_list_status",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.16",
"x": "total_rec_int",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "total_rec_late_fee",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "recoveries",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "collection_recovery_fee",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "application_type",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.17",
"x": "last_week_pay",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "acc_now_delinq",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "tot_cur_bal",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.23",
"x": "loan_status",
"xref": "x",
"y": "initial_list_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.53",
"x": "loan_amnt",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.53",
"x": "funded_amnt",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.53",
"x": "funded_amnt_inv",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.39",
"x": "term",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.45",
"x": "int_rate",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.38",
"x": "grade",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.39",
"x": "sub_grade",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "emp_title",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "emp_length",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "home_ownership",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.16",
"x": "annual_inc",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.27",
"x": "verification_status",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "purpose",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "title",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "zip_code",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "addr_state",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "dti",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "delinq_2yrs",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "inq_last_6mths",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "open_acc",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "pub_rec",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.14",
"x": "revol_bal",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.18",
"x": "revol_util",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "total_acc",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.16",
"x": "initial_list_status",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "total_rec_int",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "total_rec_late_fee",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "recoveries",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "collection_recovery_fee",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "application_type",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.17",
"x": "last_week_pay",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "acc_now_delinq",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.13",
"x": "tot_cur_bal",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "loan_status",
"xref": "x",
"y": "total_rec_int",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "loan_amnt",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "funded_amnt",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "funded_amnt_inv",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "term",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "int_rate",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "grade",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "sub_grade",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "emp_title",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "emp_length",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "home_ownership",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "annual_inc",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "verification_status",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "purpose",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "title",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "zip_code",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "addr_state",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "dti",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "delinq_2yrs",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "inq_last_6mths",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "open_acc",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "pub_rec",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "revol_bal",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "revol_util",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "total_acc",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "initial_list_status",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "total_rec_int",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "total_rec_late_fee",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "recoveries",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "collection_recovery_fee",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "application_type",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "last_week_pay",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "acc_now_delinq",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "tot_cur_bal",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "loan_status",
"xref": "x",
"y": "total_rec_late_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "loan_amnt",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "funded_amnt",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "funded_amnt_inv",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "term",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.11",
"x": "int_rate",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "grade",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.1",
"x": "sub_grade",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "emp_title",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "emp_length",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "home_ownership",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "annual_inc",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "verification_status",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "purpose",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "title",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "zip_code",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "addr_state",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "dti",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "delinq_2yrs",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "inq_last_6mths",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "open_acc",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "pub_rec",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "revol_bal",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "revol_util",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "total_acc",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "initial_list_status",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "total_rec_int",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "total_rec_late_fee",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "recoveries",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.8",
"x": "collection_recovery_fee",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "application_type",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "last_week_pay",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "acc_now_delinq",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "tot_cur_bal",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "loan_status",
"xref": "x",
"y": "recoveries",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "loan_amnt",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "funded_amnt",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "funded_amnt_inv",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "term",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "int_rate",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "grade",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "sub_grade",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "emp_title",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "emp_length",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "home_ownership",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "annual_inc",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "verification_status",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "purpose",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "title",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "zip_code",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "addr_state",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "dti",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "delinq_2yrs",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "inq_last_6mths",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "open_acc",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "pub_rec",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "revol_bal",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "revol_util",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "total_acc",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "initial_list_status",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "total_rec_int",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "total_rec_late_fee",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.8",
"x": "recoveries",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "collection_recovery_fee",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "application_type",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "last_week_pay",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "acc_now_delinq",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "tot_cur_bal",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "loan_status",
"xref": "x",
"y": "collection_recovery_fee",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "loan_amnt",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "funded_amnt",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "funded_amnt_inv",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "term",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "int_rate",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "grade",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "sub_grade",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "emp_title",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "emp_length",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "home_ownership",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "annual_inc",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "verification_status",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "purpose",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "title",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "zip_code",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "addr_state",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "dti",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "delinq_2yrs",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "inq_last_6mths",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "open_acc",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "pub_rec",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "revol_bal",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "revol_util",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "total_acc",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "initial_list_status",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "total_rec_int",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "total_rec_late_fee",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "recoveries",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "collection_recovery_fee",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "application_type",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "last_week_pay",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "acc_now_delinq",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "tot_cur_bal",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "loan_status",
"xref": "x",
"y": "collections_12_mths_ex_med",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "loan_amnt",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "funded_amnt",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "funded_amnt_inv",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "term",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "int_rate",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "grade",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "sub_grade",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "emp_title",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "emp_length",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "home_ownership",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "annual_inc",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "verification_status",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "purpose",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "title",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "zip_code",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "addr_state",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "dti",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "delinq_2yrs",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "inq_last_6mths",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "open_acc",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "pub_rec",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "revol_bal",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "revol_util",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "total_acc",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "initial_list_status",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "total_rec_int",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "total_rec_late_fee",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "recoveries",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "collection_recovery_fee",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "application_type",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "last_week_pay",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "acc_now_delinq",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "tot_cur_bal",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "loan_status",
"xref": "x",
"y": "application_type",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "loan_amnt",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "funded_amnt",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "funded_amnt_inv",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "term",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "int_rate",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "grade",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "sub_grade",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "emp_title",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "emp_length",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "home_ownership",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "annual_inc",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "verification_status",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "purpose",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.17",
"x": "title",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "zip_code",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "addr_state",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "dti",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "delinq_2yrs",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "inq_last_6mths",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "open_acc",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "pub_rec",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "revol_bal",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "revol_util",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "total_acc",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.17",
"x": "initial_list_status",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.17",
"x": "total_rec_int",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "total_rec_late_fee",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "recoveries",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "collection_recovery_fee",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "application_type",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "last_week_pay",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "acc_now_delinq",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "tot_cur_bal",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.11",
"x": "loan_status",
"xref": "x",
"y": "last_week_pay",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "loan_amnt",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "funded_amnt",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "funded_amnt_inv",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "term",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "int_rate",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "grade",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "sub_grade",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "emp_title",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "emp_length",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "home_ownership",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "annual_inc",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "verification_status",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "purpose",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "title",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "zip_code",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "addr_state",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "dti",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.13",
"x": "delinq_2yrs",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "inq_last_6mths",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "open_acc",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "pub_rec",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "revol_bal",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "revol_util",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "total_acc",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "initial_list_status",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "total_rec_int",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "total_rec_late_fee",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "recoveries",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "collection_recovery_fee",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "application_type",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "last_week_pay",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "acc_now_delinq",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "tot_cur_bal",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "loan_status",
"xref": "x",
"y": "acc_now_delinq",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.32",
"x": "loan_amnt",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.32",
"x": "funded_amnt",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.32",
"x": "funded_amnt_inv",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.11",
"x": "term",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.09",
"x": "int_rate",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "grade",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "sub_grade",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "emp_title",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "emp_length",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.49",
"x": "home_ownership",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.48",
"x": "annual_inc",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "verification_status",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "purpose",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "title",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "zip_code",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "addr_state",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "dti",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.07",
"x": "delinq_2yrs",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "inq_last_6mths",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.24",
"x": "open_acc",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.08",
"x": "pub_rec",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.44",
"x": "revol_bal",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "revol_util",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.3",
"x": "total_acc",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "initial_list_status",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.13",
"x": "total_rec_int",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "total_rec_late_fee",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "recoveries",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "collection_recovery_fee",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "application_type",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "last_week_pay",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "acc_now_delinq",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "tot_cur_bal",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.43",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "loan_status",
"xref": "x",
"y": "tot_cur_bal",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.35",
"x": "loan_amnt",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.35",
"x": "funded_amnt",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.35",
"x": "funded_amnt_inv",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "term",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.18",
"x": "int_rate",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.16",
"x": "grade",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.17",
"x": "sub_grade",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "emp_title",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "emp_length",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.17",
"x": "home_ownership",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.34",
"x": "annual_inc",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "verification_status",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "purpose",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "title",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "zip_code",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "addr_state",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "dti",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "delinq_2yrs",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "inq_last_6mths",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.36",
"x": "open_acc",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.12",
"x": "pub_rec",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.82",
"x": "revol_bal",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.13",
"x": "revol_util",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.28",
"x": "total_acc",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "initial_list_status",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.08",
"x": "total_rec_int",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "total_rec_late_fee",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "recoveries",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "collection_recovery_fee",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "application_type",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "last_week_pay",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "acc_now_delinq",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.43",
"x": "tot_cur_bal",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "loan_status",
"xref": "x",
"y": "total_rev_hi_lim",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "loan_amnt",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "funded_amnt",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.1",
"x": "funded_amnt_inv",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.13",
"x": "term",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "int_rate",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "grade",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "sub_grade",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "emp_title",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "emp_length",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "home_ownership",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "annual_inc",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "verification_status",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.06",
"x": "purpose",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.17",
"x": "title",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "zip_code",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "addr_state",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.13",
"x": "dti",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "delinq_2yrs",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.09",
"x": "inq_last_6mths",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.07",
"x": "open_acc",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "pub_rec",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "revol_bal",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.05",
"x": "revol_util",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "total_acc",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.23",
"x": "initial_list_status",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "total_rec_int",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.0",
"x": "total_rec_late_fee",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.06",
"x": "recoveries",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "collection_recovery_fee",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "collections_12_mths_ex_med",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "application_type",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.11",
"x": "last_week_pay",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "acc_now_delinq",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "tot_cur_bal",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.02",
"x": "total_rev_hi_lim",
"xref": "x",
"y": "loan_status",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "loan_status",
"xref": "x",
"y": "loan_status",
"yref": "y"
}
],
"template": {
"data": {
"bar": [
{
"error_x": {
"color": "#2a3f5f"
},
"error_y": {
"color": "#2a3f5f"
},
"marker": {
"line": {
"color": "#E5ECF6",
"width": 0.5
}
},
"type": "bar"
}
],
"barpolar": [
{
"marker": {
"line": {
"color": "#E5ECF6",
"width": 0.5
}
},
"type": "barpolar"
}
],
"carpet": [
{
"aaxis": {
"endlinecolor": "#2a3f5f",
"gridcolor": "white",
"linecolor": "white",
"minorgridcolor": "white",
"startlinecolor": "#2a3f5f"
},
"baxis": {
"endlinecolor": "#2a3f5f",
"gridcolor": "white",
"linecolor": "white",
"minorgridcolor": "white",
"startlinecolor": "#2a3f5f"
},
"type": "carpet"
}
],
"choropleth": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "choropleth"
}
],
"contour": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "contour"
}
],
"contourcarpet": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "contourcarpet"
}
],
"heatmap": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "heatmap"
}
],
"heatmapgl": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "heatmapgl"
}
],
"histogram": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "histogram"
}
],
"histogram2d": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "histogram2d"
}
],
"histogram2dcontour": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "histogram2dcontour"
}
],
"mesh3d": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "mesh3d"
}
],
"parcoords": [
{
"line": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "parcoords"
}
],
"pie": [
{
"automargin": true,
"type": "pie"
}
],
"scatter": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatter"
}
],
"scatter3d": [
{
"line": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatter3d"
}
],
"scattercarpet": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattercarpet"
}
],
"scattergeo": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattergeo"
}
],
"scattergl": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattergl"
}
],
"scattermapbox": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattermapbox"
}
],
"scatterpolar": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterpolar"
}
],
"scatterpolargl": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterpolargl"
}
],
"scatterternary": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterternary"
}
],
"surface": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "surface"
}
],
"table": [
{
"cells": {
"fill": {
"color": "#EBF0F8"
},
"line": {
"color": "white"
}
},
"header": {
"fill": {
"color": "#C8D4E3"
},
"line": {
"color": "white"
}
},
"type": "table"
}
]
},
"layout": {
"annotationdefaults": {
"arrowcolor": "#2a3f5f",
"arrowhead": 0,
"arrowwidth": 1
},
"coloraxis": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"colorscale": {
"diverging": [
[
0,
"#8e0152"
],
[
0.1,
"#c51b7d"
],
[
0.2,
"#de77ae"
],
[
0.3,
"#f1b6da"
],
[
0.4,
"#fde0ef"
],
[
0.5,
"#f7f7f7"
],
[
0.6,
"#e6f5d0"
],
[
0.7,
"#b8e186"
],
[
0.8,
"#7fbc41"
],
[
0.9,
"#4d9221"
],
[
1,
"#276419"
]
],
"sequential": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"sequentialminus": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
]
},
"colorway": [
"#636efa",
"#EF553B",
"#00cc96",
"#ab63fa",
"#FFA15A",
"#19d3f3",
"#FF6692",
"#B6E880",
"#FF97FF",
"#FECB52"
],
"font": {
"color": "#2a3f5f"
},
"geo": {
"bgcolor": "white",
"lakecolor": "white",
"landcolor": "#E5ECF6",
"showlakes": true,
"showland": true,
"subunitcolor": "white"
},
"hoverlabel": {
"align": "left"
},
"hovermode": "closest",
"mapbox": {
"style": "light"
},
"paper_bgcolor": "white",
"plot_bgcolor": "#E5ECF6",
"polar": {
"angularaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"bgcolor": "#E5ECF6",
"radialaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
}
},
"scene": {
"xaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
},
"yaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
},
"zaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
}
},
"shapedefaults": {
"line": {
"color": "#2a3f5f"
}
},
"ternary": {
"aaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"baxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"bgcolor": "#E5ECF6",
"caxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
}
},
"title": {
"x": 0.05
},
"xaxis": {
"automargin": true,
"gridcolor": "white",
"linecolor": "white",
"ticks": "",
"title": {
"standoff": 15
},
"zerolinecolor": "white",
"zerolinewidth": 2
},
"yaxis": {
"automargin": true,
"gridcolor": "white",
"linecolor": "white",
"ticks": "",
"title": {
"standoff": 15
},
"zerolinecolor": "white",
"zerolinewidth": 2
}
}
},
"xaxis": {
"dtick": 1,
"gridcolor": "rgb(0, 0, 0)",
"side": "top",
"ticks": ""
},
"yaxis": {
"dtick": 1,
"ticks": "",
"ticksuffix": " "
}
}
},
"text/html": [
"\n",
" \n",
" \n",
" \n",
" \n",
"
"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"application/vnd.plotly.v1+json": {
"config": {
"plotlyServerURL": "https://plot.ly"
},
"data": [
{
"domain": {
"x": [
0,
1
],
"y": [
0,
1
]
},
"hole": 0.4,
"hoverinfo": "label+percent+name",
"hoverlabel": {
"namelength": 0
},
"hovertemplate": "label=%{label}value=%{value}", "labels": [ 0, 1 ], "legendgroup": "", "name": "", "showlegend": true, "type": "pie", "values": [ 48802, 15197 ] } ], "layout": { "legend": { "tracegroupgap": 0 }, "template": { "data": { "bar": [ { "error_x": { "color": "#2a3f5f" }, "error_y": { "color": "#2a3f5f" }, "marker": { "line": { "color": "#E5ECF6", "width": 0.5 } }, "type": "bar" } ], "barpolar": [ { "marker": { "line": { "color": "#E5ECF6", "width": 0.5 } }, "type": "barpolar" } ], "carpet": [ { "aaxis": { "endlinecolor": "#2a3f5f", "gridcolor": "white", "linecolor": "white", "minorgridcolor": "white", "startlinecolor": "#2a3f5f" }, "baxis": { "endlinecolor": "#2a3f5f", "gridcolor": "white", "linecolor": "white", "minorgridcolor": "white", "startlinecolor": "#2a3f5f" }, "type": "carpet" } ], "choropleth": [ { "colorbar": { "outlinewidth": 0, "ticks": "" }, "type": "choropleth" } ], "contour": [ { "colorbar": { "outlinewidth": 0, "ticks": "" }, "colorscale": [ [ 0, "#0d0887" ], [ 0.1111111111111111, "#46039f" ], [ 0.2222222222222222, "#7201a8" ], [ 0.3333333333333333, "#9c179e" ], [ 0.4444444444444444, "#bd3786" ], [ 0.5555555555555556, "#d8576b" ], [ 0.6666666666666666, "#ed7953" ], [ 0.7777777777777778, "#fb9f3a" ], [ 0.8888888888888888, "#fdca26" ], [ 1, "#f0f921" ] ], "type": "contour" } ], "contourcarpet": [ { "colorbar": { "outlinewidth": 0, "ticks": "" }, "type": "contourcarpet" } ], "heatmap": [ { "colorbar": { "outlinewidth": 0, "ticks": "" }, "colorscale": [ [ 0, "#0d0887" ], [ 0.1111111111111111, "#46039f" ], [ 0.2222222222222222, "#7201a8" ], [ 0.3333333333333333, "#9c179e" ], [ 0.4444444444444444, "#bd3786" ], [ 0.5555555555555556, "#d8576b" ], [ 0.6666666666666666, "#ed7953" ], [ 0.7777777777777778, "#fb9f3a" ], [ 0.8888888888888888, "#fdca26" ], [ 1, "#f0f921" ] ], "type": "heatmap" } ], "heatmapgl": [ { "colorbar": { "outlinewidth": 0, "ticks": "" }, "colorscale": [ [ 0, "#0d0887" ], [ 0.1111111111111111, "#46039f" ], [ 0.2222222222222222, "#7201a8" ], [ 0.3333333333333333, "#9c179e" ], [ 0.4444444444444444, "#bd3786" ], [ 0.5555555555555556, "#d8576b" ], [ 0.6666666666666666, "#ed7953" ], [ 0.7777777777777778, "#fb9f3a" ], [ 0.8888888888888888, "#fdca26" ], [ 1, "#f0f921" ] ], "type": "heatmapgl" } ], "histogram": [ { "marker": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "histogram" } ], "histogram2d": [ { "colorbar": { "outlinewidth": 0, "ticks": "" }, "colorscale": [ [ 0, "#0d0887" ], [ 0.1111111111111111, "#46039f" ], [ 0.2222222222222222, "#7201a8" ], [ 0.3333333333333333, "#9c179e" ], [ 0.4444444444444444, "#bd3786" ], [ 0.5555555555555556, "#d8576b" ], [ 0.6666666666666666, "#ed7953" ], [ 0.7777777777777778, "#fb9f3a" ], [ 0.8888888888888888, "#fdca26" ], [ 1, "#f0f921" ] ], "type": "histogram2d" } ], "histogram2dcontour": [ { "colorbar": { "outlinewidth": 0, "ticks": "" }, "colorscale": [ [ 0, "#0d0887" ], [ 0.1111111111111111, "#46039f" ], [ 0.2222222222222222, "#7201a8" ], [ 0.3333333333333333, "#9c179e" ], [ 0.4444444444444444, "#bd3786" ], [ 0.5555555555555556, "#d8576b" ], [ 0.6666666666666666, "#ed7953" ], [ 0.7777777777777778, "#fb9f3a" ], [ 0.8888888888888888, "#fdca26" ], [ 1, "#f0f921" ] ], "type": "histogram2dcontour" } ], "mesh3d": [ { "colorbar": { "outlinewidth": 0, "ticks": "" }, "type": "mesh3d" } ], "parcoords": [ { "line": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "parcoords" } ], "pie": [ { "automargin": true, "type": "pie" } ], "scatter": [ { "marker": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "scatter" } ], "scatter3d": [ { "line": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "marker": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "scatter3d" } ], "scattercarpet": [ { "marker": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "scattercarpet" } ], "scattergeo": [ { "marker": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "scattergeo" } ], "scattergl": [ { "marker": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "scattergl" } ], "scattermapbox": [ { "marker": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "scattermapbox" } ], "scatterpolar": [ { "marker": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "scatterpolar" } ], "scatterpolargl": [ { "marker": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "scatterpolargl" } ], "scatterternary": [ { "marker": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "scatterternary" } ], "surface": [ { "colorbar": { "outlinewidth": 0, "ticks": "" }, "colorscale": [ [ 0, "#0d0887" ], [ 0.1111111111111111, "#46039f" ], [ 0.2222222222222222, "#7201a8" ], [ 0.3333333333333333, "#9c179e" ], [ 0.4444444444444444, "#bd3786" ], [ 0.5555555555555556, "#d8576b" ], [ 0.6666666666666666, "#ed7953" ], [ 0.7777777777777778, "#fb9f3a" ], [ 0.8888888888888888, "#fdca26" ], [ 1, "#f0f921" ] ], "type": "surface" } ], "table": [ { "cells": { "fill": { "color": "#EBF0F8" }, "line": { "color": "white" } }, "header": { "fill": { "color": "#C8D4E3" }, "line": { "color": "white" } }, "type": "table" } ] }, "layout": { "annotationdefaults": { "arrowcolor": "#2a3f5f", "arrowhead": 0, "arrowwidth": 1 }, "coloraxis": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "colorscale": { "diverging": [ [ 0, "#8e0152" ], [ 0.1, "#c51b7d" ], [ 0.2, "#de77ae" ], [ 0.3, "#f1b6da" ], [ 0.4, "#fde0ef" ], [ 0.5, "#f7f7f7" ], [ 0.6, "#e6f5d0" ], [ 0.7, "#b8e186" ], [ 0.8, "#7fbc41" ], [ 0.9, "#4d9221" ], [ 1, "#276419" ] ], "sequential": [ [ 0, "#0d0887" ], [ 0.1111111111111111, "#46039f" ], [ 0.2222222222222222, "#7201a8" ], [ 0.3333333333333333, "#9c179e" ], [ 0.4444444444444444, "#bd3786" ], [ 0.5555555555555556, "#d8576b" ], [ 0.6666666666666666, "#ed7953" ], [ 0.7777777777777778, "#fb9f3a" ], [ 0.8888888888888888, "#fdca26" ], [ 1, "#f0f921" ] ], "sequentialminus": [ [ 0, "#0d0887" ], [ 0.1111111111111111, "#46039f" ], [ 0.2222222222222222, "#7201a8" ], [ 0.3333333333333333, "#9c179e" ], [ 0.4444444444444444, "#bd3786" ], [ 0.5555555555555556, "#d8576b" ], [ 0.6666666666666666, "#ed7953" ], [ 0.7777777777777778, "#fb9f3a" ], [ 0.8888888888888888, "#fdca26" ], [ 1, "#f0f921" ] ] }, "colorway": [ "#636efa", "#EF553B", "#00cc96", "#ab63fa", "#FFA15A", "#19d3f3", "#FF6692", "#B6E880", "#FF97FF", "#FECB52" ], "font": { "color": "#2a3f5f" }, "geo": { "bgcolor": "white", "lakecolor": "white", "landcolor": "#E5ECF6", "showlakes": true, "showland": true, "subunitcolor": "white" }, "hoverlabel": { "align": "left" }, "hovermode": "closest", "mapbox": { "style": "light" }, "paper_bgcolor": "white", "plot_bgcolor": "#E5ECF6", "polar": { "angularaxis": { "gridcolor": "white", "linecolor": "white", "ticks": "" }, "bgcolor": "#E5ECF6", "radialaxis": { "gridcolor": "white", "linecolor": "white", "ticks": "" } }, "scene": { "xaxis": { "backgroundcolor": "#E5ECF6", "gridcolor": "white", "gridwidth": 2, "linecolor": "white", "showbackground": true, "ticks": "", "zerolinecolor": "white" }, "yaxis": { "backgroundcolor": "#E5ECF6", "gridcolor": "white", "gridwidth": 2, "linecolor": "white", "showbackground": true, "ticks": "", "zerolinecolor": "white" }, "zaxis": { "backgroundcolor": "#E5ECF6", "gridcolor": "white", "gridwidth": 2, "linecolor": "white", "showbackground": true, "ticks": "", "zerolinecolor": "white" } }, "shapedefaults": { "line": { "color": "#2a3f5f" } }, "ternary": { "aaxis": { "gridcolor": "white", "linecolor": "white", "ticks": "" }, "baxis": { "gridcolor": "white", "linecolor": "white", "ticks": "" }, "bgcolor": "#E5ECF6", "caxis": { "gridcolor": "white", "linecolor": "white", "ticks": "" } }, "title": { "x": 0.05 }, "xaxis": { "automargin": true, "gridcolor": "white", "linecolor": "white", "ticks": "", "title": { "standoff": 15 }, "zerolinecolor": "white", "zerolinewidth": 2 }, "yaxis": { "automargin": true, "gridcolor": "white", "linecolor": "white", "ticks": "", "title": { "standoff": 15 }, "zerolinecolor": "white", "zerolinewidth": 2 } } }, "title": { "text": "Percentage data of loan_status" } } }, "text/html": [ "
\n",
" \n",
" \n",
" \n",
" \n",
"
"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"************************************************************\n",
"\n",
"\n",
" OLS Regression Results \n",
"=======================================================================================\n",
"Dep. Variable: loan_status R-squared (uncentered): 0.357\n",
"Model: OLS Adj. R-squared (uncentered): 0.357\n",
"Method: Least Squares F-statistic: 1110.\n",
"Date: Tue, 17 Mar 2020 Prob (F-statistic): 0.00\n",
"Time: 15:52:24 Log-Likelihood: -30665.\n",
"No. Observations: 63999 AIC: 6.139e+04\n",
"Df Residuals: 63967 BIC: 6.168e+04\n",
"Df Model: 32 \n",
"Covariance Type: nonrobust \n",
"===========================================================================================\n",
" coef std err t P>|t| [0.025 0.975]\n",
"-------------------------------------------------------------------------------------------\n",
"loan_amnt -2.078e-06 2.67e-07 -7.784 0.000 -2.6e-06 -1.55e-06\n",
"term -0.0601 0.004 -14.037 0.000 -0.069 -0.052\n",
"int_rate 0.0846 0.001 64.946 0.000 0.082 0.087\n",
"grade -0.0181 0.005 -3.321 0.001 -0.029 -0.007\n",
"sub_grade -0.0515 0.001 -34.544 0.000 -0.054 -0.049\n",
"emp_title -2.238e-06 1.65e-07 -13.588 0.000 -2.56e-06 -1.92e-06\n",
"emp_length -0.0013 0.001 -2.548 0.011 -0.002 -0.000\n",
"home_ownership -0.0027 0.001 -2.926 0.003 -0.004 -0.001\n",
"annual_inc -1.405e-07 3.62e-08 -3.884 0.000 -2.11e-07 -6.96e-08\n",
"verification_status -0.0059 0.002 -2.805 0.005 -0.010 -0.002\n",
"purpose -0.0040 0.001 -5.099 0.000 -0.005 -0.002\n",
"title 3.48e-05 1.56e-06 22.313 0.000 3.17e-05 3.79e-05\n",
"zip_code -3.354e-06 5.81e-06 -0.577 0.564 -1.47e-05 8.04e-06\n",
"addr_state -0.0005 0.000 -4.756 0.000 -0.001 -0.000\n",
"dti -0.0051 0.000 -23.481 0.000 -0.005 -0.005\n",
"delinq_2yrs -0.0229 0.002 -12.517 0.000 -0.027 -0.019\n",
"inq_last_6mths 0.0232 0.002 14.117 0.000 0.020 0.026\n",
"open_acc -0.0076 0.000 -17.411 0.000 -0.008 -0.007\n",
"pub_rec -0.0394 0.003 -13.728 0.000 -0.045 -0.034\n",
"revol_bal -2.196e-07 1.51e-07 -1.451 0.147 -5.16e-07 7.71e-08\n",
"revol_util -0.0009 8.26e-05 -10.311 0.000 -0.001 -0.001\n",
"total_acc 0.0033 0.000 17.411 0.000 0.003 0.004\n",
"initial_list_status -0.1331 0.003 -40.528 0.000 -0.140 -0.127\n",
"total_rec_int -2.848e-06 1.04e-06 -2.740 0.006 -4.89e-06 -8.11e-07\n",
"total_rec_late_fee -0.0006 0.000 -1.704 0.088 -0.001 9.44e-05\n",
"recoveries -0.0001 6.84e-06 -20.976 0.000 -0.000 -0.000\n",
"collection_recovery_fee 0.0004 4.18e-05 8.410 0.000 0.000 0.000\n",
"application_type -0.0415 0.074 -0.561 0.575 -0.186 0.103\n",
"last_week_pay -0.0004 6.09e-05 -7.363 0.000 -0.001 -0.000\n",
"acc_now_delinq -0.0310 0.020 -1.588 0.112 -0.069 0.007\n",
"tot_cur_bal 1.139e-07 1.46e-08 7.819 0.000 8.54e-08 1.43e-07\n",
"total_rev_hi_lim 2.649e-07 1.11e-07 2.381 0.017 4.68e-08 4.83e-07\n",
"==============================================================================\n",
"Omnibus: 7448.626 Durbin-Watson: 2.001\n",
"Prob(Omnibus): 0.000 Jarque-Bera (JB): 10200.031\n",
"Skew: 0.970 Prob(JB): 0.00\n",
"Kurtosis: 2.750 Cond. No. 1.05e+07\n",
"==============================================================================\n",
"\n",
"Warnings:\n",
"[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.\n",
"[2] The condition number is large, 1.05e+07. This might indicate that there are\n",
"strong multicollinearity or other numerical problems.\n",
"\n",
"\n",
"******** VIF *********\n",
"\n",
" feature vif\n",
"4 sub_grade 153.09\n",
"2 int_rate 147.28\n",
"3 grade 61.36\n",
"17 open_acc 12.90\n",
"21 total_acc 11.97\n",
"31 total_rev_hi_lim 10.39\n",
"20 revol_util 10.31\n",
"0 loan_amnt 8.65\n",
"14 dti 7.85\n",
"19 revol_bal 7.45\n",
"11 title 5.76\n",
"28 last_week_pay 5.39\n",
"8 annual_inc 4.71\n",
"5 emp_title 4.33\n",
"7 home_ownership 4.27\n",
"12 zip_code 3.89\n",
"30 tot_cur_bal 3.65\n",
"13 addr_state 3.49\n",
"23 total_rec_int 3.40\n",
"9 verification_status 3.15\n",
"10 purpose 3.00\n",
"25 recoveries 2.87\n",
"26 collection_recovery_fee 2.78\n",
"1 term 2.32\n",
"22 initial_list_status 2.25\n",
"6 emp_length 2.19\n",
"16 inq_last_6mths 1.72\n",
"32 loan_status 1.56\n",
"15 delinq_2yrs 1.20\n",
"18 pub_rec 1.18\n",
"24 total_rec_late_fee 1.03\n",
"29 acc_now_delinq 1.03\n",
"27 application_type 1.00\n"
]
},
{
"data": {
"application/javascript": [
"\n",
" if (window._pyforest_update_imports_cell) { window._pyforest_update_imports_cell('from sklearn.model_selection import train_test_split'); }\n",
" "
],
"text/plain": [
""
]
},
"metadata": {
"needs_background": "light"
},
"output_type": "display_data"
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"-----------------------------------------\n",
"************* Model Results *************\n",
"-----------------------------------------\n",
"F1 Score : 0.781688137529659\n",
"Report:\n",
" precision recall f1-score support\n",
"\n",
" 0 0.87 0.82 0.85 14622\n",
" 1 0.52 0.62 0.57 4578\n",
"\n",
" accuracy 0.78 19200\n",
" macro avg 0.70 0.72 0.71 19200\n",
"weighted avg 0.79 0.78 0.78 19200\n",
"\n"
]
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAW0AAAENCAYAAADE9TR4AAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADt0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjByYzEsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy/xvVyzAAAgAElEQVR4nO3dd3wVVdrA8d+ThNBCQksCEhR8ZaWKFUEQEFRCE+yoCCqKsq4FUfoKFrCurrorLljAiqhIkI7UlY6VvqC0UJIgkASQkMTn/WMm4RJuKiHhDs+Xz3zuvWfmnDm38NxznzkzEVXFGGNMYAgq7Q4YY4wpOAvaxhgTQCxoG2NMALGgbYwxAcSCtjHGBBAL2sYYE0AsaHuIiDwqIutF5A8RURF5vAT2uU1Etp3u/ZwN3PdsYWn3w5zZLGgXgYjUF5G3RGStiCSLyDER2S0i00Wkj4iUK4U+9QDeAI4C/wSeAZaXdD/OBO4XibrLNXls94HPdiNPcZ9ti6MdY/ITUtodCDQi8jQwAucLbzkwATgERANtgXeBfsDlJdy1Llm3qrq7BPfbvgT3VVgZwAPAgpwrRCQcuM3d5kz5f9AAOFLanTBntjPlwxoQRGQozgh2J3Crqq7ws00XYEBJ9w04B6CEAzaq+mtJ7q+QpgE3iUg1Vf09x7q7gArA18CNJd4zP1R1Y2n3wZz5LD1SQCJSBxgJpAOd/AVsAFWdBsT6qX+biCx20yl/iMgaERkiImX9bLvNXSqIyCsiskNE0kRki4gMEhHx2XakiChwjfs46+e+ZvXbfTw+l+e1MGtbnzIRkd4islREkkTkqIjsFJHZInK7v776abesiAwWkV9E5IiIpIjIf0XkNj/bZvfRvT9RRPa5+13tfhEWxTigLHC3n3UP4Hz5zvJXUUT+IiIvuvtPcl//7SIyVkRicmw7nuOj+RG+74GItHW3ucd9fI+IxLqve7Lva58zpy0idUXkoIjsF5HzcuyzoohsEJFMEWlT2BfGBC4baRfcvUAZYKKqrs1rQ1VN830sIqOBIcA+4FOcdEpHYDTQQUSuU9X0HM2UAebgjKBn4vyM7w68CJTDGfEDLHRv7wHO8yk/FaPc/m4FJgHJQE3gCuBW4PO8KotIKDAbaANsBP6NM6q9BfhcRC5W1aF+qp4HrAR+Az4CqgK3A3Eicq2qnpTmyMdcYBtwP06eP6t/lwGX4LxWf+ZS9ybgIZxgvBQ4BjRy2+oqIper6i532ynubW9gEcffE9z9+7oF50t9JvAOUCe3zqvqVhG5H/gC+ExEWqtqhrv6baA+MFJVF+XWhvEgVbWlAAswD1Dg/kLWa+HW2wHU8CkPAb5x1w3NUWebWz4DKO9THgUcdJcyOeosdN7Ok/Zfx21rfC79O6ke8DsQD1Tws311P33dlqNsiE//Q3L0P+u5XeWnjwqMyNFWh6y2CvGaZ+0jBBju3m/hs/4dIBM4FycIK07w822jFlDWT9vXu3XH5Chv668dn/X3uOv/BGJz2UaBhX7K33bXveA+7uU+XgAElfb/DVtKdrH0SMHVdG/jC1nvPvf2eVXdm1WozohpAM5/4vtzqfuoqv7hUycRiAMigAsL2Y/CSscJTidQ1X0FqHsfTlB5Qo+PDLP6/5z70N9z3g48n2N/s3G+8JoVrNsneR/neTwATloBuBOYrao7cqukqrs0xy8mt3wOsA7ny6Qo4lTVb0omD08APwODRORvOEE8CbhLVXP7pWA8yoJ2wWXlkQt7LdtL3dv5OVeo6v9wvgTqikjlHKuTVXWLn/Z2urdVCtmPwvgEZ/S7TkRecHOwEQWpKCKVgAuA3er/wFrW63CJn3U/qepJXxQ4z7lIz1edA7MzgNvcGSM9gEo4+e5cuXn9niLyrZvTzvA5VtAEZyReFCsLW0FVj+KkiQ4Db+GkmnppCR90NmcGC9oFl/UfJCbPrU6WFez25LJ+T47tshzMZfuskWtwIftRGP2Bx3GCxGCc/Os+EYkTkQvyqVvQ55vzSwryfs6n8lkdB1QE7sAZce/FSU3l5TWcvHpDnPz8P3By4M/g/CIILWJf9ua/iV//A35x76/HOd5hzkIWtAvuO/e2sPOSk93bGrmsr5lju+KW9fM5t4POJwVPVc1U1TdUtSnO/PObcabG3QDM8jfjxUdpP19/ZgC7cPLbVwIf+KZtchKRKOBRYC1woar2VNVBqjpSVUcCJ6VNCqGof3VkMHAVzsHsRjjHDcxZyIJ2wX2Ak+e9WUQa5rVhjqD2o3vb1s92F+CM3Leqam6jzFN1wL2t7Wf/4cBf8qqsqomqOllVb8NJbfwf0DiP7VOBX4FaIlLPzyZZZyj+UIC+Fws35fI+zmutwHv5VDkf5//GHPf5ZHOn+53vp05WWqfYfwGJyFXAs8AmnNd+E/CMiLQq7n2ZM58F7QJS1W0487RDgeki4veMRxHJms6V5X33driIRPpsFwy8ivMe5BdEiswNOhuBlr5fNu7+XwPK+27vzq9u7zsX3C0vgzMFD/I/a+99nGMAr7j7yWqjOvB3n21K0ps4J9F00PxPCNrm3rbK0f8wnFSLv18tWSfvnHuK/TyBiFQBPsP5Uuihqgk4+e0MnGmA1Ypzf+bMZ/O0C0FVR4tICM5p7KtEZCmwmuOnsbcG6rllWXWWisjLwEBgrYh8iZMr7ogzavoOeOU0d/0VnC+GJSLyBc71Sa7BmQv+M9DUZ9vywLfANhFZgZO/LQdch3Oa9VRV3ZDP/l7FeX7dgJ9FZAbOwbNbcab9vayq3+VRv9i5s16m5Luhs+1eEZmIc9DyJxGZg5Orvw7ntfsJuDhHtU04KZgeInIMZ8aLAh+p6vZT6Pr7OF8Ej6rqT27/fhaRAcC/cH4B3nAK7ZtAU9pzDgNxwQleb+HkPFNwTrzYgzPC7oP/+b09cAJ0Ks5//HXAMKCcn223kWPus8+6kTjBoG2O8oX4mafts76Pu880nINh/wGq5ayHE8gHus9lh9vXJJzrrDwEhBakrziBfqj7Gv3hPu/vgDv8bFuHQs4lz+f92ea2F1KAbXObp10B5ySjLe5rsBPnJKGTXjOfOlfgzOdPxjmWkP0+cXye9j159OWEedrAI25ZXC7bT3bX9y/t/xO2lNwi7ptvjDEmAFhO2xhjAogFbWOMCSAWtI0xJhci8r6IJIrIWp+yV0Rko3sFy699z2YW58qdW0Rkk4h08Cm/TJwre24RkTezZme5s7U+d8tXiHM10TxZ0DbGmNyN5+RLLc8FGqvqRThnqg4BcKfU9sA5+SkWeNtnyugYoC/O7LJ6Pm32AQ6o6gXA68BL+XXotE/5aytP25FOc5JpKcNKuwvmDBRWqazkv1XeChNzFuqzee5PVRfnHP2qc9GwLMtxLrcLzhTXiepcaGyriGwBmolzvflwVV0GICIf4lxmeaZbZ6Rb/0vgXyIimscMERtpG2POWiLSV5w/dJG19C1kE/dx/GS6Why/oBs4F4Or5S7xfspPqKPOpRWScaaV5spOrjHGeEqOk3nzpH/qWGBsEfczDOfM1E+yivztIo/yvOrkyoK2McZTJPiUMyz570OkN84f027vk8qI58Rr/MTgXB00nhOvDppV7lsn3j3bOgLYn9e+LT1ijPEUkYIvRWtfYoFBwA2q6nsdnqk4lzEoKyJ1cQ44rlTVPUCqiDR3Z430wvljJll1erv3bwHm55XPBhtpG2O8pqjR2G9T8hnOFTqri0g8znWHhuD8wei5bipmuao+pKrrRGQSzvXOM4CH9fgf9eiHMxOlPE4OPCsP/h7wkXvQcj/O7JM8WdA2xnhKMcZsVPUOP8W5XpVTVUfhXLMmZ/lq/FzSWJ2/SnRrYfpkQdsY4ykSdPpz2qXJgrYxxluKc6h9BrKgbYzxlCAbaRtjTADxdsy2oG2M8RbLaRtjTADxeErbgrYxxmM8HrUtaBtjPCWoBE5jL00WtI0x3mIjbWOMCRwej9kWtI0x3lKYS7MGIgvaxhhv8XbMtqBtjPEWm6dtjDEBxIK2McYEEMtpG2NMIPH43+OyoG2M8RQbaRtjTADxeMy2oG2M8RY7EGmMMQHEgrYxxgQSj+dHLGgbYzzF4zHbgrYxxlts9ogxxgQSm6dtjDGBIyjI21HbgrYxxlPE2zHbgrYxxmMsp22MMYHD4zHbgrYxxlvs5BpjjAkkHh9qW9A2xnhKULAFbWOMCRw20jbGmMDh8Zjt9XOHjDFnGwmSAi/5tiXyvogkishan7KqIjJXRDa7t1V81g0RkS0isklEOviUXyYia9x1b4p7rr2IlBWRz93yFSJSJ78+WdA2xniLFGLJ33ggNkfZYGCeqtYD5rmPEZGGQA+gkVvnbREJduuMAfoC9dwlq80+wAFVvQB4HXgpvw5Z0DbGeEpQcFCBl/yo6mJgf47ibsAE9/4EoLtP+URVTVPVrcAWoJmI1ATCVXWZqirwYY46WW19CbSXfK54ZUHbGOMpIoVZpK+IrPZZ+hZgF9GqugfAvY1yy2sBO322i3fLarn3c5afUEdVM4BkoFpeO7cDkcYYbynEkUhVHQuMLa49+9tFHuV51cmVjbSNMZ5SnAcic5HgpjxwbxPd8nigts92McButzzGT/kJdUQkBIjg5HTMCSxoG2M8pTDpkSKaCvR27/cG4nzKe7gzQuriHHBc6aZQUkWkuZuv7pWjTlZbtwDz3bx3riw9YozxlmKcqC0inwFtgeoiEg+MAF4EJolIH2AHcCuAqq4TkUnAeiADeFhVM92m+uHMRCkPzHQXgPeAj0RkC84Iu0d+fbKgbYzxlOI8jV1V78hlVftcth8FjPJTvhpo7Kf8KG7QLygL2sYYb/H4KZEWtI0xnuLxmO39oD3wve606PIXDiYe5t4m/wbgoZev56quF5J+LJPdv+7npXuncCj5KAB3Dr6azn0uJTNTeevRGayaswWAl2feTdWalQgOCWLNf7fzz4en8eefSlTtCIZMuImwyuUIChbGDp7LipmbT+rHXy6tyeDxN1G2fAjLZ2zmrcdmAFAmNJghH97EhZedQ/Lvf/Ds7ZPYu/0gAB16Xczdw9sA8NHzi5j94U8A1KhTmacn3kZ41fL874fdjL57MhnpTurskTc60bxTPY4eSefFe75m8497AGjW4QL+9kYngoOF6e/+wKcv/fd0veQBZe/evTw9Yhi//76PoKAgbrzxZu68oyf/+c/bfD1lMlWqOGcoP/zXR2nV6mrSM9J57rmRbNy4gczMTDp37sp9995/Qpv9+z/Crl3xTJr0td99vv/Bu8TFfU1wUBBPPjWYq1q0BGDDhvWMGDmctLQ0Wra8mqeeHISIcOzYMZ4eMYwNG9YTERHBiy+8wjnnONN8v5kWx3vvjQOgT58H6NqlGwC7dsUzZOhAUlJSqF+/Ac89O5oyZcqgqrzy6kssWfJfypUrx8iRz9GgfsPT8tqWFq9fT9vzs0dmjf+RgbEfnVC2eu6v3Nv43/Rp+jY7//c7dw65GoDzGkTSrkcT7mn0LwbGfsjjb3chyP0AjLxtEvdf/Db3Nv4XEZEVaHtrIwDuHt6GBZPW8sClY3i2xxf0f7uL3370H9OVV/tO5a56bxBTrxrNYusB0KnPpRw6cJS76r3Bl68vpe9L1wFQqUp5eo9oS78rx/JQs//Qe0RbwiqXA+DBl67ny9eX0vMvb3DowFE69bkUgCs71iOmXjXuqvcG/+g7lf5jugIQFCQ89u8uDOr4Eb0b/ot2dzThvAaRxfkyB6zgkGD69x/AV1/GMf6Dj/nii8/57bdfAbjzzp589ukXfPbpF7Rq5XxGvv12DunH0pn0+WQ+/ngikyd/ye7du7Lbmz//W8pXqJDr/n777VfmzJnFF5O+5q23xvDii6PIzHS+cF944XmGDxvBlK+nsXPndpYu/Q6AKXGTCa8UTtyU6dx15928+dY/AUhOTmbcuHeYMP4TPpzwKePGvUNKSgoAb771T+66826mfD2N8ErhTImbDMCSJd+xc+d2pnw9jeHDnuaFF54v5lf0DFAC00dKU75BW0Tqi8gg9yInb7j3G5RE54rDL//dTur+P04oWz33VzIz/wRg/fJ4ImPCAWjZrT7zJ64h/Vgme7cdZNeW/dRv5kyvPJKaBkBwSBBlQkPImpSjqlQMLwtAxYhy7NudelIfqtYIo2J4WdYvd06Wmv3hT7TqXt/dZwNmTXBG0Iu+XM9l7c8H4IoOF7B67q+kHviDQwePsnrur9mB/tJ2dVn05XoAZk34iVbdG2T3P2s0vn5FPGGVy1G1Rhj1m8Wwa8t+9mw9QEZ6JvMnrqFlt/qn9Lp6RWT1yOyRZsWKFalbpy6JiYm5bi8Ifxw9QkZGBmlH0yhTpgwVK4YBcOTIET7+5CPu75P7SXULFy3g+utjCQ0NpVatGGrXPpd169aStC+JQ4cPcdFFTREROnfqysKFCwBYtGghXbrcAED79texcuUKVJVly5ZwZbMWREREEB4ezpXNWrB06XeoKqtWraR9e2cA0KXLDT5tLaBzp66ICE2aNOVQaipJ+5JO/YU8g3g8ZucdtEVkEDAR56ydlcAq9/5nIjL49Hfv9Ot036WsdNMZkbXCSdqZnL0uKT6ZyFqVsh+/PKsXUxIHcSQ1jUVfrgNg/MgFXNezKV/sHMBLM3ry5iPTT9pHZK1wkuJTfNpNIbJWuLuuUvY+MzP/5FByGhHVKrh9OblORLUKHDp4NPtLx7ePJ/ffqeO7j5z7N8ft3r2LjZs20rhxEwAmTZrI7T1u5plnns4ewba/9jrKl6tAh9j2dO5yPXf37E1ERAQAY8b8i549e1GuXLlc95GUmEiN6BrZj6OjoklMTCApMZHo6Ojj5dHRJCYlunUSsteFhIQQFhbGweSDJCYlEu3TVpRb52DyQSpVqkRIiJP9jIqKJikxAcCpU+PEOkl5fEkFIgkOKvASiPLrdR/gClV9UVU/dpcXgWbuOr98z+ffzQ/F2d9i1XNoazIzMpn7yS9OgZ9vXt9p7gNjP+Tmmq9Qpmwwl7RzRsTt77iIWeN/5Nba/2BQp48Z+tHNnHS9l7za9fN1r6q51MmtPL+2cik32Y4cOcJTA5/gyQEDCQsL45ZbbiduynQ++/QLqlevzuuvvwrAurVrCQoOYtasb/lm6kw+/ngC8fHxbNq0kZ3xO2h3jd+ZYNnUzxnKIuL3/ch62/y9U4Kc+OH0actfeVZj/vcToEPOXJzVI23gT+AcP+U13XV+qepYVb1cVS8/h0tPpX+nTYdeF9Oiy4U8f9dX2WVJ8SlE1o7IfhwZE3FSuuNYWgZLp26ilZte6NTnUhZMci61u375TkLLhRBR/cScZlJ8SnYKxmk3nH27U07aZ3BwEGERZUnZ/4dbnrNOKsn7jhBWuRzB7ijBt49J8ck5+u/UOfl5hftN45yt0jPSeWrgE3SM7Uy7dtcCUK1aNYKDg7MPTq5btwaAWbNncFWLlpQJKUPVqtVo2vQS1m9Yxy9rfmbDhg106RpLn/t7s33Hdvr2ve+kfUVFRbM3YW/244TEBCIjo4iKjiYhIeF4eUICkdWjsutkrcvIyODQoUNERES45cfbSkxIILJ6JJUrVyE1NZWMjAyn3N0HOCP7hL0n1qke6a3jGyVwGnupyi9oPw7ME5GZIjLWXWbhXEP2sdPfvdOjWYcLuGNQK4be8Alpf6Rnly+dupF2PZpQJjSYGnUqE1OvKhtXxlO+YihVazh5y+DgIK7sVI8dG508YOKO5Ow89Ln1qxNaLoSDSYdP2N/+vYc4knqMhlc6+fEOvS5mSdzG7H3G9r4YgDa3NOSH+VsBWDV7C1dcfwFhlcsRVrkcV1x/AatmOzNZflywlTa3OHnY2N4XsyRug9vWJjr0ctpqeGUMh5OPsn/vITat2kVMvarUqFOZkDLBtOvRhKVTNxbzqxqYVJXnnh1B3bp16dmzV3a5b553wYL5/N//OccTakTXZNXqlagqf/xxhDVrf6FunbrcesvtzJ41j2nfzOK9dydw3rnnMXbs+yftr03rtsyZM4tjx46xa1c8O3dup1GjxkRWj6RixYqsWfMzqsr0Gd/Qps012XWmTZsKwLx5c7niimaICC1atGT5iqWkpKSQkpLC8hVLadGiJSLC5Zdfwbx5cwGYNm0qbdq0BaB1m7ZMn/ENqsqaNT8TFlaJyOoeC9oiBV4CkeT3M1lEgnDSIbVwfpzHA6t8Ts/MU1t5ulR/h//901u4uG1dIqpX4EDCIT4YsYC7hlxNmbIhpPx+BHAORr7W7xvASZl0vO9SMjP+5F+Pz2TlrM1UiarIC9N6UqZsMEHBQfw4/zf+3X8WmZl/cl6DSJ4c143yYaGgyjsD57B6rjP74N0f+3H/JWMAuPCycxg8/kZCy5dh5czNvOHmvkPLhjD0o5uod0lNUvb/wbM9vmDP1gMAdLz3EnoObQ3AR6MWM2v8jwDUrFuFpyfeSnjV8mz+cQ+jen5F+jHn7XjsX51pFluPtCPpvHTv12z63rkuzZUd6/G3f3YkKDiIme//wMejF5fEy5+raSnDSnX/WX786Qfuv/8eLrigHkFBzhjm4b8+yuzZM9n0v42ICOfUPIehw54msnokR44cYeQzf2fr1t9QVW7o2o1eve49oc3du3fx+ON/y57yt2jRAtZvWE+/hx4G4L33xhI3dQohwcEMGDCQli2dmSnr169j5MjhHE1Lo+VVrRg4cAgiQlpaGn9/eiibNm0kIjyC0aNfJibGGQDExX3N+x+8C0Cf+x7ghhucyzTHx8czdOhAklOSufDC+jz/3AuEhoaiqrz08miWLl3iTPkb8RwNGzY6/S90AYVVKnvKkfSR2z4tcMx5a9KdARe58w3ap6q0g7Y5M50pQducWYojaD92x8QCx5w3PusRcEHb8yfXGGPOMgGaqy4oC9rGGE8J0FR1gVnQNsZ4SqAeYCwoC9rGGG+x9IgxxgQOjw+0LWgbY7wlUE9PLygL2sYYT7GctjHGBBDx9kDbgrYxxltspG2MMYHEgrYxxgQOS48YY0wAsdkjxhgTQCynbYwxAcTjMduCtjHGY+w0dmOMCRyWHjHGmAAiwRa0jTEmYNhI2xhjAkig/pX1grKgbYzxFm/HbAvaxhhvsfSIMcYEEK+nR7x9vqcx5qwjQVLgJd+2RPqLyDoRWSsin4lIORGpKiJzRWSze1vFZ/shIrJFRDaJSAef8stEZI277k05hZ8DFrSNMZ4iIgVe8mmnFvAocLmqNgaCgR7AYGCeqtYD5rmPEZGG7vpGQCzwtogEu82NAfoC9dwltqjPz4K2McZTRAq+FEAIUF5EQoAKwG6gGzDBXT8B6O7e7wZMVNU0Vd0KbAGaiUhNIFxVl6mqAh/61Ck0C9rGGE8prqCtqruAV4EdwB4gWVXnANGqusfdZg8Q5VapBez0aSLeLavl3s9ZXiQWtI0xnlKY9IiI9BWR1T5LX592quCMnusC5wAVRaRnXrv2U6Z5lBeJzR4xxnhKUCFmj6jqWGBsLquvBbaqahKAiEwGrgISRKSmqu5xUx+J7vbxQG2f+jE46ZR4937O8iKxkbYxxlOKMae9A2guIhXc2R7tgQ3AVKC3u01vIM69PxXoISJlRaQuzgHHlW4KJVVEmrvt9PKpU2g20jbGeEpxnVyjqitE5EvgByAD+BFnVB4GTBKRPjiB/VZ3+3UiMglY727/sKpmus31A8YD5YGZ7lIkFrSNMZ5SnCdEquoIYESO4jScUbe/7UcBo/yUrwYaF0efLGgbYzxFPH7xEQvaxhhP8filRyxoG2O8pTCzRwKRBW1jjKfYSNsYYwKJx6O2BW1jjKd4PGZb0DbGeIv9EQRjjAkgHo/ZFrSNMd5is0eMMSaAeDtkW9A2xniM5bSNMSaAeDxmW9A2xniLjbSNMSaA2IFIY4wJIB4faFvQNsZ4iwVtY4wJIJbTNsaYAOLxmH36g/a89JGnexcmAB0+lFbaXTAeZSNtY4wJIGKzR4wxJnDYSNsYYwKIx2O2BW1jjLfYSNsYYwKIx2O2BW1jjLfYSNsYYwKIXXvEGGMCiI20jTEmgNg8bWOMCSAeH2hb0DbGeIulR4wxJoDYgUhjjAkgNtI2xpgA4vGYbUHbGOMxHo/aQaXdAWOMKU4iUuClAG1VFpEvRWSjiGwQkRYiUlVE5orIZve2is/2Q0Rki4hsEpEOPuWXicgad92bcgo5HAvaxhhPESn4UgBvALNUtT7QFNgADAbmqWo9YJ77GBFpCPQAGgGxwNsiEuy2MwboC9Rzl9iiPj8L2sYYTwkKlgIveRGRcKA18B6Aqh5T1YNAN2CCu9kEoLt7vxswUVXTVHUrsAVoJiI1gXBVXaaqCnzoU6fwz6+oFY0x5kxUmPSIiPQVkdU+S1+fps4HkoAPRORHEXlXRCoC0aq6B8C9jXK3rwXs9Kkf75bVcu/nLC8SOxBpjPGUwqSLVXUsMDaX1SHApcAjqrpCRN7ATYXktmt/u8ijvEhspG2M8ZRizGnHA/GqusJ9/CVOEE9wUx64t4k+29f2qR8D7HbLY/yUF4kFbWOMpxTX7BFV3QvsFJEL3aL2wHpgKtDbLesNxLn3pwI9RKSsiNTFOeC40k2hpIpIc3fWSC+fOoVm6RFjjKcU8xmRjwCfiEgo8BtwL85gd5KI9AF2ALcCqOo6EZmEE9gzgIdVNdNtpx8wHigPzHSXIhHnYObpk5nx5+ndgQlIhw+llXYXzBkovHL5U464c+ZsLnDMuf76egF3Jo6NtI0xnmLXHjHGmADi8ZhtQdsY4y32l2uMMSaA2EjbGGMCiOW0jTEmgFjQNsaYAOLxmG1B2xjjLTbSNsaYAOLxmG1B2xjjLTbSNsaYABJk87SNMSZweHygbUHbGOMtFrSNMSaAiN8/FOMdFrSNMZ5iI21jjAkgdiDSGGMCiE35M8aYAOLxmG1B2xjjLTbSNsaYQOLtmG1B2xjjLTbSNsaYAGKzR4wxJoB4O2Rb0DbGeIylR4wxJoB4PGafXUF72PBhLFq0kKpVqzI17hsAnhjQn61btwGQmppCpUrhfD35a5YuXcJrr79Geno6ZcqU4ckBT9G8eXMOHz5Mz7t7ZreZkLCXrl26Mgc69AIAABAtSURBVGTI0JP2N3bcWL766iuCg4MYOmQYrVq1AmDdunUMHTaEo0fTaN26NUOHDEVEOHbsGIOHDGLduvVUrlyZ1/7xGrVq1QJgypQpvPOfMQA89GA/unfvDkB8fDwDnhxAcvJBGjZsyIsvvERoaCiqyugXRrN48WLKly/H6FGjadiw0Wl7bQPV3oS9jBw5nN/3/46IcGP3m7mjx11s+t9GXnxxFGnH0ggJDmHQwCE0atSE3bt3cVuPmzj33PMAaNL4IoYMHg7A22PeYvqMaaSmprB44bJc9/nB+PeY+s0UgoKCeHLAIFo0vwqADRvW88xzT5OWlkbLq1ox4ImB2Z+LEc8MZ+PGDURERDD6+Zc45xznczFt+lTef38cAPfd9wBdOt8AwK7duxg2fBApyclcWL8Bz44cRZkyZVBV/vHayyxZ+h3lypVjxN+fpX79Bqft9S0NXh9po6qndclIz9QzZVm+bLn+8vMv2qlTJ7/rR40arW++8aZmpGfqL7+s0d279mhGeqZuWL9BW7Vq5bdO9+7ddfmy5SeVb9ywSbt26apHDv+h27Zu1/bt22va0WOakZ6pN990s65etVrTj2Xofff10fnzF2hGeqZ+9OFHOnz43zUjPVOnxk3VRx99VDPSM3Vf0u/arl073Zf0u/6+b7+2a9dOf9+3XzPSM/WRRx7VqXFTNSM9U4cP/7t+/NHHmpGeqfPmzdf77uuj6ccy9PvV3+vNN99S6q+/75J84MgZsfy6ebuuWPa9Jh84orvjk/Ta9tfqj9+v0bt79tIZ0+do8oEjOmPabO3R4w5NPnBEN6zbrLGxHf229d3i5frr5u3atGnTXPf34/drtHOnLpqUcFDXr9us11zTTvfvS9XkA0e0e/cb9b+Ll+nB/Ye1d+97s/f/7rgPdPCgoZp84Ih+8flk/etf/6bJB47ojm17tG3ba3THtj26c/tebdv2Gt25fa8mHziif+33sH7x+WRNPnBEBw8aqu+9Oz77ufTufa8e3H9Yv1u8XG+88aZSfw98l+KIOevXJ2hBl9Md/07HElTaXxol6fLLryAiorLfdarK7Nmz6NS5MwANGzQkKioKgAsuqEdaWhrHjh07oc627dvYv38/l112+UntzV8wn46dOhEaGkpMTAzn1j6XNWt+ISkpkUOHD3HxxZcgInS7oRvz5s1z6syfT/du3QC4/voOLF++HFVlyZIltGhxFZUrVyYiIoIWLa7iu+++Q1VZsWI511/fAYDu3U5sq9sN3RARmja9mNTUFJKSEovhVfSW6tUjs0eaFStWpE6d80lKSkREOHz4MACHDh0isnpkvm01aXIR1fPZbtHihVx3XQdCQ0OpdU4tasfUZt36tezbl8Thw4e5qElTRITOHbuwaNECABYvXkjnzl0BaNfuWlatWomqsnz5Uq5s1pyIiAjCw8O5sllzli1bgqqyavUq2rW7FoDOnbtmt7Vo8UI6d+yCiNCkyUWkpqayb19S0V68M1RQkBR4CURnVXokL99/v5pq1apR57w6J62bM2cODRo0IDQ09ITyGdOnExvb0e/PscSEBC5q2jT7cXSNaBISEgkJKUN0dPQJ5YmJCQAkJCZQo0ZNAEJCQqhUqRIHDx4kITGBmjVqZNepER1NQmICBw8epFKlcEJCnLcxOroGCW5biYkJ1PCpEx1dg4SERCIjowr70pw1du/exab/baRRoyY80f8pHnnsr7zx5muo/sl74yacsN1dd99OxYph9HvwYS655NIC7yMpKZHGjS/KfhwVFU1SYiIhISFERUWfWO5+ySYmJRId5byXISEhhIWFkZx80CmPrnFCncSkRJKTD1KpUqXsz0VWedb+/dXJ78smkHg9O1LkkbaI3JvHur4islpEVo8bN7aouyhR02dMp1OnzieVb96ymdde/wcjRzxz0roZM2fS2U8dcEbuOYmI/3J3kpL/OoVsS/Jqy+Of5lNw5MgRBg1+kif6P0VYWBhfTf6CJx5/kunfzKb/40/y3Cjn/a9ePZJvps7ik48+p/9jAxj+9BAOHTpU4P0U5r0kj/fS/WAUuK08PxcemyQnIgVeAtGppEdOjmIuVR2rqper6uUPPND3FHZRMjIyMvj222/pGNvxhPK9e/fy6KOP8MLoFzn33HNPWLdx40YyMzNo1Mj/wb3oGjXYu3dv9uOEvQlERUVSo0Y0CQkJJ5RHummYGtE12Lt3T3afUlNTiYioTI3oGuzxaWtvQgJRkVFUqVKF1NQUMjIynLYS9hLljqSjo3PsP2EvUVHeGU0Vp4yMdAYNHkBsbCfaXdMegGnTv+Ea9/617a9n/bq1AISGhlLZTbE1aNCQmJgYduzcXuB9RUVFk5Bw/H1JTEygemQk0VHHf3FllWelZKKjoklI3Ov2NYNDhw4RER7ht63I6pFUrlyF1NTU7M+Fb1t+60Ta5yKQ5Bm0ReSXXJY1QHRedQPJsmXLqFu37gnphJSUFPr1e4j+jz/BpZee/PN3Ri4j8yzXXHMNM2fM4NixY8THx7N9x3aaNLmIyMgoKlaoyM8//4SqEjc1jnbt2mXXmRIXB8CcObO58srmiAgtW7Zk6dIlJCcnk5yczNKlS2jZsiUiQrNmVzJnzmwApsQdb6vdNdcQNzUOVeXnn3+iUlglS434oao89/wz1KlTl7vuvDu7PDIykh9+WA3AqtUrqV3b+dI+cGA/mZmZAMTvimfnzh3UOiemwPtr3boNc+fO5tixY+zavYsdO3fQqGFjqlePpEKFCqxZ8wuqyvSZ02jTui0AV1/dhunTndlO8+d/yxWXX4GI0Lz5VaxYsYyUlBRSUlJYsWIZzZtfhYhw+WWXM3/+twBMn/4Nrd22Wl/dhukzp6GqrFnzC2FhYZ5KjYD3R9ri96dX1kqRBKADcCDnKmCpqp6T3w4yM/7MfQcl7MknB7By1UoOHjxItWrV+NvDf+Pmm29h6NAhXNS0KT1u75G97TvvjGHcu+Oyp3YBvDvuXapVqwbA9R2u450x/+H888/PXj9//nzWrVvLI4886rTxn3f4+uvJBAcHM3jwEFpf3RqAtWvXMnTYENLS0ri61dUMGzYcESEtLY1BgwexYcMGKkdE8Oqr/6B27doAfDX5K8aOdVJNDz74IDfdeBMAO3fu5MknB3AwOZkGDRrw8ksvZ0/5e/755/huiTO1a9Tzo2ncuPFpfHUL5/ChtNLuAgA//fQjDzx4LxdcUC/7P/HD/R6hYsUw/vHay2RmZhJaNpRBTw2lQYOGzJ//Le+MfZuQ4BCCgoPo+0A/Wl/dBoA333qd2bNnkrQvicjqkXTrdiN9H+jHosUL2bBhPQ89+FcA3v9gHFO/iSM4OJgn+j9Fy6ucqaDrN6zjmWedKX9XtWjJU08Ozv5cjBg5jE3/20R4eDijnn+JmFrOF8XUqVP4YMJ7ANx7Tx9u6OpOBd0V70z5S0nhwr9cyLPPjM7+XLz8ygssW76UcuXK8fTfn6FhgzNnKmh45fKnHEl//fX3Asec//u/agEXufML2u8BH6jqd37Wfaqqd+a3gzMpaJszx5kStM2ZpTiC9m+/FTxon39+/kFbRIKB1cAuVe0iIlWBz4E6wDbgNlU94G47BOgDZAKPqupst/wyYDxQHpgBPKZ5Bd885JkeUdU+/gK2uy7fgG2MMSVNCvGvgB4DNvg8HgzMU9V6wDz3MSLSEOgBNAJigbfdgA8wBugL1HOX2KI+v7NqnrYx5iwghVjya0okBugMvOtT3A3ImgM6AejuUz5RVdNUdSuwBWgmIjWBcFVd5o6uP/SpU2gWtI0xniJSmOX49GR3yTnd7Z/AQOBPn7JoVd0D4N5mHeGvBez02S7eLavl3s9ZXiR2co0xxlMKM+9cVccCfk8mEZEuQKKqfi8ibQu0az+7yKO8SCxoG2M8pRhn8rUEbhCRTkA5IFxEPgYSRKSmqu5xUx9Z14eIB2r71I8BdrvlMX7Ki8TSI8YYTymuedqqOkRVY1S1Ds4Bxvmq2hOYCvR2N+sNxLn3pwI9RKSsiNTFOeC40k2hpIpIc3F22sunTqHZSNsY4y2nf+b1i8AkEekD7ABuBVDVdSIyCVgPZAAPq2qmW6cfx6f8zXSXIslznnZxsHnaxh+bp238KY552vE7DxY45sTUrhxwJ9fYSNsY4ymBenp6QVlO2xhjAoiNtI0xnhKof9ygoGykbYwxAcRG2sYYT/F4StuCtjHGW7z2l3hysqBtjPEWb8dsC9rGGG/x+HFIC9rGGI/xeFLbgrYxxlO8HbItaBtjPMbjA20L2sYYj/F41LagbYzxFG+HbAvaxhiP8foFoyxoG2M8xeMx2649YowxgcRG2sYYT/H6SNuCtjHGY7wdtS1oG2M8xUbaxhgTSCxoG2NM4PD6pVlt9ogxxgQQG2kbYzzF6zltG2kbY0wAsZG2McZT7DR2Y4wJJN6O2Ra0jTHe4vGYbUHbGOMxHk+P2IFIY4wJIDbSNsZ4irfH2Ra0jTEeY7NHjDEmkHg7ZlvQNsZ4i8djth2INMZ4jBRiyasZkdoiskBENojIOhF5zC2vKiJzRWSze1vFp84QEdkiIptEpINP+WUissZd96acQg7HgrYxxmOKKWpDBjBAVRsAzYGHRaQhMBiYp6r1gHnuY9x1PYBGQCzwtogEu22NAfoC9dwltqjPzoK2McZTiitkq+oeVf3BvZ8KbABqAd2ACe5mE4Du7v1uwERVTVPVrcAWoJmI1ATCVXWZqirwoU+dQrOgbYzxFJHCLNJXRFb7LH39tyl1gEuAFUC0qu4BJ7ADUe5mtYCdPtXi3bJa7v2c5UViByKNMd5SiHSxqo4FxubdnIQBXwGPq2pKHulofys0j/IisZG2McbkQkTK4ATsT1R1sluc4KY8cG8T3fJ4oLZP9Rhgt1se46e8SCxoG2M8pTDpkbzbEQHeAzao6ms+q6YCvd37vYE4n/IeIlJWROriHHBc6aZQUkWkudtmL586hWbpEWOM8a8lcDewRkR+csuGAi8Ck0SkD7ADuBVAVdeJyCRgPc7Mk4dVNdOt1w8YD5QHZrpLkYhzMPP0ycz48/TuwASkw4fSSrsL5gwUXrn8KZ8bU5iYExwSFHDn4pz2oG2OE5G+7oEPY7LZ58IUhuW0S5bf6UTmrGefC1NgFrSNMSaAWNA2xpgAYkG7ZFne0vhjnwtTYHYg0hhjAoiNtI0xJoBY0DbGmABiQbuEiEise2H0LSIyuLT7Y0qfiLwvIokisra0+2IChwXtEuBeCP3fQEegIXCHe8F0c3YbzylcDN+cnSxol4xmwBZV/U1VjwETcS6Ybs5iqroY2F/a/TCBxYJ2ycjt4ujGGFMoFrRLRrFeBN0Yc/ayoF0ycrs4ujHGFIoF7ZKxCqgnInVFJBTnLzZPLeU+GWMCkAXtEqCqGcDfgNk4f9F5kqquK91emdImIp8By4ALRSTevai+MXmy09iNMSaA2EjbGGMCiAVtY4wJIBa0jTEmgFjQNsaYAGJB2xhjAogFbWOMCSAWtI0xJoD8Px4ZOOHKTyysAAAAAElFTkSuQmCC\n",
"text/plain": [
"
"
]
},
"metadata": {
"needs_background": "light"
},
"output_type": "display_data"
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"-----------------------------------------\n"
]
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAYoAAAEWCAYAAAB42tAoAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADt0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjByYzEsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy/xvVyzAAAgAElEQVR4nO3dd5gUVdbA4d+RDCIoIEoSVERAkgxJBVFWRRxEV8WwBlz9EANm1xxWdNddw4IREV2MoGIEVFCRIIgIokgWkTCCSpYgwgzn++PUMM3sTE8zTHd195z3efphurq66nQNU6fr1r3niqrinHPOFWafsANwzjmX3DxROOeci8oThXPOuag8UTjnnIvKE4VzzrmoPFE455yLyhOF2yMiMldEuoYdR7IQkTtEZGhI+x4mIg+Ese+SJiJ/EZFxxXyv/5+MM08UKUxElorI7yKyWUR+Dk4c+8Zzn6raXFUnxHMfuUSkgoj8U0SWB5/zexG5RUQkEfsvIJ6uIpIVuUxV/6Gql8dpfyIi14rIHBHZIiJZIvKmiLSIx/6KS0TuE5FX9mYbqvqqqp4cw77+Jzkm8v9kaeWJIvX1VNV9gdZAG+D2kOPZYyJStpCX3gS6AT2AqsBFQF9gUBxiEBFJtr+HQcB1wLXAAcARwLvAaSW9oyi/g7gLc98uRqrqjxR9AEuBP0U8/zcwJuJ5R2AqsAH4Fuga8doBwH+BlcB64N2I1zKBb4L3TQVa5t8nUAf4HTgg4rU2wBqgXPD8r8D8YPtjgUMi1lXgauB74McCPls3YBtQP9/yDkAOcHjwfALwT2A6sBF4L19M0Y7BBOBBYErwWQ4HLg1i3gQsAa4I1q0SrLMT2Bw86gD3Aa8E6zQMPtclwPLgWNwZsb9KwIvB8ZgP/A3IKuR32zj4nO2j/P6HAU8BY4J4vwQOi3h9ELAC+A2YCXSOeO0+YCTwSvD65UB74IvgWK0CngTKR7ynOfAxsA74BbgD6A5sB3YEx+TbYN1qwPPBdn4CHgDKBK/1CY75f4JtPRAs+zx4XYLXfg1+p7OBo7AvCTuC/W0GRuX/OwDKBHH9EByTmeT7P+SPYpxrwg7AH3vxy9v9D6Qe8B0wKHheF1iLfRvfBzgpeF4reH0M8DqwP1AOOD5YfnTwB9oh+KO7JNhPhQL2OR74v4h4HgYGBz+fASwGmgJlgbuAqRHranDSOQCoVMBnewiYWMjnXkbeCXxCcCI6CjuZv0XeibuoYzABO6E3D2Ish31bPyw4WR0PbAWODtbvSr4TOwUniuewpNAK+ANoGvmZgmNeLzgBFpYo+gHLivj9D8NOtO2D+F8FRkS8fiFQI3jtJuBnoGJE3DuC39M+QbxtscRaNvgs84Hrg/WrYif9m4CKwfMO+Y9BxL7fBZ4NficHYok893fWB8gG+gf7qsTuieIU7ARfPfg9NAUOjvjMD0T5O7gF+ztoEry3FVAj7L/VVH+EHoA/9uKXZ38gm7FvTgp8ClQPXrsVeDnf+mOxE//B2Dfj/QvY5jPAgHzLFpKXSCL/KC8Hxgc/C/bttUvw/EPgsoht7IOddA8JnitwYpTPNjTypJfvtWkE39Sxk/1DEa81w75xlol2DCLee38Rx/hd4Lrg567ElijqRbw+HTgv+HkJcErEa5fn317Ea3cC04qIbRgwNOJ5D2BBlPXXA60i4p5UxPavB94Jfj4fmFXIeruOQfC8NpYgK0UsOx/4LPi5D7A83zb6kJcoTgQWYUlrnwI+c7REsRDoFY+/t9L8SLY2WbfnzlDVqthJ7EigZrD8EOAcEdmQ+wCOw5JEfWCdqq4vYHuHADfle199rJklv5FAJxGpA3TBTpKTI7YzKGIb67BkUjfi/SuifK41QawFOTh4vaDtLMOuDGoS/RgUGIOInCoi00RkXbB+D/KOaax+jvh5K5DbwaBOvv1F+/xrKfzzx7IvROQmEZkvIhuDz1KN3T9L/s9+hIiMDjpG/Ab8I2L9+lhzTiwOwX4HqyKO+7PYlUWB+46kquOxZq+ngF9EZIiI7BfjvvckThcjTxRpQlUnYt+2HgkWrcC+TVePeFRR1YeC1w4QkeoFbGoF8GC+91VW1eEF7HMDMA7oDVwADNfga12wnSvybaeSqk6N3ESUj/QJ0EFE6kcuFJH22MlgfMTiyHUaYE0qa4o4Bv8Tg4hUwJquHgFqq2p14AMswRUVbyxWYU1OBcWd36dAPRHJKM6ORKQzdkXVG7tyrI6190f2GMv/eZ4BFgCNVXU/rK0/d/0VWJNcQfJvZwV2RVEz4rjvp6rNo7xn9w2qPq6qbbFmwSOwJqUi31dEnK6YPFGkl4HASSLSGrtJ2VNEThGRMiJSMejeWU9VV2FNQ0+LyP4iUk5EugTbeA7oJyIdgp5AVUTkNBGpWsg+XwMuBs4Kfs41GLhdRJoDiEg1ETkn1g+iqp9gJ8u3RKR58Bk6Yu3wz6jq9xGrXygizUSkMnA/MFJVc6Idg0J2Wx6oAKwGskXkVCCyy+YvQA0RqRbr58jnDeyY7C8idYFrClsx+HxPA8ODmMsH8Z8nIrfFsK+q2H2A1UBZEbkHKOpbeVXsxvZmETkSuDLitdHAQSJyfdBtuaqIdAhe+wVomNtrLPj/NQ54VET2E5F9ROQwETk+hrgRkXbB/79ywBasU0NOxL4OjfL2ocAAEWkc/P9tKSI1YtmvK5wnijSiqquBl4C7VXUF0Av7Vrga+6Z1C3m/84uwb94LsJvX1wfbmAH8H3bpvx67Id0nym7fx3ro/KKq30bE8g7wL2BE0IwxBzh1Dz/SWcBnwEfYvZhXsJ40/fOt9zJ2NfUzdqP12iCGoo7BblR1U/DeN7DPfkHw+XJfXwAMB5YETSoFNcdFcz+QBfyIXTGNxL55F+Za8ppgNmBNKmcCo2LY11jsy8AirDluG9GbugBuxj7zJuwLw+u5LwTH5iSgJ3acvwdOCF5+M/h3rYh8Hfx8MZZ452HHciSxNaWBJbTngvctw5rhcq+UnweaBcf/3QLe+xj2+xuHJb3nsZvlbi9IXkuBc6lHRCZgN1JDGR29N0TkSuxGd0zftJ0Li19ROJcgInKwiBwbNMU0wbqavhN2XM4VJW6JQkReEJFfRWROIa+LiDwuIotFZLaIHB2vWJxLEuWx3j+bsJvx72H3IZxLanFregpujm4GXlLVowp4vQfW1twDG9w1SFU75F/POedcuOJ2RaGqk7C+84XphSURVdVpQHURifVml3POuQQJsxhXXXbvhZEVLFuVf0UR6YvVeaFKlSptjzzyyIQE6JxzqWjHDti40R6VNq7iIP2ZWexco6q1irO9MBNFQaWiC2wHU9UhwBCAjIwMnTFjRjzjcs65lKIK33wDo0bB6NEwezaAUr++cHvH9zm17DgajX5qWXG3H2aiyGL3kan1sEqmzjnnirB1K3z6qSWG0aNh5UoQgZMy1jOr7c0c1OlQaj9+JyKnA6eDPFXsfYWZKN4HrhGREdjN7I3BiE7nnHMFWLECxoyxxPDpp7BtG1StCqecApmZ0EvfofrtV8Hq1ZB5V8HtNsUQt0QhIsOxQnU1xWYFuxcrFIaqDsZq6PTARv5uxeYBcM45F9i5E6ZPz7tq+DaofXDooXDFFdCzJ3TuDOXX/wL9+8Obb0Lr1pZNji65EQdxSxSqen4Rr+dOXOOccy7w22/w8ceWGMaMsYuDMmXguOPg4YftyqFJE2tm2iX3UuPBB+GWW6BcuRKNyacgdM65kC1ZYolh1CiYONF6Le2/P5x6qiWG7t3t+W6WLbM3XHMNZGTA8uVQIz71Dz1ROOdcgmVnw9SpeU1K8+fb8qZN4YYbLDl06gRlCzpD79wJzzwDtwVFhM86Cw4+OG5JAjxROOdcQqxfDx99ZInhww/tebly0LUr9OsHp50GhxU1k8bChXD55fD553YH+9lnLUnEmScK55yLA1U7r+eObZgyBXJyoFYt6NXLrhpOPtl6LcVk61a7UZGTA8OGwcUX57tRET+eKJxzroRs3w6TJuU1Kf0QTMraujXcfrslh3btYJ89KZ60aBE0bgyVK8PLL9vGDjooLvEXxhOFc87thV9/taak0aNh7FjYtAkqVoRu3eDmm61JqX60SW8Ls20bDBgA//qXXUFceKHd1Q6BJwrnnNsDqlYiI/eq4csvbVmdOnD++Ta24cQT7QKg2KZMgcsus7arSy+1bBMiTxTOOVeE33+Hzz7LSw4rgnKm7dvD3/9uTUqtW5fQLYMBA+Dee6FBA7tEOfnkot8TZ54onHOuACtX5iWGTz6xZFGlip2377sPevQo4VsFqpZpWre2UdYPPgj77luCOyg+TxTOOYcNT5g5My85fP21LW/Y0HqkZmbC8cdDhQolvON162zwxOGHw913W9tVz54lvJO944nCOVdqbd5sVwu55TJ+/tl6JB1zDDz0kCWHZs3i2At15Ei4+mpLFnffHaed7D1PFM65UmXp0ryrhs8+sy6t1apZh6LMTCubEcdBzmbVKiu98fbb0LYtjBsHrVrFeafF54nCOZfWcnJg2rS85DBnji0/4gi7FZCZCcceW+J19KJbudJuVP/rX3DjjYXU6kgeyR2dc84Vw8aNdh4eNcrGOKxda+fiLl3gscest+kRRyQ4qKVLLaD+/e0qYsWKAir9JSdPFM65tLBoUd5Vw+TJVnivRg3rnZSZaaWRqlULIbCcHHjqKbjjDrsBcs451l0qRZIEeKJwzqWoHTusNl5uee7vv7flLVrYlAyZmdChg83lEJr5863L1NSpdhPk2WcTXn6jJHiicM6ljDVr8splfPSRTfJTvryNhL7uOmtSatgw7CgDW7daW9fOnfDSS1aCI0FF/EqaJwrnXNJShblz85qUvvjCzrsHHWQtOD17Wk2lJBmXZhYssCnoKleGV1+13ky1a4cd1V7xROGcSyrbttksb7nJYelSW962rQ01yMy06aD3qAJrIvz+uw3ZfuQRePFFu4JIgvIbJcEThXMudKtWwQcfWGL4+GPYsgUqVYKTTrJ7wD16QN26YUcZxaRJdi/i++/zhnGnEU8UzrmEU4VZs/KuGr76ypbXrw+XXGLn2a5dLVkkvb//3a4kGjWyYd7duoUdUYnzROGcS4itW+HTT62H0pgxNuZMBDp2tPp3mZnWYyll7vfmFvHLyLBaTQMGWNXANOSJwjkXN8uXW1IYPRrGj7f7D1Wr2piGzExrUqpVK+wo99CaNZYYGjeGe+6xrlYhzxcRb54onHMlJifHmpFym5S+/daWH3YY9OtnyaFzZ+vSmnJU4c03rUbT+vU2Z0Qp4YnCObdXfvvNatqNHm03pFevtkFuxx0HDz9syaFJkxRqUirIypVw1VXw3nvW1PTJJ9CyZdhRJYwnCufcHvvhh7yrhokTbZT0/vtb5dWePa1pKYUqVBTt55+t7ezhh+H665O+iF9JK12f1jlXLNnZVoUit1zGggW2vFkza67PzIROndLs/LlkCbz/viWGo4+2Gy7Vq4cdVSjS6dfqnCtB69ZZmYzRo61sxoYNVoq7a1e48kq7f3vYYWFHGQc5OfD443DnnfaBzzvPhoKX0iQBniiccwFVu1LIbVKaMsXOmbVqwRlnWJPSSSdZr6W0NXcuXHYZfPmlZcLBg1OyiF9J80ThXCm2fbsNKh41ypLDkiW2vHVruP12a1Jq1y4Jy2XEw9atNim2CLz2ml1JpPQd+JLjicK5UubXX/PKZYwbB5s2QcWKNqD4llvsi3T9+mFHmUDz5kHTplbEb8QIK+KXcoM74ssThXNpThVmz85rUvryS1tWty5ccIFdNZx4op0nS5WtW20sxGOPwbBhcNFF8Kc/hR1VUvJE4Vwa+v13682Zmxyysmx5+/ZWmigz05qXSm3LyoQJ8H//B4sXwxVXwOmnhx1RUvNE4Vya+OmnvHIZn3xiyaJKFat0/fe/W7kMvy+LXUXcf7912Ro/Hk44IeyIkp4nCudS1M6dMHNm3tiGWbNsecOGeZWujz8eKlQINczkkVvEr317uOkmSxalrr2teOKaKESkOzAIKAMMVdWH8r1eDXgFaBDE8oiq/jeeMTmXyjZvtvkaRo+2q4dffrEeScccAw89ZMmhWbNS3KRUkNWrbZ7UJk3saqIUFPEraXFLFCJSBngKOAnIAr4SkfdVdV7EalcD81S1p4jUAhaKyKuquj1ecTmXapYuzbtqmDDBurRWq2blMjIzoXt3qFEj7CiTkCoMHw7XXmsFqf7+97AjSlnxvKJoDyxW1SUAIjIC6AVEJgoFqoqIAPsC64DsOMbkXNLLybG5oXNvRM+da8ubNIH+/S05HHusDRp2hcjKsuHjo0dDhw7w/PPQvHnYUaWseCaKusCKiOdZQId86zwJvA+sBKoC56rqzvwbEpG+QF+ABg0axCVY58K0YQOMHZtXgXXdOqub1KWLDRTOzLTpD1yMVq+2kYSPPWZXFGXKhB1RSotnoiiolVTzPT8F+AY4ETgM+FhEJqvqb7u9SXUIMAQgIyMj/zacS0mLFuU1KU2ebFcSNWpY83nPntZbqVq1sKNMIYsX28G84QZo0wZWrID99gs7qrQQz0SRBUSO76yHXTlEuhR4SFUVWCwiPwJHAtPjGJdzodixwxJCbpPS99/b8hYt4G9/s6uGDh38y+8ey86GgQPh7ruti9cFF0Dt2p4kSlA8E8VXQGMRaQT8BJwHXJBvneVAN2CyiNQGmgBL4hiTcwm1Zo1VXh092iqx/vabze524olWvfq00+CQQ8KOMoV99521zX31lQ2ae/ppSxKuRMUtUahqtohcA4zFuse+oKpzRaRf8PpgYAAwTES+w5qqblXVNfGKybl4U7Wbz7lF9r74wpYddBD07m1XDd26wb77hh1pGti61QbL7bOP1Wjq3dv7BceJWKtP6sjIyNAZM2aEHYZzu2zbZt1Wc5uUli2z5W3bWmLIzLR5b0pFBdZEmDPHejCJwKefWhG/mjXDjirpichMVc0oznt9ZLZzxbBqVV4F1o8/hi1boFIlm6/hzjutSalOnbCjTDNbtth9iIED4cUXrYhft25hR1UqeKJwLgaq8PXXeVcNuRe19evDJZfYVUPXrpYsXBx8+qkV8fvxR7jqKujVK+yIShVPFM4VYssWOz/llstYudJaOzp2hAcftC6sRx3lzeJxd/fd8MADNpBk4kQbXOISyhOFcxGWL7ekMGqUFRb94w+b+rN7d7tqOPVUn9MmYXbuzCtk9be/wX33+SVbSDxRuFItJwemT89rUpo925YfdphVgMjMhM6drUurS5Bff7XR1E2aWH2mU0+1hwuNJwpX6vz2m00BmlsuY/VqG+R23HHw8MPWpHTEEd6klHCq8OqrVul182YrA+6SgicKVyr88EPe2IZJk2yU9P7722Q+mZlwyin23IVkxQro188yd6dOMHSo1Ut3ScEThUtL2dkwZUpek9KCBba8WTMrBZSZaeejsv4XkBzWrrVf2KBBcPXVXsckyfifiUsb69ZZmYzRo61sxoYNVoq7a1frUXnaaXDooWFH6XZZtAjefx9uvtkm8F6xwnoOuKTjicKlLFWYPz/vqmHKFOsoc+CBcOaZdtVw0kl+7kk62dnw6KM221ylSjZwrnZt/0UlMU8ULqX88YfdY8hNDkuCEpKtW8Mdd1hyaNfOy2UkrW+/hb/+1UYvnnkmPPWUF/FLAZ4oXNL79Ve7xzlqlPVW2rwZKlaEP/3Jutf36GEjpF2S27rVSm6ULQsjR8JZZ4UdkYuRJwqXdFTti2fuVcP06basbl34y1/squHEE6Fy5bAjdTGZPdsm3ahcGd5804r4HXBA2FG5PeCJwiWF33+3kdCjRtnI6KwsW96+vY256tnTzi8+tiGFbN5sFRKfeAKGDYOLL7ay4C7leKJwofnpp7yrhk8/tWSx7742Bej999tg3IMOCjtKVywffwx9+8LSpXDNNXY/wqUsTxQuYXbutKqruclh1ixb3rAhXH65NSkdf7zNZulS2J13wj/+YSU4Jk+2Ie8upcWcKESkiqpuiWcwLv1s2gSffGJNSh98AL/8klfn7V//suTQtKk3KaWF3CJ+xx0Ht98O99xjvQ5cyisyUYjIMcBQYF+ggYi0Aq5Q1aviHZxLTT/+mHfVMGECbN8O1apZU1JmplVirVEj7Chdifn5Z2teatYsr83Qi/illViuKP4DnAK8D6Cq34qIF4R3u2Rnw7RplhhGjYJ582x5kybQv78lh2OPtVHSLo2o2kxzN95oXV87dgw7IhcnMTU9qeoK2b1tICc+4bhUsWHD7uUy1q2z7vFduthEZKedZvPMuDS1bJndrB43zpqahg61bwYuLcWSKFYEzU8qIuWBa4H58Q3LJaOFC/OalCZPtrkcata0K4bMTOutVK1a2FG6hNiwAb76Cp580ibu8KHwaS2WRNEPGATUBbKAcYDfnygFtm+Hzz/PSw7ff2/LW7SwEdGZmdChgxf6LDUWLrQifrfcYoNali+3/swu7cWSKJqo6l8iF4jIscCU+ITkwrR6tTUljR4NY8faJD8VKthI6OuvtyalQw4JO0qXUDt2wCOP2MjHKlXgkkus8qIniVIjlkTxBHB0DMtcClKFOXPyrhq++MKWHXQQ9O5tVw3duvk5odSaNQsuu8z+Pftsa2o68MCwo3IJVmiiEJFOwDFALRG5MeKl/QBvbEhh27ZZt9XcGd+WL7flbdta1/eePaFNG292LvW2brU67eXKwVtvwZ//HHZELiTRrijKY2MnygKRheJ/A86OZ1Cu5K1aZTWURo+26gpbt1qNtpNOgrvvtgqsdeqEHaVLCrNmWd32ypWtymurVj5PbClXaKJQ1YnARBEZpqrLEhiTKwE7d9rfe+7YhpkzbXmDBtCnjzUpde1q88Y4B9gw+ttvtzkiXnzRivh17Rp2VC4JxHKPYquIPAw0B3aNx1fVE+MWlSuWLVusXMbo0Xb1sGqVlcbo2NFK72RmwlFHebkMV4CPPoIrrrDpSK+7zpuZ3G5iSRSvAq8DmVhX2UuA1fEMysVu2bK8JqXx420GuKpVrUxGZqZVUqhVK+woXVK7/XZ46CErujVlCnTqFHZELsnEkihqqOrzInJdRHPUxHgH5gqWk2MT+eQ2KX33nS0/7DAb95SZCZ07Q/ny4cbpUkBOjg2C6drVhtXfdZeX7nUFiiVR7Aj+XSUipwErgXrxC8nlt3GjVUoYPdoqsK5ZY3/fxx1n3dszM+GII7xJycVo1Sq4+mpo3hwGDIBTTrGHc4WIJVE8ICLVgJuw8RP7AdfHNSrH9u0weLANhJ040Qrv7b+/9U7KzLS/a++I4vaIqs00d+ON1kfa54lwMSoyUajq6ODHjcAJsGtktoujBx+0is3Nmtnfdc+edlO6rE815Ypj6VKr1vjJJ9Y2OXSoXYY6F4NoA+7KAL2xGk8fqeocEckE7gAqAW0SE2Lps20bPPOMXTmMGhV2NC4tbNwIX38NTz9tvZt8NKXbA9H+tzwPXA7UAB4Xkf8CjwD/VtWYkoSIdBeRhSKyWERuK2SdriLyjYjM9ZvkZvhwq7l0vTfwub0xb571ZoK8In5e6dUVg6hqwS+IzAFaqupOEakIrAEOV9WfY9qwXZEsAk7Cqs5+BZyvqvMi1qkOTAW6q+pyETlQVX+Ntt2MjAydMWNGLCGkJFUrn5GTA7Nn+w1qVwzbt8O//203qqtWtYTh9ZlKPRGZqaoZxXlvtK8W21V1J4CqbgMWxZokAu2Bxaq6RFW3AyOAXvnWuQB4W1WXB/uJmiRKg4kT4dtv7WrCk4TbYzNmQLt2Vpflz3/2JOFKRLRbo0eKyOzgZwEOC54LoKrasoht1wVWRDzPAjrkW+cIoJyITMDqSQ1S1Zfyb0hE+gJ9ARo0aFDEblPbwIE2GdAFF4QdiUs5W7ZYd7iKFeG99+D008OOyKWJaImi6V5uu6Dvw/nbucoCbYFu2A3yL0Rkmqou2u1NqkOAIWBNT3sZV9L64QfrDnvnnV6Dye2Br7+2In5VqsA770DLllC9ethRuTRSaNOTqi6L9ohh21lA/Yjn9bDBevnX+UhVt6jqGmAS0GpPP0S6eOIJ6/565ZVhR+JSwm+/wVVXWX34V16xZV26eJJwJS6e3R++AhqLSKNgru3zgPfzrfMe0FlEyopIZaxpqlTOx/3bb/DCCzZZkJf7dkX64AMbWf3sszbQ5qyzwo7IpbG4Dd9S1WwRuQYYi0109IKqzhWRfsHrg1V1voh8BMwGdgJDVXVOvGJKZi+8YFWevUusK9Ktt1qvpmbNbL6IDvlv/TlXsgrtHrvbSiKVgAaqujD+IUWXjt1jc3JskOzBB8Pnn4cdjUtKqjbJSJkyVvhryhS44w4v4udiFq/usbkb7wl8A3wUPG8tIvmbkNxeGD0alizxqwlXiJ9+gjPOgHvvtecnnwx//7snCZcwsdyjuA8bE7EBQFW/ARrGL6TSZ+BAm3nujDPCjsQlFVV47jlrYho3zvpNOxeCWO5RZKvqRvHRX3HxzTcwYQI8/LAX/HMRfvwRLrsMPvvM5ot47jk4/PCwo3KlVCynpjkicgFQRkQaA9diZTdcCRg0yLq/X3ZZ2JG4pLJ5s9VwefZZuPxyr8/kQhXL/77+2HzZfwCvYeXGvTW9BPzyC7z2GvTp43NLOGDOHJvcHKBFCyvi17evJwkXulj+BzZR1TtVtV3wuCuo/eT20uDBVr+tf/+wI3Gh2r7dbk4ffTT85z/wa1DyrHLlcONyLhBLonhMRBaIyAARaR73iEqJP/6wOSd69IAmTcKOxoXmq69sZPV998E553gRP5eUYpnh7gQROQibxGiIiOwHvK6qD8Q9ujT2+uvW9ORdYkuxLVuge3cr7PX++zaNoXNJKKYBd7tWFmkB/A04V1XLxy2qKNJhwJ2qfYn84w9rlvYOZaXMjBnWzLTPPjbCskULqFYt7Khcmov3gLumInJfMJHRk1iPp3rF2ZkzkyfDrFk+50Sps3GjTUParl1eEb/jjvMk4ZJeLN1j/wsMB05W1fzVX10xDBwINWrAhReGHYlLmFGjoF8/+PlnuPlmOPvssCNyLmax3KPomIhASoslS+Ddd7EepOUAAB8fSURBVOH2233OiVLjllvgkUesiendd+2KwrkUUmiiEJE3VLW3iHzH7hMOxTrDnSvAk09aXberrgo7EhdXqlbtsWxZq820335W9bV8KLf2nNsr0a4orgv+zUxEIKXBpk3w/PPWC7Ju3bCjcXGTlWWzT7VsCQ8+CCedZA/nUlS0Ge5WBT9eVcDsdv59uBiGDbMJirxLbJraudNKbjRrBuPHw0EHhR2RcyUilgF3BX0VOrWkA0l3O3daXadOnaB9+7CjcSVuyRI48US7Yd2+PXz3nQ+5d2kj2j2KK7Erh0NFZHbES1WBKfEOLN2MGQM//JBXyselmS1bbFT10KHw1796v2eXVqLdo3gN+BD4J3BbxPJNqrourlGloYEDoX59+POfw47ElZjvvoP33oO77rIeTcuWeVc2l5aiNT2pqi4FrgY2RTwQkQPiH1r6mD3bmqyvucbnnEgLf/wB99xjo6sffzyviJ8nCZemirqiyARmYt1jI6+lFTg0jnGllUGD7Bxy+eVhR+L22rRpNnnIvHlw0UVW7bVGjbCjci6uCk0UqpoZ/NsoceGkn9Wr4dVX4dJL4QC/DkttW7bAaafZTFMffACnep8OVzrEUuvpWBGpEvx8oYg8JiIN4h9aenj2WWupuPbasCNxxfbll9ZtrUoVK8Uxd64nCVeqxNI99hlgq4i0wirHLgNejmtUaWL7dnjqKask3bRp2NG4PbZhg7UXduyYV8TvmGOgatVw43IuwWJJFNlqtch7AYNUdRDWRdYV4Y03rAacD7BLQe++awPnhg2z0hvnnBN2RM6FJpY+OJtE5HbgIqCziJQBysU3rNSnavc5mza1Uj8uhdx4o/3yWrWypqa2bcOOyLlQxZIozgUuAP6qqj8H9ycejm9YqW/KFPj6a5sX28depYDIIn49elhPpr/9Dcr5dyLnYprhTkRqA7m1kaer6q9xjSqKVJnh7uyzbexEVhZUrhx2NC6q5cut9EabNlbEz7k0FO8Z7noD04FzsHmzvxQRn3UlimXL4J13oG9fTxJJbedOePppaN4cJk6EOnXCjsi5pBRL09OdQLvcqwgRqQV8AoyMZ2Cp7Mknrbnp6qvDjsQVavFiq8k0ebKVAB8yBBo2DDsq55JSLIlin3xNTWuJrbdUqbR5Mzz3nDU91a8fdjSuUNu2waJF8N//wiWX+I0k56KIJVF8JCJjsXmzwW5ufxC/kFLbiy/Cxo3eJTYpffONFfG791446ihYuhQqVgw7KueSXpFXBqp6C/As0BJoBQxR1VvjHVgqyp1zokMHG6PlksS2bXDnnZCRAc88k1fEz5OEczGJNh9FY+AR4DDgO+BmVf0pUYGlog8/hO+/h+HDi17XJcjUqVbEb8ECa2J67DEvuuXcHop2RfECMBo4C6sg+0RCIkphAwfaXNhnnRV2JA6wIn49e8LWrfDRRzbK2pOEc3ss2j2Kqqr6XPDzQhH5OhEBpaq5c+GTT2wGOx+jFbIvvrD2vypVYPRoux/h9ZmcK7ZoVxQVRaSNiBwtIkcDlfI9L5KIdBeRhSKyWERui7JeOxHJSeXxGYMGWZN3375hR1KKrV9vXV6POQZeDupWdurkScK5vRTtimIV8FjE858jnitwYrQNBzWhngJOArKAr0TkfVWdV8B6/wLG7lnoyWPNGjsvXXyxz2ETmrfftoErq1fD7bfDueeGHZFzaSPaxEUn7OW22wOLVXUJgIiMwCrQzsu3Xn/gLfJKhKScIUOsY81114UdSSl1ww12g6h1a5tQqE2bsCNyLq3EcwbnusCKiOdZQIfIFUSkLnAmdnVSaKIQkb5AX4AGDZJrzqTcOSdOPtmqUrsEiSzil5kJBx4IN9/sN4ici4N4jrAuaKhr/gqEA4FbVTUn2oZUdYiqZqhqRq1atUoswJIwciSsXOkD7BJq6VKbDeruu+15t27W3ORJwrm4iGeiyAIii1jUA1bmWycDGCEiS4GzgadF5Iw4xlSiVK3F44gj4JRTwo6mFNi5E554wnoxTZ0KhxwSdkTOlQpFNj2JiAB/AQ5V1fuD+SgOUtXpRbz1K6CxiDQCfgLOw+a12EVVG0XsZxgwWlXf3bOPEJ5p0+Crr6zpaR+vfhVf338Pl15qE310724TfXiicC4hYjm9PQ10As4Pnm/CejNFparZwDVYb6b5wBuqOldE+olIv2LGm1QGDoTq1a23k4uz7dvhhx/gpZfshrUnCecSJpab2R1U9WgRmQWgqutFpHwsG1fVD8hXQFBVBxeybp9Ytpksli+Ht96yWTP33TfsaNLUrFlWxO+++2zOiKVLoUKFsKNyrtSJ5YpiRzDWQWHXfBQ74xpVCngquKa65ppw40hL27bZzel27eDZZ21sBHiScC4ksSSKx4F3gANF5EHgc+AfcY0qyW3ZYmMn/vxnSLLeuqnv88+hVSt46CFr05s3D5Ksp5tzpU2RTU+q+qqIzAS6YV1ez1DV+XGPLIm99BJs2OBdYkvc5s3Qqxfstx+MG2czzznnQhdLr6cGwFZgVOQyVV0ez8CSVe6cExkZVkbIlYDPP7f6TPvuC2PGWPdXv/HjXNKIpelpDFZufAzwKbAE+DCeQSWzceNg4UK7mvDZM/fS2rXWvNS5c14Rv44dPUk4l2RiaXpqEfk8qBx7RdwiSnIDB8LBB8M554QdSQpTtSHt11wD69bZCOvzzgs7KudcIfa41pOqfi0iKVvAb2/Mmwdjx8IDD0D5mDoIuwLdcIO137Vta5dorVqFHZFzLopY7lHcGPF0H+BoYHXcIkpijz/uc04UmypkZ1s9ptNPhzp1bBBK2XjWpXTOlYRY7lFUjXhUwO5V9IpnUMlo7Vrr7XThhd5bc4/9+KOV180t4nfiifC3v3mScC5FRP1LDQba7auqtyQonqT13HPw++8+58QeycmBJ5+EO+6AMmX8xo5zKarQRCEiZVU1O9ZpT9PZjh12vuvWzXpuuhgsWgR9+tj81aeeaiOs69cv8m3OueQT7YpiOnY/4hsReR94E9iS+6Kqvh3n2JLG22/DTz9ZwVIXo+xsWLYMXnkFLrjA+xI7l8JiaSQ+AFiLzUKn2OhsBUpNohg4EA4/HHr0CDuSJDdjhhXxGzDApvtbssTrMzmXBqIligODHk9zyEsQufLPVJe2pk2zxxNP+JwThfr9d7j3Xnj0UTjoILj2Wrvj70nCubQQ7dRXBtg3eFSN+Dn3USoMGgTVqllzuyvAxInQsiU8/DBcdhnMnevdwpxLM9GuKFap6v0JiyQJZWXBm29auQ6vKlGAzZuthG716vDpp9bt1TmXdqIlilJ/9/Gpp2ycmM85kc/kyXDssZY9P/zQJhWqUiXsqJxzcRKt6albwqJIQlu3Wo/OM86Ahg3DjiZJrFljIw67dMkr4te+vScJ59JcoVcUqroukYEkm1degfXrfc4JwC6r3ngD+ve3g3LvvV7Ez7lSxGsoFEDVusQefTQcd1zY0SSB666zbl/t2tm9iBYtin6Pcy5teKIowMcfw/z5Vtup1I4TU7Uh6eXLw5lnwiGH2OVVmTJhR+acSzAfGVCAgQNtOEDv3mFHEpIffrB6JXfdZc9POAFuusmThHOllCeKfBYssI48V11VCseL5eTAY49Z09LMmdCkSdgROeeSgDc95fP445Ygrihtc/gtWACXXALTp0PPnvDMM1C3bthROeeSgCeKCOvXw4svWg27Aw8MO5oE27kTVq6E4cPh3HNL8c0Z51x+nigiDB1q4ydKzZwT06dbEb8HH7Qifj/84HO8Ouf+h9+jCGRnWw/QE04oBVM4b90KN98MnTrZJdTqYGZbTxLOuQJ4ogi88w6sWFEKBth99pndrH70Ufi///Mifs65InnTU2DgQDjsMDjttLAjiaPNm2060urVLWF07Rp2RM65FOBXFFhT/dSpNo1CWg4VmDDBblbnFvGbPduThHMuZp4osDkn9tsPLr007EhK2OrVcP75duPllVdsWbt2ULlyuHE551JKqU8UP/1k9e7++leoWjXsaEqIKrz2GjRtahN+DxjgRfycc8VW6u9RPPOMDUju3z/sSEpQ//42mUbHjvD889b11TnniqlUJ4rff4fBg6FXLzj00LCj2Us7d1of3/Ll4eyz4fDDLWGk5U0X51wixbXpSUS6i8hCEVksIrcV8PpfRGR28JgqIgkdwfDqq7B2bRp0if3+e5uG9M477XnXrl7p1TlXYuKWKESkDPAUcCrQDDhfRPK3gfwIHK+qLYEBwJB4xZNf7pwTrVvbhG0pKTsbHnkEWraEb76xexLOOVfC4tn01B5YrKpLAERkBNALmJe7gqpOjVh/GlAvjvHs5tNPbazZsGEpWtZo/ny4+GKYMcPazp5+GurUCTsq51waimfTU11gRcTzrGBZYS4DPizoBRHpKyIzRGTG6txyE3tp4EAr/JfSnYF++QVef92GlXuScM7FSTwTRUHf07XAFUVOwBLFrQW9rqpDVDVDVTNqlUC5iUWLYMwYuPLKFJtzYto0uP12+7lpUyvi17t3il4SOedSRTwTRRZQP+J5PWBl/pVEpCUwFOilqmvjGM8uTzxhnYP69UvE3krAli1www1wzDF2Bz73qqpcuXDjcs6VCvFMFF8BjUWkkYiUB84D3o9cQUQaAG8DF6nqojjGssuGDfDf/9qA5YMOSsQe99Inn8BRR1lb2VVXeRE/51zCxe1mtqpmi8g1wFigDPCCqs4VkX7B64OBe4AawNNizSfZqpoRr5jAxp9t2ZIic05s3mw3UQ44ACZNgs6dw47IOVcKiWqBtw2SVkZGhs6YMaNY783OtnFoDRtanbykNX48HH+8jYOYOdNGVleqFHZUzrkUJiIzi/tFvFTVenrvPVi2LIkH2P3yi92c7tYtr4hf27aeJJxzoSpViWLgQGjUCHr2DDuSfFTh5ZftyiF3atILLgg7KuecA0pRraeZM+Hzz+Gxx5KwssXVV1t1wk6d7CaKj7B2ziWRUpMoBg2yeXv++tewIwns3Ak7dthAjnPPteRw1VVJmMWcc6VdqWh6WrUKRoywJFGtWtjRAAsX2s3q3CJ+xx/vlV6dc0mrVCSKZ56xHk+hzzmxYwc89BC0agVz5kCLFiEH5JxzRUv7pqdt2yxR9OxpXWNDM3cuXHQRzJoFf/6zTSyUEiP+nHOlXdonitdegzVrkqBLbJkysG4djBwJZ50VcjDOORe7tG56yp1zomVLm8sn4aZOhVuDOodHHgmLF3uScM6lnLROFJ99Bt99Z+U6ElpgdfNmuPZaOO44KwO+Zo0tL5v2F3DOuTSU1oli0CCoWTPBY9fGjbMifk8+CddcYzeta9ZMYADOOVey0vYr7uLFMGoU3HUXVKyYoJ1u3gx/+QvUqAGTJ8OxxyZox845Fz9pe0XxxBPW0nPllQnY2ccfQ06OjegbN87mr/Yk4ZxLE2mZKDZuhBdesArdBx8cxx2tWmU3p08+2SYUAmjTJoGXMM45F39pmSheeMFageI254QqDBtmRfzGjLFBdF7EzzmXptLuHkVODjz+uM3x07ZtnHZy5ZXw7LPWq2noUGjSJE47ci617dixg6ysLLZt2xZ2KKVGxYoVqVevHuVKcKrktEsU778PS5fCI4+U8IYji/hdcIENzujXD/ZJy4sy50pEVlYWVatWpWHDhkhC+6iXTqrK2rVrycrKolGjRiW23bQ7yw0aBIccAr16leBG58+3S5Q77rDnXbpYpVdPEs5FtW3bNmrUqOFJIkFEhBo1apT4FVxanelmzYKJE634X4mMbduxA/7xD2jdGhYssBvVzrk94kkiseJxvNOq6WnQIKhSBS67rAQ2NncuXHihdXU95xzrb1u7dgls2DnnUkvaXFH8/DMMHw6XXgrVq5fABsuWtX62b78Nb7zhScK5FPbOO+8gIixYsGDXsgkTJpCZmbnben369GHkyJGA3Yi/7bbbaNy4MUcddRTt27fnww8/3OtY/vnPf3L44YfTpEkTxo4dW+A65557Lq1bt6Z169Y0bNiQ1q1bA/Dxxx/Ttm1bWrRoQdu2bRk/fvxexxOLtLmiGDwYtm+3EkvFNnmyzVn9yCPWk2nRIq/P5FwaGD58OMcddxwjRozgvvvui+k9d999N6tWrWLOnDlUqFCBX375hYkTJ+5VHPPmzWPEiBHMnTuXlStX8qc//YlFixZRJt+kZa+//vqun2+66SaqBTOu1axZk1GjRlGnTh3mzJnDKaecwk8//bRXMcUiLc6CuXNOZGZC48bF2MCmTXDbbfD009Cokf1cs6YnCedK0PXXW0tuSWrd2ipER7N582amTJnCZ599xumnnx5Toti6dSvPPfccP/74IxUqVACgdu3a9O7de6/ife+99zjvvPOoUKECjRo14vDDD2f69Ol06tSpwPVVlTfeeGPXlUObiPukzZs3Z9u2bfzxxx+7YoyXtGh6GjECfv21mAPsPvwQmje3THP99VZu1ov4OZc23n33Xbp3784RRxzBAQccwNdff13kexYvXkyDBg3Yb7/9ilz3hhtu2NVMFPl46KGH/mfdn376ifr16+96Xq9evahXBJMnT6Z27do0LuAb8FtvvUWbNm3iniQgDa4oVO0mdvPm0K3bHr550ya4+GI48ECbO6Jjx7jE6Jwr+pt/vAwfPpzrg5nLzjvvPIYPH87RRx9daO+gPe019J///CfmdVV1j/Y3fPhwzj///P9ZPnfuXG699VbGjRsX8773RsonikmT7HL2uedinHNCFcaOhZNOgqpV4ZNPbFKhBGRl51xirV27lvHjxzNnzhxEhJycHESEf//739SoUYP169fvtv66deuoWbMmhx9+OMuXL2fTpk1UrVo16j5uuOEGPvvss/9Zft5553HbbbfttqxevXqsWLFi1/OsrCzq1KlT4Hazs7N5++23mTlz5m7Ls7KyOPPMM3nppZc47LDDosZWYlQ1pR5t27bVSGecoVqjhurWrVq0lSvtDaD64osxvME5tzfmzZsX6v4HDx6sffv23W1Zly5ddNKkSbpt2zZt2LDhrhiXLl2qDRo00A0bNqiq6i233KJ9+vTRP/74Q1VVV65cqS+//PJexTNnzhxt2bKlbtu2TZcsWaKNGjXS7OzsAtf98MMPtUuXLrstW79+vbZs2VJHjhwZdT8FHXdghhbzvJvS9yiWLLFOSv36QaVKUVZUtUqBTZvCRx/Bv//tRfycKwWGDx/OmWeeuduys846i9dee40KFSrwyiuvcOmll9K6dWvOPvtshg4duquH0QMPPECtWrVo1qwZRx11FGeccQa1atXaq3iaN29O7969adasGd27d+epp57a1ePp8ssvZ8aMGbvWHTFixP80Oz355JMsXryYAQMG7LoX8uuvv+5VTLEQLaDNLJllZGRo7sG84QabSG7ZMijk6s1ccQUMGWKlN4YOLWbXKOfcnpo/fz5NmzYNO4xSp6DjLiIzVTWjONtL2XsUv/0Gzz8P555bSJLIybESHBUr2gjrNm2gb1+vz+Scc3soZc+a//2vdVoqsEvs3Lk2w1xuEb/Onb3Sq3POFVNKnjlzcqz00jHHQLt2ES9s3w4DBtjVw+LF+V50zoUh1Zq3U108jndKJooxY+CHH2x83C7ffQcZGXDPPTY96fz5UED/Y+dc4lSsWJG1a9d6skgQDeajqFjC0zGn5D2KgQOhfn3YrTND+fKwdat1gzr99NBic87lqVevHllZWaxevTrsUEqN3BnuSlLKJYrff4eZM62Ha9kpE21Ku0cftSJ+CxdCvuJazrnwlCtXrkRnWnPhiGvTk4h0F5GFIrJYRG4r4HURkceD12eLyNFFbfOXX6B2pd+4dv6V0LUrvPsurFljL3qScM65Ehe3RCEiZYCngFOBZsD5ItIs32qnAo2DR1/gmaK2m712I/P3aU6FF4fAjTd6ET/nnIuzeF5RtAcWq+oSVd0OjADyz2TdC3gpGGE+DaguIgdH22hDllK5TjUr4vfoo1C5cnyid845B8T3HkVdYEXE8yygQwzr1AVWRa4kIn2xKw6APyp+P3eOV3oFoCawJuwgkoQfizx+LPL4scjTpLhvjGeiKKiWa/4+crGsg6oOAYYAiMiM4g5DTzd+LPL4scjjxyKPH4s8IjKj6LUKFs+mpyygfsTzesDKYqzjnHMuRPFMFF8BjUWkkYiUB84D3s+3zvvAxUHvp47ARlVdlX9DzjnnwhO3pidVzRaRa4CxQBngBVWdKyL9gtcHAx8APYDFwFbg0hg2PSROIaciPxZ5/Fjk8WORx49FnmIfi5QrM+6ccy6xUrLWk3POucTxROGccy6qpE0U8Sj/kapiOBZ/CY7BbBGZKiKtwogzEYo6FhHrtRORHBE5O5HxJVIsx0JEuorINyIyV0QmJjrGRInhb6SaiIwSkW+DYxHL/dCUIyIviMivIjKnkNeLd94s7mTb8XxgN79/AA4FygPfAs3yrdMD+BAbi9ER+DLsuEM8FscA+wc/n1qaj0XEeuOxzhJnhx13iP8vqgPzgAbB8wPDjjvEY3EH8K/g51rAOqB82LHH4Vh0AY4G5hTyerHOm8l6RRGX8h8pqshjoapTVXV98HQaNh4lHcXy/wKgP/AWEP9Z58MTy7G4AHhbVZcDqGq6Ho9YjoUCVUVEgH2xRJGd2DDjT1UnYZ+tMMU6byZroiistMeerpMO9vRzXoZ9Y0hHRR4LEakLnAkMTmBcYYjl/8URwP4iMkFEZorIxQmLLrFiORZPAk2xAb3fAdep6s7EhJdUinXeTNb5KEqs/EcaiPlzisgJWKI4Lq4RhSeWYzEQuFVVc+zLY9qK5ViUBdoC3YBKwBciMk1VF8U7uASL5VicAnwDnAgcBnwsIpNV9bd4B5dkinXeTNZE4eU/8sT0OUWkJTAUOFVV1yYotkSL5VhkACOCJFET6CEi2ar6bmJCTJhY/0bWqOoWYIuITAJaAemWKGI5FpcCD6k11C8WkR+BI4HpiQkxaRTrvJmsTU9e/iNPkcdCRBoAbwMXpeG3xUhFHgtVbaSqDVW1ITASuCoNkwTE9jfyHtBZRMqKSGWsevP8BMeZCLEci+XYlRUiUhurpLokoVEmh2KdN5PyikLjV/4j5cR4LO4BagBPB9+kszUNK2bGeCxKhViOharOF5GPgNnATmCoqhbYbTKVxfj/YgAwTES+w5pfblXVtCs/LiLDga5ATRHJAu4FysHenTe9hIdzzrmokrXpyTnnXJLwROGccy4qTxTOOeei8kThnHMuKk8UzjnnovJE4ZJSUPn1m4hHwyjrbi6B/Q0TkR+DfX0tIp2KsY2hItIs+PmOfK9N3dsYg+3kHpc5QTXU6kWs31pEepTEvl3p5d1jXVISkc2qum9JrxtlG8OA0ao6UkROBh5R1ZZ7sb29jqmo7YrIi8AiVX0wyvp9gAxVvaakY3Glh19RuJQgIvuKyKfBt/3vROR/qsaKyMEiMiniG3fnYPnJIvJF8N43RaSoE/gk4PDgvTcG25ojItcHy6qIyJhgboM5InJusHyCiGSIyENApSCOV4PXNgf/vh75DT+4kjlLRMqIyMMi8pXYPAFXxHBYviAo6CYi7cXmIpkV/NskGKV8P3BuEMu5QewvBPuZVdBxdO5/hF0/3R/+KOgB5GBF3L4B3sGqCOwXvFYTG1mae0W8Ofj3JuDO4OcyQNVg3UlAlWD5rcA9BexvGMHcFcA5wJdYQb3vgCpYaeq5QBvgLOC5iPdWC/6dgH173xVTxDq5MZ4JvBj8XB6r5FkJ6AvcFSyvAMwAGhUQ5+aIz/cm0D14vh9QNvj5T8Bbwc99gCcj3v8P4MLg5+pY3acqYf++/ZHcj6Qs4eEc8Luqts59IiLlgH+ISBesHEVdoDbwc8R7vgJeCNZ9V1W/EZHjgWbAlKC8SXnsm3hBHhaRu4DVWBXebsA7akX1EJG3gc7AR8AjIvIvrLlq8h58rg+Bx0WkAtAdmKSqvwfNXS0lb0a+akBj4Md8768kIt8ADYGZwMcR678oIo2xaqDlCtn/ycDpInJz8Lwi0ID0rAHlSognCpcq/oLNTNZWVXeIyFLsJLeLqk4KEslpwMsi8jCwHvhYVc+PYR+3qOrI3Cci8qeCVlLVRSLSFquZ808RGaeq98fyIVR1m4hMwMpenwsMz90d0F9Vxxaxid9VtbWIVANGA1cDj2O1jD5T1TODG/8TCnm/AGep6sJY4nUO/B6FSx3VgF+DJHECcEj+FUTkkGCd54DnsSkhpwHHikjuPYfKInJEjPucBJwRvKcK1mw0WUTqAFtV9RXgkWA/+e0IrmwKMgIrxtYZK2RH8O+Vue8RkSOCfRZIVTcC1wI3B++pBvwUvNwnYtVNWBNcrrFAfwkur0SkTWH7cC6XJwqXKl4FMkRkBnZ1saCAdboC34jILOw+wiBVXY2dOIeLyGwscRwZyw5V9Wvs3sV07J7FUFWdBbQApgdNQHcCDxTw9iHA7Nyb2fmMw+Y2/kRt6k6wuUTmAV+LyBzgWYq44g9i+RYrq/1v7OpmCnb/ItdnQLPcm9nYlUe5ILY5wXPnovLusc4556LyKwrnnHNReaJwzjkXlScK55xzUXmicM45F5UnCuecc1F5onDOOReVJwrnnHNR/T9cbAREBPhNogAAAABJRU5ErkJggg==\n",
"text/plain": [
"
"
]
},
"metadata": {
"needs_background": "light"
},
"output_type": "display_data"
}
],
"source": [
"df1 = es.importdata('train_split.csv')\n",
"es.info(df1)\n",
"es.box_hist_plot(df1,'emp_length')\n",
"df1 = es.drop_columns(df1,20,'member_id','pymnt_plan','batch_enrolled')\n",
"es.missingdata(df1)\n",
"es.extract_number(df1,'emp_length')\n",
"df1 = es.fillnulls(df1,'unknown','emp_title','title')\n",
"es.box_hist_plot(df1,'revol_util','tot_cur_bal','total_rev_hi_lim')\n",
"df1 = es.dropcolumns(df1,'tot_coll_amt')\n",
"df1 = es.fillnulls(df1,'mean','revol_util','tot_cur_bal','total_rev_hi_lim')\n",
"df2 = es.label_encode(df1)\n",
"es.corr_heatmap(df2,'interactive')\n",
"es.dropcolumns(df2,'funded_amnt_inv','funded_amnt','collections_12_mths_ex_med')\n",
"es.showbias(df1,'loan_status')\n",
"X = df2.drop('loan_status',axis=1)\n",
"y = df2['loan_status']\n",
"es.stat_models(y,X)\n",
"es.VIF(df2)\n",
"X_train,X_test,y_train,y_test = train_test_split(X,y,train_size=.7,random_state=101)\n",
"print('\\n *************** Random Forest ***************\\n')\n",
"y_pred, rfc = es.randomforest_classifier(X_train,y_train,X_test,y_test)\n",
"es.classification_result(y_test,y_pred)\n",
"es.roc_curve_graph(y_test, y_pred)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### menu based classification available and All models results"
]
},
{
"cell_type": "code",
"execution_count": 11,
"metadata": {
"ExecuteTime": {
"end_time": "2020-03-17T10:24:50.376260Z",
"start_time": "2020-03-17T10:23:45.601856Z"
}
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"########## MENU ##############\n",
"\n",
"1. Logisitic Regression \n",
"2. Random Forest \n",
"3. XGB Classifier \n",
"4. LGB CLassifier \n",
"5. Gradient Boosting Classifier \n",
"6. AdaBoost Classifier \n",
"99. For all models\n",
"\n",
"Input No, which you want:6\n",
"Predicting with Ada Boost CLassifier\n"
]
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAqQAAAGwCAYAAAB/6Xe5AAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADt0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjByYzEsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy/xvVyzAAAgAElEQVR4nO3deZwlVX3//9ebAWSVEUEFFAdRQUFBGBcUENyIJgZQlCgxoDFIiBDIDw3RaCbxq4IYTdRoMlGDcd+iokbAqKzKMgMzDKjgwhgVhAjKDrJ8fn9UtXO93O6+08tUL6/n43EfXX3q1KlTdatvv7tOVXWqCkmSJKkr63XdAUmSJM1vBlJJkiR1ykAqSZKkThlIJUmS1CkDqSRJkjplIJUkSVKnDKSSBkpyapJKsqjrvkiS5jYDqTQHJXljGyYryU4d9+XUnr6MvO5NckOSbyY5rMv+jSfJorbPp05g2bMGbHvva63bnKiRvqyr9U2lJEes6/3VlSRL2m3dr+u+SOvS+l13QNLUShLgT4ECAvwZcEKnnWp8CVjRTm8IPAr4Q2D/JI+vqjd21rPp9xFg9YDyFQPKJGneMZBKc8/zgB2AU4HnA4cneUNV/abTXsEXq+rU3oIkewLLgL9K8paqurOTnk2/U6vqrK47IUkzlUP20tzzZ+3Xfwc+DmwFHDxa5STPSXJuktuS3Jjki0l2HqP+EUk+n+THSe5IcnOS85P88dp2tKqWAzcCGwGbD1jXs5Oc3vbrziRXJTkpyRaj9O0xSf4zyc+T/CbJNe33jxlQd/Mkb0pyebsNtyT5UZJPt0GZJEuAq9tFDu8bbj9ibbd3LEnWT3J0kgva/tye5NIkr01yv8/qYd+HkUsOgGe23/duw1k99X7n+7427nc9ce+lDEke2+6365Pc1zvcnOSAJP+d5JdJ7mr38SlJFk5uj/3u8HaSlyVZ3u63a5K8K8kD2nrPai9ZuDnJr5J8NMmDB7S3un1tkeR97XF0Z5LvJjm2HX0Y1I+XJjknyU3te7Eqyd+MrH+UdTyw7ePqJHe327Ia+Lu26rd636ue5R/b/gwsS/J/7T79SZKlSR4+YH37tW0sSbJ7kq8m+XW7n85O8vRRtmlBkqPaY2pku36Y5IP9P09re+xKg3iGVJpDkjyUZhj8qqr6dpKbgb8CjgQ+PaD+IW35b9qv1wJ7A98BLhtlNR8Avguc09Z/MPAC4KNJdqqqN61Ff/cAtgR+UlX/1zfvNe26bgM+C1wP7Af8NfDCJM+oql/31H8y8D80wfa0to87A4cBByZ5dlUta+sGOB14erutHwTuAR7RruNcYDlwFrAQ+EtgJfDFni5O2XB7kg2ALwMHAFcCnwDuBPYH3gs8FXhF32LDvg+/Bv4eOAJ4ZDs9YvUUdH9H4ELgKpo/gDYGbm63683t+m4EvkLzHj6R5hKSFyTZq6punoI+HEMzGvBFmvfsecDxwJZJvgR8CvgqsJTmPf9jmj/Unj+grQ1pjqOF7XIbAi8G/hnYCfiL3spJ3gb8DfBLmvft1rbdtwEHJHluVd09YB3fpDn2z6TZX1cD/wQcRPPHw2iXebwIOAr4FvBtmp/dXYBX0/xcLK6qnw9YbjHwetYc79u32/WNJLtX1ZU927Rhu7+eA/y03a6bgUU0f9yeB/ygrTuRY1e6v6ry5cvXHHkBJ9JcO/o3PWXLgfuAR/fV3Qy4AbgbWNw3791tOwUs6pu344D1bgh8o21ru755p7btfBFY0r7exppf3j8F9ulb5pHAXTS/BHfum/f+tr2lPWUBvteWH9ZX/9C2/PvAem3ZE9qyLwzYlvWAB/V8v6ite+oE3o+zRpbt2fbfvnrqLWnrvRdY0FO+APhQO+/ASb4PZzUf+aP2tYCzRpk38h4u6ikb2S8FvG3AMvu3874NLOybd0Q7791D7seR+qf2lY/st5uAx/WUPwC4AriX5hh/Zt/7+/V2ud372lvdlp8HPKCnfEvgR+28fXvK92rL/hd4WE/5+jQhrYA3jLKO/wE2HbCtI9u03yj7YrvevvWUP6/d3g/0le/X8z4d0TfvNW35+/vK39aWn9a/rnbfbj2ZY9eXr0Gvzjvgy5evqXnRhLIftr+UtuspP6b9pXBSX/3D2vKPDGhrC5oza/cLpGOs/0Vt/T/pKz+15xdi/+t24GTuH1jeyOhB50E0QfWOkV+WwDPa+t8epW/n9oYJ1gTSTwyxXYuYfCAd+GrrrEdzdu1aYP0BbSyk+YPiM5N8H84aWecoy000kP6iP7S087/Qzt9llDYvBa4fcpuOGPQe9IShtwxY5s3tvP8cMO/wdt7hfeWr2/J9xujDf/SU/XtbduSA+o+l+Vn88Sjr2G2UbR3Zpv0mcLxdNmB9+7XtnTeg/gY0f7ws6ylbQPOzfzuw7Tjrm9Jj19f8fjlkL80dz6IZPj2jfnfI7hPAO4Ejkryp1gwf7tF+Pbu/oaq6KckK2usOeyXZnmbY/Nk0w34b91XZbpT+vbLam5qSLAAeThMMltAMqS+uqlv7+vbNAX37VZJLgX1phuRXjlW/p3xv4Ek0Q9zfpRlyf1mSR9I8AeA8ml/M03Hz1/41+k1Nj6UZbv8B8LejXKZ4B/C43oJJvA9TbWVV3TWgfC+asPOSJC8ZMH9DYOskD66qGybZh2UDyq5pvy4fMG/k5+N+11zSXLrx7QHlZ7Vfn9RTNtZxelWSnwE7JFlYPZeX0Axpj3ZJzJjay00OownIu9H8gbagp8pox+/99lFV3Z3kuraNETvT/EF6YVVd079Mnwkdu9IgBlJp7jiy/Xpqb2FV3ZDkyzTXix0IfK6dNXJj0HWjtPeL/oIkjwIuovkFdi7N9W830ZwJWkQTMO93I0e/qroX+AnwD0keS/ML9hjg7X19u3aUJkbKR26MWav6VXVvkmfRnEU7hOYsLcAtST5Cc8nDrfdvZlqM3FzzGNbc0DLIZiMTU/U+TJH7HSetB9P8jhlrm2DNpSOTcdOAsnuGmLfBgHm/bI/PfiPb2XtD3TDH3fasGXEYcX1V1SjLjOddwHFt22fQhOs72nlH0FzuMsivRym/h98NtCM/U4OuQ+231seuNBoDqTQHJNma5mYIgE8m+eQoVY9kTSAd+UX90FHqPmxA2V/R/BL67dnOnj68jCYIra0LaQLpU3rKRvr2MJprAftt01evt/4g/fWpql/R3PhyfJJH05wNfg3wWppfyuvqRoyRPn2hql405DLT8T4Uo/9OGOuO+NGC1U001+xuOYG+dGmrJAsGhNKRY6s34PYedz8a0Nb9jrvWhMJokocAxwKXA0+vqlv65r9sIu32GQmuw5xhn8ixKw3k4xikueFwmiHQ5TQ3Egx6/R/wnCQ7tMtc0n4dNCy/BbD7gPU8uv36+QHz7tfOkEaGC3s/jy5tv+43oG8L277dSXMj05j1+8ovGTSzqn5YVR+i2YZbac4kjxgJJgvut+DU+D5NCHhae8fyMCbyPtwLv71cYpBf0Txl4He09QcdC+O5AHhQkl0msGyX1qe5E7/ffu3XS3vKxjpOH01zScDVfcP14xnreHsUzc/JmQPC6MPb+ZM1cjw+Mcm2Q9Zdm2NXGshAKs0Nr26/Hl1Vrx70Av6N5sankbpfogkhL0+yuK+9Jfzu0OSI1e3X/XoLkxzQ0+7QkjwIeGX77Vk9sz5Gc/3hMe0v9l5vAR4IfKzn2sXzaR45s3f7KKvedRxCc73pVTTXiZJkh1GC0oNohrrv6Cn7Fc0Zre3XauOGVFX30NyhvA3wniT914KSZJskj+8pWt1+3a+v3ljvw8iw+GjbcRGwfZLn9ZX/LaMPA4/l3e3Xfx8UbJJsmuRpE2h3XXh7ep4hmmRLmv0A8B899T7cfv3bdpRipP4Cmuu216P5Y3BtjPU+rW6/7t37h0WSzWhusJr0qGd7Zvj9NNck/2v6nqWaZMORbZ3gsSsN5JC9NMuleQj5TsCqqrpojKoforl7/ZVJ/q6qbk0y8nzSc5P0Pod0V5qbf/bta+P9NAHys0k+T3Od2a7A7wGfoXnE0mgOypoHq4/c1PRCmqHni4F/HalYVauTHAf8C3BJks/QnOF9Js3NMt+nuaFnpH4lOZzmcT6fbp89+f12vxwE3EJz1/l97SK7AV9Ispxm+PMaYGuaM6MbsOaaUtr9dCGwT5KP0wTbe4HTqmpCN6YM8Ja2T0fRPEvymzT79iE01+c9g+a9+25bfyLvwzeAlwD/leS/aUL3T6rqo+38d9I8S/JL7bFwI82Zwh1o/ljYb202qKq+keREmuuCf9Cu82qa6wkfSfNentf2eSa5luaPksuTnEZzPBxCE7reX1XnjFSs5lm/76B5vuflST5H89zc59O8H+cBp6zl+r9Fc2f625PsSvMHEVX1/6rqF0k+BfwRsCLJmTR/OD6XZsRgBRM7m93v72meH/pC4KokX6H5GXoEzeOlXseaa9XX9tiVBuv6Nn9fvnxN7kXzMPICjh2i7plt3YN7yp5L84vzdppffl+iudP2VAY/h/TpNHcV/4rml9R5NKFvv7b+kr76I+30v26mOSv3OmCjUfr7vLbPv6J5LukPgXfQ95ionvo7AR+lCRV3t18/BuzUV+/hNM9aPJ/mZpW7gJ8BXwOeP6DdR9M8V/IGmrBQ9D3TcZT+nMWQj/ChOXv9CprgeCPN3dI/b/fvG4BHTPJ9WNBu84/bfXO/xzzR/FOFZTTh5gaaB8M/ctCxwJCPw6L5A+czNKH/NzR/WKyguTln8Xj7pW3jiEHrYoxHJPUsc7/3aYx9tLp9bUHzx9DP22PjezTXbmaU/v1Ru/9vaffdFTQh7H7H9cg6xtneP2730R30PCKsnbcJ8Faan4U7aZ7j+y80f9id1Vt3rG0drz80J6xeS/MzeitN0P4BzT8X6H+m8Vodu758DXqlaqI3+kmSNHek+dedVNWibnsizT9eQypJkqROGUglSZLUKQOpJEmSOuU1pJIkSeqUj32a5bbaaqtatGhR192QJEka1/Lly39ZVVv3lxtIZ7lFixaxbNmyrrshSZI0riQ/GVTuNaSSJEnqlIFUkiRJnXLIfpb73s9uYM/X/WfX3ZAkSbPU8lP+pOsueIZUkiRJ3TKQSpIkqVMGUkmSJHXKQCpJkqROGUglSZLUKQOpJEmSOmUglSRJUqcMpJIkSeqUgVSSJEmdMpBKkiSpUwZSSZIkdcpAKkmSpE4ZSHsk+fYQdY5LsskUre+IJNtORVuSJEmzlYG0R1U9fYhqxwFDB9IkC8aYfQRgIJUkSfOagbRHklvbr/slOSvJ55J8P8nH0ziWJkB+K8m3xmonyT8kuRDYK8mbk1yc5PIkS9u2DgEWAx9PsiLJxkn2THJ2kuVJzkiyzSjtH5lkWZJl99x+yzTsCUmSpHXHQDq6J9GcDX088CjgGVX1HuAaYP+q2n+MZTcFLq+qp1bVecD7qurJVbUrsDHwB1X1OWAZcFhV7Q7cA7wXOKSq9gQ+DLx1UONVtbSqFlfV4vU32XxqtlaSJKkj63fdgRnsoqr6GUCSFcAi4Lwhl70X+HzP9/sneT3NUP+WwBXAl/uW2QnYFfh6EoAFwLUT7bwkSdJsYSAd3V090/eydvvqzqq6FyDJRsD7gcVV9dMkS4CNBiwT4Iqq2muC/ZUkSZqVHLJfe7cAazNOPhI+f5lkM+CQUdq6Etg6yV4ASTZIsstkOytJkjTTGUjX3lLga2Pd1NSrqn4N/DuwCvgicHHP7FOBf20vCVhAE1ZPTrISWAEMc9e/JEnSrJaq6roPmoRNH7ZD7fyKv++6G5IkaZZafsqfrLN1JVleVYv7yz1DKkmSpE55U9MktM8ZfUBf8SuqalUX/ZEkSZqNDKSTUFVP7boPkiRJs51D9pIkSeqUgVSSJEmdMpBKkiSpUwZSSZIkdcpAKkmSpE4ZSCVJktQpH/s0yz3u4Q9m2Tr8DwuSJElTzTOkkiRJ6pSBVJIkSZ0ykEqSJKlTBlJJkiR1ykAqSZKkThlIJUmS1Ckf+zTL/ebaK/jff3hC192QJElTYPs3r+q6C53wDKkkSZI6ZSCVJElSpwykkiRJ6pSBVJIkSZ0ykEqSJKlTBlJJkiR1ykAqSZKkThlIJUmS1CkDqSRJkjplIJUkSVKnDKSSJEnqlIFUkiRJnZoRgTTJrRNc7rgkm0x1f8ZZ56lJDlmX65QkSZrLZkQgnYTjgHUaSCVJkjS1ZlQgTbJZkm8kuSTJqiQHtuWbJvlqkpVJLk9yaJJjgW2BbyX51ijtvTTJu9rpv0zy43Z6xyTntdN7Jjk7yfIkZyTZpqfO6W35uUl2HtD+W9ozpgP3Y5LVSU5OclH7enRb/sIkFya5NMn/JHlokvWS/CDJ1m2d9ZL8MMlWA9o9MsmyJMtuvO3etd/RkiRJM8iMCqTAncDBVbUHsD/wj0kC/B5wTVXtVlW7AqdX1XuAa4D9q2r/Udo7B9innd4HuCHJdsDewLlJNgDeCxxSVXsCHwbe2tZfChzTlp8AvL+34STvAB4CvLKq7htjm26uqqcA7wP+qS07D3haVT0J+BTw+raNjwGHtXWeA6ysql/2N1hVS6tqcVUt3nLTBWOsWpIkaeZbv+sO9AnwtiT7AvcB2wEPBVYB70xyMvCVqjp3mMaq6hftWdfNgUcAnwD2pQmn/wXsBOwKfL3JvSwArk2yGfB04LNtOcADepp+E3BhVR05RDc+2fP13e30w4FPt2djNwSubss/DHyJJri+CviPYbZTkiRpNptpZ0gPA7YG9qyq3YHrgI2q6ipgT5pg+vYkb16LNr8DvBK4EjiXJozuBZxPE4CvqKrd29cTqup5NPvl1z3lu1fV43ravBjYM8mWQ6y/Bky/F3hfVT0BeA2wEUBV/RS4LsmzgKcCX1uL7ZQkSZqVZlog3QK4vqruTrI/8EiAJNsCt1fVx4B3Anu09W8BNh+nzXNohtzPAS6luRTgrqq6iSakbp1kr3Y9GyTZpapuBq5O8pK2PEl262nzdOAk4Kvt2dexHNrz9Ts92/nzdvrwvvofpBm6/0xVeYGoJEma82bakP3HgS8nWQasAL7flj8BOCXJfcDdwJ+35UuBryW5dozrSM+lGa4/p6ruTfLTkXar6jftI5zek2QLmv3xT8AVNGdrP5Dkb4ENaK71XDnSaFV9tg2jpyV5QVXdMcr6H5DkQprw/7K2bAnN5QA/By4AduipfxrNUL3D9ZIkaV5IVY1fSxOSZDWweNCNSWMssxh4d1XtM25l4InbbVxfec2jJ9hDSZI0k2z/5lVdd2FaJVleVYv7y2faGdJ5LcmJNGd/DxuvriRJ0lwxZwJpOyz+gL7iV1TVtP+pkeQL/O6wO8BfV9WitWmnqk6iuTZVkiRp3pgzgbSqntrhug/uat2SJEmz3Uy7y16SJEnzjIFUkiRJnTKQSpIkqVMGUkmSJHXKQCpJkqROGUglSZLUqTnz2Kf5asNtdmH7Ny/ruhuSJEkT5hlSSZIkdcpAKkmSpE4ZSCVJktQpA6kkSZI6ZSCVJElSpwykkiRJ6pSPfZrlvn/993nGe5/RdTckad46/5jzu+6CNOt5hlSSJEmdMpBKkiSpUwZSSZIkdcpAKkmSpE4ZSCVJktQpA6kkSZI6ZSCVJElSpwykkiRJ6pSBVJIkSZ0ykEqSJKlTBlJJkiR1ykAqSZKkTs37QJpkSZITOlz/rV2tW5IkaSaY94F0OiRZ0HUfJEmSZos5GUiTbJrkq0lWJrk8yaFJVifZqp2/OMlZPYvsluSbSX6Q5M/GaHe9JO9PckWSryT57ySHtPNWJ3lzkvOAlyT5syQXt334fJJN2no7JPlOO+8tfe2/ri2/LMnfj9GPI5MsS7Ls7lvvnsSekiRJ6t6cDKTA7wHXVNVuVbUrcPo49Z8I/D6wF/DmJNuOUu9FwCLgCcCr2/q97qyqvavqU8B/VdWTq2o34HvAn7Z1/hn4QFU9GfjFyIJJngc8BngKsDuwZ5J9B3WiqpZW1eKqWrzBZhuMs2mSJEkz21wNpKuA5yQ5Ock+VXXTOPW/VFV3VNUvgW/RhMJB9gY+W1X3VdUv2rq9Pt0zvWuSc5OsAg4DdmnLnwF8sp3+aE/957WvS4FLgJ1pAqokSdKctn7XHZgOVXVVkj2BFwBvT3ImcA9rAvhG/YuM8/2IjLPq23qmTwUOqqqVSY4A9hun/QBvr6p/G2cdkiRJc8qcPEPaDrnfXlUfA94J7AGsBvZsq7y4b5EDk2yU5ME0wfHiUZo+D3hxey3pQ/ndkNlvc+DaJBvQnCEdcT7wR+10b/kZwKuSbNZuw3ZJHjJG+5IkSXPCnDxDSnON5ylJ7gPuBv4c2Bj4UJI3ABf21b8I+CqwPfCWqrpmlHY/DzwbuBy4qm1ntMsB3tTO/wnNJQSbt+V/CXwiyV+27QFQVWcmeRzwnSQAtwJ/DFw/5DZLkiTNSqkabXRagyTZrKpubc+mXgQ8o72etBObbb9Z7fa63bpavSTNe+cfc37XXZBmjSTLq2pxf/lcPUM6nb6SZCGwIc3Z1M7CqCRJ0lxgIB0gyRP43TvgAe6qqqdW1X4ddEmSJGnOMpAOUFWraJ4FKkmSpGk2J++ylyRJ0uxhIJUkSVKnDKSSJEnqlIFUkiRJnTKQSpIkqVMGUkmSJHXKxz7Ncjs/ZGf/S4gkSZrVPEMqSZKkThlIJUmS1CkDqSRJkjplIJUkSVKnDKSSJEnqlIFUkiRJnfKxT7PcLVdeydn7PrPrbkhS5555ztldd0HSBHmGVJIkSZ0ykEqSJKlTBlJJkiR1ykAqSZKkThlIJUmS1CkDqSRJkjplIJUkSVKnDKSSJEnqlIFUkiRJnTKQSpIkqVMGUkmSJHXKQDoNkixMcnQ7vW2Sz7XTuyd5QU+9I5K8r6t+SpIkzQQG0umxEDgaoKquqapD2vLdgReMupQkSdI8tH7XHZijTgJ2TLIC+AHwOGAP4B+AjZPsDby9d4EkWwP/CmzfFh1XVeevuy5LkiR1wzOk0+NE4EdVtTvwOoCq+g3wZuDTVbV7VX26b5l/Bt5dVU8GXgx8cLTGkxyZZFmSZTfdfff0bIEkSdI64hnSmeM5wOOTjHz/wCSbV9Ut/RWraimwFGCnzTevdddFSZKkqWcgnTnWA/aqqju67ogkSdK65JD99LgF2HwtygHOBF478k2S3aehX5IkSTOOgXQaVNUNwPlJLgdO6Zn1LZph+RVJDu1b7FhgcZLLknwXOGoddVeSJKlTDtlPk6p6+YCyG4En9xWf2s77JdAfUiVJkuY8z5BKkiSpUwZSSZIkdcpAKkmSpE4ZSCVJktQpA6kkSZI6ZSCVJElSpwykkiRJ6pSBVJIkSZ0ykEqSJKlTBlJJkiR1yn8dOsttvtNOPPOcs7vuhiRJ0oR5hlSSJEmdMpBKkiSpUwZSSZIkdcpAKkmSpE4ZSCVJktQpA6kkSZI65WOfZrnrf3YT7/v/vtx1N6RZ5bX/+MKuuyBJ6uEZUkmSJHXKQCpJkqROGUglSZLUKQOpJEmSOmUglSRJUqcMpJIkSeqUgVSSJEmdMpBKkiSpUwZSSZIkdcpAKkmSpE4ZSCVJktQpA6kkSZI6tU4DaZKFSY4ep86iJC8foq1FSS6fut6NL8mSJCeMMu/bYyz3274mWZzkPdPVR0mSpNlmXZ8hXQiMGUiBRcC4gXRtJFl/KtsbpKqePmS9ZVV17HT3R5IkabZY14H0JGDHJCuSnNK+Lk+yKsmhPXX2aesc355dPDfJJe1rqOCX5Igkn03yZeDMJJsm+XCSi5NcmuTAtt6FSXbpWe6sJHuO0fTj2zo/TnJsz3K3Dtmv/ZJ8pZ1ekuQjSc5MsjrJi5K8o90fpyfZYJg2JUmSZrOhAmmSHZM8oJ3eL8mxSRZOYH0nAj+qqt2BC4Ddgd2A5wCnJNmmrXNuVe1eVe8GrgeeW1V7AIcCazPcvRdweFU9C3gj8M2qejKwf7u+TYFPAS9tt20bYNuqWj5GmzsDBwBPAf5uCkLjjsDvAwcCHwO+VVVPAO5oy+8nyZFJliVZduvtN01y9ZIkSd0a9gzp54F7kzwa+BCwA/CJSa57b+CTVXVvVV0HnA08eUC9DYB/T7IK+Czw+LVYx9er6sZ2+nnAiUlWAGcBGwHbA58BXtLWeWm7jrF8taruqqpf0oTlh65Ffwb5WlXdDawCFgCnt+WraC5fuJ+qWlpVi6tq8WabbDHJ1UuSJHVr2Gsr76uqe5IcDPxTVb03yaWTXHeGrHc8cB3NmdT1gDvXYh239a3vxVV15f06ktyQ5Ik0Z2BfM06bd/VM38vw+3DM9qrqviR3V1W15fdNQduSJEkz3rBnSO9O8jLgcOArbdlEhqpvATZvp88BDk2yIMnWwL7ARX11ALYArq2q+4BX0JxFnIgzgGOSBCDJk3rmfQp4PbBFVa2aYPuSJEmagGED6Stprsd8a1VdnWQHmusd10pV3QCc3z4CaS/gMmAl8E3g9VX1i7bsniQrkxwPvB84PMkFwGP53bOea+MtNCH6snb9b+mZ9zngj2iG7yVJkrQOZc0I8TgVk42B7QcNeas72z/sMfX6w97VdTekWeW1//jCrrsgSfNSkuVVtbi/fNi77F8IrKC94SbJ7klOm9ouSpIkaT4a9qaZJTSPOToLoKpWtMP2nUtyAHByX/HVVXXwJNp8JfCXfcXnV9VfjLPcE4CP9hXfVVVPnWhfJEmS5rphA+k9VXVTez/QiOHG+qdZVZ1Bc8PSVLb5H8B/TGC5VTTPVpUkSdKQhg2kl7f/X35BkscAxwKj/u92SZIkaVjD3mV/DLALzTMzPwHcBBw3XZ2SJEnS/DHuGdIkC4DTquo5NP9+U5IkSZoy454hrap7gduT+D8qJUmSNOWGvYb0TmBVkq/T82D6qjp2WnolSZKkeWPYQPrV9iVJkiRNqaH/U5NmpsWLF9eyZcu67oYkSdK4RvtPTUOdIU1yNQOeO1pVj5qCvkmSJGkeG3bIvjfJbgS8BNhy6rsjSZKk+Wao55BW1Q09r59X1T8Bz5rmvkmSJGkeGHbIfo+eb9ejOWO6+bT0SJIkSfPKsEP2/9gzfQ9wNfDSqe+OJEmS5pthA+mfVtqrwsgAABZsSURBVNWPewuS7DAN/ZEkSdI8M9Rjn5JcUlV79JUtr6o9p61nGsp2D35QHf38Z3fdDWnC3vixz3XdBUnSOjKhxz4l2RnYBdgiyYt6Zj2Q5m57SZIkaVLGG7LfCfgDYCHwwp7yW4A/m65OSZIkaf4YM5BW1ZeALyXZq6q+s476JEmSpHlk2JuaLk3yFzTD978dqq+qV01LryRJkjRvDPVgfOCjwMOAA4CzgYfTDNtLkiRJkzJsIH10Vb0JuK2qPgL8PvCE6euWJEmS5othA+nd7ddfJ9kV2AJYNC09kiRJ0rwy7DWkS5M8CHgTcBqwGfDmaeuVJEmS5o2hAmlVfbCdPBt41PR1R5IkSfPNUEP2SR6a5ENJvtZ+//gkfzq9XZMkSdJ8MOw1pKcCZwDbtt9fBRw3HR2SJEnS/DJsIN2qqj4D3AdQVfcA905bryRJkjRvDBtIb0vyYKAAkjwNuGnaejUBSRYmOXqcOouSvHxd9alnvUcked9aLrM6yVbT1SdJkqSZYthA+lc0d9fvmOR84D+BY6atVxOzEBgzkNI8qmraAmmSYZ9aIEmSpNaYgTTJ9gBVdQnwTODpwGuAXarqsunv3lo5iSYwr0hySvu6PMmqJIf21NmnrXP8oEaSLEjyzna5y5Ic05b/9oxlksVJzmqnlyRZmuRMmqA+mkckOT3JlUn+rmd9X0yyPMkVSY6c/G6QJEmaXcY7o/dFYI92+tNV9eJp7s9knAjsWlW7J3kxcBSwG7AVcHGSc9o6J1TVH4zRzpHADsCTquqeJFsOse49gb2r6o4x6jwF2BW4ve3PV6tqGfCqqroxycZt+eer6oaxVtYG1yMBtthk4yG6J0mSNHONN2SfnunZ9PzRvYFPVtW9VXUdzfNTnzzkss8B/rW9cYuqunGIZU4bJ4wCfL2qbmjr/VfbR4Bjk6wELgAeATxmvJVV1dKqWlxVizfd6AFDdE+SJGnmGu8MaY0yPdNl/CpjLjtoW+9hTYDfqG/ebUO0299mJdmPJgDvVVW3t5cB9LctSZI0p413hnS3JDcnuQV4Yjt9c5Jbkty8Ljq4Fm4BNm+nzwEOba8H3RrYF7ior85ozgSOGrlBqWfIfjXN0DzARC5deG6SLduh+YOA84EtgF+1YXRn4GkTaFeSJGlWGzOQVtWCqnpgVW1eVeu30yPfP3BddXIY7XWX5ye5HNgLuAxYCXwTeH1V/aItuyfJytFuagI+CPwvcFk7lD5yV/7fA/+c5Fwm9gzW84CPAiuAz7fXj54OrJ/kMuAtNMP2kiRJ80qqZtNIvPpt9+AH1dHPf3bX3ZAm7I0f+1zXXZAkrSNJllfV4v7yYZ9DKkmSJE2Lefsg9yQHACf3FV9dVQfPpDYlSZLmunkbSKvqDOCMmd6mJEnSXOeQvSRJkjplIJUkSVKnDKSSJEnqlIFUkiRJnTKQSpIkqVMGUkmSJHVq3j72aa7YZocd/U83kiRpVvMMqSRJkjplIJUkSVKnDKSSJEnqlIFUkiRJnTKQSpIkqVMGUkmSJHXKxz7Ncndeewvfe+s3u+6Gptjj3visrrsgSdI64xlSSZIkdcpAKkmSpE4ZSCVJktQpA6kkSZI6ZSCVJElSpwykkiRJ6pSBVJIkSZ0ykEqSJKlTBlJJkiR1ykAqSZKkThlIJUmS1CkDqSRJkjo16wJpkoVJjh6nzqIkLx+irUVJLp+63o0vyQeTPH6cOgeNV0eSJGmumHWBFFgIjBlIgUXAuIF0bSRZfyraqapXV9V3x6l2EGAglSRJ88JsDKQnATsmWZHklPZ1eZJVSQ7tqbNPW+f49kzouUkuaV9PH2ZFSY5I8tkkXwbOTLJpkg8nuTjJpUkObOstSPLOtg+XJTlmjDbPSrK4nb41yVuTrExyQZKHtn37Q+CUtv87TmZnSZIkzXRTctZvHTsR2LWqdk/yYuAoYDdgK+DiJOe0dU6oqj8ASLIJ8NyqujPJY4BPAouHXN9ewBOr6sYkbwO+WVWvSrIQuCjJ/wB/AuwAPKmq7kmy5ZBtbwpcUFVvTPIO4M+q6v8lOQ34SlV9btBCSY4EjgTYZouHDLkqSZKkmWk2BtJeewOfrKp7geuSnA08Gbi5r94GwPuS7A7cCzx2Ldbx9aq6sZ1+HvCHSU5ov98I2B54DvCvVXUPQE/98fwG+Eo7vRx47jALVdVSYCnArtvtVEOuS5IkaUaa7YE0Q9Y7HriO5kzqesCda7GO2/rW9+KquvJ3OpEEmEgwvLuqRpa7l9n/fkiSJK212XgN6S3A5u30OcCh7TWcWwP7Ahf11QHYAri2qu4DXgEsmOC6zwCOaQMoSZ7Ulp8JHDVy49NaDNmPpr//kiRJc9asC6RVdQNwfvu4pr2Ay4CVwDeB11fVL9qye9qbhY4H3g8cnuQCmuH62wa3Pq630Az/X9au/y1t+QeB/23LVzL5O/w/BbyuvXHKm5okSdKcljUjxpqNdt1up/rs0R/ouhuaYo9747O67oIkSVMuyfKqut+N5bPuDKkkSZLmFm+iAZIcAJzcV3x1VR08iTa/QPMoqF5/XVVnTLRNSZKkuchACrQhcUqD4mTCrCRJ0nzikL0kSZI6ZSCVJElSpwykkiRJ6pSBVJIkSZ0ykEqSJKlTBlJJkiR1ysc+zXIbbbO5/9VHkiTNap4hlSRJUqcMpJIkSeqUgVSSJEmdMpBKkiSpUwZSSZIkdcpAKkmSpE752KdZ7pprrmHJkiVdd2POct9KkjT9PEMqSZKkThlIJUmS1CkDqSRJkjplIJUkSVKnDKSSJEnqlIFUkiRJnTKQSpIkqVMGUkmSJHXKQCpJkqROGUglSZLUKQOpJEmSOmUglSRJUqfmXSBNsjDJ0ePUWZTk5UO0tSjJ5VPXO0mSpPln3gVSYCEwZiAFFgHjBlJJkiRN3nwMpCcBOyZZkeSU9nV5klVJDu2ps09b5/j2TOi5SS5pX08fZkVjLZfk9e06VyY5qS17dJL/acsuSbLjlG+9JEnSDLN+1x3owInArlW1e5IXA0cBuwFbARcnOaetc0JV/QFAkk2A51bVnUkeA3wSWDzEuq4ftFyS5wMHAU+tqtuTbNnW/zhwUlV9IclGjPIHQ5IjgSMBtthii4nsA0mSpBljPgbSXnsDn6yqe4HrkpwNPBm4ua/eBsD7kuwO3As8dsj2R1vuOcB/VNXtAFV1Y5LNge2q6gtt2Z2jNVpVS4GlANtuu20N2RdJkqQZab4H0gxZ73jgOpozqesBo4bFIZcL0B8kh+2LJEnSnDIfryG9Bdi8nT4HODTJgiRbA/sCF/XVAdgCuLaq7gNeASwYcl2jLXcm8Kr2UgCSbFlVNwM/S3JQW/aAkfmSJElz2bwLpFV1A3B++7imvYDLgJXAN4HXV9Uv2rJ72puLjgfeDxye5AKaYffbhlzdwOWq6nTgNGBZkhXACW39VwDHJrkM+DbwsElvsCRJ0gyXKi9BnM223XbbOvLII7vuxpy1ZMmSrrsgSdKckWR5Vd3vxvB5d4ZUkiRJM8t8v6lpSiQ5ADi5r/jqqjq4i/5IkiTNJgbSKVBVZwBndN0PSZKk2cghe0mSJHXKQCpJkqROGUglSZLUKQOpJEmSOmUglSRJUqcMpJIkSeqU/6lpllu8eHEtW7as625IkiSNy//UJEmSpBnJQCpJkqROGUglSZLUKQOpJEmSOmUglSRJUqcMpJIkSeqUgVSSJEmdWr/rDmhyfvWr7/GZzz6l627MWS99yUVdd0GSpDnPM6SSJEnqlIFUkiRJnTKQSpIkqVMGUkmSJHXKQCpJkqROGUglSZLUKQOpJEmSOmUglSRJUqcMpJIkSeqUgVSSJEmdMpBKkiSpUwZSSZIkdcpAOklJ1u+6D5IkSbOZgRRIsijJ95N8JMllST6XZJMkq5Ns1dZZnOSsdnpJkqVJzgT+M8kRSb6U5PQkVyb5u562/yrJ5e3ruLZs0yRfTbKyLT+0Ld8zydlJlic5I8k2635vSJIkrVue3VtjJ+BPq+r8JB8Gjh6n/p7A3lV1R5IjgKcAuwK3Axcn+SpQwCuBpwIBLkxyNvAo4Jqq+n2AJFsk2QB4L3BgVf1fG1LfCryqf8VJjgSOBNhqqw0nudmSJEndMpCu8dOqOr+d/hhw7Dj1T6uqO3q+/3pV3QCQ5L+AvWkC6Req6rae8n2A04F3JjkZ+EpVnZtkV5pA+/UkAAuAawetuKqWAksBdtxx01rrLZUkSZpBDKRr9Ae7Au5hzWUNG/XNv22I5TNwRVVXJdkTeAHw9nbo/wvAFVW119p2XJIkaTbzGtI1tk8yEgZfBpwHrKYZmgd48TjLPzfJlkk2Bg4CzgfOAQ5qr0fdFDgYODfJtsDtVfUx4J3AHsCVwNYjfUiyQZJdpm7zJEmSZibPkK7xPeDwJP8G/AD4AHAR8KEkbwAuHGf584CPAo8GPlFVywCSnNq2A/DBqro0yQHAKUnuA+4G/ryqfpPkEOA9SbageW/+CbhiKjdSkiRppjGQrnFfVR3VV3Yu8Nj+ilW1ZMDy11fVawfUfRfwrr6yM4AzBtRdAey7Fn2WJEma9RyylyRJUqc8QwpU1WqaO9wnuvypwKlT1B1JkqR5xTOkkiRJ6pSBVJIkSZ0ykEqSJKlTBlJJkiR1ykAqSZKkThlIJUmS1CkDqSRJkjrlc0hnuQc96HG89CUXjV9RkiRphvIMqSRJkjplIJUkSVKnDKSSJEnqlIFUkiRJnTKQSpIkqVMGUkmSJHXKQCpJkqRO+RzSWe67v7qZ3T53RtfdmLNWHnJA112QJGnO8wypJEmSOmUglSRJUqcMpJIkSeqUgVSSJEmdMpBKkiSpUwZSSZIkdcpAKkmSpE4ZSCVJktQpA6kkSZI6ZSCVJElSpwykkiRJ6pSBVJIkSZ2atkCa5NtD1Plgkse302+YwPK3jjFvUZLL2+nFSd4zTt2Xj7e+AcstTHL0VNWTJEmaj6YtkFbV04eo8+qq+m777Rv65o27/Fr0ZVlVHTtGlUXAWgdSYCEwTNActp4kSdK8M51nSG9tv+6X5Kwkn0vy/SQfT5J23lnt2cuTgI2TrEjy8b7lN0vyjSSXJFmV5MAJ9GW/JF9pp5/ZrmdFkkuTbA6cBOzTlh0/Shu7JLmorXNZkse0y+3Ylp0yRl/76/22P23b70tyRDt9UpLvtut45yh9OTLJsiTL7rn5prXdHZIkSTPK+utoPU8CdgGuAc4HngGcNzKzqk5M8tqq2n3AsncCB1fVzUm2Ai5IclpV1QT7cgLwF1V1fpLN2vZPBE6oqj8YY7mjgH+uqo8n2RBY0C6360i/k6w/qK8D6u03aAVJtgQOBnauqkqycFC9qloKLAXYZMfHTnQ/SJIkzQjr6qami6rqZ1V1H7CCZoh8WAHeluQy4H+A7YCHTqIv5wPvSnIssLCq7hlyue8Ab0jy18Ajq+qOaejrzTQB+YNJXgTcvhbLSpIkzUrrKpDe1TN9L2t3ZvYwYGtgz/YM43XARhPtSFWdBLwa2JjmDObOQy73CeAPgTuAM5I8axJ9vYff3fcbteu4B3gK8HngIOD0YfomSZI0m62rIfth3J1kg6q6u698C+D6qro7yf7AIyezkiQ7VtUqYFWSvYCdgZ8Cm4+z3KOAH1fVe9rpJwIr+5Ybra+39NX7CfD4JA+gCaPPBs5rLyHYpKr+O8kFwA8ns62SJEmzwUwKpEuBy5JcUlWH9ZR/HPhykmU0w/3fn+R6jmvD4r3Ad4GvAfcB9yRZCZxaVe8esNyhwB8nuRv4BfAPVXVjkvPbx0t9DTh5UF+r6obeelX1uiSfAS4DfgBc2q5jc+BLSTaiGf4feIOVJEnSXJKJ3xukmWCTHR9bjzn5vV13Y85aecgBXXdBkqQ5I8nyqlrcX+5/apIkSVKnZtKQ/YQkeQLw0b7iu6rqqRNs7wCaofdeV1fVwRNpT5IkSWOb9YG0vUFp0PNLJ9reGcAZU9WeJEmSxuaQvSRJkjplIJUkSVKnDKSSJEnqlIFUkiRJnTKQSpIkqVOz/i77+e7xD3ogy3x4uyRJmsU8QypJkqROGUglSZLUKQOpJEmSOpWq6roPmoQktwBXdt2PWWAr4Jddd2KGcx8Nx/00HPfTcNxPw3E/jW+27KNHVtXW/YXe1DT7XVlVi7vuxEyXZJn7aWzuo+G4n4bjfhqO+2k47qfxzfZ95JC9JEmSOmUglSRJUqcMpLPf0q47MEu4n8bnPhqO+2k47qfhuJ+G434a36zeR97UJEmSpE55hlSSJEmdMpBKkiSpUwbSGSTJ7yW5MskPk5w4YH6SvKedf1mSPcZbNsmWSb6e5Aft1wetq+2ZLhPdT0kekeRbSb6X5Iokf9mzzJIkP0+yon29YF1u03SY5PG0Osmqdl8s6ymfU8fTJI6lnXqOlRVJbk5yXDtvPh5LOyf5TpK7kpwwzLJz7ViCie8nP5vuN3+s42lefDbBpI6n2fn5VFW+ZsALWAD8CHgUsCGwEnh8X50XAF8DAjwNuHC8ZYF3ACe20ycCJ3e9rR3up22APdrpzYGrevbTEuCErrdvJuyndt5qYKsB7c6Z42my+6ivnV/QPOx5vh5LDwGeDLy1d9v9bBp6P/nZNMR+aufN+c+mqdhPfe3Mis8nz5DOHE8BflhVP66q3wCfAg7sq3Mg8J/VuABYmGSbcZY9EPhIO/0R4KDp3pBpNuH9VFXXVtUlAFV1C/A9YLt12fl1aDLH01jm0vE0Vfvo2cCPquon09/lToy7n6rq+qq6GLh7LZadS8cSTGI/+dk09PE0Fo+nwWbN55OBdObYDvhpz/c/4/4fSKPVGWvZh1bVtdB86NH8RTWbTWY//VaSRcCTgAt7il/bDst+eA4M90x2PxVwZpLlSY7sqTOXjqcpOZaAPwI+2Vc2346liSw7l44lmNx++i0/m8Y1Hz6bYIqOJ2bR55OBdObIgLL+Z3KNVmeYZeeKyeynZmayGfB54Liqurkt/gCwI7A7cC3wj5Pvaqcmu5+eUVV7AM8H/iLJvlPZuRliKo6lDYE/BD7bM38+HkvTsexsM+lt9bNpKPPhswmm5niaVZ9PBtKZ42fAI3q+fzhwzZB1xlr2upEhxvbr9VPY5y5MZj+RZAOaD/yPV9V/jVSoquuq6t6qug/4d5rhktlsUvupqka+Xg98gTX7Yy4dT5PaR63nA5dU1XUjBfP0WJrIsnPpWILJ7Sc/m4Y0Tz6bYJL7qTWrPp8MpDPHxcBjkuzQ/lXzR8BpfXVOA/4kjacBN7VDE2MtexpweDt9OPCl6d6QaTbh/ZQkwIeA71XVu3oX6Lsu8GDg8unbhHViMvtp0ySbAyTZFHgea/bHXDqeJvMzN+Jl9A2HzdNjaSLLzqVjCSaxn/xsGno/zZfPJpjcz92I2fX51PVdVb7WvGju6L2K5s66N7ZlRwFHtdMB/qWdvwpYPNaybfmDgW8AP2i/btn1dna1n4C9aYY8LgNWtK8XtPM+2ta9jOaHfpuut7PD/fQomjs6VwJXzOXjaZI/c5sANwBb9LU5H4+lh9Gc0bkZ+HU7/cDRlp2Lx9Jk9pOfTUPvp3nz2TSZ/dTOm3WfT/7rUEmSJHXKIXtJkiR1ykAqSZKkThlIJUmS1CkDqSRJkjplIJUkSVKnDKSSJEnqlIFUkiRJnfr/AW32BOlhzBrwAAAAAElFTkSuQmCC\n",
"text/plain": [
"
"
]
},
"metadata": {
"needs_background": "light"
},
"output_type": "display_data"
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"\n",
"Model used: AdaBoostClassifier(algorithm='SAMME.R', base_estimator=None, learning_rate=1.0,\n",
" n_estimators=100, random_state=None) \n",
" Done.\n",
"-----------------------------------------\n",
"************* Model Results *************\n",
"-----------------------------------------\n",
"F1 Score : 0.6576365174253705\n",
"Report:\n",
" precision recall f1-score support\n",
"\n",
" 0 0.76 0.87 0.81 14622\n",
" 1 0.23 0.12 0.16 4578\n",
"\n",
" accuracy 0.69 19200\n",
" macro avg 0.50 0.50 0.49 19200\n",
"weighted avg 0.63 0.69 0.66 19200\n",
"\n"
]
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAW0AAAENCAYAAADE9TR4AAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADt0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjByYzEsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy/xvVyzAAAgAElEQVR4nO3dd3wVVfrH8c+ThCaQBEIoElz1BypFBQtFFFFUUFHctWEDFURx3bUvxQauBV2VRVAUFFERkQUErIggunQQC4LigiKEklBDAKXE8/tjJuEmuamEMuP3zWte994z55w5d2547rlnzsyYcw4REQmGmEPdABERKT4FbRGRAFHQFhEJEAVtEZEAUdAWEQkQBW0RkQBR0A4RM/u7mS01s1/NzJnZXQdhmyvNbOWB3s4fgf+ZzTjU7ZDDm4J2KZjZCWY22My+M7MMM9ttZmvN7AMz62ZmFQ9BmzoDg4DfgH8D/YG5B7sdhwP/i8T5yzmF5HstIl+//dxm27KoR6QocYe6AUFjZg8Dj+B94c0FXge2A7WAtsArQE/gtIPctI7Zj865tQdxu+0O4rZKai9wC/BZ3hVmFg9c5ec5XP4fNAR2HupGyOHtcPljDQQz64vXg10NXOmcmxclT0fg3oPdNuBIgIMcsHHOrTiY2yuh94G/mFmSc25TnnXXAUcA7wJ/Pugti8I598OhboMc/jQ8UkxmdjTQD9gDXBQtYAM4594HOkQpf5WZfeEPp/xqZovNrI+ZVYiSd6W/HGFm/zKzVWa2y8yWm1kvM7OIvP3MzAHn+K+zf+677Hb7r0cW8L5mZOeNSDMz62pms81sg5n9ZmarzWyKmV0dra1R6q1gZr3N7Fsz22lm28zsv2Z2VZS8OW30n48xs43+dhf6X4SlMRyoANwQZd0teF++H0craGbHmdkAf/sb/P3/i5kNM7OUPHlHsq83/0jkZ2Bmbf08N/qvbzSzDv5+z4jc93nHtM3sGDPbamabzexPebZZ2cy+N7MsMzu7pDtGgks97eK7CSgHjHHOfVdYRufcrsjXZvYE0AfYCIzGG065EHgCaG9m5zvn9uSpphzwCV4P+iO8n/GXAQOAing9foAZ/uONwJ8i0vfH4357fwbGAhlAHeB04ErgncIKm1l5YApwNvAD8AJer/YK4B0za+qc6xul6J+A+cBPwJtAdeBqYJKZneecyzfMUYSpwEqgO944f3b7TgWa4e2r3wso+xfgNrxgPBvYDTT267rEzE5zzq3x8070H7sCn7PvM8HffqQr8L7UPwJeAo4uqPHOuZ/NrDvwH+BtM2vjnNvrr34ROAHo55z7vKA6JIScc1qKsQDTAAd0L2G5Vn65VUDtiPQ44D1/Xd88ZVb66R8ClSLSawJb/aVcnjIzvI8z3/aP9usaWUD78pUDNgGpwBFR8teI0taVedL6RLQ/Lk/7s9/bGVHa6IBH8tTVPruuEuzz7G3EAQ/6z1tFrH8JyAKOwgvCDi/4RdZRF6gQpe4L/LJD86S3jVZPxPob/fW/Ax0KyOOAGVHSX/TXPem/7uK//gyIOdT/N7Qc3EXDI8VXx39MLWG5m/3Hx5xz67MTnddjuhfvP3H3Asr+3Tn3a0SZdGASkAAcX8J2lNQevOCUi3NuYzHK3owXVO5x+3qG2e3/p/8y2nv+BXgsz/am4H3hNS9es/MZgfc+bgFvWAG4FpjinFtVUCHn3BqX5xeTn/4JsATvy6Q0Jjnnog7JFOIe4Bugl5ndgRfENwDXOecK+qUgIaWgXXzZ48glvZbtKf7j9LwrnHM/4n0JHGNmiXlWZzjnlkepb7X/WK2E7SiJt/B6v0vM7El/DDahOAXNrCpQH1jroh9Yy94PzaKs+9o5l++LAu89l+r9Ou/A7IfAVf6Mkc5AVbzx7gL54/rXm9mn/pj23ohjBSfi9cRLY35JCzjnfsMbJtoBDMYbauriDvJBZzk8KGgXX/Z/kJRCc+WXHezWFbB+XZ582bYWkD+75xpbwnaUxN3AXXhBojfe+OtGM5tkZvWLKFvc95v3SwoKf8/787c6HKgMXIPX416PNzRVmOfwxtUb4Y3PP4s3Bt4f7xdB+VK2ZX3RWaL6EfjWf74U73iH/AEpaBffTP+xpPOSM/zH2gWsr5MnX1nL/vlc0EHnfMHTOZflnBvknDsZb/755XhT4y4FPo424yXCoX6/0XwIrMEb324BvBY5bJOXmdUE/g58BxzvnLveOdfLOdfPOdcPyDdsUgKlvetIb+AMvIPZjfGOG8gfkIJ28b2GN857uZk1KixjnqD2lf/YNkq++ng995+dcwX1MvfXFv+xXpTtxwPHFVbYOZfunJvgnLsKb2jj/4AmheTPBFYAdc2sQZQs2WcoLipG28uEP+QyAm9fO+DVIooci/d/4xP//eTwp/sdG6VM9rBOmf8CMrMzgEeBZXj7fhnQ38zOLOttyeFPQbuYnHMr8eZplwc+MLOoZzyaWfZ0rmwj/McHzSw5Il8s8AzeZ1BUECk1P+j8ALSO/LLxt/8cUCkyvz+/ul3kXHA/vRzeFDwo+qy9EXjHAP7lbye7jhrAQxF5Dqbn8U6iae+KPiFopf94Zp72V8Ebaon2qyX75J2j9rOduZhZNeBtvC+Fzs65NLzx7b140wCTynJ7cvjTPO0ScM49YWZxeKexLzCz2cBC9p3G3gZo4Kdll5ltZk8D/wC+M7NxeGPFF+L1mmYC/zrATf8X3hfDLDP7D971Sc7Bmwv+DXByRN5KwKfASjObhzd+WxE4H+8068nOue+L2N4zeO+vE/CNmX2Id/DsSrxpf08752YWUr7M+bNeJhaZ0cu73szG4B20/NrMPsEbqz8fb999DTTNU2wZ3hBMZzPbjTfjxQFvOud+2Y+mj8D7Ivi7c+5rv33fmNm9wBC8X4CX7kf9EjSHes5hEBe84DUYb8xzG96JF+vwetjdiD6/tzNegM7E+4+/BHgAqBgl70ryzH2OWNcPLxi0zZM+gyjztCPWd/O3uQvvYNjLQFLecniB/B/+e1nlt3UD3nVWbgPKF6eteIG+r7+PfvXf90zgmih5j6aEc8mL+HxW+vXFFSNvQfO0j8A7yWi5vw9W450klG+fRZQ5HW8+fwbesYScz4l987RvLKQtueZpA3/z0yYVkH+Cv/7uQ/1/QsvBW8z/8EVEJAA0pi0iEiAK2iIiAaKgLSISIAraIiIBcsCn/LW1h3WkU/KZvEUn9El+8YmVrOhchStJzJnhHt3v7R1s6mmLiASIgraIhIqZFXspRl0jzCzdzL6LSPuXmf1g3l2Z3s2+Qqd/16Vfzexrf3kposyp5t2tarmZPZ99xrF/BvI7fvo88+6QVSgFbREJFYu1Yi/FMJL8tw+cCjRxzp2Ed/XFyLG+Fc65pv5yW0T6UKAH3hnTDSLq7AZscc7VBwYCTxXVIAVtEQkVs+IvRXHOfQFszpP2idt3lci5FHG5ZjOrA8Q75+Y472zGN/BuHQjepR5e95+PA/Jd9ycvBW0RCZcSRG0z62HezZuzlx4l3NrN5L5A3DFm9pWZfW5mZ/lpdcl9x6tU9t1Eoy7+jU38L4IMvEslFEgXjBKRUClODzqbc24YMKx027EH8K62+JaftA44yjm3yb959EQza8y+u17l2nR2NYWsi0pBW0RCxWIO/Cw+M+sKdATa+UMeOO+eorv851+a2Qq869WnknsIJYV9d8JKxbvWfap/BdEE8gzH5KXhEREJl7Ic1I5avXUAegGXOud2RqQnZ19/3cyOxTvg+JNzbh2QaWYt/fHqLng36AaYDHT1n18BTHdFXMVPPW0RCZWYMuxpm9nbeHedqmFmqXjX0u8DVACm+scM5/ozRdoAj5rZXrybVtzmnMvuNffEm4lSCW8MPHsc/FXgTTNbjtfD7lxUmxS0RSRcynB0xDl3TZTkqHeacs6NB8YXsG4hUW7T55z7De/mIMWmoC0ioXIwxrQPJQVtEQmVUg5VB4aCtoiES8ijtoK2iIRKTPFOTw8sBW0RCRf1tEVEgiPkMVtBW0TCpTiXXA0yBW0RCZdwx2wFbREJF83TFhEJEAVtEZEA0Zi2iEiQhPzapQraIhIq6mmLiARIyGO2graIhIsORIqIBIiCtohIkIR8fERBW0RCJeQxW0FbRMJFs0dERIJE87RFRIIjJibcUVtBW0RCxcIdsxW0RSRkNKYtIhIcIY/ZCtoiEi46uUZEJEhC3tVW0BaRUImJVdAWEQkO9bRFRIIj5DFbQVtEwkUHIkVEgiTcMVtBW0TCJSY23KdEKmiLSKhoTFtEJEhCHrUVtEUkVMJ+IDLcgz8i8odjVvyl6LpshJmlm9l3EWnVzWyqmf3Pf6wWsa6PmS03s2Vm1j4i/VQzW+yve978OzWYWQUze8dPn2dmRxfVJgVtEQmXsozaMBLokCetNzDNOdcAmOa/xswaAZ2Bxn6ZF80s1i8zFOgBNPCX7Dq7AVucc/WBgcBTRTVIQVtEQiUm1oq9FMU59wWwOU9yJ+B1//nrwGUR6WOcc7uccz8Dy4HmZlYHiHfOzXHOOeCNPGWy6xoHtLMi7pemoC0i4VK2Pe1oajnn1gH4jzX99LrA6oh8qX5aXf953vRcZZxze4EMIKmwjStoi0iolCRmm1kPM1sYsfTYn01HSXOFpBdWpkChnz3yj1cvo1XH49iavoObTnwBgNuevoAzLjmePbuzWLtiM0/dNJHtGb9x3rUn0fn+1jlljz2pFj1OeYnl36wnrlwsdw65mKZtj8b97njlgWl8MWEpAG2vbMyN/c7BOVjxzXoeu25cvnYcd0odeo/8CxUqxTH3w/8x+M4PAShXPpY+b/yF4089koxNv/Lo1WNZ/8tWANp3acoND54NwJuPfc6UN74GoPbRiTw85iriq1fix0VreeKGCezdkwXA3wZdRMuLGvDbzj0MuPFd/vfVOgCat6/PHYMuIjbW+OCVRYx+6r8HYncH0qP/fISZs76gWrXqvPP2eACW/fgDAwY8zq7du4iLjaPXP/rQuPGJrF27hqs6/4WjjvoTACc2OYk+vR8EYM+ePTz9rydZtGghFhPD7bfdwbnnnpdve6+NfJXJ700kJiaG++7tRauWZwDw/fdL6f/Ph9m1axetzziTe+/5B2bG7t27eaT/g/zww/ckJCTwxGNPceSRXkft/Q8mM2LEcABuvvkWOl58KQBr1q7hgQd7sS0jg+NPaMij/R6nXLlyOOd49rmnmTV7JhUrVuSRhx7lhBMaHtgdfJCVZPaIc24YMKyEm0gzszrOuXX+0Ee6n54K1IvIlwKs9dNToqRHlkk1szgggfzDMbmEvqf98civ+EeHN3OlLZy6gpuavEC3k19k9Y+buLbPWQB8OvpbujcbSvdmQ3n8hvGsX7mV5d+sB+D6B9qwNX0HNxz/PF0bDeGbz1cCULd+da7r04Y7Wr/CTU2GMOSuj6K24+6hl/BMj8lc12AQKQ2SaN6hAQAXdTuF7Vt+47oGgxg3cDY9njofgKrVKtH1kbb0bDGM25q/TNdH2lIlsSIAtz51AeMGzub64waxfctvXNTtFABaXNiAlAZJXNdgEM/2mMzdQy8BICbGuPOFjvS68E26NhrCudecyJ8aJpfhXg62jh0v5fl/v5grbfDgf9O9+62MHjWWW3v05Pkh/85ZV7duCqNHjWX0qLE5ARtgxGvDqV69OuPHTWbsmAmccsqp+bb1008rmDp1Cu+8PZ7nB73IU08/QVaW94U74OnH6dvnISaMm8yq1auYPWcWAJMmv0t81XjeHf8e13a+nsEvDAIgIyOD4a+8zGsjRjHytbcY/srLbNu2DYAhQ/7NtZ2vZ8L494ivGs+kye8CMHv2TFatXsWEcZPp2/shBjz9eBnuycPEgR8emQx09Z93BSZFpHf2Z4Qcg3fAcb4/hJJpZi398eouecpk13UFMN0f9y5QkUHbzE4ws17+NJVB/vPAfDV/+99fyNz8a660hVNXkJX1OwBL56aSnBKfr1y7a05i2tuLc15fdPMpvPXkFwA458jYtBOAjrecxsQX5rF9628AbN2wI19d1WtXoXJ8BZbO9Ya7przxNWdedgIArTs15OPXvR705+OWcmq7YwE4vX19Fk5dQeaWX9m+9TcWTl2RE+hPOfcYPh/n9fI/fv1rzrysoV/XCTm98aXzUqmSWJHqtatwQvMU1izfzLqft7B3TxbTxyymdacTSrYjQ+yUZqcSH5/7b8DM2LHD+yy3b99Oco2iv+QmvzeJG7t2A7w7gicmVsuX5/MvZnD++e0pX748dY+sS72UeixZ+h0bN25gx44dnHTiyZgZF1/Ykc8//wyAL76YwcUXe1/A5557HgsWzMc5x9y5s2nRvCUJCQnEx8fTonlL5syZhXOOBQsX5PTyL774kpy6Pv9iBhdf2BEz48QTTyIzM5ONGzeUcs8dnsp4yt/bwBzgeDNLNbNuwADgfDP7H3C+/xrn3BJgLLAU+Bj4q3Muy6+qJ/AK3sHJFUB27+5VIMnMlgP34M9EKUyhwyNm1gu4BhgDzPeTU4C3zWyMc25A0W/78HbRzafw2TuL86Wfc3UTHuw0GoAqCV4P9+Z/tqNp26NZu2Izg+74gC3pO6h3nHfMYPDM7sTGGiP7fcb8Kctz1ZVcN54NqdtyXm9I3UZy3Xh/XVU2rM4AICvrd7Zn7CIh6QivzOr8ZRKSjmD71t9yvnQ2pGaQXLfqvu34dUWWidxGdnqjFpG/1iSve+6+n7/deTuDnn8O537n1eGv56xbu3YN191wNZUrV6HnrX+lWbNTyMz0PquXXn6BLxctJKVuCvff14ekpNzHlDZsSKdJk5NyXtesWYsN6enExcVRs2at3OkbvF/d6RvSqVWzNgBxcXFUqVKFjIytXnqt2rnKpG9IJyNjK1WrViUuLi5Xevb2o5WpUYwvpaCwMrz2iHPumgJWtSsg/+NAvp8vzrmFQJMo6b8BV5akTUW9u27A6c65Ac65Uf4yAGjur4sqcnB/LYtK0p6D6vq+bcjam8XUt77Nld6weQq7du7h5yXeH3psXAw16yXw3axV9Dj1JZbMSaXnM+1z1qU0qM5dbUfw6DX/4f5XOuUE+RxRvtFzfgBF+bp3zhVQpqD0ouoqIF0KNH7Cf7jnrvv44L0p3H3Xffzz8f4A1KiRzHuTP+atN9/h7jvv5cGH+7B9+3aysrJIT0/j5JOaMuqNMZx44skMev65fPVG2+9mFv3z8D+3AteVoC4rpC4L2WXxDvzoyKFVVND+HTgySnodf11UzrlhzrnTnHOnHckp+9O+A6Z9l6a06ng8j103Pt+6czs3yTU0krFpJ7/u2M1/3/0egBn/+Y4Gp3i7ZUPqNmZN+oGsvb+zfuVWVi3bRN0G1XPVtyF1W64hmOSUeDau3bZvXb0EAGJjY6iSUIFtm3/10/OWySRj406qJFYk1u9NJKcksHFtpl9XRk5dkWUitxGZLgV7/4P3OOccrzN1XrsLWLrEOyGufPnyJCYkAtCwYSNSUlJYtfoXEhISqVixIm3bngtAu3bn88Oy7/PVW7NmLdLS1ue8Tk9Po0ZyMrVq1iI9PS1XevaQTK2atUhL98rs3buX7du3kxCfELWu5BrJJCZWIzMzk7179+arK2qZ5PD0ssE7EFncJYiKCtp3AdPM7CMzG+YvH+OdBXTngW/egdG8fX2u6XUmfS99i12/7sm1zsxoe2Vjpo/JPWQy571lNG17NACntjuWX5Z6vfCZE7+n6TnHAJCQdAT1jkti3U9bcpXdvH47OzN35wxJtO/SlFmTfgBg9uQf6NC1KQBnX9GIRdN/BmDBlOWcfkF9qiRWpEpiRU6/oD4L/GGXrz77mbOvaARAh65NmTXpe7+uZbTv4tXVqEUKOzJ+Y/P67SxbsIaUBtWpfXQiceViObfzicye/MN+7sVwS05OZtGihQAsWDifevWOAmDLls05Bw5T16SyevUq6h6Zgplx1pln82V2mQXzOPaYY/PV26bN2UydOoXdu3ezZu0aVq1eReNGTahRI5kjjjiCxYu/xTnHBx+9z9lt2gJw1lln88EH7wEwffqnnH7a6ZgZLVuewbx5c9i2bRvbtm1j3rw5tGx5BmbGaaeexvTpnwLwwQfv0cavq81ZZ/PBR+/jnGPx4m+pUqVKqIZGwPs/XNwliKyon8lmFoM3HFIX78d5KrAgYoC9UG3t4UP6O/yh0VfQtO0xJNQ4gi1p23ntkc+4rs9ZlKsQxzb/YOLSuak819P7T9H07KPpMeB8bm81PFc9tY5KoO+bl1MlsSJbN+zkqZveJd0fJ7792Q4071Cf37Mcox7/nOnveL2yV77qSfdmQwE4/tQj6T3yz5SvVI75H/2PQX/7AIDyFeLo++ZfaNCsDts2/8qjnf/Dup+9oH/hTc24vm8bAN58/As+HvkVAHWOqcbDY64kvnol/vfVOh6/fjx7dnsfx51DLqZ5hwbs2rmHp256l2VfejOLWlzYgDv+fSExsTF8NGIRo5744sDs8GKavKXPId1+pAce7M2XixaydetWkqpXp0ePnvzpqKN59rmnycrKonyF8vS6vy8NGzZi+vRPeWnYi8TFxhETG0OPW3rS5ixvWua6dWt5pN+DZG7PJDGxGo881J/atevw+Rcz+P77pdx26+2AN8tk8nuTiI2N5Z6776f1GWcCsPT7JfR/1Jvyd0ar1tx/X2/MjF27dvFIvwdY9uMy4uPjefyxp0ip63UAJk+eyGuvvwrATTd249JLvBPtUtekelP+tm3j+OOO59H+T1C+fHmcczz9ryeZM3c2FStW5OGH+tOoYeODvcsLFJ9Yab8j6d+uGl3smDN47LWBi9xFBu39daiDthyeDqegLYePsgjad14zptgxZ9DbnQMXtEN/co2I/MEEdKy6uBS0RSRUAjpUXWwK2iISKkE9wFhcCtoiEi4aHhERCY6Qd7QVtEUkXMryNPbDkYK2iISKxrRFRALEwt3RVtAWkXBRT1tEJEgUtEVEgkPDIyIiAaLZIyIiAaIxbRGRAAl5zFbQFpGQ0WnsIiLBoeEREZEAsVgFbRGRwFBPW0QkQIJ6l/XiUtAWkXAJd8xW0BaRcNHwiIhIgGh4REQkQBS0RUQCRMMjIiIBEvKYraAtIuGioC0iEiAaHhERCZAYHYgUEQmOkHe0FbRFJFw0PCIiEiAhj9mE+2ZqIvKHYyX4V2g9Zseb2dcRyzYzu8vM+pnZmoj0iyLK9DGz5Wa2zMzaR6SfamaL/XXP2378HFDQFpFQMSv+Uhjn3DLnXFPnXFPgVGAn8K6/emD2Oufch952rRHQGWgMdABeNLNYP/9QoAfQwF86lPb9KWiLSKjExFixlxJoB6xwzv1SSJ5OwBjn3C7n3M/AcqC5mdUB4p1zc5xzDngDuKzU76+0BUVEDkcl6WmbWQ8zWxix9Cig2s7A2xGv7zCzb81shJlV89PqAqsj8qT6aXX953nTS0VBW0TCpQRR2zk3zDl3WsQyLH91Vh64FPiPnzQU+D+gKbAOeDY7a5TWuELSS0WzR0QkVA7A7JELgUXOuTSA7EdvWzYceN9/mQrUiyiXAqz101OipJeKetoiEipmVuylmK4hYmjEH6PO9mfgO//5ZKCzmVUws2PwDjjOd86tAzLNrKU/a6QLMKm07089bREJlbLsaZvZEcD5wK0RyU+bWVO8IY6V2eucc0vMbCywFNgL/NU5l+WX6QmMBCoBH/lLqShoi0iolOW1R5xzO4GkPGk3FJL/ceDxKOkLgSZl0SYFbREJlZCfEKmgLSLhomuPiIgESMhjtoK2iISLetoiIgGimyCIiARIyDvaCtoiEi4K2iIiAaIxbRGRAAl5zD7wQXvwt7cf6E1IAFWuUuFQN0FCSj1tEZEAMc0eEREJDvW0RUQCJOQxW0FbRMJFPW0RkQAJecxW0BaRcFFPW0QkQHTtERGRAFFPW0QkQDRPW0QkQELe0VbQFpFw0fCIiEiA6ECkiEiAqKctIhIgIY/ZCtoiEjIhj9oK2iISKhoeEREJkJDHbAVtEQmXmNhwR20FbREJFQ2PiIgEiIK2iEiAhDxmK2iLSLiopy0iEiAK2iIiAaJrj4iIBIh62iIiARLymE3MoW6AiEhZshgr9lJkXWYrzWyxmX1tZgv9tOpmNtXM/uc/VovI38fMlpvZMjNrH5F+ql/PcjN73vbj54CCtoiEilnxl2I6xznX1Dl3mv+6NzDNOdcAmOa/xswaAZ2BxkAH4EUzi/XLDAV6AA38pUNp35+CtoiEipkVeymlTsDr/vPXgcsi0sc453Y5534GlgPNzawOEO+cm+Occ8AbEWVKTEFbREKlJEHbzHqY2cKIpUee6hzwiZl9GbGulnNuHYD/WNNPrwusjiib6qfV9Z/nTS8VHYgUkVApSQfaOTcMGFZIltbOubVmVhOYamY/FLbpaJsoJL1U1NMWkVApy+ER59xa/zEdeBdoDqT5Qx74j+l+9lSgXkTxFGCtn54SJb1UFLRFJFTK6kCkmVU2s6rZz4ELgO+AyUBXP1tXYJL/fDLQ2cwqmNkxeAcc5/tDKJlm1tKfNdIlokyJaXhEREKlDE+uqQW869cXB4x2zn1sZguAsWbWDVgFXAngnFtiZmOBpcBe4K/OuSy/rp7ASKAS8JG/lIp5BzMPnMWL1x/YDUggNWpYs+hM8ocTG7f/56DPnrOq2DHnjFZHBe5UHPW0RSRUwn5GpIK2iISKgraISIBY1Bl24aGgLSKhop62iEiA6HraIiIBoutpi4gESMhjtoK2iISLetoiIkES7pitoC0i4aKetohIgGj2iIhIgIQ7ZCtoi0jIaHhERCRAQh6z/3hBOysri169elC9ejJ9+w4gM3MbAwf2Iz19PTVr1uaee/pTpUpVMjMzeOaZh1mxYhlt23age/e78tU1YEAf0tLWMXDgyKjbmjBhFNOnf0hMTAw33/x3mjZtDsCKFct44YUn2b17N82ateDmm/+OmbFnz24GD36Cn376kSpV4rnnnkeoWbMOADNmfMy4cW8AcMUVXWjb1ruZs7f9/mzfvo1jjz2Ov/3tAcqVK4dzjhEjnuerr+ZRvnwF7rijD8cee9wB2Gnhkf8AAA3dSURBVKPhc9757ahcuTIxMbHExcXyn7HjABj11ihGj36L2NhYzm5zNvfdd39OmbVr13LJpZfw17/+lZtvujlfnVu3buXe++5hzZo11K1bl+eeHUhCQgIAw4YPY/z48cTGxtC3zwOceeaZACxZsoS+D/Tht9920aZNG/r26YuZsXv3bnr36cWSJUtJTEzkuWefo25d75aDEydO5KWXhwJw2609uewy7/6xqamp3HvfvWRkbKVRo0YMePIpypcvf+B24iEU9p72H+7ONR9+OI6UlD/lvJ448S1OPPFUhgwZzYknnsq7774FQLly5encuRs33NAzaj1z535BxYqVCtzO6tUrmTVrOgMHjuSBB/7F8OEDycryroc+fPhz3HrrfQwe/Bbr1qXy1VfzAJg27QMqV67KkCGj6djxSkaNehmAzMxtjB07kieffIkBA15m7NiRbN+eCcCoUS/RseOVDBkymsqVqzJ9+gcAfPXVPNatS2Xw4Le47bb7GDbsuf3cc38sI197nXcnvJsTsOfNm8f06dOY+O4k3pv8PjflCcxPPTWAs846q8D6XnllOC1btOLjj6bQskUrXnllOADLly/now8/5L3J7zHs5eH887FHc/5OHn20P/379efjjz7ml19+4b8z/wvA+PHjiI9PYMrHU+japQvPPvcM4H0xvDj0Bca8/Q7vjBnLi0NfICMjA4Bnn3uWrl268PFHU4iPT2DChPFlu8MOI2V155rD1R8qaG/alM6XX86lXbuOOWkLFszK6bW2bduBBQtmAlCxYiUaNjwpam/k11938v77Y7n88i4FbmvBgpm0bn0u5cqVp1atOtSuXZfly79ny5ZN7Ny5k+OPb4KZ0bZt+5xtem1pD0CrVmezePEinHN88818Tj75NKpWjadKlaqcfPJpfP31PJxzfPfdV7Rqdbbf/vbMnz8zZ/tt27bHzDjuuMbs3LmdLVs2lcFe/GMa884Yune/JefvISkpKWfdp9M+JaVePerXr19g+emfTeeyyzoBcNllnZg2fVpO+oUXXUT58uVJSUnhqHpHsXjxt2zYkM72Hdtp2rQZZkanSzsxbZpfZvp0Luvk1XXBBe2ZO3cuzjlmzZpFq1ZnkJiYSEJCAq1ancHMmTNxzjFv3lwuuMD727qs0766wigmxoq9BNEfKmi/9toQbrjhtlw/n7Zu3UK1at5/wGrVksjI2FJkPWPGjOCSS66iQoUKBebZvHkjNWrsuztLUlIymzdvZNOmDSQlJeekV6+ezKZNG/OViY2N44gjKpOZmcGmTRtJSqqZr0xmZgaVK1chNjbO30ZNNm/26opeZkOR7028n9fdb+nGFVdeztixYwFYuXIlX375JVd3vpouXW9g8eLFAOzcuZNXX32F23veXmidmzZtIjnZ+zySk2uyefNmANLT0qhdu3ZOvlq1a5GWlk5aWjq1atXKlZ6engZAWnoatWt7w2ZxcXFUrVqVrVu3kpaeRp2IumrXqkVaehpbt26latV44uK8v5NatWqT5tcVRuppF8DMbipkXQ8zW2hmC8eNe7O0myhTCxfOJiEhkf/7v+P3q56ff/4f69en0qJFm0LzRbuNm/dlES29NGWMaHeK2/eHWFBdUpS3Ro1m/LgJvPzSMN5+ezQLFy4gK2sv27ZtY8zbY7jv3vu55967cc4x5IUhdOnSlcqVK5dqWwV95lHT/cls0cuUsK4Q/y2U5d3YD0f7cyCyP/BatBXOuWHAMDh87hG5bNl3LFgwm0WL5rFnz2527tzBoEGPkZhYjS1bNlGtWhJbtmwiIaFaofX8+OMSfvrpR3r2vJqsrCy2bdvCww/fyaOPDsqVLykpmY0b03Neb9q0gWrVkkhKqpmrx7t58waqV6+Rq0xSUk2ysvayc+cOqlSJJykpmSVLvs5VpnHjpsTHJ7Bjx3aysvYSGxvHpk3pVKu2r65Nm9KjbkcKV7Om1yNOSkqi3Xnn8e3ixdSuVZvzzzsfM+Okk04iJiaGLVu28O233/LJJ1N49tlnyMzMxCyGCuUrcN111+WqMykpiQ0b0klOrsmGDelUr14dgFq1a7N+/fqcfGnr06hZM5natWuRlpaWKz3Zb1ftWrVZv34dtWvXZu/evWRmZpKQkEjtWrWZv2B+Tpn1aWk0P7051apVIzNzG3v37iUuLo60tPXUTNY9OoOq0J62mX1bwLIY707FgXHddT0YNmwcQ4e+w113PUyTJqdw550PctpprZkx42PAm6Fx+umtC62nffvLGD58AkOHvsNjjw2mTp16+QI2wOmnt2bWrOns2bObtLR1rFuXSv36DalWLYlKlSrx449LcM4xY8YUTj/dmy3gtWUKAHPmfE6TJt545sknN+ebbxawfXsm27dn8s03Czj55OaYGY0bN2XOnM/99k/JaX92Xc45fvxxCUccUTlnGEgKtnPnTnbs2JHzfPbsWTSo34Bz27Vj3ry5AKxc+TN79uyhWrVqjHpzFJ9OncanU6dxww1d6NGjR76ADXDOOecyceIkACZOnMS555zrp5/DRx9+yO7du0lNTeWXVb9w4oknkZxck8pHVOabb77GOcekyZM499x9ZSZO8ur65JMptGjREjOjdevWzJ49i4yMDDIyMpg9exatW7fGzGjevAWffOL9bU2ctK+uMPqj97RrAe2BvAO9Bsw+IC06yP7852t59tl+TJv2ATVq1OLee/vnrOvZ82p+/XUHe/fuZf78mTz00DPUq3d0gXUtWDCLFSt+oHPnbtSrdwxnnHEOd93VldjYWLp3v4vY2FgAbrnlHl54YQC7d++iWbMWNGvWAoB27S7i+ecf5447rqVKlarcffcjAFStGs/ll3ehd+9bAbjiiq5UrRoPwA033MbAgf0ZM+ZVjj66Pu3aXQzAKae0ZNGiudxxx7VUqFCB22/vXeb7Low2bdrE3//+NwD2Zu3l4os7ctZZZ7F7924efOhBLu10CeXKleOJx58s8j/9Qw8/yNVXdaZJkybc0r07d99zD+MnjKNOnSMZ+NxAABrUb0D7Dh245NKOxMbG8uCDD+X8nTz88CP0faAPu3bt4qwzz6LNWd6Q3OWXX0Gv3r1o36E9iQkJPPPMswAkJiZy2209uerqqwDo2fN2EhMTAbj3nnu57757GfT88zRs2JDLL7+i7HfeYSKgsbjYLNp4V85Ks1eB15xzM6OsG+2cu7aoDRwuwyNyeGnUUD/PJb/YuP2f0vHTT5uKHXOOPTYpcCG+0J62c65bIeuKDNgiIgebbuwrIhIk4Y7ZCtoiEi5hH9NW0BaRUNHwiIhIgKinLSISIEGdf11cCtoiEi7hjtkK2iISLiGP2QraIhIuYR8e+UNdmlVEJOjU0xaRUAnqzQ2KSz1tEZEAUdAWkVApqzvXmFk9M/vMzL43syVmdqef3s/M1pjZ1/5yUUSZPma23MyWmVn7iPRTzWyxv+5524+Bdw2PiEiolOEZkXuBe51zi8ysKvClmU311w10zj2Ta7tmjYDOQGPgSOBTMzvOOZcFDAV6AHOBD4EOwEelaZR62iISLlaCpRDOuXXOuUX+80zge6BuIUU6AWOcc7uccz8Dy4HmZlYHiHfOzXHetbDfAC4r7dtT0BaRUImx4i+R97P1lx7R6jSzo4FmwDw/6Q7/Ll4jzCz7HoV1gdURxVL9tLr+87zppXt/pS0oInJYKsGgtnNumHPutIhlWP7qrAowHrjLObcNb6jj/4CmwDrg2eysUVrjCkkvFQVtEQmVMhod8eoyK4cXsN9yzk0AcM6lOeeynHO/A8OB5n72VKBeRPEUYK2fnhIlvVQUtEUkVMpw9ogBrwLfO+eei0ivE5Htz8B3/vPJQGczq2BmxwANgPnOuXVAppm19OvsAkwq7fvT7BERCZeyO429NXADsNjMvvbT+gLXmFlTvCGOlcCtAM65JWY2FliKN/Pkr/7MEYCewEigEt6skVLNHIEibuxbFnRjX4lGN/aVaMrixr6bN+4odsypXqNy4E6fVE9bREIl7BeMUtAWkVAJeczWgUgRkSBRT1tEQiXsPW0FbREJmXBHbQVtEQkV9bRFRIJEQVtEJDjK8NKshyXNHhERCRD1tEUkVMI+pq2etohIgKinLSKhotPYRUSCJNwxW0FbRMIl5DFbQVtEQibkwyM6ECkiEiDqaYtIqIS7n62gLSIho9kjIiJBEu6YraAtIuES8pitoC0iIRPyqK2gLSIhE+6oraAtIqES7pCtoC0iIRPyySMK2iISMiGP2jojUkQkQNTTFpFQCXlHWz1tEZEgUU9bREIl7Kexm3PuULfhD8PMejjnhh3qdsjhRX8XUhIaHjm4ehzqBshhSX8XUmwK2iIiAaKgLSISIAraB5fGLSUa/V1IselApIhIgKinLSISIAraIiIBoqB9kJhZBzNbZmbLzaz3oW6PHHpmNsLM0s3su0PdFgkOBe2DwMxigReAC4FGwDVm1ujQtkoOAyOBDoe6ERIsCtoHR3NguXPuJ+fcbmAM0OkQt0kOMefcF8DmQ90OCRYF7YOjLrA64nWqnyYiUiIK2gdHtCvYaK6liJSYgvbBkQrUi3idAqw9RG0RkQBT0D44FgANzOwYMysPdAYmH+I2iUgAKWgfBM65vcAdwBTge2Csc27JoW2VHGpm9jYwBzjezFLNrNuhbpMc/nQau4hIgKinLSISIAraIiIBoqAtIhIgCtoiIgGioC0iEiAK2iIiAaKgLSISIP8PUScTMbQslV8AAAAASUVORK5CYII=\n",
"text/plain": [
"
"
]
},
"metadata": {
"needs_background": "light"
},
"output_type": "display_data"
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"-----------------------------------------\n"
]
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAYoAAAEWCAYAAAB42tAoAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADt0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjByYzEsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy/xvVyzAAAgAElEQVR4nO3deZxN9RvA8c9j7GMLkZ0i2ZXJUoSkEPWTFmmTLSpFESktJIqKIrtkV2RJtspWISRhxpKsYxCSfZjl+f1xjtymWa4xd+6dmef9et3X3HPP95zznO+de577/Z5zv0dUFWOMMSYhmfwdgDHGmMBmicIYY0yiLFEYY4xJlCUKY4wxibJEYYwxJlGWKIwxxiTKEoW5IiISKiIN/B1HoBCRPiIyzk/bnigi7/hj2ylNRB4TkaXJXNb+J33MEkUaJiJ7ReS8iJwRkcPugSOXL7epqpVUdYUvt3GJiGQTkYEist/dz99FpKeISGpsP554GohIuOdrqvquqnbw0fZERF4Qka0iclZEwkXkSxGp4ovtJZeIvCUiU65mHao6VVXv9mJb/0mOqfk/mVFZokj7WqhqLqA6cDPwqp/juWIikjmBWV8CjYBmQG7gCaATMMwHMYiIBNrnYRjwIvACkB+4EZgL3JvSG0rkPfA5f27beElV7ZFGH8Be4C6P6feBbzymawOrgb+B34AGHvPyA58BEcAJYK7HvObAJne51UDVuNsEigLngfwe824GjgFZ3Ol2wDZ3/UuAUh5lFXgO+B3YE8++NQIigRJxXq8FxABl3ekVwEBgHXASmBcnpsTqYAUwAPjJ3ZeywNNuzKeB3cAzbtlgt0wscMZ9FAXeAqa4ZUq7+/UUsN+ti9c8tpcD+Nytj23AK0B4Au9tOXc/ayby/k8ERgDfuPH+DNzgMX8YcAA4BfwC1POY9xYwC5jizu8A1ATWuHV1CBgOZPVYphLwLfAXcAToAzQBLgJRbp385pbNC4x313MQeAcIcue1dev8I3dd77iv/ejOF3fen+57uhmojPMlIcrd3hng67ifAyDIjesPt05+Ic7/kD2ScazxdwD2uIo3798fkOLAFmCYO10MOI7zbTwT0Nidvtad/w0wE7gGyALUd1+/xf2A1nI/dE+528kWzzaXAR094hkMjHKf/w/YBVQAMgOvA6s9yqp70MkP5Ihn3wYBKxPY731cPoCvcA9ElXEO5rO5fOBOqg5W4BzQK7kxZsH5tn6De7CqD5wDbnHLNyDOgZ34E8VYnKRQDbgAVPDcJ7fOi7sHwIQSRWdgXxLv/0ScA21NN/6pwAyP+Y8DBdx5LwOHgewecUe571MmN94aOIk1s7sv24BubvncOAf9l4Hs7nStuHXgse25wGj3PSmEk8gvvWdtgWigq7utHPw7UdyDc4DP574PFYAiHvv8TiKfg544n4Py7rLVgAL+/qym9YffA7DHVbx5zgfkDM43JwW+B/K583oBk+OUX4Jz4C+C8834mnjWORLoH+e1HVxOJJ4fyg7AMve54Hx7vcOdXgS091hHJpyDbil3WoE7E9m3cZ4HvTjz1uJ+U8c52A/ymFcR5xtnUGJ14LFsvyTqeC7wovu8Ad4liuIe89cBrd3nu4F7POZ1iLs+j3mvAWuTiG0iMM5juhmwPZHyJ4BqHnGvSmL93YA57vNHgV8TKPdPHbjThXESZA6P1x4FlrvP2wL746yjLZcTxZ3ATpyklSmefU4sUewA7vfF5y0jPwKtT9Zcuf+pam6cg9hNQEH39VLAQyLy96UHUBcnSZQA/lLVE/GsrxTwcpzlSuB0s8Q1C6gjIkWBO3AOkj94rGeYxzr+wkkmxTyWP5DIfh1zY41PEXd+fOvZh9MyKEjidRBvDCLSVETWishfbvlmXK5Tbx32eH4OuHSBQdE420ts/4+T8P57sy1E5GUR2SYiJ919ycu/9yXuvt8oIgvcCyNOAe96lC+B053jjVI478Ehj3ofjdOyiHfbnlR1GU631wjgiIiMEZE8Xm77SuI0XrJEkU6o6kqcb1tD3JcO4HybzufxCFbVQe68/CKSL55VHQAGxFkup6pOj2ebfwNLgYeBNsB0db/Wuet5Js56cqjqas9VJLJL3wG1RKSE54siUhPnYLDM42XPMiVxulSOJVEH/4lBRLLhdF0NAQqraj5gIU6CSypebxzC6XKKL+64vgeKi0hIcjYkIvVwWlQP47Qc8+H093teMRZ3f0YC24FyqpoHp6//UvkDOF1y8Ym7ngM4LYqCHvWeR1UrJbLMv1eo+rGq1sDpFrwRp0spyeWSiNMkkyWK9GUo0FhEquOcpGwhIveISJCIZHcv7yyuqodwuoY+FZFrRCSLiNzhrmMs0FlEarlXAgWLyL0ikjuBbU4DngRauc8vGQW8KiKVAEQkr4g85O2OqOp3OAfL2SJSyd2H2jj98CNV9XeP4o+LSEURyQn0A2apakxidZDAZrMC2YCjQLSINAU8L9k8AhQQkbze7kccX+DUyTUiUgx4PqGC7v59Ckx3Y87qxt9aRHp7sa3cOOcBjgKZReQNIKlv5blxTmyfEZGbgC4e8xYA14lIN/ey5dwiUsuddwQofemqMff/aynwgYjkEZFMInKDiNT3Im5E5Fb3/y8LcBbnooYYj21dn8ji44D+IlLO/f+tKiIFvNmuSZglinREVY8Ck4C+qnoAuB/nW+FRnG9aPbn8nj+B8817O87J627uOjYAHXGa/idwTki3TWSz83Gu0Dmiqr95xDIHeA+Y4XZjbAWaXuEutQKWA4txzsVMwbmSpmuccpNxWlOHcU60vuDGkFQd/IuqnnaX/QJn39u4+3dp/nZgOrDb7VKJrzsuMf2AcGAPTotpFs4374S8wOUumL9xulRaAl97sa0lOF8GduJ0x0WSeFcXQA+cfT6N84Vh5qUZbt00Blrg1PPvQEN39pfu3+MistF9/iRO4g3DqctZeNeVBk5CG+sutw+nG+5SS3k8UNGt/7nxLPshzvu3FCfpjcc5WW6uglzuKTAm7RGRFTgnUv3y6+irISJdcE50e/VN2xh/sRaFMalERIqIyO1uV0x5nEtN5/g7LmOS4rNEISITRORPEdmawHwRkY9FZJeIbBaRW3wVizEBIivO1T+ncU7Gz8M5D2FMQPNZ15N7cvQMMElVK8czvxlOX3MznB93DVPVWnHLGWOM8S+ftShUdRXOtfMJuR8niaiqrgXyiYi3J7uMMcakEn8OxlWMf1+FEe6+dihuQRHphDPOC8HBwTVuuummVAnQGGPSsthYOL3zELnPHuZXYo+p6rXJWY8/E0V8Q0XH2w+mqmOAMQAhISG6YcMGX8ZljDFp3vffKR07CZXPzuflKktpsGXEvuSuy59XPYXz71+mFscZydQYY0wyndx3gh/Lt2dZ43fJnBl6rrqP+puHX9U6/Zko5gNPulc/1QZOur/oNMYYkwzr+8wh8vqK1N75OQ1ui+K336Bevatfr8+6nkRkOs5AdQXFuSvYmzgDhaGqo3DG0GmG88vfczj3ATDGGHOFjoUeYVfTrtQ+8CXbslfn+NhvaPx4yv3iwGeJQlUfTWL+pRvXGGOMSQZVmDkTxnU+wLyT37Cs0QDqzutJ1uAsKbod+2W2McakQUfW7WNMteE8+iicLh/C/h/2c+d3fVI8SYB/r3oyxhhzhTQmljVPjqTKtN60AfSNVnR8owhBQb4bJNcShTHGpBHh3+/gxIMduO3vH1l3zT0UmjOazvV9/ztl63oyxpgAFxsLnw45R7a76lL871CWPTmRkKOLKF2/VKps31oUxhgTwP5YtJMn+5dj9ZqcHAqZTOdR1bmzxnWpGoO1KIwxJgBFnY7kp4avUapZRapsnsqkSdBvXROKpXKSAGtRGGNMwPl94k9k7tye2y/sYFnpp+m3+F4KlfdfPNaiMMaYAHHhAnxXvz83PF2PzFGR/Nh3CXfumUCh8tf4NS5rURhjTABYs1pp30G4YVt1tEJXaiweQN2SufwdFmAtCmOM8auzB/5ifcWnWHT7O5w9C88vbkHjsGHkD5AkAZYojDHGb7a8OYvzZSpQfds0atZUtm6Fe+7xd1T/ZV1PxhiTyk7tOMSuJs9zy96v2JKtBvvGLKV5u2r+DitB1qIwxphUtGABPFIvghv3LmFh/fcoe3QtNQI4SYAlCmOMSRV/bdzL5yGf0KIFHLyuBr9/f4BmK14hR+7A79gJ/AiNMSYN0+gYNnYYwU2f96ElmTjW4yG6DriOrFn9e8nrlbBEYYwxPvLnym0cb9mBGidWszpvEwp8OZqXG6f+L6uvlnU9GWNMClOFiZ+eI1PDOyh0YjsLH51ErWMLKd+4pL9DSxZLFMYYk4LCv9vO3Y2Vp5/LyaDKUzm1Joxm054gKLP4O7Rks0RhjDEpIPbseTbc1YsijStR+qepjBwJ72+6mzK1C/s7tKtm5yiMMeYq7Zu8CunUgZDI31lcvANvLmpO8cr+jirlWIvCGGOSKSoKfrjrbUo9WZ/Yi9F82+s77tk/luKV8/k7tBRlLQpjjEmGTb8q7doLRX4N4WS57ty6uD+Nrw/2d1g+YS0KY4y5AhcOHmNTlSeYG9KfiAhoP/temu/8kMLpNEmAJQpjjPGOKjvf+YIzpSpSaesMqlTNRFgYPPCAvwPzPet6MsaYJJzbFcEf9zxLld3z+C1LCKc/+Y5WXar6O6xUYy0KY4xJxLJl0LrBYUrtXsZXdQZz/ZE11M1ASQIsURhjTLxO/babmXWG0qgRbMtxC1sW7OeB1T3IfU3G64ixRGGMMZ5iYgjt8BFZbq5Mk7Vv8naXw2zeDLffm74ueb0SGS81GmNMAk78GMrx/7Wn0vGfWZn7XvJOG8UbzdPeIH4pzVoUxpgMTxVmTTpH7B31yXv8D2a3mkado19TvXlxf4cWECxRGGMytD9XhNHyf8pDT+XkjXIzOLYyjFazHiVrtrQ7iF9Ks0RhjMmQ9Ow5tjTpSYGGVci/aAqDB8Ow0LuocMe1/g4t4Ng5CmNMhnN4xgpi2nWkyvldzCvyDK8tuI8bbvF3VIHLWhTGmAwjNhbWNX2T6x5tSGSkMu/FZbQIH8UNt+T1d2gBzVoUxpgMYcd2pX0HIe9PNWlX+mVqLu7H/eVz+jusNMGnLQoRaSIiO0Rkl4j0jmd+XhH5WkR+E5FQEXnal/EYYzKe6ENHCa3ehi8q9yMsDB75/F4e2D2EEpYkvOazRCEiQcAIoClQEXhURCrGKfYcEKaq1YAGwAciktVXMRljMhBV9g6cxpkSFSj32yyuvykrYWHw5JMgdkHTFfFl11NNYJeq7gYQkRnA/UCYRxkFcouIALmAv4BoH8ZkjMkALvwRzp4mXbhp1wJ+yVKL40PG81i3Sv4OK83yZddTMeCAx3S4+5qn4UAFIALYAryoqrFxVyQinURkg4hsOHr0qK/iNcakA2vXQpvGRymyaxXTQj6kzMGfuNuSxFXxZaKIr3GncabvATYBRYHqwHARyfOfhVTHqGqIqoZce61d42yM+a9zm3cxt/5H3HYbrI++mXWzDtBmfXfyXxvk79DSPF8minCghMd0cZyWg6enga/UsQvYA9zkw5iMMelNdDS/dx5CpupVaLDqbV556gihodC41X++c5pk8mWiWA+UE5Ey7gnq1sD8OGX2A40ARKQwUB7Y7cOYjDHpyOnVW9hT9DbKje7JjznvZvusUAZ9Vpjcuf0dWfris5PZqhotIs8DS4AgYIKqhopIZ3f+KKA/MFFEtuB0VfVS1WO+iskYk34snHWO2o80JDg2E1NbzOCBGQ+TI6ddzuQLohr3tEFgCwkJ0Q0bNvg7DGOMn5z4YSvPj6zEtOlC+9Lf89yYatzcuKC/wwp4IvKLqoYkZ1kbwsMYkybombPsuPcl8t5RlaxfTOGtt+DTHY0sSaQCG8LDGBPwjs38nuh2HSl/bg9fFnqWHnPvp1Idf0eVcViLwhgTsFRhU4u+FGx9F6fPZ2ZGl5W0PDiCSnXsiqbUZC0KY0xA2rs7lk6dMxH07W08UfwVai58i9ZVcvg7rAzJWhTGmIASe/hPdtZozfSb3mbNGrjv06a03vceZS1J+I0lCmNMYFDl0OApnC5RgVIb51C4TE5CQ6FLF8hkRyq/sq4nY4zfRe85wN6mnSm7YyHrgupw6N1xPN27oo3yGiAsTxtj/Oq33+CJZscpuOMnJlQbRsl9P3D/q5YkAoklCmOMX1zcupPFdw0hJASWn6jOyskHaLfpBa4rZoP4BRpLFMaY1BUdzf7n3kOrVqXW9wPo3PIIYWFw/+M2QFOgsnMUxphUc37tbxy7vx0l/9zIohwtyTZ2BJ88VtjfYZkkWKIwxqSKlYvOUaV5I7LEZmbM3bNo/WUr8tjv5tIE63oyxvjU6Z8280wnpUGznLxw3Zf8MT+MTkssSaQlliiMMb5x5gx77nuR4LrVuTBuMj16wJjfG3J7i/z+jsxcIet6MsakuJOzvuVC206UObuXafmfp+vsltRo4O+oTHJZi8IYk2JUIeyB18j70N2cOJuNCU//wIOHPqFGA7uiKS3zukUhIsGqetaXwRhj0q6I8Fie65qJyLl1efi6V7n16zdoF5Ld32GZFJBki0JEbhORMGCbO11NRD71eWTGmDRBDx1mT8iDTCn7FosXQ6PBTXniwLtUtiSRbnjT9fQRcA9wHEBVfwPu8GVQxpg0QJVjQyZyumRFivyygFxF87B5M/ToAZnt7Ge64tXbqaoH5N8Dr8T4JhxjTFoQu2cfB5p1otT2pazOVJd9b46j8xvlbZTXdMqbt/WAiNwGqIhkFZEeuN1QxpiMZ8cOaPfA3+Tevp4RFYZT/I+VPPqWJYn0zJsWRWdgGFAMCAeWAs/6MihjTOCJDt3Bqp7zabasJzlzVqPxqP082ymXjfKaAXjzHaC8qj6mqoVVtZCqPg5U8HVgxpgAERXFoRcGElOlGtUWDeLRRn8SFgaPPWNJIqPwJlF84uVrxph05uLPvxJRshZFPunDkqwtWD02jM++KcR11/k7MpOaEux6EpE6wG3AtSLyksesPIANGG9MOrduxTnK3dUYicnCx/Vn89jsByhQwN9RGX9IrEWRFciFk0xyezxOAQ/6PjRjjD+cX/0rL3VXat+Zk07XzGLrzDBeWGFJIiNLsEWhqiuBlSIyUVX3pWJMxhh/OH2a8Cdepfi8ERzjczp3eZJBgxrYKK/Gq6uezonIYKAS8M9PLVX1Tp9FZYxJVWdnLyay7TMUPXOAiXlfpOP0B6jX1N9RmUDhzcnsqcB2oAzwNrAXWO/DmIwxqWjXQ68S/GBTjpwJ5tM2P/FwxFDqNc3l77BMAPGmRVFAVceLyIse3VErfR2YMca3jh2JodvLQRyd1YCWBTNTY87rPF83m7/DMgHIm0QR5f49JCL3AhFAcd+FZIzxJY04xMH/PcfM0ErMvNif1968h3Z97iFrVn9HZgKVN4niHRHJC7yM8/uJPEA3n0ZljEl5qvw9dCKZe71EgahIMhWvy8aFUKWKvwMzgS7JRKGqC9ynJ4GGACJyuy+DMsakLN2zl4jmHSkW9h0/Sj229xxH13dvtFFejVcSPJktIkEi8qiI9BCRyu5rzUVkNTA81SI0xlyVvXuhS5uTZA/byAc3fEqhsBV0eN+ShPFeYv8q44ESwDrgYxHZB9QBeqvqXG9WLiJNcAYUDALGqeqgeMo0AIYCWYBjqlr/ivbAGBOv2K1hrO0zn7uX9UakGrd8uJ/uLwbbKK/miiWWKEKAqqoaKyLZgWNAWVU97M2KRSQIGAE0xhl1dr2IzFfVMI8y+YBPgSaqul9ECiV3R4wxrosXOfrK++T9uD83am7ubdCO9ycWolSpYH9HZtKoxBLFRVWNBVDVSBHZ6W2ScNUEdqnqbgARmQHcD4R5lGkDfKWq+93t/HlF0Rtj/iV67Qb+atmeQoc3MztLa6I/GMaM5wvZKK/mqiSWKG4Skc3ucwFucKcFUFWtmsS6iwEHPKbDgVpxytwIZBGRFTjjSA1T1UlxVyQinYBOACVLlkxis8ZkTFvWnqVE3XuIisnOwNrzeHrOfTbKq0kRiSWKq73nRHzfYTSe7dcAGgE5gDUislZVd/5rIdUxwBiAkJCQuOswJkO7uHYj7yyozsD3gmmWew7thlbl1afy+Tssk44kNijg1Q4EGI5zMvyS4jg/1otb5piqngXOisgqoBqwE2NM4k6d4sjTvSn81Uj28jmPPvEkH310h43yalKcL69/WA+UE5EyIpIVaA3Mj1NmHlBPRDKLSE6crim7H7cxSYj8aiEnilWi4FejGZPrJR6b3YpJk7AkYXzCZ1dSq2q0iDwPLMG5PHaCqoaKSGd3/ihV3SYii4HNQCzOJbRbfRWTMenBvkd7UWrG+/xBRca0nEWXibVsKHDjU6KadJe/iOQASqrqDt+HlLiQkBDdsGGDv8MwJnWpcvJELK+8GsSeMUtpcc1PVJ3Rh/p32yB+xjsi8ouqhiRn2SS7nkSkBbAJWOxOVxeRuF1IxhhfOXiQw3X+x8TSbzJuHFR9+W7ah79tScKkGm/OUbyF85uIvwFUdRNQ2nchGWMAUOX0R2M5V6YieX9eyvnggqxZA0OGQM6c/g7OZCTenKOIVtWTYr/YMSbV6O49/HlfewqHLmeFNOC358fSfUhZslkjwviBNy2KrSLSBggSkXIi8gmw2sdxGZNhHToE3TqcISh0MwNKjib/xu958RNLEsZ/vEkUXXHul30BmIYz3Ljdj8KYFKZbtvJLq3epWBHGrKnC5Hf20+uPTlStbqP4Gf/ypuupvKq+Brzm62CMyZAuXuREr4HkGjaAkpqXerU6MGRSIW680U5EmMDgTaL4UESKAF8CM1Q11McxGZNhxP68nhMt21Hg0FZmZm7D2XeGMrfntTYUuAko3tzhrqGIXAc8DIwRkTzATFV9x+fRGZOO7fz1LIXrNuF8dA7evHk+7ea0oFQpf0dlzH959b1FVQ+r6sdAZ5zfVLzh06iMScei127gvYGxVK0TTOvs81j1aShv/WJJwgQub35wV0FE3hKRrTi3QF2NM8CfMeZKnDzJ8QefIXOdWwntM4V774XPfq9Lmy557X4RJqB5c47iM2A6cLeqxh391RjjhaivvuZ8287kO32YETl70HLMg7R8zN9RGeMdb85R1E6NQIxJryIe70nRqUPYRhVmN53LC5NvtVFeTZqSYKIQkS9U9WER2cK/bzjk7R3ujMm4VDl3Ooa+b2dm67S7aZwnD5Um9eLt+7P6OzJjrlhiLYoX3b/NUyMQY9KN8HCOPdyFL7ZV5cO/B9C5c2M6vdfYhgI3aVaCJ7NV9ZD79FlV3ef5AJ5NnfCMSUNiYzk/dDTnr69IjjXLOJr5OpYvh5EjsSRh0jRvLo9tHM9rTVM6EGPStN27OV79TnJ078xPUTUZ1n4LPfd1pUEDfwdmzNVLMFGISBf3/ER5Edns8diDc0c6Ywxw/Dj07nqWmC1hvFF0HHnWfkufcdfbUOAm3UjsHMU0YBEwEOjt8fppVf3Lp1EZkwbo5i1sHTCPRstf58SJKgS/uo/X3sxho7yadCexRKGquldEnos7Q0TyW7IwGdaFC5zuPYAcwwZSWK+hWtVOfPBdIapWzeHvyIzxiaRaFM2BX3Auj/X87agC1/swLmMCkq5Zy98PtueaiDCmZnqC430/YlHfAmT25qerxqRRCf57q2pz92+Z1AvHmMC1f9tZ8tW/l9NRwQyouJBOc5py443+jsoY3/NmrKfbRSTYff64iHwoIiV9H5oxgSF2zc8M/ziWircG0zLoaxYPCeX9LZYkTMbhzeWxI4FzIlINeAXYB0z2aVTGBIK//+bkQx3IdFtt1r04hdtvhwnbb6PTy7ntfhEmQ/Hm3z1aVRW4HximqsOA3L4Nyxj/ipk9l9MlKxI8ayJDs/Wi8eiHWLwYGwrcZEjenII7LSKvAk8A9UQkCMji27CM8Z+jT7zEtVM+4g+qMaXB17w8rQZFivg7KmP8x5tE8QjQBminqofd8xODfRuWMalMlQvnYhjwXmZ+ntaMBsEFKDf2FQa3zmL3ijAZXpJdT6p6GJgK5BWR5kCkqk7yeWTGpJb9+/n79nuZWPpN+veHQm3uotO+13jwUUsSxoB3Vz09DKwDHsK5b/bPIvKgrwMzxudiY7k49FMiy1Yiy5qVHIguyjffwOTJ2P0ijPHgTdfTa8CtqvongIhcC3wHzPJlYMb41K5d/N2qHfk2/8BSGrOyzRh6jSxto7waEw9vrnrKdClJuI57uZwxAenUKejXJ5LIzTt55drPyLpsCQOmWpIwJiHetCgWi8gSnPtmg3Nye6HvQjLGRzZtYueQeTRa+SYREZU5+8Je3hqY3UZ5NSYJ3twzu6eIPADUxRnvaYyqzvF5ZMaklMhIzvXpT7ah75FHC1L6xi7MWl2IWrWy+zsyY9KExO6ZXQ4YAtwAbAF6qOrB1ArMmJSgP63m9CPtyXNwO5PkKQ72+JDv3slvQ4EbcwUSO9cwAVgAtMIZQfaTVInImBRy+I+znGnYghMHz/F82cVU+3Uirw62JGHMlUqs6ym3qo51n+8QkY2pEZAxV0tXr+Hz7bXo/nIwVVlAy36VGfpqbhsK3JhkSqxFkV1EbhaRW0TkFiBHnOkkiUgTEdkhIrtEpHci5W4VkRj7fYa5KidOcObhdsjtt7G8/WQqV4axW+vQra8lCWOuRmIfn0PAhx7Thz2mFbgzsRW7Y0KNABoD4cB6EZmvqmHxlHsPWHJloRtzWeysrzjf/jmynzrK4CyvUuf9R/jsBWyUV2NSQGI3Lmp4leuuCexS1d0AIjIDZwTasDjlugKzgVuvcnsmgzrRtjvXfD6UnVRnbO2F9Jpxs43yakwK8mWDvBhwwGM6HKjlWUBEigEtcVonCSYKEekEdAIoWdLumWQAVaIvxPDhx5lZPq05dbIXotQnPRjR3sZnMial+bJhHt/HVeNMDwV6qWpMYitS1TGqGqKqIddee22KBWjSqL17OX17EyaX6UuvXpCjeSM67n6VpzpYkjDGF3zZoggHSnhMFwci4pQJAWaI8+kuCDQTkWhVnevDuExaFRtL1D5tIZ8AABg8SURBVLARxPZ6FaKEsNwt+eILePBBLEEY40NJJgpxjuKPAderaj/3fhTXqeq6JBZdD5QTkTLAQaA1zn0t/qGqZTy2MxFYYEnCxOv33zn94NPk3vwTi2jCkv+Nou+4UjbKqzGpwJuup0+BOsCj7vRpnKuZEqWq0cDzOFczbQO+UNVQEeksIp2TGa/JgM6dg8EDLnJm8x+8eM0kYr9eyNA5liSMSS3edD3VUtVbRORXAFU9ISJZvVm5qi4kzgCCqjoqgbJtvVmnyUB+/ZW9w+Zx149v8ccfldjXYS/vfpDNRnk1JpV506KIcn/roPDP/ShifRqVydgiI7nw0qvE1LiVbJ+PJn/MUZYtg+FjLUkY4w/etCg+BuYAhURkAPAg8LpPozIZ148/cqZ1e3Id3MlnPM0fz37AisHX2FDgxviRN8OMTxWRX4BGOJe8/k9Vt/k8MpPhHN93hmyN7ufoxTx0K7mUjl805ulaSS9njPEtb656KgmcA772fE1V9/syMJOB/PgjsyJu47muuSgX8w1NelVmxNu5bJRXYwKEN11P3+CcnxAgO1AG2AFU8mFcJiM4fpxznbuTc9ZkvmYiJWo8xYiltalWzd+BGWM8edP1VMVz2h059hmfRWTSP1X0y1lEdnyeLKf+4t2gvlR5uzXje2GjvBoTgK74Y6mqG0XEBvAzyXaqfXfyfDaMUGowvPpSXp1RjfLl/R2VMSYh3pyjeMljMhNwC3DUZxGZ9EmV2IvRjByXhYXT7+PmLEUpMvglJnTNbEOBGxPgvGlR5PZ4Ho1zzmK2b8Ix6dKePZx9vBNz99fg+fBBNG58Jx3G3Enp0v4OzBjjjUQThftDu1yq2jOV4jHpSUwMMcOGE9O7DzFRQazP8RATJkDbtjaInzFpSYKJQkQyq2q0t7c9NeZfdu7k7MNtCf5tDUtoyld3j6b/xBIUKeLvwIwxVyqxFsU6nPMRm0RkPvAlcPbSTFX9ysexmTTq4kUYMzSalr/to0fuKdw5rg1jHxJrRRiTRnlzjiI/cBznLnSXfk+hgCUK828bNnDw03ncs64/oaEV+eXR3Qz+OBsFC/o7MGPM1UgsURRyr3jayuUEcUncO9WZjOz8eaL6vEnQsA9AryPTdS+wYMG13Huv/bTamPQgsUQRBOTCu1uamoxq5UrOPdaBnAd3MYaObGv7Pj8MzUfevP4OzBiTUhJLFIdUtV+qRWLSnFMRZ8h0zwMcuZCPN4t8T/upd9Kpob+jMsaktMQShZ16NPH74QcWnbqdZ7rkosiFRTR8vhKjBwUTHOzvwIwxvpBYomiUalGYtOHYMS506Ua2WVOZwURyV3yKYWtqUru2vwMzxvhSgoMnqOpfqRmICWCqMHMmkTdUJNOsmfSTNynTuzUbN2JJwpgMwMbqNEk62/FFgsd/wmZu5YMK39NnehUbCtyYDMQShYmfKnoxikkzsjJ7ZksqBJWiQP9uTO0ZZEOBG5PB2Efe/NcffxD5REe+PhRC273vc/vtDWk3vqENBW5MBmUDPJvLYmKI/eBDoipU4cKaX1geUZ5PPoFVq7AkYUwGZi0K49i+nfOPPEWOzetYQAum1xvJwEnFbChwY4y1KAxER8OEcbEc3xxB+5zTOT5+HtNWWpIwxjisRZGRrVvHn2Pnce+mAWzYUJEH7/uDYSOzUrSovwMzxgQSa1FkROfOEdO9B7G163Bx3Oec2XOUmTPhi7mWJIwx/2Utioxm+XIin+hA9oO7GcUz/PLQe/zwaV4bCtwYkyBrUWQg5/48w9lmDxF+UHio4HJKLBjF2C8sSRhjEmctioxgxQpW6h106JSLfJGLqNWuEuM+zGlDgRtjvGItivTs6FGiHnwUGjZk/J1TiI2F95fdyvDxliSMMd6zFkV6pArTp3OxywvoqdP0pT+FX2jN5nexocCNMVfMEkU6FNmxK9nHj+AXavPu9eN5bWpFG+XVGJNslijSi9hYiI5m1vysTJ39INdnKktw767MeiOIbHbramPMVfDpOQoRaSIiO0Rkl4j0jmf+YyKy2X2sFhEbvDo5fv+di3XvZF7l13joIdh/fQOe3NiNfgMsSRhjrp7PEoWIBAEjgKZAReBREakYp9geoL6qVgX6A2N8FU+6FB2NDh5CdKWqnF+7iYV7KjBwIPz8M3a/CGNMivFl11NNYJeq7gYQkRnA/UDYpQKqutqj/FqguA/jSV+2beNC6yfJtnkDC7ifz0I+5f0pRW2UV2NMivNl11Mx4IDHdLj7WkLaA4vimyEinURkg4hsOHr0aAqGmDbFxsL06fDnliM8mW0mB4bNYc7PliSMMb7hyxaFxPOaxltQpCFOoqgb33xVHYPbLRUSEhLvOjKEtWv567N5tNw+kFWrKnDPnX8wanwWG+XVGONTvmxRhAMlPKaLAxFxC4lIVWAccL+qHvdhPGnX2bPEvtgdve02zo6ZSvivRxk/HhZ9Z0nCGON7vmxRrAfKiUgZ4CDQGmjjWUBESgJfAU+o6k4fxpJ2ffcdF5/qSNaIvQznOX5sNpAfxua2UV6NManGZ4lCVaNF5HlgCRAETFDVUBHp7M4fBbwBFAA+FRGAaFUN8VVMac3Fv84QfV9rDp7Pz0t5V/H46HpMfxgkvk49Y4zxEVFNW13+ISEhumHDBn+H4VvLlrE+Z33adQwi69ZfqPpIRQYPz2GjvBpjkk1EfknuF3EbFDCQHDlCdKuHoVEjPr1tCidOwNtf1+CzGZYkjDH+Y0N4BAJVmDKFqOe7oafO0IcBZG/fhtAh2Civxhi/sxZFALjY8Tl48knWnypP8+KbuOv7Powcm8WShDEmIFiLwl9iYyEqikXLsjFh/iMUoQJZXnyWOQOCbChwY0xAsUThDzt2ENW2A9+eqsW9YUOoUKE+L8+vb0OBG2MCknU9paaoKBg0iJgq1Tj781Zmba/C66/Dr79iScIYE7CsRZFaQkOJav0EWbb+ylweYHSVEbw/6TqqV/d3YMYYkzhrUaQCVZgzP4hDYX/ROvMsfh84m4UbLUkYY9IGa1H40urVnJo8j0f2vsfixTdxx227GD0+Mzfd5O/AjDHGe9ai8IUzZ9CuL6B163Ji9EzCVh3j449h+Q+WJIwxaY+1KFLa0qVEPd2JoIj9DOd5vm3wLis/y2WjvBpj0ixrUaSgC8fPcLblY+yOyE6zXD+Qa/zHzF9mScIYk7ZZiyIlfPstP2S5k05dcpH93FKqPFSBiR9n57rr/B2YMcZcPWtRXI1Dh7jYohXcfTdjG07l/Hl4d+HNTPrCkoQxJv2wFkVyqKITPyeqa3diz57nVRlEke5tCO2HDb9hjEl3LFEkw+nHu5B72mh+pi5DK43j9cnluflmf0dlTOCJiooiPDycyMhIf4eSYWTPnp3ixYuTJUuWFFunJQpvxcYSfT6KoSOzsXR2GyplrUrpQZ354oVMBAX5OzhjAlN4eDi5c+emdOnSiN2a0edUlePHjxMeHk6ZMmVSbL12jsIb27Zx5uZ6TC/Th549Ifvdd9D992d5sbslCWMSExkZSYECBSxJpBIRoUCBAinegrNEkZioKC68+S7RVapzYfN2fr54M7Nmwbx5ULKkv4MzJm2wJJG6fFHf1vWUkNBQTrZ4nLx7NvEFD/HLU58wYFhhu5mQMSbDsRZFPCIi4IWXMnN8z0leLPEVxX/6gvcmWpIwJq2aM2cOIsL27dv/eW3FihU0b978X+Xatm3LrFmzAOdEfO/evSlXrhyVK1emZs2aLFq06KpjGThwIGXLlqV8+fIsWbIk3jJvvfUWxYoVo3r16lSvXp2FCxde0fIpzVoUHmJX/sDm/vOov34IFy6Up0i/nQzulZmsWf0dmTHmakyfPp26desyY8YM3nrrLa+W6du3L4cOHWLr1q1ky5aNI0eOsHLlyquKIywsjBkzZhAaGkpERAR33XUXO3fuJCiek53du3enR48eyV4+JVmiADh9muMde1Ng5qfkoQx31u3N+xMKUq6cVY8xKaVbN9i0KWXXWb06DB2aeJkzZ87w008/sXz5cu677z6vEsW5c+cYO3Yse/bsIVu2bAAULlyYhx9++KrinTdvHq1btyZbtmyUKVOGsmXLsm7dOurUqZMqyydXhu96ujB3EX8Xr8Q1M0cyKns31o7ZwlerClKunL8jM8akhLlz59KkSRNuvPFG8ufPz8aNG5NcZteuXZQsWZI8efIkWbZ79+7/dBF5PgYNGvSfsgcPHqREiRL/TBcvXpyDBw/Gu97hw4dTtWpV2rVrx4kTJ654+ZSUob8yr1xwmiqtnuRQbCE+brqaZyfVpmBBf0dlTPqU1Dd/X5k+fTrdunUDoHXr1kyfPp1bbrklwauDrvSqoY8++sjrsqrq1fa6dOlC3759ERH69u3Lyy+/zIQJE7xePqVlvEShyskvltDtm8ZMnJyb5iW+o/vom3ijaTZ/R2aMSWHHjx9n2bJlbN26FREhJiYGEeH999+nQIEC/3xTv+Svv/6iYMGClC1blv3793P69Gly586d6Da6d+/O8uXL//N669at6d27979eK168OAcOHPhnOjw8nKJFi/5n2cKFC//zvGPHjv+cdPd2+RSnqmnqUaNGDU2u2IMRuu+W/6mCts30ufbpo3ruXLJXZ4xJQlhYmF+3P2rUKO3UqdO/Xrvjjjt01apVGhkZqaVLl/4nxr1792rJkiX177//VlXVnj17atu2bfXChQuqqhoREaGTJ0++qni2bt2qVatW1cjISN29e7eWKVNGo6Oj/1MuIiLin+cffvihPvLII1e0fHz1DmzQZB53M0aLQpUjgz4j+I2XuDb6AsNLvs/L89pQ2e5ZbUy6Nn369P98q2/VqhXTpk2jXr16TJkyhaeffprIyEiyZMnCuHHjyOteB//OO+/w+uuvU7FiRbJnz05wcDD9+vW7qngqVarEww8/TMWKFcmcOTMjRoz454qlDh060LlzZ0JCQnjllVfYtGkTIkLp0qUZPXp0ksv7kmg8fV6BLCQkRDds2OB1+YsXIbTuM9y8fgw/Bt3B/r7jaN23HJky/Gl8Y3xv27ZtVKhQwd9hZDjx1buI/KKqIclZX/ptUcTEsPaHKDp2zU6+rY/zxM0303x+J+oWtwxhjDFXIl0eNU+vDWVP0dtZ07APJ0/CK/Pr0WljZ4pakjDGmCuWro6ceuEioa37k63OzeT+cxcFmtxKaCi0aOHvyIzJuNJa93Za54v6TjddT4e/3UJkq8eodHoLi/O15rovPubJxtf6OyxjMrTs2bNz/PhxG2o8lah7P4rs2bOn6HrTfKKIiYHhw+HzPln58vw55rSdR4ux95E5ze+ZMWlf8eLFCQ8P5+jRo/4OJcO4dIe7lJSmD6e/j1vJutfn0+3IBzRpUp5Mn+ygZVm7k5AxgSJLliwpeqc14x8+PUchIk1EZIeI7BKR3vHMFxH52J2/WURu8Wa9Zw+dYk31LpTr2IDbj85l9uhjLFwIZSxJGGNMivNZi0JEgoARQGMgHFgvIvNVNcyjWFOgnPuoBYx0/ybo3KGTnCxRiZoxESyt/BIhi/rzQPGcvtkJY4wxPm1R1AR2qepuVb0IzADuj1PmfmCS+wvztUA+ESmS2EqzRuzlTFBeNo9czd1bPiC/JQljjPEpX56jKAYc8JgO57+thfjKFAMOeRYSkU5AJ3fyQvmLoVvpUhu6pGzAaVBB4Ji/gwgQVheXWV1cZnVxWfnkLujLRBHftXBxL/D1pgyqOgYYAyAiG5L7M/T0xuriMquLy6wuLrO6uExEvB/7KA5fdj2FAyU8posDEckoY4wxxo98mSjWA+VEpIyIZAVaA/PjlJkPPOle/VQbOKmqh+KuyBhjjP/4rOtJVaNF5HlgCRAETFDVUBHp7M4fBSwEmgG7gHPA016seoyPQk6LrC4us7q4zOriMquLy5JdF2lumHFjjDGpK10NCmiMMSblWaIwxhiTqIBNFL4a/iMt8qIuHnPrYLOIrBaRav6IMzUkVRce5W4VkRgReTA140tN3tSFiDQQkU0iEioiK1M7xtTixWckr4h8LSK/uXXhzfnQNEdEJojInyKyNYH5yTtuJvdm27584Jz8/gO4HsgK/AZUjFOmGbAI57cYtYGf/R23H+viNuAa93nTjFwXHuWW4Vws8aC/4/bj/0U+IAwo6U4X8nfcfqyLPsB77vNrgb+ArP6O3Qd1cQdwC7A1gfnJOm4GaovCJ8N/pFFJ1oWqrlbVE+7kWpzfo6RH3vxfAHQFZgN/pmZwqcybumgDfKWq+wFUNb3Whzd1oUBucW6KkQsnUUSnbpi+p6qrcPYtIck6bgZqokhoaI8rLZMeXOl+tsf5xpAeJVkXIlIMaAmMSsW4/MGb/4sbgWtEZIWI/CIiT6ZadKnLm7oYDlTA+UHvFuBFVY1NnfACSrKOm4F6P4oUG/4jHfB6P0WkIU6iqOvTiPzHm7oYCvRS1Zh0fkc1b+oiM1ADaATkANaIyFpV3enr4FKZN3VxD7AJuBO4AfhWRH5Q1VO+Di7AJOu4GaiJwob/uMyr/RSRqsA4oKmqHk+l2FKbN3URAsxwk0RBoJmIRKvq3NQJMdV4+xk5pqpngbMisgqoBqS3ROFNXTwNDFKno36XiOwBbgLWpU6IASNZx81A7Xqy4T8uS7IuRKQk8BXwRDr8tugpybpQ1TKqWlpVSwOzgGfTYZIA7z4j84B6IpJZRHLijN68LZXjTA3e1MV+nJYVIlIYZyTV3akaZWBI1nEzIFsU6rvhP9IcL+viDaAA8Kn7TTpa0+GImV7WRYbgTV2o6jYRWQxsBmKBcaoa72WTaZmX/xf9gYkisgWn+6WXqqa74cdFZDrQACgoIuHAm0AWuLrjpg3hYYwxJlGB2vVkjDEmQFiiMMYYkyhLFMYYYxJlicIYY0yiLFEYY4xJlCUKE5DckV83eTxKJ1L2TApsb6KI7HG3tVFE6iRjHeNEpKL7vE+ceauvNkZ3PZfqZas7Gmq+JMpXF5FmKbFtk3HZ5bEmIInIGVXNldJlE1nHRGCBqs4SkbuBIapa9SrWd9UxJbVeEfkc2KmqAxIp3xYIUdXnUzoWk3FYi8KkCSKSS0S+d7/tbxGR/4waKyJFRGSVxzfueu7rd4vIGnfZL0UkqQP4KqCsu+xL7rq2ikg397VgEfnGvbfBVhF5xH19hYiEiMggIIcbx1R33hn370zPb/huS6aViASJyGARWS/OfQKe8aJa1uAO6CYiNcW5F8mv7t/y7q+U+wGPuLE84sY+wd3Or/HVozH/4e/x0+1hj/geQAzOIG6bgDk4owjkcecVxPll6aUW8Rn378vAa+7zICC3W3YVEOy+3gt4I57tTcS9dwXwEPAzzoB6W4BgnKGpQ4GbgVbAWI9l87p/V+B8e/8nJo8yl2JsCXzuPs+KM5JnDqAT8Lr7ejZgA1AmnjjPeOzfl0ATdzoPkNl9fhcw233eFhjusfy7wOPu83w44z4F+/v9tkdgPwJyCA9jgPOqWv3ShIhkAd4VkTtwhqMoBhQGDnsssx6Y4Jadq6qbRKQ+UBH4yR3eJCvON/H4DBaR14GjOKPwNgLmqDOoHiLyFVAPWAwMEZH3cLqrfriC/VoEfCwi2YAmwCpVPe92d1WVy3fkywuUA/bEWT6HiGwCSgO/AN96lP9cRMrhjAaaJYHt3w3cJyI93OnsQEnS5xhQJoVYojBpxWM4dyaroapRIrIX5yD3D1Vd5SaSe4HJIjIYOAF8q6qPerGNnqo669KEiNwVXyFV3SkiNXDGzBkoIktVtZ83O6GqkSKyAmfY60eA6Zc2B3RV1SVJrOK8qlYXkbzAAuA54GOcsYyWq2pL98T/igSWF6CVqu7wJl5jwM5RmLQjL/CnmyQaAqXiFhCRUm6ZscB4nFtCrgVuF5FL5xxyisiNXm5zFfA/d5lgnG6jH0SkKHBOVacAQ9ztxBXltmziMwNnMLZ6OAPZ4f7tcmkZEbnR3Wa8VPUk8ALQw10mL3DQnd3Wo+hpnC64S5YAXcVtXonIzQltw5hLLFGYtGIqECIiG3BaF9vjKdMA2CQiv+KcRximqkdxDpzTRWQzTuK4yZsNqupGnHMX63DOWYxT1V+BKsA6twvoNeCdeBYfA2y+dDI7jqU49zb+Tp1bd4JzL5EwYKOIbAVGk0SL343lN5xhtd/Had38hHP+4pLlQMVLJ7NxWh5Z3Ni2utPGJMoujzXGGJMoa1EYY4xJlCUKY4wxibJEYYwxJlGWKIwxxiTKEoUxxphEWaIwxhiTKEsUxhhjEvV/XskSRH3VGpAAAAAASUVORK5CYII=\n",
"text/plain": [
"
"
]
},
"metadata": {
"needs_background": "light"
},
"output_type": "display_data"
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"\n",
"Please wait Training-Testing with all models..\n",
"\n",
"Done with LogisticRegression\n",
"Done with RandomForestClassifier\n",
"Done with XGBoost Classifier\n",
"Done with LGBoost Classifier\n",
"Done with AdaBoost Classifier\n",
"Done with GradientBoostingClassifier\n"
]
},
{
"data": {
"text/html": [
"
"
],
"text/plain": [
""
]
},
"execution_count": 11,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"y_pred, model = es.classification(X,y)\n",
"es.classification_result(y_test,y_pred)\n",
"es.roc_curve_graph(y_test, y_pred)\n",
"es.quick_pred(X,y,'c')"
]
},
{
"cell_type": "code",
"execution_count": 3,
"metadata": {
"ExecuteTime": {
"end_time": "2020-04-26T19:50:56.925457Z",
"start_time": "2020-04-26T19:50:02.506420Z"
}
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Dataframe Imported Successfully\n",
"*** Dataset Infomarion ***\n",
"##################################################\n",
"No of Rows : 1302\n",
"No of columns : 7\n",
"No of Numerical columns: 7\n",
"No of Categorical columns: 0\n",
"##################################################\n",
"\n",
" Total Missing values : 0 \n",
"\n",
"##################################################\n",
"Summary of DataFrame:\n",
"\n",
" Column Name Nulls/NaN outof Unique Type of Columns\n",
"0 buying_price 0 1302 4 Numerical\n",
"1 maintainence_cost 0 1302 4 Numerical\n",
"2 number_of_doors 0 1302 4 Numerical\n",
"3 number_of_seats 0 1302 3 Numerical\n",
"4 luggage_boot_size 0 1302 3 Numerical\n",
"5 safety_rating 0 1302 3 Numerical\n",
"6 popularity 0 1302 4 Numerical\n"
]
},
{
"data": {
"application/javascript": [
"\n",
" if (window._pyforest_update_imports_cell) { window._pyforest_update_imports_cell('from sklearn.model_selection import train_test_split'); }\n",
" "
],
"text/plain": [
""
]
},
"metadata": {},
"output_type": "display_data"
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"************************************************************\n",
"\n",
"\n",
" OLS Regression Results \n",
"=======================================================================================\n",
"Dep. Variable: popularity R-squared (uncentered): 0.894\n",
"Model: OLS Adj. R-squared (uncentered): 0.894\n",
"Method: Least Squares F-statistic: 1825.\n",
"Date: Mon, 27 Apr 2020 Prob (F-statistic): 0.00\n",
"Time: 01:20:02 Log-Likelihood: -915.04\n",
"No. Observations: 1302 AIC: 1842.\n",
"Df Residuals: 1296 BIC: 1873.\n",
"Df Model: 6 \n",
"Covariance Type: nonrobust \n",
"=====================================================================================\n",
" coef std err t P>|t| [0.025 0.975]\n",
"-------------------------------------------------------------------------------------\n",
"buying_price -0.1362 0.012 -11.721 0.000 -0.159 -0.113\n",
"maintainence_cost -0.1092 0.011 -9.546 0.000 -0.132 -0.087\n",
"number_of_doors 0.0537 0.011 5.102 0.000 0.033 0.074\n",
"number_of_seats 0.2138 0.009 22.528 0.000 0.195 0.232\n",
"luggage_boot_size 0.1288 0.015 8.385 0.000 0.099 0.159\n",
"safety_rating 0.3725 0.015 24.433 0.000 0.343 0.402\n",
"==============================================================================\n",
"Omnibus: 281.511 Durbin-Watson: 2.017\n",
"Prob(Omnibus): 0.000 Jarque-Bera (JB): 701.940\n",
"Skew: 1.150 Prob(JB): 3.76e-153\n",
"Kurtosis: 5.766 Cond. No. 8.35\n",
"==============================================================================\n",
"\n",
"Warnings:\n",
"[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.\n",
"\n",
"\n",
"******** VIF *********\n",
"\n",
" feature vif\n",
"3 number_of_seats 10.14\n",
"6 popularity 9.45\n",
"5 safety_rating 8.54\n",
"2 number_of_doors 8.28\n",
"4 luggage_boot_size 6.26\n",
"0 buying_price 6.20\n",
"1 maintainence_cost 5.73\n",
"########## MENU ##############\n",
"\n",
"1. Logisitic Regression \n",
"2. Random Forest \n",
"3. XGB Classifier \n",
"4. LGB CLassifier \n",
"5. Gradient Boosting Classifier \n",
"6. AdaBoost Classifier\n",
"\n",
"Input No, which you want:3\n",
"Predicting with XGB boost Classifier\n",
"--------------------------------------------------------\n",
"********************* Model Results ********************\n",
"--------------------------------------------------------\n",
"F1 Score : 0.9770320347121912\n",
"AUC-ROC Score : 0.9707396672414965\n",
"Report:\n",
" precision recall f1-score support\n",
"\n",
" 1 0.99 0.99 0.99 277\n",
" 2 0.96 0.95 0.95 94\n",
" 3 0.86 1.00 0.92 12\n",
" 4 1.00 0.88 0.93 8\n",
"\n",
" accuracy 0.98 391\n",
" macro avg 0.95 0.95 0.95 391\n",
"weighted avg 0.98 0.98 0.98 391\n",
"\n"
]
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAYEAAAEgCAYAAABSGc9vAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADt0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjByYzEsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy/xvVyzAAAgAElEQVR4nO3de5xVdb3/8ddbxlEBL6UxY0ogAcdCjpi3hEKlDBOSjiChdbwk8vP36yeVnLx1QqFTnuO1k6csUrH6laaZUqCVQYpl3lFSUTMdxcsMeUO8AM7w+f2x1uA47Blmhj17zZr1fj4e+7Fn3T/znT37vdd3XbYiAjMzK6atsi7AzMyy4xAwMyswh4CZWYE5BMzMCswhYGZWYA4BM7MCcwhYjyZppqRHJL0lKSR9pQLbrJNU193bKYL0b3Zr1nVY2xwCBoCkPSVdKukhSaslrZf0vKRFkk6StG0GNU0D/htYC3wHmAPcWek6eoI0mCJ9HNrOfPNbzHfuFm7zkHKsx3q2qqwLsOxJmg2cQ/Kh4E7gx8DrQA1wCHA58L+B/Spc2sTm54h4voLb/UQFt9VZjcDJwB9bT5C0AzA1naen/G9/CHgz6yKsbT3lhWIZkXQ2ySfslcDREXFXiXkmArMqXRvwfoAKBwAR8fdKbq+TFgJHSdo5Il5qNe3zQF/gBuBfKl5ZCRHxaNY1WPvcHVRgkgYD5wJvA0eUCgCAiFgIHF5i+amSlqbdR29J+quksyRtU2LeuvTRV9IFkp6RtE7SE5LOkKQW854rKYBD0+Hm7o1orjsdvqqN3+vW5nlbjJOk4yXdIekfktZKWinpd5I+V6rWEuvdRtKZkpZLelPSa5JulzS1xLwba0x/vkbSi+l2702DtSt+BGwD/GuJaSeThPlvSy0oabik/0y3/4+0/Z+WNE/S7q3mvYp39jbOafk3kHRIOs8J6fAJkg5P2311y7ZvfUxA0h6SXpX0sqRBrbbZT9IKSU2SDu5sw1jXeE+g2E4EtgauiYiH2psxIta1HJb0beAs4EXg5yTdR58Gvg2Ml3RYRLzdajVbA78n+YR/M0m3xWeB/wS2JdkjAbg1fT4BGNRi/Jb4VlrvU8C1wGpgV2B/4GjgF+0tLKka+B1wMPAo8D2ST91TgF9IGhURZ5dYdBBwN/Ak8FPgvcDngAWSPhkRm3TrbMYtQB0wneQ4SXN9+wL7kLTVhjaWPQo4heTN/Q5gPTAiXddnJO0XEc+l896YPh8P3MY7fxPS7bc0heRDws3AD4DBbRUfEU9Jmg5cB1wtaWxENKaTvw/sCZwbEbe1tQ4rs4jwo6APYDEQwPROLndQutwzQG2L8VXAb9JpZ7dapi4dfxOwXYvxA4BX08fWrZa5NXmJbrL9wem6rmqjvk2WA14CngX6lph/lxK11rUad1aL+qta1d/8u40uUWMA57Ra1/jmdXWizZu3UQX8e/rzQS2m/wBoAj5A8qYeJG+mLdexG7BNiXV/Kl32slbjDym1nhbTT0inbwAOb2OeAG4tMf776bTz0uHj0uE/Altl/b9RpIe7g4pt1/T52U4u98X0+T8ior55ZCSf6GaRvClMb2PZmRHxVotlVgELgB2Bf+pkHZ31Nsmb3btExIsdWPaLJG9Sp8U7n1yb6/9mOljqd34a+I9W2/sdSYAe0LGyN3Elye9xMiTdKMCxwO8i4pm2FoqI56LVHl06/vfAwyTh1BULIqJkF1Q7TgMeBM6Q9H9JQuEfwOcjoq09GesGDoFia+6H7+z9xD+SPi9pPSEiHicJlT0k7dRq8uqIeKLE+lamz+/pZB2d8TOST+cPSzov7cPesSMLStoeGAo8H6UPdDa3wz4lpj0QEZsED8nv3KXfN5ID5TcBU9MzgqYB25McL2hTelzkC5L+kB4TaGxxrGUkyZ5CV9zd2QUiYi1Jt9gbwKUkXWvHRYVPAjCHQNE1/8Pt3u5cm2p+83yhjekvtJqv2attzN/8ybpPJ+vojK8CXyF50zmTpP/6RUkLJA3dzLId/X1bhx60/ztvyf/fj4B+wDEkewT1JF1x7bmY5LjEh0mOb1xEcgxhDskeS3UXa6nf/CwlPQ4sT39+hOR4kVWYQ6DY/pQ+d/a8+NXpc20b03dtNV+5NXcXtHViwyZvxhHRFBH/HRF7k1z/MJnkVMojgd+WOqOphax/31JuAp4jOT5wIDC/ZTdVa5IGADOBh4B/iogvRMQZEXFuRJwLbNJN1Ald/WaqM4HRJCcXjCA57mIV5hAotvkk/eSTJX24vRlbvUkuS58PKTHfUJI9i6cioq1PwVvqlfR5YInt7wAMb2/hiFgVEb+KiKkkXTkfBPZqZ/41wN+B3SQNKzFL8xW893eg9rJIu5iuJGnrAK7YzCJDSP7ff5/+Phulp4cOKbFMczdW2ffQJI0G5gKPkbT9Y8AcSR8r97asfQ6BAouIOpLrBKqBRZJKXhEsqfn0v2ZXps//Lul9LebrA1xI8rra3JtSl6VvYo8CY1qGV7r9i4HtWs6fnt//iZbXIqTjtyY5ZRM2f1XrlSTHUC5It9O8jl2Ab7SYp5K+S3JR2PjY/AVudenzx1rV35+ka6nUXlXzxWgf2MI630XSe4CrSUJmWkQ0kBwfaCQ5bXTncm7P2ufrBAouIr4tqYrkthH3SLoDuJd3bhsxFhiWjmte5g5J5wOnAw9J+iVJX/unST7V/Qm4oJtLv4AkaP4s6TqS+wsdSnItwoPA3i3m3Q74A1An6S6S/u9tgcNIbmvw64hYsZntXUjy+00CHpR0E8nBzKNJThM9PyL+1M7yZZee1XTjZmdM5q2XdA3JQeQHJP2e5FjHYSRt9wAwqtVij5F0OU2TtJ7kjKYAfhoRT29B6VeSBMvMiHggre9BSbOA/yHZQz1yC9ZvnZH1Oap+9IwHyZvhpSR9xq+RXEj0AskewEmUPr98Gskb/hqSN5KHga8D25aYt45W5963mHYuyZvLIa3G30qJ6wRaTD8p3eY6koOTPwR2br0cSTCcnv4uz6S1/oPkPkmnANUdqZUkOM5O2+it9Pf+E3BMiXkH08lrGTbz96lL11fVgXnbuk6gL8lFc0+kbbCS5KK3TdqsxTL7k1xPsprkWMzGvxPvXCdwQju1vOs6AeDUdNyCNub/VTr9q1n/TxTlobThzcysgHxMwMyswBwCZmYF5hAwMyswh4CZWYHl6hRRtbpHvJmZbV5EqK1puQoBKy/fq6t8pPfjM+3KR5Lbs0xaXSO5CXcHmZkVmEPAzKzAHAJmZgXmEDAzKzCHgJlZgTkEzMwKzCFgZlZgDgEzswJzCJiZFZhDwMyswBwCZmYF5hAwMyswh4CZWYE5BMzMCswhYGZWYA4BM7MCcwiYmRWYQ8DMrMAcAmZmBeYQMDMrMIeAmVmBOQQ6affdd2fJkiU88sgjPPTQQ8ycOROAa665hmXLlrFs2TKeeuopli1b9q7lBg4cyJo1a5g1a1YWZefOunXrmDLlFI488iQmTDiB7353ftYl5d7SpUsZP348hx12GPPmzcu6nNzrLe1ZlXUBedPY2MisWbNYtmwZ/fv357777uOWW25h2rRpG+e58MILWb169buWu+SSS7j55psrXW5uVVdX8+MfX0y/fn15++1Gjj32VMaOPYBRo0ZkXVouNTU1MXfuXObPn09NTQ1Tpkxh3LhxDB06NOvScqk3taf3BDqpvr5+46f8119/nRUrVrDbbru9a56pU6dy9dVXbxyeNGkSTz75JA8//HBFa80zSfTr1xdIgrexsRFJGVeVX8uXL2fQoEEMHDiQ6upqJkyYwOLFi7MuK7d6U3s6BLbAoEGD2Geffbjrrrs2jvv4xz9OQ0MDTzzxBAB9+/bljDPOYM6cOVmVmVtNTU1MmnQSo0d/ltGj92PvvT+cdUm51dDQQG1t7cbhmpoaGhoaMqwo33pTe/aIEJB0YtY1dFa/fv24/vrr+cpXvsKaNWs2jj/mmGPetRcwZ84cLrnkEt54440sysy1Pn36sGDBFdx223UsX76Cxx9/MuuScisiNhnnPauu603t2VOOCcwBSh75kzQDmFHZctpXVVXF9ddfz89+9jNuuOGGjeP79OnDUUcdxb777rtx3IEHHsiUKVM4//zz2WmnndiwYQNr167le9/7Xhal59IOO2zPgQeO4vbb72b48CFZl5NLtbW11NfXbxxuaGhgwIABGVaUb72pPSsWApKWtzUJqGlruYiYB8xL17Fp/GbgiiuuYMWKFVxyySXvGv/JT36SRx99lOeee27juLFjx278+ZxzzuH11193AHTAyy+/SlVVH3bYYXvWrl3HHXfcx8knH5N1Wbk1cuRI6urqWLlyJTU1NSxatIiLLroo67Jyqze1ZyX3BGqA8cArrcYLuKOCdWyRMWPGcNxxx7F8+fKNB4jPPvtsbr75ZqZNm/auriDrulWrXuLMM8+jqWkDERs4/PBDOfTQ0VmXlVtVVVXMnj2b6dOn09TUxOTJkxk2bFjWZeVWb2pPlerb6pYNSVcA8yPiTyWm/Twiju3AOnrEnkBvEfF81iX0GtL7S/YTW9dIcnuWSdqWbR6wqFgIlINDoLwcAuXjECgvh0D5bC4EesTZQWZmlg2HgJlZgTkEzMwKzCFgZlZgDgEzswJzCJiZFZhDwMyswBwCZmYF5hAwMyswh4CZWYE5BMzMCswhYGZWYA4BM7MCcwiYmRWYQ8DMrMAcAmZmBeYQMDMrMIeAmVmBOQTMzArMIWBmVmAOATOzAlNEZF1Dh0nKT7FmZj1ERKitaVWVLKQcIp7PuoReQXo/MfcbWZfRa2j2N4lYk3UZvYa0PXn6gNqTSW2+/wPuDjIzKzSHgJlZgTkEzMwKzCFgZlZgDgEzswJzCJiZFZhDwMyswBwCZmYF5hAwMyswh4CZWYE5BMzMCswhYGZWYA4BM7MCcwiYmRWYQ8DMrMAcAmZmBeYQMDMrMIeAmVmBOQTMzArMIWBmVmAOATOzAnMImJkVWFXWBfQm69at4/Of/zLr179NU1MT48cfzMyZJ2ZdVr4ceBDssy9EwKoG+PWNsMvOcMSRUF0Nr74KN/wS1q/LutJceeGFek4/fTYvvvgSW221FVOn/gvHH39s1mXl2tKlS/nWt77Fhg0bOProo5kxY0bWJXWJQ6CMqqur+fGPL6Zfv768/XYjxx57KmPHHsCoUSOyLi0ftt8e9v8o/OBSaGyEyVNhxF6w/4Fwy+/gmTrYex8YPQZuXZJ1tbnSp08fzjzzq4wY8SFef/0NJk/+AmPGfJShQ4dkXVouNTU1MXfuXObPn09NTQ1Tpkxh3LhxDB06NOvSOq2i3UGS9pT0CUn9W40/vJJ1dBdJ9OvXF4DGxkYaGxuRlHFVObPVVlC1NSh9fn0N7LxzEgAAT/0d9vxwpiXm0YAB72PEiA8B0L9/P4YM2YOGhlUZV5Vfy5cvZ9CgQQwcOJDq6momTJjA4sWLsy6rSyoWApJmAguAU4GHJE1qMfnblaqjuzU1NTFp0kmMHv1ZRo/ej7339htWh61ZA3f+Gb58Gnz1a7BuLTz5d1i1Cobvmczzob1ghx2zrTPnnn32eVaseJS9994r61Jyq6Ghgdra2o3DNTU1NDQ0ZFhR11VyT+BkYN+I+CxwCPANSV9Op7X5cVnSDEn3Srq3AjVusT59+rBgwRXcdtt1LF++gscffzLrkvJj222TN/tLL4HvXJAcAxj5z/CbG2G/A2D6KbBNNTQ1ZV1pbr3xxpvMnPk1zj773+jfv//mF7CSImKTcXnd66/kMYE+EfE6QETUSToE+KWkQbQTAhExD5gHIGnTlu+hdthhew48cBS33343w4e737VD9vggvPoKvPlmMvzoI7D7B+Cvy+HnP0nGvXdnGDo8uxpz7O2332bmzK/xmc98mk99alzW5eRabW0t9fX1G4cbGhoYMGBAhhV1XSX3BOoljWoeSANhIrALMLKCdXSbl19+lddeWwPA2rXruOOO+xgy5AMZV5Ujq1fD7gOTYwEAg4fAi/+Avv3SGQQfPxjuuyezEvMqIvj617/JkCF7cOKJX8i6nNwbOXIkdXV1rFy5kvXr17No0SLGjctnsFZyT+A4oLHliIhoBI6T9MMK1tFtVq16iTPPPI+mpg1EbODwww/l0ENHZ11Wfjz/LKx4GE4+BTZsgPoX4P57Yd/9k+4ggEdXwIPLsq0zh+677wEWLFjE8OFDmTTpGABOO+1LHHzwxzKuLJ+qqqqYPXs206dPp6mpicmTJzNs2LCsy+oSlerb6qkkRcTzWZfRK0jvJ+Z+I+syeg3N/iYRa7Iuo9eQti/Z726dJ4mIaLPL3VcMm5kVmEPAzKzA2jwmIOnaTqwnIuJzZajHzMwqqL0Dw++rWBVmZpaJNkMgIg6tZCFmZlZ5PiZgZlZgHb5OQNL2wCRgOLBt6+kRcXoZ6zIzswroUAhI+iDwZ6Av0A/4B/DedPlXgNWAQ8DMLGc62h10CXAvUENyn58jgO2ALwCvAz4zyMwshzraHXQAMB1o/jqn6ohoAn4uaRfgvwHfH8HMLGc6uiewLfBaRGwAXgbe32LaQ8De5S7MzMy6X0dD4HFgUPrzMuAUSdtK2ho4CfANfczMcqij3UHXAKOAnwLfAH4HvAZsSNdxQncUZ2Zm3atDIRARF7f4+U5JewGfJukmWhIRD3VTfWZm1o269H0CEbGS9Nu+zMwsvzp6ncARm5snIm7a8nLMzKySOronsBAINv0u4Jbf+tCnLBWZmVnFdDQE9igx7r3Ap0gOCp9YroLMzKxyOnpg+OkSo58GlklqAs4GjixnYWZm1v3KcRfRZcC4MqzHzMwqbItCQFI1SXfQC2WpxszMKkoRsfmZpHt490FggGpgMLA9cGJE/KTs1W1ax+aLNTOzd4mI1if1bNTRA8MPs2kIrAWuA26MiIe7WJuZmWWoQ3sCPYWkyFO9PZkk3Jblk7Snv1KjXKTz/fosk/R/vc09gQ4dE5C0RNKebUwbLmlJVws0M7PsdPTA8CHADm1M2wEYW5ZqzMysojpzdtAm+2bp2UHjgPqyVWRmZhXT5oFhSecAs9PBAO6U2uxWuqDMdZmZWQW0d3bQTcCLJPcL+i5wEVDXap71wKMRcXu3VGdmZt2qzRCIiHuAewAkrQEWRsRLlSrMzMy6X0ePCTwAHFhqgqQjJP1z+UoyM7NK6WgIXEIbIQDsn043M7Oc6WgIfAT4cxvT/gLsU55yzMyskjoaAn2Afm1M60dyHyEzM8uZjobAPcCMNqbNAO4tTzlmZlZJHb2B3LnAHyTdBfyY5OKwXYHjgFHAJ7ulOjMz61Yd/WaxpZI+BZwHXEpy7cAG4C7gE+mzmZnlTEf3BIiIW4GDJPUF3gO8AhwEHA8sAHbujgLNzKz7dDgEWhgJHANMBWqAl4FrylmUmZlVRodCQNJeJG/800i+TWw9yRlBs4D/iYjG7irQzMy6T5tnB0kaIulsSX8FHgT+DVhBcjB4GMlxgfsdAGZm+dXensATJHcPvQv4X8D1EfEKgKQdK1CbmZl1s/auE3ia5NP+XiRfKjNaUleOIZiZWQ/VZghExB7AGJLrAj4B/AZokPSjdNhfAGpmlnPtXjEcEX+JiFOB3YDxJKeCTgZ+mc5ysqT9urdEMzPrLh26bUREbIiIWyLii0AtcBRwHfAvwF2SVnRjjbmxdOlSxo8fz2GHHca8efOyLif33J5b5qyz7uegg25i4sTFG8f91389xOGH/4HPfGYJX/rSXbz22voMK8y33vL67Mx3DAMQEesj4saImEZyncBxJAeRC62pqYm5c+dy+eWXs2jRIhYuXMgTTxS+WbrM7bnljjrqA1x++eh3jRszZgALF47jN78Zx+DB/fnhD/+WUXX51pten50OgZYi4o2I+FlEfKYj80s6QNL+6c8flnSapCO2pIaeYvny5QwaNIiBAwdSXV3NhAkTWLx48eYXtJLcnltu//13Yccdt37XuI99bABVVcm//ahR76G+/q0sSsu93vT63KIQ6Iz0i+u/C1wm6Tzgf4D+wJmSvl6pOrpLQ0MDtbW1G4drampoaGjIsKJ8c3t2v+uvf5qxY2uyLiOXetPrs5KnfE4huePoNiR3Id09Il6TdAHJtQjfKrWQpBm0fRvrHiNi05OlJGVQSe/g9uxel132GH36bMWRR+6edSm51Jten5UMgcaIaALelPT3iHgNICLekrShrYUiYh4wD0BSjz0ttba2lvr6+o3DDQ0NDBgwIMOK8s3t2X1uuOEZbr21nquuGpPbN66s9abXZ8W6g4D16R1IAfZtHplefdxmCOTFyJEjqaurY+XKlaxfv55FixYxbty4rMvKLbdn91i6tIEf/ehvXHbZR9luO1/72VW96fVZyVfB2IhYB8kppy3Gb01yO+pcq6qqYvbs2UyfPp2mpiYmT57MsGHDsi4rt9yeW+600+7h7rtf5JVX1jN27G859dQ9mTfvb6xfv4ETT0y+Mnzvvd/L3LmjMq40f3rT61Ol+rZ6KkmRp3p7Mkkl+zWta5L2PD3rMnoN6Xy/Pssk/V9vs9+vkt1BZmbWwzgEzMwKzCFgZlZgDgEzswJzCJiZFZhDwMyswBwCZmYF5hAwMyswh4CZWYE5BMzMCswhYGZWYA4BM7MCcwiYmRWYQ8DMrMAcAmZmBeYQMDMrMIeAmVmBOQTMzArMIWBmVmAOATOzAnMImJkVmEPAzKzAFBFZ19BhkvJTrJlZDxERamtaVSULKYc8hVZPJsltWUZuz/JK2nNh1mX0CtLEdqe7O8jMrMAcAmZmBeYQMDMrMIeAmVmBOQTMzArMIWBmVmAOATOzAnMImJkVmEPAzKzAHAJmZgXmEDAzKzCHgJlZgTkEzMwKzCFgZlZgDgEzswJzCJiZFZhDwMyswBwCZmYF5hAwMyswh4CZWYE5BMzMCswhUEZLly5l/PjxHHbYYcybNy/rcnLvrLPO4qCDDmLixIlZl9Ir+PVZPk8+uYpJky7c+PjIR87iqqtuy7qsLlFEZF1Dh0mKnlpvU1MT48ePZ/78+dTU1DBlyhQuvvhihg4dmnVpJUmip7Zls3vuuYe+fftyxhlnsHDhwqzLaVdPb898vj579t+8WVPTBsaOncO1136Z3XZ7b9blbEKaSESoreneEyiT5cuXM2jQIAYOHEh1dTUTJkxg8eLFWZeVa/vvvz877rhj1mX0Cn59dp+//OVvDBy4c48MgI7INAQk/STL7ZdTQ0MDtbW1G4drampoaGjIsCKzd/j12X0WLVrGxIn7ZF1Gl1VVakOSft16FHCopJ0AIuLIStXSHUp1BUht7oGZVZRfn91j/fpGlix5mFmzJmRdSpdVLASA3YFHgMuBIAmB/YCL2ltI0gxgRrdXt4Vqa2upr6/fONzQ0MCAAQMyrMjsHX59do+lSx9lxIjd2GWX7bMupcsq2R20H3Af8HVgdUTcCrwVEbdFRJuH1SNiXkTsFxH7VajOLhk5ciR1dXWsXLmS9evXs2jRIsaNG5d1WWaAX5/dZdGi+5kw4SNZl7FFKrYnEBEbgEskXZc+N1Ry+92tqqqK2bNnM336dJqampg8eTLDhg3LuqxcO+2007j77rt55ZVXGDt2LKeeeipHH3101mXlkl+f5ffWW+u5447HmTs336/JzE4RlTQBGBMRZ3dimR57imje9PRTGvPG7VleeTpFtKfb3CmimX0Sj4hFwKKstm9mZr5OwMys0BwCZmYF5hAwMyswh4CZWYE5BMzMCswhYGZWYA4BM7MCcwiYmRWYQ8DMrMAcAmZmBeYQMDMrMIeAmVmBOQTMzArMIWBmVmAOATOzAnMImJkVmEPAzKzAHAJmZgXmEDAzKzCHgJlZgTkEzMwKTBGRdQ0dJik/xZqZ9RARobam5SoE8kLSjIiYl3UdvYXbs3zcluXVG9rT3UHdY0bWBfQybs/ycVuWV+7b0yFgZlZgDgEzswJzCHSPXPcR9kBuz/JxW5ZX7tvTB4bNzArMewJmZgXmEDAzKzCHQBlJulLSKkkPZV1L3kkaKOmPklZIeljSl7OuKc8kbSvpbkkPpu05J+ua8k5SH0nLJC3MupYt4RAor6uAw7MuopdoBGZFxIeAjwJfkvThjGvKs3XAuIjYGxgFHC7poxnXlHdfBlZkXcSWcgiUUUQsBV7Ouo7eICJeiIj705/XkPyz7ZZtVfkVidfTwa3Th88K6SJJuwMTgMuzrmVLOQSsx5M0GNgHuCvbSvIt7b54AFgF3BIRbs+u+w5wOrAh60K2lEPAejRJ/YHrga9ExGtZ15NnEdEUEaOA3YEDJO2VdU15JGkisCoi7su6lnJwCFiPJWlrkgD4WUT8Kut6eouIeBW4FR+/6qoxwJGS6oBrgHGS/l+2JXWdQ8B6JEkCrgBWRMTFWdeTd5LeJ2mn9OftgE8Cj2ZbVT5FxFkRsXtEDAamAUsi4gsZl9VlDoEyknQ18BfgnyQ9K+mkrGvKsTHAv5J8ynogfRyRdVE5tivwR0nLgXtIjgnk+tRGKw/fNsLMrMC8J2BmVmAOATOzAnMImJkVmEPAzKzAHAJmZgXmELDck3SupGjxeF7S9ZI+2E3bm5huZ3A6PDgdntiJdUyVdEIZa+qf1lC2dVoxVGVdgFmZrOadK2CHAN8EFksaERFvdPO2XwAOonMXX00FdiG586xZZhwC1ls0RsSd6c93SnoGuB04Ariu5YyStouIt8q14YhYB9y52RnNeiB3B1lv1Xxzr8GS6iRdJOkbkp4FXgOQtJWkMyU9IWmdpMclHd9yJUqcm35Z0BpJPwF2aDVPye4gSSdL+quktZIaJP1S0o6SrgImAwe36MI6t8VykyTdmy5XL+n89D5KLdc9Oa33LUlLgT3L02xWNN4TsN5qcPpcnz4fCzwM/B/eed1fChwPzAXuBw4DrpT0UotbKswEZgPfJtmzOAo4f3Mbl/Tv6Xq/D3wN6Ety//n+JF1VHwB2SusBeDZdbipwNfBD4Gzgg8B5JB/Y/i2d5yPAL4AbSL7YZARwbQfaxGxTEeGHH7l+AOcCL5K8uVcBw4E/knzi3xWoI+m337bFMkNJ7gV/fKt1/QS4J/25D/A8cFmreZlxweUAAAJiSURBVG4h+UKWwenw4HR4Yjq8E/AmcHE7Nf8SuLXVOAFPA/Nbjf8i8Bawczp8LfAI6W1f0nFfT2s4Ieu/hx/5erg7yHqLnYG308djJAeHPxcRL6TTF0fE2hbzf4IkBG6QVNX8ABYDoyT1AQaShMiCVtva3G2tDwK2A+Z38ncYTrKHcG2rmpYA2wLN9/8/APh1RLS88ZdvtW1d4u4g6y1Wk9weOUi6gJ5v9SbZ0Gr+XUg+6a9uY327ArXpz6taTWs93NrO6fML7c61qV3S55vamD4wfa7tQk1mJTkErLdojIh725ne+na5L5N8mf0YSn9F4Cre+f8Y0Gpa6+HWXkqfdyXppuqo5u+nngEsKzH9qfS5vgs1mZXkELCiWkKyJ7BjRNxSagZJK0necCcBv20x6ajNrPsvJH34x5MezC1hPUkXT0uPAc+RHGv4UTvrv4fkm63OarG3s7mazEpyCFghRcRjkn4AXCPpfOBekjflEcDwiJgeEU3ptAslvUhydtBk4EObWferkr4JfEtSNUn3zjYkZwfNiYjnSC4smyTpsyRnBj0fEc9LmgX8VNIOwM0kYTEE+CwwJSLeBP4LuIvk2MEVJMcK/AVG1iU+MGxF9iWS0zWPI3mjvorkjXppi3m+Q3J66Ckk33fcHzh9cyuOiPOA/01ynGIBySmfOwFr0lm+D/weuJLkk/2MdLlfkOx5jCK5yO1XJKeR3k8SCKTdXtOAfYAbSQLic5395c3A3yxmZlZo3hMwMyswh4CZWYE5BMzMCswhYGZWYA4BM7MCcwiYmRWYQ8DMrMAcAmZmBfb/AVxyUmlOGxkqAAAAAElFTkSuQmCC\n",
"text/plain": [
"
| Model | F1 score | AUC-ROC score | Accuracy | Confustion-Matrix | |
|---|---|---|---|---|---|
| 3 | \n", "LGBoost Classifier | \n", "0.926282 | \n", "0.8 | \n", "0.933333 | \n", "[[25 0]\n", " [ 2 3]] | \n", "
| 5 | \n", "GradientBoostingClassifier | \n", "0.926282 | \n", "0.8 | \n", "0.933333 | \n", "[[25 0]\n", " [ 2 3]] | \n", "
| 2 | \n", "XGBoost Classifier | \n", "0.881402 | \n", "0.7 | \n", "0.9 | \n", "[[25 0]\n", " [ 3 2]] | \n", "
| 4 | \n", "AdaBoost Classifier | \n", "0.881402 | \n", "0.7 | \n", "0.9 | \n", "[[25 0]\n", " [ 3 2]] | \n", "
| 1 | \n", "RandomForestClassifier | \n", "0.852564 | \n", "0.68 | \n", "0.866667 | \n", "[[24 1]\n", " [ 3 2]] | \n", "
| 0 | \n", "LogisticRegression | \n", "0.757576 | \n", "0.5 | \n", "0.833333 | \n", "[[25 0]\n", " [ 5 0]] | \n", "
"
]
},
"metadata": {
"needs_background": "light"
},
"output_type": "display_data"
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"--------------------------------------------------------\n",
"\n",
"Model used: XGBClassifier(base_score=0.5, booster='gbtree', class_weight='balanced',\n",
" colsample_bylevel=1, colsample_bynode=1, colsample_bytree=1,\n",
" gamma=0, learning_rate=0.1, max_delta_step=0, max_depth=8,\n",
" min_child_weight=1, missing=None, n_estimator=100,\n",
" n_estimators=100, n_jobs=1, nthread=None,\n",
" objective='multi:softprob', random_state=0, refit='AUC',\n",
" reg_alpha=0, reg_lambda=1, scale_pos_weight=1, seed=None,\n",
" silent=None, subsample=1, verbosity=1) \n",
" Done.\n",
"\n",
"\n",
"*** Start Hypertuning ***\n",
"\n",
"Performing GridSearchCV \n",
"Please wait............\n",
"Done ¯\\_(ツ)_/¯\n",
"\n",
"best parameters: \n",
" XGBClassifier(base_score=0.5, booster='gbtree', class_weight='balanced',\n",
" colsample_bylevel=1, colsample_bynode=1, colsample_bytree=1,\n",
" gamma=0, learning_rate=0.1, max_delta_step=0, max_depth=80,\n",
" min_child_weight=1, min_samples_leaf=3, min_samples_split=8,\n",
" missing=None, n_estimator=100, n_estimators=40, n_jobs=1,\n",
" nthread=None, objective='multi:softprob', random_state=0,\n",
" refit='AUC', reg_alpha=0, reg_lambda=1, scale_pos_weight=1,\n",
" seed=None, silent=None, subsample=1, verbosity=1)\n",
"\n",
"\n",
"*** Grid Search CV Result ***\n",
"\n",
"--------------------------------------------------------\n",
"********************* Model Results ********************\n",
"--------------------------------------------------------\n",
"F1 Score : 0.9618660674598313\n",
"AUC-ROC Score : 0.959293573399994\n",
"Report:\n",
" precision recall f1-score support\n",
"\n",
" 1 0.99 0.97 0.98 277\n",
" 2 0.92 0.94 0.93 94\n",
" 3 0.91 0.83 0.87 12\n",
" 4 0.80 1.00 0.89 8\n",
"\n",
" accuracy 0.96 391\n",
" macro avg 0.90 0.94 0.92 391\n",
"weighted avg 0.96 0.96 0.96 391\n",
"\n"
]
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAYEAAAEgCAYAAABSGc9vAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADt0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjByYzEsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy/xvVyzAAAgAElEQVR4nO3dfZyVdZ3/8ddbR8RbTFhAgSBvKFNSU9zI1lUUMaEw8Abb1ruUrZ8/zcW2FXczpV3bX5nWtltJeJP9TNIsMUZLBZEtFTRRUkAjHQORIRURFRwZPvvHdQ0OZ86ZO86ca85c7+fjcR5nrvvP+c7MeZ/re90cRQRmZpZPO2RdgJmZZcchYGaWYw4BM7MccwiYmeWYQ8DMLMccAmZmOeYQsG5N0sWSlkraKCkkXVKBbdZJquvq7eRB+jubn3UdVppDwACQ9CFJ35P0tKT1khokrZZUK+nzknpnUNNk4LvAJuA7wFXAo5WuoztIgynSx3GtzHdTs/mu3M5tHluO9Vj3VpN1AZY9SVcAXyP5UPAo8GPgTWAAcCwwE/gicGSFSxvf9BwRqyu43eMruK2O2gxcADxYOEHSnsDp6Tzd5X/7IODtrIuw0rrLH4plRNLlJJ+wVwKnRcTCIvOMBy6tdG3AvgAVDgAi4k+V3F4HzQEmSuobEa8WTPs7YFfgl8BnKl5ZERGxPOsarHXuDsoxScOAK4F3gZOLBQBARMwBTiqy/OmSFqTdRxsl/UHSNEk7F5m3Ln3sKulbkv4s6R1JKyT9syQ1m/dKSQEclw43dW9EU93p8M0lXtf8pnmbjZOksyU9LOkvkjZJWinpN5LOKFZrkfXuLOkySUskvS3pDUn/I+n0IvNurTH9eZakV9LtPp4Ga2f8CNgZ+Psi0y4gCfNfF1tQ0nBJ/5Fu/y9p+78oaYakwQXz3sx7extfa/47kHRsOs856fA5kk5K231987YvPCYg6QOSXpf0mqShBdvcTdIySY2S/rajDWOd4z2BfDsX2AmYFRFPtzZjRLzTfFjS1cA04BXgpyTdR58ErgbGShoTEe8WrGYn4D6ST/j3knRbnAL8B9CbZI8EYH76fA4wtNn47fHvab0vALcD64F9gJHAacDPWltYUi/gN8DfAsuB/yb51H0q8DNJh0XE5UUWHQosAp4HfgLsDZwBzJZ0QkS06NZpw/1AHXA+yXGSpvqOAA4naastJZadCHyB5M39YaABODhd16ckHRkRL6Xz3pU+nw08xHu/E9LtN3cqyYeEe4EfAsNKFR8RL0g6H7gDuE3SMRGxOZ38feBDwJUR8VCpdViZRYQfOX0Ac4EAzu/gcqPS5f4MDGw2vgb4VTrt8oJl6tLx9wC7NBvfH3g9fexUsMz85E+0xfaHpeu6uUR9LZYDXgVWAbsWmb9fkVrrCsZNa1Z/TUH9Ta/t40VqDOBrBesa27SuDrR50zZqgH9Nfx7VbPoPgUbg/SRv6kHyZtp8HYOAnYus+8R02R8UjD+22HqaTT8nnb4FOKnEPAHMLzL+++m0b6TDZ6XDDwI7ZP2/kaeHu4PybZ/0eVUHlzsvff63iFjTNDKST3SXkrwpnF9i2YsjYmOzZdYCs4E+wAc7WEdHvUvyZreNiHilHcueR/ImNTXe++TaVP/X08Fir/lF4N8KtvcbkgA9qn1lt3Ajyeu4AJJuFOCzwG8i4s+lFoqIl6Jgjy4dfx/wDEk4dcbsiCjaBdWKqcBTwD9L+r8kofAX4O8iotSejHUBh0C+NfXDd/R+4h9Nn+cVToiI50hC5QOS9iqYvD4iVhRZ38r0+X0drKMjbiX5dP6MpG+kfdh92rOgpD2AA4DVUfxAZ1M7HF5k2pMR0SJ4SF5zp15vJAfK7wFOT88ImgzsQXK8oKT0uMjnJD2QHhPY3OxYywiSPYXOWNTRBSJiE0m32FvA90i61s6KCp8EYA6BvGv6hxvc6lwtNb15vlxi+ssF8zV5vcT8TZ+sd+xgHR3xj8AlJG86l5H0X78iabakA9pYtr2vtzD0oPXXvD3/fz8CdgPOJNkjWEPSFdeaa0mOS3yY5PjGt0mOIVxFssfSq5O1rGl7lqKeA5akPy8lOV5kFeYQyLffps8dPS9+ffo8sMT0fQrmK7em7oJSJza0eDOOiMaI+G5EHEpy/cMkklMpPw38utgZTc1k/XqLuQd4ieT4wF8DNzXvpiokqT9wMfA08MGI+FxE/HNEXBkRVwItuok6oLPfTHUZ8HGSkwsOJjnuYhXmEMi3m0j6ySdJ+nBrMxa8SS5On48tMt8BJHsWL0REqU/B22td+jykyPb3BIa3tnBErI2IX0TE6SRdOfsDh7Qy/wbgT8AgSQcWmaXpCt4n2lF7WaRdTDeStHUAN7SxyH4k/+/3pa9nq/T00P2KLNPUjVX2PTRJHwemA8+StP2zwFWSPlHubVnrHAI5FhF1JNcJ9AJqJRW9IlhS0+l/TW5Mn/9V0l81m29H4BqSv6u23pQ6LX0TWw4c3Ty80u1fC+zSfP70/P7jm1+LkI7fieSUTWj7qtYbSY6hfCvdTtM6+gFfbTZPJf0nyUVhY6PtC9zq0udPFNS/O0nXUrG9qqaL0d6/nXVuQ9L7gNtIQmZyRNSTHB/YTHLaaN9ybs9a5+sEci4irpZUQ3LbiMckPQw8znu3jTgGODAd17TMw5K+CXwFeFrSz0n62j9J8qnut8C3urj0b5EEze8k3UFyf6HjSK5FeAo4tNm8uwAPAHWSFpL0f/cGxpDc1uDuiFjWxvauIXl9E4CnJN1DcjDzNJLTRL8ZEb9tZfmyS89quqvNGZN510iaRXIQ+UlJ95Ec6xhD0nZPAocVLPYsSZfTZEkNJGc0BfCTiHhxO0q/kSRYLo6IJ9P6npJ0KfBfJHuon96O9VtHZH2Oqh/d40HyZvg9kj7jN0guJHqZZA/g8xQ/v3wyyRv+BpI3kmeAfwF6F5m3joJz75tNu5LkzeXYgvHzKXKdQLPpn0+3+Q7Jwcnrgb6Fy5EEw1fS1/LntNa/kNwn6QtAr/bUShIcl6dttDF93b8Fziwy7zA6eC1DG7+funR9Ne2Yt9R1AruSXDS3Im2DlSQXvbVos2bLjCS5nmQ9ybGYrb8n3rtO4JxWatnmOgHgonTc7BLz/yKd/o9Z/0/k5aG04c3MLId8TMDMLMccAmZmOeYQMDPLMYeAmVmOVdUpoiq4R7yZmbUtIlRqWlWFgJVX8l0xVg7SeHymXflIcnuWScE1ki24O8jMLMccAmZmOeYQMDPLMYeAmVmOOQTMzHLMIWBmlmMOATOzHHMImJnlmEPAzCzHHAJmZjnmEDAzyzGHgJlZjjkEzMxyzCFgZpZjDgEzsxxzCJiZ5ZhDwMwsxxwCZmY55hAwM8sxh4CZWY45BMzMcswh0EGDBw9m3rx5LF26lKeffpqLL74YgFmzZrF48WIWL17MCy+8wOLFi7cuc9lll/HHP/6R5cuXc+KJJ2ZVelV5/vm1TJhwzdbHRz86jZtvfijrsqraggULGDt2LGPGjGHGjBlZl1P1ekp71mRdQLXZvHkzl156KYsXL2b33Xfn97//Pffffz+TJ0/eOs8111zD+vXrATjooIOYPHkyBx98MPvuuy8PPPAAw4cPZ8uWLVm9hKqw3379mT37ywA0Nm7hmGOuYsyYERlXVb0aGxuZPn06N910EwMGDODUU09l9OjRHHDAAVmXVpV6Unt6T6CD1qxZs/VT/ptvvsmyZcsYNGjQNvOcfvrp3HbbbQBMmDCBWbNm0dDQQF1dHStWrOCoo46qeN3V7JFH/siQIX0ZNGjvrEupWkuWLGHo0KEMGTKEXr16MW7cOObOnZt1WVWrJ7WnQ2A7DB06lMMPP5yFCxduHfc3f/M31NfXs2LFCgAGDRrEypUrt05ftWpVi9Cw1tXWLmb8+MOzLqOq1dfXM3DgwK3DAwYMoL6+PsOKqltPas9uEQKSzs26ho7abbfduPPOO7nkkkvYsGHD1vFnnnnm1r0AAEktlo2IitTYEzQ0bGbevGc46aTDsi6lqhX7myv2t2nt05Pas7scE7gKuKnYBElTgCmVLad1NTU13Hnnndx666388pe/3Dp+xx13ZOLEiRxxxBFbx61atYohQ4ZsHR48eDCrV6+uaL3VbMGC5Rx88CD69dsj61Kq2sCBA1mzZs3W4fr6evr3759hRdWtJ7VnxfYEJC0p8fgDMKDUchExIyKOjIgjK1VrW2644QaWLVvGddddt834E044geXLl/PSSy9tHXf33XczefJkevXqxbBhwzjwwANZtGhRpUuuWrW1TzBu3EezLqPqjRgxgrq6OlauXElDQwO1tbWMHj0667KqVk9qz0ruCQwAxgLrCsYLeLiCdWyXo48+mrPOOoslS5ZsPUB8+eWXc++99zJ58uRtuoIAli5dyu23387SpUvZvHkzF154oc8MaqeNGxt4+OHnmD79tKxLqXo1NTVcccUVnH/++TQ2NjJp0iQOPPDArMuqWj2pPVWp/mlJNwA3RcRvi0z7aUR8th3rcGd6GUXMybqEHkMa72M9ZSTJ7VkmaVuWPGBRsRAoB4dAeTkEyschUF4OgfJpKwS6xdlBZmaWDYeAmVmOOQTMzHLMIWBmlmMOATOzHHMImJnlmEPAzCzHHAJmZjnmEDAzyzGHgJlZjjkEzMxyzCFgZpZjDgEzsxxzCJiZ5ZhDwMwsxxwCZmY55hAwM8sxh4CZWY45BMzMcswhYGaWYw4BM7McU0RkXUO7SaqeYs3MuomIUKlpNZUspBwinsu6hB5BGk5M/2rWZfQYuuLrVNMHqu5OktuzTKSS7/+Au4PMzHLNIWBmlmMOATOzHHMImJnlmEPAzCzHHAJmZjnmEDAzyzGHgJlZjjkEzMxyzCFgZpZjDgEzsxxzCJiZ5ZhDwMwsxxwCZmY55hAwM8sxh4CZWY45BMzMcswhYGaWYw4BM7MccwiYmeWYQ8DMLMccAmZmOVaTdQE9TWNjI5Mm/SMDBvTl+uu/lnU51eevR8HhR0AErK2Hu++Cfv3g5E9BTQ1s2QL3zoHVL2VdaVWZNm0a8+fPp2/fvsyZMyfrcqpeT2pP7wmU2S233M3++w/JuozqtMceMPJjMPOHcP1/ww47wMGHwPEnwoL58KMfwEPzkmHrkIkTJzJz5sysy+gxelJ7VjQEJH1I0vGSdi8Yf1Il6+gqa9a8wvz5j3HqqX6T6rQddoCanUDp85sbkvE775w+935vnLXbyJEj6dOnT9Zl9Bg9qT0r1h0k6WLgQmAZcIOkL0XE7HTy1cCvK1VLV7n66hn80z+dx1tvvZ11KdVpwwZ49Hfwpanw7mZ4fgU8/yd4Yz189iw4YSxIcPOPsq7UrMeo5DGBC4AjIuJNScOAn0saFhHfBVRqIUlTgCmVKbHzHnxwEXvvvReHHHIACxcuybqc6tS7Nwz/EHzvOti0CU49A0Z8BPYdDPf9GpYvhQ8fDONPgVt/nHW1Zj1CJUNgx4h4EyAi6iQdSxIEQ2klBCJiBjADQFJUotDOeOKJpcybt5AFCx7nnXcaePPNjXz5y9dwzTVfzrq06vGB/eH1dfB2uie1fCkMfj8c8hH4zT3JuKXPwPgJ2dVo1sNU8pjAGkmHNQ2kgTAe6AeMqGAdXeLSS89hwYIfM2/ejVx77Vf42Mc+4gDoqPXrYfCQ5FgAwLD94JW/JMcAhg57b9xrr2VWollPU8k9gbOAzc1HRMRm4CxJ11ewDuuuVq+CZc/ABV9ITgVd8zI88XjyPPbk5KDx5s0wZ3bb67JtTJ06lUWLFrFu3TqOOeYYLrroIk477bSsy6paPak9FdFte1hakBQRz2VdRo8gDSemfzXrMnoMXfF1qul/qbuT5PYsk7QtS3a5+zoBM7MccwiYmeVYyWMCkm7vwHoiIs4oQz1mZlZBrR0Y/quKVWFmZpkoGQIRcVwlCzEzs8rzMQEzsxxr93UCkvYAJgDDgd6F0yPiK2Wsy8zMKqBdISBpf+B3wK7AbsBfgL3T5dcB6wGHgJlZlWlvd9B1wOPAAJL7/JwM7AJ8DngT8JlBZmZVqL3dQUcB5wPvpMO9IqIR+KmkfsB3gY93QX1mZtaF2rsn0Bt4IyK2AK8B+zab9jRwaLkLMzOzrtfeEHgOGJr+vBj4gqTeknYCPg+s7orizMysa7W3O2gWcBjwE+CrwG+AN4At6TrO6YrizMysa7UrBCLi2mY/PyrpEOCTJN1E8yLi6S6qz8zMulCnvk8gIlaSftuXmZlVr/ZeJ3ByW/NExD3bX46ZmVVSe/cE5gBBy+8Cbv6tDzuWpSIzM6uY9obAB4qM2xs4keSg8LnlKsjMzCqnvQeGXywy+kVgsaRG4HLg0+UszMzMul457iK6GBhdhvWYmVmFbVcISOpF0h30clmqMTOzilJEtD2T9BjbHgQG6AUMA/YAzo2IW8peXcs62i7WzMy2ERGFJ/Vs1d4Dw8/QMgQ2AXcAd0XEM52szczMMtSuPYHuQlJUU73dmSTcluWTtOe1bc9o7SJN9d9nmaT/6yX3BNp1TEDSPEkfKjFtuKR5nS3QzMyy094Dw8cCe5aYtidwTFmqMTOziurI2UEt9s3Ss4NGA2vKVpGZmVVMyQPDkr4GXJEOBvCoVLJb6VtlrsvMzCqgtbOD7gFeIblf0H8C3wbqCuZpAJZHxP90SXVmZtalSoZARDwGPAYgaQMwJyJerVRhZmbW9dp7TOBJ4K+LTZB0sqSPlK8kMzOrlPaGwHWUCAFgZDrdzMyqTHtD4KPA70pMewQ4vDzlmJlZJbU3BHYEdisxbTeS+wiZmVmVaW8IPAZMKTFtCvB4ecoxM7NKau8N5K4EHpC0EPgxycVh+wBnAYcBJ3RJdWZm1qXa+81iCySdCHwD+B7JtQNbgIXA8emzmZlVmfbuCRAR84FRknYF3gesA0YBZwOzgb5dUaCZmXWddodAMyOAM4HTgQHAa8CschZlZmaV0a4QkHQIyRv/ZJJvE2sgOSPoUuC/ImJzVxVoZmZdp+TZQZL2k3S5pD8ATwFfBpaRHAw+kOS4wBMOADOz6tXansAKkruHLgT+AbgzItYBSOpTgdrMzKyLtXadwIskn/YPIflSmY9L6swxBDMz66ZKhkBEfAA4muS6gOOBXwH1kn6UDvsLQM3MqlyrVwxHxCMRcREwCBhLciroJODn6SwXSDqya0s0M7Ou0q7bRkTEloi4PyLOAwYCE4E7gM8ACyUt68Iaq8aCBQsYO3YsY8aMYcaMGVmXU/WmTZvGqFGjGD9+fNalVKVp0x5k1KibGT/+Z1vHvf76Js4991eceOJPOffcX7F+/TsZVli9etLfZke+YxiAiGiIiLsiYjLJdQJnkRxEzrXGxkamT5/OzJkzqa2tZc6cOaxYkftm2S4TJ05k5syZWZdRtSZO/CAzZ47bZtyMGYsZNWow9933WUaNGsyMGYszqq669aS/zQ6HQHMR8VZE3BoRn2rP/JKOkjQy/fnDkqZKOnl7augulixZwtChQxkyZAi9evVi3LhxzJ07N+uyqtrIkSPp08cnonXWyJH70qfPztuMmzu3jlNOGQ7AKacM54EHXsiitKrXk/42K3a2T/rF9Z8EaiTdT/IlNfOByyQdHhH/XqlaukJ9fT0DBw7cOjxgwACWLFmSYUVmLb366kb690/uCt+//2689trGjCuyrFXylM9TSe44ujPJXUgHR8Qbkr5Fci1C0RCQNIXSt7HuNiJaniwlKYNKzMzab7u6gzpoc0Q0RsTbwJ8i4g2AiNhIckfSoiJiRkQcGRHd+iykgQMHsmbNmq3D9fX19O/fP8OKzFrq23cX1q59C4C1a99i7713ybgiy1olQ6AhvQMpwBFNI9Orj0uGQLUYMWIEdXV1rFy5koaGBmpraxk9enTWZZltY/ToYdx113MA3HXXcxx//LBsC7LMqVg3RpdsSNo5IlqcjyapH7BPRPyhHeuIStXbGQ899BBXX301jY2NTJo0iS9+8YtZl1SSpKJdWN3J1KlTWbRoEevWraNv375cdNFFnHbaaVmXVVTSntdmXcY2pk59gEWLVrNu3Sb69t2Fiy46khNO+ACXXHI/L7+8gX322YPvfncMe+3VO+tSW5Cmduu/z+r724ySfdMVC4Fy6O4hUE2qIQSqSXcMgWrW3UOgmrQVApXsDjIzs27GIWBmlmMOATOzHHMImJnlmEPAzCzHHAJmZjnmEDAzyzGHgJlZjjkEzMxyzCFgZpZjDgEzsxxzCJiZ5ZhDwMwsxxwCZmY55hAwM8sxh4CZWY45BMzMcswhYGaWYw4BM7MccwiYmeWYQ8DMLMccAmZmOaaIyLqGdpNUPcWamXUTEaFS02oqWUg5VFNodWeS3JZl5PYsr6Q9b8u6jB5BOrPV6e4OMjPLMYeAmVmOOQTMzHLMIWBmlmMOATOzHHMImJnlmEPAzCzHHAJmZjnmEDAzyzGHgJlZjjkEzMxyzCFgZpZjDgEzsxxzCJiZ5ZhDwMwsxxwCZmY55hAwM8sxh4CZWY45BMzMcswhYGaWYw4BM7MccwiU0YIFCxg7dixjxoxhxowZWZdT9dye5eX2LK+bb36YceP+i/Hj/5upU+/gnXfezbqkTnEIlEljYyPTp09n5syZ1NbWMmfOHFasWJF1WVXL7Vlebs/yqq9/g1tuWcidd/4Dc+ZcSGNjUFv7dNZldYpDoEyWLFnC0KFDGTJkCL169WLcuHHMnTs367KqltuzvNye5dfYuIVNm95l8+ZGNm16l/7998i6pE7JNAQk3ZLl9supvr6egQMHbh0eMGAA9fX1GVZU3dye5eX2LK8BA/bkvPM+znHHXccnPnENu+++M5/4xAFZl9UpNZXakKS7C0cBx0naCyAiPl2pWrpCRLQYJymDSnoGt2d5uT3La/36jcyd+yxz517CHnv05ktfup3Zs59iwoRDsy6twyoWAsBgYCkwEwiSEDgS+HZrC0maAkzp8uq208CBA1mzZs3W4fr6evr3759hRdXN7Vlebs/yevjh5xk8eC/23ns3AE488SAWL15ZlSFQye6gI4HfA/8CrI+I+cDGiHgoIh4qtVBEzIiIIyPiyArV2SkjRoygrq6OlStX0tDQQG1tLaNHj866rKrl9iwvt2d57btvH556ahUbNzYQETzyyPPsv3+/rMvqlIrtCUTEFuA6SXekz/WV3H5Xq6mp4YorruD888+nsbGRSZMmceCBB2ZdVtVye5aX27O8Dj10MGPHfpjPfOZ6amp24KCDBnLGGd36c2pJKtZXWJENS+OAoyPi8g4sE1nV29NIKtpPbJ3j9iyvpD1vy7qMHkE6k4goeQAos0/iEVEL1Ga1fTMz83UCZma55hAwM8sxh4CZWY45BMzMcswhYGaWYw4BM7MccwiYmeWYQ8DMLMccAmZmOeYQMDPLMYeAmVmOOQTMzHLMIWBmlmMOATOzHHMImJnlmEPAzCzHHAJmZjnmEDAzyzGHgJlZjjkEzMxyzCFgZpZjioisa2g3SdVTrJlZNxERKjWtqkKgWkiaEhEzsq6jp3B7lo/bsrx6Qnu6O6hrTMm6gB7G7Vk+bsvyqvr2dAiYmeWYQ8DMLMccAl2jqvsIuyG3Z/m4Lcur6tvTB4bNzHLMewJmZjnmEDAzyzGHQBlJulHSWklPZ11LtZM0RNKDkpZJekbSl7KuqZpJ6i1pkaSn0va8Kuuaqp2kHSUtljQn61q2h0OgvG4GTsq6iB5iM3BpRBwEfAy4UNKHM66pmr0DjI6IQ4HDgJMkfSzjmqrdl4BlWRexvRwCZRQRC4DXsq6jJ4iIlyPiifTnDST/bIOyrap6ReLNdHCn9OGzQjpJ0mBgHDAz61q2l0PAuj1Jw4DDgYXZVlLd0u6LJ4G1wP0R4fbsvO8AXwG2ZF3I9nIIWLcmaXfgTuCSiHgj63qqWUQ0RsRhwGDgKEmHZF1TNZI0HlgbEb/PupZycAhYtyVpJ5IAuDUifpF1PT1FRLwOzMfHrzrraODTkuqAWcBoSf8/25I6zyFg3ZIkATcAyyLi2qzrqXaS/krSXunPuwAnAMuzrao6RcS0iBgcEcOAycC8iPhcxmV1mkOgjCTdBjwCfFDSKkmfz7qmKnY08Pckn7KeTB8nZ11UFdsHeFDSEuAxkmMCVX1qo5WHbxthZpZj3hMwM8sxh4CZWY45BMzMcswhYGaWYw4BM7MccwhY1ZN0paRo9lgt6U5J+3fR9san2xmWDg9Lh8d3YB2nSzqnjDXtntZQtnVaPtRkXYBZmaznvStg9wO+DsyVdHBEvNXF234ZGEXHLr46HehHcudZs8w4BKyn2BwRj6Y/Pyrpz8D/ACcDdzSfUdIuEbGxXBuOiHeAR9uc0awbcneQ9VRNN/caJqlO0rclfVXSKuANAEk7SLpM0gpJ70h6TtLZzVeixJXplwVtkHQLsGfBPEW7gyRdIOkPkjZJqpf0c0l9JN0MTAL+tlkX1pXNlpsg6fF0uTWSvpneR6n5uiel9W6UtAD4UHmazfLGewLWUw1Ln9ekz58FngH+D+/93X8POBuYDjwBjAFulPRqs1sqXAxcAVxNsmcxEfhmWxuX9K/per8P/BOwK8n953cn6ap6P7BXWg/AqnS504HbgOuBy4H9gW+QfGD7cjrPR4GfAb8k+WKTg4Hb29EmZi1FhB9+VPUDuBJ4heTNvQYYDjxI8ol/H6COpN++d7NlDiC5F/zZBeu6BXgs/XlHYDXwg4J57if5QpZh6fCwdHh8OrwX8DZwbSs1/xyYXzBOwIvATQXjzwM2An3T4duBpaS3fUnH/UtawzlZ/z78qK6Hu4Osp+gLvJs+niU5OHxGRLycTp8bEZuazX88SQj8UlJN0wOYCxwmaUdgCEmIzC7YVlu3tR4F7ALc1MHXMJxkD+H2gprmAb2Bpvv/HwXcHRHNb/zlW21bp7g7yHqK9SS3Rw6SLqDVBW+S9QXz9yP5pL++xPr2AQamP68tmFY4XKhv+vxyq3O11C99vqfE9CHp88BO1GRWlEPAeorNEfF4K9MLb5f7GsmX2R9N8a8IXMt7/x/9C6YVDhd6NX3eh6Sbqr2avp96CrC4yPQX0uc1najJrCiHgOXVPFZEJDkAAAFJSURBVJI9gT4RcX+xGSStJHnDnQD8utmkiW2s+xGSPvyzSQ/mFtFA0sXT3LPASyTHGn7UyvofI/lmq2nN9nbaqsmsKIeA5VJEPCvph8AsSd8EHid5Uz4YGB4R50dEYzrtGkmvkJwdNAk4qI11vy7p68C/S+pF0r2zM8nZQVdFxEskF5ZNkHQKyZlBqyNitaRLgZ9I2hO4lyQs9gNOAU6NiLeB/wcsJDl2cAPJsQJ/gZF1ig8MW55dSHK65lkkb9Q3k7xRL2g2z3dITg/9Asn3He8OfKWtFUfEN4AvkhynmE1yyudewIZ0lu8D9wE3knyyn5Iu9zOSPY/DSC5y+wXJaaRPkAQCabfXZOBw4C6SgDijoy/eDPzNYmZmueY9ATOzHHMImJnlmEPAzCzHHAJmZjnmEDAzyzGHgJlZjjkEzMxyzCFgZpZj/wsu8RxfA/apqgAAAABJRU5ErkJggg==\n",
"text/plain": [
"
"
]
},
"metadata": {
"needs_background": "light"
},
"output_type": "display_data"
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"--------------------------------------------------------\n"
]
}
],
"source": [
"## car popularity dataset\n",
"df = es.importdata('TrainDataset.csv')\n",
"es.info(df)\n",
"X = df.drop('popularity',axis=1)\n",
"y = df['popularity']\n",
"X_train,X_test,y_train,y_test = train_test_split(X,y,train_size=0.7,random_state=42)\n",
"es.stat_models(y,X)\n",
"es.VIF(df)\n",
"y_pred , model = es.classification(X,y)\n",
"print('\\n\\n*** Start Hypertuning ***\\n')\n",
"y_pred,grid = es.grid_search(model,'quick',X_train,y_train,X_test,y_test)\n",
"print('\\n\\n*** Grid Search CV Result ***\\n')\n",
"es.classification_result(y_test,y_pred)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Deployment\n",
"#### Deploying Model from above prediction"
]
},
{
"cell_type": "code",
"execution_count": 8,
"metadata": {
"ExecuteTime": {
"end_time": "2020-04-26T19:53:04.171870Z",
"start_time": "2020-04-26T19:53:04.156859Z"
}
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"All Deployment Files Created Successfully\n",
"\n",
"Files Created and stored in : /deployment-files named Folder\n",
"\n",
"Open deployment-files folder and open command prompt and run \"python app.py\" copy link and paste in browser to run app, enjoy.\n",
"\n",
"Files created:\n",
" 1. model.pkl - Model file using pickle\n",
" 2.app.py - Flask server file\n",
"3.index.html - User Interface file.\n"
]
}
],
"source": [
"# it will create a folder deployment-files containing all flask files\n",
"es.deploy_one(model,X_train.columns,'Cars 3 Rocks')"
]
},
{
"cell_type": "code",
"execution_count": 13,
"metadata": {
"ExecuteTime": {
"end_time": "2020-03-17T10:30:47.566234Z",
"start_time": "2020-03-17T10:30:46.336101Z"
}
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"\n",
"Please wait Training-Testing with all models..\n",
"\n",
"Done with LogisticRegression\n",
"Done with RandomForestClassifier\n",
"Done with XGBoost Classifier\n",
"Done with LGBoost Classifier\n",
"Done with AdaBoost Classifier\n",
"Done with GradientBoostingClassifier\n"
]
},
{
"data": {
"text/html": [
"
"
],
"text/plain": [
""
]
},
"execution_count": 13,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"## just again using quick_pred\n",
"es.quick_pred(X,y,'c') ## use quick pred instantly on clean data to get immidate result"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## thank you"
]
}
],
"metadata": {
"hide_input": false,
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.7.4"
}
},
"nbformat": 4,
"nbformat_minor": 2
}
�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������Chintan99-eazeml-468f933/usage-example/eazeml-testfile-mini.ipynb�����������������������������������0000664�0000000�0000000�00000530402�13704552311�0024654�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������{
"cells": [
{
"cell_type": "code",
"execution_count": 632,
"metadata": {
"ExecuteTime": {
"end_time": "2020-03-29T19:57:08.575971Z",
"start_time": "2020-03-29T19:57:08.572970Z"
}
},
"outputs": [],
"source": [
"import eazeml as ez"
]
},
{
"cell_type": "code",
"execution_count": 633,
"metadata": {
"ExecuteTime": {
"end_time": "2020-03-29T19:57:18.286583Z",
"start_time": "2020-03-29T19:57:10.350946Z"
}
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Dataframe Imported Successfully\n",
"########## MENU ##############\n",
"\n",
"1. Logisitic Regression \n",
"2. Random Forest \n",
"3. XGB Classifier \n",
"4. LGB CLassifier \n",
"5. Gradient Boosting Classifier \n",
"6. AdaBoost Classifier\n",
"\n",
"Input No, which you want:4\n",
"Predicting with Light GBM Classifier\n"
]
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAx8AAAHyCAYAAACK4XPQAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADt0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjByYzEsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy/xvVyzAAAgAElEQVR4nOzdebxVdb3/8dcHEBxQykBF0UhFUUQPQphZOd7SyMqcUiuHzDS9Djczf2lKeU1Mu+pVM61MzQKncshrDiBCzoAo6lXsCiWamiMKKoOf3x9rHdoczwRy1sbD6/l47Ad7f9d3re9n7XN8uN/n+11rR2YiSZIkSR2tS70LkCRJkrRiMHxIkiRJqoThQ5IkSVIlDB+SJEmSKmH4kCRJklQJw4ckSZKkShg+JGkZiYiREfFSK9t3iIiMiC2W8LgHlfv1bKPfYRHx5Ra29YiI4yLiwYh4IyLejoinIuKciPhYTb/+5ViNj4UR8feI+GVE9GlyzPFln182M976EfFuuX2HJTnfVs5vfJPaGh8nL4vj14yzT0QctCyPubSW9nemXiJik/K/gw/VuxZJy6du9S5AklYgU4Btgf/roOMfBjwKXF/bGBGrArcBg4HzgZOBecAWwLeAvYD1mxzreOBuoCuwGXA68FHgs036vQnsGRHfycz5Ne1fBeYArQampXAn8IMmbc8s4zH2AXoDly3j464INgFOpXjvXqtvKZKWR4YPSapIZs4G7qvD0KcDDcA2mflYTfudEXEh8M1m9nkyMxtrvTsiugMXRETPzHyzpt9dwKeBzwF/qmn/KnAjsP+yOonSKzV1fSBExCqZ+Va96+hIERFAj3rXIWn557IrSapIc0toIuLDETEmIuZExHMR8f2IODsiZjZziI9FxO1l3yci4is1xxkPDAUOrFmOdFA563EY8PMmwQOAzHw3M9+zbKoZbwBBMRNS623gBoqw0VjLAGAIMKYdx11mImLliPhpRDwTEe9ExMMR8fkmfb4REX+JiFci4tWIuDMihtVsvwzYE9i+5n0cWW6bGRFnNzneYkvian7Gn4uIGyPiTeCCctsG5c/6lYiYGxG3RsSmS3GeWS6h+1lEvBwRL0XE8eW2AyPi6Yh4LSIujYiVm6n14xExMSLeiojpEbFHM2McVS7Leyci/hoRxzXZPrIc91MR8SDF78HewE1llxnlWDPL/n3Lep6uGfc/y1DbeMzGJX/7RMTFEfF6RMyKiB9FRJcm428ZETeV5/lmRDwQEf9Ws33N8hgvRLHE8J6I2GZJ32tJy54zH5JUX5cBnwKOAZ4HjqNYurKwmb6/By4BzgL+HRgTERtm5izgO8B1wNPAaWX//6MIJI3LrpZEl4joRhE2BgLfA+7MzNeb6TsauLrmL/z7AQ8AM5ZwzPaIsq5FMnNB+fRaYDjFsp//o1g+dWNEDMvMqWWf/sAV5fbuFDMzEyJii8xsfO82AD5E8Z4CzFqKOn8N/AY4F3g7ItYE/gK8DBwOzAVOBO6IiE2WYmbku8DNFO/1F4CzImIt4OPA0eU5nANMB0Y12fcq4OfAT4BDgWsiYmhmPgwQEd+iWJ73X8CtwI7AzyKiR2bWHmtV4HLgp+U4r1As1zsb+ArwD+Cdsm/vcvt/AK9S/I6PBPoA325S308pfpf3AnYGTgEeA64u6xtIsSTwSYr38mVgGOXSwYjoAdxB8TP8HvAicATFez0gM59v/a2V1KEy04cPHz58LIMHxYepl1rZvgOQwBbl6y3K13vX9FkFeAmYWdN2UNnvkJq2jwALgMNr2iYBlzUZc99y302btHeh+ANUN6BbTXv/sn/Tx2PAek2OMZ7iA3+3sua9y/bHgGNrzm+HZfT+jm+htm4UH1IT2L7JPhOAa1o4XuN78ARwSk37tcD4ZvrPBM5u0tb4s+nZ5Gd8TpN+p1F8SF6zpu3DwOvAke39nSnbkiII1p7HPyg+1K9R0341cH8ztf6gyb5PAGNqXj8L/KZJHT8va1255nc9gS816feFsr1/Gz/LbhTB722ge5PfvSua9J3aWF/5ejRFIFylhWN/k+KapgFNxvs/4Kxl8bvow4ePpX+47EqS6qdxuU/jUhWy+Av4HS30v62m38sUf9Ht18YY0bhLk/YbgfmNj3jv3ZSOo/gr+nBgD2A2cEs0c8etLGYergO+GhFbUsyUXN1GXUVxEV0jolvNI9rYZVxZ16JHOf4uFDNHd9ceDxjLv95nImKziPhjRLxAMbs0H9iU4i/xy9LNTV7vAtwOzK6p7Q1gcm19S2Bs45PMfJdilmlyFtcVNforsF4z+/6xyb43UPycofh9Whe4psk+VwFrUNy0YNHuwC3tKTYKx0bE4xHxFsX7/juK60Q2aNK96Szd4yz+e74TcFW2PFu0C8X7OqPmvYbi+qSlea8lLUMuu5Kk+lkHeCMz327S/s8W+je9e9A8YOXmOtZ4tvy3H8XSmEbHUvz1eijwi2b2+2tmTiqfPxgRd1N8uD+I8hqGJsYA/0PxF/iJmflcudSoLWOB7Wte70gxw9GSV2vqqtWb4v2c38y2hQARsTrFB9sXKJb//I3iL++/ou33cUm90Ex9n6CYiWpqbDNtbWnud6G9vx8vNvO6b/m88d+m9Te+rv2ZvpqZ89ouFSh+386mWAJ2F8UszceBC5upsa3z+AjF71lLGt/r5n4XOupOc5LayfAhSfXzPLB6RKzcJID0aWmHpTCZ4vqCz1LMGgCQmX8FaG4mozmZ+c8ovsNksxa6NH6gPAI4cgnq+zawes3rJ5dg31qvUAStZr/npLQtRQj7t8x8orExInq1c4y3Ka4TqdVSwGo60/QKxWzTac30faOd4y8ra1EsAat93fhh/h81bbXWLv99paat6Tm2Zm+K5W8nNTZExOZLsH+tl/lXSGrOKxRLEI9oZts7zbRJqpDhQ5Lqp/Ev+F/kXxfTrgL8G0v3gfQ9f+nOzLkRcQlwZERcnpn/uzSFRsTaFH9RbvY7NTLz3Yj4CcWSl2vbe9zMXNqw0dRYiouw36wNFk2sUv676ANoRHyS4lqDyTX9WpoxmMV7w9e/NdOvpfr2AR5rZblQVfYA/hegvIvUlyhuEADFOT5HERZql1TtQ7H0blobx26cCWn6/q3Cez/4H7BEVf/LWGCfiDipmVnDxu2fBf6emU1neSTVmeFDkpat7hGxVzPtdzVtyMxHI+Im4KJySdDzFMuB5gLvLsXYTwCfi4jPUfx1eEZ5bchJFGv6742IC4CJFH/FXw84kGJZUtMPcZuWMx1R9vsexRcKjm5p8My8gOaXZFXhdoo7M90eEWdSXPS+BsX3m6ycmf+P4jtW3gR+GRE/pZgFGcm/lqY1egL4UhTfFj8LeC4zn6O4VuL8iPgB8CDFHZ0GtbO+/wK+BoyLiPPLMdemWHL2l8xs8X3tAIdGxDyKL6T8FrAxxV2zGkPkSODiiHiZ4n3dnmIW4QctfNiv1Rgmvx0RY4C5mTmtPM7REXE/xdKnA8pxl8aPKN7/CRHxM4rf9SHAy5l5KcXdzA4Hxkdxa+SnKZZqDQeez8xzlnJcScuA4UOSlq3Vee/FulBcy9Ccg4CLgP+m+GB8IcWHpY8vxdj/SXHx7tUUH7wPprj71dyI2IliOdT+FOvvu1HMYowFtmpchlWj9vssXqCYpfl2Zv5tKerqcJmZUXzvyQ8ozm8DiuU3UyluG0tmvhARe1Oc2w3AUxQfUk9ocrifU3yYvZTijlQ/oggplwAbUdzKtgfFh9z/BC5uR30vRcQnKL7w8RyK28D+g+L2u48s5Wkvra+WNfwnRbjaNzMfqqn1l+Xtao+luAX0LOC77fnQnpl/i+I7R46muB30LIqZpR9TLCf8z7LrH8o+NzVzmLbGeDIiPkVx/civyubHKX72ZObbEbFjOeaPKELeixSzOzcu6XiSlq3IXJIlm5KkjlTemedRilukHljvetR5RMRBFN89snou/i31klQZZz4kqY7Kv8SvS7GWfg2KZTADgG/Usy5JkjqC4UOS6msOxfKojSm+TXwasHtmPtDqXpIkfQC57EqSJElSJfyGc0mSJEmVMHxIkiRJqoTXfKwgevfunf379693GZIkSerkJk+e/FJm9mlum+FjBdG/f38mTZrUdkdJkiTpfYiIFr8TymVXkiRJkiph+JAkSZJUCcOHJEmSpEoYPiRJkiRVwvAhSZIkqRKGD0mSJEmVMHxIkiRJqoThQ5IkSVIlDB+SJEmSKmH4kCRJklQJw4ckSZKkShg+JEmSJFXC8CFJkiSpEoYPSZIkSZUwfEiSJEmqhOFDkiRJUiUMH5IkSZIqYfiQJEmSVAnDhyRJkqRKGD4kSZIkVcLwIUmSJKkShg9JkiRJlTB8SJIkSaqE4UOSJElSJQwfkiRJkiph+JAkSZJUCcOHJEmSpEoYPiRJkiRVwvAhSZIkqRKGD0mSJEmVMHxIkiRJqoThQ5IkSVIlDB+SJEmSKmH4kCRJklQJw4ckSZKkSnSrdwGqxrRnX6f/iTfXuwxJkqQVysxRI+pdwnLFmQ9JkiRJlTB8SJIkSaqE4UOSJElSJQwfkiRJkiph+JAkSZJUCcOHJEmSpEoYPiRJkiRVwvAhSZIkqRKGD0mSJEmVMHxIkiRJqoThQ5IkSVIlDB+SJEmSKmH4kCRJklQJw4ckSZKkShg+JEmSJFXC8CFJkiSpEoYPSZIkSZUwfEiSJEmqhOFDkiRJUiUMH5IkSVIHevLJJ2loaFj0WGONNTj33HMBOP/889l0000ZNGgQJ5xwwqJ9zjjjDDbeeGM23XRTbr311kXtkydPZvDgwWy88cYcffTRZGbl5/N+dKt3AZIkSVJntummmzJ16lQAFi5cyHrrrccee+zBnXfeyQ033MAjjzxCjx49ePHFFwF4/PHHGTNmDI899hjPPfccu+yyC9OnT6dr164cccQRXHLJJXziE5/g85//PH/+85/Zbbfd6nl6S2S5nPmIiGER8d9t9PlQRHynnce7Z9lUtvyJiB/UuwZJkiS1z9ixY9loo4346Ec/ykUXXcSJJ55Ijx49AFhrrbUAuOGGG/jqV79Kjx49+NjHPsbGG2/MAw88wD/+8Q9mz57NtttuS0TwjW98g+uvv76ep7PElsvwkZmTMvPoNrp9CGhX+MjMT77/qpZbhg9JkqQPiDFjxrDffvsBMH36dCZOnMg222zD9ttvz4MPPgjAs88+y/rrr79on379+vHss8/y7LPP0q9fv/e0f5B0WPiIiP4R8URE/CoiHo2I30XELhFxd0Q8FRHDy8c9EfFQ+e+m5b47RMSfyucjI+LSiBgfEU9HRGMoGQVsFBFTI+KsiOgZEWMjYkpETIuIL9XU8mbNccdHxLVlbb+LiCi3DY2IuyJickTcGhF9y/bxEXFmRDwQEdMj4tNle9eIOLsc65GI+PfWjtPCe7RxRNwREQ+XdW8UhbPK92xaROxb9u0bERPK8300Ij4dEaOAVcq23y3jH6EkSZKWoXnz5nHjjTey9957A7BgwQJeffVV7rvvPs466yz22WcfMrPZ6zgiosX2D5KOvuZjY2Bv4DDgQWB/4FPAFyn+Yv8N4DOZuSAidgF+AuzZzHEGAjsCqwNPRsRFwInAFpnZABAR3YA9MnN2RPQG7ouIG/O9P6UhwCDgOeBuYLuIuB84H/hSZv6z/MB/OnBIuU+3zBweEZ8HTgV2Kc/pY8CQsv41I2KlNo7T1O+AUZn5x4hYmSIMfgVoALYCegMPRsSE8r27NTNPj4iuwKqZOTEijmp8D5qKiMPKOum6Rp8WSpAkSVIVbrnlFrbeemvWXnttoJi5+MpXvkJEMHz4cLp06cJLL71Ev379eOaZZxbtN2vWLNZdd1369evHrFmz3tP+QdLRy65mZOa0zHwXeAwYW4aBaUB/oBdwTUQ8CpxDEQqac3NmvpOZLwEvAms30yeAn0TEI8AdwHot9HsgM2eVNU0t69gU2AK4PSKmAicD/Wr2+UP57+SyPxQB5BeZuQAgM19px3H+VWzE6sB6mfnHcv+3M3MuRTgbnZkLM/MF4C7g4xTh7eCIGAkMzsw3WnivFsnMSzJzWGYO67pqr7a6S5IkqQONHj160ZIrgC9/+cuMGzcOKJZgzZs3j969e/PFL36RMWPG8M477zBjxgyeeuophg8fTt++fVl99dW57777yEyuuOIKvvSlL7U03HKpo2c+3ql5/m7N63fLsU8D7szMPSKiPzC+HcdZSPN1HwD0AYZm5vyImAms3M5jBfBYZm7bxvi1YwfQdFalreM07dvu9sycEBGfAUYAv42IszLzinaMI0mSpDqbO3cut99+OxdffPGitkMOOYRDDjmELbbYgu7du3P55ZcTEQwaNIh99tmHzTffnG7dunHhhRfStWtXAC666CIOOugg3nrrLXbbbbcP1J2uoP632u0FNF4lc9AS7vsGxTKs2mO9WAaPHYGPLsGxngT6RMS2mXlvuXxqk8x8rJV9bgMOj4jxjcuuluQ45fKwWRHx5cy8PiJ6AF2BCcC3I+JyYE3gM8D3IuKjwLOZ+cuIWA3YGrgCmB8RK2Xm/CU4X0mSJFVo1VVX5eWXX16srXv37lx55ZXN9j/ppJM46aST3tM+bNgwHn300Q6psQr1vtvVT4EzIuJuig/e7ZaZLwN3lxdfn0Vx/cSwiJhEMQvyxBIcax6wF3BmRDxMsRyrrTtk/Qr4O/BIuc/+S3GcrwNHl0vF7gHWAf4IPAI8DIwDTsjM54EdgKkR8RDFdTHnlce4pKzBC84lSZK0XIsP2rciaun06Dsg+x54br3LkCRJWqHMHDWi3iVULiImZ+aw5rbVe+ZDkiRJ0gqi3td8rBAi4kJguybN52Xmb+pRjyRJklQPho8KZOaR9a5BkiRJqjeXXUmSJEmqhOFDkiRJUiUMH5IkSZIqYfiQJEmSVAnDhyRJkqRKGD4kSZIkVcLwIUmSJKkShg9JkiRJlTB8SJIkSaqE4UOSJElSJQwfkiRJkiph+JAkSZJUCcOHJEmSpEoYPiRJkiRVwvAhSZIkqRKGD0mSJEmV6FbvAlSNwev1YtKoEfUuQ5IkSSswZz4kSZIkVcLwIUmSJKkShg9JkiRJlTB8SJIkSaqE4UOSJElSJQwfkiRJkiph+JAkSZJUCcOHJEmSpEoYPiRJkiRVwvAhSZIkqRKGD0mSJEmV6FbvAlSNac++Tv8Tb653GZIkaQUxc9SIepeg5ZAzH5IkSZIqYfiQJEmSVAnDhyRJkqRKGD4kSZIkVcLwIUmSJKkShg9JkiRJlTB8SJIkSaqE4UOSJElSJQwfkiRJkiph+JAkSZJUCcOHJEmSpEoYPiRJkiRVwvAhSZIkqRKGD0mSJEmVMHxIkiRJqoThQ5IkSVIlDB+SJEmSKmH4kCRJklQJw4ckSZKkShg+JEmS1GFee+019tprLwYOHMhmm23Gvffey7777ktDQwMNDQ3079+fhoYGAObPn8+BBx7I4MGD2WyzzTjjjDMAmDt3LiNGjGDgwIEMGjSIE088sZ6npPehW70LkCRJUud1zDHHsOuuu3Lttdcyb9485s6dy1VXXbVo+3e/+1169eoFwDXXXMM777zDtGnTmDt3Lptvvjn77bcfa621Fscffzw77rgj8+bNY+edd+aWW25ht912q9dpaSl1uvAREf2BP2XmFu/zOIcDczPzimVR1wdlbEmSpGVl9uzZTJgwgcsuuwyA7t27071790XbM5Orr76acePGARARzJkzhwULFvDWW2/RvXt31lhjDVZddVV23HHHRcfYeuutmTVrVuXno/fPZVctyMxf1Cl4dKvX2JIkScvS008/TZ8+fTj44IMZMmQIhx56KHPmzFm0feLEiay99toMGDAAgL322ovVVluNvn37ssEGG3D88cez5pprLnbM1157jZtuuomdd9650nPRstFZw0e3iLg8Ih6JiGsjYtWImBkRvQEiYlhEjI+ILhHxVET0Kdu7RMRfI6J3RIyMiOPL9vERcWZEPBAR0yPi02X7qhFxdTnOVRFxf0QMa6moiHgzIn4WEVMiYmzNuOMj4icRcRdwTJOxN46IOyLi4XK/jcr270XEg+XYP+rQd1OSJGkpLFiwgClTpnDEEUfw0EMPsdpqqzFq1KhF20ePHs1+++236PUDDzxA165dee6555gxYwY/+9nPePrppxc73n777cfRRx/NhhtuWOm5aNnorOFjU+CSzNwSmA18p7lOmfkucCVwQNm0C/BwZr7UTPdumTkcOBY4tWz7DvBqOc5pwNA26loNmJKZWwN31RwH4EOZuX1m/qzJPr8DLszMrYBPAv+IiM8CA4DhQAMwNCI+03SwiDgsIiZFxKSFc19vozRJkqRlq1+/fvTr149tttkGKGY2pkyZAhRB4g9/+AP77rvvov6///3v2XXXXVlppZVYa6212G677Zg0adKi7YcddhgDBgzg2GOPrfZEtMx01vDxTGbeXT6/EvhUK30vBb5RPj8E+E0L/f5Q/jsZ6F8+/xQwBiAzHwUeaaOud4HGK6ya1nVV084RsTqwXmb+sRzj7cycC3y2fDwETAEGUoSRxWTmJZk5LDOHdV21VxulSZIkLVvrrLMO66+/Pk8++SQAY8eOZfPNNwfgjjvuYODAgfTr129R/w022IBx48aRmcyZM4f77ruPgQMHAnDyySfz+uuvc+6551Z/IlpmOt0F56Vs5vUC/hW2Vl60IfOZiHghInYCtuFfsyBNvVP+u5B/vW+xDOuc08z2lo4fwBmZefH7HF+SJKlDnX/++RxwwAHMmzePDTfckN/8pvg775gxYxZbcgVw5JFHcvDBB7PFFluQmRx88MFsueWWzJo1i9NPP52BAwey9dZbA3DUUUdx6KGHVn4+en86a/jYICK2zcx7gf2AvwCrUyyLugXYs0n/X1HMRPw2MxcuwTh/AfYB7oyIzYHBbfTvAuxFMVuyf7l/izJzdkTMiogvZ+b1EdED6ArcCpwWEb/LzDcjYj1gfma+uAS1S5IkdbiGhobFlk41arwDVq2ePXtyzTXXvKe9X79+ZDb927I+iDrrsqv/BQ6MiEeANYGLgB8B50XERIrZi1o3Aj1peclVS34O9CnH+T7FsqvWLq6YAwyKiMnATsCP2zHG14GjyzHuAdbJzNuA3wP3RsQ04FqKcCVJkiQtt8IUWdz9CjgnMz+9hPt1BVbKzLfLu1CNBTbJzHkt9H8zM3u+/4qXXI++A7Lvga6RlCRJ1Zg5akS9S1CdRMTkzGz2DrCdddlVu0XEicARtHytR2tWpVhytRLFdRhHtBQ8JEmSpBXdCh8+MnMUMKrNjs3v+wbwnlQXEfcDPZo0f71esx6SJEnS8mCFDx8dITO3qXcNkiRJ0vKms15wLkmSJGk5Y/iQJEmSVAnDhyRJkqRKGD4kSZIkVcLwIUmSJKkShg9JkiRJlTB8SJIkSaqE4UOSJElSJQwfkiRJkiph+JAkSZJUCcOHJEmSpEoYPiRJkiRVwvAhSZIkqRKGD0mSJEmVMHxIkiRJqoThQ5IkSVIlutW7AFVj8Hq9mDRqRL3LkCRJ0grMmQ9JkiRJlTB8SJIkSaqE4UOSJElSJQwfkiRJkiph+JAkSZJUCcOHJEmSpEoYPiRJkiRVwvAhSZIkqRKGD0mSJEmVMHxIkiRJqoThQ5IkSVIlutW7AFVj2rOv0//Em+tdhiRJqpOZo0bUuwTJmQ9JkiRJ1TB8SJIkSaqE4UOSJElSJQwfkiRJkiph+JAkSZJUCcOHJEmSpEoYPiRJkiRVwvAhSZIkqRKGD0mSJEmVMHxIkiRJqoThQ5IkSVIlDB+SJEmSKmH4kCRJklQJw4ckSZKkShg+JEmSJFXC8CFJkiSpEoYPSZIkSZUwfEiSJEmqhOFDkiRJUiUMH5IkSZIqYfiQJElagbz22mvstddeDBw4kM0224x777130bazzz6biOCll14C4Pbbb2fo0KEMHjyYoUOHMm7cuEV9R48ezeDBg9lyyy3ZddddF+0jtabThY+IGB8Rwyoc76yIeCwizmpn/zc7uiZJkqSWHHPMMey666488cQTPPzww2y22WYAPPPMM9x+++1ssMEGi/r27t2bm266iWnTpnH55Zfz9a9/HYAFCxZwzDHHcOedd/LII4+w5ZZbcsEFF9TlfPTB0unCx/sREd2WYrdvA1tn5veWdT0tiYiuVY0lSZI6j9mzZzNhwgS++c1vAtC9e3c+9KEPAXDcccfx05/+lIhY1H/IkCGsu+66AAwaNIi3336bd955h8wkM5kzZw6ZyezZsxf1k1pTt/AREf0j4n8j4pflzMFtEbFK7cxFRPSOiJnl84Mi4vqIuCkiZkTEURHxHxHxUETcFxFr1hz+axFxT0Q8GhHDy/1Xi4hLI+LBcp8v1Rz3moi4CbithVqjnOF4NCKmRcS+ZfuNwGrA/Y1tzez7sYi4txz3tHYcs6X2HSLizoj4PTCtPJ+bI+Lhsm+z40uSJDV6+umn6dOnDwcffDBDhgzh0EMPZc6cOdx4442st956bLXVVi3ue9111zFkyBB69OjBSiutxEUXXcTgwYNZd911efzxxxcFGqk19Z75GABcmJmDgNeAPdvovwWwPzAcOB2Ym5lDgHuBb9T0Wy0zPwl8B7i0bDsJGJeZHwd2BM6KiNXKbdsCB2bmTi2M+xWgAdgK2KXct29mfhF4KzMbMvOqFvY9D7ioHPf5to7ZSjvleZ+UmZsDuwLPZeZWmbkF8OemA0fEYRExKSImLZz7egvlSZKkFcWCBQuYMmUKRxxxBA899BCrrbYaI0eO5PTTT+fHP/5xi/s99thjfP/73+fiiy8GYP78+Vx00UU89NBDPPfcc2y55ZacccYZVZ2GPsDqHT5mZObU8vlkoH8b/e/MzDcy85/A68BNZfu0JvuOBsjMCcAaEfEh4LPAiRExFRgPrAw0Lmq8PTNfaWXcTwGjM3NhZr4A3AV8vO3TA2C7xnqA37bjmK2N9UBmzqg5510i4syI+HRmviddZOYlmTksM4d1XbVXO8uVJEmdVb9+/ejXrx/bbLMNAHvttRdTpkxhxowZbLXVVvTv359Zs2ax9dZb8/zzxd9MZ3H77+UAACAASURBVM2axR577MEVV1zBRhttBMDUqcXHt4022oiIYJ999uGee+6pz0npA6Xe4eOdmucLgW7AAv5V18qt9H+35vW75b6Nssl+CQSwZzlL0ZCZG2Tm/5bb57RRZ7SxvS1N62ntmK2NtajOzJwODKUIIWdExClLX54kSVoRrLPOOqy//vo8+eSTAIwdO5att96aF198kZkzZzJz5kz69evHlClTWGeddXjttdcYMWIEZ5xxBtttt92i46y33no8/vjj/POf/wSKu2I1Xrgutabe4aM5Myk+VAPstZTHaLxO4lPA6+WswK3Av0d5FVVEDFmC400A9o2IrhHRB/gM8EA7970b+Gr5/IB2HLNdY0XEuhTLzq4Ezga2XoLzkSRJK6jzzz+fAw44gC233JKpU6fygx/8oMW+F1xwAX/961857bTTaGhooKGhgRdffJF1112XU089lc985jPtOo7UaGnu7tTRzgaujoivA+Pa6tyCVyPiHmAN4JCy7TTgXOCRMoDMBL7QzuP9keK6kIcpZjFOyMznW99lkWOA30fEMcB1bR0zIlpqH9jkuIMprgd5F5gPHNHOeiRJ0gqsoaGBSZMmtbh95syZi56ffPLJnHzyyc32O/zwwzn88MOXdXnq5CKzuRVB6mx69B2QfQ88t95lSJKkOpk5akS9S9AKIiImZ2az37u3PC67kiRJktQJLY/LruomIgaz+B2pAN7JzG3ase9JwN5Nmq/JzNOXVX2SJEnSB5nho0ZmTqP4jo2l2fd0iu8ekSRJktQMl11JkiRJqoThQ5IkSVIlDB+SJEmSKtGu8BERG0VEj/L5DhFxdER8qGNLkyRJktSZtHfm4zpgYURsDPwa+Bjw+w6rSpIkSVKn097w8W5mLgD2AM7NzOOAvh1XliRJkqTOpr3hY35E7AccCPypbFupY0qSJEmS1Bm1N3wcDGwLnJ6ZMyLiY8CVHVeWJEmSpM6mXV8ymJmPR8T3gQ3K1zOAUR1ZmCRJkqTOpb13u9odmAr8uXzdEBE3dmRhkiRJkjqX9i67GgkMB14DyMypFHe8kiRJkqR2aW/4WJCZrzdpy2VdjCRJkqTOq13XfACPRsT+QNeIGAAcDdzTcWVJkiRJ6mzaO/Px78Ag4B2KLxd8HTi2o4qSJEmS1Pm0OfMREV2BGzNzF+Ckji9JkiRJUmfU5sxHZi4E5kZErwrqkSRJktRJtfeaj7eBaRFxOzCnsTEzj+6QqrTMDV6vF5NGjah3GZIkSVqBtTd83Fw+JEmSJGmptPcbzi/v6EIkSZIkdW7tCh8RMYNmvtcjMzdc5hVJkiRJ6pTau+xqWM3zlYG9gTWXfTmSJEmSOqt2fc9HZr5c83g2M88Fdurg2iRJkiR1Iu1ddrV1zcsuFDMhq3dIRZIkSZI6pfYuu/pZzfMFwAxgn2VfjiRJkqTOqr3h45uZ+XRtQ0R8rAPqkSRJktRJteuaD+DadrZJkiRJUrNanfmIiIHAIKBXRHylZtMaFHe9kiRJkqR2aWvZ1abAF4APAbvXtL8BfKujipIkSZLU+bQaPjLzBuCGiNg2M++tqCZJkiRJnVB7Lzh/KCKOpFiCtWi5VWYe0iFVaZmb9uzr9D/x5nqXIUlSXc0cNaLeJUgrtPZecP5bYB3gc8BdQD+KpVeSJEmS1C7tDR8bZ+YPgTmZeTkwAhjccWVJkiRJ6mzaGz7ml/++FhFbAL2A/h1SkSRJkqROqb3XfFwSER8GfgjcCPQETumwqiRJkiR1Ou0KH5n5q/LpXcCGHVeOJEmSpM6qXcuuImLtiPh1RNxSvt48Ir7ZsaVJkiRJ6kzae83HZcCtwLrl6+nAsR1RkCRJkqTOqb3ho3dmXg28C5CZC4CFHVaVJEmSpE6nveFjTkR8BEiAiPgE8HqHVSVJkiSp02nv3a7+g+IuVxtFxN1AH2CvDqtKkiRJUqfTaviIiA0y8++ZOSUitgc2BQJ4MjPnt7avJEmSJNVqa9nV9TXPr8rMxzLzUYOHJEmSpCXVVviImud+v4ckSZKkpdZW+MgWnkuSJEnSEmnrgvOtImI2xQzIKuVzyteZmWt0aHWSJEmSOo1Ww0dmdq2qEEmSJEmdW3u/50OSJEmS3hfDhyRJkqRKGD4kSZIkVcLwIUmSVjj9+/dn8ODBNDQ0MGzYsEXt559/PptuuimDBg3ihBNOWGyfv//97/Ts2ZOzzz57Udu8efM47LDD2GSTTRg4cCDXXXddZecgfRC1dbcrSZKkTunOO++kd+/ei72+4YYbeOSRR+jRowcvvvjiYv2PO+44dtttt8XaTj/9dNZaay2mT5/Ou+++yyuvvFJJ7dIHVYeHj4h4MzN7dvQ4y1JEjATezMyz2+rbxnH6A5/MzN8vxb73ZOYn38/4kiSp/S666CJOPPFEevToAcBaa621aNv111/PhhtuyGqrrbbYPpdeeilPPPEEAF26dFkszEh6L5dddaz+wP5Ls6PBQ5KkjhMRfPazn2Xo0KFccsklAEyfPp2JEyeyzTbbsP322/Pggw8CMGfOHM4880xOPfXUxY7x2muvAfDDH/6Qrbfemr333psXXnih2hORPmAqCx8RsUNE/Knm9QURcVD5/PMR8URE/CUi/ruxX0T0iYjbI2JKRFwcEX+LiN7ltusjYnJEPBYRh9Uc95sRMT0ixkfELyPigppjXRcRD5aP7dooeauIGBcRT0XEt8pjREScFRGPRsS0iNi3tXZgFPDpiJgaEce18L4MiogHyj6PRMSAsv3N8t8fl9umRsSzEfGbsv1rNftdHBHv+U6WiDgsIiZFxKSFc19v60ckSdIK4+6772bKlCnccsstXHjhhUyYMIEFCxbw6quvct9993HWWWexzz77kJmceuqpHHfccfTsufhCjgULFjBr1iy22247pkyZwrbbbsvxxx9fpzOSPhjqfs1HRKwMXAx8JjNnRMToms2nAuMy84yI2BU4rGbbIZn5SkSsAjwYEdcBPYAfAlsDbwDjgIfL/ucB52TmXyJiA+BWYLNWStsS+ASwGvBQRNwMbAs0AFsBvctxJwCfbKH9ROD4zPxCK+McDpyXmb+LiO7AYiEiM08BTomIXsBE4IKI2AzYF9guM+dHxM+BA4Armux7CXAJQI++A7KVGiRJWqGsu+66QLG0ao899uCBBx6gX79+fOUrXyEiGD58OF26dOGll17i/vvv59prr+WEE07gtddeo0uXLqy88soceeSRrLrqquyxxx4A7L333vz617+u52lJy726hw9gIPB0Zs4oX4/mXyHjU8AeAJn554h4tWa/oyNij/L5+sAAYB3grsx8BSAirgE2KfvsAmweEY37rxERq2fmGy3UdUNmvgW8FRF3AsPLekZn5kLghYi4C/h4K+2z23H+9wInRUQ/4A+Z+VTTDlEU/TuK8DQ5Io4ChlKEHIBVgBeb7idJkt5rzpw5vPvuu6y++urMmTOH2267jVNOOYWePXsybtw4dthhB6ZPn868efPo3bs3EydOXLTvyJEj6dmzJ0cddRQAu+++O+PHj2ennXZi7NixbL755vU6LekDocrwsYDFl3mtXP4bzfSltW0RsQNFmNg2M+dGxPjyeK0dq0vZ/6121tt0piBbOX5r47Y+SObvI+J+YARwa0QcmpnjmnQbCczKzN/UjHd5Zv6/pR1XkqQV1QsvvLBotmLBggXsv//+7LrrrsybN49DDjmELbbYgu7du3P55ZdT80fLZp155pl8/etf59hjj6VPnz785je/abW/tKKrMnz8jWLmoQdFUNgZ+AvwBLBhRPTPzJkUy4ka/QXYBzgzIj4LfLhs7wW8WgaPgRTLowAeAM6JiA9TLLvaE5hWbrsNOAo4CyAiGjJzaiv1fikizqBYdrUDxRKqrsC3I+JyYE3gM8D3KN7H5trXA1Zv7U2JiA0pZn7+u3y+JcVyscbtXwD+rayh0Vjghog4JzNfjIg1gdUz82+tjSVJkmDDDTfk4Ycffk979+7dufLKK1vdd+TIkYu9/uhHP8qECROWZXlSp1ZZ+MjMZyLiauAR4CngobL9rYj4DvDniHiJIkA0+hEwuryA+y7gHxSh4s/A4RHxCPAkcF95rGcj4ifA/cBzwONA45XWRwMXlvt0AyZQXG/RkgeAm4ENgNMy87mI+CPFdR8PU8yEnJCZz7fS/jKwICIeBi7LzHOaGWdf4GsRMR94Hvhxk+3fBdYFHij/+nJjZp4SEScDt0VEF2A+cCRFwJMkSZKWS5FZ/+uQI6JnZr5ZXttwIfBUZp5TzpIszMwFEbEtcFFmNrTzWN2APwKXZuYfO/4slm89+g7IvgeeW+8yJEmqq5mjRtS7BKnTi4jJmTmsuW3LwwXnAN+KiAOB7hQzIheX7RsAV5d/3Z8HfKsdxxoZEbtQLO26Dbi+A+qVJEmStISWi/BRLkd6z5Kk8s5PQ5bwWO2+wXZEHAwc06T57sw8cknGbOdYnwPObNI8IzP3aK6/JEmS1NksF+GjXsq7R1VyW4rMvJXiu0UkSZKkFVJl33AuSZIkacVm+JAkSZJUCcOHJEmSpEoYPiRJkiRVwvAhSZIkqRKGD0mSJEmVMHxIkiRJqoThQ5IkSVIlDB+SJEmSKmH4kCRJklQJw4ckSZKkShg+JEmSJFXC8CFJkiSpEoYPSZIkSZUwfEiSJEmqRLd6F6BqDF6vF5NGjah3GZIkSVqBOfMhSZIkqRKGD0mSJEmVMHxIkiRJqoThQ5IkSVIlDB+SJEmSKmH4kCRJklQJw4ckSZKkShg+JEmSJFXC8CFJkiSpEoYPSZIkSZUwfEiSJEmqhOFDkiRJUiW61bsAVWPas6/T/8Sb612GJKkCM0eNqHcJktQsZz4kSZIkVcLwIUmSJKkShg9JkiRJlTB8SJIkSaqE4UOSJElSJQwfkiRJkiph+JAkSZJUCcOHJEmSpEoYPiRJkiRVwvAhSZIkqRKGD0mSJEmVMHxIkiRJqoThQ5IkSVIlDB+SJEmSKmH4kCRJklQJw4ckSZKkShg+JEmSJFXC8CFJkiSpEoYPSZIkSZUwfEiS1IktXLiQIUOG8IUvfAGAfffdl4aGBhoaGujfvz8NDQ0AzJw5k1VWWWXRtsMPP3zRMa666iq23HJLBg0axAknnFCX85DUOXSrdwGSJKnjnHfeeWy22WbMnj0bKIJEo+9+97v06tVr0euNNtqIqVOnLrb/yy+/zPe+9z0mT55Mnz59OPDAAxk7diw777xzNScgqVNZIWc+ImJgREyNiIciYqNW+v2gglp+0OT1PR09piRpxTBr1ixuvvlmDj300Pdsy0yuvvpq9ttvv1aP8fTTT7PJJpvQp08fAHbZZReuu+66DqlXUue3QoYP4MvADZk5JDP/r5V+7zt8RETXNrosNkZmfvL9jilJEsCxxx7LT3/6U7p0ee//7idOnMjaa6/NgAEDFrXNmDGDIUOGsP322zNx4kQANt54Y5544glmzpzJggULuP7663nmmWcqOwdJnUunWXYVEasBVwP9gK7AacCmwO7AKsA9wLeB3YBjgYUR8ZnM3DEivgYcDXQH7ge+A5wOrBIRU4HHgKeBlzLzvHK804EXMvO/m6llB+BU4B9AA7B5RFwPrA+sDJyXmZdExKjaMTLzgIh4MzN7lscYCbwEbAFMBr6WmRkRnwf+q9w2BdgwM7+wjN5KSVIn8Kc//Ym11lqLoUOHMn78+PdsHz169GKzHn379uXvf/87H/nIR5g8eTJf/vKXeeyxx/jwhz/MRRddxL777kuXLl345Cc/ydNPP13hmUjqTDpN+AB2BZ7LzBEAEdELuD0zf1y+/i3whcy8KSJ+AbyZmWdHxGbAvsB2mTk/In4OHJCZJ0bEUZnZUO7fH/gDcF5EdAG+CgxvpZ7hwBaZOaN8fUhmvhIRqwAPRsR1TcdoxhBgEPAccDewXURMAi4GPpOZMyJidEsFRMRhwGEAXdfo00qpkqTO5u677+bGG2/kf/7nf3j77beZPXs2X/va17jyyitZsGABf/jDH5g8efKi/j169KBHjx4ADB06lI022ojp06czbNgwdt99d3bffXcALrnkErp2bWtSX5Ka15mWXU0DdomIMyPi05n5OrBjRNwfEdOAnSg+yDe1MzCUIhBMLV9v2LRTZs4EXo6IIcBngYcy8+VW6nmgJngAHB0RDwP3UcyADGh+t/ccY1ZmvgtMBfoDA4Gna47dYvjIzEsyc1hmDuu6aq+WukmSOqEzzjiDWbNmMXPmTMaMGcNOO+3ElVdeCcAdd9zBwIED6dev36L+//znP1m4cCFQXOfx1FNPseGGxf8OX3zxRQBeffVVfv7znzd7DYkktUenmfnIzOkRMRT4PHBGRNwGHAkMy8xnImIkxZKnpgK4PDP/XzuG+RVwELAOcGkbfecsGqBYQrULsG1mzo2I8S3U0tQ7Nc8XUvy8oh37SZLUojFjxrznQvMJEyZwyimn0K1bN7p27covfvEL1lxzTQCOOeYYHn74YQBOOeUUNtlkk8prltQ5dJrwERHrAq9k5pUR8SZFSAB4KSJ6AnsB1zaz61jghog4JzNfjIg1gdUz82/A/IhYKTPnl33/CPwYWAnYfwnK6wW8WgaPgcAnarY1HaMtTwAbRkT/cjZm3yWoQ5K0Atphhx3YYYcdFr2+7LLL3tNnzz33ZM8992x2/9GjW5xkl6Ql0mnCBzAYOCsi3gXmA0dQ3NVqGjATeLC5nTLz8Yg4GbitvJZjPsWMyd+AS4BHImJKZh6QmfMi4k7gtcxcuAS1/Rk4PCIeAZ6kWHrVaLEx2jpQZr4VEd8B/hwRLwEPLEEdkiRJUt1EZta7hg+MMpxMAfbOzKfqWEfPzHwzIgK4EHgqM89pbZ8efQdk3wPPraZASVJdzRw1ot4lSFqBRcTkzBzW3LbOdMF5h4qIzYG/AmPrGTxK36q5BXAvirtfSZIkScu1zrTsqkNl5uM0uQtWRAwGftuk6zuZuU0H13IO0OpMhyRJkrS8MXy8D5k5jeJLBCVJkiS1wWVXkiRJkiph+JAkSZJUCcOHJEmSpEoYPiRJkiRVwvAhSZIkqRKGD0mSJEmVMHxIkiRJqoThQ5IkSVIlDB+SJEmSKmH4kCRJklQJw4ckSZKkShg+JEmSJFXC8CFJkiSpEoYPSZIkSZUwfEiSJEmqRLd6F6BqDF6vF5NGjah3GZIkSVqBOfMhSZIkqRKGD0mSJEmVMHxIkiRJqoThQ5IkSVIlDB+SJEmSKmH4kCRJklQJw4ckSZKkShg+JEmSJFXC8CFJkiSpEoYPSZIkSZUwfEiSJEmqhOFDkiRJUiW61bsAVWPas6/T/8Sb612GJC1m5qgR9S5BklQhZz4kSZIkVcLwIUmSJKkShg9JkiRJlTB8SJIkSaqE4UOSJElSJQwfkiRJkiph+JAkSZJUCcOHJEmSpEoYPiRJkiRVwvAhSZIkqRKGD0mSJEmVMHxIkiRJqoThQ5IkSVIlDB+SJEmSKmH4kCRJklQJw4ckSZKkShg+JEmSJFXC8CFJkiSpEoYPSZIkSZUwfEiS6urtt99m+PDhbLXVVgwaNIhTTz110bbzzz+f/9/evQfbVdZpHv8+JiRgQogRQ6VBLloMEUI6XBrkMkjjhaBMSGsacMYxgKPSo9b0WMjQZU2XjuOlRXuosbuc0m6mUVtsYtMClm24BDqWCiGQEGIjKIbpRiKXFhBCOjd+88d+EzfHk3CSQ9Y5Sb6fql177Xetd613PZCzz++8a+19xBFHcNRRR3HppZcCsGHDBubPn8/RRx/N6173Oj796U9v2X727Nlb9nPxxRezadOmzs9HkrR1Y0d6AJKkPdv48eNZtGgREydOZMOGDZx66qmcddZZrF27luuuu44VK1Ywfvx4HnvsMQAWLFjAunXruPfee3nuuec48sgjeec738mhhx7KNddcw6RJk6gq5s2bx4IFCzj//PNH+AwlSZvtljMfSW5LcnyHx7s8yY+SXL4TjzE5yX/eWfuXpJGShIkTJwK9WY0NGzaQhC9+8YtcdtlljB8/HoCpU6du2X7NmjVs3LiRtWvXMm7cOCZNmgSw5Xnjxo2sX7+eJCNwRpKkrdkti4/hSLIjs0HvB46tqo+81OPpMxmw+JC0W9q0aROzZs1i6tSpvPnNb+bEE0/kgQce4Hvf+x4nnngib3jDG7jzzjsBmDdvHhMmTGDatGkcfPDBXHLJJUyZMmXLvs4880ymTp3Kvvvuy7x580bqlCRJgxjR4iPJoUnuS/LlNnNwY5J9+mcukuyf5KG2fEGSbyW5IcmqJB9M8uEky5LcnmRK3+7fleQHSVYmOaH1n5DkyiR3tj7n9O13QZIbgBu3Mta0GY6VSe5Ncl5rvx6YANyxuW2Qvr/f+t2TZHFrG9P2d2eSFUne39onJrklyd3tOOe03XwGeG2S5a3ftCSL2+uVSf7tsP5jSNIIGjNmDMuXL+fhhx9myZIlrFy5ko0bN/Lkk09y++23c/nll3PuuedSVSxZsoQxY8bwyCOPsGrVKj7/+c/zs5/9bMu+Fi5cyOrVq1m3bh2LFi0awbOSJA00GmY+Dgf+vKqOAp4C3vEi288A/j1wAvBJ4LmqOgb4IfDuvu0mVNXJ9GYLrmxtHwUWVdXvAL8LXJ5kQlt3EjC/qs7YynHfDswCfht4U+s7rarmAGuralZV/c1W+v4xcGZV/TYwp7W9B3i6jeV3gPcmOQz4V+D3qurYNsbPp3fdwGXAg+04H2kZLKyqzWNaPvCgSd6XZGmSpZuee3orQ5Ok0WPy5MmcfvrpfPe73+Wggw7i7W9/O0k44YQTeNnLXsYTTzzB17/+dWbPns1ee+3F1KlTOeWUU1i6dOkL9rP33nszZ84crrvuuhE6E0nSYEZD8bGqqjb/4nwXcOiLbH9rVT1TVY8DTwM3tPZ7B/S9GqCqFgOTkkwG3gJclmQ5cBuwN3Bw2/6mqvrlNo57KnB1VW2qqkeBf6BXNAzF94G/SvJeYExrewvw7jaWO4BX0ivEAnwqyQrgZuBA4IBB9nkncGGSjwFHV9UzAzeoqi9V1fFVdfyYl+83xKFKUrcef/xxnnrqKQDWrl3LzTffzPTp05k7d+6WmYsHHniA9evXs//++3PwwQezaNEiqoo1a9Zw++23M336dJ599llWr14N9O75+M53vsP06dNH7LwkSb9pNHza1bq+5U3APsBGfl0Y7b2N7Z/ve/08LzyfGtCv6P1i/46qur9/RZITgTUvMs4dvmuxqi5ux3gbsDzJrLa/D1XVwgFjuQB4FXBcVW1ol5wNzICqWpzktLbPrya5vKq+sqNjlKSRsnr1aubPn8+mTZt4/vnnOffcczn77LNZv349F110ETNmzGDcuHFcddVVJOEDH/gAF154ITNmzKCquPDCC5k5cyaPPvooc+bMYd26dWzatIkzzjiDiy++eKRPT5LUZzQUH4N5CDgOWALs6N2C5wG3JjmV3uVNTydZCHwoyYeqqpIcU1XLhri/xcD7k1wFTAFOA4Z0g3mS11bVHfTuC/l3wKuBhcAfJFnUiox/A/wc2A94rLX9LnBI280zwL59+zwE+HlVfbldOnYsYPEhaZczc+ZMli37zR/F48aN42tf+9pvtE+cOJEFCxb8RvsBBxyw5aZ0SdLoNFqLj88B1yT5j8CO3i34ZJIfAJOAi1rbJ4ArgBXtPoqHgLOHuL+/o3dfyD30ZlEurapfDLHv5Uk2X1J1S9vHCnqXid3dxvI4MBf4a+CGJEvp3cfxY4Cq+pck30+yEvh7YCXwkSQbgGd54f0ukiRJ0qiTqoFXJ2l3NH7a4TVt/hUjPQxJeoGHPvO2kR6CJOklluSuqhr0O/dGww3nkiRJkvYAo/WyqxGT5GjgqwOa11XViUPo+1Hg9wc0L6iqT75U45MkSZJ2VRYfA1TVvfS+z2NH+n6S3nePSJIkSRrAy64kSZIkdcLiQ5IkSVInLD4kSZIkdcLiQ5IkSVInLD4kSZIkdcLiQ5IkSVInLD4kSZIkdcLiQ5IkSVInLD4kSZIkdcLiQ5IkSVInLD4kSZIkdcLiQ5IkSVInLD4kSZIkdcLiQ5IkSVInLD4kSZIkdcLiQ5IkSVInxo70ANSNow/cj6WfedtID0OSJEl7MGc+JEmSJHXC4kOSJElSJyw+JEmSJHXC4kOSJElSJyw+JEmSJHXC4kOSJElSJyw+JEmSJHXC4kOSJElSJyw+JEmSJHXC4kOSJElSJyw+JEmSJHXC4kOSJElSJyw+JEmSJHXC4kOSJElSJyw+JEmSJHXC4kOSJElSJyw+JEmSJHXC4kOSJElSJyw+JEmSJHXC4kOSJElSJyw+JEmSJHXC4kOSJElSJyw+JEmSJHXC4kOSJElSJyw+JEmSJHXC4kOSJElSJyw+JEmSJHXC4kOSJElSJyw+JEmSJHXC4kOSJElSJyw+JEmSJHXC4kOSJElSJyw+JEmSJHXC4kOSJElSJyw+JEmSJHXC4kOSJElSJ1JVIz0GdSDJM8D9Iz2OXdj+wBMjPYhdmPkNj/kNnxkOj/kNj/kNj/kNz0jkd0hVvWqwFWM7HohGzv1VdfxID2JXlWSp+e048xse8xs+Mxwe8xse8xse8xue0Zafl11JkiRJ6oTFhyRJkqROWHzsOb400gPYxZnf8Jjf8Jjf8Jnh8Jjf8Jjf8Jjf8Iyq/LzhXJIkSVInnPmQJEmS1AmLjz1AktlJ7k/y0ySXjfR4RoskVyZ5LMnKvrYpSW5K8pP2/Iq+dX/UMrw/yZl97cclubet+99J0vW5dC3Jq5PcmuS+JD9K8l9au/kNQZK9kyxJck/L7+Ot3fy2Q5IxSZYl+XZ7bX7bIclD7dyXJ1na2sxwiJJMTvLNJD9uPwtPMr+hSXJE+/9u8+NXSf7Q/IYuyX9t7x8rk1zd3ld2jfyqysdu/ADGAA8CrwHGAfcAN7Yx5AAAB+tJREFUR470uEbDAzgNOBZY2df2WeCytnwZ8Cdt+ciW3XjgsJbpmLZuCXASEODvgbNG+tw6yG4acGxb3hd4oGVkfkPLL8DEtrwXcAfwevPb7hw/DHwd+HZ7bX7bl99DwP4D2sxw6PldBfyntjwOmGx+O5TjGOAXwCHmN+TMDgRWAfu019cAF+wq+Tnzsfs7AfhpVf2sqtYD3wDOGeExjQpVtRj45YDmc+i9odCe5/a1f6Oq1lXVKuCnwAlJpgGTquqH1ftX/JW+PrutqlpdVXe35WeA++j9MDS/IaieZ9vLvdqjML8hS3IQ8DbgL/qazW/4zHAIkkyi9wesvwSoqvVV9RTmtyPeCDxYVf8P89seY4F9kowFXg48wi6Sn8XH7u9A4J/7Xj/c2jS4A6pqNfR+wQamtvat5XhgWx7YvsdIcihwDL2/3pvfELVLhpYDjwE3VZX5bZ8rgEuB5/vazG/7FHBjkruSvK+1meHQvAZ4HPi/7dK/v0gyAfPbEecDV7dl8xuCqvo58Dngn4DVwNNVdSO7SH4WH7u/wa7d8yPOtt/Wctyj800yEfhb4A+r6lfb2nSQtj06v6raVFWzgIPo/QVqxjY2N78+Sc4GHququ4baZZC2PTa/PqdU1bHAWcAHkpy2jW3N8IXG0rts94tVdQywht5lLltjfoNIMg6YAyx4sU0Hadtj82v3cpxD7xKq3wImJHnXtroM0jZi+Vl87P4eBl7d9/ogelNzGtyjbRqS9vxYa99ajg+35YHtu70ke9ErPP66qq5tzea3ndqlGrcBszG/oToFmJPkIXqXkp6R5GuY33apqkfa82PA39G7TNcMh+Zh4OE2YwnwTXrFiPltn7OAu6vq0fba/IbmTcCqqnq8qjYA1wIns4vkZ/Gx+7sTODzJYe0vDOcD14/wmEaz64H5bXk+cF1f+/lJxic5DDgcWNKmNZ9J8vr2CRHv7uuz22rn+pfAfVX1p32rzG8IkrwqyeS2vA+9N5IfY35DUlV/VFUHVdWh9H6mLaqqd2F+Q5ZkQpJ9Ny8DbwFWYoZDUlW/AP45yRGt6Y3AP2J+2+ud/PqSKzC/ofon4PVJXt7O+4307r3cNfLb2Xe0+xj5B/BWep9G9CDw0ZEez2h50PuBtxrYQK/6fw/wSuAW4CfteUrf9h9tGd5P36dBAMfTe9N+EPgz2pd37s4P4FR6U7MrgOXt8VbzG3J+M4FlLb+VwB+3dvPb/ixP59efdmV+Q8/tNfQ+/eYe4Eeb3xvMcLsynAUsbf+OvwW8wvy2K7+XA/8C7NfXZn5Dz+/j9P5otRL4Kr1Pstol8vMbziVJkiR1wsuuJEmSJHXC4kOSJElSJyw+JEmSJHXC4kOSJElSJyw+JEmSJHXC4kOStNMk2ZRked/j0B3Yx9wkR770o4Mkv5Xkmztj39s45qwkb+3ymJI0Wowd6QFIknZra6tq1jD3MRf4Nr0vcRuSJGOrauOLbVe9b/meN4yxbZckY+l9P8TxwHe6Oq4kjRbOfEiSOpXkuCT/kOSuJAuTTGvt701yZ5J7kvxt+/bek4E5wOVt5uS1SW5Lcnzrs3+Sh9ryBUkWJLkBuLF9i/eVbZ/LkpwzyFgOTbKyr/+3ktyQZFWSDyb5cOt7e5IpbbvbklyR5AdJViY5obVPaf1XtO1ntvaPJflSkhuBrwD/Azivnc95SU5o+1rWno/oG8+1Sb6b5CdJPts37tlJ7m5Z3dLaXvR8JWmkOfMhSdqZ9kmyvC2vAs4FvgCcU1WPJzkP+CRwEXBtVX0ZIMn/BN5TVV9Icj29bzH/Zlu3reOdBMysql8m+RSwqKouSjIZWJLk5qpas43+M4BjgL2BnwL/raqOSfK/gHcDV7TtJlTVyUlOA65s/T4OLKuquUnOoFdobJ71OQ44tarWJrkAOL6qPtjOZxJwWlVtTPIm4FPAO1q/WW0864D7k3wB+Ffgy63Pqs1FEb1vMN7e85WkTll8SJJ2phdcdpVkBr1f1G9qRcQYYHVbPaMVHZOBicDCHTjeTVX1y7b8FmBOkkva672Bg4H7ttH/1qp6BngmydPADa39XmBm33ZXA1TV4iST2i/7p9KKhqpalOSVSfZr219fVWu3csz9gKuSHA4UsFffuluq6mmAJP8IHAK8AlhcVavasYZzvpLUKYsPSVKXAvyoqk4aZN1fAXOr6p42O3D6VvaxkV9fNrz3gHX9f+UP8I6qun87xreub/n5vtfP88L3zBrQr9rxBtq83bZmHz5Br+j5vXZD/m1bGc+mNoYMcnzYsfOVpE55z4ckqUv3A69KchJAkr2SHNXW7QusTrIX8B/6+jzT1m32EL3LmGDbN4svBD6UNsWS5JjhD3+L89o+TwWebrMTi2njTnI68ERV/WqQvgPPZz/g5235giEc+4fAG5Ic1o61+bKrnXm+kvSSsPiQJHWmqtbTKxj+JMk9wHLg5Lb6vwN3ADcBP+7r9g3gI+0m6tcCnwP+IMkPgP23cbhP0LuEaUW7qfwTL+GpPNmO/3+A97S2jwHHJ1kBfAaYv5W+twJHbr7hHPgs8Okk36d3Gdo2VdXjwPuAa1uGf9NW7czzlaSXRKoGm7mVJEmDSXIbcElVLR3psUjSrsaZD0mSJEmdcOZDkiRJUiec+ZAkSZLUCYsPSZIkSZ2w+JAkSZLUCYsPSZIkSZ2w+JAkSZLUCYsPSZIkSZ34/7KD14RCBIXpAAAAAElFTkSuQmCC\n",
"text/plain": [
""
]
},
"metadata": {
"needs_background": "light"
},
"output_type": "display_data"
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"--------------------------------------------------------\n",
"********************* Model Results ********************\n",
"--------------------------------------------------------\n",
"F1 Score : 0.9847625713245376\n",
"AUC-ROC Score : 0.9916415441328472\n",
"Report:\n",
" precision recall f1-score support\n",
"\n",
" 1 1.00 0.99 0.99 277\n",
" 2 0.97 0.97 0.97 94\n",
" 3 0.92 1.00 0.96 12\n",
" 4 0.89 1.00 0.94 8\n",
"\n",
" accuracy 0.98 391\n",
" macro avg 0.94 0.99 0.97 391\n",
"weighted avg 0.99 0.98 0.98 391\n",
"\n"
]
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAYEAAAEgCAYAAABSGc9vAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADt0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjByYzEsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy/xvVyzAAAgAElEQVR4nO3de5yUdf338dc7VlRAMCVYE4JUzEPeYnlIMVKUMDEpMEQrD4n86u7O/MnvzkOFQL/yl2l0thAP1V1aREaBVoYhlUkeUELRIl3Dw65n0OIgy+f+47oWh2Fm2V1m59rZ6/18POYxM9fxM9+dnfdc3+swigjMzCyf3pB1AWZmlh2HgJlZjjkEzMxyzCFgZpZjDgEzsxxzCJiZ5ZhDwLo0SRdIeljSOkkh6cIqrLNBUkNnrycP0r/Z4qzrsPIcAgaApAMkfVPSCklrJG2U9LSkhZLOk7RLBjVNAr4OrAe+BswA7q52HV1BGkyR3o5vZbobCqabvoPrPK4Sy7GurS7rAix7kqYBl5N8Kbgb+D7wKjAQOA6YA3wCOLzKpZ3Sch8RT1dxvSdUcV3ttQk4H/h98QhJfYGJ6TRd5X/7QODfWRdh5XWVN4plRNJlJN+wVwMfioilJaY5BZha7dqANwNUOQCIiH9Uc33ttAAYL2nPiHihaNyHgV7ALcAHq15ZCRHxSNY1WOvcHZRjkoYC04HXgJNLBQBARCwATiox/0RJS9Luo3WS/irpUkk7l5i2Ib31kvQVSf+UtEHSKkkXS1LBtNMlBXB8+ryleyNa6k6f31jmdS1umbZgmCSdLekuSc9JWi9ptaTfSDq9VK0llruzpEskLZf0b0lrJf1B0sQS026pMX18s6Tn0/XemwZrR1wL7Ax8tMS480nC/NelZpS0v6T/Sdf/XNr+T0iaLWlQ0bQ38vrWxuWFfwNJx6XTnJM+P0fSSWm7ryls++J9ApLeKullSS9KGlK0zt6SVkpqlvSe9jaMdYy3BPLtXGAn4OaIWNHahBGxofC5pC8BlwLPAz8m6T56H/AlYIyk0RHxWtFidgJ+S/IN/zaSbosPAP8D7EKyRQKwOL0/BxhSMHxHfDGt93Hgp8AaYC/gCOBDwE9am1lST+A3wHuAR4Bvk3zrPg34iaThEXFZiVmHAH8BHgN+COwBnA7Ml3RiRGzTrbMdtwMNwGSS/SQt9b0TOIykrTaXmXc88HGSD/e7gI3Awemy3i/p8Ih4Kp32F+n92cCdvP43IV1/odNIviTcBnwXGFqu+Ih4XNJkYC5wk6SREbEpHf0d4ABgekTcWW4ZVmER4VtOb8AiIIDJ7Zzv6HS+fwL1BcPrgF+l4y4rmqchHX4rsGvB8AHAy+ltp6J5Fidv0W3WPzRd1o1l6ttmPuAF4EmgV4np+5eotaFo2KUF9dcV1d/y2o4pUWMAlxcta0zLstrR5i3rqAM+lz4+umD8d4Fm4C0kH+pB8mFauIy9gZ1LLPu96bzXFA0/rtRyCsafk47fDJxUZpoAFpcY/p103BXp87PS578H3pD1/0aebu4Oyre90vsn2znfx9L7/46IxpaBkXyjm0ryoTC5zLwXRMS6gnmeBeYD/YC3tbOO9nqN5MNuKxHxfBvm/RjJh9RF8fo315b6v5A+LfWanwD+u2h9vyEJ0CPbVvY2rid5HedD0o0CnAn8JiL+WW6miHgqirbo0uG/BR4iCaeOmB8RJbugWnER8CBwsaT/QxIKzwEfjohyWzLWCRwC+dbSD9/e64m/I72/o3hERPyNJFTeKmn3otFrImJVieWtTu/f2M462uNHJN/OH5J0RdqH3a8tM0raDdgPeDpK7+hsaYfDSox7ICK2CR6S19yh1xvJjvJbgYnpEUGTgN1I9heUle4X+Yik36X7BDYV7Gs5hGRLoSP+0t4ZImI9SbfYv4BvknStnRVVPgjAHAJ51/IPN6jVqbbV8uH5TJnxzxRN1+LlMtO3fLPu0c462uM/gQtJPnQuIem/fl7SfEn7bWfetr7e4tCD1l/zjvz/XQv0Bs4g2SJoJOmKa81XSfZLHESyf+Nqkn0IM0i2WHp2sJbG7U9S0t+A5enjh0n2F1mVOQTy7Y/pfXuPi1+T3teXGb9X0XSV1tJdUO7Ahm0+jCOiOSK+HhGHkpz/MIHkUMpTgV+XOqKpQNavt5RbgadI9g8cBdxQ2E1VTNIA4AJgBfC2iPhIRFwcEdMjYjqwTTdRO3T0l6kuAY4hObjgYJL9LlZlDoF8u4Gkn3yCpINam7DoQ3JZen9cien2I9myeDwiyn0L3lEvpfeDS6y/L7B/azNHxLMR8fOImEjSlbMv8PZWpn8F+Aewt6RhJSZpOYP3/jbUXhFpF9P1JG0dwHXbmWUfkv/336avZ4v08NB9SszT0o1V8S00SccAM4FHSdr+UWCGpGMrvS5rnUMgxyKigeQ8gZ7AQkklzwiW1HL4X4vr0/vPSXpTwXQ9gKtI3lfb+1DqsPRD7BFgRGF4pev/KrBr4fTp8f0nFJ6LkA7fieSQTdj+Wa3Xk+xD+Uq6npZl9Ac+XzBNNX2D5KSwMbH9E9wa0vtji+rvQ9K1VGqrquVktLfsYJ1bkfRG4CaSkJkUEU0k+wc2kRw2umcl12et83kCORcRX5JUR3LZiHsk3QXcy+uXjRgJDEuHtcxzl6Qrgc8AKyT9jKSv/X0k3+r+CHylk0v/CknQ/EnSXJLrCx1Pci7Cg8ChBdPuCvwOaJC0lKT/exdgNMllDX4ZESu3s76rSF7fOOBBSbeS7Mz8EMlholdGxB9bmb/i0qOafrHdCZNpGyXdTLIT+QFJvyXZ1zGapO0eAIYXzfYoSZfTJEkbSY5oCuCHEfHEDpR+PUmwXBARD6T1PShpKvAtki3UU3dg+dYeWR+j6lvXuJF8GH6TpM94LcmJRM+QbAGcR+njyyeRfOC/QvJB8hDwWWCXEtM2UHTsfcG46SQfLscVDV9MifMECsafl65zA8nOye8BexbPRxIMn0lfyz/TWp8juU7Sx4GebamVJDguS9toXfq6/wicUWLaobTzXIbt/H0a0uXVtWHacucJ9CI5aW5V2garSU5626bNCuY5guR8kjUk+2K2/J14/TyBc1qpZavzBIBPpcPml5n+5+n4/8z6fyIvN6UNb2ZmOeR9AmZmOeYQMDPLMYeAmVmOOQTMzHKspg4RVdE14s3MbPsiQuXG1VQIWGX5Wl2VI70ZH2lXOZLcnhVSdI7kNtwdZGaWYw4BM7MccwiYmeWYQ8DMLMccAmZmOeYQMDPLMYeAmVmOOQTMzHLMIWBmlmMOATOzHHMImJnlmEPAzCzHHAJmZjnmEDAzyzGHgJlZjjkEzMxyzCFgZpZjDgEzsxxzCJiZ5ZhDwMwsxxwCZmY55hBop0GDBnHHHXfw8MMPs2LFCi644AIAbr75ZpYtW8ayZct4/PHHWbZs2VbzDR48mFdeeYWpU6dmUXbN2bBhA6ed9nFOPfU8xo49h29844asS6p5S5YsYcyYMYwePZrZs2dnXU7N6y7tWZd1AbVm06ZNTJ06lWXLltGnTx/uu+8+br/9diZNmrRlmquuuoo1a9ZsNd+sWbO47bbbql1uzerZsyff//5X6d27F6+9tokzz/wUI0ceyfDhB2ddWk1qbm5m5syZ3HDDDQwcOJDTTjuNUaNGsd9++2VdWk3qTu3pLYF2amxs3PIt/9VXX2XlypXsvffeW00zceJEbrrppi3Px40bx2OPPcZDDz1U1VprmSR69+4FJMG7adMmJGVcVe1avnw5Q4YMYfDgwfTs2ZOxY8eyaNGirMuqWd2pPR0CO2DIkCEcdthhLF26dMuwd7/73TQ1NbFq1SoAevXqxcUXX8yMGTOyKrNmNTc3M27ceRxzzAc45pjDOfTQg7IuqWY1NTVRX1+/5fnAgQNpamrKsKLa1p3as0uEgKRzs66hvXr37s28efO48MILeeWVV7YMP+OMM7baCpgxYwazZs3iX//6VxZl1rQePXowf/513HnnXJYvX8nf/vZY1iXVrIjYZpi3rDquO7VnV9knMAMouedP0hRgSnXLaV1dXR3z5s3jRz/6EbfccsuW4T169GD8+PG8853v3DLsqKOO4rTTTuPKK69k9913Z/Pmzaxfv55vf/vbWZRek/r23Y2jjhrOH/7wF/bff5+sy6lJ9fX1NDY2bnne1NTEgAEDMqyotnWn9qxaCEhaXm4UMLDcfBExG5idLmPb+M3Addddx8qVK5k1a9ZWw0888UQeeeQRnnrqqS3DRo4cueXx5ZdfzquvvuoAaIMXX3yZuroe9O27G+vXb+Cuu+7j/PPPyLqsmnXIIYfQ0NDA6tWrGThwIAsXLuTqq6/Ouqya1Z3as5pbAgOBMcBLRcMF3FXFOnbIiBEjOOuss1i+fPmWHcSXXXYZt912G5MmTdqqK8g67tlnX+CSS66guXkzEZs56aTjOf74Y7Iuq2bV1dUxbdo0Jk+eTHNzMxMmTGDYsGFZl1WzulN7qlTfVqesSLoOuCEi/lhi3I8j4sw2LKNLbAl0FxFPZ11CtyG9uWQ/sXWMJLdnhaRtWXaHRdVCoBIcApXlEKgch0BlOQQqZ3sh0CWODjIzs2w4BMzMcswhYGaWYw4BM7MccwiYmeWYQ8DMLMccAmZmOeYQMDPLMYeAmVmOOQTMzHLMIWBmlmMOATOzHHMImJnlmEPAzCzHHAJmZjnmEDAzyzGHgJlZjjkEzMxyzCFgZpZjDgEzsxxzCJiZ5ZgiIusa2kxS7RRrZtZFRITKjaurZiGVUEuh1ZVJIqbNyLqMbkMzL/d7s4IkuT0rRCr7+Q+4O8jMLNccAmZmOeYQMDPLMYeAmVmOOQTMzHLMIWBmlmMOATOzHHMImJnlmEPAzCzHHAJmZjnmEDAzyzGHgJlZjjkEzMxyzCFgZpZjDgEzsxxzCJiZ5ZhDwMwsxxwCZmY55hAwM8sxh4CZWY45BMzMcswhYGaWY3VZF9CdXHrppSxevJg999yTBQsWZF1ObXrXkfCOd4CA+5bB3UvhoAPh+PdA/zfBtXPg6WeyrrLm+L1ZWd2pPb0lUEHjx49nzpw5WZdRuwa8KQmAa+fANd+D/YfBHnvAs8/BzXPhiSeyrrBm+b1ZWd2pPasaApIOkHSCpD5Fw0+qZh2d5YgjjqBfv35Zl1G7+veHJ5+E1zbB5kg+9A88AJ5/Hl54Ievqaprfm5XVndqzaiEg6QJgPvApYIWkcQWjv1StOqwLe/Y5GDIEdt0VdqqDYcOgX9+sqzLr1qq5T+B84J0R8aqkocDPJA2NiK+T9ACXJGkKMKU6JVqmnn8e/vQnOOsjsHEjNDbC5s1ZV2XWrVUzBHpExKsAEdEg6TiSIBhCKyEQEbOB2QCSohqFWobufyC5AZwwCtauzbYes26umvsEGiUNb3mSBsIpQH/gkCrWYV1Z717Jfb++yf6Av67Ith6zbq6aIXAW0Fg4ICI2RcRZwMgq1tFpLrroIiZNmsTjjz/OyJEjmTt3btYl1Z7TJ8InPwFnToKFt8H69XDA2+CiC2HwIPjwGfDRD2ddZc3xe7OyulN7KqJ2elgkRS3V25VJIqbNyLqMbkMzL8fvzcqR5PaskLQty3a5+zwBM7MccwiYmeVY2aODJP20HcuJiDi9AvWYmVkVtXaI6JuqVoWZmWWibAhExPHVLMTMzKrP+wTMzHKszWcMS9oNGAfsD+xSPD4iPlPBuszMrAraFAKS9gX+BPQCegPPAXuk878ErAEcAmZmNaat3UGzgHuBgSTX+TkZ2BX4CPAq4CODzMxqUFu7g44EJgMb0uc9I6IZ+LGk/sDXgWM6oT4zM+tEbd0S2AVYGxGbgReBNxeMWwEcWunCzMys87U1BP4GDEkfLwM+LmkXSTsB5wFPd0ZxZmbWudraHXQzMBz4IfB54DfAWmBzuoxzOqM4MzPrXG0KgYj4asHjuyW9HXgfSTfRHRHhi76bmdWgDv2yWESsJv21LzMzq11tPU/g5O1NExG37ng5ZmZWTW3dElgABNv+FnDhrz70qEhFZmZWNW0NgbeWGLYH8F6SncLnVqogMzOrnrbuGH6ixOAngGWSmoHLgFMrWZiZmXW+SlxFdBkwqgLLMTOzKtuhEJDUk6Q76JmKVGNmZlWliNj+RNI9bL0TGKAnMBTYDTg3In5Q8eq2rWP7xZqZ2VYiovigni3aumP4IbYNgfXAXOAXEfFQB2szM7MMtWlLoKuQFLVUb1cmCbdl5STt6Z/UqBTpSr8/KyT9Xy+7JdCmfQKS7pB0QJlx+0u6o6MFmplZdtq6Y/g4oG+ZcX2BkRWpxszMqqo9Rwdts22WHh00CmisWEVmZlY1ZXcMS7ocmJY+DeBuqWy30lcqXJeZmVVBa0cH3Qo8T3K9oG8AVwMNRdNsBB6JiD90SnVmZtapyoZARNwD3AMg6RVgQUS8UK3CzMys87V1n8ADwFGlRkg6WdL/qlxJZmZWLW0NgVmUCQHgiHS8mZnVmLaGwDuAP5UZ92fgsMqUY2Zm1dTWEOgB9C4zrjfJdYTMzKzGtDUE7gGmlBk3Bbi3MuWYmVk1tfUCctOB30laCnyf5OSwvYCzgOHAiZ1SnZmZdaq2/rLYEknvBa4Avkly7sBmYClwQnpvZmY1pq1bAkTEYuBoSb2ANwIvAUcDZwPzgT07o0AzM+s8bQ6BAocAZwATgYHAi8DNlSzKzMyqo00hIOntJB/8k0h+TWwjyRFBU4FvRcSmzirQzMw6T9mjgyTtI+kySX8FHgT+C1hJsjN4GMl+gfsdAGZmtau1LYFVJFcPXQr8BzAvIl4CkNSvCrWZmVkna+08gSdIvu2/neRHZY6R1JF9CGZm1kWVDYGIeCswguS8gBOAXwFNkq5Nn/sHQM3MalyrZwxHxJ8j4lPA3sAYkkNBJwA/Syc5X9LhnVuimZl1ljZdNiIiNkfE7RHxMaAeGA/MBT4ILJW0shNrrBlLlixhzJgxjB49mtmzZ2ddTs1ze+6YSy+9n6OPvpVTTlm0ZdiXv7yCk076He9//x188pNLWbt2Y4YV1rbu8v5sz28MAxARGyPiFxExieQ8gbNIdiLnWnNzMzNnzmTOnDksXLiQBQsWsGpV7pulw9yeO278+LcwZ84xWw0bMWIACxaM4le/GsXQoX343vf+nlF1ta07vT/bHQKFIuJfEfGjiHh/W6aXdKSkI9LHB0m6SNLJO1JDV7F8+XKGDBnC4MGD6dmzJ2PHjmXRokXbn9FKcnvuuCOO6E+/fjttNezYYwdQV5f82w8f/kYaG9dlUVrN607vzx0KgfZIf7j+G8A1kq4AvgX0AS6R9Nlq1dFZmpqaqK+v3/J84MCBNDU1ZVhRbXN7dr55855g5MiBWZdRk7rT+7Oah3yeRnLF0Z1JrkI6KCLWSvoKybkIXyw1k6QplL+MdZcRse3BUpIyqKR7cHt2rmuueZQePd7AqacOyrqUmtSd3p/VDIFNEdEM/FvSPyJiLUBErJO0udxMETEbmA0gqcsellpfX09jY+OW501NTQwYMCDDimqb27Pz3HLLP1m8uJEbbxxRsx9cWetO78+qdQcBG9MrkAK8s2VgevZx2RCoFYcccggNDQ2sXr2ajRs3snDhQkaNGpV1WTXL7dk5lixp4tpr/84117yLXXf1uZ8d1Z3en9V8F4yMiA2QHHJaMHwnkstR17S6ujqmTZvG5MmTaW5uZsKECQwbNizrsmqW23PHXXTRPfzlL8/z0ksbGTny13zqUwcwe/bf2bhxM+eem/xk+KGH7sHMmcMzrrT2dKf3p0r1bXVVkqKW6u3KJJXs17SOSdrzM1mX0W1IV/r9WSHp/3rZfr9qdgeZmVkX4xAwM8sxh4CZWY45BMzMcswhYGaWYw4BM7MccwiYmeWYQ8DMLMccAmZmOeYQMDPLMYeAmVmOOQTMzHLMIWBmlmMOATOzHHMImJnlmEPAzCzHHAJmZjnmEDAzyzGHgJlZjjkEzMxyzCFgZpZjDgEzsxxTRGRdQ5tJqp1izcy6iIhQuXF11SykEmoptLoySW7LCnJ7VlbSnjdlXUa3IJ3R6nh3B5mZ5ZhDwMwsxxwCZmY55hAwM8sxh4CZWY45BMzMcswhYGaWYw4BM7MccwiYmeWYQ8DMLMccAmZmOeYQMDPLMYeAmVmOOQTMzHLMIWBmlmMOATOzHHMImJnlmEPAzCzHHAJmZjnmEDAzyzGHgJlZjjkEKmjJkiWMGTOG0aNHM3v27KzLqXluz8pye1bWjTfexdix3+KUU77NRRfNZcOG17IuqUMcAhXS3NzMzJkzmTNnDgsXLmTBggWsWrUq67JqltuzstyeldXUtJYf/GAp8+b9BwsWfJLm5mDhwhVZl9UhDoEKWb58OUOGDGHw4MH07NmTsWPHsmjRoqzLqlluz8pye1Zec/Nm1q9/jU2bmlm//jUGDNgt65I6JNMQkPSDLNdfSU1NTdTX1295PnDgQJqamjKsqLa5PSvL7VlZAwf25WMfO4bjj5/FscdeRZ8+O3PssftlXVaH1FVrRZJ+WTwIOF7S7gARcWq1aukMEbHNMEkZVNI9uD0ry+1ZWWvWrGPRokdZtOhCdtttFz796Z8yf/6DjBt3aNaltVvVQgAYBDwMzAGCJAQOB65ubSZJU4ApnV7dDqqvr6exsXHL86amJgYMGJBhRbXN7VlZbs/Kuuuuxxg0aHf22KM3AO9974EsW7a6JkOgmt1BhwP3AZ8F1kTEYmBdRNwZEXeWmykiZkfE4RFxeJXq7JBDDjmEhoYGVq9ezcaNG1m4cCGjRo3Kuqya5fasLLdnZb35zf148MEnWbduIxHBn//8GPvu2z/rsjqkalsCEbEZmCVpbnrfVM31d7a6ujqmTZvG5MmTaW5uZsKECQwbNizrsmqW27Oy3J6Vdeihgxgz5iA++MHvUVf3Bg48sJ7TT+/S31PLUqm+wqqsWBoLjIiIy9oxT2RVb3cjqWQ/sXWM27Oykva8KesyugXpDCKi7A6gzL6JR8RCYGFW6zczM58nYGaWaw4BM7MccwiYmeWYQ8DMLMccAmZmOeYQMDPLMYeAmVmOOQTMzHLMIWBmlmMOATOzHHMImJnlmEPAzCzHHAJmZjnmEDAzyzGHgJlZjjkEzMxyzCFgZpZjDgEzsxxzCJiZ5ZhDwMwsxxwCZmY5pojIuoY2k1Q7xZqZdRERoXLjaioEaoWkKRExO+s6ugu3Z+W4LSurO7Snu4M6x5SsC+hm3J6V47asrJpvT4eAmVmOOQTMzHLMIdA5arqPsAtye1aO27Kyar49vWPYzCzHvCVgZpZjDgEzsxxzCFSQpOslPStpRda11DpJgyX9XtJKSQ9J+nTWNdUySbtI+oukB9P2nJF1TbVOUg9JyyQtyLqWHeEQqKwbgZOyLqKb2ARMjYgDgXcBn5R0UMY11bINwKiIOBQYDpwk6V0Z11TrPg2szLqIHeUQqKCIWAK8mHUd3UFEPBMR96ePXyH5Z9s726pqVyReTZ/ulN58VEgHSRoEjAXmZF3LjnIIWJcnaShwGLA020pqW9p98QDwLHB7RLg9O+5rwGeAzVkXsqMcAtalSeoDzAMujIi1WddTyyKiOSKGA4OAIyW9PeuaapGkU4BnI+K+rGupBIeAdVmSdiIJgB9FxM+zrqe7iIiXgcV4/1VHjQBOldQA3AyMkvT/si2p4xwC1iVJEnAdsDIivpp1PbVO0psk7Z4+3hU4EXgk26pqU0RcGhGDImIoMAm4IyI+knFZHeYQqCBJNwF/Bt4m6UlJ52VdUw0bAXyU5FvWA+nt5KyLqmF7Ab+XtBy4h2SfQE0f2miV4ctGmJnlmLcEzMxyzCFgZpZjDgEzsxxzCJiZ5ZhDwMwsxxwCVvMkTZcUBbenJc2TtG8nre+UdD1D0+dD0+entGMZEyWdU8Ga+qQ1VGyZlg91WRdgViFreP0M2H2ALwCLJB0cEf/q5HU/AxxN+06+mgj0J7nyrFlmHALWXWyKiLvTx3dL+ifwB+BkYG7hhJJ2jYh1lVpxRGwA7t7uhGZdkLuDrLtqubjXUEkNkq6W9HlJTwJrASS9QdIlklZJ2iDpb5LOLlyIEtPTHwt6RdIPgL5F05TsDpJ0vqS/SlovqUnSzyT1k3QjMAF4T0EX1vSC+cZJujedr1HSlel1lAqXPSGtd52kJcABlWk2yxtvCVh3NTS9b0zvzwQeAv43r7/vvwmcDcwE7gdGA9dLeqHgkgoXANOAL5FsWYwHrtzeyiV9Ll3ud4D/C/Qiuf58H5KuqrcAu6f1ADyZzjcRuAn4HnAZsC9wBckXtv9Kp3kH8BPgFpIfNjkY+Gkb2sRsWxHhm281fQOmA8+TfLjXAfsDvyf5xr8X0EDSb79LwTz7kVwL/uyiZf0AuCd93AN4GrimaJrbSX6QZWj6fGj6/JT0+e7Av4GvtlLzz4DFRcMEPAHcUDT8Y8A6YM/0+U+Bh0kv+5IO+2xawzlZ/z18q62bu4Osu9gTeC29PUqyc/j0iHgmHb8oItYXTH8CSQjcIqmu5QYsAoZL6gEMJgmR+UXr2t5lrY8GdgVuaOdr2J9kC+GnRTXdAewCtFz//0jglxFReOEvX2rbOsTdQdZdrCG5PHKQdAE9XfQh2VQ0fX+Sb/pryixvL6A+ffxs0bji58X2TO+faXWqbfVP728tM35wel/fgZrMSnIIWHexKSLubWV88eVyXyT5MfsRlP6JwGd5/f9jQNG44ufFXkjv9yLppmqrlt+nngIsKzH+8fS+sQM1mZXkELC8uoNkS6BfRNxeagJJq0k+cMcBvy4YNX47y/4zSR/+2aQ7c0vYSNLFU+hR4CmSfQ3XtrL8e0h+2erSgq2d7dVkVpJDwHIpIh6V9F3gZklXAveSfCgfDOwfEZMjojkdd5Wk50mODpoAHLidZb8s6QvAFyX1JOne2Znk6KAZEfEUyYll4yR9gOTIoKcj4mlJU4EfSuoL3EYSFvsAHwBOi4h/A18GlpLsO7iOZF+Bf8DIOsQ7hi3PPklyuOZZJB/UN5J8UC8pmOZrJIeHfpzk9477AJ/Z3oIj4grgEyT7KeaTHPK5O/BKOsl3gN8C15N8s5+SzvcTki2P4T9PjDsAAABUSURBVCQnuf2c5DDS+0kCgbTbaxJwGPALkoA4vb0v3gz8y2JmZrnmLQEzsxxzCJiZ5ZhDwMwsxxwCZmY55hAwM8sxh4CZWY45BMzMcswhYGaWY/8fnjUD7taE1g8AAAAASUVORK5CYII=\n",
"text/plain": [
""
]
},
"metadata": {
"needs_background": "light"
},
"output_type": "display_data"
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"--------------------------------------------------------\n",
"\n",
"Model used: LGBMClassifier(boosting_type='gbdt', class_weight='balanced',\n",
" colsample_bytree=1.0, learning_rate=0.1, max_depth=8,\n",
" min_child_samples=20, min_child_weight=0.001, min_split_gain=0.0,\n",
" n_estimators=600, n_jobs=-1, num_leaves=31, objective=None,\n",
" random_state=101, reg_alpha=0.0, reg_lambda=0.0, silent=True,\n",
" subsample=1.0, subsample_for_bin=200000, subsample_freq=1,\n",
" verbose=1) \n",
" Done.\n"
]
}
],
"source": [
"df = ez.importdata('TrainDataset.csv')\n",
"X = df.drop('popularity',axis=1)\n",
"y = df.popularity\n",
"y_pred, model = ez.classification(X,y)"
]
},
{
"cell_type": "code",
"execution_count": 634,
"metadata": {
"ExecuteTime": {
"end_time": "2020-03-29T19:57:43.217847Z",
"start_time": "2020-03-29T19:57:33.057699Z"
}
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"*** Dataset Infomarion ***\n",
"##################################################\n",
"No of Rows : 1302\n",
"No of columns : 7\n",
"No of Numerical columns: 7\n",
"No of Categorical columns: 0\n",
"##################################################\n",
"\n",
" Total Missing values : 0 \n",
"\n",
"##################################################\n",
"Summary of DataFrame:\n",
"\n",
" Column Name Nulls/NaN outof Unique Type of Columns\n",
"0 buying_price 0 1302 4 Numerical\n",
"1 maintainence_cost 0 1302 4 Numerical\n",
"2 number_of_doors 0 1302 4 Numerical\n",
"3 number_of_seats 0 1302 3 Numerical\n",
"4 luggage_boot_size 0 1302 3 Numerical\n",
"5 safety_rating 0 1302 3 Numerical\n",
"6 popularity 0 1302 4 Numerical\n"
]
},
{
"data": {
"application/vnd.plotly.v1+json": {
"config": {
"plotlyServerURL": "https://plot.ly"
},
"data": [
{
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"reversescale": false,
"showscale": true,
"type": "heatmap",
"x": [
"buying_price",
"maintainence_cost",
"number_of_doors",
"number_of_seats",
"luggage_boot_size",
"safety_rating",
"popularity"
],
"y": [
"buying_price",
"maintainence_cost",
"number_of_doors",
"number_of_seats",
"luggage_boot_size",
"safety_rating",
"popularity"
],
"z": [
[
1,
-0.00601914794363575,
0.01431989962017954,
0.022869684564446633,
0.016355250728557667,
0.04381300694020507,
-0.2148840997128597
],
[
-0.00601914794363575,
1,
0.015885336815707744,
0.003790665852549147,
0.026792686209264383,
0.0004764712883163013,
-0.19645299365239596
],
[
0.01431989962017954,
0.015885336815707744,
1,
-0.025651392354451002,
0.01158000083312545,
-0.010466524889640786,
0.047387829407119234
],
[
0.022869684564446633,
0.003790665852549147,
-0.025651392354451002,
1,
-0.013527576547962002,
-0.03534956734726059,
0.36157273687024777
],
[
0.016355250728557667,
0.026792686209264383,
0.01158000083312545,
-0.013527576547962002,
1,
-0.011534135355788986,
0.12351538896214398
],
[
0.04381300694020507,
0.0004764712883163013,
-0.010466524889640786,
-0.03534956734726059,
-0.011534135355788986,
1,
0.42076893798445325
],
[
-0.2148840997128597,
-0.19645299365239596,
0.047387829407119234,
0.36157273687024777,
0.12351538896214398,
0.42076893798445325,
1
]
]
}
],
"layout": {
"annotations": [
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "buying_price",
"xref": "x",
"y": "buying_price",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "maintainence_cost",
"xref": "x",
"y": "buying_price",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "number_of_doors",
"xref": "x",
"y": "buying_price",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "number_of_seats",
"xref": "x",
"y": "buying_price",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "luggage_boot_size",
"xref": "x",
"y": "buying_price",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "safety_rating",
"xref": "x",
"y": "buying_price",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.21",
"x": "popularity",
"xref": "x",
"y": "buying_price",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "buying_price",
"xref": "x",
"y": "maintainence_cost",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "maintainence_cost",
"xref": "x",
"y": "maintainence_cost",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "number_of_doors",
"xref": "x",
"y": "maintainence_cost",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "number_of_seats",
"xref": "x",
"y": "maintainence_cost",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "luggage_boot_size",
"xref": "x",
"y": "maintainence_cost",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "safety_rating",
"xref": "x",
"y": "maintainence_cost",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.2",
"x": "popularity",
"xref": "x",
"y": "maintainence_cost",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "buying_price",
"xref": "x",
"y": "number_of_doors",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "maintainence_cost",
"xref": "x",
"y": "number_of_doors",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "number_of_doors",
"xref": "x",
"y": "number_of_doors",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "number_of_seats",
"xref": "x",
"y": "number_of_doors",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "luggage_boot_size",
"xref": "x",
"y": "number_of_doors",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "safety_rating",
"xref": "x",
"y": "number_of_doors",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "popularity",
"xref": "x",
"y": "number_of_doors",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "buying_price",
"xref": "x",
"y": "number_of_seats",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "maintainence_cost",
"xref": "x",
"y": "number_of_seats",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.03",
"x": "number_of_doors",
"xref": "x",
"y": "number_of_seats",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "number_of_seats",
"xref": "x",
"y": "number_of_seats",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "luggage_boot_size",
"xref": "x",
"y": "number_of_seats",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "safety_rating",
"xref": "x",
"y": "number_of_seats",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.36",
"x": "popularity",
"xref": "x",
"y": "number_of_seats",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.02",
"x": "buying_price",
"xref": "x",
"y": "luggage_boot_size",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.03",
"x": "maintainence_cost",
"xref": "x",
"y": "luggage_boot_size",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.01",
"x": "number_of_doors",
"xref": "x",
"y": "luggage_boot_size",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "number_of_seats",
"xref": "x",
"y": "luggage_boot_size",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "luggage_boot_size",
"xref": "x",
"y": "luggage_boot_size",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "safety_rating",
"xref": "x",
"y": "luggage_boot_size",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "popularity",
"xref": "x",
"y": "luggage_boot_size",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.04",
"x": "buying_price",
"xref": "x",
"y": "safety_rating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.0",
"x": "maintainence_cost",
"xref": "x",
"y": "safety_rating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "number_of_doors",
"xref": "x",
"y": "safety_rating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.04",
"x": "number_of_seats",
"xref": "x",
"y": "safety_rating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.01",
"x": "luggage_boot_size",
"xref": "x",
"y": "safety_rating",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "safety_rating",
"xref": "x",
"y": "safety_rating",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.42",
"x": "popularity",
"xref": "x",
"y": "safety_rating",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.21",
"x": "buying_price",
"xref": "x",
"y": "popularity",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "-0.2",
"x": "maintainence_cost",
"xref": "x",
"y": "popularity",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.05",
"x": "number_of_doors",
"xref": "x",
"y": "popularity",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.36",
"x": "number_of_seats",
"xref": "x",
"y": "popularity",
"yref": "y"
},
{
"font": {
"color": "#FFFFFF"
},
"showarrow": false,
"text": "0.12",
"x": "luggage_boot_size",
"xref": "x",
"y": "popularity",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "0.42",
"x": "safety_rating",
"xref": "x",
"y": "popularity",
"yref": "y"
},
{
"font": {
"color": "#000000"
},
"showarrow": false,
"text": "1.0",
"x": "popularity",
"xref": "x",
"y": "popularity",
"yref": "y"
}
],
"template": {
"data": {
"bar": [
{
"error_x": {
"color": "#2a3f5f"
},
"error_y": {
"color": "#2a3f5f"
},
"marker": {
"line": {
"color": "#E5ECF6",
"width": 0.5
}
},
"type": "bar"
}
],
"barpolar": [
{
"marker": {
"line": {
"color": "#E5ECF6",
"width": 0.5
}
},
"type": "barpolar"
}
],
"carpet": [
{
"aaxis": {
"endlinecolor": "#2a3f5f",
"gridcolor": "white",
"linecolor": "white",
"minorgridcolor": "white",
"startlinecolor": "#2a3f5f"
},
"baxis": {
"endlinecolor": "#2a3f5f",
"gridcolor": "white",
"linecolor": "white",
"minorgridcolor": "white",
"startlinecolor": "#2a3f5f"
},
"type": "carpet"
}
],
"choropleth": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "choropleth"
}
],
"contour": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "contour"
}
],
"contourcarpet": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "contourcarpet"
}
],
"heatmap": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "heatmap"
}
],
"heatmapgl": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "heatmapgl"
}
],
"histogram": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "histogram"
}
],
"histogram2d": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "histogram2d"
}
],
"histogram2dcontour": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "histogram2dcontour"
}
],
"mesh3d": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"type": "mesh3d"
}
],
"parcoords": [
{
"line": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "parcoords"
}
],
"pie": [
{
"automargin": true,
"type": "pie"
}
],
"scatter": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatter"
}
],
"scatter3d": [
{
"line": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatter3d"
}
],
"scattercarpet": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattercarpet"
}
],
"scattergeo": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattergeo"
}
],
"scattergl": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattergl"
}
],
"scattermapbox": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scattermapbox"
}
],
"scatterpolar": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterpolar"
}
],
"scatterpolargl": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterpolargl"
}
],
"scatterternary": [
{
"marker": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"type": "scatterternary"
}
],
"surface": [
{
"colorbar": {
"outlinewidth": 0,
"ticks": ""
},
"colorscale": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"type": "surface"
}
],
"table": [
{
"cells": {
"fill": {
"color": "#EBF0F8"
},
"line": {
"color": "white"
}
},
"header": {
"fill": {
"color": "#C8D4E3"
},
"line": {
"color": "white"
}
},
"type": "table"
}
]
},
"layout": {
"annotationdefaults": {
"arrowcolor": "#2a3f5f",
"arrowhead": 0,
"arrowwidth": 1
},
"coloraxis": {
"colorbar": {
"outlinewidth": 0,
"ticks": ""
}
},
"colorscale": {
"diverging": [
[
0,
"#8e0152"
],
[
0.1,
"#c51b7d"
],
[
0.2,
"#de77ae"
],
[
0.3,
"#f1b6da"
],
[
0.4,
"#fde0ef"
],
[
0.5,
"#f7f7f7"
],
[
0.6,
"#e6f5d0"
],
[
0.7,
"#b8e186"
],
[
0.8,
"#7fbc41"
],
[
0.9,
"#4d9221"
],
[
1,
"#276419"
]
],
"sequential": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
],
"sequentialminus": [
[
0,
"#0d0887"
],
[
0.1111111111111111,
"#46039f"
],
[
0.2222222222222222,
"#7201a8"
],
[
0.3333333333333333,
"#9c179e"
],
[
0.4444444444444444,
"#bd3786"
],
[
0.5555555555555556,
"#d8576b"
],
[
0.6666666666666666,
"#ed7953"
],
[
0.7777777777777778,
"#fb9f3a"
],
[
0.8888888888888888,
"#fdca26"
],
[
1,
"#f0f921"
]
]
},
"colorway": [
"#636efa",
"#EF553B",
"#00cc96",
"#ab63fa",
"#FFA15A",
"#19d3f3",
"#FF6692",
"#B6E880",
"#FF97FF",
"#FECB52"
],
"font": {
"color": "#2a3f5f"
},
"geo": {
"bgcolor": "white",
"lakecolor": "white",
"landcolor": "#E5ECF6",
"showlakes": true,
"showland": true,
"subunitcolor": "white"
},
"hoverlabel": {
"align": "left"
},
"hovermode": "closest",
"mapbox": {
"style": "light"
},
"paper_bgcolor": "white",
"plot_bgcolor": "#E5ECF6",
"polar": {
"angularaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"bgcolor": "#E5ECF6",
"radialaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
}
},
"scene": {
"xaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
},
"yaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
},
"zaxis": {
"backgroundcolor": "#E5ECF6",
"gridcolor": "white",
"gridwidth": 2,
"linecolor": "white",
"showbackground": true,
"ticks": "",
"zerolinecolor": "white"
}
},
"shapedefaults": {
"line": {
"color": "#2a3f5f"
}
},
"ternary": {
"aaxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"baxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
},
"bgcolor": "#E5ECF6",
"caxis": {
"gridcolor": "white",
"linecolor": "white",
"ticks": ""
}
},
"title": {
"x": 0.05
},
"xaxis": {
"automargin": true,
"gridcolor": "white",
"linecolor": "white",
"ticks": "",
"title": {
"standoff": 15
},
"zerolinecolor": "white",
"zerolinewidth": 2
},
"yaxis": {
"automargin": true,
"gridcolor": "white",
"linecolor": "white",
"ticks": "",
"title": {
"standoff": 15
},
"zerolinecolor": "white",
"zerolinewidth": 2
}
}
},
"xaxis": {
"dtick": 1,
"gridcolor": "rgb(0, 0, 0)",
"side": "top",
"ticks": ""
},
"yaxis": {
"dtick": 1,
"ticks": "",
"ticksuffix": " "
}
}
},
"text/html": [
"
value=%{value}", "labels": [ 1, 2, 3, 4 ], "legendgroup": "", "name": "", "showlegend": true, "type": "pie", "values": [ 941, 294, 36, 31 ] } ], "layout": { "legend": { "tracegroupgap": 0 }, "template": { "data": { "bar": [ { "error_x": { "color": "#2a3f5f" }, "error_y": { "color": "#2a3f5f" }, "marker": { "line": { "color": "#E5ECF6", "width": 0.5 } }, "type": "bar" } ], "barpolar": [ { "marker": { "line": { "color": "#E5ECF6", "width": 0.5 } }, "type": "barpolar" } ], "carpet": [ { "aaxis": { "endlinecolor": "#2a3f5f", "gridcolor": "white", "linecolor": "white", "minorgridcolor": "white", "startlinecolor": "#2a3f5f" }, "baxis": { "endlinecolor": "#2a3f5f", "gridcolor": "white", "linecolor": "white", "minorgridcolor": "white", "startlinecolor": "#2a3f5f" }, "type": "carpet" } ], "choropleth": [ { "colorbar": { "outlinewidth": 0, "ticks": "" }, "type": "choropleth" } ], "contour": [ { "colorbar": { "outlinewidth": 0, "ticks": "" }, "colorscale": [ [ 0, "#0d0887" ], [ 0.1111111111111111, "#46039f" ], [ 0.2222222222222222, "#7201a8" ], [ 0.3333333333333333, "#9c179e" ], [ 0.4444444444444444, "#bd3786" ], [ 0.5555555555555556, "#d8576b" ], [ 0.6666666666666666, "#ed7953" ], [ 0.7777777777777778, "#fb9f3a" ], [ 0.8888888888888888, "#fdca26" ], [ 1, "#f0f921" ] ], "type": "contour" } ], "contourcarpet": [ { "colorbar": { "outlinewidth": 0, "ticks": "" }, "type": "contourcarpet" } ], "heatmap": [ { "colorbar": { "outlinewidth": 0, "ticks": "" }, "colorscale": [ [ 0, "#0d0887" ], [ 0.1111111111111111, "#46039f" ], [ 0.2222222222222222, "#7201a8" ], [ 0.3333333333333333, "#9c179e" ], [ 0.4444444444444444, "#bd3786" ], [ 0.5555555555555556, "#d8576b" ], [ 0.6666666666666666, "#ed7953" ], [ 0.7777777777777778, "#fb9f3a" ], [ 0.8888888888888888, "#fdca26" ], [ 1, "#f0f921" ] ], "type": "heatmap" } ], "heatmapgl": [ { "colorbar": { "outlinewidth": 0, "ticks": "" }, "colorscale": [ [ 0, "#0d0887" ], [ 0.1111111111111111, "#46039f" ], [ 0.2222222222222222, "#7201a8" ], [ 0.3333333333333333, "#9c179e" ], [ 0.4444444444444444, "#bd3786" ], [ 0.5555555555555556, "#d8576b" ], [ 0.6666666666666666, "#ed7953" ], [ 0.7777777777777778, "#fb9f3a" ], [ 0.8888888888888888, "#fdca26" ], [ 1, "#f0f921" ] ], "type": "heatmapgl" } ], "histogram": [ { "marker": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "histogram" } ], "histogram2d": [ { "colorbar": { "outlinewidth": 0, "ticks": "" }, "colorscale": [ [ 0, "#0d0887" ], [ 0.1111111111111111, "#46039f" ], [ 0.2222222222222222, "#7201a8" ], [ 0.3333333333333333, "#9c179e" ], [ 0.4444444444444444, "#bd3786" ], [ 0.5555555555555556, "#d8576b" ], [ 0.6666666666666666, "#ed7953" ], [ 0.7777777777777778, "#fb9f3a" ], [ 0.8888888888888888, "#fdca26" ], [ 1, "#f0f921" ] ], "type": "histogram2d" } ], "histogram2dcontour": [ { "colorbar": { "outlinewidth": 0, "ticks": "" }, "colorscale": [ [ 0, "#0d0887" ], [ 0.1111111111111111, "#46039f" ], [ 0.2222222222222222, "#7201a8" ], [ 0.3333333333333333, "#9c179e" ], [ 0.4444444444444444, "#bd3786" ], [ 0.5555555555555556, "#d8576b" ], [ 0.6666666666666666, "#ed7953" ], [ 0.7777777777777778, "#fb9f3a" ], [ 0.8888888888888888, "#fdca26" ], [ 1, "#f0f921" ] ], "type": "histogram2dcontour" } ], "mesh3d": [ { "colorbar": { "outlinewidth": 0, "ticks": "" }, "type": "mesh3d" } ], "parcoords": [ { "line": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "parcoords" } ], "pie": [ { "automargin": true, "type": "pie" } ], "scatter": [ { "marker": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "scatter" } ], "scatter3d": [ { "line": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "marker": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "scatter3d" } ], "scattercarpet": [ { "marker": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "scattercarpet" } ], "scattergeo": [ { "marker": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "scattergeo" } ], "scattergl": [ { "marker": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "scattergl" } ], "scattermapbox": [ { "marker": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "scattermapbox" } ], "scatterpolar": [ { "marker": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "scatterpolar" } ], "scatterpolargl": [ { "marker": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "scatterpolargl" } ], "scatterternary": [ { "marker": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "scatterternary" } ], "surface": [ { "colorbar": { "outlinewidth": 0, "ticks": "" }, "colorscale": [ [ 0, "#0d0887" ], [ 0.1111111111111111, "#46039f" ], [ 0.2222222222222222, "#7201a8" ], [ 0.3333333333333333, "#9c179e" ], [ 0.4444444444444444, "#bd3786" ], [ 0.5555555555555556, "#d8576b" ], [ 0.6666666666666666, "#ed7953" ], [ 0.7777777777777778, "#fb9f3a" ], [ 0.8888888888888888, "#fdca26" ], [ 1, "#f0f921" ] ], "type": "surface" } ], "table": [ { "cells": { "fill": { "color": "#EBF0F8" }, "line": { "color": "white" } }, "header": { "fill": { "color": "#C8D4E3" }, "line": { "color": "white" } }, "type": "table" } ] }, "layout": { "annotationdefaults": { "arrowcolor": "#2a3f5f", "arrowhead": 0, "arrowwidth": 1 }, "coloraxis": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "colorscale": { "diverging": [ [ 0, "#8e0152" ], [ 0.1, "#c51b7d" ], [ 0.2, "#de77ae" ], [ 0.3, "#f1b6da" ], [ 0.4, "#fde0ef" ], [ 0.5, "#f7f7f7" ], [ 0.6, "#e6f5d0" ], [ 0.7, "#b8e186" ], [ 0.8, "#7fbc41" ], [ 0.9, "#4d9221" ], [ 1, "#276419" ] ], "sequential": [ [ 0, "#0d0887" ], [ 0.1111111111111111, "#46039f" ], [ 0.2222222222222222, "#7201a8" ], [ 0.3333333333333333, "#9c179e" ], [ 0.4444444444444444, "#bd3786" ], [ 0.5555555555555556, "#d8576b" ], [ 0.6666666666666666, "#ed7953" ], [ 0.7777777777777778, "#fb9f3a" ], [ 0.8888888888888888, "#fdca26" ], [ 1, "#f0f921" ] ], "sequentialminus": [ [ 0, "#0d0887" ], [ 0.1111111111111111, "#46039f" ], [ 0.2222222222222222, "#7201a8" ], [ 0.3333333333333333, "#9c179e" ], [ 0.4444444444444444, "#bd3786" ], [ 0.5555555555555556, "#d8576b" ], [ 0.6666666666666666, "#ed7953" ], [ 0.7777777777777778, "#fb9f3a" ], [ 0.8888888888888888, "#fdca26" ], [ 1, "#f0f921" ] ] }, "colorway": [ "#636efa", "#EF553B", "#00cc96", "#ab63fa", "#FFA15A", "#19d3f3", "#FF6692", "#B6E880", "#FF97FF", "#FECB52" ], "font": { "color": "#2a3f5f" }, "geo": { "bgcolor": "white", "lakecolor": "white", "landcolor": "#E5ECF6", "showlakes": true, "showland": true, "subunitcolor": "white" }, "hoverlabel": { "align": "left" }, "hovermode": "closest", "mapbox": { "style": "light" }, "paper_bgcolor": "white", "plot_bgcolor": "#E5ECF6", "polar": { "angularaxis": { "gridcolor": "white", "linecolor": "white", "ticks": "" }, "bgcolor": "#E5ECF6", "radialaxis": { "gridcolor": "white", "linecolor": "white", "ticks": "" } }, "scene": { "xaxis": { "backgroundcolor": "#E5ECF6", "gridcolor": "white", "gridwidth": 2, "linecolor": "white", "showbackground": true, "ticks": "", "zerolinecolor": "white" }, "yaxis": { "backgroundcolor": "#E5ECF6", "gridcolor": "white", "gridwidth": 2, "linecolor": "white", "showbackground": true, "ticks": "", "zerolinecolor": "white" }, "zaxis": { "backgroundcolor": "#E5ECF6", "gridcolor": "white", "gridwidth": 2, "linecolor": "white", "showbackground": true, "ticks": "", "zerolinecolor": "white" } }, "shapedefaults": { "line": { "color": "#2a3f5f" } }, "ternary": { "aaxis": { "gridcolor": "white", "linecolor": "white", "ticks": "" }, "baxis": { "gridcolor": "white", "linecolor": "white", "ticks": "" }, "bgcolor": "#E5ECF6", "caxis": { "gridcolor": "white", "linecolor": "white", "ticks": "" } }, "title": { "x": 0.05 }, "xaxis": { "automargin": true, "gridcolor": "white", "linecolor": "white", "ticks": "", "title": { "standoff": 15 }, "zerolinecolor": "white", "zerolinewidth": 2 }, "yaxis": { "automargin": true, "gridcolor": "white", "linecolor": "white", "ticks": "", "title": { "standoff": 15 }, "zerolinecolor": "white", "zerolinewidth": 2 } } }, "title": { "text": "Percentage data of popularity" } } }, "text/html": [ ""
]
},
"metadata": {
"needs_background": "light"
},
"output_type": "display_data"
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"--------------------------------------------------------\n",
"********************* Model Results ********************\n",
"--------------------------------------------------------\n",
"F1 Score : 0.9541854384201013\n",
"AUC-ROC Score : 0.9439188867749603\n",
"Report:\n",
" precision recall f1-score support\n",
"\n",
" 1 0.98 0.97 0.98 277\n",
" 2 0.91 0.91 0.91 94\n",
" 3 0.86 1.00 0.92 12\n",
" 4 0.75 0.75 0.75 8\n",
"\n",
" accuracy 0.95 391\n",
" macro avg 0.87 0.91 0.89 391\n",
"weighted avg 0.95 0.95 0.95 391\n",
"\n"
]
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAYEAAAEgCAYAAABSGc9vAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADt0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjByYzEsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy/xvVyzAAAgAElEQVR4nO3dfZxUdf338dcHFgJBSbnZNSEQgVJEUKEkDA1DUFAMvC28S+TKy6R+WCpYhvpLy8rus1BB7arM8oYCzQxC8g5RUUTxtlZB2BUMuRF03eVz/fE9u67DzN7Oztmz5/18POYxO+f2M2dn5j3n+z3njLk7IiKSTu3iLkBEROKjEBARSTGFgIhIiikERERSTCEgIpJiCgERkRRTCEirZmYzzOx5M9tpZm5mXy/AOkvNrLSl15MG0f9sadx1SG4KAQHAzD5pZj83s9VmtsXMKsxsvZktMrPzzKxTDDWdDvwUeBf4CXAl8Fih62gNomDy6Pa5OqabX2u6Oc1c59H5WI60bkVxFyDxM7MrgO8QvhQ8BtwKbAeKgaOBm4ALgOEFLm1i9b27ry/geo8p4LoaqxI4H/hn5ggz2ws4NZqmtby3DwR2xF2E5NZaXigSEzObTfiGvRY4xd2XZ5lmInBxoWsDPgZQ4ADA3V8t5PoaaSEw2cy6u/tbGeO+BOwB3A18oeCVZeHuL8Rdg9RNzUEpZmb9gDnA+8Dx2QIAwN0XAuOzzH+qmS2Lmo92mtmzZjbLzD6SZdrS6LaHmf3AzF43s/fM7BUzu9TMrNa0c8zMgc9Fj6ubN7y67ujxLTme19LqaWsNMzM728weMbONZvauma01s/vN7LRstWZZ7kfM7DIzW2VmO8xsq5n9y8xOzTJtTY3R37eb2aZovU9EwdoUNwIfAc7MMu58Qpj/LduMZjbIzL4XrX9jtP1fM7O5ZtY7Y9pb+GBv4zu1/wdmdnQ0zTnR43PMbHy03bfU3vaZfQJmtr+ZvW1m/zWzvhnr7GJma8ysysyOauyGkabRnkC6nQt0AG5399V1Teju79V+bGbXALOATcDvCc1HxwHXAOPMbKy7v5+xmA7A3wnf8O8jNFucBHwP6ETYIwFYGt2fA/StNbw5vhvV+x/gDmALsC8wAjgF+GNdM5tZR+B+4CjgBeCXhG/dJwN/NLNh7j47y6x9gceBfwO/BfYBTgMWmNnn3X23Zp16PACUAtMI/STV9R0OHErYVrtyzDsZ+Arhw/0RoAIYHC3rBDMb7u5vRNPeE92fDTzIB/8TovXXdjLhS8J9wK+BfrmKd/f/mNk04E/AH8xstLtXRqN/BXwSmOPuD+ZahuSZu+uW0huwGHBgWiPnGxnN9zpQUmt4EfDXaNzsjHlKo+H3Ap1rDe8FvB3dOmTMszS8RHdbf79oWbfkqG+3+YC3gHXAHlmm75Gl1tKMYbNq1V+UUX/1c/tMlhod+E7GssZVL6sR27x6HUXAt6K/R9Ya/2ugCvg44UPdCR+mtZexH/CRLMs+Npr3hozhR2dbTq3x50TjdwHjc0zjwNIsw38Vjbs2enxW9PifQLu43xtpuqk5KN32je7XNXK+L0f3/+vuZdUDPXyju5jwoTAtx7wz3H1nrXneBBYA3YBPNLKOxnqf8GH3Ie6+qQHzfpnwITXTP/jmWl3/1dHDbM/5NeB/M9Z3PyFAP9Wwsnczj/A8zofQjAJ8Ebjf3V/PNZO7v+EZe3TR8L8DzxHCqSkWuHvWJqg6zASeAS41s68SQmEj8CV3z7UnIy1AIZBu1e3wjb2e+GHR/ZLMEe7+EiFU9jezj2aM3uLur2RZ3trofu9G1tEYvyN8O3/OzK6N2rC7NWRGM9sTGACs9+wdndXb4dAs4552992Ch/Ccm/R8PXSU3wucGh0RdDqwJ6G/IKeoX2Sqmf0j6hOorNXXMoSwp9AUjzd2Bnd/l9As9g7wc0LT2lle4IMARCGQdtVvuN51TrW76g/PDTnGb8iYrtrbOaav/mbdvpF1NMb/AF8nfOhcRmi/3mRmC8xsQD3zNvT5ZoYe1P2cm/P+uxHoApxB2CMoIzTF1eV6Qr/EQYT+jR8R+hCuJOyxdGxiLWX1T5LVS8Cq6O/nCf1FUmAKgXR7KLpv7HHxW6L7khzj982YLt+qmwtyHdiw24exu1e5+0/dfSjh/IcphEMpTwT+lu2Iplrifr7Z3Au8Qegf+DQwv3YzVSYz6wXMAFYDn3D3qe5+qbvPcfc5wG7NRI3Q1F+mugz4DOHggsGEfhcpMIVAus0ntJNPMbOD6pow40NyZXR/dJbpBhD2LP7j7rm+BTfX5ui+T5b17wUMqmtmd3/T3e9y91MJTTkHAAfXMf024FVgPzMbmGWS6jN4n2pA7XkRNTHNI2xrB26uZ5b+hPf736PnUyM6PLR/lnmqm7HyvodmZp8BrgJeJGz7F4ErzezIfK9L6qYQSDF3LyWcJ9ARWGRmWc8INrPqw/+qzYvuv2VmPWtN1x74IeF1Vd+HUpNFH2IvAKNqh1e0/uuBzrWnj47vP6b2uQjR8A6EQzah/rNa5xH6UH4Qrad6GT2Ab9eappB+RjgpbJzXf4JbaXR/ZEb9XQlNS9n2qqpPRvt4M+v8EDPbG/gDIWROd/dyQv9AJeGw0e75XJ/UTecJpJy7X2NmRYTLRqwws0eAJ/jgshGjgYHRsOp5HjGz64BLgNVm9mdCW/txhG91DwE/aOHSf0AImofN7E+E6wt9jnAuwjPA0FrTdgb+AZSa2XJC+3cnYCzhsgZ/cfc19azvh4TnNwl4xszuJXRmnkI4TPQ6d3+ojvnzLjqq6Z56JwzTlpnZ7YRO5KfN7O+Evo6xhG33NDAsY7YXCU1Op5tZBeGIJgd+6+6vNaP0eYRgmeHuT0f1PWNmFwO/IOyhntiM5UtjxH2Mqm6t40b4MPw5oc14K+FEog2EPYDzyH58+emED/xthA+S54DLgU5Zpi0l49j7WuPmED5cjs4YvpQs5wnUGn9etM73CJ2TvwG6Z85HCIZLoufyelTrRsJ1kr4CdGxIrYTgmB1to53R834IOCPLtP1o5LkM9fx/SqPlFTVg2lznCexBOGnulWgbrCWc9LbbNqs1zwjC+SRbCH0xNf8nPjhP4Jw6avnQeQLARdGwBTmmvysa/z9xvyfScrNow4uISAqpT0BEJMUUAiIiKaYQEBFJMYWAiEiKJeoQUcu4RryIiNTP3S3XuESFgORX+K0YyQeziehIu/wxM23PPMk4R3I3ag4SEUkxhYCISIopBEREUkwhICKSYgoBEZEUUwiIiKSYQkBEJMUUAiIiKaYQEBFJMYWAiEiKKQRERFJMISAikmIKARGRFFMIiIikmEJARCTFFAIiIimmEBARSTGFgIhIiikERERSTCEgIpJiCgERkRRTCDRS7969WbJkCc8//zyrV69mxowZNeO++tWv8sILL7B69Wq+//3vA9ChQwfmzZvHqlWrePrppznqqKPiKj1R/v3vN5k06Yc1t8MOm8UttzwYd1mJNWvWLEaOHMnEiRPjLqXNWLZsGePGjWPs2LHMnTs37nKarCjuApKmsrKSiy++mJUrV9K1a1eefPJJHnjgAYqLi5k0aRKHHHIIFRUV9OzZE4Dzzz8fgEMOOYSePXty3333MWLECNw9zqfR6vXv34sFC74BQFXVLkaPvpKxY4fEXFVyTZ48malTp3LppZfGXUqbUFVVxVVXXcX8+fMpLi7m5JNPZsyYMQwYMCDu0hpNewKNVFZWxsqVKwHYvn07a9asYb/99uOCCy7ge9/7HhUVFQBs3LgRgIMOOojFixfXDHv77bcZPnx4PMUn1KOPvkyfPt3Zb7994i4lsUaMGEG3bt3iLqPNWLVqFX379qVPnz507NiRCRMm1LzPk0Yh0Ax9+/bl0EMPZfny5QwaNIjPfvazPPbYYyxdurTmg/6ZZ55h0qRJtG/fnn79+nH44YfTp0+fmCtPlkWLVjJx4qFxlyFSo7y8nJKSkprHxcXFlJeXx1hR07WK5iAzO9fd58ddR2N06dKFO++8k69//ets27aNoqIi9t57b4444ghGjBjBHXfcQf/+/Zk3bx4HHnggTzzxBK+99hqPPPIIlZWVcZefGBUVlSxZ8hwXXzwh7lJEamRrzjWzGCppvlYRAsCVQNYQMLPpwPTCllO3oqIi7rzzTn73u99x9913A7Bu3TruuusuAFasWMGuXbvo0aMHmzZtYubMmTXzPvzww7z88sux1J1Ey5a9wODB+9Gjx55xlyJSo6SkhLKysprH5eXl9OrVK8aKmq5gzUFmtirH7VmgONd87j7X3Ye7e6tpSL/55ptZs2YNP/7xj2uG3XPPPYwZMwaAgQMH0rFjRzZt2kTnzp3ZY489APj85z9PZWUla9asiaXuJFq06CkmTDgs7jJEPmTIkCGUlpaydu1aKioqWLRoUc37P2kKuSdQDIwDNmcMN+CRAtbRLKNGjeKss85i1apVNR3Es2fPZt68ecybN49nn32WiooKzj77bAB69erF/fffz65du3jjjTc488wz4yw/UXburOCRR17iqqtOibuUxJs5cyaPP/44mzdvZvTo0Vx00UWccoq2a1MVFRVxxRVXMG3aNKqqqpgyZQoDBw6Mu6wmsUIdqmhmNwPz3f2hLON+7+5fbMAydFxlHrkvjLuENsNsog77zSMz0/bMk2hb5uywKFgI5INCIL8UAvmjEMgvhUD+1BcCOkRURCTFFAIiIimmEBARSTGFgIhIiikERERSTCEgIpJiCgERkRRTCIiIpJhCQEQkxRQCIiIpphAQEUkxhYCISIopBEREUkwhICKSYgoBEZEUUwiIiKSYQkBEJMUUAiIiKaYQEBFJMYWAiEiKKQRERFLM3D3uGhrMzJJTrIhIK+HulmtcUSELyQf3J+MuoU0wOxy/ZlbcZbQZNvtakvSFqrUzM9y3xV1Gm2C2Z53j1RwkIpJiCgERkRRTCIiIpJhCQEQkxRQCIiIpphAQEUkxhYCISIopBEREUkwhICKSYgoBEZEUUwiIiKSYQkBEJMUUAiIiKaYQEBFJMYWAiEiKKQRERFJMISAikmIKARGRFFMIiIikmEJARCTFFAIiIimmEBARSbGiuAtoa8aMuYguXTrTrl072rdvx113XRN3SckyYhQMHR7+3lgGC++Eqko4fCQcfgTs2gWvvgj//Fu8dSbMrFmzWLp0Kd27d2fhwoVxl5N4GzaUccklV7Bp01u0a9eOU0/9Amef/cW4y2oShUALuPXWb7HPPnvFXUbydN0Lho+EG38ClZVw0hlw0CGw5W0YeCDc/DOoqoI9usRdaeJMnjyZqVOncumll8ZdSpvQvn17Lrvsfxg8+EC2b3+HKVOmMmrUEQwY0D/u0hqtoM1BZvZJMzvGzLpmDB9fyDqkFWvXDoo6gLWDDh1g+1Y47NPw2IMhAAB2vBNvjQk0YsQIunXrFncZbUavXj0ZPPhAALp27UL//vtTXv5mzFU1TcH2BMxsBnAhsAa42cy+5u4LotHXAG1k/94477xrMTNOO+0YTjvtmLgLSo7tW2H5Q3DhJWFP4D8vw39egc+Nhz794Khjw/Al98KGN+KuVgSAdevWs2bNCwwdenDcpTRJIZuDzgcOd/ftZtYP+LOZ9XP3nwKWayYzmw5ML0yJzfeHP8yhuHgf3nprC+eeew39+3+MESMOjLusZOjUKTT7/OqH8N5O+MIXYfAwaNceOnWGW2+AfXuHZqIbfhh3tSK8884OZsz4JrNnf4OuXbvWP0MrVMjmoPbuvh3A3UuBo4HjzOx66ggBd5/r7sPdfXhBqmym4uJ9AOjevRtjx45g1apXY64oQfoNgC2bYec7oQP4xeeg98dh25bwN8CGdeAOndUvIPF6//33mTHjm5xwwnEce+yYuMtpskKGQJmZDat+EAXCRKAHMKSAdbSYHTveZfv2nTV/P/zwKgYO7B1zVQmy9W34WJ/QJwDQ7wDYtBFeeh76HhCG7dMd2rcPQSESE3fn8suvpn///Tn33Klxl9MshWwOOguorD3A3SuBs8zsNwWso8W89dYWLrzwegCqqqqYOHEUo0cPq2cuqbF+Hby4Gr781bAnUL4enn4cHJgwGaZ9LRwuuvDPcVeaODNnzuTxxx9n8+bNjB49mosuuohTTjkl7rIS68knn2bBgkUMGjSASZPOAGDmzAs56qgjY66s8czd466hwczM3Z+Mu4w2wexw/JpZcZfRZtjsa0nSe6m1MzPct8VdRptgtifunrPJXWcMi4ikmEJARCTFcvYJmNkdjViOu/tpeahHREQKqK6O4Z4Fq0JERGKRMwTc/XOFLERERApPfQIiIinW4PMEzGxPYBIwCOiUOd7dL8ljXSIiUgANCgEzOwB4GNgD6AJsBPaJ5t8MbAEUAiIiCdPQ5qAfA08AxYTr/BwPdAamAtsBHRkkIpJADW0O+hQwDXgvetzR3auA35tZD+CnwGdaoD4REWlBDd0T6ARsdfddwH+Bj9UatxoYmu/CRESk5TU0BF4C+kZ/rwS+YmadzKwDcB6wviWKExGRltXQ5qDbgWHAb4FvA/cDW4Fd0TLOaYniRESkZTUoBNz9+lp/P2ZmBwPHEZqJlrj76haqT0REWlCTfk/A3dcCc/Nci4iIFFhDzxM4vr5p3P3e5pcjIiKF1NA9gYWE33fK/GGC2r+i0T4vFYmISME0NAT2zzJsH+BYQqfwufkqSERECqehHcOvZRn8GrDSzKqA2cCJ+SxMRERaXj6uIroSGJOH5YiISIE1KwTMrCOhOWhDXqoREZGCMnevfyKzFXy4ExigI9AP2BM4191vy3t1u9dRf7EiIvIh7p55UE+NhnYMP8fuIfAu8CfgHnd/rom1iYhIjBq0J9BamJknqd7WzMzQtsyfsD31kxr5YnadXp95Er3Xc+4JNKhPwMyWmNknc4wbZGZLmlqgiIjEp6Edw0cDe+UYtxcwOi/ViIhIQTXm6KDd9s2io4PGAGV5q0hERAomZ8ewmX0HuCJ66MBjZjmblX6Q57pERKQA6jo66F5gE+F6QT8DfgSUZkxTAbzg7v9qkepERKRF5QwBd18BrAAws23AQnd/q1CFiYhIy2ton8DTwKezjTCz483skPyVJCIihdLQEPgxOUIAGBGNFxGRhGloCBwGPJxj3KPAofkpR0RECqmhIdAe6JJjXBfCdYRERCRhGhoCK4DpOcZNB57ITzkiIlJIDb2A3BzgH2a2HLiVcHLYvsBZwDDg8y1SnYiItKiG/rLYMjM7FrgW+Dnh3IFdwHLgmOheREQSpqF7Arj7UmCkme0B7A1sBkYCZwMLgO4tUaCIiLScBodALUOAM4BTgWLgv8Dt+SxKREQKo0EhYGYHEz74Tyf8mlgF4Yigi4FfuHtlSxUoIiItJ+fRQWbW38xmm9mzwDPAN4A1hM7ggYR+gacUACIiyVXXnsArhKuHLgf+D3Cnu28GMLNuBahNRERaWF3nCbxG+LZ/MOFHZT5jZk3pQxARkVYqZwi4+/7AKMJ5AccAfwXKzezG6LF+AFREJOHqPGPY3R9194uA/YBxhENBpwB/jiY538yGt2yJIiLSUhp02Qh33+XuD7j7l4ESYDLwJ+ALwHIzW9OCNSbGsmXLGDduHGPHjmXu3Llxl5N42p7NM2vWU4wceS8TJy6uGfb9769m/Ph/cMIJS7jwwuVs3VoRY4XJ1lZen435jWEA3L3C3e9x99MJ5wmcRehETrWqqiquuuoqbrrpJhYtWsTChQt55ZXUb5Ym0/ZsvsmTP85NN33mQ8NGjerFwoVj+Otfx9CvX1d+85uXY6ou2drS67PRIVCbu7/j7r9z9xMaMr2ZfcrMRkR/H2RmM83s+ObU0FqsWrWKvn370qdPHzp27MiECRNYvHhx/TNKVtqezTdiRA+6devwoWFHHtmLoqLwth82bG/KynbGUVritaXXZ7NCoDGiH67/GXCDmV0L/ALoClxmZpcXqo6WUl5eTklJSc3j4uJiysvLY6wo2bQ9W96dd77G6NHFcZeRSG3p9VnIQz5PJlxx9COEq5D2dvetZvYDwrkI3802k5lNJ/dlrFsN990PljKzGCppG7Q9W9YNN7xI+/btOPHE3nGXkkht6fVZyBCodPcqYIeZveruWwHcfaeZ7co1k7vPBeYCmFmrPSy1pKSEsrKymsfl5eX06tUrxoqSTduz5dx99+ssXVrGLbeMSuwHV9za0uuzYM1BQEV0BVKAw6sHRmcf5wyBpBgyZAilpaWsXbuWiooKFi1axJgxY+IuK7G0PVvGsmXl3Hjjy9xwwxF07qxzP5uqLb0+C/kqGO3u70E45LTW8A6Ey1EnWlFREVdccQXTpk2jqqqKKVOmMHDgwLjLSixtz+abOXMFjz++ic2bKxg9+m9cdNEnmTv3ZSoqdnHuueEnw4cO3YerrhoWc6XJ05Zen5atbau1MjNPUr2tmZllbdeUpgnb85K4y2gzzK7T6zNPovd6zna/QjYHiYhIK6MQEBFJMYWAiEiKKQRERFJMISAikmIKARGRFFMIiIikmEJARCTFFAIiIimmEBARSTGFgIhIiikERERSTCEgIpJiCgERkRRTCIiIpJhCQEQkxRQCIiIpphAQEUkxhYCISIopBEREUkwhICKSYgoBEZEUM3ePu4YGM7PkFCsi0kq4u+UaV1TIQvIhSaHVmpkZ7tviLqPNMNtTr808Cq/PpXGX0SaYHV3neDUHiYikmEJARCTFFAIiIimmEBARSTGFgIhIiikERERSTCEgIpJiCgERkRRTCIiIpJhCQEQkxRQCIiIpphAQEUkxhYCISIopBEREUkwhICKSYgoBEZEUUwiIiKSYQkBEJMUUAiIiKaYQEBFJMYWAiEiKKQTyaNmyZYwbN46xY8cyd+7cuMtJtA0byjjzzOkcd9wUJkw4hVtv/X3cJSWeXp/5tXXrDmbM+DXjx3+b4467gpUrX427pCYxd4+7hgYzM2+t9VZVVTFu3Djmz59PcXExJ598Mtdffz0DBgyIu7SszAz3bXGXkdObb25k48ZNDB58INu3v8OUKVP55S9/xIAB/eMuLSuzPWmtr01I6utzadxl1OnSS+czfPgATjnls1RUVPLuuxXstdcecZe1G7OjcXfLNV57AnmyatUq+vbtS58+fejYsSMTJkxg8eLFcZeVWL169WTw4AMB6Nq1C/377095+ZsxV5Vcen3m1/btO1mx4iVOPvlIADp2LGqVAdAQsYaAmd0W5/rzqby8nJKSkprHxcXFlJeXx1hR27Fu3XrWrHmBoUMPjruUxNLrM7/Wrt3EPvvsyaxZt3DSSVdz+eW3sWPHe3GX1SQFCwEz+0vG7a/A5OrHhaqjpWRrCjDLuQcmDfTOOzuYMeObzJ79Dbp27Rp3OYml12d+VVZW8fzzr3PGGUdxzz3fpnPnjsyd+7e4y2qSogKuqzfwPHAT4IABw4Ef1TWTmU0Hprd4dc1UUlJCWVlZzePy8nJ69eoVY0XJ9/777zNjxjc54YTjOPbYMXGXk2h6feZXScnelJTszdChoY9q/PjDmTv3vpirappCNgcNB54ELge2eOj12enuD7r7g7lmcve57j7c3YcXqM4mGTJkCKWlpaxdu5aKigoWLVrEmDH64Goqd+fyy6+mf//9OffcqXGXk3h6feZXz57dKCnZm3//OwTro4+u4YADPhZzVU1T8KODzKw38GOgHDjR3T/eiHlb7dFBAA8++CDXXHMNVVVVTJkyhQsuuCDuknJq7UcHPfHESr70pWkMGjSAdu3Cd5WZMy/kqKOOjLmy7Fr70UGQxNfn0rjLqNOaNWu5/PLbeP/9Svr06cG1155Dt25d4i5rN/UdHRTbIaJmNgEY5e6zGzFPqw6BJGntIZA0SQiBJElCCCRFfSFQyD6BD3H3RcCiuNYvIiI6T0BEJNUUAiIiKaYQEBFJMYWAiEiKKQRERFJMISAikmIKARGRFFMIiIikmEJARCTFFAIiIimmEBARSTGFgIhIiikERERSTCEgIpJiCgERkRRTCIiIpJhCQEQkxRQCIiIpphAQEUkxhYCISIopBEREUszcPe4aGszMklOsiEgr4e6Wa1yiQiApzGy6u8+Nu462Qtszf7Qt86stbE81B7WM6XEX0MZoe+aPtmV+JX57KgRERFJMISAikmIKgZaR6DbCVkjbM3+0LfMr8dtTHcMiIimmPQERkRRTCIiIpJhCII/MbJ6ZvWlmq+OuJenMrI+Z/dPM1pjZc2b2tbhrSjIz62Rmj5vZM9H2vDLumpLOzNqb2UozWxh3Lc2hEMivW4DxcRfRRlQCF7v7gcARwIVmdlDMNSXZe8AYdx8KDAPGm9kRMdeUdF8D1sRdRHMpBPLI3ZcB/427jrbA3Te4+1PR39sIb7b94q0quTzYHj3sEN10VEgTmVlvYAJwU9y1NJdCQFo9M+sHHAosj7eSZIuaL54G3gQecHdtz6b7CXAJsCvuQppLISCtmpl1Be4Evu7uW+OuJ8ncvcrdhwG9gU+Z2cFx15REZjYReNPdn4y7lnxQCEirZWYdCAHwO3e/K+562gp3fxtYivqvmmoUcKKZlQK3A2PM7P/FW1LTKQSkVTIzA24G1rj79XHXk3Rm1tPMPhr93Rn4PPBCvFUlk7vPcvfe7t4POB1Y4u5TYy6ryRQCeWRmfwAeBT5hZuvM7Ly4a0qwUcCZhG9ZT0e34+MuKsH2Bf5pZquAFYQ+gUQf2ij5octGiIikmPYERERSTCEgIpJiCgERkRRTCIiIpJhCQEQkxRQCknhmNsfMvNZtvZndaWYHtND6Jkbr6Rc97hc9ntiIZZxqZufksaauUQ15W6akQ1HcBYjkyRY+OAO2P3A1sNjMBrv7Oy287g3ASBp38tWpQA/ClWdFYqMQkLai0t0fi/5+zMxeB/4FHA/8qfaEZtbZ3Xfma8Xu/h7wWL0TirRCag6Stqr64l79zKzUzH5kZt82s3XAVgAza2dml5nZK2b2npm9ZGZn116IBXOiHwvaZma3AXtlTJO1OcjMzjezZ83sXTMrN7M/m1k3M7sFmAIcVasJa06t+SaZ2RPRfGVmdl10HaXay54S1QHSr/0AAAMKSURBVLvTzJYBn8zPZpO00Z6AtFX9ovuy6P6LwHPA/+WD1/3PgbOBq4CngLHAPDN7q9YlFWYAVwDXEPYsJgPX1bdyM/tWtNxfAd8E9iBcf74roanq48BHo3oA1kXznQr8AfgNMBs4ALiW8IXtG9E0hwF/BO4m/LDJYOCOBmwTkd25u266JfoGzAE2ET7ci4BBwD8J3/j3BUoJ7fadas0zgHAt+LMzlnUbsCL6uz2wHrghY5oHCD/I0i963C96PDF6/FFgB3B9HTX/GViaMcyA14D5GcO/DOwEukeP7wCeJ7rsSzTs8qiGc+L+f+iWrJuag6St6A68H91eJHQOn+buG6Lxi9393VrTH0MIgbvNrKj6BiwGhplZe6APIUQWZKyrvstajwQ6A/Mb+RwGEfYQ7sioaQnQCai+/v+ngL+4e+0Lf+lS29Ikag6StmIL4fLITmgCWp/xIVmeMX0Pwjf9LTmWty9QEv39Zsa4zMeZukf3G+qcanc9ovt7c4zvE92XNKEmkawUAtJWVLr7E3WMz7xc7n8JP2Y/iuw/EfgmH7w/emWMy3yc6a3ofl9CM1VDVf8+9XRgZZbx/4nuy5pQk0hWCgFJqyWEPYFu7v5AtgnMbC3hA3cS8LdaoybXs+xHCW34ZxN15mZRQWjiqe1F4A1CX8ONdSx/BeGXrWbV2tupryaRrBQCkkru/qKZ/Rq43cyuA54gfCgPBga5+zR3r4rG/dDMNhGODpoCHFjPst82s6uB75pZR0LzzkcIRwdd6e5vEE4sm2RmJxGODFrv7uvN7GLgt2a2F3AfISz6AycBJ7v7DuD7wHJC38HNhL4C/YCRNIk6hiXNLiQcrnkW4YP6FsIH9bJa0/yEcHjoVwi/d9wVuKS+Bbv7tcAFhH6KBYRDPj8KbIsm+RXwd2Ae4Zv99Gi+PxL2PIYRTnK7i3AY6VOEQCBq9jodOBS4hxAQpzX2yYuAfllMRCTVtCcgIpJiCgERkRRTCIiIpJhCQEQkxRQCIiIpphAQEUkxhYCISIopBEREUuz/AwKdeyKpQuf0AAAAAElFTkSuQmCC\n",
"text/plain": [
""
]
},
"metadata": {
"needs_background": "light"
},
"output_type": "display_data"
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"--------------------------------------------------------\n",
"\n",
" please wait while performing prediction using RFE...\n",
"\n",
"Executing RFE\n",
"Please wait.........\n",
"### RFE selected columns:\n",
" Index(['buying_price', 'maintainence_cost', 'safety_rating'], dtype='object')\n",
"RFE Selected Features Index(['buying_price', 'maintainence_cost', 'safety_rating'], dtype='object')\n"
]
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAq8AAAGwCAYAAACHCYxOAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADt0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjByYzEsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy/xvVyzAAAgAElEQVR4nO3deZhkdX3v8fdHBlHBgDjggoFBMEFRkUUUkUUlXqOJaIKXqNGgJu4gyaPR671B1KjkmlyXJCpEENdERVGjcSUMRFBgBgYQBRcYBVwIqOCAbMP3/nFOOzU11d3V093T85t5v56nnu466/f86tddnz71O6dTVUiSJEktuNtCFyBJkiSNy/AqSZKkZhheJUmS1AzDqyRJkppheJUkSVIzDK+SJElqhuFV0npJclSSSnLUQtciSdp8GF6ljUAfAgcfq5P8PMnSPiRmoWtsXZLjR7Tz4GPlQte4Pvral67HeqdO0x4z3ub6GqhlyYba51xJcuiGbq+F4h+s2lgsWugCJK3ljf3XLYHdgWcChwD7Aa9cqKI2MWcBS0dM/+UGrmNj8VlgxYjpKzdwHZI0FsOrtBGpquMHnyc5EDgbeHmSf6iqqxaksE3L0uF23sx9pqpOXegiJGlcDhuQNmJVdQ5wORBg38F5SfZN8q4kF/dDDG5N8r0k/5DkPsPbGvzIL8kT+iEJv0pyU5IvJHnoqBqS7J7kk0l+keTmJOcmedpUdfe1fSrJdUluS/LDJO9J8oARy058ZLxrklcm+XZ/LCuTvH5iyESSZyU5v6/huiT/lOQeM2jOGVnPY3hwkqOTXJLk14MfJSfZPsnbknynn3djkjOSPHnE9u6e5JgkF/btfkvfHp9Ncli/zFFJJv6/9yFDH/kfPw/t8ewkZ/b13Nofx/9JstWIZZ+R5CNJvtu/XquSLO+P6W5DyxbwZ/3Tq0YN4+iPfSUjZM1wkEOHt9v38fsneX+Sa9MNxzlqYJnHJDktyU+T3J7k6iQnJnng+rbTwLYHf95+L8l/9e3w30k+kGS7frm9k3y+b9dVST6XEcMn+mOpJFsl+dskV/X98gdJ3pDk7pPU8aQkX8qa3xHfTXJCkm2n2MfdkxyX5Ip+H6f2ffkD/aIfGOpvS/r1H9ivd85Am/44yccy4vdLkiX9+qf23/9bkuv7Opcl+YMp2vfI/udn4rhWJvnXJPuNWHbsvqs2eOZV2vhNjHe9Y2j6X9ANKzgL+BqwBbAP8FfA7yd5TFX9asT2/gA4HPgi8D7gYcBTgUcneVhVXf+bHScPAb4B3LdffgXdcIbP9M/XLbZ7w/lUX/dpwA/pgvfLgMOTHFhVK0es+vfAocC/A18Bng68Bbh7kp8DJ/T7/S/g94BX9Mf8slF1zMYsjuFdwEHAF4D/AFb329uFbqjCkr7+LwFb070WX0rykqr6l4HtnAo8G/gW8CHg18ADgccDT6F7vVfQDTN5Q1/fqQPrL13fYx8lycnAC4FrgE/TDbF4LPBm4ElJfq+q7hxY5QTgLuA84FpgW+CJdO3zaOB5A8u+EXgGsFc/f2L4xlwM49ge+Cawqq/7LuBn/TG9APgX4Dbgc8DVwEOAPwf+MMljq+pHc1DD0+le58/T/bw9DjgK2DXJ64Az6PrEycAjgD8EdkvyiKq6a8T2PkHXhqfR/U44HDge2C/J06tq4g8akrwEeC9wM/BJ4Dq6n7HX9sd4YFWNaudP9fv4It3P3HV0feqX/f6Gh5pMbONg4HXAmf02VtG16RHA0/v9XTxif7sA5wNXAh+me92OBD6b5LCqOnPgmEIXov8MuJ7udf1v4EHAE4ArgGUDy8+076oFVeXDh48FfgDV/TiuM/1gugB0G/CAoXm7AFuMWOdF/fZeOzT9qH76ncCThua9rZ/310PTv9JPf9XQ9MMnagaOGpi+Dd0bymrgoKF1Xtsv/5Wh6af201cCOw1M367f1s10b04PHZi3FfDtvl12HLONj+/3s7T/fvixZA6O4Vpg1xH7XkoXnP5kaPp2dCHg18D9+mnb9ssum+T1ve+IvrN0PfrcRM2fmaQ9thvqN58G7jlJmw73j91G7O9uwAf75R8zSS1LJql1JbBymtf10FE/U3Thf9HQvN8Bbge+P9jn+nlP7F/708dsx0NHvQas/fN2yFA7fLWf93PguUPrndzPO3xEHyrgu8B9Bqbfg+4PzAKeNzB9F7qfj5uAPYa29Z5++ZMm2cclwOIRxzpxTEdN0hY7AvceMX0vuiD7xaHpSwZepzcMzfsf/fT/GJr+4n76+cC2Q/O2YOD35Pr0XR9tPBa8AB8+fKz1Rnt8/3gL8PH+DfYu4OgZbCvAjcB/Dk2f+EX+kRHr7NrPO21g2oP6aVcyOkRNvNEdNTDtuf20j41YfhFwVT9/54Hpp/bTXjRinVP6eW8aMe8N/bxDxmyXiTeryR6HzsExrPNG2L9xF/DJSeqa+EPg5f3z3+qfnwNkzL6zdD363ETNkz2W9MtdRHeGb7sR29iCLuifP+Y+9+m3fdwktSyZZL2VrF94HfnHDfCOfv7TJtnm6XShc50gNmLZQ0e9Bqz5efvwiHWe3887e8S8Qxgd5pYyFFBH1HDmwLT/3U9764jl70MXan8NbDViH4cPrzN0TEeNmj9NO30OuBXYcmDaEtb84Trqd8wPgeuHpl3ar7P3GPucs77rY+N6OGxA2ri8Yej5RKj7wPCCSbYEXgL8Cd1H/9uy9jj2nSbZx7IR067uvw6Old27//r1qlo9Yp2ldG+0g/bpv/7n8MJVdWeSs+nesPYGhj+SHVXXj/uvy0fMu7b/+qAR86byxpr6gq3ZHMP5I7Z3QP9124wei7pD//Wh/T5uSvLvdB8fr0jyKbqPlc+rqlumqHt9vaAmuWAryb3owvf1wLEZfce22yZqH1jvvsBr6IajPJhuiMSgyfrmXFtZVdeNmD7xmhyS5NEj5u9IF25+h9F9bybmul+fNWLaf9GF7b0Hpk3Vj3+R5CK6T3b2AIY/yh/Vj8eSbjz8S+nukLKYdYcnLgZ+MjRtxSS/Y65mzWtFkq2BhwM/q6qLpqljvfqu2mB4lTYiVTVxcdLWdL+0Twbel+SHVTX8JvRxujGvV9KNQfsp3S9jgGPpPlofZZ0xbn0og+4Ne8LEBR0/m2Q7Px0xbWKd4TcnhqZvN2LejSOm3TnGvC0n2df6ms0xjGqT+/Zff69/TGabge+PpBui8BzW3D7t1iSnAa+uqslek7l2H7oz+Tuw7h9WI/UXIl1Adzb/fLqP7X9O93ptB7yKyfvmXBv1esCa1+Q106y/zTTzxzHX/Xqd176qVie5gS50T5jrfjytJMfQjVv+Bd3QiB8Bt9D9ET4xrnnUaz/Z+OY7WfsP8olarx2x7LAZ9121w/AqbYSq6mbga0n+ELgQ+GCS350489ZfUftMugt3nlpVv7mYK93V3H89B2VMvLHeb5L5959inVHzAB4wtNzGaDbHUFNs71VV9e5xCqiqX9MPIUny23RnyI4C/pTurO9B42xnDkzUflFV7TPlkmv8OV1wXecMd5ID6MLrTN0FjLyantHha8Ko1wPWHNe2VXXTetSzkO7H0Bn/JFvQBfLBYxnsx5eN2M6k/biqJmu3SSVZRPeH1k+BfarqJ0PzDxi54sxMhNxxztyvT99VI7xVlrQRq6pL6K6IfhDwlwOzdu+/fm4wuPb2B+45B7uf+Fju8f2b47BDp1hnnXn9m9vj+6cXzra4eTTXx/DN/ut6Bc6qurqqPkp3Acv36F6P+w4schdrnzGfM1W1ii747Jlk+zFXm+ibnxoxb3iYyYSJj4wnO45fAPfrh8oMW+fWSGOY1WuywEa14UF0J6MGP0qfqh9vBzyKbgzqd2aw76lep8V0f0icOyK4bsOaYQzrrf+j/lt0fWHvaZZdn76rRhhepY3f39K9ybw6a+7furL/eujggkl2BP55LnZaVdfQffS3K0P/3SvJ4Yx+E/0M3UfEz07y2KF5x9KNf/xazc0tiObLnB5DVS2jG5P4R0leOGqZJI/oXzuS7JDkMSMW2xq4N91HqbcPTL8B+O1xallP/4/urOcpfehZS5L7JBkMJiv7r4cOLbc38L8m2ccN/dedJ5l/Pl04e8HQNo8CDpy89En9E92FPO9I8jvDM/v7nG6swfZvBn4PkO5ex2/rnw6Ojf8I3TEenWR31vZmugsDP1JVtzG+qV6n6+iGCOzbh9WJ+rakG0qweAb7mcrEpxcnZuhetUnulrXvwzzTvqtGOGxA2shV1bVJTqT7uPWv6QLABXRXo/9RknOBr9N9nPj7dPc5/PEkm5upV9Ddhued6W6mfzFr/m3txEVFg7Wu6gPaJ4GzknyS7iPOfYEn032k+JI5qm1ezNMxPIfuwpmT+3GB59F9BPog4JF0F6EcQBcAdgK+meQ7dGd3r6YLGn9A9xHwu2vt+/eeAfxJf5HXcrpwe3ZVnT3TYx+lqk5Jsi/wcuAHSb5M1x7b0/1hczBdaHppv8qH6MaSvjPJE+jOFj+kr//TdON5h53Rr/Mv/bjeVcAvq+qf+vn/SBdc35vkSXRtshfdPVM/3297Jsd0ef8anwJcluRLdLeg2pIumB1Ed3u2PWay3Q3kO3Q1D97ndTe6ewt/eGKhqlqZ5Fi6P2YvTPIJumM6hK6vXU43rnomvkEXUI/tz2ZOjL/9x6q6Mcm76e7zemmSz9IFxyfQ9ZUz++9n6/10n348H/hev5//prsP8hPpXtPjYb36rlqx0Lc78OHDx5pbZU0x/3509zu9mTX3A92e7n6NK+nOzP4AeCtwL0bcWojp79E48pZLdGH1NLqwdTPdG9jTptoe3Q3OT6d7U7md7g3jvcADRyx7KpPcJolJboM0zvFMsa3jx1x+To5hYJl7A6+nC5ir6G5TdBVd6HgxsHW/3HbAcXRh91q6i/B+Qnd3h2czdPssuot0PkYXJFaPe4wDNY/bfhM32r+ub4+f0p0R/VvWvY/ow+hujXRd32eW042FXdLv89QR2/8rumB2W7/McP99PN2/Sr6FbmznF+iC/8g+Mll/HlrmEX07/LDf78/pPpY+EXjimO1y6Kh9TdU/B9ZZ53WarI1Ycxurrfo2v6qv+Uq6C5K2mqS+J9Pdr/kX/fLfB/4vo28ftZQpfg/1yzyF7nfAKta9rdqi/nX8Nl3//ildoN6FET8jU/WH6eqhu6XdWXRjW2/t2+OjdONt17vv+mjjkf6FlSRJG6l0/571kOrvSCJtzhzzKkmSpGYYXiVJktQMw6skSZKa4ZhXSZIkNcNbZW0mFi9eXEuWLFnoMiRJkqa1fPny66tqh1HzDK+biSVLlrBs2bKFLkOSJGlaSX442TzHvEqSJKkZhldJkiQ1w/AqSZKkZhheJUmS1AzDqyRJkppheJUkSVIzDK+SJElqhuFVkiRJzTC8SpIkqRmGV0mSJDXD8CpJkqRmLFroArRhfOeaG9j3NR9a6DIkSVLDlr/9+QtdgmdeJUmS1A7DqyRJkppheJUkSVIzDK+SJElqhuFVkiRJzTC8SpIkqRmGV0mSJDXD8CpJkqRmGF4lSZLUDMOrJEmSmmF4lSRJUjMMr5IkSWqG4VWSJEnNMLxKkiSpGYZXSZIkNcPwKkmSpGYYXiVJktQMw6skSZKaYXiVJElSMwyvkiRJaobhVZIkSc0wvEqSJKkZhldJkiQ1w/AqSZKkZhheJUmS1AzDqyRJkppheJUkSVIzDK+SJElqhuFVkiRJzTC8SpIkqRmGV0mSJDXD8CpJkqRmGF4lSZLUDMOrJEmSmmF4lSRJUjMMr5IkSWqG4VWSJEnNMLxKkiSpGYZXSZIkNcPwKkmSpGYYXiVJktQMw6skSZKaYXiVJElSMwyvkiRJaobhVZIkSc0wvEqSJKkZhldJkiQ1w/AqSZKkZmyW4TXJHklWJLkoyW5TLPf6DVDL64eenzvf+5QkSWrVZhlegWcAn62qvavqB1MsN+vwmmSLaRZZax9V9bjZ7lOSJGlTtcmE1yRbJ/lCkouTfCvJkUmOS3JB//ykdJ4KHAv8eZIz+3X/NMn5/dnYE5NskeQE4J79tI8meXOSVw3s7y1JjpmklkOTnJnkY8Cl/bTPJFme5LIkL+6nrbWPftqqgW0sTXJaksv7GtLPe2o/7etJ3p3k85PU8eIky5Isu/OWX81RS0uSJC2cRQtdwBx6CvDjqnoaQJJtga9W1Zv65x8G/qCq/j3J+4BVVfX3SR4KHAkcWFV3JHkP8Nyqel2SV1bVo/r1lwCfBt6V5G7AnwD7T1HP/sDDq+qq/vkLq+rnSe4JXJDkU8P7GGFvYE/gx8A5wIFJlgEnAgdX1VVJ/nWyAqrqJOAkgK3vv2tNUaskSVITNpkzr3RnOA9L8ndJDqqqG4EnJDkvyaXAE+mC4LAnAfvSBcoV/fMHDy9UVSuBG5LsDTwZuKiqbpiinvMHgivAMUkuBr4J/DbwkDGO6fyquqaq7gJWAEuAPYArB7Y9aXiVJEna1GwyZ16r6rtJ9gWeCrwtyVeAVwD7VdXVSY4H7jFi1QAfrKr/NcZu3g8cBdwfOGWaZW/+zQ6SQ4HDgAOq6pYkSyepZdhtA9+vpnu9MsZ6kiRJm6RN5sxrkgcCt1TVR4C/B/bpZ12fZBvgiElWPQM4IsmO/Xa2T7JLP++OJFsOLHs63fCERwNfnkF52wK/6IPrHsBjB+YN72M6lwMP7ocxQDfkQZIkabOwyZx5BR4BvD3JXcAdwMvo7ipwKbASuGDUSlX17ST/B/hKP5b1Droztj+kGy96SZILq+q5VXV7f5HXL6tq9Qxq+xLw0iSXAFfQDR2YsNY+pttQVf06ycuBLyW5Hjh/BnVIkiQ1LVVexzOuPtxeCDyrqr63gHVsU1Wr+rsP/DPwvap6x1TrbH3/XWuP571xwxQoSZI2Scvf/vwNsp8ky6tqv1HzNplhA/MtycOA7wNnLGRw7f1Ff3HZZXRDEk5c4HokSZI2iE1p2MC8qqpvM3QXgiSPAD48tOhtVfWYea7lHcCUZ1olSZI2RYbXWaiqS4HJ7tEqSZKkOeawAUmSJDXD8CpJkqRmGF4lSZLUDMOrJEmSmmF4lSRJUjMMr5IkSWqG4VWSJEnNMLxKkiSpGYZXSZIkNcPwKkmSpGYYXiVJktQMw6skSZKaYXiVJElSMwyvkiRJaobhVZIkSc0wvEqSJKkZhldJkiQ1w/AqSZKkZhheJUmS1AzDqyRJkppheJUkSVIzDK+SJElqhuFVkiRJzTC8SpIkqRmGV0mSJDXD8CpJkqRmGF4lSZLUDMOrJEmSmmF4lSRJUjMMr5IkSWqG4VWSJEnNMLxKkiSpGYZXSZIkNcPwKkmSpGYYXiVJktQMw6skSZKaYXiVJElSMwyvkiRJaobhVZIkSc0wvEqSJKkZixa6AG0YD33QfVn29ucvdBmSJEmz4plXSZIkNcPwKkmSpGYYXiVJktQMw6skSZKaYXiVJElSMwyvkiRJaobhVZIkSc0wvEqSJKkZhldJkiQ1w/AqSZKkZhheJUmS1AzDqyRJkppheJUkSVIzDK+SJElqhuFVkiRJzTC8SpIkqRmGV0mSJDXD8CpJkqRmGF4lSZLUDMOrJEmSmmF4lSRJUjMMr5IkSWqG4VWSJEnNMLxKkiSpGYZXSZIkNWPRQhegDeP2n1zGj970iIUuQ5KkDW7n4y5d6BI0hzzzKkmSpGYYXiVJktQMw6skSZKaYXiVJElSMwyvkiRJaobhVZIkSc0wvEqSJKkZhldJkiQ1w/AqSZKkZhheJUmS1AzDqyRJkppheJUkSVIzDK+SJElqhuFVkiRJzTC8SpIkqRmGV0mSJDXD8CpJkqRmGF4lSZLUDMOrJEmSmmF4lSRJUjMMr5IkSWqG4VWSJEnNMLxKkiSpGYZXSZIkNcPwKkmSpGYYXiVJktQMw6skSZKaYXiVJElSMwyvkiRJaobhVZIkSc0wvEqSJKkZY4XXJLsl2ar//tAkxyTZbn5LkyRJktY27pnXTwGrk+wOnAzsCnxs3qqSJEmSRhg3vN5VVXcCzwTeWVV/CTxg/sqSJEmS1jVueL0jybOBPwM+30/bcn5KkiRJkkYbN7y+ADgAeEtVXZVkV+Aj81eWJEmStK5F4yxUVd9O8lpg5/75VcAJ81mYJEmSNGzcuw38IbAC+FL//FFJPjefhUmSJEnDxh02cDywP/BLgKpaQXfHAUmSJGmDGTe83llVNw5Nq7kuRpIkSZrKWGNegW8leQ6wRZKHAMcA585fWZIkSdK6xj3zejSwJ3Ab3T8nuBE4dr6KkiRJkkaZ9sxrki2Az1XVYcD/nv+SJEmSpNGmPfNaVauBW5JsuwHqkSRJkiY17pjXW4FLk3wVuHliYlUdMy9VSZIkSSOMG16/0D8kSZKkBTPuf9j64HwXIkmSJE1nrPCa5CpG3Ne1qh485xXNUpIlwOer6uGz3M5LgVuq6kNzUVcr+5YkSdqYjTtsYL+B7+8BPAvYfu7L2XhU1fsWYr9JFi3UviVJkjZ2Y93ntapuGHhcW1XvBJ44z7XNxqIkH0xySZLTktwrycokiwGS7JdkaZK7Jflekh366XdL8v0ki5Mcn+TV/fSlSf4uyflJvpvkoH76vZJ8ot/Px5Ocl2S/yYpKsirJPyS5MMkZA/tdmuStSc4CXjW0792TfC3Jxf16u/XTX5Pkgn7fb5zX1pQkSdpIjBVek+wz8Niv/1j73vNc22z8LnBSVT0SuAl4+aiFquou4CPAc/tJhwEXV9X1IxZfVFX70/1zhjf0014O/KLfz5uBfaepa2vgwqraBzhrYDsA21XVIVX1D0PrfBT456raC3gc8JMkTwYeAuwPPArYN8nBwztL8uIky5Is+/nNq6cpTZIkaeM37rCBwUB1J3AV8D/nvpw5c3VVndN//xG6f2c7mVOAzwLvBF4IfGCS5T7df10OLOm/fzzwLoCq+laSS6ap6y7g4wN1fXpg3seHF05yb2Cnqjq938et/fQnA08GLuoX3YYuzJ49uH5VnQScBPDIne65zphlSZKk1owbXl9UVVcOTkiy6zzUM1eGg1rRhe6JM833+M2MqquT/CzJE4HHsOYs7LDb+q+rWdNumcM6bx4xf7LtB3hbVZ04y/1LkiQ1ZaxhA8BpY07bWOyc5ID++2cDXwdWsuZj/T8eWv79dGdCP9H/R7FxfZ3+DHSShwGPmGb5uwFH9N8/p19/UlV1E3BNkmf0+9gqyb2ALwMvTLJNP32nJDvOoG5JkqQmTXnmNckewJ7Atkn+aGDWbzFw9nIj9B3gz5KcCHwPeC9wPnByktcD5w0t/zm64QKTDRmYzHuAD/bDBS4CLgFunGL5m4E9kyzvlztyjH08DzgxyZuAO4BnVdVXkjwU+EYSgFXAnwLXzbB+SZKkpqRq8qGQSQ4HngE8nS7gTfgV8G9Vde78lrdh9HcIeEdVHTTD9bYAtqyqW/u7AJwB/E5V3T7J8quqapvZVzxzj9zpnvX5l+y+ELuWJGlB7XzcpQtdgmYoyfKqGnkHpynPvFbVZ4HPJjmgqr4xL9UtsCSvA17G5GNdp3Iv4MwkW9KNQ33ZZMFVkiRJszfuBVsXJXkF3RCCwYudXjgvVW1AVXUCcMJ6rvsr1v4HDgAkOQ/Yamjy8xbqrKskSdKmYtzw+mHgcuB/AG+iO0v5nfkqqnVV9ZiFrkGSJGlTNO7dBnavqr8Bbq6qDwJPY/or6yVJkqQ5NW54vaP/+sskDwe2Zc2N+iVJkqQNYtxhAycluQ/wN3R3HdgGOG7eqpIkSZJGGCu8VtX7+2/PAh48f+VIkiRJkxtr2ECS+yU5OckX++cPS/Ki+S1NkiRJWtu4Y15PpfuXpA/sn38XOHY+CpIkSZImM254XVxVnwDuAqiqO4HV81aVJEmSNMK44fXmJPcFCiDJY4Eb560qSZIkaYRx7zbwV3R3GdgtyTnADsAR81aVJEmSNMKU4TXJzlX1o6q6MMkhwO8CAa6oqjumWleSJEmaa9MNG/jMwPcfr6rLqupbBldJkiQthOnCawa+9/6ukiRJWlDThdea5HtJkiRpg5vugq29ktxEdwb2nv339M+rqn5rXquTJEmSBkwZXqtqiw1ViCRJkjSdce/zKkmSJC04w6skSZKaYXiVJElSMwyvkiRJaobhVZIkSc0wvEqSJKkZhldJkiQ1w/AqSZKkZhheJUmS1AzDqyRJkppheJUkSVIzDK+SJElqhuFVkiRJzTC8SpIkqRmGV0mSJDXD8CpJkqRmGF4lSZLUDMOrJEmSmmF4lSRJUjMMr5IkSWqG4VWSJEnNMLxKkiSpGYZXSZIkNcPwKkmSpGYYXiVJktQMw6skSZKasWihC9CGcfcH7MnOxy1b6DIkSZJmxTOvkiRJaobhVZIkSc0wvEqSJKkZhldJkiQ1w/AqSZKkZhheJUmS1AzDqyRJkppheJUkSVIzDK+SJElqhuFVkiRJzTC8SpIkqRmGV0mSJDXD8CpJkqRmGF4lSZLUDMOrJEmSmmF4lSRJUjMMr5IkSWqG4VWSJEnNMLxKkiSpGYZXSZIkNcPwKkmSpGYYXiVJktQMw6skSZKaYXiVJElSMwyvkiRJasaihS5AG8bl113Ogf944EKXIUlaYOccfc5ClyDNimdeJUmS1AzDqyRJkppheJUkSVIzDK+SJElqhuFVkiRJzTC8SpIkqRmGV0mSJDXD8CpJkqRmGF4lSZLUDMOrJEmSmmF4lSRJUjMMr5IkSWqG4VWSJEnNMLxKkiSpGYZXSZIkNcPwKkmSpGYYXiVJktQMw6skSZKaYXiVJElSMwyvkiRJaobhVZIkSc0wvEqSJKkZhldJkiQ1w/AqSZKkZhheJUmS1AzDqyRJkppheJUkSVIzDK+SJElqhuFVkiRJzTC8SpIkqRmGV0mSJDXD8CpJkqRmGF4lSZLUDMOrJEmSmmF4lSRJUjMMr5IkSWqG4VWSJEnNMLxKkiSpGYZXSZIkNcPwKkmSpGYYXiVJktQMw6skSZKaYXiVJElSMwyvkiRJaobhVZIkSc0wvEqSJKkZhldJkiQ1Y6MMr0n2S/LuaZbZLsnLx9zeuXNT2cYnyesXugZJksej6WYAAAl9SURBVKQNZaMMr1W1rKqOmWax7YCxwmtVPW72VW20DK+SJGmzMW/hNcmSJJcneX+SbyX5aJLDkpyT5HtJ9u8f5ya5qP/6u/26hyb5fP/98UlOSbI0yZVJJkLtCcBuSVYkeXuSbZKckeTCJJcmOXygllUD212a5LS+to8mST9v3yRnJVme5MtJHtBPX5rk75Kcn+S7SQ7qp2+R5O/7fV2S5OiptjNJG+2e5GtJLu7r3i2dt/dtdmmSI/tlH5Dk7P54v5XkoCQnAPfsp310xPZfnGRZkmV3rLpj1q+pJEnSQls0z9vfHXgW8GLgAuA5wOOBp9OdMXw+cHBV3ZnkMOCtwB+P2M4ewBOAewNXJHkv8Drg4VX1KIAki4BnVtVNSRYD30zyuaqqoW3tDewJ/Bg4BzgwyXnAPwKHV9V/94HxLcAL+3UWVdX+SZ4KvAE4rD+mXYG9+/q3T7LlNNsZ9lHghKo6Pck96P6Y+CPgUcBewGLggiRn92335ap6S5ItgHtV1X8leeVEGwyrqpOAkwC22Xmb4XaQJElqznyH16uq6lKAJJcBZ1RVJbkUWAJsC3wwyUOAAracZDtfqKrbgNuSXAfcb8QyAd6a5GDgLmCnfrmfDi13flVd09e0oq/jl8DDga/2J2K3AH4ysM6n+6/L++WhC7Dvq6o7Aarq50kePs121hSb3BvYqapO79e/tZ/+eOBfq2o18LMkZwGPpgv/p/QB+TNVtWKStpIkSdpkzXd4vW3g+7sGnt/V7/vNwJlV9cwkS4ClY2xnNaPrfi6wA7BvVd2RZCVwjzG3FeCyqjpgmv0P7jt0gXvQdNsZXnbs6VV1dh/MnwZ8OMnbq+pDY+xHkiRpk7HQF2xtC1zbf3/UDNf9Fd0wgsFtXdcH1ycAu8xgW1cAOyQ5ACDJlkn2nGadrwAv7YcrkGT7mWynqm4CrknyjH7ZrZLcCzgbOLIfU7sDcDBwfpJd+uP7F+BkYJ9+U3f0Z2MlSZI2eQsdXv8v8LYk59B9xD62qroBOKe/eOntdONH90uyjO4s7OUz2NbtwBHA3yW5GFgBTHeHgvcDPwIu6dd5znps53nAMUkuAc4F7g+cDlwCXAz8J/DXVfVT4FBgRZKL6MYFv6vfxkl9DetcsCVJkrSpybrXM2lTtM3O29Rer9lrocuQJC2wc44+Z6FLkKaVZHlV7Tdq3kKfeZUkSZLGNt8XbAlI8s/AgUOT31VVH1iIeiRJklpleN0AquoVC12DJEnSpsBhA5IkSWqG4VWSJEnNMLxKkiSpGYZXSZIkNcPwKkmSpGYYXiVJktQMw6skSZKaYXiVJElSMwyvkiRJaobhVZIkSc0wvEqSJKkZhldJkiQ1w/AqSZKkZhheJUmS1AzDqyRJkppheJUkSVIzDK+SJElqhuFVkiRJzTC8SpIkqRmGV0mSJDXD8CpJkqRmGF4lSZLUDMOrJEmSmmF4lSRJUjMMr5IkSWqG4VWSJEnNMLxKkiSpGYZXSZIkNcPwKkmSpGYYXiVJktQMw6skSZKaYXiVJElSMwyvkiRJaobhVZIkSc0wvEqSJKkZhldJkiQ1w/AqSZKkZhheJUmS1AzDqyRJkppheJUkSVIzDK+SJElqxqKFLkAbxh477sE5R5+z0GVIkiTNimdeJUmS1AzDqyRJkppheJUkSVIzDK+SJElqhuFVkiRJzTC8SpIkqRmGV0mSJDXD8CpJkqRmGF4lSZLUDMOrJEmSmmF4lSRJUjMMr5IkSWpGqmqha9AGkORXwBULXcdGZjFw/UIXsRGxPdZme6zLNlmb7bEu22Rttse6xm2TXapqh1EzFs1tPdqIXVFV+y10ERuTJMtskzVsj7XZHuuyTdZme6zLNlmb7bGuuWgThw1IkiSpGYZXSZIkNcPwuvk4aaEL2AjZJmuzPdZme6zLNlmb7bEu22Rttse6Zt0mXrAlSZKkZnjmVZIkSc0wvEqSJKkZhtdNQJKnJLkiyfeTvG7E/CR5dz//kiT7jLtui2bZHiuTXJpkRZJlG7by+TFGe+yR5BtJbkvy6pms26pZtsnm2Eee2/+sXJLk3CR7jbtuq2bZJptjHzm8b4sVSZYlefy467Zqlm2y2fWRgeUenWR1kiNmuu5vVJWPhh/AFsAPgAcDdwcuBh42tMxTgS8CAR4LnDfuuq09ZtMe/byVwOKFPo4N3B47Ao8G3gK8eibrtviYTZtsxn3kccB9+u9/f1P+HTLbNtmM+8g2rLmO5pHA5faR0W2yufaRgeX+E/gP4Ij17SOeeW3f/sD3q+rKqrod+Dfg8KFlDgc+VJ1vAtslecCY67ZmNu2xKZq2Parquqq6ALhjpus2ajZtsikapz3Orapf9E+/CTxo3HUbNZs22RSN0x6rqk8iwNZAjbtuo2bTJpuicV/no4FPAdetx7q/YXht307A1QPPr+mnjbPMOOu2ZjbtAd0vl68kWZ7kxfNW5YYzm9d4U+wfMPvj2tz7yIvoPrlYn3VbMZs2gc20jyR5ZpLLgS8AL5zJug2aTZvAZthHkuwEPBN430zXHea/h21fRkwb/utusmXGWbc1s2kPgAOr6sdJdgS+muTyqjp7TivcsGbzGm+K/QNmf1ybbR9J8gS6oDYxdm+z7yMj2gQ20z5SVacDpyc5GHgzcNi46zZoNm0Cm2cfeSfw2qpanay1+Iz7iGde23cN8NsDzx8E/HjMZcZZtzWzaQ+qauLrdcDpdB9ntGw2r/Gm2D9glse1ufaRJI8E3g8cXlU3zGTdBs2mTTbbPjKhD2G7JVk803UbMps22Vz7yH7AvyVZCRwBvCfJM8Zcd20LPcjXx6wHSS8CrgR2Zc1A5z2Hlnkaa1+gdP6467b2mGV7bA3ce+D7c4GnLPQxzXd7DCx7PGtfsLXJ9Y85aJPNso8AOwPfBx63vm3Z0mOWbbK59pHdWXNx0j7Atf3v2M25j0zWJptlHxla/lTWXLA14z7isIHGVdWdSV4JfJnuir1TquqyJC/t57+P7qq+p9L9or0FeMFU6y7AYcyZ2bQHcD+6j3eg+2H6WFV9aQMfwpwapz2S3B9YBvwWcFeSY+mu9LxpU+sfMLs2ARazGfYR4DjgvnRnSgDurKr9NsXfITC7NmEz/T0C/DHw/CR3AL8GjqwumWzOfWRkmyTZXPvIjNadan/+e1hJkiQ1wzGvkiRJaobhVZIkSc0wvEqSJKkZhldJkiQ1w/AqSZKkZhheJUmS1AzDqyRJkprx/wHOwhcq6CPDBwAAAABJRU5ErkJggg==\n",
"text/plain": [
""
]
},
"metadata": {
"needs_background": "light"
},
"output_type": "display_data"
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"Features used for prediction\n",
" Index(['buying_price', 'maintainence_cost', 'safety_rating'], dtype='object')\n",
"\n",
"Please wait Training-Testing with all models..\n",
"\n"
]
},
{
"data": {
"application/vnd.jupyter.widget-view+json": {
"model_id": "78d5ed200cbf4c54884739c77b0023cb",
"version_major": 2,
"version_minor": 0
},
"text/plain": [
"HBox(children=(FloatProgress(value=0.0, max=6.0), HTML(value='')))"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"Done with LogisticRegression\n",
"Done with RandomForestClassifier\n",
"Done with XGBoost Classifier\n",
"Done with LGBoost Classifier\n",
"Done with AdaBoost Classifier\n",
"Done with GradientBoostingClassifier\n",
"\n",
" Model F1 score AUC-ROC score Accuracy \\\n",
"1 RandomForestClassifier 1.000000 1.000000 1.000000 \n",
"3 LGBoost Classifier 1.000000 1.000000 1.000000 \n",
"2 XGBoost Classifier 0.967137 0.976190 0.966667 \n",
"5 GradientBoostingClassifier 0.967137 0.976190 0.966667 \n",
"4 AdaBoost Classifier 0.898222 0.865079 0.900000 \n",
"0 LogisticRegression 0.861364 0.809524 0.866667 \n",
"\n",
" Balanced Accuracy Score \n",
"1 1.000000 \n",
"3 1.000000 \n",
"2 0.976190 \n",
"5 0.976190 \n",
"4 0.865079 \n",
"0 0.809524 \n",
"\n",
"Check returned table\n",
"\n"
]
}
],
"source": [
"result, model = ez.quick_ml(df,'popularity','c',3)"
]
},
{
"cell_type": "code",
"execution_count": 7,
"metadata": {
"ExecuteTime": {
"end_time": "2020-03-26T21:21:59.877676Z",
"start_time": "2020-03-26T21:21:59.872675Z"
}
},
"outputs": [
{
"data": {
"text/plain": [
"RandomForestClassifier(bootstrap=True, class_weight='balanced',\n",
" criterion='gini', max_depth=None, max_features='auto',\n",
" max_leaf_nodes=None, min_impurity_decrease=0.0,\n",
" min_impurity_split=None, min_samples_leaf=1,\n",
" min_samples_split=2, min_weight_fraction_leaf=0.0,\n",
" n_estimators=200, n_jobs=None, oob_score=False,\n",
" random_state=101, verbose=0, warm_start=False)"
]
},
"execution_count": 7,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"model"
]
},
{
"cell_type": "code",
"execution_count": 13,
"metadata": {
"ExecuteTime": {
"end_time": "2020-03-26T21:23:22.971760Z",
"start_time": "2020-03-26T21:23:22.967757Z"
}
},
"outputs": [
{
"data": {
"text/plain": [
"3"
]
},
"execution_count": 13,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"model.n_features_"
]
},
{
"cell_type": "code",
"execution_count": 14,
"metadata": {
"ExecuteTime": {
"end_time": "2020-03-26T21:23:53.042435Z",
"start_time": "2020-03-26T21:23:53.039434Z"
}
},
"outputs": [],
"source": [
"features = ['buying_price', 'maintainence_cost', 'safety_rating']"
]
},
{
"cell_type": "code",
"execution_count": 15,
"metadata": {
"ExecuteTime": {
"end_time": "2020-03-26T21:24:12.962507Z",
"start_time": "2020-03-26T21:24:12.942493Z"
}
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"All Deployment Files Created Successfully\n",
"\n",
"Files Created and stored in : /deployment-files named Folder\n",
"\n",
"Open deployment-files folder and open command prompt and run \"python app.py\" copy link and paste in browser to run app, enjoy.\n",
"\n",
"Files created:\n",
" 1. model.pkl - Model file using pickle\n",
" 2.app.py - Flask server file\n",
"3.index.html - User Interface file.\n"
]
}
],
"source": [
"ez.deploy_one(model,features,'Chintan Fucks RUles')"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": []
}
],
"metadata": {
"hide_input": false,
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.7.4"
}
},
"nbformat": 4,
"nbformat_minor": 2
}
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������
| Model | F1 score | AUC-ROC score | Accuracy | Confustion-Matrix | |
|---|---|---|---|---|---|
| 1 | \n", "RandomForestClassifier | \n", "1 | \n", "1 | \n", "1 | \n", "[[21 0]\n", " [ 0 9]] | \n", "
| 3 | \n", "LGBoost Classifier | \n", "1 | \n", "1 | \n", "1 | \n", "[[21 0]\n", " [ 0 9]] | \n", "
| 2 | \n", "XGBoost Classifier | \n", "0.967137 | \n", "0.97619 | \n", "0.966667 | \n", "[[20 1]\n", " [ 0 9]] | \n", "
| 5 | \n", "GradientBoostingClassifier | \n", "0.967137 | \n", "0.97619 | \n", "0.966667 | \n", "[[20 1]\n", " [ 0 9]] | \n", "
| 4 | \n", "AdaBoost Classifier | \n", "0.898222 | \n", "0.865079 | \n", "0.9 | \n", "[[20 1]\n", " [ 2 7]] | \n", "
| 0 | \n", "LogisticRegression | \n", "0.822222 | \n", "0.753968 | \n", "0.833333 | \n", "[[20 1]\n", " [ 4 5]] | \n", "
\n",
" \n",
" \n",
" \n",
" \n",
"
"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"application/vnd.plotly.v1+json": {
"config": {
"plotlyServerURL": "https://plot.ly"
},
"data": [
{
"domain": {
"x": [
0,
1
],
"y": [
0,
1
]
},
"hole": 0.4,
"hoverinfo": "label+percent+name",
"hoverlabel": {
"namelength": 0
},
"hovertemplate": "label=%{label}value=%{value}", "labels": [ 1, 2, 3, 4 ], "legendgroup": "", "name": "", "showlegend": true, "type": "pie", "values": [ 941, 294, 36, 31 ] } ], "layout": { "legend": { "tracegroupgap": 0 }, "template": { "data": { "bar": [ { "error_x": { "color": "#2a3f5f" }, "error_y": { "color": "#2a3f5f" }, "marker": { "line": { "color": "#E5ECF6", "width": 0.5 } }, "type": "bar" } ], "barpolar": [ { "marker": { "line": { "color": "#E5ECF6", "width": 0.5 } }, "type": "barpolar" } ], "carpet": [ { "aaxis": { "endlinecolor": "#2a3f5f", "gridcolor": "white", "linecolor": "white", "minorgridcolor": "white", "startlinecolor": "#2a3f5f" }, "baxis": { "endlinecolor": "#2a3f5f", "gridcolor": "white", "linecolor": "white", "minorgridcolor": "white", "startlinecolor": "#2a3f5f" }, "type": "carpet" } ], "choropleth": [ { "colorbar": { "outlinewidth": 0, "ticks": "" }, "type": "choropleth" } ], "contour": [ { "colorbar": { "outlinewidth": 0, "ticks": "" }, "colorscale": [ [ 0, "#0d0887" ], [ 0.1111111111111111, "#46039f" ], [ 0.2222222222222222, "#7201a8" ], [ 0.3333333333333333, "#9c179e" ], [ 0.4444444444444444, "#bd3786" ], [ 0.5555555555555556, "#d8576b" ], [ 0.6666666666666666, "#ed7953" ], [ 0.7777777777777778, "#fb9f3a" ], [ 0.8888888888888888, "#fdca26" ], [ 1, "#f0f921" ] ], "type": "contour" } ], "contourcarpet": [ { "colorbar": { "outlinewidth": 0, "ticks": "" }, "type": "contourcarpet" } ], "heatmap": [ { "colorbar": { "outlinewidth": 0, "ticks": "" }, "colorscale": [ [ 0, "#0d0887" ], [ 0.1111111111111111, "#46039f" ], [ 0.2222222222222222, "#7201a8" ], [ 0.3333333333333333, "#9c179e" ], [ 0.4444444444444444, "#bd3786" ], [ 0.5555555555555556, "#d8576b" ], [ 0.6666666666666666, "#ed7953" ], [ 0.7777777777777778, "#fb9f3a" ], [ 0.8888888888888888, "#fdca26" ], [ 1, "#f0f921" ] ], "type": "heatmap" } ], "heatmapgl": [ { "colorbar": { "outlinewidth": 0, "ticks": "" }, "colorscale": [ [ 0, "#0d0887" ], [ 0.1111111111111111, "#46039f" ], [ 0.2222222222222222, "#7201a8" ], [ 0.3333333333333333, "#9c179e" ], [ 0.4444444444444444, "#bd3786" ], [ 0.5555555555555556, "#d8576b" ], [ 0.6666666666666666, "#ed7953" ], [ 0.7777777777777778, "#fb9f3a" ], [ 0.8888888888888888, "#fdca26" ], [ 1, "#f0f921" ] ], "type": "heatmapgl" } ], "histogram": [ { "marker": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "histogram" } ], "histogram2d": [ { "colorbar": { "outlinewidth": 0, "ticks": "" }, "colorscale": [ [ 0, "#0d0887" ], [ 0.1111111111111111, "#46039f" ], [ 0.2222222222222222, "#7201a8" ], [ 0.3333333333333333, "#9c179e" ], [ 0.4444444444444444, "#bd3786" ], [ 0.5555555555555556, "#d8576b" ], [ 0.6666666666666666, "#ed7953" ], [ 0.7777777777777778, "#fb9f3a" ], [ 0.8888888888888888, "#fdca26" ], [ 1, "#f0f921" ] ], "type": "histogram2d" } ], "histogram2dcontour": [ { "colorbar": { "outlinewidth": 0, "ticks": "" }, "colorscale": [ [ 0, "#0d0887" ], [ 0.1111111111111111, "#46039f" ], [ 0.2222222222222222, "#7201a8" ], [ 0.3333333333333333, "#9c179e" ], [ 0.4444444444444444, "#bd3786" ], [ 0.5555555555555556, "#d8576b" ], [ 0.6666666666666666, "#ed7953" ], [ 0.7777777777777778, "#fb9f3a" ], [ 0.8888888888888888, "#fdca26" ], [ 1, "#f0f921" ] ], "type": "histogram2dcontour" } ], "mesh3d": [ { "colorbar": { "outlinewidth": 0, "ticks": "" }, "type": "mesh3d" } ], "parcoords": [ { "line": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "parcoords" } ], "pie": [ { "automargin": true, "type": "pie" } ], "scatter": [ { "marker": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "scatter" } ], "scatter3d": [ { "line": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "marker": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "scatter3d" } ], "scattercarpet": [ { "marker": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "scattercarpet" } ], "scattergeo": [ { "marker": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "scattergeo" } ], "scattergl": [ { "marker": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "scattergl" } ], "scattermapbox": [ { "marker": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "scattermapbox" } ], "scatterpolar": [ { "marker": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "scatterpolar" } ], "scatterpolargl": [ { "marker": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "scatterpolargl" } ], "scatterternary": [ { "marker": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "type": "scatterternary" } ], "surface": [ { "colorbar": { "outlinewidth": 0, "ticks": "" }, "colorscale": [ [ 0, "#0d0887" ], [ 0.1111111111111111, "#46039f" ], [ 0.2222222222222222, "#7201a8" ], [ 0.3333333333333333, "#9c179e" ], [ 0.4444444444444444, "#bd3786" ], [ 0.5555555555555556, "#d8576b" ], [ 0.6666666666666666, "#ed7953" ], [ 0.7777777777777778, "#fb9f3a" ], [ 0.8888888888888888, "#fdca26" ], [ 1, "#f0f921" ] ], "type": "surface" } ], "table": [ { "cells": { "fill": { "color": "#EBF0F8" }, "line": { "color": "white" } }, "header": { "fill": { "color": "#C8D4E3" }, "line": { "color": "white" } }, "type": "table" } ] }, "layout": { "annotationdefaults": { "arrowcolor": "#2a3f5f", "arrowhead": 0, "arrowwidth": 1 }, "coloraxis": { "colorbar": { "outlinewidth": 0, "ticks": "" } }, "colorscale": { "diverging": [ [ 0, "#8e0152" ], [ 0.1, "#c51b7d" ], [ 0.2, "#de77ae" ], [ 0.3, "#f1b6da" ], [ 0.4, "#fde0ef" ], [ 0.5, "#f7f7f7" ], [ 0.6, "#e6f5d0" ], [ 0.7, "#b8e186" ], [ 0.8, "#7fbc41" ], [ 0.9, "#4d9221" ], [ 1, "#276419" ] ], "sequential": [ [ 0, "#0d0887" ], [ 0.1111111111111111, "#46039f" ], [ 0.2222222222222222, "#7201a8" ], [ 0.3333333333333333, "#9c179e" ], [ 0.4444444444444444, "#bd3786" ], [ 0.5555555555555556, "#d8576b" ], [ 0.6666666666666666, "#ed7953" ], [ 0.7777777777777778, "#fb9f3a" ], [ 0.8888888888888888, "#fdca26" ], [ 1, "#f0f921" ] ], "sequentialminus": [ [ 0, "#0d0887" ], [ 0.1111111111111111, "#46039f" ], [ 0.2222222222222222, "#7201a8" ], [ 0.3333333333333333, "#9c179e" ], [ 0.4444444444444444, "#bd3786" ], [ 0.5555555555555556, "#d8576b" ], [ 0.6666666666666666, "#ed7953" ], [ 0.7777777777777778, "#fb9f3a" ], [ 0.8888888888888888, "#fdca26" ], [ 1, "#f0f921" ] ] }, "colorway": [ "#636efa", "#EF553B", "#00cc96", "#ab63fa", "#FFA15A", "#19d3f3", "#FF6692", "#B6E880", "#FF97FF", "#FECB52" ], "font": { "color": "#2a3f5f" }, "geo": { "bgcolor": "white", "lakecolor": "white", "landcolor": "#E5ECF6", "showlakes": true, "showland": true, "subunitcolor": "white" }, "hoverlabel": { "align": "left" }, "hovermode": "closest", "mapbox": { "style": "light" }, "paper_bgcolor": "white", "plot_bgcolor": "#E5ECF6", "polar": { "angularaxis": { "gridcolor": "white", "linecolor": "white", "ticks": "" }, "bgcolor": "#E5ECF6", "radialaxis": { "gridcolor": "white", "linecolor": "white", "ticks": "" } }, "scene": { "xaxis": { "backgroundcolor": "#E5ECF6", "gridcolor": "white", "gridwidth": 2, "linecolor": "white", "showbackground": true, "ticks": "", "zerolinecolor": "white" }, "yaxis": { "backgroundcolor": "#E5ECF6", "gridcolor": "white", "gridwidth": 2, "linecolor": "white", "showbackground": true, "ticks": "", "zerolinecolor": "white" }, "zaxis": { "backgroundcolor": "#E5ECF6", "gridcolor": "white", "gridwidth": 2, "linecolor": "white", "showbackground": true, "ticks": "", "zerolinecolor": "white" } }, "shapedefaults": { "line": { "color": "#2a3f5f" } }, "ternary": { "aaxis": { "gridcolor": "white", "linecolor": "white", "ticks": "" }, "baxis": { "gridcolor": "white", "linecolor": "white", "ticks": "" }, "bgcolor": "#E5ECF6", "caxis": { "gridcolor": "white", "linecolor": "white", "ticks": "" } }, "title": { "x": 0.05 }, "xaxis": { "automargin": true, "gridcolor": "white", "linecolor": "white", "ticks": "", "title": { "standoff": 15 }, "zerolinecolor": "white", "zerolinewidth": 2 }, "yaxis": { "automargin": true, "gridcolor": "white", "linecolor": "white", "ticks": "", "title": { "standoff": 15 }, "zerolinecolor": "white", "zerolinewidth": 2 } } }, "title": { "text": "Percentage data of popularity" } } }, "text/html": [ "
\n",
" \n",
" \n",
" \n",
" \n",
"
"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"Detailed Executing with RandomForest ..\n"
]
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAq8AAAGwCAYAAACHCYxOAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADt0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjByYzEsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy/xvVyzAAAgAElEQVR4nO3deZgkZZmu8fuRRkBAFhtFUWhEFBdkFUVWlXFm3HAd3AdxxA3RmXGb8QyiDooHPS7jBiqioo6KgqijoEiDgtJ0Q7MprrQDKCKCrIos7/kjouwkO6sqq7qrs6L6/l1XXpX5xRcRb0RkVj4V+WVUqgpJkiSpC+426gIkSZKkYRleJUmS1BmGV0mSJHWG4VWSJEmdYXiVJElSZxheJUmS1BmGV0nTkuTAJJXkwFHXIklacxhepVmgDYG9tzuSXJtkYRsSM+oauy7J4QP2c+9t2ahrnI629oXTmO+4SfbHlJc5XT21LFhd61xVkuy7uvfXqPgHq2aLeaMuQNJdvK39uTbwIOAZwD7ArsAhoypqjjkDWDig/Y+ruY7Z4mvA0gHty1ZzHZI0FMOrNItU1eG9j5PsAZwJvCrJe6vqspEUNrcs7N/Pa7iTquq4URchScNy2IA0i1XVWcClQIBdeqcl2SXJB5Jc0A4x+HOSnyd5b5JN+pfV+5Ffkse1QxJuTHJDkm8meeigGpI8KMmXk1yX5OYkZyd58kR1t7V9JcnVSW5N8uskH0ly3wF9xz4y3jrJIUl+3G7LsiT/PjZkIslzkixqa7g6yYeSrDuF3Tkl09yGByZ5TZILk/yp96PkJJsmeVeSn7TTrk9yWpInDlje3ZMcmuS8dr/f0u6PryXZr+1zYJKx/++9T99H/ofPwP54XpLT23r+3G7H/0myzoC+T09yfJKftcfrpiRL2m26W1/fAv6xfXjZoGEc7bYvY4AsHw6yb/9y2+f45kk+keTKNMNxDuzp8+gkJyS5Kslfklye5Ogk95vufupZdu/r7W+SfL/dD79P8qkkG7f9dkryjXa/3pTk5AwYPtFuSyVZJ8l/JrmsfV7+Mslbk9x9nDqekOTbWf474mdJjkyy0QTruHuSw5L8tF3Hce1z+VNt10/1Pd8WtPPfr53vrJ59+pskn8+A3y9JFrTzH9fe/+8k17R1Lk7ylAn27wHt62dsu5Yl+UKSXQf0Hfq5q27wzKs0+42Nd72tr/1lNMMKzgC+C6wF7Az8C/D3SR5dVTcOWN5TgP2BbwEfAx4GPAl4VJKHVdU1f11xsi3wQ+Bebf+lNMMZTmofr1hs84bzlbbuE4Bf0wTvVwL7J9mjqpYNmPU9wL7A14FTgacBRwB3T3ItcGS73u8DfwO8ut3mVw6qY2WsxDZ8ANgL+CbwP8Ad7fK2ohmqsKCt/9vA+jTH4ttJXl5VH+9ZznHA84CLgc8AfwLuB+wJ/B3N8V5KM8zkrW19x/XMv3C62z5Ikk8CBwFXAF+lGWLxGOAdwBOS/E1V3d4zy5HAncA5wJXARsDjafbPo4AX9fR9G/B0YId2+tjwjVUxjGNT4EfATW3ddwK/a7fpJcDHgVuBk4HLgW2BfwKemuQxVfW/q6CGp9Ec52/QvN4eCxwIbJ3kzcBpNM+JTwLbA08FtkmyfVXdOWB5X6LZhyfQ/E7YHzgc2DXJ06pq7A8akrwc+ChwM/Bl4Gqa19ib2m3co6oG7eevtOv4Fs1r7mqa59Qf2/X1DzUZW8bewJuB09tl3ESzT58NPK1d3wUD1rcVsAj4FfBZmuN2APC1JPtV1ek92xSaEP2PwDU0x/X3wP2BxwE/BRb39J/qc1ddUFXevHkb8Q2o5uW4QvveNAHoVuC+fdO2AtYaMM9L2+W9qa/9wLb9duAJfdPe1U57Y1/7qW37a/va9x+rGTiwp30DmjeUO4C9+uZ5U9v/1L7249r2ZcAWPe0bt8u6mebN6aE909YBftzul3sPuY8Pb9ezsL3ff1uwCrbhSmDrAeteSBOcntvXvjFNCPgTcJ+2baO27+Jxju+9Bjx3Fk7jOTdW80nj7I+N+543XwXWG2ef9j8/thmwvrsBn277P3qcWhaMU+syYNkkx3XfQa8pmvA/r2/ag4G/AL/ofc610x7fHvsTh9yP+w46Btz19bZP3374TjvtWuAFffN9sp22/4DnUAE/AzbpaV+X5g/MAl7U074VzevjBmC7vmV9pO1/zDjruBCYP2Bbx7bpwHH2xb2BDQe070ATZL/V176g5zi9tW/a37bt/9PXfnDbvgjYqG/aWvT8npzOc9dbN24jL8CbN293eaM9vL0dAXyxfYO9E3jNFJYV4Hrge33tY7/Ijx8wz9bttBN62u7ftv2KwSFq7I3uwJ62F7Rtnx/Qfx5wWTt9y57249q2lw6Y59h22tsHTHtrO22fIffL2JvVeLd9V8E2rPBG2L5xF/Dlceoa+0PgVe3je7aPzwIy5HNn4TSec2M1j3db0PY7n+YM38YDlrEWTdBfNOQ6d26Xfdg4tSwYZ75lTC+8DvzjBnhfO/3J4yzzRJrQuUIQG9B330HHgOWvt88OmOfF7bQzB0zbh8FhbiF9AXVADaf3tL2lbXvngP6b0ITaPwHrDFjH/v3z9G3TgYOmT7KfTgb+DKzd07aA5X+4Dvod82vgmr62i9p5dhpinavsuettdt0cNiDNLm/tezwW6j7V3zHJ2sDLgefSfPS/EXcdx77FOOtYPKDt8vZn71jZndqfP6iqOwbMs5DmjbbXzu3P7/V3rqrbk5xJ84a1E9D/keygun7T/lwyYNqV7c/7D5g2kbfVxF/YWpltWDRgebu3PzfK4LGom7U/H9qu44YkX6f5+Hhpkq/QfKx8TlXdMkHd0/WSGucLW0nuQRO+rwFel8FXbLt1rPae+e4FvIFmOMoDaYZI9BrvubmqLauqqwe0jx2TfZI8asD0e9OEmwcz+Lk3Fav6eX3GgLbv04TtnXraJnoeX5fkfJpPdrYD+j/KH/Q8Hkqa8fCvoLlCynxWHJ44H/htX9vScX7HXM7yY0WS9YFHAL+rqvMnqWNaz111g+FVmkWqauzLSevT/NL+JPCxJL+uqv43oS/SjHn9Fc0YtKtofhkDvI7mo/VBVhjj1oYyaN6wx4x9oeN34yznqgFtY/P0vznR177xgGnXD2i7fYhpa4+zrulamW0YtE/u1f78m/Y2ng167h9AM0Th+Sy/fNqfk5wAvL6qxjsmq9omNGfyN2PFP6wGar+IdC7N2fxFNB/bX0tzvDYGXsv4z81VbdDxgOXH5A2TzL/BJNOHsaqf1ysc+6q6I8kfaEL3mFX9PJ5UkkNpxi1fRzM04n+BW2j+CB8b1zzo2I83vvl27voH+VitVw7o22/Kz111h+FVmoWq6mbgu0meCpwHfDrJQ8bOvLXfqH0GzRd3nlRVf/0yV5pvc79xFZQx9sZ6n3Gmbz7BPIOmAdy3r99stDLbUBMs77VV9cFhCqiqP9EOIUnyAJozZAcCL6Q567vXMMtZBcZqP7+qdp6w53L/RBNcVzjDnWR3mvA6VXcCA79Nz+DwNWbQ8YDl27VRVd0wjXpG6T70nfFPshZNIO/dlt7n8SUDljPu87iqxttv40oyj+YPrauAnavqt33Tdx8449SMhdxhztxP57mrjvBSWdIsVlUX0nwj+v7AP/dMelD78+Te4NraDVhvFax+7GO5Pds3x377TjDPCtPaN7c924fnrWxxM2hVb8OP2p/TCpxVdXlVfY7mCyw/pzke9+rpcid3PWO+ylTVTTTB5+FJNh1ytrHn5lcGTOsfZjJm7CPj8bbjOuA+7VCZfitcGmkIK3VMRmzQPtyL5mRU70fpEz2PNwZ2pBmD+pMprHui4zSf5g+JswcE1w1YPoxh2to/6i+meS7sNEnf6Tx31RGGV2n2+0+aN5nXZ/n1W5e1P/ft7Zjk3sCHV8VKq+oKmo/+tqbvv3sl2Z/Bb6In0XxE/Lwkj+mb9jqa8Y/frVVzCaKZskq3oaoW04xJfGaSgwb1SbJ9e+xIslmSRw/otj6wIc1HqX/paf8D8IBhapmm/0dz1vPYNvTcRZJNkvQGk2Xtz337+u0E/Ns46/hD+3PLcaYvoglnL+lb5oHAHuOXPq4P0XyR531JHtw/sb3O6WwNtv/R83uANNc6flf7sHds/PE02/iaJA/irt5B88XA46vqVoY30XG6mmaIwC5tWB2rb22aoQTzp7CeiYx9enF0+q5Vm+Ruuet1mKf63FVHOGxAmuWq6sokR9N83PpGmgBwLs230Z+Z5GzgBzQfJ/49zXUOfzPO4qbq1TSX4Xl/movpX8Dyf1s79qWi3lpvagPal4EzknyZ5iPOXYAn0nyk+PJVVNuMmKFteD7NF2c+2Y4LPIfmI9D7A4+k+RLK7jQBYAvgR0l+QnN293KaoPEUmo+AP1h3vX7vacBz2y95LaEJt2dW1ZlT3fZBqurYJLsArwJ+meQUmv2xKc0fNnvThKZXtLN8hmYs6fuTPI7mbPG2bf1fpRnP2++0dp6Pt+N6bwL+WFUfaqf/F01w/WiSJ9Dskx1orpn6jXbZU9mmS9tjfCxwSZJv01yCam2aYLYXzeXZtpvKcleTn9DU3Hud121ori382bFOVbUsyeto/pg9L8mXaLZpH5rn2qU046qn4oc0AfV17dnMsfG3/1VV1yf5IM11Xi9K8jWa4Pg4mufK6e39lfUJmk8/Xgz8vF3P72mug/x4mmN6OEzruauuGPXlDrx587b8UlkTTL8PzfVOb2b59UA3pble4zKaM7O/BN4J3IMBlxZi8ms0DrzkEk1YPYEmbN1M8wb25ImWR3OB8xNp3lT+QvOG8VHgfgP6Hsc4l0linMsgDbM9Eyzr8CH7r5Jt6OmzIfDvNAHzJprLFF1GEzoOBtZv+20MHEYTdq+k+RLeb2mu7vA8+i6fRfMlnc/TBIk7ht3GnpqH3X9jF9q/ut0fV9GcEf1PVryO6MNoLo10dfucWUIzFnZBu87jBiz/X2iC2a1tn/7n7540/yr5Fpqxnd+kCf4DnyPjPZ/7+mzf7odft+u9luZj6aOBxw+5X/YdtK6Jnp8986xwnMbbRyy/jNU67T6/rK35VzRfSFpnnPqeSHO95uva/r8A/i+DLx+1kAl+D7V9/o7md8BNrHhZtXntcfwxzfP7KppAvRUDXiMTPR8mq4fmknZn0Ixt/XO7Pz5HM9522s9db924pT2wkiRplkrz71n3qfaKJNKazDGvkiRJ6gzDqyRJkjrD8CpJkqTOcMyrJEmSOsNLZa0h5s+fXwsWLBh1GZIkSZNasmTJNVW12aBphtc1xIIFC1i8ePGoy5AkSZpUkl+PN80xr5IkSeoMw6skSZI6w/AqSZKkzjC8SpIkqTMMr5IkSeoMrzawhvjJFX9glzd8ZtRlSJKkDlty1ItHXYJnXiVJktQdhldJkiR1huFVkiRJnWF4lSRJUmcYXiVJktQZhldJkiR1huFVkiRJnWF4lSRJUmcYXiVJktQZhldJkiR1huFVkiRJnWF4lSRJUmcYXiVJktQZhldJkiR1huFVkiRJnWF4lSRJUmcYXiVJktQZhldJkiR1huFVkiRJnWF4lSRJUmcYXiVJktQZhldJkiR1xhoZXpNsl2RpkvOTbDNBv39fDbX8e9/js2d6nZIkSV21RoZX4OnA16pqp6r65QT9Vjq8Jllrki53WUdVPXZl1ylJkjRXzZnwmmT9JN9MckGSi5MckOSwJOe2j49J40nA64B/SnJ6O+8Lkyxqz8YenWStJEcC67Vtn0vyjiSv7VnfEUkOHaeWfZOcnuTzwEVt20lJliS5JMnBbdtd1tG23dSzjIVJTkhyaVtD2mlPatt+kOSDSb4xTh0HJ1mcZPHtt9y4iva0JEnS6MwbdQGr0N8Bv6mqJwMk2Qj4TlW9vX38WeApVfX1JB8Dbqqq9yR5KHAAsEdV3ZbkI8ALqurNSQ6pqh3b+RcAXwU+kORuwHOB3SaoZzfgEVV1Wfv4oKq6Nsl6wLlJvtK/jgF2Ah4O/AY4C9gjyWLgaGDvqrosyRfGK6CqjgGOAVh/861rglolSZI6Yc6ceaU5w7lfkncn2auqrgcel+ScJBcBj6cJgv2eAOxCEyiXto8f2N+pqpYBf0iyE/BE4Pyq+sME9SzqCa4Ahya5APgR8ABg2yG2aVFVXVFVdwJLgQXAdsCvepY9bniVJEmaa+bMmdeq+lmSXYAnAe9KcirwamDXqro8yeHAugNmDfDpqvq3IVbzCeBAYHPg2En63vzXFST7AvsBu1fVLUkWjlNLv1t77t9Bc7wyxHySJElz0pw585rkfsAtVXU88B5g53bSNUk2AJ49zqynAc9Ocu92OZsm2aqddluStXv6nkgzPOFRwClTKG8j4Lo2uG4HPKZnWv86JnMp8MB2GAM0Qx4kSZLWCHPmzCuwPXBUkjuB24BX0lxV4CJgGXDuoJmq6sdJ/g9wajuW9TaaM7a/phkvemGS86rqBVX1l/ZLXn+sqjumUNu3gVckuRD4Kc3QgTF3WcdkC6qqPyV5FfDtJNcAi6ZQhyRJUqelyu/xDKsNt+cBz6mqn4+wjg2q6qb26gMfBn5eVe+baJ71N9+6tnvR21ZPgZIkaU5actSLV8t6kiypql0HTZszwwZmWpKHAb8AThtlcG29rP1y2SU0QxKOHnE9kiRJq8VcGjYwo6rqx/RdhSDJ9sBn+7reWlWPnuFa3gdMeKZVkiRpLjK8roSquggY7xqtkiRJWsUcNiBJkqTOMLxKkiSpMwyvkiRJ6gzDqyRJkjrD8CpJkqTOMLxKkiSpMwyvkiRJ6gzDqyRJkjrD8CpJkqTOMLxKkiSpMwyvkiRJ6gzDqyRJkjrD8CpJkqTOMLxKkiSpMwyvkiRJ6ox5oy5Aq8dD738vFh/14lGXIUmStFI88ypJkqTOMLxKkiSpMwyvkiRJ6gzDqyRJkjrD8CpJkqTOMLxKkiSpMwyvkiRJ6gzDqyRJkjrD8CpJkqTOMLxKkiSpMwyvkiRJ6gzDqyRJkjpj3qgL0Orxl99ewv++fftRlyFJmsW2POyiUZcgTcozr5IkSeoMw6skSZI6w/AqSZKkzjC8SpIkqTMMr5IkSeoMw6skSZI6w/AqSZKkzjC8SpIkqTMMr5IkSeoMw6skSZI6w/AqSZKkzjC8SpIkqTMMr5IkSeoMw6skSZI6w/AqSZKkzjC8SpIkqTMMr5IkSeoMw6skSZI6w/AqSZKkzjC8SpIkqTMMr5IkSeoMw6skSZI6Y86F1yQLkly8CpbziiQvXhU1dWndkiRJs9m8URcwW1XVx0ax3iTzRrVuSZKk2W7OnXltzUvy6SQXJjkhyT2SLEsyHyDJrkkWJrlbkp8n2axtv1uSXySZn+TwJK9v2xcmeXeSRUl+lmSvtv0eSb7UrueLSc5Jsut4RSW5Kcl7k5yX5LSe9S5M8s4kZwCv7Vv3g5J8N8kF7XzbtO1vSHJuu+63jbO+g5MsTrL42pvvWIW7V5IkaTTmanh9CHBMVT0SuAF41aBOVXUncDzwgrZpP+CCqrpmQPd5VbUb8DrgrW3bq4Dr2vW8A9hlkrrWB86rqp2BM3qWA7BxVe1TVe/tm+dzwIeragfgscBvkzwR2BbYDdgR2CXJ3gO275iq2rWqdt10/bUmKU2SJGn2m6vh9fKqOqu9fzyw5wR9jwXGxpceBHxqnH5fbX8uARa09/cE/hugqi4GLpykrjuBL45T1xf7OyfZENiiqk5s1/HnqroFeGJ7Ox84D9iOJsxKkiTNaXN1zGsNeHw7y8P6un+dUHV5kt8leTzwaJafhe13a/vzDpbvt6zCOm8eMH285Qd4V1UdvZLrlyRJ6pS5euZ1yyS7t/efB/wAWMbyj/Wf1df/EzRnQr9UVVMZHPoD4B8AkjwM2H6S/ncDnt3ef347/7iq6gbgiiRPb9exTpJ7AKcAByXZoG3fIsm9p1C3JElSJ83V8PoT4B+TXAhsCnwUeBvwgSTfpzl72utkYAPGHzIwno8Am7XreRPNsIHrJ+h/M/DwJEuAxwNvH2IdLwIObddxNrB5VZ0KfB74YZKLgBOADadYuyRJUuekqv8T9jVPe4WA91XVXlOcby1g7ar6c3sVgNOAB1fVX8bpf1NVbbDyFU/dI7dYr77x8geNYtWSpI7Y8rCLRl2CBECSJVU18ApOc3XM69CSvBl4JeOPdZ3IPYDTk6xNMw71leMFV0mSJK28NT68VtWRwJHTnPdGYIW/CpKcA6zT1/yiUZ11lSRJmivW+PA6E6rq0aOuQZIkaS6aq1/YkiRJ0hxkeJUkSVJnGF4lSZLUGYZXSZIkdYbhVZIkSZ1heJUkSVJnGF4lSZLUGYZXSZIkdYbhVZIkSZ1heJUkSVJnGF4lSZLUGYZXSZIkdYbhVZIkSZ1heJUkSVJnGF4lSZLUGYZXSZIkdca8UReg1ePu9304Wx62eNRlSJIkrRTPvEqSJKkzDK+SJEnqDMOrJEmSOsPwKkmSpM4wvEqSJKkzDK+SJEnqDMOrJEmSOsPwKkmSpM4wvEqSJKkzDK+SJEnqDMOrJEmSOmPeqAvQ6nHp1Zeyx3/tMeoyJElDOOs1Z426BGnW8syrJEmSOsPwKkmSpM4wvEqSJKkzDK+SJEnqDMOrJEmSOsPwKkmSpM4wvEqSJKkzDK+SJEnqDMOrJEmSOsPwKkmSpM4wvEqSJKkzDK+SJEnqDMOrJEmSOsPwKkmSpM4wvEqSJKkzDK+SJEnqDMOrJEmSOsPwKkmSpM4wvEqSJKkzDK+SJEnqDMOrJEmSOsPwKkmSpM4wvEqSJKkzZmV4TbJrkg9O0mfjJK8acnlnr5rKZp8k/z7qGiRJklaXWRleq2pxVR06SbeNgaHCa1U9duWrmrUMr5IkaY0xY+E1yYIklyb5RJKLk3wuyX5Jzkry8yS7tbezk5zf/nxIO+++Sb7R3j88ybFJFib5VZKxUHsksE2SpUmOSrJBktOSnJfkoiT799RyU89yFyY5oa3tc0nSTtslyRlJliQ5Jcl92/aFSd6dZFGSnyXZq21fK8l72nVdmOQ1Ey1nnH30oCTfTXJBW/c2aRzV7rOLkhzQ9r1vkjPb7b04yV5JjgTWa9s+N2D5BydZnGTxbTfdttLHVJIkadTmzfDyHwQ8BzgYOBd4PrAn8DSaM4YvBvauqtuT7Ae8E3jWgOVsBzwO2BD4aZKPAm8GHlFVOwIkmQc8o6puSDIf+FGSk6uq+pa1E/Bw4DfAWcAeSc4B/gvYv6p+3wbGI4CD2nnmVdVuSZ4EvBXYr92mrYGd2vo3TbL2JMvp9zngyKo6Mcm6NH9MPBPYEdgBmA+cm+TMdt+dUlVHJFkLuEdVfT/JIWP7oF9VHQMcA7DBlhv07wdJkqTOmenwellVXQSQ5BLgtKqqJBcBC4CNgE8n2RYoYO1xlvPNqroVuDXJ1cB9BvQJ8M4kewN3Alu0/a7q67eoqq5oa1ra1vFH4BHAd9oTsWsBv+2Z56vtzyVtf2gC7Meq6naAqro2ySMmWc7yYpMNgS2q6sR2/j+37XsCX6iqO4DfJTkDeBRN+D+2DcgnVdXScfaVJEnSnDXT4fXWnvt39jy+s133O4DTq+oZSRYAC4dYzh0MrvsFwGbALlV1W5JlwLpDLivAJVW1+yTr7113aAJ3r8mW09936PaqOrMN5k8GPpvkqKr6zBDrkSRJmjNG/YWtjYAr2/sHTnHeG2mGEfQu6+o2uD4O2GoKy/opsFmS3QGSrJ3k4ZPMcyrwina4Akk2ncpyquoG4IokT2/7rpPkHsCZwAHtmNrNgL2BRUm2arfv48AngZ3bRd3Wno2VJEma80YdXv8v8K4kZ9F8xD60qvoDcFb75aWjaMaP7ppkMc1Z2EunsKy/AM8G3p3kAmApMNkVCj4B/C9wYTvP86exnBcBhya5EDgb2Bw4EbgQuAD4HvDGqroK2BdYmuR8mnHBH2iXcUxbwwpf2JIkSZprsuL3mTQXbbDlBrXDG3YYdRmSpCGc9ZqzRl2CNFJJllTVroOmjfrMqyRJkjS0mf7CloAkHwb26Gv+QFV9ahT1SJIkdZXhdTWoqlePugZJkqS5wGEDkiRJ6gzDqyRJkjrD8CpJkqTOGCq8JtkmyTrt/X2THJpk45ktTZIkSbqrYc+8fgW4I8mDaP6709bA52esKkmSJGmAYcPrnVV1O/AM4P1V9c/AfWeuLEmSJGlFw4bX25I8D/hH4Btt29ozU5IkSZI02LDh9SXA7sARVXVZkq2B42euLEmSJGlFQ/2Tgqr6cZI3AVu2jy8DjpzJwiRJkqR+w15t4KnAUuDb7eMdk5w8k4VJkiRJ/YYdNnA4sBvwR4CqWkpzxQFJkiRptRk2vN5eVdf3tdWqLkaSJEmayFBjXoGLkzwfWCvJtsChwNkzV5YkSZK0omHPvL4GeDhwK80/J7geeN1MFSVJkiQNMumZ1yRrASdX1X7AW2a+JEmSJGmwScNrVd2R5JYkGw0Y96qO2O7e23HWa84adRmSJEkrZdgxr38GLkryHeDmscaqOnRGqpIkSZIGGDa8frO9SZIkSSMz7H/Y+vRMFyJJkiRNZqjwmuQyBlzXtaoeuMorkiRJksYx7LCBXXvurws8B9h01ZcjSZIkjW+o67xW1R96bldW1fuBx89wbZIkSdJdDDtsYOeeh3ejORO74YxUJEmSJI1j2GED7+25fztwGfAPq74cSZIkaXzDhteXVtWvehuSbD0D9UiSJEnjGmrMK3DCkG2SJEnSjJnwzGuS7YCHAxsleWbPpHvSXHVAkiRJWm0mGzbwEOApwMbAU3vabwReNlNFSZIkSYOkaoX/PbBip2T3qvrhaqhHM+QhG25Yx+y08+QdJWkO2+fMM0ZdgqQhJFlSVbsOmjbsF7bOT/JqmiEEfx0uUFUHrYL6JEmSpKEM+4WtzwKbA38LnAHcn2bogCRJkrTaDBteH1RV/wHcXFWfBp4MbD9zZUmSJEkrGja83tb+/GOSRwAbAQtmpCJJkiRpHMOOeT0mySbAfwAnAxsAh81YVZIkSdIAQ4XXqvpEe/cM4IEzV44kSZI0vqGGDSS5T5JPJvlW+/hhSV46s793kl4AABNbSURBVKVJkiRJdzXsmNfjgFOA+7WPfwa8biYKkiRJksYzbHidX1VfAu4EqKrbgTtmrCpJkiRpgGHD681J7gUUQJLHANfPWFWSJEnSAMNebeBfaK4ysE2Ss4DNgGfPWFWSJEnSABOG1yRbVtX/VtV5SfYBHgIE+GlV3TbRvJIkSdKqNtmwgZN67n+xqi6pqosNrpIkSRqFycJreu57fVdJkiSN1GThtca5L0mSJK12k31ha4ckN9CcgV2vvU/7uKrqnjNanSRJktRjwvBaVWutrkIkSZKkyQx7nVdJkiRp5AyvkiRJ6gzDqyRJkjrD8CpJkqTOMLxKkiSpM+ZkeE2yMMmuq3F9RyW5JMlRM7iOjZO8aqaWL0mS1AWTXed1jZNkXlXdPsXZXg5sVlW3zkRNrY2BVwEfmcF1SJIkzWojPfOaZEGSnyT5eHvm8tQk6/WeOU0yP8my9v6BSU5K8vUklyU5JMm/JDk/yY+SbNqz+BcmOTvJxUl2a+dfP8mxSc5t59m/Z7lfTvJ14NRxak17hvXiJBclOaBtPxlYHzhnrG3AvM9p57sgyZlt21rt8s5NcmGSl7ftGyQ5Lcl57Xr2bxdzJLBNkqXtfPdNcmb7+OIkew1Y78FJFidZfP1tt03x6EiSJM0+s+HM67bA86rqZUm+BDxrkv6PAHYC1gV+AbypqnZK8j7gxcD7237rV9Vjk+wNHNvO9xbge1V1UJKNgUVJvtv23x14ZFVdO856nwnsCOwAzAfOTXJmVT0tyU1VteMENR8G/G1VXdmuF+ClwPVV9agk6wBnJTkVuBx4RlXdkGQ+8KM2IL8ZeMTYepL8K3BKVR2RZC3gHv0rrapjgGMAHrLhhv57X0mS1HmzIbxeVlVL2/tLgAWT9D+9qm4EbkxyPfD1tv0i4JE9/b4AUFVnJrlnGxqfCDwtyevbPusCW7b3vzNBcAXYE/hCVd0B/C7JGcCjgJMn3UI4CziuDedfbdueCDwyybPbxxvRBPkrgHe2oftOYAvgPgOWeS5wbJK1gZN69qEkSdKcNRvCa+840TuA9YDbWT6kYd0J+t/Z8/hO7ro9/WcaCwjwrKr6ae+EJI8Gbp6kzkwyfVxV9Yp2HU8GlibZsV3ea6rqlL5aDgQ2A3apqtvaIRP9+2AslO/dLvOzSY6qqs9Mt0ZJkqQumK1XG1gG7NLef/YE/SYyNiZ1T5qP568HTgFekyTttJ2msLwzgQPasaqbAXsDi4aZMck2VXVOVR0GXAM8oK3lle2ZU5I8OMn6NGdgr26D6+OArdrF3Ahs2LPMrdp+Hwc+Cew8hW2RJEnqpNlw5nWQ9wBfSvIi4HvTXMZ1Sc4G7gkc1La9g2ZM7IVtgF0GPGXI5Z1IMy72ApqzuG+sqquGnPeoJNvSnG09rV3GhTRDJM5ra/k98HTgc8DXkywGlgKXAlTVH5KcleRi4FvAxcAbktwG3EQz3leSJGlOS5Xf41kTPGTDDeuYnTw5K2nNts+ZZ4y6BElDSLKkqgZes3+2DhuQJEmSVjBbhw2MTJLtgc/2Nd9aVY8eYt63AM/pa/5yVR2xquqTJElakxle+1TVRTTXc53OvEcABlVJkqQZ4rABSZIkdYbhVZIkSZ1heJUkSVJnGF4lSZLUGYZXSZIkdYbhVZIkSZ1heJUkSVJnGF4lSZLUGYZXSZIkdYbhVZIkSZ1heJUkSVJnGF4lSZLUGYZXSZIkdYbhVZIkSZ1heJUkSVJnGF4lSZLUGfNGXYBWjw0f8hD2OfOMUZchSZK0UjzzKkmSpM4wvEqSJKkzDK+SJEnqDMOrJEmSOsPwKkmSpM4wvEqSJKkzDK+SJEnqDMOrJEmSOsPwKkmSpM4wvEqSJKkzDK+SJEnqjHmjLkCrx9VXXM+H/vXroy5DUkcd8t6njroESQI88ypJkqQOMbxKkiSpMwyvkiRJ6gzDqyRJkjrD8CpJkqTOMLxKkiSpMwyvkiRJ6gzDqyRJkjrD8CpJkqTOMLxKkiSpMwyvkiRJ6gzDqyRJkjrD8CpJkqTOMLxKkiSpMwyvkiRJ6gzDqyRJkjrD8CpJkqTOMLxKkiSpMwyvkiRJ6gzDqyRJkjrD8CpJkqTOMLxKkiSpM2Y8vCa5aabXsaolOTzJ61fBchYkef405z17ZdcvSZI013jmdWYtAKYVXqvqsau2FEmSpO5bbeE1yb5JvtHz+ENJDmzvPynJpUl+kOSDY/2SbJbkO0nOS3J0kl8nmd9OOynJkiSXJDm4Z7kvTfKzJAuTfDzJh3qW9ZUk57a3PSYpeYck30vy8yQva5eRJEcluTjJRUkOmKgdOBLYK8nSJP88zn55eJJFbZ8Lk2zbtt/U/nx7O21pkiuTfKptf2HPfEcnWWtqR0SSJKl75o26gCTrAkcDe1fVZUm+0DP5rcD3qupdSf4OOLhn2kFVdW2S9YBzk3wFWAf4D2Bn4Ebge8AFbf8PAO+rqh8k2RI4BXjoBKU9EngMsD5wfpJvArsDOwI7APPb9Z4JPHac9jcDr6+qp0ywnlcAH6iqzyW5O3CXEFpVhwGHJdkI+D7woSQPBQ4A9qiq25J8BHgB8JneedtQfzDAJhtuNkEJkiRJ3TDy8ApsB/yqqi5rH3+B5SF1T+AZAFX17STX9cx3aJJntPcfAGwLbA6cUVXXAiT5MvDgts9+wMOSjM1/zyQbVtWN49T1tar6E/CnJKcDu7X1fKGq7gB+l+QM4FETtN8wxPb/EHhLkvsDX62qn/d3SFP052jC95IkhwC70IRkgPWAq/vnq6pjgGMAttx82xqiFkmSpFltdYbX27nrMIV1258Z0JeJpiXZlyaM7l5VtyRZ2C5vomXdre3/pyHr7Q97NcHyJ1rvxCup+nySc4AnA6ck+aeq+l5ft8OBK6rqUz3r+3RV/dt01ytJktRFq/MLW7+mOfO5TvsR+BPa9kuBByZZ0D4+oGeeHwD/AJDkicAmbftGwHVtcN2O5uN9gEXAPkk2STIPeFbPsk4FDhl7kGTHSerdP8m6Se4F7AucC5wJHJBkrSSbAXu36xyv/UZgw4lWkuSBNGeePwicTDNcoXf6U4C/AQ7taT4NeHaSe7d9Nk2y1STbI0mS1Hmr7cxrVV2e5EvAhcDPgfPb9j8leRXw7STX0IS+MW8DvtB+AeoM4Lc0gfDbwCuSXAj8FPhRu6wrk7wTOAf4DfBj4Pp2WYcCH27nmUcTOF8xQcmLgG8CWwLvqKrfJDmRZtzrBTRnYt9YVVdN0P4H4PYkFwDHVdX7BqznAOCFSW4DrgLe3jf9X4H7AYvaIQInV9VhSf4PcGqSuwG3Aa+m+QNBkiRpzkrV6IdCJtmgqm5qx3Z+GPh5Vb0vyTrAHVV1e5LdgY9W1YRnTHuWNQ84ETi2qk6c+a2Y3bbcfNt64wv+36jLkNRRh7z3qaMuQdIaJMmSqtp10LTZ8IUtgJcl+Ufg7jRnZI9u27cEvtSeXfwL8LIhlnV4kv1oxsCeCpw0A/VKkiRpBGZFeG0/Tl/hI/X2m/c7TXFZQ/9nrCQvAV7b13xWVb16Kusccl1/C7y7r/myqnrGoP6SJEla0awIr6PSfnv/U5N2XDXrOoXm2rKSJEmaJv89rCRJkjrD8CpJkqTOMLxKkiSpMwyvkiRJ6gzDqyRJkjrD8CpJkqTOMLxKkiSpMwyvkiRJ6gzDqyRJkjrD8CpJkqTOMLxKkiSpMwyvkiRJ6gzDqyRJkjrD8CpJkqTOMLxKkiSpMwyvkiRJ6ox5oy5Aq8e9778Rh7z3qaMuQ5IkaaV45lWSJEmdYXiVJElSZxheJUmS1BmGV0mSJHWG4VWSJEmdYXiVJElSZxheJUmS1BmGV0mSJHWG4VWSJEmdYXiVJElSZxheJUmS1BmGV0mSJHXGvFEXoNXjt5f9kiNe+OxRl6E1xFuOP2HUJUiS5ijPvEqSJKkzDK+SJEnqDMOrJEmSOsPwKkmSpM4wvEqSJKkzDK+SJEnqDMOrJEmSOsPwKkmSpM4wvEqSJKkzDK+SJEnqDMOrJEmSOsPwKkmSpM4wvEqSJKkzDK+SJEnqDMOrJEmSOsPwKkmSpM4wvEqSJKkzDK+SJEnqDMOrJEmSOsPwKkmSpM4wvEqSJKkzDK+SJEnqjDkXXpMsTLLralzfUUkuSXLUkP1vmumaJEmS5qp5oy5gNkkyr6pun+JsLwc2q6pbZ6KmQZKsVVV3rK71SZIkzRYjO/OaZEGSnyT5eHvm8tQk6/WeOU0yP8my9v6BSU5K8vUklyU5JMm/JDk/yY+SbNqz+BcmOTvJxUl2a+dfP8mxSc5t59m/Z7lfTvJ14NRxak17hvXiJBclOaBtPxlYHzhnrG3AvFsn+WG73ncMsczx2vdNcnqSzwMXtdvzzSQXtH1XWH+Sg5MsTrL45j+vtmwtSZI0Y0Z95nVb4HlV9bIkXwKeNUn/RwA7AesCvwDeVFU7JXkf8GLg/W2/9avqsUn2Bo5t53sL8L2qOijJxsCiJN9t++8OPLKqrh1nvc8EdgR2AOYD5yY5s6qeluSmqtpxgpo/AHy0qj6T5NWTLRN47DjtALsBj6iqy5I8C/hNVT0ZIMlG/SuuqmOAYwC2uNcmNUGNkiRJnTDqMa+XVdXS9v4SYMEk/U+vqhur6vfA9cDX2/aL+ub9AkBVnQncsw2rTwTenGQpsJAmAG/Z9v/OBMEVYE/gC1V1R1X9DjgDeNTkmwfAHmP1AJ8dYpkTrWtRVV3Ws837JXl3kr2q6voh65EkSeqsUYfX3s+y76A5E3w7y+tad4L+d/Y8vpO7nkXuP8tYQIBnVdWO7W3LqvpJO/3mSerMJNMnM+is53jLnGhdf62zqn4G7EITYt+V5LDplydJktQNow6vgyyjCWUAz57mMsbGie4JXN+elTwFeE2StNN2msLyzgQOSLJWks2AvYFFQ857FvDc9v4LhljmUOtKcj/glqo6HngPsPMUtkeSJKmTRj3mdZD3AF9K8iLge9NcxnVJzgbuCRzUtr2DZkzshW2AXQY8ZcjlnUgzLvYCmrOob6yqq4ac97XA55O8FvjKZMtMMl77dn3L3R44KsmdwG3AK4esR5IkqbNS5fd41gRb3GuTetXfP2HUZWgN8ZbjTxh1CZKkDkuypKoGXrd/Ng4bkCRJkgaajcMGRibJ9tz1igAAt1bVo4eY9y3Ac/qav1xVR6yq+iRJktZ0htceVXURzTVWpzPvEYBBVZIkaQY5bECSJEmdYXiVJElSZxheJUmS1BmGV0mSJHWG4VWSJEmdYXiVJElSZxheJUmS1BmGV0mSJHWG4VWSJEmdYXiVJElSZxheJUmS1BmGV0mSJHWG4VWSJEmdYXiVJElSZxheJUmS1BnzRl2AVo/7br0Nbzn+hFGXIUmStFI88ypJkqTOMLxKkiSpMwyvkiRJ6gzDqyRJkjrD8CpJkqTOMLxKkiSpM1JVo65Bq0GSG4GfjroOrWA+cM2oi9AKPC6zl8dmdvK4zE5dPi5bVdVmgyZ4ndc1x0+ratdRF6G7SrLY4zL7eFxmL4/N7ORxmZ3m6nFx2IAkSZI6w/AqSZKkzjC8rjmOGXUBGsjjMjt5XGYvj83s5HGZnebkcfELW5IkSeoMz7xKkiSpMwyvkiRJ6gzD6xyQ5O+S/DTJL5K8ecD0JPlgO/3CJDsPO6+mbyWPy7IkFyVZmmTx6q18bhviuGyX5IdJbk3y+qnMq+lbyePi62WGDHFcXtD+/rowydlJdhh2Xk3fSh6X7r9eqspbh2/AWsAvgQcCdwcuAB7W1+dJwLeAAI8Bzhl2Xm+r/7i005YB80e9HXPtNuRxuTfwKOAI4PVTmdfb6j8u7TRfL6M7Lo8FNmnv/73vL7P7uLSPO/968cxr9+0G/KKqflVVfwH+G9i/r8/+wGeq8SNg4yT3HXJeTc/KHBfNnEmPS1VdXVXnArdNdV5N28ocF82cYY7L2VV1XfvwR8D9h51X07Yyx2VOMLx23xbA5T2Pr2jbhukzzLyanpU5LgAFnJpkSZKDZ6zKNc/KPOd9vcycld23vl5mxlSPy0tpPk2azrwa3socF5gDrxf/PWz3ZUBb//XPxuszzLyanpU5LgB7VNVvktwb+E6SS6vqzFVa4ZppZZ7zvl5mzsruW18vM2Po45LkcTQhac+pzqspW5njAnPg9eKZ1+67AnhAz+P7A78Zss8w82p6Vua4UFVjP68GTqT5mEgrb2We875eZs5K7VtfLzNmqOOS5JHAJ4D9q+oPU5lX07Iyx2VOvF4Mr913LrBtkq2T3B14LnByX5+TgRe3325/DHB9Vf12yHk1PdM+LknWT7IhQJL1gScCF6/O4uewlXnO+3qZOdPet75eZtSkxyXJlsBXgRdV1c+mMq+mbdrHZa68Xhw20HFVdXuSQ4BTaL6BeGxVXZLkFe30jwH/Q/PN9l8AtwAvmWjeEWzGnLMyxwW4D3BiEmheo5+vqm+v5k2Yk4Y5Lkk2BxYD9wTuTPI6mm/y3uDrZWaszHEB5uPrZUYM+XvsMOBewEfaY3B7Ve3q+8vMWZnjwhx5f/Hfw0qSJKkzHDYgSZKkzjC8SpIkqTMMr5IkSeoMw6skSZI6w/AqSZKkzjC8SpIkqTMMr5IkSeqM/w8hweiE6cqA8wAAAABJRU5ErkJggg==\n",
"text/plain": [
"